mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
3dcbfd3a5b
published
20150522 Analyzing Linux Logs.md20150602 Howto Configure OpenVPN Server-Client on Ubuntu 15.04.md
201507
20150121 Syncthing--A Private And Secure Tool To Sync Files or Folders Between Computers.md20150127 25 Useful Apache '.htaccess' Tricks to Secure and Customize Websites.md20150227 Fix Minimal BASH like line editing is supported GRUB Error In Linux.md20150309 Comparative Introduction To FreeBSD For Linux Users.md20150401 ZMap Documentation.md20150407 10 Truly Amusing Easter Eggs in Linux.md20150410 10 Top Distributions in Demand to Get Your Dream Job.md20150505 How to Manage 'Systemd' Services and Units Using 'Systemctl' in Linux.md20150515 Lolcat--A Command Line Tool to Output Rainbow Of Colors in Linux Terminal.md20150520 Is Linux Better than OS X GNU Open Source and Apple in History.md20150526 20 Useful Terminal Emulators for Linux.md20150527 Animated Wallpaper Adds Live Backgrounds To Linux Distros.md20150527 How to Develop Own Custom Linux Distribution From Scratch.md20150527 How to edit your documents collaboratively on Linux.md20150601 How to monitor Linux servers with SNMP and Cacti.md20150601 How to monitor common services with Nagios.md20150603 Installing Ruby on Rails using rbenv on Ubuntu 15.04.md20150604 How to access SQLite database in Perl.md20150610 How to Manipulate Filenames Having Spaces and Special Characters in Linux.md20150610 How to secure your Linux server.md20150610 watch--Repeat Linux or Unix Commands Regular Intervals.md20150612 How to Configure Apache Containers with Docker on Fedora 22.md20150612 How to Configure Swarm Native Clustering for Docker.md20150612 Linux_Logo--A Command Line Tool to Print Color ANSI Logos of Linux Distributions.md20150615 How to combine two graphs on Cacti.md20150616 Installing LAMP Linux, Apache, MariaDB, PHP or PhpMyAdmin in RHEL or CentOS 7.0.md20150616 LINUX 101--POWER UP YOUR SHELL.md20150616 Linux Humor on the Command-line.md20150616 XBMC--build a remote control.md20150617 Tor Browser--An Ultimate Web Browser for Anonymous Web Browsing in Linux.md20150618 How to Setup Node.JS on Ubuntu 15.04 with Different Methods.md20150618 What will be the future of Linux without Linus.md20150625 Screen Capture Made Easy with these Dedicated Tools.md20150629 4 Useful Tips on mkdir, tar and kill Commands in Linux.md20150629 Backup with these DeDuplicating Encryption Tools.md20150629 First Stable Version Of Atom Code Editor Has Been Released.md20150706 PHP Security.md20150709 7 command line tools for monitoring your Linux system.md20150709 Install Google Hangouts Desktop Client In Linux.md20150709 Linus Torvalds Says People Who Believe in AI Singularity Are on Drugs.md20150709 Linux FAQs with Answers--How to fix 'tar--Exiting with failure status due to previous errors'.md20150709 Linux FAQs with Answers--How to install a Brother printer on Linux.md20150709 Linux FAQs with Answers--How to open multiple tabs in a GNOME terminal on Ubuntu 15.04.md20150709 Why is the ibdata1 file continuously growing in MySQL.md20150713 How To Fix System Program Problem Detected In Ubuntu 14.04.md20150713 How to manage Vim plugins.md20150716 4 CCleaner Alternatives For Ubuntu Linux.md20150717 Setting Up 'XR' (Crossroads) Load Balancer for Web Servers on RHEL or CentOS.md20150722 12 Useful PHP Commandline Usage Every Linux User Must Know.md20150722 How to Use and Execute PHP Codes in Linux Command Line--Part 1.mdInstall Plex Media Server On Ubuntu or CentOS 7.1 or Fedora 22.mdPHP 7 upgrading.md
sources
talk
20141219 2015 will be the year Linux takes over the enterprise and other predictions.md20141224 The Curious Case of the Disappearing Distros.md20150112 diff -u--What's New in Kernel Development.md20150121 Did this JavaScript break the console.md20150128 7 communities driving open source development.md20150320 Revealed--The best and worst of Docker.md20150709 Interviews--Linus Torvalds Answers Your Question.md20150709 command line tools for monitoring your Linux system.md
The history of Android
tech
20150225 How to set up IPv6 BGP peering and filtering in Quagga BGP router.md20150504 How to access a Linux server behind NAT via reverse SSH tunnel.md20150515 Install Plex Media Server On Ubuntu or CentOS 7.1 or Fedora 22.md20150522 Analyzing Linux Logs.md20150604 Nishita Agarwal Shares Her Interview Experience on Linux 'iptables' Firewall.md20150612 How to Configure Swarm Native Clustering for Docker.md20150625 How to Provision Swarm Clusters using Docker Machine.md20150717 How to collect NGINX metrics - Part 2.md20150717 How to monitor NGINX with Datadog - Part 3.md20150717 Howto Configure FTP Server with Proftpd on Fedora 22.md20150722 12 Useful PHP Commandline Usage Every Linux User Must Know.md20150722 How To Fix 'The Update Information Is Outdated' In Ubuntu 14.04.md20150722 How To Manage StartUp Applications In Ubuntu.md20150722 Howto Interactively Perform Tasks with Docker using Kitematic.md20150728 Process of the Linux kernel building.md20150728 Understanding Shell Commands Easily Using 'Explain Shell' Script in Linux.md20150730 How to Setup iTOP (IT Operational Portal) on CentOS 7.md20150730 Howto Configure Nginx as Rreverse Proxy or Load Balancer with Weave and Docker.md
RHCSA Series
translated
talk
20150309 Comparative Introduction To FreeBSD For Linux Users.md20150520 Is Linux Better than OS X GNU Open Source and Apple in History.md
The history of Android
tech
20150616 LINUX 101--POWER UP YOUR SHELL.md20150625 How to Provision Swarm Clusters using Docker Machine.md20150713 How to manage Vim plugins.md20150717 How to Configure Chef (server or client) on Ubuntu 14.04 or 15.04.md20150717 How to collect NGINX metrics - Part 2.md20150717 Howto Configure FTP Server with Proftpd on Fedora 22.md20150722 How To Fix 'The Update Information Is Outdated' In Ubuntu 14.04.md20150722 How To Manage StartUp Applications In Ubuntu.md20150722 Howto Interactively Perform Tasks with Docker using Kitematic.md20150727 Easy Backup Restore and Migrate Containers in Docker.md20150728 How To Fix--There is no command installed for 7-zip archive files.md20150728 How to Update Linux Kernel for Improved System Performance.md20150728 Tips to Create ISO from CD, Watch User Activity and Check Memory Usages of Browser.md
183
published/20150522 Analyzing Linux Logs.md
Normal file
183
published/20150522 Analyzing Linux Logs.md
Normal file
@ -0,0 +1,183 @@
|
||||
如何分析 Linux 日志
|
||||
==============================================================================
|
||||

|
||||
|
||||
日志中有大量的信息需要你处理,尽管有时候想要提取并非想象中的容易。在这篇文章中我们会介绍一些你现在就能做的基本日志分析例子(只需要搜索即可)。我们还将涉及一些更高级的分析,但这些需要你前期努力做出适当的设置,后期就能节省很多时间。对数据进行高级分析的例子包括生成汇总计数、对有效值进行过滤,等等。
|
||||
|
||||
我们首先会向你展示如何在命令行中使用多个不同的工具,然后展示了一个日志管理工具如何能自动完成大部分繁重工作从而使得日志分析变得简单。
|
||||
|
||||
### 用 Grep 搜索 ###
|
||||
|
||||
搜索文本是查找信息最基本的方式。搜索文本最常用的工具是 [grep][1]。这个命令行工具在大部分 Linux 发行版中都有,它允许你用正则表达式搜索日志。正则表达式是一种用特殊的语言写的、能识别匹配文本的模式。最简单的模式就是用引号把你想要查找的字符串括起来。
|
||||
|
||||
#### 正则表达式 ####
|
||||
|
||||
这是一个在 Ubuntu 系统的认证日志中查找 “user hoover” 的例子:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
构建精确的正则表达式可能很难。例如,如果我们想要搜索一个类似端口 “4792” 的数字,它可能也会匹配时间戳、URL 以及其它不需要的数据。Ubuntu 中下面的例子,它匹配了一个我们不想要的 Apache 日志。
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972 HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### 环绕搜索 ####
|
||||
|
||||
另一个有用的小技巧是你可以用 grep 做环绕搜索。这会向你展示一个匹配前面或后面几行是什么。它能帮助你调试导致错误或问题的东西。`B` 选项展示前面几行,`A` 选项展示后面几行。举个例子,我们知道当一个人以管理员员身份登录失败时,同时他们的 IP 也没有反向解析,也就意味着他们可能没有有效的域名。这非常可疑!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
你也可以把 grep 和 [tail][2] 结合使用来获取一个文件的最后几行,或者跟踪日志并实时打印。这在你做交互式更改的时候非常有用,例如启动服务器或者测试代码更改。
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
关于 grep 和正则表达式的详细介绍并不在本指南的范围,但 [Ryan’s Tutorials][3] 有更深入的介绍。
|
||||
|
||||
日志管理系统有更高的性能和更强大的搜索能力。它们通常会索引数据并进行并行查询,因此你可以很快的在几秒内就能搜索 GB 或 TB 的日志。相比之下,grep 就需要几分钟,在极端情况下可能甚至几小时。日志管理系统也使用类似 [Lucene][4] 的查询语言,它提供更简单的语法来检索数字、域以及其它。
|
||||
|
||||
### 用 Cut、 AWK、 和 Grok 解析 ###
|
||||
|
||||
#### 命令行工具 ####
|
||||
|
||||
Linux 提供了多个命令行工具用于文本解析和分析。当你想要快速解析少量数据时非常有用,但处理大量数据时可能需要很长时间。
|
||||
|
||||
#### Cut ####
|
||||
|
||||
[cut][5] 命令允许你从有分隔符的日志解析字段。分隔符是指能分开字段或键值对的等号或逗号等。
|
||||
|
||||
假设我们想从下面的日志中解析出用户:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
我们可以像下面这样用 cut 命令获取用等号分割后的第八个字段的文本。这是一个 Ubuntu 系统上的例子:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
另外,你也可以使用 [awk][6],它能提供更强大的解析字段功能。它提供了一个脚本语言,你可以过滤出几乎任何不相干的东西。
|
||||
|
||||
例如,假设在 Ubuntu 系统中我们有下面的一行日志,我们想要提取登录失败的用户名称:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
你可以像下面这样使用 awk 命令。首先,用一个正则表达式 /sshd.*invalid user/ 来匹配 sshd invalid user 行。然后用 { print $9 } 根据默认的分隔符空格打印第九个字段。这样就输出了用户名。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
你可以在 [Awk 用户指南][7] 中阅读更多关于如何使用正则表达式和输出字段的信息。
|
||||
|
||||
#### 日志管理系统 ####
|
||||
|
||||
日志管理系统使得解析变得更加简单,使用户能快速的分析很多的日志文件。他们能自动解析标准的日志格式,比如常见的 Linux 日志和 Web 服务器日志。这能节省很多时间,因为当处理系统问题的时候你不需要考虑自己写解析逻辑。
|
||||
|
||||
下面是一个 sshd 日志消息的例子,解析出了每个 remoteHost 和 user。这是 Loggly 中的一张截图,它是一个基于云的日志管理服务。
|
||||
|
||||

|
||||
|
||||
你也可以对非标准格式自定义解析。一个常用的工具是 [Grok][8],它用一个常见正则表达式库,可以解析原始文本为结构化 JSON。下面是一个 Grok 在 Logstash 中解析内核日志文件的事例配置:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
下图是 Grok 解析后输出的结果:
|
||||
|
||||

|
||||
|
||||
### 用 Rsyslog 和 AWK 过滤 ###
|
||||
|
||||
过滤使得你能检索一个特定的字段值而不是进行全文检索。这使你的日志分析更加准确,因为它会忽略来自其它部分日志信息不需要的匹配。为了对一个字段值进行搜索,你首先需要解析日志或者至少有对事件结构进行检索的方式。
|
||||
|
||||
#### 如何对应用进行过滤 ####
|
||||
|
||||
通常,你可能只想看一个应用的日志。如果你的应用把记录都保存到一个文件中就会很容易。如果你需要在一个聚集或集中式日志中过滤一个应用就会比较复杂。下面有几种方法来实现:
|
||||
|
||||
1. 用 rsyslog 守护进程解析和过滤日志。下面的例子将 sshd 应用的日志写入一个名为 sshd-message 的文件,然后丢弃事件以便它不会在其它地方重复出现。你可以将它添加到你的 rsyslog.conf 文件中测试这个例子。
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. 用类似 awk 的命令行工具提取特定字段的值,例如 sshd 用户名。下面是 Ubuntu 系统中的一个例子。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. 用日志管理系统自动解析日志,然后在需要的应用名称上点击过滤。下面是在 Loggly 日志管理服务中提取 syslog 域的截图。我们对应用名称 “sshd” 进行过滤,如维恩图图标所示。
|
||||
|
||||

|
||||
|
||||
#### 如何过滤错误 ####
|
||||
|
||||
一个人最希望看到日志中的错误。不幸的是,默认的 syslog 配置不直接输出错误的严重性,也就使得难以过滤它们。
|
||||
|
||||
这里有两个解决该问题的方法。首先,你可以修改你的 rsyslog 配置,在日志文件中输出错误的严重性,使得便于查看和检索。在你的 rsyslog 配置中你可以用 pri-text 添加一个 [模板][9],像下面这样:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
这个例子会按照下面的格式输出。你可以看到该信息中指示错误的 err。
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你可以用 awk 或者 grep 检索错误信息。在 Ubuntu 中,对这个例子,我们可以用一些语法特征,例如 . 和 >,它们只会匹配这个域。
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你的第二个选择是使用日志管理系统。好的日志管理系统能自动解析 syslog 消息并抽取错误域。它们也允许你用简单的点击过滤日志消息中的特定错误。
|
||||
|
||||
下面是 Loggly 中一个截图,显示了高亮错误严重性的 syslog 域,表示我们正在过滤错误:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a],[Amy Echeverri][b],[ Sadequl Hussain][c]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
@ -1,18 +1,18 @@
|
||||
Ubuntu 15.04上配置OpenVPN服务器-客户端
|
||||
在 Ubuntu 15.04 上配置 OpenVPN 服务器和客户端
|
||||
================================================================================
|
||||
虚拟专用网(VPN)是几种用于建立与其它网络连接的网络技术中常见的一个名称。它被称为虚拟网,因为各个节点的连接不是通过物理线路实现的。而由于没有网络所有者的正确授权是不能通过公共线路访问到网络,所以它是专用的。
|
||||
虚拟专用网(VPN)常指几种通过其它网络建立连接技术。它之所以被称为“虚拟”,是因为各个节点间的连接不是通过物理线路实现的,而“专用”是指如果没有网络所有者的正确授权是不能被公开访问到。
|
||||
|
||||

|
||||
|
||||
[OpenVPN][1]软件通过TUN/TAP驱动的帮助,使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提额外提供了灵活的配置,可以帮助你避免防火墙限制。
|
||||
[OpenVPN][1]软件借助TUN/TAP驱动使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提供了更多的灵活配置,可以帮助你避免防火墙限制。
|
||||
|
||||
OpenVPN中,由OpenSSL库和传输层安全协议(TLS)提供了安全和加密。TLS是SSL协议的一个改进版本。
|
||||
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何预备使用带有公共密钥非对称加密和TLS协议基础结构(PKI)。
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何配置使用带有公共密钥基础结构(PKI)的非对称加密和TLS协议。
|
||||
|
||||
### 服务器端配置 ###
|
||||
|
||||
首先,我们必须安装OpenVPN。在Ubuntu 15.04和其它带有‘apt’报管理器的Unix系统中,可以通过如下命令安装:
|
||||
首先,我们必须安装OpenVPN软件。在Ubuntu 15.04和其它带有‘apt’包管理器的Unix系统中,可以通过如下命令安装:
|
||||
|
||||
sudo apt-get install openvpn
|
||||
|
||||
@ -20,7 +20,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
sudo apt-get unstall easy-rsa
|
||||
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在“sudo -i”命令后;此外,你可以使用“sudo -E”作为接下来所有命令的前缀。
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在使用`sudo -i`命令后执行,或者你可以使用`sudo -E`作为接下来所有命令的前缀。
|
||||
|
||||
开始之前,我们需要拷贝“easy-rsa”到openvpn文件夹。
|
||||
|
||||
@ -32,15 +32,15 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
这里,我们开启了一个密钥生成进程。
|
||||
这里,我们开始密钥生成进程。
|
||||
|
||||
首先,我们编辑一个“var”文件。为了简化生成过程,我们需要在里面指定数据。这里是“var”文件的一个样例:
|
||||
首先,我们编辑一个“vars”文件。为了简化生成过程,我们需要在里面指定数据。这里是“vars”文件的一个样例:
|
||||
|
||||
export KEY_COUNTRY="US"
|
||||
export KEY_PROVINCE="CA"
|
||||
export KEY_CITY="SanFrancisco"
|
||||
export KEY_ORG="Fort-Funston"
|
||||
export KEY_EMAIL="my@myhost.mydomain"
|
||||
export KEY_COUNTRY="CN"
|
||||
export KEY_PROVINCE="BJ"
|
||||
export KEY_CITY="Beijing"
|
||||
export KEY_ORG="Linux.CN"
|
||||
export KEY_EMAIL="open@vpn.linux.cn"
|
||||
export KEY_OU=server
|
||||
|
||||
希望这些字段名称对你而言已经很清楚,不需要进一步说明了。
|
||||
@ -61,7 +61,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
./build-ca
|
||||
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查以下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查一下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
.............................................+++
|
||||
@ -75,14 +75,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN CA]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
接下来,我们需要生成一个服务器密钥
|
||||
|
||||
@ -102,14 +102,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [server]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN server]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
@ -119,14 +119,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'US'
|
||||
stateOrProvinceName :PRINTABLE:'CA'
|
||||
localityName :PRINTABLE:'SanFrancisco'
|
||||
organizationName :PRINTABLE:'Fort-Funston'
|
||||
organizationalUnitName:PRINTABLE:'MyOrganizationalUnit'
|
||||
commonName :PRINTABLE:'server'
|
||||
countryName :PRINTABLE:'CN'
|
||||
stateOrProvinceName :PRINTABLE:'BJ'
|
||||
localityName :PRINTABLE:'Beijing'
|
||||
organizationName :PRINTABLE:'Linux.CN'
|
||||
organizationalUnitName:PRINTABLE:'Tech'
|
||||
commonName :PRINTABLE:'Linux.CN server'
|
||||
name :PRINTABLE:'EasyRSA'
|
||||
emailAddress :IA5STRING:'me@myhost.mydomain'
|
||||
emailAddress :IA5STRING:'open@vpn.linux.cn'
|
||||
Certificate is to be certified until May 22 19:00:25 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
@ -143,7 +143,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
Generating DH parameters, 2048 bit long safe prime, generator 2
|
||||
This is going to take a long time
|
||||
................................+................<and many many dots>
|
||||
................................+................<许多的点>
|
||||
|
||||
在漫长的等待之后,我们可以继续生成最后的密钥了,该密钥用于TLS验证。命令如下:
|
||||
|
||||
@ -176,7 +176,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
### Unix的客户端配置 ###
|
||||
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要从先前的部分连接到OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的目录中:
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要连接到前面建立的OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的对应目录中:
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
@ -211,7 +211,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -243,7 +243,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
安卓设备上的OpenVPN配置和Unix系统上的十分类似,我们需要一个含有配置文件、密钥和证书的包。文件列表如下:
|
||||
|
||||
- configuration file (.ovpn),
|
||||
- 配置文件 (扩展名 .ovpn),
|
||||
- ca.crt,
|
||||
- dh2048.pem,
|
||||
- client.crt,
|
||||
@ -257,7 +257,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -274,21 +274,21 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
所有这些文件我们必须移动我们设备的SD卡上。
|
||||
|
||||
然后,我们需要安装[OpenVPN连接][2]。
|
||||
然后,我们需要安装一个[OpenVPN Connect][2] 应用。
|
||||
|
||||
接下来,配置过程很是简单:
|
||||
|
||||
open setting of OpenVPN and select Import options
|
||||
select Import Profile from SD card option
|
||||
in opened window go to folder with prepared files and select .ovpn file
|
||||
application offered us to create a new profile
|
||||
tap on the Connect button and wait a second
|
||||
- 打开 OpenVPN 并选择“Import”选项
|
||||
- 选择“Import Profile from SD card”
|
||||
- 在打开的窗口中导航到我们放置好文件的目录,并选择那个 .ovpn 文件
|
||||
- 应用会要求我们创建一个新的配置文件
|
||||
- 点击“Connect”按钮并稍等一下
|
||||
|
||||
搞定。现在,我们的安卓设备已经通过安全的VPN连接连接到我们的专用网。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和在企业中使用。
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易的客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和企业中使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -296,7 +296,7 @@ via: http://linoxide.com/ubuntu-how-to/configure-openvpn-server-client-ubuntu-15
|
||||
|
||||
作者:[Ivan Zabrovskiy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
Syncthing: 一个跨计算机的私人的文件/文件夹安全同步工具
|
||||
Syncthing: 一个在计算机之间同步文件/文件夹的私密安全同步工具
|
||||
================================================================================
|
||||
### 简介 ###
|
||||
|
||||
**Syncthing** 是一个免费开源的工具,它能在你的各个网络计算机间同步文件/文件夹。它不像其它的同步工具,如**BitTorrent Sync**和**Dropbox**那样,它的同步数据是直接从一个系统中直接传输到另一个系统的,并且它是完全开源的,安全且私有的。你所有的珍贵数据都会被存储在你的系统中,这样你就能对你的文件和文件夹拥有全面的控制权,没有任何的文件或文件夹会被存储在第三方系统中。此外,你有权决定这些数据该存于何处,是否要分享到第三方,或这些数据在互联网上的传输方式。
|
||||
**Syncthing**是一个免费开源的工具,它能在你的各个网络计算机间同步文件/文件夹。它不像其它的同步工具,如**BitTorrent Sync**和**Dropbox**那样,它的同步数据是直接从一个系统中直接传输到另一个系统的,并且它是完全开源的,安全且私密的。你所有的珍贵数据都会被存储在你的系统中,这样你就能对你的文件和文件夹拥有全面的控制权,没有任何的文件或文件夹会被存储在第三方系统中。此外,你有权决定这些数据该存于何处,是否要分享到第三方,或这些数据在互联网上的传输方式。
|
||||
|
||||
所有的信息通讯都使用TLS进行加密,这样你的数据便能十分安全地逃离窥探。Syncthing有一个强大的响应式的网页管理界面(WebGUI,下同),它能够帮助用户简便地添加,删除和管理那些通过网络进行同步的文件夹。通过使用Syncthing,你可以在多个系统上一次同步多个文件夹。在安装和使用上,Syncthing是一个可移植的,简单但强大的工具。即然文件或文件夹是从一部计算机中直接传输到另一计算机中的,那么你就无需考虑向云服务供应商支付金钱来获取额外的云空间。你所需要的仅仅是非常稳定的LAN/WAN连接和你的系统中足够的硬盘空间。它支持所有的现代操作系统,包括GNU/Linux, Windows, Mac OS X, 当然还有Android。
|
||||
所有的信息通讯都使用TLS进行加密,这样你的数据便能十分安全地逃离窥探。Syncthing有一个强大的响应式的网页管理界面(WebGUI,下同),它能够帮助用户简便地添加、删除和管理那些通过网络进行同步的文件夹。通过使用Syncthing,你可以在多个系统上一次同步多个文件夹。在安装和使用上,Syncthing是一个可移植的、简单而强大的工具。即然文件或文件夹是从一部计算机中直接传输到另一计算机中的,那么你就无需考虑向云服务供应商支付金钱来获取额外的云空间。你所需要的仅仅是非常稳定的LAN/WAN连接以及在你的系统中有足够的硬盘空间。它支持所有的现代操作系统,包括GNU/Linux, Windows, Mac OS X, 当然还有Android。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
@ -13,7 +13,7 @@ Syncthing: 一个跨计算机的私人的文件/文件夹安全同步工具
|
||||
### 系统1细节: ###
|
||||
|
||||
- **操作系统**: Ubuntu 14.04 LTS server;
|
||||
- **主机名**: server1.unixmen.local;
|
||||
- **主机名**: **server1**.unixmen.local;
|
||||
- **IP地址**: 192.168.1.150.
|
||||
- **系统用户**: sk (你可以使用你自己的系统用户)
|
||||
- **同步文件夹**: /home/Sync/ (Syncthing会默认创建)
|
||||
@ -21,7 +21,7 @@ Syncthing: 一个跨计算机的私人的文件/文件夹安全同步工具
|
||||
### 系统2细节 ###
|
||||
|
||||
- **操作系统**: Ubuntu 14.10 server;
|
||||
- **主机名**: server.unixmen.local;
|
||||
- **主机名**: **server**.unixmen.local;
|
||||
- **IP地址**: 192.168.1.151.
|
||||
- **系统用户**: sk (你可以使用你自己的系统用户)
|
||||
- **同步文件夹**: /home/Sync/ (Syncthing会默认创建)
|
||||
@ -49,7 +49,7 @@ Syncthing: 一个跨计算机的私人的文件/文件夹安全同步工具
|
||||
|
||||
cd syncthing-linux-amd64-v0.10.20/
|
||||
|
||||
复制可执行文件"Syncthing"到**$PATH**:
|
||||
复制可执行文件"syncthing"到**$PATH**:
|
||||
|
||||
sudo cp syncthing /usr/local/bin/
|
||||
|
||||
@ -57,7 +57,7 @@ Syncthing: 一个跨计算机的私人的文件/文件夹安全同步工具
|
||||
|
||||
syncthing
|
||||
|
||||
当你执行上述命令后,syncthing会生成一个配置以及一些关键值(keys),并且在你的浏览器上打开一个管理界面。,
|
||||
当你执行上述命令后,syncthing会生成一个配置以及一些配置键值,并且在你的浏览器上打开一个管理界面。
|
||||
|
||||
输入示例:
|
||||
|
||||
@ -78,11 +78,11 @@ Syncthing: 一个跨计算机的私人的文件/文件夹安全同步工具
|
||||
[BQXVO] 15:41:07 INFO: Device BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ is "server1" at [dynamic]
|
||||
[BQXVO] 15:41:07 INFO: Completed initial scan (rw) of folder default
|
||||
|
||||
Syncthing已经被成功地初始化了,网页管理接口也可以通过浏览器在URL: **http://localhost:8080**进行访问了。如上面输入所看到的,Syncthing在你的**home**目录中的Sync目录**下自动为你创建了一个名为**default**的文件夹。
|
||||
Syncthing已经被成功地初始化了,网页管理接口也可以通过浏览器访问URL: **http://localhost:8080**。如上面输入所看到的,Syncthing在你的**home**目录中的Sync目录**下自动为你创建了一个名为**default**的文件夹。
|
||||
|
||||
默认情况下,Syncthing的网页管理界面(WebGUI)只能在本地端口(localhost)中进行访问,你需要在两个系统中进行以下操作:
|
||||
默认情况下,Syncthing的网页管理界面只能在本地端口(localhost)中进行访问,要从远程进行访问,你需要在两个系统中进行以下操作:
|
||||
|
||||
首先,按下CTRL+C键来停止Syncthing初始化进程。现在你回到了终端界面。
|
||||
首先,按下CTRL+C键来终止Syncthing初始化进程。现在你回到了终端界面。
|
||||
|
||||
编辑**config.xml**文件,
|
||||
|
||||
@ -115,17 +115,18 @@ Syncthing已经被成功地初始化了,网页管理接口也可以通过浏
|
||||
现在,在你的浏览器上打开**http://ip-address:8080/**。你会看到下面的界面:
|
||||
|
||||

|
||||
|
||||
网页管理界面分为两个窗格,在左窗格中,你应该可以看到同步的文件夹列表。如前所述,文件夹**default**在你初始化Syncthing时被自动创建。如果你想同步更多文件夹,点击**Add Folder**按钮。
|
||||
|
||||
在右窗格中,你可以看到已连接的设备数。现在这里只有一个,就是你现在正在操作的计算机。
|
||||
|
||||
### 网页管理界面(WebGUI)上设置Syncthing ###
|
||||
### 网页管理界面上设置Syncthing ###
|
||||
|
||||
为了提高安全性,让我们启用TLS,并且设置访问网页管理界面的管理员用户和密码。要做到这点,点击右上角的齿轮按钮,然后选择**Settings**
|
||||
|
||||

|
||||
|
||||
输入管理员的帐户名/密码。我设置的是admin/Ubuntu。你可以使用一些更复杂的密码。
|
||||
输入管理员的帐户名/密码。我设置的是admin/Ubuntu。你应该使用一些更复杂的密码。
|
||||
|
||||

|
||||
|
||||
@ -155,7 +156,7 @@ Syncthing已经被成功地初始化了,网页管理接口也可以通过浏
|
||||
|
||||

|
||||
|
||||
接着会出现下面的界面。在Device区域粘贴**系统1 ID **。输入设备名称(可选)。在地址区域,你可以输入其它系统(译者注:即粘贴的ID所属的系统,此应为系统1)的IP地址,或者使用默认值。默认值为**dynamic**。最后,选择要同步的文件夹。在我们的例子中,同步文件夹为**default**。
|
||||
接着会出现下面的界面。在Device区域粘贴**系统1 ID **。输入设备名称(可选)。在地址区域,你可以输入其它系统( LCTT 译注:即粘贴的ID所属的系统,此应为系统1)的IP地址,或者使用默认值。默认值为**dynamic**。最后,选择要同步的文件夹。在我们的例子中,同步文件夹为**default**。
|
||||
|
||||

|
||||
|
||||
@ -181,7 +182,7 @@ Syncthing已经被成功地初始化了,网页管理接口也可以通过浏
|
||||
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
现在,在任一个系统中的“**default**”文件夹中放进任意文件或文件夹。你应该可以看到这些文件/文件夹被自动同步到其它系统。
|
||||
|
||||
@ -197,7 +198,7 @@ via: http://www.unixmen.com/syncthing-private-secure-tool-sync-filesfolders-comp
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,11 @@
|
||||
修复Linux中的提供最小化类BASH命令行编辑GRUB错误
|
||||
修复Linux中的“提供类似行编辑的袖珍BASH...”的GRUB错误
|
||||
================================================================================
|
||||
|
||||
这两天我[安装了Elementary OS和Windows双系统][1],在启动的时候遇到了一个Grub错误。命令行中呈现如下信息:
|
||||
|
||||
**提供最小化类BASH命令行编辑。对于第一个词,TAB键补全可以使用的命令。除此之外,TAB键补全可用的设备或文件。**
|
||||
**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
|
||||
|
||||
**提供类似行编辑的袖珍 BASH。TAB键补全第一个词,列出可以使用的命令。除此之外,TAB键补全可以列出可用的设备或文件。**
|
||||
|
||||

|
||||
|
||||
@ -10,7 +13,7 @@
|
||||
|
||||
通过这篇文章里我们可以学到基于Linux系统**如何修复Ubuntu中出现的“minimal BASH like line editing is supported” Grub错误**。
|
||||
|
||||
> 你可以参阅这篇教程来修复类似的高频问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||
> 你可以参阅这篇教程来修复类似的常见问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
@ -19,11 +22,11 @@
|
||||
- 一个包含相同版本、相同OS的LiveUSB或磁盘
|
||||
- 当前会话的Internet连接正常工作
|
||||
|
||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话;))。
|
||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话 ;) )。
|
||||
|
||||
### 如何在基于Ubuntu的Linux中修复“minimal BASH like line editing is supported” Grub错误 ###
|
||||
|
||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法并叫作**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复minimal BASH like line editing is supported Grub错误。
|
||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法,用个叫做**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复“minimal BASH like line editing is supported” Grub错误。
|
||||
|
||||
### 步骤 1: 引导进入lives会话 ###
|
||||
|
||||
@ -75,7 +78,7 @@ via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
FreeBSD 和 Linux 有什么不同?
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 简介 ###
|
||||
|
||||
BSD最初从UNIX继承而来,目前,有许多的类Unix操作系统是基于BSD的。FreeBSD是使用最广泛的开源的伯克利软件发行版(即 BSD 发行版)。就像它隐含的意思一样,它是一个自由开源的类Unix操作系统,并且是公共服务器平台。FreeBSD源代码通常以宽松的BSD许可证发布。它与Linux有很多相似的地方,但我们得承认它们在很多方面仍有不同。
|
||||
|
||||
本文的其余部分组织如下:FreeBSD的描述在第一部分,FreeBSD和Linux的相似点在第二部分,它们的区别将在第三部分讨论,对他们功能的讨论和总结在最后一节。
|
||||
|
||||
### FreeBSD描述 ###
|
||||
|
||||
#### 历史 ####
|
||||
|
||||
- FreeBSD的第一个版本发布于1993年,它的第一张CD-ROM是FreeBSD1.0,发行于1993年12月。接下来,FreeBSD 2.1.0在1995年发布,并且获得了所有用户的青睐。实际上许多IT公司都使用FreeBSD并且很满意,我们可以列出其中的一些:IBM、Nokia、NetApp和Juniper Network。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 关于它的许可证,FreeBSD以多种开源许可证进行发布,它的名为Kernel的最新代码以两句版BSD许可证进行了发布,给予使用和重新发布FreeBSD的绝对自由。其它的代码则以三句版或四句版BSD许可证进行发布,有些是以GPL和CDDL的许可证发布的。
|
||||
|
||||
(LCTT 译注:BSD 许可证与 GPL 许可证相比,相当简短,最初只有四句规则;1999年应 RMS 请求,删除了第三句,新的许可证称作“新 BSD”或三句版BSD;原来的 BSD 许可证称作“旧 BSD”、“修订的 BSD”或四句版BSD;也有一种删除了第三、第四两句的版本,称之为两句版 BSD,等价于 MIT 许可证。)
|
||||
|
||||
#### 用户 ####
|
||||
|
||||
- FreeBSD的重要特点之一就是它的用户多样性。实际上,FreeBSD可以作为邮件服务器、Web 服务器、FTP 服务器以及路由器等,您只需要在它上运行服务相关的软件即可。而且FreeBSD还支持ARM、PowerPC、MIPS、x86、x86-64架构。
|
||||
|
||||
### FreeBSD和Linux的相似处 ###
|
||||
|
||||
FreeBSD和Linux是两个自由开源的软件。实际上,它们的用户可以很容易的检查并修改源代码,用户拥有绝对的自由。而且,FreeBSD和Linux都是类Unix系统,它们的内核、内部组件、库程序都使用从历史上的AT&T Unix继承来的算法。FreeBSD从根基上更像Unix系统,而Linux是作为自由的类Unix系统发布的。许多工具应用都可以在FreeBSD和Linux中找到,实际上,他们几乎有同样的功能。
|
||||
|
||||
此外,FreeBSD能够运行大量的Linux应用。它可以安装一个Linux的兼容层,这个兼容层可以在编译FreeBSD时加入AAC Compact Linux得到,或通过下载已编译了Linux兼容层的FreeBSD系统,其中会包括兼容程序:aac_linux.ko。不同于FreeBSD的是,Linux无法运行FreeBSD的软件。
|
||||
|
||||
最后,我们注意到虽然二者有同样的目标,但二者还是有一些不同之处,我们在下一节中列出。
|
||||
|
||||
### FreeBSD和Linux的区别 ###
|
||||
|
||||
目前对于大多数用户来说并没有一个选择FreeBSD还是Linux的明确的准则。因为他们有着很多同样的应用程序,因为他们都被称作类Unix系统。
|
||||
|
||||
在这一章,我们将列出这两种系统的一些重要的不同之处。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 两个系统的区别首先在于它们的许可证。Linux以GPL许可证发行,它为用户提供阅读、发行和修改源代码的自由,GPL许可证帮助用户避免仅仅发行二进制。而FreeBSD以BSD许可证发布,BSD许可证比GPL更宽容,因为其衍生著作不需要仍以该许可证发布。这意味着任何用户能够使用、发布、修改代码,并且不需要维持之前的许可证。
|
||||
- 您可以依据您的需求,在两种许可证中选择一种。首先是BSD许可证,由于其特殊的条款,它更受用户青睐。实际上,这个许可证使用户在保证源代码的封闭性的同时,可以售卖以该许可证发布的软件。再说说GPL,它需要每个使用以该许可证发布的软件的用户多加注意。
|
||||
- 如果想在以不同许可证发布的两种软件中做出选择,您需要了解他们各自的许可证,以及他们开发中的方法论,从而能了解他们特性的区别,来选择更适合自己需求的。
|
||||
|
||||
#### 控制 ####
|
||||
|
||||
- 由于FreeBSD和Linux是以不同的许可证发布的,Linus Torvalds控制着Linux的内核,而FreeBSD却与Linux不同,它并未被控制。我个人更倾向于使用FreeBSD而不是Linux,这是因为FreeBSD才是绝对自由的软件,没有任何控制许可证的存在。Linux和FreeBSD还有其他的不同之处,我建议您先不急着做出选择,等读完本文后再做出您的选择。
|
||||
|
||||
#### 操作系统 ####
|
||||
|
||||
- Linux主要指内核系统,这与FreeBSD不同,FreeBSD的整个系统都被维护着。FreeBSD的内核和一组由FreeBSD团队开发的软件被作为一个整体进行维护。实际上,FreeBSD开发人员能够远程且高效的管理核心操作系统。
|
||||
- 而Linux方面,在管理系统方面有一些困难。由于不同的组件由不同的源维护,Linux开发者需要将它们汇集起来,才能达到同样的功能。
|
||||
- FreeBSD和Linux都给了用户大量的可选软件和发行版,但他们管理的方式不同。FreeBSD是统一的管理方式,而Linux需要被分别维护。
|
||||
|
||||
#### 硬件支持 ####
|
||||
|
||||
- 说到硬件支持,Linux比FreeBSD做的更好。但这不意味着FreeBSD没有像Linux那样支持硬件的能力。他们只是在管理的方式不同,这通常还依赖于您的需求。因此,如果您在寻找最新的解决方案,FreeBSD更适应您;但如果您在寻找更多的普适性,那最好使用Linux。
|
||||
|
||||
#### 原生FreeBSD Vs 原生Linux ####
|
||||
|
||||
- 两者的原生系统的区别又有不同。就像我之前说的,Linux是一个Unix的替代系统,由Linux Torvalds编写,并由网络上的许多极客一起协助实现的。Linux有一个现代系统所需要的全部功能,诸如虚拟内存、共享库、动态加载、优秀的内存管理等。它以GPL许可证发布。
|
||||
- FreeBSD也继承了Unix的许多重要的特性。FreeBSD作为在加州大学开发的BSD的一种发行版。开发BSD的最重要的原因是用一个开源的系统来替代AT&T操作系统,从而给用户无需AT&T许可证便可使用的能力。
|
||||
- 许可证的问题是开发者们最关心的问题。他们试图提供一个最大化克隆Unix的开源系统。这影响了用户的选择,由于FreeBSD使用BSD许可证进行发布,因而相比Linux更加自由。
|
||||
|
||||
#### 支持的软件包 ####
|
||||
|
||||
- 从用户的角度来看,另一个二者不同的地方便是软件包以及从源码安装的软件的可用性和支持。Linux只提供了预编译的二进制包,这与FreeBSD不同,它不但提供预编译的包,而且还提供从源码编译和安装的构建系统。使用它的 ports 工具,FreeBSD给了您选择使用预编译的软件包(默认)和在编译时定制您软件的能力。(LCTT 译注:此处说明有误。Linux 也提供了源代码方式的包,并支持自己构建。)
|
||||
- 这些 ports 允许您构建所有支持FreeBSD的软件。而且,它们的管理还是层次化的,您可以在/usr/ports下找到源文件的地址以及一些正确使用FreeBSD的文档。
|
||||
- 这些提到的 ports给予你产生不同软件包版本的可能性。FreeBSD给了您通过源代码构建以及预编译的两种软件,而不是像Linux一样只有预编译的软件包。您可以使用两种安装方式管理您的系统。
|
||||
|
||||
#### FreeBSD 和 Linux 常用工具比较 ####
|
||||
|
||||
- 有大量的常用工具在FreeBSD上可用,并且有趣的是他们由FreeBSD的团队所拥有。相反的,Linux工具来自GNU,这就是为什么在使用中有一些限制。(LCTT 译注:这也是 Linux 正式的名称被称作“GNU/Linux”的原因,因为本质上 Linux 其实只是指内核。)
|
||||
- 实际上FreeBSD采用的BSD许可证非常有益且有用。因此,您有能力维护核心操作系统,控制这些应用程序的开发。有一些工具类似于它们的祖先 - BSD和Unix的工具,但不同于GNU的套件,GNU套件只想做到最小的向后兼容。
|
||||
|
||||
#### 标准 Shell ####
|
||||
|
||||
- FreeBSD默认使用tcsh。它是csh的评估版,由于FreeBSD以BSD许可证发行,因此不建议您在其中使用GNU的组件 bash shell。bash和tcsh的区别仅仅在于tcsh的脚本功能。实际上,我们更推荐在FreeBSD中使用sh shell,因为它更加可靠,可以避免一些使用tcsh和csh时出现的脚本问题。
|
||||
|
||||
#### 一个更加层次化的文件系统 ####
|
||||
|
||||
- 像之前提到的一样,使用FreeBSD时,基础操作系统以及可选组件可以被很容易的区别开来。这导致了一些管理它们的标准。在Linux下,/bin,/sbin,/usr/bin或者/usr/sbin都是存放可执行文件的目录。FreeBSD不同,它有一些附加的对其进行组织的规范。基础操作系统被放在/usr/local/bin或者/usr/local/sbin目录下。这种方法可以帮助管理和区分基础操作系统和可选组件。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
FreeBSD和Linux都是自由且开源的系统,他们有相似点也有不同点。上面列出的内容并不能说哪个系统比另一个更好。实际上,FreeBSD和Linux都有自己的特点和技术规格,这使它们与别的系统区别开来。那么,您有什么看法呢?您已经有在使用它们中的某个系统了么?如果答案为是的话,请给我们您的反馈;如果答案是否的话,在读完我们的描述后,您怎么看?请在留言处发表您的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/comparative-introduction-freebsd-linux-users/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
@ -1,25 +1,24 @@
|
||||
sevenot translated
|
||||
10大帮助你获得理想的职业的需求分布
|
||||
10 大帮助你获得理想的职业的操作系统技能
|
||||
================================================================================
|
||||
我们用了5篇系列文章,来让人们意识到那些可以帮助他们获得理想职业的顶级技能。在这个充满竞争的社会里,你不能仅仅依赖一项仅能,你需要在多个职业技能上都有所涉猎。我们并不能权衡这些技能,但是我们可以参考这些几乎不变的惯例和统计数据。
|
||||
|
||||
下面的文章和紧跟其后的内容,是针对全球各大IT公司上一季度对员工技能要求的详细调查报告。统计数据真实的反映了需求和市场的变化。我们会尽力让这份报告保持时效性,特别是有明显变化的时候。这五篇系列文章是:
|
||||
|
||||
-10大帮助你获得理想的职业的需求分布
|
||||
-[10大帮助你获得职位的著名 IT 技能][1]
|
||||
-10大帮助你获得理想职位的项目技能
|
||||
-10大帮助你赢得理想职位的网络技能
|
||||
-10大帮助你获得理想职位的个人认证
|
||||
- 10大帮助你获得理想的职业的需求分布
|
||||
- [10大帮助你获得职位的著名 IT 技能][1]
|
||||
- [10大帮助你获得理想职位的项目技能][2]
|
||||
- [10大帮助你赢得理想职位的网络技能][3]
|
||||
- [10大帮助你获得理想职位的个人认证][4]
|
||||
|
||||
### 1. Windows ###
|
||||
|
||||
微软研发的windows操作系统不仅在PC市场上占据龙头地位,而且从职位视角来看也是最枪手的操作系统工作,不管你是赞成还是反对。有资料显示上一季度需求增长达到0.1%.
|
||||
微软研发的windows操作系统不仅在PC市场上占据龙头地位,而且从职位视角来看也是最抢手的操作系统技能,不管你是赞成还是反对。有资料显示上一季度需求增长达到0.1%.
|
||||
|
||||
最新版本 : Windows 8.1
|
||||
|
||||
### 2. Red Hat Enterprise Linux ###
|
||||
|
||||
Red Hat Enterprise Linux 是一个商业发行版本的企业级Linux,它由红帽公司研发。它是世界上运用最广的Linux发行版本,特别是在生产环境和协同工作方面。上一季度其整体需求上涨17%,位列第二。
|
||||
Red Hat Enterprise Linux 是一个商业的Linux发行版本,它由红帽公司研发。它是世界上运用最广的Linux发行版本之一,特别是在生产环境和协同工作方面。上一季度其整体需求上涨17%,位列第二。
|
||||
|
||||
最新版本 : RedHat Enterprise Linux 7.1
|
||||
|
||||
@ -50,9 +49,10 @@ Red Hat Enterprise Linux 是一个商业发行版本的企业级Linux,它由
|
||||
### 7. Ubuntu ###
|
||||
|
||||
排在第7的是Ubuntu,这是一款由Canonicals公司研发设计的Linux系统,旨在服务于个人。上一季度需求率上涨11%。
|
||||
|
||||
最新版本 :
|
||||
|
||||
- Ubuntu 14.10 (9 months security and maintenance update).
|
||||
- Ubuntu 14.10 (已有九个月的安全和维护更新).
|
||||
- Ubuntu 14.04.2 LTS
|
||||
|
||||
### 8. Suse ###
|
||||
@ -63,19 +63,16 @@ Red Hat Enterprise Linux 是一个商业发行版本的企业级Linux,它由
|
||||
|
||||
### 9. Debian ###
|
||||
|
||||
The very famous Linux Operating System, mother of 100’s of Distro and closest to GNU comes at number nine.
|
||||
排在第9的是非常有名的 Linux 操作系统Debian,非常贴近GNU。其上一季度需求率上涨9%。
|
||||
排在第9的是非常有名的 Linux 操作系统Debian,它是上百种Linux 发行版之母,非常接近GNU理念。其上一季度需求率上涨9%。
|
||||
|
||||
最新版本: Debian 7.8
|
||||
|
||||
### 10. HP-UX ###
|
||||
|
||||
The Proprietary UNIX Operating System designed by Hewlett-Packard comes at number ten. It has shown a decline in the last quarter by 5%.
|
||||
排在第10的是Hewlett-Packard公司研发的专用 Linux 操作系统HP-UX,上一季度需求率上涨5%。
|
||||
|
||||
最新版本 : 11i v3 Update 13
|
||||
|
||||
注:表格数据--不需要翻译--开始
|
||||
<table border="0" cellspacing="0">
|
||||
<colgroup width="107"></colgroup>
|
||||
<colgroup width="92"></colgroup>
|
||||
@ -133,7 +130,6 @@ The Proprietary UNIX Operating System designed by Hewlett-Packard comes at numbe
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
注:表格数据--不需要翻译--结束
|
||||
|
||||
以上便是全部信息,我会尽快推出下一篇系列文章,敬请关注Tecmint。不要忘了留下您宝贵的评论。如果您喜欢我们的文章并且与我们分享您的见解,这对我们的工作是一种鼓励。
|
||||
|
||||
@ -143,9 +139,12 @@ via: http://www.tecmint.com/top-distributions-in-demand-to-get-your-dream-job/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/top-distributions-in-demand-to-get-your-dream-job/www.tecmint.com/famous-it-skills-in-demand-that-will-get-you-hired/
|
||||
[1]:http://www.tecmint.com/famous-it-skills-in-demand-that-will-get-you-hired/
|
||||
[2]:https://linux.cn/article-5303-1.html
|
||||
[3]:http://www.tecmint.com/networking-protocols-skills-to-land-your-dream-job/
|
||||
[4]:http://www.tecmint.com/professional-certifications-in-demand-that-will-get-you-hired/
|
||||
@ -1,13 +1,14 @@
|
||||
在Linux中使用‘Systemctl’管理‘Systemd’服务和单元
|
||||
systemctl 完全指南
|
||||
================================================================================
|
||||
Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
|
||||
|
||||
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
|
||||
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有位数不多的几个尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有为数不多的几个发行版尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
|
||||

|
||||
使用Systemctl管理Linux服务
|
||||
|
||||
*使用Systemctl管理Linux服务*
|
||||
|
||||
本文旨在阐明在运行systemd的系统上“如何控制系统和服务”。
|
||||
|
||||
@ -41,11 +42,9 @@ Systemd是一个系统管理守护进程、工具和库的集合,用于取代S
|
||||
root 555 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-logind
|
||||
dbus 556 1 0 16:27 ? 00:00:00 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
|
||||
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(即 -eaf)。
|
||||
|
||||
a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(如 -eaf)。
|
||||
|
||||
也请注意上例中后随的方括号和样例剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
也请注意上例中后随的方括号和例子中剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
|
||||
#### 4. 分析systemd启动进程 ####
|
||||
|
||||
@ -147,7 +146,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
1 loaded units listed. Pass --all to see loaded but inactive units, too.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
|
||||
#### 10. 检查某个单元(cron.service)是否启用 ####
|
||||
#### 10. 检查某个单元(如 cron.service)是否启用 ####
|
||||
|
||||
# systemctl is-enabled crond.service
|
||||
|
||||
@ -187,7 +186,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
dbus-org.fedoraproject.FirewallD1.service enabled
|
||||
....
|
||||
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(httpd.service)状态 ####
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(如 httpd.service)状态 ####
|
||||
|
||||
# systemctl start httpd.service
|
||||
# systemctl restart httpd.service
|
||||
@ -214,15 +213,15 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
Apr 28 17:21:30 tecmint systemd[1]: Started The Apache HTTP Server.
|
||||
Hint: Some lines were ellipsized, use -l to show in full.
|
||||
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(系统启动时自动启动服务) ####
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(即系统启动时自动启动服务) ####
|
||||
|
||||
# systemctl is-active httpd.service
|
||||
# systemctl enable httpd.service
|
||||
# systemctl disable httpd.service
|
||||
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(httpd.service) ####
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(如 httpd.service) ####
|
||||
|
||||
# systemctl mask httpd.service
|
||||
ln -s '/dev/null' '/etc/systemd/system/httpd.service'
|
||||
@ -297,7 +296,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
# systemctl enable tmp.mount
|
||||
# systemctl disable tmp.mount
|
||||
|
||||
#### 20. 在Linux中屏蔽(让它不能启动)或显示挂载点 ####
|
||||
#### 20. 在Linux中屏蔽(让它不能启用)或可见挂载点 ####
|
||||
|
||||
# systemctl mask tmp.mount
|
||||
|
||||
@ -375,7 +374,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
|
||||
CPUShares=2000
|
||||
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(如 httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
|
||||
# vi /etc/systemd/system/httpd.service.d/90-CPUShares.conf
|
||||
|
||||
@ -528,13 +527,13 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
#### 35. 启动运行等级5,即图形模式 ####
|
||||
|
||||
# systemctl isolate runlevel5.target
|
||||
OR
|
||||
或
|
||||
# systemctl isolate graphical.target
|
||||
|
||||
#### 36. 启动运行等级3,即多用户模式(命令行) ####
|
||||
|
||||
# systemctl isolate runlevel3.target
|
||||
OR
|
||||
或
|
||||
# systemctl isolate multiuser.target
|
||||
|
||||
#### 36. 设置多用户模式或图形模式为默认运行等级 ####
|
||||
@ -572,7 +571,7 @@ via: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
GNU、开源和 Apple 的那些黑历史
|
||||
==============================================================================
|
||||
> 自由软件/开源社区与 Apple 之间的争论可以回溯到上世纪80年代,当时 Linux 的创始人称 Mac OS X 的核心就是“一堆废物”。还有其他一些软件史上的轶事。
|
||||
|
||||

|
||||
|
||||
开源拥护者们与微软之间有着很长、而且摇摆的关系。每个人都知道这个。但是,在许多方面,自由或者开源软件的支持者们与 Apple 之间的争执则更加突出——尽管这很少受到媒体的关注。
|
||||
|
||||
需要说明的是,并不是所有的开源拥护者都厌恶苹果。从各种轶事中,我已经见过很多 Linux 的黑客玩耍 iPhone 和iPad。实际上,许多 Linux 用户是十分喜欢 Apple 的 OS X 系统的,以至于他们[创造了很多Linux的发行版][1],都设计得看起来像OS X。(顺便说下,[北朝鲜政府][2]就这样做了。)
|
||||
|
||||
但是 Mac 的信徒与企鹅的信徒——即 Linux 社区(不包括别的,仅指自由与开源软件世界中的这一小部分)之间的关系,并不一直是完全的和谐。并且这绝不是一个新的现象,在我研究Linux和自由软件基金会历史的时候就发现了。
|
||||
|
||||
### GNU vs. Apple ###
|
||||
|
||||
这场战争将回溯到至少上世纪80年代后期。1988年6月,Richard Stallman 发起了 [GNU][3] 项目,希望建立一个完全自由的类 Unix 操作系统,其源代码将会免费共享,[强烈指责][4] Apple 对 [Hewlett-Packard][5](HPQ)和 [Microsoft][6](MSFT)的诉讼,称Apple的声明中说别人对 Macintosh 操作系统的界面和体验的抄袭是不正确。如果 Apple 流行的话,GNU 警告到,这家公司“将会借助大众的新力量终结掉为取代商业软件而生的自由软件。”
|
||||
|
||||
那个时候,GNU 对抗 Apple 的诉讼(这意味着,十分讽刺的是,GNU 正在支持 Microsoft,尽管当时的情况不一样),通过发布[“让你的律师远离我的电脑”按钮][7]。同时呼吁 GNU 的支持者们抵制 Apple,警告虽然 Macintosh 看起来是不错的计算机,但 Apple 一旦赢得了诉讼就会给市场带来垄断,这会极大地提高计算机的售价。
|
||||
|
||||
Apple 最终[输掉了这场诉讼][8],但是直到1994年之后,GNU 才[撤销对 Apple 的抵制][9]。这期间,GNU 一直不断指责 Apple。在上世纪90年代早期甚至之后,GNU 开始发展 GNU 软件项目,可以在其他个人电脑平台包括 MS-DOS 计算机上使用。[GNU 宣称][10],除非 Apple 停止在计算机领域垄断的野心,让用户界面可以模仿 Macintosh 的一些东西,否则“我们不会提供任何对 Apple 机器的支持。”(因此讽刺的是 Apple 在90年代后期开发的类 UNIX 系统 OS X 有一大堆软件来自GNU。但是那是另外的故事了。)
|
||||
|
||||
### Torvalds 与 Jobs ###
|
||||
|
||||
除去他对大多数发行版比较自由放任的态度,Linux内核的创造者 Liuns Torvalds 相较于 Stallman 和 GNU 过去对Apple 的态度和善得多。在他 2001 年出版的书”Just For Fun: The Story of an Accidental Revolutionary“中,Torvalds 描述到与 Steve Jobs 的一次会面,大约是 1997 年收到后者的邀请去讨论 Mac OS X,当时 Apple 正在开发中,但还没有公开发布。
|
||||
|
||||
“基本上,Jobs 一开始就试图告诉我在桌面上的玩家就两个,Microsoft 和 Apple,而且他认为我能为 Linux 做的最好的事,就是从了 Apple,努力让开源用户去支持 Mac OS X” Torvalds 写道。
|
||||
|
||||
这次会谈显然让 Torvalds 很不爽。争吵的一点集中在 Torvalds 对 Mach 技术上的藐视,对于 Apple 正在用于构建新的 OS X 操作系统的内核,Torvalds 称其“一堆废物。它包含了所有你能做到的设计错误,并且甚至打算只弥补一小部分。”
|
||||
|
||||
但是更令人不快的是,显然是 Jobs 在开发 OS X 时入侵开源的方式(OS X 的核心里上有很多开源程序):“他有点贬低了结构的瑕疵:谁在乎基础操作系统这个真正的 low-core 东西是不是开源,如果你有 Mac 层在最上面,这不是开源?”
|
||||
|
||||
一切的一切,Torvalds 总结到,Jobs “并没有太多争论。他仅仅很简单地说着,胸有成竹地认为我会对与 Apple 合作感兴趣”。“他一无所知,不能去想像还会有人并不关心 Mac 市场份额的增长。我认为他真的感到惊讶了,当我表现出对 Mac 的市场有多大,或者 Microsoft 市场有多大的毫不关心时。”
|
||||
|
||||
当然,Torvalds 并没有对所有 Linux 用户说起过。他对于 OS X 和 Apple 的看法从 2001 年开始就渐渐软化了。但实际上,早在2000年,Linux 社区的领导角色表现出对 Apple 及其高层的傲慢的深深的鄙视,可以看出一些重要的东西,关于 Apple 世界和开源/自由软件世界的矛盾是多么的根深蒂固。
|
||||
|
||||
从以上两则历史上的花边新闻中,可以看到关于 Apple 产品价值的重大争议,即是否该公司致力于提升其创造的软硬件的质量,或者仅仅是借市场的小聪明获利,让Apple产品卖出更多的钱而不是创造等同其价值的功能。但是不管怎样,我会暂时置身讨论之外。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
|
||||
[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
|
||||
[3]:http://gnu.org/
|
||||
[4]:https://www.gnu.org/bulletins/bull5.html
|
||||
[5]:http://www.hp.com/
|
||||
[6]:http://www.microsoft.com/
|
||||
[7]:http://www.duntemann.com/AppleSnakeButton.jpg
|
||||
[8]:http://www.freibrun.com/articles/articl12.htm
|
||||
[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
|
||||
[10]:https://www.gnu.org/bulletins/bull12.html
|
||||
@ -0,0 +1,98 @@
|
||||
如何配置一个 Docker Swarm 原生集群
|
||||
================================================================================
|
||||
|
||||
嗨,大家好。今天我们来学一学Swarm相关的内容吧,我们将学习通过Swarm来创建Docker原生集群。[Docker Swarm][1]是用于Docker的原生集群项目,它可以将一个Docker主机池转换成单个的虚拟主机。Swarm工作于标准的Docker API,所以任何可以和Docker守护进程通信的工具都可以使用Swarm来透明地伸缩到多个主机上。就像其它Docker项目一样,Swarm遵循“内置电池,并可拆卸”的原则(LCTT 译注:batteries included,内置电池原来是 Python 圈里面对 Python 的一种赞誉,指自给自足,无需外求的丰富环境;but removable,并可拆卸应该指的是非强制耦合)。它附带有一个开箱即用的简单的后端调度程序,而且作为初始开发套件,也为其开发了一个可插拔不同后端的API。其目标在于为一些简单的使用情况提供一个平滑的、开箱即用的体验,并且它允许切换为更强大的后端,如Mesos,以用于大规模生产环境部署。Swarm配置和使用极其简单。
|
||||
|
||||
这里给大家提供Swarm 0.2开箱的即用一些特性。
|
||||
|
||||
1. Swarm 0.2.0大约85%与Docker引擎兼容。
|
||||
2. 它支持资源管理。
|
||||
3. 它具有一些带有限制和类同功能的高级调度特性。
|
||||
4. 它支持多个发现后端(hubs,consul,etcd,zookeeper)
|
||||
5. 它使用TLS加密方法进行安全通信和验证。
|
||||
|
||||
那么,我们来看一看Swarm的一些相当简单而简用的使用步骤吧。
|
||||
|
||||
### 1. 运行Swarm的先决条件 ###
|
||||
|
||||
我们必须在所有节点安装Docker 1.4.0或更高版本。虽然各个节点的IP地址不需要要公共地址,但是Swarm管理器必须可以通过网络访问各个节点。
|
||||
|
||||
**注意**:Swarm当前还处于beta版本,因此功能特性等还有可能发生改变,我们不推荐你在生产环境中使用。
|
||||
|
||||
### 2. 创建Swarm集群 ###
|
||||
|
||||
现在,我们将通过运行下面的命令来创建Swarm集群。各个节点都将运行一个swarm节点代理,该代理会注册、监控相关的Docker守护进程,并更新发现后端获取的节点状态。下面的命令会返回一个唯一的集群ID标记,在启动节点上的Swarm代理时会用到它。
|
||||
|
||||
在集群管理器中:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
### 3. 启动各个节点上的Docker守护进程 ###
|
||||
|
||||
我们需要登录进我们将用来创建集群的每个节点,并在其上使用-H标记启动Docker守护进程。它会保证Swarm管理器能够通过TCP访问到各个节点上的Docker远程API。要启动Docker守护进程,我们需要在各个节点内部运行以下命令。
|
||||
|
||||
# docker -H tcp://0.0.0.0:2375 -d
|
||||
|
||||

|
||||
|
||||
### 4. 添加节点 ###
|
||||
|
||||
在启用Docker守护进程后,我们需要添加Swarm节点到发现服务,我们必须确保节点IP可从Swarm管理器访问到。要完成该操作,我们需要运行以下命令。
|
||||
|
||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
**注意**:我们需要用步骤2中获取到的节点IP地址和集群ID替换这里的<node_ip>和<cluster_id>。
|
||||
|
||||
### 5. 开启Swarm管理器 ###
|
||||
|
||||
现在,由于我们已经获得了连接到集群的节点,我们将启动swarm管理器。我们需要在节点中运行以下命令。
|
||||
|
||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 6. 检查配置 ###
|
||||
|
||||
一旦管理运行起来后,我们可以通过运行以下命令来检查配置。
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
|
||||

|
||||
|
||||
**注意**:我们需要替换<manager_ip:manager_port>为运行swarm管理器的主机的IP地址和端口。
|
||||
|
||||
### 7. 使用docker CLI来访问节点 ###
|
||||
|
||||
在一切都像上面说得那样完美地完成后,这一部分是Docker Swarm最为重要的部分。我们可以使用Docker CLI来访问节点,并在节点上运行容器。
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||
|
||||
### 8. 监听集群中的节点 ###
|
||||
|
||||
我们可以使用swarm list命令来获取所有运行中节点的列表。
|
||||
|
||||
# docker run --rm swarm list token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 尾声 ###
|
||||
|
||||
Swarm真的是一个有着相当不错的功能的docker,它可以用于创建和管理集群。它相当易于配置和使用,当我们在它上面使用限制器和类同器时它更为出色。高级调度程序是一个相当不错的特性,它可以应用过滤器来通过端口、标签、健康状况来排除节点,并且它使用策略来挑选最佳节点。那么,如果你有任何问题、评论、反馈,请在下面的评论框中写出来吧,好让我们知道哪些材料需要补充或改进。谢谢大家了!尽情享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.docker.com/swarm/
|
||||
177
published/201507/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
177
published/201507/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
@ -0,0 +1,177 @@
|
||||
LINUX 101: 让你的 SHELL 更强大
|
||||
================================================================================
|
||||
> 在我们的关于 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
||||
|
||||
**为何要这样做?**
|
||||
|
||||
- 使得在 shell 提示符下过得更轻松,高效
|
||||
- 在失去连接后恢复先前的会话
|
||||
- Stop pushing around that fiddly rodent!
|
||||
|
||||
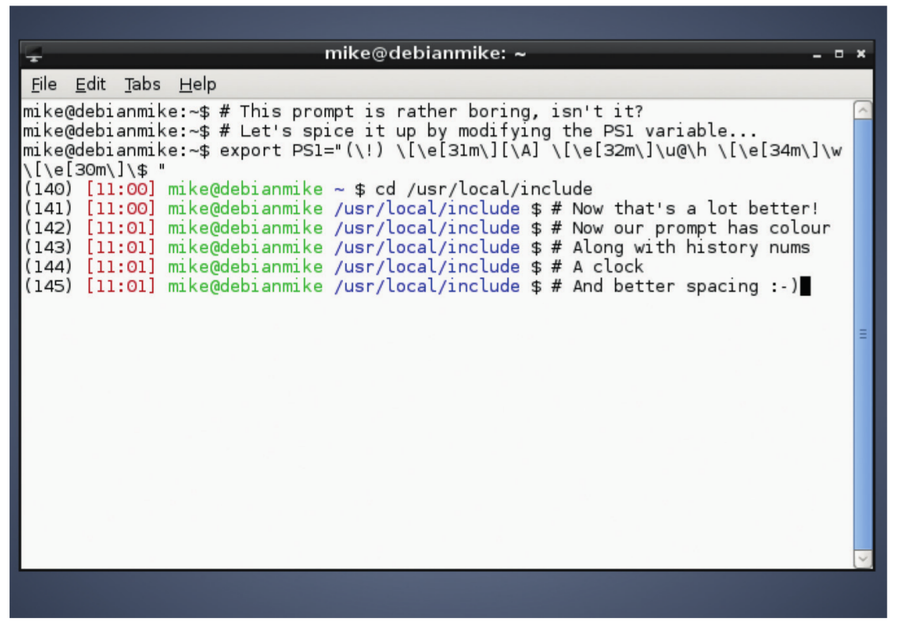
|
||||
|
||||
这是我的命令行提示符的设置。对于这个小的终端窗口来说,这或许有些长。但你可以根据你的喜好来调整它。
|
||||
|
||||
作为一个 Linux 用户, 你可能熟悉 shell (又名为命令行)。 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个将窗口铺满桌面的环境中,而 shell 是你与你的 linux 机器交互的主要方式。
|
||||
|
||||
在上面那些情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置。 尽管对于大多数的任务而言,它足够好了,但它可以更加强大。 在本教程中,我们将向你展示如何使得你的 shell 提供更多有用信息、更加实用且更适合工作。 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序。 并且,为了让眼睛舒服一点,我们还将关注配色方案。那么,进击吧,少女!
|
||||
|
||||
### 让提示符更美妙 ###
|
||||
|
||||
大多数的发行版本配置有一个非常简单的提示符,它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容。例如,在 Debian 7 下,默认的提示符是这样的:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
上面的提示符展示出了用户、主机名、当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 **#**)。 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中。 假如你键入 `echo $PS1`, 你将会在这个命令的输出字符串的最后有如下的字符:
|
||||
|
||||
\u@\h:\w$
|
||||
|
||||
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑。这不是正则表达式,这里的斜杠是转义序列,它告诉提示符进行一些特别的处理。 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
||||
|
||||
下面是一些你可以在提示符中用到的字符的列表:
|
||||
|
||||
- d 当前的日期
|
||||
- h 主机名
|
||||
- n 代表换行的字符
|
||||
- A 当前的时间 (HH:MM)
|
||||
- u 当前的用户
|
||||
- w (小写) 整个工作路径的全称
|
||||
- W (大写) 工作路径的简短名称
|
||||
- $ 一个提示符号,对于 root 用户为 # 号
|
||||
- ! 当前命令在 shell 历史记录中的序号
|
||||
|
||||
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**),而对于后者, 它则只显示 **bin** 这一部分。
|
||||
|
||||
现在,我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容,试试下面这个:
|
||||
|
||||
export PS1="I am \u and it is \A $"
|
||||
|
||||
现在,你的提示符将会像下面这样:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
从这个例子出发,你就可以按照你的想法来试验一下上面列出的其他转义序列。 但等等 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时,**PS1** 环境变量的值都会被重置。解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令。在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的加强的提示符就可以一直出现。你还可以使用额外的颜色来装扮提示符。刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的。 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
||||
|
||||
\[\e[31m\]
|
||||
|
||||
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
||||
|
||||
- 30 黑色
|
||||
- 32 绿色
|
||||
- 33 黄色
|
||||
- 34 蓝色
|
||||
- 35 洋红色
|
||||
- 36 青色
|
||||
- 37 白色
|
||||
|
||||
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容。深吸一口气,弯曲你的手指,然后键入下面这只“野兽”:
|
||||
|
||||
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
||||
|
||||
上面的命令提供了一个 Bash 命令历史序号、当前的时间、彩色的用户或主机名组合、以及工作路径。假如你“野心勃勃”,利用一些惊人的组合,你还可以更改提示符的背景色和前景色。非常有用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1]。
|
||||
|
||||
> **Shell 精要**
|
||||
>
|
||||
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力。 所以这里有一些基础知识来让你熟悉一些 shell。 通常在你的菜单中, shell 指的是 Terminal、 XTerm 或 Konsole, 当你启动它后, 最为实用的命令有这些:
|
||||
>
|
||||
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
||||
>
|
||||
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件)。
|
||||
>
|
||||
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出)。在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全。
|
||||
|
||||
### Tmux: 针对 shell 的窗口管理器 ###
|
||||
|
||||
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表。 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标。 这个功能非常有意义。
|
||||
|
||||
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦。 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起。
|
||||
|
||||
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接。想要看看这是如何运行的最好方式是自己尝试一下。在一个终端窗口中,输入 `screen` (在大多数发行版本中,它已经默认安装了或者可以在软件包仓库中找到)。 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失。 现在运行一个交互式的文本模式的程序,例如 `nano`, 并关闭这个终端窗口。
|
||||
|
||||
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的。打开一个新的终端并输入如下命令:
|
||||
|
||||
screen -r
|
||||
|
||||
瞧,你刚开打开的 Nano 会话又回来了!
|
||||
|
||||
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接(即 **-r** 选项)。
|
||||
|
||||
当你正使用 SSH 去连接另一台机器并做着某些工作时, 但并不想因为一个脆弱的连接而影响你的进度,这个方法尤其有用。假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了——不是这么悲催吧),你只需重新连接或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始。
|
||||
|
||||
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux。 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux。 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get、 yum install** 或 **pacman -S** 命令便可以安装它。
|
||||
|
||||
一旦你安装了它过后,键入 **tmux** 来启动它。接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表、机器的主机名、当前时间和日期。 现在运行一个程序,同样以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记。 Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口。你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果)。 若需要知道窗口列表,使用 Ctrl+B 再加上 W。
|
||||
|
||||
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时)。 当想同时看两个程序又该怎么办呢?
|
||||
|
||||
针对这种情况, 可以使用 tmux 中的窗格。 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分:一个在左一个在右。你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换。 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件。
|
||||
|
||||
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧。 首先你需要敲击 Ctrl+B 再加上一个 :(冒号),这将使得位于底部的 tmux 栏变为深橙色。 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux。 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动。 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令。 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号,并使用向上的箭头来取回刚才输入的命令。
|
||||
|
||||
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能。 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话。这使得这个会话的一切工作都在后台中运行、使用 `tmux a` 可以再重新连接到刚才的会话。但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
||||
|
||||
tmux ls
|
||||
|
||||
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容。
|
||||
|
||||
|
||||
|
||||
|
||||
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页。
|
||||
|
||||
> **Zsh: 另一个 shell**
|
||||
>
|
||||
> 选择是好的,但标准同样重要。 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell。 Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力。它成熟、可靠并文档丰富 – 但它不是你唯一的选择。
|
||||
>
|
||||
> 许多高级用户热衷于 Zsh, 即 Z shell。 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,另外还提供了一些额外的功能。 例如, 在 Zsh 中,你输入 **ls** ,并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述。 而不需要再打开 man page 了!
|
||||
>
|
||||
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符)。 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多。
|
||||
>
|
||||
> Zsh 在大多数的主要发行版本上都可以得到了; 安装它后并输入 **zsh** 便可启动它。 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令。 若需了解更多的信息,请访问 [www.zsh.org][2]。
|
||||
|
||||
### “未来”的终端 ###
|
||||
|
||||
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端。 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们通过某些线路,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为“哑终端”, 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息。
|
||||
|
||||
今天,我们在自己的机器上执行几乎所有的实际操作,所以我们的电脑不是传统意义下的终端,这就是为什么诸如 **XTerm**、 Gnome Terminal、 Konsole 等程序被称为“终端模拟器” 的原因 – 他们提供了同昔日的物理终端一样的功能。事实上,在许多方面它们并没有改变多少。诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作。
|
||||
|
||||
所以某些程序员正尝试改变这个状况。 **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在让终端步入到 21 世纪,例如带有在线媒体显示功能。你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频。 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们。
|
||||
|
||||
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为“命令的革新”。它就像是一个传统的 shell、一个 GUI 和一个 wiki 之间的过渡;你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令。用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分)。
|
||||
|
||||
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000。 是的,你没有看错 – $84K 来支持一个终端模拟器。这可能是最不寻常的集资活动了,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
||||
|
||||
### 下一代终端 ###
|
||||
|
||||
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效。我们的推荐有:
|
||||
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器)。 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说。它非常实用。
|
||||
|
||||
> **微调配色方案**
|
||||
>
|
||||
> 在《Linux Voice》杂志社中,我们并不迷恋那些养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性。我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果、摆弄不同的配色方案,直到我们 100% 的满意(然后出于习惯,摆弄更多的东西)。
|
||||
>
|
||||
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱,并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole 和 Xfce4 Terminal 等都是支持的应用。**),它可以输出其设定。移动滑块直到你看到配色方案最佳, 然后点击位于该页面右上角的 `得到方案` 按钮。
|
||||
>
|
||||
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费了很多的时间,使用一个精心设计的调色板也是非常值得的。 **Solarized** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
@ -1,16 +1,16 @@
|
||||
XBMC:自制遥控
|
||||
为 Kodi 自制遥控器
|
||||
================================================================================
|
||||
**通过运行在 Android 手机上的自制遥控器来控制你的家庭媒体播放器。**
|
||||
|
||||
**XBMC** 一款很优秀的软件,能够将几乎所有电脑变身成媒体中心。它可以播放音乐和视频,显示图片,甚至还能显示天气预报。为了在配置成家庭影院后方便使用,你可以通过手机 app 访问运行在已连接到 Wi-Fi 的 XBMC 机器上的服务来控制它。可以找到很多这种工具,几乎覆盖所有智能手机系统。
|
||||
**Kodi** 是一款很优秀的软件,能够将几乎所有电脑变身成媒体中心。它可以播放音乐和视频,显示图片,甚至还能显示天气预报。为了在配置成家庭影院后方便使用,你可以通过手机 app 访问运行在连接到 Wi-Fi 的 XBMC 机器上的服务来控制它。可以找到很多这种工具,几乎覆盖所有智能手机系统。
|
||||
|
||||
> ### Kodi ###
|
||||
> **XBMC**
|
||||
>
|
||||
> 在你阅读这篇文章的时候,**XBMC** 可能已经成为历史。因为法律原因(因为名字 **XBMC** 或 X**-Box Media Center** 里引用了不再支持的过时硬件)项目组决定使用新的名字 **Kodi**。不过,除了名字,其他的都会保持原样。或者说除开通常新版本中所期待的大量新改进。这一般不会影响到遥控软件,它应该能在已有的 **XBMC** 系统和新的 Kodi 系统上都能工作。
|
||||
> Kodi 原名叫做 XBMC,在你阅读这篇文章的时候,**XBMC** 已经成为历史。因为法律原因(因为名字 **XBMC** 或 X**-Box Media Center** 里引用了不再支持的过时硬件)项目组决定使用新的名字 **Kodi**。不过,除了名字,其他的都会保持原样。或者说除开通常新版本中所期待的大量新改进。这一般不会影响到遥控软件,它应该能在已有的 **XBMC** 系统和新的 Kodi 系统上都能工作。
|
||||
|
||||
我们目前配置了一个 **XBMC** 系统用于播放音乐,不过我们找到的所有 XBMC 遥控没一个好用的,特别是和媒体中心连接的电视没打开的时候。它们都有点太复杂了,集成了太多功能在手机的小屏幕上。我们希望能有这样的系统,从最开始就是设计成只用于访问音乐库和电台插件,所以我们决定自己实现一个。它不需要用到 XBMC 的所有功能,因为除了音乐以外的任务,我们可以简单地切换使用通用的 XBMC 遥控。我们的测试系统是一个刷了 RaspBMC 发行版的树莓派,但是我们要做的工具并不受限于树莓派或那个发行版,它应该可以匹配任何安装了相关插件的基于 Linux 的 XBMC 系统。
|
||||
我们目前已经配置好了一个用于播放音乐的 **Kodi** 系统,不过我们找到的所有 Kodi 遥控没一个好用的,特别是和媒体中心连接的电视没打开的时候。它们都有点太复杂了,集成了太多功能在手机的小屏幕上。我们希望能有这样的系统,从最开始就是设计成只用于访问音乐库和电台插件,所以我们决定自己实现一个。它不需要用到 Kodi 的所有功能,因为除了音乐以外的任务,我们可以简单地切换使用通用的 Kodi 遥控。我们的测试系统是一个刷了 RaspBMC 发行版的树莓派,但是我们要做的工具并不受限于树莓派或Kodi那个发行版,它应该可以匹配任何安装了相关插件的基于 Linux 的 Kodi 系统。
|
||||
|
||||
首先,遥控程序需要一个用户界面。大多数 XBMC 遥控程序都是独立的 app。不过对于我们要做的这个音乐控制程序,我们希望用户可以不用安装任何东西就可以使用。显然我们需要使用网页界面。XBMC 本身自带网页服务器,但是为了获得更多权限,我们还是使用了独立的网页框架。在同一台电脑上跑两个以上网页服务器没有问题,只不过它们不能使用相同的端口。
|
||||
首先,遥控程序需要一个用户界面。大多数 Kodi 遥控程序都是独立的 app。不过对于我们要做的这个音乐控制程序,我们希望用户可以不用安装任何东西就可以使用。显然我们需要使用网页界面。Kodi 本身自带网页服务器,但是为了获得更多权限,我们还是使用了独立的网页框架。在同一台电脑上跑两个以上网页服务器没有问题,只不过它们不能使用相同的端口。
|
||||
|
||||
有几个网页框架可以使用。而我们选用 Bottle 是因为它是一个简单高效的框架,而且我们也确实用不到任何高级功能。Bottle 是一个 Python 模块,所以这也将是我们编写服务器模块的语言。
|
||||
|
||||
@ -18,7 +18,7 @@ XBMC:自制遥控
|
||||
|
||||
sudo apt-get install python-bottle
|
||||
|
||||
遥控程序实际上只是连接用户和系统的中间层。Bottle 提供了和用户交互的方式,而我们将通过 JSON API 来和 **XBMC** 交互。这样可以让我们通过发送 JSON 格式消息的方式去控制媒体播放器。
|
||||
遥控程序实际上只是连接用户和系统的中间层。Bottle 提供了和用户交互的方式,而我们将通过 JSON API 来和 **Kodi** 交互。这样可以让我们通过发送 JSON 格式消息的方式去控制媒体播放器。
|
||||
|
||||
我们将用到一个叫做 xbmcjson 的简单 XBMC JASON API 封装。足够用来发送控制请求,而不需要关心实际的 JSON 格式以及和服务器通讯的无聊事。它没有包含在 PIP 包管理中,所以你得直接从 **GitHub** 安装:
|
||||
|
||||
@ -35,13 +35,13 @@ XBMC:自制遥控
|
||||
from xbmcjson import XBMC
|
||||
from bottle import route, run, template, redirect, static_file, request
|
||||
import os
|
||||
xbmc = XBMC(“http://192.168.0.5/jsonrpc”, “xbmc”, “xbmc”)
|
||||
@route(‘/hello/<name>’)
|
||||
xbmc = XBMC("http://192.168.0.5/jsonrpc", "xbmc", "xbmc")
|
||||
@route('/hello/<name>')
|
||||
def index(name):
|
||||
return template(‘<h1>Hello {{name}}!</h1>’, name=name)
|
||||
run(host=”0.0.0.0”, port=8000)
|
||||
return template('<h1>Hello {{name}}!</h1>', name=name)
|
||||
run(host="0.0.0.0", port=8000)
|
||||
|
||||
这样程序将连接到 **XBMC**(不过实际上用不到);然后 Bottle 会开始伺服网站。在我们的代码里,它将监听主机 0.0.0.0(意味着允许所有主机连接)的端口 8000。它只设定了一个站点,就是 /hello/XXXX,这里的 XXXX 可以是任何内容。不管 XXXX 是什么都将作为参数名传递给 index()。然后再替换进去 HTML 网页模版。
|
||||
这样程序将连接到 **Kodi**(不过实际上用不到);然后 Bottle 会开始提供网站服务。在我们的代码里,它将监听主机 0.0.0.0(意味着允许所有主机连接)的端口 8000。它只设定了一个站点,就是 /hello/XXXX,这里的 XXXX 可以是任何内容。不管 XXXX 是什么都将作为参数名传递给 index()。然后再替换进去 HTML 网页模版。
|
||||
|
||||
你可以先试着把上面内容写到一个文件(我们取的名字是 remote.py),然后用下面的命令启动:
|
||||
|
||||
@ -51,56 +51,56 @@ XBMC:自制遥控
|
||||
|
||||
@route() 用来设定网页服务器的路径,而函数 index() 会返回该路径的数据。通常是返回由模版生成的 HTML 页面,但是并不是说只能这样(后面会看到)。
|
||||
|
||||
随后,我们将给应用添加更多页面入口,让它变成一个全功能的 XBMC 遥控,但仍将采用相同代码结构。
|
||||
随后,我们将给应用添加更多页面入口,让它变成一个全功能的 Kodi 遥控,但仍将采用相同代码结构。
|
||||
|
||||
XBMC JSON API 接口可以从和 XBMC 机器同网段的任意电脑上访问。也就是说你可以在自己的笔记本上开发,然后再布置到媒体中心上,而不需要浪费时间上传每次改动。
|
||||
XBMC JSON API 接口可以从和 Kodi 机器同网段的任意电脑上访问。也就是说你可以在自己的笔记本上开发,然后再布置到媒体中心上,而不需要浪费时间上传每次改动。
|
||||
|
||||
模版 - 比如前面例子里的那个简单模版 - 是一种结合 Python 和 HTML 来控制输出的方式。理论上,这俩能做很多很多事,但是会非常混乱。我们将只是用它们来生成正确格式的数据。不过,在开始动手之前,我们先得准备点数据。
|
||||
|
||||
> ### Paste ###
|
||||
> **Paste**
|
||||
>
|
||||
> Bottle 自带网页服务器,就是我们用来测试遥控程序的。不过,我们发现它性能有时不够好。当我们的遥控程序正式上线时,我们希望页面能更快一点显示出来。Bottle 可以和很多不同的网页服务器配合工作,而我们发现 Paste 用起来非常不错。而要使用的话,只要简单地安装(Debian 系统里的 python-paste 包),然后修改一下代码里的 run 调用:
|
||||
> Bottle 自带网页服务器,我们用它来测试遥控程序。不过,我们发现它性能有时不够好。当我们的遥控程序正式上线时,我们希望页面能更快一点显示出来。Bottle 可以和很多不同的网页服务器配合工作,而我们发现 Paste 用起来非常不错。而要使用的话,只要简单地安装(Debian 系统里的 python-paste 包),然后修改一下代码里的 run 调用:
|
||||
>
|
||||
> run(host=hostname, port=hostport, server=”paste”)
|
||||
> run(host=hostname, port=hostport, server="paste")
|
||||
>
|
||||
> 你可以在 [http://bottlepy.org/docs/dev/deployment.html][1] 找到如何使用其他服务器的相关细节。
|
||||
|
||||
#### 从 XBMC 获取数据 ####
|
||||
#### 从 Kodi 获取数据 ####
|
||||
|
||||
XBMC JSON API 分成 14 个命名空间:JSONRPC, Player, Playlist, Files, AudioLibrary, VideoLibrary, Input, Application, System, Favourites, Profiles, Settings, Textures 和 XBMC。每个都可以通过 Python 的 XBMC 对象访问(Favourites 除外,明显是个疏忽)。每个命名空间都包含许多方法用于对程序的控制。例如,Playlist.GetItems() 可以用来获取某个特定播放列表的内容。服务器会返回给我们 JSON 格式的数据,但 xbmcjson 模块会为我们转化成 Python 词典。
|
||||
|
||||
我们需要用到 XBMC 里的两个组件来控制播放:播放器和播放列表。播放器带有播放列表并在每首歌结束时从列表里取下一首。为了查看当前正在播放的内容,我们需要获取正在工作的播放器的 ID,然后根据它找到当前播放列表的 ID。这个可以通过下面的代码来实现:
|
||||
我们需要用到 Kodi 里的两个组件来控制播放:播放器和播放列表。播放器处理播放列表并在每首歌结束时从列表里取下一首。为了查看当前正在播放的内容,我们需要获取正在工作的播放器的 ID,然后根据它找到当前播放列表的 ID。这个可以通过下面的代码来实现:
|
||||
|
||||
def get_playlistid():
|
||||
player = xbmc.Player.GetActivePlayers()
|
||||
if len(player[‘result’]) > 0:
|
||||
playlist_data = xbmc.Player.GetProperties({“playerid”:0, “properties”:[“playlistid”]})
|
||||
if len(playlist_data[‘result’]) > 0 and “playlistid” in playlist_data[‘result’].keys():
|
||||
return playlist_data[‘result’][‘playlistid’]
|
||||
if len(player['result']) > 0:
|
||||
playlist_data = xbmc.Player.GetProperties({"playerid":0, "properties":["playlistid"]})
|
||||
if len(playlist_data['result']) > 0 and "playlistid" in playlist_data['result'].keys():
|
||||
return playlist_data['result']['playlistid']
|
||||
return -1
|
||||
|
||||
如果当前没有播放器在工作(就是说,返回数据的结果部分的长度是 0),或者当前播放器不带播放列表,这样的话函数会返回 -1。其他时候,它会返回当前播放列表的数字 ID。
|
||||
如果当前没有播放器在工作(就是说,返回数据的结果部分的长度是 0),或者当前播放器没有处理播放列表,这样的话函数会返回 -1。其他时候,它会返回当前播放列表的数字 ID。
|
||||
|
||||
当我们拿到当前播放列表的 ID 后,就可以获取列表的细节内容。按照我们的需求,有两个重要的地方:播放列表里包含的项,以及当前播放所处的位置(已经播放过的项并不会从播放列表移除,只是移动当前播放位置)。
|
||||
当我们拿到当前播放列表的 ID 后,就可以获取该列表的细节内容。按照我们的需求,有两个重要的地方:播放列表里包含的项,以及当前播放所处的位置(已经播放过的项并不会从播放列表移除,只是移动当前播放位置)。
|
||||
|
||||
def get_playlist():
|
||||
playlistid = get_playlistid()
|
||||
if playlistid >= 0:
|
||||
data = xbmc.Playlist.GetItems({“playlistid”:playlistid, “properties”: [“title”, “album”, “artist”, “file”]})
|
||||
position_data = xbmc.Player.GetProperties({“playerid”:0, ‘properties’:[“position”]})
|
||||
position = int(position_data[‘result’][‘position’])
|
||||
return data[‘result’][‘items’][position:], position
|
||||
data = xbmc.Playlist.GetItems({"playlistid":playlistid, "properties": ["title", "album", "artist", "file"]})
|
||||
position_data = xbmc.Player.GetProperties({"playerid":0, 'properties':["position"]})
|
||||
position = int(position_data['result']['position'])
|
||||
return data['result']['items'][position:], position
|
||||
return [], -1
|
||||
|
||||
这样可以返回以正在播放的项开始的列表(因为我们并不关心已经播放过的内容),而且也包含了位置信息用来从列表里移除项。
|
||||
这样可以返回正在播放的项开始的列表(因为我们并不关心已经播放过的内容),而且也包含了用来从列表里移除项的位置信息。
|
||||
|
||||
|
||||
|
||||
API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列出了所有支持的函数,但是关于具体如何使用的描述有点太简单了。
|
||||
|
||||
> ### JSON ###
|
||||
> **JSON**
|
||||
>
|
||||
> JSON 是 JavaScript Object Notation 的缩写,开始设计用于 JavaScript 对象的序列化。目前仍然起到这个作用,但是它也是用来编码任意数据的一种很好用的方式。
|
||||
> JSON 是 JavaScript Object Notation 的缩写,最初设计用于 JavaScript 对象的序列化。目前仍然起到这个作用,但是它也是用来编码任意数据的一种很好用的方式。
|
||||
>
|
||||
> JSON 对象都是这样的格式:
|
||||
>
|
||||
@ -110,18 +110,18 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
>
|
||||
> 在字典数据结构里,值本身可以是另一个 JSON 对象,或者一个列表,所以下面的格式也是正确的:
|
||||
>
|
||||
> {“name”:“Ben”, “jobs”:[“cook”, “bottle-washer”], “appearance”: {“height”:195, “skin”:“fair”}}
|
||||
> {"name":"Ben", "jobs":["cook", "bottle-washer"], "appearance": {"height":195, "skin":"fair"}}
|
||||
>
|
||||
> JSON 通常在网络服务中用来发送和接收数据,并且大多数编程语言都能很好地支持,所以如果你熟悉 Python 的话,你应该可以使用你熟悉的编程语言调用相同的接口来轻松地控制 XBMC。
|
||||
> JSON 通常在网络服务中用来发送和接收数据,并且大多数编程语言都能很好地支持,所以如果你熟悉 Python 的话,你应该可以使用你熟悉的编程语言调用相同的接口来轻松地控制 Kodi。
|
||||
|
||||
#### 整合到一起 ####
|
||||
|
||||
把之前的功能连接到 HTML 页面很简单:
|
||||
|
||||
@route(‘/juke’)
|
||||
@route('/juke')
|
||||
def index():
|
||||
current_playlist, position = get_playlist()
|
||||
return template(‘list’, playlist=current_playlist, offset = position)
|
||||
return template('list', playlist=current_playlist, offset = position)
|
||||
|
||||
只需要抓取播放列表(调用我们之前定义的函数),然后将结果传递给负责显示的模版。
|
||||
|
||||
@ -131,57 +131,57 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
% if playlist is not None:
|
||||
% position = offset
|
||||
% for song in playlist:
|
||||
<strong> {{song[‘title’]}} </strong>
|
||||
% if song[‘type’] == ‘unknown’:
|
||||
<strong> {{song['title']}} </strong>
|
||||
% if song['type'] == 'unknown':
|
||||
Radio
|
||||
% else:
|
||||
{{song[‘artist’][0]}}
|
||||
{{song['artist'][0]}}
|
||||
% end
|
||||
% if position != offset:
|
||||
<a href=”/remove/{{position}}”>remove</a>
|
||||
<a href="/remove/{{position}}">remove</a>
|
||||
% else:
|
||||
<a href=”/skip/{{position}}”>skip</a>
|
||||
<a href="/skip/{{position}}">skip</a>
|
||||
% end
|
||||
<br>
|
||||
% position += 1
|
||||
% end
|
||||
|
||||
可以看到,模版大部分是用 HTML 写的,只有一小部分用来控制输出的其他代码。用两个括号括起来的变量是输出位置(像我们在第一个 ‘hello world’ 例子里看到的)。你也可以嵌入以百分号开头的 Python 代码。因为没有缩进,你需要用一个 % end 来结束当前的代码块(就像循环或 if 语句)。
|
||||
可以看到,模版大部分是用 HTML 写的,只有一小部分用来控制输出的其他代码。用两个大括号括起来的变量是输出位置(像我们在第一个 'hello world' 例子里看到的)。你也可以嵌入以百分号开头的 Python 代码。因为没有缩进,你需要用一个 `% end` 来结束当前的代码块(就像循环或 if 语句)。
|
||||
|
||||
这个模版首先检查列表是否为空,然后遍历里面的每一项。每一项会用粗体显示歌曲名字,然后是艺术家名字,然后是一个是否跳过(如果是当前正在播的歌曲)或从列表移除的链接。所有歌曲的类型都是 ‘song’,如果类型是 ‘unknown’,那就不是歌曲而是网络电台。
|
||||
这个模版首先检查列表是否为空,然后遍历里面的每一项。每一项会用粗体显示歌曲名字,然后是艺术家名字,然后是一个是否跳过(如果是当前正在播的歌曲)或从列表移除的链接。所有歌曲的类型都是 'song',如果类型是 'unknown',那就不是歌曲而是网络电台。
|
||||
|
||||
/remove/ 和 /skip/ 路径只是简单地封装了 XBMC 控制功能,在改动生效后重新加载 /juke:
|
||||
|
||||
@route(‘/skip/<position>’)
|
||||
@route('/skip/<position>')
|
||||
def index(position):
|
||||
print xbmc.Player.GoTo({‘playerid’:0, ‘to’:’next’})
|
||||
redirect(“/juke”)
|
||||
@route(‘/remove/<position>’)
|
||||
print xbmc.Player.GoTo({'playerid':0, 'to':'next'})
|
||||
redirect("/juke")
|
||||
@route('/remove/<position>')
|
||||
def index(position):
|
||||
playlistid = get_playlistid()
|
||||
if playlistid >= 0:
|
||||
xbmc.Playlist.Remove({‘playlistid’:int(playlistid), ‘position’:int(position)})
|
||||
redirect(“/juke”)
|
||||
xbmc.Playlist.Remove({'playlistid':int(playlistid), 'position':int(position)})
|
||||
redirect("/juke")
|
||||
|
||||
当然,如果不能往列表里添加歌曲的话那这个列表管理功能也不行。
|
||||
|
||||
因为一旦播放列表结束,它就消失了,所以你需要重新创建一个,这会让事情复杂一些。而且有点让人迷惑的是,播放列表是通过调用 Playlist.Clear() 方法来创建的。这个方法也还用来删除包含网络电台(类型是 unknown)的播放列表。另一个麻烦的地方是列表里的网络电台开始播放后就不会停,所以如果当前在播网络电台,也会需要清除播放列表。
|
||||
|
||||
这些页面包含了指向 /play/<songid> 的链接来播放歌曲。通过下面的代码处理:
|
||||
这些页面包含了指向 /play/\<songid> 的链接来播放歌曲。通过下面的代码处理:
|
||||
|
||||
@route(‘/play/<id>’)
|
||||
@route('/play/<id>')
|
||||
def index(id):
|
||||
playlistid = get_playlistid()
|
||||
playlist, not_needed= get_playlist()
|
||||
if playlistid < 0 or playlist[0][‘type’] == ‘unknown’:
|
||||
xbmc.Playlist.Clear({“playlistid”:0})
|
||||
xbmc.Playlist.Add({“playlistid”:0, “item”:{“songid”:int(id)}})
|
||||
xbmc.Player.open({“item”:{“playlistid”:0}})
|
||||
if playlistid < 0 or playlist[0]['type'] == 'unknown':
|
||||
xbmc.Playlist.Clear({"playlistid":0})
|
||||
xbmc.Playlist.Add({"playlistid":0, "item":{"songid":int(id)}})
|
||||
xbmc.Player.open({"item":{"playlistid":0}})
|
||||
playlistid = 0
|
||||
else:
|
||||
xbmc.Playlist.Add({“playlistid”:playlistid, “item”:{“songid”:int(id)}})
|
||||
xbmc.Playlist.Add({"playlistid":playlistid, "item":{"songid":int(id)}})
|
||||
remove_duplicates(playlistid)
|
||||
redirect(“/juke”)
|
||||
redirect("/juke")
|
||||
|
||||
最后一件事情是实现 remove_duplicates 调用。这并不是必须的 - 而且还有人并不喜欢这个 - 不过可以保证同一首歌不会多次出现在播放列表里。
|
||||
|
||||
@ -191,40 +191,40 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
|
||||
还需要处理一下 UI,不过功能已经有了。
|
||||
|
||||
> ### 日志 ###
|
||||
> **日志**
|
||||
>
|
||||
> 通常拿到 XBMC JSON API 并不清楚能用来做什么,而且它的文档也有点模糊。找出如何使用的一种方式是看别的遥控程序是怎么做的。如果打开日志功能,就可以在使用其他遥控程序的时候看到哪个 API 被调用了,然后就可以应用到在自己的代码里。
|
||||
>
|
||||
> 要打开日志功能,把 XBMC 媒体中心 接到显示器上,再依次进入设置 > 系统 > 调试,打开允许调试日志。在打开日志功能后,还需要登录到 XBMC 机器上(比如通过 SSH),然后就可以查看日志了。日志文件的位置应该显示在 XBMC 界面左上角。在 RaspBMC 系统里,文件位置是 /home/pi/.xbmc/temp/xbmc.log。你可以通过下面的命令实时监视哪个 API 接口被调用了:
|
||||
> 要打开日志功能,把 Kodi 媒体中心 接到显示器上,再依次进入设置 > 系统 > 调试,打开允许调试日志。在打开日志功能后,还需要登录到 Kodi 机器上(比如通过 SSH),然后就可以查看日志了。日志文件的位置应该显示在 Kodi 界面左上角。在 RaspBMC 系统里,文件位置是 /home/pi/.xbmc/temp/xbmc.log。你可以通过下面的命令实时监视哪个 API 接口被调用了:
|
||||
>
|
||||
> cd /home/pi/.xbmc/temp
|
||||
> tail -f xbmc.log | grep “JSON”
|
||||
> tail -f xbmc.log | grep "JSON"
|
||||
|
||||
#### 增加功能 ####
|
||||
|
||||
上面的代码都是用来播放 XBMC 媒体库里的歌曲的,但我们还希望能播放网络电台。每个插件都有自己的独立 URL 可以通过普通的 XBMC JSON 命令来获取信息。举个例子,要从电台插件里获取选中的电台,可以使用;
|
||||
上面的代码都是用来播放 Kodi 媒体库里的歌曲的,但我们还希望能播放网络电台。每个插件都有自己的独立 URL 可以通过普通的 XBMC JSON 命令来获取信息。举个例子,要从电台插件里获取选中的电台,可以使用;
|
||||
|
||||
@route(‘/radio/’)
|
||||
@route('/radio/')
|
||||
def index():
|
||||
my_stations = xbmc.Files.GetDirectory({“directory”:”plugin://plugin.audio.radio_de/stations/my/”, “properties”:
|
||||
[“title”,”thumbnail”,”playcount”,”artist”,”album”,”episode”,”season”,”showtitle”]})
|
||||
if ‘result’ in my_stations.keys():
|
||||
return template(‘radio’, stations=my_stations[‘result’][‘files’])
|
||||
my_stations = xbmc.Files.GetDirectory({"directory":"plugin://plugin.audio.radio_de/stations/my/", "properties":
|
||||
["title","thumbnail","playcount","artist","album","episode","season","showtitle"]})
|
||||
if 'result' in my_stations.keys():
|
||||
return template('radio', stations=my_stations['result']['files'])
|
||||
else:
|
||||
return template(‘error’, error=’radio’)
|
||||
return template('error', error='radio')
|
||||
|
||||
这样可以返回一个可以和歌曲一样能添加到播放列表的文件。不过,这些文件能一直播下去,所以(之前说过)在添加其他歌曲的时候需要重新创建列表。
|
||||
|
||||
#### 共享歌曲 ####
|
||||
|
||||
除了伺服页面模版,Bottle 还支持静态文件。方便用于那些不会因为用户输入而改变的内容。可以是 CSS 文件,一张图片或是一首 MP3 歌曲。在我们的简单遥控程序里(目前)还没有任何用来美化的 CSS 或图片,不过我们增加了一个下载歌曲的途径。这个可以让媒体中心变成一个存放歌曲的 NAS 盒子。在需要传输大量数据的时候,最好还是用类似 Samba 的功能,但只是下几首歌到手机上的话使用静态文件也是很好的方式。
|
||||
除了伺服页面模版,Bottle 还支持静态文件,方便用于那些不会因为用户输入而改变的内容。可以是 CSS 文件,一张图片或是一首 MP3 歌曲。在我们的简单遥控程序里(目前)还没有任何用来美化的 CSS 或图片,不过我们增加了一个下载歌曲的途径。这个可以让媒体中心变成一个存放歌曲的 NAS 盒子。在需要传输大量数据的时候,最好还是用类似 Samba 的功能,但只是下几首歌到手机上的话使用静态文件也是很好的方式。
|
||||
|
||||
通过歌曲 ID 来下载的 Bottle 代码:
|
||||
|
||||
@route(‘/download/<id>’)
|
||||
@route('/download/<id>')
|
||||
def index(id):
|
||||
data = xbmc.AudioLibrary.GetSongDetails({“songid”:int(id), “properties”:[“file”]})
|
||||
full_filename = data[‘result’][‘songdetails’][‘file’]
|
||||
data = xbmc.AudioLibrary.GetSongDetails({"songid":int(id), "properties":["file"]})
|
||||
full_filename = data['result']['songdetails']['file']
|
||||
path, filename = os.path.split(full_filename)
|
||||
return static_file(filename, root=path, download=True)
|
||||
|
||||
@ -232,13 +232,13 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
|
||||
我们已经把所有的代码过了一遍,不过还需要一点工作来把它们集合到一起。可以自己去 GitHub 页面 [https://github.com/ben-ev/xbmc-remote][3] 看下。
|
||||
|
||||
> ### 设置 ###
|
||||
> **设置**
|
||||
>
|
||||
> 我们的遥控程序已经开发完成,还需要保证让它在媒体中心每次开机的时候都能启动。有几种方式,最简单的是在 /etc/rc.local 里增加一行命令来启动。我们的文件位置在 /opt/xbmc-remote/remote.py,其他文件也和它一起。然后在 /etc/rc.local 最后的 exit 0 之前增加了下面一行。
|
||||
>
|
||||
> cd /opt/xbmc-remote && python remote.py &
|
||||
|
||||
> ### GitHub ###
|
||||
> **GitHub**
|
||||
>
|
||||
> 这个项目目前还只是个架子,但是 - 我们运营杂志就意味着没有太多自由时间来编程。不过,我们启动了一个 GitHub 项目,希望能持续完善, 而如果你觉得这个项目有用的话,欢迎做出贡献。
|
||||
>
|
||||
@ -252,7 +252,7 @@ via: http://www.linuxvoice.com/xbmc-build-a-remote-control/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,47 +1,46 @@
|
||||
使用去重加密工具来备份
|
||||
使用这些去重加密工具来备份你的数据
|
||||
================================================================================
|
||||
在体积和价值方面,数据都在增长。快速而可靠地备份和恢复数据正变得越来越重要。社会已经适应了技术的广泛使用,并懂得了如何依靠电脑和移动设备,但很少有人能够处理丢失重要数据的现实。在遭受数据损失的公司中,30% 的公司将在一年内损失一半市值,70% 的公司将在五年内停止交易。这更加凸显了数据的价值。
|
||||
|
||||
随着数据在体积上的增长,提高存储利用率尤为重要。In Computing(注:这里不知如何翻译),数据去重是一种特别的数据压缩技术,因为它可以消除重复数据的拷贝,所以这个技术可以提高存储利用率。
|
||||
无论是体积还是价值,数据都在不断增长。快速而可靠地备份和恢复数据正变得越来越重要。社会已经适应了技术的广泛使用,并懂得了如何依靠电脑和移动设备,但很少有人能够面对丢失重要数据的现实。在遭受数据损失的公司中,30% 的公司将在一年内损失一半市值,70% 的公司将在五年内停止交易。这更加凸显了数据的价值。
|
||||
|
||||
数据并不仅仅只有其创造者感兴趣。政府、竞争者、犯罪分子、偷窥者可能都热衷于获取你的数据。他们或许想偷取你的数据,从你那里进行敲诈,或看你正在做什么。对于保护你的数据,加密是非常必要的。
|
||||
随着数据在体积上的增长,提高存储利用率尤为重要。从计算机的角度说,数据去重是一种特别的数据压缩技术,因为它可以消除重复数据的拷贝,所以这个技术可以提高存储利用率。
|
||||
|
||||
所以,解决方法是我们需要一个去重加密备份软件。
|
||||
数据并不仅仅只有其创造者感兴趣。政府、竞争者、犯罪分子、偷窥者可能都热衷于获取你的数据。他们或许想偷取你的数据,从你那里进行敲诈,或看你正在做什么。因此,对于保护你的数据,加密是非常必要的。
|
||||
|
||||
对于所有的用户而言,做文件备份是一件非常必要的事,至今为止许多用户还没有采取足够的措施来保护他们的数据。一台电脑不论是工作在一个合作的环境中,还是供私人使用,机器的硬盘可能在没有任何警告的情况下挂掉。另外,有些数据丢失可能是人为的错误所引发的。如果没有做经常性的备份,数据也可能不可避免地失去掉,即使请了专业的数据恢复公司来帮忙。
|
||||
所以,解决方法是我们需要一个可以去重的加密备份软件。
|
||||
|
||||
对于所有的用户而言,做文件备份是一件非常必要的事,至今为止许多用户还没有采取足够的措施来保护他们的数据。一台电脑不论是工作在一个合作的环境中,还是供私人使用,机器的硬盘可能在没有任何警告的情况下挂掉。另外,有些数据丢失可能是人为的错误所引发的。如果没有做经常性的备份,数据也可能不可避免地丢失,即使请了专业的数据恢复公司来帮忙。
|
||||
|
||||
这篇文章将对 6 个去重加密备份工具进行简要的介绍。
|
||||
----------
|
||||
|
||||
### Attic ###
|
||||
|
||||
Attic 是一个可用于去重、加密,验证完整性的用 Python 写的压缩备份程序。Attic 的主要目标是提供一个高效且安全的方式来备份数据。Attic 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。
|
||||
Attic 是一个可用于去重、加密,验证完整性的压缩备份程序,它是用 Python 写的。Attic 的主要目标是提供一个高效且安全的方式来备份数据。Attic 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。
|
||||
|
||||
其特点有:
|
||||
|
||||
- 易用
|
||||
- 可高效利用存储空间,通过检查冗余的数据,数据块大小的去重被用来减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来检查
|
||||
- 可高效利用存储空间,通过检查冗余的数据,对可变块大小的去重可以减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来校验
|
||||
- 使用 SDSH 来进行离线备份
|
||||
- 备份可作为文件系统来挂载
|
||||
|
||||
网站: [attic-backup.org][1]
|
||||
|
||||
----------
|
||||
|
||||
### Borg ###
|
||||
|
||||
Borg 是 Attic 的分支。它是一个安全的开源备份程序,被设计用来高效地存储那些新的或修改过的数据。
|
||||
Borg 是 Attic 的一个分支。它是一个安全的开源备份程序,被设计用来高效地存储那些新的或修改过的数据。
|
||||
|
||||
Borg 的主要目标是提供一个高效、安全的方式来存储数据。Borg 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。认证加密使得它适用于不完全可信的目标的存储。
|
||||
Borg 的主要目标是提供一个高效、安全的方式来存储数据。Borg 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。认证加密使得它适用于存储在不完全可信的位置。
|
||||
|
||||
Borg 由 Python 写成。Borg 于 2015 年 5 月被创造出来,为了回应让新的代码或重大的改变带入 Attic 的困难。
|
||||
Borg 由 Python 写成。Borg 于 2015 年 5 月被创造出来,是为了解决让新的代码或重大的改变带入 Attic 的困难。
|
||||
|
||||
其特点包括:
|
||||
|
||||
- 易用
|
||||
- 可高效利用存储空间,通过检查冗余的数据,数据块大小的去重被用来减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来检查
|
||||
- 可高效利用存储空间,通过检查冗余的数据,对可变块大小的去重被用来减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来校验
|
||||
- 使用 SDSH 来进行离线备份
|
||||
- 备份可作为文件系统来挂载
|
||||
|
||||
@ -49,36 +48,32 @@ Borg 与 Attic 不兼容。
|
||||
|
||||
网站: [borgbackup.github.io/borgbackup][2]
|
||||
|
||||
----------
|
||||
|
||||
### Obnam ###
|
||||
|
||||
Obnam (OBligatory NAMe) 是一个易用、安全的基于 Python 的备份程序。备份可被存储在本地硬盘或通过 SSH SFTP 协议存储到网上。若使用了备份服务器,它并不需要任何特殊的软件,只需要使用 SSH 即可。
|
||||
|
||||
Obnam 通过将数据数据分成数据块,并单独存储它们来达到去重的目的,每次通过增量备份来生成备份,每次备份的生成就像是一次新的快照,但事实上是真正的增量备份。Obnam 由 Lars Wirzenius 开发。
|
||||
Obnam 通过将数据分成数据块,并单独存储它们来达到去重的目的,每次通过增量备份来生成备份,每次备份的生成就像是一次新的快照,但事实上是真正的增量备份。Obnam 由 Lars Wirzenius 开发。
|
||||
|
||||
其特点有:
|
||||
|
||||
- 易用
|
||||
- 快照备份
|
||||
- 数据去重,跨文件,生成备份
|
||||
- 数据去重,跨文件,然后生成备份
|
||||
- 可使用 GnuPG 来加密备份
|
||||
- 向一个单独的仓库中备份多个客户端的数据
|
||||
- 备份检查点 (创建一个保存点,以每 100MB 或其他容量)
|
||||
- 包含多个选项来调整性能,包括调整 lru-size 或 upload-queue-size
|
||||
- 支持 MD5 校验和算法来识别重复的数据块
|
||||
- 支持 MD5 校验算法来识别重复的数据块
|
||||
- 通过 SFTP 将备份存储到一个服务器上
|
||||
- 同时支持 push(即在客户端上运行) 和 pull(即在服务器上运行)
|
||||
|
||||
网站: [obnam.org][3]
|
||||
|
||||
----------
|
||||
|
||||
### Duplicity ###
|
||||
|
||||
Duplicity 持续地以 tar 文件格式备份文件和目录,并使用 GnuPG 来进行加密,同时将它们上传到远程(或本地)的文件服务器上。它可以使用 ssh/scp, 本地文件获取, rsync, ftp, 和 Amazon S3 等来传递数据。
|
||||
Duplicity 以 tar 文件格式增量备份文件和目录,并使用 GnuPG 来进行加密,同时将它们上传到远程(或本地)的文件服务器上。它可以使用 ssh/scp、本地文件获取、rsync、 ftp 和 Amazon S3 等来传递数据。
|
||||
|
||||
因为 duplicity 使用了 librsync, 增加的存档高效地利用了存储空间,且只记录自从上次备份依赖改变的那部分文件。由于该软件使用 GnuPG 来机密或对这些归档文件进行进行签名,这使得它们免于服务器的监视或修改。
|
||||
因为 duplicity 使用了 librsync, 增量存档可以高效地利用存储空间,且只记录自从上次备份依赖改变的那部分文件。由于该软件使用 GnuPG 来加密或对这些归档文件进行进行签名,这使得它们免于服务器的监视或修改。
|
||||
|
||||
当前 duplicity 支持备份删除的文件,全部的 unix 权限,目录,符号链接, fifo 等。
|
||||
|
||||
@ -101,39 +96,36 @@ duplicity 软件包还包含有 rdiffdir 工具。 Rdiffdir 是 librsync 的 rdi
|
||||
|
||||
网站: [duplicity.nongnu.org][4]
|
||||
|
||||
----------
|
||||
|
||||
### ZBackup ###
|
||||
|
||||
ZBackup 是一个通用的全局去重备份工具。
|
||||
|
||||
其特点包括:
|
||||
|
||||
- 存储数据的并行 LZMA 或 LZO 压缩,在一个仓库中,你还可以混合使用 LZMA 和 LZO
|
||||
- 对存储数据并行进行 LZMA 或 LZO 压缩,在一个仓库中,你还可以混合使用 LZMA 和 LZO
|
||||
- 内置对存储数据的 AES 加密
|
||||
- 可选择地删除旧的备份数据
|
||||
- 能够删除旧的备份数据
|
||||
- 可以使用 64 位的滚动哈希算法,使得文件冲突的数量几乎为零
|
||||
- Repository consists of immutable files. No existing files are ever modified ====
|
||||
- 仓库中存储的文件是不可修改的,已备份的文件不会被修改。
|
||||
- 用 C++ 写成,只需少量的库文件依赖
|
||||
- 在生成环境中可以安全使用
|
||||
- 可以在不同仓库中进行数据交换而不必再进行压缩
|
||||
- 可以使用 64 位改进型 Rabin-Karp 滚动哈希算法
|
||||
- 使用 64 位改进型 Rabin-Karp 滚动哈希算法
|
||||
|
||||
网站: [zbackup.org][5]
|
||||
|
||||
----------
|
||||
|
||||
### bup ###
|
||||
|
||||
bup 是一个用 Python 写的备份程序,其名称是 "backup" 的缩写。在 git packfile 文件的基础上, bup 提供了一个高效的方式来备份一个系统,提供快速的增量备份和全局去重(在文件中或文件里,甚至包括虚拟机镜像)。
|
||||
bup 是一个用 Python 写的备份程序,其名称是 "backup" 的缩写。基于 git packfile 文件格式, bup 提供了一个高效的方式来备份一个系统,提供快速的增量备份和全局去重(在文件中或文件里,甚至包括虚拟机镜像)。
|
||||
|
||||
bup 在 LGPL 版本 2 协议下发行。
|
||||
|
||||
其特点包括:
|
||||
|
||||
- 全局去重 (在文件中或文件里,甚至包括虚拟机镜像)
|
||||
- 全局去重 (在文件之间或文件内部,甚至包括虚拟机镜像)
|
||||
- 使用一个滚动的校验和算法(类似于 rsync) 来将大文件分为多个数据块
|
||||
- 使用来自 git 的 packfile 格式
|
||||
- 使用来自 git 的 packfile 文件格式
|
||||
- 直接写入 packfile 文件,以此提供快速的增量备份
|
||||
- 可以使用 "par2" 冗余来恢复冲突的备份
|
||||
- 可以作为一个 FUSE 文件系统来挂载你的 bup 仓库
|
||||
@ -145,7 +137,7 @@ bup 在 LGPL 版本 2 协议下发行。
|
||||
via: http://www.linuxlinks.com/article/20150628060000607/BackupTools.html
|
||||
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,83 @@
|
||||
监控 Linux 系统的 7 个命令行工具
|
||||
================================================================================
|
||||
**这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。**
|
||||
|
||||

|
||||
|
||||
### 深入 ###
|
||||
|
||||
关于Linux最棒的一件事之一是你能深入操作系统,来探索它是如何工作的,并寻找机会来微调性能或诊断问题。这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。大多数的这些命令是在你的Linux系统中已经内建的,但假如它们没有的话,就用谷歌搜索命令名和你的发行版名吧,你会找到哪些包需要安装(注意,一些命令是和其它命令捆绑起来打成一个包的,你所找的包可能写的是其它的名字)。如果你知道一些你所使用的其它工具,欢迎评论。
|
||||
|
||||
|
||||
### 我们怎么开始 ###
|
||||
|
||||
|
||||
|
||||
须知: 本文中的截图取自一台[Debian Linux 8.1][1] (“Jessie”),其运行在[OS X 10.10.3][3] (“Yosemite”)操作系统下的[Oracle VirtualBox 4.3.28][2]中的一台虚拟机里。想要建立你的Debian虚拟机,可以看看我的这篇教程——“[如何在 VirtualBox VM 下安装 Debian][4]”。
|
||||
|
||||
|
||||
### Top ###
|
||||
|
||||
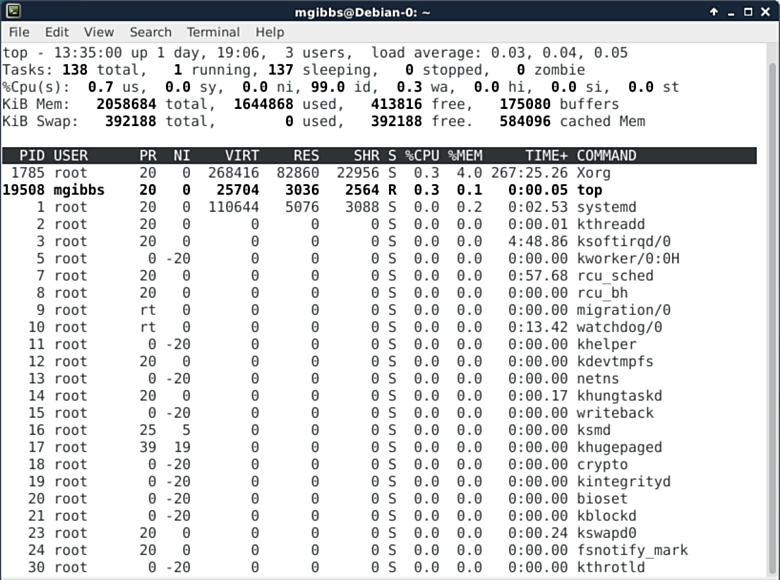
|
||||
|
||||
作为Linux系统监控工具中比较易用的一个,**top命令**能带我们一览Linux中的几乎每一处。以下这张图是它的默认界面,但是按“z”键可以切换不同的显示颜色。其它热键和命令则有其它的功能,例如显示概要信息和内存信息(第四行第二个),根据各种不一样的条件排序、终止进程任务等等(你可以在[这里][5]找到完整的列表)。
|
||||
|
||||
|
||||
### htop ###
|
||||
|
||||
|
||||
|
||||
相比top,它的替代品Htop则更为精致。维基百科是这样描述的:“用户经常会部署htop以免Unix top不能提供关于系统进程的足够信息,比如说当你在尝试发现应用程序里的一个小的内存泄露问题,Htop一般也能作为一个系统监听器来使用。相比top,它提供了一个更方便的光标控制界面来向进程发送信号。” (想了解更多细节猛戳[这里][6])
|
||||
|
||||
|
||||
### Vmstat ###
|
||||
|
||||
|
||||
|
||||
Vmstat是一款监控Linux系统性能数据的简易工具,这让它更合适使用在shell脚本中。使出你的正则表达式绝招,用vmstat和cron作业来做一些激动人心的事情吧。“后面的报告给出的是上一次系统重启之后的均值,另外一份报告给出的则是从前一个报告起间隔周期中的信息。其它的进程和内存报告是那个瞬态的情况”(猛戳[这里][7]获取更多信息)。
|
||||
|
||||
### ps ###
|
||||
|
||||
|
||||
|
||||
ps命令展现的是正在运行中的进程列表。在这种情况下,我们用“-e”选项来显示每个进程,也就是所有正在运行的进程了(我把列表滚动到了前面,否则列名就看不到了)。这个命令有很多选项允许你去按需格式化输出。只要使用上述一点点的正则表达式技巧,你就能得到一个强大的工具了。猛戳[这里][8]获取更多信息。
|
||||
|
||||
### Pstree ###
|
||||
|
||||
|
||||
|
||||
Pstree“以树状图显示正在运行中的进程。这个进程树是以某个 pid 为根节点的,如果pid被省略的话那树是以init为根节点的。如果指定用户名,那所有进程树都会以该用户所属的进程为父进程进行显示。”以树状图来帮你将进程之间的所属关系进行分类,这的确是个很有效的工具(戳[这里][9])。
|
||||
|
||||
### pmap ###
|
||||
|
||||
|
||||
|
||||
在调试过程中,理解一个应用程序如何使用内存是至关重要的,而pmap的作用就是当给出一个进程ID时显示出相关信息。上面的截图展示的是使用“-x”选项所产生的部分输出,你也可以用pmap的“-X”选项来获取更多的细节信息,但是前提是你要有个更宽的终端窗口。
|
||||
|
||||
### iostat ###
|
||||
|
||||
|
||||
|
||||
Linux系统的一个至关重要的性能指标是处理器和存储的使用率,它也是iostat命令所报告的内容。如同ps命令一样,iostat有很多选项允许你选择你需要的输出格式,除此之外还可以在某一段时间范围内的重复采样几次。详情请戳[这里][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2937219/linux/7-command-line-tools-for-monitoring-your-linux-system.html
|
||||
|
||||
作者:[Mark Gibbs][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Mark-Gibbs/
|
||||
[1]:https://www.debian.org/releases/stable/
|
||||
[2]:https://www.virtualbox.org/
|
||||
[3]:http://www.apple.com/osx/
|
||||
[4]:http://www.networkworld.com/article/2937148/how-to-install-debian-linux-8-1-in-a-virtualbox-vm
|
||||
[5]:http://linux.die.net/man/1/top
|
||||
[6]:http://linux.die.net/man/1/htop
|
||||
[7]:http://linuxcommand.org/man_pages/vmstat8.html
|
||||
[8]:http://linux.die.net/man/1/ps
|
||||
[9]:http://linux.die.net/man/1/pstree
|
||||
[10]:http://linux.die.net/man/1/iostat
|
||||
@ -1,24 +1,25 @@
|
||||
在 Linux 中安装 Google 环聊桌面客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
先前,我们已经介绍了如何[在 Linux 中安装 Facebook Messenger][1] 和[WhatsApp 桌面客户端][2]。这些应用都是非官方的应用。今天,我将为你推荐另一款非官方的应用,它就是 [Google 环聊][3]
|
||||
|
||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它把。
|
||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它吧。
|
||||
|
||||
### 在 Linux 中安装 Google 环聊 ###
|
||||
|
||||
我们将使用一个名为 [yakyak][4] 的开源项目,它是一个针对 Linux,Windows 和 OS X 平台的非官方 Google 环聊客户端。我将向你展示如何在 Ubuntu 中使用 yakyak,但我相信在其他的 Linux 发行版本中,你可以使用同样的方法来使用它。在了解如何使用它之前,让我们先看看 yakyak 的主要特点:
|
||||
|
||||
- 发送和接受聊天信息
|
||||
- 创建和更改对话 (重命名, 添加人物)
|
||||
- 创建和更改对话 (重命名, 添加参与者)
|
||||
- 离开或删除对话
|
||||
- 桌面提醒通知
|
||||
- 打开或关闭通知
|
||||
- 针对图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||
- Hangupsbot 房间同步(实际的用户图片) (注: 这里翻译不到位,希望改善一下)
|
||||
- 对于图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||
- Hangupsbot 房间同步(使用用户实际的图片)
|
||||
- 展示行内图片
|
||||
- 历史回放
|
||||
- 翻阅历史
|
||||
|
||||
听起来不错吧,你可以从下面的链接下载到该软件的安装文件:
|
||||
|
||||
@ -36,7 +37,7 @@
|
||||
|
||||

|
||||
|
||||
假如你想看看对话的配置图,你可以选择 `查看-> 展示对话缩略图`
|
||||
假如你想在联系人里面显示用户头像,你可以选择 `查看-> 展示对话缩略图`
|
||||
|
||||

|
||||
|
||||
@ -54,7 +55,7 @@ via: http://itsfoss.com/install-google-hangouts-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
|
||||
如何修复ubuntu 14.04中检测到系统程序错误的问题
|
||||
如何修复 ubuntu 中检测到系统程序错误的问题
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误(system program problem detected on startup in Ubuntu 15.04)** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||
|
||||
> 检测到系统程序错误(System program problem detected)
|
||||
>
|
||||
@ -18,15 +17,16 @@
|
||||
|
||||
#### 那么这个通知到底是关于什么的? ####
|
||||
|
||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在以前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在之前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||
|
||||
#### 那么,我们点了“报告错误”的按钮后,它以后就不再显示了?####
|
||||
|
||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”一下:
|
||||
|
||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”:
|
||||

|
||||
|
||||
[对不起,Ubuntu发生了一个内部错误(Sorry, Ubuntu has experienced an internal error)][1]是一个Apport(Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇,译者注),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成.
|
||||
[对不起,Ubuntu发生了一个内部错误][1]是个Apport(LCTT 译注:Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成。
|
||||
|
||||
#### 但是我想帮助开发者,让他们知道这个漏洞啊 !####
|
||||
|
||||
你这样想的确非常地周到体贴,而且这样做也是正确的。但是这样做的话,存在两个问题。第一,存在非常高的概率,这个漏洞已经被报告过了;第二,即使你报告了个这次崩溃,也无法保证你不会再看到它。
|
||||
@ -34,35 +34,38 @@
|
||||
#### 那么,你的意思就是说别报告这次崩溃了?####
|
||||
|
||||
对,也不对。如果你想的话,在你第一次看到它的时候报告它。你可以在上面图片显示的“显示细节(Show Details)”中,查看崩溃的程序。但是如果你总是看到它,或者你不想报告漏洞(Bug),那么我建议你还是一次性摆脱这个问题吧。
|
||||
|
||||
### 修复Ubuntu中“检测到系统程序错误”的错误 ###
|
||||
|
||||
这些错误报告被存放在Ubuntu中目录/var/crash中。如果你翻看这个目录的话,应该可以看到有一些以crash结尾的文件。
|
||||
|
||||

|
||||
|
||||
我的建议是删除这些错误报告。打开一个终端,执行下面的命令:
|
||||
|
||||
sudo rm /var/crash/*
|
||||
|
||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果有一个程序又崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果又有一个程序崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||
|
||||
#### 彻底地摆脱Ubuntu中的系统错误弹窗 ####
|
||||
|
||||
如果你这样做,系统中任何程序崩溃时,系统都不会再通知你。如果你想问问我的看法的话,我会说,这不是一件坏事,除非你愿意填写错误报告。如果你不想填写错误报告,那么这些错误通知存不存在都不会有什么区别。
|
||||
|
||||
要禁止Apport,并且彻底地摆脱Ubuntu系统中的程序崩溃报告,打开一个终端,输入以下命令:
|
||||
|
||||
gksu gedit /etc/default/apport
|
||||
|
||||
这个文件的内容是:
|
||||
|
||||
# set this to 0 to disable apport, or to 1 to enable it
|
||||
# 设置0表示禁用Apportw,或者1开启它。译者注,下同。
|
||||
# you can temporarily override this with
|
||||
# 设置0表示禁用Apportw,或者1开启它。
|
||||
# 你可以用下面的命令暂时关闭它:
|
||||
# sudo service apport start force_start=1
|
||||
enabled=1
|
||||
|
||||
把**enabled=1**改为**enabled=0**.保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||
把**enabled=1**改为**enabled=0**。保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||
|
||||
#### 你的有效吗? ####
|
||||
|
||||
我希望这篇教程能够帮助你修复Ubuntu 14.04和Ubuntu 15.04中检测到系统程序错误的问题。如果这个小窍门帮你摆脱了这个烦人的问题,请让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -71,7 +74,7 @@ via: http://itsfoss.com/how-to-fix-system-program-problem-detected-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
140
published/201507/20150713 How to manage Vim plugins.md
Normal file
140
published/201507/20150713 How to manage Vim plugins.md
Normal file
@ -0,0 +1,140 @@
|
||||
如何管理 Vim 插件
|
||||
================================================================================
|
||||
|
||||
Vim是Linux上一个轻量级的通用文本编辑器。虽然它开始时的学习曲线对于一般的Linux用户来说可能很困难,但比起它的好处,这些付出完全是值得的。vim 可以通过完全可定制的插件来增加越来越多的功能。但是,由于它的功能配置比较难,你需要花一些时间去了解它的插件系统,然后才能够有效地去个性化定置Vim。幸运的是,我们已经有一些工具能够使我们在使用Vim插件时更加轻松。而我日常所使用的就是Vundle。
|
||||
|
||||
### 什么是Vundle ###
|
||||
|
||||
[Vundle][1]意即Vim Bundle,是一个vim插件管理器。Vundle能让你很简单地实现插件的安装、升级、搜索或者清除。它还能管理你的运行环境并且在标签方面提供帮助。在本教程中我们将展示如何安装和使用Vundle。
|
||||
|
||||
### 安装Vundle ###
|
||||
|
||||
首先,如果你的Linux系统上没有Git的话,先[安装Git][2]。
|
||||
|
||||
接着,创建一个目录,Vim的插件将会被下载并且安装在这个目录上。默认情况下,这个目录为~/.vim/bundle。
|
||||
|
||||
$ mkdir -p ~/.vim/bundle
|
||||
|
||||
现在,使用如下指令安装Vundle。注意Vundle本身也是一个vim插件。因此我们同样把vundle安装到之前创建的目录~/.vim/bundle下。
|
||||
|
||||
$ git clone https://github.com/gmarik/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
|
||||
### 配置Vundle ###
|
||||
|
||||
现在配置你的.vimrc文件如下:
|
||||
|
||||
set nocompatible " 必需。
|
||||
filetype off " 必须。
|
||||
|
||||
" 在这里设置你的运行时环境的路径。
|
||||
set rtp+=~/.vim/bundle/Vundle.vim
|
||||
|
||||
" 初始化vundle
|
||||
call vundle#begin()
|
||||
|
||||
" 这一行应该永远放在开头。
|
||||
Plugin 'gmarik/Vundle.vim'
|
||||
|
||||
" 这个示范来自https://github.com/gmarik/Vundle.vim README
|
||||
Plugin 'tpope/vim-fugitive'
|
||||
|
||||
" 取自http://vim-scripts.org/vim/scripts.html的插件
|
||||
Plugin 'L9'
|
||||
|
||||
" 该Git插件没有放在GitHub上。
|
||||
Plugin 'git://git.wincent.com/command-t.git'
|
||||
|
||||
"本地计算机上的Git仓库路径 (例如,当你在开发你自己的插件时)
|
||||
Plugin 'file:///home/gmarik/path/to/plugin'
|
||||
|
||||
" vim脚本sparkup存放在这个名叫vim的仓库下的一个子目录中。
|
||||
" 将这个路径正确地设置为runtimepath。
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
|
||||
|
||||
" 避免与L9发生名字上的冲突
|
||||
Plugin 'user/L9', {'name': 'newL9'}
|
||||
|
||||
"所有的插件都应该在这一行之前。
|
||||
call vundle#end() " 必需。
|
||||
|
||||
容我简单解释一下上面的设置:默认情况下,Vundle将从github.com或者vim-scripts.org下载和安装vim插件。你也可以改变这个默认行为。
|
||||
|
||||
要从github安装插件:
|
||||
|
||||
Plugin 'user/plugin'
|
||||
|
||||
要从 http://vim-scripts.org/vim/scripts.html 处安装:
|
||||
|
||||
Plugin 'plugin_name'
|
||||
|
||||
要从另外一个git仓库中安装:
|
||||
|
||||
Plugin 'git://git.another_repo.com/plugin'
|
||||
|
||||
从本地文件中安装:
|
||||
|
||||
Plugin 'file:///home/user/path/to/plugin'
|
||||
|
||||
你同样可以定制其它东西,例如你的插件的运行时路径,当你自己在编写一个插件时,或者你只是想从其它目录——而不是~/.vim——中加载插件时,这样做就非常有用。
|
||||
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'another_vim_path/'}
|
||||
|
||||
如果你有同名的插件,你可以重命名你的插件,这样它们就不会发生冲突了。
|
||||
|
||||
Plugin 'user/plugin', {'name': 'newPlugin'}
|
||||
|
||||
### 使用Vum命令 ###
|
||||
|
||||
一旦你用vundle设置好你的插件,你就可以通过几个vundle命令来安装、升级、搜索插件,或者清除没有用的插件。
|
||||
|
||||
#### 安装一个新的插件 ####
|
||||
|
||||
`PluginInstall`命令将会安装所有列在你的.vimrc文件中的插件。你也可以通过传递一个插件名给它,来安装某个的特定插件。
|
||||
|
||||
:PluginInstall
|
||||
:PluginInstall <插件名>
|
||||
|
||||
|
||||
|
||||
#### 清除没有用的插件 ####
|
||||
|
||||
如果你有任何没有用到的插件,你可以通过`PluginClean`命令来删除它。
|
||||
|
||||
:PluginClean
|
||||
|
||||
|
||||
|
||||
#### 查找一个插件 ####
|
||||
|
||||
如果你想从提供的插件清单中安装一个插件,搜索功能会很有用。
|
||||
|
||||
:PluginSearch <文本>
|
||||
|
||||
|
||||
|
||||
在搜索的时候,你可以在交互式分割窗口中安装、清除、重新搜索或者重新加载插件清单。安装后的插件不会自动加载生效,要使其加载生效,可以将它们添加进你的.vimrc文件中。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Vim是一个妙不可言的工具。它不单单是一个能够使你的工作更加顺畅高效的默认文本编辑器,同时它还能够摇身一变,成为现存的几乎任何一门编程语言的IDE。
|
||||
|
||||
注意,有一些网站能帮你找到适合的vim插件。猛击 [http://www.vim-scripts.org][3], Github或者 [http://www.vimawesome.com][4] 获取新的脚本或插件。同时记得使用为你的插件提供的帮助。
|
||||
|
||||
和你最爱的编辑器一起嗨起来吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/manage-vim-plugins.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[XLCYun(袖里藏云)](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:https://github.com/VundleVim/Vundle.vim
|
||||
[2]:http://ask.xmodulo.com/install-git-linux.html
|
||||
[3]:http://www.vim-scripts.org/
|
||||
[4]:http://www.vimawesome.com/
|
||||
|
||||
@ -0,0 +1,201 @@
|
||||
在 Linux 命令行中使用和执行 PHP 代码(二):12 个 PHP 交互性 shell 的用法
|
||||
================================================================================
|
||||
在上一篇文章“[在 Linux 命令行中使用和执行 PHP 代码(一)][1]”中,我同时着重讨论了直接在Linux命令行中运行PHP代码以及在Linux终端中执行PHP脚本文件。
|
||||
|
||||

|
||||
|
||||
本文旨在让你了解一些相当不错的Linux终端中的PHP交互性 shell 的用法特性。
|
||||
|
||||
让我们先在PHP 的交互shell中来对`php.ini`设置进行一些配置吧。
|
||||
|
||||
**6. 设置PHP命令行提示符**
|
||||
|
||||
要设置PHP命令行提示,你需要在Linux终端中使用下面的php -a(启用PHP交互模式)命令开启一个PHP交互shell。
|
||||
|
||||
$ php -a
|
||||
|
||||
然后,设置任何东西(比如说Hi Tecmint ::)作为PHP交互shell的命令提示符,操作如下:
|
||||
|
||||
php > #cli.prompt=Hi Tecmint ::
|
||||
|
||||

|
||||
|
||||
*启用PHP交互Shell*
|
||||
|
||||
同时,你也可以设置当前时间作为你的命令行提示符,操作如下:
|
||||
|
||||
php > #cli.prompt=`echo date('H:m:s');` >
|
||||
|
||||
22:15:43 >
|
||||
|
||||
**7. 每次输出一屏**
|
||||
|
||||
在我们上一篇文章中,我们已经在原始命令中通过管道在很多地方使用了`less`命令。通过该操作,我们可以在那些不能一屏全部输出的地方获得分屏显示。但是,我们可以通过配置php.ini文件,设置pager的值为less以每次输出一屏,操作如下:
|
||||
|
||||
$ php -a
|
||||
php > #cli.pager=less
|
||||
|
||||

|
||||
|
||||
*限制PHP屏幕输出*
|
||||
|
||||
这样,下次当你运行一个命令(比如说条调试器`phpinfo();`)的时候,而该命令的输出内容又太过庞大而不能固定在一屏,它就会自动产生适合你当前屏幕的输出结果。
|
||||
|
||||
php > phpinfo();
|
||||
|
||||

|
||||
|
||||
*PHP信息输出*
|
||||
|
||||
**8. 建议和TAB补全**
|
||||
|
||||
PHP shell足够智能,它可以显示给你建议和进行TAB补全,你可以通过TAB键来使用该功能。如果对于你想要用TAB补全的字符串而言有多个选项,那么你需要使用两次TAB键来完成,其它情况则使用一次即可。
|
||||
|
||||
如果有超过一个的可能性,请使用两次TAB键。
|
||||
|
||||
php > ZIP [TAB] [TAB]
|
||||
|
||||
如果只有一个可能性,只要使用一次TAB键。
|
||||
|
||||
php > #cli.pager [TAB]
|
||||
|
||||
你可以一直按TAB键来获得建议的补全,直到该值满足要求。所有的行为都将记录到`~/.php-history`文件。
|
||||
|
||||
要检查你的PHP交互shell活动日志,你可以执行:
|
||||
|
||||
$ nano ~/.php_history | less
|
||||
|
||||

|
||||
|
||||
*检查PHP交互Shell日志*
|
||||
|
||||
**9. 你可以在PHP交互shell中使用颜色,你所需要知道的仅仅是颜色代码。**
|
||||
|
||||
使用echo来打印各种颜色的输出结果,类似这样:
|
||||
|
||||
php > echo "color_code1 TEXT second_color_code";
|
||||
|
||||
具体来说是:
|
||||
|
||||
php > echo "\033[0;31m Hi Tecmint \x1B[0m";
|
||||
|
||||

|
||||
|
||||
*在PHP Shell中启用彩色*
|
||||
|
||||
到目前为止,我们已经看到,按回车键意味着执行命令,然而PHP Shell中各个命令结尾的分号是必须的。
|
||||
|
||||
**10. 在PHP shell中用basename()输出路径中最后一部分**
|
||||
|
||||
PHP shell中的basename函数可以从给出的包含有到文件或目录路径的最后部分。
|
||||
|
||||
basename()样例#1和#2。
|
||||
|
||||
php > echo basename("/var/www/html/wp/wp-content/plugins");
|
||||
php > echo basename("www.tecmint.com/contact-us.html");
|
||||
|
||||
上述两个样例将输出:
|
||||
|
||||
plugins
|
||||
contact-us.html
|
||||
|
||||

|
||||
|
||||
*在PHP中打印基本名称*
|
||||
|
||||
**11. 你可以使用PHP交互shell在你的桌面创建文件(比如说test1.txt),就像下面这么简单**
|
||||
|
||||
php> touch("/home/avi/Desktop/test1.txt");
|
||||
|
||||
我们已经见识了PHP交互shell在数学运算中有多优秀,这里还有更多一些例子会令你吃惊。
|
||||
|
||||
**12. 使用PHP交互shell打印比如像tecmint.com这样的字符串的长度**
|
||||
|
||||
strlen函数用于获取指定字符串的长度。
|
||||
|
||||
php > echo strlen("tecmint.com");
|
||||
|
||||

|
||||
|
||||
*在PHP中打印字符串长度*
|
||||
|
||||
**13. PHP交互shell可以对数组排序,是的,你没听错**
|
||||
|
||||
声明变量a,并将其值设置为array(7,9,2,5,10)。
|
||||
|
||||
php > $a=array(7,9,2,5,10);
|
||||
|
||||
对数组中的数字进行排序。
|
||||
|
||||
php > sort($a);
|
||||
|
||||
以排序后的顺序打印数组中的数字,同时打印序号,第一个为[0]。
|
||||
|
||||
php > print_r($a);
|
||||
Array
|
||||
(
|
||||
[0] => 2
|
||||
[1] => 5
|
||||
[2] => 7
|
||||
[3] => 9
|
||||
[4] => 10
|
||||
)
|
||||
|
||||

|
||||
|
||||
*在PHP中对数组排序*
|
||||
|
||||
**14. 在PHP交互Shell中获取π的值**
|
||||
|
||||
php > echo pi();
|
||||
|
||||
3.1415926535898
|
||||
|
||||
**15. 打印某个数比如32的平方根**
|
||||
|
||||
php > echo sqrt(150);
|
||||
|
||||
12.247448713916
|
||||
|
||||
**16. 从0-10的范围内挑选一个随机数**
|
||||
|
||||
php > echo rand(0, 10);
|
||||
|
||||

|
||||
|
||||
*在PHP中获取随机数*
|
||||
|
||||
**17. 获取某个指定字符串的md5校验和sha1校验,例如,让我们在PHP Shell中检查某个字符串(比如说avi)的md5校验和sha1校验,并交叉校验bash shell生成的md5校验和sha1校验的结果。**
|
||||
|
||||
php > echo md5(avi);
|
||||
3fca379b3f0e322b7b7967bfcfb948ad
|
||||
|
||||
php > echo sha1(avi);
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f
|
||||
|
||||
----------
|
||||
|
||||
$ echo -n avi | md5sum
|
||||
3fca379b3f0e322b7b7967bfcfb948ad -
|
||||
|
||||
$ echo -n avi | sha1sum
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f -
|
||||
|
||||

|
||||
|
||||
*在PHP中检查md5校验和sha1校验*
|
||||
|
||||
这里只是PHP Shell中所能获取的功能和PHP Shell的交互特性的惊鸿一瞥,这些就是到现在为止我所讨论的一切。保持连线,在评论中为我们提供你有价值的反馈吧。为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/execute-php-codes-functions-in-linux-commandline/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://linux.cn/article-5906-1.html
|
||||
@ -1,10 +1,12 @@
|
||||
Linux命令行中使用和执行PHP代码——第一部分
|
||||
在 Linux 命令行中使用和执行 PHP 代码(一)
|
||||
================================================================================
|
||||
PHP是一个开元服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
||||

|
||||
Linux命令行中运行PHP代码——第一部分
|
||||
PHP是一个开源服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
||||
|
||||
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它眼下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|
||||

|
||||
|
||||
*在 Linux 命令行中运行 PHP 代码*
|
||||
|
||||
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它当下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|
||||
|
||||
PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页面。PHP主要用于服务器端(而Javascript则用于客户端)以通过HTTP生成动态网页,然而,当你知道可以在Linux终端中不需要网页浏览器来执行PHP时,你或许会大为惊讶。
|
||||
|
||||
@ -12,40 +14,44 @@ PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页
|
||||
|
||||
**1. 在安装完PHP和Apache2后,我们需要安装PHP命令行解释器。**
|
||||
|
||||
# apt-get install php5-cli [Debian and alike System)
|
||||
# yum install php-cli [CentOS and alike System)
|
||||
# apt-get install php5-cli [Debian 及类似系统]
|
||||
# yum install php-cli [CentOS 及类似系统]
|
||||
|
||||
接下来我们通常要做的是,在‘/var/www/html‘(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 ‘<?php phpinfo(); ?>‘,名为 ‘infophp.php‘ 的文件来测试(是否安装正确),执行以下命令即可。
|
||||
接下来我们通常要做的是,在`/var/www/html`(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 `<?php phpinfo(); ?>`,名为 `infophp.php` 的文件来测试(PHP是否安装正确),执行以下命令即可。
|
||||
|
||||
# echo '<?php phpinfo(); ?>' > /var/www/html/infophp.php
|
||||
|
||||
然后,将浏览器指向http://127.0.0.1/infophp.php, 这将会在网络浏览器中打开该文件。
|
||||
然后,将浏览器访问 http://127.0.0.1/infophp.php ,这将会在网络浏览器中打开该文件。
|
||||
|
||||

|
||||
检查PHP信息
|
||||
|
||||
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行‘/var/www/html/infophp.php‘,如:
|
||||
*检查PHP信息*
|
||||
|
||||
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行`/var/www/html/infophp.php`,如:
|
||||
|
||||
# php -f /var/www/html/infophp.php
|
||||
|
||||

|
||||
从命令行检查PHP信息
|
||||
|
||||
由于输出结果太大,我们可以通过管道将上述输出结果输送给 ‘less‘ 命令,这样就可以一次输出一屏了,命令如下:
|
||||
*从命令行检查PHP信息*
|
||||
|
||||
由于输出结果太大,我们可以通过管道将上述输出结果输送给 `less` 命令,这样就可以一次输出一屏了,命令如下:
|
||||
|
||||
# php -f /var/www/html/infophp.php | less
|
||||
|
||||

|
||||
检查所有PHP信息
|
||||
|
||||
这里,‘-f‘选项解析病执行命令后跟随的文件。
|
||||
*检查所有PHP信息*
|
||||
|
||||
这里,‘-f‘选项解析并执行命令后跟随的文件。
|
||||
|
||||
**2. 我们可以直接在Linux命令行使用`phpinfo()`这个十分有价值的调试工具而不需要从文件来调用,只需执行以下命令:**
|
||||
|
||||
# php -r 'phpinfo();'
|
||||
|
||||

|
||||
PHP调试工具
|
||||
|
||||
*PHP调试工具*
|
||||
|
||||
这里,‘-r‘ 选项会让PHP代码在Linux终端中不带`<`和`>`标记直接执行。
|
||||
|
||||
@ -74,13 +80,14 @@ PHP调试工具
|
||||
输入 ‘exit‘ 或者按下 ‘ctrl+c‘ 来关闭PHP交互模式。
|
||||
|
||||

|
||||
启用PHP交互模式
|
||||
|
||||
*启用PHP交互模式*
|
||||
|
||||
**4. 你可以仅仅将PHP脚本作为shell脚本来运行。首先,创建在你当前工作目录中创建一个PHP样例脚本。**
|
||||
|
||||
# echo -e '#!/usr/bin/php\n<?php phpinfo(); ?>' > phpscript.php
|
||||
|
||||
注意,我们在该PHP脚本的第一行使用#!/usr/bin/php,就像在shell脚本中那样(/bin/bash)。第一行的#!/usr/bin/php告诉Linux命令行将该脚本文件解析到PHP解释器中。
|
||||
注意,我们在该PHP脚本的第一行使用`#!/usr/bin/php`,就像在shell脚本中那样(`/bin/bash`)。第一行的`#!/usr/bin/php`告诉Linux命令行用 PHP 解释器来解析该脚本文件。
|
||||
|
||||
其次,让该脚本可执行:
|
||||
|
||||
@ -96,7 +103,7 @@ PHP调试工具
|
||||
|
||||
# php -a
|
||||
|
||||
创建一个函授,将它命名为 addition。同时,声明两个变量 $a 和 $b。
|
||||
创建一个函数,将它命名为 `addition`。同时,声明两个变量 `$a` 和 `$b`。
|
||||
|
||||
php > function addition ($a, $b)
|
||||
|
||||
@ -133,7 +140,8 @@ PHP调试工具
|
||||
12.3NULL
|
||||
|
||||

|
||||
创建PHP函数
|
||||
|
||||
*创建PHP函数*
|
||||
|
||||
你可以一直运行该函数,直至退出交互模式(ctrl+z)。同时,你也应该注意到了,上面输出结果中返回的数据类型为 NULL。这个问题可以通过要求 php 交互 shell用 return 代替 echo 返回结果来修复。
|
||||
|
||||
@ -152,11 +160,12 @@ PHP调试工具
|
||||
这里是一个样例,在该样例的输出结果中返回了正确的数据类型。
|
||||
|
||||

|
||||
PHP函数
|
||||
|
||||
*PHP函数*
|
||||
|
||||
永远都记住,用户定义的函数不会从一个shell会话保留到下一个shell会话,因此,一旦你退出交互shell,它就会丢失了。
|
||||
|
||||
希望你喜欢此次会话。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
||||
希望你喜欢此次教程。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
||||
|
||||
还请阅读: [12个Linux终端中有用的的PHP命令行用法——第二部分][1]
|
||||
|
||||
@ -164,9 +173,9 @@ PHP函数
|
||||
|
||||
via: http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
||||
|
||||
作者:[vishek Kumar][a]
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,188 @@
|
||||
如何在 Ubuntu/CentOS7.1/Fedora22 上安装 Plex Media Server
|
||||
================================================================================
|
||||
在本文中我们将会向你展示如何容易地在主流的最新Linux发行版上安装Plex Media Server。在Plex安装成功后你将可以使用你的中央式家庭媒体播放系统,该系统能让多个Plex播放器App共享它的媒体资源,并且该系统允许你设置你的环境,增加你的设备以及设置一个可以一起使用Plex的用户组。让我们首先在Ubuntu15.04上开始Plex的安装。
|
||||
|
||||
### 基本的系统资源 ###
|
||||
|
||||
系统资源主要取决于你打算用来连接服务的设备类型和数量, 所以根据我们的需求我们将会在一个单独的服务器上使用以下系统资源。
|
||||
|
||||
<table width="666" style="height: 181px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="670" colspan="2"><b>Plex Media Server</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>基础操作系统</b></td>
|
||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Plex Media Server</b></td>
|
||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>RAM 和 CPU</b></td>
|
||||
<td width="425">1 GB , 2.0 GHZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>硬盘</b></td>
|
||||
<td width="425">30 GB</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### 在Ubuntu 15.04上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
我们现在准备开始在Ubuntu上安装Plex Media Server,让我们从下面的步骤开始来让Plex做好准备。
|
||||
|
||||
#### 步骤 1: 系统更新 ####
|
||||
|
||||
用root权限登录你的服务器。确保你的系统是最新的,如果不是就使用下面的命令。
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
|
||||
#### 步骤 2: 下载最新的Plex Media Server包 ####
|
||||
|
||||
创建一个新目录,用wget命令从[Plex官网](https://plex.tv/)下载为Ubuntu提供的.deb包并放入该目录中。
|
||||
|
||||
root@ubuntu-15:~# cd /plex/
|
||||
root@ubuntu-15:/plex#
|
||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
#### 步骤 3: 安装Plex Media Server的Debian包 ####
|
||||
|
||||
现在在相同的目录下执行下面的命令来开始debian包的安装, 然后检查plexmediaserver服务的状态。
|
||||
|
||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# service plexmediaserver status
|
||||
|
||||

|
||||
|
||||
### 在Ubuntu 15.04上设置Plex Media Web应用 ###
|
||||
|
||||
让我们在你的本地网络主机中打开web浏览器, 并用你的本地主机IP以及端口32400来打开Web界面,并完成以下步骤来配置Plex。
|
||||
|
||||
http://172.25.10.179:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
#### 步骤 1: 登录前先注册 ####
|
||||
|
||||
在你访问到Plex Media Server的Web界面之后, 确保注册并填上你的用户名和密码来登录。
|
||||
|
||||

|
||||
|
||||
#### 输入你的PIN码来保护你的Plex Media用户####
|
||||
|
||||

|
||||
|
||||
现在你已经成功的在Plex Media下配置你的用户。
|
||||
|
||||

|
||||
|
||||
### 在设备上而不是本地服务器上打开Plex Web应用 ###
|
||||
|
||||
如我们在Plex Media主页看到的提示“你没有权限访问这个服务”。 这说明我们跟服务器计算机不在同个网络。
|
||||
|
||||

|
||||
|
||||
现在我们需要解决这个权限问题,以便我们通过设备访问服务器而不是只能在服务器上访问。通过完成下面的步骤完成。
|
||||
|
||||
### 设置SSH隧道使Windows系统可以访问到Linux服务器 ###
|
||||
|
||||
首先我们需要建立一条SSH隧道以便我们访问远程服务器资源,就好像资源在本地一样。 这仅仅是必要的初始设置。
|
||||
|
||||
如果你正在使用Windows作为你的本地系统,Linux作为服务器,那么我们可以参照下图通过Putty来设置SSH隧道。
|
||||
(LCTT译注: 首先要在Putty的Session中用Plex服务器IP配置一个SSH的会话,才能进行下面的隧道转发规则配置。
|
||||
然后点击“Open”,输入远端服务器用户名密码, 来保持SSH会话连接。)
|
||||
|
||||

|
||||
|
||||
**一旦你完成SSH隧道设置:**
|
||||
|
||||
打开你的Web浏览器窗口并在地址栏输入下面的URL。
|
||||
|
||||
http://localhost:8888/web
|
||||
|
||||
浏览器将会连接到Plex服务器并且加载与服务器本地功能一致的Plex Web应用。 同意服务条款并开始。
|
||||
|
||||

|
||||
|
||||
现在一个功能齐全的Plex Media Server已经准备好添加新的媒体库、频道、播放列表等资源。
|
||||
|
||||

|
||||
|
||||
### 在CentOS 7.1上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
我们将会按照上述在Ubuntu15.04上安装Plex Media Server的步骤来将Plex安装到CentOS 7.1上。
|
||||
|
||||
让我们从安装Plex Media Server开始。
|
||||
|
||||
#### 步骤1: 安装Plex Media Server ####
|
||||
|
||||
为了在CentOS7.1上安装Plex Media Server,我们需要从Plex官网下载rpm安装包。 因此我们使用wget命令来将rpm包下载到一个新的目录下。
|
||||
|
||||
[root@linux-tutorials ~]# cd /plex
|
||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### 步骤2: 安装RPM包 ####
|
||||
|
||||
在完成安装包完整的下载之后, 我们将会使用rpm命令在相同的目录下安装这个rpm包。
|
||||
|
||||
[root@linux-tutorials plex]# ls
|
||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### 步骤3: 启动Plexmediaservice ####
|
||||
|
||||
我们已经成功地安装Plex Media Server, 现在我们只需要重启它的服务然后让它永久地启用。
|
||||
|
||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||
|
||||
### 在CentOS-7.1上设置Plex Media Web应用 ###
|
||||
|
||||
现在我们只需要重复在Ubuntu上设置Plex Web应用的所有步骤就可以了。 让我们在Web浏览器上打开一个新窗口并用localhost或者Plex服务器的IP来访问Plex Media Web应用。
|
||||
|
||||
http://172.20.3.174:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
为了获取服务的完整权限你需要重复创建SSH隧道的步骤。 在你用新账户注册后我们将可以访问到服务的所有特性,并且可以添加新用户、添加新的媒体库以及根据我们的需求来设置它。
|
||||
|
||||

|
||||
|
||||
### 在Fedora 22工作站上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
下载和安装Plex Media Server步骤基本跟在CentOS 7.1上安装的步骤一致。我们只需要下载对应的rpm包然后用rpm命令来安装它。
|
||||
|
||||

|
||||
|
||||
### 在Fedora 22工作站上配置Plex Media Web应用 ###
|
||||
|
||||
我们在(与Plex服务器)相同的主机上配置Plex Media Server,因此不需要设置SSH隧道。只要在你的Fedora 22工作站上用Plex Media Server的默认端口号32400打开Web浏览器并同意Plex的服务条款即可。
|
||||
|
||||

|
||||
|
||||
*欢迎来到Fedora 22工作站上的Plex Media Server*
|
||||
|
||||
让我们用你的Plex账户登录,并且开始将你喜欢的电影频道添加到媒体库、创建你的播放列表、添加你的图片以及享用更多其他的特性。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功完成Plex Media Server在主流Linux发行版上安装和配置。Plex Media Server永远都是媒体管理的最佳选择。 它在跨平台上的设置是如此的简单,就像我们在Ubuntu,CentOS以及Fedora上的设置一样。它简化了你组织媒体内容的工作,并将媒体内容“流”向其他计算机以及设备以便你跟你的朋友分享媒体内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,74 +0,0 @@
|
||||
2015 will be the year Linux takes over the enterprise (and other predictions)
|
||||
================================================================================
|
||||
> Jack Wallen removes his rose-colored glasses and peers into the crystal ball to predict what 2015 has in store for Linux.
|
||||
|
||||

|
||||
|
||||
The crystal ball has been vague and fuzzy for quite some time. Every pundit and voice has opined on what the upcoming year will mean to whatever topic it is they hold dear to their heart. In my case, we're talking Linux and open source.
|
||||
|
||||
In previous years, I'd don the rose-colored glasses and make predictions that would shine a fantastic light over the Linux landscape and proclaim 20** will be the year of Linux on the _____ (name your platform). Many times, those predictions were wrong, and Linux would wind up grinding on in the background.
|
||||
|
||||
This coming year, however, there are some fairly bold predictions to be made, some of which are sure things. Read on and see if you agree.
|
||||
|
||||
### Linux takes over big data ###
|
||||
|
||||
This should come as no surprise, considering the advancements Linux and open source has made over the previous few years. With the help of SuSE, Red Hat, and SAP Hana, Linux will hold powerful sway over big data in 2015. In-memory computing and live kernel patching will be the thing that catapults big data into realms of uptime and reliability never before known. SuSE will lead this charge like a warrior rushing into a battle it cannot possibly lose.
|
||||
|
||||
This rise of Linux in the world of big data will have serious trickle down over the rest of the business world. We already know how fond enterprise businesses are of Linux and big data. What we don't know is how this relationship will alter the course of Linux with regards to the rest of the business world.
|
||||
|
||||
My prediction is that the success of Linux with big data will skyrocket the popularity of Linux throughout the business landscape. More contracts for SuSE and Red Hat will equate to more deployments of Linux servers that handle more tasks within the business world. This will especially apply to the cloud, where OpenStack should easily become an overwhelming leader.
|
||||
|
||||
As the end of 2015 draws to a close, Linux will continue its take over of more backend services, which may include the likes of collaboration servers, security, and much more.
|
||||
|
||||
### Smart machines ###
|
||||
|
||||
Linux is already leading the trend for making homes and autos more intelligent. With improvements in the likes of Nest (which currently uses an embedded Linux), the open source platform is poised to take over your machines. Because 2015 should see a massive rise in smart machines, it goes without saying that Linux will be a huge part of that growth. I firmly believe more homes and businesses will take advantage of such smart controls, and that will lead to more innovations (all of which will be built on Linux).
|
||||
|
||||
One of the issues facing Nest, however, is that it was purchased by Google. What does this mean for the thermostat controller? Will Google continue using the Linux platform -- or will it opt to scrap that in favor of Android? Of course, a switch would set the Nest platform back a bit.
|
||||
|
||||
The upcoming year will see Linux lead the rise in popularity of home automation. Wink, Iris, Q Station, Staples Connect, and more (similar) systems will help to bridge Linux and home users together.
|
||||
|
||||
### The desktop ###
|
||||
|
||||
The big question, as always, is one that tends to hang over the heads of the Linux community like a dark cloud. That question is in relation to the desktop. Unfortunately, my predictions here aren't nearly as positive. I believe that the year 2015 will remain quite stagnant for Linux on the desktop. That complacency will center around Ubuntu.
|
||||
|
||||
As much as I love Ubuntu (and the Unity desktop), this particular distribution will continue to drag the Linux desktop down. Why?
|
||||
|
||||
Convergence... or the lack thereof.
|
||||
|
||||
Canonical has been so headstrong about converging the desktop and mobile experience that they are neglecting the current state of the desktop. The last two releases of Ubuntu (one being an LTS release) have been stagnant (at best). The past year saw two of the most unexciting releases of Ubuntu that I can recall. The reason? Because the developers of Ubuntu are desperately trying to make Unity 8/Mir and the ubiquitous Ubuntu Phone a reality. The vaporware that is the Ubuntu Phone will continue on through 2015, and Unity 8/Mir may or may not be released.
|
||||
|
||||
When the new iteration of the Ubuntu Unity desktop is finally released, it will suffer a serious setback, because there will be so little hardware available to truly show it off. [System76][1] will sell their outstanding [Sable Touch][2], which will probably become the flagship system for Unity 8/Mir. As for the Ubuntu Phone? How many reports have you read that proclaimed "Ubuntu Phone will ship this year"?
|
||||
|
||||
I'm now going on the record to predict that the Ubuntu Phone will not ship in 2015. Why? Canonical created partnerships with two OEMs over a year ago. Those partnerships have yet to produce a single shippable product. The closest thing to a shippable product is the Meizu MX4 phone. The "Pro" version of that phone was supposed to have a formal launch of Sept 25. Like everything associated with the Ubuntu Phone, it didn't happen.
|
||||
|
||||
Unless Canonical stops putting all of its eggs in one vaporware basket, desktop Linux will take a major hit in 2015. Ubuntu needs to release something major -- something to make heads turn -- otherwise, 2015 will be just another year where we all look back and think "we could have done something special."
|
||||
|
||||
Outside of Ubuntu, I do believe there are some outside chances that Linux could still make some noise on the desktop. I think two distributions, in particular, will bring something rather special to the table:
|
||||
|
||||
- [Evolve OS][3] -- a ChromeOS-like Linux distribution
|
||||
- [Quantum OS][4] -- a Linux distribution that uses Android's Material Design specs
|
||||
|
||||
Both of these projects are quite exciting and offer unique, user-friendly takes on the Linux desktop. This is quickly become a necessity in a landscape being dragged down by out-of-date design standards (think the likes of Cinnamon, Mate, XFCE, LXCE -- all desperately clinging to the past).
|
||||
|
||||
This is not to say that Linux on the desktop doesn't have a chance in 2015. It does. In order to grasp the reins of that chance, it will have to move beyond the past and drop the anchors that prevent it from moving out to deeper, more viable waters.
|
||||
|
||||
Linux stands to make more waves in 2015 than it has in a very long time. From enterprise to home automation -- the world could be the oyster that Linux uses as a springboard to the desktop and beyond.
|
||||
|
||||
What are your predictions for Linux and open source in 2015? Share your thoughts in the discussion thread below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/2015-will-be-the-year-linux-takes-over-the-enterprise-and-other-predictions/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techrepublic.com/search/?a=jack+wallen
|
||||
[1]:https://system76.com/
|
||||
[2]:https://system76.com/desktops/sable
|
||||
[3]:https://evolve-os.com/
|
||||
[4]:http://quantum-os.github.io/
|
||||
@ -1,120 +0,0 @@
|
||||
The Curious Case of the Disappearing Distros
|
||||
================================================================================
|
||||

|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread, but corporations are taking control, and slowly but systematically, community distros are being killed," said Google+ blogger Alessandro Ebersol. "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return."
|
||||
|
||||
Well the holidays are pretty much upon us at last here in the Linux blogosphere, and there's nowhere left to hide. The next two weeks or so promise little more than a blur of forced social occasions and too-large meals, punctuated only -- for the luckier ones among us -- by occasional respite down at the Broken Windows Lounge.
|
||||
|
||||
Perhaps that's why Linux bloggers seized with such glee upon the good old-fashioned mystery that came up recently -- delivered in the nick of time, as if on cue.
|
||||
|
||||
"Why is the Number of Linux Distros Declining?" is the [question][1] posed over at Datamation, and it's just the distraction so many FOSS fans have been needing.
|
||||
|
||||
"Until about 2011, the number of active distributions slowly increased by a few each year," wrote author Bruce Byfield. "By contrast, the last three years have seen a 12 percent decline -- a decrease too high to be likely to be coincidence.
|
||||
|
||||
"So what's happening?" Byfield wondered.
|
||||
|
||||
It would be difficult to imagine a more thought-provoking question with which to spend the Northern hemisphere's shortest days.
|
||||
|
||||
### 'There Are Too Many Distros' ###
|
||||
|
||||

|
||||
|
||||
"That's an easy question," began blogger [Robert Pogson][2]. "There are too many distros."
|
||||
|
||||
After all, "if a fanatic like me can enjoy life having sampled only a dozen distros, why have any more?" Pogson explained. "If someone has a concept different from the dozen or so most common distros, that concept can likely be demonstrated by documenting the tweaks and package-lists and, perhaps, some code."
|
||||
|
||||
Trying to compete with some 40,000 package repositories like Debian's, however, is "just silly," he said.
|
||||
|
||||
"No startup can compete with such a distro," Pogson asserted. "Why try? Just use it to do what you want and tell the world about it."
|
||||
|
||||
### 'I Don't Distro-Hop Anymore' ###
|
||||
|
||||
The major existing distros are doing a good job, so "we don't need so many derivative works," Google+ blogger Kevin O'Brien agreed.
|
||||
|
||||
"I know I don't 'distro-hop' anymore, and my focus is on using my computer to get work done," O'Brien added.
|
||||
|
||||
"If my apps run fine every day, that is all that I need," he said. "Right now I am sticking with Ubuntu LTS 14.04, and probably will until 2016."
|
||||
|
||||
### 'The More Distros, the Better' ###
|
||||
|
||||
It stands to reason that "as distros get better, there will be less reasons to roll your own," concurred [Linux Rants][3] blogger Mike Stone.
|
||||
|
||||
"I think the modern Linux distros cover the bases of a larger portion of the Linux-using crowd, so fewer and fewer people are starting their own distribution to compensate for something that the others aren't satisfying," he explained. "Add to that the fact that corporations are more heavily involved in the development of Linux now than they ever have been, and they're going to focus their resources."
|
||||
|
||||
So, the decline isn't necessarily a bad thing, as it only points to the strength of the current offerings, he asserted.
|
||||
|
||||
At the same time, "I do think there are some negative consequences as well," Stone added. "Variation in the distros is a way that Linux grows and evolves, and with a narrower field, we're seeing less opportunity to put new ideas out there. In my mind, the more distros, the better -- hopefully the trend reverses soon."
|
||||
|
||||
### 'I Hope Some Diversity Survives' ###
|
||||
|
||||
Indeed, "the era of novelty and experimentation is over," Google+ blogger Gonzalo Velasco C. told Linux Girl.
|
||||
|
||||
"Linux is 20+ years old and got professional," he noted. "There is always room for experimentation, but the top 20 are here since more than a decade ago.
|
||||
|
||||
"Godspeed GNU/Linux," he added. "I hope some diversity survives -- especially distros without Systemd; on the other hand, some standards are reached through consensus."
|
||||
|
||||
### A Question of Package Managers ###
|
||||
|
||||
There are two trends at work here, suggested consultant and [Slashdot][4] blogger Gerhard Mack.
|
||||
|
||||
First, "there are fewer reasons to start a new distro," he said. "The basic nuts and bolts are mostly done, installation is pretty easy across most distros, and it's not difficult on most hardware to get a working system without having to resort to using the command line."
|
||||
|
||||
The second thing is that "we are seeing a reduction of distros with inferior package managers," Mack suggested. "It is clear that .deb-based distros had fewer losses and ended up with a larger overall share."
|
||||
|
||||
### Survival of the Fittest ###
|
||||
|
||||
It's like survival of the fittest, suggested consultant Rodolfo Saenz, who is certified in Linux, IBM Tivoli Storage Manager and Microsoft Active Directory.
|
||||
|
||||
"I prefer to see a strong Linux with less distros," Saenz added. "Too many distros dilutes development efforts and can confuse potential future users."
|
||||
|
||||
Fewer distros, on the other hand, "focuses development efforts into the stronger distros and also attracts new potential users with clear choices for their needs," he said.
|
||||
|
||||
### All About the Money ###
|
||||
|
||||
Google+ blogger Alessandro Ebersol also saw survival of the fittest at play, but he took a darker view.
|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread," Ebersol began. "But corporations are taking control, and slowly but systematically, community distros are being killed."
|
||||
|
||||
It's difficult for community distros to keep pace with the ever-changing field, and cash is a necessity, he conceded.
|
||||
|
||||
Still, "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return," Ebersol said. "It saddens me, but GNU/Linux's best days were 10 years ago, circa 2002 to 2004. Now, it's the survival of the fittest -- and of course, the ones with more money will prevail."
|
||||
|
||||
### 'Fewer Devs Care' ###
|
||||
|
||||
SoylentNews blogger hairyfeet focused on today's altered computing landscape.
|
||||
|
||||
"The reason there are fewer distros is simple: With everybody moving to the Google Playwall of Android, and Windows 10 looking to be the next XP, fewer devs care," hairyfeet said.
|
||||
|
||||
"Why should they?" he went on. "The desktop wars are over, MSFT won, and the mobile wars are gonna be proprietary Google, proprietary Apple and proprietary MSFT. The money is in apps and services, and with a slow economy, there just isn't time for pulling a Taco Bell and rerolling yet another distro.
|
||||
|
||||
"For the few that care about Linux desktops you have Ubuntu, Mint and Cent, and that is plenty," hairyfeet said.
|
||||
|
||||
### 'No Less Diversity' ###
|
||||
|
||||
Last but not least, Chris Travers, a [blogger][5] who works on the [LedgerSMB][6] project, took an optimistic view.
|
||||
|
||||
"Ever since I have been around Linux, there have been a few main families -- [SuSE][7], [Red Hat][8], Debian, Gentoo, Slackware -- and a number of forks of these," Travers said. "The number of major families of distros has been declining for some time -- Mandrake and Connectiva merging, for example, Caldera disappearing -- but each of these families is ending up with fewer members as well.
|
||||
|
||||
"I think this is a good thing," he concluded.
|
||||
|
||||
"The big community distros -- Debian, Slackware, Gentoo, Fedora -- are going strong and picking up a lot of the niche users that other distros catered to," he pointed out. "Many of these distros are making it easier to come up with customized variants for niche markets. So what you have is a greater connectedness within the big distros, and no less diversity."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/The-Curious-Case-of-the-Disappearing-Distros-81518.html
|
||||
|
||||
作者:Katherine Noyes
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.datamation.com/open-source/why-is-the-number-of-linux-distros-declining.html
|
||||
[2]:http://mrpogson.com/
|
||||
[3]:http://linuxrants.com/
|
||||
[4]:http://slashdot.org/
|
||||
[5]:http://ledgersmbdev.blogspot.com/
|
||||
[6]:http://www.ledgersmb.org/
|
||||
[7]:http://www.novell.com/linux
|
||||
[8]:http://www.redhat.com/
|
||||
@ -1,36 +0,0 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
**David Drysdale** wanted to add Capsicum security features to Linux after he noticed that FreeBSD already had Capsicum support. Capsicum defines fine-grained security privileges, not unlike filesystem capabilities. But as David discovered, Capsicum also has some controversy surrounding it.
|
||||
|
||||
Capsicum has been around for a while and was described in a USENIX paper in 2010: [http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf][1].
|
||||
|
||||
Part of the controversy is just because of the similarity with capabilities. As Eric Biderman pointed out during the discussion, it would be possible to implement features approaching Capsicum's as an extension of capabilities, but implementing Capsicum directly would involve creating a whole new (and extensive) abstraction layer in the kernel. Although David argued that capabilities couldn't actually be extended far enough to match Capsicum's fine-grained security controls.
|
||||
|
||||
Capsicum also was controversial within its own developer community. For example, as Eric described, it lacked a specification for how to revoke privileges. And, David pointed out that this was because the community couldn't agree on how that could best be done. David quoted an e-mail sent by Ben Laurie to the cl-capsicum-discuss mailing list in 2011, where Ben said, "It would require additional book-keeping to find and revoke outstanding capabilities, which requires knowing how to reach capabilities, and then whether they are derived from the capability being revoked. It also requires an authorization model for revocation. The former two points mean additional overhead in terms of data structure operations and synchronisation."
|
||||
|
||||
Given the ongoing controversy within the Capsicum developer community and the corresponding lack of specification of key features, and given the existence of capabilities that already perform a similar function in the kernel and the invasiveness of Capsicum patches, Eric was opposed to David implementing Capsicum in Linux.
|
||||
|
||||
But, given the fact that capabilities are much coarser-grained than Capsicum's security features, to the point that capabilities can't really be extended far enough to mimic Capsicum's features, and given that FreeBSD already has Capsicum implemented in its kernel, showing that it can be done and that people might want it, it seems there will remain a lot of folks interested in getting Capsicum into the Linux kernel.
|
||||
|
||||
Sometimes it's unclear whether there's a bug in the code or just a bug in the written specification. Henrique de Moraes Holschuh noticed that the Intel Software Developer Manual (vol. 3A, section 9.11.6) said quite clearly that microcode updates required 16-byte alignment for the P6 family of CPUs, the Pentium 4 and the Xeon. But, the code in the kernel's microcode driver didn't enforce that alignment.
|
||||
|
||||
In fact, Henrique's investigation uncovered the fact that some Intel chips, like the Xeon X5550 and the second-generation i5 chips, needed only 4-byte alignment in practice, and not 16. However, to conform to the documented specification, he suggested fixing the kernel code to match the spec.
|
||||
|
||||
Borislav Petkov objected to this. He said Henrique was looking for problems where there weren't any. He said that Henrique simply had discovered a bug in Intel's documentation, because the alignment issue clearly wasn't a problem in the real world. He suggested alerting the Intel folks to the documentation problem and moving on. As he put it, "If the processor accepts the non-16-byte-aligned update, why do you care?"
|
||||
|
||||
But, as H. Peter Anvin remarked, the written spec was Intel's guarantee that certain behaviors would work. If the kernel ignored the spec, it could lead to subtle bugs later on. And, Bill Davidsen said that if the kernel ignored the alignment requirement, and "if the requirement is enforced in some future revision, and updates then fail in some insane way, the vendor is justified in claiming 'I told you so'."
|
||||
|
||||
The end result was that Henrique sent in some patches to make the microcode driver enforce the 16-byte alignment requirement.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-6
|
||||
|
||||
作者:[Zack Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
[1]:http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf
|
||||
@ -1,91 +0,0 @@
|
||||
Did this JavaScript break the console?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
Just doing some JavaScript stuff in google chrome (don't want to try in other browsers for now, in case this is really doing real damage) and I'm not sure why this seemed to break my console.
|
||||
|
||||
```javascript
|
||||
>var x = "http://www.foo.bar/q?name=%%this%%";
|
||||
<undefined
|
||||
>x
|
||||
```
|
||||
|
||||
After x (and enter) the console stops working... I restarted chrome and now when I do a simple
|
||||
|
||||
```javascript
|
||||
console.clear();
|
||||
```
|
||||
|
||||
It's giving me
|
||||
|
||||
```javascript
|
||||
Console was cleared
|
||||
```
|
||||
|
||||
And not clearing the console. Now in my scripts console.log's do not register and I'm wondering what is going on. 99% sure it has to do with the double percent signs (%%).
|
||||
|
||||
Anyone know what I did wrong or better yet, how to fix the console?
|
||||
|
||||
[A bug report for this issue has been filed here.][1]
|
||||
Edit: Feeling pretty dumb, but I had Preserve log checked... That's why the console wasn't clearing.
|
||||
|
||||
#A:
|
||||
|
||||
As discussed in the comments, there are actually many different ways of constructing a string that causes this issue, and it is not necessary for there to be two percent signs in most cases.
|
||||
|
||||
```TXT
|
||||
http://example.com/%
|
||||
http://%%%
|
||||
http://ab%
|
||||
http://%ab
|
||||
http://%zz
|
||||
```
|
||||
|
||||
However, it's not just the presence of a percent sign that breaks the Chrome console, as when we enter the following well-formed URL, the console continues to work properly and produces a clickable link.
|
||||
|
||||
```TXT
|
||||
http://ab%20cd
|
||||
```
|
||||
|
||||
Additionally, the strings `http://%`, and `http://%%` will also print properly, since Chrome will not auto-link a URL-link string unless the [`http://`][2] is followed by at least 3 characters.
|
||||
|
||||
From here I hypothesized that the issue must be in the process of linking a URL string in the console, likely in the process of decoding a malformed URL. I remembered that the JavaScript function `decodeURI` will throw an exception if given a malformed URL, and since Chrome's developer tools are largely written in JavaScript, could this be the issue that is evidently crashing the developer console?
|
||||
|
||||
To test this theory, I ran Chrome by the command link, to see if any errors were being logged.
|
||||
|
||||
Indeed, the same error you would see if you ran decodeURI on a malformed URL (i.e. decodeURI('http://example.com/%')) was being printed to the console:
|
||||
|
||||
>[4810:1287:0107/164725:ERROR:CONSOLE(683)] "Uncaught URIError: URI malformed", source: chrome-devtools://devtools/bundled/devtools.js (683)
|
||||
>So, I opened the URL 'chrome-devtools://devtools/bundled/devtools.js' in Chrome, and on line 683, I found the following.
|
||||
|
||||
```javascript
|
||||
{var parsedURL=new WebInspector.ParsedURL(decodeURI(url));var origin;var folderPath;var name;if(parsedURL.isValid){origin=parsedURL.scheme+"://"+parsedURL.host;if(parsedURL.port)
|
||||
```
|
||||
|
||||
As we can see, `decodeURI(url)` is being called on the URL without any error checking, thus throwing the exception and crashing the developer console.
|
||||
|
||||
A real fix for this issue will come from adding error handling to the Chrome console code, but in the meantime, one way to avoid the issue would be to wrap the string in a complex data type like an array to prevent parsing when logging.
|
||||
|
||||
```javascript
|
||||
var x = "http://example.com/%";
|
||||
console.log([x]);
|
||||
```
|
||||
|
||||
Thankfully, the broken console issue does not persist once the tab is closed, and will not affect other tabs.
|
||||
|
||||
###Update:
|
||||
|
||||
Apparently, the issue can persist across tabs and restarts if Preserve Log is checked. Uncheck this if you are having this issue.
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27828804/did-this-javascript-break-the-console/27830948#27830948)
|
||||
|
||||
作者:[Alexander O'Mara][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/3155639/alexander-omara
|
||||
[1]:https://code.google.com/p/chromium/issues/detail?id=446975
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/decodeURI
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc Translating
|
||||
|
||||
7 communities driving open source development
|
||||
================================================================================
|
||||
Not so long ago, the open source model was the rebellious kid on the block, viewed with suspicion by established industry players. Today, open initiatives and foundations are flourishing with long lists of vendor committers who see the model as a key to innovation.
|
||||
@ -83,4 +85,4 @@ via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
|
||||
@ -1,66 +0,0 @@
|
||||
Revealed: The best and worst of Docker
|
||||
================================================================================
|
||||

|
||||
Credit: [Shutterstock][1]
|
||||
|
||||
> Docker experts talk about the good, the bad, and the ugly of the ubiquitous application container system
|
||||
|
||||
No question about it: Docker's app container system has made its mark and become a staple in many IT environments. With its accelerating adoption, it's bound to stick around for a good long time.
|
||||
|
||||
But there's no end to the debate about what Docker's best for, where it falls short, or how to most sensibly move it forward without alienating its existing users or damaging its utility. Here, we've turned to a few of the folks who have made Docker their business to get their takes on Docker's good, bad, and ugly sides.
|
||||
|
||||
### The good ###
|
||||
|
||||
One hardly expects Steve Francia, chief of operations of the Docker open source project, to speak of Docker in anything less than glowing terms. When asked by email about Docker's best attributes, he didn't disappoint: "I think the best thing about Docker is that it enables people, enables developers, enables users to very easily run an application anywhere," he said. "It's almost like the Holy Grail of development in that you can run an application on your desktop, and the exact same application without any changes can run on the server. That's never been done before."
|
||||
|
||||
Alexis Richardson of [Weaveworks][2], a virtual networking product, praised Docker for enabling simplicity. "Docker offers immense potential to radically simplify and speed up how software gets built," he replied in an email. "This is why it has delivered record-breaking initial mind share and traction."
|
||||
|
||||
Bob Quillin, CEO of [StackEngine][3], which makes Docker management and automation solutions, noted in an email that Docker (the company) has done a fine job of maintaining Docker's (the product) appeal to its audience. "Docker has been best at delivering strong developer support and focused investment in its product," he wrote. "Clearly, they know they have to keep the momentum, and they are doing that by putting intense effort into product functionality." He also mentioned that Docker's commitment to open source has accelerated adoption by "[allowing] people to build around their features as they are being built."
|
||||
|
||||
Though containerization itself isn't new, as Rob Markovich of IT monitoring-service makers [Moogsoft][4] pointed out, Docker's implementation makes it new. "Docker is considered a next-generation virtualization technology given its more modern, lightweight form [of containerization]," he wrote in an email. "[It] brings an opportunity for an order-of-magnitude leap forward for software development teams seeking to deploy code faster."
|
||||
|
||||
### The bad ###
|
||||
|
||||
What's less appealing about Docker boils down to two issues: the complexity of using the product, and the direction of the company behind it.
|
||||
|
||||
Samir Ghosh, CEO of enterprise PaaS outfit [WaveMaker][5], gave Docker a thumbs-up for simplifying the complex scripting typically needed for continuous delivery. That said, he added, "That doesn't mean Docker is simple. Implementing Docker is complicated. There are a lot of supporting technologies needed for things like container management, orchestration, app stack packaging, intercontainer networking, data snapshots, and so on."
|
||||
|
||||
Ghosh noted the ones who feel the most of that pain are enterprises that want to leverage Docker for continuous delivery, but "it's even more complicated for enterprises that have diverse workloads, various app stacks, heterogenous infrastructures, and limited resources, not to mention unique IT needs for visibility, control and security."
|
||||
|
||||
Complexity also becomes an issue in troubleshooting and analysis, and Markovich cited the fact that Docker provides application abstraction as the reason why. "It is nearly impossible to relate problems with application performance running on Docker to the performance of the underlying infrastructure domains," he said in an email. "IT teams are going to need visibility -- a new class of monitoring and analysis tools that can correlate across and relate how everything is working up and down the Docker stack, from the applications down to the private or public infrastructure."
|
||||
|
||||
Quillin is most concerned about Docker's direction vis-à-vis its partner community: "Where will Docker make money, and where will their partners? If [Docker] wants to be the next VMware, it will need to take a page out of VMware's playbook in how to build and support a thriving partner ecosystem.
|
||||
|
||||
"Additionally, to drive broader adoption, especially in the enterprise, Docker needs to start acting like a market leader by releasing more fully formed capabilities that organizations can count on, versus announcements of features with 'some assembly required,' that don't exist yet, or that require you to 'submit a pull request' to fix it yourself."
|
||||
|
||||
Francia pointed to Docker's rapid ascent for creating its own difficulties. "[Docker] caught on so quickly that there's definitely places that we're focused on to add some features that a lot of users are looking forward to."
|
||||
|
||||
One such feature, he noted, was having a GUI. "Right now to use Docker," he said, "you have to be comfortable with the command line. There's no visual interface to using Docker. Right now it's all command line-based. And we know if we want to really be as successful as we think we can be, we need to be more approachable and a lot of people when they see a command line, it's a bit intimidating for a lot of users."
|
||||
|
||||
### The future ###
|
||||
|
||||
In that last respect, Docker recently started to make advances. Last week it [bought the startup Kitematic][6], whose product gave Docker a convenient GUI on Mac OS X (and will eventually do the same for Windows). Another acqui-hire, [SocketPlane][7], is being spun in to work on Docker's networking.
|
||||
|
||||
What remains to be seen is whether Docker's proposed solutions to its problems will be adopted, or whether another party -- say, [Red Hat][8] -- will provide a more immediately useful solution for enterprise customers who can't wait around for the chips to stop falling.
|
||||
|
||||
"Good technology is hard and takes time to build," said Richardson. "The big risk is that expectations spin wildly out of control and customers are disappointed."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2896895/application-virtualization/best-and-worst-about-docker.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:http://shutterstock.com/
|
||||
[2]:http://weave.works/
|
||||
[3]:http://stackengine.com/
|
||||
[4]:http://www.moogsoft.com/
|
||||
[5]:http://www.wavemaker.com/
|
||||
[6]:http://www.infoworld.com/article/2896099/application-virtualization/dockers-new-acquisition-does-containers-on-the-desktop.html
|
||||
[7]:http://www.infoworld.com/article/2892916/application-virtualization/docker-snaps-up-socketplane-to-fix-networking-flaws.html
|
||||
[8]:http://www.infoworld.com/article/2895804/application-virtualization/red-hat-wants-to-do-for-containers-what-its-done-for-linux.html
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
Interviews: Linus Torvalds Answers Your Question
|
||||
================================================================================
|
||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||
@ -181,4 +182,4 @@ via: http://linux.slashdot.org/story/15/06/30/0058243/interviews-linus-torvalds-
|
||||
[a]:samzenpus@slashdot.org
|
||||
[1]:http://interviews.slashdot.org/story/15/06/24/1718247/interview-ask-linus-torvalds-a-question
|
||||
[2]:http://meta.slashdot.org/story/12/10/11/0030249/linus-torvalds-answers-your-questions
|
||||
[3]:https://lwn.net/Articles/604695/
|
||||
[3]:https://lwn.net/Articles/604695/
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
7 command line tools for monitoring your Linux system
|
||||
================================================================================
|
||||
**Here is a selection of basic command line tools that will make your exploration and optimization in Linux easier. **
|
||||
|
||||

|
||||
|
||||
### Dive on in ###
|
||||
|
||||
One of the great things about Linux is how deeply you can dive into the system to explore how it works and to look for opportunities to fine tune performance or diagnose problems. Here is a selection of basic command line tools that will make your exploration and optimization easier. Most of these commands are already built into your Linux system, but in case they aren’t, just Google “install”, the command name, and the name of your distro and you’ll find which package needs installing (note that some commands are bundled with other commands in a package that has a different name from the one you’re looking for). If you have any other tools you use, let me know for our next Linux Tools roundup.
|
||||
|
||||

|
||||
|
||||
### How we did it ###
|
||||
|
||||
FYI: The screenshots in this collection were created on [Debian Linux 8.1][1] (“Jessie”) running in a virtual machine under [Oracle VirtualBox 4.3.28][2] under [OS X 10.10.3][3] (“Yosemite”). See my next slideshow “[How to install Debian Linux in a VirtualBox VM][4]” for a tutorial on how to build your own Debian VM.
|
||||
|
||||

|
||||
|
||||
### Top command ###
|
||||
|
||||
One of the simpler Linux system monitoring tools, the **top command** comes with pretty much every flavor of Linux. This is the default display, but pressing the “z” key switches the display to color. Other hot keys and command line switches control things such as the display of summary and memory information (the second through fourth lines), sorting the list according to various criteria, killing tasks, and so on (you can find the complete list at [here][5]).
|
||||
|
||||

|
||||
|
||||
### htop ###
|
||||
|
||||
Htop is a more sophisticated alternative to top. Wikipedia: “Users often deploy htop in cases where Unix top does not provide enough information about the systems processes, for example when trying to find minor memory leaks in applications. Htop is also popularly used interactively as a system monitor. Compared to top, it provides a more convenient, cursor-controlled interface for sending signals to processes.” (For more detail go [here][6].)
|
||||
|
||||

|
||||
|
||||
### Vmstat ###
|
||||
|
||||
Vmstat is a simpler tool for monitoring your Linux system performance statistics but that makes it highly suitable for use in shell scripts. Fire up your regex-fu and you can do some amazing things with vmstat and cron jobs. “The first report produced gives averages since the last reboot. Additional reports give information on a sampling period of length delay. The process and memory reports are instantaneous in either case” (go [here][7] for more info.).
|
||||
|
||||

|
||||
|
||||
### ps ###
|
||||
|
||||
The ps command shows a list of running processes. In this case, I’ve used the “-e”switch to show everything, that is, all processes running (I’ve scrolled back to the top of the output otherwise the column names wouldn’t be visible). This command has a lot of switches that allow you to format the output as needed. Add a little of the aforementioned regex-fu and you’ve got a powerful tool. Go [here][8] for the full details.
|
||||
|
||||

|
||||
|
||||
### Pstree ###
|
||||
|
||||
Pstree “shows running processes as a tree. The tree is rooted at either pid or init if pid is omitted. If a user name is specified, all process trees rooted at processes owned by that user are shown.”This is a really useful tool as the tree helps you sort out which process is dependent on which process (go [here][9]).
|
||||
|
||||

|
||||
|
||||
### pmap ###
|
||||
|
||||
Understanding just how an app uses memory is often crucial in debugging, and the pmap produces just such information when given a process ID (PID). The screenshot shows the medium weight output generated by using the “-x”switch. You can get pmap to produce even more detailed information using the “-X”switch but you’ll need a much wider terminal window.
|
||||
|
||||

|
||||
|
||||
### iostat ###
|
||||
|
||||
A crucial factor in your Linux system’s performance is processor and storage usage, which are what the iostat command reports on. As with the ps command, iostat has loads of switches that allow you to select the output format you need as well as sample performance over a time period and then repeat that sampling a number of times before reporting. See [here][10].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2937219/linux/7-command-line-tools-for-monitoring-your-linux-system.html
|
||||
|
||||
作者:[Mark Gibbs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Mark-Gibbs/
|
||||
[1]:https://www.debian.org/releases/stable/
|
||||
[2]:https://www.virtualbox.org/
|
||||
[3]:http://www.apple.com/osx/
|
||||
[4]:http://www.networkworld.com/article/2937148/how-to-install-debian-linux-8-1-in-a-virtualbox-vm
|
||||
[5]:http://linux.die.net/man/1/top
|
||||
[6]:http://linux.die.net/man/1/htop
|
||||
[7]:http://linuxcommand.org/man_pages/vmstat8.html
|
||||
[8]:http://linux.die.net/man/1/ps
|
||||
[9]:http://linux.die.net/man/1/pstree
|
||||
[10]:http://linux.die.net/man/1/iostat
|
||||
@ -1,88 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
The Honeycomb app lineup lost a ton of apps. This also shows the notification panel and the new quick settings.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The default app icons were slashed from 32 to 25, and two of those were third-party games. Since Honeycomb was not for phones and Google wanted the default apps to all be tablet-optimized, a lot of apps didn't make the cut. We lost the Amazon MP3 store, Car Home, Facebook, Google Goggles, Messaging, News and Weather, Phone, Twitter, Google Voice, and Voice Dialer. Google was quietly building a music service that would launch soon, so the Amazon MP3 store needed to go anyway. Car Home, Messaging, and Phone made little sense on a non-phone device, Facebook and Twitter still don't have tablet Android apps, and Goggles, News and Weather, and Voice Dialer were barely supported applications that most people wouldn't miss.
|
||||
|
||||
Almost every app icon was new. Just like the switch from the G1 to the Motorola Droid, the biggest impetus for change was probably the bump in resolution. The Nexus S had an 800×480 display, and Gingerbread came with art assets to match. The Xoom used a whopping 1280×800 10-inch display, which meant nearly every piece of art had to go. But again, this time a real designer was in charge, and things were a lot more cohesive. Honeycomb marked the switch from a vertically scrolling app drawer to paginated horizontal drawer. This change made sense on a horizontal device, but on phones it was still much faster to navigate the app drawer with a flingable, vertical list.
|
||||
|
||||
The second Honeycomb screenshot shows the new notification panel. The gray and black Gingerbread design was tossed for another straight-black panel that gave off a blue glow. At the top was a block showing the time, date, connection status, battery, and a shortcut to the notification quick settings, and below that were the actual notifications. Non-permanent notifications could now be dismissed by tapping on an "X" on the right side of the notification. Honeycomb was the first version to enable controls within a notification. The first (and at the launch of Honeycomb, only) app to take advantage of this was the new Google Music app, which placed previous, play/pause, and next buttons in its notification. These new controls could be accessed from any app and made controlling music a breeze.
|
||||
|
||||
|
||||
"Add to home screen" was given a zoomed-out interface for easy organizing. The search interface split auto suggest and universal search into different panes.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Pressing the plus button in the top right corner of the home screen or long pressing on the background would open the new home screen configuration interface. Honeycomb showed a zoomed-out view of all the home screens along the top of the screen, and it filled the bottom half of the screen with a tabbed drawer containing widgets and shortcuts. Items could be dragged out of the bottom drawer and into any of the five home screens. Gingerbread would just show a list of text, but Honeycomb showed full thumbnail previews of the widgets. This gave you a much better idea of what a widget would look like instead of an app-name-only description like "calendar."
|
||||
|
||||
The larger screen of the Motorola Xoom allowed the keyboard to take on a more PC-style layout, with keys like backspace, enter, shift, and tab put in the traditional locations. The keyboard took on a blueish tint and gained even more spacing between the keys. Google also added a dedicated smiley-face button. :-)
|
||||
|
||||
|
||||
Gmail on Honeycomb versus Gmail on Gingerbread with the menu open. Buttons were placed on the main screen for easier discovery.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Gmail demonstrated all the new UI concepts in Honeycomb. Android 3.0 did away with hiding all the controls behind a menu button. There was now a strip of icons along the top of the screen called the Action Bar, which lifted many useful controls to the main screen where users could see them. Gmail showed buttons for search, compose, and refresh, and it put less useful controls like settings, help, and feedback in a dropdown called the "overflow" button. Tapping checkboxes or selecting text would cause the entire action bar to change to icons relating to those actions—for instance, selecting text would bring up cut, copy, and select all buttons.
|
||||
|
||||
The app icon displayed in the top left corner doubled as a navigation button called "Up." While "Back" worked similarly to a browser back button, navigating to previously visited screens, "Up" would navigate up the app hierarchy. For instance, if you were in the Android Market, pressed the "Email developer" button, and Gmail opened, "Back" would take you back to the Android Market, but "Up" would take you to the Gmail inbox. "Back" might close the current app, but "Up" never would. Apps could control the "Back" button, and they usually reprogrammed it to replicate the "Up" functionality. In practice, there was rarely a difference between the two buttons.
|
||||
|
||||
Honeycomb also introduced the "Fragments" API, which allowed developers to use a single app for tablets and phones. A "Fragment" was a single pane of a user interface. In the Gmail picture above, the left folder list was one fragment and the inbox was another fragment. Phones would show one fragment per screen, and tablets could show two side-by-side. The developer defined the look of individual fragments, and Android would decide how they should be displayed based on the current device.
|
||||
|
||||
|
||||
The calculator finally used regular Android buttons, but someone spilled blue ink on the calendar.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
For the first time in Android's history, the calculator got a makeover with non-custom buttons, so it actually looked like part of the OS. The bigger screen made room for more buttons, enough that all the calculator functionality could fit on one screen. The calendar greatly benefited from the extra space, gaining much more room for appointment text and controls. The action bar at the top of the screen held buttons to switch views, along with showing the current time span and common controls. Appointment blocks switched to a white background with the calendar corner only showing in the top right corner. At the bottom (or side, in horizontal view) were boxes showing the month calendar and a list of displayed calendars.
|
||||
|
||||
The scale of the calendar could be adjusted, too. By performing a pinch zoom gesture, portrait week and day views could show between five and 19 hours of appointments on a single screen. The background of the calendar was made up of an uneven blue splotch, which didn't look particularly great and was tossed on later versions.
|
||||
|
||||
|
||||
The new camera interface, showing off the live "Negative" effect.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The giant 10-inch Xoom tablet did have a camera, which meant that it also had a camera app. The Tron redesign finally got rid of the old faux-leather look that Google came up with in Android 1.6. The controls were laid out in a circle around the shutter button, bringing to mind the circular controls and dials on a real camera. The Cooliris-derived speech bubble popups were changed to glowing, semi-transparent black boxes. The Honeycomb screenshot shows the new "color effect" functionality, which applied a filter to the viewfinder in real time. Unlike the Gingerbread camera app, this didn't support a portrait orientation—it was limited to landscape only. Taking a portrait picture with a 10-inch tablet doesn't make much sense, but then neither does taking a landscape one.
|
||||
|
||||
|
||||
The clock app didn't get quite as much love as other areas. Google just threw it into a tiny box and called it a day.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Tons of functionality went out the door when it came time to remake the clock app. The entire "Deskclock" concept was kicked out the door, replaced with a simple large display of the time against a plain black background. The ability to launch other apps and view the weather was gone, as was the ability of the clock app to use your wallpaper. Google sometimes gave up when it came time to design a tablet-sized interface, like here, where it just threw the alarm interface into a tiny, centered dialog box.
|
||||
|
||||
|
||||
The Music app finally got the ground-up redesign it has needed forever.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
While music received a few minor additions during its life, this was really the first time since Android 0.9 that it received serious attention. The highlight of the redesign was a don't-call-it-coverflow scrolling 3D album art view, called "New and Recent." Instead of the tabs added in Android 2.1, navigation was handled by a Dropbox box in the Action Bar. While "New and Recent" had 3D scrolling album art, "Albums" used a flat grid of albums thumbnails. The other sections had totally different designs, too. "Songs" used a vertically scrolling list of text, and "Playlists," "Genres," and "Artists" used stacked album art.
|
||||
|
||||
In nearly every view, every single item had its own individual menu, usually little arrows in the bottom right corner of an item. For now, these would only show "Play" and "add to Playlist," but this version of Google Music was built for the future. Google was launching a Music service soon, and those individual menus would be needed for things like viewing other content from that artist in the Music Store and managing the cloud storage versus local storage options.
|
||||
|
||||
Just like the Cooliris Gallery in Android 2.1, Google Music would blow up one of your thumbnails and use it as a background. The bottom "Now Playing" bar now displayed the album art, playback controls, and a song progress bar.
|
||||
|
||||
|
||||
Some of the new Google Maps was really nice, and some of it was from Android 1.5.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Google Maps received another redesign for the big screen. This one would stick around for a while and used a semi-transparent black action bar for all the controls. Search was again the primary function, given the first spot in the action bar, but this time it was an actual search bar you could type in, instead of a search bar-shaped button that launched a completely different interface. Google finally gave up on dedicating screen space to actual zoom buttons, relying on only gestures to control the map view. While the feature has since been ported to all old versions of Maps, Honeycomb was the first version to feature 3D building outlines on the map. Dragging two fingers down on the map would "tilt" the map view and show the sides of the buildings. You could freely rotate and the buildings would adjust, too.
|
||||
|
||||
Not every part of Maps was redesigned. Navigation was untouched from Gingerbread, and some core parts of the interface, like directions, were pulled straight from Android 1.6 and centered in a tiny box.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/17/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
@ -80,4 +82,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
|
||||
[1]:http://techcrunch.com/2014/03/03/gartner-195m-tablets-sold-in-2013-android-grabs-top-spot-from-ipad-with-62-share/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating...
|
||||
|
||||
How to set up IPv6 BGP peering and filtering in Quagga BGP router
|
||||
================================================================================
|
||||
In the previous tutorials, we demonstrated how we can set up a [full-fledged BGP router][1] and configure [prefix filtering][2] with Quagga. In this tutorial, we are going to show you how we can set up IPv6 BGP peering and advertise IPv6 prefixes through BGP. We will also demonstrate how we can filter IPv6 prefixes advertised or received by using prefix-list and route-map features.
|
||||
@ -255,4 +257,4 @@ via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
2q1w2007申领
|
||||
ictlyh Translating
|
||||
How to access a Linux server behind NAT via reverse SSH tunnel
|
||||
================================================================================
|
||||
You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
|
||||
|
||||
@ -1,191 +0,0 @@
|
||||
Install Plex Media Server On Ubuntu / CentOS 7.1 / Fedora 22
|
||||
================================================================================
|
||||
In this article we will show you how easily you can setup Plex Home Media Server on major Linux distributions with their latest releases. After its successful installation of Plex you will be able to use your centralized home media playback system that streams its media to many Plex player Apps and the Plex Home will allows you to setup your environment by adding your devices and to setup a group of users that all can use Plex Together. So let’s start its installation first on Ubuntu 15.04.
|
||||
|
||||
### Basic System Resources ###
|
||||
|
||||
System resources mainly depend on the type and number of devices that you are planning to connect with the server. So according to our requirements we will be using as following system resources and software for a standalone server.
|
||||
|
||||
注:表格
|
||||
<table width="666" style="height: 181px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="670" colspan="2"><b>Plex Home Media Server</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Base Operating System</b></td>
|
||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Plex Media Server</b></td>
|
||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>RAM and CPU</b></td>
|
||||
<td width="425">1 GB , 2.0 GHZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Hard Disk</b></td>
|
||||
<td width="425">30 GB</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Plex Media Server 0.9.12.3 on Ubuntu 15.04 ###
|
||||
|
||||
We are now ready to start the installations process of Plex Media Server on Ubuntu so let’s start with the following steps to get it ready.
|
||||
|
||||
#### Step 1: System Update ####
|
||||
|
||||
Login to your server with root privileges Make your that your system is upto date if not then do by using below command.
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
|
||||
#### Step 2: Download the Latest Plex Media Server Package ####
|
||||
|
||||
Create a new directory and download .deb plex Media Package in it from the official website of Plex for Ubuntu using wget command.
|
||||
|
||||
root@ubuntu-15:~# cd /plex/
|
||||
root@ubuntu-15:/plex#
|
||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
#### Step 3: Install the Debian Package of Plex Media Server ####
|
||||
|
||||
Now within the same directory run following command to start installation of debian package and then check the status of plekmediaserver.
|
||||
|
||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# service plexmediaserver status
|
||||
|
||||

|
||||
|
||||
### Plex Home Media Web App Setup on Ubuntu 15.04 ###
|
||||
|
||||
Let's open your web browser within your localhost network and open the Web Interface with your localhost IP and port 32400 and do following steps to configure it:
|
||||
|
||||
http://172.25.10.179:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
#### Step 1:Sign UP before Login ####
|
||||
|
||||
After you have access to the web interface of Plesk Media Server make sure to Sign Up and set your username email ID and Password to login as.
|
||||
|
||||

|
||||
|
||||
#### Step 2: Enter Your Pin to Secure Your Plex Media Home User ####
|
||||
|
||||

|
||||
|
||||
Now you have successfully configured your user under Plex Home Media.
|
||||
|
||||

|
||||
|
||||
### Opening Plex Web App on Devices Other than Localhost Server ###
|
||||
|
||||
As we have seen in our Plex media home page that it indicates that "You do not have permissions to access this server". Its because of we are on a different network than the Server computer.
|
||||
|
||||

|
||||
|
||||
Now we need to resolve this permissions issue so that we can have access to server on the devices other than the hosted server by doing following setup.
|
||||
|
||||
### Setup SSH Tunnel for Windows System to access Linux Server ###
|
||||
|
||||
First we need to set up a SSH tunnel so that we can access things as if they were local. This is only necessary for the initial setup.
|
||||
|
||||
If you are using Windows as your local system and server on Linux then we can setup SSH-Tunneling using Putty as shown.
|
||||
|
||||

|
||||
|
||||
**Once you have the SSH tunnel set up:**
|
||||
|
||||
Open your Web browser window and type following URL in the address bar.
|
||||
|
||||
http://localhost:8888/web
|
||||
|
||||
The browser will connect to the server and load the Plex Web App with same functionality as on local.
|
||||
Agree to the terms of Services and start
|
||||
|
||||

|
||||
|
||||
Now a fully functional Plex Home Media Server is ready to add new media libraries, channels, playlists etc.
|
||||
|
||||

|
||||
|
||||
### Plex Media Server 0.9.12.3 on CentOS 7.1 ###
|
||||
|
||||
We will follow the same steps on CentOS-7.1 that we did for the installation of Plex Home Media Server on Ubuntu 15.04.
|
||||
|
||||
So lets start with Plex Media Servers Package Installation.
|
||||
|
||||
#### Step 1: Plex Media Server Installation ####
|
||||
|
||||
To install Plex Media Server on centOS 7.1 we need to download the .rpm package from the official website of Plex. So we will use wget command to download .rpm package for this purpose in a new directory.
|
||||
|
||||
[root@linux-tutorials ~]# cd /plex
|
||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### Step 2: Install .RPM Package ####
|
||||
|
||||
After completion of complete download package we will install this package using rpm command within the same direcory where we installed the .rpm package.
|
||||
|
||||
[root@linux-tutorials plex]# ls
|
||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### Step 3: Start Plexmediaservice ####
|
||||
|
||||
We have successfully installed Plex Media Server Now we just need to restart its service and then enable it permanently.
|
||||
|
||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||
|
||||
### Plex Home Media Web App Setup on CentOS-7.1 ###
|
||||
|
||||
Now we just need to repeat all steps that we performed during the Web app setup of Ubuntu.
|
||||
So let's Open a new window in your web browser and access the Plex Media Server Web app using localhost or IP or your Plex server.
|
||||
|
||||
http://172.20.3.174:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
Then to get full permissions on the server you need to repeat the steps to create the SSH-Tunnel.
|
||||
After signing up with new user account we will be able to access its all features and can add new users, add new libraries and setup it per our needs.
|
||||
|
||||

|
||||
|
||||
### Plex Media Server 0.9.12.3 on Fedora 22 Work Station ###
|
||||
|
||||
The Basic steps to download and install Plex Media Server are the same as its we did for in CentOS 7.1.
|
||||
We just need to download its .rpm package and then install it with rpm command.
|
||||
|
||||

|
||||
|
||||
### Plex Home Media Web App Setup on Fedora 22 Work Station ###
|
||||
|
||||
We had setup Plex Media Server on the same host so we don't need to setup SSH-Tunnel in this time scenario. Just open the web browser in your Fedora 22 Workstation with default port 32400 of Plex Home Media Server and accept the Plex Terms of Services Agreement.
|
||||
|
||||

|
||||
|
||||
**Welcome to Plex Home Media Server on Fedora 22 Workstation**
|
||||
|
||||
Lets login with your plex account and start with adding your libraries for your favorite movie channels , create your playlists, add your photos and enjoy with many other features of Plex Home Media Server.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We had successfully installed and configured Plex Media Server on Major Linux Distributions. So, Plex Home Media Server has always been a best choice for media management. Its so simple to setup on cross platform as we did for Ubuntu, CentOS and Fedora. It has simplifies the tasks of organizing your media content and streaming to other computers and devices then to share it with your friends.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,182 +0,0 @@
|
||||
translating by zhangboyue
|
||||
Analyzing Linux Logs
|
||||
================================================================================
|
||||
There’s a great deal of information waiting for you within your logs, although it’s not always as easy as you’d like to extract it. In this section we will cover some examples of basic analysis you can do with your logs right away (just search what’s there). We’ll also cover more advanced analysis that may take some upfront effort to set up properly, but will save you time on the back end. Examples of advanced analysis you can do on parsed data include generating summary counts, filtering on field values, and more.
|
||||
|
||||
We’ll show you first how to do this yourself on the command line using several different tools and then show you how a log management tool can automate much of the grunt work and make this so much more streamlined.
|
||||
|
||||
### Searching with Grep ###
|
||||
|
||||
Searching for text is the most basic way to find what you’re looking for. The most common tool for searching text is [grep][1]. This command line tool, available on most Linux distributions, allows you to search your logs using regular expressions. A regular expression is a pattern written in a special language that can identify matching text. The simplest pattern is to put the string you’re searching for surrounded by quotes
|
||||
|
||||
#### Regular Expressions ####
|
||||
|
||||
Here’s an example to find authentication logs for “user hoover” on an Ubuntu system:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
It can be hard to construct regular expressions that are accurate. For example, if we searched for a number like the port “4792” it could also match timestamps, URLs, and other undesired data. In the below example for Ubuntu, it matched an Apache log that we didn’t want.
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### Surround Search ####
|
||||
|
||||
Another useful tip is that you can do surround search with grep. This will show you what happened a few lines before or after a match. It can help you debug what lead up to a particular error or problem. The B flag gives you lines before, and A gives you lines after. For example, we can see that when someone failed to login as an admin, they also failed the reverse mapping which means they might not have a valid domain name. This is very suspicious!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
You can also pair grep with [tail][2] to get the last few lines of a file, or to follow the logs and print them in real time. This is useful if you are making interactive changes like starting a server or testing a code change.
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
A full introduction on grep and regular expressions is outside the scope of this guide, but [Ryan’s Tutorials][3] include more in-depth information.
|
||||
|
||||
Log management systems have higher performance and more powerful searching abilities. They often index their data and parallelize queries so you can quickly search gigabytes or terabytes of logs in seconds. In contrast, this would take minutes or in extreme cases hours with grep. Log management systems also use query languages like [Lucene][4] which offer an easier syntax for searching on numbers, fields, and more.
|
||||
|
||||
### Parsing with Cut, AWK, and Grok ###
|
||||
|
||||
#### Command Line Tools ####
|
||||
|
||||
Linux offers several command line tools for text parsing and analysis. They are great if you want to quickly parse a small amount of data but can take a long time to process large volumes of data
|
||||
|
||||
#### Cut ####
|
||||
|
||||
The [cut][5] command allows you to parse fields from delimited logs. Delimiters are characters like equal signs or commas that break up fields or key value pairs.
|
||||
|
||||
Let’s say we want to parse the user from this log:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
We can use the cut command like this to get the text after the eighth equal sign. This example is on an Ubuntu system:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
Alternately, you can use [awk][6], which offers more powerful features to parse out fields. It offers a scripting language so you can filter out nearly everything that’s not relevant.
|
||||
|
||||
For example, let’s say we have the following log line on an Ubuntu system and we want to extract the username that failed to login:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
Here’s how you can use the awk command. First, put a regular expression /sshd.*invalid user/ to match the sshd invalid user lines. Then print the ninth field using the default delimiter of space using { print $9 }. This outputs the usernames.
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
You can read more about how to use regular expressions and print fields in the [Awk User’s Guide][7].
|
||||
|
||||
#### Log Management Systems ####
|
||||
|
||||
Log management systems make parsing easier and enable users to quickly analyze large collections of log files. They can automatically parse standard log formats like common Linux logs or web server logs. This saves a lot of time because you don’t have to think about writing your own parsing logic when troubleshooting a system problem.
|
||||
|
||||
Here you can see an example log message from sshd which has each of the fields remoteHost and user parsed out. This is a screenshot from Loggly, a cloud-based log management service.
|
||||
|
||||

|
||||
|
||||
You can also do custom parsing for non-standard formats. A common tool to use is [Grok][8] which uses a library of common regular expressions to parse raw text into structured JSON. Here is an example configuration for Grok to parse kernel log files inside Logstash:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
And here is what the parsed output looks like from Grok:
|
||||
|
||||

|
||||
|
||||
### Filtering with Rsyslog and AWK ###
|
||||
|
||||
Filtering allows you to search on a specific field value instead of doing a full text search. This makes your log analysis more accurate because it will ignore undesired matches from other parts of the log message. In order to search on a field value, you need to parse your logs first or at least have a way of searching based on the event structure.
|
||||
|
||||
#### How to Filter on One App ####
|
||||
|
||||
Often, you just want to see the logs from just one application. This is easy if your application always logs to a single file. It’s more complicated if you need to filter one application among many in an aggregated or centralized log. Here are several ways to do this:
|
||||
|
||||
1. Use the rsyslog daemon to parse and filter logs. This example writes logs from the sshd application to a file named sshd-messages, then discards the event so it’s not repeated elsewhere. You can try this example by adding it to your rsyslog.conf file.
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. Use command line tools like awk to extract the values of a particular field like the sshd username. This example is from an Ubuntu system.
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. Use a log management system that automatically parses your logs, then click to filter on the desired application name. Here is a screenshot showing the syslog fields in a log management service called Loggly. We are filtering on the appName “sshd” as indicated by the Venn diagram icon.
|
||||
|
||||

|
||||
|
||||
#### How to Filter on Errors ####
|
||||
|
||||
One of the most common thing people want to see in their logs is errors. Unfortunately, the default syslog configuration doesn’t output the severity of errors directly, making it difficult to filter on them.
|
||||
|
||||
There are two ways you can solve this problem. First, you can modify your rsyslog configuration to output the severity in the log file to make it easier to read and search. In your rsyslog configuration you can add a [template][9] with pri-text such as the following:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
This example gives you output in the following format. You can see that the severity in this message is err.
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
You can use awk or grep to search for just the error messages. In this example for Ubuntu, we’re including some surrounding syntax like the . and the > which match only this field.
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
Your second option is to use a log management system. Good log management systems automatically parse syslog messages and extract the severity field. They also allow you to filter on log messages of a certain severity with a single click.
|
||||
|
||||
Here is a screenshot from Loggly showing the syslog fields with the error severity highlighted to show we are filtering for errors:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a] [Amy Echeverri][b] [ Sadequl Hussain][c]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
@ -1,209 +0,0 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
||||
================================================================================
|
||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
||||
|
||||

|
||||
|
||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
||||
|
||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
||||
|
||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
||||
|
||||
### 1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used? ###
|
||||
|
||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
||||
>
|
||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
||||
|
||||
### 2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line? ###
|
||||
|
||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
||||
|
||||
### 3. What are the basic differences between between iptables and firewalld? ###
|
||||
|
||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
||||
|
||||
### 4. Would you replace iptables with firewalld on all your servers, if given a chance? ###
|
||||
|
||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
||||
|
||||
### 5. You seems confident with iptables and the plus point is even we are using iptables on our server. ###
|
||||
|
||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
||||
|
||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
||||
>
|
||||
> Nat Table
|
||||
> Mangle Table
|
||||
> Filter Table
|
||||
> Raw Table
|
||||
>
|
||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
||||
>
|
||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
||||
>
|
||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
||||
>
|
||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
||||
|
||||
### 6. What are the target values (that can be specified in target) in iptables and what they do, be brief! ###
|
||||
|
||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
||||
>
|
||||
> ACCEPT : Accept Packets
|
||||
> QUEUE : Paas Package to user space (place where application and drivers reside)
|
||||
> DROP : Drop Packets
|
||||
> RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
||||
|
||||
|
||||
### 7. Lets move to the technical aspects of iptables, by technical I means practical. ###
|
||||
|
||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
||||
|
||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> If you need to install it, you may do yum to get it.
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
### 8. How to Check and ensure if iptables service is running? ###
|
||||
|
||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> If it is not running, the below command may be executed.
|
||||
>
|
||||
> ---------------- On CentOS 6/5 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- On CentOS 7 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> We may also check if the iptables module is loaded or not, as:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
### 9. How will you review the current Rules defined in iptables? ###
|
||||
|
||||
> **Answer** : The current rules in iptables can be review as simple as:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Sample Output
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
### 10. How will you flush all iptables rules or a particular chain? ###
|
||||
|
||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
||||
>
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> To Flush all the iptables rules.
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
### 11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7) ###
|
||||
|
||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> We may include standard slash or subnet mask in the source as:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables. ###
|
||||
|
||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:To ACCEPT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j ACCEPT
|
||||
>
|
||||
> To REJECT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j REJECT
|
||||
>
|
||||
> To DENY tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j DENY
|
||||
>
|
||||
> To DROP tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j DROP
|
||||
|
||||
### 13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do? ###
|
||||
|
||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
>
|
||||
> The written rules can be checked using the below command.
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
||||
|
||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
||||
|
||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
||||
|
||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com.
|
||||
|
||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -1,95 +0,0 @@
|
||||
How to Configure Swarm Native Clustering for Docker
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn about Swarm and how we can create native clusters using Docker with Swarm. [Docker Swarm][1] is a native clustering program for Docker which turns a pool of Docker hosts into a single virtual host. Swarm serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Swarm follows the "batteries included but removable" principle as other Docker Projects. It ships with a simple scheduling backend out of the box, and as initial development settles, an API will develop to enable pluggable backends. The goal is to provide a smooth out-of-box experience for simple use cases, and allow swapping in more powerful backends, like Mesos, for large scale production deployments. Swarm is extremely easy to setup and get started.
|
||||
|
||||
So, here are some features of Swarm 0.2 out of the box.
|
||||
|
||||
1. Swarm 0.2.0 is about 85% compatible with the Docker Engine.
|
||||
2. It supports Resource Management.
|
||||
3. It has Advanced Scheduling feature with constraints and affinities.
|
||||
4. It supports multiple Discovery Backends (hubs, consul, etcd, zookeeper)
|
||||
5. It uses TLS encryption method for security and authentication.
|
||||
|
||||
So, here are some very simple and easy steps on how we can use Swarm.
|
||||
|
||||
### 1. Pre-requisites to run Swarm ###
|
||||
|
||||
We must install Docker 1.4.0 or later on all nodes. While each node's IP need not be public, the Swarm manager must be able to access each node across the network.
|
||||
|
||||
Note: Swarm is currently in beta, so things are likely to change. We don't recommend you use it in production yet.
|
||||
|
||||
### 2. Creating Swarm Cluster ###
|
||||
|
||||
Now, we'll create swarm cluster by running the below command. Each node will run a swarm node agent. The agent registers the referenced Docker daemon, monitors it, and updates the discovery backend with the node's status. The below command returns a token which is a unique cluster id, it will be used when starting the Swarm Agent on nodes.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
### 3. Starting the Docker Daemon in each nodes ###
|
||||
|
||||
We'll need to login into each node that we'll use to create clusters and start the Docker Daemon into it using flag -H . It ensures that the docker remote API on the node is available over TCP for the Swarm Manager. To do start the docker daemon, we'll need to run the following command inside the nodes.
|
||||
|
||||
# docker -H tcp://0.0.0.0:2375 -d
|
||||
|
||||

|
||||
|
||||
### 4. Adding the Nodes ###
|
||||
|
||||
After enabling Docker Daemon, we'll need to add the Swarm Nodes to the discovery service. We must ensure that node's IP must be accessible from the Swarm Manager. To do so, we'll need to run the following command.
|
||||
|
||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
**Note**: Here, we'll need to replace <node_ip> and <cluster_id> with the IP address of the Node and the cluster ID we got from step 2.
|
||||
|
||||
### 5. Starting the Swarm Manager ###
|
||||
|
||||
Now, as we have got the nodes connected to the cluster. Now, we'll start the swarm manager, we'll need to run the following command in the node.
|
||||
|
||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 6. Checking the Configuration ###
|
||||
|
||||
Once the manager is running, we can check the configuration by running the following command.
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
|
||||

|
||||
|
||||
**Note**: We'll need to replace <manager_ip:manager_port> with the ip address and port of the host running the swarm manager.
|
||||
|
||||
### 7. Using the docker CLI to access nodes ###
|
||||
|
||||
After everything is done perfectly as explained above, this part is the most important part of the Docker Swarm. We can use Docker CLI to access the nodes and run containers on them.
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||
|
||||
### 8. Listing nodes in the cluster ###
|
||||
|
||||
We can get a list of all of the running nodes using the swarm list command.
|
||||
|
||||
# docker run --rm swarm list token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Swarm is really an awesome feature of docker that can be used for creating and managing clusters. It is pretty easy to setup and use. It is more beautiful when we use constraints and affinities on top of it. Advanced Scheduling is an awesome feature of it which applies filters to exclude nodes with ports, labels, health and it uses strategies to pick the best node. So, if you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.docker.com/swarm/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by DongShuaike
|
||||
|
||||
How to Provision Swarm Clusters using Docker Machine
|
||||
================================================================================
|
||||
Hi all, today we'll learn how we can deploy Swarm Clusters using Docker Machine. It serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Docker Machine is an application that helps to create Docker hosts on our computer, on cloud providers and inside our own data center. It provides easy solution for creating servers, installing Docker on them and then configuring the Docker client according the users configuration and requirements. We can provision swarm clusters with any driver we need and is highly secured with TLS Encryption.
|
||||
|
||||
Here are some quick and easy steps on how to provision swarm clusters with Docker Machine.
|
||||
|
||||
### 1. Installing Docker Machine ###
|
||||
|
||||
Docker Machine supports awesome on every Linux Operating System. First of all, we'll need to download the latest version of Docker Machine from the Github site . Here, we'll use curl to download the latest version of Docker Machine ie 0.2.0 .
|
||||
|
||||
For 64 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
For 32 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
After downloading the latest release of Docker Machine, we'll make the file named docker-machine under /usr/local/bin/ executable using the command below.
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
After doing the above, we'll wanna ensure that we have successfully installed docker-machine. To check it, we can run the docker-machine -v which will give output of the version of docker-machine installed in our system.
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
To enable Docker commands on our machines, make sure to install the Docker client as well by running the command below.
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. Creating Machine ###
|
||||
|
||||
After installing Machine into our working PC or device, we'll wanna go forward to create a machine using Docker Machine. Here, in this tutorial we'll gonna deploy a machine in the Digital Ocean Platform so we'll gonna use "digitalocean" as its Driver API then, docker swarm will be running into that Droplet which will be further configured as Swarm Master and another droplet will be created which will be configured as Swarm Node Agent.
|
||||
|
||||
So, to create the machine, we'll need to run the following command.
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**Note**: Here, linux-dev is the name of the machine we are wanting to create. <API-Token> is a security key which can be generated from the Digital Ocean Control Panel of the account holder of Digital Ocean Cloud Platform. To retrieve that key, we simply need to login to our Digital Ocean Control Panel then click on API, then click on Generate New Token and give it a name tick on both Read and Write. Then we'll get a long hex key, thats the <API-Token> now, simply replace it into the command above.
|
||||
|
||||
Now, to load the Machine configuration into the shell we are running the comamands, run the following command.
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
Then, we'll mark our machine as ACTIVE by running the below command.
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
Now, we'll check whether its been marked as ACTIVE "*" or not.
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. Running Swarm Docker Image ###
|
||||
|
||||
Now, after we finish creating the required machine. We'll gonna deploy swarm docker image in our active machine. This machine will run the docker image and will control over the Swarm master and node. To run the image, we can simply run the below command.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
If you are trying to run swarm docker image using **32 bit Operating System** in the computer where Docker Machine is running, we'll need to SSH into the Droplet.
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. Creating Swarm Master ###
|
||||
|
||||
Now, after our machine and swarm image is running into the machine, we'll now create a Swarm Master. This will also add the master as a node. To do so, here's the command below.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. Creating Swarm Nodes ###
|
||||
|
||||
Now, we'll create a swarm node which will get connected with the Swarm Master. The command below will create a new droplet which will be named as swarm-node and will get connected with the Swarm Master as node. This will create a Swarm cluster across the two nodes.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. Connecting to the Swarm Master ###
|
||||
|
||||
We, now connect to the Swarm Master so that we can deploy Docker containers across the nodes as per the requirement and configuration. To load the Swarm Master's Machine configuration into our environment, we can run the below command.
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
After that, we can run the required containers of our choice across the nodes. Here, we'll check if everything went fine or not. So, we'll run **docker info** to check the information about the Swarm Clusters.
|
||||
|
||||
# docker info
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We can pretty easily create Swarm Cluster with Docker Machine. This method is a lot productive because it reduces a lot of time of a system admin or users. In this article, we successfully provisioned clusters by creating a master and a node using a machine with Digital Ocean as driver. It can be created using any driver like VirtualBox, Google Cloud Computing, Amazon Web Service, Microsoft Azure and more according to the need and requirement of the user and the connection is highly secured with TLS Encryption. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,237 +0,0 @@
|
||||
How to collect NGINX metrics - Part 2
|
||||
================================================================================
|
||||

|
||||
|
||||
### How to get the NGINX metrics you need ###
|
||||
|
||||
How you go about capturing metrics depends on which version of NGINX you are using, as well as which metrics you wish to access. (See [the companion article][1] for an in-depth exploration of NGINX metrics.) Free, open-source NGINX and the commercial product NGINX Plus both have status modules that report metrics, and NGINX can also be configured to report certain metrics in its logs:
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th rowspan="2" style="text-align: left;">Metric</th>
|
||||
<th colspan="3" style="text-align: center;">Availability</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source">NGINX (open-source)</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus">NGINX Plus</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs">NGINX logs</a></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts / accepted</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests / total</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Metrics collection: NGINX (open-source) ####
|
||||
|
||||
Open-source NGINX exposes several basic metrics about server activity on a simple status page, provided that you have the HTTP [stub status module][2] enabled. To check if the module is already enabled, run:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
The status module is enabled if you see with-http_stub_status_module as output in the terminal.
|
||||
|
||||
If that command returns no output, you will need to enable the status module. You can use the --with-http_stub_status_module configuration parameter when [building NGINX from source][3]:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
After verifying the module is enabled or enabling it yourself, you will also need to modify your NGINX configuration to set up a locally accessible URL (e.g., /nginx_status) for the status page:
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
Note: The server blocks of the NGINX config are usually found not in the master configuration file (e.g., /etc/nginx/nginx.conf) but in supplemental configuration files that are referenced by the master config. To find the relevant configuration files, first locate the master config by running:
|
||||
|
||||
nginx -t
|
||||
|
||||
Open the master configuration file listed, and look for lines beginning with include near the end of the http block, such as:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
In one of the referenced config files you should find the main server block, which you can modify as above to configure NGINX metrics reporting. After changing any configurations, reload the configs by executing:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
Now you can view the status page to see your metrics:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
Note that if you are trying to access the status page from a remote machine, you will need to whitelist the remote machine’s IP address in your status configuration, just as 127.0.0.1 is whitelisted in the configuration snippet above.
|
||||
|
||||
The NGINX status page is an easy way to get a quick snapshot of your metrics, but for continuous monitoring you will need to automatically record that data at regular intervals. Parsers for the NGINX status page already exist for monitoring tools such as [Nagios][4] and [Datadog][5], as well as for the statistics collection daemon [collectD][6].
|
||||
|
||||
#### Metrics collection: NGINX Plus ####
|
||||
|
||||
The commercial NGINX Plus provides [many more metrics][7] through its ngx_http_status_module than are available in open-source NGINX. Among the additional metrics exposed by NGINX Plus are bytes streamed, as well as information about upstream systems and caches. NGINX Plus also reports counts of all HTTP status code types (1xx, 2xx, 3xx, 4xx, 5xx). A sample NGINX Plus status board is available [here][8].
|
||||
|
||||

|
||||
|
||||
*Note: the “Active” connections on the NGINX Plus status dashboard are defined slightly differently than the Active state connections in the metrics collected via the open-source NGINX stub status module. In NGINX Plus metrics, Active connections do not include connections in the Waiting state (aka Idle connections).*
|
||||
|
||||
NGINX Plus also reports [metrics in JSON format][9] for easy integration with other monitoring systems. With NGINX Plus, you can see the metrics and health status [for a given upstream grouping of servers][10], or drill down to get a count of just the response codes [from a single server][11] in that upstream:
|
||||
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
To enable the NGINX Plus metrics dashboard, you can add a status server block inside the http block of your NGINX configuration. ([See the section above][12] on collecting metrics from open-source NGINX for instructions on locating the relevant config files.) For example, to set up a status dashboard at http://your.ip.address:8080/status.html and a JSON interface at http://your.ip.address:8080/status, you would add the following server block:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
The status pages should be live once you reload your NGINX configuration:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
The official NGINX Plus docs have [more details][13] on how to configure the expanded status module.
|
||||
|
||||
#### Metrics collection: NGINX logs ####
|
||||
|
||||
NGINX’s [log module][14] writes configurable access logs to a destination of your choosing. You can customize the format of your logs and the data they contain by [adding or subtracting variables][15]. The simplest way to capture detailed logs is to add the following line in the server block of your config file (see [the section][16] on collecting metrics from open-source NGINX for instructions on locating your config files):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
After changing any NGINX configurations, reload the configs by executing:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
The “combined” log format, included by default, captures [a number of key data points][17], such as the actual HTTP request and the corresponding response code. In the example logs below, NGINX logged a 200 (success) status code for a request for /index.html and a 404 (not found) error for the nonexistent /fail.
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
You can log request processing time as well by adding a new log format to the http block of your NGINX config file:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
And by adding or modifying the access_log line in the server block of your config file:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
After reloading the updated configs (by running nginx -s reload), your access logs will include response times, as seen below. The units are seconds, with millisecond resolution. In this instance, the server received a request for /big.pdf, returning a 206 (success) status code after sending 33973115 bytes. Processing the request took 0.202 seconds (202 milliseconds):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
You can use a variety of tools and services to parse and analyze NGINX logs. For instance, [rsyslog][18] can monitor your logs and pass them to any number of log-analytics services; you can use a free, open-source tool such as [logstash][19] to collect and analyze logs; or you can use a unified logging layer such as [Fluentd][20] to collect and parse your NGINX logs.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Which NGINX metrics you monitor will depend on the tools available to you, and whether the insight provided by a given metric justifies the overhead of monitoring that metric. For instance, is measuring error rates important enough to your organization to justify investing in NGINX Plus or implementing a system to capture and analyze logs?
|
||||
|
||||
At Datadog, we have built integrations with both NGINX and NGINX Plus so that you can begin collecting and monitoring metrics from all your web servers with a minimum of setup. Learn how to monitor NGINX with Datadog [in this post][21], and get started right away with a [free trial of Datadog][22].
|
||||
|
||||
----------
|
||||
|
||||
Source Markdown for this post is available [on GitHub][23]. Questions, corrections, additions, etc.? Please [let us know][24].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,3 +1,4 @@
|
||||
translating wi-cuckoo
|
||||
How to monitor NGINX with Datadog - Part 3
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,188 +0,0 @@
|
||||
zpl1025
|
||||
Howto Configure FTP Server with Proftpd on Fedora 22
|
||||
================================================================================
|
||||
In this article, we'll learn about setting up an FTP server with Proftpd running Fedora 22 in our machine or server. [ProFTPD][1] is a free and open source FTP daemon software licensed under GPL. It is among most popular FTP server among machines running Linux. Its primary design aims to have an FTP server with many advanced features and provisioning users for more configuration options for easy customization. It includes a number of configuration options that are still not available with many other FTP daemons. It was initially developed by the developers as an alternative with better security and configuration to wu-ftpd server. An FTP server is a program that allows us to upload or download files and folders from a remote server where it is setup using an FTP client. Some of the features of ProFTPD daemon are as follows, you can check more features on [http://www.proftpd.org/features.html][2] .
|
||||
|
||||
- It includes a per directory ".ftpaccess" access configuration similar to Apache's ".htaccess"
|
||||
- It features multiple virtual FTP server with multiple users login and anonymous FTP services.
|
||||
- It can be run either as a stand-alone server or from inetd/xinetd.
|
||||
- Its ownership, file/folder attributes and file/folder permissions are UNIX-based.
|
||||
- It can be run as standalone mode in order to protect the system from damage that can be caused from root access.
|
||||
- The modular design of it makes it easily extensible with modules like LDAP servers, SSL/TLS encryption, RADIUS support, etc.
|
||||
- IPv6 support is also included in the ProFTPD server.
|
||||
|
||||
Here are some easy to perform steps on how we can setup an FTP Server with ProFTPD in Fedora 22 operating system.
|
||||
|
||||
### 1. Installing ProFTPD ###
|
||||
|
||||
First of all, we'll wanna install Proftpd server in our box running Fedora 22 as its operating system. As yum package manager has been depreciated, we'll use the latest and greatest built package manager called dnf. DNF is pretty easy to use and highly user friendly package manager available in Fedora 22. We'll simply use it to install proftpd daemon server. To do so, we'll need to run the following command in a terminal or a console in sudo mode.
|
||||
|
||||
$ sudo dnf -y install proftpd proftpd-utils
|
||||
|
||||
### 2. Configuring ProFTPD ###
|
||||
|
||||
Now, we'll make changes to some configurations in the daemon. To configure the daemon, we will need to edit /etc/proftpd.conf with a text editor. The main configuration file of the ProFTPD daemon is **/etc/proftpd.conf** so, any changes made to this file will affect the FTP server. Here, are some changes we make in this initial step.
|
||||
|
||||
$ sudo vi /etc/proftpd.conf
|
||||
|
||||
Next, after we open the file using a text editor, we'll wanna make changes to the ServerName and ServerAdmin as hostname and email address respectively. Here's what we have made changes to those configs.
|
||||
|
||||
ServerName "ftp.linoxide.com"
|
||||
ServerAdmin arun@linoxide.com
|
||||
|
||||
After that, we'll wanna the following lines into the configuration file so that it logs access & auth into its specified log files.
|
||||
|
||||
ExtendedLog /var/log/proftpd/access.log WRITE,READ default
|
||||
ExtendedLog /var/log/proftpd/auth.log AUTH auth
|
||||
|
||||

|
||||
|
||||
### 3. Adding FTP users ###
|
||||
|
||||
After configure the basics of the configuration file, we'll surely wanna create an FTP user which is rooted at a specific directory we want. The current users that we use to login into our machine are automatically enabled with the FTP service, we can even use it to login into the FTP server. But, in this tutorial, we'll gonna create a new user with a specified home directory to the ftp server.
|
||||
|
||||
Here, we'll create a new group named ftpgroup.
|
||||
|
||||
$ sudo groupadd ftpgroup
|
||||
|
||||
Then, we'll gonna add a new user arunftp into the group with home directory specified as /ftp-dir/
|
||||
|
||||
$ sudo useradd -G ftpgroup arunftp -s /sbin/nologin -d /ftp-dir/
|
||||
|
||||
After the user has been created and added to the group, we'll wanna set a password to the user arunftp.
|
||||
|
||||
$ sudo passwd arunftp
|
||||
|
||||
Changing password for user arunftp.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
|
||||
Now, we'll set read and write permission of the home directory by the ftp users by executing the following command.
|
||||
|
||||
$ sudo setsebool -P allow_ftpd_full_access=1
|
||||
$ sudo setsebool -P ftp_home_dir=1
|
||||
|
||||
Then, we'll wanna make that directory and its contents unable to get removed or renamed by any other users.
|
||||
|
||||
$ sudo chmod -R 1777 /ftp-dir/
|
||||
|
||||
### 4. Enabling TLS Support ###
|
||||
|
||||
FTP is considered less secure in comparison to the latest encryption methods used these days as anybody sniffing the network card can read the data pass through FTP. So, we'll enable TLS Encryption support in our FTP server. To do so, we'll need to a edit /etc/proftpd.conf configuration file. Before that, we'll wanna backup our existing configuration file to make sure we can revert our configuration if any unexpected happens.
|
||||
|
||||
$ sudo cp /etc/proftpd.conf /etc/proftpd.conf.bak
|
||||
|
||||
Then, we'll wanna edit the configuration file using our favorite text editor.
|
||||
|
||||
$ sudo vi /etc/proftpd.conf
|
||||
|
||||
Then, we'll wanna add the following lines just below line we configured in step 2 .
|
||||
|
||||
TLSEngine on
|
||||
TLSRequired on
|
||||
TLSProtocol SSLv23
|
||||
TLSLog /var/log/proftpd/tls.log
|
||||
TLSRSACertificateFile /etc/pki/tls/certs/proftpd.pem
|
||||
TLSRSACertificateKeyFile /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||

|
||||
|
||||
After finishing up with the configuration, we'll wanna save and exit it.
|
||||
|
||||
Next, we'll need to generate the SSL certificates inside **/etc/pki/tls/certs/** directory as proftpd.pem. To do so, first we'll need to install openssl in our Fedora 22 machine.
|
||||
|
||||
$ sudo dnf install openssl
|
||||
|
||||
Then, we'll gonna generate the SSL certificate by running the following command.
|
||||
|
||||
$ sudo openssl req -x509 -nodes -newkey rsa:2048 -keyout /etc/pki/tls/certs/proftpd.pem -out /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||
We'll be asked with some information that will be associated into the certificate. After completing the required information, it will generate a 2048 bit RSA private key.
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
...................+++
|
||||
...................+++
|
||||
writing new private key to '/etc/pki/tls/certs/proftpd.pem'
|
||||
-----
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [XX]:NP
|
||||
State or Province Name (full name) []:Narayani
|
||||
Locality Name (eg, city) [Default City]:Bharatpur
|
||||
Organization Name (eg, company) [Default Company Ltd]:Linoxide
|
||||
Organizational Unit Name (eg, section) []:Linux Freedom
|
||||
Common Name (eg, your name or your server's hostname) []:ftp.linoxide.com
|
||||
Email Address []:arun@linoxide.com
|
||||
|
||||
After that, we'll gonna change the permission of the generated certificate file in order to secure it.
|
||||
|
||||
$ sudo chmod 600 /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||
### 5. Allowing FTP through Firewall ###
|
||||
|
||||
Now, we'll need to allow the ftp ports that are usually blocked by the firewall by default. So, we'll allow ports and enable access to the ftp through firewall.
|
||||
|
||||
If **TLS/SSL Encryption is enabled** run the following command.
|
||||
|
||||
$sudo firewall-cmd --add-port=1024-65534/tcp
|
||||
$ sudo firewall-cmd --add-port=1024-65534/tcp --permanent
|
||||
|
||||
If **TLS/SSL Encryption is disabled** run the following command.
|
||||
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=ftp
|
||||
|
||||
success
|
||||
|
||||
Then, we'll need to reload the firewall configuration.
|
||||
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 6. Starting and Enabling ProFTPD ###
|
||||
|
||||
After everything is set, we'll finally start our ProFTPD and give it a try. To start the proftpd ftp daemon, we'll need to run the following command.
|
||||
|
||||
$ sudo systemctl start proftpd.service
|
||||
|
||||
Then, we'll wanna enable proftpd to start on every boot.
|
||||
|
||||
$ sudo systemctl enable proftpd.service
|
||||
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/proftpd.service to /usr/lib/systemd/system/proftpd.service.
|
||||
|
||||
### 7. Logging into the FTP server ###
|
||||
|
||||
Now, if everything was configured and done as expected, we must be able to connect to the ftp server and login with the details we set above. Here, we'll gonna configure our FTP client, filezilla with hostname as **server's ip or url**, Protocol as **FTP**, User as **arunftp** and password as the one we set in above step 3. If you followed step 4 for enabling TLS support, then we'll need to set the Encryption type as **Require explicit FTP over TLS** but if you didn't follow step 4 and don't wanna use TLS encryption then set the Encryption type as **Plain FTP**.
|
||||
|
||||

|
||||
|
||||
To setup the above configuration, we'll need goto File which is under the Menu and then click on Site Manager in which we can click on new site then configure as illustrated above.
|
||||
|
||||

|
||||
|
||||
Then, we're asked to accept the SSL certificate, that can be done by click OK. After that, we are able to upload and download required files and folders from our FTP server.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally, we have successfully installed and configured our Fedora 22 box with Proftpd FTP server. Proftpd is an awesome powerful highly configurable and extensible FTP daemon. The above tutorial illustrates us how we can configure a secure FTP server with TLS encryption. It is highly recommended to configure FTP server with TLS encryption as it enables SSL certificate security to the data transfer and login. Here, we haven't configured anonymous access to the FTP cause they are usually not recommended in a protected FTP system. An FTP access makes pretty easy for people to upload and download at good efficient performance. We can even change the ports for the users for additional security. So, if you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-ftp-proftpd-fedora-22/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.proftpd.org/
|
||||
[2]:http://www.proftpd.org/features.html
|
||||
@ -1,204 +0,0 @@
|
||||
Translating by GOLinu!
|
||||
12 Useful PHP Commandline Usage Every Linux User Must Know
|
||||
================================================================================
|
||||
In my last post “[How to Use and Execute PHP Codes in Linux Command – line][1]”, I emphasized on running PHP codes directly in Linux Command-line as well as executing PHP script file in Linux Terminal.
|
||||
|
||||

|
||||
|
||||
Run PHP Codes in Linux Commandline – Part 2
|
||||
|
||||
This post aims at making you aware of a few awesome features of PHP usage in Linux terminal.
|
||||
|
||||
Let us configure a few `php.ini` settings in the PHP interactive shell.
|
||||
|
||||
**6. Set PHP Command-line Prompt**
|
||||
|
||||
To set PHP command-line prompt, you need to start a PHP interactive shell from the Linux terminal using following php -a (enabling PHP Interactive mode) command.
|
||||
|
||||
$ php -a
|
||||
|
||||
and then set anything (say Hi Tecmint ::) as PHP interactive shell command prompt, simply as:
|
||||
|
||||
php > #cli.prompt=Hi Tecmint ::
|
||||
|
||||

|
||||
|
||||
Enable PHP Interactive Shell
|
||||
|
||||
Also you can set current time as your command Line Prompt, simply as:
|
||||
|
||||
php > #cli.prompt=`echo date('H:m:s');` >
|
||||
|
||||
22:15:43 >
|
||||
|
||||
**7. Produce one screen output at a time**
|
||||
|
||||
In our last article, we have used ‘less‘ command over a lots of places pipelined with original command. We did this to get one screen of output where output could not fit on one screen. But we can configure php.ini file to set pager value to less to produce one screen output at a time simply as,
|
||||
|
||||
$ php -a
|
||||
php > #cli.pager=less
|
||||
|
||||

|
||||
|
||||
Fix PHP Screen Output
|
||||
|
||||
So, next time when you run a command (say debugger `phpinfo();`) where the output is too big to fit a screen, it will automatically produce output that fits your current.
|
||||
|
||||
php > phpinfo();
|
||||
|
||||

|
||||
|
||||
PHP Info Output
|
||||
|
||||
**8. Suggestions and TAB completion**
|
||||
|
||||
PHP shell is a smart enough to show you suggestions and TAB Completion. You can use TAB key to use this feature. If more than one option is available for the string that you want to TAB completion, you have to use TAB key twice, else use it once.
|
||||
|
||||
In-case of more than one possibility, use TAB twice.
|
||||
|
||||
php > ZIP [TAB] [TAB]
|
||||
|
||||
In-case of single possibility, use TAB once.
|
||||
|
||||
php > #cli.pager [TAB]
|
||||
|
||||
You can keep pressing TAB for options till values of option are satisfied. All the activities are logged to file `~/.php-history`.
|
||||
|
||||
To check your PHP interactive shell activity log, you may run:
|
||||
|
||||
$ nano ~/.php_history | less
|
||||
|
||||

|
||||
|
||||
Check PHP Interactive Shell Logs
|
||||
|
||||
**9. You can use color inside PHP interactive shell. All you need to know are the color codes.**
|
||||
|
||||
Use echo to print the output into various colors, simply as:
|
||||
|
||||
php > echo “color_code1 TEXT second_color_code”;
|
||||
|
||||
or a more explaining example is:
|
||||
|
||||
php > echo "\033[0;31m Hi Tecmint \x1B[0m";
|
||||
|
||||

|
||||
|
||||
Enable Colors in PHP Shell
|
||||
|
||||
We have seen till now that pressing the return key means execute the command, however semicolon at the end of each command in Php shell is compulsory.
|
||||
|
||||
**10. Basename in php shell prints the trailing name component of path**
|
||||
|
||||
The basename function in php shell prints the trailing name component from a given string containing the path to a file or directory.
|
||||
|
||||
basename() example #1 and #2.
|
||||
|
||||
php > echo basename("/var/www/html/wp/wp-content/plugins");
|
||||
php > echo basename("www.tecmint.com/contact-us.html");
|
||||
|
||||
The above both examples will output:
|
||||
|
||||
plugins
|
||||
contact-us.html
|
||||
|
||||

|
||||
|
||||
Print Base Name in PHP
|
||||
|
||||
**11. You may create a file (say test1.txt) using php interactive shell at your Desktop, simply as**
|
||||
|
||||
$ touch("/home/avi/Desktop/test1.txt");
|
||||
|
||||
We have already seen how fine PHP interactive shell is in Mathematics, Here are a few more examples to stun you.
|
||||
|
||||
**12. Print the length of a string say tecmint.com using PHP interactive shell**
|
||||
|
||||
strlen function used to get a length of the given string.
|
||||
|
||||
php > echo strlen("tecmint.com");
|
||||
|
||||

|
||||
|
||||
Print Length String in PHP
|
||||
|
||||
**13. PHP Interactive shell can sort an array. Yes you heard it right**
|
||||
|
||||
Declare Variable a and set it’s value to array(7,9,2,5,10).
|
||||
|
||||
php > $a=array(7,9,2,5,10);
|
||||
|
||||
Sort the numbers in the array.
|
||||
|
||||
php > sort($a);
|
||||
|
||||
Print numbers of the array in sorted order along with their order. The first one is [0].
|
||||
|
||||
php > print_r($a);
|
||||
Array
|
||||
(
|
||||
[0] => 2
|
||||
[1] => 5
|
||||
[2] => 7
|
||||
[3] => 9
|
||||
[4] => 10
|
||||
)
|
||||
|
||||

|
||||
|
||||
Sort Arrays in PHP
|
||||
|
||||
**14. Get the value of Pi in PHP Interactive Shell**
|
||||
|
||||
php > echo pi();
|
||||
|
||||
3.1415926535898
|
||||
|
||||
**15. Print the square root of a number say 32**
|
||||
|
||||
php > echo sqrt(150);
|
||||
|
||||
12.247448713916
|
||||
|
||||
**16. Echo a random number from the range be 0-10**
|
||||
|
||||
php > echo rand(0, 10);
|
||||
|
||||

|
||||
|
||||
Get Random Number in PHP
|
||||
|
||||
**17. Get md5sum and sha1sum for a given string For example, let’s check the md5sum and sha1sum of a string (say avi) on php shell and cross check the result with those md5sum and sha1sum generated by bash shell.**
|
||||
|
||||
php > echo md5(avi);
|
||||
3fca379b3f0e322b7b7967bfcfb948ad
|
||||
|
||||
php > echo sha1(avi);
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f
|
||||
|
||||
----------
|
||||
|
||||
$ echo -n avi | md5sum
|
||||
3fca379b3f0e322b7b7967bfcfb948ad -
|
||||
|
||||
$ echo -n avi | sha1sum
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f -
|
||||
|
||||

|
||||
|
||||
Check md5sum and sha1sum in PHP
|
||||
|
||||
This is just a glimpse of what can be achieved from a PHP Shell and how interactive is PHP shell. That’s all for now from me. Keep Connected to tecmint. Provide us with your valuable feedback in the comments. Like and share us to get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/execute-php-codes-functions-in-linux-commandline/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
||||
@ -1,58 +0,0 @@
|
||||
How To Fix “The Update Information Is Outdated” In Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Seeing a red triangle in top panel in Ubuntu 14.04 that displays the following error?
|
||||
|
||||
> The update information is outdated. This may be caused by network problems or by a repository that is no longer available. Please update manually by selecting ‘Show updates’ from indicator menu, and watching for any failing repositories.
|
||||
|
||||
It looks something like this:
|
||||
|
||||

|
||||
|
||||
Instead of red triangle, there is a pink exclamation sign because I am using one of the [best Ubuntu icon themes][1], Numix. Coming back to the error, this is a common update problem which you might see every now and then. Now you might be wondering what is causing this update error.
|
||||
|
||||
### Reason for ‘update information is outdated’ error ###
|
||||
|
||||
The reason is pretty explanatory in the error description itself. It reads “this may be caused by network problems or by a repository that is no longer available”. So, either you upgraded your system and some repository or PPA is no longer supported or you are facing some similar issue.
|
||||
|
||||
While the error is self-explanatory, the action it suggests, “Please update manually by selecting ‘Show updates’ from the indicator menu, and watching for any failing repositories.”, doesn’t work properly. If you click on Show updates, all you’ll see is that the system is already updated.
|
||||
|
||||

|
||||
|
||||
Weird isn’t it? How will we find out what is failing where and why?
|
||||
|
||||
### Fix ‘update information is outdated’ ###
|
||||
|
||||
The ‘solution’ discussed here will work for Ubuntu versions be it Ubuntu 14.04, 12.04 or 14.04. All you need to do is to open a terminal (Ctrl+Alt+T) and use the following command:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
Wait for the command to finish and look at the result. Quick tip to add here, you can [add notifications in terminal][2] so that you are notified as soon as a long command finishes execution. In the last few lines at the end of the command, see what kind of error your system is facing. Yes, you’ll see an error for sure.
|
||||
|
||||
In my case, I saw the famous [GPG error: The following could not be verified][3] error. Apparently there is some problem with [Spotify installation in Ubuntu 15.04][4].
|
||||
|
||||

|
||||
|
||||
It is very much possible that you might see a different error instead of the GPG error like me. In that case, I suggest you to go through this article which I wrote to [fix various common update errors in Ubuntu][5].
|
||||
|
||||
I know few people, specially beginners have strong aversion to command line but if you are using Linux, you simply cannot avoid terminal. Moreover, it is not that scary a thing. Give it a try, you will feel accustomed to it soon enough.
|
||||
|
||||
I hope this quick tip helped you to fix the recurring “update information is outdated” in Ubuntu. Any questions or suggestions is welcomed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
[2]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
[3]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
|
||||
[4]:http://itsfoss.com/install-spotify-ubuntu-1504/
|
||||
[5]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
@ -1,113 +0,0 @@
|
||||
How To Manage StartUp Applications In Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
Ever felt the need to **control startup applications in Ubuntu**? You should, if you feel that your Ubuntu system is very slow at the boot time.
|
||||
|
||||
Every time you boot in to an operating system, a number of applications start automatically. These are called ‘startup applications’ or ‘start up programs’. Over the time, when you have plenty of application installed in your system, you’ll find that there are too many of these ‘startup applications’ which start at the boot time automatically, eats up the system resource and slows down the system. This might result in a sluggish Ubuntu experience, which I think, you don’t want at all.
|
||||
|
||||
A way to make Ubuntu faster is to control startup applications. Ubuntu provides you GUI tools that you can use to find out the startup programs, disable them entirely or delay their execution so that you won’t have each application trying to run at the same time.
|
||||
|
||||
In this post we shall see **how to control startup applications, how to run an application at startup and how to find hidden startup applications in Ubuntu**. The instructions provided here are applicable to all Ubuntu versions such as Ubuntu 12.04, Ubuntu 14.04 and Ubuntu 15.04.
|
||||
|
||||
### Manage startup applications in Ubuntu ###
|
||||
|
||||
By default, Ubuntu provides Startup Applications utility that you could use. No need of installation. Just go in Unity Dash and look for startup applications.
|
||||
|
||||

|
||||
|
||||
Click on it to start. Here is what my startup applications look like:
|
||||
|
||||

|
||||
|
||||
### Remove startup applications in Ubuntu ###
|
||||
|
||||
Now it is up to you what you find useless. For me [Caribou][1], on screen keyboard program, is not of any use at the startup. I would prefer to remove it.
|
||||
|
||||
You can choose to either prevent it from starting up at boot time but keeping it in the startup applications list for future reactivation. Click on close to save your preference.
|
||||
|
||||

|
||||
|
||||
To remove a program from startup applications list, select it and click on Remove from the right window pane.
|
||||
|
||||

|
||||
|
||||
Note that, this will NOT uninstall the program. Just that the program will not start automatically at each boot. You can do it with all the programs that you don’t like.
|
||||
|
||||
### Delay the start up programs ###
|
||||
|
||||
What if you do not want to remove programs at the start up but you are worried about system performance at the boot time. What you can do is to add a delay in various programs so that not all the programs will be starting at the same time.
|
||||
|
||||
Select a program and click Edit.
|
||||
|
||||

|
||||
|
||||
This will show the command that runs this particular program.
|
||||
|
||||

|
||||
|
||||
All you need to do is to add sleep XX; before the command. It will add a delay of XX seconds before running the actual commands to run the applications. For example if I want Variety [wallpaper management application][2] for 2 minutes, I’ll add sleep 120; before the command like this:
|
||||
|
||||

|
||||
|
||||
Save it and close it. You’ll see the impact at the next boot.
|
||||
|
||||
### Add a program in the startup applications ###
|
||||
|
||||
This could be tricky for beginners. You see, things are in commands at the bottom of everything in Linux. We just saw in the previous section that these startup programs are just some commands being run at each boot. If you want to add a new program in the startup, you’ll need to know the command that runs the application.
|
||||
|
||||
#### Step 1: How to find the command to run an application? ####
|
||||
|
||||
Go in the Unity Dash and search for Main Menu:
|
||||
|
||||

|
||||
|
||||
This contains all the program that you have installed in various categories. In old Ubuntu days, you would see similar menu for selecting and running applications.
|
||||
|
||||

|
||||
|
||||
Just look for your application under various categories and click on the Properties tab to see the command that runs this application. For example, I want to run Transmission Torrent client on start up.
|
||||
|
||||

|
||||
|
||||
This will give me the command that runs Transmission:
|
||||
|
||||

|
||||
|
||||
Now I’ll use the same information to add Transmission in startup applications.
|
||||
|
||||
#### Step 2: Adding programs in startup ####
|
||||
|
||||
Go again in Startup Applications and click on Add. This will ask you enter a name, command and description. The command is the most important of all. You can use whatever name and description you want. Use the command you got from previous step and click on Add.
|
||||
|
||||

|
||||
|
||||
That’s it. You’ll see it in the next boot up, running automatically. This is all you can do with startup applications in Ubuntu.
|
||||
|
||||
So, far we have discussed about applications that are visible in startup but there are many more services, daemons and programs that are not visible to Startup applications. In next section, we shall see how to see hidden startup programs in Ubuntu.
|
||||
|
||||
### See hidden startup program in Ubuntu ###
|
||||
|
||||
To see what are the services running at startup, open a terminal and use the following command:
|
||||
|
||||
sudo sed -i 's/NoDisplay=true/NoDisplay=false/g' /etc/xdg/autostart/*.desktop
|
||||
|
||||
This is just a quick find and replace command that changes the NoDisplay=false with NoDisplay=true in all the programs that are in autostart. Once you do this, open Startup Applications again and now you shall see many more programs here:
|
||||
|
||||

|
||||
|
||||
You can manage these startup applications the same way which were described earlier. I hope this tutorial helped you to control startup program in Ubuntu. Any questions or suggestions are always welcomed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://wiki.gnome.org/action/show/Projects/Caribou?action=show&redirect=Caribou
|
||||
[2]:http://itsfoss.com/applications-manage-wallpapers-ubuntu/
|
||||
@ -1,67 +0,0 @@
|
||||
Translating by ictlyh
|
||||
Howto Interactively Perform Tasks with Docker using Kitematic
|
||||
================================================================================
|
||||
In this article, we'll learn about the installating Kitematic in Windows Operating System and deploying a Hello World Nginx Web Server. Kitematic is a free and open source software which is a modern designed GUI software that allows us to interactively perform tasks with docker. Kitematic has a beautiful design and pretty good interface. It is pretty fast and easy to setup our containers out of the box without needing to enter commands for it, we can deploy our apps it in just a click with its GUI inteface. Kitematic has Docker Hub Intergration which allows us to search any required image, pull and deploy our apps with it. It also has a beautiful feature to switch to CUI mode simultaneously. Currently, it includes some features like automatically map ports, visually change environment variables, configuring volumes, streamline logs and many more.
|
||||
|
||||
So. here are the easy 3 steps on how we can install Kitematic and deploy Hello World Nginx Web Server in Windows.
|
||||
|
||||
### 1. Download Kitematic ###
|
||||
|
||||
First of all, we'll need to download the latest release of Kitematic available for windows operating system from the github repository ie [https://github.com/kitematic/kitematic/releases][1] . Here, we download its executable EXE file using a download manager or a web browser. After we finish downloading, we'll need to double-click the executable application file.
|
||||
|
||||

|
||||
|
||||
After double clicking the application file, we'll be asked by a security issue we'll simply click OK as shown below.
|
||||
|
||||

|
||||
|
||||
### 2. Installing Kitematic ###
|
||||
|
||||
After the executable installer has been downloaded, we'll now gonna install Kitematic in our Windows Operating System. The installer will now begin to download and install the necessary dependencies virtual box and docker to run Kitematic. If you already virtualbox installed in your system, it will upgrade it to the latest version. The installer should finish in few minutes but that depends on how fast your internet and system is. If you don't have a virtual box installed already, it may ask you for installing the virtual box network driver. It is suggested to install that as it is useful for the virtual box networking.
|
||||
|
||||

|
||||
|
||||
After the required dependencies Docker and Virtual box are installed and are running, we'll be asked to login to the Docker Hub. If we don't have an account or don't wanna login now, we can click **SKIP FOR NOW** to continue further.
|
||||
|
||||

|
||||
|
||||
If you don't have an account, you can simply click on Sign Up link in the App and create an account in Docker Hub.
|
||||
|
||||
After its done, our first interface of Kitematic App will load. Here, below is how it looks. We can search for the available docker images there as shown below.
|
||||
|
||||

|
||||
|
||||
### 3. Deploying Nginx Hello World Container ###
|
||||
|
||||
Now, as our Kitematic has been successfully installed, we'll now go for the deployment of containers. To run a container, we can simply search for the image in the search area. Then click on Create to deploy the container. Here in this tutorial, we'll go for deploying a small Nginx Web Server having Hello World homepage. To do so, we'll search for Hello World Nginx in the search area. Then, after we see the container information, we'll click on Create to deploy the container.
|
||||
|
||||

|
||||
|
||||
Once the download of the image has been completed, it will get deployed. We can see the logs of the commands fired by the Kitematic to deploy that container. We can also see the web page preview right from the Kitematic interface. Now, we can check our Hello World page from our web browser by clicking on the preview.
|
||||
|
||||

|
||||
|
||||
If we wanna switch to command line interface and manage docker with it, there is a button called Docker CLI which will open a Powershell were we can execute docker commands.
|
||||
|
||||

|
||||
|
||||
Now, if we wanna configure our container and perform stuffs like changing the container name, assigning environment variables, assign ports, configure container's storage and other advanced features, we can do that from Settings tab of the container.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally we've successfully installed Kitematic and deployed a hello world nginx web server in Windows Operating System. It is always recommended to download and install the latest release of Kitematic as many advanced features are to be embedded. As docker works in 64 bit platform, Kitematic is also currently built for 64-bit platform of operating system. It only works on the Windows 7 and greater versions of Windows. Here, in this tutorial, we deployed an Nginx web server like wise we can deploy any docker container from its image using Kitematic with few clicks only. Kitematic is already available for Mac OS X and Windows whereas a version for Linux is still under development and will be out very soon. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/interactively-docker-kitematic/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://github.com/kitematic/kitematic/releases
|
||||
674
sources/tech/20150728 Process of the Linux kernel building.md
Normal file
674
sources/tech/20150728 Process of the Linux kernel building.md
Normal file
@ -0,0 +1,674 @@
|
||||
Process of the Linux kernel building
|
||||
================================================================================
|
||||
Introduction
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
I will not tell you how to build and install custom Linux kernel on your machine, you can find many many [resources](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code) that will help you to do it. Instead, we will know what does occur when you are typed `make` in the directory with Linux kernel source code in this part. When I just started to learn source code of the Linux kernel, the [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) file was a first file that I've opened. And it was scary :) This [makefile](https://en.wikipedia.org/wiki/Make_%28software%29) contains `1591` lines of code at the time when I wrote this part and it was [third](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) release candidate.
|
||||
|
||||
This makefile is the the top makefile in the Linux kernel source code and kernel build starts here. Yes, it is big, but moreover, if you've read the source code of the Linux kernel you can noted that all directories with a source code has an own makefile. Of course it is not real to describe how each source files compiled and linked. So, we will see compilation only for the standard case. You will not find here building of the kernel's documentation, cleaning of the kernel source code, [tags](https://en.wikipedia.org/wiki/Ctags) generation, [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler) related stuff and etc. We will start from the `make` execution with the standard kernel configuration file and will finish with the building of the [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
It would be good if you're already familiar with the [make](https://en.wikipedia.org/wiki/Make_%28software%29) util, but I will anyway try to describe all code that will be in this part.
|
||||
|
||||
So let's start.
|
||||
|
||||
Preparation before the kernel compilation
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
There are many things to preparate before the kernel compilation will be started. The main point here is to find and configure
|
||||
the type of compilation, to parse command line arguments that are passed to the `make` util and etc. So let's dive into the top `Makefile` of the Linux kernel.
|
||||
|
||||
The Linux kernel top `Makefile` is responsible for building two major products: [vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (the resident kernel image) and the modules (any module files). The [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) of the Linux kernel starts from the definition of the following variables:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
These variables determine the current version of the Linux kernel and are used in the different places, for example in the forming of the `KERNELVERSION` variable:
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
After this we can see a couple of the `ifeq` condition that check some of the parameters passed to `make`. The Linux kernel `makefiles` provides a special `make help` target that prints all available targets and some of the command line arguments that can be passed to `make`. For example: `make V=1` - provides verbose builds. The first `ifeq` condition checks if the `V=n` option is passed to make:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
|
||||
If this option is passed to `make` we set the `KBUILD_VERBOSE` variable to the value of the `V` option. Otherwise we set the `KBUILD_VERBOSE` variable to zero. After this we check value of the `KBUILD_VERBOSE` variable and set values of the `quiet` and `Q` variables depends on the `KBUILD_VERBOSE` value. The `@` symbols suppress the output of the command and if it will be set before a command we will see something like this: `CC scripts/mod/empty.o` instead of the `Compiling .... scripts/mod/empty.o`. In the end we just export all of these variables. The next `ifeq` statement checks that `O=/dir` option was passed to the `make`. This option allows to locate all output files in the given `dir`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
We check the `KBUILD_SRC` that represent top directory of the source code of the linux kernel and if it is empty (it is empty every time while makefile executes first time) and the set the `KBUILD_OUTPUT` variable to the value that passed with the `O` option (if this option was passed). In the next step we check this `KBUILD_OUTPUT` variable and if we set it, we do following things:
|
||||
|
||||
* Store value of the `KBUILD_OUTPUT` in the temp `saved-output` variable;
|
||||
* Try to create given output directory;
|
||||
* Check that directory created, in other way print error;
|
||||
* If custom output directory created sucessfully, execute `make` again with the new directory (see `-C` option).
|
||||
|
||||
The next `ifeq` statements checks that `C` or `M` options was passed to the make:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
The first `C` option tells to the `makefile` that need to check all `c` source code with a tool provided by the `$CHECK` environment variable, by default it is [sparse](https://en.wikipedia.org/wiki/Sparse). The second `M` option provides build for the external modules (will not see this case in this part). As we set this variables we make a check of the `KBUILD_SRC` variable and if it is not set we set `srctree` variable to `.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
That tells to `Makefile` that source tree of the Linux kernel will be in the current directory where `make` command was executed. After this we set `objtree` and other variables to this directory and export these variables. The next step is the getting value for the `SUBARCH` variable that will represent tewhat the underlying archicecture is:
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
As you can see it executes [uname](https://en.wikipedia.org/wiki/Uname) utils that prints information about machine, operating system and architecture. As it will get output of the `uname` util, it will parse it and assign to the `SUBARCH` variable. As we got `SUBARCH`, we set the `SRCARCH` variable that provides directory of the certain architecture and `hfr-arch` that provides directory for the header files:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
Note that `ARCH` is the alias for the `SUBARCH`. In the next step we set the `KCONFIG_CONFIG` variable that represents path to the kernel configuration file and if it was not set before, it will be `.config` by default:
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
|
||||
and the [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29) that will be used during kernel compilation:
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
The next set of variables related to the compiler that will be used during Linux kernel compilation. We set the host compilers for the `c` and `c++` and flags for it:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
Next we will meet the `CC` variable that represent compiler too, so why do we need in the `HOST*` variables? The `CC` is the target compiler that will be used during kernel compilation, but `HOSTCC` will be used during compilation of the set of the `host` programs (we will see it soon). After this we can see definition of the `KBUILD_MODULES` and `KBUILD_BUILTIN` variables that are used for the determination of the what to compile (kernel, modules or both):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
Here we can see definition of these variables and the value of the `KBUILD_BUILTIN` will depens on the `CONFIG_MODVERSIONS` kernel configuration parameter if we pass only `modules` to the `make`. The next step is including of the:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
`kbuild` file. The [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) or `Kernel Build System` is the special infrastructure to manage building of the kernel and its modules. The `kbuild` files has the same syntax that makefiles. The [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) file provides some generic definitions for the `kbuild` system. As we included this `kbuild` files we can see definition of the variables that are related to the different tools that will be used during kernel and modules compilation (like linker, compilers, utils from the [binutils](http://www.gnu.org/software/binutils/) and etc...):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
After definition of these variables we define two variables: `USERINCLUDE` and `LINUXINCLUDE`. They will contain paths of the directories with headers (public for users in the first case and for kernel in the second case):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
And the standard flags for the C compiler:
|
||||
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
It is the not last compiler flags, they can be updated by the other makefiles (for example kbuilds from `arch/`). After all of these, all variables will be exported to be available in the other makefiles. The following two the `RCS_FIND_IGNORE` and the `RCS_TAR_IGNORE` variables will contain files that will be ignored in the version control system:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
That's all. We have finished with the all preparations, next point is the building of `vmlinux`.
|
||||
|
||||
Directly to the kernel build
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
As we have finished all preparations, next step in the root makefile is related to the kernel build. Before this moment we will not see in the our terminal after the execution of the `make` command. But now first steps of the compilation are started. In this moment we need to go on the [598](https://github.com/torvalds/linux/blob/master/Makefile#L598) line of the Linux kernel top makefile and we will see `vmlinux` target there:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
Don't worry that we have missed many lines in Makefile that are placed after `export RCS_FIND_IGNORE.....` and before `all: vmlinux.....`. This part of the makefile is responsible for the `make *.config` targets and as I wrote in the beginning of this part we will see only building of the kernel in a general way.
|
||||
|
||||
The `all:` target is the default when no target is given on the command line. You can see here that we include architecture specific makefile there (in our case it will be [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)). From this moment we will continue from this makefile. As we can see `all` target depends on the `vmlinux` target that defined a little lower in the top makefile:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
The `vmlinux` is is the Linux kernel in an statically linked executable file format. The [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) script links combines different compiled subsystems into vmlinux. The second target is the `vmlinux-deps` that defined as:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
and consists from the set of the `built-in.o` from the each top directory of the Linux kernel. Later, when we will go through all directories in the Linux kernel, the `Kbuild` will compile all the `$(obj-y)` files. It then calls `$(LD) -r` to merge these files into one `built-in.o` file. For this moment we have no `vmlinux-deps`, so the `vmlinux` target will not be executed now. For me `vmlinux-deps` contains following files:
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
The next target that can be executed is following:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
As we can see the `vmlinux-dirs` depends on the two targets: `prepare` and `scripts`. The first `prepare` defined in the top `Makefile` of the Linux kernel and executes three stages of preparations:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
The first `prepare0` expands to the `archprepare` that exapnds to the `archheaders` and `archscripts` that defined in the `x86_64` specific [Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile). Let's look on it. The `x86_64` specific makefile starts from the definition of the variables that are related to the archicteture-specific configs ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs) and etc.). After this it defines flags for the compiling of the [16-bit](https://en.wikipedia.org/wiki/Real_mode) code, calculating of the `BITS` variable that can be `32` for `i386` or `64` for the `x86_64` flags for the assembly source code, flags for the linker and many many more (all definitions you can find in the [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)). The first target is `archheaders` in the makefile generates syscall table:
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
And the second target is `archscripts` in this makefile is:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
We can see that it depends on the `scripts_basic` target from the top [Makefile](https://github.com/torvalds/linux/blob/master/Makefile). At the first we can see the `scripts_basic` target that executes make for the [scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) makefile:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
The `scripts/basic/Makefile` contains targets for compilation of the two host programs: `fixdep` and `bin2`:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
First program is `fixdep` - optimizes list of dependencies generated by the [gcc](https://gcc.gnu.org/) that tells make when to remake a source code file. The second program is `bin2c` depends on the value of the `CONFIG_BUILD_BIN2C` kernel configuration option and very little C program that allows to convert a binary on stdin to a C include on stdout. You can note here strange notation: `hostprogs-y` and etc. This notation is used in the all `kbuild` files and more about it you can read in the [documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt). In our case the `hostprogs-y` tells to the `kbuild` that there is one host program named `fixdep` that will be built from the will be built from `fixdep.c` that located in the same directory that `Makefile`. The first output after we will execute `make` command in our terminal will be result of this `kbuild` file:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
As `script_basic` target was executed, the `archscripts` target will execute `make` for the [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) makefile with the `relocs` target:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
The `relocs_32.c` and the `relocs_64.c` will be compiled that will contain [relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29) information and we will see it in the `make` output:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
There is checking of the `version.h` after compiling of the `relocs.c`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
We can see it in the output:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
and the building of the `generic` assembly headers with the `asm-generic` target from the `arch/x86/include/generated/asm` that generated in the top Makefile of the Linux kernel. After the `asm-generic` target the `archprepare` will be done, so the `prepare0` target will be executed. As I wrote above:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
Note on the `build`. It defined in the [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) and looks like this:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
or in our case it is current source directory - `.`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
The [scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) tries to find the `Kbuild` file by the given directory via the `obj` parameter, include this `Kbuild` files:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
and build targets from it. In our case `.` contains the [Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild) file that generates the `kernel/bounds.s` and the `arch/x86/kernel/asm-offsets.s`. After this the `prepare` target finished to work. The `vmlinux-dirs` also depends on the second target - `scripts` that compiles following programs: `file2alias`, `mk_elfconfig`, `modpost` and etc... After scripts/host-programs compilation our `vmlinux-dirs` target can be executed. First of all let's try to understand what does `vmlinux-dirs` contain. For my case it contains paths of the following kernel directories:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
We can find definition of the `vmlinux-dirs` in the top [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) of the Linux kernel:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
Here we remove the `/` symbol from the each directory with the help of the `patsubst` and `filter` functions and put it to the `vmlinux-dirs`. So we have list of directories in the `vmlinux-dirs` and the following code:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
The `$@` represents `vmlinux-dirs` here that means that it will go recursively over all directories from the `vmlinux-dirs` and its internal directories (depens on configuration) and will execute `make` in there. We can see it in the output:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
Source code in each directory will be compiled and linked to the `built-in.o`:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
Ok, all buint-in.o(s) built, now we can back to the `vmlinux` target. As you remember, the `vmlinux` target is in the top Makefile of the Linux kernel. Before the linking of the `vmlinux` it builds [samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation) and etc., but I will not describe it in this part as I wrote in the beginning of this part.
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
As you can see main purpose of it is a call of the [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) script is linking of the all `built-in.o`(s) to the one statically linked executable and creation of the [System.map](https://en.wikipedia.org/wiki/System.map). In the end we will see following output:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
and `vmlinux` and `System.map` in the root of the Linux kernel source tree:
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
That's all, `vmlinux` is ready. The next step is creation of the [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
Building bzImage
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
The `bzImage` is the compressed Linux kernel image. We can get it with the execution of the `make bzImage` after the `vmlinux` built. In other way we can just execute `make` without arguments and will get `bzImage` anyway because it is default image:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
in the [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile). Let's look on this target, it will help us to understand how this image builds. As I already said the `bzImage` target defined in the [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) and looks like this:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
We can see here, that first of all called `make` for the boot directory, in our case it is:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
The main goal now to build source code in the `arch/x86/boot` and `arch/x86/boot/compressed` directories, build `setup.bin` and `vmlinux.bin`, and build the `bzImage` from they in the end. First target in the [arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) is the `$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
We already have the `setup.ld` linker script in the `arch/x86/boot` directory and the `SETUP_OBJS` expands to the all source files from the `boot` directory. We can see first output:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
The next source code file is the [arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S), but we can't build it now because this target depends on the following two header files:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
The first is `voffset.h` generated by the `sed` script that gets two addresses from the `vmlinux` with the `nm` util:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
They are start and end of the kernel. The second is `zoffset.h` depens on the `vmlinux` target from the [arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile):
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
The `$(obj)/compressed/vmlinux` target depends on the `vmlinux-objs-y` that compiles source code files from the [arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) directory and generates `vmlinux.bin`, `vmlinux.bin.bz2`, and compiles programm - `mkpiggy`. We can see this in the output:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
Where the `vmlinux.bin` is the `vmlinux` with striped debuging information and comments and the `vmlinux.bin.bz2` compressed `vmlinux.bin.all` + `u32` size of `vmlinux.bin.all`. The `vmlinux.bin.all` is `vmlinux.bin + vmlinux.relocs`, where `vmlinux.relocs` is the `vmlinux` that was handled by the `relocs` program (see above). As we got these files, the `piggy.S` assembly files will be generated with the `mkpiggy` program and compiled:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
This assembly files will contain computed offset from a compressed kernel. After this we can see that `zoffset` generated:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
As the `zoffset.h` and the `voffset.h` are generated, compilation of the source code files from the [arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) can be continued:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
As all source code files will be compiled, they will be linked to the `setup.elf`:
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
or:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
The last two things is the creation of the `setup.bin` that will contain compiled code from the `arch/x86/boot/*` directory:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
and the creation of the `vmlinux.bin` from the `vmlinux`:
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
In the end we compile host program: [arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c) that will create our `bzImage` from the `setup.bin` and the `vmlinux.bin`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
Actually the `bzImage` is the concatenated `setup.bin` and the `vmlinux.bin`. In the end we will see the output which familiar to all who once build the Linux kernel from source:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
That's all.
|
||||
|
||||
Conclusion
|
||||
================================================================================
|
||||
|
||||
It is the end of this part and here we saw all steps from the execution of the `make` command to the generation of the `bzImage`. I know, the Linux kernel makefiles and process of the Linux kernel building may seem confusing at first glance, but it is not so hard. Hope this part will help you to understand process of the Linux kernel building.
|
||||
|
||||
Links
|
||||
================================================================================
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,121 @@
|
||||
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Understanding Shell Commands Easily Using “Explain Shell” Script in Linux
|
||||
================================================================================
|
||||
While working on Linux platform all of us need help on shell commands, at some point of time. Although inbuilt help like man pages, whatis command is helpful, but man pages output are too lengthy and until and unless one has some experience with Linux, it is very difficult to get any help from massive man pages. The output of whatis command is rarely more than one line which is not sufficient for newbies.
|
||||
|
||||

|
||||
|
||||
Explain Shell Commands in Linux Shell
|
||||
|
||||
There are third-party application like ‘cheat‘, which we have covered here “[Commandline Cheat Sheet for Linux Users][1]. Although Cheat is an exceptionally good application which shows help on shell command even when computer is not connected to Internet, it shows help on predefined commands only.
|
||||
|
||||
There is a small piece of code written by Jackson which is able to explain shell commands within the bash shell very effectively and guess what the best part is you don’t need to install any third party package. He named the file containing this piece of code as `'explain.sh'`.
|
||||
|
||||
#### Features of Explain Utility ####
|
||||
|
||||
- Easy Code Embedding.
|
||||
- No third-party utility needed to be installed.
|
||||
- Output just enough information in course of explanation.
|
||||
- Requires internet connection to work.
|
||||
- Pure command-line utility.
|
||||
- Able to explain most of the shell commands in bash shell.
|
||||
- No root Account involvement required.
|
||||
|
||||
**Prerequisite**
|
||||
|
||||
The only requirement is `'curl'` package. In most of the today’s latest Linux distributions, curl package comes pre-installed, if not you can install it using package manager as shown below.
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### Installation of explain.sh Utility in Linux ###
|
||||
|
||||
We have to insert the below piece of code as it is in the `~/.bashrc` file. The code should be inserted for each user and each `.bashrc` file. It is suggested to insert the code to the user’s .bashrc file only and not in the .bashrc of root user.
|
||||
|
||||
Notice the first line of code that starts with hash `(#)` is optional and added just to differentiate rest of the codes of .bashrc.
|
||||
|
||||
# explain.sh marks the beginning of the codes, we are inserting in .bashrc file at the bottom of this file.
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
if [ "$#" -eq 0 ]; then
|
||||
while read -p "Command: " cmd; do
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||
done
|
||||
echo "Bye!"
|
||||
elif [ "$#" -eq 1 ]; then
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||
else
|
||||
echo "Usage"
|
||||
echo "explain interactive mode."
|
||||
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||
fi
|
||||
}
|
||||
|
||||
### Working of explain.sh Utility ###
|
||||
|
||||
After inserting the code and saving it, you must logout of the current session and login back to make the changes taken into effect. Every thing is taken care of by the ‘curl’ command which transfer the input command and flag that need explanation to the mankier server and then print just necessary information to the Linux command-line. Not to mention to use this utility you must be connected to internet always.
|
||||
|
||||
Let’s test few examples of command which I don’t know the meaning with explain.sh script.
|
||||
|
||||
**1. I forgot what ‘du -h‘ does. All I need to do is:**
|
||||
|
||||
$ explain 'du -h'
|
||||
|
||||

|
||||
|
||||
Get Help on du Command
|
||||
|
||||
**2. If you forgot what ‘tar -zxvf‘ does, you may simply do:**
|
||||
|
||||
$ explain 'tar -zxvf'
|
||||
|
||||

|
||||
|
||||
Tar Command Help
|
||||
|
||||
**3. One of my friend often confuse the use of ‘whatis‘ and ‘whereis‘ command, so I advised him.**
|
||||
|
||||
Go to Interactive Mode by simply typing explain command on the terminal.
|
||||
|
||||
$ explain
|
||||
|
||||
and then type the commands one after another to see what they do in one window, as:
|
||||
|
||||
Command: whatis
|
||||
Command: whereis
|
||||
|
||||

|
||||
|
||||
Whatis Whereis Commands Help
|
||||
|
||||
To exit interactive mode he just need to do Ctrl + c.
|
||||
|
||||
**4. You can ask to explain more than one command chained by pipeline.**
|
||||
|
||||
$ explain 'ls -l | grep -i Desktop'
|
||||
|
||||

|
||||
|
||||
Get Help on Multiple Commands
|
||||
|
||||
Similarly you can ask your shell to explain any shell command. All you need is a working Internet connection. The output is generated based upon the explanation needed from the server and hence the output result is not customizable.
|
||||
|
||||
For me this utility is really helpful and it has been honored being added to my .bashrc. Let me know what is your thought on this project? How it can useful for you? Is the explanation satisfactory?
|
||||
|
||||
Provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||
@ -0,0 +1,174 @@
|
||||
How to Setup iTOP (IT Operational Portal) on CentOS 7
|
||||
================================================================================
|
||||
iTOP is a simple, Open source web based IT Service Management tool. It has all of ITIL functionality that includes with Service desk, Configuration Management, Incident Management, Problem Management, Change Management and Service Management. iTop relays on Apache/IIS, MySQL and PHP, so it can run on any operating system supporting these applications. Since iTop is a web based application you don’t need to deploy any client software on each user’s PC. A simple web browser is enough to perform day to day operations of an IT environment with iTOP.
|
||||
|
||||
To install and configure iTOP we will be using CentOS 7 as base operating with basic LAMP Stack environment installed on it that will cover its almost all prerequisites.
|
||||
|
||||
### Downloading iTOP ###
|
||||
|
||||
iTop download package is present on SourceForge, we can get its link from their official website [link][1].
|
||||
|
||||

|
||||
|
||||
We will the download link from here and get this zipped file on server with wget command as below.
|
||||
|
||||
[root@centos-007 ~]# wget http://downloads.sourceforge.net/project/itop/itop/2.1.0/iTop-2.1.0-2127.zip
|
||||
|
||||
### iTop Extensions and Web Setup ###
|
||||
|
||||
By using unzip command we will extract the downloaded packages in the document root directory of our apache web server in a new directory with name itop.
|
||||
|
||||
[root@centos-7 ~]# ls
|
||||
iTop-2.1.0-2127.zip
|
||||
[root@centos-7 ~]# unzip iTop-2.1.0-2127.zip -d /var/www/html/itop/
|
||||
|
||||
List the folder to view installation packages in it.
|
||||
|
||||
[root@centos-7 ~]# ls -lh /var/www/html/itop/
|
||||
total 68K
|
||||
-rw-r--r--. 1 root root 1.4K Dec 17 2014 INSTALL
|
||||
-rw-r--r--. 1 root root 35K Dec 17 2014 LICENSE
|
||||
-rw-r--r--. 1 root root 23K Dec 17 2014 README
|
||||
drwxr-xr-x. 19 root root 4.0K Jul 14 13:10 web
|
||||
|
||||
Here is all the extensions that we can install.
|
||||
|
||||
[root@centos-7 2.x]# ls
|
||||
authent-external itop-backup itop-config-mgmt itop-problem-mgmt itop-service-mgmt-provider itop-welcome-itil
|
||||
authent-ldap itop-bridge-virtualization-storage itop-datacenter-mgmt itop-profiles-itil itop-sla-computation version.xml
|
||||
authent-local itop-change-mgmt itop-endusers-devices itop-request-mgmt itop-storage-mgmt wizard-icons
|
||||
installation.xml itop-change-mgmt-itil itop-incident-mgmt-itil itop-request-mgmt-itil itop-tickets
|
||||
itop-attachments itop-config itop-knownerror-mgmt itop-service-mgmt itop-virtualization-mgmt
|
||||
|
||||
Now from the extracted web directory, moving through different data models we will migrate the required extensions from the datamodels into the web extensions directory of web document root directory with copy command.
|
||||
|
||||
[root@centos-7 2.x]# pwd
|
||||
/var/www/html/itop/web/datamodels/2.x
|
||||
[root@centos-7 2.x]# cp -r itop-request-mgmt itop-service-mgmt itop-service-mgmt itop-config itop-change-mgmt /var/www/html/itop/web/extensions/
|
||||
|
||||
### Installing iTop Web Interface ###
|
||||
|
||||
Most of our server side settings and configurations are done.Finally we need to complete its web interface installation process to finalize the setup.
|
||||
|
||||
Open your favorite web browser and access the WordPress web directory in your web browser using your server IP or FQDN like.
|
||||
|
||||
http://servers_ip_address/itop/web/
|
||||
|
||||
You will be redirected towards the web installation process for iTop. Let’s configure it as per your requirements like we did here in this tutorial.
|
||||
|
||||
#### Prerequisites Validation ####
|
||||
|
||||
At the stage you will be prompted for welcome screen with prerequisites validation ok. If you get some warning then you have to make resolve it by installing its prerequisites.
|
||||
|
||||

|
||||
|
||||
At this stage one optional package named php mcrypt will be missing. Download the following rpm package then try to install php mcrypt package.
|
||||
|
||||
[root@centos-7 ~]#yum localinstall php-mcrypt-5.3.3-1.el6.x86_64.rpm libmcrypt-2.5.8-9.el6.x86_64.rpm.
|
||||
|
||||
After successful installation of php-mcrypt library we need to restart apache web service, then reload the web page and this time its prerequisites validation should be OK.
|
||||
|
||||
#### Install or Upgrade iTop ####
|
||||
|
||||
Here we will choose the fresh installation as we have not installed iTop previously on our server.
|
||||
|
||||

|
||||
|
||||
#### iTop License Agreement ####
|
||||
|
||||
Chose the option to accept the terms of the licenses of all the components of iTop and click "NEXT".
|
||||
|
||||

|
||||
|
||||
#### Database Configuration ####
|
||||
|
||||
Here we the do Configuration of the database connection by giving our database servers credentials and then choose from the option to create new database as shown.
|
||||
|
||||

|
||||
|
||||
#### Administrator Account ####
|
||||
|
||||
In this step we will configure an Admin account by filling out its login details as.
|
||||
|
||||

|
||||
|
||||
#### Miscellaneous Parameters ####
|
||||
|
||||
Let's choose the additional parameters whether you want to install with demo contents or with fresh database and proceed forward.
|
||||
|
||||

|
||||
|
||||
### iTop Configurations Management ###
|
||||
|
||||
The options below allow you to configure the type of elements that are to be managed inside iTop like all the base objects that are mandatory in the iTop CMDB, Manage Data Center devices, storage device and virtualization.
|
||||
|
||||

|
||||
|
||||
#### Service Management ####
|
||||
|
||||
Select from the choices that best describes the relationships between the services and the IT infrastructure in your IT environment. So we are choosing Service Management for Service Providers here.
|
||||
|
||||

|
||||
|
||||
#### iTop Tickets Management ####
|
||||
|
||||
From the different available options we will Select the ITIL Compliant Tickets Management option to have different types of ticket for managing user requests and incidents.
|
||||
|
||||

|
||||
|
||||
#### Change Management Options ####
|
||||
|
||||
Select the type of tickets you want to use in order to manage changes to the IT infrastructure from the available options. We are going to choose ITIL change management option here.
|
||||
|
||||

|
||||
|
||||
#### iTop Extensions ####
|
||||
|
||||
In this section we can select the additional extensions to install or we can unchecked the ones that you want to skip.
|
||||
|
||||

|
||||
|
||||
### Ready to Start Web Installation ###
|
||||
|
||||
Now we are ready to start installing the components that we choose in previous steps. We can also drop down these installation parameters to view our configuration from the drop down.
|
||||
|
||||
Once you are confirmed with the installation parameters click on the install button.
|
||||
|
||||

|
||||
|
||||
Let's wait for the progress bar to complete the installation process. It might takes few minutes to complete its installation process.
|
||||
|
||||

|
||||
|
||||
### iTop Installation Done ###
|
||||
|
||||
Our iTop installation setup is complete, just need to do a simple manual operation as shown and then click to enter iTop.
|
||||
|
||||

|
||||
|
||||
### Welcome to iTop (IT Operational Portal) ###
|
||||
|
||||

|
||||
|
||||
### iTop Dashboard ###
|
||||
|
||||
You can manage configuration of everything from here Servers, computers, Contacts, Locations, Contracts, Network devices…. You can create your own. Just the fact, that the installed CMDB module is great which is an essential part of every bigger IT.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
ITOP is one of the best Open Source Service Desk solutions. We have successfully installed and configured it on our CentOS 7 cloud host. So, the most powerful aspect of iTop is the ease with which it can be customized via its “extensions”. Feel free to comment if you face any trouble during its setup.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/setup-itop-centos-7/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:http://www.combodo.com/spip.php?page=rubrique&id_rubrique=8
|
||||
@ -0,0 +1,126 @@
|
||||
Howto Configure Nginx as Rreverse Proxy / Load Balancer with Weave and Docker
|
||||
================================================================================
|
||||
Hi everyone today we'll learnHowto configure Nginx as Rreverse Proxy / Load balancer with Weave and Docker Weave creates a virtual network that connects Docker containers with each other, deploys across multiple hosts and enables their automatic discovery. It allows us to focus on developing our application, rather than our infrastructure. It provides such an awesome environment that the applications uses the network as if its containers were all plugged into the same network without need to configure ports, mappings, link, etc. The services of the application containers on the network can be easily accessible to the external world with no matter where its running. Here, in this tutorial we'll be using weave to quickly and easily deploy nginx web server as a load balancer for a simple php application running in docker containers on multiple nodes in Amazon Web Services. Here, we will be introduced to WeaveDNS, which provides a simple way for containers to find each other using hostname with no changes in codes and tells other containers to connect to those names.
|
||||
|
||||
Here, in this tutorial, we will use Nginx to load balance requests to a set of containers running Apache. Here are the simple and easy to do steps on using Weave to configure nginx as a load balancer running in ubuntu docker container.
|
||||
|
||||
### 1. Settting up AWS Instances ###
|
||||
|
||||
First of all, we'll need to setup Amazon Web Service Instances so that we can run docker containers with Weave and Ubuntu as Operating System. We will use the [AWS CLI][1] to setup and configure two AWS EC2 instances. Here, in this tutorial, we'll use the smallest available instances, t1.micro. We will need to have a valid **Amazon Web Services account** with AWS CLI setup and configured. We'll first gonna clone the repository of weave from the github by running the following command in AWS CLI.
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
After cloning the repository, we wanna run the script that will deploy two instances of t1.micro instance running Weave and Docker in Ubuntu Operating System.
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
Here, for this tutorial we'll need the IP addresses of these instances further in future. These are stored in an environment file weavedemo.env which is created during the execution of the demo-aws-setup.sh. To get those ip addresses, we need to run the following command which will give the output similar to the output below.
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
Please note these are not the IP addresses for our tutorial, AWS dynamically allocate IP addresses to our instances.
|
||||
|
||||
As were are using a bash, we will just source this file and execute it using the command below.
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. Launching Weave and WeaveDNS ###
|
||||
|
||||
After deploying the instances, we'll want to launch weave and weavedns on each hosts. Weave and weavedns allows us to easily deploy our containers to a new infrastructure and configuration without the need of changing the codes and without the need to understand concepts such as ambassador containers and links. Here are the commands to launch them in the first host.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
Next, we'll also wanna launch them in our second host.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. Launching Application Containers ###
|
||||
|
||||
Now, we wanna launch six containers across our two hosts running an Apache2 Web Server instance with our simple php site. So, we'll be running the following commands which will run 3 containers running Apache2 Web Server on our 1st instance.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
After that, we'll again launch 3 containers running apache2 web server in our 2nd instance as shown below.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
Note: Here, --with-dns option tells the container to use weavedns to resolve names and -h x.weave.local allows the host to be resolvable with WeaveDNS.
|
||||
|
||||
### 4. Launching Nginx Container ###
|
||||
|
||||
After our application containers are running well as expected, we'll wanna launch an nginx container which contains the nginx configuration which will round-robin across the severs for the reverse proxy or load balancing. To run the nginx container, we'll need to run the following command.
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
Hence, our Nginx container is publicly exposed as a http server on $WEAVE_AWS_DEMO_HOST1.
|
||||
|
||||
### 5. Testing the Load Balancer ###
|
||||
|
||||
To test our load balancer is working or not, we'll run a script that will make http requests to our nginx container. We'll make six requests so that we can see nginx moving through each of the webservers in round-robin turn.
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally, we've successfully configured nginx as a reverse proxy or load balancer with weave and docker running ubuntu server in AWS (Amazon Web Service) EC2 . From the above output in above step, it is clear that we have configured it correctly. We can see that the request is being sent to 6 application containers in round-robin turn which is running a PHP app hosted in apache web server. Here, weave and weavedns did great work to deploy a containerised PHP application using nginx across multiple hosts on AWS EC2 without need to change in codes and connected the containers to eachother with the hostname using weavedns. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
@ -1,315 +0,0 @@
|
||||
[translating by xiqingongzi]
|
||||
|
||||
RHCSA Series: Reviewing Essential Commands & System Documentation – Part 1
|
||||
================================================================================
|
||||
RHCSA (Red Hat Certified System Administrator) is a certification exam from Red Hat company, which provides an open source operating system and software to the enterprise community, It also provides support, training and consulting services for the organizations.
|
||||
|
||||

|
||||
|
||||
RHCSA Exam Preparation Guide
|
||||
|
||||
RHCSA exam is the certification obtained from Red Hat Inc, after passing the exam (codename EX200). RHCSA exam is an upgrade to the RHCT (Red Hat Certified Technician) exam, and this upgrade is compulsory as the Red Hat Enterprise Linux was upgraded. The main variation between RHCT and RHCSA is that RHCT exam based on RHEL 5, whereas RHCSA certification is based on RHEL 6 and 7, the courseware of these two certifications are also vary to a certain level.
|
||||
|
||||
This Red Hat Certified System Administrator (RHCSA) is essential to perform the following core system administration tasks needed in Red Hat Enterprise Linux environments:
|
||||
|
||||
- Understand and use necessary tools for handling files, directories, command-environments line, and system-wide / packages documentation.
|
||||
- Operate running systems, even in different run levels, identify and control processes, start and stop virtual machines.
|
||||
- Set up local storage using partitions and logical volumes.
|
||||
- Create and configure local and network file systems and its attributes (permissions, encryption, and ACLs).
|
||||
- Setup, configure, and control systems, including installing, updating and removing software.
|
||||
- Manage system users and groups, along with use of a centralized LDAP directory for authentication.
|
||||
- Ensure system security, including basic firewall and SELinux configuration.
|
||||
|
||||
To view fees and register for an exam in your country, check the [RHCSA Certification page][1].
|
||||
|
||||
To view fees and register for an exam in your country, check the RHCSA Certification page.
|
||||
|
||||
In this 15-article RHCSA series, titled Preparation for the RHCSA (Red Hat Certified System Administrator) exam, we will going to cover the following topics on the latest releases of Red Hat Enterprise Linux 7.
|
||||
|
||||
- Part 1: Reviewing Essential Commands & System Documentation
|
||||
- Part 2: How to Perform File and Directory Management in RHEL 7
|
||||
- Part 3: How to Manage Users and Groups in RHEL 7
|
||||
- Part 4: Editing Text Files with Nano and Vim / Analyzing text with grep and regexps
|
||||
- Part 5: Process Management in RHEL 7: boot, shutdown, and everything in between
|
||||
- Part 6: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage
|
||||
- Part 7: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares
|
||||
- Part 8: Securing SSH, Setting Hostname and Enabling Network Services
|
||||
- Part 9: Installing, Configuring and Securing a Web and FTP Server
|
||||
- Part 10: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs
|
||||
- Part 11: Firewall Essentials and Control Network Traffic Using FirewallD and Iptables
|
||||
- Part 12: Automate RHEL 7 Installations Using ‘Kickstart’
|
||||
- Part 13: RHEL 7: What is SELinux and how it works?
|
||||
- Part 14: Use LDAP-based authentication in RHEL 7
|
||||
- Part 15: Virtualization in RHEL 7: KVM and Virtual machine management
|
||||
|
||||
In this Part 1 of the RHCSA series, we will explain how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation.
|
||||
|
||||

|
||||
|
||||
RHCSA: Reviewing Essential Linux Commands – Part 1
|
||||
|
||||
#### Prerequisites: ####
|
||||
|
||||
At least a slight degree of familiarity with basic Linux commands such as:
|
||||
|
||||
- [cd command][2] (change directory)
|
||||
- [ls command][3] (list directory)
|
||||
- [cp command][4] (copy files)
|
||||
- [mv command][5] (move or rename files)
|
||||
- [touch command][6] (create empty files or update the timestamp of existing ones)
|
||||
- rm command (delete files)
|
||||
- mkdir command (make directory)
|
||||
|
||||
The correct usage of some of them are anyway exemplified in this article, and you can find further information about each of them using the suggested methods in this article.
|
||||
|
||||
Though not strictly required to start, as we will be discussing general commands and methods for information search in a Linux system, you should try to install RHEL 7 as explained in the following article. It will make things easier down the road.
|
||||
|
||||
- [Red Hat Enterprise Linux (RHEL) 7 Installation Guide][7]
|
||||
|
||||
### Interacting with the Linux Shell ###
|
||||
|
||||
If we log into a Linux box using a text-mode login screen, chances are we will be dropped directly into our default shell. On the other hand, if we login using a graphical user interface (GUI), we will have to open a shell manually by starting a terminal. Either way, we will be presented with the user prompt and we can start typing and executing commands (a command is executed by pressing the Enter key after we have typed it).
|
||||
|
||||
Commands are composed of two parts:
|
||||
|
||||
- the name of the command itself, and
|
||||
- arguments
|
||||
|
||||
Certain arguments, called options (usually preceded by a hyphen), alter the behavior of the command in a particular way while other arguments specify the objects upon which the command operates.
|
||||
|
||||
The type command can help us identify whether another certain command is built into the shell or if it is provided by a separate package. The need to make this distinction lies in the place where we will find more information about the command. For shell built-ins we need to look in the shell’s man page, whereas for other binaries we can refer to its own man page.
|
||||
|
||||
|
||||
|
||||
Check Shell built in Commands
|
||||
|
||||
In the examples above, cd and type are shell built-ins, while top and less are binaries external to the shell itself (in this case, the location of the command executable is returned by type).
|
||||
|
||||
Other well-known shell built-ins include:
|
||||
|
||||
- [echo command][8]: Displays strings of text.
|
||||
- [pwd command][9]: Prints the current working directory.
|
||||
|
||||

|
||||
|
||||
More Built in Shell Commands
|
||||
|
||||
**exec command**
|
||||
|
||||
Runs an external program that we specify. Note that in most cases, this is better accomplished by just typing the name of the program we want to run, but the exec command has one special feature: rather than create a new process that runs alongside the shell, the new process replaces the shell, as can verified by subsequent.
|
||||
|
||||
# ps -ef | grep [original PID of the shell process]
|
||||
|
||||
When the new process terminates, the shell terminates with it. Run exec top and then hit the q key to quit top. You will notice that the shell session ends when you do, as shown in the following screencast:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/f02w4WT73LE"></iframe>
|
||||
|
||||
**export command**
|
||||
|
||||
Exports variables to the environment of subsequently executed commands.
|
||||
|
||||
**history Command**
|
||||
|
||||
Displays the command history list with line numbers. A command in the history list can be repeated by typing the command number preceded by an exclamation sign. If we need to edit a command in history list before executing it, we can press Ctrl + r and start typing the first letters associated with the command. When we see the command completed automatically, we can edit it as per our current need:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/69vafdSMfU4"></iframe>
|
||||
|
||||
This list of commands is kept in our home directory in a file called .bash_history. The history facility is a useful resource for reducing the amount of typing, especially when combined with command line editing. By default, bash stores the last 500 commands you have entered, but this limit can be extended by using the HISTSIZE environment variable:
|
||||
|
||||

|
||||
|
||||
Linux history Command
|
||||
|
||||
But this change as performed above, will not be persistent on our next boot. In order to preserve the change in the HISTSIZE variable, we need to edit the .bashrc file by hand:
|
||||
|
||||
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
|
||||
HISTSIZE=1000
|
||||
|
||||
**Important**: Keep in mind that these changes will not take effect until we restart our shell session.
|
||||
|
||||
**alias command**
|
||||
|
||||
With no arguments or with the -p option prints the list of aliases in the form alias name=value on standard output. When arguments are provided, an alias is defined for each name whose value is given.
|
||||
|
||||
With alias, we can make up our own commands or modify existing ones by including desired options. For example, suppose we want to alias ls to ls –color=auto so that the output will display regular files, directories, symlinks, and so on, in different colors:
|
||||
|
||||
# alias ls='ls --color=auto'
|
||||
|
||||
|
||||
|
||||
Linux alias Command
|
||||
|
||||
**Note**: That you can assign any name to your “new command” and enclose as many commands as desired between single quotes, but in that case you need to separate them by semicolons, as follows:
|
||||
|
||||
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
|
||||
|
||||
**exit command**
|
||||
|
||||
The exit and logout commands both terminate the shell. The exit command terminates any shell, but the logout command terminates only login shells—that is, those that are launched automatically when you initiate a text-mode login.
|
||||
|
||||
If we are ever in doubt as to what a program does, we can refer to its man page, which can be invoked using the man command. In addition, there are also man pages for important files (inittab, fstab, hosts, to name a few), library functions, shells, devices, and other features.
|
||||
|
||||
#### Examples: ####
|
||||
|
||||
- man uname (print system information, such as kernel name, processor, operating system type, architecture, and so on).
|
||||
- man inittab (init daemon configuration).
|
||||
|
||||
Another important source of information is provided by the info command, which is used to read info documents. These documents often provide more information than the man page. It is invoked by using the info keyword followed by a command name, such as:
|
||||
|
||||
# info ls
|
||||
# info cut
|
||||
|
||||
In addition, the /usr/share/doc directory contains several subdirectories where further documentation can be found. They either contain plain-text files or other friendly formats.
|
||||
|
||||
Make sure you make it a habit to use these three methods to look up information for commands. Pay special and careful attention to the syntax of each of them, which is explained in detail in the documentation.
|
||||
|
||||
**Converting Tabs into Spaces with expand Command**
|
||||
|
||||
Sometimes text files contain tabs but programs that need to process the files don’t cope well with tabs. Or maybe we just want to convert tabs into spaces. That’s where the expand tool (provided by the GNU coreutils package) comes in handy.
|
||||
|
||||
For example, given the file NumbersList.txt, let’s run expand against it, changing tabs to one space, and display on standard output.
|
||||
|
||||
# expand --tabs=1 NumbersList.txt
|
||||
|
||||

|
||||
|
||||
Linux expand Command
|
||||
|
||||
The unexpand command performs the reverse operation (converts spaces into tabs).
|
||||
|
||||
**Display the first lines of a file with head and the last lines with tail**
|
||||
|
||||
By default, the head command followed by a filename, will display the first 10 lines of the said file. This behavior can be changed using the -n option and specifying a certain number of lines.
|
||||
|
||||
# head -n3 /etc/passwd
|
||||
# tail -n3 /etc/passwd
|
||||
|
||||

|
||||
|
||||
Linux head and tail Command
|
||||
|
||||
One of the most interesting features of tail is the possibility of displaying data (last lines) as the input file grows (tail -f my.log, where my.log is the file under observation). This is particularly useful when monitoring a log to which data is being continually added.
|
||||
|
||||
Read More: [Manage Files Effectively using head and tail Commands][10]
|
||||
|
||||
**Merging Lines with paste**
|
||||
|
||||
The paste command merges files line by line, separating the lines from each file with tabs (by default), or another delimiter that can be specified (in the following example the fields in the output are separated by an equal sign).
|
||||
|
||||
# paste -d= file1 file2
|
||||
|
||||
|
||||
|
||||
Merge Files in Linux
|
||||
|
||||
**Breaking a file into pieces using split command**
|
||||
|
||||
The split command is used split a file into two (or more) separate files, which are named according to a prefix of our choosing. The splitting can be defined by size, chunks, or number of lines, and the resulting files can have a numeric or alphabetic suffixes. In the following example, we will split bash.pdf into files of size 50 KB (-b 50KB), using numeric suffixes (-d):
|
||||
|
||||
# split -b 50KB -d bash.pdf bash_
|
||||
|
||||

|
||||
|
||||
Split Files in Linux
|
||||
|
||||
You can merge the files to recreate the original file with the following command:
|
||||
|
||||
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
|
||||
|
||||
**Translating characters with tr command**
|
||||
|
||||
The tr command can be used to translate (change) characters on a one-by-one basis or using character ranges. In the following example we will use the same file2 as previously, and we will change:
|
||||
|
||||
- lowercase o’s to uppercase,
|
||||
- and all lowercase to uppercase
|
||||
|
||||
# cat file2 | tr o O
|
||||
# cat file2 | tr [a-z] [A-Z]
|
||||
|
||||
|
||||
|
||||
Translate Characters in Linux
|
||||
|
||||
**Reporting or deleting duplicate lines with uniq and sort command**
|
||||
|
||||
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files).
|
||||
|
||||
By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option. Please note how the output returned by sort and uniq change as we change the key field in the following example:
|
||||
|
||||
# cat file3
|
||||
# sort file3 | uniq
|
||||
# sort -k2 file3 | uniq
|
||||
# sort -k3 file3 | uniq
|
||||
|
||||

|
||||
|
||||
Remove Duplicate Lines in Linux
|
||||
|
||||
**Extracting text with cut command**
|
||||
|
||||
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b), characters (-c), or fields (-f).
|
||||
|
||||
When using cut based on fields, the default field separator is a tab, but a different separator can be specified by using the -d option.
|
||||
|
||||
# cut -d: -f1,3 /etc/passwd # Extract specific fields: 1 and 3 in this case
|
||||
# cut -d: -f2-4 /etc/passwd # Extract range of fields: 2 through 4 in this example
|
||||
|
||||

|
||||
|
||||
Extract Text From a File in Linux
|
||||
|
||||
Note that the output of the two examples above was truncated for brevity.
|
||||
|
||||
**Reformatting files with fmt command**
|
||||
|
||||
fmt is used to “clean up” files with a great amount of content or lines, or with varying degrees of indentation. The new paragraph formatting defaults to no more than 75 characters wide. You can change this with the -w (width) option, which set the line length to the specified number of characters.
|
||||
|
||||
For example, let’s see what happens when we use fmt to display the /etc/passwd file setting the width of each line to 100 characters. Once again, output has been truncated for brevity.
|
||||
|
||||
# fmt -w100 /etc/passwd
|
||||
|
||||

|
||||
|
||||
File Reformatting in Linux
|
||||
|
||||
**Formatting content for printing with pr command**
|
||||
|
||||
pr paginates and displays in columns one or more files for printing. In other words, pr formats a file to make it look better when printed. For example, the following command:
|
||||
|
||||
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
|
||||
|
||||
Shows a listing of all the files found in /etc in a printer-friendly format (3 columns) with a custom header (indicated by the -h option), and numbered lines (-n).
|
||||
|
||||

|
||||
|
||||
File Formatting in Linux
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have discussed how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation. As simple as it seems, it’s a large first step in your way to becoming a RHCSA.
|
||||
|
||||
If you would like to add other commands that you use on a periodic basis and that have proven useful to fulfill your daily responsibilities, feel free to share them with the world by using the comment form below. Questions are also welcome. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.redhat.com/en/services/certification/rhcsa
|
||||
[2]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[3]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[4]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
|
||||
[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[6]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[8]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[9]:http://www.tecmint.com/pwd-command-examples/
|
||||
[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||
@ -1,3 +1,4 @@
|
||||
[translating by xiqingongzi]
|
||||
RHCSA Series: How to Perform File and Directory Management – Part 2
|
||||
================================================================================
|
||||
In this article, RHCSA Part 2: File and directory management, we will review some essential skills that are required in the day-to-day tasks of a system administrator.
|
||||
@ -319,4 +320,4 @@ via: http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
|
||||
@ -1,98 +0,0 @@
|
||||
以比较的方式向Linux用户介绍FreeBSD
|
||||
================================================================================
|
||||

|
||||
|
||||
### 简介 ###
|
||||
|
||||
BSD最初从UNIX继承而来,目前,有许多的类Unix操作系统是基于BSD的。FreeBSD是使用最广泛的开源伯克利软件发行版(BSD发行版)。就像它隐含的意思一样,它是一个免费开源的类Unix操作系统,并且是公共服务器的平台。FreeBSD源代码通常以宽松的BSD许可证发布。它与Linux有很多相似的地方,但我们得承认它们在很多方面仍有不同。
|
||||
|
||||
本文的其余部分组织如下:FreeBSD的描述在第一部分,FreeBSD和Linux的相似点在第二部分,它们的区别将在第三部分讨论,对他们功能的讨论和总结在最后一节。
|
||||
|
||||
### FreeBSD描述 ###
|
||||
|
||||
#### 历史 ####
|
||||
|
||||
- FreeBSD的第一个版本发布于1993年,它的第一张CD-ROM是FreeBSD1.0,也发行于1993年。接下来,FreeBSD 2.1.0在1995年发布并且获得了所有用户的青睐。实际上许多IT公司都使用FreeBSD并且很满意,我们可以列出其中的一些:IBM、Nokia、NetApp和Juniper Network。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 关于它的许可证,FreeBSD以多种开源许可证进行发布,它最新的名为Kernel的代码以两种子BSD许可证进行了发布,给予使用和重新发布FreeBSD的绝对自由。其它的代码则以三、四种子BSD许可证进行发布,有些是以GPL和CDDL的许可证发布的。
|
||||
|
||||
#### 用户 ####
|
||||
|
||||
- FreeBSD的重要特点之一就是它多样的用户。实际上,FreeBSD可以作为邮件服务器、Web Server、FTP服务器以及路由器等,您只需要在它上运行服务相关的软件即可。而且FreeBSD还支持ARM、PowerPC、MIPS、x86、x86-64架构。
|
||||
|
||||
### FreeBSD和Linux的相似处 ###
|
||||
|
||||
FreeBSD和Linux是两个免费开源的软件。实际上,它们的用户可以很容易的检查并修改源代码,用户拥有绝对的自由。而且,FreeBSD和Linux都是类Unix系统,它们的内核、内部组件、库程序都使用从历史上的AT&T Unix处继承的算法。FreeBSD从根基上更像Unix系统,而Linux是作为免费的类Unix系统发布的。许多工具应用都可以在FreeBSD和Linux中找到,实际上,他们几乎有同样的功能。
|
||||
|
||||
此外,FreeBSD能够运行大量的Linux应用。它可以安装一个Linux的兼容层,这个兼容层可以在编译FreeBSD时加入AAC Compact Linux得到或通过下载已编译了Linux兼容层的FreeBSD系统,其中会包括兼容程序:aac_linux.ko。不同于FreeBSD的是,Linux无法运行FreeBSD的软件。
|
||||
|
||||
最后,我们注意到虽然二者有同样的目标,但二者还是有一些不同之处,我们在下一节中列出。
|
||||
|
||||
### FreeBSD和Linux的区别 ###
|
||||
|
||||
目前对于大多数用户来说并没有一个选择FreeBSD还是Linux的清楚的准则。因为他们有着很多同样的应用程序,因为他们都被称作类Unix系统。
|
||||
|
||||
在这一章,我们将列出这两种系统的一些重要的不同之处。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 两个系统的区别首先在于它们的许可证。Linux以GPL许可证发行,它为用户提供阅读、发行和修改源代码的自由,GPL许可证帮助用户避免仅仅发行二进制。而FreeBSD以BSD许可证发布,BSD许可证比GPL更宽容,因为其衍生著作不需要仍以该许可证发布。这意味着任何用户能够使用、发布、修改代码,并且不需要维持之前的许可证。
|
||||
- 您可以依据您的需求,在两种许可证中选择一种。首先是BSD许可证,由于其特殊的条款,它更受用户青睐。实际上,这个许可证使用户在保证源代码的封闭性的同时,可以售卖以该许可证发布的软件。再说说GPL,它需要每个使用以该许可证发布的软件的用户多加注意。
|
||||
- 如果想在以不同许可证发布的两种软件中做出选择,您需要了解他们各自的许可证,以及他们开发中的方法论,从而能了解他们特性的区别,来选择更适合自己需求的。
|
||||
|
||||
#### 控制 ####
|
||||
|
||||
- 由于FreeBSD和Linux是以不同的许可证发布的,Linus Torvalds控制着Linux的内核,而FreeBSD却与Linux不同,它并未被控制。我个人更倾向于使用FreeBSD而不是Linux,这是因为FreeBSD才是绝对自由的软件,没有任何控制许可的存在。Linux和FreeBSD还有其他的不同之处,我建议您先不急着做出选择,等读完本文后再做出您的选择。
|
||||
|
||||
#### 操作系统 ####
|
||||
|
||||
- Linux聚焦于内核系统,这与FreeBSD不同,FreeBSD的整个系统都被维护着。FreeBSD的内核和一组由FreeBSD团队开发的软件被作为一个整体进行维护。实际上,FreeBSD开发人员能够远程且高效的管理核心操作系统。
|
||||
- 而Linux方面,在管理系统方面有一些困难。由于不同的组件由不同的源维护,Linux开发者需要将它们汇集起来,才能达到同样的功能。
|
||||
- FreeBSD和Linux都给了用户大量的可选软件和发行版,但他们管理的方式不同。FreeBSD是统一的管理方式,而Linux需要被分别维护。
|
||||
|
||||
#### 硬件支持 ####
|
||||
|
||||
- 说到硬件支持,Linux比FreeBSD做的更好。但这不意味着FreeBSD没有像Linux那样支持硬件的能力。他们只是在管理的方式不同,这通常还依赖于您的需求。因此,如果您在寻找最新的解决方案,FreeBSD更适应您;但如果您在寻找一幅宏大的画卷,那最好使用Linux。
|
||||
|
||||
#### 原生FreeBSD Vs 原生Linux ####
|
||||
|
||||
- 两者的原生系统的区别又有不同。就像我之前说的,Linux是一个Unix的替代系统,由Linux Torvalds编写,并由网络上的许多极客一起协助实现的。Linux有一个现代系统所需要的全部功能,诸如虚拟内存、共享库、动态加载、优秀的内存管理等。它以GPL许可证发布。
|
||||
- FreeBSD也继承了Unix的许多重要的特性。FreeBSD作为在加州大学开发的BSD的一种发行版。开发BSD的最重要的原因是用一个开源的系统来替代AT&T操作系统,从而给用户无需AT&T证书便可使用的能力。
|
||||
- 许可证的问题是开发者们最关心的问题。他们试图提供一个最大化克隆Unix的开源系统。这影响了用户的选择,由于FreeBSD相比Linux使用BSD许可证进行发布,因而更加自由。
|
||||
|
||||
#### 支持的软件包 ####
|
||||
|
||||
- 从用户的角度来看,另一个二者不同的地方便是软件包以及对源码安装的软件的可用性和支持。Linux只提供了预编译的二进制包,这与FreeBSD不同,它不但提供预编译的包,而且还提供从源码编译和安装的构建系统。由于这样的移植,FreeBSD给了您选择使用预编译的软件包(默认)和在编译时定制您软件的能力。
|
||||
- 这些可选组件允许您用FreeBSD构建所有的软件。而且,它们的管理还是层次化的,您可以在/usr/ports下找到源文件的地址以及一些正确使用FreeBSD的文档。
|
||||
- 这些提到的可选组件给予了产生不同软件包版本的可能性。FreeBSD给了您通过源代码构建以及预编译的两种软件,而不是像Linux一样只有预编译的软件包。您可以使用两种安装方式管理您的系统。
|
||||
|
||||
#### FreeBSD 和 Linux 常用工具比较 ####
|
||||
|
||||
- 有大量的常用工具在FreeBSD上可用,并且有趣的是他们由FreeBSD的团队所拥有。相反的,Linux工具来自GNU,这就是为什么在使用中有一些限制。
|
||||
- 实际上FreeBSD采用的BSD许可证非常有益且有用。因此,您有能力维护核心操作系统,控制这些应用程序的开发。有一些工具类似于它们的祖先 - BSD和Unix的工具,但不同于GNU的套件,GNU套件只想做到最小的向后兼容。
|
||||
|
||||
#### 标准 Shell ####
|
||||
|
||||
- FreeBSD默认使用tcsh。它是csh的评估版,由于FreeBSD以BSD许可证发行,因此不建议您在其中使用GNU的组件 bash shell。bash和tcsh的区别仅仅在于tcsh的脚本功能。实际上,我们更推荐在FreeBSD中使用sh shell,因为它更加可靠,可以避免一些使用tcsh和csh时出现的脚本问题。
|
||||
|
||||
#### 一个更加层次化的文件系统 ####
|
||||
|
||||
- 像之前提到的一样,使用FreeBSD时,基础操作系统以及可选组件可以被很容易的区别开来。这导致了一些管理它们的标准。在Linux下,/bin,/sbin,/usr/bin或者/usr/sbin都是存放可执行文件的目录。FreeBSD不同,它有一些附加的对其进行组织的规范。基础操作系统被放在/usr/local/bin或者/usr/local/sbin目录下。这种方法可以帮助管理和区分基础操作系统和可选组件。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
FreeBSD和Linux都是免费且开源的系统,他们有相似点也有不同点。上面列出的内容并不能说哪个系统比另一个更好。实际上,FreeBSD和Linux都有自己的特点和技术规格,这使它们与别的系统区别开来。那么,您有什么看法呢?您已经有在使用它们中的某个系统了么?如果答案为是的话,请给我们您的反馈;如果答案是否的话,在读完我们的描述后,您怎么看?请在留言处发表您的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/comparative-introduction-freebsd-linux-users/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
@ -1,57 +0,0 @@
|
||||
Linux比Mac OS X更好吗?历史中的GNU,开源和Apple
|
||||
==============================================================================
|
||||
> 自由软件/开源社区与Apple之间的争论可以回溯到上世纪80年代,当时Linux的创始人称Mac OS X的核心就是"一个废物",还有其他一些软件历史上的轶事。
|
||||
|
||||

|
||||
|
||||
开源拥护者们与微软之间有着很长,而且摇摆的关系。每个人都知道这个。但是,在许多方面,自由或者开源软件的支持者们与Apple之间的紧张关系则更加突出——尽管这很少受到媒体的关注。
|
||||
|
||||
需要说明的是,并不是所有的开源拥护者都厌恶苹果。Anecdotally(待译),我已经见过很多Linux的黑客玩弄iPhones和iPads。实际上,许多Linux用户是十分喜欢Apple的OS X系统的,以至于他们[创造了很多Linux的发行版][1],都设计得看起来像OS X。(顺便说下,[北朝鲜政府][2]就这样做了。)
|
||||
|
||||
但是Mac的信徒与企鹅——即Linux社区(未提及自由与开源软件世界的小众群体)的信徒之间的关系,并不一直是完全的和谐。并且这绝不是一个新的现象,在我研究Linux历史和开源基金会的时候就发现了。
|
||||
|
||||
### GNU vs. Apple ###
|
||||
|
||||
这场战争将回溯到至少上世界80年代后期。1988年6月,Richard Stallman发起了[GNU][3]项目,希望建立一个完全自由的类Unix操作系统,其源代码讲会免费共享,[[强烈指责][4]Apple对[Hewlett-Packard][5](HPQ)和[Microsoft][6](MSFT)的诉讼,称Apple的声明中,说别人对Macintosh操作系统的界面和体验的抄袭是不正确。如果Apple流行,GNU警告到,这家公司“将会借助大众的新力量终结掉自由软件,而自由软件可以成为商业软件的替代品。”
|
||||
|
||||
那个时候,GNU对抗Apple的诉讼(这意味着,十分讽刺的是,GNU正在支持Microsoft,尽管当时的情况不一样),通过发布["让你的律师远离我的电脑”按钮][7]。同时呼吁GNU的支持者们抵制Apple,警告如果Macintoshes看起来是不错的计算机,但Apple一旦赢得了诉讼就会给市场带来垄断,这会极大地提高计算机的售价。
|
||||
|
||||
Apple最终[输掉了诉讼][8],但是直到1994年之后,GNU才[撤销对Apple的抵制][9]。这期间,GNU一直不断指责Apple。在上世纪90年代早期甚至之后,GNU开始发展GNU软件项目,可以在其他个人电脑平台包括MS-DOS上使用。[GNU 宣称][10],除非Apple停止在计算机领域垄断的野心,让用户界面可以模仿Macintosh的一些东西,否则“我们不会提供任何对Apple机器的支持。”(因此讽刺的是一大堆软件都开发了OS X和类Unix系统的版本,于是Apple在90年代后期介绍这些软件来自GNU。但是那是另外的故事了。)
|
||||
|
||||
### Trovalds on Jobs ###
|
||||
|
||||
除去他对大多数发行版比较自由放任的态度,Liuns Trovalds,Linux内核的创造者,相较于Stallman和GNU过去对Apple的态度没有多一点仁慈。在他2001年出版的书"Just For Fun: The Story of an Accidental Revolutionary"中,Trovalds描述到与Steve Jobs的一个会面,大约是1997年收到后者的邀请去讨论Mac OS X,Apple正在开发,但还没有公开发布。
|
||||
|
||||
"基本上,Jobs一开始就试图告诉我在桌面上的玩家就两个,Microsoft和Apple,而且他认为我能为Linux做的最好的事,就是从了Apple,努力让开源用户站到Mac OS X后面去"Trovalds写道。
|
||||
|
||||
这次谈判显然让Trovalds很不爽。争吵的一点集中在Trovalds对Mach技术上的藐视,对于Apple正在用于构建新的OS X操作系统的内核,Trovalds称其“一推废物。它包含了所有你能做到的设计错误,并且甚至打算只弥补一小部分。”
|
||||
|
||||
但是更令人不快的是,显然是Jobs在开发OS X时入侵开源的方式(OS X的核心里上有很多开源程序):“他有点贬低了结构的瑕疵:谁在乎基础操作系统,真正的low-core东西是不是开源,如果你有Mac层在最上面,这不是开源?”
|
||||
|
||||
一切的一切,Trovalds总结到,Jobs“并没有使用太多争论。他仅仅很简单地说着,胸有成竹地认为我会对与Apple合作感兴趣”。“他没有任何线索,不能去想像还会有人并不关心Mac市场份额的增长。我认为他真的感到惊讶了,当我表现出对Mac的市场有多大,或者Microsoft市场有多大的可怜的关心时。”
|
||||
|
||||
当然,Trovalds并没有对所有Linux用户说起。他对于OS X和Apple的看法从2001年开始就渐渐软化了。但实际上,早在2000年,Linux社区的领导角色表现出对Apple和其高层的傲慢的深深的鄙视,可以看出一些重要的东西,关于Apple和开源/自由软件世界的矛盾是多么的根深蒂固。
|
||||
|
||||
从以上两则历史上的花边新闻中,可以看到关于Apple产品价值的重大争议,即是否该公司致力于提升软硬件的质量,或者仅仅是借市场的小聪明获利,后者会让Apple产品卖出更多的钱,**********(该处不知如何翻译)。但是不管怎样,我会暂时置身讨论之外。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
|
||||
[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
|
||||
[3]:http://gnu.org/
|
||||
[4]:https://www.gnu.org/bulletins/bull5.html
|
||||
[5]:http://www.hp.com/
|
||||
[6]:http://www.microsoft.com/
|
||||
[7]:http://www.duntemann.com/AppleSnakeButton.jpg
|
||||
[8]:http://www.freibrun.com/articles/articl12.htm
|
||||
[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
|
||||
[10]:https://www.gnu.org/bulletins/bull12.html
|
||||
@ -0,0 +1,86 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||

|
||||
蜂巢的应用列表少了很多应用。上图还展示了通知中心和新的快速设置。
|
||||
Ron Amadeo 供图
|
||||
|
||||
默认的应用图标从32个减少到了25个,其中还有两个是第三方的游戏。因为蜂巢不是为手机设计的,而且谷歌希望默认应用都是为平板优化的,很多应用因此没有成为默认应用。被去掉的应用有亚马逊 MP3 商店,Car Home,Facebook,Google Goggles,信息,新闻与天气,电话,Twitter,谷歌语音,以及语音拨号。谷歌正在悄悄打造的音乐服务将于不久后面世,所以亚马逊 MP3 商店需要为它让路。Car Home,信息以及电话对一部不是手机的设备来说没有多大意义,Facebook 和 Twitter还没有平板版应用,Goggles,新闻与天气以及语音拨号几乎没什么人注意,就算移除了大多数人也不会想念它们的。
|
||||
|
||||
几乎每个应用图标都是全新设计的。就像是从 G1 切换到摩托罗拉 Droid,变化的最大动力是分辨率的提高。Nexus S 有一块800×480分辨率的显示屏,姜饼重新设计了图标等资源来适应它。Xoom 巨大的1280×800 10英寸显示屏意味着几乎所有设计都要重做。但是再说一次,这次是有真正的设计师在负责,所有东西看起来更有整体性了。蜂巢的应用列表从纵向滚动变为了横向分页式。这个变化对横屏设备有意义,而对手机来说,查找一个应用还是纵向滚动列表比较快。
|
||||
|
||||
第二张蜂巢截图展示的是新通知中心。姜饼中的灰色和黑色设计已经被抛弃了,现在是黑色面板带蓝色光晕。上面一块显示着日期时间,连接状态,电量和打开快速设置的按钮,下面是实际的通知。非持续性通知现在可以通过通知右侧的“X”来关闭。蜂巢是第一个支持通知内控制的版本。第一个(也是蜂巢发布时唯一一个)利用了此特性的应用是新的谷歌音乐,在它的通知上有上一曲,播放/暂停,下一曲按钮。这些控制可以在任何应用中访问到,这让控制音乐播放变成了一件轻而易举的事情。
|
||||
|
||||

|
||||
“添加到主屏幕”的缩小视图更易于组织布局。搜索界面将自动搜索建议和通用搜索分为两个面板显示。
|
||||
Ron Amadeo 供图
|
||||
|
||||
点击主屏幕右上角的加号或长按背景空白处就会打开新的主屏幕设置界面。蜂巢会在屏幕上半部分显示所有主屏的缩小视图,下半部分分页显示的是小部件和快捷方式。小部件或快捷方式可以从下半部分的抽屉中拖动到五个主屏幕中的任意一个上。姜饼只会显示一个文本列表,而蜂巢会显示小部件完整的略缩图预览。这让你更清楚一个小部件是什么样子的,而不是像原来的“日历”一样只是一个只有应用名称的描述。
|
||||
|
||||
摩托罗拉 Xoom 更大的屏幕让键盘的布局更加接近 PC 风格,退格,回车,shift 以及 tab 都在传统的位置上。键盘带有浅蓝色,并且键与键之间的空间更大了。谷歌还添加了一个专门的笑脸按钮。 :-)
|
||||
|
||||

|
||||
打开菜单的 Gmail 在蜂巢和姜饼上的效果。按钮布置在首屏更容易被发现。
|
||||
Ron Amadeo 供图
|
||||
|
||||
Gmail 示范了蜂巢所有的用户界面概念。安卓 3.0不再把所有控制都隐藏在菜单按钮之后。屏幕的顶部现在有一条带有图标的条带,叫做 Action Bar(操作栏),它将许多常用的控制选项提升到了主屏幕上,用户直接就能看到它们。Gmail 的操作栏显示着搜索,新邮件,刷新按钮,不常用的选项比如设置,帮助,以及反馈放在了“更多”按钮中。点击复选框或选中文本的时候时整个操作栏的图标会变成和操作相关的——举个例子,选择文本会出现复制,粘贴和全选按钮。
|
||||
|
||||
应用左上角显示的图标同时也作为称作“上一级”的导航按钮。“后退”的作用类似浏览器的后退按钮,导航到之前访问的页面,“上一级”则会导航至应用的上一层次。举例来说,如果你在安卓市场,点击“给开发者发邮件”,会打开 Gmail,“后退”会让你返回安卓市场,但是“上一级”会带你到 Gmail 的收件箱。“后退”可能会关闭当前应用,而“上一级”永远不会。应用可以控制“后退”按钮,它们往往重新定义它为“上一级”的功能。事实上,这两个按钮之间几乎没什么不同。
|
||||
|
||||
蜂巢还引入了 “Fragments” API,允许开发者开发同时适用于平板和手机的应用。一个 “Fragments”(格子) 是一个用户界面的面板。在上图的 Gmail 中,左边的文件夹列表是一个格子,收件箱是另一个格子。手机每屏显示一个格子,而平板则可以并列显示两个。开发者可以自行定义单独每个格子的外观,安卓会根据当前的设备决定如何显示它们。
|
||||
|
||||

|
||||
计算器使用了常规的安卓按钮,但日历看起来像是被谁打翻了蓝墨水。
|
||||
Ron Amadeo 供图
|
||||
|
||||
这是安卓历史上第一次计算器换上了没有特别定制的按钮,所以它看起来确实是系统的一部分。更大的屏幕有了更多空间容纳按钮,足够将计算器基本功能容纳在一个屏幕上。日历极大地受益于额外的显示空间,有了更多的空间显示事件文本和控制选项。顶部的操作栏有切换视图的按钮,显示当前时间跨度,以及常规按钮。事件块变成了白色背景,日历标识只在左上角显示。在底部(或横屏模式的侧边)显示的是月历和显示的日历列表。
|
||||
|
||||
日历的比例同样可以调整。通过两指缩放手势,纵向的周和日视图能够在一屏内显示五到十九小时的事件。日历的背景由不均匀的蓝色斑点组成,看起来不是特别棒,在随后的版本里就被抛弃了。
|
||||
|
||||

|
||||
新相机界面,取景器显示的是“负片”效果。
|
||||
Ron Amadeo 供图
|
||||
|
||||
巨大的10英寸 Xoom 平板有个摄像头,这意味着它同样有个相机应用。电子风格的重新设计终于甩掉了谷歌从安卓 1.6 以来使用的仿皮革外观。控制选项以环形排布在快门键周围,让人想起真正的相机上的圆形控制转盘。Cooliris 衍生的弹出对话气泡变成了带光晕的半透明黑色选框。蜂巢的截图显示的是新的“颜色效果”功能,它能给取景器实时加上滤镜效果。不像姜饼的相机应用,它不支持竖屏模式——它被限制在横屏状态。用10英寸的平板拍摄纵向照片没多大意义,但拍摄横向照片也没多大意义。
|
||||
|
||||

|
||||
时钟应用相比其它地方没受到多少关照。谷歌把它扔进一个小盒子里然后就收工了。
|
||||
Ron Amadeo 供图
|
||||
|
||||
无数功能已经成形了,现在是时候来重制一下时钟了。整个“桌面时钟”概念被踢出门外,取而代之的是在纯黑背景上显示的简单又巨大的时间数字。打开其它应用查看天气的功能不见了,随之而去的还有显示你的壁纸的功能。当要设计平板尺寸的界面时,有时候谷歌就放弃了,就像这里,就只是把时钟界面扔到了一个小小的,居中的对话框里。
|
||||
|
||||

|
||||
音乐应用终于得到了一直以来都需要的完全重新设计。
|
||||
Ron Amadeo 供图
|
||||
|
||||
尽管音乐应用之前有得到一些小的加强,但这是自安卓 0.9 以来它第一次受到正视。重新设计的亮点是一个“别叫它封面流滚动 3D 专辑封面视图”,称作“最新和最近”。导航由操作栏的下拉框解决,取代了安卓 2.1 引入的标签页导航。尽管“最新和最近”有个 3D 滚动专辑封面,“专辑”使用的是专辑略缩图的平面方阵。另一个部分也有个完全不同的设计。“歌曲”使用了垂直滚动的文本列表,“播放列表”,“年代”和“艺术家”用的是堆砌专辑显示。
|
||||
|
||||
在几乎每个视图中,每个单独的项目有它自己单独的菜单,通常在每项的右下角有个小箭头。眼下这里只会显示“播放”和“添加到播放列表”,但这个版本的谷歌音乐是为未来搭建的。谷歌不久后就要发布音乐服务,这些独立菜单在像是在音乐商店里浏览该艺术家的其它内容,或是管理云存储和本地存储时将会是不可或缺的。
|
||||
|
||||
正如安卓 2.1 中的 Cooliris 风格的相册,谷歌音乐会将略缩图放大作为背景图片。底部的“正在播放”栏现在显示着专辑封面,播放控制,以及播放进度条。
|
||||
|
||||

|
||||
新谷歌地图的一些地方真的很棒,一些却是从安卓 1.5 来的。
|
||||
Ron Amadeo 供图
|
||||
|
||||
谷歌地图也为大屏幕进行了重新设计。这个设计将会持续一段时间,它对所有的控制选项用了一个半透明的黑色操作栏。搜索再次成为主要功能,占据了操作栏显要位置,但这回可是真的搜索栏,你可以在里面输入关键字,不像以前那个搜索栏形状的按钮会打开完全不同的界面。谷歌最终还是放弃了给缩放控件留屏幕空间,仅仅依靠手势来控制地图显示。尽管 3D 建筑轮廓这个特性已经被移植到了旧版本的地图中,蜂巢依然是拥有这个特性的第一个版本。双指在地图上向下拖放会“倾斜”地图的视角,展示建筑的侧面。你可以随意旋转,建筑同样会跟着进行调整。
|
||||
|
||||
并不是所有部分都进行了重新设计。导航自姜饼以来就没动过,还有些界面的核心部分,像是路线,直接从安卓 1.6 的设计拿出来,放到一个小盒子里居中放置,仅此而已。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/17/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,177 +0,0 @@
|
||||
LINUX 101: 让你的 SHELL 更强大
|
||||
================================================================================
|
||||
> 在我们的有关 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
||||
|
||||
**为何要这样做?**
|
||||
|
||||
- 使得在 shell 提示符下过得更轻松,高效
|
||||
- 在失去连接后恢复先前的会话
|
||||
- Stop pushing around that fiddly rodent! (注: 我不知道这句该如何翻译)
|
||||
|
||||

|
||||
|
||||
Here’s our souped-up prompt on steroids.(注: 我不知道该如何翻译这句)对于这个细小的终端窗口来说,这或许有些长.但你可以根据你的喜好来调整它的大小.
|
||||
|
||||
作为一个 Linux 用户, 对 shell (又名为命令行),你可能会熟悉. 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个平铺窗口管理器的环境中, 而 shell 是你与你的 linux 机器交互的主要方式.
|
||||
|
||||
在上面的任一情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置. 尽管对于大多数的任务而言,它足够强大,但它可以更加强大. 在本教程中,我们将向你展示如何使得你的 shell 更具信息性,更加实用且更适于在其中工作. 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序. 并且,为了让眼睛舒服一点,我们还将关注配色方案. 接着,就让我们向前吧!
|
||||
|
||||
### 让提示符 "唱歌" ###
|
||||
|
||||
大多数的发行版本配置有一个非常简单的提示符 – 它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容.例如,在 Debian 7 下,默认的提示符是这样的:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
上面的提示符展示出了用户,主机名,当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 # ). 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中. 假如你键入 **echo $PS1**, 你将会在这个命令的输出字符串的最后有如下的字符:
|
||||
|
||||
\u@\h:\w$ (注:这里没有加上斜杠 \,应该是没有转义 ,下面的有些命令也一样,我把 \ 都加上了,发表的时候也得注意一下)
|
||||
|
||||
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑. 这不是正则表达式, 这里的斜杠是转义序列,它告诉提示符进行一些特别的处理. 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
||||
|
||||
下面是一些你可以在提示符中用到的字符的列表:
|
||||
|
||||
- d 当前的日期.
|
||||
- h 主机名.
|
||||
- n 代表新的一行的字符.
|
||||
- A 当前的时间 (HH:MM).
|
||||
- u 当前的用户.
|
||||
- w (小写) 整个工作路径的全称.
|
||||
- W (大写) 工作路径的简短名称.
|
||||
- $ 一个提示符号,对于 root 用户为 # 号.
|
||||
- ! 当前命令在 shell 历史记录中的序号.
|
||||
|
||||
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**), 而对于后者, 它则只显示 **bin** 这一部分.
|
||||
|
||||
现在, 我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容, 试试下面这个:
|
||||
|
||||
export PS1=”I am \u and it is \A $”
|
||||
|
||||
现在, 你的提示符将会像下面这样:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
从这个例子出发, 你就可以按照你的想法来试验一下上面列出的其他转义序列. 但稍等片刻 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时, **PS1** 环境变量的值都会被重置. 解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令.在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的被加强了的提示符就可以一直出现.你还可以使用额外的颜色来装扮提示符.刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的. 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
||||
|
||||
\[\e[31m\]
|
||||
|
||||
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
||||
|
||||
- 30 黑色
|
||||
- 32 绿色
|
||||
- 33 黄色
|
||||
- 34 蓝色
|
||||
- 35 洋红色
|
||||
- 36 青色
|
||||
- 37 白色
|
||||
|
||||
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容. 深吸一口气,弯曲你的手指,然后键入下面这只"野兽":
|
||||
|
||||
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
||||
|
||||
上面的命令提供了一个 Bash 命令历史序号, 当前的时间,用户或主机名与颜色之间的组合,以及工作路径.假如你"野心勃勃",利用一些惊人的组合,你还可以更改提示符的背景色和前景色.先前实用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1].
|
||||
|
||||
> ### Shell 精要 ###
|
||||
>
|
||||
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力. 所以这里有一些基础知识来让你熟悉一些 shell. 通常在你的菜单中, shell 指的是 Terminal, XTerm 或 Konsole, 但你启动它后, 最为实用的命令有这些:
|
||||
>
|
||||
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
||||
>
|
||||
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件).
|
||||
>
|
||||
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出).在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全.
|
||||
|
||||
### Tmux: 针对 shell 的窗口管理器 ###
|
||||
|
||||
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表. 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标. 这个功能非常有意义.
|
||||
|
||||
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦. 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起.
|
||||
|
||||
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接.想要看看这是如何运行的最好方式是自己尝试一下. 在一个终端窗口中,输入 **screen** (在大多数发行版本中,它被默认安装了或者可以在软件包仓库中找到). 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失. 现在运行一个交互式的文本模式的程序,例如 **nano**, 并关闭这个终端窗口.
|
||||
|
||||
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的. 打开一个新的终端并输入如下命令:
|
||||
|
||||
screen -r
|
||||
|
||||
瞧, 你刚开打开的 Nano 会话又回来了!
|
||||
|
||||
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接( 即 **-r** 选项).
|
||||
|
||||
当你正使用 SSH 去连接另一台机器并做着某些工作, 但并不想因为一个单独的连接而毁掉你的所有进程时,这个方法尤其有用.假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了),你只需重新连接一个新的电脑或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始.
|
||||
|
||||
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux. 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux. 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get, yum install** 或 **pacman -S** 命令便可以安装它.
|
||||
|
||||
一旦你安装了它过后,键入 **tmux** 来启动它.接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表,机器的主机名,当前时间和日期. 现在运行一个程序,又以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记. Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口.你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果). 若需要知道窗口列表,使用 Ctrl+B 再加上 W.
|
||||
|
||||
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时.). 当想同时看两个程序又该怎么办呢?
|
||||
|
||||
针对这种情况, 可以使用 tmux 中的窗格. 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分,一个在左一个在右.你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换. 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件.
|
||||
|
||||
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧. 首先你需要敲击 Ctrl+B 再加上一个 :(分号),这将使得位于底部的 tmux 栏变为深橙色. 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux. 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动. 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(以前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令. 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号并使用向上的箭头来取回刚才输入的命令.
|
||||
|
||||
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能. 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话, 这使得这个会话的一切工作都在后台中运行.使用 **tmux a** 可以再重新连接到刚才的会话. 但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
||||
|
||||
tmux ls
|
||||
|
||||
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容.
|
||||
|
||||
tmux: 一个针对 shell 的窗口管理器
|
||||
|
||||

|
||||
|
||||
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页.
|
||||
|
||||
> ### Zsh: 另一个 shell ###
|
||||
>
|
||||
> 选择是好的,但标准同样重要. 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell. Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力.它成熟,可靠并文档丰富 – 但它不是你唯一的选择.
|
||||
>
|
||||
> 许多高级用户热衷于 Zsh, 即 Z shell. 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,令外还提供了一些额外的功能. 例如, 在 Zsh 中,你输入 **ls** - 并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述. 而不需要再打开 man page 了!
|
||||
>
|
||||
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符.). 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多.
|
||||
>
|
||||
> Zsh 在大多数的主要发行版本上都可以得到; 安装它后并输入 **zsh** 便可启动它. 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令. 若需了解更多的信息,请访问 [www.zsh.org][2].
|
||||
|
||||
### "未来" 的终端 ###
|
||||
|
||||
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端. 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们在某些线路的配合下,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为 "哑终端", 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息.
|
||||
|
||||
今天,几乎所有的我们在自己的机器上执行实际的操作,所以我们的电脑不是传统意义下的终端, 这就是为什么诸如 **XTerm**, Gnome Terminal, Konsole 等程序被称为 "终端模拟器" 的原因 – 他们提供了同昔日的物理终端一样的功能.事实上,在许多方面它们并没有改变多少.诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作.
|
||||
|
||||
所以某些程序员正尝试改变这个状况. **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在将终端引入 21 世纪,例如带有在线媒体显示功能.你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频. 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们.
|
||||
|
||||
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为 "命令的革新".它就像是一个传统的 shell, 一个 GUI 和一个 wiki 之间的过渡; 你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令.用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分).
|
||||
|
||||
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000. 是的,你没有看错 – $84K 来支持一个终端模拟器.这可能是最不寻常的集资活动,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
||||
|
||||
### 下一代终端 ###
|
||||
|
||||
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效. 我们的推荐有:
|
||||
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器). 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说,它非常实用.
|
||||
|
||||
> ### 微调配色方案 ###
|
||||
>
|
||||
> 在 Linux Voice 中,我们并不迷恋养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性.我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果,摆弄不同的配色方案,直到我们 100% 的满意.(然后出于习惯,摆弄更多的东西.)
|
||||
>
|
||||
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱, 并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole and Xfce4 Terminal are among the apps supported.**),它可以色设定.移动滑动条直到你看到配色方案 norvana, 然后点击位于该页面右上角的 `得到方案` 按钮.
|
||||
>
|
||||
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费很多的时间,使用一个精心设计的调色板也是非常值得的. **Solarized at** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
@ -0,0 +1,125 @@
|
||||
如何使用Docker Machine部署Swarm集群
|
||||
================================================================================
|
||||
大家好,今天我们来研究一下如何使用Docker Machine部署Swarm集群。Docker Machine提供了独立的Docker API,所以任何与Docker守护进程进行交互的工具都可以使用Swarm来(透明地)扩增到多台主机上。Docker Machine可以用来在个人电脑、云端以及的数据中心里创建Docker主机。它为创建服务器,安装Docker以及根据用户设定配置Docker客户端提供了便捷化的解决方案。我们可以使用任何驱动来部署swarm集群,并且swarm集群将由于使用了TLS加密具有极好的安全性。
|
||||
|
||||
下面是我提供的简便方法。
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
Docker Machine 在任何Linux系统上都被支持。首先,我们需要从Github上下载最新版本的Docker Machine。我们使用curl命令来下载最先版本Docker Machine ie 0.2.0。
|
||||
64位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
32位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载了最先版本的Docker Machine之后,我们需要对 /usr/local/bin/ 目录下的docker-machine文件的权限进行修改。命令如下:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
在做完上面的事情以后,我们必须确保docker-machine已经安装好。怎么检查呢?运行docker-machine -v指令,指令将会给出我们系统上所安装的docker-machine版本。
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
为了让Docker命令能够在我们的机器上运行,必须还要在机器上安装Docker客户端。命令如下。
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建Machine ###
|
||||
|
||||
在将Docker Machine安装到我们的设备上之后,我们需要使用Docker Machine创建一个machine。在这片文章中,我们会将其部署在Digital Ocean Platform上。所以我们将使用“digitalocean”作为它的Driver API,然后将docker swarm运行在其中。这个Droplet会被设置为Swarm主节点,我们还要创建另外一个Droplet,并将其设定为Swarm节点代理。
|
||||
创建machine的命令如下:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**Note**: 假设我们要创建一个名为“linux-dev”的machine。<API-Token>是用户在Digital Ocean Cloud Platform的Digital Ocean控制面板中生成的密钥。为了获取这个密钥,我们需要登录我们的Digital Ocean控制面板,然后点击API选项,之后点击Generate New Token,起个名字,然后在Read和Write两个选项上打钩。之后我们将得到一个很长的十六进制密钥,这个就是<API-Token>了。用其替换上面那条命令中的API-Token字段。
|
||||
|
||||
现在,运行下面的指令,将Machine configuration装载进shell。
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
然后,我们使用如下命令将我们的machine标记为ACTIVE状态。
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
现在,我们检查是否它(指machine)被标记为了 ACTIVE "*"。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. 运行Swarm Docker镜像 ###
|
||||
|
||||
现在,在我们创建完成了machine之后。我们需要将swarm docker镜像部署上去。这个machine将会运行这个docker镜像并且控制Swarm主节点和从节点。使用下面的指令运行镜像:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
If you are trying to run swarm docker image using **32 bit Operating System** in the computer where Docker Machine is running, we'll need to SSH into the Droplet.
|
||||
如果你想要在**32位操作系统**上运行swarm docker镜像。你需要SSH登录到Droplet当中。
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. 创建Swarm主节点 ###
|
||||
|
||||
在我们的swarm image已经运行在machine当中之后,我们将要创建一个Swarm主节点。使用下面的语句,添加一个主节点。(这里的感觉怪怪的,好像少翻译了很多东西,是我把Master翻译为主节点的原因吗?)
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. 创建Swarm结点群 ###
|
||||
|
||||
现在,我们将要创建一个swarm结点,此结点将与Swarm主节点相连接。下面的指令将创建一个新的名为swarm-node的droplet,其与Swarm主节点相连。到此,我们就拥有了一个两节点的swarm集群了。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. Connecting to the Swarm Master ###
|
||||
### 6. 与Swarm主节点连接 ###
|
||||
|
||||
现在,我们连接Swarm主节点以便我们可以依照需求和配置文件在节点间部署Docker容器。运行下列命令将Swarm主节点的Machine配置文件加载到环境当中。
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
然后,我们就可以跨结点地运行我们所需的容器了。在这里,我们还要检查一下是否一切正常。所以,运行**docker info**命令来检查Swarm集群的信息。
|
||||
|
||||
# docker info
|
||||
|
||||
### Conclusion ###
|
||||
### 总结 ###
|
||||
|
||||
我们可以用Docker Machine轻而易举地创建Swarm集群。这种方法有非常高的效率,因为它极大地减少了系统管理员和用户的时间消耗。在这篇文章中,我们以Digital Ocean作为驱动,通过创建一个主节点和一个从节点成功地部署了集群。其他类似的应用还有VirtualBox,Google Cloud Computing,Amazon Web Service,Microsoft Azure等等。这些连接都是通过TLS进行加密的,具有很高的安全性。如果你有任何的疑问,建议,反馈,欢迎在下面的评论框中注明以便我们可以更好地提高文章的质量!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,149 +0,0 @@
|
||||
|
||||
如何管理Vim插件
|
||||
================================================================================
|
||||
|
||||
|
||||
|
||||
Vim是Linux上一个轻量级的通用文本编辑器。虽然它开始时的学习曲线对于一般的Linux用户来说可能很困难,但比起它的好处,这些付出完全是值得的。随着功能的增长,在插件工具的应用下,Vim是完全可定制的。但是,由于它高级的功能配置,你需要花一些时间去了解它的插件系统,然后才能够有效地去个性化定置Vim。幸运的是,我们已经有一些工具能够使我们在使用Vim插件时更加轻松。而我日常所使用的就是Vundle.
|
||||
### 什么是Vundle ###
|
||||
|
||||
[Vundle][1]是一个vim插件管理器,用于支持Vim包。Vundle能让你很简单地实现插件的安装,升级,搜索或者清除。它还能管理你的运行环境并且在标签方面提供帮助。
|
||||
### 安装Vundle ###
|
||||
|
||||
首先,如果你的Linux系统上没有Git的话,先[安装Git][2].
|
||||
|
||||
接着,创建一个目录,Vim的插件将会被下载并且安装在这个目录上。默认情况下,这个目录为~/.vim/bundle。
|
||||
|
||||
$ mkdir -p ~/.vim/bundle
|
||||
|
||||
现在,安装Vundle如下。注意Vundle本身也是一个vim插件。因此我们同样把vundle安装到之前创建的目录~/.vim/bundle下。
|
||||
|
||||
$ git clone https://github.com/gmarik/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
|
||||
### 配置Vundle ###
|
||||
|
||||
现在配置你的.vimrc文件如下:
|
||||
|
||||
set nocompatible " This is required
|
||||
" 这是被要求的。(译注:中文注释为译者所加,下同。)
|
||||
filetype off " This is required
|
||||
" 这是被要求的。
|
||||
|
||||
" Here you set up the runtime path
|
||||
" 在这里设置你的运行时环境的路径。
|
||||
set rtp+=~/.vim/bundle/Vundle.vim
|
||||
|
||||
" Initialize vundle
|
||||
" 初始化vundle
|
||||
call vundle#begin()
|
||||
|
||||
" This should always be the first
|
||||
" 这一行应该永远放在前面。
|
||||
Plugin 'gmarik/Vundle.vim'
|
||||
|
||||
" This examples are from https://github.com/gmarik/Vundle.vim README
|
||||
" 这个示范来自https://github.com/gmarik/Vundle.vim README
|
||||
Plugin 'tpope/vim-fugitive'
|
||||
|
||||
" Plugin from http://vim-scripts.org/vim/scripts.html
|
||||
" 取自http://vim-scripts.org/vim/scripts.html的插件
|
||||
Plugin 'L9'
|
||||
|
||||
" Git plugin not hosted on GitHub
|
||||
" Git插件,但并不在GitHub上。
|
||||
Plugin 'git://git.wincent.com/command-t.git'
|
||||
|
||||
"git repos on your local machine (i.e. when working on your own plugin)
|
||||
"本地计算机上的Git仓库路径 (例如,当你在开发你自己的插件时)
|
||||
Plugin 'file:///home/gmarik/path/to/plugin'
|
||||
|
||||
" The sparkup vim script is in a subdirectory of this repo called vim.
|
||||
" Pass the path to set the runtimepath properly.
|
||||
" vim脚本sparkup存放在这个名叫vim的仓库下的一个子目录中。
|
||||
" 提交这个路径来正确地设置运行时路径
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
|
||||
|
||||
" Avoid a name conflict with L9
|
||||
" 避免与L9发生名字上的冲突
|
||||
Plugin 'user/L9', {'name': 'newL9'}
|
||||
|
||||
"Every Plugin should be before this line
|
||||
"所有的插件都应该在这一行之前。
|
||||
call vundle#end() " required 被要求的
|
||||
|
||||
容我简单解释一下上面的设置:默认情况下,Vundle将从github.com或者vim-scripts.org下载和安装vim插件。你也可以改变这个默认行为。
|
||||
|
||||
要从github安装(安装插件,译者注,下同):
|
||||
Plugin 'user/plugin'
|
||||
|
||||
要从http://vim-scripts.org/vim/scripts.html处安装:
|
||||
Plugin 'plugin_name'
|
||||
|
||||
要从另外一个git仓库中安装:
|
||||
|
||||
Plugin 'git://git.another_repo.com/plugin'
|
||||
|
||||
从本地文件中安装:
|
||||
|
||||
Plugin 'file:///home/user/path/to/plugin'
|
||||
|
||||
|
||||
你同样可以定制其它东西,例如你的插件运行时路径,当你自己在编写一个插件时,或者你只是想从其它目录——而不是~/.vim——中加载插件时,这样做就非常有用。
|
||||
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'another_vim_path/'}
|
||||
|
||||
如果你有同名的插件,你可以重命名你的插件,这样它们就不会发生冲突了。
|
||||
|
||||
Plugin 'user/plugin', {'name': 'newPlugin'}
|
||||
|
||||
### 使用Vum命令 ###
|
||||
一旦你用vundle设置好你的插件,你就可以通过几个vundle命令来安装,升级,搜索插件,或者清除没有用的插件。
|
||||
|
||||
#### 安装一个新的插件 ####
|
||||
|
||||
所有列在你的.vimrc文件中的插件,都会被PluginInstall命令安装。你也可以通递一个插件名给它,来安装某个的特定插件。
|
||||
:PluginInstall
|
||||
:PluginInstall <插件名>
|
||||
|
||||

|
||||
|
||||
#### 清除没有用的插件 ####
|
||||
|
||||
如果你有任何没有用到的插件,你可以通过PluginClean命令来删除它.
|
||||
:PluginClean
|
||||
|
||||

|
||||
|
||||
#### 查找一个插件 ####
|
||||
|
||||
如果你想从提供的插件清单中安装一个插件,搜索功能会很有用
|
||||
:PluginSearch <文本>
|
||||
|
||||

|
||||
|
||||
|
||||
在搜索的时候,你可以在交互式分割窗口中安装,清除,重新搜索或者重新加载插件清单.安装后的插件不会自动加载生效,要使其加载生效,可以将它们添加进你的.vimrc文件中.
|
||||
### 总结 ###
|
||||
|
||||
Vim是一个妙不可言的工具.它不单单是一个能够使你的工作更加顺畅高效的默认文本编辑器,同时它还能够摇身一变,成为现存的几乎任何一门编程语言的IDE.
|
||||
|
||||
注意,有一些网站能帮你找到适合的vim插件.猛击[http://www.vim-scripts.org][3], Github或者 [http://www.vimawesome.com][4] 获取新的脚本或插件.同时记得为你的插件使用帮助供应程序.
|
||||
|
||||
和你最爱的编辑器一起嗨起来吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/manage-vim-plugins.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[XLCYun(袖里藏云)](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:https://github.com/VundleVim/Vundle.vim
|
||||
[2]:http://ask.xmodulo.com/install-git-linux.html
|
||||
[3]:http://www.vim-scripts.org/
|
||||
[4]:http://www.vimawesome.com/
|
||||
|
||||
@ -1,24 +1,23 @@
|
||||
How to Configure Chef (server/client) on Ubuntu 14.04 / 15.04
|
||||
如何在Ubuntu 14.04/15.04上配置Chef(服务端/客户端)
|
||||
================================================================================
|
||||
Chef is a configuration management and automation tool for information technology professionals that configures and manages your infrastructure whether it is on-premises or in the cloud. It can be used to speed up application deployment and to coordinate the work of multiple system administrators and developers involving hundreds, or even thousands, of servers and applications to support a large customer base. The key to Chef’s power is that it turns infrastructure into code. Once you master Chef, you will be able to enable web IT with first class support for managing your cloud infrastructure with an easy automation of your internal deployments or end users systems.
|
||||
Chef是对于信息技术专业人员的一款配置管理和自动化工具,它可以配置和管理你的设备无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,涉及到成百甚至上千的服务器和程序来支持大量的客户群。chef最有用的是让设备变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端设备或者终端用户。
|
||||
|
||||
Here are the major components of Chef that we are going to setup and configure in this tutorial.
|
||||
chef components
|
||||
下面是我们将要在本篇中要设置和配置Chef的主要组件。
|
||||
|
||||

|
||||
|
||||
### Chef Prerequisites and Versions ###
|
||||
### 安装Chef的要求和版本 ###
|
||||
|
||||
We are going to setup Chef configuration management system under the following basic environment.
|
||||
我们将在下面的基础环境下设置Chef配置管理系统。
|
||||
|
||||
注:表格
|
||||
<table width="701" style="height: 284px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="660" colspan="2"><strong>Chef, Configuration Management Tool</strong></td>
|
||||
<td width="660" colspan="2"><strong>管理和配置工具:Chef</strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Base Operating System</strong></td>
|
||||
<td width="220"><strong>基础操作系统</strong></td>
|
||||
<td width="492">Ubuntu 14.04.1 LTS (x86_64)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
@ -34,135 +33,138 @@ We are going to setup Chef configuration management system under the following b
|
||||
<td width="492">Version 0.6.2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>RAM and CPU</strong></td>
|
||||
<td width="220"><strong>内存和CPU</strong></td>
|
||||
<td width="492">4 GB , 2.0+2.0 GHZ</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Chef Server's Installation and Configurations ###
|
||||
### Chef服务端的安装和配置 ###
|
||||
|
||||
Chef Server is central core component that stores recipes as well as other configuration data and interact with the workstations and nodes. let's download the installation media by selecting the latest version of chef server from its official web link.
|
||||
Chef服务端是核心组件,它存储配置以及其他和工作站交互的配置数据。让我们在他们的官网下载最新的安装文件。
|
||||
|
||||
We will get its installation package and install it by using following commands.
|
||||
我使用下面的命令来下载和安装它。
|
||||
|
||||
**1) Downloading Chef Server**
|
||||
**1) 下载Chef服务端**
|
||||
|
||||
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**2) To install Chef Server**
|
||||
**2) 安装Chef服务端**
|
||||
|
||||
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**3) Reconfigure Chef Server**
|
||||
**3) 重新配置Chef服务端**
|
||||
|
||||
Now Run the following command to start all of the chef server services ,this step may take a few minutes to complete as its composed of many different services that work together to create a functioning system.
|
||||
现在运行下面的命令来启动所有的chef服务端服务,这步也许会花费一些时间,因为它有许多不同一起工作的服务组成来创建一个正常运作的系统。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl reconfigure
|
||||
|
||||
The chef server startup command 'chef-server-ctl reconfigure' needs to be run twice so that installation ends with the following completion output.
|
||||
chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这样就会在安装后看到这样的输出。
|
||||
|
||||
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
|
||||
opscode Reconfigured!
|
||||
|
||||
**4) Reboot OS**
|
||||
**4) 重启系统 **
|
||||
|
||||
Once the installation complete reboot the operating system for the best working without doing this we you might get the following SSL_connect error during creation of User.
|
||||
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
|
||||
|
||||
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
|
||||
|
||||
**5) Create new Admin User**
|
||||
**5) 创建心的管理员**
|
||||
|
||||
Run the following command to create a new administrator user with its profile settings. During its creation user’s RSA private key is generated automatically that should be saved to a safe location. The --filename option will save the RSA private key to a specified path.
|
||||
运行下面的命令来创建一个新的用它自己的配置的管理员账户。创建过程中,用户的RSA私钥会自动生成并需要被保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi kashif.fareedi@gmail.com kashi123 --filename /root/kashi.pem
|
||||
|
||||
### Chef Manage Setup on Chef Server ###
|
||||
### Chef服务端的管理设置 ###
|
||||
|
||||
Chef Manage is a management console for Enterprise Chef that enables a web-based user interface for visualizing and managing nodes, data bags, roles, environments, cookbooks and role-based access control (RBAC).
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可视化的web用户界面并可以管理节点、数据包、规则、环境、配置和基于角色的访问控制(RBAC)
|
||||
|
||||
**1) Downloading Chef Manage**
|
||||
**1) 下载Chef Manage**
|
||||
|
||||
Copy the link for Chef Manage from the official web site and download the chef manage package.
|
||||
从官网复制链接病下载chef manage的安装包。
|
||||
|
||||
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
|
||||
|
||||
**2) Installing Chef Manage**
|
||||
**2) 安装Chef Manage**
|
||||
|
||||
Let's install it into the root's home directory with below command.
|
||||
使用下面的命令在root的家目录下安装它。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
|
||||
|
||||
**3) Restart Chef Manage and Server**
|
||||
**3) 重启Chef Manage和服务端**
|
||||
|
||||
Once the installation is complete we need to restart chef manage and chef server services by executing following commands.
|
||||
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
|
||||
|
||||
root@ubuntu-14-chef:~# opscode-manage-ctl reconfigure
|
||||
root@ubuntu-14-chef:~# chef-server-ctl reconfigure
|
||||
|
||||
### Chef Manage Web Console ###
|
||||
### Chef Manage网页控制台 ###
|
||||
|
||||
We can access chef manage web console from the localhost as wel as its fqdn and login with the already created admin user account.
|
||||
我们可以使用localhost访问网页控制台以及fqdn,并用已经创建的管理员登录
|
||||
|
||||

|
||||
|
||||
**1) Create New Organization with Chef Manage**
|
||||
**1) Chef Manage创建新的组织 **
|
||||
|
||||
You would be asked to create new organization or accept the invitation from the organizations. Let's create a new organization by providing its short and full name as shown.
|
||||
你或许被要求创建新的组织或者接受其他阻止的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
|
||||

|
||||
|
||||
**2) Create New Organization with Command line**
|
||||
**2) 用命令行创建心的组织 **
|
||||
|
||||
We can also create new Organization from the command line by executing the following command.
|
||||
我们同样也可以运行下面的命令来创建新的组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
|
||||
|
||||
### Configuration and setup of Workstation ###
|
||||
### 设置工作站 ###
|
||||
|
||||
As we had done with successful installation of chef server now we are going to setup its workstation to create and configure any recipes, cookbooks, attributes, and other changes that we want to made to our Chef configurations.
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes、cookbooks、属性和其他任何的我们想要对Chef的修改。
|
||||
|
||||
**1) Create New User and Organization on Chef Server**
|
||||
**1) 在Chef服务端上创建新的用户和组织 **
|
||||
|
||||
In order to setup workstation we create a new user and an organization for this from the command line.
|
||||
为了设置工作站,我们用命令行创建一个新的用户和组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl user-create bloger Bloger Kashif bloger.kashif@gmail.com bloger123 --filename bloger.pem
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
|
||||
|
||||
**2) Download Starter Kit for Workstation**
|
||||
**2) 下载工作站入门套件 **
|
||||
|
||||
Now Download and Save starter-kit from the chef manage web console on a workstation and use it to work with Chef server.
|
||||
在工作站的网页控制台中下面并保存入门套件用于与服务端协同工作
|
||||
|
||||

|
||||
|
||||
**3) Click to "Proceed" with starter kit download**
|
||||
**3) 点击"Proceed"下载套件 **
|
||||
|
||||

|
||||
|
||||
### Chef Development Kit Setup for Workstation ###
|
||||
### 对于工作站的Chef开发套件设置 ###
|
||||
|
||||
Chef Development Kit is a software package suite with all the development tools need to code Chef. It combines with the best of the breed tools developed by Chef community with Chef Client.
|
||||
Chef开发套件是一款包含所有开发chef所需工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
|
||||
**1) Downloading Chef DK**
|
||||
**1) 下载 Chef DK**
|
||||
|
||||
We can Download chef development kit from its official web link and choose the required operating system to get its chef development tool kit.
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来得到chef开发包。
|
||||
|
||||

|
||||
|
||||
Copy the link and download it with wget command.
|
||||
复制链接并用wget下载
|
||||
|
||||
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**1) Chef Development Kit Installatoion**
|
||||
**1) Chef开发套件安装**
|
||||
|
||||
Install chef-development kit using dpkg command
|
||||
使用dpkg命令安装开发套件
|
||||
|
||||
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**3) Chef DK Verfication**
|
||||
**3) Chef DK 验证**
|
||||
|
||||
Verify using the below command that the client got installed properly.
|
||||
使用下面的命令验证客户端是否已经正确安装。
|
||||
|
||||
root@ubuntu-15-WKS:~# chef verify
|
||||
|
||||
@ -193,9 +195,9 @@ Verify using the below command that the client got installed properly.
|
||||
Verification of component 'chefspec' succeeded.
|
||||
Verification of component 'package installation' succeeded.
|
||||
|
||||
**Connecting to Chef Server**
|
||||
**连接Chef服务端**
|
||||
|
||||
We will Create ~/.chef and copy the two user and organization pem files to this folder from chef server.
|
||||
我们将创建 ~/.chef并从chef服务端复制两个用户和组织的pem文件到chef的文件到这个目录下。
|
||||
|
||||
root@ubuntu-14-chef:~# scp bloger.pem blogs.pem kashi.pem linux.pem root@172.25.10.172:/.chef/
|
||||
|
||||
@ -207,9 +209,9 @@ We will Create ~/.chef and copy the two user and organization pem files to this
|
||||
kashi.pem 100% 1678 1.6KB/s 00:00
|
||||
linux.pem 100% 1678 1.6KB/s 00:00
|
||||
|
||||
**Knife Configurations to Manage your Chef Environment**
|
||||
** 编辑配置来管理chef环境 **
|
||||
|
||||
Now create "~/.chef/knife.rb" with following content as configured in previous steps.
|
||||
现在使用下面的内容创建"~/.chef/knife.rb"。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# vim knife.rb
|
||||
current_dir = File.dirname(__FILE__)
|
||||
@ -225,17 +227,17 @@ Now create "~/.chef/knife.rb" with following content as configured in previous s
|
||||
cache_options( :path => "#{ENV['HOME']}/.chef/checksums" )
|
||||
cookbook_path ["#{current_dir}/../cookbooks"]
|
||||
|
||||
Create "~/cookbooks" folder for cookbooks as specified knife.rb file.
|
||||
创建knife.rb中指定的“~/cookbooks”文件夹。
|
||||
|
||||
root@ubuntu-15-WKS:/# mkdir cookbooks
|
||||
|
||||
**Testing with Knife Configurations**
|
||||
**测试Knife配置**
|
||||
|
||||
Run "knife user list" and "knife client list" commands to verify whether knife configuration is working.
|
||||
运行“knife user list”和“knife client list”来验证knife是否在工作。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife user list
|
||||
|
||||
You might get the following error while first time you run this command.This occurs because we do not have our Chef server's SSL certificate on our workstation.
|
||||
第一次运行的时候可能会得到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
|
||||
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
|
||||
ERROR: Could not establish a secure connection to the server.
|
||||
@ -243,27 +245,26 @@ You might get the following error while first time you run this command.This occ
|
||||
If your Chef Server uses a self-signed certificate, you can use
|
||||
`knife ssl fetch` to make knife trust the server's certificates.
|
||||
|
||||
To recover from the above error run the following command to fetch ssl certs and once again run the knife user and client list command and it should be fine then.
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl整数并重新运行knife user和client list,这时候应该就可以了。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife ssl fetch
|
||||
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
|
||||
directory (/.chef/trusted_certs).
|
||||
|
||||
Knife has no means to verify these are the correct certificates. You should
|
||||
verify the authenticity of these certificates after downloading.
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
|
||||
Adding certificate for ubuntu-14-chef.test.com in /.chef/trusted_certs/ubuntu-14-chef_test_com.crt
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
|
||||
Now after fetching ssl certs with above command, let's again run the below command.
|
||||
在上面的命令取得ssl证书后,接着运行下面的命令。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef#knife client list
|
||||
kashi-linux
|
||||
|
||||
### New Node Configuration to interact with chef-server ###
|
||||
### 与chef服务端交互的新的节点 ###
|
||||
|
||||
Nodes contain chef-client which performs all the infrastructure automation. So, Its time to begin with adding new servers to our chef environment by Configuring a new node to interact with chef-server after we had Configured chef-server and knife workstation combinations.
|
||||
节点是执行所有设备自动化的chef客户端。因此是时侯添加新的服务端到我们的chef环境下,在配置完chef-server和knife工作站后配置新的节点与chef-server交互。
|
||||
|
||||
To configure a new node to work with chef server use below command.
|
||||
我们使用下面的命令来添加新的节点与chef服务端工作。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife bootstrap 172.25.10.170 --ssh-user root --ssh-password kashi123 --node-name mydns
|
||||
|
||||
@ -290,25 +291,25 @@ To configure a new node to work with chef server use below command.
|
||||
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
|
||||
172.25.10.170 trying wget...
|
||||
|
||||
After all we can see the vewly created node under the knife node list and new client list as it it will also creates a new client with the node.
|
||||
之后我们可以在knife节点列表下看到新创建的节点,也会新节点列表下创建新的客户端。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife node list
|
||||
mydns
|
||||
|
||||
Similarly we can add multiple number of nodes to our chef infrastructure by providing ssh credentials with the same above knofe bootstrap command.
|
||||
相似地我们只要提供ssh证书通过上面的knife命令来创建多个节点到chef设备上。
|
||||
|
||||
### Conclusion ###
|
||||
### 总结 ###
|
||||
|
||||
In this detailed article we learnt about the Chef Configuration Management tool with its basic understanding and overview of its components with installation and configuration settings. We hope you have enjoyed learning the installation and configuration of Chef server with its workstation and client nodes.
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置浏览了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,237 @@
|
||||
|
||||
如何收集NGINX指标 - 第2部分
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的NGINX指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本。(参见 [the companion article][1] 将深入探索NGINX指标。)免费,开源版的 NGINX 和商业版的 NGINX 都有指标度量的状态模块,NGINX 也可以在其日志中配置指标模块:
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th rowspan="2" style="text-align: left;">Metric</th>
|
||||
<th colspan="3" style="text-align: center;">Availability</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source">NGINX (open-source)</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus">NGINX Plus</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs">NGINX logs</a></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts / accepted</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests / total</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会显示几个与服务器状态有关的指标在状态页面上,只要你启用了 HTTP [stub status module][2] 。要检查模块是否被加载,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到 http_stub_status_module 被输出在终端,说明状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用状态模块。你可以使用 --with-http_stub_status_module 参数去配置 [building NGINX from source][3]:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
验证模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件为状态页面设置本地访问的 URL(例如,/ nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不在主配置文件中(例如,/etc/nginx/nginx.conf),但主配置中会加载补充的配置文件。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开主配置文件,在以 http 模块结尾的附近查找以 include 开头的行包,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在所包含的配置文件中,你应该会找到主服务器模块,你可以如上所示修改 NGINX 的指标报告。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以查看指标的状态页:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你正试图从远程计算机访问状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中 127.0.0.1 仅在白名单中。
|
||||
|
||||
nginx 的状态页面是一中查看指标快速又简单的方法,但当连续监测时,你需要每隔一段时间自动记录该数据。然后通过监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 来分析已保存的 NGINX 状态信息。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过 ngx_http_status_module 提供的可用指标比开源版 NGINX 更多 [many more metrics][7] 。NGINX Plus 附加了更多的字节流指标,以及负载均衡系统和高速缓存的信息。NGINX Plus 还报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个简单的 NGINX Plus 状态报告 [here][8]。
|
||||
|
||||

|
||||
|
||||
*注: NGINX Plus 在状态仪表盘"Active”连接定义的收集指标的状态模块和开源 NGINX 的略有不同。在 NGINX Plus 指标中,活动连接不包括等待状态(又叫空闲连接)连接。*
|
||||
|
||||
NGINX Plus 也集成了其他监控系统的报告 [JSON格式指标][9] 。用 NGINX Plus 时,你可以看到 [负载均衡服务器组的][10]指标和健康状况,或着再向下能取得的仅是响应代码计数[从单个服务器][11]在负载均衡服务器中:
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 ([参见上一页][12]查找相关的配置文件,收集开源 NGINX 版指标的说明。)例如,设立以下一个状态仪表盘在http://your.ip.address:8080/status.html 和一个 JSON 接口 http://your.ip.address:8080/status,可以添加以下 server block 来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
一旦你重新加载 NGINX 配置,状态页就会被加载:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 写到配置可以自定义访问日志到指定文件。你可以自定义日志的格式和时间通过 [添加或移除变量][15]。捕获日志的详细信息,最简单的方法是添加下面一行在你配置文件的server 块中(参见[此节][16] 通过加载配置文件的信息来收集开源 NGINX 的指标):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,必须要重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
“combined” 的日志格式,只包含默认参数,包括[一些关键数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了200(成功)状态码当请求 /index.html 时和404(未找到)错误不存在的请求文件 /fail。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以记录请求处理的时间通过添加一个新的日志格式在 NGINX 配置文件中的 http 块:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
通过修改配置文件中 server 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件(运行 nginx -s reload)后,你的访问日志将包括响应时间,如下图所示。单位为秒,毫秒。在这种情况下,服务器接收 /big.pdf 的请求时,发送33973115字节后返回206(成功)状态码。处理请求用时0.202秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来收集和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用免费的开源工具,如[logstash][19]来收集和分析日志;或者你可以使用一个统一日志记录层,如[Fluentd][20]来收集和分析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你提供的工具,以及是否由给定指标证明监控指标的开销。例如,通过收集和分析日志来定位问题是非常重要的在 NGINX Plus 或者 运行的系统中。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。了解如何用 NGINX Datadog来监控 [在本文中][21],并开始使用 [免费的Datadog][22]。
|
||||
|
||||
----------
|
||||
|
||||
原文在这 [on GitHub][23]。问题,更正,补充等?请[让我们知道][24]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -0,0 +1,187 @@
|
||||
如何在 Fedora 22 上配置 Proftpd 服务器
|
||||
================================================================================
|
||||
在本文中,我们将了解如何在运行 Fedora 22 的电脑或服务器上使用 Proftpd 架设 FTP 服务器。[ProFTPD][1] 是一款免费的基于 GPL 授权开源的 FTP 服务器软件,是 Linux 上的主流 FTP 服务器。它的主要设计目标是具备许多高级功能以及能为用户提供丰富的配置选项可以轻松实现定制。它的许多配置选项在其他一些 FTP 服务器软件里仍然没有集成。最初它是被开发作为 wu-ftpd 服务器的一个更安全更容易配置的替代。FTP 服务器是这样一个软件,用户可以通过 FTP 客户端从安装了它的远端服务器上传或下载文件和目录。下面是一些 ProFTPD 服务器的主要功能,更详细的资料可以访问 [http://www.proftpd.org/features.html][2]。
|
||||
|
||||
- 每个目录都包含 ".ftpaccess" 文件用于访问控制,类似 Apache 的 ".htaccess"
|
||||
- 支持多个虚拟 FTP 服务器以及多用户登录和匿名 FTP 服务。
|
||||
- 可以作为独立进程启动服务或者通过 inetd/xinetd 启动
|
||||
- 它的文件/目录属性、属主和权限采用类 UNIX 方式。
|
||||
- 它可以独立运行,保护系统避免 root 访问可能带来的损坏。
|
||||
- 模块化的设计让它可以轻松扩展其他模块,比如 LDAP 服务器,SSL/TLS 加密,RADIUS 支持,等等。
|
||||
- ProFTPD 服务器还支持 IPv6.
|
||||
|
||||
下面是如何在运行 Fedora 22 操作系统的计算机上使用 ProFTPD 架设 FTP 服务器的一些简单步骤。
|
||||
|
||||
### 1. 安装 ProFTPD ###
|
||||
|
||||
首先,我们将在运行 Fedora 22 的机器上安装 Proftpd 软件。因为 yum 包管理器已经被抛弃了,我们将使用最新最好的包管理器 dnf。DNF 很容易使用,是 Fedora 22 上采用的非常人性化的包管理器。我们将用它来安装 proftpd 软件。这需要在终端或控制台里用 sudo 模式运行下面的命令。
|
||||
|
||||
$ sudo dnf -y install proftpd proftpd-utils
|
||||
|
||||
### 2. 配置 ProFTPD ###
|
||||
|
||||
现在,我们将修改软件的一些配置。要配置它,我们需要用文本编辑器编辑 /etc/proftpd.conf 文件。**/etc/proftpd.conf** 文件是 ProFTPD 软件的主要配置文件,所以,这个文件的任何改动都会影响到 FTP 服务器。在这里,是我们在初始步骤里做出的改动。
|
||||
|
||||
$ sudo vi /etc/proftpd.conf
|
||||
|
||||
之后,在用文本编辑器打开这个文件后,我们会想改下 ServerName 以及 ServerAdmin,分别填入自己的域名和 email 地址。下面是我们改的。
|
||||
|
||||
ServerName "ftp.linoxide.com"
|
||||
ServerAdmin arun@linoxide.com
|
||||
|
||||
在这之后,我们将把下面的设定加到配置文件里,这样可以让服务器将访问和授权记录到相应的日志文件里。
|
||||
|
||||
ExtendedLog /var/log/proftpd/access.log WRITE,READ default
|
||||
ExtendedLog /var/log/proftpd/auth.log AUTH auth
|
||||
|
||||

|
||||
|
||||
### 3. 添加 FTP 用户 ###
|
||||
|
||||
在设定好了基本的配置文件后,我们很自然地希望为指定目录添加 FTP 用户。目前用来登录的用户是 FTP 服务自动生成的,可以用来登录到 FTP 服务器。但是,在这篇教程里,我们将创建一个以 ftp 服务器上指定目录为主目录的新用户。
|
||||
|
||||
下面,我们将建立一个名字是 ftpgroup 的新用户组。
|
||||
|
||||
$ sudo groupadd ftpgroup
|
||||
|
||||
然后,我们将以目录 /ftp-dir/ 作为主目录增加一个新用户 arunftp 并加入这个组中。
|
||||
|
||||
$ sudo useradd -G ftpgroup arunftp -s /sbin/nologin -d /ftp-dir/
|
||||
|
||||
在创建好用户并加入用户组后,我们将为用户 arunftp 设置一个密码。
|
||||
|
||||
$ sudo passwd arunftp
|
||||
|
||||
Changing password for user arunftp.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
|
||||
现在,我们将通过下面命令为这个 ftp 用户设定主目录的读写权限。
|
||||
|
||||
$ sudo setsebool -P allow_ftpd_full_access=1
|
||||
$ sudo setsebool -P ftp_home_dir=1
|
||||
|
||||
然后,我们会设定不允许其他用户移动或重命名这个目录以及里面的内容。
|
||||
|
||||
$ sudo chmod -R 1777 /ftp-dir/
|
||||
|
||||
### 4. 打开 TLS 支持 ###
|
||||
|
||||
目前 FTP 所用的加密手段并不安全,任何人都可以通过监听网卡来读取 FTP 传输的数据。所以,我们将为自己的服务器打开 TLS 加密支持。这样的话,需要编辑 /etc/proftpd.conf 配置文件。在这之前,我们先备份一下当前的配置文件,可以保证在改出问题后还可以恢复。
|
||||
|
||||
$ sudo cp /etc/proftpd.conf /etc/proftpd.conf.bak
|
||||
|
||||
然后,我们可以用自己喜欢的文本编辑器修改配置文件。
|
||||
|
||||
$ sudo vi /etc/proftpd.conf
|
||||
|
||||
然后,把下面几行附加到我们在第 2 步中所增加内容的后面。
|
||||
|
||||
TLSEngine on
|
||||
TLSRequired on
|
||||
TLSProtocol SSLv23
|
||||
TLSLog /var/log/proftpd/tls.log
|
||||
TLSRSACertificateFile /etc/pki/tls/certs/proftpd.pem
|
||||
TLSRSACertificateKeyFile /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||

|
||||
|
||||
完成上面的设定后,保存退出。
|
||||
|
||||
然后,我们需要生成 SSL 凭证 proftpd.pem 并放到 **/etc/pki/tls/certs/** 目录里。这样的话,首先需要在 Fedora 22 上安装 openssl。
|
||||
|
||||
$ sudo dnf install openssl
|
||||
|
||||
然后,可以通过执行下面的命令生成 SSL 凭证。
|
||||
|
||||
$ sudo openssl req -x509 -nodes -newkey rsa:2048 -keyout /etc/pki/tls/certs/proftpd.pem -out /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||
系统会询问一些将写入凭证里的基本信息。在填完资料后,就会生成一个 2048 位的 RSA 私钥。
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
...................+++
|
||||
...................+++
|
||||
writing new private key to '/etc/pki/tls/certs/proftpd.pem'
|
||||
-----
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [XX]:NP
|
||||
State or Province Name (full name) []:Narayani
|
||||
Locality Name (eg, city) [Default City]:Bharatpur
|
||||
Organization Name (eg, company) [Default Company Ltd]:Linoxide
|
||||
Organizational Unit Name (eg, section) []:Linux Freedom
|
||||
Common Name (eg, your name or your server's hostname) []:ftp.linoxide.com
|
||||
Email Address []:arun@linoxide.com
|
||||
|
||||
在这之后,我们要改变所生成凭证文件的权限以增加安全性。
|
||||
|
||||
$ sudo chmod 600 /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||
### 5. 允许 FTP 通过 Firewall ###
|
||||
|
||||
现在,需要允许 ftp 端口,一般默认被防火墙阻止了。就是说,需要允许 ftp 端口能通过防火墙访问。
|
||||
|
||||
如果 **打开了 TLS/SSL 加密**,执行下面的命令。
|
||||
|
||||
$sudo firewall-cmd --add-port=1024-65534/tcp
|
||||
$ sudo firewall-cmd --add-port=1024-65534/tcp --permanent
|
||||
|
||||
如果 **没有打开 TLS/SSL 加密**,执行下面的命令。
|
||||
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=ftp
|
||||
|
||||
success
|
||||
|
||||
然后,重新加载防火墙设定。
|
||||
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 6. 启动并激活 ProFTPD ###
|
||||
|
||||
全部设定好后,最后就是启动 ProFTPD 并试一下。可以运行下面的命令来启动 proftpd ftp 守护程序。
|
||||
|
||||
$ sudo systemctl start proftpd.service
|
||||
|
||||
然后,我们可以设定开机启动。
|
||||
|
||||
$ sudo systemctl enable proftpd.service
|
||||
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/proftpd.service to /usr/lib/systemd/system/proftpd.service.
|
||||
|
||||
### 7. 登录到 FTP 服务器 ###
|
||||
|
||||
现在,如果都是按照本教程设置好的,我们一定可以连接到 ftp 服务器并使用以上设置的信息登录上去。在这里,我们将配置一下 FTP 客户端 filezilla,使用 **服务器的 IP 或 URL **作为主机名,协议选择 **FTP**,用户名填入 **arunftp**,密码是在上面第 3 步中设定的密码。如果你按照第 4 步中的方式打开了 TLS 支持,还需要在加密类型中选择 **显式要求基于 TLS 的 FTP**,如果没有打开,也不想使用 TLS 加密,那么加密类型选择 **简单 FTP**。
|
||||
|
||||

|
||||
|
||||
要做上述设定,需要打开菜单里的文件,点击站点管理器,然后点击新建站点,再按上面的方式设置。
|
||||
|
||||

|
||||
|
||||
随后系统会要求允许 SSL 凭证,点确定。之后,就可以从我们的 FTP 服务器上传下载文件和文件夹了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们成功地在 Fedora 22 机器上安装并配置好了 Proftpd FTP 服务器。Proftpd 是一个超级强大,能高度配置和扩展的 FTP 守护软件。上面的教程展示了如何配置一个采用 TLS 加密的安全 FTP 服务器。强烈建议设置 FTP 服务器支持 TLS 加密,因为它允许使用 SSL 凭证加密数据传输和登录。本文中,我们也没有配置 FTP 的匿名访问,因为一般受保护的 FTP 系统不建议这样做。 FTP 访问让人们的上传和下载变得非常简单也更高效。我们还可以改变用户端口增加安全性。好吧,如果你有任何疑问,建议,反馈,请在下面评论区留言,这样我们就能够改善并更新文章内容。谢谢!玩的开心 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-ftp-proftpd-fedora-22/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.proftpd.org/
|
||||
[2]:http://www.proftpd.org/features.html
|
||||
@ -0,0 +1,59 @@
|
||||
Ubuntu 14.04中修复“update information is outdated”错误
|
||||
================================================================================
|
||||

|
||||
|
||||
看到Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
|
||||
> 更新信息过时。该错误可能是由网络问题,或者某个仓库不再可用而造成的。请通过从指示器菜单中选择‘显示更新’来手动更新,然后查看是否存在有失败的仓库。
|
||||
>
|
||||
|
||||
它看起来像这样:
|
||||
|
||||

|
||||
|
||||
这里的粉红色感叹号标记就是原来的红色三角形,因为我使用了[最佳的Ubuntu图标主题][1]之一,Numix。让我们回到该错误中,这是一个常见的更新问题,你也许时不时地会碰到它。现在,你或许想知道的是,到底是什么导致了这个更新错误的出现。
|
||||
|
||||
### 引起‘update information is outdated’错误的原因 ###
|
||||
|
||||
导致该错误的原因在其自身的错误描述中就讲得相当明白,它告诉你“这可能是由网络问题或者某个不再可用的仓库导致的”。所以,要么是你更新了系统和某些仓库,要么是PPA不再受到支持了,或者你正面对的类似问题。
|
||||
|
||||
虽然错误本身就讲得很明白,而它给出了的议操作“请通过从指示器菜单选择‘显示更新’来手动更新以查看失败的仓库”却并不能很好地解决问题。如果你点击显示更新,你所能看见的仅仅是系统已经更新。
|
||||
|
||||

|
||||
|
||||
很奇怪,不是吗?我们怎样才能找出是什么出错了,哪里出错了,以及为什么出错呢?
|
||||
|
||||
### 修复‘update information is outdated’错误 ###
|
||||
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04或14.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
等待命令结束,然后查看其结果。这里插个快速提示,你可以[在终端中添加通知][2],这样当一个耗时很长的命令结束执行时就会通知你。在该命令的最后几行中,可以看到你的系统正面临什么样的错误。是的,你肯定会看到一个错误。
|
||||
|
||||
在我这里,我看到了有名的[GPG error: The following could not be verified][3]错误。很明显,[在Ubuntu 15.04中安装声破天][4]有点问题。
|
||||
|
||||

|
||||
|
||||
很可能你看到的不是像我一样的GPG错误,那样的话,我建议你读一读我写的这篇文章[修复Ubuntu中的各种常见更新错误][5]。
|
||||
|
||||
我知道有不少人,尤其是初学者,很是讨厌命令行,但是如果你正在使用Linux,你就无可避免会使用到终端。此外,那东西并没你想象的那么可怕。试试吧,你会很快上手的。
|
||||
|
||||
我希望这个快速提示对于你修复Ubuntu中的“update information is outdated”错误有帮助。如果你有任何问题或建议,请不吝提出,我们将无任欢迎。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
[2]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
[3]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
|
||||
[4]:http://itsfoss.com/install-spotify-ubuntu-1504/
|
||||
[5]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
@ -0,0 +1,112 @@
|
||||
如何在 Ubuntu 中管理开机启动应用
|
||||
================================================================================
|
||||

|
||||
|
||||
你曾经考虑过 **在 Ubuntu 中管理开机启动应用** 吗?如果在开机时,你的 Ubuntu 系统启动得非常缓慢,那么你就需要考虑这个问题了。
|
||||
|
||||
每当你开机进入一个操作系统,一系列的应用将会自动启动。这些应用被称为‘开机启动应用’ 或‘开机启动程序’。随着时间的推移,当你在系统中安装了足够多的应用时,你将发现有太多的‘开机启动应用’在开机时自动地启动了,它们吃掉了很多的系统资源,并将你的系统拖慢。这可能会让你感觉卡顿,我想这种情况并不是你想要的。
|
||||
|
||||
让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你发现这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。
|
||||
|
||||
在这篇文章中,我们将看到 **在 Ubuntu 中,如何控制开机启动应用,如何让一个应用在开机时启动以及如何发现隐藏的开机启动应用。**这里提供的指导对所有的 Ubuntu 版本均适用,例如 Ubuntu 12.04, Ubuntu 14.04 和 Ubuntu 15.04。
|
||||
|
||||
### 在 Ubuntu 中管理开机启动应用 ###
|
||||
|
||||
默认情况下, Ubuntu 提供了一个`开机启动应用工具`来供你使用,你不必再进行安装。只需到 Unity 面板中就可以查找到该工具。
|
||||
|
||||

|
||||
|
||||
点击它来启动。下面是我的`开机启动应用`的样子:
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 中移除开机启动应用 ###
|
||||
|
||||
现在由你来发现哪个程序对你用处不大,对我来说,是 [Caribou][1] 这个软件,它是一个屏幕键盘程序,在开机时它并没有什么用处,所以我想将它移除出开机启动程序的列表中。
|
||||
|
||||
你可以选择阻止某个程序在开机时启动,而在开机启动程序列表中保留该选项以便以后再进行激活。点击 `关闭`按钮来保留你的偏好设置。
|
||||
|
||||

|
||||
|
||||
要将一个程序从开机启动程序列表中移除,选择对应的选项然后从窗口右边的面板中点击`移除`按钮来保留你的偏好设置。
|
||||
|
||||

|
||||
|
||||
需要提醒的是,这并不会将该程序卸载掉,只是让该程序不再在每次开机时自动启动。你可以对所有你不喜欢的程序做类似的处理。
|
||||
|
||||
### 让开机启动程序延迟启动 ###
|
||||
|
||||
若你并不想在开机启动列表中移除掉程序,但同时又忧虑着系统性能的问题,那么你所需要做的是给程序添加一个延迟启动命令,这样所有的程序就不会在开机时同时启动。
|
||||
|
||||
选择一个程序然后点击 `编辑` 按钮。
|
||||
|
||||

|
||||
|
||||
这将展示出运行这个特定的程序所需的命令。
|
||||
|
||||

|
||||
|
||||
所有你需要做的就是在程序运行命令前添加一句 `sleep XX;` 。这样就为实际运行该命令来启动的对应程序添加了 `XX` 秒的延迟。例如,假如我想让 Variety [壁纸管理应用][2] 延迟启动 2 分钟,我就需要像下面那样在命令前添加 `sleep 120;`
|
||||
|
||||

|
||||
|
||||
保存并关闭设置。你将在下一次启动时看到效果。
|
||||
|
||||
### 增添一个程序到开机启动应用列表中 ###
|
||||
|
||||
这对于新手来说需要一点技巧。我们知道,在 Linux 的底层都是一些命令,在上一节我们看到这些开机启动程序只是在每次开机时运行一些命令。假如你想在开机启动列表中添加一个新的程序,你需要知道运行该应用所需的命令。
|
||||
|
||||
#### 第 1 步:如何查找运行一个程序所需的命令? ####
|
||||
|
||||
首先来到 Unity Dash 面板然后搜索 `Main Menu`:
|
||||
|
||||

|
||||
|
||||
这将展示出在各种类别下你安装的所有程序。在 Ubuntu 的低版本中,你将看到一个相似的菜单,通过它来选择并运行应用。
|
||||
|
||||

|
||||
|
||||
在各种类别下找到你找寻的应用,然后点击 `属性` 按钮来查看运行该应用所需的命令。例如,我想在开机时运行 `Transmission Torrent 客户端`。
|
||||
|
||||

|
||||
|
||||
这就会向我给出运行 `Transmission` 应用的命令:
|
||||
|
||||

|
||||
|
||||
接着,我将用相同的信息来将 `Transmission` 应用添加到开机启动列表中。
|
||||
|
||||
#### 第 2 步: 添加一个程序到开机启动列表中 ####
|
||||
|
||||
再次来到开机启动应用工具中并点击 `添加` 按钮。这将让你输入一个应用的名称,对应的命令和相关的描述。其中命令最为重要,你可以使用任何你想用的名称和描述。使用上一步得到的命令然后点击 `添加` 按钮。
|
||||
|
||||

|
||||
|
||||
就这样,你将在下一次开机时看到这个程序会自动运行。这就是在 Ubuntu 中你能做的关于开机启动应用的所有事情。
|
||||
|
||||
到现在为止,我们已经讨论在开机时可见的应用,但仍有更多的服务,守护进程和程序并不在`开机启动应用工具`中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。
|
||||
|
||||
### 在 Ubuntu 中查看隐藏的开机启动程序 ###
|
||||
|
||||
要查看在开机时哪些服务在运行,可以打开一个终端并使用下面的命令:
|
||||
|
||||
sudo sed -i 's/NoDisplay=true/NoDisplay=false/g' /etc/xdg/autostart/*.desktop
|
||||
|
||||
上面的命令是一个快速查找和替换命令,它将在所有自动启动的程序里的 `NoDisplay=false` 改为 `NoDisplay=true` ,一旦执行了这个命令后,再次打开`开机启动应用工具`,现在你应该可以看到更多的程序:
|
||||
|
||||

|
||||
|
||||
你可以像先前我们讨论的那样管理这些开机启动应用。我希望这篇教程可以帮助你在 Ubuntu 中控制开机启动程序。任何的问题或建议总是欢迎的。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://wiki.gnome.org/action/show/Projects/Caribou?action=show&redirect=Caribou
|
||||
[2]:http://itsfoss.com/applications-manage-wallpapers-ubuntu/
|
||||
@ -0,0 +1,66 @@
|
||||
如何在 Docker 中通过 Kitematic 交互式执行任务
|
||||
================================================================================
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个 Hello World Nginx Web 服务器。Kitematic 是一个自由开源软件,它有现代化的界面设计使得允许我们在 Docker 中交互式执行任务。Kitematic 设计非常漂亮、界面也很不错。我们可以简单快速地开箱搭建我们的容器而不需要输入命令,我们可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、精简日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署 Hello World Nginx Web 服务器的 3 个简单步骤。
|
||||
|
||||
### 1. 下载 Kitematic ###
|
||||
|
||||
首先,我们需要从 github 仓库 [https://github.com/kitematic/kitematic/releases][1] 中下载 Windows 操作系统可用的最新的 Kitematic 发行版。我们用下载器或者 web 浏览器下载了它的可执行 EXE 文件。下载完成后,我们需要双击可执行应用文件。
|
||||
|
||||

|
||||
|
||||
双击应用文件之后,会问我们一个安全问题,我们只需要点击 OK 按钮,如下图所示。
|
||||
|
||||

|
||||
|
||||
### 2. 安装 Kitematic ###
|
||||
|
||||
下载好可执行安装程序之后,我们现在打算在我们的 Windows 操作系统上安装 Kitematic。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它有助于 Virtual Box 的网络。
|
||||
|
||||

|
||||
|
||||
需要的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
|
||||

|
||||
|
||||
如果你还没有账户,你可以在应用程序上点击注册链接并在 Docker Hub 上创建账户。
|
||||
|
||||
完成之后,就会出现 Kitematic 应用程序的第一个界面。正如下面看到的这样。我们可以搜索可用的 docker 镜像。
|
||||
|
||||

|
||||
|
||||
### 3. 部署 Nginx Hello World 容器 ###
|
||||
|
||||
现在,成功安装完 Kitematic 之后,我们打算部署容器。要运行一个容器,我们只需要在搜索区域中搜索镜像。然后点击 Create 按钮部署容器。在这篇教程中,我们会部署一个小的包含了 Hello World 主页的 Nginx Web 服务器。为此,我们在搜索区域中搜索 Hello World Nginx。看到了容器信息之后,我们点击 Create 来部署容器。
|
||||
|
||||

|
||||
|
||||
镜像下载完成之后,它会自动部署。我们可以查看 Kitematic 部署容器的命令日志。我们也可以在 Kitematic 界面上预览 web 页面。现在,我们通过点击预览在 web 浏览器中查看我们的 Hello World 页面。
|
||||
|
||||

|
||||
|
||||
如果我们想切换到命令行接口并用它管理 docker,这里有个称为 Docker CLI 的按钮,它会打开一个 PowerShell,在里面我们可以执行 docker 命令。
|
||||
|
||||

|
||||
|
||||
现在,如果我们想配置我们的容器并执行类似更改容器名称、设置环境变量、指定端口、配置容器存储以及其它高级功能的任务,我们可以在容器设置页面做到这些。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。总是推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/interactively-docker-kitematic/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://github.com/kitematic/kitematic/releases
|
||||
@ -0,0 +1,92 @@
|
||||
无忧之道:Docker中容器的备份、恢复和迁移
|
||||
================================================================================
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建块无需依赖于特定的堆栈或供应者。
|
||||
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在盒子中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器。
|
||||
|
||||
我们怎样才能在Linux中备份、恢复和迁移Docker容器呢?这里为您提供了一些便捷的步骤。
|
||||
|
||||
### 1. 备份容器 ###
|
||||
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行这Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
在此之后,我们要选择我们想要备份的容器,然后我们会去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
|
||||
# docker commit -p 30b8f18f20b4 container-backup
|
||||
|
||||

|
||||
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 docker images 命令来查看Docker镜像,如下。
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登陆进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tarball备份,以供今后使用。
|
||||
|
||||
如果我们想要在[Docker注册中心][2]上传或备份镜像,我们只需要运行 docker login 命令来登录进Docker注册中心,然后推送所需的镜像即可。
|
||||
|
||||
# docker login
|
||||
|
||||

|
||||
|
||||
# docker tag a25ddfec4d2a arunpyasi/container-backup:test
|
||||
# docker push arunpyasi/container-backup
|
||||
|
||||

|
||||
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tarball备份。要完成该操作,我们需要运行以下 docker save 命令。
|
||||
|
||||
# docker save -o ~/container-backup.tar container-backup
|
||||
|
||||

|
||||
|
||||
要验证tarball时候已经生成,我们只需要在保存tarball的目录中运行 ls 命令。
|
||||
|
||||
### 2. 恢复容器 ###
|
||||
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些被快照成Docker镜像的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
|
||||
# docker pull arunpyasi/container-backup:test
|
||||
|
||||

|
||||
|
||||
但是,如果我们将这些Docker镜像作为tarball文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tarball的备份路径,就可以加载该Docker镜像了。
|
||||
|
||||
# docker load -i ~/container-backup.tar
|
||||
|
||||
现在,为了确保这些Docker镜像已经加载成功,我们来运行 docker images 命令。
|
||||
|
||||
# docker images
|
||||
|
||||
在镜像被加载后,我们将从加载的镜像去运行Docker容器。
|
||||
|
||||
# docker run -d -p 80:80 container-backup
|
||||
|
||||

|
||||
|
||||
### 3. 迁移Docker容器 ###
|
||||
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将容器的备份作为快照Docker镜像。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tarball文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tarball备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/backup-restore-migrate-containers-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://docker.com/
|
||||
[2]:https://registry.hub.docker.com/
|
||||
@ -0,0 +1,51 @@
|
||||
如何修复:There is no command installed for 7-zip archive files
|
||||
================================================================================
|
||||
### 问题 ###
|
||||
|
||||
我试着在Ubuntu中安装Emerald图标主题,而这个主题被打包成了.7z归档包。和以往一样,我试着通过在GUI中右击并选择“提取到这里”来将它解压缩。但是Ubuntu 15.04却并没有解压文件,取而代之的,却是丢给了我一个下面这样的错误信息:
|
||||
|
||||
> Could not open this file
|
||||
> 无法打开该文件
|
||||
>
|
||||
> There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索命令来打开该文件?
|
||||
|
||||
错误信息看上去是这样的:
|
||||
|
||||

|
||||
|
||||
### 原因 ###
|
||||
|
||||
发生该错误的原因从错误信息本身来看就十分明了。7Z,称之为[7-zip][1]更好,该程序没有安装,因此7Z压缩文件就无法解压缩。这也暗示着Ubuntu默认不支持7-zip文件。
|
||||
|
||||
### 解决方案:在Ubuntu中安装 7zip ###
|
||||
|
||||
要解决该问题也十分简单,在Ubuntu中安装7-Zip包即可。现在,你也许想知道如何在Ubuntu中安装 7Zip吧?好吧,在前面的错误对话框中,如果你右击“Search Command”搜索命令,它会查找可用的 p7zip 包。只要点击“Install”安装,如下图:
|
||||
|
||||

|
||||
|
||||
### 可选方案:在终端中安装 7Zip ###
|
||||
|
||||
如果偏好使用终端,你可以使用以下命令在终端中安装 7zip:
|
||||
|
||||
sudo apt-get install p7zip-full
|
||||
|
||||
注意:在Ubuntu中,你会发现有3个7zip包:p7zip,p7zip-full 和 p7zip-rar。p7zip和p7zip-full的区别在于,p7zip是一个更轻量化的版本,仅仅提供了对 .7z 和 .7za 文件的支持,而完整版则提供了对更多(用于音频文件等的) 7z 压缩算法的支持。对于 p7zip-rar,它除了对 7z 文件的支持外,也提供了对 .rar 文件的支持。
|
||||
|
||||
事实上,相同的错误也会发生在[Ubuntu中的RAR文件][2]身上。解决方案也一样,安装正确的程序即可。
|
||||
|
||||
希望这篇快文帮助你解决了**Ubuntu 14.04中如何打开 7zip**的谜团。如有任何问题或建议,我们将无任欢迎。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-there-is-no-command-installed-for-7-zip-archive-files/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.7-zip.org/
|
||||
[2]:http://itsfoss.com/fix-there-is-no-command-installed-for-rar-archive-files/
|
||||
@ -0,0 +1,129 @@
|
||||
如何更新Linux内核提升系统性能
|
||||
================================================================================
|
||||

|
||||
|
||||
[Linux内核][1]内核的开发速度目前是空前,大概每2到3个月就会有一个主要的版本发布。每个发布都带来让很多人的计算更加快、更加有效率、或者更好的功能和提升。
|
||||
|
||||
问题是你不能在这些内核发布的时候就用它们-你要等到你的发行版带来新内核的发布。我们先前发布了[定期更新内核的好处][2],你不必等到那时。我们会向你展示该怎么做。
|
||||
|
||||
> 免责声明: 我们先前的一些文章已经提到过,升级内核会带来(很小的)破坏你系统的风险。在这种情况下,通常可以通过旧内核来使系统工作,但是有时还是不行。因此我们对系统的任何损坏都不负责-你自己承担风险!
|
||||
|
||||
### 预备工作 ###
|
||||
|
||||

|
||||
|
||||
要更新你的内核,你首先要确定你使用的是32位还是64位的系统。打开终端并运行:
|
||||
|
||||
uname -a
|
||||
|
||||
检查一下输出的是x86_64还是i686。如果是x86_64,你就运行64位的版本,否则就运行32位的版本。记住这个因为这个很重要。
|
||||
|
||||

|
||||
|
||||
接下来,访问[官方Linux内核网站][3],它会告诉你目前稳定内核的版本。如果你喜欢你可以尝试发布预选版,但是这比稳定版少了很多测试。除非你确定想要用发布预选版否则就用稳定内核。
|
||||
|
||||
### Ubuntu指导 ###
|
||||
|
||||
对Ubuntu及其衍生版的用户而言升级内核非常简单,这要感谢Ubuntu主线内核PPA。虽然,官方称为一个PPA。但是你不能像其他PPA一样用来添加它到你软件源列表中,并指望它自动升级你的内核。而它只是一个简单的网页,你可以下载到你想要的内核。
|
||||
|
||||

|
||||
|
||||
现在,访问[内核PPA网页][4],并滚到底部。列表的最下面会含有最新发布的预选版本(你可以在名字中看到“rc”字样),但是这上面就可以看到最新的稳定版(为了更容易地解释这个,这时最新的稳定版是4.1.2)。点击它,你会看到几个选项。你需要下载3个文件并保存到各自的文件夹中(如果你喜欢的话可以在下载文件夹中),这样就可以将它们相互隔离了:
|
||||
|
||||
- 针对架构的含“generic”的头文件(我这里是64位或者“amd64”)
|
||||
- 中间的头文件在文件名末尾有“all”
|
||||
- 针对架构的含“generic”内核文件(再说一次,我会用“amd64”,但是你如果用32位的,你需要使用“i686”)
|
||||
|
||||
你会看到还有含有“lowlatency”的文件可以下面。但最好忽略它们。这些文件相对不稳定,并且只为那些通用文件不能满足像录音这类任务想要低延迟的人准备的。再说一次,首选通用版除非你特定的任务需求不能很好地满足。一般的游戏和网络浏览不是使用低延时版的借口。
|
||||
|
||||

|
||||
|
||||
你把它们放在各自的文件夹下,对么?现在打开终端,使用
|
||||
|
||||
cd
|
||||
|
||||
命令到新创建的文件夹下,像
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行:
|
||||
|
||||
sudo dpkg -i *.deb
|
||||
|
||||
这个命令会标记所有文件夹的“.deb”文件为“待安装”,接着执行安装。这是推荐的安装放大,因为除非可以很简单地选择一个文件安装,它总会报出依赖问题。这个方法可以避免这个问题。如果你不清楚cd和sudo是什么。快速地看一下[Linux基本命令][5]这篇文章。
|
||||
|
||||
安装完成后,**重启**你的系统,这时应该就会运行刚安装的内核了!你可以在命令行中使用uname -a来检查输出。
|
||||
|
||||
### Fedora指导 ###
|
||||
|
||||
如果你使用的是Fedora或者它的衍生版,过程跟Ubuntu很类似。不同的是文件获取的位置不同,安装的命令也不同。
|
||||
|
||||

|
||||
|
||||
查看[Fedora最新内核编译][6]列表。选取列表中最新的稳定版并滚到下面选择i686或者x86_64版。这依赖于你的系统架构。这时你需要下载下面这些文件并保存到它们对应的目录下(比如“Kernel”到下载目录下):
|
||||
|
||||
- kernel
|
||||
- kernel-core
|
||||
- kernel-headers
|
||||
- kernel-modules
|
||||
- kernel-modules-extra
|
||||
- kernel-tools
|
||||
- perf and python-perf (optional)
|
||||
|
||||
如果你的系统是i686(32位)同时你有4GB或者更大的内存,你需要下载所有这些文件的PAE版本。PAE是用于32位的地址扩展技术上,它允许你使用3GB的内存。
|
||||
|
||||
现在使用
|
||||
|
||||
cd
|
||||
|
||||
命令进入文件夹,像这样
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
and then run the following command to install all the files:
|
||||
接着运行下面的命令来安装所有的文件
|
||||
|
||||
yum --nogpgcheck localinstall *.rpm
|
||||
|
||||
最后**重启**你的系统,这样你就可以运行新的内核了!
|
||||
|
||||
### 使用 Rawhide ###
|
||||
|
||||
另外一个方案是,Fedora用户也可以[切换到Rawhide][7],它会自动更新所有的包到最新版本,包括内核。然而,Rawhide经常会破坏系统(尤其是在早期的开发版中),它**不应该**在你日常使用的系统中用。
|
||||
|
||||
### Arch指导 ###
|
||||
|
||||
[Arch][8]应该总是使用的是最新和最棒的稳定版(或者相当接近的版本)。如果你想要更接近最新发布的稳定版,你可以启用测试库提前2到3周获取到主要的更新。
|
||||
|
||||
要这么做,用[你喜欢的编辑器][9]以sudo权限打开下面的文件
|
||||
|
||||
/etc/pacman.conf
|
||||
|
||||
接着取消注释带有testing的三行(删除行前面的井号)。如果你想要启用multilib仓库,就把multilib-testing也做相同的事情。如果想要了解更多参考[这个Arch的wiki界面][10]。
|
||||
|
||||
升级内核并不简单(有意这么做),但是这会给你带来很多好处。只要你的新内核不会破坏任何东西,你可以享受它带来的性能提升,更好的效率,支持更多的硬件和潜在的新特性。尤其是你正在使用相对更新的硬件,升级内核可以帮助到它。
|
||||
|
||||
|
||||
**怎么升级内核这篇文章帮助到你了么?你认为你所喜欢的发行版对内核的发布策略应该是怎样的?**。在评论栏让我们知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/update-linux-kernel-improved-system-performance/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/linux-kernel-explanation-laymans-terms/
|
||||
[2]:http://www.makeuseof.com/tag/5-reasons-update-kernel-linux/
|
||||
[3]:http://www.kernel.org/
|
||||
[4]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[5]:http://www.makeuseof.com/tag/an-a-z-of-linux-40-essential-commands-you-should-know/
|
||||
[6]:http://koji.fedoraproject.org/koji/packageinfo?packageID=8
|
||||
[7]:http://www.makeuseof.com/tag/bleeding-edge-linux-fedora-rawhide/
|
||||
[8]:http://www.makeuseof.com/tag/arch-linux-letting-you-build-your-linux-system-from-scratch/
|
||||
[9]:http://www.makeuseof.com/tag/nano-vs-vim-terminal-text-editors-compared/
|
||||
[10]:https://wiki.archlinux.org/index.php/Pacman#Repositories
|
||||
@ -0,0 +1,131 @@
|
||||
|
||||
用 CD 创建 ISO,观察用户活动和检查浏览器内存的技巧
|
||||
================================================================================
|
||||
我已经写过 [Linux 提示和技巧][1] 系列的一篇文章。写这篇文章的目的是让你知道这些小技巧可以有效地管理你的系统/服务器。
|
||||
|
||||

|
||||
|
||||
在Linux中创建 Cdrom ISO 镜像和监控用户
|
||||
|
||||
在这篇文章中,我们将看到如何使用 CD/DVD 驱动器中加载到的内容来创建 ISO 镜像,打开随机手册页学习,看到登录用户的详细情况和查看浏览器内存使用量,而所有这些完全使用本地工具/命令无任何第三方应用程序/组件。让我们开始吧...
|
||||
|
||||
### 用 CD 中创建 ISO 映像 ###
|
||||
|
||||
我们经常需要备份/复制 CD/DVD 的内容。如果你是在 Linux 平台上,不需要任何额外的软件。所有需要的是进入 Linux 终端。
|
||||
|
||||
要从 CD/DVD 上创建 ISO 镜像,你需要做两件事。第一件事就是需要找到CD/DVD 驱动器的名称。要找到 CD/DVD 驱动器的名称,可以使用以下三种方法。
|
||||
|
||||
**1. 从终端/控制台上运行 lsblk 命令(单个驱动器).**
|
||||
|
||||
$ lsblk
|
||||
|
||||

|
||||
|
||||
找驱动器
|
||||
|
||||
**2.要查看有关 CD-ROM 的信息,可以使用以下命令。**
|
||||
|
||||
$ less /proc/sys/dev/cdrom/info
|
||||
|
||||

|
||||
|
||||
检查 Cdrom 信息
|
||||
|
||||
**3. 使用 [dmesg 命令][2] 也会得到相同的信息,并使用 egrep 来自定义输出。**
|
||||
|
||||
命令 ‘dmesg‘ 命令的输出/控制内核缓冲区信息。‘egrep‘ 命令输出匹配到的行。选项 -i 和 -color 与 egrep 连用时会忽略大小写,并高亮显示匹配的字符串。
|
||||
|
||||
$ dmesg | egrep -i --color 'cdrom|dvd|cd/rw|writer'
|
||||
|
||||

|
||||
|
||||
查找设备信息
|
||||
|
||||
一旦知道 CD/DVD 的名称后,在 Linux 上你可以用下面的命令来创建 ISO 镜像。
|
||||
|
||||
$ cat /dev/sr0 > /path/to/output/folder/iso_name.iso
|
||||
|
||||
这里的‘sr0‘是我的 CD/DVD 驱动器的名称。你应该用你的 CD/DVD 名称来代替。这将帮你创建 ISO 镜像并备份 CD/DVD 的内容无需任何第三方应用程序。
|
||||
|
||||

|
||||
|
||||
创建 CDROM 的 ISO 映像
|
||||
|
||||
### 随机打开一个手册页 ###
|
||||
|
||||
如果你是 Linux 新人并想学习使用命令行开关,这个修改是为你做的。把下面的代码行添加在`〜/ .bashrc`文件的末尾。
|
||||
|
||||
/use/bin/man $(ls /bin | shuf | head -1)
|
||||
|
||||
记得把上面一行脚本添加在用户的`.bashrc`文件中,而不是根目录的 .bashrc 文件。所以,当你下次登录本地或远程使用 SSH 时,你会看到一个随机打开的手册页供你阅读。对于想要学习命令行开关的新手,这被证明是有益的。
|
||||
|
||||
下面是在终端登录两次分别看到的。
|
||||
|
||||

|
||||
|
||||
LoadKeys 手册页
|
||||
|
||||

|
||||
|
||||
Zgrep 手册页
|
||||
|
||||
### 查看登录用户的状态 ###
|
||||
|
||||
了解其他用户正在共享服务器上做什么。
|
||||
|
||||
一般情况下,你是共享的 Linux 服务器的用户或管理员的。如果你担心自己服务器的安全并想要查看哪些用户在做什么,你可以使用命令 'w'。
|
||||
|
||||
这个命令可以让你知道是否有人在执行恶意代码或篡改服务器,让他停下或使用其他方法。'w' 是查看登录用户状态的首选方式。
|
||||
|
||||
要查看登录的用户正在做什么,从终端运行命令“w”,最好是 root 用户。
|
||||
|
||||
# w
|
||||
|
||||

|
||||
|
||||
检查 Linux 用户状态
|
||||
|
||||
### 查看浏览器的内存使用状况 ###
|
||||
|
||||
最近有不少谈论关于 Google-chrome 内存使用量。如果你想知道一个浏览器的内存用量,你可以列出进程名,PID 和它的使用情况。要检查浏览器的内存使用情况,只需在地址栏输入 “about:memory” 不要带引号。
|
||||
|
||||
我已经在 Google-Chrome 和 Mozilla 的 Firefox 网页浏览器进行了测试。你可以查看任何浏览器,如果它工作得很好,你可能会承认我们在下面的评论。你也可以杀死浏览器进程在 Linux 终端的进程/服务中。
|
||||
|
||||
在 Google Chrome 中,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
查看 Chrome 内存使用状况
|
||||
|
||||
在Mozilla Firefox浏览器,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
查看 Firefox 内存使用状况
|
||||
|
||||
如果你已经了解它是什么,除了这些选项。要检查内存用量,你也可以点击最左边的 ‘Measure‘ 选项。
|
||||
|
||||

|
||||
|
||||
Firefox 主进程
|
||||
|
||||
它将通过浏览器树形展示进程内存使用量
|
||||
|
||||
目前为止就这样了。希望上述所有的提示将会帮助你。如果你有一个(或多个)技巧,分享给我们,将帮助 Linux 用户更有效地管理他们的 Linux 系统/服务器。
|
||||
|
||||
我会很快在这里发帖,到时候敬请关注。请在下面的评论里提供你的宝贵意见。喜欢请分享并帮助我们传播。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/creating-cdrom-iso-image-watch-user-activity-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/dmesg-commands/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user