mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
3d0a3d966a
@ -0,0 +1,37 @@
|
||||
"Fork Debian" Project Aims to Put Pressure on Debian Community and Systemd Adoption
|
||||
================================================================================
|
||||
> There is still a great deal of resistance in the Debian community towards the upcoming adoption of systemd
|
||||
|
||||
**The Debian project decided to adopt systemd a while ago and ditch the upstart counterpart. The decision was very controversial and it's still contested by some users. Now, a new proposition has been made, to fork Debian into something that doesn't have systemd.**
|
||||
|
||||

|
||||
|
||||
systemd is the replacement for the init system and it's the daemon that starts right after the Linux kernel. It's responsible for initiating all the other components in a system and it's also responsible for shutting them down in the correct order, so you might imagine why people think this is an important piece of software.
|
||||
|
||||
The discussions in the Debian community have been very heated, but systemd prevailed and it looked like the end of it. Linux distros based on it have already started to make the changes. For example, Ubuntu is already preparing to adopt systemd, although it's still pretty far off.
|
||||
|
||||
### Forking Debian, not really a solution ###
|
||||
|
||||
Developers have already forked systemd, but the projects resulted don't have a lot of support from the community. As you can imagine, systemd also has a big following and people are not giving up so easily. Now, someone has made a website called debianfork.org to advocate for a Debian without systemd, in an effort to put pressure on the developers.
|
||||
|
||||
"We are Veteran Unix Admins and we are concerned about what is happening to Debian GNU/Linux to the point of considering a fork of the project. Some of us are upstream developers, some professional sysadmins: we are all concerned peers interacting with Debian and derivatives on a daily basis. We don't want to be forced to use systemd in substitution to the traditional UNIX sysvinit init, because systemd betrays the UNIX philosophy."
|
||||
|
||||
"We contemplate adopting more recent alternatives to sysvinit, but not those undermining the basic design principles of 'do one thing and do it well' with a complex collection of dozens of tightly coupled binaries and opaque logs," reads the [website][1], among a lot of other things.
|
||||
|
||||
Basically, the new website is not actually about a Debian fork, but more like a form of pressure for the [upcoming vote][2] that will be taken for the "Re-Proposal - preserve freedom of choice of init systems." This is a general resolution made by Ian Jackson and he hopes to get enough support in order to turn back the decision made by the Technical Committee regarding systemd.
|
||||
|
||||
It's clear that the debate is still not over in the Debian community, but it remains to be seen if the decisions already made can be overturned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Fork-Debian-Project-Started-to-Put-Pressure-on-Debian-Community-and-Systemd-Adoption-462598.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://debianfork.org/
|
||||
[2]:https://lists.debian.org/debian-vote/2014/10/msg00001.html
|
||||
@ -0,0 +1,64 @@
|
||||
Microsoft loves Linux -- for Azure's sake
|
||||
================================================================================
|
||||

|
||||
|
||||
Scott Guthrie, executive vice president, Microsoft Cloud and Enterprise group, shows how Microsoft differentiates Azure. Credit: James Niccolai/IDG News Service
|
||||
|
||||
### Microsoft adds CoreOS and Cloudera to its growing set of Azure services ###
|
||||
|
||||
Microsoft now loves Linux.
|
||||
|
||||
This was the message from Microsoft CEO Satya Nadella, standing in front of an image that read "Microsoft [heart symbol] Linux," during a Monday webcast to announce a number of services it had added to its Azure cloud, including the Cloudera Hadoop package and the CoreOS Linux distribution.
|
||||
|
||||
In addition, the company launched a marketplace portal, now in preview mode, designed to make it easier for customers to procure and manage their cloud operations.
|
||||
|
||||
Microsoft is also planning to release an Azure appliance, in conjunction with Dell, that will allow organizations to run hybrid clouds where they can easily move operations between Microsoft's Azure cloud and their own in-house version.
|
||||
|
||||
The declaration of affection for Linux indicates a growing acceptance of software that wasn't created at Microsoft, at least for the sake of making its Azure cloud platform as comprehensive as possible.
|
||||
|
||||
For decades, the company tied most of its new products and innovations to its Windows platform, and saw other OSes, such as Linux, as a competitive threat. Former CEO Steve Ballmer [once infamously called Linux a cancer][1].
|
||||
|
||||
This animosity may be evaporating as Microsoft is finding that customers want cloud services that incorporate software from other sources in addition to Microsoft. About 20 percent of the workloads run on Azure are based on Linux, Nadella admitted.
|
||||
|
||||
Now, the company considers its newest competitors to be the cloud services offered by Amazon and Google.
|
||||
|
||||
Nadella said that by early 2015, Azure will be operational in 19 regions around the world, which will provide more local coverage than either Google or Amazon.
|
||||
|
||||
He also noted that the company is investing more than $4.5 billion in data centers, which by Microsoft's estimation is twice as much as Amazon's investments and six times as much as Google's.
|
||||
|
||||
To compete, Microsoft has been adding widely-used third party software packages to Azure at a rapid clip. Nadella noted that Azure now supports all the major data integration stacks, such as those from Oracle and IBM, as well as major new entrants such as MongoDB and Hadoop.
|
||||
|
||||
The results seem to be paying off. Today Azure is generating about $4.48 billion in annual revenue for Microsoft, and we are "still at the early days," of cloud computing, Nadella said.
|
||||
|
||||
The service attracts about 10,000 new customers per week. About 2 million developers have signed on to Visual studio online since its launch. The service runs about 1.2 million SQL databases.
|
||||
|
||||
CoreOS is now actually the fifth Linux distribution that Azure offers, joining Ubuntu, CentOS, OpenSuse, and Oracle Linux (a variant of Red Hat Enterprise Linux). Customers [can also package their own Linux distributions][2] to run in Azure.
|
||||
|
||||
CoreOS was developed as [a lightweight Linux distribution][3] to be used primarily in cloud environments. Officially launched in December, CoreOS is already offered as a service by Google, Rackspace, DigitalOcean and others.
|
||||
|
||||
Cloudera is the second Hadoop distribution offered on Azure, following Hortonworks. Cloudera CEO Mike Olson joined the Microsoft executives onstage to demonstrate how easily one can use the Cloudera Hadoop software within Azure.
|
||||
|
||||
Using the new portal, Olson showed how to start up a 90-node instance of Cloudera with a few clicks. Such a deployment can be connected to an Excel spreadsheet, where the user can query the dataset using natural language.
|
||||
|
||||
Microsoft also announced a number of other services and products.
|
||||
|
||||
Azure will have a new type of virtual machine, which is being called the "G Family." These virtual machines can have up to 32 CPU cores, 450GB of working memory and 6.5TB of storage, making it in effect "the largest virtual machine in the cloud," said Scott Guthrie, who is the Microsoft executive vice president overseeing Azure.
|
||||
|
||||
This family of virtual machines is equipped to handle the much larger workloads Microsoft is anticipating its customers will want to run. It has also upped the amount of storage each virtual machine can access, to 32TB.
|
||||
|
||||
The new cloud platform appliance, available in November, will allow customers to run Azure services on-premise, which can provide a way to bridge their on-premise and cloud operations. One early customer, integrator General Dynamics, plans to use this technology to help its U.S. government customers migrate to the cloud.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2836315/microsoft-loves-linux-for-azures-sake.html
|
||||
|
||||
作者:[Joab Jackson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Joab-Jackson/
|
||||
[1]:http://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/
|
||||
[2]:http://azure.microsoft.com/en-us/documentation/articles/virtual-machines-linux-create-upload-vhd/
|
||||
[3]:http://www.itworld.com/article/2696116/open-source-tools/coreos-linux-does-away-with-the-upgrade-cycle.html
|
||||
@ -0,0 +1,30 @@
|
||||
Red Hat acquires FeedHenry to get mobile app chops
|
||||
================================================================================
|
||||
Red Hat wants a piece of the enterprise mobile app market, so it has acquired Irish company FeedHenry for approximately $82 million.
|
||||
|
||||
The growing popularity of mobile devices has put pressure on enterprise IT departments to make existing apps available from smartphones and tablets -- a trend that Red Hat is getting in on with the FeedHenry acquisition.
|
||||
|
||||
The mobile app segment is one of the fastest growing in the enterprise software market, and organizations are looking for better tools to build mobile applications that extend and enhance traditional enterprise applications, according to Red Hat.
|
||||
|
||||
"Mobile computing for the enterprise is different than Angry Birds. Enterprise mobile applications need a backend platform that enables the mobile user to access data, build backend logic, and access corporate APIs, all in a scalable, secure manner," Craig Muzilla, senior vice president for Red Hat's Application Platform Business, said in a [blog post][1].
|
||||
|
||||
FeedHenry provides a cloud-based platform that lets users develop and deploy applications for mobile devices that meet those demands. Developers can create native apps for Android, iOS, Windows Phone and BlackBerry as well as HTML5 apps, or a mixture of native and Web apps.
|
||||
|
||||
A key building block is Node.js, an increasingly popular platform based on Chrome's JavaScript runtime for building fast and scalable applications.
|
||||
|
||||
From Red Hat's point of view, FeedHenry is a natural fit with the company's strengths in enterprise middleware and PaaS (platform-as-a-service). It adds better mobile capabilities to the JBoss Middleware portfolio and OpenShift PaaS offerings, Red Hat said.
|
||||
|
||||
Red Hat plans to continue to sell and support FeedHenry's products, and will continue to honor client contracts. For the most part, it will be business as usual, according to Red Hat. The transaction is expected to close in the third quarter of its fiscal 2015.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2685286/red-hat-acquires-feedhenry-to-get-mobile-app-chops.html
|
||||
|
||||
作者:[Mikael Ricknäs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Mikael-Rickn%C3%A4s/
|
||||
[1]:http://www.redhat.com/en/about/blog/its-time-go-mobile
|
||||
@ -0,0 +1,28 @@
|
||||
This is the name of Ubuntu 15.04 — And It’s Not Velociraptor
|
||||
================================================================================
|
||||
**Ubuntu 14.10 may not be out of the door yet, but attention is already turning to Ubuntu 15.04. Today it got its name: ‘[Vivid Vervet][1]’.**
|
||||
|
||||

|
||||
|
||||
Announcing the monkey-themed moniker in his usual loquacious style, Mark Shuttleworth cites the ‘upstart’ and playful nature of the mascot as in tune with its own foray into the mobile space.
|
||||
|
||||
> “This is a time when every electronic thing can be an Internet thing, and that’s a chance for us to bring our platform, with its security and its long term support, to a vast and important field. In a world where almost any device can be smart, and also subverted, our shared efforts to make trusted and trustworthy systems might find fertile ground.
|
||||
|
||||
Talking of plans for the release Shuttleworth states one goal is to “show the way past a simple Internet of things, to a world of Internet things-you-can-trust.”
|
||||
|
||||
Ubuntu 15.04 is due for release in April 2015. It’s not expected to arrive with either Mir or Unity 8 by default, but given the veracious speed of acceleration in ambitions, it may find its way out for testing.
|
||||
|
||||
Do you like the name? Were you hoping for velociraptor?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/ubuntu-15-04-named-vivid-vervet
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.markshuttleworth.com/archives/1425
|
||||
34
sources/news/20141021 Ubuntu 15.04 Is Called Vivid Vervet.md
Normal file
34
sources/news/20141021 Ubuntu 15.04 Is Called Vivid Vervet.md
Normal file
@ -0,0 +1,34 @@
|
||||
Ubuntu 15.04 Is Called Vivid Vervet
|
||||
================================================================================
|
||||
> Mark Shuttleworth decided on the new name for Ubuntu 15.04
|
||||
|
||||

|
||||
|
||||
**One of Mark Shuttleworth's privileges is to decide what the code name for upcoming Ubuntu versions is. It's usually a real animal and now it's a monkey whose name starts with V and, as usual, it's probably a species you’ve never heard of before.**
|
||||
|
||||
With very few exceptions, some of the names chosen for Ubuntu releases send the older users to the Encyclopedia Britannica and the new ones to Google. Shuttleworth generally chooses animals that are less known and the names usually have something in common with the release.
|
||||
|
||||
For example, Trusty Tahr, the name of Ubuntu 14.04 LTS, followed the idea of long term support for the operating system, hence the trusty adjective. Precise Pangolin did the same for Ubuntu 12.04 LTS, and so on. Intermediary releases are not all that obvious and the Ubuntu 14.10 Utopic Unicorn is proof of that.
|
||||
|
||||
### Still thinking about the monkey whose name starts with a V? ###
|
||||
|
||||
The way the version number is chosen is pretty clear. The first part is for the year and the second one is for the month, so Ubuntu 14.10 is actually Ubuntu 2014 October. On the other hand, the names only follow a simple rule, one adjective and one animal, so the choice is rather simple. Unlike other communities, where the designation is decided by users or at least with their participation, Ubuntu is different, although it's not a singular example.
|
||||
|
||||
"Release week! Already! I wouldn't call Trusty 'vintage' just yet, but Utopic is poised to leap into the torrent stream. We've all managed to land our final touches to *buntu and are excited to bring the next wave of newness to users around the world. Glad to see the unicorn theme went down well, judging from the various desktops I see on G+."
|
||||
|
||||
"In my favourite places, the smartest thing around is a particular kind of monkey. Vexatious at times, volant and vogie at others, a vervet gets in anywhere and delights in teasing cats and dogs alike. As the upstart monkey in this business I can think of no better mascot. And so let's launch our vicenary cycle, our verist varlet, the Vivid Vervet!" says Mark Shuttleworth on his [blog][1].
|
||||
|
||||
So, there you have it, Ubuntu 15.04, the operating system that is scheduled to arrive in April 2015, will be called Vivid Vervet. I won't keep you anymore for details, I'm sure you are already looking up the vervet on Wikipedia.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Ubuntu-15-04-Is-Called-Vivid-Vervet-462621.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://www.markshuttleworth.com/archives/1425
|
||||
@ -1,120 +0,0 @@
|
||||
Linux Poetry Explains the Kernel, Line By Line
|
||||
================================================================================
|
||||
> Editor's Note: Feeling inspired? Send your Linux poem to [editors@linux.com][1] for your chance to win a free pass to [LinuxCon North America][2] in Chicago, Aug. 20-22. Be sure to include your name, contact information and a brief explanation of your poem. We'll draw one winner at random from all eligible entries each week through Aug. 1, 2014.
|
||||
|
||||

|
||||
|
||||
Software developer Morgan Phillips is teaching herself how the Linux kernel works by writing poetry.
|
||||
|
||||
Writing poems about the Linux kernel has been enlightening in more ways than one for software developer Morgan Phillips.
|
||||
|
||||
Over the past few months she's begun to teach herself how the Linux kernel works by studying text books, including [Understanding the Linux Kernel][3], Unix Network Programming, and The Unix Programming Environment. But instead of taking notes, she weaves the new terminology and ideas she learns into poetry about system architecture and programming concepts. (See some examples, below, and on her [Linux Poetry blog][4].)
|
||||
|
||||
It's a “pedagogical hack” she adopted in college and took up again a few years ago when she first landed a job as a data warehouse engineer at Facebook and needed to quickly learn Hadoop.
|
||||
|
||||
“I could remember bits and pieces of information but it was too rote, too rigid in my mind, so I started writing poems,” she said. “It forced me to wrap all of these bits of information into context and helped me learn things much more effectively.”
|
||||
|
||||
The Linux kernel's history, architecture, abundant terminology and complex concepts, are rich fodder for her poetry.
|
||||
|
||||
“I could probably write thousands of poems about just one subsystem in the kernel,” she said.
|
||||
|
||||
### Why learn Linux? ###
|
||||
|
||||

|
||||
Phillips publishes on her Linux Poetry blog.
|
||||
|
||||
Phillips started her software career through a somewhat unconventional route as a physics major in a research laboratory. Instead of writing journal articles she was writing Python scripts to parse research project data on active galactic nuclei. She never learned the fundamentals of computer science (CS), but picked up the information on the job, as the need arose.
|
||||
|
||||
She soon got a job doing network security research for the Army Research Laboratory in Adelphi, Maryland, working with Linux. That was her first foray into the networking stack and the lower levels of the operating system.
|
||||
|
||||
Most recently she worked at Facebook until about six months ago when she moved from the Silicon Valley back to Nashville, near her home state of Kentucky, to work for a software startup that helps major record labels manage their business.
|
||||
|
||||
“I have all this experience but I suffer from a thing that almost every person who doesn’t have an actual background in CS does: I have islands of knowledge with big gaps in between,” she said. “Every time I'd come across some concept, some data structure in the kernel, I'd have to go educate myself on it.”
|
||||
|
||||
A few weeks ago her frustration peaked. She was trying to do a form of message passing between web application processes and a web socket server she had written and found herself having to brush up on all the ways she could do interprocess communication.
|
||||
|
||||
“I was like, that's it. I'm going to start really learning everything I should have known starting at the bottom up with the Linux kernel,” she said. “So I bought some textbooks and started reading.”
|
||||
|
||||

|
||||
|
||||
### What she's learned ###
|
||||
|
||||
Over the course of a few months of reading books and writing poems she's learned about how the virtual memory subsystem works. She's learned about the data structures that hold process information, about the virtual memory layout and how pages are mapped into memory, and about memory management.
|
||||
|
||||
“I hadn't thought about a lot of things, like that a system that's multiprocessing shouldn’t bother with semaphores,” she said. “Spin locks are often more efficient.”
|
||||
|
||||
Writing poems has also given her insight into her own way of thinking about the world. In some small way she is communicating not just her knowledge of Linux systems, but also the way that she conceptualizes them.
|
||||
|
||||
“It's a deep look into my mind,” she said. “Poetry is the best way to share these abstract ideas and things that we can't possibly truly share with other people.”
|
||||
|
||||
Writing a Linux poem
|
||||
|
||||
The inspiration for her Linux poems starts with reading a textbook chapter. She hones the topics down to the key concepts that she wants to remember and what others might find interesting, as well as things she can “wrap a conceptual bubble around.”
|
||||
|
||||
A concept like demand paging is too broad to fit into a single poem, for example. “So I'm working my way down deeper in it,” she said. “Instead I'm looking at writing a poem about the actual data structure where process memory is laid out and then mapped into a page map.”
|
||||
|
||||
She hasn't had any formal training writing poetry, but writes the lines so that they are visually appealing and have a nice rhythm when they're read aloud.
|
||||
|
||||
In her poem, “The Reentrant Kernel,” Phillips writes about an important property in software that allows a function to be paused and restarted later with the same result. System calls need to have this reentrant property in order to make the scheduler run as efficiently as possible, Phillips explains. The poem also includes a program, written in C style pseudocode, to help illustrate the concept.
|
||||
|
||||
Phillips hopes her Linux poetry helps her increase her understanding enough to start contributing to the Linux kernel.
|
||||
|
||||
“I've been very intimidated for a long time by the idea of submitting a patch to the kernel, being a kernel hacker,” she said. “To me that's the pinnacle of success.
|
||||
|
||||
“My ultimate dream is that I can gain a good enough understanding of the kernel and C to submit a patch and have it accepted.”
|
||||
|
||||
The Reentrant Kernel
|
||||
|
||||
A reentrant function,
|
||||
if interrupted,
|
||||
will return a result,
|
||||
which is not perturbed.
|
||||
|
||||
int global_int;
|
||||
int is_not_reentrant(int x) {
|
||||
int x = x;
|
||||
return global_int + x; },
|
||||
depends on a global variable,
|
||||
which may change during execution.
|
||||
|
||||
int global_int;
|
||||
int is_reentrant(int x) {
|
||||
int saved = global_int;
|
||||
return saved + x; },
|
||||
mitigates external dependency,
|
||||
it is reentrant, though not thread safe.
|
||||
|
||||
UNIX kernels are reentrant,
|
||||
a process may be interrupted while in kernel mode,
|
||||
so that, for instance, time is not wasted,
|
||||
waiting on devices.
|
||||
|
||||
Process alpha requests to read from a device,
|
||||
the kernel obliges,
|
||||
CPU switches into kernel mode,
|
||||
system call begins execution.
|
||||
|
||||
Process alpha is waiting for data,
|
||||
it yields to the scheduler,
|
||||
process beta writes to a file,
|
||||
the device signals that data is available.
|
||||
|
||||
Context switches,
|
||||
process alpha continues execution,
|
||||
data is fetched,
|
||||
CPU enters user mode.
|
||||
|
||||
注:上面代码内文本发布时请参考原文排版(第一行着重,全部居中)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/200-libby-clark/777473-linux-poetry-explains-the-kernel-line-by-line/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:editors@linux.com
|
||||
[2]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[3]:http://shop.oreilly.com/product/9780596005658.do
|
||||
[4]:http://www.linux-poetry.com/
|
||||
@ -1,5 +1,3 @@
|
||||
CNprober translating...
|
||||
|
||||
Linux Administration: A Smart Career Choice
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Love-xuan 翻译中
|
||||
Don't Fear The Command Line
|
||||
================================================================================
|
||||

|
||||
|
||||
119
sources/talk/20141021 Interview--Thomas Voß of Mir.md
Normal file
119
sources/talk/20141021 Interview--Thomas Voß of Mir.md
Normal file
@ -0,0 +1,119 @@
|
||||
Interview: Thomas Voß of Mir
|
||||
================================================================================
|
||||
**Mir was big during the space race and it’s a big part of Canonical’s unification strategy. We talk to one of its chief architects at mission control.**
|
||||
|
||||
Not since the days of 2004, when X.org split from XFree86, have we seen such exciting developments in the normally prosaic realms of display servers. These are the bits that run behind your desktop, making sure Gnome, KDE, Xfce and the rest can talk to your graphics hardware, your screen and even your keyboard and mouse. They have a profound effect on your system’s performance and capabilities. And where we once had one, we now have two more – Wayland and Mir, and both are competing to win your affections in the battle for an X replacement.
|
||||
|
||||
We spoke to Wayland’s Daniel Stone in issue 6 of Linux Voice, so we thought it was only fair to give equal coverage to Mir, Canonical’s own in-house X replacement, and a project that has so far courted controversy with some of its decisions. Which is why we headed to Frankfurt and asked its Technical Architect, Thomas Voß, for some background context…
|
||||
|
||||

|
||||
|
||||
**Linux Voice: Let’s go right back to the beginning, and look at what X was originally designed for. X solved the problems that were present 30 years ago, where people had entirely different needs, right?**
|
||||
|
||||
**Thomas Voß**: It was mainframes. It was very expensive mainframe computers with very cheap terminals, trying to keep the price as low as possible. And one of the first and foremost goals was: “Hey, I want to be able to distribute my UI across the network, ideally compressed and using as little data as possible”. So a lot of the decisions in X were motivated by that.
|
||||
|
||||
A lot of the graphics languages that X supports even today have been motivated by that decision. The X developers started off in a 2D world; everything was a 2D graphics language, the X way of drawing rectangles. And it’s present today. So X is not necessarily bad in that respect; it still solves a lot of use cases, but it’s grown over time.
|
||||
|
||||
One of the reasons is that X is a protocol, in essence. So a lot of things got added to the protocol. The problem with adding things to a protocol is that they tend to stick. To use a 2D graphics language as an example, XVideo is something that no-one really likes today. It’s difficult to support and the GPU vendors actually cry out in pain when you start talking about XVideo. It’s somewhat bloated, and it’s just old. It’s an old proven technology – and I’m all for that. I actually like X for a lot of things, and it was a good source of inspiration. But then when you look at your current use cases and the current setup we are in, where convergence is one of the buzzwords – massively overrated obviously – but at the heart of convergence lies the fact that you want to scale across different form factors.
|
||||
|
||||
**LV: And convergence is big for Canonical isn’t it?**
|
||||
|
||||
**Thomas**: It’s big, I think, for everyone, especially over time. But convergence is a use case that was always of interest to us. So we always had this idea that we want one codebase. We don’t want a situation like Apple has with OS X and iOS, which are two different codebases. We basically said “Look, whatever we want to do, we want to do it from one codebase, because it’s more efficient.” We don’t want to end up in the situation where we have to be maintaining two, three or four separate codebases.
|
||||
|
||||
That’s where we were coming from when we were looking at X, and it was just too bloated. And we looked at a lot of alternatives. We started looking at how Mac OS X was doing things. We obviously didn’t have access to the source code, but if you see the transition from OS 9 to OS X, it was as if they entirely switched to one graphics language. It was pre-PostScript at that time. But they chose one graphics language, and that’s it. From that point on, when you choose a graphics language, things suddenly become more simple to do. Today’s graphics language is EGL ES, so there was inspiration for us to say we were converged on GL and EGL. From our perspective, that’s the least common denominator.
|
||||
|
||||
> We basically said: whatever we want to do, we want to do it from one codebase, because it’s more efficient.
|
||||
|
||||
Obviously there are disadvantages to having only one graphics language, but the benefits outweigh the disadvantages. And I think that’s a common theme in the industry. Android made the same decision to go that way. Even Wayland to a certain degree has been doing that. They have to support EGL and GL, simply because it’s very convenient for app developers and toolkit developers – an open graphics language. That was the part that inspired us, and we wanted to have this one graphics language and support it well. And that takes a lot of craft.
|
||||
|
||||
So, once you can say: no more weird 2D API, no more weird phong API, and everything is mapped out to GL, you’re way better off. And you can distill down the scope of the overall project to something more manageable. So it went from being impossible to possible. And then there was me, being very opinionated. I don’t believe in extensibility from the beginning – traditionally in Linux everything is super extensible, which has got benefits for a certain audience.
|
||||
|
||||
If you think about the audience of the display server, it’s one of the few places in the system where you’ve got three audiences. So you’ve got the users, who don’t care, or shouldn’t care, about the display server.
|
||||
|
||||
**LV: It’s transparent to them.**
|
||||
|
||||
**Thomas**: Yes, it’s pixels, right? That’s all they care about. It should be smooth. It should be super nice to use. But the display server is not their main concern. It obviously feeds into a user experience, quite significantly, but there are a lot of other parts in the system that are important as well.
|
||||
|
||||
Then you’ve got developers who care about the display server in terms of the API. Obviously we said we want to satisfy this audience, and we want to provide a super-fast experience for users. It should be rock solid and stable. People have been making fun of us and saying “yeah, every project wants to be rock solid and stable”. Cool – so many fail in doing that, so let’s get that down and just write out what we really want to achieve.
|
||||
|
||||
And then you’ve got developers, and the moment you expose an API to them, or a protocol, you sign a contract with them, essentially. So they develop to your API – well, many app developers won’t directly because they’ll be using toolkits – but at some point you’ve got developers who sign up to your API.
|
||||
|
||||

|
||||
|
||||
**LV: The developers writing the toolkits, then?**
|
||||
|
||||
**Thomas**: We do a lot of work in that arena, but in general it’s a contract that we have with normal app developers. And we said: look, we don’t want the API or contract to be super extensible and trying to satisfy every need out there. We want to understand what people really want to do, and we want to commit to one API and contract. Not five different variants of the contract, but we want to say: look, this is what we support and we, as Canonical and as the Mir maintainers, will sign up to.
|
||||
|
||||
So I think that’s a very good thing. You can buy into specific shells sitting on top of Mir, but you can always assume a certain base level of functionality that we will always provide in terms of window management, in terms of rendering capabilities, and so on and so forth. And funnily enough, that also helps with convergence. Because once you start thinking about the API as very important, you really start thinking about convergence. And what happens if we think about form factor and we transfer from a phone to a tablet to a desktop to a fridge?
|
||||
|
||||
**LV: And whatever might come!**
|
||||
|
||||
**Thomas**: Right, right. How do we account for future developments? And we said we don’t feel comfortable making Mir super extensible, because it will just grow. Either it will just grow and grow, or you will end up with an organisation that just maintains your protocol and protocol extensions.
|
||||
|
||||
**LV: So that’s looking at Mir in relation to X. The obvious question is comparing Mir to Wayland – so what is it that Mir does, that Wayland doesn’t?**
|
||||
|
||||
**Thomas**: This might sound picky, but we have to distinguish what Wayland really is. Wayland is a protocol specification which is interesting because the value proposition is somewhat difficult. You’ve got a protocol and you’ve got a reference implementation. Specifically, when we started, Weston was still a test bed and everything being developed ended up in there.
|
||||
|
||||
No one was buying into that; no one was saying, “Look, we’re moving this to production-level quality with a bona fide protocol layer that is frozen and stable for a specific version that caters to application authors”. If you look at the Ubuntu repository today, or in Debian, there’s Wayland-cursor-whatever, so they have extensions already. So that’s a bit different from our approach to Mir, from my perspective at least.
|
||||
|
||||
There was this protocol that the Wayland developers finished and back then, before we did Mir and I looked into all of this, I wrote a Wayland compositor in Go, just to get to know things.
|
||||
|
||||
**LV: As you do!**
|
||||
|
||||
**Thomas**: And I said: you know, I don’t think a protocol is a good way of approaching this because versioning a protocol in a packaging scenario is super difficult. But versioning a C API, or any sort of API that has a binary stability contract, is way easier and we are way more experienced at that. So, in that respect, we are different in that we are saying the protocol is an implementation detail, at least up to a certain point.
|
||||
|
||||
I’m pretty sure for version 1.0, which we will call a golden release, we will open up the protocol for communication purposes. Under the covers it’s Google buffers and sockets. So we’ll say: this is the API, work against that, and we’re committed to it.
|
||||
|
||||
That’s one thing, and then we said: OK, there’s Weston, but we cannot use Weston because it’s not working on Android, the driver model is not well defined, and there’s so much work that we would have to do to actually implement a Wayland compositor. And then we are in a situation where we would have to cut out a set of functionality from the Wayland protocol and commit to that, no matter what happens, and ultimately that would be a fork, over time, right?.
|
||||
|
||||
**LV: It’s a difficult concept for many end users, who just want to see something working.**
|
||||
|
||||
**Thomas**: Right, and even from a developer’s perspective – and let’s jump to the political part – I find it somewhat difficult to have a party owning a protocol definition and another party building the reference implementations. Now, Gnome and KDE do two different Wayland compositors. I don’t see the benefit in that, to be quite frank, so the value proposition is difficult to my mind.
|
||||
|
||||
The driver model in Mir and Wayland is ultimately not that different – it’s GL/EGL based. That is kind of the denominator that you will find in both things, which is actually a good thing, because if you look at the contract to application developers and toolkit developers, most of them don’t want Mir or Wayland. They talk ELG and GL, and at that point, it’s not that much of a problem to support both.
|
||||
|
||||
> If there had been a full reference implementation of Wayland, our decision might have been different.
|
||||
|
||||
So we did this work for porting the Chromium browser to Mir. We actually took the Chromium Wayland back-end, factored out all the common pieces to EGL and GL ES, and split it up into Wayland and Mir.
|
||||
|
||||
And I think from a user’s or application developer’s perspective, the difference is not there. I think, in retrospect, if there would have been something like a full reference implementation of Wayland, where a company had signed up to provide something that is working, and committed to a certain protocol version, our decision might have been different. But there just wasn’t. It was five years out there, Wayland, Wayland, Wayland, and there was nothing that we could build upon.
|
||||
|
||||
**LV: The main experience we’ve had is with RebeccaBlackOS, which has Weston and Wayland, because, like you say, there’s no that much out there running it.**
|
||||
|
||||
**Thomas**: Right. I find Wayland impressive, obviously, but I think Mir will be significantly more relevant than Wayland in two years time. We just keep on bootstrapping everything, and we’ve got things working across multiple platforms. Are there issues, and are there open questions to solve? Most likely. We never said we would come up with the perfect solution in version 1. That was not our goal. I don’t think software should be built that way. So it just should be iterated.
|
||||
|
||||

|
||||
|
||||
**LV: When was Mir originally planned for? Which Ubuntu release? Because it has been pushed back a couple of times.**
|
||||
|
||||
**Thomas**: Well, we originally planned to have it by 14.04. That was the kind of stretch goal, because it highly depends on the availability of proprietary graphics drivers. So you can’t ship an LTS [Long Term Support] release of Ubuntu on a new display server without supporting the hardware of the big guys.
|
||||
|
||||
**LV: We thought that would be quite ambitious anyway – a Long Term Support release with a whole new display server!**
|
||||
|
||||
**Thomas**: Yes, it was ambitious – but for a reason. If you don’t set a stretch goal, and probably fail in reaching it, and then re-evaluate how you move forward, it’s difficult to drive a project. So if you just keep it evolving and evolving and evolving, and you don’t have a checkpoint at some point…
|
||||
|
||||
**LV: That’s like a lot of open source projects. Inkscape is still on 0.48 or something, and it works, it’s reliable, but they never get to 1.0. Because they always say: “Oh let’s add this feature, and that feature”, and the rest of us are left thinking: just release 1.0 already!.**
|
||||
|
||||
**Thomas**: And I wouldn’t actually tie it to a version number. To me, that is secondary. To me, the question is whether we call this ready for broad public consumption on all of the hardware versions we want to support?
|
||||
|
||||
In Canonical, as a company, we have OEM contracts and we are enabling Ubuntu on a host of devices, and laptops and whatever, so we have to deliver on those contracts. And the question is, can we do that? No. Well, you never like a ‘no’.
|
||||
|
||||
> The question is whether we call this ready for broad public consumption on the hardware we want to support.
|
||||
|
||||
Usually, when you encounter a problem and you tackle it, and you start thinking how to solve the problem, that’s more beneficial than never hearing a no. That’s kind of what we were aiming for. Ubuntu 14.04 was a stretch goal – everyone was aware of that and we didn’t reach it. Fine, cool. Let’s go on.
|
||||
|
||||
So how do we stage ourself for the next cycle, until an LTS? Now we have this initiative where we have a daily testable image with Unity 8 and Mir. It’s not super usable because it’s just essentially the tethered UI that you are seeing there, but still it’s something that we didn’t have a year ago. And for me, that’s a huge gain.
|
||||
|
||||
And ultimately, before we can ship something, before any new display server can ship in an LTS release, you need to have buy-in from the GPU vendors. That’s what you need.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/interview-thomas-vos-of-mir/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
@ -1,168 +0,0 @@
|
||||
(翻译中 by runningwater)
|
||||
Camicri Cube: An Offline And Portable Package Management System
|
||||
================================================================================
|
||||

|
||||
|
||||
As we all know, we must have an Internet connection in our System for downloading and installing applications using synaptic manager or software center. But, what if you don’t have an Internet connection, or the Internet connection is dead slow? This will be definitely a headache when installing packages using software center in your Linux desktop. Instead, you can manually download the applications from their official site, and install them. But, most of the Linux users doesn’t aware about the required dependencies for the applications that they wanted to install. What could you do if you have such situation? Leave all the worries now. Today, we introduce an awesome offline package manager called **Camicri Cube**.
|
||||
|
||||
You can use this package manager on any Internet connected system, download the list of packages you want to install, bring them back to your offline computer, and Install them. Sounds good? Yes, It is! Cube is a package manager like Synaptic and Ubuntu Software Center, but a portable one. It can be used and run in any platform (Windows, Apt-Based Linux Distributions), online and offline, in flashdrive or any removable devices. The main goal of this project is to enable the offline Linux users to download and install Linux applications easily.
|
||||
|
||||
Cube will gather complete details of your offline computer such as OS details, installed applications and more. Then, just the copy the cube application using any USB thumb drive, and use it on the other Internet connected system, and download the list of applications you want. After downloading all required packages, head back to your original computer and start installing them. Cube is developed and maintained by **Jake Capangpangan**. It is written using C++, and bundled with all necessary packages. So, you don’t have to install any extra software to use it.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Now, let us download and install Cube on the Offline system which doesn’t have the Internet connection. Download Cube latest version either from the [official Launchpad Page][1] or [Sourceforge site][2]. Make sure you have downloaded the correct version depending upon your offline computer architecture. As I use 64 bit system, I downloaded the 64bit version.
|
||||
|
||||
wget http://sourceforge.net/projects/camicricube/files/Camicri%20Cube%201.0.9/cube-1.0.9.2_64bit.zip/
|
||||
|
||||
Extract the zip file and move it to your home directory or anywhere you want:
|
||||
|
||||
unzip cube-1.0.9.2_64bit.zip
|
||||
|
||||
That’s it. Now it’s time to know how to use it.
|
||||
|
||||
### Usage ###
|
||||
|
||||
Here, I will be using Two Ubuntu systems. The original (Offline – no Internet) is running with **Ubuntu 14.04**, and the Internet connected system is running with **Lubuntu 14.04** Desktop.
|
||||
|
||||
#### Steps to do On Offline system: ####
|
||||
|
||||
From the offline system, Go to the extracted Cube folder. You’ll find an executable called “cube-linux”. Double click it, and Click Execute. If it not executable, set the executable permission as shown below.
|
||||
|
||||
sudo chmod -R +x cube/
|
||||
|
||||
Then, go to the cube directory,
|
||||
|
||||
cd cube/
|
||||
|
||||
And run the following command to run it.
|
||||
|
||||
./cube-linux
|
||||
|
||||
Enter the Project name (Ex.sk) and click **Create**. As I mentioned above, this will create a new project with complete details of your system such as OS details, list of installed applications, list of repositories etc.
|
||||
|
||||

|
||||
|
||||
As you know, our system is an offline computer that means I don’t have Internet connection. So I skipped the Update Repositories process by clicking on the **Cancel** button. We will update the repositories later on an Internet connected system.
|
||||
|
||||

|
||||
|
||||
Again, I clicked **No** to skip updating the offline computer, because we don’t have Internet connection.
|
||||
|
||||

|
||||
|
||||
That’s it. Now the new project has been created. The new project will be saved on your main cube folder. Go to the Cube folder, and you’ll find a folder called Projects. This folder will hold all the essential details of your offline system.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Now, close the cube application, and copy the entire main **cube** folder to any flash drive, and go to the Internet connected system.
|
||||
|
||||
#### Steps to do on an Internet connected system: ####
|
||||
|
||||
The following steps needs to be done on the Internet connected system. In our case, Its **Lubuntu 14.04**.
|
||||
|
||||
Make the cube folder executable as we did in the original computer.
|
||||
|
||||
sudo chmod -R +x cube/
|
||||
|
||||
Now, double click the file cube-linux to open it or you can launch it from the Terminal as shown below.
|
||||
|
||||
cd cube/
|
||||
./cube-linux
|
||||
|
||||
You will see that your project is now listed in the “Open Existing Projects” part of the window. Select your project
|
||||
|
||||

|
||||
|
||||
Then, the cube will ask if this is your project’s original computer. It’s not my original (Offline) computer, so I clicked **No**.
|
||||
|
||||

|
||||
|
||||
You’ll be asked if you want to update your repositories. Click **Ok** to update the repositories.
|
||||
|
||||

|
||||
|
||||
Next, we have to update all outdated packages/applications. Click on the “**Mark All updates**” button from the Cube’s tool bar. After that, click “**Download all marked**” button to update all updated packages/applications. As you see in the below screenshot, there are 302 packages needs to be updated in my case. Then, Click **Ok** to continue to download marked packages.
|
||||
|
||||

|
||||
|
||||
Now, Cube will start to download all marked packages.
|
||||
|
||||

|
||||
|
||||
We have completed updating repositories and packages. Now, you can download a new package if you want to install it on your offline system.
|
||||
|
||||
#### Downloading New Applications ####
|
||||
|
||||
For example, here I am going to download the **apache2** Package. Enter the name of the package in the **search** box, and hit Search button. The Cube will fetch the details of the application that you are looking for. Hit the “**Download this package now**” button, and click **Ok** to start download.
|
||||
|
||||

|
||||
|
||||
Cube will start downloading the apache2 package with all its dependencies.
|
||||
|
||||

|
||||
|
||||
If you want to search and download more packages, simply Click the button “**Mark this package**”, and do search the required packages. You can mark as many as packages you want to install on your original computer. Once you marked all packages, hit the “**Download all marked**” button on the top tool bar to start downloading them.
|
||||
|
||||
After you completed updating repositories, outdated packages, and downloading new applications, close the Cube application. Then, copy the entire Cube folder to any flash drive or external hdd, and go back to your Offline system.
|
||||
|
||||
#### Steps to do on Offline computer: ####
|
||||
|
||||
Copy the Cube folder back to your Offline system on any place you want. Go to the cube folder and double click **cube-linux** file to launch Cube application.
|
||||
|
||||
Or, you can launch it from Terminal as shown below.
|
||||
|
||||
cd cube/
|
||||
./cube-linux
|
||||
|
||||
Select your project and click Open.
|
||||
|
||||

|
||||
|
||||
Then a dialog will ask you to update your system, please click “Yes” especially when you download new repositories, because this will transfer all new repositories to your computer.
|
||||
|
||||

|
||||
|
||||
You’ll see that the repositories will be updated on your offline computer without Internet connection. Because, we already have updated the repositories on the Internet connected system. Seems cool, isn’t it?
|
||||
|
||||
After updating the repositories, let us install all downloaded packages. Click the “Mark All Downloaded” button to select all downloaded packages, and click “Install All Marked” to install all of them from the Cube main Tool bar. The Cube application will automatically open a new Terminal, and install all packages.
|
||||
|
||||

|
||||
|
||||
If you encountered with dependency problems, go to **Cube Menu -> Packages -> Install packages with complete dependencies** to install all packages.
|
||||
|
||||
If you want to install a specific package, Navigate to the List Packages, click the “Downloaded” button, and all downloaded packages will be listed.
|
||||
|
||||

|
||||
|
||||
Then, double click the desired package, and click “Install this”, or “Mark this” if you want to install it later.
|
||||
|
||||

|
||||
|
||||
By this way, you can download the required packages from any Internet connected system, and then you can install them in your offline computer without Internet connection.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This is one of the best and useful tool ever I have used. But during testing this tool in my Ubuntu 14.04 testbox, I faced many dependency problems, and the Cube application is suddenly closed often. Also, I could use this tool only on a fresh Ubuntu 14.04 offline system without any issues. Hope all these issues wouldn’t happen on previous versions of Ubuntu. Apart from these minor issues, this tool does this job as advertised and worked like a charm.
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/camicri-cube-offline-portable-package-management-system/
|
||||
|
||||
原文作者:
|
||||
|
||||

|
||||
|
||||
[SK][a](Senthilkumar, aka SK, is a Linux enthusiast, FOSS Supporter & Linux Consultant from Tamilnadu, India. A passionate and dynamic person, aims to deliver quality content to IT professionals and loves very much to write and explore new things about Linux, Open Source, Computers and Internet.)
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://launchpad.net/camicricube
|
||||
[2]:http://sourceforge.net/projects/camicricube/
|
||||
@ -1,4 +1,3 @@
|
||||
nd0104 is translate
|
||||
Install Google Docs on Linux with Grive Tools
|
||||
================================================================================
|
||||
Google Drive is two years old now and Google’s cloud storage solution seems to be still going strong thanks to its integration with Google Docs and Gmail. There’s one thing still missing though: a lack of an official Linux client. Apparently Google has had one floating around their offices for a while now, however it’s not seen the light of day on any Linux system.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by haimingfg
|
||||
|
||||
What are useful CLI tools for Linux system admins
|
||||
================================================================================
|
||||
System administrators (sysadmins) are responsible for day-to-day operations of production systems and services. One of the critical roles of sysadmins is to ensure that operational services are available round the clock. For that, they have to carefully plan backup policies, disaster management strategies, scheduled maintenance, security audits, etc. Like every other discipline, sysadmins have their tools of trade. Utilizing proper tools in the right case at the right time can help maintain the health of operating systems with minimal service interruptions and maximum uptime.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
chi1shi2 is translating.
|
||||
|
||||
How to use on-screen virtual keyboard on Linux
|
||||
================================================================================
|
||||
On-screen virtual keyboard is an alternative input method that can replace a real hardware keyboard. Virtual keyboard may be a necessity in various cases. For example, your hardware keyboard is just broken; you do not have enough keyboards for extra machines; your hardware does not have an available port left to connect a keyboard; you are a disabled person with difficulty in typing on a real keyboard; or you are building a touchscreen-based web kiosk.
|
||||
|
||||
@ -1,6 +1,3 @@
|
||||
>>Linchenguang is translating
|
||||
|
||||
》》延期申请
|
||||
Linux TCP/IP networking: net-tools vs. iproute2
|
||||
================================================================================
|
||||
Many sysadmins still manage and troubleshoot various network configurations by using a combination of ifconfig, route, arp and netstat command-line tools, collectively known as net-tools. Originally rooted in the BSD TCP/IP toolkit, the net-tools was developed to configure network functionality of older Linux kernels. Its development in the Linux community so far has ceased since 2001. Some Linux distros such as Arch Linux and CentOS/RHEL 7 have already deprecated net-tools in favor of iproute2.
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
|
||||
How to create a software RAID-1 array with mdadm on Linux
|
||||
================================================================================
|
||||
Redundant Array of Independent Disks (RAID) is a storage technology that combines multiple hard disks into a single logical unit to provide fault-tolerance and/or improve disk I/O performance. Depending on how data is stored in an array of disks (e.g., with striping, mirroring, parity, or any combination thereof), different RAID levels are defined (e.g., RAID-0, RAID-1, RAID-5, etc). RAID can be implemented either in software or with a hardware RAID card. On modern Linux, basic software RAID functionality is available by default.
|
||||
|
||||
@ -1,106 +0,0 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
How to configure peer-to-peer VPN on Linux
|
||||
================================================================================
|
||||
A traditional VPN (e.g., OpenVPN, PPTP) is composed of a VPN server and one or more VPN clients connected to the server. When any two VPN clients talk to each other, the VPN server needs to relay VPN traffic between them. The problem of such a hub-and-spoke type of VPN topology is that the VPN server can easily become a performance bottleneck as the number of connected clients increases. The centralized VPN server is also a single point of failure in a sense that if the VPN server goes down, the entire VPN is no longer accessible to any VPN client.
|
||||
|
||||
Peer-to-peer VPN (or P2P VPN) is an alternative VPN model that addresses these problems of the traditional server-client based VPN. In a P2P VPN, there is no longer a centralized VPN server. Any node with a public IP address can bootstrap other nodes into a VPN. Once connected to a VPN, each node can communicate with any other node in the VPN directly, without going through an intermediary server node. When any one node goes down, the rest of nodes in the VPN are not affected. Inter-node latency/bandwidth and VPN scalability naturally improve in such a setting, which is desirable if you want to use a VPN for multi-player gaming or file sharing among many friends.
|
||||
|
||||
There are several open-source implementations of P2P VPN, such as [Tinc][1], peerVPN, and [n2n][2]. In this tutorial, I am going to demonstrate **how to configure a peer-to-peer VPN using** n2n **on Linux**.
|
||||
|
||||
n2n is an open-source (GPLv3) software allowing you to construct an encrypted layer-2/3 peer-to-peer VPN among users. The VPN created by n2n is "NAT-friendly," which means that two users behind different NAT routers can directly talk to each other over the VPN. n2n supports symmetric NAT type which is the most restrictive form of NAT. For that, the VPN traffic of n2n is encapsulated by UDP.
|
||||
|
||||
A n2n VPN is composed of two kinds of nodes: edge node and super node. An edge node is a computer which is connected to a VPN, potentially from behind a NAT router. A super node is a computer with a publicly reachable IP address, which assists with initial signaling for NATed edges. To create a P2P VPN among users, we need at least one super node.
|
||||
|
||||

|
||||
|
||||
### Preparation ###
|
||||
|
||||
In this tutorial, I am going to set up a P2P VPN using three nodes: one super node, and two edge nodes. The only requirement is that edge nodes be able to ping the IP address of the super node. It does not matter whether the edge nodes are behind NAT routers or not.
|
||||
|
||||
### Install n2n on Linux ###
|
||||
|
||||
To construct a P2P VPN using n2n, you need to install n2n on every edge node as well as super node.
|
||||
|
||||
Due to its minimal dependency requirements, n2n can be built easily on most Linux platforms.
|
||||
|
||||
To install n2n on Debian-based system:
|
||||
|
||||
$ sudo apt-get install subversion build-essential libssl-dev
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
To install n2n on Red Hat-based system:
|
||||
|
||||
$ sudo yum install subversion gcc-c++ openssl-devel
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Configure a P2P VPN with n2n ###
|
||||
|
||||
As mentioned before, we need to set up at least one super node which acts as an initial bootstraping server. We assume that the IP address of the super node is 1.1.1.1.
|
||||
|
||||
#### Super node: ####
|
||||
|
||||
On a computer which acts as a super node, run the following command. The "-l <port>" specifies the listening port of the super node. No root privilege is required to run supernode.
|
||||
|
||||
$ supernode -l 5000
|
||||
|
||||
#### Edge node: ####
|
||||
|
||||
On each edge node, use the following command to connect to a P2P VPN. The edge daemon will be running in the background.
|
||||
|
||||
Edge node #1:
|
||||
|
||||
$ sudo edge -d edge0 -a 10.0.0.10 -c mynetwork -u 1000 -g 1000 -k password -l 1.1.1.1:5000 -m ae:e0:4f:e7:47:5b
|
||||
|
||||
Edge node #2:
|
||||
|
||||
$ sudo edge -d edge0 -a 10.0.0.11 -c mynetwork -u 1000 -g 1000 -k password -l 1.1.1.1:5000 -m ae:e0:4f:e7:47:5c
|
||||
|
||||
Here are some explanations on the command-line.
|
||||
|
||||
- The "-d <name>" option specifies the name of a TAP interface being created by edge command.
|
||||
- The "-a <IP-address>" option defines (statically) the VPN IP address to be assigned to the TAP interface. If you want to use DHCP, you need to set up a DHCP server on one of edge nodes, and use "-a dhcp:0.0.0.0" option instead.
|
||||
- The "-c <community-name>" option specifies the name of a VPN group (with a length of up to 16 bytes). This option is used to create multiple VPNs among the same group of nodes.
|
||||
- The "-u" and "-g" options are used to drop root priviledge after creating a TAP interface. The edge daemon will run as the specified user/group ID.
|
||||
- The "-k <key-string>" option specifies a twofish encryption key string to be used. If you want to hide a key-string from the command-line, you can define the key in N2N_KEY environment variable.
|
||||
- The "-l <IP-address:port>" option specifies super node's listening IP address and port number. For redundancy, you can specify up to two different super nodes (e.g., -l <supernode A> -l <supernode B>).
|
||||
- The "-m <mac-address> assigns a static MAC address to a TAP interface. Without this, edge command will randomly generate a MAC address. In fact, hardcoding a static MAC address for a VPN interface is highly recommended. Otherwise, in case you restart edge daemon on a node, ARP cache of other peers will be polluted due to a newly generated MAC addess, and they will not send traffic to the node until the polluted ARP entry is evicted.
|
||||
|
||||
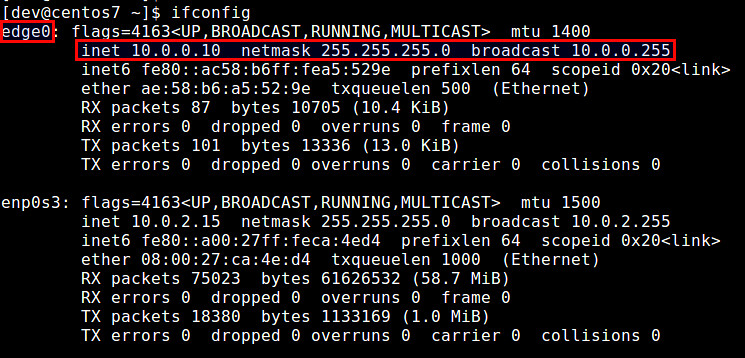
|
||||
|
||||
At this point, you should be able to ping from one edge node to the other using their VPN IP addresses.
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. You are getting the following error while invoking edge daemon.
|
||||
|
||||
n2n[4405]: ERROR: ioctl() [Operation not permitted][-1]
|
||||
|
||||
Be aware that edge daemon requires superuser privilege when creating a TAP interface. Thus make sure to use root privilege or set SUID for edge command. You can always use "-u" and "-g" option to drop root privilege afterwards.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
n2n can be a quite practical free VPN solution for you. You can easily configure a super node from your own home network or by grabbing a publicly addressable VPS instance from [cloud hosting][3]. Instead of placing sensitive credentials and encryption keys in the hands of a third-party VPN provider, you can use n2n to set up your own low-latency, high bandwidth, scalable P2P VPN among your friends.
|
||||
|
||||
What is your thought on n2n? Share your opinion in the comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-peer-to-peer-vpn-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-and-configure-tinc-vpn.html
|
||||
[2]:http://www.ntop.org/products/n2n/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
@ -1,86 +0,0 @@
|
||||
wangjiezhe translating...
|
||||
|
||||
Linux FAQs with Answers--How to change date and time from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: In Linux, how can I change date and time from the command line?
|
||||
|
||||
Keeping the date and time up-to-date in a Linux system is an important responsibility of every Linux user and system administrator. Many applications rely on accurate timing information to operate properly. Besides, inaccurate date and time render timestamp information in log files meaningless, diminishing their usefulness for system inspection and troubleshooting. For production systems, accurate date and time are even more critical. For example, the production in a retail company must be accounted precisely at all times (and stored in a database server) so that the finance department can calculate the expenses and net income of the day, current week, month, and year.
|
||||
|
||||
We must note that there are two kinds of clocks in a Linux machine: the software clock (aka system clock), which is maintained by the kernel, and the (battery-driven) hardware clock, which is used to keep track of time when the machine is powered down. During boot, the kernel sets the system clock to the same time as the hardware clock. Afterwards, both clocks run independent from each other.
|
||||
|
||||
### Method One: Date Command ###
|
||||
|
||||
In Linux, you can use the date command to change the date and time of your system:
|
||||
|
||||
# date --set='NEW_DATE'
|
||||
|
||||
where NEW_DATE is a mostly free format human readable date string such as "Sun, 28 Sep 2014 16:21:42" or "2014-09-29 16:21:42".
|
||||
|
||||
The date format can also be specified to obtain more accurate results:
|
||||
|
||||
# date +FORMAT --set='NEW_DATE'
|
||||
|
||||
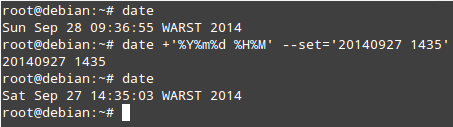
For example:
|
||||
|
||||
# date +’%Y%m%d %H%m’ --set='20140928 1518'
|
||||
|
||||
|
||||
|
||||
You can also increment or decrement date or time by a number of days, weeks, months or years, and seconds, minutes or hours, respectively. You may combine date and time parameters in one command as well.
|
||||
|
||||
# date --set='+5 minutes'
|
||||
# date --set='-2 weeks'
|
||||
# date --set='+3 months'
|
||||
# date --set='-3 months +2 weeks -5 minutes'
|
||||
|
||||
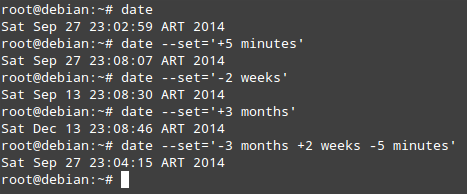
|
||||
|
||||
Finally, set the hardware clock to the current system time:
|
||||
|
||||
# hwclock --systohc
|
||||
|
||||
The purpose of running **hwclock --systohc** is to update the hardware clock with the software clock. This is to correct the systematic drift of the hardware clock, where it consistently gains or loses time at a certain rate.
|
||||
|
||||
On the other hand, if the hardware clock shows correct date and time, but the system clock does not, the latter can be updated as follows:
|
||||
|
||||
# hwclock --hctosys
|
||||
|
||||
In either case, hwclock command synchronizes both clocks. Otherwise, the time will be wrong after the next reboot, since the hardware clock keeps the time when power is turned off. However, keep in mind that this is not applicable to virtual machines, as they cannot access the hardware clock of the host machine directly.
|
||||
|
||||
If the default timezone is not correct on your Linux system, you can change it by following [this guideline][1].
|
||||
|
||||
### Method Two: NTP ###
|
||||
|
||||
Another way to keep your system's date and time accurate is using NTP (network time protocol). On Linux, ntpdate command can synchronize system clock against [public NTP servers][2] using NTP.
|
||||
|
||||
You can install **ntpdate** as follows:
|
||||
|
||||
On Debian and derivatives:
|
||||
|
||||
# aptitude install ntpdate
|
||||
|
||||
On Red Hat-based distributions:
|
||||
|
||||
# yum install ntpdate
|
||||
|
||||
To synchronize system clock using NTP:
|
||||
|
||||
# ntpdate -u <NTP server name or IP address>
|
||||
# hwclock --systohc
|
||||
|
||||

|
||||
|
||||
As opposed to one-time clock sync using ntpdate, you can also set up NTP daemon (ntpd) on your system, so that ntpd always runs in the background, continuously adjusting system clock via NTP. Refer to [this guideline][3] to set up **ntpd**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-date-time-command-line-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://ask.xmodulo.com/change-timezone-linux.html
|
||||
[2]:http://www.pool.ntp.org/
|
||||
[3]:http://xmodulo.com/how-to-synchronize-time-with-ntp.html
|
||||
@ -1,70 +0,0 @@
|
||||
Vic020
|
||||
|
||||
Linux FAQs with Answers--How to create and mount an XFS file system on Linux
|
||||
================================================================================
|
||||
> **Question**: I heard good things about XFS, and would like to create an XFS file system on my disk partition. What are the Linux commands to format and mount an XFS file system?
|
||||
|
||||
[XFS][1] is a high-performance file system which was designed by SGI for their IRIX platform. Since XFS was ported to the Linux kernel in 2001, XFS has remained a preferred choice for many enterprise systems especially with massive amount of data, due to its [high performance][2], architectural scalability and robustness. For example, RHEL/CentOS 7 and Oracle Linux have adopted XFS as their default file system, and SUSE/openSUSE have long been an avid supporter of XFS.
|
||||
|
||||
XFS has a number of unique features that make it stand out among the file system crowd, such as scalable/parallel I/O, journaling for metadata operations, online defragmentation, suspend/resume I/O, delayed allocation for performance, etc.
|
||||
|
||||
If you want to create and mount an XFS file system on your Linux platform, here is how to do it.
|
||||
|
||||
### Install XFS System Utilities ###
|
||||
|
||||
First, you need to install XFS system utilities, which allow you to perform various XFS related administration tasks (e.g., format, [expand][3], repair, setting up quota, change parameters, etc).
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo apt-get install xfsprogs
|
||||
|
||||
On Fedora, CentOS or RHEL:
|
||||
|
||||
$ sudo yum install xfsprogs
|
||||
|
||||
On Arch Linux:
|
||||
|
||||
$ sudo pacman -S xfsprogs
|
||||
|
||||
### Create an XFS-Formatted Disk Partition ###
|
||||
|
||||
Now let's first prepare a disk partition to create XFS on. Assuming that your disk is located at /dev/sdb, create a partition by:
|
||||
|
||||
$ sudo fdisk /dev/sdb
|
||||
|
||||
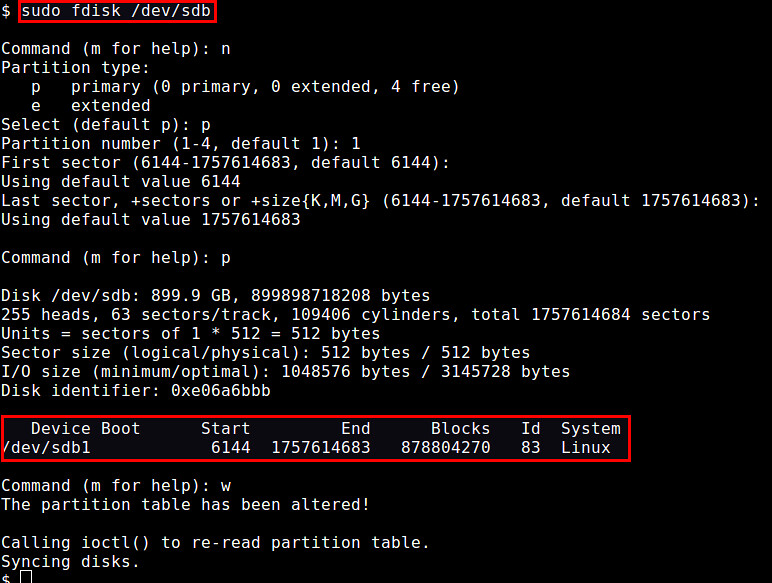
|
||||
|
||||
Let's say the created partition is assigned /dev/sdb1 device name.
|
||||
|
||||
Next, format the partition as XFS using mkfs.xfs command. The "-f" option is needed if the partition has any other file system created on it, and you want to overwrite it.
|
||||
|
||||
$ sudo mkfs.xfs -f /dev/sdb1
|
||||
|
||||
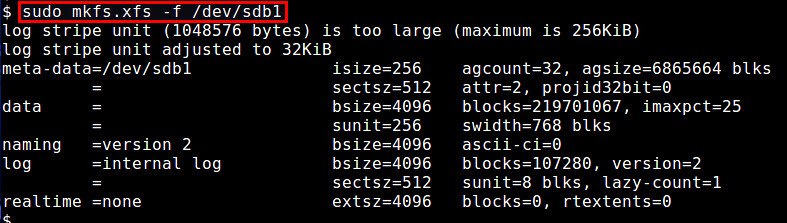
|
||||
|
||||
Now you are ready to mount the formatted partition. Let's assume that /storage is a local mount point for XFS. Go ahead and mount the partition by running:
|
||||
|
||||
$ sudo mount -t xfs /dev/sdb1 /storage
|
||||
|
||||
Verify that XFS mount is succesful by running:
|
||||
|
||||
$ df -Th /storage
|
||||
|
||||
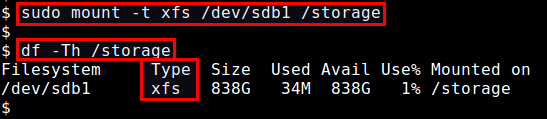
|
||||
|
||||
If you want the XFS partition to be mounted at /storage automatically upon boot, add the following line to /etc/fstab.
|
||||
|
||||
/dev/sdb1 /storage xfs defaults 0 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/create-mount-xfs-file-system-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xfs.org/
|
||||
[2]:http://lwn.net/Articles/476263/
|
||||
[3]:http://ask.xmodulo.com/expand-xfs-file-system.html
|
||||
@ -0,0 +1,84 @@
|
||||
Configuring layer-two peer-to-peer VPN using n2n
|
||||
================================================================================
|
||||
n2n is a layer-two peer-to-peer virtual private network (VPN) which allows users to exploit features typical of P2P applications at network instead of application level. This means that users can gain native IP visibility (e.g. two PCs belonging to the same n2n network can ping each other) and be reachable with the same network IP address regardless of the network where they currently belong. In a nutshell, as OpenVPN moved SSL from application (e.g. used to implement the https protocol) to network protocol, n2n moves P2P from application to network level.
|
||||
|
||||
### n2n main features ###
|
||||
|
||||
An n2n is an encrypted layer two private network based on a P2P protocol.
|
||||
|
||||
Encryption is performed on edge nodes using open protocols with user-defined encryption keys: you control your security without delegating it to companies as it happens with Skype or Hamachi.
|
||||
|
||||
Each n2n user can simultaneously belong to multiple networks (a.k.a. communities).
|
||||
|
||||
Ability to cross NAT and firewalls in the reverse traffic direction (i.e. from outside to inside) so that n2n nodes are reachable even if running on a private network. Firewalls no longer are an obstacle to direct communications at IP level.
|
||||
|
||||
n2n networks are not meant to be self-contained, but it is possible to route traffic across n2n and non-n2n networks.
|
||||
|
||||
### The n2n architecture is based on two components ###
|
||||
|
||||
**Supernode**: it is used by edge nodes at startup or for reaching nodes behind symmetrical firewalls. This application is basically a directory register and a packet router for those nodes that cannot talk directly.
|
||||
|
||||
**Edge nodes**: applications installed on user PCs that allow the n2n network to be build. Practically each edge node creates a tun/tap device that is then the entry point to the n2n network.
|
||||
|
||||
### Install n2n on Ubuntu ###
|
||||
|
||||
Open the terminal and run the following commands
|
||||
|
||||
$ sudo apt-get install subversion build-essential libssl-dev
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Configure a P2P VPN with n2n ###
|
||||
|
||||
First we need to configure one super node and any number of edge nodes
|
||||
|
||||
Decide where to place your supernode. Suppose you put it on host a.b.c.d at port xyw.
|
||||
|
||||
Decide what encryption password you want to use to secure your data. Suppose you use the password encryptme
|
||||
|
||||
Decide the network name you want to use. Suppose you call it mynetwork. Note that you can use your supernode/edge nodes to handle multiple networks, not just one.
|
||||
|
||||
Decide what IP address you plan to use on your edge nodes. Suppose you use IP address 10.1.2.0/24
|
||||
|
||||
Start your applications:
|
||||
|
||||
### Configure Super node ###
|
||||
|
||||
supernode -l xyw
|
||||
|
||||
### Configure Edge Nodes ###
|
||||
|
||||
On each edge node, use the following command to connect to a P2P VPN.
|
||||
|
||||
sudo edge -a 10.1.2.1 -c mynetwork -k encryptme -l a.b.c.d:xyw
|
||||
|
||||
sudo edge -a 10.1.2.2 -c mynetwork -k encryptme -l a.b.c.d:xyw
|
||||
|
||||
### Now test your n2n network ###
|
||||
|
||||
edge node1> ping 10.1.2.2
|
||||
|
||||
edge node2> ping 10.1.2.1
|
||||
|
||||
Windows n2n VPN Client (N2N Edge GUI)
|
||||
|
||||
You can download N2N Edge GUI from [here][1]
|
||||
|
||||
N2N Edge GUI is a basic installer and GUI configuration screen for the peer-to-peer ‘n2n' VPN solution
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/configuring-layer-two-peer-to-peer-vpn-using-n2n.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://sourceforge.net/projects/n2nedgegui/
|
||||
@ -0,0 +1,157 @@
|
||||
How to create and use Python CGI scripts
|
||||
================================================================================
|
||||
Have you ever wanted to create a webpage or process user input from a web-based form using Python? These tasks can be accomplished through the use of Python CGI (Common Gateway Interface) scripts with an Apache web server. CGI scripts are called by a web server when a user requests a particular URL or interacts with the webpage (such as clicking a "Submit" button). After the CGI script is called and finishes executing, the output is used by the web server to create a webpage displayed to the user.
|
||||
|
||||
### Configuring the Apache web server to run CGI scripts ###
|
||||
|
||||
In this tutorial we assume that an Apache web server is already set up and running. This tutorial uses an Apache web server (version 2.2.15 on CentOS release 6.5) that is hosted at the localhost (127.0.0.1) and is listening on port 80, as specified by the following Apache directives:
|
||||
|
||||
ServerName 127.0.0.1:80
|
||||
Listen 80
|
||||
|
||||
HTML files used in the upcoming examples are located in /var/www/html on the web server. This is specified via the DocumentRoot directive (specifies the directory that webpages are located in):
|
||||
|
||||
DocumentRoot "/var/www/html"
|
||||
|
||||
Consider a request for the URL: http://localhost/page1.html
|
||||
|
||||
This will return the contents of the following file on the web server:
|
||||
|
||||
/var/www/html/page1.html
|
||||
|
||||
To enable use of CGI scripts, we must specify where CGI scripts are located on the web server. To do this, we use the ScriptAlias directive:
|
||||
|
||||
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
|
||||
|
||||
The above directive indicates that CGI scripts are contained in the /var/www/cgi-bin directory on the web server and that inclusion of /cgi-bin/ in the requested URL will search this directory for the CGI script of interest.
|
||||
|
||||
We must also explicitly permit the execution of CGI scripts in the /var/www/cgi-bin directory and specify the file extensions of CGI scripts. To do this, we use the following directives:
|
||||
|
||||
<Directory "/var/www/cgi-bin">
|
||||
Options +ExecCGI
|
||||
AddHandler cgi-script .py
|
||||
</Directory>
|
||||
|
||||
Consider a request for the URL: http://localhost/cgi-bin/myscript-1.py
|
||||
|
||||
This will call the following script on the web server:
|
||||
|
||||
/var/www/cgi-bin/myscript-1.py
|
||||
|
||||
### Creating a CGI script ###
|
||||
|
||||
Before creating a Python CGI script, you will need to confirm that you have Python installed (this is generally installed by default, however the installed version may vary). Scripts in this tutorial are created using Python version 2.6.6. You can check your version of Python from the command line by entering either of the following commands (the -V and --version options display the version of Python that is installed):
|
||||
|
||||
$ python -V
|
||||
$ python --version
|
||||
|
||||
If your Python CGI script will be used to process user-entered data (from a web-based input form), then you will need to import the Python cgi module. This module provides functionality for accessing data that users have entered into web-based input forms. You can import this module via the following statement in your script:
|
||||
|
||||
import cgi
|
||||
|
||||
You must also change the execute permissions for the Python CGI script so that it can be called by the web server. Add execute permissions for others via the following command:
|
||||
|
||||
# chmod o+x myscript-1.py
|
||||
|
||||
### Python CGI Examples ###
|
||||
|
||||
Two scenarios involving Python CGI scripts will be considered in this tutorial:
|
||||
|
||||
- Create a webpage using a Python script
|
||||
- Read and display user-entered data and display results in a webpage
|
||||
|
||||
Note that the Python cgi module is required for Scenario 2 because this involves accessing user-entered data from web-based input forms.
|
||||
|
||||
### Example 1: Create a webpage using a Python script ###
|
||||
|
||||
For this scenario, we will start by creating a webpage /var/www/html/page1.html with a single submit button:
|
||||
|
||||
<html>
|
||||
<h1>Test Page 1</h1>
|
||||
<form name="input" action="/cgi-bin/myscript-1.py" method="get">
|
||||
<input type="submit" value="Submit">
|
||||
</form>
|
||||
</html>
|
||||
|
||||
When the "Submit" button is clicked, the /var/www/cgi-bin/myscript-1.py script is called (specified by the action parameter). A "GET" request is specified by setting the method parameter equal to "get". This requests that the web server return the specified webpage. An image of /var/www/html/page1.html as viewed from within a web browser is shown below:
|
||||
|
||||
|
||||
|
||||
The contents of /var/www/cgi-bin/myscript-1.py are:
|
||||
|
||||
#!/usr/bin/python
|
||||
print "Content-Type: text/html"
|
||||
print ""
|
||||
print "<html>"
|
||||
print "<h2>CGI Script Output</h2>"
|
||||
print "<p>This page was generated by a Python CGI script.</p>"
|
||||
print "</html>"
|
||||
|
||||
The first statement indicates that this is a Python script to be run with the /usr/bin/python command. The print "Content-Type: text/html" statement is required so that the web server knows what type of output it is receiving from the CGI script. The remaining statements are used to print the text of the webpage in HTML format.
|
||||
|
||||
When the "Submit" button is clicked in the above webpage, the following webpage is returned:
|
||||
|
||||
|
||||
|
||||
The take-home point with this example is that you have the freedom to decide what information is returned by the CGI script. This could include the contents of log files, a list of users currently logged on, or today's date. The possibilities are endless given that you have the entire Python library at your disposal.
|
||||
|
||||
### Example 2: Read and display user-entered data and display results in a webpage ###
|
||||
|
||||
For this scenario, we will start by creating a webpage /var/www/html/page2.html with three input fields and a submit button:
|
||||
|
||||
<html>
|
||||
<h1>Test Page 2</h1>
|
||||
<form name="input" action="/cgi-bin/myscript-2.py" method="get">
|
||||
First Name: <input type="text" name="firstName"><br>
|
||||
Last Name: <input type="text" name="lastName"><br>
|
||||
Position: <input type="text" name="position"><br>
|
||||
<input type="submit" value="Submit">
|
||||
</form>
|
||||
</html>
|
||||
|
||||
When the "Submit" button is clicked, the /var/www/cgi-bin/myscript-2.py script is called (specified by the action parameter). An image of /var/www/html/page2.html as viewed from within a web browser is shown below (note that the three input fields have already been filled in):
|
||||
|
||||
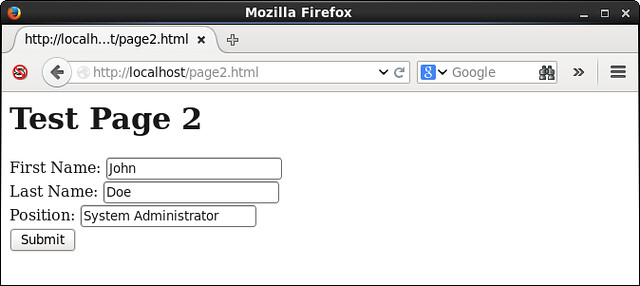
|
||||
|
||||
The contents of /var/www/cgi-bin/myscript-2.py are:
|
||||
|
||||
#!/usr/bin/python
|
||||
import cgi
|
||||
form = cgi.FieldStorage()
|
||||
print "Content-Type: text/html"
|
||||
print ""
|
||||
print "<html>"
|
||||
print "<h2>CGI Script Output</h2>"
|
||||
print "<p>"
|
||||
print "The user entered data are:<br>"
|
||||
print "<b>First Name:</b> " + form["firstName"].value + "<br>"
|
||||
print "<b>Last Name:</b> " + form["lastName"].value + "<br>"
|
||||
print "<b>Position:</b> " + form["position"].value + "<br>"
|
||||
print "</p>"
|
||||
print "</html>"
|
||||
|
||||
As mentioned previously, the import cgi statement is needed to enable functionality for accessing user-entered data from web-based input forms. The web-based input form is encapsulated in the form object, which is a cgi.FieldStorage object. Once again, the "Content-Type: text/html" line is required so that the web server knows what type of output it is receiving from the CGI script. The data entered by the user are accessed in the statements that contain form["firstName"].value, form["lastName"].value, and form["position"].value. The names in the square brackets correspond to the values of the name parameters defined in the text input fields in **/var/www/html/page2.html**.
|
||||
|
||||
When the "Submit" button is clicked in the above webpage, the following webpage is returned:
|
||||
|
||||
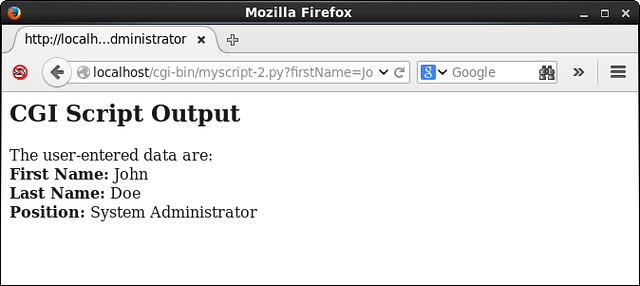
|
||||
|
||||
The take-home point with this example is that you can easily read and display user-entered data from web-based input forms. In addition to processing data as strings, you can also use Python to convert user-entered data to numbers that can be used in numerical calculations.
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial demonstrates how Python CGI scripts are useful for creating webpages and for processing user-entered data from web-based input forms. More information about Apache CGI scripts can be found [here][1] and more information about the Python cgi module can be found [here][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/create-use-python-cgi-scripts.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
[1]:http://httpd.apache.org/docs/2.2/howto/cgi.html
|
||||
[2]:https://docs.python.org/2/library/cgi.html#module-cgi
|
||||
@ -0,0 +1,132 @@
|
||||
How to monitor a log file on Linux with logwatch
|
||||
================================================================================
|
||||
Linux operating system and many applications create special files commonly referred to as "logs" to record their operational events. These system logs or application-specific log files are an essential tool when it comes to understanding and troubleshooting the behavior of the operating system and third-party applications. However, log files are not precisely what you would call "light" or "easy" reading, and analyzing raw log files by hand is often time-consuming and tedious. For that reason, any utility that can convert raw log files into a more user-friendly log digest is a great boon for sysadmins.
|
||||
|
||||
[logwatch][1] is an open-source log parser and analyzer written in Perl, which can parse and convert raw log files into a structured format, making a customizable report based on your use cases and requirements. In logwatch, the focus is on producing more easily consumable log summary, not on real-time log processing and monitoring. As such, logwatch is typically invoked as an automated cron task with desired time and frequency, or manually from the command line whenever log processing is needed. Once a log report is generated, logwatch can email the report to you, save it to a file, or display it on the screen.
|
||||
|
||||
A logwatch report is fully customizable in terms of verbosity and processing coverage. The log processing engine of logwatch is extensible, in a sense that if you want to enable logwatch for a new application, you can write a log processing script (in Perl) for the application's log file, and plug it under logwatch.
|
||||
|
||||
One downside of logwatch is that it does not include in its report detailed timestamp information available in original log files. You will only know that a particular event was logged in a requested range of time, and you will have to access original log files to get exact timing information.
|
||||
|
||||
### Installing Logwatch ###
|
||||
|
||||
On Debian and derivatives:
|
||||
|
||||
# aptitude install logwatch
|
||||
|
||||
On Red Hat-based distributions:
|
||||
|
||||
# yum install logwatch
|
||||
|
||||
### Configuring Logwatch ###
|
||||
|
||||
During installation, the main configuration file (logwatch.conf) is placed in /etc/logwatch/conf. Configuration options defined in this file override system-wide settings defined in /usr/share/logwatch/default.conf/logwatch.conf.
|
||||
|
||||
If logwatch is launched from the command line without any arguments, the custom options defined in /etc/logwatch/conf/logwatch.conf will be used. However, if any command-line arguments are specified with logwatch command, those arguments in turn override any default/custom settings in /etc/logwatch/conf/logwatch.conf.
|
||||
|
||||
In this article, we will customize several default settings of logwatch by editing /etc/logwatch/conf/logwatch.conf file.
|
||||
|
||||
Detail = <Low, Med, High, or a number>
|
||||
|
||||
"Detail" directive controls the verbosity of a logwatch report. It can be a positive integer, or High, Med, Low, which correspond to 10, 5, and 0, respectively.
|
||||
|
||||
MailTo = youremailaddress@yourdomain.com
|
||||
|
||||
"MailTo" directive is used if you want to have a logwatch report emailed to you. To send a logwatch report to multiple recipients, you can specify their email addresses separated with a space. To be able to use this directive, however, you will need to configure a local mail transfer agent (MTA) such as sendmail or Postfix on the server where logwatch is running.
|
||||
|
||||
Range = <Yesterday|Today|All>
|
||||
|
||||
"Range" directive specifies the time duration of a logwatch report. Common values for this directive are Yesterday, Today or All. When "Range = All" is used, "Archive = yes" directive is also needed, so that all archived versions of a given log file (e.g., /var/log/maillog, /var/log/maillog.X, or /var/log/maillog.X.gz) are processed.
|
||||
|
||||
Besides such common range values, you can also use more complex range options such as the following.
|
||||
|
||||
- Range = "2 hours ago for that hour"
|
||||
- Range = "-5 days"
|
||||
- Range = "between -7 days and -3 days"
|
||||
- Range = "since September 15, 2014"
|
||||
- Range = "first Friday in October"
|
||||
- Range = "2014/10/15 12:50:15 for that second"
|
||||
|
||||
To be able to use such free-form range examples, you need to install Date::Manip Perl module from CPAN. Refer to [this post][2] for CPAN module installation instructions.
|
||||
|
||||
Service = <service-name-1>
|
||||
Service = <service-name-2>
|
||||
. . .
|
||||
|
||||
"Service" option specifies one or more services to monitor using logwath. All available services are listed in /usr/share/logwatch/scripts/services, which cover essential system services (e.g., pam, secure, iptables, syslogd), as well as popular application services such as sudo, sshd, http, fail2ban, samba. If you want to add a new service to the list, you will have to write a corresponding log processing Perl script, and place it in this directory.
|
||||
|
||||
If this option is used to select specific services, you need to comment out the line "Service = All" in /usr/share/logwatch/default.conf/logwatch.conf.
|
||||
|
||||

|
||||
|
||||
Format = <text|html>
|
||||
|
||||
"Format" directive specifies the format (e.g., text or HTML) of a logwatch report.
|
||||
|
||||
Output = <file|mail|stdout>
|
||||
|
||||
"Output" directive indicates where a logwatch report should be sent. It can be saved to a file (file), emailed (mail), or shown to screen (stdout).
|
||||
|
||||
### Analyzing Log Files with Logwatch ###
|
||||
|
||||
To understand how to analyze log files using logwatch, consider the following logwatch.conf example:
|
||||
|
||||
Detail = High
|
||||
MailTo = youremailaddress@yourdomain.com
|
||||
Range = Today
|
||||
Service = http
|
||||
Service = postfix
|
||||
Service = zz-disk_space
|
||||
Format = html
|
||||
Output = mail
|
||||
|
||||
Under these settings, logwatch will process log files generated by three services (http, postfix and zz-disk_space) today, produce an HTML report with high verbosity, and email it to you.
|
||||
|
||||
If you do not want to customize /etc/logwatch/conf/logwatch.conf, you can leave the default configuration file unchanged, and instead run logwatch from the command line as follows. It will achieve the same outcome.
|
||||
|
||||
# logwatch --detail 10 --mailto youremailaddress@yourdomain.com --range today --service http --service postfix --service zz-disk_space --format html --output mail
|
||||
|
||||
The emailed report looks like the following.
|
||||
|
||||

|
||||
|
||||
The email header includes links to navigate the report sections, one per each selected service, and also "Back to top" links.
|
||||
|
||||
You will want to use the email report option when the list of recipients is small. Otherwise, you can have logwatch save a generated HTML report within a network share that can be accessed by all the individuals who need to see the report. To do so, make the following modifications in our previous example:
|
||||
|
||||
Detail = High
|
||||
Range = Today
|
||||
Service = http
|
||||
Service = postfix
|
||||
Service = zz-disk_space
|
||||
Format = html
|
||||
Output = file
|
||||
Filename = /var/www/html/logs/dev1.html
|
||||
|
||||
Equivalently, run logwatch from the command line as follows.
|
||||
|
||||
# logwatch --detail 10 --range today --service http --service postfix --service zz-disk_space --format html --output file --filename /var/www/html/logs/dev1.html
|
||||
|
||||
Finally, let's configure logwatch to be executed by cron on your desired schedules. The following example will run a logwatch cron job every business day at 12:15 pm:
|
||||
|
||||
# crontab -e
|
||||
|
||||
----------
|
||||
|
||||
15 12 * * 1,2,3,4,5 /sbin/logwatch
|
||||
|
||||
Hope this helps. Feel free to comment to share your own tips and ideas with the community!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-log-file-linux-logwatch.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://sourceforge.net/projects/logwatch/
|
||||
[2]:http://xmodulo.com/how-to-install-perl-modules-from-cpan.html
|
||||
@ -0,0 +1,37 @@
|
||||
Debian 7.7 发布了,带来了一些安全修复
|
||||
================================================================================
|
||||
** Debian项目已经宣布Debian7.7 “Wheezy”发布并提供下载。这是常规维护更新,但它打包了很多重要的更新。**
|
||||
|
||||

|
||||
|
||||
Debian发行版可以得到常规主要的更新,但如果你已经安装了它且保持最新,你无需做任何额外的东西。开发者已经开发了一些重要的修复,因此它建议尽快升级。
|
||||
|
||||
“此次更新主要给稳定版修正安全问题,以及对一些严重问题的调整。安全建议已经另外发布且在其他地方引用。”
|
||||
|
||||
开发者在正式[公告][1]中指出:“请注意,此更新不构成Debian 7的新版本,只会更新部分包,没必要扔掉旧的wheezy CD或DVD,只要在安装后通过Debian镜像升级来升级那些过期的包就行“。
|
||||
|
||||
开发着已经升级了Bash包来修复一些重要的漏洞,在boot时登录SSH不再有效,并且还做了其他一些微调。
|
||||
|
||||
要了解发布更多的细节请查看官方公告中的完整更新日志。
|
||||
|
||||
现在下载 Debian 7.7:
|
||||
|
||||
- [Debian GNU/Linux 7.7.0 (ISO) 32-bit/64-bit][2]
|
||||
- [Debian GNU/Linux 6.0.10 (ISO) 32-bit/64-bit][3]
|
||||
- [Debian GNU/Linux 8 Beta 2 (ISO) 32-bit/64-bit][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Debian-7-7-Is-Out-with-Security-Fixes-462647.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://www.debian.org/News/2014/20141018
|
||||
[2]:http://ftp.acc.umu.se/debian-cd/7.7.0/multi-arch/iso-dvd/debian-7.7.0-i386-amd64-source-DVD-1.iso
|
||||
[3]:http://ftp.au.debian.org/debian/dists/oldstable/
|
||||
[4]:http://cdimage.debian.org/cdimage/jessie_di_beta_2/
|
||||
51
translated/share/20141021 Nifty Free Image Viewers.md
Normal file
51
translated/share/20141021 Nifty Free Image Viewers.md
Normal file
@ -0,0 +1,51 @@
|
||||
实用免费图片查看器
|
||||
================================================================================
|
||||
|
||||
我最喜欢的谚语之一是“一图胜千言”。它指一张静态图片可以传递一个复杂的想法。图像相比文字而言可以迅速且更有效地描述大量信息。它们捕捉回忆,永不让你忘记你所想记住的东西,并且让它时常在你的记忆里刷新。
|
||||
|
||||
图片是互联网日常使用的一部分,并且对社交媒体互动尤其重要。一个好的图片查看器是任何操作系统必不可少的一个组成部分。
|
||||
|
||||
Linux 系统提供了一个大量开源实用小程序的集合,其中这些程序提供了从显而易见到异乎寻常的各种功能。正是由于这些工具的高质量和可供选择帮助 Linux 在生产环境中而脱颖而出,尤其是当谈到图片查看器时。Linux 有如此多的图像查看器可供选择,以至于让挑选变得困难。
|
||||
|
||||
一个不该包括在这个综述中但是值得一提的软件是 Fragment Image Viewer。它在专有许可证下发行(是的,我知道!),所以不会预先安装在 Ubuntu 上。 但它无疑看起来十分有趣!它是明日之星,尤其如果它的开发者们将它在开源许可证下发布的话。
|
||||
|
||||
现在,让我们亲眼探究一下这 13 款图像查看器。除了一个例外,它们中每个都是在开源协议下发行。由于有很多信息要阐述,我将这些详细内容从当前单一网页综述剥离,但作为替代,我为每一款图片查看器提供了一个单独页面,具有软件的完整描述,产品特点的详细分析,一张软件工作中的截图,以及相关资源和评论的链接。
|
||||
|
||||
### 图片查看器 ###
|
||||
|
||||
- [**Eye of Gnome**][1] -- 快速且多功能的图片查看器器
|
||||
- [**gThumb**][2] -- 高级图像查看器和浏览器
|
||||
- [**Shotwell**][3] -- 被设计来提供个人照片管理的图像管理器
|
||||
- [**Gwenview**][4] -- 专为 KDE 4 桌面环境开发的简易图片查看器
|
||||
- [**Imgv**][5] -- 强大的图片查看器
|
||||
- [**feh**][6] -- 基于 Imlib2 的快速且轻量的图片查看器
|
||||
- [**nomacs**][7] -- 可处理包括 RAW 在内的大部分格式
|
||||
- [**Geeqie**][8] -- 基于 Gtk+ 的轻量级图片查看器
|
||||
- [**qiv**][9] -- 基于 gdk/imlib 的非常小且精致的开源图片查看器
|
||||
- [**PhotoQT**][10] -- 好看、高度可配置、易用且快速
|
||||
- [**Viewnior**][11] -- 设计时考虑到易用性
|
||||
- [**Cornice**][12] -- 设计用来作为 ACDSee 的免费替代品
|
||||
- [**XnViewMP**][13] -- 图像查看器、浏览器、转换器(专有软件)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20141018070111434/ImageViewers.html
|
||||
|
||||
译者:[jabirus](https://github.com/jabirus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://projects.gnome.org/eog/
|
||||
[2]:https://wiki.gnome.org/Apps/gthumb
|
||||
[3]:https://wiki.gnome.org/Apps/Shotwell/
|
||||
[4]:http://gwenview.sourceforge.net/
|
||||
[5]:http://imgv.sourceforge.net/
|
||||
[6]:http://feh.finalrewind.org/
|
||||
[7]:http://www.nomacs.org/
|
||||
[8]:http://geeqie.sourceforge.net/
|
||||
[9]:http://spiegl.de/qiv/
|
||||
[10]:http://photoqt.org/
|
||||
[11]:http://siyanpanayotov.com/project/viewnior/
|
||||
[12]:http://wxglade.sourceforge.net/extra/cornice.html
|
||||
[13]:http://www.xnview.com/en/
|
||||
@ -0,0 +1,167 @@
|
||||
Camicri Cube: 可离线的便携包管理系统
|
||||
================================================================================
|
||||

|
||||
|
||||
众所周知,在系统中使用新立德包管理工具或软件中包管理工具来下载和安装应用程序的时候,我们必须得有互联网连接。但,如果您刚好没有网络或者是网络速度死慢死慢的呢?在您的 Linux 桌面系统中使用软件中心包管理工具来安装软件这绝对是一个头痛的问题。这种情况,您只能从相应的官网上手工下载应用程序包,并手工安装。但是,大多数的 Linux 用户并不知道他们希望安装的应用程序所需要的依赖关系包。如果您恰巧出现这种情况,应用怎么办呢?现在一切都不用担心了。今天,我们给您介绍一款非常棒的名叫 **Camicri Cube** 的离线包管理工具。
|
||||
|
||||
您可以把此包管理工具装在联网的系统上,下载您所需要安装的软件,然后把他们安装到没联网的机器上,就可以安装了。听起来很不错吧?是的,它就是这样操作的。Cube 是一款像新立德和 Ubuntu 软件中心这样的包管理工具,但是一款便携式的。它在任何平台(Windows 系统、基于 Apt 的 Linux 发布系统)、在线状态、离线状态、在闪存或任何可移动设备上都是可以使用和运行的。我们这个实验项目的主要目的是使处在离线状态的 Linux 用户能很容易的下载和安装 Linux 应用程序。
|
||||
|
||||
Cube 会收集您的离线电脑的完整的详细信息,如操作系统的详细信息、安装的应用程序等等。然后使用 USB 迷你盘对 cube 应用程序进行拷贝得到一副本,把其放在其它有网络连接的系统上使用,接着就可以下载您需要的应用程序包。下载完所有需要的软件包之后,回到您原来的计算机,并开始安装。Cube 是由 **Jake Capangpangan** 开发和维护的,是用 C++ 语言编写,而且已经集成了所有必须的包。因此,要使用它并不需要再安装其它额外的软件。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
现在,让我们下载 Cube 程序包,然后在没有网络连接的离线系统上进行安装。既可以从[官网主站页面][1]下载,也可以从 [Sourceforge 网站][2]下载。要确保下载的版本跟您的离线计算机架构对应的系统相匹配。比如我使用的是64位的系统,就要下载64位版本的安装包。
|
||||
|
||||
wget http://sourceforge.net/projects/camicricube/files/Camicri%20Cube%201.0.9/cube-1.0.9.2_64bit.zip/
|
||||
|
||||
对此 zip 文件解压,解压到 home 目录或者着是您想放的任何地方:
|
||||
|
||||
unzip cube-1.0.9.2_64bit.zip
|
||||
|
||||
这就好了。接着,该是知道怎么使用的时候了。
|
||||
|
||||
### 使用 ###
|
||||
|
||||
这儿,我使用的的是两台装有 Ubuntu 系统的机器。原机器(离线-没有网络连接)上面跑着的是 **Ubuntu 14.04** 系统,有网络连接的机器跑着的是 **Lubuntu 14.04** 桌面系统。
|
||||
|
||||
#### 离线系统上的操作步骤: ####
|
||||
|
||||
在离线系统上,进入已经解压的 Cube 文件目录,您会发现一个名叫 “cube-linux” 的可执行文件,双击它,并点击执行。如果它是不可执行的,用如下命令设置其可执行权限。
|
||||
|
||||
sudo chmod -R +x cube/
|
||||
|
||||
然后,进入 cube 目录,
|
||||
|
||||
cd cube/
|
||||
|
||||
接着执行如下命令来运行:
|
||||
|
||||
./cube-linux
|
||||
|
||||
输入项目的名称(比如sk)然后点击**创建**按纽。正如我上面提到的,这将会创建一个与您的系统相关的完整详细信息的新项目,如操作系统的详细信息、安装的应用程序列表、库等等。
|
||||
|
||||

|
||||
|
||||
如您所知,我们的系统是离线的,意思是没有网络连接。所以我点击**取消**按纽来跳过资源库的更新过程。随后我们会在一台有网络连接的系统上更新此资源库。
|
||||
|
||||

|
||||
|
||||
再一次,在这台离线机器上我们点击 **No** 来跳过更新,因为我们没有网络连接。
|
||||
|
||||

|
||||
|
||||
就是这样。现在新的项目已经创建好了,它会保存在我们的主 cube 目录里面。进入 Cube 目录,您就会发现一个名叫 Projects 的目录。这个目录会保存有您的离线系统的必要完整详细信息。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
现在,关闭 cube 应用程序,然后拷贝整个主 **cube** 文件夹到任何的闪存盘里,接入有网络连接的系统。
|
||||
|
||||
#### 在线系统上操作步骤: ####
|
||||
|
||||
往下的操作步骤需要在有网络连接的系统上进行。在我们的例子中,用的是 **Lubuntu 14.04** 系统的机器。
|
||||
|
||||
跟在源机器上的操作一样设置使 cube 目录具有可执行权限。
|
||||
|
||||
sudo chmod -R +x cube/
|
||||
|
||||
现在,双击 cube-linux 文件运行应用程序或者也可以在终端上加载运行,如下所示:
|
||||
|
||||
cd cube/
|
||||
./cube-linux
|
||||
|
||||
在窗口的 “Open Existing Projects” 部分会看到您的项目列表,选择您需要的项目。
|
||||
|
||||

|
||||
|
||||
随后,cube 会询问这是否是您的项目所在的源机器。它并不是我们的源(离线)机器,所以我点击 **No**。
|
||||
|
||||

|
||||
|
||||
接着会询问是否想要更新您的资源库。点击 **OK** 来更新资料库。
|
||||
|
||||

|
||||
|
||||
下一步,我们得更新所有过期的包/应用程序。点击 Cube 工具栏上的 “**Mark All updates**” 按纽。然后点击 “**Download all marked**” 按纽来更新所有过期的包/应用程序。如下截图所示,在我的例子当中,有302个包需要更新。这时,点击 **OK** 来继续下载所标记的安装包。
|
||||
|
||||

|
||||
|
||||
现在,Cube 会开始下载所有已标记的包。
|
||||
|
||||

|
||||
|
||||
我们已经完成了对资料库和安装包的更新。此时,如果您在离线系统上还需要其它的安装包,您也可以下载这些新的安装包。
|
||||
|
||||
#### 下载新的应用程序 ####
|
||||
|
||||
例如,这儿我想下载 **apache2** 包。在**搜索**框里输入包的名字,点击搜索按纽。Cube 程序会获取您想查找的应用程序的详细信息。点击 “**Download this package now**”按纽,接着点击 **OK** 就开始下载了。
|
||||
|
||||

|
||||
|
||||
Cube 将会下载 apache2 的安装包及所有的依赖包。
|
||||
|
||||

|
||||
|
||||
如果您想查找和下载更多安装包的话,只要简单的点击 “**Mark this package**” 按纽就可以搜索到需要的包了。只要您想在源机器上安装的包都可以标记上。一旦标记完所有的包,就可以点击位于顶部工具栏的 “**Download all marked**” 按纽来下载它们。
|
||||
|
||||
在完成资源库、过期软件包的更新和下载好新的应用程序后,就可以关闭 Cube 应用程序。然后,拷贝整个 Cube 文件夹到任何的闪盘或者外接硬盘。回到您的离线系统中来。
|
||||
|
||||
#### 离线机器上的操作步骤: ####
|
||||
|
||||
把 Cube 文件夹拷回您的离线系统的任意位置。进入 cube 目录,并且双击 **cube-linux** 文件来加载启动 Cube 应用程序。
|
||||
|
||||
或者,您也可以从终端下启动它,如下所示:
|
||||
|
||||
cd cube/
|
||||
./cube-linux
|
||||
|
||||
选择您的项目,点击打开。
|
||||
|
||||

|
||||
|
||||
然后会弹出一个对话框询问是否更新系统,尤其是已经下载好新的资源库的时候,请点击“是”。因为它会把所有的资源库传输到您的机器上。
|
||||
|
||||

|
||||
|
||||
您会看到,在没有网络连接的情况下这些资源库会更新到您的离线机器上。那是因为我们已经在有网络连接的系统上下载更新了此资源库。看起来很酷,不是吗?
|
||||
|
||||
更新完资源库后,让我们来安装所有的下载包。点击 “Mark all Downloaded” 按纽选中所有的下载包,然后点击 Cube 工具栏上的 “Install All Marked” 按纽来安装它们。Cube 应用程序会自动打开一个新的终端窗口来安装所有的软件包。
|
||||
|
||||

|
||||
|
||||
如果遇到依赖的问题,进入 **Cube Menu -> Packages -> Install packages with complete dependencies** 来安装所有的依赖包。
|
||||
|
||||
如果您只想安装特定的包,定位到列表包位置,点击 “Downloaded” 按纽,所有的已下载包都会被列出来。
|
||||
|
||||

|
||||
|
||||
然后选中某个特定的包,点击 “Install this”按纽来安装或者如果想过后再安装它的话可以先点击 “Mark this” 按纽。
|
||||
|
||||

|
||||
|
||||
顺便提一句,您可以在任意已经连接网络的系统上下载所需要的包,然后在没有网络连接的离线系统上安装。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
这是我曾经使用过的一款最好、最有用的软件工具。但我在用 Ubuntu 14.04 测试盒子测试的时候,遇到了很多依赖问题,还经常会出现闪退的情况。也仅仅是在最新 Ubuntu 14.04 离线系统上使用没有遇到任何问题。希望这些问题在老版本的 Ubuntu 上不会发生。除了这些小问题,这个小工具对作向外推荐以及本职工作这些方面显得魅力十足。
|
||||
|
||||
欢呼吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/camicri-cube-offline-portable-package-management-system/
|
||||
|
||||
原文作者:
|
||||
|
||||

|
||||
|
||||
[SK][a](Senthilkumar,又名SK,来自于印度的泰米尔纳德邦,Linux 爱好者,FOSS 论坛支持者和 Linux 板块顾问。一个充满激情和活力的人,致力于提供高质量的 IT 专业文章,非常喜欢写作和对 Linux、开源、电脑和互联网等新事物的探索。)
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://launchpad.net/camicricube
|
||||
[2]:http://sourceforge.net/projects/camicricube/
|
||||
@ -0,0 +1,105 @@
|
||||
如何在 Linux 上配置点对点 VPN
|
||||
================================================================================
|
||||
一个传统的 VPN(如 OpenVPN、PPTP)由一个 VPN 服务器和一个或多个连接到这台服务器的客户端组成。当任意两个 VPN 客户端彼此通信时,VPN 服务器需要中继它们之间的 VPN 数据流量。这样一个中心辐射型的 VPN 拓扑结构存在的问题是,当连接的客户端增多以后,VPN 服务器很容易成为一个性能上的瓶颈。从某种意义上来说,中心化的 VPN 服务器也同样成为一个单点故障的来源,也就是当 VPN 服务器出现故障的时候,整个 VPN 都将无法被任何 VPN 客户端访问。
|
||||
|
||||
点对点 VPN(又称 P2P VPN)是另一个 VPN 模型,它能解决传统的基于服务器-客户端模型的 VPN 存在的这些问题。一个 P2P VPN 中不再有一个中心的 VPN 服务器,任何拥有一个公开 IP 地址的节点都能引导其他节点进入 VPN。当连接到一个 VPN 之后,每一个节点都能与 VPN 中的任何其他节点直接通信,而不需要经过一个中间的服务器节点。当然任何节点出现故障时,VPN 中的剩余节点不会受到影响。节点中的延迟、带宽以及 VPN 扩展性在这样的设定中都有自然的提升,当你想要使用 VPN 进行多人游戏或者与许多朋友分享文件时,这都是十分理想的。
|
||||
|
||||
开源的 P2P VPN 实现已经有几个了,比如 [Tinc][1]、peerVPN,以及 [n2n][2]。在本教程中,我将会展示**如何在 Linux 上用** n2n **配置点对点 VPN**。
|
||||
|
||||
n2n 是一个开源(GPLv3)软件,它允许你在用户间构建一个加密的 2/3 层点对点 VPN。由 n2n 构建的 VPN 是“对 NAT 友好”的,也就是说,不同 NAT 路由器后方的两个用户可以通过 VPN 直接与对方通信。n2n 支持对称的 NAT 类型,这是 NAT 中限制最多的一种。因此,n2n 的 VPN 数据流量是用 UDP 封装的。
|
||||
|
||||
一个 n2n VPN 由两类节点组成:边缘(edge)节点和超级(super)节点。一个边缘节点是一台连接到 VPN 的电脑,它可能在一个 NAT 路由器后方。一个超级节点则是拥有一个可以公共访问的 IP 地址的电脑,它将会帮助 NAT 后方的边缘节点进行初始通信。想要在用户中创建一个 P2P VPN 的话,我们需要至少一个超级节点。
|
||||
|
||||

|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
在这篇教程中,我将会创建一个拥有 3 个节点的 P2P VPN:一个超级节点和两个边缘节点。唯一的要求是,边缘节点需要能够 ping 通超级节点的 IP 地址,而它们是否在 NAT 路由器之后则没有什么关系。
|
||||
|
||||
### 在 Linux 上安装 n2n ###
|
||||
|
||||
若想用 n2n 构建一个 P2P VPN,你需要在每个节点上安装 n2n,包括超级节点。
|
||||
|
||||
由于它非常精简的依赖需求,在大多数 Linux 平台上 n2n 都能被轻松编译。
|
||||
|
||||
在基于 Debian 的系统上安装 n2n:
|
||||
|
||||
$ sudo apt-get install subversion build-essential libssl-dev
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
在基于 Red Hat 的系统上安装 n2n:
|
||||
|
||||
$ sudo yum install subversion gcc-c++ openssl-devel
|
||||
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
|
||||
$ cd n2n/n2n_v2
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### 用 n2n 配置一个 P2P VPN ###
|
||||
|
||||
如前文所述,我们需要至少一个超级节点,它将会作为一个初始化引导服务器。我们假设这个超级节点的 IP 地址是 1.1.1.1。
|
||||
|
||||
#### 超级节点: ####
|
||||
|
||||
在一个作为超级节点的电脑上运行下面的命令。其中“-l <端口>”指定超级节点的监听端口。运行 supernode 并不需要 root 权限。
|
||||
|
||||
$ supernode -l 5000
|
||||
|
||||
#### 边缘节点: ####
|
||||
|
||||
在每个边缘节点上,使用下面的命令来连接到一个 P2P VPN。edge 守护程序将会在后台运行。
|
||||
|
||||
边缘节点 #1:
|
||||
|
||||
$ sudo edge -d edge0 -a 10.0.0.10 -c mynetwork -u 1000 -g 1000 -k password -l 1.1.1.1:5000 -m ae:e0:4f:e7:47:5b
|
||||
|
||||
边缘节点 #2:
|
||||
|
||||
$ sudo edge -d edge0 -a 10.0.0.11 -c mynetwork -u 1000 -g 1000 -k password -l 1.1.1.1:5000 -m ae:e0:4f:e7:47:5c
|
||||
|
||||
下面是对命令行的一些解释:
|
||||
|
||||
- “-d <接口名>”选项指定了由 edge 命令创建的 TAP 接口的名字。
|
||||
- “-a <IP地址>”选项(静态地)指定了分配给 TAP 接口的 VPN 的 IP 地址。如果你想要使用 DHCP,你需要在其中一台边缘节点上配置一台 DHCP 服务器,然后使用“-a dhcp:0.0.0.0”选项来代替。
|
||||
- “-c <组名>”选项指定了 VPN 组的名字(最大长度为 16 个字节)。这个选项可以被用来在同样一组节点中创建多个 VPN。
|
||||
- “-u”和“-g”选项被用来在创建一个 TAP 接口后降权放弃 root 权限。edge 守护进程将会作为指定的用户/组 ID 运行。
|
||||
- “-k <密钥>”选项指定了一个由 twofish 加密的密钥来使用。如果你想要将密钥从命令行中隐藏,你可以使用 N2N_KEY 环境变量。
|
||||
- “-l <IP地址:端口>”选项指定了超级节点的监听 IP 地址和端口号。为了冗余,你可以指定最多两个不同的超级节点(比如 -l <超级节点 A> -l <超级节点 B>)。
|
||||
- “-m <MAC 地址>”给 TAP 接口分配了一个静态的 MAC 地址。不使用这个参数的话,edge 命令将会随机生成一个 MAC 地址。事实上,为一个 VPN 接口强制指定一个静态的 MAC 地址是被强烈推荐的做法。否则,比如当你在一个节点上重启了 edge 守护程序的时候,其它节点的 ARP 缓存将会由于新生成的 MAC 地址而遭到污染,它们将不能向这个节点发送数据,直到被污染的 ARP 记录被消除。
|
||||
|
||||

|
||||
|
||||
至此,你应该能够从一个边缘节点用 VPN IP 地址 ping 通另一个边缘节点了。
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
1. 在调用 edge 守护程序的时候得到了如下错误。
|
||||
|
||||
n2n[4405]: ERROR: ioctl() [Operation not permitted][-1]
|
||||
|
||||
注意 edge 守护进程需要超级用户权限来创建一个 TAP 接口。因此需要确定用 root 权限来执行,或者对 edge 命令设置 SUID。之后你总是可以使用“-u”和“-g”选项来降权放弃 root 权限。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
n2n 可以成为对你来说非常实用的免费 VPN 解决方案。你可以轻松地配置一个超级节点,无论是用你自己家里的网络,还是从[云主机][3]提供商购买一个可以公共访问的 VPS 实例。你不再需要把敏感的凭据和密钥放在第三方 VPN 提供商的手里,使用 n2n,你可以在你的朋友中配置你自己的低延迟、高带宽、可扩展的 P2P VPN。
|
||||
|
||||
你对 n2n 有什么想法吗?请在评论中分享你的观点。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-peer-to-peer-vpn-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-and-configure-tinc-vpn.html
|
||||
[2]:http://www.ntop.org/products/n2n/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
@ -0,0 +1,84 @@
|
||||
Linux 有问必答 -- 在 Linux 上如何通过命令行来更改日期和时间
|
||||
================================================================================
|
||||
> **问题**: 在 Linux 上, 我怎样通过命令行来改变日期和时间?
|
||||
|
||||
在 Linux 系统中保持日期和时间的同步是每一个 Linux 用户和系统管理员的重要责任. 很多程序都依靠精确的时间信息得以正常工作. 另外, 不精确的日期和时间会使得日志文件中的时间戳变得毫无意义, 减少了它们在系统检查和检修中的作用. 对于生产系统来说, 精确的日期和时间甚至更为重要. 例如, 在零售公司中, 所有产品必须时刻准确地计数(并储存在数据库服务器中)以便于财政部门计算每天及每周,每月,每年的支出和收入.
|
||||
|
||||
我们必须注意, 在 Linux 机器上有两种时钟: 由内核维持的软件时钟(又称系统时钟)和在机器关机后记录时间的(电池驱动的)硬件时钟. 启动的时候, 内核会把系统时钟与硬件时钟同步. 之后, 两个时钟各自独立运行.
|
||||
|
||||
### 方法一: Date 命令 ###
|
||||
|
||||
在 Linux 中, 你可以通过 date 命令来更改系统的日期和时间:
|
||||
|
||||
# date --set='NEW_DATE'
|
||||
|
||||
其中 NEW_DATE 是诸如 "Sun, 28 Sep 2014 16:21:42" 或者 "2014-09-29 16:21:42" 的可读格式的日期字符串.
|
||||
|
||||
日期格式也可以手动指定以获得更精确的结果:
|
||||
|
||||
# date +FORMAT --set='NEW_DATE'
|
||||
|
||||
例如:
|
||||
|
||||
# date +’%Y%m%d %H%m’ --set='20140928 1518'
|
||||
|
||||

|
||||
|
||||
你也可以相对地增加或减少一定的天数,周数,月数和秒数,分钟数,小时数. 你也可以把日期和时间的参数放到一个命令中.
|
||||
|
||||
# date --set='+5 minutes'
|
||||
# date --set='-2 weeks'
|
||||
# date --set='+3 months'
|
||||
# date --set='-3 months +2 weeks -5 minutes'
|
||||
|
||||

|
||||
|
||||
最后, 把硬件时钟设置为当前系统时钟:
|
||||
|
||||
# hwclock --systohc
|
||||
|
||||
运行 **hwclock --systohc** 的目的是将硬件时钟同软件时钟同步, 这可以更正硬件时钟的系统漂移(即时钟按照一定的速度走快或走慢).
|
||||
|
||||
另一方面, 如果硬件时钟是正确的, 但系统时钟有误, 可以用下面的命令更正:
|
||||
|
||||
# hwclock --hctosys
|
||||
|
||||
在两种情况下, hwclock 命令都是将两个时钟同步. 否则, 重启后时间会是错误的, 因为当电源关闭时硬件时钟会记忆时间. 然而, 这对于虚拟机器并不适用, 因为虚拟机器并不能访问硬件时钟.
|
||||
|
||||
如果你的 Linux 系统上的默认时区是错误的, 你可以按照[这个指导][1]进行更正.
|
||||
|
||||
### 方法二: NTP ###
|
||||
|
||||
另一种使系统日期和时间保持精确的方法是使用 NTP (网络时间协议). 在 Linux 上, ntpdate 命令通过 NTP 将系统时钟和[公共 NTP 服务器][2]同步.
|
||||
|
||||
你可以使用如下命令来安装 **ntpdate**:
|
||||
|
||||
在 Debian 及基于 Debian 的发行版上:
|
||||
|
||||
# aptitude install ntpdate
|
||||
|
||||
在基于 Ret Hat 的发行版上:
|
||||
|
||||
# yum install ntpdate
|
||||
|
||||
使用 NTP 同步系统时钟:
|
||||
|
||||
# ntpdate -u <NTP server name or IP address>
|
||||
# hwclock --systohc
|
||||
|
||||

|
||||
|
||||
除了一次性使用 ntpdate 来同步时钟, 你也可以使用 NTP 守护进程(ntpd), 它会始终在后台运行, 不断地通过 NTP 来调整系统时钟. 关于 NTP 的设置, 请参考[这个指导][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-date-time-command-line-linux.html
|
||||
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://ask.xmodulo.com/change-timezone-linux.html
|
||||
[2]:http://www.pool.ntp.org/
|
||||
[3]:http://xmodulo.com/how-to-synchronize-time-with-ntp.html
|
||||
@ -0,0 +1,68 @@
|
||||
Linux有问必答-如何创建和挂载XFS文件系统
|
||||
================================================================================
|
||||
> **问题**: 我听说一个厉害的文件系统XFS,打算在我的磁盘上试试XFS。那格式化和挂载XFS文件系统的Linux命令是什么呢?
|
||||
|
||||
[XFS][1]是高性能文件系统,SGI为他们的IRIX平台设计。自从2001年移植到Linux内核上,由于它的[高性能][2],XFS作为许多企业级系统的首选,特别是有大量数据,需要结构化伸缩性和稳定性的。例如,RHEL/CentOS 7 和Oracle Linux将XFS作为默认文件系统,SUSE/openSUSE已经为XFS做了长期支持。
|
||||
|
||||
XFS有许多独特的功能使他从众多文件系统中脱颖而出,像 伸缩/并行 IO,元数据日志,热整理,暂停/回复 IO,延迟分配等。
|
||||
|
||||
如果你想要创建和挂载XFS文件系统到你的Linux平台,下面是相关命令。
|
||||
|
||||
### 安装 XFS系统工具集 ###
|
||||
|
||||
首先,你需要安装XFS系统工具集,这样允许你执行许多XFS相关的管理任务。(例如,格式化,[扩展][3],修复,设置配额,改变参数等)
|
||||
|
||||
Debian, Ubuntu , Linux Mint系统:
|
||||
|
||||
$ sudo apt-get install xfsprogs
|
||||
|
||||
Fedora, CentOS, RHEL系统:
|
||||
|
||||
$ sudo yum install xfsprogs
|
||||
|
||||
其他版本Linux:
|
||||
|
||||
$ sudo pacman -S xfsprogs
|
||||
|
||||
### 创建 XFS格式分区 ###
|
||||
|
||||
先准备一个分区来创建XFS。假设你的分区在/dev/sdb,如下:
|
||||
|
||||
$ sudo fdisk /dev/sdb
|
||||
|
||||

|
||||
|
||||
假设此创建的分区叫/dev/sdb1。
|
||||
|
||||
接下来,格式化分区为XFS,使用mkfs.xfs命令。如果已有其他文件系统创建在此分区,必须加上"-f"参数来覆盖它。
|
||||
|
||||
$ sudo mkfs.xfs -f /dev/sdb1
|
||||
|
||||

|
||||
|
||||
至此你已经准备好格式化后分区来挂载。假设/storage是XFS本地挂载点。使用下述命令挂载:
|
||||
|
||||
$ sudo mount -t xfs /dev/sdb1 /storage
|
||||
|
||||
验证XFS挂载是否成功:
|
||||
|
||||
$ df -Th /storage
|
||||
|
||||

|
||||
|
||||
如果你想要启动时自动挂载XFS分区在/storage上,加入下行到/etc/fstab:
|
||||
|
||||
/dev/sdb1 /storage xfs defaults 0 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/create-mount-xfs-file-system-linux.html
|
||||
|
||||
译者:[Vic___/VicYu](http://www.vicyul.net/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xfs.org/
|
||||
[2]:http://lwn.net/Articles/476263/
|
||||
[3]:http://ask.xmodulo.com/expand-xfs-file-system.html
|
||||
Loading…
Reference in New Issue
Block a user