mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
3cdef948c8
@ -1,223 +1,272 @@
|
||||
Translated by shipsw
|
||||
20 个 OpenSSH 最佳安全实践
|
||||
======
|
||||
|
||||
20 个 OpenSSH 安全实践
|
||||
======
|
||||
![OpenSSH 安全提示][1]
|
||||
|
||||
OpenSSH 是 SSH 协议的一个实现。一般被 scp 或 sftp 用在远程登录、备份、远程文件传输等功能上。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,他主要用在使用公匙加密的服务器验证上。不时出现关于 OpenSSH 零日漏洞的[谣言][2]。本文描述**如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性**。
|
||||
OpenSSH 是 SSH 协议的一个实现。一般通过 `scp` 或 `sftp` 用于远程登录、备份、远程文件传输等功能。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,它最大的优势是使用公匙加密来进行服务器验证。时不时会出现关于 OpenSSH 零日漏洞的[传言][2]。本文将描述如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性。
|
||||
|
||||
|
||||
#### OpenSSH 默认设置
|
||||
### OpenSSH 默认设置
|
||||
|
||||
* TCP 端口 - 22
|
||||
* OpenSSH 服务配置文件 - sshd_config (位于 /etc/ssh/)
|
||||
* TCP 端口 - 22
|
||||
* OpenSSH 服务配置文件 - `sshd_config` (位于 `/etc/ssh/`)
|
||||
|
||||
### 1、 基于公匙的登录
|
||||
|
||||
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 `ssh-keygen` 命令在本地电脑上创建密匙对:
|
||||
|
||||
#### 1. 基于公匙的登录
|
||||
|
||||
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 ssh-keygen 命令在本地电脑上创建密匙对:
|
||||
|
||||
低于 1024 位的 DSA 和 RSA 加密是很弱的,请不要使用。RSA 密匙主要是在考虑 ssh 客户端兼容性的时候代替 ECDSA 密匙使用的。
|
||||
> 1024 位或低于它的 DSA 和 RSA 加密是很弱的,请不要使用。当考虑 ssh 客户端向后兼容性的时候,请使用 RSA密匙代替 ECDSA 密匙。所有的 ssh 密钥要么使用 ED25519 ,要么使用 RSA,不要使用其它类型。
|
||||
|
||||
```
|
||||
$ ssh-keygen -t key_type -b bits -C "comment"
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
|
||||
或
|
||||
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
|
||||
```
|
||||
下一步,使用 ssh-copy-id 命令安装公匙:
|
||||
|
||||
下一步,使用 `ssh-copy-id` 命令安装公匙:
|
||||
|
||||
```
|
||||
$ ssh-copy-id -i /path/to/public-key-file user@host
|
||||
或
|
||||
$ ssh-copy-id user@remote-server-ip-or-dns-name
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-copy-id vivek@rhel7-aws-server
|
||||
```
|
||||
提示输入用户名和密码的时候,使用你自己的 ssh 公匙:
|
||||
`$ ssh vivek@rhel7-aws-server`
|
||||
[![OpenSSH 服务安全最佳实践][3]][3]
|
||||
|
||||
提示输入用户名和密码的时候,确认基于 ssh 公匙的登录是否工作:
|
||||
|
||||
```
|
||||
$ ssh vivek@rhel7-aws-server
|
||||
```
|
||||
|
||||
[![OpenSSH 服务安全最佳实践][3]][3]
|
||||
|
||||
更多有关 ssh 公匙的信息,参照以下文章:
|
||||
|
||||
* [为备份脚本设置无密码安全登录][48]
|
||||
|
||||
* [sshpass: 使用脚本密码登录SSH服务器][49]
|
||||
|
||||
* [如何为一个 Linux/类Unix 系统设置 SSH 登录密匙][50]
|
||||
|
||||
* [如何使用 Ansible 工具上传 ssh 登录授权公匙][51]
|
||||
* [为备份脚本设置无密码安全登录][48]
|
||||
* [sshpass:使用脚本密码登录 SSH 服务器][49]
|
||||
* [如何为一个 Linux/类 Unix 系统设置 SSH 登录密匙][50]
|
||||
* [如何使用 Ansible 工具上传 ssh 登录授权公匙][51]
|
||||
|
||||
|
||||
#### 2. 禁用 root 用户登录
|
||||
### 2、 禁用 root 用户登录
|
||||
|
||||
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 sudo 命令以 root 身份登录。
|
||||
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 `sudo` 命令以 root 身份登录。
|
||||
|
||||
##### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
#### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中][4]:
|
||||
`$ sudo adduser vivek sudo`
|
||||
使用 [id 命令][5] 验证用户组。
|
||||
`$ id vivek`
|
||||
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中][4]:
|
||||
|
||||
##### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
```
|
||||
$ sudo adduser vivek sudo
|
||||
```
|
||||
|
||||
使用 [id 命令][5] 验证用户组。
|
||||
|
||||
```
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
#### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 `usermod` 命令将用户 vivek 添加到 wheel 组中:
|
||||
|
||||
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 uermod 命令将用户 vivek 添加到 wheel 组中:
|
||||
```
|
||||
$ sudo usermod -aG wheel vivek
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
##### 测试 sudo 权限并禁用 ssh root 登录
|
||||
#### 测试 sudo 权限并禁用 ssh root 登录
|
||||
|
||||
测试并确保用户 vivek 可以以 root 身份登录执行以下命令:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
$ sudo /etc/init.d/sshd status
|
||||
$ sudo systemctl status httpd
|
||||
```
|
||||
添加以下内容到 sshd_config 文件中来禁用 root 登录。
|
||||
|
||||
添加以下内容到 `sshd_config` 文件中来禁用 root 登录:
|
||||
|
||||
```
|
||||
PermitRootLogin no
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
```
|
||||
|
||||
更多信息参见“[如何通过禁用 Linux 的 ssh 密码登录来增强系统安全][6]” 。
|
||||
|
||||
#### 3. 禁用密码登录
|
||||
### 3、 禁用密码登录
|
||||
|
||||
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 `sshd_config` 文件中:
|
||||
|
||||
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 sshd_config 文件中:
|
||||
```
|
||||
AuthenticationMethods publickey
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
CentOS 6.x/RHEL 6.x 系统中老版本的 SSHD 用户可以使用以下设置:
|
||||
|
||||
CentOS 6.x/RHEL 6.x 系统中老版本的 sshd 用户可以使用以下设置:
|
||||
|
||||
```
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
#### 4. 限制用户的 ssh 权限
|
||||
### 4、 限制用户的 ssh 访问
|
||||
|
||||
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。然而,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情)等的脚本语言。通过添加以下内容到 `sshd_config` 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
|
||||
|
||||
```
|
||||
AllowUsers vivek jerry
|
||||
```
|
||||
|
||||
当然,你也可以添加以下内容到 `sshd_config` 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
|
||||
|
||||
```
|
||||
DenyUsers root saroj anjali foo
|
||||
```
|
||||
|
||||
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。所以,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情) 等的脚本语言。通过添加以下内容到 sshd_config 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
|
||||
`AllowUsers vivek jerry`
|
||||
当然,你也可以添加以下内容到 sshd_config 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
|
||||
`DenyUsers root saroj anjali foo`
|
||||
你也可以通过[配置 Linux PAM][7] 来禁用或允许用户通过 sshd 登录。也可以允许或禁止一个[用户组列表][8]通过 ssh 登录系统。
|
||||
|
||||
#### 5. 禁用空密码
|
||||
### 5、 禁用空密码
|
||||
|
||||
你需要明确禁止空密码账户远程登录系统,更新 sshd_config 文件的以下内容:
|
||||
`PermitEmptyPasswords no`
|
||||
你需要明确禁止空密码账户远程登录系统,更新 `sshd_config` 文件的以下内容:
|
||||
|
||||
#### 6. 为 ssh 用户或者密匙使用强密码
|
||||
```
|
||||
PermitEmptyPasswords no
|
||||
```
|
||||
|
||||
### 6、 为 ssh 用户或者密匙使用强密码
|
||||
|
||||
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开[字典密码][9]并使用[约翰的开膛手工具][10]来检测弱密码。以下是一个随机密码生成器(放到你的 `~/.bashrc` 下):
|
||||
|
||||
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开字典密码并使用[约翰的开膛手工具][10]来检测弱密码。以下是一个随机密码生成器(放到你的 ~/.bashrc 下):
|
||||
```
|
||||
genpasswd() {
|
||||
local l=$1
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
}
|
||||
```
|
||||
|
||||
运行:
|
||||
`genpasswd 16`
|
||||
输出:
|
||||
运行:
|
||||
|
||||
```
|
||||
genpasswd 16
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
uw8CnDVMwC6vOKgW
|
||||
```
|
||||
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码][52]
|
||||
|
||||
* [Linux / UNIX: 生成密码][53]
|
||||
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码][52]
|
||||
* [Linux / UNIX: 生成密码][53]
|
||||
* [Linux 随机密码生成命令][54]
|
||||
|
||||
* [Linux 随机密码生成命令][54]
|
||||
### 7、 为 SSH 的 22端口配置防火墙
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
你需要更新 `iptables`/`ufw`/`firewall-cmd` 或 pf 防火墙配置来为 ssh 的 TCP 端口 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
|
||||
|
||||
#### 7. 为 SSH 端口 # 22 配置防火墙
|
||||
#### Netfilter(Iptables) 配置
|
||||
|
||||
你需要更新 iptables/ufw/firewall-cmd 或 pf firewall 来为 ssh TCP 端口 # 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
|
||||
更新 [/etc/sysconfig/iptables (Redhat 和其派生系统特有文件) ][11] 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接,输入:
|
||||
|
||||
##### Netfilter (Iptables) 配置
|
||||
|
||||
更新 [/etc/sysconfig/iptables (Redhat和其派生系统特有文件) ][11] 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接, 输入:
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
如果同时使用 IPv6 的话,可以编辑/etc/sysconfig/ip6tables(Redhat 和其派生系统特有文件),输入:
|
||||
如果同时使用 IPv6 的话,可以编辑 `/etc/sysconfig/ip6tables` (Redhat 和其派生系统特有文件),输入:
|
||||
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
将 ipv6network::/ipv6mask 替换为实际的 IPv6 网段。
|
||||
将 `ipv6network::/ipv6mask` 替换为实际的 IPv6 网段。
|
||||
|
||||
##### Debian/Ubuntu Linux 下的 UFW
|
||||
#### Debian/Ubuntu Linux 下的 UFW
|
||||
|
||||
[UFW 是 uncomplicated firewall 的首字母缩写,主要用来管理 Linux 防火墙][12],目的是提供一种用户友好的界面。输入[以下命令使得系统进允许网段 202.54.1.5/29 接入端口 22][13]:
|
||||
`$ sudo ufw allow from 202.54.1.5/29 to any port 22`
|
||||
更多信息请参见 "[Linux: 菜鸟管理员的 25 个 Iptables Netfilter 命令][14]"。
|
||||
[UFW 是 Uncomplicated FireWall 的首字母缩写,主要用来管理 Linux 防火墙][12],目的是提供一种用户友好的界面。输入[以下命令使得系统仅允许网段 202.54.1.5/29 接入端口 22][13]:
|
||||
|
||||
##### *BSD PF 防火墙配置
|
||||
```
|
||||
$ sudo ufw allow from 202.54.1.5/29 to any port 22
|
||||
```
|
||||
|
||||
更多信息请参见 “[Linux:菜鸟管理员的 25 个 Iptables Netfilter 命令][14]”。
|
||||
|
||||
#### *BSD PF 防火墙配置
|
||||
|
||||
如果使用 PF 防火墙 [/etc/pf.conf][15] 配置如下:
|
||||
|
||||
```
|
||||
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
|
||||
```
|
||||
|
||||
#### 8. 修改 SSH 端口和绑定 IP
|
||||
### 8、 修改 SSH 端口和绑定 IP
|
||||
|
||||
ssh 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 `sshd_config` 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
|
||||
|
||||
SSH 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 sshd_config 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
|
||||
```
|
||||
Port 300
|
||||
ListenAddress 192.168.1.5
|
||||
ListenAddress 202.54.1.5
|
||||
```
|
||||
|
||||
端口 300 监听地址 192.168.1.5 监听地址 202.54.1.5
|
||||
|
||||
当需要接受动态广域网地址的连接时,使用主动脚本是个不错的选择,比如 fail2ban 或 denyhosts。
|
||||
|
||||
#### 9. 使用 TCP wrappers (可选的)
|
||||
### 9、 使用 TCP wrappers (可选的)
|
||||
|
||||
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 `/etc/hosts.allow` 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
|
||||
|
||||
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 /etc/hosts.allow 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
|
||||
```
|
||||
sshd : 192.168.1.2 172.16.23.12
|
||||
```
|
||||
|
||||
在 Linux/Mac OS X 和类 UNIX 系统中参见 [TCP wrappers 设置和使用的常见问题][16]。
|
||||
|
||||
#### 10. 阻止 SSH 破解或暴力攻击
|
||||
### 10、 阻止 SSH 破解或暴力攻击
|
||||
|
||||
暴力破解是一种在单一或者分布式网络中使用大量组合(用户名和密码的组合)来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
|
||||
暴力破解是一种在单一或者分布式网络中使用大量(用户名和密码的)组合来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
|
||||
|
||||
* [DenyHosts][17] 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始IP的方式来应对暴力攻击。
|
||||
* RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts][18]。
|
||||
* [Fail2ban][19] 是另一个类似的用来预防针对 SSH 攻击的工具。
|
||||
* [sshguard][20] 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
|
||||
* [security/sshblock][21] 阻止滥用 SSH 尝试登录。
|
||||
* [IPQ BDB filter][22] 可以看做是 fail2ban 的一个简化版。
|
||||
* [DenyHosts][17] 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始 IP 的方式来应对暴力攻击。
|
||||
* RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts][18]。
|
||||
* [Fail2ban][19] 是另一个类似的用来预防针对 SSH 攻击的工具。
|
||||
* [sshguard][20] 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
|
||||
* [security/sshblock][21] 阻止滥用 SSH 尝试登录。
|
||||
* [IPQ BDB filter][22] 可以看做是 fail2ban 的一个简化版。
|
||||
|
||||
### 11、 限制 TCP 端口 22 的传入速率(可选的)
|
||||
|
||||
netfilter 和 pf 都提供速率限制选项可以对端口 22 的传入速率进行简单的限制。
|
||||
|
||||
#### 11. 限制 TCP 端口 # 22 的传入速率 (可选的)
|
||||
|
||||
netfilter 和 pf 都提供速率限制选项可以对端口 # 22 的传入速率进行简单的限制。
|
||||
|
||||
##### Iptables 示例
|
||||
#### Iptables 示例
|
||||
|
||||
以下脚本将会阻止 60 秒内尝试登录 5 次以上的客户端的连入。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
inet_if=eth1
|
||||
ssh_port=22
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
```
|
||||
|
||||
在你的 iptables 脚本中调用以上脚本。其他配置选项:
|
||||
|
||||
```
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
# another one line example
|
||||
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
|
||||
@ -225,9 +274,10 @@ $IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLI
|
||||
|
||||
其他细节参见 iptables 用户手册。
|
||||
|
||||
##### *BSD PF 示例
|
||||
#### *BSD PF 示例
|
||||
|
||||
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒内的连接不超过 15 个。如果客户端触发此规则,则将其加入 abusive_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的连接。
|
||||
|
||||
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒范围的连接不超过 15 个。如果客户端触发此规则则将其加入 abusive_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的状态。
|
||||
```
|
||||
sshd_server_ip = "202.54.1.5"
|
||||
table <abusive_ips> persist
|
||||
@ -235,9 +285,10 @@ block in quick from <abusive_ips>
|
||||
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
|
||||
```
|
||||
|
||||
#### 12. 使用端口敲门 (可选的)
|
||||
### 12、 使用端口敲门(可选的)
|
||||
|
||||
[端口敲门][23]是通过在一组预先指定的封闭端口上生成连接尝试,以便从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
|
||||
|
||||
[端口敲门][23]是通过在一组预先指定的封闭端口上生成连接尝试来从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
|
||||
```
|
||||
$IPT -N stage1
|
||||
$IPT -A stage1 -m recent --remove --name knock
|
||||
@ -257,24 +308,31 @@ $IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j
|
||||
$IPT -A INPUT -p tcp --syn -j door
|
||||
```
|
||||
|
||||
更多信息请参见:
|
||||
|
||||
更多信息请参见:
|
||||
[Debian / Ubuntu: 使用 Knockd and Iptables 设置端口敲门][55]
|
||||
|
||||
#### 13. 配置空闲超时注销时长
|
||||
### 13、 配置空闲超时注销时长
|
||||
|
||||
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 `sshd_config` 并确保配置以下值:
|
||||
|
||||
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 sshd_config 并确保配置以下值:
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户][24]。
|
||||
|
||||
#### 14. 为 ssh 用户启用警示标语
|
||||
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户][24]。
|
||||
|
||||
### 14、 为 ssh 用户启用警示标语
|
||||
|
||||
更新 `sshd_config` 文件如下行来设置用户的警示标语:
|
||||
|
||||
```
|
||||
Banner /etc/issue
|
||||
```
|
||||
|
||||
`/etc/issue 示例文件:
|
||||
|
||||
更新 sshd_config 文件如下来设置用户的警示标语
|
||||
`Banner /etc/issue`
|
||||
/etc/issue 示例文件:
|
||||
```
|
||||
----------------------------------------------------------------------------------------------
|
||||
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
|
||||
@ -297,45 +355,61 @@ or monitoring of the content of privileged communications, or work product, rela
|
||||
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
|
||||
product are private and confidential. See User Agreement for details.
|
||||
----------------------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
以上是一个标准的示例,更多的用户协议和法律细节请咨询你的律师团队。
|
||||
|
||||
#### 15. 禁用 .rhosts 文件 (核实)
|
||||
### 15、 禁用 .rhosts 文件(需核实)
|
||||
|
||||
禁止读取用户的 `~/.rhosts` 和 `~/.shosts` 文件。更新 `sshd_config` 文件中的以下内容:
|
||||
|
||||
```
|
||||
IgnoreRhosts yes
|
||||
```
|
||||
|
||||
禁止读取用户的 ~/.rhosts 和 ~/.shosts 文件。更新 sshd_config 文件中的以下内容:
|
||||
`IgnoreRhosts yes`
|
||||
SSH 可以模拟过时的 rsh 命令,所以应该禁用不安全的 RSH 连接。
|
||||
|
||||
#### 16. 禁用 host-based 授权 (核实)
|
||||
### 16、 禁用基于主机的授权(需核实)
|
||||
|
||||
禁用 host-based 授权,更新 sshd_config 文件的以下选项:
|
||||
`HostbasedAuthentication no`
|
||||
禁用基于主机的授权,更新 `sshd_config` 文件的以下选项:
|
||||
|
||||
#### 17. 为 OpenSSH 和 操作系统打补丁
|
||||
```
|
||||
HostbasedAuthentication no
|
||||
```
|
||||
|
||||
### 17、 为 OpenSSH 和操作系统打补丁
|
||||
|
||||
推荐你使用类似 [yum][25]、[apt-get][26] 和 [freebsd-update][27] 等工具保持系统安装了最新的安全补丁。
|
||||
|
||||
#### 18. Chroot OpenSSH (将用户锁定在主目录)
|
||||
### 18、 Chroot OpenSSH (将用户锁定在主目录)
|
||||
|
||||
默认设置下用户可以浏览诸如 /etc/、/bin 等目录。可以使用 chroot 或者其他专有工具如 [rssh][28] 来保护ssh连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 ChrootDirectory 指令将用户锁定在其主目录,参见[这篇博文][29]。
|
||||
默认设置下用户可以浏览诸如 `/etc`、`/bin` 等目录。可以使用 chroot 或者其他专有工具如 [rssh][28] 来保护 ssh 连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 `ChrootDirectory` 指令将用户锁定在其主目录,参见[这篇博文][29]。
|
||||
|
||||
#### 19. 禁用客户端的 OpenSSH 服务
|
||||
### 19. 禁用客户端的 OpenSSH 服务
|
||||
|
||||
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 ssh 远程登录和文件传输功能的话,可以禁用 sshd 服务。CentOS / RHEL 用户可以使用 [yum 命令][30] 禁用或删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo yum erase openssh-server
|
||||
```
|
||||
|
||||
Debian / Ubuntu 用户可以使用 [apt 命令][31]/[apt-get 命令][32] 删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo apt-get remove openssh-server
|
||||
```
|
||||
|
||||
有可能需要更新 iptables 脚本来移除 ssh 的例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 `/etc/sysconfig/iptables` 和 `/etc/sysconfig/ip6tables`。最后[重启 iptables][33] 服务:
|
||||
|
||||
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 SSH 远程登录和文件传输功能的话,可以禁用 SSHD 服务。CentOS / RHEL 用户可以使用 [yum 命令][30] 禁用或删除openssh-server:
|
||||
`$ sudo yum erase openssh-server`
|
||||
Debian / Ubuntu 用户可以使用 [apt 命令][31]/[apt-get 命令][32] 删除 openssh-server:
|
||||
`$ sudo apt-get remove openssh-server`
|
||||
有可能需要更新 iptables 脚本来移除 ssh 例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 /etc/sysconfig/iptables 和 /etc/sysconfig/ip6tables。最后[重启 iptables][33] 服务:
|
||||
```
|
||||
# service iptables restart
|
||||
# service ip6tables restart
|
||||
```
|
||||
|
||||
#### 20. 来自 Mozilla 的额外提示
|
||||
### 20. 来自 Mozilla 的额外提示
|
||||
|
||||
如果使用 6.7+ 版本的 OpenSSH,可以尝试下[以下设置][34]:
|
||||
|
||||
如果使用 6.7+ 版本的 OpenSSH,可以尝试下以下设置:
|
||||
```
|
||||
#################[ WARNING ]########################
|
||||
# Do not use any setting blindly. Read sshd_config #
|
||||
@ -361,10 +435,11 @@ MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@op
|
||||
LogLevel VERBOSE
|
||||
|
||||
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
```
|
||||
|
||||
使用以下命令获取 OpenSSH 支持的加密方法:
|
||||
|
||||
```
|
||||
$ ssh -Q cipher
|
||||
$ ssh -Q cipher-auth
|
||||
@ -372,15 +447,25 @@ $ ssh -Q mac
|
||||
$ ssh -Q kex
|
||||
$ ssh -Q key
|
||||
```
|
||||
[![OpenSSH安全教程查询密码和算法选择][35]][35]
|
||||
|
||||
#### 如何测试 sshd_config 文件并重启/重新加载 SSH 服务?
|
||||
[![OpenSSH安全教程查询密码和算法选择][35]][35]
|
||||
|
||||
### 如何测试 sshd_config 文件并重启/重新加载 SSH 服务?
|
||||
|
||||
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
|
||||
|
||||
```
|
||||
$ sudo sshd -t
|
||||
```
|
||||
|
||||
扩展测试模式:
|
||||
|
||||
```
|
||||
$ sudo sshd -T
|
||||
```
|
||||
|
||||
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
|
||||
`$ sudo sshd -t`
|
||||
扩展测试模式:
|
||||
`$ sudo sshd -T`
|
||||
最后,根据系统的的版本[重启 Linux 或类 Unix 系统中的 sshd 服务][37]:
|
||||
|
||||
```
|
||||
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
|
||||
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
|
||||
@ -388,25 +473,21 @@ $ doas /etc/rc.d/sshd restart ## OpenBSD##
|
||||
$ sudo service sshd restart ## FreeBSD##
|
||||
```
|
||||
|
||||
#### 其他建议
|
||||
### 其他建议
|
||||
|
||||
1. [使用 2FA 加强 SSH 的安全性][40] - 可以使用[OATH Toolkit][41] 或 [DuoSecurity][42] 启用多重身份验证。
|
||||
2. [基于密匙链的身份验证][43] - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
|
||||
1. [使用 2FA 加强 SSH 的安全性][40] - 可以使用 [OATH Toolkit][41] 或 [DuoSecurity][42] 启用多重身份验证。
|
||||
2. [基于密匙链的身份验证][43] - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
|
||||
|
||||
### 更多信息:
|
||||
|
||||
* [OpenSSH 官方][44] 项目。
|
||||
* 用户手册: sshd(8)、ssh(1)、ssh-add(1)、ssh-agent(1)。
|
||||
|
||||
#### 更多信息:
|
||||
如果知道这里没用提及的方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
|
||||
|
||||
* [OpenSSH 官方][44] 项目.
|
||||
* 用户手册: sshd(8),ssh(1),ssh-add(1),ssh-agent(1)
|
||||
### 关于作者
|
||||
|
||||
|
||||
|
||||
如果你发现一个方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
|
||||
|
||||
#### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][45]、[Facebook][46]、[Google+][47] 上关注他。
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][45]、[Facebook][46]、[Google+][47] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -414,7 +495,7 @@ via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -467,7 +548,7 @@ via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[48]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[49]:https://www.cyberciti.biz/faq/noninteractive-shell-script-ssh-password-provider/
|
||||
[49]:https://linux.cn/article-8086-1.html
|
||||
[50]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[51]:https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/
|
||||
[52]:https://www.cyberciti.biz/faq/generating-random-password/
|
||||
@ -0,0 +1,124 @@
|
||||
在 Linux 上安装必应桌面墙纸更换器
|
||||
======
|
||||
|
||||
你是否厌倦了 Linux 桌面背景,想要设置好看的壁纸,但是不知道在哪里可以找到?别担心,我们在这里会帮助你。
|
||||
|
||||
我们都知道必应搜索引擎,但是由于一些原因很少有人使用它,每个人都喜欢必应网站的背景壁纸,它是非常漂亮和惊人的高分辨率图像。
|
||||
|
||||
如果你想使用这些图片作为你的桌面壁纸,你可以手动下载它,但是很难去每天下载一个新的图片,然后把它设置为壁纸。这就是自动壁纸改变的地方。
|
||||
|
||||
[必应桌面墙纸更换器][1]会自动下载并将桌面壁纸更改为当天的必应照片。所有的壁纸都储存在 `/home/[user]/Pictures/BingWallpapers/`。
|
||||
|
||||
### 方法 1: 使用 Utkarsh Gupta Shell 脚本
|
||||
|
||||
这个小型 Python 脚本会自动下载并将桌面壁纸更改为当天的必应照片。该脚本在机器启动时自动运行,并工作于 GNU/Linux 上的 Gnome 或 Cinnamon 环境。它不需要手动工作,安装程序会为你做所有事情。
|
||||
|
||||
从 2.0+ 版本开始,该脚本的安装程序就可以像普通的 Linux 二进制命令一样工作,它会为某些任务请求 sudo 权限。
|
||||
|
||||
只需克隆仓库并切换到项目目录,然后运行 shell 脚本即可安装必应桌面墙纸更换器。
|
||||
|
||||
```
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
```
|
||||
|
||||
运行 `installer.sh` 使用 `--install` 选项来安装必应桌面墙纸更换器。它会下载并设置必应照片为你的 Linux 桌面。
|
||||
|
||||
```
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: ******
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? :Press Enter
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : y
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : y
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
要卸载该脚本:
|
||||
|
||||
```
|
||||
$ ./installer.sh --uninstall
|
||||
```
|
||||
|
||||
使用帮助页面了解更多关于此脚本的选项。
|
||||
|
||||
```
|
||||
$ ./installer.sh --help
|
||||
```
|
||||
|
||||
### 方法 2: 使用 GNOME Shell 扩展
|
||||
|
||||
这个轻量级 [GNOME shell 扩展][4],可将你的壁纸每天更改为微软必应的壁纸。它还会显示一个包含图像标题和解释的通知。
|
||||
|
||||
该扩展大部分基于 Elinvention 的 NASA APOD 扩展,受到了 Utkarsh Gupta 的 Bing Desktop WallpaperChanger 启发。
|
||||
|
||||
#### 特点
|
||||
|
||||
- 获取当天的必应壁纸并设置为锁屏和桌面墙纸(这两者都是用户可选的)
|
||||
- 可强制选择某个特定区域(即地区)
|
||||
- 为多个显示器自动选择最高分辨率(和最合适的墙纸)
|
||||
- 可以选择在 1 到 7 天之后清理墙纸目录(删除最旧的)
|
||||
- 只有当它们被更新时,才会尝试下载壁纸
|
||||
- 不会持续进行更新 - 每天只进行一次,启动时也要进行一次(更新是在必应更新时进行的)
|
||||
|
||||
#### 如何安装
|
||||
|
||||
访问 [extenisons.gnome.org][5] 网站并将切换按钮拖到 “ON”,然后点击 “Install” 按钮安装必应壁纸 GNOME 扩展。(LCTT 译注:页面上并没有发现 ON 按钮,但是有 Download 按钮)
|
||||
|
||||
![][6]
|
||||
|
||||
安装必应壁纸 GNOME 扩展后,它会自动下载并为你的 Linux 桌面设置当天的必应照片,并显示关于壁纸的通知。
|
||||
|
||||
![][7]
|
||||
|
||||
托盘指示器将帮助你执行少量操作,也可以打开设置。
|
||||
|
||||
![][8]
|
||||
|
||||
根据你的要求自定义设置。
|
||||
|
||||
![][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
@ -1,28 +1,21 @@
|
||||
|
||||
如何提供有帮助的回答
|
||||
=============================
|
||||
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧。他们都是非常实用的。
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧,它们都是非常实用的。
|
||||
|
||||
一开始 - 有时向你提问的人不尊重你的时间,这很糟糕。
|
||||
|
||||
理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
一开始 —— 有时向你提问的人不尊重你的时间,这很糟糕。理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题,而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
|
||||
下面是有助于回答问题的一些方法!
|
||||
|
||||
|
||||
### 如果他们提问不清楚,帮他们澄清
|
||||
### 如果他们的提问不清楚,帮他们澄清
|
||||
|
||||
通常初学者不会提出很清晰的问题,或者问一些对回答问题没有必要信息的问题。你可以尝试以下方法 澄清问题:
|
||||
|
||||
* ** 重述为一个更明确的问题 ** 来回复他们(”你是想问 X 吗?“)
|
||||
|
||||
* ** 向他们了解更具体的他们并没有提供的信息 ** (”你使用 IPv6 ?”)
|
||||
|
||||
* ** 问是什么导致了他们的问题 ** 例如,有时有些人会进入我的团队频道,询问我们的服务发现(service discovery )如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的 pull requests 吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自 [如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完 “如何提出有意义的问题”这篇文章后再来像我提问)
|
||||
* **重述为一个更明确的问题**来回复他们(“你是想问 X 吗?”)
|
||||
* **向他们了解更具体的他们并没有提供的信息** (“你使用 IPv6 ?”)
|
||||
* **问是什么导致了他们的问题**。例如,有时有些人会进入我的团队频道,询问我们的<ruby>服务发现<rt>service discovery</rt></ruby>如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的‘拉取请求’吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自[如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完《如何提出有意义的问题》这篇文章后再来向我提问)
|
||||
|
||||
### 弄清楚他们已经知道了什么
|
||||
|
||||
@ -30,66 +23,54 @@
|
||||
|
||||
Harold Treen 给了我一个很好的例子:
|
||||
|
||||
> 前几天,有人请我解释“ Redux-Sagas ”。与其深入解释不如说“ 他们就像 worker threads 监听行为(actions),让你更新 Redux store 。
|
||||
> 前几天,有人请我解释 “Redux-Sagas”。与其深入解释,不如说 “它们就像监听 action 的工人线程,并可以让你更新 Redux store。
|
||||
|
||||
> 我开始搞清楚他们对 Redux 、行为(actions)、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
> 我开始搞清楚他们对 Redux、action、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“ Redux 是什么?“),或者他们可能是专家但是恰巧遇到了微妙的极端情况(corner case)。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“Redux 是什么?”),或者他们可能是专家,但是恰巧遇到了微妙的<ruby>极端情况<rt>corner case</rt></ruby>。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
|
||||
这里有一个很实用的技巧来了解他们已经知道什么 - 比如可以尝试用“你对 X 了解多少?”而不是问“你知道 X 吗?”。
|
||||
|
||||
|
||||
### 给他们一个文档
|
||||
|
||||
“RTFM” (“去读那些他妈的手册”(Read The Fucking Manual))是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
“RTFM” (<ruby>“去读那些他妈的手册”<rt>Read The Fucking Manual</rt></ruby>)是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
|
||||
我认为明确你所给的文档的确能够解决问题是非常重要的,或者至少经过查阅后确认它对解决问题有帮助。否则,你可能将以下面这种情形结束对话(非常常见):
|
||||
|
||||
* Ali:我应该如何处理 X ?
|
||||
* Jada:\<文档链接>
|
||||
* Ali: 这个没有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
* Jada:<文档链接>
|
||||
|
||||
* Ali: 这个并有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有44000个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的:)
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有 44000 个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的 :)
|
||||
|
||||
### 告诉他们一个有用的搜索
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案:)
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索来找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案 :)
|
||||
|
||||
### 写新文档
|
||||
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有10个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有 10 个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
|
||||
1. 马上写新文档
|
||||
|
||||
2. 给他们我们刚刚写好的新文档
|
||||
|
||||
3. 公示
|
||||
|
||||
写文档有时往往比回答问题需要花很多时间,但这是值得的。写文档尤其重要,如果:
|
||||
|
||||
a. 这个问题被问了一遍又一遍
|
||||
|
||||
b. 随着时间的推移,这个答案不会变化太大(如果这个答案每一个星期或者一个月就会变化,文档就会过时并且令人受挫)
|
||||
|
||||
|
||||
### 解释你做了什么
|
||||
|
||||
对于一个话题,作为初学者来说,这样的交流会真让人沮丧:
|
||||
|
||||
* 新人:“嗨!你如何处理 X ?”
|
||||
|
||||
* 有经验的人:“我已经处理过了,而且它已经完美解决了”
|
||||
|
||||
* 新人:”...... 但是你做了什么?!“
|
||||
|
||||
如果问你问题的人想知道事情是如何进行的,这样是有帮助的:
|
||||
|
||||
* 让他们去完成任务而不是自己做
|
||||
|
||||
* 告诉他们你是如何得到你给他们的答案的。
|
||||
|
||||
这可能比你自己做的时间还要长,但对于被问的人来说这是一个学习机会,因为那样做使得他们将来能够更好地解决问题。
|
||||
@ -97,88 +78,74 @@ b. 随着时间的推移,这个答案不会变化太大(如果这个答案
|
||||
这样,你可以进行更好的交流,像这:
|
||||
|
||||
* 新人:“这个网站出现了错误,发生了什么?”
|
||||
|
||||
* 有经验的人:(2分钟后)”oh 这是因为发生了数据库故障转移“
|
||||
|
||||
* 新人: ”你是怎么知道的??!?!?“
|
||||
|
||||
* 有经验的人:“以下是我所做的!“:
|
||||
|
||||
* 有经验的人:(2分钟后)“oh 这是因为发生了数据库故障转移”
|
||||
* 新人: “你是怎么知道的??!?!?”
|
||||
* 有经验的人:“以下是我所做的!”:
|
||||
1. 通常这些错误是因为服务器 Y 被关闭了。我查看了一下 `$PLACE` 但它表明服务器 Y 开着。所以,并不是这个原因导致的。
|
||||
|
||||
2. 然后我查看 X 的仪表盘 ,仪表盘的这个部分显示这里发生了数据库故障转移。
|
||||
|
||||
3. 然后我在日志中找到了相应服务器,并且它显示连接数据库错误,看起来错误就是这里。
|
||||
|
||||
如果你正在解释你是如何调试一个问题,解释你是如何发现问题,以及如何找出问题的。尽管看起来你好像已经得到正确答案,但感觉更好的是能够帮助他们提高学习和诊断能力,并了解可用的资源。
|
||||
|
||||
|
||||
### 解决根本问题
|
||||
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只要再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
|
||||
* Jasminda:”你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。“
|
||||
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。“
|
||||
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
|
||||
* Jasminda:“你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。”
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。”
|
||||
|
||||
Jasminda 一点都没有回答 George 的问题!反而,她猜测 George 并不想处理 X ,并且她是猜对了。这是非常有用的!
|
||||
|
||||
如果你这样做可能会产生高高在上的感觉:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
|
||||
* Jasminda:“不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。”
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。”
|
||||
|
||||
* Jasminda:不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。
|
||||
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。
|
||||
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。”
|
||||
|
||||
|
||||
### 询问”那个回答可以解决您的问题吗?”
|
||||
### 询问“那个回答可以解决您的问题吗?”
|
||||
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:”这个回答解决了您的问题吗?您还有其他问题吗?“在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:“这个回答解决了您的问题吗?您还有其他问题吗?”在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
|
||||
我发现尤其是问“这个回答解决了您的问题吗”这个额外的步骤在写完文档后是非常有用的。通常,在写关于我熟悉的东西的文档时,我会忽略掉重要的东西而不会意识到它。
|
||||
|
||||
|
||||
### 结对编程和面对面交谈
|
||||
|
||||
我是远程工作的,所以我的很多对话都是基于文本的。我认为这是沟通的默认方式。
|
||||
|
||||
今天,我们生活在一个方便进行小视频会议和屏幕共享的世界!在工作时候,在任何时间我都可以点击一个按钮并快速加入与他人的视频对话或者屏幕共享的对话中!
|
||||
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视屏会话并在5分钟后,我们解决了他们问题。
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视频会话并在 5 分钟后,我们解决了他们问题。
|
||||
|
||||
我认为,特别是如果有人真的被困在该如何开始一项任务时,开启视频进行结对编程几分钟真的比电子邮件或者一些即时通信更有效。
|
||||
|
||||
|
||||
### 不要表现得过于惊讶
|
||||
|
||||
这是源自 Recurse Center 的一则法则:[不要故作惊讶][4]。这里有一个常见的情景:
|
||||
|
||||
* 某人1:“什么是 Linux 内核”
|
||||
* 某甲:“什么是 Linux 内核”
|
||||
* 某乙:“你竟然不知道什么是 Linux 内核?!!!!?!!!????”
|
||||
|
||||
* 某人2:“你竟然不知道什么是 Linux 内核(LINUX KERNEL)?!!!!?!!!????”
|
||||
某乙的表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某甲不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
|
||||
某人2表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某人1不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
我一直在假装不惊讶,即使我事实上确实有点惊讶那个人不知道这种东西。
|
||||
|
||||
我一直在假装不惊讶即使我事实上确实有点惊讶那个人不知道这种东西但它是令人敬畏的。
|
||||
|
||||
### 回答问题是令人敬畏的
|
||||
### 回答问题真的很棒
|
||||
|
||||
显然并不是所有方法都是合适的,但希望你能够发现这里有些是有帮助的!我发现花时间去回答问题并教导人们是其实是很有收获的。
|
||||
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder的阅读或评论。
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder 的阅读或评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/answer-questions-well/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
112
sources/talk/20170210 Evolutional Steps of Computer Systems.md
Normal file
112
sources/talk/20170210 Evolutional Steps of Computer Systems.md
Normal file
@ -0,0 +1,112 @@
|
||||
Evolutional Steps of Computer Systems
|
||||
======
|
||||
Throughout the history of the modern computer, there were several evolutional steps related to the way we interact with the system. I tend to categorize those steps as following:
|
||||
|
||||
1. Numeric Systems
|
||||
2. Application-Specific Systems
|
||||
3. Application-Centric Systems
|
||||
4. Information-Centric Systems
|
||||
5. Application-Less Systems
|
||||
|
||||
|
||||
|
||||
Following sections describe how I see those categories.
|
||||
|
||||
### Numeric Systems
|
||||
|
||||
[Early computers][1] were designed with numbers in mind. They could add, subtract, multiply, divide. Some of them were able to perform more complex mathematical operations such as differentiate or integrate.
|
||||
|
||||
If you map characters to numbers, they were able to «compute» [strings][2] as well but this is somewhat «creative use of numbers» instead of meaningful processing arbitrary information.
|
||||
|
||||
### Application-Specific Systems
|
||||
|
||||
For higher-level problems, pure numeric systems are not sufficient. Application-specific systems were developed to do one single task. They were very similar to numeric systems. However, with sufficiently complex number calculations, systems were able to accomplish very well-defined higher level tasks such as calculations related to scheduling problems or other optimization problems.
|
||||
|
||||
Systems of this category were built for one single purpose, one distinct problem they solved.
|
||||
|
||||
### Application-Centric Systems
|
||||
|
||||
Systems that are application-centric are the first real general purpose systems. Their main usage style is still mostly application-specific but with multiple applications working either time-sliced (one app after another) or in multi-tasking mode (multiple apps at the same time).
|
||||
|
||||
Early personal computers [from the 70s][3] of the previous century were the first application-centric systems that became popular for a wide group of people.
|
||||
|
||||
Yet modern operating systems - Windows, macOS, most GNU/Linux desktop environments - still follow the same principles.
|
||||
|
||||
Of course, there are sub-categories as well:
|
||||
|
||||
1. Strict Application-Centric Systems
|
||||
2. Loose Application-Centric Systems
|
||||
|
||||
|
||||
|
||||
Strict application-centric systems such as [Windows 3.1][4] (Program Manager and File Manager) or even the initial version of [Windows 95][5] had no pre-defined folder hierarchy. The user did start text processing software like [WinWord][6] and saved the files in the program folder of WinWord. When working with a spreadsheet program, its files were saved in the application folder of the spreadsheet tool. And so on. Users did not create their own hierarchy of folders mostly because of convenience, laziness, or because they did not saw any necessity. The number of files per user were sill within dozens up to a few hundreds.
|
||||
|
||||
For accessing information, the user typically opened an application and within the application, the files containing the generated data were retrieved using file/open.
|
||||
|
||||
It was [Windows 95][5] SP2 that introduced «[My Documents][7]» for the Windows platform. With this file hierarchy template, application designers began switching to «My Documents» as a default file save/open location instead of using the software product installation path. This made the users embrace this pattern and start to maintain folder hierarchies on their own.
|
||||
|
||||
This resulted in loose application-centric systems: typical file retrieval is done via a file manager. When a file is opened, the associated application is started by the operating system. It is a small or subtle but very important usage shift. Application-centric systems are still the dominant usage pattern for personal computers.
|
||||
|
||||
Nevertheless, this pattern comes with many disadvantages. For example in order to prevent data retrieval problems, there is the need to maintain a strict hierarchy of folders that contain all related files of a given project. Unfortunately, nature does not fit well in strict hierarchy of folders. Further more, [this does not scale well][8]. Desktop search engines and advanced data organizing tools like [tagstore][9] are able to smooth the edged a bit. As studies show, only a minority of users are using such advanced retrieval tools. Most users still navigate through the file system without using any alternative or supplemental retrieval techniques.
|
||||
|
||||
### Information-Centric Systems
|
||||
|
||||
One possible way of dealing with the issue that a certain topic needs to have a folder that holds all related files is to switch from an application-centric system to an information-centric systems.
|
||||
|
||||
Instead of opening a spreadsheet application to work with the project budget, opening a word processor application to write the project report, and opening another tool to work with image files, an information-centric system combines all the information on the project in one place, in one application.
|
||||
|
||||
The calculations for the previous month is right beneath notes from a client meeting which is right beneath a photography of the whiteboard notes which is right beneath some todo tasks. Without any application or file border in between.
|
||||
|
||||
Early attempts to create such an environment were IBM [OS/2][10], Microsoft [OLE][11] or [NeXT][12]. None of them were a major success for a variety of reasons. A very interesting information-centric environment is [Acme][13] from [Plan 9][14]. It combines [a wide variety of applications][15] within one application but it never reached a notable distribution even with its ports to Windows or GNU/Linux.
|
||||
|
||||
Modern approaches for an information-centric system are advanced [personal wikis][16] like [TheBrain][17] or [Microsoft OneNote][18].
|
||||
|
||||
My personal tool of choice is the [GNU/Emacs][19] platform with its [Org-mode][19] extension. I hardly leave Org-mode when I work with my computer. For accessing external data sources, I created [Memacs][20] which brings me a broad variety of data into Org-mode. I love to do spreadsheet calculations right beneath scheduled tasks, in-line images, internal and external links, and so forth. It is truly an information-centric system where the user doesn't have to deal with application borders or strictly hierarchical file-system folders. Multi-classifications is possible using simple or advanced tagging. All kinds of views can be derived with a single command. One of those views is my calendar, the agenda. Another derived view is the list of borrowed things. And so on. There are no limits for Org-mode users. If you can think of it, it is most likely possible within Org-mode.
|
||||
|
||||
Is this the end of the evolution? Certainly not.
|
||||
|
||||
### Application-Less Systems
|
||||
|
||||
I can think of a class of systems which I refer to as application-less systems. As the next logical step, there is no need to have single-domain applications even when they are as capable as Org-mode. The computer offers a nice to use interface to information and features, not files and applications. Even a classical operating system is not accessible.
|
||||
|
||||
Application-less systems might as well be combined with [artificial intelligence][21]. Think of it as some kind of [HAL 9000][22] from [A Space Odyssey][23]. Or [LCARS][24] from Star Trek.
|
||||
|
||||
It is hard to believe that there is a transition between our application-based, vendor-based software culture and application-less systems. Maybe the open source movement with its slow but constant development will be able to form a truly application-less environment where all kinds of organizations and people are contributing to.
|
||||
|
||||
Information and features to retrieve and manipulate information, this is all it takes. This is all we need. Everything else is just limiting distraction.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -0,0 +1,91 @@
|
||||
Why culture is the most important issue in a DevOps transformation
|
||||
======
|
||||
|
||||

|
||||
|
||||
You've been appointed the DevOps champion in your organisation: congratulations. So, what's the most important issue that you need to address?
|
||||
|
||||
It's the technology—tools and the toolchain—right? Everybody knows that unless you get the right tools for the job, you're never going to make things work. You need integration with your existing stack (though whether you go with tight or loose integration will be an interesting question), a support plan (vendor, third party, or internal), and a bug-tracking system to go with your source code management system. And that's just the start.
|
||||
|
||||
No! Don't be ridiculous: It's clearly the process that's most important. If the team doesn't agree on how stand-ups are run, who participates, the frequency and length of the meetings, and how many people are required for a quorum, then you'll never be able to institute a consistent, repeatable working pattern.
|
||||
|
||||
In fact, although both the technology and the process are important, there's a third component that is equally important, but typically even harder to get right: culture. Yup, it's that touch-feely thing we techies tend to struggle with.1
|
||||
|
||||
### Culture
|
||||
|
||||
I was visiting a midsized government institution a few months ago (not in the UK, as it happens), and we arrived a little early to meet the CEO and CTO. We were ushered into the CEO's office and waited for a while as the two of them finished participating in the daily stand-up. They apologised for being a minute or two late, but far from being offended, I was impressed. Here was an organisation where the culture of participation was clearly infused all the way up to the top.
|
||||
|
||||
Not that culture can be imposed from the top—nor can you rely on it percolating up from the bottom3—but these two C-level execs were not only modelling the behaviour they expected from the rest of their team, but also seemed, from the brief discussion we had about the process afterwards, to be truly invested in it. If you can get management to buy into the process—and be seen buying in—you are at least likely to have problems with other groups finding plausible excuses to keep their distance and get away with it.
|
||||
|
||||
So let's assume management believes you should give DevOps a go. Where do you start?
|
||||
|
||||
Developers may well be your easiest target group. They are often keen to try new things and find ways to move things along faster, so they are often the group that can be expected to adopt new technologies and methodologies. DevOps arguably has been driven mainly by the development community.
|
||||
|
||||
But you shouldn't assume all developers will be keen to embrace this change. For some, the way things have always been done—your Rick Parfitts of dev, if you will7—is fine. Finding ways to help them work efficiently in the new world is part of your job, not just theirs. If you have superstar developers who aren't happy with change, you risk alienating and losing them if you try to force them into your brave new world. What's worse, if they dig their heels in, you risk the adoption of your DevSecOps vision being compromised when they explain to their managers that things aren't going to change if it makes their lives more difficult and reduces their productivity.
|
||||
|
||||
Maybe you're not going to be able to move all the systems and people to DevOps immediately. Maybe you're going to need to choose which apps start with and who will be your first DevOps champions. Maybe it's time to move slowly.
|
||||
|
||||
### Not maybe: definitely
|
||||
|
||||
No—I lied. You're definitely going to need to move slowly. Trying to change everything at once is a recipe for disaster.
|
||||
|
||||
This goes for all elements of the change—which people to choose, which technologies to choose, which applications to choose, which user base to choose, which use cases to choose—bar one. For those elements, if you try to move everything in one go, you will fail. You'll fail for a number of reasons. You'll fail for reasons I can't imagine and, more importantly, for reasons you can't imagine. But some of the reasons will include:
|
||||
|
||||
* People—most people—don't like change.
|
||||
* Technologies don't like change (you can't just switch and expect everything to still work).
|
||||
* Applications don't like change (things worked before, or at least failed in known ways). You want to change everything in one go? Well, they'll all fail in new and exciting9 ways.
|
||||
* Users don't like change.
|
||||
* Use cases don't like change.
|
||||
|
||||
|
||||
|
||||
### The one exception
|
||||
|
||||
You noticed I wrote "bar one" when discussing which elements you shouldn't choose to change all in one go? Well done.
|
||||
|
||||
What's that exception? It's the initial team. When you choose your initial application to change and you're thinking about choosing the team to make that change, select the members carefully and select a complete set. This is important. If you choose just developers, just test folks, just security folks, just ops folks, or just management—if you leave out one functional group from your list—you won't have proved anything at all. Well, you might have proved to a small section of your community that it kind of works, but you'll have missed out on a trick. And that trick is: If you choose keen people from across your functional groups, it's much harder to fail.
|
||||
|
||||
Say your first attempt goes brilliantly. How are you going to convince other people to replicate your success and adopt DevOps? Well, the company newsletter, of course. And that will convince how many people, exactly? Yes, that number.12 If, on the other hand, you have team members from across the functional parts or the organisation, when you succeed, they'll tell their colleagues and you'll get more buy-in next time.
|
||||
|
||||
If it fails, if you've chosen your team wisely—if they're all enthusiastic and know that "fail often, fail fast" is good—they'll be ready to go again.
|
||||
|
||||
Therefore, you need to choose enthusiasts from across your functional groups. They can work on the technologies and the process, and once that's working, it's the people who will create that cultural change. You can just sit back and enjoy. Until the next crisis, of course.
|
||||
|
||||
1\. OK, you're right. It should be "with which we techies tend to struggle."2
|
||||
|
||||
2\. You thought I was going to qualify that bit about techies struggling with touchy-feely stuff, didn't you? Read it again: I put "tend to." That's the best you're getting.
|
||||
|
||||
3\. Is percolating a bottom-up process? I don't drink coffee,4 so I wouldn't know.
|
||||
|
||||
4\. Do people even use percolators to make coffee anymore? Feel free to let me know in the comments. I may pretend interest if you're lucky.
|
||||
|
||||
5\. For U.S. readers (and some other countries, maybe?), please substitute "check" for "tick" here.6
|
||||
|
||||
6\. For U.S. techie readers, feel free to perform `s/tick/check/;`.
|
||||
|
||||
7\. This is a Status Quo8 reference for which I'm extremely sorry.
|
||||
|
||||
8\. For millennial readers, please consult your favourite online reference engine or just roll your eyes and move on.
|
||||
|
||||
9\. For people who say, "but I love excitement," try being on call at 2 a.m. on a Sunday at the end of the quarter when your chief financial officer calls you up to ask why all of last month's sales figures have been corrupted with the letters "DEADBEEF."10
|
||||
|
||||
10\. For people not in the know, this is a string often used by techies as test data because a) it's non-numerical; b) it's numerical (in hexadecimal); c) it's easy to search for in debug files; and d) it's funny.11
|
||||
|
||||
11\. Though see.9
|
||||
|
||||
12\. It's a low number, is all I'm saying.
|
||||
|
||||
This article originally appeared on [Alice, Eve, and Bob – a security blog][1] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/most-important-issue-devops-transformation
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://aliceevebob.com/2018/02/06/moving-to-devops-whats-most-important/
|
||||
85
sources/talk/20180226 5 keys to building open hardware.md
Normal file
85
sources/talk/20180226 5 keys to building open hardware.md
Normal file
@ -0,0 +1,85 @@
|
||||
5 keys to building open hardware
|
||||
======
|
||||
|
||||
|
||||
The science community is increasingly embracing free and open source hardware ([FOSH][1]). Researchers have been busy [hacking their own equipment][2] and creating hundreds of devices based on the distributed digital manufacturing model to advance their scientific experiments.
|
||||
|
||||
A major reason for all this interest in distributed digital manufacturing of scientific FOSH is money: Research indicates that FOSH [slashes costs by 90% to 99%][3] compared to proprietary tools. Commercializing scientific FOSH with [open hardware business models][4] has supported the rapid growth of an engineering subfield to develop FOSH for science, which comes together annually at the [Gathering for Open Science Hardware][5].
|
||||
|
||||
Remarkably, not one, but [two new academic journals][6] are devoted to the topic: the [Journal of Open Hardware][7] (from Ubiquity Press, a new open access publisher that also publishes the [Journal of Open Research Software][8] ) and [HardwareX][9] (an [open access journal][10] from Elsevier, one of the world's largest academic publishers).
|
||||
|
||||
Because of the academic community's support, scientific FOSH developers can get academic credit while having fun designing open hardware and pushing science forward faster.
|
||||
|
||||
### 5 steps for scientific FOSH
|
||||
|
||||
Shane Oberloier and I co-authored a new [article][11] published in Designs, an open access engineering design journal, about the principles of designing FOSH scientific equipment. We used the example of a slide dryer, fabricated for under $20, which costs up to 300 times less than proprietary equivalents. [Scientific][1] and [medical][12] equipment tends to be complex with huge payoffs for developing FOSH alternatives.
|
||||
|
||||
I've summarized the five steps (including six design principles) that Shane and I detail in our Designs article. These design principles can be generalized to non-scientific devices, although the more complex the design or equipment, the larger the potential savings.
|
||||
|
||||
If you are interested in designing open hardware for scientific projects, these steps will maximize your project's impact.
|
||||
|
||||
1. Evaluate similar existing tools for their functions but base your FOSH design on replicating their physical effects, not pre-existing designs. If necessary, evaluate a proof of concept.
|
||||
|
||||
|
||||
2. Use the following design principles:
|
||||
|
||||
|
||||
* Use only free and open source software toolchains (e.g., open source CAD packages such as [OpenSCAD][13], [FreeCAD][14], or [Blender][15]) and open hardware for device fabrication.
|
||||
* Attempt to minimize the number and type of parts and the complexity of the tools.
|
||||
* Minimize the amount of material and the cost of production.
|
||||
* Maximize the use of components that can be distributed or digitally manufactured by using widespread and accessible tools such as the open source [RepRap 3D printer][16].
|
||||
* Create [parametric designs][17] with predesigned components, which enable others to customize your design. By making parametric designs rather than solving a specific case, all future cases can also be solved while enabling future users to alter the core variables to make the device useful for them.
|
||||
* All components that are not easily and economically fabricated with existing open hardware equipment in a distributed fashion should be chosen from off-the-shelf parts that are readily available throughout the world.
|
||||
|
||||
|
||||
3. Validate the design for the targeted function(s).
|
||||
|
||||
|
||||
4. Meticulously document the design, manufacture, assembly, calibration, and operation of the device. This should include the raw source of the design, not just the files used for production. The Open Source Hardware Association has extensive [guidelines][18] for properly documenting and releasing open source designs, which can be summarized as follows:
|
||||
|
||||
|
||||
* Share design files in a universal type.
|
||||
* Include a fully detailed bill of materials, including prices and sourcing information.
|
||||
* If software is involved, make sure the code is clear and understandable to the general public.
|
||||
* Include many photos so that nothing is obscured, and they can be used as a reference while manufacturing.
|
||||
* In the methods section, the entire manufacturing process must be detailed to act as instructions for users to replicate the design.
|
||||
* Share online and specify a license. This gives users information on what constitutes fair use of the design.
|
||||
|
||||
|
||||
5. Share aggressively! For FOSH to proliferate, designs must be shared widely, frequently, and noticeably to raise awareness of their existence. All documentation should be published in the open access literature and shared with appropriate communities. One nice universal repository to consider is the [Open Science Framework][19], hosted by the Center for Open Science, which is set up to take any type of file and handle large datasets.
|
||||
|
||||
|
||||
|
||||
This article was supported by [Fulbright Finland][20], which is sponsoring Joshua Pearce's research in open source scientific hardware in Finland as the Fulbright-Aalto University Distinguished Chair.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/5-steps-creating-successful-open-hardware
|
||||
|
||||
作者:[Joshua Pearce][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jmpearce
|
||||
[1]:https://opensource.com/business/16/4/how-calculate-open-source-hardware-return-investment
|
||||
[2]:https://opensource.com/node/16840
|
||||
[3]:http://www.appropedia.org/Open-source_Lab
|
||||
[4]:https://www.academia.edu/32004903/Emerging_Business_Models_for_Open_Source_Hardware
|
||||
[5]:http://openhardware.science/
|
||||
[6]:https://opensource.com/life/16/7/hardwarex-open-access-journal
|
||||
[7]:https://openhardware.metajnl.com/
|
||||
[8]:https://openresearchsoftware.metajnl.com/
|
||||
[9]:https://www.journals.elsevier.com/hardwarex
|
||||
[10]:https://opensource.com/node/30041
|
||||
[11]:https://www.academia.edu/35603319/General_Design_Procedure_for_Free_and_Open-Source_Hardware_for_Scientific_Equipment
|
||||
[12]:https://www.academia.edu/35382852/Maximizing_Returns_for_Public_Funding_of_Medical_Research_with_Open_source_Hardware
|
||||
[13]:http://www.openscad.org/
|
||||
[14]:https://www.freecadweb.org/
|
||||
[15]:https://www.blender.org/
|
||||
[16]:http://reprap.org/
|
||||
[17]:https://en.wikipedia.org/wiki/Parametric_design
|
||||
[18]:https://www.oshwa.org/sharing-best-practices/
|
||||
[19]:https://osf.io/
|
||||
[20]:http://www.fulbright.fi/en
|
||||
@ -0,0 +1,73 @@
|
||||
Emacs #1: Ditching a bunch of stuff and moving to Emacs and org-mode
|
||||
======
|
||||
I’ll admit it. After over a decade of vim, I’m hooked on [Emacs][1].
|
||||
|
||||
I’ve long had this frustration over how to organize things. I’ve followed approaches like [GTD][2] and [ZTD][3], but things like email or large files are really hard to organize.
|
||||
|
||||
I had been using Asana for tasks, Evernote for notes, Thunderbird for email, a combination of ikiwiki and some other items for a personal knowledge base, and various files in an archive directory on my PC. When my new job added Slack to the mix, that was finally the last straw.
|
||||
|
||||
A lot of todo-management tools integrate with email — poorly. When you want to do something like “remind me to reply to this in a week”, a lot of times that’s impossible because the tool doesn’t store the email in a fashion you can easily reply to. And that problem is even worse with Slack.
|
||||
|
||||
It was right around then that I stumbled onto [Carsten Dominik’s Google Talk on org-mode][4]. Carsten was the author of org-mode, and although the talk is 10 years old, it is still highly relevant.
|
||||
|
||||
I’d stumbled across [org-mode][5] before, but each time I didn’t really dig in because I had the reaction of “an outliner? But I need a todo list.” Turns out I was missing out. org-mode is all that.
|
||||
|
||||
### Just what IS Emacs? And org-mode?
|
||||
|
||||
Emacs grew up as a text editor. It still is, and that heritage is definitely present throughout. But to say Emacs is an editor would be rather unfair.
|
||||
|
||||
Emacs is something more like a platform or a toolkit. Not only do you have source code to it, but the very configuration is a program, and there are hooks all over the place. It’s as if it was super easy to write a Firefox plugin. A couple lines, and boom, behavior changed.
|
||||
|
||||
org-mode is very similar. Yes, it’s an outliner, but that’s not really what it is. It’s an information organization platform. Its website says “Your life in plain text: Org mode is for keeping notes, maintaining TODO lists, planning projects, and authoring documents with a fast and effective plain-text system.”
|
||||
|
||||
### Capturing
|
||||
|
||||
If you’ve ever read productivity guides based on GTD, one of the things they stress is effortless capture of items. The idea is that when something pops into your head, get it down into a trusted system quickly so you can get on with what you were doing. org-mode has a capture system for just this. I can press `C-c c` from anywhere in Emacs, and up pops a spot to type my note. But, critically, automatically embedded in that note is a link back to what I was doing when I pressed `C-c c`. If I was editing a file, it’ll have a link back to that file and the line I was on. If I was viewing an email, it’ll link back to that email (by Message-Id, no less, so it finds it in any folder). Same for participating in a chat, or even viewing another org-mode entry.
|
||||
|
||||
So I can make a note that will remind me in a week to reply to a certain email, and when I click the link in that note, it’ll bring up the email in my mail reader — even if I subsequently archived it out of my inbox.
|
||||
|
||||
YES, this is what I was looking for!
|
||||
|
||||
### The tool suite
|
||||
|
||||
Once you’re using org-mode, pretty soon you want to integrate everything with it. There are browser plugins for capturing things from the web. Multiple Emacs mail or news readers integrate with it. ERC (IRC client) does as well. So I found myself switching from Thunderbird and mairix+mutt (for the mail archives) to mu4e, and from xchat+slack to ERC.
|
||||
|
||||
And wouldn’t you know it, I liked each of those Emacs-based tools **better** than the standalone they replaced.
|
||||
|
||||
A small side tidbit: I’m using OfflineIMAP again! I even used it with GNUS way back when.
|
||||
|
||||
### One Emacs process to rule them
|
||||
|
||||
I used to use Emacs extensively, way back. Back then, Emacs was a “large” program. (Now my battery status applet literally uses more RAM than Emacs). There was this problem of startup time back then, so there was a way to connect to a running Emacs process.
|
||||
|
||||
I like to spawn programs with Mod-p (an xmonad shortcut to a dzen menubar, but Alt-F2 in more traditional DEs would do the trick). It’s convenient to not run several emacsen with this setup, so you don’t run into issues with trying to capture to a file that’s open in another one. The solution is very simple: I created a script, named it `em`, and put it on my path. All it does is this:
|
||||
|
||||
`#!/bin/bash exec emacsclient -c -a "" "$@"`
|
||||
|
||||
It creates a new emacs process if one doesn’t already exist; otherwise, it uses what you’ve got. A bonus here: parameters such as `-nw` work just fine, so it really acts just as if you’d typed `emacs` at the shell prompt. It’s a suitable setting for `EDITOR`.
|
||||
|
||||
### Up next…
|
||||
|
||||
I’ll be talking about my use of, and showing off configurations for:
|
||||
|
||||
* org-mode, including syncing between computers, capturing, agenda and todos, files, linking, keywords and tags, various exporting (slideshows), etc.
|
||||
* mu4e for email, including multiple accounts, bbdb integration
|
||||
* ERC for IRC and IM
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://www.gnu.org/software/emacs/
|
||||
[2]:https://gettingthingsdone.com/
|
||||
[3]:https://zenhabits.net/zen-to-done-the-simple-productivity-e-book/
|
||||
[4]:https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]:https://orgmode.org/
|
||||
@ -1,341 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How To Create sar Graphs With kSar To Identifying Linux Bottlenecks
|
||||
======
|
||||
The sar command collects, report, or save UNIX / Linux system activity information. It will save selected counters in the operating system to the /var/log/sa/sadd file. From the collected data, you get lots of information about your server:
|
||||
|
||||
1. CPU utilization
|
||||
2. Memory paging and its utilization
|
||||
3. Network I/O, and transfer statistics
|
||||
4. Process creation activity
|
||||
5. All block devices activity
|
||||
6. Interrupts/sec etc.
|
||||
|
||||
|
||||
|
||||
The sar command output can be used for identifying server bottlenecks. However, analyzing information provided by sar can be difficult, so use kSar tool. kSar takes sar command output and plots a nice easy to understand graph over a period of time.
|
||||
|
||||
|
||||
## sysstat Package
|
||||
|
||||
The sar, sa1, and sa2 commands are part of sysstat package. Collection of performance monitoring tools for Linux includes
|
||||
|
||||
1. sar : Displays the data.
|
||||
2. sa1 and sa2: Collect and store the data for later analysis. The sa2 shell script write a daily report in the /var/log/sa directory. The sa1 shell script collect and store binary data in the system activity daily data file.
|
||||
3. sadc - System activity data collector. You can configure various options by modifying sa1 and sa2 scripts. They are located at the following location:
|
||||
* /usr/lib64/sa/sa1 (64bit) or /usr/lib/sa/sa1 (32bit) - This calls sadc to log reports to/var/log/sa/sadX format.
|
||||
* /usr/lib64/sa/sa2 (64bit) or /usr/lib/sa/sa2 (32bit) - This calls sar to log reports to /var/log/sa/sarX format.
|
||||
|
||||
|
||||
|
||||
### How do I install sar on my system?
|
||||
|
||||
Type the following [yum command][1] to install sysstat on a CentOS/RHEL based system:
|
||||
`# yum install sysstat`
|
||||
Sample outputs:
|
||||
```
|
||||
Loaded plugins: downloadonly, fastestmirror, priorities,
|
||||
: protectbase, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* addons: mirror.cs.vt.edu
|
||||
* base: mirror.ash.fastserv.com
|
||||
* epel: serverbeach1.fedoraproject.org
|
||||
* extras: mirror.cogentco.com
|
||||
* updates: centos.mirror.nac.net
|
||||
0 packages excluded due to repository protections
|
||||
Setting up Install Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
====================================================================
|
||||
Package Arch Version Repository Size
|
||||
====================================================================
|
||||
Installing:
|
||||
sysstat x86_64 7.0.2-3.el5 base 173 k
|
||||
|
||||
Transaction Summary
|
||||
====================================================================
|
||||
Install 1 Package(s)
|
||||
Update 0 Package(s)
|
||||
Remove 0 Package(s)
|
||||
|
||||
Total download size: 173 k
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Finished Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : sysstat 1/1
|
||||
|
||||
Installed:
|
||||
sysstat.x86_64 0:7.0.2-3.el5
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
|
||||
### Configuration files for sysstat
|
||||
|
||||
Edit /etc/sysconfig/sysstat file specify how long to keep log files in days, maximum is a month:
|
||||
`# vi /etc/sysconfig/sysstat`
|
||||
Sample outputs:
|
||||
```
|
||||
# keep log for 28 days
|
||||
# the default is 7
|
||||
HISTORY=28
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
### Find the default cron job for sar
|
||||
|
||||
[The default cron job is located][2] at /etc/cron.d/sysstat:
|
||||
`# cat /etc/cron.d/sysstat`
|
||||
Sample outputs:
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
### Tell sadc to report statistics for disks
|
||||
|
||||
Edit the /etc/cron.d/sysstat file using a text editor such as NA command or vim command, enter:
|
||||
`# vi /etc/cron.d/sysstat`
|
||||
Update it as follows to log all disk stats (the -d option force to log stats for each block device and the -I option force report statistics for all system interrupts):
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
On a CentOS/RHEL 7.x you need to pass the -S DISK option to collect data for block devices. Pass the -S XALL to collect data about:
|
||||
|
||||
1. Disk
|
||||
2. Partition
|
||||
3. System interrupts
|
||||
4. SNMP
|
||||
5. IPv6
|
||||
|
||||
|
||||
```
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
|
||||
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
|
||||
# Generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
```
|
||||
|
||||
Save and close the file. Turn on the service for a CentOS/RHEL version 5.x/6.x, enter:
|
||||
`# chkconfig sysstat on
|
||||
# service sysstat start`
|
||||
Sample outputs:
|
||||
```
|
||||
Calling the system activity data collector (sadc):
|
||||
```
|
||||
|
||||
For a CentOS/RHEL 7.x, run the following commands:
|
||||
```
|
||||
# systemctl enable sysstat
|
||||
# systemctl start sysstat.service
|
||||
# systemctl status sysstat.service
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
● sysstat.service - Resets System Activity Logs
|
||||
Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
|
||||
Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
|
||||
Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
|
||||
Main PID: 28297 (code=exited, status=0/SUCCESS)
|
||||
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
|
||||
```
|
||||
|
||||
## How Do I Use sar? How do I View Stats?
|
||||
|
||||
Use the sar command to display output the contents of selected cumulative activity counters in the operating system. In this example, sar is run to get real-time reporting from the command line about CPU utilization:
|
||||
`# sar -u 3 10`
|
||||
Sample outputs:
|
||||
```
|
||||
Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
|
||||
|
||||
09:49:47 PM CPU %user %nice %system %iowait %steal %idle
|
||||
09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
|
||||
09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
|
||||
09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
|
||||
09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
|
||||
09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
|
||||
09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
|
||||
09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
|
||||
09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
|
||||
09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
|
||||
09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
|
||||
Average: all 9.24 0.69 1.84 0.03 0.00 88.20
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
* 3 = interval
|
||||
* 10 = count
|
||||
|
||||
|
||||
|
||||
To view process creation statistics, enter:
|
||||
`# sar -c 3 10`
|
||||
To view I/O and transfer rate statistics, enter:
|
||||
`# sar -b 3 10`
|
||||
To view paging statistics, enter:
|
||||
`# sar -B 3 10`
|
||||
To view block device statistics, enter:
|
||||
`# sar -d 3 10`
|
||||
To view statistics for all interrupt statistics, enter:
|
||||
`# sar -I XALL 3 10`
|
||||
To view device specific network statistics, enter:
|
||||
```
|
||||
# sar -n DEV 3 10
|
||||
# sar -n EDEV 3 10
|
||||
```
|
||||
To view CPU specific statistics, enter:
|
||||
```
|
||||
# sar -P ALL
|
||||
# Only 1st CPU stats
|
||||
# sar -P 1 3 10
|
||||
```
|
||||
To view queue length and load averages statistics, enter:
|
||||
`# sar -q 3 10`
|
||||
To view memory and swap space utilization statistics, enter:
|
||||
```
|
||||
# sar -r 3 10
|
||||
# sar -R 3 10
|
||||
```
|
||||
To view status of inode, file and other kernel tables statistics, enter:
|
||||
`# sar -v 3 10`
|
||||
To view system switching activity statistics, enter:
|
||||
`# sar -w 3 10`
|
||||
To view swapping statistics, enter:
|
||||
`# sar -W 3 10`
|
||||
To view statistics for a given process called Apache with PID # 3256, enter:
|
||||
`# sar -x 3256 3 10`
|
||||
|
||||
## Say Hello To kSar
|
||||
|
||||
sar and sadf provides CLI based output. The output may confuse all new users / sys admin. So you need to use kSar which is a java application that graph your sar data. It also permit to export data to PDF/JPG/PNG/CSV. You can load data from three method : local file, local command execution, and remote command execution via SSH. kSar supports the sar output of the following OS:
|
||||
|
||||
1. Solaris 8, 9 and 10
|
||||
2. Mac OS/X 10.4+
|
||||
3. Linux (Systat Version >= 5.0.5)
|
||||
4. AIX (4.3 & 5.3)
|
||||
5. HPUX 11.00+
|
||||
|
||||
|
||||
|
||||
### Download And Install kSar
|
||||
|
||||
Visit the [official][3] website and grab the latest source code. Use [wget to][4] download the source code, enter:
|
||||
`$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar`
|
||||
|
||||
#### How Do I Run kSar?
|
||||
|
||||
Make sure [JAVA jdk][5] is installed and working correctly. Type the following command to start kSar, run:
|
||||
`$ java -jar ksar-5.2.4-SNAPSHOT-all.jar`
|
||||
|
||||
![Fig.01: kSar welcome screen][6]
|
||||
Next you will see main kSar window, and menus with two panels.
|
||||
![Fig.02: kSar - the main window][7]
|
||||
The left one will have a list of graphs available depending on the data kSar has parsed. The right window will show you the graph you have selected.
|
||||
|
||||
## How Do I Generate sar Graphs Using kSar?
|
||||
|
||||
First, you need to grab sar command statistics from the server named server1. Type the following command to get stats, run:
|
||||
`[ **server1** ]# LC_ALL=C sar -A > /tmp/sar.data.txt`
|
||||
Next copy file to local desktop from a remote box using the scp command:
|
||||
`[ **desktop** ]$ scp user@server1.nixcraft.com:/tmp/sar.data.txt /tmp/`
|
||||
Switch to kSar Windows. Click on **Data** > **Load data from text file** > Select sar.data.txt from /tmp/ > Click the **Open** button.
|
||||
Now, the graph type tree is deployed in left pane and a graph has been selected:
|
||||
![Fig.03: Processes for server1][8]
|
||||
|
||||
![Fig.03: Disk stats \(blok device\) stats for server1][9]![Fig.05: Memory stats for server1][10]
|
||||
|
||||
#### Zoom in and out
|
||||
|
||||
Using the move, you can interactively zoom onto up a part of a graph. To select a zone to zoom, click on the upper left conner and while still holding the mouse but on move to the lower-right of the zone you want to zoom. To come back to unzoomed view click and drag the mouse to any corner location except a lower-right one. You can also right click and select zoom options
|
||||
|
||||
#### Understanding kSar Graphs And sar Data
|
||||
|
||||
I strongly recommend reading sar and sadf command man page:
|
||||
`$ man sar
|
||||
$ man sadf`
|
||||
|
||||
## Case Study: Identifying Linux Server CPU Bottlenecks
|
||||
|
||||
With sar command and kSar tool, one can get the detailed snapshot of memory, CPU, and other subsystems. For example, if CPU utilization is more than 80% for a long period, a CPU bottleneck is most likely occurring. Using **sar -x ALL** you can find out CPU eating process. The output of [mpstat command][11] (part of sysstat package itself) will also help you understand the cpu utilization. You can easily analyze this information with kSar.
|
||||
|
||||
### I Found CPU Bottlenecks…
|
||||
|
||||
Performance tuning options for the CPU are as follows:
|
||||
|
||||
1. Make sure that no unnecessary programs are running in the background. Turn off [all unnecessary services on Linux][12].
|
||||
2. Use [cron to schedule][13] jobs (e.g., backup) to run at off-peak hours.
|
||||
3. Use [top and ps command][14] to find out all non-critical background jobs / services. Make sure you lower their priority using [renice command][15].
|
||||
4. Use [taskset command to set a processes's][16] CPU affinity (offload cpu) i.e. bind processes to different CPUs. For example, run MySQL database on cpu #2 and Apache on cpu # 3.
|
||||
5. Make sure you are using latest drivers and firmware for your server.
|
||||
6. If possible add additional CPUs to the system.
|
||||
7. Use faster CPUs for a single-threaded application (e.g. Lighttpd web server app).
|
||||
8. Use more CPUs for a multi-threaded application (e.g. MySQL database server app).
|
||||
9. Use more computer nodes and set up a [load balancer][17] for a web app.
|
||||
|
||||
|
||||
|
||||
## isag - Interactive System Activity Grapher (alternate tool)
|
||||
|
||||
The isag command graphically displays the system activity data stored in a binary data file by a previous sar run. The isag command invokes sar to extract the data to be plotted. isag has limited set of options as compare to kSar.
|
||||
|
||||
![Fig.06: isag CPU utilization graphs][18]
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][19], [Facebook][20], [Google+][21].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[3]:https://github.com/vlsi/ksar
|
||||
[4]:https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html
|
||||
[5]:https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/12/sar-welcome.png (kSar welcome screen)
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/12/screenshot-kSar-a-sar-grapher-01.png (kSar - the main window)
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/12/cpu-ksar.png (Linux kSar Processes for server1 )
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/12/disk-stats-ksar.png (Linux Disk I/O Stats Using kSar)
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/12/memory-ksar.png (Linux Memory paging and its utilization stats)
|
||||
[11]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
|
||||
[12]:https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/
|
||||
[13]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[14]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
|
||||
[15]:https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/
|
||||
[16]:https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/
|
||||
[17]:https://www.cyberciti.biz/tips/load-balancer-open-source-software.html
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2009/12/isag.cpu_.png (Fig.06: isag CPU utilization graphs)
|
||||
[19]:https://twitter.com/nixcraft
|
||||
[20]:https://facebook.com/nixcraft
|
||||
[21]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,89 +0,0 @@
|
||||
Translating by qhwdw
|
||||
What’s next in DevOps: 5 trends to watch
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "DevOps" is typically credited [to this 2008 presentation][1] on agile infrastructure and operations. Now ubiquitous in IT vocabulary, the mashup word is less than 10 years old: We're still figuring out this modern way of working in IT.
|
||||
|
||||
Sure, people who have been "doing DevOps" for years have accrued plenty of wisdom along the way. But most DevOps environments - and the mix of people and [culture][2], process and methodology, and tools and technology - are far from mature.
|
||||
|
||||
More change is coming. That's kind of the whole point. "DevOps is a process, an algorithm," says Robert Reeves, CTO at [Datical][3]. "Its entire purpose is to change and evolve over time."
|
||||
|
||||
What should we expect next? Here are some key trends to watch, according to DevOps experts.
|
||||
|
||||
### 1. Expect increasing interdependence between DevOps, containers, and microservices
|
||||
|
||||
The forces driving the proliferation of DevOps culture themselves may evolve. Sure, DevOps will still fundamentally knock down traditional IT silos and bottlenecks, but the reasons for doing so may become more urgent. Exhibits A & B: Growing interest in and [adoption of containers and microservices][4]. The technologies pack a powerful, scalable one-two punch, best paired with planned, [ongoing management][5].
|
||||
|
||||
"One of the major factors impacting DevOps is the shift towards microservices," says Arvind Soni, VP of product at [Netsil][6], adding that containers and orchestration are enabling developers to package and deliver services at an ever-increasing pace. DevOps teams will likely be tasked with helping to fuel that pace and to manage the ongoing complexity of a scalable microservices architecture.
|
||||
|
||||
### 2. Expect fewer safety nets
|
||||
|
||||
DevOps enables teams to build software with greater speed and agility, deploying faster and more frequently, while improving quality and stability. But good IT leaders don't typically ignore risk management, so plenty of early DevOps iterations began with safeguards and fallback positions in place. To get to the next level of speed and agility, more teams will take off their training wheels.
|
||||
|
||||
"As teams mature, they may decide that some of the guard rails that were added early on may not be required anymore," says Nic Grange, CTO of [Retriever Communications][7]. Grange gives the example of a staging server: As DevOps teams mature, they may decide it's no longer necessary, especially if they're rarely catching issues in that pre-production environment. (Grange points out that this move isn't advisable for inexperienced teams.)
|
||||
|
||||
"The team may be at a point where it is confident enough with its monitoring and ability to identify and resolve issues in production," Grange says. "The process of deploying and testing in staging may just be slowing them down without any demonstrable value."
|
||||
|
||||
### 3. Expect DevOps to spread elsewhere
|
||||
|
||||
DevOps brings two traditional IT groups, development and operations, into much closer alignment. As more companies see the benefits in the trenches, the culture is likely to spread. It's already happening in some organizations, evident in the increasing appearance of the term "DevSecOps," which reflects the intentional and much earlier inclusion of security in the software development lifecycle.
|
||||
|
||||
"DevSecOps is not only tools, it is integrating a security mindset into development practices early on," says Derek Weeks, VP and DevOps advocate at [Sonatype][8].
|
||||
|
||||
Doing that isn't a technology challenge, it's a cultural challenge, says [Red Hat][9] security strategist Kirsten Newcomer.
|
||||
|
||||
"Security teams have historically been isolated from development teams - and each team has developed deep expertise in different areas of IT," Newcomer says. "It doesn't need to be this way. Enterprises that care deeply about security and also care deeply about their ability to quickly deliver business value through software are finding ways to move security left in their application development lifecycles. They're adopting DevSecOps by integrating security practices, tooling, and automation throughout the CI/CD pipeline. To do this well, they're integrating their teams - security professionals are embedded with application development teams from inception (design) through to production deployment. Both sides are seeing the value - each team expands their skill sets and knowledge base, making them more valuable technologists. DevOps done right - or DevSecOps - improves IT security."
|
||||
|
||||
Beyond security, look for DevOps expansion into areas such as database teams, QA, and even potentially outside of IT altogether.
|
||||
|
||||
"This is a very DevOps thing to do: Identify areas of friction and resolve them," Datical's Reeves says. "Security and databases are currently the big bottlenecks for companies that have previously adopted DevOps."
|
||||
|
||||
### 4. Expect ROI to increase
|
||||
|
||||
As companies get deeper into their DevOps work, IT teams will be able to show greater return on investment in methodologies, processes, containers, and microservices, says Eric Schabell, global technology evangelist director, Red Hat. "The Holy Grail was to be moving faster, accomplishing more and becoming flexible. As these components find broader adoption and organizations become more vested in their application the results shall appear," Schabell says.
|
||||
|
||||
"Everything has a learning curve with a peak of excitement as the emerging technologies gain our attention, but also go through a trough of disillusionment when the realization hits that applying it all is hard. Finally, we'll start to see a climb out of the trough and reap the benefits that we've been chasing with DevOps, containers, and microservices."
|
||||
|
||||
### 5. Expect success metrics to keep evolving
|
||||
|
||||
"I believe that two of the core tenets of the DevOps culture, automation and measurement, are never 'done,'" says Mike Kail, CTO at [CYBRIC][10] and former CIO at Yahoo. "There will always be opportunities to automate a task or improve upon an already automated solution, and what is important to measure will likely change and expand over time. This maturation process is a continuous journey, not a destination or completed task."
|
||||
|
||||
In the spirit of DevOps, that maturation and learning will also depend on collaboration and sharing. Kail thinks it's still very much early days for Agile methodologies and DevOps culture, and that means plenty of room for growth.
|
||||
|
||||
"As more mature organizations continue to measure actionable metrics, I believe - [I] hope - that those learnings will be broadly shared so we can all learn and improve from them," Kail says.
|
||||
|
||||
As Red Hat technology evangelist [Gordon Haff][11] recently noted, organizations working hard to improve their DevOps metrics are using factors tied to business outcomes. "You probably don't really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is," [writes Haff][12]. "In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor."
|
||||
|
||||
Some examples of DevOps metrics tied to business outcomes include customer ticket volume (as an indicator of overall customer satisfaction) and Net Promoter Score (the willingness of customers to recommend a company's products or services). For more on this topic, see his full article, [DevOps metrics: Are you measuring what matters? ][12]
|
||||
|
||||
### No rest for the speedy
|
||||
|
||||
By the way, if you were hoping things would get a little more leisurely anytime soon, you're out of luck.
|
||||
|
||||
"If you think releases are fast today, you ain't seen nothing yet," Reeves says. "That's why bringing all stakeholders, including security and database teams, into the DevOps tent is so crucial. The friction caused by these two groups today will only grow as releases increase exponentially."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:http://www.jedi.be/presentations/agile-infrastructure-agile-2008.pdf
|
||||
[2]:https://enterprisersproject.com/article/2017/9/5-ways-nurture-devops-culture
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time
|
||||
[5]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[6]:https://netsil.com/
|
||||
[7]:http://retrievercommunications.com/
|
||||
[8]:https://www.sonatype.com/
|
||||
[9]:https://www.redhat.com/en/
|
||||
[10]:https://www.cybric.io/
|
||||
[11]:https://enterprisersproject.com/user/gordon-haff
|
||||
[12]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by MjSeven
|
||||
|
||||
What Are the Hidden Files in my Linux Home Directory For?
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora)
|
||||
======
|
||||
Learn how to create login banners in Linux to display different warning or information messages to user who is about to log in or after he logs in.
|
||||
|
||||
@ -1,72 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How DevOps eliminated bottlenecks for Ranger community
|
||||
======
|
||||

|
||||
The Visual Studio Application Lifecycle Management (ALM) [Ranger][1] program is a community of volunteers that gives professional guidance, practical experience, and gap-filling solutions to the developer community. It was created in 2006 as an internal Microsoft community to "connect the product group with the field and remove adoption blockers." By 2009, the community had more than 200 members, which led to collaboration and planning challenges, bottlenecks due to dependencies and manual processes, and increasing delays and dissatisfaction within the developer community. In 2010, the program evolved to include Microsoft Most Valued Professionals (MVPs), expanding into a geographically distributed community that spans the globe.
|
||||
|
||||
The community is divided into roughly a dozen active teams. Each team is committed to design, build, and support one guidance or tooling project through its lifetime. In the past, teams typically bottlenecked at the team management level due to a rigid, waterfall-style process and high dependency on one or more program managers. The program managers intervened in decision making, releases, and driving the "why, what, and how" for projects. Also, a lack of real-time metrics prevented teams from effectively monitoring their solutions, and alerts about bugs and issues typically came from the community.
|
||||
|
||||
It was time to find a better way of doing things and delivering value to the developer community.
|
||||
|
||||
### DevOps to the rescue
|
||||
|
||||
> "DevOps is the union of people, process, and products to enable continuous delivery of value to our end users." --[Donovan Brown][2]
|
||||
|
||||
To address these challenges, the community stopped all new projects for a couple of sprints to explore Agile practices and new products. The aim was to re-energize the community, to find ways to promote autonomy, mastery, and purpose, as outlined in the book [Drive][3], by Daniel H. Pink, and to overhaul the rigid processes and products.
|
||||
|
||||
> Mature self-organizing, self-managed, and cross-functional teams thrive on autonomy, mastery, and purpose." --Drive, Daniel H. Pink.
|
||||
|
||||
Getting the culture--the people--right was the first step to embrace DevOps. The community implemented the [Scrum][4] framework, used [kanban][5] to improve the engineering process, and adopted visualization to improve transparency, awareness, and most important, trust. With self-organization of teams, the traditional hierarchy and chain-of-command disappeared. Self-management encouraged teams to actively monitor and evolve their own process.
|
||||
|
||||
In April 2010, the community took another pivotal step by switching and committing its culture, process, and products to the cloud. While the core focus of the free "by-the-community-for-the-community" [solutions][6] remains on guidance and filling gaps, there's a growing investment in open source solutions (OSS) to research and share outcomes from the DevOps transformations.
|
||||
|
||||
Continuous integration (CI) and continuous delivery (CD) replaced rigid manual processes with automated pipelines. This empowered teams to deploy solutions to canary and early-adopter users without intervention from program management. Adding telemetry enabled teams to watch their solutions and often detect and address unknown issues before users noticed them.
|
||||
|
||||
The DevOps transformation is an ongoing evolution, using experiments to explore and validate people, process, and product innovations. Recent experiments introduced pipeline innovations that are continuously improving the value flow. Scanning components automatically, continuously, and silently checks security, licensing, and quality of open source components. Deployment rings and feature flags enable teams to have fine-grained control of features for all or specific users.
|
||||
|
||||
In October 2017, the community moved most of its private version control repositories to [GitHub][7]. Transferring ownership and administration responsibilities for all repositories to the ALM DevOps Rangers community gives the teams autonomy and an opportunity to energize the broader community to contribute to the open source solutions. Teams are empowered to deliver quality and value to their end users.
|
||||
|
||||
### Benefits and accomplishments
|
||||
|
||||
Embracing DevOps enabled the Ranger community to become nimble, realize faster-to-market and quicker-to-learn-and-react processes, reduce investment of precious time, and proclaim autonomy.
|
||||
|
||||
Here's a list of our observations from the transition, listed in no specific order:
|
||||
|
||||
* Autonomy, mastery, and purpose are core.
|
||||
* Start with something tangible and iterate--avoid the big bang.
|
||||
* Tangible and actionable metrics are important--ensure it does not turn into noise.
|
||||
* The most challenging parts of transformation are the people (culture).
|
||||
* There's no blueprint; every organization and every team is unique.
|
||||
* Transformation is continuous.
|
||||
* Transparency and visibility are key.
|
||||
* Use the engineering process to reinforce desired behavior.
|
||||
|
||||
|
||||
|
||||
Table of transformation changes:
|
||||
|
||||
PAST CURRENT ENVISIONED Branching Servicing and release isolation Feature Master Build Manual and error prone Automated and consistent Issue detection Call from user Proactive telemetry Issue resolution Days to weeks Minutes to days Minutes Planning Detailed design Prototyping and storyboards Program management 2 program managers (PM) 0.25 PM 0.125 PM Release cadence 6 to 12 months 3 to 5 sprints Every sprint Release Manual and error prone Automated and consistent Sprints 1 month 3 weeks Team size 10 to 15 2 to 5 Time to build Hours Seconds Time to release Days Minutes
|
||||
|
||||
But, we're not done! Instead, we're part of an exciting, continuous, and likely never-ending transformation.
|
||||
|
||||
If you'd like to learn more about our transformation, positive experiences, and known challenges that need to be addressed, see "[Our journey of transforming to a DevOps culture][8]."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/devops-rangers-transformation
|
||||
|
||||
作者:[Willy Schaub][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wpschaub
|
||||
[1]:https://aka.ms/vsaraboutus
|
||||
[2]:http://donovanbrown.com/post/what-is-devops
|
||||
[3]:http://www.danpink.com/books/drive/
|
||||
[4]:http://www.scrumguides.org/scrum-guide.html
|
||||
[5]:https://leankit.com/learn/kanban/what-is-kanban/
|
||||
[6]:https://aka.ms/vsarsolutions
|
||||
[7]:https://github.com/ALM-Rangers
|
||||
[8]:https://github.com/ALM-Rangers/Guidance/blob/master/src/Stories/our-journey-of-transforming-to-a-devops-culture.md
|
||||
@ -1,119 +0,0 @@
|
||||
Translating by qhwdw
|
||||
6 open source home automation tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
The [Internet of Things][13] isn't just a buzzword, it's a reality that's expanded rapidly since we last published a review article on home automation tools in 2016\. In 2017, [26.5% of U.S. households][14] already had some type of smart home technology in use; within five years that percentage is expected to double.
|
||||
|
||||
With an ever-expanding number of devices available to help you automate, protect, and monitor your home, it has never been easier nor more tempting to try your hand at home automation. Whether you're looking to control your HVAC system remotely, integrate a home theater, protect your home from theft, fire, or other threats, reduce your energy usage, or just control a few lights, there are countless devices available at your disposal.
|
||||
|
||||
But at the same time, many users worry about the security and privacy implications of bringing new devices into their homes—a very real and [serious consideration][15]. They want to control who has access to the vital systems that control their appliances and record every moment of their everyday lives. And understandably so: In an era when even your refrigerator may now be a smart device, don't you want to know if your fridge is phoning home? Wouldn't you want some basic assurance that, even if you give a device permission to communicate externally, it is only accessible to those who are explicitly authorized?
|
||||
|
||||
[Security concerns][16] are among the many reasons why open source will be critical to our future with connected devices. Being able to fully understand the programs that control your home means you can view, and if necessary modify, the source code running on the devices themselves.
|
||||
|
||||
While connected devices often contain proprietary components, a good first step in bringing open source into your home automation system is to ensure that the device that ties your devices together—and presents you with an interface to them (the "hub")—is open source. Fortunately, there are many choices out there, with options to run on everything from your always-on personal computer to a Raspberry Pi.
|
||||
|
||||
Here are just a few of our favorites.
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] is designed as a full-stack home automation platform, including a server application, touchscreen interface, web application, native mobile applications for iOS and Android, and a preconfigured Linux operating system to run underneath. The Calaos project emerged from a French company, so its support forums are primarily in French, although most of the instructional material and documentation have been translated into English.
|
||||
|
||||
Calaos is licensed under version 3 of the [GPL][18] and you can view its source on [GitHub][19].
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] is a home automation system with a pretty wide library of supported devices, ranging from weather stations to smoke detectors to remote controls, and a large number of additional third-party [integrations][21] are documented on the project's website. It is designed with an HTML5 frontend, making it accessible from desktop browsers and most modern smartphones, and is lightweight, running on many low-power devices like the Raspberry Pi.
|
||||
|
||||
Domoticz is written primarily in C/C++ under the [GPLv3][22], and its [source code][23] can be browsed on GitHub.
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] is an open source home automation platform designed to be easily deployed on almost any machine that can run Python 3, from a Raspberry Pi to a network-attached storage (NAS) device, and it even ships with a Docker container to make deploying on other systems a breeze. It integrates with a large number of open source as well as commercial offerings, allowing you to link, for example, IFTTT, weather information, or your Amazon Echo device, to control hardware from locks to lights.
|
||||
|
||||
Home Assistant is released under an [MIT license][25], and its source can be downloaded from [GitHub][26].
|
||||
|
||||
### MisterHouse
|
||||
|
||||
[MisterHouse][27] has gained a lot of ground since 2016, when we mentioned it as "another option to consider" on this list. It uses Perl scripts to monitor anything that can be queried by a computer or control anything capable of being remote controlled. It responds to voice commands, time of day, weather, location, and other events to turn on the lights, wake you up, record your favorite TV show, announce phone callers, warn that your front door is open, report how long your son has been online, tell you if your daughter's car is speeding, and much more. It runs on Linux, macOS, and Windows computers and can read/write from a wide variety of devices including security systems, weather stations, caller ID, routers, vehicle location systems, and more
|
||||
|
||||
MisterHouse is licensed under the [GPLv2][28] and you can view its source code on [GitHub][29].
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30] (short for Open Home Automation Bus) is one of the best-known home automation tools among open source enthusiasts, with a large user community and quite a number of supported devices and integrations. Written in Java, openHAB is portable across most major operating systems and even runs nicely on the Raspberry Pi. Supporting hundreds of devices, openHAB is designed to be device-agnostic while making it easier for developers to add their own devices or plugins to the system. OpenHAB also ships iOS and Android apps for device control, as well as design tools so you can create your own UI for your home system.
|
||||
|
||||
You can find openHAB's [source code][31] on GitHub licensed under the [Eclipse Public License][32].
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] is a home automation system with both hardware and software under open source licenses. It's designed to provide a comprehensive system for controlling devices, rather than stitching together many devices from different providers. Unlike many of the other systems designed primarily for easy retrofitting, OpenMotics focuses on a hardwired solution. For more, see our [full article][34] from OpenMotics backend developer Frederick Ryckbosch.
|
||||
|
||||
The source code for OpenMotics is licensed under the [GPLv2][35] and is available for download on [GitHub][36].
|
||||
|
||||
These aren't the only options available, of course. Many home automation enthusiasts go with a different solution, or even decide to roll their own. Other users choose to use individual smart home devices without integrating them into a single comprehensive system.
|
||||
|
||||
If the solutions above don't meet your needs, here are some potential alternatives to consider:
|
||||
|
||||
* [EventGhost][1] is an open source ([GPL v2][2]) home theater automation tool that operates only on Microsoft Windows PCs. It allows users to control media PCs and attached hardware by using plugins that trigger macros or by writing custom Python scripts.
|
||||
|
||||
* [ioBroker][3] is a JavaScript-based IoT platform that can control lights, locks, thermostats, media, webcams, and more. It will run on any hardware that runs Node.js, including Windows, Linux, and macOS, and is open sourced under the [MIT license][4].
|
||||
|
||||
* [Jeedom][5] is a home automation platform comprised of open source software ([GPL v2][6]) to control lights, locks, media, and more. It includes a mobile app (Android and iOS) and operates on Linux PCs; the company also sells hubs that it says provide a ready-to-use solution for setting up home automation.
|
||||
|
||||
* [LinuxMCE][7] bills itself as the "'digital glue' between your media and all of your electrical appliances." It runs on Linux (including Raspberry Pi), is released under the Pluto open source [license][8], and can be used for home security, telecom (VoIP and voice mail), A/V equipment, home automation, and—uniquely—to play video games.
|
||||
|
||||
* [OpenNetHome][9], like the other solutions in this category, is open source software for controlling lights, alarms, appliances, etc. It's based on Java and Apache Maven, operates on Windows, macOS, and Linux—including Raspberry Pi, and is released under [GPLv3][10].
|
||||
|
||||
* [Smarthomatic][11] is an open source home automation framework that concentrates on hardware devices and software, rather than user interfaces. Licensed under [GPLv3][12], it's used for things such as controlling lights, appliances, and air humidity, measuring ambient temperature, and remembering to water your plants.
|
||||
|
||||
Now it's your turn: Do you already have an open source home automation system in place? Or perhaps you're researching the options to create one. What advice would you have to a newcomer to home automation, and what system or systems would you recommend?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://www.eventghost.net/
|
||||
[2]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[3]:http://iobroker.net/
|
||||
[4]:https://github.com/ioBroker/ioBroker#license
|
||||
[5]:https://www.jeedom.com/site/en/index.html
|
||||
[6]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[7]:http://www.linuxmce.com/
|
||||
[8]:http://wiki.linuxmce.org/index.php/License
|
||||
[9]:http://opennethome.org/
|
||||
[10]:https://github.com/NetHome/NetHomeServer/blob/master/LICENSE
|
||||
[11]:https://www.smarthomatic.org/
|
||||
[12]:https://github.com/breaker27/smarthomatic/blob/develop/GPL3.txt
|
||||
[13]:https://opensource.com/resources/internet-of-things
|
||||
[14]:https://www.statista.com/outlook/279/109/smart-home/united-states
|
||||
[15]:http://www.crn.com/slide-shows/internet-of-things/300089496/black-hat-2017-9-iot-security-threats-to-watch.htm
|
||||
[16]:https://opensource.com/business/15/5/why-open-source-means-stronger-security
|
||||
[17]:https://calaos.fr/en/
|
||||
[18]:https://github.com/calaos/calaos-os/blob/master/LICENSE
|
||||
[19]:https://github.com/calaos
|
||||
[20]:https://domoticz.com/
|
||||
[21]:https://www.domoticz.com/wiki/Integrations_and_Protocols
|
||||
[22]:https://github.com/domoticz/domoticz/blob/master/License.txt
|
||||
[23]:https://github.com/domoticz/domoticz
|
||||
[24]:https://home-assistant.io/
|
||||
[25]:https://github.com/home-assistant/home-assistant/blob/dev/LICENSE.md
|
||||
[26]:https://github.com/balloob/home-assistant
|
||||
[27]:http://misterhouse.sourceforge.net/
|
||||
[28]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[29]:https://github.com/hollie/misterhouse
|
||||
[30]:http://www.openhab.org/
|
||||
[31]:https://github.com/openhab/openhab
|
||||
[32]:https://github.com/openhab/openhab/blob/master/LICENSE.TXT
|
||||
[33]:https://www.openmotics.com/
|
||||
[34]:https://opensource.com/life/14/12/open-source-home-automation-system-opemmotics
|
||||
[35]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[36]:https://github.com/openmotics
|
||||
@ -1,3 +1,5 @@
|
||||
translated by cyleft
|
||||
|
||||
Migrating to Linux: The Command Line
|
||||
======
|
||||
|
||||
|
||||
@ -1,64 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Check Your Linux PC for Meltdown or Spectre Vulnerability
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the scariest realities of the Meltdown and Spectre vulnerabilities is just how widespread they are. Virtually every modern computer is affected in some way. The real question is how exactly are _you_ affected? Every system is at a different state of vulnerability depending on which software has and hasn’t been patched.
|
||||
|
||||
Since Meltdown and Spectre are both fairly new and things are moving quickly, it’s not all that easy to tell what you need to look out for or what’s been fixed on your system. There are a couple of tools available that can help. They’re not perfect, but they can help you figure out what you need to know.
|
||||
|
||||
### Simple Test
|
||||
|
||||
One of the top Linux kernel developers provided a simple way of checking the status of your system in regards to the Meltdown and Spectre vulnerabilities. This one is the easiest, and is most concise, but it doesn’t work on every system. Some distributions decided not to include support for this report. Even still, it’s worth a shot to check.
|
||||
```
|
||||
grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
|
||||
```
|
||||
|
||||
![Kernel Vulnerability Check][1]
|
||||
|
||||
You should see output similar to the image above. Chances are, you’ll see that at least one of the vulnerabilities remains unchecked on your system. This is especially true since Linux hasn’t made any progress in mitigating Spectre v1 yet.
|
||||
|
||||
### The Script
|
||||
|
||||
If the above method didn’t work for you, or you want a more detailed report of your system, a developer has created a shell script that will check your system to see what exactly it is susceptible to and what has been done to mitigate Meltdown and Spectre.
|
||||
|
||||
In order to get the script, make sure you have Git installed on your system, and then clone the script’s repository into a directory that you don’t mind running it out of.
|
||||
```
|
||||
cd ~/Downloads
|
||||
git clone https://github.com/speed47/spectre-meltdown-checker.git
|
||||
|
||||
```
|
||||
|
||||
It’s not a large repository, so it should only take a few seconds to clone. When it’s done, enter the newly created directory and run the provided script.
|
||||
```
|
||||
cd spectre-meltdown-checker
|
||||
./spectre-meltdown-checker.sh
|
||||
|
||||
```
|
||||
|
||||
You’ll see a bunch of junk spit out into the terminal. Don’t worry, its not too hard to follow. First, the script checks your hardware, and then it runs through the three vulnerabilities: Spectre v1, Spectre v2, and Meltdown. Each gets its own section. In between, the script tells you plainly whether you are vulnerable to each of the three.
|
||||
|
||||
![Meltdown Spectre Check Script Ubuntu][2]
|
||||
|
||||
Each section provides you with a breakdown of potential mitigation and whether or not they have been applied. Here’s where you need to exercise a bit of common sense. The determinations that it gives might seem like they’re in conflict. Do a bit of digging to see if the fixes that it says are applied actually do fully mitigate the problem or not.
|
||||
|
||||
### What This Means
|
||||
|
||||
So, what’s the takeaway? Most Linux systems have been patched against Meltdown. If you haven’t updated yet for that, you should. Spectre v1 is still a big problem, and not a lot of progress has been made there as of yet. Spectre v2 will depend a lot on your distribution and what patches it’s chosen to apply. Regardless of what either tool says, nothing is perfect. Do your research and stay on the lookout for information coming straight from the kernel and distribution developers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2018/01/lmc-kernel-check.jpg (Kernel Vulnerability Check)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/lmc-script.jpg (Meltdown Spectre Check Script Ubuntu)
|
||||
@ -1,115 +0,0 @@
|
||||
Create a wiki on your Linux desktop with Zim
|
||||
======
|
||||
|
||||
|
||||
|
||||
There's no denying the usefulness of a wiki, even to a non-geek. You can do so much with one—write notes and drafts, collaborate on projects, build complete websites. And so much more.
|
||||
|
||||
I've used more than a few wikis over the years, either for my own work or at various contract and full-time gigs I've held. While traditional wikis are fine, I really like the idea of [desktop wikis][1] . They're small, easy to install and maintain, and even easier to use. And, as you've probably guessed, there are a number a desktop wikis available for Linux.
|
||||
|
||||
Let's take a look at one of the better desktop wikis: [Zim][2].
|
||||
|
||||
### Getting going
|
||||
|
||||
You can either [download][3] and install Zim from the software's website, or do it the easy way and install it through your distro's package manager.
|
||||
|
||||
Once Zim's installed, start it up.
|
||||
|
||||
A key concept in Zim is notebooks. They're like a collection of wiki pages on a single subject. When you first start Zim, it asks you to specify a folder for your notebooks and the name of a notebook. Zim suggests "Notes" for the name, and `~/Notebooks/` for the folder. Change that if you want. I did.
|
||||
|
||||
|
||||
|
||||
After you set the name and the folder for your notebook, click **OK**. You get what's essentially a container for your wiki pages.
|
||||
|
||||
|
||||
|
||||
### Adding pages to a notebook
|
||||
|
||||
So you have a container. Now what? You start adding pages to it, of course. To do that, select **File > New Page**.
|
||||
|
||||
|
||||
|
||||
Enter a name for the page, then click **OK**. From there, you can start typing to add information to that page.
|
||||
|
||||
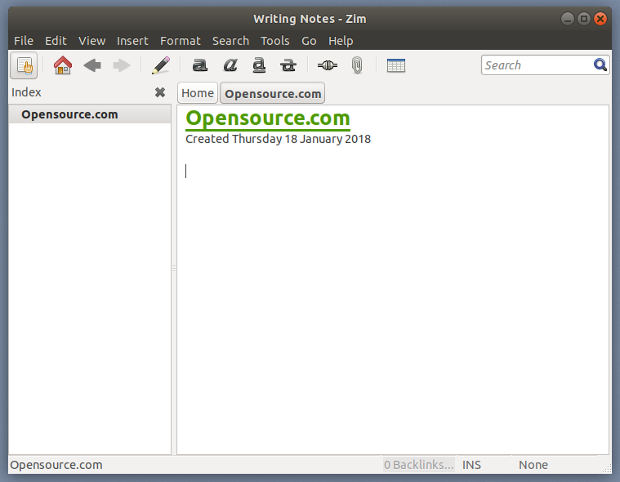
|
||||
|
||||
That page can be whatever you want it to be: notes for a course you're taking, the outline for a book or article or essay, or an inventory of your books. It's up to you.
|
||||
|
||||
Zim has a number of formatting options, including:
|
||||
|
||||
* Headings
|
||||
* Character formatting
|
||||
* Bullet and numbered lists
|
||||
* Checklists
|
||||
|
||||
|
||||
|
||||
You can also add images and attach files to your wiki pages, and even pull in text from a text file.
|
||||
|
||||
### Zim's wiki syntax
|
||||
|
||||
You can add formatting to a page using the toolbar, but that's not the only way to do the deed. If, like me, you're kind of old school, you can use wiki markup for formatting.
|
||||
|
||||
[Zim's markup][4] is based on the markup that's used with [DokuWiki][5]. It's essentially [WikiText][6] with a few minor variations. To create a bullet list, for example, type an asterisk. Surround a word or a phrase with two asterisks to make it bold.
|
||||
|
||||
### Adding links
|
||||
|
||||
If you have a number of pages in a notebook, it's easy to link them. There are two ways to do that.
|
||||
|
||||
The first way is to use [CamelCase][7] to name the pages. Let's say I have a notebook called "Course Notes." I can rename the notebook for the data analysis course I'm taking by typing "AnalysisCourse." When I want to link to it from another page in the notebook, I just type "AnalysisCourse" and press the space bar. Instant hyperlink.
|
||||
|
||||
The second way is to click the **Insert link** button on the toolbar. Type the name of the page you want to link to in the **Link to** field, select it from the displayed list of options, then click **Link**.
|
||||
|
||||
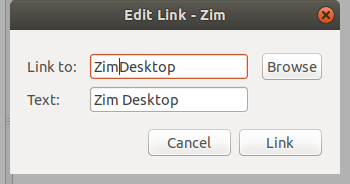
|
||||
|
||||
I've only been able to link between pages in the same notebook. Whenever I've tried to link to a page in another notebook, the file (which has the extension .txt) always opens in a text editor.
|
||||
|
||||
### Exporting your wiki pages
|
||||
|
||||
There might come a time when you want to use the information in a notebook elsewhere—say, in a document or on a web page. Instead of copying and pasting (and losing formatting), you can export your notebook pages to any of the following formats:
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
|
||||
|
||||
To do that, click on the wiki page you want to export. Then, select **File > Export**. Decide whether to export the whole notebook or just a single page, then click **Forward**.
|
||||
|
||||
|
||||
|
||||
Select the file format you want to use to save the page or notebook. With HTML and LaTeX, you can choose a template. Play around to see what works best for you. For example, if you want to turn your wiki pages into HTML presentation slides, you can choose "SlideShow_s5" from the **Template** list. If you're wondering, that produces slides driven by the [S5 slide framework][8].
|
||||
|
||||
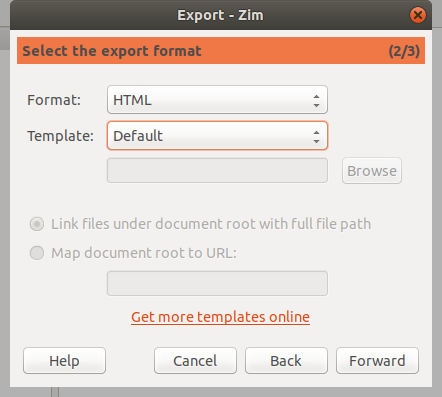
|
||||
|
||||
Click **Forward**. If you're exporting a notebook, you can choose to export the pages as individual files or as one file. You can also point to the folder where you want to save the exported file.
|
||||
|
||||
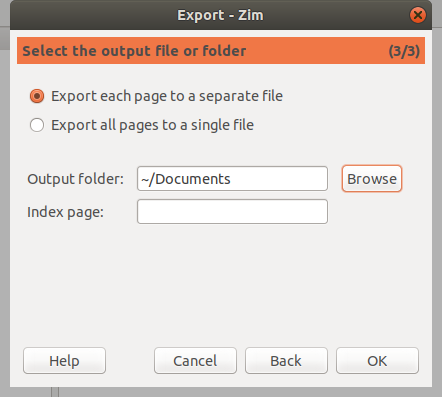
|
||||
|
||||
### Is that all Zim can do?
|
||||
|
||||
Not even close. Zim also has a number of [plugins][9] that expand its capabilities. It even packs a built-in web server that lets you view your notebooks as static HTML files. This is useful for sharing your pages and notebooks on an internal network.
|
||||
|
||||
All in all, Zim is a powerful, yet compact tool for managing your information. It's easily the best desktop wiki I've used, and it's one that I keep going back to.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -0,0 +1,123 @@
|
||||
Plasma Mobile Could Give Life to a Mobile Linux Experience
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the past few years, it’s become clear that, outside of powering Android, Linux on mobile devices has been a resounding failure. Canonical came close, even releasing devices running Ubuntu Touch. Unfortunately, the idea of [Scopes][1]was doomed before it touched down on its first piece of hardware and subsequently died a silent death.
|
||||
|
||||
The next best hope for mobile Linux comes in the form of the [Samsung DeX][2] program. With DeX, users will be able to install an app (Linux On Galaxy—not available yet) on their Samsung devices, which would in turn allow them to run a full-blown Linux distribution. The caveat here is that you’ll be running both Android and Linux at the same time—which is not exactly an efficient use of resources. On top of that, most Linux distributions aren’t designed to run on such small form factors. The good news for DeX is that, when you run Linux on Galaxy and dock your Samsung device to DeX, that Linux OS will be running on your connected monitor—so form factor issues need not apply.
|
||||
|
||||
Outside of those two options, a pure Linux on mobile experience doesn’t exist. Or does it?
|
||||
|
||||
You may have heard of the [Purism Librem 5][3]. It’s a crowdfunded device that promises to finally bring a pure Linux experience to the mobile landscape. This device will be powered by a i.MX8 SoC chip, so it should run most any Linux operating system.
|
||||
|
||||
Out of the box, the device will run an encrypted version of [PureOS][4]. However, last year Purism and KDE joined together to create a mobile version of the KDE desktop that could run on the Librem 5. Recently [ISOs were made available for a beta version of Plasma Mobile][5] and, judging from first glance, they’re onto something that makes perfect sense for a mobile Linux platform. I’ve booted up a live instance of Plasma Mobile to kick the tires a bit.
|
||||
|
||||
What I saw seriously impressed me. Let’s take a look.
|
||||
|
||||
### Testing platform
|
||||
|
||||
Before you download the ISO and attempt to fire it up as a VirtualBox VM, you should know that it won’t work well. Because Plasma Mobile uses Wayland (and VirtualBox has yet to play well with that particular X replacement), you’ll find VirtualBox VM a less-than-ideal platform for the beta release. Also know that the Calamares installer doesn’t function well either. In fact, I have yet to get the OS installed on a non-mobile device. And since I don’t own a supported mobile device, I’ve had to run it as a live session on either a laptop or an [Antsle][6] antlet VM every time.
|
||||
|
||||
### What makes Plasma Mobile special?
|
||||
|
||||
This could be easily summed up by saying, Plasma Mobile got it all right. Instead of Canonical re-inventing a perfectly functioning wheel, the developers of KDE simply re-tooled the interface such that a full-functioning Linux distribution (complete with all the apps you’ve grown to love and depend upon) could work on a smaller platform. And they did a spectacular job. Even better, they’ve created an interface that any user of a mobile device could instantly feel familiar with.
|
||||
|
||||
What you have with the Plasma Mobile interface (Figure 1) are the elements common to most Android home screens:
|
||||
|
||||
* Quick Launchers
|
||||
|
||||
* Notification Shade
|
||||
|
||||
* App Drawer
|
||||
|
||||
* Overview button (so you can go back to a previously used app, still running in memory)
|
||||
|
||||
* Home button
|
||||
|
||||
|
||||
|
||||
|
||||
![KDE mobile][8]
|
||||
|
||||
Figure 1: The Plasma Mobile desktop interface.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Because KDE went this route with the UX, it means there’s zero learning curve. And because this is an actual Linux platform, it takes that user-friendly mobile interface and overlays it onto a system that allows for easy installation and usage of apps like:
|
||||
|
||||
* GIMP
|
||||
|
||||
* LibreOffice
|
||||
|
||||
* Audacity
|
||||
|
||||
* Clementine
|
||||
|
||||
* Dropbox
|
||||
|
||||
* And so much more
|
||||
|
||||
|
||||
|
||||
|
||||
Unfortunately, without being able to install Plasma Mobile, you cannot really kick the tires too much, as the live user doesn’t have permission to install applications. However, once Plasma Mobile is fully installed, the Discover software center will allow you to install a host of applications (Figure 2).
|
||||
|
||||
|
||||
![Discover center][11]
|
||||
|
||||
Figure 2: The Discover software center on Plasma Mobile.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Swipe up (or scroll down—depending on what hardware you’re using) to reveal the app drawer, where you can launch all of your installed applications (Figure 3).
|
||||
|
||||
![KDE mobile][13]
|
||||
|
||||
Figure 3: The Plasma Mobile app drawer ready to launch applications.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Open up a terminal window and you can take care of standard Linux admin tasks, such as using SSH to log into a remote server. Using apt, you can install all of the developer tools you need to make Plasma Mobile a powerful development platform.
|
||||
|
||||
We’re talking serious mobile power—either from a phone or a tablet.
|
||||
|
||||
### A ways to go
|
||||
|
||||
Clearly Plasma Mobile is still way too early in development for it to be of any use to the average user. And because most virtual machine technology doesn’t play well with Wayland, you’re likely to get too frustrated with the current ISO image to thoroughly try it out. However, even without being able to fully install the platform (or get full usage out of it), it’s obvious KDE and Purism are going to have the ideal platform that will put Linux into the hands of mobile users.
|
||||
|
||||
If you want to test the waters of Plasma Mobile on an actual mobile device, a handy list of supported hardware can be found [here][14] (for PostmarketOS) or [here][15] (for Halium). If you happen to be lucky enough to have a device that also includes Wi-Fi support, you’ll find you get more out of testing the environment.
|
||||
|
||||
If you do have a supported device, you’ll need to use either [PostmarketOS][16] (a touch-optimized, pre-configured Alpine Linux that can be installed on smartphones and other mobile devices) or [Halium][15] (an application that creates an minimal Android layer which allows a new interface to interact with the Android kernel). Using Halium further limits the number of supported devices, as it has only been built for select hardware. However, if you’re willing, you can build your own Halium images (documentation for this process is found [here][17]). If you want to give PostmarketOS a go, [here are the necessary build instructions][18].
|
||||
|
||||
Suffice it to say, Plasma Mobile isn’t nearly ready for mass market. If you’re a Linux enthusiast and want to give it a go, let either PostmarketOS or Halium help you get the operating system up and running on your device. Otherwise, your best bet is to wait it out and hope Purism and KDE succeed in bringing this oustanding mobile take on Linux to the masses.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][19]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/plasma-mobile-could-give-life-mobile-linux-experience
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://launchpad.net/unity-scopes
|
||||
[2]:http://www.samsung.com/global/galaxy/apps/samsung-dex/
|
||||
[3]:https://puri.sm/shop/librem-5/
|
||||
[4]:https://www.pureos.net/
|
||||
[5]:http://blog.bshah.in/2018/01/26/trying-out-plasma-mobile/
|
||||
[6]:https://antsle.com/
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_1.jpg?itok=EK3_vFVP (KDE mobile)
|
||||
[9]:https://www.linux.com/licenses/category/used-permission
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_2.jpg?itok=CiUQ-MnB (Discover center)
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_3.jpg?itok=i6V8fgK8 (KDE mobile)
|
||||
[14]:http://blog.bshah.in/2018/02/02/trying-out-plasma-mobile-part-two/
|
||||
[15]:https://github.com/halium/projectmanagement/issues?q=is%3Aissue+is%3Aopen+label%3APorts
|
||||
[16]:https://postmarketos.org/
|
||||
[17]:http://docs.halium.org/en/latest/
|
||||
[18]:https://wiki.postmarketos.org/wiki/Installation_guide
|
||||
[19]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,107 @@
|
||||
How To Run A Command For A Specific Time In Linux
|
||||
======
|
||||

|
||||
|
||||
The other day I was transferring a large file using rsync to another system on my local area network. Since it is very big file, It took around 20 minutes to complete. I don’t want to wait that longer, and I don’t want to terminate the process by pressing CTRL+C either. I was just wondering if there could be any easy ways to run a command for a specific time and kill it automatically once the time is out in Unix-like operating systems – hence this post. Read on.
|
||||
|
||||
### Run A Command For A Specific Time In Linux
|
||||
|
||||
We can do this in two methods.
|
||||
|
||||
#### Method 1 – Using “timeout” command
|
||||
|
||||
The most common method is using **timeout** command. For those who don’t know, the timeout command will effectively limit the absolute execution time of a process. The timeout command is part of the GNU coreutils package, so it comes pre-installed in all GNU/Linux systems.
|
||||
|
||||
Let us say, you want to run a command for only 5 seconds, and then kill it. To do so, we use:
|
||||
```
|
||||
$ timeout <time-limit-interval> <command>
|
||||
|
||||
```
|
||||
|
||||
For example, the following command will terminate after 10 seconds.
|
||||
```
|
||||
$ timeout 10s tail -f /var/log/pacman.log
|
||||
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
You also don’t have to specify the suffix “s” for seconds. The following command is same as above.
|
||||
```
|
||||
$ timeout 10 tail -f /var/log/pacman.log
|
||||
|
||||
```
|
||||
|
||||
The other available suffixes are:
|
||||
|
||||
* ‘m’ for minutes,
|
||||
* ‘h’ for hours
|
||||
* ‘d’ for days.
|
||||
|
||||
|
||||
|
||||
If you run this **tail -f /var/log/pacman.log** command, it will keep running until you manually end it by pressing CTRL+C. However, if you run it along with **timeout** command, it will be killed automatically after the given time interval. If the command is till running after the time out, you can send a **kill** signal like below.
|
||||
```
|
||||
$ timeout -k 20 10 tail -f /var/log/pacman.log
|
||||
|
||||
```
|
||||
|
||||
In this case, if you the tail command still running after 10 seconds, the timeout command will send it a kill signal after 20 seconds and end it.
|
||||
|
||||
For more details, check the man pages.
|
||||
```
|
||||
$ man timeout
|
||||
|
||||
```
|
||||
|
||||
Sometimes, a particular program might take long time to complete and end up freezing your system. In such cases, you can use this trick to end the process automatically after a particular time.
|
||||
|
||||
Also, consider using **Cpulimit** , a simple application to limit the CPU usage of a process. For more details, check the following link.
|
||||
|
||||
#### Method 2 – Using “Timelimit” program
|
||||
|
||||
The Timelimit utility executes a given command with the supplied arguments and terminates the spawned process after a given time with a given signal. First, it will pass the warning signal and then after timeout, it will send the **kill** signal.
|
||||
|
||||
Unlike the timeout utility, the Timelimit has more options. You can pass number of arguments such as killsig, warnsig, killtime, warntime etc. It is available in the default repositories of Debian-based systems. So, you can install it using command:
|
||||
```
|
||||
$ sudo apt-get install timelimit
|
||||
|
||||
```
|
||||
|
||||
For Arch-based systems, it is available in the AUR. So, you can install it using any AUR helper programs such as [**Pacaur**][3], [**Packer**][4], [**Yay**][5], [**Yaourt**][6] etc.
|
||||
|
||||
For other distributions, download the source [**from here**][7] and manually install it. After installing Timelimit program, run the following command for a specific time, for example 10 seconds:
|
||||
```
|
||||
$ timelimit -t10 tail -f /var/log/pacman.log
|
||||
|
||||
```
|
||||
|
||||
If you run timelimit without any arguments, it will use the default values: warntime=3600 seconds, warnsig=15, killtime=120, killsig=9. For more details, refer the man pages and the project’s website given at the end of this guide.
|
||||
```
|
||||
$ man timelimit
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for today. I hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/run-command-specific-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/Timeout.gif
|
||||
[3]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[4]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:http://devel.ringlet.net/sysutils/timelimit/#download
|
||||
@ -0,0 +1,126 @@
|
||||
'Getting to Done' on the Linux command line
|
||||
======
|
||||
|
||||

|
||||
There is a lot of talk about getting things done at the command line. How many articles are there about using obscure flags with `ls`, nifty regular expressions with Sed and Awk, and how to parse out lots of text with Perl? That isn't what this is about.
|
||||
|
||||
This is about [Getting _to_ Done][1], making sure that the stuff we have to do actually gets tracked and done using tools that don't require a graphical desktop, a web browser, or an internet connection. To do this, we'll look at four ways of tracking your to-do list: plaintext files, Todo.txt, TaskWarrior, and Org-mode.
|
||||
|
||||
### Plain (and simple) text
|
||||
|
||||
|
||||
![plaintext][3]
|
||||
|
||||
I like to use Vim, but you can use Nano too.
|
||||
|
||||
The most straightforward way to manage your to-do list is using a plaintext file in your editor of choice. Just open an empty file and add tasks, one per line. When you are done, delete the line. Simple, effective, and it doesn't matter what you use to do it. There are a couple of drawbacks to this method, though. Once you delete a line and save the file, it is gone forever. That can be a problem if you have to report on what you have done this week or last week. And while using a simple file is flexible, it can also get cluttered really easily.
|
||||
|
||||
### Todo.txt: Plaintext leveled up
|
||||
|
||||
|
||||
![todo.txt screen][5]
|
||||
|
||||
Neat, organized, and easy to use
|
||||
|
||||
That leads us to the [Todo.txt][6] file format and application. Installation is simple—[download][7] the latest release from GitHub and run `sudo make install` from the unpacked archive.
|
||||
|
||||
|
||||
![Installing todo.txt][9]
|
||||
|
||||
It works from a Git clone as well.
|
||||
|
||||
Todo.txt makes it very easy to add tasks, list tasks, and mark them as done:
|
||||
|
||||
| `todo.sh add "Some Task"` | add "Some Task" to my todo list |
|
||||
| `todo.sh ls` | list all my tasks |
|
||||
| `todo.sh ls due:2018-02-15` | list all tasks due on February 15, 2018 |
|
||||
| `todo.sh do 3` | mark task number 3 as "done" |
|
||||
|
||||
The actual list is still in plaintext, and you can edit it with your favorite text editor as long as you follow the [correct format][10].
|
||||
|
||||
There is also a very robust help built into the application.
|
||||
|
||||
|
||||
![Syntax highlighting in todo.txt][12]
|
||||
|
||||
You can even get syntax highlighting.
|
||||
|
||||
There is also a large selection of add-ons, as well as specifications for writing your own. There are even browser extensions, mobile apps, and desktop apps that support the Todo.txt format.
|
||||
|
||||
|
||||
![GNOME extensions in todo.txt][14]
|
||||
|
||||
Even GNOME extensions.
|
||||
|
||||
The biggest drawback to Todo.txt is the lack of an automatic or built-in synchronization mechanism. Most (if not all) of the browser extensions and mobile apps require Dropbox to perform synchronization between the app and the copy on your desktop. If you would like something with sync built-in, we have...
|
||||
|
||||
### Taskwarrior: Now we're cooking with Python
|
||||
|
||||
[Taskwarrior][15] is a Python application with many of the same features as Todo.txt. However, it stores the data in a database and has built-in synchronization capabilities. It also keeps track of what is next, notes how old tasks are, and will warn you if you have something more important to do than what you just did.
|
||||
|
||||
[Installation][16] of Taskwarrior can be done either with your distribution's package manager, through Python's `pip` utility, or built from source. Using it is also pretty straightforward, with commands similar to Todo.txt:
|
||||
|
||||
| `task add "Some Task"` | Add "Some Task" to the list |
|
||||
| `task list` | List all tasks |
|
||||
| `task list due ``:today` | List all tasks due on today's date |
|
||||
| `task do 3` | Complete task number 3 |
|
||||
|
||||
Taskwarrior also has some pretty nice text user interfaces.
|
||||
|
||||
![Taskwarrior in Vit][18]
|
||||
|
||||
I like Vit, which was inspired by Vim.
|
||||
|
||||
Unlike Todo.txt, Taskwarrior can synchronize with a local or remote server. A very basic synchronization server called `taskd` is available if you wish to run your own, and there are several services available if you do not.
|
||||
|
||||
Taskwarrior also has a thriving and extensive ecosystem of add-ons and extensions, as well as mobile and desktop apps.
|
||||
|
||||
![Taskwarrior on GNOME][20]
|
||||
|
||||
Taskwarrior looks really nice on GNOME.
|
||||
|
||||
The only disadvantage to Taskwarrior is that, unlike the other programs listed here, you cannot directly modify the to-do list itself. You can export the task list to various formats, modify the export, and then re-import the files, but it is a lot clunkier than just opening the file directly in a text editor.
|
||||
|
||||
Which brings us to the most powerful of them all...
|
||||
|
||||
### Emacs Org-mode: Hulk smash tasks
|
||||
|
||||
![Org-mode][22]
|
||||
|
||||
Emacs has everything.
|
||||
|
||||
Emacs [Org-mode][23] is by far the most powerful, most flexible open source to-do list manager out there. It supports multiple files, uses plaintext, is almost infinitely customizable, and understands calendars, due dates, and schedules. It is also significantly more complicated to set up than the other applications listed here. But once it is set up, it does everything the other applications do and more. If you are familiar with or a fan of [Bullet Journals][24], Org-mode is possibly the closest you can get on a computer.
|
||||
|
||||
Org-mode will run anywhere Emacs runs, and there are a few mobile applications that can interact with it as well. Unfortunately, there are no desktop apps or browser extensions that support Org. Despite all that, Org-mode is still one of the best applications for tracking your to-do list, since it is so very powerful.
|
||||
|
||||
### Choose your tool
|
||||
|
||||
In the end, the goal of all these programs is to help you track what you need to do and make sure you don't forget to do something. While they all have the same basic functions, choosing which one is right for you depends on a lot of factors. Do you want synchronization built-in or not? Do you need a mobile app? Do any of the add-ons include a "must have" feature? Whatever your choice, remember that the program alone cannot make you more organized, but it can help.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-to-done-agile-linux-command-line
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://www.scruminc.com/getting-done/
|
||||
[3]:https://opensource.com/sites/default/files/u128651/plain-text.png (plaintext)
|
||||
[5]:https://opensource.com/sites/default/files/u128651/todo-txt.png (todo.txt screen)
|
||||
[6]:http://todotxt.org/
|
||||
[7]:https://github.com/todotxt/todo.txt-cli/releases
|
||||
[9]:https://opensource.com/sites/default/files/u128651/todo-txt-install.png (Installing todo.txt)
|
||||
[10]:https://github.com/todotxt/todo.txt
|
||||
[12]:https://opensource.com/sites/default/files/u128651/todo-txt-vim.png (Syntax highlighting in todo.txt)
|
||||
[14]:https://opensource.com/sites/default/files/u128651/tod-txt-gnome.png (GNOME extensions in todo.txt)
|
||||
[15]:https://taskwarrior.org/
|
||||
[16]:https://taskwarrior.org/download/
|
||||
[18]:https://opensource.com/sites/default/files/u128651/taskwarrior-vit.png (Taskwarrior in Vit)
|
||||
[20]:https://opensource.com/sites/default/files/u128651/taskwarrior-gnome.png (Taskwarrior on GNOME)
|
||||
[22]:https://opensource.com/sites/default/files/u128651/emacs-org-mode.png (Org-mode)
|
||||
[23]:https://orgmode.org/
|
||||
[24]:http://bulletjournal.com/
|
||||
@ -0,0 +1,58 @@
|
||||
Linux Virtual Machines vs Linux Live Images
|
||||
======
|
||||
I'll be the first to admit that I tend to try out new [Linux distros][1] on a far too frequent basis. Yet the method I use to test them, does vary depending on my goals for each instance. In this article, we're going to look at both running Linux virtual machines and running Linux live images. There are advantages to each method, but there are some hurdles with each method as well.
|
||||
|
||||
### Testing out a new Linux distro for the first time
|
||||
|
||||
When I test out a brand new Linux distro for the first time, the method I use depends heavily on the resources of the PC I'm currently on. If I have access to my desktop PC, I'm going to run the distro to be tested in a virtual machine. The reason for this approach is that I can download and test the distro in not only a live environment, but also as an installed product with persistent storage abilities.
|
||||
|
||||
On the other hand, if I am working with much less robust hardware on a PC, then testing out a distro with a virtual machine installation of Linux is counter-productive. I'd be pushing that PC to its limits and honestly would be better off using a live Linux image instead running from a flash drive.
|
||||
|
||||
### Touring software on a new Linux distro
|
||||
|
||||
If you're interested in checking out a distro's desktop environment or the available software, you can't go wrong with a live image of the distro. A live environment provides you with a birds eye view of what to expect in terms of overall layout, applications provided and how the user experience flows overall.
|
||||
|
||||
To be fair, you could do the same thing with a virtual machine installation, but it may be a bit overkill if you would rather avoid filling up hard drive space with yet more data. After all, this is a simple tour of the distro. Remember what I said in the first section – I like to run Linux in a virtual machine to test it. This means I'm going to see how it installs, what the partition options look like and other elements you wouldn't see from using a live image of any given distro.
|
||||
|
||||
Touring usually indicates that you're only looking to take a quick look at a distro, so in this case the method that can be done with the least amount of resistance and time investment is a good course of action.
|
||||
|
||||
### Taking a Linux distro with you
|
||||
|
||||
While it's not as common as it was a few years ago, the ability to take a Linux distro with you may be a consideration for some users. Obviously, virtual machine installations don't necessarily lend themselves favorably to portability. However a live image of a Linux distro is actually quite portable. A live image can be written to a DVD or copied onto a flash drive for easy traveling.
|
||||
|
||||
Expanding on this concept of Linux portability, it's also beneficial to have a live image on a flash drive when showing off how Linux works on a friend's computer. This empowers you to demonstrate how Linux can enrich their life while not relying on running a virtual machine on their PC. It's a bit of a win-win in favor of using a live image.
|
||||
|
||||
### Alternative to dual-booting Linux
|
||||
|
||||
This next item is a huge one. Consider this – perhaps you're a Windows user. You like playing with Linux, but would rather not take the plunge. Dual-booting is out of the question in case something goes wrong or perhaps you're not comfortable identifying individual partitions. Whatever the case may be, both using Linux in a virtual machine or from a live image might be a great option for you.
|
||||
|
||||
Now I'm going to take a rather odd stance on something. I think you'll get far more value in the long term running Linux on a flash drive using a live image than with a virtual machine. There are two reasons for this. First of all, you'll get used to truly running Linux vs running it inside of a virtual machine on top of Windows. Second, you can setup your flash drive to contain user data with persistent storage.
|
||||
|
||||
I'll grant you the same could be said with a virtual machine running Linux, however you will never have an update break anything using the live image approach. Why? Because you're not updating a host OS or the guest OS. Remember there are entire distros that are designed to be nothing more than persistent storage Linux distros. Puppy Linux is one great example. Not only can it run on PCs that would otherwise be recycled or thrown away, it allows you to never be bothered again with tedious system updates thanks to the way the distro handles security. It's not a normal Linux distro and it's walled off in such a way that the persistent live image is free from anything scary.
|
||||
|
||||
### When a Linux virtual machine is absolutely the best option
|
||||
|
||||
As I bring this article to a close, let me leave you with this. There is one instance where using a virtual machine such as Virtual Box is absolutely better than using a live image – recording the desktop environment of any Linux distro.
|
||||
|
||||
For example, I make videos that provide a tour and review of a variety of Linux distros. Doing this with live images would require me to capture the screen with a hardware device or install a software capture device from the live image's repositories. Clearly, a virtual machine is better suited for this job than a live image of a Linux distro.
|
||||
|
||||
Once you toss audio capture into the mix, there is no question that if you're going to use software to capture your review, you really want to have a host OS that has all the basic needs covered for a reasonably decent capture environment. Again, you could do all of this with a hardware device...but that might be cost prohibitive if you're only do video/audio capturing as a part time endeavor.
|
||||
|
||||
### A Linux virtual machine vs a Linux live image
|
||||
|
||||
What is your preferred method of trying out new distros? Perhaps you're someone who is fine with formatting their hard drive and throwing caution to the wind, thus, making the idea of any of this unneeded?
|
||||
|
||||
Most people I've interacted with online tend to follow much of the methodology I've touched on above, but I'd love to hear what approach works best for you. Hit the comments, let me know which method you prefer when checking out the greatest and latest from the Linux distro world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/linux-virtual-machines-vs-linux-live-images.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.datamation.com/open-source/best-linux-distro.html
|
||||
@ -0,0 +1,79 @@
|
||||
How to block local spoofed addresses using the Linux firewall
|
||||
======
|
||||
|
||||

|
||||
|
||||
Attackers are finding sophisticated ways to penetrate even remote networks that are protected by intrusion detection and prevention systems. No IDS/IPS can halt or minimize attacks by hackers who are determined to take over your network. Improper configuration allows attackers to bypass all implemented network security measures.
|
||||
|
||||
In this article, I will explain how security engineers or system administrators can prevent these attacks.
|
||||
|
||||
Almost all Linux distributions come with a built-in firewall to secure processes and applications running on the Linux host. Most firewalls are designed as IDS/IPS solutions, whose primary purpose is to detect and prevent malicious packets from gaining access to a network.
|
||||
|
||||
A Linux firewall usually comes with two interfaces: iptables and ipchains. Most people refer to these interfaces as the "iptables firewall" or the "ipchains firewall." Both interfaces are designed as packet filters. Iptables acts as a stateful firewall, making decisions based on previous packets. Ipchains does not make decisions based on previous packets; hence, it is designed as a stateless firewall.
|
||||
|
||||
In this article, we will focus on the iptables firewall, which comes with kernel version 2.4 and beyond.
|
||||
|
||||
With the iptables firewall, you can create policies, or ordered sets of rules, which communicate to the kernel how it should treat specific classes of packets. Inside the kernel is the Netfilter framework. Netfilter is both a framework and the project name for the iptables firewall. As a framework, Netfilter allows iptables to hook functions designed to perform operations on packets. In a nutshell, iptables relies on the Netfilter framework to build firewall functionality such as filtering packet data.
|
||||
|
||||
Each iptables rule is applied to a chain within a table. An iptables chain is a collection of rules that are compared against packets with similar characteristics, while a table (such as nat or mangle) describes diverse categories of functionality. For instance, a mangle table alters packet data. Thus, specialized rules that alter packet data are applied to it, and filtering rules are applied to the filter table because the filter table filters packet data.
|
||||
|
||||
Iptables rules have a set of matches, along with a target, such as `Drop` or `Deny`, that instructs iptables what to do with a packet that conforms to the rule. Thus, without a target and a set of matches, iptables can’t effectively process packets. A target simply refers to a specific action to be taken if a packet matches a rule. Matches, on the other hand, must be met by every packet in order for iptables to process them.
|
||||
|
||||
Now that we understand how the iptables firewall operates, let's look at how to use iptables firewall to detect and reject or drop spoofed addresses.
|
||||
|
||||
### Turning on source address verification
|
||||
|
||||
The first step I, as a security engineer, take when I deal with spoofed addresses from remote hosts is to turn on source address verification in the kernel.
|
||||
|
||||
Source address verification is a kernel-level feature that drops packets pretending to come from your network. It uses the reverse path filter method to check whether the source of the received packet is reachable through the interface it came in.
|
||||
|
||||
To turn source address verification, utilize the simple shell script below instead of doing it manually:
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
#author’s name: Michael K Aboagye
|
||||
|
||||
#purpose of program: to enable reverse path filtering
|
||||
|
||||
#date: 7/02/18
|
||||
|
||||
#displays “enabling source address verification” on the screen
|
||||
|
||||
echo -n "Enabling source address verification…"
|
||||
|
||||
#Overwrites the value 0 to 1 to enable source address verification
|
||||
|
||||
echo 1 > /proc/sys/net/ipv4/conf/default/rp_filter
|
||||
|
||||
echo "completed"
|
||||
|
||||
```
|
||||
|
||||
The preceding script, when executed, displays the message `Enabling source address verification` without appending a new line. The default value of the reverse path filter is 0.0, which means no source validation. Thus, the second line simply overwrites the default value 0 to 1. 1 means that the kernel will validate the source by confirming the reverse path.
|
||||
|
||||
Finally, you can use the following command to drop or reject spoofed addresses from remote hosts by choosing either one of these targets: `DROP` or `REJECT`. However, I recommend using `DROP` for security reasons.
|
||||
|
||||
Replace the “IP-address” placeholder with your own IP address, as shown below. Also, you must choose to use either `REJECT` or `DROP`; the two targets don’t work together.
|
||||
```
|
||||
iptables -A INPUT -i internal_interface -s IP_address -j REJECT / DROP
|
||||
|
||||
|
||||
|
||||
iptables -A INPUT -i internal_interface -s 192.168.0.0/16 -j REJECT/ DROP
|
||||
|
||||
```
|
||||
|
||||
This article provides only the basics of how to prevent spoofing attacks from remote hosts using the iptables firewall.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/block-local-spoofed-addresses-using-linux-firewall
|
||||
|
||||
作者:[Michael Kwaku Aboagye][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/revoks
|
||||
133
sources/tech/20180228 Why Python devs should use Pipenv.md
Normal file
133
sources/tech/20180228 Why Python devs should use Pipenv.md
Normal file
@ -0,0 +1,133 @@
|
||||
Why Python devs should use Pipenv
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article was co-written with [Jeff Triplett][1].
|
||||
|
||||
Pipenv, the "Python Development Workflow for Humans" created by Kenneth Reitz a little more than a year ago, has become the [official Python-recommended resource][2] for managing package dependencies. But there is still confusion about what problems it solves and how it's more useful than the standard workflow using `pip` and a `requirements.txt` file. In this month's Python column, we'll fill in the gaps.
|
||||
|
||||
### A brief history of Python package installation
|
||||
|
||||
To understand the problems that Pipenv solves, it's useful to show how Python package management has evolved.
|
||||
|
||||
Take yourself back to the first Python iteration. We had Python, but there was no clean way to install packages.
|
||||
|
||||
Then came [Easy Install][3], a package that installs other Python packages with relative ease. But it came with a catch: it wasn't easy to uninstall packages that were no longer needed.
|
||||
|
||||
Enter [pip][4], which most Python users are familiar with. `pip` lets us install and uninstall packages. We could specify versions, run `pip freeze > requirements.txt` to output a list of installed packages to a text file, and use that same text file to install everything an app needed with `pip install -r requirements.txt`.
|
||||
|
||||
But `pip` didn't include a way to isolate packages from each other. We might work on apps that use different versions of the same libraries, so we needed a way to enable that. Along came [virtual environments][5], which enabled us to create small, isolated environments for each app we worked on. We've seen many tools for managing virtual environments: [virtualenv][6], [venv][7], [virtualenvwrapper][8], [pyenv][9], [pyenv-virtualenv][10], [pyenv-virtualenvwrapper][11], and even more. They all play well with `pip` and `requirements.txt` files.
|
||||
|
||||
### The new kid: Pipenv
|
||||
|
||||
Pipenv aims to solve several problems.
|
||||
|
||||
`pip` library for package installation, plus a library for creating a virtual environment, plus a library for managing virtual environments, plus all the commands associated with those libraries. That's a lot to manage. Pipenv ships with package management and virtual environment support, so you can use one tool to install, uninstall, track, and document your dependencies and to create, use, and organize your virtual environments. When you start a project with it, Pipenv will automatically create a virtual environment for that project if you aren't already using one.
|
||||
|
||||
First, the problem of needing thelibrary for package installation, plus a library for creating a virtual environment, plus a library for managing virtual environments, plus all the commands associated with those libraries. That's a lot to manage. Pipenv ships with package management and virtual environment support, so you can use one tool to install, uninstall, track, and document your dependencies and to create, use, and organize your virtual environments. When you start a project with it, Pipenv will automatically create a virtual environment for that project if you aren't already using one.
|
||||
|
||||
Pipenv accomplishes this dependency management by abandoning the `requirements.txt` norm and trading it for a new document called a [Pipfile][12]. When you install a library with Pipenv, a `Pipfile` for your project is automatically updated with the details of that installation, including version information and possibly the Git repository location, file path, and other information.
|
||||
|
||||
Second, Pipenv wants to make it easier to manage complex interdependencies. Your app might depend on a specific version of a library, and that library might depend on a specific version of another library, and it's just dependencies and turtles all the way down. When two libraries your app uses have conflicting dependencies, your life can become hard. Pipenv wants to ease that pain by keeping track of a tree of your app's interdependencies in a file called `Pipfile.lock`. `Pipfile.lock` also verifies that the right versions of dependencies are used in production.
|
||||
|
||||
Also, Pipenv is handy when multiple developers are working on a project. With a `pip` workflow, Casey might install a library and spend two days implementing a new feature using that library. When Casey commits the changes, they might forget to run `pip freeze` to update the requirements file. The next day, Jamie pulls down Casey's changes, and suddenly tests are failing. It takes time to realize that the problem is libraries missing from the requirements file that Jamie doesn't have installed in the virtual environment.
|
||||
|
||||
Because Pipenv auto-documents dependencies as you install them, if Jamie and Casey had been using Pipenv, the `Pipfile` would have been automatically updated and included in Casey's commit. Jamie and Casey would have saved time and shipped their product faster.
|
||||
|
||||
Finally, using Pipenv signals to other people who work on your project that it ships with a standardized way to install project dependencies and development and testing requirements. Using a workflow with `pip` and requirements files means that you may have one single `requirements.txt` file, or several requirements files for different environments. It might not be clear to your colleagues whether they should run `dev.txt` or `local.txt` when they're running the project on their laptops, for example. It can also create confusion when two similar requirements files get wildly out of sync with each other: Is `local.txt` out of date, or is it really supposed to be that different from `dev.txt`? Multiple requirements files require more context and documentation to enable others to install the dependencies properly and as expected. This workflow has the potential to confuse colleagues and increase your maintenance burden.
|
||||
|
||||
Using Pipenv, which gives you `Pipfile`, lets you avoid these problems by managing dependencies for different environments for you. This command will install the main project dependencies:
|
||||
```
|
||||
pipenv install
|
||||
|
||||
```
|
||||
|
||||
Adding the `--dev` tag will install the dev/testing requirements:
|
||||
```
|
||||
pipenv install --dev
|
||||
|
||||
```
|
||||
|
||||
There are other benefits to using Pipenv: It has better security features, graphs your dependencies in an easier-to-understand format, seamlessly handles `.env` files, and can automatically handle differing dependencies for development versus production environments in one file. You can read more in the [documentation][13].
|
||||
|
||||
### Pipenv in action
|
||||
|
||||
The basics of using Pipenv are detailed in the [Managing Application Dependencies][14] section of the official Python packaging tutorial. To install Pipenv, use `pip`:
|
||||
```
|
||||
pip install pipenv
|
||||
|
||||
```
|
||||
|
||||
To install packages to use in your project, change into the directory for your project. Then to install a package (we'll use Django as an example), run:
|
||||
```
|
||||
pipenv install django
|
||||
|
||||
```
|
||||
|
||||
You will see some output that indicates that Pipenv is creating a `Pipfile` for your project.
|
||||
|
||||
If you aren't already using a virtual environment, you will also see some output from Pipenv saying it is creating a virtual environment for you.
|
||||
|
||||
Then, you will see the output you are used to seeing when you install packages.
|
||||
|
||||
To generate a `Pipfile.lock` file, run:
|
||||
```
|
||||
pipenv lock
|
||||
|
||||
```
|
||||
|
||||
You can also run Python scripts with Pipenv. To run a top-level Python script called `hello.py`, run:
|
||||
```
|
||||
pipenv run python hello.py
|
||||
|
||||
```
|
||||
|
||||
And you will see your expected result in the console.
|
||||
|
||||
To start a shell, run:
|
||||
```
|
||||
pipenv shell
|
||||
|
||||
```
|
||||
|
||||
If you would like to convert a project that currently uses a `requirements.txt` file to use Pipenv, install Pipenv and run:
|
||||
```
|
||||
pipenv install requirements.txt
|
||||
|
||||
```
|
||||
|
||||
This will create a Pipfile and install the specified requirements. Consider your project upgraded!
|
||||
|
||||
### Learn more
|
||||
|
||||
Check out the Pipenv documentation, particularly [Basic Usage of Pipenv][15], to take you further. Pipenv creator Kenneth Reitz gave a talk on Pipenv, "[The Future of Python Dependency Management][16]," at a recent PyTennessee event. The talk wasn't recorded, but his [slides][17] are helpful in understanding what Pipenv does and the problems it solves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/why-python-devs-should-use-pipenv
|
||||
|
||||
作者:[Lacey Williams Henschel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://opensource.com/users/jefftriplett
|
||||
[2]:https://packaging.python.org/tutorials/managing-dependencies/#managing-dependencies
|
||||
[3]:http://peak.telecommunity.com/DevCenter/EasyInstall
|
||||
[4]:https://packaging.python.org/tutorials/installing-packages/#use-pip-for-installing
|
||||
[5]:https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments
|
||||
[6]:https://virtualenv.pypa.io/en/stable/
|
||||
[7]:https://docs.python.org/3/library/venv.html
|
||||
[8]:https://virtualenvwrapper.readthedocs.io/en/latest/
|
||||
[9]:https://github.com/pyenv/pyenv
|
||||
[10]:https://github.com/pyenv/pyenv-virtualenv
|
||||
[11]:https://github.com/pyenv/pyenv-virtualenvwrapper
|
||||
[12]:https://github.com/pypa/pipfile
|
||||
[13]:https://docs.pipenv.org/
|
||||
[14]:https://packaging.python.org/tutorials/managing-dependencies/
|
||||
[15]:https://docs.pipenv.org/basics/
|
||||
[16]:https://www.pytennessee.org/schedule/presentation/158/
|
||||
[17]:https://speakerdeck.com/kennethreitz/the-future-of-python-dependency-management
|
||||
@ -0,0 +1,350 @@
|
||||
如何使用 kSar 去创建 sar 图表来发现 Linux 瓶颈
|
||||
======
|
||||
sar 命令收集、报告、或者保存 UNIX / Linux 系统的活动信息。它保存选择的计数器到操作系统的 `/var/log/sa/sadd` 文件中。从收集的数据中,你可以得到许多关于你的服务器的信息:
|
||||
|
||||
1. CPU 使用率
|
||||
2. 内存页面和使用率
|
||||
3. 网络 I/O 和传输统计
|
||||
4. 进程创建活动
|
||||
5. 所有的块设备活动
|
||||
6. 每秒中断数等等
|
||||
|
||||
|
||||
|
||||
sar 命令的输出能够用于识别服务器瓶颈。但是,分析 sar 命令提供的信息可能比较困难,所以要使用 kSar 工具。kSar 工具将 sar 命令的输出绘制成基于时间周期的、易于理解的图表。
|
||||
|
||||
|
||||
## sysstat 包
|
||||
|
||||
sar、sa1、和 sa2 命令都是 sysstat 包的一部分。它是 Linux 包含的性能监视工具集合。
|
||||
|
||||
1. sar:显示数据
|
||||
2. sa1 和 sa2:为以后分析去收集和保存数据。sa2 shell 脚本在 `/var/log/sa` 目录中每日写入一个报告。sa1 shell 脚本将每日的系统活动信息以二进制数据的形式写入到文件中。
|
||||
3. sadc —— 系统活动数据收集器。你可以通过修改 sa1 和 sa2 脚本去配置各种选项。它们位于以下的目录:
|
||||
* /usr/lib64/sa/sa1 (64bit) 或者 /usr/lib/sa/sa1 (32bit) —— 它调用 sadc 去记录报告到 /var/log/sa/sadX 格式。
|
||||
* /usr/lib64/sa/sa2 (64bit) 或者 /usr/lib/sa/sa2 (32bit) —— 它调用 sar 去记录报告到 /var/log/sa/sarX 格式。
|
||||
|
||||
|
||||
|
||||
### 如何在我的系统上安装 sar?
|
||||
|
||||
在一个基于 CentOS/RHEL 的系统上,输入如下的 [yum 命令][1] 去安装 sysstat:
|
||||
`# yum install sysstat`
|
||||
示例输出如下:
|
||||
```
|
||||
Loaded plugins: downloadonly, fastestmirror, priorities,
|
||||
: protectbase, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* addons: mirror.cs.vt.edu
|
||||
* base: mirror.ash.fastserv.com
|
||||
* epel: serverbeach1.fedoraproject.org
|
||||
* extras: mirror.cogentco.com
|
||||
* updates: centos.mirror.nac.net
|
||||
0 packages excluded due to repository protections
|
||||
Setting up Install Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
====================================================================
|
||||
Package Arch Version Repository Size
|
||||
====================================================================
|
||||
Installing:
|
||||
sysstat x86_64 7.0.2-3.el5 base 173 k
|
||||
|
||||
Transaction Summary
|
||||
====================================================================
|
||||
Install 1 Package(s)
|
||||
Update 0 Package(s)
|
||||
Remove 0 Package(s)
|
||||
|
||||
Total download size: 173 k
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Finished Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : sysstat 1/1
|
||||
|
||||
Installed:
|
||||
sysstat.x86_64 0:7.0.2-3.el5
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
|
||||
### 为 sysstat 配置文件
|
||||
|
||||
编辑 /etc/sysconfig/sysstat 文件去指定日志文件保存多少天(最长为一个月):
|
||||
`# vi /etc/sysconfig/sysstat`
|
||||
示例输出如下 :
|
||||
```
|
||||
# keep log for 28 days
|
||||
# the default is 7
|
||||
HISTORY=28
|
||||
```
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
### 找到 sar 默认的 cron 作业
|
||||
|
||||
[默认的 cron 作业位于][2] `/etc/cron.d/sysstat`:
|
||||
`# cat /etc/cron.d/sysstat`
|
||||
示例输出如下:
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
### 告诉 sadc 去报告磁盘的统计数据
|
||||
|
||||
使用一个文本编辑器去编辑 `/etc/cron.d/sysstat` 文件,比如使用 NA 命令或者 vim 命令,输入如下:
|
||||
`# vi /etc/cron.d/sysstat`
|
||||
像下面的示例那样更新这个文件,以记录所有的硬盘统计数据(`-d` 选项强制记录每个块设备的统计数据,而 `-I` 选项强制记录所有系统中断的统计数据):
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
在一个 CentOS/RHEL 7.x 系统上你需要传递 `-S DISK` 选项去收集块设备的数据。传递`-S XALL` 选项去采集如下所列的数据:
|
||||
|
||||
1. 磁盘
|
||||
2. 分区
|
||||
3. 系统中断
|
||||
4. SNMP
|
||||
5. IPv6
|
||||
|
||||
|
||||
```
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
|
||||
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
|
||||
# Generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
```
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
###打开 CentOS/RHEL 版本 5.x/6.x 的服务
|
||||
|
||||
输入如下命令:
|
||||
|
||||
```
|
||||
chkconfig sysstat on
|
||||
service sysstat start
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
```
|
||||
Calling the system activity data collector (sadc):
|
||||
```
|
||||
|
||||
对于 CentOS/RHEL 7.x,运行如下的命令:
|
||||
```
|
||||
# systemctl enable sysstat
|
||||
# systemctl start sysstat.service
|
||||
# systemctl status sysstat.service
|
||||
```
|
||||
示例输出:
|
||||
```
|
||||
● sysstat.service - Resets System Activity Logs
|
||||
Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
|
||||
Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
|
||||
Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
|
||||
Main PID: 28297 (code=exited, status=0/SUCCESS)
|
||||
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
|
||||
```
|
||||
|
||||
## 如何使用 sar?如何查看统计数据?
|
||||
|
||||
使用 sar 命令去显示操作系统中选定的累积活动计数器输出。在这个示例中,运行 sar 命令行,去实时获得 CPU 使用率的报告:
|
||||
`# sar -u 3 10`
|
||||
示例输出:
|
||||
```
|
||||
Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
|
||||
|
||||
09:49:47 PM CPU %user %nice %system %iowait %steal %idle
|
||||
09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
|
||||
09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
|
||||
09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
|
||||
09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
|
||||
09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
|
||||
09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
|
||||
09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
|
||||
09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
|
||||
09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
|
||||
09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
|
||||
Average: all 9.24 0.69 1.84 0.03 0.00 88.20
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* 3 = 间隔时间
|
||||
* 10 = 次数
|
||||
|
||||
|
||||
|
||||
查看进程创建的统计数据,输入:
|
||||
`# sar -c 3 10`
|
||||
查看 I/O 和传输率统计数据,输入:
|
||||
`# sar -b 3 10`
|
||||
查看内存页面统计数据,输入:
|
||||
`# sar -B 3 10`
|
||||
查看块设备统计数据,输入:
|
||||
`# sar -d 3 10`
|
||||
查看所有中断的统计数据,输入:
|
||||
`# sar -I XALL 3 10`
|
||||
查看网络设备特定的统计数据,输入:
|
||||
```
|
||||
# sar -n DEV 3 10
|
||||
# sar -n EDEV 3 10
|
||||
```
|
||||
查看 CPU 特定的统计数据,输入:
|
||||
```
|
||||
# sar -P ALL
|
||||
# Only 1st CPU stats
|
||||
# sar -P 1 3 10
|
||||
```
|
||||
查看队列长度和平均负载的统计数据,输入:
|
||||
`# sar -q 3 10`
|
||||
查看内存和 swap 空间的使用统计数据,输入:
|
||||
```
|
||||
# sar -r 3 10
|
||||
# sar -R 3 10
|
||||
```
|
||||
查看 inode、文件、和其它内核表统计数据状态,输入:
|
||||
`# sar -v 3 10`
|
||||
查看系统切换活动统计数据,输入:
|
||||
`# sar -w 3 10`
|
||||
查看 swapping 统计数据,输入:
|
||||
`# sar -W 3 10`
|
||||
查看一个 PID 为 3256 的 Apache 进程,输入:
|
||||
`# sar -x 3256 3 10`
|
||||
|
||||
## kSar 介绍
|
||||
|
||||
sar 和 sadf 提供了基于命令行界面的输出。这种输出可能会使新手用户/系统管理员感到无从下手。因此,你需要使用 kSar,它是一个图形化显示你的 sar 数据的 Java 应用程序。它也允许你以 PDF/JPG/PNG/CSV 格式导出数据。你可以用三种方式去加载数据:本地文件、运行本地命令、以及通过 SSH 远程运行的命令。kSar 可以处理下列操作系统的 sar 输出:
|
||||
|
||||
1. Solaris 8, 9 和 10
|
||||
2. Mac OS/X 10.4+
|
||||
3. Linux (Systat Version >= 5.0.5)
|
||||
4. AIX (4.3 & 5.3)
|
||||
5. HPUX 11.00+
|
||||
|
||||
|
||||
|
||||
### 下载和安装 kSar
|
||||
|
||||
访问 [官方][3] 网站去获得最新版本的源代码。使用 [wget][4] 去下载源代码,输入:
|
||||
`$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar`
|
||||
|
||||
#### 如何运行 kSar?
|
||||
|
||||
首先要确保你的机器上 [JAVA jdk][5] 已安装并能够正常工作。输入下列命令去启动 kSar:
|
||||
`$ java -jar ksar-5.2.4-SNAPSHOT-all.jar`
|
||||
|
||||
![Fig.01: kSar welcome screen][6]
|
||||
接下来你将看到 kSar 的主窗口,和有两个菜单的面板。
|
||||
![Fig.02: kSar - the main window][7]
|
||||
左侧有一个列表,是 kSar 根据数据已经解析出的可用图表的列表。右侧窗口将展示你选定的图表。
|
||||
|
||||
## 如何使用 kSar 去生成 sar 图表?
|
||||
|
||||
首先,你需要从命名为 server1 的服务器上采集 sar 命令的统计数据。输入如下的命令:
|
||||
`[ **server1** ]# LC_ALL=C sar -A > /tmp/sar.data.txt`
|
||||
接下来,使用 scp 命令从本地桌面拷贝到远程电脑上:
|
||||
`[ **desktop** ]$ scp user@server1.nixcraft.com:/tmp/sar.data.txt /tmp/`
|
||||
切换到 kSar 窗口,点击 **Data** > **Load data from text file** > 从 /tmp/ 中选择 sar.data.txt > 点击 **Open** 按扭。
|
||||
现在,图表类型树已经出现在左侧面板中并选定了一个图形:
|
||||
![Fig.03: Processes for server1][8]
|
||||
|
||||
![Fig.03: Disk stats \(blok device\) stats for server1][9]![Fig.05: Memory stats for server1][10]
|
||||
|
||||
#### 放大和缩小
|
||||
|
||||
通过移动你可以交互式缩放图像的一部分。在要缩放的图像的左上角点击并按下鼠标,移动到要缩放区域的右下角,可以选定要缩放的区域。返回到未缩放状态,点击并拖动鼠标到除了右下角外的任意位置,你也可以点击并选择 zoom 选项。
|
||||
|
||||
#### 了解 kSar 图像和 sar 数据
|
||||
|
||||
我强烈建议你去阅读 sar 和 sadf 命令的 man 页面:
|
||||
```
|
||||
$ man sar
|
||||
$ man sadf
|
||||
```
|
||||
|
||||
## 案例学习:识别 Linux 服务器的 CPU 瓶颈
|
||||
|
||||
使用 sar 命令和 kSar 工具,可以得到内存、CPU、以及其它子系统的详细快照。例如,如果 CPU 使用率在一个很长的时间内持续高于 80%,有可能就是出现了一个 CPU 瓶颈。使用 **sar -x ALL** 你可以找到大量消耗 CPU 的进程。[mpstat 命令][11] 的输出(sysstat 包的一部分)也会帮你去了解 CPU 的使用率。你可以使用 kSar 很容易地去分析这些信息。
|
||||
|
||||
### 找出 CPU 瓶颈 …
|
||||
|
||||
然后对 CPU 选择执行如下的调整:
|
||||
|
||||
1. 确保没有不需要的进程在后台运行。关闭 [Linux 上所有不需要的服务][12]。
|
||||
2. 使用 [cron 去计划作业][13] (比如,备份)运行在一个非高峰时刻。
|
||||
3. 使用 [top 和 ps 命令][14] 去找出所有非关键的后台作业/服务。使用 [renice 命令][15] 去调整低优先级作业。
|
||||
4. 使用 [taskset 命令去设置进程使用的 CPU ][16] (卸载 CPU),即,绑定进程到不同的 CPU 上。例如,在 2# CPU 上运行 MySQL 数据库,而在 3# CPU 上运行 Apache。
|
||||
5. 确保你的系统使用了最新的驱动程序和固件。
|
||||
6. 如有可能在系统上增加额外的 CPU。
|
||||
7. 为单线程应用程序使用更快的 CPU(比如,Lighttpd web 服务器应用程序)。
|
||||
8. 为多线程应用程序使用多个 CPU(比如,MySQL 数据库服务器应用程序)。
|
||||
9. 为一个 web 应用程序使用多个计算节点并设置一个 [负载均衡器][17]。
|
||||
|
||||
|
||||
|
||||
## isag —— 交互式系统活动记录器(替代工具)
|
||||
|
||||
isag 命令图形化显示了以前运行 sar 命令时存储在二进制文件中的系统活动数据。isag 命令引用 sar 并提取出它的数据来绘制图形。与 kSar 相比,isag 的选项比较少。
|
||||
|
||||
![Fig.06: isag CPU utilization graphs][18]
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
本文作者是 nixCraft 的创始人和一位经验丰富的 Linux 操作系统/Unix shell 脚本培训师。他与包括 IT、教育、国防和空间研究、以及非营利组织等全球各行业客户一起合作。可以在 [Twitter][19]、[Facebook][20]、[Google+][21] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[3]:https://github.com/vlsi/ksar
|
||||
[4]:https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html
|
||||
[5]:https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/12/sar-welcome.png "kSar welcome screen"
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/12/screenshot-kSar-a-sar-grapher-01.png "kSar - the main window"
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/12/cpu-ksar.png "Linux kSar Processes for server1 "
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/12/disk-stats-ksar.png "Linux Disk I/O Stats Using kSar"
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/12/memory-ksar.png "Linux Memory paging and its utilization stats"
|
||||
[11]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
|
||||
[12]:https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/
|
||||
[13]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[14]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
|
||||
[15]:https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/
|
||||
[16]:https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/
|
||||
[17]:https://www.cyberciti.biz/tips/load-balancer-open-source-software.html
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2009/12/isag.cpu_.png "Fig.06: isag CPU utilization graphs"
|
||||
[19]:https://twitter.com/nixcraft
|
||||
[20]:https://facebook.com/nixcraft
|
||||
[21]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,126 +0,0 @@
|
||||
两种简单的方式在 Linux 安装必应桌面墙纸更换器
|
||||
======
|
||||
|
||||
你是否厌倦了 Linux 桌面背景,想要设置好看的壁纸,但是不知道在哪里可以找到?别担心,我们在这里会帮助你。
|
||||
|
||||
我们都知道必应搜索引擎但是由于一些原因很少有人使用它,每个人都喜欢必应网站的背景壁纸,它是非常漂亮和惊人的高分辨率图像。
|
||||
|
||||
如果你想使用这些图片作为你的桌面壁纸,你可以手动下载它,但是很难去每天下载一个新的图片,然后把它设置为壁纸。这就是自动壁纸改变的地方。
|
||||
|
||||
[必应桌面墙纸更换器][1]会自动下载并将桌面壁纸更改为当天的必应照片。所有的壁纸都储存在 `/home/[user]/Pictures/BingWallpapers/`。
|
||||
|
||||
### 方法 1: 使用 Utkarsh Gupta Shell 脚本
|
||||
|
||||
这个小型 python 脚本会自动下载并将桌面壁纸更改为当天的必应照片。该脚本在机器时自动运行,并在 GNU/Linux 上使用 Gnome 或 Cinnamon 工作。它不需要手动工作,安装程序会为你做所有事情。
|
||||
|
||||
从 2.0+ 版本开始,安装程序就像普通的 Linux 二进制命令一样工作,它会为某些任务请求 sudo 权限。
|
||||
|
||||
只需克隆仓库并切换到项目目录,然后运行 shell 脚本即可安装必应桌面墙纸更换器。
|
||||
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
|
||||
运行 `installer.sh` 使用 `--install` 选项来安装必应桌面墙纸更换器。它会下载并设置必应照片为你的 Linux 桌面。
|
||||
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: **
|
||||
|
||||
******
|
||||
|
||||
**
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? : **
|
||||
|
||||
Press Enter
|
||||
|
||||
**
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : **
|
||||
|
||||
y
|
||||
|
||||
**
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : **
|
||||
|
||||
y
|
||||
|
||||
**
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
|
||||
[![][2]![][2]][3]
|
||||
|
||||
卸载脚本
|
||||
|
||||
$ ./installer.sh --uninstall
|
||||
|
||||
使用帮助页面了解更多关于此脚本的选项。
|
||||
|
||||
$ ./installer.sh --help
|
||||
|
||||
### 方法 2: 使用 GNOME Shell 扩展
|
||||
|
||||
轻量级[GNOME shell 扩展][4],可将你的壁纸每天更改为微软必应的壁纸。它还会显示一个包含图像标题和解释的通知。
|
||||
|
||||
该扩展广泛地基于 Elinvention 的 NASA APOD 扩展,受到了 Utkarsh Gupta 的 Bing Desktop WallpaperChanger 启发。
|
||||
|
||||
### 特点
|
||||
|
||||
- 获取当天的必应壁纸并设置为锁屏和桌面墙纸(这两者都是用户可选的)
|
||||
- 可强制选择某个特定区域(即地区)
|
||||
- 在多个监视器设置中自动选择最高分辨率(和最合适的墙纸)
|
||||
- 可以选择在1到7天之后清理墙纸目录(删除最旧的)
|
||||
- 只有当他们被更新时,才会尝试下载壁纸
|
||||
- 不会持续进行更新 - 每天只进行一次,启动时也要进行一次(更新是在必应更新时进行的)
|
||||
|
||||
### 如何安装
|
||||
|
||||
访问 [extenisons.gnome.org][5]网站并将切换按钮拖到 `ON`,然后点击 `Install` 按钮安装必应壁纸 GNOME 扩展。(译者注:页面上并没有发现 ON 按钮,但是有 Download 按钮)
|
||||
[![][2]![][2]][6]
|
||||
|
||||
安装必应壁纸 GNOME 扩展后,它会自动下载并为你的 Linux 桌面设置当天的必应照片,并显示关于壁纸的通知。
|
||||
[![][2]![][2]][7]
|
||||
|
||||
托盘指示器将帮助你执行少量操作,也可以打开设置。
|
||||
[![][2]![][2]][8]
|
||||
|
||||
根据你的要求自定义设置。
|
||||
[![][2]![][2]][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/](https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/)
|
||||
|
||||
作者:[2daygeek](https://www.2daygeek.com/author/2daygeek/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[校对者 ID](a)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
@ -0,0 +1,88 @@
|
||||
DevOps 接下来会发生什么:观察到的 5 个趋势
|
||||
======
|
||||
|
||||

|
||||
|
||||
"DevOps" 一词通常认为是来源于 [2008 年关于敏捷基础设施和运营的介绍][1]。现在的 IT 词汇中,它无处不在,这个“混搭”的词汇出现还不到 10 年:我们还在研究它在 IT 中更现代化的工作方法。
|
||||
|
||||
当然,多年来一直在 “从事 DevOps" 的人积累了丰富的知识。但是大多数的 DevOps 环境 —— 人与 [文化][2] 、流程与方法、工具与技术的融合 —— 还远远没有成熟。
|
||||
|
||||
更多的变化即将到来。Robert Reeves 说 ”DevOps 是一个过程,一种算法“,他是 [Datical][3] 的 CTO, "它的绝对目标就是随着时间进行改变和演进”,这就是重点。
|
||||
|
||||
那我们预计接下来会发生什么呢?这里有一些专家们观察到的重要趋势。
|
||||
|
||||
### 1. 预计 DevOps、容器、以及微服务之间的相互依赖会增强
|
||||
|
||||
驱动 DevOps 发展的文化本身可能会演进。当然,DevOps 仍然将在根本上摧毁传统的 IT 站点和瓶颈,但这样做的理由可能会变得更加急迫。展示(证据) A & B: [对容器和微服务的兴趣][4] 与日俱增。这个技术组合很强大、可连续扩展、与规划和 [持续进行的管理][5]配合最佳。
|
||||
|
||||
Arvind Soni 说 "影响 DevOps 的其中一个主要因素是向微服务转变“,它是 [Netsil][6] 的产品副总裁,添加容器和业务流程,使开发者打包和交付的速度越来越快。DevOps 团队的任务可能是帮助去加速打包并管理越来越复杂的微服务弹性架构。
|
||||
|
||||
### 2. 预计 ”安全网“ 更少
|
||||
|
||||
DevOps 使团队可以更快更敏捷地去构建软件,部署速度也更快更频繁、同时还能提升软件质量和稳定性。但是好的 IT 领导通常都不会忽视管理风险,因此,早期大量的 DevOps 迭代都是使用了安全防护 —— 从后备的不重要业务开始的。为了实现更快的速度和敏捷性,越来越多的团队将抛弃他们的 ”辅助轮“(译者注:意思说减少了安全防护措施)。
|
||||
|
||||
Nic Grange 说 "随着团队的成熟,他们决定不再需要一些早期增加的安全 ”防护栏“ 了”,他是 [Retriever Communications][7] 的 CTO。Grange 给出了一个展示服务器的示例:随着 DevOps 团队的成熟,他们决定不再需要了,尤其是他们很少在试生产环境中发现问题。(Grange 指出,这一举措对于缺乏 DevOps 经验的团队来说,不可轻易效仿)
|
||||
|
||||
Grange 说 "这个团队可能在监视和发现并解决生产系统中出现的问题的能力上有足够的信心“,"部署过程和测试阶段,如果没有任何证据证明它的价值,那么它可能会把整个进度拖慢”。
|
||||
|
||||
### 3. 预计 DevOps 将在其它领域大面积展开
|
||||
|
||||
DevOps 将两个传统的 IT 组(开发和运营)结合的更紧密。越来越多的公司看到了这种结合的好处,这种文化可能会传播开来。这种情况在一些组织中已经出现,在 “DevSecOps” 一词越来越多出现的情况下,它反映出了在软件开发周期中有意地、越来越早地包含了安全性。
|
||||
|
||||
Derek Weeks 说 "DevSecOps 不仅是一个工具,它是将安全思维更早地集成到开发实践中“,它是 [Sonatype][8] 的副总裁和 DevOps 拥挤者。
|
||||
|
||||
[Red Hat][9] 的安全策略师 Kirsten Newcomer 说,这种做法并不是一个技术挑战,而是一个文化挑战。
|
||||
|
||||
Newcomer 说 "从历史来看,安全团队都是从开发团队中分离出来的 —— 每个团队在它们不同的 IT 领域中形成了各自的专长” ,"它并不需要这种方法。每个关心安全性的企业也关心他们通过软件快速交付业务价值的能力,这些企业正在寻找方法,将安全放进应用程序的开发周期中。它们采用 DevSecOps 通过 CI/CD 流水线去集成安全实践、工具、和自动化。为了做的更好,他们整合他们的团队 —— 将安全专家整合到应用程序开发团队中,参与到从设计到产品部署的全过程中。这种做法使双方都看到了价值 —— 每个团队都扩充了它们的技能和知识,使他们成为更有价值的技术专家。DevOps 做对了—— 或者说是 DevSecOps —— 提升了 IT 安全性。“
|
||||
|
||||
除了安全以外,让 DevOps 扩展到其它领域,比如数据库团队、QA、甚至是 IT 以外的潜在领域。
|
||||
|
||||
Datical 的 Reeves 说 "这是一件非常 DevOps 化的事情:发现相互掣肘的地方并解决它们”,"对于以前采用 DevOps 的企业来说,安全和数据库是他们面临的最大瓶颈。“
|
||||
|
||||
### 4. 预计 ROI 将会增加
|
||||
|
||||
Eric Schabell 说,”由于公司深入推进他们的 DevOps 工作,IT 团队在方法、流程、容器、和微服务方面的投资将得到更多的回报。“ 他是 Red Hat 的全球技术传播总监,Schabell 说 "Holy Grail 将移动的更快、完成的更多、并且变得更灵活。由于这些组件找到了更宽阔的天地,组织在应用程序中更有归属感时,结果就会出现。”
|
||||
|
||||
"每当新兴技术获得我们的关注时,任何事都有一个令人兴奋的学习曲线,但当认识到它应用很困难的时候,同时也会经历一个从兴奋到幻灭的低谷。最终,我们将开始看到从低谷中爬出来,并收获到应用 DevOps、容器、和微服务的好处。“
|
||||
|
||||
### 5. 预计成功的指标将持续演进
|
||||
|
||||
Mike Kail 说 "我相信 DevOps 文化的两个核心原则 —— 自动化和可衡量是从来不会变的”,它是 [CYBRIC][10] 的 CTO,也是 Yahoo 前 CIO。“总是有办法去自动化一个任务,或者提升一个已经自动化的解决方案,而随着时间的推移,重要的事情是测量可能的变化和扩展。这个成熟的过程是一个永不停步的旅行,而不是一个目的地或者已完成的任务。”
|
||||
|
||||
在 DevOps 的精神中,成熟和学习也与协作者和分享精神有关。Kail 认为,对于敏捷方法和 DevOps 文化来说,它仍然为时尚早,这意味着它们还有足够的增长空间。
|
||||
|
||||
Kail 说 "随着越来越多的成熟组织持续去测量可控指标,我相信(希望) —— 这些经验应该被广泛的分享,以便我们去学习并改善它们。“
|
||||
|
||||
作为 Red Hat 技术传播专家 [Gordon Haff][11] 最近注意到,组织使用业务成果相关的因素去改善他们的 DevOps 指标的工作越来越困难。 [Haff 写道][12] "你或许并不真正关心你的开发者写了多少行代码、服务器是否在一夜之间出现了硬件故障、或者你的测试覆盖面是否全面”。事实上,你可能并不直接关心你的网站的响应速度和更新快慢。但是你要注意的是,这些指标可能与消费者放弃购物车或者转到你的竞争对手那里有关。“
|
||||
|
||||
与业务成果相关的一些 DevOps 指标的例子包括,消费者交易金额(作为消费者花销统计的指标)和净推荐值(消费者推荐公司产品和服务的意愿)。关于这个主题更多的内容,请查看这篇完整的文章—— [DevOps 指标:你是否测量了重要的东西 ][12]。
|
||||
|
||||
### 唯一不变的就是改变
|
||||
|
||||
顺利说一句,如果你希望这件事一蹴而就,那你就要倒霉了。
|
||||
|
||||
Reeves 说 "如果你认为今天发布非常快,那你就什么也没有看到”,“这就是为什么要让相关者包括数据库团队进入到 DevOps 中的重要原因。因为今天这两组人员的冲突会随着发布速度的提升而呈指数级增长。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:http://www.jedi.be/presentations/agile-infrastructure-agile-2008.pdf
|
||||
[2]:https://enterprisersproject.com/article/2017/9/5-ways-nurture-devops-culture
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://enterprisersproject.com/article/2017/9/microservices-and-containers-6-things-know-start-time
|
||||
[5]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[6]:https://netsil.com/
|
||||
[7]:http://retrievercommunications.com/
|
||||
[8]:https://www.sonatype.com/
|
||||
[9]:https://www.redhat.com/en/
|
||||
[10]:https://www.cybric.io/
|
||||
[11]:https://enterprisersproject.com/user/gordon-haff
|
||||
[12]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
@ -0,0 +1,72 @@
|
||||
DevOps 如何消除掉 Ranger 社区的瓶颈
|
||||
======
|
||||

|
||||
|
||||
Visual Studio Application Lifecycle Management(ALM)项目 —— [Ranger][1] 是一个志愿者社区,它提供专业的指导、实践经验、以及开发者社区的漏洞修补解决方案。它创建于 2006 年,作为微软内部社区去 "connect the product group with the field and remove adoption blockers"。 在 2009 时,社区已经有超过 200 位成员,这导致了协作和计划面临很大的挑战,在依赖和手工流程上产生了瓶颈,并导致了开发者社区不断增加的延迟和各种报怨。在 2010 时,计划进一步去扩充包括微软最有价值专家(MVP)在内的分布在全球的社区。
|
||||
|
||||
这个社区被分割成十几个活跃的团队。每个团队都致力于通过它的生命周期去设计、构建和支持一个指导或处理项目。在以前,团队的瓶颈在团队管理级别上,原因是严格的、瀑布式的流程和高度依赖一个或多个项目经理。在制作、发布和“为什么、做什么、和怎么做”驱动的决定上,项目经理都要介入其中。另外,缺乏一个实时的指标阻止了团队对他们的解决方案效率的监控,以及对来自社区的关于 bug 和常见问题的关注。
|
||||
|
||||
是时候去寻找一些做好这些事情的方法了,更好地实现开发者社区的价值。
|
||||
|
||||
### DevOps 去“灭火”
|
||||
|
||||
> "DevOps 是人员、流程、和产品的结合,使我们的最终用户能够持续传递价值。" --[Donovan Brown][2]
|
||||
|
||||
为解决这些挑战,社区停止了所有对新项目的冲刺,去探索敏捷实践和新产品。致力于使社区重新活跃起来,为找到促进自治、掌控、和目标的方法,正如在 Daniel H. Pink 的书 —— [Drive][3] 中所说的那样,对僵化的流程和产品进行彻底的改革。
|
||||
|
||||
> “成熟的自组织、自管理、和跨职能团队,在自治、掌控、和目标上茁壮成长。" --Drive, Daniel H. Pink.
|
||||
|
||||
从文化开始 —— 人 —— 第一步是去拥抱 DevOps。社区实现了 [Scrum][4] 框架,使用 [kanban][5] 去提升工程化流程,并且通过可视化去提升透明度、意识和最重要的东西 —— 信任。使用自组织团队后,传统的等级制度和指挥系统消失了。自管理促使团队去积极监视和设计它们自己的流程。
|
||||
|
||||
在 2010 年 4 月份,社区再次实施了另外的关键一步,切换并提交它们的文化、流程、以及产品到云上。虽然开放的”为社区而社区“的核心 [解决方案][6] 仍然是指导和补充,但是在开源解决方案(OSS)上大量增加投资去研究和共享 DevOps 转换的成就。
|
||||
|
||||
持续集成(CI)和持续交付(CD)使用自动化流水线代替了死板的人工流程。这使得团队在不受来自项目经理的干预的情况下为早期问题和早期应用者部署解决方案。增加遥测技术可以使团队关注他们的解决方案,以及在用户注意到它们之前,检测和处理未知的问题。
|
||||
|
||||
DevOps 转变是一个持续进化的过程,通过实验去探索和验证人、流程、和产品的改革。最新的试验引入了流水线革新,它可以持续提升价值流。自动扫描组件、持续地、以及静默地检查安全、协议、和开源组件的品质。部署环和特性标志允许团队对所有或者特定用户进行更细粒度的控制。
|
||||
|
||||
在 2017 年 10 月,社区将大部分的私有版本控制仓库转移到 [GitHub][7] 上。对所有仓库转移所有者和管理职责到 ALM DevOps Rangers 社区,给团队提供自治和机会,去激励更多的社区对开源解决方案作贡献。团队被授权向他们的最终用户交付质量和价值。
|
||||
|
||||
### 好处和成就
|
||||
|
||||
拥抱 DevOps 使 Ranger 社区变得更加敏捷,实现了对市场的快速反应和快速学习和反应的流程,减少了宝贵的时间投入,并宣布自治。
|
||||
|
||||
下面是从这个转变中观察到的一个列表,排列没有特定的顺序:
|
||||
|
||||
* 自治、掌控、和目标是核心。
|
||||
* 从可触摸的和可迭代的东西开始 —— 避免摊子铺的过大。
|
||||
* 可触摸的和可操作的指标很重要 —— 确保不要掺杂其它东西。
|
||||
* 人(文化)的转变是最具挑战的部分。
|
||||
* 没有蓝图;任何一个组织和任何一个团队都是独一无二的。
|
||||
* 转变是一个持续的过程。
|
||||
* 透明和可视非常关键。
|
||||
* 使用工程化流程去强化预期行为。
|
||||
|
||||
|
||||
|
||||
转换变化表:~~(致核对:以下是表格,格式转换造成错乱了。)~~
|
||||
|
||||
PAST CURRENT ENVISIONED Branching Servicing and release isolation Feature Master Build Manual and error prone Automated and consistent Issue detection Call from user Proactive telemetry Issue resolution Days to weeks Minutes to days Minutes Planning Detailed design Prototyping and storyboards Program management 2 program managers (PM) 0.25 PM 0.125 PM Release cadence 6 to 12 months 3 to 5 sprints Every sprint Release Manual and error prone Automated and consistent Sprints 1 month 3 weeks Team size 10 to 15 2 to 5 Time to build Hours Seconds Time to release Days Minutes
|
||||
|
||||
但是,我们还没有做完,相反,我们就是一个令人兴奋的、持续不断的、几乎从不结束的转变的一部分。
|
||||
|
||||
如果你想去学习更多的关于我们的转变、有益的经验、以及想知道我们所经历的挑战,请查看 [转变到 DevOps 文化的记录][8]。"
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/devops-rangers-transformation
|
||||
|
||||
作者:[Willy Schaub][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wpschaub
|
||||
[1]:https://aka.ms/vsaraboutus
|
||||
[2]:http://donovanbrown.com/post/what-is-devops
|
||||
[3]:http://www.danpink.com/books/drive/
|
||||
[4]:http://www.scrumguides.org/scrum-guide.html
|
||||
[5]:https://leankit.com/learn/kanban/what-is-kanban/
|
||||
[6]:https://aka.ms/vsarsolutions
|
||||
[7]:https://github.com/ALM-Rangers
|
||||
[8]:https://github.com/ALM-Rangers/Guidance/blob/master/src/Stories/our-journey-of-transforming-to-a-devops-culture.md
|
||||
113
translated/tech/20171214 6 open source home automation tools.md
Normal file
113
translated/tech/20171214 6 open source home automation tools.md
Normal file
@ -0,0 +1,113 @@
|
||||
6 个开源的家庭自动化工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
[物联网][13] 不仅是一个时髦词,在现实中,自 2016 年我们发布了一篇关于家庭自动化工具的评论文章以来,它也在迅速占领着我们的生活。在 2017,[26.5% 的美国家庭][14] 已经使用了一些智能家居技术;预计五年内,这一数字还将翻倍。
|
||||
|
||||
使用数量持续增加的各种设备,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人能够访问它呢?
|
||||
|
||||
[对安全的担心][16] 是为什么开源对我们将来使用的互联设备至关重要的众多理由之一。由于源代码运行在他们自己的设备上,完全可以去搞明白控制你的家庭的程序,也就是说你可以查看它的代码,如果必要的话甚至可以去修改它。
|
||||
|
||||
虽然联网设备通常都包含他们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口—— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
|
||||
这里有几个我比较喜欢的。
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] 是一个设计为全栈家庭自动化的平台,包含一个服务器应用程序、触摸屏接口、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
|
||||
Calaos 使用的是 [GPL][18] v3 的许可证,你可以在 [GitHub][19] 上查看它的源代码。
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
|
||||
Domoticz 是用 C++ 写的,使用 [GPLv3][22] 许可证。它的 [源代码][23] 在 GitHub 上。
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络附加存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源的和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
|
||||
Home Assistant 以 [MIT 许可证][25] 发布,它的源代码可以从 [GitHub][26] 上下载。
|
||||
|
||||
### MisterHouse
|
||||
|
||||
从 2016 年起,[MisterHouse][27] 取得了很多的进展,我们把它作为一个“可以考虑的另外选择”列在这个清单上。它使用 Perl 脚本去监视任何东西,它可以通过一台计算机来查询或者控制任何可以远程控制的东西。它可以响应语音命令,查询当前时间、天气、位置、以及其它事件,比如去打开灯、唤醒你、记下你喜欢的电视节目、通报呼入的来电、开门报警、记录你儿子上了多长时间的网、如果你女儿汽车超速它也可以告诉你等等。它可以运行在 Linux、macOS、以及 Windows 计算机上,它可以读/写很多的设备,包括安全系统、气象站、来电显示、路由器、机动车位置系统等等。
|
||||
|
||||
MisterHouse 使用 [GPLv2][28] 许可证,你可以在 [GitHub][29] 上查看它的源代码。
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中大家熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
|
||||
你可以在 GitHub 上找到 OpenHAB 的 [源代码][31],它使用 [Eclipse 公共许可证][32]。
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便的改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
|
||||
OpenMotics 使用 [GPLv2][35] 许可证,它的源代码可以从 [GitHub][36] 上下载。
|
||||
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是它们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
|
||||
如果上面的解决方案并不能满足你的需求,下面还有一些潜在的替代者可以去考虑:
|
||||
|
||||
* [EventGhost][1] 是一个开源的([GPL v2][2])家庭影院自动化工具,它只能运行在 Microsoft Windows PC 上。它允许用户去控制多媒体电脑和连接的硬件,它通过触发宏指令的插件或者定制的 Python 脚本来使用。
|
||||
* [ioBroker][3] 是一个基于 JavaScript 的物联网平台,它能够控制灯、锁、空调、多媒体、网络摄像头等等。它可以运行在任何可以运行 Node.js 的硬件上,包括 Windows、Linux、以及 macOS,它使用 [MIT 许可证][4]。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hubs,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [LinuxMCE][7] 标称它是你的多媒体与电子设备之间的“数字粘合剂”。它运行在 Linux(包括树莓派)上,它基于 Pluto 开源 [许可证][8] 发布,它可以用于家庭安全、电话(VoIP 和语音信箱)、A/V 设备、家庭自动化、以及玩视频游戏。
|
||||
* [OpenNetHome][9],和这一类中的其它解决方案一样,是一个控制灯、报警、应用程序等等的一个开源软件。它基于 Java 和 Apache Maven,可以运行在 Windows、macOS、以及 Linux —— 包括树莓派,它以 [GPLv3][10] 许可证发布。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户接口。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
|
||||
现在该轮到你了:你已经准备好家庭自动化系统了吗?或者正在研究去设计一个。你对家庭自动化的新手有什么建议,你会推荐什么样的系统?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://www.eventghost.net/
|
||||
[2]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[3]:http://iobroker.net/
|
||||
[4]:https://github.com/ioBroker/ioBroker#license
|
||||
[5]:https://www.jeedom.com/site/en/index.html
|
||||
[6]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[7]:http://www.linuxmce.com/
|
||||
[8]:http://wiki.linuxmce.org/index.php/License
|
||||
[9]:http://opennethome.org/
|
||||
[10]:https://github.com/NetHome/NetHomeServer/blob/master/LICENSE
|
||||
[11]:https://www.smarthomatic.org/
|
||||
[12]:https://github.com/breaker27/smarthomatic/blob/develop/GPL3.txt
|
||||
[13]:https://opensource.com/resources/internet-of-things
|
||||
[14]:https://www.statista.com/outlook/279/109/smart-home/united-states
|
||||
[15]:http://www.crn.com/slide-shows/internet-of-things/300089496/black-hat-2017-9-iot-security-threats-to-watch.htm
|
||||
[16]:https://opensource.com/business/15/5/why-open-source-means-stronger-security
|
||||
[17]:https://calaos.fr/en/
|
||||
[18]:https://github.com/calaos/calaos-os/blob/master/LICENSE
|
||||
[19]:https://github.com/calaos
|
||||
[20]:https://domoticz.com/
|
||||
[21]:https://www.domoticz.com/wiki/Integrations_and_Protocols
|
||||
[22]:https://github.com/domoticz/domoticz/blob/master/License.txt
|
||||
[23]:https://github.com/domoticz/domoticz
|
||||
[24]:https://home-assistant.io/
|
||||
[25]:https://github.com/home-assistant/home-assistant/blob/dev/LICENSE.md
|
||||
[26]:https://github.com/balloob/home-assistant
|
||||
[27]:http://misterhouse.sourceforge.net/
|
||||
[28]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[29]:https://github.com/hollie/misterhouse
|
||||
[30]:http://www.openhab.org/
|
||||
[31]:https://github.com/openhab/openhab
|
||||
[32]:https://github.com/openhab/openhab/blob/master/LICENSE.TXT
|
||||
[33]:https://www.openmotics.com/
|
||||
[34]:https://opensource.com/life/14/12/open-source-home-automation-system-opemmotics
|
||||
[35]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[36]:https://github.com/openmotics
|
||||
@ -0,0 +1,62 @@
|
||||
如何检查你的 Linux PC 是否存在 Meltdown 或者 Spectre 漏洞
|
||||
======
|
||||
|
||||

|
||||
|
||||
Meltdown 和 Specter 漏洞的最恐怖的现实之一是它们涉及非常广泛。几乎每台现代计算机都会受到一些影响。真正的问题是_你_是否受到了影响?每个系统都处于不同的脆弱状态,具体取决于已经或者还没有打补丁的软件。
|
||||
|
||||
由于 Meltdown 和 Spectre 都是相当新的,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
|
||||
### 简单测试
|
||||
|
||||
顶级的 Linux 内核开发人员之一提供了一种简单的方式来检查系统在 Meltdown 和 Specter 漏洞方面的状态。它是简单的,也是最简洁的,但它不适用于每个系统。有些发行版不支持它。即使如此,也值得一试。
|
||||
```
|
||||
grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
|
||||
```
|
||||
|
||||
![Kernel Vulnerability Check][1]
|
||||
|
||||
你应该看到与上面截图类似的输出。很有可能你会发现系统中至少有一个漏洞还存在。这的确是真的,因为 Linux 在减轻 Specter v1 影响方面还没有取得任何进展。
|
||||
|
||||
### 脚本
|
||||
|
||||
如果上面的方法不适合你,或者你希望看到更详细的系统报告,一位开发人员已创建了一个 shell 脚本,它将检查你的系统来查看系统收到什么漏洞影响,还有做了什么来减轻 Meltdown 和 Spectre 的影响。
|
||||
|
||||
要得到脚本,请确保你的系统上安装了 Git,然后将脚本仓库克隆到一个你不介意运行它的目录中。
|
||||
```
|
||||
cd ~/Downloads
|
||||
git clone https://github.com/speed47/spectre-meltdown-checker.git
|
||||
|
||||
```
|
||||
|
||||
这不是一个大型仓库,所以它应该只需要几秒钟就克隆完成。完成后,输入新创建的目录并运行提供的脚本。
|
||||
```
|
||||
cd spectre-meltdown-checker
|
||||
./spectre-meltdown-checker.sh
|
||||
|
||||
```
|
||||
|
||||
你会在中断看到很多输出。别担心,它不是太难查看。首先,脚本检查你的硬件,然后运行三个漏洞:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
|
||||
![Meltdown Spectre Check Script Ubuntu][2]
|
||||
|
||||
每个部分为你提供潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
|
||||
### 这意味着什么
|
||||
|
||||
所以,要点是什么?大多数 Linux 系统已经针对 Meltdown 进行了修补。如果你还没有更新,你应该更新一下。 Specter v1 仍然是一个大问题,到目前为止还没有取得很大进展。Spectre v2 将取决于你的发行版以及它选择应用的补丁。无论哪种工具都说,没有什么是完美的。做好研究并留意直接来自内核和发行版开发者的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2018/01/lmc-kernel-check.jpg (Kernel Vulnerability Check)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/lmc-script.jpg (Meltdown Spectre Check Script Ubuntu)
|
||||
@ -0,0 +1,116 @@
|
||||
|
||||
使用 Zim 在你的 Linux 桌面上创建一个 wiki
|
||||
======
|
||||
|
||||

|
||||
|
||||
不可否认 wiki 的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了超过几条维基百科,要么是为了我自己的工作,要么就是为了我所持有的各种合约和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版 wiki][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,Linux 中有许多可用的桌面版 wiki。
|
||||
|
||||
让我们来看看更好的桌面版的 wiki 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
一旦安装了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是笔记本,它们就像一个主题上的 wiki 页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 "Notes" 来表示文件夹的名称和指定文件夹为`~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||

|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 **OK** 。你得到的本质上是你的 wiki 页面的容器。
|
||||
|
||||

|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 **File > New Page**。
|
||||
|
||||

|
||||
|
||||
输入该页面的名称,然后单击 **OK**。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||

|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记,一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 子弹和编号清单
|
||||
* 核对清单
|
||||
|
||||
|
||||
|
||||
你可以添加图片和附加文件到你的 wiki 页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的 wiki 语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用 wiki 标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(*)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [CamelCase][7] 来命名这些页面。假设我有个叫做 "Course Notes." 的笔记本。我可以通过输入 "AnalysisCourse." 来重命名我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 "AnalysisCourse" 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 **Insert link** 按钮。 在 **Link to** 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 **Link**。
|
||||
|
||||

|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的 wiki 页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息ーー比如, 在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种, 而不是复制和粘贴(和丢失格式) :
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
|
||||
|
||||
为此,点击你想要导出的 wiki 页面。然后,选择 **File > Export**。决定是要导出整个笔记本还是一个页面,然后点击 **Forward**。
|
||||
|
||||

|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。 使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如, 如果你想把你的 wiki 页面变成 HTML 演示幻灯片, 你可以在 **Template** 中选择 "SlideShow s5"。 如果你想知道, 这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||

|
||||
|
||||
点击 **Forward**,如果你在导出一个笔记本, 你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||

|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版 wik ,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
Loading…
Reference in New Issue
Block a user