mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge pull request #12432 from lujun9972/add-MjAxOTAyMTIgVHdvIGdyYXBoaWNhbCB0b29scyBmb3IgbWFuaXB1bGF0aW5nIFBERnMgb24gdGhlIExpbnV4IGRlc2t0b3AubWQK
选题: 20190212 Two graphical tools for manipulating PDFs on the Linux d…
This commit is contained in:
commit
3cb1dec486
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Two graphical tools for manipulating PDFs on the Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/2/manipulating-pdfs-linux)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Two graphical tools for manipulating PDFs on the Linux desktop
|
||||
======
|
||||
PDF-Shuffler and PDF Chain are great tools for modifying PDFs in Linux.
|
||||

|
||||
|
||||
With the way I talk and write about PDFs and tools for working with them, some people think I'm in love with the format. I'm not, for a variety of reasons I won't go into here.
|
||||
|
||||
I won't go so far as saying PDFs are a necessary evil in my personal and professional life—rather they're a necessary not-so-good. Often I have to use PDFs, even though there are better alternatives for delivering documents.
|
||||
|
||||
When I work with PDFs, usually at the day job and with one of those other operating systems, I fiddle with them using Adobe Acrobat. But what about when I have to work with PDFs on the Linux desktop? Let's take a look at two of the graphical tools I use to manipulate PDFs.
|
||||
|
||||
### PDF-Shuffler
|
||||
|
||||
As its name suggests, you can use [PDF-Shuffler][1] to move pages around in a PDF file. It can do a little more, but the software's capabilities are limited. That doesn't mean PDF-Shuffler isn't useful. It is. Very useful.
|
||||
|
||||
You can use PDF-Shuffler to:
|
||||
|
||||
* Extract pages from PDF files
|
||||
* Add pages to a file
|
||||
* Rearrange the pages in a file
|
||||
|
||||
|
||||
|
||||
Be aware that PDF-Shuffler has a few dependencies, like pyPDF and python-gtk. Usually, installing it via a package manager is the fastest and least frustrating route.
|
||||
|
||||
Let's say you want to extract pages from a PDF, maybe to act as a sample chapter from your book. Open the PDF file by selecting **File > Add**.
|
||||
|
||||
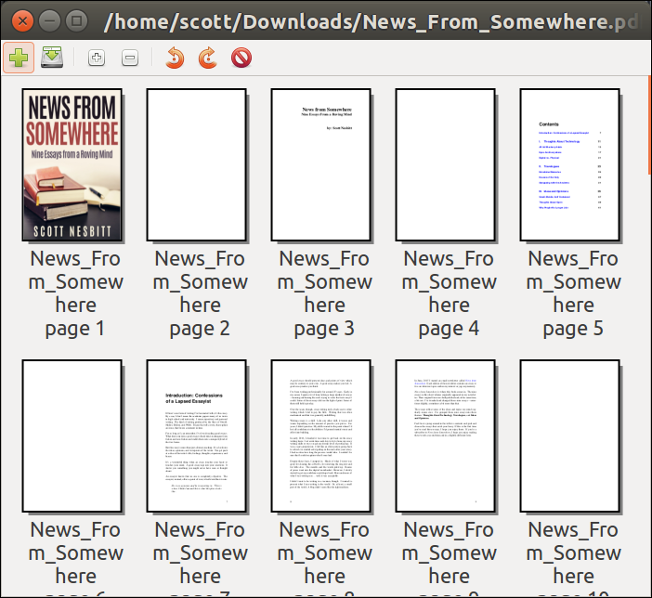
|
||||
|
||||
To extract pages 7 to 9, press Ctrl and click-select the pages. Then, right-click and select **Export selection**.
|
||||
|
||||
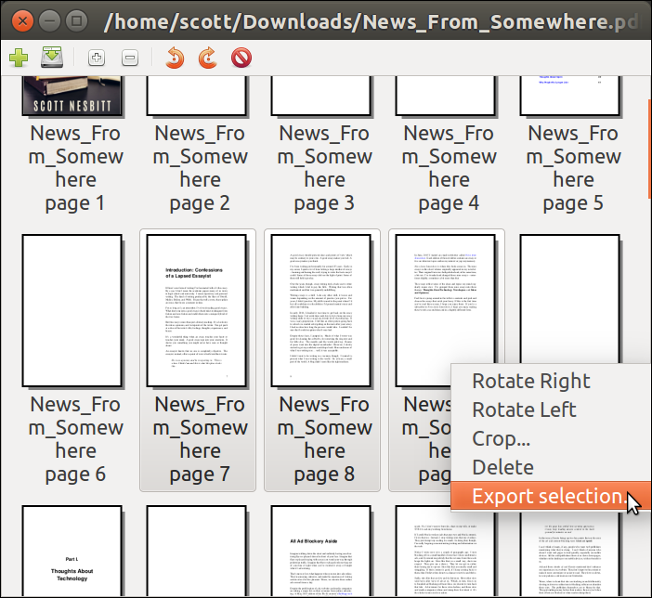
|
||||
|
||||
Choose the directory where you want to save the file, give it a name, and click **Save**.
|
||||
|
||||
To add a file—for example, to add a cover or re-insert scanned, signed pages of a contract or application—open a PDF file, then select **File > Add** and find the PDF file that you want to add. Click **Open**.
|
||||
|
||||
PDF-Shuffler has an annoying habit of adding pages at the end of the PDF file you're working on. Click and drag the page you added to where you want it to go in the file. You can only click and drag one page in a file at a time.
|
||||
|
||||
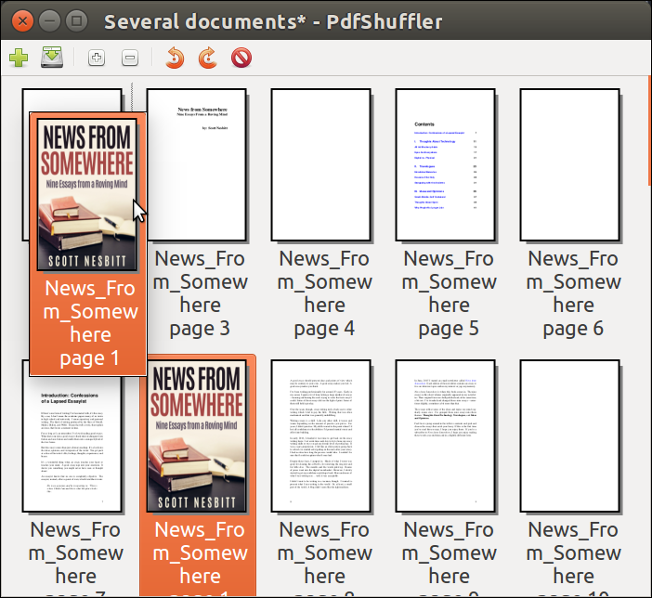
|
||||
|
||||
### PDF Chain
|
||||
|
||||
I'm a big fan of [PDFtk][2], a command-line app for doing some interesting things with and to PDFs. Since I don't use it frequently, I don't remember all of PDFtk's commands and options.
|
||||
|
||||
[PDF Chain][3] is a very good alternative to PDFtk's command line. It gives you one-click access to PDFtk's most frequently used commands. Without touching a menu, you can:
|
||||
|
||||
* Merge PDFs (including rotating the pages of one or more files)
|
||||
* Extract pages from a PDF and save them to individual files
|
||||
* Add a background or watermark to a PDF
|
||||
* Add attachments to a file
|
||||
|
||||
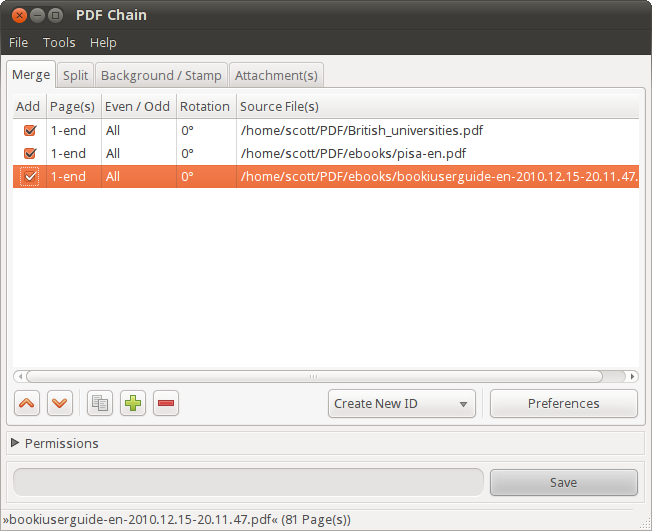
|
||||
|
||||
You can also do more. Click on the **Tools** menu to:
|
||||
|
||||
* Extract attachments from a PDF
|
||||
* Compress or uncompress a file
|
||||
* Extract the metadata from the file
|
||||
* Fill in PDF forms from an external [data file][4]
|
||||
* [Flatten][5] a PDF
|
||||
* Drop [XML Forms Architecture][6] (XFA) data from PDF forms
|
||||
|
||||
|
||||
|
||||
To be honest, I only use the commands to extract attachments and compress or uncompress PDFs with PDF Chain or PDFtk. The rest are pretty much terra incognita for me.
|
||||
|
||||
### Summing up
|
||||
|
||||
The number of tools available on Linux for working with PDFs never ceases to amaze me. And neither does the breadth and depth of their features and functions. I can usually find one, whether command line or graphical, that does what I need to do. For the most part, PDF Mod and PDF Chain work well for me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/manipulating-pdfs-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://savannah.nongnu.org/projects/pdfshuffler/
|
||||
[2]: https://en.wikipedia.org/wiki/PDFtk
|
||||
[3]: http://pdfchain.sourceforge.net/
|
||||
[4]: http://www.verypdf.com/pdfform/fdf.htm
|
||||
[5]: http://pdf-tips-tricks.blogspot.com/2009/03/flattening-pdf-layers.html
|
||||
[6]: http://en.wikipedia.org/wiki/XFA
|
||||
Loading…
Reference in New Issue
Block a user