mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
3c5f0491a9
published
201508
20141211 Open source all over the world.md20150128 7 communities driving open source development.md20150205 Install Strongswan - A Tool to Setup IPsec Based VPN in Linux.md20150209 Install OpenQRM Cloud Computing Platform In Debian.md20150318 How to Manage and Use LVM (Logical Volume Management) in Ubuntu.md20150318 How to Use LVM on Ubuntu for Easy Partition Resizing and Snapshots.md20150410 How to run Ubuntu Snappy Core on Raspberry Pi 2.md20150504 How to access a Linux server behind NAT via reverse SSH tunnel.md20150518 How to set up a Replica Set on MongoDB.md20150522 Analyzing Linux Logs.md20150527 Howto Manage Host Using Docker Machine in a VirtualBox.md20150602 Howto Configure OpenVPN Server-Client on Ubuntu 15.04.md20150604 Nishita Agarwal Shares Her Interview Experience on Linux 'iptables' Firewall.md20150610 Tickr Is An Open-Source RSS News Ticker for Linux Desktops.md20150625 How to Provision Swarm Clusters using Docker Machine.md20150629 Autojump--An Advanced 'cd' Command to Quickly Navigate Linux Filesystem.md20150716 A Week With GNOME As My Linux Desktop--What They Get Right & Wrong - Page 1 - Introduction.md20150716 A Week With GNOME As My Linux Desktop--What They Get Right & Wrong - Page 2 - The GNOME Desktop.md20150716 A Week With GNOME As My Linux Desktop--What They Get Right & Wrong - Page 3 - GNOME Applications.md20150716 A Week With GNOME As My Linux Desktop--What They Get Right & Wrong - Page 4 - GNOME Settings.md20150716 A Week With GNOME As My Linux Desktop--What They Get Right & Wrong - Page 5 - Conclusion.md20150717 How to Configure Chef (server or client) on Ubuntu 14.04 or 15.04.md20150717 How to collect NGINX metrics - Part 2.md20150717 How to monitor NGINX with Datadog - Part 3.md20150717 How to monitor NGINX- Part 1.md20150717 Howto Configure FTP Server with Proftpd on Fedora 22.md20150722 How To Fix 'The Update Information Is Outdated' In Ubuntu 14.04.md20150722 How To Manage StartUp Applications In Ubuntu.md20150727 Easy Backup Restore and Migrate Containers in Docker.md20150728 How To Fix--There is no command installed for 7-zip archive files.md20150728 How to Update Linux Kernel for Improved System Performance.md20150728 Tips to Create ISO from CD, Watch User Activity and Check Memory Usages of Browser.md20150728 Understanding Shell Commands Easily Using 'Explain Shell' Script in Linux.md20150729 What is Logical Volume Management and How Do You Enable It in Ubuntu.md20150730 Compare PDF Files on Ubuntu.md20150730 Must-Know Linux Commands For New Users.md20150803 Handy commands for profiling your Unix file systems.md20150803 Linux Logging Basics.md20150803 Troubleshooting with Linux Logs.md20150806 5 Reasons Why Software Developer is a Great Career Choice.md20150806 Linux FAQs with Answers--How to fix 'ImportError--No module named wxversion' on Linux.md20150806 Linux FAQs with Answers--How to install git on Linux.md20150807 How To--Temporarily Clear Bash Environment Variables on a Linux and Unix-like System.md20150810 For Linux, Supercomputers R Us.md20150811 Darkstat is a Web Based Network Traffic Analyzer--Install it on Linux.md20150811 How to download apk files from Google Play Store on Linux.md20150813 How to Install Logwatch on Ubuntu 15.04.md20150813 How to get Public IP from Linux Terminal.md20150813 Ubuntu Want To Make It Easier For You To Install The Latest Nvidia Linux Driver.md20150816 Ubuntu NVIDIA Graphics Drivers PPA Is Ready For Action.md20150816 shellinabox--A Web based AJAX Terminal Emulator.md20150817 Top 5 Torrent Clients For Ubuntu Linux.md20150818 How to monitor stock quotes from the command line on Linux.md20150818 Linux Without Limits--IBM Launch LinuxONE Mainframes.md20150818 Ubuntu Linux is coming to IBM mainframes.md20150821 How to Install Visual Studio Code in Linux.md20150821 Linux FAQs with Answers--How to check MariaDB server version.md20150826 How to Run Kali Linux 2.0 In Docker Container.md20150827 How to Convert From RPM to DEB and DEB to RPM Package Using Alien.md20150827 Linux or UNIX--Bash Read a File Line By Line.mdLinux and Unix Test Disk IO Performance With dd Command.mdPart 1 - Introduction to RAID, Concepts of RAID and RAID Levels.mdPart 2 - Creating Software RAID0 (Stripe) on ‘Two Devices’ Using ‘mdadm’ Tool in Linux.mdPart 3 - Setting up RAID 1 (Mirroring) using 'Two Disks' in Linux.mdPart 4 - Creating RAID 5 (Striping with Distributed Parity) in Linux.mdPart 5 - Setup RAID Level 6 (Striping with Double Distributed Parity) in Linux.mdPart 6 - Setting Up RAID 10 or 1+0 (Nested) in Linux.mdPart 7 - Growing an Existing RAID Array and Removing Failed Disks in Raid.mdkde-plasma-5.4.md
20150811 fdupes--A Comamndline Tool to Find and Delete Duplicate Files in Linux.mdsources
news
share
20150824 Great Open Source Collaborative Editing Tools.md20150826 Five Super Cool Open Source Games.md20150827 Xtreme Download Manager Updated With Fresh GUI.md20150901 5 best open source board games to play online.md
talk
20141223 Defending the Free Linux World.md20150709 Interviews--Linus Torvalds Answers Your Question.md20150716 Interview--Larry Wall.md20150818 Debian GNU or Linux Birthday-- A 22 Years of Journey and Still Counting.md20150827 The Strangest Most Unique Linux Distros.md20150901 Is Linux Right For You.md
tech
20150205 Install Strongswan - A Tool to Setup IPsec Based VPN in Linux.md20150813 Howto Run JBoss Data Virtualization GA with OData in Docker Container.md20150813 Linux file system hierarchy v2.0.md20150824 Fix No Bootable Device Found Error After Installing Ubuntu.md20150826 How to set up a system status page of your infrastructure.md20150831 How to switch from NetworkManager to systemd-networkd on Linux.md20150831 Linux workstation security checklist.md20150901 How to Defragment Linux Systems.md20150901 How to Install or Upgrade to Linux Kernel 4.2 in Ubuntu.md20150901 How to automatically dim your screen on Linux.md20150901 Install The Latest Linux Kernel in Ubuntu Easily via A Script.md20150901 Setting Up High-Performance 'HHVM' and Nginx or Apache with MariaDB on Debian or Ubuntu.md
LFCS
RAID
RHCE
RHCSA Series
@ -0,0 +1,114 @@
|
||||
安装 Strongswan :Linux 上一个基于 IPsec 的 VPN 工具
|
||||
================================================================================
|
||||
|
||||
IPsec是一个提供网络层安全的标准。它包含认证头(AH)和安全负载封装(ESP)组件。AH提供包的完整性,ESP组件提供包的保密性。IPsec确保了在网络层的安全特性。
|
||||
|
||||
- 保密性
|
||||
- 数据包完整性
|
||||
- 来源不可抵赖性
|
||||
- 重放攻击防护
|
||||
|
||||
[Strongswan][1]是一个IPsec协议的开源代码实现,Strongswan的意思是强安全广域网(StrongS/WAN)。它支持IPsec的VPN中的两个版本的密钥自动交换(网络密钥交换(IKE)V1和V2)。
|
||||
|
||||
Strongswan基本上提供了在VPN的两个节点/网关之间自动交换密钥的共享,然后它使用了Linux内核的IPsec(AH和ESP)实现。密钥共享使用了之后用于ESP数据加密的IKE 机制。在IKE阶段,strongswan使用OpenSSL的加密算法(AES,SHA等等)和其他加密类库。无论如何,IPsec中的ESP组件使用的安全算法是由Linux内核实现的。Strongswan的主要特性如下:
|
||||
|
||||
- x.509证书或基于预共享密钥认证
|
||||
- 支持IKEv1和IKEv2密钥交换协议
|
||||
- 可选的,对于插件和库的内置完整性和加密测试
|
||||
- 支持椭圆曲线DH群和ECDSA证书
|
||||
- 在智能卡上存储RSA私钥和证书
|
||||
|
||||
它能被使用在客户端/服务器(road warrior模式)和网关到网关的情景。
|
||||
|
||||
### 如何安装 ###
|
||||
|
||||
几乎所有的Linux发行版都支持Strongswan的二进制包。在这个教程,我们会从二进制包安装strongswan,也会从源代码编译带有合适的特性的strongswan。
|
||||
|
||||
### 使用二进制包 ###
|
||||
|
||||
可以使用以下命令安装Strongswan到Ubuntu 14.04 LTS
|
||||
|
||||
$ sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
strongswan的全局配置(strongswan.conf)文件和ipsec配置(ipsec.conf/ipsec.secrets)文件都在/etc/目录下。
|
||||
|
||||
### strongswan源码编译安装的依赖包 ###
|
||||
|
||||
- GMP(strongswan使用的高精度数学库)
|
||||
- OpenSSL(加密算法来自这个库)
|
||||
- PKCS(1,7,8,11,12)(证书编码和智能卡集成)
|
||||
|
||||
#### 步骤 ####
|
||||
|
||||
**1)** 在终端使用下面命令到/usr/src/目录
|
||||
|
||||
$ cd /usr/src
|
||||
|
||||
**2)** 用下面命令从strongswan网站下载源代码
|
||||
|
||||
$ sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz 是当前最新版。)
|
||||
|
||||

|
||||
|
||||
**3)** 用下面命令提取下载的软件,然后进入目录。
|
||||
|
||||
$ sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** 使用configure命令配置strongswan每个想要的选项。
|
||||
|
||||
$ ./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
如果GMP库没有安装,配置脚本将会发生下面的错误。
|
||||
|
||||

|
||||
|
||||
因此,首先,使用下面命令安装GMP库然后执行配置脚本。
|
||||
|
||||

|
||||
|
||||
不过,如果GMP已经安装还报上述错误的话,在Ubuntu上使用如下命令,给在路径 /usr/lib,/lib/,/usr/lib/x86_64-linux-gnu/ 下的libgmp.so库创建软连接。
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
创建libgmp.so软连接后,再执行./configure脚本也许就找到gmp库了。然而,如果gmp头文件发生其他错误,像下面这样。
|
||||
|
||||

|
||||
|
||||
为解决上面的错误,使用下面命令安装libgmp-dev包
|
||||
|
||||
$ sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
安装gmp的开发库后,在运行一遍配置脚本,如果没有发生错误,则将看见下面的这些输出。
|
||||
|
||||

|
||||
|
||||
使用下面的命令编译安装strongswan。
|
||||
|
||||
$ sudo make ; sudo make install
|
||||
|
||||
安装strongswan后,全局配置(strongswan.conf)和ipsec策略/密码配置文件(ipsec.conf/ipsec.secretes)被放在**/usr/local/etc**目录。
|
||||
|
||||
根据我们的安全需要Strongswan可以用作隧道或者传输模式。它提供众所周知的site-2-site模式和road warrior模式的VPN。它很容易使用在Cisco,Juniper设备上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
@ -1,14 +1,14 @@
|
||||
Ubuntu上使用LVM轻松调整分区并制作快照
|
||||
Ubuntu 上使用 LVM 轻松调整分区并制作快照
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。说明中说,它启用了逻辑卷管理,因此你可以制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。它的描述中说,启用逻辑卷管理可以让你制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的存储空间][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的“存储空间”][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
|
||||
### 你应该在新安装Ubuntu时使用LVM吗? ###
|
||||
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、合并多个磁盘到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[调整这些不使用的分区][3]。
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、将多个磁盘合并到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[当这些分区不使用时才能调整][3]。
|
||||
|
||||
完全坦率地说,普通Ubuntu桌面用户可能不会意识到他们是否正在使用LVM。但是,如果你想要在今后做一些更高深的事情,那么LVM就会有所帮助了。LVM可能更复杂,可能会在你今后恢复数据时会导致问题——尤其是在你经验不足时。这里不会有显著的性能损失——LVM是彻底地在Linux内核中实现的。
|
||||
|
||||
@ -18,7 +18,7 @@ LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的存储空
|
||||
|
||||
前面,我们已经[说明了何谓LVM][4]。概括来讲,它在你的物理磁盘和呈现在你系统中的分区之间提供了一个抽象层。例如,你的计算机可能装有两个硬盘驱动器,它们的大小都是 1 TB。你必须得在这些磁盘上至少分两个区,每个区大小 1 TB。
|
||||
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个标准的系统只会有一个卷组。
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个典型的系统只会有一个卷组。
|
||||
|
||||
该抽象层使得调整分区、将多个磁盘组合成单个卷、甚至为一个运行着的分区的文件系统创建“快照”变得十分简单,而完成所有这一切都无需先卸载分区。
|
||||
|
||||
@ -28,11 +28,11 @@ LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传
|
||||
|
||||
通常,[LVM通过Linux终端命令来管理][5]。这在Ubuntu上也行得通,但是有个更简单的图形化方法可供大家采用。如果你是一个Linux用户,对GParted或者与其类似的分区管理器熟悉,算了,别瞎掰了——GParted根本不支持LVM磁盘。
|
||||
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击停靠盘上的图标来开启它吧,搜索磁盘然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击dash中的图标来开启它吧,搜索“磁盘”然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
|
||||

|
||||
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是你没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从停靠盘上打开逻辑卷管理工具了。
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从dash上打开逻辑卷管理工具了。
|
||||
|
||||
这个图形化配置工具是由红帽公司开发的,虽然有点陈旧了,但却是唯一的图形化方式,你可以通过它来完成上述操作,将那些终端命令抛诸脑后了。
|
||||
|
||||
@ -40,11 +40,11 @@ LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传
|
||||
|
||||

|
||||
|
||||
卷组视图会列出你所有物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,就像Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
卷组视图会列出你所有的物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,这是Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
|
||||

|
||||
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩减分区。
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩小分区。
|
||||
|
||||

|
||||
|
||||
@ -55,7 +55,7 @@ system-config-lvm的其它选项允许你设置快照和镜像。对于传统桌
|
||||
via: http://www.howtogeek.com/211937/how-to-use-lvm-on-ubuntu-for-easy-partition-resizing-and-snapshots/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
如何在树莓派 2 运行 ubuntu Snappy Core
|
||||
================================================================================
|
||||
物联网(Internet of Things, IoT) 时代即将来临。很快,过不了几年,我们就会问自己当初是怎么在没有物联网的情况下生存的,就像我们现在怀疑过去没有手机的年代。Canonical 就是一个物联网快速发展却还是开放市场下的竞争者。这家公司宣称自己把赌注压到了IoT 上,就像他们已经在“云”上做过的一样。在今年一月底,Canonical 启动了一个基于Ubuntu Core 的小型操作系统,名字叫做 [Ubuntu Snappy Core][1] 。
|
||||
|
||||
Snappy 代表了两种意思,它是一种用来替代 deb 的新的打包格式;也是一个用来更新系统的前端,从CoreOS、红帽子和其他系统借鉴了**原子更新**这个想法。自从树莓派 2 投入市场,Canonical 很快就发布了用于树莓派的Snappy Core 版本。而第一代树莓派因为是基于ARMv6 ,Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布 Snappy Core 的RPI2 镜像,抓住机会证明了Snappy 就是一个用于云计算,特别是用于物联网的系统。
|
||||
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google的 Compute Engine 这样的云端上,也可以虚拟化在 KVM、Virtuabox 和vagrant 上。Canonical Ubuntu 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,比如 Ninja Sphere、Erle Robotics,还有一些开发板生产商,比如 Odroid、Banana Pro, Udoo, PCDuino 和 Parallella 、全志,Snappy 也提供了支持。Snappy Core 同时也希望尽快运行到路由器上来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
|
||||
接下来,让我们看看怎么样在树莓派 2 上运行 Ubuntu Snappy Core。
|
||||
|
||||
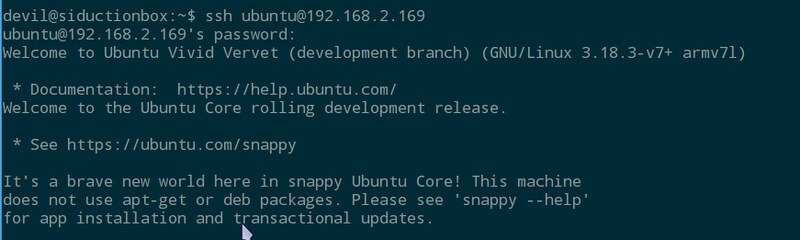
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是原子升级和回滚功能会占用不小的空间。使用 Snappy 启动树莓派 2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
|
||||
|
||||
|
||||
sudo 已经配置好了可以直接用,安全起见,你应该使用以下命令来修改你的用户名
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
或者也可以使用`adduser` 为你添加一个新用户。
|
||||
|
||||
因为RPI缺少硬件时钟,而 Snappy Core 镜像并不知道这一点,所以系统会有一个小 bug:处理某些命令时会报很多错。不过这个很容易解决:
|
||||
|
||||
使用这个命令来确认这个bug 是否影响:
|
||||
|
||||
$ date
|
||||
|
||||
如果输出类似 "Thu Jan 1 01:56:44 UTC 1970", 你可以这样做来改正:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
改成你的实际时间。
|
||||
|
||||

|
||||
|
||||
现在你可能打算检查一下,看看有没有可用的更新。注意通常使用的命令是不行的:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
这时系统不会让你通过,因为 Snappy 使用它自己精简过的、基于dpkg 的包管理系统。这么做的原因是 Snappy 会运行很多嵌入式程序,而同时你也会试图所有事情尽可能的简化。
|
||||
|
||||
让我们来看看最关键的部分,理解一下程序是如何与 Snappy 工作的。运行 Snappy 的SD 卡上除了 boot 分区外还有3个分区。其中的两个构成了一个重复的文件系统。这两个平行文件系统被固定挂载为只读模式,并且任何时刻只有一个是激活的。第三个分区是一个部分可写的文件系统,用来让用户存储数据。通过更新系统,标记为'system-a' 的分区会保持一个完整的文件系统,被称作核心,而另一个平行的文件系统仍然会是空的。
|
||||
|
||||

|
||||
|
||||
如果我们运行以下命令:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
系统将会在'system-b' 上作为一个整体进行更新,这有点像是更新一个镜像文件。接下来你将会被告知要重启系统来激活新核心。
|
||||
|
||||
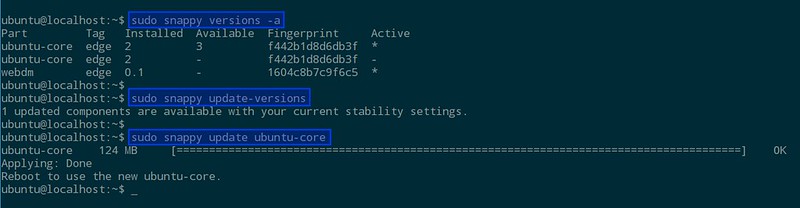
重启之后,运行下面的命令可以检查你的系统是否已经更新到最新版本,以及当前被激活的是哪个核心
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
经过更新-重启两步操作,你应该可以看到被激活的核心已经被改变了。
|
||||
|
||||
因为到目前为止我们还没有安装任何软件,所以可以用下面的命令更新:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
如果你打算仅仅更新特定的OS 版本这就够了。如果出了问题,你可以使用下面的命令回滚:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
这将会把系统状态回滚到更新之前。
|
||||
|
||||
|
||||
|
||||
再来说说那些让 Snappy 变得有用的软件。这里不会讲的太多关于如何构建软件、向 Snappy 应用商店添加软件的基础知识,但是你可以通过 Freenode 上的IRC 频道 #snappy 了解更多信息,那个上面有很多人参与。你可以通过浏览器访问http://\<ip-address>:4200 来浏览应用商店,然后从商店安装软件,再在浏览器里访问 http://webdm.local 来启动程序。如何构建用于 Snappy 的软件并不难,而且也有了现成的[参考文档][4] 。你也可以很容易的把 DEB 安装包使用Snappy 格式移植到Snappy 上。
|
||||
|
||||
|
||||
|
||||
尽管 Ubuntu Snappy Core 吸引了我们去研究新型的 Snappy 安装包格式和 Canonical 式的原子更新操作,但是因为有限的可用应用,它现在在生产环境里还不是很有用。但是既然搭建一个 Snappy 环境如此简单,这看起来是一个学点新东西的好机会。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -1,10 +1,11 @@
|
||||
如何配置MongoDB副本集(Replica Set)
|
||||
如何配置 MongoDB 副本集
|
||||
================================================================================
|
||||
MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档的,它的无模式设计使得它在各种各样的WEB应用当中广受欢迎。最让我喜欢的特性之一是它的副本集,副本集将同一数据的多份拷贝放在一组mongod节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
这篇教程将向你介绍如何配置一个MongoDB副本集。
|
||||
MongoDB 已经成为市面上最知名的 NoSQL 数据库。MongoDB 是面向文档的,它的无模式设计使得它在各种各样的WEB 应用当中广受欢迎。最让我喜欢的特性之一是它的副本集(Replica Set),副本集将同一数据的多份拷贝放在一组 mongod 节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
副本集的最常见配置涉及到一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的结点从而提高了数据库客户端数据读取的吞吐量。
|
||||
这篇教程将向你介绍如何配置一个 MongoDB 副本集。
|
||||
|
||||
副本集的最常见配置需要一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的节点从而提高了数据库客户端数据读取的吞吐量。
|
||||
|
||||
### 配置环境 ###
|
||||
|
||||
@ -12,25 +13,25 @@ MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档
|
||||
|
||||

|
||||
|
||||
为了达到这个目的,我们使用了3个运行在VirtualBox上的虚拟机。我会在这些虚拟机上安装Ubuntu 14.04,并且安装MongoDB官方包。
|
||||
为了达到这个目的,我们使用了3个运行在 VirtualBox 上的虚拟机。我会在这些虚拟机上安装 Ubuntu 14.04,并且安装 MongoDB 官方包。
|
||||
|
||||
我会在一个虚拟机实例上配置好需要的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为master的虚拟机,执行以下安装过程。
|
||||
我会在一个虚拟机实例上配置好所需的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为 master 的虚拟机,执行以下安装过程。
|
||||
|
||||
首先,我们需要在apt中增加一个MongoDB密钥:
|
||||
首先,我们需要给 apt 增加一个 MongoDB 密钥:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
然后,将官方的MongoDB仓库添加到source.list中:
|
||||
然后,将官方的 MongoDB 仓库添加到 source.list 中:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
接下来更新apt仓库并且安装MongoDB。
|
||||
接下来更新 apt 仓库并且安装 MongoDB。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
现在对/etc/mongodb.conf做一些更改
|
||||
现在对 /etc/mongodb.conf 做一些更改
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
@ -39,17 +40,17 @@ MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
第一行的作用是确认我们的数据库需要验证才可以使用的。keyfile用来配置用于MongoDB结点间复制行为的密钥文件。replSet用来为副本集设置一个名称。
|
||||
第一行的作用是表明我们的数据库需要验证才可以使用。keyfile 配置用于 MongoDB 节点间复制行为的密钥文件。replSet 为副本集设置一个名称。
|
||||
|
||||
接下来我们创建一个用于所有实例的密钥文件。
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
这将会创建一个含有MD5字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在MongoDB中使用。
|
||||
这将会创建一个含有 MD5 字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在 MongoDB 中使用。
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
grep命令的作用的是把将空格等我们不想要的内容过滤掉之后的MD5字符串打印出来。
|
||||
grep 命令的作用的是把将空格等我们不想要的内容过滤掉之后的 MD5 字符串打印出来。
|
||||
|
||||
现在我们对密钥文件进行一些操作,让它真正可用。
|
||||
|
||||
@ -57,7 +58,7 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
接下来,关闭此虚拟机。将其Ubuntu系统克隆到其他虚拟机上。
|
||||
接下来,关闭此虚拟机。将其 Ubuntu 系统克隆到其他虚拟机上。
|
||||
|
||||

|
||||
|
||||
@ -67,55 +68,55 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
|
||||
请注意,三个虚拟机示例需要在同一个网络中以便相互通讯。因此,我们需要它们弄到“互联网"上去。
|
||||
|
||||
这里推荐给每个虚拟机设置一个静态IP地址,而不是使用DHCP。这样它们就不至于在DHCP分配IP地址给他们的时候失去连接。
|
||||
这里推荐给每个虚拟机设置一个静态 IP 地址,而不是使用 DHCP。这样它们就不至于在 DHCP 分配IP地址给他们的时候失去连接。
|
||||
|
||||
像下面这样编辑每个虚拟机的/etc/networks/interfaces文件。
|
||||
像下面这样编辑每个虚拟机的 /etc/networks/interfaces 文件。
|
||||
|
||||
在主结点上:
|
||||
在主节点上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副结点1上:
|
||||
在副节点1上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副结点2上:
|
||||
在副节点2上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
由于我们没有DNS服务,所以需要设置设置一下/etc/hosts这个文件,手工将主机名称放到次文件中。
|
||||
由于我们没有 DNS 服务,所以需要设置设置一下 /etc/hosts 这个文件,手工将主机名称放到此文件中。
|
||||
|
||||
在主结点上:
|
||||
在主节点上:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副结点1上:
|
||||
在副节点1上:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副结点2上:
|
||||
在副节点2上:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
使用ping命令检查各个结点之间的连接。
|
||||
使用 ping 命令检查各个节点之间的连接。
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
@ -123,9 +124,9 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
|
||||
### 配置副本集 ###
|
||||
|
||||
验证各个结点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
验证各个节点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
|
||||
在主节点上,打开/etc/mongodb.conf文件,将auth和replSet两项注释掉。
|
||||
在主节点上,打开 /etc/mongodb.conf 文件,将 auth 和 replSet 两项注释掉。
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
@ -133,21 +134,30 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
在一个新安装的 MongoDB 上配置任何用户或副本集之前,你需要注释掉 auth 行。默认情况下,MongoDB 并没有创建任何用户。而如果在你创建用户前启用了 auth,你就不能够做任何事情。你可以在创建一个用户后再次启用 auth。
|
||||
|
||||
重启mongod进程。
|
||||
修改 /etc/mongodb.conf 之后,重启 mongod 进程。
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
连接MongoDB后,新建管理员用户。
|
||||
现在连接到 MongoDB master:
|
||||
|
||||
$ mongo <master-ip-address>:27017
|
||||
|
||||
连接 MongoDB 后,新建管理员用户。
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
|
||||
重启 MongoDB:
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
连接到MongoDB,用以下命令将secondary1和secondary2节点添加到我们的副本集中。
|
||||
再次连接到 MongoDB,用以下命令将 副节点1 和副节点2节点添加到我们的副本集中。
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
@ -156,7 +166,7 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [official driver documentation][1] 来了解如何连接到副本集。如果你想要用Shell来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用附件点操作,那么以下错误信息就蹦出来招呼你了。
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [官方驱动文档][1] 来了解如何连接到副本集。如果你想要用 Shell 来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用副本集操作,那么以下错误信息就蹦出来招呼你了。
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
@ -166,6 +176,12 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
如果你要从 shell 连接到整个副本集,你可以安装如下命令。在副本集中的失败切换是自动的。
|
||||
|
||||
$ mongo primary,secondary1,secondary2:27017/?replicaSet=myReplica
|
||||
|
||||
如果你使用其它驱动语言(例如,JavaScript、Ruby 等等),格式也许不同。
|
||||
|
||||
希望这篇教程能对你有所帮助。你可以使用Vagrant来自动完成你的本地环境配置,并且加速你的代码。
|
||||
|
||||
@ -175,7 +191,7 @@ via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
在 VirtualBox 中使用 Docker Machine 管理主机
|
||||
================================================================================
|
||||
大家好,今天我们学习在 VirtualBox 中使用 Docker Machine 来创建和管理 Docker 主机。Docker Machine 是一个应用,用于在我们的电脑上、在云端、在数据中心创建 Docker 主机,然后用户可以使用 Docker 客户端来配置一些东西。这个 API 为本地主机、或数据中心的虚拟机、或云端的实例提供 Docker 服务。Docker Machine 支持 Windows、OSX 和 Linux,并且是以一个独立的二进制文件包形式安装的。使用(与现有 Docker 工具)相同的接口,我们就可以充分利用已经提供 Docker 基础框架的生态系统。只要一个命令,用户就能快速部署 Docker 容器。
|
||||
大家好,今天我们学习在 VirtualBox 中使用 Docker Machine 来创建和管理 Docker 主机。Docker Machine 是一个可以帮助我们在电脑上、在云端、在数据中心内创建 Docker 主机的应用。它为根据用户的配置和需求创建服务器并在其上安装 Docker和客户端提供了一个轻松的解决方案。这个 API 可以用于在本地主机、或数据中心的虚拟机、或云端的实例提供 Docker 服务。Docker Machine 支持 Windows、OSX 和 Linux,并且是以一个独立的二进制文件包形式安装的。仍然使用(与现有 Docker 工具)相同的接口,我们就可以充分利用已经提供 Docker 基础框架的生态系统。只要一个命令,用户就能快速部署 Docker 容器。
|
||||
|
||||
本文列出一些简单的步骤用 Docker Machine 来部署 docker 容器。
|
||||
|
||||
@ -8,15 +8,15 @@
|
||||
|
||||
Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [github][1] 下载最新版本的 Docker Machine,本文使用 curl 作为下载工具,Docker Machine 版本为 0.2.0。
|
||||
|
||||
** 64 位操作系统 **
|
||||
**64 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
** 32 位操作系统 **
|
||||
**32 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载完成后,找到 **/usr/local/bin** 目录下的 **docker-machine** 文件,执行一下:
|
||||
下载完成后,找到 **/usr/local/bin** 目录下的 **docker-machine** 文件,让其可以执行:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
@ -28,12 +28,12 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
运行下面的命令,安装 Docker 客户端,以便于在我们自己的电脑止运行 Docker 命令:
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建 VirtualBox 虚拟机 ###
|
||||
|
||||
在 Linux 系统上安装完 Docker Machine 后,接下来我们可以安装 VirtualBox 虚拟机,运行下面的就可以了。--driver virtualbox 选项表示我们要在 VirtualBox 的虚拟机里面部署 docker,最后的参数“linux” 是虚拟机的名称。这个命令会下载 [boot2docker][2] iso,它是个基于 Tiny Core Linux 的轻量级发行版,自带 Docker 程序,然后 docker-machine 命令会创建一个 VirtualBox 虚拟机(LCTT:当然,我们也可以选择其他的虚拟机软件)来运行这个 boot2docker 系统。
|
||||
在 Linux 系统上安装完 Docker Machine 后,接下来我们可以安装 VirtualBox 虚拟机,运行下面的就可以了。`--driver virtualbox` 选项表示我们要在 VirtualBox 的虚拟机里面部署 docker,最后的参数“linux” 是虚拟机的名称。这个命令会下载 [boot2docker][2] iso,它是个基于 Tiny Core Linux 的轻量级发行版,自带 Docker 程序,然后 `docker-machine` 命令会创建一个 VirtualBox 虚拟机(LCTT译注:当然,我们也可以选择其他的虚拟机软件)来运行这个 boot2docker 系统。
|
||||
|
||||
# docker-machine create --driver virtualbox linux
|
||||
|
||||
@ -49,7 +49,7 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 3. 设置环境变量 ###
|
||||
|
||||
现在我们需要让 docker 与虚拟机通信,运行 docker-machine env <虚拟机名称> 来实现这个目的。
|
||||
现在我们需要让 docker 与 docker-machine 通信,运行 `docker-machine env <虚拟机名称>` 来实现这个目的。
|
||||
|
||||
# eval "$(docker-machine env linux)"
|
||||
# docker ps
|
||||
@ -64,7 +64,7 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 4. 运行 Docker 容器 ###
|
||||
|
||||
完成配置后我们就可以在 VirtualBox 上运行 docker 容器了。测试一下,在虚拟机里执行 **docker run busybox echo hello world** 命令,我们可以看到容器的输出信息。
|
||||
完成配置后我们就可以在 VirtualBox 上运行 docker 容器了。测试一下,我们可以运行虚拟机 `docker run busybox` ,并在里面里执行 `echo hello world` 命令,我们可以看到容器的输出信息。
|
||||
|
||||
# docker run busybox echo hello world
|
||||
|
||||
@ -72,7 +72,7 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 5. 拿到 Docker 主机的 IP ###
|
||||
|
||||
我们可以执行下面的命令获取 Docker 主机的 IP 地址。
|
||||
我们可以执行下面的命令获取运行 Docker 的主机的 IP 地址。我们可以看到在 Docker 主机的 IP 地址上的任何暴露出来的端口。
|
||||
|
||||
# docker-machine ip
|
||||
|
||||
@ -94,7 +94,9 @@ Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [gi
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们使用 Docker Machine 成功在 VirtualBox 上创建并管理一台 Docker 主机。Docker Machine 确实能让用户快速地在不同的平台上部署 Docker 主机,就像我们这里部署在 VirtualBox 上一样。这个 --driver virtulbox 驱动可以在本地机器上使用,也可以在数据中心的虚拟机上使用。Docker Machine 驱动除了支持本地的 VirtualBox 之外,还支持远端的 Digital Ocean、AWS、Azure、VMware 以及其他基础设施。如果你有任何疑问,或者建议,请在评论栏中写出来,我们会不断改进我们的内容。谢谢,祝愉快。
|
||||
最后,我们使用 Docker Machine 成功在 VirtualBox 上创建并管理一台 Docker 主机。Docker Machine 确实能让用户快速地在不同的平台上部署 Docker 主机,就像我们这里部署在 VirtualBox 上一样。这个 virtualbox 驱动可以在本地机器上使用,也可以在数据中心的虚拟机上使用。Docker Machine 驱动除了支持本地的 VirtualBox 之外,还支持远端的 Digital Ocean、AWS、Azure、VMware 以及其它基础设施。
|
||||
|
||||
如果你有任何疑问,或者建议,请在评论栏中写出来,我们会不断改进我们的内容。谢谢,祝愉快。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -102,7 +104,7 @@ via: http://linoxide.com/linux-how-to/host-virtualbox-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
================================================================================
|
||||

|
||||
|
||||
看到Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
看到过Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
|
||||
> 更新信息过时。该错误可能是由网络问题,或者某个仓库不再可用而造成的。请通过从指示器菜单中选择‘显示更新’来手动更新,然后查看是否存在有失败的仓库。
|
||||
>
|
||||
@ -25,7 +25,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
|
||||
### 修复‘update information is outdated’错误 ###
|
||||
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04或14.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -47,7 +47,7 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -56,4 +56,4 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
[2]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
[3]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
|
||||
[4]:http://itsfoss.com/install-spotify-ubuntu-1504/
|
||||
[5]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
[5]:https://linux.cn/article-5603-1.html
|
||||
@ -1,10 +1,11 @@
|
||||
在 Linux 中使用日志来排错
|
||||
================================================================================
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一些列事件可以给你提供造成根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一系列的事件可以给你提供找出根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
### 登录失败原因 ###
|
||||
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,经常使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权。这些是由[插入式验证模块][1]来记录,或 PAM 进行短期记录。在你的日志中会看到像 Failed 这样的字符串密码和未知的用户。成功认证记录包括像 Accepted 这样的字符串密码并打开会话。
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,这通常发生在使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权时。这些是由[插入式验证模块(PAM)][1]来记录的。在你的日志中会看到像 Failed password 和 user unknown 这样的字符串。而成功认证记录则会包括像 Accepted password 和 session opened 这样的字符串。
|
||||
|
||||
失败的例子:
|
||||
|
||||
@ -30,22 +31,21 @@
|
||||
|
||||
由于没有标准格式,所以你需要为每个应用程序的日志使用不同的命令。日志管理系统,可以自动分析日志,将它们有效的归类,帮助你提取关键字,如用户名。
|
||||
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能单个的筛选。在这个例子中,我们可以看到,root 用户登录了 2700 次,因为我们筛选的日志显示尝试登录的只有 root 用户。
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能通过点击过滤。在下面这个例子中,我们可以看到,root 用户登录了 2700 次之多,因为我们筛选的日志仅显示 root 用户的尝试登录记录。
|
||||
|
||||

|
||||
|
||||
日志管理系统也让你以时间为做坐标轴的图标来查看使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
日志管理系统也可以让你以时间为做坐标轴的图表来查看,使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
|
||||

|
||||
|
||||
### 重启的原因 ###
|
||||
|
||||
|
||||
有时候,一台服务器由于系统崩溃或重启而宕机。你怎么知道它何时发生,是谁做的?
|
||||
|
||||
#### 关机命令 ####
|
||||
|
||||
如果有人手动运行 shutdown 命令,你可以看到它的身份在验证日志文件中。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
如果有人手动运行 shutdown 命令,你可以在验证日志文件中看到它。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
|
||||
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh
|
||||
Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0)
|
||||
@ -53,7 +53,7 @@
|
||||
|
||||
#### 内核初始化 ####
|
||||
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核设施和初始化 cpu 的信息。
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核类(kernel)和 cpu 初始化(Initializing)的信息。
|
||||
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu
|
||||
@ -61,9 +61,9 @@
|
||||
|
||||
### 检测内存问题 ###
|
||||
|
||||
有很多原因可能导致服务器崩溃,但一个普遍的原因是内存用尽。
|
||||
有很多原因可能导致服务器崩溃,但一个常见的原因是内存用尽。
|
||||
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统正在使用的内存发生错误并且有新的或现有的进程试图使用更多的内存。在你的日志文件查找像 Out of Memory 这样的字符串,内核也会发出杀死进程的警告。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统使用了所有内存,而新的或现有的进程试图使用更多的内存时就会出现错误。在你的日志文件查找像 Out of Memory 这样的字符串或类似 kill 这样的内核警告信息。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
|
||||
例如:
|
||||
|
||||
@ -75,20 +75,20 @@
|
||||
$ grep “Out of memory” /var/log/syslog
|
||||
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
|
||||
|
||||
请记住,grep 也要使用内存,所以导致内存不足的错误可能只是运行的 grep。这是另一个分析日志的独特方法!
|
||||
请记住,grep 也要使用内存,所以只是运行 grep 也可能导致内存不足的错误。这是另一个你应该中央化存储日志的原因!
|
||||
|
||||
### 定时任务错误日志 ###
|
||||
|
||||
cron 守护程序是一个调度器只在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。你可以找到这些文件在 /var/log/cron,/var/log/messages,和 /var/log/syslog 中,具体取决于你的发行版。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
cron 守护程序是一个调度器,可以在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。具体取决于你的发行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 几个位置找到这个日志。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
|
||||
默认情况下,cron 作业会通过电子邮件发送信息。这里是一个日志中记录的发送电子邮件的内容。不幸的是,你不能看到邮件的内容在这里。
|
||||
默认情况下,cron 任务的输出会通过 postfix 发送电子邮件。这是一个显示了该邮件已经发送的日志。不幸的是,你不能在这里看到邮件的内容。
|
||||
|
||||
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover>
|
||||
Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110>
|
||||
Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<hoover@loggly.com>, size=607, nrcpt=1 (queue active)
|
||||
Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<hoover@loggly.com>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp)
|
||||
|
||||
你应该想想 cron 在日志中的标准输出以帮助你定位问题。这里展示你可以使用 logger 命令重定向 cron 标准输出到 syslog。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
你可以考虑将 cron 的标准输出记录到日志中,以帮助你定位问题。这是一个你怎样使用 logger 命令重定向 cron 标准输出到 syslog的例子。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
|
||||
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
|
||||
|
||||
@ -97,7 +97,9 @@ cron 守护程序是一个调度器只在指定的日期和时间运行进程。
|
||||
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron)
|
||||
Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World!
|
||||
|
||||
每个 cron 作业将根据作业的具体类型以及如何输出数据来记录不同的日志。希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
每个 cron 任务将根据任务的具体类型以及如何输出数据来记录不同的日志。
|
||||
|
||||
希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -107,7 +109,7 @@ via: http://www.loggly.com/ultimate-guide/logging/troubleshooting-with-linux-log
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
Ubuntu 15.04 and系统中安装 Logwatch
|
||||
如何在 Ubuntu 15.04 系统中安装 Logwatch
|
||||
================================================================================
|
||||
大家好,今天我们会讲述在 Ubuntu 15.04 操作系统上如何安装 Logwatch 软件,它也可以在任意的 Linux 系统和类 Unix 系统上安装。Logwatch 是一款可定制的日志分析和日志监控报告生成系统,它可以根据一段时间的日志文件生成您所希望关注的详细报告。它具有易安装、易配置、可审查等特性,同时对其提供的数据的安全性上也有一些保障措施。Logwatch 会扫描重要的操作系统组件像 SSH、网站服务等的日志文件,然后生成用户所关心的有价值的条目汇总报告。
|
||||
|
||||
大家好,今天我们会讲述在 Ubuntu 15.04 操作系统上如何安装 Logwatch 软件,它也可以在各种 Linux 系统和类 Unix 系统上安装。Logwatch 是一款可定制的日志分析和日志监控报告生成系统,它可以根据一段时间的日志文件生成您所希望关注的详细报告。它具有易安装、易配置、可审查等特性,同时对其提供的数据的安全性上也有一些保障措施。Logwatch 会扫描重要的操作系统组件像 SSH、网站服务等的日志文件,然后生成用户所关心的有价值的条目汇总报告。
|
||||
|
||||
### 预安装设置 ###
|
||||
|
||||
@ -16,13 +17,13 @@ Ubuntu 15.04 and系统中安装 Logwatch
|
||||
|
||||
root@ubuntu-15:~# apt-get install logwatch
|
||||
|
||||
在安装过程中,一旦您按提示按下“Y”健同意对系统修改的话,Logwatch 将会开始安装一些额外的必须软件包。
|
||||
在安装过程中,一旦您按提示按下“Y”键同意对系统修改的话,Logwatch 将会开始安装一些额外的必须软件包。
|
||||
|
||||
在安装过程中会根据您机器上的邮件服务器设置情况弹出提示对 Postfix 设置的配置界面。在这篇教程中我们使用最容易的 “仅本地” 选项。根据您的基础设施情况也可以选择其它的可选项,然后点击“确定”继续。
|
||||
在安装过程中会根据您机器上的邮件服务器设置情况弹出提示对 Postfix 设置的配置界面。在这篇教程中我们使用最容易的 “仅本地(Local only)” 选项。根据您的基础设施情况也可以选择其它的可选项,然后点击“确定”继续。
|
||||
|
||||

|
||||
|
||||
随后您得选择邮件服务器名,这邮件服务器名也会被其它程序使用,所以它应该是一个完全合格域名/全称域名(FQDN),且只一个。
|
||||
随后您得选择邮件服务器名,这邮件服务器名也会被其它程序使用,所以它应该是一个完全合格域名/全称域名(FQDN)。
|
||||
|
||||

|
||||
|
||||
@ -70,11 +71,11 @@ Ubuntu 15.04 and系统中安装 Logwatch
|
||||
# complete email address.
|
||||
MailFrom = Logwatch
|
||||
|
||||
对这个配置文件保存修改,至于其它的参数就让它是默认的,无需改动。
|
||||
对这个配置文件保存修改,至于其它的参数就让它保持默认,无需改动。
|
||||
|
||||
**调度任务配置**
|
||||
|
||||
现在编辑在日常 crons 目录下的 “00logwatch” 文件来配置从 logwatch 生成的报告需要发送的邮件地址。
|
||||
现在编辑在 “daily crons” 目录下的 “00logwatch” 文件来配置从 logwatch 生成的报告需要发送的邮件地址。
|
||||
|
||||
root@ubuntu-15:~# vim /etc/cron.daily/00logwatch
|
||||
|
||||
@ -88,25 +89,25 @@ Ubuntu 15.04 and系统中安装 Logwatch
|
||||
|
||||
root@ubuntu-15:~#logwatch
|
||||
|
||||
生成的报告开始部分显示的是执行的时间和日期。它包含不同的部分,每个部分以开始标识开始而以结束标识结束,中间显示的标识部分提到的完整日志信息。
|
||||
生成的报告开始部分显示的是执行的时间和日期。它包含不同的部分,每个部分以开始标识开始而以结束标识结束,中间显示的是该部分的完整信息。
|
||||
|
||||
这儿演示的是开始标识头的样子,要显示系统上所有安装包的信息,如下所示:
|
||||
这儿显示的是开始的样子,它以显示系统上所有安装的软件包的部分开始,如下所示:
|
||||
|
||||

|
||||
|
||||
接下来的部分显示的日志信息是关于当前系统登陆会话、rsyslogs 和当前及最后可用的会话 SSH 连接信息。
|
||||
接下来的部分显示的日志信息是关于当前系统登录会话、rsyslogs 和当前及最近的 SSH 会话信息。
|
||||
|
||||

|
||||
|
||||
Logwatch 报告最后显示的是安全 sudo 日志及root目录磁盘使用情况,如下示:
|
||||
Logwatch 报告最后显示的是安全方面的 sudo 日志及根目录磁盘使用情况,如下示:
|
||||
|
||||

|
||||
|
||||
您也可以打开如下的文件来检查生成的 logwatch 报告电子邮件。
|
||||
您也可以打开如下的文件来查看生成的 logwatch 报告电子邮件。
|
||||
|
||||
root@ubuntu-15:~# vim /var/mail/root
|
||||
|
||||
您会看到所有已生成的邮件到其配置用户的信息传送状态。
|
||||
您会看到发送给你配置的用户的所有已生成的邮件及其邮件递交状态。
|
||||
|
||||
### 更多详情 ###
|
||||
|
||||
@ -130,7 +131,7 @@ via: http://linoxide.com/ubuntu-how-to/install-use-logwatch-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,19 @@
|
||||
Linux中通过命令行监控股票报价
|
||||
================================================================================
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将成为你日常工作中的其中一项任务。最有可能是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者阅读市场的必备,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是你的恩赐。
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将是你的日常工作之一。最有可能的是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者了解市场的必备工具,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是给你的恩赐。
|
||||
|
||||
在本教程中,让我来介绍一个灵巧而简洁的命令行工具,它可以让你在Linux上从命令行监控股票报价。
|
||||
|
||||
这个工具叫做[Mop][1]。它是用GO编写的一个轻量级命令行工具,可以极其方便地跟踪来自美国市场的最新股票报价。你可以很轻松地自定义要监控的证券列表,它会在一个基于ncurses的便于阅读的界面显示最新的股票报价。
|
||||
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。对于上面讲得,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。了解这些之后,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
|
||||
### 安装 Mop 到 Linux ###
|
||||
|
||||
由于Mop部署在Go中,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
由于Mop是用Go实现的,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
|
||||
安装完Go后,继续像下面这样安装Mop。
|
||||
|
||||
@ -42,7 +43,7 @@ Linux中通过命令行监控股票报价
|
||||
|
||||
### 使用Mop来通过命令行监控股票报价 ###
|
||||
|
||||
要启动Mop,只需运行名为cmd的命令。
|
||||
要启动Mop,只需运行名为cmd的命令(LCTT 译注:这名字实在是……)。
|
||||
|
||||
$ cmd
|
||||
|
||||
@ -50,7 +51,7 @@ Linux中通过命令行监控股票报价
|
||||
|
||||

|
||||
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股利以及年产量等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股息以及年收益率等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
|
||||
### 自定义Mop中的股票报价 ###
|
||||
|
||||
@ -78,7 +79,7 @@ Linux中通过命令行监控股票报价
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在终端环境中花费大量时间,Mop可以很容易地适应你的工作空间,希望没有让你过多地从你的公罗流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,就让它在那干着吧。
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在整天使用终端环境,Mop可以很容易地适应你的工作环境,希望没有让你过多地从你的工作流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,那就够了。
|
||||
|
||||
交易快乐!
|
||||
|
||||
@ -88,7 +89,7 @@ via: http://xmodulo.com/monitor-stock-quotes-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
如何在 Linux 中安装 Visual Studio Code
|
||||
================================================================================
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器和库,并构建通用任务使得加速每日的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的支持包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是可以用于我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、代码片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器、库、构建,以及其它通用任务,以加速日常的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
|
||||
注意:请注意 Visual Studio Code 只支持 64 位 Linux 发行版。
|
||||
注意:请注意 Visual Studio Code 只支持 64 位的 Linux 发行版。
|
||||
|
||||
下面是在所有 Linux 发行版中安装 Visual Studio Code 的几个简单步骤。
|
||||
|
||||
@ -32,12 +32,12 @@
|
||||
|
||||
### 3. 运行 Visual Studio Code ###
|
||||
|
||||
提取软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
展开软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
|
||||
# sudo chmod +x /opt/VSCode-linux-x64/Code
|
||||
# sudo /opt/VSCode-linux-x64/Code
|
||||
|
||||
如果我们想启动 Code 并通过终端能在任何地方打开,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
如果我们想通过终端在任何地方启动 Code,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
|
||||
# ln -s /opt/VSCode-linux-x64/Code /usr/local/bin/code
|
||||
|
||||
@ -47,11 +47,11 @@
|
||||
|
||||
### 4. 创建桌面启动 ###
|
||||
|
||||
下一步,成功抽取 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
下一步,成功展开 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
|
||||
# cp /opt/VSCode-linux-x64/resources/app/vso.png /usr/share/icons/
|
||||
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们在 /tmp/VSCODE/ 目录中使用喜欢的文本编辑器创建名为 visualstudiocode.desktop 的文件。
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们使用喜欢的文本编辑器在 /tmp/VSCODE/ 目录中创建名为 visualstudiocode.desktop 的文件。
|
||||
|
||||
# vi /tmp/vscode/visualstudiocode.desktop
|
||||
|
||||
@ -99,17 +99,19 @@
|
||||
# apt-get update
|
||||
# apt-get install ubuntu-make
|
||||
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们打算在一个终端中运行以下命令安装 Code。
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们可以在一个终端中运行以下命令来安装 Code。
|
||||
|
||||
# umake web visual-studio-code
|
||||
|
||||

|
||||
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们敲击 “a”。点击完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们输入“a”(接受)。输入完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们同样可以使用 umake 在 linux 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言流行的工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们也可以使用 umake 在 Ubuntu 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言的流行工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -117,7 +119,7 @@ via: http://linoxide.com/linux-how-to/install-visual-studio-code-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答--如何检查MatiaDB服务端版本
|
||||
Linux有问必答:如何检查MariaDB服务端版本
|
||||
================================================================================
|
||||
> **提问**: 我使用的是一台运行MariaDB的VPS。我该如何检查MariaDB服务端的版本?
|
||||
|
||||
你需要知道数据库版本的情况有:当你生你数据库或者为服务器打补丁。这里有几种方法找出MariaDB版本的方法。
|
||||
有时候你需要知道你的数据库版本,比如当你升级你数据库或对已知缺陷打补丁时。这里有几种方法找出MariaDB版本的方法。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
@ -16,7 +16,7 @@ Linux有问必答--如何检查MatiaDB服务端版本
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
如果你不能访问MariaDB,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
如果你不能访问MariaDB服务器,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
|
||||
你可以用下面的方法检查MariaDB的安装包。
|
||||
|
||||
@ -42,7 +42,7 @@ via: http://ask.xmodulo.com/check-mariadb-server-version.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
如何在 Docker 容器中运行 Kali Linux 2.0
|
||||
================================================================================
|
||||
### 介绍 ###
|
||||
|
||||
Kali Linux 是一个对于安全测试人员和白帽的一个知名操作系统。它带有大量安全相关的程序,这让它很容易用于渗透测试。最近,[Kali Linux 2.0][1] 发布了,它被认为是这个操作系统最重要的一次发布。另一方面,Docker 技术由于它的可扩展性和易用性让它变得很流行。Dokcer 让你非常容易地将你的程序带给你的用户。好消息是你可以通过 Docker 运行Kali Linux 了,让我们看看该怎么做 :)
|
||||
|
||||
### 在 Docker 中运行 Kali Linux 2.0 ###
|
||||
|
||||
**相关提示**
|
||||
|
||||
> 如果你还没有在系统中安装docker,你可以运行下面的命令:
|
||||
|
||||
> **对于 Ubuntu/Linux Mint/Debian:**
|
||||
|
||||
> sudo apt-get install docker
|
||||
|
||||
> **对于 Fedora/RHEL/CentOS:**
|
||||
|
||||
> sudo yum install docker
|
||||
|
||||
> **对于 Fedora 22:**
|
||||
|
||||
> dnf install docker
|
||||
|
||||
> 你可以运行下面的命令来启动docker:
|
||||
|
||||
> sudo docker start
|
||||
|
||||
首先运行下面的命令确保 Docker 服务运行正常:
|
||||
|
||||
sudo docker status
|
||||
|
||||
Kali Linux 的开发团队已将 Kali Linux 的 docker 镜像上传了,只需要输入下面的命令来下载镜像。
|
||||
|
||||
docker pull kalilinux/kali-linux-docker
|
||||
|
||||

|
||||
|
||||
下载完成后,运行下面的命令来找出你下载的 docker 镜像的 ID。
|
||||
|
||||
docker images
|
||||
|
||||

|
||||
|
||||
现在运行下面的命令来从镜像文件启动 kali linux docker 容器(这里需用正确的镜像ID替换)。
|
||||
|
||||
docker run -i -t 198cd6df71ab3 /bin/bash
|
||||
|
||||
它会立刻启动容器并且让你登录到该操作系统,你现在可以在 Kaili Linux 中工作了。
|
||||
|
||||

|
||||
|
||||
你可以在容器外面通过下面的命令来验证容器已经启动/运行中了:
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker 是一种最聪明的用来部署和分发包的方式。Kali Linux docker 镜像非常容易上手,也不会消耗很大的硬盘空间,这样也可以很容易地在任何安装了 docker 的操作系统上测试这个很棒的发行版了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/run-kali-linux-2-0-in-docker-container/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
[1]:https://linux.cn/article-6005-1.html
|
||||
@ -0,0 +1,160 @@
|
||||
Alien 魔法:RPM 和 DEB 互转
|
||||
================================================================================
|
||||
|
||||
正如我确信,你们一定知道Linux下的多种软件安装方式:使用发行版所提供的包管理系统([aptitude,yum,或者zypper][1],还可以举很多例子),从源码编译(尽管现在很少用了,但在Linux发展早期却是唯一可用的方法),或者使用各自的低级工具dpkg用于.deb,以及rpm用于.rpm,预编译包,如此这般。
|
||||
|
||||

|
||||
|
||||
*使用Alien将RPM转换成DEB以及将DEB转换成RPM*
|
||||
|
||||
在本文中,我们将为你介绍alien,一个用于在各种不同的Linux包格式相互转换的工具,其最常见的用法是将.rpm转换成.deb(或者反过来)。
|
||||
|
||||
如果你需要某个特定类型的包,而你只能找到其它格式的包的时候,该工具迟早能派得上用场——即使是其作者不再维护,并且在其网站声明:alien将可能永远维持在实验状态。
|
||||
|
||||
例如,有一次,我正查找一个用于喷墨打印机的.deb驱动,但是却没有找到——生产厂家只提供.rpm包,这时候alien拯救了我。我安装了alien,将包进行转换,不久之后我就可以使用我的打印机了,没有任何问题。
|
||||
|
||||
即便如此,我们也必须澄清一下,这个工具不应当用来转换重要的系统文件和库,因为它们在不同的发行版中有不同的配置。只有在前面说的那种情况下所建议的安装方法根本不适合时,alien才能作为最后手段使用。
|
||||
|
||||
最后一项要点是,我们必须注意,虽然我们在本文中使用CentOS和Debian,除了前两个发行版及其各自的家族体系外,据我们所知,alien可以工作在Slackware中,甚至Solaris中。
|
||||
|
||||
### 步骤1:安装Alien及其依赖包 ###
|
||||
|
||||
要安装alien到CentOS/RHEL 7中,你需要启用EPEL和Nux Dextop(是的,是Dextop——不是Desktop)仓库,顺序如下:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
启用Nux Dextop仓库的包的当前最新版本是0.5(2015年8月10日发布),在安装之前你可以查看[http://li.nux.ro/download/nux/dextop/el7/x86_64/][2]上是否有更新的版本。
|
||||
|
||||
# rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
|
||||
# rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm
|
||||
|
||||
然后再做,
|
||||
|
||||
# yum update && yum install alien
|
||||
|
||||
在Fedora中,你只需要运行上面的命令即可。
|
||||
|
||||
在Debian及其衍生版中,只需要:
|
||||
|
||||
# aptitude install alien
|
||||
|
||||
### 步骤2:将.deb转换成.rpm包 ###
|
||||
|
||||
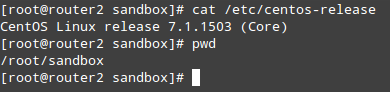
对于本次测试,我们选择了date工具,它提供了一系列日期和时间工具用于处理大量金融数据。我们将下载.deb包到我们的CentOS 7机器中,将它转换成.rpm并安装:
|
||||
|
||||
|
||||
|
||||
检查CentOS版本
|
||||
|
||||
# cat /etc/centos-release
|
||||
# wget http://ftp.us.debian.org/debian/pool/main/d/dateutils/dateutils_0.3.1-1.1_amd64.deb
|
||||
# alien --to-rpm --scripts dateutils_0.3.1-1.1_amd64.deb
|
||||
|
||||

|
||||
|
||||
*在Linux中将.deb转换成.rpm*
|
||||
|
||||
**重要**:(请注意alien是怎样来增加目标包的次版本号的。如果你想要无视该行为,请添加-keep-version标识)。
|
||||
|
||||
如果我们尝试马上安装该包,我们将碰到些许问题:
|
||||
|
||||
# rpm -Uvh dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
*安装RPM包*
|
||||
|
||||
要解决该问题,我们需要启用epel-testing仓库,然后安装rpmbuild工具来编辑该包的配置以重建包:
|
||||
|
||||
# yum --enablerepo=epel-testing install rpmrebuild
|
||||
|
||||
然后运行,
|
||||
|
||||
# rpmrebuild -pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||
它会打开你的默认文本编辑器。请转到`%files`章节并删除涉及到错误信息中提到的目录的行,然后保存文件并退出:
|
||||
|
||||
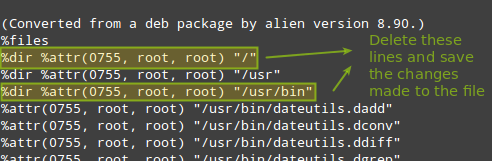
|
||||
|
||||
*转换.deb到Alien版*
|
||||
|
||||
但你退出该文件后,将提示你继续去重构。如果你选择“Y”,该文件会重构到指定的目录(与当前工作目录不同):
|
||||
|
||||
# rpmrebuild –pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
*构建RPM包*
|
||||
|
||||
现在你可以像以往一样继续来安装包并验证:
|
||||
|
||||
# rpm -Uvh /root/rpmbuild/RPMS/x86_64/dateutils-0.3.1-2.1.x86_64.rpm
|
||||
# rpm -qa | grep dateutils
|
||||
|
||||

|
||||
|
||||
*安装构建RPM包*
|
||||
|
||||
最后,你可以列出date工具包含的各个工具,也可以查看各自的手册页:
|
||||
|
||||
# ls -l /usr/bin | grep dateutils
|
||||
|
||||
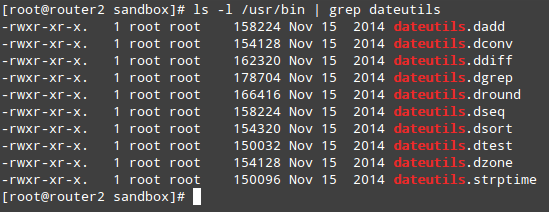
|
||||
|
||||
*验证安装的RPM包*
|
||||
|
||||
### 步骤3:将.rpm转换成.deb包 ###
|
||||
|
||||
在本节中,我们将演示如何将.rpm转换成.deb。在一台32位的Debian Wheezy机器中,让我们从CentOS 6操作系统仓库中下载用于zsh shell的.rpm包。注意,该shell在Debian及其衍生版的默认安装中是不可用的。
|
||||
|
||||
# cat /etc/shells
|
||||
# lsb_release -a | tail -n 4
|
||||
|
||||
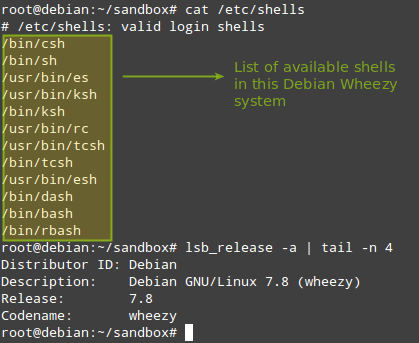
|
||||
|
||||
*检查Shell和Debian操作系统版本*
|
||||
|
||||
# wget http://mirror.centos.org/centos/6/os/i386/Packages/zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
# alien --to-deb --scripts zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
|
||||
你可以安全地无视关于签名丢失的信息:
|
||||
|
||||

|
||||
|
||||
*将.rpm转换成.deb包*
|
||||
|
||||
过了一会儿后,.deb包应该已经生成,并可以安装了:
|
||||
|
||||
# dpkg -i zsh_4.3.11-5_i386.deb
|
||||
|
||||

|
||||
|
||||
*安装RPM转换来的Deb包*
|
||||
|
||||
安装完后,你看看可以zsh是否添加到了合法shell列表中:
|
||||
|
||||
# cat /etc/shells
|
||||
|
||||
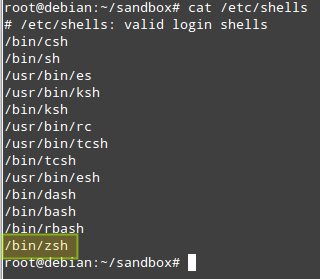
|
||||
|
||||
*确认安装的Zsh包*
|
||||
|
||||
### 小结 ###
|
||||
|
||||
在本文中,我们已经解释了如何将.rpm转换成.deb及其反向转换,这可以作为这类程序不能从仓库中或者作为可分发源代码获得的最后安装手段。你一定想要将本文添加到书签中,因为我们都需要alien。
|
||||
|
||||
请自由分享你关于本文的想法,写到下面的表单中吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/convert-from-rpm-to-deb-and-deb-to-rpm-package-using-alien/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-package-management/
|
||||
[2]:http://li.nux.ro/download/nux/dextop/el7/x86_64/
|
||||
@ -0,0 +1,169 @@
|
||||
Bash 下如何逐行读取一个文件
|
||||
================================================================================
|
||||
|
||||
在 Linux 或类 UNIX 系统下如何使用 KSH 或 BASH shell 逐行读取一个文件?
|
||||
|
||||
在 Linux、OSX、 *BSD 或者类 Unix 系统下你可以使用 while..do..done 的 bash 循环来逐行读取一个文件。
|
||||
|
||||
###在 Bash Unix 或者 Linux shell 中逐行读取一个文件的语法
|
||||
|
||||
对于 bash、ksh、 zsh 和其他的 shells 语法如下
|
||||
|
||||
while read -r line; do COMMAND; done < input.file
|
||||
|
||||
通过 -r 选项传递给 read 命令以防止阻止解释其中的反斜杠转义符。
|
||||
|
||||
在 read 命令之前添加 `IFS=` 选项,来防止首尾的空白字符被去掉。
|
||||
|
||||
while IFS= read -r line; do COMMAND_on $line; done < input.file
|
||||
|
||||
这是更适合人类阅读的语法:
|
||||
|
||||
#!/bin/bash
|
||||
input="/path/to/txt/file"
|
||||
while IFS= read -r var
|
||||
do
|
||||
echo "$var"
|
||||
done < "$input"
|
||||
|
||||
**示例**
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
#!/bin/ksh
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
echo "$line"
|
||||
done <"$file"
|
||||
|
||||
在 bash shell 中相同的例子:
|
||||
|
||||
#!/bin/bash
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read -r line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
printf '%s\n' "$line"
|
||||
done <"$file"
|
||||
|
||||
你还可以看看这个更好的:
|
||||
|
||||
#!/bin/bash
|
||||
file="/etc/passwd"
|
||||
while IFS=: read -r f1 f2 f3 f4 f5 f6 f7
|
||||
do
|
||||
# display fields using f1, f2,..,f7
|
||||
printf 'Username: %s, Shell: %s, Home Dir: %s\n' "$f1" "$f7" "$f6"
|
||||
done <"$file"
|
||||
|
||||
示例输出:
|
||||
|
||||
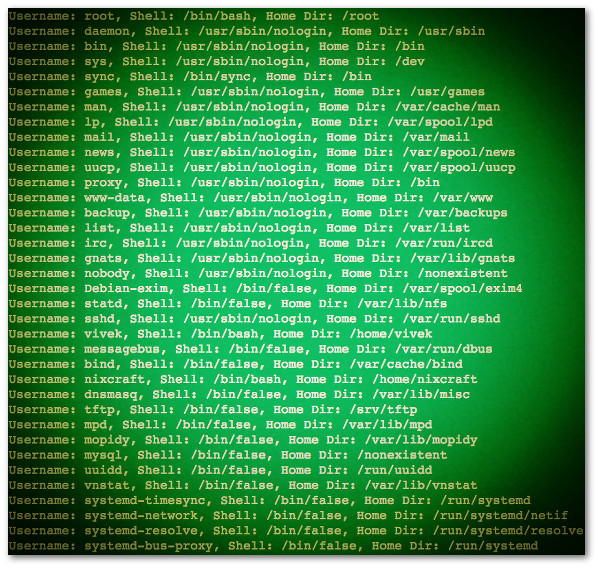
|
||||
|
||||
*图01:Bash 脚本:读取文件并逐行输出文件*
|
||||
|
||||
###Bash 脚本:逐行读取文本文件并创建为 pdf 文件
|
||||
|
||||
我的输入文件如下(faq.txt):
|
||||
|
||||
4|http://www.cyberciti.biz/faq/mysql-user-creation/|Mysql User Creation: Setting Up a New MySQL User Account
|
||||
4096|http://www.cyberciti.biz/faq/ksh-korn-shell/|What is UNIX / Linux Korn Shell?
|
||||
4101|http://www.cyberciti.biz/faq/what-is-posix-shell/|What Is POSIX Shell?
|
||||
17267|http://www.cyberciti.biz/faq/linux-check-battery-status/|Linux: Check Battery Status Command
|
||||
17245|http://www.cyberciti.biz/faq/restarting-ntp-service-on-linux/|Linux Restart NTPD Service Command
|
||||
17183|http://www.cyberciti.biz/faq/ubuntu-linux-determine-your-ip-address/|Ubuntu Linux: Determine Your IP Address
|
||||
17172|http://www.cyberciti.biz/faq/determine-ip-address-of-linux-server/|HowTo: Determine an IP Address My Linux Server
|
||||
16510|http://www.cyberciti.biz/faq/unix-linux-restart-php-service-command/|Linux / Unix: Restart PHP Service Command
|
||||
8292|http://www.cyberciti.biz/faq/mounting-harddisks-in-freebsd-with-mount-command/|FreeBSD: Mount Hard Drive / Disk Command
|
||||
8190|http://www.cyberciti.biz/faq/rebooting-solaris-unix-server/|Reboot a Solaris UNIX System
|
||||
|
||||
我的 bash 脚本:
|
||||
|
||||
#!/bin/bash
|
||||
# Usage: Create pdf files from input (wrapper script)
|
||||
# Author: Vivek Gite <Www.cyberciti.biz> under GPL v2.x+
|
||||
#---------------------------------------------------------
|
||||
|
||||
#Input file
|
||||
_db="/tmp/wordpress/faq.txt"
|
||||
|
||||
#Output location
|
||||
o="/var/www/prviate/pdf/faq"
|
||||
|
||||
_writer="~/bin/py/pdfwriter.py"
|
||||
|
||||
# If file exists
|
||||
if [[ -f "$_db" ]]
|
||||
then
|
||||
# read it
|
||||
while IFS='|' read -r pdfid pdfurl pdftitle
|
||||
do
|
||||
local pdf="$o/$pdfid.pdf"
|
||||
echo "Creating $pdf file ..."
|
||||
#Genrate pdf file
|
||||
$_writer --quiet --footer-spacing 2 \
|
||||
--footer-left "nixCraft is GIT UL++++ W+++ C++++ M+ e+++ d-" \
|
||||
--footer-right "Page [page] of [toPage]" --footer-line \
|
||||
--footer-font-size 7 --print-media-type "$pdfurl" "$pdf"
|
||||
done <"$_db"
|
||||
fi
|
||||
|
||||
###技巧:从 bash 变量中读取
|
||||
|
||||
让我们看看如何在 Debian 或者 Ubuntu Linux 下列出所有安装过的 php 包,请输入:
|
||||
|
||||
# 我将输出内容赋值到一个变量名为 $list中 #
|
||||
|
||||
list=$(dpkg --list php\* | awk '/ii/{print $2}')
|
||||
printf '%s\n' "$list"
|
||||
|
||||
示例输出:
|
||||
|
||||
php-pear
|
||||
php5-cli
|
||||
php5-common
|
||||
php5-fpm
|
||||
php5-gd
|
||||
php5-json
|
||||
php5-memcache
|
||||
php5-mysql
|
||||
php5-readline
|
||||
php5-suhosin-extension
|
||||
|
||||
你现在可以从 $list 中看到它们,并安装这些包:
|
||||
|
||||
#!/bin/bash
|
||||
# BASH can iterate over $list variable using a "here string" #
|
||||
while IFS= read -r pkg
|
||||
do
|
||||
printf 'Installing php package %s...\n' "$pkg"
|
||||
/usr/bin/apt-get -qq install $pkg
|
||||
done <<< "$list"
|
||||
printf '*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***\n'
|
||||
|
||||
示例输出:
|
||||
|
||||
Installing php package php-pear...
|
||||
Installing php package php5-cli...
|
||||
Installing php package php5-common...
|
||||
Installing php package php5-fpm...
|
||||
Installing php package php5-gd...
|
||||
Installing php package php5-json...
|
||||
Installing php package php5-memcache...
|
||||
Installing php package php5-mysql...
|
||||
Installing php package php5-readline...
|
||||
Installing php package php5-suhosin-extension...
|
||||
|
||||
*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/unix-howto-read-line-by-line-from-file/
|
||||
|
||||
作者: VIVEK GIT
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,24 +1,25 @@
|
||||
使用dd命令在Linux和Unix环境下进行硬盘I/O性能检测
|
||||
使用 dd 命令进行硬盘 I/O 性能检测
|
||||
================================================================================
|
||||
如何使用dd命令测试硬盘的性能?如何在linux操作系统下检测硬盘的读写能力?
|
||||
|
||||
如何使用dd命令测试我的硬盘性能?如何在linux操作系统下检测硬盘的读写速度?
|
||||
|
||||
你可以使用以下命令在一个Linux或类Unix操作系统上进行简单的I/O性能测试。
|
||||
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它被用来获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它用来在基于 Linux 的系统上获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
|
||||
在这篇指南中,你将会学到如何使用dd命令来测试硬盘性能。
|
||||
|
||||
### 使用dd命令来监控硬盘的读写性能:###
|
||||
|
||||
- 打开shell终端(这里貌似不能翻译为终端提示符)。
|
||||
- 通过ssh登录到远程服务器。
|
||||
- 打开shell终端。
|
||||
- 或者通过ssh登录到远程服务器。
|
||||
- 使用dd命令来测量服务器的吞吐率(写速度) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- 使用dd命令测量服务器延迟 `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
####理解dd命令的选项###
|
||||
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd语法 ##
|
||||
@ -29,18 +30,19 @@
|
||||
输出样例:
|
||||
|
||||

|
||||
Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
|
||||
*图01: 使用dd命令获取的服务器吞吐率*
|
||||
|
||||
请各位注意在这个实验中,我们写入一个G的数据,可以发现,服务器的吞吐率是135 MB/s,这其中
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` :dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G (bs=block-size)` :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1 (count=number-of-blocks)`: dd命令读取的块的个数。
|
||||
- `oflag=dsync (oflag=dsync)` :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `if=/dev/zero` (if=/dev/input.file) :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img` (of=/path/to/output.file):dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G` (bs=block-size) :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1` (count=number-of-blocks):dd命令读取的块的个数。
|
||||
- `oflag=dsync` (oflag=dsync) :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `conv=fdatasyn`: 这个选项和`oflag=dsync`含义一样。
|
||||
|
||||
在这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
在下面这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
@ -50,11 +52,11 @@ Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的加载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的负载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
|
||||
####为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
###为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是HARDWARE RAID10的控制器缓存导致的。
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是硬件 RAID10的控制器缓存导致的。
|
||||
|
||||
使用hdparm命令来查看硬盘缓存的读速度。
|
||||
|
||||
@ -79,11 +81,12 @@ Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
输出样例:
|
||||
|
||||
|
||||
Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
|
||||
请再一次注意由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
*图02: 检测硬盘读入以及缓存性能的Linux hdparm命令*
|
||||
|
||||
**使用dd命令来测试读入速度**
|
||||
请再次注意,由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
|
||||
###使用dd命令来测试读取速度###
|
||||
|
||||
为了获得精确的读测试数据,首先在测试前运行下列命令,来将缓存设置为无效:
|
||||
|
||||
@ -91,11 +94,11 @@ Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**笔记本上的示例**
|
||||
####笔记本上的示例####
|
||||
|
||||
运行下列命令:
|
||||
|
||||
### Cache存在的Debian系统笔记本吞吐率###
|
||||
### 带有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
###使cache失效###
|
||||
@ -104,10 +107,11 @@ Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
###没有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**苹果OS X Unix(Macbook pro)的例子**
|
||||
####苹果OS X Unix(Macbook pro)的例子####
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
GNU dd命令有其他许多选项,但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
## 运行这个命令2-3次来获得更好地结果 ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
@ -124,26 +128,29 @@ GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令
|
||||
|
||||
本人Macbook Pro的写速度是635346520字节(635.347MB/s)。
|
||||
|
||||
**不喜欢用命令行?^_^**
|
||||
###不喜欢用命令行?\^_^###
|
||||
|
||||
你可以在Linux或基于Unix的系统上使用disk utility(gnome-disk-utility)这款工具来得到同样的信息。下面的那个图就是在我的Fedora Linux v22 VM上截取的。
|
||||
|
||||
**图形化方法**
|
||||
####图形化方法####
|
||||
|
||||
点击“Activites”或者“Super”按键来在桌面和Activites视图间切换。输入“Disks”
|
||||
|
||||
|
||||
Fig.03: 打开Gnome硬盘工具
|
||||
|
||||
*图03: 打开Gnome硬盘工具*
|
||||
|
||||
在左边的面板上选择你的硬盘,点击configure按钮,然后点击“Benchmark partition”:
|
||||
|
||||
|
||||
Fig.04: 评测硬盘/分区
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能被要求输入管理员用户名和密码):
|
||||
*图04: 评测硬盘/分区*
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能需要输入管理员用户名和密码):
|
||||
|
||||
|
||||
Fig.05: 最终的评测结果
|
||||
|
||||
*图05: 最终的评测结果*
|
||||
|
||||
如果你要问,我推荐使用哪种命令和方法?
|
||||
|
||||
@ -158,7 +165,7 @@ via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,89 +1,90 @@
|
||||
|
||||
在 Linux 中创建 RAID 5(条带化与分布式奇偶校验) - 第4部分
|
||||
在 Linux 下使用 RAID(四):创建 RAID 5(条带化与分布式奇偶校验)
|
||||
================================================================================
|
||||
在 RAID 5 中,条带化数据跨多个驱磁盘使用分布式奇偶校验。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带中的数据分布在多个磁盘上,它将有很好的数据冗余。
|
||||
|
||||
在 RAID 5 中,数据条带化后存储在分布式奇偶校验的多个磁盘上。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带化数据分布在多个磁盘上,这样会有很好的数据冗余。
|
||||
|
||||

|
||||
|
||||
在 Linux 中配置 RAID 5
|
||||
*在 Linux 中配置 RAID 5*
|
||||
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中花费更多的成本来提供更好的数据冗余性能。
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中,以花费更多的成本来提供更好的数据冗余性能。
|
||||
|
||||
#### 什么是奇偶校验? ####
|
||||
|
||||
奇偶校验是在数据存储中检测错误最简单的一个方法。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中一个磁盘空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
奇偶校验是在数据存储中检测错误最简单的常见方式。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中相当于一个磁盘大小的空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
|
||||
#### RAID 5 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能
|
||||
- 提供更好的性能。
|
||||
- 支持冗余和容错。
|
||||
- 支持热备份。
|
||||
- 将失去一个磁盘的容量存储奇偶校验信息。
|
||||
- 将用掉一个磁盘的容量存储奇偶校验信息。
|
||||
- 单个磁盘发生故障后不会丢失数据。我们可以更换故障硬盘后从奇偶校验信息中重建数据。
|
||||
- 事务处理读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作将是缓慢的。
|
||||
- 适合于面向事务处理的环境,读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作会慢一些。
|
||||
- 重建需要很长的时间。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 5 最少需要3个磁盘,你也可以添加更多的磁盘,前提是你要有多端口的专用硬件 RAID 控制器。在这里,我们使用“mdadm”包来创建软件 RAID。
|
||||
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下 RAID 没有可用的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件中,例如:mdadm.conf。
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下没有 RAID 的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件 mdadm.conf 中。
|
||||
|
||||
在进一步学习之前,我建议你通过下面的文章去了解 Linux 中 RAID 的基础知识。
|
||||
|
||||
- [Basic Concepts of RAID in Linux – Part 1][1]
|
||||
- [Creating RAID 0 (Stripe) in Linux – Part 2][2]
|
||||
- [Setting up RAID 1 (Mirroring) in Linux – Part 3][3]
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.227
|
||||
Hostname : rd5.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.227
|
||||
主机名 : rd5.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
|
||||
这篇文章是 RAID 系列9教程的第4部分,在这里我们要建立一个软件 RAID 5(分布式奇偶校验)使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘在 Linux 系统或服务器中上。
|
||||
这是9篇系列教程的第4部分,在这里我们要在 Linux 系统或服务器上使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘建立带有分布式奇偶校验的软件 RAID 5。
|
||||
|
||||
### 第1步:安装 mdadm 并检验磁盘 ###
|
||||
|
||||
1.正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
1、 正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
|
||||
# lsb_release -a
|
||||
# ifconfig | grep inet
|
||||
|
||||

|
||||
|
||||
CentOS 6.5 摘要
|
||||
*CentOS 6.5 摘要*
|
||||
|
||||
2. 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
2、 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
3. “mdadm”包安装后,先使用‘fdisk‘命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
3、 “mdadm”包安装后,先使用`fdisk`命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
|
||||
|
||||
安装 mdadm 工具
|
||||
*安装 mdadm 工具*
|
||||
|
||||
4. 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
4、 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
|
||||
# mdadm -E /dev/sd[b-d]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd # 或
|
||||
|
||||
|
||||
|
||||
检查 Raid 磁盘
|
||||
*检查 Raid 磁盘*
|
||||
|
||||
**注意**: 上面的图片说明,没有检测到任何超级块。所以,这三个磁盘中没有定义 RAID。让我们现在开始创建一个吧!
|
||||
|
||||
### 第2步:为磁盘创建 RAID 分区 ###
|
||||
|
||||
5. 首先,在创建 RAID 前我们要为磁盘分区(/dev/sdb, /dev/sdc 和 /dev/sdd),在进行下一步之前,先使用‘fdisk’命令进行分区。
|
||||
5、 首先,在创建 RAID 前磁盘(/dev/sdb, /dev/sdc 和 /dev/sdd)必须有分区,因此,在进行下一步之前,先使用`fdisk`命令进行分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
@ -93,20 +94,20 @@ CentOS 6.5 摘要
|
||||
|
||||
请按照下面的说明在 /dev/sdb 硬盘上创建分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1.
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1。
|
||||
- 这里是选择柱面大小,我们没必要选择指定的大小,因为我们需要为 RAID 使用整个分区,所以只需按两次 Enter 键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 改变分区类型,按 ‘L’可以列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 这里使用‘fd’设置为 RAID 的类型。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 改变分区类型,按 `L`可以列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 这里使用`fd`设置为 RAID 的类型。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建 sdb 分区
|
||||
*创建 sdb 分区*
|
||||
|
||||
**注意**: 我们仍要按照上面的步骤来创建 sdc 和 sdd 的分区。
|
||||
|
||||
@ -118,7 +119,7 @@ CentOS 6.5 摘要
|
||||
|
||||

|
||||
|
||||
创建 sdc 分区
|
||||
*创建 sdc 分区*
|
||||
|
||||
#### 创建 /dev/sdd 分区 ####
|
||||
|
||||
@ -126,93 +127,87 @@ CentOS 6.5 摘要
|
||||
|
||||

|
||||
|
||||
创建 sdd 分区
|
||||
*创建 sdd 分区*
|
||||
|
||||
6. 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
6、 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
or
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
# mdadm -E /dev/sd[b-c] # 或
|
||||
|
||||
|
||||
|
||||
检查磁盘变化
|
||||
*检查磁盘变化*
|
||||
|
||||
**注意**: 在上面的图片中,磁盘的类型是 fd。
|
||||
|
||||
7.现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,创建一个新的 RAID 5 的设置在这些磁盘中。
|
||||
7、 现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,在这些磁盘中创建一个新的 RAID 5 配置。
|
||||
|
||||
|
||||
|
||||
在分区中检查 Raid
|
||||
*在分区中检查 RAID *
|
||||
|
||||
### 第3步:创建 md 设备 md0 ###
|
||||
|
||||
8. 现在创建一个 RAID 设备“md0”(即 /dev/md0)使用所有新创建的分区(sdb1, sdc1 and sdd1) ,使用以下命令。
|
||||
8、 现在使用所有新创建的分区(sdb1, sdc1 和 sdd1)创建一个 RAID 设备“md0”(即 /dev/md0),使用以下命令。
|
||||
|
||||
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
|
||||
or
|
||||
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1 # 或
|
||||
|
||||
9. 创建 RAID 设备后,检查并确认 RAID,包括设备和从 mdstat 中输出的 RAID 级别。
|
||||
9、 创建 RAID 设备后,检查并确认 RAID,从 mdstat 中输出中可以看到包括的设备的 RAID 级别。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
*验证 Raid 设备*
|
||||
|
||||
如果你想监视当前的创建过程,你可以使用‘watch‘命令,使用 watch ‘cat /proc/mdstat‘,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
如果你想监视当前的创建过程,你可以使用`watch`命令,将 `cat /proc/mdstat` 传递给它,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||
|
||||
|
||||
监控 Raid 5 过程
|
||||
*监控 RAID 5 构建过程*
|
||||
|
||||

|
||||
|
||||
Raid 5 过程概要
|
||||
*Raid 5 过程概要*
|
||||
|
||||
10. 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
10、 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
|
||||
# mdadm -E /dev/sd[b-d]1
|
||||
|
||||

|
||||
|
||||
验证 Raid 级别
|
||||
*验证 Raid 级别*
|
||||
|
||||
**注意**: 因为它显示三个磁盘的信息,上述命令的输出会有点长。
|
||||
|
||||
11. 接下来,验证 RAID 阵列的假设,这包含正在运行 RAID 的设备,并开始重新同步。
|
||||
11、 接下来,验证 RAID 阵列,假定包含 RAID 的设备正在运行并已经开始了重新同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 阵列
|
||||
*验证 RAID 阵列*
|
||||
|
||||
### 第4步:为 md0 创建文件系统###
|
||||
|
||||
12. 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
12、 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 md0 文件系统
|
||||
*创建 md0 文件系统*
|
||||
|
||||
13.现在,在‘/mnt‘下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下并检查下挂载点的文件,你会看到 lost+found 目录。
|
||||
13、 现在,在`/mnt`下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下,并检查挂载点下的文件,你会看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid5
|
||||
# mount /dev/md0 /mnt/raid5/
|
||||
# ls -l /mnt/raid5/
|
||||
|
||||
14. 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
14、 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
|
||||
# touch /mnt/raid5/raid5_tecmint_{1..5}
|
||||
# ls -l /mnt/raid5/
|
||||
@ -222,9 +217,9 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
挂载 Raid 设备
|
||||
*挂载 RAID 设备*
|
||||
|
||||
15. 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。然后编辑 fstab 文件添加条目,在文件尾追加以下行,如下图所示。挂载点会根据你环境的不同而不同。
|
||||
15、 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。编辑 fstab 文件添加条目,在文件尾追加以下行。挂载点会根据你环境的不同而不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
@ -232,19 +227,19 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 5
|
||||
*自动挂载 RAID 5*
|
||||
|
||||
16. 接下来,运行‘mount -av‘命令检查 fstab 条目中是否有错误。
|
||||
16、 接下来,运行`mount -av`命令检查 fstab 条目中是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
|
||||
|
||||
检查 Fstab 错误
|
||||
*检查 Fstab 错误*
|
||||
|
||||
### 第5步:保存 Raid 5 的配置 ###
|
||||
|
||||
17. 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步不跟 RAID 设备将不会存在 md0,它将会跟一些其他数子。
|
||||
17、 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步中没有跟随不属于 md0 的 RAID 设备,它会是一些其他随机数字。
|
||||
|
||||
所以,我们必须要在系统重新启动之前保存配置。如果配置保存它在系统重新启动时会被加载到内核中然后 RAID 也将被加载。
|
||||
|
||||
@ -252,17 +247,17 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
保存 Raid 5 配置
|
||||
*保存 RAID 5 配置*
|
||||
|
||||
注意:保存配置将保持 RAID 级别的稳定性在 md0 设备中。
|
||||
注意:保存配置将保持 md0 设备的 RAID 级别稳定不变。
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
18.备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会主动添加并重建进程,并从其他磁盘上同步数据,所以我们可以在这里看到冗余。
|
||||
18、 备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会进入激活重建过程,并从其他磁盘上同步数据,这样就有了冗余。
|
||||
|
||||
更多关于添加备用磁盘和检查 RAID 5 容错的指令,请阅读下面文章中的第6步和第7步。
|
||||
|
||||
- [Add Spare Drive to Raid 5 Setup][4]
|
||||
- [在 RAID 5 中添加备用磁盘][4]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
@ -274,12 +269,12 @@ via: http://www.tecmint.com/create-raid-5-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:http://www.tecmint.com/create-raid-6-in-linux/
|
||||
@ -1,77 +1,78 @@
|
||||
|
||||
在 Linux 中安装 RAID 6(条带化双分布式奇偶校验) - 第5部分
|
||||
在 Linux 下使用 RAID(五):安装 RAID 6(条带化双分布式奇偶校验)
|
||||
================================================================================
|
||||
RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两个磁盘发生故障后依然有容错能力。两并列的磁盘发生故障时,系统的关键任务仍然能运行。它与 RAID 5 相似,但性能更健壮,因为它多用了一个磁盘来进行奇偶校验。
|
||||
|
||||
在之前的文章中,我们已经在 RAID 5 看了分布式奇偶校验,但在本文中,我们将看到的是 RAID 6 双分布式奇偶校验。不要期望比其他 RAID 有额外的性能,我们仍然需要安装一个专用的 RAID 控制器。在 RAID 6 中,即使我们失去了2个磁盘,我们仍可以取回数据通过更换磁盘,然后从校验中构建数据。
|
||||
RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即使两个磁盘发生故障后依然有容错能力。在两个磁盘同时发生故障时,系统的关键任务仍然能运行。它与 RAID 5 相似,但性能更健壮,因为它多用了一个磁盘来进行奇偶校验。
|
||||
|
||||
在之前的文章中,我们已经在 RAID 5 看了分布式奇偶校验,但在本文中,我们将看到的是 RAID 6 双分布式奇偶校验。不要期望比其他 RAID 有更好的性能,除非你也安装了一个专用的 RAID 控制器。在 RAID 6 中,即使我们失去了2个磁盘,我们仍可以通过更换磁盘,从校验中构建数据,然后取回数据。
|
||||
|
||||
|
||||
|
||||
在 Linux 中安装 RAID 6
|
||||
*在 Linux 中安装 RAID 6*
|
||||
|
||||
要建立一个 RAID 6,一组最少需要4个磁盘。RAID 6 甚至在有些设定中会有多组磁盘,当读取数据时,它会同时从所有磁盘读取,所以读取速度会更快,当写数据时,因为它要将数据写在条带化的多个磁盘上,所以性能会较差。
|
||||
要建立一个 RAID 6,一组最少需要4个磁盘。RAID 6 甚至在有些组中会有更多磁盘,这样将多个硬盘捆在一起,当读取数据时,它会同时从所有磁盘读取,所以读取速度会更快,当写数据时,因为它要将数据写在条带化的多个磁盘上,所以性能会较差。
|
||||
|
||||
现在,很多人都在讨论为什么我们需要使用 RAID 6,它的性能和其他 RAID 相比并不太好。提出这个问题首先需要知道的是,如果需要高容错的必须选择 RAID 6。在每一个对数据库的高可用性要求较高的环境中,他们需要 RAID 6 因为数据库是最重要,无论花费多少都需要保护其安全,它在视频流环境中也是非常有用的。
|
||||
现在,很多人都在讨论为什么我们需要使用 RAID 6,它的性能和其他 RAID 相比并不太好。提出这个问题首先需要知道的是,如果需要高容错性就选择 RAID 6。在每一个用于数据库的高可用性要求较高的环境中,他们需要 RAID 6 因为数据库是最重要,无论花费多少都需要保护其安全,它在视频流环境中也是非常有用的。
|
||||
|
||||
#### RAID 6 的的优点和缺点 ####
|
||||
|
||||
- 性能很不错。
|
||||
- RAID 6 非常昂贵,因为它要求两个独立的磁盘用于奇偶校验功能。
|
||||
- 性能不错。
|
||||
- RAID 6 比较昂贵,因为它要求两个独立的磁盘用于奇偶校验功能。
|
||||
- 将失去两个磁盘的容量来保存奇偶校验信息(双奇偶校验)。
|
||||
- 不存在数据丢失,即时两个磁盘损坏。我们可以在更换损坏的磁盘后从校验中重建数据。
|
||||
- 即使两个磁盘损坏,数据也不会丢失。我们可以在更换损坏的磁盘后从校验中重建数据。
|
||||
- 读性能比 RAID 5 更好,因为它从多个磁盘读取,但对于没有专用的 RAID 控制器的设备写性能将非常差。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
要创建一个 RAID 6 最少需要4个磁盘.你也可以添加更多的磁盘,但你必须有专用的 RAID 控制器。在软件 RAID 中,我们在 RAID 6 中不会得到更好的性能,所以我们需要一个物理 RAID 控制器。
|
||||
要创建一个 RAID 6 最少需要4个磁盘。你也可以添加更多的磁盘,但你必须有专用的 RAID 控制器。使用软件 RAID 我们在 RAID 6 中不会得到更好的性能,所以我们需要一个物理 RAID 控制器。
|
||||
|
||||
这些是新建一个 RAID 需要的设置,我们建议先看完以下 RAID 文章。
|
||||
如果你新接触 RAID 设置,我们建议先看完以下 RAID 文章。
|
||||
|
||||
- [Linux 中 RAID 的基本概念 – 第一部分][1]
|
||||
- [在 Linux 上创建软件 RAID 0 (条带化) – 第二部分][2]
|
||||
- [在 Linux 上创建软件 RAID 1 (镜像) – 第三部分][3]
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
- [创建 RAID 5(条带化与分布式奇偶校验)](4)
|
||||
|
||||
#### My Server Setup ####
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.228
|
||||
Hostname : rd6.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
Disk 4 [20GB] : /dev/sde
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.228
|
||||
主机名 : rd6.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
这篇文章是9系列 RAID 教程的第5部分,在这里我们将看到我们如何在 Linux 系统或者服务器上创建和设置软件 RAID 6 或条带化双分布式奇偶校验,使用四个 20GB 的磁盘 /dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde.
|
||||
这是9篇系列教程的第5部分,在这里我们将看到如何在 Linux 系统或者服务器上使用四个 20GB 的磁盘(名为 /dev/sdb、 /dev/sdc、 /dev/sdd 和 /dev/sde)创建和设置软件 RAID 6 (条带化双分布式奇偶校验)。
|
||||
|
||||
### 第1步:安装 mdadm 工具,并检查磁盘 ###
|
||||
|
||||
1.如果你按照我们最进的两篇 RAID 文章(第2篇和第3篇),我们已经展示了如何安装‘mdadm‘工具。如果你直接看的这篇文章,我们先来解释下在Linux系统中如何使用‘mdadm‘工具来创建和管理 RAID,首先根据你的 Linux 发行版使用以下命令来安装。
|
||||
1、 如果你按照我们最进的两篇 RAID 文章(第2篇和第3篇),我们已经展示了如何安装`mdadm`工具。如果你直接看的这篇文章,我们先来解释下在 Linux 系统中如何使用`mdadm`工具来创建和管理 RAID,首先根据你的 Linux 发行版使用以下命令来安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
2.安装该工具后,然后来验证需要的四个磁盘,我们将会使用下面的‘fdisk‘命令来检验用于创建 RAID 的磁盘。
|
||||
2、 安装该工具后,然后来验证所需的四个磁盘,我们将会使用下面的`fdisk`命令来检查用于创建 RAID 的磁盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
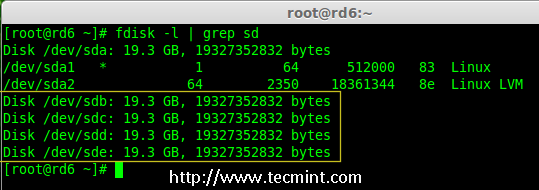
|
||||
|
||||
在 Linux 中检查磁盘
|
||||
*在 Linux 中检查磁盘*
|
||||
|
||||
3.在创建 RAID 磁盘前,先检查下我们的磁盘是否创建过 RAID 分区。
|
||||
3、 在创建 RAID 磁盘前,先检查下我们的磁盘是否创建过 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
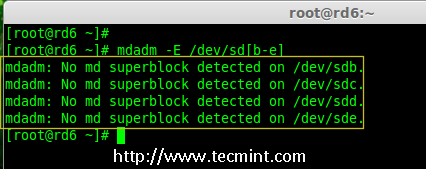
|
||||
|
||||
在磁盘上检查 Raid 分区
|
||||
*在磁盘上检查 RAID 分区*
|
||||
|
||||
**注意**: 在上面的图片中,没有检测到任何 super-block 或者说在四个磁盘上没有 RAID 存在。现在我们开始创建 RAID 6。
|
||||
|
||||
### 第2步:为 RAID 6 创建磁盘分区 ###
|
||||
|
||||
4.现在为 raid 创建分区‘/dev/sdb‘, ‘/dev/sdc‘, ‘/dev/sdd‘ 和 ‘/dev/sde‘使用下面 fdisk 命令。在这里,我们将展示如何创建分区在 sdb 磁盘,同样的步骤也适用于其他分区。
|
||||
4、 现在在 `/dev/sdb`, `/dev/sdc`, `/dev/sdd` 和 `/dev/sde`上为 RAID 创建分区,使用下面的 fdisk 命令。在这里,我们将展示如何在 sdb 磁盘创建分区,同样的步骤也适用于其他分区。
|
||||
|
||||
**创建 /dev/sdb 分区**
|
||||
|
||||
@ -79,20 +80,20 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
请按照说明进行操作,如下图所示创建分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 按 `n`创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 去修改分区。
|
||||
- 键入 ‘fd’ 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建 /dev/sdb 分区
|
||||
*创建 /dev/sdb 分区*
|
||||
|
||||
**创建 /dev/sdc 分区**
|
||||
|
||||
@ -100,7 +101,7 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
创建 /dev/sdc 分区
|
||||
*创建 /dev/sdc 分区*
|
||||
|
||||
**创建 /dev/sdd 分区**
|
||||
|
||||
@ -108,7 +109,7 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
创建 /dev/sdd 分区
|
||||
*创建 /dev/sdd 分区*
|
||||
|
||||
**创建 /dev/sde 分区**
|
||||
|
||||
@ -116,71 +117,67 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
创建 /dev/sde 分区
|
||||
*创建 /dev/sde 分区*
|
||||
|
||||
5.创建好分区后,检查磁盘的 super-blocks 是个好的习惯。如果 super-blocks 不存在我们可以按前面的创建一个新的 RAID。
|
||||
5、 创建好分区后,检查磁盘的 super-blocks 是个好的习惯。如果 super-blocks 不存在我们可以按前面的创建一个新的 RAID。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
|
||||
或者
|
||||
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
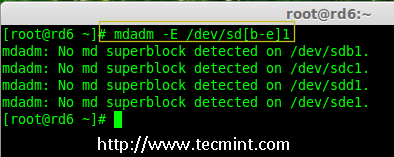
|
||||
|
||||
在新分区中检查 Raid
|
||||
*在新分区中检查 RAID *
|
||||
|
||||
### 步骤3:创建 md 设备(RAID) ###
|
||||
|
||||
6,现在是时候来创建 RAID 设备‘md0‘ (即 /dev/md0)并应用 RAID 级别在所有新创建的分区中,确认 raid 使用以下命令。
|
||||
6、 现在可以使用以下命令创建 RAID 设备`md0` (即 /dev/md0),并在所有新创建的分区中应用 RAID 级别,然后确认 RAID 设置。
|
||||
|
||||
# mdadm --create /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建 Raid 6 设备
|
||||
*创建 Raid 6 设备*
|
||||
|
||||
7.你还可以使用 watch 命令来查看当前 raid 的进程,如下图所示。
|
||||
7、 你还可以使用 watch 命令来查看当前创建 RAID 的进程,如下图所示。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
检查 Raid 6 进程
|
||||
*检查 RAID 6 创建过程*
|
||||
|
||||
8.使用以下命令验证 RAID 设备。
|
||||
8、 使用以下命令验证 RAID 设备。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
**注意**::上述命令将显示四个磁盘的信息,这是相当长的,所以没有截取其完整的输出。
|
||||
|
||||
9.接下来,验证 RAID 阵列,以确认 re-syncing 被启动。
|
||||
9、 接下来,验证 RAID 阵列,以确认重新同步过程已经开始。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 Raid 6 阵列
|
||||
*检查 Raid 6 阵列*
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
10.使用 ext4 为‘/dev/md0‘创建一个文件系统并将它挂载在 /mnt/raid5 。这里我们使用的是 ext4,但你可以根据你的选择使用任意类型的文件系统。
|
||||
10、 使用 ext4 为`/dev/md0`创建一个文件系统,并将它挂载在 /mnt/raid6 。这里我们使用的是 ext4,但你可以根据你的选择使用任意类型的文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
在 Raid 6 上创建文件系统
|
||||
*在 RAID 6 上创建文件系统*
|
||||
|
||||
11.挂载创建的文件系统到 /mnt/raid6,并验证挂载点下的文件,我们可以看到 lost+found 目录。
|
||||
11、 将创建的文件系统挂载到 /mnt/raid6,并验证挂载点下的文件,我们可以看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid6
|
||||
# mount /dev/md0 /mnt/raid6/
|
||||
# ls -l /mnt/raid6/
|
||||
|
||||
12.在挂载点下创建一些文件,在任意文件中添加一些文字并验证其内容。
|
||||
12、 在挂载点下创建一些文件,在任意文件中添加一些文字并验证其内容。
|
||||
|
||||
# touch /mnt/raid6/raid6_test.txt
|
||||
# ls -l /mnt/raid6/
|
||||
@ -189,9 +186,9 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
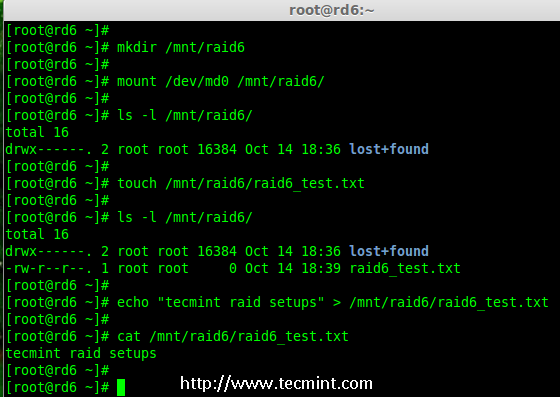
|
||||
|
||||
验证 Raid 内容
|
||||
*验证 RAID 内容*
|
||||
|
||||
13.在 /etc/fstab 中添加以下条目使系统启动时自动挂载设备,环境不同挂载点可能会有所不同。
|
||||
13、 在 /etc/fstab 中添加以下条目使系统启动时自动挂载设备,操作系统环境不同挂载点可能会有所不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
@ -199,36 +196,37 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 6 设备
|
||||
*自动挂载 RAID 6 设备*
|
||||
|
||||
14.接下来,执行‘mount -a‘命令来验证 fstab 中的条目是否有错误。
|
||||
14、 接下来,执行`mount -a`命令来验证 fstab 中的条目是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
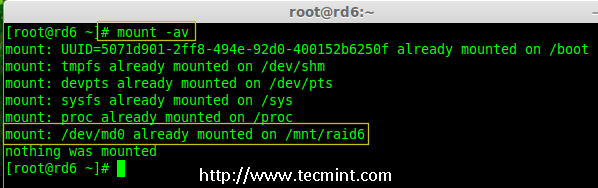
|
||||
|
||||
验证 Raid 是否自动挂载
|
||||
*验证 RAID 是否自动挂载*
|
||||
|
||||
### 第5步:保存 RAID 6 的配置 ###
|
||||
|
||||
15.请注意默认 RAID 没有配置文件。我们需要使用以下命令手动保存它,然后检查设备‘/dev/md0‘的状态。
|
||||
15、 请注意,默认情况下 RAID 没有配置文件。我们需要使用以下命令手动保存它,然后检查设备`/dev/md0`的状态。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
# cat /etc/mdadm.conf
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
保存 Raid 6 配置
|
||||
*保存 RAID 6 配置*
|
||||
|
||||

|
||||
|
||||
检查 Raid 6 状态
|
||||
*检查 RAID 6 状态*
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
16.现在,它使用了4个磁盘,并且有两个作为奇偶校验信息来使用。在某些情况下,如果任意一个磁盘出现故障,我们仍可以得到数据,因为在 RAID 6 使用双奇偶校验。
|
||||
16、 现在,已经使用了4个磁盘,并且其中两个作为奇偶校验信息来使用。在某些情况下,如果任意一个磁盘出现故障,我们仍可以得到数据,因为在 RAID 6 使用双奇偶校验。
|
||||
|
||||
如果第二个磁盘也出现故障,在第三块磁盘损坏前我们可以添加一个新的。它可以作为一个备用磁盘并入 RAID 集合,但我在创建 raid 集合前没有定义备用的磁盘。但是,在磁盘损坏后或者创建 RAId 集合时我们可以添加一块磁盘。现在,我们已经创建好了 RAID,下面让我演示如何添加备用磁盘。
|
||||
如果第二个磁盘也出现故障,在第三块磁盘损坏前我们可以添加一个新的。可以在创建 RAID 集时加入一个备用磁盘,但我在创建 RAID 集合前没有定义备用的磁盘。不过,我们可以在磁盘损坏后或者创建 RAID 集合时添加一块备用磁盘。现在,我们已经创建好了 RAID,下面让我演示如何添加备用磁盘。
|
||||
|
||||
为了达到演示的目的,我已经热插入了一个新的 HDD 磁盘(即 /dev/sdf),让我们来验证接入的磁盘。
|
||||
|
||||
@ -236,15 +234,15 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
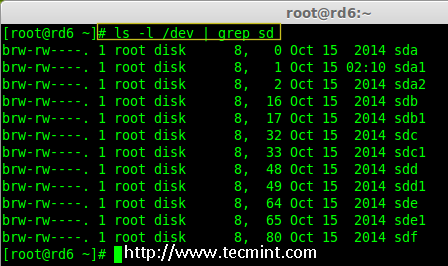
|
||||
|
||||
检查新 Disk
|
||||
*检查新磁盘*
|
||||
|
||||
17.现在再次确认新连接的磁盘没有配置过 RAID ,使用 mdadm 来检查。
|
||||
17、 现在再次确认新连接的磁盘没有配置过 RAID ,使用 mdadm 来检查。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
|
||||
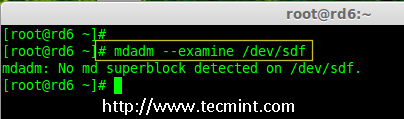
|
||||
|
||||
在新磁盘中检查 Raid
|
||||
*在新磁盘中检查 RAID*
|
||||
|
||||
**注意**: 像往常一样,我们早前已经为四个磁盘创建了分区,同样,我们使用 fdisk 命令为新插入的磁盘创建新分区。
|
||||
|
||||
@ -252,9 +250,9 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
为 /dev/sdf 创建分区
|
||||
*为 /dev/sdf 创建分区*
|
||||
|
||||
18.在 /dev/sdf 创建新的分区后,在新分区上确认 raid,包括/dev/md0 raid 设备的备用磁盘,并验证添加的设备。
|
||||
18、 在 /dev/sdf 创建新的分区后,在新分区上确认没有 RAID,然后将备用磁盘添加到 RAID 设备 /dev/md0 中,并验证添加的设备。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
# mdadm --examine /dev/sdf1
|
||||
@ -263,19 +261,19 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
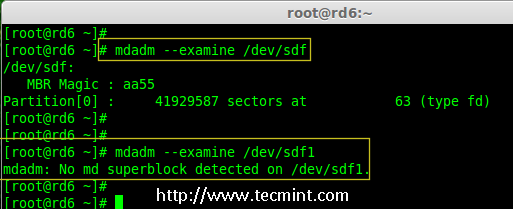
|
||||
|
||||
在 sdf 分区上验证 Raid
|
||||
*在 sdf 分区上验证 Raid*
|
||||
|
||||
|
||||
|
||||
为 RAID 添加 sdf 分区
|
||||
*添加 sdf 分区到 RAID *
|
||||
|
||||

|
||||
|
||||
验证 sdf 分区信息
|
||||
*验证 sdf 分区信息*
|
||||
|
||||
### 第7步:检查 RAID 6 容错 ###
|
||||
|
||||
19.现在,让我们检查备用驱动器是否能自动工作,当我们阵列中的任何一个磁盘出现故障时。为了测试,我亲自将一个磁盘模拟为故障设备。
|
||||
19、 现在,让我们检查备用驱动器是否能自动工作,当我们阵列中的任何一个磁盘出现故障时。为了测试,我将一个磁盘手工标记为故障设备。
|
||||
|
||||
在这里,我们标记 /dev/sdd1 为故障磁盘。
|
||||
|
||||
@ -283,15 +281,15 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
|
||||
|
||||
检查 Raid 6 容错
|
||||
*检查 RAID 6 容错*
|
||||
|
||||
20.让我们查看 RAID 的详细信息,并检查备用磁盘是否开始同步。
|
||||
20、 让我们查看 RAID 的详细信息,并检查备用磁盘是否开始同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 Raid 自动同步
|
||||
*检查 RAID 自动同步*
|
||||
|
||||
**哇塞!** 这里,我们看到备用磁盘激活了,并开始重建进程。在底部,我们可以看到有故障的磁盘 /dev/sdd1 标记为 faulty。可以使用下面的命令查看进程重建。
|
||||
|
||||
@ -299,11 +297,11 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
Raid 6 自动同步
|
||||
*RAID 6 自动同步*
|
||||
|
||||
### 结论: ###
|
||||
|
||||
在这里,我们看到了如何使用四个磁盘设置 RAID 6。这种 RAID 级别是具有高冗余的昂贵设置之一。在接下来的文章中,我们将看到如何建立一个嵌套的 RAID 10 甚至更多。至此,请继续关注 TECMINT。
|
||||
在这里,我们看到了如何使用四个磁盘设置 RAID 6。这种 RAID 级别是具有高冗余的昂贵设置之一。在接下来的文章中,我们将看到如何建立一个嵌套的 RAID 10 甚至更多。请继续关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -311,11 +309,12 @@ via: http://www.tecmint.com/create-raid-6-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:https://linux.cn/article-6102-1.html
|
||||
@ -0,0 +1,275 @@
|
||||
在 Linux 下使用 RAID(六):设置 RAID 10 或 1 + 0(嵌套)
|
||||
================================================================================
|
||||
|
||||
RAID 10 是组合 RAID 1 和 RAID 0 形成的。要设置 RAID 10,我们至少需要4个磁盘。在之前的文章中,我们已经看到了如何使用最少两个磁盘设置 RAID 1 和 RAID 0。
|
||||
|
||||
在这里,我们将使用最少4个磁盘组合 RAID 1 和 RAID 0 来设置 RAID 10。假设我们已经在用 RAID 10 创建的逻辑卷保存了一些数据。比如我们要保存数据 “TECMINT”,它将使用以下方法将其保存在4个磁盘中。
|
||||
|
||||
|
||||
|
||||
*在 Linux 中创建 Raid 10(LCTT 译注:此图有误,请参照文字说明和本系列第一篇文章)*
|
||||
|
||||
RAID 10 是先做镜像,再做条带。因此,在 RAID 1 中,相同的数据将被写入到两个磁盘中,“T”将同时被写入到第一和第二个磁盘中。接着的数据被条带化到另外两个磁盘,“E”将被同时写入到第三和第四个磁盘中。它将继续循环此过程,“C”将同时被写入到第一和第二个磁盘,以此类推。
|
||||
|
||||
(LCTT 译注:原文中此处描述混淆有误,已经根据实际情况进行修改。)
|
||||
|
||||
现在你已经了解 RAID 10 怎样组合 RAID 1 和 RAID 0 来工作的了。如果我们有4个20 GB 的磁盘,总共为 80 GB,但我们将只能得到40 GB 的容量,另一半的容量在构建 RAID 10 中丢失。
|
||||
|
||||
#### RAID 10 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能。
|
||||
- 在 RAID 10 中我们将失去一半的磁盘容量。
|
||||
- 读与写的性能都很好,因为它会同时进行写入和读取。
|
||||
- 它能解决数据库的高 I/O 磁盘写操作。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
在 RAID 10 中,我们至少需要4个磁盘,前2个磁盘为 RAID 1,其他2个磁盘为 RAID 0,就像我之前说的,RAID 10 仅仅是组合了 RAID 0和1。如果我们需要扩展 RAID 组,最少需要添加4个磁盘。
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.229
|
||||
主机名 : rd10.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdd
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
有两种方法来设置 RAID 10,在这里两种方法我都会演示,但我更喜欢第一种方法,使用它来设置 RAID 10 更简单。
|
||||
|
||||
### 方法1:设置 RAID 10 ###
|
||||
|
||||
1、 首先,使用以下命令确认所添加的4块磁盘没有被使用。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
2、 四个磁盘被检测后,然后来检查磁盘是否存在 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
|
||||
|
||||
*验证添加的4块磁盘*
|
||||
|
||||
**注意**: 在上面的输出中,如果没有检测到 super-block 意味着在4块磁盘中没有定义过 RAID。
|
||||
|
||||
#### 第1步:为 RAID 分区 ####
|
||||
|
||||
3、 现在,使用`fdisk`,命令为4个磁盘(/dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde)创建新分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
#####为 /dev/sdb 创建分区#####
|
||||
|
||||
我来告诉你如何使用 fdisk 为磁盘(/dev/sdb)进行分区,此步也适用于其他磁盘。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请使用以下步骤为 /dev/sdb 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为磁盘 sdb 分区*
|
||||
|
||||
**注意**: 请使用上面相同的指令对其他磁盘(sdc, sdd sdd sde)进行分区。
|
||||
|
||||
4、 创建好4个分区后,需要使用下面的命令来检查磁盘是否存在 raid。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
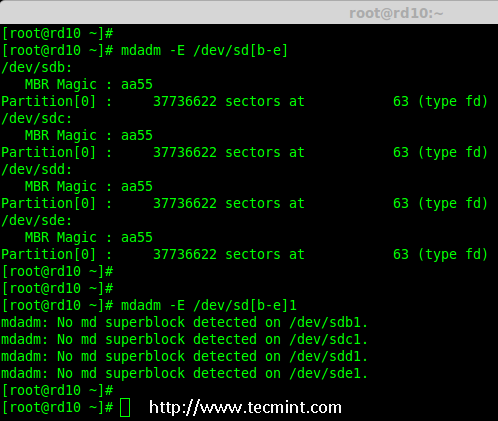
|
||||
|
||||
*检查磁盘*
|
||||
|
||||
**注意**: 以上输出显示,新创建的四个分区中没有检测到 super-block,这意味着我们可以继续在这些磁盘上创建 RAID 10。
|
||||
|
||||
#### 第2步: 创建 RAID 设备 `md` ####
|
||||
|
||||
5、 现在该创建一个`md`(即 /dev/md0)设备了,使用“mdadm” raid 管理工具。在创建设备之前,必须确保系统已经安装了`mdadm`工具,如果没有请使用下面的命令来安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
`mdadm`工具安装完成后,可以使用下面的命令创建一个`md` raid 设备。
|
||||
|
||||
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1
|
||||
|
||||
6、 接下来使用`cat`命令验证新创建的 raid 设备。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 md RAID 设备*
|
||||
|
||||
7、 接下来,使用下面的命令来检查4个磁盘。下面命令的输出会很长,因为它会显示4个磁盘的所有信息。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
8、 接下来,使用以下命令来查看 RAID 阵列的详细信息。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*查看 RAID 阵列详细信息*
|
||||
|
||||
**注意**: 你在上面看到的结果,该 RAID 的状态是 active 和re-syncing。
|
||||
|
||||
#### 第3步:创建文件系统 ####
|
||||
|
||||
9、 使用 ext4 作为`md0′的文件系统,并将它挂载到`/mnt/raid10`下。在这里,我用的是 ext4,你可以使用你想要的文件系统类型。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 md 文件系统*
|
||||
|
||||
10、 在创建文件系统后,挂载文件系统到`/mnt/raid10`下,并使用`ls -l`命令列出挂载点下的内容。
|
||||
|
||||
# mkdir /mnt/raid10
|
||||
# mount /dev/md0 /mnt/raid10/
|
||||
# ls -l /mnt/raid10/
|
||||
|
||||
接下来,在挂载点下创建一些文件,并在文件中添加些内容,然后检查内容。
|
||||
|
||||
# touch /mnt/raid10/raid10_files.txt
|
||||
# ls -l /mnt/raid10/
|
||||
# echo "raid 10 setup with 4 disks" > /mnt/raid10/raid10_files.txt
|
||||
# cat /mnt/raid10/raid10_files.txt
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
11、 要想自动挂载,打开`/etc/fstab`文件并添加下面的条目,挂载点根据你环境的不同来添加。使用 wq! 保存并退出。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid10 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
12、 接下来,在重新启动系统前使用`mount -a`来确认`/etc/fstab`文件是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
|
||||
|
||||
*检查 Fstab 中的错误*
|
||||
|
||||
#### 第四步:保存 RAID 配置 ####
|
||||
|
||||
13、 默认情况下 RAID 没有配置文件,所以我们需要在上述步骤完成后手动保存它。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID10 的配置*
|
||||
|
||||
就这样,我们使用方法1创建完了 RAID 10,这种方法是比较容易的。现在,让我们使用方法2来设置 RAID 10。
|
||||
|
||||
### 方法2:创建 RAID 10 ###
|
||||
|
||||
1、 在方法2中,我们必须定义2组 RAID 1,然后我们需要使用这些创建好的 RAID 1 的集合来定义一个 RAID 0。在这里,我们将要做的是先创建2个镜像(RAID1),然后创建 RAID0 (条带化)。
|
||||
|
||||
首先,列出所有的可用于创建 RAID 10 的磁盘。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
|
||||
|
||||
*列出了 4 个设备*
|
||||
|
||||
2、 将4个磁盘使用`fdisk`命令进行分区。对于如何分区,您可以按照上面的第1步。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
3、 在完成4个磁盘的分区后,现在检查磁盘是否存在 RAID块。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
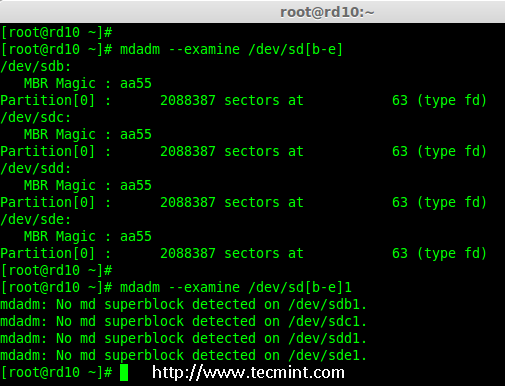
|
||||
|
||||
*检查 4 个磁盘*
|
||||
|
||||
#### 第1步:创建 RAID 1 ####
|
||||
|
||||
4、 首先,使用4块磁盘创建2组 RAID 1,一组为`sdb1′和 `sdc1′,另一组是`sdd1′ 和 `sde1′。
|
||||
|
||||
# mdadm --create /dev/md1 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md2 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[d-e]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 1*
|
||||
|
||||

|
||||
|
||||
*查看 RAID 1 的详细信息*
|
||||
|
||||
#### 第2步:创建 RAID 0 ####
|
||||
|
||||
5、 接下来,使用 md1 和 md2 来创建 RAID 0。
|
||||
|
||||
# mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/md1 /dev/md2
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 0*
|
||||
|
||||
#### 第3步:保存 RAID 配置 ####
|
||||
|
||||
6、 我们需要将配置文件保存在`/etc/mdadm.conf`文件中,使其每次重新启动后都能加载所有的 RAID 设备。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||
在此之后,我们需要按照方法1中的第3步来创建文件系统。
|
||||
|
||||
就是这样!我们采用的方法2创建完了 RAID 1+0。我们将会失去一半的磁盘空间,但相比其他 RAID ,它的性能将是非常好的。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这里,我们采用两种方法创建 RAID 10。RAID 10 具有良好的性能和冗余性。希望这篇文章可以帮助你了解 RAID 10 嵌套 RAID。在后面的文章中我们会看到如何扩展现有的 RAID 阵列以及更多精彩的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-10-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,182 @@
|
||||
在 Linux 下使用 RAID(七):在 Raid 中扩展现有的 RAID 阵列和删除故障的磁盘
|
||||
================================================================================
|
||||
|
||||
每个新手都会对阵列(array)这个词所代表的意思产生疑惑。阵列只是磁盘的一个集合。换句话说,我们可以称阵列为一个集合(set)或一组(group)。就像一组鸡蛋中包含6个一样。同样 RAID 阵列中包含着多个磁盘,可能是2,4,6,8,12,16等,希望你现在知道了什么是阵列。
|
||||
|
||||
在这里,我们将看到如何扩展现有的阵列或 RAID 组。例如,如果我们在阵列中使用2个磁盘形成一个 raid 1 集合,在某些情况,如果该组中需要更多的空间,就可以使用 mdadm -grow 命令来扩展阵列大小,只需要将一个磁盘加入到现有的阵列中即可。在说完扩展(添加磁盘到现有的阵列中)后,我们将看看如何从阵列中删除故障的磁盘。
|
||||
|
||||
|
||||
|
||||
*扩展 RAID 阵列和删除故障的磁盘*
|
||||
|
||||
假设磁盘中的一个有问题了需要删除该磁盘,但我们需要在删除磁盘前添加一个备用磁盘来扩展该镜像,因为我们需要保存我们的数据。当磁盘发生故障时我们需要从阵列中删除它,这是这个主题中我们将要学习到的。
|
||||
|
||||
#### 扩展 RAID 的特性 ####
|
||||
|
||||
- 我们可以增加(扩展)任意 RAID 集合的大小。
|
||||
- 我们可以在使用新磁盘扩展 RAID 阵列后删除故障的磁盘。
|
||||
- 我们可以扩展 RAID 阵列而无需停机。
|
||||
|
||||
####要求 ####
|
||||
|
||||
- 为了扩展一个RAID阵列,我们需要一个已有的 RAID 组(阵列)。
|
||||
- 我们需要额外的磁盘来扩展阵列。
|
||||
- 在这里,我们使用一块磁盘来扩展现有的阵列。
|
||||
|
||||
在我们了解扩展和恢复阵列前,我们必须了解有关 RAID 级别和设置的基本知识。点击下面的链接了解这些。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP地址 : 192.168.0.230
|
||||
主机名 : grow.tecmintlocal.com
|
||||
2 块现有磁盘 : 1 GB
|
||||
1 块额外磁盘 : 1 GB
|
||||
|
||||
在这里,我们已有一个 RAID ,有2块磁盘,每个大小为1GB,我们现在再增加一个磁盘到我们现有的 RAID 阵列中,其大小为1GB。
|
||||
|
||||
### 扩展现有的 RAID 阵列 ###
|
||||
|
||||
1、 在扩展阵列前,首先使用下面的命令列出现有的 RAID 阵列。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查现有的 RAID 阵列*
|
||||
|
||||
**注意**: 以上输出显示,已经有了两个磁盘在 RAID 阵列中,级别为 RAID 1。现在我们增加一个磁盘到现有的阵列里。
|
||||
|
||||
2、 现在让我们添加新的磁盘“sdd”,并使用`fdisk`命令来创建分区。
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
请使用以下步骤为 /dev/sdd 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为 sdd 创建新的分区*
|
||||
|
||||
3、 一旦新的 sdd 分区创建完成后,你可以使用下面的命令验证它。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
|
||||
|
||||
*确认 sdd 分区*
|
||||
|
||||
4、 接下来,在添加到阵列前先检查磁盘是否有 RAID 分区。
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||
|
||||
|
||||
*在 sdd 分区中检查 RAID*
|
||||
|
||||
**注意**:以上输出显示,该盘有没有发现 super-blocks,意味着我们可以将新的磁盘添加到现有阵列。
|
||||
|
||||
5、 要添加新的分区 /dev/sdd1 到现有的阵列 md0,请使用以下命令。
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
|
||||
|
||||
*添加磁盘到 RAID 阵列*
|
||||
|
||||
6、 一旦新的磁盘被添加后,在我们的阵列中检查新添加的磁盘。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认将新磁盘添加到 RAID 中*
|
||||
|
||||
**注意**: 在上面的输出,你可以看到磁盘已经被添加作为备用的。在这里,我们的阵列中已经有了2个磁盘,但我们期待阵列中有3个磁盘,因此我们需要扩展阵列。
|
||||
|
||||
7、 要扩展阵列,我们需要使用下面的命令。
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||
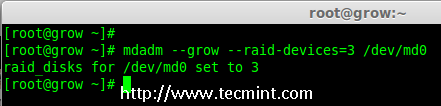
|
||||
|
||||
*扩展 Raid 阵列*
|
||||
|
||||
现在我们可以看到第三块磁盘(sdd1)已被添加到阵列中,在第三块磁盘被添加后,它将从另外两块磁盘上同步数据。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认 Raid 阵列*
|
||||
|
||||
**注意**: 对于大容量磁盘会需要几个小时来同步数据。在这里,我们使用的是1GB的虚拟磁盘,所以它非常快在几秒钟内便会完成。
|
||||
|
||||
### 从阵列中删除磁盘 ###
|
||||
|
||||
8、 在数据被从其他两个磁盘同步到新磁盘`sdd1`后,现在三个磁盘中的数据已经相同了(镜像)。
|
||||
|
||||
正如我前面所说的,假定一个磁盘出问题了需要被删除。所以,现在假设磁盘`sdc1`出问题了,需要从现有阵列中删除。
|
||||
|
||||
在删除磁盘前我们要将其标记为失效,然后我们才可以将其删除。
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列中模拟磁盘故障*
|
||||
|
||||
从上面的输出中,我们清楚地看到,磁盘在下面被标记为 faulty。即使它是 faulty 的,我们仍然可以看到 raid 设备有3个,1个损坏了,状态是 degraded。
|
||||
|
||||
现在我们要从阵列中删除 faulty 的磁盘,raid 设备将像之前一样继续有2个设备。
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||
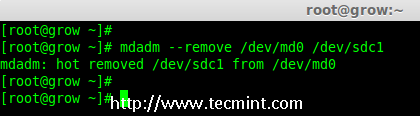
|
||||
|
||||
*在 Raid 阵列中删除磁盘*
|
||||
|
||||
9、 一旦故障的磁盘被删除,然后我们只能使用2个磁盘来扩展 raid 阵列了。
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列扩展磁盘*
|
||||
|
||||
从上面的输出中可以看到,我们的阵列中仅有2台设备。如果你需要再次扩展阵列,按照如上所述的同样步骤进行。如果你需要添加一个磁盘作为备用,将其标记为 spare,因此,如果磁盘出现故障时,它会自动顶上去并重建数据。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何扩展现有的 RAID 集合,以及如何在重新同步已有磁盘的数据后从一个阵列中删除故障磁盘。所有这些步骤都可以不用停机来完成。在数据同步期间,系统用户,文件和应用程序不会受到任何影响。
|
||||
|
||||
在接下来的文章我将告诉你如何管理 RAID,敬请关注更新,不要忘了写评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
@ -1,16 +1,16 @@
|
||||
fdupes——Linux中查找并删除重复文件的命令行工具
|
||||
fdupes:Linux中查找并删除重复文件的命令行工具
|
||||
================================================================================
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项领人不胜其烦的工作,它耗时又耗力。如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`**fdupes**`工具。
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项令人不胜其烦的工作,它耗时又耗力。但如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`fdupes`工具。
|
||||
|
||||

|
||||
|
||||
Fdupes——在Linux中查找并删除重复文件
|
||||
*fdupes——在Linux中查找并删除重复文件*
|
||||
|
||||
### fdupes是啥东东? ###
|
||||
|
||||
**Fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。Fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,可以为Fdupes指定大量的选项以实现对文件的列出、删除、替换到文件副本的硬链接等操作。
|
||||
**fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,fdupes有各种选项,可以实现对文件的列出、删除、替换为文件副本的硬链接等操作。
|
||||
|
||||
对比以下列顺序开始:
|
||||
文件对比以下列顺序开始:
|
||||
|
||||
**大小对比 > 部分 MD5 签名对比 > 完整 MD5 签名对比 > 逐字节对比**
|
||||
|
||||
@ -27,8 +27,9 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
**注意**:自Fedora 22之后,默认的包管理器yum被dnf取代了。
|
||||
|
||||
### fdupes命令咋个搞? ###
|
||||
1.作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
### fdupes命令如何使用 ###
|
||||
|
||||
1、 作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
|
||||
$ mkdir /home/"$USER"/Desktop/tecmint && cd /home/"$USER"/Desktop/tecmint && for i in {1..15}; do echo "I Love Tecmint. Tecmint is a very nice community of Linux Users." > tecmint${i}.txt ; done
|
||||
|
||||
@ -57,7 +58,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
"I Love Tecmint. Tecmint is a very nice community of Linux Users."
|
||||
|
||||
2.现在在**tecmint**文件夹内搜索重复的文件。
|
||||
2、 现在在**tecmint**文件夹内搜索重复的文件。
|
||||
|
||||
$ fdupes /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -77,7 +78,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
3.使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
3、 使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
|
||||
它会递归搜索所有文件和文件夹,花一点时间来扫描重复文件,时间的长短取决于文件和文件夹的数量。在此其间,终端中会显示全部过程,像下面这样。
|
||||
|
||||
@ -85,7 +86,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
Progress [37780/54747] 69%
|
||||
|
||||
4.使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
4、 使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
|
||||
$ fdupes -S /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -106,7 +107,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
5.你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
5、 你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
|
||||
$ fdupes -Sr /home/avi/Desktop/
|
||||
|
||||
@ -131,11 +132,11 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/resume_files/r-csc.html
|
||||
/home/tecmint/Desktop/resume_files/fc.html
|
||||
|
||||
6.不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
6、 不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
|
||||
$ fdupes /home/avi/Desktop/ /home/avi/Templates/
|
||||
|
||||
7.要删除重复文件,同时保留一个副本,你可以使用`**-d**`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
7、 要删除重复文件,同时保留一个副本,你可以使用`-d`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
|
||||
$ fdupes -d /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -177,13 +178,13 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
8.从安全角度出发,你可能想要打印`**fdupes**`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
8、 从安全角度出发,你可能想要打印`fdupes`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
|
||||
$ fdupes -Sr /home > /home/fdupes.txt
|
||||
|
||||
**注意**:你可以替换`**/home**`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`**-r**`和`**-S**`选项。
|
||||
**注意**:你应该替换`/home`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`-r`和`-S`选项。
|
||||
|
||||
9.你可以使用`**-f**`选项来忽略每个匹配集中的首个文件。
|
||||
9、 你可以使用`-f`选项来忽略每个匹配集中的首个文件。
|
||||
|
||||
首先列出该目录中的文件。
|
||||
|
||||
@ -205,13 +206,13 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint9 (another copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (4th copy).txt
|
||||
|
||||
10.检查已安装的fdupes版本。
|
||||
10、 检查已安装的fdupes版本。
|
||||
|
||||
$ fdupes --version
|
||||
|
||||
fdupes 1.51
|
||||
|
||||
11.如果你需要关于fdupes的帮助,可以使用`**-h**`开关。
|
||||
11、 如果你需要关于fdupes的帮助,可以使用`-h`开关。
|
||||
|
||||
$ fdupes -h
|
||||
|
||||
@ -245,7 +246,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
-v --version display fdupes version
|
||||
-h --help display this help message
|
||||
|
||||
到此为止了。让我知道你到现在为止你是怎么在Linux中查找并删除重复文件的?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
到此为止了。让我知道你以前怎么在Linux中查找并删除重复文件的吧?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
我正在使用另外一个移除重复文件的工具,它叫**fslint**。很快就会把使用心得分享给大家哦,你们一定会喜欢看的。
|
||||
|
||||
@ -254,10 +255,10 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
via: http://www.tecmint.com/fdupes-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[1]:https://linux.cn/article-2324-1.html
|
||||
[2]:https://linux.cn/article-5109-1.html
|
||||
20
sign.md
20
sign.md
@ -1,8 +1,22 @@
|
||||
|
||||
---
|
||||
|
||||
via:
|
||||
via:来源链接
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
作者:[作者名][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:作者链接
|
||||
[1]:文内链接
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
@ -1,87 +0,0 @@
|
||||
Plasma 5.4 Is Out And It’s Packed Full Of Features
|
||||
================================================================================
|
||||
KDE has [announced][1] a brand new feature release of Plasma 5 — and it’s a corker.
|
||||
|
||||
|
||||
|
||||
Better network details are among the changes
|
||||
|
||||
Plasma 5.4.0 builds on [April’s 5.3.0 milestone][2] in a number of ways, ranging from the inherently technical, Wayland preview session, ahoy, to lavish aesthetic touches, like **1,400 brand new icons**.
|
||||
|
||||
A handful of new components also feature in the release, including a new Plasma Widget for volume control, a monitor calibration tool and an improved user management tool.
|
||||
|
||||
The ‘Kicker’ application menu has been powered up to let you favourite all types of content, not just applications.
|
||||
|
||||
**KRunner now remembers searches** so that it can automatically offer suggestions based on your earlier queries as you type.
|
||||
|
||||
The **network applet displays a graph** to give you a better understanding of your network traffic. It also gains two new VPN plugins for SSH and SSTP connections.
|
||||
|
||||
Minor tweaks to the digital clock see it adapt better in slim panel mode, it gains ISO date support and makes it easier for you to toggle between 12 hour and 24 hour clock. Week numbers have been added to the calendar.
|
||||
|
||||
### Application Dashboard ###
|
||||
|
||||
|
||||
|
||||
The new ‘Application Dashboard’ in KDE Plasma 5.4.0
|
||||
|
||||
**A new full screen launcher, called ‘Application Dashboard’**, is also available.
|
||||
|
||||
This full-screen dash offers the same features as the traditional Application Menu but with “sophisticated scaling to screen size and full spatial keyboard navigation”.
|
||||
|
||||
Like the Unity launch, the new Plasma Application Dashboard helps you quickly find applications, sift through files and contacts based on your previous activity.
|
||||
|
||||
### Changes in KDE Plasma 5.4.0 at a glance ###
|
||||
|
||||
- Improved high DPI support
|
||||
- KRunner autocompletion
|
||||
- KRunner search history
|
||||
- Application Dashboard add on
|
||||
- 1,400 New icons
|
||||
- Wayland tech preview
|
||||
|
||||
For a full list of changes in Plasma 5.4 refer to [this changelog][3].
|
||||
|
||||
### Install Plasma 5.4 in Kubuntu 15.04 ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
To **install Plasma 5.4 in Kubuntu 15.04** you will need to add the KDE Backports PPA to your Software Sources.
|
||||
|
||||
Adding the Kubuntu backports PPA **is not strictly advised** as it may upgrade other parts of the KDE desktop, application suite, developer frameworks or Kubuntu specific config files.
|
||||
|
||||
If you like your desktop being stable, don’t proceed.
|
||||
|
||||
The quickest way to upgrade to Plasma 5.4 once it lands in the Kubuntu Backports PPA is to use the Terminal:
|
||||
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
|
||||
sudo apt-get update && sudo apt-get dist-upgrade
|
||||
|
||||
Let the upgrade process complete. Assuming no errors emerge, reboot your computer for changes to take effect.
|
||||
|
||||
If you’re not already using Kubuntu, i.e. you’re using the Unity version of Ubuntu, you should first install the Kubuntu desktop package (you’ll find it in the Ubuntu Software Centre).
|
||||
|
||||
To undo the changes above and downgrade to the most recent version of Plasma available in the Ubuntu archives use the PPA-Purge tool:
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
sudo ppa-purge ppa:kubuntu-ppa/backports
|
||||
|
||||
Let us know how your upgrade/testing goes in the comments below and don’t forget to mention the features you hope to see added to the Plasma 5 desktop next.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/plasma-5-4-new-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://dot.kde.org/2015/08/25/kde-ships-plasma-540-feature-release-august
|
||||
[2]:http://www.omgubuntu.co.uk/2015/04/kde-plasma-5-3-released-heres-how-to-upgrade-in-kubuntu-15-04
|
||||
[3]:https://www.kde.org/announcements/plasma-5.3.2-5.4.0-changelog.php
|
||||
@ -1,3 +1,4 @@
|
||||
cygmris is translating...
|
||||
Great Open Source Collaborative Editing Tools
|
||||
================================================================================
|
||||
In a nutshell, collaborative writing is writing done by more than one person. There are benefits and risks of collaborative working. Some of the benefits include a more integrated / co-ordinated approach, better use of existing resources, and a stronger, united voice. For me, the greatest advantage is one of the most transparent. That's when I need to take colleagues' views. Sending files back and forth between colleagues is inefficient, causes unnecessary delays and leaves people (i.e. me) unhappy with the whole notion of collaboration. With good collaborative software, I can share notes, data and files, and use comments to share thoughts in real-time or asynchronously. Working together on documents, images, video, presentations, and tasks is made less of a chore.
|
||||
@ -225,4 +226,4 @@ via: http://www.linuxlinks.com/article/20150823085112605/CollaborativeEditing.ht
|
||||
[10]:https://gobby.github.io/
|
||||
[11]:https://github.com/gobby
|
||||
[12]:https://www.onlyoffice.com/free-edition.aspx
|
||||
[13]:https://github.com/ONLYOFFICE/DocumentServer
|
||||
[13]:https://github.com/ONLYOFFICE/DocumentServer
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by H-mudcup
|
||||
Five Super Cool Open Source Games
|
||||
================================================================================
|
||||
In 2014 and 2015, Linux became home to a list of popular commercial titles such as the popular Borderlands, Witcher, Dead Island, and Counter Strike series of games. While this is exciting news, what of the gamer on a budget? Commercial titles are good, but even better are free-to-play alternatives made by developers who know what players like.
|
||||
@ -62,4 +63,4 @@ via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
|
||||
@ -0,0 +1,68 @@
|
||||
Translating by Ping
|
||||
Xtreme Download Manager Updated With Fresh GUI
|
||||
================================================================================
|
||||

|
||||
|
||||
[Xtreme Download Manager][1], unarguably one of the [best download managers for Linux][2], has a new version named XDM 2015 which brings a fresh new look to it.
|
||||
|
||||
Xtreme Download Manager, also known as XDM or XDMAN, is a popular cross-platform download manager available for Linux, Windows and Mac OS X. It is also compatible with all major web browsers such as Chrome, Firefox, Safari enabling you to download directly from XDM when you try to download something in your web browser.
|
||||
|
||||
Applications such as XDM are particularly useful when you have slow/limited network connectivity and you need to manage your downloads. Imagine downloading a huge file from internet on a slow network. What if you could pause and resume the download at will? XDM helps you in such situations.
|
||||
|
||||
Some of the main features of XDM are:
|
||||
|
||||
- Pause and resume download
|
||||
- [Download videos from YouTube][3] and other video sites
|
||||
- Force assemble
|
||||
- Download speed acceleration
|
||||
- Schedule downloads
|
||||
- Limit download speed
|
||||
- Web browser integration
|
||||
- Support for proxy servers
|
||||
|
||||
Here you can see the difference between the old and new XDM.
|
||||
|
||||

|
||||
|
||||
Old XDM
|
||||
|
||||

|
||||
|
||||
New XDM
|
||||
|
||||
### Install Xtreme Download Manager in Ubuntu based Linux distros ###
|
||||
|
||||
Thanks to the PPA by Noobslab, you can easily install Xtreme Download Manager using the commands below. XDM requires Java but thanks to the PPA, you don’t need to bother with installing dependencies separately.
|
||||
|
||||
sudo add-apt-repository ppa:noobslab/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install xdman
|
||||
|
||||
The above PPA should be available for Ubuntu and other Ubuntu based Linux distributions such as Linux Mint, elementary OS, Linux Lite etc.
|
||||
|
||||
#### Remove XDM ####
|
||||
|
||||
To remove XDM (installed using the PPA), use the commands below:
|
||||
|
||||
sudo apt-get remove xdman
|
||||
sudo add-apt-repository --remove ppa:noobslab/apps
|
||||
|
||||
For other Linux distributions, you can download it from the link below:
|
||||
|
||||
- [Download Xtreme Download Manager][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/xtreme-download-manager-install/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://xdman.sourceforge.net/
|
||||
[2]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[3]:http://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[4]:http://xdman.sourceforge.net/download.html
|
||||
@ -0,0 +1,194 @@
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
|
||||
I had a panache for abstract strategy games such as chess and draughts, as well as word games. I can still never resist a game of Escape from Colditz, a strategy card and dice-based board game, or Risk; two timeless multi-player strategy board games. But Catan remains my favourite board game.
|
||||
|
||||
Board games have seen a resurgence in recent years, and Linux has a good range of board games to choose from. There is a credible implementation of Catan called Pioneers. But for my favourite implementations of classic board games to play online, check out the recommendations below.
|
||||
|
||||
----------
|
||||
|
||||
### TripleA ###
|
||||
|
||||

|
||||
|
||||
TripleA is an open source online turn based strategy game. It allows people to implement and play various strategy board games (ie. Axis & Allies). The TripleA engine has full networking support for online play, support for sounds, XML support for game files, and has its own imaging subsystem that allows for customized user editable maps to be used. TripleA is versatile, scalable and robust.
|
||||
|
||||
TripleA started out as a World War II simulation, but now includes different conflicts, as well as variations and mods of popular games and maps. TripleA comes with multiple games and over 100 more games can be downloaded from the user community.
|
||||
|
||||
Features include:
|
||||
|
||||
- Good interface and attractive graphics
|
||||
- Optional scenarios
|
||||
- Multiplayer games
|
||||
- TripleA comes with the following supported games that uses its game engine (just to name a few):
|
||||
- Axis & Allies : Classic edition (2nd, 3rd with options enabled)
|
||||
- Axis & Allies : Revised Edition
|
||||
- Pact of Steel A&A Variant
|
||||
- Big World 1942 A&A Variant
|
||||
- Four if by Sea
|
||||
- Battle Ship Row
|
||||
- Capture The Flag
|
||||
- Minimap
|
||||
- Hot-seat
|
||||
- Play By EMail mode allows persons to play a game via EMail without having to be connected to each other online
|
||||
- More time to think out moves
|
||||
- Only need to come online to send your turn to the next player
|
||||
- Dice rolls are done by a dedicated dice server that is independent of TripleA
|
||||
- All dice rolls are PGP Verified and email to every player
|
||||
- Every move and every dice roll is logged and saved in TripleA's History Window
|
||||
- An online game can be later continued under PBEM mode
|
||||
- Hard for others to cheat
|
||||
- Hosted online lobby
|
||||
- Utilities for editing maps
|
||||
- Website: [triplea.sourceforge.net][1]
|
||||
- Developer: Sean Bridges (original developer), Mark Christopher Duncan
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.0.7
|
||||
|
||||
----------
|
||||
|
||||
### Domination ###
|
||||
|
||||

|
||||
|
||||
Domination is an open source game that shares common themes with the hugely popular Risk board game. It has many game options and includes many maps.
|
||||
|
||||
In the classic “World Domination” game of military strategy, you are battling to conquer the world. To win, you must launch daring attacks, defend yourself to all fronts, and sweep across vast continents with boldness and cunning. But remember, the dangers, as well as the rewards, are high. Just when the world is within your grasp, your opponent might strike and take it all away!
|
||||
|
||||
Features include:
|
||||
|
||||
- Simple to learn
|
||||
- Domination - you must occupy all countries on the map, and thereby eliminate all opponents. These can be long, drawn out games
|
||||
- Capital - each player has a country they have selected as a Capital. To win the game, you must occupy all Capitals
|
||||
- Mission - each player draws a random mission. The first to complete their mission wins. Missions may include the elimination of a certain colour, occupation of a particular continent, or a mix of both
|
||||
- Map editor
|
||||
- Simple map format
|
||||
- Multiplayer network play
|
||||
- Single player
|
||||
- Hotseat
|
||||
- 5 user interfaces
|
||||
- Game types:
|
||||
- Play online
|
||||
- Website: [domination.sourceforge.net][2]
|
||||
- Developer: Yura Mamyrin, Christian Weiske, Mike Chaten, and many others
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 1.1.1.5
|
||||
|
||||
----------
|
||||
|
||||
### PyChess ###
|
||||
|
||||

|
||||
|
||||
PyChess is a Gnome inspired chess client written in Python.
|
||||
|
||||
The goal of PyChess, is to provide a fully featured, nice looking, easy to use chess client for the gnome-desktop.
|
||||
|
||||
The client should be usable both to those totally new to chess, those who want to play an occasional game, and those who wants to use the computer to further enhance their play.
|
||||
|
||||
Features include:
|
||||
|
||||
- Attractive interface
|
||||
- Chess Engine Communication Protocol (CECP) and Univeral Chess Interface (UCI) Engine support
|
||||
- Free online play on the Free Internet Chess Server (FICS)
|
||||
- Read and writes PGN, EPD and FEN chess file formats
|
||||
- Built-in Python based engine
|
||||
- Undo and pause functions
|
||||
- Board and piece animation
|
||||
- Drag and drop
|
||||
- Tabbed interface
|
||||
- Hints and spyarrows
|
||||
- Opening book sidepanel using sqlite
|
||||
- Score plot sidepanel
|
||||
- "Enter game" in pgn dialog
|
||||
- Optional sounds
|
||||
- Legal move highlighting
|
||||
- Internationalised or figure pieces in notation
|
||||
- Website: [www.pychess.org][3]
|
||||
- Developer: Thomas Dybdahl Ahle
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.12 Anderssen rc4
|
||||
|
||||
----------
|
||||
|
||||
### Scrabble ###
|
||||
|
||||

|
||||
|
||||
Scrabble3D is a highly customizable Scrabble game that not only supports Classic Scrabble and Superscrabble but also 3D games and own boards. You can play local against the computer or connect to a game server to find other players.
|
||||
|
||||
Scrabble is a board game with the goal to place letters crossword like. Up to four players take part and get a limited amount of letters (usually 7 or 8). Consecutively, each player tries to compose his letters to one or more word combining with the placed words on the game array. The value of the move depends on the letters (rare letter get more points) and bonus fields which multiply the value of a letter or the whole word. The player with most points win.
|
||||
|
||||
This idea is extended with Scrabble3D to the third dimension. Of course, a classic game with 15x15 fields or Superscrabble with 21x21 fields can be played and you may configure any field setting by yourself. The game can be played by the provided freeware program against Computer, other local players or via internet. Last but not least it's possible to connect to a game server to find other players and to obtain a rating. Most options are configurable, including the number and valuation of letters, the used dictionary, the language of dialogs and certainly colors, fonts etc.
|
||||
|
||||
Features include:
|
||||
|
||||
- Configurable board, letterset and design
|
||||
- Board in OpenGL graphics with user-definable wavefront model
|
||||
- Game against computer with support of multithreading
|
||||
- Post-hoc game analysis with calculation of best move by computer
|
||||
- Match with other players connected on a game server
|
||||
- NSA rating and highscore at game server
|
||||
- Time limit of games
|
||||
- Localization; use of non-standard digraphs like CH, RR, LL and right to left reading
|
||||
- Multilanguage help / wiki
|
||||
- Network games are buffered and asynchronous games are possible
|
||||
- Running games can be kibitzed
|
||||
- International rules including italian "Cambio Secco"
|
||||
- Challenge mode, What-if-variant, CLABBERS, etc
|
||||
- Website: [sourceforge.net/projects/scrabble][4]
|
||||
- Developer: Heiko Tietze
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 3.1.3
|
||||
|
||||
----------
|
||||
|
||||
### Backgammon ###
|
||||
|
||||

|
||||
|
||||
GNU Backgammon (gnubg) is a strong backgammon program (world-class with a bearoff database installed) usable either as an engine by other programs or as a standalone backgammon game. It is able to play and analyze both money games and tournament matches, evaluate and roll out positions, and more.
|
||||
|
||||
In addition to supporting simple play, it also has extensive analysis features, a tutor mode, adjustable difficulty, and support for exporting annotated games.
|
||||
|
||||
It currently plays at about the level of a championship flight tournament player and is gradually improving.
|
||||
|
||||
gnubg can be played on numerous on-line backgammon servers, such as the First Internet Backgammon Server (FIBS).
|
||||
|
||||
Features include:
|
||||
|
||||
- A command line interface (with full command editing features if GNU readline is available) that lets you play matches and sessions against GNU Backgammon with a rough ASCII representation of the board on text terminals
|
||||
- Support for a GTK+ interface with a graphical board window. Both 2D and 3D graphics are available
|
||||
- Tournament match and money session cube handling and cubeful play
|
||||
- Support for both 1-sided and 2-sided bearoff databases: 1-sided bearoff database for 15 checkers on the first 6 points and optional 2-sided database kept in memory. Optional larger 1-sided and 2-sided databases stored on disk
|
||||
- Automated rollouts of positions, with lookahead and race variance reduction where appropriate. Rollouts may be extended
|
||||
- Functions to generate legal moves and evaluate positions at varying search depths
|
||||
- Neural net functions for giving cubeless evaluations of all other contact and race positions
|
||||
- Automatic and manual annotation (analysis and commentary) of games and matches
|
||||
- Record keeping of statistics of players in games and matches (both native inside GNU Backgammon and externally using relational databases and Python)
|
||||
- Loading and saving analyzed games and matches as .sgf files (Smart Game Format)
|
||||
- Exporting positions, games and matches to: (.eps) Encapsulated Postscript, (.gam) Jellyfish Game, (.html) HTML, (.mat) Jellyfish Match, (.pdf) PDF, (.png) Portable Network Graphics, (.pos) Jellyfish Position, (.ps) PostScript, (.sgf) Gnu Backgammon File, (.tex) LaTeX, (.txt) Plain Text, (.txt) Snowie Text
|
||||
- Import of matches and positions from a number of file formats: (.bkg) Hans Berliner's BKG Format, (.gam) GammonEmpire Game, (.gam) PartyGammon Game, (.mat) Jellyfish Match, (.pos) Jellyfish Position, (.sgf) Gnu Backgammon File, (.sgg) GamesGrid Save Game, (.tmg) TrueMoneyGames, (.txt) Snowie Text
|
||||
- Python Scripting
|
||||
- Native language support; 10 languages complete or in progress
|
||||
- Website: [www.gnubg.org][5]
|
||||
- Developer: Joseph Heled, Oystein Johansen, Jonathan Kinsey, David Montgomery, Jim Segrave, Joern Thyssen, Gary Wong and contributors
|
||||
- License: GPL v2
|
||||
- Version Number: 1.05.000
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150830011533893/BoardGames.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://triplea.sourceforge.net/
|
||||
[2]:http://domination.sourceforge.net/
|
||||
[3]:http://www.pychess.org/
|
||||
[4]:http://sourceforge.net/projects/scrabble/
|
||||
[5]:http://www.gnubg.org/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
Defending the Free Linux World
|
||||
================================================================================
|
||||

|
||||
|
||||
**Co-opetition is a part of open source. The Open Invention Network model allows companies to decide where they will compete and where they will collaborate, explained OIN CEO Keith Bergelt. As open source evolved, "we had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology."**
|
||||
|
||||
The [Open Invention Network][1], or OIN, is waging a global campaign to keep Linux out of harm's way in patent litigation. Its efforts have resulted in more than 1,000 companies joining forces to become the largest defense patent management organization in history.
|
||||
|
||||
The Open Invention Network was created in 2005 as a white hat organization to protect Linux from license assaults. It has considerable financial backing from original board members that include Google, IBM, NEC, Novell, Philips, [Red Hat][2] and Sony. Organizations worldwide have joined the OIN community by signing the free OIN license.
|
||||
|
||||
Organizers founded the Open Invention Network as a bold endeavor to leverage intellectual property to protect Linux. Its business model was difficult to comprehend. It asked its members to take a royalty-free license and forever forgo the chance to sue other members over their Linux-oriented intellectual property.
|
||||
|
||||
However, the surge in Linux adoptions since then -- think server and cloud platforms -- has made protecting Linux intellectual property a critically necessary strategy.
|
||||
|
||||
Over the past year or so, there has been a shift in the Linux landscape. OIN is doing a lot less talking to people about what the organization is and a lot less explaining why Linux needs protection. There is now a global awareness of the centrality of Linux, according to Keith Bergelt, CEO of OIN.
|
||||
|
||||
"We have seen a culture shift to recognizing how OIN benefits collaboration," he told LinuxInsider.
|
||||
|
||||
### How It Works ###
|
||||
|
||||
The Open Invention Network uses patents to create a collaborative environment. This approach helps ensure the continuation of innovation that has benefited software vendors, customers, emerging markets and investors.
|
||||
|
||||
Patents owned by Open Invention Network are available royalty-free to any company, institution or individual. All that is required to qualify is the signer's agreement not to assert its patents against the Linux system.
|
||||
|
||||
OIN ensures the openness of the Linux source code. This allows programmers, equipment vendors, independent software vendors and institutions to invest in and use Linux without excessive worry about intellectual property issues. This makes it more economical for companies to repackage, embed and use Linux.
|
||||
|
||||
"With the diffusion of copyright licenses, the need for OIN licenses becomes more acute. People are now looking for a simpler or more utilitarian solution," said Bergelt.
|
||||
|
||||
OIN legal defenses are free of charge to members. Members commit to not initiating patent litigation against the software in OIN's list. They also agree to offer their own patents in defense of that software. Ultimately, these commitments result in access to hundreds of thousands of patents cross-licensed by the network, Bergelt explained.
|
||||
|
||||
### Closing the Legal Loopholes ###
|
||||
|
||||
"What OIN is doing is very essential. It offers another layer of IP protection, said Greg R. Vetter, associate professor of law at the [University of Houston Law Center][3].
|
||||
|
||||
Version 2 of the GPL license is thought by some to provide an implied patent license, but lawyers always feel better with an explicit license, he told LinuxInsider.
|
||||
|
||||
What OIN provides is something that bridges that gap. It also provides explicit coverage of the Linux kernel. An explicit patent license is not necessarily part of the GPLv2, but it was added in GPLv3, according to Vetter.
|
||||
|
||||
Take the case of a code writer who produces 10,000 lines of code under GPLv3, for example. Over time, other code writers contribute many more lines of code, which adds to the IP. The software patent license provisions in GPLv3 would protect the use of the entire code base under all of the participating contributors' patents, Vetter said.
|
||||
|
||||
### Not Quite the Same ###
|
||||
|
||||
Patents and licenses are overlapping legal constructs. Figuring out how the two entities work with open source software can be like traversing a minefield.
|
||||
|
||||
"Licenses are legal constructs granting additional rights based on, typically, patent and copyright laws. Licenses are thought to give a permission to do something that might otherwise be infringement of someone else's IP rights," Vetter said.
|
||||
|
||||
Many free and open source licenses (such as the Mozilla Public License, the GNU GPLv3, and the Apache Software License) incorporate some form of reciprocal patent rights clearance. Older licenses like BSD and MIT do not mention patents, Vetter pointed out.
|
||||
|
||||
A software license gives someone else certain rights to use the code the programmer created. Copyright to establish ownership is automatic, as soon as someone writes or draws something original. However, copyright covers only that particular expression and derivative works. It does not cover code functionality or ideas for use.
|
||||
|
||||
Patents cover functionality. Patent rights also can be licensed. A copyright may not protect how someone independently developed implementation of another's code, but a patent fills this niche, Vetter explained.
|
||||
|
||||
### Looking for Safe Passage ###
|
||||
|
||||
The mixing of license and patent legalities can appear threatening to open source developers. For some, even the GPL qualifies as threatening, according to William Hurley, cofounder of [Chaotic Moon Studios][4] and [IEEE][5] Computer Society member.
|
||||
|
||||
"Way back in the day, open source was a different world. Driven by mutual respect and a view of code as art, not property, things were far more open than they are today. I believe that many efforts set upon with the best of intentions almost always end up bearing unintended consequences," Hurley told LinuxInsider.
|
||||
|
||||
Surpassing the 1,000-member mark might carry a mixed message about the significance of intellectual property right protection, he suggested. It might just continue to muddy the already murky waters of today's open source ecosystem.
|
||||
|
||||
"At the end of the day, this shows some of the common misconceptions around intellectual property. Having thousands of developers does not decrease risk -- it increases it. The more developers licensing the patents, the more valuable they appear to be," Hurley said. "The more valuable they appear to be, the more likely someone with similar patents or other intellectual property will try to take advantage and extract value for their own financial gain."
|
||||
|
||||
### Sharing While Competing ###
|
||||
|
||||
Co-opetition is a part of open source. The OIN model allows companies to decide where they will compete and where they will collaborate, explained Bergelt.
|
||||
|
||||
"Many of the changes in the evolution of open source in terms of process have moved us into a different direction. We had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology," he said.
|
||||
|
||||
A glaring example of this is the early evolution of the cellphone industry. Multiple standards were put forward by multiple companies. There was no sharing and no collaboration, noted Bergelt.
|
||||
|
||||
"That damaged our ability to access technology by seven to 10 years in the U.S. Our experience with devices was far behind what everybody else in the world had. We were complacent with GSM (Global System for Mobile Communications) while we were waiting for CDMA (Code Division Multiple Access)," he said.
|
||||
|
||||
### Changing Landscape ###
|
||||
|
||||
OIN experienced a growth surge of 400 new licensees in the last year. That is indicative of a new trend involving open source.
|
||||
|
||||
"The marketplace reached a critical mass where finally people within organizations recognized the need to explicitly collaborate and to compete. The result is doing both at the same time. This can be messy and taxing," Bergelt said.
|
||||
|
||||
However, it is a sustainable transformation driven by a cultural shift in how people think about collaboration and competition. It is also a shift in how people are embracing open source -- and Linux in particular -- as the lead project in the open source community, he explained.
|
||||
|
||||
One indication is that most significant new projects are not being developed under the GPLv3 license.
|
||||
|
||||
### Two Better Than One ###
|
||||
|
||||
"The GPL is incredibly important, but the reality is there are a number of licensing models being used. The relative addressability of patent issues is generally far lower in Eclipse and Apache and Berkeley licenses that it is in GPLv3," said Bergelt.
|
||||
|
||||
GPLv3 is a natural complement for addressing patent issues -- but the GPL is not sufficient on its own to address the issues of potential conflicts around the use of patents. So OIN is designed as a complement to copyright licenses, he added.
|
||||
|
||||
However, the overlap of patent and license may not do much good. In the end, patents are for offensive purposes -- not defensive -- in almost every case, Bergelt suggested.
|
||||
|
||||
"If you are not prepared to take legal action against others, then a patent may not be the best form of legal protection for your intellectual properties," he said. "We now live in a world where the misconceptions around software, both open and proprietary, combined with an ill-conceived and outdated patent system, leave us floundering as an industry and stifling innovation on a daily basis," he said.
|
||||
|
||||
### Court of Last Resort ###
|
||||
|
||||
It would be nice to think the presence of OIN has dampened a flood of litigation, Bergelt said, or at the very least, that OIN's presence is neutralizing specific threats.
|
||||
|
||||
"We are getting people to lay down their arms, so to say. At the same time, we are creating a new cultural norm. Once you buy into patent nonaggression in this model, the correlative effect is to encourage collaboration," he observed.
|
||||
|
||||
If you are committed to collaboration, you tend not to rush to litigation as a first response. Instead, you think in terms of how can we enable you to use what we have and make some money out of it while we use what you have, Bergelt explained.
|
||||
|
||||
"OIN is a multilateral solution. It encourages signers to create bilateral agreements," he said. "That makes litigation the last course of action. That is where it should be."
|
||||
|
||||
### Bottom Line ###
|
||||
|
||||
OIN is working to prevent Linux patent challenges, Bergelt is convinced. There has not been litigation in this space involving Linux.
|
||||
|
||||
The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. Those legal challenges may be designed to raise the cost of ownership involving the use of Linux products, Bergelt noted.
|
||||
|
||||
Still, "these are not Linux-related law suits," he said. "They do not focus on what is core to Linux. They focus on what is in the Linux system."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -1,4 +1,3 @@
|
||||
zpl1025
|
||||
Interviews: Linus Torvalds Answers Your Question
|
||||
================================================================================
|
||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
martin
|
||||
translating...
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
|
||||
@ -1,109 +0,0 @@
|
||||
Debian GNU/Linux Birthday : A 22 Years of Journey and Still Counting…
|
||||
================================================================================
|
||||
On 16th August 2015, the Debian project has celebrated its 22nd anniversary, making it one of the oldest popular distribution in open source world. Debian project was conceived and founded in the year 1993 by Ian Murdock. By that time Slackware had already made a remarkable presence as one of the earliest Linux Distribution.
|
||||
|
||||

|
||||
|
||||
Happy 22nd Birthday to Debian Linux
|
||||
|
||||
Ian Ashley Murdock, an American Software Engineer by profession, conceived the idea of Debian project, when he was a student of Purdue University. He named the project Debian after the name of his then-girlfriend Debra Lynn (Deb) and his name. He later married her and then got divorced in January 2008.
|
||||
|
||||

|
||||
|
||||
Debian Creator: Ian Murdock
|
||||
|
||||
Ian is currently serving as Vice President of Platform and Development Community at ExactTarget.
|
||||
|
||||
Debian (as Slackware) was the result of unavailability of up-to mark Linux Distribution, that time. Ian in an interview said – “Providing the first class Product without profit would be the sole aim of Debian Project. Even Linux was not reliable and up-to mark that time. I Remember…. Moving files between file-system and dealing with voluminous file would often result in Kernel Panic. However the project Linux was promising. The availability of Source Code freely and the potential it seemed was qualitative.”
|
||||
|
||||
I remember … like everyone else I wanted to solve problem, run something like UNIX at home, but it was not possible…neither financially nor legally, in the other sense . Then I come to know about GNU kernel Development and its non-association with any kind of legal issues, he added. He was sponsored by Free Software Foundation (FSF) in the early days when he was working on Debian, it also helped Debian to take a giant step though Ian needed to finish his degree and hence quited FSF roughly after one year of sponsorship.
|
||||
|
||||
### Debian Development History ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : Released between August 1993 – December 1993.
|
||||
- **Debian 0.91 ** – Released in January 1994 with primitive package system, No dependencies.
|
||||
- **Debian 0.93 rc5** : March 1995. It is the first modern release of Debian, dpkg was used to install and maintain packages after base system installation.
|
||||
- **Debian 0.93 rc6**: Released in November 1995. It was last a.out release, deselect made an appearance for the first time – 60 developers were maintaining packages, then at that time.
|
||||
- **Debian 1.1**: Released in June 1996. Code name – Buzz, Packages count – 474, Package Manager dpkg, Kernel 2.0, ELF.
|
||||
- **Debian 1.2**: Released in December 1996. Code name – Rex, Packages count – 848, Developers Count – 120.
|
||||
- **Debian 1.3**: Released in July 1997. Code name – Bo, package count 974, Developers count – 200.
|
||||
- **Debian 2.0**: Released in July 1998. Code name: Hamm, Support for architecture – Intel i386 and Motorola 68000 series, Number of Packages: 1500+, Number of Developers: 400+, glibc included.
|
||||
- **Debian 2.1**: Released on March 09, 1999. Code name – slink, support architecture Alpha and Sparc, apt came in picture, Number of package – 2250.
|
||||
- **Debian 2.2**: Released on August 15, 2000. Code name – Potato, Supported architecture – Intel i386, Motorola 68000 series, Alpha, SUN Sparc, PowerPC and ARM architecture. Number of packages: 3900+ (binary) and 2600+ (Source), Number of Developers – 450. There were a group of people studied and came with an article called Counting potatoes, which shows – How a free software effort could lead to a modern operating system despite all the issues around it.
|
||||
- **Debian 3.0** : Released on July 19th, 2002. Code name – woody, Architecture supported increased– HP, PA_RISC, IA-64, MIPS and IBM, First release in DVD, Package Count – 8500+, Developers Count – 900+, Cryptography.
|
||||
- **Debian 3.1**: Release on June 6th, 2005. Code name – sarge, Architecture support – same as woody + AMD64 – Unofficial Port released, Kernel – 2.4 qnd 2.6 series, Number of Packages: 15000+, Number of Developers : 1500+, packages like – OpenOffice Suite, Firefox Browser, Thunderbird, Gnome 2.8, kernel 3.3 Advanced Installation Support: RAID, XFS, LVM, Modular Installer.
|
||||
- **Debian 4.0**: Released on April 8th, 2007. Code name – etch, architecture support – same as sarge, included AMD64. Number of packages: 18,200+ Developers count : 1030+, Graphical Installer.
|
||||
- **Debian 5.0**: Released on February 14th, 2009. Code name – lenny, Architecture Support – Same as before + ARM. Number of packages: 23000+, Developers Count: 1010+.
|
||||
- **Debian 6.0** : Released on July 29th, 2009. Code name – squeeze, Package included : kernel 2.6.32, Gnome 2.3. Xorg 7.5, DKMS included, Dependency-based. Architecture : Same as pervious + kfreebsd-i386 and kfreebsd-amd64, Dependency based booting.
|
||||
- **Debian 7.0**: Released on may 4, 2013. Code name: wheezy, Support for Multiarch, Tools for private cloud, Improved Installer, Third party repo need removed, full featured multimedia-codec, Kernel 3.2, Xen Hypervisor 4.1.4 Package Count: 37400+.
|
||||
- **Debian 8.0**: Released on May 25, 2015 and Code name: Jessie, Systemd as the default init system, powered by Kernel 3.16, fast booting, cgroups for services, possibility of isolating part of the services, 43000+ packages. Sysvinit init system available in Jessie.
|
||||
|
||||
**Note**: Linux Kernel initial release was on October 05, 1991 and Debian initial release was on September 15, 1993. So, Debian is there for 22 Years running Linux Kernel which is there for 24 years.
|
||||
|
||||
### Debian Facts ###
|
||||
|
||||
Year 1994 was spent on organizing and managing Debian project so that it would be easy for others to contribute. Hence no release for users were made this year however there were certain internal release.
|
||||
|
||||
Debian 1.0 was never released. A CDROM manufacturer company by mistakenly labelled an unreleased version as Debian 1.0. Hence to avoid confusion Debian 1.0 was released as Debian 1.1 and since then only the concept of official CDROM images came into existence.
|
||||
|
||||
Each release of Debian is a character of Toy Story.
|
||||
|
||||
Debian remains available in old stable, stable, testing and experimental, all the time.
|
||||
|
||||
The Debian Project continues to work on the unstable distribution (codenamed sid, after the evil kid from the Toy Story). Sid is the permanent name for the unstable distribution and is remains ‘Still In Development’. The testing release is intended to become the next stable release and is currently codenamed jessie.
|
||||
|
||||
Debian official distribution includes only Free and OpenSource Software and nothing else. However the availability of contrib and Non-free Packages makes it possible to install those packages which are free but their dependencies are not licensed free (contrib) and Packages licensed under non-free softwares.
|
||||
|
||||
Debian is the mother of a lot of Linux distribution. Some of these Includes:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (No more active)
|
||||
- LMDE
|
||||
|
||||
Debian is the world’s largest non commercial Linux Distribution. It is written in C (32.1%) programming language and rest in 70 other languages.
|
||||
|
||||

|
||||
|
||||
Debian Contribution
|
||||
|
||||
Image Source: [Xmodulo][1]
|
||||
|
||||
Debian project contains 68.5 million actual loc (lines of code) + 4.5 million lines of comments and white spaces.
|
||||
|
||||
International Space station dropped Windows & Red Hat for adopting Debian – These astronauts are using one release back – now “squeeze” for stability and strength from community.
|
||||
|
||||
Thank God! Who would have heard the scream from space on Windows Metro Screen :P
|
||||
|
||||
#### The Black Wednesday ####
|
||||
|
||||
On November 20th, 2002 the University of Twente Network Operation Center (NOC) caught fire. The fire department gave up protecting the server area. NOC hosted satie.debian.org which included Security, non-US archive, New Maintainer, quality assurance, databases – Everything was turned to ashes. Later these services were re-built by debian.
|
||||
|
||||
#### The Future Distro ####
|
||||
|
||||
Next in the list is Debian 9, code name – Stretch, what it will have is yet to be revealed. The best is yet to come, Just Wait for it!
|
||||
|
||||
A lot of distribution made an appearance in Linux Distro genre and then disappeared. In most cases managing as it gets bigger was a concern. But certainly this is not the case with Debian. It has hundreds of thousands of developer and maintainer all across the globe. It is a one Distro which was there from the initial days of Linux.
|
||||
|
||||
The contribution of Debian in Linux ecosystem can’t be measured in words. If there had been no Debian, Linux would not have been so rich and user-friendly. Debian is among one of the disto which is considered highly reliable, secure and stable and a perfect choice for Web Servers.
|
||||
|
||||
That’s the beginning of Debian. It came a long way and still going. The Future is Here! The world is here! If you have not used Debian till now, What are you Waiting for. Just Download Your Image and get started, we will be here if you get into trouble.
|
||||
|
||||
- [Debian Homepage][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -0,0 +1,67 @@
|
||||
The Strangest, Most Unique Linux Distros
|
||||
================================================================================
|
||||
From the most consumer focused distros like Ubuntu, Fedora, Mint or elementary OS to the more obscure, minimal and enterprise focused ones such as Slackware, Arch Linux or RHEL, I thought I've seen them all. Couldn't have been any further from the truth. Linux eco-system is very diverse. There's one for everyone. Let's discuss the weird and wacky world of niche Linux distros that represents the true diversity of open platforms.
|
||||
|
||||

|
||||
|
||||
**Puppy Linux**: An operating system which is about 1/10th the size of an average DVD quality movie rip, that's Puppy Linux for you. The OS is just 100 MB in size! And it can run from RAM making it unusually fast even in older PCs. You can even remove the boot medium after the operating system has started! Can it get any better than that? System requirements are bare minimum, most hardware are automatically detected, and it comes loaded with software catering to your basic needs. [Experience Puppy Linux][1].
|
||||
|
||||

|
||||
|
||||
**Suicide Linux**: Did the name scare you? Well it should. 'Any time - any time - you type any remotely incorrect command, the interpreter creatively resolves it into rm -rf / and wipes your hard drive'. Simple as that. I really want to know the ones who are confident enough to risk their production machines with [Suicide Linux][2]. **Warning: DO NOT try this on production machines!** The whole thing is available in a neat [DEB package][3] if you're interested.
|
||||
|
||||
|
||||
|
||||
**PapyrOS**: "Strange" in a good way. PapyrOS is trying to adapt the material design language of Android into their brand new Linux distribution. Though the project is in early stages, it already looks very promising. The project page says the OS is 80% complete and one can expect the first Alpha release anytime soon. We did a small write up on [PapyrOS][4] when it was announced and by the looks of it, PapyrOS might even become a trend-setter of sorts. Follow the project on [Google+][5] and contribute via [BountySource][6] if you're interested.
|
||||
|
||||
|
||||
|
||||
**Qubes OS**: Qubes is an open-source operating system designed to provide strong security using a Security by Compartmentalization approach. The assumption is that there can be no perfect, bug-free desktop environment. And by implementing a 'Security by Isolation' approach, [Qubes Linux][7] intends to remedy that. Qubes is based on Xen, the X Window System, and Linux, and can run most Linux applications and supports most Linux drivers. Qubes was selected as a finalist of Access Innovation Prize 2014 for Endpoint Security Solution.
|
||||
|
||||

|
||||
|
||||
**Ubuntu Satanic Edition**: Ubuntu SE is a Linux distribution based on Ubuntu. "It brings together the best of free software and free metal music" in one comprehensive package consisting of themes, wallpapers, and even some heavy-metal music sourced from talented new artists. Though the project doesn't look actively developed anymore, Ubuntu Satanic Edition is strange in every sense of that word. [Ubuntu SE (Slightly NSFW)][8].
|
||||
|
||||
|
||||
|
||||
**Tiny Core Linux**: Puppy Linux not small enough? Try this. Tiny Core Linux is a 12 MB graphical Linux desktop! Yep, you read it right. One major caveat: It is not a complete desktop nor is all hardware completely supported. It represents only the core needed to boot into a very minimal X desktop typically with wired internet access. There is even a version without the GUI called Micro Core Linux which is just 9MB in size. [Tiny Core Linux][9] folks.
|
||||
|
||||
|
||||
|
||||
**NixOS**: A very experienced-user focused Linux distribution with a unique approach to package and configuration management. In other distributions, actions such as upgrades can be dangerous. Upgrading a package can cause other packages to break, upgrading an entire system is much less reliable than reinstalling from scratch. And top of all that you can't safely test what the results of a configuration change will be, there's no "Undo" so to speak. In NixOS, the entire operating system is built by the Nix package manager from a description in a purely functional build language. This means that building a new configuration cannot overwrite previous configurations. Most of the other features follow this pattern. Nix stores all packages in isolation from each other. [More about NixOS][10].
|
||||
|
||||
|
||||
|
||||
**GoboLinux**: This is another very unique Linux distro. What makes GoboLinux so different from the rest is its unique re-arrangement of the filesystem. It has its own subdirectory tree, where all of its files and programs are stored. GoboLinux does not have a package database because the filesystem is its database. In some ways, this sort of arrangement is similar to that seen in OS X. [Get GoboLinux][11].
|
||||
|
||||

|
||||
|
||||
**Hannah Montana Linux**: Here is a Linux distro based on Kubuntu with a Hannah Montana themed boot screen, KDM, icon set, ksplash, plasma, color scheme, and wallpapers (I'm so sorry). [Link][12]. Project not active anymore.
|
||||
|
||||
**RLSD Linux**: An extremely minimalistic, small, lightweight and security-hardened, text-based operating system built on Linux. "It's a unique distribution that provides a selection of console applications and home-grown security features which might appeal to hackers," developers claim. [RLSD Linux][13].
|
||||
|
||||
Did we miss anything even stranger? Let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techdrivein.com/2015/08/the-strangest-most-unique-linux-distros.html
|
||||
|
||||
作者:Manuel Jose
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||
[2]:http://qntm.org/suicide
|
||||
[3]:http://sourceforge.net/projects/suicide-linux/files/
|
||||
[4]:http://www.techdrivein.com/2015/02/papyros-material-design-linux-coming-soon.html
|
||||
[5]:https://plus.google.com/communities/109966288908859324845/stream/3262a3d3-0797-4344-bbe0-56c3adaacb69
|
||||
[6]:https://www.bountysource.com/teams/papyros
|
||||
[7]:https://www.qubes-os.org/
|
||||
[8]:http://ubuntusatanic.org/
|
||||
[9]:http://tinycorelinux.net/
|
||||
[10]:https://nixos.org/
|
||||
[11]:http://www.gobolinux.org/
|
||||
[12]:http://hannahmontana.sourceforge.net/
|
||||
[13]:http://rlsd2.dimakrasner.com/
|
||||
63
sources/talk/20150901 Is Linux Right For You.md
Normal file
63
sources/talk/20150901 Is Linux Right For You.md
Normal file
@ -0,0 +1,63 @@
|
||||
Is Linux Right For You?
|
||||
================================================================================
|
||||
> Not everyone should opt for Linux -- for many users, remaining with Windows or OSX is the better choice.
|
||||
|
||||
I enjoy using Linux on the desktop. Not because of software politics or because I despise other operating systems. I simply like Linux because it just works.
|
||||
|
||||
It's been my experience that not everyone is cut out for the Linux lifestyle. In this article, I'll help you run through the pros and cons of making the switch to Linux so you can determine if switching is right for you.
|
||||
|
||||
### When to make the switch ###
|
||||
|
||||
Switching to Linux makes sense when there is a decisive reason to do so. The same can be said about moving from Windows to OS X or vice versa. In order to have success with switching, you must be able to identify your reason for jumping ship in the first place.
|
||||
|
||||
For some people, the reason for switching is frustration with their current platform. Maybe the latest upgrade left them with a lousy experience and they're ready to chart new horizons. In other instances, perhaps it's simply a matter of curiosity. Whatever the motivation, you must have a good reason for switching operating systems. If you're pushing yourself in this direction without a good reason, then no one wins.
|
||||
|
||||
However, there are exceptions to every rule. And if you're really interested in trying Linux on the desktop, then maybe coming to terms with a workable compromise is the way to go.
|
||||
|
||||
### Starting off slow ###
|
||||
|
||||
After trying Linux for the first time, I've seen people blast their Windows installation to bits because they had a good experience with Ubuntu on a flash drive for 20 minutes. Folks, this isn't a test. Instead I'd suggest the following:
|
||||
|
||||
- Run the [Linux distro in a virtual machine][1] for a week. This means you are committing to running that distro for all browser work, email and other tasks you might otherwise do on that machine.
|
||||
- If running a VM for a week is too resource intensive, try doing the same with a USB drive running Linux that offers [some persistent storage][2]. This will allow you to leave your main OS alone and intact. At the same time, you'll still be able to "live inside" of your Linux distribution for a week.
|
||||
- If you find that everything is successful after a week of running Linux, the next step is to examine how many times you booted into Windows that week. If only occasionally, then the next step is to look into [dual-booting Windows][3] and Linux. For those of you that only found themselves using their Linux distro, it might be worth considering making the switch full time.
|
||||
- Before you hose your Windows partition completely, it might make more sense to purchase a second hard drive to install Linux onto instead. This allows you to dual-boot, but to do so with ample hard drive space. It also makes Windows available to you if something should come up.
|
||||
|
||||
### What do you gain adopting Linux? ###
|
||||
|
||||
So what does one gain by switching to Linux? Generally it comes down to personal freedom for most people. With Linux, if something isn't to your liking, you're free to change it. Using Linux also saves users oodles of money in avoiding hardware upgrades and unnecessary software expenses. Additionally, you're not burdened with tracking down lost license keys for software. And if you dislike the direction a particular distribution is headed, you can switch to another distribution with minimal hassle.
|
||||
|
||||
The sheer volume of desktop choice on the Linux desktop is staggering. This level of choice might even seem overwhelming to the newcomer. But if you find a distro base (Debian, Fedora, Arch, etc) that you like, the hard work is already done. All you need to do now is find a variation of the distro and the desktop environment you prefer.
|
||||
|
||||
Now one of the most common complaints I hear is that there isn't much in the way of software for Linux. However, this isn't accurate at all. While other operating systems may have more of it, today's Linux desktop has applications to do just about anything you can think of. Video editing (home and pro-level), photography, office management, remote access, music (listening and creation), plus much, much more.
|
||||
|
||||
### What you lose adopting Linux? ###
|
||||
|
||||
As much as I enjoy using Linux, my wife's home office relies on OS X. She's perfectly content using Linux for some tasks, however she relies on OS X for specific software not available for Linux. This is a common problem that many people face when first looking at making the switch. You must decide whether or not you're going to be losing out on critical software if you make the switch.
|
||||
|
||||
Sometimes the issue is because the software has content locked down with it. In other cases, it's a workflow and functionality that was found with the legacy applications and not with the software available for Linux. I myself have never experienced this type of challenge, but I know those who have. Many of the software titles available for Linux are also available for other operating systems. So if there is a concern about such things, I encourage you to try out comparable apps on your native OS first.
|
||||
|
||||
Another thing you might lose by switching to Linux is the luxury of local support when you need it. People scoff at this, but I know of countless instances where a newcomer to Linux was dismayed to find their only recourse for solving Linux challenges was from strangers on the Web. This is especially problematic if their only PC is the one having issues. Windows and OS X users are spoiled in that there are endless support techs in cities all over the world that support their platform(s).
|
||||
|
||||
### How to proceed from here ###
|
||||
|
||||
Perhaps the single biggest piece of advice to remember is always have a fallback plan. Remember, once you wipe that copy of Windows 10 from your hard drive, you may find yourself spending money to get it reinstalled. This is especially true for those of you who upgrade from other Windows releases. Accepting this, persistent flash drives with Linux or dual-booting Windows and Linux is always a preferable way forward for newcomers. Odds are that you may be just fine and take to Linux like a fish to water. But having that fallback plan in place just means you'll sleep better at night.
|
||||
|
||||
If instead you've been relying on a dual-boot installation for weeks and feel ready to take the plunge, then by all means do it. Wipe your drive and start off with a clean installation of your favorite Linux distribution. I've been a full time Linux enthusiast for years and I can tell you for certain, it's a great feeling. How long? Let's just say my first Linux experience was with early Red Hat. I finally installed a dedicated installation on my laptop by 2003.
|
||||
|
||||
Existing Linux enthusiasts, where did you first get started? Was your switch an exciting one or was it filled with angst? Hit the Comments and share your experiences.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/is-linux-right-for-you.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://www.psychocats.net/ubuntu/virtualbox
|
||||
[2]:http://www.howtogeek.com/howto/14912/create-a-persistent-bootable-ubuntu-usb-flash-drive/
|
||||
[3]:http://www.linuxandubuntu.com/home/dual-boot-ubuntu-15-04-14-10-and-windows-10-8-1-8-step-by-step-tutorial-with-screenshots
|
||||
@ -1,114 +0,0 @@
|
||||
wyangsun translating
|
||||
Install Strongswan - A Tool to Setup IPsec Based VPN in Linux
|
||||
================================================================================
|
||||
IPsec is a standard which provides the security at network layer. It consist of authentication header (AH) and encapsulating security payload (ESP) components. AH provides the packet Integrity and confidentiality is provided by ESP component . IPsec ensures the following security features at network layer.
|
||||
|
||||
- Confidentiality
|
||||
- Integrity of packet
|
||||
- Source Non. Repudiation
|
||||
- Replay attack protection
|
||||
|
||||
[Strongswan][1] is an open source implementation of IPsec protocol and Strongswan stands for Strong Secure WAN (StrongS/WAN). It supports the both version of automatic keying exchange in IPsec VPN (Internet keying Exchange (IKE) V1 & V2).
|
||||
|
||||
Strongswan basically provides the automatic keying sharing between two nodes/gateway of the VPN and after that it uses the Linux Kernel implementation of IPsec (AH & ESP). Key shared using IKE mechanism is further used in the ESP for the encryption of data. In IKE phase, strongswan uses the encryption algorithms (AES,SHA etc) of OpenSSL and other crypto libraries. However, ESP component of IPsec uses the security algorithm which are implemented in the Linux Kernel. The main features of Strongswan are given below.
|
||||
|
||||
- 509 certificates or pre-shared keys based Authentication
|
||||
- Support of IKEv1 and IKEv2 key exchange protocols
|
||||
- Optional built-in integrity and crypto tests for plugins and libraries
|
||||
- Support of elliptic curve DH groups and ECDSA certificates
|
||||
- Storage of RSA private keys and certificates on a smartcard.
|
||||
|
||||
It can be used in the client / server (road warrior) and gateway to gateway scenarios.
|
||||
|
||||
### How to Install ###
|
||||
|
||||
Almost all Linux distro’s, supports the binary package of Strongswan. In this tutorial, we will install the strongswan from binary package and also the compilation of strongswan source code with desirable features.
|
||||
|
||||
### Using binary package ###
|
||||
|
||||
Strongswan can be installed using following command on Ubuntu 14.04 LTS .
|
||||
|
||||
$sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
The global configuration (strongswan.conf) file and ipsec configuration (ipsec.conf/ipsec.secrets) files of strongswan are under /etc/ directory.
|
||||
|
||||
### Pre-requisite for strongswan source compilation & installation ###
|
||||
|
||||
- GMP (Mathematical/Precision Library used by strongswan)
|
||||
- OpenSSL (Crypto Algorithms from this library)
|
||||
- PKCS (1,7,8,11,12)(Certificate encoding and smart card integration with Strongswan )
|
||||
|
||||
#### Procedure ####
|
||||
|
||||
**1)** Go to /usr/src/ directory using following command in the terminal.
|
||||
|
||||
$cd /usr/src
|
||||
|
||||
**2)** Download the source code from strongswan site suing following command
|
||||
|
||||
$sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz is the latest version.)
|
||||
|
||||

|
||||
|
||||
**3)** Extract the downloaded software and go inside it using following command.
|
||||
|
||||
$sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** Configure the strongswan as per desired options using configure command.
|
||||
|
||||
./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
If GMP library is not installed, then configure script will generate following error.
|
||||
|
||||

|
||||
|
||||
Therefore, first of all, install the GMP library using following command and then run the configure script.
|
||||
|
||||

|
||||
|
||||
However, if GMP is already installed and still above error exists then create soft link of libgmp.so library at /usr/lib , /lib/, /usr/lib/x86_64-linux-gnu/ paths in Ubuntu using following command.
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
After the creation of libgmp.so softlink, again run the ./configure script and it may find the gmp library. However, it may generate another error of gmp header file which is shown the following figure.
|
||||
|
||||

|
||||
|
||||
Install the libgmp-dev package using following command for the solution of above error.
|
||||
|
||||
$sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
After installation of development package of gmp library, again run the configure script and if it does not produce any error, then the following output will be displayed.
|
||||
|
||||

|
||||
|
||||
Type the following commands for the compilation and installation of strongswan.
|
||||
|
||||
$ sudo make ; sudo make install
|
||||
|
||||
After the installation of strongswan , the Global configuration (strongswan.conf) and ipsec policy/secret configuration files (ipsec.conf/ipsec.secretes) are placed in **/usr/local/etc** directory.
|
||||
|
||||
Strongswan can be used as tunnel or transport mode depends on our security need. It provides well known site-2-site and road warrior VPNs. It can be use easily with Cisco,Juniper devices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to run JBoss Data Virtualization 6.0.0.GA with OData in a Docker Container. JBoss Data Virtualization is a data supply and integration solution platform that transforms various scatered multiple sources data, treats them as single source and delivers the required data into actionable information at business speed to any applications or users. JBoss Data Virtualization can help us easily combine and transform data into reusable business friendly data models and make unified data easily consumable through open standard interfaces. It offers comprehensive data abstraction, federation, integration, transformation, and delivery capabilities to combine data from one or multiple sources into reusable for agile data utilization and sharing.For more information about JBoss Data Virtualization, we can check out [its official page][1]. Docker is an open source platform that provides an open platform to pack, ship and run any application as a lightweight container. Running JBoss Data Virtualization with OData in Docker Container makes us easy to handle and launch.
|
||||
|
||||
@ -1,440 +0,0 @@
|
||||
translating by tnuoccalanosrep
|
||||
|
||||
Linux file system hierarchy v2.0
|
||||
================================================================================
|
||||
What is a file in Linux? What is file system in Linux? Where are all the configuration files? Where do I keep my downloaded applications? Is there really a filesystem standard structure in Linux? Well, the above image explains Linux file system hierarchy in a very simple and non-complex way. It’s very useful when you’re looking for a configuration file or a binary file. I’ve added some explanation and examples below, but that’s TL;DR.
|
||||
|
||||
Another issue is when you got configuration and binary files all over the system that creates inconsistency and if you’re a large organization or even an end user, it can compromise your system (binary talking with old lib files etc.) and when you do [security audit of your Linux system][1], you find it is vulnerable to different exploits. So keeping a clean operating system (no matter Windows or Linux) is important.
|
||||
|
||||
### What is a file in Linux? ###
|
||||
|
||||
A simple description of the UNIX system, also applicable to Linux, is this:
|
||||
|
||||
> On a UNIX system, everything is a file; if something is not a file, it is a process.
|
||||
|
||||
This statement is true because there are special files that are more than just files (named pipes and sockets, for instance), but to keep things simple, saying that everything is a file is an acceptable generalization. A Linux system, just like UNIX, makes no difference between a file and a directory, since a directory is just a file containing names of other files. Programs, services, texts, images, and so forth, are all files. Input and output devices, and generally all devices, are considered to be files, according to the system.
|
||||
|
||||

|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: Added title and version history.
|
||||
- – Improved: Added /srv, /media and /proc.
|
||||
- – Improved: Updated descriptions to reflect modern Linux File Systems.
|
||||
- – Fixed: Multiple typo’s.
|
||||
- – Fixed: Appearance and colour.
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: Initial diagram.
|
||||
- – Note: Discarded lowercase version.
|
||||
|
||||
### Download Links ###
|
||||
|
||||
Following are two links for download. If you need this in any other format, let me know and I will try to create that and upload it somewhere.
|
||||
|
||||
- [Large (PNG) Format – 2480×1755 px – 184KB][2]
|
||||
- [Largest (PDF) Format – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**Note**: PDF Format is best for printing and very high in quality
|
||||
|
||||
### Linux file system description ###
|
||||
|
||||
In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from `MS-DOS` (Disk Operating System) for instance. The large branches contain more branches, and the branches at the end contain the tree’s leaves or normal files. For now we will use this image of the tree, but we will find out later why this is not a fully accurate image.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">Directory</th>
|
||||
<th scope="col">Description</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/</code></dd>
|
||||
</dl></td>
|
||||
<td><i>Primary hierarchy</i> root and root directory of the entire file system hierarchy.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential command binaries that need to be available in single user mode; for all users, <i>e.g.</i>, cat, ls, cp.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/boot</code></dd>
|
||||
</dl></td>
|
||||
<td>Boot loader files, <i>e.g.</i>, kernels, initrd.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/dev</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential devices, <i>e.g.</i>, <code>/dev/null</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/etc</code></dd>
|
||||
</dl></td>
|
||||
<td>Host-specific system-wide configuration filesThere has been controversy over the meaning of the name itself. In early versions of the UNIX Implementation Document from Bell labs, /etc is referred to as the <i>etcetera directory</i>, as this directory historically held everything that did not belong elsewhere (however, the FHS restricts /etc to static configuration files and may not contain binaries). Since the publication of early documentation, the directory name has been re-designated in various ways. Recent interpretations include backronyms such as “Editable Text Configuration” or “Extended Tool Chest”.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files for add-on packages that are stored in <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sgml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files, such as catalogs, for software that processes SGML.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files for the X Window System, version 11.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/xml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files, such as catalogs, for software that processes XML.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/home</code></dd>
|
||||
</dl></td>
|
||||
<td>Users’ home directories, containing saved files, personal settings, etc.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl></td>
|
||||
<td>Libraries essential for the binaries in <code>/bin/</code> and <code>/sbin/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl></td>
|
||||
<td>Alternate format essential libraries. Such directories are optional, but if they exist, they have some requirements.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/media</code></dd>
|
||||
</dl></td>
|
||||
<td>Mount points for removable media such as CD-ROMs (appeared in FHS-2.3).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/mnt</code></dd>
|
||||
</dl></td>
|
||||
<td>Temporarily mounted filesystems.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl></td>
|
||||
<td>Optional application software packages.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/proc</code></dd>
|
||||
</dl></td>
|
||||
<td>Virtual filesystem providing process and kernel information as files. In Linux, corresponds to a procfs mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/root</code></dd>
|
||||
</dl></td>
|
||||
<td>Home directory for the root user.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential system binaries, <i>e.g.</i>, init, ip, mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/srv</code></dd>
|
||||
</dl></td>
|
||||
<td>Site-specific data which are served by the system.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl></td>
|
||||
<td>Temporary files (see also <code>/var/tmp</code>). Often not preserved between system reboots.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/usr</code></dd>
|
||||
</dl></td>
|
||||
<td><i>Secondary hierarchy</i> for read-only user data; contains the majority of (multi-)user utilities and applications.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Non-essential command binaries (not needed in single user mode); for all users.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/include</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Standard include files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Libraries for the binaries in <code>/usr/bin/</code> and <code>/usr/sbin/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Alternate format libraries (optional).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/local</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td><i>Tertiary hierarchy</i> for local data, specific to this host. Typically has further subdirectories, <i>e.g.</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Non-essential system binaries, <i>e.g.</i>, daemons for various network-services.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/share</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Architecture-independent (shared) data.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/src</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Source code, <i>e.g.</i>, the kernel source code with its header files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11R6</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window System, Version 11, Release 6.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/var</code></dd>
|
||||
</dl></td>
|
||||
<td>Variable files—files whose content is expected to continually change during normal operation of the system—such as logs, spool files, and temporary e-mail files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/cache</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Application cache data. Such data are locally generated as a result of time-consuming I/O or calculation. The application must be able to regenerate or restore the data. The cached files can be deleted without loss of data.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>State information. Persistent data modified by programs as they run, <i>e.g.</i>, databases, packaging system metadata, etc.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lock</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Lock files. Files keeping track of resources currently in use.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/log</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Log files. Various logs.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Users’ mailboxes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Variable data from add-on packages that are stored in <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/run</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Information about the running system since last boot, <i>e.g.</i>, currently logged-in users and running <a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/spool</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Spool for tasks waiting to be processed, <i>e.g.</i>, print queues and outgoing mail queue.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Deprecated location for users’ mailboxes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Temporary files to be preserved between reboots.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Types of files in Linux ###
|
||||
|
||||
Most files are just files, called `regular` files; they contain normal data, for example text files, executable files or programs, input for or output from a program and so on.
|
||||
|
||||
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
|
||||
|
||||
- `Directories`: files that are lists of other files.
|
||||
- `Special files`: the mechanism used for input and output. Most special files are in `/dev`, we will discuss them later.
|
||||
- `Links`: a system to make a file or directory visible in multiple parts of the system’s file tree. We will talk about links in detail.
|
||||
- `(Domain) sockets`: a special file type, similar to TCP/IP sockets, providing inter-process networking protected by the file system’s access control.
|
||||
- `Named pipes`: act more or less like sockets and form a way for processes to communicate with each other, without using network socket semantics.
|
||||
|
||||
### File system in reality ###
|
||||
|
||||
For most users and for most common system administration tasks, it is enough to accept that files and directories are ordered in a tree-like structure. The computer, however, doesn’t understand a thing about trees or tree-structures.
|
||||
|
||||
Every partition has its own file system. By imagining all those file systems together, we can form an idea of the tree-structure of the entire system, but it is not as simple as that. In a file system, a file is represented by an `inode`, a kind of serial number containing information about the actual data that makes up the file: to whom this file belongs, and where is it located on the hard disk.
|
||||
|
||||
Every partition has its own set of inodes; throughout a system with multiple partitions, files with the same inode number can exist.
|
||||
|
||||
Each inode describes a data structure on the hard disk, storing the properties of a file, including the physical location of the file data. When a hard disk is initialized to accept data storage, usually during the initial system installation process or when adding extra disks to an existing system, a fixed number of inodes per partition is created. This number will be the maximum amount of files, of all types (including directories, special files, links etc.) that can exist at the same time on the partition. We typically count on having 1 inode per 2 to 8 kilobytes of storage.At the time a new file is created, it gets a free inode. In that inode is the following information:
|
||||
|
||||
- Owner and group owner of the file.
|
||||
- File type (regular, directory, …)
|
||||
- Permissions on the file
|
||||
- Date and time of creation, last read and change.
|
||||
- Date and time this information has been changed in the inode.
|
||||
- Number of links to this file (see later in this chapter).
|
||||
- File size
|
||||
- An address defining the actual location of the file data.
|
||||
|
||||
The only information not included in an inode, is the file name and directory. These are stored in the special directory files. By comparing file names and inode numbers, the system can make up a tree-structure that the user understands. Users can display inode numbers using the -i option to ls. The inodes have their own separate space on the disk.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -1,97 +0,0 @@
|
||||
Fix No Bootable Device Found Error After Installing Ubuntu
|
||||
================================================================================
|
||||
Usually, I dual boot Ubuntu and Windows but this time I decided to go for a clean Ubuntu installation i.e. eliminating Windows completely. After the clean install of Ubuntu, I ended up with a screen saying **no bootable device found** instead of the Grub screen. Clearly, the installation messed up with the UEFI boot settings.
|
||||
|
||||

|
||||
|
||||
I am going to show you how I fixed **no bootable device found error after installing Ubuntu in Acer laptops**. It is important that I mention that I am using Acer Aspire R13 because we have to change things in firmware settings and those settings might look different from manufacturer to manufacturer and from device to device.
|
||||
|
||||
So before you go on trying the steps mentioned here, let’s first see what state my computer was in during this error:
|
||||
|
||||
- My Acer Aspire R13 came preinstalled with Windows 8.1 and with UEFI boot manager
|
||||
- Secure boot was not turned off (my laptop has just come from repair and the service guy had put the secure boot on again, I did not know until I ran up in the problem). You can read this post to know [how disable secure boot in Acer laptops][1]
|
||||
- I chose to install Ubuntu by erasing everything i.e. existing Windows 8.1, various partitions etc.
|
||||
- After installing Ubuntu, I saw no bootable device found error while booting from the hard disk. Booting from live USB worked just fine
|
||||
|
||||
In my opinion, not disabling the secure boot was the reason of this error. However, I have no data to backup my claim. It is just a hunch. Interestingly, dual booting Windows and Linux often ends up in common Grub issues like these two:
|
||||
|
||||
- [error: no such partition grub rescue][2]
|
||||
- [Minimal BASH like line editing is supported][3]
|
||||
|
||||
If you are in similar situation, you can try the fix which worked for me.
|
||||
|
||||
### Fix no bootable device found error after installing Ubuntu ###
|
||||
|
||||
Pardon me for poor quality images. My OnePlus camera seems to be not very happy with my laptop screen.
|
||||
|
||||
#### Step 1 ####
|
||||
|
||||
Turn the power off and boot into boot settings. I had to press Fn+F2 (to press F2 key) on Acer Aspire R13 quickly. You have to be very quick with it if you are using SSD hard disk because SSDs are very fast in booting. Depending upon your manufacturer/model, you might need to use Del or F10 or F12 keys.
|
||||
|
||||
#### Step 2 ####
|
||||
|
||||
In the boot settings, make sure that Secure Boot is turned on. It should be under the Boot tab.
|
||||
|
||||
#### Step 3 ####
|
||||
|
||||
Go to Security tab and look for “Select an UEFI file as trusted for executing” and click enter.
|
||||
|
||||

|
||||
|
||||
Just for your information, what we are going to do here is to add the UEFI settings file (it was generated while Ubuntu installation) among the trusted UEFI boots in your device. If you remember, UEFI boot’s main aim is to provide security and since Secure Boot was not disabled (perhaps) the device did not intend to boot from the newly installed OS. Adding it as trusted, kind of whitelisting, will let the device boot from the Ubuntu UEFI file.
|
||||
|
||||
#### Step 4 ####
|
||||
|
||||
You should see your hard disk like HDD0 etc here. If you have more than one hard disk, I hope you remember where did you install Ubuntu. Press Enter here as well.
|
||||
|
||||

|
||||
|
||||
#### Step 5 ####
|
||||
|
||||
You should see <EFI> here. Press enter.
|
||||
|
||||

|
||||
|
||||
#### Step 6 ####
|
||||
|
||||
You’ll see <Ubuntu> in next screen. Don’t get impatient, you are almost there
|
||||
|
||||

|
||||
|
||||
#### Step 7 ####
|
||||
|
||||
You’ll see shimx64.efi, grubx64.efi and MokManager.efi file here. The important one is shimx64.efi here. Select it and click enter.
|
||||
|
||||
|
||||

|
||||
|
||||
In next screen, type Yes and click enter.
|
||||
|
||||

|
||||
|
||||
#### Step 8 ####
|
||||
|
||||
Once we have added it as trused EFI file to be executed, press F10 to save and exit.
|
||||
|
||||

|
||||
|
||||
Reboot your system and this time you should be seeing the familiar Grub screen. Even if you do not see Grub screen, you should at least not be seeing “no bootable device found” screen anymore. You should be able to boot into Ubuntu.
|
||||
|
||||
If your Grub screen was messed up after the fix but you got to login into it, you can reinstall Grub to boot into the familiar purple Grub screen of Ubuntu.
|
||||
|
||||
I hope this tutorial helped you to fix no bootable device found error. Any questions or suggestions or a word of thanks is always welcomed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/no-bootable-device-found-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/disable-secure-boot-in-acer/
|
||||
[2]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[3]:http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
@ -1,294 +0,0 @@
|
||||
How to set up a system status page of your infrastructure
|
||||
================================================================================
|
||||
If you are a system administrator who is responsible for critical IT infrastructure or services of your organization, you will understand the importance of effective communication in your day-to-day tasks. Suppose your production storage server is on fire. You want your entire team on the same page in order to resolve the issue as fast as you can. While you are at it, you don't want half of all users contacting you asking why they cannot access their documents. When a scheduled maintenance is coming up, you want to notify interested parties of the event ahead of the schedule, so that unnecessary support tickets can be avoided.
|
||||
|
||||
All these require some sort of streamlined communication channel between you, your team and people you serve. One way to achieve that is to maintain a centralized system status page, where the detail of downtime incidents, progress updates and maintenance schedules are reported and chronicled. That way, you can minimize unnecessary distractions during downtime, and also have any interested party informed and opt-in for any status update.
|
||||
|
||||
One good **open-source, self-hosted system status page solution** is [Cachet][1]. In this tutorial, I am going to describe how to set up a self-hosted system status page using Cachet.
|
||||
|
||||
### Cachet Features ###
|
||||
|
||||
Before going into the detail of setting up Cachet, let me briefly introduce its main features.
|
||||
|
||||
- **Full JSON API**: The Cachet API allows you to connect any external program or script (e.g., uptime script) to Cachet to report incidents or update status automatically.
|
||||
- **Authentication**: Cachet supports Basic Auth and API token in JSON API, so that only authorized personnel can update the status page.
|
||||
- **Metrics system**: This is useful to visualize custom data over time (e.g., server load or response time).
|
||||
- **Notification**: Optionally you can send notification emails about reported incidents to anyone who signed up to the status page.
|
||||
- **Multiple languages**: The status page can be translated into 11 different languages.
|
||||
- **Two factor authentication**: This allows you to lock your Cachet admin account with Google's two-factor authentication.
|
||||
- **Cross database support**: You can choose between MySQL, SQLite, Redis, APC, and PostgreSQL for a backend storage.
|
||||
|
||||
In the rest of the tutorial, I explain how to install and configure Cachet on Linux.
|
||||
|
||||
### Step One: Download and Install Cachet ###
|
||||
|
||||
Cachet requires a web server and a backend database to operate. In this tutorial, I am going to use the LAMP stack. Here are distro-specific instructions to install Cachet and LAMP stack.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install curl git apache2 mysql-server mysql-client php5 php5-mysql
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R www-data:www-data .
|
||||
|
||||
For more detail on setting up LAMP stack on Debian-based systems, refer to [this tutorial][2].
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
On Red Hat based systems, you first need to [enable REMI repository][3] (to meet PHP version requirement). Then proceed as follows.
|
||||
|
||||
$ sudo yum install curl git httpd mariadb-server
|
||||
$ sudo yum --enablerepo=remi-php56 install php php-mysql php-mbstring
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R apache:apache .
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=http
|
||||
$ sudo firewall-cmd --reload
|
||||
$ sudo systemctl enable httpd.service; sudo systemctl start httpd.service
|
||||
$ sudo systemctl enable mariadb.service; sudo systemctl start mariadb.service
|
||||
|
||||
For more details on setting up LAMP on Red Hat-based systems, refer to [this tutorial][4].
|
||||
|
||||
### Configure a Backend Database for Cachet ###
|
||||
|
||||
The next step is to configure database backend.
|
||||
|
||||
Log in to MySQL/MariaDB server, and create an empty database called 'cachet'.
|
||||
|
||||
$ sudo mysql -uroot -p
|
||||
|
||||
----------
|
||||
|
||||
mysql> create database cachet;
|
||||
mysql> quit
|
||||
|
||||
Now create a Cachet configuration file by using a sample configuration file.
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo mv .env.example .env
|
||||
|
||||
In .env file, fill in database information (i.e., DB_*) according to your setup. Leave other fields unchanged for now.
|
||||
|
||||
APP_ENV=production
|
||||
APP_DEBUG=false
|
||||
APP_URL=http://localhost
|
||||
APP_KEY=SomeRandomString
|
||||
|
||||
DB_DRIVER=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=cachet
|
||||
DB_USERNAME=root
|
||||
DB_PASSWORD=<root-password>
|
||||
|
||||
CACHE_DRIVER=apc
|
||||
SESSION_DRIVER=apc
|
||||
QUEUE_DRIVER=database
|
||||
|
||||
MAIL_DRIVER=smtp
|
||||
MAIL_HOST=mailtrap.io
|
||||
MAIL_PORT=2525
|
||||
MAIL_USERNAME=null
|
||||
MAIL_PASSWORD=null
|
||||
MAIL_ADDRESS=null
|
||||
MAIL_NAME=null
|
||||
|
||||
REDIS_HOST=null
|
||||
REDIS_DATABASE=null
|
||||
REDIS_PORT=null
|
||||
|
||||
### Step Three: Install PHP Dependencies and Perform DB Migration ###
|
||||
|
||||
Next, we are going to install necessary PHP dependencies. For that we will use composer. If you do not have composer installed on your system, install it first:
|
||||
|
||||
$ curl -sS https://getcomposer.org/installer | sudo php -- --install-dir=/usr/local/bin --filename=composer
|
||||
|
||||
Now go ahead and install PHP dependencies using composer.
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo composer install --no-dev -o
|
||||
|
||||
Next, perform one-time database migration. This step will populate the empty database we created earlier with necessary tables.
|
||||
|
||||
$ sudo php artisan migrate
|
||||
|
||||
Assuming the database config in /var/www/cachet/.env is correct, database migration should be completed successfully as shown below.
|
||||
|
||||
|
||||
|
||||
Next, create a security key, which will be used to encrypt the data entered in Cachet.
|
||||
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
|
||||
|
||||
The generated app key will be automatically added to the APP_KEY variable of your .env file. No need to edit .env on your own here.
|
||||
|
||||
### Step Four: Configure Apache HTTP Server ###
|
||||
|
||||
Now it's time to configure the web server that Cachet will be running on. As we are using Apache HTTP server, create a new [virtual host][5] for Cachet as follows.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo vi /etc/apache2/sites-available/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Enable the new Virtual Host and mod_rewrite with:
|
||||
|
||||
$ sudo a2ensite cachet.conf
|
||||
$ sudo a2enmod rewrite
|
||||
$ sudo service apache2 restart
|
||||
|
||||
#### Fedora, CentOS or RHEL ####
|
||||
|
||||
On Red Hat based systems, create a virtual host file as follows.
|
||||
|
||||
$ sudo vi /etc/httpd/conf.d/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Now reload Apache configuration:
|
||||
|
||||
$ sudo systemctl reload httpd.service
|
||||
|
||||
### Step Five: Configure /etc/hosts for Testing Cachet ###
|
||||
|
||||
At this point, the initial Cachet status page should be up and running, and now it's time to test.
|
||||
|
||||
Since Cachet is configured as a virtual host of Apache HTTP server, we need to tweak /etc/hosts of your client computer to be able to access it. Here the client computer is the one from which you will be accessing the Cachet page.
|
||||
|
||||
Open /etc/hosts, and add the following entry.
|
||||
|
||||
$ sudo vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
<cachet-server-ip-address> cachethost
|
||||
|
||||
In the above, the name "cachethost" must match with ServerName specified in the Apache virtual host file for Cachet.
|
||||
|
||||
### Test Cachet Status Page ###
|
||||
|
||||
Now you are ready to access Cachet status page. Type http://cachethost in your browser address bar. You will be redirected to the initial Cachet setup page as follows.
|
||||
|
||||
|
||||
|
||||
Choose cache/session driver. Here let's choose "File" for both cache and session drivers.
|
||||
|
||||
Next, type basic information about the status page (e.g., site name, domain, timezone and language), as well as administrator account.
|
||||
|
||||
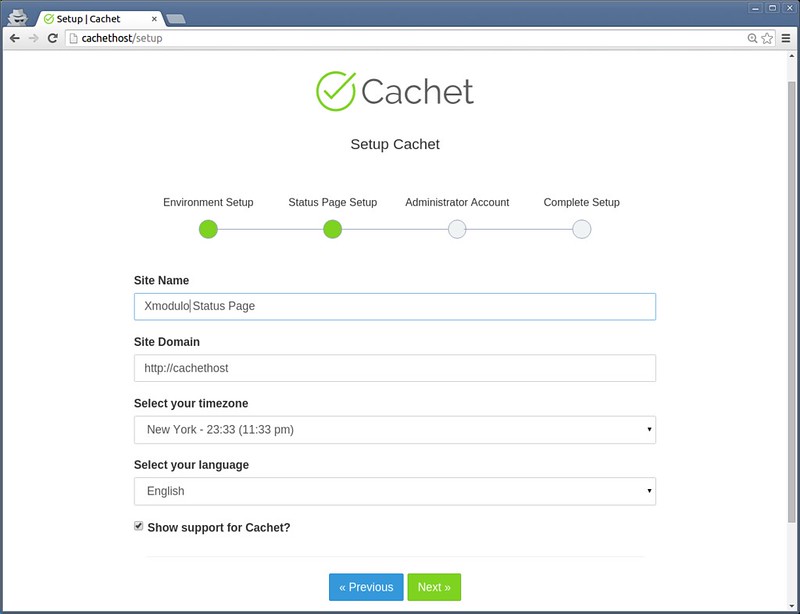
|
||||
|
||||
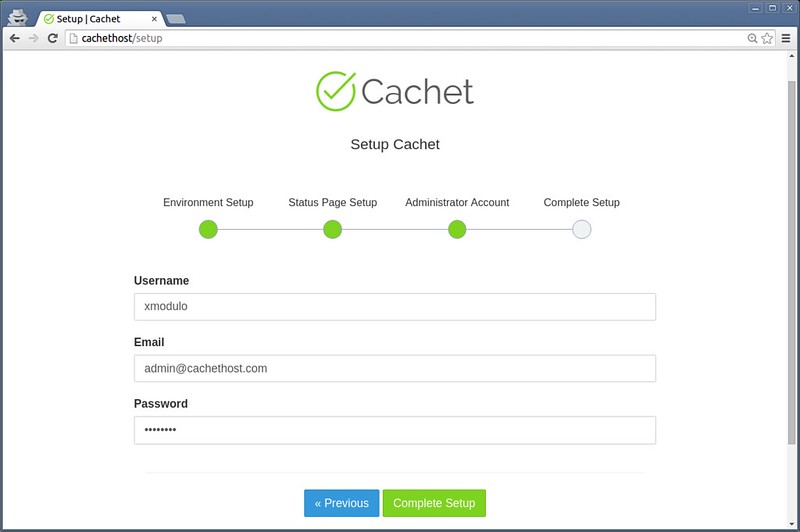
|
||||
|
||||
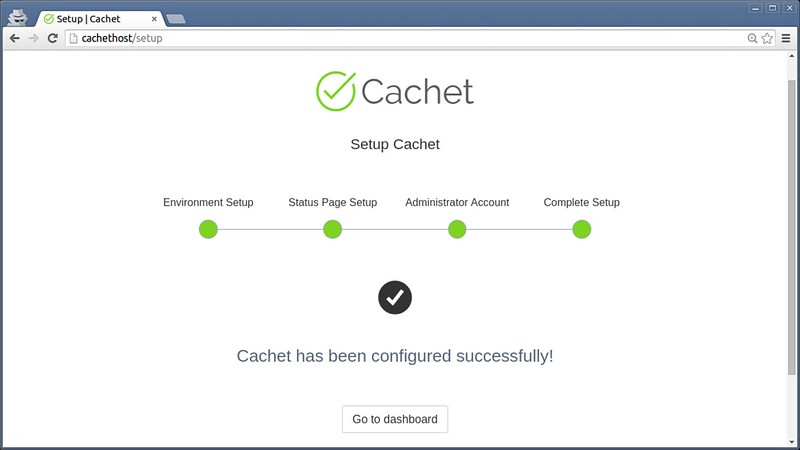
|
||||
|
||||
Your initial status page will finally be ready.
|
||||
|
||||
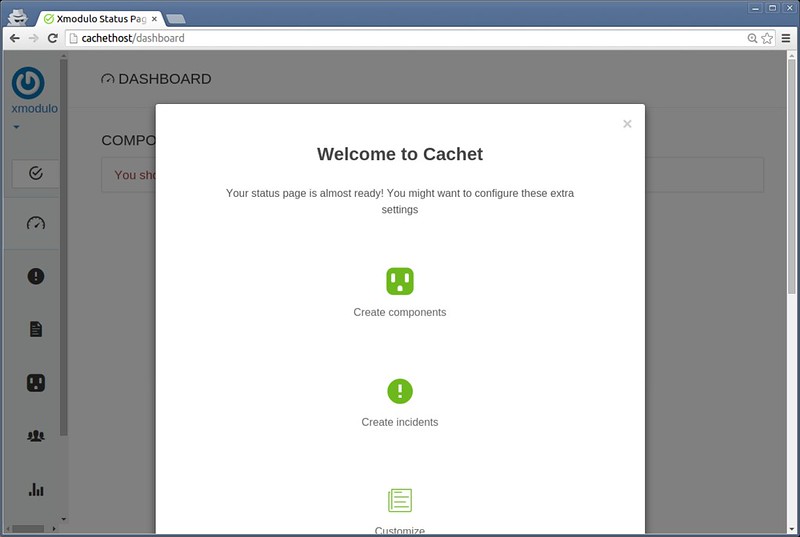
|
||||
|
||||
Go ahead and create components (units of your system), incidents or any scheduled maintenance as you want.
|
||||
|
||||
For example, to add a new component:
|
||||
|
||||
|
||||
|
||||
To add a scheduled maintenance:
|
||||
|
||||
This is what the public Cachet status page looks like:
|
||||
|
||||
|
||||
|
||||
With SMTP integration, you can send out emails on status updates to any subscribers. Also, you can fully customize the layout and style of the status page using CSS and markdown formatting.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Cachet is pretty easy-to-use, self-hosted status page software. One of the nicest features of Cachet is its support for full JSON API. Using its RESTful API, one can easily hook up Cachet with separate monitoring backends (e.g., [Nagios][6]), and feed Cachet with incident reports and status updates automatically. This is far quicker and efficient than manually manage a status page.
|
||||
|
||||
As final words, I'd like to mention one thing. While setting up a fancy status page with Cachet is straightforward, making the best use of the software is not as easy as installing it. You need total commitment from the IT team on updating the status page in an accurate and timely manner, thereby building credibility of the published information. At the same time, you need to educate users to turn to the status page. At the end of the day, it would be pointless to set up a status page if it's not populated well, and/or no one is checking it. Remember this when you consider deploying Cachet in your work environment.
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
As a bonus, here are some useful troubleshooting tips in case you encounter problems while setting up Cachet.
|
||||
|
||||
1. The Cachet page does not load anything, and you are getting the following error.
|
||||
|
||||
production.ERROR: exception 'RuntimeException' with message 'No supported encrypter found. The cipher and / or key length are invalid.' in /var/www/cachet/bootstrap/cache/compiled.php:6695
|
||||
|
||||
**Solution**: Make sure that you create an app key, as well as clear configuration cache as follows.
|
||||
|
||||
$ cd /path/to/cachet
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
2. You are getting the following error while invoking composer command.
|
||||
|
||||
- danielstjules/stringy 1.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- laravel/framework v5.1.8 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- league/commonmark 0.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
|
||||
**Solution**: Make sure to install the required PHP extension mbstring on your system which is compatible with your PHP. On Red Hat based system, since we installed PHP from REMI-56 repository, we install the extension from the same repository.
|
||||
|
||||
$ sudo yum --enablerepo=remi-php56 install php-mbstring
|
||||
|
||||
3. You are getting a blank page while trying to access Cachet status page. The HTTP log shows the following error.
|
||||
|
||||
PHP Fatal error: Uncaught exception 'UnexpectedValueException' with message 'The stream or file "/var/www/cachet/storage/logs/laravel-2015-08-21.log" could not be opened: failed to open stream: Permission denied' in /var/www/cachet/bootstrap/cache/compiled.php:12851
|
||||
|
||||
**Solution**: Try the following commands.
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo php artisan cache:clear
|
||||
$ sudo chmod -R 777 storage
|
||||
$ sudo composer dump-autoload
|
||||
|
||||
If the above solution does not work, try disabling SELinux:
|
||||
|
||||
$ sudo setenforce 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-system-status-page.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://cachethq.io/
|
||||
[2]:http://xmodulo.com/install-lamp-stack-ubuntu-server.html
|
||||
[3]:http://ask.xmodulo.com/install-remi-repository-centos-rhel.html
|
||||
[4]:http://xmodulo.com/install-lamp-stack-centos.html
|
||||
[5]:http://xmodulo.com/configure-virtual-hosts-apache-http-server.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
@ -0,0 +1,165 @@
|
||||
How to switch from NetworkManager to systemd-networkd on Linux
|
||||
================================================================================
|
||||
In the world of Linux, adoption of [systemd][1] has been a subject of heated controversy, and the debate between its proponents and critics is still going on. As of today, most major Linux distributions have adopted systemd as a default init system.
|
||||
|
||||
Billed as a "never finished, never complete, but tracking progress of technology" by its author, systemd is not just the init daemon, but is designed as a more broad system and service management platform which encompasses the growing ecosystem of core system daemons, libraries and utilities.
|
||||
|
||||
One of many additions to **systemd** is **systemd-networkd**, which is responsible for network configuration within the systemd ecosystem. Using systemd-networkd, you can configure basic DHCP/static IP networking for network devices. It can also configure virtual networking features such as bridges, tunnels or VLANs. Wireless networking is not directly handled by systemd-networkd, but you can use wpa_supplicant service to configure wireless adapters, and then hook it up with **systemd-networkd**.
|
||||
|
||||
On many Linux distributions, NetworkManager has been and is still used as a default network configuration manager. Compared to NetworkManager, **systemd-networkd** is still under active development, and missing features. For example, it does not have NetworkManager's intelligence to keep your computer connected across various interfaces at all times. It does not provide ifup/ifdown hooks for advanced scripting. Yet, systemd-networkd is integrated well with the rest of systemd components (e.g., **resolved** for DNS, **timesyncd** for NTP, udevd for naming), and the role of **systemd-networkd** may only grow over time in the systemd environment.
|
||||
|
||||
If you are happy with the way **systemd** is evolving, one thing you can consider is to switch from NetworkManager to systemd-networkd. If you are feverishly against systemd, and perfectly happy with NetworkManager or [basic network service][2], that is totally cool.
|
||||
|
||||
But for those of you who want to try out systemd-networkd, you can read on, and find out in this tutorial how to switch from NetworkManager to systemd-networkd on Linux.
|
||||
|
||||
### Requirement ###
|
||||
|
||||
systemd-networkd is available in systemd version 210 and higher. Thus distributions like Debian 8 "Jessie" (systemd 215), Fedora 21 (systemd 217), Ubuntu 15.04 (systemd 219) or later are compatible with systemd-networkd.
|
||||
|
||||
For other distributions, check the version of your systemd before proceeding.
|
||||
|
||||
$ systemctl --version
|
||||
|
||||
### Switch from Network Manager to Systemd-Networkd ###
|
||||
|
||||
It is relatively straightforward to switch from Network Manager to systemd-networkd (and vice versa).
|
||||
|
||||
First, disable Network Manager service, and enable systemd-networkd as follows.
|
||||
|
||||
$ sudo systemctl disable NetworkManager
|
||||
$ sudo systemctl enable systemd-networkd
|
||||
|
||||
You also need to enable **systemd-resolved** service, which is used by systemd-networkd for network name resolution. This service implements a caching DNS server.
|
||||
|
||||
$ sudo systemctl enable systemd-resolved
|
||||
$ sudo systemctl start systemd-resolved
|
||||
|
||||
Once started, **systemd-resolved** will create its own resolv.conf somewhere under /run/systemd directory. However, it is a common practise to store DNS resolver information in /etc/resolv.conf, and many applications still rely on /etc/resolv.conf. Thus for compatibility reason, create a symlink to /etc/resolv.conf as follows.
|
||||
|
||||
$ sudo rm /etc/resolv.conf
|
||||
$ sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
|
||||
|
||||
### Configure Network Connections with Systemd-networkd ###
|
||||
|
||||
To configure network devices with systemd-networkd, you must specify configuration information in text files with .network extension. These network configuration files are then stored and loaded from /etc/systemd/network. When there are multiple files, systemd-networkd loads and processes them one by one in lexical order.
|
||||
|
||||
Let's start by creating a folder /etc/systemd/network.
|
||||
|
||||
$ sudo mkdir /etc/systemd/network
|
||||
|
||||
#### DHCP Networking ####
|
||||
|
||||
Let's configure DHCP networking first. For this, create the following configuration file. The name of a file can be arbitrary, but remember that files are processed in lexical order.
|
||||
|
||||
$ sudo vi /etc/systemd/network/20-dhcp.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3*
|
||||
|
||||
[Network]
|
||||
DHCP=yes
|
||||
|
||||
As you can see above, each network configuration file contains one or more "sections" with each section preceded by [XXX] heading. Each section contains one or more key/value pairs. The [Match] section determine which network device(s) are configured by this configuration file. For example, this file matches any network interface whose name starts with ens3 (e.g., enp3s0, enp3s1, enp3s2, etc). For matched interface(s), it then applies DHCP network configuration specified under [Network] section.
|
||||
|
||||
### Static IP Networking ###
|
||||
|
||||
If you want to assign a static IP address to a network interface, create the following configuration file.
|
||||
|
||||
$ sudo vi /etc/systemd/network/10-static-enp3s0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3s0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.50/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
As you can guess, the interface enp3s0 will be assigned an address 192.168.10.50/24, a default gateway 192.168.10.1, and a DNS server 8.8.8.8. One subtlety here is that the name of an interface enp3s0, in facts, matches the pattern rule defined in the earlier DHCP configuration as well. However, since the file "10-static-enp3s0.network" is processed before "20-dhcp.network" according to lexical order, the static configuration takes priority over DHCP configuration in case of enp3s0 interface.
|
||||
|
||||
Once you are done with creating configuration files, restart systemd-networkd service or reboot.
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
Check the status of the service by running:
|
||||
|
||||
$ systemctl status systemd-networkd
|
||||
$ systemctl status systemd-resolved
|
||||
|
||||
|
||||
|
||||
### Configure Virtual Network Devices with Systemd-networkd ###
|
||||
|
||||
**systemd-networkd** also allows you to configure virtual network devices such as bridges, VLANs, tunnel, VXLAN, bonding, etc. You must configure these virtual devices in files with .netdev extension.
|
||||
|
||||
Here I'll show how to configure a bridge interface.
|
||||
|
||||
#### Linux Bridge ####
|
||||
|
||||
If you want to create a Linux bridge (br0) and add a physical interface (eth1) to the bridge, create the following configuration.
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.netdev
|
||||
|
||||
----------
|
||||
|
||||
[NetDev]
|
||||
Name=br0
|
||||
Kind=bridge
|
||||
|
||||
Then configure the bridge interface br0 and the slave interface eth1 using .network files as follows.
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0-slave.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=eth1
|
||||
|
||||
[Network]
|
||||
Bridge=br0
|
||||
|
||||
----------
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=br0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.100/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
Finally, restart systemd-networkd:
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
You can use [brctl tool][3] to verify that a bridge br0 has been created.
|
||||
|
||||
### Summary ###
|
||||
|
||||
When systemd promises to be a system manager for Linux, it is no wonder something like systemd-networkd came into being to manage network configurations. At this stage, however, systemd-networkd seems more suitable for a server environment where network configurations are relatively stable. For desktop/laptop environments which involve various transient wired/wireless interfaces, NetworkManager may still be a preferred choice.
|
||||
|
||||
For those who want to check out more on systemd-networkd, refer to the official [man page][4] for a complete list of supported sections and keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
|
||||
[2]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
|
||||
800
sources/tech/20150831 Linux workstation security checklist.md
Normal file
800
sources/tech/20150831 Linux workstation security checklist.md
Normal file
@ -0,0 +1,800 @@
|
||||
Linux workstation security checklist
|
||||
================================================================================
|
||||
This is a set of recommendations used by the Linux Foundation for their systems
|
||||
administrators. All of LF employees are remote workers and we use this set of
|
||||
guidelines to ensure that a sysadmin's system passes core security requirements
|
||||
in order to reduce the risk of it becoming an attack vector against the rest
|
||||
of our infrastructure.
|
||||
|
||||
Even if your systems administrators are not remote workers, chances are that
|
||||
they perform a lot of their work either from a portable laptop in a work
|
||||
environment, or set up their home systems to access the work infrastructure
|
||||
for after-hours/emergency support. In either case, you can adapt this set of
|
||||
recommendations to suit your environment.
|
||||
|
||||
This, by no means, is an exhaustive "workstation hardening" document, but
|
||||
rather an attempt at a set of baseline recommendations to avoid most glaring
|
||||
security errors without introducing too much inconvenience. You may read this
|
||||
document and think it is way too paranoid, while someone else may think this
|
||||
barely scratches the surface. Security is just like driving on the highway --
|
||||
anyone going slower than you is an idiot, while anyone driving faster than you
|
||||
is a crazy person. These guidelines are merely a basic set of core safety
|
||||
rules that is neither exhaustive, nor a replacement for experience, vigilance,
|
||||
and common sense.
|
||||
|
||||
Each section is split into two areas:
|
||||
|
||||
- The checklist that can be adapted to your project's needs
|
||||
- Free-form list of considerations that explain what dictated these decisions
|
||||
|
||||
## Severity levels
|
||||
|
||||
The items in each checklist include the severity level, which we hope will help
|
||||
guide your decision:
|
||||
|
||||
- _(CRITICAL)_ items should definitely be high on the consideration list.
|
||||
If not implemented, they will introduce high risks to your workstation
|
||||
security.
|
||||
- _(MODERATE)_ items will improve your security posture, but are less
|
||||
important, especially if they interfere too much with your workflow.
|
||||
- _(LOW)_ items may improve the overall security, but may not be worth the
|
||||
convenience trade-offs.
|
||||
- _(PARANOID)_ is reserved for items we feel will dramatically improve your
|
||||
workstation security, but will probably require a lot of adjustment to the
|
||||
way you interact with your operating system.
|
||||
|
||||
Remember, these are only guidelines. If you feel these severity levels do not
|
||||
reflect your project's commitment to security, you should adjust them as you
|
||||
see fit.
|
||||
|
||||
## Choosing the right hardware
|
||||
|
||||
We do not mandate that our admins use a specific vendor or a specific model, so
|
||||
this section addresses core considerations when choosing a work system.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] System supports SecureBoot _(CRITICAL)_
|
||||
- [ ] System has no firewire, thunderbolt or ExpressCard ports _(MODERATE)_
|
||||
- [ ] System has a TPM chip _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SecureBoot
|
||||
|
||||
Despite its controversial nature, SecureBoot offers prevention against many
|
||||
attacks targeting workstations (Rootkits, "Evil Maid," etc), without
|
||||
introducing too much extra hassle. It will not stop a truly dedicated attacker,
|
||||
plus there is a pretty high degree of certainty that state security agencies
|
||||
have ways to defeat it (probably by design), but having SecureBoot is better
|
||||
than having nothing at all.
|
||||
|
||||
Alternatively, you may set up [Anti Evil Maid][1] which offers a more
|
||||
wholesome protection against the type of attacks that SecureBoot is supposed
|
||||
to prevent, but it will require more effort to set up and maintain.
|
||||
|
||||
#### Firewire, thunderbolt, and ExpressCard ports
|
||||
|
||||
Firewire is a standard that, by design, allows any connecting device full
|
||||
direct memory access to your system ([see Wikipedia][2]). Thunderbolt and
|
||||
ExpressCard are guilty of the same, though some later implementations of
|
||||
Thunderbolt attempt to limit the scope of memory access. It is best if the
|
||||
system you are getting has none of these ports, but it is not critical, as
|
||||
they usually can be turned off via UEFI or disabled in the kernel itself.
|
||||
|
||||
#### TPM Chip
|
||||
|
||||
Trusted Platform Module (TPM) is a crypto chip bundled with the motherboard
|
||||
separately from the core processor, which can be used for additional platform
|
||||
security (such as to store full-disk encryption keys), but is not normally used
|
||||
for day-to-day workstation operation. At best, this is a nice-to-have, unless
|
||||
you have a specific need to use TPM for your workstation security.
|
||||
|
||||
## Pre-boot environment
|
||||
|
||||
This is a set of recommendations for your workstation before you even start
|
||||
with OS installation.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] UEFI boot mode is used (not legacy BIOS) _(CRITICAL)_
|
||||
- [ ] Password is required to enter UEFI configuration _(CRITICAL)_
|
||||
- [ ] SecureBoot is enabled _(CRITICAL)_
|
||||
- [ ] UEFI-level password is required to boot the system _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### UEFI and SecureBoot
|
||||
|
||||
UEFI, with all its warts, offers a lot of goodies that legacy BIOS doesn't,
|
||||
such as SecureBoot. Most modern systems come with UEFI mode on by default.
|
||||
|
||||
Make sure a strong password is required to enter UEFI configuration mode. Pay
|
||||
attention, as many manufacturers quietly limit the length of the password you
|
||||
are allowed to use, so you may need to choose high-entropy short passwords vs.
|
||||
long passphrases (see below for more on passphrases).
|
||||
|
||||
Depending on the Linux distribution you decide to use, you may or may not have
|
||||
to jump through additional hoops in order to import your distribution's
|
||||
SecureBoot key that would allow you to boot the distro. Many distributions have
|
||||
partnered with Microsoft to sign their released kernels with a key that is
|
||||
already recognized by most system manufacturers, therefore saving you the
|
||||
trouble of having to deal with key importing.
|
||||
|
||||
As an extra measure, before someone is allowed to even get to the boot
|
||||
partition and try some badness there, let's make them enter a password. This
|
||||
password should be different from your UEFI management password, in order to
|
||||
prevent shoulder-surfing. If you shut down and start a lot, you may choose to
|
||||
not bother with this, as you will already have to enter a LUKS passphrase and
|
||||
this will save you a few extra keystrokes.
|
||||
|
||||
## Distro choice considerations
|
||||
|
||||
Chances are you'll stick with a fairly widely-used distribution such as Fedora,
|
||||
Ubuntu, Arch, Debian, or one of their close spin-offs. In any case, this is
|
||||
what you should consider when picking a distribution to use.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Has a robust MAC/RBAC implementation (SELinux/AppArmor/Grsecurity) _(CRITICAL)_
|
||||
- [ ] Publishes security bulletins _(CRITICAL)_
|
||||
- [ ] Provides timely security patches _(CRITICAL)_
|
||||
- [ ] Provides cryptographic verification of packages _(CRITICAL)_
|
||||
- [ ] Fully supports UEFI and SecureBoot _(CRITICAL)_
|
||||
- [ ] Has robust native full disk encryption support _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SELinux, AppArmor, and GrSecurity/PaX
|
||||
|
||||
Mandatory Access Controls (MAC) or Role-Based Access Controls (RBAC) are an
|
||||
extension of the basic user/group security mechanism used in legacy POSIX
|
||||
systems. Most distributions these days either already come bundled with a
|
||||
MAC/RBAC implementation (Fedora, Ubuntu), or provide a mechanism to add it via
|
||||
an optional post-installation step (Gentoo, Arch, Debian). Obviously, it is
|
||||
highly advised that you pick a distribution that comes pre-configured with a
|
||||
MAC/RBAC system, but if you have strong feelings about a distribution that
|
||||
doesn't have one enabled by default, do plan to configure it
|
||||
post-installation.
|
||||
|
||||
Distributions that do not provide any MAC/RBAC mechanisms should be strongly
|
||||
avoided, as traditional POSIX user- and group-based security should be
|
||||
considered insufficient in this day and age. If you would like to start out
|
||||
with a MAC/RBAC workstation, AppArmor and PaX are generally considered easier
|
||||
to learn than SELinux. Furthermore, on a workstation, where there are few or
|
||||
no externally listening daemons, and where user-run applications pose the
|
||||
highest risk, GrSecurity/PaX will _probably_ offer more security benefits than
|
||||
SELinux.
|
||||
|
||||
#### Distro security bulletins
|
||||
|
||||
Most of the widely used distributions have a mechanism to deliver security
|
||||
bulletins to their users, but if you are fond of something esoteric, check
|
||||
whether the developers have a documented mechanism of alerting the users about
|
||||
security vulnerabilities and patches. Absence of such mechanism is a major
|
||||
warning sign that the distribution is not mature enough to be considered for a
|
||||
primary admin workstation.
|
||||
|
||||
#### Timely and trusted security updates
|
||||
|
||||
Most of the widely used distributions deliver regular security updates, but is
|
||||
worth checking to ensure that critical package updates are provided in a
|
||||
timely fashion. Avoid using spin-offs and "community rebuilds" for this
|
||||
reason, as they routinely delay security updates due to having to wait for the
|
||||
upstream distribution to release it first.
|
||||
|
||||
You'll be hard-pressed to find a distribution that does not use cryptographic
|
||||
signatures on packages, updates metadata, or both. That being said, fairly
|
||||
widely used distributions have been known to go for years before introducing
|
||||
this basic security measure (Arch, I'm looking at you), so this is a thing
|
||||
worth checking.
|
||||
|
||||
#### Distros supporting UEFI and SecureBoot
|
||||
|
||||
Check that the distribution supports UEFI and SecureBoot. Find out whether it
|
||||
requires importing an extra key or whether it signs its boot kernels with a key
|
||||
already trusted by systems manufacturers (e.g. via an agreement with
|
||||
Microsoft). Some distributions do not support UEFI/SecureBoot but offer
|
||||
alternatives to ensure tamper-proof or tamper-evident boot environments
|
||||
([Qubes-OS][3] uses Anti Evil Maid, mentioned earlier). If a distribution
|
||||
doesn't support SecureBoot and has no mechanisms to prevent boot-level attacks,
|
||||
look elsewhere.
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Full disk encryption is a requirement for securing data at rest, and is
|
||||
supported by most distributions. As an alternative, systems with
|
||||
self-encrypting hard drives may be used (normally implemented via the on-board
|
||||
TPM chip) and offer comparable levels of security plus faster operation, but at
|
||||
a considerably higher cost.
|
||||
|
||||
## Distro installation guidelines
|
||||
|
||||
All distributions are different, but here are general guidelines:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Use full disk encryption (LUKS) with a robust passphrase _(CRITICAL)_
|
||||
- [ ] Make sure swap is also encrypted _(CRITICAL)_
|
||||
- [ ] Require a password to edit bootloader (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Set up a robust root password (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Use an unprivileged account, part of administrators group _(CRITICAL)_
|
||||
- [ ] Set up a robust user-account password, different from root _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Unless you are using self-encrypting hard drives, it is important to configure
|
||||
your installer to fully encrypt all the disks that will be used for storing
|
||||
your data and your system files. It is not sufficient to simply encrypt the
|
||||
user directory via auto-mounting cryptfs loop files (I'm looking at you, older
|
||||
versions of Ubuntu), as this offers no protection for system binaries or swap,
|
||||
which is likely to contain a slew of sensitive data. The recommended
|
||||
encryption strategy is to encrypt the LVM device, so only one passphrase is
|
||||
required during the boot process.
|
||||
|
||||
The `/boot` partition will always remain unencrypted, as the bootloader needs
|
||||
to be able to actually boot the kernel before invoking LUKS/dm-crypt. The
|
||||
kernel image itself should be protected against tampering with a cryptographic
|
||||
signature checked by SecureBoot.
|
||||
|
||||
In other words, `/boot` should always be the only unencrypted partition on your
|
||||
system.
|
||||
|
||||
#### Choosing good passphrases
|
||||
|
||||
Modern Linux systems have no limitation of password/passphrase length, so the
|
||||
only real limitation is your level of paranoia and your stubbornness. If you
|
||||
boot your system a lot, you will probably have to type at least two different
|
||||
passwords: one to unlock LUKS, and another one to log in, so having long
|
||||
passphrases will probably get old really fast. Pick passphrases that are 2-3
|
||||
words long, easy to type, and preferably from rich/mixed vocabularies.
|
||||
|
||||
Examples of good passphrases (yes, you can use spaces):
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
You can also stick with non-vocabulary passwords that are at least 10-12
|
||||
characters long, if you prefer that to typing passphrases.
|
||||
|
||||
Unless you have concerns about physical security, it is fine to write down your
|
||||
passphrases and keep them in a safe place away from your work desk.
|
||||
|
||||
#### Root, user passwords and the admin group
|
||||
|
||||
We recommend that you use the same passphrase for your root password as you
|
||||
use for your LUKS encryption (unless you share your laptop with other trusted
|
||||
people who should be able to unlock the drives, but shouldn't be able to
|
||||
become root). If you are the sole user of the laptop, then having your root
|
||||
password be different from your LUKS password has no meaningful security
|
||||
advantages. Generally, you can use the same passphrase for your UEFI
|
||||
administration, disk encryption, and root account -- knowing any of these will
|
||||
give an attacker full control of your system anyway, so there is little
|
||||
security benefit to have them be different on a single-user workstation.
|
||||
|
||||
You should have a different, but equally strong password for your regular user
|
||||
account that you will be using for day-to-day tasks. This user should be member
|
||||
of the admin group (e.g. `wheel` or similar, depending on the distribution),
|
||||
allowing you to perform `sudo` to elevate privileges.
|
||||
|
||||
In other words, if you are the sole user on your workstation, you should have 2
|
||||
distinct, robust, equally strong passphrases you will need to remember:
|
||||
|
||||
**Admin-level**, used in the following locations:
|
||||
|
||||
- UEFI administration
|
||||
- Bootloader (GRUB)
|
||||
- Disk encryption (LUKS)
|
||||
- Workstation admin (root user)
|
||||
|
||||
**User-level**, used for the following:
|
||||
|
||||
- User account and sudo
|
||||
- Master password for the password manager
|
||||
|
||||
All of them, obviously, can be different if there is a compelling reason.
|
||||
|
||||
## Post-installation hardening
|
||||
|
||||
Post-installation security hardening will depend greatly on your distribution
|
||||
of choice, so it is futile to provide detailed instructions in a general
|
||||
document such as this one. However, here are some steps you should take:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Globally disable firewire and thunderbolt modules _(CRITICAL)_
|
||||
- [ ] Check your firewalls to ensure all incoming ports are filtered _(CRITICAL)_
|
||||
- [ ] Make sure root mail is forwarded to an account you check _(CRITICAL)_
|
||||
- [ ] Check to ensure sshd service is disabled by default _(MODERATE)_
|
||||
- [ ] Set up an automatic OS update schedule, or update reminders _(MODERATE)_
|
||||
- [ ] Configure the screensaver to auto-lock after a period of inactivity _(MODERATE)_
|
||||
- [ ] Set up logwatch _(MODERATE)_
|
||||
- [ ] Install and use rkhunter _(LOW)_
|
||||
- [ ] Install an Intrusion Detection System _(PARANOID)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Blacklisting modules
|
||||
|
||||
To blacklist a firewire and thunderbolt modules, add the following lines to a
|
||||
file in `/etc/modprobe.d/blacklist-dma.conf`:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
The modules will be blacklisted upon reboot. It doesn't hurt doing this even if
|
||||
you don't have these ports (but it doesn't do anything either).
|
||||
|
||||
#### Root mail
|
||||
|
||||
By default, root mail is just saved on the system and tends to never be read.
|
||||
Make sure you set your `/etc/aliases` to forward root mail to a mailbox that
|
||||
you actually read, otherwise you may miss important system notifications and
|
||||
reports:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
Run `newaliases` after this edit and test it out to make sure that it actually
|
||||
gets delivered, as some email providers will reject email coming in from
|
||||
nonexistent or non-routable domain names. If that is the case, you will need to
|
||||
play with your mail forwarding configuration until this actually works.
|
||||
|
||||
#### Firewalls, sshd, and listening daemons
|
||||
|
||||
The default firewall settings will depend on your distribution, but many of
|
||||
them will allow incoming `sshd` ports. Unless you have a compelling legitimate
|
||||
reason to allow incoming ssh, you should filter that out and disable the `sshd`
|
||||
daemon.
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
You can always start it temporarily if you need to use it.
|
||||
|
||||
In general, your system shouldn't have any listening ports apart from
|
||||
responding to ping. This will help safeguard you against network-level 0-day
|
||||
exploits.
|
||||
|
||||
#### Automatic updates or notifications
|
||||
|
||||
It is recommended to turn on automatic updates, unless you have a very good
|
||||
reason not to do so, such as fear that an automatic update would render your
|
||||
system unusable (it's happened in the past, so this fear is not unfounded). At
|
||||
the very least, you should enable automatic notifications of available updates.
|
||||
Most distributions already have this service automatically running for you, so
|
||||
chances are you don't have to do anything. Consult your distribution
|
||||
documentation to find out more.
|
||||
|
||||
You should apply all outstanding errata as soon as possible, even if something
|
||||
isn't specifically labeled as "security update" or has an associated CVE code.
|
||||
All bugs have the potential of being security bugs and erring on the side of
|
||||
newer, unknown bugs is _generally_ a safer strategy than sticking with old,
|
||||
known ones.
|
||||
|
||||
#### Watching logs
|
||||
|
||||
You should have a keen interest in what happens on your system. For this
|
||||
reason, you should install `logwatch` and configure it to send nightly activity
|
||||
reports of everything that happens on your system. This won't prevent a
|
||||
dedicated attacker, but is a good safety-net feature to have in place.
|
||||
|
||||
Note, that many systemd distros will no longer automatically install a syslog
|
||||
server that `logwatch` needs (due to systemd relying on its own journal), so
|
||||
you will need to install and enable `rsyslog` to make sure your `/var/log` is
|
||||
not empty before logwatch will be of any use.
|
||||
|
||||
#### Rkhunter and IDS
|
||||
|
||||
Installing `rkhunter` and an intrusion detection system (IDS) like `aide` or
|
||||
`tripwire` will not be that useful unless you actually understand how they work
|
||||
and take the necessary steps to set them up properly (such as, keeping the
|
||||
databases on external media, running checks from a trusted environment,
|
||||
remembering to refresh the hash databases after performing system updates and
|
||||
configuration changes, etc). If you are not willing to take these steps and
|
||||
adjust how you do things on your own workstation, these tools will introduce
|
||||
hassle without any tangible security benefit.
|
||||
|
||||
We do recommend that you install `rkhunter` and run it nightly. It's fairly
|
||||
easy to learn and use, and though it will not deter a sophisticated attacker,
|
||||
it may help you catch your own mistakes.
|
||||
|
||||
## Personal workstation backups
|
||||
|
||||
Workstation backups tend to be overlooked or done in a haphazard, often unsafe
|
||||
manner.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Set up encrypted workstation backups to external storage _(CRITICAL)_
|
||||
- [ ] Use zero-knowledge backup tools for cloud backups _(MODERATE)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full encrypted backups to external storage
|
||||
|
||||
It is handy to have an external hard drive where one can dump full backups
|
||||
without having to worry about such things like bandwidth and upstream speeds
|
||||
(in this day and age most providers still offer dramatically asymmetric
|
||||
upload/download speeds). Needless to say, this hard drive needs to be in itself
|
||||
encrypted (again, via LUKS), or you should use a backup tool that creates
|
||||
encrypted backups, such as `duplicity` or its GUI companion, `deja-dup`. I
|
||||
recommend using the latter with a good randomly generated passphrase, stored in
|
||||
your password manager. If you travel with your laptop, leave this drive at home
|
||||
to have something to come back to in case your laptop is lost or stolen.
|
||||
|
||||
In addition to your home directory, you should also back up `/etc` and
|
||||
`/var/log` for various forensic purposes.
|
||||
|
||||
Above all, avoid copying your home directory onto any unencrypted storage, even
|
||||
as a quick way to move your files around between systems, as you will most
|
||||
certainly forget to erase it once you're done, exposing potentially private or
|
||||
otherwise security sensitive data to snooping hands -- especially if you keep
|
||||
that storage media in the same bag with your laptop.
|
||||
|
||||
#### Selective zero-knowledge backups off-site
|
||||
|
||||
Off-site backups are also extremely important and can be done either to your
|
||||
employer, if they offer space for it, or to a cloud provider. You can set up a
|
||||
separate duplicity/deja-dup profile to only include most important files in
|
||||
order to avoid transferring huge amounts of data that you don't really care to
|
||||
back up off-site (internet cache, music, downloads, etc).
|
||||
|
||||
Alternatively, you can use a zero-knowledge backup tool, such as
|
||||
[SpiderOak][5], which offers an excellent Linux GUI tool and has additional
|
||||
useful features such as synchronizing content between multiple systems and
|
||||
platforms.
|
||||
|
||||
## Best practices
|
||||
|
||||
What follows is a curated list of best practices that we think you should
|
||||
adopt. It is most certainly non-exhaustive, but rather attempts to offer
|
||||
practical advice that strikes a workable balance between security and overall
|
||||
usability.
|
||||
|
||||
### Browsing
|
||||
|
||||
There is no question that the web browser will be the piece of software with
|
||||
the largest and the most exposed attack surface on your system. It is a tool
|
||||
written specifically to download and execute untrusted, frequently hostile
|
||||
code. It attempts to shield you from this danger by employing multiple
|
||||
mechanisms such as sandboxes and code sanitization, but they have all been
|
||||
previously defeated on multiple occasions. You should learn to approach
|
||||
browsing websites as the most insecure activity you'll engage in on any given
|
||||
day.
|
||||
|
||||
There are several ways you can reduce the impact of a compromised browser, but
|
||||
the truly effective ways will require significant changes in the way you
|
||||
operate your workstation.
|
||||
|
||||
#### 1: Use two different browsers
|
||||
|
||||
This is the easiest to do, but only offers minor security benefits. Not all
|
||||
browser compromises give an attacker full unfettered access to your system --
|
||||
sometimes they are limited to allowing one to read local browser storage,
|
||||
steal active sessions from other tabs, capture input entered into the browser,
|
||||
etc. Using two different browsers, one for work/high security sites, and
|
||||
another for everything else will help prevent minor compromises from giving
|
||||
attackers access to the whole cookie jar. The main inconvenience will be the
|
||||
amount of memory consumed by two different browser processes.
|
||||
|
||||
Here's what we recommend:
|
||||
|
||||
##### Firefox for work and high security sites
|
||||
|
||||
Use Firefox to access work-related sites, where extra care should be taken to
|
||||
ensure that data like cookies, sessions, login information, keystrokes, etc,
|
||||
should most definitely not fall into attackers' hands. You should NOT use
|
||||
this browser for accessing any other sites except select few.
|
||||
|
||||
You should install the following Firefox add-ons:
|
||||
|
||||
- [ ] NoScript _(CRITICAL)_
|
||||
- NoScript prevents active content from loading, except from user
|
||||
whitelisted domains. It is a great hassle to use with your default browser
|
||||
(though offers really good security benefits), so we recommend only
|
||||
enabling it on the browser you use to access work-related sites.
|
||||
|
||||
- [ ] Privacy Badger _(CRITICAL)_
|
||||
- EFF's Privacy Badger will prevent most external trackers and ad platforms
|
||||
from being loaded, which will help avoid compromises on these tracking
|
||||
sites from affecting your browser (trackers and ad sites are very commonly
|
||||
targeted by attackers, as they allow rapid infection of thousands of
|
||||
systems worldwide).
|
||||
|
||||
- [ ] HTTPS Everywhere _(CRITICAL)_
|
||||
- This EFF-developed Add-on will ensure that most of your sites are accessed
|
||||
over a secure connection, even if a link you click is using http:// (great
|
||||
to avoid a number of attacks, such as [SSL-strip][7]).
|
||||
|
||||
- [ ] Certificate Patrol _(MODERATE)_
|
||||
- This tool will alert you if the site you're accessing has recently changed
|
||||
their TLS certificates -- especially if it wasn't nearing expiration dates
|
||||
or if it is now using a different certification authority. It helps
|
||||
alert you if someone is trying to man-in-the-middle your connection,
|
||||
but generates a lot of benign false-positives.
|
||||
|
||||
You should leave Firefox as your default browser for opening links, as
|
||||
NoScript will prevent most active content from loading or executing.
|
||||
|
||||
##### Chrome/Chromium for everything else
|
||||
|
||||
Chromium developers are ahead of Firefox in adding a lot of nice security
|
||||
features (at least [on Linux][6]), such as seccomp sandboxes, kernel user
|
||||
namespaces, etc, which act as an added layer of isolation between the sites
|
||||
you visit and the rest of your system. Chromium is the upstream open-source
|
||||
project, and Chrome is Google's proprietary binary build based on it (insert
|
||||
the usual paranoid caution about not using it for anything you don't want
|
||||
Google to know about).
|
||||
|
||||
It is recommended that you install **Privacy Badger** and **HTTPS Everywhere**
|
||||
extensions in Chrome as well and give it a distinct theme from Firefox to
|
||||
indicate that this is your "untrusted sites" browser.
|
||||
|
||||
#### 2: Use two different browsers, one inside a dedicated VM
|
||||
|
||||
This is a similar recommendation to the above, except you will add an extra
|
||||
step of running Chrome inside a dedicated VM that you access via a fast
|
||||
protocol, allowing you to share clipboards and forward sound events (e.g.
|
||||
Spice or RDP). This will add an excellent layer of isolation between the
|
||||
untrusted browser and the rest of your work environment, ensuring that
|
||||
attackers who manage to fully compromise your browser will then have to
|
||||
additionally break out of the VM isolation layer in order to get to the rest
|
||||
of your system.
|
||||
|
||||
This is a surprisingly workable configuration, but requires a lot of RAM and
|
||||
fast processors that can handle the increased load. It will also require an
|
||||
important amount of dedication on the part of the admin who will need to
|
||||
adjust their work practices accordingly.
|
||||
|
||||
#### 3: Fully separate your work and play environments via virtualization
|
||||
|
||||
See [Qubes-OS project][3], which strives to provide a high-security
|
||||
workstation environment via compartmentalizing your applications into separate
|
||||
fully isolated VMs.
|
||||
|
||||
### Password managers
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Use a password manager _(CRITICAL_)
|
||||
- [ ] Use unique passwords on unrelated sites _(CRITICAL)_
|
||||
- [ ] Use a password manager that supports team sharing _(MODERATE)_
|
||||
- [ ] Use a separate password manager for non-website accounts _(PARANOID)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
Using good, unique passwords should be a critical requirement for every member
|
||||
of your team. Credential theft is happening all the time -- either via
|
||||
compromised computers, stolen database dumps, remote site exploits, or any
|
||||
number of other means. No credentials should ever be reused across sites,
|
||||
especially for critical applications.
|
||||
|
||||
##### In-browser password manager
|
||||
|
||||
Every browser has a mechanism for saving passwords that is fairly secure and
|
||||
can sync with vendor-maintained cloud storage while keeping the data encrypted
|
||||
with a user-provided passphrase. However, this mechanism has important
|
||||
disadvantages:
|
||||
|
||||
1. It does not work across browsers
|
||||
2. It does not offer any way of sharing credentials with team members
|
||||
|
||||
There are several well-supported, free-or-cheap password managers that are
|
||||
well-integrated into multiple browsers, work across platforms, and offer
|
||||
group sharing (usually as a paid service). Solutions can be easily found via
|
||||
search engines.
|
||||
|
||||
##### Standalone password manager
|
||||
|
||||
One of the major drawbacks of any password manager that comes integrated with
|
||||
the browser is the fact that it's part of the application that is most likely
|
||||
to be attacked by intruders. If this makes you uncomfortable (and it should),
|
||||
you may choose to have two different password managers -- one for websites
|
||||
that is integrated into your browser, and one that runs as a standalone
|
||||
application. The latter can be used to store high-risk credentials such as
|
||||
root passwords, database passwords, other shell account credentials, etc.
|
||||
|
||||
It may be particularly useful to have such tool for sharing superuser account
|
||||
credentials with other members of your team (server root passwords, ILO
|
||||
passwords, database admin passwords, bootloader passwords, etc).
|
||||
|
||||
A few tools can help you:
|
||||
|
||||
- [KeePassX][8], which improves team sharing in version 2
|
||||
- [Pass][9], which uses text files and PGP and integrates with git
|
||||
- [Django-Pstore][10], which uses GPG to share credentials between admins
|
||||
- [Hiera-Eyaml][11], which, if you are already using Puppet for your
|
||||
infrastructure, may be a handy way to track your server/service credentials
|
||||
as part of your encrypted Hiera data store
|
||||
|
||||
### Securing SSH and PGP private keys
|
||||
|
||||
Personal encryption keys, including SSH and PGP private keys, are going to be
|
||||
the most prized items on your workstation -- something the attackers will be
|
||||
most interested in obtaining, as that would allow them to further attack your
|
||||
infrastructure or impersonate you to other admins. You should take extra steps
|
||||
to ensure that your private keys are well protected against theft.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Strong passphrases are used to protect private keys _(CRITICAL)_
|
||||
- [ ] PGP Master key is stored on removable storage _(MODERATE)_
|
||||
- [ ] Auth, Sign and Encrypt Subkeys are stored on a smartcard device _(MODERATE)_
|
||||
- [ ] SSH is configured to use PGP Auth key as ssh private key _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
The best way to prevent private key theft is to use a smartcard to store your
|
||||
encryption private keys and never copy them onto the workstation. There are
|
||||
several manufacturers that offer OpenPGP capable devices:
|
||||
|
||||
- [Kernel Concepts][12], where you can purchase both the OpenPGP compatible
|
||||
smartcards and the USB readers, should you need one.
|
||||
- [Yubikey NEO][13], which offers OpenPGP smartcard functionality in addition
|
||||
to many other cool features (U2F, PIV, HOTP, etc).
|
||||
|
||||
It is also important to make sure that the master PGP key is not stored on the
|
||||
main workstation, and only subkeys are used. The master key will only be
|
||||
needed when signing someone else's keys or creating new subkeys -- operations
|
||||
which do not happen very frequently. You may follow [the Debian's subkeys][14]
|
||||
guide to learn how to move your master key to removable storage and how to
|
||||
create subkeys.
|
||||
|
||||
You should then configure your gnupg agent to act as ssh agent and use the
|
||||
smartcard-based PGP Auth key to act as your ssh private key. We publish a
|
||||
[detailed guide][15] on how to do that using either a smartcard reader or a
|
||||
Yubikey NEO.
|
||||
|
||||
If you are not willing to go that far, at least make sure you have a strong
|
||||
passphrase on both your PGP private key and your SSH private key, which will
|
||||
make it harder for attackers to steal and use them.
|
||||
|
||||
### SELinux on the workstation
|
||||
|
||||
If you are using a distribution that comes bundled with SELinux (such as
|
||||
Fedora), here are some recommendation of how to make the best use of it to
|
||||
maximize your workstation security.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Make sure SELinux is enforcing on your workstation _(CRITICAL)_
|
||||
- [ ] Never blindly run `audit2allow -M`, always check _(CRITICAL)_
|
||||
- [ ] Never `setenforce 0` _(MODERATE)_
|
||||
- [ ] Switch your account to SELinux user `staff_u` _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
SELinux is a Mandatory Access Controls (MAC) extension to core POSIX
|
||||
permissions functionality. It is mature, robust, and has come a long way since
|
||||
its initial roll-out. Regardless, many sysadmins to this day repeat the
|
||||
outdated mantra of "just turn it off."
|
||||
|
||||
That being said, SELinux will have limited security benefits on the
|
||||
workstation, as most applications you will be running as a user are going to
|
||||
be running unconfined. It does provide enough net benefit to warrant leaving
|
||||
it on, as it will likely help prevent an attacker from escalating privileges
|
||||
to gain root-level access via a vulnerable daemon service.
|
||||
|
||||
Our recommendation is to leave it on and enforcing.
|
||||
|
||||
##### Never `setenforce 0`
|
||||
|
||||
It's tempting to use `setenforce 0` to flip SELinux into permissive mode
|
||||
on a temporary basis, but you should avoid doing that. This essentially turns
|
||||
off SELinux for the entire system, while what you really want is to
|
||||
troubleshoot a particular application or daemon.
|
||||
|
||||
Instead of `setenforce 0` you should be using `semanage permissive -a
|
||||
[somedomain_t]` to put only that domain into permissive mode. First, find out
|
||||
which domain is causing troubles by running `ausearch`:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
and then look for `scontext=` (source SELinux context) line, like so:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
This tells you that the domain being denied is `gpg_pinentry_t`, so if you
|
||||
want to troubleshoot the application, you should add it to permissive domains:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
This will allow you to use the application and collect the rest of the AVCs,
|
||||
which you can then use in conjunction with `audit2allow` to write a local
|
||||
policy. Once that is done and you see no new AVC denials, you can remove that
|
||||
domain from permissive by running:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### Use your workstation as SELinux role staff_r
|
||||
|
||||
SELinux comes with a native implementation of roles that prohibit or grant
|
||||
certain privileges based on the role associated with the user account. As an
|
||||
administrator, you should be using the `staff_r` role, which will restrict
|
||||
access to many configuration and other security-sensitive files, unless you
|
||||
first perform `sudo`.
|
||||
|
||||
By default, accounts are created as `unconfined_r` and most applications you
|
||||
execute will run unconfined, without any (or with only very few) SELinux
|
||||
constraints. To switch your account to the `staff_r` role, run the following
|
||||
command:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
You should log out and log back in to enable the new role, at which point if
|
||||
you run `id -Z`, you'll see:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
When performing `sudo`, you should remember to add an extra flag to tell
|
||||
SELinux to transition to the "sysadmin" role. The command you want is:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
At which point `id -Z` will show:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**WARNING**: you should be comfortable using `ausearch` and `audit2allow`
|
||||
before you make this switch, as it's possible some of your applications will
|
||||
no longer work when you're running as role `staff_r`. At the time of writing,
|
||||
the following popular applications are known to not work under `staff_r`
|
||||
without policy tweaks:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
To switch back to `unconfined_r`, run the following command:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
and then log out and back in to get back into the comfort zone.
|
||||
|
||||
## Further reading
|
||||
|
||||
The world of IT security is a rabbit hole with no bottom. If you would like to
|
||||
go deeper, or find out more about security features on your particular
|
||||
distribution, please check out the following links:
|
||||
|
||||
- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX Security](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## License
|
||||
This work is licensed under a
|
||||
[Creative Commons Attribution-ShareAlike 4.0 International License][0].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#linux-workstation-security-checklist
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
125
sources/tech/20150901 How to Defragment Linux Systems.md
Normal file
125
sources/tech/20150901 How to Defragment Linux Systems.md
Normal file
@ -0,0 +1,125 @@
|
||||
How to Defragment Linux Systems
|
||||
================================================================================
|
||||

|
||||
|
||||
There is a common myth that Linux disks never need defragmentation at all. In most cases, this is true, due mostly to the excellent journaling filesystems Linux uses (ext2, 3, 4, btrfs, etc.) to handle the filesystem. However, in some specific cases, fragmentation might still occur. If that happens to you, the solution is fortunately very simple.
|
||||
|
||||
### What is fragmentation? ###
|
||||
|
||||
Fragmentation occurs when a file system updates files in little chunks, but these chunks do not form a contiguous whole and are scattered around the disk instead. This is particularly true for FAT and FAT32 filesystems. It was somewhat mitigated in NTFS and almost never happens in Linux (extX). Here is why.
|
||||
|
||||
In filesystems such as FAT and FAT32, files are written right next to each other on the disk. There is no room left for file growth or updates:
|
||||
|
||||

|
||||
|
||||
The NTFS leaves somewhat more room between the files, so there is room to grow. As the space between chunks is limited, fragmentation will still occur over time.
|
||||
|
||||

|
||||
|
||||
Linux’s journaling filesystems take a different approach. Instead of placing files beside each other, each file is scattered all over the disk, leaving generous amounts of free space between each file. There is sufficient room for file updates/growth and fragmentation rarely occurs.
|
||||
|
||||

|
||||
|
||||
Additionally, if fragmentation does happen, most Linux filesystems would attempt to shuffle files and chunks around to make them contiguous again.
|
||||
|
||||
### Disk fragmentation on Linux ###
|
||||
|
||||
Disk fragmentation seldom occurs in Linux unless you have a small hard drive, or it is running out of space. Some possible fragmentation cases include:
|
||||
|
||||
- if you edit large video files or raw image files, and disk space is limited
|
||||
- if you use older hardware like an old laptop, and you have a small hard drive
|
||||
- if your hard drives start filling up (above 85% used)
|
||||
- if you have many small partitions cluttering your home folder
|
||||
|
||||
The best solution is to buy a larger hard drive. If it’s not possible, this is where defragmentation becomes useful.
|
||||
|
||||
### How to check for fragmentation ###
|
||||
|
||||
The `fsck` command will do this for you – that is, if you have an opportunity to run it from a live CD, with **all affected partitions unmounted**.
|
||||
|
||||
This is very important: **RUNNING FSCK ON A MOUNTED PARTITION CAN AND WILL SEVERELY DAMAGE YOUR DATA AND YOUR DISK**.
|
||||
|
||||
You have been warned. Before proceeding, make a full system backup.
|
||||
|
||||
**Disclaimer**: The author of this article and Make Tech Easier take no responsibility for any damage to your files, data, system, or any other damage, caused by your actions after following this advice. You may proceed at your own risk. If you do proceed, you accept and acknowledge this.
|
||||
|
||||
You should just boot into a live session (like an installer disk, system rescue CD, etc.) and run `fsck` on your UNMOUNTED partitions. To check for any problems, run the following command with root permission:
|
||||
|
||||
fsck -fn [/path/to/your/partition]
|
||||
|
||||
You can check what the `[/path/to/your/partition]` is by running
|
||||
|
||||
sudo fdisk -l
|
||||
|
||||
There is a way to run `fsck` (relatively) safely on a mounted partition – that is by using the `-n` switch. This will result in a read only file system check without touching anything. Of course, there is no guarantee of safety here, and you should only proceed after creating a backup. On an ext2 filesystem, running
|
||||
|
||||
sudo fsck.ext2 -fn /path/to/your/partition
|
||||
|
||||
would result in plenty of output – most of them error messages resulting from the fact that the partition is mounted. In the end it will give you fragmentation related information.
|
||||
|
||||

|
||||
|
||||
If your fragmentation is above 20%, you should proceed to defragment your system.
|
||||
|
||||
### How to easily defragment Linux filesystems ###
|
||||
|
||||
All you need to do is to back up **ALL** your files and data to another drive (by manually **copying** them over), format the partition, and copy your files back (don’t use a backup program for this). The journalling file system will handle them as new files and place them neatly to the disk without fragmentation.
|
||||
|
||||
To back up your files, run
|
||||
|
||||
cp -afv [/path/to/source/partition]/* [/path/to/destination/folder]
|
||||
|
||||
Mind the asterix (*); it is important.
|
||||
|
||||
Note: It is generally agreed that to copy large files or large amounts of data, the dd command might be best. This is a very low level operation and does copy everything “as is”, including the empty space, and even the junk left over. This is not what we want, so it is probably better to use `cp`.
|
||||
|
||||
Now you only need to remove all the original files.
|
||||
|
||||
sudo rm -rf [/path/to/source/partition]/*
|
||||
|
||||
**Optional**: you can fill the empty space with zeros. You could achieve this with formatting as well, but if for example you did not copy the whole partition, only large files (which are most likely to cause fragmentation), this might not be an option.
|
||||
|
||||
sudo dd if=/dev/zero of=[/path/to/source/partition]/temp-zero.txt
|
||||
|
||||
Wait for it to finish. You could also monitor the progress with `pv`.
|
||||
|
||||
sudo apt-get install pv
|
||||
sudo pv -tpreb | of=[/path/to/source/partition]/temp-zero.txt
|
||||
|
||||

|
||||
|
||||
When it is done, just delete the temporary file.
|
||||
|
||||
sudo rm [/path/to/source/partition]/temp-zero.txt
|
||||
|
||||
After you zeroed out the empty space (or just skipped that step entirely), copy your files back, reversing the first cp command:
|
||||
|
||||
cp -afv [/path/to/original/destination/folder]/* [/path/to/original/source/partition]
|
||||
|
||||
### Using e4defrag ###
|
||||
|
||||
If you prefer a simpler approach, install `e2fsprogs`,
|
||||
|
||||
sudo apt-get install e2fsprogs
|
||||
|
||||
and run `e4defrag` as root on the affected partition. If you don’t want to or cannot unmount the partition, you can use its mount point instead of its path. To defragment your whole system, run
|
||||
|
||||
sudo e4defrag /
|
||||
|
||||
It is not guaranteed to succeed while mounted (you should also stop using your system while it is running), but it is much easier than copying all files away and back.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Fragmentation should rarely be an issue on a Linux system due to the the journalling filesystem’s efficient data handling. If you do run into fragmentation due to any circumstances, there are simple ways to reallocate your disk space like copying all files away and back or using `e4defrag`. It is important, however, to keep your data safe, so before attempting any operation that would affect all or most of your files, make sure you make a backup just to be on the safe side.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/defragment-linux/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
@ -0,0 +1,89 @@
|
||||
translation by strugglingyouth
|
||||
How to Install / Upgrade to Linux Kernel 4.2 in Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
Linux Kernel 4.2 was released yesterday, at noon. Linus Torvalds wrote on [lkml.org][1]:
|
||||
|
||||
> So judging by how little happened this week, it wouldn’t have been a mistake to release 4.2 last week after all, but hey, there’s certainly a few fixes here, and it’s not like delaying 4.2 for a week should have caused any problems either.
|
||||
>
|
||||
> So here it is, and the merge window for 4.3 is now open. I already have a few pending early pull requests, but as usual I’ll start processing them tomorrow and give the release some time to actually sit.
|
||||
>
|
||||
> The shortlog from rc8 is tiny, and appended. The patch is pretty tiny too…
|
||||
|
||||
### What’s New in Kernel 4.2: ###
|
||||
|
||||
- rewrites of Intel Assembly x86 code
|
||||
- support for new ARM boards and SoCs
|
||||
- F2FS per-file encryption
|
||||
- The AMDGPU kernel DRM driver
|
||||
- VCE1 video encode support for the Radeon DRM driver
|
||||
- Initial support for Intel Broxton Atom SoCs
|
||||
- Support for ARCv2 and HS38 CPU cores.
|
||||
- added queue spinlocks support
|
||||
- many other improvements and updated drivers.
|
||||
|
||||
### How to Install Kernel 4.2 in Ubuntu: ###
|
||||
|
||||
The binary packages of this kernel release are available for download at link below:
|
||||
|
||||
- [Download Kernel 4.2 (.DEB)][1]
|
||||
|
||||
First check out your OS type, 32-bit (i386) or 64-bit (amd64), then download and install the packages below in turn:
|
||||
|
||||
1. linux-headers-4.2.0-xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
|
||||
After installing the kernel, you may run `sudo update-grub` command in terminal (Ctrl+Alt+T) to refresh grub boot-loader.
|
||||
|
||||
If you need a low latency system (e.g. for recording audio) then download & install below packages instead:
|
||||
|
||||
1. linux-headers-4.2.0_xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
|
||||
For Ubuntu Server without a graphical UI, you may run below commands one by one to grab packages via wget and install them via dpkg:
|
||||
|
||||
For 64-bit system run:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
For 32-bit system, run:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
Finally restart your computer to take effect.
|
||||
|
||||
To revert back, remove old kernels, see [install kernel simply via a script][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/upgrade-kernel-4-2-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://lkml.org/lkml/2015/8/30/96
|
||||
[2]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/
|
||||
[3]:http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
@ -0,0 +1,52 @@
|
||||
How to automatically dim your screen on Linux
|
||||
================================================================================
|
||||
When you start spending the majority of your time in front of a computer, natural questions start arising. Is this healthy? How can I diminish the strain on my eyes? Why is the sunlight burning me? Although active research is still going on to answer these questions, a lot of programmers have already adopted a few applications to make their daily habits a little healthier for their eyes. Among those applications, there are two which I found particularly interesting: Calise and Redshift.
|
||||
|
||||
### Calise ###
|
||||
|
||||
In and out of development limbo, [Calise][1] stands for "Camera Light Sensor." In other terms, it is an open source program that computes the best backlight level for your screen based on the light intensity received by your webcam. And for more precision, Calise is capable of taking in account the weather in your area based on your geographical coordinates. What I like about it is the compatibility with every desktops, even non-X ones.
|
||||
|
||||

|
||||
|
||||
It comes with a command line interface and a GUI, supports multiple user profiles, and can even export its data to CSV. After installation, you will have to calibrate it quickly before the magic happens.
|
||||
|
||||

|
||||
|
||||
What is less likeable is unfortunately that if you are as paranoid as I am, you have a little piece of tape in front of your webcam, which greatly affects Calise's precision. But that aside, Calise is a great application, which deserves our attention and support. As I mentioned earlier, it has gone through some rough patches in its development schedule over the last couple of years, so I really hope that this project will continue.
|
||||
|
||||

|
||||
|
||||
### Redshift ###
|
||||
|
||||
If you already considered decreasing the strain on your eyes caused by your screen, it is possible that you have heard of f.lux, a free proprietary software that modifies the luminosity and color scheme of your display based on the time of the day. However, if you really prefer open source software, there is an alternative: [Redshift][2]. Inspired by f.lux, Redshift also alters the color scheme and luminosity to enhance the experience of sitting in front of your screen at night. On startup, you can configure it with you geographic position as longitude and latitude, and then let it run in tray. Redshift will smoothly adjust the color scheme or your screen based on the position of the sun. At night, you will see the screen's color temperature turn towards red, making it a lot less painful for your eyes.
|
||||
|
||||

|
||||
|
||||
Just like Calise, it proposes a command line interface as well as a GUI client. To start Redshift quickly, just use the command:
|
||||
|
||||
$ redshift -l [LAT]:[LON]
|
||||
|
||||
Replacing [LAT]:[LON] by your latitude and longitude.
|
||||
|
||||
However, it is also possible to input your coordinates by GPS via the gpsd module. For Arch Linux users, I recommend this [wiki page][3].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
To conclude, Linux users have no excuse for not taking care of their eyes. Calise and Redshift are both amazing. I really hope that their development will continue and that they get the support they deserve. Of course, there are more than just two programs out there to fulfill the purpose of protecting your eyes and staying healthy, but I feel that Calise and Redshift are a good start.
|
||||
|
||||
If there is a program that you really like and that you use regularly to reduce the strain on your eyes, please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/automatically-dim-your-screen-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calise.sourceforge.net/
|
||||
[2]:http://jonls.dk/redshift/
|
||||
[3]:https://wiki.archlinux.org/index.php/Redshift#Automatic_location_based_on_GPS
|
||||
@ -0,0 +1,79 @@
|
||||
Install The Latest Linux Kernel in Ubuntu Easily via A Script
|
||||
================================================================================
|
||||

|
||||
|
||||
Want to install the latest Linux Kernel? A simple script can always do the job and make things easier in Ubuntu.
|
||||
|
||||
Michael Murphy has created a script makes installing the latest RC, stable, or lowlatency Kernel easier in Ubuntu. The script asks some questions and automatically downloads and installs the latest Kernel packages from [Ubuntu kernel mainline page][1].
|
||||
|
||||
### Install / Upgrade Linux Kernel via the Script: ###
|
||||
|
||||
1. Download the script from the right sidebar of the [github page][2] (click the “Download Zip” button).
|
||||
|
||||
2. Decompress the Zip archive by right-clicking on it in your user Downloads folder and select “Extract Here”.
|
||||
|
||||
3. Navigate to the result folder in terminal by right-clicking on that folder and select “Open in Terminal”:
|
||||
|
||||
|
||||
|
||||
It opens a terminal window and automatically navigates into the result folder. If you **DON’T** find the “Open in Terminal” option, search for and install `nautilus-open-terminal` in Ubuntu Software Center and then log out and back in (or run `nautilus -q` command in terminal instead to apply changes).
|
||||
|
||||
4. When you’re in terminal, give the script executable permission for once.
|
||||
|
||||
chmod +x *
|
||||
|
||||
FINALLY run the script every time you want to install / upgrade Linux Kernel in Ubuntu:
|
||||
|
||||
./*
|
||||
|
||||
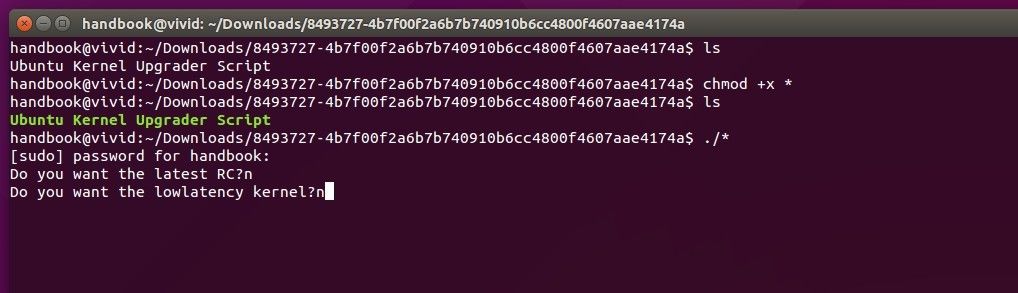
|
||||
|
||||
I use * instead of the SCRIPT NAME in both commands since it’s the only file in that folder.
|
||||
|
||||
If the script runs successfully, restart your computer when done.
|
||||
|
||||
### Revert back and Uninstall the new Kernel: ###
|
||||
|
||||
To revert back and remove the new kernel for any reason, restart your computer and select boot with the old kernel entry under **Advanced Options** menu when you’re at Grub boot-loader.
|
||||
|
||||
When it boots up, see below section.
|
||||
|
||||
### How to Remove the old (or new) Kernels: ###
|
||||
|
||||
1. Install Synaptic Package Manager from Ubuntu Software Center.
|
||||
|
||||
2. Launch Synaptic Package Manager and do:
|
||||
|
||||
- click the **Reload** button in case you want to remove the new kernel.
|
||||
- select **Status -> Installed** on the left pane to make search list clear.
|
||||
- search **linux-image**- using Quick filter box.
|
||||
- select a kernel image “linux-image-x.xx.xx-generic” and mark for (complete) removal
|
||||
- finally apply changes
|
||||
|
||||
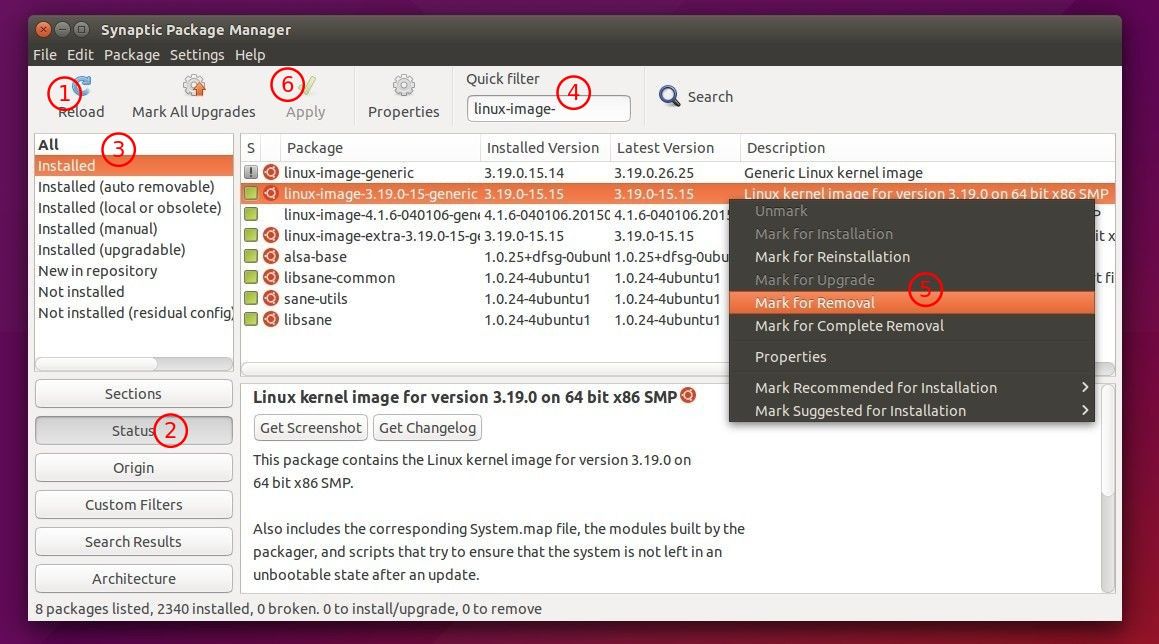
|
||||
|
||||
Repeat until you removed all unwanted kernels. DON’T carelessly remove the current running kernel, check it out via `uname -r` (see below pic.) command.
|
||||
|
||||
For Ubuntu Server, you may run below commands one by one:
|
||||
|
||||
uname -r
|
||||
|
||||
dpkg -l | grep linux-image-
|
||||
|
||||
sudo apt-get autoremove KERNEL_IMAGE_NAME
|
||||
|
||||
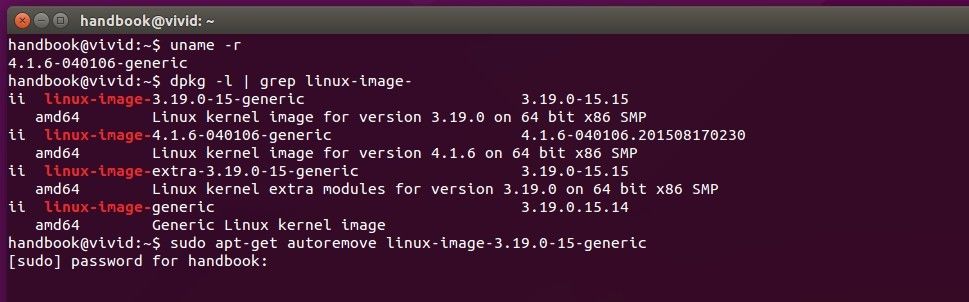
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[2]:https://gist.github.com/mmstick/8493727
|
||||
@ -0,0 +1,182 @@
|
||||
Setting Up High-Performance ‘HHVM’ and Nginx/Apache with MariaDB on Debian/Ubuntu
|
||||
================================================================================
|
||||
HHVM stands for HipHop Virtual Machine, is an open source virtual machine created for running Hack (it’s a programming language for HHVM) and PHP written applications. HHVM uses a last minute compilation path to achieve remarkable performance while keeping the flexibility that PHP programmers are addicted to. Till date, HHVM has achieved over a 9x increase in http request throughput and more than 5x cut in memory utilization (when running on low system memory) for Facebook compared with the PHP engine + [APC (Alternative PHP Cache)][1].
|
||||
|
||||
HHVM can also be used along with a FastCGI-based web-server like Nginx or Apache.
|
||||
|
||||

|
||||
|
||||
Install HHVM, Nginx and Apache with MariaDB
|
||||
|
||||
In this tutorial we shall look at steps for setting up Nginx/Apache web server, MariaDB database server and HHVM. For this setup, we will use Ubuntu 15.04 (64-bit) as HHVM runs on 64-bit system only, although Debian and Linux Mint distributions are also supported.
|
||||
|
||||
### Step 1: Installing Nginx and Apache Web Server ###
|
||||
|
||||
1. First do a system upgrade to update repository list with the help of following commands.
|
||||
|
||||
# apt-get update && apt-get upgrade
|
||||
|
||||

|
||||
|
||||
System Upgrade
|
||||
|
||||
2. As I said HHVM can be used with both Nginx and Apache web server. So, it’s your choice which web server you will going to use, but here we will show you both web servers installation and how to use them with HHVM.
|
||||
|
||||
#### Installing Nginx ####
|
||||
|
||||
In this step, we will install Nginx/Apache web server from the packages repository using following command.
|
||||
|
||||
# apt-get install nginx
|
||||
|
||||

|
||||
|
||||
Install Nginx Web Server
|
||||
|
||||
#### Installing Apache ####
|
||||
|
||||
# apt-get install apache2
|
||||
|
||||

|
||||
|
||||
Install Apache Web Server
|
||||
|
||||
At this point, you should be able to navigate to following URL and you will able to see Nginx or Apache default page.
|
||||
|
||||
http://localhost
|
||||
OR
|
||||
http://IP-Address
|
||||
|
||||
#### Nginx Default Page ####
|
||||
|
||||

|
||||
|
||||
Nginx Welcome Page
|
||||
|
||||
#### Apache Default Page ####
|
||||
|
||||

|
||||
|
||||
Apache Default Page
|
||||
|
||||
### Step 2: Install and Configure MariaDB ###
|
||||
|
||||
3. In this step, we will install MariaDB, as it providers better performance as compared to MySQL.
|
||||
|
||||
# apt-get install mariadb-client mariadb-server
|
||||
|
||||

|
||||
|
||||
Install MariaDB Database
|
||||
|
||||
4. After MariaDB successful installation, you can start MariaDB and set root password to secure the database:
|
||||
|
||||
# systemctl start mysql
|
||||
# mysql_secure_installation
|
||||
|
||||
Answer the following questions by typing `y` or `n` and press enter. Make sure you read the instructions carefully before answering the questions.
|
||||
|
||||
Enter current password for root (enter for none) = press enter
|
||||
Set root password? [Y/n] = y
|
||||
Remove anonymous users[y/n] = y
|
||||
Disallow root login remotely[y/n] = y
|
||||
Remove test database and access to it [y/n] = y
|
||||
Reload privileges tables now[y/n] = y
|
||||
|
||||
5. After setting root password for MariaDB, you can connect to MariaDB prompt with the new root password.
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
### Step 3: Installation of HHVM ###
|
||||
|
||||
6. At this stage we shall install and configure HHVM. You need to add the HHVM repository to your `sources.list` file and then you have to update your repository list using following series of commands.
|
||||
|
||||
# wget -O - http://dl.hhvm.com/conf/hhvm.gpg.key | apt-key add -
|
||||
# echo deb http://dl.hhvm.com/ubuntu DISTRIBUTION_VERSION main | sudo tee /etc/apt/sources.list.d/hhvm.list
|
||||
# apt-get update
|
||||
|
||||
**Important**: Don’t forget to replace DISTRIBUTION_VERSION with your Ubuntu distribution version (i.e. lucid, precise, or trusty.) and also on Debian replace with jessie or wheezy. On Linux Mint installation instructions are same, but petra is the only currently supported distribution.
|
||||
|
||||
After adding HHVM repository, you can easily install it as shown.
|
||||
|
||||
# apt-get install -y hhvm
|
||||
|
||||
Installing HHVM will start it up now, but it not configured to auto start at next system boot. To set auto start at next boot use the following command.
|
||||
|
||||
# update-rc.d hhvm defaults
|
||||
|
||||
### Step 4: Configuring Nginx/Apache to Talk to HHVM ###
|
||||
|
||||
7. Now, nginx/apache and HHVM are installed and running as independent, so we need to configure both web servers to talk to each other. The crucial part is that we have to tell nginx/apache to forward all PHP files to HHVM to execute.
|
||||
|
||||
If you are using Nginx, follow this instructions as explained..
|
||||
|
||||
By default, the nginx configuration lives under /etc/nginx/sites-available/default and these config looks in /usr/share/nginx/html for files to execute, but it don’t know what to do with PHP.
|
||||
|
||||
To make Nginx to talk with HHVM, we need to run the following include script that will configure nginx correctly by placing a hhvm.conf at the beginning of the nginx config as mentioned above.
|
||||
|
||||
This script makes the nginx to talk to any file that ends with .hh or .php and send it to HHVM via fastcgi.
|
||||
|
||||
# /usr/share/hhvm/install_fastcgi.sh
|
||||
|
||||

|
||||
|
||||
Configure Nginx for HHVM
|
||||
|
||||
**Important**: If you are using Apache, there isn’t any configuration is needed now.
|
||||
|
||||
8. Next, you need to use /usr/bin/hhvm to provide /usr/bin/php (php) by running this command below.
|
||||
|
||||
# /usr/bin/update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
|
||||
After all the above steps are done, you can now start HHVM and test it.
|
||||
|
||||
# systemctl start hhvm
|
||||
|
||||
### Step 5: Testing HHVM with Nginx/Apache ###
|
||||
|
||||
9. To verify that hhvm working, you need to create a hello.php file under nginx/apache document root directory.
|
||||
|
||||
# nano /usr/share/nginx/html/hello.php [For Nginx]
|
||||
OR
|
||||
# nano /var/www/html/hello.php [For Nginx and Apache]
|
||||
|
||||
Add the following snippet to this file.
|
||||
|
||||
<?php
|
||||
if (defined('HHVM_VERSION')) {
|
||||
echo 'HHVM is working';
|
||||
phpinfo();
|
||||
}
|
||||
else {
|
||||
echo 'HHVM is not working';
|
||||
}
|
||||
?>
|
||||
|
||||
and then navigate to the following URL and verify to see “hello world“.
|
||||
|
||||
http://localhost/info.php
|
||||
OR
|
||||
http://IP-Address/info.php
|
||||
|
||||

|
||||
|
||||
HHVM Page
|
||||
|
||||
If “HHVM” page appears, then it means you’re all set!
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
These steps are very easy to follow and hope your find this tutorial useful and if you get any error during installation of any packages, post a comment and we shall find solutions together. And any additional ideas are welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-hhvm-and-nginx-apache-with-mariadb-on-debian-ubuntu/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/install-apc-alternative-php-cache-in-rhel-centos-fedora/
|
||||
@ -1,222 +0,0 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 1 - LFCS: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
================================================================================
|
||||
The Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, a new program that aims at helping individuals all over the world to get certified in basic to intermediate system administration tasks for Linux systems. This includes supporting running systems and services, along with first-hand troubleshooting and analysis, and smart decision-making to escalate issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 1
|
||||
|
||||
Please watch the following video that demonstrates about The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
The series will be titled Preparation for the LFCS (Linux Foundation Certified Sysadmin) Parts 1 through 10 and cover the following topics for Ubuntu, CentOS, and openSUSE:
|
||||
|
||||
- Part 1: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
- Part 2: How to Install and Use vi/m as a full Text Editor
|
||||
- Part 3: Archiving Files/Directories and Finding Files on the Filesystem
|
||||
- Part 4: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
- Part 5: Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
- Part 6: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
- Part 7: Managing System Startup Process and Services (SysVinit, Systemd and Upstart
|
||||
- Part 8: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
- Part 9: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
- Part 10: Learning Basic Shell Scripting and Filesystem Troubleshooting
|
||||
|
||||
|
||||
This post is Part 1 of a 10-tutorial series, which will cover the necessary domains and competencies that are required for the LFCS certification exam. That being said, fire up your terminal, and let’s start.
|
||||
|
||||
### Processing Text Streams in Linux ###
|
||||
|
||||
Linux treats the input to and the output from programs as streams (or sequences) of characters. To begin understanding redirection and pipes, we must first understand the three most important types of I/O (Input and Output) streams, which are in fact special files (by convention in UNIX and Linux, data streams and peripherals, or device files, are also treated as ordinary files).
|
||||
|
||||
The difference between > (redirection operator) and | (pipeline operator) is that while the first connects a command with a file, the latter connects the output of a command with another command.
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
Since the redirection operator creates or overwrites files silently, we must use it with extreme caution, and never mistake it with a pipeline. One advantage of pipes on Linux and UNIX systems is that there is no intermediate file involved with a pipe – the stdout of the first command is not written to a file and then read by the second command.
|
||||
|
||||
For the following practice exercises we will use the poem “A happy child” (anonymous author).
|
||||
|
||||
|
||||
|
||||
cat command example
|
||||
|
||||
#### Using sed ####
|
||||
|
||||
The name sed is short for stream editor. For those unfamiliar with the term, a stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
|
||||
|
||||
The most basic (and popular) usage of sed is the substitution of characters. We will begin by changing every occurrence of the lowercase y to UPPERCASE Y and redirecting the output to ahappychild2.txt. The g flag indicates that sed should perform the substitution for all instances of term on every line of file. If this flag is omitted, sed will replace only the first occurrence of term on each line.
|
||||
|
||||
**Basic syntax:**
|
||||
|
||||
# sed ‘s/term/replacement/flag’ file
|
||||
|
||||
**Our example:**
|
||||
|
||||
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
sed command example
|
||||
|
||||
Should you want to search for or replace a special character (such as /, \, &) you need to escape it, in the term or replacement strings, with a backward slash.
|
||||
|
||||
For example, we will substitute the word and for an ampersand. At the same time, we will replace the word I with You when the first one is found at the beginning of a line.
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
sed replace string
|
||||
|
||||
In the above command, a ^ (caret sign) is a well-known regular expression that is used to represent the beginning of a line.
|
||||
|
||||
As you can see, we can combine two or more substitution commands (and use regular expressions inside them) by separating them with a semicolon and enclosing the set inside single quotes.
|
||||
|
||||
Another use of sed is showing (or deleting) a chosen portion of a file. In the following example, we will display the first 5 lines of /var/log/messages from Jun 8.
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
Note that by default, sed prints every line. We can override this behaviour with the -n option and then tell sed to print (indicated by p) only the part of the file (or the pipe) that matches the pattern (Jun 8 at the beginning of line in the first case and lines 1 through 5 inclusive in the second case).
|
||||
|
||||
Finally, it can be useful while inspecting scripts or configuration files to inspect the code itself and leave out comments. The following sed one-liner deletes (d) blank lines or those starting with # (the | character indicates a boolean OR between the two regular expressions).
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
sed match string
|
||||
|
||||
#### uniq Command ####
|
||||
|
||||
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files). By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option.
|
||||
|
||||
**Examples**
|
||||
|
||||
The du –sch /path/to/directory/* command returns the disk space usage per subdirectories and files within the specified directory in human-readable format (also shows a total per directory), and does not order the output by size, but by subdirectory and file name. We can use the following command to sort by size.
|
||||
|
||||
# du -sch /var/* | sort –h
|
||||
|
||||
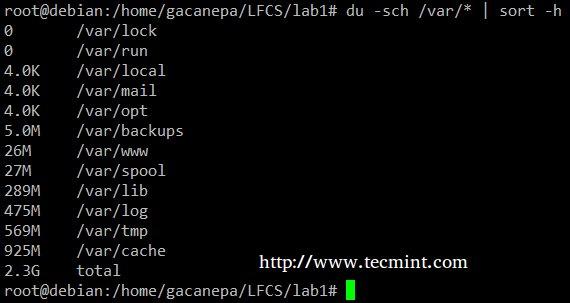
|
||||
|
||||
sort command example
|
||||
|
||||
You can count the number of events in a log by date by telling uniq to perform the comparison using the first 6 characters (-w 6) of each line (where the date is specified), and prefixing each output line by the number of occurrences (-c) with the following command.
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
Count Numbers in File
|
||||
|
||||
Finally, you can combine sort and uniq (as they usually are). Consider the following file with a list of donors, donation date, and amount. Suppose we want to know how many unique donors there are. We will use the following command to cut the first field (fields are delimited by a colon), sort by name, and remove duplicate lines.
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
Find Unique Records in File
|
||||
|
||||
- Read Also: [13 “cat” Command Examples][1]
|
||||
|
||||
#### grep Command ####
|
||||
|
||||
grep searches text files or (command output) for the occurrence of a specified regular expression and outputs any line containing a match to standard output.
|
||||
|
||||
**Examples**
|
||||
|
||||
Display the information from /etc/passwd for user gacanepa, ignoring case.
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
grep command example
|
||||
|
||||
Show all the contents of /etc whose name begins with rc followed by any single number.
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
List Content Using grep
|
||||
|
||||
- Read Also: [12 “grep” Command Examples][2]
|
||||
|
||||
#### tr Command Usage ####
|
||||
|
||||
The tr command can be used to translate (change) or delete characters from stdin, and write the result to stdout.
|
||||
|
||||
**Examples**
|
||||
|
||||
Change all lowercase to uppercase in sortuniq.txt file.
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
Sort Strings in File
|
||||
|
||||
Squeeze the delimiter in the output of ls –l to only one space.
|
||||
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
Squeeze Delimiter
|
||||
|
||||
#### cut Command Usage ####
|
||||
|
||||
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b option), characters (-c), or fields (-f). In this last case (based on fields), the default field separator is a tab, but a different delimiter can be specified by using the -d option.
|
||||
|
||||
**Examples**
|
||||
|
||||
Extract the user accounts and the default shells assigned to them from /etc/passwd (the –d option allows us to specify the field delimiter, and the –f switch indicates which field(s) will be extracted.
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
Extract User Accounts
|
||||
|
||||
Summing up, we will create a text stream consisting of the first and third non-blank files of the output of the last command. We will use grep as a first filter to check for sessions of user gacanepa, then squeeze delimiters to only one space (tr -s ‘ ‘). Next, we’ll extract the first and third fields with cut, and finally sort by the second field (IP addresses in this case) showing unique.
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
last command example
|
||||
|
||||
The above command shows how multiple commands and pipes can be combined so as to obtain filtered data according to our desires. Feel free to also run it by parts, to help you see the output that is pipelined from one command to the next (this can be a great learning experience, by the way!).
|
||||
|
||||
### Summary ###
|
||||
|
||||
Although this example (along with the rest of the examples in the current tutorial) may not seem very useful at first sight, they are a nice starting point to begin experimenting with commands that are used to create, edit, and manipulate files from the Linux command line. Feel free to leave your questions and comments below – they will be much appreciated!
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [About the LFCS][3]
|
||||
- [Why get a Linux Foundation Certification?][4]
|
||||
- [Register for the LFCS exam][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,180 +0,0 @@
|
||||
struggling 翻译中
|
||||
Growing an Existing RAID Array and Removing Failed Disks in Raid – Part 7
|
||||
================================================================================
|
||||
Every newbies will get confuse of the word array. Array is just a collection of disks. In other words, we can call array as a set or group. Just like a set of eggs containing 6 numbers. Likewise RAID Array contains number of disks, it may be 2, 4, 6, 8, 12, 16 etc. Hope now you know what Array is.
|
||||
|
||||
Here we will see how to grow (extend) an existing array or raid group. For example, if we are using 2 disks in an array to form a raid 1 set, and in some situation if we need more space in that group, we can extend the size of an array using mdadm –grow command, just by adding one of the disk to the existing array. After growing (adding disk to an existing array), we will see how to remove one of the failed disk from array.
|
||||
|
||||

|
||||
|
||||
Growing Raid Array and Removing Failed Disks
|
||||
|
||||
Assume that one of the disk is little weak and need to remove that disk, till it fails let it under use, but we need to add one of the spare drive and grow the mirror before it fails, because we need to save our data. While the weak disk fails we can remove it from array this is the concept we are going to see in this topic.
|
||||
|
||||
#### Features of RAID Growth ####
|
||||
|
||||
- We can grow (extend) the size of any raid set.
|
||||
- We can remove the faulty disk after growing raid array with new disk.
|
||||
- We can grow raid array without any downtime.
|
||||
|
||||
Requirements
|
||||
|
||||
- To grow an RAID array, we need an existing RAID set (Array).
|
||||
- We need extra disks to grow the Array.
|
||||
- Here I’m using 1 disk to grow the existing array.
|
||||
|
||||
Before we learn about growing and recovering of Array, we have to know about the basics of RAID levels and setups. Follow the below links to know about those setups.
|
||||
|
||||
- [Understanding Basic RAID Concepts – Part 1][1]
|
||||
- [Creating a Software Raid 0 in Linux – Part 2][2]
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.230
|
||||
Hostname : grow.tecmintlocal.com
|
||||
2 Existing Disks : 1 GB
|
||||
1 Additional Disk : 1 GB
|
||||
|
||||
Here, my already existing RAID has 2 number of disks with each size is 1GB and we are now adding one more disk whose size is 1GB to our existing raid array.
|
||||
|
||||
### Growing an Existing RAID Array ###
|
||||
|
||||
1. Before growing an array, first list the existing Raid array using the following command.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Check Existing Raid Array
|
||||
|
||||
**Note**: The above output shows that I’ve already has two disks in Raid array with raid1 level. Now here we are adding one more disk to an existing array,
|
||||
|
||||
2. Now let’s add the new disk “sdd” and create a partition using ‘fdisk‘ command.
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
Please use the below instructions to create a partition on /dev/sdd drive.
|
||||
|
||||
- Press ‘n‘ for creating new partition.
|
||||
- Then choose ‘P‘ for Primary partition.
|
||||
- Then choose ‘1‘ to be the first partition.
|
||||
- Next press ‘p‘ to print the created partition.
|
||||
- Here, we are selecting ‘fd‘ as my type is RAID.
|
||||
- Next press ‘p‘ to print the defined partition.
|
||||
- Then again use ‘p‘ to print the changes what we have made.
|
||||
- Use ‘w‘ to write the changes.
|
||||
|
||||

|
||||
|
||||
Create New sdd Partition
|
||||
|
||||
3. Once new sdd partition created, you can verify it using below command.
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||

|
||||
|
||||
Confirm sdd Partition
|
||||
|
||||
4. Next, examine the newly created disk for any existing raid, before adding to the array.
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||

|
||||
|
||||
Check Raid on sdd Partition
|
||||
|
||||
**Note**: The above output shows that the disk has no super-blocks detected, means we can move forward to add a new disk to an existing array.
|
||||
|
||||
4. To add the new partition /dev/sdd1 in existing array md0, use the following command.
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||

|
||||
|
||||
Add Disk To Raid-Array
|
||||
|
||||
5. Once the new disk has been added, check for the added disk in our array using.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Confirm Disk Added to Raid
|
||||
|
||||
**Note**: In the above output, you can see the drive has been added as a spare. Here, we already having 2 disks in the array, but what we are expecting is 3 devices in array for that we need to grow the array.
|
||||
|
||||
6. To grow the array we have to use the below command.
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||

|
||||
|
||||
Grow Raid Array
|
||||
|
||||
Now we can see the third disk (sdd1) has been added to array, after adding third disk it will sync the data from other two disks.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Confirm Raid Array
|
||||
|
||||
**Note**: For large size disk it will take hours to sync the contents. Here I have used 1GB virtual disk, so its done very quickly within seconds.
|
||||
|
||||
### Removing Disks from Array ###
|
||||
|
||||
7. After the data has been synced to new disk ‘sdd1‘ from other two disks, that means all three disks now have same contents.
|
||||
|
||||
As I told earlier let’s assume that one of the disk is weak and needs to be removed, before it fails. So, now assume disk ‘sdc1‘ is weak and needs to be removed from an existing array.
|
||||
|
||||
Before removing a disk we have to mark the disk as failed one, then only we can able to remove it.
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Disk Fail in Raid Array
|
||||
|
||||
From the above output, we clearly see that the disk was marked as faulty at the bottom. Even its faulty, we can see the raid devices are 3, failed 1 and state was degraded.
|
||||
|
||||
Now we have to remove the faulty drive from the array and grow the array with 2 devices, so that the raid devices will be set to 2 devices as before.
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
Remove Disk in Raid Array
|
||||
|
||||
8. Once the faulty drive is removed, now we’ve to grow the raid array using 2 disks.
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Grow Disks in Raid Array
|
||||
|
||||
From the about output, you can see that our array having only 2 devices. If you need to grow the array again, follow the same steps as described above. If you need to add a drive as spare, mark it as spare so that if the disk fails, it will automatically active and rebuild.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In the article, we’ve seen how to grow an existing raid set and how to remove a faulty disk from an array after re-syncing the existing contents. All these steps can be done without any downtime. During data syncing, system users, files and applications will not get affected in any case.
|
||||
|
||||
In next, article I will show you how to manage the RAID, till then stay tuned to updates and don’t forget to add your comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
@ -1,166 +0,0 @@
|
||||
ictlyh Translating
|
||||
Part 5 - How to Manage System Logs (Configure, Rotate and Import Into Database) in RHEL 7
|
||||
================================================================================
|
||||
In order to keep your RHEL 7 systems secure, you need to know how to monitor all of the activities that take place on such systems by examining log files. Thus, you will be able to detect any unusual or potentially malicious activity and perform system troubleshooting or take another appropriate action.
|
||||
|
||||

|
||||
|
||||
RHCE Exam: Manage System LogsUsing Rsyslogd and Logrotate – Part 5
|
||||
|
||||
In RHEL 7, the [rsyslogd][1] daemon is responsible for system logging and reads its configuration from /etc/rsyslog.conf (this file specifies the default location for all system logs) and from files inside /etc/rsyslog.d, if any.
|
||||
|
||||
### Rsyslogd Configuration ###
|
||||
|
||||
A quick inspection of the [rsyslog.conf][2] will be helpful to start. This file is divided into 3 main sections: Modules (since rsyslog follows a modular design), Global directives (used to set global properties of the rsyslogd daemon), and Rules. As you will probably guess, this last section indicates what gets logged or shown (also known as the selector) and where, and will be our focus throughout this article.
|
||||
|
||||
A typical line in rsyslog.conf is as follows:
|
||||
|
||||

|
||||
|
||||
Rsyslogd Configuration
|
||||
|
||||
In the image above, we can see that a selector consists of one or more pairs Facility:Priority separated by semicolons, where Facility describes the type of message (refer to [section 4.1.1 in RFC 3164][3] to see the complete list of facilities available for rsyslog) and Priority indicates its severity, which can be one of the following self-explanatory words:
|
||||
|
||||
- debug
|
||||
- info
|
||||
- notice
|
||||
- warning
|
||||
- err
|
||||
- crit
|
||||
- alert
|
||||
- emerg
|
||||
|
||||
Though not a priority itself, the keyword none means no priority at all of the given facility.
|
||||
|
||||
**Note**: That a given priority indicates that all messages of such priority and above should be logged. Thus, the line in the example above instructs the rsyslogd daemon to log all messages of priority info or higher (regardless of the facility) except those belonging to mail, authpriv, and cron services (no messages coming from this facilities will be taken into account) to /var/log/messages.
|
||||
|
||||
You can also group multiple facilities using the colon sign to apply the same priority to all of them. Thus, the line:
|
||||
|
||||
*.info;mail.none;authpriv.none;cron.none /var/log/messages
|
||||
|
||||
Could be rewritten as
|
||||
|
||||
*.info;mail,authpriv,cron.none /var/log/messages
|
||||
|
||||
In other words, the facilities mail, authpriv, and cron are grouped and the keyword none is applied to the three of them.
|
||||
|
||||
#### Creating a custom log file ####
|
||||
|
||||
To log all daemon messages to /var/log/tecmint.log, we need to add the following line either in rsyslog.conf or in a separate file (easier to manage) inside /etc/rsyslog.d:
|
||||
|
||||
daemon.* /var/log/tecmint.log
|
||||
|
||||
Let’s restart the daemon (note that the service name does not end with a d):
|
||||
|
||||
# systemctl restart rsyslog
|
||||
|
||||
And check the contents of our custom log before and after restarting two random daemons:
|
||||
|
||||

|
||||
|
||||
Create Custom Log File
|
||||
|
||||
As a self-study exercise, I would recommend you play around with the facilities and priorities and either log additional messages to existing log files or create new ones as in the previous example.
|
||||
|
||||
### Rotating Logs using Logrotate ###
|
||||
|
||||
To prevent log files from growing endlessly, the logrotate utility is used to rotate, compress, remove, and alternatively mail logs, thus easing the administration of systems that generate large numbers of log files.
|
||||
|
||||
Logrotate runs daily as a cron job (/etc/cron.daily/logrotate) and reads its configuration from /etc/logrotate.conf and from files located in /etc/logrotate.d, if any.
|
||||
|
||||
As with the case of rsyslog, even when you can include settings for specific services in the main file, creating separate configuration files for each one will help organize your settings better.
|
||||
|
||||
Let’s take a look at a typical logrotate.conf:
|
||||
|
||||

|
||||
|
||||
Logrotate Configuration
|
||||
|
||||
In the example above, logrotate will perform the following actions for /var/loh/wtmp: attempt to rotate only once a month, but only if the file is at least 1 MB in size, then create a brand new log file with permissions set to 0664 and ownership given to user root and group utmp. Next, only keep one archived log, as specified by the rotate directive:
|
||||
|
||||
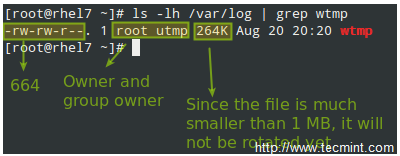
|
||||
|
||||
Logrotate Logs Monthly
|
||||
|
||||
Let’s now consider another example as found in /etc/logrotate.d/httpd:
|
||||
|
||||

|
||||
|
||||
Rotate Apache Log Files
|
||||
|
||||
You can read more about the settings for logrotate in its man pages ([man logrotate][4] and [man logrotate.conf][5]). Both files are provided along with this article in PDF format for your reading convenience.
|
||||
|
||||
As a system engineer, it will be pretty much up to you to decide for how long logs will be stored and in what format, depending on whether you have /var in a separate partition / logical volume. Otherwise, you really want to consider removing old logs to save storage space. On the other hand, you may be forced to keep several logs for future security auditing according to your company’s or client’s internal policies.
|
||||
|
||||
#### Saving Logs to a Database ####
|
||||
|
||||
Of course examining logs (even with the help of tools such as grep and regular expressions) can become a rather tedious task. For that reason, rsyslog allows us to export them into a database (OTB supported RDBMS include MySQL, MariaDB, PostgreSQL, and Oracle.
|
||||
|
||||
This section of the tutorial assumes that you have already installed the MariaDB server and client in the same RHEL 7 box where the logs are being managed:
|
||||
|
||||
# yum update && yum install mariadb mariadb-server mariadb-client rsyslog-mysql
|
||||
# systemctl enable mariadb && systemctl start mariadb
|
||||
|
||||
Then use the `mysql_secure_installation` utility to set the password for the root user and other security considerations:
|
||||
|
||||

|
||||
|
||||
Secure MySQL Database
|
||||
|
||||
Note: If you don’t want to use the MariaDB root user to insert log messages to the database, you can configure another user account to do so. Explaining how to do that is out of the scope of this tutorial but is explained in detail in [MariaDB knowledge][6] base. In this tutorial we will use the root account for simplicity.
|
||||
|
||||
Next, download the createDB.sql script from [GitHub][7] and import it into your database server:
|
||||
|
||||
# mysql -u root -p < createDB.sql
|
||||
|
||||

|
||||
|
||||
Save Server Logs to Database
|
||||
|
||||
Finally, add the following lines to /etc/rsyslog.conf:
|
||||
|
||||
$ModLoad ommysql
|
||||
$ActionOmmysqlServerPort 3306
|
||||
*.* :ommysql:localhost,Syslog,root,YourPasswordHere
|
||||
|
||||
Restart rsyslog and the database server:
|
||||
|
||||
# systemctl restart rsyslog
|
||||
# systemctl restart mariadb
|
||||
|
||||
#### Querying the Logs using SQL syntax ####
|
||||
|
||||
Now perform some tasks that will modify the logs (like stopping and starting services, for example), then log to your DB server and use standard SQL commands to display and search in the logs:
|
||||
|
||||
USE Syslog;
|
||||
SELECT ReceivedAt, Message FROM SystemEvents;
|
||||
|
||||

|
||||
|
||||
Query Logs in Database
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have explained how to set up system logging, how to rotate logs, and how to redirect the messages to a database for easier search. We hope that these skills will be helpful as you prepare for the [RHCE exam][8] and in your daily responsibilities as well.
|
||||
|
||||
As always, your feedback is more than welcome. Feel free to use the form below to reach us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-system-logs-using-rsyslogd-and-logrotate/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/pdf/rsyslogd.pdf
|
||||
[2]:http://www.tecmint.com/wp-content/pdf/rsyslog.conf.pdf
|
||||
[3]:https://tools.ietf.org/html/rfc3164#section-4.1.1
|
||||
[4]:http://www.tecmint.com/wp-content/pdf/logrotate.pdf
|
||||
[5]:http://www.tecmint.com/wp-content/pdf/logrotate.conf.pdf
|
||||
[6]:https://mariadb.com/kb/en/mariadb/create-user/
|
||||
[7]:https://github.com/sematext/rsyslog/blob/master/plugins/ommysql/createDB.sql
|
||||
[8]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
@ -1,249 +0,0 @@
|
||||
[translated by xiqingongzi]
|
||||
RHCSA Series: How to Manage Users and Groups in RHEL 7 – Part 3
|
||||
================================================================================
|
||||
Managing a RHEL 7 server, as it is the case with any other Linux server, will require that you know how to add, edit, suspend, or delete user accounts, and grant users the necessary permissions to files, directories, and other system resources to perform their assigned tasks.
|
||||
|
||||

|
||||
|
||||
RHCSA: User and Group Management – Part 3
|
||||
|
||||
### Managing User Accounts ###
|
||||
|
||||
To add a new user account to a RHEL 7 server, you can run either of the following two commands as root:
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
When a new user account is added, by default the following operations are performed.
|
||||
|
||||
- His/her home directory is created (`/home/username` unless specified otherwise).
|
||||
- These `.bash_logout`, `.bash_profile` and `.bashrc` hidden files are copied inside the user’s home directory, and will be used to provide environment variables for his/her user session. You can explore each of them for further details.
|
||||
- A mail spool directory is created for the added user account.
|
||||
- A group is created with the same name as the new user account.
|
||||
|
||||
The full account summary is stored in the `/etc/passwd `file. This file holds a record per system user account and has the following format (fields are separated by a colon):
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- These two fields `[username]` and `[Comment]` are self explanatory.
|
||||
- The second filed ‘x’ indicates that the account is secured by a shadowed password (in `/etc/shadow`), which is used to logon as `[username]`.
|
||||
- The fields `[UID]` and `[GID]` are integers that shows the User IDentification and the primary Group IDentification to which `[username]` belongs, equally.
|
||||
|
||||
Finally,
|
||||
|
||||
- The `[Home directory]` shows the absolute location of `[username]’s` home directory, and
|
||||
- `[Default shell]` is the shell that is commit to this user when he/she logins into the system.
|
||||
|
||||
Another important file that you must become familiar with is `/etc/group`, where group information is stored. As it is the case with `/etc/passwd`, there is one record per line and its fields are also delimited by a colon:
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
where,
|
||||
|
||||
- `[Group name]` is the name of group.
|
||||
- Does this group use a group password? (An “x” means no).
|
||||
- `[GID]`: same as in `/etc/passwd`.
|
||||
- `[Group members]`: a list of users, separated by commas, that are members of each group.
|
||||
|
||||
After adding an account, at anytime, you can edit the user’s account information using usermod, whose basic syntax is:
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
Read Also:
|
||||
|
||||
- [15 ‘useradd’ Command Examples][1]
|
||||
- [15 ‘usermod’ Command Examples][2]
|
||||
|
||||
#### EXAMPLE 1: Setting the expiry date for an account ####
|
||||
|
||||
If you work for a company that has some kind of policy to enable account for a certain interval of time, or if you want to grant access to a limited period of time, you can use the `--expiredate` flag followed by a date in YYYY-MM-DD format. To verify that the change has been applied, you can compare the output of
|
||||
|
||||
# chage -l [username]
|
||||
|
||||
before and after updating the account expiry date, as shown in the following image.
|
||||
|
||||
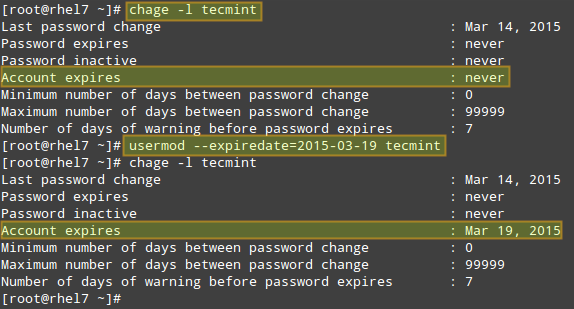
|
||||
|
||||
Change User Account Information
|
||||
|
||||
#### EXAMPLE 2: Adding the user to supplementary groups ####
|
||||
|
||||
Besides the primary group that is created when a new user account is added to the system, a user can be added to supplementary groups using the combined -aG, or –append –groups options, followed by a comma separated list of groups.
|
||||
|
||||
#### EXAMPLE 3: Changing the default location of the user’s home directory and / or changing its shell ####
|
||||
|
||||
If for some reason you need to change the default location of the user’s home directory (other than /home/username), you will need to use the -d, or –home options, followed by the absolute path to the new home directory.
|
||||
|
||||
If a user wants to use another shell other than bash (for example, sh), which gets assigned by default, use usermod with the –shell flag, followed by the path to the new shell.
|
||||
|
||||
#### EXAMPLE 4: Displaying the groups an user is a member of ####
|
||||
|
||||
After adding the user to a supplementary group, you can verify that it now actually belongs to such group(s):
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
The following image depicts Examples 2 through 4:
|
||||
|
||||

|
||||
|
||||
Adding User to Supplementary Group
|
||||
|
||||
In the example above:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
To remove a user from a group, omit the `--append` switch in the command above and list the groups you want the user to belong to following the `--groups` flag.
|
||||
|
||||
#### EXAMPLE 5: Disabling account by locking password ####
|
||||
|
||||
To disable an account, you will need to use either the -l (lowercase L) or the –lock option to lock a user’s password. This will prevent the user from being able to log on.
|
||||
|
||||
#### EXAMPLE 6: Unlocking password ####
|
||||
|
||||
When you need to re-enable the user so that he can log on to the server again, use the -u or the –unlock option to unlock a user’s password that was previously blocked, as explained in Example 5 above.
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
The following image illustrates Examples 5 and 6:
|
||||
|
||||

|
||||
|
||||
Lock Unlock User Account
|
||||
|
||||
#### EXAMPLE 7: Deleting a group or an user account ####
|
||||
|
||||
To delete a group, you’ll want to use groupdel, whereas to delete a user account you will use userdel (add the –r switch if you also want to delete the contents of its home directory and mail spool):
|
||||
|
||||
# groupdel [group_name] # Delete a group
|
||||
# userdel -r [user_name] # Remove user_name from the system, along with his/her home directory and mail spool
|
||||
|
||||
If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
|
||||
|
||||
### Listing, Setting and Changing Standard ugo/rwx Permissions ###
|
||||
|
||||
The well-known [ls command][3] is one of the best friends of any system administrator. When used with the -l flag, this tool allows you to view a list a directory’s contents in long (or detailed) format.
|
||||
|
||||
However, this command can also be applied to a single file. Either way, the first 10 characters in the output of `ls -l` represent each file’s attributes.
|
||||
|
||||
The first char of this 10-character sequence is used to indicate the file type:
|
||||
|
||||
- – (hyphen): a regular file
|
||||
- d: a directory
|
||||
- l: a symbolic link
|
||||
- c: a character device (which treats data as a stream of bytes, i.e. a terminal)
|
||||
- b: a block device (which handles data in blocks, i.e. storage devices)
|
||||
|
||||
The next nine characters of the file attributes, divided in groups of three from left to right, are called the file mode and indicate the read (r), write(w), and execute (x) permissions granted to the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”), respectively.
|
||||
|
||||
While the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run.
|
||||
|
||||
File permissions are changed with the chmod command, whose basic syntax is as follows:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
where new_mode is either an octal number or an expression that specifies the new permissions. Feel free to use the mode that works best for you in each case. Or perhaps you already have a preferred way to set a file’s permissions – so feel free to use the method that works best for you.
|
||||
|
||||
The octal number can be calculated based on the binary equivalent, which can in turn be obtained from the desired file permissions for the owner of the file, the owner group, and the world.The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence means 0. For example:
|
||||
|
||||

|
||||
|
||||
File Permissions
|
||||
|
||||
To set the file’s permissions as indicated above in octal form, type:
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
Please take a minute to compare our previous calculation to the actual output of `ls -l` after changing the file’s permissions:
|
||||
|
||||
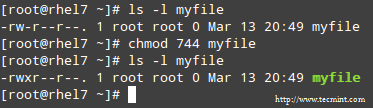
|
||||
|
||||
Long List Format
|
||||
|
||||
#### EXAMPLE 8: Searching for files with 777 permissions ####
|
||||
|
||||
As a security measure, you should make sure that files with 777 permissions (read, write, and execute for everyone) are avoided like the plague under normal circumstances. Although we will explain in a later tutorial how to more effectively locate all the files in your system with a certain permission set, you can -by now- combine ls with grep to obtain such information.
|
||||
|
||||
In the following example, we will look for file with 777 permissions in the /etc directory only. Note that we will use pipelining as explained in [Part 2: File and Directory Management][4] of this RHCSA series:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
Find All Files with 777 Permission
|
||||
|
||||
#### EXAMPLE 9: Assigning a specific permission to all users ####
|
||||
|
||||
Shell scripts, along with some binaries that all users should have access to (not just their corresponding owner and group), should have the execute bit set accordingly (please note that we will discuss a special case later):
|
||||
|
||||
# chmod a+x script.sh
|
||||
|
||||
**Note**: That we can also set a file’s mode using an expression that indicates the owner’s rights with the letter `u`, the group owner’s rights with the letter `g`, and the rest with `o`. All of these rights can be represented at the same time with the letter `a`. Permissions are granted (or revoked) with the `+` or `-` signs, respectively.
|
||||
|
||||

|
||||
|
||||
Set Execute Permission on File
|
||||
|
||||
A long directory listing also shows the file’s owner and its group owner in the first and second columns, respectively. This feature serves as a first-level access control method to files in a system:
|
||||
|
||||
|
||||
|
||||
Check File Owner and Group
|
||||
|
||||
To change file ownership, you will use the chown command. Note that you can change the file and group ownership at the same time or separately:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
**Note**: That you can change the user or group, or the two attributes at the same time, as long as you don’t forget the colon, leaving user or group blank if you want to update the other attribute, for example:
|
||||
|
||||
# chown :group file # Change group ownership only
|
||||
# chown user: file # Change user ownership only
|
||||
|
||||
#### EXAMPLE 10: Cloning permissions from one file to another ####
|
||||
|
||||
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
|
||||
|
||||
# chown --reference=ref_file file
|
||||
|
||||
where the owner and group of ref_file will be assigned to file as well:
|
||||
|
||||

|
||||
|
||||
Clone File Ownership
|
||||
|
||||
### Setting Up SETGID Directories for Collaboration ###
|
||||
|
||||
Should you need to grant access to all the files owned by a certain group inside a specific directory, you will most likely use the approach of setting the setgid bit for such directory. When the setgid bit is set, the effective GID of the real user becomes that of the group owner.
|
||||
|
||||
Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory.
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
A solid knowledge of user and group management, along with standard and special Linux permissions, when coupled with practice, will allow you to quickly identify and troubleshoot issues with file permissions in your RHEL 7 server.
|
||||
|
||||
I assure you that as you follow the steps outlined in this article and use the system documentation (as explained in [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) you will master this essential competence of system administration.
|
||||
|
||||
Feel free to let us know if you have any questions or comments using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc Translating
|
||||
|
||||
RHCSA Series: Installing, Configuring and Securing a Web and FTP Server – Part 9
|
||||
================================================================================
|
||||
A web server (also known as a HTTP server) is a service that handles content (most commonly web pages, but other types of documents as well) over to a client in a network.
|
||||
@ -173,4 +175,4 @@ via: http://www.tecmint.com/rhcsa-series-install-and-secure-apache-web-server-an
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
[2]:http://www.tecmint.com/manage-and-limit-downloadupload-bandwidth-with-trickle-in-linux/
|
||||
[3]:http://www.google.com/cse?cx=partner-pub-2601749019656699:2173448976&ie=UTF-8&q=virtual+hosts&sa=Search&gws_rd=cr&ei=Dy9EVbb0IdHisASnroG4Bw#gsc.tab=0&gsc.q=apache
|
||||
[3]:http://www.google.com/cse?cx=partner-pub-2601749019656699:2173448976&ie=UTF-8&q=virtual+hosts&sa=Search&gws_rd=cr&ei=Dy9EVbb0IdHisASnroG4Bw#gsc.tab=0&gsc.q=apache
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[xiqingongzi translating]
|
||||
RHCSA Series: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs – Part 10
|
||||
================================================================================
|
||||
In this article we will review how to install, update, and remove packages in Red Hat Enterprise Linux 7. We will also cover how to automate tasks using cron, and will finish this guide explaining how to locate and interpret system logs files with the focus of teaching you why all of these are essential skills for every system administrator.
|
||||
@ -194,4 +195,4 @@ via: http://www.tecmint.com/yum-package-management-cron-job-scheduling-monitorin
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user