mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
commit
3bb132e506
@ -1,14 +1,14 @@
|
||||
Ubuntu上使用LVM轻松调整分区并制作快照
|
||||
Ubuntu 上使用 LVM 轻松调整分区并制作快照
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。说明中说,它启用了逻辑卷管理,因此你可以制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。它的描述中说,启用逻辑卷管理可以让你制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的存储空间][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的“存储空间”][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
|
||||
### 你应该在新安装Ubuntu时使用LVM吗? ###
|
||||
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、合并多个磁盘到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[调整这些不使用的分区][3]。
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、将多个磁盘合并到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[当这些分区不使用时才能调整][3]。
|
||||
|
||||
完全坦率地说,普通Ubuntu桌面用户可能不会意识到他们是否正在使用LVM。但是,如果你想要在今后做一些更高深的事情,那么LVM就会有所帮助了。LVM可能更复杂,可能会在你今后恢复数据时会导致问题——尤其是在你经验不足时。这里不会有显著的性能损失——LVM是彻底地在Linux内核中实现的。
|
||||
|
||||
@ -18,7 +18,7 @@ LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的存储空
|
||||
|
||||
前面,我们已经[说明了何谓LVM][4]。概括来讲,它在你的物理磁盘和呈现在你系统中的分区之间提供了一个抽象层。例如,你的计算机可能装有两个硬盘驱动器,它们的大小都是 1 TB。你必须得在这些磁盘上至少分两个区,每个区大小 1 TB。
|
||||
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个标准的系统只会有一个卷组。
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个典型的系统只会有一个卷组。
|
||||
|
||||
该抽象层使得调整分区、将多个磁盘组合成单个卷、甚至为一个运行着的分区的文件系统创建“快照”变得十分简单,而完成所有这一切都无需先卸载分区。
|
||||
|
||||
@ -28,11 +28,11 @@ LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传
|
||||
|
||||
通常,[LVM通过Linux终端命令来管理][5]。这在Ubuntu上也行得通,但是有个更简单的图形化方法可供大家采用。如果你是一个Linux用户,对GParted或者与其类似的分区管理器熟悉,算了,别瞎掰了——GParted根本不支持LVM磁盘。
|
||||
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击停靠盘上的图标来开启它吧,搜索磁盘然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击dash中的图标来开启它吧,搜索“磁盘”然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
|
||||

|
||||
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是你没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从停靠盘上打开逻辑卷管理工具了。
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从dash上打开逻辑卷管理工具了。
|
||||
|
||||
这个图形化配置工具是由红帽公司开发的,虽然有点陈旧了,但却是唯一的图形化方式,你可以通过它来完成上述操作,将那些终端命令抛诸脑后了。
|
||||
|
||||
@ -40,11 +40,11 @@ LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传
|
||||
|
||||

|
||||
|
||||
卷组视图会列出你所有物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,就像Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
卷组视图会列出你所有的物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,这是Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
|
||||

|
||||
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩减分区。
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩小分区。
|
||||
|
||||

|
||||
|
||||
@ -55,7 +55,7 @@ system-config-lvm的其它选项允许你设置快照和镜像。对于传统桌
|
||||
via: http://www.howtogeek.com/211937/how-to-use-lvm-on-ubuntu-for-easy-partition-resizing-and-snapshots/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,77 +1,78 @@
|
||||
|
||||
在 Linux 中安装 RAID 6(条带化双分布式奇偶校验) - 第5部分
|
||||
在 Linux 下使用 RAID(五):安装 RAID 6(条带化双分布式奇偶校验)
|
||||
================================================================================
|
||||
RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两个磁盘发生故障后依然有容错能力。两并列的磁盘发生故障时,系统的关键任务仍然能运行。它与 RAID 5 相似,但性能更健壮,因为它多用了一个磁盘来进行奇偶校验。
|
||||
|
||||
在之前的文章中,我们已经在 RAID 5 看了分布式奇偶校验,但在本文中,我们将看到的是 RAID 6 双分布式奇偶校验。不要期望比其他 RAID 有额外的性能,我们仍然需要安装一个专用的 RAID 控制器。在 RAID 6 中,即使我们失去了2个磁盘,我们仍可以取回数据通过更换磁盘,然后从校验中构建数据。
|
||||
RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即使两个磁盘发生故障后依然有容错能力。在两个磁盘同时发生故障时,系统的关键任务仍然能运行。它与 RAID 5 相似,但性能更健壮,因为它多用了一个磁盘来进行奇偶校验。
|
||||
|
||||
在之前的文章中,我们已经在 RAID 5 看了分布式奇偶校验,但在本文中,我们将看到的是 RAID 6 双分布式奇偶校验。不要期望比其他 RAID 有更好的性能,除非你也安装了一个专用的 RAID 控制器。在 RAID 6 中,即使我们失去了2个磁盘,我们仍可以通过更换磁盘,从校验中构建数据,然后取回数据。
|
||||
|
||||
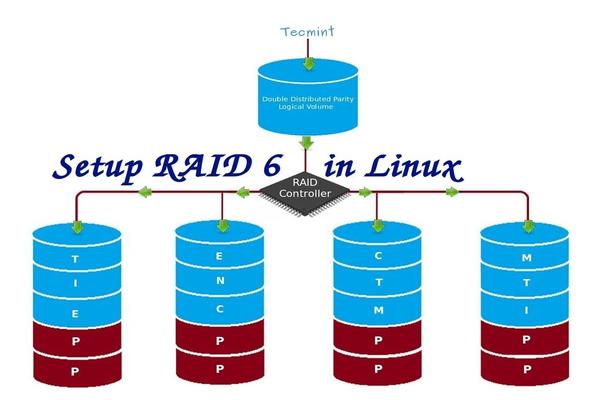
|
||||
|
||||
在 Linux 中安装 RAID 6
|
||||
*在 Linux 中安装 RAID 6*
|
||||
|
||||
要建立一个 RAID 6,一组最少需要4个磁盘。RAID 6 甚至在有些设定中会有多组磁盘,当读取数据时,它会同时从所有磁盘读取,所以读取速度会更快,当写数据时,因为它要将数据写在条带化的多个磁盘上,所以性能会较差。
|
||||
要建立一个 RAID 6,一组最少需要4个磁盘。RAID 6 甚至在有些组中会有更多磁盘,这样将多个硬盘捆在一起,当读取数据时,它会同时从所有磁盘读取,所以读取速度会更快,当写数据时,因为它要将数据写在条带化的多个磁盘上,所以性能会较差。
|
||||
|
||||
现在,很多人都在讨论为什么我们需要使用 RAID 6,它的性能和其他 RAID 相比并不太好。提出这个问题首先需要知道的是,如果需要高容错的必须选择 RAID 6。在每一个对数据库的高可用性要求较高的环境中,他们需要 RAID 6 因为数据库是最重要,无论花费多少都需要保护其安全,它在视频流环境中也是非常有用的。
|
||||
现在,很多人都在讨论为什么我们需要使用 RAID 6,它的性能和其他 RAID 相比并不太好。提出这个问题首先需要知道的是,如果需要高容错性就选择 RAID 6。在每一个用于数据库的高可用性要求较高的环境中,他们需要 RAID 6 因为数据库是最重要,无论花费多少都需要保护其安全,它在视频流环境中也是非常有用的。
|
||||
|
||||
#### RAID 6 的的优点和缺点 ####
|
||||
|
||||
- 性能很不错。
|
||||
- RAID 6 非常昂贵,因为它要求两个独立的磁盘用于奇偶校验功能。
|
||||
- 性能不错。
|
||||
- RAID 6 比较昂贵,因为它要求两个独立的磁盘用于奇偶校验功能。
|
||||
- 将失去两个磁盘的容量来保存奇偶校验信息(双奇偶校验)。
|
||||
- 不存在数据丢失,即时两个磁盘损坏。我们可以在更换损坏的磁盘后从校验中重建数据。
|
||||
- 即使两个磁盘损坏,数据也不会丢失。我们可以在更换损坏的磁盘后从校验中重建数据。
|
||||
- 读性能比 RAID 5 更好,因为它从多个磁盘读取,但对于没有专用的 RAID 控制器的设备写性能将非常差。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
要创建一个 RAID 6 最少需要4个磁盘.你也可以添加更多的磁盘,但你必须有专用的 RAID 控制器。在软件 RAID 中,我们在 RAID 6 中不会得到更好的性能,所以我们需要一个物理 RAID 控制器。
|
||||
要创建一个 RAID 6 最少需要4个磁盘。你也可以添加更多的磁盘,但你必须有专用的 RAID 控制器。使用软件 RAID 我们在 RAID 6 中不会得到更好的性能,所以我们需要一个物理 RAID 控制器。
|
||||
|
||||
这些是新建一个 RAID 需要的设置,我们建议先看完以下 RAID 文章。
|
||||
如果你新接触 RAID 设置,我们建议先看完以下 RAID 文章。
|
||||
|
||||
- [Linux 中 RAID 的基本概念 – 第一部分][1]
|
||||
- [在 Linux 上创建软件 RAID 0 (条带化) – 第二部分][2]
|
||||
- [在 Linux 上创建软件 RAID 1 (镜像) – 第三部分][3]
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
- [创建 RAID 5(条带化与分布式奇偶校验)](4)
|
||||
|
||||
#### My Server Setup ####
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.228
|
||||
Hostname : rd6.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
Disk 4 [20GB] : /dev/sde
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.228
|
||||
主机名 : rd6.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
这篇文章是9系列 RAID 教程的第5部分,在这里我们将看到我们如何在 Linux 系统或者服务器上创建和设置软件 RAID 6 或条带化双分布式奇偶校验,使用四个 20GB 的磁盘 /dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde.
|
||||
这是9篇系列教程的第5部分,在这里我们将看到如何在 Linux 系统或者服务器上使用四个 20GB 的磁盘(名为 /dev/sdb、 /dev/sdc、 /dev/sdd 和 /dev/sde)创建和设置软件 RAID 6 (条带化双分布式奇偶校验)。
|
||||
|
||||
### 第1步:安装 mdadm 工具,并检查磁盘 ###
|
||||
|
||||
1.如果你按照我们最进的两篇 RAID 文章(第2篇和第3篇),我们已经展示了如何安装‘mdadm‘工具。如果你直接看的这篇文章,我们先来解释下在Linux系统中如何使用‘mdadm‘工具来创建和管理 RAID,首先根据你的 Linux 发行版使用以下命令来安装。
|
||||
1、 如果你按照我们最进的两篇 RAID 文章(第2篇和第3篇),我们已经展示了如何安装`mdadm`工具。如果你直接看的这篇文章,我们先来解释下在 Linux 系统中如何使用`mdadm`工具来创建和管理 RAID,首先根据你的 Linux 发行版使用以下命令来安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
2.安装该工具后,然后来验证需要的四个磁盘,我们将会使用下面的‘fdisk‘命令来检验用于创建 RAID 的磁盘。
|
||||
2、 安装该工具后,然后来验证所需的四个磁盘,我们将会使用下面的`fdisk`命令来检查用于创建 RAID 的磁盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
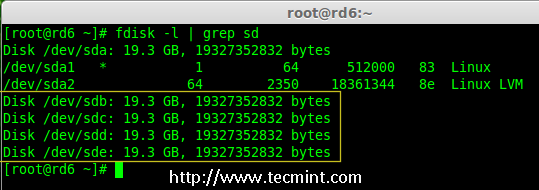
|
||||
|
||||
在 Linux 中检查磁盘
|
||||
*在 Linux 中检查磁盘*
|
||||
|
||||
3.在创建 RAID 磁盘前,先检查下我们的磁盘是否创建过 RAID 分区。
|
||||
3、 在创建 RAID 磁盘前,先检查下我们的磁盘是否创建过 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
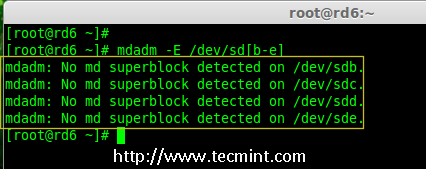
|
||||
|
||||
在磁盘上检查 Raid 分区
|
||||
*在磁盘上检查 RAID 分区*
|
||||
|
||||
**注意**: 在上面的图片中,没有检测到任何 super-block 或者说在四个磁盘上没有 RAID 存在。现在我们开始创建 RAID 6。
|
||||
|
||||
### 第2步:为 RAID 6 创建磁盘分区 ###
|
||||
|
||||
4.现在为 raid 创建分区‘/dev/sdb‘, ‘/dev/sdc‘, ‘/dev/sdd‘ 和 ‘/dev/sde‘使用下面 fdisk 命令。在这里,我们将展示如何创建分区在 sdb 磁盘,同样的步骤也适用于其他分区。
|
||||
4、 现在在 `/dev/sdb`, `/dev/sdc`, `/dev/sdd` 和 `/dev/sde`上为 RAID 创建分区,使用下面的 fdisk 命令。在这里,我们将展示如何在 sdb 磁盘创建分区,同样的步骤也适用于其他分区。
|
||||
|
||||
**创建 /dev/sdb 分区**
|
||||
|
||||
@ -79,20 +80,20 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
请按照说明进行操作,如下图所示创建分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 按 `n`创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 去修改分区。
|
||||
- 键入 ‘fd’ 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建 /dev/sdb 分区
|
||||
*创建 /dev/sdb 分区*
|
||||
|
||||
**创建 /dev/sdc 分区**
|
||||
|
||||
@ -100,7 +101,7 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
创建 /dev/sdc 分区
|
||||
*创建 /dev/sdc 分区*
|
||||
|
||||
**创建 /dev/sdd 分区**
|
||||
|
||||
@ -108,7 +109,7 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
创建 /dev/sdd 分区
|
||||
*创建 /dev/sdd 分区*
|
||||
|
||||
**创建 /dev/sde 分区**
|
||||
|
||||
@ -116,71 +117,67 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
创建 /dev/sde 分区
|
||||
*创建 /dev/sde 分区*
|
||||
|
||||
5.创建好分区后,检查磁盘的 super-blocks 是个好的习惯。如果 super-blocks 不存在我们可以按前面的创建一个新的 RAID。
|
||||
5、 创建好分区后,检查磁盘的 super-blocks 是个好的习惯。如果 super-blocks 不存在我们可以按前面的创建一个新的 RAID。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
|
||||
或者
|
||||
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
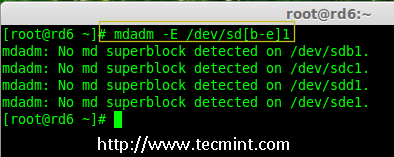
|
||||
|
||||
在新分区中检查 Raid
|
||||
*在新分区中检查 RAID *
|
||||
|
||||
### 步骤3:创建 md 设备(RAID) ###
|
||||
|
||||
6,现在是时候来创建 RAID 设备‘md0‘ (即 /dev/md0)并应用 RAID 级别在所有新创建的分区中,确认 raid 使用以下命令。
|
||||
6、 现在可以使用以下命令创建 RAID 设备`md0` (即 /dev/md0),并在所有新创建的分区中应用 RAID 级别,然后确认 RAID 设置。
|
||||
|
||||
# mdadm --create /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建 Raid 6 设备
|
||||
*创建 Raid 6 设备*
|
||||
|
||||
7.你还可以使用 watch 命令来查看当前 raid 的进程,如下图所示。
|
||||
7、 你还可以使用 watch 命令来查看当前创建 RAID 的进程,如下图所示。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
检查 Raid 6 进程
|
||||
*检查 RAID 6 创建过程*
|
||||
|
||||
8.使用以下命令验证 RAID 设备。
|
||||
8、 使用以下命令验证 RAID 设备。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
**注意**::上述命令将显示四个磁盘的信息,这是相当长的,所以没有截取其完整的输出。
|
||||
|
||||
9.接下来,验证 RAID 阵列,以确认 re-syncing 被启动。
|
||||
9、 接下来,验证 RAID 阵列,以确认重新同步过程已经开始。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 Raid 6 阵列
|
||||
*检查 Raid 6 阵列*
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
10.使用 ext4 为‘/dev/md0‘创建一个文件系统并将它挂载在 /mnt/raid5 。这里我们使用的是 ext4,但你可以根据你的选择使用任意类型的文件系统。
|
||||
10、 使用 ext4 为`/dev/md0`创建一个文件系统,并将它挂载在 /mnt/raid6 。这里我们使用的是 ext4,但你可以根据你的选择使用任意类型的文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
在 Raid 6 上创建文件系统
|
||||
*在 RAID 6 上创建文件系统*
|
||||
|
||||
11.挂载创建的文件系统到 /mnt/raid6,并验证挂载点下的文件,我们可以看到 lost+found 目录。
|
||||
11、 将创建的文件系统挂载到 /mnt/raid6,并验证挂载点下的文件,我们可以看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid6
|
||||
# mount /dev/md0 /mnt/raid6/
|
||||
# ls -l /mnt/raid6/
|
||||
|
||||
12.在挂载点下创建一些文件,在任意文件中添加一些文字并验证其内容。
|
||||
12、 在挂载点下创建一些文件,在任意文件中添加一些文字并验证其内容。
|
||||
|
||||
# touch /mnt/raid6/raid6_test.txt
|
||||
# ls -l /mnt/raid6/
|
||||
@ -189,9 +186,9 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
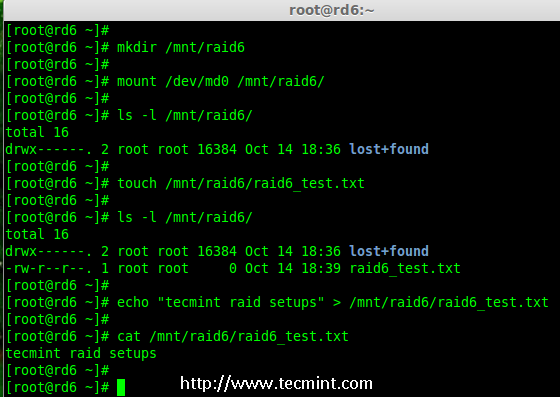
|
||||
|
||||
验证 Raid 内容
|
||||
*验证 RAID 内容*
|
||||
|
||||
13.在 /etc/fstab 中添加以下条目使系统启动时自动挂载设备,环境不同挂载点可能会有所不同。
|
||||
13、 在 /etc/fstab 中添加以下条目使系统启动时自动挂载设备,操作系统环境不同挂载点可能会有所不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
@ -199,36 +196,37 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 6 设备
|
||||
*自动挂载 RAID 6 设备*
|
||||
|
||||
14.接下来,执行‘mount -a‘命令来验证 fstab 中的条目是否有错误。
|
||||
14、 接下来,执行`mount -a`命令来验证 fstab 中的条目是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
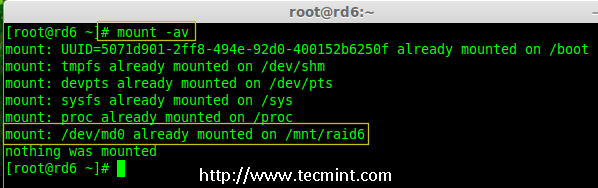
|
||||
|
||||
验证 Raid 是否自动挂载
|
||||
*验证 RAID 是否自动挂载*
|
||||
|
||||
### 第5步:保存 RAID 6 的配置 ###
|
||||
|
||||
15.请注意默认 RAID 没有配置文件。我们需要使用以下命令手动保存它,然后检查设备‘/dev/md0‘的状态。
|
||||
15、 请注意,默认情况下 RAID 没有配置文件。我们需要使用以下命令手动保存它,然后检查设备`/dev/md0`的状态。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
# cat /etc/mdadm.conf
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
保存 Raid 6 配置
|
||||
*保存 RAID 6 配置*
|
||||
|
||||

|
||||
|
||||
检查 Raid 6 状态
|
||||
*检查 RAID 6 状态*
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
16.现在,它使用了4个磁盘,并且有两个作为奇偶校验信息来使用。在某些情况下,如果任意一个磁盘出现故障,我们仍可以得到数据,因为在 RAID 6 使用双奇偶校验。
|
||||
16、 现在,已经使用了4个磁盘,并且其中两个作为奇偶校验信息来使用。在某些情况下,如果任意一个磁盘出现故障,我们仍可以得到数据,因为在 RAID 6 使用双奇偶校验。
|
||||
|
||||
如果第二个磁盘也出现故障,在第三块磁盘损坏前我们可以添加一个新的。它可以作为一个备用磁盘并入 RAID 集合,但我在创建 raid 集合前没有定义备用的磁盘。但是,在磁盘损坏后或者创建 RAId 集合时我们可以添加一块磁盘。现在,我们已经创建好了 RAID,下面让我演示如何添加备用磁盘。
|
||||
如果第二个磁盘也出现故障,在第三块磁盘损坏前我们可以添加一个新的。可以在创建 RAID 集时加入一个备用磁盘,但我在创建 RAID 集合前没有定义备用的磁盘。不过,我们可以在磁盘损坏后或者创建 RAID 集合时添加一块备用磁盘。现在,我们已经创建好了 RAID,下面让我演示如何添加备用磁盘。
|
||||
|
||||
为了达到演示的目的,我已经热插入了一个新的 HDD 磁盘(即 /dev/sdf),让我们来验证接入的磁盘。
|
||||
|
||||
@ -236,15 +234,15 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
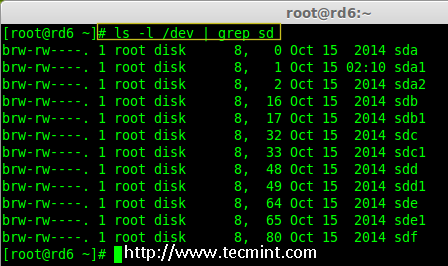
|
||||
|
||||
检查新 Disk
|
||||
*检查新磁盘*
|
||||
|
||||
17.现在再次确认新连接的磁盘没有配置过 RAID ,使用 mdadm 来检查。
|
||||
17、 现在再次确认新连接的磁盘没有配置过 RAID ,使用 mdadm 来检查。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
|
||||
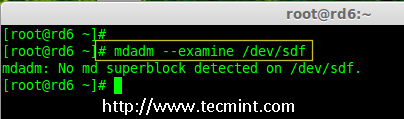
|
||||
|
||||
在新磁盘中检查 Raid
|
||||
*在新磁盘中检查 RAID*
|
||||
|
||||
**注意**: 像往常一样,我们早前已经为四个磁盘创建了分区,同样,我们使用 fdisk 命令为新插入的磁盘创建新分区。
|
||||
|
||||
@ -252,9 +250,9 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
为 /dev/sdf 创建分区
|
||||
*为 /dev/sdf 创建分区*
|
||||
|
||||
18.在 /dev/sdf 创建新的分区后,在新分区上确认 raid,包括/dev/md0 raid 设备的备用磁盘,并验证添加的设备。
|
||||
18、 在 /dev/sdf 创建新的分区后,在新分区上确认没有 RAID,然后将备用磁盘添加到 RAID 设备 /dev/md0 中,并验证添加的设备。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
# mdadm --examine /dev/sdf1
|
||||
@ -263,19 +261,19 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
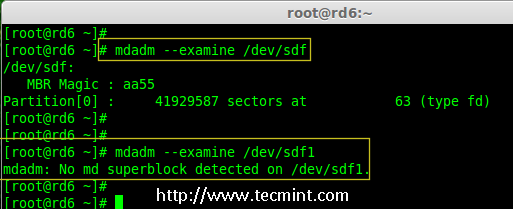
|
||||
|
||||
在 sdf 分区上验证 Raid
|
||||
*在 sdf 分区上验证 Raid*
|
||||
|
||||
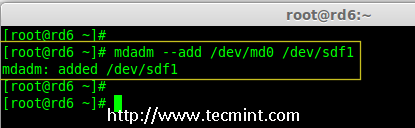
|
||||
|
||||
为 RAID 添加 sdf 分区
|
||||
*添加 sdf 分区到 RAID *
|
||||
|
||||

|
||||
|
||||
验证 sdf 分区信息
|
||||
*验证 sdf 分区信息*
|
||||
|
||||
### 第7步:检查 RAID 6 容错 ###
|
||||
|
||||
19.现在,让我们检查备用驱动器是否能自动工作,当我们阵列中的任何一个磁盘出现故障时。为了测试,我亲自将一个磁盘模拟为故障设备。
|
||||
19、 现在,让我们检查备用驱动器是否能自动工作,当我们阵列中的任何一个磁盘出现故障时。为了测试,我将一个磁盘手工标记为故障设备。
|
||||
|
||||
在这里,我们标记 /dev/sdd1 为故障磁盘。
|
||||
|
||||
@ -283,15 +281,15 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||
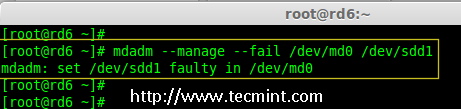
|
||||
|
||||
检查 Raid 6 容错
|
||||
*检查 RAID 6 容错*
|
||||
|
||||
20.让我们查看 RAID 的详细信息,并检查备用磁盘是否开始同步。
|
||||
20、 让我们查看 RAID 的详细信息,并检查备用磁盘是否开始同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查 Raid 自动同步
|
||||
*检查 RAID 自动同步*
|
||||
|
||||
**哇塞!** 这里,我们看到备用磁盘激活了,并开始重建进程。在底部,我们可以看到有故障的磁盘 /dev/sdd1 标记为 faulty。可以使用下面的命令查看进程重建。
|
||||
|
||||
@ -299,11 +297,11 @@ RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即时两
|
||||
|
||||

|
||||
|
||||
Raid 6 自动同步
|
||||
*RAID 6 自动同步*
|
||||
|
||||
### 结论: ###
|
||||
|
||||
在这里,我们看到了如何使用四个磁盘设置 RAID 6。这种 RAID 级别是具有高冗余的昂贵设置之一。在接下来的文章中,我们将看到如何建立一个嵌套的 RAID 10 甚至更多。至此,请继续关注 TECMINT。
|
||||
在这里,我们看到了如何使用四个磁盘设置 RAID 6。这种 RAID 级别是具有高冗余的昂贵设置之一。在接下来的文章中,我们将看到如何建立一个嵌套的 RAID 10 甚至更多。请继续关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -311,11 +309,12 @@ via: http://www.tecmint.com/create-raid-6-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:https://linux.cn/article-6102-1.html
|
||||
@ -0,0 +1,275 @@
|
||||
在 Linux 下使用 RAID(六):设置 RAID 10 或 1 + 0(嵌套)
|
||||
================================================================================
|
||||
|
||||
RAID 10 是组合 RAID 1 和 RAID 0 形成的。要设置 RAID 10,我们至少需要4个磁盘。在之前的文章中,我们已经看到了如何使用最少两个磁盘设置 RAID 1 和 RAID 0。
|
||||
|
||||
在这里,我们将使用最少4个磁盘组合 RAID 1 和 RAID 0 来设置 RAID 10。假设我们已经在用 RAID 10 创建的逻辑卷保存了一些数据。比如我们要保存数据 “TECMINT”,它将使用以下方法将其保存在4个磁盘中。
|
||||
|
||||
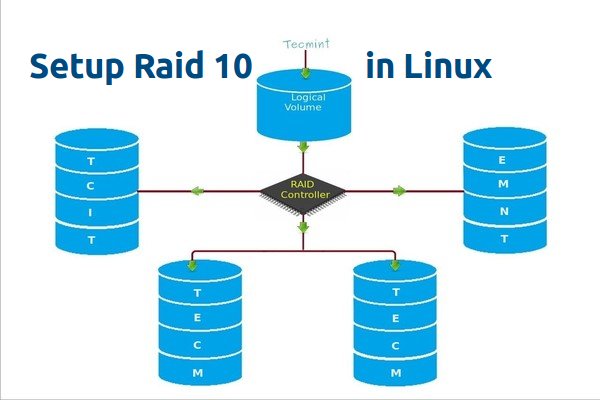
|
||||
|
||||
*在 Linux 中创建 Raid 10(LCTT 译注:此图有误,请参照文字说明和本系列第一篇文章)*
|
||||
|
||||
RAID 10 是先做镜像,再做条带。因此,在 RAID 1 中,相同的数据将被写入到两个磁盘中,“T”将同时被写入到第一和第二个磁盘中。接着的数据被条带化到另外两个磁盘,“E”将被同时写入到第三和第四个磁盘中。它将继续循环此过程,“C”将同时被写入到第一和第二个磁盘,以此类推。
|
||||
|
||||
(LCTT 译注:原文中此处描述混淆有误,已经根据实际情况进行修改。)
|
||||
|
||||
现在你已经了解 RAID 10 怎样组合 RAID 1 和 RAID 0 来工作的了。如果我们有4个20 GB 的磁盘,总共为 80 GB,但我们将只能得到40 GB 的容量,另一半的容量在构建 RAID 10 中丢失。
|
||||
|
||||
#### RAID 10 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能。
|
||||
- 在 RAID 10 中我们将失去一半的磁盘容量。
|
||||
- 读与写的性能都很好,因为它会同时进行写入和读取。
|
||||
- 它能解决数据库的高 I/O 磁盘写操作。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
在 RAID 10 中,我们至少需要4个磁盘,前2个磁盘为 RAID 1,其他2个磁盘为 RAID 0,就像我之前说的,RAID 10 仅仅是组合了 RAID 0和1。如果我们需要扩展 RAID 组,最少需要添加4个磁盘。
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.229
|
||||
主机名 : rd10.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdd
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
有两种方法来设置 RAID 10,在这里两种方法我都会演示,但我更喜欢第一种方法,使用它来设置 RAID 10 更简单。
|
||||
|
||||
### 方法1:设置 RAID 10 ###
|
||||
|
||||
1、 首先,使用以下命令确认所添加的4块磁盘没有被使用。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
2、 四个磁盘被检测后,然后来检查磁盘是否存在 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
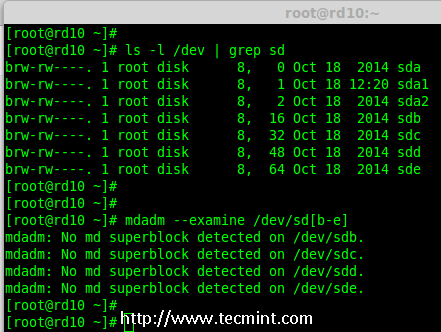
|
||||
|
||||
*验证添加的4块磁盘*
|
||||
|
||||
**注意**: 在上面的输出中,如果没有检测到 super-block 意味着在4块磁盘中没有定义过 RAID。
|
||||
|
||||
#### 第1步:为 RAID 分区 ####
|
||||
|
||||
3、 现在,使用`fdisk`,命令为4个磁盘(/dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde)创建新分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
#####为 /dev/sdb 创建分区#####
|
||||
|
||||
我来告诉你如何使用 fdisk 为磁盘(/dev/sdb)进行分区,此步也适用于其他磁盘。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请使用以下步骤为 /dev/sdb 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为磁盘 sdb 分区*
|
||||
|
||||
**注意**: 请使用上面相同的指令对其他磁盘(sdc, sdd sdd sde)进行分区。
|
||||
|
||||
4、 创建好4个分区后,需要使用下面的命令来检查磁盘是否存在 raid。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
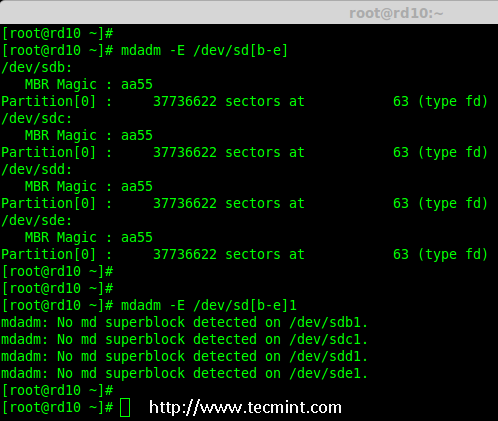
|
||||
|
||||
*检查磁盘*
|
||||
|
||||
**注意**: 以上输出显示,新创建的四个分区中没有检测到 super-block,这意味着我们可以继续在这些磁盘上创建 RAID 10。
|
||||
|
||||
#### 第2步: 创建 RAID 设备 `md` ####
|
||||
|
||||
5、 现在该创建一个`md`(即 /dev/md0)设备了,使用“mdadm” raid 管理工具。在创建设备之前,必须确保系统已经安装了`mdadm`工具,如果没有请使用下面的命令来安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
`mdadm`工具安装完成后,可以使用下面的命令创建一个`md` raid 设备。
|
||||
|
||||
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1
|
||||
|
||||
6、 接下来使用`cat`命令验证新创建的 raid 设备。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 md RAID 设备*
|
||||
|
||||
7、 接下来,使用下面的命令来检查4个磁盘。下面命令的输出会很长,因为它会显示4个磁盘的所有信息。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
8、 接下来,使用以下命令来查看 RAID 阵列的详细信息。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*查看 RAID 阵列详细信息*
|
||||
|
||||
**注意**: 你在上面看到的结果,该 RAID 的状态是 active 和re-syncing。
|
||||
|
||||
#### 第3步:创建文件系统 ####
|
||||
|
||||
9、 使用 ext4 作为`md0′的文件系统,并将它挂载到`/mnt/raid10`下。在这里,我用的是 ext4,你可以使用你想要的文件系统类型。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 md 文件系统*
|
||||
|
||||
10、 在创建文件系统后,挂载文件系统到`/mnt/raid10`下,并使用`ls -l`命令列出挂载点下的内容。
|
||||
|
||||
# mkdir /mnt/raid10
|
||||
# mount /dev/md0 /mnt/raid10/
|
||||
# ls -l /mnt/raid10/
|
||||
|
||||
接下来,在挂载点下创建一些文件,并在文件中添加些内容,然后检查内容。
|
||||
|
||||
# touch /mnt/raid10/raid10_files.txt
|
||||
# ls -l /mnt/raid10/
|
||||
# echo "raid 10 setup with 4 disks" > /mnt/raid10/raid10_files.txt
|
||||
# cat /mnt/raid10/raid10_files.txt
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
11、 要想自动挂载,打开`/etc/fstab`文件并添加下面的条目,挂载点根据你环境的不同来添加。使用 wq! 保存并退出。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid10 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
12、 接下来,在重新启动系统前使用`mount -a`来确认`/etc/fstab`文件是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
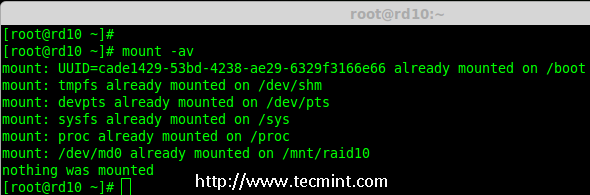
|
||||
|
||||
*检查 Fstab 中的错误*
|
||||
|
||||
#### 第四步:保存 RAID 配置 ####
|
||||
|
||||
13、 默认情况下 RAID 没有配置文件,所以我们需要在上述步骤完成后手动保存它。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID10 的配置*
|
||||
|
||||
就这样,我们使用方法1创建完了 RAID 10,这种方法是比较容易的。现在,让我们使用方法2来设置 RAID 10。
|
||||
|
||||
### 方法2:创建 RAID 10 ###
|
||||
|
||||
1、 在方法2中,我们必须定义2组 RAID 1,然后我们需要使用这些创建好的 RAID 1 的集合来定义一个 RAID 0。在这里,我们将要做的是先创建2个镜像(RAID1),然后创建 RAID0 (条带化)。
|
||||
|
||||
首先,列出所有的可用于创建 RAID 10 的磁盘。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
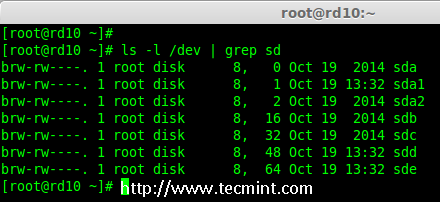
|
||||
|
||||
*列出了 4 个设备*
|
||||
|
||||
2、 将4个磁盘使用`fdisk`命令进行分区。对于如何分区,您可以按照上面的第1步。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
3、 在完成4个磁盘的分区后,现在检查磁盘是否存在 RAID块。
|
||||
|
||||
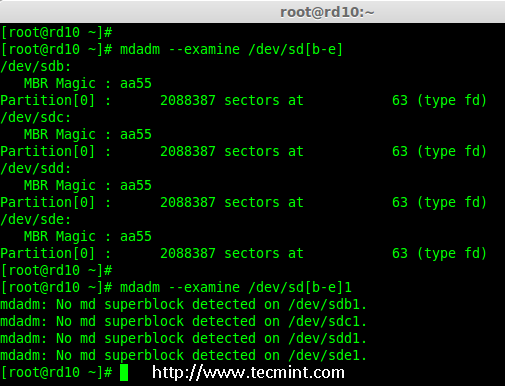
# mdadm --examine /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
|
||||
|
||||
*检查 4 个磁盘*
|
||||
|
||||
#### 第1步:创建 RAID 1 ####
|
||||
|
||||
4、 首先,使用4块磁盘创建2组 RAID 1,一组为`sdb1′和 `sdc1′,另一组是`sdd1′ 和 `sde1′。
|
||||
|
||||
# mdadm --create /dev/md1 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md2 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[d-e]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 1*
|
||||
|
||||

|
||||
|
||||
*查看 RAID 1 的详细信息*
|
||||
|
||||
#### 第2步:创建 RAID 0 ####
|
||||
|
||||
5、 接下来,使用 md1 和 md2 来创建 RAID 0。
|
||||
|
||||
# mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/md1 /dev/md2
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 0*
|
||||
|
||||
#### 第3步:保存 RAID 配置 ####
|
||||
|
||||
6、 我们需要将配置文件保存在`/etc/mdadm.conf`文件中,使其每次重新启动后都能加载所有的 RAID 设备。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||
在此之后,我们需要按照方法1中的第3步来创建文件系统。
|
||||
|
||||
就是这样!我们采用的方法2创建完了 RAID 1+0。我们将会失去一半的磁盘空间,但相比其他 RAID ,它的性能将是非常好的。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这里,我们采用两种方法创建 RAID 10。RAID 10 具有良好的性能和冗余性。希望这篇文章可以帮助你了解 RAID 10 嵌套 RAID。在后面的文章中我们会看到如何扩展现有的 RAID 阵列以及更多精彩的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-10-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,182 @@
|
||||
在 Linux 下使用 RAID(七):在 Raid 中扩展现有的 RAID 阵列和删除故障的磁盘
|
||||
================================================================================
|
||||
|
||||
每个新手都会对阵列(array)这个词所代表的意思产生疑惑。阵列只是磁盘的一个集合。换句话说,我们可以称阵列为一个集合(set)或一组(group)。就像一组鸡蛋中包含6个一样。同样 RAID 阵列中包含着多个磁盘,可能是2,4,6,8,12,16等,希望你现在知道了什么是阵列。
|
||||
|
||||
在这里,我们将看到如何扩展现有的阵列或 RAID 组。例如,如果我们在阵列中使用2个磁盘形成一个 raid 1 集合,在某些情况,如果该组中需要更多的空间,就可以使用 mdadm -grow 命令来扩展阵列大小,只需要将一个磁盘加入到现有的阵列中即可。在说完扩展(添加磁盘到现有的阵列中)后,我们将看看如何从阵列中删除故障的磁盘。
|
||||
|
||||
|
||||
|
||||
*扩展 RAID 阵列和删除故障的磁盘*
|
||||
|
||||
假设磁盘中的一个有问题了需要删除该磁盘,但我们需要在删除磁盘前添加一个备用磁盘来扩展该镜像,因为我们需要保存我们的数据。当磁盘发生故障时我们需要从阵列中删除它,这是这个主题中我们将要学习到的。
|
||||
|
||||
#### 扩展 RAID 的特性 ####
|
||||
|
||||
- 我们可以增加(扩展)任意 RAID 集合的大小。
|
||||
- 我们可以在使用新磁盘扩展 RAID 阵列后删除故障的磁盘。
|
||||
- 我们可以扩展 RAID 阵列而无需停机。
|
||||
|
||||
####要求 ####
|
||||
|
||||
- 为了扩展一个RAID阵列,我们需要一个已有的 RAID 组(阵列)。
|
||||
- 我们需要额外的磁盘来扩展阵列。
|
||||
- 在这里,我们使用一块磁盘来扩展现有的阵列。
|
||||
|
||||
在我们了解扩展和恢复阵列前,我们必须了解有关 RAID 级别和设置的基本知识。点击下面的链接了解这些。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP地址 : 192.168.0.230
|
||||
主机名 : grow.tecmintlocal.com
|
||||
2 块现有磁盘 : 1 GB
|
||||
1 块额外磁盘 : 1 GB
|
||||
|
||||
在这里,我们已有一个 RAID ,有2块磁盘,每个大小为1GB,我们现在再增加一个磁盘到我们现有的 RAID 阵列中,其大小为1GB。
|
||||
|
||||
### 扩展现有的 RAID 阵列 ###
|
||||
|
||||
1、 在扩展阵列前,首先使用下面的命令列出现有的 RAID 阵列。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查现有的 RAID 阵列*
|
||||
|
||||
**注意**: 以上输出显示,已经有了两个磁盘在 RAID 阵列中,级别为 RAID 1。现在我们增加一个磁盘到现有的阵列里。
|
||||
|
||||
2、 现在让我们添加新的磁盘“sdd”,并使用`fdisk`命令来创建分区。
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
请使用以下步骤为 /dev/sdd 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为 sdd 创建新的分区*
|
||||
|
||||
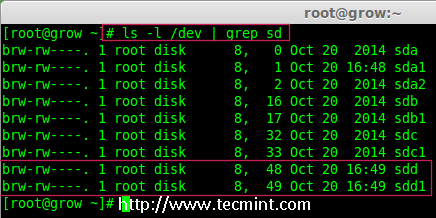
3、 一旦新的 sdd 分区创建完成后,你可以使用下面的命令验证它。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
|
||||
|
||||
*确认 sdd 分区*
|
||||
|
||||
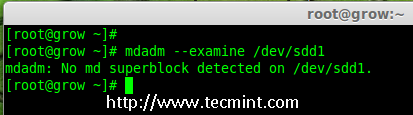
4、 接下来,在添加到阵列前先检查磁盘是否有 RAID 分区。
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||
|
||||
|
||||
*在 sdd 分区中检查 RAID*
|
||||
|
||||
**注意**:以上输出显示,该盘有没有发现 super-blocks,意味着我们可以将新的磁盘添加到现有阵列。
|
||||
|
||||
5、 要添加新的分区 /dev/sdd1 到现有的阵列 md0,请使用以下命令。
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
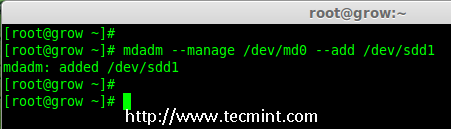
|
||||
|
||||
*添加磁盘到 RAID 阵列*
|
||||
|
||||
6、 一旦新的磁盘被添加后,在我们的阵列中检查新添加的磁盘。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认将新磁盘添加到 RAID 中*
|
||||
|
||||
**注意**: 在上面的输出,你可以看到磁盘已经被添加作为备用的。在这里,我们的阵列中已经有了2个磁盘,但我们期待阵列中有3个磁盘,因此我们需要扩展阵列。
|
||||
|
||||
7、 要扩展阵列,我们需要使用下面的命令。
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||
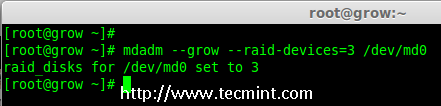
|
||||
|
||||
*扩展 Raid 阵列*
|
||||
|
||||
现在我们可以看到第三块磁盘(sdd1)已被添加到阵列中,在第三块磁盘被添加后,它将从另外两块磁盘上同步数据。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认 Raid 阵列*
|
||||
|
||||
**注意**: 对于大容量磁盘会需要几个小时来同步数据。在这里,我们使用的是1GB的虚拟磁盘,所以它非常快在几秒钟内便会完成。
|
||||
|
||||
### 从阵列中删除磁盘 ###
|
||||
|
||||
8、 在数据被从其他两个磁盘同步到新磁盘`sdd1`后,现在三个磁盘中的数据已经相同了(镜像)。
|
||||
|
||||
正如我前面所说的,假定一个磁盘出问题了需要被删除。所以,现在假设磁盘`sdc1`出问题了,需要从现有阵列中删除。
|
||||
|
||||
在删除磁盘前我们要将其标记为失效,然后我们才可以将其删除。
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列中模拟磁盘故障*
|
||||
|
||||
从上面的输出中,我们清楚地看到,磁盘在下面被标记为 faulty。即使它是 faulty 的,我们仍然可以看到 raid 设备有3个,1个损坏了,状态是 degraded。
|
||||
|
||||
现在我们要从阵列中删除 faulty 的磁盘,raid 设备将像之前一样继续有2个设备。
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||
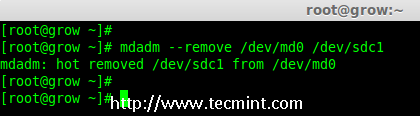
|
||||
|
||||
*在 Raid 阵列中删除磁盘*
|
||||
|
||||
9、 一旦故障的磁盘被删除,然后我们只能使用2个磁盘来扩展 raid 阵列了。
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列扩展磁盘*
|
||||
|
||||
从上面的输出中可以看到,我们的阵列中仅有2台设备。如果你需要再次扩展阵列,按照如上所述的同样步骤进行。如果你需要添加一个磁盘作为备用,将其标记为 spare,因此,如果磁盘出现故障时,它会自动顶上去并重建数据。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何扩展现有的 RAID 集合,以及如何在重新同步已有磁盘的数据后从一个阵列中删除故障磁盘。所有这些步骤都可以不用停机来完成。在数据同步期间,系统用户,文件和应用程序不会受到任何影响。
|
||||
|
||||
在接下来的文章我将告诉你如何管理 RAID,敬请关注更新,不要忘了写评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
@ -1,16 +1,16 @@
|
||||
fdupes——Linux中查找并删除重复文件的命令行工具
|
||||
fdupes:Linux中查找并删除重复文件的命令行工具
|
||||
================================================================================
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项领人不胜其烦的工作,它耗时又耗力。如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`**fdupes**`工具。
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项令人不胜其烦的工作,它耗时又耗力。但如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`fdupes`工具。
|
||||
|
||||

|
||||
|
||||
Fdupes——在Linux中查找并删除重复文件
|
||||
*fdupes——在Linux中查找并删除重复文件*
|
||||
|
||||
### fdupes是啥东东? ###
|
||||
|
||||
**Fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。Fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,可以为Fdupes指定大量的选项以实现对文件的列出、删除、替换到文件副本的硬链接等操作。
|
||||
**fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,fdupes有各种选项,可以实现对文件的列出、删除、替换为文件副本的硬链接等操作。
|
||||
|
||||
对比以下列顺序开始:
|
||||
文件对比以下列顺序开始:
|
||||
|
||||
**大小对比 > 部分 MD5 签名对比 > 完整 MD5 签名对比 > 逐字节对比**
|
||||
|
||||
@ -27,8 +27,9 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
**注意**:自Fedora 22之后,默认的包管理器yum被dnf取代了。
|
||||
|
||||
### fdupes命令咋个搞? ###
|
||||
1.作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
### fdupes命令如何使用 ###
|
||||
|
||||
1、 作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
|
||||
$ mkdir /home/"$USER"/Desktop/tecmint && cd /home/"$USER"/Desktop/tecmint && for i in {1..15}; do echo "I Love Tecmint. Tecmint is a very nice community of Linux Users." > tecmint${i}.txt ; done
|
||||
|
||||
@ -57,7 +58,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
"I Love Tecmint. Tecmint is a very nice community of Linux Users."
|
||||
|
||||
2.现在在**tecmint**文件夹内搜索重复的文件。
|
||||
2、 现在在**tecmint**文件夹内搜索重复的文件。
|
||||
|
||||
$ fdupes /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -77,7 +78,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
3.使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
3、 使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
|
||||
它会递归搜索所有文件和文件夹,花一点时间来扫描重复文件,时间的长短取决于文件和文件夹的数量。在此其间,终端中会显示全部过程,像下面这样。
|
||||
|
||||
@ -85,7 +86,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
|
||||
Progress [37780/54747] 69%
|
||||
|
||||
4.使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
4、 使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
|
||||
$ fdupes -S /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -106,7 +107,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
5.你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
5、 你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
|
||||
$ fdupes -Sr /home/avi/Desktop/
|
||||
|
||||
@ -131,11 +132,11 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/resume_files/r-csc.html
|
||||
/home/tecmint/Desktop/resume_files/fc.html
|
||||
|
||||
6.不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
6、 不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
|
||||
$ fdupes /home/avi/Desktop/ /home/avi/Templates/
|
||||
|
||||
7.要删除重复文件,同时保留一个副本,你可以使用`**-d**`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
7、 要删除重复文件,同时保留一个副本,你可以使用`-d`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
|
||||
$ fdupes -d /home/$USER/Desktop/tecmint
|
||||
|
||||
@ -177,13 +178,13 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
8.从安全角度出发,你可能想要打印`**fdupes**`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
8、 从安全角度出发,你可能想要打印`fdupes`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
|
||||
$ fdupes -Sr /home > /home/fdupes.txt
|
||||
|
||||
**注意**:你可以替换`**/home**`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`**-r**`和`**-S**`选项。
|
||||
**注意**:你应该替换`/home`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`-r`和`-S`选项。
|
||||
|
||||
9.你可以使用`**-f**`选项来忽略每个匹配集中的首个文件。
|
||||
9、 你可以使用`-f`选项来忽略每个匹配集中的首个文件。
|
||||
|
||||
首先列出该目录中的文件。
|
||||
|
||||
@ -205,13 +206,13 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
/home/tecmint/Desktop/tecmint9 (another copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (4th copy).txt
|
||||
|
||||
10.检查已安装的fdupes版本。
|
||||
10、 检查已安装的fdupes版本。
|
||||
|
||||
$ fdupes --version
|
||||
|
||||
fdupes 1.51
|
||||
|
||||
11.如果你需要关于fdupes的帮助,可以使用`**-h**`开关。
|
||||
11、 如果你需要关于fdupes的帮助,可以使用`-h`开关。
|
||||
|
||||
$ fdupes -h
|
||||
|
||||
@ -245,7 +246,7 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
-v --version display fdupes version
|
||||
-h --help display this help message
|
||||
|
||||
到此为止了。让我知道你到现在为止你是怎么在Linux中查找并删除重复文件的?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
到此为止了。让我知道你以前怎么在Linux中查找并删除重复文件的吧?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
我正在使用另外一个移除重复文件的工具,它叫**fslint**。很快就会把使用心得分享给大家哦,你们一定会喜欢看的。
|
||||
|
||||
@ -254,10 +255,10 @@ Fdupes——在Linux中查找并删除重复文件
|
||||
via: http://www.tecmint.com/fdupes-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[1]:https://linux.cn/article-2324-1.html
|
||||
[2]:https://linux.cn/article-5109-1.html
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by H-mudcup
|
||||
Five Super Cool Open Source Games
|
||||
================================================================================
|
||||
In 2014 and 2015, Linux became home to a list of popular commercial titles such as the popular Borderlands, Witcher, Dead Island, and Counter Strike series of games. While this is exciting news, what of the gamer on a budget? Commercial titles are good, but even better are free-to-play alternatives made by developers who know what players like.
|
||||
@ -62,4 +63,4 @@ via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to run JBoss Data Virtualization 6.0.0.GA with OData in a Docker Container. JBoss Data Virtualization is a data supply and integration solution platform that transforms various scatered multiple sources data, treats them as single source and delivers the required data into actionable information at business speed to any applications or users. JBoss Data Virtualization can help us easily combine and transform data into reusable business friendly data models and make unified data easily consumable through open standard interfaces. It offers comprehensive data abstraction, federation, integration, transformation, and delivery capabilities to combine data from one or multiple sources into reusable for agile data utilization and sharing.For more information about JBoss Data Virtualization, we can check out [its official page][1]. Docker is an open source platform that provides an open platform to pack, ship and run any application as a lightweight container. Running JBoss Data Virtualization with OData in Docker Container makes us easy to handle and launch.
|
||||
|
||||
@ -0,0 +1,165 @@
|
||||
How to switch from NetworkManager to systemd-networkd on Linux
|
||||
================================================================================
|
||||
In the world of Linux, adoption of [systemd][1] has been a subject of heated controversy, and the debate between its proponents and critics is still going on. As of today, most major Linux distributions have adopted systemd as a default init system.
|
||||
|
||||
Billed as a "never finished, never complete, but tracking progress of technology" by its author, systemd is not just the init daemon, but is designed as a more broad system and service management platform which encompasses the growing ecosystem of core system daemons, libraries and utilities.
|
||||
|
||||
One of many additions to **systemd** is **systemd-networkd**, which is responsible for network configuration within the systemd ecosystem. Using systemd-networkd, you can configure basic DHCP/static IP networking for network devices. It can also configure virtual networking features such as bridges, tunnels or VLANs. Wireless networking is not directly handled by systemd-networkd, but you can use wpa_supplicant service to configure wireless adapters, and then hook it up with **systemd-networkd**.
|
||||
|
||||
On many Linux distributions, NetworkManager has been and is still used as a default network configuration manager. Compared to NetworkManager, **systemd-networkd** is still under active development, and missing features. For example, it does not have NetworkManager's intelligence to keep your computer connected across various interfaces at all times. It does not provide ifup/ifdown hooks for advanced scripting. Yet, systemd-networkd is integrated well with the rest of systemd components (e.g., **resolved** for DNS, **timesyncd** for NTP, udevd for naming), and the role of **systemd-networkd** may only grow over time in the systemd environment.
|
||||
|
||||
If you are happy with the way **systemd** is evolving, one thing you can consider is to switch from NetworkManager to systemd-networkd. If you are feverishly against systemd, and perfectly happy with NetworkManager or [basic network service][2], that is totally cool.
|
||||
|
||||
But for those of you who want to try out systemd-networkd, you can read on, and find out in this tutorial how to switch from NetworkManager to systemd-networkd on Linux.
|
||||
|
||||
### Requirement ###
|
||||
|
||||
systemd-networkd is available in systemd version 210 and higher. Thus distributions like Debian 8 "Jessie" (systemd 215), Fedora 21 (systemd 217), Ubuntu 15.04 (systemd 219) or later are compatible with systemd-networkd.
|
||||
|
||||
For other distributions, check the version of your systemd before proceeding.
|
||||
|
||||
$ systemctl --version
|
||||
|
||||
### Switch from Network Manager to Systemd-Networkd ###
|
||||
|
||||
It is relatively straightforward to switch from Network Manager to systemd-networkd (and vice versa).
|
||||
|
||||
First, disable Network Manager service, and enable systemd-networkd as follows.
|
||||
|
||||
$ sudo systemctl disable NetworkManager
|
||||
$ sudo systemctl enable systemd-networkd
|
||||
|
||||
You also need to enable **systemd-resolved** service, which is used by systemd-networkd for network name resolution. This service implements a caching DNS server.
|
||||
|
||||
$ sudo systemctl enable systemd-resolved
|
||||
$ sudo systemctl start systemd-resolved
|
||||
|
||||
Once started, **systemd-resolved** will create its own resolv.conf somewhere under /run/systemd directory. However, it is a common practise to store DNS resolver information in /etc/resolv.conf, and many applications still rely on /etc/resolv.conf. Thus for compatibility reason, create a symlink to /etc/resolv.conf as follows.
|
||||
|
||||
$ sudo rm /etc/resolv.conf
|
||||
$ sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
|
||||
|
||||
### Configure Network Connections with Systemd-networkd ###
|
||||
|
||||
To configure network devices with systemd-networkd, you must specify configuration information in text files with .network extension. These network configuration files are then stored and loaded from /etc/systemd/network. When there are multiple files, systemd-networkd loads and processes them one by one in lexical order.
|
||||
|
||||
Let's start by creating a folder /etc/systemd/network.
|
||||
|
||||
$ sudo mkdir /etc/systemd/network
|
||||
|
||||
#### DHCP Networking ####
|
||||
|
||||
Let's configure DHCP networking first. For this, create the following configuration file. The name of a file can be arbitrary, but remember that files are processed in lexical order.
|
||||
|
||||
$ sudo vi /etc/systemd/network/20-dhcp.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3*
|
||||
|
||||
[Network]
|
||||
DHCP=yes
|
||||
|
||||
As you can see above, each network configuration file contains one or more "sections" with each section preceded by [XXX] heading. Each section contains one or more key/value pairs. The [Match] section determine which network device(s) are configured by this configuration file. For example, this file matches any network interface whose name starts with ens3 (e.g., enp3s0, enp3s1, enp3s2, etc). For matched interface(s), it then applies DHCP network configuration specified under [Network] section.
|
||||
|
||||
### Static IP Networking ###
|
||||
|
||||
If you want to assign a static IP address to a network interface, create the following configuration file.
|
||||
|
||||
$ sudo vi /etc/systemd/network/10-static-enp3s0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3s0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.50/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
As you can guess, the interface enp3s0 will be assigned an address 192.168.10.50/24, a default gateway 192.168.10.1, and a DNS server 8.8.8.8. One subtlety here is that the name of an interface enp3s0, in facts, matches the pattern rule defined in the earlier DHCP configuration as well. However, since the file "10-static-enp3s0.network" is processed before "20-dhcp.network" according to lexical order, the static configuration takes priority over DHCP configuration in case of enp3s0 interface.
|
||||
|
||||
Once you are done with creating configuration files, restart systemd-networkd service or reboot.
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
Check the status of the service by running:
|
||||
|
||||
$ systemctl status systemd-networkd
|
||||
$ systemctl status systemd-resolved
|
||||
|
||||
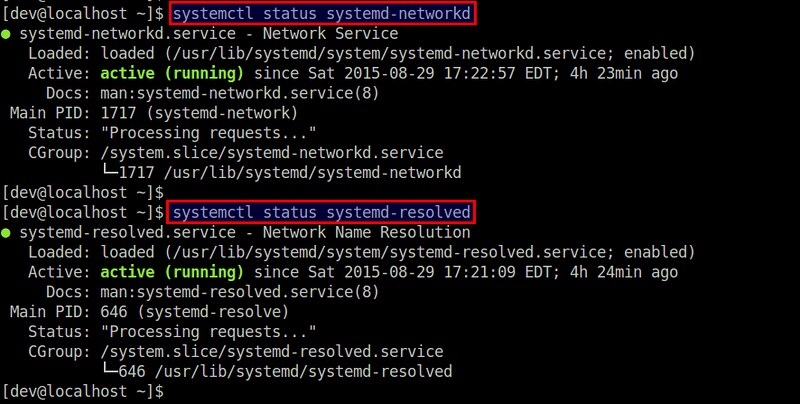
|
||||
|
||||
### Configure Virtual Network Devices with Systemd-networkd ###
|
||||
|
||||
**systemd-networkd** also allows you to configure virtual network devices such as bridges, VLANs, tunnel, VXLAN, bonding, etc. You must configure these virtual devices in files with .netdev extension.
|
||||
|
||||
Here I'll show how to configure a bridge interface.
|
||||
|
||||
#### Linux Bridge ####
|
||||
|
||||
If you want to create a Linux bridge (br0) and add a physical interface (eth1) to the bridge, create the following configuration.
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.netdev
|
||||
|
||||
----------
|
||||
|
||||
[NetDev]
|
||||
Name=br0
|
||||
Kind=bridge
|
||||
|
||||
Then configure the bridge interface br0 and the slave interface eth1 using .network files as follows.
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0-slave.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=eth1
|
||||
|
||||
[Network]
|
||||
Bridge=br0
|
||||
|
||||
----------
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=br0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.100/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
Finally, restart systemd-networkd:
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
You can use [brctl tool][3] to verify that a bridge br0 has been created.
|
||||
|
||||
### Summary ###
|
||||
|
||||
When systemd promises to be a system manager for Linux, it is no wonder something like systemd-networkd came into being to manage network configurations. At this stage, however, systemd-networkd seems more suitable for a server environment where network configurations are relatively stable. For desktop/laptop environments which involve various transient wired/wireless interfaces, NetworkManager may still be a preferred choice.
|
||||
|
||||
For those who want to check out more on systemd-networkd, refer to the official [man page][4] for a complete list of supported sections and keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
|
||||
[2]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
|
||||
800
sources/tech/20150831 Linux workstation security checklist.md
Normal file
800
sources/tech/20150831 Linux workstation security checklist.md
Normal file
@ -0,0 +1,800 @@
|
||||
Linux workstation security checklist
|
||||
================================================================================
|
||||
This is a set of recommendations used by the Linux Foundation for their systems
|
||||
administrators. All of LF employees are remote workers and we use this set of
|
||||
guidelines to ensure that a sysadmin's system passes core security requirements
|
||||
in order to reduce the risk of it becoming an attack vector against the rest
|
||||
of our infrastructure.
|
||||
|
||||
Even if your systems administrators are not remote workers, chances are that
|
||||
they perform a lot of their work either from a portable laptop in a work
|
||||
environment, or set up their home systems to access the work infrastructure
|
||||
for after-hours/emergency support. In either case, you can adapt this set of
|
||||
recommendations to suit your environment.
|
||||
|
||||
This, by no means, is an exhaustive "workstation hardening" document, but
|
||||
rather an attempt at a set of baseline recommendations to avoid most glaring
|
||||
security errors without introducing too much inconvenience. You may read this
|
||||
document and think it is way too paranoid, while someone else may think this
|
||||
barely scratches the surface. Security is just like driving on the highway --
|
||||
anyone going slower than you is an idiot, while anyone driving faster than you
|
||||
is a crazy person. These guidelines are merely a basic set of core safety
|
||||
rules that is neither exhaustive, nor a replacement for experience, vigilance,
|
||||
and common sense.
|
||||
|
||||
Each section is split into two areas:
|
||||
|
||||
- The checklist that can be adapted to your project's needs
|
||||
- Free-form list of considerations that explain what dictated these decisions
|
||||
|
||||
## Severity levels
|
||||
|
||||
The items in each checklist include the severity level, which we hope will help
|
||||
guide your decision:
|
||||
|
||||
- _(CRITICAL)_ items should definitely be high on the consideration list.
|
||||
If not implemented, they will introduce high risks to your workstation
|
||||
security.
|
||||
- _(MODERATE)_ items will improve your security posture, but are less
|
||||
important, especially if they interfere too much with your workflow.
|
||||
- _(LOW)_ items may improve the overall security, but may not be worth the
|
||||
convenience trade-offs.
|
||||
- _(PARANOID)_ is reserved for items we feel will dramatically improve your
|
||||
workstation security, but will probably require a lot of adjustment to the
|
||||
way you interact with your operating system.
|
||||
|
||||
Remember, these are only guidelines. If you feel these severity levels do not
|
||||
reflect your project's commitment to security, you should adjust them as you
|
||||
see fit.
|
||||
|
||||
## Choosing the right hardware
|
||||
|
||||
We do not mandate that our admins use a specific vendor or a specific model, so
|
||||
this section addresses core considerations when choosing a work system.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] System supports SecureBoot _(CRITICAL)_
|
||||
- [ ] System has no firewire, thunderbolt or ExpressCard ports _(MODERATE)_
|
||||
- [ ] System has a TPM chip _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SecureBoot
|
||||
|
||||
Despite its controversial nature, SecureBoot offers prevention against many
|
||||
attacks targeting workstations (Rootkits, "Evil Maid," etc), without
|
||||
introducing too much extra hassle. It will not stop a truly dedicated attacker,
|
||||
plus there is a pretty high degree of certainty that state security agencies
|
||||
have ways to defeat it (probably by design), but having SecureBoot is better
|
||||
than having nothing at all.
|
||||
|
||||
Alternatively, you may set up [Anti Evil Maid][1] which offers a more
|
||||
wholesome protection against the type of attacks that SecureBoot is supposed
|
||||
to prevent, but it will require more effort to set up and maintain.
|
||||
|
||||
#### Firewire, thunderbolt, and ExpressCard ports
|
||||
|
||||
Firewire is a standard that, by design, allows any connecting device full
|
||||
direct memory access to your system ([see Wikipedia][2]). Thunderbolt and
|
||||
ExpressCard are guilty of the same, though some later implementations of
|
||||
Thunderbolt attempt to limit the scope of memory access. It is best if the
|
||||
system you are getting has none of these ports, but it is not critical, as
|
||||
they usually can be turned off via UEFI or disabled in the kernel itself.
|
||||
|
||||
#### TPM Chip
|
||||
|
||||
Trusted Platform Module (TPM) is a crypto chip bundled with the motherboard
|
||||
separately from the core processor, which can be used for additional platform
|
||||
security (such as to store full-disk encryption keys), but is not normally used
|
||||
for day-to-day workstation operation. At best, this is a nice-to-have, unless
|
||||
you have a specific need to use TPM for your workstation security.
|
||||
|
||||
## Pre-boot environment
|
||||
|
||||
This is a set of recommendations for your workstation before you even start
|
||||
with OS installation.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] UEFI boot mode is used (not legacy BIOS) _(CRITICAL)_
|
||||
- [ ] Password is required to enter UEFI configuration _(CRITICAL)_
|
||||
- [ ] SecureBoot is enabled _(CRITICAL)_
|
||||
- [ ] UEFI-level password is required to boot the system _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### UEFI and SecureBoot
|
||||
|
||||
UEFI, with all its warts, offers a lot of goodies that legacy BIOS doesn't,
|
||||
such as SecureBoot. Most modern systems come with UEFI mode on by default.
|
||||
|
||||
Make sure a strong password is required to enter UEFI configuration mode. Pay
|
||||
attention, as many manufacturers quietly limit the length of the password you
|
||||
are allowed to use, so you may need to choose high-entropy short passwords vs.
|
||||
long passphrases (see below for more on passphrases).
|
||||
|
||||
Depending on the Linux distribution you decide to use, you may or may not have
|
||||
to jump through additional hoops in order to import your distribution's
|
||||
SecureBoot key that would allow you to boot the distro. Many distributions have
|
||||
partnered with Microsoft to sign their released kernels with a key that is
|
||||
already recognized by most system manufacturers, therefore saving you the
|
||||
trouble of having to deal with key importing.
|
||||
|
||||
As an extra measure, before someone is allowed to even get to the boot
|
||||
partition and try some badness there, let's make them enter a password. This
|
||||
password should be different from your UEFI management password, in order to
|
||||
prevent shoulder-surfing. If you shut down and start a lot, you may choose to
|
||||
not bother with this, as you will already have to enter a LUKS passphrase and
|
||||
this will save you a few extra keystrokes.
|
||||
|
||||
## Distro choice considerations
|
||||
|
||||
Chances are you'll stick with a fairly widely-used distribution such as Fedora,
|
||||
Ubuntu, Arch, Debian, or one of their close spin-offs. In any case, this is
|
||||
what you should consider when picking a distribution to use.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Has a robust MAC/RBAC implementation (SELinux/AppArmor/Grsecurity) _(CRITICAL)_
|
||||
- [ ] Publishes security bulletins _(CRITICAL)_
|
||||
- [ ] Provides timely security patches _(CRITICAL)_
|
||||
- [ ] Provides cryptographic verification of packages _(CRITICAL)_
|
||||
- [ ] Fully supports UEFI and SecureBoot _(CRITICAL)_
|
||||
- [ ] Has robust native full disk encryption support _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SELinux, AppArmor, and GrSecurity/PaX
|
||||
|
||||
Mandatory Access Controls (MAC) or Role-Based Access Controls (RBAC) are an
|
||||
extension of the basic user/group security mechanism used in legacy POSIX
|
||||
systems. Most distributions these days either already come bundled with a
|
||||
MAC/RBAC implementation (Fedora, Ubuntu), or provide a mechanism to add it via
|
||||
an optional post-installation step (Gentoo, Arch, Debian). Obviously, it is
|
||||
highly advised that you pick a distribution that comes pre-configured with a
|
||||
MAC/RBAC system, but if you have strong feelings about a distribution that
|
||||
doesn't have one enabled by default, do plan to configure it
|
||||
post-installation.
|
||||
|
||||
Distributions that do not provide any MAC/RBAC mechanisms should be strongly
|
||||
avoided, as traditional POSIX user- and group-based security should be
|
||||
considered insufficient in this day and age. If you would like to start out
|
||||
with a MAC/RBAC workstation, AppArmor and PaX are generally considered easier
|
||||
to learn than SELinux. Furthermore, on a workstation, where there are few or
|
||||
no externally listening daemons, and where user-run applications pose the
|
||||
highest risk, GrSecurity/PaX will _probably_ offer more security benefits than
|
||||
SELinux.
|
||||
|
||||
#### Distro security bulletins
|
||||
|
||||
Most of the widely used distributions have a mechanism to deliver security
|
||||
bulletins to their users, but if you are fond of something esoteric, check
|
||||
whether the developers have a documented mechanism of alerting the users about
|
||||
security vulnerabilities and patches. Absence of such mechanism is a major
|
||||
warning sign that the distribution is not mature enough to be considered for a
|
||||
primary admin workstation.
|
||||
|
||||
#### Timely and trusted security updates
|
||||
|
||||
Most of the widely used distributions deliver regular security updates, but is
|
||||
worth checking to ensure that critical package updates are provided in a
|
||||
timely fashion. Avoid using spin-offs and "community rebuilds" for this
|
||||
reason, as they routinely delay security updates due to having to wait for the
|
||||
upstream distribution to release it first.
|
||||
|
||||
You'll be hard-pressed to find a distribution that does not use cryptographic
|
||||
signatures on packages, updates metadata, or both. That being said, fairly
|
||||
widely used distributions have been known to go for years before introducing
|
||||
this basic security measure (Arch, I'm looking at you), so this is a thing
|
||||
worth checking.
|
||||
|
||||
#### Distros supporting UEFI and SecureBoot
|
||||
|
||||
Check that the distribution supports UEFI and SecureBoot. Find out whether it
|
||||
requires importing an extra key or whether it signs its boot kernels with a key
|
||||
already trusted by systems manufacturers (e.g. via an agreement with
|
||||
Microsoft). Some distributions do not support UEFI/SecureBoot but offer
|
||||
alternatives to ensure tamper-proof or tamper-evident boot environments
|
||||
([Qubes-OS][3] uses Anti Evil Maid, mentioned earlier). If a distribution
|
||||
doesn't support SecureBoot and has no mechanisms to prevent boot-level attacks,
|
||||
look elsewhere.
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Full disk encryption is a requirement for securing data at rest, and is
|
||||
supported by most distributions. As an alternative, systems with
|
||||
self-encrypting hard drives may be used (normally implemented via the on-board
|
||||
TPM chip) and offer comparable levels of security plus faster operation, but at
|
||||
a considerably higher cost.
|
||||
|
||||
## Distro installation guidelines
|
||||
|
||||
All distributions are different, but here are general guidelines:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Use full disk encryption (LUKS) with a robust passphrase _(CRITICAL)_
|
||||
- [ ] Make sure swap is also encrypted _(CRITICAL)_
|
||||
- [ ] Require a password to edit bootloader (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Set up a robust root password (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Use an unprivileged account, part of administrators group _(CRITICAL)_
|
||||
- [ ] Set up a robust user-account password, different from root _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Unless you are using self-encrypting hard drives, it is important to configure
|
||||
your installer to fully encrypt all the disks that will be used for storing
|
||||
your data and your system files. It is not sufficient to simply encrypt the
|
||||
user directory via auto-mounting cryptfs loop files (I'm looking at you, older
|
||||
versions of Ubuntu), as this offers no protection for system binaries or swap,
|
||||
which is likely to contain a slew of sensitive data. The recommended
|
||||
encryption strategy is to encrypt the LVM device, so only one passphrase is
|
||||
required during the boot process.
|
||||
|
||||
The `/boot` partition will always remain unencrypted, as the bootloader needs
|
||||
to be able to actually boot the kernel before invoking LUKS/dm-crypt. The
|
||||
kernel image itself should be protected against tampering with a cryptographic
|
||||
signature checked by SecureBoot.
|
||||
|
||||
In other words, `/boot` should always be the only unencrypted partition on your
|
||||
system.
|
||||
|
||||
#### Choosing good passphrases
|
||||
|
||||
Modern Linux systems have no limitation of password/passphrase length, so the
|
||||
only real limitation is your level of paranoia and your stubbornness. If you
|
||||
boot your system a lot, you will probably have to type at least two different
|
||||
passwords: one to unlock LUKS, and another one to log in, so having long
|
||||
passphrases will probably get old really fast. Pick passphrases that are 2-3
|
||||
words long, easy to type, and preferably from rich/mixed vocabularies.
|
||||
|
||||
Examples of good passphrases (yes, you can use spaces):
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
You can also stick with non-vocabulary passwords that are at least 10-12
|
||||
characters long, if you prefer that to typing passphrases.
|
||||
|
||||
Unless you have concerns about physical security, it is fine to write down your
|
||||
passphrases and keep them in a safe place away from your work desk.
|
||||
|
||||
#### Root, user passwords and the admin group
|
||||
|
||||
We recommend that you use the same passphrase for your root password as you
|
||||
use for your LUKS encryption (unless you share your laptop with other trusted
|
||||
people who should be able to unlock the drives, but shouldn't be able to
|
||||
become root). If you are the sole user of the laptop, then having your root
|
||||
password be different from your LUKS password has no meaningful security
|
||||
advantages. Generally, you can use the same passphrase for your UEFI
|
||||
administration, disk encryption, and root account -- knowing any of these will
|
||||
give an attacker full control of your system anyway, so there is little
|
||||
security benefit to have them be different on a single-user workstation.
|
||||
|
||||
You should have a different, but equally strong password for your regular user
|
||||
account that you will be using for day-to-day tasks. This user should be member
|
||||
of the admin group (e.g. `wheel` or similar, depending on the distribution),
|
||||
allowing you to perform `sudo` to elevate privileges.
|
||||
|
||||
In other words, if you are the sole user on your workstation, you should have 2
|
||||
distinct, robust, equally strong passphrases you will need to remember:
|
||||
|
||||
**Admin-level**, used in the following locations:
|
||||
|
||||
- UEFI administration
|
||||
- Bootloader (GRUB)
|
||||
- Disk encryption (LUKS)
|
||||
- Workstation admin (root user)
|
||||
|
||||
**User-level**, used for the following:
|
||||
|
||||
- User account and sudo
|
||||
- Master password for the password manager
|
||||
|
||||
All of them, obviously, can be different if there is a compelling reason.
|
||||
|
||||
## Post-installation hardening
|
||||
|
||||
Post-installation security hardening will depend greatly on your distribution
|
||||
of choice, so it is futile to provide detailed instructions in a general
|
||||
document such as this one. However, here are some steps you should take:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Globally disable firewire and thunderbolt modules _(CRITICAL)_
|
||||
- [ ] Check your firewalls to ensure all incoming ports are filtered _(CRITICAL)_
|
||||
- [ ] Make sure root mail is forwarded to an account you check _(CRITICAL)_
|
||||
- [ ] Check to ensure sshd service is disabled by default _(MODERATE)_
|
||||
- [ ] Set up an automatic OS update schedule, or update reminders _(MODERATE)_
|
||||
- [ ] Configure the screensaver to auto-lock after a period of inactivity _(MODERATE)_
|
||||
- [ ] Set up logwatch _(MODERATE)_
|
||||
- [ ] Install and use rkhunter _(LOW)_
|
||||
- [ ] Install an Intrusion Detection System _(PARANOID)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Blacklisting modules
|
||||
|
||||
To blacklist a firewire and thunderbolt modules, add the following lines to a
|
||||
file in `/etc/modprobe.d/blacklist-dma.conf`:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
The modules will be blacklisted upon reboot. It doesn't hurt doing this even if
|
||||
you don't have these ports (but it doesn't do anything either).
|
||||
|
||||
#### Root mail
|
||||
|
||||
By default, root mail is just saved on the system and tends to never be read.
|
||||
Make sure you set your `/etc/aliases` to forward root mail to a mailbox that
|
||||
you actually read, otherwise you may miss important system notifications and
|
||||
reports:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
Run `newaliases` after this edit and test it out to make sure that it actually
|
||||
gets delivered, as some email providers will reject email coming in from
|
||||
nonexistent or non-routable domain names. If that is the case, you will need to
|
||||
play with your mail forwarding configuration until this actually works.
|
||||
|
||||
#### Firewalls, sshd, and listening daemons
|
||||
|
||||
The default firewall settings will depend on your distribution, but many of
|
||||
them will allow incoming `sshd` ports. Unless you have a compelling legitimate
|
||||
reason to allow incoming ssh, you should filter that out and disable the `sshd`
|
||||
daemon.
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
You can always start it temporarily if you need to use it.
|
||||
|
||||
In general, your system shouldn't have any listening ports apart from
|
||||
responding to ping. This will help safeguard you against network-level 0-day
|
||||
exploits.
|
||||
|
||||
#### Automatic updates or notifications
|
||||
|
||||
It is recommended to turn on automatic updates, unless you have a very good
|
||||
reason not to do so, such as fear that an automatic update would render your
|
||||
system unusable (it's happened in the past, so this fear is not unfounded). At
|
||||
the very least, you should enable automatic notifications of available updates.
|
||||
Most distributions already have this service automatically running for you, so
|
||||
chances are you don't have to do anything. Consult your distribution
|
||||
documentation to find out more.
|
||||
|
||||
You should apply all outstanding errata as soon as possible, even if something
|
||||
isn't specifically labeled as "security update" or has an associated CVE code.
|
||||
All bugs have the potential of being security bugs and erring on the side of
|
||||
newer, unknown bugs is _generally_ a safer strategy than sticking with old,
|
||||
known ones.
|
||||
|
||||
#### Watching logs
|
||||
|
||||
You should have a keen interest in what happens on your system. For this
|
||||
reason, you should install `logwatch` and configure it to send nightly activity
|
||||
reports of everything that happens on your system. This won't prevent a
|
||||
dedicated attacker, but is a good safety-net feature to have in place.
|
||||
|
||||
Note, that many systemd distros will no longer automatically install a syslog
|
||||
server that `logwatch` needs (due to systemd relying on its own journal), so
|
||||
you will need to install and enable `rsyslog` to make sure your `/var/log` is
|
||||
not empty before logwatch will be of any use.
|
||||
|
||||
#### Rkhunter and IDS
|
||||
|
||||
Installing `rkhunter` and an intrusion detection system (IDS) like `aide` or
|
||||
`tripwire` will not be that useful unless you actually understand how they work
|
||||
and take the necessary steps to set them up properly (such as, keeping the
|
||||
databases on external media, running checks from a trusted environment,
|
||||
remembering to refresh the hash databases after performing system updates and
|
||||
configuration changes, etc). If you are not willing to take these steps and
|
||||
adjust how you do things on your own workstation, these tools will introduce
|
||||
hassle without any tangible security benefit.
|
||||
|
||||
We do recommend that you install `rkhunter` and run it nightly. It's fairly
|
||||
easy to learn and use, and though it will not deter a sophisticated attacker,
|
||||
it may help you catch your own mistakes.
|
||||
|
||||
## Personal workstation backups
|
||||
|
||||
Workstation backups tend to be overlooked or done in a haphazard, often unsafe
|
||||
manner.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Set up encrypted workstation backups to external storage _(CRITICAL)_
|
||||
- [ ] Use zero-knowledge backup tools for cloud backups _(MODERATE)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full encrypted backups to external storage
|
||||
|
||||
It is handy to have an external hard drive where one can dump full backups
|
||||
without having to worry about such things like bandwidth and upstream speeds
|
||||
(in this day and age most providers still offer dramatically asymmetric
|
||||
upload/download speeds). Needless to say, this hard drive needs to be in itself
|
||||
encrypted (again, via LUKS), or you should use a backup tool that creates
|
||||
encrypted backups, such as `duplicity` or its GUI companion, `deja-dup`. I
|
||||
recommend using the latter with a good randomly generated passphrase, stored in
|
||||
your password manager. If you travel with your laptop, leave this drive at home
|
||||
to have something to come back to in case your laptop is lost or stolen.
|
||||
|
||||
In addition to your home directory, you should also back up `/etc` and
|
||||
`/var/log` for various forensic purposes.
|
||||
|
||||
Above all, avoid copying your home directory onto any unencrypted storage, even
|
||||
as a quick way to move your files around between systems, as you will most
|
||||
certainly forget to erase it once you're done, exposing potentially private or
|
||||
otherwise security sensitive data to snooping hands -- especially if you keep
|
||||
that storage media in the same bag with your laptop.
|
||||
|
||||
#### Selective zero-knowledge backups off-site
|
||||
|
||||
Off-site backups are also extremely important and can be done either to your
|
||||
employer, if they offer space for it, or to a cloud provider. You can set up a
|
||||
separate duplicity/deja-dup profile to only include most important files in
|
||||
order to avoid transferring huge amounts of data that you don't really care to
|
||||
back up off-site (internet cache, music, downloads, etc).
|
||||
|
||||
Alternatively, you can use a zero-knowledge backup tool, such as
|
||||
[SpiderOak][5], which offers an excellent Linux GUI tool and has additional
|
||||
useful features such as synchronizing content between multiple systems and
|
||||
platforms.
|
||||
|
||||
## Best practices
|
||||
|
||||
What follows is a curated list of best practices that we think you should
|
||||
adopt. It is most certainly non-exhaustive, but rather attempts to offer
|
||||
practical advice that strikes a workable balance between security and overall
|
||||
usability.
|
||||
|
||||
### Browsing
|
||||
|
||||
There is no question that the web browser will be the piece of software with
|
||||
the largest and the most exposed attack surface on your system. It is a tool
|
||||
written specifically to download and execute untrusted, frequently hostile
|
||||
code. It attempts to shield you from this danger by employing multiple
|
||||
mechanisms such as sandboxes and code sanitization, but they have all been
|
||||
previously defeated on multiple occasions. You should learn to approach
|
||||
browsing websites as the most insecure activity you'll engage in on any given
|
||||
day.
|
||||
|
||||
There are several ways you can reduce the impact of a compromised browser, but
|
||||
the truly effective ways will require significant changes in the way you
|
||||
operate your workstation.
|
||||
|
||||
#### 1: Use two different browsers
|
||||
|
||||
This is the easiest to do, but only offers minor security benefits. Not all
|
||||
browser compromises give an attacker full unfettered access to your system --
|
||||
sometimes they are limited to allowing one to read local browser storage,
|
||||
steal active sessions from other tabs, capture input entered into the browser,
|
||||
etc. Using two different browsers, one for work/high security sites, and
|
||||
another for everything else will help prevent minor compromises from giving
|
||||
attackers access to the whole cookie jar. The main inconvenience will be the
|
||||
amount of memory consumed by two different browser processes.
|
||||
|
||||
Here's what we recommend:
|
||||
|
||||
##### Firefox for work and high security sites
|
||||
|
||||
Use Firefox to access work-related sites, where extra care should be taken to
|
||||
ensure that data like cookies, sessions, login information, keystrokes, etc,
|
||||
should most definitely not fall into attackers' hands. You should NOT use
|
||||
this browser for accessing any other sites except select few.
|
||||
|
||||
You should install the following Firefox add-ons:
|
||||
|
||||
- [ ] NoScript _(CRITICAL)_
|
||||
- NoScript prevents active content from loading, except from user
|
||||
whitelisted domains. It is a great hassle to use with your default browser
|
||||
(though offers really good security benefits), so we recommend only
|
||||
enabling it on the browser you use to access work-related sites.
|
||||
|
||||
- [ ] Privacy Badger _(CRITICAL)_
|
||||
- EFF's Privacy Badger will prevent most external trackers and ad platforms
|
||||
from being loaded, which will help avoid compromises on these tracking
|
||||
sites from affecting your browser (trackers and ad sites are very commonly
|
||||
targeted by attackers, as they allow rapid infection of thousands of
|
||||
systems worldwide).
|
||||
|
||||
- [ ] HTTPS Everywhere _(CRITICAL)_
|
||||
- This EFF-developed Add-on will ensure that most of your sites are accessed
|
||||
over a secure connection, even if a link you click is using http:// (great
|
||||
to avoid a number of attacks, such as [SSL-strip][7]).
|
||||
|
||||
- [ ] Certificate Patrol _(MODERATE)_
|
||||
- This tool will alert you if the site you're accessing has recently changed
|
||||
their TLS certificates -- especially if it wasn't nearing expiration dates
|
||||
or if it is now using a different certification authority. It helps
|
||||
alert you if someone is trying to man-in-the-middle your connection,
|
||||
but generates a lot of benign false-positives.
|
||||
|
||||
You should leave Firefox as your default browser for opening links, as
|
||||
NoScript will prevent most active content from loading or executing.
|
||||
|
||||
##### Chrome/Chromium for everything else
|
||||
|
||||
Chromium developers are ahead of Firefox in adding a lot of nice security
|
||||
features (at least [on Linux][6]), such as seccomp sandboxes, kernel user
|
||||
namespaces, etc, which act as an added layer of isolation between the sites
|
||||
you visit and the rest of your system. Chromium is the upstream open-source
|
||||
project, and Chrome is Google's proprietary binary build based on it (insert
|
||||
the usual paranoid caution about not using it for anything you don't want
|
||||
Google to know about).
|
||||
|
||||
It is recommended that you install **Privacy Badger** and **HTTPS Everywhere**
|
||||
extensions in Chrome as well and give it a distinct theme from Firefox to
|
||||
indicate that this is your "untrusted sites" browser.
|
||||
|
||||
#### 2: Use two different browsers, one inside a dedicated VM
|
||||
|
||||
This is a similar recommendation to the above, except you will add an extra
|
||||
step of running Chrome inside a dedicated VM that you access via a fast
|
||||
protocol, allowing you to share clipboards and forward sound events (e.g.
|
||||
Spice or RDP). This will add an excellent layer of isolation between the
|
||||
untrusted browser and the rest of your work environment, ensuring that
|
||||
attackers who manage to fully compromise your browser will then have to
|
||||
additionally break out of the VM isolation layer in order to get to the rest
|
||||
of your system.
|
||||
|
||||
This is a surprisingly workable configuration, but requires a lot of RAM and
|
||||
fast processors that can handle the increased load. It will also require an
|
||||
important amount of dedication on the part of the admin who will need to
|
||||
adjust their work practices accordingly.
|
||||
|
||||
#### 3: Fully separate your work and play environments via virtualization
|
||||
|
||||
See [Qubes-OS project][3], which strives to provide a high-security
|
||||
workstation environment via compartmentalizing your applications into separate
|
||||
fully isolated VMs.
|
||||
|
||||
### Password managers
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Use a password manager _(CRITICAL_)
|
||||
- [ ] Use unique passwords on unrelated sites _(CRITICAL)_
|
||||
- [ ] Use a password manager that supports team sharing _(MODERATE)_
|
||||
- [ ] Use a separate password manager for non-website accounts _(PARANOID)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
Using good, unique passwords should be a critical requirement for every member
|
||||
of your team. Credential theft is happening all the time -- either via
|
||||
compromised computers, stolen database dumps, remote site exploits, or any
|
||||
number of other means. No credentials should ever be reused across sites,
|
||||
especially for critical applications.
|
||||
|
||||
##### In-browser password manager
|
||||
|
||||
Every browser has a mechanism for saving passwords that is fairly secure and
|
||||
can sync with vendor-maintained cloud storage while keeping the data encrypted
|
||||
with a user-provided passphrase. However, this mechanism has important
|
||||
disadvantages:
|
||||
|
||||
1. It does not work across browsers
|
||||
2. It does not offer any way of sharing credentials with team members
|
||||
|
||||
There are several well-supported, free-or-cheap password managers that are
|
||||
well-integrated into multiple browsers, work across platforms, and offer
|
||||
group sharing (usually as a paid service). Solutions can be easily found via
|
||||
search engines.
|
||||
|
||||
##### Standalone password manager
|
||||
|
||||
One of the major drawbacks of any password manager that comes integrated with
|
||||
the browser is the fact that it's part of the application that is most likely
|
||||
to be attacked by intruders. If this makes you uncomfortable (and it should),
|
||||
you may choose to have two different password managers -- one for websites
|
||||
that is integrated into your browser, and one that runs as a standalone
|
||||
application. The latter can be used to store high-risk credentials such as
|
||||
root passwords, database passwords, other shell account credentials, etc.
|
||||
|
||||
It may be particularly useful to have such tool for sharing superuser account
|
||||
credentials with other members of your team (server root passwords, ILO
|
||||
passwords, database admin passwords, bootloader passwords, etc).
|
||||
|
||||
A few tools can help you:
|
||||
|
||||
- [KeePassX][8], which improves team sharing in version 2
|
||||
- [Pass][9], which uses text files and PGP and integrates with git
|
||||
- [Django-Pstore][10], which uses GPG to share credentials between admins
|
||||
- [Hiera-Eyaml][11], which, if you are already using Puppet for your
|
||||
infrastructure, may be a handy way to track your server/service credentials
|
||||
as part of your encrypted Hiera data store
|
||||
|
||||
### Securing SSH and PGP private keys
|
||||
|
||||
Personal encryption keys, including SSH and PGP private keys, are going to be
|
||||
the most prized items on your workstation -- something the attackers will be
|
||||
most interested in obtaining, as that would allow them to further attack your
|
||||
infrastructure or impersonate you to other admins. You should take extra steps
|
||||
to ensure that your private keys are well protected against theft.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Strong passphrases are used to protect private keys _(CRITICAL)_
|
||||
- [ ] PGP Master key is stored on removable storage _(MODERATE)_
|
||||
- [ ] Auth, Sign and Encrypt Subkeys are stored on a smartcard device _(MODERATE)_
|
||||
- [ ] SSH is configured to use PGP Auth key as ssh private key _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
The best way to prevent private key theft is to use a smartcard to store your
|
||||
encryption private keys and never copy them onto the workstation. There are
|
||||
several manufacturers that offer OpenPGP capable devices:
|
||||
|
||||
- [Kernel Concepts][12], where you can purchase both the OpenPGP compatible
|
||||
smartcards and the USB readers, should you need one.
|
||||
- [Yubikey NEO][13], which offers OpenPGP smartcard functionality in addition
|
||||
to many other cool features (U2F, PIV, HOTP, etc).
|
||||
|
||||
It is also important to make sure that the master PGP key is not stored on the
|
||||
main workstation, and only subkeys are used. The master key will only be
|
||||
needed when signing someone else's keys or creating new subkeys -- operations
|
||||
which do not happen very frequently. You may follow [the Debian's subkeys][14]
|
||||
guide to learn how to move your master key to removable storage and how to
|
||||
create subkeys.
|
||||
|
||||
You should then configure your gnupg agent to act as ssh agent and use the
|
||||
smartcard-based PGP Auth key to act as your ssh private key. We publish a
|
||||
[detailed guide][15] on how to do that using either a smartcard reader or a
|
||||
Yubikey NEO.
|
||||
|
||||
If you are not willing to go that far, at least make sure you have a strong
|
||||
passphrase on both your PGP private key and your SSH private key, which will
|
||||
make it harder for attackers to steal and use them.
|
||||
|
||||
### SELinux on the workstation
|
||||
|
||||
If you are using a distribution that comes bundled with SELinux (such as
|
||||
Fedora), here are some recommendation of how to make the best use of it to
|
||||
maximize your workstation security.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Make sure SELinux is enforcing on your workstation _(CRITICAL)_
|
||||
- [ ] Never blindly run `audit2allow -M`, always check _(CRITICAL)_
|
||||
- [ ] Never `setenforce 0` _(MODERATE)_
|
||||
- [ ] Switch your account to SELinux user `staff_u` _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
SELinux is a Mandatory Access Controls (MAC) extension to core POSIX
|
||||
permissions functionality. It is mature, robust, and has come a long way since
|
||||
its initial roll-out. Regardless, many sysadmins to this day repeat the
|
||||
outdated mantra of "just turn it off."
|
||||
|
||||
That being said, SELinux will have limited security benefits on the
|
||||
workstation, as most applications you will be running as a user are going to
|
||||
be running unconfined. It does provide enough net benefit to warrant leaving
|
||||
it on, as it will likely help prevent an attacker from escalating privileges
|
||||
to gain root-level access via a vulnerable daemon service.
|
||||
|
||||
Our recommendation is to leave it on and enforcing.
|
||||
|
||||
##### Never `setenforce 0`
|
||||
|
||||
It's tempting to use `setenforce 0` to flip SELinux into permissive mode
|
||||
on a temporary basis, but you should avoid doing that. This essentially turns
|
||||
off SELinux for the entire system, while what you really want is to
|
||||
troubleshoot a particular application or daemon.
|
||||
|
||||
Instead of `setenforce 0` you should be using `semanage permissive -a
|
||||
[somedomain_t]` to put only that domain into permissive mode. First, find out
|
||||
which domain is causing troubles by running `ausearch`:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
and then look for `scontext=` (source SELinux context) line, like so:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
This tells you that the domain being denied is `gpg_pinentry_t`, so if you
|
||||
want to troubleshoot the application, you should add it to permissive domains:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
This will allow you to use the application and collect the rest of the AVCs,
|
||||
which you can then use in conjunction with `audit2allow` to write a local
|
||||
policy. Once that is done and you see no new AVC denials, you can remove that
|
||||
domain from permissive by running:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### Use your workstation as SELinux role staff_r
|
||||
|
||||
SELinux comes with a native implementation of roles that prohibit or grant
|
||||
certain privileges based on the role associated with the user account. As an
|
||||
administrator, you should be using the `staff_r` role, which will restrict
|
||||
access to many configuration and other security-sensitive files, unless you
|
||||
first perform `sudo`.
|
||||
|
||||
By default, accounts are created as `unconfined_r` and most applications you
|
||||
execute will run unconfined, without any (or with only very few) SELinux
|
||||
constraints. To switch your account to the `staff_r` role, run the following
|
||||
command:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
You should log out and log back in to enable the new role, at which point if
|
||||
you run `id -Z`, you'll see:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
When performing `sudo`, you should remember to add an extra flag to tell
|
||||
SELinux to transition to the "sysadmin" role. The command you want is:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
At which point `id -Z` will show:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**WARNING**: you should be comfortable using `ausearch` and `audit2allow`
|
||||
before you make this switch, as it's possible some of your applications will
|
||||
no longer work when you're running as role `staff_r`. At the time of writing,
|
||||
the following popular applications are known to not work under `staff_r`
|
||||
without policy tweaks:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
To switch back to `unconfined_r`, run the following command:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
and then log out and back in to get back into the comfort zone.
|
||||
|
||||
## Further reading
|
||||
|
||||
The world of IT security is a rabbit hole with no bottom. If you would like to
|
||||
go deeper, or find out more about security features on your particular
|
||||
distribution, please check out the following links:
|
||||
|
||||
- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX Security](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## License
|
||||
This work is licensed under a
|
||||
[Creative Commons Attribution-ShareAlike 4.0 International License][0].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#linux-workstation-security-checklist
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
@ -1,277 +0,0 @@
|
||||
|
||||
在 Linux 中设置 RAID 10 或 1 + 0(嵌套) - 第6部分
|
||||
================================================================================
|
||||
RAID 10 是结合 RAID 0 和 RAID 1 形成的。要设置 RAID 10,我们至少需要4个磁盘。在之前的文章中,我们已经看到了如何使用两个磁盘设置 RAID 0 和 RAID 1。
|
||||
|
||||
在这里,我们将使用最少4个磁盘结合 RAID 0 和 RAID 1 来设置 RAID 10。假设,我们已经在逻辑卷保存了一些数据,这是 RAID 10 创建的,如果我们要保存数据“apple”,它将使用以下方法将其保存在4个磁盘中。
|
||||
|
||||

|
||||
|
||||
在 Linux 中创建 Raid 10
|
||||
|
||||
使用 RAID 0 时,它将“A”保存在第一个磁盘,“p”保存在第二个磁盘,下一个“P”又在第一个磁盘,“L”在第二个磁盘。然后,“e”又在第一个磁盘,像这样它会继续循环此过程将数据保存完整。由此我们知道,RAID 0 是将数据的一半保存到第一个磁盘,另一半保存到第二个磁盘。
|
||||
|
||||
在 RAID 1 方法中,相同的数据将被写入到两个磁盘中。 “A”将同时被写入到第一和第二个磁盘中,“P”也将被同时写入到两个磁盘中,下一个“P”也将同时被写入到两个磁盘。因此,使用 RAID 1 将同时写入到两个磁盘。它将继续循环此过程。
|
||||
|
||||
现在大家来了解 RAID 10 怎样结合 RAID 0 和 RAID 1 来工作。如果我们有4个20 GB 的磁盘,总共为 80 GB,但我们将只能得到40 GB 的容量,另一半的容量将用于构建 RAID 10。
|
||||
|
||||
#### RAID 10 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能。
|
||||
- 在 RAID 10 中我们将失去两个磁盘的容量。
|
||||
- 读与写的性能将会很好,因为它会同时进行写入和读取。
|
||||
- 它能解决数据库的高 I/O 磁盘写操作。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
在 RAID 10 中,我们至少需要4个磁盘,2个磁盘为 RAID 0,其他2个磁盘为 RAID 1,就像我之前说的,RAID 10 仅仅是结合了 RAID 0和1。如果我们需要扩展 RAID 组,最少需要添加4个磁盘。
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.229
|
||||
Hostname : rd10.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdd
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
Disk 4 [20GB] : /dev/sde
|
||||
|
||||
有两种方法来设置 RAID 10,在这里两种方法我都会演示,但我更喜欢第一种方法,使用它来设置 RAID 10 更简单。
|
||||
|
||||
### 方法1:设置 RAID 10 ###
|
||||
|
||||
1.首先,使用以下命令确认所添加的4块磁盘没有被使用。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
2.四个磁盘被检测后,然后来检查磁盘是否存在 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde
|
||||
|
||||

|
||||
|
||||
验证添加的4块磁盘
|
||||
|
||||
**注意**: 在上面的输出中,如果没有检测到 super-block 意味着在4块磁盘中没有定义过 RAID。
|
||||
|
||||
#### 第1步:为 RAID 分区 ####
|
||||
|
||||
3.现在,使用‘fdisk’,命令为4个磁盘(/dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde)创建新分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
**为 /dev/sdb 创建分区**
|
||||
|
||||
我来告诉你如何使用 fdisk 为磁盘(/dev/sdb)进行分区,此步也适用于其他磁盘。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请使用以下步骤为 /dev/sdb 创建一个新的分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 去修改分区。
|
||||
- 键入 ‘fd’ 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
|
||||

|
||||
|
||||
为磁盘 sdb 分区
|
||||
|
||||
**注意**: 请使用上面相同的指令对其他磁盘(sdc, sdd sdd sde)进行分区。
|
||||
|
||||
4.创建好4个分区后,需要使用下面的命令来检查磁盘是否存在 raid。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
或者
|
||||
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
|
||||

|
||||
|
||||
检查磁盘
|
||||
|
||||
**注意**: 以上输出显示,新创建的四个分区中没有检测到 super-block,这意味着我们可以继续在这些磁盘上创建 RAID 10。
|
||||
|
||||
#### 第2步: 创建 RAID 设备 ‘md’ ####
|
||||
|
||||
5.现在改创建一个‘md’(即 /dev/md0)设备,使用“mdadm” raid 管理工具。在创建设备之前,必须确保系统已经安装了‘mdadm’工具,如果没有请使用下面的命令来安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
|
||||
‘mdadm’工具安装完成后,可以使用下面的命令创建一个‘md’ raid 设备。
|
||||
|
||||
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1
|
||||
|
||||
6.接下来使用‘cat’命令验证新创建的 raid 设备。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建 md raid 设备
|
||||
|
||||
7.接下来,使用下面的命令来检查4个磁盘。下面命令的输出会很长,因为它会显示4个磁盘的所有信息。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
8.接下来,使用以下命令来查看 RAID 阵列的详细信息。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
查看 Raid 阵列详细信息
|
||||
|
||||
**注意**: 你在上面看到的结果,该 RAID 的状态是 active 和re-syncing。
|
||||
|
||||
#### 第3步:创建文件系统 ####
|
||||
|
||||
9.使用 ext4 作为‘md0′的文件系统并将它挂载到‘/mnt/raid10‘下。在这里,我用的是 ext4,你可以使用你想要的文件系统类型。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 md 文件系统
|
||||
|
||||
10.在创建文件系统后,挂载文件系统到‘/mnt/raid10‘下,并使用‘ls -l’命令列出挂载点下的内容。
|
||||
|
||||
# mkdir /mnt/raid10
|
||||
# mount /dev/md0 /mnt/raid10/
|
||||
# ls -l /mnt/raid10/
|
||||
|
||||
接下来,在挂载点下创建一些文件,并在文件中添加些内容,然后检查内容。
|
||||
|
||||
# touch /mnt/raid10/raid10_files.txt
|
||||
# ls -l /mnt/raid10/
|
||||
# echo "raid 10 setup with 4 disks" > /mnt/raid10/raid10_files.txt
|
||||
# cat /mnt/raid10/raid10_files.txt
|
||||
|
||||

|
||||
|
||||
挂载 md 设备
|
||||
|
||||
11.要想自动挂载,打开‘/etc/fstab‘文件并添加下面的条目,挂载点根据你环境的不同来添加。使用 wq! 保存并退出。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid10 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
挂载 md 设备
|
||||
|
||||
12.接下来,在重新启动系统前使用‘mount -a‘来确认‘/etc/fstab‘文件是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||

|
||||
|
||||
检查 Fstab 中的错误
|
||||
|
||||
#### 第四步:保存 RAID 配置 ####
|
||||
|
||||
13.默认情况下 RAID 没有配置文件,所以我们需要在上述步骤完成后手动保存它。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
保存 Raid10 的配置
|
||||
|
||||
就这样,我们使用方法1创建完了 RAID 10,这种方法是比较容易的。现在,让我们使用方法2来设置 RAID 10。
|
||||
|
||||
### 方法2:创建 RAID 10 ###
|
||||
|
||||
1.在方法2中,我们必须定义2组 RAID 1,然后我们需要使用这些创建好的 RAID 1 的集来定义一个 RAID 0。在这里,我们将要做的是先创建2个镜像(RAID1),然后创建 RAID0 (条带化)。
|
||||
|
||||
首先,列出所有的可用于创建 RAID 10 的磁盘。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||

|
||||
|
||||
列出了 4 设备
|
||||
|
||||
2.将4个磁盘使用‘fdisk’命令进行分区。对于如何分区,您可以按照 #步骤 3。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
3.在完成4个磁盘的分区后,现在检查磁盘是否存在 RAID块。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||

|
||||
|
||||
检查 4 个磁盘
|
||||
|
||||
#### 第1步:创建 RAID 1 ####
|
||||
|
||||
4.首先,使用4块磁盘创建2组 RAID 1,一组为‘sdb1′和 ‘sdc1′,另一组是‘sdd1′ 和 ‘sde1′。
|
||||
|
||||
# mdadm --create /dev/md1 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md2 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[d-e]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建 Raid 1
|
||||
|
||||

|
||||
|
||||
查看 Raid 1 的详细信息
|
||||
|
||||
#### 第2步:创建 RAID 0 ####
|
||||
|
||||
5.接下来,使用 md1 和 md2 来创建 RAID 0。
|
||||
|
||||
# mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/md1 /dev/md2
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
创建 Raid 0
|
||||
|
||||
#### 第3步:保存 RAID 配置 ####
|
||||
|
||||
6.我们需要将配置文件保存在‘/etc/mdadm.conf‘文件中,使其每次重新启动后都能加载所有的 raid 设备。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||
在此之后,我们需要按照方法1中的#第3步来创建文件系统。
|
||||
|
||||
就是这样!我们采用的方法2创建完了 RAID 1+0.我们将会失去两个磁盘的空间,但相比其他 RAID ,它的性能将是非常好的。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这里,我们采用两种方法创建 RAID 10。RAID 10 具有良好的性能和冗余性。希望这篇文章可以帮助你了解 RAID 10(嵌套 RAID 的级别)。在后面的文章中我们会看到如何扩展现有的 RAID 阵列以及更多精彩的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-10-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -1,182 +0,0 @@
|
||||
|
||||
在 Raid 中扩展现有的 RAID 阵列和删除故障的磁盘 - 第7部分
|
||||
================================================================================
|
||||
每个新手都会对阵列的意思产生疑惑。阵列只是磁盘的一个集合。换句话说,我们可以称阵列为一个集合或一组。就像一组鸡蛋中包含6个。同样 RAID 阵列中包含着多个磁盘,可能是2,4,6,8,12,16等,希望你现在知道了什么是阵列。
|
||||
|
||||
在这里,我们将看到如何扩展现有的阵列或 raid 组。例如,如果我们在一组 raid 中使用2个磁盘形成一个 raid 1,在某些情况,如果该组中需要更多的空间,就可以使用mdadm -grow 命令来扩展阵列大小,只是将一个磁盘加入到现有的阵列中。在扩展(添加磁盘到现有的阵列中)后,我们将看看如何从阵列中删除故障的磁盘。
|
||||
|
||||

|
||||
|
||||
扩展 RAID 阵列和删除故障的磁盘
|
||||
|
||||
假设磁盘中的一个有问题了需要删除该磁盘,但我们需要添加一个备用磁盘来扩展该镜像再删除磁盘前,因为我们需要保存数据。当磁盘发生故障时我们需要从阵列中删除它,这是这个主题中我们将要学习到的。
|
||||
|
||||
#### 扩展 RAID 的特性 ####
|
||||
|
||||
- 我们可以增加(扩大)所有 RAID 集和的大小。
|
||||
- 我们在使用新磁盘扩展 RAID 阵列后删除故障的磁盘。
|
||||
- 我们可以扩展 RAID 阵列不存在宕机时间。
|
||||
|
||||
要求
|
||||
|
||||
- 为了扩展一个RAID阵列,我们需要已有的 RAID 组(阵列)。
|
||||
- 我们需要额外的磁盘来扩展阵列。
|
||||
- 在这里,我们使用一块磁盘来扩展现有的阵列。
|
||||
|
||||
在我们了解扩展和恢复阵列前,我们必须了解有关 RAID 级别和设置的基本知识。点击下面的链接了解这些。
|
||||
|
||||
- [理解 RAID 的基础概念 – 第一部分][1]
|
||||
- [在 Linux 中创建软件 Raid 0 – 第二部分][2]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP地址 : 192.168.0.230
|
||||
主机名 : grow.tecmintlocal.com
|
||||
2 块现有磁盘 : 1 GB
|
||||
1 块额外磁盘 : 1 GB
|
||||
|
||||
在这里,现有的 RAID 有2块磁盘,每个大小为1GB,我们现在再增加一个磁盘到我们现有的 RAID 阵列中,其大小为1GB。
|
||||
|
||||
### 扩展现有的 RAID 阵列 ###
|
||||
|
||||
1. 在扩展阵列前,首先使用下面的命令列出现有的 RAID 阵列。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查现有的 RAID 阵列
|
||||
|
||||
**注意**: 以上输出显示,已经有了两个磁盘在 RAID 阵列中,级别为 RAID 1。现在我们在这里再增加一个磁盘到现有的阵列。
|
||||
|
||||
2.现在让我们添加新的磁盘“sdd”,并使用‘fdisk‘命令来创建分区。
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
请使用以下步骤为 /dev/sdd 创建一个新的分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 去修改分区。
|
||||
- 键入 ‘fd’ 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
|
||||

|
||||
|
||||
为 sdd 创建新的分区
|
||||
|
||||
3. 一旦新的 sdd 分区创建完成后,你可以使用下面的命令验证它。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||

|
||||
|
||||
确认 sdd 分区
|
||||
|
||||
4.接下来,在添加到阵列前先检查磁盘是否有 RAID 分区。
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||

|
||||
|
||||
在 sdd 分区中检查 raid
|
||||
|
||||
**注意**:以上输出显示,该盘有没有发现 super-blocks,意味着我们可以将新的磁盘添加到现有阵列。
|
||||
|
||||
4. 要添加新的分区 /dev/sdd1 到现有的阵列 md0,请使用以下命令。
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||

|
||||
|
||||
添加磁盘到 Raid 阵列
|
||||
|
||||
5. 一旦新的磁盘被添加后,在我们的阵列中检查新添加的磁盘。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
确认将新磁盘添加到 Raid 中
|
||||
|
||||
**注意**: 在上面的输出,你可以看到磁盘已经被添加作为备用的。在这里,我们的阵列中已经有了2个磁盘,但我们期待阵列中有3个磁盘,因此我们需要扩展阵列。
|
||||
|
||||
6. 要扩展阵列,我们需要使用下面的命令。
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||

|
||||
|
||||
扩展 Raid 阵列
|
||||
|
||||
现在我们可以看到第三块磁盘(sdd1)已被添加到阵列中,在第三块磁盘被添加后,它将从另外两块磁盘上同步数据。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
确认 Raid 阵列
|
||||
|
||||
**注意**: 对于容量磁盘会需要几个小时来同步数据。在这里,我们使用的是1GB的虚拟磁盘,所以它非常快在几秒钟内便会完成。
|
||||
|
||||
### 从阵列中删除磁盘 ###
|
||||
|
||||
7. 在数据被从其他两个磁盘同步到新磁盘‘sdd1‘后,现在三个磁盘中的数据已经相同了。
|
||||
|
||||
正如我前面所说的,假定一个磁盘出问题了需要被删除。所以,现在假设磁盘‘sdc1‘出问题了,需要从现有阵列中删除。
|
||||
|
||||
在删除磁盘前我们要将其标记为 failed,然后我们才可以将其删除。
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
在 Raid 阵列中模拟磁盘故障
|
||||
|
||||
从上面的输出中,我们清楚地看到,磁盘在底部被标记为 faulty。即使它是 faulty 的,我们仍然可以看到 raid 设备有3个,1个损坏了 state 是 degraded。
|
||||
|
||||
现在我们要从阵列中删除 faulty 的磁盘,raid 设备将像之前一样继续有2个设备。
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
在 Raid 阵列中删除磁盘
|
||||
|
||||
8. 一旦故障的磁盘被删除,然后我们只能使用2个磁盘来扩展 raid 阵列了。
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
在 RAID 阵列扩展磁盘
|
||||
|
||||
从上面的输出中可以看到,我们的阵列中仅有2台设备。如果你需要再次扩展阵列,按照同样的步骤,如上所述。如果你需要添加一个磁盘作为备用,将其标记为 spare,因此,如果磁盘出现故障时,它会自动顶上去并重建数据。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何扩展现有的 RAID 集合,以及如何从一个阵列中删除故障磁盘在重新同步已有磁盘的数据后。所有这些步骤都可以不用停机来完成。在数据同步期间,系统用户,文件和应用程序不会受到任何影响。
|
||||
|
||||
在接下来的文章我将告诉你如何管理 RAID,敬请关注更新,不要忘了写评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user