mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
3b964ad01b
@ -1,24 +1,24 @@
|
||||
Trickr:一个开源的Linux桌面RSS新闻速递
|
||||
Tickr:一个开源的 Linux 桌面 RSS 新闻速递应用
|
||||
================================================================================
|
||||

|
||||
|
||||
**最新的!最新的!阅读关于它的一切!**
|
||||
|
||||
好了,所以我们今天要强调的应用程序不是相当于旧报纸的二进制版本—而是它会以一个伟大的方式,将最新的新闻推送到你的桌面上。
|
||||
好了,我们今天要推荐的应用程序可不是旧式报纸的二进制版本——它会以一种漂亮的方式将最新的新闻推送到你的桌面上。
|
||||
|
||||
Tick是一个基于GTK的Linux桌面新闻速递,能够在水平带滚动显示最新头条新闻,以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
Tickr 是一个基于 GTK 的 Linux 桌面新闻速递应用,能够以横条方式滚动显示最新头条新闻以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
|
||||
请叫我Joey Calamezzo;我把我的放在底部,有电视新闻台的风格。
|
||||
请叫我 Joey Calamezzo;我把它放在底部,就像电视新闻台的滚动字幕一样。 (LCTT 译注: Joan Callamezzo 是 Pawnee Today 的主持人,一位 Pawnee 的本地新闻/脱口秀主持人。而本文作者是 Joey。)
|
||||
|
||||
“到你了,子标题”
|
||||
“到你了,副标题”。
|
||||
|
||||
### RSS -还记得吗? ###
|
||||
|
||||
“谢谢段落结尾。”
|
||||
“谢谢,这段结束了。”
|
||||
|
||||
在一个推送通知,社交媒体,以及点击诱饵的时代,哄骗我们阅读最新的令人惊奇的,人人都爱读的清单,RSS看起来有一点过时了。
|
||||
在一个充斥着推送通知、社交媒体、标题党,以及哄骗人们点击的清单体的时代,RSS看起来有一点过时了。
|
||||
|
||||
对我来说?恩,RSS是名副其实的真正简单的聚合。这是将消息通知给我的最简单,最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
对我来说呢?恩,RSS是名副其实的真正简单的聚合(RSS : Really Simple Syndication)。这是将消息通知给我的最简单、最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
|
||||
tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的底部,然后不时地瞥一眼。
|
||||
|
||||
@ -32,31 +32,30 @@ tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的
|
||||
|
||||
尽管虽然tickr可以从Ubuntu软件中心安装,然而它已经很久没有更新了。当你打开笨拙的不直观的控制面板的时候,没有什么能够比这更让人感觉被遗弃的了。
|
||||
|
||||
打开它:
|
||||
要打开它:
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至编辑>首选项
|
||||
1. 调整各种设置
|
||||
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是知己知彼你能够几乎掌控一切,包括:
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是详细了解这些你才能够掌握一切,包括:
|
||||
|
||||
- 设置滚动速度
|
||||
- 选择鼠标经过时的行为
|
||||
- 资讯更新频率
|
||||
- 字体,包括字体大小和颜色
|
||||
- 分隔符(“delineator”)
|
||||
- 消息分隔符(“delineator”)
|
||||
- tickr在屏幕上的位置
|
||||
- tickr条的颜色和不透明度
|
||||
- 选择每种资讯显示多少文章
|
||||
|
||||
有个值得一提的“怪癖”是,当你点击“应用”按钮,只会更新tickr的屏幕预览。当您退出“首选项”窗口时,请单击“确定”。
|
||||
|
||||
想要滚动条在你的显示屏上水平显示,也需要公平一点的调整,特别是统一显示。
|
||||
想要得到完美的显示效果, 你需要一点点调整,特别是在 Unity 上。
|
||||
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序被创建在过去的GNOME2.x桌面)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序以前是在GNOME2.x桌面上创建的)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;
|
||||
是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
|
||||
#### 添加资讯 ####
|
||||
|
||||
@ -76,9 +75,9 @@ tickr自带的有超过30种不同的资讯列表,从技术博客到主流新
|
||||
|
||||
### 在Ubuntu 14.04 LTS或更高版本上安装Tickr ###
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本上安装Tickr
|
||||
这就是 Tickr,它不会改变世界,但是它能让你知道世界上发生了什么。
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,转到Ubuntu软件中心,但要点击下面的按钮。
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,点击下面的按钮转到Ubuntu软件中心。
|
||||
|
||||
- [点击此处进入Ubuntu软件中心安装tickr][1]
|
||||
|
||||
@ -88,7 +87,7 @@ via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticke
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
如何在 Linux 终端中获取公有 IP
|
||||
如何在 Linux 终端中知道你的公有 IP
|
||||
================================================================================
|
||||

|
||||
|
||||
公有地址由InterNIC分配并由基于类的网络 ID 或基于 CIDR 地址块构成(被称为 CIDR 块)并保证了在全球英特网中的唯一性。当公有地址被分配时,路径将会被记录到互联网中的路由器中,这样访问公有地址的流量就能顺利到达。访问目标公有地址的流量可通过互联网获取。比如,当一个一个 CIDR 块被以网络 ID 和子网掩码的形式分配给一个组织时,对应的 [网络 ID,子网掩码] 也会同时作为路径储存在英特网中的路由器中。访问 CIDR 块中的地址的 IP 封包会被导向对应的位置。在本文中我将会介绍在几种在 Linux 终端中查看你的公有 IP 地址的方法。这对普通用户来说并无意义,但 Linux 服务器(无GUI或者作为只能使用基本工具的用户登录时)会很有用。无论如何,从 Linux 终端中获取公有 IP 在各种方面都很意义,说不定某一天就能用得着。
|
||||
公有地址由 InterNIC 分配并由基于类的网络 ID 或基于 CIDR 的地址块构成(被称为 CIDR 块),并保证了在全球互联网中的唯一性。当公有地址被分配时,其路由将会被记录到互联网中的路由器中,这样访问公有地址的流量就能顺利到达。访问目标公有地址的流量可经由互联网抵达。比如,当一个 CIDR 块被以网络 ID 和子网掩码的形式分配给一个组织时,对应的 [网络 ID,子网掩码] 也会同时作为路由储存在互联网中的路由器中。目标是 CIDR 块中的地址的 IP 封包会被导向对应的位置。
|
||||
|
||||
在本文中我将会介绍在几种在 Linux 终端中查看你的公有 IP 地址的方法。这对普通用户来说并无意义,但 Linux 服务器(无GUI或者作为只能使用基本工具的用户登录时)会很有用。无论如何,从 Linux 终端中获取公有 IP 在各种方面都很意义,说不定某一天就能用得着。
|
||||
|
||||
以下是我们主要使用的两个命令,curl 和 wget。你可以换着用。
|
||||
|
||||
@ -21,17 +22,17 @@
|
||||
|
||||
curl ipinfo.io/json
|
||||
curl ifconfig.me/all.json
|
||||
curl www.trackip.net/ip?json (bit ugly)
|
||||
curl www.trackip.net/ip?json (有点丑陋)
|
||||
|
||||
### curl XML格式输出: ###
|
||||
|
||||
curl ifconfig.me/all.xml
|
||||
|
||||
### curl 所有IP细节 ###
|
||||
### curl 得到所有IP细节 (挖掘机)###
|
||||
|
||||
curl ifconfig.me/all
|
||||
|
||||
### 使用 DYDNS (当你使用 DYDNS 服务时有用)Using DYNDNS (Useful when you’re using DYNDNS service) ###
|
||||
### 使用 DYDNS (当你使用 DYDNS 服务时有用)###
|
||||
|
||||
curl -s 'http://checkip.dyndns.org' | sed 's/.*Current IP Address: \([0-9\.]*\).*/\1/g'
|
||||
curl -s http://checkip.dyndns.org/ | grep -o "[[:digit:].]\+"
|
||||
@ -43,7 +44,7 @@
|
||||
|
||||
### 使用 host 和 dig 命令 ###
|
||||
|
||||
在可用时,你可以直接使用 host 和 dig 命令。
|
||||
如果有的话,你也可以直接使用 host 和 dig 命令。
|
||||
|
||||
host -t a dartsclink.com | sed 's/.*has address //'
|
||||
dig +short myip.opendns.com @resolver1.opendns.com
|
||||
@ -55,15 +56,15 @@
|
||||
PUBLIC_IP=`wget http://ipecho.net/plain -O - -q ; echo`
|
||||
echo $PUBLIC_IP
|
||||
|
||||
已经由不少选项了。
|
||||
简单易用。
|
||||
|
||||
我实际上写了一个用于记录每日我的路由器中所有 IP 变化并保存到一个文件的脚本。我在搜索过程中找到了这些很好用的命令。希望某天它能帮到其他人。
|
||||
我实际上是在写一个用于记录每日我的路由器中所有 IP 变化并保存到一个文件的脚本。我在搜索过程中找到了这些很好用的命令。希望某天它能帮到其他人。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/14/how-to-get-public-ip-from-linux-terminal/
|
||||
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,52 @@
|
||||
Linux无极限:IBM发布LinuxONE大型机
|
||||
================================================================================
|
||||

|
||||
|
||||
LinuxONE Emperor MainframeGood的Ubuntu服务器团队今天发布了一条消息关于[IBM发布了LinuxONE][1],一种只支持Linux的大型机,也可以运行Ubuntu。
|
||||
|
||||
IBM发布的最大的LinuxONE系统称作‘Emperor’,它可以扩展到8000台虚拟机或者上万台容器- 对任何一台Linux系统都可能的记录。
|
||||
|
||||
LinuxONE被IBM称作‘游戏改变者’,它‘释放了Linux的商业潜力’。
|
||||
|
||||
IBM和Canonical正在一起协作为LinuxONE和其他IBM z系统创建Ubuntu发行版。Ubuntu将会在IBM z加入RedHat和SUSE作为首屈一指的Linux发行版。
|
||||
|
||||
随着IBM ‘Emperor’发布的还有LinuxONE Rockhopper,一个为中等规模商业或者组织小一点的大型机。
|
||||
|
||||
IBM是大型机中的领导者,并且占有大型机市场中90%的份额。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/2ABfNrWs-ns?feature=oembed"></iframe>
|
||||
|
||||
### 大型机用于什么? ###
|
||||
|
||||
你阅读这篇文章所使用的电脑在一个‘大铁块’一样的大型机前会显得很矮小。它们是巨大的,笨重的机柜里面充满了高端的组件、自己设计的技术和眼花缭乱的大量存储(就是数据存储,没有空间放钢笔和尺子)。
|
||||
|
||||
大型机被大型机构和商业用来处理和存储大量数据,通过统计来处理数据和处理大规模的事务处理。
|
||||
|
||||
### ‘世界最快的处理器’ ###
|
||||
|
||||
IBM已经与Canonical Ltd组成了团队来在LinuxONE和其他IBM z系统中使用Ubuntu。
|
||||
|
||||
LinuxONE Emperor使用IBM z13处理器。发布于一月的芯片声称是时间上最快的微处理器。它可以在几毫秒内响应事务。
|
||||
|
||||
但是也可以很好地处理高容量的移动事务,z13中的LinuxONE系统也是一个理想的云系统。
|
||||
|
||||
每个核心可以处理超过50个虚拟服务器,总共可以超过8000台虚拟服务器么,这使它以更便宜,更环保、更高效的方式扩展到云。
|
||||
|
||||
**在阅读这篇文章时你不必是一个CIO或者大型机巡查员。LinuxONE提供的可能性足够清晰。**
|
||||
|
||||
来源: [Reuters (h/t @popey)][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www-03.ibm.com/systems/z/announcement.html
|
||||
[2]:http://www.reuters.com/article/2015/08/17/us-ibm-linuxone-idUSKCN0QM09P20150817
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu Linux 来到 IBM 大型机
|
||||
================================================================================
|
||||
最终来到了。在 [LinuxCon][1] 上,IBM 和 [Canonical][2] 宣布 [Ubuntu Linux][3] 不久就会运行在 IBM 大型机 [LinuxONE][1] 上,这是一种只支持 Linux 的大型机,现在也可以运行 Ubuntu 了。
|
||||
|
||||
这个 IBM 发布的最大的 LinuxONE 系统称作‘Emperor’,它可以扩展到 8000 台虚拟机或者上万台容器,这可能是单独一台 Linux 系统的记录。
|
||||
|
||||
LinuxONE 被 IBM 称作‘游戏改变者’,它‘释放了 Linux 的商业潜力’。
|
||||
|
||||

|
||||
|
||||
*很快你就可以在你的 IBM 大型机上安装 Ubuntu Linux orange 啦*
|
||||
|
||||
根据 IBM z 系统的总经理 Ross Mauri 以及 Canonical 和 Ubuntu 的创立者 Mark Shuttleworth 所言,这是因为客户需要。十多年来,IBM 大型机只支持 [红帽企业版 Linux (RHEL)][4] 和 [SUSE Linux 企业版 (SLES)][5] Linux 发行版。
|
||||
|
||||
随着 Ubuntu 越来越成熟,更多的企业把它作为企业级 Linux,也有更多的人希望它能运行在 IBM 大型机上。尤其是银行希望如此。不久,金融 CIO 们就可以满足他们的需求啦。
|
||||
|
||||
在一次采访中 Shuttleworth 说 Ubuntu Linux 在 2016 年 4 月下一次长期支持版 Ubuntu 16.04 中就可以用到大型机上。而在 2014 年底 Canonical 和 IBM 将 [Ubuntu 带到 IBM 的 POWER][6] 架构中就迈出了第一步。
|
||||
|
||||
在那之前,Canonical 和 IBM 差点签署了协议 [在 2011 年实现 Ubuntu 支持 IBM 大型机][7],但最终也没有实现。这次,真的发生了。
|
||||
|
||||
Canonical 的 CEO Jane Silber 解释说 “[把 Ubuntu 平台支持扩大][8]到 [IBM z 系统][9] 是因为认识到需要 z 系统运行其业务的客户数量以及混合云市场的成熟。”
|
||||
|
||||
**Silber 还说:**
|
||||
|
||||
> 由于 z 系统的支持,包括 [LinuxONE][10],Canonical 和 IBM 的关系进一步加深,构建了对 POWER 架构的支持和 OpenPOWER 生态系统。正如 Power 系统的客户受益于 Ubuntu 的可扩展能力,我们的敏捷开发过程也使得类似 POWER8 CAPI (Coherent Accelerator Processor Interface,一致性加速器接口)得到了市场支持,z 系统的客户也可以期望技术进步能快速部署,并从 [Juju][11] 和我们的其它云工具中获益,使得能快速向端用户提供新服务。另外,我们和 IBM 的合作包括实现扩展部署很多 IBM 和 Juju 的软件解决方案。大型机客户对于能通过 Juju 将丰富‘迷人的’ IBM 解决方案、其它软件供应商的产品、开源解决方案部署到大型机上感到高兴。
|
||||
|
||||
Shuttleworth 期望 z 系统上的 Ubuntu 能取得巨大成功。它发展很快,由于对 OpenStack 的支持,希望有卓越云性能的人会感到非常高兴。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-linux-is-coming-to-the-mainframe/
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a],[Joey-Elijah Sneddon][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh),[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.canonical.com/
|
||||
[3]:http://www.ubuntu.comj/
|
||||
[4]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[5]:https://www.suse.com/products/server/
|
||||
[6]:http://www.zdnet.com/article/ibm-doubles-down-on-linux/
|
||||
[7]:http://www.zdnet.com/article/mainframe-ubuntu-linux/
|
||||
[8]:https://insights.ubuntu.com/2015/08/17/ibm-and-canonical-plan-ubuntu-support-on-ibm-z-systems-mainframe/
|
||||
[9]:http://www-03.ibm.com/systems/uk/z/
|
||||
[10]:http://www.zdnet.com/article/linuxone-ibms-new-linux-mainframes/
|
||||
[11]:https://jujucharms.com/
|
||||
@ -1,52 +0,0 @@
|
||||
Linux Without Limits: IBM Launch LinuxONE Mainframes
|
||||
================================================================================
|
||||

|
||||
|
||||
LinuxONE Emperor MainframeGood news for Ubuntu’s server team today as [IBM launch the LinuxONE][1] a Linux-only mainframe that is also able to run Ubuntu.
|
||||
|
||||
The largest of the LinuxONE systems launched by IBM is called ‘Emperor’ and can scale up to 8000 virtual machines or tens of thousands of containers – a possible record for any one single Linux system.
|
||||
|
||||
The LinuxONE is described by IBM as a ‘game changer’ that ‘unleashes the potential of Linux for business’.
|
||||
|
||||
IBM and Canonical are working together on the creation of an Ubuntu distribution for LinuxONE and other IBM z Systems. Ubuntu will join RedHat and SUSE as ‘premier Linux distributions’ on IBM z.
|
||||
|
||||
Alongside the ‘Emperor’ IBM is also offering the LinuxONE Rockhopper, a smaller mainframe for medium-sized businesses and organisations.
|
||||
|
||||
IBM is the market leader in mainframes and commands over 90% of the mainframe market.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/2ABfNrWs-ns?feature=oembed"></iframe>
|
||||
|
||||
### What Is a Mainframe Computer Used For? ###
|
||||
|
||||
The computer you’re reading this article on would be dwarfed by a ‘big iron’ mainframe. They are large, hulking great cabinets packed full of high-end components, custom designed technology and dizzying amounts of storage (that is data storage, not ample room for pens and rulers).
|
||||
|
||||
Mainframes computers are used by large organizations and businesses to process and store large amounts of data, crunch through statistics, and handle large-scale transaction processing.
|
||||
|
||||
### ‘World’s Fastest Processor’ ###
|
||||
|
||||
IBM has teamed up with Canonical Ltd to use Ubuntu on the LinuxONE and other IBM z Systems.
|
||||
|
||||
The LinuxONE Emperor uses the IBM z13 processor. The chip, announced back in January, is said to be the world’s fastest microprocessor. It is able to deliver transaction response times in the milliseconds.
|
||||
|
||||
But as well as being well equipped to handle for high-volume mobile transactions, the z13 inside the LinuxONE is also an ideal cloud system.
|
||||
|
||||
It can handle more than 50 virtual servers per core for a total of 8000 virtual servers, making it a cheaper, greener and more performant way to scale-out to the cloud.
|
||||
|
||||
**You don’t have to be a CIO or mainframe spotter to appreciate this announcement. The possibilities LinuxONE provides are clear enough. **
|
||||
|
||||
Source: [Reuters (h/t @popey)][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www-03.ibm.com/systems/z/announcement.html
|
||||
[2]:http://www.reuters.com/article/2015/08/17/us-ibm-linuxone-idUSKCN0QM09P20150817
|
||||
@ -1,46 +0,0 @@
|
||||
Ubuntu Linux is coming to IBM mainframes
|
||||
================================================================================
|
||||
SEATTLE -- It's finally happened. At [LinuxCon][1], IBM and [Canonical][2] announced that [Ubuntu Linux][3] will soon be running on IBM mainframes.
|
||||
|
||||

|
||||
|
||||
You'll soon to be able to get your IBM mainframe in Ubuntu Linux orange
|
||||
|
||||
According to Ross Mauri, IBM's General Manager of System z, and Mark Shuttleworth, Canonical and Ubuntu's founder, this move came about because of customer demand. For over a decade, [Red Hat Enterprise Linux (RHEL)][4] and [SUSE Linux Enterprise Server (SLES)][5] were the only supported IBM mainframe Linux distributions.
|
||||
|
||||
As Ubuntu matured, more and more businesses turned to it for the enterprise Linux, and more and more of them wanted it on IBM big iron hardware. In particular, banks wanted Ubuntu there. Soon, financial CIOs will have their wish granted.
|
||||
|
||||
In an interview Shuttleworth said that Ubuntu Linux will be available on the mainframe by April 2016 in the next long-term support version of Ubuntu: Ubuntu 16.04. Canonical and IBM already took the first move in this direction in late 2014 by bringing [Ubuntu to IBM's POWER][6] architecture.
|
||||
|
||||
Before that, Canonical and IBM almost signed the dotted line to bring [Ubuntu to IBM mainframes in 2011][7] but that deal was never finalized. This time, it's happening.
|
||||
|
||||
Jane Silber, Canonical's CEO, explained in a statement, "Our [expansion of Ubuntu platform][8] support to [IBM z Systems][9] is a recognition of the number of customers that count on z Systems to run their businesses, and the maturity the hybrid cloud is reaching in the marketplace.
|
||||
|
||||
**Silber continued:**
|
||||
|
||||
> With support of z Systems, including [LinuxONE][10], Canonical is also expanding our relationship with IBM, building on our support for the POWER architecture and OpenPOWER ecosystem. Just as Power Systems clients are now benefiting from the scaleout capabilities of Ubuntu, and our agile development process which results in first to market support of new technologies such as CAPI (Coherent Accelerator Processor Interface) on POWER8, z Systems clients can expect the same rapid rollout of technology advancements, and benefit from [Juju][11] and our other cloud tools to enable faster delivery of new services to end users. In addition, our collaboration with IBM includes the enablement of scale-out deployment of many IBM software solutions with Juju Charms. Mainframe clients will delight in having a wealth of 'charmed' IBM solutions, other software provider products, and open source solutions, deployable on mainframes via Juju.
|
||||
|
||||
Shuttleworth expects Ubuntu on z to be very successful. "It's blazingly fast, and with its support for OpenStack, people who want exceptional cloud region performance will be very happy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-linux-is-coming-to-the-mainframe/#ftag=RSSbaffb68
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.canonical.com/
|
||||
[3]:http://www.ubuntu.comj/
|
||||
[4]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[5]:https://www.suse.com/products/server/
|
||||
[6]:http://www.zdnet.com/article/ibm-doubles-down-on-linux/
|
||||
[7]:http://www.zdnet.com/article/mainframe-ubuntu-linux/
|
||||
[8]:https://insights.ubuntu.com/2015/08/17/ibm-and-canonical-plan-ubuntu-support-on-ibm-z-systems-mainframe/
|
||||
[9]:http://www-03.ibm.com/systems/uk/z/
|
||||
[10]:http://www.zdnet.com/article/linuxone-ibms-new-linux-mainframes/
|
||||
[11]:https://jujucharms.com/
|
||||
@ -1,3 +1,4 @@
|
||||
KevinSJ Translating
|
||||
Top 4 open source command-line email clients
|
||||
================================================================================
|
||||

|
||||
@ -76,4 +77,4 @@ via: http://opensource.com/life/15/8/top-4-open-source-command-line-email-client
|
||||
[9]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[10]:http://notmuchmail.org/
|
||||
[11]:http://notmuchmail.org/releases/
|
||||
[12]:http://www.gnu.org/licenses/gpl.html
|
||||
[12]:http://www.gnu.org/licenses/gpl.html
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[bazz2 translating]
|
||||
Docker Working on Security Components, Live Container Migration
|
||||
================================================================================
|
||||

|
||||
@ -50,4 +51,4 @@ via: http://www.eweek.com/virtualization/docker-working-on-security-components-l
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.eweek.com/cp/bio/Sean-Michael-Kerner/
|
||||
[a]:http://www.eweek.com/cp/bio/Sean-Michael-Kerner/
|
||||
|
||||
@ -0,0 +1,126 @@
|
||||
How learning data structures and algorithms make you a better developer
|
||||
================================================================================
|
||||
|
||||
> "I'm a huge proponent of designing your code around the data, rather than the other way around, and I think it's one of the reasons git has been fairly successful […] I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important."
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "Smart data structures and dumb code works a lot better than the other way around."
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
Learning about data structures and algorithms makes you a stonking good programmer.
|
||||
|
||||
**Data structures and algorithms are patterns for solving problems.** The more of them you have in your utility belt, the greater variety of problems you'll be able to solve. You'll also be able to come up with more elegant solutions to new problems than you would otherwise be able to.
|
||||
|
||||
You'll understand, ***in depth***, how your computer gets things done. This informs any technical decisions you make, regardless of whether or not you're using a given algorithm directly. Everything from memory allocation in the depths of your operating system, to the inner workings of your RDBMS to how your networking stack manages to send data from one corner of Earth to another. All computers rely on fundamental data structures and algorithms, so understanding them better makes you understand the computer better.
|
||||
|
||||
Cultivate a broad and deep knowledge of algorithms and you'll have stock solutions to large classes of problems. Problem spaces that you had difficulty modelling before often slot neatly into well-worn data structures that elegantly handle the known use-cases. Dive deep into the implementation of even the most basic data structures and you'll start seeing applications for them in your day-to-day programming tasks.
|
||||
|
||||
You'll also be able to come up with novel solutions to the somewhat fruitier problems you're faced with. Data structures and algorithms have the habit of proving themselves useful in situations that they weren't originally intended for, and the only way you'll discover these on your own is by having a deep and intuitive knowledge of at least the basics.
|
||||
|
||||
But enough with the theory, have a look at some examples
|
||||
|
||||
###Figuring out the fastest way to get somewhere###
|
||||
Let's say we're creating software to figure out the shortest distance from one international airport to another. Assume we're constrained to following routes:
|
||||
|
||||

|
||||
|
||||
graph of destinations and the distances between them, how can we find the shortest distance say, from Helsinki to London? **Dijkstra's algorithm** is the algorithm that will definitely get us the right answer in the shortest time.
|
||||
|
||||
In all likelihood, if you ever came across this problem and knew that Dijkstra's algorithm was the solution, you'd probably never have to implement it from scratch. Just ***knowing*** about it would point you to a library implementation that solves the problem for you.
|
||||
|
||||
If you did dive deep into the implementation, you'd be working through one of the most important graph algorithms we know of. You'd know that in practice it's a little resource intensive so an extension called A* is often used in it's place. It gets used everywhere from robot guidance to routing TCP packets to GPS pathfinding.
|
||||
|
||||
###Figuring out the order to do things in###
|
||||
Let's say you're trying to model courses on a new Massive Open Online Courses platform (like Udemy or Khan Academy). Some of the courses depend on each other. For example, a user has to have taken Calculus before she's eligible for the course on Newtonian Mechanics. Courses can have multiple dependencies. Here's are some examples of what that might look like written out in YAML:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
# If you're a physcist or a mathematicisn and you're reading this, sincere
|
||||
# apologies for the completely made-up dependency tree :)
|
||||
courses:
|
||||
arithmetic: []
|
||||
algebra: [arithmetic]
|
||||
trigonometry: [algebra]
|
||||
calculus: [algebra, trigonometry]
|
||||
geometry: [algebra]
|
||||
mechanics: [calculus, trigonometry]
|
||||
atomic_physics: [mechanics, calculus]
|
||||
electromagnetism: [calculus, atomic_physics]
|
||||
radioactivity: [algebra, atomic_physics]
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
Given those dependencies, as a user, I want to be able to pick any course and have the system give me an ordered list of courses that I would have to take to be eligible. So if I picked `calculus`, I'd want the system to return the list:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
Two important constraints on this that may not be self-evident:
|
||||
|
||||
- At every stage in the course list, the dependencies of the next course must be met.
|
||||
- We don't want any duplicate courses in the list.
|
||||
|
||||
This is an example of resolving dependencies and the algorithm we're looking for to solve this problem is called topological sort (tsort). Tsort works on a dependency graph like we've outlined in the YAML above. Here's what that would look like in a graph (where each arrow means `requires`):
|
||||
|
||||

|
||||
|
||||
topological sort does is take a graph like the one above and find an ordering in which all the dependencies are met at each stage. So if we took a sub-graph that only contained `radioactivity` and it's dependencies, then ran tsort on it, we might get the following ordering:
|
||||
|
||||
arithmetic
|
||||
algebra
|
||||
trigonometry
|
||||
calculus
|
||||
mechanics
|
||||
atomic_physics
|
||||
radioactivity
|
||||
|
||||
This meets the requirements set out by the use case we described above. A user just has to pick `radioactivity` and they'll get an ordered list of all the courses they have to work through before they're allowed to.
|
||||
|
||||
We don't even need to go into the details of how topological sort works before we put it to good use. In all likelihood, your programming language of choice probably has an implementation of it in the standard library. In the worst case scenario, your Unix probably has the `tsort` utility installed by default, run man `tsort` and have a play with it.
|
||||
|
||||
###Other places tsort get's used###
|
||||
|
||||
- **Tools like** `make` allow you to declare task dependencies. Topological sort is used under the hood to figure out what order the tasks should be executed in.
|
||||
- **Any programming language that has a `require` directive**, indicating that the current file requires the code in a different file to be run first. Here topological sort can be used to figure out what order the files should be loaded in so that each is only loaded once and all dependencies are met.
|
||||
- **Project management tools with Gantt charts**. A Gantt chart is a graph that outlines all the dependencies of a given task and gives you an estimate of when it will be complete based on those dependencies. I'm not a fan of Gantt charts, but it's highly likely that tsort will be used to draw them.
|
||||
|
||||
###Squeezing data with Huffman coding###
|
||||
[Huffman coding](http://en.wikipedia.org/wiki/Huffman_coding) is an algorithm used for lossless data compression. It works by analyzing the data you want to compress and creating a binary code for each character. More frequently occurring characters get smaller codes, so `e` might be encoded as `111` while `x` might be `10010`. The codes are created so that they can be concatenated without a delimeter and still be decoded accurately.
|
||||
|
||||
Huffman coding is used along with LZ77 in the DEFLATE algorithm which is used by gzip to compress things. gzip is used all over the place, in particular for compressing files (typically anything with a `.gz` extension) and for http requests/responses in transit.
|
||||
|
||||
Knowing how to implement and use Huffman coding has a number of benefits:
|
||||
|
||||
- You'll know why a larger compression context results in better compression overall (e.g. the more you compress, the better the compression ratio). This is one of the proposed benefits of SPDY: that you get better compression on multiple HTTP requests/responses.
|
||||
- You'll know that if you're compressing your javascript/css in transit anyway, it's completely pointless to run a minifier on them. Sames goes for PNG files, which use DEFLATE internally for compression already.
|
||||
- If you ever find yourself trying to forcibly decipher encrypted information , you may realize that since repeating data compresses better, the compression ratio of a given bit of ciphertext will help you determine it's [block cipher mode of operation](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
|
||||
###Picking what to learn next is hard###
|
||||
Being a programmer involves learning constantly. To operate as a web developer you need to know markup languages, high level languages like ruby/python, regular expressions, SQL and JavaScript. You need to know the fine details of HTTP, how to drive a unix terminal and the subtle art of object oriented programming. It's difficult to navigate that landscape effectively and choose what to learn next.
|
||||
|
||||
I'm not a fast learner so I have to choose what to spend time on very carefully. As much as possible, I want to learn skills and techniques that are evergreen, that is, won't be rendered obsolete in a few years time. That means I'm hesitant to learn the javascript framework of the week or untested programming languages and environments.
|
||||
|
||||
As long as our dominant model of computation stays the same, data structures and algorithms that we use today will be used in some form or another in the future. You can safely spend time on gaining a deep and thorough knowledge of them and know that they will pay dividends for your entire career as a programmer.
|
||||
|
||||
###Sign up to the Happy Bear Software List###
|
||||
Find this article useful? For a regular dose of freshly squeezed technical content delivered straight to your inbox, **click on the big green button below to sign up to the Happy Bear Software mailing list.**
|
||||
|
||||
We'll only be in touch a few times per month and you can unsubscribe at any time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithms-makes-you-a-better-developer
|
||||
|
||||
作者:[Happy Bear][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
@ -1,138 +0,0 @@
|
||||
(translating by runningwater)
|
||||
How to Install Logwatch on Ubuntu 15.04
|
||||
================================================================================
|
||||
Hi, Today we are going to illustrate the setup of Logwatch on Ubuntu 15.04 Operating system where as it can be used for any Linux and UNIX like operating systems. Logwatch is a customizable system log analyzer and reporting log-monitoring system that go through your logs for a given period of time and make a report in the areas that you wish with the details you want. Its an easy tool to install, configure, review and to take actions that will improve security from data it provides. Logwatch scans the log files of major operating system components, like SSH, Web Server and forwards a summary that contains the valuable items in it that needs to be looked at.
|
||||
|
||||
### Pre-installation Setup ###
|
||||
|
||||
We will be using Ubuntu 15.04 operating system to deploy Logwatch on it so as a perquisite for the installation of Logwatch, make sure that your emails setup is working as it will be used to send email to the administrators for daily reports on the gathered reports.Your system repositories should be enabled as we will be installing it from its available universal repositories.
|
||||
|
||||
Then open the terminal of your ubuntu operating system and login with root user to update your system packages before moving to Logwatch installation.
|
||||
|
||||
root@ubuntu-15:~# apt-get update
|
||||
|
||||
### Installing Logwatch ###
|
||||
|
||||
Once your system is updated and your have fulfilled all its prerequisites then run the following command to start the installation of Logwatch in your server.
|
||||
|
||||
root@ubuntu-15:~# apt-get install logwatch
|
||||
|
||||
The logwatch installation process will starts with addition of some extra required packages as shown once you press “Y” to accept the required changes to the system.
|
||||
|
||||
During the installation process you will be prompted to configure the Postfix Configurations according to your mail server’s setup. Here we used “Local only” in the tutorial for ease, we can choose from the other available options as per your infrastructure requirements and then press “OK” to proceed.
|
||||
|
||||

|
||||
|
||||
Then you have to choose your mail server’s name that will also be used by other programs, so it should be single fully qualified domain name (FQDN).
|
||||
|
||||

|
||||
|
||||
Once you press “OK” after postfix configurations, then it will completes the Logwatch installation process with default configurations of Postfix.
|
||||
|
||||

|
||||
|
||||
You can check the status of Logwatch by issuing the following command in the terminal that should be in active state.
|
||||
|
||||
root@ubuntu-15:~# service postfix status
|
||||
|
||||

|
||||
|
||||
To confirm the installation of Logwatch with its default configurations, issue the simple “logwatch” command as shown.
|
||||
|
||||
root@ubuntu-15:~# logwatch
|
||||
|
||||
The output from the above executed command will results in following compiled report form in the terminal.
|
||||
|
||||

|
||||
|
||||
### Logwatch Configurations ###
|
||||
|
||||
Now after successful installation of Logwatch, we need to make few configuration changes in its configuration file located under following shown path. So, let’s open it with the file editor to update its configurations as required.
|
||||
|
||||
root@ubuntu-15:~# vim /usr/share/logwatch/default.conf/logwatch.conf
|
||||
|
||||
**Output/Format Options**
|
||||
|
||||
By default Logwatch will print to stdout in text with no encoding.To make email Default set “Output = mail” and to save to file set “Output = file”. So you can comment out the its default configurations as per your required settings.
|
||||
|
||||
Output = stdout
|
||||
|
||||
To make Html the default formatting update the following line if you are using Internet email configurations.
|
||||
|
||||
Format = text
|
||||
|
||||
Now add the default person to mail reports should be sent to, it could be a local account or a complete email address that you are free to mention in this line
|
||||
|
||||
MailTo = root
|
||||
#MailTo = user@test.com
|
||||
|
||||
Default person to mail reports sent from can be a local account or any other you wish to use.
|
||||
|
||||
# complete email address.
|
||||
MailFrom = Logwatch
|
||||
|
||||
Save the changes made in the configuration file of Logwatch while leaving the other parameter as default.
|
||||
|
||||
**Cronjob Configuration**
|
||||
|
||||
Now edit the "00logwatch" file in daily crons directory to configure your desired email address to forward reports from logwatch.
|
||||
|
||||
root@ubuntu-15:~# vim /etc/cron.daily/00logwatch
|
||||
|
||||
Here you need to use "--mailto" user@test.com instead of --output mail and save the file.
|
||||
|
||||

|
||||
|
||||
### Using Logwatch Report ###
|
||||
|
||||
Now we generate the test report by executing the "logwatch" command in the terminal to get its result shown in the Text format within the terminal.
|
||||
|
||||
root@ubuntu-15:~#logwatch
|
||||
|
||||
The generated report starts with showing its execution time and date, it will be comprising of different sections that starts with its begin status and closed with end status after showing the complete information about its logs of the mentioned sections.
|
||||
|
||||
Here is its starting point looks like, where it starts by showing all the installed packages in the system as shown below.
|
||||
|
||||

|
||||
|
||||
The following sections shows the logs informmation about the login sessions, rsyslogs and SSH connections about the current and last sessions enabled on the system.
|
||||
|
||||

|
||||
|
||||
The logwatch report will ends up by showing the secure sudo logs and the disk space usage of the root diretory as shown below.
|
||||
|
||||

|
||||
|
||||
You can also check for the generated emails about the logwatch reports by opening the following file.
|
||||
|
||||
root@ubuntu-15:~# vim /var/mail/root
|
||||
|
||||
Here you will be able to see all the generated emails to your configured users with their message delivery status.
|
||||
|
||||
### More about Logwatch ###
|
||||
|
||||
Logwatch is a great tool to lern more about it, so if your more interested to learn more about its logwatch then you can also get much help from the below few commands.
|
||||
|
||||
root@ubuntu-15:~# man logwatch
|
||||
|
||||
The above command contains all the users manual about the logwatch, so read it carefully and to exit from the manuals section simply press "q".
|
||||
|
||||
To get help about the logwatch commands usage you can run the following help command for further information in details.
|
||||
|
||||
root@ubuntu-15:~# logwatch --help
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
At the end of this tutorial you learn about the complete setup of Logwatch on Ubuntu 15.04 that includes with its installation and configurations guide. Now you can start monitoring your logs in a customize able form, whether you monitor the logs of all the services rnning on your system or you customize it to send you the reports about the specific services on the scheduled days. So, let's use this tool and feel free to leave us a comment if you face any issue or need to know more about logwatch usage.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-use-logwatch-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,127 +0,0 @@
|
||||
How to Install Visual Studio Code in Linux
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to install Visual Studio Code in Linux Distributions. Visual Studio Code is a code-optimized editor based on Electron, a piece of software that is based on Chromium, which is used to deploy io.js applications for the desktop. It is a source code editor and text editor developed by Microsoft for all the operating system platforms including Linux. Visual Studio Code is free but not an open source software ie. its under proprietary software license terms. It is an awesome powerful and fast code editor for our day to day use. Some of the cool features of visual studio code are navigation, intellisense support, syntax highlighting, bracket matching, auto indentation, and snippets, keyboard support with customizable bindings and support for dozens of languages like Python, C++, jade, PHP, XML, Batch, F#, DockerFile, Coffee Script, Java, HandleBars, R, Objective-C, PowerShell, Luna, Visual Basic, .Net, Asp.Net, C#, JSON, Node.js, Javascript, HTML, CSS, Less, Sass and Markdown. Visual Studio Code integrates with package managers and repositories, and builds and other common tasks to make everyday workflows faster. The most popular feature in Visual Studio Code is its debugging feature which includes a streamlined support for Node.js debugging in the preview.
|
||||
|
||||
Note: Please note that, Visual Studio Code is only available for 64-bit versions of Linux Distributions.
|
||||
|
||||
Here, are some easy to follow steps on how to install Visual Sudio Code in all Linux Distribution.
|
||||
|
||||
### 1. Downloading Visual Studio Code Package ###
|
||||
|
||||
First of all, we'll gonna download the Visual Studio Code Package for 64-bit Linux Operating System from the Microsoft server using the given url [http://go.microsoft.com/fwlink/?LinkID=534108][1] . Here, we'll use wget to download it and keep it under /tmp/VSCODE directory as shown below.
|
||||
|
||||
# mkdir /tmp/vscode; cd /tmp/vscode/
|
||||
# wget https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
|
||||
--2015-06-24 06:02:54-- https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
Resolving az764295.vo.msecnd.net (az764295.vo.msecnd.net)... 93.184.215.200, 2606:2800:11f:179a:1972:2405:35b:459
|
||||
Connecting to az764295.vo.msecnd.net (az764295.vo.msecnd.net)|93.184.215.200|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 64992671 (62M) [application/octet-stream]
|
||||
Saving to: ‘VSCode-linux-x64.zip’
|
||||
100%[================================================>] 64,992,671 14.9MB/s in 4.1s
|
||||
2015-06-24 06:02:58 (15.0 MB/s) - ‘VSCode-linux-x64.zip’ saved [64992671/64992671]
|
||||
|
||||
### 2. Extracting the Package ###
|
||||
|
||||
Now, after we have successfully downloaded the zipped package of Visual Studio Code, we'll gonna extract it using the unzip command to /opt/directory. To do so, we'll need to run the following command in a terminal or a console.
|
||||
|
||||
# unzip /tmp/vscode/VSCode-linux-x64.zip -d /opt/
|
||||
|
||||
Note: If we don't have unzip already installed, we'll need to install it via our Package Manager. If you're running Ubuntu, apt-get whereas if you're running Fedora, CentOS, dnf or yum can be used to install it.
|
||||
|
||||
### 3. Running Visual Studio Code ###
|
||||
|
||||
After we have extracted the package, we can directly launch the Visual Studio Code by executing a file named Code.
|
||||
|
||||
# sudo chmod +x /opt/VSCode-linux-x64/Code
|
||||
# sudo /opt/VSCode-linux-x64/Code
|
||||
|
||||
If we want to launch Code and want to be available globally via terminal in any place, we'll need to create the link of /opt/vscode/Code as/usr/local/bin/code .
|
||||
|
||||
# ln -s /opt/VSCode-linux-x64/Code /usr/local/bin/code
|
||||
|
||||
Now, we can launch Visual Studio Code by running the following command in a terminal.
|
||||
|
||||
# code .
|
||||
|
||||
### 4. Creating a Desktop Launcher ###
|
||||
|
||||
Next, after we have successfully extracted the Visual Studio Code package, we'll gonna create a desktop launcher so that it will be easily available in the launchers, menus, desktop, according to the desktop environment so that anyone can launch it from them. So, first we'll gonna copy the icon file to /usr/share/icons/ directory.
|
||||
|
||||
# cp /opt/VSCode-linux-x64/resources/app/vso.png /usr/share/icons/
|
||||
|
||||
Then, we'll gonna create the desktop launcher having the extension as .desktop. Here, we'll create a file named visualstudiocode.desktop under /tmp/VSCODE/ folder using our favorite text editor.
|
||||
|
||||
# vi /tmp/vscode/visualstudiocode.desktop
|
||||
|
||||
Then, we'll gonna paste the following lines into that file.
|
||||
|
||||
[Desktop Entry]
|
||||
Name=Visual Studio Code
|
||||
Comment=Multi-platform code editor for Linux
|
||||
Exec=/opt/VSCode-linux-x64/Code
|
||||
Icon=/usr/share/icons/vso.png
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=TextEditor;Development;Utility;
|
||||
MimeType=text/plain;
|
||||
|
||||
After we're done creating the desktop file, we'll wanna copy that desktop file to /usr/share/applications/ directory so that it will be available in launchers and menus for use with single click.
|
||||
|
||||
# cp /tmp/vscode/visualstudiocode.desktop /usr/share/applications/
|
||||
|
||||
Once its done, we can launch it by opening it from the Launcher or Menu.
|
||||
|
||||

|
||||
|
||||
### Installing Visual Studio Code in Ubuntu ###
|
||||
|
||||
We can use Ubuntu Make 0.7 in order to install Visual Studio Code in Ubuntu 14.04/14.10/15.04 distribution of linux. This method is the most easiest way to setup Code in ubuntu as we just need to execute few commands for it. First of all, we'll need to install Ubuntu Make 0.7 in our ubuntu distribution of linux. To install it, we'll need to add PPA for it. This can be done by running the command below.
|
||||
|
||||
# add-apt-repository ppa:ubuntu-desktop/ubuntu-make
|
||||
|
||||
This ppa proposes package backport of Ubuntu make for supported releases.
|
||||
More info: https://launchpad.net/~ubuntu-desktop/+archive/ubuntu/ubuntu-make
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpv0vf24us/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpv0vf24us/pubring.gpg' created
|
||||
gpg: requesting key A1231595 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpv0vf24us/trustdb.gpg: trustdb created
|
||||
gpg: key A1231595: public key "Launchpad PPA for Ubuntu Desktop" imported
|
||||
gpg: no ultimately trusted keys found
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Then, we'll gonna update the local repository index and install ubuntu-make.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install ubuntu-make
|
||||
|
||||
After Ubuntu Make is installed in our ubuntu operating system, we'll gonna install Code by running the following command in a terminal.
|
||||
|
||||
# umake web visual-studio-code
|
||||
|
||||

|
||||
|
||||
After running the above command, we'll be asked to enter the path where we want to install it. Then, it will ask for permission to install Visual Studio Code in our ubuntu system. Then, we'll press "a". Once we do that, it will download and install it in our ubuntu machine. Finally, we can launch it by opening it from the Launcher or Menu.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We have successfully installed Visual Studio Code in Linux Distribution. Installing Visual Studio Code in every linux distribution is the same as shown in the above steps where we can also use umake to install it in ubuntu distributions. Umake is a popular tool for the development tools, IDEs, Languages. We can easily install Android Studios, Eclipse and many other popular IDEs with umake. Visual Studio Code is based on a project in Github called [Electron][2] which is a part of [Atom.io][3] Editor. It has a bunch of new cool and improved features that Atom.io Editor doesn't have. Visual Studio Code is currently only available in 64-bit platform of linux operating system. So, If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-visual-studio-code-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://go.microsoft.com/fwlink/?LinkID=534108
|
||||
[2]:https://github.com/atom/electron
|
||||
[3]:https://github.com/atom/atom
|
||||
@ -1,49 +0,0 @@
|
||||
Linux FAQs with Answers--How to check MariaDB server version
|
||||
================================================================================
|
||||
> **Question**: I am on a VPS server where MariaDB server is running. How can I find out which version of MariaDB server it is running?
|
||||
|
||||
There are circumstances where you need to know the version of your database server, e.g., when upgrading the database or patching any known server vulnerabilities. There are a few ways to find out what the version of your MariaDB server is.
|
||||
|
||||
### Method One ###
|
||||
|
||||
The first method to identify MariaDB server version is by logging in to the MariaDB server. Right after you log in, your will see a welcome message where MariaDB server version is indicated.
|
||||
|
||||

|
||||
|
||||
Alternatively, simply type 'status' command at the MariaDB prompt any time while you are logged in. The output will show server version as well as protocol version as follows.
|
||||
|
||||
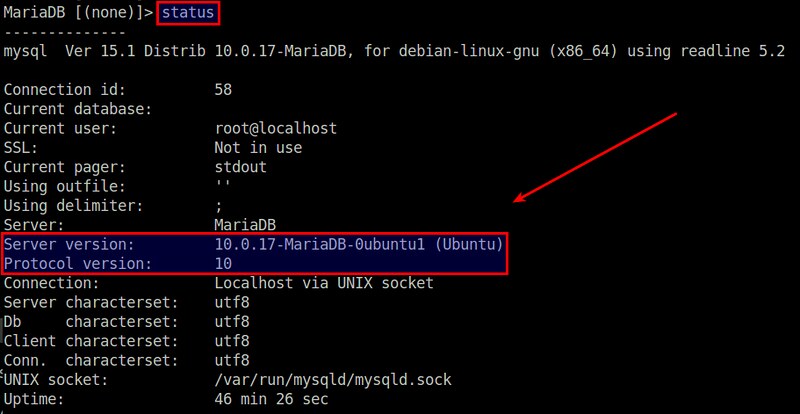
|
||||
|
||||
### Method Two ###
|
||||
|
||||
If you don't have access to the MariaDB server, you cannot use the first method. In this case, you can infer MariaDB server version by checking which MariaDB package was installed. This works only when the MariaDB server was installed using a distribution's package manager.
|
||||
|
||||
You can search for the installed MariaDB server package as follows.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint: ####
|
||||
|
||||
$ dpkg -l | grep mariadb
|
||||
|
||||
The output below indicates that installed MariaDB server is version 10.0.17.
|
||||
|
||||

|
||||
|
||||
#### Fedora, CentOS or RHEL: ####
|
||||
|
||||
$ rpm -qa | grep mariadb
|
||||
|
||||
The output below indicates that the installed version is 5.5.41.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-mariadb-server-version.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -1,208 +0,0 @@
|
||||
ictlyh Translating
|
||||
Part 4 - Using Shell Scripting to Automate Linux System Maintenance Tasks
|
||||
================================================================================
|
||||
Some time ago I read that one of the distinguishing characteristics of an effective system administrator / engineer is laziness. It seemed a little contradictory at first but the author then proceeded to explain why:
|
||||
|
||||

|
||||
|
||||
RHCE Series: Automate Linux System Maintenance Tasks – Part 4
|
||||
|
||||
if a sysadmin spends most of his time solving issues and doing repetitive tasks, you can suspect he or she is not doing things quite right. In other words, an effective system administrator / engineer should develop a plan to perform repetitive tasks with as less action on his / her part as possible, and should foresee problems by using,
|
||||
|
||||
for example, the tools reviewed in Part 3 – [Monitor System Activity Reports Using Linux Toolsets][1] of this series. Thus, although he or she may not seem to be doing much, it’s because most of his / her responsibilities have been taken care of with the help of shell scripting, which is what we’re going to talk about in this tutorial.
|
||||
|
||||
### What is a shell script? ###
|
||||
|
||||
In few words, a shell script is nothing more and nothing less than a program that is executed step by step by a shell, which is another program that provides an interface layer between the Linux kernel and the end user.
|
||||
|
||||
By default, the shell used for user accounts in RHEL 7 is bash (/bin/bash). If you want a detailed description and some historical background, you can refer to [this Wikipedia article][2].
|
||||
|
||||
To find out more about the enormous set of features provided by this shell, you may want to check out its **man page**, which is downloaded in in PDF format at ([Bash Commands][3]). Other than that, it is assumed that you are familiar with Linux commands (if not, I strongly advise you to go through [A Guide from Newbies to SysAdmin][4] article in **Tecmint.com** before proceeding). Now let’s get started.
|
||||
|
||||
### Writing a script to display system information ###
|
||||
|
||||
For our convenience, let’s create a directory to store our shell scripts:
|
||||
|
||||
# mkdir scripts
|
||||
# cd scripts
|
||||
|
||||
And open a new text file named `system_info.sh` with your preferred text editor. We will begin by inserting a few comments at the top and some commands afterwards:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# Sample script written for Part 4 of the RHCE series
|
||||
# This script will return the following set of system information:
|
||||
# -Hostname information:
|
||||
echo -e "\e[31;43m***** HOSTNAME INFORMATION *****\e[0m"
|
||||
hostnamectl
|
||||
echo ""
|
||||
# -File system disk space usage:
|
||||
echo -e "\e[31;43m***** FILE SYSTEM DISK SPACE USAGE *****\e[0m"
|
||||
df -h
|
||||
echo ""
|
||||
# -Free and used memory in the system:
|
||||
echo -e "\e[31;43m ***** FREE AND USED MEMORY *****\e[0m"
|
||||
free
|
||||
echo ""
|
||||
# -System uptime and load:
|
||||
echo -e "\e[31;43m***** SYSTEM UPTIME AND LOAD *****\e[0m"
|
||||
uptime
|
||||
echo ""
|
||||
# -Logged-in users:
|
||||
echo -e "\e[31;43m***** CURRENTLY LOGGED-IN USERS *****\e[0m"
|
||||
who
|
||||
echo ""
|
||||
# -Top 5 processes as far as memory usage is concerned
|
||||
echo -e "\e[31;43m***** TOP 5 MEMORY-CONSUMING PROCESSES *****\e[0m"
|
||||
ps -eo %mem,%cpu,comm --sort=-%mem | head -n 6
|
||||
echo ""
|
||||
echo -e "\e[1;32mDone.\e[0m"
|
||||
|
||||
Next, give the script execute permissions:
|
||||
|
||||
# chmod +x system_info.sh
|
||||
|
||||
and run it:
|
||||
|
||||
./system_info.sh
|
||||
|
||||
Note that the headers of each section are shown in color for better visualization:
|
||||
|
||||
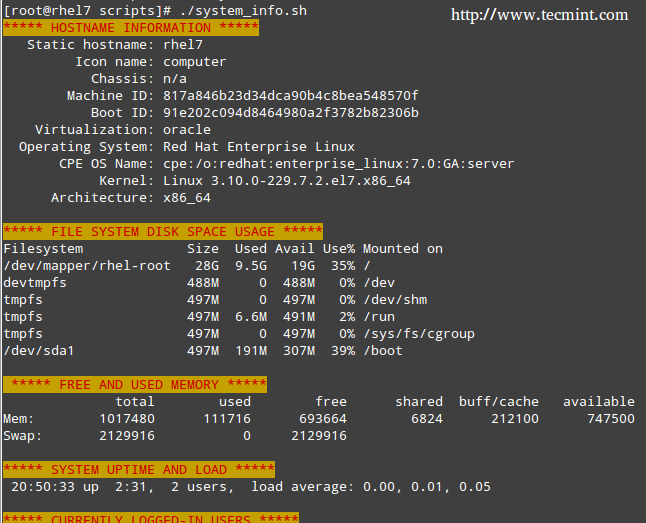
|
||||
|
||||
Server Monitoring Shell Script
|
||||
|
||||
That functionality is provided by this command:
|
||||
|
||||
echo -e "\e[COLOR1;COLOR2m<YOUR TEXT HERE>\e[0m"
|
||||
|
||||
Where COLOR1 and COLOR2 are the foreground and background colors, respectively (more info and options are explained in this entry from the [Arch Linux Wiki][5]) and <YOUR TEXT HERE> is the string that you want to show in color.
|
||||
|
||||
### Automating Tasks ###
|
||||
|
||||
The tasks that you may need to automate may vary from case to case. Thus, we cannot possibly cover all of the possible scenarios in a single article, but we will present three classic tasks that can be automated using shell scripting:
|
||||
|
||||
**1)** update the local file database, 2) find (and alternatively delete) files with 777 permissions, and 3) alert when filesystem usage surpasses a defined limit.
|
||||
|
||||
Let’s create a file named `auto_tasks.sh` in our scripts directory with the following content:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# Sample script to automate tasks:
|
||||
# -Update local file database:
|
||||
echo -e "\e[4;32mUPDATING LOCAL FILE DATABASE\e[0m"
|
||||
updatedb
|
||||
if [ $? == 0 ]; then
|
||||
echo "The local file database was updated correctly."
|
||||
else
|
||||
echo "The local file database was not updated correctly."
|
||||
fi
|
||||
echo ""
|
||||
|
||||
# -Find and / or delete files with 777 permissions.
|
||||
echo -e "\e[4;32mLOOKING FOR FILES WITH 777 PERMISSIONS\e[0m"
|
||||
# Enable either option (comment out the other line), but not both.
|
||||
# Option 1: Delete files without prompting for confirmation. Assumes GNU version of find.
|
||||
#find -type f -perm 0777 -delete
|
||||
# Option 2: Ask for confirmation before deleting files. More portable across systems.
|
||||
find -type f -perm 0777 -exec rm -i {} +;
|
||||
echo ""
|
||||
# -Alert when file system usage surpasses a defined limit
|
||||
echo -e "\e[4;32mCHECKING FILE SYSTEM USAGE\e[0m"
|
||||
THRESHOLD=30
|
||||
while read line; do
|
||||
# This variable stores the file system path as a string
|
||||
FILESYSTEM=$(echo $line | awk '{print $1}')
|
||||
# This variable stores the use percentage (XX%)
|
||||
PERCENTAGE=$(echo $line | awk '{print $5}')
|
||||
# Use percentage without the % sign.
|
||||
USAGE=${PERCENTAGE%?}
|
||||
if [ $USAGE -gt $THRESHOLD ]; then
|
||||
echo "The remaining available space in $FILESYSTEM is critically low. Used: $PERCENTAGE"
|
||||
fi
|
||||
done < <(df -h --total | grep -vi filesystem)
|
||||
|
||||
Please note that there is a space between the two `<` signs in the last line of the script.
|
||||
|
||||

|
||||
|
||||
Shell Script to Find 777 Permissions
|
||||
|
||||
### Using Cron ###
|
||||
|
||||
To take efficiency one step further, you will not want to sit in front of your computer and run those scripts manually. Rather, you will use cron to schedule those tasks to run on a periodic basis and sends the results to a predefined list of recipients via email or save them to a file that can be viewed using a web browser.
|
||||
|
||||
The following script (filesystem_usage.sh) will run the well-known **df -h** command, format the output into a HTML table and save it in the **report.html** file:
|
||||
|
||||
#!/bin/bash
|
||||
# Sample script to demonstrate the creation of an HTML report using shell scripting
|
||||
# Web directory
|
||||
WEB_DIR=/var/www/html
|
||||
# A little CSS and table layout to make the report look a little nicer
|
||||
echo "<HTML>
|
||||
<HEAD>
|
||||
<style>
|
||||
.titulo{font-size: 1em; color: white; background:#0863CE; padding: 0.1em 0.2em;}
|
||||
table
|
||||
{
|
||||
border-collapse:collapse;
|
||||
}
|
||||
table, td, th
|
||||
{
|
||||
border:1px solid black;
|
||||
}
|
||||
</style>
|
||||
<meta http-equiv='Content-Type' content='text/html; charset=UTF-8' />
|
||||
</HEAD>
|
||||
<BODY>" > $WEB_DIR/report.html
|
||||
# View hostname and insert it at the top of the html body
|
||||
HOST=$(hostname)
|
||||
echo "Filesystem usage for host <strong>$HOST</strong><br>
|
||||
Last updated: <strong>$(date)</strong><br><br>
|
||||
<table border='1'>
|
||||
<tr><th class='titulo'>Filesystem</td>
|
||||
<th class='titulo'>Size</td>
|
||||
<th class='titulo'>Use %</td>
|
||||
</tr>" >> $WEB_DIR/report.html
|
||||
# Read the output of df -h line by line
|
||||
while read line; do
|
||||
echo "<tr><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $1}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $2}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $5}' >> $WEB_DIR/report.html
|
||||
echo "</td></tr>" >> $WEB_DIR/report.html
|
||||
done < <(df -h | grep -vi filesystem)
|
||||
echo "</table></BODY></HTML>" >> $WEB_DIR/report.html
|
||||
|
||||
In our **RHEL 7** server (**192.168.0.18**), this looks as follows:
|
||||
|
||||
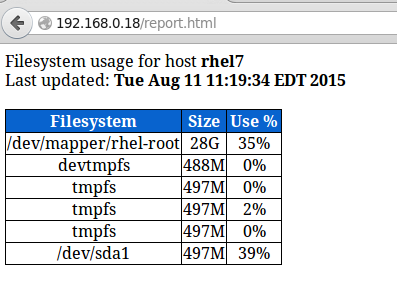
|
||||
|
||||
Server Monitoring Report
|
||||
|
||||
You can add to that report as much information as you want. To run the script every day at 1:30 pm, add the following crontab entry:
|
||||
|
||||
30 13 * * * /root/scripts/filesystem_usage.sh
|
||||
|
||||
### Summary ###
|
||||
|
||||
You will most likely think of several other tasks that you want or need to automate; as you can see, using shell scripting will greatly simplify this effort. Feel free to let us know if you find this article helpful and don't hesitate to add your own ideas or comments via the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
[2]:https://en.wikipedia.org/wiki/Bash_%28Unix_shell%29
|
||||
[3]:http://www.tecmint.com/wp-content/pdf/bash.pdf
|
||||
[4]:http://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
|
||||
[5]:https://wiki.archlinux.org/index.php/Color_Bash_Prompt
|
||||
@ -1,214 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares – Part 7
|
||||
================================================================================
|
||||
In the last article ([RHCSA series Part 6][1]) we started explaining how to set up and configure local system storage using parted and ssm.
|
||||
|
||||

|
||||
|
||||
RHCSA Series:: Configure ACL’s and Mounting NFS / Samba Shares – Part 7
|
||||
|
||||
We also discussed how to create and mount encrypted volumes with a password during system boot. In addition, we warned you to avoid performing critical storage management operations on mounted filesystems. With that in mind we will now review the most used file system formats in Red Hat Enterprise Linux 7 and then proceed to cover the topics of mounting, using, and unmounting both manually and automatically network filesystems (CIFS and NFS), along with the implementation of access control lists for your system.
|
||||
|
||||
#### Prerequisites ####
|
||||
|
||||
Before proceeding further, please make sure you have a Samba server and a NFS server available (note that NFSv2 is no longer supported in RHEL 7).
|
||||
|
||||
During this guide we will use a machine with IP 192.168.0.10 with both services running in it as server, and a RHEL 7 box as client with IP address 192.168.0.18. Later in the article we will tell you which packages you need to install on the client.
|
||||
|
||||
### File System Formats in RHEL 7 ###
|
||||
|
||||
Beginning with RHEL 7, XFS has been introduced as the default file system for all architectures due to its high performance and scalability. It currently supports a maximum filesystem size of 500 TB as per the latest tests performed by Red Hat and its partners for mainstream hardware.
|
||||
|
||||
Also, XFS enables user_xattr (extended user attributes) and acl (POSIX access control lists) as default mount options, unlike ext3 or ext4 (ext2 is considered deprecated as of RHEL 7), which means that you don’t need to specify those options explicitly either on the command line or in /etc/fstab when mounting a XFS filesystem (if you want to disable such options in this last case, you have to explicitly use no_acl and no_user_xattr).
|
||||
|
||||
Keep in mind that the extended user attributes can be assigned to files and directories for storing arbitrary additional information such as the mime type, character set or encoding of a file, whereas the access permissions for user attributes are defined by the regular file permission bits.
|
||||
|
||||
#### Access Control Lists ####
|
||||
|
||||
As every system administrator, either beginner or expert, is well acquainted with regular access permissions on files and directories, which specify certain privileges (read, write, and execute) for the owner, the group, and “the world” (all others). However, feel free to refer to [Part 3 of the RHCSA series][2] if you need to refresh your memory a little bit.
|
||||
|
||||
However, since the standard ugo/rwx set does not allow to configure different permissions for different users, ACLs were introduced in order to define more detailed access rights for files and directories than those specified by regular permissions.
|
||||
|
||||
In fact, ACL-defined permissions are a superset of the permissions specified by the file permission bits. Let’s see how all of this translates is applied in the real world.
|
||||
|
||||
1. There are two types of ACLs: access ACLs, which can be applied to either a specific file or a directory), and default ACLs, which can only be applied to a directory. If files contained therein do not have a ACL set, they inherit the default ACL of their parent directory.
|
||||
|
||||
2. To begin, ACLs can be configured per user, per group, or per an user not in the owning group of a file.
|
||||
|
||||
3. ACLs are set (and removed) using setfacl, with either the -m or -x options, respectively.
|
||||
|
||||
For example, let us create a group named tecmint and add users johndoe and davenull to it:
|
||||
|
||||
# groupadd tecmint
|
||||
# useradd johndoe
|
||||
# useradd davenull
|
||||
# usermod -a -G tecmint johndoe
|
||||
# usermod -a -G tecmint davenull
|
||||
|
||||
And let’s verify that both users belong to supplementary group tecmint:
|
||||
|
||||
# id johndoe
|
||||
# id davenull
|
||||
|
||||

|
||||
|
||||
Verify Users
|
||||
|
||||
Let’s now create a directory called playground within /mnt, and a file named testfile.txt inside. We will set the group owner to tecmint and change its default ugo/rwx permissions to 770 (read, write, and execute permissions granted to both the owner and the group owner of the file):
|
||||
|
||||
# mkdir /mnt/playground
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chmod 770 /mnt/playground/testfile.txt
|
||||
|
||||
Then switch user to johndoe and davenull, in that order, and write to the file:
|
||||
|
||||
echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
|
||||
So far so good. Now let’s have user gacanepa write to the file – and the write operation will, which was to be expected.
|
||||
|
||||
But what if we actually need user gacanepa (who is not a member of group tecmint) to have write permissions on /mnt/playground/testfile.txt? The first thing that may come to your mind is adding that user account to group tecmint. But that will give him write permissions on ALL files were the write bit is set for the group, and we don’t want that. We only want him to be able to write to /mnt/playground/testfile.txt.
|
||||
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chown :tecmint /mnt/playground/testfile.txt
|
||||
# chmod 777 /mnt/playground/testfile.txt
|
||||
# su johndoe
|
||||
$ echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
$ su davenull
|
||||
$ echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
$ su gacanepa
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
Manage User Permissions
|
||||
|
||||
Let’s give user gacanepa read and write access to /mnt/playground/testfile.txt.
|
||||
|
||||
Run as root,
|
||||
|
||||
# setfacl -R -m u:gacanepa:rwx /mnt/playground
|
||||
|
||||
and you’ll have successfully added an ACL that allows gacanepa to write to the test file. Then switch to user gacanepa and try to write to the file again:
|
||||
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||
To view the ACLs for a specific file or directory, use getfacl:
|
||||
|
||||
# getfacl /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
Check ACLs of Files
|
||||
|
||||
To set a default ACL to a directory (which its contents will inherit unless overwritten otherwise), add d: before the rule and specify a directory instead of a file name:
|
||||
|
||||
# setfacl -m d:o:r /mnt/playground
|
||||
|
||||
The ACL above will allow users not in the owner group to have read access to the future contents of the /mnt/playground directory. Note the difference in the output of getfacl /mnt/playground before and after the change:
|
||||
|
||||

|
||||
|
||||
Set Default ACL in Linux
|
||||
|
||||
[Chapter 20 in the official RHEL 7 Storage Administration Guide][3] provides more ACL examples, and I highly recommend you take a look at it and have it handy as reference.
|
||||
|
||||
#### Mounting NFS Network Shares ####
|
||||
|
||||
To show the list of NFS shares available in your server, you can use the showmount command with the -e option, followed by the machine name or its IP address. This tool is included in the nfs-utils package:
|
||||
|
||||
# yum update && yum install nfs-utils
|
||||
|
||||
Then do:
|
||||
|
||||
# showmount -e 192.168.0.10
|
||||
|
||||
and you will get a list of the available NFS shares on 192.168.0.10:
|
||||
|
||||
|
||||
|
||||
Check Available NFS Shares
|
||||
|
||||
To mount NFS network shares on the local client using the command line on demand, use the following syntax:
|
||||
|
||||
# mount -t nfs -o [options] remote_host:/remote/directory /local/directory
|
||||
|
||||
which, in our case, translates to:
|
||||
|
||||
# mount -t nfs 192.168.0.10:/NFS-SHARE /mnt/nfs
|
||||
|
||||
If you get the following error message: “Job for rpc-statd.service failed. See “systemctl status rpc-statd.service” and “journalctl -xn” for details.”, make sure the rpcbind service is enabled and started in your system first:
|
||||
|
||||
# systemctl enable rpcbind.socket
|
||||
# systemctl restart rpcbind.service
|
||||
|
||||
and then reboot. That should do the trick and you will be able to mount your NFS share as explained earlier. If you need to mount the NFS share automatically on system boot, add a valid entry to the /etc/fstab file:
|
||||
|
||||
remote_host:/remote/directory /local/directory nfs options 0 0
|
||||
|
||||
The variables remote_host, /remote/directory, /local/directory, and options (which is optional) are the same ones used when manually mounting an NFS share from the command line. As per our previous example:
|
||||
|
||||
192.168.0.10:/NFS-SHARE /mnt/nfs nfs defaults 0 0
|
||||
|
||||
#### Mounting CIFS (Samba) Network Shares ####
|
||||
|
||||
Samba represents the tool of choice to make a network share available in a network with *nix and Windows machines. To show the Samba shares that are available, use the smbclient command with the -L flag, followed by the machine name or its IP address. This tool is included in the samba-client package:
|
||||
|
||||
You will be prompted for root’s password in the remote host:
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
|
||||

|
||||
|
||||
Check Samba Shares
|
||||
|
||||
To mount Samba network shares on the local client you will need to install first the cifs-utils package:
|
||||
|
||||
# yum update && yum install cifs-utils
|
||||
|
||||
Then use the following syntax on the command line:
|
||||
|
||||
# mount -t cifs -o credentials=/path/to/credentials/file //remote_host/samba_share /local/directory
|
||||
|
||||
which, in our case, translates to:
|
||||
|
||||
# mount -t cifs -o credentials=~/.smbcredentials //192.168.0.10/gacanepa /mnt/samba
|
||||
|
||||
where smbcredentials:
|
||||
|
||||
username=gacanepa
|
||||
password=XXXXXX
|
||||
|
||||
is a hidden file inside root’s home (/root/) with permissions set to 600, so that no one else but the owner of the file can read or write to it.
|
||||
|
||||
Please note that the samba_share is the name of the Samba share as returned by smbclient -L remote_host as shown above.
|
||||
|
||||
Now, if you need the Samba share to be available automatically on system boot, add a valid entry to the /etc/fstab file as follows:
|
||||
|
||||
//remote_host:/samba_share /local/directory cifs options 0 0
|
||||
|
||||
The variables remote_host, /samba_share, /local/directory, and options (which is optional) are the same ones used when manually mounting a Samba share from the command line. Following the definitions given in our previous example:
|
||||
|
||||
//192.168.0.10/gacanepa /mnt/samba cifs credentials=/root/smbcredentials,defaults 0 0
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explained how to set up ACLs in Linux, and discussed how to mount CIFS and NFS network shares in a RHEL 7 client.
|
||||
|
||||
I recommend you to practice these concepts and even mix them (go ahead and try to set ACLs in mounted network shares) until you feel comfortable. If you have questions or comments feel free to use the form below to contact us anytime. Also, feel free to share this article through your social networks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Storage_Administration_Guide/ch-acls.html
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Securing SSH, Setting Hostname and Enabling Network Services – Part 8
|
||||
================================================================================
|
||||
As a system administrator you will often have to log on to remote systems to perform a variety of administration tasks using a terminal emulator. You will rarely sit in front of a real (physical) terminal, so you need to set up a way to log on remotely to the machines that you will be asked to manage.
|
||||
@ -212,4 +214,4 @@ via: http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[2]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[2]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
|
||||
@ -0,0 +1,137 @@
|
||||
Ubuntu 15.04 and系统中安装 Logwatch
|
||||
================================================================================
|
||||
大家好,今天我们会讲述在 Ubuntu 15.04 操作系统上如何安装 Logwatch 软件,它也可以在任意的 Linux 系统和类 Unix 系统上安装。Logwatch 是一款可定制的日志分析和日志监控报告生成系统,它可以根据一段时间的日志文件生成您所希望关注的详细报告。它具有易安装、易配置、可审查等特性,同时对其提供的数据的安全性上也有一些保障措施。Logwatch 会扫描重要的操作系统组件像 SSH、网站服务等的日志文件,然后生成用户所关心的有价值的条目汇总报告。
|
||||
|
||||
### 预安装设置 ###
|
||||
|
||||
我们会使用 Ubuntu 15.04 版本的操作系统来部署 Logwatch,所以安装 Logwatch 之前,要确保系统上邮件服务设置是正常可用的。因为它会每天把生成的报告通过日报的形式发送邮件给管理员。您的系统的源库也应该设置可用,以便可以从通用源库来安装 Logwatch。
|
||||
|
||||
然后打开您 ubuntu 系统的终端,用 root 账号登陆,在进入 Logwatch 的安装操作前,先更新您的系统软件包。
|
||||
|
||||
root@ubuntu-15:~# apt-get update
|
||||
|
||||
### 安装 Logwatch ###
|
||||
|
||||
只要你的系统已经更新和已经满足前面说的先决条件,那么就可以在您的机器上输入如下命令来安装 Logwatch。
|
||||
|
||||
root@ubuntu-15:~# apt-get install logwatch
|
||||
|
||||
在安装过程中,一旦您按提示按下“Y”健同意对系统修改的话,Logwatch 将会开始安装一些额外的必须软件包。
|
||||
|
||||
在安装过程中会根据您机器上的邮件服务器设置情况弹出提示对 Postfix 设置的配置界面。在这篇教程中我们使用最容易的 “仅本地” 选项。根据您的基础设施情况也可以选择其它的可选项,然后点击“确定”继续。
|
||||
|
||||

|
||||
|
||||
随后您得选择邮件服务器名,这邮件服务器名也会被其它程序使用,所以它应该是一个完全合格域名/全称域名(FQDN),且只一个。
|
||||
|
||||

|
||||
|
||||
一旦按下在 postfix 配置提示底端的 “OK”,安装进程就会用 Postfix 的默认配置来安装,并且完成 Logwatch 的整个安装。
|
||||
|
||||

|
||||
|
||||
您可以在终端下发出如下命令来检查 Logwatch 状态,正常情况下它应该是激活状态。
|
||||
|
||||
root@ubuntu-15:~# service postfix status
|
||||
|
||||

|
||||
|
||||
要确认 Logwatch 在默认配置下的安装信息,可以如下示简单的发出“logwatch” 命令。
|
||||
|
||||
root@ubuntu-15:~# logwatch
|
||||
|
||||
上面执行命令的输出就是终端下编制出的报表展现格式。
|
||||
|
||||

|
||||
|
||||
### 配置 Logwatch ###
|
||||
|
||||
在成功安装好 Logwatch 后,我们需要在它的配置文件中做一些修改,配置文件位于如下所示的路径。那么,就让我们用文本编辑器打开它,然后按需要做些变动。
|
||||
|
||||
root@ubuntu-15:~# vim /usr/share/logwatch/default.conf/logwatch.conf
|
||||
|
||||
**输出/格式化选项**
|
||||
|
||||
默认情况下 Logwatch 会以无编码的文本打印到标准输出方式。要改为以邮件为默认方式,需设置“Output = mail”,要改为保存成文件方式,需设置“Output = file”。所以您可以根据您的要求设置其默认配置。
|
||||
|
||||
Output = stdout
|
||||
|
||||
如果使用的是因特网电子邮件配置,要用 Html 格式为默认出格式,需要修改成如下行所示的样子。
|
||||
|
||||
Format = text
|
||||
|
||||
现在增加默认的邮件报告接收人地址,可以是本地账号也可以是完整的邮件地址,需要的都可以在这行上写上
|
||||
|
||||
MailTo = root
|
||||
#MailTo = user@test.com
|
||||
|
||||
默认的邮件发送人可以是本地账号,也可以是您需要使用的其它名字。
|
||||
|
||||
# complete email address.
|
||||
MailFrom = Logwatch
|
||||
|
||||
对这个配置文件保存修改,至于其它的参数就让它是默认的,无需改动。
|
||||
|
||||
**调度任务配置**
|
||||
|
||||
现在编辑在日常 crons 目录下的 “00logwatch” 文件来配置从 logwatch 生成的报告需要发送的邮件地址。
|
||||
|
||||
root@ubuntu-15:~# vim /etc/cron.daily/00logwatch
|
||||
|
||||
在这儿您需要作用“--mailto user@test.com”来替换掉“--output mail”,然后保存文件。
|
||||
|
||||

|
||||
|
||||
### 生成报告 ###
|
||||
|
||||
现在我们在终端中执行“logwatch”命令来生成测试报告,生成的结果在终端中会以文本格式显示出来。
|
||||
|
||||
root@ubuntu-15:~#logwatch
|
||||
|
||||
生成的报告开始部分显示的是执行的时间和日期。它包含不同的部分,每个部分以开始标识开始而以结束标识结束,中间显示的标识部分提到的完整日志信息。
|
||||
|
||||
这儿演示的是开始标识头的样子,要显示系统上所有安装包的信息,如下所示:
|
||||
|
||||

|
||||
|
||||
接下来的部分显示的日志信息是关于当前系统登陆会话、rsyslogs 和当前及最后可用的会话 SSH 连接信息。
|
||||
|
||||

|
||||
|
||||
Logwatch 报告最后显示的是安全 sudo 日志及root目录磁盘使用情况,如下示:
|
||||
|
||||

|
||||
|
||||
您也可以打开如下的文件来检查生成的 logwatch 报告电子邮件。
|
||||
|
||||
root@ubuntu-15:~# vim /var/mail/root
|
||||
|
||||
您会看到所有已生成的邮件到其配置用户的信息传送状态。
|
||||
|
||||
### 更多详情 ###
|
||||
|
||||
Logwatch 是一款很不错的工具,可以学习的很多很多,所以如果您对它的日志监控功能很感兴趣的话,也以通过如下所示的简短命令来获得更多帮助。
|
||||
|
||||
root@ubuntu-15:~# man logwatch
|
||||
|
||||
上面的命令包含所有关于 logwatch 的用户手册,所以仔细阅读,要退出手册的话可以简单的输入“q”。
|
||||
|
||||
关于 logwatch 命令的使用,您可以使用如下所示的帮助命令来获得更多的详细信息。
|
||||
|
||||
root@ubuntu-15:~# logwatch --help
|
||||
|
||||
### 结论 ###
|
||||
|
||||
教程结束,您也学会了如何在 Ubuntu 15.04 上对 Logwatch 的安装、配置等全部设置指导。现在您就可以自定义监控您的系统日志,不管是监控所有服务的运行情况还是对特定的服务在指定的时间发送报告都可以。所以,开始使用这工具吧,无论何时有问题或想知道更多关于 logwatch 的使用的都可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-use-logwatch-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,127 @@
|
||||
如何在 Linux 中安装 Visual Studio Code
|
||||
================================================================================
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器和库,并构建通用任务使得加速每日的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
|
||||
注意:请注意 Visual Studio Code 只支持 64 位 Linux 发行版。
|
||||
|
||||
下面是在所有 Linux 发行版中安装 Visual Studio Code 的几个简单步骤。
|
||||
|
||||
### 1. 下载 Visual Studio Code 软件包 ###
|
||||
|
||||
首先,我们要从微软服务器中下载 64 位 Linux 操作系统的 Visual Studio Code 安装包,链接是 [http://go.microsoft.com/fwlink/?LinkID=534108][1]。这里我们使用 wget 下载并保存到 tmp/VSCODE 目录。
|
||||
|
||||
# mkdir /tmp/vscode; cd /tmp/vscode/
|
||||
# wget https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
|
||||
--2015-06-24 06:02:54-- https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
Resolving az764295.vo.msecnd.net (az764295.vo.msecnd.net)... 93.184.215.200, 2606:2800:11f:179a:1972:2405:35b:459
|
||||
Connecting to az764295.vo.msecnd.net (az764295.vo.msecnd.net)|93.184.215.200|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 64992671 (62M) [application/octet-stream]
|
||||
Saving to: ‘VSCode-linux-x64.zip’
|
||||
100%[================================================>] 64,992,671 14.9MB/s in 4.1s
|
||||
2015-06-24 06:02:58 (15.0 MB/s) - ‘VSCode-linux-x64.zip’ saved [64992671/64992671]
|
||||
|
||||
### 2. 提取软件包 ###
|
||||
|
||||
现在,下载好 Visual Studio Code 的 zip 压缩包之后,我们打算使用 unzip 命令解压它。我们要在终端或者控制台中运行以下命令。
|
||||
|
||||
# unzip /tmp/vscode/VSCode-linux-x64.zip -d /opt/
|
||||
|
||||
注意:如果我们还没有安装 unzip,我们首先需要通过软件包管理器安装它。如果你运行的是 Ubuntu,使用 apt-get,如果运行的是 Fedora、CentOS、可以用 dnf 或 yum 安装它。
|
||||
|
||||
### 3. 运行 Visual Studio Code ###
|
||||
|
||||
提取软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
|
||||
# sudo chmod +x /opt/VSCode-linux-x64/Code
|
||||
# sudo /opt/VSCode-linux-x64/Code
|
||||
|
||||
如果我们想启动 Code 并通过终端能在任何地方打开,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
|
||||
# ln -s /opt/VSCode-linux-x64/Code /usr/local/bin/code
|
||||
|
||||
现在,我们就可以在终端中运行以下命令启动 Visual Studio Code 了。
|
||||
|
||||
# code .
|
||||
|
||||
### 4. 创建桌面启动 ###
|
||||
|
||||
下一步,成功抽取 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
|
||||
# cp /opt/VSCode-linux-x64/resources/app/vso.png /usr/share/icons/
|
||||
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们在 /tmp/VSCODE/ 目录中使用喜欢的文本编辑器创建名为 visualstudiocode.desktop 的文件。
|
||||
|
||||
# vi /tmp/vscode/visualstudiocode.desktop
|
||||
|
||||
然后,粘贴下面的行到那个文件中。
|
||||
|
||||
[Desktop Entry]
|
||||
Name=Visual Studio Code
|
||||
Comment=Multi-platform code editor for Linux
|
||||
Exec=/opt/VSCode-linux-x64/Code
|
||||
Icon=/usr/share/icons/vso.png
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=TextEditor;Development;Utility;
|
||||
MimeType=text/plain;
|
||||
|
||||
创建完桌面文件之后,我们会复制这个桌面文件到 /usr/share/applications/ 目录,这样启动器和菜单中就可以单击启动 Visual Studio Code 了。
|
||||
|
||||
# cp /tmp/vscode/visualstudiocode.desktop /usr/share/applications/
|
||||
|
||||
完成之后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 中 Visual Studio Code ###
|
||||
|
||||
要在 Ubuntu 14.04/14.10/15.04 Linux 发行版中安装 Visual Studio Code,我们可以使用 Ubuntu Make 0.7。这是在 ubuntu 中安装 code 最简单的方法,因为我们只需要执行几个命令。首先,我们要在我们的 ubuntu linux 发行版中安装 Ubuntu Make 0.7。要安装它,首先要为它添加 PPA。可以通过运行下面命令完成。
|
||||
|
||||
# add-apt-repository ppa:ubuntu-desktop/ubuntu-make
|
||||
|
||||
This ppa proposes package backport of Ubuntu make for supported releases.
|
||||
More info: https://launchpad.net/~ubuntu-desktop/+archive/ubuntu/ubuntu-make
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpv0vf24us/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpv0vf24us/pubring.gpg' created
|
||||
gpg: requesting key A1231595 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpv0vf24us/trustdb.gpg: trustdb created
|
||||
gpg: key A1231595: public key "Launchpad PPA for Ubuntu Desktop" imported
|
||||
gpg: no ultimately trusted keys found
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
然后,更新本地库索引并安装 ubuntu-make。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install ubuntu-make
|
||||
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们打算在一个终端中运行以下命令安装 Code。
|
||||
|
||||
# umake web visual-studio-code
|
||||
|
||||

|
||||
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们敲击 “a”。点击完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们同样可以使用 umake 在 linux 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言流行的工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-visual-studio-code-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://go.microsoft.com/fwlink/?LinkID=534108
|
||||
[2]:https://github.com/atom/electron
|
||||
[3]:https://github.com/atom/atom
|
||||
@ -0,0 +1,49 @@
|
||||
Linux有问必答--如何检查MatiaDB服务端版本
|
||||
================================================================================
|
||||
> **提问**: 我使用的是一台运行MariaDB的VPS。我该如何检查MariaDB服务端的版本?
|
||||
|
||||
你需要知道数据库版本的情况有:当你生你数据库或者为服务器打补丁。这里有几种方法找出MariaDB版本的方法。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
第一种找出版本的方法是登录MariaDB服务器,登录之后,你会看到一些MariaDB的版本信息。
|
||||
|
||||

|
||||
|
||||
另一种方法是在登录MariaDB后出现的命令行中输入‘status’命令。输出会显示服务器的版本还有协议版本。
|
||||
|
||||

|
||||
|
||||
### 方法二 ###
|
||||
|
||||
如果你不能访问MariaDB,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
|
||||
你可以用下面的方法检查MariaDB的安装包。
|
||||
|
||||
#### Debian、Ubuntu或者Linux Mint: ####
|
||||
|
||||
$ dpkg -l | grep mariadb
|
||||
|
||||
下面的输出说明MariaDB的版本是10.0.17。
|
||||
|
||||

|
||||
|
||||
#### Fedora、CentOS或者 RHEL: ####
|
||||
|
||||
$ rpm -qa | grep mariadb
|
||||
|
||||
下面的输出说明安装的版本是5.5.41。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-mariadb-server-version.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,205 @@
|
||||
第四部分 - 使用 Shell 脚本自动化 Linux 系统维护任务
|
||||
================================================================================
|
||||
之前我听说高效系统管理员/工程师的其中一个特点是懒惰。一开始看起来很矛盾,但作者接下来解释了其中的原因:
|
||||
|
||||

|
||||
|
||||
RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
|
||||
如果一个系统管理员花费大量的时间解决问题以及做重复的工作,你就应该怀疑他这么做是否正确。换句话说,一个高效的系统管理员/工程师应该制定一个计划使得尽量花费少的时间去做重复的工作,以及通过使用该系列中第三部分 [使用 Linux 工具集监视系统活动报告][1] 介绍的工具预见问题。因此,尽管看起来他/她没有做很多的工作,但那是因为 shell 脚本帮助完成了他的/她的大部分任务,这也就是本章我们将要探讨的东西。
|
||||
|
||||
### 什么是 shell 脚本? ###
|
||||
|
||||
简单的说,shell 脚本就是一个由 shell 一步一步执行的程序,而 shell 是在 Linux 内核和端用户之间提供接口的另一个程序。
|
||||
|
||||
默认情况下,RHEL 7 中用户使用的 shell 是 bash(/bin/bash)。如果你想知道详细的信息和历史背景,你可以查看 [维基页面][2]。
|
||||
|
||||
关于这个 shell 提供的众多功能的介绍,可以查看 **man 手册**,也可以从 ([Bash 命令][3])下载 PDF 格式。除此之外,假设你已经熟悉 Linux 命令(否则我强烈建议你首先看一下 **Tecmint.com** 中的文章 [从新手到系统管理员指南][4] )。现在让我们开始吧。
|
||||
|
||||
### 写一个脚本显示系统信息 ###
|
||||
|
||||
为了方便,首先让我们新建一个目录用于保存我们的 shell 脚本:
|
||||
|
||||
# mkdir scripts
|
||||
# cd scripts
|
||||
|
||||
然后用喜欢的文本编辑器打开新的文本文件 `system_info.sh`。我们首先在头部插入一些注释以及一些命令:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# RHCE 系列第四部分事例脚本
|
||||
# 该脚本会返回以下这些系统信息:
|
||||
# -主机名称:
|
||||
echo -e "\e[31;43m***** HOSTNAME INFORMATION *****\e[0m"
|
||||
hostnamectl
|
||||
echo ""
|
||||
# -文件系统磁盘空间使用:
|
||||
echo -e "\e[31;43m***** FILE SYSTEM DISK SPACE USAGE *****\e[0m"
|
||||
df -h
|
||||
echo ""
|
||||
# -系统空闲和使用中的内存:
|
||||
echo -e "\e[31;43m ***** FREE AND USED MEMORY *****\e[0m"
|
||||
free
|
||||
echo ""
|
||||
# -系统启动时间:
|
||||
echo -e "\e[31;43m***** SYSTEM UPTIME AND LOAD *****\e[0m"
|
||||
uptime
|
||||
echo ""
|
||||
# -登录的用户:
|
||||
echo -e "\e[31;43m***** CURRENTLY LOGGED-IN USERS *****\e[0m"
|
||||
who
|
||||
echo ""
|
||||
# -使用内存最多的 5 个进程
|
||||
echo -e "\e[31;43m***** TOP 5 MEMORY-CONSUMING PROCESSES *****\e[0m"
|
||||
ps -eo %mem,%cpu,comm --sort=-%mem | head -n 6
|
||||
echo ""
|
||||
echo -e "\e[1;32mDone.\e[0m"
|
||||
|
||||
然后,给脚本可执行权限:
|
||||
|
||||
# chmod +x system_info.sh
|
||||
|
||||
运行脚本:
|
||||
|
||||
./system_info.sh
|
||||
|
||||
注意为了更好的可视化效果各部分标题都用颜色显示:
|
||||
|
||||

|
||||
|
||||
服务器监视 Shell 脚本
|
||||
|
||||
该功能用以下命令提供:
|
||||
|
||||
echo -e "\e[COLOR1;COLOR2m<YOUR TEXT HERE>\e[0m"
|
||||
|
||||
其中 COLOR1 和 COLOR2 是前景色和背景色([Arch Linux Wiki][5] 有更多的信息和选项解释),<YOUR TEXT HERE> 是你想用颜色显示的字符串。
|
||||
|
||||
### 使任务自动化 ###
|
||||
|
||||
你想使其自动化的任务可能因情况而不同。因此,我们不可能在一篇文章中覆盖所有可能的场景,但是我们会介绍使用 shell 脚本可以使其自动化的三种典型任务:
|
||||
|
||||
**1)** 更新本地文件数据库, 2) 查找(或者删除)有 777 权限的文件, 以及 3) 文件系统使用超过定义的阀值时发出警告。
|
||||
|
||||
让我们在脚本目录中新建一个名为 `auto_tasks.sh` 的文件并添加以下内容:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# 自动化任务事例脚本:
|
||||
# -更新本地文件数据库:
|
||||
echo -e "\e[4;32mUPDATING LOCAL FILE DATABASE\e[0m"
|
||||
updatedb
|
||||
if [ $? == 0 ]; then
|
||||
echo "The local file database was updated correctly."
|
||||
else
|
||||
echo "The local file database was not updated correctly."
|
||||
fi
|
||||
echo ""
|
||||
|
||||
# -查找 和/或 删除有 777 权限的文件。
|
||||
echo -e "\e[4;32mLOOKING FOR FILES WITH 777 PERMISSIONS\e[0m"
|
||||
# Enable either option (comment out the other line), but not both.
|
||||
# Option 1: Delete files without prompting for confirmation. Assumes GNU version of find.
|
||||
#find -type f -perm 0777 -delete
|
||||
# Option 2: Ask for confirmation before deleting files. More portable across systems.
|
||||
find -type f -perm 0777 -exec rm -i {} +;
|
||||
echo ""
|
||||
# -文件系统使用率超过定义的阀值时发出警告
|
||||
echo -e "\e[4;32mCHECKING FILE SYSTEM USAGE\e[0m"
|
||||
THRESHOLD=30
|
||||
while read line; do
|
||||
# This variable stores the file system path as a string
|
||||
FILESYSTEM=$(echo $line | awk '{print $1}')
|
||||
# This variable stores the use percentage (XX%)
|
||||
PERCENTAGE=$(echo $line | awk '{print $5}')
|
||||
# Use percentage without the % sign.
|
||||
USAGE=${PERCENTAGE%?}
|
||||
if [ $USAGE -gt $THRESHOLD ]; then
|
||||
echo "The remaining available space in $FILESYSTEM is critically low. Used: $PERCENTAGE"
|
||||
fi
|
||||
done < <(df -h --total | grep -vi filesystem)
|
||||
|
||||
请注意该脚本最后一行两个 `<` 符号之间有个空格。
|
||||
|
||||

|
||||
|
||||
查找 777 权限文件的 Shell 脚本
|
||||
|
||||
### 使用 Cron ###
|
||||
|
||||
想更进一步提高效率,你不会想只是坐在你的电脑前手动执行这些脚本。相反,你会使用 cron 来调度这些任务周期性地执行,并把结果通过邮件发动给预定义的接收者或者将它们保存到使用 web 浏览器可以查看的文件中。
|
||||
|
||||
下面的脚本(filesystem_usage.sh)会运行有名的 **df -h** 命令,格式化输出到 HTML 表格并保存到 **report.html** 文件中:
|
||||
|
||||
#!/bin/bash
|
||||
# Sample script to demonstrate the creation of an HTML report using shell scripting
|
||||
# Web directory
|
||||
WEB_DIR=/var/www/html
|
||||
# A little CSS and table layout to make the report look a little nicer
|
||||
echo "<HTML>
|
||||
<HEAD>
|
||||
<style>
|
||||
.titulo{font-size: 1em; color: white; background:#0863CE; padding: 0.1em 0.2em;}
|
||||
table
|
||||
{
|
||||
border-collapse:collapse;
|
||||
}
|
||||
table, td, th
|
||||
{
|
||||
border:1px solid black;
|
||||
}
|
||||
</style>
|
||||
<meta http-equiv='Content-Type' content='text/html; charset=UTF-8' />
|
||||
</HEAD>
|
||||
<BODY>" > $WEB_DIR/report.html
|
||||
# View hostname and insert it at the top of the html body
|
||||
HOST=$(hostname)
|
||||
echo "Filesystem usage for host <strong>$HOST</strong><br>
|
||||
Last updated: <strong>$(date)</strong><br><br>
|
||||
<table border='1'>
|
||||
<tr><th class='titulo'>Filesystem</td>
|
||||
<th class='titulo'>Size</td>
|
||||
<th class='titulo'>Use %</td>
|
||||
</tr>" >> $WEB_DIR/report.html
|
||||
# Read the output of df -h line by line
|
||||
while read line; do
|
||||
echo "<tr><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $1}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $2}' >> $WEB_DIR/report.html
|
||||
echo "</td><td align='center'>" >> $WEB_DIR/report.html
|
||||
echo $line | awk '{print $5}' >> $WEB_DIR/report.html
|
||||
echo "</td></tr>" >> $WEB_DIR/report.html
|
||||
done < <(df -h | grep -vi filesystem)
|
||||
echo "</table></BODY></HTML>" >> $WEB_DIR/report.html
|
||||
|
||||
在我们的 **RHEL 7** 服务器(**192.168.0.18**)中,看起来像下面这样:
|
||||
|
||||

|
||||
|
||||
服务器监视报告
|
||||
|
||||
你可以添加任何你想要的信息到那个报告中。添加下面的 crontab 条目在每天下午的 1:30 运行该脚本:
|
||||
|
||||
30 13 * * * /root/scripts/filesystem_usage.sh
|
||||
|
||||
### 总结 ###
|
||||
|
||||
你很可能想起各种其他想要自动化的任务;正如你看到的,使用 shell 脚本能极大的简化任务。如果你觉得这篇文章对你有所帮助就告诉我们吧,别犹豫在下面的表格中添加你自己的想法或评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
[2]:https://en.wikipedia.org/wiki/Bash_%28Unix_shell%29
|
||||
[3]:http://www.tecmint.com/wp-content/pdf/bash.pdf
|
||||
[4]:http://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
|
||||
[5]:https://wiki.archlinux.org/index.php/Color_Bash_Prompt
|
||||
@ -0,0 +1,215 @@
|
||||
RHCSA 系列:使用 ACL(访问控制列表) 和挂载 Samba/NFS 共享 – Part 7
|
||||
================================================================================
|
||||
在上一篇文章([RHCSA 系列 Part 6][1])中,我们解释了如何使用 parted 和 ssm 来设置和配置本地系统存储。
|
||||
|
||||

|
||||
|
||||
RHCSA Series: 配置 ACL 及挂载 NFS/Samba 共享 – Part 7
|
||||
|
||||
我们也讨论了如何创建和在系统启动时使用一个密码来挂载加密的卷。另外,我们告诫过你要避免在挂载的文件系统上执行苛刻的存储管理操作。记住了这点后,现在,我们将回顾在 RHEL 7 中最常使用的文件系统格式,然后将涵盖有关手动或自动挂载、使用和卸载网络文件系统(CIFS 和 NFS)的话题以及在你的操作系统上实现访问控制列表的使用。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
在进一步深入之前,请确保你可使用 Samba 服务和 NFS 服务(注意在 RHEL 7 中 NFSv2 已不再被支持)。
|
||||
|
||||
在本次指导中,我们将使用一个IP 地址为 192.168.0.10 且同时运行着 Samba 服务和 NFS 服务的机子来作为服务器,使用一个 IP 地址为 192.168.0.18 的 RHEL 7 机子来作为客户端。在这篇文章的后面部分,我们将告诉你在客户端上你需要安装哪些软件包。
|
||||
|
||||
### RHEL 7 中的文件系统格式 ###
|
||||
|
||||
从 RHEL 7 开始,由于 XFS 的高性能和可扩展性,它已经被引入所有的架构中来作为默认的文件系统。
|
||||
根据 Red Hat 及其合作伙伴在主流硬件上执行的最新测试,当前 XFS 已支持最大为 500 TB 大小的文件系统。
|
||||
|
||||
另外, XFS 启用了 user_xattr(扩展用户属性) 和 acl(
|
||||
POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext4(对于 RHEL 7 来说, ext2 已过时),这意味着当挂载一个 XFS 文件系统时,你不必显式地在命令行或 /etc/fstab 中指定这些选项(假如你想在后一种情况下禁用这些选项,你必须显式地使用 no_acl 和 no_user_xattr)。
|
||||
|
||||
请记住扩展用户属性可以被指定到文件和目录中来存储任意的额外信息如 mime 类型,字符集或文件的编码,而用户属性中的访问权限由一般的文件权限位来定义。
|
||||
|
||||
#### 访问控制列表 ####
|
||||
|
||||
作为一名系统管理员,无论你是新手还是专家,你一定非常熟悉与文件和目录有关的常规访问权限,这些权限为所有者,所有组和"世界"(所有的其他人)指定了特定的权限(可读,可写及可执行)。但如若你需要稍微更新你的记忆,请随意参考 [RHCSA 系列的 Part 3][3].
|
||||
|
||||
但是,由于标准的 `ugo/rwx` 集合并不允许为不同的用户配置不同的权限,所以 ACL 便被引入了进来,为的是为文件和目录定义更加详细的访问权限,而不仅仅是这些特别指定的特定权限。
|
||||
|
||||
事实上, ACL 定义的权限是由文件权限位所特别指定的权限的一个超集。下面就让我们看看这个转换是如何在真实世界中被应用的吧。
|
||||
|
||||
1. 存在两种类型的 ACL:访问 ACL,可被应用到一个特定的文件或目录上,以及默认 ACL,只可被应用到一个目录上。假如目录中的文件没有 ACL,则它们将继承它们的父目录的默认 ACL 。
|
||||
|
||||
2. 从一开始, ACL 就可以为每个用户,每个组或不在文件所属组中的用户配置相应的权限。
|
||||
|
||||
3. ACL 可使用 `setfacl` 来设置(和移除),可相应地使用 -m 或 -x 选项。
|
||||
|
||||
例如,让我们创建一个名为 tecmint 的组,并将用户 johndoe 和 davenull 加入该组:
|
||||
|
||||
# groupadd tecmint
|
||||
# useradd johndoe
|
||||
# useradd davenull
|
||||
# usermod -a -G tecmint johndoe
|
||||
# usermod -a -G tecmint davenull
|
||||
|
||||
并且让我们检验这两个用户都已属于追加的组 tecmint:
|
||||
|
||||
# id johndoe
|
||||
# id davenull
|
||||
|
||||

|
||||
|
||||
检验用户
|
||||
|
||||
现在,我们在 /mnt 下创建一个名为 playground 的目录,并在该目录下创建一个名为 testfile.txt 的文件。我们将设定该文件的属组为 tecmint,并更改它的默认 ugo/rwx 权限为 770(即赋予该文件的属主和属组可读,可写和可执行权限):
|
||||
|
||||
# mkdir /mnt/playground
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chmod 770 /mnt/playground/testfile.txt
|
||||
|
||||
接着,依次切换为 johndoe 和 davenull 用户,并在文件中写入一些信息:
|
||||
|
||||
echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
|
||||
到目前为止,一切正常。现在我们让用户 gacanepa 来向该文件执行写操作 – 则写操作将会失败,这是可以预料的。
|
||||
|
||||
但实际上我们需要用户 gacanepa(TA 不是组 tecmint 的成员)在文件 /mnt/playground/testfile.txt 上有写权限,那又该怎么办呢?首先映入你脑海里的可能是将该用户添加到组 tecmint 中。但那将使得他在所有该组具有写权限位的文件上均拥有写权限,但我们并不想这样,我们只想他能够在文件 /mnt/playground/testfile.txt 上有写权限。
|
||||
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chown :tecmint /mnt/playground/testfile.txt
|
||||
# chmod 777 /mnt/playground/testfile.txt
|
||||
# su johndoe
|
||||
$ echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
$ su davenull
|
||||
$ echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
$ su gacanepa
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
管理用户的权限
|
||||
|
||||
现在,让我们给用户 gacanepa 在 /mnt/playground/testfile.txt 文件上有读和写权限。
|
||||
|
||||
以 root 的身份运行如下命令:
|
||||
|
||||
# setfacl -R -m u:gacanepa:rwx /mnt/playground
|
||||
|
||||
则你将成功地添加一条 ACL,运行 gacanepa 对那个测试文件可写。然后切换为 gacanepa 用户,并再次尝试向该文件写入一些信息:
|
||||
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||
要观察一个特定的文件或目录的 ACL,可以使用 `getfacl` 命令:
|
||||
|
||||
# getfacl /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
检查文件的 ACL
|
||||
|
||||
要为目录设定默认 ACL(它的内容将被该目录下的文件继承,除非另外被覆写),在规则前添加 `d:`并特别指定一个目录名,而不是文件名:
|
||||
|
||||
# setfacl -m d:o:r /mnt/playground
|
||||
|
||||
上面的 ACL 将允许不在属组中的用户对目录 /mnt/playground 中的内容有读权限。请注意观察这次更改前后
|
||||
`getfacl /mnt/playground` 的输出结果的不同:
|
||||
|
||||

|
||||
|
||||
在 Linux 中设定默认 ACL
|
||||
|
||||
[在官方的 RHEL 7 存储管理指导手册的第 20 章][3] 中提供了更多有关 ACL 的例子,我极力推荐你看一看它并将它放在身边作为参考。
|
||||
|
||||
#### 挂载 NFS 网络共享 ####
|
||||
|
||||
要显示你服务器上可用的 NFS 共享的列表,你可以使用带有 -e 选项的 `showmount` 命令,再跟上机器的名称或它的 IP 地址。这个工具包含在 `nfs-utils` 软件包中:
|
||||
|
||||
# yum update && yum install nfs-utils
|
||||
|
||||
接着运行:
|
||||
|
||||
# showmount -e 192.168.0.10
|
||||
|
||||
则你将得到一个在 192.168.0.10 上可用的 NFS 共享的列表:
|
||||
|
||||

|
||||
|
||||
检查可用的 NFS 共享
|
||||
|
||||
要按照需求在本地客户端上使用命令行来挂载 NFS 网络共享,可使用下面的语法:
|
||||
|
||||
# mount -t nfs -o [options] remote_host:/remote/directory /local/directory
|
||||
|
||||
其中,在我们的例子中,对应为:
|
||||
|
||||
# mount -t nfs 192.168.0.10:/NFS-SHARE /mnt/nfs
|
||||
|
||||
若你得到如下的错误信息:“Job for rpc-statd.service failed. See “systemctl status rpc-statd.service”及“journalctl -xn” for details.”,请确保 `rpcbind` 服务被启用且已在你的系统中启动了。
|
||||
|
||||
# systemctl enable rpcbind.socket
|
||||
# systemctl restart rpcbind.service
|
||||
|
||||
接着重启。这就应该达到了上面的目的,且你将能够像先前解释的那样挂载你的 NFS 共享了。若你需要在系统启动时自动挂载 NFS 共享,可以向 /etc/fstab 文件添加一个有效的条目:
|
||||
|
||||
remote_host:/remote/directory /local/directory nfs options 0 0
|
||||
|
||||
上面的变量 remote_host, /remote/directory, /local/directory 和 options(可选) 和在命令行中手动挂载一个 NFS 共享时使用的一样。按照我们前面的例子,对应为:
|
||||
|
||||
192.168.0.10:/NFS-SHARE /mnt/nfs nfs defaults 0 0
|
||||
|
||||
#### 挂载 CIFS (Samba) 网络共享 ####
|
||||
|
||||
Samba 代表一个特别的工具,使得在由 *nix 和 Windows 机器组成的网络中进行网络共享成为可能。要显示可用的 Samba 共享,可使用带有 -L 选项的 smbclient 命令,再跟上机器的名称或它的 IP 地址。这个工具包含在 samba_client 软件包中:
|
||||
|
||||
你将被提示在远程主机上输入 root 用户的密码:
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
|
||||

|
||||
|
||||
检查 Samba 共享
|
||||
|
||||
要在本地客户端上挂载 Samba 网络共享,你需要已安装好 cifs-utils 软件包:
|
||||
|
||||
# yum update && yum install cifs-utils
|
||||
|
||||
然后在命令行中使用下面的语法:
|
||||
|
||||
# mount -t cifs -o credentials=/path/to/credentials/file //remote_host/samba_share /local/directory
|
||||
|
||||
其中,在我们的例子中,对应为:
|
||||
|
||||
# mount -t cifs -o credentials=~/.smbcredentials //192.168.0.10/gacanepa /mnt/samba
|
||||
|
||||
其中 `smbcredentials`
|
||||
|
||||
username=gacanepa
|
||||
password=XXXXXX
|
||||
|
||||
是一个位于 root 用户的家目录(/root/) 中的隐藏文件,其权限被设置为 600,所以除了该文件的属主外,其他人对该文件既不可读也不可写。
|
||||
|
||||
请注意 samba_share 是 Samba 分享的名称,由上面展示的 `smbclient -L remote_host` 所返回。
|
||||
|
||||
现在,若你需要在系统启动时自动地使得 Samba 分享可用,可以向 /etc/fstab 文件添加一个像下面这样的有效条目:
|
||||
|
||||
//remote_host:/samba_share /local/directory cifs options 0 0
|
||||
|
||||
上面的变量 remote_host, /remote/directory, /local/directory 和 options(可选) 和在命令行中手动挂载一个 Samba 共享时使用的一样。按照我们前面的例子中所给的定义,对应为:
|
||||
|
||||
//192.168.0.10/gacanepa /mnt/samba cifs credentials=/root/smbcredentials,defaults 0 0
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经解释了如何在 Linux 中设置 ACL,并讨论了如何在一个 RHEL 7 客户端上挂载 CIFS 和 NFS 网络共享。
|
||||
|
||||
我建议你去练习这些概念,甚至混合使用它们(试着在一个挂载的网络共享上设置 ACL),直至你感觉舒适。假如你有问题或评论,请随时随意地使用下面的评论框来联系我们。另外,请随意通过你的社交网络分享这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Storage_Administration_Guide/ch-acls.html
|
||||
Loading…
Reference in New Issue
Block a user