mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
3b1e5c1cee
@ -1,19 +1,19 @@
|
||||
学习数据结构与算法分析如何帮助您成为更优秀的开发人员?
|
||||
学习数据结构与算法分析如何帮助您成为更优秀的开发人员
|
||||
================================================================================
|
||||
|
||||
> "相较于其它方式,我一直热衷于推崇围绕数据设计代码,我想这也是Git能够如此成功的一大原因[…]在我看来,区别程序员优劣的一大标准就在于他是否认为自己设计的代码或数据结构更为重要。"
|
||||
> "相较于其它方式,我一直热衷于推崇围绕数据设计代码,我想这也是Git能够如此成功的一大原因[…]在我看来,区别程序员优劣的一大标准就在于他是否认为自己设计的代码还是数据结构更为重要。"
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "优秀的数据结构与简陋的代码组合远比倒过来的组合方式更好。"
|
||||
> "优秀的数据结构与简陋的代码组合远比反之的组合更好。"
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
学习数据结构与算法分析会让您成为一名出色的程序员。
|
||||
|
||||
**数据结构与算法分析是一种解决问题的思维模式** 在您的个人知识库中,数据结构与算法分析的相关知识储备越多,您将具备应对并解决越多各类繁杂问题的能力。掌握了这种思维模式,您还将有能力针对新问题提出更多以前想不到的漂亮的解决方案。
|
||||
**数据结构与算法分析是一种解决问题的思维模式。** 在您的个人知识库中,数据结构与算法分析的相关知识储备越多,您将越多具备应对并解决各类繁杂问题的能力。掌握了这种思维模式,您还将有能力针对新问题提出更多以前想不到的漂亮的解决方案。
|
||||
|
||||
您将***更深入地***了解,计算机如何完成各项操作。无论您是否是直接使用给定的算法,它都影响着您作出的各种技术决定。从计算机操作系统的内存分配到RDBMS的内在工作机制,以及网络堆栈如何实现将数据从地球的一个角落发送至另一个角落这些大大小小的工作的完成,都离不开基础的数据结构与算法,理解并掌握它将会让您更了解计算机的运作机理。
|
||||
您将*更深入地*了解,计算机如何完成各项操作。无论您是否是直接使用给定的算法,它都影响着您作出的各种技术决定。从计算机操作系统的内存分配到RDBMS的内在工作机制,以及网络协议如何实现将数据从地球的一个角落发送至另一个角落,这些大大小小的工作的完成,都离不开基础的数据结构与算法,理解并掌握它将会让您更了解计算机的运作机理。
|
||||
|
||||
对算法广泛深入的学习能为您储备解决方案来应对大体系的问题。之前建模困难时遇到的问题如今通常都能融合进经典的数据结构中得到很好地解决。即使是最基础的数据结构,只要对它进行足够深入的钻研,您将会发现在每天的编程任务中都能经常用到这些知识。
|
||||
|
||||
@ -27,15 +27,15 @@
|
||||
|
||||

|
||||
|
||||
从这张画出机场各自之间的距离以及目的地的图中,我们如何才能找到最短距离,比方说从赫尔辛基到伦敦?**Dijkstra算法**是能让我们在最短的时间得到正确答案的适用算法。
|
||||
从这张画出机场各自之间的距离以及目的地的图中,我们如何才能找到最短距离,比方说从赫尔辛基到伦敦?**[Dijkstra算法][3]**是能让我们在最短的时间得到正确答案的适用算法。
|
||||
|
||||
在所有可能的解法中,如果您曾经遇到过这类问题,知道可以用Dijkstra算法求解,您大可不必从零开始实现它,只需***知道***该算法能指向固定的代码库帮助您解决相关的实现问题。
|
||||
在所有可能的解法中,如果您曾经遇到过这类问题,知道可以用Dijkstra算法求解,您大可不必从零开始实现它,只需***知道***该算法的代码库能帮助您解决相关的实现问题。
|
||||
|
||||
实现了该算法,您将深入理解一项著名的重要图论算法。您会发现实际上该算法太集成化,因此名为A*的扩展包经常会代替该算法使用。这个算法应用广泛,从机器人指引的功能实现到TCP数据包路由,以及GPS寻径问题都能应用到这个算法。
|
||||
如果你深入到该算法的实现中,您将深入理解一项著名的重要图论算法。您会发现实际上该算法比较消耗资源,因此名为[A*][4]的扩展经常用于代替该算法。这个算法应用广泛,从机器人寻路的功能实现到TCP数据包路由,以及GPS寻径问题都能应用到这个算法。
|
||||
|
||||
###先后排序问题###
|
||||
|
||||
您想要在开放式在线课程平台上(如Udemy或Khan学院)学习某课程,有些课程之间彼此依赖。例如,用户学习牛顿力学机制课程前必须先修微积分课程,课程之间可以有多种依赖关系。用YAML表述举例如下:
|
||||
您想要在开放式在线课程(MOOC,Massive Open Online Courses)平台上(如Udemy或Khan学院)学习某课程,有些课程之间彼此依赖。例如,用户学习牛顿力学(Newtonian Mechanics)课程前必须先修微积分(Calculus)课程,课程之间可以有多种依赖关系。用YAML表述举例如下:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
@ -54,7 +54,7 @@
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
鉴于以上这些依赖关系,作为一名用户,我希望系统能帮我列出必修课列表,让我在之后可以选择任意一门课程学习。如果我选择了`微积分`课程,我希望系统能返回以下列表:
|
||||
鉴于以上这些依赖关系,作为一名用户,我希望系统能帮我列出必修课列表,让我在之后可以选择任意一门课程学习。如果我选择了微积分(calculus)课程,我希望系统能返回以下列表:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
@ -63,7 +63,7 @@
|
||||
- 返回的必修课列表中,每门课都与下一门课存在依赖关系
|
||||
- 我们不希望列表中有任何重复课程
|
||||
|
||||
这是解决数据间依赖关系的例子,解决该问题的排序算法称作拓扑排序算法(tsort)。它适用于解决上述我们用YAML列出的依赖关系图的情况,以下是在图中显示的相关结果(其中箭头代表`需要先修的课程`):
|
||||
这是解决数据间依赖关系的例子,解决该问题的排序算法称作拓扑排序算法(tsort,topological sort)。它适用于解决上述我们用YAML列出的依赖关系图的情况,以下是在图中显示的相关结果(其中箭头代表`需要先修的课程`):
|
||||
|
||||

|
||||
|
||||
@ -79,16 +79,17 @@
|
||||
|
||||
这符合我们上面描述的需求,用户只需选出`radioactivity`,就能得到在此之前所有必修课程的有序列表。
|
||||
|
||||
在运用该排序算法之前,我们甚至不需要深入了解算法的实现细节。一般来说,选择不同的编程语言在其标准库中都会有相应的算法实现。即使最坏的情况,Unix也会默认安装`tsort`程序,运行`tsort`程序,您就可以实现该算法。
|
||||
在运用该排序算法之前,我们甚至不需要深入了解算法的实现细节。一般来说,你可能选择的各种编程语言在其标准库中都会有相应的算法实现。即使最坏的情况,Unix也会默认安装`tsort`程序,运行`man tsort` 来了解该程序。
|
||||
|
||||
###其它拓扑排序适用场合###
|
||||
|
||||
- **工具** 使用诸如`make`的工具您可以声明任务之间的依赖关系,这里拓扑排序算法将从底层实现具有依赖关系的任务顺序执行的功能。
|
||||
- **有`require`指令的编程语言**,适用于要运行当前文件需先运行另一个文件的情况。这里拓扑排序用于识别文件运行顺序以保证每个文件只加载一次,且满足所有文件间的依赖关系要求。
|
||||
- **包含甘特图的项目管理工具**.甘特图能直观列出给定任务的所有依赖关系,在这些依赖关系之上能提供给用户任务完成的预估时间。我不常用到甘特图,但这些绘制甘特图的工具很可能会用到拓扑排序算法。
|
||||
- **类似`make`的工具** 可以让您声明任务之间的依赖关系,这里拓扑排序算法将从底层实现具有依赖关系的任务顺序执行的功能。
|
||||
- **具有`require`指令的编程语言**适用于要运行当前文件需先运行另一个文件的情况。这里拓扑排序用于识别文件运行顺序以保证每个文件只加载一次,且满足所有文件间的依赖关系要求。
|
||||
- **带有甘特图的项目管理工具**。甘特图能直观列出给定任务的所有依赖关系,在这些依赖关系之上能提供给用户任务完成的预估时间。我不常用到甘特图,但这些绘制甘特图的工具很可能会用到拓扑排序算法。
|
||||
|
||||
###霍夫曼编码实现数据压缩###
|
||||
[霍夫曼编码](http://en.wikipedia.org/wiki/Huffman_coding)是一种用于无损数据压缩的编码算法。它的工作原理是先分析要压缩的数据,再为每个字符创建一个二进制编码。字符出现的越频繁,编码赋值越小。因此在一个数据集中`e`可能会编码为`111`,而`x`会编码为`10010`。创建了这种编码模式,就可以串联无定界符,也能正确地进行解码。
|
||||
|
||||
[霍夫曼编码][5](Huffman coding)是一种用于无损数据压缩的编码算法。它的工作原理是先分析要压缩的数据,再为每个字符创建一个二进制编码。字符出现的越频繁,编码赋值越小。因此在一个数据集中`e`可能会编码为`111`,而`x`会编码为`10010`。创建了这种编码模式,就可以串联无定界符,也能正确地进行解码。
|
||||
|
||||
在gzip中使用的DEFLATE算法就结合了霍夫曼编码与LZ77一同用于实现数据压缩功能。gzip应用领域很广,特别适用于文件压缩(以`.gz`为扩展名的文件)以及用于数据传输中的http请求与应答。
|
||||
|
||||
@ -96,10 +97,11 @@
|
||||
|
||||
- 您会理解为什么较大的压缩文件会获得较好的整体压缩效果(如压缩的越多,压缩率也越高)。这也是SPDY协议得以推崇的原因之一:在复杂的HTTP请求/响应过程数据有更好的压缩效果。
|
||||
- 您会了解数据传输过程中如果想要压缩JavaScript/CSS文件,运行压缩软件是完全没有意义的。PNG文件也是类似,因为它们已经使用DEFLATE算法完成了压缩。
|
||||
- 如果您试图强行破译加密的信息,您可能会发现由于重复数据压缩质量更好,给定的密文单位bit的数据压缩将帮助您确定相关的[分组密码工作模式](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
- 如果您试图强行破译加密的信息,您可能会发现由于重复数据压缩质量更好,密文给定位的数据压缩率将帮助您确定相关的[分组密码工作模式][6](block cipher mode of operation.)。
|
||||
|
||||
###下一步选择学习什么是困难的###
|
||||
作为一名程序员应当做好持续学习的准备。为成为一名web开发人员,您需要了解标记语言以及Ruby/Python,正则表达式,SQL,JavaScript等高级编程语言,还需要了解HTTP的工作原理,如何运行UNIX终端以及面向对象的编程艺术。您很难有效地预览到未来的职业全景,因此选择下一步要学习哪些知识是困难的。
|
||||
|
||||
作为一名程序员应当做好持续学习的准备。为了成为一名web开发人员,您需要了解标记语言以及Ruby/Python、正则表达式、SQL、JavaScript等高级编程语言,还需要了解HTTP的工作原理,如何运行UNIX终端以及面向对象的编程艺术。您很难有效地预览到未来的职业全景,因此选择下一步要学习哪些知识是困难的。
|
||||
|
||||
我没有快速学习的能力,因此我不得不在时间花费上非常谨慎。我希望尽可能地学习到有持久生命力的技能,即不会在几年内就过时的技术。这意味着我也会犹豫这周是要学习JavaScript框架还是那些新的编程语言。
|
||||
|
||||
@ -118,6 +120,7 @@ via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithm
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
[3]:http://en.wikipedia.org/wiki/Dijkstra's_algorithm
|
||||
[4]:http://en.wikipedia.org/wiki/A*_search_algorithm
|
||||
[5]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[6]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
@ -0,0 +1,88 @@
|
||||
那些奇特的 Linux 发行版本
|
||||
================================================================================
|
||||
从大多数消费者所关注的诸如 Ubuntu,Fedora,Mint 或 elementary OS 到更加复杂、轻量级和企业级的诸如 Slackware,Arch Linux 或 RHEL,这些发行版本我都已经见识过了。除了这些,难道没有其他别的了吗?其实 Linux 的生态系统是非常多样化的,对每个人来说,总有一款适合你。下面就让我们讨论一些稀奇古怪的小众 Linux 发行版本吧,它们代表着开源平台真正的多样性。
|
||||
|
||||
### Puppy Linux
|
||||
|
||||

|
||||
|
||||
它是一个仅有一个普通 DVD 光盘容量十分之一大小的操作系统,这就是 Puppy Linux。整个操作系统仅有 100MB 大小!并且它还可以从内存中运行,这使得它运行极快,即便是在老式的 PC 机上。 在操作系统启动后,你甚至可以移除启动介质!还有什么比这个更好的吗? 系统所需的资源极小,大多数的硬件都会被自动检测到,并且它预装了能够满足你基本需求的软件。[在这里体验 Puppy Linux 吧][1].
|
||||
|
||||
### Suicide Linux(自杀 Linux)
|
||||
|
||||

|
||||
|
||||
这个名字吓到你了吗?我想应该是。 ‘任何时候 -注意是任何时候-一旦你远程输入不正确的命令,解释器都会创造性地将它重定向为 `rm -rf /` 命令,然后擦除你的硬盘’。它就是这么简单。我真的很想知道谁自信到将[Suicide Linux][2] 安装到生产机上。 **警告:千万不要在生产机上尝试这个!** 假如你感兴趣的话,现在可以通过一个简洁的[DEB 包][3]来获取到它。
|
||||
|
||||
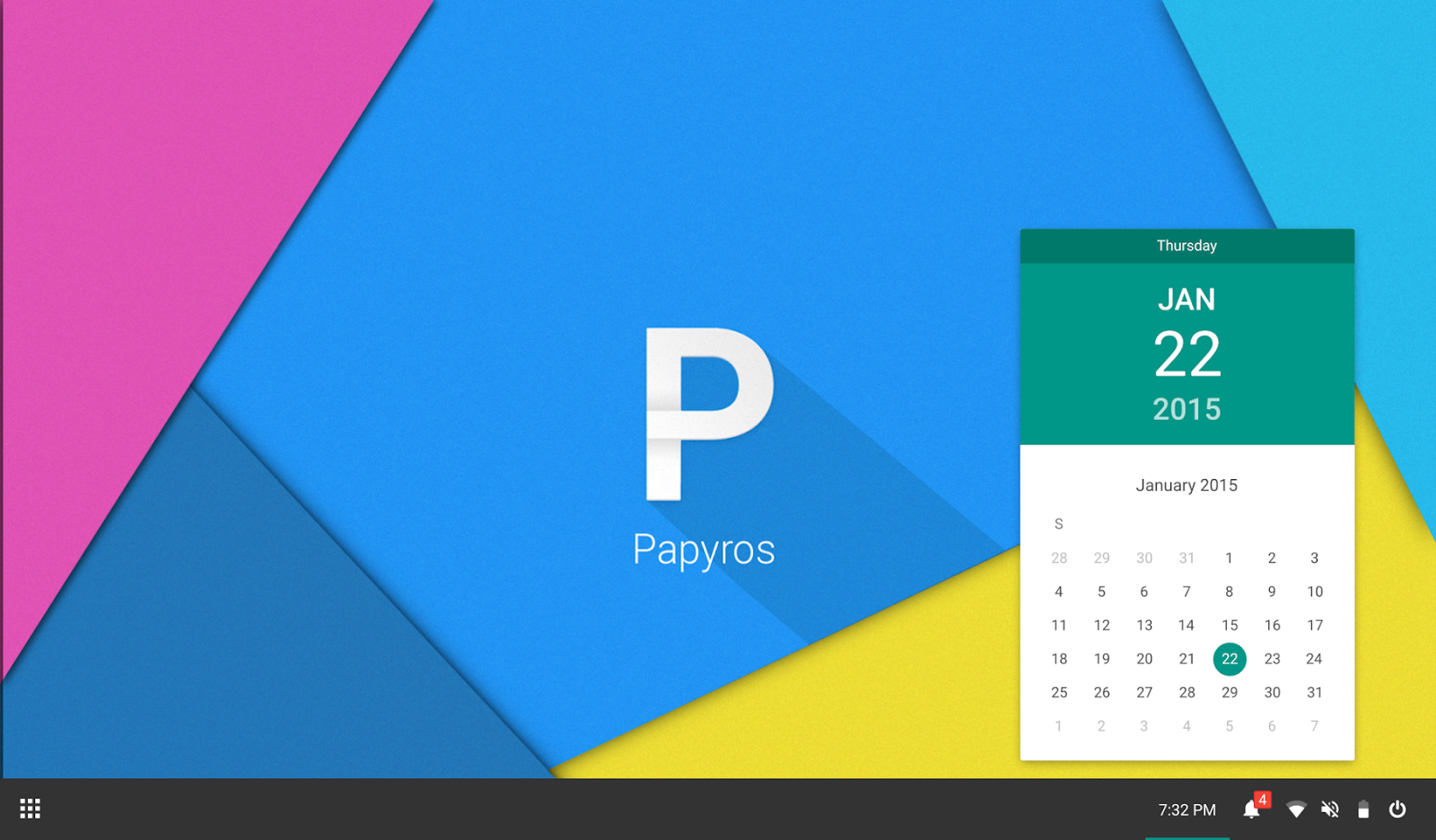
### PapyrOS
|
||||
|
||||
|
||||
|
||||
它的 “奇怪”是好的方面。PapyrOS 正尝试着将 Android 的 material design 设计语言引入到新的 Linux 发行版本上。尽管这个项目还处于早期阶段,看起来它已经很有前景。该项目的网页上说该系统已经完成了 80%,随后人们可以期待它的第一个 Alpha 发行版本。在该项目被宣告提出时,我们做了 [PapyrOS][4] 的小幅报道,从它的外观上看,它甚至可能会引领潮流。假如你感兴趣的话,可在 [Google+][5] 上关注该项目并可通过 [BountySource][6] 来贡献出你的力量。
|
||||
|
||||
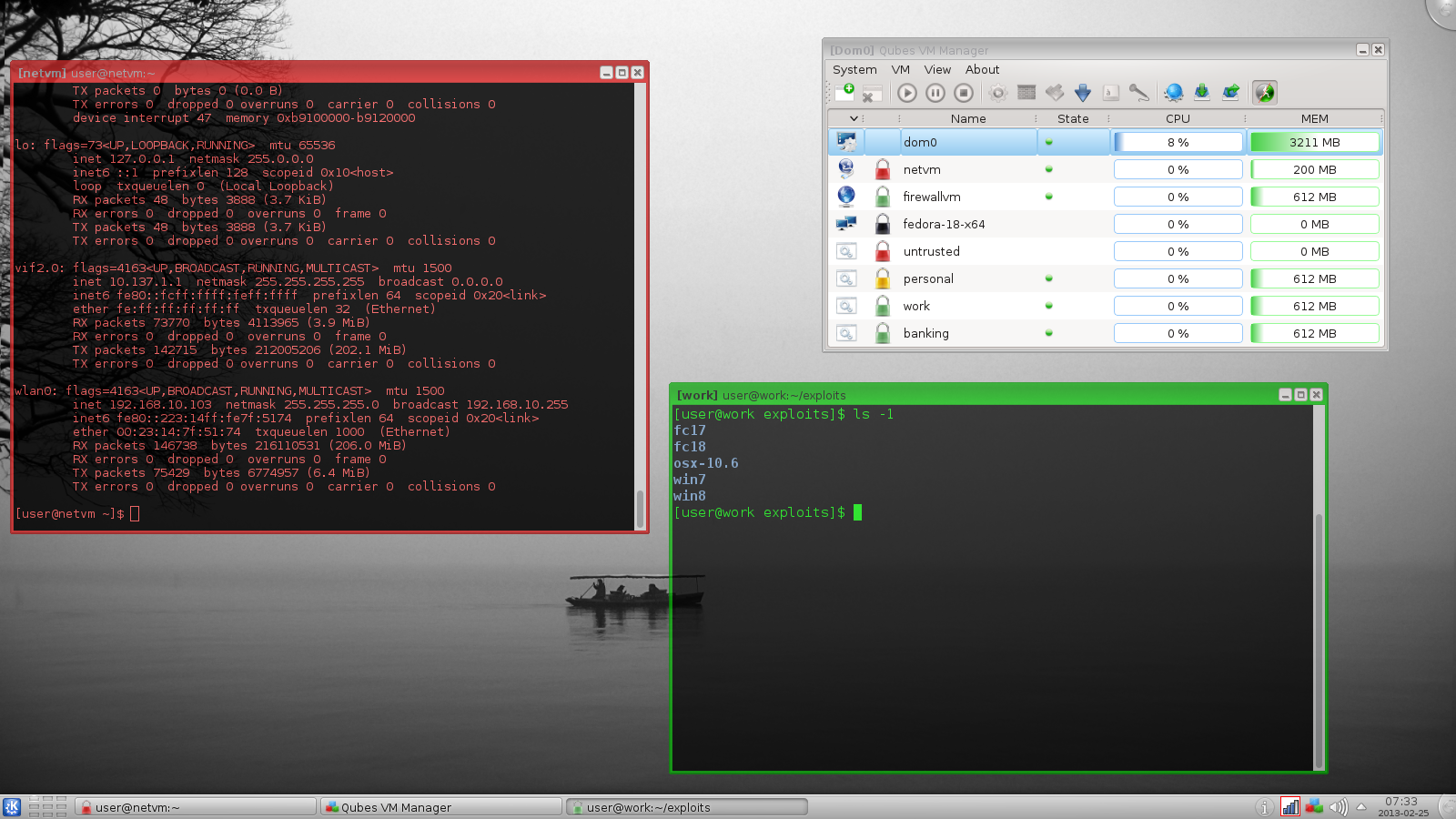
### Qubes OS
|
||||
|
||||
|
||||
|
||||
Qubes 是一个开源的操作系统,其设计通过使用[安全分级(Security by Compartmentalization)][14]的方法,来提供强安全性。其前提假设是不存在完美的没有 bug 的桌面环境。并通过实现一个‘安全隔离(Security by Isolation)’ 的方法,[Qubes Linux][7]试图去解决这些问题。Qubes 基于 Xen、X 视窗系统和 Linux,并可运行大多数的 Linux 应用,支持大多数的 Linux 驱动。Qubes 入选了 Access Innovation Prize 2014 for Endpoint Security Solution 决赛名单。
|
||||
|
||||
### Ubuntu Satanic Edition
|
||||
|
||||

|
||||
|
||||
Ubuntu SE 是一个基于 Ubuntu 的发行版本。通过一个含有主题、壁纸甚至来源于某些天才新晋艺术家的重金属音乐的综合软件包,“它同时带来了最好的自由软件和免费的金属音乐” 。尽管这个项目看起来不再积极开发了, Ubuntu Satanic Edition 甚至在其名字上都显得奇异。 [Ubuntu SE (Slightly NSFW)][8]。
|
||||
|
||||
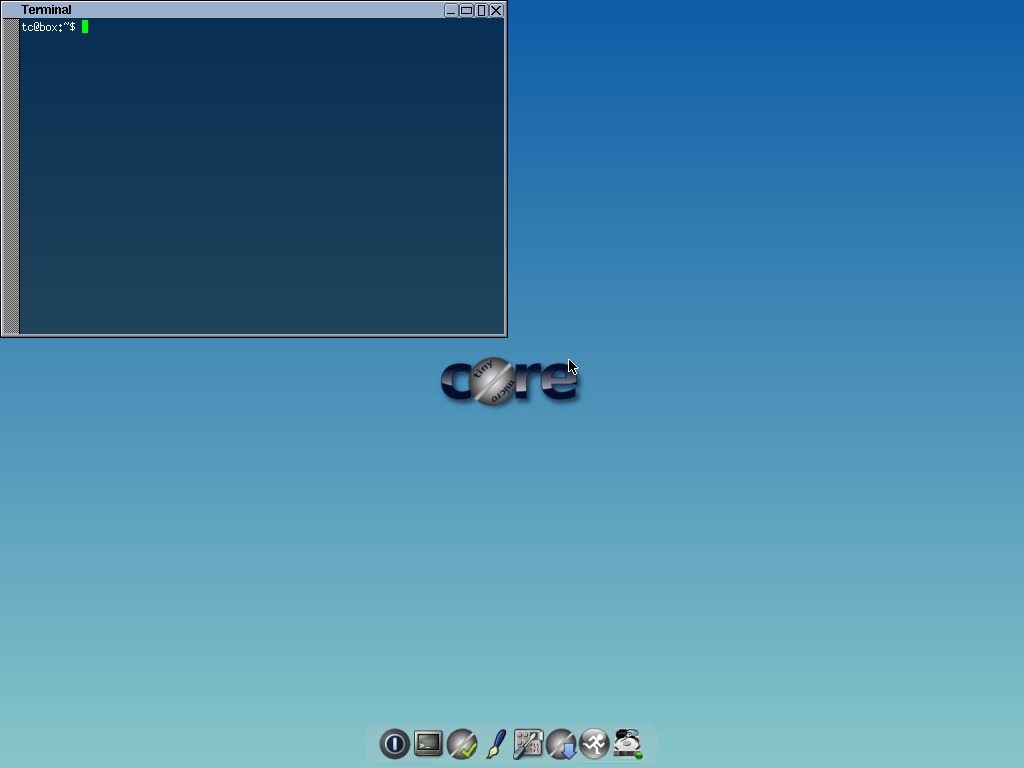
### Tiny Core Linux
|
||||
|
||||
|
||||
|
||||
Puppy Linux 还不够小?试试这个吧。 Tiny Core Linux 是一个 12MB 大小的图形化 Linux 桌面!是的,你没有看错。一个主要的补充说明:它不是一个完整的桌面,也并不完全支持所有的硬件。它只含有能够启动进入一个非常小巧的 X 桌面,支持有线网络连接的核心部件。它甚至还有一个名为 Micro Core Linux 的没有 GUI 的版本,仅有 9MB 大小。[Tiny Core Linux][9]。
|
||||
|
||||
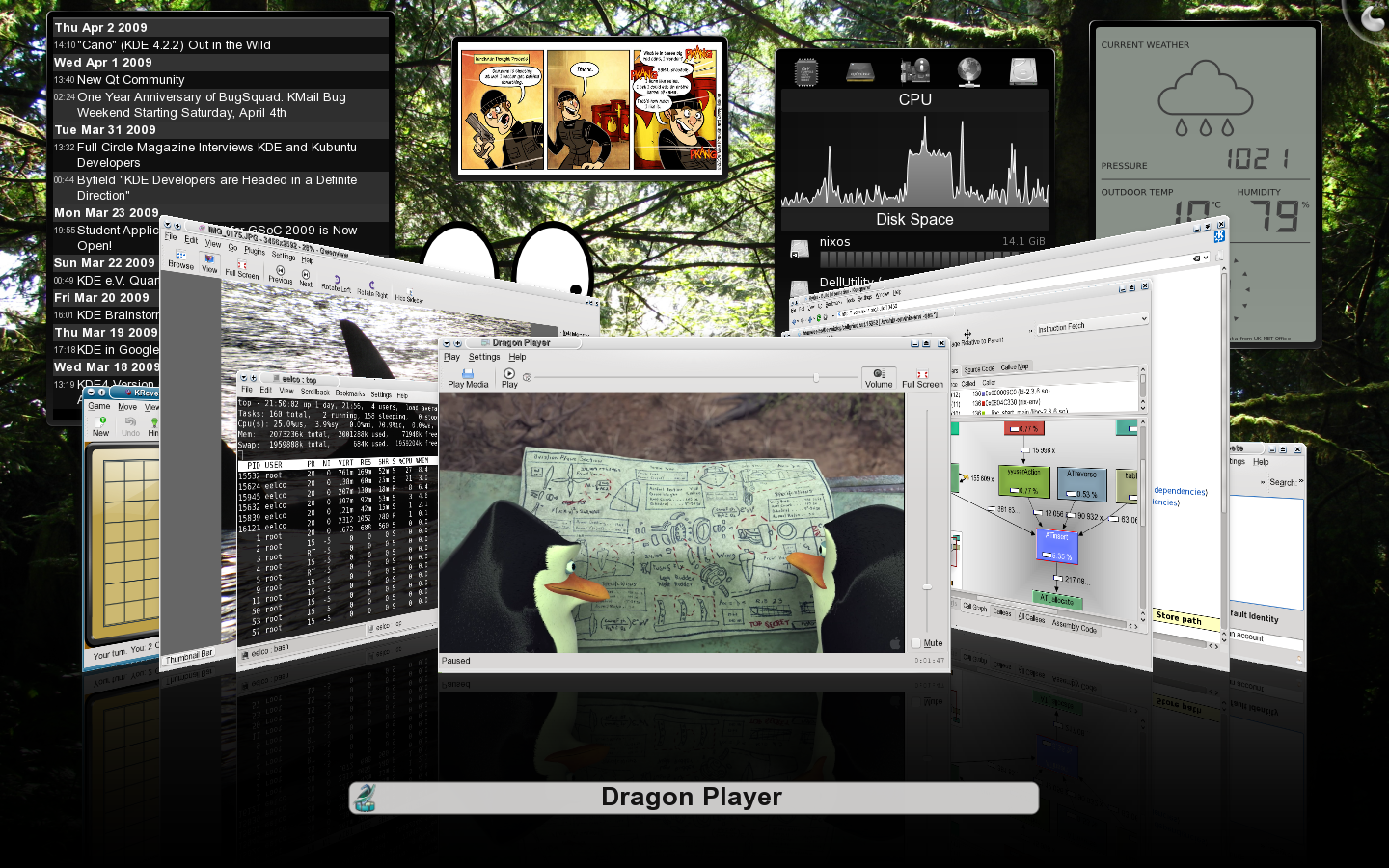
### NixOS
|
||||
|
||||
|
||||
|
||||
它是一个资深用户所关注的 Linux 发行版本,有着独特的打包和配置管理方式。在其他的发行版本中,诸如升级的操作可能是非常危险的。升级一个软件包可能会引起其他包无法使用,而升级整个系统感觉还不如重新安装一个。在那些你不能安全地测试由一个配置的改变所带来的结果的更改之上,它们通常没有“重来”这个选项。在 NixOS 中,整个系统由 Nix 包管理器按照一个纯功能性的构建语言的描述来构建。这意味着构建一个新的配置并不会重写先前的配置。大多数其他的特色功能也遵循着这个模式。Nix 相互隔离地存储所有的软件包。有关 NixOS 的更多内容请看[这里][10]。
|
||||
|
||||
### GoboLinux
|
||||
|
||||
|
||||
|
||||
这是另一个非常奇特的 Linux 发行版本。它与其他系统如此不同的原因是它有着独特的重新整理的文件系统。它有着自己独特的子目录树,其中存储着所有的文件和程序。GoboLinux 没有专门的包数据库,因为其文件系统就是它的数据库。在某些方面,这类重整有些类似于 OS X 上所看到的功能。
|
||||
|
||||
### Hannah Montana Linux
|
||||
|
||||

|
||||
|
||||
它是一个基于 Kubuntu 的 Linux 发行版本,它有着汉娜·蒙塔娜( Hannah Montana) 主题的开机启动界面、KDM(KDE Display Manager)、图标集、ksplash、plasma、颜色主题和壁纸(I'm so sorry)。[这是它的链接][12]。这个项目现在不再活跃了。
|
||||
|
||||
### RLSD Linux
|
||||
|
||||
它是一个极其精简、小巧、轻量和安全可靠的,基于 Linux 文本的操作系统。开发者称 “它是一个独特的发行版本,提供一系列的控制台应用和自带的安全特性,对黑客或许有吸引力。” [RLSD Linux][13].
|
||||
|
||||
我们还错过了某些更加奇特的发行版本吗?请让我们知晓吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techdrivein.com/2015/08/the-strangest-most-unique-linux-distros.html
|
||||
|
||||
作者:Manuel Jose
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||
[2]:http://qntm.org/suicide
|
||||
[3]:http://sourceforge.net/projects/suicide-linux/files/
|
||||
[4]:http://www.techdrivein.com/2015/02/papyros-material-design-linux-coming-soon.html
|
||||
[5]:https://plus.google.com/communities/109966288908859324845/stream/3262a3d3-0797-4344-bbe0-56c3adaacb69
|
||||
[6]:https://www.bountysource.com/teams/papyros
|
||||
[7]:https://www.qubes-os.org/
|
||||
[8]:http://ubuntusatanic.org/
|
||||
[9]:http://tinycorelinux.net/
|
||||
[10]:https://nixos.org/
|
||||
[11]:http://www.gobolinux.org/
|
||||
[12]:http://hannahmontana.sourceforge.net/
|
||||
[13]:http://rlsd2.dimakrasner.com/
|
||||
[14]:https://en.wikipedia.org/wiki/Compartmentalization_(information_security)
|
||||
@ -0,0 +1,165 @@
|
||||
如何在 Linux 上从 NetworkManager 切换为 systemd-network
|
||||
================================================================================
|
||||
在 Linux 世界里,对 [systemd][1] 的采用一直是激烈争论的主题,它的支持者和反对者之间的战火仍然在燃烧。到了今天,大部分主流 Linux 发行版都已经采用了 systemd 作为默认的初始化(init)系统。
|
||||
|
||||
正如其作者所说,作为一个 “从未完成、从未完善、但一直追随技术进步” 的系统,systemd 已经不只是一个初始化进程,它被设计为一个更广泛的系统以及服务管理平台,这个平台是一个包含了不断增长的核心系统进程、库和工具的生态系统。
|
||||
|
||||
**systemd** 的其中一部分是 **systemd-networkd**,它负责 systemd 生态中的网络配置。使用 systemd-networkd,你可以为网络设备配置基础的 DHCP/静态 IP 网络。它还可以配置虚拟网络功能,例如网桥、隧道和 VLAN。systemd-networkd 目前还不能直接支持无线网络,但你可以使用 wpa_supplicant 服务配置无线适配器,然后把它和 **systemd-networkd** 联系起来。
|
||||
|
||||
在很多 Linux 发行版中,NetworkManager 仍然作为默认的网络配置管理器。和 NetworkManager 相比,**systemd-networkd** 仍处于积极的开发状态,还缺少一些功能。例如,它还不能像 NetworkManager 那样能让你的计算机在任何时候通过多种接口保持连接。它还没有为更高层面的脚本编程提供 ifup/ifdown 钩子函数。但是,systemd-networkd 和其它 systemd 组件(例如用于域名解析的 **resolved**、NTP 的**timesyncd**,用于命名的 udevd)结合的非常好。随着时间增长,**systemd-networkd**只会在 systemd 环境中扮演越来越重要的角色。
|
||||
|
||||
如果你对 **systemd-networkd** 的进步感到高兴,从 NetworkManager 切换到 systemd-networkd 是值得你考虑的一件事。如果你强烈反对 systemd,对 NetworkManager 或[基础网络服务][2]感到很满意,那也很好。
|
||||
|
||||
但对于那些想尝试 systemd-networkd 的人,可以继续看下去,在这篇指南中学会在 Linux 中怎么从 NetworkManager 切换到 systemd-networkd。
|
||||
|
||||
### 需求 ###
|
||||
|
||||
systemd 210 及其更高版本提供了 systemd-networkd。因此诸如 Debian 8 "Jessie" (systemd 215)、 Fedora 21 (systemd 217)、 Ubuntu 15.04 (systemd 219) 或更高版本的 Linux 发行版和 systemd-networkd 兼容。
|
||||
|
||||
对于其它发行版,在开始下一步之前先检查一下你的 systemd 版本。
|
||||
|
||||
$ systemctl --version
|
||||
|
||||
### 从 NetworkManager 切换到 Systemd-networkd ###
|
||||
|
||||
从 NetworkManager 切换到 systemd-networkd 其实非常简答(反过来也一样)。
|
||||
|
||||
首先,按照下面这样先停用 NetworkManager 服务,然后启用 systemd-networkd。
|
||||
|
||||
$ sudo systemctl disable NetworkManager
|
||||
$ sudo systemctl enable systemd-networkd
|
||||
|
||||
你还要启用 **systemd-resolved** 服务,systemd-networkd用它来进行域名解析。该服务还实现了一个缓存式 DNS 服务器。
|
||||
|
||||
$ sudo systemctl enable systemd-resolved
|
||||
$ sudo systemctl start systemd-resolved
|
||||
|
||||
当启动后,**systemd-resolved** 就会在 /run/systemd 目录下某个地方创建它自己的 resolv.conf。但是,把 DNS 解析信息存放在 /etc/resolv.conf 是更普遍的做法,很多应用程序也会依赖于 /etc/resolv.conf。因此为了兼容性,按照下面的方式创建一个到 /etc/resolv.conf 的符号链接。
|
||||
|
||||
$ sudo rm /etc/resolv.conf
|
||||
$ sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
|
||||
|
||||
### 用 systemd-networkd 配置网络连接 ###
|
||||
|
||||
要用 systemd-networkd 配置网络服务,你必须指定带.network 扩展名的配置信息文本文件。这些网络配置文件保存到 /etc/systemd/network 并从这里加载。当有多个文件时,systemd-networkd 会按照字母顺序一个个加载并处理。
|
||||
|
||||
首先创建 /etc/systemd/network 目录。
|
||||
|
||||
$ sudo mkdir /etc/systemd/network
|
||||
|
||||
#### DHCP 网络 ####
|
||||
|
||||
首先来配置 DHCP 网络。对于此,先要创建下面的配置文件。文件名可以任意,但记住文件是按照字母顺序处理的。
|
||||
|
||||
$ sudo vi /etc/systemd/network/20-dhcp.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3*
|
||||
|
||||
[Network]
|
||||
DHCP=yes
|
||||
|
||||
正如你上面看到的,每个网络配置文件包括了一个或多个 “sections”,每个 “section”都用 [XXX] 开头。每个 section 包括了一个或多个键值对。`[Match]` 部分决定这个配置文件配置哪个(些)网络设备。例如,这个文件匹配所有名称以 ens3 开头的网络设备(例如 enp3s0、 enp3s1、 enp3s2 等等)对于匹配的接口,然后启用 [Network] 部分指定的 DHCP 网络配置。
|
||||
|
||||
### 静态 IP 网络 ###
|
||||
|
||||
如果你想给网络设备分配一个静态 IP 地址,那就新建下面的配置文件。
|
||||
|
||||
$ sudo vi /etc/systemd/network/10-static-enp3s0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3s0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.50/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
正如你猜测的, enp3s0 接口地址会被指定为 192.168.10.50/24,默认网关是 192.168.10.1, DNS 服务器是 8.8.8.8。这里微妙的一点是,接口名 enp3s0 事实上也匹配了之前 DHCP 配置中定义的模式规则。但是,根据词汇顺序,文件 "10-static-enp3s0.network" 在 "20-dhcp.network" 之前被处理,对于 enp3s0 接口静态配置比 DHCP 配置有更高的优先级。
|
||||
|
||||
一旦你完成了创建配置文件,重启 systemd-networkd 服务或者重启机器。
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
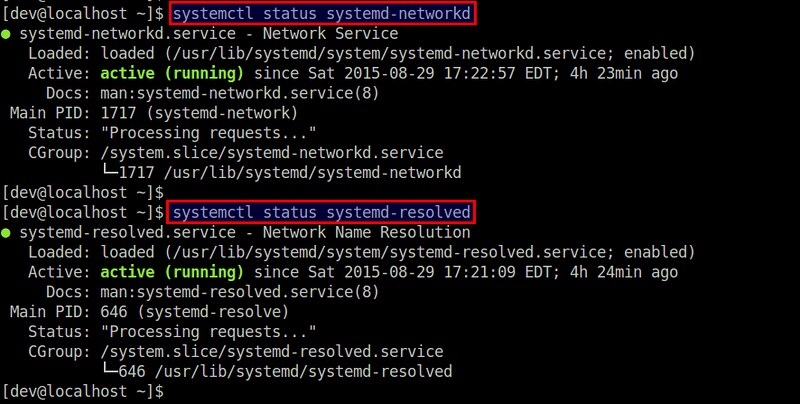
运行以下命令检查服务状态:
|
||||
|
||||
$ systemctl status systemd-networkd
|
||||
$ systemctl status systemd-resolved
|
||||
|
||||
|
||||
|
||||
### 用 systemd-networkd 配置虚拟网络设备 ###
|
||||
|
||||
**systemd-networkd** 同样允许你配置虚拟网络设备,例如网桥、VLAN、隧道、VXLAN、绑定等。你必须在用 .netdev 作为扩展名的文件中配置这些虚拟设备。
|
||||
|
||||
这里我展示了如何配置一个桥接接口。
|
||||
|
||||
#### Linux 网桥 ####
|
||||
|
||||
如果你想创建一个 Linux 网桥(br0) 并把物理接口(eth1) 添加到网桥,你可以新建下面的配置。
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.netdev
|
||||
|
||||
----------
|
||||
|
||||
[NetDev]
|
||||
Name=br0
|
||||
Kind=bridge
|
||||
|
||||
然后按照下面这样用 .network 文件配置网桥接口 br0 和从接口 eth1。
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0-slave.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=eth1
|
||||
|
||||
[Network]
|
||||
Bridge=br0
|
||||
|
||||
----------
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=br0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.100/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
最后,重启 systemd-networkd。
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
你可以用 [brctl 工具][3] 来验证是否创建好了网桥 br0。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
当 systemd 誓言成为 Linux 的系统管理器时,有类似 systemd-networkd 的东西来管理网络配置也就不足为奇。但是在现阶段,systemd-networkd 看起来更适合于网络配置相对稳定的服务器环境。对于桌面/笔记本环境,它们有多种临时有线/无线接口,NetworkManager 仍然是比较好的选择。
|
||||
|
||||
对于想进一步了解 systemd-networkd 的人,可以参考官方[man 手册][4]了解完整的支持列表和关键点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
|
||||
[2]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
|
||||
@ -0,0 +1,427 @@
|
||||
超神们:15 位健在的世界级程序员!
|
||||
================================================================================
|
||||
|
||||
当开发人员说起世界顶级程序员时,他们的名字往往会被提及。
|
||||
|
||||
好像现在程序员有很多,其中不乏有许多优秀的程序员。但是哪些程序员更好呢?
|
||||
|
||||
虽然这很难客观评价,不过在这个话题确实是开发者们津津乐道的。ITworld 深入程序员社区,避开四溅的争执口水,试图找出可能存在的所谓共识。事实证明,屈指可数的某些名字经常是讨论的焦点。
|
||||
|
||||

|
||||
|
||||
*图片来源: [tom_bullock CC BY 2.0][1]*
|
||||
|
||||
下面就让我们来看看这些世界顶级的程序员吧!
|
||||
|
||||
### 玛格丽特·汉密尔顿(Margaret Hamilton) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [NASA][2]*
|
||||
|
||||
**成就: 阿波罗飞行控制软件背后的大脑**
|
||||
|
||||
生平: 查尔斯·斯塔克·德雷珀实验室(Charles Stark Draper Laboratory)软件工程部的主任,以她为首的团队负责设计和打造 NASA 的阿波罗的舰载飞行控制器软件和空间实验室(Skylab)的任务。基于阿波罗这段的工作经历,她又后续开发了[通用系统语言(Universal Systems Language)][5]和[开发先于事实( Development Before the Fact)][6]的范例。开创了[异步软件、优先调度和超可靠的软件设计][7]理念。被认为发明了“[软件工程( software engineering)][8]”一词。1986年获[奥古斯塔·埃达·洛夫莱斯奖(Augusta Ada Lovelace Award)][9],2003年获 [NASA 杰出太空行动奖(Exceptional Space Act Award)][10]。
|
||||
|
||||
评论:
|
||||
|
||||
> “汉密尔顿发明了测试,使美国计算机工程规范了很多” —— [ford_beeblebrox][11]
|
||||
|
||||
> “我认为在她之前(不敬地说,包括高德纳(Knuth)在内的)计算机编程是(另一种形式上留存的)数学分支。然而这个宇宙飞船的飞行控制系统明确地将编程带入了一个崭新的领域。” —— [Dan Allen][12]
|
||||
|
||||
> “... 她引入了‘软件工程’这个术语 — 并作出了最好的示范。” —— [David Hamilton][13]
|
||||
|
||||
> “真是个坏家伙” [Drukered][14]
|
||||
|
||||
|
||||
### 唐纳德·克努斯(Donald Knuth),即 高德纳 ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [vonguard CC BY-SA 2.0][15]*
|
||||
|
||||
**成就: 《计算机程序设计艺术(The Art of Computer Programming,TAOCP)》 作者**
|
||||
|
||||
生平: 撰写了[编程理论的权威书籍][16]。发明了数字排版系统 Tex。1971年,[ACM(美国计算机协会)葛丽丝·穆雷·霍普奖(Grace Murray Hopper Award)][17] 的首位获奖者。1974年获 ACM [图灵奖(A. M. Turing)][18],1979年获[美国国家科学奖章(National Medal of Science)][19],1995年获IEEE[约翰·冯·诺依曼奖章(John von Neumann Medal)][20]。1998年入选[计算机历史博物馆(Computer History Museum)名人录(Hall of Fellows)][21]。
|
||||
|
||||
评论:
|
||||
|
||||
> “... 写的计算机编程艺术(The Art of Computer Programming,TAOCP)可能是有史以来计算机编程方面最大的贡献。”—— [佚名][22]
|
||||
|
||||
> “唐·克努斯的 TeX 是我所用过的计算机程序中唯一一个几乎没有 bug 的。真是让人印象深刻!”—— [Jaap Weel][23]
|
||||
|
||||
> “如果你要问我的话,我只能说太棒了!” —— [Mitch Rees-Jones][24]
|
||||
|
||||
### 肯·汤普逊(Ken Thompson) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Association for Computing Machinery][25]*
|
||||
|
||||
**成就: Unix 之父**
|
||||
|
||||
生平:与[丹尼斯·里奇(Dennis Ritchie)][26]共同创造了 Unix。创造了 [B 语言][27]、[UTF-8 字符编码方案][28]、[ed 文本编辑器][29],同时也是 Go 语言的共同开发者。(和里奇)共同获得1983年的[图灵奖(A.M. Turing Award )][30],1994年获 [IEEE 计算机先驱奖( IEEE Computer Pioneer Award)][31],1998年获颁[美国国家科技奖章( National Medal of Technology )][32]。在1997年入选[计算机历史博物馆(Computer History Museum)名人录(Hall of Fellows)][33]。
|
||||
|
||||
评论:
|
||||
|
||||
> “... 可能是有史以来最能成事的程序员了。Unix 内核,Unix 工具,国际象棋程序世界冠军 Belle,Plan 9,Go 语言。” —— [Pete Prokopowicz][34]
|
||||
|
||||
> “肯所做出的贡献,据我所知无人能及,是如此的根本、实用、经得住时间的考验,时至今日仍在使用。” —— [Jan Jannink][35]
|
||||
|
||||
|
||||
### 理查德·斯托曼(Richard Stallman) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Jiel Beaumadier CC BY-SA 3.0][135]*
|
||||
|
||||
**成就: Emacs 和 GCC 缔造者**
|
||||
|
||||
生平: 成立了 [GNU 工程(GNU Project)] [36],并创造了它的许多核心工具,如 [Emacs、GCC、GDB][37] 和 [GNU Make][38]。还创办了[自由软件基金会(Free Software Foundation)] [39]。1990年荣获 ACM 的[葛丽丝·穆雷·霍普奖( Grace Murray Hopper Award)][40],1998年获 [EFF 先驱奖(Pioneer Award)][41].
|
||||
|
||||
评论:
|
||||
|
||||
> “... 在 Symbolics 对阵 LMI 的战斗中,独自一人与一众 Lisp 黑客好手对码。” —— [Srinivasan Krishnan][42]
|
||||
|
||||
> “通过他在编程上的精湛造诣与强大信念,开辟了一整套编程与计算机的亚文化。” —— [Dan Dunay][43]
|
||||
|
||||
> “我可以不赞同这位伟人的很多方面,不必盖棺论定,他不可否认都已经是一位伟大的程序员了。” —— [Marko Poutiainen][44]
|
||||
|
||||
> “试想 Linux 如果没有 GNU 工程的前期工作会怎么样。(多亏了)斯托曼的炸弹!” —— [John Burnette][45]
|
||||
|
||||
### 安德斯·海尔斯伯格(Anders Hejlsberg) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [D.Begley CC BY 2.0][46]*
|
||||
|
||||
**成就: 创造了Turbo Pascal**
|
||||
|
||||
生平: [Turbo Pascal 的原作者][47],是最流行的 Pascal 编译器和第一个集成开发环境。而后,[领导了 Turbo Pascal 的继任者 Delphi][48] 的构建。[C# 的主要设计师和架构师][49]。2001年荣获[ Dr. Dobb 的杰出编程奖(Dr. Dobb's Excellence in Programming Award )][50]。
|
||||
|
||||
评论:
|
||||
|
||||
> “他用汇编语言为当时两个主流的 PC 操作系统(DOS 和 CPM)编写了 [Pascal] 编译器。用它来编译、链接并运行仅需几秒钟而不是几分钟。” —— [Steve Wood][51]
|
||||
|
||||
> “我佩服他 - 他创造了我最喜欢的开发工具,陪伴着我度过了三个关键的时期直至我成为一位专业的软件工程师。” —— [Stefan Kiryazov][52]
|
||||
|
||||
### Doug Cutting ###
|
||||
|
||||

|
||||
|
||||
图片来源: [vonguard CC BY-SA 2.0][53]
|
||||
|
||||
**成就: 创造了 Lucene**
|
||||
|
||||
生平: [开发了 Lucene 搜索引擎以及 Web 爬虫 Nutch][54] 和用于大型数据集的分布式处理套件 [Hadoop][55]。一位强有力的开源支持者(Lucene、Nutch 以及 Hadoop 都是开源的)。前 [Apache 软件基金(Apache Software Foundation)的理事][56]。
|
||||
|
||||
评论:
|
||||
|
||||
|
||||
> “...他就是那个既写出了优秀搜索框架(lucene/solr),又为世界开启大数据之门(hadoop)的男人。” —— [Rajesh Rao][57]
|
||||
|
||||
> “他在 Lucene 和 Hadoop(及其它工程)的创造/工作中为世界创造了巨大的财富和就业...” —— [Amit Nithianandan][58]
|
||||
|
||||
### Sanjay Ghemawat ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Association for Computing Machinery][59]*
|
||||
|
||||
**成就: 谷歌核心架构师**
|
||||
|
||||
生平: [协助设计和实现了一些谷歌大型分布式系统的功能][60],包括 MapReduce、BigTable、Spanner 和谷歌文件系统(Google File System)。[创造了 Unix 的 ical ][61]日历系统。2009年入选[美国国家工程院(National Academy of Engineering)][62]。2012年荣获 [ACM-Infosys 基金计算机科学奖( ACM-Infosys Foundation Award in the Computing Sciences)][63]。
|
||||
|
||||
评论:
|
||||
|
||||
|
||||
> “Jeff Dean的僚机。” —— [Ahmet Alp Balkan][64]
|
||||
|
||||
### Jeff Dean ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Google][65]*
|
||||
|
||||
**成就: 谷歌搜索索引背后的大脑**
|
||||
|
||||
生平:协助设计和实现了[许多谷歌大型分布式系统的功能][66],包括网页爬虫,索引搜索,AdSense,MapReduce,BigTable 和 Spanner。2009年入选[美国国家工程院( National Academy of Engineering)][67]。2012年荣获ACM 的[SIGOPS 马克·维瑟奖( SIGOPS Mark Weiser Award)][68]及[ACM-Infosys基金计算机科学奖( ACM-Infosys Foundation Award in the Computing Sciences)][69]。
|
||||
|
||||
评论:
|
||||
|
||||
> “... 带来了在数据挖掘(GFS、MapReduce、BigTable)上的突破。” —— [Natu Lauchande][70]
|
||||
|
||||
> “... 设计、构建并部署 MapReduce 和 BigTable,和以及数不清的其它东西” —— [Erik Goldman][71]
|
||||
|
||||
### 林纳斯·托瓦兹(Linus Torvalds) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Krd CC BY-SA 4.0][72]*
|
||||
|
||||
**成就: Linux缔造者**
|
||||
|
||||
生平:创造了 [Linux 内核][73]与[开源的版本控制系统 Git][74]。收获了许多奖项和荣誉,包括有1998年的 [EFF 先驱奖(EFF Pioneer Award)][75],2000年荣获[英国电脑学会(British Computer Society)授予的洛夫莱斯勋章(Lovelace Medal)][76],2012年荣获[千禧技术奖(Millenium Technology Prize)][77]还有2014年[IEEE计算机学会( IEEE Computer Society)授予的计算机先驱奖(Computer Pioneer Award)][78]。同样入选了2008年的[计算机历史博物馆( Computer History Museum)名人录(Hall of Fellows)][79]与2012年的[互联网名人堂(Internet Hall of Fame )][80]。
|
||||
|
||||
评论:
|
||||
|
||||
> “他只用了几年的时间就写出了 Linux 内核,而 GNU Hurd(GNU 开发的内核)历经25年的开发却丝毫没有准备发布的意思。他的成就就是带来了希望。” —— [Erich Ficker][81]
|
||||
|
||||
> “托沃兹可能是程序员的程序员。” —— [Dan Allen][82]
|
||||
|
||||
> “他真的很棒。” —— [Alok Tripathy][83]
|
||||
|
||||
### 约翰·卡马克(John Carmack) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [QuakeCon CC BY 2.0][84]*
|
||||
|
||||
**成就: 毁灭战士的缔造者**
|
||||
|
||||
生平: ID 社联合创始人,打造了德军总部3D(Wolfenstein 3D)、毁灭战士(Doom)和雷神之锤(Quake)等所谓的即时 FPS 游戏。引领了[切片适配刷新(adaptive tile refresh)][86], [二叉空间分割(binary space partitioning)][87],表面缓存(surface caching)等开创性的计算机图像技术。2001年入选[互动艺术与科学学会名人堂(Academy of Interactive Arts and Sciences Hall of Fame)][88],2007年和2008年荣获工程技术类[艾美奖(Emmy awards)][89]并于2010年由[游戏开发者甄选奖( Game Developers Choice Awards)][90]授予终生成就奖。
|
||||
|
||||
评论:
|
||||
|
||||
> “他在写第一个渲染引擎的时候不到20岁。这家伙这是个天才。我若有他四分之一的天赋便心满意足了。” —— [Alex Dolinsky][91]
|
||||
|
||||
> “... 德军总部3D(Wolfenstein 3D)、毁灭战士(Doom)还有雷神之锤(Quake)在那时都是革命性的,影响了一代游戏设计师。” —— [dniblock][92]
|
||||
|
||||
> “一个周末他几乎可以写出任何东西....” —— [Greg Naughton][93]
|
||||
|
||||
> “他是编程界的莫扎特... ” —— [Chris Morris][94]
|
||||
|
||||
### 法布里斯·贝拉(Fabrice Bellard) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Duff][95]*
|
||||
|
||||
**成就: 创造了 QEMU**
|
||||
|
||||
生平: 创造了[一系列耳熟能详的开源软件][96],其中包括硬件模拟和虚拟化的平台 QEMU,用于处理多媒体数据的 FFmpeg,微型C编译器(Tiny C Compiler)和 一个可执行文件压缩软件 LZEXE。2000年和2001年[C语言混乱代码大赛(Obfuscated C Code Contest)的获胜者][97]并在2011年荣获[Google-O'Reilly 开源奖(Google-O'Reilly Open Source Award )][98]。[计算 Pi 最多位数][99]的前世界纪录保持着。
|
||||
|
||||
评论:
|
||||
|
||||
|
||||
> “我觉得法布里斯·贝拉做的每一件事都是那么显著而又震撼。” —— [raphinou][100]
|
||||
|
||||
> “法布里斯·贝拉是世界上最高产的程序员...” —— [Pavan Yara][101]
|
||||
|
||||
> “他就像软件工程界的尼古拉·特斯拉(Nikola Tesla)。” —— [Michael Valladolid][102]
|
||||
|
||||
> “自80年代以来,他一直高产出一系列的成功作品。” —— [Michael Biggins][103]
|
||||
|
||||
### Jon Skeet ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Craig Murphy CC BY 2.0][104]*
|
||||
|
||||
**成就: Stack Overflow 的传说级贡献者**
|
||||
|
||||
生平: Google 工程师,[深入解析C#(C# in Depth)][105]的作者。保持着[有史以来在 Stack Overflow 上最高的声誉][106],平均每月解答390个问题。
|
||||
|
||||
评论:
|
||||
|
||||
|
||||
> “他根本不需要调试器,只要他盯一下代码,错误之处自会原形毕露。” —— [Steven A. Lowe][107]
|
||||
|
||||
> “如果他的代码没有通过编译,那编译器应该道歉。” —— [Dan Dyer][108]
|
||||
|
||||
> “他根本不需要什么编程规范,他的代码就是编程规范。” —— [佚名][109]
|
||||
|
||||
### 亚当·安捷罗(Adam D'Angelo) ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Philip Neustrom CC BY 2.0][110]*
|
||||
|
||||
**成就: Quora 的创办人之一**
|
||||
|
||||
生平: 还是 Facebook 工程师时,[为其搭建了 news feed 功能的基础][111]。直至其离开并联合创始了 Quora,已经成为了 Facebook 的CTO和工程 VP。2001年以高中生的身份在[美国计算机奥林匹克(USA Computing Olympiad)上第八位完成比赛][112]。2004年ACM国际大学生编程大赛(International Collegiate Programming Contest)[获得银牌的团队 - 加利福尼亚技术研究所( California Institute of Technology)][113]的成员。2005年入围 Topcoder 大学生[算法编程挑战赛(Algorithm Coding Competition)][114]。
|
||||
|
||||
评论:
|
||||
|
||||
> “一位程序设计全才。” —— [佚名][115]
|
||||
|
||||
> "我做的每个好东西,他都已有了六个。" —— [马克.扎克伯格(Mark Zuckerberg)][116]
|
||||
|
||||
### Petr Mitrechev ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Facebook][117]*
|
||||
|
||||
**成就: 有史以来最具竞技能力的程序员之一**
|
||||
|
||||
生平: 在国际信息学奥林匹克(International Olympiad in Informatics)中[两次获得金牌][118](2000,2002)。在2006,[赢得 Google Code Jam][119] 同时也是[TopCoder Open 算法大赛冠军][120]。也同样,两次赢得 Facebook黑客杯(Facebook Hacker Cup)([2011][121],[2013][122])。写这篇文章的时候,[TopCoder 榜中排第二][123] (即:Petr)、在 [Codeforces 榜同样排第二][124]。
|
||||
|
||||
评论:
|
||||
|
||||
> “他是竞技程序员的偶像,即使在印度也是如此...” —— [Kavish Dwivedi][125]
|
||||
|
||||
### Gennady Korotkevich ###
|
||||
|
||||

|
||||
|
||||
*图片来源: [Ishandutta2007 CC BY-SA 3.0][126]*
|
||||
|
||||
**成就: 竞技编程小神童**
|
||||
|
||||
生平: 国际信息学奥林匹克(International Olympiad in Informatics)中最小参赛者(11岁),[6次获得金牌][127] (2007-2012)。2013年 ACM 国际大学生编程大赛(International Collegiate Programming Contest)[获胜队伍][128]成员及[2014 Facebook 黑客杯(Facebook Hacker Cup)][129]获胜者。写这篇文章的时候,[Codeforces 榜排名第一][130] (即:Tourist)、[TopCoder榜第一][131]。
|
||||
|
||||
评论:
|
||||
|
||||
> “一个编程神童!” —— [Prateek Joshi][132]
|
||||
|
||||
> “Gennady 真是棒,也是为什么我在白俄罗斯拥有一个强大开发团队的例证。” —— [Chris Howard][133]
|
||||
|
||||
> “Tourist 真是天才” —— [Nuka Shrinivas Rao][134]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
|
||||
|
||||
作者:[Phil Johnson][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Phil-Johnson/
|
||||
[1]:https://www.flickr.com/photos/tombullock/15713223772
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
|
||||
[3]:http://klabs.org/home_page/hamilton.htm
|
||||
[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
|
||||
[5]:http://www.htius.com/Articles/r12ham.pdf
|
||||
[6]:http://www.htius.com/Articles/Inside_DBTF.htm
|
||||
[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
|
||||
[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
|
||||
[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
|
||||
[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
|
||||
[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
|
||||
[12]:http://qr.ae/RFEZLk
|
||||
[13]:http://qr.ae/RFEZUn
|
||||
[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
|
||||
[15]:https://www.flickr.com/photos/44451574@N00/5347112697
|
||||
[16]:http://cs.stanford.edu/~uno/taocp.html
|
||||
[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
|
||||
[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
|
||||
[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
|
||||
[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
|
||||
[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
|
||||
[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
|
||||
[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
|
||||
[24]:http://qr.ae/RFE94x
|
||||
[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
|
||||
[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
|
||||
[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
|
||||
[28]:http://doc.cat-v.org/bell_labs/utf-8_history
|
||||
[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
|
||||
[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
|
||||
[31]:http://www.computer.org/portal/web/awards/cp-thompson
|
||||
[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
|
||||
[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
|
||||
[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
|
||||
[35]:http://qr.ae/RFEWBY
|
||||
[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[37]:http://www.emacswiki.org/emacs/RichardStallman
|
||||
[38]:https://www.gnu.org/gnu/thegnuproject.html
|
||||
[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
|
||||
[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
|
||||
[41]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
|
||||
[43]:http://qr.ae/RFEaib
|
||||
[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
|
||||
[45]:http://qr.ae/RFEUqp
|
||||
[46]:https://www.flickr.com/photos/begley/2979906130
|
||||
[47]:http://www.taoyue.com/tutorials/pascal/history.html
|
||||
[48]:http://c2.com/cgi/wiki?AndersHejlsberg
|
||||
[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
|
||||
[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
|
||||
[51]:http://qr.ae/RFEZrv
|
||||
[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
|
||||
[53]:https://www.flickr.com/photos/vonguard/4076389963/
|
||||
[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
|
||||
[55]:http://hadoop.apache.org/
|
||||
[56]:https://www.linkedin.com/in/cutting
|
||||
[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
|
||||
[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
|
||||
[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[60]:http://research.google.com/pubs/SanjayGhemawat.html
|
||||
[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
|
||||
[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
|
||||
[65]:http://research.google.com/people/jeff/index.html
|
||||
[66]:http://research.google.com/people/jeff/index.html
|
||||
[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
|
||||
[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
|
||||
[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
|
||||
[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
|
||||
[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
|
||||
[73]:http://www.linuxfoundation.org/about/staff#torvalds
|
||||
[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
|
||||
[75]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[76]:http://www.bcs.org/content/ConWebDoc/14769
|
||||
[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
|
||||
[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
|
||||
[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
|
||||
[80]:http://www.internethalloffame.org/inductees/linus-torvalds
|
||||
[81]:http://qr.ae/RFEeeo
|
||||
[82]:http://qr.ae/RFEZLk
|
||||
[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
|
||||
[84]:https://www.flickr.com/photos/quakecon/9434713998
|
||||
[85]:http://doom.wikia.com/wiki/John_Carmack
|
||||
[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
|
||||
[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
|
||||
[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
|
||||
[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
|
||||
[90]:http://www.gamechoiceawards.com/archive/lifetime.html
|
||||
[91]:http://qr.ae/RFEEgr
|
||||
[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
|
||||
[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
|
||||
[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
|
||||
[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
|
||||
[96]:http://bellard.org/
|
||||
[97]:http://www.ioccc.org/winners.html#B
|
||||
[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
|
||||
[99]:http://bellard.org/pi/pi2700e9/
|
||||
[100]:https://news.ycombinator.com/item?id=7850797
|
||||
[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
|
||||
[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
|
||||
[103]:http://qr.ae/RFEjhZ
|
||||
[104]:https://www.flickr.com/photos/craigmurphy/4325516497
|
||||
[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
|
||||
[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
|
||||
[107]:http://meta.stackexchange.com/a/9156
|
||||
[108]:http://meta.stackexchange.com/a/9138
|
||||
[109]:http://meta.stackexchange.com/a/9182
|
||||
[110]:https://www.flickr.com/photos/philipn/5326344032
|
||||
[111]:http://www.crunchbase.com/person/adam-d-angelo
|
||||
[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
|
||||
[113]:http://icpc.baylor.edu/community/results-2004
|
||||
[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
|
||||
[115]:http://qr.ae/RFfOfe
|
||||
[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
|
||||
[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[118]:http://stats.ioinformatics.org/people/1849
|
||||
[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
|
||||
[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
|
||||
[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
|
||||
[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[123]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[124]:http://codeforces.com/ratings
|
||||
[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
|
||||
[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
|
||||
[127]:http://stats.ioinformatics.org/people/804
|
||||
[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
|
||||
[129]:https://www.facebook.com/hackercup/posts/10152022955628845
|
||||
[130]:http://codeforces.com/ratings
|
||||
[131]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
|
||||
[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
|
||||
[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
|
||||
[135]:http://commons.wikimedia.org/wiki/File:Jielbeaumadier_richard_stallman_2010.jpg
|
||||
@ -1,9 +1,9 @@
|
||||
|
||||
在 Ubuntu 14.04 中配置 PXE 服务器
|
||||
在 Ubuntu 14.04 中配置 PXE 服务器
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
PXE(Preboot Execution Environment--预启动执行环境)服务器允许用户从网络中启动 Linux 发行版并且可以同时在数百台 PC 中安装而不需要 Linux ISO 镜像。如果你客户端的计算机没有 CD/DVD 或USB 引导盘,或者如果你想在大型企业中同时安装多台计算机,那么 PXE 服务器可以帮你节省时间和金钱。
|
||||
PXE(Preboot Execution Environment--预启动执行环境)服务器允许用户从网络中启动 Linux 发行版并且可以不需要 Linux ISO 镜像就能同时在数百台 PC 中安装。如果你客户端的计算机没有 CD/DVD 或USB 引导盘,或者如果你想在大型企业中同时安装多台计算机,那么 PXE 服务器可以帮你节省时间和金钱。
|
||||
|
||||
在这篇文章中,我们将告诉你如何在 Ubuntu 14.04 配置 PXE 服务器。
|
||||
|
||||
@ -11,11 +11,11 @@ PXE(Preboot Execution Environment--预启动执行环境)服务器允许用
|
||||
|
||||
开始前,你需要先设置 PXE 服务器使用静态 IP。在你的系统中要使用静态 IP 地址,需要编辑 “/etc/network/interfaces” 文件。
|
||||
|
||||
1. 打开 “/etc/network/interfaces” 文件.
|
||||
打开 “/etc/network/interfaces” 文件.
|
||||
|
||||
sudo nano /etc/network/interfaces
|
||||
|
||||
作如下修改:
|
||||
作如下修改:
|
||||
|
||||
# 回环网络接口
|
||||
auto lo
|
||||
@ -43,23 +43,23 @@ DHCP,TFTP 和 NFS 是 PXE 服务器的重要组成部分。首先,需要更
|
||||
|
||||
### 配置 DHCP 服务: ###
|
||||
|
||||
DHCP 代表动态主机配置协议(Dynamic Host Configuration Protocol),并且它主要用于动态分配网络配置参数,如用于接口和服务的 IP 地址。在 PXE 环境中,DHCP 服务器允许客户端请求并自动获得一个 IP 地址来访问网络。
|
||||
DHCP 代表动态主机配置协议(Dynamic Host Configuration Protocol),它主要用于动态分配网络配置参数,如用于接口和服务的 IP 地址。在 PXE 环境中,DHCP 服务器允许客户端请求并自动获得一个 IP 地址来访问网络。
|
||||
|
||||
1. 编辑 “/etc/default/dhcp3-server” 文件.
|
||||
1、编辑 “/etc/default/dhcp3-server” 文件.
|
||||
|
||||
sudo nano /etc/default/dhcp3-server
|
||||
|
||||
作如下修改:
|
||||
作如下修改:
|
||||
|
||||
INTERFACES="eth0"
|
||||
|
||||
保存 (Ctrl + o) 并退出 (Ctrl + x) 文件.
|
||||
|
||||
2. 编辑 “/etc/dhcp3/dhcpd.conf” 文件:
|
||||
2、编辑 “/etc/dhcp3/dhcpd.conf” 文件:
|
||||
|
||||
sudo nano /etc/dhcp/dhcpd.conf
|
||||
|
||||
作如下修改:
|
||||
作如下修改:
|
||||
|
||||
default-lease-time 600;
|
||||
max-lease-time 7200;
|
||||
@ -74,29 +74,29 @@ DHCP 代表动态主机配置协议(Dynamic Host Configuration Protocol),
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
3. 启动 DHCP 服务.
|
||||
3、启动 DHCP 服务.
|
||||
|
||||
sudo /etc/init.d/isc-dhcp-server start
|
||||
|
||||
### 配置 TFTP 服务器: ###
|
||||
|
||||
TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证也不能列出目录。TFTP 服务器总是监听网络上的 PXE 客户端。当它检测到网络中有 PXE 客户端请求 PXE 服务器时,它将提供包含引导菜单的网络数据包。
|
||||
TFTP 是一种文件传输协议,类似于 FTP,但它不用进行用户认证也不能列出目录。TFTP 服务器总是监听网络上的 PXE 客户端的请求。当它检测到网络中有 PXE 客户端请求 PXE 服务时,它将提供包含引导菜单的网络数据包。
|
||||
|
||||
1. 配置 TFTP 时,需要编辑 “/etc/inetd.conf” 文件.
|
||||
1、配置 TFTP 时,需要编辑 “/etc/inetd.conf” 文件.
|
||||
|
||||
sudo nano /etc/inetd.conf
|
||||
|
||||
作如下修改:
|
||||
作如下修改:
|
||||
|
||||
tftp dgram udp wait root /usr/sbin/in.tftpd /usr/sbin/in.tftpd -s /var/lib/tftpboot
|
||||
|
||||
保存文件并退出。
|
||||
保存文件并退出。
|
||||
|
||||
2. 编辑 “/etc/default/tftpd-hpa” 文件。
|
||||
2、编辑 “/etc/default/tftpd-hpa” 文件。
|
||||
|
||||
sudo nano /etc/default/tftpd-hpa
|
||||
|
||||
作如下修改:
|
||||
作如下修改:
|
||||
|
||||
TFTP_USERNAME="tftp"
|
||||
TFTP_DIRECTORY="/var/lib/tftpboot"
|
||||
@ -105,14 +105,14 @@ TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证
|
||||
RUN_DAEMON="yes"
|
||||
OPTIONS="-l -s /var/lib/tftpboot"
|
||||
|
||||
保存文件并退出。
|
||||
保存文件并退出。
|
||||
|
||||
3. 使用 `xinetd` 让 boot 服务在每次系统开机时自动启动,并启动tftpd服务。
|
||||
3、 使用 `xinetd` 让 boot 服务在每次系统开机时自动启动,并启动tftpd服务。
|
||||
|
||||
sudo update-inetd --enable BOOT
|
||||
sudo service tftpd-hpa start
|
||||
|
||||
4. 检查状态。
|
||||
4、检查状态。
|
||||
|
||||
sudo netstat -lu
|
||||
|
||||
@ -123,7 +123,7 @@ TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证
|
||||
|
||||
### 配置 PXE 启动文件 ###
|
||||
|
||||
现在,你需要将 PXE 引导文件 “pxelinux.0” 放在 TFTP 根目录下。为 TFTP 创建一个目录,并复制 syslinux 在 “/usr/lib/syslinux/” 下提供的所有引导程序文件到 “/var/lib/tftpboot/” 下,操作如下:
|
||||
现在,你需要将 PXE 引导文件 “pxelinux.0” 放在 TFTP 根目录下。为 TFTP 创建目录结构,并从 “/usr/lib/syslinux/” 复制 syslinux 提供的所有引导程序文件到 “/var/lib/tftpboot/” 下,操作如下:
|
||||
|
||||
sudo mkdir /var/lib/tftpboot
|
||||
sudo mkdir /var/lib/tftpboot/pxelinux.cfg
|
||||
@ -135,13 +135,13 @@ TFTP 是一种文件传输协议,类似于 FTP。它不用进行用户认证
|
||||
|
||||
PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导并与 TFTP 服务器关联。默认情况下,当一个 PXE 客户端启动时,它会使用自己的 MAC 地址指定要读取的配置文件,所以我们需要创建一个包含可引导内核列表的默认文件。
|
||||
|
||||
编辑 PXE 服务器配置文件使用可用的安装选项。.
|
||||
编辑 PXE 服务器配置文件,使用有效的安装选项。
|
||||
|
||||
编辑 “/var/lib/tftpboot/pxelinux.cfg/default,”
|
||||
编辑 “/var/lib/tftpboot/pxelinux.cfg/default”:
|
||||
|
||||
sudo nano /var/lib/tftpboot/pxelinux.cfg/default
|
||||
|
||||
作如下修改:
|
||||
作如下修改:
|
||||
|
||||
DEFAULT vesamenu.c32
|
||||
TIMEOUT 100
|
||||
@ -183,12 +183,12 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
|
||||
|
||||
### 为 PXE 服务器添加 Ubuntu 14.04 桌面启动镜像 ###
|
||||
|
||||
对于这一步,Ubuntu 内核和 initrd 文件是必需的。要获得这些文件,你需要 Ubuntu 14.04 桌面 ISO 镜像。你可以通过以下命令下载 Ubuntu 14.04 ISO 镜像到 /mnt 目录:
|
||||
对于这一步需要 Ubuntu 内核和 initrd 文件。要获得这些文件,你需要 Ubuntu 14.04 桌面 ISO 镜像。你可以通过以下命令下载 Ubuntu 14.04 ISO 镜像到 /mnt 目录:
|
||||
|
||||
sudo cd /mnt
|
||||
sudo wget http://releases.ubuntu.com/14.04/ubuntu-14.04.3-desktop-amd64.iso
|
||||
|
||||
**注意**: 下载用的 URL 可能会改变,因为 ISO 镜像会进行更新。如果上面的网址无法访问,看看这个网站,了解最新的下载链接。
|
||||
**注意**: 下载用的 URL 可能会改变,因为 ISO 镜像会进行更新。如果上面的网址无法访问,看看[这个网站][4],了解最新的下载链接。
|
||||
|
||||
挂载 ISO 文件,使用以下命令将所有文件复制到 TFTP文件夹中:
|
||||
|
||||
@ -199,9 +199,9 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
|
||||
|
||||
### 将导出的 ISO 目录配置到 NFS 服务器上 ###
|
||||
|
||||
现在,你需要通过 NFS 协议安装源镜像。你还可以使用 HTTP 和 FTP 来安装源镜像。在这里,我已经使用 NFS 导出 ISO 内容。
|
||||
现在,你需要通过 NFS 协议来设置“安装源镜像( Installation Source Mirrors)”。你还可以使用 HTTP 和 FTP 来安装源镜像。在这里,我已经使用 NFS 输出 ISO 内容。
|
||||
|
||||
要配置 NFS 服务器,你需要编辑 “etc/exports” 文件。
|
||||
要配置 NFS 服务器,你需要编辑 “/etc/exports” 文件。
|
||||
|
||||
sudo nano /etc/exports
|
||||
|
||||
@ -209,7 +209,7 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
|
||||
|
||||
/var/lib/tftpboot/Ubuntu/14.04/amd64 *(ro,async,no_root_squash,no_subtree_check)
|
||||
|
||||
保存文件并退出。为使更改生效,启动 NFS 服务。
|
||||
保存文件并退出。为使更改生效,输出并启动 NFS 服务。
|
||||
|
||||
sudo exportfs -a
|
||||
sudo /etc/init.d/nfs-kernel-server start
|
||||
@ -218,9 +218,9 @@ PXE 配置文件定义了 PXE 客户端启动时显示的菜单,它能引导
|
||||
|
||||
### 配置网络引导 PXE 客户端 ###
|
||||
|
||||
PXE 客户端可以被任何具备 PXE 网络引导的系统来启用。现在,你的客户端可以启动并安装 Ubuntu 14.04 桌面,需要在系统的 BIOS 中设置 “Boot From Network” 选项。
|
||||
PXE 客户端可以是任何支持 PXE 网络引导的计算机系统。现在,你的客户端只需要在系统的 BIOS 中设置 “从网络引导(Boot From Network)” 选项就可以启动并安装 Ubuntu 14.04 桌面。
|
||||
|
||||
现在你可以去做 - 用网络引导启动你的 PXE 客户端计算机,你现在应该看到一个子菜单,显示了我们创建的 Ubuntu 14.04 桌面。
|
||||
现在准备出发吧 - 用网络引导启动你的 PXE 客户端计算机,你现在应该看到一个子菜单,显示了我们创建的 Ubuntu 14.04 桌面的菜单项。
|
||||
|
||||

|
||||
|
||||
@ -241,7 +241,7 @@ via: https://www.maketecheasier.com/configure-pxe-server-ubuntu/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -249,3 +249,4 @@ via: https://www.maketecheasier.com/configure-pxe-server-ubuntu/
|
||||
[1]:https://en.wikipedia.org/wiki/Preboot_Execution_Environment
|
||||
[2]:https://help.ubuntu.com/community/PXEInstallServer
|
||||
[3]:https://www.flickr.com/photos/jhcalderon/3681926417/
|
||||
[4]:http://releases.ubuntu.com/14.04/
|
||||
@ -0,0 +1,128 @@
|
||||
一位开发者的 Linux 容器之旅
|
||||
================================================================================
|
||||

|
||||
|
||||
我告诉你一个秘密:使得我的应用程序进入到全世界的 DevOps 云计算之类的东西对我来说仍然有一点神秘。但随着时间流逝,我意识到理解大规模的机器增减和应用程序部署的来龙去脉对一个开发者来说是非常重要的知识。这类似于成为一个专业的音乐家,当然你肯定需要知道如何使用你的乐器,但是,如果你不知道一个录音棚是如何工作的,或者如何适应一个交响乐团,那么你在这样的环境中工作会变得非常困难。
|
||||
|
||||
在软件开发的世界里,使你的代码进入我们的更大的世界如同把它编写出来一样重要。DevOps 重要,而且是很重要。
|
||||
|
||||
因此,为了弥合开发(Dev)和部署(Ops)之间的空隙,我会从头开始介绍容器技术。为什么是容器?因为有强力的证据表明,容器是机器抽象的下一步:使计算机成为场所而不再是一个东西。理解容器是我们共同的旅程。
|
||||
|
||||
在这篇文章中,我会介绍容器化(containerization)背后的概念。包括容器和虚拟机的区别,以及容器构建背后的逻辑以及它是如何适应应用程序架构的。我会探讨轻量级的 Linux 操作系统是如何适应容器生态系统。我还会讨论使用镜像创建可重用的容器。最后我会介绍容器集群如何使你的应用程序可以快速扩展。
|
||||
|
||||
在后面的文章中,我会一步一步向你介绍容器化一个示例应用程序的过程,以及如何为你的应用程序容器创建一个托管集群。同时,我会向你展示如何使用 Deis 将你的示例应用程序部署到你本地系统以及多种云供应商的虚拟机上。
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
### 虚拟机的好处 ###
|
||||
|
||||
为了理解容器如何适应事物发展,你首先要了解容器的前任:虚拟机。
|
||||
|
||||
[虚拟机][1] (virtual machine (VM))是运行在物理宿主机上的软件抽象。配置一个虚拟机就像是购买一台计算机:你需要定义你想要的 CPU 数目、RAM 和磁盘存储容量。配置好了机器后,你为它加载操作系统,以及你想让虚拟机支持的任何服务器或者应用程序。
|
||||
|
||||
虚拟机允许你在一台硬件主机上运行多个模拟计算机。这是一个简单的示意图:
|
||||
|
||||

|
||||
|
||||
虚拟机可以让你能充分利用你的硬件资源。你可以购买一台巨大的、轰隆作响的机器,然后在上面运行多个虚拟机。你可以有一个数据库虚拟机以及很多运行相同版本的定制应用程序的虚拟机所构成的集群。你可以在有限的硬件资源获得很多的扩展能力。如果你觉得你需要更多的虚拟机而且你的宿主硬件还有容量,你可以添加任何你需要的虚拟机。或者,如果你不再需要一个虚拟机,你可以关闭该虚拟机并删除虚拟机镜像。
|
||||
|
||||
### 虚拟机的局限 ###
|
||||
|
||||
但是,虚拟机确实有局限。
|
||||
|
||||
如上面所示,假如你在一个主机上创建了三个虚拟机。主机有 12 个 CPU,48 GB 内存和 3TB 的存储空间。每个虚拟机配置为有 4 个 CPU,16 GB 内存和 1TB 存储空间。到现在为止,一切都还好。主机有这个容量。
|
||||
|
||||
但这里有个缺陷。所有分配给一个虚拟机的资源,无论是什么,都是专有的。每台机器都分配了 16 GB 的内存。但是,如果第一个虚拟机永不会使用超过 1GB 分配的内存,剩余的 15 GB 就会被浪费在那里。如果第三个虚拟机只使用分配的 1TB 存储空间中的 100GB,其余的 900GB 就成为浪费空间。
|
||||
|
||||
这里没有资源的流动。每台虚拟机拥有分配给它的所有资源。因此,在某种方式上我们又回到了虚拟机之前,把大部分金钱花费在未使用的资源上。
|
||||
|
||||
虚拟机还有*另一个*缺陷。让它们跑起来需要很长时间。如果你处于基础设施需要快速增长的情形,即使增加虚拟机是自动的,你仍然会发现你的很多时间都浪费在等待机器上线。
|
||||
|
||||
### 来到:容器 ###
|
||||
|
||||
概念上来说,容器是一个 Linux 进程,Linux 认为它只是一个运行中的进程。该进程只知道它被告知的东西。另外,在容器化方面,该容器进程也分配了它自己的 IP 地址。这点很重要,重要的事情讲三遍,这是第二遍。**在容器化方面,容器进程有它自己的 IP 地址。**一旦给予了一个 IP 地址,该进程就是宿主网络中可识别的资源。然后,你可以在容器管理器上运行命令,使容器 IP 映射到主机中能访问公网的 IP 地址。建立了该映射,无论出于什么意图和目的,容器就是网络上一个可访问的独立机器,从概念上类似于虚拟机。
|
||||
|
||||
这是第三遍,容器是拥有不同 IP 地址从而使其成为网络上可识别的独立 Linux 进程。下面是一个示意图:
|
||||
|
||||

|
||||
|
||||
容器/进程以动态、合作的方式共享主机上的资源。如果容器只需要 1GB 内存,它就只会使用 1GB。如果它需要 4GB,就会使用 4GB。CPU 和存储空间利用也是如此。CPU、内存和存储空间的分配是动态的,和典型虚拟机的静态方式不同。所有这些资源的共享都由容器管理器来管理。
|
||||
|
||||
最后,容器能非常快速地启动。
|
||||
|
||||
因此,容器的好处是:**你获得了虚拟机独立和封装的好处,而抛弃了静态资源专有的缺陷**。另外,由于容器能快速加载到内存,在扩展到多个容器时你能获得更好的性能。
|
||||
|
||||
### 容器托管、配置和管理 ###
|
||||
|
||||
托管容器的计算机运行着被剥离的只剩下主要部分的某个 Linux 版本。现在,宿主计算机流行的底层操作系统是之前提到的 [CoreOS][2]。当然还有其它,例如 [Red Hat Atomic Host][3] 和 [Ubuntu Snappy][4]。
|
||||
|
||||
该 Linux 操作系统被所有容器所共享,减少了容器足迹的重复和冗余。每个容器只包括该容器特有的部分。下面是一个示意图:
|
||||
|
||||

|
||||
|
||||
你可以用它所需的组件来配置容器。一个容器组件被称为**层(layer)**。层是一个容器镜像,(你会在后面的部分看到更多关于容器镜像的介绍)。你从一个基本层开始,这通常是你想在容器中使用的操作系统。(容器管理器只提供你所要的操作系统在宿主操作系统中不存在的部分。)当你构建你的容器配置时,你需要添加层,例如你想要添加网络服务器时这个层就是 Apache,如果容器要运行脚本,则需要添加 PHP 或 Python 运行时环境。
|
||||
|
||||
分层非常灵活。如果应用程序或者服务容器需要 PHP 5.2 版本,你相应地配置该容器即可。如果你有另一个应用程序或者服务需要 PHP 5.6 版本,没问题,你可以使用 PHP 5.6 配置该容器。不像虚拟机,更改一个版本的运行时依赖时你需要经过大量的配置和安装过程;对于容器你只需要在容器配置文件中重新定义层。
|
||||
|
||||
所有上面描述的容器的各种功能都由一个称为容器管理器(container manager)的软件控制。现在,最流行的容器管理器是 [Docker][5] 和 [Rocket][6]。上面的示意图展示了容器管理器是 Docker,宿主操作系统是 CentOS 的主机情景。
|
||||
|
||||
### 容器由镜像构成 ###
|
||||
|
||||
当你需要将我们的应用程序构建到容器时,你就要编译镜像。镜像代表了你的容器需要完成其工作的容器模板。(容器里可以在容器里面,如下图)。镜像存储在注册库(registry)中,注册库通过网络访问。
|
||||
|
||||
从概念上讲,注册库类似于一个使用 Java 的人眼中的 [Maven][7] 仓库、使用 .NET 的人眼中的 [NuGet][8] 服务器。你会创建一个列出了你应用程序所需镜像的容器配置文件。然后你使用容器管理器创建一个包括了你的应用程序代码以及从容器注册库中下载的部分资源。例如,如果你的应用程序包括了一些 PHP 文件,你的容器配置文件会声明你会从注册库中获取 PHP 运行时环境。另外,你还要使用容器配置文件声明需要复制到容器文件系统中的 .php 文件。容器管理器会封装你应用程序的所有东西为一个独立容器,该容器将会在容器管理器的管理下运行在宿主计算机上。
|
||||
|
||||
这是一个容器创建背后概念的示意图:
|
||||
|
||||

|
||||
|
||||
让我们仔细看看这个示意图。
|
||||
|
||||
(1)代表一个定义了你容器所需东西以及你容器如何构建的容器配置文件。当你在主机上运行容器时,容器管理器会读取该配置文件,从云上的注册库中获取你需要的容器镜像,(2)将镜像作为层添加到你的容器中。
|
||||
|
||||
另外,如果组成镜像需要其它镜像,容器管理器也会获取这些镜像并把它们作为层添加进来。(3)容器管理器会将需要的文件复制到容器中。
|
||||
|
||||
如果你使用了配置(provisioning)服务,例如 [Deis][9],你刚刚创建的应用程序容器做成镜像,(4)配置服务会将它部署到你选择的云供应商上,比如类似 AWS 和 Rackspace 云供应商。
|
||||
|
||||
### 集群中的容器 ###
|
||||
|
||||
好了。这里有一个很好的例子说明了容器比虚拟机提供了更好的配置灵活性和资源利用率。但是,这并不是全部。
|
||||
|
||||
容器真正的灵活是在集群中。记住,每个容器有一个独立的 IP 地址。因此,能把它放到负载均衡器后面。将容器放到负载均衡器后面,这就上升了一个层面。
|
||||
|
||||
你可以在一个负载均衡容器后运行容器集群以获得更高的性能和高可用计算。这是一个例子:
|
||||
|
||||

|
||||
|
||||
假如你开发了一个资源密集型的应用程序,例如图片处理。使用类似 [Deis][9] 的容器配置技术,你可以创建一个包括了你图片处理程序以及你图片处理程序需要的所有资源的容器镜像。然后,你可以部署一个或多个容器镜像到主机上的负载均衡器下。一旦创建了容器镜像,你可以随时使用它。当系统繁忙时可以添加更多的容器实例来满足手中的工作。
|
||||
|
||||
这里还有更多好消息。每次添加实例到环境中时,你不需要手动配置负载均衡器以便接受你的容器镜像。你可以使用服务发现技术让容器告知均衡器它可用。然后,一旦获知,均衡器就会将流量分发到新的结点。
|
||||
|
||||
### 全部放在一起 ###
|
||||
|
||||
容器技术完善了虚拟机缺失的部分。类似 CoreOS、RHEL Atomic、和 Ubuntu 的 Snappy 宿主操作系统,和类似 Docker 和 Rocket 的容器管理技术结合起来,使得容器变得日益流行。
|
||||
|
||||
尽管容器变得更加越来越普遍,掌握它们还是需要一段时间。但是,一旦你懂得了它们的窍门,你可以使用类似 [Deis][9] 这样的配置技术使容器创建和部署变得更加简单。
|
||||
|
||||
从概念上理解容器和进一步实际使用它们完成工作一样重要。但我认为不实际动手把想法付诸实践,概念也难以理解。因此,我们该系列的下一阶段就是:创建一些容器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://deis.com/blog/2015/developer-journey-linux-containers
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[2]:https://coreos.com/using-coreos/
|
||||
[3]:http://www.projectatomic.io/
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://coreos.com/blog/rocket/
|
||||
[7]:https://en.wikipedia.org/wiki/Apache_Maven
|
||||
[8]:https://www.nuget.org/
|
||||
[9]:http://deis.com/learn
|
||||
@ -1,26 +1,26 @@
|
||||
修复Sheell脚本在Ubuntu中用文本编辑器打开的方式
|
||||
修复 Shell 脚本在 Ubuntu 中的默认打开方式
|
||||
================================================================================
|
||||

|
||||
|
||||
当你双击一个脚本(.sh文件)的时候,你想要做的是什么?通常的想法是执行它。但是在Ubuntu下面却不是这样,或者我应该更确切地说是在Files(Nautilus)中。你可能会疯狂地大叫“运行文件,运行文件”,但是文件没有运行而是用Gedit打开了。
|
||||
当你双击一个脚本(.sh文件)的时候,你想要做的是什么?通常的想法是执行它。但是在Ubuntu下面却不是这样,或者我应该更确切地说是在Files(Nautilus)中。你可能会疯狂地大叫“运行文件,运行文件”,但是文件没有运行而是用Gedit打开了。
|
||||
|
||||
我知道你也许会说文件有可执行权限么?我会说是的。脚本有可执行权限但是当我双击它的时候,它还是用文本编辑器打开了。我不希望这样如果你遇到了同样的问题,我想你也许也不需要这样。
|
||||
我知道你也许会说文件有可执行权限么?我会说是的。脚本有可执行权限但是当我双击它的时候,它还是用文本编辑器打开了。我不希望这样,如果你遇到了同样的问题,我想你也许也想要这样。
|
||||
|
||||
我知道你或许已经被建议在终端下面运行,我知道这个可行但是这不是一个在GUI下不能运行的借口是么?
|
||||
我知道你或许已经被建议在终端下面执行,我知道这个可行,但是这不是一个在GUI下不能运行的借口是么?
|
||||
|
||||
这篇教程中,我们会看到**如何在双击后运行shell脚本。**
|
||||
|
||||
#### 修复在Ubuntu中shell脚本用文本编辑器打开的方式 ####
|
||||
|
||||
shell脚本用文件编辑器打开的原因是Files(Ubuntu中的文件管理器)中的默认行为设置。在更早的版本中,它或许会询问你是否运行文件或者用编辑器打开。默认的行位在新的版本中被修改了。
|
||||
shell脚本用文件编辑器打开的原因是Files(Ubuntu中的文件管理器)中的默认行为设置。在更早的版本中,它或许会询问你是否运行文件或者用编辑器打开。默认的行为在新的版本中被修改了。
|
||||
|
||||
要修复这个,进入文件管理器,并在菜单中点击**选项**:
|
||||
|
||||

|
||||
|
||||
接下来在**文件选项**中进入**行为**标签中,你会看到**文本文件执行**选项。
|
||||
接下来在**文件选项(Files Preferences)**中进入**行为(Behavior)**标签中,你会看到**可执行的文本文件(Executable Text Files)**选项。
|
||||
|
||||
默认情况下,它被设置成“在打开是显示文本文件”。我建议你把它改成“每次询问”,这样你可以选择是执行还是编辑了,当然了你也可以选择默认执行。你可以自行选择。
|
||||
默认情况下,它被设置成“在打开时显示文本文件(View executable text files when they are opend)”。我建议你把它改成“每次询问(Ask each time)”,这样你可以选择是执行还是编辑了,当然了你也可以选择“在打开时云可执行文本文件(Run executable text files when they are opend)”。你可以自行选择。
|
||||
|
||||

|
||||
|
||||
@ -32,7 +32,7 @@ via: http://itsfoss.com/shell-script-opens-text-editor/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,22 @@
|
||||
如何在Antergos Linux中使用iPhone
|
||||
如何在 Antergos Linux 中使用 iPhone
|
||||
================================================================================
|
||||

|
||||
|
||||
在Arch Linux中使用iPhone遇到麻烦了么?iPhone和Linux从来都没有集成的很好。本教程中,我会向你展示如何在Antergos Linux中使用iPhone,对于同样基于Arch的的Linux发行版如Manjaro也应该同样管用。
|
||||
在Arch Linux中使用iPhone遇到麻烦了么?iPhone和Linux从来都没有很好地集成。本教程中,我会向你展示如何在Antergos Linux中使用iPhone,对于同样基于Arch的的Linux发行版如Manjaro也应该同样管用。
|
||||
|
||||
我最近购买了一台全新的iPhone 6S,当我连接到Antergos Linux中要拷贝一些照片时,它完全没有检测到它。我看见iPhone正在被充电并且我已经允许了iPhone“信任这台电脑”,但是还是完全没有检测到。我尝试运行dmseg但是没有关于iPhone或者Apple的信息。有趣的是我已经安装了[libimobiledevice][1]。这个可以可以解决[iPhone在Ubuntu中的挂载问题][2]。
|
||||
我最近购买了一台全新的iPhone 6S,当我连接到Antergos Linux中要拷贝一些照片时,它完全没有检测到它。我看见iPhone正在被充电并且我已经允许了iPhone“信任这台电脑”,但是还是完全没有检测到。我尝试运行`dmseg`但是没有关于iPhone或者Apple的信息。有趣的是我当我安装好了[libimobiledevice][1],这个就可以解决[iPhone在Ubuntu中的挂载问题][2]。
|
||||
|
||||
我会向你展示如何在Antergos中使用运行iOS 9的iPhone 6S。这会有更多的命令行,但是我假设你用的是ArchLinux,并不惧怕使用终端(也不应该惧怕)、
|
||||
我会向你展示如何在Antergos中使用运行iOS 9的iPhone 6S。这会有更多的命令行,但是我假设你用的是ArchLinux,并不惧怕使用终端(也不应该惧怕)。
|
||||
|
||||
### 在Arch Linux中挂载iPhone ###
|
||||
|
||||
**第一步**:如果已经插入拔下你的iPhone
|
||||
**第一步**:如果已经插入,请拔下你的iPhone。
|
||||
|
||||
**第二步**:现在,打开终端输入下面的命令来安装必要的包。不要担心如果它们已经安装过了。
|
||||
**第二步**:现在,打开终端输入下面的命令来安装必要的包。如果它们已经安装过了也没有关系。
|
||||
|
||||
sudo pacman -Sy ifuse usbmuxd libplist libimobiledevice
|
||||
|
||||
**第三步**: 这些库和程序安装完成后,重启系统
|
||||
**第三步**: 这些库和程序安装完成后,重启系统。
|
||||
|
||||
sudo reboot
|
||||
|
||||
@ -24,11 +24,11 @@
|
||||
|
||||
mkdir ~/iPhone
|
||||
|
||||
**第五步**:解锁你的手机并插入,如果询问是否允许,请允许。
|
||||
**第五步**:解锁你的手机并插入,如果询问是否信任该计算机,请允许信任。
|
||||
|
||||

|
||||
|
||||
**第六步**: 验证这时iPhone已经被机器识别了。
|
||||
**第六步**: 看看这时iPhone是否已经被机器识别了。
|
||||
|
||||
dmesg | grep -i iphone
|
||||
|
||||
@ -46,7 +46,7 @@
|
||||
|
||||
ifuse ~/iPhone
|
||||
|
||||
由于我们在家目录中创建了挂载目录,你不需要root权限就可以在家目录中看见。如果命令成功了,你就不会看见输出。
|
||||
由于我们在家目录中创建了挂载目录,你不需要root权限就可以在家目录中看见。如果命令成功了,你就不会看见任何输出。
|
||||
|
||||
回到Files看下iPhone是否已经识别。对于我而言,在Antergos中看上去这样:
|
||||
|
||||
@ -62,7 +62,7 @@
|
||||
|
||||
### 对你有用么? ###
|
||||
|
||||
我知道这并不是非常方便和理想,iPhone应该像其他USB其他usb设备那样但是事情并不总是像人们想的那样。好事是一点小的DIY就能解决这个问题带来了一点成就感(至少对我而言)。我必须要说的是Antergos应该修复这个问题让iPhone可以默认挂载。
|
||||
我知道这并不是非常方便和理想,iPhone应该像其他USB设备那样工作,但是事情并不总是像人们想的那样。好的是一点小的DIY就能解决这个问题带来了一点成就感(至少对我而言)。我必须要说的是Antergos应该修复这个问题让iPhone可以默认挂载。
|
||||
|
||||
这个技巧对你有用么?如果你有任何问题或者建议,欢迎留下评论。
|
||||
|
||||
@ -72,7 +72,7 @@ via: http://itsfoss.com/iphone-antergos-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,25 @@
|
||||
命令行下使用Mop 监视股票价格
|
||||
命令行下使用 Mop 监视股票价格
|
||||
================================================================================
|
||||
有一份隐性收入通常很不错,特别是当你可以轻松的协调业余和全职工作。如果你的日常工作使用了联网的电脑,交易股票是一个很流行的选项来获取额外收入。
|
||||

|
||||
|
||||
有一份隐性收入通常很不错,特别是当你可以轻松的协调业余和全职工作。如果你的日常工作使用了联网的电脑,交易股票就是一个获取额外收入的很流行的选项。
|
||||
|
||||
但是目前只有很少的股票监视软件可以运行在 linux 上,其中大多数还是基于图形界面的。如果你是一个 Linux 专家,并且大量的工作时间是在没有图形界面的电脑上呢?你是不是就没办法了?不,还是有一些命令行下的股票追踪工具,包括Mop,也就是本文要聊一聊的工具。
|
||||
|
||||
但是目前只有很少的股票监视软件可以用在linux 上,其中大多数还是基于图形界面的。如果你是一个Linux 专家,并且大量的工作时间是在没有图形界面的电脑上呢?你是不是就没办法了?不,这里还有一个命令行下的股票追踪工具,包括Mop,也就是本文要聊一聊的工具。
|
||||
### Mop ###
|
||||
|
||||
Mop,如上所述,是一个命令行下连续显示和更新美股和独立股票信息的工具。使用GO 实现的,是Michael Dvorkin 大脑的产物。
|
||||
Mop,如上所述,是一个命令行下连续显示和更新美股和独立股票信息的工具。使用 GO 语言实现的,是 Michael Dvorkin 的智慧结晶。
|
||||
|
||||
### 下载安装 ###
|
||||
|
||||
|
||||
因为这个工程使用GO 实现的,所以你要做的第一步是在你的计算机上安装这种编程语言,下面就是在Debian 系系统,比如Ubuntu上安装GO的步骤:
|
||||
因为这个项目使用 GO 实现的,所以你要做的第一步是在你的计算机上安装这种编程语言,下面就是在 Debian 系的系统,比如 Ubuntu 上安装 GO 的步骤:
|
||||
|
||||
sudo apt-get install golang
|
||||
mkdir ~/workspace
|
||||
echo 'export GOPATH="$HOME/workspace"' >> ~/.bashrc
|
||||
source ~/.bashrc
|
||||
|
||||
GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是运行下面的命令:
|
||||
GO 安装好后的下一步是安装 Mop 工具和配置环境,你要做的是运行下面的命令:
|
||||
|
||||
sudo apt-get install git
|
||||
go get github.com/michaeldv/mop
|
||||
@ -24,12 +27,13 @@ GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是
|
||||
make install
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
完成之后就可以运行下面的命令执行Mop:
|
||||
完成之后就可以运行下面的命令执行 Mop:
|
||||
|
||||
cmd
|
||||
|
||||
### 特性 ###
|
||||
|
||||
当你第一次运行Mop 时,你会看到类似下面的输出信息:
|
||||
当你第一次运行 Mop 时,你会看到类似下面的输出信息:
|
||||
|
||||

|
||||
|
||||
@ -37,19 +41,19 @@ GO 安装好后的下一步是安装Mop 工具和配置环境,你要做的是
|
||||
|
||||
### 添加删除股票 ###
|
||||
|
||||
Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,你全部要做的是按”+“和输入股票名称。举个例子,下图就是添加Facebook (FB) 到列表里。
|
||||
Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,你全部要做的是按“+”和输入股票名称。举个例子,下图就是添加 Facebook (FB) 到列表里。
|
||||
|
||||

|
||||
|
||||
因为我按下了”+“键,一列包含文本”Add tickers:“出现了,提示我添加股票名称—— 我添加了FB 然后按下回车。输出列表更新了,我添加的新股票也出现在列表了:
|
||||
我按下了“+”键,就出现了包含文本“Add tickers:”的一列,提示我添加股票名称—— 我添加了 FB 然后按下回车。输出列表更新了,我添加的新股票也出现在列表了:
|
||||
|
||||

|
||||
|
||||
类似的,你可以使用”-“ 键和提供股票名称删除一个股票。
|
||||
类似的,你可以使用“-”键和提供股票名称删除一个股票。
|
||||
|
||||
#### 根据价格分组 ####
|
||||
|
||||
还有一个把股票分组的办法:依据他们的股价升跌,你索要做的就是按下”g“ 键。接下来,股票会分组显示:升的在一起使用绿色字体显示,而下跌的股票会黑色字体显示。
|
||||
还有一个把股票分组的办法:依据他们的股价升跌,你所要做的就是按下“g”键。接下来,股票会分组显示:升的在一起使用绿色字体显示,而下跌的股票会黑色字体显示。
|
||||
|
||||
如下所示:
|
||||
|
||||
@ -57,7 +61,7 @@ Mop 允许你轻松的从输出列表上添加/删除个股信息。要添加,
|
||||
|
||||
#### 列排序 ####
|
||||
|
||||
Mop 同时也允许你根据不同的列类型改变排序规则。这种用法需要你按下”o“(这个命令默认使用第一列的值来排序),然后使用左右键来选择你要使用的列。完成之后按下回车对内容重新排序。
|
||||
Mop 同时也允许你根据不同的列类型改变排序规则。这种用法需要你按下“o”(这个命令默认使用第一列的值来排序),然后使用左右键来选择你要排序的列。完成之后按下回车对内容重新排序。
|
||||
|
||||
举个例子,下面的截图就是根据输出内容的第一列、按照字母表排序之后的结果。
|
||||
|
||||
@ -67,12 +71,13 @@ Mop 同时也允许你根据不同的列类型改变排序规则。这种用法
|
||||
|
||||
#### 其他选项 ####
|
||||
|
||||
其它的可用选项包括”p“:暂停市场和股票信息更新,”q“ 或者”esc“ 来退出命令行程序,”?“ 显示帮助页。
|
||||
其它的可用选项包括“p”:暂停市场和股票信息更新,“q”或者“esc” 来退出命令行程序,“?”显示帮助页。
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
Mop 是一个基础的股票监控工具,并没有提供太多的特性,只提供了他声称的功能。很明显,这个工具并不是为专业股票交易者提供的,而仅仅为你在只有命令行的机器上得体的提供了一个跟踪股票信息的选择。
|
||||
Mop 是一个基础的股票监控工具,并没有提供太多的特性,只提供了它所声称的功能。很明显,这个工具并不是为专业股票交易者提供的,而仅仅为你在只有命令行的机器上得体的提供了一个跟踪股票信息的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -80,7 +85,7 @@ via: https://www.maketecheasier.com/monitor-stock-prices-ubuntu-command-line/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,8 @@
|
||||
如何在 CentOS 7.0 上配置 Ceph 存储
|
||||
How to Setup Red Hat Ceph Storage on CentOS 7.0
|
||||
================================================================================
|
||||
Ceph 是一个将数据存储在单一分布式计算机集群上的开源软件平台。当你计划构建一个云时,你首先需要决定如何实现你的存储。开源的 CEPH 是红帽原生技术之一,它基于称为 RADOS 的对象存储系统,用一组网关 API 表示块、文件、和对象模式中的数据。由于它自身开源的特性,这种便携存储平台能在公有和私有云上安装和使用。Ceph 集群的拓扑结构是按照备份和信息分布设计的,这内在设计能提供数据完整性。它的设计目标就是容错、通过正确配置能运行于商业硬件和一些更高级的系统。
|
||||
Ceph 是一个将数据存储在单一分布式计算机集群上的开源软件平台。当你计划构建一个云时,你首先需要决定如何实现你的存储。开源的 Ceph 是红帽原生技术之一,它基于称为 RADOS 的对象存储系统,用一组网关 API 表示块、文件、和对象模式中的数据。由于它自身开源的特性,这种便携存储平台能在公有云和私有云上安装和使用。Ceph 集群的拓扑结构是按照备份和信息分布设计的,这种内在设计能提供数据完整性。它的设计目标就是容错、通过正确配置能运行于商业硬件和一些更高级的系统。
|
||||
|
||||
Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要求最近的内核以及其它最新的库。在这篇指南中,我们会使用最小化安装的 CentOS-7.0。
|
||||
Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它需要最近的内核以及其它最新的库。在这篇指南中,我们会使用最小化安装的 CentOS-7.0。
|
||||
|
||||
### 系统资源 ###
|
||||
|
||||
@ -25,11 +24,11 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
### 安装前的配置 ###
|
||||
|
||||
在安装 CEPH 存储之前,我们要在每个节点上完成一些步骤。第一件事情就是确保每个节点的网络已经配置好并且能相互访问。
|
||||
在安装 Ceph 存储之前,我们要在每个节点上完成一些步骤。第一件事情就是确保每个节点的网络已经配置好并且能相互访问。
|
||||
|
||||
**配置 Hosts**
|
||||
|
||||
要在每个节点上配置 hosts 条目,要像下面这样打开默认的 hosts 配置文件。
|
||||
要在每个节点上配置 hosts 条目,要像下面这样打开默认的 hosts 配置文件(LCTT 译注:或者做相应的 DNS 解析)。
|
||||
|
||||
# vi /etc/hosts
|
||||
|
||||
@ -46,9 +45,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
**配置防火墙**
|
||||
|
||||
如果你正在使用启用了防火墙的限制性环境,确保在你的 CEPH 存储管理节点和客户端节点中开放了以下的端口。
|
||||
如果你正在使用启用了防火墙的限制性环境,确保在你的 Ceph 存储管理节点和客户端节点中开放了以下的端口。
|
||||
|
||||
你必须在你的 Admin Calamari 节点开放 80、2003、以及4505-4506 端口,并且允许通过 80 号端口到 CEPH 或 Calamari 管理节点,以便你网络中的客户端能访问 Calamari web 用户界面。
|
||||
你必须在你的 Admin Calamari 节点开放 80、2003、以及4505-4506 端口,并且允许通过 80 号端口到 CEPH 或 Calamari 管理节点,以便你网络中的客户端能访问 Calamari web 用户界面。
|
||||
|
||||
你可以使用下面的命令在 CentOS 7 中启动并启用防火墙。
|
||||
|
||||
@ -62,7 +61,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
#firewall-cmd --zone=public --add-port=4505-4506/tcp --permanent
|
||||
#firewall-cmd --reload
|
||||
|
||||
在 CEPH Monitor 节点,你要在防火墙中允许通过以下端口。
|
||||
在 Ceph Monitor 节点,你要在防火墙中允许通过以下端口。
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6789/tcp --permanent
|
||||
|
||||
@ -82,9 +81,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
#yum update
|
||||
#shutdown -r 0
|
||||
|
||||
### 设置 CEPH 用户 ###
|
||||
### 设置 Ceph 用户 ###
|
||||
|
||||
现在我们会新建一个单独的 sudo 用户用于在每个节点安装 ceph-deploy工具,并允许该用户无密码访问每个节点,因为它需要在 CEPH 节点上安装软件和配置文件而不会有输入密码提示。
|
||||
现在我们会新建一个单独的 sudo 用户用于在每个节点安装 ceph-deploy工具,并允许该用户无密码访问每个节点,因为它需要在 Ceph 节点上安装软件和配置文件而不会有输入密码提示。
|
||||
|
||||
运行下面的命令在 ceph-storage 主机上新建有独立 home 目录的新用户。
|
||||
|
||||
@ -100,7 +99,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
### 设置 SSH 密钥 ###
|
||||
|
||||
现在我们会在 ceph 管理节点生成 SSH 密钥并把密钥复制到每个 Ceph 集群节点。
|
||||
现在我们会在 Ceph 管理节点生成 SSH 密钥并把密钥复制到每个 Ceph 集群节点。
|
||||
|
||||
在 ceph-node 运行下面的命令复制它的 ssh 密钥到 ceph-storage。
|
||||
|
||||
@ -125,7 +124,8 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
### 配置 PID 数目 ###
|
||||
|
||||
要配置 PID 数目的值,我们会使用下面的命令检查默认的内核值。默认情况下,是一个小的最大线程数 32768.
|
||||
要配置 PID 数目的值,我们会使用下面的命令检查默认的内核值。默认情况下,是一个小的最大线程数 32768。
|
||||
|
||||
如下图所示通过编辑系统配置文件配置该值为一个更大的数。
|
||||
|
||||

|
||||
@ -142,9 +142,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
#rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm
|
||||
|
||||

|
||||

|
||||
|
||||
或者创建一个新文件并更新 CEPH 库参数,别忘了替换你当前的 Release 和版本号。
|
||||
或者创建一个新文件并更新 Ceph 库参数,别忘了替换你当前的 Release 和版本号。
|
||||
|
||||
[root@ceph-storage ~]# vi /etc/yum.repos.d/ceph.repo
|
||||
|
||||
@ -160,7 +160,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
之后更新你的系统并安装 ceph-deploy 软件包。
|
||||
|
||||
### 安装 CEPH-Deploy 软件包 ###
|
||||
### 安装 ceph-deploy 软件包 ###
|
||||
|
||||
我们运行下面的命令以及 ceph-deploy 安装命令来更新系统以及最新的 ceph 库和其它软件包。
|
||||
|
||||
@ -181,15 +181,16 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||

|
||||
|
||||
如果成功执行了上面的命令,你会看到它新建了配置文件。
|
||||
现在配置 CEPH 默认的配置文件,用任意编辑器打开它并在会影响你公共网络的 global 参数下面添加以下两行。
|
||||
|
||||
现在配置 Ceph 默认的配置文件,用任意编辑器打开它并在会影响你公共网络的 global 参数下面添加以下两行。
|
||||
|
||||
#vim ceph.conf
|
||||
osd pool default size = 1
|
||||
public network = 45.79.0.0/16
|
||||
|
||||
### 安装 CEPH ###
|
||||
### 安装 Ceph ###
|
||||
|
||||
现在我们准备在和 CEPH 集群相关的每个节点上安装 CEPH。我们使用下面的命令在 ceph-storage 和 ceph-node 上安装 CEPH。
|
||||
现在我们准备在和 Ceph 集群相关的每个节点上安装 Ceph。我们使用下面的命令在 ceph-storage 和 ceph-node 上安装 Ceph。
|
||||
|
||||
#ceph-deploy install ceph-node ceph-storage
|
||||
|
||||
@ -201,7 +202,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
#ceph-deploy mon create-initial
|
||||
|
||||

|
||||

|
||||
|
||||
### 设置 OSDs 和 OSD 守护进程 ###
|
||||
|
||||
@ -223,9 +224,9 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
#ceph-deploy admin ceph-node ceph-storage
|
||||
|
||||
### 测试 CEPH ###
|
||||
### 测试 Ceph ###
|
||||
|
||||
我们几乎完成了 CEPH 集群设置,让我们在 ceph 管理节点上运行下面的命令检查正在运行的 ceph 状态。
|
||||
我们快完成了 Ceph 集群设置,让我们在 ceph 管理节点上运行下面的命令检查正在运行的 ceph 状态。
|
||||
|
||||
#ceph status
|
||||
#ceph health
|
||||
@ -235,7 +236,7 @@ Ceph 能在任何 Linux 发行版上安装,但为了能正确运行,它要
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇详细的文章中我们学习了如何使用两台安装了 CentOS 7 的虚拟机设置 CEPH 存储集群,这能用于备份或者作为用于处理其它虚拟机的本地存储。我们希望这篇文章能对你有所帮助。当你试着安装的时候记得分享你的经验。
|
||||
在这篇详细的文章中我们学习了如何使用两台安装了 CentOS 7 的虚拟机设置 Ceph 存储集群,这能用于备份或者作为用于处理其它虚拟机的本地存储。我们希望这篇文章能对你有所帮助。当你试着安装的时候记得分享你的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -243,7 +244,7 @@ via: http://linoxide.com/storage/setup-red-hat-ceph-storage-centos-7-0/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Linux有问必答--如何在代理中安装Ubuntu
|
||||
Linux有问必答: 当使用代理服务器连接互联网时如何安装 Ubuntu 桌面版
|
||||
================================================================================
|
||||
> **提问:** 我的电脑连接到的是使用HTTP代理的公司网络。当我想使用CD-ROM安装Ubuntu时,安装在尝试获取文件时被停滞了,可能是由于代理的原因。然而问题是Ubuntu的安装程序从来没有在安装过程中提示我配置代理。我该怎样在代理中安装Ubuntu桌面版?
|
||||
> **提问:** 我的电脑连接到的公司网络是使用HTTP代理连上互联网的。当我想使用CD-ROM安装Ubuntu时,安装在尝试获取文件时被停滞了,可能是由于代理的原因。然而问题是Ubuntu的安装程序从来没有在安装过程中提示我配置代理。我该怎样通过代理服务器安装Ubuntu桌面版?
|
||||
|
||||
不像Ubuntu服务器版,Ubuntu桌面版的安装非常自动化,没有留下太多的自定义空间,就像自定义磁盘分区,手动网络设置,包选择等等。虽然这种简单的,一键安装被认为是用户友好的,但却是那些寻找“高级安装模式”来定制自己的Ubuntu桌面安装的用户不希望的。
|
||||
|
||||
@ -8,9 +8,9 @@ Linux有问必答--如何在代理中安装Ubuntu
|
||||
|
||||

|
||||
|
||||
这篇文章描述了如何解除Ubuntu安装限制以及**如何在代理中安装Ubuntu桌面**。
|
||||
这篇文章描述了如何解除Ubuntu安装限制以及**如何通过代理服务器安装Ubuntu桌面**。
|
||||
|
||||
基本的想打是这样的。首先启动到live Ubuntu桌面中而不是直接启动Ubuntu安装器,配置代理设置并且手动在live Ubuntu中启动Ubuntu安装器。下面是步骤。
|
||||
基本的想法是这样的。首先启动到live Ubuntu桌面中而不是直接启动Ubuntu安装器,配置代理设置并且手动在live Ubuntu中启动Ubuntu安装器。下面是步骤。
|
||||
|
||||
从Ubuntu桌面版CD/DVD或者USB启动后,在欢迎页面点击“Try Ubuntu”。
|
||||
|
||||
@ -24,7 +24,7 @@ Linux有问必答--如何在代理中安装Ubuntu
|
||||
|
||||

|
||||
|
||||
手动配置代理
|
||||
手动配置代理。
|
||||
|
||||

|
||||
|
||||
@ -54,7 +54,7 @@ via: http://ask.xmodulo.com/install-ubuntu-desktop-behind-proxy.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
Nautilus 的文件搜索将迎来巨大提升
|
||||
================================================================================
|
||||

|
||||
|
||||
*在Nautilus中搜索零散文件和文件夹将会将会变得相当简单。*
|
||||
|
||||
[GNOME文件管理器][1]中正在开发一个新的**搜索过滤器**。它大量使用 GNOME 漂亮的弹出式菜单,以通过简单的方法来缩小搜索结果并精确地找到你所需要的。
|
||||
|
||||
开发者Georges Stavracas正致力于开发新的UI,他[说][2]这个新的界面“更干净、更合理、更直观”。
|
||||
|
||||
根据他[上传到Youtube][3]的视频来展示的新方式-他还没有嵌入它-他没有错。
|
||||
|
||||
> 他在他的博客中写到:“ Nautilus 有非常复杂但是强大的内部组成,它允许我们做很多事情。事实上在代码上存在各种可能。那么,为何它曾经看上去这么糟糕?”
|
||||
|
||||
这个问题的部分原因比较令人吃惊:新的搜索过滤器界面向用户展示了“强大的内部组成”。搜索结果可以根据类型、名字或者日期范围来进行过滤。
|
||||
|
||||
对于像 Nautilus 这类 app 的任何修改有可能让一些用户不安,因此像这样帮助性的、直接的新UI会带来一些争议。
|
||||
|
||||
虽然对于不满的担心貌似会影响进度(毫无疑问,虽然像[移除输入优先搜索][4]的争议自2014年以来一直在争论)。GNOME 3.18 在[上个月发布了][5],给 Nautilus 引入了新的文件进度对话框,以及远程共享的更好整合,包括 Google Drive。
|
||||
|
||||
Stavracas 的搜索过滤器还没被合并进 Files 的 trunk 中,但是复刻的搜索 UI 已经初步计划在明年春天的 GNOME 3.20 中实现。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://wiki.gnome.org/Apps/Nautilus
|
||||
[2]:http://feaneron.com/2015/10/12/the-new-search-for-gnome-files-aka-nautilus/
|
||||
[3]:https://www.youtube.com/watch?v=X2sPRXDzmUw
|
||||
[4]:http://www.omgubuntu.co.uk/2014/01/ubuntu-14-04-nautilus-type-ahead-patch
|
||||
[5]:http://www.omgubuntu.co.uk/2015/09/gnome-3-18-release-new-features
|
||||
74
published/20151027 How To Install Retro Terminal In Linux.md
Normal file
74
published/20151027 How To Install Retro Terminal In Linux.md
Normal file
@ -0,0 +1,74 @@
|
||||
Linux 下如何安装 Retro Terminal
|
||||
================================================================================
|
||||

|
||||
|
||||
你有怀旧情节?那就试试 **安装复古终端应用** [cool-retro-term][1] 来一瞥过去的时光吧。顾名思义,`cool-retro-term` 是一个兼具酷炫和怀旧的终端。
|
||||
|
||||
你还记得那段遍地都是 CRT 显示器、终端屏幕闪烁不停的时光吗?现在你并不需要穿越到过去来见证那段时光。假如你观看背景设置在上世纪 90 年代的电影,你就可以看到大量带有绿色或黑底白字的显像管显示器。这种极客光环让它们看起来非常酷!
|
||||
|
||||
若你已经厌倦了你机器中终端的外表,正寻找某些炫酷且‘新奇’的东西,则 `cool-retro-term` 将会带给你一个复古的终端外表,使你可以重温过去。你也可以改变它的颜色、动画类型并添加一些额外的特效。
|
||||
|
||||
下面是不同外观下 `cool-retro-term` 的一些截图:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 在基于 Ubuntu 的 Linux 发行版本下安装 cool-retro-term ###
|
||||
|
||||
如果想在基于 Ubuntu 的 Linux 发行版本下安装 cool-retro-term,例如 Linux Mint,elementary OS, Linux Lite 等,可以使用下面的 PPA:
|
||||
|
||||
sudo add-apt-repository ppa:noobslab/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install cool-retro-term
|
||||
|
||||
### 在基于 Arch 的 Linux 发行版本下安装 cool-retro-term ###
|
||||
|
||||
若你想在诸如 [Antergos][2] 和 [Manjaro][3] 等基于 Arch 的 Linux 发行版本下安装 cool-retro-term ,则可以使用下面的命令:
|
||||
|
||||
sudo pacman -S cool-retro-term
|
||||
|
||||
### 从源代码安装 cool-retro-term ###
|
||||
|
||||
如果你想从源代码安装这个应用,那么首先你需要安装一些依赖。在基于 Ubuntu 的发行版本中,已知的依赖有:
|
||||
|
||||
sudo apt-get install git build-essential qmlscene qt5-qmake qt5-default qtdeclarative5-dev qtdeclarative5-controls-plugin qtdeclarative5-qtquick2-plugin libqt5qml-graphicaleffects qtdeclarative5-dialogs-plugin qtdeclarative5-localstorage-plugin qtdeclarative5-window-plugin
|
||||
|
||||
对于其他发行版本,已知的依赖可以在 [cool-retro-term 的 github 页面][4] 中找到。
|
||||
|
||||
现在使用下面的命令来编译这个程序吧:
|
||||
|
||||
git clone https://github.com/Swordfish90/cool-retro-term.git
|
||||
cd cool-retro-term
|
||||
qmake && make
|
||||
|
||||
一旦程序编译成功,你就可以使用下面的命令来运行它了:
|
||||
|
||||
./cool-retro-term
|
||||
|
||||
假如你想把这个应用放在程序菜单中以便快速找到,这样你就不用再每次手动地用命令来启动它,则你可以使用下面的命令:
|
||||
|
||||
sudo cp cool-retro-term.desktop /usr/share/applications
|
||||
|
||||
在这里你可以学到更多的终端技巧。在 Linux 中享受这个复古的终端吧 :)
|
||||
|
||||
稿件来自: [Abhishek Prakash][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/cool-retro-term/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://github.com/Swordfish90/cool-retro-term
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
[3]:https://manjaro.github.io/
|
||||
[4]:https://github.com/Swordfish90/cool-retro-term
|
||||
[5]:http://itsfoss.com/author/abhishek/
|
||||
@ -12,7 +12,7 @@
|
||||
|
||||
### 在GNOME 3 中添加显示桌面的快捷键 ###
|
||||
|
||||
我在本教程的使用的是GNOME 3.18的[Antergos Linux][2]但是这些步骤对于任何GNOME 3版本的Linux发行版都适用。同时也使用了[Numix主题][3]作为默认主题。因此你也许不会看到平常的GNOME图标。但是我相信步骤是一目了然的,很容易就能理解。
|
||||
我在本教程的使用的是带有GNOME 3.18的[Antergos Linux][2],但是这些步骤对于任何GNOME 3版本的Linux发行版都适用。同时,Antergos也使用了[Numix主题][3]作为默认主题。因此你也许不会看到平常的GNOME图标。但是我相信步骤是一目了然的,很容易就能理解。
|
||||
|
||||
#### 第一步 ####
|
||||
|
||||
@ -34,7 +34,7 @@
|
||||
|
||||
#### 第四步 ####
|
||||
|
||||
在“Hide all normla windows”上面点击一下。你会看到它变成了**New accelerator**。现在无论你按下哪个键,他都会被指定为显示桌面。
|
||||
在“Hide all normla windows”上面点击一下。你会看到它变成了**New accelerator**。现在无论你按下哪个键,它都会被指定为显示桌面的快捷键。
|
||||
|
||||
如果你不小心按下了错误的组合键,只要按下退格它就会被禁用。再次点击并使用需要的组合键。
|
||||
|
||||
@ -42,7 +42,7 @@
|
||||
|
||||
#### 第五步 ####
|
||||
|
||||
一旦设置了组合键,只要关闭系统设置。没有保存设置因为更改是立即生效的。在本例中,我使用Ctrl+Super+D来与我在Ubuntu Unity中的使用习惯保持一致。
|
||||
一旦设置了组合键,只要关闭系统设置。不用保存设置因为更改是立即生效的。在本例中,我使用Ctrl+Super+D来与我在Ubuntu Unity中的使用习惯保持一致。
|
||||
|
||||

|
||||
|
||||
@ -61,4 +61,4 @@ via: http://itsfoss.com/show-desktop-gnome-3/
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.gnome.org/gnome-3/
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
[3]:http://itsfoss.com/install-numix-ubuntu/
|
||||
[3]:https://linux.cn/article-3281-1.html
|
||||
@ -1,6 +1,6 @@
|
||||
如何在 Linux 上使用 SSHfs 挂载一个远程文件系统
|
||||
================================================================================
|
||||
你有想通过安全 shell 挂载一个远程文件系统到本地的经历吗?如果有的话,SSHfs 也许就是你所需要的。它通过使用 SSH 和 Fuse(LCTT 译注:Filesystem in Userspace,用户态文件系统,是 Linux 中用于挂载某些网络空间,如 SSH,到本地文件系统的模块) 允许你挂载远程计算机(或者服务器)到本地。
|
||||
你曾经想过用安全 shell 挂载一个远程文件系统到本地吗?如果有的话,SSHfs 也许就是你所需要的。它通过使用 SSH 和 Fuse(LCTT 译注:Filesystem in Userspace,用户态文件系统,是 Linux 中用于挂载某些网络空间,如 SSH,到本地文件系统的模块) 允许你挂载远程计算机(或者服务器)到本地。
|
||||
|
||||
**注意**: 这篇文章假设你明白[SSH 如何工作并在你的系统中配置 SSH][1]。
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
如果你使用的不是 Ubuntu,那就在你的发行版软件包管理器中搜索软件包名称。最好搜索和 fuse 或 SSHfs 相关的关键字,因为取决于你运行的系统,软件包名称可能稍微有些不同。
|
||||
|
||||
在你的系统上安装完软件包之后,就该创建 fuse 组了。在你安装 fuse 的时候,应该会在你的系统上创建一个组。如果没有的话,在终端窗口中输入以下命令以便在你的 Linux 系统中创建组:
|
||||
在你的系统上安装完软件包之后,就该创建好 fuse 组了。在你安装 fuse 的时候,应该会在你的系统上创建一个组。如果没有的话,在终端窗口中输入以下命令以便在你的 Linux 系统中创建组:
|
||||
|
||||
sudo groupadd fuse
|
||||
|
||||
@ -26,7 +26,7 @@
|
||||
|
||||

|
||||
|
||||
别担心上面命令的 `$USER`。shell 会自动用你自己的用户名替换。处理了和组相关的事之后,就是时候创建要挂载远程文件的目录了。
|
||||
别担心上面命令的 `$USER`。shell 会自动用你自己的用户名替换。处理了和组相关的工作之后,就是时候创建要挂载远程文件的目录了。
|
||||
|
||||
mkdir ~/remote_folder
|
||||
|
||||
@ -54,9 +54,9 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在 Linux 上有很多工具可以用于访问远程文件并挂载到本地。如之前所说,如果有的话,也只有很少的工具能充分利用 SSH 的强大功能。我希望在这篇指南的帮助下,也能认识到 SSHfs 是一个多么强大的工具。
|
||||
在 Linux 上有很多工具可以用于访问远程文件并挂载到本地。但是如之前所说,如果有的话,也只有很少的工具能充分利用 SSH 的强大功能。我希望在这篇指南的帮助下,也能认识到 SSHfs 是一个多么强大的工具。
|
||||
|
||||
你觉得 SSHfs 怎么样呢?在线的评论框里告诉我们吧!
|
||||
你觉得 SSHfs 怎么样呢?在下面的评论框里告诉我们吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -64,7 +64,7 @@ via: https://www.maketecheasier.com/sshfs-mount-remote-filesystem-linux/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu 软件中心将在 16.04 LTS 中被替换
|
||||
================================================================================
|
||||

|
||||
|
||||
*Ubuntu 软件中心将在 Ubuntu 16.04 LTS 中被替换。*
|
||||
|
||||
Ubuntu Xenial Xerus 桌面用户将会发现,这个熟悉的(并有些繁琐的)Ubuntu 软件中心将不再可用。
|
||||
|
||||
按照目前的计划,GNOME 的 [软件应用(Software application)][1] 将作为基于 Unity 7 的桌面的默认包管理工具。
|
||||
|
||||
|
||||
|
||||
*GNOME 软件应用*
|
||||
|
||||
作为这次变化的一个结果是,会新开发插件来支持软件中心的评级、评论和应用程序付费的功能。
|
||||
|
||||
该决定是在伦敦的 Canonical 总部最近举行的一次桌面峰会中通过的。
|
||||
|
||||
“相对于 Ubuntu 软件中心,我们认为我们在 GNOME 软件中心(sic)添加 Snaps 支持上能做的更好。所以,现在看起来我们将使用 GNOME 软件中心来取代 [Ubuntu 软件中心]”,Ubuntu 桌面经理 Will Cooke 在 Ubuntu 在线峰会解释说。
|
||||
|
||||
GNOME 3.18 架构与也将出现在 Ubuntu 16.04 中,其中一些应用程序将更新到 GNOME 3.20 , ‘这么做也是有道理的’,Will Cooke 补充说。
|
||||
|
||||
我们最近在 Twitter 上做了一项民意调查,询问如何在 Ubuntu 上安装软件。结果表明,只有少数人怀念现在的软件中心...
|
||||
|
||||
你使用什么方式在 Ubuntu 上安装软件?
|
||||
|
||||
- 软件中心
|
||||
- 终端
|
||||
|
||||
### 在 Ubuntu 16.04 其他应用程序也将会减少 ###
|
||||
|
||||
Ubuntu 软件中心并不是唯一一个在 Xenial Xerus 中被丢弃的。
|
||||
|
||||
光盘刻录工具 Brasero 和即时通讯工具 **Empathy** 也将从默认镜像中删除。
|
||||
|
||||
虽然这些应用程序还在不断的开发,但随着笔记本减少了光驱以及基于移动网络的聊天服务,它们看起来越来越过时了。
|
||||
|
||||
如果你还在使用它们请不要惊慌:Brasero 和 Empathy 将 **仍然可以通过存档在 Ubuntu 上安装**。
|
||||
|
||||
也并不全是丢弃和替换,默认还包括了一个新的桌面应用程序:GNOME 日历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/11/the-ubuntu-software-centre-is-being-replace-in-16-04-lts
|
||||
|
||||
作者:[Sam Tran][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/111008502832304483939?rel=author
|
||||
[1]:https://wiki.gnome.org/Apps/Software
|
||||
@ -0,0 +1,84 @@
|
||||
如何在 Ubuntu 上用 Go For It 管理您的待办清单
|
||||
================================================================================
|
||||

|
||||
|
||||
任务管理可以说是工作及日常生活中最重要也最具挑战性的事情之一。当您在工作中承担越来越多的责任时,您的表现将与您管理任务的能力直接挂钩。
|
||||
|
||||
若您的工作有部分需要在电脑上完成,那么您一定很乐意知道,有多款应用软件自称可以为您减轻任务管理的负担。即便这些软件中的大多数都是为 Windows 用户服务的,在 Linux 系统中仍然有不少选择。在本文中,我们就来讨论这样一款软件:Go For It.
|
||||
|
||||
### Go For It ###
|
||||
|
||||
[Go For It][1] (GFI) 由 Manuel Kehl 开发,他声称:“这是款简单易用且时尚优雅的生产力软件,以待办清单(To-Do List)为主打特色,并整合了一个能让你专注于当前事务的定时器。”这款软件的定时器功能尤其有趣,它还可以让您在继续工作之前暂停下来,放松一段时间。
|
||||
|
||||
### 下载并安装 ###
|
||||
|
||||
使用基于 Debian 系统(如Ubuntu)的用户可以通过运行以下终端命令轻松地安装这款软件:
|
||||
|
||||
sudo add-apt-repository ppa:mank319/go-for-it
|
||||
sudo apt-get update
|
||||
sudo apt-get install go-for-it
|
||||
|
||||
以上命令执行完毕后,您就可以使用这条命令运行这款应用软件了:
|
||||
|
||||
go-for-it
|
||||
|
||||
### 使用及配置###
|
||||
|
||||
当你第一次运行 GFI 时,它的界面是长这样的:
|
||||
|
||||

|
||||
|
||||
可以看到,界面由三个标签页组成,分别是*待办* (To-Do),*定时器* (Timer)和*完成* (Done)。*待办*页是一个任务列表(上图所示的4个任务是默认生成的——您可以点击头部的方框删除它们),*定时器*页内含有任务定时器,而*完成*页则是已完成任务的列表。底部有个文本框,您可以在此输入任务描述,并点击“+”号将任务添加到上面的列表中。
|
||||
|
||||
举个例子,我将一个名为“MTE-research-work”的任务添加到了列表中,并点击选中了它,如下图所示:
|
||||
|
||||

|
||||
|
||||
然后我进入*定时器*页,在这里我可以看到一个为当前“MTE-reaserch-work”任务设定的定时器,定时25分钟。
|
||||
|
||||

|
||||
|
||||
当然,您可以将定时器设定为你喜欢的任何值。然而我并没有修改,而是直接点击下方的“开始 (Start)”按钮启动定时器。一旦剩余时间为60秒,GFI 就会给出一个提示。
|
||||
|
||||

|
||||
|
||||
一旦时间到,它会提醒我休息5分钟。
|
||||
|
||||

|
||||
|
||||
5分钟过后,我可以为我的任务再次开启定时器。
|
||||
|
||||

|
||||
|
||||
任务完成以后,您可以点击*定时器*页中的“完成 (Done)”按钮,然后这个任务就会从*待办*页被转移到*完成*页。
|
||||
|
||||

|
||||
|
||||
GFI 也能让您稍微调整一些它的设置。例如,下图所示的设置窗口就包含了一些选项,让您修改默认的任务时长,休息时长和提示时刻。
|
||||
|
||||

|
||||
|
||||
值得一提的是,GFI 是以 TODO.txt 格式保存待办清单的,这种格式方便了移动设备之间的同步,也让您能使用其他前端程序来编辑任务——更多详情请阅读[这里][2]。
|
||||
|
||||
您还可以通过以下视频观看 GFI 的动态展示。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe frameborder="0" src="http://www.youtube.com/embed/mnw556C9FZQ?autoplay=1&autohide=2&border=1&wmode=opaque&enablejsapi=1&controls=1&showinfo=0" id="youtube-iframe"></iframe>
|
||||
|
||||
### 结论###
|
||||
|
||||
正如您所看到的,GFI 是一款简洁明了且易于使用的任务管理软件。虽然它没有提供非常丰富的功能,但它实现了它的承诺,定时器的整合特别有用。如果您正在寻找一款实现了基础功能,并且开源的 Linux 任务管理软件,Go For It 值得您一试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/to-do-lists-ubuntu-go-for-it/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[Ricky-Gong](https://github.com/Ricky-Gong)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[2]:http://todotxt.com/
|
||||
@ -0,0 +1,51 @@
|
||||
Linux 有问必答:如何在 Linux 中改变默认的 Java 版本
|
||||
================================================================================
|
||||
> **提问**:当我尝试在Linux中运行一个Java程序时,我遇到了一个错误。看上去像程序编译所使用的Java版本与我本地的不同。我该如何在Linux上切换默认的Java版本?
|
||||
|
||||
|
||||
当Java程序编译时,编译环境会设置一个“target”变量来设置程序可以运行的最低Java版本。如果你Linux系统上运行的程序不能满足最低的JRE版本要求,那么你会在运行的时候遇到下面的错误。
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/xmodulo/hmon/gui/NetConf : Unsupported major.minor version 51.0
|
||||
|
||||
比如,程序在Java JRE 1.7下编译,但是系统只有Java JRE 1.6。
|
||||
|
||||
要解决这个问题,你需要改变默认的Java版本到Java JRE 1.7或者更高(假设JRE已经安装了)。
|
||||
|
||||
首先,试用下面的update-alternatives命令**检查你系统上可用的Java版本**:
|
||||
|
||||
$ sudo update-alternatives --display java
|
||||
|
||||
|
||||
|
||||
本例中,总共安装了4个不同的Java版本:OpenJDK JRE 1.6、Oracle Java JRE 1.6、OpenJDK JRE 1.7 和 Oracle Java JRE 1.7。现在默认的Java版本是OpenJDK JRE 1.6。
|
||||
|
||||
如果没有安装需要的Java JRE,你可以参考[这些指导][1]来完成安装。
|
||||
|
||||
现在有可用的候选版本,你可以用下面的命令在可用的Java JRE之间**切换默认的Java版本**:
|
||||
|
||||
$ sudo update-alternatives --config java
|
||||
|
||||
看到提示的时候,选择你想试用的Java版本。本例中,我们选择Oracle Java JRE 1.7。
|
||||
|
||||

|
||||
|
||||
现在用下面的命令验证默认的Java版本。
|
||||
|
||||
$ java -version
|
||||
|
||||

|
||||
|
||||
最后,如果你定义了JAVA_HOME环境变量,根据你设置的Java版本更新变量。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-default-java-version-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/install-java-runtime-linux.html
|
||||
131
published/20151109 Open Source Alternatives to LastPass.md
Normal file
131
published/20151109 Open Source Alternatives to LastPass.md
Normal file
@ -0,0 +1,131 @@
|
||||
LastPass 的开源替代品
|
||||
================================================================================
|
||||
LastPass是一个跨平台的密码管理程序。在Linux平台中,它可作为Firefox, Chrome和Opera浏览器的插件使用。LastPass Sesame支持Ubuntu/Debian与Fedora系统。此外,LastPass还有安装在Firefox Portable的便携版,可将其安装在USB设备上。再加上适用于Ubuntu/Debian, Fedora和openSUSE的LastPass Pocket, 其具有良好的跨平台覆盖性。虽然LastPass备受好评,但它是一个专有软件。此外,LastPass最近被LogMeIn收购。如果你在找一个开源的替代品,这篇文章可能会对你有所帮助。
|
||||
|
||||
我们正面临着信息大爆炸。无论你是要在线经营生意,找工作,还是只为了休闲来进行阅读,互联网都是一个海量的信息源。在这种情况下,长期保留信息是很困难的。然而,及时地获取某些特定信息非常重要。密码就是这样的一个例子。
|
||||
|
||||
作为一个电脑用户,你可能会面临在不同服务或网站使用相同或不同密码的困境。这个事情非常复杂,因为有些网站会限制你对密码的选择。比如,一个网站可能会限制密码的最小位数,大写字母,数字或者特殊字符,这使得在所有网站使用统一密码变得不可能。更重要的是,不在不同网站中使用同一密码有安全方面的原因。这样就不可避免地意味着人们经常会有很多密码要记。一个解决方案是将所有的密码写下来。然而,这种做法也极度的不安全。
|
||||
|
||||
为了解决需要记忆无穷多串密码的问题,目前比较流行的解决方案是使用密码管理软件。事实上,这类软件对于活跃的互联网用户来说极为实用。它使得你获取、管理和安全保存所有密码变得极为容易,而大多数密码都是用软件或文件系统加密过的。因此,用户只需要记住一个简单的密码就可以获取到其它所有密码。密码管理软件鼓励用户对于不同服务去采用独一无二的,非直观的高强度的密码。
|
||||
|
||||
为了让大家更深入地了解Linux软件的质量,我将介绍4款优秀的、可替代LastPass的开源软件。
|
||||
|
||||
### KeePassX ###
|
||||
|
||||

|
||||
|
||||
KeePassX是KeePass的多平台移植,是一款开源、跨平台的密码管理软件。这款软件可以帮助你以安全的方式保管密码。你可以将所有密码保存在一个数据库中,而这个数据库被一个主密码或密码盘来保管。这使得用户只需要记住一个单一的主密码或插入密码盘即可解锁整个数据库。
|
||||
|
||||
密码数据库使用AES(即Rijndael)或者TwoFish算法进行加密,密钥长度为256位。
|
||||
|
||||
该软件功能包括:
|
||||
|
||||
- 管理模式丰富
|
||||
- 通过标题使每条密码更容易被识别
|
||||
- 可设置密码过期时间
|
||||
- 可插入附件
|
||||
- 可为不同分组或密码自定义标志
|
||||
- 在分组中对密码排序
|
||||
- 搜索功能:可在特定分组或整个数据库中搜索
|
||||
- 自动键入: 这个功能允许你在登录网站时只需要按下几个键。KeePassX可以帮助你输入剩下的密码。自动键入通过读取当前窗口的标题,对密码数据库进行搜索来获取相应的密码
|
||||
- 数据库安全性强,用户可通过密码或一个密钥文件(可存储在CD或U盘中)访问数据库(或两者)
|
||||
- 安全密码自动生成
|
||||
- 具有预防措施,获取用星号隐藏的密码并检查其安全性
|
||||
- 加密 - 用256位密钥,通过AES(高级加密标准)或TwoFish算法加密数据库,
|
||||
- 密码可以导入或导出。可从PwManager文件(*.pwm)或KWallet文件(*.xml)中导入密码,可导出为文本(*.txt)格式。
|
||||
|
||||
---
|
||||
- 软件官网:[www.keepassx.org][1]
|
||||
- 开发者:KeepassX Team
|
||||
- 软件许可证:GNU GPL V2
|
||||
- 版本号:0.4.3
|
||||
|
||||
### Encryptr ###
|
||||
|
||||

|
||||
|
||||
Encryptr是一个开源的、零知识(zero-knowledge)的、基于云端的密码管理/电子钱包软件,以Crypton为基础开发。Crypton是一个Javascript库,允许开发者利用其开发应用来上传文件至服务器,而服务器无法知道用户所存储的文件内容。
|
||||
|
||||
Encryptr可将你的敏感信息,比如密码、信用卡数据、PIN码、或认证码存储在云端。然而,由于它基于零知识的Cypton框架开发,Encryptr可保证只有用户才拥有访问或读取秘密信息的权限。
|
||||
|
||||
由于其跨平台的特性,Encryptr允许用户随时随地、安全地通过一个账户从云端获取机密信息。
|
||||
|
||||
软件特性包括:
|
||||
|
||||
- 使用非常安全的零知识Crypton框架,只在你的本地加密/解密数据
|
||||
- 易于使用
|
||||
- 基于云端
|
||||
- 可存储三种类型的数据:密码、信用卡账号以及通用的键值对
|
||||
- 可对每条密码设置“备注”项
|
||||
- 过滤和搜索密码
|
||||
- 对密码进行本地加密缓存,以节省载入时间
|
||||
|
||||
---
|
||||
- 软件官网: [encryptr.org][2]
|
||||
- 开发者: Tommy Williams
|
||||
- 软件许可证: GNU GPL v3
|
||||
- 版本号: 1.2.0
|
||||
|
||||
### RatticDB ###
|
||||
|
||||

|
||||
|
||||
RatticDB是一个开源的、基于Django的密码管理服务。
|
||||
|
||||
RatticDB被设计为一个“密码生命周期管理工具”而不是单单一个“密码存储工具”。RatticDB致力于及时提醒用户哪些密码在何时需要更改。它不提供应用层面的密码加密。
|
||||
|
||||
软件特性包括:
|
||||
|
||||
- 简洁的ACL设计
|
||||
- 可改变队列功能,可让用户知晓何时需要更改某应用的密码
|
||||
- 支持Ansible配置
|
||||
|
||||
---
|
||||
|
||||
- 软件官网: [rattic.org][3]
|
||||
- 开发者: Daniel Hall
|
||||
- 软件许可证: GNU GPL v2
|
||||
- 版本号: 1.3.1
|
||||
|
||||
### Seahorse ###
|
||||
|
||||

|
||||
|
||||
Seahorse是一个GnuPG(GNU隐私保护软件)的Gnome前端界面。它的目标是提供一个易于使用密钥管理工具,以及一个易于使用的界面来控制加密操作。
|
||||
|
||||
Seahorse是一个工具,用来提供安全传输和数据存储服务。数据加密和数字密钥生成操作可以轻易通过GUI来操作,密钥管理操作也可以轻易通过直观的界面来进行。
|
||||
|
||||
此外,Seahorse包含一个Gedit插件,可以使用鹦鹉螺文件管理器管理文件,一个管理剪贴板中事物的小程序,一个存储私密密码的代理,还有一个GnuPG和OpenSSH的密钥管理工具。
|
||||
|
||||
软件特性包括:
|
||||
|
||||
- 对文本进行加密/解密/签名
|
||||
- 管理密钥及密钥环
|
||||
- 将密钥及密钥环与密钥服务器同步
|
||||
- 密码签名及发布
|
||||
- 将密码缓存起来,无需多次重复键入
|
||||
- 对密钥及密钥环进行备份
|
||||
- 可添加一个GDK支持格式的图片作为OpenGPG图片ID
|
||||
- 生成SSH密钥,对其进行验证及储存
|
||||
- 多语言支持
|
||||
|
||||
---
|
||||
|
||||
- 软件官网: [www.gnome.org/projects/seahorse][4]
|
||||
- 开发者: Jacob Perkins, Jose Carlos, Garcia Sogo, Jean Schurger, Stef Walter, Adam Schreiber
|
||||
- 软件许可证: GNU GPL v2
|
||||
- 版本号: 3.18.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151108125950773/LastPassAlternatives.html
|
||||
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.keepassx.org/
|
||||
[2]:https://encryptr.org/
|
||||
[3]:http://rattic.org/
|
||||
[4]:http://www.gnome.org/projects/seahorse/
|
||||
@ -0,0 +1,48 @@
|
||||
Linux 有问必答:如何在 Linux 上自动设置 JAVA_HOME 环境变量
|
||||
================================================================================
|
||||
> **问题**:我需要在我的 Linux 机器上编译 Java 程序。为此我已经安装了 JDK (Java Development Kit),而现在我正试图设置 JAVA\_HOME 环境变量使其指向安装好的 JDK 。关于在 Linux 上设置 JAVA\_HOME 环境变量,最受推崇的办法是什么?
|
||||
|
||||
许多 Java 程序或基于 Java 的*集成开发环境* (IDE)都需要设置好 JAVA_HOME 环境变量。该变量应指向 *Java 开发工具包* (JDK)或 *Java 运行时环境* (JRE)的安装目录。JDK 不仅包含了 JRE 提供的一切,还带有用于编译 Java 程序的额外的二进制代码和库文件(例如编译器,调试器及 JavaDoc 文档生成器)。JDK 是用来构建 Java 程序的,如果只是运行已经构建好的 Java 程序,单独一份 JRE 就足够了。
|
||||
|
||||
当您正试图设置 JAVA\_HOME 环境变量时,麻烦的事情在于 JAVA\_HOME 变量需要根据以下几点而改变:(1) 您是否安装了 JDK 或 JRE;(2) 您安装了哪个版本;(3) 您安装的是 Oracle JDK 还是 Open JDK。
|
||||
|
||||
因此每当您的开发环境或运行时环境发生改变(例如为 JDK 更新版本)时,您需要根据实际情况调整 JAVA\_HOME 变量,而这种做法是繁重且缺乏效率的。
|
||||
|
||||
以下 export 命令能为您**自动设置** JAVA\_HOME 环境变量,而无须顾及上述的因素。
|
||||
|
||||
若您安装的是 JRE:
|
||||
|
||||
export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))
|
||||
|
||||
若您安装的是 JDK:
|
||||
|
||||
export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which javac))))
|
||||
|
||||
根据您的情况,将上述命令中的一条写入 ~/.bashrc(或 /etc/profile)文件中,它就会永久地设置好 JAVA\_HOME 变量。
|
||||
|
||||
注意,由于 java 或 javac 可以建立起多个层次的符号链接,为此"readlink -f"命令是用来获取它们真正的执行路径的。
|
||||
|
||||
举个例子,假如您安装的是 Oracle JRE 7,那么上述的第一条 export 命令将自动设置 JAVA\_HOME 为:
|
||||
|
||||
/usr/lib/jvm/java-7-oracle/jre
|
||||
|
||||
若您安装的是 Open JDK 第8版,那么第二条 export 命令将设置 JAVA\_HOME 为:
|
||||
|
||||
/usr/lib/jvm/java-8-openjdk-amd64
|
||||
|
||||
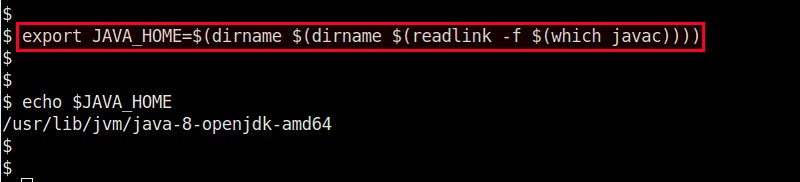
|
||||
|
||||
简而言之,这些 export 命令会在您重装/升级您的JDK/JRE,或[更换默认 Java 版本][1]时自动更新 JAVA\_HOME 变量。您不再需要手动调整它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/set-java_home-environment-variable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Ricky-Gong](https://github.com/Ricky-Gong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/change-default-java-version-linux.html
|
||||
@ -0,0 +1,48 @@
|
||||
N1:下一代开源邮件客户端
|
||||
================================================================================
|
||||

|
||||
|
||||
当我们谈论到Linux中的邮件客户端,通常 Thunderbird、Geary 和 [Evolution][3] 就会出现在我们的脑海。作为对这些大咖们的挑战,一款新的开源邮件客户端正在涌入市场。
|
||||
|
||||
### 设计和功能 ###
|
||||
|
||||
[N1][4]是一个设计与功能并重的新一代开源邮件客户端。作为一个开源软件,N1目前支持 Linux 和 Mac OS X,Windows的版本还在开发中。
|
||||
|
||||
N1宣传它自己为“可扩展的开源邮件客户端”,因为它包含了 Javascript 插件框架,任何人都可以为它创建强大的新功能。可扩展是一个非常流行的功能,它帮助[开源编辑器Atom][5]变得流行。N1同样把重点放在了可扩展上面。
|
||||
|
||||
除了可扩展性,N1同样着重设计了程序的外观。下面N1的截图就是个很好的例子:
|
||||
|
||||

|
||||
|
||||
*Mac OS X上的N1客户端。图片来自:N1*
|
||||
|
||||
除了这个功能,N1兼容上百个邮件服务提供商,包括Gmail、Yahoo、iCloud、Microsoft Exchange等等,这个桌面应用提供了离线功能。
|
||||
|
||||
### 目前只能邀请使用 ###
|
||||
|
||||
我不知道为什么每个人都选择了 OnePlus 的‘只能邀请使用’的市场策略。目前,N1桌面端只能被邀请才能下载。你可以用下面的链接请求一个邀请。N1团队会在几天内邮件给你下载链接。
|
||||
|
||||
|
||||
- [请求N1邀请][6]
|
||||
|
||||
### 感兴趣了么? ###
|
||||
|
||||
我并不是桌面邮件客户端的粉丝,但是 N1 的确引起了我的兴趣,让我想要试一试。你呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/n1-open-source-email-client/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.mozilla.org/en-US/thunderbird/
|
||||
[2]:https://wiki.gnome.org/Apps/Geary
|
||||
[3]:https://help.gnome.org/users/evolution/stable/
|
||||
[4]:https://nylas.com/N1/
|
||||
[5]:http://itsfoss.com/atom-stable-released/
|
||||
[6]:https://invite.nylas.com/download
|
||||
@ -0,0 +1,126 @@
|
||||
与 Linux 一起学习:使用这些 Linux 应用来征服你的数学学习
|
||||
================================================================================
|
||||

|
||||
|
||||
这篇文章是[与 Linux 一起学习][1]系列的一部分:
|
||||
|
||||
- [与 Linux 一起学习: 学习类型][2]
|
||||
- [与 Linux 一起学习: 物理模拟][3]
|
||||
- [与 Linux 一起学习: 学习音乐][4]
|
||||
- [与 Linux 一起学习: 两个地理应用程序][5]
|
||||
- [与 Linux 一起学习: 使用这些 Linux 应用来征服你的数学学习][6]
|
||||
|
||||
Linux 提供了大量的教育软件和许多优秀的工具来帮助各种年龄段和年级的学生学习和练习各种各样的习题,这通常是以交互的方式进行。“与 Linux 一起学习”这一系列的文章则为这些各种各样的教育软件和应用提供了一个介绍。
|
||||
|
||||
数学是计算机的核心。如果有人预期一个类如 GNU/ Linux 这样的伟大的操作系统精确而严格,那么这就是数学所起到的作用。如果你在寻求一些数学应用程序,那么你将不会感到失望。Linux 提供了很多优秀的工具使得数学看起来和你曾经做过的一样令人畏惧,但实际上他们会简化你使用它的方式。
|
||||
|
||||
### Gnuplot ###
|
||||
|
||||
Gnuplot 是一个适用于不同平台的命令行脚本化和多功能的图形工具。尽管它的名字中带有“GNU”,但是它并不是 GNU 操作系统的一部分。虽然不是自由授权,但它是免费软件(这意味着它受版权保护,但免费使用)。
|
||||
|
||||
要在 Ubuntu 系统(或者衍生系统)上安装 `gnuplot`,输入:
|
||||
|
||||
sudo apt-get install gnuplot gnuplot-x11
|
||||
|
||||
进入一个终端窗口。启动该程序,输入:
|
||||
|
||||
gnuplot
|
||||
|
||||
你会看到一个简单的命令行界面:
|
||||
|
||||

|
||||
|
||||
在其中您可以直接输入函数开始。绘图命令将绘制一个曲线图。
|
||||
|
||||
输入内容,例如,
|
||||
|
||||
plot sin(x)/x
|
||||
|
||||
随着`gnuplot的`提示,将会打开一个新的窗口,图像便会在里面呈现。
|
||||
|
||||

|
||||
|
||||
你也可以即时设置设置这个图的不同属性,比如像这样指定“title”
|
||||
|
||||
plot sin(x) title 'Sine Function', tan(x) title 'Tangent'
|
||||
|
||||

|
||||
|
||||
你可以做的更深入一点,使用`splot`命令绘制3D图形:
|
||||
|
||||
splot sin(x*y/20)
|
||||
|
||||

|
||||
|
||||
这个图形窗口有几个基本的配置选项,
|
||||
|
||||

|
||||
|
||||
但是`gnuplot`的真正力量在于在它的命令行和脚本功能,`gnuplot`更完整的文档在[Duke大学网站][8]上面[找到][7],带有这个了不起的教程的原始版本。
|
||||
|
||||
### Maxima ###
|
||||
|
||||
[Maxima][9]是一个源于 Macsyma 开发的一个计算机代数系统,根据它的 SourceForge 页面所述:
|
||||
|
||||
> “Maxima 是一个操作符号和数值表达式的系统,包括微分,积分,泰勒级数,拉普拉斯变换,常微分方程,线性方程组,多项式,集合,列表,向量,矩阵和张量等。Maxima 通过精确的分数,任意精度的整数和可变精度浮点数产生高精度的计算结果。Maxima 可以以二维和三维的方式绘制函数和数据。“
|
||||
|
||||
大多数Ubuntu衍生系统都有 Maxima 二进制包以及它的图形界面,要安装这些软件包,输入:
|
||||
|
||||
sudo apt-get install maxima xmaxima wxmaxima
|
||||
|
||||
在终端窗口中,Maxima 是一个没有什么 UI 的命令行工具,但如果你开始 wxmaxima,你会进入一个简单但功能强大的图形用户界面。
|
||||
|
||||

|
||||
|
||||
你可以通过简单的输入来开始。(提示:回车会增加更多的行,如果你想计算一个表达式,使用“Shift + Enter”。)
|
||||
|
||||
Maxima 可以用于一些简单的问题,因此也可以作为一个计算器:
|
||||
|
||||

|
||||
|
||||
以及一些更复杂的问题:
|
||||
|
||||

|
||||
|
||||
它使用`gnuplot`使得绘制简单:
|
||||
|
||||

|
||||
|
||||
或者绘制一些复杂的图形。
|
||||
|
||||

|
||||
|
||||
(它需要 gnuplot-X11 的软件包来显示它们。)
|
||||
|
||||
除了将表达式表示为图形,Maxima 也可以用 latex 格式导出它们,或者通过右键快捷菜单进行一些常用操作.
|
||||
|
||||

|
||||
|
||||
不过其主菜单还是提供了大量重磅功能,当然 Maxima 的功能远不止如此,这里也有一个广泛使用的[在线文档][10]。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
数学不是一门容易的学科,这些在 Linux 上的优秀软件也没有使得数学更加容易,但是这些应用使得使用数学变得更加的简单和方便。以上两种应用都只是介绍一下 Linux 所提供的。如果你是认真从事数学和需要更多的功能与丰富的文档,那你更应该看看这些 [Mathbuntu][11] 项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/learn-linux-maths/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[KnightJoker](https://github.com/KnightJoker/KnightJoker)
|
||||
校对:[wxyD](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
[7]:http://www.gnuplot.info/documentation.html
|
||||
[8]:http://people.duke.edu/~hpgavin/gnuplot.html
|
||||
[9]:http://maxima.sourceforge.net/
|
||||
[10]:http://maxima.sourceforge.net/documentation.html
|
||||
[11]:http://www.mathbuntu.org/
|
||||
112
published/LetsEncrypt.md
Normal file
112
published/LetsEncrypt.md
Normal file
@ -0,0 +1,112 @@
|
||||
# SSL/TLS 加密新纪元 - Let's Encrypt
|
||||
|
||||
根据 Let's Encrypt 官方博客消息,Let's Encrypt 服务将在下周(11 月 16 日)正式对外开放。
|
||||
|
||||
Let's Encrypt 项目是由互联网安全研究小组(ISRG,Internet Security Research Group)主导并开发的一个新型数字证书认证机构(CA,Certificate Authority)。该项目旨在开发一个自由且开放的自动化 CA 套件,并向公众提供相关的证书免费签发服务以降低安全通讯的财务、技术和教育成本。在过去的一年中,互联网安全研究小组拟定了 [ACME 协议草案][1],并首次实现了使用该协议的应用套件:服务端 [Boulder][2] 和客户端 [letsencrypt][3]。
|
||||
|
||||
至于为什么 Let's Encrypt 让我们如此激动,以及 HTTPS 协议如何保护我们的通讯请参考[浅谈 HTTPS 和 SSL/TLS 协议的背景与基础][4]。
|
||||
|
||||
## ACME 协议
|
||||
|
||||
Let's Encrypt 的诞生离不开 ACME(Automated Certificate Management Environment,自动证书管理环境)协议的拟定。
|
||||
|
||||
说到 ACME 协议,我们不得不提一下传统 CA 的认证方式。Let's Encrypt 服务所签发的证书为域名认证证书(DV,Domain-validated Certificate),签发这类证书需要域名所有者完成以下至少一种挑战(Challenge)以证明自己对域名的所有权:
|
||||
|
||||
* 验证申请人对域名的 Whois 信息中邮箱的控制权;
|
||||
* 验证申请人对域名的常见管理员邮箱(如以 `admin@`、`postmaster@` 开头的邮箱等)的控制权;
|
||||
* 在 DNS 的 TXT 记录中发布一条 CA 提供的字符串;
|
||||
* 在包含域名的网址中特定路径发布一条 CA 提供的字符串。
|
||||
|
||||
不难发现,其中最容易实现自动化的一种操作必然为最后一条,ACME 协议中的 [Simple HTTP][5] 认证即是用一种类似的方法对从未签发过任何证书的域名进行认证。该协议要求在访问 `http://域名/.well-known/acme-challenge/指定字符串` 时返回特定的字符串。
|
||||
|
||||
然而实现该协议的客户端 [letsencrypt][3] 做了更多——它不仅可以通过 ACME 协议配合服务端 [Boulder][2] 的域名进行独立(standalone)的认证工作,同时还可以自动配置常见的服务器软件(目前支持 Nginx 和 Apache)以完成认证。
|
||||
|
||||
## Let's Encrypt 免费证书签发服务
|
||||
|
||||
对于大多数网站管理员来讲,想要对自己的 Web 服务器进行加密需要一笔不小的支出进行证书签发并且难以配置。根据早些年 SSL Labs 公布的 [2010 年互联网 SSL 调查报告(PDF)][6] 指出超过半数的 Web 服务器没能正确使用 Web 服务器证书,主要的问题有证书不被浏览器信任、证书和域名不匹配、证书过期、证书信任链没有正确配置、使用已知有缺陷的协议和算法等。而且证书过期后的续签和泄漏后的吊销仍需进行繁琐的人工操作。
|
||||
|
||||
幸运的是 Let's Encrypt 免费证书签发服务在经历了漫长的开发和测试之后终于来临,在 Let's Encrypt 官方 CA 被广泛信任之前,IdenTrust 的根证书对 Let's Encrypt 的二级 CA 进行了交叉签名使得大部分浏览器已经信任 Let's Encrypt 签发的证书。
|
||||
|
||||
## 使用 letsencrypt
|
||||
|
||||
由于当前 Let's Encrypt 官方的证书签发服务还未公开,你只能尝试开发版本。这个版本会签发一个 CA 标识为 `happy hacker fake CA` 的测试证书,注意这个证书不受信任。
|
||||
|
||||
要获取开发版本请直接 `$ git clone https://github.com/letsencrypt/letsencrypt`。
|
||||
|
||||
以下的[使用方法][7]摘自 Let's Encrypt 官方网站。
|
||||
|
||||
### 签发证书
|
||||
|
||||
`letsencrypt` 工具可以协助你处理证书请求和验证工作。
|
||||
|
||||
#### 自动配置 Web 服务器
|
||||
|
||||
下面的操作将会自动帮你将新证书配置到 Nginx 和 Apache 中。
|
||||
|
||||
```
|
||||
$ letsencrypt run
|
||||
```
|
||||
|
||||
#### 独立签发证书
|
||||
|
||||
下面的操作将会将新证书置于当前目录下。
|
||||
|
||||
```
|
||||
$ letsencrypt -d example.com auth
|
||||
```
|
||||
|
||||
### 续签证书
|
||||
|
||||
默认情况下 `letsencrypt` 工具将协助你跟踪当前证书的有效期限并在需要时自动帮你续签。如果需要手动续签,执行下面的操作。
|
||||
|
||||
```
|
||||
$ letsencrypt renew --cert-path example-cert.pem
|
||||
```
|
||||
|
||||
### 吊销证书
|
||||
|
||||
列出当前托管的证书菜单以吊销。
|
||||
|
||||
```
|
||||
$ letsencrypt revoke
|
||||
```
|
||||
|
||||
你也可以吊销某一个证书或者属于某个私钥的所有证书。
|
||||
|
||||
```
|
||||
$ letsencrypt revoke --cert-path example-cert.pem
|
||||
```
|
||||
|
||||
```
|
||||
$ letsencrypt revoke --key-path example-key.pem
|
||||
```
|
||||
|
||||
## Docker 化 letsencrypt
|
||||
|
||||
如果你不想让 letsencrypt 自动配置你的 Web 服务器的话,使用 Docker 跑一份独立的版本将是一个不错的选择。你所要做的只是在装有 Docker 的系统中执行:
|
||||
|
||||
```
|
||||
$ sudo docker run -it --rm -p 443:443 -p 80:80 --name letsencrypt \
|
||||
-v "/etc/letsencrypt:/etc/letsencrypt" \
|
||||
-v "/var/lib/letsencrypt:/var/lib/letsencrypt" \
|
||||
quay.io/letsencrypt/letsencrypt:latest auth
|
||||
```
|
||||
|
||||
你就可以快速的为自己的 Web 服务器签发一个免费而且受信任的 DV 证书啦!
|
||||
|
||||
## Let's Encrypt 的注意事项
|
||||
|
||||
* Let's Encrypt 当前发行的 DV 证书仅能验证域名的所有权,并不能验证其所有者身份;
|
||||
* Let's Encrypt 不像其他 CA 那样对安全事故有保险赔付;
|
||||
* Let's Encrypt 目前不提共 Wildcard 证书;
|
||||
* Let's Encrypt 的有效时间仅为 90 天,逾期需要续签(可自动续签)。
|
||||
|
||||
对于 Let's Encrypt 的介绍就到这里,让我们一起目睹这场互联网的安全革命吧。
|
||||
|
||||
[1]: https://github.com/letsencrypt/acme-spec
|
||||
[2]: https://github.com/letsencrypt/boulder
|
||||
[3]: https://github.com/letsencrypt/letsencrypt
|
||||
[4]: https://linux.cn/article-5175-1.html
|
||||
[5]: https://letsencrypt.github.io/acme-spec/#simple-http
|
||||
[6]: https://community.qualys.com/servlet/JiveServlet/download/38-1636/Qualys_SSL_Labs-State_of_SSL_2010-v1.6.pdf
|
||||
[7]: https://letsencrypt.org/howitworks/
|
||||
@ -1,20 +1,20 @@
|
||||
第四部分 - 使用 Shell 脚本自动化 Linux 系统维护任务
|
||||
RHCE 系列(四): 使用 Shell 脚本自动化 Linux 系统维护任务
|
||||
================================================================================
|
||||
之前我听说高效系统管理员/工程师的其中一个特点是懒惰。一开始看起来很矛盾,但作者接下来解释了其中的原因:
|
||||
之前我听说高效的系统管理员的一个特点是懒惰。一开始看起来很矛盾,但作者接下来解释了其中的原因:
|
||||
|
||||

|
||||
|
||||
RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
*RHCE 系列:第四部分 - 自动化 Linux 系统维护任务*
|
||||
|
||||
如果一个系统管理员花费大量的时间解决问题以及做重复的工作,你就应该怀疑他这么做是否正确。换句话说,一个高效的系统管理员/工程师应该制定一个计划使得尽量花费少的时间去做重复的工作,以及通过使用该系列中第三部分 [使用 Linux 工具集监视系统活动报告][1] 介绍的工具预见问题。因此,尽管看起来他/她没有做很多的工作,但那是因为 shell 脚本帮助完成了他的/她的大部分任务,这也就是本章我们将要探讨的东西。
|
||||
如果一个系统管理员花费大量的时间解决问题以及做重复的工作,你就应该怀疑他这么做是否正确。换句话说,一个高效的系统管理员/工程师应该制定一个计划使得其尽量花费少的时间去做重复的工作,以及通过使用本系列中第三部分 [使用 Linux 工具集监视系统活动报告][1] 介绍的工具来预见问题。因此,尽管看起来他/她没有做很多的工作,但那是因为 shell 脚本帮助完成了他的/她的大部分任务,这也就是本章我们将要探讨的东西。
|
||||
|
||||
### 什么是 shell 脚本? ###
|
||||
|
||||
简单的说,shell 脚本就是一个由 shell 一步一步执行的程序,而 shell 是在 Linux 内核和端用户之间提供接口的另一个程序。
|
||||
简单的说,shell 脚本就是一个由 shell 一步一步执行的程序,而 shell 是在 Linux 内核和最终用户之间提供接口的另一个程序。
|
||||
|
||||
默认情况下,RHEL 7 中用户使用的 shell 是 bash(/bin/bash)。如果你想知道详细的信息和历史背景,你可以查看 [维基页面][2]。
|
||||
默认情况下,RHEL 7 中用户使用的 shell 是 bash(/bin/bash)。如果你想知道详细的信息和历史背景,你可以查看这个[维基页面][2]。
|
||||
|
||||
关于这个 shell 提供的众多功能的介绍,可以查看 **man 手册**,也可以从 ([Bash 命令][3])下载 PDF 格式。除此之外,假设你已经熟悉 Linux 命令(否则我强烈建议你首先看一下 **Tecmint.com** 中的文章 [从新手到系统管理员指南][4] )。现在让我们开始吧。
|
||||
关于这个 shell 提供的众多功能的介绍,可以查看 **man 手册**,也可以从 ([Bash 命令][3])处下载 PDF 格式。除此之外,假设你已经熟悉 Linux 命令(否则我强烈建议你首先看一下 **Tecmint.com** 中的文章 [从新手到系统管理员指南][4] )。现在让我们开始吧。
|
||||
|
||||
### 写一个脚本显示系统信息 ###
|
||||
|
||||
@ -27,7 +27,7 @@ RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# RHCE 系列第四部分事例脚本
|
||||
# RHCE 系列第四部分示例脚本
|
||||
# 该脚本会返回以下这些系统信息:
|
||||
# -主机名称:
|
||||
echo -e "\e[31;43m***** HOSTNAME INFORMATION *****\e[0m"
|
||||
@ -67,9 +67,9 @@ RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
|
||||
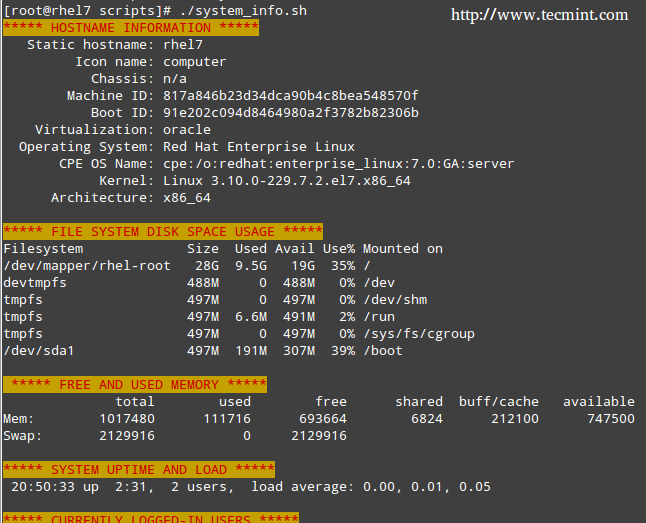
|
||||
|
||||
服务器监视 Shell 脚本
|
||||
*服务器监视 Shell 脚本*
|
||||
|
||||
该功能用以下命令提供:
|
||||
颜色功能是由以下命令提供的:
|
||||
|
||||
echo -e "\e[COLOR1;COLOR2m<YOUR TEXT HERE>\e[0m"
|
||||
|
||||
@ -79,13 +79,13 @@ RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
|
||||
你想使其自动化的任务可能因情况而不同。因此,我们不可能在一篇文章中覆盖所有可能的场景,但是我们会介绍使用 shell 脚本可以使其自动化的三种典型任务:
|
||||
|
||||
**1)** 更新本地文件数据库, 2) 查找(或者删除)有 777 权限的文件, 以及 3) 文件系统使用超过定义的阀值时发出警告。
|
||||
1) 更新本地文件数据库, 2) 查找(或者删除)有 777 权限的文件, 以及 3) 文件系统使用超过定义的阀值时发出警告。
|
||||
|
||||
让我们在脚本目录中新建一个名为 `auto_tasks.sh` 的文件并添加以下内容:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
# 自动化任务事例脚本:
|
||||
# 自动化任务示例脚本:
|
||||
# -更新本地文件数据库:
|
||||
echo -e "\e[4;32mUPDATING LOCAL FILE DATABASE\e[0m"
|
||||
updatedb
|
||||
@ -123,16 +123,16 @@ RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
|
||||

|
||||
|
||||
查找 777 权限文件的 Shell 脚本
|
||||
*查找 777 权限文件的 Shell 脚本*
|
||||
|
||||
### 使用 Cron ###
|
||||
|
||||
想更进一步提高效率,你不会想只是坐在你的电脑前手动执行这些脚本。相反,你会使用 cron 来调度这些任务周期性地执行,并把结果通过邮件发动给预定义的接收者或者将它们保存到使用 web 浏览器可以查看的文件中。
|
||||
想更进一步提高效率,你不会想只是坐在你的电脑前手动执行这些脚本。相反,你会使用 cron 来调度这些任务周期性地执行,并把结果通过邮件发动给预先指定的接收者,或者将它们保存到使用 web 浏览器可以查看的文件中。
|
||||
|
||||
下面的脚本(filesystem_usage.sh)会运行有名的 **df -h** 命令,格式化输出到 HTML 表格并保存到 **report.html** 文件中:
|
||||
|
||||
#!/bin/bash
|
||||
# Sample script to demonstrate the creation of an HTML report using shell scripting
|
||||
# 演示使用 shell 脚本创建 HTML 报告的示例脚本
|
||||
# Web directory
|
||||
WEB_DIR=/var/www/html
|
||||
# A little CSS and table layout to make the report look a little nicer
|
||||
@ -177,7 +177,7 @@ RHCE 系列:第四部分 - 自动化 Linux 系统维护任务
|
||||
|
||||
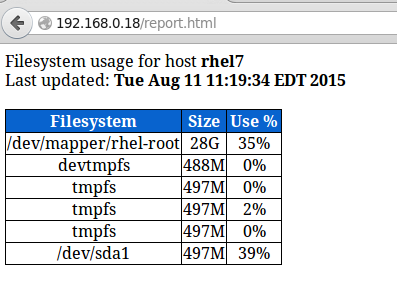
|
||||
|
||||
服务器监视报告
|
||||
*服务器监视报告*
|
||||
|
||||
你可以添加任何你想要的信息到那个报告中。添加下面的 crontab 条目在每天下午的 1:30 运行该脚本:
|
||||
|
||||
@ -193,12 +193,12 @@ via: http://www.tecmint.com/using-shell-script-to-automate-linux-system-maintena
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-and-file-system-statistics-reports/
|
||||
[1]:https://linux.cn/article-6512-1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Bash_%28Unix_shell%29
|
||||
[3]:http://www.tecmint.com/wp-content/pdf/bash.pdf
|
||||
[4]:http://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
|
||||
@ -1,26 +1,24 @@
|
||||
第五部分 - 如何在 RHEL 7 中管理系统日志(配置、旋转以及导入到数据库)
|
||||
RHCE 系列(五):如何在 RHEL 7 中管理系统日志(配置、轮换以及导入到数据库)
|
||||
================================================================================
|
||||
为了确保你的 RHEL 7 系统安全,你需要通过查看日志文件监控系统中发生的所有活动。这样,你就可以检测任何不正常或有潜在破坏的活动并进行系统故障排除或者其它恰当的操作。
|
||||
为了确保你的 RHEL 7 系统安全,你需要通过查看日志文件来监控系统中发生的所有活动。这样,你就可以检测到任何不正常或有潜在破坏的活动并进行系统故障排除或者其它恰当的操作。
|
||||
|
||||

|
||||

|
||||
|
||||
(译者注:[日志旋转][9]是系统管理中归档每天产生的日志文件的自动化过程)
|
||||
|
||||
RHCE 考试 - 第五部分:使用 Rsyslog 和 Logrotate 管理系统日志
|
||||
*RHCE 考试 - 第五部分:使用 Rsyslog 和 Logrotate 管理系统日志*
|
||||
|
||||
在 RHEL 7 中,[rsyslogd][1] 守护进程负责系统日志,它从 /etc/rsyslog.conf(该文件指定所有系统日志的默认路径)和 /etc/rsyslog.d 中的所有文件(如果有的话)读取配置信息。
|
||||
|
||||
### Rsyslogd 配置 ###
|
||||
|
||||
快速浏览一下 [rsyslog.conf][2] 会是一个好的开端。该文件分为 3 个主要部分:模块(rsyslong 按照模块化设计),全局指令(用于设置 rsyslogd 守护进程的全局属性),以及规则。正如你可能猜想的,最后一个部分指示获取,显示以及在哪里保存什么的日志(也称为选择子),这也是这篇博文关注的重点。
|
||||
快速浏览一下 [rsyslog.conf][2] 会是一个好的开端。该文件分为 3 个主要部分:模块(rsyslong 按照模块化设计),全局指令(用于设置 rsyslogd 守护进程的全局属性),以及规则。正如你可能猜想的,最后一个部分指示记录或显示什么以及在哪里保存(也称为选择子(selector)),这也是这篇文章关注的重点。
|
||||
|
||||
rsyslog.conf 中典型的一行如下所示:
|
||||
|
||||

|
||||
|
||||
Rsyslogd 配置
|
||||
*Rsyslogd 配置*
|
||||
|
||||
在上面的图片中,我们可以看到一个选择子包括了一个或多个用分号分隔的设备:优先级(Facility:Priority)对,其中设备描述了消息类型(参考 [RFC 3164 4.1.1 章节][3] 查看 rsyslog 可用的完整设备列表),优先级指示它的严重性,这可能是以下几种之一:
|
||||
在上面的图片中,我们可以看到一个选择子包括了一个或多个用分号分隔的“设备:优先级”(Facility:Priority)对,其中设备描述了消息类型(参考 [RFC 3164 4.1.1 章节][3],查看 rsyslog 可用的完整设备列表),优先级指示它的严重性,这可能是以下几种之一:
|
||||
|
||||
- debug
|
||||
- info
|
||||
@ -31,7 +29,7 @@ Rsyslogd 配置
|
||||
- alert
|
||||
- emerg
|
||||
|
||||
尽管自身并不是一个优先级,关键字 none 意味着指定设备没有任何优先级。
|
||||
尽管 none 并不是一个优先级,不过它意味着指定设备没有任何优先级。
|
||||
|
||||
**注意**:给定一个优先级表示该优先级以及之上的消息都应该记录到日志中。因此,上面例子中的行指示 rsyslogd 守护进程记录所有优先级为 info 以及以上(不管是什么设备)的除了属于 mail、authpriv、以及 cron 服务(不考虑来自这些设备的消息)的消息到 /var/log/messages。
|
||||
|
||||
@ -47,7 +45,7 @@ Rsyslogd 配置
|
||||
|
||||
#### 创建自定义日志文件 ####
|
||||
|
||||
要把所有的守护进程消息记录到 /var/log/tecmint.log,我们需要在 rsyslog.conf 或者 /etc/rsyslog.d 目录中的单独文件(易于管理)添加下面一行:
|
||||
要把所有的守护进程消息记录到 /var/log/tecmint.log,我们需要在 rsyslog.conf 或者 /etc/rsyslog.d 目录中的单独文件(这样易于管理)添加下面一行:
|
||||
|
||||
daemon.* /var/log/tecmint.log
|
||||
|
||||
@ -55,19 +53,19 @@ Rsyslogd 配置
|
||||
|
||||
# systemctl restart rsyslog
|
||||
|
||||
在随机重启两个守护进程之前和之后查看自定义日志的内容:
|
||||
在随便重启两个守护进程之前和之后查看下自定义日志的内容:
|
||||
|
||||

|
||||
|
||||
创建自定义日志文件
|
||||
*创建自定义日志文件*
|
||||
|
||||
作为一个自学练习,我建议你重点关注设备和优先级,添加额外的消息到已有的日志文件或者像上面那样创建一个新的日志文件。
|
||||
|
||||
### 使用 Logrotate 旋转日志 ###
|
||||
### 使用 Logrotate 轮换日志 ###
|
||||
|
||||
为了防止日志文件无限制增长,logrotate 工具用于旋转、压缩、移除或者通过电子邮件发送日志,从而减轻管理会产生大量日志文件系统的困难。
|
||||
为了防止日志文件无限制增长,logrotate 工具用于轮换、压缩、移除或者通过电子邮件发送日志,从而减轻管理会产生大量日志文件系统的困难。(译者注:[日志轮换][9](rotate)是系统管理中归档每天产生的日志文件的自动化过程)
|
||||
|
||||
Logrotate 作为一个 cron 作业(/etc/cron.daily/logrotate)每天运行,并从 /etc/logrotate.conf 和 /etc/logrotate.d 中的文件(如果有的话)读取配置信息。
|
||||
Logrotate 作为一个 cron 任务(/etc/cron.daily/logrotate)每天运行,并从 /etc/logrotate.conf 和 /etc/logrotate.d 中的文件(如果有的话)读取配置信息。
|
||||
|
||||
对于 rsyslog,即使你可以在主文件中为指定服务包含设置,为每个服务创建单独的配置文件能帮助你更好地组织设置。
|
||||
|
||||
@ -75,27 +73,27 @@ Logrotate 作为一个 cron 作业(/etc/cron.daily/logrotate)每天运行,
|
||||
|
||||

|
||||
|
||||
Logrotate 配置
|
||||
*Logrotate 配置*
|
||||
|
||||
在上面的例子中,logrotate 会为 /var/log/wtmp 进行以下操作:尝试每个月旋转一次,但至少文件要大于 1MB,然后用 0664 权限、用户 root、组 utmp 创建一个新的日志文件。下一步只保存一个归档日志,正如旋转指令指定的:
|
||||
在上面的例子中,logrotate 会为 /var/log/wtmp 进行以下操作:尝试每个月轮换一次,但至少文件要大于 1MB,然后用 0664 权限、用户 root、组 utmp 创建一个新的日志文件。下一步只保存一个归档日志,正如轮换指令指定的:
|
||||
|
||||
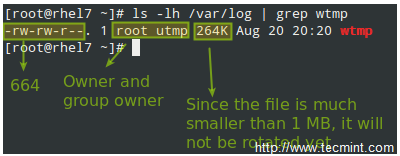
|
||||
|
||||
每月 Logrotate 日志
|
||||
*每月 Logrotate 日志*
|
||||
|
||||
让我们再来看看 /etc/logrotate.d/httpd 中的另一个例子:
|
||||
|
||||

|
||||

|
||||
|
||||
旋转 Apache 日志文件
|
||||
*轮换 Apache 日志文件*
|
||||
|
||||
你可以在 logrotate 的 man 手册([man logrotate][4] 和 [man logrotate.conf][5])中阅读更多有关它的设置。为了方便你的阅读,本文还提供了两篇文章的 PDF 格式。
|
||||
|
||||
作为一个系统工程师,很可能由你决定多久按照什么格式保存一次日志,取决于你是否有一个单独的分区/逻辑卷给 /var。否则,你真的要考虑删除旧日志以节省存储空间。另一方面,根据你公司和客户内部的政策,为了以后的安全审核,你可能被迫要保留多个日志。
|
||||
作为一个系统工程师,很可能由你决定多久按照什么格式保存一次日志,这取决于你是否有一个单独的分区/逻辑卷给 `/var`。否则,你真的要考虑删除旧日志以节省存储空间。另一方面,根据你公司和客户内部的政策,为了以后的安全审核,你可能必须要保留多个日志。
|
||||
|
||||
#### 保存日志到数据库 ####
|
||||
|
||||
当然检查日志可能是一个很繁琐的工作(即使有类似 grep 工具和正则表达式的帮助)。因为这个原因,rsyslog 允许我们把它们导出到数据库(OTB 支持的关系数据库管理系统包括 MySQL、MariaDB、PostgreSQL 和 Oracle)。
|
||||
当然检查日志可能是一个很繁琐的工作(即使有类似 grep 工具和正则表达式的帮助)。因为这个原因,rsyslog 允许我们把它们导出到数据库(OTB 支持的关系数据库管理系统包括 MySQL、MariaDB、PostgreSQL 和 Oracle 等)。
|
||||
|
||||
指南的这部分假设你已经在要管理日志的 RHEL 7 上安装了 MariaDB 服务器和客户端:
|
||||
|
||||
@ -104,10 +102,9 @@ Logrotate 配置
|
||||
|
||||
然后使用 `mysql_secure_installation` 工具为 root 用户设置密码以及其它安全考量:
|
||||
|
||||
|
||||

|
||||
|
||||
保证 MySQL 数据库安全
|
||||
*保证 MySQL 数据库安全*
|
||||
|
||||
注意:如果你不想用 MariaDB root 用户插入日志消息到数据库,你也可以配置用另一个用户账户。如何实现的介绍已经超出了本文的范围,但在 [MariaDB 知识][6] 中有详细解析。为了简单在这篇指南中我们会使用 root 账户。
|
||||
|
||||
@ -117,7 +114,7 @@ Logrotate 配置
|
||||
|
||||

|
||||
|
||||
保存服务器日志到数据库
|
||||
*保存服务器日志到数据库*
|
||||
|
||||
最后,添加下面的行到 /etc/rsyslog.conf:
|
||||
|
||||
@ -132,18 +129,18 @@ Logrotate 配置
|
||||
|
||||
#### 使用 SQL 语法查询日志 ####
|
||||
|
||||
现在执行一些会改变日志的操作(例如停止和启动服务),然后登陆到你的 DB 服务器并使用标准的 SQL 命令显示和查询日志:
|
||||
现在执行一些会改变日志的操作(例如停止和启动服务),然后登录到你的数据库服务器并使用标准的 SQL 命令显示和查询日志:
|
||||
|
||||
USE Syslog;
|
||||
SELECT ReceivedAt, Message FROM SystemEvents;
|
||||
|
||||

|
||||
|
||||
在数据库中查询日志
|
||||
*在数据库中查询日志*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们介绍了如何设置系统日志,如果旋转日志以及为了简化查询如何重定向消息到数据库。我们希望这些技巧能对你准备 [RHCE 考试][8] 和日常工作有所帮助。
|
||||
在这篇文章中我们介绍了如何设置系统日志,如果轮换日志以及为了简化查询如何重定向消息到数据库。我们希望这些技巧能对你准备 [RHCE 考试][8] 和日常工作有所帮助。
|
||||
|
||||
正如往常,非常欢迎你的反馈。用下面的表单和我们联系吧。
|
||||
|
||||
@ -153,7 +150,7 @@ via: http://www.tecmint.com/manage-linux-system-logs-using-rsyslogd-and-logrotat
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -165,5 +162,5 @@ via: http://www.tecmint.com/manage-linux-system-logs-using-rsyslogd-and-logrotat
|
||||
[5]:http://www.tecmint.com/wp-content/pdf/logrotate.conf.pdf
|
||||
[6]:https://mariadb.com/kb/en/mariadb/create-user/
|
||||
[7]:https://github.com/sematext/rsyslog/blob/master/plugins/ommysql/createDB.sql
|
||||
[8]:http://www.tecmint.com/how-to-setup-and-configure-static-network-routing-in-rhel/
|
||||
[8]:https://linux.cn/article-6451-1.html
|
||||
[9]:https://en.wikipedia.org/wiki/Log_rotation
|
||||
@ -1,4 +1,4 @@
|
||||
安装 Samba 并配置 Firewalld 和 SELinux 使得能在 Linux 和 Windows 之间共享文件 - 第六部分
|
||||
RHCE 系列(六):安装 Samba 并配置 Firewalld 和 SELinux 让 Linux 和 Windows 共享文件
|
||||
================================================================================
|
||||
由于计算机很少作为一个独立的系统工作,作为一个系统管理员或工程师,就应该知道如何在有多种类型的服务器之间搭设和维护网络。
|
||||
|
||||
@ -6,9 +6,9 @@
|
||||
|
||||

|
||||
|
||||
RHCE 系列第六部分 - 设置 Samba 文件共享
|
||||
*RHCE 系列第六部分 - 设置 Samba 文件共享*
|
||||
|
||||
如果有人叫你设置文件服务器用于协作或者配置很可能有多种不同类型操作系统和设备的企业环境,这篇文章就能派上用场。
|
||||
如果有人让你设置文件服务器用于协作或者配置很可能有多种不同类型操作系统和设备的企业环境,这篇文章就能派上用场。
|
||||
|
||||
由于你可以在网上找到很多关于 Samba 和 NFS 背景和技术方面的介绍,在这篇文章以及后续文章中我们就省略了这些部分直接进入到我们的主题。
|
||||
|
||||
@ -22,7 +22,7 @@ RHCE 系列第六部分 - 设置 Samba 文件共享
|
||||
|
||||

|
||||
|
||||
测试安装 Samba
|
||||
*测试安装 Samba*
|
||||
|
||||
在 box1 中安装以下软件包:
|
||||
|
||||
@ -36,7 +36,7 @@ RHCE 系列第六部分 - 设置 Samba 文件共享
|
||||
|
||||
### 步骤二: 设置通过 Samba 进行文件共享 ###
|
||||
|
||||
Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB 是微软和英特尔制定的一种通信协议,CIFS 是其中一个版本,更详细的介绍可以参考[Wiki][6])提供了文件和打印设备,这使得客户端看起来服务器就是一个 Windows 系统(我必须承认写这篇文章的时候我有一点激动,因为这是我多年前作为一个新手 Linux 系统管理员的第一次设置)。
|
||||
Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(LCTT 译注:SMB 是微软和英特尔制定的一种通信协议,CIFS 是其中一个版本,更详细的介绍可以参考 [Wiki][6])提供了文件和打印设备,这使得服务器在客户端看起来就是一个 Windows 系统(我必须承认写这篇文章的时候我有一点激动,因为这是我多年前作为一个新手 Linux 系统管理员的第一次设置)。
|
||||
|
||||
**添加系统用户并设置权限和属性**
|
||||
|
||||
@ -91,9 +91,9 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||
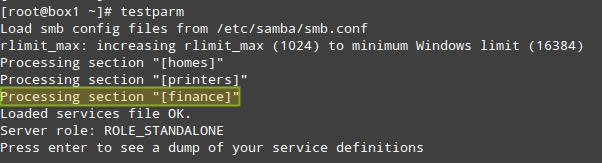
|
||||
|
||||
测试 Samba 配置
|
||||
*测试 Samba 配置*
|
||||
|
||||
如果你要添加另一个公开的共享目录(意味着没有任何验证),在 /etc/samba/smb.conf 中创建另一章节,在共享目录名称下面复制上面的章节,只需要把 public=no 更改为 public=yes 并去掉有效用户和写列表命令。
|
||||
如果你要添加另一个公开的共享目录(意味着不需要任何验证),在 /etc/samba/smb.conf 中创建另一章节,在共享目录名称下面复制上面的章节,只需要把 public=no 更改为 public=yes 并去掉有效用户(valid users)和写列表(write list)命令。
|
||||
|
||||
### 步骤五: 添加 Samba 用户 ###
|
||||
|
||||
@ -102,7 +102,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
# smbpasswd -a user1
|
||||
# smbpasswd -a user2
|
||||
|
||||
最后,重启 Samda,启用系统启动时自动启动服务,并确保共享目录对网络客户端可用:
|
||||
最后,重启 Samda,并让系统启动时自动启动该服务,确保共享目录对网络客户端可用:
|
||||
|
||||
# systemctl start smb
|
||||
# systemctl enable smb
|
||||
@ -112,7 +112,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||

|
||||
|
||||
验证 Samba 共享
|
||||
*验证 Samba 共享*
|
||||
|
||||
到这里,已经正确安装和配置了 Samba 文件服务器。现在让我们在 RHEL 7 和 Windows 8 客户端中测试该配置。
|
||||
|
||||
@ -120,12 +120,11 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||
首先,确保客户端可以访问 Samba 共享:
|
||||
|
||||
# smbclient –L 192.168.0.18 -U user2
|
||||
|
||||
# smbclient –L 192.168.0.18 -U user2
|
||||
|
||||

|
||||
|
||||
在 Linux 上挂载 Samba 共享
|
||||
*在 Linux 上挂载 Samba 共享*
|
||||
|
||||
(为 user1 重复上面的命令)
|
||||
|
||||
@ -135,11 +134,11 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||

|
||||
|
||||
挂载 Samba 网络共享
|
||||
*挂载 Samba 网络共享*
|
||||
|
||||
(其中 /media/samba 是一个已有的目录)
|
||||
|
||||
或者在 /etc/fstab 文件中添加下面的条目自动挂载:
|
||||
或者在 /etc/fstab 文件中添加下面的条目以自动挂载:
|
||||
|
||||
**fstab**
|
||||
|
||||
@ -147,7 +146,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||
//192.168.0.18/finance /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
|
||||
|
||||
其中隐藏文件 /media/samba/.smbcredentials(它的权限被设置为 600 和 root:root)有两行,指示允许使用共享的账户的用户名和密码:
|
||||
其中隐藏文件 /media/samba/.smbcredentials(它的权限被设置为 600 和 root:root)有两行内容,指示允许使用共享的账户的用户名和密码:
|
||||
|
||||
**.smbcredentials**
|
||||
|
||||
@ -162,17 +161,17 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||

|
||||
|
||||
在 Samba 共享中创建文件
|
||||
*在 Samba 共享中创建文件*
|
||||
|
||||
正如你看到的,用权限 0770 和属主 user1:finance 创建了文件。
|
||||
|
||||
### 步骤七: 在 Windows 上挂载 Samba 共享 ###
|
||||
|
||||
要在 Windows 上挂载 Samba 共享,进入 ‘我的计算机’ 并选择 ‘计算机’,‘网络驱动映射’。下一步,为要映射的驱动分配一个字母并用不同的认证检查连接(下面的截图使用我的母语西班牙语):
|
||||
要在 Windows 上挂载 Samba 共享,进入 ‘我的计算机’ 并选择 ‘计算机’,‘网络驱动映射’。下一步,为要映射的驱动分配一个驱动器盘符并用不同的认证身份检查是否可以连接(下面的截图使用我的母语西班牙语):
|
||||
|
||||

|
||||
|
||||
在 Windows 中挂载 Samba 共享
|
||||
*在 Windows 中挂载 Samba 共享*
|
||||
|
||||
最后,让我们新建一个文件并检查权限和属性:
|
||||
|
||||
@ -188,7 +187,7 @@ Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB
|
||||
|
||||
在这篇文章中我们不仅介绍了如何使用不同操作系统设置 Samba 服务器和两个客户端,也介绍了[如何配置 Firewalld][3] 和 [服务器中的 SELinux][4] 以获取所需的组协作功能。
|
||||
|
||||
最后,同样重要的是,我推荐阅读网上的 [smb.conf man 手册][5] 查看其它可能针对你的情况比本文中介绍的场景更加合适的配置命令。
|
||||
最后,同样重要的是,我推荐阅读网上的 [smb.conf man 手册][5] ,查看其它比本文中介绍的场景更加合适你的场景的配置命令。
|
||||
|
||||
正如往常,欢迎在下面的评论框中留下你的评论或建议。
|
||||
|
||||
@ -198,7 +197,7 @@ via: http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,10 @@
|
||||
第七部分 - 在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
|
||||
RHCE 系列(七):在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
|
||||
================================================================================
|
||||
在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类-Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
|
||||
|
||||
在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类 Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
|
||||
|
||||

|
||||
|
||||
RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器
|
||||
*RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器*
|
||||
|
||||
在这篇文章中我们会介绍配置基于 Kerberos 身份验证的 NFS 共享的整个流程。假设你已经配置好了一个 NFS 服务器和一个客户端。如果还没有,可以参考 [安装和配置 NFS 服务器][2] - 它列出了需要安装的依赖软件包并解释了在进行下一步之前如何在服务器上进行初始化配置。
|
||||
|
||||
@ -24,28 +23,26 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
#### 创建 NFS 组并配置 NFS 共享目录 ####
|
||||
|
||||
1. 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(译者注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
|
||||
1、 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(LCTT 译注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
|
||||
|
||||
# groupadd nfs
|
||||
# usermod -a -G nfs nfsnobody
|
||||
# chmod 0770 /nfs
|
||||
# chgrp nfs /nfs
|
||||
|
||||
2. 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
|
||||
2、 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
|
||||
|
||||
**注意**:anongid 的值设置为之前新建的组 nfs 的 GID:
|
||||
|
||||
**exports – 添加 NFS 共享**
|
||||
|
||||
----------
|
||||
|
||||
/nfs box1(rw,sec=krb5,anongid=1004)
|
||||
|
||||
3. 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
|
||||
3、 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
|
||||
|
||||
# exportfs -arv
|
||||
|
||||
4. 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
|
||||
4、 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
|
||||
|
||||
# systemctl restart rpcbind nfs-server nfs-lock nfs-idmap
|
||||
# systemctl enable rpcbind nfs-server
|
||||
@ -61,14 +58,12 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
正如你看到的,为了简便,NFS 服务器和 KDC 在同一台机器上,当然如果你有更多可用机器你也可以把它们安装在不同的机器上。两台机器都在 `mydomain.com` 域。
|
||||
|
||||
最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本模式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
|
||||
最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本方式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
|
||||
|
||||
为了配置域名解析,我们在客户端和服务器中编辑 /etc/hosts 文件:
|
||||
|
||||
**host 文件 – 为域添加 DNS**
|
||||
|
||||
----------
|
||||
|
||||
192.168.0.18 box1.mydomain.com box1
|
||||
192.168.0.20 box2.mydomain.com box2
|
||||
|
||||
@ -82,10 +77,9 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
# chronyc tracking
|
||||
|
||||
|
||||

|
||||
|
||||
用 Chrony 同步服务器时间
|
||||
*用 Chrony 同步服务器时间*
|
||||
|
||||
### 安装和配置 Kerberos ###
|
||||
|
||||
@ -109,7 +103,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
创建 Kerberos 数据库
|
||||
*创建 Kerberos 数据库*
|
||||
|
||||
下一步,使用 kadmin.local 工具为 root 创建管理权限:
|
||||
|
||||
@ -129,7 +123,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
添加 Kerberos 到 NFS 服务器
|
||||
*添加 Kerberos 到 NFS 服务器*
|
||||
|
||||
为 root/admin 获取和缓存票据授权票据(ticket-granting ticket):
|
||||
|
||||
@ -138,7 +132,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||
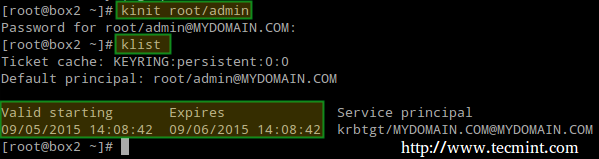
|
||||
|
||||
缓存 Kerberos
|
||||
*缓存 Kerberos*
|
||||
|
||||
真正使用 Kerberos 之前的最后一步是保存被授权使用 Kerberos 身份验证的规则到一个密钥表文件(在服务器中):
|
||||
|
||||
@ -154,7 +148,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
挂载 NFS 共享
|
||||
*挂载 NFS 共享*
|
||||
|
||||
现在让我们卸载共享,在客户端中重命名密钥表文件(模拟它不存在)然后试着再次挂载共享目录:
|
||||
|
||||
@ -163,7 +157,7 @@ RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服
|
||||
|
||||

|
||||
|
||||
挂载/卸载 Kerberos NFS 共享
|
||||
*挂载/卸载 Kerberos NFS 共享*
|
||||
|
||||
现在你可以使用基于 Kerberos 身份验证的 NFS 共享了。
|
||||
|
||||
@ -177,12 +171,12 @@ via: http://www.tecmint.com/setting-up-nfs-server-with-kerberos-based-authentica
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[1]:https://linux.cn/article-6550-1.html
|
||||
[2]:http://www.tecmint.com/configure-nfs-server/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[4]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
@ -1,48 +1,48 @@
|
||||
The history of Android
|
||||
安卓编年史(6)
|
||||
================================================================================
|
||||

|
||||
T-Mobile G1
|
||||
T-Mobile供图
|
||||
|
||||
*T-Mobile G1 [T-Mobile供图]*
|
||||
|
||||
### 安卓1.0——谷歌系app和实体硬件的引入 ###
|
||||
|
||||
到了2008年10月,安卓1.0已经准备好发布,这个系统在[T-Mobile G1][1](又以HTC Dream为人周知)上初次登台。G1进入了被iPhone 3G和[Nokia 1680 classic][2]所主宰的市场。(这些手机并列获得了2008年[销量最佳手机][3]称号,各自卖出了350万台。)G1的销量数字已难以获得,但T-Mobile宣称截至2009年4月该设备的销量突破了100万台。无论从哪方面来说这在竞争中都处于落后地位。
|
||||
到了2008年10月,安卓1.0已经准备好发布,这个系统在[T-Mobile G1][1](又以HTC Dream为人周知)上初次登台。G1进入了被iPhone 3G和[Nokia 1680 classic][2]所主宰的市场。(这些手机并列获得了2008年[销量最佳手机][3]称号,各自卖出了350万台。)G1的具体销量数字已难以获得,但T-Mobile宣称截至2009年4月该设备的销量突破了100万台。无论从哪方面来说这在竞争中都处于落后地位。
|
||||
|
||||
G1拥有单核528Mhz的ARM 11处理器,一个Adreno 130的GPU,192MB内存,以及多达256MB的存储空间供给系统以及应用使用。它有一块3.2英寸,320x480分辨率的显示屏,被布置在一个含有实体全键盘的滑动结构之上。所以尽管安卓软件的确走过了很长的一段路,硬件也是的。时至今日,我们可以在厂商的一个手表中得到比这更好的参数:最新的[三星智能手表][4]拥有512MB内存以及1GHz的双核处理器。
|
||||
G1拥有单核528Mhz的ARM 11处理器,一个Adreno 130的GPU,192MB内存,以及多达256MB的存储空间提供给系统以及应用使用。它有一块3.2英寸、320x480分辨率的显示屏,被布置在一个含有实体全键盘的滑动结构之上。所以尽管安卓软件的确走过了很长的一段路,硬件也是的。时至今日,我们可以在一个厂商提供手表中得到比这更好的参数:最新的[三星智能手表][4]拥有512MB内存以及1GHz的双核处理器。
|
||||
|
||||
当iPhone有着最少数量的按键的时候,G1确实完全相反的,按键几乎支持每个硬件控制。它有拨通和挂断按钮,home键,后退,以及菜单键,一个相机快门键,音量控制键,一个轨迹球,当然,还有50个键盘按钮。未来安卓设备将会慢慢离开按键多多的界面设计,几乎每部新旗舰都在减少按键的数量。
|
||||
当iPhone有着最少数量的按键的时候,G1确实完全相反的,按键几乎支持每个硬件控制。它有拨通和挂断按钮,home键,后退,以及菜单键,一个相机快门键,音量控制键,一个轨迹球,当然,还有50个键盘按键。未来安卓设备将会慢慢离开按键多多的界面设计,几乎每部新旗舰都在减少按键的数量。
|
||||
|
||||
但是这是第一次,人们见到了运行在实机上的安卓,而不是跑在一个令人沮丧的慢吞吞的模拟器上。安卓1.0没有iPhone那样顺滑流畅,闪亮耀眼,或拥有那么多的新闻报道。它也不像Windows Mobile 6.5那样才华横溢。但这仍然是个好的开始。
|
||||
|
||||

|
||||
安卓1.0和0.9的默认应用列表。
|
||||
Ron Amadeo供图
|
||||
|
||||
安卓1.0的核心与两个月前发布的beta版本相比看起来并没有什么引人注目的不同,但消费者产品带来了不少应用,包括一套完整的谷歌系应用。日历,电子邮件,Gmail,即时通讯,市场,设置,语音拨号,以及YouTube都是全新登场。那时候,音乐是智能手机上占据主宰地位的媒体类型,其王者是iTunes音乐商店。谷歌没有自家的音乐服务,所以它选择了亚马逊并绑定了亚马逊MP3商店。
|
||||
*安卓1.0和0.9的默认应用列表。[Ron Amadeo供图]*
|
||||
|
||||
安卓最重要的新增是谷歌商店的首次登场,叫做“安卓市场Beta”。与此同时大部分公司满足于将它们的软件目录称作一些不同的“应用商店”——意思是一个出售应用的商店,并且只出售应用——谷歌明显有着更大的野心。它搭配了一个更为通用的名字,“安卓市场”。这个名字的想法是安卓市场不仅仅拥有应用,还拥有一切你的安卓设备所需要的东西。
|
||||
安卓1.0的核心与两个月前发布的beta版本相比看起来并没有什么引人注目的不同,但这个消费产品带来了不少应用,包括一套完整的谷歌系应用。日历,电子邮件,Gmail,即时通讯,市场,设置,语音拨号,以及YouTube都是全新登场。那时候,音乐是智能手机上占据主宰地位的媒体类型,其王者是iTunes音乐商店。谷歌没有自家的音乐服务,所以它选择了亚马逊并绑定了亚马逊MP3商店。
|
||||
|
||||
安卓最重要的新增内容是首次登场的谷歌商店,叫做“安卓市场Beta”。与此同时大部分公司满足于将它们的软件目录称作各种“应用商店”——意思是一个出售应用的商店,并且只出售应用——谷歌明显有着更大的野心。它搭配了一个更为通用的名字,“安卓市场”。这个名字的想法是安卓市场不仅仅拥有应用,还拥有一切你的安卓设备所需要的东西。
|
||||
|
||||
|
||||
第一个安卓市场客户端。截图展示了主页,“我的下载”,一个应用页面,以及一个应用权限页面。
|
||||
[Google][5]供图
|
||||
|
||||
那时候,安卓市场只提供应用和游戏,开发者们甚至还不能为它们收费。苹果的App Store相对与安卓市场有4个月的先发优势,但是谷歌的主要差异化在于安卓的商店几乎是完全开放的。在iPhone上,应用受制于苹果的审查,必须遵循设计和技术指南。潜在的新应用不允许在功能上复制已有应用。在安卓市场,开发者可以自由地做任何想做的,包括开发替代已有的应用。控制的缺失会转变成祝福同时也是诅咒。它允许开发者革新已有的功能,但同时意味着甚至是毫无价值的垃圾应用也被允许进入市场。
|
||||
*第一个安卓市场客户端。截图展示了主页,“我的下载”,一个应用页面,以及一个应用权限页面。[[Google][5]供图]*
|
||||
|
||||
现在,这个客户端是又一个不再能够和谷歌服务器通讯的应用。幸运的是,它也是在因特网上被[真正记录][6]的为数不多的早期安卓应用之一。主页提供了通向一般区域的连接,像应用,游戏,搜索,以及下载,顶部有横向滚动显示的特色应用图标。搜索结果和“我的下载”页面以滚动列表的方式显示应用,显示应用名,开发者,费用(在那时都是免费的),以及评分。单独的应用页面展示了一个简短的描述,安装数,用户评论和评分,以及最重要的安装按钮。早期的安卓市场不支持图片,开发者唯一能使用的区域是应用描述,还有着500字的限制。这使得类似维护一个更新日志变的十分困难,因为只有描述的位置可以供其使用。
|
||||
那时候,安卓市场只提供应用和游戏,开发者们甚至还不能为它们收费。苹果的App Store相对与安卓市场有4个月的先发优势,但是谷歌的主要差异化在于安卓的商店几乎是完全开放的。在iPhone上,应用受制于苹果的审查,必须遵循设计和技术指南。潜在的新应用不允许在功能上复制已有应用。在安卓市场,开发者可以自由地做任何想做的,包括开发替代已有的应用。控制的缺失导致福祸相依。它允许开发者革新已有的功能,但同时意味着甚至是毫无价值的垃圾应用也被允许进入市场。
|
||||
|
||||
时至今日,这个安卓市场的客户端是又一个不再能够和谷歌服务器通讯的应用。幸运的是,它也是在因特网上被[真正记录][6]的为数不多的早期安卓应用之一。主页提供了通向一般区域的连接,像应用,游戏,搜索,以及下载,顶部有横向滚动显示的特色应用图标。搜索结果和“我的下载”页面以滚动列表的方式显示应用,显示应用名,开发者,费用(在那时都是免费的),以及评分。单独的应用页面展示了一个简短的描述,安装数,用户评论和评分,以及最重要的安装按钮。早期的安卓市场不支持图片,开发者唯一能使用的区域是应用描述,还有着500字的限制。这使得类似维护一个更新日志变的十分困难,因为只有描述的位置可以供其使用。
|
||||
|
||||
就在安装之前,安卓市场显示了应用所需要的权限。这是苹果直至2012年之前都避免做的,那年一个iOS应用被发现在用户不知情的情况下[将完整的通讯录上传][7]到云端。权限显示给出了一个完整的应用用到的权限列表,尽管这个版本强迫用户同意应用权限。界面有个“OK”按钮,但是除了后退按钮没有办法取消。
|
||||
|
||||
|
||||
Gmail展示收件箱,打开菜单的收件箱。
|
||||
Ron Amadeo供图
|
||||
|
||||
下一个重要的应用也许就是Gmail。大多数基本的功能此时已经准备好了。未读邮件以加粗显示,标签是个有颜色的标记。在收件箱中每封独立邮件显示着主题,发件人,以及一个会话中的回复数。Gmail加星标志也在这里——快速点击即可给邮件加星或取消。一如往常,对于早期版本的安卓,菜单里有收件箱视图应有的所有按钮。但是,一旦打开了一封邮件,界面看起来就更加的现代了,“回复”和“转发”按钮永久固定在了屏幕底部。各个独立回复可以点击它们来展开和收缩。
|
||||
*Gmail展示收件箱,打开菜单的收件箱。[Ron Amadeo供图]*
|
||||
|
||||
下一个重要的应用也许就是Gmail。大多数基本的功能此时已经准备好了。未读邮件以加粗显示,标签是个有颜色的标记。在收件箱中每封独立邮件显示着主题,发件人,以及一个会话中的回复数。Gmail加星标志也在这里——快速点击即可给邮件加星或取消。一如往常,对于早期版本的安卓,菜单里有收件箱视图应有的所有按钮。但是,一旦打开了一封邮件,界面看起来就更加的现代了,“回复”和“转发”按钮永久固定在了屏幕底部。单独回复可以点击它们来展开和收缩。
|
||||
|
||||
圆角,阴影,以及气泡图标给了整个应用“卡通”的外表,但是这是个好的开始。安卓的功能第一哲学真正从此开始:Gmail支持标签,邮件会话,搜索,以及邮件推送。
|
||||
|
||||
|
||||
Gmail在安卓1.0的标签视图,写邮件界面,以及设置。
|
||||
Ron Amadeo供图
|
||||
|
||||
*Gmail在安卓1.0的标签视图,写邮件界面,以及设置。[Ron Amadeo供图]*
|
||||
|
||||
但是如果你认为Gmail很丑,电子邮件应用又拉低了下限。它没有分离的收件箱或文件夹视图——所有东西都糊在一个界面。应用呈现给你一个文件夹列表,点击一个文件夹会以内嵌的方式展开内容。未读邮件左侧有条绿色的线指示,这就是电子邮件应用的界面。这个应用支持IMAP和POP3,但是没有Exchange。
|
||||
|
||||
@ -58,7 +58,7 @@ Ron Amadeo供图
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/6/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,90 +1,90 @@
|
||||
安卓编年史
|
||||
安卓编年史(7)
|
||||
================================================================================
|
||||
|
||||
电子邮件应用的所有界面。前两张截图展示了标签/收件箱结合的视图,最后一张截图展示了一封邮件。
|
||||
Ron Amadeo供图
|
||||
|
||||
邮件视图是——令人惊讶的!——白色。安卓的电子邮件应用从历史角度来说算是个打了折扣的Gmail应用,你可以在这里看到紧密的联系。读邮件以及写邮件视图几乎没有任何修改地就从Gmail那里直接取过来使用。
|
||||
*电子邮件应用的所有界面。前两张截图展示了标签/收件箱结合的视图,最后一张截图展示了一封邮件。 [Ron Amadeo供图]*
|
||||
|
||||
邮件视图是——令人惊讶的!居然是白色。安卓的电子邮件应用从历史角度来说算是个打了折扣的Gmail应用,你可以在这里看到紧密的联系。读邮件以及写邮件视图几乎没有任何修改地就从Gmail那里直接取过来使用。
|
||||
|
||||
|
||||
即时通讯应用。截图展示了服务提供商选择界面,朋友列表,以及一个对话。
|
||||
Ron Amadeo供图
|
||||
|
||||
在Google Hangouts之前,甚至是Google Talk之前,就有“IM”——安卓1.0带来的唯一一个即时通讯客户端。令人惊奇的是,它支持多种IM服务:用户可以从AIM,Google Talk,Windows Live Messenger以及Yahoo中挑选。还记得操作系统开发者什么时候关心过互通性吗?
|
||||
*即时通讯应用。截图展示了服务提供商选择界面,朋友列表,以及一个对话。[Ron Amadeo供图]*
|
||||
|
||||
朋友列表是聊天中带有白色聊天气泡的黑色背景界面。状态用一个带颜色的圆形来指示,右侧的小安卓机器人指示出某人正在使用移动设备。IM应用相比Google Hangouts远比它有沟通性,这真是十分神奇的。绿色代表着某人正在使用设备并且已经登录,黄色代表着他们登录了但处于空闲状态,红色代表他们手动设置状态为忙,不想被打扰,灰色表示离线。现在Hangouts只显示用户是否打开了应用。
|
||||
在Google Hangouts之前,甚至是Google Talk之前,就有了“IM”——安卓1.0带来的唯一一个即时通讯客户端。令人惊奇的是,它支持多种IM服务:用户可以从AIM,Google Talk,Windows Live Messenger以及Yahoo中挑选。还记得操作系统开发者什么时候关心过互通性吗?
|
||||
|
||||
朋友列表是黑色背景界面,如果在聊天中则带有白色聊天气泡。状态用一个带颜色的圆形来指示,右侧的小安卓机器人指示出某人正在使用移动设备。IM应用相比Google Hangouts远比它有沟通性,这真是十分神奇的。绿色代表着某人正在使用设备并且已经登录,黄色代表着他们登录了但处于空闲状态,红色代表他们手动设置状态为忙,不想被打扰,灰色表示离线。现在Hangouts只显示用户是否打开了应用。
|
||||
|
||||
聊天对话界面明显基于信息应用,聊天的背景从白色和蓝色被换成了白色和绿色。但是没人更改信息输入框的颜色,所以加上橙色的高亮效果,界面共使用了白色,绿色,蓝色和橙色。
|
||||
|
||||
|
||||
安卓1.0上的YouTube。截图展示了主界面,打开菜单的主界面,分类界面,视频播放界面。
|
||||
Ron Amadeo供图
|
||||
|
||||
YouTube仅仅以G1的320p屏幕和3G网络速度可能不会有今天这样的移动意识,但谷歌的视频服务在安卓1.0上就被置入发布了。主界面看起来就像是安卓市场调整过的版本,顶部带有一个横向滚动选择部分,下面有垂直滚动分类列表。谷歌的一些分类选择还真是奇怪:“最热门”和“最多观看”有什么区别?
|
||||
*安卓1.0上的YouTube。截图展示了主界面,打开菜单的主界面,分类界面,视频播放界面。[Ron Amadeo供图]*
|
||||
|
||||
一个谷歌没有意识到YouTube最终能达到多庞大的标志——有一个视频分类是“最近更新”。在今天,每分钟有[100小时时长的视频][1]上传到Youtube上,如果这个分类能正常工作的话,它会是一个快速滚动的视频列表,快到以至于变为一片无法阅读的模糊。
|
||||
以G1的320p屏幕和3G网络速度,YouTube可能不会有今天这样的手机上的表现,但谷歌的视频服务在安卓1.0上就被置入发布了。主界面看起来就像是安卓市场调整过的版本,顶部带有一个横向滚动选择部分,下面有垂直滚动分类列表。谷歌的一些分类选择还真是奇怪:“最热门”和“最多观看”有什么区别?
|
||||
|
||||
菜单含有搜索,喜爱,分类,设置。设置(没有图片)是有史以来最简陋的,只有个清除搜索历史的选项。分类都是一样的平淡,仅仅是个黑色的文本列表。
|
||||
这是一个谷歌没有意识到YouTube最终能达到多庞大的标志——有一个视频分类是“最近更新”。在今天,每分钟有[100小时时长的视频][1]上传到Youtube上,如果这个分类能正常工作的话,它会是一个快速滚动的视频列表,快到以至于变为一片无法阅读的模糊。
|
||||
|
||||
菜单含有搜索,喜爱,分类,设置。设置(没有该图片)是有史以来最简陋的,只有个清除搜索历史的选项。分类都是一样的平淡,仅仅是个黑色的文本列表。
|
||||
|
||||
最后一张截图展示了视频播放界面,只支持横屏模式。尽管自动隐藏的播放控制有个进度条,但它还是很奇怪地包含了后退和前进按钮。
|
||||
|
||||
|
||||
YouTube的视频菜单,描述页面,评论。
|
||||
Ron Amadeo供图
|
||||
|
||||
每个视频的更多选项可以通过点击菜单按钮来打开。在这里你可以把视频标记为喜爱,查看详细信息,以及阅读评论。所有的这些界面,和视频播放一样,是锁定横屏模式的。
|
||||
*YouTube的视频菜单,描述页面,评论。[Ron Amadeo供图]*
|
||||
|
||||
每个视频的更多选项可以通过点击菜单按钮来打开。在这里你可以把视频标记为“喜爱”,查看详细信息,以及阅读评论。所有的这些界面,和视频播放一样,是锁定横屏模式的。
|
||||
|
||||
然而“共享”不会打开一个对话框,它只是向Gmail邮件中加入了视频的链接。想要把链接通过短信或即时消息发送给别人是不可能的。你可以阅读评论,但是没办法评价他们或发表自己的评论。你同样无法给视频评分或赞。
|
||||
|
||||
|
||||
相机应用的拍照界面,菜单,照片浏览模式。
|
||||
Ron Amadeo供图
|
||||
|
||||
在实体机上跑上真正的安卓意味着相机功能可以正常运作,即便那里没什么太多可关注的。左边的黑色方块是相机的界面,原本应该显示取景器图像,但SDK的截图工具没办法捕捉下来。G1有个硬件实体的拍照键(还记得吗?),所以相机没必要有个屏幕上的快门键。相机没有曝光,白平衡,或HDR设置——你可以拍摄照片,仅此而已。
|
||||
*相机应用的拍照界面,菜单,照片浏览模式。[Ron Amadeo供图]*
|
||||
|
||||
在实体机上跑真正的安卓意味着相机功能可以正常运作,即便那里没什么太多可关注的。左边的黑色方块是相机的界面,原本应该显示取景器图像,但SDK的截图工具没办法捕捉下来。G1有个硬件实体的拍照键(还记得吗?),所以相机没必要有个屏幕上的快门键。相机没有曝光,白平衡,或HDR设置——你可以拍摄照片,仅此而已。
|
||||
|
||||
菜单按钮显示两个选项:跳转到相册应用和带有两个选项的设置界面。第一个设置选项是是否给照片加上地理标记,第二个是在每次拍摄后显示提示菜单,你可以在上面右边看到截图。同样的,你目前还只能拍照——还不支持视频拍摄。
|
||||
|
||||
|
||||
日历的月视图,打开菜单的周视图,日视图,以及日程。
|
||||
Ron Amadeo供图
|
||||
|
||||
*日历的月视图,打开菜单的周视图,日视图,以及日程。[Ron Amadeo供图]*
|
||||
|
||||
就像这个时期的大多数应用一样,日历的主命令界面是菜单。菜单用来切换视图,添加新事件,导航至当天,选择要显示的日程,以及打开设置。菜单扮演着每个单独按钮的入口的作用。
|
||||
|
||||
月视图不能显示约会事件的文字。每个日期旁边有个侧边,约会会显示为侧边上的绿色部分,通过位置来表示约会是在一天中的什么时候。周视图同样不能显示预约文字——G1的320×480的显示屏像素还不够密——所以你会在日历中看到一个带有颜色指示条的白块。唯一一个显示文字的是日程和日视图。你可以用滑动来切换日期——左右滑动切换周和日,上下滑动切换月份和日程。
|
||||
|
||||
|
||||
设置主界面,无线设置,关于页面的底部。
|
||||
Ron Amadeo供图
|
||||
|
||||
安卓1.0最终带来了设置界面。这个界面是个带有文字的黑白界面,粗略地分为各个部分。每个列表项边的下箭头让人误以为点击它会展开折叠的更多东西,但是触摸列表项的任何位置只会加载下一屏幕。所有的界面看起来确实无趣,都差不多一样,但是嘿,这可是设置啊。
|
||||
*设置主界面,无线设置,关于页面的底部。[Ron Amadeo供图]*
|
||||
|
||||
任何带有开/关状态的选项都使用了卡通风的复选框。安卓1.0最初的复选框真是奇怪——就算是在“未选中”状态时,它们还是有个灰色的勾选标记在里面。安卓把勾选标记当作了灯泡,打开时亮起来,关闭的时候变得黯淡,但这不是复选框的工作方式。然而我们最终还是见到了“关于”页面。安卓1.0运行Linux内核2.6.25版本。
|
||||
安卓1.0最终带来了设置界面。这个界面是个带有文字的黑白界面,粗略地分为各个部分。每个列表项边上的下箭头让人误以为点击它会展开折叠的更多东西,但是触摸列表项的任何位置只会加载下一屏幕。所有的界面看起来确实无趣,都差不多一样,但是嘿,这可是设置啊。
|
||||
|
||||
任何带有开/关状态的选项都使用了卡通风格的复选框。安卓1.0最初的复选框真是奇怪——就算是在“未选中”状态时,它们还是有个灰色的勾选标记在里面。安卓把勾选标记当作了灯泡,打开时亮起来,关闭的时候变得黯淡,但这不是复选框的工作方式。然而我们最终还是见到了“关于”页面。安卓1.0运行Linux内核2.6.25版本。
|
||||
|
||||
设置界面意味着我们终于可以打开安全设置并更改锁屏。安卓1.0只有两种风格,安卓0.9那样的灰色方形锁屏,以及需要你在9个点组成的网格中画出图案的图形解锁。像这样的滑动图案相比PIN码更加容易记忆和输入,尽管它没有增加多少安全性。
|
||||
|
||||
|
||||
语音拨号,图形锁屏,电池低电量警告,时间设置。
|
||||
Ron Amadeo供图
|
||||
|
||||
语音功能和语音拨号一同来到了1.0。这个特性以各种功能实现在AOSP徘徊了一段时间,然而它是一个简单的拨打号码和联系人的语音命令应用。语音拨号是个和谷歌未来的语音产品完全无关的应用,但是,它的工作方式和非智能机上的语音拨号一样。
|
||||
*语音拨号,图形锁屏,电池低电量警告,时间设置。[Ron Amadeo供图]*
|
||||
|
||||
语音功能和语音拨号一同来到了1.0。这个特性以各种功能实现在AOSP徘徊了一段时间,然而它是一个简单的拨打号码和联系人的语音命令应用。语音拨号是个和谷歌未来的语音产品完全无关的应用,它的工作方式和非智能机上的语音拨号一样。
|
||||
|
||||
关于最后一个值得注意的,当电池电量低于百分之十五的时候会触发低电量弹窗。这是个有趣的图案,它把电源线错误的一端插入手机。谷歌,那可不是(现在依然不是)手机应该有的充电方式。
|
||||
|
||||
安卓1.0是个伟大的开头,但是功能上仍然有许多缺失。实体键盘和大量硬件按钮被强制要求配备,因为不带有十字方向键或轨迹球的安卓设备依然不被允许销售。另外,基本的智能手机功能比如自动旋转依然缺失。内置应用不可能像今天这样通过安卓市场来更新。所有的谷歌系应用和系统交织在一起。如果谷歌想要升级一个单独的应用,需要通过运营商推送整个系统的更新。安卓依然还有许多工作要做。
|
||||
安卓1.0是个伟大的开端,但是功能上仍然有许多缺失。强制配备了实体键盘和大量硬件按钮,因为不带有十字方向键或轨迹球的安卓设备依然不被允许销售。另外,基本的智能手机功能比如自动旋转依然缺失。内置应用不可能像今天这样通过安卓市场来更新。所有的谷歌系应用和系统交织在一起。如果谷歌想要升级一个单独的应用,需要通过运营商推送整个系统的更新。安卓依然还有许多工作要做。
|
||||
|
||||
### 安卓1.1——第一个真正的增量更新 ###
|
||||
|
||||
|
||||
安卓1.1的所有新特性:语音搜索,安卓市场付费应用支持,谷歌纵横,设置中的新“系统更新”选项。
|
||||
Ron Amadeo供图
|
||||
|
||||
安卓1.0发布四个半月后,2009年2月,安卓在安卓1.1中得到了它的第一个公开更新。系统方面没有太多变化,谷歌向1.1中添加新东西现如今也都已被关闭。谷歌语音搜索是安卓向云端语音搜索的第一个突击,它在应用抽屉里有自己的图标。尽管这个应用已经不能与谷歌服务器通讯,你可以[在iPhone上][2]看到它以前是怎么工作的。它还没有语音操作,但你可以说出想要搜索的,结果会显示在一个简单的谷歌搜索中。
|
||||
*安卓1.1的所有新特性:语音搜索,安卓市场付费应用支持,谷歌纵横,设置中的新“系统更新”选项。[Ron Amadeo供图]*
|
||||
|
||||
安卓市场添加了对付费应用的支持,但是就像beta客户端中一样,这个版本的安卓市场不再能够连接Google Play服务器。我们最多能够看到分类界面,你可以在免费应用,付费应用和全部应用中选择。
|
||||
安卓1.0发布四个半月后,2009年2月,安卓在安卓1.1中得到了它的第一个公开更新。系统方面没有太多变化,谷歌向1.1中添加的新东西现如今也都已被关闭。谷歌语音搜索是安卓向云端语音搜索的第一个突击,它在应用抽屉里有自己的图标。尽管这个应用已经不能与谷歌服务器通讯,你可以[在iPhone上][2]看到它以前是怎么工作的。它还没有语音操作,但你可以说出想要搜索的,结果会显示在一个简单的谷歌搜索中。
|
||||
|
||||
安卓市场添加了对付费应用的支持,但是就像beta客户端中一样,这个版本的安卓市场已经不能连接Google Play服务器。我们最多能够看到分类界面,你可以在免费应用、付费应用和全部应用中选择。
|
||||
|
||||
地图添加了[谷歌纵横][3],一个向朋友分享自己位置的方法。纵横在几个月前为了支持Google+而被关闭并且不再能够工作。地图菜单里有个纵横的选项,但点击它现在只会打开一个带载入中圆圈的画面,并永远停留在这里。
|
||||
|
||||
安卓世界的系统更新来得更加迅速——或者至少是一条在运营商和OEM推送之前获得更新的途径——谷歌向“关于手机”界面添加了检查系统更新按钮。
|
||||
安卓世界的系统更新来得更加迅速——或者至少是一条在运营商和OEM推送之前获得更新的途径——谷歌也在“关于手机”界面添加了检查系统更新按钮。
|
||||
|
||||
----------
|
||||
|
||||
@ -98,7 +98,7 @@ Ron Amadeo供图
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/7/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
cygmris is translating...
|
||||
Great Open Source Collaborative Editing Tools
|
||||
================================================================================
|
||||
In a nutshell, collaborative writing is writing done by more than one person. There are benefits and risks of collaborative working. Some of the benefits include a more integrated / co-ordinated approach, better use of existing resources, and a stronger, united voice. For me, the greatest advantage is one of the most transparent. That's when I need to take colleagues' views. Sending files back and forth between colleagues is inefficient, causes unnecessary delays and leaves people (i.e. me) unhappy with the whole notion of collaboration. With good collaborative software, I can share notes, data and files, and use comments to share thoughts in real-time or asynchronously. Working together on documents, images, video, presentations, and tasks is made less of a chore.
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by H-mudcup
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
|
||||
@ -1,44 +0,0 @@
|
||||
Curious about Linux? Try Linux Desktop on the Cloud
|
||||
================================================================================
|
||||
Linux maintains a very small market share as a desktop operating system. Current surveys estimate its share to be a mere 2%; contrast that with the various strains (no pun intended) of Windows which total nearly 90% of the desktop market. For Linux to challenge Microsoft's monopoly on the desktop, there needs to be a simple way of learning about this different operating system. And it would be naive to believe a typical Windows user is going to buy a second machine, tinker with partitioning a hard disk to set up a multi-boot system, or just jump ship to Linux without an easy way back.
|
||||
|
||||

|
||||
|
||||
We have examined a number of risk-free ways users can experiment with Linux without dabbling with partition management. Various options include Live CD/DVDs, USB keys and desktop virtualization software. For the latter, I can strongly recommend VMWare (VMWare Player) or Oracle VirtualBox, two relatively easy and free ways of installing and running multiple operating systems on a desktop or laptop computer. Each virtual machine has its own share of CPU, memory, network interfaces etc which is isolated from other virtual machines. But virtual machines still require some effort to get Linux up and running, and a reasonably powerful machine. Too much effort for a mere inquisitive mind.
|
||||
|
||||
It can be difficult to break down preconceptions. Many Windows users will have experimented with free software that is available on Linux. But there are many facets to learn on Linux. And it takes time to become accustomed to the way things work in Linux.
|
||||
|
||||
Surely there should be an effortless way for a beginner to experiment with Linux for the first time? Indeed there is; step forward the online cloud lab.
|
||||
|
||||
### LabxNow ###
|
||||
|
||||

|
||||
|
||||
LabxNow provides a free service for general users offering Linux remote desktop over the browser. The developers promote the service as having a personal remote lab (to play around, develop, whatever!) that will be accessible from anywhere, with the internet of course.
|
||||
|
||||
The service currently offers a free virtual private server with 2 cores, 4GB RAM and 10GB SSD space. The service runs on a 4 AMD 6272 CPU with 128GB RAM.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Machine images: Ubuntu 14.04 with Xfce 4.10, RHEL 6.5, CentOS with Gnome, and Oracle
|
||||
- Hardware: CPU - 1 or 2 cores; RAM: 512MB, 1GB, 2GB or 4GB
|
||||
- Fast network for data transfers
|
||||
- Works with all popular browsers
|
||||
- Install anything, run anything - an excellent way to experiment and learn all about Linux without any risk
|
||||
- Easily add, delete, manage and customize VMs
|
||||
- Share VMs, Remote desktop support
|
||||
|
||||
All you need is a reasonable Internet connected device. Forget about high cost VPS, domain space or hardware support. LabxNow offers a great way of experimenting with Ubuntu, RHEL and CentOS. It gives Windows users an excellent environment to dip their toes into the wonderful world of Linux. Further, it allows users to do (programming) work from anywhere in the word without having the stress of installing Linux on each machine. Point your web browser at [www.labxnow.org/labxweb/][1].
|
||||
|
||||
There are other services (mostly paid services) that allow users to experiment with Linux. These include Cloudsigma which offers a free 7 day trial, and Icebergs.io (full root access via HTML5). But for now, LabxNow gets my recommendation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.labxnow.org/labxweb/
|
||||
@ -0,0 +1,195 @@
|
||||
Optimize Web Delivery with these Open Source Tools
|
||||
================================================================================
|
||||
Web proxy software forwards HTTP requests without modifying traffic in any way. They can be configured as a transparent proxy with no client-side configuration required. They can also be used as a reverse proxy front-end to websites; here the cache serves an unlimited number of clients for one or some web servers.
|
||||
|
||||
Web proxies are versatile tools. They have a wide variety of uses, from caching web, DNS and other lookups, to speeding up the delivery of a web server / reducing bandwidth consumption. Web proxy software can also harden security by filtering traffic and anonymizing connections, and offer media-range limitations. This software is used by high-profile, high-traffic websites such as The New York Times, The Guardian, and social media and content sites such as Twitter, Facebook, and Wikipedia.
|
||||
|
||||
Web caches have become a vital mechanism for optimising the amount of data that is delivered in a given period of time. Good web caches also help to minimise latency, serving pages as quickly as possible. This helps to prevent the end user from becoming impatient having to wait for content to be delivered. Web caches optimise the data flow between client and server. They also help to converse bandwidth by caching frequently-delivered content. If you need to reduce server load and improve delivery speed of your content, it is definitely worth exploring the benefits offered by web cache software.
|
||||
|
||||
To provide an insight into the quality of software available for Linux, I feature below 5 excellent open source web proxy tools. Some of the them are full-featured; a couple of them have very modest resource needs.
|
||||
|
||||
### Squid ###
|
||||
|
||||
Squid is a high-performance open source proxy caching server and web cache daemon. It supports FTP, Internet Gopher, HTTPS, TLS, and SSL. It handles all requests in a single, non-blocking, I/O-driven process over IPv4 or IPv6.
|
||||
|
||||
Squid consists of a main server program squid, a Domain Name System lookup program dnsserver, some optional programs for rewriting requests and performing authentication, together with some management and client tools.
|
||||
|
||||
Squid offers a rich access control, authorization and logging environment to develop web proxy and content serving applications.
|
||||
|
||||
Features include:
|
||||
|
||||
- Web proxy:
|
||||
- Caching to reduce access time and bandwidth use
|
||||
- Keeps meta data and especially hot objects cached in RAM
|
||||
- Caches DNS lookups
|
||||
- Supports non-blocking DNS lookups
|
||||
- Implements negative chacking of failed requests
|
||||
- Squid caches can be arranged in a hierarchy or mesh for additional bandwidth savings
|
||||
- Enforce site-usage policies with extensive access controls
|
||||
- Anonymize connections, such as disabling or changing specific header fields in a client's HTTP request
|
||||
- Reverse proxy
|
||||
- Media-range limitations
|
||||
- Supports SSL
|
||||
- Support for IPv6
|
||||
- Error Page Localization - error pages presented by Squid may now be localized per-request to match the visitors local preferred language
|
||||
- Connection Pinning (for NTLM Auth Passthrough) - a workaround which permits Web servers to use Microsoft NTLM Authentication instead of HTTP standard authentication through a web proxy
|
||||
- Quality of Service (QoS) Flow support
|
||||
- Select a TOS/Diffserv value to mark local hits
|
||||
- Select a TOS/Diffserv value to mark peer hits
|
||||
- Selectively mark only sibling or parent requests
|
||||
- Allows any HTTP response towards clients to have the TOS value of the response coming from the remote server preserved
|
||||
- Mask certain bits in the TOS received from the remote server, before copying the value to the TOS send towards clients
|
||||
- SSL Bump (for HTTPS Filtering and Adaptation) - Squid-in-the-middle decryption and encryption of CONNECT tunneled SSL traffic, using configurable client- and server-side certificates
|
||||
- eCAP Adaptation Module support
|
||||
- ICAP Bypass and Retry enhancements - ICAP is now extended with full bypass and dynamic chain routing to handle multiple adaptation services.
|
||||
- ICY streaming protocol support - commonly known as SHOUTcast multimedia streams
|
||||
- Dynamic SSL Certificate Generation
|
||||
- Support for the Internet Content Adaptation Protocol (ICAP)
|
||||
- Full request logging
|
||||
- Anonymize connections
|
||||
|
||||
- Website: [www.squid-cache.org][1]
|
||||
- Developer: National Laboratory for Applied Networking Research (NLANR) and Internet volunteers
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 4.0.1
|
||||
|
||||
### Privoxy ###
|
||||
|
||||
Privoxy (Privacy Enhancing Proxy) is a non-caching Web proxy with advanced filtering capabilities for enhancing privacy, modifying web page data and HTTP headers, controlling access, and removing ads and other obnoxious Internet junk. Privoxy has a flexible configuration and can be customized to suit individual needs and tastes. It supports both stand-alone systems and multi-user networks.
|
||||
|
||||
Privoxy uses the concept of actions in order to manipulate the data stream between the browser and remote sites.
|
||||
|
||||
Features include:
|
||||
|
||||
- Highly configurable - completely personalize your installation
|
||||
- Ad blocking
|
||||
- Cookie management
|
||||
- Supports "Connection: keep-alive". Outgoing connections can be kept alive independently from the client
|
||||
- Supports IPv6
|
||||
- Tagging which allows to change the behaviour based on client and server headers
|
||||
- Run as an "intercepting" proxy
|
||||
- Sophisticated actions and filters for manipulating both server and client headers
|
||||
- Can be chained with other proxies
|
||||
- Integrated browser-based configuration and control utility. Browser-based tracing of rule and filter effects. Remote toggling
|
||||
- Web page filtering (text replacements, removes banners based on size, invisible "web-bugs" and HTML annoyances, etc)
|
||||
- Modularized configuration that allows for standard settings and user settings to reside in separate files, so that installing updated actions files won't overwrite individual user settings
|
||||
- Support for Perl Compatible Regular Expressions in the configuration files, and a more sophisticated and flexible configuration syntax
|
||||
- GIF de-animation
|
||||
- Bypass many click-tracking scripts (avoids script redirection)
|
||||
- User-customizable HTML templates for most proxy-generated pages (e.g. "blocked" page)
|
||||
- Auto-detection and re-reading of config file changes
|
||||
- Most features are controllable on a per-site or per-location basis
|
||||
|
||||
- Website: [www.privoxy.org][2]
|
||||
- Developer: Fabian Keil (lead developer), David Schmidt, and many other contributors
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 3.4.2
|
||||
|
||||
### Varnish Cache ###
|
||||
|
||||
Varnish Cache is a web accelerator written with performance and flexibility in mind. It's modern architecture offers significantly better performance. It typically speeds up delivery with a factor of 300 - 1000x, depending on your architecture. Varnish stores web pages in memory so the web servers do not have to create the same web page repeatedly. The web server only recreates a page when it is changed. When content is served from memory this happens a lot faster then anything.
|
||||
|
||||
Additionally Varnish can serve web pages much faster then any application server is capable of - giving the website a significant speed enhancement.
|
||||
|
||||
For a cost-effective configuration, Varnish Cache uses between 1-16GB and a SSD disk.
|
||||
|
||||
Features include:
|
||||
|
||||
- Modern design
|
||||
- VCL - a very flexible configuration language. The VCL configuration is translated to C, compiled, loaded and executed giving flexibility and speed
|
||||
- Load balancing using both a round-robin and a random director, both with a per-backend weighting
|
||||
- DNS, Random, Hashing and Client IP based Directors
|
||||
- Load balance between multiple backends
|
||||
- Support for Edge Side Includes including stitching together compressed ESI fragments
|
||||
- Heavily threaded
|
||||
- URL rewriting
|
||||
- Cache multiple vhosts with a single Varnish
|
||||
- Log data is stored in shared memory
|
||||
- Basic health-checking of backends
|
||||
- Graceful handling of "dead" backends
|
||||
- Administered by a command line interface
|
||||
- Use In-line C to extend Varnish
|
||||
- Can be used on the same system as Apache
|
||||
- Run multiple Varnish on the same system
|
||||
- Support for HAProxy's PROXY protocol. This is a protocol adds a small header on each incoming TCP connection that describes who the real client is, added by (for example) an SSL terminating process
|
||||
- Warm and cold VCL states
|
||||
- Plugin support with Varnish Modules, called VMODs
|
||||
- Backends defined through VMODs
|
||||
- Gzip Compression and Decompression
|
||||
- HTTP Streaming Pass & Fetch
|
||||
- Saint and Grace mode. Saint Mode allows for unhealthy backends to be blacklisted for a period of time, preventing them from serving traffic when using Varnish as a load balancer. Grace mode allows Varnish to serve an expired version of a page or other asset in cases where Varnish is unable to retrieve a healthy response from the backend
|
||||
- Experimental support for Persistent Storage, without LRU eviction
|
||||
|
||||
- Website: [www.varnish-cache.org][3]
|
||||
- Developer: Varnish Software
|
||||
- License: FreeBSD
|
||||
- Version Number: 4.1.0
|
||||
|
||||
### Polipo ###
|
||||
|
||||
Polipo is an open source caching HTTP proxy which has modest resource needs.
|
||||
|
||||
It listens to requests for web pages from your browser and forwards them to web servers, and forwards the servers’ replies to your browser. In the process, it optimises and cleans up the network traffic. It is similar in spirit to WWWOFFLE, but the implementation techniques are more like the ones ones used by Squid.
|
||||
|
||||
Polipo aims at being a compliant HTTP/1.1 proxy. It should work with any web site that complies with either HTTP/1.1 or the older HTTP/1.0.
|
||||
|
||||
Features include:
|
||||
|
||||
- HTTP 1.1, IPv4 & IPv6, traffic filtering and privacy-enhancement
|
||||
- Uses HTTP/1.1 pipelining if it believes that the remote server supports it, whether the incoming requests are pipelined or come in simultaneously on multiple connections
|
||||
- Cache the initial segment of an instance if the download has been interrupted, and, if necessary, complete it later using Range requests
|
||||
- Upgrade client requests to HTTP/1.1 even if they come in as HTTP/1.0, and up- or downgrade server replies to the client's capabilities
|
||||
- Complete support for IPv6 (except for scoped (link-local) addresses)
|
||||
- Use as a bridge between the IPv4 and IPv6 Internets
|
||||
- Content-filtering
|
||||
- Can use a technique known as Poor Man's Multiplexing to reduce latency
|
||||
- SOCKS 4 and SOCKS 5 protocol support
|
||||
- HTTPS proxying
|
||||
- Behaves as a transparent proxy
|
||||
- Run Polipo together with Privoxy or tor
|
||||
|
||||
- Website: [www.pps.univ-paris-diderot.fr/~jch/software/polipo/][4]
|
||||
- Developer: Juliusz Chroboczek, Christopher Davis
|
||||
- License: MIT License
|
||||
- Version Number: 1.1.1
|
||||
|
||||
### Tinyproxy ###
|
||||
|
||||
Tinyproxy is a lightweight open source web proxy daemon. It is designed to be fast and yet small. It is useful for cases such as embedded deployments where a full featured HTTP proxy is required, but the system resources for a larger proxy are unavailable.
|
||||
|
||||
Tinyproxy is very useful in a small network setting, where a larger proxy would either be too resource intensive, or a security risk. One of the key features of Tinyproxy is the buffering connection concept. In effect, Tinyproxy will buffer a high speed response from a server, and then relay it to a client at the highest speed the client will accept. This feature greatly reduces the problems with sluggishness on the net.
|
||||
|
||||
Features:
|
||||
|
||||
- Easy to modify
|
||||
- Anonymous mode - allows specification of individual HTTP headers that should be allowed through, and which should be blocked
|
||||
- HTTPS support - Tinyproxy allows forwarding of HTTPS connections without modifying traffic in any way through the CONNECT method
|
||||
- Remote monitoring - access proxy statistics from afar, letting you know exactly how busy the proxy is
|
||||
- Load average monitoring - configure software to refuse connections after the server load reaches a certain point
|
||||
- Access control - configure to only allow connections from certain subnets or IP addresses
|
||||
- Secure - run without any special privileges, thus minimizing the chance of system compromise
|
||||
- URL based filtering - allows domain and URL-based black- and whitelisting
|
||||
- Transparent proxying - configure as a transparent proxy, so that a proxy can be used without any client-side configuration
|
||||
- Proxy chaining - use an upstream proxy server for outbound connections, instead of direct connections to the target server, creating a so-called proxy chain
|
||||
- Privacy features - restrict both what data comes to your web browser from the HTTP server (e.g., cookies), and to restrict what data is allowed through from your web browser to the HTTP server (e.g., version information)
|
||||
- Small footprint - the memory footprint is about 2MB with glibc, and the CPU load increases linearly with the number of simultaneous connections (depending on the speed of the connection). Tinyproxy can be run on an old machine without affecting performance
|
||||
|
||||
- Website: [banu.com/tinyproxy][5]
|
||||
- Developer: Robert James Kaes and contributors
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151101020309690/WebDelivery.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.squid-cache.org/
|
||||
[2]:http://www.privoxy.org/
|
||||
[3]:https://www.varnish-cache.org/
|
||||
[4]:http://www.pps.univ-paris-diderot.fr/%7Ejch/software/polipo/
|
||||
[5]:https://banu.com/tinyproxy/
|
||||
@ -0,0 +1,69 @@
|
||||
7 ways hackers can use Wi-Fi against you
|
||||
================================================================================
|
||||

|
||||
|
||||
### 7 ways hackers can use Wi-Fi against you ###
|
||||
|
||||
Wi-Fi — oh so convenient, yet oh so dangerous. Here are seven ways you could be giving away your identity through a Wi-Fi connection and what to do instead.
|
||||
|
||||

|
||||
|
||||
### Using free hotspots ###
|
||||
|
||||
They seem to be everywhere, and their numbers are expected to [quadruple over the next four years][1]. But many of them are untrustworthy, created just so your login credentials, to email or even more sensitive accounts, can be picked up by hackers using “sniffers” — software that captures any information you submit over the connection. The best defense against sniffing hackers is to use a VPN (virtual private network). A VPN keeps your private data protected because it encrypts what you input.
|
||||
|
||||

|
||||
|
||||
### Banking online ###
|
||||
|
||||
You might think that no one needs to be warned against banking online using free Wi-Fi, but cybersecurity firm Kaspersky Lab says that [more than 100 banks worldwide have lost $900 million][2] from cyberhacking, so it would seem that a lot of people are doing it. If you want to use the free Wi-Fi in a coffee shop because you’re confident it will be legitimate, confirm the exact network name with the barista. It’s pretty easy for [someone else in the shop with a router to set up an open connection][3] with a name that seems like it would be the name of the shop’s Wi-Fi.
|
||||
|
||||

|
||||
|
||||
### Keeping Wi-Fi on all the time ###
|
||||
|
||||
When your phone’s Wi-Fi is automatically enabled, you can be connected to an unsecure network without even realizing it. Use your phone’s [location-based Wi-Fi feature][4], if it’s available. It will turn off your Wi-Fi when you’re away from your saved networks and will turn back on when you’re within range.
|
||||
|
||||

|
||||
|
||||
### Not using a firewall ###
|
||||
|
||||
A firewall is your first line of defense against malicious intruders. It’s meant to let good traffic through your computer on a network and keep hackers and malware out. You should turn it off only when your antivirus software has its own firewall.
|
||||
|
||||

|
||||
|
||||
### Browsing unencrypted websites ###
|
||||
|
||||
Sad to say, [55% of the Web’s top 1 million sites don’t offer encryption][5]. An unencrypted website allows all data transmissions to be viewed by the prying eyes of hackers. Your browser will indicate when a site is secure (you’ll see a gray padlock with Mozilla Firefox, for example, and a green lock icon with Chrome). But even a secure website can’t protect you from sidejackers, who can steal the cookies from a website you visited, whether it’s a valid site or not, through a public network.
|
||||
|
||||

|
||||
|
||||
### Not updating your security software ###
|
||||
|
||||
If you want to ensure that your own network is well protected, upgrade the firmware of your router. All you have to do is go to your router’s administration page to check. Normally, you can download the newest firmware right from the manufacturer’s site.
|
||||
|
||||

|
||||
|
||||
### Not securing your home Wi-Fi ###
|
||||
|
||||
Needless to say, it is important to set up a password that is not too easy to guess, and change your connection’s default name. You can also filter your MAC address so your router will recognize only certain devices.
|
||||
|
||||
**Josh Althuser** is an open software advocate, Web architect and tech entrepreneur. Over the past 12 years, he has spent most of his time advocating for open-source software and managing teams and projects, as well as providing enterprise-level consultancy for Web applications and helping bring their products to the market. You may connect with him on [Twitter][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/3003170/mobile-security/7-ways-hackers-can-use-wi-fi-against-you.html
|
||||
|
||||
作者:[Josh Althuser][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/JoshAlthuser
|
||||
[1]:http://www.pcworld.com/article/243464/number_of_wifi_hotspots_to_quadruple_by_2015_says_study.html
|
||||
[2]:http://www.nytimes.com/2015/02/15/world/bank-hackers-steal-millions-via-malware.html?hp&action=click&pgtype=Homepage&module=first-column-region%C2%AEion=top-news&WT.nav=top-news&_r=3
|
||||
[3]:http://news.yahoo.com/blogs/upgrade-your-life/banking-online-not-hacked-182159934.html
|
||||
[4]:http://pocketnow.com/2014/10/15/should-you-leave-your-smartphones-wifi-on-or-turn-it-off
|
||||
[5]:http://www.cnet.com/news/chrome-becoming-tool-in-googles-push-for-encrypted-web/
|
||||
[6]:https://twitter.com/JoshAlthuser
|
||||
@ -1,3 +1,4 @@
|
||||
sevenot translating
|
||||
A Linux User Using ‘Windows 10′ After More than 8 Years – See Comparison
|
||||
================================================================================
|
||||
Windows 10 is the newest member of windows NT family of which general availability was made on July 29, 2015. It is the successor of Windows 8.1. Windows 10 is supported on Intel Architecture 32 bit, AMD64 and ARMv7 processors.
|
||||
|
||||
@ -1,46 +0,0 @@
|
||||
LinuxCon's surprise keynote speaker Linus Torvalds muses about open-source software
|
||||
================================================================================
|
||||
> In a broad-ranging question and answer session, Linus Torvalds, Linux's founder, shared his thoughts on the current state of open source and Linux.
|
||||
|
||||
**SEATTLE** -- [LinuxCon][1] attendees got an early Christmas present when the Wednesday morning "surprise" keynote speaker turned out to be Linux's founder, Linus Torvalds.
|
||||
|
||||

|
||||
|
||||
Jim Zemlin and Linus Torvalds shooting the breeze at LinuxCon in Seattle. -- sjvn
|
||||
|
||||
Jim Zemlin, the Linux Foundation's executive director, opened the question and answer session by quoting from a recent article about Linus, "[Torvalds may be the most influential individual economic force][2] of the past 20 years. ... Torvalds has, in effect, been as instrumental in retooling the production lines of the modern economy as Henry Ford was 100 years earlier."
|
||||
|
||||
Torvalds replied, "I don't think I'm all that powerful, but I'm glad to get all the credit for open source." For someone who's arguably been more influential on technology than Bill Gates, Steve Jobs, or Larry Ellison, Torvalds remains amusingly modest. That's probably one reason [Torvalds, who doesn't suffer fools gladly][3], remains the unchallenged leader of Linux.
|
||||
|
||||
It also helps that he doesn't take himself seriously, except when it comes to code quality. Zemlin reminded him that he was also described in the same article as being "5-feet, ho-hum tall with a paunch, ... his body type and gait resemble that of Tux, the penguin mascot of Linux." Torvald's reply was to grin and say "What is this? A roast?" He added that 5'8" was a perfectly good height.
|
||||
|
||||
More seriously, Zemlin asked Torvalds what he thought about the current excitement over containers. Indeed, at times LinuxCon has felt like DockerCon. Torvalds replied, "I'm glad that the kernel is far removed from containers and other buzzwords. We only care about just the kernel. I'm so focused on the kernel I really don't care. I don't get involved in the politics above the kernel and I'm really happy that I don't know."
|
||||
|
||||
Moving on, Zemlin asked Torvalds what he thought about the demand from the Internet of Things (IoT) for an even smaller Linux kernel. "Everyone has always wished for a smaller kernel," Torvalds said. "But, with all the modules it's still tens of MegaBytes in size. It's shocking that it used to fit into a MB. We'd like it to be mean lean, mean IT machine again."
|
||||
|
||||
But, "Torvalds continued, "It's hard to get rid of unnecessary fat. Things tend to grow. Realistically I don't think we can get down to the sizes we were 20 years ago."
|
||||
|
||||
As for security, the next topic, Torvalds said, "I'm at odds with the security community. They tend to see technology as black and white. If it's not security they don't care at all about it." The truth is "security is bugs. Most of the security issues we've had in the kernel hasn't been that big. Most of them have been really stupid and then some clever person takes advantage of it."
|
||||
|
||||
The bottom line is, "We'll never get rid of bugs so security will never be perfect. We do try to be really careful about code. With user space we have to be very strict." But, "Bugs happen and all you can do is mitigate them. Open source is doing fairly well, but anyone who thinks we'll ever be completely secure is foolish."
|
||||
|
||||
Zemlin concluded by asking Torvalds where he saw Linux ten years from now. Torvalds replied that he doesn't look at it this way. "I'm plodding, pedestrian, I look ahead six months, I don't plan 10 years ahead. I think that's insane."
|
||||
|
||||
Sure, "companies plan ten years, and their plans use open source. Their whole process is very forward thinking. But I'm not worried about 10 years ahead. I look to the next release and the release beyond that."
|
||||
|
||||
For Torvalds, who works at home where "the FedEx guy is no longer surprised to find me in my bathrobe at 2 in the afternoon," looking ahead a few months works just fine. And so do all the businesses -- both technology-based Amazon, Google, Facebook and more mainstream, WalMart, the New York Stock Exchange, and McDonalds -- that live on Linux every day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linus-torvalds-muses-about-open-source-software/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.bloomberg.com/news/articles/2015-06-16/the-creator-of-linux-on-the-future-without-him
|
||||
[3]:http://www.zdnet.com/article/linus-torvalds-finds-gnome-3-4-to-be-a-total-user-experience-design-failure/
|
||||
@ -1,4 +1,3 @@
|
||||
KevinSJ translating
|
||||
Why did you start using Linux?
|
||||
================================================================================
|
||||
> In today's open source roundup: What got you started with Linux? Plus: IBM's Linux only Mainframe. And why you should skip Windows 10 and go with Linux
|
||||
|
||||
@ -1,92 +0,0 @@
|
||||
LinuxCon exclusive: Mark Shuttleworth says Snappy was born long before CoreOS and the Atomic Project
|
||||
================================================================================
|
||||

|
||||
|
||||
Mark Shuttleworth at LinuxCon Credit: Swapnil Bhartiya
|
||||
|
||||
> Mark Shuttleworth, founder of Canonical and Ubuntu, made a surprise visit at LinuxCon. I sat down with him for a video interview and talked about Ubuntu on IBM’s new LinuxONE systems, Canonical’s plans for containers, open source in the enterprise space and much more.
|
||||
|
||||
### You made a surprise entry during the keynote. What brought you to LinuxCon? ###
|
||||
|
||||
**Mark Shuttleworth**: I am here at LinuxCon to support IBM and Canonical in their announcement of Ubuntu on their new Linux-only super-high-end mainframe LinuxONE. These are the biggest machines in the world, purpose-built to run only Linux. And we will be bringing Ubuntu to them, which is a real privilege for us and is going to be incredible for developers.
|
||||
|
||||

|
||||
|
||||
Swapnil Bhartiya
|
||||
|
||||
Mark Shuttleworth and Swapnil Bhartiya, mandatory selfie at LinuxCon
|
||||
|
||||
### Only Red Hat and SUSE were supported on it. Why was Ubuntu missing from the mainframe scene? ###
|
||||
|
||||
**Mark**: Ubuntu has always been about developers. It has been about enabling the free software platform from where it is collaboratively built to be available at no cost to developers in the world, so they are limited only by their imagination—not by money, not by geography.
|
||||
|
||||
There was an incredible story told today about a 12-year-old kid who started out with Ubuntu; there are incredible stories about people building giant businesses with Ubuntu. And for me, being able to empower people, whether they come from one part of the world or another to express their ideas on free software, is what Ubuntu is all about. It's been a journey for us essentially, going to the platforms those developers care about, and just in the last year, we suddenly saw a flood of requests from companies who run mainframes, who are using Ubuntu for their infrastructure—70% of OpenStack deployments are on Ubuntu. Those same people said, “Look, there is the mainframe, and we like to unleash it and think of it as a region in the cloud.” So when IBM started talking to us, saying that they have this project in the works, it felt like a very natural fit: You are going to be able to take your Ubuntu laptop, build code there and ship it straight to every cloud, every virtualization environment, every bare metal in every architecture including the mainframe, and that's going to be beautiful.
|
||||
|
||||
### Will Canonical be offering support for these systems? ###
|
||||
|
||||
**Mark**: Yes. Ubuntu on z Systems is going to be completely supported. We will make long-term commitments to that. The idea is to bring together scale-out-fast cloud-like workloads, which is really born on Ubuntu; 70% of workloads on Amazon and other public clouds run on Ubuntu. Now you can think of running that on a mainframe if that makes sense to you.
|
||||
|
||||
We are going to provide exactly the same platform that we do on the cloud, and we are going to provide that on the mainframe as well. We are also going to expose it to the OpenStack API so you can consume it on a mainframe with exactly the same tools and exactly the same processes that you would consume on a laptop, or OpenStack or public cloud resources. So all of the things that Ubuntu builds to make your life easy as a developer are going to be available across that full range of platforms and systems, and all of that is commercially supported.
|
||||
|
||||
### Canonical is doing a lot of things: It is into enterprise, and it’s in the consumer space with mobile and desktop. So what is the core focus of Canonical now? ###
|
||||
|
||||
**Mark**: The trick for us is to enable the reuse of specifically the same parts [of our technology] in as many useful ways as possible. So if you look at the work that we do at z Systems, it's absolutely defined by the work that we do on the cloud. We want to deliver exactly the same libraries on exactly the same date for the mainframe as we do for public clouds and for x86, ARM and Power servers today.
|
||||
|
||||
We don't allow Ubuntu or our focus to fragment very dramatically because we don't allow different products managers to find Ubuntu in different ways in different environments. We just want to bring that standard experience that developers love to this new environment.
|
||||
|
||||
Similarly if you look at the work we are doing on IoT [Internet of Things], Snappy Ubuntu is the heart of the phone. It’s the phone without the GUI. So the definitions, the tools, the kernels, the mechanisms are shared across those projects. So we are able to multiply the impact of the work. We have an incredible community, and we try to enable the community to do things that they want to do that we can’t do. So that's why we have so many buntus, and it's kind of incredible for me to see what they do with that.
|
||||
|
||||
We also see the community climbing in. We see hundreds of developers working with Snappy for IoT, and we see developers working with Snappy on mobile, for personal computing as convergence becomes real. And, of course, there is the cloud server story: 70% of the world is Ubuntu, so there is a huge audience. We don't have to do all the work that we do; we just have to be open and willing to, kind of, do the core infrastructure and then reuse it as efficiently as possible.
|
||||
|
||||
### Is Snappy a response to Atomic or CoreOS? ###
|
||||
|
||||
**Mark**: Snappy as a project was born four years ago when we started working on the phone, which was long before the CoreOS, long before Atomic. I think the principles of atomicity, transactionality are beautiful, but remember: We needed to build the same things for the phone. And with Snappy, we have the ability to deliver transactional updates to any of these systems—phones, servers and cloud devices.
|
||||
|
||||
Of course, it feels a little different because in order to provide those guarantees, we have to shape the system in such a way that we can guarantee the guarantees. And that's why Snappy is snappy; it's a new thing. It's not based on an old packaging system. Though we will keep both of them: All Snaps for us that Canonical makes, the core snaps that define the OS, are all built from Debian packages. They are two different faces of the same coin for us, and developers will use them as tools. We use the right tools for the job.
|
||||
|
||||
There are couple of key advantages for Snappy over CoreOS and Atomic, and the main one is this: We took the view that we wanted the base idea to be extensible. So with Snappy, the core operating system is tiny. You make all the choices, and you take all the decisions about things you want to bolt on that: you want to bolt on Docker; you want to bolt on Kubernete; you want to bolt on Mesos; you want to bolt on Lattice from Pivotal; you want to bolt on OpenStack. Those are the things you choose to add with Snappy. Whereas with Atomic and CoreOS, it's one blob and you have to do it exactly the way they want you to do it. You have to live with the versions of software and the choices they make.
|
||||
|
||||
Whereas with Snappy, we really preserve this idea of the choices you have got in Ubuntu are now transactionally available on Snappy systems. That makes the core much smaller, and it gives you the choice of different container systems, different container management systems, different cloud infrastructure systems or different apps of every description. I think that's the winning idea. In fullness of time, people will realize that they wanted to make those choices themselves; they just want Canonical to do the work of providing the updates in a really efficient manner.
|
||||
|
||||
### There is so much competition in the container space with Docker, Rocket and many other players. Where will Canonical stand amid this competition? ###
|
||||
|
||||
**Mark**: Canonical is focused on platform tools, and we see things like the Rocket and Docker as things super-useful for developers; we just make sure that those work best on Ubuntu. Docker, for years, ran only Ubuntu because we work very closely with them, and we are glad now that it's available everywhere else. But if you look at the numbers, the vast majority of Docker containers are on Ubuntu. Because we work really hard, as developers, you get the best experience with all of these tools on Ubuntu. We don't want to try and control everything, and it’s great for us to have those guys competing.
|
||||
|
||||
I think in the end people will see that there is really two kinds of containers. 1) There are cases where a container is just like a VM machine. It feels like a whole machine, it runs all processes, all the logs and cron jobs are there. It's like a VM, just that it's much cheaper, much lighter, much faster, and that's LXD. 2) And then there would be process containers, which are like Docker or Rocket; they are there to run a specific application very fast. I think we lead the world in general machine container story, which is our hypervisor LXD, and I think Docker leads the story when it comes to applications containers, process containers. And those two work together really beautifully.
|
||||
|
||||
### Microsoft and Canonical are working together on LXD? Can you tell us about this engagement? ###
|
||||
|
||||
Mark: LXD is two things. First, it's an implementation on top of Canonical's work on the kernel so that you can start to create full machine containers on any host. But it's also a REST API. That’s the transitions from LXC to LXD. We got a daemon there so you can talk to the daemon over the network, if it's listening on the network, and says tell me about the containers on that machine, tell me about the file systems on that machine, the networks on that machine, start or stop the container.
|
||||
|
||||
So LXD becomes a distributed hypervisor effectively. Very interestingly, last week Microsoft announced that they like REST API. It is very clean, very simple, very well engineered, and they are going to implement the same API for Windows machines. It's completely cross-platform, which means you will be able to talk to any machine—Linux or Windows. So it gives you very clean and simple APIs to talk about containers on any host on the network.
|
||||
|
||||
Of course, we have led the work in [OpenStack to bind LXD to Nova][1], which is the control system to compute in OpenStack, so that's how we create a whole cloud with OpenStack API with the individual VMs being actually containers, so much denser, much faster, much lighter, much cheaper.
|
||||
|
||||
### Open Source is becoming a norm in the enterprise segment. What do you think is driving the adoption of open source in the enterprise? ###
|
||||
|
||||
**Mark**: The reason why open source has become so popular in the enterprise is because it enables them to go faster. We are all competing at some level, and if you can't make progress because you have to call up some vendor, you can't dig in and help yourself go faster, then you feel frustrated. And given the choice between frustration and at least the ability to dig into a problem, enterprises over time will always choose to give themselves the ability to dig in and help themselves. So that is why open source is phenomenal.
|
||||
|
||||
I think it goes a bit deeper than that. I think people have started to realize as much as we compete, 99% of what we need to do is shared, and there is something meaningful about contributing to something that is shared. As I have seen Ubuntu go from something that developers love, to something that CIOs love that developers love Ubuntu. As that happens, it's not a one-way ticket. They often want to say how can we help contribute to make this whole thing go faster.
|
||||
|
||||
We have always seen a curve of complexity, and open source has traditionally been higher up on the curve of complexity and therefore considered threatening or difficult or too uncertain for people who are not comfortable with the complexity. What's wonderful to me is that many open source projects have identified that as a blocker for their own future. So in Ubuntu we have made user experience, design and “making it easy” a first-class goal. We have done the same for OpenStack. With Ubuntu tools for OpenStack anybody can build an OpenStack cloud in an hour, and if you want, that cloud can run itself, scale itself, manage itself, can deal with failures. It becomes something you can just fire up and forget, which also makes it really cheap. It also makes it something that's not a distraction, and so by making open source easier and easier, we are broadening its appeal to consumers and into the enterprise and potentially into the government.
|
||||
|
||||
### How open are governments to open source? Can you tell us about the utilization of open source by governments, especially in the U.S.? ###
|
||||
|
||||
**Mark**: I don't track the usage in government, but part of government utilization in the modern era is the realization that how untrustworthy other governments might be. There is a desire for people to be able to say, “Look, I want to review or check and potentially self-build all the things that I depend on.” That's a really important mission. At the end of the day, some people see this as a game where maybe they can get something out of the other guy. I see it as a game where we can make a level playing field, where everybody gets to compete. I have a very strong interest in making sure that Ubuntu is trustworthy, which means the way we build it, the way we run it, the governance around it is such that people can have confidence in it as an independent thing.
|
||||
|
||||
### You are quite vocal about freedom, privacy and other social issues on Google+. How do you see yourself, your company and Ubuntu playing a role in making the world a better place? ###
|
||||
|
||||
**Mark**: The most important thing for us to do is to build confidence in trusted platforms, platforms that are freely available but also trustworthy. At any given time, there will always be people who can make arguments about why they should have access to something. But we know from history that at the end of the day, due process of law, justice, doesn't depend on the abuse of privacy, abuse of infrastructure, the abuse of data. So I am very strongly of the view that in the fullness of time, all of the different major actors will come to the view that their primary interest is in having something that is conceptually trustworthy. This isn't about what America can steal from Germany or what China can learn in Russia. This is about saying we’re all going to be able to trust our infrastructure; that's a generational journey. But I believe Ubuntu can be right at the center of people's thinking about that.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2973116/linux/linuxcon-exclusive-mark-shuttleworth-says-snappy-was-born-long-before-coreos-and-the-atomic-project.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://wiki.openstack.org/wiki/HypervisorSupportMatrix
|
||||
@ -1,67 +0,0 @@
|
||||
The Strangest, Most Unique Linux Distros
|
||||
================================================================================
|
||||
From the most consumer focused distros like Ubuntu, Fedora, Mint or elementary OS to the more obscure, minimal and enterprise focused ones such as Slackware, Arch Linux or RHEL, I thought I've seen them all. Couldn't have been any further from the truth. Linux eco-system is very diverse. There's one for everyone. Let's discuss the weird and wacky world of niche Linux distros that represents the true diversity of open platforms.
|
||||
|
||||

|
||||
|
||||
**Puppy Linux**: An operating system which is about 1/10th the size of an average DVD quality movie rip, that's Puppy Linux for you. The OS is just 100 MB in size! And it can run from RAM making it unusually fast even in older PCs. You can even remove the boot medium after the operating system has started! Can it get any better than that? System requirements are bare minimum, most hardware are automatically detected, and it comes loaded with software catering to your basic needs. [Experience Puppy Linux][1].
|
||||
|
||||

|
||||
|
||||
**Suicide Linux**: Did the name scare you? Well it should. 'Any time - any time - you type any remotely incorrect command, the interpreter creatively resolves it into rm -rf / and wipes your hard drive'. Simple as that. I really want to know the ones who are confident enough to risk their production machines with [Suicide Linux][2]. **Warning: DO NOT try this on production machines!** The whole thing is available in a neat [DEB package][3] if you're interested.
|
||||
|
||||

|
||||
|
||||
**PapyrOS**: "Strange" in a good way. PapyrOS is trying to adapt the material design language of Android into their brand new Linux distribution. Though the project is in early stages, it already looks very promising. The project page says the OS is 80% complete and one can expect the first Alpha release anytime soon. We did a small write up on [PapyrOS][4] when it was announced and by the looks of it, PapyrOS might even become a trend-setter of sorts. Follow the project on [Google+][5] and contribute via [BountySource][6] if you're interested.
|
||||
|
||||

|
||||
|
||||
**Qubes OS**: Qubes is an open-source operating system designed to provide strong security using a Security by Compartmentalization approach. The assumption is that there can be no perfect, bug-free desktop environment. And by implementing a 'Security by Isolation' approach, [Qubes Linux][7] intends to remedy that. Qubes is based on Xen, the X Window System, and Linux, and can run most Linux applications and supports most Linux drivers. Qubes was selected as a finalist of Access Innovation Prize 2014 for Endpoint Security Solution.
|
||||
|
||||

|
||||
|
||||
**Ubuntu Satanic Edition**: Ubuntu SE is a Linux distribution based on Ubuntu. "It brings together the best of free software and free metal music" in one comprehensive package consisting of themes, wallpapers, and even some heavy-metal music sourced from talented new artists. Though the project doesn't look actively developed anymore, Ubuntu Satanic Edition is strange in every sense of that word. [Ubuntu SE (Slightly NSFW)][8].
|
||||
|
||||

|
||||
|
||||
**Tiny Core Linux**: Puppy Linux not small enough? Try this. Tiny Core Linux is a 12 MB graphical Linux desktop! Yep, you read it right. One major caveat: It is not a complete desktop nor is all hardware completely supported. It represents only the core needed to boot into a very minimal X desktop typically with wired internet access. There is even a version without the GUI called Micro Core Linux which is just 9MB in size. [Tiny Core Linux][9] folks.
|
||||
|
||||

|
||||
|
||||
**NixOS**: A very experienced-user focused Linux distribution with a unique approach to package and configuration management. In other distributions, actions such as upgrades can be dangerous. Upgrading a package can cause other packages to break, upgrading an entire system is much less reliable than reinstalling from scratch. And top of all that you can't safely test what the results of a configuration change will be, there's no "Undo" so to speak. In NixOS, the entire operating system is built by the Nix package manager from a description in a purely functional build language. This means that building a new configuration cannot overwrite previous configurations. Most of the other features follow this pattern. Nix stores all packages in isolation from each other. [More about NixOS][10].
|
||||
|
||||

|
||||
|
||||
**GoboLinux**: This is another very unique Linux distro. What makes GoboLinux so different from the rest is its unique re-arrangement of the filesystem. It has its own subdirectory tree, where all of its files and programs are stored. GoboLinux does not have a package database because the filesystem is its database. In some ways, this sort of arrangement is similar to that seen in OS X. [Get GoboLinux][11].
|
||||
|
||||

|
||||
|
||||
**Hannah Montana Linux**: Here is a Linux distro based on Kubuntu with a Hannah Montana themed boot screen, KDM, icon set, ksplash, plasma, color scheme, and wallpapers (I'm so sorry). [Link][12]. Project not active anymore.
|
||||
|
||||
**RLSD Linux**: An extremely minimalistic, small, lightweight and security-hardened, text-based operating system built on Linux. "It's a unique distribution that provides a selection of console applications and home-grown security features which might appeal to hackers," developers claim. [RLSD Linux][13].
|
||||
|
||||
Did we miss anything even stranger? Let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techdrivein.com/2015/08/the-strangest-most-unique-linux-distros.html
|
||||
|
||||
作者:Manuel Jose
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||
[2]:http://qntm.org/suicide
|
||||
[3]:http://sourceforge.net/projects/suicide-linux/files/
|
||||
[4]:http://www.techdrivein.com/2015/02/papyros-material-design-linux-coming-soon.html
|
||||
[5]:https://plus.google.com/communities/109966288908859324845/stream/3262a3d3-0797-4344-bbe0-56c3adaacb69
|
||||
[6]:https://www.bountysource.com/teams/papyros
|
||||
[7]:https://www.qubes-os.org/
|
||||
[8]:http://ubuntusatanic.org/
|
||||
[9]:http://tinycorelinux.net/
|
||||
[10]:https://nixos.org/
|
||||
[11]:http://www.gobolinux.org/
|
||||
[12]:http://hannahmontana.sourceforge.net/
|
||||
[13]:http://rlsd2.dimakrasner.com/
|
||||
@ -1,391 +0,0 @@
|
||||
martin translating...
|
||||
|
||||
Superclass: 15 of the world’s best living programmers
|
||||
================================================================================
|
||||
When developers discuss who the world’s top programmer is, these names tend to come up a lot.
|
||||
|
||||

|
||||
|
||||
Image courtesy [tom_bullock CC BY 2.0][1]
|
||||
|
||||
It seems like there are lots of programmers out there these days, and lots of really good programmers. But which one is the very best?
|
||||
|
||||
Even though there’s no way to really say who the best living programmer is, that hasn’t stopped developers from frequently kicking the topic around. ITworld has solicited input and scoured coder discussion forums to see if there was any consensus. As it turned out, a handful of names did frequently get mentioned in these discussions.
|
||||
|
||||
Use the arrows above to read about 15 people commonly cited as the world’s best living programmer.
|
||||
|
||||

|
||||
|
||||
Image courtesy [NASA][2]
|
||||
|
||||
### Margaret Hamilton ###
|
||||
|
||||
**Main claim to fame: The brains behind Apollo’s flight control software**
|
||||
|
||||
Credentials: As the Director of the Software Engineering Division at Charles Stark Draper Laboratory, she headed up the team which [designed and built][3] the on-board [flight control software for NASA’s Apollo][4] and Skylab missions. Based on her Apollo work, she later developed the [Universal Systems Language][5] and [Development Before the Fact][6] paradigm. Pioneered the concepts of [asynchronous software, priority scheduling, and ultra-reliable software design][7]. Coined the term “[software engineering][8].” Winner of the [Augusta Ada Lovelace Award][9] in 1986 and [NASA’s Exceptional Space Act Award in 2003][10].
|
||||
|
||||
Quotes: “Hamilton invented testing , she pretty much formalised Computer Engineering in the US.” [ford_beeblebrox][11]
|
||||
|
||||
“I think before her (and without disrespect including Knuth) computer programming was (and to an extent remains) a branch of mathematics. However a flight control system for a spacecraft clearly moves programming into a different paradigm.” [Dan Allen][12]
|
||||
|
||||
“... she originated the term ‘software engineering’ — and offered a great example of how to do it.” [David Hamilton][13]
|
||||
|
||||
“What a badass” [Drukered][14]
|
||||
|
||||

|
||||
|
||||
Image courtesy [vonguard CC BY-SA 2.0][15]
|
||||
|
||||
### Donald Knuth ###
|
||||
|
||||
**Main claim to fame: Author of The Art of Computer Programming**
|
||||
|
||||
Credentials: Wrote the [definitive book on the theory of programming][16]. Created the TeX digital typesetting system. [First winner of the ACM’s Grace Murray Hopper Award][17] in 1971. Winner of the ACM’s [A. M. Turing][18] Award in 1974, the [National Medal of Science][19] in 1979 and the IEEE’s [John von Neumann Medal][20] in 1995. Named a [Fellow at the Computer History Museum][21] in 1998.
|
||||
|
||||
Quotes: “... wrote The Art of Computer Programming which is probably the most comprehensive work on computer programming ever.” [Anonymous][22]
|
||||
|
||||
“There is only one large computer program I have used in which there are to a decent approximation 0 bugs: Don Knuth's TeX. That's impressive.” [Jaap Weel][23]
|
||||
|
||||
“Pretty awesome if you ask me.” [Mitch Rees-Jones][24]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Association for Computing Machinery][25]
|
||||
|
||||
### Ken Thompson ###
|
||||
|
||||
**Main claim to fame: Creator of Unix**
|
||||
|
||||
Credentials: Co-creator, [along with Dennis Ritchie][26], of Unix. Creator of the [B programming language][27], the [UTF-8 character encoding scheme][28], the ed [text editor][29], and co-developer of the Go programming language. Co-winner (along with Ritchie) of the [A.M. Turing Award][30] in 1983, [IEEE Computer Pioneer Award][31] in 1994, and the [National Medal of Technology][32] in 1998. Inducted as a [fellow of the Computer History Museum][33] in 1997.
|
||||
|
||||
Quotes: “... probably the most accomplished programmer ever. Unix kernel, Unix tools, world-champion chess program Belle, Plan 9, Go Language.” [Pete Prokopowicz][34]
|
||||
|
||||
“Ken's contributions, more than anyone else I can think of, were fundamental and yet so practical and timeless they are still in daily use.“ [Jan Jannink][35]
|
||||
|
||||

|
||||
|
||||
Image courtesy Jiel Beaumadier CC BY-SA 3.0
|
||||
|
||||
### Richard Stallman ###
|
||||
|
||||
**Main claim to fame: Creator of Emacs, GCC**
|
||||
|
||||
Credentials: Founded the [GNU Project][36] and created many of its core tools, such as [Emacs, GCC, GDB][37], and [GNU Make][38]. Also founded the [Free Software Foundation][39]. Winner of the ACM's [Grace Murray Hopper Award][40] in 1990 and the [EFF's Pioneer Award in 1998][41].
|
||||
|
||||
Quotes: “... there was the time when he single-handedly outcoded several of the best Lisp hackers around, in the Symbolics vs LMI fight.” [Srinivasan Krishnan][42]
|
||||
|
||||
“Through his amazing mastery of programming and force of will, he created a whole sub-culture in programming and computers.” [Dan Dunay][43]
|
||||
|
||||
“I might disagree on many things with the great man, but he is still one of the most important programmers, alive or dead” [Marko Poutiainen][44]
|
||||
|
||||
“Try to imagine Linux without the prior work on the GNu project. Stallman's the bomb, yo.” [John Burnette][45]
|
||||
|
||||

|
||||
|
||||
Image courtesy [D.Begley CC BY 2.0][46]
|
||||
|
||||
### Anders Hejlsberg ###
|
||||
|
||||
**Main claim to fame: Creator of Turbo Pascal**
|
||||
|
||||
Credentials: [The original author of what became Turbo Pascal][47], one of the most popular Pascal compilers and the first integrated development environment. Later, [led the building of Delphi][48], Turbo Pascal’s successor. [Chief designer and architect of C#][49]. Winner of [Dr. Dobb's Excellence in Programming Award][50] in 2001.
|
||||
|
||||
Quotes: “He wrote the [Pascal] compiler in assembly language for both of the dominant PC operating systems of the day (DOS and CPM). It was designed to compile, link and run a program in seconds rather than minutes.” [Steve Wood][51]
|
||||
|
||||
“I revere this guy - he created the development tools that were my favourite through three key periods along my path to becoming a professional software engineer.” [Stefan Kiryazov][52]
|
||||
|
||||

|
||||
|
||||
Image courtesy [vonguard CC BY-SA 2.0][53]
|
||||
|
||||
### Doug Cutting ###
|
||||
|
||||
**Main claim to fame: Creator of Lucene**
|
||||
|
||||
Credentials: [Developed the Lucene search engine, as well as Nutch][54], a web crawler, and [Hadoop][55], a set of tools for distributed processing of large data sets. A strong proponent of open-source (Lucene, Nutch and Hadoop are all open-source). Currently [a former director of the Apache Software Foundation][56].
|
||||
|
||||
Quotes: “... he is the same guy who has written an exceptional search framework(lucene/solr) and opened the big-data gateway to the world(hadoop).” [Rajesh Rao][57]
|
||||
|
||||
“His creation/work on Lucene and Hadoop (among other projects) has created a tremendous amount of wealth and employment for folks in the world….” [Amit Nithianandan][58]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Association for Computing Machinery][59]
|
||||
|
||||
### Sanjay Ghemawat ###
|
||||
|
||||
**Main claim to fame: Key Google architect**
|
||||
|
||||
Credentials: [Helped to design and implement some of Google’s large distributed systems][60], including MapReduce, BigTable, Spanner and Google File System. [Created Unix’s ical][61] calendaring system. Elected to the [National Academy of Engineering][62] in 2009. Winner of the [ACM-Infosys Foundation Award in the Computing Sciences][63] in 2012.
|
||||
|
||||
Quote: “Jeff Dean's wingman.” [Ahmet Alp Balkan][64]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Google][65]
|
||||
|
||||
### Jeff Dean ###
|
||||
|
||||
**Main claim to fame: The brains behind Google search indexing**
|
||||
|
||||
Credentials: Helped to design and implement [many of Google’s large-scale distributed systems][66], including website crawling, indexing and searching, AdSense, MapReduce, BigTable and Spanner. Elected to the [National Academy of Engineering][67] in 2009. 2012 winner of the ACM’s [SIGOPS Mark Weiser Award][68] and the [ACM-Infosys Foundation Award in the Computing Sciences][69].
|
||||
|
||||
Quotes: “... for bringing breakthroughs in data mining( GFS, Map and Reduce, Big Table ).” [Natu Lauchande][70]
|
||||
|
||||
“... conceived, built, and deployed MapReduce and BigTable, among a bazillion other things” [Erik Goldman][71]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Krd CC BY-SA 4.0][72]
|
||||
|
||||
### Linus Torvalds ###
|
||||
|
||||
**Main claim to fame: Creator of Linux**
|
||||
|
||||
Credentials: Created the [Linux kernel][73] and [Git][74], an open source version control system. Winner of numerous awards and honors, including the [EFF Pioneer Award][75] in 1998, the [British Computer Society’s Lovelace Medal][76] in 2000, the [Millenium Technology Prize][77] in 2012 and the [IEEE Computer Society’s Computer Pioneer Award][78] in 2014. Also inducted into the [Computer History Museum’s Hall of Fellows][79] in 2008 and the [Internet Hall of Fame][80] in 2012.
|
||||
|
||||
Quotes: “To put into prospective what an achievement this is, he wrote the Linux kernel in a few years while the GNU Hurd (a GNU-developed kernel) has been under development for 25 years and has still yet to release a production-ready example.” [Erich Ficker][81]
|
||||
|
||||
“Torvalds is probably the programmer's programmer.” [Dan Allen][82]
|
||||
|
||||
“He's pretty darn good.” [Alok Tripathy][83]
|
||||
|
||||

|
||||
|
||||
Image courtesy [QuakeCon CC BY 2.0][84]
|
||||
|
||||
### John Carmack ###
|
||||
|
||||
**Main claim to fame: Creator of Doom**
|
||||
|
||||
Credentials: Cofounded id Software and [created such influential FPS games][85] as Wolfenstein 3D, Doom and Quake. Pioneered such ground-breaking computer graphic techniques [adaptive tile refresh][86], [binary space partitioning][87], and surface caching. Inducted into the [Academy of Interactive Arts and Sciences Hall of Fame][88] in 2001, [won Emmy awards][89] in the Engineering & Technology category in 2007 and 2008, and given a lifetime achievement award by the [Game Developers Choice Awards][90] in 2010.
|
||||
|
||||
Quotes: “He wrote his first rendering engine before he was 20 years old. The guy's a genius. I wish I were a quarter a programmer he is.” [Alex Dolinsky][91]
|
||||
|
||||
“... Wolfenstein 3D, Doom and Quake were revolutionary at the time and have influenced a generation of game designers.” [dniblock][92]
|
||||
|
||||
“He can write basically anything in a weekend....” [Greg Naughton][93]
|
||||
|
||||
“He is the Mozart of computer coding….” [Chris Morris][94]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Duff][95]
|
||||
|
||||
### Fabrice Bellard ###
|
||||
|
||||
**Main claim to fame: Creator of QEMU**
|
||||
|
||||
Credentials: Created a [variety of well-known open-source software programs][96], including QEMU, a platform for hardware emulation and virtualization, FFmpeg, for handling multimedia data, the Tiny C Compiler and LZEXE, an executable file compressor. [Winner of the Obfuscated C Code Contest][97] in 2000 and 2001 and the [Google-O'Reilly Open Source Award][98] in 2011. Former world record holder for [calculating the most number of digits in Pi][99].
|
||||
|
||||
Quotes: “I find Fabrice Bellard's work remarkable and impressive.” [raphinou][100]
|
||||
|
||||
“Fabrice Bellard is the most productive programmer in the world....” [Pavan Yara][101]
|
||||
|
||||
“Hes like the Nikola Tesla of sofware engineering.” [Michael Valladolid][102]
|
||||
|
||||
“He's a prolific serial achiever since the 1980s.” M[ichael Biggins][103]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Craig Murphy CC BY 2.0][104]
|
||||
|
||||
### Jon Skeet ###
|
||||
|
||||
**Main claim to fame: Legendary Stack Overflow contributor**
|
||||
|
||||
Credentials: Google engineer and author of [C# in Depth][105]. Holds [highest reputation score of all time on Stack Overflow][106], answering, on average, 390 questions per month.
|
||||
|
||||
Quotes: “Jon Skeet doesn't need a debugger, he just stares down the bug until the code confesses” [Steven A. Lowe][107]
|
||||
|
||||
“When Jon Skeet's code fails to compile the compiler apologises.” [Dan Dyer][108]
|
||||
|
||||
“Jon Skeet's code doesn't follow a coding convention. It is the coding convention.” [Anonymous][109]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Philip Neustrom CC BY 2.0][110]
|
||||
|
||||
### Adam D'Angelo ###
|
||||
|
||||
**Main claim to fame: Co-founder of Quora**
|
||||
|
||||
Credentials: As an engineer at Facebook, [built initial infrastructure for its news feed][111]. Went on to become CTO and VP of engineering at Facebook, before leaving to co-found Quora. [Eighth place finisher at the USA Computing Olympiad][112] as a high school student in 2001. Member of [California Institute of Technology’s silver medal winning team][113] at the ACM International Collegiate Programming Contest in 2004. [Finalist in the Algorithm Coding Competition][114] of Topcoder Collegiate Challenge in 2005.
|
||||
|
||||
Quotes: “An "All-Rounder" Programmer.” [Anonymous][115]
|
||||
|
||||
"For every good thing I make he has like six." [Mark Zuckerberg][116]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Facebook][117]
|
||||
|
||||
### Petr Mitrechev ###
|
||||
|
||||
**Main claim to fame: One of the top competitive programmers of all time**
|
||||
|
||||
Credentials: [Two-time gold medal winner][118] in the International Olympiad in Informatics (2000, 2002). In 2006, [won the Google Code Jam][119] and was also the [TopCoder Open Algorithm champion][120]. Also, two-time winner of the Facebook Hacker Cup ([2011][121], [2013][122]). At the time of this writing, [the second ranked algorithm competitor on TopCoder][123] (handle: Petr) and also [ranked second by Codeforces][124]
|
||||
|
||||
Quote: “He is an idol in competitive programming even here in India…” [Kavish Dwivedi][125]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Ishandutta2007 CC BY-SA 3.0][126]
|
||||
|
||||
### Gennady Korotkevich ###
|
||||
|
||||
**Main claim to fame: Competitive programming prodigy**
|
||||
|
||||
Credentials: Youngest participant ever (age 11) and [6 time gold medalist][127] (2007-2012) in the International Olympiad in Informatics. Part of [the winning team][128] at the ACM International Collegiate Programming Contest in 2013 and winner of the [2014 Facebook Hacker Cup][129]. At the time of this writing, [ranked first by Codeforces][130] (handle: Tourist) and [first among algorithm competitors by TopCoder][131].
|
||||
|
||||
Quotes: “A programming prodigy!” [Prateek Joshi][132]
|
||||
|
||||
“Gennady is definitely amazing, and visible example of why I have a large development team in Belarus.” [Chris Howard][133]
|
||||
|
||||
“Tourist is genius” [Nuka Shrinivas Rao][134]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
|
||||
|
||||
作者:[Phil Johnson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Phil-Johnson/
|
||||
[1]:https://www.flickr.com/photos/tombullock/15713223772
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
|
||||
[3]:http://klabs.org/home_page/hamilton.htm
|
||||
[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
|
||||
[5]:http://www.htius.com/Articles/r12ham.pdf
|
||||
[6]:http://www.htius.com/Articles/Inside_DBTF.htm
|
||||
[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
|
||||
[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
|
||||
[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
|
||||
[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
|
||||
[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
|
||||
[12]:http://qr.ae/RFEZLk
|
||||
[13]:http://qr.ae/RFEZUn
|
||||
[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
|
||||
[15]:https://www.flickr.com/photos/44451574@N00/5347112697
|
||||
[16]:http://cs.stanford.edu/~uno/taocp.html
|
||||
[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
|
||||
[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
|
||||
[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
|
||||
[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
|
||||
[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
|
||||
[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
|
||||
[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
|
||||
[24]:http://qr.ae/RFE94x
|
||||
[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
|
||||
[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
|
||||
[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
|
||||
[28]:http://doc.cat-v.org/bell_labs/utf-8_history
|
||||
[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
|
||||
[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
|
||||
[31]:http://www.computer.org/portal/web/awards/cp-thompson
|
||||
[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
|
||||
[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
|
||||
[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
|
||||
[35]:http://qr.ae/RFEWBY
|
||||
[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[37]:http://www.emacswiki.org/emacs/RichardStallman
|
||||
[38]:https://www.gnu.org/gnu/thegnuproject.html
|
||||
[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
|
||||
[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
|
||||
[41]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
|
||||
[43]:http://qr.ae/RFEaib
|
||||
[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
|
||||
[45]:http://qr.ae/RFEUqp
|
||||
[46]:https://www.flickr.com/photos/begley/2979906130
|
||||
[47]:http://www.taoyue.com/tutorials/pascal/history.html
|
||||
[48]:http://c2.com/cgi/wiki?AndersHejlsberg
|
||||
[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
|
||||
[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
|
||||
[51]:http://qr.ae/RFEZrv
|
||||
[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
|
||||
[53]:https://www.flickr.com/photos/vonguard/4076389963/
|
||||
[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
|
||||
[55]:http://hadoop.apache.org/
|
||||
[56]:https://www.linkedin.com/in/cutting
|
||||
[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
|
||||
[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
|
||||
[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[60]:http://research.google.com/pubs/SanjayGhemawat.html
|
||||
[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
|
||||
[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
|
||||
[65]:http://research.google.com/people/jeff/index.html
|
||||
[66]:http://research.google.com/people/jeff/index.html
|
||||
[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
|
||||
[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
|
||||
[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
|
||||
[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
|
||||
[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
|
||||
[73]:http://www.linuxfoundation.org/about/staff#torvalds
|
||||
[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
|
||||
[75]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[76]:http://www.bcs.org/content/ConWebDoc/14769
|
||||
[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
|
||||
[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
|
||||
[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
|
||||
[80]:http://www.internethalloffame.org/inductees/linus-torvalds
|
||||
[81]:http://qr.ae/RFEeeo
|
||||
[82]:http://qr.ae/RFEZLk
|
||||
[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
|
||||
[84]:https://www.flickr.com/photos/quakecon/9434713998
|
||||
[85]:http://doom.wikia.com/wiki/John_Carmack
|
||||
[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
|
||||
[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
|
||||
[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
|
||||
[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
|
||||
[90]:http://www.gamechoiceawards.com/archive/lifetime.html
|
||||
[91]:http://qr.ae/RFEEgr
|
||||
[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
|
||||
[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
|
||||
[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
|
||||
[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
|
||||
[96]:http://bellard.org/
|
||||
[97]:http://www.ioccc.org/winners.html#B
|
||||
[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
|
||||
[99]:http://bellard.org/pi/pi2700e9/
|
||||
[100]:https://news.ycombinator.com/item?id=7850797
|
||||
[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
|
||||
[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
|
||||
[103]:http://qr.ae/RFEjhZ
|
||||
[104]:https://www.flickr.com/photos/craigmurphy/4325516497
|
||||
[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
|
||||
[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
|
||||
[107]:http://meta.stackexchange.com/a/9156
|
||||
[108]:http://meta.stackexchange.com/a/9138
|
||||
[109]:http://meta.stackexchange.com/a/9182
|
||||
[110]:https://www.flickr.com/photos/philipn/5326344032
|
||||
[111]:http://www.crunchbase.com/person/adam-d-angelo
|
||||
[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
|
||||
[113]:http://icpc.baylor.edu/community/results-2004
|
||||
[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
|
||||
[115]:http://qr.ae/RFfOfe
|
||||
[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
|
||||
[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[118]:http://stats.ioinformatics.org/people/1849
|
||||
[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
|
||||
[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
|
||||
[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
|
||||
[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[123]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[124]:http://codeforces.com/ratings
|
||||
[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
|
||||
[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
|
||||
[127]:http://stats.ioinformatics.org/people/804
|
||||
[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
|
||||
[129]:https://www.facebook.com/hackercup/posts/10152022955628845
|
||||
[130]:http://codeforces.com/ratings
|
||||
[131]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
|
||||
[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
|
||||
[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
|
||||
@ -1,149 +0,0 @@
|
||||
The Free Software Foundation: 30 years in
|
||||
================================================================================
|
||||

|
||||
|
||||
Welcome back, folks, to a new Six Degrees column. As usual, please send your thoughts on this piece to the comment box and your suggestions for future columns to [my inbox][1].
|
||||
|
||||
Now, I have to be honest with you all, this column went a little differently than I expected.
|
||||
|
||||
A few weeks ago when thinking what to write, I mused over the notion of a piece about the [Free Software Foundation][2] celebrating its 30 year anniversary and how relevant and important its work is in today's computing climate.
|
||||
|
||||
To add some meat I figured I would interview [John Sullivan][3], executive director of the FSF. My plan was typical of many of my pieces: thread together an interesting narrative and quote pieces of the interview to give it color.
|
||||
|
||||
Well, that all went out the window when John sent me a tremendously detailed, thoughtful, and descriptive interview. I decided therefore to present it in full as the main event, and to add some commentary throughout. Thus, this is quite a long column, but I think it paints a fascinating picture of a fascinating organization. I recommend you grab a cup of something delicious and settle in for a solid read.
|
||||
|
||||
### The sands of change ###
|
||||
|
||||
The Free Software Foundation was founded in 1985. To paint a picture of what computing was like back then, the [Amiga 1000][4] was released, C++ was becoming a dominant language, [Aldus PageMaker][5] was announced, and networking was just starting to grow. Oh, and that year [Careless Whisper][6] by Wham! was a major hit.
|
||||
|
||||
Things have changed a lot in 30 years. Back in 1985 the FSF was primarily focused on building free pieces of software that were primarily useful to nerdy computer people. These days we have software, services, social networks, and more to consider.
|
||||
|
||||
I first wanted to get a sense of what John feels are most prominent risks to software freedom today.
|
||||
|
||||
"I think there's widespread agreement on the biggest risks for computer user freedom today, but maybe not on the names for them."
|
||||
|
||||
"The first is what we might as well just call 'tiny computers everywhere.' The free software movement has succeeded to the point where laptops, desktops, and servers can run fully free operating systems doing anything users of proprietary systems can do. There are still a few holes, but they'll be closed. The challenge that remains in this area is to cut through the billion dollar marketing budgets and legal regimes working against us to actually get the systems into users hands."
|
||||
|
||||
"However, we have a serious problem on the set of computers whose primary common trait is that they are very small. Even though a car is not especially small, the computers in it are, so I include that form factor in this category, along with phones, tablets, glasses, watches, and so on. While these computers often have a basis in free software—for example, using the kernel Linux along with other free software like Android or GNU—their primary uses are to run proprietary applications and be shims for services that replace local computing with computing done on a server over which the user has no control. Since these devices serve vital functions, with some being primary means of communication for huge populations, some sitting very close to our bodies and our actual vital functions, some bearing responsibility for our physical safety, it is imperative that they run fully free systems under their users' control. Right now, they don't."
|
||||
|
||||
John feels the risk here is not just the platforms and form factors, but the services integrates into them.
|
||||
|
||||
"The services many of these devices talk to are the second major threat we face. It does us little good booting into a free system if we do our actual work and entertainment on companies' servers running software we have no access to at all. The point of free software is that we can see, modify, and share code. The existence of those freedoms even for nontechnical users provides a shield that prevents companies from controlling us. None of these freedoms exist for users of Facebook or Salesforce or Google Docs. Even more worrisome, we see a trend where people are accepting proprietary restrictions imposed on their local machines in order to have access to certain services. Browsers—including Firefox—are now automatically installing a DRM plugin in order to appease Netflix and other video giants. We need to work harder at developing free software decentralized replacements for media distribution that can actually empower users, artists, and user-artists, and for other services as well. For Facebook we have GNU social, pump.io, Diaspora, Movim, and others. For Salesforce, we have CiviCRM. For Google Docs, we have Etherpad. For media, we have GNU MediaGoblin. But all of these projects need more help, and many services don't have any replacement contenders yet."
|
||||
|
||||
It is interesting that John mentions finding free software equivalents for common applications and services today. The FSF maintains a list of "High Priority Projects" that are designed to fill this gap. Unfortunately the capabilities of these projects varies tremendously and in an age where social media is so prominent, the software is only part of the problem: the real challenge is getting people to use it.
|
||||
|
||||
This all begs the question of where the FSF fit in today's modern computing world. I am a fan of the FSF. I think the work they do is valuable and I contribute financially to support it too. They are an important organization for building an open computing culture, but all organizations need to grow, adjust, and adapt, particularly ones in the technology space.
|
||||
|
||||
I wanted to get a better sense of what the FSF is doing today that it wasn't doing at it's inception.
|
||||
|
||||
"We're speaking to a much larger audience than we were 30 years ago, and to a much broader audience. It's no longer just hackers and developers and researchers that need to know about free software. Everyone using a computer does, and it's quickly becoming the case that everyone uses a computer."
|
||||
|
||||
John went on to provide some examples of these efforts.
|
||||
|
||||
"We're doing coordinated public advocacy campaigns on issues of concern to the free software movement. Earlier in our history, we expressed opinions on these things, and took action on a handful, but in the last ten years we've put more emphasis on formulating and carrying out coherent campaigns. We've made especially significant noise in the area of Digital Restrictions Management (DRM) with Defective by Design, which I believe played a role in getting iTunes music off DRM (now of course, Apple is bringing DRM back with Apple Music). We've made attractive and useful introductory materials for people new to free software, like our [User Liberation animated video][7] and our [Email Self-Defense Guide][8].
|
||||
|
||||
We're also endorsing hardware that [respects users' freedoms][9]. Hardware distributors whose devices have been certified by the FSF to contain and require only free software can display a logo saying so. Expanding the base of free software users and the free software movement has two parts: convincing people to care, and then making it possible for them to act on that. Through this initiative, we encourage manufacturers and distributors to do the right thing, and we make it easy for users who have started to care about free software to buy what they need without suffering through hours and hours of research. We've certified a home WiFi router, 3D printers, laptops, and USB WiFi adapters, with more on the way.
|
||||
|
||||
We're collecting all of the free software we can find in our [Free Software Directory][10]. We still have a long way to go on this—we're at only about 15,500 packages right now, and we can imagine many improvements to the design and function of the site—but I think this resource has great potential for helping users find the free software they need, especially users who aren't yet using a full GNU/Linux system. With the dangers inherent in downloading random programs off the Internet, there is a definite need for a curated collection like this. It also happens to provide a wealth of machine-readable data of use to researchers.
|
||||
|
||||
We're acting as the fiscal sponsor for several specific free software projects, enabling them to raise funds for development. Most of these projects are part of GNU (which we continue to provide many kinds of infrastructure for), but we also sponsor [Replicant][11], a fully free fork of Android designed to give users the free-est mobile devices currently possible.
|
||||
|
||||
We're helping developers use free software licenses properly, and we're following up on complaints about companies that aren't following the terms of the GPL. We help them fix their mistakes and distribute properly. RMS was in fact doing similar work with the precursors of the GPL very early on, but it's now an ongoing part of our work.
|
||||
|
||||
Most of the specific things the FSF does now it wasn't doing 30 years ago, but the vision is little changed from the original paperwork—we aim to create a world where everything users want to do on any computer can be done using free software; a world where users control their computers and not the other way around."
|
||||
|
||||
### A cult of personality ###
|
||||
|
||||
There is little doubt in anyone's minds about the value the FSF brings. As John just highlighted, its efforts span not just the creation and licensing of free software, but also recognizing, certifying, and advocating a culture of freedom in technology.
|
||||
|
||||
The head of the FSF is the inimitable Richard M. Stallman, commonly referred to as RMS.
|
||||
|
||||
RMS is a curious character. He has demonstrated an unbelievable level of commitment to his ideas, philosophy, and ethical devotion to freedom in software.
|
||||
|
||||
While he is sometimes mocked online for his social awkwardness, be it things said in his speeches, his bizarre travel requirements, or other sometimes cringeworthy moments, RMS's perspectives on software and freedom are generally rock-solid. He takes a remarkably consistent approach to his perspectives and he is clearly a careful thinker about not just his own thoughts but the wider movement he is leading. My only criticism is that I think from time to time he somewhat over-eggs the pudding with the voracity of his words. But hey, given his importance in our world, I would rather take an extra egg than no pudding for anyone. O.K., I get that the whole pudding thing here was strained...
|
||||
|
||||
So RMS is a key part of the FSF, but the organization is also much more than that. There are employees, a board, and many contributors. I was curious to see how much of a role RMS plays these days in the FSF. John shared this with me.
|
||||
|
||||
"RMS is the FSF's President, and does that work without receiving a salary from the FSF. He continues his grueling global speaking schedule, advocating for free software and computer user freedom in dozens of countries each year. In the course of that, he meets with government officials as well as local activists connected with all varieties of social movements. He also raises funds for the FSF and inspires many people to volunteer."
|
||||
|
||||
"In between engagements, he does deep thinking on issues facing the free software movement, and anticipates new challenges. Often this leads to new articles—he wrote a 3-part series for Wired earlier this year about free software and free hardware designs—or new ideas communicated to the FSF's staff as the basis for future projects."
|
||||
|
||||
As we delved into the cult of personality, I wanted to tap John's perspectives on how wide the free software movement has grown.
|
||||
|
||||
I remember being at the [Open Source Think Tank][12] (an event that brings together execs from various open source organizations) and there was a case study where attendees were asked to recommend license choice for a particular project. The vast majority of break-out groups recommended the Apache Software License (APL) over the GNU Public License (GPL).
|
||||
|
||||
This stuck in my mind as since then I have noticed that many companies seem to have opted for open licenses other than the GPL. I was curious to see if John had noticed a trend towards the APL as opposed to the GPL.
|
||||
|
||||
"Has there been? I'm not so sure. I gave a presentation at FOSDEM a few years ago called 'Is Copyleft Being Framed?' that showed some of the problems with the supposed data behind claims of shifts in license adoption. I'll be publishing an article soon on this, but here's some of the major problems:
|
||||
|
||||
|
||||
- Free software license choices do not exist in a vacuum. The number of people choosing proprietary software licenses also needs to be considered in order to draw the kinds of conclusions that people want to draw. I find it much more likely that lax permissive license choices (such as the Apache License or 3-clause BSD) are trading off with proprietary license choices, rather than with the GPL.
|
||||
- License counters often, ironically, don't publish the software they use to collect that data as free software. That means we can't inspect their methods or reproduce their results. Some people are now publishing the code they use, but certainly any that don't should be completely disregarded. Science has rules.
|
||||
- What counts as a thing with a license? Are we really counting an app under the APL that makes funny noises as 1:1 with GNU Emacs under GPLv3? If not, how do we decide which things to treat as equals? Are we only looking at software that actually works? Are we making sure not to double- and triple- count programs that exist on multiple hosting sites, and what about ports for different OSes?
|
||||
|
||||
The question is interesting to ponder, but every conclusion I've seen so far has been extremely premature in light of the actual data. I'd much rather see a survey of developers asking about why they chose particular licenses for their projects than any more of these attempts to programmatically ascertain the license of programs and then ascribe human intentions on to patterns in that data.
|
||||
|
||||
Copyleft is as vital as it ever was. Permissively licensed software is still free software and on-face a good thing, but it is contingent and needs an accompanying strong social commitment to not incorporate it in proprietary software. If free software's major long-term impact is enabling businesses to more efficiently make products that restrict us, then we have achieved nothing for computer user freedom."
|
||||
|
||||
### Rising to new challenges ###
|
||||
|
||||
30 years is an impressive time for any organization to be around, and particularly one with such important goals that span so many different industries, professions, governments, and cultures.
|
||||
|
||||
As I started to wrap up the interview I wanted to get a better sense of what the FSF's primary function is today, 30 years after the mission started.
|
||||
|
||||
"I think the FSF is in a very interesting position of both being a steady rock and actively pushing the envelope."
|
||||
|
||||
"We have core documents like the [Free Software Definition][13], the [GNU General Public License][14], and the [list we maintain of free and nonfree software licenses][15], which have been keystones in the construction of the world of free software we have today. People place a great deal of trust in us to stay true to the principles outlined in those documents, and to apply them correctly and wisely in our assessments of new products or practices in computing. In this role, we hold the ladder for others to climb. As a 501(c)(3) charity held legally accountable to the public interest, and about 85% funded by individuals, we have the right structure for this."
|
||||
|
||||
"But we also push the envelope. We take on challenges that others say are too hard. I guess that means we also build ladders? Or maybe I should stop with the metaphors."
|
||||
|
||||
While John may not be great with metaphors (like I am one to talk), the FSF is great at setting a mission and demonstrating a devout commitment to it. This mission starts with a belief that free software should be everywhere.
|
||||
|
||||
"We are not satisfied with the idea that you can get a laptop that works with free software except for a few components. We're not satisfied that you can have a tablet that runs a lot of free software, and just uses proprietary software to communicate with networks and to accelerate video and to take pictures and to check in on your flight and to call an Über and to.. Well, we are happy about some such developments for sure, but we are also unhappy about the suggestion that we should be fully content with them. Any proprietary software on a system is both an injustice to the user and inherently a threat to users' security. These almost-free things can be stepping stones on the way to a free world, but only if we keep our feet moving."
|
||||
|
||||
In the early years of the FSF, we actually had to get a free operating system written. This has now been done by GNU and Linux and many collaborators, although there is always more software to write and bugs to fix. So while the FSF does still sponsor free software development in specific areas, there are thankfully many other organizations also doing this."
|
||||
|
||||
A key part of the challenge John is referring to is getting the right hardware into the hands of the right people.
|
||||
|
||||
"What we have been focusing on now are the challenges I highlighted in the first question. We are in desperate need of hardware in several different areas that fully supports free software. We have been talking a lot at the FSF about what we can do to address this, and I expect us to be making some significant moves to both increase our support for some of the projects already out there—as we having been doing to some extent through our Respects Your Freedom certification program—and possibly to launch some projects of our own. The same goes for the network service problem. I think we need to tackle them together, because having full control over the mobile components has great potential for changing how we relate to services, and decentralizing more and more services will in turn shape the mobile components."
|
||||
|
||||
I hope folks will support the FSF as we work to grow and tackle these challenges. Hardware is expensive and difficult, as is making usable, decentralized, federated replacements for network services. We're going to need the resources and creativity of a lot of people. But, 30 years ago, a community rallied around RMS and the concept of copyleft to write an entire operating system. I've spent my last 12 years at the FSF because I believe we can rise to the new challenges in the same way."
|
||||
|
||||
### Final thoughts ###
|
||||
|
||||
In reading John's thoughtful responses to my questions, and in knowing various FSF members, the one sense that resonates for me is the sheer level of passion that is alive and kicking in the FSF. This is not an organization that has got bored or disillusioned with its mission. Its passion and commitment is as voracious as it has ever been.
|
||||
|
||||
While I don't always agree with the FSF and I sometimes think its approach is a little one-dimensional at times, I have been and will continue to be a huge fan and supporter of its work. The FSF represent the ethical heartbeat of much of the free software and open source work that happens across the world. It represents a world view that is pretty hard to the left, but I believe its passion and conviction helps to bring people further to the right a little closer to the left too.
|
||||
|
||||
Sure, RMS can be odd, somewhat hardline, and a little sensational, but he is precisely the kind of leader that is valuable in a movement that encapsulates a mixture of technology, ethics, and culture. We need an RMS in much the same way we need a Torvalds, a Shuttleworth, a Whitehurst, and a Zemlin. These different people bring together mixture of perspectives that ultimately maps to technology that can be adaptable to almost any set of use cases, ethics, and ambitions.
|
||||
|
||||
So, in closing, I want to thank the FSF for its tremendous efforts, and I wish the FSF and its fearless leaders, one Richard M. Stallman and one John Sullivan, another 30 years of fighting the good fight. Go get 'em!
|
||||
|
||||
> This article is part of Jono Bacon's Six Degrees column, where he shares his thoughts and perspectives on culture, communities, and trends in open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/business/15/9/free-software-foundation-30-years
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/jonobacon
|
||||
[1]:Welcome back, folks, to a new Six Degrees column. As usual, please send your thoughts on this piece to the comment box and your suggestions for future columns to my inbox.
|
||||
[2]:http://www.fsf.org/
|
||||
[3]:http://twitter.com/johns_fsf/
|
||||
[4]:https://en.wikipedia.org/wiki/Amiga_1000
|
||||
[5]:https://en.wikipedia.org/wiki/Adobe_PageMaker
|
||||
[6]:https://www.youtube.com/watch?v=izGwDsrQ1eQ
|
||||
[7]:http://fsf.org/
|
||||
[8]:http://emailselfdefense.fsf.org/
|
||||
[9]:http://fsf.org/ryf
|
||||
[10]:http://directory.fsf.org/
|
||||
[11]:http://www.replicant.us/
|
||||
[12]:http://www.osthinktank.com/
|
||||
[13]:http://www.fsf.org/about/what-is-free-software
|
||||
[14]:http://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[15]:http://www.gnu.org/licenses/licenses.en.html
|
||||
@ -1,30 +0,0 @@
|
||||
Italy's Ministry of Defense to Drop Microsoft Office in Favor of LibreOffice
|
||||
================================================================================
|
||||
>**LibreItalia's Italo Vignoli [reports][1] that the Italian Ministry of Defense is about to migrate to the LibreOffice open-source software for productivity and adopt the Open Document Format (ODF), while moving away from proprietary software products.**
|
||||
|
||||
The movement comes in the form of a [collaboration][1] between Italy's Ministry of Defense and the LibreItalia Association. Sonia Montegiove, President of the LibreItalia Association, and Ruggiero Di Biase, Rear Admiral and General Executive Manager of Automated Information Systems of the Ministry of Defense in Italy signed an agreement for a collaboration to adopt the LibreOffice office suite in all of the Ministry's offices.
|
||||
|
||||
While the LibreItalia non-profit organization promises to help the Italian Ministry of Defense with trainers for their offices across the country, the Ministry will start the implementation of the LibreOffice software on October 2015 with online training courses for their staff. The entire transition process is expected to be completed by the end of year 2016\. An Italian law lets officials find open source software alternatives to well-known commercial software.
|
||||
|
||||
"Under the agreement, the Italian Ministry of Defense will develop educational content for a series of online training courses on LibreOffice, which will be released to the community under Creative Commons, while the partners, LibreItalia, will manage voluntarily the communication and training of trainers in the Ministry," says Italo Vignoli, Honorary President of LibreItalia.
|
||||
|
||||
### The Ministry of Defense will adopt the Open Document Format (ODF)
|
||||
|
||||
The initiative will allow the Italian Ministry of Defense to be independent from proprietary software applications, which are aimed at individual productivity, and adopt open source document format standards like Open Document Format (ODF), which is used by default in the LibreOffice office suite. The project follows similar movements already made by governments of other European countries, including United Kingdom, France, Spain, Germany, and Holland.
|
||||
|
||||
It would appear that numerous other public institutions all over Italy are using open source alternatives, including the Italian Region Emilia Romagna, Galliera Hospital in Genoa, Macerata, Cremona, Trento and Bolzano, Perugia, the municipalities of Bologna, ASL 5 of Veneto, Piacenza and Reggio Emilia, and many others. AGID (Agency for Digital Italy) welcomes this project and hopes that other public institutions will do the same.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/italy-s-ministry-of-defense-to-drop-microsoft-office-in-favor-of-libreoffice-491850.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://www.libreitalia.it/accordo-di-collaborazione-tra-associazione-libreitalia-onlus-e-difesa-per-ladozione-del-prodotto-libreoffice-quale-pacchetto-di-produttivita-open-source-per-loffice-automation/
|
||||
[2]:http://www.libreitalia.it/chi-siamo/
|
||||
@ -1,3 +1,4 @@
|
||||
icybreaker translating...
|
||||
14 tips for teaching open source development
|
||||
================================================================================
|
||||
Academia is an excellent platform for training and preparing the open source developers of tomorrow. In research, we occasionally open source software we write. We do this for two reasons. One, to promote the use of the tools we produce. And two, to learn more about the impact and issues other people face when using them. With this background of writing research software, I was tasked with redesigning the undergraduate software engineering course for second-year students at the University of Bradford.
|
||||
|
||||
@ -1,49 +0,0 @@
|
||||
A Slick New Set-Up Wizard Is Coming To Ubuntu and Ubuntu Touch
|
||||
================================================================================
|
||||
> Canonical aims to 'seduce and reassure' those unfamiliar with the OS by making a good first impression
|
||||
|
||||
**The Ubuntu installer is set to undergo a dramatic makeover.**
|
||||
|
||||
Ubuntu will modernise its out-of-the-box experience (OOBE) to be easier and quicker to complete, look more ‘seductive’ to new users, and better present the Ubuntu brand through its design.
|
||||
|
||||
Ubiquity, the current Ubuntu installer, has largely remained unchanged since its [introduction back in 2010][1].
|
||||
|
||||
### First Impressions Are Everything ###
|
||||
|
||||
Since the first thing most users see when trying Ubuntu for the first time is an installer (or set-up wizard, depending on device) the design team feel it’s “one of the most important categories of software usability”.
|
||||
|
||||
“It essentially says how easy your software is to use, as well as introducing the user into your brand through visual design and tone of voice, which can convey familiarity and trust within your product.”
|
||||
|
||||
Canonical’s new OOBE designs show a striking departure from the current look of the Ubiquity installer used by the Ubuntu desktop, and presents a refined approach to the way mobile users ‘set up’ a new Ubuntu Phone.
|
||||
|
||||

|
||||
|
||||
Old design (left) and the new proposed design
|
||||
|
||||
Detailing the designs in [new blog post][2], the Canonical Design team say the aim of the revamp is to create a consistent out-of-the-box experience across Ubuntu devices.
|
||||
|
||||
To do this it groups together “common first experiences found on the mobile, tablet and desktop” and unifies the steps and screens between each, something they say moves the OS closer to “achieving a seamless convergent platform.”
|
||||
|
||||
|
||||
|
||||
New Ubuntu installer on desktop/tablet (left) and phone
|
||||
|
||||
Implementation of the new ‘OOBE’ has already begun’ according to Canonical, though as of writing there’s no firm word on when a revamped installer may land on either desktop or phone images.
|
||||
|
||||
With the march to ‘desktop’ convergence now in full swing, and a(nother) stack of design changes set to hit the mobile build in lieu of the first Ubuntu Phone that ‘transforms’ in to a PC, chances are you won’t have to wait too long to try it out.
|
||||
|
||||
**What do you think of the designs? How would you go about improving the Ubuntu set-up experience? Let us know in the comments below.**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/09/new-look-ubuntu-installer-coming-soon
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2010/09/ubuntu-10-10s-installer-slideshow-oozes-class
|
||||
[2]:http://design.canonical.com/wp-content/uploads/Convergence.jpg
|
||||
@ -1,101 +0,0 @@
|
||||
The Brief History Of Aix, HP-UX, Solaris, BSD, And LINUX
|
||||
================================================================================
|
||||

|
||||
|
||||
Always remember that when doors close on you, other doors open. [Ken Thompson][1] and [Dennis Richie][2] are a great example for such saying. They were two of the best information technology specialists in the **20th** century as they created the **UNIX** system which is considered one the most influential and inspirational software that ever written.
|
||||
|
||||
### The UNIX systems beginning at Bell Labs ###
|
||||
|
||||
**UNIX** which was originally called **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice) has a great family and was never born by itself. The grandfather of UNIX was **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem) and the father was the **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice) project which supports interactive timesharing for mainframe computers by huge communities of users.
|
||||
|
||||
UNIX was born at **Bell Labs** in **1969** by **Ken Thompson** and later **Dennis Richie**. These two great researchers and scientists worked on a collaborative project with **General Electric** and the **Massachusetts Institute of Technology** to create an interactive timesharing system called the Multics.
|
||||
|
||||
Multics was created to combine timesharing with other technological advances, allowing the users to phone the computer from remote terminals, then edit documents, read e-mail, run calculations, and so on.
|
||||
|
||||
Over the next five years, AT&T corporate invested millions of dollars in the Multics project. They purchased mainframe computer called GE-645 and they dedicated to the effort of the top researchers at Bell Labs such as Ken Thompson, Stuart Feldman, Dennis Ritchie, M. Douglas McIlroy, Joseph F. Ossanna, and Robert Morris. The project was too ambitious, but it fell troublingly behind the schedule. And at the end, AT&T leaders decided to leave the project.
|
||||
|
||||
Bell Labs managers decided to stop any further work on operating systems which made many researchers frustrated and upset. But thanks to Thompson, Richie, and some researchers who ignored their bosses’ instructions and continued working with love on their labs, UNIX was created as one the greatest operating systems of all times.
|
||||
|
||||
UNIX started its life on a PDP-7 minicomputer which was a testing machine for Thompson’s ideas about the operating systems design and a platform for Thompsons and Richie’s game simulation that was called Space and Travel.
|
||||
|
||||
> “What we wanted to preserve was not just a good environment in which to do programming, but a system around which a fellowship could form. We knew from experience that the essence of communal computing, as supplied by remote-access, time-shared machines, is not just to type programs into a terminal instead of a keypunch, but to encourage close communication”. Dennis Richie Said.
|
||||
|
||||
UNIX was so close to be the first system under which the programmer could directly sit down at a machine and start composing programs on the fly, explore possibilities and also test while composing. All through UNIX lifetime, it has had a growing more capabilities pattern by attracting skilled volunteer effort from different programmers impatient with the other operating systems limitations.
|
||||
|
||||
UNIX has received its first funding for a PDP-11/20 in 1970, the UNIX operating system was then officially named and could run on the PDP-11/20. The first real job from UNIX was in 1971, it was to support word processing for the patent department at Bell Labs.
|
||||
|
||||
### The C revolution on UNIX systems ###
|
||||
|
||||
Dennis Richie invented a higher level programming language called “**C**” in **1972**, later he decided with Ken Thompson to rewrite the UNIX in “C” to give the system more portability options. They wrote and debugged almost 100,000 code lines that year. The migration to the “C” language resulted in highly portable software that require only a relatively small machine-dependent code to be then replaced when porting UNIX to another computing platform.
|
||||
|
||||
The UNIX was first formally presented to the outside world in 1973 on Operating Systems Principles, where Dennis Ritchie and Ken Thompson delivered a paper, then AT&T released Version 5 of the UNIX system and licensed it to the educational institutions, and then in 1975 they licensed Version 6 of UNIX to companies for the first time with a cost **$20.000**. The most widely used version of UNIX was Version 7 in 1980 where anybody could purchase a license but it was very restrictive terms in this license. The license included the source code, the machine dependents kernel which was written in PDP-11 assembly language. At all, versions of UNIX systems were determined by its user manuals editions.
|
||||
|
||||
### The AIX System ###
|
||||
|
||||
In **1983**, **Microsoft** had a plan to make a **Xenix** MS-DOS’s multiuser successor, and they created Xenix-based Altos 586 with **512 KB** RAM and **10 MB** hard drive by this year with cost $8,000. By 1984, 100,000 UNIX installations around the world for the System V Release 2. In 1986, 4.3BSD was released that included internet name server and the **AIX system** was announced by **IBM** with Installation base over 250,000. AIX is based on Unix System V, this system has BSD roots and is a hybrid of both.
|
||||
|
||||
AIX was the first operating system that introduced a **journaled file system (JFS)** and an integrated Logical Volume Manager (LVM). IBM ported AIX to its RS/6000 platform by 1989. The Version 5L was a breakthrough release that was introduced in 2001 to provide Linux affinity and logical partitioning with the Power4 servers.
|
||||
|
||||
AIX introduced virtualization by 2004 in AIX 5.3 with Advanced Power Virtualization (APV) which offered Symmetric multi-threading, micro-partitioning, and shared processor pools.
|
||||
|
||||
In 2007, IBM started to enhance its virtualization product, by coinciding with the AIX 6.1 release and the architecture of Power6. They also rebranded Advanced Power Virtualization to PowerVM.
|
||||
|
||||
The enhancements included form of workload partitioning that was called WPARs, that are similar to Solaris zones/Containers, but with much better functionality.
|
||||
|
||||
### The HP-UX System ###
|
||||
|
||||
The **Hewlett-Packard’s UNIX (HP-UX)** was based originally on System V release 3. The system initially ran exclusively on the PA-RISC HP 9000 platform. The Version 1 of HP-UX was released in 1984.
|
||||
|
||||
The Version 9, introduced SAM, its character-based graphical user interface (GUI), from which one can administrate the system. The Version 10, was introduced in 1995, and brought some changes in the layout of the system file and directory structure, which made it similar to AT&T SVR4.
|
||||
|
||||
The Version 11 was introduced in 1997. It was HP’s first release to support 64-bit addressing. But in 2000, this release was rebranded to 11i, as HP introduced operating environments and bundled groups of layered applications for specific Information Technology purposes.
|
||||
|
||||
In 2001, The Version 11.20 was introduced with support for Itanium systems. The HP-UX was the first UNIX that used ACLs (Access Control Lists) for file permissions and it was also one of the first that introduced built-in support for Logical Volume Manager.
|
||||
|
||||
Nowadays, HP-UX uses Veritas as primary file system due to partnership between Veritas and HP.
|
||||
|
||||
The HP-UX is up to release 11iv3, update 4.
|
||||
|
||||
### The Solaris System ###
|
||||
|
||||
The Sun’s UNIX version, **Solaris**, was the successor of **SunOS**, which was founded in 1992. SunOS was originally based on the BSD (Berkeley Software Distribution) flavor of UNIX but SunOS versions 5.0 and later were based on Unix System V Release 4 which was rebranded as Solaris.
|
||||
|
||||
SunOS version 1.0 was introduced with support for Sun-1 and Sun-2 systems in 1983. Version 2.0 was introduced later in 1985. In 1987, Sun and AT&T announced that they would collaborate on a project to merge System V and BSD into only one release, based on SVR4.
|
||||
|
||||
The Solaris 2.4 was first Sparc/x86 release by Sun. The last release of the SunOS was version 4.1.4 announced in November 1994. The Solaris 7 was the first 64-bit Ultra Sparc release and it added native support for file system metadata logging.
|
||||
|
||||
Solaris 9 was introduced in 2002, with support for Linux capabilities and Solaris Volume Manager. Then, Solaris 10 was introduced in 2005, and has number of innovations, such as support for its Solaris Containers, new ZFS file system, and Logical Domains.
|
||||
|
||||
The Solaris system is presently up to version 10 as the latest update was released in 2008.
|
||||
|
||||
### Linux ###
|
||||
|
||||
By 1991 there were growing requirements for a free commercial alternative. Therefore **Linus Torvalds** set out to create new free operating system kernel that eventually became **Linux**. Linux started with a small number of “C” files and under a license which prohibited commercial distribution. Linux is a UNIX-like system and is different than UNIX.
|
||||
|
||||
Version 3.18 was introduced in 2015 under a GNU Public License. IBM said that more than 18 million lines of code are Open Source and available to developers.
|
||||
|
||||
The GNU Public License becomes the most widely available free software license which you can find nowadays. In accordance with the Open Source principles, this license permits individuals and organizations the freedom to distribute, run, share by copying, study, and also modify the code of the software.
|
||||
|
||||
### UNIX vs. Linux: Technical Overview ###
|
||||
|
||||
- Linux can encourage more diversity, and Linux developers come from wider range of backgrounds with different experiences and opinions.
|
||||
- Linux can run on wider range of platforms and also types of architecture than UNIX.
|
||||
- Developers of UNIX commercial editions have a specific target platform and audience in mind for their operating system.
|
||||
- **Linux is more secure than UNIX** as it is less affected by virus threats or malware attacks. Linux has had about 60-100 viruses to date, but at the same time none of them are currently spreading. On the other hand, UNIX has had 85-120 viruses but some of them are still spreading.
|
||||
- With commands of UNIX, tools and elements are rarely changed, and even some interfaces and command lines arguments still remain in later versions of UNIX.
|
||||
- Some Linux development projects get funded on a voluntary basis such as Debian. The other projects maintain a community version of commercial Linux distributions such as SUSE with openSUSE and Red Hat with Fedora.
|
||||
- Traditional UNIX is about scale up, but on the other hand Linux is about scale out.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
|
||||
[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
|
||||
@ -1,38 +0,0 @@
|
||||
Nautilus File Search Is About To Get A Big Power Up
|
||||
================================================================================
|
||||

|
||||
|
||||
**Finding stray files and folders in Nautilus is about to get a whole lot easier. **
|
||||
|
||||
A new **search filter** for the default [GNOME file manager][1] is in development. It makes heavy use of GNOME’s spiffy pop-over menus in an effort to offer a simpler way to narrow in on search results and find exactly what you’re after.
|
||||
|
||||
Developer Georges Stavracas is working on the new UI and [describes][2] the new editor as “cleaner, saner and more intuitive”.
|
||||
|
||||
Based on a video he’s [uploaded to YouTube][3] demoing the new approach – which he hasn’t made available for embedding – he’s not wrong.
|
||||
|
||||
> “Nautilus has very complex but powerful internals, which allows us to do many things. And indeed, there is code for the many options in there. So, why did it used to look so poorly implemented/broken?”, he writes on his blog.
|
||||
|
||||
The question is part rhetorical; the new search filter interface surfaces many of these ‘powerful internals’ to yhe user. Searches can be filtered ad **hoc** based on content type, name or by date range.
|
||||
|
||||
Changing anything in an app like Nautilus is likely to upset some users, so as helpful and straightforward as the new UI seems it could come in for some heat.
|
||||
|
||||
Not that worry of discontent seems to hamper progress (though the outcry at the [removal of ‘type ahead’ search][4] in 2014 still rings loud in many ears, no doubt). GNOME 3.18, [released last month][5], introduced a new file progress dialog to Nautilus and better integration for remote shares, including Google Drive.
|
||||
|
||||
Stavracas’ search filter are not yet merged in to Files’ trunk, but the reworked search UI is tentatively targeted for inclusion in GNOME 3.20, due spring next year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/10/new-nautilus-search-filter-ui
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://wiki.gnome.org/Apps/Nautilus
|
||||
[2]:http://feaneron.com/2015/10/12/the-new-search-for-gnome-files-aka-nautilus/
|
||||
[3]:https://www.youtube.com/watch?v=X2sPRXDzmUw
|
||||
[4]:http://www.omgubuntu.co.uk/2014/01/ubuntu-14-04-nautilus-type-ahead-patch
|
||||
[5]:http://www.omgubuntu.co.uk/2015/09/gnome-3-18-release-new-features
|
||||
@ -1,68 +0,0 @@
|
||||
Ubuntu 15.10, Codenamed Wily Werewolf, Review
|
||||
================================================================================
|
||||

|
||||
|
||||
The problem we have with reviewing Ubuntu on any occasion, is readers consistently expect to read of a revolutionary new release, every 6 months. If you’re expecting Ubuntu 15.10 to be just that, then you may want to click out of this review right now. It’s important to clarify that this is nothing negative towards 15.10 as a release, but it is a maintenance release and not a release which purports to introduce a great deal of new software.
|
||||
|
||||
With that opening disclaimer out of the way, let’s take a look at what 15.10 does offer.
|
||||
|
||||
### Linux kernel 4.2 ###
|
||||
|
||||
The biggest change you will find with Ubuntu 15.10 is the kernel branch has been upgraded to **Linux 4.2**.
|
||||
|
||||
This is long overdue for Ubuntu. It feels like it has been lagging behind other distributions by sticking with the 3.x branch of Linux for the entirety of the 15.04 cycle.
|
||||
|
||||
If you’re going to be installing Ubuntu 15.10 on new hardware, then you will benefit greatly from the Linux kernel upgrade to 4.x branch as there is loads of updates which directly improve performance on new hardware. Support for AMDGPU kernel DRM is included, which is a boon for owners of recent Radeon graphics cards. The latest iteration of the driver will reside alongside the current Radeon DRM drivers, which was already in the kernel in addition to the usual open-source driver offerings.
|
||||
|
||||
Support for Intel Broxton is also included in Linux 4.2, albeit Ubuntu 15.10 users are probably going to get nothing out of this update, yet it’s still worthy of a mention we think. There are also some erroneous updates for Skylake CPU’s. Finally, there is a host of code updates and fixes for Ext4 filesystems.
|
||||
|
||||
That pretty much rounds out the Linux kernel 4.2 updates. So what else is new? Let’s take a closer look at the software that you may be more familiar with and get more excited about.
|
||||
|
||||
### Software ###
|
||||
|
||||
LibreOffice has been upgraded to 5.0.1.2, a major update for LibreOffice users. Firefox on the version that we tested is sitting at 41.0.2. By the time you read this, it will most-likely be updated again and you may see a newer version be pushed out through the Ubuntu Repositories.
|
||||
|
||||
On the desktop front, a vanilla Ubuntu installation will see you running Unity 7.3.2 while GNOME sits at 3.8. On the KDE end, a Plasma 5 desktop will see you running version 5.4.2. For the alternative desktop-environments, XFCE has been upgraded to the latest revision, 4.12 while the version of MATE includes 1.10.
|
||||
|
||||
### User Experience/Screenshots ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Ubuntu 15.10 as a operating system for Review is pretty lackluster. There’s nothing new as such and there’s nothing we can really say that is going to change your opinion from its predecessor, 15.04. Therefore, we recommend you to upgrade either out of habit and according to your regular upgrade schedule rather than out of a specific necessity for a specific feature of this release. Because there is really nothing that could possibly differentiate it from the older, yet still very stable 15.04 release. But if you’re going to stick with 15.04 for a little longer, we do recommend that you look at [upgrading the kernel to the latest 4.2 branch][2]. It is worth it.
|
||||
|
||||
If you really want a reason to upgrade? Linux kernel 4.2 would be our sole reason for taking Ubuntu 15.10 into consideration.
|
||||
|
||||
### Looking Ahead ###
|
||||
|
||||
What we really look forward to is the release of Ubuntu 16.04. We have been promised over and over again for several releases that Mir will be the default display server included in Ubuntu. We still see releases pushed out that rely on X.org. It has resulted in us adopting a “yeah right” attitude as we have become accustomed to the usual delay announcements.
|
||||
|
||||
We are hopeful that Mir Developers can push out a working version in time for the release of 16.04 next year. As precaution though, we urge you to not get too excited because it may very well not happen.
|
||||
|
||||
It remains much the same with Unity 8. It’s most certainly a possibility, but we can’t guarantee that it will be included in 16.04, yet we remain hopeful.
|
||||
|
||||
As we’ve mentioned for this release, there’s nothing really ground-breaking with this release. In fact, it has been much the same story for the last couple of releases of Ubuntu Linux. It is in dire need of a distribution-wide reboot. Developers and Ubuntu users alike are positive that Mir and Unity 8 will be the two primary packages that may just provide the popular, yet ailing, distribution the reboot that it needs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/ubuntu-15-10-codenamed-wily-werewolf-review/
|
||||
|
||||
作者:[Chris Jones][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/chris/
|
||||
[1]:http://www.unixmen.com/how-to-install-linux-kernel-4-2-3/
|
||||
@ -1,194 +0,0 @@
|
||||
10 Things To Do After Installing Ubuntu 15.10 'Wily Werewolf'
|
||||
================================================================================
|
||||

|
||||
|
||||
Yesterday Ubuntu 15.10 was made [available to download][1] with some new features, improvements and updated apps. If you've upgraded to Ubuntu 15.10 then this article is going to show you 10 things/tweaks that you need to do to make your Ubuntu more handy and fruitful.
|
||||
|
||||
### What's New In Ubuntu 15.10? ###
|
||||
|
||||
Ubuntu 15.10 codenamed 'Wily Werewolf' was released yesterday with new features, improvements, fixes and updated apps. Read our complete article to know more stuff added with Ubuntu 15.10.
|
||||
|
||||
### Things To Do After Installing Ubuntu 15.10 ###
|
||||
|
||||
Ubuntu 15.10 is shipping with new features that are activated by default, no need to tweak for anyone. But, changes made in the last release of Ubuntu 15.04, were not activated by default and so in Ubuntu 15.10. Other than those changes you need to install useful/must have applications. So first tweak our newly installed Wily Werewolf.
|
||||
|
||||
### 1. Update Ubuntu 15.10 ###
|
||||
|
||||
Before you use the system and any app first check for updates. Updating the system is necessary to keep the OS more stable and secure. Updates also adds new features in the system. Although there won't be larger size of updates after you within some days of release as all the packages are already to their newest versions.
|
||||
|
||||

|
||||
|
||||
#### Tweak Ubuntu 15.10 ####
|
||||
|
||||
One of things to notice is that the tweaks that were presented in the last Ubuntu release are not activated by default. Those are still at your wish, if you want go ahead and activate them. For example, Always Show Menus, Where to show menu, in the window's title bar or in the menu bar.
|
||||
|
||||
### 2. Set Menus Position ###
|
||||
|
||||
By default in Ubuntu 15.10, the menu are set to show in the menu bar which is sometimes uneasy to reach to but you can set the menus to show in the window's title bar. Go to **Settings >> Appearances >> Behavior >> in the window's title bar**.
|
||||
|
||||

|
||||
|
||||
3. Install Unity Tweak Tool
|
||||
|
||||
To tweak system more install Unity Tweak Tool, It has more options than the default system settings. You can change theme, icons, workspaces settings and many more. Check the screenshot below -
|
||||
|
||||

|
||||
|
||||
### 4. Install Firewall To Block Harmful Incoming/Outgoing Connections ###
|
||||
|
||||

|
||||
|
||||
One of the favorite ways of hackers to get access to individuals' system is to scan for the open ports and attack through them. A firewall protect your system from such attacks by blocking harmful incoming/outgoing connections.
|
||||
|
||||
UFW stands ofr Uncomplicated Firewall. As the name suggests it's the most easy to use firewall you ever used. Just install and switch it on. Configure firewall rules, block particular ports etc. easily. To know all about UFW and how to use all of its features read our following article -
|
||||
|
||||
[Install UFW Firewall In Linux And Secure Computer From Harmful Incoming/Outgoing Connections][2]
|
||||
|
||||
#### Install UFW Firewall ####
|
||||
|
||||
$ sudo apt-get install ufw
|
||||
Install Graphical Interface
|
||||
$ sudo apt-get install gufw
|
||||
|
||||
### 5. Install Graphics Drivers ###
|
||||
|
||||
If you're a game lover or you play HD videos or do video editing kind of things then you need to have proprietary drivers installed available for your hardware for better graphics performance.
|
||||
|
||||
To install graphics driver -
|
||||
|
||||
Go to **Settings >> Software & Updates >> Additional Drivers**
|
||||
|
||||
It will search for the latest drivers available for you hardware.
|
||||
|
||||

|
||||
|
||||
### 6. Install VLC & Media Codecs For More Media Support ###
|
||||
|
||||
VLC supports most file formats so it's better to use VLC to escape the error while playing audio files.
|
||||
|
||||
Sometimes you play a mp3 and it does not play. To solve this problem, Ubuntu gives an option while you're installing Ubuntu to install all the necessary media codecs. If you checked that then don't worry, if you haven't then do the following -
|
||||
|
||||
$ sudo apt-get install vlc
|
||||
Install Media Codecs
|
||||
$ sudo apt-get install ubuntu-restricted-extras
|
||||
|
||||
### 7. Configure Cloud Storage ###
|
||||
|
||||
Cloud storage are very useful to share files across your local devices like, Mobile to PC or Laptops and vice-versa. User can easily install Storages like, Dropbox, Copy, Gdrive (Using Grive) etc.
|
||||
|
||||
#### Dropbox ####
|
||||
|
||||
To install Dropbox, download Dropbox installation client first.
|
||||
|
||||
- [Download Dropbox][3]
|
||||
|
||||
Download Dropbox for your system architecture. To check whether your system is 64-Bit or 32-Bit
|
||||
|
||||
Goto **Settings >> Details**
|
||||
|
||||
Open the downloaded .deb file with Ubuntu Software Center and click install.
|
||||
|
||||

|
||||
|
||||
When installed search Dropbox in Ubuntu dash and open it. It's just an installation client, so now this will install Dropbox app. Once the download competes you'll have the app asking for your Dropbox credentials. Enter your email id and password and login. All of your cloud files will be synced in your Ubuntu desktop.
|
||||
|
||||
### 8. Enhance Look By Installing Themes ###
|
||||
|
||||
The default two themes are not too much attractive. You can download and install cool themes from our Linux Themes Page.
|
||||
|
||||
[][4]
|
||||
|
||||
[][5]
|
||||
|
||||
[][6]
|
||||
|
||||
[][7]
|
||||
|
||||
- [Download More Themes][8]
|
||||
|
||||
### 9. Install & Configure Email Client ###
|
||||
|
||||
Email clients are very useful because you can check for new emails without opening up web browser. Ubuntu 15.10 comes with Thunderbird email client, one of the most popular email clients, supports multiple email accounts and desktop notifications.
|
||||
|
||||
Thunderbird is simple to configure. Just use your email id and password to login and sync your emails right into your desktop/laptop.
|
||||
|
||||
If you don't want to use Thunderbird then check out our article [Top 4 Open Source Email Clients For Linux][9]
|
||||
|
||||

|
||||
|
||||
### 10. Take The Poll ###
|
||||
|
||||
After you have upgraded to Ubuntu 15.10, configure all the necessary or must have apps. Please take the poll to tell us what you like the most in Ubuntu 15.10 'Wily Werewolf'.
|
||||
|
||||
注:投票项目
|
||||
What Do You Like The Most In Ubuntu 15.10?
|
||||
|
||||
- Linux Kernel 4.2
|
||||
- Unity Improvements
|
||||
- Steam Controller Support
|
||||
- Ubuntu Make
|
||||
- Persistent Network Interface Names
|
||||
- New Wallpapers
|
||||
- Other? Please Comment Below
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-ubuntu-1510-wily-werewolf
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://in.linkedin.com/in/mohdsohail
|
||||
[1]:http://www.linuxandubuntu.com/linux/ubuntu-1510-wily-werewolf-released-with-new-features-and-improvements-download-now
|
||||
[2]:http://www.linuxandubuntu.com/linux/install-ufw-firewall-in-linux-and-secure-computer-from-harmful-incoming-outgoing-connections
|
||||
[3]:https://db.tt/CbUWY1ca
|
||||
[4]:http://www.linuxandubuntu.com/linux-themes/arc-dark-red-cinnamon-install-in-ubuntu-and-derivatives
|
||||
[5]:http://www.linuxandubuntu.com/linux-themes/windows-8-gtk3-modern-ui-09-install-in-ubuntu-linux
|
||||
[6]:http://www.linuxandubuntu.com/linux-themes/ubuntu-touch-unity-17-install-in-ubuntu-gtk
|
||||
[7]:http://www.linuxandubuntu.com/linux-themes/numixdarkred-cinnamon-021-install-in-ubuntulinux-mint
|
||||
[8]:http://www.linuxandubuntu.com/linux-themes.html
|
||||
[9]:http://www.linuxandubuntu.com/linux/top-5-open-source-email-clients-for-linux
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
[21]:
|
||||
[22]:
|
||||
[23]:
|
||||
[24]:
|
||||
[25]:
|
||||
[26]:
|
||||
[27]:
|
||||
[28]:
|
||||
[29]:
|
||||
[30]:
|
||||
[31]:
|
||||
[32]:
|
||||
[33]:
|
||||
[34]:
|
||||
[35]:
|
||||
[36]:
|
||||
[37]:
|
||||
[38]:
|
||||
[39]:
|
||||
[40]:
|
||||
[41]:
|
||||
[42]:
|
||||
[43]:
|
||||
[44]:
|
||||
[45]:
|
||||
[46]:
|
||||
[47]:
|
||||
[48]:
|
||||
[49]:
|
||||
[50]:
|
||||
@ -1,109 +0,0 @@
|
||||
Here are the 9 New Ubuntu 15.10 Features You Should Know
|
||||
================================================================================
|
||||
The stable edition of Ubuntu 15.10 wily werewolf is just released by canonical few days a ago and it now available to download and install on your computer. Lets take a look at the features that are implemented in the new release of ubuntu 15.10 and see what important packages have been updated.
|
||||
|
||||
Watch – A quick video about “What’s new in Ubuntu 15.10“, thanks to [linuxscoop][1] for making this video.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/VoeCcCQuJrM?feature=oembed&wmode=opaque" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
Below we are can mention the new features of Ubuntu 15.10 Wily Werewolf
|
||||
|
||||
### Linux kernel 4.2 ###
|
||||
|
||||

|
||||
|
||||
Ubuntu 15.10 ships with linux kernel 4.2. This introduces lots of changes, like support for the new AMD GPU driver, NCQ TRIM handling, queue spinlocks, F2FS per-file encryption and lots of new and updated drivers.
|
||||
|
||||
### Unity 7.3.2 ###
|
||||
|
||||

|
||||
|
||||
Unity as the main desktop of ubuntu 15.10 has been updated to version 7.3.2. it comes with bug fixes, polish and small usability improvements. The following we can mention the features of Unity 7.3.2:
|
||||
|
||||
- Allows drag and drop apps from the Dash to the desktop to create shortcuts
|
||||
- Page up/down keyboard navigation works as scroll in the Dash
|
||||
- Dash title & BFB tooltip is updated based on your privacy settings
|
||||
- Session exit buttons now have a click effect
|
||||
- Fix to prevent ‘shutdown’ of computer when screen is locked
|
||||
- Active app icons now show unfolded when launcher accordion triggered
|
||||
- Fix for full screen menubar
|
||||
- Fixes issues with ‘show desktop’ that caused window decoration for two windows of same app to vanish
|
||||
- Dash: Non-expandable category headers skipped in keyboard navigation
|
||||
- Dash: Non-expandable category headers are no longer highlighted on mouse over
|
||||
- Dash: screenreader and KeyNav fixes
|
||||
- New setting to control the show-now delay (when pressing Alt key)
|
||||
- Logic tweak to stop adjacent menu opening when moving from an indicator icon to its menu
|
||||
|
||||
### GNOME 3.16 stack ###
|
||||
|
||||

|
||||
|
||||
Another important changes for this release, the most of the packages from the GNOME stack updated to version 3.16.x. This is a good thing since these packages do come with lots of improvements.Unfortunately, the nautilus file manager for Ubuntu 15.10 is still in version 3.14 and Gedit text editor file still dating from 3.10.
|
||||
|
||||
### Introduce GNOME Overlay Scrollbars ###
|
||||
|
||||

|
||||
|
||||
In Ubuntu 15.10, Ubuntu developers have decided to implement the GNOME Overlay scrollbars, it replacement of Unity’s overlay scrollbars for GTK3 applications. That’s no different than before, but it does serve as a stark and regular reminder of how much easier it is to use scrollbars that are always present in a predicable spot and wider than the pinpoint tip of a mouse cursor.
|
||||
|
||||
### Ubuntu Make ###
|
||||
|
||||

|
||||
|
||||
Ubuntu Make, a command-line utility that allows you to download the latest version of popular developer tools easier on Ubuntu, now supports even more platforms, frameworks and services, including a full Android development environment.
|
||||
|
||||
### Persistent Network Interface Names ###
|
||||
|
||||

|
||||
|
||||
Ubuntu developer also introduces stateless persistent network interface names in Ubuntu 15.10. This means that naming the network interfaces like eth0 or eth1 will be a thing of the past and that new more comprehensive names will be used. Also, the names will remain valid even after a restart or if the hardware is removed.
|
||||
|
||||
### Steam Controller Support ###
|
||||
|
||||

|
||||
|
||||
In this release, Ubuntu Developer also add support for the Steam Controller in Ubuntu 15.10. For now, the updated Steam package seems to be available only for Ubuntu 15.10, but it’s possible that the patch will be backported to other supported distributions. This means that Ubuntu 15.10 users will be able to plug the new controller, open Steam, and just play without having to read and apply any kind of advice from tutorials.
|
||||
|
||||
### New Default Wallpaper ###
|
||||
|
||||

|
||||
|
||||
Ubuntu 15.10 bring a new default wallpaper, the wallpaper desaign concept adopted from origami and it called suru. A new set of community sourced wallpapers are also included.
|
||||
|
||||
### Core Applications Updates ###
|
||||
|
||||

|
||||
|
||||
Ubuntu 15.10 updates the core applications. among them:
|
||||
|
||||
- Firefox 41
|
||||
- Chromium 45
|
||||
- LibreOffice 5.0.2
|
||||
- Totem (aka ‘Videos’) 3.16
|
||||
- Nautilus (aka ‘Files’) 3.14.2
|
||||
- Rhythmbox 3.2.1
|
||||
- GNOME Terminal 3.16
|
||||
- Eye of GNOME 3.16
|
||||
- Empathy 3.12.10
|
||||
- Shotwell 0.22
|
||||
|
||||
Download Ubuntu 15.10 Final Release
|
||||
|
||||
The image of Ubuntu 15.10 ready to download and install. it available in 64-bit and 32-bit, the both can download from the official ISO downloads page by hitting the link below
|
||||
|
||||
- [Download Ubuntu 15.10][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuportal.com/2015/10/ubuntu-15-10.html
|
||||
|
||||
作者:[ncode][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuportal.com/author/ncode/
|
||||
[1]:https://www.youtube.com/user/linuxscoop
|
||||
[2]:http://releases.ubuntu.com/15.10/
|
||||
@ -0,0 +1,35 @@
|
||||
Linus Torvalds Lambasts Open Source Programmers over Insecure Code
|
||||
================================================================================
|
||||

|
||||
|
||||
Linus Torvalds's latest rant underscores the high expectations the Linux developer places on open source programmers—as well the importance of security for Linux kernel code.
|
||||
|
||||
Torvalds is the unofficial "benevolent dictator" of the Linux kernel project. That means he gets to decide which code contributions go into the kernel, and which ones land in the reject pile.
|
||||
|
||||
On Oct. 28, open source coders whose work did not meet Torvalds's expectations faced an [angry rant][1]. "Christ people," Torvalds wrote about the code. "This is just sh*t."
|
||||
|
||||
He went on to call the coders "just incompetent and out to lunch."
|
||||
|
||||
What made Torvalds so angry? He believed the code could have been written more efficiently. It could have been easier for other programmers to understand and would run better through a compiler, the program that translates human-readable code into the binaries that computers understand.
|
||||
|
||||
Torvalds posted his own substitution for the code in question and suggested that the programmers should have written it his way.
|
||||
|
||||
Torvalds has a history of lashing out against people with whom he disagrees. It stretches back to 1991, when he famously [flamed Andrew Tanenbaum][2]—whose Minix operating system he later described as a series of "brain-damages." No doubt this latest criticism of fellow open source coders will go down as another example of Torvalds's confrontational personality.
|
||||
|
||||
But Torvalds may also have been acting strategically during this latest rant. "I want to make it clear to *everybody* that code like this is completely unacceptable," he wrote, suggesting that his goal was to send a message to all Linux programmers, not just vent his anger at particular ones.
|
||||
|
||||
Torvalds also used the incident as an opportunity to highlight the security concerns that arise from poorly written code. Those are issues dear to open source programmers' hearts in an age when enterprises are finally taking software security seriously, and demanding top-notch performance from their code in this regard. Lambasting open source programmers who write insecure code thus helps Linux's image.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/110415/linus-torvalds-lambasts-open-source-programmers-over-inse
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[2]:https://en.wikipedia.org/wiki/Tanenbaum%E2%80%93Torvalds_debate
|
||||
77
sources/talk/20151117 How bad a boss is Linus Torvalds.md
Normal file
77
sources/talk/20151117 How bad a boss is Linus Torvalds.md
Normal file
@ -0,0 +1,77 @@
|
||||
How bad a boss is Linus Torvalds?
|
||||
================================================================================
|
||||

|
||||
|
||||
*Linus Torvalds addressed a packed auditorium of Linux enthusiasts during his speech at the LinuxWorld show in San Jose, California, on August 10, 1999. Credit: James Niccolai*
|
||||
|
||||
**It depends on context. In the world of software development, he’s what passes for normal. The question is whether that situation should be allowed to continue.**
|
||||
|
||||
I've known Linus Torvalds, Linux's inventor, for over 20 years. We're not chums, but we like each other.
|
||||
|
||||
Lately, Torvalds has been getting a lot of flack for his management style. Linus doesn't suffer fools gladly. He has one way of judging people in his business of developing the Linux kernel: How good is your code?
|
||||
|
||||
Nothing else matters. As Torvalds said earlier this year at the Linux.conf.au Conference, "I'm not a nice person, and I don't care about you. [I care about the technology and the kernel][1] -- that's what's important to me."
|
||||
|
||||
Now, I can deal with that kind of person. If you can't, you should avoid the Linux kernel community, where you'll find a lot of this kind of meritocratic thinking. Which is not to say that I think everything in Linuxland is hunky-dory and should be impervious to calls for change. A meritocracy I can live with; a bastion of male dominance where women are subjected to scorn and disrespect is a problem.
|
||||
|
||||
That's why I see the recent brouhaha about Torvalds' management style -- or more accurately, his total indifference to the personal side of management -- as nothing more than standard operating procedure in the world of software development. And at the same time, I see another instance that has come to light as evidence of a need for things to really change.
|
||||
|
||||
The first situation arose with the [release of Linux 4.3][2], when Torvalds used the Linux Kernel Mailing List to tear into a developer who had inserted some networking code that Torvalds thought was -- well, let's say "crappy." "[[A]nd it generates [crappy] code.][3] It looks bad, and there's no reason for it." He goes on in this vein for quite a while. Besides the word "crap" and its earthier synonym, he uses the word "idiotic" pretty often.
|
||||
|
||||
Here's the thing, though. He's right. I read the code. It's badly written and it does indeed seem to have been designed to use the new "overflow_usub()" function just for the sake of using it.
|
||||
|
||||
Now, some people see this diatribe as evidence that Torvalds is a bad-tempered bully. I see a perfectionist who, within his field, doesn't put up with crap.
|
||||
|
||||
Many people have told me that this is not how professional programmers should act. People, have you ever worked with top developers? That's exactly how they act, at Apple, Microsoft, Oracle and everywhere else I've known them.
|
||||
|
||||
I've heard Steve Jobs rip a developer to pieces. I've cringed while a senior Oracle developer lead tore into a room of new programmers like a piranha through goldfish.
|
||||
|
||||
In Accidental Empires, his classic book on the rise of PCs, Robert X. Cringely described Microsoft's software management style when Bill Gates was in charge as a system where "Each level, from Gates on down, screams at the next, goading and humiliating them." Ah, yes, that's the Microsoft I knew and hated.
|
||||
|
||||
The difference between the leaders at big proprietary software companies and Torvalds is that he says everything in the open for the whole world to see. The others do it in private conference rooms. I've heard people claim that Torvalds would be fired in their company. Nope. He'd be right where he is now: on top of his programming world.
|
||||
|
||||
Oh, and there's another difference. If you get, say, Larry Ellison mad at you, you can kiss your job goodbye. When you get Torvalds angry at your work, you'll get yelled at in an email. That's it.
|
||||
|
||||
You see, Torvalds isn't anyone's boss. He's the guy in charge of a project with about 10,000 contributors, but he has zero hiring and firing authority. He can hurt your feelings, but that's about it.
|
||||
|
||||
That said, there is a serious problem within both open-source and proprietary software development circles. No matter how good a programmer you are, if you're a woman, the cards are stacked against you.
|
||||
|
||||
No case shows this better than that of Sarah Sharp, an Intel developer and formerly a top Linux programmer. [In a post on her blog in October][4], she explained why she had stopped contributing to the Linux kernel more than a year earlier: "I finally realized that I could no longer contribute to a community where I was technically respected, but I could not ask for personal respect.... I did not want to work professionally with people who were allowed to get away with subtle sexist or homophobic jokes."
|
||||
|
||||
Who can blame her? I can't. Torvalds, like almost every software manager I've ever known, I'm sorry to say, has permitted a hostile work environment.
|
||||
|
||||
He would probably say that it's not his job to ensure that Linux contributors behave with professionalism and mutual respect. He's concerned with the code and nothing but the code.
|
||||
|
||||
As Sharp wrote:
|
||||
|
||||
> I have the utmost respect for the technical efforts of the Linux kernel community. They have scaled and grown a project that is focused on maintaining some of the highest coding standards out there. The focus on technical excellence, in combination with overloaded maintainers, and people with different cultural and social norms, means that Linux kernel maintainers are often blunt, rude, or brutal to get their job done. Top Linux kernel developers often yell at each other in order to correct each other's behavior.
|
||||
>
|
||||
> That's not a communication style that works for me. …
|
||||
>
|
||||
> Many senior Linux kernel developers stand by the right of maintainers to be technically and personally brutal. Even if they are very nice people in person, they do not want to see the Linux kernel communication style change.
|
||||
|
||||
She's right.
|
||||
|
||||
Where I differ from other observers is that I don't think that this problem is in any way unique to Linux or open-source communities. With five years of work in the technology business and 25 years as a technology journalist, I've seen this kind of immature boy behavior everywhere.
|
||||
|
||||
It's not Torvalds' fault. He's a technical leader with a vision, not a manager. The real problem is that there seems to be no one in the software development universe who can set a supportive tone for teams and communities.
|
||||
|
||||
Looking ahead, I hope that companies and organizations, such as the Linux Foundation, can find a way to empower community managers or other managers to encourage and enforce civil behavior.
|
||||
|
||||
We won't, unfortunately, find that kind of managerial finesse in our pure technical or business leaders. It's not in their DNA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
@ -0,0 +1,284 @@
|
||||
Review: 5 memory debuggers for Linux coding
|
||||
================================================================================
|
||||

|
||||
Credit: [Moini][1]
|
||||
|
||||
As a programmer, I'm aware that I tend to make mistakes -- and why not? Even programmers are human. Some errors are detected during code compilation, while others get caught during software testing. However, a category of error exists that usually does not get detected at either of these stages and that may cause the software to behave unexpectedly -- or worse, terminate prematurely.
|
||||
|
||||
If you haven't already guessed it, I am talking about memory-related errors. Manually debugging these errors can be not only time-consuming but difficult to find and correct. Also, it's worth mentioning that these errors are surprisingly common, especially in software written in programming languages like C and C++, which were designed for use with [manual memory management][2].
|
||||
|
||||
Thankfully, several programming tools exist that can help you find memory errors in your software programs. In this roundup, I assess five popular, free and open-source memory debuggers that are available for Linux: Dmalloc, Electric Fence, Memcheck, Memwatch and Mtrace. I've used all five in my day-to-day programming, and so these reviews are based on practical experience.
|
||||
|
||||
eviews are based on practical experience.
|
||||
|
||||
### [Dmalloc][3] ###
|
||||
|
||||
**Developer**: Gray Watson
|
||||
**Reviewed version**: 5.5.2
|
||||
**Linux support**: All flavors
|
||||
**License**: Creative Commons Attribution-Share Alike 3.0 License
|
||||
|
||||
Dmalloc is a memory-debugging tool developed by Gray Watson. It is implemented as a library that provides wrappers around standard memory management functions like **malloc(), calloc(), free()** and more, enabling programmers to detect problematic code.
|
||||
|
||||

|
||||
Dmalloc
|
||||
|
||||
As listed on the tool's Web page, the debugging features it provides includes memory-leak tracking, [double free][4] error tracking and [fence-post write detection][5]. Other features include file/line number reporting, and general logging of statistics.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
Version 5.5.2 is primarily a [bug-fix release][6] containing corrections for a couple of build and install problems.
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
The best part about Dmalloc is that it's extremely configurable. For example, you can configure it to include support for C++ programs as well as threaded applications. A useful functionality it provides is runtime configurability, which means that you can easily enable/disable the features the tool provides while it is being executed.
|
||||
|
||||
You can also use Dmalloc with the [GNU Project Debugger (GDB)][7] -- just add the contents of the dmalloc.gdb file (located in the contrib subdirectory in Dmalloc's source package) to the .gdbinit file in your home directory.
|
||||
|
||||
Another thing that I really like about Dmalloc is its extensive documentation. Just head to the [documentation section][8] on its official website, and you'll get everything from how to download, install, run and use the library to detailed descriptions of the features it provides and an explanation of the output file it produces. There's also a section containing solutions to some common problems.
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
Like Mtrace, Dmalloc requires programmers to make changes to their program's source code. In this case you may, at the very least, want to add the **dmalloc.h** header, because it allows the tool to report the file/line numbers of calls that generate problems, something that is very useful as it saves time while debugging.
|
||||
|
||||
In addition, the Dmalloc library, which is produced after the package is compiled, needs to be linked with your program while the program is being compiled.
|
||||
|
||||
However, complicating things somewhat is the fact that you also need to set an environment variable, dubbed **DMALLOC_OPTION**, that the debugging tool uses to configure the memory debugging features -- as well as the location of the output file -- at runtime. While you can manually assign a value to the environment variable, beginners may find that process a bit tough, given that the Dmalloc features you want to enable are listed as part of that value, and are actually represented as a sum of their respective hexadecimal values -- you can read more about it [here][9].
|
||||
|
||||
An easier way to set the environment variable is to use the [Dmalloc Utility Program][10], which was designed for just that purpose.
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Dmalloc's real strength lies in the configurability options it provides. It is also highly portable, having being successfully ported to many OSes, including AIX, BSD/OS, DG/UX, Free/Net/OpenBSD, GNU/Hurd, HPUX, Irix, Linux, MS-DOG, NeXT, OSF, SCO, Solaris, SunOS, Ultrix, Unixware and even Unicos (on a Cray T3E). Although the tool has a bit of a learning curve associated with it, the features it provides are worth it.
|
||||
|
||||
### [Electric Fence][15] ###
|
||||
|
||||
**Developer**: Bruce Perens
|
||||
**Reviewed version**: 2.2.3
|
||||
**Linux support**: All flavors
|
||||
**License**: GNU GPL (version 2)
|
||||
|
||||
Electric Fence is a memory-debugging tool developed by Bruce Perens. It is implemented in the form of a library that your program needs to link to, and is capable of detecting overruns of memory allocated on a [heap][11] ) as well as memory accesses that have already been released.
|
||||
|
||||
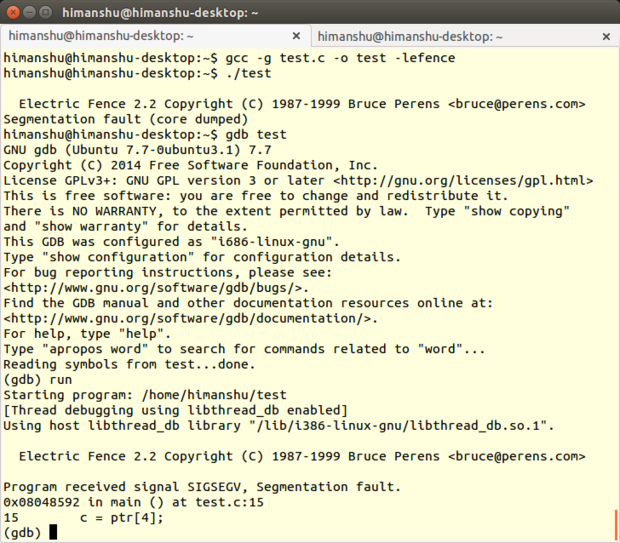
|
||||
Electric Fence
|
||||
|
||||
As the name suggests, Electric Fence creates a virtual fence around each allocated buffer in a way that any illegal memory access results in a [segmentation fault][12]. The tool supports both C and C++ programs.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
Version 2.2.3 contains a fix for the tool's build system, allowing it to actually pass the -fno-builtin-malloc option to the [GNU Compiler Collection (GCC)][13].
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
The first thing that I liked about Electric Fence is that -- unlike Memwatch, Dmalloc and Mtrace -- it doesn't require you to make any changes in the source code of your program. You just need to link your program with the tool's library during compilation.
|
||||
|
||||
Secondly, the way the debugging tool is implemented makes sure that a segmentation fault is generated on the very first instruction that causes a bounds violation, which is always better than having the problem detected at a later stage.
|
||||
|
||||
Electric Fence always produces a copyright message in output irrespective of whether an error was detected or not. This behavior is quite useful, as it also acts as a confirmation that you are actually running an Electric Fence-enabled version of your program.
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
On the other hand, what I really miss in Electric Fence is the ability to detect memory leaks, as it is one of the most common and potentially serious problems that software written in C/C++ has. In addition, the tool cannot detect overruns of memory allocated on the stack, and is not thread-safe.
|
||||
|
||||
Given that the tool allocates an inaccessible virtual memory page both before and after a user-allocated memory buffer, it ends up consuming a lot of extra memory if your program makes too many dynamic memory allocations.
|
||||
|
||||
Another limitation of the tool is that it cannot explicitly tell exactly where the problem lies in your programs' code -- all it does is produce a segmentation fault whenever it detects a memory-related error. To find out the exact line number, you'll have to debug your Electric Fence-enabled program with a tool like [The Gnu Project Debugger (GDB)][14], which in turn depends on the -g compiler option to produce line numbers in output.
|
||||
|
||||
Finally, although Electric Fence is capable of detecting most buffer overruns, an exception is the scenario where the allocated buffer size is not a multiple of the word size of the system -- in that case, an overrun (even if it's only a few bytes) won't be detected.
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Despite all its limitations, where Electric Fence scores is the ease of use -- just link your program with the tool once, and it'll alert you every time it detects a memory issue it's capable of detecting. However, as already mentioned, the tool requires you to use a source-code debugger like GDB.
|
||||
|
||||
### [Memcheck][16] ###
|
||||
|
||||
**Developer**: [Valgrind Developers][17]
|
||||
**Reviewed version**: 3.10.1
|
||||
**Linux support**: All flavors
|
||||
**License**: GPL
|
||||
|
||||
[Valgrind][18] is a suite that provides several tools for debugging and profiling Linux programs. Although it works with programs written in many different languages -- such as Java, Perl, Python, Assembly code, Fortran, Ada and more -- the tools it provides are largely aimed at programs written in C and C++.
|
||||
|
||||
The most popular Valgrind tool is Memcheck, a memory-error detector that can detect issues such as memory leaks, invalid memory access, uses of undefined values and problems related to allocation and deallocation of heap memory.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
This [release][19] of the suite (3.10.1) is a minor one that primarily contains fixes to bugs reported in version 3.10.0. In addition, it also "backports fixes for all reported missing AArch64 ARMv8 instructions and syscalls from the trunk."
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
Memcheck, like all other Valgrind tools, is basically a command line utility. It's very easy to use: If you normally run your program on the command line in a form such as prog arg1 arg2, you just need to add a few values, like this: valgrind --leak-check=full prog arg1 arg2.
|
||||
|
||||
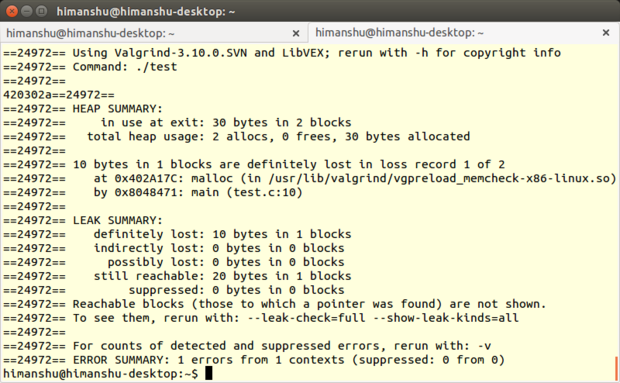
|
||||
Memcheck
|
||||
|
||||
(Note: You don't need to mention Memcheck anywhere in the command line because it's the default Valgrind tool. However, you do need to initially compile your program with the -g option -- which adds debugging information -- so that Memcheck's error messages include exact line numbers.)
|
||||
|
||||
What I really like about Memcheck is that it provides a lot of command line options (such as the --leak-check option mentioned above), allowing you to not only control how the tool works but also how it produces the output.
|
||||
|
||||
For example, you can enable the --track-origins option to see information on the sources of uninitialized data in your program. Enabling the --show-mismatched-frees option will let Memcheck match the memory allocation and deallocation techniques. For code written in C language, Memcheck will make sure that only the free() function is used to deallocate memory allocated by malloc(), while for code written in C++, the tool will check whether or not the delete and delete[] operators are used to deallocate memory allocated by new and new[], respectively. If a mismatch is detected, an error is reported.
|
||||
|
||||
But the best part, especially for beginners, is that the tool even produces suggestions about which command line option the user should use to make the output more meaningful. For example, if you do not use the basic --leak-check option, it will produce an output suggesting: "Rerun with --leak-check=full to see details of leaked memory." And if there are uninitialized variables in the program, the tool will generate a message that says, "Use --track-origins=yes to see where uninitialized values come from."
|
||||
|
||||
Another useful feature of Memcheck is that it lets you [create suppression files][20], allowing you to suppress certain errors that you can't fix at the moment -- this way you won't be reminded of them every time the tool is run. It's worth mentioning that there already exists a default suppression file that Memcheck reads to suppress errors in the system libraries, such as the C library, that come pre-installed with your OS. You can either create a new suppression file for your use, or edit the existing one (usually /usr/lib/valgrind/default.supp).
|
||||
|
||||
For those seeking advanced functionality, it's worth knowing that Memcheck can also [detect memory errors][21] in programs that use [custom memory allocators][22]. In addition, it also provides [monitor commands][23] that can be used while working with Valgrind's built-in gdbserver, as well as a [client request mechanism][24] that allows you not only to tell the tool facts about the behavior of your program, but make queries as well.
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
While there's no denying that Memcheck can save you a lot of debugging time and frustration, the tool uses a lot of memory, and so can make your program execution significantly slower (around 20 to 30 times, [according to the documentation][25]).
|
||||
|
||||
Aside from this, there are some other limitations, too. According to some user comments, Memcheck apparently isn't [thread-safe][26]; it doesn't detect [static buffer overruns][27]). Also, there are some Linux programs, like [GNU Emacs][28], that currently do not work with Memcheck.
|
||||
|
||||
If you're interested in taking a look, an exhaustive list of Valgrind's limitations can be found [here][29].
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Memcheck is a handy memory-debugging tool for both beginners as well as those looking for advanced features. While it's very easy to use if all you need is basic debugging and error checking, there's a bit of learning curve if you want to use features like suppression files or monitor commands.
|
||||
|
||||
Although it has a long list of limitations, Valgrind (and hence Memcheck) claims on its site that it is used by [thousands of programmers][30] across the world -- the team behind the tool says it's received feedback from users in over 30 countries, with some of them working on projects with up to a whopping 25 million lines of code.
|
||||
|
||||
### [Memwatch][31] ###
|
||||
|
||||
**Developer**: Johan Lindh
|
||||
**Reviewed version**: 2.71
|
||||
**Linux support**: All flavors
|
||||
**License**: GNU GPL
|
||||
|
||||
Memwatch is a memory-debugging tool developed by Johan Lindh. Although it's primarily a memory-leak detector, it is also capable (according to its Web page) of detecting other memory-related issues like [double-free error tracking and erroneous frees][32], buffer overflow and underflow, [wild pointer][33] writes, and more.
|
||||
|
||||
The tool works with programs written in C. Although you can also use it with C++ programs, it's not recommended (according to the Q&A file that comes with the tool's source package).
|
||||
|
||||
#### What's new ####
|
||||
|
||||
This version adds ULONG_LONG_MAX to detect whether a program is 32-bit or 64-bit.
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
Like Dmalloc, Memwatch comes with good documentation. You can refer to the USING file if you want to learn things like how the tool works; how it performs initialization, cleanup and I/O operations; and more. Then there is a FAQ file that is aimed at helping users in case they face any common error while using Memcheck. Finally, there is a test.c file that contains a working example of the tool for your reference.
|
||||
|
||||
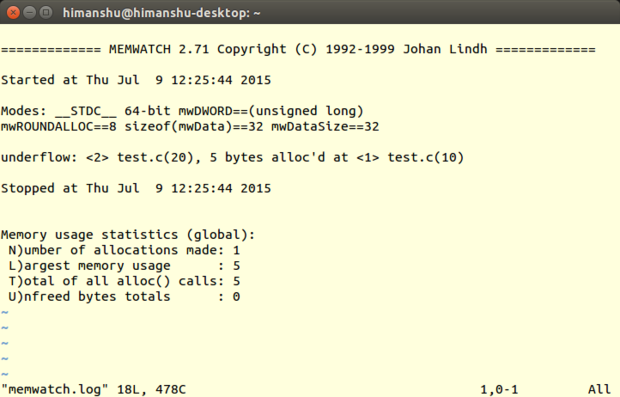
|
||||
Memwatch
|
||||
|
||||
Unlike Mtrace, the log file to which Memwatch writes the output (usually memwatch.log) is in human-readable form. Also, instead of truncating, Memwatch appends the memory-debugging output to the file each time the tool is run, allowing you to easily refer to the previous outputs should the need arise.
|
||||
|
||||
It's also worth mentioning that when you execute your program with Memwatch enabled, the tool produces a one-line output on [stdout][34] informing you that some errors were found -- you can then head to the log file for details. If no such error message is produced, you can rest assured that the log file won't contain any mistakes -- this actually saves time if you're running the tool several times.
|
||||
|
||||
Another thing that I liked about Memwatch is that it also provides a way through which you can capture the tool's output from within the code, and handle it the way you like (refer to the mwSetOutFunc() function in the Memwatch source code for more on this).
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
Like Mtrace and Dmalloc, Memwatch requires you to add extra code to your source file -- you have to include the memwatch.h header file in your code. Also, while compiling your program, you need to either compile memwatch.c along with your program's source files or include the object module from the compile of the file, as well as define the MEMWATCH and MW_STDIO variables on the command line. Needless to say, the -g compiler option is also required for your program if you want exact line numbers in the output.
|
||||
|
||||
There are some features that it doesn't contain. For example, the tool cannot detect attempts to write to an address that has already been freed or read data from outside the allocated memory. Also, it's not thread-safe. Finally, as I've already pointed out in the beginning, there is no guarantee on how the tool will behave if you use it with programs written in C++.
|
||||
|
||||
#### Bottom line ####
|
||||
|
||||
Memcheck can detect many memory-related problems, making it a handy debugging tool when dealing with projects written in C. Given that it has a very small source code, you can learn how the tool works, debug it if the need arises, and even extend or update its functionality as per your requirements.
|
||||
|
||||
### [Mtrace][35] ###
|
||||
|
||||
**Developers**: Roland McGrath and Ulrich Drepper
|
||||
**Reviewed version**: 2.21
|
||||
**Linux support**: All flavors
|
||||
**License**: GNU LGPL
|
||||
|
||||
Mtrace is a memory-debugging tool included in [the GNU C library][36]. It works with both C and C++ programs on Linux, and detects memory leaks caused by unbalanced calls to the malloc() and free() functions.
|
||||
|
||||
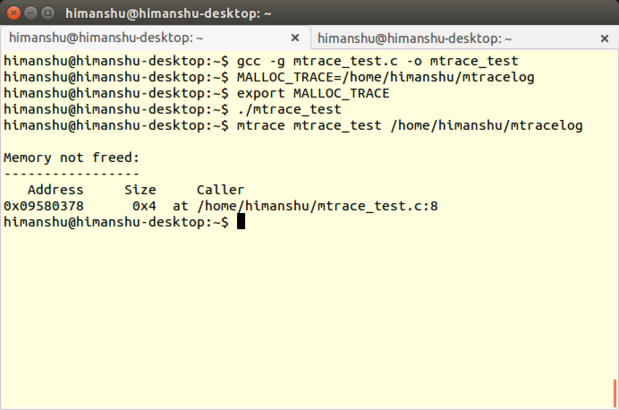
|
||||
Mtrace
|
||||
|
||||
The tool is implemented in the form of a function called mtrace(), which traces all malloc/free calls made by a program and logs the information in a user-specified file. Because the file contains data in computer-readable format, a Perl script -- also named mtrace -- is used to convert and display it in human-readable form.
|
||||
|
||||
#### What's new ####
|
||||
|
||||
[The Mtrace source][37] and [the Perl file][38] that now come with the GNU C library (version 2.21) add nothing new to the tool aside from an update to the copyright dates.
|
||||
|
||||
#### What's good about it ####
|
||||
|
||||
The best part about Mtrace is that the learning curve for it isn't steep; all you need to understand is how and where to add the mtrace() -- and the corresponding muntrace() -- function in your code, and how to use the Mtrace Perl script. The latter is very straightforward -- all you have to do is run the mtrace() <program-executable> <log-file-generated-upon-program-execution> command. (For an example, see the last command in the screenshot above.)
|
||||
|
||||
Another thing that I like about Mtrace is that it's scalable -- which means that you can not only use it to debug a complete program, but can also use it to detect memory leaks in individual modules of the program. Just call the mtrace() and muntrace() functions within each module.
|
||||
|
||||
Finally, since the tool is triggered when the mtrace() function -- which you add in your program's source code -- is executed, you have the flexibility to enable the tool dynamically (during program execution) [using signals][39].
|
||||
|
||||
#### Other considerations ####
|
||||
|
||||
Because the calls to mtrace() and mauntrace() functions -- which are declared in the mcheck.h file that you need to include in your program's source -- are fundamental to Mtrace's operation (the mauntrace() function is not [always required][40]), the tool requires programmers to make changes in their code at least once.
|
||||
|
||||
Be aware that you need to compile your program with the -g option (provided by both the [GCC][41] and [G++][42] compilers), which enables the debugging tool to display exact line numbers in the output. In addition, some programs (depending on how big their source code is) can take a long time to compile. Finally, compiling with -g increases the size of the executable (because it produces extra information for debugging), so you have to remember that the program needs to be recompiled without -g after the testing has been completed.
|
||||
|
||||
To use Mtrace, you need to have some basic knowledge of environment variables in Linux, given that the path to the user-specified file -- which the mtrace() function uses to log all the information -- has to be set as a value for the MALLOC_TRACE environment variable before the program is executed.
|
||||
|
||||
Feature-wise, Mtrace is limited to detecting memory leaks and attempts to free up memory that was never allocated. It can't detect other memory-related issues such as illegal memory access or use of uninitialized memory. Also, [there have been complaints][43] that it's not [thread-safe][44].
|
||||
|
||||
### Conclusions ###
|
||||
|
||||
Needless to say, each memory debugger that I've discussed here has its own qualities and limitations. So, which one is best suited for you mostly depends on what features you require, although ease of setup and use might also be a deciding factor in some cases.
|
||||
|
||||
Mtrace is best suited for cases where you just want to catch memory leaks in your software program. It can save you some time, too, since the tool comes pre-installed on your Linux system, something which is also helpful in situations where the development machines aren't connected to the Internet or you aren't allowed to download a third party tool for any kind of debugging.
|
||||
|
||||
Dmalloc, on the other hand, can not only detect more error types compared to Mtrace, but also provides more features, such as runtime configurability and GDB integration. Also, unlike any other tool discussed here, Dmalloc is thread-safe. Not to mention that it comes with detailed documentation, making it ideal for beginners.
|
||||
|
||||
Although Memwatch comes with even more comprehensive documentation than Dmalloc, and can detect even more error types, you can only use it with software written in the C programming language. One of its features that stands out is that it lets you handle its output from within the code of your program, something that is helpful in case you want to customize the format of the output.
|
||||
|
||||
If making changes to your program's source code is not what you want, you can use Electric Fence. However, keep in mind that it can only detect a couple of error types, and that doesn't include memory leaks. Plus, you also need to know GDB basics to make the most out of this memory-debugging tool.
|
||||
|
||||
Memcheck is probably the most comprehensive of them all. It detects more error types and provides more features than any other tool discussed here -- and it doesn't require you to make any changes in your program's source code.But be aware that, while the learning curve is not very high for basic usage, if you want to use its advanced features, a level of expertise is definitely required.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debuggers-for-linux-coding.html
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Himanshu-Arora/
|
||||
[1]:https://openclipart.org/detail/132427/penguin-admin
|
||||
[2]:https://en.wikipedia.org/wiki/Manual_memory_management
|
||||
[3]:http://dmalloc.com/
|
||||
[4]:https://www.owasp.org/index.php/Double_Free
|
||||
[5]:https://stuff.mit.edu/afs/sipb/project/gnucash-test/src/dmalloc-4.8.2/dmalloc.html#Fence-Post%20Overruns
|
||||
[6]:http://dmalloc.com/releases/notes/dmalloc-5.5.2.html
|
||||
[7]:http://www.gnu.org/software/gdb/
|
||||
[8]:http://dmalloc.com/docs/
|
||||
[9]:http://dmalloc.com/docs/latest/online/dmalloc_26.html#SEC32
|
||||
[10]:http://dmalloc.com/docs/latest/online/dmalloc_23.html#SEC29
|
||||
[11]:https://en.wikipedia.org/wiki/Memory_management#Dynamic_memory_allocation
|
||||
[12]:https://en.wikipedia.org/wiki/Segmentation_fault
|
||||
[13]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[14]:http://www.gnu.org/software/gdb/
|
||||
[15]:https://launchpad.net/ubuntu/+source/electric-fence/2.2.3
|
||||
[16]:http://valgrind.org/docs/manual/mc-manual.html
|
||||
[17]:http://valgrind.org/info/developers.html
|
||||
[18]:http://valgrind.org/
|
||||
[19]:http://valgrind.org/docs/manual/dist.news.html
|
||||
[20]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.suppfiles
|
||||
[21]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.mempools
|
||||
[22]:http://stackoverflow.com/questions/4642671/c-memory-allocators
|
||||
[23]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.monitor-commands
|
||||
[24]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.clientreqs
|
||||
[25]:http://valgrind.org/docs/manual/valgrind_manual.pdf
|
||||
[26]:http://sourceforge.net/p/valgrind/mailman/message/30292453/
|
||||
[27]:https://msdn.microsoft.com/en-us/library/ee798431%28v=cs.20%29.aspx
|
||||
[28]:http://www.computerworld.com/article/2484425/linux/5-free-linux-text-editors-for-programming-and-word-processing.html?nsdr=true&page=2
|
||||
[29]:http://valgrind.org/docs/manual/manual-core.html#manual-core.limits
|
||||
[30]:http://valgrind.org/info/
|
||||
[31]:http://www.linkdata.se/sourcecode/memwatch/
|
||||
[32]:http://www.cecalc.ula.ve/documentacion/tutoriales/WorkshopDebugger/007-2579-007/sgi_html/ch09.html
|
||||
[33]:http://c2.com/cgi/wiki?WildPointer
|
||||
[34]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
[35]:http://www.gnu.org/software/libc/manual/html_node/Tracing-malloc.html
|
||||
[36]:https://www.gnu.org/software/libc/
|
||||
[37]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.c;h=df10128b872b4adc4086cf74e5d965c1c11d35d2;hb=HEAD
|
||||
[38]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.pl;h=0737890510e9837f26ebee2ba36c9058affb0bf1;hb=HEAD
|
||||
[39]:http://webcache.googleusercontent.com/search?q=cache:s6ywlLtkSqQJ:www.gnu.org/s/libc/manual/html_node/Tips-for-the-Memory-Debugger.html+&cd=1&hl=en&ct=clnk&gl=in&client=Ubuntu
|
||||
[40]:http://www.gnu.org/software/libc/manual/html_node/Using-the-Memory-Debugger.html#Using-the-Memory-Debugger
|
||||
[41]:http://linux.die.net/man/1/gcc
|
||||
[42]:http://linux.die.net/man/1/g++
|
||||
[43]:https://sourceware.org/ml/libc-help/2014-05/msg00008.html
|
||||
[44]:https://en.wikipedia.org/wiki/Thread_safety
|
||||
@ -0,0 +1,171 @@
|
||||
20 Years of GIMP Evolution: Step by Step
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/PSJAzJ6mkVw?feature=oembed"></iframe>
|
||||
|
||||
[GIMP][1] (GNU Image Manipulation Program) – superb open source and free graphics editor. Development began in 1995 as students project of the University of California, Berkeley by Peter Mattis and Spencer Kimball. In 1997 the project was renamed in “GIMP” and became an official part of [GNU Project][2]. During these years the GIMP is one of the best graphics editor and platinum holy wars “GIMP vs Photoshop” – one of the most popular.
|
||||
|
||||
The first announce, 21.11.1995:
|
||||
|
||||
> From: Peter Mattis
|
||||
>
|
||||
> Subject: ANNOUNCE: The GIMP
|
||||
>
|
||||
> Date: 1995-11-21
|
||||
>
|
||||
> Message-ID: <48s543$r7b@agate.berkeley.edu>
|
||||
>
|
||||
> Newsgroups: comp.os.linux.development.apps,comp.os.linux.misc,comp.windows.x.apps
|
||||
>
|
||||
> The GIMP: the General Image Manipulation Program
|
||||
> ------------------------------------------------
|
||||
>
|
||||
> The GIMP is designed to provide an intuitive graphical interface to a
|
||||
> variety of image editing operations. Here is a list of the GIMP's
|
||||
> major features:
|
||||
>
|
||||
> Image viewing
|
||||
> -------------
|
||||
>
|
||||
> * Supports 8, 15, 16 and 24 bit color.
|
||||
> * Ordered and Floyd-Steinberg dithering for 8 bit displays.
|
||||
> * View images as rgb color, grayscale or indexed color.
|
||||
> * Simultaneously edit multiple images.
|
||||
> * Zoom and pan in real-time.
|
||||
> * GIF, JPEG, PNG, TIFF and XPM support.
|
||||
>
|
||||
> Image editing
|
||||
> -------------
|
||||
>
|
||||
> * Selection tools including rectangle, ellipse, free, fuzzy, bezier
|
||||
> and intelligent.
|
||||
> * Transformation tools including rotate, scale, shear and flip.
|
||||
> * Painting tools including bucket, brush, airbrush, clone, convolve,
|
||||
> blend and text.
|
||||
> * Effects filters (such as blur, edge detect).
|
||||
> * Channel & color operations (such as add, composite, decompose).
|
||||
> * Plug-ins which allow for the easy addition of new file formats and
|
||||
> new effect filters.
|
||||
> * Multiple undo/redo.
|
||||
|
||||
GIMP 0.54, 1996
|
||||
|
||||

|
||||
|
||||
GIMP 0.54 was required X11 displays, X-server and Motif 1.2 wigdets and supported 8, 15, 16 & 24 color depths with RGB & grayscale colors. Supported images format: GIF, JPEG, PNG, TIFF and XPM.
|
||||
|
||||
Basic functionality: rectangle, ellipse, free, fuzzy, bezier, intelligent selection tools, and rotate, scale, shear, clone, blend and flip images.
|
||||
|
||||
Extended tools: text operations, effects filters, tools for channel and colors manipulation, undo and redo operations. Since the first version GIMP support the plugin system.
|
||||
|
||||
GIMP 0.54 can be ran in Linux, HP-UX, Solaris, SGI IRIX.
|
||||
|
||||
### GIMP 0.60, 1997 ###
|
||||
|
||||

|
||||
|
||||
This is development release, not for all users. GIMP has the new toolkits – GDK (GIMP Drawing Kit) and GTK (GIMP Toolkit), Motif support is deprecated. GIMP Toolkit is also begin of the GTK+ cross-platform widget toolkit. New features:
|
||||
|
||||
- basic layers
|
||||
- sub-pixel sampling
|
||||
- brush spacing
|
||||
- improver airbrush
|
||||
- paint modes
|
||||
|
||||
### GIMP 0.99, 1997 ###
|
||||
|
||||

|
||||
|
||||
Since 0.99 version GIMP has the scripts add macros (Script-Fus) support. GTK and GDK with some improvements has now the new name – GTK+. Other improvements:
|
||||
|
||||
- support big images (rather than 100 MB)
|
||||
- new native format – XCF
|
||||
- new API – write plugins and extensions is easy
|
||||
|
||||
### GIMP 1.0, 1998 ###
|
||||
|
||||

|
||||
|
||||
GIMP and GTK+ was splitted into separate projects. The GIMP official website has
|
||||
reconstructed and contained new tutorials, plugins and documentation. New features:
|
||||
|
||||
- tile-based memory management
|
||||
- massive changes in plugin API
|
||||
- XFC format now support layers, guides and selections
|
||||
- web interface
|
||||
- online graphics generation
|
||||
|
||||
### GIMP 1.2, 2000 ###
|
||||
|
||||
New features:
|
||||
|
||||
- translation for non-english languages
|
||||
- fixed many bugs in GTK+ and GIMP
|
||||
- many new plugins
|
||||
- image map
|
||||
- new toolbox: resize, measure, dodge, burn, smugle, samle colorize and curve bend
|
||||
- image pipes
|
||||
- images preview before saving
|
||||
- scaled brush preview
|
||||
- recursive selection by path
|
||||
- new navigation window
|
||||
- drag’n’drop
|
||||
- watermarks support
|
||||
|
||||
### GIMP 2.0, 2004 ###
|
||||
|
||||

|
||||
|
||||
The biggest change – new GTK+ 2.x toolkit.
|
||||
|
||||
### GIMP 2.2, 2004 ###
|
||||
|
||||

|
||||
|
||||
Many bugfixes and drag’n’drop support.
|
||||
|
||||
### GIMP 2.4, 2007 ###
|
||||
|
||||

|
||||
|
||||
New features:
|
||||
|
||||
- better drag’n’drop support
|
||||
- Ti-Fu was replaced to Script-Fu – the new script interpreter
|
||||
- new plugins: photocopy, softglow, neon, cartoon, dog, glob and others
|
||||
|
||||
### GIMP 2.6, 2008 ###
|
||||
|
||||
New features:
|
||||
|
||||
- renew graphics interface
|
||||
- new select and tool
|
||||
- GEGL (GEneric Graphics Library) integration
|
||||
- “The Utility Window Hint” for MDI behavior
|
||||
|
||||
### GIMP 2.8, 2012 ###
|
||||
|
||||

|
||||
|
||||
New features:
|
||||
|
||||
- GUI has some visual changes
|
||||
- new save and export menu
|
||||
- renew text editor
|
||||
- layers group support
|
||||
- JPEG2000 and export to PDF support
|
||||
- webpage screenshot tool
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/20-years-of-gimp-evolution/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://gimp.org/
|
||||
[2]:http://www.gnu.org/
|
||||
@ -0,0 +1,51 @@
|
||||
Linux Foundation Explains a "World without Linux" and Open Source
|
||||
================================================================================
|
||||
> The Linux Foundation responds to questions about its "World without Linux" movies, including what the Internet would be like without Linux and other open source software.
|
||||
|
||||

|
||||
|
||||
Would the world really be tremendously different if Linux, the open source operating system kernel, did not exist? Would there be no Internet or movies? Those are the questions some viewers of the [Linux Foundation's][1] ongoing "[World without Linux][2]" video series are asking. Here are some answers.
|
||||
|
||||
In case you've missed it, the "World without Linux" series is a collection of quirky short films that depict, well, a world without Linux (and open source software more generally). They have emphasized themes like [Linux's role in movie-making][3] and in [serving the Internet][4].
|
||||
|
||||
To offer perspective on the series's claims, direction and hidden symbols, Jennifer Cloer, vice president of communications at The Linux Foundation, recently sent The VAR Guy responses to some common queries about the movies. Below are the answers, in her own words.
|
||||
|
||||
### The latest episode takes Sam and Annie to the movies. Would today's graphics really be that much different without Linux? ###
|
||||
|
||||
In episode #4, we do a bit of a parody on "Avatar." Love it or hate it, the graphics in the real "Avatar" are pretty impressive. In a world without Linux, the graphics would be horrible but we wouldn't even know it because we wouldn't know any better. But in fact, "Avatar" was created using Linux. Weta Digital used one of the world's largest Linux clusters to render the film and do 3D modeling. It's also been reported that "Lord of the Rings," "Fantastic Four" and "King Kong," among others, have used Linux. We hope this episode can bring attention to that work, which hasn't been widely reported.
|
||||
|
||||
### Some people criticized the original episode for concluding there would be no Internet without Linux. What's your reaction? ###
|
||||
|
||||
We enjoyed the debate that resulted from the debut episode. With more than 100,000 views to date of that episode alone, it brought awareness to the role that Linux plays in society and to the worldwide community of contributors and supporters. Of course the Internet would exist without Linux but it wouldn't be the Internet we know today and it wouldn't have matured at the pace it has. Each episode makes a bold and fun statement about Linux's role in our every day lives. We hope this can help extend the story of Linux to more people around the world.
|
||||
|
||||
### Why is Sam and Annie's cat named String? ###
|
||||
|
||||
Nothing in the series is a coincidence. Look closely and you'll find all kinds of inside Linux and geek jokes. String is named after String theory and was named by our Linux.com Editor Libby Clark. In physics, string theory is a theoretical framework in which the point-like particles of particle physics are replaced by one-dimensional objects called strings. String theory describes how these strings propagate through space and interact with each other. Kind of like Sam, Annie and String in a World Without Linux.
|
||||
|
||||
### What can we expect from the next two episodes and, in particular, the finale? When will it air? ###
|
||||
|
||||
In episode #5, we'll go to space and experience what a world without Linux would mean to exploration. It's a wild ride. In the finale, we finally get to see Linus in a world without Linux. There have been clues throughout the series as to what this finale will include but I can't give more than that away since there are ongoing contests to find the clues. And I can't give away the air date for the finale! You'll have to follow #WorldWithoutLinux to learn more.
|
||||
|
||||
### Can you give us a hint on the clues in episode #4? ###
|
||||
|
||||
There is another reference to the Free Burger Restaurant in this episode. Linux also actually does appear in this world without Linux but in a very covert way; you could say it's like reading Linux in another language. And, of course, just for fun, String makes another appearance.
|
||||
|
||||
### Is the series achieving what you hoped? ###
|
||||
|
||||
Yes. We're really happy to see people share and engage with these stories. We hope that it's reaching people who might not otherwise know the story of Linux or understand its pervasiveness in the world today. It's really about surfacing this to a broader audience and giving thanks to the worldwide community of developers and companies that support Linux and all the things it makes possible.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/linux-foundation-explains-world-without-linux-and-open-so
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://linuxfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/world-without-linux
|
||||
[3]:http://thevarguy.com/open-source-application-software-companies/new-linux-foundation-video-highlights-role-open-source-3d
|
||||
[4]:http://thevarguy.com/open-source-application-software-companies/100715/would-internet-exist-without-linux-yes-without-open-sourc
|
||||
@ -0,0 +1,77 @@
|
||||
Microsoft and Linux: True Romance or Toxic Love?
|
||||
================================================================================
|
||||
Every now and then, you come across a news story that makes you choke on your coffee or splutter hot latte all over your monitor. Microsoft's recent proclamations of love for Linux is an outstanding example of such a story.
|
||||
|
||||
Common sense says that Microsoft and the FOSS movement should be perpetual enemies. In the eyes of many, Microsoft embodies most of the greedy excesses that the Free Software movement rejects. In addition, Microsoft previously has labeled Linux as a cancer and the FOSS community as a "pack of thieves".
|
||||
|
||||
We can understand why Microsoft has been afraid of a free operating system. When combined with open-source applications that challenge Microsoft's core line, it threatens Microsoft's grip on the desktop/laptop market.
|
||||
|
||||
In spite of Microsoft's fears over its desktop dominance, the Web server marketplace is one arena where Linux has had the greatest impact. Today, the majority of Web servers are Linux boxes. This includes most of the world's busiest sites. The sight of so much unclaimed licensing revenue must be painful indeed for Microsoft.
|
||||
|
||||
Handheld devices are another realm where Microsoft has lost ground to free software. At one point, its Windows CE and Pocket PC operating systems were at the forefront of mobile computing. Windows-powered PDA devices were the shiniest and flashiest gadgets around. But, that all ended when Apple released its iPhone. Since then, Android has stepped into the limelight, with Windows Mobile largely ignored and forgotten. The Android platform is built on free and open-source components.
|
||||
|
||||
The rapid expansion in Android's market share is due to the open nature of the platform. Unlike with iOS, any phone manufacturer can release an Android handset. And, unlike with Windows Mobile, there are no licensing fees. This has been really good news for consumers. It has led to lots of powerful and cheap handsets appearing from manufacturers all over the world. It's a very definite vindication of the value of FOSS software.
|
||||
|
||||
Losing the battle for the Web and mobile computing is a brutal loss for Microsoft. When you consider the size of those two markets combined, the desktop market seems like a stagnant backwater. Nobody likes to lose, especially when money is on the line. And, Microsoft does have a lot to lose. You would expect Microsoft to be bitter about it. And in the past, it has been.
|
||||
|
||||
Microsoft has fought back against Linux and FOSS using every weapon at its disposal, from propaganda to patent threats, and although these attacks have slowed the adoption of Linux, they haven't stopped it.
|
||||
|
||||
So, you can forgive us for being shocked when Microsoft starts handing out t-shirts and badges that say "Microsoft Loves Linux" at open-source conferences and events. Could it be true? Does Microsoft really love Linux?
|
||||
|
||||
Of course, PR slogans and free t-shirts do not equal truth. Actions speak louder than words. And when you consider Microsoft's actions, Microsoft's stance becomes a little more ambiguous.
|
||||
|
||||
On the one hand, Microsoft is recruiting hundreds of Linux developers and sysadmins. It's releasing its .NET Core framework as an open-source project with cross-platform support (so that .NET apps can run on OS X and Linux). And, it is partnering with Linux companies to bring popular distros to its Azure platform. In fact, Microsoft even has gone so far as to create its own Linux distro for its Azure data center.
|
||||
|
||||
On the other hand, Microsoft continues to launch legal attacks on open-source projects directly and through puppet corporations. It's clear that Microsoft hasn't had some big moral change of heart over proprietary vs. free software, so why the public declarations of adoration?
|
||||
|
||||
To state the obvious, Microsoft is a profit-making entity. It's an investment vehicle for its shareholders and a source of income for its employees. Everything it does has a single ultimate goal: revenue. Microsoft doesn't act out of love or even hate (although that's a common accusation).
|
||||
|
||||
So the question shouldn't be "does Microsoft really love Linux?" Instead, we should ask how Microsoft is going to profit from all this.
|
||||
|
||||
Let's take the open-source release of .NET Core. This move makes it easy to port the .NET runtime to any platform. That extends the reach of Microsoft's .NET framework far beyond the Windows platform.
|
||||
|
||||
Opening .NET Core ultimately will make it possible for .NET developers to produce cross-platform apps for OS X, Linux, iOS and even Android--all from a single codebase.
|
||||
|
||||
From a developer's perspective, this makes the .NET framework much more attractive than before. Being able to reach many platforms from a single codebase dramatically increases the potential target market for any app developed using the .NET framework.
|
||||
|
||||
What's more, a strong Open Source community would provide developers with lots of code to reuse in their own projects. So, the availability of open-source projects would make the .NET framework.
|
||||
|
||||
On the plus side, opening .NET Core reduces fragmentation across different platforms and means a wider choice of apps for consumers. That means more choice, both in terms of open-source software and proprietary apps.
|
||||
|
||||
From Microsoft's point of view, it would gain a huge army of developers. Microsoft profits by selling training, certification, technical support, development tools (including Visual Studio) and proprietary extensions.
|
||||
|
||||
The question we should ask ourselves is does this benefit or hurt the Free Software community?
|
||||
|
||||
Widespread adoption of the .NET framework could mean the eventual death of competing open-source projects, forcing us all to dance to Microsoft's tune.
|
||||
|
||||
Moving beyond .NET, Microsoft is drawing a lot of attention to its Linux support on its Azure cloud computing platform. Remember, Azure originally was Windows Azure. That's because Windows Server was the only supported operating system. Today, Azure offers support for a number of Linux distros too.
|
||||
|
||||
There's one reason for this: paying customers who need and want Linux services. If Microsoft didn't offer Linux virtual machines, those customers would do business with someone else.
|
||||
|
||||
It looks like Microsoft is waking up to the fact that Linux is here to stay. Microsoft cannot feasibly wipe it out, so it has to embrace it.
|
||||
|
||||
This brings us back to the question of why there is so much buzz about Microsoft and Linux. We're all talking about it, because Microsoft wants us to think about it. After all, all these stories trace back to Microsoft, whether it's through press releases, blog posts or public announcements at conferences. The company is working hard to draw attention to its Linux expertise.
|
||||
|
||||
What other possible purpose could be behind Chief Architect Kamala Subramaniam's blog post announcing Azure Cloud Switch? ACS is a custom Linux distro that Microsoft uses to automate the configuration of its switch hardware in the Azure data centers.
|
||||
|
||||
ACS is not publicly available. It's intended for internal use in the Azure data center, and it's unlikely that anyone else would be able to find a use for it. In fact, Subramaniam states the same thing herself in her post.
|
||||
|
||||
So, Microsoft won't be making any money from selling ACS, and it won't attract a user base by giving it away. Instead, Microsoft gets to draw attention to Linux and Azure, strengthening its position as a Linux cloud computing platform.
|
||||
|
||||
Is Microsoft's new-found love for Linux good news for the community?
|
||||
|
||||
We shouldn't be slow to forget Microsoft's mantra of Embrace, Extend and Exterminate. Right now, Microsoft is very much in the early stages of embracing Linux. Will Microsoft seek to splinter the community through custom extensions and proprietary "standards"?
|
||||
|
||||
Let us know what you think in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/microsoft-and-linux-true-romance-or-toxic-love-0
|
||||
|
||||
作者:[James Darvell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/james-darvell
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by ZTinoZ
|
||||
Installation Guide for Puppet on Ubuntu 15.04
|
||||
================================================================================
|
||||
Hi everyone, today in this article we'll learn how to install puppet to manage your server infrastructure running ubuntu 15.04. Puppet is an open source software configuration management tool which is developed and maintained by Puppet Labs that allows us to automate the provisioning, configuration and management of a server infrastructure. Whether we're managing just a few servers or thousands of physical and virtual machines to orchestration and reporting, puppet automates tasks that system administrators often do manually which frees up time and mental space so sysadmins can work on improving other aspects of your overall setup. It ensures consistency, reliability and stability of the automated jobs processed. It facilitates closer collaboration between sysadmins and developers, enabling more efficient delivery of cleaner, better-designed code. Puppet is available in two solutions configuration management and data center automation. They are **puppet open source and puppet enterprise**. Puppet open source is a flexible, customizable solution available under the Apache 2.0 license, designed to help system administrators automate the many repetitive tasks they regularly perform. Whereas puppet enterprise edition is a proven commercial solution for diverse enterprise IT environments which lets us get all the benefits of open source puppet, plus puppet apps, commercial-only enhancements, supported modules and integrations, and the assurance of a fully supported platform. Puppet uses SSL certificates to authenticate communication between master and agent nodes.
|
||||
|
||||
@ -1,167 +0,0 @@
|
||||
Translating by Ping
|
||||
|
||||
How to switch from NetworkManager to systemd-networkd on Linux
|
||||
================================================================================
|
||||
In the world of Linux, adoption of [systemd][1] has been a subject of heated controversy, and the debate between its proponents and critics is still going on. As of today, most major Linux distributions have adopted systemd as a default init system.
|
||||
|
||||
Billed as a "never finished, never complete, but tracking progress of technology" by its author, systemd is not just the init daemon, but is designed as a more broad system and service management platform which encompasses the growing ecosystem of core system daemons, libraries and utilities.
|
||||
|
||||
One of many additions to **systemd** is **systemd-networkd**, which is responsible for network configuration within the systemd ecosystem. Using systemd-networkd, you can configure basic DHCP/static IP networking for network devices. It can also configure virtual networking features such as bridges, tunnels or VLANs. Wireless networking is not directly handled by systemd-networkd, but you can use wpa_supplicant service to configure wireless adapters, and then hook it up with **systemd-networkd**.
|
||||
|
||||
On many Linux distributions, NetworkManager has been and is still used as a default network configuration manager. Compared to NetworkManager, **systemd-networkd** is still under active development, and missing features. For example, it does not have NetworkManager's intelligence to keep your computer connected across various interfaces at all times. It does not provide ifup/ifdown hooks for advanced scripting. Yet, systemd-networkd is integrated well with the rest of systemd components (e.g., **resolved** for DNS, **timesyncd** for NTP, udevd for naming), and the role of **systemd-networkd** may only grow over time in the systemd environment.
|
||||
|
||||
If you are happy with the way **systemd** is evolving, one thing you can consider is to switch from NetworkManager to systemd-networkd. If you are feverishly against systemd, and perfectly happy with NetworkManager or [basic network service][2], that is totally cool.
|
||||
|
||||
But for those of you who want to try out systemd-networkd, you can read on, and find out in this tutorial how to switch from NetworkManager to systemd-networkd on Linux.
|
||||
|
||||
### Requirement ###
|
||||
|
||||
systemd-networkd is available in systemd version 210 and higher. Thus distributions like Debian 8 "Jessie" (systemd 215), Fedora 21 (systemd 217), Ubuntu 15.04 (systemd 219) or later are compatible with systemd-networkd.
|
||||
|
||||
For other distributions, check the version of your systemd before proceeding.
|
||||
|
||||
$ systemctl --version
|
||||
|
||||
### Switch from Network Manager to Systemd-Networkd ###
|
||||
|
||||
It is relatively straightforward to switch from Network Manager to systemd-networkd (and vice versa).
|
||||
|
||||
First, disable Network Manager service, and enable systemd-networkd as follows.
|
||||
|
||||
$ sudo systemctl disable NetworkManager
|
||||
$ sudo systemctl enable systemd-networkd
|
||||
|
||||
You also need to enable **systemd-resolved** service, which is used by systemd-networkd for network name resolution. This service implements a caching DNS server.
|
||||
|
||||
$ sudo systemctl enable systemd-resolved
|
||||
$ sudo systemctl start systemd-resolved
|
||||
|
||||
Once started, **systemd-resolved** will create its own resolv.conf somewhere under /run/systemd directory. However, it is a common practise to store DNS resolver information in /etc/resolv.conf, and many applications still rely on /etc/resolv.conf. Thus for compatibility reason, create a symlink to /etc/resolv.conf as follows.
|
||||
|
||||
$ sudo rm /etc/resolv.conf
|
||||
$ sudo ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf
|
||||
|
||||
### Configure Network Connections with Systemd-networkd ###
|
||||
|
||||
To configure network devices with systemd-networkd, you must specify configuration information in text files with .network extension. These network configuration files are then stored and loaded from /etc/systemd/network. When there are multiple files, systemd-networkd loads and processes them one by one in lexical order.
|
||||
|
||||
Let's start by creating a folder /etc/systemd/network.
|
||||
|
||||
$ sudo mkdir /etc/systemd/network
|
||||
|
||||
#### DHCP Networking ####
|
||||
|
||||
Let's configure DHCP networking first. For this, create the following configuration file. The name of a file can be arbitrary, but remember that files are processed in lexical order.
|
||||
|
||||
$ sudo vi /etc/systemd/network/20-dhcp.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3*
|
||||
|
||||
[Network]
|
||||
DHCP=yes
|
||||
|
||||
As you can see above, each network configuration file contains one or more "sections" with each section preceded by [XXX] heading. Each section contains one or more key/value pairs. The [Match] section determine which network device(s) are configured by this configuration file. For example, this file matches any network interface whose name starts with ens3 (e.g., enp3s0, enp3s1, enp3s2, etc). For matched interface(s), it then applies DHCP network configuration specified under [Network] section.
|
||||
|
||||
### Static IP Networking ###
|
||||
|
||||
If you want to assign a static IP address to a network interface, create the following configuration file.
|
||||
|
||||
$ sudo vi /etc/systemd/network/10-static-enp3s0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=enp3s0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.50/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
As you can guess, the interface enp3s0 will be assigned an address 192.168.10.50/24, a default gateway 192.168.10.1, and a DNS server 8.8.8.8. One subtlety here is that the name of an interface enp3s0, in facts, matches the pattern rule defined in the earlier DHCP configuration as well. However, since the file "10-static-enp3s0.network" is processed before "20-dhcp.network" according to lexical order, the static configuration takes priority over DHCP configuration in case of enp3s0 interface.
|
||||
|
||||
Once you are done with creating configuration files, restart systemd-networkd service or reboot.
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
Check the status of the service by running:
|
||||
|
||||
$ systemctl status systemd-networkd
|
||||
$ systemctl status systemd-resolved
|
||||
|
||||

|
||||
|
||||
### Configure Virtual Network Devices with Systemd-networkd ###
|
||||
|
||||
**systemd-networkd** also allows you to configure virtual network devices such as bridges, VLANs, tunnel, VXLAN, bonding, etc. You must configure these virtual devices in files with .netdev extension.
|
||||
|
||||
Here I'll show how to configure a bridge interface.
|
||||
|
||||
#### Linux Bridge ####
|
||||
|
||||
If you want to create a Linux bridge (br0) and add a physical interface (eth1) to the bridge, create the following configuration.
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.netdev
|
||||
|
||||
----------
|
||||
|
||||
[NetDev]
|
||||
Name=br0
|
||||
Kind=bridge
|
||||
|
||||
Then configure the bridge interface br0 and the slave interface eth1 using .network files as follows.
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0-slave.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=eth1
|
||||
|
||||
[Network]
|
||||
Bridge=br0
|
||||
|
||||
----------
|
||||
|
||||
$ sudo vi /etc/systemd/network/bridge-br0.network
|
||||
|
||||
----------
|
||||
|
||||
[Match]
|
||||
Name=br0
|
||||
|
||||
[Network]
|
||||
Address=192.168.10.100/24
|
||||
Gateway=192.168.10.1
|
||||
DNS=8.8.8.8
|
||||
|
||||
Finally, restart systemd-networkd:
|
||||
|
||||
$ sudo systemctl restart systemd-networkd
|
||||
|
||||
You can use [brctl tool][3] to verify that a bridge br0 has been created.
|
||||
|
||||
### Summary ###
|
||||
|
||||
When systemd promises to be a system manager for Linux, it is no wonder something like systemd-networkd came into being to manage network configurations. At this stage, however, systemd-networkd seems more suitable for a server environment where network configurations are relatively stable. For desktop/laptop environments which involve various transient wired/wireless interfaces, NetworkManager may still be a preferred choice.
|
||||
|
||||
For those who want to check out more on systemd-networkd, refer to the official [man page][4] for a complete list of supported sections and keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
|
||||
[2]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
|
||||
@ -1,801 +0,0 @@
|
||||
wyangsun translating
|
||||
Linux workstation security checklist
|
||||
================================================================================
|
||||
This is a set of recommendations used by the Linux Foundation for their systems
|
||||
administrators. All of LF employees are remote workers and we use this set of
|
||||
guidelines to ensure that a sysadmin's system passes core security requirements
|
||||
in order to reduce the risk of it becoming an attack vector against the rest
|
||||
of our infrastructure.
|
||||
|
||||
Even if your systems administrators are not remote workers, chances are that
|
||||
they perform a lot of their work either from a portable laptop in a work
|
||||
environment, or set up their home systems to access the work infrastructure
|
||||
for after-hours/emergency support. In either case, you can adapt this set of
|
||||
recommendations to suit your environment.
|
||||
|
||||
This, by no means, is an exhaustive "workstation hardening" document, but
|
||||
rather an attempt at a set of baseline recommendations to avoid most glaring
|
||||
security errors without introducing too much inconvenience. You may read this
|
||||
document and think it is way too paranoid, while someone else may think this
|
||||
barely scratches the surface. Security is just like driving on the highway --
|
||||
anyone going slower than you is an idiot, while anyone driving faster than you
|
||||
is a crazy person. These guidelines are merely a basic set of core safety
|
||||
rules that is neither exhaustive, nor a replacement for experience, vigilance,
|
||||
and common sense.
|
||||
|
||||
Each section is split into two areas:
|
||||
|
||||
- The checklist that can be adapted to your project's needs
|
||||
- Free-form list of considerations that explain what dictated these decisions
|
||||
|
||||
## Severity levels
|
||||
|
||||
The items in each checklist include the severity level, which we hope will help
|
||||
guide your decision:
|
||||
|
||||
- _(CRITICAL)_ items should definitely be high on the consideration list.
|
||||
If not implemented, they will introduce high risks to your workstation
|
||||
security.
|
||||
- _(MODERATE)_ items will improve your security posture, but are less
|
||||
important, especially if they interfere too much with your workflow.
|
||||
- _(LOW)_ items may improve the overall security, but may not be worth the
|
||||
convenience trade-offs.
|
||||
- _(PARANOID)_ is reserved for items we feel will dramatically improve your
|
||||
workstation security, but will probably require a lot of adjustment to the
|
||||
way you interact with your operating system.
|
||||
|
||||
Remember, these are only guidelines. If you feel these severity levels do not
|
||||
reflect your project's commitment to security, you should adjust them as you
|
||||
see fit.
|
||||
|
||||
## Choosing the right hardware
|
||||
|
||||
We do not mandate that our admins use a specific vendor or a specific model, so
|
||||
this section addresses core considerations when choosing a work system.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] System supports SecureBoot _(CRITICAL)_
|
||||
- [ ] System has no firewire, thunderbolt or ExpressCard ports _(MODERATE)_
|
||||
- [ ] System has a TPM chip _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SecureBoot
|
||||
|
||||
Despite its controversial nature, SecureBoot offers prevention against many
|
||||
attacks targeting workstations (Rootkits, "Evil Maid," etc), without
|
||||
introducing too much extra hassle. It will not stop a truly dedicated attacker,
|
||||
plus there is a pretty high degree of certainty that state security agencies
|
||||
have ways to defeat it (probably by design), but having SecureBoot is better
|
||||
than having nothing at all.
|
||||
|
||||
Alternatively, you may set up [Anti Evil Maid][1] which offers a more
|
||||
wholesome protection against the type of attacks that SecureBoot is supposed
|
||||
to prevent, but it will require more effort to set up and maintain.
|
||||
|
||||
#### Firewire, thunderbolt, and ExpressCard ports
|
||||
|
||||
Firewire is a standard that, by design, allows any connecting device full
|
||||
direct memory access to your system ([see Wikipedia][2]). Thunderbolt and
|
||||
ExpressCard are guilty of the same, though some later implementations of
|
||||
Thunderbolt attempt to limit the scope of memory access. It is best if the
|
||||
system you are getting has none of these ports, but it is not critical, as
|
||||
they usually can be turned off via UEFI or disabled in the kernel itself.
|
||||
|
||||
#### TPM Chip
|
||||
|
||||
Trusted Platform Module (TPM) is a crypto chip bundled with the motherboard
|
||||
separately from the core processor, which can be used for additional platform
|
||||
security (such as to store full-disk encryption keys), but is not normally used
|
||||
for day-to-day workstation operation. At best, this is a nice-to-have, unless
|
||||
you have a specific need to use TPM for your workstation security.
|
||||
|
||||
## Pre-boot environment
|
||||
|
||||
This is a set of recommendations for your workstation before you even start
|
||||
with OS installation.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] UEFI boot mode is used (not legacy BIOS) _(CRITICAL)_
|
||||
- [ ] Password is required to enter UEFI configuration _(CRITICAL)_
|
||||
- [ ] SecureBoot is enabled _(CRITICAL)_
|
||||
- [ ] UEFI-level password is required to boot the system _(LOW)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### UEFI and SecureBoot
|
||||
|
||||
UEFI, with all its warts, offers a lot of goodies that legacy BIOS doesn't,
|
||||
such as SecureBoot. Most modern systems come with UEFI mode on by default.
|
||||
|
||||
Make sure a strong password is required to enter UEFI configuration mode. Pay
|
||||
attention, as many manufacturers quietly limit the length of the password you
|
||||
are allowed to use, so you may need to choose high-entropy short passwords vs.
|
||||
long passphrases (see below for more on passphrases).
|
||||
|
||||
Depending on the Linux distribution you decide to use, you may or may not have
|
||||
to jump through additional hoops in order to import your distribution's
|
||||
SecureBoot key that would allow you to boot the distro. Many distributions have
|
||||
partnered with Microsoft to sign their released kernels with a key that is
|
||||
already recognized by most system manufacturers, therefore saving you the
|
||||
trouble of having to deal with key importing.
|
||||
|
||||
As an extra measure, before someone is allowed to even get to the boot
|
||||
partition and try some badness there, let's make them enter a password. This
|
||||
password should be different from your UEFI management password, in order to
|
||||
prevent shoulder-surfing. If you shut down and start a lot, you may choose to
|
||||
not bother with this, as you will already have to enter a LUKS passphrase and
|
||||
this will save you a few extra keystrokes.
|
||||
|
||||
## Distro choice considerations
|
||||
|
||||
Chances are you'll stick with a fairly widely-used distribution such as Fedora,
|
||||
Ubuntu, Arch, Debian, or one of their close spin-offs. In any case, this is
|
||||
what you should consider when picking a distribution to use.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Has a robust MAC/RBAC implementation (SELinux/AppArmor/Grsecurity) _(CRITICAL)_
|
||||
- [ ] Publishes security bulletins _(CRITICAL)_
|
||||
- [ ] Provides timely security patches _(CRITICAL)_
|
||||
- [ ] Provides cryptographic verification of packages _(CRITICAL)_
|
||||
- [ ] Fully supports UEFI and SecureBoot _(CRITICAL)_
|
||||
- [ ] Has robust native full disk encryption support _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### SELinux, AppArmor, and GrSecurity/PaX
|
||||
|
||||
Mandatory Access Controls (MAC) or Role-Based Access Controls (RBAC) are an
|
||||
extension of the basic user/group security mechanism used in legacy POSIX
|
||||
systems. Most distributions these days either already come bundled with a
|
||||
MAC/RBAC implementation (Fedora, Ubuntu), or provide a mechanism to add it via
|
||||
an optional post-installation step (Gentoo, Arch, Debian). Obviously, it is
|
||||
highly advised that you pick a distribution that comes pre-configured with a
|
||||
MAC/RBAC system, but if you have strong feelings about a distribution that
|
||||
doesn't have one enabled by default, do plan to configure it
|
||||
post-installation.
|
||||
|
||||
Distributions that do not provide any MAC/RBAC mechanisms should be strongly
|
||||
avoided, as traditional POSIX user- and group-based security should be
|
||||
considered insufficient in this day and age. If you would like to start out
|
||||
with a MAC/RBAC workstation, AppArmor and PaX are generally considered easier
|
||||
to learn than SELinux. Furthermore, on a workstation, where there are few or
|
||||
no externally listening daemons, and where user-run applications pose the
|
||||
highest risk, GrSecurity/PaX will _probably_ offer more security benefits than
|
||||
SELinux.
|
||||
|
||||
#### Distro security bulletins
|
||||
|
||||
Most of the widely used distributions have a mechanism to deliver security
|
||||
bulletins to their users, but if you are fond of something esoteric, check
|
||||
whether the developers have a documented mechanism of alerting the users about
|
||||
security vulnerabilities and patches. Absence of such mechanism is a major
|
||||
warning sign that the distribution is not mature enough to be considered for a
|
||||
primary admin workstation.
|
||||
|
||||
#### Timely and trusted security updates
|
||||
|
||||
Most of the widely used distributions deliver regular security updates, but is
|
||||
worth checking to ensure that critical package updates are provided in a
|
||||
timely fashion. Avoid using spin-offs and "community rebuilds" for this
|
||||
reason, as they routinely delay security updates due to having to wait for the
|
||||
upstream distribution to release it first.
|
||||
|
||||
You'll be hard-pressed to find a distribution that does not use cryptographic
|
||||
signatures on packages, updates metadata, or both. That being said, fairly
|
||||
widely used distributions have been known to go for years before introducing
|
||||
this basic security measure (Arch, I'm looking at you), so this is a thing
|
||||
worth checking.
|
||||
|
||||
#### Distros supporting UEFI and SecureBoot
|
||||
|
||||
Check that the distribution supports UEFI and SecureBoot. Find out whether it
|
||||
requires importing an extra key or whether it signs its boot kernels with a key
|
||||
already trusted by systems manufacturers (e.g. via an agreement with
|
||||
Microsoft). Some distributions do not support UEFI/SecureBoot but offer
|
||||
alternatives to ensure tamper-proof or tamper-evident boot environments
|
||||
([Qubes-OS][3] uses Anti Evil Maid, mentioned earlier). If a distribution
|
||||
doesn't support SecureBoot and has no mechanisms to prevent boot-level attacks,
|
||||
look elsewhere.
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Full disk encryption is a requirement for securing data at rest, and is
|
||||
supported by most distributions. As an alternative, systems with
|
||||
self-encrypting hard drives may be used (normally implemented via the on-board
|
||||
TPM chip) and offer comparable levels of security plus faster operation, but at
|
||||
a considerably higher cost.
|
||||
|
||||
## Distro installation guidelines
|
||||
|
||||
All distributions are different, but here are general guidelines:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Use full disk encryption (LUKS) with a robust passphrase _(CRITICAL)_
|
||||
- [ ] Make sure swap is also encrypted _(CRITICAL)_
|
||||
- [ ] Require a password to edit bootloader (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Set up a robust root password (can be same as LUKS) _(CRITICAL)_
|
||||
- [ ] Use an unprivileged account, part of administrators group _(CRITICAL)_
|
||||
- [ ] Set up a robust user-account password, different from root _(CRITICAL)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full disk encryption
|
||||
|
||||
Unless you are using self-encrypting hard drives, it is important to configure
|
||||
your installer to fully encrypt all the disks that will be used for storing
|
||||
your data and your system files. It is not sufficient to simply encrypt the
|
||||
user directory via auto-mounting cryptfs loop files (I'm looking at you, older
|
||||
versions of Ubuntu), as this offers no protection for system binaries or swap,
|
||||
which is likely to contain a slew of sensitive data. The recommended
|
||||
encryption strategy is to encrypt the LVM device, so only one passphrase is
|
||||
required during the boot process.
|
||||
|
||||
The `/boot` partition will always remain unencrypted, as the bootloader needs
|
||||
to be able to actually boot the kernel before invoking LUKS/dm-crypt. The
|
||||
kernel image itself should be protected against tampering with a cryptographic
|
||||
signature checked by SecureBoot.
|
||||
|
||||
In other words, `/boot` should always be the only unencrypted partition on your
|
||||
system.
|
||||
|
||||
#### Choosing good passphrases
|
||||
|
||||
Modern Linux systems have no limitation of password/passphrase length, so the
|
||||
only real limitation is your level of paranoia and your stubbornness. If you
|
||||
boot your system a lot, you will probably have to type at least two different
|
||||
passwords: one to unlock LUKS, and another one to log in, so having long
|
||||
passphrases will probably get old really fast. Pick passphrases that are 2-3
|
||||
words long, easy to type, and preferably from rich/mixed vocabularies.
|
||||
|
||||
Examples of good passphrases (yes, you can use spaces):
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
You can also stick with non-vocabulary passwords that are at least 10-12
|
||||
characters long, if you prefer that to typing passphrases.
|
||||
|
||||
Unless you have concerns about physical security, it is fine to write down your
|
||||
passphrases and keep them in a safe place away from your work desk.
|
||||
|
||||
#### Root, user passwords and the admin group
|
||||
|
||||
We recommend that you use the same passphrase for your root password as you
|
||||
use for your LUKS encryption (unless you share your laptop with other trusted
|
||||
people who should be able to unlock the drives, but shouldn't be able to
|
||||
become root). If you are the sole user of the laptop, then having your root
|
||||
password be different from your LUKS password has no meaningful security
|
||||
advantages. Generally, you can use the same passphrase for your UEFI
|
||||
administration, disk encryption, and root account -- knowing any of these will
|
||||
give an attacker full control of your system anyway, so there is little
|
||||
security benefit to have them be different on a single-user workstation.
|
||||
|
||||
You should have a different, but equally strong password for your regular user
|
||||
account that you will be using for day-to-day tasks. This user should be member
|
||||
of the admin group (e.g. `wheel` or similar, depending on the distribution),
|
||||
allowing you to perform `sudo` to elevate privileges.
|
||||
|
||||
In other words, if you are the sole user on your workstation, you should have 2
|
||||
distinct, robust, equally strong passphrases you will need to remember:
|
||||
|
||||
**Admin-level**, used in the following locations:
|
||||
|
||||
- UEFI administration
|
||||
- Bootloader (GRUB)
|
||||
- Disk encryption (LUKS)
|
||||
- Workstation admin (root user)
|
||||
|
||||
**User-level**, used for the following:
|
||||
|
||||
- User account and sudo
|
||||
- Master password for the password manager
|
||||
|
||||
All of them, obviously, can be different if there is a compelling reason.
|
||||
|
||||
## Post-installation hardening
|
||||
|
||||
Post-installation security hardening will depend greatly on your distribution
|
||||
of choice, so it is futile to provide detailed instructions in a general
|
||||
document such as this one. However, here are some steps you should take:
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Globally disable firewire and thunderbolt modules _(CRITICAL)_
|
||||
- [ ] Check your firewalls to ensure all incoming ports are filtered _(CRITICAL)_
|
||||
- [ ] Make sure root mail is forwarded to an account you check _(CRITICAL)_
|
||||
- [ ] Check to ensure sshd service is disabled by default _(MODERATE)_
|
||||
- [ ] Set up an automatic OS update schedule, or update reminders _(MODERATE)_
|
||||
- [ ] Configure the screensaver to auto-lock after a period of inactivity _(MODERATE)_
|
||||
- [ ] Set up logwatch _(MODERATE)_
|
||||
- [ ] Install and use rkhunter _(LOW)_
|
||||
- [ ] Install an Intrusion Detection System _(PARANOID)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Blacklisting modules
|
||||
|
||||
To blacklist a firewire and thunderbolt modules, add the following lines to a
|
||||
file in `/etc/modprobe.d/blacklist-dma.conf`:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
The modules will be blacklisted upon reboot. It doesn't hurt doing this even if
|
||||
you don't have these ports (but it doesn't do anything either).
|
||||
|
||||
#### Root mail
|
||||
|
||||
By default, root mail is just saved on the system and tends to never be read.
|
||||
Make sure you set your `/etc/aliases` to forward root mail to a mailbox that
|
||||
you actually read, otherwise you may miss important system notifications and
|
||||
reports:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
Run `newaliases` after this edit and test it out to make sure that it actually
|
||||
gets delivered, as some email providers will reject email coming in from
|
||||
nonexistent or non-routable domain names. If that is the case, you will need to
|
||||
play with your mail forwarding configuration until this actually works.
|
||||
|
||||
#### Firewalls, sshd, and listening daemons
|
||||
|
||||
The default firewall settings will depend on your distribution, but many of
|
||||
them will allow incoming `sshd` ports. Unless you have a compelling legitimate
|
||||
reason to allow incoming ssh, you should filter that out and disable the `sshd`
|
||||
daemon.
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
You can always start it temporarily if you need to use it.
|
||||
|
||||
In general, your system shouldn't have any listening ports apart from
|
||||
responding to ping. This will help safeguard you against network-level 0-day
|
||||
exploits.
|
||||
|
||||
#### Automatic updates or notifications
|
||||
|
||||
It is recommended to turn on automatic updates, unless you have a very good
|
||||
reason not to do so, such as fear that an automatic update would render your
|
||||
system unusable (it's happened in the past, so this fear is not unfounded). At
|
||||
the very least, you should enable automatic notifications of available updates.
|
||||
Most distributions already have this service automatically running for you, so
|
||||
chances are you don't have to do anything. Consult your distribution
|
||||
documentation to find out more.
|
||||
|
||||
You should apply all outstanding errata as soon as possible, even if something
|
||||
isn't specifically labeled as "security update" or has an associated CVE code.
|
||||
All bugs have the potential of being security bugs and erring on the side of
|
||||
newer, unknown bugs is _generally_ a safer strategy than sticking with old,
|
||||
known ones.
|
||||
|
||||
#### Watching logs
|
||||
|
||||
You should have a keen interest in what happens on your system. For this
|
||||
reason, you should install `logwatch` and configure it to send nightly activity
|
||||
reports of everything that happens on your system. This won't prevent a
|
||||
dedicated attacker, but is a good safety-net feature to have in place.
|
||||
|
||||
Note, that many systemd distros will no longer automatically install a syslog
|
||||
server that `logwatch` needs (due to systemd relying on its own journal), so
|
||||
you will need to install and enable `rsyslog` to make sure your `/var/log` is
|
||||
not empty before logwatch will be of any use.
|
||||
|
||||
#### Rkhunter and IDS
|
||||
|
||||
Installing `rkhunter` and an intrusion detection system (IDS) like `aide` or
|
||||
`tripwire` will not be that useful unless you actually understand how they work
|
||||
and take the necessary steps to set them up properly (such as, keeping the
|
||||
databases on external media, running checks from a trusted environment,
|
||||
remembering to refresh the hash databases after performing system updates and
|
||||
configuration changes, etc). If you are not willing to take these steps and
|
||||
adjust how you do things on your own workstation, these tools will introduce
|
||||
hassle without any tangible security benefit.
|
||||
|
||||
We do recommend that you install `rkhunter` and run it nightly. It's fairly
|
||||
easy to learn and use, and though it will not deter a sophisticated attacker,
|
||||
it may help you catch your own mistakes.
|
||||
|
||||
## Personal workstation backups
|
||||
|
||||
Workstation backups tend to be overlooked or done in a haphazard, often unsafe
|
||||
manner.
|
||||
|
||||
### Checklist
|
||||
|
||||
- [ ] Set up encrypted workstation backups to external storage _(CRITICAL)_
|
||||
- [ ] Use zero-knowledge backup tools for cloud backups _(MODERATE)_
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Full encrypted backups to external storage
|
||||
|
||||
It is handy to have an external hard drive where one can dump full backups
|
||||
without having to worry about such things like bandwidth and upstream speeds
|
||||
(in this day and age most providers still offer dramatically asymmetric
|
||||
upload/download speeds). Needless to say, this hard drive needs to be in itself
|
||||
encrypted (again, via LUKS), or you should use a backup tool that creates
|
||||
encrypted backups, such as `duplicity` or its GUI companion, `deja-dup`. I
|
||||
recommend using the latter with a good randomly generated passphrase, stored in
|
||||
your password manager. If you travel with your laptop, leave this drive at home
|
||||
to have something to come back to in case your laptop is lost or stolen.
|
||||
|
||||
In addition to your home directory, you should also back up `/etc` and
|
||||
`/var/log` for various forensic purposes.
|
||||
|
||||
Above all, avoid copying your home directory onto any unencrypted storage, even
|
||||
as a quick way to move your files around between systems, as you will most
|
||||
certainly forget to erase it once you're done, exposing potentially private or
|
||||
otherwise security sensitive data to snooping hands -- especially if you keep
|
||||
that storage media in the same bag with your laptop.
|
||||
|
||||
#### Selective zero-knowledge backups off-site
|
||||
|
||||
Off-site backups are also extremely important and can be done either to your
|
||||
employer, if they offer space for it, or to a cloud provider. You can set up a
|
||||
separate duplicity/deja-dup profile to only include most important files in
|
||||
order to avoid transferring huge amounts of data that you don't really care to
|
||||
back up off-site (internet cache, music, downloads, etc).
|
||||
|
||||
Alternatively, you can use a zero-knowledge backup tool, such as
|
||||
[SpiderOak][5], which offers an excellent Linux GUI tool and has additional
|
||||
useful features such as synchronizing content between multiple systems and
|
||||
platforms.
|
||||
|
||||
## Best practices
|
||||
|
||||
What follows is a curated list of best practices that we think you should
|
||||
adopt. It is most certainly non-exhaustive, but rather attempts to offer
|
||||
practical advice that strikes a workable balance between security and overall
|
||||
usability.
|
||||
|
||||
### Browsing
|
||||
|
||||
There is no question that the web browser will be the piece of software with
|
||||
the largest and the most exposed attack surface on your system. It is a tool
|
||||
written specifically to download and execute untrusted, frequently hostile
|
||||
code. It attempts to shield you from this danger by employing multiple
|
||||
mechanisms such as sandboxes and code sanitization, but they have all been
|
||||
previously defeated on multiple occasions. You should learn to approach
|
||||
browsing websites as the most insecure activity you'll engage in on any given
|
||||
day.
|
||||
|
||||
There are several ways you can reduce the impact of a compromised browser, but
|
||||
the truly effective ways will require significant changes in the way you
|
||||
operate your workstation.
|
||||
|
||||
#### 1: Use two different browsers
|
||||
|
||||
This is the easiest to do, but only offers minor security benefits. Not all
|
||||
browser compromises give an attacker full unfettered access to your system --
|
||||
sometimes they are limited to allowing one to read local browser storage,
|
||||
steal active sessions from other tabs, capture input entered into the browser,
|
||||
etc. Using two different browsers, one for work/high security sites, and
|
||||
another for everything else will help prevent minor compromises from giving
|
||||
attackers access to the whole cookie jar. The main inconvenience will be the
|
||||
amount of memory consumed by two different browser processes.
|
||||
|
||||
Here's what we recommend:
|
||||
|
||||
##### Firefox for work and high security sites
|
||||
|
||||
Use Firefox to access work-related sites, where extra care should be taken to
|
||||
ensure that data like cookies, sessions, login information, keystrokes, etc,
|
||||
should most definitely not fall into attackers' hands. You should NOT use
|
||||
this browser for accessing any other sites except select few.
|
||||
|
||||
You should install the following Firefox add-ons:
|
||||
|
||||
- [ ] NoScript _(CRITICAL)_
|
||||
- NoScript prevents active content from loading, except from user
|
||||
whitelisted domains. It is a great hassle to use with your default browser
|
||||
(though offers really good security benefits), so we recommend only
|
||||
enabling it on the browser you use to access work-related sites.
|
||||
|
||||
- [ ] Privacy Badger _(CRITICAL)_
|
||||
- EFF's Privacy Badger will prevent most external trackers and ad platforms
|
||||
from being loaded, which will help avoid compromises on these tracking
|
||||
sites from affecting your browser (trackers and ad sites are very commonly
|
||||
targeted by attackers, as they allow rapid infection of thousands of
|
||||
systems worldwide).
|
||||
|
||||
- [ ] HTTPS Everywhere _(CRITICAL)_
|
||||
- This EFF-developed Add-on will ensure that most of your sites are accessed
|
||||
over a secure connection, even if a link you click is using http:// (great
|
||||
to avoid a number of attacks, such as [SSL-strip][7]).
|
||||
|
||||
- [ ] Certificate Patrol _(MODERATE)_
|
||||
- This tool will alert you if the site you're accessing has recently changed
|
||||
their TLS certificates -- especially if it wasn't nearing expiration dates
|
||||
or if it is now using a different certification authority. It helps
|
||||
alert you if someone is trying to man-in-the-middle your connection,
|
||||
but generates a lot of benign false-positives.
|
||||
|
||||
You should leave Firefox as your default browser for opening links, as
|
||||
NoScript will prevent most active content from loading or executing.
|
||||
|
||||
##### Chrome/Chromium for everything else
|
||||
|
||||
Chromium developers are ahead of Firefox in adding a lot of nice security
|
||||
features (at least [on Linux][6]), such as seccomp sandboxes, kernel user
|
||||
namespaces, etc, which act as an added layer of isolation between the sites
|
||||
you visit and the rest of your system. Chromium is the upstream open-source
|
||||
project, and Chrome is Google's proprietary binary build based on it (insert
|
||||
the usual paranoid caution about not using it for anything you don't want
|
||||
Google to know about).
|
||||
|
||||
It is recommended that you install **Privacy Badger** and **HTTPS Everywhere**
|
||||
extensions in Chrome as well and give it a distinct theme from Firefox to
|
||||
indicate that this is your "untrusted sites" browser.
|
||||
|
||||
#### 2: Use two different browsers, one inside a dedicated VM
|
||||
|
||||
This is a similar recommendation to the above, except you will add an extra
|
||||
step of running Chrome inside a dedicated VM that you access via a fast
|
||||
protocol, allowing you to share clipboards and forward sound events (e.g.
|
||||
Spice or RDP). This will add an excellent layer of isolation between the
|
||||
untrusted browser and the rest of your work environment, ensuring that
|
||||
attackers who manage to fully compromise your browser will then have to
|
||||
additionally break out of the VM isolation layer in order to get to the rest
|
||||
of your system.
|
||||
|
||||
This is a surprisingly workable configuration, but requires a lot of RAM and
|
||||
fast processors that can handle the increased load. It will also require an
|
||||
important amount of dedication on the part of the admin who will need to
|
||||
adjust their work practices accordingly.
|
||||
|
||||
#### 3: Fully separate your work and play environments via virtualization
|
||||
|
||||
See [Qubes-OS project][3], which strives to provide a high-security
|
||||
workstation environment via compartmentalizing your applications into separate
|
||||
fully isolated VMs.
|
||||
|
||||
### Password managers
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Use a password manager _(CRITICAL_)
|
||||
- [ ] Use unique passwords on unrelated sites _(CRITICAL)_
|
||||
- [ ] Use a password manager that supports team sharing _(MODERATE)_
|
||||
- [ ] Use a separate password manager for non-website accounts _(PARANOID)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
Using good, unique passwords should be a critical requirement for every member
|
||||
of your team. Credential theft is happening all the time -- either via
|
||||
compromised computers, stolen database dumps, remote site exploits, or any
|
||||
number of other means. No credentials should ever be reused across sites,
|
||||
especially for critical applications.
|
||||
|
||||
##### In-browser password manager
|
||||
|
||||
Every browser has a mechanism for saving passwords that is fairly secure and
|
||||
can sync with vendor-maintained cloud storage while keeping the data encrypted
|
||||
with a user-provided passphrase. However, this mechanism has important
|
||||
disadvantages:
|
||||
|
||||
1. It does not work across browsers
|
||||
2. It does not offer any way of sharing credentials with team members
|
||||
|
||||
There are several well-supported, free-or-cheap password managers that are
|
||||
well-integrated into multiple browsers, work across platforms, and offer
|
||||
group sharing (usually as a paid service). Solutions can be easily found via
|
||||
search engines.
|
||||
|
||||
##### Standalone password manager
|
||||
|
||||
One of the major drawbacks of any password manager that comes integrated with
|
||||
the browser is the fact that it's part of the application that is most likely
|
||||
to be attacked by intruders. If this makes you uncomfortable (and it should),
|
||||
you may choose to have two different password managers -- one for websites
|
||||
that is integrated into your browser, and one that runs as a standalone
|
||||
application. The latter can be used to store high-risk credentials such as
|
||||
root passwords, database passwords, other shell account credentials, etc.
|
||||
|
||||
It may be particularly useful to have such tool for sharing superuser account
|
||||
credentials with other members of your team (server root passwords, ILO
|
||||
passwords, database admin passwords, bootloader passwords, etc).
|
||||
|
||||
A few tools can help you:
|
||||
|
||||
- [KeePassX][8], which improves team sharing in version 2
|
||||
- [Pass][9], which uses text files and PGP and integrates with git
|
||||
- [Django-Pstore][10], which uses GPG to share credentials between admins
|
||||
- [Hiera-Eyaml][11], which, if you are already using Puppet for your
|
||||
infrastructure, may be a handy way to track your server/service credentials
|
||||
as part of your encrypted Hiera data store
|
||||
|
||||
### Securing SSH and PGP private keys
|
||||
|
||||
Personal encryption keys, including SSH and PGP private keys, are going to be
|
||||
the most prized items on your workstation -- something the attackers will be
|
||||
most interested in obtaining, as that would allow them to further attack your
|
||||
infrastructure or impersonate you to other admins. You should take extra steps
|
||||
to ensure that your private keys are well protected against theft.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Strong passphrases are used to protect private keys _(CRITICAL)_
|
||||
- [ ] PGP Master key is stored on removable storage _(MODERATE)_
|
||||
- [ ] Auth, Sign and Encrypt Subkeys are stored on a smartcard device _(MODERATE)_
|
||||
- [ ] SSH is configured to use PGP Auth key as ssh private key _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
The best way to prevent private key theft is to use a smartcard to store your
|
||||
encryption private keys and never copy them onto the workstation. There are
|
||||
several manufacturers that offer OpenPGP capable devices:
|
||||
|
||||
- [Kernel Concepts][12], where you can purchase both the OpenPGP compatible
|
||||
smartcards and the USB readers, should you need one.
|
||||
- [Yubikey NEO][13], which offers OpenPGP smartcard functionality in addition
|
||||
to many other cool features (U2F, PIV, HOTP, etc).
|
||||
|
||||
It is also important to make sure that the master PGP key is not stored on the
|
||||
main workstation, and only subkeys are used. The master key will only be
|
||||
needed when signing someone else's keys or creating new subkeys -- operations
|
||||
which do not happen very frequently. You may follow [the Debian's subkeys][14]
|
||||
guide to learn how to move your master key to removable storage and how to
|
||||
create subkeys.
|
||||
|
||||
You should then configure your gnupg agent to act as ssh agent and use the
|
||||
smartcard-based PGP Auth key to act as your ssh private key. We publish a
|
||||
[detailed guide][15] on how to do that using either a smartcard reader or a
|
||||
Yubikey NEO.
|
||||
|
||||
If you are not willing to go that far, at least make sure you have a strong
|
||||
passphrase on both your PGP private key and your SSH private key, which will
|
||||
make it harder for attackers to steal and use them.
|
||||
|
||||
### SELinux on the workstation
|
||||
|
||||
If you are using a distribution that comes bundled with SELinux (such as
|
||||
Fedora), here are some recommendation of how to make the best use of it to
|
||||
maximize your workstation security.
|
||||
|
||||
#### Checklist
|
||||
|
||||
- [ ] Make sure SELinux is enforcing on your workstation _(CRITICAL)_
|
||||
- [ ] Never blindly run `audit2allow -M`, always check _(CRITICAL)_
|
||||
- [ ] Never `setenforce 0` _(MODERATE)_
|
||||
- [ ] Switch your account to SELinux user `staff_u` _(MODERATE)_
|
||||
|
||||
#### Considerations
|
||||
|
||||
SELinux is a Mandatory Access Controls (MAC) extension to core POSIX
|
||||
permissions functionality. It is mature, robust, and has come a long way since
|
||||
its initial roll-out. Regardless, many sysadmins to this day repeat the
|
||||
outdated mantra of "just turn it off."
|
||||
|
||||
That being said, SELinux will have limited security benefits on the
|
||||
workstation, as most applications you will be running as a user are going to
|
||||
be running unconfined. It does provide enough net benefit to warrant leaving
|
||||
it on, as it will likely help prevent an attacker from escalating privileges
|
||||
to gain root-level access via a vulnerable daemon service.
|
||||
|
||||
Our recommendation is to leave it on and enforcing.
|
||||
|
||||
##### Never `setenforce 0`
|
||||
|
||||
It's tempting to use `setenforce 0` to flip SELinux into permissive mode
|
||||
on a temporary basis, but you should avoid doing that. This essentially turns
|
||||
off SELinux for the entire system, while what you really want is to
|
||||
troubleshoot a particular application or daemon.
|
||||
|
||||
Instead of `setenforce 0` you should be using `semanage permissive -a
|
||||
[somedomain_t]` to put only that domain into permissive mode. First, find out
|
||||
which domain is causing troubles by running `ausearch`:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
and then look for `scontext=` (source SELinux context) line, like so:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
This tells you that the domain being denied is `gpg_pinentry_t`, so if you
|
||||
want to troubleshoot the application, you should add it to permissive domains:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
This will allow you to use the application and collect the rest of the AVCs,
|
||||
which you can then use in conjunction with `audit2allow` to write a local
|
||||
policy. Once that is done and you see no new AVC denials, you can remove that
|
||||
domain from permissive by running:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### Use your workstation as SELinux role staff_r
|
||||
|
||||
SELinux comes with a native implementation of roles that prohibit or grant
|
||||
certain privileges based on the role associated with the user account. As an
|
||||
administrator, you should be using the `staff_r` role, which will restrict
|
||||
access to many configuration and other security-sensitive files, unless you
|
||||
first perform `sudo`.
|
||||
|
||||
By default, accounts are created as `unconfined_r` and most applications you
|
||||
execute will run unconfined, without any (or with only very few) SELinux
|
||||
constraints. To switch your account to the `staff_r` role, run the following
|
||||
command:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
You should log out and log back in to enable the new role, at which point if
|
||||
you run `id -Z`, you'll see:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
When performing `sudo`, you should remember to add an extra flag to tell
|
||||
SELinux to transition to the "sysadmin" role. The command you want is:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
At which point `id -Z` will show:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**WARNING**: you should be comfortable using `ausearch` and `audit2allow`
|
||||
before you make this switch, as it's possible some of your applications will
|
||||
no longer work when you're running as role `staff_r`. At the time of writing,
|
||||
the following popular applications are known to not work under `staff_r`
|
||||
without policy tweaks:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
To switch back to `unconfined_r`, run the following command:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
and then log out and back in to get back into the comfort zone.
|
||||
|
||||
## Further reading
|
||||
|
||||
The world of IT security is a rabbit hole with no bottom. If you would like to
|
||||
go deeper, or find out more about security features on your particular
|
||||
distribution, please check out the following links:
|
||||
|
||||
- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX Security](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## License
|
||||
This work is licensed under a
|
||||
[Creative Commons Attribution-ShareAlike 4.0 International License][0].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#linux-workstation-security-checklist
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
@ -1,114 +0,0 @@
|
||||
translating by Ezio
|
||||
|
||||
|
||||
How to Setup DockerUI - a Web Interface for Docker
|
||||
================================================================================
|
||||
Docker is getting more popularity day by day. The idea of running a complete Operating System inside a container rather than running inside a virtual machine is an awesome technology. Docker has made lives of millions of system administrators and developers pretty easy for getting their work done in no time. It is an open source technology that provides an open platform to pack, ship, share and run any application as a lightweight container without caring on which operating system we are running on the host. It has no boundaries of Language support, Frameworks or packaging system and can be run anywhere, anytime from a small home computers to high-end servers. Running docker containers and managing them may come a bit difficult and time consuming, so there is a web based application named DockerUI which is make managing and running container pretty simple. DockerUI is highly beneficial to people who are not much aware of linux command lines and want to run containerized applications. DockerUI is an open source web based application best known for its beautiful design and ease simple interface for running and managing docker containers.
|
||||
|
||||
Here are some easy steps on how we can setup Docker Engine with DockerUI in our linux machine.
|
||||
|
||||
### 1. Installing Docker Engine ###
|
||||
|
||||
First of all, we'll gonna install docker engine in our linux machine. Thanks to its developers, docker is very easy to install in any major linux distribution. To install docker engine, we'll need to run the following command with respect to which distribution we are running.
|
||||
|
||||
#### On Ubuntu/Fedora/CentOS/RHEL/Debian ####
|
||||
|
||||
Docker maintainers have written an awesome script that can be used to install docker engine in Ubuntu 15.04/14.10/14.04, CentOS 6.x/7, Fedora 22, RHEL 7 and Debian 8.x distributions of linux. This script recognizes the distribution of linux installed in our machine, then adds the required repository to the filesystem, updates the local repository index and finally installs docker engine and required dependencies from it. To install docker engine using that script, we'll need to run the following command under root or sudo mode.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||
#### On OpenSuse/SUSE Linux Enterprise ####
|
||||
|
||||
To install docker engine in the machine running OpenSuse 13.1/13.2 or SUSE Linux Enterprise Server 12, we'll simply need to execute the zypper command. We'll gonna install docker using zypper command as the latest docker engine is available on the official repository. To do so, we'll run the following command under root/sudo mode.
|
||||
|
||||
# zypper in docker
|
||||
|
||||
#### On ArchLinux ####
|
||||
|
||||
Docker is available in the official repository of Archlinux as well as in the AUR packages maintained by the community. So, we have two options to install docker in archlinux. To install docker using the official arch repository, we'll need to run the following pacman command.
|
||||
|
||||
# pacman -S docker
|
||||
|
||||
But if we want to install docker from the Archlinux User Repository ie AUR, then we'll need to execute the following command.
|
||||
|
||||
# yaourt -S docker-git
|
||||
|
||||
### 2. Starting Docker Daemon ###
|
||||
|
||||
After docker is installed, we'll now gonna start our docker daemon so that we can run docker containers and manage them. We'll run the following command to make sure that docker daemon is installed and to start the docker daemon.
|
||||
|
||||
#### On SysVinit ####
|
||||
|
||||
# service docker start
|
||||
|
||||
#### On Systemd ####
|
||||
|
||||
# systemctl start docker
|
||||
|
||||
### 3. Installing DockerUI ###
|
||||
|
||||
Installing DockerUI is pretty easy than installing docker engine. We just need to pull the dockerui from the Docker Registry Hub and run it inside a container. To do so, we'll simply need to run the following command.
|
||||
|
||||
# docker run -d -p 9000:9000 --privileged -v /var/run/docker.sock:/var/run/docker.sock dockerui/dockerui
|
||||
|
||||

|
||||
|
||||
Here, in the above command, as the default port of the dockerui web application server 9000, we'll simply map the default port of it with -p flag. With -v flag, we specify the docker socket. The --privileged flag is required for hosts using SELinux.
|
||||
|
||||
After executing the above command, we'll now check if the dockerui container is running or not by running the following command.
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
### 4. Pulling an Image ###
|
||||
|
||||
Currently, we cannot pull an image directly from DockerUI so, we'll need to pull a docker image from the linux console/terminal. To do so, we'll need to run the following command.
|
||||
|
||||
# docker pull ubuntu
|
||||
|
||||

|
||||
|
||||
The above command will pull an image tagged as ubuntu from the official [Docker Hub][1]. Similarly, we can pull more images that we require and are available in the hub.
|
||||
|
||||
### 4. Managing with DockerUI ###
|
||||
|
||||
After we have started the dockerui container, we'll now have fun with it to start, pause, stop, remove and perform many possible activities featured by dockerui with docker containers and images. First of all, we'll need to open the web application using our web browser. To do so, we'll need to point our browser to http://ip-address:9000 or http://mydomain.com:9000 according to the configuration of our system. By default, there is no login authentication needed for the user access but we can configure our web server for adding authentication. To start a container, first we'll need to have images of the required application we want to run a container with.
|
||||
|
||||
#### Create a Container ####
|
||||
|
||||
To create a container, we'll need to go to the section named Images then, we'll need to click on the image id which we want to create a container of. After clicking on the required image id, we'll need to click on Create button then we'll be asked to enter the required properties for our container. And after everything is set and done. We'll need to click on Create button to finally create a container.
|
||||
|
||||

|
||||
|
||||
#### Stop a Container ####
|
||||
|
||||
To stop a container, we'll need to move towards the Containers page and then select the required container we want to stop. Now, we'll want to click on Stop option which we can see under Actions drop-down menu.
|
||||
|
||||

|
||||
|
||||
#### Pause and Resume ####
|
||||
|
||||
To pause a container, we simply select the required container we want to pause by keeping a check mark on the container and then click the Pause option under Actions . This is will pause the running container and then, we can simply resume the container by selecting Unpause option from the Actions drop down menu.
|
||||
|
||||
#### Kill and Remove ####
|
||||
|
||||
Like we had performed the above tasks, its pretty easy to kill and remove a container or an image. We just need to check/select the required container or image and then select the Kill or Remove button from the application according to our need.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
DockerUI is a beautiful utilization of Docker Remote API to develop an awesome web interface for managing docker containers. The developers have designed and developed this application in pure HTML and JS language. It is currently incomplete and is under heavy development so we don't recommend it for the use in production currently. It makes users pretty easy to manage their containers and images with simple clicks without needing to execute lines of commands to do small jobs. If we want to contribute DockerUI, we can simply visit its [Github Repository][2]. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-dockerui-web-interface-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://hub.docker.com/
|
||||
[2]:https://github.com/crosbymichael/dockerui/
|
||||
@ -1,5 +1,3 @@
|
||||
translating by Ezio
|
||||
|
||||
Remember sed and awk? All Linux admins should
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,376 +0,0 @@
|
||||
ictlyh Translating
|
||||
how to h2 in apache
|
||||
================================================================================
|
||||
Copyright (C) 2015 greenbytes GmbH
|
||||
|
||||
Support for HTTP/2 is finally being released with Apache httpd 2.4.17! This pages gives advice on how to build/deploy/configure it. The plan is to update this as people find out new things (read: bugs) or give recommendations on what works best for them.
|
||||
|
||||
Ultimately, this will then flow back into the official Apache documentation and this page will only contain a single link to it. But we are not quite there yet...
|
||||
|
||||
### Sources ###
|
||||
|
||||
You can get the Apache release from [here][1]. HTTP/2 support is included in Apache 2.4.17 and upwards. I will not repeat instructions on how to build the server in general. There is excellent material available in several places, for example [here][2].
|
||||
|
||||
(Any links to experimental packages? Drop me a note on twitter @icing.)
|
||||
|
||||
#### Building with HTTP/2 Support ####
|
||||
|
||||
Should you build from a release, you will need to **configure** first. There are tons of options. The ones specific for HTTP/2 are:
|
||||
|
||||
- **--enable-http2**
|
||||
|
||||
This enables the module 'http2' which does implement the protocol inside the Apache server.
|
||||
|
||||
- **--with-nghttp2=<dir>**
|
||||
|
||||
This specifies a non-standard location for the library libnghttp2 which is necessary for the http2 module. If nghttp2 is in a standard place, the configure process will pick it up automatically.
|
||||
|
||||
- **--enable-nghttp2-staticlib-deps**
|
||||
|
||||
Ultra-rarely needed option that you may use to static link the nghttp2 library to the server. On most platforms, this only has an effect when there is no shared nghttp2 library to be found.
|
||||
|
||||
In case you want to build nghttp2 for yourself, you find documentation at [nghttp2.org][3]. The library is also being shipped in the latest Fedora and other distros will follow.
|
||||
|
||||
#### TLS Support ####
|
||||
|
||||
Most people will want to use HTTP/2 with browsers and browser only support it on TLS connections (**https://** urls). You'll need proper configuration for that which I cover below. But foremost what you will need is an TLS library that supports the ALPN extension.
|
||||
|
||||
ALPN is neccessary to negotiate the protocol to use between server and client. If it is not implemented by the TLS lib on your server, the client will only ever talk HTTP/1.1. So, who does link with Apache and support it?
|
||||
|
||||
- **OpenSSL 1.0.2** and onward.
|
||||
- ???
|
||||
|
||||
If you get your OpenSSL library from your Linux distro, the version number used there might be different from the official OpenSSL releases. Check with your distro in case of doubt.
|
||||
|
||||
### Configuration ###
|
||||
|
||||
One useful addition to your server is to set a good logging level for the http2 module. Add this:
|
||||
|
||||
# this needs to be somewhere
|
||||
LoadModule http2_module modules/mod_http2.so
|
||||
|
||||
<IfModule http2_module>
|
||||
LogLevel http2:info
|
||||
</IfModule>
|
||||
|
||||
When you start your server and look in the error log, you should see one line like:
|
||||
|
||||
[timestamp] [http2:info] [pid XXXXX:tid numbers]
|
||||
mod_http2 (v1.0.0, nghttp2 1.3.4), initializing...
|
||||
|
||||
#### Protocols ####
|
||||
|
||||
So, assume you have the server built and deployed, the TLS library is bleeding edge (sorry), your server starts, you open your browser and...how do you know it is working?
|
||||
|
||||
If you have not added more to your server config, it probably isn't.
|
||||
|
||||
You need to tell the server where to use the protocol. By default, the HTTP/2 protocol is not enabled anywhere in your server. Because that is the safe route and you might have an existing deployment should continue to work.
|
||||
|
||||
You enable the HTTP/2 protocol with the new **Protocols** directive:
|
||||
|
||||
# for a https server
|
||||
Protocols h2 http/1.1
|
||||
...
|
||||
|
||||
# for a http server
|
||||
Protocols h2c http/1.1
|
||||
|
||||
You can add this for the server in general or for specific **vhosts**.
|
||||
|
||||
#### SSL Parameter ####
|
||||
|
||||
HTTP/2 has some special requirements regarding TLS (SSL). See the chapter about [https:// connections][4] for more information.
|
||||
|
||||
### http:// Connections (h2c) ###
|
||||
|
||||
Although no browser currently supports it, the HTTP/2 protocol also works for http:// urls and mod_h[ttp]2 supports this. The only thing you need to do in order to enable it is the Protocols configuration:
|
||||
|
||||
# for a http server
|
||||
Protocols h2c http/1.1
|
||||
|
||||
inside your **httpd.conf**.
|
||||
|
||||
There are several client (and client libraries) that support **h2c**. I'll dicusss some specifics below:
|
||||
|
||||
#### curl ####
|
||||
|
||||
Of course, the command line client for network resources, maintained by Daniel Stenberg. If you have curl on your system, there is an easy way to check its http/2 support:
|
||||
|
||||
sh> curl -V
|
||||
curl 7.43.0 (x86_64-apple-darwin15.0) libcurl/7.43.0 SecureTransport zlib/1.2.5
|
||||
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp smb smbs smtp smtps telnet tftp
|
||||
Features: AsynchDNS IPv6 Largefile GSS-API Kerberos SPNEGO NTLM NTLM_WB SSL libz UnixSockets
|
||||
|
||||
which is no good. There is no 'HTTP2' among the features. You'd want something like this:
|
||||
|
||||
sh> curl -V
|
||||
url 7.45.0 (x86_64-apple-darwin15.0.0) libcurl/7.45.0 OpenSSL/1.0.2d zlib/1.2.8 nghttp2/1.3.4
|
||||
Protocols: dict file ftp ftps gopher http https imap imaps ldap ldaps pop3 pop3s rtsp smb smbs smtp smtps telnet tftp
|
||||
Features: IPv6 Largefile NTLM NTLM_WB SSL libz TLS-SRP HTTP2 UnixSockets
|
||||
|
||||
If you have a curl with the HTTP2 feature, you may check your server with some simple commands:
|
||||
|
||||
sh> curl -v --http2 http://<yourserver>/
|
||||
...
|
||||
> Connection: Upgrade, HTTP2-Settings
|
||||
> Upgrade: h2c
|
||||
> HTTP2-Settings: AAMAAABkAAQAAP__
|
||||
>
|
||||
< HTTP/1.1 101 Switching Protocols
|
||||
< Upgrade: h2c
|
||||
< Connection: Upgrade
|
||||
* Received 101
|
||||
* Using HTTP2, server supports multi-use
|
||||
* Connection state changed (HTTP/2 confirmed)
|
||||
...
|
||||
<the resource>
|
||||
|
||||
Congratulations, id you see the line with **...101 Switching...**, it's working!
|
||||
|
||||
There are cases, where the upgrade to HTTP/2 will not happen. When your first request does have content, for example you do a file upload, the Upgrade will not trigger. For a detailed explanation, see the section [h2c restrictions][5].
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
nghttp2 has its own client and servers that can be build with it. If you have the client on your system, you can verify your installation by simply retrieving a resource:
|
||||
|
||||
sh> nghttp -uv http://<yourserver>/
|
||||
[ 0.001] Connected
|
||||
[ 0.001] HTTP Upgrade request
|
||||
...
|
||||
Connection: Upgrade, HTTP2-Settings
|
||||
Upgrade: h2c
|
||||
HTTP2-Settings: AAMAAABkAAQAAP__
|
||||
...
|
||||
[ 0.005] HTTP Upgrade response
|
||||
HTTP/1.1 101 Switching Protocols
|
||||
Upgrade: h2c
|
||||
Connection: Upgrade
|
||||
|
||||
[ 0.006] HTTP Upgrade success
|
||||
...
|
||||
|
||||
which is very similar to the Upgrade dance we see in the **curl** example above.
|
||||
|
||||
There is another way to use **h2c** hidden in the command line arguments: **-u**. This instructs **nghttp** to perform the HTTP/1 Upgrade dance. But what if we leave this out?
|
||||
|
||||
sh> nghttp -v http://<yourserver>/
|
||||
[ 0.002] Connected
|
||||
[ 0.002] send SETTINGS frame
|
||||
...
|
||||
[ 0.002] send HEADERS frame
|
||||
; END_STREAM | END_HEADERS | PRIORITY
|
||||
(padlen=0, dep_stream_id=11, weight=16, exclusive=0)
|
||||
; Open new stream
|
||||
:method: GET
|
||||
:path: /
|
||||
:scheme: http
|
||||
...
|
||||
|
||||
The connection immediately speaks HTTP/2! This is what the protocol calls the direct mode and it works by some magic 24 bytes that the client sends to the server right away:
|
||||
|
||||
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a
|
||||
or in ASCII: PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
A **h2c** capable server sees this on a new connection and can immediately switch its HTTP/2 processing on. A HTTP/1.1 server will see a funny request, answer it and close the connection.
|
||||
|
||||
Therefore **direct** mode is only good for clients if they can be resonably sure that the server supports this. For example, because a previous Upgrade dance was successful.
|
||||
|
||||
The charme of **direct** is the zero overhead and that it works for all requests, even those that carry a body (see [h2c restrictions][6]). The direct mode is enabled by default on any server that allows the h2c protocol. If you want to disable it, add the configuration directive:
|
||||
|
||||
注:下面这行打删除线
|
||||
|
||||
H2Direct off
|
||||
|
||||
注:下面这行打删除线
|
||||
to your server.
|
||||
|
||||
For the 2.4.17 release, **H2Direct** is enabled by default on cleartext connection. However there are some modules with whom this is incompatible with. Therefore, in the next release, the default will change to **off** and if you want your server to support it, you need to set it to
|
||||
|
||||
H2Direct on
|
||||
|
||||
### https:// Connections (h2) ###
|
||||
|
||||
Once you get mod_h[ttp]2 working for h2c connections, it's time to get the **h2** sibling going, as browsers only do it with **https:** nowadays.
|
||||
|
||||
The HTTP/2 standard imposes some extra requirements on https: (TLS) connections. The ALPN extension has already been mentioned above. An additional requirement is that no cipher from a specified [black list][7] may be used.
|
||||
|
||||
While the current version of **mod_h[ttp]2** does not enforce these ciphers (but some day will), most clients will do so. If you point your browser at a **h2** server with inappropriate ciphers, you will get the obscure warning **INADEQUATE_SECURITY** and the browser will simply refuse to continue.
|
||||
|
||||
An acceptable Apache SSL configuration regarding this is:
|
||||
|
||||
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!3DES:!MD5:!PSK
|
||||
SSLProtocol All -SSLv2 -SSLv3
|
||||
...
|
||||
|
||||
(Yes, it's that long.)
|
||||
|
||||
There are other SSL configuration parameters that should be tweaked, but do not have to: **SSLSessionCache**, **SSLUseStapling**, etc. but those are covered elsewhere. See the excellent [High Performance Browser Networking][8] by Ilya Grigorik, for example.
|
||||
|
||||
#### curl ####
|
||||
|
||||
Time to fire up a shell and use curl again (see the [h2c section about curl][9] for requirements). Using curl, you may check your server with some simple commands:
|
||||
|
||||
sh> curl -v --http2 https://<yourserver>/
|
||||
...
|
||||
* ALPN, offering h2
|
||||
* ALPN, offering http/1.1
|
||||
...
|
||||
* ALPN, server accepted to use h2
|
||||
...
|
||||
<the resource>
|
||||
|
||||
Congratulations, it's working! If not, the reason might be:
|
||||
|
||||
- Your curl does not support HTTP/2, see [this check][10].
|
||||
- Your openssl is old and does not support ALPN.
|
||||
- Your certificate could not be verified or your cipher configuration is not accepted. Try adding the command line option -k to disable those checks in curl. If that works, review yor SSL configuration and certificate.
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
**nghttp** we discussed already for **h2c**. If you use it for a **https:** connection, you will either see the resource or an error like this:
|
||||
|
||||
sh> nghttp https://<yourserver>/
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
There are two possiblities for this which you can check by adding -v. Either your get this:
|
||||
|
||||
sh> nghttp -v https://<yourserver>/
|
||||
[ 0.034] Connected
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
This means that the TLS library your server uses does not implement ALPN. Getting this installtion correct is sometimes tricky. Use stackoverflow.
|
||||
|
||||
Or you get this:
|
||||
|
||||
sh> nghttp -v https://<yourserver>/
|
||||
[ 0.034] Connected
|
||||
The negotiated protocol: http/1.1
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
which means ALPN is working, only the h2 protocol was not selected. You need to check that Protocols is set as described above for yourserver. Try setting it in the general section, in case you do not get it working in a vhost at first.
|
||||
|
||||
#### Firefox ####
|
||||
|
||||
Update: Steffen Land from [Apache Lounge][11] pointed me to the [HTTP/2 indicator Add-on for Firefox][12]. Nice if you want to see in how many places you already talk h2 (Hint: Apache Lounge talks h2 for some time now...).
|
||||
|
||||
In Firefox you can to open the Developer Tools and there the Network tab to check for HTTP/2 connections. When you have those open and reload your html page, you see something like the following:
|
||||
|
||||
|
||||
|
||||
Among the response headers, you see this strange **X-Firefox-Spdy** entry listing "h2". That is the indication that HTTP/2 is used on this **https:** connection.
|
||||
|
||||
#### Google Chrome ####
|
||||
|
||||
In Google Chrome, you will not see a HTTP/2 indicator in the developer tools. Instead, Chrome uses the special location **chrome://net-internals/#http2** to give information.
|
||||
|
||||
If you have opened a page on your server and look at that net-internals page, you will see something like this:
|
||||
|
||||
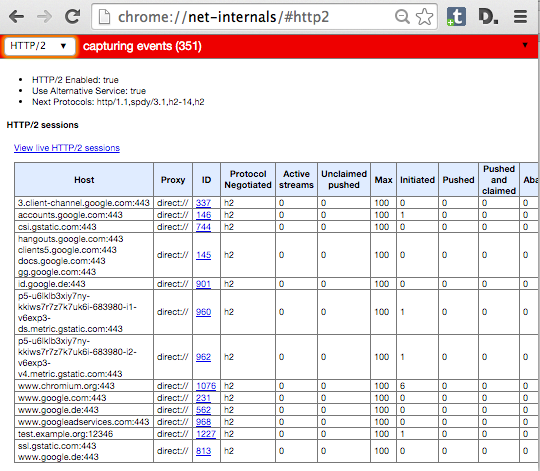
|
||||
|
||||
If your server is among the ones listed here, it is working.
|
||||
|
||||
#### Microsoft Edge ####
|
||||
|
||||
HTTP/2 is supported in the Windows 10 successor to Internet Explorer: Edge. Here you can also see the protocol used in the Developer Tools in the Network tab:
|
||||
|
||||
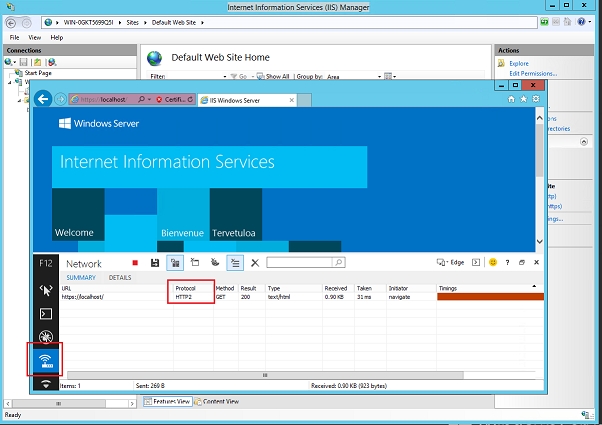
|
||||
|
||||
#### Safari ####
|
||||
|
||||
In Apple's Safari, you open the Developer Tools and there the Network tab. Reload your server page and select the row in the Developer Tools that shows the load. If you enable the right side details view, look at the **Status**. It should show **HTTP/2.0 200** like here:
|
||||
|
||||
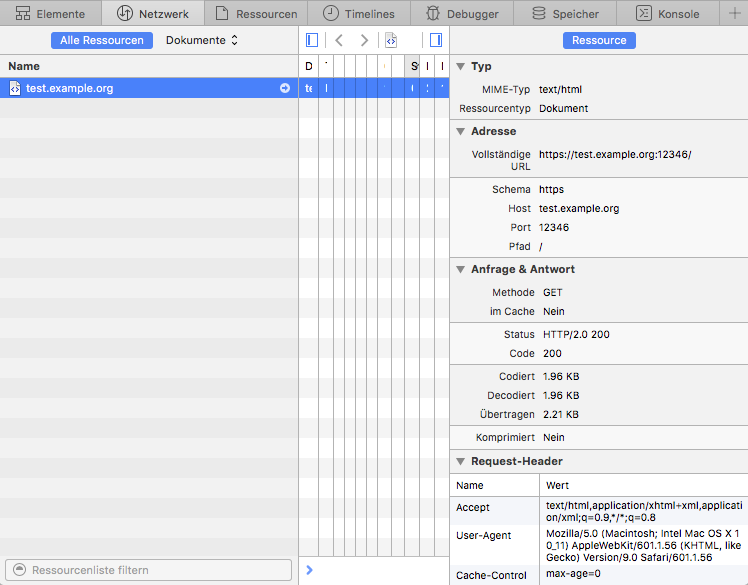
|
||||
|
||||
#### Renegotiations ####
|
||||
|
||||
Renegotiations on a https: connection means that certain TLS parameters are changed on the running connection. In Apache httpd you can change TLS parameters in directory configurations. If a request arrives for a resource in a certain location, configured TLS parameter are compared to the current TLS parameters. If they differ, renegotiation is triggered.
|
||||
|
||||
Most common use cases for this are cipher changes and client certificates. You can require clients to meet authentication only for special locations, or you might enable more secure, but CPU intensive ciphers for specific resources.
|
||||
|
||||
Whatever your good use cases are, renegotiation are a **MUST NOT** in HTTP/2. With 100s of requests ongoing on the same connection, which renegotiation would otherwise occur when?
|
||||
|
||||
The current **mod_h[ttp]2** does not protect you from such configuration. If you have a site which uses TLS renegotiation, DO NOT enable h2 on it!
|
||||
|
||||
Again, we will address that in future releases so that you can enable it safely.
|
||||
|
||||
### Restrictions ###
|
||||
|
||||
#### Non-HTTP Protocols ####
|
||||
|
||||
Modules implementing protocols other than HTTP may be incompatible with **mod_http2**. This will most certainly be the case when this other protocol requires the server to send data first.
|
||||
|
||||
**NNTP** is one example of such a protocol. If you have a **mod_nntp_like_ssl** configured in your server, do not even load mod_http2. Wait for the next release.
|
||||
|
||||
#### h2c Restrictions ####
|
||||
|
||||
There are some restrictions on the **h2c** implementation, you should be aware of:
|
||||
|
||||
#### Deny h2c on virtual host ####
|
||||
|
||||
You cannot deny **h2c direct** on specific virtual hosts. **direct** gets triggered at connection setup when there is not request to be seen yet. Which makes it impossible to foresee which virtual host Apache needs to look at.
|
||||
|
||||
#### Upgrade on request body ####
|
||||
|
||||
The **h2c** Upgrade dance will not work on requests that have a body. Those are PUT and POST requests (form submits and uploads). If you write a client, you may precede those requests with a simple GET or an OPTIONS * to trigger the upgrade.
|
||||
|
||||
The reason is quite technical in nature, but in case you want to know: during Upgrade, the connection is in a half insane state. The request is coming in HTTP/1.1 format and the response is being written in HTTP/2 frames. If the request carries a body, the server needs to read the whole body before it sends a response back. Because the response might need answers from the client for flow control among other things. But if the HTTP/1.1 request is still being sent, the client is unable to talk HTTP/2 yet.
|
||||
|
||||
In order to make behaviour predictable, several server implementors decided to not do an Upgrade in the presence of any request bodies, even small ones.
|
||||
|
||||
#### Upgrade on 302s ####
|
||||
|
||||
The h2c Upgrade dance also does currently not work when there is a general redirect in place. Seems that rewrite happens before the mod_http2 has a chance to act. Certainly not a deal breaker, but might be confusing when you test a site that has it.
|
||||
|
||||
#### h2 Restrictions ####
|
||||
|
||||
There are some restrictions on the h2 implementation you should be aware of:
|
||||
|
||||
#### Connection Reuse ####
|
||||
|
||||
The HTTP/2 protocol allows reuse of TLS connections under certain conditions: if you have a certiface with wildcards or several altSubject names, browsers will reuse any existing connection they might have. Example:
|
||||
|
||||
You have a certificate for **a.example.org** that has as additional name **b.example.org**. You open in your browser the url **https://a.example.org/**, open another tab and load **https://b.example.org/**.
|
||||
|
||||
Before opening a new connection, the browser sees that it still has the one to **a.example.org** open and that the certificate is also valid for **b.example.org**. So, it sends the request for second tab over the connection of the first one.
|
||||
|
||||
This connection reuse is intentional and makes it easier for sites that have invested in sharding for efficiency in HTTP/1 to also benefit from HTTP/2 without much change.
|
||||
|
||||
In Apache **mod_h[ttp]2** this is not fully implemented, yet. When **a.example.org** and **b.example.org** are separate virtual hosts, Apache will not allow such connection reuse and inform the browser with status code **421 Misdirected Request** about it. The browser will understand that it has to open a new connection to **b.example.org**. All will work, however some efficiency gets lost.
|
||||
|
||||
We expect to have the proper checks in place for the next release.
|
||||
|
||||
Münster, 12.10.2015,
|
||||
|
||||
Stefan Eissing, greenbytes GmbH
|
||||
|
||||
Copying and distribution of this file, with or without modification, are permitted in any medium without royalty provided the copyright notice and this notice are preserved. This file is offered as-is, without warranty of any kind. See LICENSE for details.
|
||||
|
||||
|
||||
----------
|
||||
|
||||
This project is maintained by [icing][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://icing.github.io/mod_h2/howto.html
|
||||
|
||||
作者:[icing][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/icing
|
||||
[1]:https://httpd.apache.org/download.cgi
|
||||
[2]:https://httpd.apache.org/docs/2.4/install.html
|
||||
[3]:https://nghttp2.org/
|
||||
[4]:https://icing.github.io/mod_h2/howto.html#https
|
||||
[5]:https://icing.github.io/mod_h2/howto.html#h2c-restrictions
|
||||
[6]:https://icing.github.io/mod_h2/howto.html#h2c-restrictions
|
||||
[7]:https://httpwg.github.io/specs/rfc7540.html#BadCipherSuites
|
||||
[8]:http://chimera.labs.oreilly.com/books/1230000000545
|
||||
[9]:https://icing.github.io/mod_h2/howto.html#curl
|
||||
[10]:https://icing.github.io/mod_h2/howto.html#curl
|
||||
[11]:https://www.apachelounge.com/
|
||||
[12]:https://addons.mozilla.org/en-US/firefox/addon/spdy-indicator/
|
||||
[13]:https://github.com/icing
|
||||
@ -1,513 +0,0 @@
|
||||
struggling 翻译中...
|
||||
9 Tips for Improving WordPress Performance
|
||||
================================================================================
|
||||
WordPress is the single largest platform for website creation and web application delivery worldwide. About [a quarter][1] of all sites are now built on open-source WordPress software, including sites for eBay, Mozilla, RackSpace, TechCrunch, CNN, MTV, the New York Times, the Wall Street Journal.
|
||||
|
||||
WordPress.com, the most popular site for user-created blogs, also runs on WordPress open source software. [NGINX powers WordPress.com][2]. Among WordPress customers, many sites start on WordPress.com and then move to hosted WordPress open-source software; more and more of these sites use NGINX software as well.
|
||||
|
||||
WordPress’ appeal is its simplicity, both for end users and for implementation. However, the architecture of a WordPress site presents problems when usage ramps upward – and several steps, including caching and combining WordPress and NGINX, can solve these problems.
|
||||
|
||||
In this blog post, we provide nine performance tips to help overcome typical WordPress performance challenges:
|
||||
|
||||
- [Cache static resources][3]
|
||||
- [Cache dynamic files][4]
|
||||
- [Move to NGINX][5]
|
||||
- [Add permalink support to NGINX][6]
|
||||
- [Configure NGINX for FastCGI][7]
|
||||
- [Configure NGINX for W3_Total_Cache][8]
|
||||
- [Configure NGINX for WP-Super-Cache][9]
|
||||
- [Add security precautions to your NGINX configuration][10]
|
||||
- [Configure NGINX to support WordPress Multisite][11]
|
||||
|
||||
### WordPress Performance on LAMP Sites ###
|
||||
|
||||
Most WordPress sites are run on a traditional LAMP software stack: the Linux OS, Apache web server software, MySQL database software – often on a separate database server – and the PHP programming language. Each of these is a very well-known, widely used, open source tool. Most people in the WordPress world “speak” LAMP, so it’s easy to get help and support.
|
||||
|
||||
When a user visits a WordPress site, a browser running the Linux/Apache combination creates six to eight connections per user. As the user moves around the site, PHP assembles each page on the fly, grabbing resources from the MySQL database to answer requests.
|
||||
|
||||
LAMP stacks work well for anywhere from a few to, perhaps, hundreds of simultaneous users. However, sudden increases in traffic are common online and – usually – a good thing.
|
||||
|
||||
But when a LAMP-stack site gets busy, with the number of simultaneous users climbing into the many hundreds or thousands, it can develop serious bottlenecks. Two main causes of bottlenecks are:
|
||||
|
||||
1. The Apache web server – Apache consumes substantial resources for each and every connection. If Apache accepts too many simultaneous connections, memory can be exhausted and performance slows because data has to be paged back and forth to disk. If connections are limited to protect response time, new connections have to wait, which also leads to a poor user experience.
|
||||
1. The PHP/MySQL interaction – Together, an application server running PHP and a MySQL database server can serve a maximum number of requests per second. When the number of requests exceeds the maximum, users have to wait. Exceeding the maximum by a relatively small amount can cause a large slowdown in responsiveness for all users. Exceeding it by two or more times can cause significant performance problems.
|
||||
|
||||
The performance bottlenecks in a LAMP site are particularly resistant to the usual instinctive response, which is to upgrade to more powerful hardware – more CPUs, more disk space, and so on. Incremental increases in hardware performance can’t keep up with the exponential increases in demand for system resources that Apache and the PHP/MySQL combination experience when they get overloaded.
|
||||
|
||||
The leading alternative to a LAMP stack is a LEMP stack – Linux, NGINX, MySQL, and PHP. (In the LEMP acronym, the E stands for the sound at the start of “engine-x.”) We describe a LEMP stack in [Tip 3][12].
|
||||
|
||||
### Tip 1. Cache Static Resources ###
|
||||
|
||||
Static resources are unchanging files such as CSS files, JavaScript files, and image files. These files often make up half or more of the data on a web page. The remainder of the page is dynamically generated content like comments in a forum, a performance dashboard, or personalized content (think Amazon.com product recommendations).
|
||||
|
||||
Caching static resources has two big benefits:
|
||||
|
||||
- Faster delivery to the user – The user gets the static file from their browser cache or a caching server closer to them on the Internet. These are sometimes big files, so reducing latency for them helps a lot.
|
||||
- Reduced load on the application server – Every file that’s retrieved from a cache is one less request the web server has to process. The more you cache, the more you avoid thrashing because resources have run out.
|
||||
|
||||
To support browser caching, set the correct HTTP headers for static files. Look into the HTTP Cache-Control header, specifically the max-age setting, the Expires header, and Entity tags. You can find a good introduction [here][13].
|
||||
|
||||
When local caching is enabled and a user requests a previously accessed file, the browser first checks whether the file is in the cache. If so, it asks the web server if the file has changed. If the file hasn’t changed, the web server can respond immediately with code 304 (Not Modified) meaning that the file is unchanged, instead of returning code 200 OK and then retrieving and delivering the changed file.
|
||||
|
||||
To support caching beyond the browser, consider the Tips below, and consider a content delivery network (CDN).CDNs are a popular and powerful tool for caching, but we don’t describe them in detail here. Consider a CDN after you implement the other techniques mentioned here. Also, CDNs may be less useful as you transition your site from HTTP/1.x to the new HTTP/2 standard; investigate and test as needed to find the right answer for your site.
|
||||
|
||||
If you move to NGINX Plus or the open source NGINX software as part of your software stack, as suggested in [Tip 3][14], then configure NGINX to cache static resources. Use the following configuration, replacing www.example.com with the URL of your web server.
|
||||
|
||||
server {
|
||||
# substitute your web server's URL for www.example.com
|
||||
server_name www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri =404;
|
||||
include fastcgi_params;
|
||||
# substitute the socket, or address and port, of your WordPress server
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
#fastcgi_pass 127.0.0.1:9000;
|
||||
}
|
||||
|
||||
location ~* .(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 2. Cache Dynamic Files ###
|
||||
|
||||
WordPress generates web pages dynamically, meaning that it generates a given web page every time it is requested (even if the result is the same as the time before). This means that users always get the freshest content.
|
||||
|
||||
Think of a user visiting a blog post that has comments enabled at the bottom of the post. You want the user to see all comments – even a comment that just came in a moment ago. Dynamic content makes this happen.
|
||||
|
||||
But now let’s say that the blog post is getting ten or twenty requests per second. The application server might start to thrash under the pressure of trying to regenerate the page so often, causing big delays. The goal of delivering the latest content to new visitors becomes relevant only in theory, because they’re have to wait so long to get the page in the first place.
|
||||
|
||||
To prevent page delivery from slowing down due to increasing load, cache the dynamic file. This makes the file less dynamic, but makes the whole system more responsive.
|
||||
|
||||
To enable caching in WordPress, use one of several popular plug-ins – described below. A WordPress caching plug-in asks for a fresh page, then caches it for a brief period of time – perhaps just a few seconds. So, if the site is getting several requests a second, most users get their copy of the page from the cache. This helps the retrieval time for all users:
|
||||
|
||||
- Most users get a cached copy of the page. The application server does no work at all.
|
||||
- Users who do get a fresh copy get it fast. The application server only has to generate a fresh page every so often. When the server does generate a fresh page (for the first user to come along after the cached page expires), it does this much faster because it’s not overloaded with requests.
|
||||
|
||||
You can cache dynamic files for WordPress running on a LAMP stack or on a [LEMP stack][15] (described in [Tip 3][16]). There are several caching plug-ins you can use with WordPress. Here are the most popular caching plug-ins and caching techniques, listed from the simplest to the most powerful:
|
||||
|
||||
- [Hyper-Cache][17] and [Quick-Cache][18] – These two plug-ins create a single PHP file for each WordPress page or post. This supports some dynamic functionality while bypassing much WordPress core processing and the database connection, creating a faster user experience. They don’t bypass all PHP processing, so they don’t give the same performance boost as the following options. They also don’t require changes to the NGINX configuration.
|
||||
- [WP Super Cache][19] – The most popular caching plug-in for WordPress. It has many settings, which are presented through an easy-to-use interface, shown below. We show a sample NGINX configuration in [Tip 7][20].
|
||||
- [W3 Total Cache][21] – This is the second most popular cache plug-in for WordPress. It has even more option settings than WP Super Cache, making it a powerful but somewhat complex option. For a sample NGINX configuration, see [Tip 6][22].
|
||||
- [FastCGI][23] – CGI stands for Common Gateway Interface, a language-neutral way to request and receive files on the Internet. FastCGI is not a plug-in but a way to interact with a cache. FastCGI can be used in Apache as well as in NGINX, where it’s the most popular dynamic caching approach; we describe how to configure NGINX to use it in [Tip 5][24].
|
||||
|
||||
The documentation for these plug-ins and techniques explains how to configure them in a typical LAMP stack. Configuration options include database and object caching; minification for HTML, CSS, and JavaScript files; and integration options for popular CDNs. For NGINX configuration, see the Tips referenced in the list.
|
||||
|
||||
**Note**: Caches do not work for users who are logged into WordPress, because their view of WordPress pages is personalized. (For most sites, only a small minority of users are likely to be logged in.) Also, most caches do not show a cached page to users who have recently left a comment, as that user will want to see their comment appear when they refresh the page. To cache the non-personalized content of a page, you can use a technique called [fragment caching][25], if it’s important to overall performance.
|
||||
|
||||
### Tip 3. Move to NGINX ###
|
||||
|
||||
As mentioned above, Apache can cause performance problems when the number of simultaneous users rises above a certain point – perhaps hundreds of simultaneous users. Apache allocates substantial resources to each connection, and therefore tends to run out of memory. Apache can be configured to limit connections to avoid exhausting memory, but that means, when the limit is exceeded, new connection requests have to wait.
|
||||
|
||||
In addition, Apache loads another copy of the mod_php module into memory for every connection, even if it’s only serving static files (images, CSS, JavaScript, etc.). This consumes even more resources for each connection and limits the capacity of the server further.
|
||||
|
||||
To start solving these problems, move from a LAMP stack to a LEMP stack – replace Apache with (e)NGINX. NGINX handles many thousands of simultaneous connections in a fixed memory footprint, so you don’t have to experience thrashing, nor limit simultaneous connections to a small number.
|
||||
|
||||
NGINX also deals with static files better, with built-in, easily tuned [caching][26] controls. The load on the application server is reduced, and your site can serve far more traffic with a faster, more enjoyable experience for your users.
|
||||
|
||||
You can use NGINX on all the web servers in your deployment, or you can put an NGINX server “in front” of Apache as a reverse proxy – the NGINX server receives client requests, serves static files, and sends PHP requests to Apache, which processes them.
|
||||
|
||||
For dynamically generated pages – the core use case for WordPress experience – choose a caching tool, as described in [Tip 2][27]. In the Tips below, you can find NGINX configuration suggestions for FastCGI, W3_Total_Cache, and WP-Super-Cache. (Hyper-Cache and Quick-Cache don’t require changes to NGINX configuration.)
|
||||
|
||||
**Tip.** Caches are typically saved to disk, but you can use [tmpfs][28] to store the cache in memory and increase performance.
|
||||
|
||||
Setting up NGINX for WordPress is easy. Just follow these four steps, which are described in further detail in the indicated Tips:
|
||||
|
||||
1. Add permalink support – Add permalink support to NGINX. This eliminates dependence on the **.htaccess** configuration file, which is Apache-specific. See [Tip 4][29].
|
||||
1. Configure for caching – Choose a caching tool and implement it. Choices include FastCGI cache, W3 Total Cache, WP Super Cache, Hyper Cache, and Quick Cache. See Tips [5][30], [6][31], and [7][32].
|
||||
1. Implement security precautions – Adopt best practices for WordPress security on NGINX. See [Tip 8][33].
|
||||
1. Configure WordPress Multisite – If you use WordPress Multisite, configure NGINX for a subdirectory, subdomain, or multiple-domain architecture. See [Tip 9][34].
|
||||
|
||||
### Tip 4. Add Permalink Support to NGINX ###
|
||||
|
||||
Many WordPress sites depend on **.htaccess** files, which are required for several WordPress features, including permalink support, plug-ins, and file caching. NGINX does not support **.htaccess** files. Fortunately, you can use NGINX’s simple, yet comprehensive, configuration language to achieve most of the same functionality.
|
||||
|
||||
You can enable [Permalinks][35] in WordPress with NGINX by including the following location block in your main [server][36] block. (This location block is also included in other code samples below.)
|
||||
|
||||
The **try_files** directive tells NGINX to check whether the requested URL exists as a file ( **$uri**) or directory (**$uri/**) in the document root, **/var/www/example.com/htdocs**. If not, NGINX does a redirect to **/index.php**, passing the query string arguments as parameters.
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 5. Configure NGINX for FastCGI ###
|
||||
|
||||
NGINX can cache responses from FastCGI applications like PHP. This method offers the best performance.
|
||||
|
||||
For NGINX open source, compile in the third-party module [ngx_cache_purge][37], which provides cache purging capability, and use the configuration code below. NGINX Plus includes its own implementation of this code.
|
||||
|
||||
When using FastCGI, we recommend you install the [Nginx Helper plug-in][38] and use a configuration such as the one below, especially the use of **fastcgi_cache_key** and the location block including **fastcgi_cache_purge**. The plug-in automatically purges your cache when a page or a post is published or modified, a new comment is published, or the cache is manually purged from the WordPress Admin Dashboard.
|
||||
|
||||
The Nginx Helper plug-in can also add a short HTML snippet to the bottom of your pages, confirming the cache is working and displaying some statistics. (You can also confirm the cache is functioning properly using the [$upstream_cache_status][39] variable.)
|
||||
|
||||
fastcgi_cache_path /var/run/nginx-cache levels=1:2
|
||||
keys_zone=WORDPRESS:100m inactive=60m;
|
||||
fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
set $skip_cache 0;
|
||||
|
||||
# POST requests and urls with a query string should always go to PHP
|
||||
if ($request_method = POST) {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
if ($query_string != "") {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
# Don't cache uris containing the following segments
|
||||
if ($request_uri ~* "/wp-admin/|/xmlrpc.php|wp-.*.php|/feed/|index.php
|
||||
|sitemap(_index)?.xml") {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
# Don't use the cache for logged in users or recent commenters
|
||||
if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass
|
||||
|wordpress_no_cache|wordpress_logged_in") {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri /index.php;
|
||||
include fastcgi_params;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
fastcgi_cache_bypass $skip_cache;
|
||||
fastcgi_no_cache $skip_cache;
|
||||
fastcgi_cache WORDPRESS;
|
||||
fastcgi_cache_valid 60m;
|
||||
}
|
||||
|
||||
location ~ /purge(/.*) {
|
||||
fastcgi_cache_purge WORDPRESS "$scheme$request_method$host$1";
|
||||
}
|
||||
|
||||
location ~* ^.+\.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css|rss|atom|js|jpg|jpeg|gif|png
|
||||
|ico|zip|tgz|gz|rar|bz2|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
|
||||
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
}
|
||||
|
||||
location ~ /\. {
|
||||
deny all;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 6. Configure NGINX for W3_Total_Cache ###
|
||||
|
||||
[W3 Total Cache][40], by Frederick Townes of [W3-Edge][41], is a WordPress caching framework that supports NGINX. It’s an alternative to FastCGI cache with a wide range of option settings.
|
||||
|
||||
The caching plug-in offers a variety of caching configurations and also includes options for database and object caching, minification of HTML, CSS, and JavaScript, as well as options to integrate with popular CDNs.
|
||||
|
||||
The plug-in handles NGINX configuration by writing to an NGINX configuration file located in the root directory of your domain.
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log;
|
||||
|
||||
include /path/to/wordpress/installation/nginx.conf;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri =404;
|
||||
include fastcgi_params;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 7. Configure NGINX for WP Super Cache ###
|
||||
|
||||
[WP Super Cache][42] by Donncha O Caoimh, a WordPress developer at [Automattic][43], is a WordPress caching engine that turns dynamic WordPress pages into static HTML files that NGINX can serve very quickly. It was one of the first caching plug-ins for WordPress and has a smaller, more focused range of options than others.
|
||||
|
||||
NGINX configurations for WP-Super-Cache can vary depending on your preference. One possible configuration follows.
|
||||
|
||||
In the configuration below, the location block with supercache named in it is the WP Super Cache-specific part, and is needed for the configuration to work. The rest of the code is made up of WordPress rules for not caching users who are logged into WordPress, not caching POST requests, and setting expires headers for static assets, plus standard PHP implementation; these parts can be customized to fit your needs.
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
root /var/www/example.com/htdocs;
|
||||
index index.php;
|
||||
|
||||
access_log /var/log/nginx/example.com.access.log;
|
||||
error_log /var/log/nginx/example.com.error.log debug;
|
||||
|
||||
set $cache_uri $request_uri;
|
||||
|
||||
# POST requests and urls with a query string should always go to PHP
|
||||
if ($request_method = POST) {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
if ($query_string != "") {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
# Don't cache uris containing the following segments
|
||||
if ($request_uri ~* "(/wp-admin/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php
|
||||
|wp-.*.php|/feed/|index.php|wp-comments-popup.php
|
||||
|wp-links-opml.php|wp-locations.php |sitemap(_index)?.xml
|
||||
|[a-z0-9_-]+-sitemap([0-9]+)?.xml)") {
|
||||
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
# Don't use the cache for logged-in users or recent commenters
|
||||
if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+
|
||||
|wp-postpass|wordpress_logged_in") {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
# Use cached or actual file if it exists, otherwise pass request to WordPress
|
||||
location / {
|
||||
try_files /wp-content/cache/supercache/$http_host/$cache_uri/index.html
|
||||
$uri $uri/ /index.php;
|
||||
}
|
||||
|
||||
location = /favicon.ico {
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
log_not_found off
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location ~ .php$ {
|
||||
try_files $uri /index.php;
|
||||
include fastcgi_params;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
#fastcgi_pass 127.0.0.1:9000;
|
||||
}
|
||||
|
||||
# Cache static files for as long as possible
|
||||
location ~*.(ogg|ogv|svg|svgz|eot|otf|woff|mp4|ttf|css
|
||||
|rss|atom|js|jpg|jpeg|gif|png|ico|zip|tgz|gz|rar|bz2
|
||||
|doc|xls|exe|ppt|tar|mid|midi|wav|bmp|rtf)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
}
|
||||
|
||||
### Tip 8. Add Security Precautions to Your NGINX Configuration ###
|
||||
|
||||
To protect against attacks, you can control access to key resources and limit the ability of bots to overload the login utility.
|
||||
|
||||
Allow only specific IP addresses to access the WordPress Dashboard.
|
||||
|
||||
# Restrict access to WordPress Dashboard
|
||||
location /wp-admin {
|
||||
deny 192.192.9.9;
|
||||
allow 192.192.1.0/24;
|
||||
allow 10.1.1.0/16;
|
||||
deny all;
|
||||
}
|
||||
|
||||
Only allow uploading of specific types of files to prevent programs with malicious intent from being uploaded and running.
|
||||
|
||||
# Deny access to uploads which aren’t images, videos, music, etc.
|
||||
location ~* ^/wp-content/uploads/.*.(html|htm|shtml|php|js|swf)$ {
|
||||
deny all;
|
||||
}
|
||||
|
||||
Deny access to **wp-config.php**, the WordPress configuration file. Another way to deny access is to move the file one directory level above the domain root.
|
||||
|
||||
# Deny public access to wp-config.php
|
||||
location ~* wp-config.php {
|
||||
deny all;
|
||||
}
|
||||
|
||||
Rate limit **wp-login.php** to block against brute force attacks.
|
||||
|
||||
# Deny access to wp-login.php
|
||||
location = /wp-login.php {
|
||||
limit_req zone=one burst=1 nodelay;
|
||||
fastcgi_pass unix:/var/run/php5-fpm.sock;
|
||||
#fastcgi_pass 127.0.0.1:9000;
|
||||
}
|
||||
|
||||
### Tip 9. Use NGINX with WordPress Multisite ###
|
||||
|
||||
WordPress Multisite, as its name implies, is a version of WordPress software that allows you to manage two or more sites from a single WordPress instance. The [WordPress.com][44] service, which hosts thousands of user blogs, is run from WordPress Multisite.
|
||||
|
||||
You can run separate sites from either subdirectories of a single domain or from separate subdomains.
|
||||
|
||||
Use this code block to add support for a subdirectory structure.
|
||||
|
||||
# Add support for subdirectory structure in WordPress Multisite
|
||||
if (!-e $request_filename) {
|
||||
rewrite /wp-admin$ $scheme://$host$uri/ permanent;
|
||||
rewrite ^(/[^/]+)?(/wp-.*) $2 last;
|
||||
rewrite ^(/[^/]+)?(/.*\.php) $2 last;
|
||||
}
|
||||
|
||||
Use this code block instead of the code block above to add support for a subdirectory structure, substituting your own subdirectory names.
|
||||
|
||||
# Add support for subdomains
|
||||
server_name example.com *.example.com;
|
||||
|
||||
Older versions of WordPress Multisite (3.4 and earlier) use readfile() to serve static content. However, readfile() is PHP code, which causes a significant performance hit when it executes. We can use NGINX to bypass this unnecessary PHP processing. The code snippets below are separated by separator lines (==============).
|
||||
|
||||
# Avoid PHP readfile() for /blogs.dir/structure in the subdirectory path.
|
||||
location ^~ /blogs.dir {
|
||||
internal;
|
||||
alias /var/www/example.com/htdocs/wp-content/blogs.dir;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
============================================================
|
||||
|
||||
# Avoid php readfile() for /files/structure in the subdirectory path
|
||||
location ~ ^(/[^/]+/)?files/(?.+) {
|
||||
try_files /wp-content/blogs.dir/$blogid/files/$rt_file /wp-includes/ms-files.php?file=$rt_file;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
============================================================
|
||||
|
||||
# WPMU files structure for the subdomain path
|
||||
location ~ ^/files/(.*)$ {
|
||||
try_files /wp-includes/ms-files.php?file=$1 =404;
|
||||
access_log off;
|
||||
log_not_found off;
|
||||
expires max;
|
||||
}
|
||||
|
||||
============================================================
|
||||
|
||||
# Map blog ID to specific directory
|
||||
map $http_host $blogid {
|
||||
default 0;
|
||||
example.com 1;
|
||||
site1.example.com 2;
|
||||
site1.com 2;
|
||||
}
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Scalability is a challenge for more and more site developers as they achieve success with their WordPress sites. (And for new sites that want to head WordPress performance problems off at the pass.) Adding WordPress caching, and combining WordPress and NGINX, are solid answers.
|
||||
|
||||
NGINX is not only useful with WordPress sites. NGINX is the [leading web server][45] among the busiest 1,000, 10,000, and 100,000 sites in the world.
|
||||
|
||||
For more on NGINX performance, see our recent blog post, [10 Tips for 10x Application Performance][46].
|
||||
|
||||
NGINX software comes in two versions:
|
||||
|
||||
- NGINX open source software – Like WordPress, this is software you download, configure, and compile yourself.
|
||||
- NGINX Plus – NGINX Plus includes a pre-built reference version of the software, as well as service and technical support.
|
||||
|
||||
To get started, go to [nginx.org][47] for the open source software or check out [NGINX Plus][48].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/
|
||||
|
||||
作者:[Floyd Smith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/floyd/
|
||||
[1]:http://w3techs.com/technologies/overview/content_management/all
|
||||
[2]:https://www.nginx.com/press/choosing-nginx-growth-wordpresscom/
|
||||
[3]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-static
|
||||
[4]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
|
||||
[5]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[6]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
|
||||
[7]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
|
||||
[8]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
|
||||
[9]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
|
||||
[10]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
|
||||
[11]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
|
||||
[12]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[13]:http://www.mobify.com/blog/beginners-guide-to-http-cache-headers/
|
||||
[14]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[15]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#lamp
|
||||
[16]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#adopt-nginx
|
||||
[17]:https://wordpress.org/plugins/hyper-cache/
|
||||
[18]:https://wordpress.org/plugins/quick-cache/
|
||||
[19]:https://wordpress.org/plugins/wp-super-cache/
|
||||
[20]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
|
||||
[21]:https://wordpress.org/plugins/w3-total-cache/
|
||||
[22]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
|
||||
[23]:http://www.fastcgi.com/
|
||||
[24]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
|
||||
[25]:https://css-tricks.com/wordpress-fragment-caching-revisited/
|
||||
[26]:https://www.nginx.com/resources/admin-guide/content-caching/
|
||||
[27]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#cache-dynamic
|
||||
[28]:https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt
|
||||
[29]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#permalink
|
||||
[30]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#fastcgi
|
||||
[31]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#w3-total-cache
|
||||
[32]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#wp-super-cache
|
||||
[33]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#security
|
||||
[34]:https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-nginx/#multisite
|
||||
[35]:http://codex.wordpress.org/Using_Permalinks
|
||||
[36]:http://nginx.org/en/docs/http/ngx_http_core_module.html#server
|
||||
[37]:https://github.com/FRiCKLE/ngx_cache_purge
|
||||
[38]:https://wordpress.org/plugins/nginx-helper/
|
||||
[39]:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#variables
|
||||
[40]:https://wordpress.org/plugins/w3-total-cache/
|
||||
[41]:http://www.w3-edge.com/
|
||||
[42]:https://wordpress.org/plugins/wp-super-cache/
|
||||
[43]:http://automattic.com/
|
||||
[44]:https://wordpress.com/
|
||||
[45]:http://w3techs.com/technologies/cross/web_server/ranking
|
||||
[46]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/
|
||||
[47]:http://www.nginx.org/en
|
||||
[48]:https://www.nginx.com/products/
|
||||
[49]:
|
||||
[50]:
|
||||
@ -1,74 +0,0 @@
|
||||
How To Install Retro Terminal In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Nostalgic about the past? Get a slice of the past by **installing retro terminal app** [cool-retro-term][1] which, as the name suggests, is both cool and retro at the same.
|
||||
|
||||
Do you remember the time when there were CRT monitors everywhere and the terminal screen used to flicker? You don’t need to be old to have witnessed it. If you watch movies set in early 90’s, you’ll see plenty of CRT monitors with green/B&W command prompt. It has a geeky aura which makes it cooler.
|
||||
|
||||
If you are tired of terminal appearance and you need something cool and ‘new’, cool-retro-term will give you a vintage terminal appearance to relive the past. You also can change its color, animation kind, and add some effect to it.
|
||||
|
||||
Here are few screenshots of the different looks of cool-retro-term:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Install cool-retro-term in Ubuntu based Linux distributions ###
|
||||
|
||||
To install cool-retro-term in Ubuntu based Linux distributions, such as Linux Mint, elementary OS, Linux Lite etc, use the PPA below:
|
||||
|
||||
sudo add-apt-repository ppa:noobslab/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install cool-retro-term
|
||||
|
||||
### Install cool-retro-term in Arch based Linux distributions ###
|
||||
|
||||
Installing cool-retro-term in Arch based Linux distributions such as [Antergos][2] and [Manjaro][3], use the following command:
|
||||
|
||||
sudo pacman -S cool-retro-term
|
||||
|
||||
### Install cool-retro-term from source code ###
|
||||
|
||||
For installing this application from source code, you need to install a number of dependencies first. Some of the know dependencies in Ubuntu based distributions are:
|
||||
|
||||
sudo apt-get install git build-essential qmlscene qt5-qmake qt5-default qtdeclarative5-dev qtdeclarative5-controls-plugin qtdeclarative5-qtquick2-plugin libqt5qml-graphicaleffects qtdeclarative5-dialogs-plugin qtdeclarative5-localstorage-plugin qtdeclarative5-window-plugin
|
||||
|
||||
Known dependencies for other distributions can be found on the [github of cool-retro-term][4].
|
||||
|
||||
Now use commands below to compile the program:
|
||||
|
||||
git clone https://github.com/Swordfish90/cool-retro-term.git
|
||||
cd cool-retro-term
|
||||
qmake && make
|
||||
|
||||
Once the program is compiled, you can run it with this command:
|
||||
|
||||
./cool-retro-term
|
||||
|
||||
If you like to have this app in program menu for quick access so that you won’t have to run it manually each time with the commands, you can use the command below:
|
||||
|
||||
sudo cp cool-retro-term.desktop /usr/share/applications
|
||||
|
||||
You can learn some more terminal tricks here. Enjoy the vintage terminal in Linux :)
|
||||
|
||||
With inputs from: [Abhishek Prakash][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/cool-retro-term/
|
||||
|
||||
作者:[Hossein Heydari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/hossein/
|
||||
[1]:https://github.com/Swordfish90/cool-retro-term
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
[3]:https://manjaro.github.io/
|
||||
[4]:https://github.com/Swordfish90/cool-retro-term
|
||||
[5]:http://itsfoss.com/author/abhishek/
|
||||
@ -1,277 +0,0 @@
|
||||
10 Tips for 10x Application Performance
|
||||
================================================================================
|
||||
Improving web application performance is more critical than ever. The share of economic activity that’s online is growing; more than 5% of the developed world’s economy is now on the Internet (see Resources below for statistics). And our always-on, hyper-connected modern world means that user expectations are higher than ever. If your site does not respond instantly, or if your app does not work without delay, users quickly move on to your competitors.
|
||||
|
||||
For example, a study done by Amazon almost 10 years ago proved that, even then, a 100-millisecond decrease in page-loading time translated to a 1% increase in its revenue. Another recent study highlighted the fact that that more than half of site owners surveyed said they lost revenue or customers due to poor application performance.
|
||||
|
||||
How fast does a website need to be? For each second a page takes to load, about 4% of users abandon it. Top e-commerce sites offer a time to first interaction ranging from one to three seconds, which offers the highest conversion rate. It’s clear that the stakes for web application performance are high and likely to grow.
|
||||
|
||||
Wanting to improve performance is easy, but actually seeing results is difficult. To help you on your journey, this blog post offers you ten tips to help you increase your website performance by as much as 10x. It’s the first in a series detailing how you can increase your application performance with the help of some well-tested optimization techniques, and with a little support from NGINX. This series also outlines potential improvements in security that you can gain along the way.
|
||||
|
||||
### Tip #1: Accelerate and Secure Applications with a Reverse Proxy Server ###
|
||||
|
||||
If your web application runs on a single machine, the solution to performance problems might seem obvious: just get a faster machine, with more processor, more RAM, a fast disk array, and so on. Then the new machine can run your WordPress server, Node.js application, Java application, etc., faster than before. (If your application accesses a database server, the solution might still seem simple: get two faster machines, and a faster connection between them.)
|
||||
|
||||
Trouble is, machine speed might not be the problem. Web applications often run slowly because the computer is switching among different kinds of tasks: interacting with users on thousands of connections, accessing files from disk, and running application code, among others. The application server may be thrashing – running out of memory, swapping chunks of memory out to disk, and making many requests wait on a single task such as disk I/O.
|
||||
|
||||
Instead of upgrading your hardware, you can take an entirely different approach: adding a reverse proxy server to offload some of these tasks. A [reverse proxy server][1] sits in front of the machine running the application and handles Internet traffic. Only the reverse proxy server is connected directly to the Internet; communication with the application servers is over a fast internal network.
|
||||
|
||||
Using a reverse proxy server frees the application server from having to wait for users to interact with the web app and lets it concentrate on building pages for the reverse proxy server to send across the Internet. The application server, which no longer has to wait for client responses, can run at speeds close to those achieved in optimized benchmarks.
|
||||
|
||||
Adding a reverse proxy server also adds flexibility to your web server setup. For instance, if a server of a given type is overloaded, another server of the same type can easily be added; if a server is down, it can easily be replaced.
|
||||
|
||||
Because of the flexibility it provides, a reverse proxy server is also a prerequisite for many other performance-boosting capabilities, such as:
|
||||
|
||||
- **Load balancing** (see [Tip #2][2]) – A load balancer runs on a reverse proxy server to share traffic evenly across a number of application servers. With a load balancer in place, you can add application servers without changing your application at all.
|
||||
- **Caching static files** (see [Tip #3][3]) – Files that are requested directly, such as image files or code files, can be stored on the reverse proxy server and sent directly to the client, which serves assets more quickly and offloads the application server, allowing the application to run faster.
|
||||
- **Securing your site** – The reverse proxy server can be configured for high security and monitored for fast recognition and response to attacks, keeping the application servers protected.
|
||||
|
||||
NGINX software is specifically designed for use as a reverse proxy server, with the additional capabilities described above. NGINX uses an event-driven processing approach which is more efficient than traditional servers. NGINX Plus adds more advanced reverse proxy features, such as application [health checks][4], specialized request routing, advanced caching, and support.
|
||||
|
||||
|
||||
|
||||
### Tip #2: Add a Load Balancer ###
|
||||
|
||||
Adding a [load balancer][5] is a relatively easy change which can create a dramatic improvement in the performance and security of your site. Instead of making a core web server bigger and more powerful, you use a load balancer to distribute traffic across a number of servers. Even if an application is poorly written, or has problems with scaling, a load balancer can improve the user experience without any other changes.
|
||||
|
||||
A load balancer is, first, a reverse proxy server (see [Tip #1][6]) – it receives Internet traffic and forwards requests to another server. The trick is that the load balancer supports two or more application servers, using [a choice of algorithms][7] to split requests between servers. The simplest load balancing approach is round robin, with each new request sent to the next server on the list. Other methods include sending requests to the server with the fewest active connections. NGINX Plus has [capabilities][8] for continuing a given user session on the same server, which is called session persistence.
|
||||
|
||||
Load balancers can lead to strong improvements in performance because they prevent one server from being overloaded while other servers wait for traffic. They also make it easy to expand your web server capacity, as you can add relatively low-cost servers and be sure they’ll be put to full use.
|
||||
|
||||
Protocols that can be load balanced include HTTP, HTTPS, SPDY, HTTP/2, WebSocket, [FastCGI][9], SCGI, uwsgi, memcached, and several other application types, including TCP-based applications and other Layer 4 protocols. Analyze your web applications to determine which you use and where performance is lagging.
|
||||
|
||||
The same server or servers used for load balancing can also handle several other tasks, such as SSL termination, support for HTTP/1/x and HTTP/2 use by clients, and caching for static files.
|
||||
|
||||
NGINX is often used for load balancing; to learn more, please see our [overview blog post][10], [configuration blog post][11], [ebook][12] and associated [webinar][13], and [documentation][14]. Our commercial version, [NGINX Plus][15], supports more specialized load balancing features such as load routing based on server response time and the ability to load balance on Microsoft’s NTLM protocol.
|
||||
|
||||
### Tip #3: Cache Static and Dynamic Content ###
|
||||
|
||||
Caching improves web application performance by delivering content to clients faster. Caching can involve several strategies: preprocessing content for fast delivery when needed, storing content on faster devices, storing content closer to the client, or a combination.
|
||||
|
||||
There are two different types of caching to consider:
|
||||
|
||||
- **Caching of static content**. Infrequently changing files, such as image files (JPEG, PNG) and code files (CSS, JavaScript), can be stored on an edge server for fast retrieval from memory or disk.
|
||||
- **Caching of dynamic content**. Many Web applications generate fresh HTML for each page request. By briefly caching one copy of the generated HTML for a brief period of time, you can dramatically reduce the total number of pages that have to be generated while still delivering content that’s fresh enough to meet your requirements.
|
||||
|
||||
If a page gets ten views per second, for instance, and you cache it for one second, 90% of requests for the page will come from the cache. If you separately cache static content, even the freshly generated versions of the page might be made up largely of cached content.
|
||||
|
||||
There are three main techniques for caching content generated by web applications:
|
||||
|
||||
- **Moving content closer to users**. Keeping a copy of content closer to the user reduces its transmission time.
|
||||
- **Moving content to faster machines**. Content can be kept on a faster machine for faster retrieval.
|
||||
- **Moving content off of overused machines**. Machines sometimes operate much slower than their benchmark performance on a particular task because they are busy with other tasks. Caching on a different machine improves performance for the cached resources and also for non-cached resources, because the host machine is less overloaded.
|
||||
|
||||
Caching for web applications can be implemented from the inside – the web application server – out. First, caching is used for dynamic content, to reduce the load on application servers. Then, caching is used for static content (including temporary copies of what would otherwise be dynamic content), further off-loading application servers. And caching is then moved off of application servers and onto machines that are faster and/or closer to the user, unburdening the application servers, and reducing retrieval and transmission times.
|
||||
|
||||
Improved caching can speed up applications tremendously. For many web pages, static data, such as large image files, makes up more than half the content. It might take several seconds to retrieve and transmit such data without caching, but only fractions of a second if the data is cached locally.
|
||||
|
||||
As an example of how caching is used in practice, NGINX and NGINX Plus use two directives to [set up caching][16]: proxy_cache_path and proxy_cache. You specify the cache location and size, the maximum time files are kept in the cache, and other parameters. Using a third (and quite popular) directive, proxy_cache_use_stale, you can even direct the cache to supply stale content when the server that supplies fresh content is busy or down, giving the client something rather than nothing. From the user’s perspective, this may strongly improves your site or application’s uptime.
|
||||
|
||||
NGINX Plus has [advanced caching features][17], including support for [cache purging][18] and visualization of cache status on a [dashboard][19] for live activity monitoring.
|
||||
|
||||
For more information on caching with NGINX, see the [reference documentation][20] and [NGINX Content Caching][21] in the NGINX Plus Admin Guide.
|
||||
|
||||
**Note**: Caching crosses organizational lines between people who develop applications, people who make capital investment decisions, and people who run networks in real time. Sophisticated caching strategies, like those alluded to here, are a good example of the value of a [DevOps perspective][22], in which application developer, architectural, and operations perspectives are merged to help meet goals for site functionality, response time, security, and business results, )such as completed transactions or sales.
|
||||
|
||||
### Tip #4: Compress Data ###
|
||||
|
||||
Compression is a huge potential performance accelerator. There are carefully engineered and highly effective compression standards for photos (JPEG and PNG), videos (MPEG-4), and music (MP3), among others. Each of these standards reduces file size by an order of magnitude or more.
|
||||
|
||||
Text data – including HTML (which includes plain text and HTML tags), CSS, and code such as JavaScript – is often transmitted uncompressed. Compressing this data can have a disproportionate impact on perceived web application performance, especially for clients with slow or constrained mobile connections.
|
||||
|
||||
That’s because text data is often sufficient for a user to interact with a page, where multimedia data may be more supportive or decorative. Smart content compression can reduce the bandwidth requirements of HTML, Javascript, CSS and other text-based content, typically by 30% or more, with a corresponding reduction in load time.
|
||||
|
||||
If you use SSL, compression reduces the amount of data that has to be SSL-encoded, which offsets some of the CPU time it takes to compress the data.
|
||||
|
||||
Methods for compressing text data vary. For example, see the [section on HTTP/2][23] for a novel text compression scheme, adapted specifically for header data. As another example of text compression you can [turn on][24] GZIP compression in NGINX. After you [pre-compress text data][25] on your services, you can serve the compressed .gz version directly using the gzip_static directive.
|
||||
|
||||
### Tip #5: Optimize SSL/TLS ###
|
||||
|
||||
The Secure Sockets Layer ([SSL][26]) protocol and its successor, the Transport Layer Security (TLS) protocol, are being used on more and more websites. SSL/TLS encrypts the data transported from origin servers to users to help improve site security. Part of what may be influencing this trend is that Google now uses the presence of SSL/TLS as a positive influence on search engine rankings.
|
||||
|
||||
Despite rising popularity, the performance hit involved in SSL/TLS is a sticking point for many sites. SSL/TLS slows website performance for two reasons:
|
||||
|
||||
1. The initial handshake required to establish encryption keys whenever a new connection is opened. The way that browsers using HTTP/1.x establish multiple connections per server multiplies that hit.
|
||||
1. Ongoing overhead from encrypting data on the server and decrypting it on the client.
|
||||
|
||||
To encourage the use of SSL/TLS, the authors of HTTP/2 and SPDY (described in the [next section][27]) designed these protocols so that browsers need just one connection per browser session. This greatly reduces one of the two major sources of SSL overhead. However, even more can be done today to improve the performance of applications delivered over SSL/TLS.
|
||||
|
||||
The mechanism for optimizing SSL/TLS varies by web server. As an example, NGINX uses [OpenSSL][28], running on standard commodity hardware, to provide performance similar to dedicated hardware solutions. NGINX [SSL performance][29] is well-documented and minimizes the time and CPU penalty from performing SSL/TLS encryption and decryption.
|
||||
|
||||
In addition, see [this blog post][30] for details on ways to increase SSL/TLS performance. To summarize briefly, the techniques are:
|
||||
|
||||
- **Session caching**. Uses the [ssl_session_cache][31] directive to cache the parameters used when securing each new connection with SSL/TLS.
|
||||
- **Session tickets or IDs**. These store information about specific SSL/TLS sessions in a ticket or ID so a connection can be reused smoothly, without new handshaking.
|
||||
- **OCSP stapling**. Cuts handshaking time by caching SSL/TLS certificate information.
|
||||
|
||||
NGINX and NGINX Plus can be used for SSL/TLS termination – handling encryption and decyption for client traffic, while communicating with other servers in clear text. Use [these steps][32] to set up NGINX or NGINX Plus to handle SSL/TLS termination. Also, here are [specific steps][33] for NGINX Plus when used with servers that accept TCP connections.
|
||||
|
||||
### Tip #6: Implement HTTP/2 or SPDY ###
|
||||
|
||||
For sites that already use SSL/TLS, HTTP/2 and SPDY are very likely to improve performance, because the single connection requires just one handshake. For sites that don’t yet use SSL/TLS, HTTP/2 and SPDY makes a move to SSL/TLS (which normally slows performance) a wash from a responsiveness point of view.
|
||||
|
||||
Google introduced SPDY in 2012 as a way to achieve faster performance on top of HTTP/1.x. HTTP/2 is the recently approved IETF standard based on SPDY. SPDY is broadly supported, but is soon to be deprecated, replaced by HTTP/2.
|
||||
|
||||
The key feature of SPDY and HTTP/2 is the use of a single connection rather than multiple connections. The single connection is multiplexed, so it can carry pieces of multiple requests and responses at the same time.
|
||||
|
||||
By getting the most out of one connection, these protocols avoid the overhead of setting up and managing multiple connections, as required by the way browsers implement HTTP/1.x. The use of a single connection is especially helpful with SSL, because it minimizes the time-consuming handshaking that SSL/TLS needs to set up a secure connection.
|
||||
|
||||
The SPDY protocol required the use of SSL/TLS; HTTP/2 does not officially require it, but all browsers so far that support HTTP/2 use it only if SSL/TLS is enabled. That is, a browser that supports HTTP/2 uses it only if the website is using SSL and its server accepts HTTP/2 traffic. Otherwise, the browser communicates over HTTP/1.x.
|
||||
|
||||
When you implement SPDY or HTTP/2, you no longer need typical HTTP performance optimizations such as domain sharding, resource merging, and image spriting. These changes make your code and deployments simpler and easier to manage. To learn more about the changes that HTTP/2 is bringing about, read our [white paper][34].
|
||||
|
||||

|
||||
|
||||
As an example of support for these protocols, NGINX has supported SPDY from early on, and [most sites][35] that use SPDY today run on NGINX. NGINX is also [pioneering support][36] for HTTP/2, with [support][37] for HTTP/2 in NGINX open source and NGINX Plus as of September 2015.
|
||||
|
||||
Over time, we at NGINX expect most sites to fully enable SSL and to move to HTTP/2. This will lead to increased security and, as new optimizations are found and implemented, simpler code that performs better.
|
||||
|
||||
### Tip #7: Update Software Versions ###
|
||||
|
||||
One simple way to boost application performance is to select components for your software stack based on their reputation for stability and performance. In addition, because developers of high-quality components are likely to pursue performance enhancements and fix bugs over time, it pays to use the latest stable version of software. New releases receive more attention from developers and the user community. Newer builds also take advantage of new compiler optimizations, including tuning for new hardware.
|
||||
|
||||
Stable new releases are typically more compatible and higher-performing than older releases. It’s also easier to keep on top of tuning optimizations, bug fixes, and security alerts when you stay on top of software updates.
|
||||
|
||||
Staying with older software can also prevent you from taking advantage of new capabilities. For example, HTTP/2, described above, currently requires OpenSSL 1.0.1. Starting in mid-2016, HTTP/2 will require OpenSSL 1.0.2, which was released in January 2015.
|
||||
|
||||
NGINX users can start by moving to the [[latest version of the NGINX open source software][38] or [NGINX Plus][39]; they include new capabilities such as socket sharding and thread pools (see below), and both are constantly being tuned for performance. Then look at the software deeper in your stack and move to the most recent version wherever you can.
|
||||
|
||||
### Tip #8: Tune Linux for Performance ###
|
||||
|
||||
Linux is the underlying operating system for most web server implementations today, and as the foundation of your infrastructure, Linux represents a significant opportunity to improve performance. By default, many Linux systems are conservatively tuned to use few resources and to match a typical desktop workload. This means that web application use cases require at least some degree of tuning for maximum performance.
|
||||
|
||||
Linux optimizations are web server-specific. Using NGINX as an example, here are a few highlights of changes you can consider to speed up Linux:
|
||||
|
||||
- **Backlog queue**. If you have connections that appear to be stalling, consider increasing net.core.somaxconn, the maximum number of connections that can be queued awaiting attention from NGINX. You will see error messages if the existing connection limit is too small, and you can gradually increase this parameter until the error messages stop.
|
||||
- **File descriptors**. NGINX uses up to two file descriptors for each connection. If your system is serving a lot of connections, you might need to increase sys.fs.file_max, the system-wide limit for file descriptors, and nofile, the user file descriptor limit, to support the increased load.
|
||||
- **Ephemeral ports**. When used as a proxy, NGINX creates temporary (“ephemeral”) ports for each upstream server. You can increase the range of port values, set by net.ipv4.ip_local_port_range, to increase the number of ports available. You can also reduce the timeout before an inactive port gets reused with the net.ipv4.tcp_fin_timeout setting, allowing for faster turnover.
|
||||
|
||||
For NGINX, check out the [NGINX performance tuning guides][40] to learn how to optimize your Linux system so that it can cope with large volumes of network traffic without breaking a sweat!
|
||||
|
||||
### Tip #9: Tune Your Web Server for Performance ###
|
||||
|
||||
Whatever web server you use, you need to tune it for web application performance. The following recommendations apply generally to any web server, but specific settings are given for NGINX. Key optimizations include:
|
||||
|
||||
- **Access logging**. Instead of writing a log entry for every request to disk immediately, you can buffer entries in memory and write them to disk as a group. For NGINX, add the *buffer=size* parameter to the *access_log* directive to write log entries to disk when the memory buffer fills up. If you add the **flush=time** parameter, the buffer contents are also be written to disk after the specified amount of time.
|
||||
- **Buffering**. Buffering holds part of a response in memory until the buffer fills, which can make communications with the client more efficient. Responses that don’t fit in memory are written to disk, which can slow performance. When NGINX buffering is [on][42], you use the *proxy_buffer_size* and *proxy_buffers* directives to manage it.
|
||||
- **Client keepalives**. Keepalive connections reduce overhead, especially when SSL/TLS is in use. For NGINX, you can increase the maximum number of *keepalive_requests* a client can make over a given connection from the default of 100, and you can increase the *keepalive_timeout* to allow the keepalive connection to stay open longer, resulting in faster subsequent requests.
|
||||
- **Upstream keepalives**. Upstream connections – connections to application servers, database servers, and so on – benefit from keepalive connections as well. For upstream connections, you can increase *keepalive*, the number of idle keepalive connections that remain open for each worker process. This allows for increased connection reuse, cutting down on the need to open brand new connections. For more information about keepalives, refer to this [blog post][41].
|
||||
- **Limits**. Limiting the resources that clients use can improve performance and security. For NGINX,the *limit_conn* and *limit_conn_zone* directives restrict the number of connections from a given source, while *limit_rate* constrains bandwidth. These settings can stop a legitimate user from “hogging” resources and also help prevent against attacks. The *limit_req* and *limit_req_zone* directives limit client requests. For connections to upstream servers, use the max_conns parameter to the server directive in an upstream configuration block. This limits connections to an upstream server, preventing overloading. The associated queue directive creates a queue that holds a specified number of requests for a specified length of time after the *max_conns* limit is reached.
|
||||
- **Worker processes**. Worker processes are responsible for the processing of requests. NGINX employs an event-based model and OS-dependent mechanisms to efficiently distribute requests among worker processes. The recommendation is to set the value of *worker_processes* to one per CPU. The maximum number of worker_connections (512 by default) can safely be raised on most systems if needed; experiment to find the value that works best for your system.
|
||||
- **Socket sharding**. Typically, a single socket listener distributes new connections to all worker processes. Socket sharding creates a socket listener for each worker process, with the kernel assigning connections to socket listeners as they become available. This can reduce lock contention and improve performance on multicore systems. To enable [socket sharding][43], include the reuseport parameter on the listen directive.
|
||||
- **Thread pools**. Any computer process can be held up by a single, slow operation. For web server software, disk access can hold up many faster operations, such as calculating or copying information in memory. When a thread pool is used, the slow operation is assigned to a separate set of tasks, while the main processing loop keeps running faster operations. When the disk operation completes, the results go back into the main processing loop. In NGINX, two operations – the read() system call and sendfile() – are offloaded to [thread pools][44].
|
||||
|
||||
|
||||
|
||||
**Tip**. When changing settings for any operating system or supporting service, change a single setting at a time, then test performance. If the change causes problems, or if it doesn’t make your site run faster, change it back.
|
||||
|
||||
See this [blog post][45] for more details on tuning NGINX.
|
||||
|
||||
### Tip #10: Monitor Live Activity to Resolve Issues and Bottlenecks ###
|
||||
|
||||
The key to a high-performance approach to application development and delivery is watching your application’s real-world performance closely and in real time. You must be able to monitor activity within specific devices and across your web infrastructure.
|
||||
|
||||
Monitoring site activity is mostly passive – it tells you what’s going on, and leaves it to you to spot problems and fix them.
|
||||
|
||||
Monitoring can catch several different kinds of issues. They include:
|
||||
|
||||
- A server is down.
|
||||
- A server is limping, dropping connections.
|
||||
- A server is suffering from a high proportion of cache misses.
|
||||
- A server is not sending correct content.
|
||||
|
||||
A global application performance monitoring tool like New Relic or Dynatrace helps you monitor page load time from remote locations, while NGINX helps you monitor the application delivery side. Application performance data tells you when your optimizations are making a real difference to your users, and when you need to consider adding capacity to your infrastructure to sustain the traffic.
|
||||
|
||||
To help identify and resolve issues quickly, NGINX Plus adds [application-aware health checks][46] – synthetic transactions that are repeated regularly and are used to alert you to problems. NGINX Plus also has [session draining][47], which stops new connections while existing tasks complete, and a slow start capability, allowing a recovered server to come up to speed within a load-balanced group. When used effectively, health checks allow you to identify issues before they significantly impact the user experience, while session draining and slow start allow you to replace servers and ensure the process does not negatively affect perceived performance or uptime. The figure shows the built-in NGINX Plus [live activity monitoring][48] dashboard for a web infrastructure with servers, TCP connections, and caching.
|
||||
|
||||

|
||||
|
||||
### Conclusion: Seeing 10x Performance Improvement ###
|
||||
|
||||
The performance improvements that are available for any one web application vary tremendously, and actual gains depend on your budget, the time you can invest, and gaps in your existing implementation. So, how might you achieve 10x performance improvement for your own applications?
|
||||
|
||||
To help guide you on the potential impact of each optimization, here are pointers to the improvement that may be possible with each tip detailed above, though your mileage will almost certainly vary:
|
||||
|
||||
- **Reverse proxy server and load balancing**. No load balancing, or poor load balancing, can cause episodes of very poor performance. Adding a reverse proxy server, such as NGINX, can prevent web applications from thrashing between memory and disk. Load balancing can move processing from overburdened servers to available ones and make scaling easy. These changes can result in dramatic performance improvement, with a 10x improvement easily achieved compared to the worst moments for your current implementation, and lesser but substantial achievements available for overall performance.
|
||||
- **Caching dynamic and static content**. If you have an overburdened web server that’s doubling as your application server, 10x improvements in peak-time performance can be achieved by caching dynamic content alone. Caching for static files can improve performance by single-digit multiples as well.
|
||||
- **Compressing data**. Using media file compression such as JPEG for photos, PNG for graphics, MPEG-4 for movies, and MP3 for music files can greatly improve performance. Once these are all in use, then compressing text data (code and HTML) can improve initial page load times by a factor of two.
|
||||
- **Optimizing SSL/TLS**. Secure handshakes can have a big impact on performance, so optimizing them can lead to perhaps a 2x improvement in initial responsiveness, particularly for text-heavy sites. Optimizing media file transmission under SSL/TLS is likely to yield only small performance improvements.
|
||||
- **Implementing HTTP/2 and SPDY**. When used with SSL/TLS, these protocols are likely to result in incremental improvements for overall site performance.
|
||||
- **Tuning Linux and web server software (such as NGINX)**. Fixes such as optimizing buffering, using keepalive connections, and offloading time-intensive tasks to a separate thread pool can significantly boost performance; thread pools, for instance, can speed disk-intensive tasks by [nearly an order of magnitude][49].
|
||||
|
||||
We hope you try out these techniques for yourself. We want to hear the kind of application performance improvements you’re able to achieve. Share your results in the comments below, or tweet your story with the hash tags #NGINX and #webperf!
|
||||
|
||||
### Resources for Internet Statistics ###
|
||||
|
||||
[Statista.com – Share of the internet economy in the gross domestic product in G-20 countries in 2016][50]
|
||||
|
||||
[Load Impact – How Bad Performance Impacts Ecommerce Sales][51]
|
||||
|
||||
[Kissmetrics – How Loading Time Affects Your Bottom Line (infographic)][52]
|
||||
|
||||
[Econsultancy – Site speed: case studies, tips and tools for improving your conversion rate][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
|
||||
|
||||
作者:[Floyd Smith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/floyd/
|
||||
[1]:https://www.nginx.com/resources/glossary/reverse-proxy-server
|
||||
[2]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip2
|
||||
[3]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip3
|
||||
[4]:https://www.nginx.com/products/application-health-checks/
|
||||
[5]:https://www.nginx.com/solutions/load-balancing/
|
||||
[6]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip1
|
||||
[7]:https://www.nginx.com/resources/admin-guide/load-balancer/
|
||||
[8]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[9]:https://www.digitalocean.com/community/tutorials/understanding-and-implementing-fastcgi-proxying-in-nginx
|
||||
[10]:https://www.nginx.com/blog/five-reasons-use-software-load-balancer/
|
||||
[11]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[12]:https://www.nginx.com/resources/ebook/five-reasons-choose-software-load-balancer/
|
||||
[13]:https://www.nginx.com/resources/webinars/choose-software-based-load-balancer-45-min/
|
||||
[14]:https://www.nginx.com/resources/admin-guide/load-balancer/
|
||||
[15]:https://www.nginx.com/products/
|
||||
[16]:https://www.nginx.com/blog/nginx-caching-guide/
|
||||
[17]:https://www.nginx.com/products/content-caching-nginx-plus/
|
||||
[18]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&_ga=1.95342300.1348073562.1438712874#proxy_cache_purge
|
||||
[19]:https://www.nginx.com/products/live-activity-monitoring/
|
||||
[20]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&&&_ga=1.61156076.1348073562.1438712874#proxy_cache
|
||||
[21]:https://www.nginx.com/resources/admin-guide/content-caching
|
||||
[22]:https://www.nginx.com/blog/network-vs-devops-how-to-manage-your-control-issues/
|
||||
[23]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
|
||||
[24]:https://www.nginx.com/resources/admin-guide/compression-and-decompression/
|
||||
[25]:http://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
|
||||
[26]:https://www.digicert.com/ssl.htm
|
||||
[27]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
|
||||
[28]:http://openssl.org/
|
||||
[29]:https://www.nginx.com/blog/nginx-ssl-performance/
|
||||
[30]:https://www.nginx.com/blog/improve-seo-https-nginx/
|
||||
[31]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_session_cache
|
||||
[32]:https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/
|
||||
[33]:https://www.nginx.com/resources/admin-guide/nginx-tcp-ssl-termination/
|
||||
[34]:https://www.nginx.com/resources/datasheet/datasheet-nginx-http2-whitepaper/
|
||||
[35]:http://w3techs.com/blog/entry/25_percent_of_the_web_runs_nginx_including_46_6_percent_of_the_top_10000_sites
|
||||
[36]:https://www.nginx.com/blog/how-nginx-plans-to-support-http2/
|
||||
[37]:https://www.nginx.com/blog/nginx-plus-r7-released/
|
||||
[38]:http://nginx.org/en/download.html
|
||||
[39]:https://www.nginx.com/products/
|
||||
[40]:https://www.nginx.com/blog/tuning-nginx/
|
||||
[41]:https://www.nginx.com/blog/http-keepalives-and-web-performance/
|
||||
[42]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_buffering
|
||||
[43]:https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[44]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
|
||||
[45]:https://www.nginx.com/blog/tuning-nginx/
|
||||
[46]:https://www.nginx.com/products/application-health-checks/
|
||||
[47]:https://www.nginx.com/products/session-persistence/#session-draining
|
||||
[48]:https://www.nginx.com/products/live-activity-monitoring/
|
||||
[49]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
|
||||
[50]:http://www.statista.com/statistics/250703/forecast-of-internet-economy-as-percentage-of-gdp-in-g-20-countries/
|
||||
[51]:http://blog.loadimpact.com/blog/how-bad-performance-impacts-ecommerce-sales-part-i/
|
||||
[52]:https://blog.kissmetrics.com/loading-time/?wide=1
|
||||
[53]:https://econsultancy.com/blog/10936-site-speed-case-studies-tips-and-tools-for-improving-your-conversion-rate/
|
||||
@ -0,0 +1,154 @@
|
||||
How to Install Pure-FTPd with TLS on FreeBSD 10.2
|
||||
================================================================================
|
||||
FTP or File Transfer Protocol is application layer standard network protocol used to transfer file from the client to the server, after user logged in to the FTP server over the TCP-Network, such as internet. FTP has been round long time ago, much longer then P2P Program, or World Wide Web, and until this day it was a primary method for sharing file with other over the internet and it it remain very popular even today. FTP provide an secure transmission, that protect username, password and encrypt the content with SSL/TLS.
|
||||
|
||||
Pure-FTPd is free FTP Server with strong and focus on the software security. It was great choice for you if you want to provide a fast, secure, lightweight with feature rich FTP Services. Pure-FTPd can be install on variety of Unix-like operating system, include Linux and FreeBSD. Pure-FTPd is created by Frank Dennis in 2001, based on Troll-FTPd, and until now is actively developed by a team led by Dennis.
|
||||
|
||||
In this tutorial we will provide about installation and configuration of "**Pure-FTPd**" with Unix-like operating system FreeBSD 10.2.
|
||||
|
||||
### Step 1 - Update system ###
|
||||
|
||||
The first thing you must do is to install and update the freebsd repository, please connect to your server with SSH and then type command below as sudo/root :
|
||||
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### Step 2 - Install Pure-FTPd ###
|
||||
|
||||
You can install Pure-FTPd from the ports method, but in this tutorial we will install from the freebsd repository with "**pkg**" command. So, now let's install :
|
||||
|
||||
pkg install pure-ftpd
|
||||
|
||||
Once installation is finished, please add pure-ftpd to the start at the boot time with sysrc command below :
|
||||
|
||||
sysrc pureftpd_enable=yes
|
||||
|
||||
### Step 3 - Configure Pure-FTPd ###
|
||||
|
||||
Configuration file for Pure-FTPd is located at directory "/usr/local/etc/", please go to the directory and copy the sample configuration for pure-ftpd to "**pure-ftpd.conf**".
|
||||
|
||||
cd /usr/local/etc/
|
||||
cp pure-ftpd.conf.sample pure-ftpd.conf
|
||||
|
||||
Now edit the file configuration with nano editor :
|
||||
|
||||
nano -c pure-ftpd.conf
|
||||
|
||||
Note : -c option to show line number on nano.
|
||||
|
||||
Go to line 59 and change the value of "VerboseLog" to "**yes**". This option is allow you as administrator to see the log all command used by the users.
|
||||
|
||||
VerboseLog yes
|
||||
|
||||
And now look at line 126 "PureDB" for virtual-users configuration. Virtual users is a simple mechanism to store a list of users, with their password, name, uid, directory, etc. It's just like /etc/passwd. But it's not /etc/passwd. It's a different file and only for FTP. In this tutorial we will store the list of user to the file "**/usr/local/etc/pureftpd.passwd**" and "**/usr/local/etc/pureftpd.pdb**". Please uncomment that line and change the path for the file to "/usr/local/etc/pureftpd.pdb".
|
||||
|
||||
PureDB /usr/local/etc/pureftpd.pdb
|
||||
|
||||
Next, uncomment on the line 336 "**CreateHomeDir**", this option make you easy to add the virtual users, allow automatically create home directories if they are missing.
|
||||
|
||||
CreateHomeDir yes
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, start pure-ftpd with service command :
|
||||
|
||||
service pure-ftpd start
|
||||
|
||||
### Step 4 - Adding New Users ###
|
||||
|
||||
At this step FTP server is started without error, but you can not log in to the FTP Server, because the default configuration of pure-ftpd is disabled for anonymous users. We need to create new users with home directory, and then give it the password for login.
|
||||
|
||||
On thing you must do befere you add new user to pure-ftpd virtual-user is to create a system user for this, lets create new system user "**vftp**" and the default group is same as username, with home directory "**/home/vftp/**".
|
||||
|
||||
pw useradd vftp -s /sbin/nologin -w no -d /home/vftp \
|
||||
-c "Virtual User Pure-FTPd" -m
|
||||
|
||||
Now you can add the new user for the FTP Server with "**pure-pw**" command. For an example here, we will create new user named "**akari**", so please see command below :
|
||||
|
||||
pure-pw useradd akari -u vftp -g vftp -d /home/vftp/akari
|
||||
Password: TYPE YOUR PASSWORD
|
||||
|
||||
that command will create user "**akari**" and the data stored at the file "**/usr/local/etc/pureftpd.passwd**", not at /etc/passwd file, so this means is that you can easily create FTP-only accounts without messing up your system accounts.
|
||||
|
||||
Next, you must generate the PureDB user database with this command :
|
||||
|
||||
pure-pw mkdb
|
||||
|
||||
Now restart the pure-ftpd services and try connect with user "akari" :
|
||||
|
||||
service pure-ftpd restart
|
||||
|
||||
Trying to connect with user akari :
|
||||
|
||||
ftp SERVERIP
|
||||
|
||||

|
||||
|
||||
**NOTE :**
|
||||
|
||||
If you want to add new user again, you can use "**pure-pw**" command. And if you want to delete the current user, you can use this :
|
||||
|
||||
pure-pw userdel useryouwanttodelete
|
||||
pure-pw mkdb
|
||||
|
||||
### Step 5 - Add SSL/TLS to Pure-FTPd ###
|
||||
|
||||
Pure-FTPd supports encryption using TLS security mechanisms. To support for TLS/SSL, make sure the OpenSSL library is already installed on your freebsd system.
|
||||
|
||||
Now you must generate new "**self-signed certificate**" on the directory "**/etc/ssl/private**". Before you generate the certificate, please create new directory there called "private".
|
||||
|
||||
cd /etc/ssl/
|
||||
mkdir private
|
||||
cd private/
|
||||
|
||||
Now generate "self-signed certificate" with openssl command below :
|
||||
|
||||
openssl req -x509 -nodes -newkey rsa:2048 -sha256 -keyout \
|
||||
/etc/ssl/private/pure-ftpd.pem \
|
||||
-out /etc/ssl/private/pure-ftpd.pem
|
||||
|
||||
FILL ALL WITH YOUR PERSONAL INFO.
|
||||
|
||||

|
||||
|
||||
Next, change the certificate permission :
|
||||
|
||||
chmod 600 /etc/ssl/private/*.pem
|
||||
|
||||
Once the certifcate is generated, Edit the pure-ftpd configuration file :
|
||||
|
||||
nano -c /usr/local/etc/pure-ftpd.conf
|
||||
|
||||
Uncomment on line **423** to enable the TLS :
|
||||
|
||||
TLS 1
|
||||
|
||||
And line **439** for the certificate file path :
|
||||
|
||||
CertFile /etc/ssl/private/pure-ftpd.pem
|
||||
|
||||
Save and exit, then restart the pure-ftpd services :
|
||||
|
||||
service pure-ftpd restart
|
||||
|
||||
Now let's test the Pure-FTPd that work with TLS/SSL. I'm here use "**FileZilla**" to connect to the FTP Server, and use user "**akari**" that have been created.
|
||||
|
||||

|
||||
|
||||
Pure-FTPd with TLS on FreeBSD 10.2 successfully.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
FTP or File Transfer Protocol is standart protocol used to transfer file between users and the server. One of the best, lightweight and secure FTP Server Software is Pure-FTPd. It is secure and support for TLS/SSL encryption mechanism. Pure-FTPd is easy to to install and configure, you can manage the user with virtual user support, and it is make you as sysadmin is easy to manage the user if you have a much user ftp server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-pure-ftpd-tls-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -0,0 +1,266 @@
|
||||
How to Setup Pfsense Firewall and Basic Configuration
|
||||
================================================================================
|
||||
In this article our focus is Pfsense setup, basic configuration and overview of features available in the security distribution of FreeBSD. In this tutorial we will run network wizard for basic setting of firewall and detailed overview of services. After the [installation process][1] following snapshot shows the IP addresses of WAN/LAN and different options for the management of Pfsense firewall.
|
||||
|
||||

|
||||
|
||||
After setup , following window appear which shows the url for configuration of Pfsense.
|
||||
|
||||

|
||||
|
||||
Open above given URL in the browser and login with username **admin** and password **pfsense**
|
||||
|
||||

|
||||
|
||||
After successful login, following wizard appears for the basic setting of Pfsense firewall. However setup wizard option can be bypassed and user can run it from the **System** menu from the web interface.
|
||||
|
||||
Click on the **Next** button to start basic configuration process on Pfsense firewall.
|
||||
|
||||

|
||||
|
||||
Setting hostname, domain and DNS addresses is shown in the following figure.
|
||||
|
||||

|
||||
|
||||
Setting time zone is shown in the below given snapshot.
|
||||
|
||||

|
||||
|
||||
Next window shows setting for the WAN interface. By defaults Pfsense firewall block bogus and private networks.
|
||||
|
||||

|
||||
|
||||
Setting LAN IP address which is used to access the Pfsense web interface for further configuration.
|
||||
|
||||

|
||||
|
||||
By default password for web interface is "pfsense". Enter new password for admin user on the following window to access the web interface for further configuration.
|
||||
|
||||

|
||||
|
||||
Click on the "reload" button which is shown below. It applies the setting and redirect firewall user to main dashboard of Pfsense.
|
||||
|
||||
 and status of ethernet/wireless interfaces etc.
|
||||
|
||||

|
||||
|
||||
### Menu detail ###
|
||||
|
||||
PFsense consist of System, interfaces, firewall,services,vpn,status,diagnostics and help menus.
|
||||
|
||||

|
||||
|
||||
### System Menu ###
|
||||
|
||||
Sub menus of **System** is given below.
|
||||
|
||||

|
||||
|
||||
In the **Advanced** sub menu user can perform following operations.
|
||||
|
||||
1. Configuration of web interface
|
||||
1. Firewall/Nat setting
|
||||
1. Networking setting
|
||||
1. System tuneables setting
|
||||
1. Notification setting
|
||||
|
||||

|
||||
|
||||
In the **Cert manager** sub menu, firewall administrator generates certificates for CA and users.
|
||||
|
||||

|
||||
|
||||
In the **Firmware** sub menu, user can update Pfsense firmware manually/automatically. User can take full backup of Pfsense configurations.
|
||||
|
||||

|
||||
|
||||
In the **General Setup** sub menu, user can change basic setting such as hostname and domain etc.
|
||||
|
||||

|
||||
|
||||
As menu title indicates, user can enable/disable high availability feature from this sub menu.
|
||||
|
||||

|
||||
|
||||
Packages sub menu provides package manager facility in the web interface for Pfsense .
|
||||
|
||||

|
||||
|
||||
User can perform gateway and route management using **Routing** sub menu.
|
||||
|
||||

|
||||
|
||||
**Setup Wizard** sub menu opens following window which start basic configuration of Pfsense.
|
||||
|
||||

|
||||
|
||||
Management of user can be done from the **User manager** sub menu.
|
||||
|
||||

|
||||
|
||||
### Interfaces Menu ###
|
||||
|
||||
This menu is used for the assignment of interfaces (LAN/WAN), VLAN setting,wireless and GRE configuration etc.
|
||||
|
||||

|
||||
|
||||
### Firewall Menu ###
|
||||
|
||||
Firewall is the main and core part of Pfsense distribution and it provides following features.
|
||||
|
||||

|
||||
|
||||
**Aliases**
|
||||
|
||||
Aliases are defined for real hosts, networks or ports and they can be used to minimize the number of changes.
|
||||
|
||||

|
||||
|
||||
**NAT (Network Address Translation)**
|
||||
|
||||
NAT binds a specific internal address to a specific external address. Incoming traffic from the Internet to the specified IP will be directed toward the associated internal IP.
|
||||
|
||||

|
||||
|
||||
**Firewall Rules**
|
||||
|
||||
Firewall rules control what traffic is allowed to enter an interface on the firewall. After traffic is passed on the interface, it enters an entry in the state table is created.
|
||||
|
||||

|
||||
|
||||
**Schedules**
|
||||
|
||||
Firewall rules can be scheduled so that they are only active at certain times of day or on certain specific days or days of the week.
|
||||
|
||||

|
||||
|
||||
**Traffic Shaper**
|
||||
|
||||
Traffic shaping is the control of computer network traffic in order to optimize performance and lower latency.
|
||||
|
||||

|
||||
|
||||
**Virtual IPs**
|
||||
|
||||
Virtual IPs add knowledge of additional IP addresses to the firewall that are different from the firewall's real interface addresses.
|
||||
|
||||

|
||||
|
||||
### Services Menu ###
|
||||
|
||||
Services menu shows services which are provided by the Pfsense distribution along firewall.
|
||||
|
||||

|
||||
|
||||
New program/software installed for some specific service is also shown in this menu such as snort. By default following services are listed in services menu.
|
||||
|
||||
**Captive portal**
|
||||
|
||||
The captive portal functionality in Pfsense allows securing a network by requiring a username and password entered on a portal page.
|
||||
|
||||

|
||||
|
||||
**DHCP Relay**
|
||||
|
||||
The DHCP Relay daemon will relay DHCP requests between broadcast domains for IPv4 DHCP.
|
||||
|
||||

|
||||
|
||||
**DHCP Server**
|
||||
|
||||
User can run DHCP service on the firewall for the network devices.
|
||||
|
||||

|
||||
|
||||
**DNS Forwarder/Resolver/Dynamic DNS**
|
||||
|
||||
DNS different services can be configured on the Pfsense firewall.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**IGMP Proxy**
|
||||
|
||||
User can configure IGMP on the Pfsense firewall from services menu.
|
||||
|
||||

|
||||
|
||||
**Load Balancer**
|
||||
|
||||
Load Balancing is one of the important feature which is also supported by the Pfsense firewall.
|
||||
|
||||

|
||||
|
||||
**SNMP (Simple Network Management Protocol)**
|
||||
|
||||
Pfsense supports all versions of snmp for remote management of firewall.
|
||||
|
||||

|
||||
|
||||
**Wake on Lan**
|
||||
|
||||
Using this feature packet sent to a workstation on a locally connected network which will power on a workstation.
|
||||
|
||||

|
||||
|
||||
### VPN Menu ###
|
||||
|
||||
It is one of the most important feature of Pfsense. Its supports following types of vpn configuration.
|
||||
|
||||
**VPN IPsec**
|
||||
|
||||
IPsec is a standard for providing security to IP protocols via encryption and/or authentication.
|
||||
|
||||

|
||||
|
||||
**L2TP IPsec**
|
||||
|
||||
L2TP/IPsec is a common VPN type that wraps L2TP, an insecure tunneling protocol, inside a secure channel built using transport mode IPsec.
|
||||
|
||||

|
||||
|
||||
**OpenVPN**
|
||||
|
||||
OpenVPN is an Open Source VPN server and client that is supported on pfSense.
|
||||
|
||||

|
||||
|
||||
**Status Menu**
|
||||
|
||||
It shows the status of services provided by Pfsense such as dhcp server, ipsec and load balancer etc.
|
||||
|
||||

|
||||
|
||||
**Diagnostic Menu**
|
||||
|
||||
This menu helps administrator/user for the rectification of Pfsense issues or problems.
|
||||
|
||||

|
||||
|
||||
**Help Menu**
|
||||
|
||||
This menu provides links for different useful resources such as FreeBSD handbook,developer wiki, paid support and pfsense book.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article our focus was on the basic configuration and features set of Pfsense distribution. It is based on FreeBSD distribution and widely used due to security and stability features. In our future articles on Pfsense, our focus will be on the basic firewall rules setting, snort (IDS/IPS) and IPSEC VPN configuration.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:http://linoxide.com/firewall/install-pfsense-firewall/
|
||||
@ -0,0 +1,62 @@
|
||||
translation by strugglingyouth
|
||||
Linux FAQs with Answers--How to install Ubuntu desktop behind a proxy
|
||||
================================================================================
|
||||
> **Question**: My computer is connected to a corporate network sitting behind an HTTP proxy. When I try to install Ubuntu desktop on the computer from a CD-ROM drive, the installation hangs and never finishes while trying to retrieve files, which is presumably due to the proxy. However, the problem is that Ubuntu installer never asks me to configure proxy during installation procedure. Then how can I install Ubuntu desktop behind a proxy?
|
||||
|
||||
Unlike Ubuntu server, installation of Ubuntu desktop is pretty much auto-pilot, not leaving much room for customization, such as custom disk partitioning, manual network settings, package selection, etc. While such simple, one-shot installation is considered user-friendly, it leaves much to be desired for those users looking for "advanced installation mode" to customize their Ubuntu desktop installation.
|
||||
|
||||
In addition, one big problem of the default Ubuntu desktop installer is the absense of proxy settings. If your computer is connected behind a proxy, you will notice that Ubuntu installation gets stuck while preparing to download files.
|
||||
|
||||

|
||||
|
||||
This post describes how to get around the limitation of Ubuntu **installer and install Ubuntu desktop when you are behind a proxy**.
|
||||
|
||||
The basic idea is as follows. Instead of starting with Ubuntu installer directly, boot into live Ubuntu desktop first, configure proxy settings, and finally launch Ubuntu installer manually from live desktop. The following is the step by step procedure.
|
||||
|
||||
After booting from Ubuntu desktop CD/DVD or USB, click on "Try Ubuntu" on the first welcome screen.
|
||||
|
||||

|
||||
|
||||
Once you boot into live Ubuntu desktop, click on Settings icon in the left.
|
||||
|
||||

|
||||
|
||||
Go to Network menu.
|
||||
|
||||

|
||||
|
||||
Configure proxy settings manually.
|
||||
|
||||

|
||||
|
||||
Next, open a terminal.
|
||||
|
||||

|
||||
|
||||
Enter a root session by typing the following:
|
||||
|
||||
$ sudo su
|
||||
|
||||
Finally, type the following command as the root.
|
||||
|
||||
# ubiquity gtk_ui
|
||||
|
||||
This will launch GUI-based Ubuntu installer as follows.
|
||||
|
||||

|
||||
|
||||
Proceed with the rest of installation.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-ubuntu-desktop-behind-proxy.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
380
sources/tech/20151109 How to Configure Tripwire IDS on Debian.md
Normal file
380
sources/tech/20151109 How to Configure Tripwire IDS on Debian.md
Normal file
@ -0,0 +1,380 @@
|
||||
正在翻译:zky001
|
||||
How to Configure Tripwire IDS on Debian
|
||||
================================================================================
|
||||
This article is about Tripwire installation and configuration on Debian OS. It is a host based Intrusion detection system (IDS) for Linux environment. Prime function of tripwire IDS is to detect and report any unauthorized change (files and directories ) on linux system. After tripwire installation, baseline database created first, tripwire monitors and detects changes such as new file addition/creation, file modification and user who changed it etc. If the changes are legitimate, you can accept the changes to update tripwire database.
|
||||
|
||||
### Installation and Configuration ###
|
||||
|
||||
Tripwire installation on Debian VM is shown below.
|
||||
|
||||
# apt-get install tripwire
|
||||
|
||||

|
||||
|
||||
During installation, tripwire prompt for following configuration.
|
||||
|
||||
#### Site key Creation ####
|
||||
|
||||
Tripwire required a site passphrase to secure the tw.cfg tripwire configuration file and tw.pol tripwire policy file. Tripewire encrypte both files using given passphrase. Site passphrase is must even for a single instance tripwire.
|
||||
|
||||

|
||||
|
||||
#### Local Key passphrase ####
|
||||
|
||||
Local passphrase is needed for the protection of tripwire database and report files . Local key used by the tripwire to avoid unauthorized modification of tripwire baseline database.
|
||||
|
||||

|
||||
|
||||
#### Tripwire configuration path ####
|
||||
|
||||
Tripwire configuration saved in the /etc/tripwire/twcfg.txt file. It is used to generate encrypted configuration file tw.cfg.
|
||||
|
||||

|
||||
|
||||
**Tripwire Policy path**
|
||||
|
||||
Tripwire saves policies in /etc/tripwire/twpol.txt file . It is used for the generation of encrypted policy file tw.pol used by the tripwire.
|
||||
|
||||

|
||||
|
||||
Final installation of tripwire is shown in the following snapshot.
|
||||
|
||||

|
||||
|
||||
#### Tripwire Configuration file (twcfg.txt) ####
|
||||
|
||||
Tripwire configuration file (twcfg.txt) details is given below. Paths of encrypted policy file (tw.pol), site key (site.key) and local key (hostname-local.key) etc are given below.
|
||||
|
||||
ROOT =/usr/sbin
|
||||
|
||||
POLFILE =/etc/tripwire/tw.pol
|
||||
|
||||
DBFILE =/var/lib/tripwire/$(HOSTNAME).twd
|
||||
|
||||
REPORTFILE =/var/lib/tripwire/report/$(HOSTNAME)-$(DATE).twr
|
||||
|
||||
SITEKEYFILE =/etc/tripwire/site.key
|
||||
|
||||
LOCALKEYFILE =/etc/tripwire/$(HOSTNAME)-local.key
|
||||
|
||||
EDITOR =/usr/bin/editor
|
||||
|
||||
LATEPROMPTING =false
|
||||
|
||||
LOOSEDIRECTORYCHECKING =false
|
||||
|
||||
MAILNOVIOLATIONS =true
|
||||
|
||||
EMAILREPORTLEVEL =3
|
||||
|
||||
REPORTLEVEL =3
|
||||
|
||||
SYSLOGREPORTING =true
|
||||
|
||||
MAILMETHOD =SMTP
|
||||
|
||||
SMTPHOST =localhost
|
||||
|
||||
SMTPPORT =25
|
||||
|
||||
TEMPDIRECTORY =/tmp
|
||||
|
||||
#### Tripwire Policy Configuration ####
|
||||
|
||||
Configure tripwire configuration before generation of baseline database. It is necessary to disable few policies such as /dev , /proc ,/root/mail etc. Detailed policy file twpol.txt is given below.
|
||||
|
||||
@@section GLOBAL
|
||||
TWBIN = /usr/sbin;
|
||||
TWETC = /etc/tripwire;
|
||||
TWVAR = /var/lib/tripwire;
|
||||
|
||||
#
|
||||
# File System Definitions
|
||||
#
|
||||
@@section FS
|
||||
|
||||
#
|
||||
# First, some variables to make configuration easier
|
||||
#
|
||||
SEC_CRIT = $(IgnoreNone)-SHa ; # Critical files that cannot change
|
||||
|
||||
SEC_BIN = $(ReadOnly) ; # Binaries that should not change
|
||||
|
||||
SEC_CONFIG = $(Dynamic) ; # Config files that are changed
|
||||
# infrequently but accessed
|
||||
# often
|
||||
|
||||
SEC_LOG = $(Growing) ; # Files that grow, but that
|
||||
# should never change ownership
|
||||
|
||||
SEC_INVARIANT = +tpug ; # Directories that should never
|
||||
# change permission or ownership
|
||||
|
||||
SIG_LOW = 33 ; # Non-critical files that are of
|
||||
# minimal security impact
|
||||
|
||||
SIG_MED = 66 ; # Non-critical files that are of
|
||||
# significant security impact
|
||||
|
||||
SIG_HI = 100 ; # Critical files that are
|
||||
# significant points of
|
||||
# vulnerability
|
||||
|
||||
#
|
||||
# Tripwire Binaries
|
||||
#
|
||||
(
|
||||
rulename = "Tripwire Binaries",
|
||||
severity = $(SIG_HI)
|
||||
)
|
||||
{
|
||||
$(TWBIN)/siggen -> $(SEC_BIN) ;
|
||||
$(TWBIN)/tripwire -> $(SEC_BIN) ;
|
||||
$(TWBIN)/twadmin -> $(SEC_BIN) ;
|
||||
$(TWBIN)/twprint -> $(SEC_BIN) ;
|
||||
}
|
||||
{
|
||||
/boot -> $(SEC_CRIT) ;
|
||||
/lib/modules -> $(SEC_CRIT) ;
|
||||
}
|
||||
|
||||
(
|
||||
rulename = "Boot Scripts",
|
||||
severity = $(SIG_HI)
|
||||
)
|
||||
{
|
||||
/etc/init.d -> $(SEC_BIN) ;
|
||||
#/etc/rc.boot -> $(SEC_BIN) ;
|
||||
/etc/rcS.d -> $(SEC_BIN) ;
|
||||
/etc/rc0.d -> $(SEC_BIN) ;
|
||||
/etc/rc1.d -> $(SEC_BIN) ;
|
||||
/etc/rc2.d -> $(SEC_BIN) ;
|
||||
/etc/rc3.d -> $(SEC_BIN) ;
|
||||
/etc/rc4.d -> $(SEC_BIN) ;
|
||||
/etc/rc5.d -> $(SEC_BIN) ;
|
||||
/etc/rc6.d -> $(SEC_BIN) ;
|
||||
}
|
||||
|
||||
(
|
||||
rulename = "Root file-system executables",
|
||||
severity = $(SIG_HI)
|
||||
)
|
||||
{
|
||||
/bin -> $(SEC_BIN) ;
|
||||
/sbin -> $(SEC_BIN) ;
|
||||
}
|
||||
|
||||
#
|
||||
# Critical Libraries
|
||||
#
|
||||
(
|
||||
rulename = "Root file-system libraries",
|
||||
severity = $(SIG_HI)
|
||||
)
|
||||
{
|
||||
/lib -> $(SEC_BIN) ;
|
||||
}
|
||||
|
||||
#
|
||||
# Login and Privilege Raising Programs
|
||||
#
|
||||
(
|
||||
rulename = "Security Control",
|
||||
severity = $(SIG_MED)
|
||||
)
|
||||
{
|
||||
/etc/passwd -> $(SEC_CONFIG) ;
|
||||
/etc/shadow -> $(SEC_CONFIG) ;
|
||||
}
|
||||
{
|
||||
#/var/lock -> $(SEC_CONFIG) ;
|
||||
#/var/run -> $(SEC_CONFIG) ; # daemon PIDs
|
||||
/var/log -> $(SEC_CONFIG) ;
|
||||
}
|
||||
|
||||
# These files change the behavior of the root account
|
||||
(
|
||||
rulename = "Root config files",
|
||||
severity = 100
|
||||
)
|
||||
{
|
||||
/root -> $(SEC_CRIT) ; # Catch all additions to /root
|
||||
#/root/mail -> $(SEC_CONFIG) ;
|
||||
#/root/Mail -> $(SEC_CONFIG) ;
|
||||
/root/.xsession-errors -> $(SEC_CONFIG) ;
|
||||
#/root/.xauth -> $(SEC_CONFIG) ;
|
||||
#/root/.tcshrc -> $(SEC_CONFIG) ;
|
||||
#/root/.sawfish -> $(SEC_CONFIG) ;
|
||||
#/root/.pinerc -> $(SEC_CONFIG) ;
|
||||
#/root/.mc -> $(SEC_CONFIG) ;
|
||||
#/root/.gnome_private -> $(SEC_CONFIG) ;
|
||||
#/root/.gnome-desktop -> $(SEC_CONFIG) ;
|
||||
#/root/.gnome -> $(SEC_CONFIG) ;
|
||||
#/root/.esd_auth -> $(SEC_CONFIG) ;
|
||||
# /root/.elm -> $(SEC_CONFIG) ;
|
||||
#/root/.cshrc -> $(SEC_CONFIG) ;
|
||||
#/root/.bashrc -> $(SEC_CONFIG) ;
|
||||
#/root/.bash_profile -> $(SEC_CONFIG) ;
|
||||
# /root/.bash_logout -> $(SEC_CONFIG) ;
|
||||
#/root/.bash_history -> $(SEC_CONFIG) ;
|
||||
#/root/.amandahosts -> $(SEC_CONFIG) ;
|
||||
#/root/.addressbook.lu -> $(SEC_CONFIG) ;
|
||||
#/root/.addressbook -> $(SEC_CONFIG) ;
|
||||
#/root/.Xresources -> $(SEC_CONFIG) ;
|
||||
#/root/.Xauthority -> $(SEC_CONFIG) -i ; # Changes Inode number on login
|
||||
/root/.ICEauthority -> $(SEC_CONFIG) ;
|
||||
}
|
||||
|
||||
#
|
||||
# Critical devices
|
||||
#
|
||||
(
|
||||
rulename = "Devices & Kernel information",
|
||||
severity = $(SIG_HI),
|
||||
)
|
||||
{
|
||||
#/dev -> $(Device) ;
|
||||
#/proc -> $(Device) ;
|
||||
}
|
||||
|
||||
#### Tripwire Report ####
|
||||
|
||||
**tripwire –check** command checks the twpol.txt file and based on this file generates tripwire report which is shown below. If this is any error in the twpol.txt file, tripwire does not generate report.
|
||||
|
||||

|
||||
|
||||
**Report in text form**
|
||||
|
||||
root@VMdebian:/home/labadmin# tripwire --check
|
||||
|
||||
Parsing policy file: /etc/tripwire/tw.pol
|
||||
|
||||
*** Processing Unix File System ***
|
||||
|
||||
Performing integrity check...
|
||||
|
||||
Wrote report file: /var/lib/tripwire/report/VMdebian-20151024-122322.twr
|
||||
|
||||
Open Source Tripwire(R) 2.4.2.2 Integrity Check Report
|
||||
|
||||
Report generated by: root
|
||||
|
||||
Report created on: Sat Oct 24 12:23:22 2015
|
||||
|
||||
Database last updated on: Never
|
||||
|
||||
Report Summary:
|
||||
|
||||
=========================================================
|
||||
|
||||
Host name: VMdebian
|
||||
|
||||
Host IP address: 127.0.1.1
|
||||
|
||||
Host ID: None
|
||||
|
||||
Policy file used: /etc/tripwire/tw.pol
|
||||
|
||||
Configuration file used: /etc/tripwire/tw.cfg
|
||||
|
||||
Database file used: /var/lib/tripwire/VMdebian.twd
|
||||
|
||||
Command line used: tripwire --check
|
||||
|
||||
=========================================================
|
||||
|
||||
Rule Summary:
|
||||
|
||||
=========================================================
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
Section: Unix File System
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
Rule Name Severity Level Added Removed Modified
|
||||
|
||||
--------- -------------- ----- ------- --------
|
||||
|
||||
Other binaries 66 0 0 0
|
||||
|
||||
Tripwire Binaries 100 0 0 0
|
||||
|
||||
Other libraries 66 0 0 0
|
||||
|
||||
Root file-system executables 100 0 0 0
|
||||
|
||||
Tripwire Data Files 100 0 0 0
|
||||
|
||||
System boot changes 100 0 0 0
|
||||
|
||||
(/var/log)
|
||||
|
||||
Root file-system libraries 100 0 0 0
|
||||
|
||||
(/lib)
|
||||
|
||||
Critical system boot files 100 0 0 0
|
||||
|
||||
Other configuration files 66 0 0 0
|
||||
|
||||
(/etc)
|
||||
|
||||
Boot Scripts 100 0 0 0
|
||||
|
||||
Security Control 66 0 0 0
|
||||
|
||||
Root config files 100 0 0 0
|
||||
|
||||
Invariant Directories 66 0 0 0
|
||||
|
||||
Total objects scanned: 25943
|
||||
|
||||
Total violations found: 0
|
||||
|
||||
=========================Object Summary:================================
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
# Section: Unix File System
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
No violations.
|
||||
|
||||
===========================Error Report:=====================================
|
||||
|
||||
No Errors
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
*** End of report ***
|
||||
|
||||
Open Source Tripwire 2.4 Portions copyright 2000 Tripwire, Inc. Tripwire is a registered
|
||||
|
||||
trademark of Tripwire, Inc. This software comes with ABSOLUTELY NO WARRANTY;
|
||||
|
||||
for details use --version. This is free software which may be redistributed
|
||||
|
||||
or modified only under certain conditions; see COPYING for details.
|
||||
|
||||
All rights reserved.
|
||||
|
||||
Integrity check complete.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, we learned installation and basic configuration of open source IDS tool Tripwire. First it generates baseline database and detects any change (file/folder) by comparing it with already generated baseline. However, tripwire is not live monitoring IDS.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/configure-tripwire-ids-debian/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者zky001](https://github.com/zky001)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
@ -0,0 +1,156 @@
|
||||
How to send email notifications using Gmail SMTP server on Linux
|
||||
================================================================================
|
||||
Suppose you want to configure a Linux app to send out email messages from your server or desktop. The email messages can be part of email newsletters, status updates (e.g., [Cachet][1]), monitoring alerts (e.g., [Monit][2]), disk events (e.g., [RAID mdadm][3]), and so on. While you can set up your [own outgoing mail server][4] to deliver messages, you can alternatively rely on a freely available public SMTP server as a maintenance-free option.
|
||||
|
||||
One of the most reliable **free SMTP servers** is from Google's Gmail service. All you have to do to send email notifications within your app is to add Gmail's SMTP server address and your credentials to the app, and you are good to go.
|
||||
|
||||
One catch with using Gmail's SMTP server is that there are various restrictions in place, mainly to combat spammers and email marketers who often abuse the server. For example, you can send messages to no more than 100 addresses at once, and no more than 500 recipients per day. Also, if you don't want to be flagged as a spammer, you cannot send a large number of undeliverable messages. When any of these limitations is reached, your Gmail account will temporarily be locked out for a day. In short, Gmail's SMTP server is perfectly fine for your personal use, but not meant for commercial bulk emails.
|
||||
|
||||
With that being said, let me demonstrate **how to use Gmail's SMTP server in Linux environment**.
|
||||
|
||||
### Google Gmail SMTP Server Setting ###
|
||||
|
||||
If you want to send emails from your app using Gmail's SMTP server, remember the following details.
|
||||
|
||||
- **Outgoing mail server (SMTP server)**: smtp.gmail.com
|
||||
- **Use authentication**: yes
|
||||
- **Use secure connection**: yes
|
||||
- **Username**: your Gmail account ID (e.g., "alice" if your email is alice@gmail.com)
|
||||
- **Password**: your Gmail password
|
||||
- **Port**: 587
|
||||
|
||||
Exact configuration syntax may vary depending on apps. In the rest of this tutorial, I will show you several useful examples of using Gmail SMTP server in Linux.
|
||||
|
||||
### Send Emails from the Command Line ###
|
||||
|
||||
As the first example, let's try the most basic email functionality: send an email from the command line using Gmail SMTP server. For this, I am going to use a command-line email client called mutt.
|
||||
|
||||
First, install mutt:
|
||||
|
||||
For Debian-based system:
|
||||
|
||||
$ sudo apt-get install mutt
|
||||
|
||||
For Red Hat based system:
|
||||
|
||||
$ sudo yum install mutt
|
||||
|
||||
Create a mutt configuration file (~/.muttrc) and specify in the file Gmail SMTP server information as follows. Replace <gmail-id> with your own Gmail ID. Note that this configuration is for sending emails only (not receiving emails).
|
||||
|
||||
$ vi ~/.muttrc
|
||||
|
||||
----------
|
||||
|
||||
set from = "<gmail-id>@gmail.com"
|
||||
set realname = "Dan Nanni"
|
||||
set smtp_url = "smtp://<gmail-id>@smtp.gmail.com:587/"
|
||||
set smtp_pass = "<gmail-password>"
|
||||
|
||||
Now you are ready to send out an email using mutt:
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com
|
||||
|
||||
To attach a file in an email, use "-a" option:
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com -a ~/test_attachment.jpg
|
||||
|
||||

|
||||
|
||||
Using Gmail SMTP server means that the emails appear as sent from your Gmail account. In other words, a recepient will see your Gmail address as the sender's address. If you want to use your domain as the email sender, you need to use Gmail SMTP relay service instead.
|
||||
|
||||
### Send Email Notification When a Server is Rebooted ###
|
||||
|
||||
If you are running a [virtual private server (VPS)][5] for some critical website, one recommendation is to monitor VPS reboot activities. As a more practical example, let's consider how to set up email notifications for every reboot event on your VPS. Here I assume you are using systemd on your VPS, and show you how to create a custom systemd boot-time service for automatic email notifications.
|
||||
|
||||
First create the following script reboot_notify.sh which takes care of email notifications.
|
||||
|
||||
$ sudo vi /usr/local/bin/reboot_notify.sh
|
||||
|
||||
----------
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
echo "`hostname` was rebooted on `date`" | mutt -F /etc/muttrc -s "Notification on `hostname`" alice@yahoo.com
|
||||
|
||||
----------
|
||||
|
||||
$ sudo chmod +x /usr/local/bin/reboot_notify.sh
|
||||
|
||||
In the script, I use "-F" option to specify the location of system-wide mutt configuration file. So don't forget to create /etc/muttrc file and populate Gmail SMTP information as described earlier.
|
||||
|
||||
Now let's create a custom systemd service as follows.
|
||||
|
||||
$ sudo mkdir -p /usr/local/lib/systemd/system
|
||||
$ sudo vi /usr/local/lib/systemd/system/reboot-task.service
|
||||
|
||||
----------
|
||||
|
||||
[Unit]
|
||||
Description=Send a notification email when the server gets rebooted
|
||||
DefaultDependencies=no
|
||||
Before=reboot.target
|
||||
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=/usr/local/bin/reboot_notify.sh
|
||||
|
||||
[Install]
|
||||
WantedBy=reboot.target
|
||||
|
||||
Once the service file is created, enable and start the service.
|
||||
|
||||
$ sudo systemctl enable reboot-task
|
||||
$ sudo systemctl start reboot-task
|
||||
|
||||
From now on, you will be receiving a notification email every time the VPS gets rebooted.
|
||||
|
||||
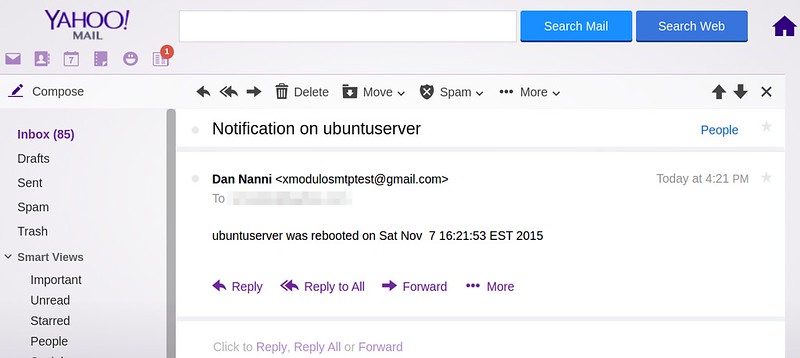
|
||||
|
||||
### Send Email Notification from Server Usage Monitoring ###
|
||||
|
||||
As a final example, let me present a real-world application called [Monit][6], which is a pretty useful server monitoring application. It comes with comprehensive [VPS][7] monitoring capabilities (e.g., CPU, memory, processes, file system), as well as email notification functions.
|
||||
|
||||
If you want to receive email notifications for any event on your VPS (e.g., server overload) generated by Monit, you can add the following SMTP information to Monit configuration file.
|
||||
|
||||
set mailserver smtp.gmail.com port 587
|
||||
username "<your-gmail-ID>" password "<gmail-password>"
|
||||
using tlsv12
|
||||
|
||||
set mail-format {
|
||||
from: <your-gmail-ID>@gmail.com
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
}
|
||||
|
||||
# the person who will receive notification emails
|
||||
set alert alice@yahoo.com
|
||||
|
||||
Here is the example email notification sent by Monit for excessive CPU load.
|
||||
|
||||
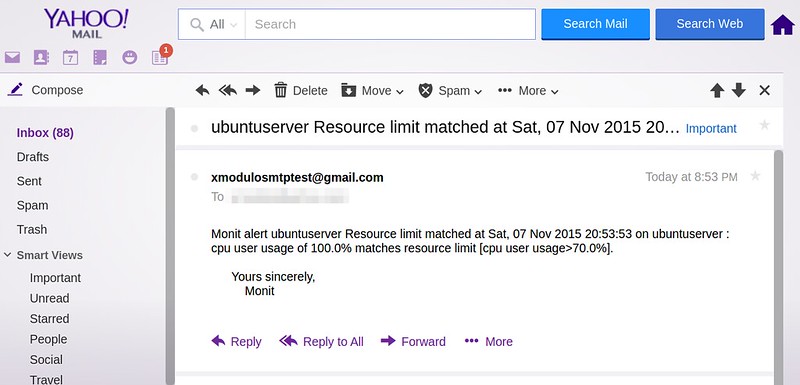
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you can imagine, there will be so many different ways to take advantage of free SMTP servers like Gmail. But once again, remember that the free SMTP server is not meant for commercial usage, but only for your own personal project. If you are using Gmail SMTP server inside any app, feel free to share your use case.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/send-email-notifications-gmail-smtp-server-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/setup-system-status-page.html
|
||||
[2]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[3]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[4]:http://xmodulo.com/mail-server-ubuntu-debian.html
|
||||
[5]:http://xmodulo.com/go/digitalocean
|
||||
[6]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[7]:http://xmodulo.com/go/digitalocean
|
||||
@ -0,0 +1,126 @@
|
||||
zpl1025
|
||||
Install Android On BQ Aquaris Ubuntu Phone In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
|
||||
|
||||
There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
|
||||
|
||||
Let’s see what to do we need to install Android on bq Aquaris.
|
||||
|
||||
### Prerequisite ###
|
||||
|
||||
- Working Internet connection to download Android factory image and install tools for flashing Android
|
||||
- USB data cable
|
||||
- A system running Linux
|
||||
|
||||
This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
|
||||
|
||||
### Replace Ubuntu with Android in bq Aquaris e4.5 ###
|
||||
|
||||
#### Step 1: Download Android firmware ####
|
||||
|
||||
First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
|
||||
|
||||
- [Download Android for bq Aquaris e4.5][1]
|
||||
|
||||
Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
|
||||
|
||||
I suggest to check the [bq support page and download][2] the latest firmware from there.
|
||||
|
||||
Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
|
||||
|
||||
#### Step 2: Download flash tool ####
|
||||
|
||||
bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
|
||||
|
||||
- [Download MTK Flash Tool][3]
|
||||
|
||||
Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
|
||||
|
||||
Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
|
||||
|
||||
#### Step 3: Remove conflicting packages (optional) ####
|
||||
|
||||
If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
|
||||
|
||||
To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
|
||||
|
||||
sudo apt-get remove modemmanager
|
||||
|
||||
Restart udev service with the command below:
|
||||
|
||||
sudo service udev restart
|
||||
|
||||
Just to check for any possible side effects on kernel module cdc_acm, run the command below:
|
||||
|
||||
lsmod | grep cdc_acm
|
||||
|
||||
If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
|
||||
|
||||
sudo modprobe cdc_acm
|
||||
|
||||
#### Step 4: Prepare to flash Android ####
|
||||
|
||||
Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
|
||||
|
||||
Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
|
||||
|
||||
cd ~/Downloads/SP_Flash*
|
||||
|
||||
After that use the command below to run the flash tool as root:
|
||||
|
||||
sudo ./flash_tool
|
||||
|
||||
You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
|
||||
|
||||

|
||||
|
||||
Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
|
||||
|
||||
When you do that, you’ll see several green lines like the one below:
|
||||
|
||||

|
||||
|
||||
#### Step 5: Flashing Android ####
|
||||
|
||||
We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
|
||||
|
||||
Select Firmware Upgrade from the dropdown and after that click on the big download button.
|
||||
|
||||

|
||||
|
||||
If everything is correct, you should see a flash status in the bottom of the tool:
|
||||
|
||||

|
||||
|
||||
When the procedure is successfully completed, you’ll see a notification like this:
|
||||
|
||||

|
||||
|
||||
Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
|
||||
|
||||
Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
|
||||
|
||||
I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-android-ubuntu-phone/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
|
||||
[2]:http://www.bq.com/gb/support/aquaris-e4-5
|
||||
[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
|
||||
[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
|
||||
@ -0,0 +1,317 @@
|
||||
How to Setup Drone - a Continuous Integration Service in Linux
|
||||
==============================================================
|
||||
|
||||
Are you tired of cloning, building, testing, and deploying codes time and again? If yes, switch to continuous integration. Continuous Integration aka CI is practice in software engineering of making frequent commits to the code base, building, testing and deploying as we go. CI helps to quickly integrate new codes into the existing code base. If this process is made automated, then this will speed up the development process as it reduces the time taken for the developer to build and test things manually. [Drone][1] is a free and open source project which provides an awesome environment of continuous integration service and is released under Apache License Version 2.0. It integrates with many repository providers like Github, Bitbucket and Google Code and has the ability to pull codes from the repositories enabling us to build the source code written in number of languages including PHP, Node, Ruby, Go, Dart, Python, C/C++, JAVA and more. It is made such a powerful platform cause it uses containers and docker technology for every build making users a complete control over their build environment with guaranteed isolation.
|
||||
|
||||
### 1. Installing Docker ###
|
||||
|
||||
First of all, we'll gonna install Docker as its the most vital element for the complete workflow of Drone. Drone does a proper utilization of docker for the purpose of building and testing application. This container technology speeds up the development of the applications. To install docker, we'll need to run the following commands with respective the distribution of linux. In this tutorial, we'll cover the steps with Ubuntu 14.04 and CentOS 7 linux distributions.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
To install Docker in Ubuntu, we can simply run the following commands in a terminal or console.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install docker.io
|
||||
|
||||
After the installation is done, we'll restart our docker engine using service command.
|
||||
|
||||
# service docker restart
|
||||
|
||||
Then, we'll make docker start automatically in every system boot.
|
||||
|
||||
# update-rc.d docker defaults
|
||||
|
||||
Adding system startup for /etc/init.d/docker ...
|
||||
/etc/rc0.d/K20docker -> ../init.d/docker
|
||||
/etc/rc1.d/K20docker -> ../init.d/docker
|
||||
/etc/rc6.d/K20docker -> ../init.d/docker
|
||||
/etc/rc2.d/S20docker -> ../init.d/docker
|
||||
/etc/rc3.d/S20docker -> ../init.d/docker
|
||||
/etc/rc4.d/S20docker -> ../init.d/docker
|
||||
/etc/rc5.d/S20docker -> ../init.d/docker
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
First, we'll gonna update every packages installed in our centos machine. We can do that by running the following command.
|
||||
|
||||
# sudo yum update
|
||||
|
||||
To install docker in centos, we can simply run the following commands.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||
After our docker engine is installed in our centos machine, we'll simply start it by running the following systemd command as systemd is the default init system in centos 7.
|
||||
|
||||
# systemctl start docker
|
||||
|
||||
Then, we'll enable docker to start automatically in every system startup.
|
||||
|
||||
# systemctl enable docker
|
||||
|
||||
ln -s '/usr/lib/systemd/system/docker.service' '/etc/systemd/system/multi-user.target.wants/docker.service'
|
||||
|
||||
### 2. Installing SQlite Driver ###
|
||||
|
||||
It uses SQlite3 database server for storing its data and information by default. It will automatically create a database file named drone.sqlite under /var/lib/drone/ which will handle database schema setup and migration. To setup SQlite3 drivers, we'll need to follow the below steps.
|
||||
|
||||
#### On Ubuntu 14.04 ####
|
||||
|
||||
As SQlite3 is available on the default respository of Ubuntu 14.04, we'll simply install it by running the following apt command.
|
||||
|
||||
# apt-get install libsqlite3-dev
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
To install it on CentOS 7 machine, we'll need to run the following yum command.
|
||||
|
||||
# yum install sqlite-devel
|
||||
|
||||
### 3. Installing Drone ###
|
||||
|
||||
Finally, after we have installed those dependencies successfully, we'll now go further towards the installation of drone in our machine. In this step, we'll simply download the binary package of it from the official download link of the respective binary formats and then install them using the default package manager.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
We'll use wget to download the debian package of drone for ubuntu from the [official Debian file download link][2]. Here is the command to download the required debian package of drone.
|
||||
|
||||
# wget downloads.drone.io/master/drone.deb
|
||||
|
||||
Resolving downloads.drone.io (downloads.drone.io)... 54.231.48.98
|
||||
Connecting to downloads.drone.io (downloads.drone.io)|54.231.48.98|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7722384 (7.4M) [application/x-debian-package]
|
||||
Saving to: 'drone.deb'
|
||||
100%[======================================>] 7,722,384 1.38MB/s in 17s
|
||||
2015-11-06 14:09:28 (456 KB/s) - 'drone.deb' saved [7722384/7722384]
|
||||
|
||||
After its downloaded, we'll gonna install it with dpkg package manager.
|
||||
|
||||
# dpkg -i drone.deb
|
||||
|
||||
Selecting previously unselected package drone.
|
||||
(Reading database ... 28077 files and directories currently installed.)
|
||||
Preparing to unpack drone.deb ...
|
||||
Unpacking drone (0.3.0-alpha-1442513246) ...
|
||||
Setting up drone (0.3.0-alpha-1442513246) ...
|
||||
Your system ubuntu 14: using upstart to control Drone
|
||||
drone start/running, process 9512
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
In the machine running CentOS, we'll download the RPM package from the [official download link for RPM][3] using wget command as shown below.
|
||||
|
||||
# wget downloads.drone.io/master/drone.rpm
|
||||
|
||||
--2015-11-06 11:06:45-- http://downloads.drone.io/master/drone.rpm
|
||||
Resolving downloads.drone.io (downloads.drone.io)... 54.231.114.18
|
||||
Connecting to downloads.drone.io (downloads.drone.io)|54.231.114.18|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7763311 (7.4M) [application/x-redhat-package-manager]
|
||||
Saving to: ‘drone.rpm’
|
||||
100%[======================================>] 7,763,311 1.18MB/s in 20s
|
||||
2015-11-06 11:07:06 (374 KB/s) - ‘drone.rpm’ saved [7763311/7763311]
|
||||
|
||||
Then, we'll install the download rpm package using yum package manager.
|
||||
|
||||
# yum localinstall drone.rpm
|
||||
|
||||
### 4. Configuring Port ###
|
||||
|
||||
After the installation is completed, we'll gonna configure drone to make it workable. The configuration of drone is inside **/etc/drone/drone.toml** file. By default, drone web interface is exposed under port 80 which is the default port of http, if we wanna change it, we can change it by replacing the value under server block as shown below.
|
||||
|
||||
[server]
|
||||
port=":80"
|
||||
|
||||
### 5. Integrating Github ###
|
||||
|
||||
In order to run Drone we must setup at least one integration points between GitHub, GitHub Enterprise, Gitlab, Gogs, Bitbucket. In this tutorial, we'll only integrate github but if we wanna integrate other we can do that from the configuration file. In order to integrate github, we'll need to create a new application in our [github settings][4].
|
||||
|
||||

|
||||
|
||||
To create, we'll need to click on Register a New Application then fill out the form as shown in the following image.
|
||||
|
||||

|
||||
|
||||
We should make sure that **Authorization callback URL** looks like http://drone.linoxide.com/api/auth/github.com under the configuration of the application. Then, we'll click on Register application. After done, we'll note the Client ID and Client Secret key as we'll need to configure it in our drone configuration.
|
||||
|
||||

|
||||
|
||||
After thats done, we'll need to edit our drone configuration using a text editor by running the following command.
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
Then, we'll find the [github] section and append the section with the above noted configuration as shown below.
|
||||
|
||||
[github]
|
||||
client="3dd44b969709c518603c"
|
||||
secret="4ee261abdb431bdc5e96b19cc3c498403853632a"
|
||||
# orgs=[]
|
||||
# open=false
|
||||
|
||||

|
||||
|
||||
### 6. Configuring SMTP server ###
|
||||
|
||||
If we wanna enable drone to send notifications via emails, then we'll need to specify the SMTP configuration of our SMTP server. If we already have an SMTP server, we can use its configuration but as we don't have an SMTP server, we'll need to install an MTA ie Postfix and then specify the SMTP configuration in the drone configuration.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
We can install postfix in ubuntu by running the following apt command.
|
||||
|
||||
# apt-get install postfix
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
We can install postfix in CentOS by running the following yum command.
|
||||
|
||||
# yum install postfix
|
||||
|
||||
After installing, we'll need to edit the configuration of our postfix configuration using a text editor.
|
||||
|
||||
# nano /etc/postfix/main.cf
|
||||
|
||||
Then, we'll need to replace the value of myhostname parameter to our FQDN ie drone.linoxide.com .
|
||||
|
||||
myhostname = drone.linoxide.com
|
||||
|
||||
Now, we'll gonna finally configure the SMTP section of our drone configuration file.
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
Then, we'll find the [stmp] section and then we'll need to append the setting as follows.
|
||||
|
||||
[smtp]
|
||||
host = "drone.linoxide.com"
|
||||
port = "587"
|
||||
from = "root@drone.linoxide.com"
|
||||
user = "root"
|
||||
pass = "password"
|
||||
|
||||

|
||||
|
||||
Note: Here, **user** and **pass** parameters are strongly recommended to be changed according to one's user configuration.
|
||||
|
||||
### 7. Configuring Worker ###
|
||||
|
||||
As we know that drone utilizes docker for its building and testing task, we'll need to configure docker as the worker for our drone. To do so, we'll need to edit the [worker] section in the drone configuration file.
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
Then, we'll uncomment the following lines and append as shown below.
|
||||
|
||||
[worker]
|
||||
nodes=[
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock"
|
||||
]
|
||||
|
||||
Here, we have set only 2 node which means the above configuration is capable of executing only 2 build at a time. In order to increase concurrency, we can increase the number of nodes.
|
||||
|
||||
[worker]
|
||||
nodes=[
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock"
|
||||
]
|
||||
|
||||
Here, in the above configuration, drone is configured to process four builds at a time, using the local docker daemon.
|
||||
|
||||
### 8. Restarting Drone ###
|
||||
|
||||
Finally, after everything is done regarding the installation and configuration, we'll now start our drone server in our linux machine.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
To start drone in our Ubuntu 14.04 machine, we'll simply run service command as the default init system of Ubuntu 14.04 is SysVinit.
|
||||
|
||||
# service drone restart
|
||||
|
||||
To make drone start automatically in every boot of the system, we'll run the following command.
|
||||
|
||||
# update-rc.d drone defaults
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
To start drone in CentOS machine, we'll simply run systemd command as CentOS 7 is shipped with systemd as init system.
|
||||
|
||||
# systemctl restart drone
|
||||
|
||||
Then, we'll enable drone to start automatically in every system boot.
|
||||
|
||||
# systemctl enable drone
|
||||
|
||||
### 9. Allowing Firewalls ###
|
||||
|
||||
As we know drone utilizes port 80 by default and we haven't changed the port, we'll gonna configure our firewall programs to allow port 80 (http) and be accessible from other machines in the network.
|
||||
|
||||
#### On Ubuntu 14.04 ####
|
||||
|
||||
Iptables is a popular firewall program which is installed in the ubuntu distributions by default. We'll make iptables to expose port 80 so that we can make our Drone web interface accessible in the network.
|
||||
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# /etc/init.d/iptables save
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
As CentOS 7 has systemd installed by default, it contains firewalld running as firewall problem. In order to open the port 80 (http service) on firewalld, we'll need to execute the following commands.
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
|
||||
success
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 10. Accessing Web Interface ###
|
||||
|
||||
Now, we'll gonna open the web interface of drone using our favourite web browser. To do so, we'll need to point our web browser to our machine running drone in it. As the default port of drone is 80 and we have also set 80 in this tutorial, we'll simply point our browser to http://ip-address/ or http://drone.linoxide.com according to our configuration. After we have done that correctly, we'll see the first page of it having options to login into our dashboard.
|
||||
|
||||

|
||||
|
||||
As we have configured Github in the above step, we'll simply select github and we'll go through the app authentication process and after its done, we'll be forwarded to our Dashboard.
|
||||
|
||||

|
||||
|
||||
Here, it will synchronize all our github repository and will ask us to activate the repo which we want to build with drone.
|
||||
|
||||

|
||||
|
||||
After its activated, it will ask us to add a new file named .drone.yml in our repository and define the build process and configuration in that file like which image to fetch and which command/script to run while compiling, etc.
|
||||
|
||||
We'll need to configure our .drone.yml as shown below.
|
||||
|
||||
image: python
|
||||
script:
|
||||
- python helloworld.py
|
||||
- echo "Build has been completed."
|
||||
|
||||
After its done, we'll be able to build our application using the configuration YAML file .drone.yml in our drone appliation. All the commits made into the repository is synced in realtime. It automatically syncs the commit and changes made to the repository. Once the commit is made in the repository, build is automatically started in our drone application.
|
||||
|
||||

|
||||
|
||||
After the build is completed, we'll be able to see the output of the build with the output console.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, we learned to completely setup a workable Continuous Intergration platform with Drone. If we want, we can even get started with the services provided by the official Drone.io project. We can start with free service or paid service according to our requirements. It has changed the world of Continuous integration with its beautiful web interface and powerful bunches of features. It has the ability to integrate with many third party applications and deployment platforms. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-drone-continuous-integration-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://drone.io/
|
||||
[2]:http://downloads.drone.io/master/drone.deb
|
||||
[3]:http://downloads.drone.io/master/drone.rpm
|
||||
[4]:https://github.com/settings/developers
|
||||
@ -0,0 +1,125 @@
|
||||
Install Android On BQ Aquaris Ubuntu Phone In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
If you happen to own the first Ubuntu phone and want to **replace Ubuntu with Android on the bq Aquaris e4.5**, this post is going to help you.
|
||||
|
||||
There can be plenty of reasons why you might want to remove Ubuntu and use the mainstream Android OS. One of the foremost reason is that the OS itself is at an early stage and intend to target developers and enthusiasts. Whatever may be your reason, installing Android on bq Aquaris is a piece of cake, thanks to the tools provided by bq.
|
||||
|
||||
Let’s see what to do we need to install Android on bq Aquaris.
|
||||
|
||||
### Prerequisite ###
|
||||
|
||||
- Working Internet connection to download Android factory image and install tools for flashing Android
|
||||
- USB data cable
|
||||
- A system running Linux
|
||||
|
||||
This tutorial is performed using Ubuntu 15.10. But the steps should be applicable to most other Linux distributions.
|
||||
|
||||
### Replace Ubuntu with Android in bq Aquaris e4.5 ###
|
||||
|
||||
#### Step 1: Download Android firmware ####
|
||||
|
||||
First step is to download the Android image for bq Aquaris e4.5. Good thing is that it is available from the bq’s support website. You can download the firmware, around 650 MB in size, from the link below:
|
||||
|
||||
- [Download Android for bq Aquaris e4.5][1]
|
||||
|
||||
Yes, you would get OTA updates with it. At present the firmware version is 2.0.1 which is based on Android Lolipop. Over time, there could be a new firmware based on Marshmallow and then the above link could be outdated.
|
||||
|
||||
I suggest to check the [bq support page][2] and download the latest firmware from there.
|
||||
|
||||
Once downloaded, extract it. In the extracted directory, look for **MT6582_Android_scatter.txt** file. We shall be using it later.
|
||||
|
||||
#### Step 2: Download flash tool ####
|
||||
|
||||
bq has provided its own flash tool, Herramienta MTK Flash Tool, for easier installation of Android or Ubuntu on the device. You can download the tool from the link below:
|
||||
|
||||
- [Download MTK Flash Tool][3]
|
||||
|
||||
Since the flash tool might be upgraded in future, you can always get the latest version of flash tool from the [bq support page][4].
|
||||
|
||||
Once downloaded extract the downloaded file. You should see an executable file named **flash_tool** in it. We shall be using it later.
|
||||
|
||||
#### Step 3: Remove conflicting packages (optional) ####
|
||||
|
||||
If you are using recent version of Ubuntu or Ubuntu based Linux distributions, you may encounter “BROM ERROR : S_UNDEFINED_ERROR (1001)” later in this tutorial.
|
||||
|
||||
To avoid this error, you’ll have to uninstall conflicting package. Use the commands below:
|
||||
|
||||
sudo apt-get remove modemmanager
|
||||
|
||||
Restart udev service with the command below:
|
||||
|
||||
sudo service udev restart
|
||||
|
||||
Just to check for any possible side effects on kernel module cdc_acm, run the command below:
|
||||
|
||||
lsmod | grep cdc_acm
|
||||
|
||||
If the output of the above command is an empty list, you’ll have to reinstall this kernel module:
|
||||
|
||||
sudo modprobe cdc_acm
|
||||
|
||||
#### Step 4: Prepare to flash Android ####
|
||||
|
||||
Go to the downloaded and extracted flash tool directory (in step 2). Use command line for this purpose because you’ll have to use the root privileges here.
|
||||
|
||||
Presuming that you saved it in the Downloads directory, use the command below to go to this directory (in case you do not know how to navigate between directories in command line).
|
||||
|
||||
cd ~/Downloads/SP_Flash*
|
||||
|
||||
After that use the command below to run the flash tool as root:
|
||||
|
||||
sudo ./flash_tool
|
||||
|
||||
You’ll see a window popped as the one below. Don’t bother about Download Agent field, it will be automatically filled. Just focus on Scatter-loading field.
|
||||
|
||||

|
||||
|
||||
Remember we talked about **MT6582_Android_scatter.txt** in step 1? This text file is in the extracted directory of the Andriod firmware you downloaded in step 1. Click on Scatter-loading (in the above picture) and point to MT6582_Android_scatter.txt file.
|
||||
|
||||
When you do that, you’ll see several green lines like the one below:
|
||||
|
||||

|
||||
|
||||
#### Step 5: Flashing Android ####
|
||||
|
||||
We are almost ready. Switch off your phone and connect it to your computer via a USB cable.
|
||||
|
||||
Select Firmware Upgrade from the dropdown and after that click on the big download button.
|
||||
|
||||

|
||||
|
||||
If everything is correct, you should see a flash status in the bottom of the tool:
|
||||
|
||||

|
||||
|
||||
When the procedure is successfully completed, you’ll see a notification like this:
|
||||
|
||||

|
||||
|
||||
Unplug your phone and power it on. You should see a white screen with AQUARIS written in the middle and at bottom, “powered by Android” would be displayed. It might take upto 10 minutes before you could configure and start using Android.
|
||||
|
||||
Note: If something goes wrong in the process, Press power, volume up, volume down button together and boot in to fast boot mode. Turn off again and connect the cable again. Repeat the process of firmware upgrade. It should work.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Thanks to the tools provided, it becomes easier to **flash Android on bq Ubuntu Phone**. Of course, you can use the same steps to replace Android with Ubuntu. All you need is to download Ubuntu firmware instead of Android.
|
||||
|
||||
I hope this tutorial helped you to replace Ubuntu with Android on your bq phone. If you have questions or suggestions, feel free to ask in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-android-ubuntu-phone/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5_L/2.0.1_20150623-1900_bq-FW.zip
|
||||
[2]:http://www.bq.com/gb/support/aquaris-e4-5
|
||||
[3]:https://storage.googleapis.com/otas/2014/Smartphones/Aquaris_E4.5/Ubuntu/Web%20version/Web%20version/SP_Flash_Tool_exe_linux_v5.1424.00.zip
|
||||
[4]:http://www.bq.com/gb/support/aquaris-e4-5-ubuntu-edition
|
||||
@ -0,0 +1,330 @@
|
||||
translating by ezio
|
||||
|
||||
Going Beyond Hello World Containers is Hard Stuff
|
||||
================================================================================
|
||||
In [my previous post][1], I provided the basic concepts behind Linux container technology. I wrote as much for you as I did for me. Containers are new to me. And I figured having the opportunity to blog about the subject would provide the motivation to really learn the stuff.
|
||||
|
||||
I intend to learn by doing. First get the concepts down, then get hands-on and write about it as I go. I assumed there must be a lot of Hello World type stuff out there to give me up to speed with the basics. Then, I could take things a bit further and build a microservice container or something.
|
||||
|
||||
I mean, it can’t be that hard, right?
|
||||
|
||||
Wrong.
|
||||
|
||||
Maybe it’s easy for someone who spends significant amount of their life immersed in operations work. But for me, getting started with this stuff turned out to be hard to the point of posting my frustrations to Facebook...
|
||||
|
||||
But, there is good news: I got it to work! And it’s always nice being able to make lemonade from lemons. So I am going to share the story of how I made my first microservice container with you. Maybe my pain will save you some time.
|
||||
|
||||
If you've ever found yourself in a situation like this, fear not: folks like me are here to deal with the problems so you don't have to!
|
||||
|
||||
Let’s begin.
|
||||
|
||||
### A Thumbnail Micro Service ###
|
||||
|
||||
The microservice I designed was simple in concept. Post a digital image in JPG or PNG format to an HTTP endpoint and get back a a 100px wide thumbnail.
|
||||
|
||||
Here’s what that looks like:
|
||||
|
||||

|
||||
|
||||
I decide to use a NodeJS for my code and version of [ImageMagick][2] to do the thumbnail transformation.
|
||||
|
||||
I did my first version of the service, using the logic shown here:
|
||||
|
||||

|
||||
|
||||
I download the [Docker Toolbox][3] which installs an the Docker Quickstart Terminal. Docker Quickstart Terminal makes creating containers easier. The terminal fires up a Linux virtual machine that has Docker installed, allowing you to run Docker commands from within a terminal.
|
||||
|
||||
In my case, I am running on OS X. But there’s a Windows version too.
|
||||
|
||||
I am going to use Docker Quickstart Terminal to build a container image for my microservice and run a container from that image.
|
||||
|
||||
The Docker Quickstart Terminal runs in your regular terminal, like so:
|
||||
|
||||

|
||||
|
||||
### The First Little Problem and the First Big Problem ###
|
||||
|
||||
So I fiddled around with NodeJS and ImageMagick and I got the service to work on my local machine.
|
||||
|
||||
Then, I created the Dockerfile, which is the configuration script Docker uses to build your container. (I’ll go more into builds and Dockerfile more later on.)
|
||||
|
||||
Here’s the build command I ran on the Docker Quickstart Terminal:
|
||||
|
||||
$ docker build -t thumbnailer:0.1
|
||||
|
||||
I got this response:
|
||||
|
||||
docker: "build" requires 1 argument.
|
||||
|
||||
Huh.
|
||||
|
||||
After 15 minutes I realized: I forgot to put a period . as the last argument!
|
||||
|
||||
It needs to be:
|
||||
|
||||
$ docker build -t thumbnailer:0.1 .
|
||||
|
||||
But this wasn’t the end of my problems.
|
||||
|
||||
I got the image to build and then I typed [the the `run` command][4] on the Docker Quickstart Terminal to fire up a container based on the image, called `thumbnailer:0.1`:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
The `-p 3001:3000` argument makes it so the NodeJS microservice running on port 3000 within the container binds to port 3001 on the host virtual machine.
|
||||
|
||||
Looks so good so far, right?
|
||||
|
||||
Wrong. Things are about to get pretty bad.
|
||||
|
||||
I determined the IP address of the virtual machine created by Docker Quickstart Terminal by running the `docker-machine` command:
|
||||
|
||||
$ docker-machine ip default
|
||||
|
||||
This returns the IP address of the default virtual machine, the one that is run under the Docker Quickstart Terminal. For me, this IP address was 192.168.99.100.
|
||||
|
||||
I browsed to http://192.168.99.100:3001/ and got the file upload page I built:
|
||||
|
||||

|
||||
|
||||
I selected a file and clicked the Upload Image button.
|
||||
|
||||
But it didn’t work.
|
||||
|
||||
The terminal is telling me it can’t find the `/upload` directory my microservice requires.
|
||||
|
||||
Now, keep in mind, I had been at this for about a day—between the fiddling and research. I’m feeling a little frustrated by this point.
|
||||
|
||||
Then, a brain spark flew. Somewhere along the line remembered reading a microservice should not do any data persistence on its own! Saving data should be the job of another service.
|
||||
|
||||
So what if the container can’t find the `/upload` directory? The real issue is: my microservice has a fundamentally flawed design.
|
||||
|
||||
Let’s take another look:
|
||||
|
||||

|
||||
|
||||
Why am I saving a file to disk? Microservices are supposed to be fast. Why not do all my work in memory? Using memory buffers will make the "I can’t find no stickin’ directory" error go away and will increase the performance of my app dramatically.
|
||||
|
||||
So that’s what I did. And here’s what the plan was:
|
||||
|
||||

|
||||
|
||||
Here’s the NodeJS I wrote to do all the in-memory work for creating a thumbnail:
|
||||
|
||||
// Bind to the packages
|
||||
var express = require('express');
|
||||
var router = express.Router();
|
||||
var path = require('path'); // used for file path
|
||||
var im = require("imagemagick");
|
||||
|
||||
// Simple get that allows you test that you can access the thumbnail process
|
||||
router.get('/', function (req, res, next) {
|
||||
res.status(200).send('Thumbnailer processor is up and running');
|
||||
});
|
||||
|
||||
// This is the POST handler. It will take the uploaded file and make a thumbnail from the
|
||||
// submitted byte array. I know, it's not rocket science, but it serves a purpose
|
||||
router.post('/', function (req, res, next) {
|
||||
req.pipe(req.busboy);
|
||||
req.busboy.on('file', function (fieldname, file, filename) {
|
||||
var ext = path.extname(filename)
|
||||
|
||||
// Make sure that only png and jpg is allowed
|
||||
if(ext.toLowerCase() != '.jpg' && ext.toLowerCase() != '.png'){
|
||||
res.status(406).send("Service accepts only jpg or png files");
|
||||
}
|
||||
|
||||
var bytes = [];
|
||||
|
||||
// put the bytes from the request into a byte array
|
||||
file.on('data', function(data) {
|
||||
for (var i = 0; i < data.length; ++i) {
|
||||
bytes.push(data[i]);
|
||||
}
|
||||
console.log('File [' + fieldname + '] got bytes ' + bytes.length + ' bytes');
|
||||
});
|
||||
|
||||
// Once the request is finished pushing the file bytes into the array, put the bytes in
|
||||
// a buffer and process that buffer with the imagemagick resize function
|
||||
file.on('end', function() {
|
||||
var buffer = new Buffer(bytes,'binary');
|
||||
console.log('Bytes got ' + bytes.length + ' bytes');
|
||||
|
||||
//resize
|
||||
im.resize({
|
||||
srcData: buffer,
|
||||
height: 100
|
||||
}, function(err, stdout, stderr){
|
||||
if (err){
|
||||
throw err;
|
||||
}
|
||||
// get the extension without the period
|
||||
var typ = path.extname(filename).replace('.','');
|
||||
res.setHeader("content-type", "image/" + typ);
|
||||
res.status(200);
|
||||
// send the image back as a response
|
||||
res.send(new Buffer(stdout,'binary'));
|
||||
});
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
module.exports = router;
|
||||
|
||||
Okay, so we’re back on track and everything is hunky dory on my local machine. I go to sleep.
|
||||
|
||||
But, before I do I test the microservice code running as standard Node app on localhost...
|
||||
|
||||

|
||||
|
||||
It works fine. Now all I needed to do was get it working in a container.
|
||||
|
||||
The next day I woke up, grabbed some coffee, and built an image—not forgetting to put in the period!
|
||||
|
||||
$ docker build -t thumbnailer:01 .
|
||||
|
||||
I am building from the root directory of my thumbnailer project. The build command uses the Dockerfile that is in the root directory. That’s how it goes: put the Dockerfile in the same place you want to run build and the Dockerfile will be used by default.
|
||||
|
||||
Here is the text of the Dockerfile I was using:
|
||||
|
||||
FROM ubuntu:latest
|
||||
MAINTAINER bob@CogArtTech.com
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
COPY ./package.json src/
|
||||
|
||||
RUN cd src && npm install
|
||||
|
||||
COPY . /src
|
||||
|
||||
WORKDIR src/
|
||||
|
||||
CMD npm start
|
||||
|
||||
What could go wrong?
|
||||
|
||||
### The Second Big Problem ###
|
||||
|
||||
I ran the `build` command and I got this error:
|
||||
|
||||
Do you want to continue? [Y/n] Abort.
|
||||
|
||||
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
|
||||
|
||||
I figured something was wrong with the microservice. I went back to my machine, fired up the service on localhost, and uploaded a file.
|
||||
|
||||
Then I got this error from NodeJS:
|
||||
|
||||
Error: spawn convert ENOENT
|
||||
|
||||
What’s going on? This worked the other night!
|
||||
|
||||
I searched and searched, for every permutation of the error I could think of. After about four hours of replacing different node modules here and there, I figured: why not restart the machine?
|
||||
|
||||
I did. And guess what? The error went away!
|
||||
|
||||
Go figure.
|
||||
|
||||
### Putting the Genie Back in the Bottle ###
|
||||
|
||||
So, back to the original quest: I needed to get this build working.
|
||||
|
||||
I removed all of the containers running on the VM, using [the `rm` command][5]:
|
||||
|
||||
$ docker rm -f $(docker ps -a -q)
|
||||
|
||||
The `-f` flag here force removes running images.
|
||||
|
||||
Then I removed all of my Docker images, using [the `rmi` command][6]:
|
||||
|
||||
$ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
|
||||
|
||||
I go through the whole process of rebuilding the image, installing the container and try to get the microservice running. Then after about an hour of self-doubt and accompanying frustration, I thought to myself: maybe this isn’t a problem with the microservice.
|
||||
|
||||
So, I looked that the the error again:
|
||||
|
||||
Do you want to continue? [Y/n] Abort.
|
||||
|
||||
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
|
||||
|
||||
Then it hit me: the build is looking for a Y input from the keyboard! But, this is a non-interactive Dockerfile script. There is no keyboard.
|
||||
|
||||
I went back to the Dockerfile, and there it was:
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
The second `apt-get` command is missing the `-y` flag which causes "yes" to be given automatically where usually it would be prompted for.
|
||||
|
||||
I added the missing `-y` to the command:
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install -y imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
And guess what: after two days of trial and tribulation, it worked! Two whole days!
|
||||
|
||||
So, I did my build:
|
||||
|
||||
$ docker build -t thumbnailer:0.1 .
|
||||
|
||||
I fired up the container:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
Got the IP address of the Virtual Machine:
|
||||
|
||||
$ docker-machine ip default
|
||||
|
||||
Went to my browser and entered http://192.168.99.100:3001/ into the address bar.
|
||||
|
||||
The upload page loaded.
|
||||
|
||||
I selected an image, and this is what I got:
|
||||
|
||||

|
||||
|
||||
It worked!
|
||||
|
||||
Inside a container, for the first time!
|
||||
|
||||
### So What Does It All Mean? ###
|
||||
|
||||
A long time ago, I accepted the fact when it comes to tech, sometimes even the easy stuff is hard. Along with that, I abandoned the desire to be the smartest guy in the room. Still, the last few days trying get basic competency with containers has been, at times, a journey of self doubt.
|
||||
|
||||
But, you wanna know something? It’s 2 AM on an early morning as I write this, and every nerve wracking hour has been worth it. Why? Because you gotta put in the time. This stuff is hard and it does not come easy for anyone. And don’t forget: you’re learning tech and tech runs the world!
|
||||
|
||||
P.S. Check out this two part video of Hello World containers, check out [Raziel Tabib’s][7] excellent work in this video...
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/PJ95WY2DqXo" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
And don't miss part two...
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/lss2rZ3Ppuk" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:http://deis.com/blog/2015/developer-journey-linux-containers
|
||||
[2]:https://github.com/rsms/node-imagemagick
|
||||
[3]:https://www.docker.com/toolbox
|
||||
[4]:https://docs.docker.com/reference/commandline/run/
|
||||
[5]:https://docs.docker.com/reference/commandline/rm/
|
||||
[6]:https://docs.docker.com/reference/commandline/rmi/
|
||||
[7]:http://twitter.com/RazielTabib
|
||||
@ -0,0 +1,242 @@
|
||||
How to Install Revive Adserver on Ubuntu 15.04 / CentOS 7
|
||||
================================================================================
|
||||
Revive AdserverHow to Install Revive Adserver on Ubuntu 15.04 / CentOS 7 is a free and open source advertisement management system that enables publishers, ad networks and advertisers to serve ads on websites, apps, videos and manage campaigns for multiple advertiser with many features. Revive Adserver is licensed under GNU Public License which is also known as OpenX Source. It features an integrated banner management interface, URL targeting, geo-targeting and tracking system for gathering statistics. This application enables website owners to manage banners from both in-house advertisement campaigns as well as from paid or third-party sources, such as Google's AdSense. Here, in this tutorial, we'll gonna install Revive Adserver in our machine running Ubuntu 15.04 or CentOS 7.
|
||||
|
||||
### 1. Installing LAMP Stack ###
|
||||
|
||||
First of all, as Revive Adserver requires a complete LAMP Stack to work, we'll gonna install it. LAMP Stack is the combination of Apache Web Server, MySQL/MariaDB Database Server and PHP modules. To run Revive properly, we'll need to install some PHP modules like apc, zlib, xml, pcre, mysql and mbstring. To setup LAMP Stack, we'll need to run the following command with respect to the distribution of linux we are currently running.
|
||||
|
||||
#### On Ubuntu 15.04 ####
|
||||
|
||||
# apt-get install apache2 mariadb-server php5 php5-gd php5-mysql php5-curl php-apc zlibc zlib1g zlib1g-dev libpcre3 libpcre3-dev libapache2-mod-php5 zip
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
# yum install httpd mariadb php php-gd php-mysql php-curl php-mbstring php-xml php-apc zlibc zlib1g zlib1g-dev libpcre3 libpcre3-dev zip
|
||||
|
||||
### 2. Starting Apache and MariaDB server ###
|
||||
|
||||
We’ll now start our newly installed Apache web server and MariaDB database server in our linux machine. To do so, we'll need to execute the following commands.
|
||||
|
||||
#### On Ubuntu 15.04 ####
|
||||
|
||||
Ubuntu 15.04 is shipped with Systemd as its default init system, so we'll need to execute the following commands to start apache and mariadb daemons.
|
||||
|
||||
# systemctl start apache2 mysql
|
||||
|
||||
After its started, we'll now make it able to start automatically in every system boot by running the following command.
|
||||
|
||||
# systemctl enable apache2 mysql
|
||||
|
||||
Synchronizing state for apache2.service with sysvinit using update-rc.d...
|
||||
Executing /usr/sbin/update-rc.d apache2 defaults
|
||||
Executing /usr/sbin/update-rc.d apache2 enable
|
||||
Synchronizing state for mysql.service with sysvinit using update-rc.d...
|
||||
Executing /usr/sbin/update-rc.d mysql defaults
|
||||
Executing /usr/sbin/update-rc.d mysql enable
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
Also in CentOS 7, systemd is the default init system so, we'll run the following command to start them.
|
||||
|
||||
# systemctl start httpd mariadb
|
||||
|
||||
Next, we'll enable them to start automatically in every startup of init system using the following command.
|
||||
|
||||
# systemctl enable httpd mariadb
|
||||
|
||||
ln -s '/usr/lib/systemd/system/httpd.service' '/etc/systemd/system/multi-user.target.wants/httpd.service'
|
||||
ln -s '/usr/lib/systemd/system/mariadb.service' '/etc/systemd/system/multi-user.target.wants/mariadb.service'
|
||||
|
||||
### 3. Configuring MariaDB ###
|
||||
|
||||
#### On CentOS 7/Ubuntu 15.04 ####
|
||||
|
||||
Now, as we are starting MariaDB for the first time and no password has been assigned for MariaDB so, we’ll first need to configure a root password for it. Then, we’ll gonna create a new database so that it can store data for our Revive Adserver installation.
|
||||
|
||||
To configure MariaDB and assign a root password, we’ll need to run the following command.
|
||||
|
||||
# mysql_secure_installation
|
||||
|
||||
This will ask us to enter the password for root but as we haven’t set any password before and its our first time we’ve installed mariadb, we’ll simply press enter and go further. Then, we’ll be asked to set root password, here we’ll hit Y and enter our password for root of MariaDB. Then, we’ll simply hit enter to set the default values for the further configurations.
|
||||
|
||||
….
|
||||
so you should just press enter here.
|
||||
|
||||
Enter current password for root (enter for none):
|
||||
OK, successfully used password, moving on…
|
||||
|
||||
Setting the root password ensures that nobody can log into the MariaDB
|
||||
root user without the proper authorisation.
|
||||
|
||||
Set root password? [Y/n] y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
Password updated successfully!
|
||||
Reloading privilege tables..
|
||||
… Success!
|
||||
…
|
||||
installation should now be secure.
|
||||
Thanks for using MariaDB!
|
||||
|
||||

|
||||
|
||||
### 4. Creating new Database ###
|
||||
|
||||
After we have assigned the password to our root user of mariadb server, we'll now create a new database for Revive Adserver application so that it can store its data into the database server. To do so, first we'll need to login to our MariaDB console by running the following command.
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
Then, it will ask us to enter the password of root user which we had just set in the above step. Then, we'll be welcomed into the MariaDB console in which we'll create our new database, database user and assign its password and grant all privileges to create, remove and edit the tables and data stored in it.
|
||||
|
||||
> CREATE DATABASE revivedb;
|
||||
> CREATE USER 'reviveuser'@'localhost' IDENTIFIED BY 'Pa$$worD123';
|
||||
> GRANT ALL PRIVILEGES ON revivedb.* TO 'reviveuser'@'localhost';
|
||||
> FLUSH PRIVILEGES;
|
||||
> EXIT;
|
||||
|
||||

|
||||
|
||||
### 5. Downloading Revive Adserver Package ###
|
||||
|
||||
Next, we'll download the latest release of Revive Adserver ie version 3.2.2 in the time of writing this article. So, we'll first get the download link from the official Download Page of Revive Adserver ie [http://www.revive-adserver.com/download/][1] then we'll download the compressed zip file using wget command under /tmp/ directory as shown bellow.
|
||||
|
||||
# cd /tmp/
|
||||
# wget http://download.revive-adserver.com/revive-adserver-3.2.2.zip
|
||||
|
||||
--2015-11-09 17:03:48-- http://download.revive-adserver.com/revive-adserver-3.2.2.zip
|
||||
Resolving download.revive-adserver.com (download.revive-adserver.com)... 54.230.119.219, 54.239.132.177, 54.230.116.214, ...
|
||||
Connecting to download.revive-adserver.com (download.revive-adserver.com)|54.230.119.219|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 11663620 (11M) [application/zip]
|
||||
Saving to: 'revive-adserver-3.2.2.zip'
|
||||
revive-adserver-3.2 100%[=====================>] 11.12M 1.80MB/s in 13s
|
||||
2015-11-09 17:04:02 (906 KB/s) - 'revive-adserver-3.2.2.zip' saved [11663620/11663620]
|
||||
|
||||
After the file is downloaded, we'll simply extract its files and directories using unzip command.
|
||||
|
||||
# unzip revive-adserver-3.2.2.zip
|
||||
|
||||
Then, we'll gonna move the entire Revive directories including every files from /tmp to the default webroot of Apache Web Server ie /var/www/html/ directory.
|
||||
|
||||
# mv revive-adserver-3.2.2 /var/www/html/reviveads
|
||||
|
||||
### 6. Configuring Apache Web Server ###
|
||||
|
||||
We'll now configure our Apache Server so that revive will run with proper configuration. To do so, we'll create a new virtualhost by creating a new configuration file named reviveads.conf . The directory here may differ from one distribution to another, here is how we create in the following distributions of linux.
|
||||
|
||||
#### On Ubuntu 15.04 ####
|
||||
|
||||
# touch /etc/apache2/sites-available/reviveads.conf
|
||||
# ln -s /etc/apache2/sites-available/reviveads.conf /etc/apache2/sites-enabled/reviveads.conf
|
||||
# nano /etc/apache2/sites-available/reviveads.conf
|
||||
|
||||
Now, we'll gonna add the following lines of configuration into this file using our favorite text editor.
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin info@reviveads.linoxide.com
|
||||
DocumentRoot /var/www/html/reviveads/
|
||||
ServerName reviveads.linoxide.com
|
||||
ServerAlias www.reviveads.linoxide.com
|
||||
<Directory /var/www/html/reviveads/>
|
||||
Options FollowSymLinks
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
ErrorLog /var/log/apache2/reviveads.linoxide.com-error_log
|
||||
CustomLog /var/log/apache2/reviveads.linoxide.com-access_log common
|
||||
</VirtualHost>
|
||||
|
||||

|
||||
|
||||
After done, we'll gonna save the file and exit our text editor. Then, we'll restart our Apache Web server.
|
||||
|
||||
# systemctl restart apache2
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
In CentOS, we'll directly create the file reviveads.conf under /etc/httpd/conf.d/ directory using our favorite text editor.
|
||||
|
||||
# nano /etc/httpd/conf.d/reviveads.conf
|
||||
|
||||
Then, we'll gonna add the following lines of configuration into the file.
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin info@reviveads.linoxide.com
|
||||
DocumentRoot /var/www/html/reviveads/
|
||||
ServerName reviveads.linoxide.com
|
||||
ServerAlias www.reviveads.linoxide.com
|
||||
<Directory /var/www/html/reviveads/>
|
||||
Options FollowSymLinks
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
ErrorLog /var/log/httpd/reviveads.linoxide.com-error_log
|
||||
CustomLog /var/log/httpd/reviveads.linoxide.com-access_log common
|
||||
</VirtualHost>
|
||||
|
||||

|
||||
|
||||
Once done, we'll simply save the file and exit the editor. And then, we'll gonna restart our apache web server.
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||
### 7. Fixing Permissions and Ownership ###
|
||||
|
||||
Now, we'll gonna fix some file permissions and ownership of the installation path. First, we'll gonna set the ownership of the installation directory to Apache process owner so that apache web server will have full access of the files and directories to edit, create and delete.
|
||||
|
||||
#### On Ubuntu 15.04 ####
|
||||
|
||||
# chown www-data: -R /var/www/html/reviveads
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
# chown apache: -R /var/www/html/reviveads
|
||||
|
||||
### 8. Allowing Firewall ###
|
||||
|
||||
Now, we'll gonna configure our firewall programs to allow port 80 (http) so that our apache web server running Revive Adserver will be accessible from other machines in the network across the default http port ie 80.
|
||||
|
||||
#### On Ubuntu 15.04/CentOS 7 ####
|
||||
|
||||
As CentOS 7 and Ubuntu 15.04 both has systemd installed by default, it contains firewalld running as firewall program. In order to open the port 80 (http service) on firewalld, we'll need to execute the following commands.
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
|
||||
success
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 9. Web Installation ###
|
||||
|
||||
Finally, after everything is done as expected, we'll now be able to access the web interface of the application using a web browser. We can go further towards the web installation, by pointing the web browser to the web server we are running in our linux machine. To do so, we'll need to point our web browser to http://ip-address/ or http://domain.com assigned to our linux machine. Here, in this tutorial, we'll point our browser to http://reviveads.linoxide.com/ .
|
||||
|
||||
Here, we'll see the Welcome page of the installation of Revive Adserver with the GNU General Public License V2 as Revive Adserver is released under this license. Then, we'll simply click on I agree button in order to continue the installation.
|
||||
|
||||
In the next page, we'll need to enter the required database information in order to connect Revive Adserver with the MariaDB database server. Here, we'll need to enter the database name, user and password that we had set in the above step. In this tutorial, we entered database name, user and password as revivedb, reviveuser and Pa$$worD123 respectively then, we set the hostname as localhost and continue further.
|
||||
|
||||

|
||||
|
||||
We'll now enter the required information like administration username, password and email address so that we can use these information to login to the dashboard of our Adserver. After done, we'll head towards the Finish page in which we'll see that we have successfully installed Revive Adserver in our server.
|
||||
|
||||
Next, we'll be redirected to the Adverstiser page where we'll add new Advertisers and manage them. Then, we'll be able to navigate to our Dashboard, add new users to the adserver, add new campaign for our advertisers, banners, websites, video ads and everything that its built with.
|
||||
|
||||
For enabling more configurations and access towards the administrative settings, we can switch our Dashboard user to the Administrator account. This will add new administrative menus in the dashboard like Plugins, Configuration through which we can add and manage plugins and configure many features and elements of Revive Adserver.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, we learned some information on what is Revive Adserver and how we can setup on linux machine running Ubuntu 15.04 and CentOS 7 distributions. Though Revive Adserver's initial source code was bought from OpenX, currently the code base for OpenX Enterprise and Revive Adserver are completely separate. To extend more features, we can install more plugins which we can also find from [http://www.adserverplugins.com/][2] . Really, this piece of software has changed the way of managing the ads for websites, apps, videos and made it very easy and efficient. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-revive-adserver-ubuntu-15-04-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.revive-adserver.com/download/
|
||||
[2]:http://www.adserverplugins.com/
|
||||
257
sources/tech/20151122 Doubly linked list in the Linux Kernel.md
Normal file
257
sources/tech/20151122 Doubly linked list in the Linux Kernel.md
Normal file
@ -0,0 +1,257 @@
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
Doubly linked list
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Linux kernel provides its own implementation of doubly linked list, which you can find in the [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h). We will start `Data Structures in the Linux kernel` from the doubly linked list data structure. Why? Because it is very popular in the kernel, just try to [search](http://lxr.free-electrons.com/ident?i=list_head)
|
||||
|
||||
First of all, let's look on the main structure in the [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h):
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
struct list_head *next, *prev;
|
||||
};
|
||||
```
|
||||
|
||||
You can note that it is different from many implementations of doubly linked list which you have seen. For example, this doubly linked list structure from the [glib](http://www.gnu.org/software/libc/) library looks like :
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
gpointer data;
|
||||
GList *next;
|
||||
GList *prev;
|
||||
};
|
||||
```
|
||||
|
||||
Usually a linked list structure contains a pointer to the item. The implementation of linked list in Linux kernel does not. So the main question is - `where does the list store the data?`. The actual implementation of linked list in the kernel is - `Intrusive list`. An intrusive linked list does not contain data in its nodes - A node just contains pointers to the next and previous node and list nodes part of the data that are added to the list. This makes the data structure generic, so it does not care about entry data type anymore.
|
||||
|
||||
For example:
|
||||
|
||||
```C
|
||||
struct nmi_desc {
|
||||
spinlock_t lock;
|
||||
struct list_head head;
|
||||
};
|
||||
```
|
||||
|
||||
Let's look at some examples to understand how `list_head` is used in the kernel. As I already wrote about, there are many, really many different places where lists are used in the kernel. Let's look for an example in miscellaneous character drivers. Misc character drivers API from the [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) is used for writing small drivers for handling simple hardware or virtual devices. Those drivers share same major number:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
```
|
||||
|
||||
but have their own minor number. For example you can see it with:
|
||||
|
||||
```
|
||||
ls -l /dev | grep 10
|
||||
crw------- 1 root root 10, 235 Mar 21 12:01 autofs
|
||||
drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
|
||||
crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
|
||||
crw------- 1 root root 10, 203 Mar 21 12:01 cuse
|
||||
drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
|
||||
crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
|
||||
crw------- 1 root root 10, 228 Mar 21 12:01 hpet
|
||||
crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
|
||||
crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
|
||||
crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
|
||||
crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
|
||||
crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
|
||||
crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
|
||||
crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
|
||||
crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
|
||||
brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
|
||||
crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
|
||||
crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
|
||||
crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
Now let's have a close look at how lists are used in the misc device drivers. First of all, let's look on `miscdevice` structure:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
{
|
||||
int minor;
|
||||
const char *name;
|
||||
const struct file_operations *fops;
|
||||
struct list_head list;
|
||||
struct device *parent;
|
||||
struct device *this_device;
|
||||
const char *nodename;
|
||||
mode_t mode;
|
||||
};
|
||||
```
|
||||
|
||||
We can see the fourth field in the `miscdevice` structure - `list` which is a list of registered devices. In the beginning of the source code file we can see the definition of misc_list:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
```
|
||||
|
||||
which expands to the definition of variables with `list_head` type:
|
||||
|
||||
```C
|
||||
#define LIST_HEAD(name) \
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
and initializes it with the `LIST_HEAD_INIT` macro, which sets previous and next entries with the address of variable - name:
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
Now let's look on the `misc_register` function which registers a miscellaneous device. At the start it initializes `miscdevice->list` with the `INIT_LIST_HEAD` function:
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
```
|
||||
|
||||
which does the same as the `LIST_HEAD_INIT` macro:
|
||||
|
||||
```C
|
||||
static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
{
|
||||
list->next = list;
|
||||
list->prev = list;
|
||||
}
|
||||
```
|
||||
|
||||
In the next step after a device is created by the `device_create` function, we add it to the miscellaneous devices list with:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
Kernel `list.h` provides this API for the addition of a new entry to the list. Let's look at its implementation:
|
||||
|
||||
```C
|
||||
static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
{
|
||||
__list_add(new, head, head->next);
|
||||
}
|
||||
```
|
||||
|
||||
It just calls internal function `__list_add` with the 3 given parameters:
|
||||
|
||||
* new - new entry.
|
||||
* head - list head after which the new item will be inserted.
|
||||
* head->next - next item after list head.
|
||||
|
||||
Implementation of the `__list_add` is pretty simple:
|
||||
|
||||
```C
|
||||
static inline void __list_add(struct list_head *new,
|
||||
struct list_head *prev,
|
||||
struct list_head *next)
|
||||
{
|
||||
next->prev = new;
|
||||
new->next = next;
|
||||
new->prev = prev;
|
||||
prev->next = new;
|
||||
}
|
||||
```
|
||||
|
||||
Here we add a new item between `prev` and `next`. So `misc` list which we defined at the start with the `LIST_HEAD_INIT` macro will contain previous and next pointers to the `miscdevice->list`.
|
||||
|
||||
There is still one question: how to get list's entry. There is a special macro:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
which gets three parameters:
|
||||
|
||||
* ptr - the structure list_head pointer;
|
||||
* type - structure type;
|
||||
* member - the name of the list_head within the structure;
|
||||
|
||||
For example:
|
||||
|
||||
```C
|
||||
const struct miscdevice *p = list_entry(v, struct miscdevice, list)
|
||||
```
|
||||
|
||||
After this we can access to any `miscdevice` field with `p->minor` or `p->name` and etc... Let's look on the `list_entry` implementation:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
As we can see it just calls `container_of` macro with the same arguments. At first sight, the `container_of` looks strange:
|
||||
|
||||
```C
|
||||
#define container_of(ptr, type, member) ({ \
|
||||
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
|
||||
(type *)( (char *)__mptr - offsetof(type,member) );})
|
||||
```
|
||||
|
||||
First of all you can note that it consists of two expressions in curly brackets. The compiler will evaluate the whole block in the curly braces and use the value of the last expression.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int i = 0;
|
||||
printf("i = %d\n", ({++i; ++i;}));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
will print `2`.
|
||||
|
||||
The next point is `typeof`, it's simple. As you can understand from its name, it just returns the type of the given variable. When I first saw the implementation of the `container_of` macro, the strangest thing I found was the zero in the `((type *)0)` expression. Actually this pointer magic calculates the offset of the given field from the address of the structure, but as we have `0` here, it will be just a zero offset along with the field width. Let's look at a simple example:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
|
||||
struct s {
|
||||
int field1;
|
||||
char field2;
|
||||
char field3;
|
||||
};
|
||||
|
||||
int main() {
|
||||
printf("%p\n", &((struct s*)0)->field3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
will print `0x5`.
|
||||
|
||||
The next `offsetof` macro calculates offset from the beginning of the structure to the given structure's field. Its implementation is very similar to the previous code:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
Let's summarize all about `container_of` macro. The `container_of` macro returns the address of the structure by the given address of the structure's field with `list_head` type, the name of the structure field with `list_head` type and type of the container structure. At the first line this macro declares the `__mptr` pointer which points to the field of the structure that `ptr` points to and assigns `ptr` to it. Now `ptr` and `__mptr` point to the same address. Technically we don't need this line but it's useful for type checking. The first line ensures that the given structure (`type` parameter) has a member called `member`. In the second line it calculates offset of the field from the structure with the `offsetof` macro and subtracts it from the structure address. That's all.
|
||||
|
||||
Of course `list_add` and `list_entry` is not the only functions which `<linux/list.h>` provides. Implementation of the doubly linked list provides the following API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
|
||||
and many more.
|
||||
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,236 @@
|
||||
Assign Multiple IP Addresses To One Interface On Ubuntu 15.10
|
||||
================================================================================
|
||||
Some times you might want to use more than one IP address for your network interface card. What will you do in such cases? Buy an extra network card and assign new IP? No, It’s not necessary(at least in the small networks). We can now assign multiple IP addresses to one interface on Ubuntu systems. Curious to know how? Well, Follow me, It is not that difficult.
|
||||
|
||||
This method will work on Debian and it’s derivatives too.
|
||||
|
||||
### Add additional IP addresses temporarily ###
|
||||
|
||||
First, let us find the IP address of the network card. In my Ubuntu 15.10 server, I use only one network card.
|
||||
|
||||
Run the following command to find out the IP address:
|
||||
|
||||
sudo ip addr
|
||||
|
||||
**Sample output:**
|
||||
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4b brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
Or
|
||||
|
||||
sudo ifconfig
|
||||
|
||||
**Sample output:**
|
||||
|
||||
enp0s3 Link encap:Ethernet HWaddr 08:00:27:2a:03:4b
|
||||
inet addr:192.168.1.103 Bcast:192.168.1.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::a00:27ff:fe2a:34e/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:186 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:70 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:21872 (21.8 KB) TX bytes:9666 (9.6 KB)
|
||||
lo Link encap:Local Loopback
|
||||
inet addr:127.0.0.1 Mask:255.0.0.0
|
||||
inet6 addr: ::1/128 Scope:Host
|
||||
UP LOOPBACK RUNNING MTU:65536 Metric:1
|
||||
RX packets:217 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:217 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:0
|
||||
RX bytes:38793 (38.7 KB) TX bytes:38793 (38.7 KB)
|
||||
|
||||
As you see in the above output, my network card name is **enp0s3**, and its IP address is **192.168.1.103**.
|
||||
|
||||
Now let us add an additional IP address, for example **192.168.1.104**, to the Interface card.
|
||||
|
||||
Open your Terminal and run the following command to add additional IP.
|
||||
|
||||
sudo ip addr add 192.168.1.104/24 dev enp0s3
|
||||
|
||||
Now, let us check if the IP is added using command:
|
||||
|
||||
sudo ip address show enp0s3
|
||||
|
||||
**Sample output:**
|
||||
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet 192.168.1.104/24 scope global secondary enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
Similarly, you can add as many IP addresses as you want.
|
||||
|
||||
Let us ping the IP address to verify it.
|
||||
|
||||
sudo ping 192.168.1.104
|
||||
|
||||
**Sample output:**
|
||||
|
||||
PING 192.168.1.104 (192.168.1.104) 56(84) bytes of data.
|
||||
64 bytes from 192.168.1.104: icmp_seq=1 ttl=64 time=0.901 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=2 ttl=64 time=0.571 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=3 ttl=64 time=0.521 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=4 ttl=64 time=0.524 ms
|
||||
|
||||
Yeah, It’s working!!
|
||||
|
||||
To remove the IP, just run:
|
||||
|
||||
sudo ip addr del 192.168.1.104/24 dev enp0s3
|
||||
|
||||
Let us check if it is removed.
|
||||
|
||||
sudo ip address show enp0s3
|
||||
|
||||
**Sample output:**
|
||||
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
See, It’s gone!!
|
||||
|
||||
Well, as you may know, the changes will lost after you reboot your system. How do I make it permanent? That’s easy too.
|
||||
|
||||
### Add additional IP addresses permanently ###
|
||||
|
||||
The network card configuration file of your Ubuntu system is **/etc/network/interfaces**.
|
||||
|
||||
Let us check the details of the above file.
|
||||
|
||||
sudo cat /etc/network/interfaces
|
||||
|
||||
**Sample output:**
|
||||
|
||||
# This file describes the network interfaces available on your system
|
||||
# and how to activate them. For more information, see interfaces(5).
|
||||
source /etc/network/interfaces.d/*
|
||||
# The loopback network interface
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
# The primary network interface
|
||||
auto enp0s3
|
||||
iface enp0s3 inet dhcp
|
||||
|
||||
As you see in the above output, the Interface is DHCP enabled.
|
||||
|
||||
Okay, now we will assign an additional address, for example **192.168.1.104/24**.
|
||||
|
||||
Edit file **/etc/network/interfaces**:
|
||||
|
||||
sudo nano /etc/network/interfaces
|
||||
|
||||
Add additional IP address as shown in the black letters.
|
||||
|
||||
# This file describes the network interfaces available on your system
|
||||
# and how to activate them. For more information, see interfaces(5).
|
||||
source /etc/network/interfaces.d/*
|
||||
# The loopback network interface
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
# The primary network interface
|
||||
auto enp0s3
|
||||
iface enp0s3 inet dhcp
|
||||
iface enp0s3 inet static
|
||||
address 192.168.1.104/24
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Run the following file to take effect the changes without rebooting.
|
||||
|
||||
sudo ifdown enp0s3 && sudo ifup enp0s3
|
||||
|
||||
**Sample output:**
|
||||
|
||||
Killed old client process
|
||||
Internet Systems Consortium DHCP Client 4.3.1
|
||||
Copyright 2004-2014 Internet Systems Consortium.
|
||||
All rights reserved.
|
||||
For info, please visit https://www.isc.org/software/dhcp/
|
||||
Listening on LPF/enp0s3/08:00:27:2a:03:4e
|
||||
Sending on LPF/enp0s3/08:00:27:2a:03:4e
|
||||
Sending on Socket/fallback
|
||||
DHCPRELEASE on enp0s3 to 192.168.1.1 port 67 (xid=0x225f35)
|
||||
Internet Systems Consortium DHCP Client 4.3.1
|
||||
Copyright 2004-2014 Internet Systems Consortium.
|
||||
All rights reserved.
|
||||
For info, please visit https://www.isc.org/software/dhcp/
|
||||
Listening on LPF/enp0s3/08:00:27:2a:03:4e
|
||||
Sending on LPF/enp0s3/08:00:27:2a:03:4e
|
||||
Sending on Socket/fallback
|
||||
DHCPDISCOVER on enp0s3 to 255.255.255.255 port 67 interval 3 (xid=0xdfb94764)
|
||||
DHCPREQUEST of 192.168.1.103 on enp0s3 to 255.255.255.255 port 67 (xid=0x6447b9df)
|
||||
DHCPOFFER of 192.168.1.103 from 192.168.1.1
|
||||
DHCPACK of 192.168.1.103 from 192.168.1.1
|
||||
bound to 192.168.1.103 -- renewal in 35146 seconds.
|
||||
|
||||
**Note**: It is **very important** to run the above two commands into **one** line if you are remoting into the server because the first one will drop your connection. Given in this way the ssh-session will survive.
|
||||
|
||||
Now, let us check if IP is added using command:
|
||||
|
||||
sudo ip address show enp0s3
|
||||
|
||||
**Sample output:**
|
||||
|
||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 08:00:27:2a:03:4e brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.1.103/24 brd 192.168.1.255 scope global enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet 192.168.1.104/24 brd 192.168.1.255 scope global secondary enp0s3
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
Cool! Additional IP has been added.
|
||||
|
||||
Well then let us ping the IP address to verify.
|
||||
|
||||
sudo ping 192.168.1.104
|
||||
|
||||
**Sample output:**
|
||||
|
||||
PING 192.168.1.104 (192.168.1.104) 56(84) bytes of data.
|
||||
64 bytes from 192.168.1.104: icmp_seq=1 ttl=64 time=0.137 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=2 ttl=64 time=0.050 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=3 ttl=64 time=0.054 ms
|
||||
64 bytes from 192.168.1.104: icmp_seq=4 ttl=64 time=0.067 ms
|
||||
|
||||
Voila! It’s working. That’s it.
|
||||
|
||||
Want to know how to add additional IP addresses on CentOS/RHEL/Scientific Linux/Fedora systems, check the following link.
|
||||
|
||||
注:此篇文章以前做过选题:20150205 Linux Basics--Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7.md
|
||||
- [Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7][1]
|
||||
|
||||
Happy weekend!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/assign-multiple-ip-addresses-to-one-interface-on-ubuntu-15-10/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.unixmen.com/linux-basics-assign-multiple-ip-addresses-single-network-interface-card-centos-7/
|
||||
201
sources/tech/20151123 Data Structures in the Linux Kernel.md
Normal file
201
sources/tech/20151123 Data Structures in the Linux Kernel.md
Normal file
@ -0,0 +1,201 @@
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
Radix tree
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
As you already know linux kernel provides many different libraries and functions which implement different data structures and algorithms. In this part we will consider one of these data structures - [Radix tree](http://en.wikipedia.org/wiki/Radix_tree). There are two files which are related to `radix tree` implementation and API in the linux kernel:
|
||||
|
||||
* [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)
|
||||
* [lib/radix-tree.c](https://github.com/torvalds/linux/blob/master/lib/radix-tree.c)
|
||||
|
||||
Lets talk about what a `radix tree` is. Radix tree is a `compressed trie` where a [trie](http://en.wikipedia.org/wiki/Trie) is a data structure which implements an interface of an associative array and allows to store values as `key-value`. The keys are usually strings, but any data type can be used. A trie is different from an `n-tree` because of its nodes. Nodes of a trie do not store keys; instead, a node of a trie stores single character labels. The key which is related to a given node is derived by traversing from the root of the tree to this node. For example:
|
||||
|
||||
|
||||
```
|
||||
+-----------+
|
||||
| |
|
||||
| " " |
|
||||
| |
|
||||
+------+-----------+------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| g | | c |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| o | | a |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
+-----v-----+
|
||||
| |
|
||||
| t |
|
||||
| |
|
||||
+-----------+
|
||||
```
|
||||
|
||||
So in this example, we can see the `trie` with keys, `go` and `cat`. The compressed trie or `radix tree` differs from `trie` in that all intermediates nodes which have only one child are removed.
|
||||
|
||||
Radix tree in linux kernel is the datastructure which maps values to integer keys. It is represented by the following structures from the file [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h):
|
||||
|
||||
```C
|
||||
struct radix_tree_root {
|
||||
unsigned int height;
|
||||
gfp_t gfp_mask;
|
||||
struct radix_tree_node __rcu *rnode;
|
||||
};
|
||||
```
|
||||
|
||||
This structure presents the root of a radix tree and contains three fields:
|
||||
|
||||
* `height` - height of the tree;
|
||||
* `gfp_mask` - tells how memory allocations will be performed;
|
||||
* `rnode` - pointer to the child node.
|
||||
|
||||
The first field we will discuss is `gfp_mask`:
|
||||
|
||||
Low-level kernel memory allocation functions take a set of flags as - `gfp_mask`, which describes how that allocation is to be performed. These `GFP_` flags which control the allocation process can have following values: (`GF_NOIO` flag) means sleep and wait for memory, (`__GFP_HIGHMEM` flag) means high memory can be used, (`GFP_ATOMIC` flag) means the allocation process has high-priority and can't sleep etc.
|
||||
|
||||
* `GFP_NOIO` - can sleep and wait for memory;
|
||||
* `__GFP_HIGHMEM` - high memory can be used;
|
||||
* `GFP_ATOMIC` - allocation process is high-priority and can't sleep;
|
||||
|
||||
etc.
|
||||
|
||||
The next field is `rnode`:
|
||||
|
||||
```C
|
||||
struct radix_tree_node {
|
||||
unsigned int path;
|
||||
unsigned int count;
|
||||
union {
|
||||
struct {
|
||||
struct radix_tree_node *parent;
|
||||
void *private_data;
|
||||
};
|
||||
struct rcu_head rcu_head;
|
||||
};
|
||||
/* For tree user */
|
||||
struct list_head private_list;
|
||||
void __rcu *slots[RADIX_TREE_MAP_SIZE];
|
||||
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
|
||||
};
|
||||
```
|
||||
|
||||
This structure contains information about the offset in a parent and height from the bottom, count of the child nodes and fields for accessing and freeing a node. This fields are described below:
|
||||
|
||||
* `path` - offset in parent & height from the bottom;
|
||||
* `count` - count of the child nodes;
|
||||
* `parent` - pointer to the parent node;
|
||||
* `private_data` - used by the user of a tree;
|
||||
* `rcu_head` - used for freeing a node;
|
||||
* `private_list` - used by the user of a tree;
|
||||
|
||||
The two last fields of the `radix_tree_node` - `tags` and `slots` are important and interesting. Every node can contains a set of slots which are store pointers to the data. Empty slots in the linux kernel radix tree implementation store `NULL`. Radix trees in the linux kernel also supports tags which are associated with the `tags` fields in the `radix_tree_node` structure. Tags allow individual bits to be set on records which are stored in the radix tree.
|
||||
|
||||
Now that we know about radix tree structure, it is time to look on its API.
|
||||
|
||||
Linux kernel radix tree API
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
We start from the datastructure initialization. There are two ways to initialize a new radix tree. The first is to use `RADIX_TREE` macro:
|
||||
|
||||
```C
|
||||
RADIX_TREE(name, gfp_mask);
|
||||
````
|
||||
|
||||
As you can see we pass the `name` parameter, so with the `RADIX_TREE` macro we can define and initialize radix tree with the given name. Implementation of the `RADIX_TREE` is easy:
|
||||
|
||||
```C
|
||||
#define RADIX_TREE(name, mask) \
|
||||
struct radix_tree_root name = RADIX_TREE_INIT(mask)
|
||||
|
||||
#define RADIX_TREE_INIT(mask) { \
|
||||
.height = 0, \
|
||||
.gfp_mask = (mask), \
|
||||
.rnode = NULL, \
|
||||
}
|
||||
```
|
||||
|
||||
At the beginning of the `RADIX_TREE` macro we define instance of the `radix_tree_root` structure with the given name and call `RADIX_TREE_INIT` macro with the given mask. The `RADIX_TREE_INIT` macro just initializes `radix_tree_root` structure with the default values and the given mask.
|
||||
|
||||
The second way is to define `radix_tree_root` structure by hand and pass it with mask to the `INIT_RADIX_TREE` macro:
|
||||
|
||||
```C
|
||||
struct radix_tree_root my_radix_tree;
|
||||
INIT_RADIX_TREE(my_tree, gfp_mask_for_my_radix_tree);
|
||||
```
|
||||
|
||||
where:
|
||||
|
||||
```C
|
||||
#define INIT_RADIX_TREE(root, mask) \
|
||||
do { \
|
||||
(root)->height = 0; \
|
||||
(root)->gfp_mask = (mask); \
|
||||
(root)->rnode = NULL; \
|
||||
} while (0)
|
||||
```
|
||||
|
||||
makes the same initialziation with default values as it does `RADIX_TREE_INIT` macro.
|
||||
|
||||
The next are two functions for inserting and deleting records to/from a radix tree:
|
||||
|
||||
* `radix_tree_insert`;
|
||||
* `radix_tree_delete`;
|
||||
|
||||
The first `radix_tree_insert` function takes three parameters:
|
||||
|
||||
* root of a radix tree;
|
||||
* index key;
|
||||
* data to insert;
|
||||
|
||||
The `radix_tree_delete` function takes the same set of parameters as the `radix_tree_insert`, but without data.
|
||||
|
||||
The search in a radix tree implemented in two ways:
|
||||
|
||||
* `radix_tree_lookup`;
|
||||
* `radix_tree_gang_lookup`;
|
||||
* `radix_tree_lookup_slot`.
|
||||
|
||||
The first `radix_tree_lookup` function takes two parameters:
|
||||
|
||||
* root of a radix tree;
|
||||
* index key;
|
||||
|
||||
This function tries to find the given key in the tree and return the record associated with this key. The second `radix_tree_gang_lookup` function have the following signature
|
||||
|
||||
```C
|
||||
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
void **results,
|
||||
unsigned long first_index,
|
||||
unsigned int max_items);
|
||||
```
|
||||
|
||||
and returns number of records, sorted by the keys, starting from the first index. Number of the returned records will not be greater than `max_items` value.
|
||||
|
||||
And the last `radix_tree_lookup_slot` function will return the slot which will contain the data.
|
||||
|
||||
Links
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
* [Radix tree](http://en.wikipedia.org/wiki/Radix_tree)
|
||||
* [Trie](http://en.wikipedia.org/wiki/Trie)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/radix-tree.md
|
||||
|
||||
作者:[0xAX]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
How To Install Microsoft Visual Studio Code on Linux
|
||||
================================================================================
|
||||
Visual Studio code (VScode) is the cross-platform Chromium-based code editor is being open sourced today by Microsoft. How do I install Microsoft Visual Studio Code on a Debian or Ubuntu or Fedora Linux desktop?
|
||||
|
||||
Visual Studio supports debugging Linux apps and code editor now open source by Microsoft. It is a preview (beta) version but you can test it and use it on your own Linux based desktop.
|
||||
|
||||
### Why use Visual Studio Code? ###
|
||||
|
||||
From the project website:
|
||||
|
||||
> Visual Studio Code provides developers with a new choice of developer tool that combines the simplicity and streamlined experience of a code editor with the best of what developers need for their core code-edit-debug cycle. Visual Studio Code is the first code editor, and first cross-platform development tool - supporting OS X, Linux, and Windows - in the Visual Studio family. If you use Unity, ASP.NET 5, NODE.JS or related tool, give it a try.
|
||||
|
||||
### Requirements for Visual Studio Code on Linux ###
|
||||
|
||||
1. Ubuntu Desktop version 14.04
|
||||
1. GLIBCXX version 3.4.15 or later
|
||||
1. GLIBC version 2.15 or later
|
||||
|
||||
The following installation instructions are tested on:
|
||||
|
||||
1. Fedora Linux 22 and 23
|
||||
1. Debian Linux 8
|
||||
1. Ubuntu Linux 14.04 LTS
|
||||
|
||||
### Download Visual Studio Code ###
|
||||
|
||||
Visit [this page][1] to grab the latest version and save it to ~/Downloads/ folder on Linux desktop:
|
||||
|
||||
|
||||
|
||||
Fig.01: Download Visual Studio Code For Linux
|
||||
|
||||
Make a new folder (say $HOME/VSCode) and extract VSCode-linux-x64.zip inside that folder or in /usr/local/ folder. Unzip VSCode-linux64.zip to that folder.
|
||||
|
||||
Make a new folder (say $HOME/VSCode) and extract VSCode-linux-x64.zip inside that folder or in /usr/local/ folder. Unzip VSCode-linux64.zip to that folder.
|
||||
|
||||
### Alternate install method ###
|
||||
|
||||
You can use the wget command to download VScode as follows:
|
||||
|
||||
$ wget 'https://az764295.vo.msecnd.net/public/0.10.1-release/VSCode-linux64.zip'
|
||||
|
||||
Sample outputs:
|
||||
|
||||
--2015-11-18 13:55:23-- https://az764295.vo.msecnd.net/public/0.10.1-release/VSCode-linux64.zip
|
||||
Resolving az764295.vo.msecnd.net (az764295.vo.msecnd.net)... 93.184.215.200, 2606:2800:11f:179a:1972:2405:35b:459
|
||||
Connecting to az764295.vo.msecnd.net (az764295.vo.msecnd.net)|93.184.215.200|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 64638315 (62M) [application/octet-stream]
|
||||
Saving to: 'VSCode-linux64.zip'
|
||||
|
||||
100%[======================================>] 64,638,315 84.9MB/s in 0.7s
|
||||
|
||||
2015-11-18 13:55:23 (84.9 MB/s) - 'VSCode-linux64.zip' saved [64638315/64638315]
|
||||
|
||||
### Install VScode using the command line ###
|
||||
|
||||
Cd to ~/Download/ location, enter:
|
||||
|
||||
$ cd ~/Download/
|
||||
$ ls -l
|
||||
|
||||
Sample outputs:
|
||||
|
||||
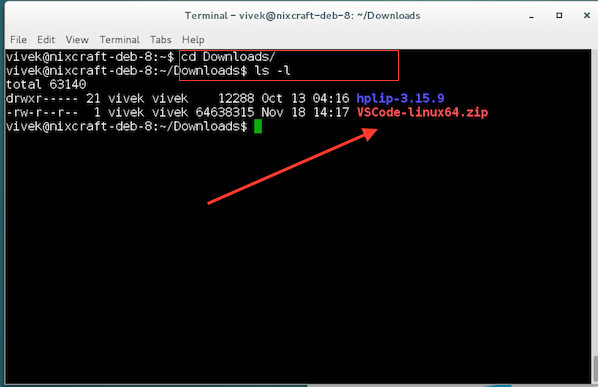
|
||||
|
||||
Fig.02: VSCode downloaded to my ~/Downloads/ folder
|
||||
|
||||
Unzip VSCode-linux64.zip in /usr/local/ directory, enter:
|
||||
|
||||
$ sudo unzip VSCode-linux64.zip -d /usr/local/
|
||||
|
||||
Cd into /usr/local/ to create the soft-link as follows using the ln command for the Code executable. This is useful to run VSCode from the terminal application:
|
||||
|
||||
$ su -
|
||||
# cd /usr/local/
|
||||
# ls -l
|
||||
# cd bin/
|
||||
# ln -s ../VSCode-linux-x64/Code code
|
||||
# exit
|
||||
|
||||
Sample session:
|
||||
|
||||
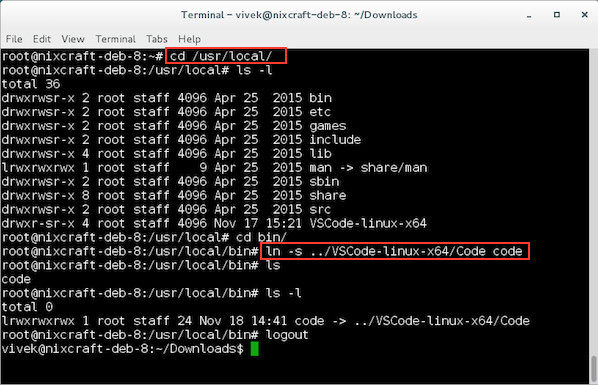
|
||||
|
||||
Fig.03 Create the sym-link with the absolute path to the Code executable
|
||||
|
||||
### How do I use VSCode on Linux? ###
|
||||
|
||||
Open the Terminal app and type the following command:
|
||||
|
||||
$ /usr/local/bin/code
|
||||
|
||||
Sample outputs:
|
||||
|
||||
|
||||
|
||||
Fig.04: VSCode in action on Linux
|
||||
|
||||
And, there you have it, the VSCode installed and working correctly on the latest version of Debian, Ubuntu and Fedora Linux. I suggest that you read [getting started pages from Microsoft][2] to understand the core concepts that will make you more productive writing and navigating your code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/debian-ubuntu-fedora-linux-installing-visual-studio-code/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://code.visualstudio.com/Download
|
||||
[2]:https://code.visualstudio.com/docs
|
||||
@ -0,0 +1,133 @@
|
||||
How to Configure Apache Solr on Ubuntu 14 / 15
|
||||
================================================================================
|
||||
Hello and welcome to our today's article on Apache Solr. The brief description about Apache Solr is that it is an Open Source most famous search platform with Apache Lucene at the back end for Web sites that enables you to easily create search engines which searches websites, databases and files. It can index and search multiple sites and return recommendations for related contents based on the searched text.
|
||||
|
||||
Solr works with HTTP Extensible Markup Language (XML) that offers application program interfaces (APIs) for Javascript Object Notation, Python, and Ruby. According to the Apache Lucene Project, Solr offers capabilities that have made it popular with administrators including it many featuring like:
|
||||
|
||||
- Full Text Search
|
||||
- Faceted Navigation
|
||||
- Snippet generation/highting
|
||||
- Spell Suggestion/Auto complete
|
||||
- Custom document ranking/ordering
|
||||
|
||||
#### Prerequisites: ####
|
||||
|
||||
On a fresh Linux Ubuntu 14/15 with minimal packages installed, you only have to take care of few prerequisites in order to install Apache Solr.
|
||||
|
||||
### 1)System Update ###
|
||||
|
||||
Login to your Ubuntu server with a non-root sudo user that will be used to perform all the steps to install and use Solr.
|
||||
|
||||
After successful login, issue the following command to update your system with latest updates and patches.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
### 2) JRE Setup ###
|
||||
|
||||
The Solr setup needs Java Runtime Environment to be installed on the system as its basic requirement because solr and tomcat both are the Java based applications. So, we need to install and configure its home environment with latest Java.
|
||||
|
||||
To install the latest version on Oracle Java 8, we need to install Python Software Properties using the below command.
|
||||
|
||||
$ sudo apt-get install python-software-properties
|
||||
|
||||
Upon completion, run the setup its the repository for the latest version of Java 8.
|
||||
|
||||
$ sudo add-apt-repository ppa:webupd8team/java
|
||||
|
||||
Now you are able to install the latest version of Oracle Java 8 with 'wget' by issuing the below commands to update the packages source list and then to install Java.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
----------
|
||||
|
||||
$ sudo apt-get install oracle-java8-installer
|
||||
|
||||
Accept the Oracle Binary Code License Agreement for the Java SE Platform Products and JavaFX as you will be asked during the Java installation and configuration process by a click on the 'OK' button.
|
||||
|
||||
When the installation process complete, run the below command to test the successful installation of Java and check its version.
|
||||
|
||||
kash@solr:~$ java -version
|
||||
java version "1.8.0_66"
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
|
||||
Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
|
||||
|
||||
The output indicates that we have successfully fulfilled the basic requirement of Solr by installing the Java. Now move to the next step to install Solr.
|
||||
|
||||
### Installing Solr ###
|
||||
|
||||
Installing Solr on Ubuntu can be done by using two different ways but in this article we prefer to install its latest package from the source.
|
||||
|
||||
To install Solr from its source, download its available package with latest version from there Official [Web Page][1], copy the link address and get it using 'wget' command.
|
||||
|
||||
$ wget http://www.us.apache.org/dist/lucene/solr/5.3.1/solr-5.3.1.tgz
|
||||
|
||||
Run the command below to extract the archived service into '/bin' folder.
|
||||
|
||||
$ tar -xzf solr-5.3.1.tgz solr-5.3.1/bin/install_solr_service.sh --strip-components=2
|
||||
|
||||
Then run the script to start Solr service that will creates a new 'solr' user and then installs solr as a service.
|
||||
|
||||
$ sudo bash ./install_solr_service.sh solr-5.3.1.tgz
|
||||
|
||||

|
||||
|
||||
To check the status of Solr service, you use the below command.
|
||||
|
||||
$ service solr status
|
||||
|
||||

|
||||
|
||||
### Creating Solr Collection: ###
|
||||
|
||||
Now we can create multiple collections using Solr user. To do so just run the below command by mentioning the name of the collection you want to create and by specifying its configuration set as shown.
|
||||
|
||||
$ sudo su - solr -c "/opt/solr/bin/solr create -c myfirstcollection -n data_driven_schema_configs"
|
||||
|
||||

|
||||
|
||||
We have successfully created the new core instance directory for our our first collection where we can add new data in it. To view its default schema file in directory '/opt/solr/server/solr/configsets/data_driven_schema_configs/conf' .
|
||||
|
||||
### Using Solr Web ###
|
||||
|
||||
Apache Solr can be accessible on the default port of Solr that 8983. Open your favorite browser and navigate to http://your_server_ip:8983/solr or http://your-domain.com:8983/solr. Make sure that the port is allowed in your firewall.
|
||||
|
||||
http://172.25.10.171:8983/solr/
|
||||
|
||||

|
||||
|
||||
From the Solr Web Console click on the 'Core Admin' button from the left bar, then you will see your first collection that we created earlier using CLI. While you can also create new cores by pointing on the 'Add Core' button.
|
||||
|
||||

|
||||
|
||||
You can also add the document and query from the document as shown in below image by selecting your particular collection and pointing the document. Add the data in the specified format as shown in the box.
|
||||
|
||||
{
|
||||
"number": 1,
|
||||
"Name": "George Washington",
|
||||
"birth_year": 1989,
|
||||
"Starting_Job": 2002,
|
||||
"End_Job": "2009-04-30",
|
||||
"Qualification": "Graduation",
|
||||
"skills": "Linux and Virtualization"
|
||||
}
|
||||
|
||||
After adding the document click on the 'Submit Document' button.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
You are now able to insert and query data using the Solr web interface after its successful installation on Ubuntu. Now add more collections and insert you own data and documents that you wish to put and manage through Solr. We hope you have got this article much helpful and enjoyed reading this.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-apache-solr-ubuntu-14-15/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:http://lucene.apache.org/solr/
|
||||
@ -0,0 +1,148 @@
|
||||
How to Install Cockpit in Fedora / CentOS / RHEL/ Arch Linux
|
||||
================================================================================
|
||||
Cockpit is a free and open source server management software that makes us easy to administer our GNU/Linux servers via its beautiful web interface frontend. Cockpit helps make linux system administrator, system maintainers and DevOps easy to manage their server and to perform simple tasks, such as administering storage, inspecting journals, starting and stopping services and more. Its journal interface adds aroma in flower making people easy to switch between the terminal and web interface. And moreover, it makes easy to manage not only one server but several multiple networked servers from a single place at the same time with just a single click. It is very light weight and has easy to use web based interface. In this tutorial, we'll learn how we can setup Cockpit and use it to manage our server running Fedora, CentOS, Arch Linux and RHEL distributions as their operating system software. Some of the awesome benefits of Cockpit in our GNU/Linux servers are as follows:
|
||||
|
||||
1. It consist of systemd service manager for ease.
|
||||
1. It has a Journal log viewer to perform troubleshoots and log analysis.
|
||||
1. Storage setup including LVM was never easier before.
|
||||
1. Basic Network configuration can be applied with Cockpit
|
||||
1. We can easily add and remove local users and manage multiple servers.
|
||||
|
||||
### 1. Installing Cockpit ###
|
||||
|
||||
First of all, we'll need to setup Cockpit in our linux based server. In most of the distributions, the cockpit package is already available in their official repositories. Here, in this tutorial, we'll setup Cockpit in Fedora 22, CentOS 7, Arch Linux and RHEL 7 from their official repositories.
|
||||
|
||||
#### On CentOS / RHEL ####
|
||||
|
||||
Cockpit is available in the official repository of CenOS and RHEL. So, we'll simply install it using yum manager. To do so, we'll simply run the following command under sudo/root access.
|
||||
|
||||
# yum install cockpit
|
||||
|
||||

|
||||
|
||||
#### On Fedora 22/21 ####
|
||||
|
||||
Alike, CentOS, it is also available by default in Fedora's official repository, we'll simply install cockpit using dnf package manager.
|
||||
|
||||
# dnf install cockpit
|
||||
|
||||

|
||||
|
||||
#### On Arch Linux ####
|
||||
|
||||
Cockpit is currently not available in the official repository of Arch Linux but it is available in the Arch User Repository also know as AUR. So, we'll simply run the following yaourt command to install it.
|
||||
|
||||
# yaourt cockpit
|
||||
|
||||

|
||||
|
||||
### 2. Starting and Enabling Cockpit ###
|
||||
|
||||
After we have successfully installed it, we'll gonna start the cockpit server with our service/daemon manager. As of 2015, most of the linux distributions have adopted Systemd whereas some of the linux distributions still run SysVinit to manage daemon, but Cockpit uses systemd for almost everything from running daemons to services. So, we can only setup Cockpit in the latest releases of linux distributions running Systemd. In order to start Cockpit and make it start in every boot of the system, we'll need to run the following command in a terminal or a console.
|
||||
|
||||
# systemctl start cockpit
|
||||
|
||||
# systemctl enable cockpit.socket
|
||||
|
||||
Created symlink from /etc/systemd/system/sockets.target.wants/cockpit.socket to /usr/lib/systemd/system/cockpit.socket.
|
||||
|
||||
### 3. Allowing Firewall ###
|
||||
|
||||
After we have started our cockpit server and enable it to start in every boot, we'll now go for configuring firewall. As we have firewall programs running in our server, we'll need to allow ports in order to make cockpit accessible outside of the server.
|
||||
|
||||
#### On Firewalld ####
|
||||
|
||||
# firewall-cmd --add-service=cockpit --permanent
|
||||
|
||||
success
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||

|
||||
|
||||
#### On Iptables ####
|
||||
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
|
||||
# service iptables save
|
||||
|
||||
### 4. Accessing Cockpit Web Interface ###
|
||||
|
||||
Next, we'll gonna finally access the Cockpit web interface using a web browser. We'll simply need to point our web browser to https://ip-address:9090 or https://server.domain.com:9090 according to the configuration. Here, in our tutorial, we'll gonna point our browser to https://128.199.114.17:9090 as shown in the image below.
|
||||
|
||||

|
||||
|
||||
We'll be displayed an SSL certification warning as we are using a self-signed SSL certificate. So, we'll simply ignore it and go forward towards the login page, in chrome/chromium, we'll need to click on Show Advanced and then we'll need to click on **Proceed to 128.199.114.17 (unsafe)** .
|
||||
|
||||

|
||||
|
||||
Now, we'll be asked to enter the login details in order to enter into the dashboard. Here, the username and password is the same as that of the login details we use to login to our linux server. After we enter the login details and click on Log In button, we will be welcomed into the Cockpit Dashboard.
|
||||
|
||||

|
||||
|
||||
Here, we'll see all the menu and visualization of CPU, Disk, Network, Storage usages of the server. We'll see the dashboard as shown above.
|
||||
|
||||
#### Services ####
|
||||
|
||||
To manage services, we'll need to click on Services button on the menu situated in the right side of the web page. Then, we'll see the services under 5 categories, Targets, System Services, Sockets, Timers and Paths.
|
||||
|
||||

|
||||
|
||||
#### Docker Containers ####
|
||||
|
||||
We can even manage docker containers with Cockpit. It is pretty easy to monitor and administer Docker containers with Cockpit. As docker isn't installed and running in our server, we'll need to click on Start Docker.
|
||||
|
||||

|
||||
|
||||
Cockpit will automatically install and run docker in our server. After its running, we see the following screen. Then, we can manage the docker images, containers as per our requirement.
|
||||
|
||||

|
||||
|
||||
#### Journal Log Viewer ####
|
||||
|
||||
Cockpit has a managed log viewer which separates the Errors, Warnings, Notices into different tabs. And we also have a tab All where we can see them all in a single place.
|
||||
|
||||

|
||||
|
||||
#### Networking ####
|
||||
|
||||
Under the networking section, we see two graphs in which there is the visualization of Sending and Receiving speed. And we can see there the list of available interfaces with option to Add Bond, Bridge, VLAN. If we need to configure an interface, we can do so by simply clicking on the interface name. Below everything, we can see the Journal Log Viewer for Networking.
|
||||
|
||||

|
||||
|
||||
#### Storage ####
|
||||
|
||||
Now, its easy with Cockpit to see the R/W speed of our hard disk. We can see the Journal log of the Storage in order to perform troubleshoot and fixes. A clear visualization bar of how much space is occupied is shown in the page. We can even Unmount, Format, Delete a partition of a Hard Disk and more. Features like creating RAID Device, Volume Group is also available in it.
|
||||
|
||||

|
||||
|
||||
#### Account Management ####
|
||||
|
||||
We can easily create new accounts with Cockpit Web Interface. The accounts created in it is applied to the system's user account. We can change password, specify roles, delete, rename user accounts with it.
|
||||
|
||||

|
||||
|
||||
#### Live Terminal ####
|
||||
|
||||
This is an awesome feature built-in with Cockpit. Yes, we can execute commands, do stuffs with the live terminal provided by Cockpit interface. This makes us really easy to switch between the web interface and terminal according to our need.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Cockpit is a good free and open source software developed by [Red Hat][1] for making the server management easy and simple. It is best for performing simple system administration tasks and is good for the new system administrators. It is still under pre-release as its stable release hasn't been released yet. So, it is not suitable for production. It is currently developed on the latest release of Fedora, CentOS, Arch Linux, RHEL where systemd is installed by default. If you are willing to install Cockpit in Ubuntu, you can get the PPA access but is currently outdated. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank You !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-cockpit-fedora-centos-rhel-arch-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/
|
||||
@ -0,0 +1,97 @@
|
||||
How to access Dropbox from the command line in Linux
|
||||
================================================================================
|
||||
Cloud storage is everywhere in today's multi-device environment, where people want to access content across multiple devices wherever they go. Dropbox is the most widely used cloud storage service thanks to its elegant UI and flawless multi-platform compatibility. The popularity of Dropbox has led to a flurry of official or unofficial Dropbox clients that are available across different operating system platforms.
|
||||
|
||||
Linux has its own share of Dropbox clients: CLI clients as well as GUI-based clients. [Dropbox Uploader][1] is an easy-to-use Dropbox CLI client written in BASH scripting language. In this tutorial, I describe** how to access Dropbox from the command line in Linux by using Dropbox Uploader**.
|
||||
|
||||
### Install and Configure Dropbox Uploader on Linux ###
|
||||
|
||||
To use Dropbox Uploader, download the script and make it executable.
|
||||
|
||||
$ wget https://raw.github.com/andreafabrizi/Dropbox-Uploader/master/dropbox_uploader.sh
|
||||
$ chmod +x dropbox_uploader.sh
|
||||
|
||||
Make sure that you have installed curl on your system, since Dropbox Uploader runs Dropbox APIs via curl.
|
||||
|
||||
To configure Dropbox Uploader, simply run dropbox_uploader.sh. When you run the script for the first time, it will ask you to grant the script access to your Dropbox account.
|
||||
|
||||
$ ./dropbox_uploader.sh
|
||||
|
||||

|
||||
|
||||
As instructed above, go to [https://www.dropbox.com/developers/apps][2] on your web browser, and create a new Dropbox app. Fill in the information of the new app as shown below, and enter the app name as generated by Dropbox Uploader.
|
||||
|
||||

|
||||
|
||||
After you have created a new app, you will see app key/secret on the next page. Make a note of them.
|
||||
|
||||

|
||||
|
||||
Enter the app key and secret in the terminal window where dropbox_uploader.sh is running. dropbox_uploader.sh will then generate an oAUTH URL (e.g., https://www.dropbox.com/1/oauth/authorize?oauth_token=XXXXXXXXXXXX).
|
||||
|
||||
|
||||
|
||||
Go to the oAUTH URL generated above on your web browser, and allow access to your Dropbox account.
|
||||
|
||||
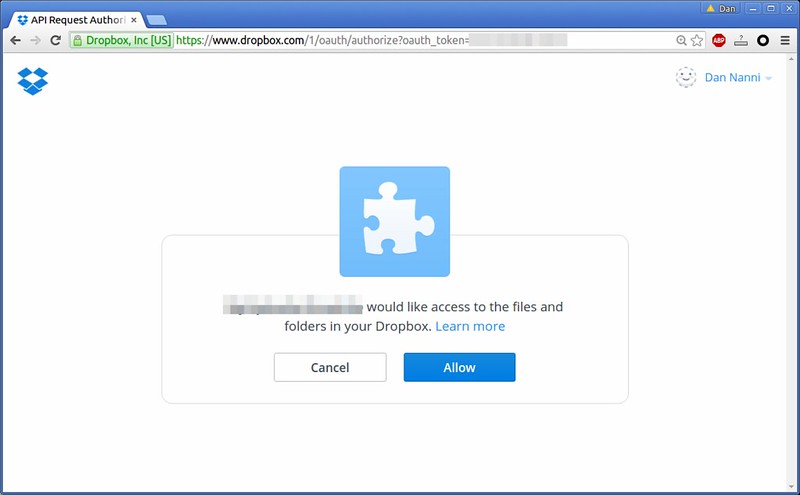
|
||||
|
||||
This completes Dropbox Uploader configuration. To check whether Dropbox Uploader is successfully authenticated, run the following command.
|
||||
|
||||
$ ./dropbox_uploader.sh info
|
||||
|
||||
----------
|
||||
|
||||
Dropbox Uploader v0.12
|
||||
|
||||
> Getting info...
|
||||
|
||||
Name: Dan Nanni
|
||||
UID: XXXXXXXXXX
|
||||
Email: my@email_address
|
||||
Quota: 2048 Mb
|
||||
Used: 13 Mb
|
||||
Free: 2034 Mb
|
||||
|
||||
### Dropbox Uploader Examples ###
|
||||
|
||||
To list all contents in the top-level directory:
|
||||
|
||||
$ ./dropbox_uploader.sh list
|
||||
|
||||
To list all contents in a specific folder:
|
||||
|
||||
$ ./dropbox_uploader.sh list Documents/manuals
|
||||
|
||||
To upload a local file to a remote Dropbox folder:
|
||||
|
||||
$ ./dropbox_uploader.sh upload snort.pdf Documents/manuals
|
||||
|
||||
To download a remote file from Dropbox to a local file:
|
||||
|
||||
$ ./dropbox_uploader.sh download Documents/manuals/mysql.pdf ./mysql.pdf
|
||||
|
||||
To download an entire remote folder from Dropbox to a local folder:
|
||||
|
||||
$ ./dropbox_uploader.sh download Documents/manuals ./manuals
|
||||
|
||||
To create a new remote folder on Dropbox:
|
||||
|
||||
$ ./dropbox_uploader.sh mkdir Documents/whitepapers
|
||||
|
||||
To delete an entire remote folder (including all its contents) on Dropbox:
|
||||
|
||||
$ ./dropbox_uploader.sh delete Documents/manuals
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-dropbox-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.andreafabrizi.it/?dropbox_uploader
|
||||
[2]:https://www.dropbox.com/developers/apps
|
||||
@ -0,0 +1,139 @@
|
||||
How to install Android Studio on Ubuntu 15.04 / CentOS 7
|
||||
================================================================================
|
||||
With the advancement of smart phones in the recent years, Android has become one of the biggest phone platforms and all the tools required to build Android applications are also freely available. Android Studio is an Integrated Development Environment (IDE) for developing Android applications based on [IntelliJ IDEA][1]. It is a free and open source software by Google released in 2014 and succeeds Eclipse as the main IDE.
|
||||
|
||||
In this article, we will learn how to install Android Studio on Ubuntu 15.04 and CentOS 7.
|
||||
|
||||
### Installation on Ubuntu 15.04 ###
|
||||
|
||||
We can install Android Studio in two ways. One is to set up the required repository and install it; other is to download it from the official Android site and install it locally. In the following example, we will be setting up the repo using command line and install it. Before proceeding, we need to make sure that we have JDK version1.6 or greater installed.
|
||||
|
||||
Here, I'm installing JDK 1.8.
|
||||
|
||||
$ sudo add-apt-repository ppa:webupd8team/java
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install oracle-java8-installer oracle-java8-set-default
|
||||
|
||||
Verify if java installation was successful:
|
||||
|
||||
poornima@poornima-Lenovo:~$ java -version
|
||||
|
||||
Now, setup the repo for installing Android Studio
|
||||
|
||||
$ sudo apt-add-repository ppa:paolorotolo/android-studio
|
||||
|
||||

|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install android-studio
|
||||
|
||||
Above install command will install android-studio in the directory /opt.
|
||||
|
||||
Now, run the following command to start the setup wizard:
|
||||
|
||||
$ /opt/android-studio/bin/studio.sh
|
||||
|
||||
This will invoke the setup screen. Following are the screen shots that follow to set up Android studio:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Once you press the Finish button, Licence agreement will be displayed. After you accept the licence, it starts downloading the required components.
|
||||
|
||||

|
||||
|
||||
Android studio installation will be complete after this step. When you relaunch Android studio, you will be shown the following welcome screen from where you will be able to start working with your Android Studio.
|
||||
|
||||

|
||||
|
||||
### Installation on CentOS 7 ###
|
||||
|
||||
Let us now learn how to install Android Studio on CentOS 7. Here also, you need to install JDK 1.6 or later. Remember to use 'sudo' before the commands if you are not a root user. You can download the [latest version][2] of JDK. In case you already have an older version installed, remove the same before installing the new one. In the below example, I will be installing JDK version 1.8.0_65 by downloading the required rpm.
|
||||
|
||||
[root@li1260-39 ~]# rpm -ivh jdk-8u65-linux-x64.rpm
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:jdk1.8.0_65-2000:1.8.0_65-fcs ################################# [100%]
|
||||
Unpacking JAR files...
|
||||
tools.jar...
|
||||
plugin.jar...
|
||||
javaws.jar...
|
||||
deploy.jar...
|
||||
rt.jar...
|
||||
jsse.jar...
|
||||
charsets.jar...
|
||||
localedata.jar...
|
||||
jfxrt.jar...
|
||||
|
||||
If Java path is not set properly, you will get error messages. Hence, set the correct path:
|
||||
|
||||
export JAVA_HOME=/usr/java/jdk1.8.0_25/
|
||||
export PATH=$PATH:$JAVA_HOME
|
||||
|
||||
Check if the correct version has been installed:
|
||||
|
||||
[root@li1260-39 ~]# java -version
|
||||
java version "1.8.0_65"
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
|
||||
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
|
||||
|
||||
If you notice any error message of the sort "unable-to-run-mksdcard-sdk-tool:" while trying to install Android Studio, you might also have to install the following packages on CentOS 7 64-bit:
|
||||
|
||||
glibc.i686
|
||||
|
||||
glibc-devel.i686
|
||||
|
||||
libstdc++.i686
|
||||
|
||||
zlib-devel.i686
|
||||
|
||||
ncurses-devel.i686
|
||||
|
||||
libX11-devel.i686
|
||||
|
||||
libXrender.i686
|
||||
|
||||
libXrandr.i686
|
||||
|
||||
Let us know install studio by downloading the ide file from [Android site][3] and unzipping the same.
|
||||
|
||||
[root@li1260-39 tmp]# unzip android-studio-ide-141.2343393-linux.zip
|
||||
|
||||
Move android-studio directory to /opt directory
|
||||
|
||||
[root@li1260-39 tmp]# mv /tmp/android-studio/ /opt/
|
||||
|
||||
You can create a simlink to the studio executable to quickly start it whenever you need it.
|
||||
|
||||
[root@li1260-39 tmp]# ln -s /opt/android-studio/bin/studio.sh /usr/local/bin/android-studio
|
||||
|
||||
Now launch the studio from a terminal:
|
||||
|
||||
[root@localhost ~]#studio
|
||||
|
||||
The screens that follow for completing the installation are same as the ones shown above for Ubuntu. When the installation completes, you can start creating your own Android applications.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Within a year of its release, Android Studio has taken over as the primary IDE for Android development by eclipsing Eclipse. It is the only official IDE tool that will support future Android SDKs and other Android features that will be provided by Google. So, what are you waiting for? Go install Android Studio and have fun developing Android apps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-android-studio-ubuntu-15-04-centos-7/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bnpoornima/
|
||||
[1]:https://www.jetbrains.com/idea/
|
||||
[2]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||
[3]:http://developer.android.com/sdk/index.html
|
||||
@ -0,0 +1,47 @@
|
||||
Translating by XLCYun
|
||||
Install Intel Graphics Installer in Ubuntu 15.10
|
||||
================================================================================
|
||||

|
||||
|
||||
Intel has announced a new release of its Linux graphics installer recently. Ubuntu 15.10 Wily is required and support for Ubuntu 15.04 is deprecated in the new release.
|
||||
|
||||
> The Intel® Graphics Installer for Linux* allows you to easily install the latest graphics and video drivers for your Intel graphics hardware. This allows you to stay current with the latest enhancements, optimizations, and fixes to the Intel® Graphics Stack to ensure the best user experience with your Intel® graphics hardware. The Intel® Graphics Installer for Linux* is available for the latest version of Ubuntu*.
|
||||
|
||||
|
||||
|
||||
### How to Install: ###
|
||||
|
||||
**1.** Download the installer from [the link page][1]. The current is version 1.2.1 for Ubuntu 15.10. Check your OS type, 32-bit or 64-bit, via **System Settings -> Details**.
|
||||
|
||||
|
||||
|
||||
**2.** Once the download process finished, go to your Download folder and click open the .deb package with Ubuntu Software Center and finally click the install button.
|
||||
|
||||
|
||||
|
||||
**3.** In order to trust the Intel Graphics Installer, you will need to add keys via below commands.
|
||||
|
||||
Open terminal from Unity Dash, App Launcher, or via Ctrl+Alt+T shortcut key. When it opens, paste below commands and run one by one:
|
||||
|
||||
wget --no-check-certificate https://download.01.org/gfx/RPM-GPG-KEY-ilg -O - | sudo apt-key add -
|
||||
|
||||
wget --no-check-certificate https://download.01.org/gfx/RPM-GPG-KEY-ilg-2 -O - | sudo apt-key add -
|
||||
|
||||
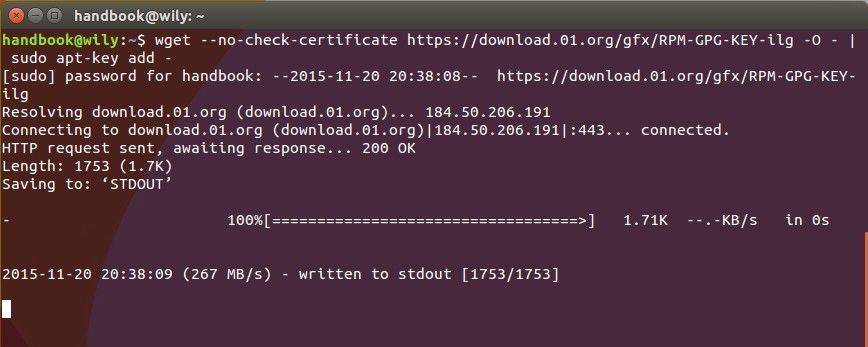
|
||||
|
||||
NOTE: While running the first command, if the cursor is stuck and blinking after downloading the key, as above picture shows, type your password (no visual feedback) and hit enter to continue.
|
||||
|
||||
Finally launch Intel Graphics Installer via Unity Dash or Application launcher.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/11/install-intel-graphics-installer-in-ubuntu-15-10/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://01.org/linuxgraphics/downloads
|
||||
83
sources/tech/20151123 LNAV--Ncurses based log file viewer.md
Normal file
83
sources/tech/20151123 LNAV--Ncurses based log file viewer.md
Normal file
@ -0,0 +1,83 @@
|
||||
LNAV – Ncurses based log file viewer
|
||||
================================================================================
|
||||
The Logfile Navigator, lnav for short, is a curses-based tool for viewing and analyzing log files. The value added by lnav over text viewers / editors is that it takes advantage of any semantic information that can be gleaned from the log file, such as timestamps and log levels. Using this extra semantic information, lnav can do things like: interleaving messages from different files; generate histograms of messages over time; and providing hotkeys for navigating through the file. It is hoped that these features will allow the user to quickly and efficiently zero-in on problems.
|
||||
|
||||
### lnav Features ###
|
||||
|
||||
#### Support for the following log file formats: ####
|
||||
|
||||
Syslog, Apache access log, strace, tcsh history, and generic log files with timestamps. The file format is automatically detected when the file is read in.
|
||||
|
||||
#### Histogram view: ####
|
||||
|
||||
Displays the number of log messages per bucket-of-time. Useful for getting an overview of what was happening over a long period of time.
|
||||
|
||||
#### Filters: ####
|
||||
|
||||
Display only lines that match or do not match a set of regular expressions. Useful for removing extraneous log lines that you are not interested in.
|
||||
|
||||
#### "Live" operation: ####
|
||||
|
||||
Searches are done as you type; new log lines are automatically loaded and searched as they are added; filters apply to lines as they are loaded; and, SQL queries are checked for correctness as you type.
|
||||
|
||||
#### Automatic tailing: ####
|
||||
|
||||
The log file view automatically scrolls down to follow new lines that are added to files. Simply scroll up to lock the view in place and then scroll down to the bottom to resume tailing.
|
||||
|
||||
#### Time-of-day ordering of lines: ####
|
||||
|
||||
The log lines from all the files are loaded and then sorted by time-of-day. Relieves you of having to manually line up log messages from different files.
|
||||
|
||||
#### Syntax highlighting: ####
|
||||
|
||||
Errors and warnings are colored in red and yellow, respectively. Highlights are also applied to: SQL keywords, XML tags, file and line numbers in Java backtraces, and quoted strings.
|
||||
|
||||
#### Navigation: ####
|
||||
|
||||
There are hotkeys for jumping to the next or previous error or warning and moving forward or backward by an amount of time.
|
||||
|
||||
#### Use SQL to query logs: ####
|
||||
|
||||
Each log file line is treated as a row in a database that can be queried using SQL. The columns that are available depend on logs file types being viewed.
|
||||
|
||||
#### Command and search history: ####
|
||||
|
||||
Your previously entered commands and searches are saved so you can access them between sessions.
|
||||
|
||||
#### Compressed files: ####
|
||||
|
||||
Compressed log files are automatically detected and uncompressed on the fly.
|
||||
|
||||
### Install lnav on ubuntu 15.10 ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install lnav
|
||||
|
||||
### Using lnav ###
|
||||
|
||||
If you want to view logs using lnav you can do using the following command by default it shows syslogs
|
||||
|
||||
lnav
|
||||
|
||||

|
||||
|
||||
If you want to view specific logs provide the path
|
||||
|
||||
If you want to view CUPS logs run the following command from your terminal
|
||||
|
||||
lnav /var/log/cups
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/lnav-ncurses-based-log-file-viewer.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -0,0 +1,60 @@
|
||||
translation by strugglingyouth
|
||||
How to Install GIMP 2.8.16 in Ubuntu 16.04, 15.10, 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
GIMP image editor 2.8.16 was released on its 20th birthday. Here’s how to install or upgrade in Ubuntu 16.04, Ubuntu 15.10, Ubuntu 14.04, Ubuntu 12.04 and their derivatives, e.g., Linux Mint 17.x/13, Elementary OS Freya.
|
||||
|
||||
GIMP 2.8.16 features support for layer groups in OpenRaster files, fixes for layer groups support in PSD, various user inrterface improvements, OSX build system fixes, translation updates, and more changes. Read the [official announcement][1].
|
||||
|
||||

|
||||
|
||||
### How to Install or Upgrade: ###
|
||||
|
||||
Thanks to Otto Meier, an [Ubuntu PPA][2] with latest GIMP packages is available for all current Ubuntu releases and derivatives.
|
||||
|
||||
**1. Add GIMP PPA**
|
||||
|
||||
Open terminal from Unity Dash, App launcher, or via Ctrl+Alt+T shortcut key. When it opens, paste below command and hit Enter:
|
||||
|
||||
sudo add-apt-repository ppa:otto-kesselgulasch/gimp
|
||||
|
||||

|
||||
|
||||
Type in your password when it asks, no visual feedback so just type in mind, and hit enter to continue.
|
||||
|
||||
**2. Install or Upgrade the editor.**
|
||||
|
||||
After added the PPA, launch **Software Updater** (or Software Manager in Mint). After checking for updates, you’ll see GIMP in the update list. Click “Install Now” to upgrade it.
|
||||
|
||||
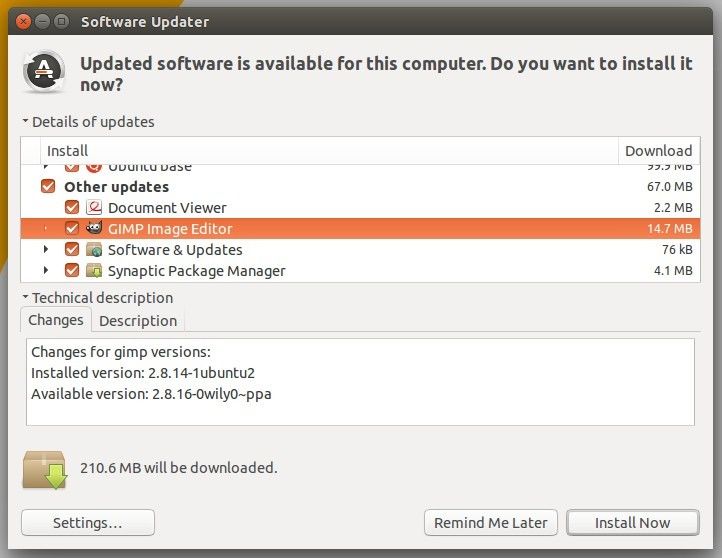
|
||||
|
||||
For those who prefer Linux commands, run below commands one by one to refresh your repository caches and install GIMP:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install gimp
|
||||
|
||||
**3. (Optional) Uninstall.**
|
||||
|
||||
Just in case you want to uninstall or downgrade GIMP image editor. Use Software Center to remove it, or run below commands one by one to purge PPA as well as downgrade the software:
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
sudo ppa-purge ppa:otto-kesselgulasch/gimp
|
||||
|
||||
That’s it. Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/11/how-to-install-gimp-2-8-16-in-ubuntu-16-04-15-10-14-04/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.gimp.org/news/2015/11/22/20-years-of-gimp-release-of-gimp-2816/
|
||||
[2]:https://launchpad.net/~otto-kesselgulasch/+archive/ubuntu/gimp
|
||||
@ -0,0 +1,40 @@
|
||||
Running a mainline kernel on a cellphone
|
||||
================================================================================
|
||||
|
||||
One of the biggest freedoms associated with free software is the ability to replace a program with an updated or modified version. Even so, of the many millions of people using Linux-powered phones, few are able to run a mainline kernel on those phones, even if they have the technical skills to do the replacement. The sad fact is that no mainstream phone available runs mainline kernels. A session at the 2015 Kernel Summit, led by Rob Herring, explored this problem and what might be done to address it.
|
||||
|
||||
When asked, most of the developers in the room indicated that they would prefer to be able to run mainline kernels on their phones — though a handful did say that they would rather not do so. Rob has been working on this problem for the last year and a half in support of Project Ara (mentioned in this article). But the news is not good.
|
||||
|
||||
There is, he said, too much out-of-tree code running on a typical handset; mainline kernels simply lack the drivers needed to make that handset work. A typical phone is running 1-3 million lines of out-of-tree code. Almost all of those phones are stuck on the 3.10 kernel — or something even older. There are all kinds of reasons for this, but the simple fact is that things seem to move too quickly in the handset world for the kernel community to keep up. Is that, he asked, something that we care about?
|
||||
|
||||
Tim Bird noted that the Nexus 1, one of the original Android phones, never ran a mainline kernel and never will. It broke the promise of open source, making it impossible for users to put a new kernel onto their devices. At this point, no phone supports that ability. Peter Zijlstra wondered about how much of that out-of-tree code was duplicated functionality from one handset to the next; Rob noted that he has run into three independently developed hotplug governors so far.
|
||||
|
||||
Dirk Hohndel suggested that few people care. Of the billion phones out there, he said, approximately 27 of them have owners who care about running mainline kernels. The rest just want to get the phone to work. Perhaps developers who are concerned about running mainline kernels are trying to solve the wrong problem.
|
||||
|
||||
Chris Mason said that handset vendors are currently facing the same sorts of problems that distributors dealt with many years ago. They are coping with a lot of inefficient, repeated, duplicated work. Once the distributors [Rob Herring] decided to put their work into the mainline instead of carrying it themselves, things got a lot better. The key is to help the phone manufacturers to realize that they can benefit in the same way; that, rather than pressure from users, is how the problem will be solved.
|
||||
|
||||
Grant Likely raised concerns about security in a world where phones cannot be upgraded. What we need is a real distribution market for phones. But, as long as the vendors are in charge of the operating software, phones will not be upgradeable. We have a big security mess coming, he said. Peter added that, with Stagefright, that mess is already upon us.
|
||||
|
||||
Ted Ts'o said that running mainline kernels is not his biggest concern. He would be happy if the phones on sale this holiday season would be running a 3.18 or 4.1 kernel, rather than being stuck on 3.10. That, he suggested, is a more solvable problem. Steve Rostedt said that would not solve the security problem, but Ted remarked that a newer kernel would at least make it easier to backport fixes. Grant replied that, one year from now, it would all just happen again; shipping newer kernels is just an incremental fix. Kees Cook added that there is not much to be gained from backporting fixes; the real problem is that there are no defenses from bugs (he would expand on this theme in a separate session later in the day).
|
||||
|
||||
Rob said that any kind of solution would require getting the vendors on board. That, though, will likely run into trouble with the sort of lockdown that vendors like to apply to their devices. Paolo Bonzini asked whether it would be possible to sue vendors over unfixed security vulnerabilities, especially when the devices are still under warranty. Grant said that upgradeability had to become a market requirement or it simply wasn't going to happen. It might be a nasty security issue that causes this to happen, or carriers might start requiring it. Meanwhile, kernel developers need to keep pushing in that direction. Rob noted that, beyond the advantages noted thus far, the ability to run mainline kernels would help developers to test and validate new features on Android devices.
|
||||
|
||||
Josh Triplett asked whether the community would be prepared to do what it would take if the industry were to come around to the idea of mainline kernel support. There would be lots of testing and validation of kernels on handsets required; Android Compatibility Test Suite failures would have to be treated as regressions. Rob suggested that this could be discussed next year, after the basic functionality is in place, but Josh insisted that, if the demand were to show up, we would have to be able to give a good answer.
|
||||
|
||||
Tim said that there is currently a big disconnect with the vendor world; vendors are not reporting or contributing anything back to the community at all. They are completely disconnected, so there is no forward progress ever. Josh noted that when vendors do report bugs with the old kernels they are using, the reception tends to be less than friendly. Arnd Bergmann said that what was needed was to get one of the big silicon vendors to commit to the idea and get its hardware to a point where running mainline kernels was possible; that would put pressure on the others. But, he added, that would require the existence of one free GPU driver that got shipped with the hardware — something that does not exist currently.
|
||||
|
||||
Rob put up a list of problem areas, but there was not much time for discussion of the particulars. WiFi drivers continue to be an issue, especially with the new features being added in the Android world. Johannes Berg agreed that the new features are an issue; the Android developers do not even talk about them until they ship with the hardware. Support for most of those features does eventually land in the mainline kernel, though.
|
||||
|
||||
As things wound down, Ben Herrenschmidt reiterated that the key was to get vendors to realize that working with the mainline kernel is in their own best interest; it saves work in the long run. Mark Brown said that, in past years when the kernel version shipped with Android moved forward more reliably, the benefits of working upstream were more apparent to vendors. Now that things seem to be stuck on 3.10, that pressure is not there in the same way. The session ended with developers determined to improve the situation, but without any clear plan for getting there.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/662147/
|
||||
|
||||
作者:[Jonathan Corbet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/KernelSummit2015/
|
||||
137
sources/tech/20151125 The tar command explained.md
Normal file
137
sources/tech/20151125 The tar command explained.md
Normal file
@ -0,0 +1,137 @@
|
||||
The tar command explained
|
||||
================================================================================
|
||||
The Linux [tar][1] command is the swiss army of the Linux admin when it comes to archiving or distributing files. Gnu Tar archives can contain multiple files and directories, file permissions can be preserved and it supports multiple compression formats. The name tar stands for "**T**ape **Ar**chiver", the format is an official POSIX standard.
|
||||
|
||||
### Tar file formats ###
|
||||
|
||||
A short introduction into tar compression levels.
|
||||
|
||||
- **No compression** Uncompressed files have the file ending .tar.
|
||||
- **Gzip Compression** The Gzip format is the most widely used compression format for tar, it is fast for creating and extracting files. Files with gz compression have normally the file ending .tar.gz or .tgz. Here some examples on how to [create][2] and [extract][3] a tar.gz file.
|
||||
- **Bzip2 Compression** The Bzip2 format offers a better compression then the Gzip format. Creating files is slower, the file ending is usually .tar.bz2.
|
||||
- **Lzip (LZMA) Compression** The Lzip compression combines the speed of Gzip with a compression level that is similar to Bzip2 (or even better). Independently from these good attributes, this format is not widely used.
|
||||
- **Lzop Compression** This compress option is probably the fastest compression format for tar, it has a compression level similar to gzip and is not widely used.
|
||||
|
||||
The common formats are tar.gz and tar.bz2. If you goal is fast compression, then use gzip. When the archive file size is critical, then use tar.bz2.
|
||||
|
||||
### What is the tar command used for? ###
|
||||
|
||||
Here a few common use cases of the tar command.
|
||||
|
||||
- Backup of Servers and Desktops.
|
||||
- Document archiving.
|
||||
- Software Distribution.
|
||||
|
||||
### Installing tar ###
|
||||
|
||||
The command is installed on most Linux Systems by default. Here are the instructions to install tar in case that the command is missing.
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
Execute the following command as root user on the shell to install tar on CentOS.
|
||||
|
||||
yum install tar
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
This command will install tar on Ubuntu. The "sudo" command ensures that the apt command is run with root privileges.
|
||||
|
||||
sudo apt-get install tar
|
||||
|
||||
#### Debian ####
|
||||
|
||||
The following apt command installs tar on Debian.
|
||||
|
||||
apt-get install tar
|
||||
|
||||
#### Windows ####
|
||||
|
||||
The tar command is available for Windows as well, you can download it from the Gunwin project. [http://gnuwin32.sourceforge.net/packages/gtar.htm][4]
|
||||
|
||||
### Create tar.gz Files ###
|
||||
|
||||
Here is the [tar command][5] that has to be run on the shell. I will explain the command line options below.
|
||||
|
||||
tar pczf myarchive.tar.gz /home/till/mydocuments
|
||||
|
||||
This command creates the archive myarchive.tar.gz which contains the files and folders from the path /home/till/mydocuments. **The command line options explained**:
|
||||
|
||||
- **[p]** This option stand for "preserve", it instructs tar to store details on file owner and file permissions in the archive.
|
||||
- **[c]** Stands for create. This option is mandatory when a file is created.
|
||||
- **[z]** The z option enables gzip compression.
|
||||
- **[f]** The file option tells tar to create an archive file. Tar will send the output to stdout if this option is omitted.
|
||||
|
||||
#### Tar command examples ####
|
||||
|
||||
**Example 1: Backup the /etc Directory** Create a backup of the /etc config directory. The backup is stored in the root folder.
|
||||
|
||||
tar pczvf /root/etc.tar.gz /etc
|
||||
|
||||
|
||||
|
||||
The command should be run as root to ensure that all files in /etc are included in the backup. This time, I've added the [v] option in the command. This option stands for verbose, it tells tar to show all file names that get added into the archive.
|
||||
|
||||
**Example 2: Backup your /home directory** Create a backup of your home directory. The backup will be stored in a directory /backup.
|
||||
|
||||
tar czf /backup/myuser.tar.gz /home/myuser
|
||||
|
||||
Replace myuser with your username. In this command, I've omitted the [p] switch, so the permissions get not preserved.
|
||||
|
||||
**Example 3: A file-based backup of MySQL databases** The MySQL databases are stored in /var/lib/mysql on most Linux distributions. You can check that with the command:
|
||||
|
||||
ls /var/lib/mysql
|
||||
|
||||
|
||||
|
||||
Stop the database server to get a consistent MySQL file backup with tar. The backup will be written to the /backup folder.
|
||||
|
||||
1) Create the backup folder
|
||||
|
||||
mkdir /backup
|
||||
chmod 600 /backup
|
||||
|
||||
2) Stop MySQL, run the backup with tar and start the database server again.
|
||||
|
||||
service mysql stop
|
||||
tar pczf /backup/mysql.tar.gz /var/lib/mysql
|
||||
service mysql start
|
||||
ls -lah /backup
|
||||
|
||||
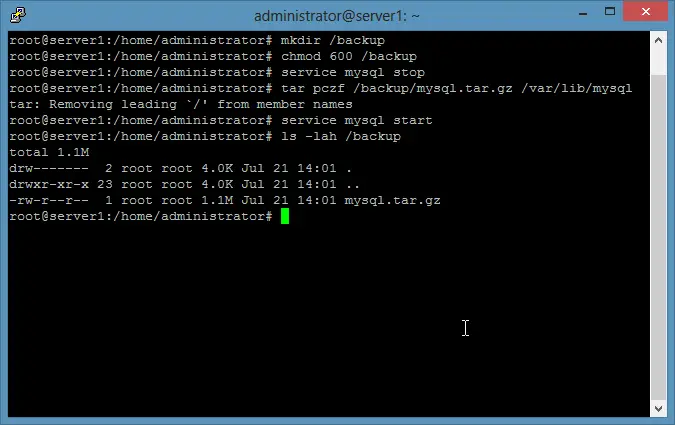
|
||||
|
||||
### Extract tar.gz Files ###
|
||||
|
||||
The command to extract tar.gz files is:
|
||||
|
||||
tar xzf myarchive.tar.gz
|
||||
|
||||
#### The tar command options explained ####
|
||||
|
||||
- **[x]** The x stand for extract, it is mandatory when a tar file shall be extracted.
|
||||
- **[z]** The z option tells tar that the archive that shall be unpacked is in gzip format.
|
||||
- **[f]** This option instructs tar to read the archive content from a file, in this case the file myarchive.tar.gz.
|
||||
|
||||
The above tar command will silently extract that tar.gz file, it will show only error messages. If you like to see which files get extracted, then add the "v" option.
|
||||
|
||||
tar xzvf myarchive.tar.gz
|
||||
|
||||
The **[v]** option stands for verbose, it will show the file names while they get unpacked.
|
||||
|
||||
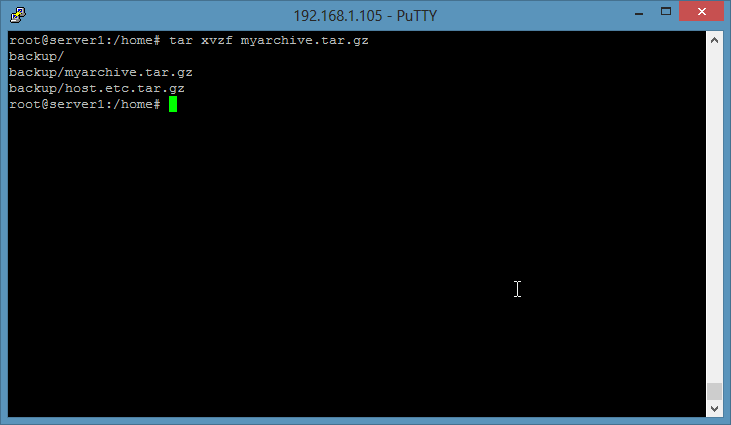
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-tar-command/
|
||||
|
||||
作者:[howtoforge][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/
|
||||
[1]:https://en.wikipedia.org/wiki/Tar_(computing)
|
||||
[2]:http://www.faqforge.com/linux/create-tar-gz/
|
||||
[3]:http://www.faqforge.com/linux/extract-tar-gz/
|
||||
[4]:http://gnuwin32.sourceforge.net/packages/gtar.htm
|
||||
[5]:http://www.faqforge.com/linux/tar-command/
|
||||
@ -0,0 +1,326 @@
|
||||
How to Install Nginx as Reverse Proxy for Apache on FreeBSD 10.2
|
||||
================================================================================
|
||||
Nginx is free and open source HTTP server and reverse proxy, as well as an mail proxy server for IMAP/POP3. Nginx is high performance web server with rich of features, simple configuration and low memory usage. Originally written by Igor Sysoev on 2002, and until now has been used by a big technology company including Netflix, Github, Cloudflare, WordPress.com etc.
|
||||
|
||||
In this tutorial we will "**install and configure nginx web server as reverse proxy for apache on freebsd 10.2**". Apache will run with php on port 8080, and then we need to configure nginx run on port 80 to receive a request from user/visitor. If user request for web page from the browser on port 80, then nginx will pass the request to apache webserver and PHP that running on port 8080.
|
||||
|
||||
#### Prerequisite ####
|
||||
|
||||
- FreeBSD 10.2.
|
||||
- Root privileges.
|
||||
|
||||
### Step 1 - Update the System ###
|
||||
|
||||
Log in to your freebsd server with ssh credential and update system with command below :
|
||||
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### Step 2 - Install Apache ###
|
||||
|
||||
pache is open source HTTP server and the most widely used web server. Apache is not installed by default on freebsd, but we can install it from the ports or package on "/usr/ports/www/apache24" or install it from freebsd repository with pkg command. In this tutorial we will use pkg command to install from the freebsd repository :
|
||||
|
||||
pkg install apache24
|
||||
|
||||
### Step 3 - Install PHP ###
|
||||
|
||||
Once apache is installed, followed with installing php for handling a PHP file request by a user. We will install php with pkg command as below :
|
||||
|
||||
pkg install php56 mod_php56 php56-mysql php56-mysqli
|
||||
|
||||
### Step 4 - Configure Apache and PHP ###
|
||||
|
||||
Once all is installed, we will configure apache to run on port 8080, and php working with apache. To configure apache, we can edit the configuration file "httpd.conf", and for PHP we just need to copy the php configuration file php.ini on "/usr/local/etc/" directory.
|
||||
|
||||
Go to "/usr/local/etc/" directory and copy php.ini-production file to php.ini :
|
||||
|
||||
cd /usr/local/etc/
|
||||
cp php.ini-production php.ini
|
||||
|
||||
Next, configure apache by editing file "httpd.conf" on apache directory :
|
||||
|
||||
cd /usr/local/etc/apache24
|
||||
nano -c httpd.conf
|
||||
|
||||
Port configuration on line **52** :
|
||||
|
||||
Listen 8080
|
||||
|
||||
ServerName configuration on line **219** :
|
||||
|
||||
ServerName 127.0.0.1:8080
|
||||
|
||||
Add DirectoryIndex file that apache will serve it if a directory requested on line **277** :
|
||||
|
||||
DirectoryIndex index.php index.html
|
||||
|
||||
Configure apache to work with php by adding script below under line **287** :
|
||||
|
||||
<FilesMatch "\.php$">
|
||||
SetHandler application/x-httpd-php
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.phps$">
|
||||
SetHandler application/x-httpd-php-source
|
||||
</FilesMatch>
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now add apache to start at boot time with sysrc command :
|
||||
|
||||
sysrc apache24_enable=yes
|
||||
|
||||
And test apache configuration with command below :
|
||||
|
||||
apachectl configtest
|
||||
|
||||
If there is no error, start apache :
|
||||
|
||||
service apache24 start
|
||||
|
||||
If all is done, verify that php is running well with apache by creating phpinfo file on "/usr/local/www/apache24/data" directory :
|
||||
|
||||
cd /usr/local/www/apache24/data
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
Now visit the freebsd server IP : 192.168.1.123:8080/info.php.
|
||||
|
||||

|
||||
|
||||
Apache is working with php on port 8080.
|
||||
|
||||
### Step 5 - Install Nginx ###
|
||||
|
||||
Nginx high performance web server and reverse proxy with low memory consumption. In this step we will use nginx as reverse proxy for apache, so let's install it with pkg command :
|
||||
|
||||
pkg install nginx
|
||||
|
||||
### Step 6 - Configure Nginx ###
|
||||
|
||||
Once nginx is installed, we must configure it by replacing nginx file "**nginx.conf**" with new configuration below. Change the directory to "/usr/local/etc/nginx/" and backup default nginx.conf :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mv nginx.conf nginx.conf.oroginal
|
||||
|
||||
Now create new nginx configuration file :
|
||||
|
||||
nano -c nginx.conf
|
||||
|
||||
and paste configuration below :
|
||||
|
||||
user www;
|
||||
worker_processes 1;
|
||||
error_log /var/log/nginx/error.log;
|
||||
|
||||
events {
|
||||
worker_connections 1024;
|
||||
}
|
||||
|
||||
http {
|
||||
include mime.types;
|
||||
default_type application/octet-stream;
|
||||
|
||||
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
|
||||
'$status $body_bytes_sent "$http_referer" '
|
||||
'"$http_user_agent" "$http_x_forwarded_for"';
|
||||
access_log /var/log/nginx/access.log;
|
||||
|
||||
sendfile on;
|
||||
keepalive_timeout 65;
|
||||
|
||||
# Nginx cache configuration
|
||||
proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=my-cache:8m max_size=1000m inactive=600m;
|
||||
proxy_temp_path /var/nginx/cache/tmp;
|
||||
proxy_cache_key "$scheme$host$request_uri";
|
||||
|
||||
gzip on;
|
||||
|
||||
server {
|
||||
#listen 80;
|
||||
server_name _;
|
||||
|
||||
location /nginx_status {
|
||||
|
||||
stub_status on;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
# redirect server error pages to the static page /50x.html
|
||||
#
|
||||
error_page 500 502 503 504 /50x.html;
|
||||
location = /50x.html {
|
||||
root /usr/local/www/nginx-dist;
|
||||
}
|
||||
|
||||
# proxy the PHP scripts to Apache listening on 127.0.0.1:8080
|
||||
#
|
||||
location ~ \.php$ {
|
||||
proxy_pass http://127.0.0.1:8080;
|
||||
include /usr/local/etc/nginx/proxy.conf;
|
||||
}
|
||||
}
|
||||
|
||||
include /usr/local/etc/nginx/vhost/*;
|
||||
|
||||
}
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, create new file called **proxy.conf** for reverse proxy configuration on nginx directory :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
nano -c proxy.conf
|
||||
|
||||
Paste configuration below :
|
||||
|
||||
proxy_buffering on;
|
||||
proxy_redirect off;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
client_max_body_size 10m;
|
||||
client_body_buffer_size 128k;
|
||||
proxy_connect_timeout 90;
|
||||
proxy_send_timeout 90;
|
||||
proxy_read_timeout 90;
|
||||
proxy_buffers 100 8k;
|
||||
add_header X-Cache $upstream_cache_status;
|
||||
|
||||
Save and exit.
|
||||
|
||||
And the last, create new directory for nginx cache on "/var/nginx/cache" :
|
||||
|
||||
mkdir -p /var/nginx/cache
|
||||
|
||||
### Step 7 - Configure Nginx VirtualHost ###
|
||||
|
||||
In this step we will create new virtualhost for domain "saitama.me", with document root on "/usr/local/www/saitama.me" and the log file on "/var/log/nginx" directory.
|
||||
|
||||
First thing we must do is creating new directory to store the virtualhost file, we here use new directory called "**vhost**". Let's create it :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mkdir vhost
|
||||
|
||||
vhost directory has been created, now go to the directory and create new file virtualhost. I'me here will create new file "**saitama.conf**" :
|
||||
|
||||
cd vhost/
|
||||
nano -c saitama.conf
|
||||
|
||||
Paste virtualhost configuration below :
|
||||
|
||||
server {
|
||||
# Replace with your freebsd IP
|
||||
listen 192.168.1.123:80;
|
||||
|
||||
# Document Root
|
||||
root /usr/local/www/saitama.me;
|
||||
index index.php index.html index.htm;
|
||||
|
||||
# Domain
|
||||
server_name www.saitama.me saitama.me;
|
||||
|
||||
# Error and Access log file
|
||||
error_log /var/log/nginx/saitama-error.log;
|
||||
access_log /var/log/nginx/saitama-access.log main;
|
||||
|
||||
# Reverse Proxy Configuration
|
||||
location ~ \.php$ {
|
||||
proxy_pass http://127.0.0.1:8080;
|
||||
include /usr/local/etc/nginx/proxy.conf;
|
||||
|
||||
# Cache configuration
|
||||
proxy_cache my-cache;
|
||||
proxy_cache_valid 10s;
|
||||
proxy_no_cache $cookie_PHPSESSID;
|
||||
proxy_cache_bypass $cookie_PHPSESSID;
|
||||
proxy_cache_key "$scheme$host$request_uri";
|
||||
|
||||
}
|
||||
|
||||
# Disable Cache for the file type html, json
|
||||
location ~* .(?:manifest|appcache|html?|xml|json)$ {
|
||||
expires -1;
|
||||
}
|
||||
|
||||
# Enable Cache the file 30 days
|
||||
location ~* .(jpg|png|gif|jpeg|css|mp3|wav|swf|mov|doc|pdf|xls|ppt|docx|pptx|xlsx)$ {
|
||||
proxy_cache_valid 200 120m;
|
||||
expires 30d;
|
||||
proxy_cache my-cache;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, create new log directory for nginx and virtualhost on "/var/log/" :
|
||||
|
||||
mkdir -p /var/log/nginx/
|
||||
|
||||
If all is done, let's create a directory for document root for saitama.me :
|
||||
|
||||
cd /usr/local/www/
|
||||
mkdir saitama.me
|
||||
|
||||
### Step 8 - Testing ###
|
||||
|
||||
This step is just test our nginx configuration and test the nginx virtualhost.
|
||||
|
||||
Test nginx configuration with command below :
|
||||
|
||||
nginx -t
|
||||
|
||||
If there is no problem, add nginx to boot time with sysrc command, and then start it and restart apache:
|
||||
|
||||
sysrc nginx_enable=yes
|
||||
service nginx start
|
||||
service apache24 restart
|
||||
|
||||
All is done, now verify the the php is working by adding new file phpinfo on saitama.me directory :
|
||||
|
||||
cd /usr/local/www/saitama.me
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
Visit the domain : **www.saitama.me/info.php**.
|
||||
|
||||

|
||||
|
||||
Nginx as reverse proxy for apache is working, and php is working too.
|
||||
|
||||
And this is another results :
|
||||
|
||||
Test .html file with no-cache.
|
||||
|
||||
curl -I www.saitama.me
|
||||
|
||||

|
||||
|
||||
Test .css file with 30day cache.
|
||||
|
||||
curl -I www.saitama.me/test.css
|
||||
|
||||

|
||||
|
||||
Test .php file with cache :
|
||||
|
||||
curl -I www.saitama.me/info.php
|
||||
|
||||

|
||||
|
||||
All is done.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Nginx is most popular HTTP server and reverse proxy. Has a rich of features with high performance and low memory/RAM usage. Nginx use too for caching, we can cache a static file on the web to make the web fast load, and cache for php file if a user request for it. Nginx is easy to configure and use, use for HTTP server or act as reverse proxy for apache.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-nginx-reverse-proxy-apache-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -0,0 +1,53 @@
|
||||
Linux FAQs with Answers--How to remove trailing whitespaces in a file on Linux
|
||||
================================================================================
|
||||
> Question: I have a text file in which I need to remove all trailing whitespsaces (e.g., spaces and tabs) in each line for formatting purpose. Is there a quick and easy Linux command line tool I can use for this?
|
||||
|
||||
When you are writing code for your program, you must understand that there are standard coding styles to follow. For example, "trailing whitespaces" are typically considered evil because when they get into a code repository for revision control, they can cause a lot of problems and confusion (e.g., "false diffs"). Many IDEs and text editors are capable of highlighting and automatically trimming trailing whitepsaces at the end of each line.
|
||||
|
||||
Here are a few ways to **remove trailing whitespaces in Linux command-line environment**.
|
||||
|
||||
### Method One ###
|
||||
|
||||
A simple command line approach to remove unwanted whitespaces is via sed.
|
||||
|
||||
The following command deletes all spaces and tabs at the end of each line in input.java.
|
||||
|
||||
$ sed -i 's/[[:space:]]*$//' input.java
|
||||
|
||||
If there are multiple files that need trailing whitespaces removed, you can use a combination of find and sed. For example, the following command deletes trailing whitespaces in all *.java files recursively found in the current directory as well as all its sub-directories.
|
||||
|
||||
$ find . -name "*.java" -type f -print0 | xargs -0 sed -i 's/[[:space:]]*$//'
|
||||
|
||||
### Method Two ###
|
||||
|
||||
Vim text editor is able to highlight and trim whitespaces in a file as well.
|
||||
|
||||
To highlight all trailing whitespaces in a file, open the file with Vim editor and enable text highlighting by typing the following in Vim command line mode.
|
||||
|
||||
:set hlsearch
|
||||
|
||||
Then search for trailing whitespaces by typing:
|
||||
|
||||
/\s\+$
|
||||
|
||||
This will show all trailing spaces and tabs found throughout the file.
|
||||
|
||||
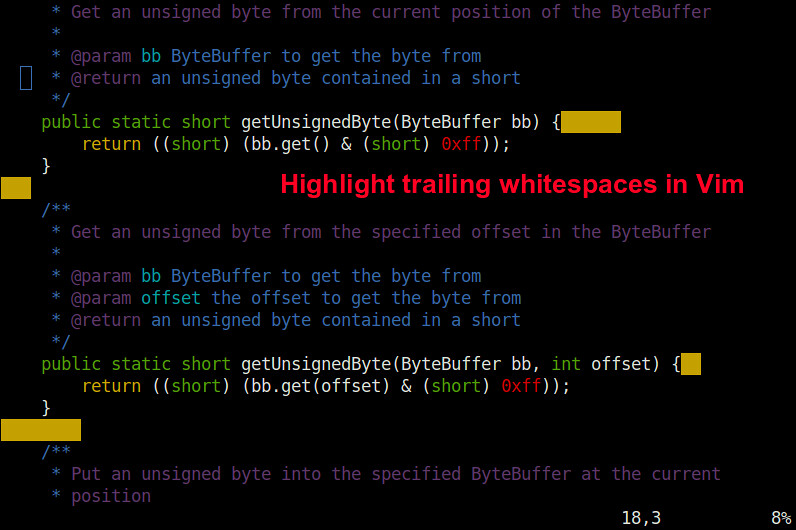
|
||||
|
||||
Then to clean up all trailing whitespaces in a file with Vim, type the following Vim command.
|
||||
|
||||
:%s/\s\+$//
|
||||
|
||||
This command means substituting all whitespace characters found at the end of the line (\s\+$) with no character.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/remove-trailing-whitespaces-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 2 - LFCS: How to Install and Use vi/vim as a Full Text Editor
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification in order to help individuals from all over the world to verify they are capable of doing basic to intermediate system administration tasks on Linux systems: system support, first-hand troubleshooting and maintenance, plus intelligent decision-making to know when it’s time to raise issues to upper support teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 3 - LFCS: How to Archive/Compress Files & Directories, Setting File Attributes and Finding Files in Linux
|
||||
================================================================================
|
||||
Recently, the Linux Foundation started the LFCS (Linux Foundation Certified Sysadmin) certification, a brand new program whose purpose is allowing individuals from all corners of the globe to have access to an exam, which if approved, certifies that the person is knowledgeable in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-level troubleshooting and analysis, plus the ability to decide when to escalate issues to engineering teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 4 - LFCS: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
================================================================================
|
||||
Last August, the Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators to show, through a performance-based exam, that they can perform overall operational support of Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation – if needed – to other support teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 5 - LFCS: How to Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is allowing individuals from all corners of the globe to get certified in basic to intermediate system administration tasks for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 6 - LFCS: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
================================================================================
|
||||
Recently, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification, a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of performing overall operational support on Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation, when required, to other support teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 8 - LFCS: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
================================================================================
|
||||
Last August, the Linux Foundation started the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is to allow individuals everywhere and anywhere take an exam in order to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus intelligent decision-making to be able to decide when it’s necessary to escalate issues to higher level support teams.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 9 - LFCS: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
================================================================================
|
||||
Last August, the Linux Foundation announced the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of succeeding at overall operational support for Linux systems. A Linux Foundation Certified Sysadmin has the expertise to ensure effective system support, first-level troubleshooting and monitoring, including finally issue escalation, when needed, to engineering support teams.
|
||||
|
||||
@ -1,126 +0,0 @@
|
||||
Translated by KnightJoker
|
||||
|
||||
用Linux学习:使用这些Linux应用来征服你的数学
|
||||
================================================================================
|
||||

|
||||
|
||||
这篇文章是[用Linux学习][1]系列的一部分:
|
||||
|
||||
- [用Linux学习: 学习类型][2]
|
||||
- [用Linux学习: 物理模拟][3]
|
||||
- [用Linux学习: 学习音乐][4]
|
||||
- [用Linux学习: 两个地理应用程序][5]
|
||||
- [用Linux学习: 用这些Linux应用来征服你的数学][6]
|
||||
|
||||
|
||||
Linux提供了大量的教育软件和许多优秀的工具来帮助所有年龄段的学生学习和练习各种各样的话题,常常以交互的方式。与Linux一起学习这一系列的文章则为这些各种各样的教育软件和应用提供了一个介绍。
|
||||
|
||||
数学是计算机的核心。如果有人用精益求精和纪律来预期一个伟大的操作系统,比如GNU/ Linux,那么这将是数学。如果你在寻求一些数学应用程序,那么你将不会感到失望。Linux提供了很多优秀的工具使得数学看起来和你曾经做过的一样令人畏惧,但实际上他们会简化你使用它的方式。
|
||||
### Gnuplot ###
|
||||
|
||||
Gnuplot 是一个适用于不同平台的命令行脚本化和多功能的图形工具。尽管它的名字,并不是GNU操作系统的一部分。也没有免费授权,但它是免费软件(这意味着它受版权保护,但免费使用)。
|
||||
|
||||
要在Ubuntu系统(或者衍生系统)上安装 `gnuplot`,输入:
|
||||
sudo apt-get install gnuplot gnuplot-x11
|
||||
|
||||
进入一个终端窗口。启动该程序,输入:
|
||||
|
||||
gnuplot
|
||||
|
||||
你会看到一个简单的命令行界面:
|
||||
|
||||

|
||||
|
||||
在其中您可以直接开始输入函数。绘图命令将绘制一个曲线图。
|
||||
|
||||
输入内容,例如,
|
||||
|
||||
plot sin(x)/x
|
||||
|
||||
随着`gnuplot的`提示,将会打开一个新的窗口,图像便会在里面呈现。
|
||||
|
||||

|
||||
|
||||
你也可以在线这个图设置不同的属性,比如像这样指定“title”
|
||||
|
||||
plot sin(x) title 'Sine Function', tan(x) title 'Tangent'
|
||||
|
||||

|
||||
|
||||
使用`splot`命令,你可以给的东西更深入一点并且绘制3D图形
|
||||
|
||||
splot sin(x*y/20)
|
||||
|
||||

|
||||
|
||||
这个窗口有几个基本的配置选项,
|
||||
|
||||

|
||||
|
||||
但是`gnuplot`的真正力量在于在它的命令行和脚本功能,`gnuplot`广泛完整的文档可在这里找到,并在[Duke大学网站][8]上面看见这个了不起的教程[7]的原始版本。
|
||||
|
||||
### Maxima ###
|
||||
|
||||
[Maxima][9]是从Macsyma原始资料开发的一个计算机代数系统,根据它的 SourceForge 页面,
|
||||
|
||||
> “Maxima是符号和数值的表达,包括微分,积分,泰勒级数,拉普拉斯变换,常微分方程,线性方程组,多项式,集合,列表,向量,矩阵和张量系统的操纵系统。Maxima通过精确的分数,任意精度的整数和可变精度浮点数产生高精度的计算结果。Maxima可以二维和三维中绘制函数和数据。“
|
||||
|
||||
你将会获得二进制包用于大多数Ubuntu衍生系统的Maxima以及它的图形界面中,插入所有包,输入:
|
||||
|
||||
sudo apt-get install maxima xmaxima wxmaxima
|
||||
|
||||
在终端窗口中,Maxima是一个没有太多UI的命令行工具,但如果你开始wxmaxima,你会进入一个简单但功能强大的图形用户界面。
|
||||
|
||||

|
||||
|
||||
你可以开始输入这个来简单的一个开始。(提示:如果你想计算一个表达式,使用“Shift + Enter”回车后会增加更多的方法)
|
||||
|
||||
Maxima可以用于一些简单的问题,因此也可以作为一个计算器,
|
||||
|
||||

|
||||
|
||||
以及一些更复杂的问题,
|
||||
|
||||

|
||||
|
||||
它使用`gnuplot`使得绘制简单,
|
||||
|
||||

|
||||
|
||||
或者绘制一些复杂的图形.
|
||||
|
||||

|
||||
|
||||
(它需要gnuplot-X11的包,来显示它们。)
|
||||
|
||||
除了美化一些图形,Maxima也尽可能用latex格式导出它们,或者通过右键是捷菜单进行一些突出的操作.
|
||||
|
||||

|
||||
|
||||
然而其主菜单还是提供了大量压倒性的功能,当然Maxima的功能远不止如此,这里也有一个广泛使用的在线文档。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
数学不是一个简单的学科,这些在Linux上的优秀软件也没有使得数学更加简单,但是这些应用使得使用数学变得更加的简单和工程化。以上两种应用都只是介绍一下Linux的所提供的。如果你是认真从事数学和需要更多的功能与丰富的文档,那你更应该看看这些Mathbuntu项目。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/learn-linux-maths/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[KnightJoker](https://github.com/KnightJoker/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
[7]:http://www.gnuplot.info/documentation.html
|
||||
[8]:http://people.duke.edu/~hpgavin/gnuplot.html
|
||||
[9]:http://maxima.sourceforge.net/
|
||||
[10]:http://maxima.sourceforge.net/documentation.html
|
||||
[11]:http://www.mathbuntu.org/
|
||||
@ -0,0 +1,43 @@
|
||||
sevenot translated
|
||||
好奇Linux?试试云端的Linux桌面
|
||||
================================================================================
|
||||
Linux在桌面操作系统市场上只占据了非常小的份额,目前调查来看,估计只有2%的市场份额;对比来看丰富多变的Windows系统占据了接近90%的市场份额。对于Linux来说要挑战Windows在桌面操作系统市场的垄断,需要一个简单的方式来让用户学习不同的操作系统。如果你相信传统的Windows用户再买一台机器来使用Linux,你就太天真了。我们只能去试想用户重新分盘,设置引导程序来使用双系统,或者跳过所有步骤回到一个最简单的方法。
|
||||

|
||||
|
||||
我们实验过一系列无风险的使用方法让用户试操作Linux,并且不涉及任何分区管理,包括CD/DVDs光盘、USB钥匙和桌面虚拟化软件。通过实验,我强烈推荐使用VMware的VMware Player或者Oracle VirtualBox虚拟机,对于桌面操作系统或者便携式电脑的用户,这是一种相对简单而且免费的的方法来安装运行多操作系统。每一台虚拟机和其他虚拟机相隔离,但是共享CPU,存贮,网络接口等等。但是虚拟机仍需要一定的资源来安装运行Linux,也需要一台相当强劲的主机。对于一个好奇心不大的人,这样做实在是太麻烦了。
|
||||
|
||||
要打破用户传统的使用观念市非常困难的。很多Windows用户可以尝试使用Linux提供的免费软件,但也有太多要学习的Linux系统知识。这会花掉相当一部分时间来习惯Linux的工作方式。
|
||||
|
||||
当然了,对于一个第一次在Linux上操作的新手,有没有一个更高效的方法呢?答案是肯定的,接着往下看看云实验平台。
|
||||
|
||||
### LabxNow ###
|
||||
|
||||

|
||||
|
||||
LabxNow提供了一个免费服务,方便广大用户通过浏览器来访问远程Liunx桌面。开发者将其加强为一个用户个人远程实验室(用户可以在系统里运行、开发任何程序),用户可以在任何地方通过互联网登入远程实验室。
|
||||
|
||||
这项服务现在可以为个人用户提供2核处理器,4GB RAM和10GB的固态硬盘,运行在128G RAM的4 AMD 6272处理器上。
|
||||
|
||||
#### 配置参数: ####
|
||||
|
||||
- 系统镜像:基于Ubuntu 14.04的Xface 4.10,RHEL 6.5,CentOS(Gnome桌面),Oracle
|
||||
- 硬件: CPU - 1核或者2核; 内存: 512MB, 1GB, 2GB or 4GB
|
||||
- 超快的网络数据传输
|
||||
- 可以运行在所有流行的浏览器上
|
||||
- 可以安装任意程序,可以运行任何程序 – 这是一个非常棒的方法,可以随意做实验学你你想学的所有知识, 没有 一点风险
|
||||
- 添加、删除、管理、制定虚拟机非常方便
|
||||
- 支持虚拟机共享,远程桌面
|
||||
|
||||
你所需要的只是一台有稳定网络的设备。不用担心虚拟专用系统(VPS)、域名、或者硬件带来的高费用。LabxNow提供了一个非常好的方法在Ubuntu、RHEL和CentOS上实验。它给Windows用户一个极好的环境,让他们探索美妙的Linux世界。说得深一点,它可以让用户随时随地在里面工作,而没有了要在每台设备上安装Linux的压力。点击下面这个链接进入[www.labxnow.org/labxweb/][1]。
|
||||
|
||||
这里还有一些其它服务(大部分市收费服务)可以让用户在Linux使用。包括Cloudsigma环境的7天使用权和Icebergs.io(通过HTML5实现root权限)。但是现在,我推荐LabxNow。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
来自: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
|
||||
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.labxnow.org/labxweb/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user