mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
39c035a503
@ -1,76 +0,0 @@
|
||||
Translating by qhwdw [20090211 Page Cache, the Affair Between Memory and Files][1]
|
||||
============================================================
|
||||
|
||||
|
||||
Previously we looked at how the kernel [manages virtual memory][2] for a user process, but files and I/O were left out. This post covers the important and often misunderstood relationship between files and memory and its consequences for performance.
|
||||
|
||||
Two serious problems must be solved by the OS when it comes to files. The first one is the mind-blowing slowness of hard drives, and [disk seeks in particular][3], relative to memory. The second is the need to load file contents in physical memory once and share the contents among programs. If you use [Process Explorer][4] to poke at Windows processes, you'll see there are ~15MB worth of common DLLs loaded in every process. My Windows box right now is running 100 processes, so without sharing I'd be using up to ~1.5 GB of physical RAM just for common DLLs. No good. Likewise, nearly all Linux programs need [ld.so][5] and libc, plus other common libraries.
|
||||
|
||||
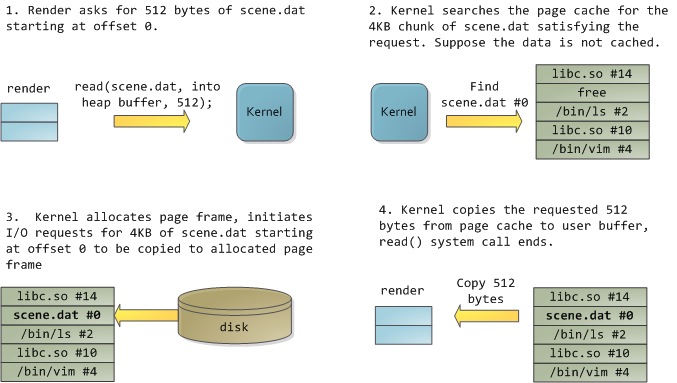
Happily, both problems can be dealt with in one shot: the page cache, where the kernel stores page-sized chunks of files. To illustrate the page cache, I'll conjure a Linux program named render, which opens file scene.dat and reads it 512 bytes at a time, storing the file contents into a heap-allocated block. The first read goes like this:
|
||||
|
||||
|
||||
|
||||
After 12KB have been read, render's heap and the relevant page frames look thus:
|
||||
|
||||
|
||||
|
||||
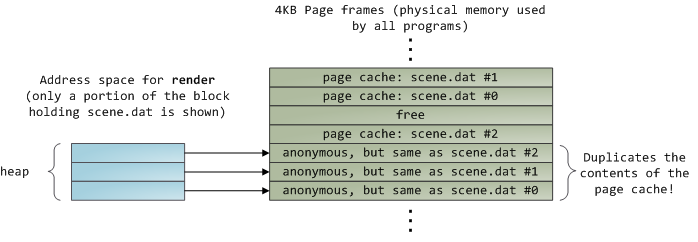
This looks innocent enough, but there's a lot going on. First, even though this program uses regular read calls, three 4KB page frames are now in the page cache storing part of scene.dat. People are sometimes surprised by this, but all regular file I/O happens through the page cache. In x86 Linux, the kernel thinks of a file as a sequence of 4KB chunks. If you read a single byte from a file, the whole 4KB chunk containing the byte you asked for is read from disk and placed into the page cache. This makes sense because sustained disk throughput is pretty good and programs normally read more than just a few bytes from a file region. The page cache knows the position of each 4KB chunk within the file, depicted above as #0, #1, etc. Windows uses 256KB views analogous to pages in the Linux page cache.
|
||||
|
||||
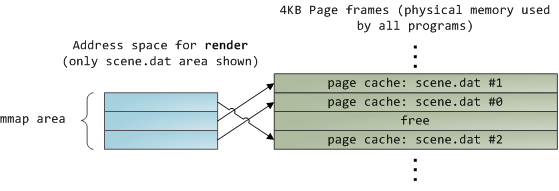
Sadly, in a regular file read the kernel must copy the contents of the page cache into a user buffer, which not only takes cpu time and hurts the [cpu caches][6], but also wastes physical memory with duplicate data. As per the diagram above, the scene.dat contents are stored twice, and each instance of the program would store the contents an additional time. We've mitigated the disk latency problem but failed miserably at everything else. Memory-mapped files are the way out of this madness:
|
||||
|
||||
|
||||
|
||||
When you use file mapping, the kernel maps your program's virtual pages directly onto the page cache. This can deliver a significant performance boost: [Windows System Programming][7] reports run time improvements of 30% and up relative to regular file reads, while similar figures are reported for Linux and Solaris in [Advanced Programming in the Unix Environment][8]. You might also save large amounts of physical memory, depending on the nature of your application.
|
||||
|
||||
As always with performance, [measurement is everything][9], but memory mapping earns its keep in a programmer's toolbox. The API is pretty nice too, it allows you to access a file as bytes in memory and does not require your soul and code readability in exchange for its benefits. Mind your [address space][10] and experiment with [mmap][11] in Unix-like systems, [CreateFileMapping][12] in Windows, or the many wrappers available in high level languages. When you map a file its contents are not brought into memory all at once, but rather on demand via [page faults][13]. The fault handler [maps your virtual pages][14] onto the page cache after [obtaining][15] a page frame with the needed file contents. This involves disk I/O if the contents weren't cached to begin with.
|
||||
|
||||
Now for a pop quiz. Imagine that the last instance of our render program exits. Would the pages storing scene.dat in the page cache be freed immediately? People often think so, but that would be a bad idea. When you think about it, it is very common for us to create a file in one program, exit, then use the file in a second program. The page cache must handle that case. When you think more about it, why should the kernel ever get rid of page cache contents? Remember that disk is 5 orders of magnitude slower than RAM, hence a page cache hit is a huge win. So long as there's enough free physical memory, the cache should be kept full. It is therefore not dependent on a particular process, but rather it's a system-wide resource. If you run render a week from now and scene.dat is still cached, bonus! This is why the kernel cache size climbs steadily until it hits a ceiling. It's not because the OS is garbage and hogs your RAM, it's actually good behavior because in a way free physical memory is a waste. Better use as much of the stuff for caching as possible.
|
||||
|
||||
Due to the page cache architecture, when a program calls [write()][16] bytes are simply copied to the page cache and the page is marked dirty. Disk I/O normally does not happen immediately, thus your program doesn't block waiting for the disk. On the downside, if the computer crashes your writes will never make it, hence critical files like database transaction logs must be [fsync()][17]ed (though one must still worry about drive controller caches, oy!). Reads, on the other hand, normally block your program until the data is available. Kernels employ eager loading to mitigate this problem, an example of which is read ahead where the kernel preloads a few pages into the page cache in anticipation of your reads. You can help the kernel tune its eager loading behavior by providing hints on whether you plan to read a file sequentially or randomly (see [madvise()][18], [readahead()][19], [Windows cache hints][20] ). Linux [does read-ahead][21] for memory-mapped files, but I'm not sure about Windows. Finally, it's possible to bypass the page cache using [O_DIRECT][22] in Linux or [NO_BUFFERING][23] in Windows, something database software often does.
|
||||
|
||||
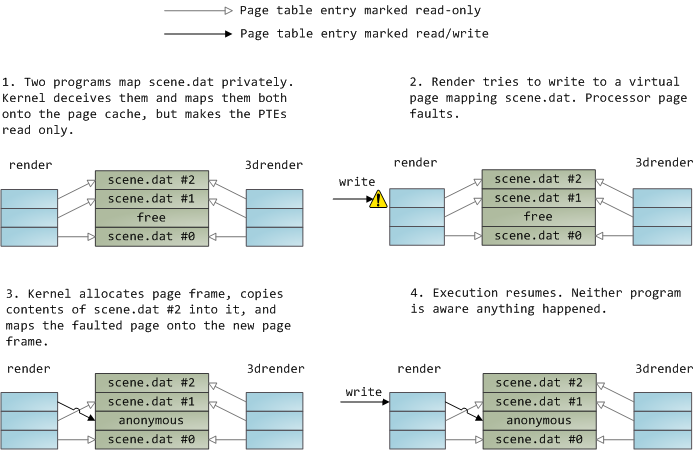
A file mapping may be private or shared. This refers only to updates made to the contents in memory: in a private mapping the updates are not committed to disk or made visible to other processes, whereas in a shared mapping they are. Kernels use the copy on write mechanism, enabled by page table entries, to implement private mappings. In the example below, both render and another program called render3d (am I creative or what?) have mapped scene.dat privately. Render then writes to its virtual memory area that maps the file:
|
||||
|
||||
|
||||
|
||||
The read-only page table entries shown above do not mean the mapping is read only, they're merely a kernel trick to share physical memory until the last possible moment. You can see how 'private' is a bit of a misnomer until you remember it only applies to updates. A consequence of this design is that a virtual page that maps a file privately sees changes done to the file by other programs as long as the page has only been read from. Once copy-on-write is done, changes by others are no longer seen. This behavior is not guaranteed by the kernel, but it's what you get in x86 and makes sense from an API perspective. By contrast, a shared mapping is simply mapped onto the page cache and that's it. Updates are visible to other processes and end up in the disk. Finally, if the mapping above were read-only, page faults would trigger a segmentation fault instead of copy on write.
|
||||
|
||||
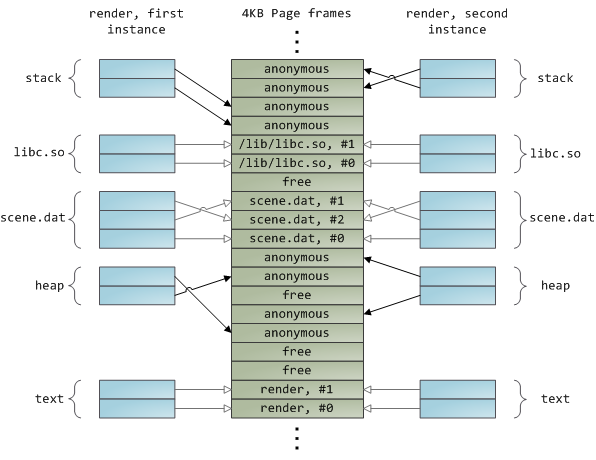
Dynamically loaded libraries are brought into your program's address space via file mapping. There's nothing magical about it, it's the same private file mapping available to you via regular APIs. Below is an example showing part of the address spaces from two running instances of the file-mapping render program, along with physical memory, to tie together many of the concepts we've seen.
|
||||
|
||||
|
||||
|
||||
This concludes our 3-part series on memory fundamentals. I hope the series was useful and provided you with a good mental model of these OS topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Creating a YUM repository from ISO & Online repo
|
||||
======
|
||||
|
||||
|
||||
@ -1,82 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
What Are Bitcoins?
|
||||
======
|
||||
|
||||

|
||||
|
||||
**[Bitcoin][1]** is a digital currency or electronic cash the relies on peer to peer technology for completing transactions. Since peer to peer technology is used as the major network, bitcoins provide a community like managed economy. This is to mean, bitcoins eliminate the centralized authority way of managing currency and promotes community management of currency. Most Also of the software related to bitcoin mining and managing of bitcoin digital cash is open source.
|
||||
|
||||
The first Bitcoin software was developed by Satoshi Nakamoto and it's based on open source cryptographic protocol. Bitcoins smallest unit is known as the Satoshi which is basically one-hundredth millionth of a single bitcoin (0.00000001 BTC).
|
||||
|
||||
One cannot underestimate the boundaries BITCOINS eliminate in the digital economy. For instance, the BITCOIN eliminates governed controls over currency by a centralised agency and offers control and management to the community as a whole. Furthermore, the fact that the BITCOIN is based on an open source cryptographic protocol makes it an open place where there are scrupulous activities such as fluctuating value, deflation and inflation among others. While many internet users are becoming aware of the privacy they should exercise to complete some online transactions, bitcoin is gaining more popularity than ever before. However, for those who know about the dark web and how it works can acknowledge that some people began using it long ago.
|
||||
|
||||
On the downside, the bitcoin is also very secure in making anonymous payments which may be a threat to security or personal health. For instance, the dark web markets are the major suppliers and retailers of imported drugs and even weapons. The use of BITCOINs in the dark web facilitates a safe network for such criminal activities. Despite that, if put to good use, bitcoin has many benefits that can eliminate some of the economic fallacy as a result of centralized agency management of currency. In addition, the bitcoin allows for instance exchange of cash anywhere in the world. The use of bitcoins also mitigates counterfeiting, printing, or devaluation over time. Also, while relying on peer to peer network as its backbone, it promotes the distributed authority of transaction records making it safe to make exchanges.
|
||||
|
||||
Other advantages of the bitcoin include;
|
||||
|
||||
* In the online business world, bitcoin promotes money security and total control. This is because buyers are protected against merchants who may want to charge extra for a lower cost service. The buyer can also choose not to share personal information after making a transaction. Besides, identity theft protection is achieved as a result of backed up hiding personal information.
|
||||
|
||||
* Bitcoins are provided alternatives to major common currency catastrophes such as getting lost, frozen or damaged. However, it is recommended to always make a backup of your bitcoins and encrypt them with a password.
|
||||
|
||||
* In making online purchases and payments using bitcoins, there is a small fee or zero transaction fee charged. This promotes affordability of use.
|
||||
|
||||
* Merchants also face fewer risks that could result from fraud as bitcoin transactions cannot be reversed, unlike other currencies in electronic form. Bitcoins also prove useful even in moments of high crime rate and fraud since it is difficult to con someone over an open public ledger (Blockchain).
|
||||
|
||||
* Bitcoin currency is also hard to be manipulated as it is open source and the cryptographic protocol is very secure.
|
||||
|
||||
* Transactions can also be verified and approved, anywhere, anytime. This is the level of flexibility offered by this digital currency.
|
||||
|
||||
Also Read - [Bitkey A Linux Distribution Dedicated To Bitcoin Transactions][2]
|
||||
|
||||
### How To Mine Bitcoins and The Applications to Accomplish Necessary Bitcoin Management Tasks
|
||||
|
||||
In the digital currency, BITCOIN mining and management requires additional software. There are numerous open source bitcoin management software that make it easy to make payments, receive payments, encrypt and backup of your bitcoins and also bitcoin mining software. There are sites such as; [Freebitcoin][4] where one earns free bitcoins by viewing ads, [MoonBitcoin][5] is another site that one can sign up for free and earn bitcoins. However, it is convenient if one has spare time and a sizable network of friends participating in the same. There are many sites offering bitcoin mining and one can easily sign up and start mining. One of the major secrets is referring as many people as you can to create a large network.
|
||||
|
||||
Applications required for use with bitcoins include the bitcoin wallet which allows one to safely keep bitcoins. This is just like the physical wallet using to keep hard cash but in a digital form. The wallet can be downloaded here - [Bitcoin - Wallet][6] . Other similar applications include; the [Blockchain][7] which works similar to the Bitcoin Wallet.
|
||||
|
||||
The screenshots below show the Freebitco and MoonBitco mining sites respectively.
|
||||
|
||||
[][8]
|
||||
[][9]
|
||||
|
||||
There are various ways of acquiring the bitcoin currency. Some of them include the use of bitcoin mining rigs, purchasing of bitcoins in exchange markets and doing free bitcoin mining online. Purchasing of bitcoins can be done at; [MtGox][10] , [bitNZ][11] , [Bitstamp][12] , [BTC-E][13] , [VertEx][14] , etc.. Several mining open source applications are available online. These applications include; Bitminter, [5OMiner][15] , [BFG Miner][16] among others. These applications make use of some graphics card and processor features to generate bitcoins. The efficiency of mining bitcoins on a pc largely depends on the type of graphics card and the processor of the mining rig. Besides, there are many secure online storages for backing up bitcoins. These sites provide bitcoin storage services free of charge. Examples of bitcoin managing sites include; [xapo][17] , [BlockChain][18] etc. signing up on these sites require a valid email and phone number for verification. Xapo offers additional security through the phone application by requesting for verification whenever a new sign in is made.
|
||||
|
||||
### Disadvantages Of Bitcoins
|
||||
|
||||
The numerous advantages ripped from using bitcoins digital currency cannot be overlooked. However, as it is still in its infancy stage, the bitcoin currency meets several points of resistance. For instance, the majority of individual are not fully aware of the bitcoin digital currency and how it works. The lack of awareness can be mitigated through education and creation of awareness. Bitcoin users also face volatility as the demand for bitcoins is higher than the available amount of coins. However, given more time, volatility will be lowered as when many people will start using bitcoins.
|
||||
|
||||
### Improvements Can be Made
|
||||
|
||||
Based on the infancy of the [bitcoin technology][19] , there is still room for changes to make it more secure and reliable. Given more time, the bitcoin currency will be developed enough to provide flexibility as a common currency. For the bitcoin to succeed, many people need to be made aware of it besides being given information on how it works and its benefits.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -0,0 +1,76 @@
|
||||
[页面缓存,内存和文件之间的那些事][1]
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而忽略了文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘查找][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间共享文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLLs。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLLs 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 [ld.so][5] 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
幸运的是,所有的这些问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 Render 的 Linux 程序,它打开了文件 scene.dat,并且一次读取 512 字节,并将文件内容存储到一个分配的堆块中。第一次读取的过程如下:
|
||||
|
||||

|
||||
|
||||
读取完 12KB 的文件内容以后,Render 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||

|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,普通的文件 I/O 就是这样通过页面缓存来进行的。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序读取的磁盘区域也不仅仅只保存几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 #0、#1、等等来描述。Windows 也是类似的,使用 256KB 大小的页面缓存。
|
||||
|
||||
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到一个用户缓存中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],在复制数据时也浪费物理内存。如前面的图示,scene.dat 的内存被保存了两次,并且,程序中的每个实例都在另外的时间中去保存了内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||

|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 的报告指出,在相关的普通文件读取上运行时性能有多达 30% 的提升,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永衡不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。而 API 提供了非常好用的实现方式,它允许你通过内存中的字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄在页面缓存上 [映射你的虚拟页面][14] 。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
假设我们的 Reader 程序是持续存在的实例,现在出现一个突发的状况。在页面缓存中保存着 scene.dat 内容的页面要立刻释放掉吗?这是一个人们经常要考虑的问题,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该始终完整保存。并且,这一原则适用于所有的进程。如果你现在运行 Render,一周后 scene.dat 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(译者注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“赃”页面。磁盘 I/O 通常并不会立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。如果这时候发生了电脑死机,你的写入将不会被标记,因此,对于至关重要的文件,像数据库事务日志,必须要求 [fsync()][17]ed(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,走到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows cache hints][20] ),你可以通过提示(hint)帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是,在 Windows 上并不能确保被内存映射的文件也会预读。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
一个内存映射的文件可以是私有的,也可以是共享的。当然,这只是针对内存中内容的更新而言:在一个私有的内存映射文件上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射文件,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核在写机制上使用拷贝,这是通过页面表条目来实现这种私有的映射。在下面的例子中,Render 和另一个被称为 render3d 都私有映射到 scene.dat 上。然后 Render 去写入映射的文件的虚拟内存区域:
|
||||
|
||||

|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于去共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 APIs 为你提供与私有文件映射相同的效果。下面的示例展示了 Reader 程序映射的文件的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||

|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
75
translated/tech/20170919 What Are Bitcoins.md
Normal file
75
translated/tech/20170919 What Are Bitcoins.md
Normal file
@ -0,0 +1,75 @@
|
||||
比特币是什么?
|
||||
======
|
||||
|
||||

|
||||
|
||||
**[比特币][1]** 是一种数字货币或者说是电子现金,依靠点对点技术来完成交易。 由于使用点对点技术作为主要网络,比特币提供了一个类似于管理型经济的社区。 这就是说,比特币消除了货币管理的集中式管理方式,促进了货币的社区管理。 大部分比特币数字现金的挖掘和管理软件也是开源的。
|
||||
|
||||
第一个比特币软件是由Satoshi Nakamoto开发的,基于开源的密码协议。 比特币最小单位被称为Satoshi,它基本上是单比特币(0.00000001 BTC)的百万分之一。
|
||||
|
||||
人们不能低估BITCOINS在数字经济中消除的界限。 例如,BITCOIN消除了由中央机构对货币进行的管理控制,并向整个社区提供控制和管理。 此外,BITCOIN基于开放源代码密码协议的事实使其成为一个开放的领域,其中存在价值波动,通货紧缩和通货膨胀等严格的活动。 当许多互联网用户正在意识到他们在网上完成交易的隐私性时,但是比特币正在变得比以往更受欢迎。 但是,对于那些了解暗网及其工作原理的人们,可以确认有些人早就开始使用它了。
|
||||
|
||||
不利的一面是,比特币在匿名支付方面也非常安全,可能会对安全或个人健康构成威胁。 例如,暗网市场是进口药物甚至武器的主要供应商和零售商。 在暗网中使用BITCOINs有助于这种犯罪活动。 尽管如此,如果使用得当,比特币有许多的好处,可以消除一些由于集中的货币代理管理导致的经济上的谬误。 另外,比特币允许在世界任何地方交换现金。 比特币的使用也可以减少假冒,印刷或贬值。 同时,依托对等网络作为骨干网络,促进交易记录的分布式权限,交易会更加安全。
|
||||
|
||||
比特币的其他优点包括:
|
||||
|
||||
- 在网上商业世界里,比特币促进资金安全和完全控制。这是因为买家受到保护,以免商家可能想要为较低成本的服务额外收取钱财。买家也可以选择在交易后不分享个人信息。此外,由于隐藏了个人信息,也就保护了身份不被盗窃。
|
||||
- 对于主要的共同货币灾难,比如如丢失,冻结或损坏,比特币是一种替代品。但是,始终都建议对比特币进行备份并使用密码加密。
|
||||
- 使用比特币进行网上购物和付款时,收取的费用少或者不收取。这就提高了使用时的可承受性。
|
||||
- 与其他电子货币不同,商家也面临较少的欺诈风险,因为比特币交易是无法逆转的。即使在高犯罪率和高欺诈的时刻,比特币也是有用的,因为在公开的公共总账(区块链)上难以对付某个人。
|
||||
- 比特币货币也很难被操纵,因为它是开源的,密码协议是非常安全的。
|
||||
- 交易也可以随时随地进行验证和批准。这是数字货币提供的灵活性水准。
|
||||
|
||||
还可以阅读 - [Bitkey:专用于比特币交易的Linux发行版][2]
|
||||
|
||||
### 如何挖掘比特币和完成必要的比特币管理任务的应用程序
|
||||
|
||||
在数字货币中,BITCOIN挖矿和管理需要额外的软件。有许多开源的比特币管理软件,便于进行支付,接收付款,加密和备份比特币,还有很多的比特币挖掘软件。有些网站,比如:通过查看广告赚取免费比特币的[Freebitcoin][4],MoonBitcoin是另一个可以免费注册并获得比特币的网站。但是,如果有空闲时间和相当多的人脉圈参与,会很方便。有很多提供比特币挖矿的网站,可以轻松注册然后开始挖矿。其中一个主要秘诀就是尽可能引入更多的人构建成一个大型的网络。
|
||||
|
||||
与比特币一起使用时需要的应用程序包括比特币钱包,使得人们可以安全的持有比特币。这就像使用实物钱包来保存硬通货币一样,而这里是以数字形式存在d的。钱包可以在这里下载 - [比特币-钱包][6]。其他类似的应用包括:与比特币钱包类似的[区块链][7]。
|
||||
|
||||
下面的屏幕截图分别显示了Freebitco和MoonBitco这两个挖矿网站。
|
||||
|
||||
[][8]
|
||||
[][9]
|
||||
|
||||
获得比特币的方式多种多样。其中一些包括比特币挖矿机的使用,比特币在交易市场的购买以及免费的比特币在线采矿。比特币可以在[MtGox][10],[bitNZ][11],[Bitstamp][12],[BTC-E][13],[VertEx][14]等等这些网站买到,这些网站都提供了开源开源应用程序。这些应用包括:Bitminter,[5OMiner][15],[BFG Miner][16]等等。这些应用程序使用一些图形卡和处理器功能来生成比特币。在个人电脑上开采比特币的效率在很大程度上取决于显卡的类型和采矿设备的处理器。此外,还有很多安全的在线存储用于备份比特币。这些网站免费提供比特币存储服务。比特币管理网站的例子包括:[xapo][17] , [BlockChain][18] 等。在这些网站上注册需要有效的电子邮件和电话号码进行验证。 Xapo通过电话应用程序提供额外的安全性,无论何时进行新的登录都需要做请求验证。
|
||||
|
||||
### 比特币的缺点
|
||||
|
||||
使用比特币数字货币所带来的众多优势不容忽视。 但是,由于比特币还处于起步阶段,因此遇到了几个阻力点。 例如,大多数人没有完全意识到比特币数字货币及其工作方式。 缺乏意识可以通过教育和意识的创造来缓解。 比特币用户也面临波动,因为比特币的需求量高于可用的货币数量。 但是,考虑到更长的时间,很多人开始使用比特币的时候,波动性会降低。
|
||||
|
||||
### 改进点
|
||||
|
||||
基于[比特币技术][19]的起步,仍然有变化的余地使其更安全更可靠。 考虑到更长的时间,比特币货币将会发展到足以提供作为普通货币的灵活性。 为了让比特币成功,除了给出有关比特币如何工作及其好处的信息之外,还需要更多人了解比特币。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -1,19 +1,18 @@
|
||||
translating---geekpi
|
||||
|
||||
Fixing vim in Debian – There and back again
|
||||
在 Debian 中修复 vim - 去而复得
|
||||
======
|
||||
I was wondering for quite some time why on my server vim behaves so stupid with respect to the mouse: Jumping around, copy and paste wasn't possible the usual way. All this despite having
|
||||
我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了
|
||||
```
|
||||
set mouse=
|
||||
```
|
||||
|
||||
in my `/etc/vim/vimrc.local`. Finally I found out why, thanks to bug [#864074][1] and fixed it.
|
||||
最后我终于知道为什么了,多谢 bug [#864074][1] 并且修复了它。
|
||||
|
||||
![][2]
|
||||
|
||||
The whole mess comes from the fact that, when there is no `~/.vimrc`, vim loads `defaults.vim` **after** ` vimrc.local` and thus overwriting several settings put in there.
|
||||
原因是,当没有 `~/.vimrc` 的时候,vim在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
|
||||
|
||||
There is a comment (I didn't see, though) in `/etc/vim/vimrc` explaining this:
|
||||
在 `/etc/vim/vimrc` 中有一个注释(虽然我没有看到)解释了这一点:
|
||||
```
|
||||
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
|
||||
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
|
||||
@ -24,11 +23,11 @@ There is a comment (I didn't see, though) in `/etc/vim/vimrc` explaining this:
|
||||
```
|
||||
|
||||
|
||||
I agree that this is a good way to setup vim on a normal installation of Vim, but the Debian package could do better. The problem is laid out clearly in the bug report: If there is no `~/.vimrc`, settings in `/etc/vim/vimrc.local` are overwritten.
|
||||
我同意这是在正常安装 vim 后设置 vim 的好方法,但 Debian 包可以做得更好。在错误报告中清楚地说明了这个问题:如果没有 `~/.vimrc`,`/etc/vim/vimrc.local` 中的设置被覆盖。
|
||||
|
||||
This is as counterintuitive as it can be in Debian - and I don't know any other package that does it in a similar way.
|
||||
这在Debian中是违反直觉的 - 而且我也不知道其他包中是否采用类似的方法。
|
||||
|
||||
Since the settings in `defaults.vim` are quite reasonable, I want to have them, but only fix a few of the items I disagree with, like the mouse. At the end what I did is the following in my `/etc/vim/vimrc.local`:
|
||||
由于 `defaults.vim` 中的设置非常合理,所以我希望使用它,但只修改了一些我不同意的项目,比如鼠标。最后,我在 `/etc/vim/vimrc.local` 中做了以下操作:
|
||||
```
|
||||
if filereadable("/usr/share/vim/vim80/defaults.vim")
|
||||
source /usr/share/vim/vim80/defaults.vim
|
||||
@ -42,14 +41,14 @@ set mouse=
|
||||
```
|
||||
|
||||
|
||||
There is probably a better way to get a generic load statement that does not depend on the Vim version, but for now I am fine with that.
|
||||
可能有更好的方式来获得一个不依赖于 vim 版本的通用加载语句, 但现在我对此很满意。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.preining.info/blog/2017/10/fixing-vim-in-debian/
|
||||
|
||||
作者:[Norbert Preining][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user