mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
389a50e1ac
@ -1,77 +0,0 @@
|
||||
Translating by Wuod3n
|
||||
Deep learning wars: Facebook-backed PyTorch vs Google's TensorFlow
|
||||
======
|
||||
The rapid rise of tools and techniques in Artificial Intelligence and Machine learning of late has been astounding. Deep Learning, or "Machine learning on steroids" as some say, is one area where data scientists and machine learning experts are spoilt for choice in terms of the libraries and frameworks available. A lot of these frameworks are Python-based, as Python is a more general-purpose and a relatively easier language to work with. [Theano][1], [Keras][2] [TensorFlow][3] are a few of the popular deep learning libraries built on Python, developed with an aim to make the life of machine learning experts easier.
|
||||
|
||||
Google's TensorFlow is a widely used machine learning and deep learning framework. Open sourced in 2015 and backed by a huge community of machine learning experts, TensorFlow has quickly grown to be THE framework of choice by many organizations for their machine learning and deep learning needs. PyTorch, on the other hand, a recently developed Python package by Facebook for training neural networks is adapted from the Lua-based deep learning library Torch. PyTorch is one of the few available DL frameworks that uses tape-based autograd system to allow building dynamic neural networks in a fast and flexible manner.
|
||||
|
||||
In this article, we pit PyTorch against TensorFlow and compare different aspects where one edges the other out.
|
||||
|
||||
Let's get started!
|
||||
|
||||
### What programming languages support PyTorch and TensorFlow?
|
||||
|
||||
Although primarily written in C++ and CUDA, Tensorflow contains a Python API sitting over the core engine, making it easier for Pythonistas to use. Additional APIs for C++, Haskell, Java, Go, and Rust are also included which means developers can code in their preferred language.
|
||||
|
||||
Although PyTorch is a Python package, there's provision for you to code using the basic C/ C++ languages using the APIs provided. If you are comfortable using Lua programming language, you can code neural network models in PyTorch using the Torch API.
|
||||
|
||||
### How easy are PyTorch and TensorFlow to use?
|
||||
|
||||
TensorFlow can be a bit complex to use if used as a standalone framework, and can pose some difficulty in training Deep Learning models. To reduce this complexity, one can use the Keras wrapper which sits on top of TensorFlow's complex engine and simplifies the development and training of deep learning models. TensorFlow also supports [Distributed training][4], which PyTorch currently doesn't. Due to the inclusion of Python API, TensorFlow is also production-ready i.e., it can be used to train and deploy enterprise-level deep learning models.
|
||||
|
||||
PyTorch was rewritten in Python due to the complexities of Torch. This makes PyTorch more native to developers. It has an easy to use framework that provides maximum flexibility and speed. It also allows quick changes within the code during training without hampering its performance. If you already have some experience with deep learning and have used Torch before, you will like PyTorch even more, because of its speed, efficiency, and ease of use. PyTorch includes custom-made GPU allocator, which makes deep learning models highly memory efficient. Due to this, training large deep learning models becomes easier. Hence, large organizations such as Facebook, Twitter, Salesforce, and many more are embracing Pytorch.
|
||||
|
||||
### Training Deep Learning models with PyTorch and TensorFlow
|
||||
|
||||
Both TensorFlow and PyTorch are used to build and train Neural Network models.
|
||||
|
||||
TensorFlow works on SCG (Static Computational Graph) that includes defining the graph statically before the model starts execution. However, once the execution starts the only way to tweak changes within the model is using [tf.session and tf.placeholder tensors][5].
|
||||
|
||||
PyTorch is well suited to train RNNs( Recursive Neural Networks) as they run faster in [PyTorch ][6]than in TensorFlow. It works on DCG (Dynamic Computational Graph) and one can define and make changes within the model on the go. In a DCG, each block can be debugged separately, which makes training of neural networks easier.
|
||||
|
||||
TensorFlow has recently come up with TensorFlow Fold, a library designed to create TensorFlow models that works on structured data. Like PyTorch, it implements the DCGs and gives massive computational speeds of up to 10x on CPU and more than 100x on GPU! With the help of [Dynamic Batching][7], you can now implement deep learning models which vary in size as well as structure.
|
||||
|
||||
### Comparing GPU and CPU optimizations
|
||||
|
||||
TensorFlow has faster compile times than PyTorch and provides flexibility for building real-world applications. It can run on literally any kind of processor from a CPU, GPU, TPU, mobile devices, to a Raspberry Pi (IoT Devices).
|
||||
|
||||
PyTorch, on the other hand, includes Tensor computations which can speed up deep neural network models upto [50x or more][8] using GPUs. These tensors can dwell on CPU or GPU. Both CPU and GPU are written as independent libraries; making PyTorch efficient to use, irrespective of the Neural Network size.
|
||||
|
||||
### Community Support
|
||||
|
||||
TensorFlow is one of the most popular Deep Learning frameworks today, and with this comes a huge community support. It has great documentation, and an eloquent set of online tutorials. TensorFlow also includes numerous pre-trained models which are hosted and available on [github][9]. These models aid developers and researchers who are keen to work with TensorFlow with some ready-made material to save their time and efforts.
|
||||
|
||||
PyTorch, on the other hand, has a relatively smaller community since it has been developed fairly recently. As compared to TensorFlow, the documentation isn't that great, and codes are not readily available. However, PyTorch does allow individuals to share their pre-trained models with others.
|
||||
|
||||
### PyTorch and TensorFlow - A David & Goliath story
|
||||
|
||||
As it stands, Tensorflow is clearly favoured and used more than PyTorch for a variety of reasons.
|
||||
|
||||
Tensorflow is vast, experienced, and best suited for practical purposes. It is easily the obvious choice of most of the machine learning and deep learning experts because of the vast array of features it offers, and most importantly, its maturity in the market. It has a better community support along with multiple language APIs available. It has a good documentation and is production-ready due to the availability of ready-to-use code. Hence, it is better suited for someone who wants to get started with Deep Learning, or for organizations wanting to productize their Deep Learning models.
|
||||
|
||||
Although PyTorch is relatively newer and has a smaller community, it is fast and efficient. In short, it gives you all the power of Torch wrapped in the usefulness and ease of Python. Because of its efficiency and speed, it is a good option to have for small, research based projects. As mentioned earlier, companies such as Facebook, Twitter, and many others are using Pytorch to train deep learning models. However, its adoption is yet to go mainstream. The potential is evident, PyTorch is just not ready yet to challenge the beast that is TensorFlow. However considering its growth, the day is not far when PyTorch is further optimized and offers more functionalities - to the point that it becomes the David to TensorFlow's Goliath.
|
||||
|
||||
### Savia Lobo
|
||||
A Data science fanatic. Loves to be updated with the tech happenings around the globe. Loves singing and composing songs. Believes in putting the art in smart.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/
|
||||
|
||||
作者:[Savia Lobo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://datahub.packtpub.com/author/savial/
|
||||
[1]:https://www.packtpub.com/web-development/deep-learning-theano
|
||||
[2]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-keras
|
||||
[3]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-tensorflow
|
||||
[4]:https://www.tensorflow.org/deploy/distributed
|
||||
[5]:https://www.tensorflow.org/versions/r0.12/get_started/basic_usage
|
||||
[6]:https://www.reddit.com/r/MachineLearning/comments/66rriz/d_rnns_are_much_faster_in_pytorch_than_tensorflow/
|
||||
[7]:https://arxiv.org/abs/1702.02181
|
||||
[8]:https://github.com/jcjohnson/pytorch-examples#pytorch-tensors
|
||||
[9]:https://github.com/tensorflow/models
|
||||
@ -1,173 +0,0 @@
|
||||
#Translating by qhwdw [Tail Calls, Optimization, and ES6][1]
|
||||
|
||||
|
||||
In this penultimate post about the stack, we take a quick look at tail calls, compiler optimizations, and the proper tail calls landing in the newest version of JavaScript.
|
||||
|
||||
A tail call happens when a function F makes a function call as its final action. At that point F will do absolutely no more work: it passes the ball to whatever function is being called and vanishes from the game. This is notable because it opens up the possibility of tail call optimization: instead of [creating a new stack frame][6] for the function call, we can simply reuse F's stack frame, thereby saving stack space and avoiding the work involved in setting up a new frame. Here are some examples in C and their results compiled with [mild optimization][7]:
|
||||
|
||||
Simple Tail Calls[download][2]
|
||||
|
||||
```
|
||||
int add5(int a)
|
||||
{
|
||||
return a + 5;
|
||||
}
|
||||
|
||||
int add10(int a)
|
||||
{
|
||||
int b = add5(a); // not tail
|
||||
return add5(b); // tail
|
||||
}
|
||||
|
||||
int add5AndTriple(int a){
|
||||
int b = add5(a); // not tail
|
||||
return 3 * add5(a); // not tail, doing work after the call
|
||||
}
|
||||
|
||||
int finicky(int a){
|
||||
if (a > 10){
|
||||
return add5AndTriple(a); // tail
|
||||
}
|
||||
|
||||
if (a > 5){
|
||||
int b = add5(a); // not tail
|
||||
return finicky(b); // tail
|
||||
}
|
||||
|
||||
return add10(a); // tail
|
||||
}
|
||||
```
|
||||
|
||||
You can normally spot tail call optimization (hereafter, TCO) in compiler output by seeing a [jump][8] instruction where a [call][9] would have been expected. At runtime TCO leads to a reduced call stack.
|
||||
|
||||
A common misconception is that tail calls are necessarily [recursive][10]. That's not the case: a tail call may be recursive, such as in finicky() above, but it need not be. As long as caller F is completely done at the call site, we've got ourselves a tail call. Whether it can be optimized is a different question whose answer depends on your programming environment.
|
||||
|
||||
"Yes, it can, always!" is the best answer we can hope for, which is famously the case for Scheme, as discussed in [SICP][11] (by the way, if when you program you don't feel like "a Sorcerer conjuring the spirits of the computer with your spells," I urge you to read that book). It's also the case for [Lua][12]. And most importantly, it is the case for the next version of JavaScript, ES6, whose spec does a good job defining [tail position][13] and clarifying the few conditions required for optimization, such as [strict mode][14]. When a language guarantees TCO, it supports proper tail calls.
|
||||
|
||||
Now some of us can't kick that C habit, heart bleed and all, and the answer there is a more complicated "sometimes" that takes us into compiler optimization territory. We've seen the [simple examples][15] above; now let's resurrect our factorial from [last post][16]:
|
||||
|
||||
Recursive Factorial[download][3]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
So, is line 11 a tail call? It's not, because of the multiplication by n afterwards. But if you're not used to optimizations, gcc's [result][17] with [O2 optimization][18] might shock you: not only it transforms factorial into a [recursion-free loop][19], but the factorial(5) call is eliminated entirely and replaced by a [compile-time constant][20] of 120 (5! == 120). This is why debugging optimized code can be hard sometimes. On the plus side, if you call this function it will use a single stack frame regardless of n's initial value. Compiler algorithms are pretty fun, and if you're interested I suggest you check out [Building an Optimizing Compiler][21] and [ACDI][22].
|
||||
|
||||
However, what happened here was not tail call optimization, since there was no tail call to begin with. gcc outsmarted us by analyzing what the function does and optimizing away the needless recursion. The task was made easier by the simple, deterministic nature of the operations being done. By adding a dash of chaos (e.g., getpid()) we can throw gcc off:
|
||||
|
||||
Recursive PID Factorial[download][4]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int pidFactorial(int n)
|
||||
{
|
||||
if (1 == n) {
|
||||
return getpid(); // tail
|
||||
}
|
||||
|
||||
return n * pidFactorial(n-1) * getpid(); // not tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = pidFactorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
Optimize that, unix fairies! So now we have a regular [recursive call][23] and this function allocates O(n) stack frames to do its work. Heroically, gcc still does [TCO for getpid][24] in the recursion base case. If we now wished to make this function tail recursive, we'd need a slight change:
|
||||
|
||||
tailPidFactorial.c[download][5]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int tailPidFactorial(int n, int acc)
|
||||
{
|
||||
if (1 == n) {
|
||||
return acc * getpid(); // not tail
|
||||
}
|
||||
|
||||
acc = (acc * getpid() * n);
|
||||
return tailPidFactorial(n-1, acc); // tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = tailPidFactorial(5, 1);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
The accumulation of the result is now [a loop][25] and we've achieved true TCO. But before you go out partying, what can we say about the general case in C? Sadly, while good C compilers do TCO in a number of cases, there are many situations where they cannot do it. For example, as we saw in our [function epilogues][26], the caller is responsible for cleaning up the stack after a function call using the standard C calling convention. So if function F takes two arguments, it can only make TCO calls to functions taking two or fewer arguments. This is one among many restrictions. Mark Probst wrote an excellent thesis discussing [Proper Tail Recursion in C][27] where he discusses these issues along with C stack behavior. He also does [insanely cool juggling][28].
|
||||
|
||||
"Sometimes" is a rocky foundation for any relationship, so you can't rely on TCO in C. It's a discrete optimization that may or may not take place, rather than a language feature like proper tail calls, though in practice the compiler will optimize the vast majority of cases. But if you must have it, say for transpiling Scheme into C, you will [suffer][29].
|
||||
|
||||
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It's like Christmas for JS programmers.
|
||||
|
||||
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/tail.c
|
||||
[3]:https://manybutfinite.com/code/x86-stack/factorial.c
|
||||
[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
|
||||
[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
|
||||
[6]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
|
||||
[10]:https://manybutfinite.com/post/recursion/
|
||||
[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
|
||||
[12]:http://www.lua.org/pil/6.3.html
|
||||
[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
|
||||
[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
|
||||
[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
|
||||
[16]:https://manybutfinite.com/post/recursion/
|
||||
[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
|
||||
[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
|
||||
[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
|
||||
[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
|
||||
[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
|
||||
[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
|
||||
[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
|
||||
[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
|
||||
[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
|
||||
[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
|
||||
[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
|
||||
[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
|
||||
91
sources/tech/20141029 What does an idle CPU do.md
Normal file
91
sources/tech/20141029 What does an idle CPU do.md
Normal file
@ -0,0 +1,91 @@
|
||||
Translating by qhwdw [What does an idle CPU do?][1]
|
||||
============================================================
|
||||
|
||||
In the [last post][2] I said the fundamental axiom of OS behavior is that at any given time, exactly one and only one task is active on a CPU. But if there's absolutely nothing to do, then what?
|
||||
|
||||
It turns out that this situation is extremely common, and for most personal computers it's actually the norm: an ocean of sleeping processes, all waiting on some condition to wake up, while nearly 100% of CPU time is going into the mythical "idle task." In fact, if the CPU is consistently busy for a normal user, it's often a misconfiguration, bug, or malware.
|
||||
|
||||
Since we can't violate our axiom, some task needs to be active on a CPU. First because it's good design: it would be unwise to spread special cases all over the kernel checking whether there is in fact an active task. A design is far better when there are no exceptions. Whenever you write an if statement, Nyan Cat cries. And second, we need to do something with all those idle CPUs, lest they get spunky and, you know, create Skynet.
|
||||
|
||||
So to keep design consistency and be one step ahead of the devil, OS developers create an idle task that gets scheduled to run when there's no other work. We have seen in the Linux [boot process][3] that the idle task is process 0, a direct descendent of the very first instruction that runs when a computer is first turned on. It is initialized in [rest_init][4], where [init_idle_bootup_task][5] initializes the idle scheduling class.
|
||||
|
||||
Briefly, Linux supports different scheduling classes for things like real-time processes, regular user processes, and so on. When it's time to choose a process to become the active task, these classes are queried in order of priority. That way, the nuclear reactor control code always gets to run before the web browser. Often, though, these classes return NULL, meaning they don't have a suitable process to run - they're all sleeping. But the idle scheduling class, which runs last, never fails: it always returns the idle task.
|
||||
|
||||
That's all good, but let's get down to just what exactly this idle task is doing. So here is [cpu_idle_loop][6], courtesy of open source:
|
||||
|
||||
cpu_idle_loop
|
||||
|
||||
```
|
||||
while (1) {
|
||||
while(!need_resched()) {
|
||||
cpuidle_idle_call();
|
||||
}
|
||||
|
||||
/*
|
||||
[Note: Switch to a different task. We will return to this loop when the idle task is again selected to run.]
|
||||
*/
|
||||
schedule_preempt_disabled();
|
||||
}
|
||||
```
|
||||
|
||||
I've omitted many details, and we'll look at task switching closely later on, but if you read the code you'll get the gist of it: as long as there's no need to reschedule, meaning change the active task, stay idle. Measured in elapsed time, this loop and its cousins in other OSes are probably the most executed pieces of code in computing history. For Intel processors, staying idle traditionally meant running the [halt][7] instruction:
|
||||
|
||||
native_halt
|
||||
|
||||
```
|
||||
static inline void native_halt(void)
|
||||
{
|
||||
asm volatile("hlt": : :"memory");
|
||||
}
|
||||
```
|
||||
|
||||
hlt stops code execution in the processor and puts it in a halted state. It's weird to think that across the world millions and millions of Intel-like CPUs are spending the majority of their time halted, even while they're powered up. It's also not terribly efficient, energy wise, which led chip makers to develop deeper sleep states for processors, which trade off less power consumption for longer wake-up latency. The kernel's [cpuidle subsystem][8] is responsible for taking advantage of these power-saving modes.
|
||||
|
||||
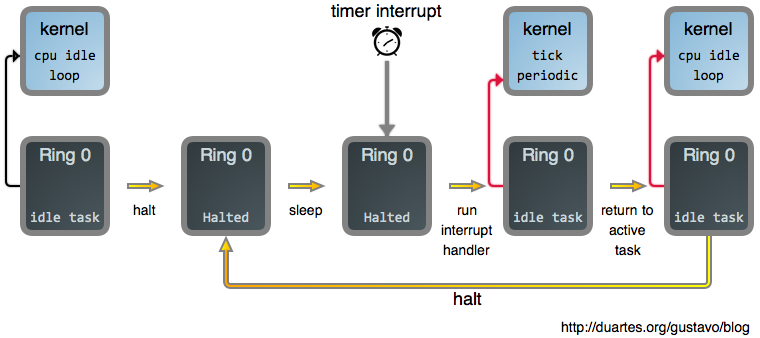
Now once we tell the CPU to halt, or sleep, we need to somehow bring it back to life. If you've read the [last post][9], you might suspect interrupts are involved, and indeed they are. Interrupts spur the CPU out of its halted state and back into action. So putting this all together, here's what your system mostly does as you read a fully rendered web page:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Other interrupts besides the timer interrupt also get the processor moving again. That's what happens if you click on a web page, for example: your mouse issues an interrupt, its driver processes it, and suddenly a process is runnable because it has fresh input. At that point need_resched() returns true, and the idle task is booted out in favor of your browser.
|
||||
|
||||
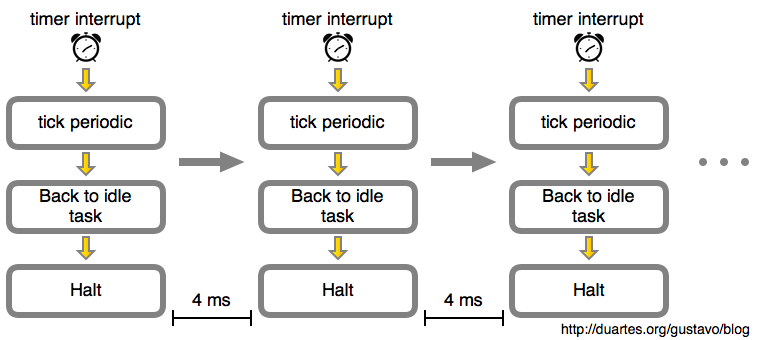
But let's stick to idleness in this post. Here's the idle loop over time:
|
||||
|
||||
|
||||
|
||||
In this example the timer interrupt was programmed by the kernel to happen every 4 milliseconds (ms). This is the tick period. That means we get 250 ticks per second, so the tick rate or tick frequency is 250 Hz. That's a typical value for Linux running on Intel processors, with 100 Hz being another crowd favorite. This is defined in the CONFIG_HZ option when you build the kernel.
|
||||
|
||||
Now that looks like an awful lot of pointless work for an idle CPU, and it is. Without fresh input from the outside world, the CPU will remain stuck in this hellish nap getting woken up 250 times a second while your laptop battery is drained. If this is running in a virtual machine, we're burning both power and valuable cycles from the host CPU.
|
||||
|
||||
The solution here is to have a [dynamic tick][10] so that when the CPU is idle, the timer interrupt is either [deactivated or reprogrammed][11] to happen at a point where the kernel knows there will be work to do (for example, a process might have a timer expiring in 5 seconds, so we must not sleep past that). This is also called tickless mode.
|
||||
|
||||
Finally, suppose you have one active process in a system, for example a long-running CPU-intensive task. That's nearly identical to an idle system: these diagrams remain about the same, just substitute the one process for the idle task and the pictures are accurate. In that case it's still pointless to interrupt the task every 4 ms for no good reason: it's merely OS jitter slowing your work ever so slightly. Linux can also stop the fixed-rate tick in this one-process scenario, in what's called [adaptive-tick][12] mode. Eventually, a fixed-rate tick may be gone [altogether][13].
|
||||
|
||||
That's enough idleness for one post. The kernel's idle behavior is an important part of the OS puzzle, and it's very similar to other situations we'll see, so this helps us build the picture of a running kernel. More next week, [RSS][14] and [Twitter][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
[2]:https://manybutfinite.com/post/when-does-your-os-run
|
||||
[3]:https://manybutfinite.com/post/kernel-boot-process
|
||||
[4]:https://github.com/torvalds/linux/blob/v3.17/init/main.c#L393
|
||||
[5]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/core.c#L4538
|
||||
[6]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/idle.c#L183
|
||||
[7]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/include/asm/irqflags.h#L52
|
||||
[8]:http://lwn.net/Articles/384146/
|
||||
[9]:https://manybutfinite.com/post/when-does-your-os-run
|
||||
[10]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L17
|
||||
[11]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/highres.txt#L215
|
||||
[12]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L100
|
||||
[13]:http://lwn.net/Articles/549580/
|
||||
[14]:https://manybutfinite.com/feed.xml
|
||||
[15]:http://twitter.com/manybutfinite
|
||||
@ -1,63 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Boot Into Linux Command Line
|
||||
======
|
||||

|
||||
|
||||
There may be times where you need or want to boot up a [Linux][1] system without using a GUI, that is with no X, but rather opt for the command line. Whatever the reason, fortunately, booting straight into the Linux **command-line** is very simple. It requires a simple change to the boot parameter after the other kernel options. This change specifies the runlevel to boot the system into.
|
||||
|
||||
### Why Do This?
|
||||
|
||||
If your system does not run Xorg because the configuration is invalid, or if the display manager is broken, or whatever may prevent the GUI from starting properly, booting into the command-line will allow you to troubleshoot by logging into a terminal (assuming you know what you’re doing to start with) and do whatever you need to do. Booting into the command-line is also a great way to become more familiar with the terminal, otherwise, you can do it just for fun.
|
||||
|
||||
### Accessing GRUB Menu
|
||||
|
||||
On startup, you will need access to the GRUB boot menu. You may need to hold the SHIFT key down before the system boots if the menu isn’t set to display every time the computer is started. In the menu, the [Linux distribution][2] entry must be selected. Once highlighted, press ‘e’ to edit the boot parameters.
|
||||
|
||||
[][3]
|
||||
|
||||
Older GRUB versions follow a similar mechanism. The boot manager should provide instructions on how to edit the boot parameters.
|
||||
|
||||
### Specify the Runlevel
|
||||
|
||||
An editor will appear and you will see the options that GRUB parses to the kernel. Navigate to the line that starts with ‘linux’ (older GRUB versions may be ‘kernel’; select that and follow the instructions). This specifies parameters to parse into the kernel. At the end of that line (may appear to span multiple lines, depending on resolution), you simply specify the runlevel to boot into, which is 3 (multi-user mode, text-only).
|
||||
|
||||
[][4]
|
||||
|
||||
Pressing Ctrl-X or F10 will boot the system using those parameters. Boot-up will continue as normal. The only thing that has changed is the runlevel to boot into.
|
||||
|
||||
|
||||
|
||||
This is what was started up:
|
||||
|
||||
[][5]
|
||||
|
||||
### Runlevels
|
||||
|
||||
You can specify different runlevels to boot into with runlevel 5 being the default one. 1 boots into “single-user” mode, which boots into a root shell. 3 provides a multi-user, command-line only system.
|
||||
|
||||
### Switch From Command-Line
|
||||
|
||||
At some point, you may want to run the display manager again to use a GUI, and the quickest way to do that is running this:
|
||||
```
|
||||
$ sudo init 5
|
||||
```
|
||||
|
||||
And it is as simple as that. Personally, I find the command-line much more exciting and hands-on than using GUI tools; however, that’s just my preference.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/how-to-boot-into-linux-command-line
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnu-grub_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_1_orig.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating by heart4lor
|
||||
|
||||
8 ways to generate random password in Linux
|
||||
======
|
||||
Learn 8 different ways to generate random password in Linux using Linux native commands or third party utilities.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wenwensnow
|
||||
Linux whereis Command Explained for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
深度学习战争:Facebook支持的PyTorch与Google的TensorFlow
|
||||
======
|
||||
有一个令人震惊的事实,即人工智能和机器学习的工具和技术在近期迅速兴起。深度学习,或者说“注射了激素的机器学习”是数据科学家和机器学习专家在可用的库和框架方面被宠坏的一个领域。很多这样的框架都是基于Python的,因为Python是一个更通用,相对简单的语言。[Theano] [1],[Keras] [2] [TensorFlow] [3]是一些基于Python构建的流行的深度学习库,目的是使机器学习专家更轻松。
|
||||
|
||||
Google的TensorFlow是一个广泛使用的机器学习和深度学习框架。 TensorFlow开源于2015年,得到了机器学习专家的广泛支持,TensorFlow已经迅速成长为许多机构为其机器学习和深度学习需求所选择的框架。 另一方面,PyTorch最近开发的用于训练神经网络的Python包被改编自基于Lua的深度学习库Torch。 PyTorch是少数可用的DL框架之一,它使用基于磁带的autograd系统(tape-based autograd system),以快速和灵活的方式构建动态神经网络。
|
||||
|
||||
在这篇文章中,我们将PyTorch与TensorFlow进行不同方面的比较。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
###什么编程语言支持 PyTorch和TensorFlow?
|
||||
|
||||
虽然主要是用C ++和CUDA编写的,但Tensorflow包含一个位于核心引擎上的Python API,使得更便于被Pythonistas使用。 除了Python,它还包括C ++,Haskell,Java,Go和Rust等其他API,这意味着开发人员可以用他们的首选语言进行编码。
|
||||
|
||||
虽然PyTorch是一个Python软件包,但你也可以提供使用基本的C / C ++语言的API进行编码。 如果你习惯使用Lua编程语言,你也可以使用Torch API在PyTorch中编写神经网络模型。
|
||||
|
||||
###PyTorch和TensorFlow有多么易于使用?
|
||||
|
||||
如果将TensorFlow作为一个独立的框架使用,它可能会有点复杂,并且会给深度学习模型的训练带来一些困难。 为了减少这种复杂性,可以使用位于TensorFlow复杂引擎之上的Keras封装,简化深度学习模型的开发和训练。 TensorFlow也支持PyTorch目前没有的[分布式培训] [4]。 由于包含Python API,TensorFlow也可以在生产环境中使用,即可用于培训练和部署企业级深度学习模型。
|
||||
|
||||
PyTorch由于Torch的复杂而被Python重写。 这使得PyTorch对于开发人员更为原生。 它有一个易于使用的框架,提供最大化的灵活和速度。 它还允许在训练过程中快速更改代码而不妨碍其性能。 如果你已经有了一些深度学习的经验,并且以前使用过Torch,那么基于它的速度,效率和易用性,你会更喜欢PyTorch。 PyTorch包含定制的GPU分配器,这使得深度学习模型具有高度的内存效率。 由此,训练大型深度学习模型变得更容易。 因此,Pytorch
|
||||
在Facebook,Twitter,Salesforce等大型组织广受欢迎。
|
||||
|
||||
###用PyTorch和TensorFlow训练深度学习模型
|
||||
|
||||
PyTorch和TensorFlow都可以用来建立和训练神经网络模型。
|
||||
|
||||
TensorFlow在SCG(静态计算图)上工作,包括在模型开始执行之前定义静态图形。 但是,一旦开始执行,在模型内的调整更改的唯一方法是使用[tf.session and tf.placeholder tensors][5]。
|
||||
|
||||
PyTorch非常适合训练RNNs(递归神经网络),因为它们在[PyTorch] [6]中比在TensorFlow中运行得更快。 它适用于DCG(动态计算图),可以随时在模型中定义和更改。 在DCG中,每个模块可以单独调试,这使得神经网络的训练更简单。
|
||||
|
||||
TensorFlow最近提出了TensorFlow Fold,这是一个旨在创建TensorFlow模型的库,用于处理结构化数据。 像PyTorch一样,它实现了DCGs,在CPU上提供高达10倍的计算速度,在GPU上提供超过100倍的计算速度! 在[Dynamic Batching] [7]的帮助下,你现在可以执行尺寸和结构都不相同的深度学习模型。
|
||||
|
||||
###GPU和CPU优化的比较
|
||||
|
||||
TensorFlow的编译时间比PyTorch短,为构建真实世界的应用程序提供了灵活性。 它可以从CPU,GPU,TPU,移动设备到Raspberry Pi(物联网设备)等各种处理器上运行。
|
||||
|
||||
另一方面,PyTorch包括张量(tensor)计算,可以使用GPU将深度神经网络模型加速到[50倍或更多] [8]。 这些张量可以停留在CPU或GPU上。 CPU和GPU都是独立的库, 无论神经网络大小如何,PyTorch都可以高效地利用。
|
||||
|
||||
###社区支持
|
||||
|
||||
TensorFlow是当今最流行的深度学习框架之一,由此也给它带来了庞大的社区支持。 它有很好的文档和一套详细的在线教程。 TensorFlow还包括许多预先训练过的模型,这些模型在[github] [9]上托管和提供。 这些模型提供给热衷于使用TensorFlow开发者和研究人员一些现成的材料来节省他们的时间和精力。
|
||||
|
||||
另一方面,PyTorch的社区相对较小,因为它最近才发展起来。 与TensorFlow相比,文档并不是很好,代码也不是很容易获得。 然而,PyTorch确实允许个人与他人分享他们的预训练模型。
|
||||
|
||||
### PyTorch和TensorFlow-力量悬殊的故事
|
||||
|
||||
就目前而言,由于各种原因,Tensorflow显然比PyTorch更受青睐。
|
||||
|
||||
Tensorflow很大,经验丰富,最适合实际应用。 是大多数机器学习和深度学习专家明显的选择,因为它提供了大量的功能,最重要的是它在市场上的成熟应用。 它具有更好的社区支持以及多语言API可用。 它有一个很好的文档库,由于从准备到使用的代码使之易于生产。 因此,它更适合想要开始深度学习的人,或者希望开发深度学习模型的组织。
|
||||
|
||||
虽然PyTorch相对较新,社区较小,但它速度快,效率高。 总之,它给你所有的优势在于Python的有用性和易用性。 由于其效率和速度,对于基于研究的小型项目来说,这是一个很好的选择。 如前所述,Facebook,Twitter等公司正在使用Pytorch来训练深度学习模型。 但是,使用它尚未成为主流。 PyTorch的潜力是显而易见的,但它还没有准备好去挑战这个TensorFlow的野兽。 然而,考虑到它的增长,PyTorch进一步优化并提供更多功能的日子并不遥远,直到与TensorFlow可以比较。
|
||||
|
||||
###Savia Lobo
|
||||
非常喜欢数据科学。 喜欢更新世界各地的科技事件。 喜欢歌唱和创作歌曲。 相信才智上的艺术。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/
|
||||
|
||||
作者:[Savia Lobo][a]
|
||||
译者:[Wuod3n](https://github.com/Wuod3n)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://datahub.packtpub.com/author/savial/
|
||||
[1]:https://www.packtpub.com/web-development/deep-learning-theano
|
||||
[2]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-keras
|
||||
[3]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-tensorflow
|
||||
[4]:https://www.tensorflow.org/deploy/distributed
|
||||
[5]:https://www.tensorflow.org/versions/r0.12/get_started/basic_usage
|
||||
[6]:https://www.reddit.com/r/MachineLearning/comments/66rriz/d_rnns_are_much_faster_in_pytorch_than_tensorflow/
|
||||
[7]:https://arxiv.org/abs/1702.02181
|
||||
[8]:https://github.com/jcjohnson/pytorch-examples#pytorch-tensors
|
||||
[9]:https://github.com/tensorflow/models
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
如何启动进入 Linux 命令行
|
||||
======
|
||||

|
||||
|
||||
可能有时候你需要或者不想使用 GUI,也就是没有 X,而是选择命令行启动 [Linux][1]。不管是什么原因,幸运的是,直接启动进入 Linux **命令行** 非常简单。在其他内核选项之后,它需要对引导参数进行简单的更改。此更改将系统引导到指定的运行级别。
|
||||
|
||||
### 为什么要这样做?
|
||||
|
||||
如果你的系统由于无效配置或者显示管理器损坏或任何可能导致 GUI 无法正常启动的情况而无法运行 Xorg,那么启动到命令行将允许你通过登录到终端进行故障排除(假设你知道要怎么开始),并能做任何你需要做的东西。引导到命令行也是一个很好的熟悉终端的方式,不然,你也可以为了好玩这么做。
|
||||
|
||||
### 访问 GRUB 菜单
|
||||
|
||||
在启动时,你需要访问 GRUB 启动菜单。如果在每次启动计算机时菜单未设置为显示,那么可能需要在系统启动之前按住 SHIFT 键。在菜单中,需要选择 [Linux 发行版][2]条目。高亮显示后,按下 “e” 编辑引导参数。
|
||||
|
||||
[][3]
|
||||
|
||||
较老的 GRUB 版本遵循类似的机制。启动管理器应提供有关如何编辑启动参数的说明。
|
||||
|
||||
### 指定运行级别
|
||||
|
||||
编辑器将出现,你将看到 GRUB 解析到内核的选项。移动到以 “linux” 开头的行(旧的 GRUB 版本可能是 “kernel”,选择它并按照说明操作)。这指定了解析到内核的参数。在该行的末尾(可能会出现跨越多行,具体取决于分辨率),只需指定要引导的运行级别,即 3(多用户模式,纯文本)。
|
||||
|
||||
[][4]
|
||||
|
||||
按下 Ctrl-X 或 F10 将使用这些参数启动系统。开机和以前一样。唯一改变的是启动的运行级别。
|
||||
|
||||
|
||||
|
||||
这是启动后的页面:
|
||||
|
||||
[][5]
|
||||
|
||||
### 运行级别
|
||||
|
||||
你可以指定不同的运行级别,默认运行级别是 5。1 启动到“单用户”模式,它会启动进入 root shell。3 提供了一个多用户命令行系统。
|
||||
|
||||
### 从命令行切换
|
||||
|
||||
在某个时候,你可能想要再次运行显示管理器来使用 GUI,最快的方法是运行这个:
|
||||
```
|
||||
$ sudo init 5
|
||||
```
|
||||
|
||||
就这么简单。就我个人而言,我发现命令行比使用 GUI 工具更令人兴奋和上手。不过,这只是我的个人偏好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/how-to-boot-into-linux-command-line
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnu-grub_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_1_orig.png
|
||||
Loading…
Reference in New Issue
Block a user