mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-19 00:30:12 +08:00
Merge branch 'master' of https://github.com/ZTinoZ/TranslateProject.git
This commit is contained in:
commit
382f6da61b
@ -4,7 +4,7 @@
|
||||
|
||||
### Puppet 是什么? ###
|
||||
|
||||
Puppet 是一款为 IT 系统管理员和顾问设计的自动化软件,你可以用它自动化地完成诸如安装应用程序和服务、补丁管理和部署等工作。所有资源的相关配置都以“manifests”的方式保存,单台机器或者多台机器都可以使用。如果你想了解更多内容,Puppet 实验室的网站上有关于 [Puppet 及其工作原理][1]的更详细的介绍。
|
||||
Puppet 是一款为 IT 系统管理员和顾问们设计的自动化软件,你可以用它自动化地完成诸如安装应用程序和服务、补丁管理和部署等工作。所有资源的相关配置都以“manifests”的方式保存,单台机器或者多台机器都可以使用。如果你想了解更多内容,Puppet 实验室的网站上有关于 [Puppet 及其工作原理][1]的更详细的介绍。
|
||||
|
||||
### 本教程要做些什么? ###
|
||||
|
||||
@ -58,7 +58,7 @@ Puppet 是一款为 IT 系统管理员和顾问设计的自动化软件,你可
|
||||
|
||||
# chkconfig puppet on
|
||||
|
||||
Puppet 客户端需要知道 Puppet master 服务器的地址。最佳方案是使用 DNS 服务器解析 Puppet master 服务器地址。如果你没有 DNS 服务器,在 `/etc/hosts` 里添加下面这几行也可以:
|
||||
Puppet 客户端需要知道 Puppet master 服务器的地址。最佳方案是使用 DNS 服务器解析 Puppet master 服务器地址。如果你没有 DNS 服务器,在 `/etc/hosts` 里添加类似下面这几行也可以:
|
||||
|
||||
> 1.2.3.4 server.your.domain
|
||||
|
||||
@ -125,7 +125,7 @@ master 服务器名也要在 `/etc/puppet/puppet.conf` 文件的“[agent]”小
|
||||
|
||||
> runinterval = <yourtime>
|
||||
|
||||
这个选项的值可以是秒(格式比如 30 或者 30s),分钟(30m),小时(6h),天(2d)以及年(5y)。值得注意的是,0 意味着“立即执行”而不是“从不执行”。
|
||||
这个选项的值可以是秒(格式比如 30 或者 30s),分钟(30m),小时(6h),天(2d)以及年(5y)。值得注意的是,**0 意味着“立即执行”而不是“从不执行”**。
|
||||
|
||||
### 提示和技巧 ###
|
||||
|
||||
@ -139,7 +139,7 @@ master 服务器名也要在 `/etc/puppet/puppet.conf` 文件的“[agent]”小
|
||||
|
||||
# puppet agent -t --debug
|
||||
|
||||
Debug 选项会显示 Puppet 本次运行时的差不多每一个步骤,这在调试非常复杂的问题时很有用。另一个很有用的选项是:
|
||||
debug 选项会显示 Puppet 本次运行时的差不多每一个步骤,这在调试非常复杂的问题时很有用。另一个很有用的选项是:
|
||||
|
||||
# puppet agent -t --noop
|
||||
|
||||
@ -187,7 +187,7 @@ via: http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[sailing](https://github.com/sailing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
如何使用Tmux提高终端环境下的生产率
|
||||
如何使用Tmux提高终端环境下的效率
|
||||
===
|
||||
|
||||
鼠标的采用是次精彩的创新,它让电脑更加接近普通人。但从程序员和系统管理员的角度,使用电脑办公时,手一旦离开键盘,就会有些分心
|
||||
鼠标的发明是了不起的创新,它让电脑更加接近普通人。但从程序员和系统管理员的角度,使用电脑工作时,手一旦离开键盘,就会有些分心。
|
||||
|
||||
作为一名系统管理员,我大量的工作都需要在终端环境下。打开很多标签,然后在多个终端之间切换窗口会让我慢下来。而且当我的服务器出问题的时候,我不能浪费任何时间
|
||||
作为一名系统管理员,我大量的工作都需要在终端环境下。打开很多标签,然后在多个终端之间切换窗口会让我慢下来。尤其是当我的服务器出问题的时候,我不能浪费任何时间!
|
||||
|
||||
|
||||
|
||||
[Tmux][1]是我日常工作必要的工具之一。我可以借助Tmux创造出复杂的开发环境,同时还可以在一旁进行SSH远程连接。我可以开出很多窗口,拆分成很多面板,附加和分离会话等等。掌握了Tmux之后,你就可以扔掉鼠标了(只是个玩笑:D)
|
||||
[Tmux][1]是我日常工作必要的工具之一。我可以借助Tmux构建出复杂的开发环境,同时还可以在一旁进行SSH远程连接。我可以开出很多窗口,将其拆分成很多面板,接管和分离会话等等。掌握了Tmux之后,你就可以扔掉鼠标了(只是个玩笑:D)。
|
||||
|
||||
Tmux("Terminal Multiplexer"的简称)可以让我们在单个屏幕的灵活布局下开出很多终端,我们就可以协作地使用它们。举个例子,在一个面板中,我们用Vim修改一些配置文件,在另一个面板,我们使用irssi聊天,而在其余的面板,跟踪一些日志。然后,我们还可以打开新的窗口来升级系统,再开一个新窗口来进行服务器的ssh连接。在这些窗口面板间浏览切换和创建它们一样简单。它的高度可配置和可定制的,让其成为你心中的延伸
|
||||
Tmux("Terminal Multiplexer"的简称)可以让我们在单个屏幕的灵活布局下开出很多终端,我们就可以协作地使用它们。举个例子,在一个面板中,我们用Vim修改一些配置文件,在另一个面板,我们使用`irssi`聊天,而在其余的面板,可以跟踪一些日志。然后,我们还可以打开新的窗口来升级系统,再开一个新窗口来进行服务器的ssh连接。在这些窗口面板间浏览切换和创建它们一样简单。它的高度可配置和可定制的,让其成为你心中的延伸
|
||||
|
||||
### 在Linux/OSX下安装Tmux ###
|
||||
|
||||
@ -20,22 +20,21 @@ Tmux("Terminal Multiplexer"的简称)可以让我们在单个屏幕的灵活布
|
||||
# sudo brew install tmux
|
||||
# sudo port install tmux
|
||||
|
||||
### Debian/Ubuntu ###
|
||||
#### Debian/Ubuntu: ####
|
||||
|
||||
# sudo apt-get install tmux
|
||||
|
||||
RHEL/CentOS/Fedora(RHEL/CentOS 要求 [EPEL repo][2]):
|
||||
####RHEL/CentOS/Fedora(RHEL/CentOS 要求 [EPEL repo][2]):####
|
||||
|
||||
$ sudo yum install tmux
|
||||
|
||||
Archlinux:
|
||||
####Archlinux:####
|
||||
|
||||
$ sudo pacman -S tmux
|
||||
|
||||
### 使用不同会话工作 ###
|
||||
|
||||
使用Tmux的最好方式是使用不同的会话,这样你就可以以你想要的方式,将任务和应用组织到不同的会话中。如果你想改变一个会话,会话里面的任何工作都无须停止或者杀掉,让我们来看看这是怎么工作的
|
||||
|
||||
使用Tmux的最好方式是使用会话的方式,这样你就可以以你想要的方式,将任务和应用组织到不同的会话中。如果你想改变一个会话,会话里面的任何工作都无须停止或者杀掉。让我们来看看这是怎么工作的。
|
||||
|
||||
让我们开始一个叫做"session"的会话,并且运行top命令
|
||||
|
||||
@ -46,20 +45,20 @@ Archlinux:
|
||||
|
||||
$ tmux attach-session -t session
|
||||
|
||||
之后你会看到top操作仍然运行在重新连接的会话上
|
||||
之后你会看到top操作仍然运行在重新连接的会话上。
|
||||
|
||||
一些管理sessions的命令:
|
||||
|
||||
$ tmux list-session
|
||||
$ tmux new-session <session-name>
|
||||
$ tmux attach-session -t <session-name>
|
||||
$ tmux rename-session -t <session-name>
|
||||
$ tmux choose-session -t <session-name>
|
||||
$ tmux kill-session -t <session-name>
|
||||
$ tmux new-session <会话名>
|
||||
$ tmux attach-session -t <会话名>
|
||||
$ tmux rename-session -t <会话名>
|
||||
$ tmux choose-session -t <会话名>
|
||||
$ tmux kill-session -t <会话名>
|
||||
|
||||
### 使用不同的窗口工作
|
||||
|
||||
很多情况下,你需要在一个会话中运行多个命令,并且执行多个任务。我们可以在一个会话的多个窗口里组织他们。在现代化的GUI终端(比如 iTerm或者Konsole),一个窗口被视为一个标签。在会话中配置了我们默认的环境,我们就能够在一个会话中创建许多我们需要的窗口。窗口就像运行在会话中的应用程序,当我们脱离当前会话的时候,它仍在持续,让我们来看一个例子:
|
||||
很多情况下,你需要在一个会话中运行多个命令,执行多个任务。我们可以在一个会话的多个窗口里组织他们。在现代的GUI终端(比如 iTerm或者Konsole),一个窗口被视为一个标签。在会话中配置了我们默认的环境之后,我们就能够在一个会话中创建许多我们需要的窗口。窗口就像运行在会话中的应用程序,当我们脱离当前会话的时候,它仍在持续,让我们来看一个例子:
|
||||
|
||||
$ tmux new -s my_session
|
||||
|
||||
@ -67,7 +66,7 @@ Archlinux:
|
||||
|
||||
按下**CTRL-b c**
|
||||
|
||||
这将会创建一个新的窗口,然后屏幕的光标移向它。现在你就可以在新窗口下运行你的新应用。你可以写下你当前窗口的名字。在目前的案例下,我运行的top程序,所以top就是该窗口的名字
|
||||
这将会创建一个新的窗口,然后屏幕的光标移向它。现在你就可以在新窗口下运行你的新应用。你可以修改你当前窗口的名字。在目前的例子里,我运行的top程序,所以top就是该窗口的名字
|
||||
|
||||
如果你想要重命名,只需要按下:
|
||||
|
||||
@ -77,15 +76,15 @@ Archlinux:
|
||||
|
||||
|
||||
|
||||
一旦在一个会话中创建多个窗口,我们需要在这些窗口间移动的办法。窗口以数组的形式被组织在一起,每个窗口都有一个从0开始计数的号码,想要快速跳转到其余窗口:
|
||||
一旦在一个会话中创建多个窗口,我们需要在这些窗口间移动的办法。窗口像数组一样组织在一起,从0开始用数字标记每个窗口,想要快速跳转到其余窗口:
|
||||
|
||||
**CTRL-b <window number>**
|
||||
**CTRL-b <窗口号>**
|
||||
|
||||
如果我们给窗口起了名字,我们可以使用下面的命令切换:
|
||||
如果我们给窗口起了名字,我们可以使用下面的命令找到它们:
|
||||
|
||||
**CTRL-b f**
|
||||
|
||||
列出所有窗口:
|
||||
也可以列出所有窗口:
|
||||
|
||||
**CTRL-b w**
|
||||
|
||||
@ -94,21 +93,21 @@ Archlinux:
|
||||
**CTRL-b n**(到达下一个窗口)
|
||||
**CTRL-b p**(到达上一个窗口)
|
||||
|
||||
想要离开一个窗口:
|
||||
想要离开一个窗口,可以输入 exit 或者:
|
||||
|
||||
**CTRL-b &**
|
||||
|
||||
关闭窗口之前,你需要确认一下
|
||||
关闭窗口之前,你需要确认一下。
|
||||
|
||||
### 把窗口分成许多面板
|
||||
|
||||
有时候你在编辑器工作的同时,需要查看日志文件。编辑的同时追踪日志真的很有帮助。Tmux可以让我们把窗口分成许多面板。举了例子,我们可以创建一个控制台监测我们的服务器,同时拥有一个复杂的编辑器环境,这样就能同时进行编译和debug
|
||||
有时候你在编辑器工作的同时,需要查看日志文件。在编辑的同时追踪日志真的很有帮助。Tmux可以让我们把窗口分成许多面板。举个例子,我们可以创建一个控制台监测我们的服务器,同时用编辑器构造复杂的开发环境,这样就能同时进行编译和调试了。
|
||||
|
||||
让我们创建另一个Tmux会话,让其以面板的方式工作。首先,如果我们在某个会话中,那就从Tmux会话中脱离出来
|
||||
让我们创建另一个Tmux会话,让其以面板的方式工作。首先,如果我们在某个会话中,那就从Tmux会话中脱离出来:
|
||||
|
||||
**CTRL-b d**
|
||||
|
||||
开始一个叫做"panes"的新会话
|
||||
开始一个叫做"panes"的新会话:
|
||||
|
||||
$ tmux new -s panes
|
||||
|
||||
@ -120,17 +119,17 @@ Archlinux:
|
||||
|
||||
**CRTL-b %**
|
||||
|
||||
又增加了两个
|
||||
又增加了两个:
|
||||
|
||||
|
||||
|
||||
在他们之间移动:
|
||||
|
||||
**CTRL-b <Arrow keys>**
|
||||
**CTRL-b <光标键>**
|
||||
|
||||
### 结论
|
||||
|
||||
我希望这篇教程能对你有作用。作为奖励,像[Tmuxinator][3] 或者 [Tmuxifier][4]这样的工具,可以简化Tmux会话,窗口和面板的创建及加载,你可以很容易就配置Tmux。如果你没有使用过这些,尝试一下吧
|
||||
我希望这篇教程能对你有作用。此外,像[Tmuxinator][3] 或者 [Tmuxifier][4]这样的工具,可以简化Tmux会话,窗口和面板的创建及加载,你可以很容易就配置Tmux。如果你没有使用过这些,尝试一下吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -138,7 +137,7 @@ via: http://xmodulo.com/2014/08/improve-productivity-terminal-environment-tmux.h
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,15 @@
|
||||
移除Linux系统上的文件元数据
|
||||
如何在Linux上移除文件内的隐私数据
|
||||
================================================================================
|
||||
|
||||
典型的数据文件通常关联着“元数据”,其包含这个文件的描述信息,表现为一系列属性-值的集合。元数据一般包括创建者名称、生成文件的工具、文件创建/修改时期、创建位置和编辑历史等等。EXIF(镜像标准)、RDF(web资源)和DOI(数字文档)是几种流行的元数据标准。
|
||||
|
||||
典型的数据文件通常关联着“元数据”,其包含这个文件的描述信息,表现为一系列属性-值的集合。元数据一般包括创建者名称、生成文件的工具、文件创建/修改时期、创建位置和编辑历史等等。几种流行的元数据标准有 EXIF(图片)、RDF(web资源)和DOI(数字文档)等。
|
||||
|
||||
虽然元数据在数据管理领域有它的优点,但事实上它会[危害][1]你的隐私。相机图片中的EXIF格式数据会泄露出可识别的个人信息,比如相机型号、拍摄相关的GPS坐标和用户偏爱的照片编辑软件等。在文档和电子表格中的元数据包含作者/所属单位信息和相关的编辑历史。不一定这么绝对,但诸如[metagoofil][2]一类的元数据收集工具在信息收集的过程中常最作为入侵测试的一部分被利用。
|
||||
|
||||
对那些想要从共享数据中擦除一切个人元数据的用户来说,有一些方法从数据文件中移除元数据。你可以使用已有的文档或图片编辑软件,通常有自带的元数据编辑功能。在这个教程里,我会介绍一种不错的、单独的**元数据清理工具**,其目标只有一个:**匿名一切私有元数据**。
|
||||
|
||||
[MAT][3](元数据匿名工具箱)是一款专业的元数据清理器,使用Python编写。它在Tor工程旗下开发而成,在[Trails][4]上衍生出标准,后者是一种私人增强的live操作系统。【翻译得别扭,麻烦修正:)】
|
||||
[MAT][3](元数据匿名工具箱)是一款专业的元数据清理器,使用Python编写。它属于Tor旗下的项目,而且是Live 版的隐私增强操作系统 [Trails][4] 的标配应用。
|
||||
|
||||
与诸如[exiftool][5]等只能对有限数量的文件类型进行写入的工具相比,MAT支持从各种各样的文件中消除元数据:图片(png、jpg)、文档(odt、docx、pptx、xlsx和pdf)、归档文件(tar、tar.bz2)和音频(mp3、ogg、flac)等。
|
||||
与诸如[exiftool][5]等只能对有限种类的文件类型进行写入的工具相比,MAT支持从各种各样的文件中消除元数据:图片(png、jpg)、文档(odt、docx、pptx、xlsx和pdf)、归档文件(tar、tar.bz2)和音频(mp3、ogg、flac)等。
|
||||
|
||||
### 在Linux上安装MAT ###
|
||||
|
||||
@ -18,7 +17,7 @@
|
||||
|
||||
$ sudo apt-get install mat
|
||||
|
||||
在Fedora上,并没有预先生成的MAT包,所以你需要从源码生成。这是我在Fedora上生成MAT的步骤(不成功的话,请查看教程底部):
|
||||
在Fedora上,并没有预先生成的MAT软件包,所以你需要从源码生成。这是我在Fedora上生成MAT的步骤(不成功的话,请查看教程底部):
|
||||
|
||||
$ sudo yum install python-devel intltool python-pdfrw perl-Image-ExifTool python-mutagen
|
||||
$ sudo pip install hachoir-core hachoir-parser
|
||||
@ -95,7 +94,7 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
MAT是一款简单但非常好用的工具,用来预防从元数据中无意泄露私人数据。请注意如果有必要,还是需要你去隐藏文件内容。MAT能做的是消除与文件相关的元数据,但并不会对文件本身进行任何操作。简而言之,MAT是一名救生员,因为它可以处理大多数常见的元数据移除,但不应该只指望它来保证你的隐私。[译者注:养成良好的隐私保护意识和习惯才是最好的方法]
|
||||
MAT是一款简单但非常好用的工具,用来预防从元数据中无意泄露私人数据。请注意如果有必要,文件内容也需要保护。MAT能做的是消除与文件相关的元数据,但并不会对文件本身进行任何操作。简而言之,MAT是一名救生员,因为它可以处理大多数常见的元数据移除,但不应该只指望它来保证你的隐私。[译者注:养成良好的隐私保护意识和习惯才是最好的方法]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -103,7 +102,7 @@ via: http://xmodulo.com/2014/08/remove-file-metadata-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
在Linux中使用逻辑卷管理器构建灵活的磁盘存储——第一部分
|
||||
在Linux中使用LVM构建灵活的磁盘存储(第一部分)
|
||||
================================================================================
|
||||
**逻辑卷管理器(LVM)**让磁盘空间管理更为便捷。如果一个文件系统需要更多的空间,它可以在它的卷组中将空闲空间添加到它的逻辑卷中,而文件系统可以根据你的意愿调整大小。如果某个磁盘启动失败,替换磁盘可以使用卷组注册成一个物理卷,而逻辑卷扩展可以将数据迁移到新磁盘而不会丢失数据。
|
||||
**逻辑卷管理器(LVM)**让磁盘空间管理更为便捷。如果一个文件系统需要更多的空间,可以在它的卷组中将空闲空间添加到其逻辑卷中,而文件系统可以根据你的意愿调整大小。如果某个磁盘启动失败,用于替换的磁盘可以使用卷组注册成一个物理卷,而逻辑卷扩展可以将数据迁移到新磁盘而不会丢失数据。
|
||||
|
||||
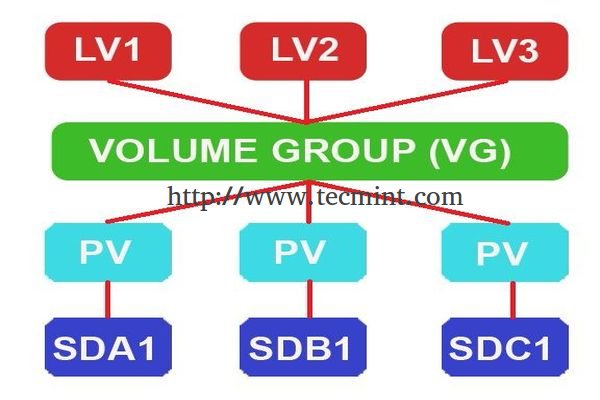
|
||||
在Linux中创建LVM存储
|
||||
<center></center>
|
||||
|
||||
在现代世界中,每台服务器空间都会因为我们的需求增长而不断扩展。逻辑卷可以用于RAID,SAN。单个物理卷将会被加入组以创建卷组,在卷组中,我们需要切割空间以创建逻辑卷。在使用逻辑卷时,我们可以使用某些命令来跨磁盘、跨逻辑卷扩展,或者减少逻辑卷大小,而不用重新格式化和重新对当前磁盘分区。卷可以跨磁盘抽取数据,这会增加I/O数据量。
|
||||
<center>*在Linux中创建LVM存储*</center>
|
||||
|
||||
在如今,每台服务器空间都会因为我们的需求增长而不断扩展。逻辑卷可以用于RAID,SAN。单个物理卷将会被加入组以创建卷组,在卷组中,我们需要切割空间以创建逻辑卷。在使用逻辑卷时,我们可以使用某些命令来跨磁盘、跨逻辑卷扩展,或者减少逻辑卷大小,而不用重新格式化和重新对当前磁盘分区。卷可以跨磁盘抽取数据,这会增加I/O数据量。
|
||||
|
||||
### LVM特性 ###
|
||||
|
||||
@ -27,8 +28,8 @@
|
||||
# vgs
|
||||
# lvs
|
||||
|
||||

|
||||
检查物理卷
|
||||
<center></center>
|
||||
<center>*检查物理卷*</center>
|
||||
|
||||
下面是上面截图中各个参数的说明。
|
||||
|
||||
@ -52,8 +53,8 @@
|
||||
|
||||
# fdisk -l
|
||||
|
||||

|
||||
验证添加的磁盘
|
||||
<center></center>
|
||||
<center>*验证添加的磁盘*</center>
|
||||
|
||||
- 用于操作系统(CentOS 6.5)的默认磁盘。
|
||||
- 默认磁盘上定义的分区(vda1 = swap),(vda2 = /)。
|
||||
@ -61,8 +62,8 @@
|
||||
|
||||
各个磁盘大小都是20GB,默认的卷组的PE大小为4MB,我们在该服务器上配置的卷组使用默认PE。
|
||||
|
||||

|
||||
卷组显示
|
||||
<center></center>
|
||||
<center>*卷组显示*</center>
|
||||
|
||||
- **VG Name** – 卷组名称。
|
||||
- **Format** – LVM架构使用LVM2。
|
||||
@ -82,8 +83,8 @@
|
||||
|
||||
# df -TH
|
||||
|
||||
|
||||
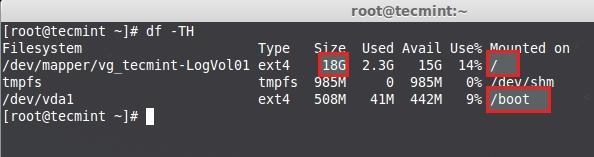
检查磁盘空间
|
||||
<center></center>
|
||||
<center>*检查磁盘空间*</center>
|
||||
|
||||
上面的图片中显示了用于根的挂载点已使用了**18GB**,因此没有空闲空间可用了。
|
||||
|
||||
@ -91,15 +92,15 @@
|
||||
|
||||
我们可以扩展当前使用的卷组以获得更多空间。但在这里,我们将要做的是,创建新的卷组,然后在里面肆意妄为吧。过会儿,我们可以看到怎样来扩展使用中的卷组的文件系统。
|
||||
|
||||
在使用新磁盘钱,我们需要使用fdisk来对磁盘分区。
|
||||
在使用新磁盘前,我们需要使用fdisk来对磁盘分区。
|
||||
|
||||
# fdisk -cu /dev/sda
|
||||
|
||||
- **c** – 关闭DOS兼容模式,推荐使用该选项。
|
||||
- **u** – 当列出分区表时,会以扇区而不是柱面显示。
|
||||
|
||||

|
||||
创建新的物理分区
|
||||
<center></center>
|
||||
<center>*创建新的物理分区*</center>
|
||||
|
||||
接下来,请遵循以下步骤来创建新分区。
|
||||
|
||||
@ -118,8 +119,8 @@
|
||||
|
||||
# fdisk -l
|
||||
|
||||

|
||||
验证分区表
|
||||
<center></center>
|
||||
<center>*验证分区表*</center>
|
||||
|
||||
### 创建物理卷 ###
|
||||
|
||||
@ -135,8 +136,8 @@
|
||||
|
||||
# pvs
|
||||
|
||||

|
||||
创建物理卷
|
||||
<center></center>
|
||||
<center>*创建物理卷*</center>
|
||||
|
||||
### 创建卷组 ###
|
||||
|
||||
@ -152,11 +153,11 @@
|
||||
|
||||
# vgs
|
||||
|
||||

|
||||
创建卷组
|
||||
<center></center>
|
||||
<center>*创建卷组*</center>
|
||||
|
||||

|
||||
验证卷组
|
||||
<center></center>
|
||||
<center>*验证卷组*</center>
|
||||
|
||||
理解vgs命令输出:
|
||||
|
||||
@ -173,15 +174,15 @@
|
||||
|
||||
# vgs -v
|
||||
|
||||

|
||||
检查卷组信息
|
||||
<center></center>
|
||||
<center>*检查卷组信息*</center>
|
||||
|
||||
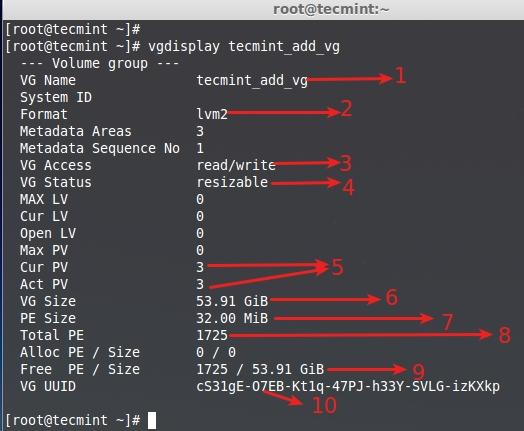
**8.** 要获取更多关于新创建的卷组信息,运行以下命令。
|
||||
|
||||
# vgdisplay tecmint_add_vg
|
||||
|
||||
|
||||
列出新卷组
|
||||
<center></center>
|
||||
<center>*列出新卷组*</center>
|
||||
|
||||
- 卷组名称
|
||||
- 使用的LVM架构。
|
||||
@ -200,15 +201,15 @@
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
列出当前卷组
|
||||
<center></center>
|
||||
<center>*列出当前卷组*</center>
|
||||
|
||||
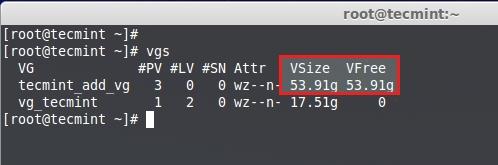
**10.** 这些逻辑卷处于**vg_tecmint**卷组中使用**pvs**命令来列出并查看有多少空闲空间可以创建逻辑卷。
|
||||
|
||||
# pvs
|
||||
|
||||
|
||||
检查空闲空间
|
||||
<center></center>
|
||||
<center>*检查空闲空间*</center>
|
||||
|
||||
**11.** 卷组大小为**54GB**,而且未被使用,所以我们可以在该组内创建LV。让我们将卷组平均划分大小来创建3个逻辑卷,就是说**54GB**/3 = **18GB**,创建出来的单个逻辑卷应该会是18GB。
|
||||
|
||||
@ -218,8 +219,8 @@
|
||||
|
||||
# vgdisplay tecmint_add_vg
|
||||
|
||||
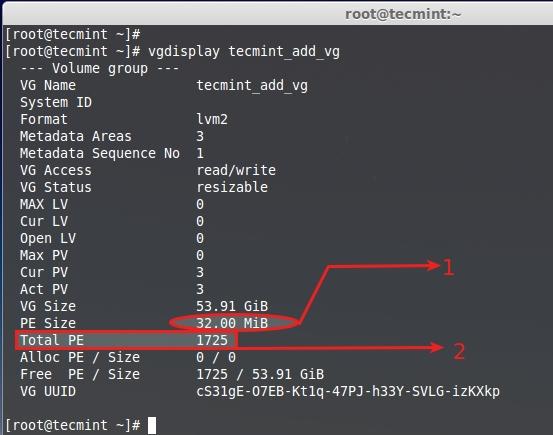
|
||||
创建新逻辑卷
|
||||
<center></center>
|
||||
<center>*创建新逻辑卷*</center>
|
||||
|
||||
- 默认分配给该卷组的PE为32MB,这里单个的PE大小为32MB。
|
||||
- 总可用PE是1725。
|
||||
@ -233,8 +234,8 @@
|
||||
1725PE/3 = 575 PE.
|
||||
575 PE x 32MB = 18400 --> 18GB
|
||||
|
||||
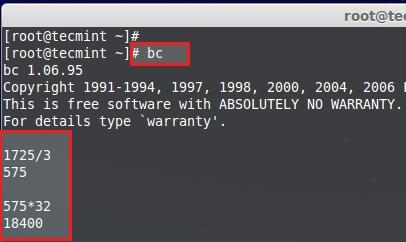
|
||||
计算磁盘空间
|
||||
<center></center>
|
||||
<center>*计算磁盘空间*</center>
|
||||
|
||||
按**CRTL+D**退出**bc**。现在让我们使用575个PE来创建3个逻辑卷。
|
||||
|
||||
@ -253,8 +254,8 @@
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
列出创建的逻辑卷
|
||||
<center></center>
|
||||
<center>*列出创建的逻辑卷*</center>
|
||||
|
||||
#### 方法2: 使用GB大小创建逻辑卷 ####
|
||||
|
||||
@ -272,8 +273,8 @@
|
||||
|
||||
# lvs
|
||||
|
||||

|
||||
验证创建的逻辑卷
|
||||
<center></center>
|
||||
<center>*验证创建的逻辑卷*</center>
|
||||
|
||||
这里,我们可以看到,当创建第三个LV的时候,我们不能收集到18GB空间。这是因为尺寸有小小的改变,但在使用或者尺寸来创建LV时,这个问题会被忽略。
|
||||
|
||||
@ -287,8 +288,8 @@
|
||||
|
||||
# mkfs.ext4 /dev/tecmint_add_vg/tecmint_manager
|
||||
|
||||

|
||||
创建Ext4文件系统
|
||||
<center></center>
|
||||
<center>*创建Ext4文件系统*</center>
|
||||
|
||||
**13.** 让我们在**/mnt**下创建目录,并将已创建好文件系统的逻辑卷挂载上去。
|
||||
|
||||
@ -302,8 +303,8 @@
|
||||
|
||||
# df -h
|
||||
|
||||

|
||||
挂载逻辑卷
|
||||
<center></center>
|
||||
<center>*挂载逻辑卷*</center>
|
||||
|
||||
#### 永久挂载 ####
|
||||
|
||||
@ -321,32 +322,31 @@
|
||||
/dev/mapper/tecmint_add_vg-tecmint_public /mnt/tecmint_public ext4 defaults 0 0
|
||||
/dev/mapper/tecmint_add_vg-tecmint_manager /mnt/tecmint_manager ext4 defaults 0 0
|
||||
|
||||

|
||||
获取mtab挂载条目
|
||||
<center>*</center>
|
||||
<center>*获取mtab挂载条目*</center>
|
||||
|
||||
|
||||
打开fstab文件
|
||||
<center></center>
|
||||
<center>*打开fstab文件*</center>
|
||||
|
||||

|
||||
添加自动挂载条目
|
||||
<center></center>
|
||||
<center>*添加自动挂载条目*</center>
|
||||
|
||||
重启前,执行mount -a命令来检查fstab条目。
|
||||
|
||||
# mount -av
|
||||
|
||||

|
||||
验证fstab条目
|
||||
<center></center>
|
||||
<center>*验证fstab条目*</center>
|
||||
|
||||
这里,我们已经了解了怎样来使用逻辑卷构建灵活的存储,从使用物理磁盘到物理卷,物理卷到卷组,卷组再到逻辑卷。
|
||||
|
||||
在我即将奉献的文章中,我将介绍如何扩展卷组、逻辑卷,减少逻辑卷,拍快照以及从快照中恢复。到那时,保持TecMint更新到这些精彩文章中的内容。
|
||||
--------------------------------------------------------------------------------
|
||||
在我即将奉献的文章中,我将介绍如何扩展卷组、逻辑卷,减少逻辑卷,拍快照以及从快照中恢复。 --------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
配置Linux访问控制列表(ACL)
|
||||
配置 Linux 的访问控制列表(ACL)
|
||||
================================================================================
|
||||
使用拥有权限控制的Liunx,工作是一件轻松的任务。它可以定义任何user,group和other的权限。无论是在桌面电脑或者不会有很多用户的虚拟Linux实例,或者当用户不愿意分享他们之间的文件时,这样的工作是很棒的。然而,如果你是在一个大型组织,你运行了NFS或者Samba服务给不同的用户。然后你将会需要灵活的挑选并设置很多复杂的配置和权限去满足你的组织不同的需求。
|
||||
使用拥有权限控制的Liunx,工作是一件轻松的任务。它可以定义任何user,group和other的权限。无论是在桌面电脑或者不会有很多用户的虚拟Linux实例,或者当用户不愿意分享他们之间的文件时,这样的工作是很棒的。然而,如果你是在一个大型组织,你运行了NFS或者Samba服务给不同的用户,然后你将会需要灵活的挑选并设置很多复杂的配置和权限去满足你的组织不同的需求。
|
||||
|
||||
Linux(和其他Unix,兼容POSIX的)所以拥有访问控制列表(ACL),它是一种分配权限之外的普遍范式。例如,默认情况下你需要确认3个权限组:owner,group和other。使用ACL,你可以增加权限给其他用户或组别,而不单只是简单的"other"或者是拥有者不存在的组别。可以允许指定的用户A、B、C拥有写权限而不再是让他们整个组拥有写权限。
|
||||
Linux(和其他Unix等POSIX兼容的操作系统)有一种被称为访问控制列表(ACL)的权限控制方法,它是一种权限分配之外的普遍范式。例如,默认情况下你需要确认3个权限组:owner、group和other。而使用ACL,你可以增加权限给其他用户或组别,而不单只是简单的"other"或者是拥有者不存在的组别。可以允许指定的用户A、B、C拥有写权限而不再是让他们整个组拥有写权限。
|
||||
|
||||
ACL支持多种Linux文件系统,包括ext2, ext3, ext4, XFS, Btfrs, 等。如果你不确定你的文件系统是否支持ACL,请参考文档。
|
||||
|
||||
@ -32,15 +32,15 @@ Archlinux 中:
|
||||
|
||||
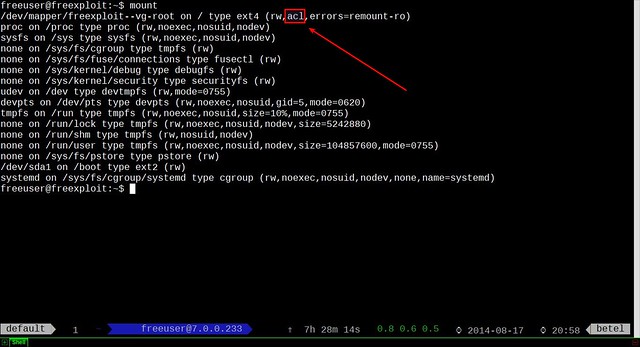
|
||||
|
||||
你可以注意到,我的root分区中ACL属性已经开启。万一你没有开启,你需要编辑/etc/fstab文件。增加acl标记,在你需要开启ACL的分区之前。
|
||||
你可以注意到,我的root分区中ACL属性已经开启。万一你没有开启,你需要编辑/etc/fstab文件,在你需要开启ACL的分区的选项前增加acl标记。
|
||||
|
||||
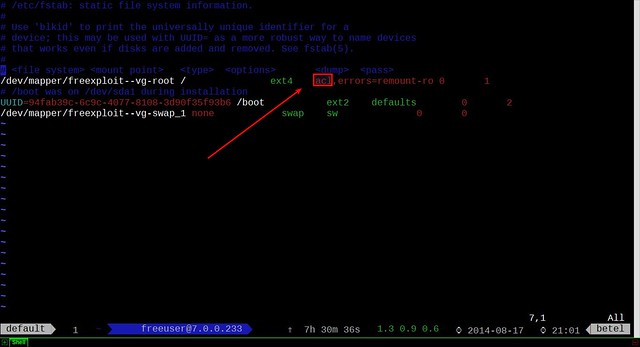
|
||||
|
||||
现在我们需要重新挂载分区(我喜欢完全重启,因为我不想丢掉数据),如果你对任何分区开启ACL,你必须也重新挂载它。
|
||||
现在我们需要重新挂载分区(我喜欢完全重启,因为我不想丢失数据),如果你对其它分区开启ACL,你必须也重新挂载它。
|
||||
|
||||
$ sudo mount / -o remount
|
||||
|
||||
令人敬佩!现在我们已经在我们的系统中开启ACL,让我们开始和它一起工作。
|
||||
干的不错!现在我们已经在我们的系统中开启ACL,让我们开始和它一起工作。
|
||||
|
||||
### ACL 范例 ###
|
||||
|
||||
@ -54,7 +54,6 @@ Archlinux 中:
|
||||
|
||||
我想要分享这个目录给其他两个用户test和test2,一个拥有完整权限,另一个只有读权限。
|
||||
|
||||
First, to set ACLs for user test:
|
||||
首先,为用户test设置ACL:
|
||||
|
||||
$ sudo setfacl -m u:test:rwx /shared
|
||||
@ -84,7 +83,7 @@ First, to set ACLs for user test:
|
||||
|
||||

|
||||
|
||||
你可以注意到,正常权限后多一个+标记。这表示ACL已经设置成功。为了真正读取ACL,我们需要运行:
|
||||
你可以注意到,正常权限后多一个+标记。这表示ACL已经设置成功。要具体看一下ACL,我们需要运行:
|
||||
|
||||
$ sudo getfacl /shared
|
||||
|
||||
@ -102,11 +101,11 @@ First, to set ACLs for user test:
|
||||
|
||||

|
||||
|
||||
最后一件事。在设置了ACL文件或目录工作时,cp和mv命令会改变这些设置。在cp的情况下,需要添加“p”参数来复制ACL设置。如果这不可行,它将会展示一个警告。mv默认移动ACL设置,如果这也不可行,它也会向您展示一个警告。
|
||||
最后,在设置了ACL文件或目录工作时,cp和mv命令会改变这些设置。在cp的情况下,需要添加“p”参数来复制ACL设置。如果这不可行,它将会展示一个警告。mv默认移动ACL设置,如果这也不可行,它也会向您展示一个警告。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
使用ACL给了在你想要分享的文件上巨大的权利和控制,特别是在NFS/Samba服务。此外,如果你的主管共享主机,这个工具是必备的。
|
||||
使用ACL让在你想要分享的文件上拥有更多的能力和控制,特别是在NFS/Samba服务。此外,如果你的主管共享主机,这个工具是必备的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -114,7 +113,7 @@ via: http://xmodulo.com/2014/08/configure-access-control-lists-acls-linux.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
Linux有问必答——如何在CentOS上安装Shutter
|
||||
Linux有问必答:如何在CentOS上安装Shutter
|
||||
================================================================================
|
||||
> **问题**:我想要在我的CentOS桌面上试试Shutter屏幕截图程序,但是,当我试着用yum来安装Shutter时,它总是告诉我“没有shutter包可用”。我怎样才能在CentOS上安装Shutter啊?
|
||||
|
||||
[Shutter][1]是一个用于Linux桌面的开源(GPLv3)屏幕截图工具。它打包有大量用户友好的功能,这让它成为Linux中功能最强大的屏幕截图程序之一。你可以用Shutter来捕捉一个规则区域、一个窗口、整个桌面屏幕、或者甚至是来自任意专用地址的一个网页的截图。除此之外,你也可以用它内建的图像编辑器来对捕获的截图进行编辑,应用不同的效果,将图像导出为不同的图像格式(svg,pdf,ps),或者上传图片到公共图像主机或者FTP站点。
|
||||
Shutter is not available as a pre-built package on CentOS (as of version 7). Fortunately, there exists a third-party RPM repository called Nux Dextop, which offers Shutter package. So [enable Nux Dextop repository][2] on CentOS. Then use the following command to install Shutter.
|
||||
|
||||
Shutter 在 CentOS (截止至版本 7)上没有预先构建好的软件包。幸运的是,有一个第三方提供的叫做 Nux Dextop 的 RPM 中提供了 Shutter 软件包。 所以在 CentOS 上[启用 Nux Dextop 软件库][2],然后使用下列命令来安装它:
|
||||
|
||||
$ sudo yum --enablerepo=nux-dextop install shutter
|
||||
|
||||
@ -14,9 +15,9 @@ Shutter is not available as a pre-built package on CentOS (as of version 7). For
|
||||
via: http://ask.xmodulo.com/install-shutter-centos.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://shutter-project.org/
|
||||
[2]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
||||
[2]:http://linux.cn/article-3889-1.html
|
||||
@ -1,6 +1,6 @@
|
||||
Google drive和Ubuntu 14.04 LTS的胶合
|
||||
墙外香花:Google drive和Ubuntu 14.04 LTS的胶合
|
||||
================================================================================
|
||||
Google尚未发布其**官方Linux客户端**,以用于从Ubuntu访问其drive。然开源社区却业已开发完毕非官方之软件包‘**grive-tools**’。
|
||||
Google尚未发布用于从Ubuntu访问其drive的**官方Linux客户端**。然开源社区却业已开发完毕非官方之软件包‘**grive-tools**’。
|
||||
|
||||
Grive乃是Google Drive(**在线存储服务**)的GNU/Linux系统客户端,允许你**同步**所选目录到云端,以及上传新文件到Google Drive。
|
||||
|
||||
@ -22,7 +22,7 @@ Grive乃是Google Drive(**在线存储服务**)的GNU/Linux系统客户端
|
||||
|
||||
**步骤:1** 安装完了,通过输入**Grive**在**Unity Dash**搜索应用,并打开之。
|
||||
|
||||

|
||||

|
||||
|
||||
**步骤:2** 登入google drive,你将被问及访问google drive的权限。
|
||||
|
||||
@ -36,25 +36,25 @@ Grive乃是Google Drive(**在线存储服务**)的GNU/Linux系统客户端
|
||||
|
||||
**步骤:3** 下面将提供给你一个 **google代码**,复制并粘贴到**Grive设置框**内。
|
||||
|
||||
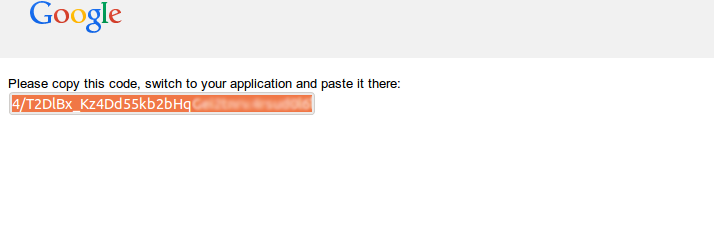
|
||||
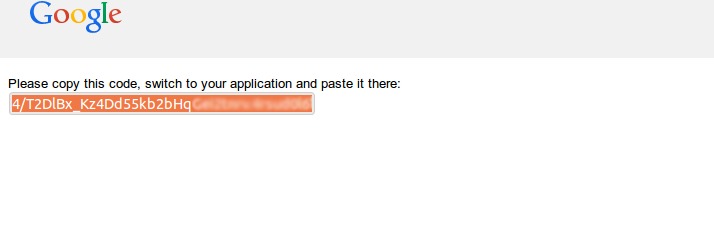
|
||||
|
||||
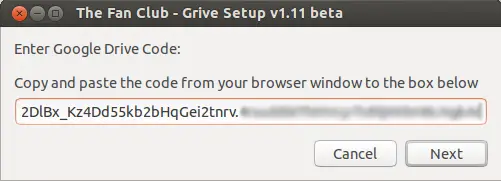
|
||||
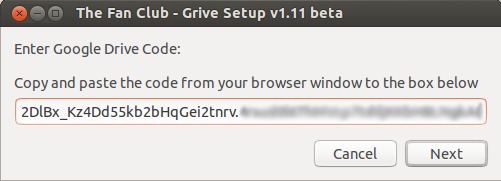
|
||||
|
||||
点击下一步后,将会开始同步google drive到你**家目录**下的‘**Google Drive**’文件夹。完成后,将出现如下窗口。
|
||||
|
||||
|
||||
|
||||
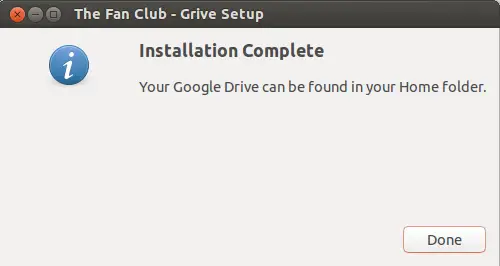
Google Drive folder created under **user's home directory**
|
||||
Google Drive 文件夹会创建在**用户的主目录**下。
|
||||
|
||||

|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/mount-google-drive-in-ubuntu/
|
||||
|
||||
作者:[Pradeep Kumar ][a]
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答——如何使用tcpdump来捕获TCP SYN,ACK和FIN包
|
||||
Linux有问必答:如何使用tcpdump来捕获TCP SYN,ACK和FIN包
|
||||
================================================================================
|
||||
> **问题**:我想要监控TCP连接活动(如,建立连接的三次握手,以及断开连接的四次握手)。要完成此事,我只需要捕获TCP控制包,如SYN,ACK或FIN标记相关的包。我怎样使用tcpdump来仅仅捕获TCP SYN,ACK和/或FYN包?
|
||||
|
||||
作为事实上的捕获工具,tcpdump提供了强大而又灵活的包过滤功能。作为tcpdump基础的libpcap包捕获引擎支持标准的包过滤规则,如基于5重包头的过滤(如基于源/目的IP地址/端口和IP协议类型)。
|
||||
作为业界标准的捕获工具,tcpdump提供了强大而又灵活的包过滤功能。作为tcpdump基础的libpcap包捕获引擎支持标准的包过滤规则,如基于5重包头的过滤(如基于源/目的IP地址/端口和IP协议类型)。
|
||||
|
||||
tcpdump/libpcap的包过滤规则也支持更多通用分组表达式,在这些表达式中,包中的任意字节范围都可以使用关系或二进制操作符进行检查。对于字节范围表达,你可以使用以下格式:
|
||||
|
||||
@ -34,8 +34,8 @@ tcpdump/libpcap的包过滤规则也支持更多通用分组表达式,在这
|
||||
|
||||
via: http://ask.xmodulo.com/capture-tcp-syn-ack-fin-packets-tcpdump.html
|
||||
|
||||
作者:[作者名][a]
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,15 +1,14 @@
|
||||
Linux FAQ - Ubuntu如何使用命令行移除PPA仓库
|
||||
Linux有问必答:Ubuntu如何使用命令行移除PPA仓库
|
||||
================================================================================
|
||||
> **问题**: 前段时间,我的Ubuntu增加了一个第三方的PPA仓库,如何才能移除这个PPA仓库呢?
|
||||
|
||||
个人软件包档案(PPA)是Ubuntu独有的解决方案,允许独立开发者和贡献者构建、贡献任何定制的软件包来作为通过启动面板的第三方APT仓库。如果你是Ubuntu用户,有可能你已经增加一些流行的第三方PPA仓库到你的Ubuntu系统。如果你需要删除掉已经预先配置好的PPA仓库,下面将教你怎么做。
|
||||
|
||||
|
||||
假如你有一个第三方PPA仓库叫“ppa:webapps/preview”增加到了你的系统中,如下。
|
||||
假如你想增加一个叫“ppa:webapps/preview”第三方PPA仓库到你的系统中,如下:
|
||||
|
||||
$ sudo add-apt-repository ppa:webapps/preview
|
||||
|
||||
如果你想要 **单独地删除一个PPA仓库**,运行下面的命令。
|
||||
如果你想要 **单独地删除某个PPA仓库**,运行下面的命令:
|
||||
|
||||
$ sudo add-apt-repository --remove ppa:someppa/ppa
|
||||
|
||||
@ -17,22 +16,22 @@ Linux FAQ - Ubuntu如何使用命令行移除PPA仓库
|
||||
|
||||
如果你想要 **完整的删除一个PPA仓库并包括来自这个PPA安装或更新过的软件包**,你需要ppa-purge命令。
|
||||
|
||||
安装ppa-purge软件包:
|
||||
首先要安装ppa-purge软件包:
|
||||
|
||||
$ sudo apt-get install ppa-purge
|
||||
|
||||
删除PPA仓库和与之相关的软件包,运行下列命令:
|
||||
然后使用如下命令删除PPA仓库和与之相关的软件包:
|
||||
|
||||
$ sudo ppa-purge ppa:webapps/preview
|
||||
|
||||
特别滴,在发行版更新后,你需要[分辨和清除已损坏的PPA仓库][1],这个方法特别有用!
|
||||
特别滴,在发行版更新后,当你[分辨和清除已损坏的PPA仓库][1]时这个方法特别有用!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/how-to-remove-ppa-repository-from-command-line-on-ubuntu.html
|
||||
|
||||
译者:[Vic___](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答-- 如何用Perl检测Linux的发行版本
|
||||
Linux有问必答:如何用Perl检测Linux的发行版本
|
||||
================================================================================
|
||||
> **提问**:我需要写一个Perl程序,它会包含Linux发行版相关的代码。为此,Perl程序需要能够自动检测运行中的Linux的发行版(如Ubuntu、CentOS、Debian、Fedora等等),以及它是什么版本号。如何用Perl检测Linux的发行版本?
|
||||
|
||||
如果要用Perl脚本检测Linux的发行版,你可以使用一个名为[Linux::Distribution][1]的Perl模块。该模块通过检查/etc/lsb-release以及其他特定的/etc下的发行版特定的目录来猜测底层Linux操作系统。它支持检测所有主要的Linux发行版,包括Fedora、CentOS、Arch Linux、Debian、Ubuntu、SUSE、Red Hat、Gentoo、Slackware、Knoppix和Mandrake。
|
||||
如果要用Perl脚本检测Linux的发行版,你可以使用一个名为[Linux::Distribution][1]的Perl模块。该模块通过检查/etc/lsb-release以及其他在/etc下的发行版特定的目录来猜测底层Linux操作系统。它支持检测所有主要的Linux发行版,包括Fedora、CentOS、Arch Linux、Debian、Ubuntu、SUSE、Red Hat、Gentoo、Slackware、Knoppix和Mandrake。
|
||||
|
||||
要在Perl中使用这个模块,你首先需要安装它。
|
||||
|
||||
@ -20,7 +20,7 @@ Linux有问必答-- 如何用Perl检测Linux的发行版本
|
||||
|
||||
$ sudo yum -y install perl-CPAN
|
||||
|
||||
使用这条命令来构建并安装模块:
|
||||
然后,使用这条命令来构建并安装模块:
|
||||
|
||||
$ sudo perl -MCPAN -e 'install Linux::Distribution'
|
||||
|
||||
@ -46,7 +46,7 @@ Linux::Distribution模块安装完成之后,你可以使用下面的代码片
|
||||
via: http://ask.xmodulo.com/detect-linux-distribution-in-perl.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -47,6 +47,6 @@ via: http://www.unixmen.com/reset-root-password-centos-7/
|
||||
|
||||
作者:M.el Khamlichi
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
快速地向你展示**如何检查你的系统是否受到Shellshock的影响**如果有,**怎样修复你的系统免于被Bash漏洞利用**。
|
||||
快速地向你展示**如何检查你的系统是否受到Shellshock的影响**,如果有,**怎样修复你的系统免于被Bash漏洞利用**。
|
||||
|
||||
如果你正跟踪新闻,你可能已经听说过在[Bash][1]中发现了一个漏洞,这被称为**Bash Bug**或者** Shellshock**。 [红帽][2]是第一个发现这个漏洞的机构。Shellshock错误允许攻击者注入自己的代码,从而使系统开放各给种恶意软件和远程攻击。事实上,[黑客已经利用它来启动DDoS攻击][3]。
|
||||
|
||||
@ -55,7 +55,7 @@ via: http://itsfoss.com/linux-shellshock-check-fix/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,27 @@
|
||||
7 Improvements The Linux Desktop Needs
|
||||
7个Linux桌面需要改善之处
|
||||
======================================
|
||||
|
||||
In the last fifteen years, the Linux desktop has gone from a collection of marginally adequate solutions to an unparalleled source of innovation and choice. Many of its standard features are either unavailable in Windows, or else available only as a proprietary extension. As a result, using Linux is increasingly not only a matter of principle, but of preference as well.
|
||||
在过去的15年内,Linux桌面从一个还算凑合的边缘化解决方案集合发展到了一个空前的创新和选择源。它的标准特点中有许多是要么不适用于Windows系统,要么就只适合作为一个专有的扩展。因此,使用Linux愈发变得不仅是一个原则问题,也是一种偏好。
|
||||
|
||||
Yet, despite this progress, gaps remain. Some are missing features, others missing features, and still others pie-in-the sky extras that could be easily implemented to extend the desktop metaphor without straining users' tolerance of change.
|
||||
然而,尽管Linux桌面不停在进步,但是仍然存在差距。一些正在丢失它们的特点,一些已经丢失了,还有一些如同天上掉的馅饼般的附加设备能轻易地实现在不考虑用户对于改变的容忍度的情况下来扩展桌面。
|
||||
|
||||
For instance, here are 7 improvements that would benefit the Linux desktop:
|
||||
比如说,以下是7个有利于Linux桌面发展的改善建议:
|
||||
|
||||
### 7. Easy Email Encryption
|
||||
### 7. 简单的Email加密技术
|
||||
|
||||
These days, every email reader from Alpine to Thunderbird and Kmail include email encryption. However, documentation is often either non-existent or poor.
|
||||
如今,每个Email阅读器从Alpine到Thunderbird再到Kmail,都包括了Email加密技术。然而,文件编制通常是不存在或者非常劣质。
|
||||
|
||||
But, even if you understand the theory, the practice is difficult. Controls are generally scattered throughout the configuration menus and tabs, requiring a thorough search for all the settings that you require or want. Should you fail to set up encryption properly, usually you receive no feedback about why.
|
||||
但是,即使你理论上看懂了,但是实践起来还是很困难的。控件通常分散在整个配置菜单和选项卡中,需要为所有你需要和想要的设置进行一次彻底的搜索。如果你未能进行适当的加密,你就收不到反馈。
|
||||
|
||||
The closest to an easy process is [Enigmail][1], a Thunderbird extension that includes a setup wizard aimed at beginners. But you have to know about Enigmail to use it, and the menu it adds to the composition window buries the encryption option one level down and places it with other options guaranteed to mystify everyday users.
|
||||
最新的一个简易加密进程是 [Enigmail][1] ,一个包含面向初学者设置向导的Thunderbird扩展。但是你一定要知道怎么用Enigmail,而且菜单新增了合成窗口并把加密设置项添加了进去,如果把它弄到其它的设置里势必会使每个用户都难以理解。
|
||||
|
||||
No matter what the desktop, the assumption is that, if you want encrypted email, you already understand it. Today, though, the constant media references to security and privacy have ensured that such an assumption no longer applies.
|
||||
无论桌面怎么样,假设如果你想接收加密过的Email,你就要先知道密码。可如今,不断有媒体涉及安全和隐私方面就已经确定了这样的假设不再适用。
|
||||
|
||||
### 6. Thumbnails for Virtual Workspaces
|
||||
### 6. 虚拟工作空间缩略图
|
||||
|
||||
Virtual workspaces offer more desktop space without requiring additional monitors. Yet, despite their usefulness, management of virtual workspaces hasn't changed in over a decade. On most desktops, you control them through a pager in which each workspace is represented by an unadorned rectangle that gives few indications of what might be on it except for its name or number -- or, in the case of Ubuntu's Unity, which workspace is currently active.
|
||||
虚拟工作空间提供了更多不需要额外监听的桌面空间。然而,尽管它们很实用,但是虚拟工作空间的管理并没有在过去十年发生改变。在大多数桌面产品中,你控制On most desktops, you control them through a pager in which each workspace is represented by an unadorned rectangle that gives few indications of what might be on it except for its name or number -- or, in the case of Ubuntu's Unity, which workspace is currently active.
|
||||
|
||||
True, GNOME and Cinnamon do offer better views, but the usefulness of these views is limited by the fact that they require a change of screens. Nor is KDE's written list of contents, which is jarring in the primarily graphic-oriented desktop.
|
||||
确实,GNOME和Cinnamon能提供出不错的视图,但是它们的实用性受限于它们需要显示屏大小的事实和会与主要的图形化桌面发生冲突的KDE的内容书面列表。
|
||||
|
||||
A less distracting solution might be mouseover thumbnails large enough for those with normal vision to see exactly what is on each workspace.
|
||||
|
||||
@ -71,7 +71,7 @@ For years, Stardock Systems has been selling a Windows extension called [Fences]
|
||||
|
||||
In other words, fences automate the sort of arrangements that users make on their desktop all the time. Yet aside from one or two minor functions they share with KDE's Folder Views, fences remain completely unknown on Linux desktops. Perhaps the reason is that designers are focused on mobile devices as the source of ideas, and fences are decidedly a feature of the traditional workstation desktop.
|
||||
|
||||
### Personalized Lists
|
||||
### 个性化列表
|
||||
|
||||
As I made this list, what struck me was how few of the improvements were general. Several of these improvement would appeal largely to specific audiences, and only one even implies the porting of a proprietary application. At least one is cosmetic rather than functional.
|
||||
|
||||
@ -85,7 +85,7 @@ All of which raises the question: what other improvements do you think would ben
|
||||
|
||||
via: http://www.datamation.com/open-source/7-improvements-the-linux-desktop-needs-1.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
shaohaolin translating
|
||||
Can Ubuntu Do This? — Answers to The 4 Questions New Users Ask Most
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
Upstream and Downstream: why packaging takes time
|
||||
================================================================================
|
||||
Here in the KDE office in Barcelona some people spend their time on purely upstream KDE projects and some of us are primarily interested in making distros work which mean our users can get all the stuff we make. I've been asked why we don't just automate the packaging and go and do more productive things. One view of making on a distro like Kubuntu is that its just a way to package up the hard work done by others to take all the credit. I don't deny that, but there's quite a lot to the packaging of all that hard work, for a start there's a lot of it these days.
|
||||
|
||||
@ -1,41 +0,0 @@
|
||||
Linus Torvalds Started a Revolution on August 25, 1991. Happy Birthday, Linux!
|
||||
================================================================================
|
||||

|
||||
Linus Torvalds
|
||||
|
||||
**The Linux project has just turned 23 and it's now the biggest collaborative endeavor in the world, with thousands of people working on it.**
|
||||
|
||||
Back in 1991, a young programmer called Linus Torvalds wanted to make a free operating system that wasn't going to be as big as the GNU project and that was just a hobby. He started something that would turn out to be the most successful operating system on the planet, but no one would have been able to guess it back then.
|
||||
|
||||
Linus Torvalds sent an email on August 25, 1991, asking for help in testing his new operating system. Things haven't changed all that much in the meantime and he still sends emails about new Linux releases, although back then it wasn't called like that.
|
||||
|
||||
"I'm doing a (free) operating system (just a hobby, won't be big and professional like gnu) for 386(486) AT clones. This has been brewing since april, and is starting to get ready. I'd like any feedback on things people like/dislike in minix, as my OS resembles it somewhat (same physical layout of the file-system (due to practical reasons) among other things). I've currently ported bash(1.08) and gcc(1.40), and things seem to work."
|
||||
|
||||
"This implies that I'll get something practical within a few months, and I'd like to know what features most people would want. Any suggestions are welcome, but I won't promise I'll implement them :-) PS. Yes - it's free of any minix code, and it has a multi-threaded fs. It is NOT protable (uses 386 task switching etc), and it probably never will support anything other than AT-harddisks, as that's all I have :-(. " [wrote][1] Linus Torvalds.
|
||||
|
||||
This is the entire mails that started it all, although it's interesting to see how things have evolved since then. The Linux operating system caught on, especially on the server market, but the power of Linux also extended in other areas.
|
||||
|
||||
In fact, it's hard to find any technology that hasn't been influenced by a Linus OS. Phones, TVs, fridges, minicomputers, consoles, tablets, and basically everything that has a chip in it is capable of running Linux or it already has some sort of Linux-based OS installed on it.
|
||||
|
||||
Linux is omnipresent on billions of devices and its influence is growing each year on an exponential basis. You might think that Linus is also the wealthiest man on the planet, but remember, Linux is free software and anyone can use it, modify it, and make money of it. He didn't do it for the money.
|
||||
|
||||
Linus Torvalds started a revolution in 1991, but it hasn't ended. In fact, you could say that it's just getting started.
|
||||
|
||||
> Happy Anniversary, Linux! Please join us in celebrating 23 years of the free OS that has changed the world. [pic.twitter.com/mTVApV85gD][2]
|
||||
>
|
||||
> — The Linux Foundation (@linuxfoundation) [August 25, 2014][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Started-a-Revolution-on-August-25-1991-Happy-Birthday-Linux-456212.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[2]:http://t.co/mTVApV85gD
|
||||
[3]:https://twitter.com/linuxfoundation/statuses/503799441900314624
|
||||
@ -1,86 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Why Do Some Old Programming Languages Never Die?
|
||||
================================================================================
|
||||
> We like what we already know.
|
||||
|
||||

|
||||
|
||||
Many of today’s most well-known programming languages are old enough to vote. PHP is 20. Python is 23. HTML is 21. Ruby and JavaScript are 19. C is a whopping 42 years old.
|
||||
|
||||
Nobody could have predicted this. Not even computer scientist [Brian Kernighan][1], co-author of the very first book on C, which is still being printed today. (The language itself was the work of Kernighan's [co-author Dennis Ritchie][2], who passed away in 2011.)
|
||||
|
||||
“I dimly recall a conversation early on with the editors, telling them that we’d sell something like 5,000 copies of the book,” Kernighan told me in a recent interview. “We managed to do better than that. I didn’t think students would still be using a version of it as a textbook in 2014.”
|
||||
|
||||
What’s especially remarkable about C's persistence is that Google developed a new language, Go, specifically to more efficiently solve the problems C solves now. Still, it’s hard for Kernighan to imagine something like Go outright killing C no matter how good it is.
|
||||
|
||||
“Most languages don’t die—or at least once they get to a certain level of acceptance they don’t die," he said. "C still solves certain problems better than anything else, so it sticks around.”
|
||||
|
||||
### Write What You Know ###
|
||||
|
||||
Why do some computer languages become more successful than others? Because developers choose to use them. That’s logical enough, but it gets tricky when you want to figure out why developers choose to use the languages they do.
|
||||
|
||||
Ari Rabkin and Leo Meyerovich are researchers from, respectively, Princeton and the University of California at Berkeley who devoted two years to answering just that question. Their resulting paper, [Empirical Analysis of Programming Language Adoption][3], describes their analysis of more than 200,000 Sourceforge projects and polling of more than 13,000 programmers.
|
||||
|
||||
Their main finding? Most of the time programmers choose programming languages they know.
|
||||
|
||||
“There are languages we use because we’ve always used them,” Rabkin told me. “For example, astronomers historically use IDL [Interactive Data Language] for their computer programs, not because it has special features for stars or anything, but because it has tremendous inertia. They have good programs they’ve built with it that they want to keep.”
|
||||
|
||||
In other words, it’s partly thanks to name recognition that established languages retain monumental staying power. Of course, that doesn’t mean popular languages don’t change. Rabkin noted that the C we use today is nothing like the language Kernighan first wrote about, which probably wouldn’t be fully compatible with a modern C compiler.
|
||||
|
||||
“There’s an old, relevant joke in which an engineer is asked which language he thinks people will be using in 30 years and he says, ‘I don’t know, but it’ll be called Fortran’,” Rabkin said. “Long-lived languages are not the same as how they were when they were designed in the '70s and '80s. People have mostly added things instead of removed because that doesn’t break backwards compatibility, but many features have been fixed.”
|
||||
|
||||
This backwards compatibility means that not only can programmers continue to use languages as they update programs, they also don’t need to go back and rewrite the oldest sections. That older ‘legacy code’ keeps languages around forever, but at a cost. As long as it’s there, people’s beliefs about a language will stick around, too.
|
||||
|
||||
### PHP: A Case Study Of A Long-Lived Language ###
|
||||
|
||||
Legacy code refers to programs—or portions of programs—written in outdated source code. Think, for instance, of key programming functions for a business or engineering project that are written in a language that no one supports. They still carry out their original purpose and are too difficult or expensive to rewrite in modern code, so they stick around, forcing programmers to turn handsprings to ensure they keep working even as other code changes around them.
|
||||
|
||||
Any language that's been around more than a few years has a legacy-code problem of some sort, and PHP is no exception. PHP is an interesting example because its legacy code is distinctly different from its modern code, in what proponents say—and critics admit—is a huge improvement.
|
||||
|
||||
Andi Gutmans is a co-inventor of the Zend Engine, the compiler that became standard by the time PHP4 came around. Gutmans said he and his partner originally wanted to improve PHP3, and were so successful that the original PHP inventor, Rasmus Lerdorf, joined their project. The result was a compiler for PHP4 and its successor, PHP5.
|
||||
|
||||
As a consequence, the PHP of today is quite different from its progenitor, the original PHP. Yet in Gutmans' view, the base of legacy code written in older PHP versions keeps alive old prejudices against the language—such as the notion that PHP is riddled with security holes, or that it can't "scale" to handle large computing tasks.
|
||||
|
||||
"People who criticize PHP are usually criticizing where it was in 1998,” he says. “These people are not up-to-date with where it is today. PHP today is a very mature ecosystem.”
|
||||
|
||||
Today, Gutmans says, the most important thing for him as a steward is to encouraging people to keep updating to the latest versions. “PHP is a big enough community now that you have big legacy code bases," he says. "But generally speaking, most of our communities are on PHP5.3 at minimum.”
|
||||
|
||||
The issue is that users never fully upgrade to the latest version of any language. It’s why many Python users are still using Python 2, released in 2000, instead of Python 3, released in 2008. Even after six years major users like Google still aren’t upgrading. There are a variety of reasons for this, but it made many developers wary about taking the plunge.
|
||||
|
||||
“Nothing ever dies," Rabkin says. "Any language with legacy code will last forever. Rewrites are expensive and if it’s not broke don’t fix it.”
|
||||
|
||||
### Developer Brains As Scarce Resources ###
|
||||
|
||||
Of course, developers aren’t choosing these languages merely to maintain pesky legacy code. Rabkin and Meyerovich found that when it comes to language preference, age is just a number. As Rabkin told me:
|
||||
|
||||
> A thing that really shocked us and that I think is important is that we grouped people by age and asked them how many languages they know. Our intuition was that it would gradually rise over time; it doesn’t. Twenty-five-year-olds and 45-year-olds all know about the same number of languages. This was constant through several rewordings of the question. Your chance of knowing a given language does not vary with your age.
|
||||
|
||||
In other words, it’s not just old developers who cling to the classics; young programmers are also discovering and adopting old languages for the first time. That could be because the languages have interesting libraries and features, or because the communities these developers are a part of have adopted the language as a group.
|
||||
|
||||
“There’s a fixed amount of programmer attention in the world,” said Rabkin. “If a language delivers enough distinctive value, people will learn it and use it. If the people you exchange code and knowledge with you share a language, you’ll want to learn it. So for example, as long as those libraries are Python libraries and community expertise is Python experience, Python will do well.”
|
||||
|
||||
Communities are a huge factor in how languages do, the researchers discovered. While there's not much difference between high level languages like Python and Ruby, for example, programmers are prone to develop strong feelings about the superiority of one over the other.
|
||||
|
||||
“Rails didn’t have to be written in Ruby, but since it was, it proves there were social factors at work,” Rabkin says. “For example, the thing that resurrected Objective-C is that the Apple engineering team said, ‘Let’s use this.’ They didn’t have to pick it.”
|
||||
|
||||
Through social influence and legacy code, our oldest and most popular computer languages have powerful inertia. How could Go surpass C? If the right people and companies say it ought to.
|
||||
|
||||
“It comes down to who is better at evangelizing a language,” says Rabkin.
|
||||
|
||||
Lead image by [Blake Patterson][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/09/02/programming-language-coding-lifetime
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:http://en.wikipedia.org/wiki/Brian_Kernighan
|
||||
[2]:http://en.wikipedia.org/wiki/Dennis_Ritchie
|
||||
[3]:http://asrabkin.bitbucket.org/papers/oopsla13.pdf
|
||||
[4]:https://www.flickr.com/photos/blakespot/2444037775/
|
||||
@ -1,3 +1,5 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
10 Open Source Cloning Software For Linux Users
|
||||
================================================================================
|
||||
> These cloning software take all disk data, convert them into a single .img file and you can copy it to another hard drive.
|
||||
@ -84,4 +86,4 @@ via: http://www.efytimes.com/e1/fullnews.asp?edid=148039
|
||||
[7]:http://doclone.nongnu.org/
|
||||
[8]:http://www.macrium.com/reflectfree.aspx
|
||||
[9]:http://www.runtime.org/driveimage-xml.htm
|
||||
[10]:http://www.paragon-software.com/home/br-free/
|
||||
[10]:http://www.paragon-software.com/home/br-free/
|
||||
|
||||
@ -1,108 +0,0 @@
|
||||
barney-ro translating
|
||||
|
||||
ChromeOS vs Linux: The Good, the Bad and the Ugly
|
||||
ChromeOS 对战 Linux : 孰优孰劣 仁者见仁 智者见智
|
||||
================================================================================
|
||||
> In the battle between ChromeOS and Linux, both desktop environments have strengths and weaknesses.
|
||||
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,不管是哪一家的操作系统都是有优有劣。
|
||||
|
||||
Anyone who believes Google isn't "making a play" for desktop users isn't paying attention. In recent years, I've seen [ChromeOS][1] making quite a splash on the [Google Chromebook][2]. Exploding with popularity on sites such as Amazon.com, it looks as if ChromeOS could be unstoppable.
|
||||
|
||||
任何不关注Google的人都不会相信Google在桌面用户当中扮演这一个很重要的角色。在近几年,我们见到的[ChromeOS][1]制造的[Google Chromebook][2]相当的轰动。和同期的人气火爆的Amazon一样,似乎ChromeOS势不可挡。
|
||||
|
||||
In this article, I'm going to look at ChromeOS as a concept to market, how it's affecting Linux adoption and whether or not it's a good/bad thing for the Linux community as a whole. Plus, I'll talk about the biggest issue of all and how no one is doing anything about it.
|
||||
|
||||
在本文中,我们要了解的是ChromeOS概念的市场,ChromeOS怎么影响着Linux的使用,和整个 ChromeOS 对于一个社区来说,是好事还是坏事。另外,我将会谈到一些重大的事情,和为什么没人去为他做点什么事情。
|
||||
|
||||
### ChromeOS isn't really Linux ###
|
||||
|
||||
### ChromeOS 并不是真正的Linux ###
|
||||
|
||||
When folks ask me if ChromeOS is a Linux distribution, I usually reply that ChromeOS is to Linux what OS X is to BSD. In other words, I consider ChromeOS to be a forked operating system that uses the Linux kernel under the hood. Much of the operating system is made up of Google's own proprietary blend of code and software.
|
||||
|
||||
每当有朋友问我说是否ChromeOS 是否是Linux 的一个分支时,我都会这样回答:ChromeOS 对于Linux 就好像是 OS X 对于BSD 。换句话说,我认为,ChromeOS 是一个派生的操作系统,运行于Linux 内核的引擎之下。很多操作系统就组成了Google 的专利代码和软件。
|
||||
|
||||
So while the ChromeOS is using the Linux kernel under its hood, it's still very different from what we might find with today's modern Linux distributions.
|
||||
|
||||
尽管ChromeOS 是利用了Linux 内核引擎,但是它仍然有很大的不同和现在流行的Linux分支版本。
|
||||
|
||||
Where ChromeOS's difference becomes most apparent, however, is in the apps it offers the end user: Web applications. With everything being launched from a browser window, Linux users might find using ChromeOS to be a bit vanilla. But for non-Linux users, the experience is not all that different than what they may have used on their old PCs.
|
||||
|
||||
ChromeOS和它们最大的不同就在于它给终端用户提供的app,包括Web 应用。因为ChromeOS 每一个操作都是开始于浏览器窗口,对于Linux 用户来说,可能会有很多不一样的感受,但是,对于没有Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
For example: Anyone who is living a Google-centric lifestyle on Windows will feel right at home on ChromeOS. Odds are this individual is already relying on the Chrome browser, Google Drive and Gmail. By extension, moving over to ChromeOS feels fairly natural for these folks, as they're simply using the browser they're already used to.
|
||||
|
||||
就是说,每一个以Google-centric为生活方式的人来说,当他们回到家时在ChromeOS上的感觉将会非常良好。这样的优势就是这个人已经接受了Chrome 浏览器,Google 驱动器和Gmail 。久而久之,他们的亲朋好友也都对ChromeOs有了好感,就好像是他们很容易接受Chrome 流浪器,因为他们早已经用过。
|
||||
|
||||
Linux enthusiasts, however, tend to feel constrained almost immediately. Software choices feel limited and boxed in, plus games and VoIP are totally out of the question. Sorry, but [GooglePlus Hangouts][3] isn't a replacement for [VoIP][4] software. Not even by a long shot.
|
||||
|
||||
然而,对于Linux 爱好者来说,这样就立即带来了不适应。软件的选择是受限制的,盒装的,在加上游戏和VoIP 是完全不可能的。对不起,因为[GooglePlus Hangouts][3]是代替不了VoIP 软件的。甚至在很长的一段时间里。
|
||||
|
||||
### ChromeOS or Linux on the desktop ###
|
||||
|
||||
### ChromeOS 和Linux 的桌面化 ###
|
||||
Anyone making the claim that ChromeOS hurts Linux adoption on the desktop needs to come up for air and meet non-technical users sometime.
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统中对Linux 产生影响,只有在Linux 停下来浮出水面换气的时候或者是满足某个非技术用户的时候。
|
||||
|
||||
Yes, desktop Linux is absolutely fine for most casual computer users. However it helps to have someone to install the OS and offer "maintenance" services like we see in the Windows and OS X camps. Sadly Linux lacks this here in the States, which is where I see ChromeOS coming into play.
|
||||
|
||||
是的,桌面Linux 对于大多数休闲型的用户来说绝对是一个好东西。它有助于有专人安装操作系统,并且提供“维修”服务,从windows 和 OS X 的阵营来看。但是,令人失望的是,在美国Linux 正好在这个方面很缺乏。所以,我们看到,ChromeOS 慢慢的走入我们的视线。
|
||||
|
||||
I've found the Linux desktop is best suited for environments where on-site tech support can manage things on the down-low. Examples include: Homes where advanced users can drop by and handle updates, governments and schools with IT departments. These are environments where Linux on the desktop is set up to be used by users of any skill level or background.
|
||||
|
||||
By contrast, ChromeOS is built to be completely maintenance free, thus not requiring any third part assistance short of turning it on and allowing updates to do the magic behind the scenes. This is partly made possible due to the ChromeOS being designed for specific hardware builds, in a similar spirit to how Apple develops their own computers. Because Google has a pulse on the hardware ChromeOS is bundled with, it allows for a generally error free experience. And for some individuals, this is fantastic!
|
||||
|
||||
Comically, the folks who exclaim that there's a problem here are not even remotely the target market for ChromeOS. In short, these are passionate Linux enthusiasts looking for something to gripe about. My advice? Stop inventing problems where none exist.
|
||||
|
||||
The point is: the market share for ChromeOS and Linux on the desktop are not even remotely the same. This could change in the future, but at this time, these two groups are largely separate.
|
||||
|
||||
### ChromeOS use is growing ###
|
||||
|
||||
No matter what your view of ChromeOS happens to be, the fact remains that its adoption is growing. New computers built for ChromeOS are being released all the time. One of the most recent ChromeOS computer releases is from Dell. Appropriately named the [Dell Chromebox][5], this desktop ChromeOS appliance is yet another shot at traditional computing. It has zero software DVDs, no anti-malware software, and offfers completely seamless updates behind the scenes. For casual users, Chromeboxes and Chromebooks are becoming a viable option for those who do most of their work from within a web browser.
|
||||
|
||||
Despite this growth, ChromeOS appliances face one huge downside – storage. Bound by limited hard drive size and a heavy reliance on cloud storage, ChromeOS isn't going to cut it for anyone who uses their computers outside of basic web browser functionality.
|
||||
|
||||
### ChromeOS and Linux crossing streams ###
|
||||
|
||||
Previously, I mentioned that ChromeOS and Linux on the desktop are in two completely separate markets. The reason why this is the case stems from the fact that the Linux community has done a horrid job at promoting Linux on the desktop offline.
|
||||
|
||||
Yes, there are occasional events where casual folks might discover this "Linux thing" for the first time. But there isn't a single entity to then follow up with these folks, making sure they’re getting their questions answered and that they're getting the most out of Linux.
|
||||
|
||||
In reality, the likely offline discovery breakdown goes something like this:
|
||||
|
||||
- Casual user finds out Linux from their local Linux event.
|
||||
- They bring the DVD/USB device home and attempt to install the OS.
|
||||
- While some folks very well may have success with the install process, I've been contacted by a number of folks with the opposite experience.
|
||||
- Frustrated, these folks are then expected to "search" online forums for help. Difficult to do on a primary computer experiencing network or video issues.
|
||||
- Completely fed up, some of the above frustrated bring their computers back into a Windows shop for "repair." In addition to Windows being re-installed, they also receive an earful about how "Linux isn't for them" and should be avoided.
|
||||
|
||||
Some of you might charge that the above example is exaggerated. I would respond with this: It's happened to people I know personally and it happens often. Wake up Linux community, our adoption model is broken and tired.
|
||||
|
||||
### Great platforms, horrible marketing and closing thoughts ###
|
||||
|
||||
If there is one thing that I feel ChromeOS and Linux on the desktop have in common...besides the Linux kernel, it's that they both happen to be great products with rotten marketing. The advantage however, goes to Google with this one, due to their ability to spend big money online and reserve shelf space at big box stores.
|
||||
|
||||
Google believes that because they have the "online advantage" that offline efforts aren't really that important. This is incredibly short-sighted and reflects one of Google's biggest missteps. The belief that if you're not exposed to their online efforts, you're not worth bothering with, is only countered by local shelf-space at select big box stores.
|
||||
|
||||
My suggestion is this – offer Linux on the desktop to the ChromeOS market through offline efforts. This means Linux User Groups need to start raising funds to be present at county fairs, mall kiosks during the holiday season and teaching free classes at community centers. This will immediately put Linux on the desktop in front of the same audience that might otherwise end up with a ChromeOS powered appliance.
|
||||
|
||||
If local offline efforts like this don't happen, not to worry. Linux on the desktop will continue to grow as will the ChromeOS market. Sadly though, it will absolutely keep the two markets separate as they are now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -1,3 +1,5 @@
|
||||
barney-ro translating
|
||||
|
||||
What is a good subtitle editor on Linux
|
||||
================================================================================
|
||||
If you watch foreign movies regularly, chances are you prefer having subtitles rather than the dub. Grown up in France, I know that most Disney movies during my childhood sounded weird because of the French dub. If now I have the chance to be able to watch them in their original version, I know that for a lot of people subtitles are still required. And I surprise myself sometimes making subtitles for my family. Hopefully for me, Linux is not devoid of fancy and open source subtitle editors. In short, this is the non-exhaustive list of open source subtitle editors for Linux. Share your opinion on what you think of the best subtitle editor.
|
||||
@ -47,7 +49,7 @@ Which subtitle editor do you use and why? Or is there another one that you prefe
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -61,4 +63,4 @@ via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
(翻译中 by runningwater)
|
||||
Camicri Cube: An Offline And Portable Package Management System
|
||||
================================================================================
|
||||

|
||||
@ -158,7 +159,7 @@ via: http://www.unixmen.com/camicri-cube-offline-portable-package-management-sys
|
||||
|
||||
[SK][a](Senthilkumar, aka SK, is a Linux enthusiast, FOSS Supporter & Linux Consultant from Tamilnadu, India. A passionate and dynamic person, aims to deliver quality content to IT professionals and loves very much to write and explore new things about Linux, Open Source, Computers and Internet.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[runningwater](https://github.com/runningwater) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by haimingfg
|
||||
|
||||
What are useful CLI tools for Linux system admins
|
||||
================================================================================
|
||||
System administrators (sysadmins) are responsible for day-to-day operations of production systems and services. One of the critical roles of sysadmins is to ensure that operational services are available round the clock. For that, they have to carefully plan backup policies, disaster management strategies, scheduled maintenance, security audits, etc. Like every other discipline, sysadmins have their tools of trade. Utilizing proper tools in the right case at the right time can help maintain the health of operating systems with minimal service interruptions and maximum uptime.
|
||||
@ -184,4 +186,4 @@ via: http://xmodulo.com/2014/08/useful-cli-tools-linux-system-admins.html
|
||||
[17]:http://rsync.samba.org/
|
||||
[18]:http://www.nongnu.org/rdiff-backup/
|
||||
[19]:http://nethogs.sourceforge.net/
|
||||
[20]:http://code.google.com/p/inxi/
|
||||
[20]:http://code.google.com/p/inxi/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[bazz2 bazz2 bazz2]
|
||||
20 Postfix Interview Questions & Answers
|
||||
================================================================================
|
||||
### Q:1 What is postfix and default port used for postfix ? ###
|
||||
@ -119,4 +120,4 @@ via: http://www.linuxtechi.com/postfix-interview-questions-answers/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
|
||||
@ -1,209 +0,0 @@
|
||||
How to install and configure ownCloud on Debian
|
||||
================================================================================
|
||||
According to its official website, ownCloud gives you universal access to your files through a web interface or WebDAV. It also provides a platform to easily view, edit and sync your contacts, calendars and bookmarks across all your devices. Even though ownCloud is very similar to the widely-used Dropbox cloud storage, the primary difference is that ownCloud is free and open-source, making it possible to set up a Dropbox-like cloud storage service on your own server. With ownCloud, only you have complete access and control over your private data, with no limits on storage space (except for hard disk capacity) or the number of connected clients.
|
||||
|
||||
ownCloud is available in Community Edition (free of charge) and Enterprise Edition (business-oriented with paid support). The pre-built package of ownCloud Community Edition is available for CentOS, Debian, Fedora openSUSE, SLE and Ubuntu. This tutorial will demonstrate how to install and configure ownCloud Community Edition on Debian Wheezy.
|
||||
|
||||
### Installing ownCloud on Debian ###
|
||||
|
||||
Go to the official website: [http://owncloud.org][1], and click on the 'Install' button (upper right corner).
|
||||
|
||||

|
||||
|
||||
Now choose "Packages for auto updates" for the current version (v7 in the image below). This will allow you to easily keep ownCloud up to date using Debian's package management system, with packages maintained by the ownCloud community.
|
||||
|
||||

|
||||
|
||||
Then click on Continue on the next screen:
|
||||
|
||||

|
||||
|
||||
Select Debian 7 [Wheezy] from the list of available operating systems:
|
||||
|
||||

|
||||
|
||||
Add the ownCloud's official Debian repository:
|
||||
|
||||
# echo 'deb http://download.opensuse.org/repositories/isv:/ownCloud:/community/Debian_7.0/ /' >> /etc/apt/sources.list.d/owncloud.list
|
||||
|
||||
Add the repository key to apt:
|
||||
|
||||
# wget http://download.opensuse.org/repositories/isv:ownCloud:community/Debian_7.0/Release.key
|
||||
# apt-key add - < Release.key
|
||||
|
||||
Go ahead and install ownCloud:
|
||||
|
||||
# aptitude update
|
||||
# aptitude install owncloud
|
||||
|
||||
Open your web browser and navigate to your ownCloud instance, which can be found at http://<server-ip>/owncloud:
|
||||
|
||||

|
||||
|
||||
Note that ownCloud may be alerting about an Apache misconfiguration. Follow the steps below to solve this issue, and get rid of that error message.
|
||||
|
||||
a) Edit the /etc/apache2/apache2.conf file (set the AllowOverride directive to All):
|
||||
|
||||
<Directory /var/www/>
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
b) Edit the /etc/apache2/conf.d/owncloud.conf file
|
||||
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
c) Restart the web server:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
d) Refresh the web browser. Verify that the security warning has disappeared.
|
||||
|
||||

|
||||
|
||||
### Setting up a Database ###
|
||||
|
||||
Now it's time to set up a database for ownCloud.
|
||||
|
||||
First, log in to the local MySQL/MariaDB server:
|
||||
|
||||
$ mysql -u root -h localhost -p
|
||||
|
||||
Create a database and user account for ownCloud as follows.
|
||||
|
||||
mysql> CREATE DATABASE owncloud_DB;
|
||||
mysql> CREATE USER ‘owncloud-web’@'localhost' IDENTIFIED BY ‘whateverpasswordyouchoose’;
|
||||
mysql> GRANT ALL PRIVILEGES ON owncloud_DB.* TO ‘owncloud-web’@'localhost';
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
Go to ownCloud page at http://<server-ip>/owncloud, and choose the 'Storage & database' section. Enter the rest of the requested information (MySQL/MariaDB user, password, database and hostname), and click on Finish setup.
|
||||
|
||||

|
||||
|
||||
### Configuring ownCloud for SSL Connections ###
|
||||
|
||||
Before you start using ownCloud, it is strongly recommended to enable SSL support in ownCloud. Using SSL provides important security benefits such as encrypting ownCloud traffic and providing proper authentication. In this tutorial, a self-signed certificate will be used for SSL.
|
||||
|
||||
Create a new directory where we will store the server key and certificate:
|
||||
|
||||
# mkdir /etc/apache2/ssl
|
||||
|
||||
Create a certificate (and the key that will protect it) which will remain valid for one year.
|
||||
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/apache2/ssl/apache.key -out /etc/apache2/ssl/apache.crt
|
||||
|
||||

|
||||
|
||||
Edit the /etc/apache2/conf.d/owncloud.conf file to enable HTTPS. For details on the meaning of the rewrite rules NC, R, and L, you can refer to the [Apache docs][2]:
|
||||
|
||||
Alias /owncloud /var/www/owncloud
|
||||
|
||||
<VirtualHost 192.168.0.15:80>
|
||||
RewriteEngine on
|
||||
ReWriteCond %{SERVER_PORT} !^443$
|
||||
RewriteRule ^/(.*) https://%{HTTP_HOST}/$1 [NC,R,L]
|
||||
</VirtualHost>
|
||||
|
||||
<VirtualHost 192.168.0.15:443>
|
||||
SSLEngine on
|
||||
SSLCertificateFile /etc/apache2/ssl/apache.crt
|
||||
SSLCertificateKeyFile /etc/apache2/ssl/apache.key
|
||||
DocumentRoot /var/www/owncloud/
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Enable the rewrite module and restart Apache:
|
||||
|
||||
# a2enmod rewrite
|
||||
# service apache2 restart
|
||||
|
||||
Open your ownCloud instance. Notice that even if you try to use plain HTTP, you will be automatically redirected to HTTPS.
|
||||
|
||||
Be advised that even having followed the above steps, the first time that you launch your ownCloud instance, an error message will be displayed stating that the certificate has not been issued by a trusted authority (that is because we created a self-signed certificate). You can safely ignore this message, but if you are considering deploying ownCloud in a production server, you may want to purchase a certificate from a trusted company.
|
||||
|
||||
### Create an Account ###
|
||||
|
||||
Now we are ready to create an ownCloud admin account.
|
||||
|
||||

|
||||
|
||||
Welcome to your new personal cloud! Note that you can install a desktop or mobile client app to sync your files, calendars, contacts and more.
|
||||
|
||||

|
||||
|
||||
In the upper right corner, click on your user name, and a drop-down menu is displayed:
|
||||
|
||||
|
||||
|
||||
Click on Personal to change your settings, such as password, display name, email address, profile picture, and more.
|
||||
|
||||
### ownCloud Use Case: Access Calendar ###
|
||||
|
||||
Let's start by adding an event to your calendar and later downloading it.
|
||||
|
||||
Click on the upper left corner drop-down menu and choose Calendar.
|
||||
|
||||

|
||||
|
||||
Add a new event and save it to your calendar.
|
||||
|
||||

|
||||
|
||||
Download your calendar and add it to your Thunderbird calendar by going to 'Event and Tasks' -> 'Import...' -> 'Select file':
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
TIP: You also need to set your time zone in order to successfully import your calendar in another application (by default, the Calendar application uses the UTC +00:00 time zone). To change the time zone, go to the bottom left corner and click on the small gear icon. The Calendar settings menu will appear and you will be able to select your time zone:
|
||||
|
||||

|
||||
|
||||
### ownCloud Use Case: Upload a File ###
|
||||
|
||||
Next, we will upload a file from the client computer.
|
||||
|
||||
Go to the Files menu (upper left corner) and click on the up arrow to open a select-file dialog.
|
||||
|
||||

|
||||
|
||||
Select a file and click on Open.
|
||||
|
||||

|
||||
|
||||
You can then open/edit the selected file, move it into another folder, or delete it.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
ownCloud is a versatile and powerful cloud storage that makes the transition from another provider quick, easy, and painless. In addition, it is FOSS, and with little time and effort you can configure it to meet all your needs. For further information, you can always refer to the [User][3], [Admin][4], or [Developer][5] manuals.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-configure-owncloud-debian.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.gabrielcanepa.com.ar/
|
||||
[1]:http://owncloud.org/
|
||||
[2]:http://httpd.apache.org/docs/2.2/rewrite/flags.html
|
||||
[3]:http://doc.owncloud.org/server/7.0/ownCloudUserManual.pdf
|
||||
[4]:http://doc.owncloud.org/server/7.0/ownCloudAdminManual.pdf
|
||||
[5]:http://doc.owncloud.org/server/7.0/ownCloudDeveloperManual.pdf
|
||||
@ -1,158 +0,0 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
How to create a cloud-based encrypted file system on Linux
|
||||
================================================================================
|
||||
Commercial cloud storage services such as [Amazon S3][1] and [Google Cloud Storage][2] offer highly available, scalable, infinite-capacity object store at affordable costs. To accelerate wide adoption of their cloud offerings, these providers are fostering rich developer ecosystems around their products based on well-defined APIs and SDKs. Cloud-backed file systems are one popular by-product of such active developer communities, for which several open-source implementations exist.
|
||||
|
||||
[S3QL][3] is one of the most popular open-source cloud-based file systems. It is a FUSE-based file system backed by several commercial or open-source cloud storages, such as Amazon S3, Google Cloud Storage, Rackspace CloudFiles, or OpenStack. As a full featured file system, S3QL boasts of a number of powerful capabilities, such as unlimited capacity, up to 2TB file sizes, compression, UNIX attributes, encryption, snapshots with copy-on-write, immutable trees, de-duplication, hardlink/symlink support, etc. Any bytes written to an S3QL file system are compressed/encrypted locally before being transmitted to cloud backend. When you attempt to read contents stored in an S3QL file system, the corresponding objects are downloaded from cloud (if not in the local cache), and decrypted/uncompressed on the fly.
|
||||
|
||||
To be clear, S3QL does have limitations. For example, you cannot mount the same S3FS file system on several computers simultaneously, but only once at a time. Also, no ACL (access control list) support is available.
|
||||
|
||||
In this tutorial, I am going to describe **how to set up an encrypted file system on top of Amazon S3, using S3QL**. As an example use case, I will also demonstrate how to run rsync backup tool on top of a mounted S3QL file system.
|
||||
|
||||
### Preparation ###
|
||||
|
||||
To use this tutorial, you will need to create an [Amazon AWS account][4] (sign up is free, but requires a valid credit card).
|
||||
|
||||
If you haven't done so, first [create an AWS access key][4] (access key ID and secret access key) which is needed to authorize S3QL to access your AWS account.
|
||||
|
||||
Now, go to AWS S3 via AWS management console, and create a new empty bucket for S3QL.
|
||||
|
||||
|
||||
|
||||
For best performance, choose a region which is geographically closest to you.
|
||||
|
||||
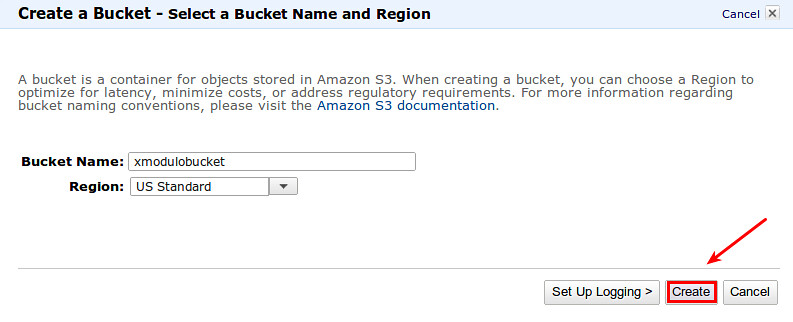
|
||||
|
||||
### Install S3QL on Linux ###
|
||||
|
||||
S3QL is available as a pre-built package on most Linux distros.
|
||||
|
||||
#### On Debian, Ubuntu or Linux Mint: ####
|
||||
|
||||
$ sudo apt-get install s3ql
|
||||
|
||||
#### On Fedora: ####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
|
||||
On Arch Linux, use [AUR][6].
|
||||
|
||||
### Configure S3QL for the First Time ###
|
||||
|
||||
Create authinfo2 file in ~/.s3ql directory, which is a default S3QL configuration file. This file contains information about a required AWS access key, S3 bucket name and encryption passphrase. The encryption passphrase is used to encrypt the randomly-generated master encryption key. This master key is then used to encrypt actual S3QL file system data.
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
[s3]
|
||||
storage-url: s3://[bucket-name]
|
||||
backend-login: [your-access-key-id]
|
||||
backend-password: [your-secret-access-key]
|
||||
fs-passphrase: [your-encryption-passphrase]
|
||||
|
||||
The AWS S3 bucket that you specify should be created via AWS management console beforehand.
|
||||
|
||||
Make the authinfo2 file readable to you only for security.
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### Create an S3QL File System ###
|
||||
|
||||
You are now ready to create an S3QL file system on top of AWS S3.
|
||||
|
||||
Use mkfs.s3ql command to create a new S3QL file system. The bucket name you supply with the command should be matched with the one in authinfo2 file. The "--ssl" option forces you to use SSL to connect to backend storage servers. By default, the mkfs.s3ql command will enable compression and encryption in the S3QL file system.
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
You will be asked to enter an encryption passphrase. Type the same passphrase as you defined in ~/.s3ql/autoinfo2 (under "fs-passphrase").
|
||||
|
||||
If a new file system was created successfully, you will see the following output.
|
||||
|
||||
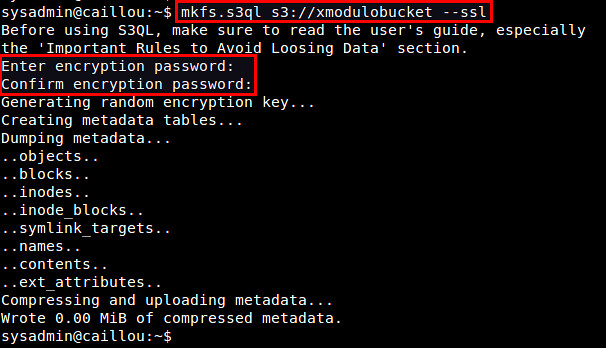
|
||||
|
||||
### Mount an S3QL File System ###
|
||||
|
||||
Once you created an S3QL file system, the next step is to mount it.
|
||||
|
||||
First, create a local mount point, and then use mount.s3ql command to mount an S3QL file system.
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
You do not need privileged access to mount an S3QL file system. Just make sure that you have write access to the local mount point.
|
||||
|
||||
Optionally, you can specify a compression algorithm to use (e.g., lzma, bzip2, zlib) with "--compress" option. Without it, lzma algorithm is used by default. Note that when you specify a custom compression algorithm, it will apply to newly created data objects, not existing ones.
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
For performance reason, an S3QL file system maintains a local file cache, which stores recently accessed (partial or full) files. You can customize the file cache size using "--cachesize" and "--max-cache-entries" options.
|
||||
|
||||
To allow other users than you to access a mounted S3QL file system, use "--allow-other" option.
|
||||
|
||||
If you want to export a mounted S3QL file system to other machines over NFS, use "--nfs" option.
|
||||
|
||||
After running mount.s3ql, check if the S3QL file system is successfully mounted:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||
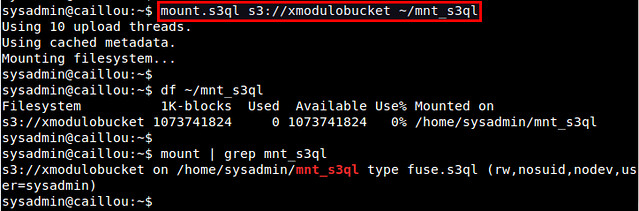
|
||||
|
||||
### Unmount an S3QL File System ###
|
||||
|
||||
To unmount an S3QL file system (with potentially uncommitted data) safely, use umount.s3ql command. It will wait until all data (including the one in local file system cache) has been successfully transferred and written to backend servers. Depending on the amount of write-pending data, this process can take some time.
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
View S3QL File System Statistics and Repair an S3QL File System
|
||||
|
||||
To view S3QL file system statistics, you can use s3qlstat command, which shows information such as total data/metadata size, de-duplication and compression ratio.
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||
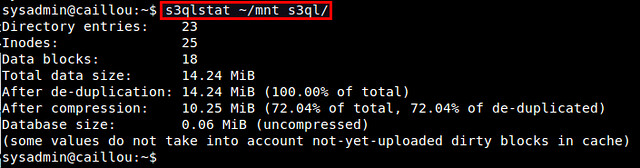
|
||||
|
||||
You can check and repair an S3QL file system with fsck.s3ql command. Similar to fsck command, the file system being checked needs to be unmounted first.
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL Use Case: Rsync Backup ###
|
||||
|
||||
Let me conclude this tutorial with one popular use case of S3QL: local file system backup. For this, I recommend using rsync incremental backup tool especially because S3QL comes with a rsync wrapper script (/usr/lib/s3ql/pcp.py). This script allows you to recursively copy a source tree to a S3QL destination using multiple rsync processes.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||
|
||||
|
||||
The following command will back up everything in ~/Documents to an S3QL file system via four concurrent rsync connections.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
The files will first be copied to the local file cache, and then gradually flushed to the backend servers over time in the background.
|
||||
|
||||
For more information about S3QL such as automatic mounting, snapshotting, immuntable trees, I strongly recommend checking out the [official user's guide][7]. Let me know what you think of S3QL. Share your experience with any other tools.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://aws.amazon.com/s3
|
||||
[2]:http://code.google.com/apis/storage/
|
||||
[3]:https://bitbucket.org/nikratio/s3ql/
|
||||
[4]:http://aws.amazon.com/
|
||||
[5]:http://ask.xmodulo.com/create-amazon-aws-access-key.html
|
||||
[6]:https://aur.archlinux.org/packages/s3ql/
|
||||
[7]:http://www.rath.org/s3ql-docs/
|
||||
@ -1,155 +0,0 @@
|
||||
How to monitor server memory usage with Nagios Remote Plugin Executor (NRPE)
|
||||
================================================================================
|
||||
In a [previous tutorial][1]注:此篇文章在同一个更新中,如果也翻译了,发布的时候可修改相应的链接, we have seen how we can set up Nagios Remote Plugin Executor (NRPE) in an existing Nagios setup. However, the scripts and plugins needed to monitor memory usage do not come with stock Nagios. In this tutorial, we will see how we can configure NRPE to monitor RAM usage of a remote server.
|
||||
|
||||
The script that we will use for monitoring RAM is available at [Nagios Exchange][2], as well as the creators' [Github repository][3].
|
||||
|
||||
Assuming that NRPE has already been set up, we start the process by downloading the script in the server that we want to monitor.
|
||||
|
||||
### Preparing Remote Servers ###
|
||||
|
||||
#### On Debain/Ubuntu: ####
|
||||
|
||||
# cd /usr/lib/nagios/plugins/
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
#### On RHEL/CentOS: ####
|
||||
|
||||
# cd /usr/lib64/nagios/plugins/ (or /usr/lib/nagios/plugins/ for 32-bit)
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
You can check whether the script generates output properly by manually running the following command on localhost. When used with NRPE, this command is supposed to check free memory, warn when free memory is less than 20%, and generate critical alarm when free memory is less than 10%.
|
||||
|
||||
# ./check_mem -f -w 20 -c 10
|
||||
|
||||
----------
|
||||
|
||||
OK - 34.0% (2735744 kB) free.|TOTAL=8035340KB;;;; USED=5299596KB;6428272;7231806;; FREE=2735744KB;;;; CACHES=2703504KB;;;;
|
||||
|
||||
If you see something like the above as an output, that means the command is working okay.
|
||||
|
||||
Now that the script is ready, we define the command to check RAM usage for NRPE. As mentioned before, the command will check free memory, warn when free memory is less than 20%, and generate critical alarm when free memory is less than 10%.
|
||||
|
||||
# vim /etc/nagios/nrpe.cfg
|
||||
|
||||
#### For Debian/Ubuntu: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### For RHEL/CentOS 32 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### For RHEL/CentOS 64 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib64/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
### Preparing Nagios Server ###
|
||||
|
||||
In the Nagios server, we define a custom command for NRPE. The command can be stored in any directory within Nagios. To keep the tutorial simple, we will put the command definition in /etc/nagios directory.
|
||||
|
||||
#### For Debian/Ubuntu: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
#### For RHEL/CentOS 32 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
#### For RHEL/CentOS 64 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib64/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
Now we define the service check in Nagios.
|
||||
|
||||
#### On Debian/Ubuntu: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
#### On RHEL/CentOS: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
Finally, we restart the Nagios service.
|
||||
|
||||
#### On Debian/Ubuntu: ####
|
||||
|
||||
# service nagios3 restart
|
||||
|
||||
#### On RHEL/CentOS 6: ####
|
||||
|
||||
# service nagios restart
|
||||
|
||||
#### On RHEL/CentOS 7: ####
|
||||
|
||||
# systemctl restart nagios.service
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
Nagios should start checking RAM usage of a remote-server using NRPE. If you are having any problem, you could check the following.
|
||||
|
||||
|
||||
- Make sure that NRPE port is allowed all the way to the remote host. Default NRPE port is TCP 5666.
|
||||
- You could try manually checking NRPE operation by executing the check_nrpe command: /usr/lib/nagios/plugins/check_nrpe -H remote-server
|
||||
- You could also try to run the check_mem command manually: /usr/lib/nagios/plugins/check_nrpe -H remote-server –c check_mem
|
||||
- In the remote server, set debug=1 in /etc/nagios/nrpe.cfg. Restart the NRPE service and check the log file /var/log/messages (RHEL/CentOS) or /var/log/syslog (Debain/Ubuntu). The log files should contain relevant information if there is any configuration or permission errors. If there are not hits in the log, it is very likely that the requests are not reaching the remote server due to port filtering at some point.
|
||||
|
||||
To sum up, this tutorial demonstrated how we can easily tune NRPE to monitor RAM usage of remote servers. The process is as simple as downloading the script, defining the commands, and restarting the services. Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/monitor-server-memory-usage-nagios-remote-plugin-executor.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/2014/03/nagios-remote-plugin-executor-nrpe-linux.html
|
||||
[2]:http://exchange.nagios.org/directory/Plugins/Operating-Systems/Solaris/check_mem-2Epl/details
|
||||
[3]:https://github.com/justintime/nagios-plugins/blob/master/check_mem/check_mem.pl
|
||||
@ -1,125 +0,0 @@
|
||||
translating by cvsher
|
||||
Sysstat – All-in-One System Performance and Usage Activity Monitoring Tool For Linux
|
||||
================================================================================
|
||||
**Sysstat** is really a handy tool which comes with number of utilities to monitor system resources, their performance and usage activities. Number of utilities that we all use in our daily bases comes with sysstat package. It also provide the tool which can be scheduled using cron to collect all performance and activity data.
|
||||
|
||||

|
||||
|
||||
Install Sysstat in Linux
|
||||
|
||||
Following are the list of tools included in sysstat packages.
|
||||
|
||||
### Sysstat Features ###
|
||||
|
||||
- [**iostat**][1]: Reports all statistics about your CPU and I/O statistics for I/O devices.
|
||||
- **mpstat**: Details about CPUs (individual or combined).
|
||||
- **pidstat**: Statistics about running processes/task, CPU, memory etc.
|
||||
- **sar**: Save and report details about different resources (CPU, Memory, IO, Network, kernel etc..).
|
||||
- **sadc**: System activity data collector, used for collecting data in backend for sar.
|
||||
- **sa1**: Fetch and store binary data in sadc data file. This is used with sadc.
|
||||
- **sa2**: Summaries daily report to be used with sar.
|
||||
- **Sadf**: Used for displaying data generated by sar in different formats (CSV or XML).
|
||||
- **Sysstat**: Man page for sysstat utility.
|
||||
- **nfsiostat**-sysstat: I/O statistics for NFS.
|
||||
- **cifsiostat**: Statistics for CIFS.
|
||||
|
||||
Recenlty, on 17th of June 2014, **Sysstat 11.0.0** (stable version) has been released with some new interesting features as follows.
|
||||
|
||||
pidstat command has been enhanced with some new options: first is “-R” which will provide information about the policy and task scheduling priority. And second one is “**-G**” which we can search processes with name and to get the list of all matching threads.
|
||||
|
||||
Some new enhancement have been brought to sar, sadc and sadf with regards to the data files: Now data files can be renamed using “**saYYYYMMDD**” instead of “**saDD**” using option **–D** and can be located in directory different from “**/var/log/sa**”. We can define new directory by setting variable “SA_DIR”, which is being used by sa1 and sa2.
|
||||
|
||||
### Installation of Sysstat in Linux ###
|
||||
|
||||
The ‘**Sysstat**‘ package also available to install from default repository as a package in all major Linux distributions. However, the package which is available from the repo is little old and outdated version. So, that’s the reason, we here going to download and install the latest version of sysstat (i.e. version **11.0.0**) from source package.
|
||||
|
||||
First download the latest version of sysstat package using the following link or you may also use **wget** command to download directly on the terminal.
|
||||
|
||||
- [http://sebastien.godard.pagesperso-orange.fr/download.html][2]
|
||||
|
||||
# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.0.0.tar.gz
|
||||
|
||||

|
||||
|
||||
Download Sysstat Package
|
||||
|
||||
Next, extract the downloaded package and go inside that directory to begin compile process.
|
||||
|
||||
# tar -xvf sysstat-11.0.0.tar.gz
|
||||
# cd sysstat-11.0.0/
|
||||
|
||||
Here you will have two options for compilation:
|
||||
|
||||
a). Firstly, you can use **iconfig** (which will give you flexibility for choosing/entering the customized values for each parameters).
|
||||
|
||||
# ./iconfig
|
||||
|
||||

|
||||
|
||||
Sysstat iconfig Command
|
||||
|
||||
b). Secondly, you can use standard **configure** command to define options in single line. You can run **./configure –help command** to get list of different supported options.
|
||||
|
||||
# ./configure --help
|
||||
|
||||

|
||||
|
||||
Sysstat Configure Help
|
||||
|
||||
Here, we are moving ahead with standard option i.e. **./configure** command to compile sysstat package.
|
||||
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
Configure Sysstat in Linux
|
||||
|
||||
After compilation process completes, you will see the output similar to above. Now, verify the sysstat version by running following command.
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
### Updating Sysstat in Linux ###
|
||||
|
||||
By default sysstat use “**/usr/local**” as its prefix directory. So, all binary/utilities will get installed in “**/usr/local/bin**” directory. If you have existing sysstat package installed, then those will be there in “**/usr/bin**”.
|
||||
|
||||
Due to existing sysstat package, you will not get your updated version reflected, because your “**$PATH**” variable don’t have “**/usr/local/bin set**”. So, make sure that “**/usr/local/bin**” exist there in your “$PATH” or set **–prefix** option to “**/usr**” during compilation and remove existing version before starting updating.
|
||||
|
||||
# yum remove sysstat [On RedHat based System]
|
||||
# apt-get remove sysstat [On Debian based System]
|
||||
|
||||
----------
|
||||
|
||||
# ./configure --prefix=/usr
|
||||
# make
|
||||
# make install
|
||||
|
||||
Now again, verify the updated version of systat using same ‘mpstat’ command with option ‘**-V**’.
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
**Reference**: For more information please go through [Sysstat Documentation][3]
|
||||
|
||||
That’s it for now, in my upcoming article, I will show some practical examples and usages of sysstat command, till then stay tuned to updates and don’t forget to add your valuable thoughts about the article at below comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-sysstat-in-linux/
|
||||
|
||||
作者:[Kuldeep Sharma][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/kuldeepsharma47/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[2]:http://sebastien.godard.pagesperso-orange.fr/download.html
|
||||
[3]:http://sebastien.godard.pagesperso-orange.fr/documentation.html
|
||||
@ -1,151 +0,0 @@
|
||||
How to manage configurations in Linux with Puppet and Augeas
|
||||
================================================================================
|
||||
Although [Puppet][1](注:此文原文原文中曾今做过,文件名:“20140808 How to install Puppet server and client on CentOS and RHEL.md”,如果翻译发布过,可修改此链接为发布地址) is a really unique and useful tool, there are situations where you could use a bit of a different approach. Situations like modification of configuration files which are already present on several of your servers and are unique on each one of them at the same time. Folks from Puppet labs realized this as well, and integrated a great tool called [Augeas][2] that is designed exactly for this usage.
|
||||
|
||||
Augeas can be best thought of as filling for the gaps in Puppet's capabilities where an objectspecific resource type (such as the host resource to manipulate /etc/hosts entries) is not yet available. In this howto, you will learn how to use Augeas to ease your configuration file management.
|
||||
|
||||
### What is Augeas? ###
|
||||
|
||||
Augeas is basically a configuration editing tool. It parses configuration files in their native formats and transforms them into a tree. Configuration changes are made by manipulating this tree and saving it back into native config files.
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
We will install and configure the Augeas tool for use with our previously built Puppet server. We will create and test several different configurations with this tool, and learn how to properly use it to manage our system configurations.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
We will need a working Puppet server and client setup. If you don't have it, please follow my previous tutorial.
|
||||
|
||||
Augeas package can be found in our standard CentOS/RHEL repositories. Unfortunately, Puppet uses Augeas ruby wrapper which is only available in the puppetlabs repository (or [EPEL][4]). If you don't have this repository in your system already, add it using following command:
|
||||
|
||||
On CentOS/RHEL 6.5:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabsrelease610.noarch.rpm
|
||||
|
||||
On CentOS/RHEL 7:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabsrelease710.noarch.rpm
|
||||
|
||||
After you have successfully added this repository, install RubyAugeas in your system:
|
||||
|
||||
# yum install rubyaugeas
|
||||
|
||||
Or if you are continuing from my last tutorial, install this package using the Puppet way. Modify your custom_utils class inside of your /etc/puppet/manifests/site.pp to contain "rubyaugeas" inside of the packages array:
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
### Augeas without Puppet ###
|
||||
|
||||
As it was said in the beginning, Augeas is not originally from Puppet Labs, which means we can still use it even without Puppet itself. This approach can be useful for verifying your modifications and ideas before applying them in your Puppet environment. To make this possible, you need to install one additional package in your system. To do so, please execute following command:
|
||||
|
||||
# yum install augeas
|
||||
|
||||
### Puppet Augeas Examples ###
|
||||
|
||||
For demonstration, here are a few example Augeas use cases.
|
||||
|
||||
#### Management of /etc/sudoers file ####
|
||||
|
||||
1. Add sudo rights to wheel group
|
||||
|
||||
This example will show you how to add simple sudo rights for group %wheel in your GNU/Linux system.
|
||||
|
||||
# Install sudo package
|
||||
package { 'sudo':
|
||||
ensure => installed, # ensure sudo package installed
|
||||
}
|
||||
|
||||
# Allow users belonging to wheel group to use sudo
|
||||
augeas { 'sudo_wheel':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
# allow wheel users to use sudo
|
||||
'set spec[user = "%wheel"]/user %wheel',
|
||||
'set spec[user = "%wheel"]/host_group/host ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command/runas_user ALL',
|
||||
]
|
||||
}
|
||||
|
||||
Now let's explain what the code does: **spec** defines the user section in /etc/sudoers, **[user]** defines given user from the array, and all definitions behind slash ( / ) are subparts of this user. So in typical configuration this would be represented as:
|
||||
|
||||
user host_group/host host_group/command host_group/command/runas_user
|
||||
|
||||
Which is translated into this line of /etc/sudoers:
|
||||
|
||||
%wheel ALL = (ALL) ALL
|
||||
|
||||
2. Add command alias
|
||||
|
||||
The following part will show you how to define command alias which you can use inside your sudoers file.
|
||||
|
||||
# Create new alias SERVICES which contains some basic privileged commands
|
||||
augeas { 'sudo_cmdalias':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/name SERVICES",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[1] /sbin/service",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[2] /sbin/chkconfig",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[3] /bin/hostname",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[4] /sbin/shutdown",
|
||||
]
|
||||
}
|
||||
|
||||
Syntax of sudo command aliases is pretty simple: **Cmnd_Alias** defines the section of command aliases, **[alias/name]** binds all to given alias name, /alias/name **SERVICES** defines the actual alias name and alias/command is the array of all the commands that should be part of this alias. The output of this command will be following:
|
||||
|
||||
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
||||
|
||||
For more information about /etc/sudoers, visit the [official documentation][5].
|
||||
|
||||
#### Adding users to a group ####
|
||||
|
||||
To add users to groups using Augeas, you might want to add the new user either after the gid field or after the last user. We'll use group SVN for the sake of this example. This can be achieved by using the following command:
|
||||
|
||||
In Puppet:
|
||||
|
||||
augeas { 'augeas_mod_group:
|
||||
context => '/files/etc/group', # The target file is /etc/group
|
||||
changes => [
|
||||
"ins user after svn/*[self::gid or self::user][last()]",
|
||||
"set svn/user[last()] john",
|
||||
]
|
||||
}
|
||||
|
||||
Using augtool:
|
||||
|
||||
augtool> ins user after /files/etc/group/svn/*[self::gid or self::user][last()] augtool> set /files/etc/group/svn/user[last()] john
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now, you should have a good idea on how to use Augeas in your Puppet projects. Feel free to experiment with it and definitely go through the official Augeas documentation. It will help you get the idea how to use Augeas properly in your own projects, and it will show you how much time you can actually save by using it.
|
||||
|
||||
If you have any questions feel free to post them in the comments and I will do my best to answer them and advise you.
|
||||
|
||||
### Useful Links ###
|
||||
|
||||
- [http://www.watzmann.net/categories/augeas.html][6]: contains a lot of tutorials focused on Augeas usage.
|
||||
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki with a lot of practical examples.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/manage-configurations-linux-puppet-augeas.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
[2]:http://augeas.net/
|
||||
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
||||
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://augeas.net/docs/references/lenses/files/sudoers-aug.html
|
||||
[6]:http://www.watzmann.net/categories/augeas.html
|
||||
[7]:http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas
|
||||
@ -1,112 +0,0 @@
|
||||
Translating by johnhoow...
|
||||
How to Use Systemd Timers
|
||||
================================================================================
|
||||
I was setting up some scripts to run backups recently, and decided I would try to set them up to use [systemd timers][1] rather than the more familiar to me [cron jobs][2].
|
||||
|
||||
As I went about trying to set them up, I had the hardest time, since it seems like the required information is spread around in various places. I wanted to record what I did so firstly, I can remember, but also so that others don’t have to go searching as far and wide as I did.
|
||||
|
||||
There are additional options associated with the each step I mention below, but this is the bare minimum to get started. Look at the man pages for **systemd.service**, **systemd.timer**, and **systemd.target** for all that you can do with them.
|
||||
|
||||
### Running a Single Script ###
|
||||
|
||||
Let’s say you have a script **/usr/local/bin/myscript** that you want to run every hour.
|
||||
|
||||
#### Service File ####
|
||||
|
||||
First, create a service file, and put it wherever it goes on your Linux distribution (on Arch, it is either **/etc/systemd/system/** or **/usr/lib/systemd/system**).
|
||||
|
||||
myscript.service
|
||||
|
||||
[Unit]
|
||||
Description=MyScript
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/usr/local/bin/myscript
|
||||
|
||||
Note that it is important to set the **Type** variable to be “simple”, not “oneshot”. Using “oneshot” makes it so that the script will be run the first time, and then systemd thinks that you don’t want to run it again, and will turn off the timer we make next.
|
||||
|
||||
#### Timer File ####
|
||||
|
||||
Next, create a timer file, and put it also in the same directory as the service file above.
|
||||
|
||||
myscript.timer
|
||||
|
||||
[Unit]
|
||||
Description=Runs myscript every hour
|
||||
|
||||
[Timer]
|
||||
# Time to wait after booting before we run first time
|
||||
OnBootSec=10min
|
||||
# Time between running each consecutive time
|
||||
OnUnitActiveSec=1h
|
||||
Unit=myscript.service
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
#### Enable / Start ####
|
||||
|
||||
Rather than starting / enabling the service file, you use the timer.
|
||||
|
||||
# Start timer, as root
|
||||
systemctl start myscript.timer
|
||||
# Enable timer to start at boot
|
||||
systemctl enable myscript.timer
|
||||
|
||||
### Running Multiple Scripts on the Same Timer ###
|
||||
|
||||
Now let’s say there a bunch of scripts you want to run all at the same time. In this case, you will want make a couple changes on the above formula.
|
||||
|
||||
#### Service Files ####
|
||||
|
||||
Create the service files to run your scripts as I [showed previously][3], but include the following section at the end of each service file.
|
||||
|
||||
[Install]
|
||||
WantedBy=mytimer.target
|
||||
|
||||
If there is any ordering dependency in your service files, be sure you specify it with the **After=something.service** and/or **Before=whatever.service** parameters within the **Description** section.
|
||||
|
||||
Alternatively (and perhaps more simply), create a wrapper script that runs the appropriate commands in the correct order, and use the wrapper in your service file.
|
||||
|
||||
#### Timer File ####
|
||||
|
||||
You only need a single timer file. Create **mytimer.timer**, as I [outlined above][4].
|
||||
|
||||
#### Target File ####
|
||||
|
||||
You can create the target that all these scripts depend upon.
|
||||
|
||||
mytimer.target
|
||||
|
||||
[Unit]
|
||||
Description=Mytimer
|
||||
# Lots more stuff could go here, but it's situational.
|
||||
# Look at systemd.unit man page.
|
||||
|
||||
#### Enable / Start ####
|
||||
|
||||
You need to enable each of the service files, as well as the timer.
|
||||
|
||||
systemctl enable script1.service
|
||||
systemctl enable script2.service
|
||||
...
|
||||
systemctl enable mytimer.timer
|
||||
systemctl start mytimer.service
|
||||
|
||||
Good luck.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#enable--start-1
|
||||
|
||||
作者:Jason Graham
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://fedoraproject.org/wiki/User:Johannbg/QA/Systemd/Systemd.timer
|
||||
[2]:https://en.wikipedia.org/wiki/Cron
|
||||
[3]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#service-file
|
||||
[4]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#timer-file-1
|
||||
@ -1,108 +0,0 @@
|
||||
Git Rebase Tutorial: Going Back in Time with Git Rebase
|
||||
================================================================================
|
||||

|
||||
|
||||
A programmer since the tender age of 10, Christoph Burgdorf is the the founder of the HannoverJS meetup, and he has been an active member in the AngularJS community since its very beginning. He is also very knowledgeable about the ins and outs of git, where he hosts workshops at [thoughtram][1] to help beginners master the technology.
|
||||
|
||||
The following tutorial was originally posted on his [blog][2].
|
||||
|
||||
----------
|
||||
|
||||
### Tutorial: Git Rebase ###
|
||||
|
||||
Imagine you are working on that radical new feature. It’s going to be brilliant but it takes a while. You’ve been working on that for a couple of days now, maybe weeks.
|
||||
|
||||
Your feature branch is already six commits ahead of master. You’ve been a good developer and have crafted meaningful semantical commits. But there’s the thing: you are slowly realizing that this beast will still take some more time before it’s really ready to be merged back into master.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
|
||||
What you also realize is that some parts are actually less coupled to the new feature. They could land in master earlier. Unfortunately, the part that you want to port back into master earlier is in a commit somewhere in the middle of your six commits. Even worse, it also contains a change that relies on a previous commits of your feature branch. One could argue that you should have made that two commits in the first place, but then nobody is perfect.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
^
|
||||
|
|
||||
mixed commit
|
||||
|
||||
At the time that you crafted the commit, you didn’t foresee that you might come into a situation where you want to gradually bring the feature into master. Heck! You wouldn’t have guessed that this whole thing could take us so long.
|
||||
|
||||
What you need is a way to go back in history, open up the commit and split it into two commits so that you can separate out all the things that are safe to be ported back into master by now.
|
||||
|
||||
Speaking in terms of a graph, we want to have it like this.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3a-f3b-f4-f5-f6(feature)
|
||||
|
||||
With the work split into two commits, we could just cherry-pick the precious bits into master.
|
||||
|
||||
Turns out, git comes with a powerful command git rebase -i which lets us do exactly that. It lets us change the history. Changing the history can be problematic and as a rule of thumb should be avoided as soon as the history is shared with others. In our case though, we are just changing history of our local feature branch. Nobody will get hurt. Promised!
|
||||
|
||||
Ok, let’s take a closer look at what exactly happened in commit f3. Turns out we modified two files: userService.js and wishlistService.js. Let’s say that the changes to userService.js could go straight back into master whereas the changes to wishlistService.js could not. Because wishlistService.js does not even exist in master. It was introduced in commit f1.
|
||||
|
||||
> Pro Tip: even if the changes would have been in one file, git could handle that. We keep things simple for this blog post though.
|
||||
|
||||
We’ve set up a [public demo repository][3] that we will use for this exercise. To make it easier to follow, each commit message is prefixed with the pseudo SHAs used in the graphs above. What follows is the branch graph as printed by git before we start to split the commit f3.
|
||||
|
||||

|
||||
|
||||
Now the first thing we want to do is to checkout our feature branch with git checkout feature. To get started with the rebase we run git rebase -i master.
|
||||
|
||||
Now what follows is that git opens a temporary file in the configured editor (defaults to Vim).
|
||||
|
||||

|
||||
|
||||
This file is meant to provide you some options for the rebase and it comes with a little cheat sheet (the blue text). For each commit we could choose between the actions pick, reword, edit, squash, fixup and exec. Each action can also be referred to by its short form p, r, e, s, f and e. It’s out of the scope of this article to describe each and every option so let’s focus on our specific task.
|
||||
|
||||
We want to choose the edit option for our f3 commit hence we change the contents to look like that.
|
||||
|
||||
Now we save the file (in Vim <ESC> followed by :wq, followed by <RETURN>). The next thing we notice is that git stops the rebase at the commit for which we choose the edit option.
|
||||
|
||||
What this means is that git started to apply f1, f2 and f3 as if it was a regular rebase but then stopped **after** applying f3. In fact, we can prove that if we just look at the log at the point where we stopped.
|
||||
|
||||
To split our commit f3 into two commits, all we have to do at this point is to reset gits pointer to the previous commit (f2) while keeping the working directory the same as it is right now. This is exactly what the mixed mode of git reset does. Since mixed is the default mode of git reset we can just write git reset head~1. Let’s do that and also run git status right after it to see what happened.
|
||||
|
||||
The git status tells us that both our userService.js and our wishlistService.js are modified. If we run git diff we can see that those are exactly the changes of our f3 commit.
|
||||
|
||||
If we look at the log again at this point we see that the f3 is gone though.
|
||||
|
||||
We are now at the point that we have the changes of our previous f3 commit ready to be committed whereas the original f3 commit itself is gone. Keep in mind though that we are still in the middle of a rebase. Our f4, f5 and f6 commits are not lost, they’ll be back in a moment.
|
||||
|
||||
Let’s make two new commits: Let’s start with the commit for the changes made to the userService.js which are fine to get picked into master. Run git add userService.js followed by git commit -m "f3a: add updateUser method".
|
||||
|
||||
Great! Let’s create another commit for the changes made to wishlistService.js. Run git add wishlistService.js followed by git commit -m "f3b: add addItems method".
|
||||
|
||||
Let’s take a look at the log again.
|
||||
|
||||
This is exactly what we wanted except our commits f4, f5 and f6 are still missing. This is because we are still in the middle of the interactive rebase and we need to tell git to continue with the rebase. This is done with the command git rebase --continue.
|
||||
|
||||
Let’s check out the log again.
|
||||
|
||||
And that’s it. We now have the history we wanted. The previous f3 commit is now split into two commits f3a and f3b. The only thing left to do is to cherry-pick the f3a commit over to the master branch.
|
||||
|
||||
To finish the last step we first switch to the master branch. We do this with git checkout master. Now we can pick the f3a commit with the cherry-pick command. We can refer to the commit by its SHA key which is bd47ee1 in this case.
|
||||
|
||||
We now have the f3a commit sitting on top of latest master. Exactly what we wanted!
|
||||
|
||||
Given the length of the post this may seem like a lot of effort but it’s really only a matter of seconds for an advanced git user.
|
||||
|
||||
> Note: Christoph is currently writing a book on [rebasing with Git][4] together with Pascal Precht, and you can subscribe to it at leanpub to get notified when it’s ready.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/git-tutorial/git-rebase-split-old-commit-master
|
||||
|
||||
作者:[cburgdorf][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/cburgdorf
|
||||
[1]:http://thoughtram.io/
|
||||
[2]:http://blog.thoughtram.io/posts/going-back-in-time-to-split-older-commits/
|
||||
[3]:https://github.com/thoughtram/interactive-rebase-demo
|
||||
[4]:https://leanpub.com/rebase-the-complete-guide-on-rebasing-in-git
|
||||
@ -1,89 +0,0 @@
|
||||
Learning Vim in 2014: Working with Files
|
||||
================================================================================
|
||||
As a software developer, you shouldn't have to spend time thinking about how to get to the code you want to edit. One of the messiest parts of my transition to using Vim full time was its way of dealing with files. Coming to Vim after primarily using Eclipse and Sublime Text, it frustrated me that Vim doesn't bundle a persistent file system viewer, and the built-in ways of opening and switching files always felt extremely painful.
|
||||
|
||||
At this point I appreciate the depth of Vim's file management features. I've put together a system that works for me even better than more visual editors once did. Because it's purely keyboard based, it allows me to move through my code much faster. That took some time though, and involves several plugins. But the first step was me understanding Vim's built in options for dealing with files. This post will be looking at the most important structures Vim provides you for file management, with a quick peek at some of the more advanced features you can get through plugins.
|
||||
|
||||
### The Basics: Opening a new file ###
|
||||
|
||||
One of the biggest obstacles to learning Vim is its lack of visual affordances. Unlike modern GUI based editors, there is no obvious way to do anything when you open a new instance of Vim in the terminal. Everything is done through keyboard commands, and while that ends up being more efficient for experienced users, new Vim users will find themselves looking up even basic commands routinely. So lets start with the basics.
|
||||
|
||||
The command to open a new file in Vim is **:e <filename>. :e** opens up a new buffer with the contents of the file inside. If the file doesn't exist yet it opens up an empty buffer and will write to the file location you specify once you make changes and save. Buffers are Vim's term for a "block of text stored in memory". That text can be associated with an existing file or not, but there will be one buffer for each file you have open.
|
||||
|
||||
After you open a file and make changes, you can save the contents of the buffer back to the file with the write command **:w**. If the buffer is not yet associated with a file or you want to save to a different location, you can save to a specific file with **:w <filename>**. You may need to add a ! and use **:w! <filename>** if you're overwriting an existing file.
|
||||
|
||||
This is the survival level knowledge for dealing with Vim files. Plenty of developers get by with just these commands, and its technically all you need. But Vim offers a lot more for those who dig a bit deeper.
|
||||
|
||||
### Buffer Management ###
|
||||
|
||||
Moving beyond the basics, let's talk some more about buffers. Vim handles open files a bit differently than other editors. Rather than leaving all open files visible as tabs, or only allowing you to have one file open at a time, Vim allows you to have multiple buffers open. Some of these may be visible while others are not. You can view a list of all open buffers at any time with **:ls**. This shows each open buffer, along with their buffer number. You can then switch to a specific buffer with the **:b <buffer-number>** command, or move in order along the list with the **:bnext** and **:bprevious** commands. (these can be shortened to **:bn** and **:bp** respectively).
|
||||
|
||||
While these commands are the fundamental Vim solutions for managing buffers, I've found that they don't map well to my own way of thinking about files. I don't want to care about the order of buffers, I just want to go to the file I'm thinking about, or maybe to the file I was just in before the current one. So while its important to understand Vim's underlying buffer model, I wouldn't necessarily recommend its builtin commands as your main file management strategy. There are more powerful options available.
|
||||
|
||||

|
||||
|
||||
### Splits ###
|
||||
|
||||
One of the best parts of managing files in Vim is its splits. With Vim, you can split your current window into 2 windows at any time, and then resize and arrange them into any configuration you like. Its not unusual for me to have 6 files open at a given time, each with its own small split of the window.
|
||||
|
||||
You can open a new split with **:sp <filename>** or **:vs <filename>**, for horizontal and vertical splits respectively. There are keyword commands you can use to then resize the windows the way you want them, but to be honest this is the one Vim task I prefer to do with my mouse. A mouse gives me more precision without having to guess the number of columns I want or fiddle back and forth between 2 widths.
|
||||
|
||||
After you create some splits, you can switch back and forth between them with **ctrl-w [h|j|k|l]**. This is a bit clunky though, and it's important for common operations to be efficient and easy. If you use splits heavily, I would personally recommend aliasing these commands to **ctrl-h** **ctrl-j** etc in your .vimrc using this snippet.
|
||||
|
||||
nnoremap <C-J> <C-W><C-J> "Ctrl-j to move down a split
|
||||
nnoremap <C-K> <C-W><C-K> "Ctrl-k to move up a split
|
||||
nnoremap <C-L> <C-W><C-L> "Ctrl-l to move right a split
|
||||
nnoremap <C-H> <C-W><C-H> "Ctrl-h to move left a split
|
||||
|
||||
### The jumplist ###
|
||||
|
||||
Splits solve the problem of viewing multiple related files at a time, but we still haven't seen a satisfactory solution for moving quickly between open and hidden files. The jumplist is one tool you can use for that.
|
||||
|
||||
The jumplist is one of those Vim features that can appear weird or even useless at first. Vim keeps track of every motion command and file switch you make as you're editing files. Every time you "jump" from one place to another in a split, Vim adds an entry to the jumplist. While this may initially seem like a small thing, it becomes powerful when you're switching files a lot, or moving around in a large file. Instead of having to remember your place, or worry about what file you were in, you can instead retrace your footsteps quickly using some quick key commands. **Ctrl-o** allows you to jump back to your last jump location. Repeating it multiple times allows you to quickly jump back to the last file or code chunk you were working on, without having to keep the details of where that code is in your head. You can then move back up the chain with **ctrl-i**. This turns out to be immensely powerful when you're moving around in code quickly, debugging a problem in multiple files or flipping back and forth between 2 files. Instead of typing file names or remembering buffer numbers, you can just move up and down the existing path. It's not the answer to everything, but like other Vim concepts, it's a small focused tool that adds to the overall power of the editor without trying to do everything.
|
||||
|
||||
### Plugins ###
|
||||
|
||||
So let's be real, if you're coming to Vim from something like Sublime Text or Atom, there's a good chance all of this looks a bit arcane, scary, and inefficient. "Why would I want to type the full path to open a file when Sublime has fuzzy finding?" "How can I get a view of a project's structure without a sidebar to show the directory tree?" Legitimate questions. The good news is that Vim has solutions. They're just not baked into the Vim core. I'll touch more on Vim configuration and plugins in later posts, but for now here's a pointer to 3 helpful plugins that you can use to get Sublime-like file management.
|
||||
|
||||
- [CtrlP][1] is a fuzzy finding file search similar to Sublime's "Go to Anything" bar. It's lightning fast and pretty configurable. I use it as my main way of opening new files. With it I only need to know part of the file name and don't need to memorize my project's directory structure.
|
||||
- [The NERDTree][2] is a "file navigation drawer" plugin that replicates the side file navigation that many editors have. I actually rarely use it, as fuzzy search always seems faster to me. But it can be useful coming into a project, when you're trying to learn the project structure and see what's available. NERDTree is immensely configurable, and also replaces Vim's built in directory tools when installed.
|
||||
- [Ack.vim][3] is a code search plugin for Vim that allows you to search across your project for text expressions. It acts as a light wrapper around Ack or Ag, [2 great code search tools][4], and allows you to quickly jump to any occurrence of a search term in your project.
|
||||
|
||||
Between it's core and its plugin ecosystem, Vim offers enough tools to allow you to craft your workflow anyway you want. File management is a key part of a good software development system, and it's worth experimenting to get it right.
|
||||
|
||||
Start with the basics for long enough to understand them, and then start adding tools on top until you find a comfortable workflow. It will all be worth it when you're able to seamlessly move to the code you want to work on without the mental overhead of figuring out how to get there.
|
||||
|
||||
### More Resources ###
|
||||
|
||||
- [Seamlessly Navigate Vim & Tmux Splits][5] This is a must read for anyone who wants to use vim with [tmux][6]. It presents an easy system for treating Vim and Tmux splits as equals, and moving between them easily.
|
||||
- [Using Tab Pages][7] One file management feature I didn't cover, since it's poorly named and a bit confusing to use, is Vim's "tab" feature. This post on the Vim wiki gives a good overview of how you can use "tab pages" to have multiple views of your current workspace
|
||||
- [Vimcasts: The edit command][8] Vimcasts in general is a great resource for anyone learning Vim, but this screenshot does a good job of covering the file opening basics mentioned above, with some suggestions on improving the builtin workflow
|
||||
|
||||
### Subscribe ###
|
||||
|
||||
This was the third in a series of posts on learning Vim in a modern way. If you enjoyed the post consider subscribing to the [feed][8] or joining my [mailing list][10]. I'll be continuing with [a post on Vim configuration next week][11] after a brief JavaScript interlude later this week. You should also checkout the first 2 posts in this series, on [the basics of using Vim][12], and [the language of Vim and Vi][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
|
||||
作者:[Ben McCormick][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
[1]:https://github.com/kien/ctrlp.vim
|
||||
[2]:https://github.com/scrooloose/nerdtree
|
||||
[3]:https://github.com/mileszs/ack.vim
|
||||
[4]:http://benmccormick.org/2013/11/25/a-look-at-ack/
|
||||
[5]:http://robots.thoughtbot.com/seamlessly-navigate-vim-and-tmux-splits
|
||||
[6]:http://tmux.sourceforge.net/
|
||||
[7]:http://vim.wikia.com/wiki/Using_tab_pages
|
||||
[8]:http://vimcasts.org/episodes/the-edit-command/
|
||||
[9]:http://feedpress.me/benmccormick
|
||||
[10]:http://eepurl.com/WFYon
|
||||
[11]:http://benmccormick.org/2014/07/14/learning-vim-in-2014-configuring-vim/
|
||||
[12]:http://benmccormick.org/2014/06/30/learning-vim-in-2014-the-basics/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
138
sources/tech/20141004 Practical Lessons in Peer Code Review.md
Normal file
138
sources/tech/20141004 Practical Lessons in Peer Code Review.md
Normal file
@ -0,0 +1,138 @@
|
||||
johnhoow translating...
|
||||
# Practical Lessons in Peer Code Review #
|
||||
|
||||
Millions of years ago, apes descended from the trees, evolved opposable thumbs and—eventually—turned into human beings.
|
||||
|
||||
We see mandatory code reviews in a similar light: something that separates human from beast on the rolling grasslands of the software
|
||||
development savanna.
|
||||
|
||||
Nonetheless, I sometimes hear comments like these from our team members:
|
||||
|
||||
"Code reviews on this project are a waste of time."
|
||||
"I don't have time to do code reviews."
|
||||
"My release is delayed because my dastardly colleague hasn't done my review yet."
|
||||
"Can you believe my colleague wants me to change something in my code? Please explain to them that the delicate balance of the universe will
|
||||
be disrupted if my pristine, elegant code is altered in any way."
|
||||
|
||||
### Why do we do code reviews? ###
|
||||
|
||||
Let us remember, first of all, why we do code reviews. One of the most important goals of any professional software developer is to
|
||||
continually improve the quality of their work. Even if your team is packed with talented programmers, you aren't going to distinguish
|
||||
yourselves from a capable freelancer unless you work as a team. Code reviews are one of the most important ways to achieve this. In
|
||||
particular, they:
|
||||
|
||||
provide a second pair of eyes to find defects and better ways of doing something.
|
||||
ensure that at least one other person is familiar with your code.
|
||||
help train new staff by exposing them to the code of more experienced developers.
|
||||
promote knowledge sharing by exposing both the reviewer and reviewee to the good ideas and practices of the other.
|
||||
encourage developers to be more thorough in their work since they know it will be reviewed by one of their colleagues.
|
||||
|
||||
### Doing thorough reviews ###
|
||||
|
||||
However, these goals cannot be achieved unless appropriate time and care are devoted to reviews. Just scrolling through a patch, making sure
|
||||
that the indentation is correct and that all the variables use lower camel case, does not constitute a thorough code review. It is
|
||||
instructive to consider pair programming, which is a fairly popular practice and adds an overhead of 100% to all development time, as the
|
||||
baseline for code review effort. You can spend a lot of time on code reviews and still use much less overall engineer time than pair
|
||||
programming.
|
||||
|
||||
My feeling is that something around 25% of the original development time should be spent on code reviews. For example, if a developer takes
|
||||
two days to implement a story, the reviewer should spend roughly four hours reviewing it.
|
||||
|
||||
Of course, it isn't primarily important how much time you spend on a review as long as the review is done correctly. Specifically, you must
|
||||
understand the code you are reviewing. This doesn't just mean that you know the syntax of the language it is written in. It means that you
|
||||
must understand how the code fits into the larger context of the application, component or library it is part of. If you don't grasp all the
|
||||
implications of every line of code, then your reviews are not going to be very valuable. This is why good reviews cannot be done quickly: it
|
||||
takes time to investigate the various code paths that can trigger a given function, to ensure that third-party APIs are used correctly
|
||||
(including any edge cases) and so forth.
|
||||
|
||||
In addition to looking for defects or other problems in the code you are reviewing, you should ensure that:
|
||||
|
||||
All necessary tests are included.
|
||||
Appropriate design documentation has been written.
|
||||
Even developers who are good about writing tests and documentation don't always remember to update them when they change their code. A
|
||||
gentle nudge from the code reviewer when appropriate is vital to ensure that they don't go stale over time.
|
||||
|
||||
### Preventing code review overload ###
|
||||
|
||||
If your team does mandatory code reviews, there is the danger that your code review backlog will build up to the point where it is
|
||||
unmanageable. If you don't do any reviews for two weeks, you can easily have several days of reviews to catch up on. This means that your
|
||||
own development work will take a large and unexpected hit when you finally decide to deal with them. It also makes it a lot harder to do
|
||||
good reviews since proper code reviews require intense and sustained mental effort. It is difficult to keep this up for days on end.
|
||||
|
||||
For this reason, developers should strive to empty their review backlog every day. One approach is to tackle reviews first thing in the
|
||||
morning. By doing all outstanding reviews before you start your own development work, you can keep the review situation from getting out of
|
||||
hand. Some might prefer to do reviews before or after the midday break or at the end of the day. Whenever you do them, by considering code
|
||||
reviews as part of your regular daily work and not a distraction, you avoid:
|
||||
|
||||
Not having time to deal with your review backlog.
|
||||
Delaying a release because your reviews aren't done yet.
|
||||
Posting reviews that are no longer relevant since the code has changed so much in the meantime.
|
||||
Doing poor reviews since you have to rush through them at the last minute.
|
||||
|
||||
### Writing reviewable code ###
|
||||
|
||||
The reviewer is not always the one responsible for out-of-control review backlogs. If my colleague spends a week adding code willy-nilly
|
||||
across a large project then the patch they post is going to be really hard to review. There will be too much to get through in one session.
|
||||
It will be difficult to understand the purpose and underlying architecture of the code.
|
||||
|
||||
This is one of many reasons why it is important to split your work into manageable units. We use scrum methodology so the appropriate unit
|
||||
for us is the story. By making an effort to organize our work by story and submit reviews that pertain only to the specific story we are
|
||||
working on, we write code that is much easier to review. Your team may use another methodology but the principle is the same.
|
||||
|
||||
There are other prerequisites to writing reviewable code. If there are tricky architectural decisions to be made, it makes sense to meet
|
||||
with the reviewer beforehand to discuss them. This will make it much easier for the reviewer to understand your code, since they will know
|
||||
what you are trying to achieve and how you plan to achieve it. This also helps avoid the situation where you have to rewrite large swathes
|
||||
of code after the reviewer suggests a different and better approach.
|
||||
|
||||
Project architecture should be described in detail in your design documentation. This is important anyway since it enables a new project
|
||||
member to get up to speed and understand the existing code base. It has the further advantage of helping a reviewer to do their job
|
||||
properly. Unit tests are also helpful in illustrating to the reviewer how components should be used.
|
||||
|
||||
If you are including third-party code in your patch, commit it separately. It is much harder to review code properly when 9000 lines of
|
||||
jQuery are dropped into the middle.
|
||||
|
||||
One of the most important steps for creating reviewable code is to annotate your code reviews. This means that you go through the review
|
||||
yourself and add comments anywhere you feel that this will help the reviewer to understand what is going on. I have found that annotating
|
||||
code takes relatively little time (often just a few minutes) and makes a massive difference in how quickly and well the code can be
|
||||
reviewed. Of course, code comments have many of the same advantages and should be used where appropriate, but often a review annotation
|
||||
makes more sense. As a bonus, studies have shown that developers find many defects in their own code while rereading and annotating it.
|
||||
|
||||
### Large code refactorings ###
|
||||
|
||||
Sometimes it is necessary to refactor a code base in a way that affects many components. In the case of a large application, this can take
|
||||
several days (or more) and result in a huge patch. In these cases a standard code review may be impractical.
|
||||
|
||||
The best solution is to refactor code incrementally. Figure out a partial change of reasonable scope that results in a working code base and
|
||||
brings you in the direction you want to go. Once that change has been completed and a review posted, proceed to a second incremental change
|
||||
and so forth until the full refactoring has been completed. This might not always be possible, but with thought and planning it is usually
|
||||
realistic to avoid massive monolithic patches when refactoring. It might take more time for the developer to refactor in this way, but it
|
||||
also leads to better quality code as well as making reviews much easier.
|
||||
|
||||
If it really isn't possible to refactor code incrementally (which probably says something about how well the original code was written and
|
||||
organized), one solution might be to do pair programming instead of code reviews while working on the refactoring.
|
||||
|
||||
### Resolving disputes ###
|
||||
|
||||
Your team is doubtless made up of intelligent professionals, and in almost all cases it should be possible to come an agreement when
|
||||
opinions about a specific coding question differ. As a developer, keep an open mind and be prepared to compromise if your reviewer prefers a
|
||||
different approach. Don't take a proprietary attitude to your code and don't take review comments personally. Just because someone feels
|
||||
that you should refactor some duplicated code into a reusable function, it doesn't mean that you are any less of an attractive, brilliant
|
||||
and charming individual.
|
||||
|
||||
As a reviewer, be tactful. Before suggesting changes, consider whether your proposal is really better or just a matter of taste. You will
|
||||
have more success if you choose your battles and concentrate on areas where the original code clearly requires improvement. Say things like
|
||||
"it might be worth considering..." or "some people recommend..." instead of "my pet hamster could write a more efficient sorting algorithm
|
||||
than this."
|
||||
|
||||
If you really can't find middle ground, ask a third developer who both of you respect to take a look and give their opinion.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.salsitasoft.com/practical-lessons-in-peer-code-review/
|
||||
作者:[Matt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,43 @@
|
||||
|
||||
生日快乐,Linux! 1991年8月25日,Linus Torvalds 开启新的篇章。
|
||||
================================================================================
|
||||

|
||||
Linus Torvalds
|
||||
|
||||
**Linux工程刚刚进入第23个年头。有着成千上万的人一起开源的努力,Linux 现在是全世界最大的合作结晶。**
|
||||
|
||||
时光倒流到1991年,一个名字叫Linus Torvalds的程序员想开发一个免费的操作系统。当时他并没有打算把这个软件做得像GNU工程那么大,他做这个工程仅仅是因为他的爱好。他开始研发的东西变成了全世界最成功的操作系统,但是在当时没有人可以想像这个东西是什么样子的。
|
||||
|
||||
Linus Torvalds 在1991年8月25日发了一封邮件。邮件内容是请求帮助测试他新开发的操作系统。尽管那时候他的软件还没改变太多,但是他仍然坚持发送Linux更新发布的邮件。那个时候他的软件还没有被命名为Linux。
|
||||
|
||||
“我正在做一个(免费的)386(486)先进技术处理器操作系统(仅仅是为了个人喜好,不会像GNU那样大和专业)。” 自从4月份,我已经酝酿这个想法,并且已经开始准备好了。我很乐意听见各种关于喜欢与不喜欢minix的反馈,因为我的操作系统(在文件管理系统的物理层面(由于实际的原因)或者在其他方面)于它(minix)相似。最近,我发布了bash(1.08)版本和gcc(1.40)版本,暂时来说它们运行正常。
|
||||
|
||||
“这意味着在未来几个月内,我会得到一些实际的东西。与此同时,我很乐意
|
||||
知道用户希望添加哪些功能。任何建议都是可以,但是我不保证都会去开发它们 :-) 附言:嗯-它是不受限于任何minix代码,并且它有多线程的文件系统。 它不是很轻便(使用386任务交互等), 它可能永远都不会支持任何设备,除了先进的硬盘。 这就是目前为止我所知道的。 :-(. " [发信人][1] Linus Torvalds.
|
||||
|
||||
一切都是由这封邮件开始的,很有趣的是从那时候起已经可以感受到东西是怎么养逐步形成的。Linux操作系统不仅赶上了时代的步伐,尤其是在服务器市场上,而且强大的Linux覆盖了其他领域。
|
||||
|
||||
事实上,现在已经很难去寻找一个技术还没有被Linus操作系统影响的。手机,电视,冰箱,微型电脑,操纵台,平板电脑,基本每一个带有电子芯片都是可以运行Linux或者它已经安装了一些以Linux为基础研发的操作系统。
|
||||
|
||||
Linux无处不在,它已经覆盖了无数的设备,并且它的影响力以每年幂指数的数率增长。你可能认为Linus(先生)是世界上最有财富的人,但是不要忘记了,Linux是一个免费的软件。每个人都可以使用它,修改它,甚至以它为赚钱的工具。他(Linus)做这个不是为了金钱。
|
||||
|
||||
Linus Torvalds 在1991年开启的时代的改革,但是这个改革还没有结束。 实际上,你可以认为这仅仅是个开始。
|
||||
|
||||
> 生日快乐,Linux!请加入我们庆祝一个已经改变世界的免费操作系统的23岁生日。[pic.twitter.com/mTVApV85gD][2]
|
||||
>
|
||||
> — The Linux Foundation (@linuxfoundation) [August 25, 2014][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Started-a-Revolution-on-August-25-1991-Happy-Birthday-Linux-456212.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[Shaohao Lin](https://github.com/shaohaolin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[2]:http://t.co/mTVApV85gD
|
||||
[3]:https://twitter.com/linuxfoundation/statuses/503799441900314624
|
||||
@ -0,0 +1,85 @@
|
||||
为什么一些古老的编程语言不会消亡?
|
||||
================================================================================
|
||||
> 我们中意于我们所知道的。
|
||||
|
||||

|
||||
|
||||
当今许多知名的编程语言已经都非常古老了。PHP 语言20年、Python 语言23年、HTML 语言21年、Ruby 语言和 JavaScript 语言已经19年,C 语言更是高达42年之久。
|
||||
|
||||
这是没人能预料得到的,即使是计算机科学家 [Brian Kernighan][1] 也一样。他是写著第一本关于 C 语言的作者之一,只到今天这本书还在印刷着。(C 语言本身的发明者 [Dennis Ritchie][2] 是 Kernighan 的合著者,他于 2011 年已辞世。)
|
||||
|
||||
“我依稀记得早期跟编辑们的谈话,告诉他们我们已经卖出了5000册左右的量,”最近采访 Kernighan 时他告诉我说。“我们设法做的更好。我没有想到的是在2014年的教科书里学生仍然在使用第一个版本的书。”
|
||||
|
||||
关于 C 语言的持久性特别显著的就是 Google 开发出了新的语言 Go,解决同一问题比用 C 语言更有效率。
|
||||
|
||||
“大多数语言并不会消失或者至少很大一部分用户承认它们不会消失,”他说。“C 语言仍然在一定的领域独领风骚,所以它很接地气。”
|
||||
|
||||
### 编写所熟悉的 ###
|
||||
|
||||
为什么某些计算机编程语言要比其它的更流行?因为开发者都选择使用它们。逻辑上来说,这解释已经足够,但还想深入了解为什么开发人员会选择使用它们呢,这就有点棘手了。
|
||||
|
||||
分别来自普林斯顿大学和加州大学伯克利分校的研究者 Ari Rabkin 和 Leo Meyerovich 花费了两年时间来研究解决上面的问题。他们的研究报告,[《编程语言使用情况实例分析》][3],记录了对超过 200,000 个 Sourceforge 项目和超过 13,000 个程序员投票结果的分析。
|
||||
|
||||
他们主要的发现呢?大多数时候程序员选择的编程语言都是他们所熟悉的。
|
||||
|
||||
“存在着我们使用的语言是因为我们经常使用他们,” Rabkin 告诉我。“例如:天文学家就经常使用 IDL [交互式数据语言]来开发他们的计算机程序,并不是因为它具有什么特殊的星级功能或其它特点,而是因为用它形成习惯了。他们已经用些语言构建出很优秀的程序了,并且想保持原状。”
|
||||
|
||||
换句话说,它部分要归功于创建其的语言的的知名度仍保留较大劲头。当然,这并不意味着流行的语言不会变化。Rabkin 指出我们今天在使用的 C 语言就跟 Kernighan 第一次创建时的一点都不同,那时的 C 编译器跟现代的也不是完全兼容。
|
||||
|
||||
“有一个古老的,关于工程师的笑话。工程师被问到哪一种编程语言人们会使用30年,他说,‘我不知道,但它总会被叫做 Fortran’,” Rabkin 说到。“长期存活的语言跟他们在70年代和80年代刚设计出来的时候不一样了。人们通常都是在上面增加功能,而不会删除功能,因为要保持向后兼容,但有些功能会被修正。”
|
||||
|
||||
向后兼容意思就是当语言升级后,程序员不仅可以使用升级语言的新特性,也不用回去重写已经实现的老代码块。老的“遗留代码”的语法规则已经不用了,但舍弃是要花成本的。只要它们存在,我们就有理由相信相关的语言也会存在。
|
||||
|
||||
### PHP: 存活长久语言的一个案例学习 ###
|
||||
|
||||
遗留代码指的是用过时的源代码编写的程序或部分程序。想想看,一个企业或工程项目的关键程序功能部分是用没人维护的编程语言写出来的。因为它们仍起着作用,用现代的源代码重写非常困难或着代价太高,所以它们不得不保留下来,即使其它部分的代码都变动了,程序员也必须不断折腾以保证它们能正常工作。
|
||||
|
||||
任何的编程语言,存在了超过几十年时间都具有某种形式的遗留代码问题, PHP 也不加例外。PHP 是一个很有趣的例子,因为它的遗留代码跟现在的代码明显不同,支持者或评论家都承认这是一个巨大的进步。
|
||||
|
||||
Andi Gutmans 是 已经成为 PHP4 的标准编译器的 Zend Engine 的发明者之一。Gutmans 说他和搭档本来是想改进完善 PHP3 的,他们的工作如此成功,以至于 PHP 的原发明者 Rasmus Lerdorf 也加入他们的项目。结果就成为了 PHP4 和他的后续者 PHP5 的编译器。
|
||||
|
||||
因此,当今的 PHP 与它的祖先即最开始的 PHP 是完全不同的。然而,在 Gutmans 看来,在用古老的 PHP 语言版本写的遗留代码的地方一直存在着偏见以至于上升到整个语言的高度。比如 PHP 充满着安全漏洞或没有“集群”功能来支持大规模的计算任务等概念。
|
||||
|
||||
“批评 PHP 的人们通常批评的是在 1998 年时候的 PHP 版本,”他说。“这些人都没有与时俱进。当今的 PHP 已经有了很成熟的生态系统了。”
|
||||
|
||||
如今,Gutmans 说,他作为一个管理者最重要的事情就是鼓励人们升级到最新版本。“PHP有个很大的社区,足以支持您的遗留代码的问题,”他说。“但总的来说,我们的社区大部分都在 PHP5.3 及以上的。”
|
||||
|
||||
问题是,任何语言用户都不会全部升级到最新版本。这就是为什么 Python 用户仍在使用 2000 年发布的 Python 2,而不是使用 2008 年发布的 Python 3 的原因。甚至是已经六年了喜欢 Google 的大多数用户仍没有升级。这种情况是多种原因造成的,但它使得很多开发者在承担风险。
|
||||
|
||||
“任何东西都不会消亡的,”Rabkin 说。“任何语言的遗留代码都会一直存在。重写的代价是非常高昂的,如果它们不出问题就不要去改动。”
|
||||
|
||||
### 开发者是稀缺的资源 ###
|
||||
|
||||
当然,开发者是不会选择那些仅仅只是为了维护老旧代码的的程序语言的。当谈论到对语言选择的偏好时,Rabkin 和 Meyerovich 发现年龄仅仅只代表个数字。Rabkin 告诉我说:
|
||||
|
||||
> 有一件事使我们被深深震撼到了。这事最重要的就是我们给人们按年龄分组,然后询问他们知道多少编程语言。我们主观的认为随着年龄的增长知道的会越来越多,但实际上却不是,25岁年龄组和45岁年龄组知道的语言数目是一样的。几个反复询问的问题这里持续不变的。您知道一种语言的几率并不与您的年龄挂钩。
|
||||
|
||||
换句话说,不仅仅里年长的开发者坚持传统,年轻的程序员会承认并采用古老的编程语言作为他们的第一们语言。这可能是因为这些语言具有很有趣的开发库及功能特点,也可能是因为在社区里开发者都是一个组的都喜爱这种开发语言。
|
||||
|
||||
“在全球程序员关注的语言的数量是有定数的,” Rabkin 说。“如果一们语言表现出足够独特的价值,人们将会学习和使用它。如果是和您交流代码和知识的的某个人分享一门编程语言,您将会学习它。因此,例如,只要那些开发库是 Python 库和社区特长是 Python 语言的经验,那么 Python 将会大行其道。”
|
||||
|
||||
研究人员发现关于语言实现的功能,社区是一个巨大的因素。虽然像 Python 和 Ruby 这样的高级语言并没有太大的差别,但,例如程序员就更容易觉得一种比另一种优越。
|
||||
|
||||
“Rails 不一定要用 Ruby 语言编写,但它用了,这就是社会因素在起作用,” Rabkin 说。“例如,复活 Objective-C 语言这件事就是苹果的工程师团队说‘让我们使用它吧,’ 他们就没得选择了。”
|
||||
|
||||
通观社会的影响及老旧代码这些问题,我们发现最古老的和最新的计算机语言都有巨大的惰性。Go 语言怎么样能超越 C 语言呢?如果有合适的人或公司说它超越它就超越。
|
||||
|
||||
“它归结为谁传播的更好谁就好,” Rabkin 说。
|
||||
|
||||
开始的图片来自 [Blake Patterson][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/09/02/programming-language-coding-lifetime
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:http://en.wikipedia.org/wiki/Brian_Kernighan
|
||||
[2]:http://en.wikipedia.org/wiki/Dennis_Ritchie
|
||||
[3]:http://asrabkin.bitbucket.org/papers/oopsla13.pdf
|
||||
[4]:https://www.flickr.com/photos/blakespot/2444037775/
|
||||
@ -0,0 +1,82 @@
|
||||
ChromeOS 对战 Linux : 孰优孰劣,仁者见仁,智者见智
|
||||
================================================================================
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,不管是哪一家的操作系统都是有优有劣。
|
||||
|
||||
任何不关注Google 的人都不会相信Google在桌面用户当中扮演着一个很重要的角色。在近几年,我们见到的[ChromeOS][1]制造的[Google Chromebook][2]相当的轰动。和同期的人气火爆的Amazon 一样,似乎ChromeOS 势不可挡。
|
||||
|
||||
在本文中,我们要了解的是ChromeOS 的概念市场,ChromeOS 怎么影响着Linux 的份额,和整个 ChromeOS 对于linux 社区来说,是好事还是坏事。另外,我将会谈到一些重大的事情,和为什么没人去为他做点什么事情。
|
||||
|
||||
### ChromeOS 并非真正的Linux ###
|
||||
|
||||
每当有朋友问我说是否ChromeOS 是否是Linux 的一个版本时,我都会这样回答:ChromeOS 对于Linux 就好像是 OS X 对于BSD 。换句话说,我认为,ChromeOS 是linux 的一个派生操作系统,运行于Linux 内核的引擎之下。而很多操作系统就组成了Google 的专利代码和软件。
|
||||
|
||||
尽管ChromeOS 是利用了Linux 内核引擎,但是它仍然有很大的不同和现在流行的Linux 分支版本。
|
||||
|
||||
尽管ChromeOS 的差异化越来越明显,是在于它给终端用户提供的app,包括Web 应用。因为ChromeOS 的每一个操作都是开始于浏览器窗口,这对于Linux 用户来说,可能会有很多不一样的感受,但是,对于没有Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
就是说,每一个以Google-centric 为生活方式的人来说,在ChromeOS上的感觉将会非常良好,就好像是回家一样。这样的优势就是这个人已经接受了Chrome 浏览器,Google 驱动器和Gmail 。久而久之,他们的亲朋好友使用ChromeOs 也就是很自然的事情了,就好像是他们很容易接受Chrome 浏览器,因为他们觉得早已经用过。
|
||||
|
||||
然而,对于Linux 爱好者来说,这样的约束就立即带来了不适应。因为软件的选择被限制,有范围的,在加上要想玩游戏和VoIP 是完全不可能的。那么对不起,因为[GooglePlus Hangouts][3]是代替不了VoIP 软件的。甚至在很长的一段时间里。
|
||||
|
||||
### ChromeOS 还是Linux 桌面 ###
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统的浪潮中对Linux 产生影响,只有在Linux 停下来浮出水面栖息的时候或者是满足某个非技术用户的时候。
|
||||
|
||||
是的,桌面Linux 对于大多数休闲型的用户来说绝对是一个好东西。然而,它必须有专人帮助你安装操作系统,并且提供“维修”服务,从windows 和 OS X 的阵营来看。但是,令人失望的是,在美国Linux 正好在这个方面很缺乏。所以,我们看到,ChromeOS 正慢慢的走入我们的视线。
|
||||
|
||||
我发现Linux 桌面系统最适合做网上技术支持来管理。比如说:家里的高级用户可以操作和处理更新政府和学校的IT 部门。Linux 还可以应用于这样的环境,Linux桌面系统可以被配置给任何技能水平和背景的人使用。
|
||||
|
||||
相比之下,ChromeOS 是建立在完全免维护的初衷之下的,因此,不需要第三者的帮忙,你只需要允许更新,然后让他静默完成即可。这在一定程度上可能是由于ChromeOS 是为某些特定的硬件结构设计的,这与苹果开发自己的PC 电脑也有异曲同工之妙。因为Google 的ChromeOS 附带一个硬件脉冲,它允许“犯错误”。对于某些人来说,这是一个很奇妙的地方。
|
||||
|
||||
滑稽的是,有些人却宣称,ChomeOs 的远期的市场存在很多问题。简言之,这只是一些Linux 激情的爱好者在找对于ChomeOS 的抱怨罢了。在我看来,停止造谣这些子虚乌有的事情才是关键。
|
||||
|
||||
问题是:ChromeOS 的市场份额和Linux 桌面系统在很长的一段时间内是不同的。这个存在可能会在将来被打破,然而在现在,仍然会是两军对峙的局面。
|
||||
|
||||
### ChromeOS 的使用率正在增长 ###
|
||||
|
||||
不管你对ChromeOS 有怎么样的看法,事实是,ChromeOS 的使用率正在增长。专门针对ChromeOS 的电脑也一直有发布。最近,戴尔(Dell)也发布了一款针对ChromeOS 的电脑。命名为[Dell Chromebox][5],这款ChromeOS 设备将会是另一些传统设备的终结者。它没有软件光驱,没有反病毒软件,offers 能够无缝的在屏幕后面自动更新。对于一般的用户,Chromebox 和Chromebook 正逐渐成为那些工作在web 浏览器上的人的一个选择。
|
||||
|
||||
尽管增长速度很快,ChromeOS 设备仍然面临着一个很严峻的问题 - 存储。受限于有限的硬盘的大小和严重依赖于云存储,并且ChromeOS 不会为了任何使用它们电脑的人消减基本的web 浏览器的功能。
|
||||
|
||||
### ChromeOS 和Linux 的异同点 ###
|
||||
|
||||
以前,我注意到ChromeOS 和Linux 桌面系统分别占有着两个完全不同的市场。出现这样的情况是源于,Linux 社区的致力于提升Linux 桌面系统的脱机性能。
|
||||
|
||||
是的,偶然的,有些人可能会第一时间发现这个“Linux 的问题”。但是,并没有一个人接着跟进这些问题,确保得到问题的答案,确保他们得到Linux 最多的帮助。
|
||||
|
||||
事实上,脱机故障可能是这样发现的:
|
||||
|
||||
- 有些用户偶然的在Linux 本地事件发现了Linux 的问题。
|
||||
- 他们带回了DVD/USB 设备,并尝试安装这个操作系统。
|
||||
- 当然,有些人很幸运的成功的安装成功了这个进程,但是,据我所知大多数的人并没有那么幸运。
|
||||
- 令人失望的是,这些人希望在网上论坛里搜索帮助。很难做一个主计算机,没有网络和视频的问题。
|
||||
- 我真的是受够了,后来有很多失望的用户拿着他们的电脑到windows 商店来“维修”。除了重装一个windows 操作系统,他们很多时候都会听到一句话,“Linux 并不适合你们”,应该尽量避免。
|
||||
|
||||
有些人肯定会说,上面的举例肯定夸大其词了。让我来告诉你:这是发生在我身边真实的事的,而且是经常发生。醒醒吧,Linux 社区的人们,我们的这种模式已经过时了。
|
||||
|
||||
### 伟大的平台,强大的营销和结论 ###
|
||||
|
||||
如果非要说ChromeOS 和Linux 桌面系统相同的地方,除了它们都使用了Linux 内核,就是它们都伟大的产品却拥有极其差劲的市场营销。而Google 的好处就是,他们投入大量的资金在网上构建大面积存储空间。
|
||||
|
||||
Google 相信他们拥有“网上的优势”,而线下的影响不是很重要。这真是一个让人难以置信的目光短浅,这也成了Google 历史上最大的一个失误之一。相信,如果你没有接触到他们在线的努力,你不值得困扰,仅仅就当是他们在是在选择网上存储空间上做出反击。
|
||||
|
||||
我的建议是:通过Google 的线下影响,提供Linux 桌面系统给ChromeOS 的市场。这就意味着Linux 社区的人需要筹集资金来出席县博览会、商场展览,在节日季节,和在社区中进行免费的教学课程。这会立即使Linux 桌面系统走入人们的视线,否则,最终将会是一个ChromeOS 设备出现在人们的面前。
|
||||
|
||||
如果说本地的线下市场并没有想我说的这样,别担心。Linux 桌面系统的市场仍然会像ChromeOS 一样增长。最坏也能保持现在这种两军对峙的市场局面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -0,0 +1,209 @@
|
||||
如何在Debian上安装配置ownCloud
|
||||
================================================================================
|
||||
据其官方网站,ownCloud可以让你通过一个网络接口或者WebDAV访问你的文件。它还提供了一个平台,可以轻松地查看、编辑和同步您所有设备的通讯录、日历和书签。尽管ownCloud与广泛使用Dropbox非常相似,但主要区别在于ownCloud是免费的,开源的,从而可以自己的服务器上建立与Dropbox类似的云存储服务。使用ownCloud你可以完整地访问和控制您的私人数据而对存储空间没有限制(除了硬盘容量)或者连客户端的连接数量。
|
||||
|
||||
ownCloud提供了社区版(免费)和企业版(面向企业的有偿支持)。预编译的ownCloud社区版可以提供了CentOS、Debian、Fedora、openSUSE、,SLE和Ubuntu版本。本教程将演示如何在Debian Wheezy上安装和在配置ownCloud社区版。
|
||||
|
||||
### 在Debian上安装 ownCloud ###
|
||||
|
||||
进入官方网站:[http://owncloud.org][1],并点击‘Install’按钮(右上角)。
|
||||
|
||||

|
||||
|
||||
为当前的版本选择“Packages for auto updates”(下面的图是v7)。这可以让你轻松的让你使用的ownCloud与Debian的包管理系统保持一致,包是由ownCloud社区维护的。
|
||||
|
||||

|
||||
|
||||
在下一屏职工点击继续:
|
||||
|
||||

|
||||
|
||||
在可用的操作系统列表中选择Debian 7 [Wheezy]:
|
||||
|
||||

|
||||
|
||||
加入ownCloud的官方Debian仓库:
|
||||
|
||||
# echo 'deb http://download.opensuse.org/repositories/isv:/ownCloud:/community/Debian_7.0/ /' >> /etc/apt/sources.list.d/owncloud.list
|
||||
|
||||
加入仓库密钥到apt中:
|
||||
|
||||
# wget http://download.opensuse.org/repositories/isv:ownCloud:community/Debian_7.0/Release.key
|
||||
# apt-key add - < Release.key
|
||||
|
||||
继续安装ownCLoud:
|
||||
|
||||
# aptitude update
|
||||
# aptitude install owncloud
|
||||
|
||||
打开你的浏览器并定位到你的ownCloud实例中,地址是http://<server-ip>/owncloud:
|
||||
|
||||

|
||||
|
||||
注意ownCloud可能会包一个Apache配置错误的警告。使用下面的步骤来解决这个错误来摆脱这些错误信息。
|
||||
|
||||
a) 编辑 the /etc/apache2/apache2.conf (设置 AllowOverride 为 All):
|
||||
|
||||
<Directory /var/www/>
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
b) 编辑 the /etc/apache2/conf.d/owncloud.conf
|
||||
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
c) 重启web服务器:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
d) 刷新浏览器,确认安全警告已经消失
|
||||
|
||||

|
||||
|
||||
### 设置数据库 ###
|
||||
|
||||
是时候为ownCloud设置数据库了。
|
||||
|
||||
首先登录本地的MySQL/MariaDB数据库:
|
||||
|
||||
$ mysql -u root -h localhost -p
|
||||
|
||||
为ownCloud创建数据库和用户账户。
|
||||
|
||||
mysql> CREATE DATABASE owncloud_DB;
|
||||
mysql> CREATE USER ‘owncloud-web’@'localhost' IDENTIFIED BY ‘whateverpasswordyouchoose’;
|
||||
mysql> GRANT ALL PRIVILEGES ON owncloud_DB.* TO ‘owncloud-web’@'localhost';
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
通过http://<server-ip>/owncloud 进入ownCloud页面,并选择‘Storage & database’ 选项。输入所需的信息(MySQL/MariaDB用户名,密码,数据库和主机名),并点击完成按钮。
|
||||
|
||||

|
||||
|
||||
### 为ownCloud配置SSL连接 ###
|
||||
|
||||
在你开始使用ownCloud之前,强烈建议你在ownCloud中启用SSL支持。使用SSL可以提供重要的安全好处,比如加密ownCloud流量并提供适当的验证。在本教程中,将会为SSL使用一个自签名的证书。
|
||||
|
||||
创建一个储存服务器密钥和证书的目录:
|
||||
|
||||
# mkdir /etc/apache2/ssl
|
||||
|
||||
创建一个证书(并有一个密钥来保护它),它有一年的有效期。
|
||||
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/apache2/ssl/apache.key -out /etc/apache2/ssl/apache.crt
|
||||
|
||||

|
||||
|
||||
编辑/etc/apache2/conf.d/owncloud.conf 启用HTTPS。对于余下的NC、R和L重写规则的意义,你可以参考[Apache 文档][2]:
|
||||
|
||||
Alias /owncloud /var/www/owncloud
|
||||
|
||||
<VirtualHost 192.168.0.15:80>
|
||||
RewriteEngine on
|
||||
ReWriteCond %{SERVER_PORT} !^443$
|
||||
RewriteRule ^/(.*) https://%{HTTP_HOST}/$1 [NC,R,L]
|
||||
</VirtualHost>
|
||||
|
||||
<VirtualHost 192.168.0.15:443>
|
||||
SSLEngine on
|
||||
SSLCertificateFile /etc/apache2/ssl/apache.crt
|
||||
SSLCertificateKeyFile /etc/apache2/ssl/apache.key
|
||||
DocumentRoot /var/www/owncloud/
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
启用重写模块并重启Apache:
|
||||
|
||||
# a2enmod rewrite
|
||||
# service apache2 restart
|
||||
|
||||
打开你的ownCloud实例。注意一下,即使你尝试使用HTTP,你也会自动被重定向到HTTPS。
|
||||
|
||||
注意,即使你已经按照上述步骤做了,在你启动ownCloud你仍将看到一条错误消息,指出该证书尚未被受信的机构颁发(那是因为我们创建了一个自签名证书)。您可以放心地忽略此消息,但如果你考虑在生产服务器上部署ownCloud,你可以从一个值得信赖的公司购买证书。
|
||||
|
||||
### 创建一个账号 ###
|
||||
|
||||
现在我们准备创建一个ownCloud管理员帐号了。
|
||||
|
||||

|
||||
|
||||
欢迎来自你的个人云!注意你可以安装一个桌面或者移动端app来同步你的文件、日历、通讯录或者更多了。
|
||||
|
||||

|
||||
|
||||
在右上叫,点击你的用户名,会显示一个下拉菜单:
|
||||
|
||||

|
||||
|
||||
点击Personal来改变你的设置,比如密码,显示名,email地址、头像还有更多。
|
||||
|
||||
### ownCloud 使用案例:访问日历 ###
|
||||
|
||||
让我开始添加一个事件到日历中并稍后下载。
|
||||
|
||||
点击左上角的下拉菜单并选择日历。
|
||||
|
||||

|
||||
|
||||
添加一个时间并保存到你的日历中。
|
||||
|
||||

|
||||
|
||||
通过 'Event and Tasks' -> 'Import...' -> 'Select file' 下载你的日历并添加到你的Thunderbird日历中:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
提示:你还需要设置你的时区以便在其他程序中成功地导入你的日历(默认情况下,日历程序将使用UTC+00:00时区)。要更改时区在左下角点击小齿轮图标,接着日历设置菜单就会出现,你就可以选择时区了:
|
||||
|
||||

|
||||
|
||||
### ownCloud 使用案例:上传一个文件 ###
|
||||
|
||||
接下来,我们会从本机上传一个文件
|
||||
|
||||
进入文件菜单(左上角)并点击向上箭头来打开一个选择文件对话框。
|
||||
|
||||

|
||||
|
||||
选择一个文件并点击打开。
|
||||
|
||||

|
||||
|
||||
接下来你就可以打开/编辑选中的文件,把它移到另外一个文件夹或者删除它了。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
ownCloud是一个灵活和强大的云存储,可以从其他供应商快速、简便、无痛的过渡。此外,它是开源软件,你只需要很少有时间和精力对其进行配置以满足你的所有需求。欲了解更多信息,可以随时参考[用户][3]、[管理][4]或[开发][5]手册。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-configure-owncloud-debian.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.gabrielcanepa.com.ar/
|
||||
[1]:http://owncloud.org/
|
||||
[2]:http://httpd.apache.org/docs/2.2/rewrite/flags.html
|
||||
[3]:http://doc.owncloud.org/server/7.0/ownCloudUserManual.pdf
|
||||
[4]:http://doc.owncloud.org/server/7.0/ownCloudAdminManual.pdf
|
||||
[5]:http://doc.owncloud.org/server/7.0/ownCloudDeveloperManual.pdf
|
||||
@ -0,0 +1,156 @@
|
||||
如何在 Linux 系统中创建一个云端的加密文件系统
|
||||
================================================================================
|
||||
[Amazon S3][1] 和 [Google Cloud Storage][2] 之类的商业云存储服务以能承受的价格提供了高可用性、可扩展、无限容量的对象存储服务。为了加速这些云产品的广泛采用,这些提供商为他们的产品基于明确的 API 和 SDK 培养了一个良好的开发者生态系统。而基于云的文件系统便是这些活跃的开发者社区中的典型产品,已经有了好几个开源的实现。
|
||||
|
||||
[S3QL][3] 便是最流行的开源云端文件系统之一。它是一个基于 FUSE 的文件系统,提供了好几个商业或开源的云存储后端,比如 Amazon S3、Google Cloud Storage、Rackspace CloudFiles,还有 OpenStack。作为一个功能完整的文件系统,S3QL 拥有不少强大的功能:最大 2T 的文件大小、压缩、UNIX 属性、加密、基于写入时复制的快照、不可变树、重复数据删除,以及软、硬链接支持等等。写入 S3QL 文件系统任何数据都将首先被本地压缩、加密,之后才会传输到云后端。当你试图从 S3QL 文件系统中取出内容的时候,如果它们不在本地缓存中,相应的对象会从云端下载回来,然后再即时地解密、解压缩。
|
||||
|
||||
需要明确的是,S3QL 的确也有它的限制。比如,你不能把同一个 S3FS 文件系统在几个不同的电脑上同时挂载,只能有一台电脑同时访问它。另外,ACL(访问控制列表)也并没有被支持。
|
||||
|
||||
在这篇教程中,我将会描述“如何基于 Amazon S3 用 S3QL 配置一个加密文件系统”。作为一个使用范例,我还会说明如何在挂载的 S3QL 文件系统上运行 rsync 备份工具。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
本教程首先需要你创建一个 [Amazon AWS 帐号][4](注册是免费的,但是需要一张有效的信用卡)。
|
||||
|
||||
然后 [创建一个 AWS access key][4](access key ID 和 secret access key),S3QL 使用这些信息来访问你的 AWS 帐号。
|
||||
|
||||
之后通过 AWS 管理面板访问 AWS S3,并为 S3QL 创建一个新的空 bucket。
|
||||
|
||||

|
||||
|
||||
为最佳性能考虑,请选择一个地理上距离你最近的区域。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 上安装 S3QL ###
|
||||
|
||||
在大多数 Linux 发行版中都有预先编译好的 S3QL 软件包。
|
||||
|
||||
#### 对于 Debian、Ubuntu 或 Linux Mint:####
|
||||
|
||||
$ sudo apt-get install s3ql
|
||||
|
||||
#### 对于 Fedora:####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
|
||||
对于 Arch Linux,使用 [AUR][6]。
|
||||
|
||||
### 首次配置 S3QL ###
|
||||
|
||||
在 ~/.s3ql 目录中创建 autoinfo2 文件,它是 S3QL 的一个默认的配置文件。这个文件里的信息包括必须的 AWS access key,S3 bucket 名,以及加密口令。这个加密口令将被用来加密一个随机生成的主密钥,而主密钥将被用来实际地加密 S3QL 文件系统数据。
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
[s3]
|
||||
storage-url: s3://[bucket-name]
|
||||
backend-login: [your-access-key-id]
|
||||
backend-password: [your-secret-access-key]
|
||||
fs-passphrase: [your-encryption-passphrase]
|
||||
|
||||
指定的 AWS S3 bucket 需要预先通过 AWS 管理面板来创建。
|
||||
|
||||
为了安全起见,让 authinfo2 文件仅对你可访问。
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### 创建 S3QL 文件系统 ###
|
||||
|
||||
现在你已经准备好可以在 AWS S3 上创建一个 S3QL 文件系统了。
|
||||
|
||||
使用 mkfs.s3ql 工具来创建一个新的 S3QL 文件系统。这个命令中的 bucket 名应该与 authinfo2 文件中所指定的相符。使用“--ssl”参数将强制使用 SSL 连接到后端存储服务器。默认情况下,mkfs.s3ql 命令会在 S3QL 文件系统中启用压缩和加密。
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
你会被要求输入一个加密口令。请输入你在 ~/.s3ql/autoinfo2 中通过“fs-passphrase”指定的那个口令。
|
||||
|
||||
如果一个新文件系统被成功创建,你将会看到这样的输出:
|
||||
|
||||

|
||||
|
||||
### 挂载 S3QL 文件系统 ###
|
||||
|
||||
当你创建了一个 S3QL 文件系统之后,下一步便是要挂载它。
|
||||
|
||||
首先创建一个本地的挂载点,然后使用 mount.s3ql 命令来挂载 S3QL 文件系统。
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
挂载一个 S3QL 文件系统不需要特权用户,只要确定你对该挂载点有写权限即可。
|
||||
|
||||
视情况,你可以使用“--compress”参数来指定一个压缩算法(如 lzma、bzip2、zlib)。在不指定的情况下,lzma 将被默认使用。注意如果你指定了一个自定义的压缩算法,它将只会应用到新创建的数据对象上,并不会影响已经存在的数据对象。
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
因为性能原因,S3QL 文件系统维护了一份本地文件缓存,里面包括了最近访问的(部分或全部的)文件。你可以通过“--cachesize”和“--max-cache-entries”选项来自定义文件缓存的大小。
|
||||
|
||||
如果想要除你以外的用户访问一个已挂载的 S3QL 文件系统,请使用“--allow-other”选项。
|
||||
|
||||
如果你想通过 NFS 导出已挂载的 S3QL 文件系统到其他机器,请使用“--nfs”选项。
|
||||
|
||||
运行 mount.s3ql 之后,检查 S3QL 文件系统是否被成功挂载了:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||

|
||||
|
||||
### 卸载 S3QL 文件系统 ###
|
||||
|
||||
想要安全地卸载一个(可能含有未提交数据的)S3QL 文件系统,请使用 umount.s3ql 命令。它将会等待所有数据(包括本地文件系统缓存中的部分)成功传输到后端服务器。取决于等待写的数据的多少,这个过程可能需要一些时间。
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
### 查看 S3QL 文件系统统计信息及修复 S3QL 文件系统 ###
|
||||
|
||||
若要查看 S3QL 文件系统统计信息,你可以使用 s3qlstat 命令,它将会显示诸如总的数据、元数据大小、重复文件删除率和压缩率等信息。
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||

|
||||
|
||||
你可以使用 fsck.s3ql 命令来检查和修复 S3QL 文件系统。与 fsck 命令类似,待检查的文件系统必须首先被卸载。
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL 使用案例:Rsync 备份 ###
|
||||
|
||||
让我用一个流行的使用案例来结束这篇教程:本地文件系统备份。为此,我推荐使用 rsync 增量备份工具,特别是因为 S3QL 提供了一个 rsync 的封装脚本(/usr/lib/s3ql/pcp.py)。这个脚本允许你使用多个 rsync 进程递归地复制目录树到 S3QL 目标。
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||

|
||||
|
||||
下面这个命令将会使用 4 个并发的 rsync 连接来备份 ~/Documents 里的所有内容到一个 S3QL 文件系统。
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
这些文件将首先被复制到本地文件缓存中,然后在后台再逐步地同步到后端服务器。
|
||||
|
||||
若想了解与 S3QL 有关的更多信息,如自动挂载、快照、不可变树,我强烈推荐阅读 [官方用户指南][7]。欢迎告诉我你对 S3QL 怎么看,以及你对任何其他工具的使用经验。
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://aws.amazon.com/s3
|
||||
[2]:http://code.google.com/apis/storage/
|
||||
[3]:https://bitbucket.org/nikratio/s3ql/
|
||||
[4]:http://aws.amazon.com/
|
||||
[5]:http://ask.xmodulo.com/create-amazon-aws-access-key.html
|
||||
[6]:https://aur.archlinux.org/packages/s3ql/
|
||||
[7]:http://www.rath.org/s3ql-docs/
|
||||
@ -0,0 +1,155 @@
|
||||
如何用Nagios远程执行插件(NRPE)来检测服务器内存使用率
|
||||
================================================================================
|
||||
在[先前的教程中][1]注:此篇文章在同一个更新中,如果也翻译了,发布的时候可修改相应的链接,我们已经见到了如何在Nagios设置中设置Nagios远程执行插件(NRPE)。然而,监控内存使用率的脚本和插件并没有在原生的Nagios中。本篇中,我们会看到如何配置NRPE来监控远程服务器上的内存使用率。
|
||||
|
||||
我们要用的监控内存的脚本在[Nagios 市场][2]上,也在创建者的[Github仓库][3]中。
|
||||
|
||||
假设我们已经安装了NRPE,我们首先在我们想要监控的服务器上下载脚本。
|
||||
|
||||
### 准备远程服务器 ###
|
||||
|
||||
#### 在 Debain/Ubuntu 中: ####
|
||||
|
||||
# cd /usr/lib/nagios/plugins/
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
#### 在 RHEL/CentOS 中: ####
|
||||
|
||||
# cd /usr/lib64/nagios/plugins/ (or /usr/lib/nagios/plugins/ for 32-bit)
|
||||
# wget https://raw.githubusercontent.com/justintime/nagios-plugins/master/check_mem/check_mem.pl
|
||||
# mv check_mem.pl check_mem
|
||||
# chmod +x check_mem
|
||||
|
||||
你可以通过手工在本地运行下面的命令来检查脚本的输出是否正常。当使用NRPE时,这条命令应该会检测空闲的内存,当可用内存小于20%时会发出警告,并且在可用内存小于10%时会生成一个严重警告。
|
||||
|
||||
# ./check_mem -f -w 20 -c 10
|
||||
|
||||
----------
|
||||
|
||||
OK - 34.0% (2735744 kB) free.|TOTAL=8035340KB;;;; USED=5299596KB;6428272;7231806;; FREE=2735744KB;;;; CACHES=2703504KB;;;;
|
||||
|
||||
如果你看到像上面那样的输出,那就意味这命令正常工作着。
|
||||
|
||||
现在脚本已经准备好了,我们要定义NRPE检查内存使用率的命令了。如上所述,命令会检查可用内存,在可用率小于20%时发出警报,小于10%时发出严重警告。
|
||||
|
||||
# vim /etc/nagios/nrpe.cfg
|
||||
|
||||
#### 对于 Debian/Ubuntu: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### 对于 RHEL/CentOS 32 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
#### 对于 RHEL/CentOS 64 bit: ####
|
||||
|
||||
command[check_mem]=/usr/lib64/nagios/plugins/check_mem -f -w 20 -c 10
|
||||
|
||||
### 准备 Nagios 服务器 ###
|
||||
|
||||
在Nagios服务器中,我们为NRPE定义了一条自定义命令。该命令可存储在Nagios内的任何目录中。为了让本教程简单,我们会将命令定义放在/etc/nagios目录中。
|
||||
|
||||
#### 对于 Debian/Ubuntu: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
#### 对于 RHEL/CentOS 32 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
#### 对于 RHEL/CentOS 64 bit: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_command.cfg
|
||||
|
||||
----------
|
||||
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib64/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
|
||||
}
|
||||
|
||||
现在我们定义Nagios的服务检查
|
||||
|
||||
#### 在 Debian/Ubuntu 上: ####
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
#### 在 RHEL/CentOS 上: ####
|
||||
|
||||
# vim /etc/nagios/objects/nrpe_service_check.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use local-service
|
||||
host_name remote-server
|
||||
service_description Check RAM
|
||||
check_command check_nrpe!check_mem
|
||||
}
|
||||
|
||||
最后我们重启Nagios服务
|
||||
|
||||
#### 在 Debian/Ubuntu 上: ####
|
||||
|
||||
# service nagios3 restart
|
||||
|
||||
#### 在 RHEL/CentOS 6 上: ####
|
||||
|
||||
# service nagios restart
|
||||
|
||||
#### 在 RHEL/CentOS 7 上: ####
|
||||
|
||||
# systemctl restart nagios.service
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
Nagios应该开始在使用NRPE的远程服务器上检查内存使用率了。如果你有任何问题,你可以检查下面这些情况。
|
||||
|
||||
|
||||
- 确保NRPE的端口在远程主机上是总是允许的。默认NRPE的端口是TCP 5666。
|
||||
- 你可以尝试通过执行check_nrpe 命令: /usr/lib/nagios/plugins/check_nrpe -H remote-server 手工检查NRPE操作。
|
||||
- 你同样可以尝试运行check_mem 命令:/usr/lib/nagios/plugins/check_nrpe -H remote-server –c check_mem
|
||||
- 在远程服务器上,在/etc/nagios/nrpe.cfg中设置debug=1。重启NRPE服务并检查这些日志文件,/var/log/messages (RHEL/CentOS)或者/var/log/syslog (Debain/Ubuntu)。如果有任何的配置或者权限错误,日志中应该包含了相关的信息。如果日志中没有反映出什么,很有可能是由于请求在某些端口上有过滤而没有到达远程服务器上。
|
||||
|
||||
总结一下,这边教程描述了我们该如何调试NRPE来监控远程服务器的内存使用率。过程只需要下载脚本、定义命令和重启服务就行了。希望这对你们有帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/monitor-server-memory-usage-nagios-remote-plugin-executor.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/2014/03/nagios-remote-plugin-executor-nrpe-linux.html
|
||||
[2]:http://exchange.nagios.org/directory/Plugins/Operating-Systems/Solaris/check_mem-2Epl/details
|
||||
[3]:https://github.com/justintime/nagios-plugins/blob/master/check_mem/check_mem.pl
|
||||
@ -0,0 +1,152 @@
|
||||
如何用Puppet和Augeas管理Linux配置
|
||||
================================================================================
|
||||
虽然[Puppet][1](注:此文原文原文中曾今做过,文件名:“20140808 How to install Puppet server and client on CentOS and RHEL.md”,如果翻译发布过,可修改此链接为发布地址)是一个非常独特的和有用的工具,在有些情况下你可以使用一点不同的方法。要修改的配置文件已经在几个不同的服务器上且它们在这时是互补相同的。Puppet实验室的人也意识到了这一点并集成了一个伟大的工具,称之为[Augeas][2],它是专为这种使用情况而设计的。
|
||||
|
||||
|
||||
Augeas可被认为填补了Puppet能力的缺陷,其中一个特定对象的资源类型(如主机资源来处理/etc/hosts中的条目)还不可用。在这个文档中,您将学习如何使用Augeas来减轻你管理配置文件的负担。
|
||||
|
||||
### Augeas是什么? ###
|
||||
|
||||
Augeas基本上就是一个配置编辑工具。它以他们原生的格式解析配置文件并且将它们转换成树。配置的更改可以通过操作树来完成,并可以以原生配置文件格式保存配置。
|
||||
|
||||
### 这篇教程要达成什么目的? ###
|
||||
|
||||
我们会安装并配置Augeas用于我们之前构建的Puppet服务器。我们会使用这个工具创建并测试几个不同的配置文件,并学习如何适当地使用它来管理我们的系统配置。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
我们需要一台工作的Puppet服务器和客户端。如果你还没有,请先按照我先前的教程来。
|
||||
|
||||
Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet用到的ruby封装的Augeas只在puppetlabs仓库中(或者[EPEL][4])中才有。如果你系统中还没有这个仓库,请使用下面的命令:
|
||||
|
||||
在CentOS/RHEL 6.5上:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabsrelease610.noarch.rpm
|
||||
|
||||
在CentOS/RHEL 7上:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabsrelease710.noarch.rpm
|
||||
|
||||
在你成功地安装了这个仓库后,在你的系统中安装RubyAugeas:
|
||||
|
||||
# yum install rubyaugeas
|
||||
|
||||
或者如果你是从我的上一篇教程中继续的,使用puppet的方法安装这个包。在/etc/puppet/manifests/site.pp中修改你的custom_utils类,在packages这行中加入“rubyaugeas”。
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
### 不带Puppet的Augeas ###
|
||||
|
||||
如我先前所说,最初Augeas并不是来自Puppet实验室,这意味着即使没有Puppet本身我们仍然可以使用它。这种方法可在你将它们部署到Puppet环境之前,验证你的修改和想法是否是正确的。要做到这一点,你需要在你的系统中安装一个额外的软件包。请执行以下命令:
|
||||
|
||||
# yum install augeas
|
||||
|
||||
### Puppet Augeas 示例 ###
|
||||
|
||||
用于演示,这里有几个Augeas使用案例。
|
||||
|
||||
#### 管理 /etc/sudoers 文件 ####
|
||||
|
||||
1. 给wheel组加上sudo权限。
|
||||
|
||||
这个例子会向你战士如何在你的GNU/Linux系统中为%wheel组加上sudo权限。
|
||||
|
||||
# 安装sudo包
|
||||
package { 'sudo':
|
||||
ensure => installed, # 确保sudo包已安装
|
||||
}
|
||||
|
||||
# 允许用户属于wheel组来使用sudo
|
||||
augeas { 'sudo_wheel':
|
||||
context => '/files/etc/sudoers', # 目标文件是 /etc/sudoers
|
||||
changes => [
|
||||
# 允许wheel用户使用sudo
|
||||
'set spec[user = "%wheel"]/user %wheel',
|
||||
'set spec[user = "%wheel"]/host_group/host ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command/runas_user ALL',
|
||||
]
|
||||
}
|
||||
|
||||
现在来解释这些代码做了什么:**spec**定义了/etc/sudoers中的用户段,**[user]**定义了数组中给定的用户,所有的定义的斜杠( / ) 后用户的子部分。因此在典型的配置中这个可以这么表达:
|
||||
|
||||
user host_group/host host_group/command host_group/command/runas_user
|
||||
|
||||
这个将被转换成/etc/sudoers下的这一行:
|
||||
|
||||
%wheel ALL = (ALL) ALL
|
||||
|
||||
2. 添加命令别称
|
||||
|
||||
下面这部分会向你展示如何定义命令别名,他可以在你的sudoer文件中使用。
|
||||
|
||||
# 创建新的SERVICE别名,包含了一些基本的特权命令。
|
||||
augeas { 'sudo_cmdalias':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/name SERVICES",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[1] /sbin/service",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[2] /sbin/chkconfig",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[3] /bin/hostname",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[4] /sbin/shutdown",
|
||||
]
|
||||
}
|
||||
|
||||
sudo命令别名的语法很简单:**Cmnd_Alias**定义了命令别名字段,**[alias/name]**绑定所有给定的别名,/alias/name **SERVICES** 定义真实的别名以及alias/command 是所有命令的数组,每条命令是这个别名的一部分。
|
||||
|
||||
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
||||
|
||||
关于/etc/sudoers的更多信息,请访问[官方文档][5]。
|
||||
|
||||
#### 向一个组中加入用户 ####
|
||||
|
||||
要使用Augeas向组中添加用户,你有也许要添加一个新用户,无论是在gid字段后或者在最后一个用户后。我们在这个例子中使用组SVN。这可以通过下面的命令达成:
|
||||
|
||||
在Puppet中:
|
||||
|
||||
augeas { 'augeas_mod_group:
|
||||
context => '/files/etc/group', # The target file is /etc/group
|
||||
changes => [
|
||||
"ins user after svn/*[self::gid or self::user][last()]",
|
||||
"set svn/user[last()] john",
|
||||
]
|
||||
}
|
||||
|
||||
使用 augtool:
|
||||
|
||||
augtool> ins user after /files/etc/group/svn/*[self::gid or self::user][last()] augtool> set /files/etc/group/svn/user[last()] john
|
||||
|
||||
### 总结 ###
|
||||
|
||||
目前为止,你应该对如何在Puppet项目中使用Augeas有一个好想法了。随意地试一下,你肯定会经历官方的Augeas文档。这会帮助你了解如何在你的个人项目中正确地使用Augeas,并且它会想你展示你可以用它节省多少时间。
|
||||
|
||||
如有任何问题,欢迎在下面的评论中发布,我会尽力解答和向你建议。
|
||||
|
||||
### 有用的链接 ###
|
||||
|
||||
- [http://www.watzmann.net/categories/augeas.html][6]: contains a lot of tutorials focused on Augeas usage.
|
||||
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki with a lot of practical examples.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/manage-configurations-linux-puppet-augeas.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
[2]:http://augeas.net/
|
||||
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
||||
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://augeas.net/docs/references/lenses/files/sudoers-aug.html
|
||||
[6]:http://www.watzmann.net/categories/augeas.html
|
||||
[7]:http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas
|
||||
111
translated/tech/20140928 How to Use Systemd Timers.md
Normal file
111
translated/tech/20140928 How to Use Systemd Timers.md
Normal file
@ -0,0 +1,111 @@
|
||||
如何使用系统定时器
|
||||
================================================================================
|
||||
我最近在写一些运行备份的脚本,我决定使用[systemd timers][1]而不是对我而已更熟悉的[cron jobs][2]来管理它们。
|
||||
|
||||
在我使用时,出现了很多问题需要我去各个地方找资料,这个过程非常麻烦。因此,我想要把我目前所做的记录下来,方便自己的记忆,也方便读者不必像我这样,满世界的找资料了。
|
||||
|
||||
在我下面提到的步骤中有其他的选择,但是这边是最简单的方法。在此之前,查看**systemd.service**, **systemd.timer**,和**systemd.target**的帮助页面(man),学习你能用它们做些什么。
|
||||
|
||||
### 运行一个简单的脚本 ###
|
||||
|
||||
假设你有一个脚本叫:**/usr/local/bin/myscript** ,你想要每隔一小时就运行一次。
|
||||
|
||||
#### Service 文件 ####
|
||||
|
||||
第一步,创建一个service文件,根据你Linux的发行版本放到相应的系统目录(在Arch中,这个目录是**/etc/systemd/system/** 或 **/usr/lib/systemd/system**)
|
||||
|
||||
myscript.service
|
||||
|
||||
[Unit]
|
||||
Description=MyScript
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/usr/local/bin/myscript
|
||||
|
||||
注意,务必将**Type**变量的值设置为"simple"而不是"oneshot"。使用"oneshot"使得脚本只在第一次运行,之后系统会认为你不想再次运行它,从而关掉我们接下去创建的定时器(Timer)。
|
||||
|
||||
#### Timer 文件 ####
|
||||
|
||||
第二步,创建一个timer文件,把它放在第一步中service文件放置的目录。
|
||||
|
||||
myscript.timer
|
||||
|
||||
[Unit]
|
||||
Description=Runs myscript every hour
|
||||
|
||||
[Timer]
|
||||
# Time to wait after booting before we run first time
|
||||
OnBootSec=10min
|
||||
# Time between running each consecutive time
|
||||
OnUnitActiveSec=1h
|
||||
Unit=myscript.service
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
#### 授权 / 运行 ####
|
||||
|
||||
授权并运行的是timer文件,而不是service文件。
|
||||
|
||||
# Start timer, as root
|
||||
systemctl start myscript.timer
|
||||
# Enable timer to start at boot
|
||||
systemctl enable myscript.timer
|
||||
|
||||
### 在同一个Timer上运行多个脚本 ###
|
||||
|
||||
现在我们假设你在相同时间想要运行多个脚本。这种情况,你需要在上面的文件中做适当的修改。
|
||||
|
||||
#### Service 文件 ####
|
||||
|
||||
像我[之前说过的][3]那样创建你的service文件来运行你的脚本,但是在每个service 文件最后都要包含下面的内容:
|
||||
|
||||
[Install]
|
||||
WantedBy=mytimer.target
|
||||
|
||||
如果在你的service 文件中有一些规则,确保你使用**Description**字段中的值具体化**After=something.service**和**Before=whatever.service**中的参数。
|
||||
|
||||
另外的一种选择是(或许更加简单),创建一个包装者脚本来使用正确的规则运行合理的命令,并在你的service文件中使用这个脚本。
|
||||
|
||||
#### Timer 文件 ####
|
||||
|
||||
你只需要一个timer文件,创建**mytimer.timer**,像我在[上面指出的](4)。
|
||||
|
||||
#### target 文件 ####
|
||||
|
||||
你可以创建一个以上所有的脚本依赖的target文件。
|
||||
|
||||
mytimer.target
|
||||
|
||||
[Unit]
|
||||
Description=Mytimer
|
||||
# Lots more stuff could go here, but it's situational.
|
||||
# Look at systemd.unit man page.
|
||||
|
||||
#### 授权 / 启动 ####
|
||||
|
||||
你需要将所有的service文件和timer文件授权。
|
||||
|
||||
systemctl enable script1.service
|
||||
systemctl enable script2.service
|
||||
...
|
||||
systemctl enable mytimer.timer
|
||||
systemctl start mytimer.service
|
||||
|
||||
Good luck.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#enable--start-1
|
||||
|
||||
作者:Jason Graham
|
||||
译者:[译者ID](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://fedoraproject.org/wiki/User:Johannbg/QA/Systemd/Systemd.timer
|
||||
[2]:https://en.wikipedia.org/wiki/Cron
|
||||
[3]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#service-file
|
||||
[4]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#timer-file-1
|
||||
@ -0,0 +1,109 @@
|
||||
Git Rebase教程: 用Git Rebase让时光倒流
|
||||
================================================================================
|
||||

|
||||
|
||||
Christoph Burgdorf自10岁时就是一名程序员,他是HannoverJS Meetup网站的创始人,并且一直活跃在AngularJS社区。他也是非常了解gti的内内外外,在那里他举办一个[thoughtram][1]的工作室来帮助初学者掌握该技术。
|
||||
|
||||
下面的教程最初发表在他的[blog][2]。
|
||||
|
||||
----------
|
||||
|
||||
### 教程: Git Rebase ###
|
||||
|
||||
想象一下你正在开发一个激进的新功能。这将是很灿烂的但它需要一段时间。您这几天也许是几个星期一直在做这个。
|
||||
|
||||
你的功能分支已经超前master有6个提交了。你是一个优秀的开发人员并做了有意义的语义提交。但有一件事情:你开始慢慢意识到,这个野兽仍需要更多的时间才能真的做好准备被合并回主分支。
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
|
||||
你也知道的是,一些地方实际上是少耦合的新功能。它们可以更早地合并到主分支。不幸的是,你想将部分合并到主分支的内容存在于你六个提交中的某个地方。更糟糕的是,它也包含了依赖于你的功能分支的之前的提交。有人可能会说,你应该在第一处地方做两次提交,但没有人是完美的。
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
^
|
||||
|
|
||||
mixed commit
|
||||
|
||||
在你准备提交的时间,你没有预见到,你可能要逐步把该功能合并入主分支。哎呀!你不会想到这件事会有这么久。
|
||||
|
||||
你需要的是一种方法可以回溯历史,把它并分成两次提交,这样就可以把代码都安全地分离出来,并可以移植到master分支。
|
||||
|
||||
用图说话,就是我们需要这样。
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3a-f3b-f4-f5-f6(feature)
|
||||
|
||||
在将工作分成两个提交后,我们就可以cherry-pick出前面的部分到主分支了。
|
||||
|
||||
原来Git自带了一个功能强大的命令git rebase -i ,它可以让我们这样做。它可以让我们改变历史。改变历史可能会产生问题,并作为一个经验法应尽快避免历史与他人共享。在我们的例子中,虽然我们只是改变我们的本地功能分支的历史。没有人会受到伤害。这这么做了!
|
||||
|
||||
好吧,让我们来仔细看看f3提交究竟修改了什么。原来我们共修改了两个文件:userService.js和wishlistService.js。比方说,userService.js的更改可以直接合入主分支而wishlistService.js不能。因为wishlistService.js甚至没有在主分支存在。这根据的是f1提交中的介绍。
|
||||
|
||||
>>专家提示:即使是在一个文件中更改,git也可以搞定。但这篇博客中我们要让事情变得简单。
|
||||
|
||||
我们已经建立了一个[公众演示仓库][3],我们将使用这个来练习。为了便于跟踪,每一个提交信息的前缀是在上面的图表中使用的假的SHA。以下是git在分开提交f3时的分支图。
|
||||
|
||||

|
||||
|
||||
现在,我们要做的第一件事就是使用git的checkout功能checkout出我们的功能分支。用git rebase -i master开始做rebase。
|
||||
|
||||
现在接下来git会用配置的编辑器打开(默认为Vim)一个临时文件。
|
||||
|
||||

|
||||
|
||||
该文件为您提供一些rebase选择,它带有一个提示(蓝色文字)。对于每一个提交,我们可以选择的动作有pick、rwork、edit、squash、fixup和exec。每一个动作也可以通过它的缩写形式p、r、e、s、f和e引用。描述每一个选项超出了本文范畴,所以让我们专注于我们的具体任务。
|
||||
|
||||
我们要为f3提交选择编辑选项,因此我们把内容改变成这样。
|
||||
|
||||
现在我们保存文件(在Vim中是按下<ESC>后输入:wq,最后是按下回车)。接下来我们注意到git在编辑选项中选择的提交处停止了rebase。
|
||||
|
||||
这意味这git开始为f1、f2、f3生效仿佛它就是常规的rebase但是在f3**之后**停止。事实上,我们可以看一眼停止的地方的日志就可以证明这一点。
|
||||
|
||||
要将f3分成两个提交,我们所要做的是重置git的指针到先前的提交(f2)而保持工作目录和现在一样。这就是git reset在混合模式在做的。由于混合模式是git reset的默认模式,我们可以直接用git reset head~1。就这么做并在运行后用git status看下发生了什么。
|
||||
|
||||
git status告诉我们userService.js和wishlistService.js被修改了。如果我们与行git diff 我们就可以看见在f3里面确切地做了哪些更改。
|
||||
|
||||
如果我们看一眼日志我们会发现f3已经消失了。
|
||||
|
||||
现在我们有了准备提交的先前的f3提交而原先的f3提交已经消失了。记住虽然我们仍旧在rebase的中间过程。我们的f4、f5、f6提交还没有缺失,它们会在接下来回来。
|
||||
|
||||
|
||||
让我们创建两个新的提交:首先让我们为可以提交到主分支的userService.js创建一个提交。运行git add userService.js 接着运行 git commit -m "f3a: add updateUser method"。
|
||||
|
||||
太棒了!让我们为wishlistService.js的改变创建另外一个提交。运行git add wishlistService.js,接着运行git commit -m "f3b: add addItems method".
|
||||
|
||||
让我们在看一眼日志。
|
||||
|
||||
这就是我们想要的除了f4、f5、f6仍旧缺失。这是因为我们仍在rebase交互的中间,我们需要告诉git继续rebase。用下面的命令继续:git rebase --continue。
|
||||
|
||||
让我们再次检查一下日志。
|
||||
|
||||
就是这样。我们现在已经得到我们想要的历史了。先前的f3提交现在已经被分割成两个提交f3a和f3b。剩下的最后一件事是cherry-pick出f3a提交到主分支上。
|
||||
|
||||
为了完成最后一步,我们首先切换到主分支。我们用git checkout master。现在我们就可以用cherry-pick命令来拾取f3a commit了。本例中我们可以用它的SHA值bd47ee1来引用它。
|
||||
|
||||
现在f3a这个提交i就在主分支的最上面了。这就是我们需要的!
|
||||
|
||||
这篇文章的长度看起来需要花费很大的功夫,但实际上对于一个git高级用户而言这只是一会会。
|
||||
|
||||
>注:Christoph目前正在与Pascal Precht写一本关于[Git rebase][4]的书,您可以在leanpub订阅它并在准备出版时获得通知。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/git-tutorial/git-rebase-split-old-commit-master
|
||||
|
||||
作者:[cburgdorf][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/cburgdorf
|
||||
[1]:http://thoughtram.io/
|
||||
[2]:http://blog.thoughtram.io/posts/going-back-in-time-to-split-older-commits/
|
||||
[3]:https://github.com/thoughtram/interactive-rebase-demo
|
||||
[4]:https://leanpub.com/rebase-the-complete-guide-on-rebasing-in-git
|
||||
@ -0,0 +1,122 @@
|
||||
集所有功能与一身的Linux系统性能和使用活动监控工具-Sysstat
|
||||
===========================================================================
|
||||
**Sysstat**是一个非常方便的工具,它带有众多的系统资源监控工具,用于监控系统的性能和使用情况。我们在日常使用的工具中有相当一部分是来自sysstat工具包的。同时,它还提供了一种使用cron表达式来制定性能和活动数据的收集计划。
|
||||
|
||||

|
||||
|
||||
在Linux系统中安装Sysstat
|
||||
|
||||
下表是包含在sysstat包中的工具
|
||||
|
||||
- [**isstat**][1]: 输出CPU的统计信息和所有I/O设备的输入输出(I/O)统计信息。
|
||||
- **mpstat**: 关于多有CPU的详细信息(单独输出或者分组输出)。
|
||||
- **pidstat**: 关于运行中的进程/任务、CPU、内存等的统计信息。
|
||||
- **sar**: 保存并输出不同系统资源(CPU、内存、IO、网络、内核、等。。。)的详细信息。
|
||||
- **sadc**: 系统活动数据收集器,用于手机sar工具的后端数据。
|
||||
- **sa1**: 系统手机并存储sadc数据文件的二进制数据,与sadc工具配合使用
|
||||
- **sa2**: 配合sar工具使用,产生每日的摘要报告。
|
||||
- **sadf**: 用于以不同的数据格式(CVS或者XML)来格式化sar工具的输出。
|
||||
- **Sysstat**: sysstat工具的man帮助页面。
|
||||
- **nfsiostat**: NFS(Network File System)的I/O统计信息。
|
||||
- **cifsiostat**: CIFS(Common Internet File System)的统计信息。
|
||||
|
||||
最近(在2014年6月17日),**sysstat 11.0.0**(稳定版)已经发布了,同时还新增了一些有趣的特性,如下:
|
||||
|
||||
pidstat命令新增了一些新的选项:首先是“-R”选项,该选项将会输出有关策略和任务调度的优先级信息。然后是“**-G**”选项,通过这个选项我们可以使用名称搜索进程,然后列出所有匹配的线程。
|
||||
|
||||
sar、sadc和sadf命令在数据文件方面同样带来了一些功能上的增强。与以往只能使用“**saDD**”来命名数据文件。现在使用**-D**选项可以用“**saYYYYMMDD**”来重命名数据文件,同样的,现在的数据文件不必放在“**var/log/sa**”目录中,我们可以使用“SA_DIR”变量来定义新的目录,该变量将应用与sa1和sa2命令。
|
||||
|
||||
###在Linux系统中安装Sysstat####
|
||||
|
||||
在主要的linux发行版中,‘**Sysstat**’工具包可以在默认的程序库中安装。然而,在默认程序库中的版本通常有点旧,因此,我们将会下载源代码包,编译安装最新版本(**11.0.0**版本)。
|
||||
|
||||
首先,使用下面的连接下载最新版本的sysstat包,或者你可以使用**wget**命令直接在终端中下载。
|
||||
|
||||
- [http://sebastien.godard.pagesperso-orange.fr/download.html][2]
|
||||
|
||||
# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.0.0.tar.gz
|
||||
|
||||

|
||||
|
||||
下载Sysstat包
|
||||
|
||||
然后解压缩下载下来的包,进去该目录,开始编译安装
|
||||
|
||||
# tar -xvf sysstat-11.0.0.tar.gz
|
||||
# cd sysstat-11.0.0/
|
||||
|
||||
这里,你有两种编译安装的方法:
|
||||
|
||||
a).第一,你可以使用**iconfig**(这将会给予你很大的灵活性,你可以选择/输入每个参数的自定义值)
|
||||
|
||||
# ./iconfig
|
||||
|
||||

|
||||
|
||||
Sysstat的iconfig命令
|
||||
|
||||
b).第二,你可以使用标准的**configure**命令在当行中定义所有选项。你可以运行 **./configure –help 命令**来列出该命令所支持的所有限选项。
|
||||
|
||||
# ./configure --help
|
||||
|
||||

|
||||
|
||||
Stsstat的cofigure -help
|
||||
|
||||
在这里,我们使用标准的**./configure**命令来编译安装sysstat工具包。
|
||||
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
在Linux系统中配置sysstat
|
||||
|
||||
在编译完成后,我们将会看到一些类似于上图的输出。现在运行如下命令来查看sysstat的版本。
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
###在Linux 系统中更新sysstat###
|
||||
|
||||
默认的,sysstat使用“**/usr/local**”作为其目录前缀。因此,所有的二进制数据/工具都会安装在“**/usr/local/bin**”目录中。如果你的系统已经安装了sysstat 工具包,则上面提到的二进制数据/工具有可能在“**/usr/bin**”目录中。
|
||||
|
||||
因为“**$PATH**”变量不包含“**/usr/local/bin**”路径,你在更新时可能会失败。因此,确保“**/usr/local/bin**”路径包含在“$PATH”环境变量中,或者在更新前,在编译和卸载旧版本时将**-prefix**选项指定值为“**/usr**”。
|
||||
|
||||
# yum remove sysstat [On RedHat based System]
|
||||
# apt-get remove sysstat [On Debian based System]
|
||||
|
||||
----------
|
||||
|
||||
# ./configure --prefix=/usr
|
||||
# make
|
||||
# make install
|
||||
|
||||
现在,使用‘mpstat’命令的‘**-V**’选项查看更新后的版本。
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
**参考**: 更多详细的信息请到 [Sysstat Documentation][3]
|
||||
|
||||
在我的下一篇文章中,我将会展示一些sysstat命令使用的实际例子,敬请关注更新。别忘了在下面评论框中留下您宝贵的意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-sysstat-in-linux/
|
||||
|
||||
作者:[Kuldeep Sharma][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/kuldeepsharma47/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[2]:http://sebastien.godard.pagesperso-orange.fr/download.html
|
||||
[3]:http://sebastien.godard.pagesperso-orange.fr/documentation.html
|
||||
@ -0,0 +1,113 @@
|
||||
2014年学习如何使用vim处理文件工作
|
||||
================================================================================
|
||||
|
||||
作为一名开发者你不能够只化时间去写你想要的代码。其中最难以处理的部分是我的工作只使用vim来处理文本。我感觉到很无语与无比的蛋疼,vim没有自己额外文件查看系统与内部打开与切换文件功能。因此,继vim之后,我主要使用Eclipse 和 Sublime Text.
|
||||
|
||||
就此,我非常欣赏深度定制的vim文件管理功能。在工作环境上我已经装配了这些工具,甚至比起那些视觉编辑器好很多。因为这个是纯键盘操作,促使我可以更加快地移动我的代码。第一篇文章使我明白这个vim内建功能只是处理文件的另一选择。在这篇文章里我会带你去认识vim文件管理功能与使用更高级的插件。
|
||||
|
||||
### 基础篇:打开新文件 ###
|
||||
|
||||
学习vim其中最大的一个障碍是缺少可视提示,不像现在的GUI图形编辑器,当你在终端打开一个新的vim是没有明显的提示去提醒你去走什么,所有事情都是靠键盘输入,同时也没有更多更好的界面交互,vim新手需要习惯如何靠自己去查找一些基本的操作指令。好吧,让我开始学习基础吧。
|
||||
|
||||
创建新文件的命令是**:e <filename>或:e** 打开一个新缓冲区保存文件内容。如果文件不存在它会开辟一个缓冲区去保存与修改你指定文件。缓冲区是vim是术语,意为"保存文本块到内存"。文本是否能够与存在的文件关联,要看是否每个你打开的文件都对应一个缓冲区。
|
||||
|
||||
|
||||
打开文件与修改文件之后,你可以使用**:w**命令来保存在缓冲区的文件内容到文件里面,如果缓冲区不能关联你的文件或者你想保存到另外一个地方,你需要使用**:w <filename>**来保存指定地方。
|
||||
|
||||
这些是vim处理文件的基本知识,很多的开发者都掌握了这些命令,这些技巧你都需要掌握。vim提供了很多技巧让人去深挖。
|
||||
|
||||
|
||||
### 缓冲区管理 ###
|
||||
|
||||
基础掌握了,就让我来说更多关于缓冲区得东西,vim处理打开文件与其他编辑器有一点不同,打开的文件不会作为一个标签留在一个可视地方,而是只允许你同时只有一个文件在缓冲区打开,vim允许你多个缓存打开。一些会显示出来,另外一些就不会,你需要用**:ls**来查看已经打开的缓存,这个命令会显示每个打开的缓存区,同时会有它们的序码,你可以通过这些序码实用**:b <buffer-number>**来切换或者使用循序移动命令**:bnext** 和 **:bprevious** 也可以使用它们的缩写**:bn**和**:bp**。
|
||||
|
||||
这些命令是vim管理文件缓冲区的一个基础,我发现他们不会按照我的思维去映射出来。我不想关心缓冲区的顺序,我只想按照我的思维去到那个文件或者想在当前这个文件.因此必需了解vim更深的缓存模式,我不是推荐你必须内部命令来作为主要的文件管理方案。但这些的确是很强大可行的选择。
|
||||
|
||||

|
||||
|
||||
### 分屏 ###
|
||||
|
||||
分屏是vim其中一个最好用的管理文件功能,在vim
|
||||
你可以在当前窗同时分开2个窗口,可以按照你喜欢的配置去重设大小和分配,这个很特别可以在不同地方同时打开6文件每个文件都拥有自己的窗口大少
|
||||
|
||||
你可以通过命令**:sp <filename>**来新建水平分割窗口或者 **:vs <filename>**垂直分割窗口。你可以使用这些关键命令去重置你想要的窗口,
|
||||
老实说,我喜欢用鼠标处理vim任务,因为鼠标能够给我更加准确的两列的宽度而不需要猜大概的宽度。
|
||||
|
||||
创建新的分屏后,你需要使用**ctrl-w
|
||||
[h|j|k|l]**来向后向前切换。这个有少少笨拙,但这个确实很重要很普遍很容易很高效的操作.如果你经常使用分屏,我建议你去.vimrc使用以下代码q去设置别名为**ctrl-h** **ctrl-j** 等等。
|
||||
|
||||
nnoremap <C-J> <C-W><C-J> "Ctrl-j to move down a split
|
||||
nnoremap <C-K> <C-W><C-K> "Ctrl-k to move up a split
|
||||
nnoremap <C-L> <C-W><C-L> "Ctrl-l to move right a split
|
||||
nnoremap <C-H> <C-W><C-H> "Ctrl-h to move left a split
|
||||
|
||||
### 跳转表 ###
|
||||
|
||||
分屏是解决多个关联文件同时查看问题,但我们仍然不能满足打开文件与隐藏文件之间快速移动。这时跳转表是一个能够解决的工具。
|
||||
|
||||
跳转表是众多插件中看其来奇怪而且很少使用。vim能够追踪每一步命令还有切换你正在修改的文件。每次从一个分屏窗口跳到另外一个,vim都会添加记录到跳转表里面。这个记录你去过的地方,这样就不需要担心之前的文件在哪里,你可以使用快捷键去快速追溯你的踪迹。**Ctrl-o**允许你返回你上一次地方。重复操作几次就能够返回到你最先编写的代码段地方。你可以使用**ctrl-i**来向前返回。当你在调试多个文件或两个文件之间切换能够发挥极大的快速移动功能。
|
||||
|
||||
|
||||
### 插件 ###
|
||||
|
||||
如果你想vim像Sublime Text 或者Atom一样,我就让你认清一下,这里有很好的机会让你看到一些难懂,可怕和低效的事情。例如大家会发出"当Sublime有了模糊查找功能,为什么我一定要输入全路径才能够打开文件" "没有侧边栏显示目录树我怎样查看项目结构" 。但vim有了解决方案。这些方案不需要破坏vim的核心。我只需要经常修改vim配置与添加一些最新的插件,这里有3个有用的插件可以让你像Sublime管理文件
|
||||
|
||||
- [CtrlP][1] 是一个跟Sublime的"Go to Anything"栏一样模糊查找文件.它快如闪电并且非常可配置性。我使用它最主要打开文件。我只需知道部分的文件名字不需要记住整个项目结构就可以查找了
|
||||
|
||||
- [The NERDTree][2]
|
||||
这个一个文件管理夹插件,它重复了很多编辑器的有的侧边文件管理夹功能。我实际上很少用它,对于我模糊查找会更加快。对于你接手一个项目,尝试学习项目结构与了解什么可以用是非常方便的,NERDTree是可以自己定制配置,安装它能够代替vim内置的目录工具。
|
||||
|
||||
|
||||
- [Ack.vim][3] 是一个专为vim的代码搜索插件,它允许你跨项目搜索文本。通过Ack 或 Ag 去高亮查找
|
||||
[第二个极其好用的搜索工具][4],允许你在任何时候在你项目之间快速搜索跳转
|
||||
|
||||
|
||||
在vim核心与它的插件生态系统之间,vim 提供足够的工具允许你构建你想要得工作环境。文件管理是软件开发系统的最核心部分并且你值得拥有体验的权利
|
||||
|
||||
|
||||
开始是需要通过很长的时间去理解它们,然后才找到你感觉舒服的工作流程之后才开始添加工具在上面。但依然值得你去使用,当你不需要头爆去理解如何去使用就能够轻易编写你的代码。
|
||||
|
||||
|
||||
### 更多插件资源 ###
|
||||
|
||||
- [Seamlessly Navigate Vim & Tmux Splits][5] 这个插件需要每一个想使用它的人都要懂得实用[tmux][6],这个跟vim的splits 一样简单好用
|
||||
|
||||
|
||||
- [Using Tab Pages][7] 它是一个vim的标签功能插件,虽然它的名字用起来有一点疑惑,但我不能说它是文件管理器。
|
||||
对如何在有多个工作可视区使用"tab
|
||||
pages" 在vim wiki 网站上有更好的概述
|
||||
|
||||
- [Vimcasts: The edit command][8] 一般来说 Vimcasts
|
||||
是大家学习vim的一个好资源。这个屏幕截图与一些内置工作流程是很好描述之前说得文件操作方面的知识
|
||||
|
||||
|
||||
### 订阅 ###
|
||||
|
||||
这篇文章通过第三个方面介绍如何通过一些好的手法学习vim。如果你喜欢这篇文章你可以通过[feed][8]来订阅或email我[mailing
|
||||
list][10]。在这个星期javascript小插曲之后,下星期我会继续介绍vim的配置方面的东西,你可以先看基础篇:使用vim
|
||||
看我前2篇系列文章和vim与vi的语言
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
|
||||
作者:[Ben McCormick][a]
|
||||
译者:[译者ID](https://github.com/haimingfg)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
[1]:https://github.com/kien/ctrlp.vim
|
||||
[2]:https://github.com/scrooloose/nerdtree
|
||||
[3]:https://github.com/mileszs/ack.vim
|
||||
[4]:http://benmccormick.org/2013/11/25/a-look-at-ack/
|
||||
[5]:http://robots.thoughtbot.com/seamlessly-navigate-vim-and-tmux-splits
|
||||
[6]:http://tmux.sourceforge.net/
|
||||
[7]:http://vim.wikia.com/wiki/Using_tab_pages
|
||||
[8]:http://vimcasts.org/episodes/the-edit-command/
|
||||
[9]:http://feedpress.me/benmccormick
|
||||
[10]:http://eepurl.com/WFYon
|
||||
[11]:http://benmccormick.org/2014/07/14/learning-vim-in-2014-configuring-vim/
|
||||
[12]:http://benmccormick.org/2014/06/30/learning-vim-in-2014-the-basics/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
Loading…
Reference in New Issue
Block a user