mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
375de44bbd
published
20160503 Cloud Commander - A Web File Manager With Console And Editor.md20171003 Trash-Cli - A Command Line Interface For Trashcan On Linux.md20180131 What I Learned from Programming Interviews.md20180720 How to build a URL shortener with Apache.md
sources
talk
tech
20171005 10 Games You Can Play on Linux with Wine.md20171124 How do groups work on Linux.md20180828 How to Play Windows-only Games on Linux with Steam Play.md20180910 3 open source log aggregation tools.md20180917 4 scanning tools for the Linux desktop.md20180917 Linux tricks that can save you time and trouble.md20180918 Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files.md20180918 How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04.md20180918 Linux firewalls- What you need to know about iptables and firewalld.md20180918 Top 3 Python libraries for data science.md
translated/tech
@ -1,9 +1,9 @@
|
||||
Cloud Commander – 一个有控制台和编辑器在 Web 上的文件管家
|
||||
Cloud Commander:一个有控制台和编辑器的 Web 文件管理器
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Cloud Commander** 是一个基于 web 的文件管理程序,它允许你通过任何计算机、移动端或平板电脑的浏览器查看、访问或管理系统文件或文件夹。他有两个简单而又经典的面板,并且会像你设备的显示尺寸一样自动转换大小。它也拥有两款内置的叫做 **Dword** 和 **Edward** 的文本编辑器,它们支持语法高亮和带有一个支持系统命令行的控制台。因此,您可以随时随地编辑文件。Cloud Commander 服务器是一款在 Linux,Windows,Mac OS X 运行的跨平台应用,而且该应用客户端将在任何一款浏览器上运行。它是用 **JavaScript/Node.Js** 写的,并使用 **MIT** 许可。
|
||||
**Cloud Commander** 是一个基于 web 的文件管理程序,它允许你通过任何计算机、移动端或平板电脑的浏览器查看、访问或管理系统文件或文件夹。它有两个简单而又经典的面板,并且会像你设备的显示尺寸一样自动转换大小。它也拥有两款内置的叫做 **Dword** 和 **Edward** 的文本编辑器,它们支持语法高亮,并带有一个支持系统命令行的控制台。因此,您可以随时随地编辑文件。Cloud Commander 服务器是一款在 Linux、Windows、Mac OS X 运行的跨平台应用,而且该应用客户端可以在任何一款浏览器上运行。它是用 **JavaScript/Node.Js** 写的,并使用 **MIT** 许可证。
|
||||
|
||||
在这个简易教程中,让我们看一看如何在 Ubuntu 18.04 LTS 服务器上安装 Cloud Commander。
|
||||
|
||||
@ -11,53 +11,52 @@ Cloud Commander – 一个有控制台和编辑器在 Web 上的文件管家
|
||||
|
||||
像我之前提到的,是用 Node.js 写的。所以为了安装 Cloud Commander,我们需要首先安装 Node.js。要执行安装,参考下面的指南。
|
||||
|
||||
- [如何在 Linux 上安装 Node.js](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
### 安装 Cloud Commander
|
||||
|
||||
在安装 Node.js 之后,运行下列命令安装 Cloud Commander:
|
||||
|
||||
```
|
||||
$ npm i cloudcmd -g
|
||||
|
||||
```
|
||||
|
||||
祝贺!Cloud Commander 已经被安装了。让我们往下继续看看 Cloud Commander 的基本使用。
|
||||
祝贺!Cloud Commander 已经安装好了。让我们往下继续看看 Cloud Commander 的基本使用。
|
||||
|
||||
### 开始使用 Cloud Commander
|
||||
|
||||
运行以下命令启动 Cloud Commander:
|
||||
运行以下命令启动 Cloud Commander:
|
||||
|
||||
```
|
||||
$ cloudcmd
|
||||
|
||||
```
|
||||
|
||||
**输出示例:**
|
||||
|
||||
```
|
||||
url: http://localhost:8000
|
||||
|
||||
```
|
||||
|
||||
现在,打开你的浏览器并转到链接:**http://localhost:8000** or **<http://IP-address:8000>**.
|
||||
现在,打开你的浏览器并转到链接:`http://localhost:8000` 或 `http://IP-address:8000`。
|
||||
|
||||
从现在开始,您可以直接在本地系统或远程系统或移动设备,平板电脑等Web浏览器中创建,删除,查看,管理文件或文件夹。
|
||||
|
||||
![][2]
|
||||
|
||||
当你看见上面的截图时,Clouder Commander 有两个面板,十个热键 (F1 to F10),还有控制台。
|
||||
如你所见上面的截图,Clouder Commander 有两个面板,十个热键 (`F1` 到 `F10`),还有控制台。
|
||||
|
||||
每个热键执行的都是一个任务。
|
||||
|
||||
* F1 – 帮助
|
||||
* F2 – 重命名文件/文件夹
|
||||
* F3 – 查看文件/文件夹
|
||||
* F4 – 编辑文件
|
||||
* F5 – 复制文件/文件夹
|
||||
* F6 – 移动文件/文件夹
|
||||
* F7 – 创建新目录
|
||||
* F8 – 删除文件/文件夹
|
||||
* F9 – 打开菜单
|
||||
* F10 – 打开设置
|
||||
|
||||
|
||||
* `F1` – 帮助
|
||||
* `F2` – 重命名文件/文件夹
|
||||
* `F3` – 查看文件/文件夹
|
||||
* `F4` – 编辑文件
|
||||
* `F5` – 复制文件/文件夹
|
||||
* `F6` – 移动文件/文件夹
|
||||
* `F7` – 创建新目录
|
||||
* `F8` – 删除文件/文件夹
|
||||
* `F9` – 打开菜单
|
||||
* `F10` – 打开设置
|
||||
|
||||
#### Cloud Commmander 控制台
|
||||
|
||||
@ -65,11 +64,11 @@ url: http://localhost:8000
|
||||
|
||||
![][3]
|
||||
|
||||
在此控制台中,您可以执行各种管理任务,例如安装软件包,删除软件包,更新系统等。您甚至可以关闭或重新引导系统。 因此,Cloud Commander 不仅仅是一个文件管理器,还具有远程管理工具的功能。
|
||||
在此控制台中,您可以执行各种管理任务,例如安装软件包、删除软件包、更新系统等。您甚至可以关闭或重新引导系统。 因此,Cloud Commander 不仅仅是一个文件管理器,还具有远程管理工具的功能。
|
||||
|
||||
#### 创建文件/文件夹
|
||||
|
||||
要创建新的文件或文件夹就右键单击任意空位置并找到 **New - >File or Directory**。
|
||||
要创建新的文件或文件夹就右键单击任意空位置并找到 “New - >File or Directory”。
|
||||
|
||||
![][4]
|
||||
|
||||
@ -83,39 +82,39 @@ url: http://localhost:8000
|
||||
|
||||
另一个很酷的特性是我们可以从任何系统或设备简单地上传一个文件到 Cloud Commander 系统。
|
||||
|
||||
要上传文件,右键单击 Cloud Commander 面板的任意空白处,并且单击**上传**选项。
|
||||
要上传文件,右键单击 Cloud Commander 面板的任意空白处,并且单击“Upload”选项。
|
||||
|
||||
![][6]
|
||||
|
||||
选择你想要上传的文件。
|
||||
|
||||
另外,你也可以上传来自像 Google 云盘, Dropbox, Amazon 云盘, Facebook, Twitter, Gmail, GtiHub, Picasa, Instagram 还有很多的云服务上的文件。
|
||||
另外,你也可以上传来自像 Google 云盘、Dropbox、Amazon 云盘、Facebook、Twitter、Gmail、GitHub、Picasa、Instagram 还有很多的云服务上的文件。
|
||||
|
||||
要从云端上传文件, 右键单击面板的任意空白处,并且右键单击面板任意空白处并选择**从云端上传**。
|
||||
要从云端上传文件, 右键单击面板的任意空白处,并且右键单击面板任意空白处并选择“Upload from Cloud”。
|
||||
|
||||
![][7]
|
||||
|
||||
选择任意一个你选择的网络服务,例如谷歌云盘。点击**连接到谷歌云盘**按钮。
|
||||
选择任意一个你选择的网络服务,例如谷歌云盘。点击“Connect to Google drive”按钮。
|
||||
|
||||
![][8]
|
||||
|
||||
下一步,用 Cloud Commander 验证你的谷歌云端硬盘,从谷歌云端硬盘选择文件并点击**上传**。
|
||||
下一步,用 Cloud Commander 验证你的谷歌云端硬盘,从谷歌云端硬盘选择文件并点击“Upload”。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 更新 Cloud Commander
|
||||
|
||||
要更新到最新的可用版本,执行下面的命令:
|
||||
|
||||
```
|
||||
$ npm update cloudcmd -g
|
||||
|
||||
```
|
||||
|
||||
#### 总结
|
||||
|
||||
据我测试,它运行地像魔幻一般。在我的Ubuntu服务器测试期间,我没有遇到任何问题。此外,Cloud Commander不仅是基于 Web 的文件管理器,还充当执行大多数Linux管理任务的远程管理工具。 您可以创建文件/文件夹,重命名,删除,编辑和查看它们。此外,您可以像在终端中在本地系统中那样安装,更新,升级和删除任何软件包。当然,您甚至可以从 Cloud Commander 控制台本身关闭或重启系统。 还有什么需要的吗? 尝试一下,你会发现它很有用。
|
||||
据我测试,它运行很好。在我的 Ubuntu 服务器测试期间,我没有遇到任何问题。此外,Cloud Commander 不仅是基于 Web 的文件管理器,还可以充当执行大多数 Linux 管理任务的远程管理工具。 您可以创建文件/文件夹、重命名、删除、编辑和查看它们。此外,您可以像在终端中在本地系统中那样安装、更新、升级和删除任何软件包。当然,您甚至可以从 Cloud Commander 控制台本身关闭或重启系统。 还有什么需要的吗? 尝试一下,你会发现它很有用。
|
||||
|
||||
目前为止就这样吧。 我将很快在这里发表另一篇有趣的文章。 在此之前,请继续关注 OSTechNix。
|
||||
目前为止就这样吧。 我将很快在这里发表另一篇有趣的文章。 在此之前,请继续关注我们。
|
||||
|
||||
祝贺!
|
||||
|
||||
@ -128,7 +127,7 @@ via: https://www.ostechnix.com/cloud-commander-a-web-file-manager-with-console-a
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Trash-Cli : Linux 上的命令行回收站工具
|
||||
Trash-Cli:Linux 上的命令行回收站工具
|
||||
======
|
||||
|
||||
相信每个人都对<ruby>回收站<rt>trashcan</rt></ruby>很熟悉,因为无论是对 Linux 用户,还是 Windows 用户,或者 Mac 用户来说,它都很常见。当你删除一个文件或目录的时候,该文件或目录会被移动到回收站中。
|
||||
@ -33,31 +33,27 @@ $ sudo apt install trash-cli
|
||||
|
||||
```
|
||||
$ sudo yum install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Fedora 用户,使用 [dnf][6] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo dnf install trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 Arch Linux 用户,使用 [pacman][7] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo pacman -S trash-cli
|
||||
|
||||
```
|
||||
|
||||
对于 openSUSE 用户,使用 [zypper][8] 命令来安装 Trash-Cli:
|
||||
|
||||
```
|
||||
$ sudo zypper in trash-cli
|
||||
|
||||
```
|
||||
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 pip 来安装。为了能够安装 python 包,你的系统中应该会有 pip 包管理器。
|
||||
如果你的发行版中没有提供 Trash-Cli 的安装包,那么你也可以使用 `pip` 来安装。为了能够安装 python 包,你的系统中应该会有 `pip` 包管理器。
|
||||
|
||||
```
|
||||
$ sudo pip install trash-cli
|
||||
@ -66,7 +62,6 @@ Collecting trash-cli
|
||||
Installing collected packages: trash-cli
|
||||
Running setup.py bdist_wheel for trash-cli ... done
|
||||
Successfully installed trash-cli-0.17.1.14
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 Trash-Cli
|
||||
@ -81,7 +76,7 @@ Trash-Cli 的使用不难,因为它提供了一个很简单的语法。Trash-C
|
||||
|
||||
下面,让我们通过一些例子来试验一下。
|
||||
|
||||
1)删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 2g.txt 这一文件和 magi 这一文件夹移动到回收站中。
|
||||
1) 删除文件和目录:在这个例子中,我们通过运行下面这个命令,将 `2g.txt` 这一文件和 `magi` 这一文件夹移动到回收站中。
|
||||
|
||||
```
|
||||
$ trash-put 2g.txt magi
|
||||
@ -89,7 +84,7 @@ $ trash-put 2g.txt magi
|
||||
|
||||
和你在文件管理器中看到的一样。
|
||||
|
||||
2)列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
2) 列出被删除了的文件和目录:为了查看被删除了的文件和目录,你需要运行下面这个命令。之后,你可以在输出中看到被删除文件和目录的详细信息,比如名字、删除日期和时间,以及文件路径。
|
||||
|
||||
```
|
||||
$ trash-list
|
||||
@ -97,7 +92,7 @@ $ trash-list
|
||||
2017-10-01 01:40:50 /home/magi/magi/magi
|
||||
```
|
||||
|
||||
3)从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 2g.txt 文件,所以我的选择是 0 。
|
||||
3) 从回收站中恢复文件或目录:任何时候,你都可以通过运行下面这个命令来恢复文件和目录。它将会询问你来选择你想要恢复的文件或目录。在这个例子中,我打算恢复 `2g.txt` 文件,所以我的选择是 `0` 。
|
||||
|
||||
```
|
||||
$ trash-restore
|
||||
@ -106,7 +101,7 @@ $ trash-restore
|
||||
What file to restore [0..1]: 0
|
||||
```
|
||||
|
||||
4)从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 magi 目录。
|
||||
4) 从回收站中删除文件:如果你想删除回收站中的特定文件,那么可以运行下面这个命令。在这个例子中,我将删除 `magi` 目录。
|
||||
|
||||
```
|
||||
$ trash-rm magi
|
||||
@ -118,11 +113,10 @@ $ trash-rm magi
|
||||
$ trash-empty
|
||||
```
|
||||
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 10 天的项目。
|
||||
6)删除超过 X 天的垃圾文件:或者,你可以通过运行下面这个命令来删除回收站中超过 X 天的文件。在这个例子中,我将删除回收站中超过 `10` 天的项目。
|
||||
|
||||
```
|
||||
$ trash-empty 10
|
||||
|
||||
```
|
||||
|
||||
Trash-Cli 可以工作的很好,但是如果你想尝试它的一些替代品,那么你也可以试一试 [gvfs-trash][9] 和 [autotrash][10] 。
|
||||
@ -133,7 +127,7 @@ via: https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,28 @@
|
||||
|
||||
我从编程面试中学到的
|
||||
============================================================
|
||||
|
||||
======
|
||||
|
||||

|
||||
聊聊白板编程面试
|
||||
|
||||
在2017年,我参加了[Grace Hopper Celebration][1]‘计算机行业中的女性’这一活动。这个活动是这类科技活动中最大的一个。共有17,000名女性IT工作者参加。
|
||||
*聊聊白板编程面试*
|
||||
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
在 2017 年,我参加了 ‘计算机行业中的女性’ 的[Grace Hopper 庆祝活动][1]。这个活动是这类科技活动中最大的一个。共有 17,000 名女性IT工作者参加。
|
||||
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到 offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
|
||||
为了能更多的帮到像她们一样的白面面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了[prodcast episode][2]上。它们也是这篇文章的主题。
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
|
||||
为了能更多的帮到像她们一样的小白面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了 [prodcast episode][2] 上。它们也是这篇文章的主题。
|
||||
|
||||
为了实习生职位和全职工作,我做过很多次的面试。当我还在大学主修计算机科学时,学校每个秋季学期都有招聘会,第一轮招聘会在校园里举行。(我在第一和最后一轮都搞砸过。)不过,每次面试后,我都会反思哪些方面我能做的更好,我还会和朋友们做模拟面试,这样我就能从他们那儿得到更多的面试反馈。
|
||||
|
||||
不管我们怎么样找工作: 工作中介,网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
不管我们怎么样找工作: 工作中介、网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
|
||||
近年来,我注意到了一些新的不同的面试形式出现了:
|
||||
|
||||
* 与招聘方的一位工程师结对编程
|
||||
* 网络在线测试及在线编码
|
||||
* 白板编程(LCTT译者注: 这种形式应该不新了)
|
||||
|
||||
* 白板编程(LCTT 译注: 这种形式应该不新了)
|
||||
|
||||
我将重点谈谈白板面试,这种形式我经历的最多。我有过很多次面试,有些挺不错的,有些被我搞砸了。
|
||||
|
||||
@ -31,7 +30,7 @@
|
||||
|
||||
首先,我想回顾一下我做的不好的地方。知错能改,善莫大焉。
|
||||
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
|
||||
这里我犯了两个错误:
|
||||
|
||||
@ -41,7 +40,7 @@
|
||||
|
||||
#### 只会默默思考,不去记录想法或和面试官沟通
|
||||
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得要么我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
|
||||
### 想到一个解题方法
|
||||
|
||||
@ -50,30 +49,27 @@
|
||||
这是对我管用的步骤:
|
||||
|
||||
1. 头脑风暴
|
||||
|
||||
2. 写代码
|
||||
|
||||
3. 处理错误路径
|
||||
|
||||
4. 测试
|
||||
|
||||
#### 1\. 头脑风暴
|
||||
#### 1、 头脑风暴
|
||||
|
||||
对我来说,我会首先通过一些例子来视觉化我要解决的问题。比如说如果这个问题和数据结构中的树有关,我就会从树底层的空节点开始思考,如何处理一个节点的情况呢?两个节点呢?三个节点呢?这能帮助你从具体例子里抽象出你的解决方案。
|
||||
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现bug和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),'我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧'
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现 bug 和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),“我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧”。
|
||||
|
||||
#### 2\. 开始写代码,一气呵成
|
||||
#### 2、 开始写代码,一气呵成
|
||||
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总的可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始,未加优化的。(请熟悉算法中的O()的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, ‘还有更好的方法吗?’,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总是可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始的,未加优化的。(请熟悉算法中的 `O()` 的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, “还有更好的方法吗?”,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
|
||||
#### 3\. 错误处理
|
||||
#### 3、 错误处理
|
||||
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,'很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?',这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,“很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?”,这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
|
||||
#### 4\. 测试
|
||||
#### 4、 测试
|
||||
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,‘让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果。。。’
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,“让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果……”
|
||||
|
||||
在你结束之后,面试者有时会问你你将会怎么测试你的代码,你会涉及什么样的测试用例。我建议你用下面不同的分类来组织你的错误用例:
|
||||
|
||||
@ -83,7 +79,7 @@
|
||||
2. 错误用例
|
||||
3. 期望的正常用例
|
||||
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是[How We Test Software at Microsoft][3]。
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是 《[我们在微软如何测试软件][3]》。
|
||||
|
||||
对于错误用例,想一下什么是期望的错误情况并一一写下。
|
||||
|
||||
@ -91,50 +87,45 @@
|
||||
|
||||
### “你还有什么要问我的吗?”
|
||||
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,‘我没什么问题了’,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,“我没什么问题了”,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
|
||||
### 申请一份工作
|
||||
|
||||
|
||||
关于找工作申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
关于找工作和申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
|
||||
我个人并不推荐你用上述的方法去找工作。你会排除很多很好的公司,特别是你是在找实习工作或者入门级的职位时。
|
||||
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web开发?或是人工智能?当在招聘会上与招聘公司沟通是,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web 开发?或是人工智能?当在招聘会上与招聘公司沟通时,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
|
||||
#### 换组
|
||||
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了4轮面试。结果我搞砸了。
|
||||
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快2年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了 4 轮面试。结果我搞砸了。
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快 2 年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
|
||||
我在面试前也没有刷过数据结构和算法题。如果我做了的话,我将会在面试中更有信心。就算你已经在一家公司担任了软件工程师,在你去另外一个组面试前,我强烈建议你在一块白板上演练一下如何写代码。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我,你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我, 你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到 offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
以上内容来自["Programming interviews"][4] 章节,选自 [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]
|
||||
以上内容选自 《[The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]》的 “[编程面试][4]”章节,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
微软研究院Software Engineer II, www.thewomenintechshow.com站长,所有观点都只代表本人意见。
|
||||
微软研究院 Software Engineer II, www.thewomenintechshow.com 站长,所有观点都只代表本人意见。
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:DavidChenLiang (https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Edaena Salinas][a]
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
如何使用 Apache 构建 URL 缩短服务
|
||||
======
|
||||
> 用 Apache HTTP 服务器的 mod_rewrite 功能创建你自己的短链接。
|
||||
|
||||

|
||||
|
||||
很久以前,人们开始在 Twitter 上分享链接。140 个字符的限制意味着 URL 可能消耗一条推文的大部分(或全部),因此人们使用 URL 缩短服务。最终,Twitter 加入了一个内置的 URL 缩短服务([t.co][1])。
|
||||
|
||||
字符数现在不重要了,但还有其他原因要缩短链接。首先,缩短服务可以提供分析功能 —— 你可以看到你分享的链接的受欢迎程度。它还简化了制作易于记忆的 URL。例如,[bit.ly/INtravel][2] 比<https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>更容易记住。如果你想预先共享一个链接,但还不知道最终地址,这时 URL 缩短服务可以派上用场。。
|
||||
|
||||
与任何技术一样,URL 缩短服务并非都是正面的。通过屏蔽最终地址,缩短的链接可用于指向恶意或冒犯性内容。但是,如果你仔细上网,URL 缩短服务是一个有用的工具。
|
||||
|
||||
我们之前在网站上[发布过缩短服务的文章][3],但也许你想要运行一些由简单的文本文件支持的缩短服务。在本文中,我们将展示如何使用 Apache HTTP 服务器的 mod_rewrite 功能来设置自己的 URL 缩短服务。如果你不熟悉 Apache HTTP 服务器,请查看 David Both 关于[安装和配置][4]它的文章。
|
||||
|
||||
### 创建一个 VirtualHost
|
||||
|
||||
在本教程中,我假设你购买了一个很酷的域名,你将它专门用于 URL 缩短服务。例如,我的网站是 [funnelfiasco.com][5],所以我买了 [funnelfias.co][6] 用于我的 URL 缩短服务(好吧,它不是很短,但它可以满足我的虚荣心)。如果你不将缩短服务作为单独的域运行,请跳到下一部分。
|
||||
|
||||
第一步是设置将用于 URL 缩短服务的 VirtualHost。有关 VirtualHost 的更多信息,请参阅 [David Both 的文章][7]。这步只需要几行:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerName funnelfias.co
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
### 创建重写规则
|
||||
|
||||
此服务使用 HTTPD 的重写引擎来重写 URL。如果你在上面的部分中创建了 VirtualHost,则下面的配置跳到你的 VirtualHost 部分。否则跳到服务器的 VirtualHost 或主 HTTPD 配置。
|
||||
|
||||
```
|
||||
RewriteEngine on
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
```
|
||||
|
||||
第一行只是启用重写引擎。第二行在文本文件构建短链接的映射。上面的路径只是一个例子。你需要使用系统上使用有效路径(确保它可由运行 HTTPD 的用户帐户读取)。最后一行重写 URL。在此例中,它接受任何字符并在重写映射中查找它们。你可能希望重写时使用特定的字符串。例如,如果你希望所有缩短的链接都是 “slX”(其中 X 是数字),则将上面的 `(.+)` 替换为 `(sl\d+)`。
|
||||
|
||||
我在这里使用了临时重定向(HTTP 302)。这能让我稍后更新目标 URL。如果希望短链接始终指向同一目标,则可以使用永久重定向(HTTP 301)。用 `permanent` 替换第三行的 `temp`。
|
||||
|
||||
### 构建你的映射
|
||||
|
||||
编辑配置文件 `RewriteMap` 行中的指定文件。格式是空格分隔的键值存储。在每一行上放一个链接:
|
||||
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
```
|
||||
|
||||
### 重启 HTTPD
|
||||
|
||||
最后一步是重启 HTTPD 进程。这是通过 `systemctl restart httpd` 或类似命令完成的(命令和守护进程名称可能因发行版而不同)。你的链接缩短服务现已启动并运行。当你准备编辑映射时,无需重新启动 Web 服务器。你所要做的就是保存文件,Web 服务器将获取到差异。
|
||||
|
||||
### 未来的工作
|
||||
|
||||
此示例为你提供了基本的 URL 缩短服务。如果你想将开发自己的管理接口作为学习项目,它可以作为一个很好的起点。或者你可以使用它分享容易记住的链接到那些容易忘记的 URL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
@ -1,3 +1,6 @@
|
||||
heguangzhi translating
|
||||
|
||||
|
||||
Linus, His Apology, And Why We Should Support Him
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
### fuzheng1998 translating
|
||||
10 Games You Can Play on Linux with Wine
|
||||
======
|
||||

|
||||
|
||||
@ -1,143 +0,0 @@
|
||||
Translating by DavidChen
|
||||
|
||||
How do groups work on Linux?
|
||||
============================================================
|
||||
|
||||
Hello! Last week, I thought I knew how users and groups worked on Linux. Here is what I thought:
|
||||
|
||||
1. Every process belongs to a user (like `julia`)
|
||||
|
||||
2. When a process tries to read a file owned by a group, Linux a) checks if the user `julia` can access the file, and b) checks which groups `julia` belongs to, and whether any of those groups owns & can access that file
|
||||
|
||||
3. If either of those is true (or if the ‘any’ bits are set right) then the process can access the file
|
||||
|
||||
So, for example, if a process is owned by the `julia` user and `julia` is in the `awesome` group, then the process would be allowed to read this file.
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
|
||||
```
|
||||
|
||||
I had not thought carefully about this, but if pressed I would have said that it probably checks the `/etc/group` file at runtime to see what groups you’re in.
|
||||
|
||||
### that is not how groups work
|
||||
|
||||
I found out at work last week that, no, what I describe above is not how groups work. In particular Linux does **not** check which groups a process’s user belongs to every time that process tries to access a file.
|
||||
|
||||
Here is how groups actually work! I learned this by reading Chapter 9 (“Process Credentials”) of [The Linux Programming Interface][1] which is an incredible book. As soon as I realized that I did not understand how users and groups worked, I opened up the table of contents with absolute confidence that it would tell me what’s up, and I was right.
|
||||
|
||||
### how users and groups checks are done
|
||||
|
||||
They key new insight for me was pretty simple! The chapter starts out by saying that user and group IDs are **attributes of the process**:
|
||||
|
||||
* real user ID and group ID;
|
||||
|
||||
* effective user ID and group ID;
|
||||
|
||||
* saved set-user-ID and saved set-group-ID;
|
||||
|
||||
* file-system user ID and group ID (Linux-specific); and
|
||||
|
||||
* supplementary group IDs.
|
||||
|
||||
This means that the way Linux **actually** does group checks to see a process can read a file is:
|
||||
|
||||
* look at the process’s group IDs & supplementary group IDs (from the attributes on the process, **not** by looking them up in `/etc/group`)
|
||||
|
||||
* look at the group on the file
|
||||
|
||||
* see if they match
|
||||
|
||||
Generally when doing access control checks it uses the **effective** user/group ID, not the real user/group ID. Technically when accessing a file it actually uses the **file-system** ids but those are usually the same as the effective uid/gid.
|
||||
|
||||
### Adding a user to a group doesn’t put existing processes in that group
|
||||
|
||||
Here’s another fun example that follows from this: if I create a new `panda` group and add myself (bork) to it, then run `groups` to check my group memberships – I’m not in the panda group!
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
no `panda` in that list! To double check, let’s try making a file owned by the `panda`group and see if I can access it:
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
|
||||
```
|
||||
|
||||
Sure enough, I can’t access `panda-file.txt`. No big surprise there. My shell didn’t have the `panda` group as a supplementary GID before, and running `adduser bork panda` didn’t do anything to change that.
|
||||
|
||||
### how do you get your groups in the first place?
|
||||
|
||||
So this raises kind of a confusing question, right – if processes have groups baked into them, how do you get assigned your groups in the first place? Obviously you can’t assign yourself more groups (that would defeat the purpose of access control).
|
||||
|
||||
It’s relatively clear how processes I **execute** from my shell (bash/fish) get their groups – my shell runs as me, and it has a bunch of group IDs on it. Processes I execute from my shell are forked from the shell so they get the same groups as the shell had.
|
||||
|
||||
So there needs to be some “first” process that has your groups set on it, and all the other processes you set inherit their groups from that. That process is called your **login shell** and it’s run by the `login` program (`/bin/login`) on my laptop. `login` runs as root and calls a C function called `initgroups` to set up your groups (by reading `/etc/group`). It’s allowed to set up your groups because it runs as root.
|
||||
|
||||
### let’s try logging in again!
|
||||
|
||||
So! Let’s say I am running in a shell, and I want to refresh my groups! From what we’ve learned about how groups are initialized, I should be able to run `login` to refresh my groups and start a new login shell!
|
||||
|
||||
Let’s try it:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
|
||||
```
|
||||
|
||||
Sure enough, it works! Now the new shell that `login` spawned is part of the `panda` group! Awesome! This won’t affect any other shells I already have running. If I really want the new `panda` group everywhere, I need to restart my login session completely, which means quitting my window manager and logging in again.
|
||||
|
||||
### newgrp
|
||||
|
||||
Somebody on Twitter told me that if you want to start a new shell with a new group that you’ve been added to, you can use `newgrp`. Like this:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
|
||||
```
|
||||
|
||||
You can accomplish the same(ish) thing with `sg panda bash` which will start a `bash` shell that runs with the `panda` group.
|
||||
|
||||
### setuid sets the effective user ID
|
||||
|
||||
I’ve also always been a little vague about what it means for a process to run as “setuid root”. It turns out that setuid sets the effective user ID! So if I (`julia`) run a setuid root process (like `passwd`), then the **real** user ID will be set to `julia`, and the **effective** user ID will be set to `root`.
|
||||
|
||||
`passwd` needs to run as root, but it can look at its real user ID to see that `julia`started the process, and prevent `julia` from editing any passwords except for `julia`’s password.
|
||||
|
||||
### that’s all!
|
||||
|
||||
There are a bunch more details about all the edge cases and exactly how everything works in The Linux Programming Interface so I will not get into all the details here. That book is amazing. Everything I talked about in this post is from Chapter 9, which is a 17-page chapter inside a 1300-page book.
|
||||
|
||||
The thing I love most about that book is that reading 17 pages about how users and groups work is really approachable, self-contained, super useful, and I don’t have to tackle all 1300 pages of it at once to learn helpful things :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Play Windows-only Games on Linux with Steam Play
|
||||
======
|
||||
The new experimental feature of Steam allows you to play Windows-only games on Linux. Here’s how to use this feature in Steam right now.
|
||||
|
||||
@ -1,112 +0,0 @@
|
||||
heguangzhi Translating
|
||||
|
||||
3 open source log aggregation tools
|
||||
======
|
||||
Log aggregation systems can help with troubleshooting and other tasks. Here are three top options.
|
||||
|
||||

|
||||
|
||||
How is metrics aggregation different from log aggregation? Can’t logs include metrics? Can’t log aggregation systems do the same things as metrics aggregation systems?
|
||||
|
||||
These are questions I hear often. I’ve also seen vendors pitching their log aggregation system as the solution to all observability problems. Log aggregation is a valuable tool, but it isn’t normally a good tool for time-series data.
|
||||
|
||||
A couple of valuable features in a time-series metrics aggregation system are the regular interval and the storage system customized specifically for time-series data. The regular interval allows a user to derive real mathematical results consistently. If a log aggregation system is collecting metrics in a regular interval, it can potentially work the same way. However, the storage system isn’t optimized for the types of queries that are typical in a metrics aggregation system. These queries will take more resources and time to process using storage systems found in log aggregation tools.
|
||||
|
||||
So, we know a log aggregation system is likely not suitable for time-series data, but what is it good for? A log aggregation system is a great place for collecting event data. These are irregular activities that are significant. An example might be access logs for a web service. These are significant because we want to know what is accessing our systems and when. Another example would be an application error condition—because it is not a normal operating condition, it might be valuable during troubleshooting.
|
||||
|
||||
A handful of rules for logging:
|
||||
|
||||
* DO include a timestamp
|
||||
* DO format in JSON
|
||||
* DON’T log insignificant events
|
||||
* DO log all application errors
|
||||
* MAYBE log warnings
|
||||
* DO turn on logging
|
||||
* DO write messages in a human-readable form
|
||||
* DON’T log informational data in production
|
||||
* DON’T log anything a human can’t read or react to
|
||||
|
||||
|
||||
|
||||
### Cloud costs
|
||||
|
||||
When investigating log aggregation tools, the cloud might seem like an attractive option. However, it can come with significant costs. Logs represent a lot of data when aggregated across hundreds or thousands of hosts and applications. The ingestion, storage, and retrieval of that data are expensive in cloud-based systems.
|
||||
|
||||
As a point of reference from a real system, a collection of around 500 nodes with a few hundred apps results in 200GB of log data per day. There’s probably room for improvement in that system, but even reducing it by half will cost nearly $10,000 per month in many SaaS offerings. This often includes retention of only 30 days, which isn’t very long if you want to look at trending data year-over-year.
|
||||
|
||||
This isn’t to discourage the use of these systems, as they can be very valuable—especially for smaller organizations. The purpose is to point out that there could be significant costs, and it can be discouraging when they are realized. The rest of this article will focus on open source and commercial solutions that are self-hosted.
|
||||
|
||||
### Tool options
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1], short for Elasticsearch, Logstash, and Kibana, is the most popular open source log aggregation tool on the market. It’s used by Netflix, Facebook, Microsoft, LinkedIn, and Cisco. The three components are all developed and maintained by [Elastic][2]. [Elasticsearch][3] is essentially a NoSQL, Lucene search engine implementation. [Logstash][4] is a log pipeline system that can ingest data, transform it, and load it into a store like Elasticsearch. [Kibana][5] is a visualization layer on top of Elasticsearch.
|
||||
|
||||
A few years ago, Beats were introduced. Beats are data collectors. They simplify the process of shipping data to Logstash. Instead of needing to understand the proper syntax of each type of log, a user can install a Beat that will export NGINX logs or Envoy proxy logs properly so they can be used effectively within Elasticsearch.
|
||||
|
||||
When installing a production-level ELK stack, a few other pieces might be included, like [Kafka][6], [Redis][7], and [NGINX][8]. Also, it is common to replace Logstash with Fluentd, which we’ll discuss later. This system can be complex to operate, which in its early days led to a lot of problems and complaints. These have largely been fixed, but it’s still a complex system, so you might not want to try it if you’re a smaller operation.
|
||||
|
||||
That said, there are services available so you don’t have to worry about that. [Logz.io][9] will run it for you, but its list pricing is a little steep if you have a lot of data. Of course, you’re probably smaller and may not have a lot of data. If you can’t afford Logz.io, you could look at something like [AWS Elasticsearch Service][10] (ES). ES is a service Amazon Web Services (AWS) offers that makes it very easy to get Elasticsearch working quickly. It also has tooling to get all AWS logs into ES using Lambda and S3. This is a much cheaper option, but there is some management required and there are a few limitations.
|
||||
|
||||
Elastic, the parent company of the stack, [offers][11] a more robust product that uses the open core model, which provides additional options around analytics tools, and reporting. It can also be hosted on Google Cloud Platform or AWS. This might be the best option, as this combination of tools and hosting platforms offers a cheaper solution than most SaaS options and still provides a lot of value. This system could effectively replace or give you the capability of a [security information and event management][12] (SIEM) system.
|
||||
|
||||
The ELK stack also offers great visualization tools through Kibana, but it lacks an alerting function. Elastic provides alerting functionality within the paid X-Pack add-on, but there is nothing built in for the open source system. Yelp has created a solution to this problem, called [ElastAlert][13], and there are probably others. This additional piece of software is fairly robust, but it increases the complexity of an already complex system.
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] has recently risen in popularity, but it got its start when Lennart Koopmann created it back in 2010. A company was born with the same name two years later. Despite its increasing use, it still lags far behind the ELK stack. This also means it has fewer community-developed features, but it can use the same Beats that the ELK stack uses. Graylog has gained praise in the Go community with the introduction of the Graylog Collector Sidecar written in [Go][15].
|
||||
|
||||
Graylog uses Elasticsearch, [MongoDB][16], and the Graylog Server under the hood. This makes it as complex to run as the ELK stack and maybe a little more. However, Graylog comes with alerting built into the open source version, as well as several other notable features like streaming, message rewriting, and geolocation.
|
||||
|
||||
The streaming feature allows for data to be routed to specific Streams in real time while they are being processed. With this feature, a user can see all database errors in a single Stream and web server errors in a different Stream. Alerts can even be based on these Streams as new items are added or when a threshold is exceeded. Latency is probably one of the biggest issues with log aggregation systems, and Streams eliminate that issue in Graylog. As soon as the log comes in, it can be routed to other systems through a Stream without being processed fully.
|
||||
|
||||
The message rewriting feature uses the open source rules engine [Drools][17]. This allows all incoming messages to be evaluated against a user-defined rules file enabling a message to be dropped (called Blacklisting), a field to be added or removed, or the message to be modified.
|
||||
|
||||
The coolest feature might be Graylog’s geolocation capability, which supports plotting IP addresses on a map. This is a fairly common feature and is available in Kibana as well, but it adds a lot of value—especially if you want to use this as your SIEM system. The geolocation functionality is provided in the open source version of the system.
|
||||
|
||||
Graylog, the company, charges for support on the open source version if you want it. It also offers an open core model for its Enterprise version that offers archiving, audit logging, and additional support. There aren’t many other options for support or hosting, so you’ll likely be on your own if you don’t use Graylog (the company).
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] was developed at [Treasure Data][19], and the [CNCF][20] has adopted it as an Incubating project. It was written in C and Ruby and is recommended by [AWS][21] and [Google Cloud][22]. Fluentd has become a common replacement for Logstash in many installations. It acts as a local aggregator to collect all node logs and send them off to central storage systems. It is not a log aggregation system.
|
||||
|
||||
It uses a robust plugin system to provide quick and easy integrations with different data sources and data outputs. Since there are over 500 plugins available, most of your use cases should be covered. If they aren’t, this sounds like an opportunity to contribute back to the open source community.
|
||||
|
||||
Fluentd is a common choice in Kubernetes environments due to its low memory requirements (just tens of megabytes) and its high throughput. In an environment like [Kubernetes][23], where each pod has a Fluentd sidecar, memory consumption will increase linearly with each new pod created. Using Fluentd will drastically reduce your system utilization. This is becoming a common problem with tools developed in Java that are intended to run one per node where the memory overhead hasn’t been a major issue.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
@ -0,0 +1,72 @@
|
||||
4 scanning tools for the Linux desktop
|
||||
======
|
||||
Go paperless by driving your scanner with one of these open source applications.
|
||||
|
||||

|
||||
|
||||
While the paperless world isn't here quite yet, more and more people are getting rid of paper by scanning documents and photos. Having a scanner isn't enough to do the deed, though. You need software to drive that scanner.
|
||||
|
||||
But the catch is many scanner makers don't have Linux versions of the software they bundle with their devices. For the most part, that doesn't matter. Why? Because there are good scanning applications available for the Linux desktop. They work with a variety of scanners and do a good job.
|
||||
|
||||
Let's take a look at four simple but flexible open source Linux scanning tools. I've used each of these tools (and even wrote about three of them [back in 2014][1]) and found them very useful. You might, too.
|
||||
|
||||
### Simple Scan
|
||||
|
||||
One of my longtime favorites, [Simple Scan][2] is small, quick, efficient, and easy to use. If you've seen it before, that's because Simple Scan is the default scanner application on the GNOME desktop, as well as for a number of Linux distributions.
|
||||
|
||||
Scanning a document or photo takes one click. After scanning something, you can rotate or crop it and save it as an image (JPEG or PNG only) or as a PDF. That said, Simple Scan can be slow, even if you scan documents at lower resolutions. On top of that, Simple Scan uses a set of global defaults for scanning, like 150dpi for text and 300dpi for photos. You need to go into Simple Scan's preferences to change those settings.
|
||||
|
||||
If you've scanned something with more than a couple of pages, you can reorder the pages before you save. And if necessary—say you're submitting a signed form—you can email from within Simple Scan.
|
||||
|
||||
### Skanlite
|
||||
|
||||
In many ways, [Skanlite][3] is Simple Scan's cousin in the KDE world. Skanlite has few features, but it gets the job done nicely.
|
||||
|
||||
The software has options that you can configure, including automatically saving scanned files, setting the quality of the scan, and identifying where to save your scans. Skanlite can save to these image formats: JPEG, PNG, BMP, PPM, XBM, and XPM.
|
||||
|
||||
One nifty feature is the software's ability to save portions of what you've scanned to separate files. That comes in handy when, say, you want to excise someone or something from a photo.
|
||||
|
||||
### Gscan2pdf
|
||||
|
||||
Another old favorite, [gscan2pdf][4] might be showing its age, but it still packs a few more features than some of the other applications mentioned here. Even so, gscan2pdf is still comparatively light.
|
||||
|
||||
In addition to saving scans in various image formats (JPEG, PNG, and TIFF), gscan2pdf also saves them as PDF or [DjVu][5] files. You can set the scan's resolution, whether it's black and white or color, and paper size before you click the Scan button. That beats going into gscan2pdf's preferences every time you want to change any of those settings. You can also rotate, crop, and delete pages.
|
||||
|
||||
While none of those features are truly killer, they give you a bit more flexibility.
|
||||
|
||||
### GIMP
|
||||
|
||||
You probably know [GIMP][6] as an image-editing tool. But did you know you can use it to drive your scanner?
|
||||
|
||||
You'll need to install the [XSane][7] scanner software and the GIMP XSane plugin. Both of those should be available from your Linux distro's package manager. From there, select File > Create > Scanner/Camera. From there, click on your scanner and then the Scan button.
|
||||
|
||||
If that's not your cup of tea, or if it doesn't work, you can combine GIMP with a plugin called [QuiteInsane][8]. With either plugin, GIMP becomes a powerful scanning application that lets you set a number of options like whether to scan in color or black and white, the resolution of the scan, and whether or not to compress results. You can also use GIMP's tools to touch up or apply effects to your scans. This makes it great for scanning photos and art.
|
||||
|
||||
### Do they really just work?
|
||||
|
||||
All of this software works well for the most part and with a variety of hardware. I've used them with several multifunction printers that I've owned over the years—whether connecting using a USB cable or over wireless.
|
||||
|
||||
You might have noticed that I wrote "works well for the most part" in the previous paragraph. I did run into one exception: an inexpensive Canon multifunction printer. None of the software I used could detect it. I had to download and install Canon's Linux scanner software, which did work.
|
||||
|
||||
What's your favorite open source scanning tool for Linux? Share your pick by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-scanner-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
|
||||
[2]: https://gitlab.gnome.org/GNOME/simple-scan
|
||||
[3]: https://www.kde.org/applications/graphics/skanlite/
|
||||
[4]: http://gscan2pdf.sourceforge.net/
|
||||
[5]: http://en.wikipedia.org/wiki/DjVu
|
||||
[6]: http://www.gimp.org/
|
||||
[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
|
||||
[8]: http://sourceforge.net/projects/quiteinsane/
|
||||
@ -0,0 +1,169 @@
|
||||
Linux tricks that can save you time and trouble
|
||||
======
|
||||
Some command line tricks can make you even more productive on the Linux command line.
|
||||
|
||||

|
||||
|
||||
Good Linux command line tricks don’t only save you time and trouble. They also help you remember and reuse complex commands, making it easier for you to focus on what you need to do, not how you should go about doing it. In this post, we’ll look at some handy command line tricks that you might come to appreciate.
|
||||
|
||||
### Editing your commands
|
||||
|
||||
When making changes to a command that you're about to run on the command line, you can move your cursor to the beginning or the end of the command line to facilitate your changes using the ^a (control key plus “a”) and ^e (control key plus “e”) sequences.
|
||||
|
||||
You can also fix and rerun a previously entered command with an easy text substitution by putting your before and after strings between **^** characters -- as in ^before^after^.
|
||||
|
||||
```
|
||||
$ eho hello world <== oops!
|
||||
|
||||
Command 'eho' not found, did you mean:
|
||||
|
||||
command 'echo' from deb coreutils
|
||||
command 'who' from deb coreutils
|
||||
|
||||
Try: sudo apt install <deb name>
|
||||
|
||||
$ ^e^ec^ <== replace text
|
||||
echo hello world
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
### Logging into a remote system with just its name
|
||||
|
||||
If you log into other systems from the command line (I do this all the time), you might consider adding some aliases to your system to supply the details. Your alias can provide the username you want to use (which may or may not be the same as your username on your local system) and the identity of the remote server. Use an alias server_name=’ssh -v -l username IP-address' type of command like this:
|
||||
|
||||
```
|
||||
$ alias butterfly=”ssh -v -l jdoe 192.168.0.11”
|
||||
```
|
||||
|
||||
You can use the system name in place of the IP address if it’s listed in your /etc/hosts file or available through your DNS server.
|
||||
|
||||
And remember you can list your aliases with the **alias** command.
|
||||
|
||||
```
|
||||
$ alias
|
||||
alias butterfly='ssh -v -l jdoe 192.168.0.11'
|
||||
alias c='clear'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias grep='grep --color=auto'
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
alias list_repos='grep ^[^#] /etc/apt/sources.list /etc/apt/sources.list.d/*'
|
||||
alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
alias show_dimensions='xdpyinfo | grep '\''dimensions:'\'''
|
||||
```
|
||||
|
||||
It's good practice to test new aliases and then add them to your ~/.bashrc or similar file to be sure they will be available any time you log in.
|
||||
|
||||
### Freezing and thawing out your terminal window
|
||||
|
||||
The ^s (control key plus “s”) sequence will stop a terminal from providing output by running an XOFF (transmit off) flow control. This affects PuTTY sessions, as well as terminal windows on your desktop. Sometimes typed by mistake, however, the way to make the terminal window responsive again is to enter ^q (control key plus “q”). The only real trick here is remembering ^q since you aren't very likely run into this situation very often.
|
||||
|
||||
### Repeating commands
|
||||
|
||||
Linux provides many ways to reuse commands. The key to command reuse is your history buffer and the commands it collects for you. The easiest way to repeat a command is to type an ! followed by the beginning letters of a recently used command. Another is to press the up-arrow on your keyboard until you see the command you want to reuse and then press enter. You can also display previously entered commands and then type ! followed by the number shown next to the command you want to reuse in the displayed command history entries.
|
||||
|
||||
```
|
||||
!! <== repeat previous command
|
||||
!ec <== repeat last command that started with "ec"
|
||||
!76 <== repeat command #76 from command history
|
||||
```
|
||||
|
||||
### Watching a log file for updates
|
||||
|
||||
Commands such as tail -f /var/log/syslog will show you lines as they are being added to the specified log file — very useful if you are waiting for some particular activity or want to track what’s happening right now. The command will show the end of the file and then additional lines as they are added.
|
||||
|
||||
```
|
||||
$ tail -f /var/log/auth.log
|
||||
Sep 17 09:41:01 fly CRON[8071]: pam_unix(cron:session): session closed for user smmsp
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session closed for user root
|
||||
Sep 17 09:47:00 fly sshd[8124]: Accepted password for shs from 192.168.0.22 port 47792
|
||||
Sep 17 09:47:00 fly sshd[8124]: pam_unix(sshd:session): session opened for user shs by
|
||||
Sep 17 09:47:00 fly systemd-logind[776]: New session 215 of user shs.
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session closed for user root
|
||||
<== waits for additional lines to be added
|
||||
```
|
||||
|
||||
### Asking for help
|
||||
|
||||
For most Linux commands, you can enter the name of the command followed by the option **\--help** to get some fairly succinct information on what the command does and how to use it. Less extensive than the man command, the --help option often tells you just what you need to know without expanding on all of the options available.
|
||||
|
||||
```
|
||||
$ mkdir --help
|
||||
Usage: mkdir [OPTION]... DIRECTORY...
|
||||
Create the DIRECTORY(ies), if they do not already exist.
|
||||
|
||||
Mandatory arguments to long options are mandatory for short options too.
|
||||
-m, --mode=MODE set file mode (as in chmod), not a=rwx - umask
|
||||
-p, --parents no error if existing, make parent directories as needed
|
||||
-v, --verbose print a message for each created directory
|
||||
-Z set SELinux security context of each created directory
|
||||
to the default type
|
||||
--context[=CTX] like -Z, or if CTX is specified then set the SELinux
|
||||
or SMACK security context to CTX
|
||||
--help display this help and exit
|
||||
--version output version information and exit
|
||||
|
||||
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
|
||||
Full documentation at: <http://www.gnu.org/software/coreutils/mkdir>
|
||||
or available locally via: info '(coreutils) mkdir invocation'
|
||||
```
|
||||
|
||||
### Removing files with care
|
||||
|
||||
To add a little caution to your use of the rm command, you can set it up with an alias that asks you to confirm your request to delete files before it goes ahead and deletes them. Some sysadmins make this the default. In that case, you might like the next option even more.
|
||||
|
||||
```
|
||||
$ rm -i <== prompt for confirmation
|
||||
```
|
||||
|
||||
### Turning off aliases
|
||||
|
||||
You can always disable an alias interactively by using the unalias command. It doesn’t change the configuration of the alias in question; it just disables it until the next time you log in or source the file in which the alias is set up.
|
||||
|
||||
```
|
||||
$ unalias rm
|
||||
```
|
||||
|
||||
If the **rm -i** alias is set up as the default and you prefer to never have to provide confirmation before deleting files, you can put your **unalias** command in one of your startup files (e.g., ~/.bashrc).
|
||||
|
||||
### Remembering to use sudo
|
||||
|
||||
If you often forget to precede commands that only root can run with “sudo”, there are two things you can do. You can take advantage of your command history by using the “sudo !!” (use sudo to run your most recent command with sudo prepended to it), or you can turn some of these commands into aliases with the required "sudo" attached.
|
||||
|
||||
```
|
||||
$ alias update=’sudo apt update’
|
||||
```
|
||||
|
||||
### More complex tricks
|
||||
|
||||
Some useful command line tricks require a little more than a clever alias. An alias, after all, replaces a command, often inserting options so you don't have to enter them and allowing you to tack on additional information. If you want something more complex than an alias can manage, you can write a simple script or add a function to your .bashrc or other start-up file. The function below, for example, creates a directory and moves you into it. Once it's been set up, source your .bashrc or other file and you can use commands such as "md temp" to set up a directory and cd into it.
|
||||
|
||||
```
|
||||
md () { mkdir -p "$@" && cd "$1"; }
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
Working on the Linux command line remains one of the most productive and enjoyable ways to get work done on my Linux systems, but a group of command line tricks and clever aliases can make that experience even better.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-you-can-love.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,72 @@
|
||||
Cozy Is A Nice Linux Audiobook Player For DRM-Free Audio Files
|
||||
======
|
||||
[Cozy][1] **is a free and open source audiobook player for the Linux desktop. The application lets you listen to DRM-free audiobooks (mp3, m4a, flac, ogg and wav) using a modern Gtk3 interface.**
|
||||
|
||||
|
||||
|
||||
You could use any audio player to listen to audiobooks, but a specialized audiobook player like Cozy makes everything easier, by **remembering your playback position and continuing from where you left off for each audiobook** , or by letting you **set the playback speed of each book individually** , among others.
|
||||
|
||||
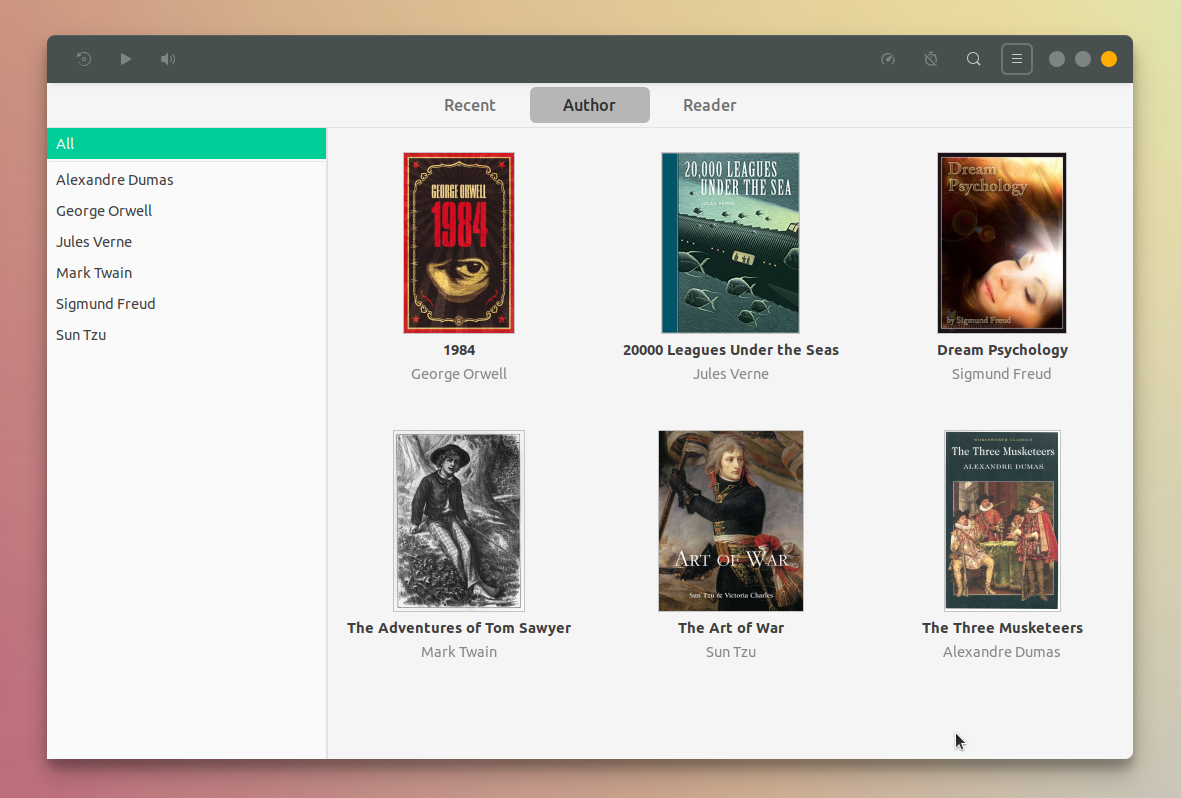
The Cozy interface lets you browse books by author, reader or recency, while also providing search functionality. **Books front covers are supported by Cozy** \- either by using embedded images, or by adding a cover.jpg or cover.png image in the book folder, which is automatically picked up and displayed by Cozy.
|
||||
|
||||
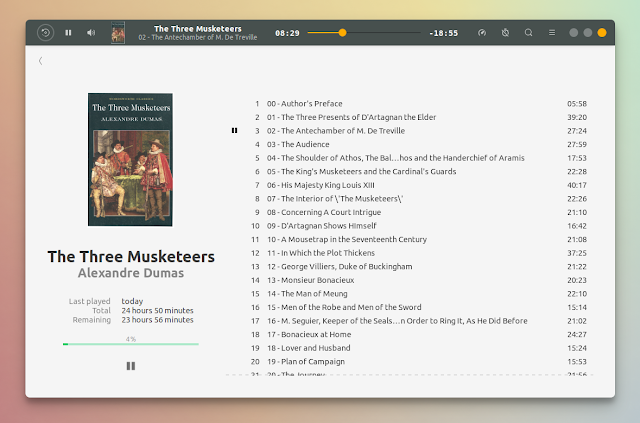
When you click on an audiobook, Cozy lists the book chapters on the right, while displaying the book cover (if available) on the left, along with the book name, author and the last played time, along with total and remaining time:
|
||||
|
||||
|
||||
|
||||
From the application toolbar you can easily **go back 30 seconds** by clicking the rewind icon from its top left-hand side corner. Besides regular controls, cover and title, you'll also find a playback speed button on the toolbar, which lets you increase the playback speed up to 2X.
|
||||
|
||||
**A sleep timer is also available**. It can be set to stop after the current chapter or after a given number of minutes.
|
||||
|
||||
Other Cozy features worth mentioning:
|
||||
|
||||
* **Mpris integration** (Media keys & playback info)
|
||||
* **Supports multiple storage locations**
|
||||
* **Drag'n'drop support for importing new audiobooks**
|
||||
* **Offline Mode**. If your audiobooks are on an external or network drive, you can switch the download button to keep a local cached copy of the book to listen to on the go. To enable this feature you have to set your storage location to external in the settings
|
||||
* **Prevents your system from suspend during playback**
|
||||
* **Dark mode**
|
||||
|
||||
|
||||
|
||||
What I'd like to see in Cozy is a way to get audiobooks metadata, including the book cover, automatically. A feature to retrieve metadata from Audible.com was proposed on the Cozy GitHub project page and the developer seems interested in this, but it's not clear when or if this will be implemented.
|
||||
|
||||
Like I was mentioning in the beginning of the article, Cozy only supports DRM-free audio files. Currently it supports mp3, m4a, flac, ogg and wav. Support for more formats will probably come in the future, with m4b being listed on the Cozy 0.7.0 todo list.
|
||||
|
||||
Cozy cannot play Audible audiobooks due to DRM. But you'll find some solutions out there for converting Audible (.aa/.aax) audiobooks to mp3, like
|
||||
|
||||
### Install Cozy
|
||||
|
||||
**Any Linux distribution / Flatpak** : Cozy is available as a Flatpak on FlatHub. To install it, follow the quick Flatpak [setup][4], then go to the Cozy FlaHub [page][5] and click the install button, or use the install command at the bottom if its page.
|
||||
|
||||
**elementary OS** : Cozy is available in the [AppCenter][6].
|
||||
|
||||
**Ubuntu 18.04 / Linux Mint 19** : you can install Cozy from its repository:
|
||||
|
||||
```
|
||||
wget -nv https://download.opensuse.org/repositories/home:geigi/Ubuntu_18.04/Release.key -O Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/geigi/Ubuntu_18.04/ /' > /etc/apt/sources.list.d/home:geigi.list"
|
||||
sudo apt update
|
||||
sudo apt install com.github.geigi.cozy
|
||||
```
|
||||
|
||||
**For other ways of installing Cozy check out its[website][2].**
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/09/cozy-is-nice-linux-audiobook-player-for.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/118280394805678839070
|
||||
[1]: https://cozy.geigi.de/
|
||||
[2]: https://cozy.geigi.de/#how-can-i-get-it
|
||||
[3]: https://gitlab.com/ReverendJ1/audiblefreedom/blob/master/audiblefreedom
|
||||
[4]: https://flatpak.org/setup/
|
||||
[5]: https://flathub.org/apps/details/com.github.geigi.cozy
|
||||
[6]: https://appcenter.elementary.io/com.github.geigi.cozy/
|
||||
@ -0,0 +1,47 @@
|
||||
How To Force APT Package Manager To Use IPv4 In Ubuntu 16.04
|
||||
======
|
||||
|
||||

|
||||
|
||||
**APT** , short or **A** dvanced **P** ackage **T** ool, is the default package manager for Debian-based systems. Using APT, we can install, update, upgrade and remove applications from the system. Lately, I have been facing a strange error. Whenever I try update my Ubuntu 16.04 box, I get this error – **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** and the update process gets stuck for a long time. My Internet connection is working well and I can able to ping all websites including Ubuntu official site. After a couple Google searches, I realized that sometimes the Ubuntu mirrors are not reachable over IPv6. This problem is solved after I force APT package manager to use IPv4 in place of IPv6 to access Ubuntu mirrors while updating the system. If you ever encountered with this error, you can solve it as described below.
|
||||
|
||||
### Force APT Package Manager To Use IPv4 In Ubuntu 16.04
|
||||
|
||||
To force APT to use IPv4 in place of IPv6 while updating and upgrading your Ubuntu 16.04 LTS systems, simply use the following commands:
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
Voila! This time update process run and completed quickly.
|
||||
|
||||
You can also make this persistent for all **apt-get** transactions in the future by adding the following line in **/etc/apt/apt.conf.d/99force-ipv4** file using command:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
```
|
||||
|
||||
**Disclaimer:**
|
||||
|
||||
I don’t know if anyone is having this issue lately, but I kept getting this error today at least four to five times in my Ubuntu 16.04 LTS virtual machine and I solved it as described above. I am not sure that it is the recommended solution. Go through Ubuntu forums and make sure this method is legitimate. Since mine is just a VM which I use it only for testing and learning purposes, I don’t mind about the authenticity of this method. Use it on your own risk.
|
||||
|
||||
Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-ubuntu-16-04/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,168 @@
|
||||
Linux firewalls: What you need to know about iptables and firewalld
|
||||
======
|
||||
Here's how to use the iptables and firewalld tools to manage Linux firewall connectivity rules.
|
||||
|
||||

|
||||
This article is excerpted from my book, [Linux in Action][1], and a second Manning project that’s yet to be released.
|
||||
|
||||
### The firewall
|
||||
|
||||
A firewall is a set of rules. When a data packet moves into or out of a protected network space, its contents (in particular, information about its origin, target, and the protocol it plans to use) are tested against the firewall rules to see if it should be allowed through. Here’s a simple example:
|
||||
|
||||
![firewall filtering request][3]
|
||||
|
||||
A firewall can filter requests based on protocol or target-based rules.
|
||||
|
||||
On the one hand, [iptables][4] is a tool for managing firewall rules on a Linux machine.
|
||||
|
||||
On the other hand, [firewalld][5] is also a tool for managing firewall rules on a Linux machine.
|
||||
|
||||
You got a problem with that? And would it spoil your day if I told you that there was another tool out there, called [nftables][6]?
|
||||
|
||||
OK, I’ll admit that the whole thing does smell a bit funny, so let me explain. It all starts with Netfilter, which controls access to and from the network stack at the Linux kernel module level. For decades, the primary command-line tool for managing Netfilter hooks was the iptables ruleset.
|
||||
|
||||
Because the syntax needed to invoke those rules could come across as a bit arcane, various user-friendly implementations like [ufw][7] and firewalld were introduced as higher-level Netfilter interpreters. Ufw and firewalld are, however, primarily designed to solve the kinds of problems faced by stand-alone computers. Building full-sized network solutions will often require the extra muscle of iptables or, since 2014, its replacement, nftables (through the nft command line tool).
|
||||
|
||||
iptables hasn’t gone anywhere and is still widely used. In fact, you should expect to run into iptables-protected networks in your work as an admin for many years to come. But nftables, by adding on to the classic Netfilter toolset, has brought some important new functionality.
|
||||
|
||||
From here on, I’ll show by example how firewalld and iptables solve simple connectivity problems.
|
||||
|
||||
### Configure HTTP access using firewalld
|
||||
|
||||
As you might have guessed from its name, firewalld is part of the [systemd][8] family. Firewalld can be installed on Debian/Ubuntu machines, but it’s there by default on Red Hat and CentOS. If you’ve got a web server like Apache running on your machine, you can confirm that the firewall is working by browsing to your server’s web root. If the site is unreachable, then firewalld is doing its job.
|
||||
|
||||
You’ll use the `firewall-cmd` tool to manage firewalld settings from the command line. Adding the `–state` argument returns the current firewall status:
|
||||
|
||||
```
|
||||
# firewall-cmd --state
|
||||
running
|
||||
```
|
||||
|
||||
By default, firewalld will be active and will reject all incoming traffic with a couple of exceptions, like SSH. That means your website won’t be getting too many visitors, which will certainly save you a lot of data transfer costs. As that’s probably not what you had in mind for your web server, though, you’ll want to open the HTTP and HTTPS ports that by convention are designated as 80 and 443, respectively. firewalld offers two ways to do that. One is through the `–add-port` argument that references the port number directly along with the network protocol it’ll use (TCP in this case). The `–permanent` argument tells firewalld to load this rule each time the server boots:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --add-port=80/tcp
|
||||
# firewall-cmd --permanent --add-port=443/tcp
|
||||
```
|
||||
|
||||
The `–reload` argument will apply those rules to the current session:
|
||||
|
||||
```
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
Curious as to the current settings on your firewall? Run `–list-services`:
|
||||
|
||||
```
|
||||
# firewall-cmd --list-services
|
||||
dhcpv6-client http https ssh
|
||||
```
|
||||
|
||||
Assuming you’ve added browser access as described earlier, the HTTP, HTTPS, and SSH ports should now all be open—along with `dhcpv6-client`, which allows Linux to request an IPv6 IP address from a local DHCP server.
|
||||
|
||||
### Configure a locked-down customer kiosk using iptables
|
||||
|
||||
I’m sure you’ve seen kiosks—they’re the tablets, touchscreens, and ATM-like PCs in a box that airports, libraries, and business leave lying around, inviting customers and passersby to browse content. The thing about most kiosks is that you don’t usually want users to make themselves at home and treat them like their own devices. They’re not generally meant for browsing, viewing YouTube videos, or launching denial-of-service attacks against the Pentagon. So to make sure they’re not misused, you need to lock them down.
|
||||
|
||||
One way is to apply some kind of kiosk mode, whether it’s through clever use of a Linux display manager or at the browser level. But to make sure you’ve got all the holes plugged, you’ll probably also want to add some hard network controls through a firewall. In the following section, I'll describe how I would do it using iptables.
|
||||
|
||||
There are two important things to remember about using iptables: The order you give your rules is critical, and by themselves, iptables rules won’t survive a reboot. I’ll address those here one at a time.
|
||||
|
||||
### The kiosk project
|
||||
|
||||
To illustrate all this, let’s imagine we work for a store that’s part of a larger chain called BigMart. They’ve been around for decades; in fact, our imaginary grandparents probably grew up shopping there. But these days, the guys at BigMart corporate headquarters are probably just counting the hours before Amazon drives them under for good.
|
||||
|
||||
Nevertheless, BigMart’s IT department is doing its best, and they’ve just sent you some WiFi-ready kiosk devices that you’re expected to install at strategic locations throughout your store. The idea is that they’ll display a web browser logged into the BigMart.com products pages, allowing them to look up merchandise features, aisle location, and stock levels. The kiosks will also need access to bigmart-data.com, where many of the images and video media are stored.
|
||||
|
||||
Besides those, you’ll want to permit updates and, whenever necessary, package downloads. Finally, you’ll want to permit inbound SSH access only from your local workstation, and block everyone else. The figure below illustrates how it will all work:
|
||||
|
||||
![kiosk traffic flow ip tables][10]
|
||||
|
||||
The kiosk traffic flow being controlled by iptables.
|
||||
|
||||
### The script
|
||||
|
||||
Here’s how that will all fit into a Bash script:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp --dport 80 -j DROP
|
||||
iptables -A OUTPUT -p tcp --dport 443 -j DROP
|
||||
iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
|
||||
```
|
||||
|
||||
The basic anatomy of our rules starts with `-A`, telling iptables that we want to add the following rule. `OUTPUT` means that this rule should become part of the OUTPUT chain. `-p` indicates that this rule will apply only to packets using the TCP protocol, where, as `-d` tells us, the destination is [bigmart.com][11]. The `-j` flag points to `ACCEPT` as the action to take when a packet matches the rule. In this first rule, that action is to permit, or accept, the request. But further down, you can see requests that will be dropped, or denied.
|
||||
|
||||
Remember that order matters. And that’s because iptables will run a request past each of its rules, but only until it gets a match. So an outgoing browser request for, say, [youtube.com][12] will pass the first four rules, but when it gets to either the `–dport 80` or `–dport 443` rule—depending on whether it’s an HTTP or HTTPS request—it’ll be dropped. iptables won’t bother checking any further because that was a match.
|
||||
|
||||
On the other hand, a system request to ubuntu.com for a software upgrade will get through when it hits its appropriate rule. What we’re doing here, obviously, is permitting outgoing HTTP or HTTPS requests to only our BigMart or Ubuntu destinations and no others.
|
||||
|
||||
The final two rules will deal with incoming SSH requests. They won’t already have been denied by the two previous drop rules since they don’t use ports 80 or 443, but 22. In this case, login requests from my workstation will be accepted but requests for anywhere else will be dropped. This is important: Make sure the IP address you use for your port 22 rule matches the address of the machine you’re using to log in—if you don’t do that, you’ll be instantly locked out. It's no big deal, of course, because the way it’s currently configured, you could simply reboot the server and the iptables rules will all be dropped. If you’re using an LXC container as your server and logging on from your LXC host, then use the IP address your host uses to connect to the container, not its public address.
|
||||
|
||||
You’ll need to remember to update this rule if my machine’s IP ever changes; otherwise, you’ll be locked out.
|
||||
|
||||
Playing along at home (hopefully on a throwaway VM of some sort)? Great. Create your own script. Now I can save the script, use `chmod` to make it executable, and run it as `sudo`. Don’t worry about that `bigmart-data.com not found` error—of course it’s not found; it doesn’t exist.
|
||||
|
||||
```
|
||||
chmod +X scriptname.sh
|
||||
sudo ./scriptname.sh
|
||||
```
|
||||
|
||||
You can test your firewall from the command line using `cURL`. Requesting ubuntu.com works, but [manning.com][13] fails.
|
||||
|
||||
```
|
||||
curl ubuntu.com
|
||||
curl manning.com
|
||||
```
|
||||
|
||||
### Configuring iptables to load on system boot
|
||||
|
||||
Now, how do I get these rules to automatically load each time the kiosk boots? The first step is to save the current rules to a .rules file using the `iptables-save` tool. That’ll create a file in the root directory containing a list of the rules. The pipe, followed by the tee command, is necessary to apply my `sudo` authority to the second part of the string: the actual saving of a file to the otherwise restricted root directory.
|
||||
|
||||
I can then tell the system to run a related tool called `iptables-restore` every time it boots. A regular cron job of the kind we saw in the previous module won’t help because they’re run at set times, but we have no idea when our computer might decide to crash and reboot.
|
||||
|
||||
There are lots of ways to handle this problem. Here’s one:
|
||||
|
||||
On my Linux machine, I’ll install a program called [anacron][14] that will give us a file in the /etc/ directory called anacrontab. I’ll edit the file and add this `iptables-restore` command, telling it to load the current values of that .rules file into iptables each day (when necessary) one minute after a boot. I’ll give the job an identifier (`iptables-restore`) and then add the command itself. Since you’re playing along with me at home, you should test all this out by rebooting your system.
|
||||
|
||||
```
|
||||
sudo iptables-save | sudo tee /root/my.active.firewall.rules
|
||||
sudo apt install anacron
|
||||
sudo nano /etc/anacrontab
|
||||
1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
|
||||
|
||||
```
|
||||
|
||||
I hope these practical examples have illustrated how to use iptables and firewalld for managing connectivity issues on Linux-based firewalls.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-iptables-firewalld
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
[2]: /file/409116
|
||||
[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
|
||||
[4]: https://en.wikipedia.org/wiki/Iptables
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
|
||||
[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
|
||||
[8]: https://en.wikipedia.org/wiki/Systemd
|
||||
[9]: /file/409121
|
||||
[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
|
||||
[11]: http://bigmart.com/
|
||||
[12]: http://youtube.com/
|
||||
[13]: http://manning.com/
|
||||
[14]: https://sourceforge.net/projects/anacron/
|
||||
244
sources/tech/20180918 Top 3 Python libraries for data science.md
Normal file
244
sources/tech/20180918 Top 3 Python libraries for data science.md
Normal file
@ -0,0 +1,244 @@
|
||||
ucasFL translating
|
||||
|
||||
Top 3 Python libraries for data science
|
||||
======
|
||||
Turn Python into a scientific data analysis and modeling tool with these libraries.
|
||||
|
||||

|
||||
|
||||
Python's many attractions—such as efficiency, code readability, and speed—have made it the go-to programming language for data science enthusiasts. Python is usually the preferred choice for data scientists and machine learning experts who want to escalate the functionalities of their applications. (For example, Andrey Bulezyuk used the Python programming language to create an amazing [machine learning application][1].)
|
||||
|
||||
Because of its extensive usage, Python has a huge number of libraries that make it easier for data scientists to complete complicated tasks without many coding hassles. Here are the top 3 Python libraries for data science; check them out if you want to kickstart your career in the field.
|
||||
|
||||
### 1\. NumPy
|
||||
|
||||
[NumPy][2] (short for Numerical Python) is one of the top libraries equipped with useful resources to help data scientists turn Python into a powerful scientific analysis and modelling tool. The popular open source library is available under the BSD license. It is the foundational Python library for performing tasks in scientific computing. NumPy is part of a bigger Python-based ecosystem of open source tools called SciPy.
|
||||
|
||||
The library empowers Python with substantial data structures for effortlessly performing multi-dimensional arrays and matrices calculations. Besides its uses in solving linear algebra equations and other mathematical calculations, NumPy is also used as a versatile multi-dimensional container for different types of generic data.
|
||||
|
||||
Furthermore, it integrates flawlessly with other programming languages like C/C++ and Fortran. The versatility of the NumPy library allows it to easily and swiftly coalesce with an extensive range of databases and tools. For example, let's see how NumPy (abbreviated **np** ) can be used for multiplying two matrices.
|
||||
|
||||
Let's start by importing the library (we'll be using the Jupyter notebook for these examples).
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
```
|
||||
|
||||
Next, let's use the **eye()** function to generate an identity matrix with the stipulated dimensions.
|
||||
|
||||
```
|
||||
matrix_one = np.eye(3)
|
||||
matrix_one
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
array([[1., 0., 0.],
|
||||
[0., 1., 0.],
|
||||
[0., 0., 1.]])
|
||||
```
|
||||
|
||||
Let's generate another 3x3 matrix.
|
||||
|
||||
We'll use the **arange([starting number], [stopping number])** function to arrange numbers. Note that the first parameter in the function is the initial number to be listed and the last number is not included in the generated results.
|
||||
|
||||
Also, the **reshape()** function is applied to modify the dimensions of the originally generated matrix into the desired dimension. For the matrices to be "multiply-able," they should be of the same dimension.
|
||||
|
||||
```
|
||||
matrix_two = np.arange(1,10).reshape(3,3)
|
||||
matrix_two
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
array([[1, 2, 3],
|
||||
[4, 5, 6],
|
||||
[7, 8, 9]])
|
||||
```
|
||||
|
||||
Let's use the **dot()** function to multiply the two matrices.
|
||||
|
||||
```
|
||||
matrix_multiply = np.dot(matrix_one, matrix_two)
|
||||
|
||||
matrix_multiply
|
||||
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
array([[1., 2., 3.],
|
||||
[4., 5., 6.],
|
||||
[7., 8., 9.]])
|
||||
```
|
||||
|
||||
Great!
|
||||
|
||||
We managed to multiply two matrices without using vanilla Python.
|
||||
|
||||
Here is the entire code for this example:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
#generating a 3 by 3 identity matrix
|
||||
matrix_one = np.eye(3)
|
||||
matrix_one
|
||||
#generating another 3 by 3 matrix for multiplication
|
||||
matrix_two = np.arange(1,10).reshape(3,3)
|
||||
matrix_two
|
||||
#multiplying the two arrays
|
||||
matrix_multiply = np.dot(matrix_one, matrix_two)
|
||||
matrix_multiply
|
||||
```
|
||||
|
||||
### 2\. Pandas
|
||||
|
||||
[Pandas][3] is another great library that can enhance your Python skills for data science. Just like NumPy, it belongs to the family of SciPy open source software and is available under the BSD free software license.
|
||||
|
||||
Pandas offers versatile and powerful tools for munging data structures and performing extensive data analysis. The library works well with incomplete, unstructured, and unordered real-world data—and comes with tools for shaping, aggregating, analyzing, and visualizing datasets.
|
||||
|
||||
There are three types of data structures in this library:
|
||||
|
||||
* Series: single-dimensional, homogeneous array
|
||||
* DataFrame: two-dimensional with heterogeneously typed columns
|
||||
* Panel: three-dimensional, size-mutable array
|
||||
|
||||
|
||||
|
||||
For example, let's see how the Panda Python library (abbreviated **pd** ) can be used for performing some descriptive statistical calculations.
|
||||
|
||||
Let's start by importing the library.
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
```
|
||||
|
||||
Let's create a dictionary of series.
|
||||
|
||||
```
|
||||
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
|
||||
'Irene','Sagar','Simon','James','Rose']),
|
||||
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
|
||||
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
|
||||
}
|
||||
```
|
||||
|
||||
Let's create a DataFrame.
|
||||
|
||||
```
|
||||
df = pd.DataFrame(d)
|
||||
```
|
||||
|
||||
Here is a nice table of the output:
|
||||
|
||||
```
|
||||
Name Programming Language Years of Experience
|
||||
0 Alfrick Python 5
|
||||
1 Michael JavaScript 9
|
||||
2 Wendy PHP 1
|
||||
3 Paul C++ 4
|
||||
4 Dusan Java 3
|
||||
5 George Scala 4
|
||||
6 Andreas React 7
|
||||
7 Irene Ruby 9
|
||||
8 Sagar Angular 6
|
||||
9 Simon PHP 8
|
||||
10 James Python 3
|
||||
11 Rose JavaScript 1
|
||||
```
|
||||
|
||||
Here is the entire code for this example:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
#creating a dictionary of series
|
||||
d = {'Name':pd.Series(['Alfrick','Michael','Wendy','Paul','Dusan','George','Andreas',
|
||||
'Irene','Sagar','Simon','James','Rose']),
|
||||
'Years of Experience':pd.Series([5,9,1,4,3,4,7,9,6,8,3,1]),
|
||||
'Programming Language':pd.Series(['Python','JavaScript','PHP','C++','Java','Scala','React','Ruby','Angular','PHP','Python','JavaScript'])
|
||||
}
|
||||
|
||||
#Create a DataFrame
|
||||
df = pd.DataFrame(d)
|
||||
print(df)
|
||||
```
|
||||
|
||||
### 3\. Matplotlib
|
||||
|
||||
[Matplotlib][4] is also part of the SciPy core packages and offered under the BSD license. It is a popular Python scientific library used for producing simple and powerful visualizations. You can use the Python framework for data science for generating creative graphs, charts, histograms, and other shapes and figures—without worrying about writing many lines of code. For example, let's see how the Matplotlib library can be used to create a simple bar chart.
|
||||
|
||||
Let's start by importing the library.
|
||||
|
||||
```
|
||||
from matplotlib import pyplot as plt
|
||||
```
|
||||
|
||||
Let's generate values for both the x-axis and the y-axis.
|
||||
|
||||
```
|
||||
x = [2, 4, 6, 8, 10]
|
||||
y = [10, 11, 6, 7, 4]
|
||||
```
|
||||
|
||||
Let's call the function for plotting the bar chart.
|
||||
|
||||
```
|
||||
plt.bar(x,y)
|
||||
```
|
||||
|
||||
Let's show the plot.
|
||||
|
||||
```
|
||||
plt.show()
|
||||
```
|
||||
|
||||
Here is the bar chart:
|
||||
|
||||
|
||||
|
||||
Here is the entire code for this example:
|
||||
|
||||
```
|
||||
#importing Matplotlib Python library
|
||||
from matplotlib import pyplot as plt
|
||||
#same as import matplotlib.pyplot as plt
|
||||
|
||||
#generating values for x-axis
|
||||
x = [2, 4, 6, 8, 10]
|
||||
|
||||
#generating vaues for y-axis
|
||||
y = [10, 11, 6, 7, 4]
|
||||
|
||||
#calling function for plotting the bar chart
|
||||
plt.bar(x,y)
|
||||
|
||||
#showing the plot
|
||||
plt.show()
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
The Python programming language has always done a good job in data crunching and preparation, but less so for complicated scientific data analysis and modeling. The top Python frameworks for [data science][5] help fill this gap, allowing you to carry out complex mathematical computations and create sophisticated models that make sense of your data.
|
||||
|
||||
Which other Python data-mining libraries do you know? What's your experience with them? Please share your comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/top-3-python-libraries-data-science
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
|
||||
[2]: http://www.numpy.org/
|
||||
[3]: http://pandas.pydata.org/
|
||||
[4]: https://matplotlib.org/
|
||||
[5]: https://www.liveedu.tv/guides/data-science/
|
||||
152
translated/tech/20171124 How do groups work on Linux.md
Normal file
152
translated/tech/20171124 How do groups work on Linux.md
Normal file
@ -0,0 +1,152 @@
|
||||
"组"在 Linux 上到底是怎么工作的?
|
||||
============================================================
|
||||
|
||||
|
||||
你好!就在上周,我还自认为对 Linux 上的用户和组的工作机制了如指掌。我认为它们的关系是这样的:
|
||||
|
||||
1. 每个进程都属于一个用户( 比如用户`julia`)
|
||||
|
||||
2. 当这个进程试图读取一个被某个组所拥有的文件时, Linux 会 a)先检查用户`julia` 是否有权限访问文件。(LCTT译注:检查文件的所有者是否就是`julia`) b)检查`julia` 属于哪些组,并进一步检查在这些组里是否有某个组拥有这个文件或者有权限访问这个文件。
|
||||
|
||||
3. 如果上述a,b任一为真( 或者`其他`位设为有权限访问),那么这个进程就有权限访问这个文件。
|
||||
|
||||
比如说,如果一个进程被用户`julia`拥有并且`julia` 在`awesome`组,那么这个进程就能访问下面这个文件。
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
|
||||
```
|
||||
|
||||
然而上述的机制我并没有考虑得非常清楚,如果你硬要我阐述清楚,我会说进程可能会在**运行时**去检查`/etc/group` 文件里是否有某些组拥有当前的用户。
|
||||
|
||||
### 然而这并不是Linux 里“组”的工作机制
|
||||
|
||||
我在上个星期的工作中发现了一件有趣的事,事实证明我前面的理解错了,我对组的工作机制的描述并不准确。特别是Linux**并不会**在进程每次试图访问一个文件时就去检查这个进程的用户属于哪些组。
|
||||
|
||||
我在读了[The Linux Programming
|
||||
Interface][1]这本书的第九章后才恍然大悟(这本书真是太棒了。)这才是组真正的工作方式!我意识到之前我并没有真正理解用户和组是怎么工作的,我信心满满的尝试了下面的内容并且验证到底发生了什么,事实证明现在我的理解才是对的。
|
||||
|
||||
### 用户和组权限检查是怎么完成的
|
||||
|
||||
现在这些关键的知识在我看来非常简单! 这本书的第九章上来就告诉我如下事实:用户和组ID是**进程的属性**,它们是:
|
||||
|
||||
* 真实用户ID和组ID;
|
||||
|
||||
* 有效用户ID和组ID;
|
||||
|
||||
* 被保存的set-user-ID和被保存的set-group-ID;
|
||||
|
||||
* 文件系统用户ID和组ID(特定于 Linux);
|
||||
|
||||
* 增补的组ID;
|
||||
|
||||
这说明Linux**实际上**检查一个进程能否访问一个文件所做的组检查是这样的:
|
||||
|
||||
* 检查一个进程的组ID和补充组ID(这些ID就在进程的属性里,**并不是**实时在`/etc/group`里查找这些ID)
|
||||
|
||||
* 检查要访问的文件的访问属性里的组设置
|
||||
|
||||
|
||||
* 确定进程对文件是否有权限访问(LCTT 译注:即文件的组是否是以上的组之一)
|
||||
|
||||
通常当访问控制的时候使用的是**有效**用户/组ID,而不是**真实**用户/组ID。技术上来说当访问一个文件时使用的是**文件系统**ID,他们实际上和有效用户/组ID一样。(LCTT译注:这句话针对 Linux 而言。)
|
||||
|
||||
### 将一个用户加入一个组并不会将一个已存在的进程(的用户)加入那个组
|
||||
|
||||
下面是一个有趣的例子:如果我创建了一个新的组:`panda` 组并且将我自己(bork)加入到这个组,然后运行`groups` 来检查我是否在这个组里:结果是我(bork)竟然不在这个组?!
|
||||
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
`panda`并不在上面的组里!为了再次确定我们的发现,让我们建一个文件,这个文件被`panda`组拥有,看看我能否访问它。
|
||||
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
|
||||
```
|
||||
|
||||
好吧,确定了,我(bork)无法访问`panda-file.txt`。这一点都不让人吃惊,我的命令解释器并没有`panda` 组作为补充组ID,运行`adduser bork panda`并不会改变这一点。
|
||||
|
||||
|
||||
### 那进程一开始是怎么得到用户的组的呢?
|
||||
|
||||
|
||||
这真是个非常令人困惑的问题,对吗?如果进程会将组的信息预置到进程的属性里面,进程在初始化的时候怎么取到组的呢?很明显你无法给你自己指定更多的组(否则就会和Linux访问控制的初衷相违背了。。。)
|
||||
|
||||
有一点还是很清楚的:一个新的进程是怎么从我的命令行解释器(/bash/fish)里被**执行**而得到它的组的。(新的)进程将拥有我的用户 ID(bork),并且进程属性里还有很多组ID。从我的命令解释器里执行的所有进程是从这个命令解释器里`复刻`而来的,所以这个新进程得到了和命令解释器同样的组。
|
||||
|
||||
因此一定存在一个“第一个”进程来把你的组设置到进程属性里,而所有由此进程而衍生的进程将都设置这些组。而那个“第一个”进程就是你的**登录命令**,在我的笔记本电脑上,它是由‘登录’程序(`/bin/login`)实例化而来。` 登录程序` 以root身份运行,然后调用了一个 C 的库函数-`initgroups`来设置你的进程的组(具体来说是通过读取`/etc/group` 文件),因为登录程序是以root运行的,所以它能设置你的进程的组。
|
||||
|
||||
|
||||
### 让我们再登录一次
|
||||
|
||||
好了!既然我们的`login shell`正在运行,而我又想刷新我的进程的组设置,从我们前面所学到的进程是怎么初始化组ID的,我应该可以通过再次运行`login` 程序来刷新我的进程组并启动一个新的`login shell`!
|
||||
|
||||
让我们试试下边的方法:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
|
||||
```
|
||||
|
||||
当然,成功了!现在由登录程序衍生的程序的用户是组`panda`的一部分了!太棒了!这并不会影响我其他的已经在运行的登录程序(及其子进程),如果我真的希望“所有的”进程都能对`panda`
|
||||
组有访问权限。我必须完全的重启我的登陆会话,这意味着我必须退出我的窗口管理器然后再重新`login`。(LCTT译注:即更新进程树的树根进程,这里是窗口管理器进程。)
|
||||
|
||||
### newgrp命令
|
||||
|
||||
|
||||
在 Twitter 上有人告诉我如果只是想启动一个刷新了组信息的命令解释器的话,你可以使用`newgrp`(LCTT译注:不启动新的命令解释器),如下:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
|
||||
```
|
||||
|
||||
|
||||
你也可以用`sg panda bash` 来完成同样的效果,这个命令能启动一个`bash` 登录程序,而这个程序就有`panda` 组。
|
||||
|
||||
### seduid 将设置有效用户 ID
|
||||
|
||||
其实我一直对一个进程如何以`setuid root`的权限来运行意味着什么有点似是而非。现在我知道了,事实上所发生的是:setuid 设置了`有效用户ID`! 如果我('julia')运行了一个`setuid root` 的进程( 比如`passwd`),那么进程的**真实**用户 ID 将为`julia`,而**有效**用户 ID 将被设置为`root`。
|
||||
|
||||
`passwd` 需要以root权限来运行,但是它能看到进程的真实用户ID是`julia` ,是`julia`启动了这个进程,`passwd`会阻止这个进程修改除了`julia`之外的用户密码。
|
||||
|
||||
### 就是这些了!
|
||||
|
||||
在 Linux Programming Interface 这本书里有很多Linux上一些功能的罕见使用方法以及Linux上所有的事物到底是怎么运行的详细解释,这里我就不一一展开了。那本书棒极了,我上面所说的都在该书的第九章,这章在1300页的书里只占了17页。
|
||||
|
||||
我最爱这本书的一点是我只用读17页关于用户和组是怎么工作的内容,而这区区17页就能做到内容完备,详实有用。我不用读完所有的1300页书就能得到有用的东西,太棒了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[DavidChen](https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,82 +0,0 @@
|
||||
如何使用 Apache 构建 URL 缩短器
|
||||
======
|
||||
|
||||

|
||||
|
||||
很久以前,人们开始在 Twitter 上分享链接。140 个字符的限制意味着 URL 可能消耗一条推文的大部分(或全部),因此人们使用 URL 缩短器。最终,Twitter 加入了一个内置的 URL 缩短器([t.co][1])。
|
||||
|
||||
字符数现在不重要了,但还有其他原因要缩短链接。首先,缩短服务可以提供分析 - 你可以看到你分享的链接的受欢迎程度。它还简化了制作易于记忆的 URL。例如,[bit.ly/INtravel][2] 比<https://www.in.gov/ai/appfiles/dhs-countyMap/dhsCountyMap.html>更容易记住。如果你想预先共享一个链接,但还不知道最终地址,这时 URL 缩短器可以派上用场。。
|
||||
|
||||
与任何技术一样,URL 缩短器并非都是正面的。通过屏蔽最终地址,缩短的链接可用于指向恶意或冒犯性内容。但是,如果你仔细上网,URL 缩短器是一个有用的工具。
|
||||
|
||||
我们之前在网站上[发布过缩短器的文章][3],但也许你想要运行一些由简单的文本驱动的缩短器。在本文中,我们将展示如何使用 Apache HTTP 服务器的 mod_rewrite 功能来设置自己的 URL 缩短器。如果你不熟悉 Apache HTTP 服务器,请查看 David Both 关于[安装和配置][4]的文章。
|
||||
|
||||
### 创建一个 VirtualHost
|
||||
|
||||
在本教程中,我假设你购买了一个很酷的域名,你将它专门用于 URL 缩短器。例如,我的网站是 [funnelfiasco.com][5],所以我买了 [funnelfias.co][6] 用于我的 URL 缩短器(好吧,它不是很短,但它可以满足我的虚荣心)。如果你不将缩短器作为单独的域运行,请跳到下一部分。
|
||||
|
||||
第一步是设置将用于 URL 缩短器的 VirtualHost。有关 VirtualHosts 的更多信息,请参[ David Both 的文章][7]。这步只需要几行:
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
|
||||
ServerName funnelfias.co
|
||||
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
### 创建 rewrite
|
||||
|
||||
此服务使用 HTTPD 的重写引擎来重写 URL。如果你在上面的部分中创建了 VirtualHost,则下面的配置跳到你的 VirtualHost 部分。否则跳到服务器的 VirtualHost 或主 HTTPD 配置。
|
||||
```
|
||||
RewriteEngine on
|
||||
|
||||
RewriteMap shortlinks txt:/data/web/shortlink/links.txt
|
||||
|
||||
RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
|
||||
|
||||
```
|
||||
|
||||
第一行只是启用重写引擎。第二行在文本文件构建短链接的映射。上面的路径只是一个例子。你需要使用系统上使用有效路径(确保它可由运行 HTTPD 的用户帐户读取)。最后一行重写 URL。在此例中,它接受任何字符并在重写映射中查找它们。你可能希望重写时使用特定的字符串。例如,如果你希望所有缩短的链接都是 “slX”(其中 X 是数字),则将上面的 `(.+)` 替换为 `(sl\d+)`。
|
||||
|
||||
我在这里使用了临时 (HTTP 302) 重定向。这能让我稍后更新目标 URL。如果希望短链接始终指向同一目标,则可以使用永久 (HTTP 301) 重定向。用 `permanent` 替换第三行的 `temp`。
|
||||
|
||||
### 构建你的映射
|
||||
|
||||
编辑配置文件 “RewriteMap” 行中的指定文件。格式是空格分隔的键值存储。在每一行上放一个链接:
|
||||
```
|
||||
osdc https://opensource.com/users/bcotton
|
||||
|
||||
twitter https://twitter.com/funnelfiasco
|
||||
|
||||
swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
|
||||
|
||||
```
|
||||
|
||||
### 重启 HTTPD
|
||||
|
||||
最后一步是重启 HTTPD 进程。这是通过 `systemctl restart httpd` 或类似命令完成的(命令和守护进程名称可能因发行版而不同)。你的链接缩短器现已启动并运行。当你准备编辑映射时,无需重新启动 Web 服务器。你所要做的就是保存文件,Web 服务器将获取到差异。
|
||||
|
||||
### 未来的工作
|
||||
|
||||
此示例为你提供了基本的 URL 缩短器。如果你想将开发自己的管理接口作为学习项目,它可以作为一个很好的起点。或者你可以使用它分享容易记住的链接到那些容易忘记的 URL。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/apache-url-shortener
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:http://t.co
|
||||
[2]:http://bit.ly/INtravel
|
||||
[3]:https://opensource.com/article/17/3/url-link-shortener
|
||||
[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
[5]:http://funnelfiasco.com
|
||||
[6]:http://funnelfias.co
|
||||
[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
|
||||
118
translated/tech/20180910 3 open source log aggregation tools.md
Normal file
118
translated/tech/20180910 3 open source log aggregation tools.md
Normal file
@ -0,0 +1,118 @@
|
||||
|
||||
|
||||
|
||||
3个开源日志聚合工具
|
||||
======
|
||||
|
||||
日志聚合系统可以帮助我们故障排除并进行其他的任务。以下是三个主要工具介绍。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
指标聚合与日志聚合有何不同?日志不能包括指标吗?日志聚合系统不能做与指标聚合系统相同的事情吗?
|
||||
|
||||
这些是我经常听到的问题。我还看到供应商推销他们的日志聚合系统作为所有可观察问题的解决方案。日志聚合是一个有价值的工具,但它通常对时间序列数据的支持不够好。
|
||||
|
||||
时间序列指标聚合系统中几个有价值的功能为规则间隔与专门为时间序列数据定制的存储系统。规则间隔允许用户一次性地导出真实的数据结果。如果要求日志聚合系统定期收集指标数据,它也可以。但是,它的存储系统没有针对指标聚合系统中典型的查询类型进行优化。使用日志聚合工具中的存储系统处理这些查询将花费更多的资源和时间。
|
||||
|
||||
所以,我们知道日志聚合系统可能不适合时间序列数据,但是它有什么好处呢?日志聚合系统是收集事件数据的好地方。这些是非常重要的不规则活动。最好的例子为 web 服务的访问日志。这些都很重要,因为我们想知道什么东西正在访问我们的系统,什么时候访问。另一个例子是应用程序错误记录——因为它不是正常的操作记录,所以在故障排除过程中可能很有价值的。
|
||||
|
||||
日志记录的一些规则:
|
||||
|
||||
* 包含时间戳
|
||||
* 包含 JSON 格式
|
||||
* 不记录无关紧要的事件
|
||||
* 记录所有应用程序的错误
|
||||
* 记录警告错误
|
||||
* 日志记录开关
|
||||
* 以可读的形式记录信息
|
||||
* 不在生产环境中记录信息
|
||||
* 不记录任何无法阅读或无反馈的内容
|
||||
|
||||
|
||||
### 云的成本
|
||||
|
||||
当研究日志聚合工具时,云可能看起来是一个有吸引力的选择。然而,这可能会带来巨大的成本。当跨数百或数千台主机和应用程序聚合时,日志数据是大量的。在基于云的系统中,数据的接收、存储和检索是昂贵的。
|
||||
|
||||
作为一个真实的系统,大约500个节点和几百个应用程序的集合每天产生 200GB 的日志数据。这个系统可能还有改进的空间,但是在许多 SaaS 产品中,即使将它减少一半,每月也要花费将近10,000美元。这通常包括仅保留30天,如果你想查看一年一年的趋势数据,就不可能了。
|
||||
|
||||
并不是要不使用这些系统,尤其是对于较小的组织它们可能非常有价值的。目的是指出可能会有很大的成本,当这些成本达到时,就可能令人非常的沮丧。本文的其余部分将集中讨论自托管的开源和商业解决方案。
|
||||
|
||||
|
||||
### 工具选择
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1] ,简称 Elasticsearch、Logstash 和 Kibana,是最流行的开源日志聚合工具。它被Netflix、Facebook、微软、LinkedIn 和思科使用。这三个组件都是由 [Elastic][2] 开发和维护的。[Elasticsearch][3] 本质上是一个NoSQL,Lucene 搜索引擎实现的。[Logstash][4] 是一个日志管道系统,可以接收数据,转换数据,并将其加载到像 Elasticsearch 这样的应用中。[Kibana][5] 是 Elasticsearch 之上的可视化层。
|
||||
|
||||
几年前,Beats 被引入。Beats 是数据采集器。它们简化了将数据运送到日志存储的过程。用户不需要了解每种日志的正确语法,而是可以安装一个 Beats 来正确导出 NGINX 日志或代理日志,以便在Elasticsearch 中有效地使用它们。
|
||||
|
||||
安装生产环境级 ELK stack 时,可能会包括其他几个部分,如 [Kafka][6], [Redis][7], and [NGINX][8]。此外,用 Fluentd 替换 Logstash 也很常见,我们将在后面讨论。这个系统操作起来很复杂,这在早期导致很多问题和投诉。目前,这些基本上已经被修复,不过它仍然是一个复杂的系统,如果你使用少部分的功能,建议不要使用它了。
|
||||
|
||||
也就是说,服务是可用的,所以你不必担心。[Logz.io][9] 也可以使用,但是如果你有很多数据,它的标价有点高。当然,你可能没有很多数据,来使用用它。如果你买不起 Logz.io,你可以看看 [AWS Elasticsearch Service][10] (ES) 。ES 是 Amazon Web Services (AWS) 提供的一项服务,它使得 Elasticsearch 很容易快速工作。它还拥有使用 Lambda 和 S3 将所有AWS日志记录到 ES 的工具。这是一个更便宜的选择,但是需要一些管理操作,并有一些功能限制。
|
||||
|
||||
|
||||
Elastic [offers][11] 的母公司提供一款更强大的产品,它使用开放核心模型,为分析工具和报告提供了额外的选项。它也可以在谷歌云平台或 AWS 上托管。由于这种工具和托管平台的组合提供了比大多数 SaaS 选项更加便宜,这将是最好的选择并且具有很大的价值。该系统可以有效地取代或提供[security information and event management][12] ( SIEM )系统的功能。
|
||||
|
||||
ELK 栈通过 Kibana 提供了很好的可视化工具,但是它缺少警报功能。Elastic 在付费的 X-Pack 插件中提供了提醒功能,但是在开源系统没有内置任何功能。Yelp 已经开发了一种解决这个问题的方法,[ElastAlert][13], 不过还有其他方式。这个额外的软件相当健壮,但是它增加了已经复杂的系统的复杂性。
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] 最近越来越受欢迎,但它是在2010年 Lennart Koopmann 创建并开发的。两年后,一家公司以同样的名字诞生了。尽管它的使用者越来越多,但仍然远远落后于 ELK 栈。这也意味着它具有较少的社区开发特征,但是它可以使用与 ELK stack 相同的 Beats 。Graylog 由于 Graylog Collector Sidecar 使用 [Go][15] 编写所以在 Go 社区赢得了赞誉。
|
||||
|
||||
Graylog 使用 Elasticsearch、[MongoDB][16] 并且 提供 Graylog Server 。这使得它像ELK 栈一样复杂,也许还要复杂一些。然而,Graylog 附带了内置于开源版本中的报警功能,以及其他一些值得注意的功能,如 streaming 、消息重写 和 地理定位。
|
||||
|
||||
streaming 能允许数据在被处理时被实时路由到特定的 Streams。使用此功能,用户可以在单个Stream 中看到所有数据库错误,在不同的 Stream 中看到 web 服务器错误。当添加新项目或超过阈值时,甚至可以基于这些 Stream 提供警报。延迟可能是日志聚合系统中最大的问题之一,Stream消除了灰色日志中的这一问题。一旦日志进入,它就可以通过 Stream 路由到其他系统,而无需全部处理。
|
||||
|
||||
消息重写功能使用开源规则引擎 [Drools][17] 。允许根据用户定义的规则文件评估所有传入的消息,从而可以删除消息(称为黑名单)、添加或删除字段或修改消息。
|
||||
|
||||
Graylog 最酷的功能是它的地理定位功能,它支持在地图上绘制 IP 地址。这是一个相当常见的功能,在 Kibana 也可以这样使用,但是它增加了很多价值——特别是如果你想将它用作 SIEM 系统。地理定位功能在系统的开源版本中提供。
|
||||
|
||||
Graylog 如果你想要的话,它会对开源版本的支持收费。它还为其企业版提供了一个开放的核心模型,提供存档、审计日志记录和其他支持。如果你不需要 Graylog (the company) 支持或托管的,你可以独立使用。
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] 是 [Treasure Data][19] 开发的,[CNCF][20] 已经将它作为一个孵化项目。它是用 C 和 Ruby 编写的,并由[AWS][21] 和 [Google Cloud][22]推荐。fluentd已经成为许多装置中logstach的常用替代品。它充当本地聚合器,收集所有节点日志并将其发送到中央存储系统。它不是日志聚合系统。
|
||||
|
||||
它使用一个强大的插件系统,提供不同数据源和数据输出的快速和简单的集成功能。因为有超过500个插件可用,所以你的大多数用例都应该包括在内。如果没有,这听起来是一个为开源社区做出贡献的机会。
|
||||
|
||||
Fluentd 由于占用内存少(只有几十兆字节)和高吞吐量特性,是 Kubernetes 环境中的常见选择。在像 [Kubernetes][23] 这样的环境中,每个pod 都有一个 Fluentd sidecar ,内存消耗会随着每个新 pod 的创建而线性增加。在这中情况下,使用 Fluentd 将大大降低你的系统利用率。这对于Java开发的工具来说,这是一个常见的问题,这些工具旨在为每个节点运行一个工具,而内存开销并不是主要问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
|
||||
Loading…
Reference in New Issue
Block a user