mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
35c4dcacaa
@ -1,13 +1,15 @@
|
||||
我们能否建立一个服务于用户而非广告商的社交网络?
|
||||
=====
|
||||
|
||||
> 找出 Human Connection 是如何将透明度和社区放在首位的。
|
||||
|
||||

|
||||
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的,中立的,透明的在线平台来迎接我们这个时代的挑战。
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
|
||||
|
||||
开放的原则可能会成为让我们到达那里的方法(to 校正者:这句上下文没有理解)。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们自然倾向,于乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
|
||||
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
|
||||
|
||||
@ -15,31 +17,28 @@
|
||||
|
||||
### 首先是透明
|
||||
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript, Vue, nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些对让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team (to 校正者:这里如果可以,请翻译得稍微优雅,我想不出来一个词)活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
|
||||
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
|
||||
|
||||
一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章(UN Charter)][4]和“世界人权宣言(Universal Declaration of Human Rights)”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (译者注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用<ruby>[联合国宪章][4]<rt>UN Charter</rt></ruby>和“<ruby>世界人权宣言<rt>Universal Declaration of Human Rights</rt></ruby>”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
|
||||
### 一个合作的社会
|
||||
|
||||
以一种[以社区为中心的协作方法][5]来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
|
||||
|
||||
一个抛弃了以利润为导向的算法,为广告商而不是最终用户服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并破坏(to 校正:这里译为改变较好)现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学(University Sorbonne)的国家东方语言与文明研究所(National Institute for Oriental Languages and Civilizations (INALCO) )和德国斯图加特媒体大学(Stuttgart Media University )合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动(Take Action)”领域,每个人都可以实现。
|
||||
|
||||
* “Versus” 功能是另一个定义结果的方式(to 校正者:这句话稍微注意一下)。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎<ruby>索邦大学<rt>University Sorbonne</rt></ruby>的<ruby>国家东方语言与文明研究所<rt>National Institute for Oriental Languages and Civilizations</rt></ruby>(INALCO)和德国<ruby>斯图加特媒体大学<rt>Stuttgart Media University</rt></ruby>合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“<ruby>采取行动<rt>Take Action</rt></ruby>”领域,每个人都可以实现。
|
||||
* “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
|
||||
|
||||
|
||||
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
|
||||
|
||||
[订阅我们的每周时事通讯][12]以了解有关开放组织的更多信息。
|
||||
@ -51,7 +50,7 @@ via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,294 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Intercepting and Emulating Linux System Calls with Ptrace « null program
|
||||
======
|
||||
|
||||
The `ptrace(2)` (“process trace”) system call is usually associated with debugging. It’s the primary mechanism through which native debuggers monitor debuggees on unix-like systems. It’s also the usual approach for implementing [strace][1] — system call trace. With Ptrace, tracers can pause tracees, [inspect and set registers and memory][2], monitor system calls, or even intercept system calls.
|
||||
|
||||
By intercept, I mean that the tracer can mutate system call arguments, mutate the system call return value, or even block certain system calls. Reading between the lines, this means a tracer can fully service system calls itself. This is particularly interesting because it also means **a tracer can emulate an entire foreign operating system**. This is done without any special help from the kernel beyond Ptrace.
|
||||
|
||||
The catch is that a process can only have one tracer attached at a time, so it’s not possible emulate a foreign operating system while also debugging that process with, say, GDB. The other issue is that emulated systems calls will have higher overhead.
|
||||
|
||||
For this article I’m going to focus on [Linux’s Ptrace][3] on x86-64, and I’ll be taking advantage of a few Linux-specific extensions. For the article I’ll also be omitting error checks, but the full source code listings will have them.
|
||||
|
||||
You can find runnable code for the examples in this article here:
|
||||
|
||||
**<https://github.com/skeeto/ptrace-examples>**
|
||||
|
||||
### strace
|
||||
|
||||
Before getting into the really interesting stuff, let’s start by reviewing a bare bones implementation of strace. It’s [no DTrace][4], but strace is still incredibly useful.
|
||||
|
||||
Ptrace has never been standardized. Its interface is similar across different operating systems, especially in its core functionality, but it’s still subtly different from system to system. The `ptrace(2)` prototype generally looks something like this, though the specific types may be different.
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
|
||||
```
|
||||
|
||||
The `pid` is the tracee’s process ID. While a tracee can have only one tracer attached at a time, a tracer can be attached to many tracees.
|
||||
|
||||
The `request` field selects a specific Ptrace function, just like the `ioctl(2)` interface. For strace, only two are needed:
|
||||
|
||||
* `PTRACE_TRACEME`: This process is to be traced by its parent.
|
||||
* `PTRACE_SYSCALL`: Continue, but stop at the next system call entrance or exit.
|
||||
* `PTRACE_GETREGS`: Get a copy of the tracee’s registers.
|
||||
|
||||
|
||||
|
||||
The other two fields, `addr` and `data`, serve as generic arguments for the selected Ptrace function. One or both are often ignored, in which case I pass zero.
|
||||
|
||||
The strace interface is essentially a prefix to another command.
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
|
||||
```
|
||||
|
||||
My minimal strace doesn’t have any options, so the first thing to do — assuming it has at least one argument — is `fork(2)` and `exec(2)` the tracee process on the tail of `argv`. But before loading the target program, the new process will inform the kernel that it’s going to be traced by its parent. The tracee will be paused by this Ptrace system call.
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The parent waits for the child’s `PTRACE_TRACEME` using `wait(2)`. When `wait(2)` returns, the child will be paused.
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
Before allowing the child to continue, we tell the operating system that the tracee should be terminated along with its parent. A real strace implementation may want to set other options, such as `PTRACE_O_TRACEFORK`.
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
|
||||
```
|
||||
|
||||
All that’s left is a simple, endless loop that catches on system calls one at a time. The body of the loop has four steps:
|
||||
|
||||
1. Wait for the process to enter the next system call.
|
||||
2. Print a representation of the system call.
|
||||
3. Allow the system call to execute and wait for the return.
|
||||
4. Print the system call return value.
|
||||
|
||||
|
||||
|
||||
The `PTRACE_SYSCALL` request is used in both waiting for the next system call to begin, and waiting for that system call to exit. As before, a `wait(2)` is needed to wait for the tracee to enter the desired state.
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
When `wait(2)` returns, the registers for the thread that made the system call are filled with the system call number and its arguments. However, the operating system has not yet serviced this system call. This detail will be important later.
|
||||
|
||||
The next step is to gather the system call information. This is where it gets architecture specific. On x86-64, [the system call number is passed in `rax`][5], and the arguments (up to 6) are passed in `rdi`, `rsi`, `rdx`, `r10`, `r8`, and `r9`. Reading the registers is another Ptrace call, though there’s no need to `wait(2)` since the tracee isn’t changing state.
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
|
||||
```
|
||||
|
||||
There’s one caveat. For [internal kernel purposes][6], the system call number is stored in `orig_rax` rather than `rax`. All the other system call arguments are straightforward.
|
||||
|
||||
Next it’s another `PTRACE_SYSCALL` and `wait(2)`, then another `PTRACE_GETREGS` to fetch the result. The result is stored in `rax`.
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
|
||||
```
|
||||
|
||||
The output from this simple program is very crude. There is no symbolic name for the system call and every argument is printed numerically, even if it’s a pointer to a buffer. A more complete strace would know which arguments are pointers and use `process_vm_readv(2)` to read those buffers from the tracee in order to print them appropriately.
|
||||
|
||||
However, this does lay the groundwork for system call interception.
|
||||
|
||||
### System call interception
|
||||
|
||||
Suppose we want to use Ptrace to implement something like OpenBSD’s [`pledge(2)`][7], in which [a process pledges to use only a restricted set of system calls][8]. The idea is that many programs typically have an initialization phase where they need lots of system access (opening files, binding sockets, etc.). After initialization they enter a main loop in which they processing input and only a small set of system calls are needed.
|
||||
|
||||
Before entering this main loop, a process can limit itself to the few operations that it needs. If [the program has a flaw][9] allowing it to be exploited by bad input, the pledge significantly limits what the exploit can accomplish.
|
||||
|
||||
Using the same strace model, rather than print out all system calls, we could either block certain system calls or simply terminate the tracee when it misbehaves. Termination is easy: just call `exit(2)` in the tracer. Since it’s configured to also terminate the tracee. Blocking the system call and allowing the child to continue is a little trickier.
|
||||
|
||||
The tricky part is that **there’s no way to abort a system call once it’s started**. When tracer returns from `wait(2)` on the entrance to the system call, the only way to stop a system call from happening is to terminate the tracee.
|
||||
|
||||
However, not only can we mess with the system call arguments, we can change the system call number itself, converting it to a system call that doesn’t exist. On return we can report a “friendly” `EPERM` error in `errno` [via the normal in-band signaling][10].
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This simple example only checks against a whitelist or blacklist of system calls. And there’s no nuance, such as allowing files to be opened (`open(2)`) read-only but not as writable, allowing anonymous memory maps but not non-anonymous mappings, etc. There’s also no way to the tracee to dynamically drop privileges.
|
||||
|
||||
How could the tracee communicate to the tracer? Use an artificial system call!
|
||||
|
||||
### Creating an artificial system call
|
||||
|
||||
For my new pledge-like system call — which I call `xpledge()` to distinguish it from the real thing — I picked system call number 10000, a nice high number that’s unlikely to ever be used for a real system call.
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
|
||||
```
|
||||
|
||||
Just for demonstration purposes, I put together a minuscule interface that’s not good for much in practice. It has little in common with OpenBSD’s `pledge(2)`, which uses a [string interface][11]. Actually designing robust and secure sets of privileges is really complicated, as the `pledge(2)` manpage shows. Here’s the entire interface and implementation of the system call for the tracee:
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
|
||||
```
|
||||
|
||||
If it passes zero for the argument, only a few basic system calls are allowed, including those used to allocate memory (e.g. `brk(2)`). The `PLEDGE_RDWR` bit allows [various][12] read and write system calls (`read(2)`, `readv(2)`, `pread(2)`, `preadv(2)`, etc.). The `PLEDGE_OPEN` bit allows `open(2)`.
|
||||
|
||||
To prevent privileges from being escalated back, `pledge()` blocks itself — though this also prevents dropping more privileges later down the line.
|
||||
|
||||
In the xpledge tracer, I just need to check for this system call:
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The operating system will return `ENOSYS` (Function not implemented) since this isn’t a real system call. So on the way out I overwrite this with a success (0).
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I wrote a little test program that opens `/dev/urandom`, makes a read, tries to pledge, then tries to open `/dev/urandom` a second time, then confirms it can read from the original `/dev/urandom` file descriptor. Running without a pledge tracer, the output looks like this:
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
|
||||
```
|
||||
|
||||
Making an invalid system call doesn’t crash an application. It just fails, which is a rather convenient fallback. When run under the tracer, it looks like this:
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
|
||||
```
|
||||
|
||||
The pledge succeeds but the second `fopen(3)` does not since the tracer blocked it with `EPERM`.
|
||||
|
||||
This concept could be taken much further, to, say, change file paths or return fake results. A tracer could effectively chroot its tracee, prepending some chroot path to the root of any path passed through a system call. It could even lie to the process about what user it is, claiming that it’s running as root. In fact, this is exactly how the [Fakeroot NG][13] program works.
|
||||
|
||||
### Foreign system emulation
|
||||
|
||||
Suppose you don’t just want to intercept some system calls, but all system calls. You’ve got [a binary intended to run on another operating system][14], so none of the system calls it makes will ever work.
|
||||
|
||||
You could manage all this using only what I’ve described so far. The tracer would always replace the system call number with a dummy, allow it to fail, then service the system call itself. But that’s really inefficient. That’s essentially three context switches for each system call: one to stop on the entrance, one to make the always-failing system call, and one to stop on the exit.
|
||||
|
||||
The Linux version of PTrace has had a more efficient operation for this technique since 2005: `PTRACE_SYSEMU`. PTrace stops only once per a system call, and it’s up to the tracer to service that system call before allowing the tracee to continue.
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To run binaries for the same architecture from any system with a stable (enough) system call ABI, you just need this `PTRACE_SYSEMU` tracer, a loader (to take the place of `exec(2)`), and whatever system libraries the binary needs (or only run static binaries).
|
||||
|
||||
In fact, this sounds like a fun weekend project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nullprogram.com
|
||||
[1]:https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]:http://nullprogram.com/blog/2016/09/03/
|
||||
[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]:http://nullprogram.com/blog/2018/01/17/
|
||||
[5]:http://nullprogram.com/blog/2015/05/15/
|
||||
[6]:https://stackoverflow.com/a/6469069
|
||||
[7]:https://man.openbsd.org/pledge.2
|
||||
[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]:http://nullprogram.com/blog/2017/07/19/
|
||||
[10]:http://nullprogram.com/blog/2016/09/23/
|
||||
[11]:https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]:http://nullprogram.com/blog/2017/03/01/
|
||||
[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]:http://nullprogram.com/blog/2017/11/30/
|
||||
@ -1,614 +0,0 @@
|
||||
MjSeven is translating
|
||||
|
||||
Understanding Python Dataclasses — Part 1
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
If you’re reading this, then you are already aware of Python 3.7 and the new features that come packed with it. Personally, I am most excited about `Dataclasses`. I have been waiting for them to arrive for a while.
|
||||
|
||||
This is a two part post:
|
||||
1\. Dataclass features overview in this post
|
||||
2\. Dataclass `fields` overview in the [next post][1]
|
||||
|
||||
### Introduction
|
||||
|
||||
`Dataclasses` are python classes but are suited for storing data objects. What are data objects, you ask? Here is a non-exhaustive list of features that define data objects:
|
||||
|
||||
* They store data and represent a certain data type. Ex: A number. For people familiar with ORMs, a model instance is a data object. It represents a specific kind of entity. It holds attributes that define or represent the entity.
|
||||
|
||||
* They can be compared to other objects of the same type. Ex: A number can be `greater than`, `less than`, or `equal to` another number
|
||||
|
||||
There are certainly more features, but this list is sufficient to help you understand the crux.
|
||||
|
||||
To understand `Dataclasses`, we shall be implementing a simple class that holds a number, and allows us to perform the above mentioned operations.
|
||||
First, we shall be using normal classes, and then we shall use `Dataclasses` to achieve the same result.
|
||||
|
||||
But before we begin, a word on the usage of `Dataclasses`
|
||||
|
||||
Python 3.7 provides a decorator [dataclass][2] that is used to convert a class into a dataclass.
|
||||
|
||||
All you have to do is wrap the class in the decorator:
|
||||
|
||||
```
|
||||
from dataclasses import dataclass
|
||||
```
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class A:
|
||||
…
|
||||
```
|
||||
|
||||
Now, lets dive into the usage of how and what `dataclass` changes for us.
|
||||
|
||||
### Initialization
|
||||
|
||||
Usual
|
||||
|
||||
```
|
||||
class Number:
|
||||
```
|
||||
|
||||
```
|
||||
__init__(self, val):
|
||||
self.val = val
|
||||
|
||||
>>> one = Number(1)
|
||||
>>> one.val
|
||||
>>> 1
|
||||
```
|
||||
|
||||
With `dataclass`
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Number:
|
||||
val:int
|
||||
|
||||
>>> one = Number(1)
|
||||
>>> one.val
|
||||
>>> 1
|
||||
```
|
||||
|
||||
Here’s what’s changed with the dataclass decorator:
|
||||
|
||||
1\. No need of defining `__init__`and then assigning values to `self`, `d` takes care of it
|
||||
2\. We defined the member attributes in advance in a much more readable fashion, along with [type hinting][3]. We now know instantly that `val` is of type `int`. This is definitely more readable than the usual way of defining class members.
|
||||
|
||||
> Zen of Python: Readability counts
|
||||
|
||||
It is also possible to define default values:
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Number:
|
||||
val:int = 0
|
||||
```
|
||||
|
||||
### Representation
|
||||
|
||||
Object representation is a meaningful string representation of the object that is very useful in debugging.
|
||||
|
||||
Default python objects representation is not very meaningful:
|
||||
|
||||
```
|
||||
class Number:
|
||||
def __init__(self, val = 0):
|
||||
self.val = val
|
||||
|
||||
>>> a = Number(1)
|
||||
>>> a
|
||||
>>> <__main__.Number object at 0x7ff395b2ccc0>
|
||||
```
|
||||
|
||||
This gives us no insight as to the utility of the object, and will result in horrible a debugging experience.
|
||||
|
||||
A meaningful representation could be implemented by defining a `__repr__`method in the class definition.
|
||||
|
||||
```
|
||||
def __repr__(self):
|
||||
return self.val
|
||||
```
|
||||
|
||||
Now we get a meaningful representation of the object:
|
||||
|
||||
```
|
||||
>>> a = Number(1)
|
||||
>>> a
|
||||
>>> 1
|
||||
```
|
||||
|
||||
`dataclass` automatically add a `__repr__ `function, so that we don’t have to manually implement it.
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Number:
|
||||
val: int = 0
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = Number(1)
|
||||
>>> a
|
||||
>>> Number(val = 1)
|
||||
```
|
||||
|
||||
### Data Comparison
|
||||
|
||||
Generally, data objects come with a need to be compared with each other.
|
||||
|
||||
Comparison between two objects `a` and `b` generally consists of the following operations:
|
||||
|
||||
* a < b
|
||||
|
||||
* a > b
|
||||
|
||||
* a == b
|
||||
|
||||
* a >= b
|
||||
|
||||
* a <= b
|
||||
|
||||
In python, it is possible to define [methods][4] in classes that can do the above operations. For the sake of simplicity and to not let this post run amuck, I shall be only demonstrating implementation of `==` and `<`.
|
||||
|
||||
Usual
|
||||
|
||||
```
|
||||
class Number:
|
||||
def __init__( self, val = 0):
|
||||
self.val = val
|
||||
|
||||
def __eq__(self, other):
|
||||
return self.val == other.val
|
||||
|
||||
def __lt__(self, other):
|
||||
return self.val < other.val
|
||||
```
|
||||
|
||||
With `dataclass`
|
||||
|
||||
```
|
||||
@dataclass(order = True)
|
||||
class Number:
|
||||
val: int = 0
|
||||
```
|
||||
|
||||
Yup, that’s it.
|
||||
|
||||
We dont need to define the `__eq__`and `__lt__` methods, because `dataclass`decorator automatically adds them to the class definition for us when called with `order = True`
|
||||
|
||||
Well, how does it do that?
|
||||
|
||||
When you use `dataclass,` it adds a functions `__eq__` and `__lt__` to the class definition. We already know that. So, how do these functions know how to check equality and do comparison?
|
||||
|
||||
A dataclass generated `__eq__` function will compare a tuple of its attributes with a tuple of attributes of the other instance of the same class. In our case here’s what the `automatically` generated `__eq__` function would be equivalent to:
|
||||
|
||||
```
|
||||
def __eq__(self, other):
|
||||
return (self.val,) == (other.val,)
|
||||
```
|
||||
|
||||
Let’s look at a more elaborate example:
|
||||
|
||||
We shall write a dataclass `Person `to hold their `name` and `age`.
|
||||
|
||||
```
|
||||
@dataclass(order = True)
|
||||
class Person:
|
||||
name: str
|
||||
age:int = 0
|
||||
```
|
||||
|
||||
The automatically generated `__eq__` method will be equivalent of:
|
||||
|
||||
```
|
||||
def __eq__(self, other):
|
||||
return (self.name, self.age) == ( other.name, other.age)
|
||||
```
|
||||
|
||||
Pay attention to the order of the attributes. They will always be generated in the order you defined them in the dataclass definition.
|
||||
|
||||
Similarly, the equivalent `__le__` function would be akin to:
|
||||
|
||||
```
|
||||
def __le__(self, other):
|
||||
return (self.name, self.age) <= (other.name, other.age)
|
||||
```
|
||||
|
||||
A need for defining a function like `__le__` generally arises, when you have to sort a list of your data objects. Python’s built-in [sorted][5] function relies on comparing two objects.
|
||||
|
||||
```
|
||||
|
||||
>>> import random
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = [Number(random.randint(1,10)) for _ in range(10)] #generate list of random numbers
|
||||
```
|
||||
|
||||
```
|
||||
>>> a
|
||||
```
|
||||
|
||||
```
|
||||
>>> [Number(val=2), Number(val=7), Number(val=6), Number(val=5), Number(val=10), Number(val=9), Number(val=1), Number(val=10), Number(val=1), Number(val=7)]
|
||||
```
|
||||
|
||||
```
|
||||
>>> sorted_a = sorted(a) #Sort Numbers in ascending order
|
||||
```
|
||||
|
||||
```
|
||||
>>> [Number(val=1), Number(val=1), Number(val=2), Number(val=5), Number(val=6), Number(val=7), Number(val=7), Number(val=9), Number(val=10), Number(val=10)]
|
||||
```
|
||||
|
||||
```
|
||||
>>> reverse_sorted_a = sorted(a, reverse = True) #Sort Numbers in descending order
|
||||
```
|
||||
|
||||
```
|
||||
>>> reverse_sorted_a
|
||||
```
|
||||
|
||||
```
|
||||
>>> [Number(val=10), Number(val=10), Number(val=9), Number(val=7), Number(val=7), Number(val=6), Number(val=5), Number(val=2), Number(val=1), Number(val=1)]
|
||||
|
||||
```
|
||||
|
||||
### `dataclass` as a callable decorator
|
||||
|
||||
It is not always desirable to have all the `dunder` methods defined. Your use case might only consist of storing the values and checking equality. Thus, you only need the `__init__` and `__eq__` methods defined. If we could tell the decorator to not generate the other methods, it would reduce some overhead and we shall have correct operations available on the data object.
|
||||
|
||||
Fortunately, this can be achieved by using `dataclass` decorator as a callable.
|
||||
|
||||
From the official [docs][6], the decorator can be used as a callable with the following arguments:
|
||||
|
||||
```
|
||||
@dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
|
||||
class C:
|
||||
…
|
||||
```
|
||||
|
||||
1. `init` : By default an `__init__` method will be generated. If passed as `False`, the class will not have an `__init__` method.
|
||||
|
||||
2. `repr` : `__repr__` method is generated by default. If passed as `False`, the class will not have an `__repr__` method.
|
||||
|
||||
3. `eq`: By default the `__eq__` method will be generated. If passed as `False`, the `__eq__` method will not be added by `dataclass`, but will default to the `object.__eq__`.
|
||||
|
||||
4. `order` : By default `__gt__` , `__ge__`, `__lt__`, `__le__` methods will be generated. If passed as `False`, they are omitted.
|
||||
|
||||
We shall discuss `frozen` in a while. The `unsafe_hash` argument deserves a separate post because of its complicated use cases.
|
||||
|
||||
Now, back to our use case, here’s what we need:
|
||||
|
||||
1. `__init__`
|
||||
2. `__eq__`
|
||||
|
||||
These functions are generated by default, so what we need is to not have the other functions generated. How do we do that? Simply pass the relevant arguments as false to the generator.
|
||||
|
||||
```
|
||||
@dataclass(repr = False) # order, unsafe_hash and frozen are False
|
||||
class Number:
|
||||
val: int = 0
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = Number(1)
|
||||
```
|
||||
|
||||
```
|
||||
>>> a
|
||||
```
|
||||
|
||||
```
|
||||
>>> <__main__.Number object at 0x7ff395afe898>
|
||||
```
|
||||
|
||||
```
|
||||
>>> b = Number(2)
|
||||
```
|
||||
|
||||
```
|
||||
>>> c = Number(1)
|
||||
```
|
||||
|
||||
```
|
||||
>>> a == b
|
||||
```
|
||||
|
||||
```
|
||||
>>> False
|
||||
```
|
||||
|
||||
```
|
||||
>>> a < b
|
||||
```
|
||||
|
||||
```
|
||||
>>> Traceback (most recent call last):
|
||||
File “<stdin>”, line 1, in <module>
|
||||
TypeError: ‘<’ not supported between instances of ‘Number’ and ‘Number’
|
||||
```
|
||||
|
||||
### Frozen Instances
|
||||
|
||||
Frozen Instances are objects whose attributes cannot be modified after the object has been initialized.
|
||||
|
||||
> It is not possible to create truly immutable Python objects
|
||||
|
||||
To create immutable attributes on an object in Python is an arduous task, and something that I won’t dive into in this post.
|
||||
|
||||
Here’s what we expect from an immutable object:
|
||||
|
||||
```
|
||||
>>> a = Number(10) #Assuming Number class is immutable
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.val = 10 # Raises Error
|
||||
```
|
||||
|
||||
With Dataclasses it is possible to define a frozen object by using `dataclass`decorator as a callable with argument `frozen=True` .
|
||||
|
||||
When a frozen dataclass object is instantiated, any attempt to modify the attributes of the object raises `FrozenInstanceError`.
|
||||
|
||||
```
|
||||
@dataclass(frozen = True)
|
||||
class Number:
|
||||
val: int = 0
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = Number(1)
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.val
|
||||
```
|
||||
|
||||
```
|
||||
>>> 1
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.val = 2
|
||||
```
|
||||
|
||||
```
|
||||
>>> Traceback (most recent call last):
|
||||
File “<stdin>”, line 1, in <module>
|
||||
File “<string>”, line 3, in __setattr__
|
||||
dataclasses.FrozenInstanceError: cannot assign to field ‘val’
|
||||
```
|
||||
|
||||
So a frozen instance is a great way of storing
|
||||
|
||||
* constants
|
||||
|
||||
* settings
|
||||
|
||||
These generally do not change over the lifetime of the application and any attempt to modify them should generally be warded off.
|
||||
|
||||
### Post init processing
|
||||
|
||||
With Dataclasses the requirement of defining an `__init__` method to assign variables to `self` has been taken care of. But now we lose the flexibility of making function-calls/processing that might be required immediately after the variables have been assigned.
|
||||
|
||||
Let us discuss a use case where we define a class `Float` to contain float numbers, and we calculate the integer and decimal parts immediately after initialization.
|
||||
|
||||
Usual
|
||||
|
||||
```
|
||||
import math
|
||||
```
|
||||
|
||||
```
|
||||
class Float:
|
||||
def __init__(self, val = 0):
|
||||
self.val = val
|
||||
self.process()
|
||||
|
||||
def process(self):
|
||||
self.decimal, self.integer = math.modf(self.val)
|
||||
|
||||
>>> a = Float( 2.2)
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.decimal
|
||||
```
|
||||
|
||||
```
|
||||
>>> 0.2000
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.integer
|
||||
```
|
||||
|
||||
```
|
||||
>>> 2.0
|
||||
```
|
||||
|
||||
Fortunately, post initialization processing is already taken care of with [__post_init__][9] method.
|
||||
|
||||
The generated `__init__` method calls the `__post_init__` method before returning. So, any processing can be made in this functions.
|
||||
|
||||
```
|
||||
import math
|
||||
```
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class FloatNumber:
|
||||
val: float = 0.0
|
||||
|
||||
def __post_init__(self):
|
||||
self.decimal, self.integer = math.modf(self.val)
|
||||
|
||||
>>> a = Number(2.2)
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.val
|
||||
```
|
||||
|
||||
```
|
||||
>>> 2.2
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.integer
|
||||
```
|
||||
|
||||
```
|
||||
>>> 2.0
|
||||
```
|
||||
|
||||
```
|
||||
>>> a.decimal
|
||||
```
|
||||
|
||||
```
|
||||
>>> 0.2
|
||||
```
|
||||
|
||||
Neat!
|
||||
|
||||
|
||||
### Inheritance
|
||||
|
||||
`Dataclasses` support inheritance like normal python classes.
|
||||
|
||||
So, the attributes defined in the parent class will be available in the child class.
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Person:
|
||||
age: int = 0
|
||||
name: str
|
||||
```
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Student(Person):
|
||||
grade: int
|
||||
```
|
||||
|
||||
```
|
||||
>>> s = Student(20, "John Doe", 12)
|
||||
```
|
||||
|
||||
```
|
||||
>>> s.age
|
||||
```
|
||||
|
||||
```
|
||||
>>> 20
|
||||
```
|
||||
|
||||
```
|
||||
>>> s.name
|
||||
```
|
||||
|
||||
```
|
||||
>>> "John Doe"
|
||||
```
|
||||
|
||||
```
|
||||
>>> s.grade
|
||||
```
|
||||
|
||||
```
|
||||
>>> 12
|
||||
```
|
||||
|
||||
Pay attention to the fact that the arguments to `Student` are in the order of fields defined in the class definition.
|
||||
|
||||
What about the behavior of `__post_init__` during inheritance?
|
||||
|
||||
Since `__post_init__` is just another function, it has to be invoked in the conventional form:
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class A:
|
||||
a: int
|
||||
|
||||
def __post_init__(self):
|
||||
print("A")
|
||||
```
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class B(A):
|
||||
b: int
|
||||
|
||||
def __post_init__(self):
|
||||
print("B")
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = B(1,2)
|
||||
```
|
||||
|
||||
```
|
||||
>>> B
|
||||
```
|
||||
|
||||
In the above example, only `B's` `__post_init__` is called. How do we invoke `A's` `__post_init__` ?
|
||||
|
||||
Since it is a function of the parent class, it can be invoked using `super.`
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class B(A):
|
||||
b: int
|
||||
|
||||
def __post_init__(self):
|
||||
super().__post_init__() #Call post init of A
|
||||
print("B")
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = B(1,2)
|
||||
```
|
||||
|
||||
```
|
||||
>>> A
|
||||
B
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
So, above are a few ways in which Dataclasses make life easier for Python developers.
|
||||
I have tried to be thorough and cover most of the use cases, yet, no man is perfect. Reach out if you find mistakes, or want me to pay attention to relevant use cases.
|
||||
|
||||
I shall cover [dataclasses.field][10] and `unsafe_hash` in different posts.
|
||||
|
||||
Follow me on [Github][11], [Twitter][12].
|
||||
|
||||
Update: Post for `dataclasses.field` can be found [here][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/mindorks/understanding-python-dataclasses-part-1-c3ccd4355c34
|
||||
|
||||
作者:[Shikhar Chauhan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@xsschauhan?source=post_header_lockup
|
||||
[1]:https://medium.com/@xsschauhan/understanding-python-dataclasses-part-2-660ecc11c9b8
|
||||
[2]:https://docs.python.org/3.7/library/dataclasses.html#dataclasses.dataclass
|
||||
[3]:https://stackoverflow.com/q/32557920/4333721
|
||||
[4]:https://docs.python.org/3/reference/datamodel.html#object.__lt__
|
||||
[5]:https://docs.python.org/3.7/library/functions.html#sorted
|
||||
[6]:https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass
|
||||
[7]:http://twitter.com/dataclass
|
||||
[8]:http://twitter.com/dataclass
|
||||
[9]:https://docs.python.org/3/library/dataclasses.html#post-init-processing
|
||||
[10]:https://docs.python.org/3/library/dataclasses.html#dataclasses.field
|
||||
[11]:http://github.com/xssChauhan/
|
||||
[12]:https://twitter.com/xssChauhan
|
||||
[13]:https://medium.com/@xsschauhan/understanding-python-dataclasses-part-2-660ecc11c9b8
|
||||
@ -0,0 +1,293 @@
|
||||
使用 Ptrace 去监听和仿真 Linux 系统调用 « null program
|
||||
======
|
||||
|
||||
`ptrace(2)`(”进程跟踪“)系统调用通常都与调试有关。它是类 Unix 系统上通过原生调试器监测调试进程的主要机制。它也是实现 [strace][1](系统调用跟踪)的常见方法。使用 Ptrace,跟踪器可以暂停跟踪过程,[检查和设置寄存器和内存][2],监视系统调用,甚至可以监听系统调用。
|
||||
|
||||
通过监听功能,意味着跟踪器可以修改系统调用参数,修改系统调用的返回值,甚至监听某些系统调用。言外之意就是,一个跟踪器可以完全服务于系统调用本身。这是件非常有趣的事,因为这意味着**一个跟踪器可以仿真一个完整的外部操作系统**,而这些都是在没有得到内核任何帮助的情况下由 Ptrace 实现的。
|
||||
|
||||
问题是,在同一时间一个进程只能被一个跟踪器附着,因此在那个进程的调试期间,不可能再使用诸如 GDB 这样的工具去仿真一个外部操作系统。另外的问题是,仿真系统调用的开销非常高。
|
||||
|
||||
在本文中,我们将专注于 x86-64 [Linux 的 Ptrace][3],并将使用一些 Linux 专用的扩展。同时,在本文中,我们将忽略掉一些错误检查,但是完整的源代码仍然会包含这些错误检查。
|
||||
|
||||
本文中的可直接运行的示例代码在这里:
|
||||
|
||||
**<https://github.com/skeeto/ptrace-examples>**
|
||||
|
||||
### strace
|
||||
|
||||
在进入到最有趣的部分之前,我们先从回顾 strace 的基本实现来开始。它不是 [DTrace][4],但 strace 仍然非常有用。
|
||||
|
||||
Ptrace 还没有被标准化。它的界面在不同的操作系统上非常类似,尤其是在核心功能方面,但是在不同的系统之间仍然存在细微的差别。`ptrace(2)` 的样子看起来应该像下面这样,但特定的类型可能有些差别。
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
|
||||
```
|
||||
|
||||
`pid` 是跟踪的进程 ID。虽然**同一个时间**只有一个跟踪器可以附着到进程上,但是一个跟踪器可以附着跟踪多个进程。
|
||||
|
||||
`request` 字段选择一个具体的 Ptrace 函数,比如 `ioctl(2)` 接口。对于 strace,只需要两个:
|
||||
|
||||
* `PTRACE_TRACEME`:这个进程被它的父进程跟踪。
|
||||
* `PTRACE_SYSCALL`:继续跟踪,但是在下一下系统调用入口或出口时停止。
|
||||
* `PTRACE_GETREGS`:取得被跟踪进程的寄存器内容副本。
|
||||
|
||||
|
||||
|
||||
另外两个字段,`addr` 和 `data`,作为所选的 Ptrace 函数的一般参数。一般情况下,可以忽略一个或全部忽略,在那种情况下,传递零个参数。
|
||||
|
||||
strace 接口实质上是另一个命令的前缀。
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
|
||||
```
|
||||
|
||||
最小化的 strace 不需要任何选项,因此需要做的第一件事情是 — 假设它至少有一个参数 — 在 `argv` 尾部的 `fork(2)` 和 `exec(2)` 被跟踪进程。但是在加载目标程序之前,新的进程将告知内核,目标程序将被它的父进程继续跟踪。被跟踪进程将被这个 Ptrace 系统调用暂停。
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
父进程使用 `wait(2)` 等待子进程的 `PTRACE_TRACEME`,当 `wait(2)` 返回后,子进程将被暂停。
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
在允许子进程继续运行之前,我们告诉操作系统,被跟踪进程被它的父进程的跟踪应该被终止。一个真实的 strace 实现可能会设置其它的选择,比如: `PTRACE_O_TRACEFORK`。
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
|
||||
```
|
||||
|
||||
剩余部分就是一个简单的、无休止的循环了,每循环一次捕获一个系统调用。循环体总共有四步:
|
||||
|
||||
1. 等待进程进入下一个系统调用。
|
||||
2. 输出一个系统调用的描述。
|
||||
3. 允许系统调用去运行和等待返回。
|
||||
4. 输出系统调用返回值。
|
||||
|
||||
|
||||
|
||||
`PTRACE_SYSCALL` 要求用于等待下一个系统调用时开始,和等待那个系统调用去退出。和前面一样,需要一个 `wait(2)` 去等待跟踪进入期望的状态。
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
当 `wait(2)` 返回时,线程寄存器中写入了被系统调用所产生的系统调用号和它的参数。尽管如此,操作系统将不再为这个系统调用提供服务。线程寄存器中的详细内容对后续操作很重要。
|
||||
|
||||
接下来的一步是采集系统调用信息。这是得到特定系统架构的地方。在 x86-64 上,[系统调用号是在 `rax` 中传递的][5],而参数(最多 6 个)是在 `rdi`、`rsi`、`rdx`、`r10`、`r8`、和 `r9` 中传递的。另外的 Ptrace 调用将读取这些寄存器,不过这里再也不需要 `wait(2)` 了,因为跟踪状态再也不会发生变化了。
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
|
||||
```
|
||||
|
||||
这里有一个敬告。由于 [内核的内部用途][6],系统调用号是保存在 `orig_rax` 中而不是 `rax` 中。而所有的其它系统调用参数都是非常简单明了的。
|
||||
|
||||
接下来是它的另一个 `PTRACE_SYSCALL` 和 `wait(2)`,然后是另一个 `PTRACE_GETREGS` 去获取结果。结果保存在 `rax` 中。
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
|
||||
```
|
||||
|
||||
这个简单程序的输出也是非常粗糙的。这里的系统调用都没有符号名,并且所有的参数都是以数字形式输出,甚至是一个指向缓冲区的指针。更完整的 strace 输出将能知道哪个参数是指针,以及 `process_vm_readv(2)` 为了从跟踪中正确输出内容而读取了哪些缓冲区。
|
||||
|
||||
然后,这些仅仅是系统调用监听的基础工作。
|
||||
|
||||
### 系统调用监听
|
||||
|
||||
假设我们想使用 Ptrace 去实现如 OpenBSD 的 [`pledge(2)`][7] 这样的功能,它是 [一个进程承诺只使用一套受限的系统调用][8]。初步想法是,许多程序一般都有一个初始化阶段,这个阶段它们都需要进行许多的系统访问(比如,打开文件、绑定套接字、等等)。初始化完成以后,它们进行一个主循环,在主循环中它们处理输入,并且仅使用所需的、很少的一套系统调用。
|
||||
|
||||
在进入主循环之前,可以限制一个进程只能运行它自己所需要的几个操作。如果 [程序有 Bug][9],允许通过恶意的输入去利用这个 Bug,这个承诺可以有效地限制漏洞利用的实现。
|
||||
|
||||
使用与 strace 相同的模型,但不是输出所有的系统调用,我们既能够拦截某些系统调用,也可以在它的行为异常时简单地终止被跟踪进程。终止它很容易:只需要在跟踪器中调用 `exit(2)`。因此,它也可以被设置为去终止被跟踪进程。拦截系统调用和允许子进程继续运行都只是些雕虫小技而已。
|
||||
|
||||
最棘手的部分是**当系统调用启动后没有办法去中断它**。进入系统调用之后,当跟踪器从 `wait(2)` 中返回,停止一个系统调用的仅有方式是,发生被跟踪进程终止的情况。
|
||||
|
||||
然而,我们不仅可以“搞乱”系统调用的参数,也可以改变系统调用号本身,将它修改为一个不存在的系统调用。返回时,在 `errno` 中 [通过正常的内部信号][10],我们就可以报告一个“友好的”错误信息。
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个简单的示例只是检查了系统调用是否违反白名单或黑名单。而它们在这里并没有差别,比如,允许文件以只读而不是读写方式打开(`open(2)`),允许匿名内存映射但不允许非匿名映射等等。但是这里仍然没有办法去动态撤销被跟踪进程的权限。
|
||||
|
||||
跟踪器与被跟踪进程如何沟通?使用人为的系统调用!
|
||||
|
||||
### 创建一个人为的系统调用
|
||||
|
||||
对于我的这个类似于 pledge 的系统调用 — 我可以通过调用 `xpledge()` 将它与真实的系统调用区分开 — 我设置 10000 作为它的系统调用号,这是一个非常大的数字,真实的系统调用中从来不会用到它。
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
|
||||
```
|
||||
|
||||
为演示需要,我同时构建了一个非常小的界面,这在实践中并不是个好主意。它与 OpenBSD 的 `pledge(2)` 稍有一些相似之处,它使用了一个 [字符串界面][11]。事实上,设计一个健壮且安全的权限集是非常复杂的,正如在 `pledge(2)` 的手册页面上所显示的那样。下面是对被跟踪进程的完整界面和系统调用的实现:
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
|
||||
```
|
||||
|
||||
如果给它传递零个参数,仅允许一些基本的系统调用,包括那些用于去分配内存的系统调用(比如 `brk(2)`)。 `PLEDGE_RDWR` 位允许 [各种][12] 读和写的系统调用(`read(2)`、`readv(2)`、`pread(2)`、`preadv(2)` 等等)。`PLEDGE_OPEN` 位允许 `open(2)`。
|
||||
|
||||
为防止发生提升权限的行为,`pledge()` 会拦截它自己 — 但这样也防止了权限撤销,以后再细说这方面内容。
|
||||
|
||||
在 xpledge 跟踪器中,我需要去检查这个系统调用:
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
操作系统将返回 `ENOSYS`(因为函数还没有实现),因此它不是一个真实的系统调用。为此在退出时我用一个 `success (0)` 去覆写它。
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我写了一小段测试程序去打开 `/dev/urandom`,做一个读操作,尝试去承诺后,我第二次打开 `/dev/urandom`,然后确认它能够读取原始的 `/dev/urandom` 文件描述符。在没有承诺跟踪器的情况下运行,输出如下:
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
|
||||
```
|
||||
|
||||
做一个无效的系统调用并不会让应用程序崩溃。它只是失败,这是一个很方便的返回方式。当它在跟踪器下运行时,它的输出如下:
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
|
||||
```
|
||||
|
||||
这个承诺很成功,第二次的 `fopen(3)` 并没有实现,因为跟踪器用一个 `EPERM` 拦截了它。
|
||||
|
||||
可以将这种思路进一步发扬光大,比如,改变文件路径或返回一个假的结果。一个跟踪器可以很高效地 chroot 它的被跟踪进程,通过一个系统调用将任意路径传递给 root 从而实现 chroot 路径。它甚至可以对用户进行欺骗,告诉用户它以 root 运行。事实上,这些就是 [Fakeroot NG][13] 程序所做的事情。
|
||||
|
||||
### 仿真外部系统
|
||||
|
||||
假设你不满足于仅监听一些系统调用,而是想监听全部系统调用。你收到 [一个打算在其它操作系统上运行的二进制程序][14],因为没有系统调用,这个二进制程序将无法正常运行。
|
||||
|
||||
使用我在前面所描述的这些内容你就可以管理这一切。跟踪器可以使用一个假冒的东西去代替系统调用号,允许它去失败,以及为系统调用本身提供服务。但那样做的效率很低。其实质上是对每个系统调用做了三个上下文切换:一个是在入口上停止,一个是让系统调用总是以失败告终,还有一个是在系统调用退出时停止。
|
||||
|
||||
从 2005 年以后,对于这个技术,PTrace 的 Linux 版本有更高效的操作:`PTRACE_SYSEMU`。PTrace 仅在每个系统调用发出时停止一次,在允许被跟踪进程继续运行之前,由跟踪器为系统调用提供服务。
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
从任何使用(足够)稳定的系统调用 ABI(译注:应用程序二进制接口),在相同架构的机器上运行一个二进制程序时,你只需要 `PTRACE_SYSEMU` 跟踪器,一个加载器(用于代替 `exec(2)`),和这个二进制程序所需要(或仅运行静态的二进制程序)的任何系统库即可。
|
||||
|
||||
事实上,这听起来有点像一个有趣的周末项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nullprogram.com
|
||||
[1]:https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]:http://nullprogram.com/blog/2016/09/03/
|
||||
[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]:http://nullprogram.com/blog/2018/01/17/
|
||||
[5]:http://nullprogram.com/blog/2015/05/15/
|
||||
[6]:https://stackoverflow.com/a/6469069
|
||||
[7]:https://man.openbsd.org/pledge.2
|
||||
[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]:http://nullprogram.com/blog/2017/07/19/
|
||||
[10]:http://nullprogram.com/blog/2016/09/23/
|
||||
[11]:https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]:http://nullprogram.com/blog/2017/03/01/
|
||||
[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]:http://nullprogram.com/blog/2017/11/30/
|
||||
@ -0,0 +1,513 @@
|
||||
理解 Python 的 Dataclasses -- 第一部分
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你正在阅读本文,那么你已经意识到了 Python 3.7 以及它所包含的新特性。就我个人而言,我对 `Dataclasses` 感到非常兴奋,因为我有一段时间在等待它了。
|
||||
|
||||
本系列包含两部分:
|
||||
1\. Dataclass 特点概述
|
||||
2\. 在下一篇文章概述 Dataclass 的 `fields`
|
||||
|
||||
### 介绍
|
||||
|
||||
`Dataclasses` 是 Python 的类(译注:更准确的说,它是一个模块),适用于存储数据对象。你可能会问什么是数据对象?下面是定义数据对象的一个不太详细的特性列表:
|
||||
|
||||
* 它们存储数据并代表某种数据类型。例如:一个数字。对于熟悉 ORM 的人来说,模型实例是一个数据对象。它代表一种特定的实体。它包含那些定义或表示实体的属性。
|
||||
|
||||
* 它们可以与同一类型的其他对象进行比较。例如:一个数字可以是 `greater than(大于)`, `less than(小于)` 或 `equal(等于)` 另一个数字。
|
||||
|
||||
当然还有更多的特性,但是这个列表足以帮助你理解问题的关键。
|
||||
|
||||
为了理解 `Dataclasses`,我们将实现一个包含数字的简单类,并允许我们执行上面提到的操作。
|
||||
首先,我们将使用普通类,然后我们再使用 `Dataclasses` 来实现相同的结果。
|
||||
|
||||
但在我们开始之前,先来谈谈 `dataclasses` 的用法。
|
||||
|
||||
Python 3.7 提供了一个装饰器 [dataclass][2],用于将类转换为 `dataclass`。
|
||||
|
||||
你所要做的就是将类包在装饰器中:
|
||||
|
||||
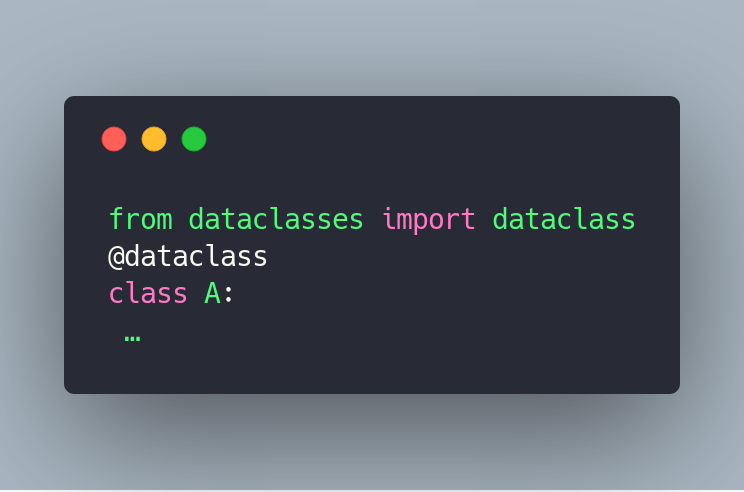
```
|
||||
from dataclasses import dataclass
|
||||
|
||||
@dataclass
|
||||
class A:
|
||||
…
|
||||
```
|
||||
|
||||
现在,让我们深入了解一下 `dataclass` 带给我们的变化和用途。
|
||||
|
||||
### 初始化
|
||||
|
||||
通常是这样:
|
||||
|
||||
```
|
||||
class Number:
|
||||
|
||||
def __init__(self, val):
|
||||
self.val = val
|
||||
|
||||
>>> one = Number(1)
|
||||
>>> one.val
|
||||
>>> 1
|
||||
```
|
||||
|
||||
用 `dataclass` 是这样:
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Number:
|
||||
val:int
|
||||
|
||||
>>> one = Number(1)
|
||||
>>> one.val
|
||||
>>> 1
|
||||
```
|
||||
|
||||
以下是 dataclass 装饰器带来的变化:
|
||||
|
||||
1\. 无需定义 `__init__`,然后将值赋给 `self.d` 负责处理它(to 校正:这里真不知道 d 在哪里)
|
||||
2\. 我们以更加易读的方式预先定义了成员属性,以及[类型提示][3]。我们现在立即能知道 `val` 是 `int` 类型。这无疑比一般定义类成员的方式更具可读性。
|
||||
|
||||
> Python 之禅: 可读性很重要
|
||||
|
||||
它也可以定义默认值:
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Number:
|
||||
val:int = 0
|
||||
```
|
||||
|
||||
### 表示
|
||||
|
||||
对象表示指的是对象的一个有意义的字符串表示,它在调试时非常有用。
|
||||
|
||||
默认的 Python 对象表示不是很直观:
|
||||
|
||||
```
|
||||
class Number:
|
||||
def __init__(self, val = 0):
|
||||
self.val = val
|
||||
|
||||
>>> a = Number(1)
|
||||
>>> a
|
||||
>>> <__main__.Number object at 0x7ff395b2ccc0>
|
||||
```
|
||||
|
||||
这让我们无法知悉对象的作用,并且会导致糟糕的调试体验。
|
||||
|
||||
一个有意义的表示可以通过在类中定义一个 `__repr__` 方法来实现。
|
||||
|
||||
```
|
||||
def __repr__(self):
|
||||
return self.val
|
||||
```
|
||||
|
||||
现在我们得到这个对象有意义的表示:
|
||||
|
||||
```
|
||||
>>> a = Number(1)
|
||||
>>> a
|
||||
>>> 1
|
||||
```
|
||||
|
||||
`dataclass` 会自动添加一个 `__repr__ ` 函数,这样我们就不必手动实现它了。
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Number:
|
||||
val: int = 0
|
||||
```
|
||||
|
||||
```
|
||||
>>> a = Number(1)
|
||||
>>> a
|
||||
>>> Number(val = 1)
|
||||
```
|
||||
|
||||
### 数据比较
|
||||
|
||||
通常,数据对象之间需要相互比较。
|
||||
|
||||
两个对象 `a` 和 `b` 之间的比较通常包括以下操作:
|
||||
|
||||
* a < b
|
||||
|
||||
* a > b
|
||||
|
||||
* a == b
|
||||
|
||||
* a >= b
|
||||
|
||||
* a <= b
|
||||
|
||||
在 Python 中,能够在可以执行上述操作的类中定义[方法][4]。为了简单起见,不让这篇文章过于冗长,我将只展示 `==` 和 `<` 的实现。
|
||||
|
||||
通常这样写:
|
||||
|
||||
```
|
||||
class Number:
|
||||
def __init__( self, val = 0):
|
||||
self.val = val
|
||||
|
||||
def __eq__(self, other):
|
||||
return self.val == other.val
|
||||
|
||||
def __lt__(self, other):
|
||||
return self.val < other.val
|
||||
```
|
||||
|
||||
使用 `dataclass`:
|
||||
|
||||
```
|
||||
@dataclass(order = True)
|
||||
class Number:
|
||||
val: int = 0
|
||||
```
|
||||
|
||||
是的,就是这样简单。
|
||||
|
||||
我们不需要定义 `__eq__` 和 `__lt__` 方法,因为当 `order = True` 被调用时,`dataclass` 装饰器会自动将它们添加到我们的类定义中。
|
||||
|
||||
那么,它是如何做到的呢?
|
||||
|
||||
当你使用 `dataclass` 时,它会在类定义中添加函数 `__eq__` 和 `__lt__` 。我们已经知道这点了。那么,这些函数是怎样知道如何检查相等并进行比较呢?
|
||||
|
||||
生成 `__eq__` 函数的 `dataclass` 类会比较两个属性构成的元组,一个由自己属性构成的,另一个由同类的其他实例的属性构成。在我们的例子中,`自动`生成的 `__eq__` 函数相当于:
|
||||
|
||||
```
|
||||
def __eq__(self, other):
|
||||
return (self.val,) == (other.val,)
|
||||
```
|
||||
|
||||
让我们来看一个更详细的例子:
|
||||
|
||||
我们会编写一个 `dataclass` 类 `Person` 来保存 `name` 和 `age`。
|
||||
|
||||
```
|
||||
@dataclass(order = True)
|
||||
class Person:
|
||||
name: str
|
||||
age:int = 0
|
||||
```
|
||||
|
||||
自动生成的 `__eq__` 方法等同于:
|
||||
|
||||
```
|
||||
def __eq__(self, other):
|
||||
return (self.name, self.age) == ( other.name, other.age)
|
||||
```
|
||||
|
||||
请注意属性的顺序。它们总是按照你在 dataclass 类中定义的顺序生成。
|
||||
|
||||
同样,等效的 `__le__` 函数类似于:
|
||||
|
||||
```
|
||||
def __le__(self, other):
|
||||
return (self.name, self.age) <= (other.name, other.age)
|
||||
```
|
||||
|
||||
当你需要对数据对象列表进行排序时,通常会出现像 `__le__` 这样的函数的定义。Python 内置的 [sorted][5] 函数依赖于比较两个对象。
|
||||
|
||||
```
|
||||
>>> import random
|
||||
|
||||
>>> a = [Number(random.randint(1,10)) for _ in range(10)] #generate list of random numbers
|
||||
|
||||
>>> a
|
||||
|
||||
>>> [Number(val=2), Number(val=7), Number(val=6), Number(val=5), Number(val=10), Number(val=9), Number(val=1), Number(val=10), Number(val=1), Number(val=7)]
|
||||
|
||||
>>> sorted_a = sorted(a) #Sort Numbers in ascending order
|
||||
|
||||
>>> [Number(val=1), Number(val=1), Number(val=2), Number(val=5), Number(val=6), Number(val=7), Number(val=7), Number(val=9), Number(val=10), Number(val=10)]
|
||||
|
||||
>>> reverse_sorted_a = sorted(a, reverse = True) #Sort Numbers in descending order
|
||||
|
||||
>>> reverse_sorted_a
|
||||
|
||||
>>> [Number(val=10), Number(val=10), Number(val=9), Number(val=7), Number(val=7), Number(val=6), Number(val=5), Number(val=2), Number(val=1), Number(val=1)]
|
||||
|
||||
```
|
||||
|
||||
### `dataclass` 作为一个可调用的装饰器
|
||||
|
||||
定义所有的 `dunder`(译注:这是指双下划线方法,即魔法方法)方法并不总是值得的。你的用例可能只包括存储值和检查相等性。因此,你只需定义 `__init__` 和 `__eq__` 方法。如果我们可以告诉装饰器不生成其他方法,那么它会减少一些开销,并且我们将在数据对象上有正确的操作。
|
||||
|
||||
幸运的是,这可以通过将 `dataclass` 装饰器作为可调用对象来实现。
|
||||
|
||||
从官方[文档][6]来看,装饰器可以用作具有如下参数的可调用对象:
|
||||
|
||||
```
|
||||
@dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
|
||||
class C:
|
||||
…
|
||||
```
|
||||
|
||||
1. `init`:默认将生成 `__init__` 方法。如果传入 `False`,那么该类将不会有 `__init__` 方法。
|
||||
|
||||
2. `repr`:`__repr__` 方法默认生成。如果传入 `False`,那么该类将不会有 `__repr__` 方法。
|
||||
|
||||
3. `eq`:默认将生成 `__eq__` 方法。如果传入 `False`,那么 `__eq__` 方法将不会被 `dataclass` 添加,但默认为 `object.__eq__`。
|
||||
|
||||
4. `order`:默认将生成 `__gt__`、`__ge__`、`__lt__`、`__le__` 方法。如果传入 `False`,则省略它们。
|
||||
|
||||
我们在接下来会讨论 `frozen`。由于 `unsafe_hash` 参数复杂的用例,它值得单独发布一篇文章。
|
||||
|
||||
现在回到我们的用例,以下是我们需要的:
|
||||
|
||||
1. `__init__`
|
||||
2. `__eq__`
|
||||
|
||||
默认会生成这些函数,因此我们需要的是不生成其他函数。那么我们该怎么做呢?很简单,只需将相关参数作为 false 传入给生成器即可。
|
||||
|
||||
```
|
||||
@dataclass(repr = False) # order, unsafe_hash and frozen are False
|
||||
class Number:
|
||||
val: int = 0
|
||||
|
||||
|
||||
>>> a = Number(1)
|
||||
|
||||
>>> a
|
||||
|
||||
>>> <__main__.Number object at 0x7ff395afe898>
|
||||
|
||||
>>> b = Number(2)
|
||||
|
||||
>>> c = Number(1)
|
||||
|
||||
>>> a == b
|
||||
|
||||
>>> False
|
||||
|
||||
>>> a < b
|
||||
|
||||
>>> Traceback (most recent call last):
|
||||
File “<stdin>”, line 1, in <module>
|
||||
TypeError: ‘<’ not supported between instances of ‘Number’ and ‘Number’
|
||||
```
|
||||
|
||||
### Frozen(不可变) 实例
|
||||
|
||||
Frozen 实例是在初始化对象后无法修改其属性的对象。
|
||||
|
||||
> 无法创建真正不可变的 Python 对象
|
||||
|
||||
在 Python 中创建对象的不可变属性是一项艰巨的任务,我将不会在本篇文章中深入探讨。
|
||||
|
||||
以下是我们期望不可变对象能够做到的:
|
||||
|
||||
```
|
||||
>>> a = Number(10) #Assuming Number class is immutable
|
||||
|
||||
>>> a.val = 10 # Raises Error
|
||||
```
|
||||
|
||||
有了 `dataclass`,就可以通过使用 `dataclass` 装饰器作为可调用对象配合参数 `frozen=True` 来定义一个 `frozen` 对象。
|
||||
|
||||
当实例化一个 `frozen` 对象时,任何企图修改对象属性的行为都会引发 `FrozenInstanceError`。
|
||||
|
||||
```
|
||||
@dataclass(frozen = True)
|
||||
class Number:
|
||||
val: int = 0
|
||||
|
||||
>>> a = Number(1)
|
||||
|
||||
>>> a.val
|
||||
|
||||
>>> 1
|
||||
|
||||
>>> a.val = 2
|
||||
|
||||
>>> Traceback (most recent call last):
|
||||
File “<stdin>”, line 1, in <module>
|
||||
File “<string>”, line 3, in __setattr__
|
||||
dataclasses.FrozenInstanceError: cannot assign to field ‘val’
|
||||
```
|
||||
|
||||
因此,一个 `frozen` 实例是一种很好方式来存储:
|
||||
|
||||
* 常数
|
||||
|
||||
* 设置
|
||||
|
||||
这些通常不会在应用程序的生命周期内发生变化,任何企图修改它们的行为都应该被禁止。
|
||||
|
||||
### 后期初始化处理
|
||||
|
||||
有了 `dataclass`,需要定义一个 `__init__` 方法来将变量赋给 `self` 这种初始化操作已经得到了处理。但是我们失去了在变量被赋值之后立即需要的函数调用或处理的灵活性。
|
||||
|
||||
让我们来讨论一个用例,在这个用例中,我们定义一个 `Float` 类来包含浮点数,然后在初始化之后立即计算整数和小数部分。
|
||||
|
||||
通常是这样:
|
||||
|
||||
```
|
||||
import math
|
||||
|
||||
class Float:
|
||||
def __init__(self, val = 0):
|
||||
self.val = val
|
||||
self.process()
|
||||
|
||||
def process(self):
|
||||
self.decimal, self.integer = math.modf(self.val)
|
||||
|
||||
>>> a = Float( 2.2)
|
||||
|
||||
>>> a.decimal
|
||||
|
||||
>>> 0.2000
|
||||
|
||||
>>> a.integer
|
||||
|
||||
>>> 2.0
|
||||
```
|
||||
|
||||
幸运的是,使用 [__post_init__][9] 方法已经能够处理后期初始化操作。
|
||||
|
||||
生成的 `__init__` 方法在返回之前调用 `__post_init__` 返回。因此,可以在函数中进行任何处理。
|
||||
|
||||
```
|
||||
import math
|
||||
|
||||
@dataclass
|
||||
class FloatNumber:
|
||||
val: float = 0.0
|
||||
|
||||
def __post_init__(self):
|
||||
self.decimal, self.integer = math.modf(self.val)
|
||||
|
||||
>>> a = Number(2.2)
|
||||
|
||||
>>> a.val
|
||||
|
||||
>>> 2.2
|
||||
|
||||
>>> a.integer
|
||||
|
||||
>>> 2.0
|
||||
|
||||
>>> a.decimal
|
||||
|
||||
>>> 0.2
|
||||
```
|
||||
|
||||
多么方便!
|
||||
|
||||
### 继承
|
||||
|
||||
`Dataclasses` 支持继承,就像普通的 Python 类一样。
|
||||
|
||||
因此,父类中定义的属性将在子类中可用。
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class Person:
|
||||
age: int = 0
|
||||
name: str
|
||||
|
||||
@dataclass
|
||||
class Student(Person):
|
||||
grade: int
|
||||
|
||||
>>> s = Student(20, "John Doe", 12)
|
||||
|
||||
>>> s.age
|
||||
|
||||
>>> 20
|
||||
|
||||
>>> s.name
|
||||
|
||||
>>> "John Doe"
|
||||
|
||||
>>> s.grade
|
||||
|
||||
>>> 12
|
||||
```
|
||||
|
||||
请注意,`Student` 的参数是在类中定义的字段的顺序。
|
||||
|
||||
继承过程中 `__post_init__` 的行为是怎样的?
|
||||
|
||||
由于 `__post_init__` 只是另一个函数,因此必须以传统方式调用它:
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class A:
|
||||
a: int
|
||||
|
||||
def __post_init__(self):
|
||||
print("A")
|
||||
|
||||
@dataclass
|
||||
class B(A):
|
||||
b: int
|
||||
|
||||
def __post_init__(self):
|
||||
print("B")
|
||||
|
||||
>>> a = B(1,2)
|
||||
|
||||
>>> B
|
||||
```
|
||||
|
||||
在上面的例子中,只有 `B` 的 `__post_init__` 被调用,那么我们如何调用 `A` 的 `__post_init__` 呢?
|
||||
|
||||
因为它是父类的函数,所以可以用 `super` 来调用它。
|
||||
|
||||
```
|
||||
@dataclass
|
||||
class B(A):
|
||||
b: int
|
||||
|
||||
def __post_init__(self):
|
||||
super().__post_init__() # 调用 A 的 post init
|
||||
print("B")
|
||||
|
||||
>>> a = B(1,2)
|
||||
|
||||
>>> A
|
||||
B
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
因此,以上是 dataclasses 使 Python 开发人员变得更轻松的几种方法。
|
||||
|
||||
我试着彻底覆盖大部分的用例,但是,没有人是完美的。如果你发现了错误,或者想让我注意相关的用例,请联系我。
|
||||
|
||||
我将在另一篇文章中介绍 [dataclasses.field][10] 和 `unsafe_hash`。
|
||||
|
||||
在 [Github][11] 和 [Twitter][12] 关注我。
|
||||
|
||||
更新:`dataclasses.field` 的文章可以在[这里][13]找到。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/mindorks/understanding-python-dataclasses-part-1-c3ccd4355c34
|
||||
|
||||
作者:[Shikhar Chauhan][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@xsschauhan?source=post_header_lockup
|
||||
[1]:https://medium.com/@xsschauhan/understanding-python-dataclasses-part-2-660ecc11c9b8
|
||||
[2]:https://docs.python.org/3.7/library/dataclasses.html#dataclasses.dataclass
|
||||
[3]:https://stackoverflow.com/q/32557920/4333721
|
||||
[4]:https://docs.python.org/3/reference/datamodel.html#object.__lt__
|
||||
[5]:https://docs.python.org/3.7/library/functions.html#sorted
|
||||
[6]:https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass
|
||||
[7]:http://twitter.com/dataclass
|
||||
[8]:http://twitter.com/dataclass
|
||||
[9]:https://docs.python.org/3/library/dataclasses.html#post-init-processing
|
||||
[10]:https://docs.python.org/3/library/dataclasses.html#dataclasses.field
|
||||
[11]:http://github.com/xssChauhan/
|
||||
[12]:https://twitter.com/xssChauhan
|
||||
[13]:https://medium.com/@xsschauhan/understanding-python-dataclasses-part-2-660ecc11c9b8
|
||||
Loading…
Reference in New Issue
Block a user