mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
35a2fa4a52
320
published/20140804 Group Test--Linux Text Editors.md
Normal file
320
published/20140804 Group Test--Linux Text Editors.md
Normal file
@ -0,0 +1,320 @@
|
||||
五款 Linux 文本编辑器测评
|
||||
================================================================================
|
||||
|
||||
> Mayank Sharma 测试了5款不仅仅是能处理文字的超强文本编辑器。
|
||||
|
||||
如果你使用Linux已经有很长一段时间,你知道,不管是编辑一款app的配置文件,还是修改shell脚本,或者编写/查看代码,类似LibreOffice的工具并不适合。尽管字面上看起来都是一样,但是你并不需要一个文字处理器来完成这些任务;你需要的是一个文本编辑器。
|
||||
|
||||
在这个测评中,我们将着眼于5款更能胜任繁重文本工作的轻量级的文本编辑器。他们支持语法高亮,像拼写检查一样轻松处理代码缩进。你可以像你复制/粘贴文本那样容易地使用它们记录宏以及管理代码片段。
|
||||
|
||||
得益于它们的插件,使得它们足以抗衡其它的以文本为中心的应用程序,一些简单的文本编辑器甚至超出了它们的设计目标。它们能胜任一个源代码编辑器的任务,甚至就是一个集成开发环境。
|
||||
|
||||
Emacs和Vim是两款最流行和强大的纯文本编辑器。但是,由于一些原因,我们在这个测评中并没有包括它们。首先,如果你使用它们中的任何一个,那么恭喜你:你不需要更换了。其次,它们都有陡峭的学习曲线,尤其是那些熟悉了桌面环境的用户:他们很更愿意投入其他有图形界面的文本编辑器。
|
||||
|
||||
### 目录: ###
|
||||
|
||||
#### Gedit ####
|
||||
|
||||
- URL:http://projects.gnome.org/gedit/
|
||||
- 版本: 3.10
|
||||
- 许可证: GPL
|
||||
- Gnome的默认文本编辑器准备好挑战了吗?
|
||||
|
||||
#### Kate ####
|
||||
|
||||
- URL: www.kate-editor.org
|
||||
- 版本: 3.11
|
||||
- 许可证: LGPL/GPL
|
||||
- Kate会挑战命运吗?
|
||||
|
||||
#### Sublime Text ####
|
||||
|
||||
- URL: www.sublimetext.com
|
||||
- 版本: 2.0.2
|
||||
- 许可证: Proprietary
|
||||
- 在自由的土地上的带有黄金般的心脏的专利软件。
|
||||
|
||||
#### UltraEdit ####
|
||||
|
||||
- URL: www.ultraedit.com
|
||||
- 版本: 4.1.0.4
|
||||
- 许可证: Proprietary
|
||||
- 足够证明它的价值了吗?
|
||||
|
||||
#### jEdit ####
|
||||
|
||||
- URL: www.jedit.org
|
||||
- 版本: 5.1.0
|
||||
- 许可证: GPL
|
||||
- 基于Java的编辑器是否会毁掉其他编辑器的世界?
|
||||
|
||||
|
||||
### 关键标准 ###
|
||||
|
||||
除了Gedit和jEdit以外的所有工具,都是通过其推荐的安装方法安装在Fedora和Ubuntu上。前者已经兼容默认的Gnome桌面,后者仍然固执地反对安装在Fedora上。由于这些是相对简单的应用程序,他们没有复杂的依赖,唯一例外的是jEdit,它要求要有Oracle Java。
|
||||
|
||||
得益于Gnome和KDE持续的努力,所有编辑器无论在哪个桌面上的外观看起来很好,功能也很正常。这不仅是作为评价的标准,也意味着你不再受制于你的桌面环境兼容的工具。
|
||||
|
||||
除了它们独特的功能,我们也对所有候选者测试了常规的文本编辑功能。然而,它们并没有被设计为模仿现代字处理器的所有功能,我们也不以此评判。
|
||||
|
||||
|
||||
### 编程语言支持 ###
|
||||
|
||||
UltraEdit 能进行语法高亮、代码折叠以及拥有项目管理的能力。也有一个罗列源文件中所有函数的功能列表,但并不适用于我们测试的任何代码文件。UltraEdit也支持HTML5,有一个能添加常用HTML标记的HTML工具栏。
|
||||
|
||||
即使Gnome的默认文本编辑器Gedit,也有几个面向编码的功能特性,例如括号匹配、自动缩进以及为包括C, C++, Java, HTML, XML, Python, Perl, 以及许多其它编程语言进行语法高亮。
|
||||
|
||||
如果你需要更多的编程辅助功能,看一下Sublime和Kate。
|
||||
|
||||
Sublime支持多种编程语言并且能为(那些流行的)C#, D, Dylan, Erlang, Groovy, Haskell, Lisp, Lua, MATLAB, OCaml, R, 甚至 SQL 进行语法高亮。如果这还不够,你可以下载插件以支持更多的语言。另外,它的语法高亮功能提供了多个可定制选项。这个应用程序也会进行括号匹配,确保代码段都正确,Sublime的自动补全功能也支持用户创建的变量。就像Komodo IDE,Sublime也可以显示一个全部源代码的滚动预览图,这对于长代码文件导航和在文件中的不同部分跳转很方便。Sublime最好的功能之一就是能在编辑器内部运行特定语言,例如C++, Python, Ruby等的代码,当然假设在你的电脑上安装有编译器以及其它系统工具。省时间而且不用再开终端.
|
||||
|
||||
你也可以用插件在Kate中开启构建系统功能。另外,你可以为GDB调试器添加一个简单的前端。Kate能和Git,Subversion以及Mercurial版本控制系统一起工作,也提供了一些项目管理的功能。除了能为超过180种语言进行语法高亮,它支持所有的这些辅助功能,例如括号匹配,自动补全和自动缩进。它也支持代码折叠,甚至在一个程序中折叠函数。
|
||||
|
||||
唯一的遗憾的是jEdit,它声称自己是一个程序员的文本编辑器,但它缺少其他的基本功能,例如代码折叠,它甚至不能提示或者补全函数.
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:3/5
|
||||
- Kate:5/5
|
||||
- Sublime:5/5
|
||||
- UltraEdit:3/5
|
||||
- jEdit:1/5
|
||||
|
||||
|
||||
### 键盘控制 ###
|
||||
|
||||
高级文本编辑器的用户希望能完全通过键盘控制和操作,一些应用程序甚至支持用户自定义快捷方式的键盘绑定。
|
||||
|
||||
你可以轻松的使用Gedit的扩展键盘快捷键。可以在编辑文件时通过工具的快捷键调用工具,例如对一个文档进行拼写检查。你可以看到应用程序内部的一系列默认快捷键,但并没有图形化的方式去自定义它们。相似的,在Sublime中自定义键盘绑定,你需要修改它的XML的键盘映射文件。Sublime由于缺少定义键盘快捷键的图形化界面而饱受批评,但长期使用的用户支持当前的基于文件的机制:这给了他们更多的控制能力。
|
||||
|
||||
UltraEdit为它"一切都可自定义"的座右铭感到自豪,这也包括键盘快捷键。你可以自定义菜单导航的热键,以及定义你自己的访问大量功能的组合键映射。
|
||||
|
||||
除了完全可自定义的键盘快捷键以外,jEdit也有为Emacs预定义的键映射。Kate在这方面尤其令人映像深刻。它有简单可访问的自定义键绑定窗口。你可以更改默认的键,或者定义替代的键。另外,Kate也有一个能使用户使用Vi键操作Kate的Vi模式。
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:2/5
|
||||
- Kate:5/5
|
||||
- Sublime:3/5
|
||||
- UltraEdit:4/5
|
||||
- jEdit:5/5
|
||||
|
||||
### 片段和宏 ###
|
||||
|
||||
宏通过自动化重复的步骤帮助你降低花费在编辑和组织数据上的时间,而代码片段通过创建可重用的源代码块为程序员扩展类似的功能。这两者都能节省你的时间。
|
||||
|
||||
标准的Gedit安装没有这两种功能中的任何一种,但是你可以通过独立的插件启用这些功能。片段插件随Gedit一起发布,但在Gedit内启用宏插件,则需要你手动下载和安装(被称为gedit-macropy,托管在GitHub上)。
|
||||
|
||||
Kate也同样通过插件的形式启用片段功能。一旦加入,插件也增加了PHP,Bash和Java的片段库。你可以在侧边栏中显示片段列表以便于访问。可以通过右击片段或者快捷键组合方式编辑它的内容。然而,令人惊讶的是,它不支持宏-尽管用户从2002年就不断要求!
|
||||
|
||||
jEdit也有一个启用片段的插件。它还可以从用户行为中记录宏或者你也可以用BeanShell 脚本语言(BeanShell支持像Perl和JavaScript那样将脚本对象封装为简单的方法)中写宏。jEdit也有一个可以从jEdit的网站中下载多种宏的插件。
|
||||
|
||||
Sublime有创建片段和宏的内建功能,也有为大多数编程语言经常使用的函数多种片段。
|
||||
|
||||
在UltraEdit中片段被称为智能模板,就像Sublime中一样,你可以根据正在编辑的源代码文件类型插入片段。要完成宏记录功能,UltraEdit还有集成了一个基于JavaScript的脚本语言引擎来完成自动任务。你也可以从该编辑器的网站中下载用户提交的宏和脚本。
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:3/5
|
||||
- Kate:1/5
|
||||
- Sublime:5/5
|
||||
- UltraEdit:5/5
|
||||
- jEdit:5/5
|
||||
|
||||
|
||||
### 易用性 ###
|
||||
|
||||
不像那些简陋的文本编辑器,这些文本编辑器在这方面可以适应从文档写作者到程序员的各种用户的需要。与精简应用程序相反,他们的开发者在寻找添加更多功能的途径。
|
||||
|
||||
尽管第一眼看上去这次测评中的大部分应用有一个很相似的布局,经过仔细的检查,你会发现一些可用性的差异。我们通过用户界面的合理使用来介绍它们的功能和特性,而不是铺天盖地地告诉读者。
|
||||
|
||||
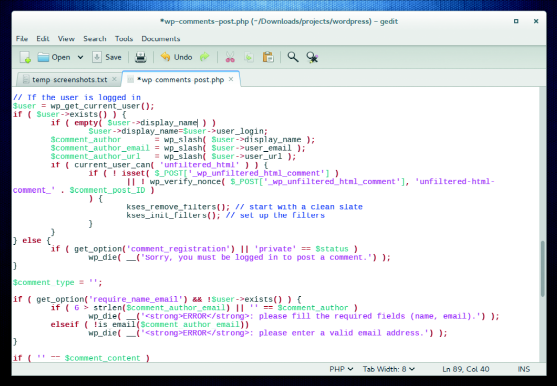
#### Gedit: 4/5 ####
|
||||
|
||||
Gedit的外观很普通,它有一个带有很少的菜单和按钮的简单界面。这是一把双刃剑,因为有些用户可能不会发现它真正的潜能。
|
||||
|
||||
Gedit可以在选项卡中打开多个文件,这些选项卡可以重排和在多个 Gedit窗口之间移动。用户可以选择通过插件来启用侧边栏来浏览文件或者在底部面板显示工具输出内容。这个应用程序会检测到被其它应用程序更改的文件并可以重新加载该文件。
|
||||
|
||||
为了适配Gnome,在应用程序的最新版本中做了大量的 UI 修改。然而修改还还不稳定,尽管包括了所有的功能,但是菜单交互的一些插件还需要升级。
|
||||
|
||||
|
||||
|
||||
*在功能与界面之间取得了良好的平衡,Gedit将其大部分功能隐藏在背后。*
|
||||
|
||||
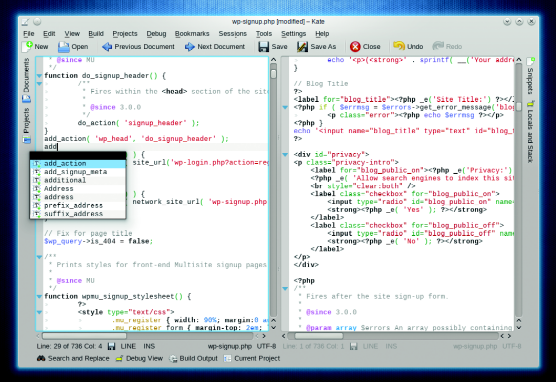
#### Kate: 5/5 ####
|
||||
|
||||
尽管用户界面的主要部分和Gedit相似,Kate可以在两边显示选项卡并且它的菜单更加丰富。该应用程序平易近人,吸引用户来挖掘它的其它功能。
|
||||
|
||||
Kate可以在KDE的KIO支持的所有协议上透明地打开和保存文件,包括通过HTTP, FTP, SSH, SMB 和 WebDAV。你可以用这个应用同时处理多个文件。但不同于大部分应用程序传统的水平选项卡选择栏,Kate在屏幕的两个方向都有选项卡。左侧的侧边栏显示打开的文件列表。需要同时查看一个文件不同部分的程序员也会感激它可以水平或者竖直分隔界面的能力。
|
||||
|
||||
|
||||
|
||||
*Kate能搭建为功能丰富的集成开发环境。*
|
||||
|
||||
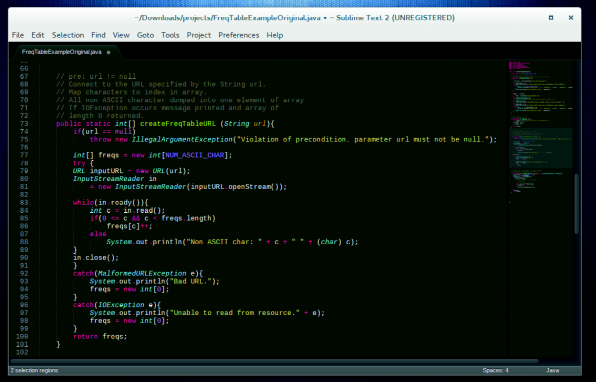
#### Sublime: 5/5 ####
|
||||
|
||||
Sublime支持你在不同方式同时查看多达四个文件。当你在集中精力编程时,它也有一个只显示文件和菜单的全屏无扰模式。
|
||||
|
||||
这个编辑器还在右边有个缩略地图,这在长文件中导航非常有用。应用程序为多种编程语言提供多种常用函数的片段,这使得它对于开发者非常有用。另一个精巧的功能是,无论你使用都是文本文档或者代码,都可以任意选择和替换。
|
||||
|
||||
|
||||
|
||||
*如果你不喜欢Sublime的Charcoal外观,你可以选择它包含的其它22种主题。*
|
||||
|
||||
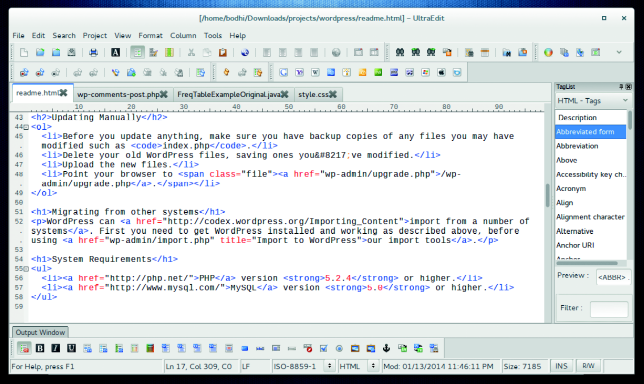
#### UltraEdit: 3/5 ####
|
||||
|
||||
UltraEdit在界面的顶部和底部加载了多种工具栏。加上切换文档的选项卡、两边的面板,以及分隔区域,使得只剩下一点空间给编辑窗口。
|
||||
|
||||
使用HTML的网络开发者有很多唾手可得的帮助。你可以通过FTP和SFTP访问远程文件。高级功能,例如记录一个宏以及比较文件,也简单易用。
|
||||
|
||||
使用应用程序的偏好设置窗口,你可以调整应用程序的多个方面,包括颜色主题和类似语法高亮的其它功能。
|
||||
|
||||
|
||||
|
||||
*UltraEdit的用户界面是高度可配置的 — 你可以像改变其它许多方面那样简单的自定义工具栏和菜单的布局。*
|
||||
|
||||
#### jEdit: 3/5 ####
|
||||
|
||||
在可用性方面,首先一个不好就是jEdit不能在基于RPM的发行版上安装。导航编辑器需要一些时间来适应,因为它的菜单和其它流行的应用程序顺序不同,而且有些普通桌面用户不熟悉的名字。但是,该应用程序有详细的内部帮助,这有利于缓解学习曲线。
|
||||
|
||||
jEdit会高亮你所在的当前行,并使你能以多种查看方式分隔窗口。你可以简单地从应用程序中安装和管理插件,除了使用完整的宏,jEdit也支持你快速记录一个临时的宏。
|
||||
|
||||
|
||||
|
||||
*由于它的Java基础,jEdit在任何桌面环境中都不能给人宾至如归的感觉*
|
||||
|
||||
### 可用性和支持 ###
|
||||
|
||||
在Gedit和Kate之间有很多相似性。两个应用程序都得益于他们各自的父项目,Gnome和KDE,捆绑在各种主流的发行版中。另外两个项目都是跨平台的,有Windows和Mac OS X版本以及原生的Linux版本。
|
||||
|
||||
Gedit托管在Gnome的网站上,并有一个简单的用户指南、关于多种插件的信息,以及包括邮件列表和IRC通道在内的常用联系方式。你也可以在其它基于Gnome的发行版,例如Ubuntu中找到使用信息。相似地,Kate得益于KDE的资源,并包括详细的用户信息以及邮件列表和IRC通道。你也可以从应用程序中获取相应的离线用户指南。
|
||||
|
||||
除了Linux,UltraEdit在Windows和Mac OS X中也可用,虽然在应用程序中并没有包括,但在启动时也有详细的用户指南。为了辅助用户的使用,UltraEdit保存了一个常见问题的数据库,一系列关于多种特定功能的详细介绍,用户还可以在论坛版块彼此帮助。另外,付费用户也可以通过邮件从开发者中获取支持。
|
||||
|
||||
Sublime支持一样多的平台,但是你需要单独为每种平台购买许可证。开发者通过博客让用户了解正在进行的开发,并积极参加它的论坛。这个项目支持设施的亮点是提供免费的详细教程和视频课程。Sublime非常漂亮。
|
||||
|
||||
由于jEdit是用java编写的,所以它在多种平台中都可用。在它的网站上你可以找到一个详细的用户指南以及一些插件帮助文档的链接。然而,这里没有能使用户和其他用户或者开发者交流的途径。
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:4/5
|
||||
- Kate:4/5
|
||||
- Sublime:5/5
|
||||
- UltraEdit:3/5
|
||||
- jEdit:2/5
|
||||
|
||||
### 附加组件和插件 ###
|
||||
|
||||
不同的用户有不同的需求,一个简单的轻量级应用程序只能做到这么多。这就是为什么需要插件的原因。应用程序依赖于这些小部件来扩展它们的功能集并让更多的用户使用。
|
||||
|
||||
UltraEdit是一个例外。它没有第三方插件,但开发者将例如HtmlTidy这样的第三方工具集成到了UltraEdit。
|
||||
|
||||
Gedit附带了好多已安装的插件,你可以下载更多的更多gedit插件包。基于和Gedit版本的兼容性,项目网站也有到多个第三方插件的链接。
|
||||
|
||||
三个对程序员非常有用的插件是:Code Comment、在底部面板增加一个终端的Terminal Plugin以及Session Saver。当你用多个文件开发项目的时候Session Saver相当有用。你可以在选项卡中打开文件,保存会话,你可以用一键恢复,就可以按照你保存时的选项卡顺序打开所有的文件。
|
||||
|
||||
类似的,你可以通过用内部的插件管理器增加插件来扩展Kate。除了令人映像深刻的项目插件,一些开发者使用的插件包括嵌入式终端,它能编译和调试代码,以及对数据库执行SQL查询。
|
||||
|
||||
Sublime的插件是用Python写的,文本编辑器包括了一个类似于apt-get,能使用户查找,安装,升级和移除插件包的名为Package Control的工具。通过插件,你可以在Sublime中使用Git版本控制,以及美化JavaScript代码的JSLint工具。Sublime Linter能指出你代码中的错误,是编码人员必备的插件。
|
||||
|
||||
jEdit拥有最令人印象深刻的插件设施。该应用有超过200个插件,可以在它们自己的专用网站中浏览。网站通过不同的类型列出了插件,例如文件管理,版本控制,文本等。你可以在每个类型下找到很多的插件。
|
||||
|
||||
一些最好的插件是Android插件,它们提供了和Android项目协同工作的工具;你可以使用TomcatSwitch插件创建和控制外部Jakarta Tomcat服务器进程;以及类似于Vi功能的Vimulator插件。你可以通过使用jEdit的插件管理器安装这些插件。
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:3/5
|
||||
- Kate:4/5
|
||||
- Sublime:4/5
|
||||
- UltraEdit:1/5
|
||||
- jEdit:5/5
|
||||
|
||||
### 纯文本编辑 ###
|
||||
|
||||
尽管它们强大的额外功能甚至可能会取代几种完全成熟的应用程序,有时候可能只需要使用这些庞大的文本编辑器读、写或者编辑简单的纯文本。虽然你可以使用它们中的任何一个输入文本,我们通过普通文本编辑的方便性评价它们。
|
||||
|
||||
Gnome的默认文本编辑器Gedit,支持取消和重做机制以及搜索和替换。它可以对多种语言进行拼写检查,并能通过使用Gnome GVFS库访问和编辑远程文件。
|
||||
|
||||
你也可以使用Kate进行拼写检查,它也可以让你对任何高亮文本进行Google搜索。它还有一个能可视化告知用户文件中更改过但没有保存的行的行修改系统。另外,它通过允许用户在文件中使用书签简化长文档的导航。
|
||||
|
||||
Sublime有很多可选择的编辑命令,例如缩进文本和格式化段落。它的自动保存功能帮助防止用户丢失他们的更改。高级用户还会喜欢基于正则表达式的递归查找和替换功能,以及选择多个不连续的文本块并执行统一操作。
|
||||
|
||||
UltraEdit也允许用户在查找和替换功能中使用正则表达式,并能通过FTP编辑远程文件。
|
||||
|
||||
JEdit一个独特的功能是它支持被称为寄存器的不限数目的剪切板。你可以复制文本片段到这些寄存器中,在编辑会话过程中都可用。
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:4/5
|
||||
- Kate:5/5
|
||||
- Sublime:5/5
|
||||
- UltraEdit:4/5
|
||||
- jEdit:4/5
|
||||
|
||||
### 我们的评比 ###
|
||||
|
||||
在这里的所有编辑器都足以替换你已有的文本编辑器,来编辑文本和调整配置文件。事实上,没准它们会组合起来作为你的集成开发环境。这些应用程序都有各种各样功能,它们的开发者不会考虑剥离功能,而是增加越来越多的功能。
|
||||
|
||||
jEdit排在这次测试的最后面。因为它不仅坚持使用专有的Oracle Java运行时环境,不能在你的Fedora机器上安装,而且开发者并不积极和用户交互。
|
||||
|
||||
UltraEdit做的稍微好一点。这个商业专用工具专注于网络开发者,不为非开发者的高级用户提供任何功能,使得它不值得推荐为免费软件的替代品。
|
||||
|
||||
排在第三的是Gedit。作为Gnome的默认编辑器,它没有任何内在的问题,但尽管有很多积极的方面,它还是略微被Sublime和Kate超越。开诚布公地说,Kate是比Gedit更通用的编辑器,甚至考虑到他们的插件系统,评分也优于Gnome的默认编辑器。
|
||||
|
||||
Sublime和Kate都相当好。他们在我们的大多数测试中表现同样出色。Kate由于不支持宏而落后于Sublime,但键盘友好和能简单定义自定义键绑定又使Kate找回优势。
|
||||
|
||||
Kate成功的原因可以归结为它通过最小化学习曲线提供了最大化的功能。尽管使用它吧,不仅作为简单文本编辑器使用,或者容易使用语法高亮编辑配置文件,甚至得益于其项目管理能力能使用它协作一个复杂的编程项目。
|
||||
|
||||
我们不是选择Kate去替换一个类似“[XX,在这里插入你最喜欢的专业工具]”的全面的集成开发环境。但是它是一个专业工具理想的、全面的、以及完美的垫脚石。
|
||||
|
||||
Kate为能快速响应你的需要而设计,它的界面并不会使你茫然,并且和那些过于复杂的应用一样的有用。
|
||||
|
||||
### 1st Kate ###
|
||||
|
||||
- Licence LGPL/GPL Version 3.11
|
||||
- www.kate-editor.org
|
||||
- 拥有超能力,态度温和的文本编辑器。
|
||||
- Kate是KDE项目中最有用的应用程序之一。
|
||||
|
||||
### 2nd Sublime Text ###
|
||||
|
||||
- Licence 专利 Version 2.0.2
|
||||
- www.sublimetext.com
|
||||
- 值得你每分钱的专业文本编辑器 - 简单易用,功能全面而且看起来很棒。
|
||||
|
||||
### 3rd Gedit ###
|
||||
|
||||
- Licence GPL Version 3.10
|
||||
- http://projects.gnome.org/gedit
|
||||
- 在Gnome中就用它吧。这是一个奇妙的文本编辑器,确实令人钦佩的工作,但这里的竞争实在太大了。
|
||||
|
||||
### 4th UltraEdit ###
|
||||
|
||||
- Licence Proprietary Version 4.1.0.4
|
||||
- www.ultraedit.com
|
||||
- 关注于为网络开发者提供各种便利,而不为普通用户提供任何特殊功能。
|
||||
|
||||
### 5th jEdit ###
|
||||
|
||||
- Licence GPL Version 5.1.0
|
||||
- www.jedit.org
|
||||
- 缺乏支持,不支持Fedora,缺乏好看的界面,jEdit被贬低到最后。
|
||||
|
||||
### 你也许希望尝试… ###
|
||||
|
||||
随你发行版发布的默认文本编辑器也能帮助你一些高级任务。例如KDE的KWrite和Raspbian的Nano。得益于KDE的katepart组件,KWrite继承了一些Kate的功能,得益于在树莓派上的可用性,Nano也开始重现风头。
|
||||
|
||||
如果你希望跟随Linux大师的脚步,你总是可以尝试高大上的文本编辑器Emacs和Vim。想尝试Vim强大的用户首先可以考虑gVim,它通过图形界面展现了Vim的强大。
|
||||
|
||||
除了jEdit和Kate,这里还有其他模仿Emacs和Vim之类的旧式高级编辑器的编辑器,比如JED 编辑器和Joe's Own Editor,这两者都有Emacs的模拟模式。另一方面,如果你在寻找轻量级的代码编辑器,可以看看Bluefish和Geany。他们的存在是为了填补文本编辑器和全面集成的开发平台之间的空隙。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/text-editors/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[royaso](https://github.com/royaso),[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
@ -0,0 +1,136 @@
|
||||
又一波你可能不知道的 Linux 命令行网络监控工具
|
||||
===============================================================================
|
||||
|
||||
对任何规模的业务来说,网络监控工具都是一个重要的功能。网络监控的目标可能千差万别。比如,监控活动的目标可以是保证长期的网络服务、安全保护、对性能进行排查、网络使用统计等。由于它的目标不同,网络监控器使用很多不同的方式来完成任务。比如对包层面的嗅探,对数据流层面的统计数据,向网络中注入探测的流量,分析服务器日志等。
|
||||
|
||||
尽管有许多专用的网络监控系统可以365天24小时监控,但您依旧可以在特定的情况下使用命令行式的网络监控器,某些命令行式的网络监控器在某方面很有用。如果您是系统管理员,那您就应该有亲身使用一些知名的命令行式网络监控器的经历。这里有一份**Linux上流行且实用的网络监控器**列表。
|
||||
|
||||
### 包层面的嗅探器 ###
|
||||
|
||||
在这个类别下,监控工具在链路上捕捉独立的包,分析它们的内容,展示解码后的内容或者包层面的统计数据。这些工具在最底层对网络进行监控、管理,同样的也能进行最细粒度的监控,其代价是影响网络I/O和分析的过程。
|
||||
|
||||
1. **dhcpdump**:一个命令行式的DHCP流量嗅探工具,捕捉DHCP的请求/回复流量,并以用户友好的方式显示解码的DHCP协议消息。这是一款排查DHCP相关故障的实用工具。
|
||||
|
||||
2. **[dsniff][1]**:一个基于命令行的嗅探、伪造和劫持的工具合集,被设计用于网络审查和渗透测试。它可以嗅探多种信息,比如密码、NSF流量(LCTT 译注:此处疑为 NFS 流量)、email消息、网络地址等。
|
||||
|
||||
3. **[httpry][2]**:一个HTTP报文嗅探器,用于捕获、解码HTTP请求和回复报文,并以用户友好的方式显示这些信息。(LCTT 译注:[延伸阅读](https://linux.cn/article-4148-1.html)。 )
|
||||
|
||||
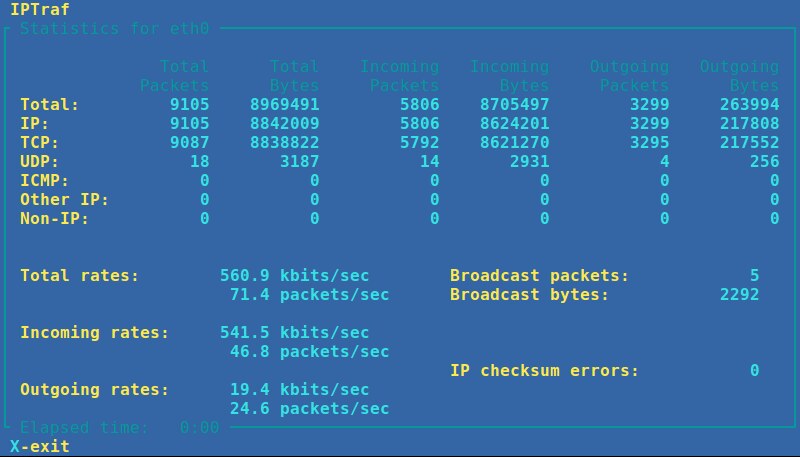
4. **IPTraf**:基于命令行的网络统计数据查看器。它实时显示包层面、连接层面、接口层面、协议层面的报文/字节数。抓包过程由协议过滤器控制,且操作过程全部是菜单驱动的。(LCTT 译注:[延伸阅读](https://linux.cn/article-5430-1.html)。)
|
||||
|
||||
|
||||
|
||||
5. **[mysql-sniffer][3]**:一个用于抓取、解码MySQL请求相关的数据包的工具。它以可读的方式显示最频繁或全部的请求。
|
||||
|
||||
6. **[ngrep][4]**:在网络报文中执行grep。它能实时抓取报文,并用正则表达式或十六进制表达式的方式匹配(过滤)报文。它是一个可以对异常流量进行检测、存储或者对实时流中特定模式报文进行抓取的实用工具。
|
||||
|
||||
7. **[p0f][5]**:一个被动的基于包嗅探的指纹采集工具,可以可靠地识别操作系统、NAT或者代理设置、网络链路类型以及许多其它与活动的TCP连接相关的属性。
|
||||
|
||||
8. **pktstat**:一个命令行式的工具,通过实时分析报文,显示连接带宽使用情况以及相关的协议(例如,HTTP GET/POST、FTP、X11)等描述信息。
|
||||
|
||||
|
||||
|
||||
9. **Snort**:一个入侵检测和预防工具,通过规则驱动的协议分析和内容匹配,来检测/预防活跃流量中各种各样的后门、僵尸网络、网络钓鱼、间谍软件攻击。
|
||||
|
||||
10. **tcpdump**:一个命令行的嗅探工具,可以基于过滤表达式抓取网络中的报文,分析报文,并且在包层面输出报文内容以便于包层面的分析。他在许多网络相关的错误排查、网络程序debug、或[安全][6]监测方面应用广泛。
|
||||
|
||||
11. **tshark**:一个与Wireshark窗口程序一起使用的命令行式的嗅探工具。它能捕捉、解码网络上的实时报文,并能以用户友好的方式显示其内容。
|
||||
|
||||
### 流/进程/接口层面的监控 ###
|
||||
|
||||
在这个分类中,网络监控器通过把流量按照流、相关进程或接口分类,收集每个流、每个进程、每个接口的统计数据。其信息的来源可以是libpcap抓包库或者sysfs内核虚拟文件系统。这些工具的监控成本很低,但是缺乏包层面的检视能力。
|
||||
|
||||
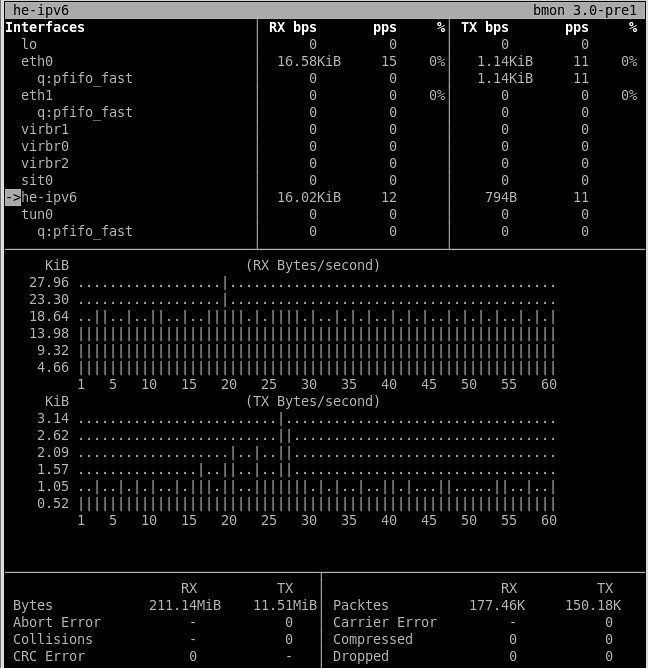
12. **bmon**:一个基于命令行的带宽监测工具,可以显示各种接口相关的信息,不但包括接收/发送的总量/平均值统计数据,而且拥有历史带宽使用视图。
|
||||
|
||||
|
||||
|
||||
13. **[iftop][7]**:一个带宽使用监测工具,可以实时显示某个网络连接的带宽使用情况。它对所有带宽使用情况排序并通过ncurses的接口来进行可视化。他可以方便的监控哪个连接消耗了最多的带宽。(LCTT 译注:[延伸阅读](https://linux.cn/article-1843-1.html)。)
|
||||
|
||||
14. **nethogs**:一个基于ncurses显示的进程监控工具,提供进程相关的实时的上行/下行带宽使用信息。它对检测占用大量带宽的进程很有用。(LCTT 译注:[延伸阅读](https://linux.cn/article-2808-1.html)。)
|
||||
|
||||
15. **netstat**:一个显示许多TCP/UDP的网络堆栈的统计信息的工具。诸如打开的TCP/UDP连接书、网络接口发送/接收、路由表、协议/套接字的统计信息和属性。当您诊断与网络堆栈相关的性能、资源使用时它很有用。
|
||||
|
||||
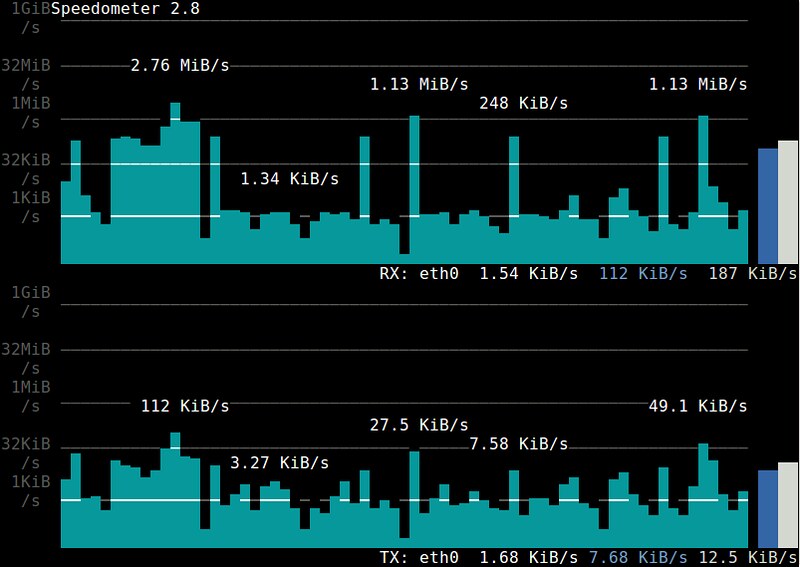
16. **[speedometer][8]**:一个可视化某个接口发送/接收的带宽使用的历史趋势,并且基于ncurses的条状图进行显示的终端工具。
|
||||
|
||||
|
||||
|
||||
17. **[sysdig][9]**:一个可以通过统一的界面对各个Linux子系统进行系统级综合性调试的工具。它的网络监控模块可以监控在线或离线、许多进程/主机相关的网络统计数据,例如带宽、连接/请求数等。(LCTT 译注:[延伸阅读](https://linux.cn/article-4341-1.html)。)
|
||||
|
||||
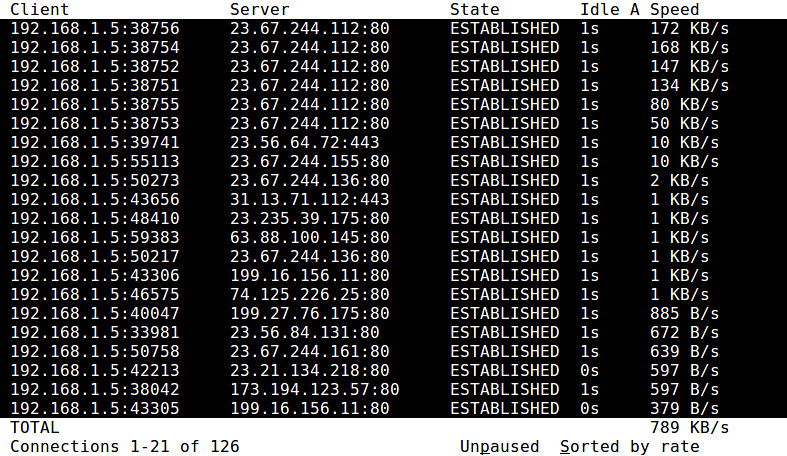
18. **tcptrack**:一个TCP连接监控工具,可以显示活动的TCP连接,包括源/目的IP地址/端口、TCP状态、带宽使用等。
|
||||
|
||||
|
||||
|
||||
19. **vnStat**:一个存储并显示每个接口的历史接收/发送带宽视图(例如,当前、每日、每月)的流量监控器。作为一个后台守护进程,它收集并存储统计数据,包括接口带宽使用率和传输字节总数。(LCTT 译注:[延伸阅读](https://linux.cn/article-5256-1.html)。)
|
||||
|
||||
### 主动网络监控器 ###
|
||||
|
||||
不同于前面提到的被动的监听工具,这个类别的工具们在监听时会主动的“注入”探测内容到网络中,并且会收集相应的反应。监听目标包括路由路径、可供使用的带宽、丢包率、延时、抖动(jitter)、系统设置或者缺陷等。
|
||||
|
||||
20. **[dnsyo][10]**:一个DNS检测工具,能够管理跨越多达1500个不同网络的开放解析器的DNS查询。它在您检查DNS传播或排查DNS设置的时候很有用。
|
||||
|
||||
21. **[iperf][11]**:一个TCP/UDP带宽测量工具,能够测量两个端点间最大可用带宽。它通过在两个主机间单向或双向的输出TCP/UDP探测流量来测量可用的带宽。它在监测网络容量、调谐网络协议栈参数时很有用。一个叫做[netperf][12]的变种拥有更多的功能及更好的统计数据。
|
||||
|
||||
22. **[netcat][13]/socat**:通用的网络调试工具,可以对TCP/UDP套接字进行读、写或监听。它通常和其他的程序或脚本结合起来在后端对网络传输或端口进行监听。(LCTT 译注:[延伸阅读](https://linux.cn/article-1171-1.html)。)
|
||||
|
||||
23. **nmap**:一个命令行的端口扫描和网络发现工具。它依赖于若干基于TCP/UDP的扫描技术来查找开放的端口、活动的主机或者在本地网络存在的操作系统。它在你审查本地主机漏洞或者建立维护所用的主机映射时很有用。[zmap][14]是一个类似的替代品,是一个用于互联网范围的扫描工具。(LCTT 译注:[延伸阅读](https://linux.cn/article-2561-1.html)。)
|
||||
|
||||
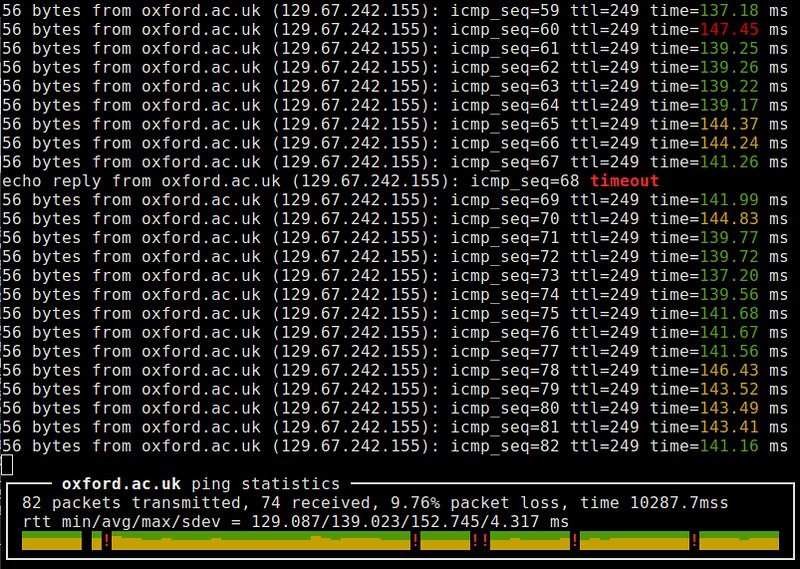
24. ping:一个常用的网络测试工具。通过交换ICMP的echo和reply报文来实现其功能。它在测量路由的RTT、丢包率以及检测远端系统防火墙规则时很有用。ping的变种有更漂亮的界面(例如,[noping][15])、多协议支持(例如,[hping][16])或者并行探测能力(例如,[fping][17])。(LCTT 译注:[延伸阅读](https://linux.cn/article-2303-1.html)。)
|
||||
|
||||
|
||||
|
||||
25. **[sprobe][18]**:一个启发式推断本地主机和任意远端IP地址之间的网络带宽瓶颈的命令行工具。它使用TCP三次握手机制来评估带宽的瓶颈。它在检测大范围网络性能和路由相关的问题时很有用。
|
||||
|
||||
26. **traceroute**:一个能发现从本地到远端主机的第三层路由/转发路径的网络发现工具。它发送限制了TTL的探测报文,收集中间路由的ICMP反馈信息。它在排查低速网络连接或者路由相关的问题时很有用。traceroute的变种有更好的RTT统计功能(例如,[mtr][19])。
|
||||
|
||||
### 应用日志解析器 ###
|
||||
|
||||
在这个类别下的网络监测器把特定的服务器应用程序作为目标(例如,web服务器或者数据库服务器)。由服务器程序产生或消耗的网络流量通过它的日志被分析和监测。不像前面提到的网络层的监控器,这个类别的工具能够在应用层面分析和监控网络流量。
|
||||
|
||||
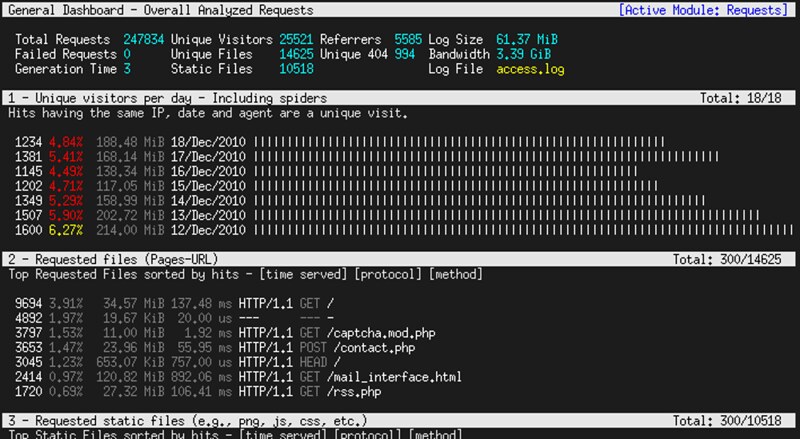
27. **[GoAccess][20]**:一个针对Apache和Nginx服务器流量的交互式查看器。基于对获取到的日志的分析,它能展示包括日访问量、最多请求、客户端操作系统、客户端位置、客户端浏览器等在内的多个实时的统计信息,并以滚动方式显示。
|
||||
|
||||
|
||||
|
||||
28. **[mtop][21]**:一个面向MySQL/MariaDB服务器的命令行监控器,它可以将成本最大的查询和当前数据库服务器负载以可视化的方式显示出来。它在您优化MySQL服务器性能、调谐服务器参数时很有用。
|
||||
|
||||
|
||||
|
||||
29. **[ngxtop][22]**:一个面向Nginx和Apache服务器的流量监测工具,能够以类似top指令的方式可视化的显示Web服务器的流量。它解析web服务器的查询日志文件并收集某个目的地或请求的流量统计信息。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我展示了许多命令行式监测工具,从最底层的包层面的监控器到最高层应用程序层面的网络监控器。了解那个工具的作用是一回事,选择哪个工具使用又是另外一回事。单一的一个工具不能作为您每天使用的通用的解决方案。一个好的系统管理员应该能决定哪个工具更适合当前的环境。希望这个列表对此有所帮助。
|
||||
|
||||
欢迎您通过回复来改进这个列表的内容!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.monkey.org/~dugsong/dsniff/
|
||||
[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
|
||||
[3]:https://github.com/zorkian/mysql-sniffer
|
||||
[4]:http://ngrep.sourceforge.net/
|
||||
[5]:http://lcamtuf.coredump.cx/p0f3/
|
||||
[6]:http://xmodulo.com/recommend/firewallbook
|
||||
[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
|
||||
[8]:https://excess.org/speedometer/
|
||||
[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
|
||||
[10]:http://xmodulo.com/check-dns-propagation-linux.html
|
||||
[11]:https://iperf.fr/
|
||||
[12]:http://www.netperf.org/netperf/
|
||||
[13]:http://xmodulo.com/useful-netcat-examples-linux.html
|
||||
[14]:https://zmap.io/
|
||||
[15]:http://noping.cc/
|
||||
[16]:http://www.hping.org/
|
||||
[17]:http://fping.org/
|
||||
[18]:http://sprobe.cs.washington.edu/
|
||||
[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
|
||||
[20]:http://goaccess.io/
|
||||
[21]:http://mtop.sourceforge.net/
|
||||
[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
|
||||
@ -0,0 +1,58 @@
|
||||
‘Unity Greeter Badges’:将丢失的会话图标带回Ubuntu登录屏幕
|
||||
================================================================================
|
||||

|
||||
|
||||
新出现在**Ubuntu 15.04中的一个软件包解决了我对Unity 欢迎屏的微词:像Cinnamon这样的其它Linux桌面会话没有徽章图标。**
|
||||
|
||||
我知道这有点吹毛求疵了;这只是对大多数人而言几乎毫无影响的视觉瑕疵罢了。但是这种不一致性时时刻刻缠绕着我,让我不胜其烦,因为Ubuntu的一些会话带有徽章图标,包括Unity、GNOME和KDE。而剩下的其它桌面环境,包括它自己的一些旁系产品,像Xubuntu,只会在会话切换列表和主用户界面显示了一个不能再简单的白点。
|
||||
|
||||
这些点点们造成的这种不一致性刺激着我的神经,即使它只是稍纵即逝,但这种刺激不仅仅来自设计,也来自可用性方面。标牌式的标志符号对于让我们知道我们即将登陆到哪个会话很有帮助。
|
||||
|
||||
例如,你能告诉我们这个是个什么会话呢?
|
||||
|
||||

|
||||
|
||||
Budgie? 也许是 MATE? 也能是 Cinnamon……我必须点开它才能知道。
|
||||
|
||||
没有必要这样做啊。构建Unity Greeter,就是为了让桌面环境开发者能够部署徽章到欢迎屏幕中(有些确实这样做了)。但在许多情况下,像MATE,它的包来自上游的Debian,想要移植一个“Ubuntu专用的补丁包”不太可取,也不太可能。
|
||||
|
||||
### 一个解决方案出炉了 ###
|
||||
|
||||
一位有经验的Debian维护者[Doug Torrance][1]有了修复该可用性瑕疵的解决方案。与其依赖桌面制造者自己来添加品牌式徽章到他们的包中,与其给Ubuntu增加维护它的责任重担,Torrance还不如自己创建了一个独立的‘unity-greeter-badges’包来收容它们。
|
||||
|
||||
承担起了直接提供会话标志的假定责任后,该包确保能同时迎合新旧窗口管理器、会话和桌面。
|
||||
|
||||
在30个左右的桌面环境列表中,它为以下桌面捆绑了新的会话徽章:
|
||||
|
||||
- Xubuntu
|
||||
- Cinnamon
|
||||
- MATE
|
||||
- Cairo-Dock
|
||||
- Xmonad
|
||||
- Awesome
|
||||
- OpenBox
|
||||
- Pantheon
|
||||
|
||||
最重要的是,‘**Unity-Greeter-Badges**’已经被Ubuntu 15.04收录进去。这就意味着Torrance的包将可以直接安装,不需要PPA,也不需要下载。没有像Unity Greeter一样成为核心包的一部分,它可以以更高效和更及时的方式更新新的图标。
|
||||
|
||||
如果你真运行着Ubuntu 15.04,在不久的将来,你就可以从软件中心获取并安装该包了。
|
||||
|
||||
不想等到15.04?Torrance已经为Ubuntu 14.04和Ubuntu 14.10用户做了个.deb安装器。
|
||||
|
||||
- [下载用于Ubuntu 14.04的unity-greeter-badges][2]
|
||||
- [下载用于Ubuntu 14.10的unity-greeter-badges][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/unity-greeter-badges-brings-missing-session-icons-ubuntu-login-screen
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://launchpad.net/~profzoom
|
||||
[2]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.04.1_all.deb
|
||||
[3]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.10.1_all.deb
|
||||
73
published/20150123 How to make a file immutable on Linux.md
Normal file
73
published/20150123 How to make a file immutable on Linux.md
Normal file
@ -0,0 +1,73 @@
|
||||
如何在Linux下创建一个不可变更的文件
|
||||
================================================================================
|
||||
|
||||
假如你想对Linux中的一些重要文件做写保护,这样它们就不能被删除或者被篡改成之前的版本或者其他东西,或者在其他情况下,你可能想避免某些配置文件被软件自动修改。使用`chown`和`chmod`命令修改文件的归属关系或者权限位是处理这种情况的一个解决方法,但这并不完美,因为这样无法避免有root权限的操作。这时`chattr`就派上用场了。
|
||||
|
||||
`chattr`是一个可以设置或取消文件的标志位的Linux命令,它和标准的文件权限(读、写、执行)是分离的。与此相关的另一个命令是`lsattr`,它可以显示文件的哪些标志位被设置上了。最初只有EXT文件系统(EXT2/3/4)支持`chattr`和`lsattr`所管理的标志位,但现在很多其他的原生的Linux文件系统都支持了,比如XFS、Btrfs、ReiserFS等等。
|
||||
|
||||
在这个教程中,我会示范如果使用`chattr`来让Linux中的文件不可变更。
|
||||
|
||||
`chattr`和`lsattr`命令是e2fsprogs包的一部分,它在所有现代Linux发行版都预装了。
|
||||
|
||||
下面是`chattr`的基本语法。
|
||||
|
||||
$ chattr [-RVf] [操作符][标志位] 文件...
|
||||
|
||||
其中操作符可以是“+”(把选定的标志位添加到标志位列表)、“-”(从标志位列表中移除选定的标志位)、或者“=”(强制使用选定的标志位)。
|
||||
|
||||
下面是一些可用的标志位。
|
||||
|
||||
- **a**: 只能以追加模式打开。
|
||||
- **A**: 不能更新atime(文件访问时间)。
|
||||
- **c**: 当被写入磁盘时被自动压缩。
|
||||
- **C**: 关掉“写时复制”。
|
||||
- **i**: 不可变更。
|
||||
- **s**: 通过自动归零来安全删除。(LCTT 译注:一般情况文件被删后内容不会被修改,改标志位会使得文件被删后原有内容被“0”取代)
|
||||
|
||||
### “不可变更”标志位 ###
|
||||
|
||||
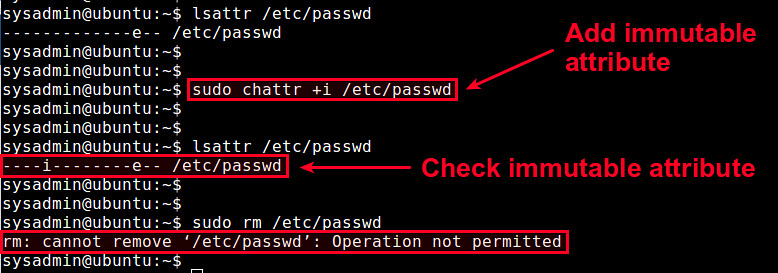
为了让一个文件不可变更,你需要按照如下方法为这个文件添加“不可变更”标志位。例如,对/etc/passwd文件做写保护:
|
||||
|
||||
$ sudo chattr +i /etc/passwd
|
||||
|
||||
注意设置或取消一个文件的“不可变更”标志位是需要root用户权限的。现在检查该文件“不可变更”标志位是否被添加上了。
|
||||
|
||||
$ lsattr /etc/passwd
|
||||
|
||||
一旦文件被设置为不可变更,任何用户都将无法修改该文件。即使是root用户也不可以修改、删除、覆盖、移动或者重命名这个文件。如果你想再次修改这个文件,需要先把“不可变更”标志位取消了。
|
||||
|
||||
用如下命令取消“不可变更”标志位:
|
||||
|
||||
$ sudo chattr -i /etc/passwd
|
||||
|
||||
|
||||
|
||||
如果你想让一个目录(比如/etc)连同它下边的所有内容不可变更,使用“-R”选项:
|
||||
|
||||
$ sudo chattr -R +i /etc
|
||||
|
||||
### “只可追加”标志位 ###
|
||||
|
||||
另一个有用的的标志位是“只可追加”,它只允许文件内容被追加的方式修改。你不能覆盖或者删除一个设置了“只可追加”标志位的文件。这个标志位在你想避免日志文件被意外清理掉的情况很有用。
|
||||
|
||||
和“不可变更”标志位类似,你可以使用如下命令让文件变成“只可追加”模式:
|
||||
|
||||
$ sudo chattr +a /var/log/syslog
|
||||
|
||||
注意当你复制一个“不可变更”或者“只可追加”的文件到其他地方后,新文件不会保留这些标志位!
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这个教程中,我展示了如何使用`chattr`和`lsattr`命令来管理额外的文件标志位,来避免文件被篡改(意外或者其他情况)的方法。注意你不能将`chattr`作为一个安全措施,因为“不可变更”标志位可以很容易被取消掉。解决这个问题的一个可能的方式是限制`chattr`命令自身的可用性,或者去掉CAP_LINUX_IMMUTABLE内核权能标志。关于`chattr`以及可用的标志位的更多细节,请参考它的man手册。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/make-file-immutable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
@ -1,7 +1,7 @@
|
||||
既然float不能表示所有的int,那为什么在类型转换时C++将int转换成float?
|
||||
---------
|
||||
=============
|
||||
|
||||
#问题:
|
||||
###问题:
|
||||
|
||||
代码如下:
|
||||
|
||||
@ -13,7 +13,7 @@ if (i == f) // 执行某段代码
|
||||
|
||||
编译器会将i转换成float类型,然后比较这两个float的大小,但是float能够表示所有的int吗?为什么没有将int和float转换成double类型进行比较呢?
|
||||
|
||||
#回答:
|
||||
###回答:
|
||||
|
||||
在整型数的演变中,当`int`变成`unsigned`时,会丢掉负数部分(有趣的是,这样的话,`0u < -1`就是对的了)。
|
||||
|
||||
@ -32,11 +32,11 @@ if((double) i < (double) f)
|
||||
顺便提一下,在这个问题中有趣的是,`unsigned`的优先级高于`int`,所以把`int`和`unsigned`进行比较时,最终进行的是unsigned类型的比较(开头提到的`0u < -1`就是这个道理)。我猜测这可能是在早些时候(计算机发展初期),当时的人们认为`unsigned`比`int`在所表示的数值范围上受到的限制更小:现在还不需要符号位,所以可以使用额外的位来表示更大的数值范围。如果你觉得`int`可能会溢出,那么就使用unsigned好了——在使用16位表示的ints时这个担心会更明显。
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/28010565/why-does-c-promote-an-int-to-a-float-when-a-float-cannot-represent-all-int-val/28011249#28011249)
|
||||
via: [stackoverflow](http://stackoverflow.com/questions/28010565/why-does-c-promote-an-int-to-a-float-when-a-float-cannot-represent-all-int-val/28011249#28011249)
|
||||
|
||||
作者:[wintermute][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
iptraf:一个实用的TCP/UDP网络监控工具
|
||||
================================================================================
|
||||
|
||||
[iptraf][1]是一个基于ncurses的IP局域网监控器,用来生成包括TCP信息、UDP计数、ICMP和OSPF信息、以太网负载信息、节点状态信息、IP校验和错误等等统计数据。
|
||||
|
||||
它基于ncurses的用户界面可以使用户免于记忆繁琐的命令行开关。
|
||||
|
||||
### 特征 ###
|
||||
|
||||
- IP流量监控器,用来显示你的网络中的IP流量变化信息。包括TCP标识信息、包以及字节计数,ICMP细节,OSPF包类型。
|
||||
- 简单的和详细的接口统计数据,包括IP、TCP、UDP、ICMP、非IP以及其他的IP包计数、IP校验和错误,接口活动、包大小计数。
|
||||
- TCP和UDP服务监控器,能够显示常见的TCP和UDP应用端口上发送的和接收的包的数量。
|
||||
- 局域网数据统计模块,能够发现在线的主机,并显示其上的数据活动统计信息。
|
||||
- TCP、UDP、及其他协议的显示过滤器,允许你只查看感兴趣的流量。
|
||||
- 日志功能。
|
||||
- 支持以太网、FDDI、ISDN、SLIP、PPP以及本地回环接口类型。
|
||||
- 利用Linux内核内置的原始套接字接口,允许它(指iptraf)能够用于各种支持的网卡上
|
||||
- 全屏,菜单式驱动的操作。
|
||||
|
||||
###安装方法###
|
||||
|
||||
**Ubuntu以及其衍生版本**
|
||||
|
||||
sudo apt-get install iptraf
|
||||
|
||||
**Arch Linux以及其衍生版本**
|
||||
|
||||
sudo pacman -S iptra
|
||||
|
||||
**Fedora以及其衍生版本**
|
||||
|
||||
sudo yum install iptraf
|
||||
|
||||
### 用法 ###
|
||||
|
||||
如果不加任何命令行选项地运行**iptraf**命令,程序将进入一种交互模式,通过主菜单可以访问多种功能。
|
||||
|
||||

|
||||
|
||||
简易的上手导航菜单。
|
||||
|
||||

|
||||
|
||||
选择要监控的接口。
|
||||
|
||||

|
||||
|
||||
接口**ppp0**处的流量。
|
||||
|
||||

|
||||
|
||||
试试吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
|
||||
|
||||
作者:[Enock Seth Nyamador][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
@ -1,171 +1,172 @@
|
||||
Inxi: Find System And Hardware Information On Linux
|
||||
================================================================================
|
||||
We already have shown different [applications][1] and ways to find the system and hardware information on Linux. In that series, today we will see how to find such details using **inxi**. It can be used for forum technical support, as a debugging tool, to quickly ascertain user system configuration and hardware.
|
||||
|
||||
**Inxi** is a command line tool that can be used to find the complete system and hardware details such as;
|
||||
|
||||
- Hardware,
|
||||
- CPU,
|
||||
- Drivers,
|
||||
- Xorg,
|
||||
- Desktop,
|
||||
- Kernel,
|
||||
- GCC version,
|
||||
- Processes,
|
||||
- RAM usage,
|
||||
- and other useful information.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Inxi is available in the default repositories of most modern GNU/Linux operating systems. So, we can simply install it by running the following commands.
|
||||
|
||||
**On Debian based system:**
|
||||
|
||||
sudo apt-get install inxi
|
||||
|
||||
**On Fedora:**
|
||||
|
||||
sudo yum install inxi
|
||||
|
||||
**On RHEL based systems:**
|
||||
|
||||
Install EPEL repository:
|
||||
|
||||
sudo yum install epel-release
|
||||
|
||||
Then, install inxi using command:
|
||||
|
||||
sudo yum install inxi
|
||||
|
||||
### Usage ###
|
||||
|
||||
To find the quick view of the system information, run the following command from Terminal.
|
||||
|
||||
inxi
|
||||
|
||||
**Sample output:**
|
||||
|
||||
CPU~Dual core Intel Core i3-2350M CPU (-HT-MCP-) clocked at Min:800.000Mhz Max:1200.000Mhz Kernel~3.13.0-45-generic x86_64 Up~6:41 Mem~1537.7/3861.3MB HDD~500.1GB(52.5% used) Procs~183 Client~Shell inxi~1.9.17
|
||||
|
||||
Ofcourse, we can retrieve a particular hardware details. For example to retrieve the **Audio/Sound hardware details**, run the following command:
|
||||
|
||||
inxi -A
|
||||
|
||||
**Sample output:**
|
||||
|
||||
Audio: Card: Intel 6 Series/C200 Series Family High Definition Audio Controller driver: snd_hda_intel
|
||||
Sound: Advanced Linux Sound Architecture ver: k3.13.0-45-generic
|
||||
|
||||
Cool, isn’t it?
|
||||
|
||||
Likewise, you can retrieve the details of **Graphic card** information.
|
||||
|
||||
inxi -G
|
||||
|
||||
**Sample output:**
|
||||
|
||||
Graphics: Card: Intel 2nd Generation Core Processor Family Integrated Graphics Controller
|
||||
X.Org: 1.15.1 drivers: intel (unloaded: fbdev,vesa) Resolution: 1366x768@60.0hz
|
||||
GLX Renderer: Mesa DRI Intel Sandybridge Mobile GLX Version: 3.0 Mesa 10.3.0
|
||||
|
||||
What about harddisk information? That’s also possible. To view the full **harddisk** information, run the following command.
|
||||
|
||||
inxi -D
|
||||
|
||||
**Sample Output:**
|
||||
|
||||
Drives: HDD Total Size: 500.1GB (52.5% used) 1: id: /dev/sda model: ST9601325BD size: 500.1GB
|
||||
|
||||
To display the Bios and Motherboard details:
|
||||
|
||||
inxi -M
|
||||
|
||||
**Sample output:**
|
||||
|
||||
Machine: System: Dell (portable) product: Inspiron N5050
|
||||
Mobo: Dell model: 01HXXJ version: A05 Bios: Dell version: A05 date: 08/03/2012
|
||||
|
||||
Not only hardware details, it can also displays the **list of available repositories** in our system.
|
||||
|
||||
inxi -r
|
||||
|
||||
**Sample output:**
|
||||
|
||||
Repos: Active apt sources in file: /etc/apt/sources.list
|
||||
deb http://ubuntu.excellmedia.net/archive/ trusty main restricted
|
||||
deb-src http://ubuntu.excellmedia.net/archive/ trusty main restricted
|
||||
deb http://ubuntu.excellmedia.net/archive/ trusty-updates main restricted
|
||||
deb-src http://ubuntu.excellmedia.net/archive/ trusty-updates main restricted
|
||||
deb http://ubuntu.excellmedia.net/archive/ trusty universe
|
||||
.
|
||||
.
|
||||
Active apt sources in file: /etc/apt/sources.list.d/intellinuxgraphics.list
|
||||
deb https://download.01.org/gfx/ubuntu/14.04/main trusty main #Intel Graphics drivers
|
||||
Active apt sources in file: /etc/apt/sources.list.d/linrunner-tlp-trusty.list
|
||||
Active apt sources in file: /etc/apt/sources.list.d/wseverin-ppa-trusty.list
|
||||
deb http://ppa.launchpad.net/wseverin/ppa/ubuntu trusty main
|
||||
|
||||
Inxi will also display the Weather details of your location. Surprised? Yes, It should.
|
||||
|
||||
inxi -W Erode,Tamilnadu
|
||||
|
||||
Here **Erode** is the District and **Tamilnadu** is a state in India.
|
||||
|
||||
Sample output:
|
||||
|
||||
Weather: Conditions: 79 F (26 C) - Clear Time: February 4, 6:00 PM IST
|
||||
|
||||
### Viewing Complete Hardware details ###
|
||||
|
||||
Tired of finding each hardware details? Well, you can list all details at once using command:
|
||||
|
||||
inxi -F
|
||||
|
||||
**Sample output:**
|
||||
|
||||
System: Host: sk Kernel: 3.13.0-45-generic x86_64 (64 bit) Desktop: LXDE (Openbox 3.5.2) Distro: Ubuntu 14.04 trusty
|
||||
Machine: System: Dell (portable) product: Inspiron N5050
|
||||
Mobo: Dell model: 01HXXJ version: A05 Bios: Dell version: A05 date: 08/03/2012
|
||||
CPU: Dual core Intel Core i3-2350M CPU (-HT-MCP-) cache: 3072 KB flags: (lm nx sse sse2 sse3 sse4_1 sse4_2 ssse3 vmx)
|
||||
Clock Speeds: 1: 800.00 MHz 2: 1000.00 MHz 3: 800.00 MHz 4: 800.00 MHz
|
||||
Graphics: Card: Intel 2nd Generation Core Processor Family Integrated Graphics Controller
|
||||
X.Org: 1.15.1 drivers: intel (unloaded: fbdev,vesa) Resolution: 1366x768@60.0hz
|
||||
GLX Renderer: Mesa DRI Intel Sandybridge Mobile GLX Version: 3.0 Mesa 10.3.0
|
||||
Audio: Card: Intel 6 Series/C200 Series Family High Definition Audio Controller driver: snd_hda_intel
|
||||
Sound: Advanced Linux Sound Architecture ver: k3.13.0-45-generic
|
||||
Network: Card-1: Qualcomm Atheros AR9285 Wireless Network Adapter (PCI-Express) driver: ath9k
|
||||
IF: wlan0 state: up mac:
|
||||
Card-2: Realtek RTL8101E/RTL8102E PCI Express Fast Ethernet controller driver: r8169
|
||||
IF: eth0 state: down mac:
|
||||
Drives: HDD Total Size: 500.1GB (52.5% used) 1: id: /dev/sda model: ST9500325AS size: 500.1GB
|
||||
Partition: ID: / size: 455G used: 245G (57%) fs: ext4 ID: /boot size: 236M used: 159M (72%) fs: ext2
|
||||
ID: swap-1 size: 4.19GB used: 0.00GB (0%) fs: swap
|
||||
RAID: No RAID devices detected - /proc/mdstat and md_mod kernel raid module present
|
||||
Sensors: System Temperatures: cpu: 64.5C mobo: N/A
|
||||
Fan Speeds (in rpm): cpu: N/A
|
||||
Info: Processes: 186 Uptime: 6:52 Memory: 1547.2/3861.3MB Client: Shell (bash) inxi: 1.9.17
|
||||
|
||||
As you see in the above, inxi displays the complete hardware details.
|
||||
|
||||
For more details, refer the man pages.
|
||||
|
||||
man inxi
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Are you searching for a simple tool which displays your complete system and hardware details? Then, don’t look anywhere, inxi will give you what actually want. And, it is light weight tool available in your default repositories. What else you want more? Give it a try, you won’t be disappointed.
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/inxi-find-system-hardware-information-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.unixmen.com/screenfetch-bash-screenshot-information-tool/
|
||||
Inxi:获取Linux的系统和硬件信息
|
||||
================================================================================
|
||||
|
||||
我们已经展示了一些不同的[应用程序][1]和方法来获取Linux的系统和硬件信息。在这一系列里,我们将看到如何使用**inxi**来获取这些详情信息。在论坛技术支持中,它可以作为调试工具,迅速确定用户的系统配置和硬件信息。
|
||||
|
||||
**Inxi**是一个可以获取完整的系统和硬件详情信息的命令行工具,内容包括:
|
||||
|
||||
- 硬件
|
||||
- CPU
|
||||
- 磁盘驱动器
|
||||
- Xorg
|
||||
- 桌面环境
|
||||
- 内核
|
||||
- GCC版本
|
||||
- 进程
|
||||
- 内存占用
|
||||
- 和其他有用的信息
|
||||
|
||||
### 安装方法 ###
|
||||
|
||||
Inxi在多数现代GNU/Linux操作系统的默认软件仓库中。所以我们可以简单地运行下列命令安装。
|
||||
|
||||
**在基于Debian的发行版:**
|
||||
|
||||
sudo apt-get install inxi
|
||||
|
||||
**在Fedora:**
|
||||
|
||||
sudo yum install inxi
|
||||
|
||||
**在基于RHEL的发行版:**
|
||||
|
||||
安装EPEL软件仓库:
|
||||
|
||||
sudo yum install epel-release
|
||||
|
||||
然后使用如下命令安装inxi:
|
||||
|
||||
sudo yum install inxi
|
||||
|
||||
### 使用方法 ###
|
||||
|
||||
在终端运行如下命令可以获取系统的概况信息。
|
||||
|
||||
inxi
|
||||
|
||||
**示例输出:**
|
||||
|
||||
CPU~Dual core Intel Core i3-2350M CPU (-HT-MCP-) clocked at Min:800.000Mhz Max:1200.000Mhz Kernel~3.13.0-45-generic x86_64 Up~6:41 Mem~1537.7/3861.3MB HDD~500.1GB(52.5% used) Procs~183 Client~Shell inxi~1.9.17
|
||||
|
||||
当然,我们可以获取一个特定硬件的详情信息。比如获取**声音/音频硬件详情信息**,可以运行如下命令:
|
||||
|
||||
inxi -A
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Audio: Card: Intel 6 Series/C200 Series Family High Definition Audio Controller driver: snd_hda_intel
|
||||
Sound: Advanced Linux Sound Architecture ver: k3.13.0-45-generic
|
||||
|
||||
很酷是吧?
|
||||
|
||||
同样的,你可以获取**显卡**的详情信息。
|
||||
|
||||
inxi -G
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Graphics: Card: Intel 2nd Generation Core Processor Family Integrated Graphics Controller
|
||||
X.Org: 1.15.1 drivers: intel (unloaded: fbdev,vesa) Resolution: 1366x768@60.0hz
|
||||
GLX Renderer: Mesa DRI Intel Sandybridge Mobile GLX Version: 3.0 Mesa 10.3.0
|
||||
|
||||
硬盘信息呢?也是可以的。运行如下命令来获取完整的**硬盘**信息。
|
||||
|
||||
inxi -D
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Drives: HDD Total Size: 500.1GB (52.5% used) 1: id: /dev/sda model: ST9601325BD size: 500.1GB
|
||||
|
||||
显示Bios和主板详情信息:
|
||||
|
||||
inxi -M
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Machine: System: Dell (portable) product: Inspiron N5050
|
||||
Mobo: Dell model: 01HXXJ version: A05 Bios: Dell version: A05 date: 08/03/2012
|
||||
|
||||
不仅是硬性详情信息,它也可以显示我们系统中的**可用软件仓库列表**。
|
||||
|
||||
inxi -r
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Repos: Active apt sources in file: /etc/apt/sources.list
|
||||
deb http://ubuntu.excellmedia.net/archive/ trusty main restricted
|
||||
deb-src http://ubuntu.excellmedia.net/archive/ trusty main restricted
|
||||
deb http://ubuntu.excellmedia.net/archive/ trusty-updates main restricted
|
||||
deb-src http://ubuntu.excellmedia.net/archive/ trusty-updates main restricted
|
||||
deb http://ubuntu.excellmedia.net/archive/ trusty universe
|
||||
.
|
||||
.
|
||||
Active apt sources in file: /etc/apt/sources.list.d/intellinuxgraphics.list
|
||||
deb https://download.01.org/gfx/ubuntu/14.04/main trusty main #Intel Graphics drivers
|
||||
Active apt sources in file: /etc/apt/sources.list.d/linrunner-tlp-trusty.list
|
||||
Active apt sources in file: /etc/apt/sources.list.d/wseverin-ppa-trusty.list
|
||||
deb http://ppa.launchpad.net/wseverin/ppa/ubuntu trusty main
|
||||
|
||||
Inxi还可以显示你所在位置的天气信息。感到意外吗?是的,它可以。
|
||||
|
||||
inxi -W Erode,Tamilnadu
|
||||
|
||||
这里**Erode**是地区,**Tamilnadu**是印度的一个邦。
|
||||
|
||||
示例输出:
|
||||
|
||||
Weather: Conditions: 79 F (26 C) - Clear Time: February 4, 6:00 PM IST
|
||||
|
||||
### 查看完整的硬件详情信息 ###
|
||||
|
||||
厌倦了逐一获取每种硬件的信息?你可以使用如下命令将所有信息一次列出:
|
||||
|
||||
inxi -F
|
||||
|
||||
**示例输出:**
|
||||
|
||||
System: Host: sk Kernel: 3.13.0-45-generic x86_64 (64 bit) Desktop: LXDE (Openbox 3.5.2) Distro: Ubuntu 14.04 trusty
|
||||
Machine: System: Dell (portable) product: Inspiron N5050
|
||||
Mobo: Dell model: 01HXXJ version: A05 Bios: Dell version: A05 date: 08/03/2012
|
||||
CPU: Dual core Intel Core i3-2350M CPU (-HT-MCP-) cache: 3072 KB flags: (lm nx sse sse2 sse3 sse4_1 sse4_2 ssse3 vmx)
|
||||
Clock Speeds: 1: 800.00 MHz 2: 1000.00 MHz 3: 800.00 MHz 4: 800.00 MHz
|
||||
Graphics: Card: Intel 2nd Generation Core Processor Family Integrated Graphics Controller
|
||||
X.Org: 1.15.1 drivers: intel (unloaded: fbdev,vesa) Resolution: 1366x768@60.0hz
|
||||
GLX Renderer: Mesa DRI Intel Sandybridge Mobile GLX Version: 3.0 Mesa 10.3.0
|
||||
Audio: Card: Intel 6 Series/C200 Series Family High Definition Audio Controller driver: snd_hda_intel
|
||||
Sound: Advanced Linux Sound Architecture ver: k3.13.0-45-generic
|
||||
Network: Card-1: Qualcomm Atheros AR9285 Wireless Network Adapter (PCI-Express) driver: ath9k
|
||||
IF: wlan0 state: up mac:
|
||||
Card-2: Realtek RTL8101E/RTL8102E PCI Express Fast Ethernet controller driver: r8169
|
||||
IF: eth0 state: down mac:
|
||||
Drives: HDD Total Size: 500.1GB (52.5% used) 1: id: /dev/sda model: ST9500325AS size: 500.1GB
|
||||
Partition: ID: / size: 455G used: 245G (57%) fs: ext4 ID: /boot size: 236M used: 159M (72%) fs: ext2
|
||||
ID: swap-1 size: 4.19GB used: 0.00GB (0%) fs: swap
|
||||
RAID: No RAID devices detected - /proc/mdstat and md_mod kernel raid module present
|
||||
Sensors: System Temperatures: cpu: 64.5C mobo: N/A
|
||||
Fan Speeds (in rpm): cpu: N/A
|
||||
Info: Processes: 186 Uptime: 6:52 Memory: 1547.2/3861.3MB Client: Shell (bash) inxi: 1.9.17
|
||||
|
||||
就像上面你看到的那样,inxi显示出了完整的硬件详情信息。
|
||||
|
||||
更多的细节可以参考man手册。
|
||||
|
||||
man inxi
|
||||
|
||||
### 结论 ###
|
||||
|
||||
你在寻找一个可以显示完整的系统和硬件详情信息的简单工具吗?那么不用再找了,inxi会提供你所需要的。并且,它还是在你系统默认的软件仓库中的轻量级工具。你还想要更多东西吗?试一试它,你不会失望。
|
||||
|
||||
欢呼吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/inxi-find-system-hardware-information-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://linux.cn/article-1947-1.html
|
||||
@ -0,0 +1,67 @@
|
||||
在Ubuntu 14.10上安装基于Web的监控工具:Linux-Dash
|
||||
================================================================================
|
||||
|
||||
Linux-Dash是一个用于GNU/Linux机器的,低开销的监控仪表盘。您可以安装试试!Linux Dash的界面提供了您的服务器的所有关键信息的详细视图,可监测的信息包括RAM、磁盘使用率、网络、安装的软件、用户、运行的进程等。所有的信息都被分成几类,您可以通过主页工具栏中的按钮跳到任何一类中。Linux Dash并不是最先进的监测工具,但它十分适合寻找灵活、轻量级、容易部署的应用的用户。
|
||||
|
||||
### Linux-Dash的功能 ###
|
||||
|
||||
- 使用一个基于Web的漂亮的仪表盘界面来监控服务器信息
|
||||
- 实时的按照你的要求监控RAM、负载、运行时间、磁盘配置、用户和许多其他系统状态
|
||||
- 支持基于Apache2/niginx + PHP的服务器
|
||||
- 通过点击和拖动来重排列控件
|
||||
- 支持多种类型的linux服务器
|
||||
|
||||
### 当前控件列表 ###
|
||||
|
||||
- 通用信息
|
||||
- 平均负载
|
||||
- RAM
|
||||
- 磁盘使用量
|
||||
- 用户
|
||||
- 软件
|
||||
- IP
|
||||
- 网络速率
|
||||
- 在线状态
|
||||
- 处理器
|
||||
- 日志
|
||||
|
||||
### 在Ubuntu server 14.10上安装Linux-Dash ###
|
||||
|
||||
首先您需要确认您安装了[Ubuntu LAMP server 14.10][1],接下来您需要安装下面的包:
|
||||
|
||||
sudo apt-get install php5-json unzip
|
||||
|
||||
安装这个模块后,需要在apache2中启用该模块,所以您需要使用下面的命令重启apache2服务器:
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
现在您需要下载linux-dash的安装包并安装它:
|
||||
|
||||
wget https://github.com/afaqurk/linux-dash/archive/master.zip
|
||||
|
||||
unzip master.zip
|
||||
|
||||
sudo mv linux-dash-master/ /var/www/html/linux-dash-master/
|
||||
|
||||
接下来您需要使用下面的命令来改变权限:
|
||||
|
||||
sudo chmod 755 /var/www/html/linux-dash-master/
|
||||
|
||||
现在您便可以访问http://serverip/linux-dash-master/了。您应该会看到类似下面的输出:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-linux-dash-web-based-monitoring-tool-on-ubntu-14-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||
@ -1,18 +1,18 @@
|
||||
领略一些最著名的 Linux 网络工具
|
||||
一大波你可能不知道的 Linux 网络工具
|
||||
================================================================================
|
||||
在你的系统上使用命令行工具来监控你的网络是非常实用的,并且对于 Linux 用户来说,有着许许多多现成的工具可以使用,如 nethogs, ntopng, nload, iftop, iptraf, bmon, slurm, tcptrack, cbm, netwatch, collectl, trafshow, cacti, etherape, ipband, jnettop, netspeed 以及 speedometer。
|
||||
如果要在你的系统上监控网络,那么使用命令行工具是非常实用的,并且对于 Linux 用户来说,有着许许多多现成的工具可以使用,如: nethogs, ntopng, nload, iftop, iptraf, bmon, slurm, tcptrack, cbm, netwatch, collectl, trafshow, cacti, etherape, ipband, jnettop, netspeed 以及 speedometer。
|
||||
|
||||
鉴于世上有着许多的 Linux 专家和开发者,显然还存在其他的网络监控工具,但在这篇教程中,我不打算将它们所有包括在内。
|
||||
|
||||
上面列出的工具都有着自己的独特之处,但归根结底,它们都做着监控网络流量的工作,且并不是只有一种方法来完成这件事。例如 nethogs 可以被用来展示每个进程的带宽使用情况,以防你想知道究竟是哪个应用在消耗了你的整个网络资源; iftop 可以被用来展示每个套接字连接的带宽使用情况,而 像 nload 这类的工具可以帮助你得到有关整个带宽的信息。
|
||||
上面列出的工具都有着自己的独特之处,但归根结底,它们都做着监控网络流量的工作,只是通过各种不同的方法。例如 nethogs 可以被用来展示每个进程的带宽使用情况,以防你想知道究竟是哪个应用在消耗了你的整个网络资源; iftop 可以被用来展示每个套接字连接的带宽使用情况,而像 nload 这类的工具可以帮助你得到有关整个带宽的信息。
|
||||
|
||||
### 1) nethogs ###
|
||||
|
||||
nethogs 是一个免费的工具,当要查找哪个 PID (注:即 process identifier,进程 ID) 给你的网络流量带来了麻烦时,它是非常方便的。它按每个进程来组织带宽,而不是像大多数的工具那样按照每个协议或每个子网来划分流量。它功能丰富,同时支持 IPv4 和 IPv6,并且我认为,若你想在你的 Linux 主机上确定哪个程序正消耗着你的全部带宽,它是来做这件事的最佳的程序。
|
||||
nethogs 是一个免费的工具,当要查找哪个 PID (注:即 process identifier,进程 ID) 给你的网络流量带来了麻烦时,它是非常方便的。它按每个进程来分组带宽,而不是像大多数的工具那样按照每个协议或每个子网来划分流量。它功能丰富,同时支持 IPv4 和 IPv6,并且我认为,若你想在你的 Linux 主机上确定哪个程序正消耗着你的全部带宽,它是来做这件事的最佳的程序。
|
||||
|
||||
一个 Linux 用户可以使用 **nethogs** 来显示每个进程的 TCP 下载和上传速率,使用命令 **nethogs eth0** 来监控一个特定的设备,上面的 eth0 是那个你想获取信息的设备的名称,你还可以得到有关正在被传输的数据的传输速率的信息。
|
||||
一个 Linux 用户可以使用 **nethogs** 来显示每个进程的 TCP 下载和上传速率,可以使用命令 **nethogs eth0** 来监控一个指定的设备,上面的 eth0 是那个你想获取信息的设备的名称,你还可以得到有关正在传输的数据的传输速率信息。
|
||||
|
||||
对我而言, nethogs 是非常容易使用的,或许是因为我非常喜欢它以至于我总是在我的 Ubuntu 12.04 LTS 机器中使用它来监控我的网络带宽。
|
||||
对我而言, nethogs 是非常容易使用的,或许是因为我非常喜欢它,以至于我总是在我的 Ubuntu 12.04 LTS 机器中使用它来监控我的网络带宽。
|
||||
|
||||
例如要想使用混杂模式来嗅探,可以像下面展示的命令那样使用选项 -p:
|
||||
|
||||
@ -20,6 +20,8 @@ nethogs 是一个免费的工具,当要查找哪个 PID (注:即 process ide
|
||||
|
||||
假如你想更多地了解 nethogs 并深入探索它,那么请毫不犹豫地阅读我们做的关于这个网络带宽监控工具的整个教程。
|
||||
|
||||
(LCTT 译注:关于 nethogs 的更多信息可以参考:https://linux.cn/article-2808-1.html )
|
||||
|
||||
### 2) nload ###
|
||||
|
||||
nload 是一个控制台应用,可以被用来实时地监控网络流量和带宽使用情况,它还通过提供两个简单易懂的图表来对流量进行可视化。这个绝妙的网络监控工具还可以在监控过程中切换被监控的设备,而这可以通过按左右箭头来完成。
|
||||
@ -28,19 +30,21 @@ nload 是一个控制台应用,可以被用来实时地监控网络流量和
|
||||
|
||||
正如你在上面的截图中所看到的那样,由 nload 提供的图表是非常容易理解的。nload 提供了有用的信息,也展示了诸如被传输数据的总量和最小/最大网络速率等信息。
|
||||
|
||||
而更酷的是你可以在下面的命令的帮助下运行 nload 这个工具,这个命令是非常的短小且易记的:
|
||||
而更酷的是你只需要直接运行 nload 这个工具就行,这个命令是非常的短小且易记的:
|
||||
|
||||
nload
|
||||
|
||||
我很确信的是:我们关于如何使用 nload 的详细教程将帮助到新的 Linux 用户,甚至可以帮助那些正寻找关于 nload 信息的老手。
|
||||
|
||||
(LCTT 译注:关于 nload 的更新信息可以参考:https://linux.cn/article-5114-1.html )
|
||||
|
||||
### 3) slurm ###
|
||||
|
||||
slurm 是另一个 Linux 网络负载监控工具,它以一个不错的 ASCII 图来显示结果,它还支持许多键值用以交互,例如 **c** 用来切换到经典模式, **s** 切换到分图模式, **r** 用来重绘屏幕, **L** 用来启用 TX/RX(注:TX,发送流量;RX,接收流量) LED,**m** 用来在经典分图模式和大图模式之间进行切换, **q** 退出 slurm。
|
||||
slurm 是另一个 Linux 网络负载监控工具,它以一个不错的 ASCII 图来显示结果,它还支持许多按键用以交互,例如 **c** 用来切换到经典模式, **s** 切换到分图模式, **r** 用来重绘屏幕, **L** 用来启用 TX/RX 灯(注:TX,发送流量;RX,接收流量) ,**m** 用来在经典分图模式和大图模式之间进行切换, **q** 退出 slurm。
|
||||
|
||||

|
||||
|
||||
在网络负载监控工具 slurm 中,还有许多其它的键值可用,你可以很容易地使用下面的命令在 man 手册中学习它们。
|
||||
在网络负载监控工具 slurm 中,还有许多其它的按键可用,你可以很容易地使用下面的命令在 man 手册中学习它们。
|
||||
|
||||
man slurm
|
||||
|
||||
@ -48,11 +52,11 @@ slurm 在 Ubuntu 和 Debian 的官方软件仓库中可以找到,所以使用
|
||||
|
||||
sudo apt-get install slurm
|
||||
|
||||
我们已经在一个教程中对 slurm 的使用做了介绍,所以请访问相关网页( 注:应该指的是[这篇文章](http://linoxide.com/ubuntu-how-to/monitor-network-load-slurm-tool/) ),并不要忘记和其它使用 Linux 的朋友分享这些知识。
|
||||
我们已经在一个[教程](http://linoxide.com/ubuntu-how-to/monitor-network-load-slurm-tool/)中对 slurm 的使用做了介绍,不要忘记和其它使用 Linux 的朋友分享这些知识。
|
||||
|
||||
### 4) iftop ###
|
||||
|
||||
当你想在一个接口上按照主机来展示带宽使用情况时,iftop 是一个非常有用的工具。根据 man 手册,**iftop** 在一个已命名的接口或在它可以找到的第一个接口(假如没有任何特殊情况,它就像一个外部的接口)上监听网络流量,并且展示出一个表格来显示当前一对主机间的带宽使用情况。
|
||||
当你想显示连接到网卡上的各个主机的带宽使用情况时,iftop 是一个非常有用的工具。根据 man 手册,**iftop** 在一个指定的接口或在它可以找到的第一个接口(假如没有任何特殊情况,它应该是一个对外的接口)上监听网络流量,并且展示出一个表格来显示当前的一对主机间的带宽使用情况。
|
||||
|
||||
通过在虚拟终端中使用下面的命令,Ubuntu 和 Debian 用户可以在他们的机器中轻易地安装 iftop:
|
||||
|
||||
@ -61,6 +65,8 @@ slurm 在 Ubuntu 和 Debian 的官方软件仓库中可以找到,所以使用
|
||||
在你的机器上,可以使用下面的命令通过 yum 来安装 iftop:
|
||||
|
||||
yum -y install iftop
|
||||
|
||||
(LCTT 译注:关于 nload 的更多信息请参考:https://linux.cn/article-1843-1.html )
|
||||
|
||||
### 5) collectl ###
|
||||
|
||||
@ -69,7 +75,7 @@ collectl 可以被用来收集描述当前系统状态的数据,并且它支
|
||||
- 记录模式
|
||||
- 回放模式
|
||||
|
||||
**记录模式** 允许从一个正在运行的系统中读取数据,然后将这些数据要么显示在终端中,要么写入一个或多个文件或套接字中。
|
||||
**记录模式** 允许从一个正在运行的系统中读取数据,然后将这些数据要么显示在终端中,要么写入一个或多个文件或一个套接字中。
|
||||
|
||||
**回放模式**
|
||||
|
||||
@ -79,13 +85,15 @@ Ubuntu 和 Debian 用户可以在他们的机器上使用他们默认的包管
|
||||
|
||||
sudo apt-get install collectl
|
||||
|
||||
还可以使用下面的命令来安装 collectl, 因为对于这些发行版本(注:这里指的是用 yum 作为包管理器的发行版本),在它们官方的软件仓库中也含有 collectl:
|
||||
还可以使用下面的命令来安装 collectl, 因为对于这些发行版本(注:这里指的是用 yum 作为包管理器的发行版本),在它们官方的软件仓库中也含有 collectl:
|
||||
|
||||
yum install collectl
|
||||
|
||||
(LCTT 译注:关于 collectl 的更多信息请参考: https://linux.cn/article-3154-1.html )
|
||||
|
||||
### 6) Netstat ###
|
||||
|
||||
Netstat 是一个用来监控**传入和传出的网络数据包统计数据**和接口统计数据的命令行工具。它为传输控制协议 TCP (包括上传和下行),路由表,及一系列的网络接口(网络接口控制器或者软件定义的网络接口) 和网络协议统计数据展示网络连接情况。
|
||||
Netstat 是一个用来监控**传入和传出的网络数据包统计数据**的接口统计数据命令行工具。它会显示 TCP 连接 (包括上传和下行),路由表,及一系列的网络接口(网卡或者SDN接口)和网络协议统计数据。
|
||||
|
||||
Ubuntu 和 Debian 用户可以在他们的机器上使用默认的包管理器来安装 netstat。Netsta 软件被包括在 net-tools 软件包中,并可以在 shell 或虚拟终端中运行下面的命令来安装它:
|
||||
|
||||
@ -107,6 +115,8 @@ CentOS, Fedora, RHEL 用户可以在他们的机器上使用默认的包管理
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:关于 netstat 的更多信息请参考:https://linux.cn/article-2434-1.html )
|
||||
|
||||
### 7) Netload ###
|
||||
|
||||
netload 命令只展示一个关于当前网络荷载和自从程序运行之后传输数据总的字节数目的简要报告,它没有更多的功能。它是 netdiag 软件的一部分。
|
||||
@ -115,9 +125,9 @@ netload 命令只展示一个关于当前网络荷载和自从程序运行之后
|
||||
|
||||
# yum install netdiag
|
||||
|
||||
Netload 在默认仓库中作为 netdiag 的一部分可以被找到,我们可以轻易地使用下面的命令来利用 **apt** 包管理器安装 **netdiag**:
|
||||
Netload 是默认仓库中 netdiag 的一部分,我们可以轻易地使用下面的命令来利用 **apt** 包管理器安装 **netdiag**:
|
||||
|
||||
$ sudo apt-get install netdiag (注:这里原文为 sudo install netdiag,应该加上 apt-get)
|
||||
$ sudo apt-get install netdiag
|
||||
|
||||
为了运行 netload,我们需要确保选择了一个正在工作的网络接口的名称,如 eth0, eh1, wlan0, mon0等,然后在 shell 或虚拟终端中运行下面的命令:
|
||||
|
||||
@ -127,21 +137,23 @@ Netload 在默认仓库中作为 netdiag 的一部分可以被找到,我们可
|
||||
|
||||
### 8) Nagios ###
|
||||
|
||||
Nagios 是一个领先且功能强大的开源监控系统,它使得网络或系统管理员在服务器相关的问题影响到服务器的主要事务之前,鉴定并解决这些问题。 有了 Nagios 系统,管理员便可以在一个单一的窗口中监控远程的 Linux 、Windows 系统、交换机、路由器和打印机等。它显示出重要的警告并指示出在你的网络或服务器中是否出现某些故障,这间接地帮助你在问题发生之前,着手执行补救行动。
|
||||
Nagios 是一个领先且功能强大的开源监控系统,它使得网络或系统管理员可以在服务器的各种问题影响到服务器的主要事务之前,发现并解决这些问题。 有了 Nagios 系统,管理员便可以在一个单一的窗口中监控远程的 Linux 、Windows 系统、交换机、路由器和打印机等。它会显示出重要的警告并指出在你的网络或服务器中是否出现某些故障,这可以间接地帮助你在问题发生前就着手执行补救行动。
|
||||
|
||||
Nagios 有一个 web 界面,其中有一个图形化的活动监视器。通过浏览网页 http://localhost/nagios/ 或 http://localhost/nagios3/ 便可以登录到这个 web 界面。假如你在远程的机器上进行操作,请使用你的 IP 地址来替换 localhost,然后键入用户名和密码,我们便会看到如下图所展示的信息:
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:关于 Nagios 的更多信息请参考:https://linux.cn/article-2436-1.html )
|
||||
|
||||
### 9) EtherApe ###
|
||||
|
||||
EtherApe 是一个针对 Unix 的图形化网络监控工具,它仿照了 etherman 软件。它具有链路层,IP 和 TCP 模式并支持 Ethernet, FDDI, Token Ring, ISDN, PPP, SLIP 及 WLAN 设备等接口,再加上支持一些封装的格式。主机和链接随着流量大小和被着色的协议名称展示而变化。它可以过滤要展示的流量,并可从一个文件或运行的网络中读取数据报。
|
||||
EtherApe 是一个针对 Unix 的图形化网络监控工具,它仿照了 etherman 软件。它支持链路层、IP 和 TCP 等模式,并支持以太网, FDDI, 令牌环, ISDN, PPP, SLIP 及 WLAN 设备等接口,以及一些封装格式。主机和连接随着流量和协议而改变其尺寸和颜色。它可以过滤要展示的流量,并可从一个文件或运行的网络中读取数据包。
|
||||
|
||||
在 CentOS、Fedora、RHEL 等 Linux 发行版本中安装 etherape 是一件容易的事,因为在它们的官方软件仓库中就可以找到 etherape。我们可以像下面展示的命令那样使用 yum 包管理器来安装它:
|
||||
|
||||
yum install etherape
|
||||
|
||||
我们可以使用下面的命令在 Ubuntu、Debian 及它们的衍生发行版本中使用 **apt** 包管理器来安装 EtherApe :
|
||||
我们也可以使用下面的命令在 Ubuntu、Debian 及它们的衍生发行版本中使用 **apt** 包管理器来安装 EtherApe :
|
||||
|
||||
sudo apt-get install etherape
|
||||
|
||||
@ -149,13 +161,13 @@ EtherApe 是一个针对 Unix 的图形化网络监控工具,它仿照了 ethe
|
||||
|
||||
sudo etherape
|
||||
|
||||
然后, **etherape** 的 **图形用户界面** 便会被执行。接着,在菜单上面的 **捕捉** 选项下,我们可以选择 **模式**(IP,链路层,TCP) 和 **接口**。一切设定完毕后,我们需要点击 **开始** 按钮。接着我们便会看到类似下面截图的东西:
|
||||
然后, **etherape** 的 **图形用户界面** 便会被执行。接着,在菜单上面的 **捕捉** 选项下,我们可以选择 **模式**(IP,链路层,TCP) 和 **接口**。一切设定完毕后,我们需要点击 **开始** 按钮。接着我们便会看到类似下面截图的东西:
|
||||
|
||||

|
||||
|
||||
### 10) tcpflow ###
|
||||
|
||||
tcpflow 是一个命令行工具,它可以捕捉作为 TCP 连接(流)的一部分的传输数据,并以一种方便协议分析或除错的方式来存储数据。它重建了实际的数据流并将每个流存储在不同的文件中,以备日后的分析。它理解 TCP 序列号并可以正确地重建数据流,不管是在重发或乱序发送状态下。
|
||||
tcpflow 是一个命令行工具,它可以捕捉 TCP 连接(流)的部分传输数据,并以一种方便协议分析或除错的方式来存储数据。它重构了实际的数据流并将每个流存储在不同的文件中,以备日后的分析。它能识别 TCP 序列号并可以正确地重构数据流,不管是在重发还是乱序发送状态下。
|
||||
|
||||
通过 **apt** 包管理器在 Ubuntu 、Debian 系统中安装 tcpflow 是很容易的,因为默认情况下在官方软件仓库中可以找到它。
|
||||
|
||||
@ -175,7 +187,7 @@ tcpflow 是一个命令行工具,它可以捕捉作为 TCP 连接(流)的一
|
||||
|
||||
# yum install --nogpgcheck http://pkgs.repoforge.org/tcpflow/tcpflow-0.21-1.2.el6.rf.i686.rpm
|
||||
|
||||
我们可以使用 tcpflow 来捕捉全部或部分 tcp 流量并以一种简单的方式把它们写到一个可读文件中。下面的命令执行着我们想要做的事情,但我们需要在一个空目录中运行下面的命令,因为它将创建诸如 x.x.x.x.y-a.a.a.a.z 格式的文件,做完这些之后,只需按 Ctrl-C 便可停止这个命令。
|
||||
我们可以使用 tcpflow 来捕捉全部或部分 tcp 流量,并以一种简单的方式把它们写到一个可读的文件中。下面的命令就可以完成这个事情,但我们需要在一个空目录中运行下面的命令,因为它将创建诸如 x.x.x.x.y-a.a.a.a.z 格式的文件,运行之后,只需按 Ctrl-C 便可停止这个命令。
|
||||
|
||||
$ sudo tcpflow -i eth0 port 8000
|
||||
|
||||
@ -183,49 +195,51 @@ tcpflow 是一个命令行工具,它可以捕捉作为 TCP 连接(流)的一
|
||||
|
||||
### 11) IPTraf ###
|
||||
|
||||
[IPTraf][2] 是一个针对 Linux 平台的基于控制台的网络统计应用。它生成一系列的图形,如 TCP 连接包和字节的数目、接口信息和活动指示器、 TCP/UDP 流量故障以及 LAN 状态包和字节的数目。
|
||||
[IPTraf][2] 是一个针对 Linux 平台的基于控制台的网络统计应用。它生成一系列的图形,如 TCP 连接的包/字节计数、接口信息和活动指示器、 TCP/UDP 流量故障以及局域网内设备的包/字节计数。
|
||||
|
||||
在默认的软件仓库中可以找到 IPTraf,所以我们可以使用下面的命令通过 **apt** 包管理器轻松地安装 IPTraf:
|
||||
|
||||
$ sudo apt-get install iptraf
|
||||
|
||||
在默认的软件仓库中可以找到 IPTraf,所以我们可以使用下面的命令通过 **yum** 包管理器轻松地安装 IPTraf:
|
||||
我们可以使用下面的命令通过 **yum** 包管理器轻松地安装 IPTraf:
|
||||
|
||||
# yum install iptraf
|
||||
|
||||
我们需要以管理员权限来运行 IPTraf(注:这里原文写错为 TPTraf),并带有一个可用的网络接口名。这里,我们的网络接口名为 wlan2,所以我们使用 wlan2 来作为接口的名称:
|
||||
我们需要以管理员权限来运行 IPTraf,并带有一个有效的网络接口名。这里,我们的网络接口名为 wlan2,所以我们使用 wlan2 来作为参数:
|
||||
|
||||
$ sudo iptraf wlan2 (注:这里原文为 sudo iptraf,应该加上 wlan2)
|
||||
$ sudo iptraf wlan2
|
||||
|
||||

|
||||
|
||||
开始一般的网络接口统计,键入:
|
||||
开始通常的网络接口统计,键入:
|
||||
|
||||
# iptraf -g
|
||||
|
||||
为了在一个名为 eth0 的接口设备上看详细的统计信息,使用:
|
||||
查看接口 eth0 的详细统计信息,使用:
|
||||
|
||||
# iptraf -d wlan2 (注:这里的 wlan2 和 上面的 eth0 不一致,下面的几句也是这种情况,请相应地改正)
|
||||
# iptraf -d eth0
|
||||
|
||||
为了看一个名为 eth0 的接口的 TCP 和 UDP 监控,使用:
|
||||
查看接口 eth0 的 TCP 和 UDP 监控信息,使用:
|
||||
|
||||
# iptraf -z wlan2
|
||||
# iptraf -z eth0
|
||||
|
||||
为了展示在一个名为 eth0 的接口上的包的大小和数目,使用:
|
||||
查看接口 eth0 的包的大小和数目,使用:
|
||||
|
||||
# iptraf -z wlan2
|
||||
# iptraf -z eth0
|
||||
|
||||
注意:请将上面的 wlan2 替换为你的接口名称。你可以通过运行`ip link show`命令来检查你的接口。
|
||||
注意:请将上面的 eth0 替换为你的接口名称。你可以通过运行`ip link show`命令来检查你的接口。
|
||||
|
||||
(LCTT 译注:关于 iptraf 的更多详细信息请参考:https://linux.cn/article-5430-1.html )
|
||||
|
||||
### 12) Speedometer ###
|
||||
|
||||
Speedometer 是一个小巧且简单的工具,它只绘出一幅包含有通过某个给定端口的上行、下行流量的好看的图。
|
||||
Speedometer 是一个小巧且简单的工具,它只用来绘出一幅包含有通过某个给定端口的上行、下行流量的好看的图。
|
||||
|
||||
在默认的软件仓库中可以找到 Speedometer ,所以我们可以使用下面的命令通过 **yum** 包管理器轻松地安装 Speedometer:
|
||||
|
||||
# yum install speedometer
|
||||
|
||||
在默认的软件仓库中可以找到 Speedometer ,所以我们可以使用下面的命令通过 **apt** 包管理器轻松地安装 Speedometer:
|
||||
我们可以使用下面的命令通过 **apt** 包管理器轻松地安装 Speedometer:
|
||||
|
||||
$ sudo apt-get install speedometer
|
||||
|
||||
@ -239,15 +253,15 @@ Speedometer 可以简单地通过在 shell 或虚拟终端中执行下面的命
|
||||
|
||||
### 13) Netwatch ###
|
||||
|
||||
Netwatch 是 netdiag 工具集里的一部分,并且它也显示出当前主机和其他远程主机的连接情况,以及在每个连接中数据传输的速率。
|
||||
Netwatch 是 netdiag 工具集里的一部分,它也显示当前主机和其他远程主机的连接情况,以及在每个连接中数据传输的速率。
|
||||
|
||||
我们可以使用 yum 在 fedora 中安装 Netwatch,因为它在 fedora 的默认软件仓库中。但若你运行着 CentOS 或 RHEL , 我们需要安装 [rpmforge 软件仓库][3]。
|
||||
|
||||
# yum install netwatch
|
||||
|
||||
Netwatch 作为 netdiag 的一部分可以在默认的软件仓库中找到,所以我们可以轻松地使用下面的命令来利用 **apt** 包管理器安装 **netdiag**:
|
||||
Netwatch 是 netdiag 的一部分,可以在默认的软件仓库中找到,所以我们可以轻松地使用下面的命令来利用 **apt** 包管理器安装 **netdiag**:
|
||||
|
||||
$ sudo apt-get install netdiag(注:这里应该加上 apt-get
|
||||
$ sudo apt-get install netdiag
|
||||
|
||||
为了运行 netwatch, 我们需要在虚拟终端或 shell 中执行下面的命令:
|
||||
|
||||
@ -259,15 +273,15 @@ Netwatch 作为 netdiag 的一部分可以在默认的软件仓库中找到,
|
||||
|
||||
### 14) Trafshow ###
|
||||
|
||||
Trafshow 同 netwatch 和 pktstat(注:这里原文中多了一个 trafshow)一样,可以报告当前激活的连接里使用的协议和每个连接中数据传输的速率。它可以使用 pcap 类型的滤波器来筛选出特定的连接。
|
||||
Trafshow 同 netwatch 和 pktstat 一样,可以报告当前活动的连接里使用的协议和每个连接中数据传输的速率。它可以使用 pcap 类型的过滤器来筛选出特定的连接。
|
||||
|
||||
我们可以使用 yum 在 fedora 中安装 trafshow(注:这里原文为 Netwatch,应该为 trafshow),因为它在 fedora 的默认软件仓库中。但若你正运行着 CentOS 或 RHEL , 我们需要安装 [rpmforge 软件仓库][4]。
|
||||
我们可以使用 yum 在 fedora 中安装 trafshow ,因为它在 fedora 的默认软件仓库中。但若你正运行着 CentOS 或 RHEL , 我们需要安装 [rpmforge 软件仓库][4]。
|
||||
|
||||
# yum install trafshow
|
||||
|
||||
Trafshow 在默认仓库中可以找到,所以我们可以轻松地使用下面的命令来利用 **apt** 包管理器安装它:
|
||||
|
||||
$ sudo apt-get install trafshow(注:原文少了 apt-get)
|
||||
$ sudo apt-get install trafshow
|
||||
|
||||
为了使用 trafshow 来执行监控任务,我们需要在虚拟终端或 shell 中执行下面的命令:
|
||||
|
||||
@ -275,7 +289,7 @@ Trafshow 在默认仓库中可以找到,所以我们可以轻松地使用下
|
||||
|
||||

|
||||
|
||||
为了特别地监控 tcp 连接,如下面一样添加上 tcp 参数:
|
||||
为了专门监控 tcp 连接,如下面一样添加上 tcp 参数:
|
||||
|
||||
$ sudo trafshow -i wlan2 tcp
|
||||
|
||||
@ -285,7 +299,7 @@ Trafshow 在默认仓库中可以找到,所以我们可以轻松地使用下
|
||||
|
||||
### 15) Vnstat ###
|
||||
|
||||
与大多数的其他工具相比,Vnstat 有一点不同。实际上它运行一个后台服务或守护进程,并时刻记录着传输数据的大小。另外,它可以被用来生成一个带有网络使用历史记录的报告。
|
||||
与大多数的其他工具相比,Vnstat 有一点不同。实际上它运行着一个后台服务或守护进程,并时刻记录着传输数据的大小。另外,它可以被用来生成一个网络使用历史记录的报告。
|
||||
|
||||
我们需要开启 EPEL 软件仓库,然后运行 **yum** 包管理器来安装 vnstat。
|
||||
|
||||
@ -301,7 +315,7 @@ Vnstat 在默认软件仓库中可以找到,所以我们可以使用下面的
|
||||
|
||||

|
||||
|
||||
为了实时地监控带宽使用情况,使用 ‘-l’ 选项(实时模式)。然后它将以一种非常精确的方式来展示被上行和下行数据所使用的带宽总量,但不会显示任何有关主机连接或进程的内部细节。
|
||||
为了实时地监控带宽使用情况,使用 ‘-l’ 选项(live 模式)。然后它将以一种非常精确的方式来展示上行和下行数据所使用的带宽总量,但不会显示任何有关主机连接或进程的内部细节。
|
||||
|
||||
$ vnstat -l
|
||||
|
||||
@ -313,7 +327,7 @@ Vnstat 在默认软件仓库中可以找到,所以我们可以使用下面的
|
||||
|
||||
### 16) tcptrack ###
|
||||
|
||||
[tcptrack][5] 可以展示 TCP 连接的状态,它在一个给定的网络端口上进行监听。tcptrack 监控它们的状态并展示出一个经过排列且不断更新的有关来源/目标地址、带宽使用情况等信息的列表,这与 **top** 命令的输出非常类似 。
|
||||
[tcptrack][5] 可以展示 TCP 连接的状态,它在一个给定的网络端口上进行监听。tcptrack 监控它们的状态并展示出排序且不断更新的列表,包括来源/目标地址、带宽使用情况等信息,这与 **top** 命令的输出非常类似 。
|
||||
|
||||
鉴于 tcptrack 在软件仓库中,我们可以轻松地在 Debian、Ubuntu 系统中从软件仓库使用 **apt** 包管理器来安装 tcptrack。为此,我们需要在 shell 或虚拟终端中执行下面的命令:
|
||||
|
||||
@ -329,7 +343,7 @@ Vnstat 在默认软件仓库中可以找到,所以我们可以使用下面的
|
||||
|
||||
注:这里我们下载了 rpmforge-release 的当前最新版本,即 0.5.3-1,你总是可以从 rpmforge 软件仓库中下载其最新版本,并请在上面的命令中替换为你下载的版本。
|
||||
|
||||
**tcptrack** 需要以 root 权限或超级用户身份来运行。执行 tcptrack 时,我们需要带上那个我们想监视的网络接口 TCP 连接状况的接口名称。这里我们的接口名称为 wlan2,所以如下面这样使用:
|
||||
**tcptrack** 需要以 root 权限或超级用户身份来运行。执行 tcptrack 时,我们需要带上要监视的网络接口 TCP 连接状况的接口名称。这里我们的接口名称为 wlan2,所以如下面这样使用:
|
||||
|
||||
sudo tcptrack -i wlan2
|
||||
|
||||
@ -345,7 +359,7 @@ Vnstat 在默认软件仓库中可以找到,所以我们可以使用下面的
|
||||
|
||||
### 17) CBM ###
|
||||
|
||||
CBM 或 Color Bandwidth Meter 可以展示出当前所有网络设备的流量使用情况。这个程序是如此的简单,以至于应该可以从它的名称中看出其功能。CBM 的源代码和新版本可以在 [http://www.isotton.com/utils/cbm/][7] 上找到。
|
||||
CBM ( Color Bandwidth Meter) 可以展示出当前所有网络设备的流量使用情况。这个程序是如此的简单,以至于都可以从它的名称中看出其功能。CBM 的源代码和新版本可以在 [http://www.isotton.com/utils/cbm/][7] 上找到。
|
||||
|
||||
鉴于 CBM 已经包含在软件仓库中,我们可以简单地使用 **apt** 包管理器从 Debian、Ubuntu 的软件仓库中安装 CBM。为此,我们需要在一个 shell 窗口或虚拟终端中运行下面的命令:
|
||||
|
||||
@ -359,7 +373,7 @@ CBM 或 Color Bandwidth Meter 可以展示出当前所有网络设备的流量
|
||||
|
||||
### 18) bmon ###
|
||||
|
||||
[Bmon][8] 或 Bandwidth Monitoring ,是一个用于调试和实时监控带宽的工具。这个工具能够检索各种输入模块的统计数据。它提供了多种输出方式,包括一个基于 curses 库的界面,轻量级的HTML输出,以及 ASCII 输出格式。
|
||||
[Bmon][8] ( Bandwidth Monitoring) ,是一个用于调试和实时监控带宽的工具。这个工具能够检索各种输入模块的统计数据。它提供了多种输出方式,包括一个基于 curses 库的界面,轻量级的HTML输出,以及 ASCII 输出格式。
|
||||
|
||||
bmon 可以在软件仓库中找到,所以我们可以通过使用 apt 包管理器来在 Debian、Ubuntu 中安装它。为此,我们需要在一个 shell 窗口或虚拟终端中运行下面的命令:
|
||||
|
||||
@ -373,7 +387,7 @@ bmon 可以在软件仓库中找到,所以我们可以通过使用 apt 包管
|
||||
|
||||
### 19) tcpdump ###
|
||||
|
||||
[TCPDump][9] 是一个用于网络监控和数据获取的工具。它可以为我们节省很多的时间,并可用来调试网络或服务器 的相关问题。它打印出在某个网络接口上与布尔表达式匹配的数据包所包含的内容的一个描述。
|
||||
[TCPDump][9] 是一个用于网络监控和数据获取的工具。它可以为我们节省很多的时间,并可用来调试网络或服务器的相关问题。它可以打印出在某个网络接口上与布尔表达式相匹配的数据包所包含的内容的一个描述。
|
||||
|
||||
tcpdump 可以在 Debian、Ubuntu 的默认软件仓库中找到,我们可以简单地以 sudo 权限使用 apt 包管理器来安装它。为此,我们需要在一个 shell 窗口或虚拟终端中运行下面的命令:
|
||||
|
||||
@ -389,7 +403,6 @@ tcpdump 需要以 root 权限或超级用户来运行,我们需要带上我们
|
||||
|
||||

|
||||
|
||||
|
||||
假如你只想监视一个特定的端口,则可以运行下面的命令。下面是一个针对 80 端口(网络服务器)的例子:
|
||||
|
||||
$ sudo tcpdump -i wlan2 'port 80'
|
||||
@ -419,14 +432,15 @@ tcpdump 需要以 root 权限或超级用户来运行,我们需要带上我们
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在第一部分中(注:我认为原文多了 first 这个单词,总之是前后文的内容有些不连贯),我们介绍了一些在 Linux 下的网络负载监控工具,这对于系统管理员甚至是新手来说,都是很有帮助的。在这篇文章中介绍的每一个工具都有其特点,不同的选项等,但最终它们都可以帮助你来监控你的网络流量。
|
||||
在这篇文章中,我们介绍了一些在 Linux 下的网络负载监控工具,这对于系统管理员甚至是新手来说,都是很有帮助的。在这篇文章中介绍的每一个工具都具有其特点,不同的选项等,但最终它们都可以帮助你来监控你的网络流量。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/network-monitoring-tools-linux/
|
||||
|
||||
作者:[Bobbin Zachariah][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,300 @@
|
||||
指南:使用Trickle限制应用程序带宽占用
|
||||
================================================================================
|
||||
|
||||
有没有遇到过系统中的某个应用程序独占了你所有的网络带宽的情形?如果你有过这样的遭遇,那么你就会感受到Trickle这种带宽调整应用的价值。不管你是一个系统管理员还只是普通Linux用户,都需要学习如何控制应用程序的上下行速度,来确保你的网络带宽不会被某个程序霸占。
|
||||
|
||||

|
||||
|
||||
*在 Linux 上安装 Trickle 带宽限制*
|
||||
|
||||
### 什么是 Trickle? ###
|
||||
|
||||
Trickle是一个网络带宽调整工具,可以让我们管理应用程序的网络上下行速度,使得可以避免其中的某个应用程序霸占了全部或大部分可用的带宽。换句话说,Trickle可以让你基于单个应用程序来控制网络流量速率,而不是仅仅针对与单个用户——这是在客户端网络环境中经典的带宽调整情况。
|
||||
|
||||
### Trickle 是如何工作的?###
|
||||
|
||||
另外,trickle 可以帮助我们基于应用来定义优先级,所以当对整个系统进行了全局限制设定,高优先级的应用依然会自动地获取更多的带宽。为了实现这个目标,trickle 对 TCP 连接上的套接字的数据发送、接收设置流量限制。我们必须注意到,除了影响传输速率之外,在这个过程中,trickle任何时候都不会以任何方式来改变其中的数据。
|
||||
|
||||
### Trickle不能做什么? ###
|
||||
|
||||
这么说吧,唯一的限制就是,trickle不支持静态链接的应用程序或者具有SUID或SGID位设置的二进制程序,因为它使用动态链接的方式将其载入到需要调整的进程和其关联的网络套接字之间。 Trickle此时会在这两种软件组件之间扮演代理的角色。
|
||||
|
||||
由于trickle并不需要超级用户的权限来运行,所以用户可以设置他们自己的流量限制。可能这并不是你想要的,我们会探索如何使用全局设定来限制系统中的所有用户的流量限制。也即是说,此时系统中的每个用户具有管理各自的流量速率,但是无论如何,都会受到系统管理员给他们设置的总体限制。
|
||||
|
||||
在这篇文章中,我们会描述如何通过trickle在linux平台上管理应用程序使用的网络带宽。为了生成所需的流量,在此会在客户端(CentOS 7 server – dev1: 192.168.0.17)上使用 ncftpput 和 ncftpget, 在服务器(Debian Wheezy 7.5 – dev2: 192.168.0.15)上使用vsftpd 来进行演示。 相同的指令也可以在RedHat,Fedora和Ubuntu等系统使用。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
1. 对于 RHEL/CentOS 7/6, [开启EPEL仓库][1]。这些用于企业版 Linux 的额外软件包是一个由Fedora项目维护的高质量、开源的软件仓库,而且百分之百与其衍生产品相兼容,如企业版本Linux和CentOS。 在这个仓库中trickle和ncftp两者都是可用的。
|
||||
|
||||
2. 按照如下方式安装ncftp:
|
||||
|
||||
# yum update && sudo yum install ncftp [基于 RedHat 的系统]
|
||||
# aptitude update && aptitude install ncftp [基于 Debian 的系统]
|
||||
|
||||
3. 在单独的服务器上设置一个FTP服务器。需要注意的是,尽管FTP天生就不安全,但是仍然被广泛应用在安全性无关紧要的文件上传下载中。 在这篇文章中我们使用它来演示trickle的优点,同时它也会在客户端的标准输出流中显示传输速率。我们将是否在其它时间使用它放在一边讨论。
|
||||
|
||||
# yum update && yum install vsftpd [基于 RedHat 的系统]
|
||||
# aptitude update && aptitude install vsftpd [基于 Debian 的系统]
|
||||
|
||||
现在,在FTP服务器上按照以下方式编辑 /etc/vsftpd/vsftpd.conf 文件。
|
||||
|
||||
anonymous_enable=NO
|
||||
local_enable=YES
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
|
||||
在此之后,确保在你的当前会话中启动了vsftpd,并在之后的启动中让其自动启动。
|
||||
|
||||
# systemctl start vsftpd [基于 systemd 的系统]
|
||||
# systemctl enable vsftpd
|
||||
# service vsftpd start [基于 init 的系统]
|
||||
# chkconfig vsftpd on
|
||||
|
||||
4. 如果你选择在一个使用 SSH 密钥进行远程访问的 CentOS/RHEL 7中搭建FTP服务器,你需要一个密码受保护的用户账户,它能访问**root目录之外**的某个目录,并有能在其中上传和下载文件的权限。
|
||||
|
||||
你可以通过在你的浏览器中输入以下的URL来浏览你的家目录。一个登录窗口会弹出来提示你输入FTP服务器中的有效的用户名和密码。
|
||||
|
||||
ftp://192.168.0.15
|
||||
|
||||
如果验证成功,你就会看到你的家目录中的内容。该教程的稍后部分中,你将可以刷新页面来显示在你之前上传过的文件。
|
||||
|
||||

|
||||
|
||||
*FTP 目录树*
|
||||
|
||||
### 如何在Linux中安装 trickle ###
|
||||
|
||||
1. 通过yum或aptitude来安装trickle.
|
||||
|
||||
为了确保能够成功安装,最好在安装工具之前,保证当前的安装包是最新的版本。
|
||||
|
||||
|
||||
# yum -y update && yum install trickle [基于 RedHat 的系统]
|
||||
# aptitude -y update && aptitude install trickle [基于 Debian 的系统]
|
||||
|
||||
2. 确认trickle是否对特定的二进制包有用。
|
||||
|
||||
之前我们解释过,trickle只对使用动态或共享的库的二进制包有用。为了确认我们是否可以对某个特定的应用使用trickle,我们可以使用著名的ldd(列出动态依赖)工具。 特别地,我们会查看任何给定程序的动态依赖中其当前使用的glibc,因为其准确地定义了通过套接字通讯所使用的系统调用。
|
||||
|
||||
对一个给定的二进制包执行以下命令来查看是否能对其使用trickle进行带宽调整:
|
||||
|
||||
# ldd $(which [binary]) | grep libc.so
|
||||
|
||||
例如,
|
||||
|
||||
# ldd $(which ncftp) | grep libc.so
|
||||
|
||||
其输出是:
|
||||
|
||||
# libc.so.6 => /lib64/libc.so.6 (0x00007efff2e6c000)
|
||||
|
||||
输出中的括号中的字符可能在不同的系统平台有所不同,甚至相同的命令在不同的时候运行也会不同,因为其代表包加载到物理内存中的地址。
|
||||
|
||||
如果上面的命令没有返回任何的结果,就说明这个二进制包没有使用libc包,因此trickle对其不能起到带宽调整的作用。
|
||||
|
||||
### 学习如何使用Trickle###
|
||||
|
||||
最基本的用法就是使用其独立模式,通过这种方式,trickle用来显式地定义给定应用程序的上传下载速率。如前所述,为了简单,我们会使用相同的应用来进行上传下载测试。
|
||||
|
||||
#### 在独立模式下运行trickle####
|
||||
|
||||
我们会比较在有无trickle的情况下的上传下载速率, ‘-d’选项指示下载速率(KB/s单位),而'-u'选项指示相同单位的上传速率。另外我们会使用到‘-s’选项来指定trickle应该以独立模式运行。
|
||||
|
||||
以独立模式运行trickle的基本语法如下:
|
||||
|
||||
# trickle -s -d [下载速率,KB/s] -u [上传速率,KB/s]
|
||||
|
||||
为了能够让你自己运行以下样例,确保你在自己的客户端安装了trickle和ncftp(我的是192.168.0.17)。
|
||||
|
||||
**样例1:在有无trickle的情况下上传一个2.8 MB的PDF文件。**
|
||||
|
||||
我们使用一个自由发布的[LInux基础知识PDF文件][2]来进行下面的测试。
|
||||
|
||||
你可以首先使用下面的命令将这个文件下载到你当前的工作目录中:
|
||||
|
||||
# wget http://linux-training.be/files/books/LinuxFun.pdf
|
||||
|
||||
下面是在没有trickle的情况下将一个文件上传到我们的FTP服务器的语法:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /remote_directory local-filename
|
||||
|
||||
其中的 /remote_directory 是相对于该用户的家目录的上传路径,而local-filename是一个你当前工作目录中的文件。
|
||||
|
||||
特别的是,在没有trickle的情形下,我们可以得到上传峰值速率52.02MB/s(请注意,这个不是真正的平均上传速率,而是峰值开始的瞬时值),而且这个文件几乎在瞬间就完成了上传。
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /testdir LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 52.02 MB/s
|
||||
|
||||
在使用trickle的情况下,我们会限制上传速率在5KB/s。在第二次上传文件之前,我们需要在目标目录中删除这个文件,否则ncftp就会通知我们在目标目录中已经存在了与上传文件相同的文件,从而不会执行文件的传输:
|
||||
|
||||
# rm /absolute/path/to/destination/directory/LinuxFun.pdf
|
||||
|
||||
然后:
|
||||
|
||||
# trickle -s -u 5 ncftpput -u username -p password 111.111.111.111 /testdir LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 4.94 kB/s
|
||||
|
||||
在上面的样例中,我们看到平均的上传速率下降到了5KB/s。
|
||||
|
||||
**样例2:在有无trickle的情况下下载相同的2.8MB的PDF文件**
|
||||
|
||||
首先,记得从原来的源目录中删除这个PDF:
|
||||
|
||||
# rm /absolute/path/to/source/directory/LinuxFun.pdf
|
||||
|
||||
请注意,下面的样例中将远程的文件下载到客户端机器的当前目录下,这是由FTP服务器的IP地址后面的“.”决定的。
|
||||
|
||||
没有trickle的情况下:
|
||||
|
||||
# ncftpget -u username -p password 111.111.111.111 . /testdir/LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 260.53 MB/s
|
||||
|
||||
在有trickle的情况下,限制下载速率在20KB/s:
|
||||
|
||||
# trickle -s -d 30 ncftpget -u username -p password 111.111.111.111 . /testdir/LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 17.76 kB/s
|
||||
|
||||
### 在监督[非托管]模式下运行Trickle ###
|
||||
|
||||
trickle也可以按照/etc/trickled.conf文件中定义的一系列参数运行在非托管模式下。 这个文件定义了守护线程 trickled的行为以及如何管理trickle。
|
||||
|
||||
另外,如果你想要全局设置被所有的应用程序使用的话,我们就会需要使用trickle命令。 这个命令运行守护进程,并允许我们通过trickle定义所有应用程序共享的上传下载限制,不需要我们每次来进行指定。
|
||||
|
||||
例如,运行:
|
||||
|
||||
# trickled -d 50 -u 10
|
||||
|
||||
会导致任何通过trickle运行的应用程序的上传下载速率分别限制在30kb/s和10kb/s。
|
||||
|
||||
请注意,你可以在任何时间都能确认守护线程trickled是否正在运行以及其运行参数:
|
||||
|
||||
# ps -ef | grep trickled | grep -v grep
|
||||
|
||||
输出:
|
||||
|
||||
root 16475 1 0 Dec24 ? 00:00:04 trickled -d 50 -u 10
|
||||
|
||||
**样例3:在使用/不使用trickle的情形下上传一个 19MB 的mp4文件到我们的FTP服务器。**
|
||||
|
||||
在这个样例中,我们会使用“He is the gift”的自由分发视频,可以通过这个[链接][3]下载。
|
||||
|
||||
我们将会在开始时通过以下的命令将这个文件下载到你的当前工作目录中:
|
||||
|
||||
# wget http://media2.ldscdn.org/assets/missionary/our-people-2014/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
首先,我们会使用之前列出的命令来开启守护进程trickled:
|
||||
|
||||
# trickled -d 30 -u 10
|
||||
|
||||
在不使用trickle时:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /testdir 2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 36.31 MB/s
|
||||
|
||||
在使用trickle时:
|
||||
|
||||
# trickle ncftpput -u username -p password 192.168.0.15 /testdir 2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 9.51 kB/s
|
||||
|
||||
我们可以看到上面的输出,上传的速率下降到了约 10KB/s。
|
||||
|
||||
** 样例4:在使用/不使用trickle的情形下下载这个相同的视频 **
|
||||
|
||||
与样例2一样,我们会将该文件下载到当前工作目录中。
|
||||
|
||||
在没有trickle时:
|
||||
|
||||
# ncftpget -u username -p password 192.168.0.15 . /testdir/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 108.34 MB/s
|
||||
|
||||
有trickle的时:
|
||||
|
||||
# trickle ncftpget -u username -p password 111.111.111.111 . /testdir/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 29.28 kB/s
|
||||
|
||||
上面的结果与我们之前设置的下载限速相对应(30KB/s)。
|
||||
|
||||
**注意:** 一旦守护进程开启之后,就没有必要使用trickle来为每个应用程序来单独设置限制。
|
||||
|
||||
如前所述,人们可以进一步地通过trickled.conf来客制化trickle的带宽速率调整,该文件的一个典型的分段有以下部分组成:
|
||||
|
||||
[service]
|
||||
Priority = <value>
|
||||
Time-Smoothing = <value>
|
||||
Length-Smoothing = <value>
|
||||
|
||||
其中,
|
||||
|
||||
- [service] 用来指示我们想要对其进行带宽使用调整的应用程序名称
|
||||
- Priority 用来让我们为某个服务制定一个相对于其他服务高的优先级,这样就不允许守护进程管理中的一个单独的应用程序来占用所有的带宽。越小的数字代表更高的优先级。
|
||||
- Time-Smoothing [以秒计]: 定义了trickled让各个应用程序传输或接收数据的时间间隔。小的间隔值(0.1-1秒)对于交互式应用程序是理想的,因为这样会具有一个更加平滑的会话体验,而一个相对较大的时间间隔值(1-10秒)对于需要批量传输应用程序就会显得更好。如果没有指定该值,默认是5秒。
|
||||
- Length-smoothing [KB 单位]: 该想法与Time-Smoothing如出一辙,但是是基于I/O操作而言。如果没有指定值,会使用默认的10KB。
|
||||
|
||||
上述平滑值(Time-Smoothing、 Length-smoothing)的改变会被翻译为将指定的服务的使用一个间隔值而不是一个固定值。不幸的是,没有一个特定的公式来计算间隔值的上下限,主要依赖于特定的应用场景。
|
||||
|
||||
下面是一个在CentOS 7 客户端中的trickled.conf 样例文件(192.168.0.17):
|
||||
|
||||
[ssh]
|
||||
Priority = 1
|
||||
Time-Smoothing = 0.1
|
||||
Length-Smoothing = 2
|
||||
|
||||
[ftp]
|
||||
Priority = 2
|
||||
Time-Smoothing = 1
|
||||
Length-Smoothing = 3
|
||||
|
||||
使用该设置,trickled会为SSH赋予比FTP较高的传输优先级。值得注意的是,一个交互进程,例如SSH,使用了一个较小的时间间隔值,然而一个处理批量数据传输的服务如FTP,则使用一个较大的时间间隔来控制之前的样例中的上传下载速率,尽管不是百分百的由trickled指定的值,但是也已经非常接近了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在该文章中,我们探索了使用trickle在基于Fedora发行版和Debian衍生版平台上来限制应用程序的带宽使用。也包含了其他的可能用法,但是不对以下情形进行限制:
|
||||
|
||||
- 限制系统工具的下载速度,例如[wget][4],或 BT客户端.
|
||||
- 限制你的系统的包管理工具[`yum`][5]更新的速度 (如果是基于Debian系统的话,其包管理工具为[`aptitude`][6])。
|
||||
- 如果你的服务器是在一个代理或防火墙后面(或者其本身即是代理或防火墙的话),你可以使用trickle来同时设定下载和上传速率,或者客户端或外部通讯的速率。
|
||||
|
||||
欢迎提问或留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-and-limit-downloadupload-bandwidth-with-trickle-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-2324-1.html
|
||||
[2]:http://linux-training.be/files/books/LinuxFun.pdf
|
||||
[3]:http://media2.ldscdn.org/assets/missionary/our-people-2014/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
[4]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]:http://www.tecmint.com/dpkg-command-examples/
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||

|
||||
|
||||
Linux系统的KVM管理
|
||||
*Linux系统的KVM管理*
|
||||
|
||||
在这篇文章里没有什么新的概念,我们只是用命令行工具重复之前所做过的事情,也没有什么前提条件,都是相同的过程,之前的文章我们都讨论过。
|
||||
|
||||
@ -31,35 +31,40 @@ Virsh命令行工具是一款管理virsh客户域的用户界面。virsh程序
|
||||
# virsh pool-define-as Spool1 dir - - - - "/mnt/personal-data/SPool1/"
|
||||
|
||||

|
||||
创建新存储池
|
||||
|
||||
*创建新存储池*
|
||||
|
||||
**2. 查看环境中我们所有的存储池,用以下命令。**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
列出所有存储池
|
||||
|
||||
*列出所有存储池*
|
||||
|
||||
**3. 现在我们来构造存储池了,用以下命令来构造我们刚才定义的存储池。**
|
||||
|
||||
# virsh pool-build Spool1
|
||||
|
||||

|
||||
构造存储池
|
||||
|
||||
**4. 用virsh带pool-start的命令来激活并启动我们刚才创建并构造完成的存储池。**
|
||||
*构造存储池*
|
||||
|
||||
**4. 用带pool-start参数的virsh命令来激活并启动我们刚才创建并构造完成的存储池。**
|
||||
|
||||
# virsh pool-start Spool1
|
||||
|
||||

|
||||
激活存储池
|
||||
|
||||
*激活存储池*
|
||||
|
||||
**5. 查看环境中存储池的状态,用以下命令。**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
查看存储池状态
|
||||
|
||||
*查看存储池状态*
|
||||
|
||||
你会发现Spool1的状态变成了已激活。
|
||||
|
||||
@ -68,14 +73,16 @@ Virsh命令行工具是一款管理virsh客户域的用户界面。virsh程序
|
||||
# virsh pool-autostart Spool1
|
||||
|
||||

|
||||
配置KVM存储池
|
||||
|
||||
*配置KVM存储池*
|
||||
|
||||
**7. 最后来看看我们新的存储池的信息吧。**
|
||||
|
||||
# virsh pool-info Spool1
|
||||
|
||||

|
||||
查看KVM存储池信息
|
||||
|
||||
*查看KVM存储池信息*
|
||||
|
||||
恭喜你,Spool1已经准备好待命,接下来我们试着创建存储卷来使用它。
|
||||
|
||||
@ -90,12 +97,14 @@ Virsh命令行工具是一款管理virsh客户域的用户界面。virsh程序
|
||||
# qemu-img create -f raw /mnt/personal-data/SPool1/SVol1.img 10G
|
||||
|
||||

|
||||
创建存储卷
|
||||
|
||||
*创建存储卷*
|
||||
|
||||
**9. 通过使用带info的qemu-img命令,你可以获取到你的新磁盘映像的一些信息。**
|
||||
|
||||

|
||||
查看存储卷信息
|
||||
|
||||
*查看存储卷信息*
|
||||
|
||||
**警告**: 不要用qemu-img命令来修改被运行中的虚拟机或任何其它进程所正在使用的映像,那样映像会被破坏。
|
||||
|
||||
@ -120,15 +129,18 @@ Virsh命令行工具是一款管理virsh客户域的用户界面。virsh程序
|
||||
# virt-install --name=rhel7 --disk path=/mnt/personal-data/SPool1/SVol1.img --graphics spice --vcpu=1 --ram=1024 --location=/run/media/dos/9e6f605a-f502-4e98-826e-e6376caea288/rhel-server-7.0-x86_64-dvd.iso --network bridge=virbr0
|
||||
|
||||

|
||||
创建新的虚拟机
|
||||
|
||||
*创建新的虚拟机*
|
||||
|
||||
**11. 你会看到弹出一个virt-vierwer窗口,像是在通过它在与虚拟机通信。**
|
||||
|
||||

|
||||
虚拟机启动程式
|
||||
|
||||
*虚拟机启动程式*
|
||||
|
||||

|
||||
虚拟机安装过程
|
||||
|
||||
*虚拟机安装过程*
|
||||
|
||||
### 结论 ###
|
||||
|
||||
@ -143,7 +155,7 @@ via: http://www.tecmint.com/kvm-management-tools-to-manage-virtual-machines/
|
||||
|
||||
作者:[Mohammad Dosoukey][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,174 @@
|
||||
使用Observium来监控你的网络和服务器
|
||||
================================================================================
|
||||
### 简介###
|
||||
|
||||
在监控你的服务器、交换机或者设备时遇到过问题吗?**Observium** 可以满足你的需求。这是一个免费的监控系统,它可以帮助你远程监控你的服务器。它是一个由PHP编写的基于自动发现 SNMP 的网络监控平台,支持非常广泛的网络硬件和操作系统,包括 Cisco、Windows、Linux、HP、NetApp 等等。在此我会给出在 Ubuntu 12.04 上一步步地设置一个 **Observium** 服务器的介绍。
|
||||
|
||||
|
||||
|
||||
目前有两种不同的 **observium** 版本。
|
||||
|
||||
- Observium 社区版本是一个在 QPL 开源许可证下的免费工具,这个版本是对于较小部署的最好解决方案。该版本每6个月进行一次安全性更新。
|
||||
- 第2个版本是 Observium 专业版,该版本采用基于 SVN 的发布机制。 会得到每日安全性更新。 该工具适用于服务提供商和企业级部署。
|
||||
|
||||
更多信息可以通过其[官网][1]获得。
|
||||
|
||||
### 系统需求###
|
||||
|
||||
要安装 **Observium**, 需要具有一个最新安装的服务器。**Observium** 是在 Ubuntu LTS 和 Debian 系统上进行开发的,所以推荐在 Ubuntu 或 Debian 上安装 **Observium**,因为可能在别的平台上会有一些小问题。
|
||||
|
||||
该文章会引导你在 Ubuntu 12.04 上安装 **Observium**。对于小型的 **Observium** 安装,建议使用 256MB 内存和双核处理器的配置。
|
||||
|
||||
### 安装需求 ###
|
||||
|
||||
在安装 **Observuim** 之前,你需要确认安装所有的依赖关系包。
|
||||
|
||||
首先,使用下面的命令更新你的服务器:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
然后你需要安装下列运行 Observuim 所需的全部软件包。
|
||||
|
||||
Observium 需要使用下面所列出的软件才能正确的运行:
|
||||
|
||||
- LAMP 服务器
|
||||
- fping
|
||||
- Net-SNMP 5.4+
|
||||
- RRDtool 1.3+
|
||||
- Graphviz
|
||||
|
||||
对于可选特性的要求:
|
||||
|
||||
- Ipmitool - 仅在当你想要获取服务器上的 IPMI(Intelligent Platform Management Interface 智能平台管理接口)基板控制器时。
|
||||
- Libvirt-bin - 仅在当你想要使用 libvirt 进行远程 VM 主机监控时。
|
||||
|
||||
sudo apt-get install libapache2-mod-php5 php5-cli php5-mysql php5-gd php5-mcrypt php5-json php-pear snmp fping mysql-server mysql-client python-mysqldb rrdtool subversion whois mtr-tiny ipmitool graphviz imagemagick libvirt ipmitool
|
||||
|
||||
### 为 Observium 创建 MySQL 数据库及其用户。
|
||||
|
||||
现在你需要登录到 MySQL 中并为 **Observium** 创建数据库:
|
||||
|
||||
mysql -u root -p
|
||||
|
||||
在用户验证成功之后,你需要按照下面的命令创建该数据库。
|
||||
|
||||
CREATE DATABASE observium;
|
||||
|
||||
数据库名为 **Observium**,稍后你会需要这个信息。
|
||||
|
||||
现在你需要创建数据库管理员用户。
|
||||
|
||||
CREATE USER observiumadmin@localhost IDENTIFIED BY 'observiumpassword';
|
||||
|
||||
接下来,你需要给该管理员用户相应的权限来管理创建的数据库。
|
||||
|
||||
GRANT ALL PRIVILEGES ON observium.* TO observiumadmin@localhost;
|
||||
|
||||
你需要将权限信息写回到磁盘中来激活新的 MySQL 用户:
|
||||
|
||||
FLUSH PRIVILEGES;
|
||||
exit
|
||||
|
||||
### 下载并安装 Observium###
|
||||
|
||||
现在我们的系统已经准备好了, 可以开始Observium的安装了。
|
||||
|
||||
第一步,创建 Observium 将要使用的文件目录:
|
||||
|
||||
mkdir -p /opt/observium && cd /opt
|
||||
|
||||
按本教程的目的,我们将会使用 Observium 的社区/开源版本。使用下面的命令下载并解压:
|
||||
|
||||
wget http://www.observium.org/observium-community-latest.tar.gz
|
||||
tar zxvf observium-community-latest.tar.gz
|
||||
|
||||
现在进入到 Observium 目录。
|
||||
|
||||
cd observium
|
||||
|
||||
将默认的配置文件 '**config.php.default**' 复制到 '**config.php**',并将数据库配置选项填充到配置文件中:
|
||||
|
||||
cp config.php.default config.php
|
||||
nano config.php
|
||||
|
||||
----------
|
||||
|
||||
/ Database config
|
||||
$config['db_host'] = 'localhost';
|
||||
$config['db_user'] = 'observiumadmin';
|
||||
$config['db_pass'] = 'observiumpassword';
|
||||
$config['db_name'] = 'observium';
|
||||
|
||||
现在为 MySQL 数据库设置默认的数据库模式:
|
||||
|
||||
php includes/update/update.php
|
||||
|
||||
现在你需要创建一个文件目录来存储 rrd 文件,并修改其权限以便让 apache 能将写入到文件中。
|
||||
|
||||
mkdir rrd
|
||||
chown apache:apache rrd
|
||||
|
||||
为了在出现问题时排错,你需要创建日志文件。
|
||||
|
||||
mkdir -p /var/log/observium
|
||||
chown apache:apache /var/log/observium
|
||||
|
||||
现在你需要为 Observium 创建虚拟主机配置。
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /opt/observium/html/
|
||||
ServerName observium.domain.com
|
||||
CustomLog /var/log/observium/access_log combined
|
||||
ErrorLog /var/log/observium/error_log
|
||||
<Directory "/opt/observium/html/">
|
||||
AllowOverride All
|
||||
Options FollowSymLinks MultiViews
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
下一步你需要让你的 Apache 服务器的 rewrite (重写)功能生效。
|
||||
|
||||
为了让 'mod_rewrite' 生效,输入以下命令:
|
||||
|
||||
sudo a2enmod rewrite
|
||||
|
||||
该模块在下一次 Apache 服务重启之后就会生效。
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
###配置 Observium###
|
||||
|
||||
在登入 Web 界面之前,你需要为 Observium 创建一个管理员账户(级别10)。
|
||||
|
||||
# cd /opt/observium
|
||||
# ./adduser.php admin adminpassword 10
|
||||
User admin added successfully.
|
||||
|
||||
下一步为发现和探寻任务设置一个 cron 任务,创建一个新的文件 ‘**/etc/cron.d/observium**’ 并在其中添加以下的内容。
|
||||
|
||||
33 */6 * * * root /opt/observium/discovery.php -h all >> /dev/null 2>&1
|
||||
*/5 * * * * root /opt/observium/discovery.php -h new >> /dev/null 2>&1
|
||||
*/5 * * * * root /opt/observium/poller-wrapper.py 1 >> /dev/null 2>&1
|
||||
|
||||
重载 cron 进程来增加新的任务。
|
||||
|
||||
# /etc/init.d/cron reload
|
||||
|
||||
好啦,你已经完成了 Observium 服务器的安装拉! 使用你的浏览器登录到 **http://\<Server IP>**,然后上路吧。
|
||||
|
||||
|
||||
|
||||
尽情享受吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/monitoring-network-servers-observium/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[theo-l](http://github.com/theo-l)
|
||||
校对:[wxy](http://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](http://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/anis/
|
||||
[1]:http://www.observium.org/
|
||||
@ -1,10 +1,10 @@
|
||||
局域网中实现Ubuntu和Windows共享文件夹
|
||||
如何在局域网中将Ubuntu文件夹共享给Windows
|
||||
================================================================================
|
||||

|
||||
|
||||
本文全面详细地向你描述了**在Ubuntu中如何实现局域网内的文件夹共享**。
|
||||
|
||||
你的家中是不是有多台电脑?当你需要从一台Ubuntu电脑向另一台电脑传输数据时,是不是必须用到U盘或SD卡?你是否也觉得这个方法很烦人?我想肯定是。本文的目的就是使你在局域网内快速方便地传输文件、文档和其它较大的数据,来节省你的宝贵时间。只需一次设置,然后轻点鼠标,你就可以自由地**在Ubuntu和Windows之间共享文件**,当然这对其它Linux系统同样使用。不要担心这很容易操作,不会花费太多时间。
|
||||
你的家中是不是有多台电脑?当你需要从一台Ubuntu电脑向另一台电脑传输数据时,是不是必须用到U盘或SD卡?你是否也觉得这个方法很烦人?我想肯定是。本文的目的就是使你在局域网内快速方便地传输文件、文档和其它较大的数据,以节省你的宝贵时间。只需一次设置,然后轻点鼠标,你就可以自由地**在Ubuntu和Windows之间共享文件**,当然这对其它Linux系统同样使用。不要担心,这很容易操作,不会花费太多时间。
|
||||
|
||||
除此之外,尽管本文是在Ubuntu上进行实践,但这个教程在其它Linux系统上同样有用。
|
||||
|
||||
@ -21,11 +21,11 @@
|
||||
|
||||
#### 步骤一:####
|
||||
|
||||
为了在Ubuntu上实现局域网共享文件夹,右键点击打算共享的文件夹,并选择“Local Network Share”:
|
||||
为了在Ubuntu上实现局域网共享文件夹,右键点击打算共享的文件夹,并选择“Local Network Share(本地网络共享)”:
|
||||
|
||||

|
||||
|
||||
**可能有用的故障方案**:如果在右键菜单中看不到“Local Network Share”的选项,那就新建一个终端,使用下面的命令去安装nautlius-share:
|
||||
**可能有用的故障解决方案**:如果在右键菜单中看不到“Local Network Share”的选项,那就新建一个终端,使用下面的命令去安装nautlius-share插件:
|
||||
|
||||
sudo apt-get install nautilus-share
|
||||
|
||||
@ -35,17 +35,17 @@
|
||||
|
||||
#### 步骤二:####
|
||||
|
||||
一旦点击“Local Network Share”,就会出现共享文件夹的选项。只需选中“Share this folder”这一项:
|
||||
一旦点击“Local Network Share”,就会出现共享文件夹的选项。只需选中“Share this folder(共享该文件夹)”这一项:
|
||||
|
||||

|
||||
|
||||
可能的故障方案:如果提示共享服务还未安装,就像下图所示,那就点击安装服务,按照提示操作。
|
||||
**可能的故障解决方案**:如果提示共享服务还未安装,就像下图所示,那就点击安装服务,按照提示操作。
|
||||
|
||||

|
||||
|
||||
#### 步骤三:####
|
||||
|
||||
一旦选中“Share this folder”的选项,就会看到按钮“Create Share”变成可用了。你也可以允许其他用户在共享文件夹中编辑文件。选项“Guest access”也是如此。
|
||||
当选中“Share this folder”的选项,就会看到按钮“Create Share(创建共享)”变得可以点击了。你也可以“Allow others to create and delete fies in this folder(允许其他用户在共享文件夹中编辑文件)”。选项“Guest access(允许访客访问)”也是如此。
|
||||
|
||||

|
||||
|
||||
@ -55,13 +55,13 @@
|
||||
|
||||
### 2. 在Ubuntu上使用密码保护实现局域网共享文件夹###
|
||||
|
||||
为了达到目的,首先需要配置Samba服务器。事实上,在这篇教程的前一部分我们已经用到了Samba,只是我们没有刻意强调。在介绍如何在Ubuntu上搭建Samba服务器实现局域网共享的方法之前,先快速预览一下[Samba][1]到底是什么。
|
||||
为了达到这个目的,首先需要配置Samba服务器。事实上,在这篇教程的前一部分我们已经用到了Samba,只是我们没有刻意强调。在介绍如何在Ubuntu上搭建Samba服务器实现局域网共享的方法之前,先快速预览一下[Samba][1]到底是什么。
|
||||
|
||||
#### Samba是什么? ####
|
||||
|
||||
Samba是一个允许用户通过网络共享文件、文档和打印机的软件包,无论是在Linux、Windows,还是Mac上。它适用于所有的主流平台,可以在所有支持系统上流畅运行。下面是维基百科的介绍:
|
||||
|
||||
> Samba是一款重新实现SMB/CIFS网络协议的自由软件,最初由安德鲁·垂鸠开发。在第三版中,Smaba不仅支持通过不同的Windows客户端访问及分享SMB的文件夹及打印机,还可以集成到Windows Server域名,作为主要域名控制站(PDC)或者域名成员。它也可以作为Active Directory域名的一部分。
|
||||
> Samba是一款重新实现SMB/CIFS网络协议的自由软件,最初由安德鲁·垂鸠开发。在第三版中,Smaba不仅支持通过不同的Windows客户端访问及分享SMB的文件夹及打印机,还可以集成到Windows Server域,作为主域控制器(PDC)或者域成员。它也可以作为活动目录域的一部分。
|
||||
|
||||
#### 在Ubuntu上安装Samba服务器 ####
|
||||
|
||||
@ -77,7 +77,7 @@ Samba是一个允许用户通过网络共享文件、文档和打印机的软件
|
||||
|
||||
#### 在Ubuntu上配置Samba服务器 ####
|
||||
|
||||
从dash打开Samba配置工具:
|
||||
从dash中打开Samba配置工具:
|
||||
|
||||

|
||||
|
||||
@ -86,7 +86,7 @@ Samba是一个允许用户通过网络共享文件、文档和打印机的软件
|
||||
在Server Setting中可以看到两个选项卡,‘Basic’和‘Security’。在Basic选项卡下的选项含义如下:
|
||||
|
||||
- 工作组 - 用户要连接的电脑所在工作组的名字。比如,如果你想连接到一台Windows电脑,你就要输入Windows电脑的工作组名字。在Windows的Samba服务器设置中,已经默认设置好统一的工作组名字。但如果你有不同的工作组名字,就在这个字段中输入自定义的工作组名字。(在Windows 7中获取工作组名字,右击计算机图标,进到属性,就能看到Windows工作组名字。)
|
||||
- 描述 - 其他用户看到的你的电脑名字。不要使用空格或计算机不支持(望更正!)的字符。
|
||||
- 描述 - 其他用户看到的你的电脑名字。不要使用空格或不适用于网络的字符。
|
||||
|
||||

|
||||
|
||||
@ -101,14 +101,14 @@ Samba是一个允许用户通过网络共享文件、文档和打印机的软件
|
||||
现在我们需要为网络共享文件创建一个系统用户。下面是非常简单的步骤:
|
||||
|
||||
- 在Systems Settings下点击**User Accounts**。
|
||||
- 点击**unlock**使其可用,以及+(**plus**)图标。
|
||||
- 点击+(plus)图标,创建一个新的系统用户。
|
||||
- 点击**unlock**使其可用,以及+(**加号**)图标。
|
||||
- 点击+(加号)图标,创建一个新的系统用户。
|
||||
|
||||

|
||||
|
||||
如上图所示,需要输入‘Full name’。当你输入‘Full name’时,Username会自动填充为Full name。因为创建这个用户是为了共享文件,所以还要指定Account Type为‘**Standard**’。
|
||||
|
||||
完成上述步骤,点击添加,你就创建好一个系统用户。这个用户还没有被激活,所以需要为其设置密码来激活。确保Users accounts界面已经解锁。点击Account disabled。输入一个新密码,然后确认密码,点击Change。
|
||||
完成上述步骤,点击添加,你就创建好一个系统用户。这个用户还没有被激活,所以需要为其设置密码来激活。确保Users accounts界面已经解锁。点击尚不可用的账户,输入一个新密码,然后确认密码,点击Change。
|
||||
|
||||

|
||||
|
||||
@ -132,7 +132,7 @@ Samba是一个允许用户通过网络共享文件、文档和打印机的软件
|
||||
|
||||
#### 通过网络共享文件夹或文件 ####
|
||||
|
||||
在图形用户界面下通过Samba共享文件是很简单的。点击Plus图标,会看到如图所示的对话框:
|
||||
在图形用户界面下通过Samba共享文件是很简单的。点击加号图标,会看到如图所示的对话框:
|
||||
|
||||

|
||||
|
||||
@ -157,9 +157,8 @@ Samba是一个允许用户通过网络共享文件、文档和打印机的软件
|
||||
|
||||
全部搞定!我们也可以使用终端进行网络文件共享,但这样没有本文介绍的方法这么容易。如果你确实想知道命令行操作,我会再写一篇关于在Linux上使用命令行实现网络文件共享的文章。
|
||||
|
||||
所以,你是怎么找到这篇教程的呢?我希望看了这篇教程你可以**很容易地在Ubuntu和Windows之间共享文件**。如果你有任何问题或建议,请再评论里说出来。
|
||||
所以,你是怎么找到这篇教程的呢?我希望看了这篇教程你可以**很容易地在Ubuntu和Windows之间共享文件**。如果你有任何问题或建议,请在评论里说出来。
|
||||
|
||||
这篇教程是在Kalc的请求下写出的。如果你也想,你可以[请求你自己的教程][2]。我们很乐意帮助你和面临同样问题的读者解决问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -167,7 +166,7 @@ via: http://itsfoss.com/share-folders-local-network-ubuntu-windows/
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
如何设置lftp - 一个简易的命令行FTP程序
|
||||
LFTP : 一个功能强大的命令行FTP程序
|
||||
================================================================================
|
||||
大家好,这篇文章是介绍Lftp以及如何在Linux操作系统下安装的。[Lftp][1]是一个基于命令行的文件传输软件也被称为FTP客户端,由Alexander Lukyanov开发并以GNU GPL协议许可发行。除了FTP,它还支持FTPS,HTTP,HTTPS,HFTP,FISH,以及SFTP。这个程序还支持FXP,允许数据绕过客户端直接在两个FTP服务器之间传输。
|
||||
大家好,这篇文章是介绍Lftp以及如何在Linux操作系统下安装的。[Lftp][1]是一个基于命令行的文件传输软件(也被称为FTP客户端),由Alexander Lukyanov开发并以GNU GPL协议许可发行。除了FTP协议外,它还支持FTPS,HTTP,HTTPS,HFTP,FISH,以及SFTP等协议。这个程序还支持FXP,允许数据绕过客户端直接在两个FTP服务器之间传输。
|
||||
|
||||
他有很多很棒的高级功能,比如完整目录树递归镜像以及断点续传下载。传输任务可以安排在稍后的时间段执行,可以限制带宽,可以创建传输列表,还支持类似Unix shell的任务控制。客户端还可以在交互式或自动脚本里使用。
|
||||
它有很多很棒的高级功能,比如递归镜像整个目录树以及断点续传下载。传输任务可以安排在稍后的时间段计划执行,可以限制带宽,可以创建传输列表,还支持类似Unix shell的任务控制。客户端还可以在交互式或自动脚本里使用。
|
||||
|
||||
### 安装Lftp ###
|
||||
|
||||
@ -44,7 +44,7 @@ OpenSuse系统里的包管理软件Zypper可以用来安装lftp。下面是在Op
|
||||
|
||||
要登录到ftp服务器或sftp服务器,我们首先需要知道所要求的认证信息,比如用户名,密码,端口。
|
||||
|
||||
之后,我们想通过lftp来登录。
|
||||
之后,我们可以通过lftp来登录。
|
||||
|
||||
$ lftp ftp://linoxide@localhost
|
||||
|
||||
@ -56,9 +56,9 @@ OpenSuse系统里的包管理软件Zypper可以用来安装lftp。下面是在Op
|
||||
|
||||

|
||||
|
||||
### 浏览 ###
|
||||
### 导航 ###
|
||||
|
||||
我们可以用**ls**命令来列出文件和目录,用**cd**命令打开目录。
|
||||
我们可以用**ls**命令来列出文件和目录,用**cd**命令进入到目录。
|
||||
|
||||

|
||||
|
||||
@ -158,7 +158,7 @@ OpenSuse系统里的包管理软件Zypper可以用来安装lftp。下面是在Op
|
||||
|
||||
### 总结 ###
|
||||
|
||||
哇!我们已经成功地安装了lftp并学会了使用它的一些基础的主要方式。lftp是一个非常棒的命令行ftp客户端,它支持许多额外的功能以及很酷的特性。它比其他普通ftp客户端多了很多东西。好吧,你要是有任何问题,建议,反馈,请在下面的评论区里留言。谢谢!享用lftp吧 :-)
|
||||
哇!我们已经成功地安装了lftp并学会了它的一些基础的主要使用方式。lftp是一个非常棒的命令行ftp客户端,它支持许多额外的功能以及很酷的特性。它比其他普通ftp客户端多了很多东西。好吧,你要是有任何问题,建议,反馈,请在下面的评论区里留言。谢谢!享用lftp吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -166,7 +166,7 @@ via: http://linoxide.com/linux-how-to/setup-lftp-command-line-ftp/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
Windows 下的免费 SSH 客户端工具
|
||||
================================================================================
|
||||
|
||||
如果你的操作系统是 Windows,而你想要连接 Linux 服务器相互传送文件,那么你需要一个简称 SSH 的 Secure Shell 软件。实际上,SSH 是一个网络协议,它允许你通过网络连接到 Linux 和 Unix 服务器。SSH 使用公钥加密来认证远程的计算机。你可以有多种途径使用 SSH,无论是自动连接,还是使用密码认证登录。
|
||||
|
||||
本篇文章介绍了几种可以连接 Linux 服务器 SSH 客户端。
|
||||
|
||||
让我们开始。
|
||||
|
||||
### Putty ###
|
||||
|
||||
**Putty** 是最有名的 SSH 和 telnet 客户端,最初由 Simon Tatham 为 Windows 平台开发。Putty 是一款开源软件,有可用的源代码,和一群志愿者的开发和支持。
|
||||
|
||||

|
||||
|
||||
Putty 非常易于安装和使用,通常大部分的配置选项你都不需要修改。你只需要输入少量基本的参数,就可以开始很简单地建立连接会话。[点此下载][1] Putty。
|
||||
|
||||
### Bitvise SSH Client ###
|
||||
|
||||
**Bitvise SSH** 是一款支持 SSH 和 SFTP 的 Windows 客户端。由 Bitvise 开发和提供专业支持。这款 SSH 客户端性能强悍,易于安装、便于使用。Bitvise SSH 客户端拥有功能丰富的图形界面,通过一个有自动重连功能的内置代理进行动态端口转发。
|
||||
|
||||
|
||||
|
||||
Bitvise SSH 客户端对**个人用户使用是免费的**,同时对于在组织内部的个人商业使用也一样。你可以[在这里下载 Bitvise SSH 客户端][2]。
|
||||
|
||||
### MobaXterm ###
|
||||
|
||||
**MobaXterm** 是你的**远程计算的终极工具箱**。在一个 Windows 应用里,它为程序员、网管、IT 管理员及其它用户提供了精心裁剪的一揽子功能,让他们的远程操作变得简约时尚。
|
||||
|
||||
|
||||
|
||||
MobaXterm 提供了所有重要的**远程网络工具** (如SSH、 X11、 RDP、 VNC、 FTP、 MOSH 等等),以及 Windows 桌面上的 **Unix 命令**(bash、 ls、 cat、sed、 grep、 awk、 rsync等等),而这些都是由一个开箱即用的**单一的便携程序**所提供。MobaXterm 对**个人使用免费**,你可以[在这里][3]下载 MobaXterm。
|
||||
|
||||
### DameWare SSH ###
|
||||
|
||||
我认为 **DameWare SSH** 是最好的免费SSH客户端。
|
||||
|
||||
|
||||
|
||||
这个免费工具是一个终端模拟器,可以让你从一个易用的控制台建立多个 telnet 和 SSH 连接。
|
||||
|
||||
-用一个带标签的控制台界面管理多个会话
|
||||
-将常用的会话保存在 Windows 文件系统中
|
||||
-使用多套保存的证书来轻松登录不同的设备
|
||||
-使用 telnet、SSH1 和 SSH2 协议连接计算机和设备
|
||||
|
||||
你可以从[这个链接][4]下载 **DameWare SSH**。
|
||||
|
||||
### SmarTTY ###
|
||||
|
||||
SmarTTY 是一款免费的多标签 SSH 客户端,支持使用 SCP 命令随时复制文件和目录。
|
||||
|
||||

|
||||
|
||||
大多数 SSH 服务器每个连接支持最多10个子会话.SmarTTY 在这方面做得很好:没有烦人的多个窗口,不需要重新登录,仅仅打开一个新的标签页就可以开始了!
|
||||
|
||||
### Cygwin ###
|
||||
|
||||
Cygwin 是一款 GNU 和开源工具的大杂烩,提供的功能近似于一个 Windows 平台下的 Linux。
|
||||
|
||||

|
||||
|
||||
**Cygwin** 包括了一个称为模拟库的 Unix 系统:cygwin.dll,集成了大量的 GNU 和其它的免费软件,以大量的可选包方式组织而成。在这些安装包中,有高质量的编译器和其他软件开发工具、一个X11服务器、一套完整的X11开发套件、GNU emacs 编辑器、Tex 和 LaTeX、openSSH(客户端和服务器),除此之外还有很多,包括在微软 Windows 下需要编译和使用 PhysioToolkit 软件的每一样东西。
|
||||
|
||||
读完我们的文章后,不知你中意哪一款 SSH 客户端?你可以留下你的评论,描述你喜欢的系统和选择的原因。当然,如果有另外的 SSH 客户端没有被本文列举出来,你可以帮助我们补充。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/list-free-windows-ssh-client-tools-connect-linux-server/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[wi-cuckoo](http://github.com/wi-cuckoo)
|
||||
校对:[wxy](http://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](http://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/anis/
|
||||
[1]:http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||
[2]:http://www.bitvise.com/download-area
|
||||
[3]:http://mobaxterm.mobatek.net/download.html
|
||||
[4]:http://www.dameware.com/downloads/registration.aspx?productType=ssh&AppID=17471&CampaignID=70150000000PcNM
|
||||
[5]:http://cygwin.com/packages/
|
||||
@ -1,5 +1,6 @@
|
||||
[已解决] Ubuntu 14.04从待机中唤醒后鼠标键盘出现僵死情况 [快速小贴士]
|
||||
================================================================================
|
||||
修复 Ubuntu 14.04 从待机中唤醒后鼠标键盘出现僵死情况
|
||||
=========
|
||||
|
||||
### 问题: ###
|
||||
|
||||
当Ubuntu14.04或14.10从睡眠和待机状态恢复时,鼠标和键盘出现僵死,不能点击也不能输入。解决这种情况是唯一方法就是按关机键强关系统,这不仅非常不便且令人恼火。因为在Ubuntu的默认情况中合上笔记本等同于切换到睡眠模式。
|
||||
@ -12,15 +13,15 @@
|
||||
|
||||
sudo apt-get install --reinstall xserver-xorg-input-all
|
||||
|
||||
这则贴士源自一个自由开源读者Dev的提问。快试试这篇贴士,看看是否对你也有效。在一个类似的问题中,你可以[修复Ubuntu登录后无Unity界面、侧边栏和Dash的问题][1]
|
||||
这则贴士源自一个我们的读者Dev的提问。快试试这篇贴士,看看是否对你也有效。在一个类似的问题中,你可以[修复Ubuntu登录后无Unity界面、侧边栏和Dash的问题][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/keyboard-mouse-freeze-suspend/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,132 @@
|
||||
5个有趣的Linux命令行技巧
|
||||
================================================================================
|
||||
你有将Linux物尽其用吗?对很多Linux用户来说,有很多看起来是技巧的有用特性。有些时候你会需要这些技巧。本文会帮助你更好得使用一些命令,发挥其更强大的功能。
|
||||
|
||||

|
||||
|
||||
*图1:5个命令行技巧*
|
||||
|
||||
我们开始一个新的系列,在这里我们还会写一些技巧,并且用尽量小的篇幅写清楚。
|
||||
|
||||
### 1. 我们可以使用[`history`命令][1]来查看曾经运行过的命令。 ###
|
||||
|
||||
这里是一个`history`命令的示例输出。
|
||||
|
||||
# history
|
||||
|
||||
|
||||
|
||||
*图2:history命令例子*
|
||||
|
||||
从`history`命令输出看,很明显,命令的执行时间没有被打出来。有解决方法吗?有的!运行如下命令:
|
||||
|
||||
# HISTTIMEFORMAT="%d/%m/%y %T "
|
||||
# history
|
||||
|
||||
如果你想让这个修改永久生效,添加如下的一行内容到`~/.bashrc`文件中:
|
||||
|
||||
export HISTTIMEFORMAT="%d/%m/%y %T "
|
||||
|
||||
然后,在终端中运行:
|
||||
|
||||
# source ~/.bashrc
|
||||
|
||||
命令和选项的解释:
|
||||
|
||||
- history – 查看运行过的命令
|
||||
- HISTIMEFORMAT – 设置时间格式的环境变量
|
||||
- %d – 天
|
||||
- %m – 月
|
||||
- %y – 年
|
||||
- %T – 时间戳
|
||||
- source – 简而言之就是将文件内容发送给shell来执行
|
||||
- .bashrc – BASH以交互方式启动时运行的脚本文件
|
||||
|
||||
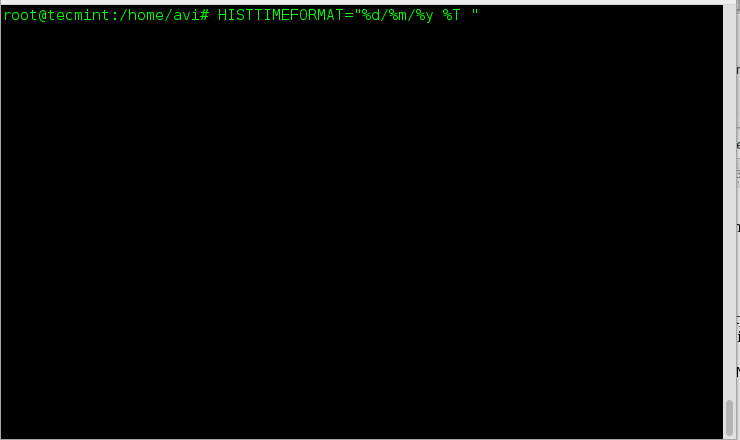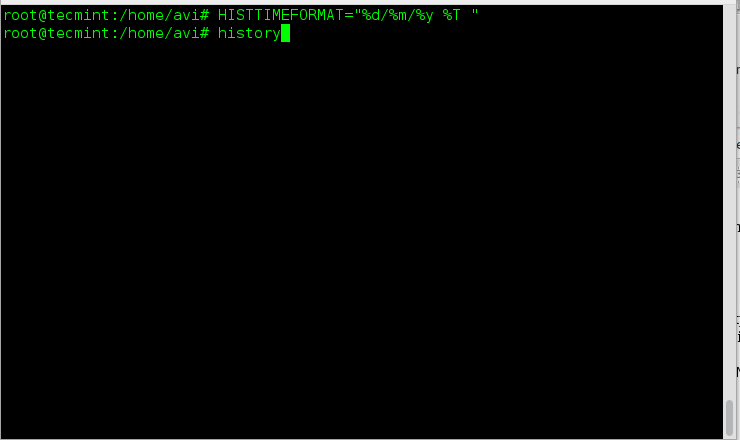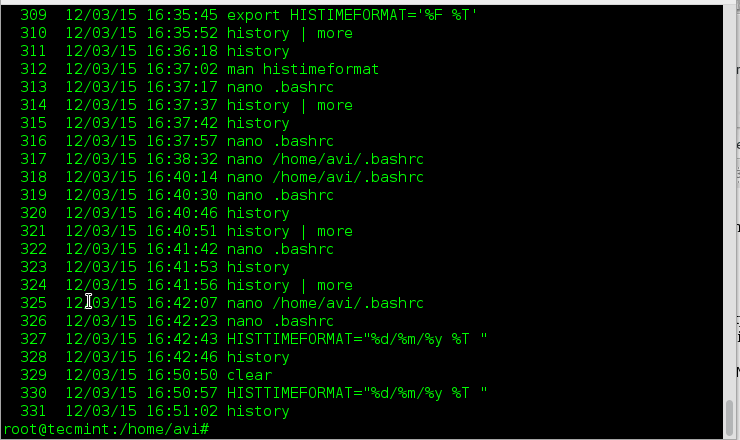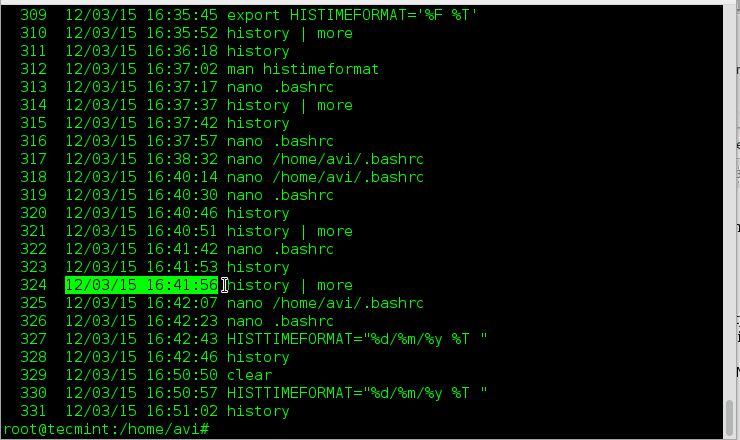
|
||||
|
||||
*图3:`history`命令输出的日志*
|
||||
|
||||
### 2. 如何测试磁盘写入速度?###
|
||||
|
||||
一行`dd`命令脚本就可以实现。
|
||||
|
||||
# dd if=/dev/zero of=/tmp/output.img bs=8k count=256k conv=fdatasync; rm -rf /tmp/output.img
|
||||
|
||||
|
||||
|
||||
*图4:`dd`命令例子*
|
||||
|
||||
命令和选项的解释:
|
||||
|
||||
- dd – 转换和复制文件
|
||||
- if=/dev/zero – 指定输入文件,默认为stdin(标准输入)
|
||||
- of=/tmp/output.img – 指定输出文件,默认为stdout(标准输出)
|
||||
- bs – 一次读和写的块大小,最大可以以MB为单位
|
||||
- count – 复制次数
|
||||
- conv – 使用逗号分隔的策略来转换文件(LCTT 译注:比如将大写字母转换成小写,echo AA | dd conv=lcase)
|
||||
- rm – 删除文件和目录
|
||||
- -rf – (-r) 递归地删除目录和其中的内容,(-f)强行删除而不输出确认信息
|
||||
|
||||
### 3. 你如何获取吃掉你磁盘空间的最大的6个文件?###
|
||||
|
||||
一个使用[`du`命令][2]的简单单行脚本即可实现,`du`命令主要用于获取文件的空间使用情况。
|
||||
|
||||
# du -hsx * | sort -rh | head -6
|
||||
|
||||

|
||||
|
||||
*图5:获取磁盘空间使用情况的方法*
|
||||
|
||||
命令和选项的解释:
|
||||
|
||||
- du – 估计文件的空间使用情况
|
||||
- -hsx – (-h)更易读的格式,(-s)汇总输出,(-x)跳过其他文件系统的文件
|
||||
- sort – 对文本文件按行排序
|
||||
- -rf – (-r)将比较的结果逆序输出,(-f)忽略大小写
|
||||
- head – 输出文件的头几行
|
||||
|
||||
### 4. 获取一个文件的详细状态信息###
|
||||
|
||||
可以使用`stat`命令
|
||||
|
||||
# stat filename_ext (例如:stat abc.pdf)
|
||||
|
||||

|
||||
|
||||
*图6:获取文件的详细信息*
|
||||
|
||||
### 5. 显示帮助 ###
|
||||
|
||||
最后一个技巧是为那些入门者准备的,如果你是有经验的用户,可能不需要它,除非你想从中寻找乐趣。入门者可能有Linux命令行恐惧症,下面的命令会随机显示一个man手册页。对入门者来说,好处是总会学到新的东西,而且不会厌倦。
|
||||
|
||||
# man $(ls /bin | shuf | head -1)
|
||||
|
||||
|
||||
|
||||
*图7:查看随机的man手册页*
|
||||
|
||||
命令和选项的解释:
|
||||
|
||||
- man – Linux man手册
|
||||
- ls – 列出文件
|
||||
- /bin – 系统可执行文件的路径
|
||||
- shuf – 把输入内容按行随机打乱并输出
|
||||
- head – 输出文件的头几行
|
||||
|
||||
这就是所有的内容了。如果你知道任何类似的技巧,可以分享给我们,我们会用你的语言在网站上发表出来。
|
||||
|
||||
不要忘记在下边评论框中留下有价值的反馈。保持联系。可以点赞或者将本文分享来帮助我们更好地传播内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://linux.cn/article-1143-1.html
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
@ -1,12 +1,13 @@
|
||||
如何在 Linux 中使用 Alpine 在命令行里获取 Gmail
|
||||
如何在 Linux 中使用 Alpine 在命令行里访问 Gmail
|
||||
================================================================================
|
||||
假如你是一个命令行爱好者,我很确信你将张开双臂欢迎任何可以使你使用这个强大的工作环境来执行哪怕一项日常任务的工具,例如从 [安排日程][1] 、 [管理财务][2] 到 获取 [Facebook][3] 、[Twitter][4]等任务。
|
||||
|
||||
在这个帖子中,我将为你展示 Linux 命令行的另一个漂亮干练的使用案例:**获取 Google 的 Gmail 服务**,为此,我们将使用 Alpine,一个基于 ncurses 的多功能命令行邮件客户端(不要和 Alpine Linux 搞混淆)。我们将在 Alphine 中配置 Gmail 的 IMAP 和 SMTP 设定来通过 Google 的邮件服务器在终端环境中收取和发送邮件。在这个教程的最后,你将意识到只需几步就可以在 Alpine 中使用其他的邮件服务。
|
||||
假如你是一个命令行爱好者,我很确信你会使用这个强大的工作环境来执行哪怕是一项日常任务的工具,并为之欢呼,例如从 [安排日程][1] 、 [管理财务][2] 到 获取 [Facebook][3] 、[Twitter][4]等任务。(LCTT 译注:阅读本文的另一个前提是,假如你还能访问 Gmail 或者知道 Gmail 是什么的话。)
|
||||
|
||||
诚然,已有许多卓越的基于 GUI 的邮件客户端存在,例如 Thunderbird, Evolution 或者甚至是 Web 界面,那么为什么还有人对使用命令行的邮件客户端来收取 Gmail 这样的事感兴趣呢?答案很简单。假如你需要快速地处理好事情并想避免使用不必要系统资源;或者你正工作在一个最小化安装(注:这里我感觉自己翻译有误)的服务器上,而它没有安装 X 服务(注:这里也需要更改);又或者是 X 服务在你的桌面上崩溃了,而你需要在解决这个问题之前急切地发送一些邮件。在上述所有的情况下, Alpine 都可以派上用场并在任何时间满足你的需求。
|
||||
在这个帖子中,我将为你展示 Linux 命令行的另一个漂亮干练的使用案例:**访问 Google 的 Gmail 服务**,为此,我们将使用 Alpine,一个基于 ncurses 的多功能命令行邮件客户端(不要和 Alpine Linux 搞混淆)。我们将在 Alphine 中配置 Gmail 的 IMAP 和 SMTP 设定,通过 Google 的邮件服务器在终端环境中收取和发送邮件。在这个教程的最后,你将发现只需几步就可以在 Alpine 中使用其他的邮件服务。
|
||||
|
||||
除了简单的编辑,发送和接收文本类的邮件信息等功能外, Alpine 还可以进行加密,解密和对邮件信息进行数字签名,以及与 TLS(注:Transport Layer Security) 无缝集成。
|
||||
诚然,已有许多卓越的基于 GUI 的邮件客户端存在,例如 Thunderbird, Evolution 或者甚至是 Web 界面,那么为什么还有人对使用命令行的邮件客户端来收取 Gmail 这样的事感兴趣呢?答案很简单。假如你需要快速地处理好事情并想避免浪费不必要系统资源;或者你正工作在一个精简安装无操作台的服务器上,它没有安装用于图形显示的 X 服务;又或者是 X 服务在你的桌面上崩溃了,而你需要在解决这个问题之前急切地发送一些邮件。在上述所有的情况下, Alpine 都可以派上用场并在任何时间满足你的需求。
|
||||
|
||||
除了简单的编辑,发送和接收文本类的邮件信息等功能外, Alpine 还可以进行加密,解密和对邮件信息进行数字签名,以及与 TLS(注:Transport Layer Security,传输层加密)无缝集成。
|
||||
|
||||
### 在 Linux 上安装 Alpine ###
|
||||
|
||||
@ -22,16 +23,13 @@
|
||||
|
||||
# alpine
|
||||
|
||||
在你第一次启用 Alpine 时,它将在当前用户的家目录下创建一个邮件文件夹(`~/mail`),并显现出主界面,正如下面的截屏所显示的那样:
|
||||
|
||||
注:youtube视频,发布的时候做个链接吧(注:这里我不知道该如何操作,不过我已经下载了该视频,如有需要,可以发送)
|
||||
<iframe width="615" height="346" frameborder="0" allowfullscreen="" src="http://www.youtube.com/embed/kuKiv3uze4U?feature=oembed"></iframe>
|
||||
在你第一次启用 Alpine 时,它将在当前用户的家目录下创建一个邮件文件夹(`~/mail`),并显现出主界面,正如下面的视频所显示的那样:YOUTUBU 视频 - http://www.youtube.com/kuKiv3uze4U 。
|
||||
|
||||
它的用户界面有下列几个模块:
|
||||
|
||||
|
||||
|
||||
请随意地浏览,操作来熟悉 Alpine。你总是可以在任何时候通过敲 'Q' 来回到命令提示符界面。请注意,所有的字符界面下方都有与操作相关的帮助。
|
||||
请随意地浏览、操作来熟悉 Alpine。你总是可以在任何时候通过敲 'Q' 来回到命令提示符界面。请注意,所有的字符界面下方都有与操作相关的帮助。
|
||||
|
||||
在进一步深入之前,我们将为 Alpine 创建一个默认的配置文件。为此,请关闭 Alpine,然后在命令行中执行下面的命令:
|
||||
|
||||
@ -39,9 +37,9 @@
|
||||
|
||||
### 配置 Alpine 来使用 Gmail 账号 ###
|
||||
|
||||
一旦你安装了 Alpine 并至少花费了几分钟的时间来熟悉它的界面和菜单,下面便是实际配置它来使用一个已有的 Gmail 账户的时候了。
|
||||
当你安装了 Alpine 并至少花费了几分钟的时间来熟悉它的界面和菜单,下面便是实际配置它来使用一个已有的 Gmail 账户的时候了。
|
||||
|
||||
在 Alpine 中执行下面的步骤之前,记得要通过你的 Web 邮件界面,在你的 Gmail 设定里启用 IMAP 协议。一旦在你的 Gmail 账户中 IMAP 被启用,执行下面的步骤来在 Alpine 中启用阅读 Gmail 信息的功能。
|
||||
在 Alpine 中执行下面的步骤之前,记得首先要通过你的 Web 邮件界面,在你的 Gmail 设定里启用 IMAP 协议。一旦在你的 Gmail 账户中启用了 IMAP ,执行下面的步骤来在 Alpine 中启用阅读 Gmail 信息的功能。
|
||||
|
||||
首先,启动 Alpine。
|
||||
|
||||
@ -51,12 +49,12 @@
|
||||
|
||||
按 'A' 来新建一个文件夹并填写必要的信息:
|
||||
|
||||
- **昵称**: 填写任何你想写的名字;
|
||||
- **服务器**: imap.gmail.com/ssl/user=yourgmailusername@gmail.com
|
||||
- **Nickname**: 填写任何你想写的名字;
|
||||
- **Server**: imap.gmail.com/ssl/user=yourgmailusername@gmail.com
|
||||
|
||||
你可以将 `Path` 和 `View` 留白不填。
|
||||
|
||||
然后按 `Ctrl+X` 并在有提示时输入你的 Gmail 密码:
|
||||
然后按 `Ctrl+X` 并在提示时输入你的 Gmail 密码:
|
||||
|
||||
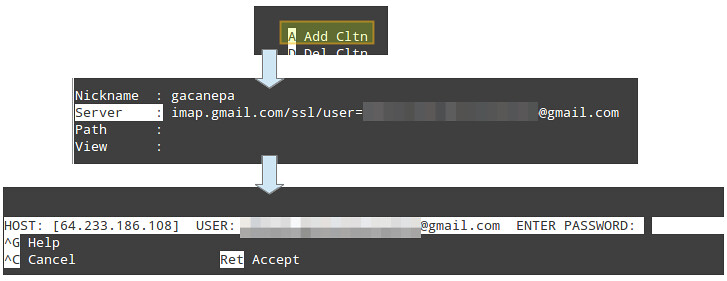
|
||||
|
||||
@ -64,7 +62,7 @@
|
||||
|
||||
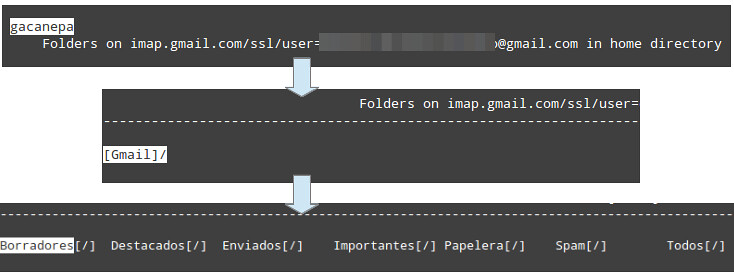
|
||||
|
||||
为了验证,你可以比较在 Alpine 中显示的 "Gmail Sent" 信箱和在 Web 界面下的信箱:
|
||||
要验证的话,你可以比较在 Alpine 中显示的 "Gmail Sent" 信箱和在 Web 界面下的信箱:
|
||||
|
||||
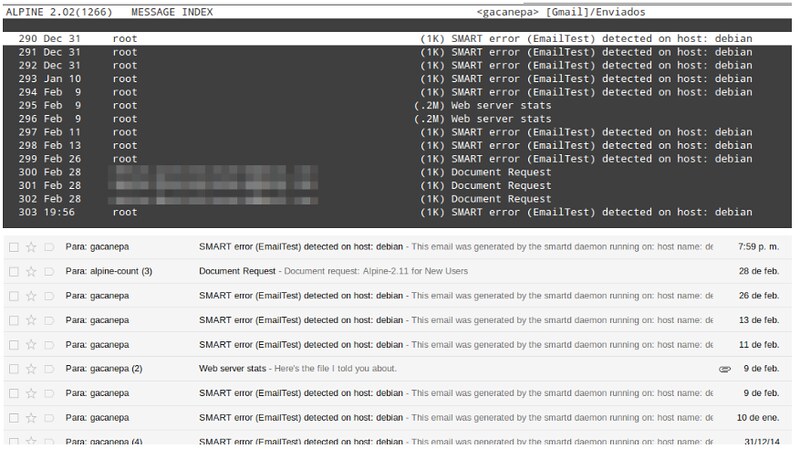
|
||||
|
||||
@ -73,7 +71,7 @@
|
||||
# The approximate number of seconds between checks for new mail
|
||||
mail-check-interval=10
|
||||
|
||||
最后,我们需要配置一个 SMTP 服务器来通过 Alpine 发送邮件信息。回到先前解释过的 Alpine 的设置界面,然后按 'C' 来设定一个 Google 的 SMTP 服务器地址,你需要像下面这样编辑 `SMTP Server`(为了发送) 这一行内容:
|
||||
最后,我们需要配置一个 SMTP 服务器来通过 Alpine 发送邮件。回到先前解释过的 Alpine 的设置界面,然后按 'C' 来设定一个 Google 的 SMTP 服务器地址,你需要像下面这样编辑 `SMTP Server`(用于发送邮件)这一行内容:
|
||||
|
||||
smtp.gmail.com:587/tls/user=yourgmailusername@gmail.com
|
||||
|
||||
@ -81,7 +79,7 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这个帖子里,我们讨论了在终端环境中如何通过一个名为 Alpha 的轻量且强大的命令行邮件客户端来获取 Gmail。 Alpine 是一个发布在 Apache Software License 2.0 协议下的自由软件,该协议与 GPL 协议相兼容。 Alpine 引以自豪的是:它不仅对新手友好,同时还做到了让那些经验丰富的系统管理员认为它是强大的。我希望在你阅读完这篇文章后,你能意识到我最后一个论断是多么的正确。
|
||||
在这个帖子里,我们讨论了在终端环境中如何通过一个名为 Alpine 的轻量且强大的命令行邮件客户端来访问 Gmail。 Alpine 是一个发布在 Apache Software License 2.0 协议下的自由软件,该协议与 GPL 协议相兼容。 Alpine 引以自豪的是:它不仅对新手友好,同时还做到了让那些经验丰富的系统管理员认为它是强大的。我希望在你阅读完这篇文章后,你能意识到我最后一个论断是多么的正确。
|
||||
|
||||
非常欢迎使用下面的输入框来留下你的评论或问题。我期待着你们的反馈!
|
||||
|
||||
@ -91,7 +89,7 @@ via: http://xmodulo.com/gmail-command-line-linux-alpine.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -100,4 +98,4 @@ via: http://xmodulo.com/gmail-command-line-linux-alpine.html
|
||||
[2]:http://xmodulo.com/manage-personal-expenses-command-line.html
|
||||
[3]:http://xmodulo.com/access-facebook-command-line-linux.html
|
||||
[4]:http://xmodulo.com/access-twitter-command-line-linux.html
|
||||
[5]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:https://linux.cn/article-2324-1.html
|
||||
@ -1,12 +1,13 @@
|
||||
走进Linux之systemd启动过程
|
||||
================================================================================
|
||||
Linux系统的启动方式有点复杂,而且总是有需要优化的地方。传统的Linux系统启动过程主要由著名的init进程(也被称为SysV init启动系统)处理,而基于init的启动系统也被确认会有效率不足的问题,systemd是Linux系统机器的另一种启动方式,宣称弥补了以[传统Linux SysV init][2]为基础的系统的缺点。在这里我们将着重讨论systemd的特性和争议,但是为了更好地理解它,也会看一下通过传统的以SysV init为基础的系统的Linux启动过程是什么样的。友情提醒一下systemd仍然处在测试阶段,而未来发布的Linux操作系统也正准备用systemd启动管理程序替代当前的启动过程。
|
||||
|
||||
Linux系统的启动方式有点复杂,而且总是有需要优化的地方。传统的Linux系统启动过程主要由著名的init进程(也被称为SysV init启动系统)处理,而基于init的启动系统被认为有效率不足的问题,systemd是Linux系统机器的另一种启动方式,宣称弥补了以[传统Linux SysV init][2]为基础的系统的缺点。在这里我们将着重讨论systemd的特性和争议,但是为了更好地理解它,也会看一下通过传统的以SysV init为基础的系统的Linux启动过程是什么样的。友情提醒一下,systemd仍然处在测试阶段,而未来发布的Linux操作系统也正准备用systemd启动管理程序替代当前的启动过程(LCTT 译注:截止到本文发表,主流的Linux发行版已经有很多采用了 systemd)。
|
||||
|
||||
### 理解Linux启动过程 ###
|
||||
|
||||
在我们打开Linux电脑的电源后第一个启动的进程就是init。分配给init进程的PID是1。它是系统其他所有进程的父进程。当一台Linux电脑启动后,处理器会先在系统存储中查找BIOS,之后BIOS会测试系统资源然后找到第一个引导设备,通常设置为硬盘,然后会查找硬盘的主引导记录(MBR),然后加载到内存中并把控制权交给它,以后的启动过程就由MBR控制。
|
||||
在我们打开Linux电脑的电源后第一个启动的进程就是init。分配给init进程的PID是1。它是系统其他所有进程的父进程。当一台Linux电脑启动后,处理器会先在系统存储中查找BIOS,之后BIOS会检测系统资源然后找到第一个引导设备,通常为硬盘,然后会查找硬盘的主引导记录(MBR),然后加载到内存中并把控制权交给它,以后的启动过程就由MBR控制。
|
||||
|
||||
主引导记录会初始化引导程序(Linux上有两个著名的引导程序,GRUB和LILO,80%的Linux系统在用GRUB引导程序),这个时候GRUB或LILO会加载内核模块。内核会马上查找/sbin下的init进程并执行它。从这里开始init成为了Linux系统的父进程。init读取的第一个文件是/etc/inittab,通过它init会确定我们Linux操作系统的运行级别。它会从文件/etc/fstab里查找分区表信息然后做相应的挂载。然后init会启动/etc/init.d里指定的默认启动级别的所有服务/脚本。所有服务在这里通过init一个一个被初始化。在这个过程里,init每次只启动一个服务,所有服务/守护进程都在后台执行并由init来管理。
|
||||
主引导记录会初始化引导程序(Linux上有两个著名的引导程序,GRUB和LILO,80%的Linux系统在用GRUB引导程序),这个时候GRUB或LILO会加载内核模块。内核会马上查找/sbin下的“init”程序并执行它。从这里开始init成为了Linux系统的父进程。init读取的第一个文件是/etc/inittab,通过它init会确定我们Linux操作系统的运行级别。它会从文件/etc/fstab里查找分区表信息然后做相应的挂载。然后init会启动/etc/init.d里指定的默认启动级别的所有服务/脚本。所有服务在这里通过init一个一个被初始化。在这个过程里,init每次只启动一个服务,所有服务/守护进程都在后台执行并由init来管理。
|
||||
|
||||
关机过程差不多是相反的过程,首先init停止所有服务,最后阶段会卸载文件系统。
|
||||
|
||||
@ -14,9 +15,9 @@ Linux系统的启动方式有点复杂,而且总是有需要优化的地方。
|
||||
|
||||
### 理解Systemd ###
|
||||
|
||||
开发Systemd的主要目的就是减少系统引导时间和计算开销。Systemd(系统管理守护进程),最开始以GNU GPL协议授权开发,现在已转为使用GNU LGPL协议,它是如今讨论最热烈的引导和服务管理程序。如果你的Linux系统配置为使用Systemd引导程序,那么代替传统的SysV init,启动过程将交给systemd处理。Systemd的一个核心功能是它同时支持SysV init的后开机启动脚本。
|
||||
开发Systemd的主要目的就是减少系统引导时间和计算开销。Systemd(系统管理守护进程),最开始以GNU GPL协议授权开发,现在已转为使用GNU LGPL协议,它是如今讨论最热烈的引导和服务管理程序。如果你的Linux系统配置为使用Systemd引导程序,它取替传统的SysV init,启动过程将交给systemd处理。Systemd的一个核心功能是它同时支持SysV init的后开机启动脚本。
|
||||
|
||||
Systemd引入了并行启动的概念,它会为每个需要启动的守护进程建立一个管道套接字,这些套接字对于使用它们的进程来说是抽象的,这样它们可以允许不同守护进程之间进行交互。Systemd会创建新进程并为每个进程分配一个控制组。处于不同控制组的进程之间可以通过内核来互相通信。[systemd处理开机启动进程][2]的方式非常漂亮,和传统基于init的系统比起来优化了太多。让我们看下Systemd的一些核心功能。
|
||||
Systemd引入了并行启动的概念,它会为每个需要启动的守护进程建立一个套接字,这些套接字对于使用它们的进程来说是抽象的,这样它们可以允许不同守护进程之间进行交互。Systemd会创建新进程并为每个进程分配一个控制组(cgroup)。处于不同控制组的进程之间可以通过内核来互相通信。[systemd处理开机启动进程][2]的方式非常漂亮,和传统基于init的系统比起来优化了太多。让我们看下Systemd的一些核心功能。
|
||||
|
||||
- 和init比起来引导过程简化了很多
|
||||
- Systemd支持并发引导过程从而可以更快启动
|
||||
@ -81,7 +82,9 @@ Systemd提供了工具用于识别和定位引导相关的问题或性能影响
|
||||
234ms httpd.service
|
||||
191ms vmms.service
|
||||
|
||||
**systemd-analyze verify** 显示在所有系统单元中是否有语法错误。**systemd-analyze plot** 可以用来把整个引导过程写入一个SVG格式文件里。整个引导过程非常长不方便阅读,所以通过这个命令我们可以把输出写入一个文件,之后再查看和分析。下面这个命令就是做这个。
|
||||
**systemd-analyze verify** 显示在所有系统单元中是否有语法错误。
|
||||
|
||||
**systemd-analyze plot** 可以用来把整个引导过程写入一个SVG格式文件里。整个引导过程非常长不方便阅读,所以通过这个命令我们可以把输出写入一个文件,之后再查看和分析。下面这个命令就是做这个。
|
||||
|
||||
systemd-analyze plot > boot.svg
|
||||
|
||||
@ -89,9 +92,9 @@ Systemd提供了工具用于识别和定位引导相关的问题或性能影响
|
||||
|
||||
Systemd并没有幸运地获得所有人的青睐,一些专家和管理员对于它的工作方式和开发有不同意见。根据对于Systemd的批评,它不是“类Unix”方式因为它试着替换一些系统服务。一些专家也不喜欢使用二进制配置文件的想法。据说编辑systemd配置非常困难而且没有一个可用的图形工具。
|
||||
|
||||
### 在Ubuntu 14.04和12.04上测试Systemd ###
|
||||
### 如何在Ubuntu 14.04和12.04上测试Systemd ###
|
||||
|
||||
本来,Ubuntu决定从Ubuntu 16.04 LTS开始使用Systemd来替换当前的引导过程。Ubuntu 16.04预计在2016年4月发布,但是考虑到Systemd的流行和需求,即将发布的**Ubuntu 15.04**将采用它作为默认引导程序。好消息是Ubuntu 14.04 Trusty Tahr和Ubuntu 12.04 Precise Pangolin的用户可以在他们的机器上测试Systemd。测试过程并不复杂,你所要做的只是把相关的PPA包含到系统中,更新仓库并升级系统。
|
||||
本来,Ubuntu决定从Ubuntu 16.04 LTS开始使用Systemd来替换当前的引导过程。Ubuntu 16.04预计在2016年4月发布,但是考虑到Systemd的流行和需求,刚刚发布的**Ubuntu 15.04**采用它作为默认引导程序。另外,Ubuntu 14.04 Trusty Tahr和Ubuntu 12.04 Precise Pangolin的用户可以在他们的机器上测试Systemd。测试过程并不复杂,你所要做的只是把相关的PPA包含到系统中,更新仓库并升级系统。
|
||||
|
||||
**声明**:请注意它仍然处于Ubuntu的测试和开发阶段。升级测试包可能会带来一些未知错误,最坏的情况下有可能损坏你的系统配置。请确保在尝试升级前已经备份好重要数据。
|
||||
|
||||
@ -127,7 +130,7 @@ Systemd并没有幸运地获得所有人的青睐,一些专家和管理员对
|
||||
|
||||

|
||||
|
||||
就这样,你的Ubuntu系统已经不在使用传统的引导程序了,改为使用Systemd管理器。重启你的机器然后查看systemd引导过程吧。
|
||||
就这样,你的Ubuntu系统已经不再使用传统的引导程序了,改为使用Systemd管理器。重启你的机器然后查看systemd引导过程吧。
|
||||
|
||||

|
||||
|
||||
@ -141,7 +144,7 @@ via: http://linoxide.com/linux-how-to/systemd-boot-process/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
11个Linux终端命令,让你的世界摇滚起来
|
||||
11个让你吃惊的 Linux 终端命令
|
||||
================================================================================
|
||||
我已经用了十年的Linux了,通过今天这篇文章我将向大家展示一系列的,我希望一开始就有人教导而不是曾在我成长道路上绊住我的Linux命令、工具和花招。
|
||||
|
||||

|
||||
Linux的快捷键。
|
||||
我已经用了十年的Linux了,通过今天这篇文章我将向大家展示一系列的命令、工具和技巧,我希望一开始就有人告诉我这些,而不是曾在我成长道路上绊住我。
|
||||
|
||||
### 1. 命令行日常系快捷键 ###
|
||||
|
||||

|
||||
|
||||
*Linux的快捷键。*
|
||||
|
||||
如下的快捷方式非常有用,能够极大的提升你的工作效率:
|
||||
|
||||
- CTRL + U - 剪切光标前的内容
|
||||
@ -16,11 +17,11 @@ Linux的快捷键。
|
||||
- CTRL + A - 移动光标到行首
|
||||
- ALT + F - 跳向下一个空格
|
||||
- ALT + B - 跳回上一个空格
|
||||
- ALT + Backspace - 删除前一个字
|
||||
- CTRL + W - 剪切光标后一个字
|
||||
- ALT + Backspace - 删除前一个单词
|
||||
- CTRL + W - 剪切光标后一个单词
|
||||
- Shift + Insert - 向终端内粘贴文本
|
||||
|
||||
那么为了让上诉内容更易理解来看下面的这行命令。
|
||||
那么为了让上述内容更易理解来看下面的这行命令。
|
||||
|
||||
sudo apt-get intall programname
|
||||
|
||||
@ -28,7 +29,7 @@ Linux的快捷键。
|
||||
|
||||
想象现在光标正在行末,我们有很多的方法将她退回单词install并替换它。
|
||||
|
||||
我可以按两次ALT+B这样光标就会在如下的位置(这里用^代替光标的位置)。
|
||||
我可以按两次ALT+B这样光标就会在如下的位置(这里用^指代光标的位置)。
|
||||
|
||||
sudo apt-get^intall programname
|
||||
|
||||
@ -36,32 +37,36 @@ Linux的快捷键。
|
||||
|
||||
如果你想将浏览器中的文本复制到终端,可以使用快捷键"shift + insert"。
|
||||
|
||||

|
||||
|
||||
### 2. SUDO !! ###
|
||||
|
||||
这个命令如果你还不知道我觉得你应该好好感谢我,因为如果你不知道那每次你在输入长串命令后看到“permission denied”后一定会痛恼不堪。
|
||||

|
||||
|
||||
*sudo !!*
|
||||
|
||||
如果你还不知道这个命令,我觉得你应该好好感谢我,因为如果你不知道的话,那每次你在输入长串命令后看到“permission denied”后一定会痛恼不堪。
|
||||
|
||||
- sudo !!
|
||||
|
||||
如何使用sudo !!?很简单。试想你刚输入了如下命令:
|
||||
如何使用sudo !!?很简单。试想你刚输入了如下命令:
|
||||
|
||||
apt-get install ranger
|
||||
|
||||
一定会出现"Permission denied"除非你的登录了足够高权限的账户。
|
||||
一定会出现“Permission denied”,除非你已经登录了足够高权限的账户。
|
||||
|
||||
sudo !!就会用sudo的形式运行上一条命令。所以上一条命令可以看成是这样:
|
||||
sudo !! 就会用 sudo 的形式运行上一条命令。所以上一条命令就变成了这样:
|
||||
|
||||
sudo apt-get install ranger
|
||||
|
||||
如果你不知道什么是sudo[戳这里][1]。
|
||||
|
||||

|
||||
暂停终端运行的应用程序。
|
||||
如果你不知道什么是sudo,[戳这里][1]。
|
||||
|
||||
### 3. 暂停并在后台运行命令 ###
|
||||
|
||||
我曾经写过一篇如何在终端后台运行命令的指南。
|
||||

|
||||
|
||||
*暂停终端运行的应用程序。*
|
||||
|
||||
我曾经写过一篇[如何在终端后台运行命令的指南][13]。
|
||||
|
||||
- CTRL + Z - 暂停应用程序
|
||||
- fg - 重新将程序唤到前台
|
||||
@ -74,41 +79,42 @@ sudo !!就会用sudo的形式运行上一条命令。所以上一条命令可以
|
||||
|
||||
文件编辑到一半你意识到你需要马上在终端输入些命令,但是nano在前台运行让你不能输入。
|
||||
|
||||
你可能觉得唯一的方法就是保存文件,推出nano,运行命令以后在重新打开nano。
|
||||
你可能觉得唯一的方法就是保存文件,退出 nano,运行命令以后在重新打开nano。
|
||||
|
||||
其实你只要按CTRL + Z前台的命令就会暂停,画面就切回到命令行了。然后你就能运行你想要运行命令,等命令运行完后在终端窗口输入“fg”就可以回到先前暂停的任务。
|
||||
其实你只要按CTRL + Z,前台的命令就会暂停,画面就切回到命令行了。然后你就能运行你想要运行命令,等命令运行完后在终端窗口输入“fg”就可以回到先前暂停的任务。
|
||||
|
||||
有一个尝试非常有趣就是用nano打开文件,输入一些东西然后暂停会话。再用nano打开另一个文件,输入一些什么后再暂停会话。如果你输入“fg”你将回到第二个用nano打开的文件。只有退出nano再输入“fg”,你才会回到第一个用nano打开的文件。
|
||||
|
||||

|
||||
nohup.
|
||||
|
||||
### 4. 使用nohup在登出SSH会话后仍运行命令 ###
|
||||
|
||||
如果你用ssh登录别的机器时,[nohup命令]真的非常有用。
|
||||

|
||||
|
||||
*nohup*
|
||||
|
||||
如果你用ssh登录别的机器时,[nohup命令][2]真的非常有用。
|
||||
|
||||
那么怎么使用nohup呢?
|
||||
|
||||
想象一下你使用ssh远程登录到另一台电脑上,你运行了一条非常耗时的命令然后退出了ssh会话,不过命令仍在执行。而nohup可以将这一场景变成现实。
|
||||
|
||||
举个例子以测试为目的我用[树莓派][3]来下载发行版。
|
||||
举个例子,因为测试的需要,我用我的[树莓派][3]来下载发行版。我绝对不会给我的树莓派外接显示器、键盘或鼠标。
|
||||
|
||||
我绝对不会给我的树莓派外接显示器、键盘或鼠标。
|
||||
|
||||
一般我总是用[SSH] [4]从笔记本电脑连接到树莓派。如果我在不用nohup的情况下使用树莓派下载大型文件,那我就必须等待到下载完成后才能登出ssh会话关掉笔记本。如果是这样那我为什么要使用树莓派下文件呢?
|
||||
一般我总是用[SSH][4]从笔记本电脑连接到树莓派。如果我在不用nohup的情况下使用树莓派下载大型文件,那我就必须等待到下载完成后,才能登出ssh会话关掉笔记本。可如果是这样,那我为什么要使用树莓派下文件呢?
|
||||
|
||||
使用nohup的方法也很简单,只需如下例中在nohup后输入要执行的命令即可:
|
||||
|
||||
nohup wget http://mirror.is.co.za/mirrors/linuxmint.com/iso//stable/17.1/linuxmint-17.1-cinnamon-64bit.iso &
|
||||
|
||||

|
||||
At管理任务日程
|
||||
|
||||
### 5. ‘在’特定的时间运行Linux命令 ###
|
||||
|
||||

|
||||
|
||||
*At管理任务日程*
|
||||
|
||||
‘nohup’命令在你用SSH连接到服务器,并在上面保持执行SSH登出前任务的时候十分有用。
|
||||
|
||||
想一下如果你需要在特定的时间执行同一个命令,这种情况该怎么办呢?
|
||||
想一下如果你需要在特定的时间执行相同的命令,这种情况该怎么办呢?
|
||||
|
||||
命令‘at’就能妥善解决这一情况。以下是‘at’使用示例。
|
||||
|
||||
@ -116,78 +122,80 @@ At管理任务日程
|
||||
at> cowsay 'hello'
|
||||
at> CTRL + D
|
||||
|
||||
上面的命令能在周五下午10时38分运行程序[cowsay] [5]。
|
||||
上面的命令能在周五下午10时38分运行程序[cowsay][5]。
|
||||
|
||||
使用的语法就是‘at’后追加日期时间。
|
||||
使用的语法就是‘at’后追加日期时间。当at>提示符出现后就可以输入你想在那个时间运行的命令了。
|
||||
|
||||
当at>提示符出现后就可以输入你想在那个时间运行的命令了。
|
||||
CTRL + D 返回终端。
|
||||
|
||||
CTRL + D返回终端。
|
||||
还有许多日期和时间的格式,都需要你好好翻一翻‘at’的man手册来找到更多的使用方式。
|
||||
|
||||
还有许多日期和时间的格式都是值得的你好好翻一翻‘at’的man手册来找到更多的使用方式。
|
||||
|
||||

|
||||
|
||||
### 6. Man手册 ###
|
||||
|
||||
Man手册会为你列出命令和参数的使用大纲,教你如何使用她们。
|
||||

|
||||
|
||||
Man手册看起开沉闷呆板。(我思忖她们也不是被设计来娱乐我们的)。
|
||||
*彩色man 手册*
|
||||
|
||||
不过这不代表你不能做些什么来使她们变得性感点。
|
||||
Man手册会为你列出命令和参数的使用大纲,教你如何使用她们。Man手册看起来沉闷呆板。(我思忖她们也不是被设计来娱乐我们的)。
|
||||
|
||||
不过这不代表你不能做些什么来使她们变得漂亮些。
|
||||
|
||||
export PAGER=most
|
||||
|
||||
你需要 ‘most’;她会使你的你的man手册的色彩更加绚丽。
|
||||
你需要安装 ‘most’;她会使你的你的man手册的色彩更加绚丽。
|
||||
|
||||
你可以用一下命令给man手册设定指定的行长:
|
||||
你可以用以下命令给man手册设定指定的行长:
|
||||
|
||||
export MANWIDTH=80
|
||||
|
||||
最后,如果你有浏览器,你可以使用-H在默认浏览器中打开任意的man页。
|
||||
最后,如果你有一个可用的浏览器,你可以使用-H在默认浏览器中打开任意的man页。
|
||||
|
||||
man -H <command>
|
||||
|
||||
注意啦,以上的命令只有在你将默认的浏览器已经设置到环境变量$BROWSER中了之后才效果哟。
|
||||
注意啦,以上的命令只有在你将默认的浏览器设置到环境变量$BROWSER中了之后才效果哟。
|
||||
|
||||

|
||||
使用htop查看进程。
|
||||
|
||||
### 7. 使用htop查看和管理进程 ###
|
||||
|
||||
你用哪个命令找出电脑上正在运行的进程的呢?我敢打赌是‘[ps][6]’并在其后加不同的参数来得到你所想要的不同输出。
|
||||

|
||||
|
||||
*使用htop查看进程。*
|
||||
|
||||
你用哪个命令找出电脑上正在运行的进程的呢?我敢打赌是‘[ps][6]’并在其后加不同的参数来得到你所想要的不同输出。
|
||||
|
||||
安装‘[htop][7]’吧!绝对让你相见恨晚。
|
||||
|
||||
htop在终端中将进程以列表的方式呈现,有点类似于Windows中的任务管理器。
|
||||
|
||||
你可以使用功能键的组合来切换排列的方式和展示出来的项。你也可以在htop中直接杀死进程。
|
||||
htop在终端中将进程以列表的方式呈现,有点类似于Windows中的任务管理器。你可以使用功能键的组合来切换排列的方式和展示出来的项。你也可以在htop中直接杀死进程。
|
||||
|
||||
在终端中简单的输入htop即可运行。
|
||||
|
||||
htop
|
||||
|
||||

|
||||
命令行文件管理 - Ranger.
|
||||
|
||||
### 8. 使用ranger浏览文件系统 ###
|
||||
|
||||
如果说htop是命令行进程控制的好帮手那么[ranger][8]就是命令行浏览文件系统的好帮手。
|
||||

|
||||
|
||||
*命令行文件管理 - Ranger*
|
||||
|
||||
如果说htop是命令行进程控制的好帮手,那么[ranger][8]就是命令行浏览文件系统的好帮手。
|
||||
|
||||
你在用之前可能需要先安装,不过一旦安装了以后就可以在命令行输入以下命令启动她:
|
||||
|
||||
ranger
|
||||
|
||||
在命令行窗口中ranger和一些别的文件管理器很像,但是她是左右结构的比起上下的来意味着你按左方向键你将前进到上一个文件夹结构而右方向键则会切换到下一个。
|
||||
在命令行窗口中ranger和一些别的文件管理器很像,但是相比上下结构布局,她是左右结构的,这意味着你按左方向键你将前进到上一个文件夹,而右方向键则会切换到下一个。
|
||||
|
||||
在使用前ranger的man手册还是值得一读的,这样你就可以用快捷键操作ranger了。
|
||||
|
||||

|
||||
Linux取消关机。
|
||||
|
||||
### 9. 取消关机 ###
|
||||
|
||||
无论是在命令行还是图形用户界面[关机][9]后发现自己不是真的想要关机。
|
||||

|
||||
|
||||
*Linux取消关机。*
|
||||
|
||||
无论是在命令行还是图形用户界面[关机][9]后,才发现自己不是真的想要关机。
|
||||
|
||||
shutdown -c
|
||||
|
||||
@ -197,11 +205,13 @@ Linux取消关机。
|
||||
|
||||
- [pkill][10] shutdown
|
||||
|
||||

|
||||
使用XKill杀死挂起进程。
|
||||
|
||||
### 10. 杀死挂起进程的简单方法 ###
|
||||
|
||||

|
||||
|
||||
*使用XKill杀死挂起进程。*
|
||||
|
||||
想象一下,你正在运行的应用程序不明原因的僵死了。
|
||||
|
||||
你可以使用‘ps -ef’来找到该进程后杀掉或者使用‘htop’。
|
||||
@ -214,18 +224,20 @@ Linux取消关机。
|
||||
|
||||
那如果整个系统挂掉了怎么办呢?
|
||||
|
||||
按住键盘上的‘alt’和‘sysrq’同时输入:
|
||||
按住键盘上的‘alt’和‘sysrq’不放,然后慢慢输入以下键:
|
||||
|
||||
- [REISUB][12]
|
||||
|
||||
这样不按电源键你的计算机也能重启了。
|
||||
|
||||

|
||||
youtube-dl.
|
||||
|
||||
### 11. 下载Youtube视频 ###
|
||||
|
||||
一般来说我们大多数人都喜欢看Youtube的视频,也会通过钟爱的播放器播放Youtube的流。
|
||||

|
||||
|
||||
*youtube-dl.*
|
||||
|
||||
一般来说我们大多数人都喜欢看Youtube的视频,也会通过钟爱的播放器播放Youtube的流媒体。
|
||||
|
||||
如果你需要离线一段时间(比如:从苏格兰南部坐飞机到英格兰南部旅游的这段时间)那么你可能希望下载一些视频到存储设备中,到闲暇时观看。
|
||||
|
||||
@ -235,7 +247,7 @@ youtube-dl.
|
||||
|
||||
youtube-dl url-to-video
|
||||
|
||||
你能在Youtubu视频页面点击分享链接得到视频的url。只要简单的复制链接在粘帖到命令行就行了(要用shift + insert快捷键哟)。
|
||||
你可以在Youtubu视频页面点击分享链接得到视频的url。只要简单的复制链接在粘帖到命令行就行了(要用shift + insert快捷键哟)。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
@ -246,8 +258,8 @@ youtube-dl.
|
||||
via: http://linux.about.com/od/commands/tp/11-Linux-Terminal-Commands-That-Will-Rock-Your-World.htm
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -264,3 +276,4 @@ via: http://linux.about.com/od/commands/tp/11-Linux-Terminal-Commands-That-Will-
|
||||
[10]:http://linux.about.com/library/cmd/blcmdl1_pkill.htm
|
||||
[11]:http://linux.about.com/od/funnymanpages/a/funman_xkill.htm
|
||||
[12]:http://blog.kember.net/articles/reisub-the-gentle-linux-restart/
|
||||
[13]:http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-The-Terminal-In-Background-Mode.htm
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
$ cat .ssh/id_rsa.pub | ssh aliceB@hostB 'cat >> .ssh/authorized_keys'
|
||||
|
||||
自此以后,从aliceA@hostA上ssh到aliceB@hostB上再也不需要输入密码。
|
||||
自此以后,从aliceA@hostA上ssh到aliceB@hostB上再也不需要输入密码。(LCTT 译注:上述的创建目录并复制的操作也可以通过一个 ssh-copy-id 命令一步完成:`ssh-copy-id -i ~/.ssh/id_rsa.pub aliceB@hostB`)
|
||||
|
||||
### 疑难解答 ###
|
||||
|
||||
@ -34,7 +34,7 @@ via: http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
Linux有问必答--如何使用命令行压缩JPEG图像
|
||||
Linux有问必答:如何在命令行下压缩JPEG图像
|
||||
================================================================================
|
||||
> **问题**: 我有许多数码照相机拍出来的照片。我想在上传到Dropbox之前,优化和压缩下JPEG图片。有没有什么简单的方法压缩JPEG图片并不损耗他们的质量?
|
||||
|
||||
如今拍照设备(如智能手机、数码相机)拍出来的图片分辨率越来越大。甚至3630万像素的Nikon D800已经冲入市场,并且这个趋势根本停不下来。如今的拍照设备不断地提高着照片分辨率,使得我们不得不压缩后,再上传到有储存限制、带宽限制的云。
|
||||
|
||||
事实上,这里有一个非常简单的方法压缩JPEG图像。一个叫“jpegoptim”命令行工具可以帮助你“无损”美化JPEG图像,所以你可以压缩JPEG图片而不至于牺牲他们的质量。万一你的存储空间和带宽预算真的很少,jpegoptim也支持“有损耗”压缩来调整图像大小。
|
||||
事实上,这里有一个非常简单的方法压缩JPEG图像。一个叫“jpegoptim”命令行工具可以帮助你“无损”美化JPEG图像,让你可以压缩JPEG图片而不至于牺牲他们的质量。万一你的存储空间和带宽预算真的很少,jpegoptim也支持“有损”压缩来调整图像大小。
|
||||
|
||||
如果要压缩PNG图像,参考[this guideline][1]例子。
|
||||
如果要压缩PNG图像,参考[这个指南][1]的例子。
|
||||
|
||||
### 安装jpegoptim ###
|
||||
|
||||
@ -34,7 +34,7 @@ CentOS/RHEL安装,先开启[EPEL库][2],然后运行下列命令:
|
||||
|
||||
注意,原始图像会被压缩后图像覆盖。
|
||||
|
||||
如果jpegoptim不能无损美化图像,将不会覆盖
|
||||
如果jpegoptim不能无损美化图像,将不会覆盖它:
|
||||
|
||||
$ jpegoptim -v photo.jpg
|
||||
|
||||
@ -46,21 +46,21 @@ CentOS/RHEL安装,先开启[EPEL库][2],然后运行下列命令:
|
||||
|
||||
$ jpegoptim -d ./compressed photo.jpg
|
||||
|
||||
这样,压缩的图片将会保存在./compressed目录(已同样的输入文件名)
|
||||
这样,压缩的图片将会保存在./compressed目录(以同样的输入文件名)
|
||||
|
||||
如果你想要保护文件的创建修改时间,使用"-p"参数。这样压缩后的图片会得到与原始图片相同的日期时间。
|
||||
|
||||
$ jpegoptim -d ./compressed -p photo.jpg
|
||||
|
||||
如果你只是想获得无损压缩率,使用"-n"参数来模拟压缩,然后它会打印压缩率。
|
||||
如果你只是想看看无损压缩率而不是真的想压缩它们,使用"-n"参数来模拟压缩,然后它会显示出压缩率。
|
||||
|
||||
$ jpegoptim -n photo.jpg
|
||||
|
||||
### 有损压缩JPG图像 ###
|
||||
|
||||
万一你真的需要要保存在云空间上,你可以使用有损压缩JPG图片。
|
||||
万一你真的需要要保存在云空间上,你还可以使用有损压缩JPG图片。
|
||||
|
||||
这种情况下,使用"-m<质量>"选项,质量数范围0到100。(0是最好质量,100是最坏质量)
|
||||
这种情况下,使用"-m<质量>"选项,质量数范围0到100。(0是最好质量,100是最差质量)
|
||||
|
||||
例如,用50%质量压缩图片:
|
||||
|
||||
@ -76,7 +76,7 @@ CentOS/RHEL安装,先开启[EPEL库][2],然后运行下列命令:
|
||||
|
||||
### 一次压缩多张JPEG图像 ###
|
||||
|
||||
最常见的情况是需要压缩一个目录下的多张JPEG图像文件。为了应付这种情况,你可以使用接下里的脚本。
|
||||
最常见的情况是需要压缩一个目录下的多张JPEG图像文件。为了应付这种情况,你可以使用接下来的脚本。
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
@ -90,11 +90,11 @@ CentOS/RHEL安装,先开启[EPEL库][2],然后运行下列命令:
|
||||
via: http://ask.xmodulo.com/compress-jpeg-images-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[VicYu/Vic020](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[VicYu/Vic020](https://github.com/Vic020)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-compress-png-files-on-linux.html
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
@ -1,6 +1,6 @@
|
||||
Linux有问必答-- 如何在VPS上安装和访问CentOS远程桌面
|
||||
Linux有问必答:如何在VPS上安装和访问CentOS 7远程桌面
|
||||
================================================================================
|
||||
> **提问**: 我想在VPS中安装CentOS桌面,并可以直接从我家远程访问GUI桌面。有什么建议可以在VPS上设置和访问CentOS远程桌面?
|
||||
> **提问**: 我想在VPS中安装CentOS桌面,并可以直接从我家远程访问GUI桌面。在VPS上设置和访问CentOS远程桌面有什么建议吗?
|
||||
|
||||
如何远程办公或者远程弹性化工作制在技术领域正变得越来越流行。这个趋势背后的一个技术就是远程桌面。你的桌面环境在云中,你可以在任何你去的地方,或者在家或者工作场所访问你的远程桌面。
|
||||
|
||||
@ -10,7 +10,7 @@ Linux有问必答-- 如何在VPS上安装和访问CentOS远程桌面
|
||||
|
||||
### 第一步: 安装CentOS桌面 ###
|
||||
|
||||
如果现在的CentOS版本是没有桌面的最小版本,你需要先在VPS上安装桌面(比如GNOME)。比如,DigitalOcean的镜像就是最小版本,它需要如下安装[桌面GUI][2]
|
||||
如果你现在安装的CentOS版本是没有桌面的最小版本,你需要先在VPS上安装桌面(比如GNOME)。比如,DigitalOcean的镜像就是最小版本,它需要如下安装[桌面GUI][2]
|
||||
|
||||
# yum groupinstall "GNOME Desktop"
|
||||
|
||||
@ -36,15 +36,15 @@ CentOS依靠systemd来管理和配置系统服务。所以我们将使用systemd
|
||||
# systemctl status vncserver@:.service
|
||||
# systemctl is-enabled vncserver@.service
|
||||
|
||||
默认上,刚安装的VNC服务并没有激活(禁用)。
|
||||
默认的,刚安装的VNC服务并没有激活(禁用)。
|
||||
|
||||
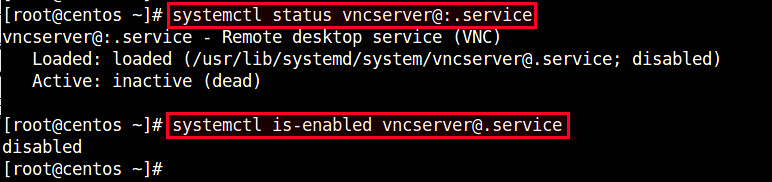
|
||||
|
||||
现在服务一份通用的VNC服务文件来位用户xmodulo创建一个VNC服务配置。
|
||||
现在复制一份通用的VNC服务文件来为用户xmodulo创建一个VNC服务配置。
|
||||
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
|
||||
用本文编辑器来打开配置文件,用实际的用户名(比如:xmodulo)来替换[Service]下面的<USER>。同样。在ExecStart后面追加 "-geometry <resolution>" 参数。最后,要修改下面两行加粗字体的两行。
|
||||
用本文编辑器来打开配置文件,用实际的用户名(比如:xmodulo)来替换[Service]下面的<USER>。同样。在ExecStart后面追加 "-geometry <resolution>" 参数。最后,要修改下面“ExecStart”和“PIDFile”两行。
|
||||
|
||||
# vi /etc/systemd/system/vncserver@:1.service
|
||||
|
||||
@ -85,7 +85,7 @@ CentOS依靠systemd来管理和配置系统服务。所以我们将使用systemd
|
||||
|
||||
### 第三步:通过SSH连接到远程桌面 ###
|
||||
|
||||
设计上,VNC使用的远程帧缓存(RFB)并不是一种安全的协议。那么在VNC客户端上直接连接到VNC服务器上并不是一个好主意。任何敏感信息比如密码都可以在VNC流量中被轻易地泄露。因此,我强烈建议使用SSH隧道来[加密你的VNC流量][3]。
|
||||
从设计上说,VNC使用的远程帧缓存(RFB)并不是一种安全的协议,那么在VNC客户端上直接连接到VNC服务器上并不是一个好主意。任何敏感信息比如密码都可以在VNC流量中被轻易地泄露。因此,我强烈建议使用SSH隧道来[加密你的VNC流量][3]。
|
||||
|
||||
在你要运行VNC客户端的本机上,使用下面的命令来创建一个连接到远程VPS的SSH通道。当被要输入SSH密码时,输入用户的密码。
|
||||
|
||||
@ -99,7 +99,7 @@ CentOS依靠systemd来管理和配置系统服务。所以我们将使用systemd
|
||||
|
||||
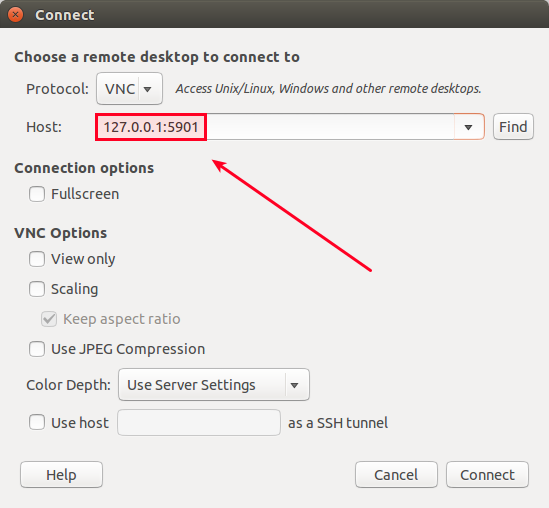
|
||||
|
||||
你将被要求输入VNC密码。当你输入VNC密码时,你就可以安全地连接到CentOS的远程桌面了.
|
||||
你将被要求输入VNC密码。当你输入VNC密码时,你就可以安全地连接到CentOS的远程桌面了。
|
||||
|
||||
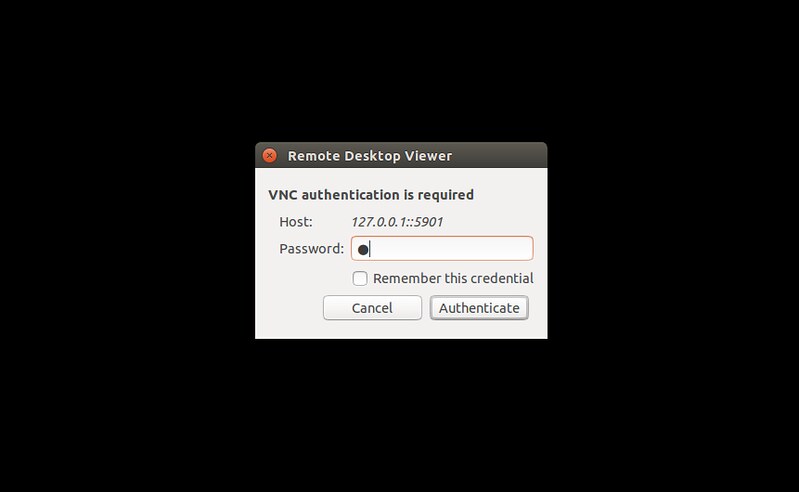
|
||||
|
||||
@ -111,7 +111,7 @@ via: http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,55 @@
|
||||
更漂亮的 Square 2.0图标包
|
||||
================================================================================
|
||||

|
||||
|
||||
优雅、现代的[Square图标主题][1]最近更新到了2.0版,它比以前更漂亮了。Square图标包与其他主要的桌面环境如**Unity、 GNOME、KDE、 MATE等等**兼容。这意味着你可以在所有的流行Linux发行版如Ubuntu、Fedora、Linux Mint、elementary OS等等中使用它。 这个图标包估计包含超过了15000个图标。
|
||||
|
||||
### 在Linux中安装Square 2.0图标包 ###
|
||||
|
||||
有两种不同的Square图标,暗色和亮色。基于你的喜好,你可以选择二者之一。出于体验的目的,我建议你两个主题包都下载。
|
||||
|
||||
你可以用下面的链接下载图标包。文件存储在Google Drive,因此如果你没有看见像[SourceForge][2]这样标准的下载网站时不要怀疑。
|
||||
|
||||
- [Square Dark Icons][3]
|
||||
- [Square Light Icons][4]
|
||||
|
||||
要使用图标主题,解压下载的文件到~/.icons文件夹下。如果它不存在,就创建它。当这些文件放好后,基于你的桌面环境,使用一个工具来改变图标主题。我以前写了一些关于这个主题的教程。如果你需要额外的帮助,那么欢迎指出来:
|
||||
|
||||
- [如何在Ubuntu Unity中改变主题][5]
|
||||
- [如何在GNOME Shell中改变主题][6]
|
||||
- [如何在Linux Mint中改变主题][7]
|
||||
- [如何在Elementary OS Freya中改变主题][8]
|
||||
|
||||
### 试一下 ###
|
||||
|
||||
这是我用Square图标在Ubuntu 14.04中的效果。我背景使用的是[Ubuntu 15.04 默认壁纸][9]。
|
||||
|
||||

|
||||
|
||||
Square主题中几个图标的样子:
|
||||
|
||||

|
||||
|
||||
你觉得怎么样?你认为它是[Ubuntu 14.04中最佳的图标主题][10]之一么?你会分享它并期待更多关于自定义Linux桌面的文章么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/square-2-0-icon-pack-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://gnome-look.org/content/show.php/Square?content=163513
|
||||
[2]:http://sourceforge.net/
|
||||
[3]:http://gnome-look.org/content/download.php?content=163513&id=1&tan=62806435
|
||||
[4]:http://gnome-look.org/content/download.php?content=163513&id=2&tan=19789941
|
||||
[5]:http://itsfoss.com/how-to-install-themes-in-ubuntu-13-10/
|
||||
[6]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[7]:http://itsfoss.com/install-icon-linux-mint/
|
||||
[8]:http://itsfoss.com/install-themes-icons-elementary-os-freya/
|
||||
[9]:http://itsfoss.com/default-wallpapers-ubuntu-1504/
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -1,12 +1,13 @@
|
||||
# Linux 下四种安全删除文件的工具 #
|
||||
Linux 下四种安全删除文件的工具
|
||||
===============
|
||||
|
||||
任何一个普通水平的计算机用户都知道,从计算机系统中删除的任意数据都可以稍候通过一些努力恢复出来。当你不小心删除了你的重要数据,这是一个不错的方案。但是大多数情况,你不希望你的隐私数据被轻易地恢复。不论何时,我们删除任意的文件,操作系统删除的仅仅是特定数据的索引。这就意味着,数据仍然保存在磁盘的某块地方,这种方法是不安全的,任何一个聪明的计算机黑客可以使用任意不错的数据恢复工具来恢复你删除的数据。Linux 用户利用我们都知晓的 "rm" 命令来从他们的操作系统中删除数据,但是 "rm" 命令在约定俗成的场景下工作。从这个命令删除的数据也可以使用特殊的文件恢复工具恢复。
|
||||
任何一个普通水平的计算机用户都知道,从计算机系统中删除的任意数据都可以稍后通过一些努力恢复出来。当你不小心删除了你的重要数据时,这是一个不错的方案。但是大多数情况,你不希望你的隐私数据被轻易地恢复。不论何时,我们删除的任意文件,操作系统删除的仅仅是对特定数据的索引。这就意味着,数据仍然保存在磁盘的某块地方,这种方法是不安全的,任何一个聪明的计算机黑客可以使用各种不错的数据恢复工具来恢复你删除的数据。Linux 用户利用我们都知晓的 "rm" 命令来从他们的操作系统中删除数据,但是 "rm" 命令也是像上面说的那样删除文件。从这个命令删除的数据也可以使用特殊的文件恢复工具恢复。
|
||||
|
||||
让我们看看怎样安全并且完整地从你地 Linux 系统中删除文件或者文件夹。以下提到的工具可以完全地删除数据,因此那些恢复工具很难找到真实数据的痕迹然后恢复它。
|
||||
让我们看看怎样安全并完整地从你的 Linux 系统中删除文件或者文件夹。以下提到的工具可以完全地删除数据,因此那些恢复工具很难找到真实数据的痕迹然后恢复它。
|
||||
|
||||
### Secure-Delete ###
|
||||
|
||||
Secure-Delete 是一组为 Linux 操作系统而生的工具集合,他们为永久删除文件提供高级的技术支持。一旦 Secure-Delete 安装在任意的 Linux 系统,它会提供如下的四个命令:
|
||||
Secure-Delete 是一组为 Linux 操作系统而生的工具集合,他们为永久删除文件提供了先进的技术支持。一旦 Secure-Delete 安装在各种 Linux 系统上,就提供了如下的四个命令:
|
||||
|
||||
- srm
|
||||
- smem
|
||||
@ -45,13 +46,13 @@ Secure-Delete 是一组为 Linux 操作系统而生的工具集合,他们为
|
||||
|
||||
sudo sswap /dev/sda5
|
||||
|
||||
“**smem**” 用来清理在内存中的内容,它保证当系统重启或者关机时随机存取存储器(RAM)中的内容被清理,但是残余的数据痕迹仍然保存在内存。这个命令提供安全的内存清理,简单地在终端中运行 smem 命令。
|
||||
“**smem**” 用来清理在内存中的内容,虽然当系统重启或者关机时会清理随机存取存储器(RAM)中的内容,但是内存中仍然会保留一些数据的残留痕迹。这个命令提供安全的内存清理,简单地在终端中运行 smem 命令即可。
|
||||
|
||||
smem
|
||||
|
||||
### Shred ###
|
||||
|
||||
"shred" 命令销毁文件或者文件夹的内容,在某种程度上,不可能恢复。它使用随机生成的数据模式来持续重写文件,因此很难恢复任意的被销毁的数据,即使是那些黑客或者窃贼使用高水平的数据恢复工具或者设备。Shred 在 Linux 发行版中时默认安装的,如果你想,你可以运行如下命令来找到它的安装目录:
|
||||
"shred" 命令以一种不可恢复的方式来销毁文件或者文件夹的内容。它使用随机生成的数据模式来持续覆写文件,因此很难恢复任意的被销毁的数据,即使是那些黑客或者窃贼使用高水平的数据恢复工具或者设备。Shred 默认安装在所有 Linux 发行版中,如果你想,你可以运行如下命令来找到它的安装目录:
|
||||
|
||||
aun@eagle:~$ whereis shred
|
||||
|
||||
@ -75,17 +76,17 @@ Shred 默认情况下使用随机内容重写数据 25 次。如果你想它重
|
||||
|
||||
### dd ###
|
||||
|
||||
这个命令起初是用于磁盘克隆的。它用于一个分区或者一个磁盘复制到另一个分区或者磁盘。但是它还用于安全地清除硬盘或者分区的内容。运行如下命令使用随机数据来重写你的当前数据。你不需要安装 dd 命令,所有的 Linux 分发版都已经包含了此命令。
|
||||
这个命令起初是用于磁盘克隆的。它用于将一个分区或者一个磁盘复制到另一个分区或者磁盘。但是它还可用于安全地清除硬盘或者分区的内容。运行如下命令使用随机数据来重写你的当前数据。你不需要安装 dd 命令,所有的 Linux 分发版都已经包含了此命令。
|
||||
|
||||
sudo dd if=/dev/random of=/dev/sda
|
||||
|
||||
你也可以重写磁盘或者分区中的内容,只需要简单地将所有替换为 “zero”。
|
||||
你也可以覆写磁盘或者分区中的内容,只需要简单地将所有替换为 “zero”。
|
||||
|
||||
sudo dd if=/dev/zero of=/dev/sda
|
||||
|
||||
### Wipe ###
|
||||
|
||||
Wipe 起初开发的目的是从磁媒体中安全地擦除文件。这个命令行工具使用特殊的模式来重复地写文件。它使用 fsync() 调用和或 O_SYNC 位来强制访问磁盘,并且使用 Gutmann 算法来重复地写。你可以使用此命令删除单个文件,文件夹或者整个磁盘的内容,但是使用 wipe 命令来删除整个磁盘的模式会耗费大量的时间。另外,安装和使用这个工具相当容易。
|
||||
Wipe 起初开发的目的是从磁性介质中安全地擦除文件。这个命令行工具使用特殊的模式来重复地写文件。它使用 fsync() 调用和/或 O_SYNC 位来强制访问磁盘,并且使用 Gutmann 算法来重复地写。你可以使用此命令删除单个文件、文件夹或者整个磁盘的内容,但是使用 wipe 命令来删除整个磁盘的模式会耗费大量的时间。另外,安装和使用这个工具相当容易。
|
||||
|
||||
在 ubuntu 的终端中运行如下命令来安装 wipe。
|
||||
|
||||
@ -123,7 +124,7 @@ via: http://linoxide.com/security/delete-files-permanatly-linux/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[dbarobin](https://github.com/dbarobin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
怎样在Github上做开源代码库的主人
|
||||
怎样在Github上托管开源代码库
|
||||
================================================================================
|
||||
大家好,今天我们要学习一下怎样管理github.com库中的开源软件源代码。GitHub是一个基于web的Git库托管服务,提供分布式修改控制和Git的源代码管理(SCM)功能并加入了自身的特点。它给开源和私有项目提供了一个互相协作的工作区、代码预览和代码管理功能。不像Git,一个完完全全的命令行工具,GitHub提供了一个基于web的图形化界面和桌面,也整合了手机。GitHub同时提供了私有库付费计划和免费账号,都是用来管理开源软件项目的。
|
||||
|
||||
大家好,今天我们要学习一下怎样在github.com提供的仓库中托管开源软件源代码。GitHub是一个基于web的Git仓库托管服务,提供基于 git 的分布式版本控制和源代码管理(SCM)功能,并加入了自身的特点。它给开源项目和私有项目提供了一个互相协作的工作区、代码预览和代码管理功能。不像Git是一个完完全全的命令行工具,GitHub提供了一个基于web的图形化界面和桌面,也整合了手机操作。GitHub同时提供了私有库付费计划和通常用来管理开源软件项目的免费账号。
|
||||
|
||||

|
||||
|
||||
这是一种快速灵活,基于web的托管服务,它使用方便,管理分布式修改控制系统也是相当容易,任何人都能为了将它们使用、贡献、共享、问题跟踪和更多的全球各地数以百万计的人在github的库里管理他们的软件源代码。这里有一些简单快速地管理软件源代码的方法。
|
||||
这是一种快速灵活,基于web的托管服务,它使用方便,管理分布式版本控制系统也是相当容易,任何人都能将他们的软件源代码托管到 github,让全球各地数以百万计的人可以使用它、参与贡献、共享它、进行问题跟踪以及更多的用途。这里有一些简单快速地托管软件源代码的方法。
|
||||
|
||||
### 1. 创建一个新的Github账号 ###
|
||||
|
||||
@ -20,7 +21,7 @@
|
||||
|
||||
### 2. 创建一个新的库 ###
|
||||
|
||||
成功注册新账号或登录上Github之后,我们需要创建一个新的库来开始我们的正题。
|
||||
成功注册新账号或登录上Github之后,我们需要创建一个新的库来开始我们的征程。
|
||||
|
||||
点击位于顶部靠右账号id旁边的**(+)**按钮,然后点击“New Repository”。
|
||||
|
||||
@ -46,13 +47,13 @@
|
||||
|
||||
现在git已经准备就绪,我们要上传代码了。
|
||||
|
||||
**注意**:为了避免错误,不要用**README**文件、许可证或gitignore文件来初始化新库,你可以在项目推送到Github上之后再添加它们。
|
||||
**注意**:为了避免错误,不要在初始化的新库中包含**README**、license或gitignore等文件,你可以在项目推送到Github上之后再添加它们。
|
||||
|
||||
在终端上,我们需要把当前工作目录更改为你的本地项目,然后将本地目录初始化为Git库。
|
||||
在终端上,我们需要切换当前工作目录为你的本地项目的目录,然后将其初始化为Git库。
|
||||
|
||||
$ git init
|
||||
|
||||
接着我们在我们的新的本地库里添加的文件来作为我们的首次提交内容。
|
||||
接着我们添加新的本地库里中的文件,作为我们的首次提交内容。
|
||||
|
||||
$ git add .
|
||||
|
||||
@ -62,16 +63,16 @@
|
||||
|
||||

|
||||
|
||||
在终端上,我们要给远程库添加URL地址,用于以后我们能提交我们本地的库。
|
||||
在终端上,添加远程库的URL地址,以便我们的本地库推送到远程。
|
||||
|
||||
$ git remote add origin remote Repository url
|
||||
$ git remote add origin 远程库的URL
|
||||
$ git remote -v
|
||||
|
||||

|
||||
|
||||
注意:请确保将远程库的URL替换成了自己的远程库的URL。
|
||||
注意:请确保将上述“远程库的URL”替换成了你自己的远程库的URL。
|
||||
|
||||
现在,要将我们的本地库提交至GitHub版本库中,我们需要运行一下命令并且输入所需的用户名和密码。
|
||||
现在,要将我们的本地库的改变推送至GitHub的版本库中,我们需要运行以下命令,并且输入所需的用户名和密码。
|
||||
|
||||
$ git push origin master
|
||||
|
||||
@ -87,9 +88,9 @@
|
||||
|
||||
请把以上这条URL地址更改成你想要克隆的地址。
|
||||
|
||||
### 更新改动 ###
|
||||
### 推送改动 ###
|
||||
|
||||
如果我们对我们的代码做了更改并想把它们提交至我们的远程库中,我们应该在该目录下运行以下命令。
|
||||
如果我们对我们的代码做了更改并想把它们推送至我们的远程库中,我们应该在该目录下运行以下命令。
|
||||
|
||||
$ git add .
|
||||
$ git commit -m "Updating"
|
||||
@ -97,7 +98,7 @@
|
||||
|
||||
### 结论 ###
|
||||
|
||||
啊哈!我们已经成功地管理我们在Github库中的项目源代码了。快速灵活的Github基于web的托管服务,分布式修改控制系统使用起来方便容易。数百万个非常棒的开源项目驻扎在github上。所以,如果你有任何问题、建议或反馈,请在评论中告诉我们。谢谢大家!好好享受吧 :-)
|
||||
啊哈!我们已经成功地将我们的项目源代码托管到Github的库中了。Github是快速灵活的基于web的托管服务,分布式版本控制系统使用起来方便容易。数百万个非常棒的开源项目驻扎在github上。所以,如果你有任何问题、建议或反馈,请在评论中告诉我们。谢谢大家!好好享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -105,7 +106,7 @@ via: http://linoxide.com/usr-mgmt/host-open-source-code-repository-github/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
如何交互式地创建一个Docker容器
|
||||
===============================================================================
|
||||
|
||||
大家好,今天我们来学习如何使用一个docker镜像交互式地创建一个Docker容器。当我们从镜像中启动一个Docker进程,Docker就会获取该镜像及其父镜像,并重复这个过程,直到到达基础镜像。然后联合文件系统(UFS)会在其顶层添加一个读写层。读写层被称之为容器,它包含了一些关于父镜像信息及一些其他的信息,如唯一ID,网络配置和资源限制等。容器是有状态的,其状态可以从 **运行态** 切换到 **退出态**。一个处于 **运行态**的容器包含了在CPU上面运行的进程树,于其它在该主机上运行的进程相隔离,而**退出态**是指文件系统的状态,并保留了其退出值。你可以使用它来启动,停止和重启一个容器。
|
||||
|
||||
Docker技术为IT界带来了巨大的改变,它使得云服务可以用来共享应用和工作流程自动化,使得应用可以用组件快速组合,消除了开发、品质保证、产品环境间的摩擦。在这篇文章中,我们将会建立CentOS环境,然后用Apache网络服务器提供一个网站服务。
|
||||
|
||||
这是一个快速且容易的教程,讨论我们怎样使用交互的shell,以交互的方式来创建一个容器。
|
||||
|
||||
### 1. 运行一个Docker实例 ###
|
||||
|
||||
Docker首先会尝试从本地取得并运行所需的镜像,如果在本地主机上没有发现,它就会从[Docker公共注册中心][1]拉取。这里,我们将会拉取镜像并在 Docker 容器中创建一个fedora实例,并连接到它的 tty 上的bash shell。
|
||||
|
||||
# docker run -i -t fedora bash
|
||||
|
||||

|
||||
|
||||
### 2.安装Apache网络服务器 ###
|
||||
|
||||
现在,在我们的Fedora基本镜像实例准备好后,我们将会开始交互式地安装Apache网络服务器,而不是为它创建Dockerfile。为了做到这点,我们需要在终端或者shell运行以下命令。
|
||||
|
||||
# yum update
|
||||
|
||||

|
||||
|
||||
# yum install httpd
|
||||
|
||||

|
||||
|
||||
# exit
|
||||
|
||||
### 3.保存镜像 ###
|
||||
|
||||
现在,我们要去保存在Fedora实例里做的修改。要做到这个,我们首先需要知道实例的容器ID。而为了得到ID,我们又需要运行以下命令(LCTT 译注:在容器外执行该命令)。
|
||||
|
||||
# docker ps -a
|
||||
|
||||

|
||||
|
||||
然后,我们会保存这些改变为一个新的镜像,请运行以下命令。
|
||||
|
||||
# docker commit c16378f943fe fedora-httpd
|
||||
|
||||

|
||||
|
||||
这里,修改已经通过使用容器ID保存起来了,镜像名字叫fedora-httpd。为了确认新的镜像是否在运行,我们将运行以下命令。
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
### 4. 添加内容到新的镜像 ###
|
||||
|
||||
我们自己新的Fedora Apache镜像正成功的运行,现在我们想添加一些我们网站的网页内容到Apache网络服务器,使得网站能够开箱即用。为做到这点,我们需要创建一个新的Dockerfile,它会处理从复制网页内容到启用80端口的所有操作。要达到这样的目的,我们需要使用我们最喜欢的文本编辑器创建Dockerfile文件,像下面演示的一样。
|
||||
|
||||
# nano Dockerfile
|
||||
|
||||
现在,我们需要添加以下的命令行到文件中。
|
||||
|
||||
FROM fedora-httpd
|
||||
ADD mysite.tar /tmp/
|
||||
RUN mv /tmp/mysite/* /var/www/html
|
||||
EXPOSE 80
|
||||
ENTRYPOINT [ "/usr/sbin/httpd" ]
|
||||
CMD [ "-D", "FOREGROUND" ]
|
||||
|
||||

|
||||
|
||||
这里,上述的Dockerfile中,放在mysite.tar里的网页内容会自动解压到/tmp/文件夹里。然后,整个站点会被移动到Apache的网页根目录/var/www/html/,命令expose 80会打开80端口,这样网站就能正常访问了。其次,入口点放在了/usr/sbin/https里面,保证Apache服务器能够执行。
|
||||
|
||||
### 5. 构建并运行一个容器 ###
|
||||
|
||||
现在,我们要用刚刚创建的Dockerfile创建我们的容器,以便将我们的网站添加到上面。为做到这,我们需要运行以下命令。
|
||||
|
||||
# docker build -rm -t mysite .
|
||||
|
||||

|
||||
|
||||
建立好我们的新容器后,我们需要要用下面的命令来运行容器。
|
||||
|
||||
# docker run -d -P mysite
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们已经成功的以交互式的方式建立了一个Docker容器。在本节方法中,我们是直接通过交互的shell命令建立我们的容器和镜像。在建立与配置镜像与容器时,这种方法十分简单且快速。如果你有任何问题,建议和反馈,请在下方的评论框里写下来,以便我们可以提升或者更新我们的文章。谢谢!祝生活快乐 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/interactively-create-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://registry.hub.docker.com/
|
||||
@ -0,0 +1,57 @@
|
||||
两种方式创建你自己的 Docker 基本映像
|
||||
================================================================================
|
||||
|
||||
欢迎大家,今天我们学习一下 docker 基本映像以及如何构建我们自己的 docker 基本映像。[Docker][1] 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。这使它们可以不依赖于特定软件栈和供应商,像一块块积木一样部署和扩展网络应用、数据库和后端服务。
|
||||
|
||||
Docker 映像是不可更改的只读层。Docker 使用 **Union File System** 在只读文件系统上增加可读写的文件系统,但所有更改都发生在最顶层的可写层,而其下的只读映像上的原始文件仍然不会改变。由于映像不会改变,也就没有状态。基本映像是没有父类的那些映像。Docker 基本映像主要的好处是它允许我们有一个独立运行的 Linux 操作系统。
|
||||
|
||||
下面是我们如何可以创建自定义的基本映像的方式。
|
||||
|
||||
### 1. 使用 Tar 创建 Docker 基本映像 ###
|
||||
|
||||
我们可以使用 tar 构建我们自己的基本映像,我们从一个运行中的 Linux 发行版开始,将其打包为基本映像。这过程可能会有些不同,它取决于我们打算构建的发行版。在 Debian 发行版中,已经预带了 debootstrap。在开始下面的步骤之前,我们需要安装 debootstrap。debootstrap 用来获取构建基本系统需要的包。这里,我们构建基于 Ubuntu 14.04 "Trusty" 的映像。要完成这些,我们需要在终端或者 shell 中运行以下命令。
|
||||
|
||||
$ sudo debootstrap trusty trusty > /dev/null
|
||||
$ sudo tar -C trusty -c . | sudo docker import - trusty
|
||||
|
||||

|
||||
|
||||
上面的命令为当前文件夹创建了一个 tar 文件并输出到标准输出中,"docker import - trusty" 通过管道从标准输入中获取这个 tar 文件并根据它创建一个名为 trusty 的基本映像。然后,如下所示,我们将运行映像内部的一条测试命令。
|
||||
|
||||
$ docker run trusty cat /etc/lsb-release
|
||||
|
||||
[Docker GitHub Repo][2] 中有一些允许我们快速构建基本映像的事例脚本.
|
||||
|
||||
### 2. 使用Scratch构建基本映像 ###
|
||||
|
||||
在 Docker registry 中,有一个被称为 Scratch 的使用空 tar 文件构建的特殊库:
|
||||
|
||||
$ tar cv --files-from /dev/null | docker import - scratch
|
||||
|
||||

|
||||
|
||||
我们可以使用这个映像构建新的小容器:
|
||||
|
||||
FROM scratch
|
||||
ADD script.sh /usr/local/bin/run.sh
|
||||
CMD ["/usr/local/bin/run.sh"]
|
||||
|
||||
上面的 Dockerfile 文件来自一个很小的映像。这里,它首先从一个完全空的文件系统开始,然后它复制新建的 /usr/local/bin/run.sh 为 script.sh ,然后运行脚本 /usr/local/bin/run.sh。
|
||||
|
||||
### 结尾 ###
|
||||
|
||||
这这个教程中,我们学习了如何构建一个开箱即用的自定义 Docker 基本映像。构建一个 docker 基本映像是一个很简单的任务,因为这里有很多已经可用的包和脚本。如果我们想要在里面安装想要的东西,构建 docker 基本映像非常有用。如果有任何疑问,建议或者反馈,请在下面的评论框中写下来。非常感谢!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/2-ways-create-docker-base-image/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://github.com/docker/docker/blob/master/contrib/mkimage-busybox.sh
|
||||
@ -1,10 +1,10 @@
|
||||
使用 SSH 和一次性密码安全登录 Linux
|
||||
使用一次性密码本通过 SSH 安全登录 Linux
|
||||
================================================================================
|
||||
有人说,安全不是一个产品,而是一个过程(LCTT 注:安全公司 McAfee 认为,安全风险管理是一个方法论,而不是安全产品的堆叠)。虽然 SSH 协议被设计成使用加密技术来确保安全,但如果使用不当,别人还是能够破坏你的系统:比如弱密码、密钥泄露、使用的 SSH 客户端过时等,都能引发安全问题。
|
||||
有人说,安全不是一个产品,而是一个过程(LCTT 注:安全公司 McAfee 认为,安全风险管理是一个方法论,而不是安全产品的堆叠)。虽然 SSH 协议被设计成使用加密技术来确保安全,但如果使用不当,别人还是能够破坏你的系统:比如弱密码、密钥泄露、使用过时的 SSH 客户端等,都能引发安全问题。
|
||||
|
||||
在考虑 SSH 认证方案时,大家普遍认为[公钥认证][1]比密码认证更安全。然而,公钥认证技术并不是为公共环境设置的,如果你在一台公用电脑上使用公钥认证登录 SSH 服务器,你的服务器已经毫无安全可言了,公用的电脑可能会记录你的公钥,或从你的内存中读取公钥。如果你不信任本地电脑,那你最好还是使用其他方式登录服务器。现在就是“一次性密码”派上用场的时候了,就像名字所示,一次性密码只能被使用一次。这种一次性密码非常合适在不安全的环境下发挥作用,就算它被窃取,也无法再次使用。
|
||||
在考虑 SSH 认证方案时,大家普遍认为[公钥认证][1]比密码认证更安全。然而,公钥认证技术并不是为公共环境设置的,如果你在一台公用电脑上使用公钥认证登录 SSH 服务器,你的服务器已经毫无安全可言了,公用的电脑可能会记录你的公钥,或从你的内存中读取公钥。如果你不信任本地电脑,那你最好还是使用其他方式登录服务器。现在就是“一次性密码(OTP)”派上用场的时候了,就像名字所示,一次性密码只能被使用一次。这种一次性密码非常合适在不安全的环境下发挥作用,就算它被窃取,也无法再次使用。
|
||||
|
||||
有个一次性密码方案叫[谷歌认证][2],但在本文中,我要介绍的是另一种 SSH 登录方案:[OTPW][3],它是个一次性密码登录的软件包。不像谷歌认证,OTPW 不需要依赖任何第三方库。
|
||||
有个生成一次性密码的方法是通过[谷歌认证器][2],但在本文中,我要介绍的是另一种 SSH 登录方案:[OTPW][3],它是个一次性密码登录的软件包。不像谷歌认证,OTPW 不需要依赖任何第三方库。
|
||||
|
||||
### OTPW 是什么 ###
|
||||
|
||||
@ -39,7 +39,7 @@ OTPW 由一次性密码生成器和 PAM 认证规则组成。在 OTPW 中一次
|
||||
$ git clone https://www.cl.cam.ac.uk/~mgk25/git/otpw
|
||||
$ cd otpw
|
||||
|
||||
打开 Makefile 文件,编辑以“PAMLIB=”开头的那行配置:
|
||||
打开 Makefile 文件,编辑以“PAMLIB=”开头的那行配置:
|
||||
|
||||
64 位系统:
|
||||
|
||||
@ -49,12 +49,12 @@ OTPW 由一次性密码生成器和 PAM 认证规则组成。在 OTPW 中一次
|
||||
|
||||
PAMLIB=/usr/lib/security
|
||||
|
||||
编译安装。需要注意的是安装过程会把 SSH 服务重启一下,所以如果你是使用 SSH 连接到服务器,做好被断开连接的准备吧。
|
||||
编译安装。需要注意的是安装过程会自动重启 SSH 服务一下,所以如果你是使用 SSH 连接到服务器,做好被断开连接的准备吧(LCTT 译注:也许不会被断开连接,即便被断开连接,请使用原来的方式重新连接即可,现在还没有换成一次性口令方式。)。
|
||||
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
现在你需要更新 SELinux 策略,因为 /usr/sbin/sshd 会往你的 home 目录写数据,而 SELinux 默认是不允许这么做的。如果你使用了 SELinux 服务(LCTT 注:使用 getenforce 命令查看结果,如果是 enforcing,就是打开了 SELinux 服务),如果没有使用 SELinux 服务,请跳过这一步。
|
||||
现在你需要更新 SELinux 策略,因为 /usr/sbin/sshd 会往你的 home 目录写数据,而 SELinux 默认是不允许这么做的。如果没有使用 SELinux 服务(LCTT 注:使用 getenforce 命令查看结果,如果是 enforcing,就是打开了 SELinux 服务),请跳过这一步。
|
||||
|
||||
$ sudo grep sshd /var/log/audit/audit.log | audit2allow -M mypol
|
||||
$ sudo semodule -i mypol.pp
|
||||
@ -90,6 +90,8 @@ Debian, Ubuntu 或 Linux Mint 发行版:
|
||||
Fedora 或 CentOS/RHEL 7 发行版:
|
||||
|
||||
$ sudo systemctl restart sshd
|
||||
|
||||
(LCTT 译注:虽然这里重启了 sshd 服务,但是你当前的 ssh 连接应该不受影响,只是在你完成下述步骤之前,无法按照原有方式建立新的连接了。因此,保险起见,要么多开一个 ssh 连接,避免误退出当前连接;要么将重启 sshd 服务器步骤放到步骤3完成之后。)
|
||||
|
||||
#### 步骤3:使用 OTPW 产生一次性密码 ####
|
||||
|
||||
@ -102,7 +104,7 @@ Fedora 或 CentOS/RHEL 7 发行版:
|
||||
|
||||
这个命令会让你输入密码前缀,当你以后登录的时候,你需要同时输入这个前缀以及一次性密码。密码前缀是另外一层保护,就算你的一次性密码表被泄漏,别人也无法通过暴力破解你的 SSH 密码。
|
||||
|
||||
设置好密码前缀后,这个命令会产生 280 个一次性密码,并将它们保存在一个文本文件中(如 temporary_password.txt)。每个密码(默认是 8 个字符)由一个 3 位十进制数索引。你需要将这个密码表打印出来,并随身携带。
|
||||
设置好密码前缀后,这个命令会产生 280 个一次性密码(LCTT 译注:保存到 ~/.otpw 下),并将它们导出到一个文本文件中(如 temporary_password.txt)。每个密码(默认是 8 个字符)由一个 3 位十进制数索引。你需要将这个密码表打印出来,并随身携带。
|
||||
|
||||
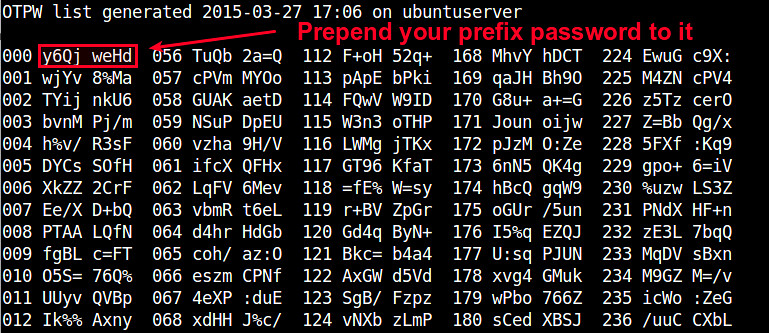
|
||||
|
||||
@ -160,7 +162,7 @@ Fedora 或 CentOS/RHEL 7 发行版:
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这个教程中,我介绍了如何使用 OTPW 工具来设置一次性登录密码。你也许意识到了在这种两个因子的认证方式中,打印一张密码表让人感觉好 low,但是这种方式是最简单的,并且不用依赖任何第三方软件。无论你用哪种方式创建一次性密码,在你需要在一个不被信任的环境登录 SSH 服务器的时候,它们都很有用。你可以就这个主题来分享你的经验和观点。
|
||||
在这个教程中,我介绍了如何使用 OTPW 工具来设置一次性登录密码。你也许意识到了在这种双因子的认证方式中,打印一张密码表让人感觉好 low,但是这种方式是最简单的,并且不用依赖任何第三方软件。无论你用哪种方式创建一次性密码,在你需要在一个不可信任的环境登录 SSH 服务器的时候,它们都很有用。你可以就这个主题来分享你的经验和观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -168,11 +170,11 @@ via: http://xmodulo.com/secure-ssh-login-one-time-passwords-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-force-ssh-login-via-public-key-authentication.html
|
||||
[2]:http://xmodulo.com/two-factor-authentication-ssh-login-linux.html
|
||||
[1]:https://linux.cn/article-5444-1.html
|
||||
[2]:https://linux.cn/article-2642-1.html
|
||||
[3]:http://www.cl.cam.ac.uk/~mgk25/otpw.html
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答-- 如何在Ubuntu中升级Docker
|
||||
Linux有问必答:如何在Ubuntu中升级Docker
|
||||
================================================================================
|
||||
> **提问**: 我使用了Ubuntu的标准仓库安装了Docker。然而,默认安装的Docker不能满足我另外一个依赖Docker程序的版本需要。我该如何在Ubuntu中升级到Docker的最新版本?
|
||||
|
||||
Docker第一次在2013年发布,它快速地演变成了一个针对分布式程序的开发平台。为了满足工业期望,Docker正在紧密地开发并持续地带来新特性的升级。这样Ubuntu发行版中的Docker版本可能很快就会过时。比如,, Ubuntu 14.10 Utopic 中的Docker版本是1.2.0, 然而最新的Docker版本是1.5.0。
|
||||
Docker第一次在2013年发布,它快速地演变成了一个针对分布式程序的开发平台。为了满足工业期望,Docker正在紧密地开发并持续地带来新特性的升级。这样Ubuntu发行版中的Docker版本可能很快就会过时。比如, Ubuntu 14.10 Utopic 中的Docker版本是1.2.0, 然而最新的Docker版本是1.6.0。
|
||||
|
||||
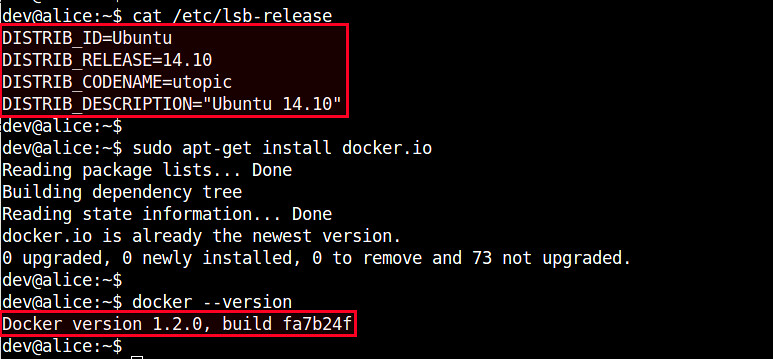
|
||||
|
||||
@ -28,7 +28,7 @@ via: http://ask.xmodulo.com/upgrade-docker-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,151 @@
|
||||
Conky - 终极的 X 视窗系统监视器应用
|
||||
================================================================================
|
||||
Conky 是一个用 ‘C’ 语言写就的系统监视器,并在 GNU GPL 和 BSD 许可协议下发布,在 Linux 和 BSD 操作系统中都可以获取到它。这个应用是基于 X 视窗系统的,原本由 [Torsmo][1] 分支而来。
|
||||
|
||||
#### 特点 ####
|
||||
|
||||
- 简洁的用户界面;
|
||||
- 高度可配置;
|
||||
- 它既可使用内置的部件(超过 300 多个) 也可使用外部脚本,来在桌面或其自有容器中展示系统的状态;
|
||||
- 低资源消耗;
|
||||
- 它可显示范围广泛的系统参数,包括但不限于 CPU,内存,swap 分区 ,温度,进程,磁盘使用情况,网络状态,电池电量,邮件收发,系统消息,音乐播放器的控制,天气信息,最新新闻,升级信息等等;
|
||||
- 在许多操作系统中如 CrunchBang Linux 和 Pinguy OS 被默认安装;
|
||||
|
||||
#### 关于 Conky 的少有人知的事实 ####
|
||||
|
||||
- conky 这个名称来自于一个加拿大电视节目;
|
||||
- 它已被移植到 Nokia N900 上;
|
||||
- 官方已经不再维护它了;
|
||||
|
||||
### 在 Linux 中 Conky 的安装和使用 ###
|
||||
|
||||
在我们安装 conky 之前,我们需要使用下面的命令来安装诸如 `lm-sensors`, `curl` 和 `hddtemp` 之类的软件包:
|
||||
|
||||
# apt-get install lm-sensors curl hddtemp
|
||||
|
||||
然后是检测传感器:
|
||||
|
||||
# sensors-detect
|
||||
|
||||
**注**: 在被系统提示时,回答 ‘Yes’ 。
|
||||
|
||||
检测所有探测到的传感器:
|
||||
|
||||
# sensors
|
||||
|
||||
#### 样例输出 ####
|
||||
|
||||
acpitz-virtual-0
|
||||
Adapter: Virtual device
|
||||
temp1: +49.5°C (crit = +99.0°C)
|
||||
|
||||
coretemp-isa-0000
|
||||
Adapter: ISA adapter
|
||||
Physical id 0: +49.0°C (high = +100.0°C, crit = +100.0°C)
|
||||
Core 0: +49.0°C (high = +100.0°C, crit = +100.0°C)
|
||||
Core 1: +49.0°C (high = +100.0°C, crit = +100.0°C)
|
||||
|
||||
Conky 既可以从软件仓库中安装,也可从源代码编译得到:
|
||||
|
||||
# yum install conky [在 RedHat 系的系统上]
|
||||
# apt-get install conky-all [在 Debian 系的系统上]
|
||||
|
||||
**注**: 在 Fedora/CentOS 上安装 conky 之前,你必须启用 [EPEL 软件仓库][2]。
|
||||
|
||||
在安装完 conky 之后,只需输入如下命令来开启它:
|
||||
|
||||
$ conky &
|
||||
|
||||

|
||||
|
||||
*正在运行的 Conky 监视器*
|
||||
|
||||
这使得 conky 以一个弹窗的形式运行,并使用位于 `/etc/conky/conky.conf` 的 conky 基本配置文件。
|
||||
|
||||
你可能想将 conky 集成到桌面上,并不想让它每次以弹窗的形式出现,下面就是你需要做的:
|
||||
|
||||
将配置文件 `/etc/conky/conky.conf` 复制到你的家目录中,并将它重命名为 `.conkyrc`,开头的点号 (.) 是为了确保这个配置文件是隐藏的。
|
||||
|
||||
$ cp /etc/conky/conky.conf /home/$USER/.conkyrc
|
||||
|
||||
现在重启 conky 来应用新的更改:
|
||||
|
||||
$ killall -SIGUSR1 conky
|
||||
|
||||

|
||||
|
||||
*Conky 监视器窗口*
|
||||
|
||||
你可能想编辑位于你的家目录的 conky 的配置文件,这个配置文件的内容是非常容易理解的。
|
||||
|
||||
下面是 conky 配置文件的一个样例:
|
||||
|
||||

|
||||
|
||||
*Conky 的配置*
|
||||
|
||||
从上面的窗口中,你可以更改颜色,边框,大小,缩放比例,背景,对齐方式及几个其他属性。通过为不同的 conky 窗口设定不同的对齐方式,我们可以同时运行几个 conky 脚本。
|
||||
|
||||
**让 conky 使用其它脚本而不是默认配置,以及如何找到这些脚本?**
|
||||
|
||||
你可以编写你自己的 conky 脚本或使用来自于互联网的脚本;我们并不建议你使用从互联网中找到的具有潜在危险的任何脚本,除非你清楚你正在做什么。然而,有一些著名的主题和网页包含可信赖的 conky 脚本,例如下面所提及的:
|
||||
|
||||
- [http://ubuntuforums.org/showthread.php?t=281865][3]
|
||||
- [http://conky.sourceforge.net/screenshots.html][4]
|
||||
|
||||
在上面的 URL 地址中,你将发现其中每个截图都有一个超链接,它们将指向到脚本文件。
|
||||
|
||||
#### 测试 Conky 脚本 ####
|
||||
|
||||
这里我将在我的 Debian Jessie 系统中运行一个由第三方写的 conky 脚本,以此来进行测试:
|
||||
|
||||
$ wget https://github.com/alexbel/conky/archive/master.zip
|
||||
$ unzip master.zip
|
||||
|
||||
切换当前工作目录到刚才解压的目录:
|
||||
|
||||
$ cd conky-master
|
||||
|
||||
将 `secrets.yml.example` 重命名为 `secrets.yml`:
|
||||
|
||||
$ mv secrets.yml.example secrets.yml
|
||||
|
||||
在你需要运行这个(ruby)脚本之前安装 Ruby:
|
||||
|
||||
$ sudo apt-get install ruby
|
||||
$ ruby starter.rb
|
||||
|
||||

|
||||
|
||||
*华丽的 conky 外观*
|
||||
|
||||
**注**: 可以修改这个脚本以展示你当前的天气,温度等;
|
||||
|
||||
假如你想让 conky 开机自启,请在开机启动应用设置(startup Applications) 中添加如下的几行命令:
|
||||
|
||||
conky --pause 10
|
||||
save and exit.
|
||||
|
||||
最后,如此轻量级且吸引眼球的实用 GUI 软件包不再处于活跃状态且官方不再进行维护了。最新的稳定发布版本为 conky 1.9.0, 于 2012 年 5 月 3 号发布。在 Ubuntu 论坛上,一个有关用户分享 conky 配置的主题已经超过了 2000 多页。(这个论坛主题的链接为: [http://ubuntuforums.org/showthread.php?t=281865/][5])
|
||||
|
||||
- [Conky 主页][6]
|
||||
|
||||
这就是全部内容了。保持联系,保持评论。请在下面的评论框里分享你的想法和配置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-conky-in-ubuntu-debian-fedora/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://torsmo.sourceforge.net/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://ubuntuforums.org/showthread.php?t=281865
|
||||
[4]:http://conky.sourceforge.net/screenshots.html
|
||||
[5]:http://ubuntuforums.org/showthread.php?t=281865/
|
||||
[6]:http://conky.sourceforge.net/
|
||||
@ -2,42 +2,45 @@
|
||||
================================================================================
|
||||
我们一直积极地提供有关 Linux 技巧的系列文章,如果你错过了这个系列的最新文章,你或许可以去访问下面的链接。
|
||||
|
||||
注:此篇文章做过原文
|
||||
- [Linux 中 5 个有趣的命令行技巧][1] (注:这篇文章还没有被翻译,在 20150316 选的题)
|
||||
- [Linux 中 5 个有趣的命令行技巧][1]
|
||||
|
||||
在这篇文章中,我们将分享一些有趣 Linux 技巧,内容是有关如何产生随机密码以及加密或解密这些经过加盐或没有加盐处理的密码。
|
||||
|
||||
安全是数字时代中的一个主要话题。在电脑,email,云端,手机,文档和其他的场合中,我们都会使用到密码。众所周知,选择密码的基本原则是 “易记,难猜”。考虑过使用基于机器自动生成的密码吗?相信我,Linux 非常擅长这方面的工作。
|
||||
|
||||
**1. 使用命令 `pwgen` 来生成一个长度为 10 个字符的唯一的随机密码。假如你还没有安装 pwgen,请使用 Apt 或 YUM 等包管理器来安装它。**
|
||||
**1. 使用命令 `pwgen` 来生成一个长度为 10 个字符的独特的随机密码。假如你还没有安装 pwgen,请使用 Apt 或 YUM 等包管理器来安装它。**
|
||||
|
||||
$ pwgen 10 1
|
||||
|
||||
|
||||
生成一个唯一的随机密码
|
||||

|
||||
|
||||
*生成一个独特的随机密码*
|
||||
|
||||
一口气生成若干组长度为 50 个字符的唯一的随机密码!
|
||||
|
||||
$ pwgen 50
|
||||
|
||||

|
||||
生成多组随机密码
|
||||
|
||||
**2. 你还可以使用 `makepasswd` 来每次生成一个给定长度的唯一的随机密码。在你把玩 makepasswd 命令之前,请确保你已经安装了它。如若没有安装它,试试使用 Apt 或 YUM 包管理器来安装 `makepasswd`这个软件包。**
|
||||
*生成多组随机密码*
|
||||
|
||||
**2. 你还可以使用 `makepasswd` 来每次生成一个给定长度的独特的随机密码。在你把玩 makepasswd 命令之前,请确保你已经安装了它。如若没有安装它,试试使用 Apt 或 YUM 包管理器来安装 `makepasswd`这个软件包。**
|
||||
|
||||
生成一个长度为 10 个字符的随机密码。该命令产生的密码的长度默认为 10。
|
||||
|
||||
$ makepasswd
|
||||
|
||||
|
||||
使用 makepasswd 生成唯一的密码
|
||||

|
||||
|
||||
*使用 makepasswd 生成独特的密码*
|
||||
|
||||
生成一个长度为 50 个字符的随机密码。
|
||||
|
||||
$ makepasswd --char 50
|
||||
|
||||
|
||||
生成长度为 50 的密码
|
||||
|
||||
*生成长度为 50 的密码*
|
||||
|
||||
生成 7 个长度为 20 个字符的随机密码。
|
||||
|
||||
@ -47,9 +50,7 @@
|
||||
|
||||
**3. 使用带“盐”的 Crypt(注:这里应该指的是一个函数,可以参考[这里](http://man7.org/linux/man-pages/man3/crypt.3.html) ) 来加密一个密码。提供手动或自动添加 “盐”。**
|
||||
|
||||
对于那些不清楚 **盐** 的意义的人,
|
||||
|
||||
这里的 “盐” 指的是一个随机数据,它作为密码生成函数的一个额外的输入, 目的是保护密码免受词典攻击。
|
||||
对于那些不清楚 **盐** 的意义的人,这里的 “盐” 指的是一个随机数据,它作为密码生成函数的一个额外的输入, 目的是保护密码免受词典攻击。
|
||||
|
||||
在执行下面的操作前,请确保你已经安装了 `mkpasswd`。
|
||||
|
||||
@ -58,46 +59,51 @@
|
||||
$ mkpasswd tecmint
|
||||
|
||||
|
||||
使用 Crypt 来加密密码
|
||||
|
||||
*使用 Crypt 来加密密码*
|
||||
|
||||
现在让我们来手动定义 “盐” 的值。每次它将产生相同的结果。请注意你可以输入任何你想输入的值来作为 “盐” 的值。
|
||||
|
||||
$ mkpasswd tecmint -s tt
|
||||
|
||||
|
||||
带“盐”加密密码
|
||||
|
||||
*带“盐”加密密码*
|
||||
|
||||
另外, mkpasswd 还是交互式的,假如你在命令中没有提供密码,它将主动询问你来输入密码。
|
||||
|
||||
**4. 使用 aes-256-cbc 加密算法并使用密码(如 “tecmint”) 并带“盐” 加密一个字符串(如 “Tecmint-is-a-Linux-Community”)。**
|
||||
**4. 使用 aes-256-cbc 加密算法并使用带“盐”的密码(如 “tecmint”) 加密一个字符串(如 “Tecmint-is-a-Linux-Community”)。**
|
||||
|
||||
# echo Tecmint-is-a-Linux-Community | openssl enc -aes-256-cbc -a -salt -pass pass:tecmint
|
||||
|
||||
|
||||
在 Linux 中加密一个字符串
|
||||
|
||||
在上面例子中, [echo 命令][2](注:此篇原文也做过,这里是链接 http://linux.cn/article-3948-1.html) 的输出通过管道传递给了 openssl 命令,使得该输出被 Cipher(enc) 所加密,这个过程中使用了 aes-256-cbc 加密算法,并附带了密码 (tecmint) 和 “盐” 。
|
||||
*在 Linux 中加密一个字符串*
|
||||
|
||||
在上面例子中, [echo 命令][2]的输出通过管道传递给了 openssl 命令,使得该输出通过加密编码方式(enc:Encoding with Cipher ) 所加密,这个过程中使用了 aes-256-cbc 加密算法,并附带了密码 (tecmint) 和 “盐” 。
|
||||
|
||||
**5. 使用 openssl 命令的 -aes-256-cbc 解密选项来解密上面的字符串。**
|
||||
|
||||
# echo U2FsdGVkX18Zgoc+dfAdpIK58JbcEYFdJBPMINU91DKPeVVrU2k9oXWsgpvpdO/Z | openssl enc -aes-256-cbc -a -d -salt -pass pass:tecmint
|
||||
|
||||

|
||||
在 Linux 中解密字符串
|
||||
|
||||
现在就是这些内容了。假如你知道任何这类的技巧,请将你的技巧发送到 admin@tecmint.com 邮箱中,你的技巧将会以你的名义来发表,同时我们也将在我们将来的文章中把它包含进去。
|
||||
*在 Linux 中解密字符串*
|
||||
|
||||
现在就是这些内容了。
|
||||
|
||||
保持联系,保持连接,敬请关注。不要忘了在下面的评论中提供给我们您有价值的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/generate-encrypt-decrypt-random-passwords-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
[2]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[1]:https://linux.cn/article-5485-1.html
|
||||
[2]:http://linux.cn/article-3948-1.html
|
||||
@ -1,29 +1,30 @@
|
||||
现在值得去尝试一下在CentOS 7.x或Fedora 21上面安装PHP 7.0
|
||||
在CentOS 7.x / Fedora 21 上面体验 PHP 7.0
|
||||
===============================================================================
|
||||
PHP是一种为我们熟知的通用的,服务器网页脚本语言。超大量的在线网站都是用PHP编写的。PHP过去一直在更新,丰富功能,易于使用,而且很好组织的脚本语言。目前PHP的开发团队正筹备下一个PHP版本的发行,名字是PHP 7。现在的PHP版本为PHP 5.6,可能你清楚PHP 6已经流产了,PHP 7的支持者们不希望下一个重要的版本被其他分支混淆,即过去已经停止很久的PHP 6。所以决定下一个PHP主要的发行版本叫PHP 7,而不是PHP 6。PHP 7.0预计在今年十一月份发行。
|
||||
|
||||
在下一个主要的PHP发行版里有一些不错的功能。
|
||||
PHP是一种为我们熟知的通用服务器网页脚本语言。非常多的在线网站都是用PHP编写的。PHP这些年来一直在持续进化,丰富其功能,变得易于使用,更好地组织的脚本语言。目前PHP的开发团队正筹备下一个PHP版本的发行,名字是PHP 7。现在的PHP版本为PHP 5.6,可能你清楚PHP 6已经流产了,PHP 7的支持者们不希望下一个重要的版本被其他分支混淆,即过去已经停止很久的PHP 6。所以决定下一个PHP主要的发行版本叫PHP 7,而不是PHP 6。PHP 7.0预计在今年十一月份发行。
|
||||
|
||||
- 为了提升执行效率与记忆痕迹,PHPNG功能被添加到新的发行版中。
|
||||
- JIT引擎被收入来动态编译Zend操作码为自然机器码,以此来达到更快的处理性能。这项功能允许随后的程序调用同一份代码,这样会运行快很多。
|
||||
在下一代主要PHP版本里有一些不错的功能:
|
||||
|
||||
- 为了改善执行效率与内存占用,新的版本添加了PHPNG功能。
|
||||
- 引入了JIT引擎来动态编译Zend操作码为自然机器码,以此来达到更快的处理性能。这项功能允许随后的程序调用同一份代码,这样会运行快很多。
|
||||
- AST(抽象语法树)是最新添加的功能,它可以增强支持PHP的扩展性和用户应用。
|
||||
- 异步编程功能会添加支持并行任务,在同样的需求下。
|
||||
-新的版本会支持独立多线程网页服务,这样可以使用一个单独的存储块处理很多并发的请求。
|
||||
- 添加异步编程功能以支持同一个请求中的并行任务。
|
||||
- 新的版本会支持独立的多线程网页服务器,这样可以使用一个单独的存储池处理很多并发的请求。
|
||||
|
||||
### 在CcentOS/Fedora上安装PHP 7 ###
|
||||
### 在CentOS/Fedora上安装PHP 7 ###
|
||||
|
||||
让我们来看看怎样在CentOS 7和Fedora 21安装PHP7。为了安装PHP7,我们首先需要克隆php-src 仓库。当克隆工作完成,我们会配置和编译它。进行下一步之前,我们要确保已经在LInux系统下安装了如下的东西,否则PHP编译会返回错误,然后流产。
|
||||
让我们来看看怎样在CentOS 7和Fedora 21安装PHP7。为了安装PHP7,我们首先需要克隆php-src 仓库。当克隆工作完成,我们再配置和编译它。进行下一步之前,我们要确保已经在LInux系统下安装了如下的组件,否则PHP编译会返回错误中止。
|
||||
|
||||
- Git
|
||||
- autoconf
|
||||
- gcc
|
||||
- bison
|
||||
|
||||
所有上面提到的要求可以使用Yum软件包管理器安装。用连续的一个命令应该这样:
|
||||
所有上面提到的要求可以使用Yum软件包管理器安装。以下一条命令即可完成:
|
||||
|
||||
yum install git autoconf gcc bison
|
||||
|
||||
准备好开始安装PHP7了吗?让我们先创建一个PHP7目录,作为你的工作目录。
|
||||
准备好开始安装PHP7了吗?让我们先创建一个PHP7目录,作为你的当前工作目录。
|
||||
|
||||
mkdir php7
|
||||
|
||||
@ -143,7 +144,7 @@ PHP是一种为我们熟知的通用的,服务器网页脚本语言。超大
|
||||
|
||||
--with-mysqli=/usr/bin/mysql_config
|
||||
|
||||
这会花去不少的时间,一旦完成,你应该会看到如下面的输出:
|
||||
这会花去不少的时间,当完成后你应该会看到如下面的输出:
|
||||
|
||||
creating libtool
|
||||
|
||||
@ -206,9 +207,9 @@ PHP是一种为我们熟知的通用的,服务器网页脚本语言。超大
|
||||
|
||||
运行下面的命令,完成编译过程。
|
||||
|
||||
manke
|
||||
make
|
||||
|
||||
“make”命令过后的样例输出如下所示:
|
||||
“make”命令的样例输出如下所示:
|
||||
|
||||
Generating phar.php
|
||||
|
||||
@ -294,7 +295,7 @@ PHP是一种为我们熟知的通用的,服务器网页脚本语言。超大
|
||||
|
||||
cd sapi/cli
|
||||
|
||||
在这里验证PHP的版本。
|
||||
验证一下PHP的版本。
|
||||
|
||||
[root@localhost cli]# ./php -v
|
||||
|
||||
@ -306,7 +307,7 @@ PHP是一种为我们熟知的通用的,服务器网页脚本语言。超大
|
||||
|
||||
### 总结 ###
|
||||
|
||||
PHP 7也被[添加到了remi仓库][1],即将到来的版本主要关注执行效率的提升,新的特性致力于使PHP较好满足现代编程的需求和趋势。PHP 7.0将会有许多新的特性,丢弃一些老版本的东西。在接下来的日子里,我们希望看到新特性和弃用功能的具体情况。尽情享受吧!
|
||||
PHP 7也[添加到了remi仓库][1],这个即将到来的版本主要关注执行效率的提升,它的新特性致力于使PHP较好满足现代编程的需求和趋势。PHP 7.0将会有许多新的特性、丢弃一些老版本的东西。在接下来的日子里,我们希望看到新特性和弃用功能的具体情况。希望你喜欢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -314,7 +315,7 @@ via: http://linoxide.com/linux-how-to/install-php-7-centos-7-fedora-21/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,20 +1,21 @@
|
||||
Linux Email应用 Geary 更新了 — 如何在Ubuntu上安装
|
||||
Linux Email应用 Geary 更新了
|
||||
================================================================================
|
||||
**Geary,Linux上流行的桌面email客户端,更新到版本0.10了 — 并且有了很多新的功能。**
|
||||
|
||||

|
||||
elementary OS上运行的旧版本的Geary
|
||||
|
||||
Geary 0.10有一些可惜的用户界面改进以及额外的UI选项,包括:
|
||||
*elementary OS上运行的旧版本的Geary*
|
||||
|
||||
- 新增: 可以对归档,删除以及移动做'Undo'操作
|
||||
Geary 0.10有一些不错的用户界面改进以及额外的UI功能,包括:
|
||||
|
||||
- 新增: 可以撤销归档、删除以及移动等操作
|
||||
- 新增: 在2列或者2列布局之间切换
|
||||
- 新的 “split header bar” — 改进邮件列表,发件人布局
|
||||
- 新的快捷键 — 使用j/k切换到上/下一封邮件
|
||||
|
||||
根据Yorba介绍,这次更新还提出了一个 **全新的全文检索算法** ,用来改进Geary的搜索体验。
|
||||
根据Yorba介绍,这次更新还引入了一个**全新的全文检索算法** ,用来改进Geary的搜索体验。
|
||||
|
||||
这个更新应该能平息一下对应用搜索能力的抱怨,那些经常觉得Geary返回的搜索结果仅仅是包装软件自身"看起来和查询语句毫不相关"的观点。
|
||||
这个更新应该能平息一下对该应用的搜索能力的抱怨:Geary返回的搜索结果就如同软件自己所宣称的“看起来和查询语句毫不相关”。
|
||||
|
||||
> ‘Yorba 建议所有这个软件客户端的用户升级到这个版本’
|
||||
|
||||
@ -36,7 +37,7 @@ Yorba的最新版本可以从GNOME的Git账户下载可编译的源代码。但
|
||||
|
||||
Ubuntu用户想知道如何在 **14.04,14.10** 以及 **15.04**(那些更新爱好者) 上安装Geary 0.10。
|
||||
|
||||
官方的Youba PPA包括了 **Geary最新版本** 以及Shotwell(照片管理器)和[California][2](日历应用)。请注意添加这个PPA会使你电脑上任何已经安装的这些应用更新到最近的版本。
|
||||
官方的Youba PPA包括了 **Geary 最新版本** 以及Shotwell(照片管理器)和[California][2](日历应用)。请注意添加这个PPA会使你电脑上任何已经安装的这些应用更新到最近的版本。
|
||||
|
||||
Capiche? Coolio.
|
||||
|
||||
@ -52,7 +53,7 @@ Capiche? Coolio.
|
||||
|
||||
完成后,打开你的桌面环境应用启动面板并查找‘Geary’图标。点击它,添加你的账户并查看[通过信息高速公路下载了什么][3],开始使用简单的图形界面吧。
|
||||
|
||||
**别忘记:你可以通过电子邮件告诉我们你想看的新闻,应用建议,以及任何你想我们包括的东西,直接点击joey@oho.io**
|
||||
**别忘记:你可以通过电子邮件告诉我们你想看的新闻,应用建议,以及任何你想我们包括的东西。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -60,7 +61,7 @@ via: http://www.omgubuntu.co.uk/2015/03/install-geary-ubuntu-linux-email-update
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,62 +1,61 @@
|
||||
如何在CentOS上面安装CentOS网页面板
|
||||
如何在CentOS上面安装“CentOS网页面板”
|
||||
===========================================================================
|
||||

|
||||
|
||||
### 关于CentOS网页面板 ###
|
||||
|
||||
目前有很多免费的或者付费的控制面板。今天,我们来讨论[CentOS网页面板(CWP)][1],这是特别为基于如CentOS,RHEL,科研用Linux系统等发行版的RPM设计的。**CWP** 是免费且开源的控制面板,可以被广泛用于简单地配置一个网页集群环境。不同于其他的控制面板,CWP是自动用高速缓存来配置LAMP的栈区。
|
||||
目前有很多免费的或者付费的控制面板。今天,我们来讨论[CentOS网页面板(CWP)][1],这是特别为基于RPM 的发行版,如CentOS,RHEL,Scientific Linux等设计的。**CWP** 是免费且开源的控制面板,可以被广泛用于简单地配置一个网页托管环境。不同于其他的控制面板,CWP能自动部署LAMP的软件栈及Varnish 缓存服务器。
|
||||
|
||||
### 特性 ###
|
||||
|
||||
CWP有很多的特性和免费的服务。如我前面提到的一样,CWP自动在你的服务器上安装全套LAMP服务(apache,php,phpmyadmin,webmail,mailserver等等)。
|
||||
CWP有很多的特性和免费的服务。如我前面提到的一样,CWP会在你的服务器上自动安装全套的LAMP服务(apache,php,phpmyadmin,webmail,mailserver等等)。
|
||||
|
||||
### CWP安装过程中会安装和配置的软件列表 ###
|
||||
|
||||
- Apache Web Server
|
||||
- Apache 网页服务器
|
||||
- PHP 5.4
|
||||
- MySQL + phpMyAdmin
|
||||
- Postfix + Dovecot + roundcube webmail
|
||||
- CSF Firewall
|
||||
- File System Lock (no more website hacking, all your files are locked from changes)
|
||||
- Backups; AutoFixer for server configuration
|
||||
- CSF 防火墙
|
||||
- File System Lock (不需要修改网站,你的所有文件都会被锁定修改)
|
||||
- Backups; AutoFixer ,用于服务器配置
|
||||
|
||||
### 第三方应用: ###
|
||||
|
||||
|
||||
- CloudLinux + CageFS + PHP Selector
|
||||
- Softaculous – Script Installer (Free and Premium)
|
||||
- Softaculous – 脚本安装器 (免费版和白金版)
|
||||
|
||||
#### 网页服务器: ####
|
||||
|
||||
- Varnish Cache server
|
||||
- Compiles Apache from source
|
||||
- Apache reCompiler + Additional modules
|
||||
- Apache server status, configuration
|
||||
- Edit apache vhosts, vhosts templates, include configuration
|
||||
- Rebuild all apache Virtual hosts
|
||||
- Varnish 缓存服务器
|
||||
- 从代码编译 Apache
|
||||
- Apache 重新编译+附加模块
|
||||
- Apache 服务器状态,配置
|
||||
- 编辑 Apache 虚拟主机、虚拟主机模版,包括配置
|
||||
- 重建所有 Apache 虚拟主机
|
||||
- suPHP & suExec
|
||||
- Mod Security + OWASP rules
|
||||
- Tomcat 8 server management
|
||||
- DoS protection
|
||||
- Perl cgi script support
|
||||
- Mod Security + OWASP 规则
|
||||
- Tomcat 8 服务器管理
|
||||
- DoS 防护
|
||||
- Perl cgi 脚本支持
|
||||
|
||||
#### PHP: ####
|
||||
|
||||
- PHP 切换器 (在PHP版本如: 5.2, 5.3, 5.4, 5.5之间切换)
|
||||
- PHP选择器选择每个用户或者每个文件的PHP版本(PHP 4.4, 5.2, 5.3, 5.4, 5.5, 5.6)
|
||||
- 简单的php编辑软件
|
||||
- PHP 切换器 (在PHP版本如: 5.2、 5.3、 5.4、 5.5之间切换)
|
||||
- PHP选择器,选择每个用户或者每个文件的PHP版本(PHP 4.4、 5.2、 5.3、 5.4、5.5、 5.6)
|
||||
- 简单的php编辑器
|
||||
- 在用户面板下简单的php.ini生成器
|
||||
- PHP 插件
|
||||
- PHP.ini editor & PHP info & List modules
|
||||
- PHP.ini 编辑器 & PHP 信息 和列出模块
|
||||
- 每个帐号一个php.ini
|
||||
- FFMPEG,用于视频流网站
|
||||
- FFMPEG,用于视频流网站
|
||||
- CloudLinux + PHP 选择器
|
||||
|
||||
#### 用户管理 ####
|
||||
|
||||
- 添加,列举,编辑和移除用户
|
||||
- 添加、列出、编辑和移除用户
|
||||
- 用户监管
|
||||
- Shell接入管理
|
||||
- Shell访问管理
|
||||
- 用户限制管理
|
||||
- 限制进程
|
||||
- 限制访问文件
|
||||
@ -67,85 +66,85 @@ CWP有很多的特性和免费的服务。如我前面提到的一样,CWP自
|
||||
#### DNS: ####
|
||||
|
||||
- FreeDNS
|
||||
- 添加,编辑,列举和移除DNS区块
|
||||
- 添加、编辑、列出和移除DNS区块
|
||||
- 编辑域名服务的IP
|
||||
- DNS区块模板编辑器
|
||||
- 新的易用DNS区块管理器 (用ajax)
|
||||
- 新的DNS区块列表,带有额外的修复信息 (同时检测 rDNS, 域名服务….)
|
||||
- 新的DNS区块列表,带有额外的google解析信息 (同时检测 rDNS, 域名服务…)
|
||||
|
||||
#### Email: ####
|
||||
|
||||
- Postfix & dovecot
|
||||
- MailBoxes, Alias
|
||||
- 邮箱、别名
|
||||
- Roundcube webmail
|
||||
- Postfix Mail queue
|
||||
- rDNS Checker Module
|
||||
- Postfix 邮件队列
|
||||
- rDNS 检查器模块
|
||||
- 垃圾邮件拦截
|
||||
- SPF & DKIM集成
|
||||
- Re-Build Postfix/Dovecot Mail server with AntiVirus, AntiSpam Protection
|
||||
- Email Auto Responder
|
||||
- 重构带有反病毒、反垃圾邮件防护的 Postfix/Dovecot 的邮件服务器
|
||||
- Email 自动应答器
|
||||
|
||||
#### 系统: ####
|
||||
|
||||
- CPU核心和时钟信息
|
||||
- 内存使用信息
|
||||
- 详细的磁盘状态
|
||||
- 软件信息如内核版本,正常运行时间等等.
|
||||
- 软件信息如内核版本、正常运行时间等等.
|
||||
- 服务器状态
|
||||
- 检查配置管理
|
||||
- ChkConfig管理
|
||||
- 网络端口使用
|
||||
- 网络配置
|
||||
- SSHD配置
|
||||
- sshd 配置
|
||||
- 自动修复(检查重要的配置并尝试自动修复问题)
|
||||
|
||||
#### 监控: ####
|
||||
|
||||
- 监控服务 eg. top, apache stats, mysql etc.
|
||||
- 在面板内使用Java SSH Terminal/Console
|
||||
- 服务器配置 (eg. Apache, PHP, MySQL etc)
|
||||
- 监控服务,例如 top、 apache 状态、 mysql 等
|
||||
- 在面板内使用Java SSH 终端/控制台
|
||||
- 服务器配置 (例如 Apache、 PHP、 MySQL 等)
|
||||
- 在屏幕/后台运行命令行
|
||||
|
||||
#### 安全: ####
|
||||
|
||||
- CSF防火墙
|
||||
- SSL产生器
|
||||
- SSL生成器
|
||||
- SSL证书管理
|
||||
- CloudLinux + CageFS
|
||||
|
||||
#### SQL: ####
|
||||
|
||||
- MySQL 数据库管理
|
||||
- 添加本地或者远程接入用户
|
||||
- 添加本地或者远程访问的用户
|
||||
- 实时监控MySQL进程列表
|
||||
- 创建,移除数据库
|
||||
- 为每个数据库添加额外的用户
|
||||
- MySQL服务器配置
|
||||
- PhpMyAdmin(这个不知道要不要译过来)
|
||||
- PhpMyAdmin
|
||||
- PostgreSQL, phpPgAdmin支持
|
||||
|
||||
#### 额外功能: ####
|
||||
|
||||
- 语言通话3 管理
|
||||
- 网络电台管理
|
||||
- TeamSpeak 3 管理器
|
||||
- Shoutcast 管理器
|
||||
- 自动更新
|
||||
- 备份管理
|
||||
- 文件管理
|
||||
- 备份管理器
|
||||
- 文件管理器
|
||||
- 每个域名的虚拟FTP用户
|
||||
- 控制面板帐号移植 (恢复文件,数据库和数据库用户)
|
||||
- 还有更多.
|
||||
- cPanel帐号迁移 (恢复文件,数据库和数据库用户)
|
||||
- 还有更多
|
||||
|
||||
### 在CentOS 6上安装CentOS网页面板 ###
|
||||
|
||||
写这篇教程的时候,CWP仅仅支持最高CentOS 6.x版本。在CentOS 7和更高的版本中是行不通的。
|
||||
写这篇教程的时候,CWP仅仅支持最高CentOS 6.x版本。在CentOS 7和更高的版本中是不支持的。
|
||||
|
||||
#### 前期准备: ####
|
||||
|
||||
**安装CWP之前,里必须知道以下的信息:**
|
||||
**安装CWP之前,你必须知道以下的信息:**
|
||||
|
||||
- CWP 仅支持静态IP地址。它并不支持动态的,固定的,或者内部的IP地址。
|
||||
- CWP 并没有卸载程序。当你安装CWP后,里必须重新安装服务器来移除它。
|
||||
- 之安装CWP在一个新装的还没做任何配置改变的操作系统上。
|
||||
- 对与32位操作系统至少需要512MB RAM。
|
||||
- CWP 仅支持静态IP地址。它并不支持动态的,或者内部的IP地址。
|
||||
- CWP 并没有卸载程序。当你安装CWP后,你必须重新安装服务器来移除它。
|
||||
- 只能在一个新装的还没做任何配置改变的操作系统上安装CWP。
|
||||
- 对于32位操作系统至少需要512MB RAM。
|
||||
- 64位系统需要1024MB RAM。
|
||||
- 要求至少20GB的硬盘空间。
|
||||
|
||||
@ -175,7 +174,7 @@ CWP有很多的特性和免费的服务。如我前面提到的一样,CWP自
|
||||
|
||||
如果上面的URL出现错误,用下面的链接代替。
|
||||
|
||||
wget http://dll.centos-webpanle.com/files/cwp-latest
|
||||
wget http://dl1.centos-webpanle.com/files/cwp-latest
|
||||
|
||||
然后,用命令开始安装CWP:
|
||||
|
||||
@ -189,8 +188,7 @@ CWP有很多的特性和免费的服务。如我前面提到的一样,CWP自
|
||||
|
||||
安装过程会持续到30分钟或者更多,取决于你的网速。
|
||||
|
||||
最后,你会看到如下安装完成的信息。
|
||||
记下一些详细信息,如mysql超级用户密码和CWP的登录URLs。你随后会需要。然后,按下回车Enter重启系统。
|
||||
最后,你会看到如下安装完成的信息。记下一些详细信息,如mysql超级用户密码和CWP的登录URL,你随后会需要它们。然后,按下回车Enter重启系统。
|
||||
|
||||

|
||||
|
||||
@ -200,7 +198,7 @@ CWP有很多的特性和免费的服务。如我前面提到的一样,CWP自
|
||||
|
||||
#### 调整防火墙/路由: ####
|
||||
|
||||
CWP的默认网络控制接口是**2030(http)**和**2031(https)**。你应该通过防火墙/路由允许使用这两个端口,以便远程接入CWP网络控制台。
|
||||
CWP的默认网页控制界面的端口是**2030(http)**和**2031(https)**。你应该通过防火墙/路由允许使用这两个端口,以便远程接入CWP网络控制台。
|
||||
|
||||
编辑iptables文件:
|
||||
|
||||
@ -242,43 +240,42 @@ CWP的默认网络控制接口是**2030(http)**和**2031(https)**。你
|
||||
|
||||
接下来,我们得做一些事,比如:
|
||||
|
||||
1.建立域名服务
|
||||
1.建立ip共享(必须是你的公共IP地址)
|
||||
1.建立至少一个集合包(或者编辑默认的包)
|
||||
1.建立root电子邮件,等等。
|
||||
1. 设置域名服务器
|
||||
1. 设置 ip 共享(必须是你的公共IP地址)
|
||||
1. 设置至少一个托管包(或者编辑默认的包)
|
||||
1. 设置 root 电子邮件,等等。
|
||||
|
||||
#### 建立域名服务: ####
|
||||
#### 设置域名服务器: ####
|
||||
|
||||
为建立域名服务,找到**DNS Functions -> Edit nameservers IPs**。
|
||||
为建立域名服务器,找到**DNS Functions -> Edit nameservers IPs**。
|
||||
|
||||

|
||||
|
||||
设置你的域名服务器,点击保存按钮。
|
||||
|
||||
|
||||

|
||||
|
||||
#### 建立共享IP和Root邮箱ID: ####
|
||||
#### 建立共享IP和Root邮件地址: ####
|
||||
|
||||
在你的主机上管理网站,这是非常重要的一步。为了建立共享IP,进入**CWP Setting -> Edit settings**。
|
||||
在你的主机上托管网站,这是非常重要的一步。为了建立共享IP,进入**CWP Setting -> Edit settings**。
|
||||
|
||||

|
||||
|
||||
输入你的静态IP和邮箱ID,然后点击保存设置按钮。
|
||||
输入你的静态IP和邮件地址,然后点击保存设置按钮。
|
||||
|
||||

|
||||
|
||||
现在,CWP可以进行网站维护了。
|
||||
|
||||
#### 建立主机包 ####
|
||||
#### 建立托管包 ####
|
||||
|
||||
一个主机包什么都没有,除了一个网站托管计划,包括允许访问的磁盘空间,带宽,但没有FTP帐号,邮箱IDs和数据库等等。你可以建立任意数量的网站托管计划,只要你喜欢。
|
||||
一个托管包就是一个网站托管计划,包括允许访问的磁盘空间,带宽,但没有FTP帐号,邮箱地址和数据库等等。你可以建立任意数量的网站托管计划,只要你喜欢。
|
||||
|
||||
添加一个包,从CWP的控制台进入**Packages — Add a Package**
|
||||
要添加一个包,从CWP的控制台进入**Packages — Add a Package**
|
||||
|
||||

|
||||
|
||||
输入包的名字,允许访问的磁盘配额/RAM数量,FTP/Email帐号,数据库和子域名等等。点击保持设置按钮,建立一个网站托管计划。
|
||||
输入包的名字,允许访问的磁盘配额/RAM数量,FTP/Email帐号,数据库和子域名等等。点击保存设置按钮,建立一个网站托管计划。
|
||||
|
||||

|
||||
|
||||
@ -290,7 +287,7 @@ CWP的默认网络控制接口是**2030(http)**和**2031(https)**。你
|
||||
|
||||
而添加一个用户,请进入**User Account -> New Account**。
|
||||
|
||||
输入域名(ex.unixmen.com),用户名,密码和邮箱id等等。最后,点击**Create**。
|
||||
输入域名(ex.unixmen.com),用户名,密码和邮箱地址等等。最后,点击**Create**。
|
||||
|
||||

|
||||
|
||||
@ -312,12 +309,11 @@ CWP的默认网络控制接口是**2030(http)**和**2031(https)**。你
|
||||
|
||||
---------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.unixmen.com/how-to-install-centos-web-panel-in-centos/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,261 @@
|
||||
4个可以发送完整电子邮件的命令行工具
|
||||
================================================================================
|
||||
今天的文章里我们会讲到一些使用Linux命令行工具来发送带附件的电子邮件的方法。它有很多用处,比如在应用程序所在服务器上,使用电子邮件发送一个文件过来,或者你可以在脚本中使用这些命令来做一些自动化操作。在本文的例子中,我们会使用foo.tar.gz文件作为附件。
|
||||
|
||||
有不同的命令行工具可以发送邮件,这里我分享几个多数用户会使用的工具,如`mailx`、`mutt`和`swaks`。
|
||||
|
||||
我们即将呈现的这些工具都是非常有名的,并且存在于多数Linux发行版默认的软件仓库中,你可以使用如下命令安装:
|
||||
|
||||
在 **Debian / Ubuntu** 系统
|
||||
|
||||
apt-get install mutt
|
||||
apt-get install swaks
|
||||
apt-get install mailx
|
||||
apt-get install sharutils
|
||||
|
||||
在基于Red Hat的系统,如 **CentOS** 或者 **Fedora**
|
||||
|
||||
yum install mutt
|
||||
yum install swaks
|
||||
yum install mailx
|
||||
yum install sharutils
|
||||
|
||||
### 1) 使用 mail / mailx ###
|
||||
|
||||
`mailx`工具在多数Linux发行版中是默认的邮件程序,现在已经支持发送附件了。如果它不在你的系统中,你可以使用上边的命令安装。有一点需要注意,老版本的mailx可能不支持发送附件,运行如下命令查看是否支持。
|
||||
|
||||
$ man mail
|
||||
|
||||
第一行看起来是这样的:
|
||||
|
||||
mailx [-BDdEFintv~] [-s subject] [-a attachment ] [-c cc-addr] [-b bcc-addr] [-r from-addr] [-h hops] [-A account] [-S variable[=value]] to-addr . . .
|
||||
|
||||
如果你看到它支持`-a`的选项(-a 文件名,将文件作为附件添加到邮件)和`-s`选项(-s 主题,指定邮件的主题),那就是支持的。可以使用如下的几个例子发送邮件。
|
||||
|
||||
**a) 简单的邮件**
|
||||
|
||||
运行`mail`命令,然后`mailx`会等待你输入邮件内容。你可以按回车来换行。当输入完成后,按Ctrl + D,`mailx`会显示EOT表示结束。
|
||||
|
||||
然后`mailx`会自动将邮件发送给收件人。
|
||||
|
||||
$ mail user@example.com
|
||||
|
||||
HI,
|
||||
Good Morning
|
||||
How are you
|
||||
EOT
|
||||
|
||||
**b) 发送有主题的邮件**
|
||||
|
||||
$ echo "Email text" | mail -s "Test Subject" user@example.com
|
||||
|
||||
`-s`的用处是指定邮件的主题。
|
||||
|
||||
**c) 从文件中读取邮件内容并发送**
|
||||
|
||||
$ mail -s "message send from file" user@example.com < /path/to/file
|
||||
|
||||
**d) 将从管道获取到的`echo`命令输出作为邮件内容发送**
|
||||
|
||||
$ echo "This is message body" | mail -s "This is Subject" user@example.com
|
||||
|
||||
**e) 发送带附件的邮件**
|
||||
|
||||
$ echo “Body with attachment "| mail -a foo.tar.gz -s "attached file" user@example.com
|
||||
|
||||
`-a`选项用于指定附件。
|
||||
|
||||
### 2) mutt ###
|
||||
|
||||
Mutt是类Unix系统上的一个文本界面邮件客户端。它有20多年的历史,在Linux历史中也是一个很重要的部分,它是最早支持进程打分和多线程处理的客户端程序之一。按照如下的例子来发送邮件。
|
||||
|
||||
**a) 带有主题,从文件中读取邮件的正文,并发送**
|
||||
|
||||
$ mutt -s "Testing from mutt" user@example.com < /tmp/message.txt
|
||||
|
||||
**b) 通过管道获取`echo`命令输出作为邮件内容发送**
|
||||
|
||||
$ echo "This is the body" | mutt -s "Testing mutt" user@example.com
|
||||
|
||||
**c) 发送带附件的邮件**
|
||||
|
||||
$ echo "This is the body" | mutt -s "Testing mutt" user@example.com -a /tmp/foo.tar.gz
|
||||
|
||||
**d) 发送带有多个附件的邮件**
|
||||
|
||||
$ echo "This is the body" | mutt -s "Testing" user@example.com -a foo.tar.gz –a bar.tar.gz
|
||||
|
||||
### 3) swaks ###
|
||||
|
||||
Swaks(Swiss Army Knife,瑞士军刀)是SMTP服务上的瑞士军刀,它是一个功能强大、灵活、可编程、面向事务的SMTP测试工具,由John Jetmore开发和维护。你可以使用如下语法发送带附件的邮件:
|
||||
|
||||
$ swaks -t "foo@bar.com" --header "Subject: Subject" --body "Email Text" --attach foo.tar.gz
|
||||
|
||||
关于Swaks一个重要的地方是,它会为你显示整个邮件发送过程,所以如果你想调试邮件发送过程,它是一个非常有用的工具。
|
||||
|
||||
它会给你提供了邮件发送过程的所有细节,包括邮件接收服务器的功能支持、两个服务器之间的每一步交互。
|
||||
|
||||
### 4) uuencode ###
|
||||
|
||||
邮件传输系统最初是被设计来传送7位编码(类似ASCII)的内容的。这就意味这它是用来发送文本内容,而不能发会使用8位的二进制内容(如程序文件或者图片)。`uuencode`(“UNIX to UNIX encoding”,UNIX之间使用的编码方式)程序用来解决这个限制。使用`uuencode`,发送端将二进制格式的转换成文本格式来传输,接收端再转换回去。
|
||||
|
||||
我们可以简单地使用`uuencode`和`mailx`或者`mutt`配合,来发送二进制内容,类似这样:
|
||||
|
||||
$ uuencode example.jpeg example.jpeg | mail user@example.com
|
||||
|
||||
### Shell脚本:解释如何发送邮件 ###
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
FROM=""
|
||||
SUBJECT=""
|
||||
ATTACHMENTS=""
|
||||
TO=""
|
||||
BODY=""
|
||||
|
||||
# 检查文件名对应的文件是否存在
|
||||
function check_files()
|
||||
{
|
||||
output_files=""
|
||||
for file in $1
|
||||
do
|
||||
if [ -s $file ]
|
||||
then
|
||||
output_files="${output_files}${file} "
|
||||
fi
|
||||
done
|
||||
echo $output_files
|
||||
}
|
||||
|
||||
echo "*********************"
|
||||
echo "E-mail sending script."
|
||||
echo "*********************"
|
||||
echo
|
||||
|
||||
# 读取用户输入的邮件地址
|
||||
while [ 1 ]
|
||||
do
|
||||
if [ ! $FROM ]
|
||||
then
|
||||
echo -n -e "Enter the e-mail address you wish to send mail from:\n[Enter] "
|
||||
else
|
||||
echo -n -e "The address you provided is not valid:\n[Enter] "
|
||||
fi
|
||||
|
||||
read FROM
|
||||
echo $FROM | grep -E '^.+@.+$' > /dev/null
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
break
|
||||
fi
|
||||
done
|
||||
|
||||
echo
|
||||
|
||||
# 读取用户输入的收件人地址
|
||||
while [ 1 ]
|
||||
do
|
||||
if [ ! $TO ]
|
||||
then
|
||||
echo -n -e "Enter the e-mail address you wish to send mail to:\n[Enter] "
|
||||
else
|
||||
echo -n -e "The address you provided is not valid:\n[Enter] "
|
||||
fi
|
||||
|
||||
read TO
|
||||
echo $TO | grep -E '^.+@.+$' > /dev/null
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
break
|
||||
fi
|
||||
done
|
||||
|
||||
echo
|
||||
|
||||
# 读取用户输入的邮件主题
|
||||
echo -n -e "Enter e-mail subject:\n[Enter] "
|
||||
read SUBJECT
|
||||
|
||||
echo
|
||||
|
||||
if [ "$SUBJECT" == "" ]
|
||||
then
|
||||
echo "Proceeding without the subject..."
|
||||
fi
|
||||
|
||||
# 读取作为附件的文件名
|
||||
echo -e "Provide the list of attachments. Separate names by space.
|
||||
If there are spaces in file name, quote file name with \"."
|
||||
read att
|
||||
|
||||
echo
|
||||
|
||||
# 确保文件名指向真实文件
|
||||
attachments=$(check_files "$att")
|
||||
echo "Attachments: $attachments"
|
||||
|
||||
for attachment in $attachments
|
||||
do
|
||||
ATTACHMENTS="$ATTACHMENTS-a $attachment "
|
||||
done
|
||||
|
||||
echo
|
||||
|
||||
# 读取完整的邮件正文
|
||||
echo "Enter message. To mark the end of message type ;; in new line."
|
||||
read line
|
||||
|
||||
while [ "$line" != ";;" ]
|
||||
do
|
||||
BODY="$BODY$line\n"
|
||||
read line
|
||||
done
|
||||
|
||||
SENDMAILCMD="mutt -e \"set from=$FROM\" -s \"$SUBJECT\" \
|
||||
$ATTACHMENTS -- \"$TO\" <<< \"$BODY\""
|
||||
echo $SENDMAILCMD
|
||||
|
||||
mutt -e "set from=$FROM" -s "$SUBJECT" $ATTACHMENTS -- $TO <<< $BODY
|
||||
|
||||
** 脚本输出 **
|
||||
|
||||
$ bash send_mail.sh
|
||||
*********************
|
||||
E-mail sending script.
|
||||
*********************
|
||||
|
||||
Enter the e-mail address you wish to send mail from:
|
||||
[Enter] test@gmail.com
|
||||
|
||||
Enter the e-mail address you wish to send mail to:
|
||||
[Enter] test@gmail.com
|
||||
|
||||
Enter e-mail subject:
|
||||
[Enter] Message subject
|
||||
|
||||
Provide the list of attachments. Separate names by space.
|
||||
If there are spaces in file name, quote file name with ".
|
||||
send_mail.sh
|
||||
|
||||
Attachments: send_mail.sh
|
||||
|
||||
Enter message. To mark the end of message type ;; in new line.
|
||||
This is a message
|
||||
text
|
||||
;;
|
||||
|
||||
### 总结 ###
|
||||
|
||||
有很多方法可以使用命令行/Shell脚本来发送邮件,这里我们只分享了其中4个类Unix系统可用的工具。希望你喜欢我们的文章,并且提供您的宝贵意见,让我们知道您想了解哪些新工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-shell-script/send-email-subject-body-attachment-linux/
|
||||
|
||||
作者:[Bobbin Zachariah][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bobbin/
|
||||
@ -1,8 +1,8 @@
|
||||
安装Inkscape - 开源适量图形编辑器
|
||||
Inkscape - 开源适量图形编辑器
|
||||
================================================================================
|
||||
Inkscape是一款开源矢量图形编辑工具,它使用可缩放矢量图形(SVG)图形格式并不同于它的竞争对手如Xara X、Corel Draw和Adobe Illustrator等等。SVG是一个广泛部署、免版税使用的图形格式,由W3C SVG工作组开发和维护。这是一个跨平台工具,完美运行于Linux、Windows和Mac OS上。
|
||||
Inkscape是一款开源矢量图形编辑工具,并不同于Xara X、Corel Draw和Adobe Illustrator等竞争对手,它使用的是可缩放矢量图形(SVG)图形格式。SVG是一个广泛部署、免版税使用的图形格式,由W3C SVG工作组开发和维护。这是一个跨平台工具,完美运行于Linux、Windows和Mac OS上。
|
||||
|
||||
Inkscape始于2003年,起初它的bug跟踪系统托管于Sourceforge上但是 后来迁移到了Launchpad上。当前它最新的一个稳定版本是0.91,它不断地在发展和修改中。我们将在本文里了解一下它的突出特点和安装过程。
|
||||
Inkscape始于2003年,起初它的bug跟踪系统托管于Sourceforge上,但是后来迁移到了Launchpad上。当前它最新的一个稳定版本是0.91,它不断地在发展和修改中。我们将在本文里了解一下它的突出特点和安装过程。
|
||||
|
||||
### 显著特性 ###
|
||||
|
||||
@ -12,30 +12,30 @@ Inkscape始于2003年,起初它的bug跟踪系统托管于Sourceforge上但是
|
||||
|
||||
- 用铅笔工具来画出不同颜色、大小和形状的手绘线,用贝塞尔曲线(笔式)工具来画出直线和曲线,通过书法工具来应用到手写的书法笔画上等等
|
||||
- 用文本工具来创建、选择、编辑和格式化文本。在纯文本框、在路径上或在形状里操作文本
|
||||
- 有效绘制各种形状,像矩形、椭圆形、圆形、弧线、多边形、星形和螺旋形等等并调整其大小、旋转并修改(圆角化)它们
|
||||
- 方便绘制各种形状,像矩形、椭圆形、圆形、弧线、多边形、星形和螺旋形等等并调整其大小、旋转并修改(圆角化)它们
|
||||
- 用简单地命令创建并嵌入位图
|
||||
|
||||
#### 对象处理 ####
|
||||
|
||||
- 通过交互式操作和调整数值来扭曲、移动、测量、旋转目标
|
||||
- 执行力提升并减少了Z-order操作。
|
||||
- 对象群组化或取消群组化可以去创建一个虚拟层阶用来编辑或处理
|
||||
- 图层采用层次结构树的结构并且能锁定或以各式各样的处理方式来重新布置
|
||||
- 通过交互式操作和调整参量来扭曲、移动、测量、旋转目标
|
||||
- 可以对 Z 轴进行提升或降低操作。
|
||||
- 通过对象组合和取消组合可以创建一个虚拟层用来编辑或处理
|
||||
- 图层采用层次结构树的结构,并且能锁定或以各式各样的处理方式来重新布置
|
||||
- 分布与对齐指令
|
||||
|
||||
#### 填充与边框 ####
|
||||
|
||||
- 复制/粘贴风格
|
||||
- 可以复制/粘贴不同风格
|
||||
- 取色工具
|
||||
- 用RGB, HSL, CMS, CMYK和色盘这四种不同的方式选色
|
||||
- 渐层编辑器能创建和管理多停点渐层
|
||||
- 定义一个图像或其它选择用来进行花纹填充
|
||||
- 用一些预定义泼洒花纹可对边框进行花纹泼洒
|
||||
- 通过路径标示器来开始、对折和结束标示
|
||||
- 渐变层编辑器能创建和管理多停点渐变层
|
||||
- 使用图像或其它选择区作为花纹填充
|
||||
- 用一些预定义点状花纹进行笔触填充
|
||||
- 通过路径标示器标示开始、对折和结束点
|
||||
|
||||
#### 路径上的操作 ####
|
||||
|
||||
- 节点编辑:移动节点和贝塞尔曲线掌控,节点的对齐和分布等等
|
||||
- 节点编辑:移动节点和贝塞尔曲线控制点,节点的对齐和分布等等
|
||||
- 布尔运算(是或否)
|
||||
- 运用可变的路径起迄点可简化路径
|
||||
- 路径插入和增设连同动态和链接偏移对象
|
||||
@ -43,9 +43,9 @@ Inkscape始于2003年,起初它的bug跟踪系统托管于Sourceforge上但是
|
||||
|
||||
#### 文本处理 ####
|
||||
|
||||
- 所有安装好的外框字体都能用甚至可以从右至左对齐对象
|
||||
- 所有安装好的框线字体都能用,甚至可以从右至左对齐对象
|
||||
- 格式化文本、调整字母间距、行间距或列间距
|
||||
- 路径上的文本和形状上的文本和路径或形状都可以被编辑和修改
|
||||
- 路径上和形状上的文本中的文本、路径或形状都可以被编辑和修改
|
||||
|
||||
#### 渲染 ####
|
||||
|
||||
@ -78,7 +78,7 @@ PPA添加到APT库中后,我们要用以下命令进行更新:
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Inkscape是一款特点鲜明的图形编辑工具,它给予用户充分发挥自己艺术力的权利。它还是一款自由安装和自定义开源应用并且支持大范围文件类型包括JPEG, PNG, GIF和PDF且不仅这些。访问它的 [官方网站][2] 来获取更多新闻和应用更新。
|
||||
Inkscape是一款特点鲜明的图形编辑工具,它给予用户充分发挥自己艺术能力的权利。它还是一款自由安装和自定义的开源应用,并且支持各种文件类型,包括JPEG, PNG, GIF和PDF及更多。访问它的 [官方网站][2] 来获取更多新闻和应用更新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -86,7 +86,7 @@ via: http://linoxide.com/tools/install-inkscape-open-source-vector-graphic-edito
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
Linux 上 wget 或 curl 的更佳替代品
|
||||
用腻了 wget 或 curl,有什么更好的替代品吗?
|
||||
================================================================================
|
||||
如果你经常需要通过终端以非交互模式访问网络服务器(例如,从网络上下载文件,或者是测试 RESTful 网络服务接口),可能你会选择的工具是 wget 或 curl。通过大量的命令行选项,这两种工具都可以处理很多非交互网络访问的情况(比如[这里][1],[这里][2],还有[这里][3])。然而,即使像这些一样的强大的工具,也只是与你对如何使用它们的了解程度等同。除非你很精通那些又多又笨(原文是 nitty and gritty)的语法细节,这些工具对于你来说只不过是简单的网络下载器。
|
||||
|
||||
就像宣传的那样,“为人类着想的类 curl 工具”,[HTTPie][4] 设计用来增强 wget 和 curl 的可用性。它的主要目标是使通过命令行与网络服务器进行交互的过程变得尽可能的人性化。为此,HTTPie 支持具有表现力,但又很简单很直观的语法。它以彩色模式显示响应,并且还有一些不错的优点,比如对 JSON 的良好支持,和持久性会话用以作业流程化。
|
||||
如果你经常需要通过终端以非交互模式访问网络服务器(例如,从网络上下载文件,或者是测试 RESTful 网络服务接口),可能你会选择的工具是 wget 或 curl。通过大量的命令行选项,这两种工具都可以处理很多非交互网络访问的情况(比如[这里][1]、[这里][2],还有[这里][3])。然而,即使像这些一样的强大的工具,你也只能发挥你所了解的那些选项的功能。除非你很精通那些繁冗的语法细节,这些工具对于你来说只不过是简单的网络下载器而已。
|
||||
|
||||
我知道很多人对把像 wget 和 curl 这样的无处不在的可用的完美工具换成完全没听说过的软件心存怀疑。这种观点是好的,特别是如果你是一个系统管理员、要处理很多不同的硬件的话。然而,对于开发者和终端用户来说,重要的是效率。如果我发现了一个工具的用户友好替代,我没有看到任何问题如果你采用易于使用的版本来节省你宝贵的时间。没有必要对替换掉的工具保持信仰忠诚。毕竟,对于 Linux 来说,最好的事情是可以选择。
|
||||
就像其宣传的那样,“给人用 curl 类工具”,[HTTPie][4] 设计用来增强 wget 和 curl 的可用性。它的主要目标是使通过命令行与网络服务器进行交互的过程变得尽可能的人性化。为此,HTTPie 支持具有表现力、但又很简单很直观的语法。它以彩色模式显示响应,并且还有一些不错的优点,比如对 JSON 的良好支持,和持久性会话用以作业流程化。
|
||||
|
||||
在这篇文章中,让我们来回顾并展示一下我所说的 HTTPie,一个用户友好的 wget 和 curl 的替代。
|
||||
我知道很多人对把像 wget 和 curl 这样的无处不在的、可用的、完美的工具换成完全没听说过的软件心存疑虑。这种观点是好的,特别是如果你是一个系统管理员、要处理很多不同的硬件的话。然而,对于开发者和终端用户来说,重要的是效率。如果我发现了一个工具的用户更佳替代品,那么我认为采用易于使用的版本来节省宝贵的时间是毫无疑问的。没有必要对替换掉的工具保持信仰忠诚。毕竟,对于 Linux 来说,最好的事情就是可以选择。
|
||||
|
||||
在这篇文章中,让我们来了解并展示一下我所说的 HTTPie,一个用户友好的 wget 和 curl 的替代。
|
||||
|
||||
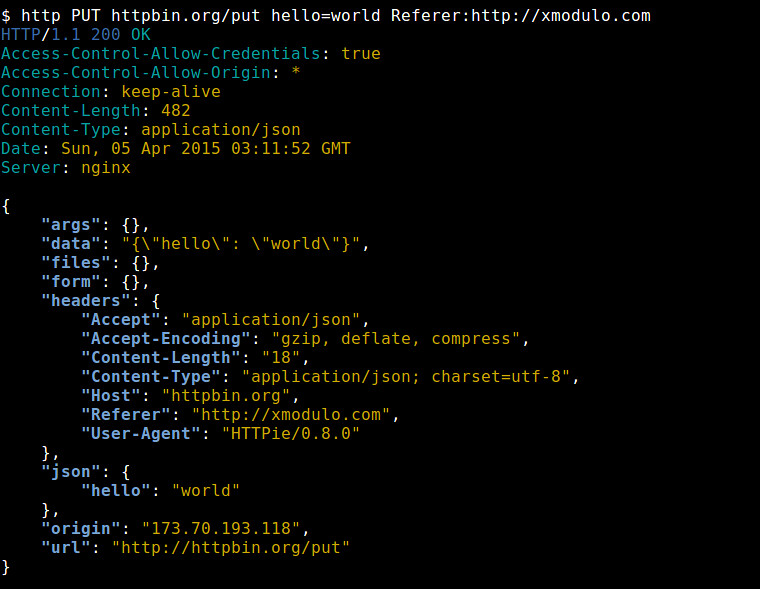
|
||||
|
||||
@ -40,10 +41,9 @@ HTTPie 是用 Python 写的,所以你可以在几乎所有地方(Linux,Mac
|
||||
|
||||
你可以使用 <header:value> 的格式来定制头部。例如,我们发送一个 HTTP GET 请求到 www.test.com ,使用定制用户代理(user-agent)和来源(referer),还有定制头部(比如 MyParam)。
|
||||
|
||||
|
||||
$ http www.test.com User-Agent:Xmodulo/1.0 Referer:http://xmodulo.com MyParam:Foo
|
||||
|
||||
注意到当使用 HTTP GET 方法时,你无需指定任何 HTTP 方法。
|
||||
注意到当使用 HTTP GET 方法时,就无需明确指定 HTTP 方法。
|
||||
|
||||
这个 HTTP 请求看起来如下:
|
||||
|
||||
@ -121,7 +121,7 @@ HTTPie 的另外一个用户友好特性是输入重定向,你可以使用缓
|
||||
|
||||
### 结束语 ###
|
||||
|
||||
在这篇文章中,我介绍了 HTTPie,一个 wget 和 curl 的可能替代工具。除了这里展示的几个简单的例子,你可以在[官方网站][7]上找到 HTTPie 的很多有趣的应用。再次重复一遍,一款强大的工具也只相当于你对它的了解程度。从个人而言,我更热衷于 HTTPie,因为我在寻找一种更简洁的测试复杂网络接口的方法。
|
||||
在这篇文章中,我介绍了 HTTPie,一个 wget 和 curl 的可能替代工具。除了这里展示的几个简单的例子,你可以在其[官方网站][7]上找到 HTTPie 的很多有趣的应用。再次重复一遍,一款再强大的工具也取决于你对它的了解程度。从个人而言,我更倾向于 HTTPie,因为我在寻找一种更简洁的测试复杂网络接口的方法。
|
||||
|
||||
你怎么看?
|
||||
|
||||
@ -131,15 +131,15 @@ via: http://xmodulo.com/wget-curl-alternative-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-download-multiple-files-with-wget.html
|
||||
[2]:http://xmodulo.com/how-to-use-custom-http-headers-with-wget.html
|
||||
[3]:http://ask.xmodulo.com/custom-http-header-curl.html
|
||||
[3]:https://linux.cn/article-4957-1.html
|
||||
[4]:https://github.com/jakubroztocil/httpie
|
||||
[5]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:https://linux.cn/article-2324-1.html
|
||||
[6]:http://ask.xmodulo.com/install-pip-linux.html
|
||||
[7]:https://github.com/jakubroztocil/httpie
|
||||
@ -1,12 +1,12 @@
|
||||
一些重要Docker命令的简单介绍
|
||||
一些重要 Docker 命令的简单介绍
|
||||
================================================================================
|
||||
大家好,今天我们来学习一些在你使用Docker之前需要了解的重要的 Docker 命令。Docker 是一个提供开发平台去打包,装载和运行任何应用的轻量级容器开源项目。它没有语言支持,框架和打包系统的限制,能从一个小的家庭电脑到高端服务器,在任何地方任何时间运行。这使得它们成为不依赖于一个特定的栈或供应商,部署和扩展web应用,数据库和后端服务很好的构建块。
|
||||
大家好,今天我们来学习一些在你使用 Docker 之前需要了解的重要的 Docker 命令。[Docker][1] 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。这使它们可以不依赖于特定软件栈和供应商,像一块块积木一样部署和扩展网络应用、数据库和后端服务。
|
||||
|
||||
Docker 命令简单易学,也很容易实现或实践。这是一些你运行 Docker 并充分利用它需要知道的简单 Docker 命令。
|
||||
|
||||
### 1. 拉取一个 Docker 镜像 ###
|
||||
### 1. 拉取 Docker 镜像 ###
|
||||
|
||||
由于容器是由 Docker 镜像构建的,首先我们需要拉取一个 docker 镜像来开始。我们可以从 Docker 注册 Hub 获取需要的 docker 镜像。在我们使用 pull 命令拉取任何镜像之前,由于pull命令被标识为恶意命令,我们需要保护我们的系统。为了保护我们的系统不受这个问题影响,我们需要添加 **127.0.0.1 index.docker.io** 到 /etc/hosts 条目。我们可以通过使用喜欢的文本编辑器完成。
|
||||
由于容器是由 Docker 镜像构建的,首先我们需要拉取一个 docker 镜像来开始。我们可以从 Docker Registry Hub 获取所需的 docker 镜像。在我们使用 pull 命令拉取任何镜像之前,为了避免 pull 命令的一些恶意风险,我们需要保护我们的系统。为了保护我们的系统不受这个风险影响,我们需要添加 **127.0.0.1 index.docker.io** 到 /etc/hosts 条目。我们可以通过使用喜欢的文本编辑器完成。
|
||||
|
||||
# nano /etc/hosts
|
||||
|
||||
@ -16,7 +16,7 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
要拉取一个 docker 进行,我们需要运行下面的命令。
|
||||
要拉取一个 docker 镜像,我们需要运行下面的命令。
|
||||
|
||||
# docker pull registry.hub.docker.com/busybox
|
||||
|
||||
@ -28,9 +28,9 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
### 2. 运行一个 Docker 容器 ###
|
||||
### 2. 运行 Docker 容器 ###
|
||||
|
||||
现在,成功地拉取要求或需要的 Docker 镜像之后,我们当然想运行这个 Docker 镜像。我们可以用 docker run 命令在镜像上运行一个 docker 容器。在 Docker 镜像之上运行一个 docker 容易时我们有很多选项和标记。我们使用 -t 和 -i 标记运行一个 docker 镜像并进入容器,如下面所示。
|
||||
现在,成功地拉取要求的或所需的 Docker 镜像之后,我们当然想运行这个 Docker 镜像。我们可以用 docker run 命令在镜像上运行一个 docker 容器。在 Docker 镜像上运行一个 docker 容器时我们有很多选项和标记。我们使用 -t 和 -i 选项来运行一个 docker 镜像并进入容器,如下面所示。
|
||||
|
||||
# docker run -it busybox
|
||||
|
||||
@ -50,7 +50,7 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
### 3. 查看容器 ###
|
||||
### 3. 检查容器运行 ###
|
||||
|
||||
不论容器是否运行,查看日志文件都很简单。我们可以使用下面的命令去检查是否有 docker 容器在实时运行。
|
||||
|
||||
@ -62,17 +62,17 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
### 4. 检查 Docker 容器 ###
|
||||
### 4. 查看容器信息 ###
|
||||
|
||||
我们可以使用 inspect 命令检查一个 Docker 容器的每条信息。
|
||||
我们可以使用 inspect 命令查看一个 Docker 容器的各种信息。
|
||||
|
||||
# docker inspect <container id>
|
||||
|
||||

|
||||
|
||||
### 5. 杀死或删除命令 ###
|
||||
### 5. 杀死或删除 ###
|
||||
|
||||
我们可以使用 docker id 杀死或者停止进程或 docker 容器,如下所示。
|
||||
我们可以使用容器 id 杀死或者停止 docker 容器(进程),如下所示。
|
||||
|
||||
# docker stop <container id>
|
||||
|
||||
@ -90,7 +90,7 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||
### 结论 ###
|
||||
|
||||
这些都是学习充分实现和利用 Docker 很基本的 docker 命令。有了这些命令,Docker 变得很简单,提供给端用户一个简单的计算平台。根据上面的教程,任何人学习 Docker 命令都非常简单。如果你有任何问题,建议,反馈,请写到下面的评论框中以便我们改进和更新内容。多谢!享受吧 :-)
|
||||
这些都是充分学习和使用 Docker 很基本的 docker 命令。有了这些命令,Docker 变得很简单,可以提供给最终用户一个易用的计算平台。根据上面的教程,任何人学习 Docker 命令都非常简单。如果你有任何问题,建议,反馈,请写到下面的评论框中以便我们改进和更新内容。多谢! 希望你喜欢 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -98,8 +98,9 @@ via: http://linoxide.com/linux-how-to/important-docker-commands/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://www.docker.com/
|
||||
@ -1,4 +1,4 @@
|
||||
Linux有问必答--如何在Linux中修改环境变量PATH
|
||||
Linux有问必答:如何在Linux中修改环境变量PATH
|
||||
================================================================================
|
||||
> **提问**: 当我试着运行一个程序时,它提示“command not found”。 但这个程序就在/usr/local/bin下。我该如何添加/usr/local/bin到我的PATH变量下,这样我就可以不用指定路径来运行这个命令了。
|
||||
|
||||
@ -38,7 +38,7 @@ Linux有问必答--如何在Linux中修改环境变量PATH
|
||||
|
||||
/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/sbin:/sbin:/home/xmodulo/bin:/usr/local/bin
|
||||
|
||||
更新的PATH会在当前的PATH一直有效。然而,更改将在新的会话中失效。
|
||||
更新后的PATH会在当前的会话一直有效。然而,更改将在新的会话中失效。
|
||||
|
||||
如果你想要永久更改PATH变量,用编辑器打开~/.bashrc (或者 ~/.bash_profile),接着在最后添加下面这行。
|
||||
|
||||
@ -46,7 +46,7 @@ Linux有问必答--如何在Linux中修改环境变量PATH
|
||||
|
||||
接着运行下面这行永久激活更改:
|
||||
|
||||
$ source ~/.bashrc (or source ~/.bash_profile)
|
||||
$ source ~/.bashrc (或者 source ~/.bash_profile)
|
||||
|
||||
### 改变系统级的环境变量 ###
|
||||
|
||||
@ -66,7 +66,7 @@ via: http://ask.xmodulo.com/change-path-environment-variable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
[已解决] Ubuntu下不能记住亮度设置问题
|
||||
如何解决 Ubuntu 下不能记住亮度设置的问题
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -22,7 +22,7 @@ via: http://itsfoss.com/ubuntu-mint-brightness-settings/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,26 @@
|
||||
如何在 CentOS Linux 中配置 MariADB 复制
|
||||
如何在 CentOS Linux 中配置 MariaDB 复制
|
||||
================================================================================
|
||||
这是一个创建数据库重复版本的过程。复制过程不仅仅是复制一个数据库,同时也包括从主节点到一个从节点的更改同步。但这并不意味着从数据库就是和主数据库完全相同的副本,因为复制可以配置为只有表或者行或者列的一个模式将被复制,例如,局部复制。复制保证了特定的配置对象在不同的数据库之间保持同步。
|
||||
这是一个创建数据库重复版本的过程。复制过程不仅仅是复制一个数据库,同时也包括从主节点到一个从节点的更改同步。但这并不意味着从数据库就是和主数据库完全相同的副本,因为复制可以配置为只复制表结构、行或者列,这叫做局部复制。复制保证了特定的配置对象在不同的数据库之间保持一致。
|
||||
|
||||
### Mariadb 复制概念 ###
|
||||
|
||||
**备份** :复制可以用来进行数据库备份。例如,你有主->从复制。如果主节点丢失(比如hdd损坏),你可以从从节点中恢复你的数据库。
|
||||
**备份** :复制可以用来进行数据库备份。例如,当你做了主->从复制。如果主节点数据丢失(比如硬盘损坏),你可以从从节点中恢复你的数据库。
|
||||
|
||||
**扩展** :你可以使用主->从复制作为扩展的解决方案。例如,如果你有一些大的数据库以及SQL查询,使用复制你可以将这些查询单独分到每个复制节点。写SQL应该只在主节点进行,而只读查询可以在从节点上进行。
|
||||
**扩展** :你可以使用主->从复制作为扩展解决方案。例如,如果你有一些大的数据库以及SQL查询,使用复制你可以将这些查询分离到每个复制节点。写入操作的SQL应该只在主节点进行,而只读查询可以在从节点上进行。
|
||||
|
||||
**传播解决方案** :你可以用复制来进行分发。例如,你可以将不同的销售数据分发到不同的数据库。
|
||||
**分发解决方案** :你可以用复制来进行分发。例如,你可以将不同的销售数据分发到不同的数据库。
|
||||
|
||||
**故障解决方案** : 假如你有主节点->从节点1->从节点2->从节点3的复制。你可以为主节点写脚本监控,如果主节点出故障了,脚本可以快速的将从节点1作为新的主节点,有主节点->从节点1->从节点2,你的应用可以继续工作而不会停机。
|
||||
**故障解决方案** : 假如你建立有主节点->从节点1->从节点2->从节点3的复制结构。你可以为主节点写脚本监控,如果主节点出故障了,脚本可以快速的将从节点1切换为新的主节点,这样复制结构变成了主节点->从节点1->从节点2,你的应用可以继续工作而不会停机。
|
||||
|
||||
### 复制的简单图解示范 ###
|
||||
|
||||

|
||||
|
||||
开始之前,你应该知道什么是**二进制日志文件**以及 Ibdata1。二进制日志文件中包括关于数据库,数据和结构的所有更改的记录,以及每条语句的执行时间。二进制日志文件包括设置日志文件和一个索引。这意味着主要的SQL语句,例如CREATE, ALTER, INSERT, UPDATE 和 DELETE 会放到这个日志文件中,而例如SELECT语句就不会被记录。这些信息可以被记录到普通的query.log文件。简单的说 **Ibdata1** 是一个包括所有表和所有数据库信息的文件。
|
||||
开始之前,你应该知道什么是**二进制日志文件**以及 Ibdata1。
|
||||
|
||||
二进制日志文件中包括关于数据库,数据和结构的所有更改的记录,以及每条语句的执行了多长时间。二进制日志文件包括一系列日志文件和一个索引文件。这意味着主要的SQL语句,例如CREATE, ALTER, INSERT, UPDATE 和 DELETE 会放到这个日志文件中;而例如SELECT这样的语句就不会被记录,它们可以被记录到普通的query.log文件中。
|
||||
|
||||
而 **Ibdata1** 简单的说据是一个包括所有表和所有数据库信息的文件。
|
||||
|
||||
### 主服务器配置 ###
|
||||
|
||||
@ -39,7 +43,7 @@
|
||||
sudo systemctl start mariadb.service
|
||||
sudo systemctl enable mariadb.service
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
ln -s '/usr/lib/systemd/system/mariadb.service' '/etc/systemd/system/multi-user.target.wants/mariadb.service'
|
||||
|
||||
@ -51,7 +55,7 @@
|
||||
|
||||
sudo systemctl is-active mariadb.service
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
Redirecting to /bin/systemctl status mariadb.service
|
||||
mariadb.service - MariaDB database server
|
||||
@ -65,11 +69,11 @@
|
||||
mysql> flush privileges;
|
||||
mysql> exit
|
||||
|
||||
SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后尝试登陆:
|
||||
这里 SOME_ROOT_PASSWORD 是你的 root 密码。 例如我用"q"作为密码,然后尝试登录:
|
||||
|
||||
sudo mysql -u root -pSOME_ROOT_PASSWORD
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MariaDB connection id is 5
|
||||
@ -89,7 +93,7 @@ SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后
|
||||
|
||||
test_repl - 将要被复制的模式的名字
|
||||
|
||||
输出:
|
||||
输出:如下
|
||||
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
@ -105,7 +109,7 @@ SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后
|
||||
City varchar(255)
|
||||
);
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
mysql> MariaDB [test_repl]> CREATE TABLE Persons (
|
||||
-> PersonID int,
|
||||
@ -124,7 +128,7 @@ SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后
|
||||
mysql> INSERT INTO Persons VALUES (4, "LastName4", "FirstName4", "Address4", "City4");
|
||||
mysql> INSERT INTO Persons VALUES (5, "LastName5", "FirstName5", "Address5", "City5");
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
Query OK, 5 row affected (0.00 sec)
|
||||
|
||||
@ -132,7 +136,7 @@ SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后
|
||||
|
||||
mysql> select * from Persons;
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
+----------+-----------+------------+----------+-------+
|
||||
| PersonID | LastName | FirstName | Address | City |
|
||||
@ -145,9 +149,9 @@ SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后
|
||||
| 5 | LastName5 | FirstName5 | Address5 | City5 |
|
||||
+----------+-----------+------------+----------+-------+
|
||||
|
||||
### 配置 MariaDB 重复 ###
|
||||
### 配置 MariaDB 复制 ###
|
||||
|
||||
你需要在主结点服务器上编辑 my.cnf文件来启用二进制日志以及设置服务器id。我会使用vi文本编辑器,但你可以使用任何你喜欢的,例如nano,joe。
|
||||
你需要在主节点服务器上编辑 my.cnf文件来启用二进制日志以及设置服务器id。我会使用vi文本编辑器,但你可以使用任何你喜欢的,例如nano,joe。
|
||||
|
||||
sudo vi /etc/my.cnf
|
||||
|
||||
@ -159,7 +163,7 @@ SOME_ROOT_PASSWORD - 你的 root 密码。 例如我用"q"作为密码,然后
|
||||
binlog-format=row
|
||||
server_id=1
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||

|
||||
|
||||
@ -173,7 +177,7 @@ sudo mysql -u root -pq test_repl
|
||||
|
||||
mysql> SHOW MASTER STATUS;
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
+--------------------+----------+--------------+------------------+
|
||||
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
|
||||
@ -183,12 +187,12 @@ mysql> SHOW MASTER STATUS;
|
||||
|
||||
**记住** : "File" 和 "Position" 的值。在从节点中你需要使用这些值
|
||||
|
||||
创建用来重复的用户
|
||||
创建用来复制的用户
|
||||
|
||||
mysql> GRANT REPLICATION SLAVE ON *.* TO replication_user IDENTIFIED BY 'bigs3cret' WITH GRANT OPTION;
|
||||
mysql> flush privileges;
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
@ -197,7 +201,7 @@ mysql> SHOW MASTER STATUS;
|
||||
|
||||
mysql> select * from mysql.user WHERE user="replication_user"\G;
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
mysql> select * from mysql.user WHERE user="replication_user"\G;
|
||||
*************************** 1. row ***************************
|
||||
@ -220,11 +224,11 @@ mysql> SHOW MASTER STATUS;
|
||||
|
||||
### 从节点配置 ###
|
||||
|
||||
所有这些命令需要在从节点中进行
|
||||
所有这些命令需要在从节点中进行。
|
||||
|
||||
假设我们已经更新/升级了包括有最新的MariaDB服务器的 CentOS 7.x,而且你可以用root账号登陆到MariaDBs服务器(这在这篇文章的第一部分已经介绍过)
|
||||
假设我们已经更新/升级了包括有最新的MariaDB服务器的 CentOS 7.x,而且你可以用root账号登陆到MariaDB服务器(这在这篇文章的第一部分已经介绍过)
|
||||
|
||||
登陆到Maria 数据库控制台并创建数据库
|
||||
登录到Maria 数据库控制台并创建数据库
|
||||
|
||||
mysql -u root -pSOME_ROOT_PASSWORD;
|
||||
mysql> create database test_repl;
|
||||
@ -264,7 +268,7 @@ full-dump.sql - 你在测试服务器中创建的DB Dump。
|
||||
|
||||
mysql> slave start;
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
|
||||
@ -272,7 +276,7 @@ full-dump.sql - 你在测试服务器中创建的DB Dump。
|
||||
|
||||
mysql> show slave status\G;
|
||||
|
||||
输出:
|
||||
输出如下:
|
||||
|
||||
*************************** 1. row ***************************
|
||||
Slave_IO_State: Waiting for master to send event
|
||||
@ -352,7 +356,7 @@ via: http://linoxide.com/how-tos/configure-mariadb-replication-centos-linux/
|
||||
|
||||
作者:[Bobbin Zachariah][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,22 @@
|
||||
Docker 1.6 发布 - 如何在Fedora / CentOS上面升级
|
||||
如何在Fedora / CentOS上面升级Docker 1.6
|
||||
=============================================================================
|
||||
Docker,一个为软件打包的流行开源容器平台,有了新的发行版1.6,增加了许多新的特性。该版本在Docker注册,引擎,云集,组合和机器方面都有更新。这次发行旨在提升体验,开发者和系统管理员的经验(这里不太确定)。让我们来快速看看有哪些新特性吧。
|
||||
Docker,一个流行的将软件打包的开源容器平台,已经有了新的1.6版,增加了许多新的特性。该版本主要更新了Docker Registry、Engine、 Swarm、 Compose 和 Machine等方面。这次发布旨在提升性能、改善开发者和系统管理员的体验。让我们来快速看看有哪些新特性吧。
|
||||
|
||||
**Docker Registry (2.0)**是一项推送Docker镜像用于存储和分享的服务,经历过架构的改变,因为面临加载下的体验问题。它仍然向下兼容。Docker Registry的编写语言现在从Python改为Google的Go语言了,为了提升表现力。与Docker引擎1.6结合后,拉取镜像的能力更快了。早先的镜像被队列式地输送,而现在是并行的啦。
|
||||
**Docker Registry (2.0)**是一项推送Docker镜像用于存储和分享的服务,因为面临加载下的体验问题而经历了架构的改变。它仍然向后兼容。Docker Registry的编写语言现在从Python改为Google的Go语言了,以提升性能。与Docker Engine 1.6结合后,拉取镜像的能力更快了。早先的镜像是队列式输送的,而现在是并行的啦。
|
||||
|
||||
**Docker Engine (1.6)**相比之前的版本有很大的提高。目前支持容器与镜像标签。通过标签,你可以附加用户自定义的元数据到镜像和容器上,而镜像和容器反过来可以被其他工具使用。标签对正在运行的应用是不可见的,可以用来加速搜索容器和镜像。
|
||||
**Docker Engine (1.6)**相比之前的版本有很大的提高。目前支持容器与镜像的标签。通过标签,你可以附加用户自定义的元数据到镜像和容器上,而镜像和容器反过来可以被其他工具使用。标签对正在运行的应用是不可见的,可以用来加速搜索容器和镜像。
|
||||
|
||||
Windows版本的Docker客户端可以连接一个远程的运行linux的Docker引擎。
|
||||
Windows版本的Docker客户端可以连接到远程的运行在linux上的Docker Engine。
|
||||
|
||||
Docker目前支持日志驱动API,这允许我们发送容器日志给系统如Syslog,或者第三方。这将会使得系统管理员受益。
|
||||
|
||||
**Swarm (0.2)**是一个Docker集群工具,将一个Docker主机池转换为一个虚拟主机。在新特性里,容器甚至被放在了可用的节点上。通过添加更多的Docker命令,所有的努力都朝着支持完整的Docker API。将来,使用第三方驱动来集群会成为可能。
|
||||
**Swarm (0.2)**是一个Docker集群工具,可以将一个Docker主机池转换为一个虚拟主机。在新特性里,容器甚至被放在了可用的节点上。通过添加更多的Docker命令,努力支持完整的Docker API。将来,使用第三方驱动来集群会成为可能。
|
||||
|
||||
**Compose (1.2)** 是一个Docker里定义和运行复杂应用的工具, 也得到了升级。在新版本里,一个可以创建多个子文件,而不是一个没有结构的文件描述一个多容器应用。
|
||||
**Compose (1.2)** 是一个Docker里定义和运行复杂应用的工具, 也得到了升级。在新版本里,可以创建多个子文件,而不是用一个没有结构的文件描述一个多容器应用。
|
||||
|
||||
通过**Machine (0.2)**,我们可以很容易地在本地计算机,云和数据中心上搭建Docker主机。新的发行版为开发者提供了一个相对干净地驱动界面来写驱动。供应被Machine牢牢地掌握,而不是每个独立的驱动。新的命令被添加,可以用来生成主机的TLS证书,以提高安全性。
|
||||
通过**Machine (0.2)**,我们可以很容易地在本地计算机、云和数据中心上搭建Docker主机。新的发布版本为开发者提供了一个相对干净地驱动界面来编写驱动。Machine集中控制供给,而不是每个独立的驱动。增加了新的命令,可以用来生成主机的TLS证书,以提高安全性。
|
||||
|
||||
### 在Fedora / CentOS 上升级架构 ###
|
||||
### 在Fedora / CentOS 上的升级指导 ###
|
||||
|
||||
在这一部分里,我们将会学习如何在Fedora和CentOS上升级已有的docker到最新版本。请注意,目前的Docker仅运行在64位的架构上,Fedora和CentOS都源于RedHat,命令的使用是差不多相同的,除了在Fedora20和CentOS6.5里Docker包被叫做“docker-io”。
|
||||
|
||||
@ -28,7 +28,7 @@ Docker目前支持日志驱动API,这允许我们发送容器日志给系统
|
||||
|
||||
在升级之前,备份一下docker镜像和容器卷是个不错的主意。
|
||||
|
||||
参考[filesystem to a tar archive][1]与[volumes backups, restores or migrations options][2],获取更多信息。
|
||||
参考[“将文件系统打成 tar 包”][1]与[“卷备份、恢复或迁移”][2],获取更多信息。
|
||||
|
||||
目前,测试系统安装了Docker1.5。样例输出显示是来自一个Fedora20的系统。
|
||||
|
||||
@ -42,7 +42,7 @@ Docker目前支持日志驱动API,这允许我们发送容器日志给系统
|
||||
|
||||
[root@TestNode1 ~]# sudo systemctl stop docker
|
||||
|
||||
升级到最新版使用yum update。但是写这篇文章的时候,仓库并不是最新版本(1.6)。因此你需要使用二进制的升级方法。
|
||||
使用yum update升级到最新版,但是写这篇文章的时候,仓库并不是最新版本(1.6),因此你需要使用二进制的升级方法。
|
||||
|
||||
[root@TestNode1 ~]#sudo yum -y update docker-io
|
||||
|
||||
@ -66,7 +66,7 @@ Docker目前支持日志驱动API,这允许我们发送容器日志给系统
|
||||
|
||||
2015-04-19 13:40:50 (8.72 MB/s) - /usr/bin/docker saved
|
||||
|
||||
检查更新版本
|
||||
检查更新后的版本
|
||||
|
||||
[root@TestNode1 ~]#sudo docker -v
|
||||
|
||||
@ -88,7 +88,7 @@ Docker目前支持日志驱动API,这允许我们发送容器日志给系统
|
||||
|
||||
Hello World
|
||||
|
||||
CentOS安装时需要**注意**,在CentOS上安装完Docker后,当你试图启动Docker服务的时候,你可能会得到错误的信息,如下所示
|
||||
CentOS安装时需要**注意**,在CentOS上安装完Docker后,当你试图启动Docker服务的时候,你可能会得到错误的信息,如下所示:
|
||||
|
||||
docker.service - Docker Application Container Engine
|
||||
|
||||
@ -116,7 +116,7 @@ CentOS安装时需要**注意**,在CentOS上安装完Docker后,当你试图
|
||||
|
||||
Apr 20 03:24:24 centos7 systemd[1]: Unit docker.service entered failed state.
|
||||
|
||||
这是一个熟知的bug([https://bugzilla.redhat.com/show_bug.cgi?id=1207839][3]),需要一个设备映射的升级,到最新的水平。
|
||||
这是一个已知的bug([https://bugzilla.redhat.com/show_bug.cgi?id=1207839][3]),需要将设备映射升级到最新。
|
||||
|
||||
[root@centos7 ~]# rpm -qa device-mapper
|
||||
|
||||
@ -132,7 +132,7 @@ CentOS安装时需要**注意**,在CentOS上安装完Docker后,当你试图
|
||||
|
||||
### 总结 ###
|
||||
|
||||
尽管docker技术出现时间不长,当很快获得了流行。它使得开发者的生活变得容易,运维团队可以快速独立地创建和部署应用。通过公司发布快速的Docker更新,来提升产品质量,满足用户需求,未来对于Docker来说一片光明。
|
||||
尽管docker技术出现时间不长,但很快就变得非常流行了。它使得开发者的生活变得轻松,运维团队可以快速独立地创建和部署应用。通过该公司的发布,Docker的快速更新,产品质量的提升,满足用户需求,未来对于Docker来说一片光明。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -140,7 +140,7 @@ via: http://linoxide.com/linux-how-to/docker-1-6-features-upgrade-fedora-centos/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,181 @@
|
||||
Web缓存基础:术语、HTTP报头和缓存策略
|
||||
=====================================================================
|
||||
|
||||
### 简介
|
||||
|
||||
对于您的站点的访问者来说,智能化的内容缓存是提高用户体验最有效的方式之一。缓存,或者对之前的请求的临时存储,是HTTP协议实现中最核心的内容分发策略之一。分发路径中的组件均可以缓存内容来加速后续的请求,这受控于对该内容所声明的缓存策略。
|
||||
|
||||
在这份指南中,我们将讨论一些Web内容缓存的基本概念。这主要包括如何选择缓存策略以保证互联网范围内的缓存能够正确的处理您的内容。我们将谈一谈缓存带来的好处、副作用以及不同的策略能带来的性能和灵活性的最大结合。
|
||||
|
||||
###什么是缓存(caching)?
|
||||
|
||||
缓存(caching)是一个描述存储可重用资源以便加快后续请求的行为的术语。有许多不同类型的缓存,每种都有其自身的特点,应用程序缓存和内存缓存由于其对特定回复的加速,都很常用。
|
||||
|
||||
这份指南的主要讲述的Web缓存是一种不同类型的缓存。Web缓存是HTTP协议的一个核心特性,它能最小化网络流量,并且提升用户所感知的整个系统响应速度。内容从服务器到浏览器的传输过程中,每个层面都可以找到缓存的身影。
|
||||
|
||||
Web缓存根据特定的规则缓存相应HTTP请求的响应。对于缓存内容的后续请求便可以直接由缓存满足而不是重新发送请求到Web服务器。
|
||||
|
||||
###好处
|
||||
|
||||
有效的缓存技术不仅可以帮助用户,还可以帮助内容的提供者。缓存对内容分发带来的好处有:
|
||||
|
||||
- **减少网络开销**:内容可以在从内容提供者到内容消费者网络路径之间的许多不同的地方被缓存。当内容在距离内容消费者更近的地方被缓存时,由于缓存的存在,请求将不会消耗额外的网络资源。
|
||||
- **加快响应速度**:由于并不是必须通过整个网络往返,缓存可以使内容的获得变得更快。缓存放在距用户更近的地方,例如浏览器缓存,使得内容的获取几乎是瞬时的。
|
||||
- **在同样的硬件上提高速度**:对于保存原始内容的服务器来说,更多的性能可以通过允许激进的缓存策略从硬件上压榨出来。内容拥有者们可以利用分发路径上某个强大的服务器来应对特定内容负载的冲击。
|
||||
- **网络中断时内容依旧可用**:使用某种策略,缓存可以保证在原始服务器变得不可用时,相应的内容对用户依旧可用。
|
||||
|
||||
###术语
|
||||
|
||||
在面对缓存时,您可能对一些经常遇到的术语可能不太熟悉。一些常见的术语如下:
|
||||
|
||||
- **原始服务器**:原始服务器是内容的原始存放地点。如果您是Web服务器管理员,它就是您所管理的机器。它负责为任何不能从缓存中得到的内容进行回复,并且负责设置所有内容的缓存策略。
|
||||
- **缓存命中率**:一个缓存的有效性依照缓存的命中率进行度量。它是可以从缓存中得到数据的请求数与所有请求数的比率。缓存命中率高意味着有很高比例的数据可以从缓存中获得。这通常是大多数管理员想要的结果。
|
||||
- **新鲜度**:新鲜度用来描述一个缓存中的项目是否依旧适合返回给客户端。缓存中的内容只有在由缓存策略指定的新鲜期内才会被返回。
|
||||
- **过期内容**:缓存中根据缓存策略的新鲜期设置已过期的内容。过期的内容被标记为“陈旧”。通常,过期内容不能用于回复客户端的请求。必须重新从原始服务器请求新的内容或者至少验证缓存的内容是否仍然准确。
|
||||
- **校验**:缓存中的过期内容可以验证是否有效以便刷新过期时间。验证过程包括联系原始服务器以检查缓存的数据是否依旧代表了最近的版本。
|
||||
- **失效**:失效是依据过期日期从缓存中移除内容的过程。当内容在原始服务器上已被改变时就必须这样做,缓存中过期的内容会导致客户端发生问题。
|
||||
|
||||
还有许多其他的缓存术语,不过上面的这些应该能帮助您开始。
|
||||
|
||||
###什么能被缓存?
|
||||
|
||||
某些特定的内容比其他内容更容易被缓存。对大多数站点来说,一些适合缓存的内容如下:
|
||||
|
||||
- Logo和商标图像
|
||||
- 普通的不变化的图像(例如,导航图标)
|
||||
- CSS样式表
|
||||
- 普通的Javascript文件
|
||||
- 可下载的内容
|
||||
- 媒体文件
|
||||
|
||||
这些文件更倾向于不经常改变,所以长时间的对它们进行缓存能获得好处。
|
||||
|
||||
一些项目在缓存中必须加以注意:
|
||||
|
||||
- HTML页面
|
||||
- 会替换改变的图像
|
||||
- 经常修改的Javascript和CSS文件
|
||||
- 需要有认证后的cookies才能访问的内容
|
||||
|
||||
一些内容从来不应该被缓存:
|
||||
|
||||
- 与敏感信息相关的资源(银行数据,等)
|
||||
- 用户相关且经常更改的数据
|
||||
|
||||
除上面的通用规则外,通常您需要指定一些规则以便于更好地缓存不同种类的内容。例如,如果登录的用户都看到的是同样的网站视图,就应该在任何地方缓存这个页面。如果登录的用户会在一段时间内看到站点中用户特定的视图,您应该让用户的浏览器缓存该数据而不应让任何中介节点缓存该视图。
|
||||
|
||||
###Web内容缓存的位置
|
||||
|
||||
Web内容会在整个分发路径中的许多不同的位置被缓存:
|
||||
|
||||
- **浏览器缓存**:Web浏览器自身会维护一个小型缓存。典型地,浏览器使用一种策略指示缓存最重要的内容。这可能是用户相关的内容或可能会再次请求且下载代价较高。
|
||||
- **中间缓存代理**:任何在客户端和您的基础架构之间的服务器都可以按期望缓存一些内容。这些缓存可能由ISP(网络服务提供者)或者其他独立组织提供。
|
||||
- **反向缓存**:您的服务器基础架构可以为后端的服务实现自己的缓存。如果实现了缓存,那么便可以在处理请求的位置返回相应的内容而不用每次请求都使用后端服务。
|
||||
|
||||
上面的这些位置通常都可以根据它们自身的缓存策略和内容源的缓存策略缓存一些相应的内容。
|
||||
|
||||
###缓存头部
|
||||
|
||||
缓存策略依赖于两个不同的因素。所缓存的实体本身需要决定是否应该缓存可接受的内容。它可以只缓存部分可以缓存的内容,但不能缓存超过限制的内容。
|
||||
|
||||
缓存行为主要由缓存策略决定,而缓存策略由内容拥有者设置。这些策略主要通过特定的HTTP头部来清晰地表达。
|
||||
|
||||
经过几个不同HTTP协议的变化,出现了一些不同的针对缓存方面的头部,它们的复杂度各不相同。下面列出了那些你也许应该注意的:
|
||||
|
||||
- **`Expires`**:尽管使用范围相当有限,但`Expires`头部是非常简洁明了的。通常它设置一个未来的时间,内容会在此时间过期。这时,任何对同样内容的请求都应该回到原始服务器处。这个头部或许仅仅最适合回退模式(fall back)。
|
||||
- **`Cache-Control`**:这是`Expires`的一个更加现代化的替换物。它已被很好的支持,且拥有更加灵活的实现。在大多数案例中,它比`Expires`更好,但同时设置两者的值也无妨。稍后我们将讨论您可以设置的`Cache-Control`的详细选项。
|
||||
- **`ETag`**:`ETag`用于缓存验证。源服务器可以在首次服务一个内容时为该内容提供一个独特的`ETag`。当一个缓存需要验证这个内容是否即将过期,他会将相应的`ETag`发送回服务器。源服务器或者告诉缓存内容是一致的,或者发送更新后的内容(带着新的`ETag`)。
|
||||
- **`Last-Modified`**:这个头部指明了相应的内容最后一次被修改的时间。它可能会作为保证内容新鲜度的验证策略的一部分被使用。
|
||||
- **`Content-Length`**:尽管并没有在缓存中明确涉及,`Content-Length`头部在设置缓存策略时很重要。某些软件如果不提前获知内容的大小以留出足够空间,则会拒绝缓存该内容。
|
||||
- **`Vary`**:缓存系统通常使用请求的主机和路径作为存储该资源的键。当判断一个请求是否是请求同样内容时,`Vary`头部可以被用来提醒缓存系统需要注意另一个附加头部。它通常被用来告诉缓存系统同样注意`Accept-Encoding`头部,以便缓存系统能够区分压缩和未压缩的内容。
|
||||
|
||||
### Vary头部的隐语
|
||||
|
||||
`Vary`头部提供给您存储同一个内容的不同版本的能力,代价是降低了缓存的容量。
|
||||
|
||||
在使用`Accept-Encoding`时,设置`Vary`头部允许明确区分压缩和未压缩的内容。这在服务某些不能处理压缩数据的浏览器时很重要,它可以保证基本的可用性。`Vary`的一个典型的值是`Accept-Encoding`,它只有两到三个可选的值。
|
||||
|
||||
一开始看上去`User-Agent`这样的头部可以用于区分移动浏览器和桌面浏览器,以便您的站点提供差异化的服务。但`User-Agent`字符串是非标准的,结果将会造成在中间缓存中保存同一内容的许多不同版本的缓存,这会导致缓存命中率的降低。`Vary`头部应该谨慎使用,尤其是您不具备在您控制的中间缓存中使请求标准化的能力(也许可以,比如您可以控制CDN的话)。
|
||||
|
||||
###缓存控制标志怎样影响缓存
|
||||
|
||||
上面我们提到了`Cache-Control`头部如何被用与现代缓存策略标准。能够通过这个头部设定许多不同的缓存指令,多个不同的指令通过逗号分隔。
|
||||
|
||||
一些您可以使用的指示内容缓存策略的`Cache-Control`的选项如下:
|
||||
|
||||
- **`no-cache`**:这个指令指示所有缓存的内容在新的请求到达时必须先重新验证,再发送给客户端。这条指令实际将内容立刻标记为过期的,但允许通过验证手段重新验证以避免重新下载整个内容。
|
||||
- **`no-store`**:这条指令指示缓存的内容不能以任何方式被缓存。它适合在回复敏感信息时设置。
|
||||
- **`public`**:它将内容标记为公有的,这意味着它能被浏览器和其他任何中间节点缓存。通常,对于使用了HTTP验证的请求,其回复被默认标记为`private`。`public`标记将会覆盖这个设置。
|
||||
- **`private`**:它将内容标记为私有的。私有数据可以被用户的浏览器缓存,但*不能*被任何中间节点缓存。它通常用于用户相关的数据。
|
||||
- **`max-age`**:这个设置指示了缓存内容的最大生存期,它在最大生存期后必须在源服务器处被验证或被重新下载。在现代浏览器中这个选项大体上取代了`Expires`头部,浏览器也将其作为决定内容的新鲜度的基础。这个选项的值以秒为单位表示,最大可以表示一年的新鲜期(31536000秒)。
|
||||
- **`s-maxage`**:这个选项非常类似于`max-age`,它指明了内容能够被缓存的时间。区别是这个选项只在中间节点的缓存中有效。结合这两个选项可以构建更加灵活的缓存策略。
|
||||
- **`must-revalidate`**:它指明了由`max-age`、`s-maxage`或`Expires`头部指明的新鲜度信息必须被严格的遵守。它避免了缓存的数据在网络中断等类似的场景中被使用。
|
||||
- **`proxy-revalidate`**:它和上面的选项有着一样的作用,但只应用于中间的代理节点。在这种情况下,用户的浏览器可以在网络中断时使用过期内容,但中间缓存内容不能用于此目的。
|
||||
- **`no-transform`**:这个选项告诉缓存在任何情况下都不能因为性能的原因修改接收到的内容。这意味着,缓存不允许压缩接收到的内容(没有从原始服务器处接收过压缩版本的该内容)并发送。
|
||||
|
||||
这些选项能够以不同的方式结合以获得不同的缓存行为。一些互斥的值如下:
|
||||
|
||||
- `no-cache`,`no-store`以及由其他前面未提到的选项指明的常用的缓存行为
|
||||
- `public`和`private`
|
||||
|
||||
如果`no-store`和`no-cache`都被设置,那么`no-store`会取代`no-cache`。对于非授权的请求的回复,`public`是隐含的设置。对于授权的请求的回复,`private`选项是隐含的。他们可以通过在`Cache-Control`头部中指明相应的相反的选项以覆盖。
|
||||
|
||||
###开发一种缓存策略
|
||||
|
||||
在理想情况下,任何内容都可以被尽可能缓存,而您的服务器只需要偶尔的提供一些验证内容即可。但这在现实中很少发生,因此您应该尝试设置一些明智的缓存策略,以在长期缓存和站点改变的需求间达到平衡。
|
||||
|
||||
### 常见问题
|
||||
|
||||
在许多情况中,由于内容被产生的方式(如根据每个用户动态的产生)或者内容的特性(例如银行的敏感数据),这些内容不应该被缓存。另一些许多管理员在设置缓存时可能面对的问题是外部缓存的数据未过期,但新版本的数据已经产生。
|
||||
|
||||
这些都是经常遇到的问题,它们会影响缓存的性能和您提供的数据的准确性。然而,我们可以通过开发提前预见这些问题的缓存策略来缓解这些问题。
|
||||
|
||||
### 一般性建议
|
||||
|
||||
尽管您的实际情况会指导您选择的缓存策略,但是下面的建议能帮助您获得一些合理的决定。
|
||||
|
||||
在您担心使用哪一个特定的头部之前,有一些特定的步骤可以帮助您提高您的缓存命中率。一些建议如下:
|
||||
|
||||
- **为图像、CSS和共享的内容建立特定的文件夹**:将内容放到特定的文件夹内使得您可以方便的从您的站点中的任何页面引用这些内容。
|
||||
- **使用同样的URL来表示同样的内容**:由于缓存使用内容请求中的主机名和路径作为键,因此应保证您的所有页面中的该内容的引用方式相同,前一个建议能让这点更加容易做到。
|
||||
- **尽可能使用CSS图像拼接**:对于像图标和导航等内容,使用CSS图像拼接能够减少渲染您页面所需要的请求往返,并且允许对拼接缓存很长一段时间。
|
||||
- **尽可能将主机脚本和外部资源本地化**:如果您使用Javascript脚本和其他外部资源,如果上游没有提供合适的缓存头部,那么您应考虑将这些内容放在您自己的服务器上。您应该注意上游的任何更新,以便更新本地的拷贝。
|
||||
- **对缓存内容收集文件摘要**:静态的内容比如CSS和Javascript文件等通常比较适合收集文件摘要。这意味着为文件名增加一个独特的标志符(通常是这个文件的哈希值)可以在文件修改后绕开缓存保证新的内容被重新获取。有很多工具可以帮助您创建文件摘要并且修改HTML文档中的引用。
|
||||
|
||||
对于不同的文件正确地选择不同的头部这件事,下面的内容可以作为一般性的参考:
|
||||
|
||||
- **允许所有的缓存存储一般内容**:静态内容以及非用户相关的内容应该在分发链的所有节点被缓存。这使得中间节点可以将该内容回复给多个用户。
|
||||
- **允许浏览器缓存用户相关的内容**:对于每个用户的数据,通常在用户自己的浏览器中缓存是可以被接受且有益的。缓存在用户自身的浏览器能够使得用户在接下来的浏览中能够瞬时读取,但这些内容不适合在任何中间代理节点缓存。
|
||||
- **将时间敏感的内容作为特例**:如果您的数据是时间敏感的,那么相对上面两条参考,应该将这些数据作为特例,以保证过期的数据不会在关键的情况下被使用。例如,您的站点有一个购物车,它应该立刻反应购物车里面的物品。依据内容的特点,可以在`Cache-Control`头部中使用`no-cache`或`no-store`选项。
|
||||
- **总是提供验证器**:验证器使得过期的内容可以无需重新下载而得到刷新。设置`ETag`和`Last-Modified`头部将允许缓存向原始服务器验证内容,并在内容未修改时刷新该内容新鲜度以减少负载。
|
||||
- **对于支持的内容设置长的新鲜期**:为了更加有效的利用缓存,一些作为支持性的内容应该被设置较长的新鲜期。这通常比较适合图像和CSS等由用户请求用来渲染HTML页面的内容。和文件摘要一起,设置延长的新鲜期将允许缓存长时间的存储这些资源。如果资源发生改变,修改的文件摘要将会使缓存的数据无效并触发对新的内容的下载。那时,新的支持的内容会继续被缓存。
|
||||
- **对父内容设置短的新鲜期**:为了使得前面的模式正常工作,容器类的内容应该相应的设置短的新鲜期,或者设置不全部缓存。这通常是在其他协助内容中使用的HTML页面。这个HTML页面将会被频繁的下载,使得它能快速的响应改变。支持性的内容因此可以被尽量缓存。
|
||||
|
||||
关键之处便在于达到平衡,一方面可以尽量的进行缓存,另一方面为未来保留当改变发生时从而改变整个内容的机会。您的站点应该同时具有:
|
||||
|
||||
- 尽量缓存的内容
|
||||
- 拥有短的新鲜期的缓存内容,可以被重新验证
|
||||
- 完全不被缓存的内容
|
||||
|
||||
这样做的目的便是将内容尽可能的移动到第一个分类(尽量缓存)中的同时,维持可以接受的缓存命中率。
|
||||
|
||||
结论
|
||||
----
|
||||
|
||||
花时间确保您的站点使用了合适的缓存策略将对您的站点产生重要的影响。缓存使得您可以在保证服务同样内容的同时减少带宽的使用。您的服务器因此可以靠同样的硬件处理更多的流量。或许更重要的是,客户们能在您的网站中获得更快的体验,这会使得他们更愿意频繁的访问您的站点。尽管有效的Web缓存并不是银弹,但设置合适的缓存策略会使您以最小的代价获得可观的收获。
|
||||
|
||||
---
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
|
||||
|
||||
作者: [Justin Ellingwood](https://www.digitalocean.com/community/users/jellingwood)
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
推荐:[royaso](https://github.com/royaso)
|
||||
|
||||
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
@ -1,25 +1,26 @@
|
||||
Bodhi Linux引入Moksha桌面
|
||||
Bodhi Linux 将引入 Moksha 桌面
|
||||
================================================================================
|
||||

|
||||
|
||||
基于Ubuntu的轻量级Linux发行版[Bodhi Linux][1]致力于构建其自家的桌面环境,这个全新桌面环境被称之为Moksha(梵文意为‘完全自由’)。Moksha将替换常用的[Enlightenment桌面环境][2]。
|
||||
基于Ubuntu的轻量级Linux发行版[Bodhi Linux][1]致力于构建其自家的桌面环境,这个全新桌面环境被称之为Moksha(梵文意为‘完全自由’)。Moksha将替换其原来的[Enlightenment桌面环境][2]。
|
||||
|
||||
### 为何用Moksha替换Englightenment? ###
|
||||
|
||||
Bodhi Linux的Jeff Hoogland最近[表示][3]了他对新版Enlightenment的不满。直到E17,Enlightenment都十分稳定,并且能满足轻量级Linux的部署需求。而E18则到处都充满了问题,Bodhi Linux只好弃之不用了。
|
||||
Bodhi Linux的Jeff Hoogland最近[表示][3]了他对新版Enlightenment的不满。直到E17,Enlightenment都十分稳定,并且能满足轻量级Linux的部署需求。而E18则到处都充满了问题,Bodhi Linux只好弃之不用了。
|
||||
|
||||
虽然最新的[Bodhi Linux 3.0发行版][4]仍然使用了E19作为其桌面(除传统模式外,这意味着,对于旧的硬件,仍然会使用E17),Jeff对E19也十分不满。他说道:
|
||||
|
||||
>除了性能问题外,对于我个人而言,E19并没有给我带来与E17下相同的工作流程,因为它移除了很多E17的特性。鉴于此,我不得不将我所有的3台Bodhi计算机桌面改成E17——这3台机器都是我高端的了。这不由得让我想到,我们还有多少现存的Bodhi用户也怀着和我同样的感受,所以,我[在我们的用户论坛上开启一个与此相关的讨论][5]。
|
||||
> 除了性能问题外,对于我个人而言,E19并没有给我带来与E17下相同的工作流程,因为它移除了很多E17的特性。鉴于此,我不得不将我所有的3台Bodhi计算机桌面改成E17——这3台机器都是我高端的了。这不由得让我想到,我们还有多少现存的Bodhi用户也怀着和我同样的感受,所以,我[在我们的用户论坛上开启一个与此相关的讨论][5]。
|
||||
|
||||
### Moksha是E17桌面的延续 ###
|
||||
|
||||
Moksha将会是Bodhi所热衷的E17桌面的延续。Jeff进一步提到:
|
||||
>我们将从整合所有Bodhi修改开始。多年来我们一直都只是给源代码打补丁,并修复桌面所具有的问题。如果该工作完成,我们将开始移植一些E18和E19引入的更为有用的特性,最后,我们将引入一些我们认为会改善最终用户体验的东西。
|
||||
|
||||
> 我们将从整合所有Bodhi修改开始。多年来我们一直都只是给源代码打补丁,并修复桌面所带有的问题。如果该工作完成,我们将开始移植一些E18和E19引入的更为有用的特性,最后,我们将引入一些我们认为会改善最终用户体验的东西。
|
||||
|
||||
### Moksha何时发布? ###
|
||||
|
||||
下一个Bodhi更新将会是Bodhi 3.1.0,就在今年八月。这个新版本将为所有其缺省ISO带来Moksha。让我们拭目以待,看看Moksha是否是一个好的决定。
|
||||
下一个Bodhi更新将会是Bodhi 3.1.0,就在今年八月。这个新版本将为所有其默认安装镜像带来Moksha。让我们拭目以待,看看Moksha是否是一个好的决定。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -27,7 +28,7 @@ via: http://itsfoss.com/bodhi-linux-introduces-moksha-desktop/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
Linux 有问必答:如何在Ubuntu上配置网桥
|
||||
===============================================================================
|
||||
> **Question**: 我需要在我的Ubuntu主机上建立一个Linux网桥,共享一个网卡给其他一些虚拟主机或在主机上创建的容器。我目前正在Ubuntu上使用网络管理器(Network Manager),所以最好>能使用网络管理器来配置一个网桥。我该怎么做?
|
||||
|
||||
网桥是一个硬件装备,用来将两个或多个数据链路层(OSI七层模型中第二层)互联,以使得不同网段上的网络设备可以互相访问。当你想要互联一个主机里的多个虚拟机器或者以太接口时,就需要在Linux主机里有一个类似桥接的概念。这里使用的是一种软网桥。
|
||||
|
||||
有很多的方法来配置一个Linux网桥。举个例子,在一个无外接显示/键盘的服务器环境里,你可以使用[brct][1]手动地配置一个网桥。而在桌面环境下,在网络管理器里也支持网桥设置。那就让我们测试一下如何用网络管理器配置一个网桥吧。
|
||||
|
||||
### 要求 ###
|
||||
|
||||
为了避免[任何问题][2],建议你的网络管理器版本为0.9.9或者更高,它用在 Ubuntu 15.04或者更新的版本。
|
||||
|
||||
$ apt-cache show network-manager | grep Version
|
||||
|
||||
----------
|
||||
|
||||
Version: 0.9.10.0-4ubuntu15.1
|
||||
Version: 0.9.10.0-4ubuntu15
|
||||
|
||||
### 创建一个网桥 ###
|
||||
|
||||
使用网络管理器创建网桥最简单的方式就是通过nm-connection-editor。这款GUI(图形用户界面)的工具允许你傻瓜式地配置一个网桥。
|
||||
|
||||
首先,启动nm-connection-editor。
|
||||
|
||||
$ nm-connection-editor
|
||||
|
||||
该编辑器的窗口会显示给你一个列表,列出目前配置好的网络连接。点击右上角的“添加”按钮,创建一个网桥。
|
||||
|
||||
|
||||
|
||||
接下来,选择“Bridge”(网桥)作为连接类型。
|
||||
|
||||
|
||||
|
||||
现在,开始配置网桥,包括它的名字和所桥接的连接。如果没有创建过其他网桥,那么默认的网桥接口会被命名为bridge0。
|
||||
|
||||
回顾一下,创建网桥的目的是为了通过网桥共享你的以太网卡接口,所以你需要添加以太网卡接口到网桥。在图形界面添加一个新的“桥接的连接”可以实现上述目的。点击“Add”按钮。
|
||||
|
||||
|
||||
|
||||
选择“以太网”作为连接类型。
|
||||
|
||||
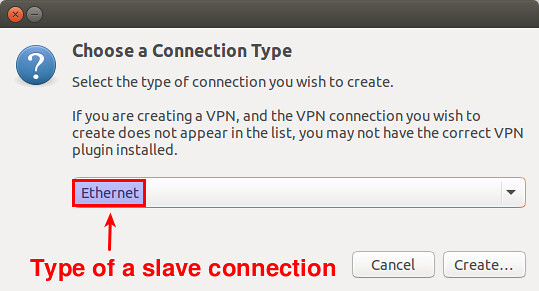
|
||||
|
||||
在“设备的 MAC 地址”区域,选择你想要从属于网桥的接口。本例中,假设该接口是eth0。
|
||||
|
||||

|
||||
|
||||
点击“常规”标签,并且选中两个复选框,分别是“当其可用时自动连接到该网络”和“所有用户都可以连接到该网络”。
|
||||
|
||||
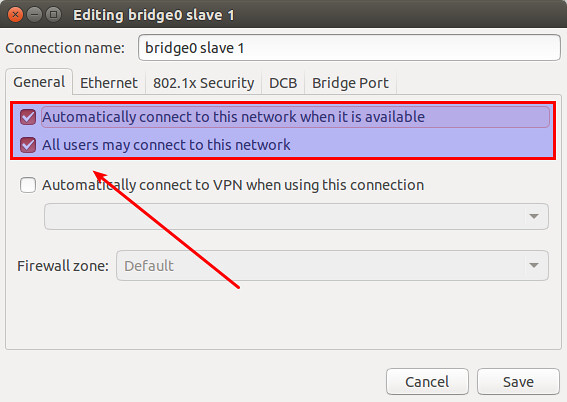
|
||||
|
||||
切换到“IPv4 设置”标签,为网桥配置DHCP或者是静态IP地址。注意,你应该为从属的以太网卡接口eth0使用相同的IPv4设定。本例中,我们假设eth0是用过DHCP配置的。因此,此处选择“自动(DHCP)”。如果eth0被指定了一个静态IP地址,那么你也应该指定相同的IP地址给网桥。
|
||||
|
||||
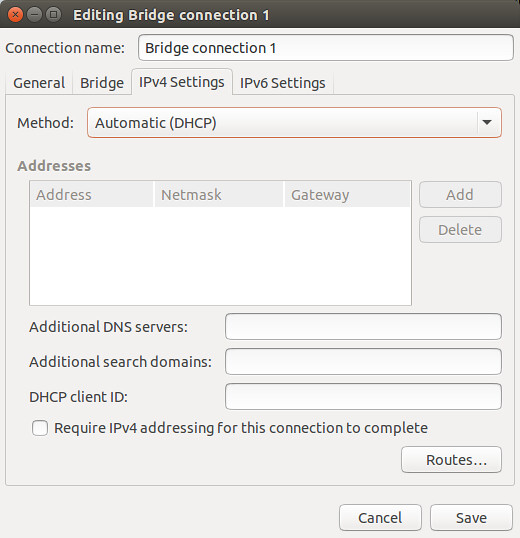
|
||||
|
||||
最后,保存网桥的设置。
|
||||
|
||||
现在,你会看见一个新增的网桥连接被创建在“网络连接”窗口里。因为已经从属与网桥,以前配置好的有线连接 eth0 就不再需要了,所以去删除原来的有线连接吧。
|
||||
|
||||
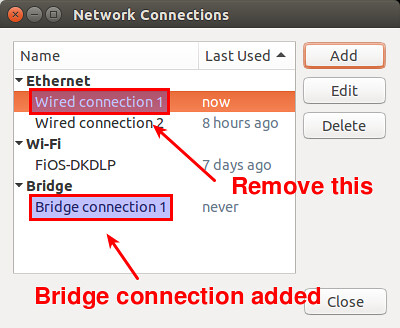
|
||||
|
||||
这时候,网桥连接会被自动激活。从指定给eth0的IP地址被网桥接管起,你将会暂时丢失一下连接。当IP地址赋给了网桥,你将会通过网桥连接回你的以太网卡接口。你可以通过“Network”设置确认一下。
|
||||
|
||||
|
||||
|
||||
同时,检查可用的接口。提醒一下,网桥接口必须已经取代了任何你的以太网卡接口拥有的IP地址。
|
||||
|
||||
|
||||
|
||||
就这么多了,现在,网桥已经可以用了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/configure-linux-bridge-network-manager-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[2]:https://bugs.launchpad.net/ubuntu/+source/network-manager/+bug/1273201
|
||||
@ -1,12 +1,11 @@
|
||||
Linux有问必答--如何安装autossh
|
||||
Linux有问必答:如何安装autossh
|
||||
================================================================================
|
||||
> **提问**: 我打算在linux上安装autossh,我应该怎么做呢?
|
||||
|
||||
[autossh][1] 是一款开源工具,可以帮助管理SSH会话,自动重连和停止转发流量。autossh会假定目标主机已经设定[无密码SSH登陆][2],以便autossh可以重连断开的SSH会话而不用用户操作。
|
||||
[autossh][1] 是一款开源工具,可以帮助管理SSH会话、自动重连和停止转发流量。autossh会假定目标主机已经设定[无密码SSH登陆][2],以便autossh可以重连断开的SSH会话而不用用户操作。
|
||||
|
||||
只要你建立[反向SSH隧道][3]或者[挂载基于SSH的远程文件夹][4],autossh迟早会派上用场。基本上只要需要维持SSH会话,autossh肯定是有用的。
|
||||
|
||||
|
||||
|
||||
|
||||
下面有许多linux发行版autossh的安装方法。
|
||||
@ -29,8 +28,7 @@ CentOS/RHEL 6 或早期版本, 需要开启第三库[Repoforge库][5], 然后才
|
||||
|
||||
$ sudo yum install autossh
|
||||
|
||||
CentOS/RHEL 7以后,autossh 已经不在Repoforge库中. 你需要从源码编译安装(例子在下面).
|
||||
|
||||
CentOS/RHEL 7以后,autossh 已经不在Repoforge库中. 你需要从源码编译安装(例子在下面)。
|
||||
|
||||
### Arch Linux 系统 ###
|
||||
|
||||
@ -66,13 +64,13 @@ via: http://ask.xmodulo.com/install-autossh-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://www.harding.motd.ca/autossh/
|
||||
[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
[4]:http://xmodulo.com/how-to-mount-remote-directory-over-ssh-on-linux.html
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
@ -1,6 +1,6 @@
|
||||
监控Linux容器性能的命令行神器
|
||||
监控 Linux 容器性能的命令行神器
|
||||
================================================================================
|
||||
ctop是一个新的基于命令行的工具,它可用于在容器层级监控进程。容器通过利用控制器组(cgroup)的资源管理功能,提供了操作系统层级的虚拟化环境。该工具收集来自cgroup的与内存、CPU、块输入输出和诸如拥有者、开机时间等相关的元数据,并以人性化的格式呈现给用户,这样就可以快速对系统健康状况进行评估。基于所获得的数据,它可以尝试推测潜在的容器技术。ctop也有助于在低内存环境中检测出谁在消耗大量的内存。
|
||||
ctop是一个新的基于命令行的工具,它可用于在容器层级监控进程。容器通过利用控制器组(cgroup)的资源管理功能,提供了操作系统层级的虚拟化环境。该工具从cgroup收集与内存、CPU、块输入输出的相关数据,以及拥有者、开机时间等元数据,并以人性化的格式呈现给用户,这样就可以快速对系统健康状况进行评估。基于所获得的数据,它可以尝试推测下层的容器技术。ctop也有助于在低内存环境中检测出谁在消耗大量的内存。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
@ -8,11 +8,11 @@ ctop的一些功能如下:
|
||||
|
||||
- 收集CPU、内存和块输入输出的度量值
|
||||
- 收集与拥有者、容器技术和任务统计相关的信息
|
||||
- 使用任何栏目对信息排序
|
||||
- 通过任意栏对信息排序
|
||||
- 以树状视图显示信息
|
||||
- 折叠/展开cgroup树
|
||||
- 选择并跟踪cgroup/容器
|
||||
- 选择显示数据刷新时间框架
|
||||
- 选择显示数据刷新的时间窗口
|
||||
- 暂停刷新数据
|
||||
- 检测基于systemd、Docker和LXC的容器
|
||||
- 基于Docker和LXC的容器的高级特性
|
||||
@ -21,7 +21,7 @@ ctop的一些功能如下:
|
||||
|
||||
### 安装 ###
|
||||
|
||||
**ctop**是由Python写成的,因此,除了需要Python 2.6或其更高版本外(支持内建光标),别无其它外部依赖。推荐使用Python的pip进行安装,如果还没有安装pip,请先安装,然后使用pip安装ctop。
|
||||
**ctop**是由Python写成的,因此,除了需要Python 2.6或其更高版本外(带有内建的光标支持),别无其它外部依赖。推荐使用Python的pip进行安装,如果还没有安装pip,请先安装,然后使用pip安装ctop。
|
||||
|
||||
*注意:本文样例来自Ubuntu(14.10)系统*
|
||||
|
||||
@ -84,19 +84,18 @@ ctop的一些功能如下:
|
||||
下面是ctop的输出样例:
|
||||
|
||||

|
||||
ctop屏幕
|
||||
|
||||
*ctop屏幕*
|
||||
|
||||
### 用法选项 ###
|
||||
|
||||
ctop [--tree] [--refresh=] [--columns=] [--sort-col=] [--follow=] [--fold=, ...] ctop (-h | --help)
|
||||
|
||||
一旦你进入ctop屏幕,使用上(↑)和下(↓)箭头键在容器间导航。点击某个容器就选定了该容器,按q或Ctrl+C退出容器。
|
||||
当你进入ctop屏幕,可使用上(↑)和下(↓)箭头键在容器间导航。点击某个容器就选定了该容器,按q或Ctrl+C退出该容器。
|
||||
|
||||
现在,让我们来看看上面列出的那一堆选项究竟是怎么用的吧。
|
||||
|
||||
-h / --help - Show the help screen
|
||||
|
||||
----------
|
||||
**-h / --help - 显示帮助信息**
|
||||
|
||||
poornima@poornima-Lenovo:~$ ctop -h
|
||||
Usage: ctop [options]
|
||||
@ -111,72 +110,66 @@ ctop屏幕
|
||||
--sort-col=SORT_COL Select column to sort by initially. Can be changed
|
||||
dynamically.
|
||||
|
||||
----------
|
||||
|
||||
--tree - Display tree view of the containers
|
||||
**--tree - 显示容器的树形视图**
|
||||
|
||||
默认情况下,会显示列表视图
|
||||
|
||||
一旦你进入ctop窗口,你可以使用F5按钮在树状/列表视图间切换。
|
||||
当你进入ctop窗口,你可以使用F5按钮在树状/列表视图间切换。
|
||||
|
||||
--fold=<name> - Fold the <name> cgroup path in the tree view.
|
||||
**--fold=<name> - 在树形视图中折叠名为 \<name> 的 cgroup 路径**
|
||||
|
||||
This option needs to be used in combination with --tree.
|
||||
该选项需要与 --tree 选项组合使用。
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --tree --fold=/user.slice
|
||||
例子: ctop --tree --fold=/user.slice
|
||||
|
||||

|
||||
‘ctop --fold’的输出
|
||||
|
||||
*'ctop --fold'的输出*
|
||||
|
||||
在ctop窗口中,使用+/-键来展开或折叠子cgroup。
|
||||
|
||||
注意:在写本文时,pip仓库中还没有最新版的ctop,还不支持命令行的‘--fold’选项
|
||||
|
||||
--follow= - Follow/Highlight the cgroup path.
|
||||
**--follow= - 跟踪/高亮 cgroup 路径**
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --follow=/user.slice/user-1000.slice
|
||||
例子: ctop --follow=/user.slice/user-1000.slice
|
||||
|
||||
正如你在下面屏幕中所见到的那样,带有“/user.slice/user-1000.slice”路径的cgroup被高亮显示,这让用户易于跟踪,就算显示位置变了也一样。
|
||||
|
||||

|
||||
‘ctop --follow’的输出
|
||||
|
||||
*'ctop --follow'的输出*
|
||||
|
||||
你也可以使用‘f’按钮来让高亮的行跟踪选定的容器。默认情况下,跟踪是关闭的。
|
||||
|
||||
--refresh= - Refresh the display at the given rate. Default 1 sec
|
||||
**--refresh= - 按指定频率刷新显示,默认1秒**
|
||||
|
||||
这对于按每用户需求来显示改变刷新率时很有用。使用‘p’按钮可以暂停刷新并选择文本。
|
||||
|
||||
--columns=<columns> - Can limit the display to selected <columns>. 'name' should be the first entry followed by other columns. By default, the columns include owner, processes,memory, cpu-sys, cpu-user, blkio, cpu-time.
|
||||
**--columns=<columns> - 限定只显示选定的列。'name' 需要是第一个字段,其后跟着其它字段。默认情况下,字段包括:owner, processes,memory, cpu-sys, cpu-user, blkio, cpu-time**
|
||||
|
||||
----------
|
||||
|
||||
Eg: ctop --columns=name,owner,type,memory
|
||||
例子: ctop --columns=name,owner,type,memory
|
||||
|
||||

|
||||
‘ctop --column’的输出
|
||||
|
||||
-sort-col=<sort-col> - column using which the displayed data should be sorted. By default it is sorted using cpu-user
|
||||
*'ctop --column'的输出*
|
||||
|
||||
----------
|
||||
**-sort-col=<sort-col> - 按指定的列排序。默认使用 cpu-user 排序**
|
||||
|
||||
Eg: ctop --sort-col=blkio
|
||||
例子: ctop --sort-col=blkio
|
||||
|
||||
如果有Docker和LXC支持的额外容器,跟踪选项也是可用的:
|
||||
|
||||
press 'a' - attach to console output
|
||||
press 'a' - 接驳到终端输出
|
||||
|
||||
press 'e' - open a shell in the container context
|
||||
press 'e' - 打开容器中的一个 shell
|
||||
|
||||
press 's' – stop the container (SIGTERM)
|
||||
press 's' - 停止容器 (SIGTERM)
|
||||
|
||||
press 'k' - kill the container (SIGKILL)
|
||||
press 'k' - 杀死容器 (SIGKILL)
|
||||
|
||||
[ctop][1]当前还处于Jean-Tiare Le Bigot的开发中,希望我们能在该工具中见到像本地top命令一样的特性 :-)
|
||||
目前 Jean-Tiare Le Bigot 还在积极开发 [ctop][1] 中,希望我们能在该工具中见到像本地 top 命令一样的特性 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -184,7 +177,7 @@ via: http://linoxide.com/how-tos/monitor-linux-containers-performance/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,406 @@
|
||||
建立你自己的 CA 服务:OpenSSL 命令行 CA 操作快速指南
|
||||
================================================================================
|
||||
|
||||
这些是关于使用 OpenSSL 生成证书授权(CA)、中间证书授权和末端证书的速记随笔,内容包括 OCSP、CRL 和 CA 颁发者信息,以及指定颁发和有效期限等。
|
||||
|
||||
我们将建立我们自己的根 CA,我们将使用根 CA 来生成一个中间 CA 的例子,我们将使用中间 CA 来签署末端用户证书。
|
||||
|
||||
### 根 CA ###
|
||||
|
||||
创建根 CA 授权目录并切换到该目录:
|
||||
|
||||
mkdir ~/SSLCA/root/
|
||||
cd ~/SSLCA/root/
|
||||
|
||||
为我们的根 CA 生成一个8192位长的 SHA-256 RSA 密钥:
|
||||
|
||||
openssl genrsa -aes256 -out rootca.key 8192
|
||||
|
||||
样例输出:
|
||||
|
||||
Generating RSA private key, 8192 bit long modulus
|
||||
.........++
|
||||
....................................................................................................................++
|
||||
e is 65537 (0x10001)
|
||||
|
||||
如果你想要用密码保护该密钥,请添加 `-aes256` 选项。
|
||||
|
||||
创建自签名根 CA 证书 `ca.crt`;你需要为你的根 CA 提供一个身份:
|
||||
|
||||
openssl req -sha256 -new -x509 -days 1826 -key rootca.key -out rootca.crt
|
||||
|
||||
样例输出:
|
||||
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [AU]:NL
|
||||
State or Province Name (full name) [Some-State]:Zuid Holland
|
||||
Locality Name (eg, city) []:Rotterdam
|
||||
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Sparkling Network
|
||||
Organizational Unit Name (eg, section) []:Sparkling CA
|
||||
Common Name (e.g. server FQDN or YOUR name) []:Sparkling Root CA
|
||||
Email Address []:
|
||||
|
||||
创建一个存储 CA 序列的文件:
|
||||
|
||||
touch certindex
|
||||
echo 1000 > certserial
|
||||
echo 1000 > crlnumber
|
||||
|
||||
放置 CA 配置文件,该文件持有 CRL 和 OCSP 末端的存根。
|
||||
|
||||
# vim ca.conf
|
||||
[ ca ]
|
||||
default_ca = myca
|
||||
|
||||
[ crl_ext ]
|
||||
issuerAltName=issuer:copy
|
||||
authorityKeyIdentifier=keyid:always
|
||||
|
||||
[ myca ]
|
||||
dir = ./
|
||||
new_certs_dir = $dir
|
||||
unique_subject = no
|
||||
certificate = $dir/rootca.crt
|
||||
database = $dir/certindex
|
||||
private_key = $dir/rootca.key
|
||||
serial = $dir/certserial
|
||||
default_days = 730
|
||||
default_md = sha1
|
||||
policy = myca_policy
|
||||
x509_extensions = myca_extensions
|
||||
crlnumber = $dir/crlnumber
|
||||
default_crl_days = 730
|
||||
|
||||
[ myca_policy ]
|
||||
commonName = supplied
|
||||
stateOrProvinceName = supplied
|
||||
countryName = optional
|
||||
emailAddress = optional
|
||||
organizationName = supplied
|
||||
organizationalUnitName = optional
|
||||
|
||||
[ myca_extensions ]
|
||||
basicConstraints = critical,CA:TRUE
|
||||
keyUsage = critical,any
|
||||
subjectKeyIdentifier = hash
|
||||
authorityKeyIdentifier = keyid:always,issuer
|
||||
keyUsage = digitalSignature,keyEncipherment,cRLSign,keyCertSign
|
||||
extendedKeyUsage = serverAuth
|
||||
crlDistributionPoints = @crl_section
|
||||
subjectAltName = @alt_names
|
||||
authorityInfoAccess = @ocsp_section
|
||||
|
||||
[ v3_ca ]
|
||||
basicConstraints = critical,CA:TRUE,pathlen:0
|
||||
keyUsage = critical,any
|
||||
subjectKeyIdentifier = hash
|
||||
authorityKeyIdentifier = keyid:always,issuer
|
||||
keyUsage = digitalSignature,keyEncipherment,cRLSign,keyCertSign
|
||||
extendedKeyUsage = serverAuth
|
||||
crlDistributionPoints = @crl_section
|
||||
subjectAltName = @alt_names
|
||||
authorityInfoAccess = @ocsp_section
|
||||
|
||||
[alt_names]
|
||||
DNS.0 = Sparkling Intermidiate CA 1
|
||||
DNS.1 = Sparkling CA Intermidiate 1
|
||||
|
||||
[crl_section]
|
||||
URI.0 = http://pki.sparklingca.com/SparklingRoot.crl
|
||||
URI.1 = http://pki.backup.com/SparklingRoot.crl
|
||||
|
||||
[ocsp_section]
|
||||
caIssuers;URI.0 = http://pki.sparklingca.com/SparklingRoot.crt
|
||||
caIssuers;URI.1 = http://pki.backup.com/SparklingRoot.crt
|
||||
OCSP;URI.0 = http://pki.sparklingca.com/ocsp/
|
||||
OCSP;URI.1 = http://pki.backup.com/ocsp/
|
||||
|
||||
如果你需要设置某个特定的证书生效/过期日期,请添加以下内容到`[myca]`:
|
||||
|
||||
# format: YYYYMMDDHHMMSS
|
||||
default_enddate = 20191222035911
|
||||
default_startdate = 20181222035911
|
||||
|
||||
### 创建中间 CA###
|
||||
|
||||
生成中间 CA (名为 intermediate1)的私钥:
|
||||
|
||||
openssl genrsa -out intermediate1.key 4096
|
||||
|
||||
生成中间 CA 的 CSR:
|
||||
|
||||
openssl req -new -sha256 -key intermediate1.key -out intermediate1.csr
|
||||
|
||||
样例输出:
|
||||
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [AU]:NL
|
||||
State or Province Name (full name) [Some-State]:Zuid Holland
|
||||
Locality Name (eg, city) []:Rotterdam
|
||||
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Sparkling Network
|
||||
Organizational Unit Name (eg, section) []:Sparkling CA
|
||||
Common Name (e.g. server FQDN or YOUR name) []:Sparkling Intermediate CA
|
||||
Email Address []:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
A challenge password []:
|
||||
An optional company name []:
|
||||
|
||||
确保中间 CA 的主体(CN)和根 CA 不同。
|
||||
|
||||
用根 CA 签署 中间 CA 的 CSR:
|
||||
|
||||
openssl ca -batch -config ca.conf -notext -in intermediate1.csr -out intermediate1.crt
|
||||
|
||||
样例输出:
|
||||
|
||||
Using configuration from ca.conf
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'NL'
|
||||
stateOrProvinceName :ASN.1 12:'Zuid Holland'
|
||||
localityName :ASN.1 12:'Rotterdam'
|
||||
organizationName :ASN.1 12:'Sparkling Network'
|
||||
organizationalUnitName:ASN.1 12:'Sparkling CA'
|
||||
commonName :ASN.1 12:'Sparkling Intermediate CA'
|
||||
Certificate is to be certified until Mar 30 15:07:43 2017 GMT (730 days)
|
||||
|
||||
Write out database with 1 new entries
|
||||
Data Base Updated
|
||||
|
||||
生成 CRL(同时采用 PEM 和 DER 格式):
|
||||
|
||||
openssl ca -config ca.conf -gencrl -keyfile rootca.key -cert rootca.crt -out rootca.crl.pem
|
||||
|
||||
openssl crl -inform PEM -in rootca.crl.pem -outform DER -out rootca.crl
|
||||
|
||||
每次使用该 CA 签署证书后,请生成 CRL。
|
||||
|
||||
如果你需要撤销该中间证书:
|
||||
|
||||
openssl ca -config ca.conf -revoke intermediate1.crt -keyfile rootca.key -cert rootca.crt
|
||||
|
||||
### 配置中间 CA ###
|
||||
|
||||
为该中间 CA 创建一个新文件夹,然后进入该文件夹:
|
||||
|
||||
mkdir ~/SSLCA/intermediate1/
|
||||
cd ~/SSLCA/intermediate1/
|
||||
|
||||
从根 CA 拷贝中间证书和密钥:
|
||||
|
||||
cp ~/SSLCA/root/intermediate1.key ./
|
||||
cp ~/SSLCA/root/intermediate1.crt ./
|
||||
|
||||
创建索引文件:
|
||||
|
||||
touch certindex
|
||||
echo 1000 > certserial
|
||||
echo 1000 > crlnumber
|
||||
|
||||
创建一个新的 `ca.conf` 文件:
|
||||
|
||||
# vim ca.conf
|
||||
[ ca ]
|
||||
default_ca = myca
|
||||
|
||||
[ crl_ext ]
|
||||
issuerAltName=issuer:copy
|
||||
authorityKeyIdentifier=keyid:always
|
||||
|
||||
[ myca ]
|
||||
dir = ./
|
||||
new_certs_dir = $dir
|
||||
unique_subject = no
|
||||
certificate = $dir/intermediate1.crt
|
||||
database = $dir/certindex
|
||||
private_key = $dir/intermediate1.key
|
||||
serial = $dir/certserial
|
||||
default_days = 365
|
||||
default_md = sha1
|
||||
policy = myca_policy
|
||||
x509_extensions = myca_extensions
|
||||
crlnumber = $dir/crlnumber
|
||||
default_crl_days = 365
|
||||
|
||||
[ myca_policy ]
|
||||
commonName = supplied
|
||||
stateOrProvinceName = supplied
|
||||
countryName = optional
|
||||
emailAddress = optional
|
||||
organizationName = supplied
|
||||
organizationalUnitName = optional
|
||||
|
||||
[ myca_extensions ]
|
||||
basicConstraints = critical,CA:FALSE
|
||||
keyUsage = critical,any
|
||||
subjectKeyIdentifier = hash
|
||||
authorityKeyIdentifier = keyid:always,issuer
|
||||
keyUsage = digitalSignature,keyEncipherment
|
||||
extendedKeyUsage = serverAuth
|
||||
crlDistributionPoints = @crl_section
|
||||
subjectAltName = @alt_names
|
||||
authorityInfoAccess = @ocsp_section
|
||||
|
||||
[alt_names]
|
||||
DNS.0 = example.com
|
||||
DNS.1 = example.org
|
||||
|
||||
[crl_section]
|
||||
URI.0 = http://pki.sparklingca.com/SparklingIntermidiate1.crl
|
||||
URI.1 = http://pki.backup.com/SparklingIntermidiate1.crl
|
||||
|
||||
[ocsp_section]
|
||||
caIssuers;URI.0 = http://pki.sparklingca.com/SparklingIntermediate1.crt
|
||||
caIssuers;URI.1 = http://pki.backup.com/SparklingIntermediate1.crt
|
||||
OCSP;URI.0 = http://pki.sparklingca.com/ocsp/
|
||||
OCSP;URI.1 = http://pki.backup.com/ocsp/
|
||||
|
||||
修改 `[alt_names]` 部分,添加你需要的主体备选名。如果你不需要主体备选名,请移除该部分包括`subjectAltName = @alt_names`的行。
|
||||
|
||||
如果你需要设置一个指定的生效/到期日期,请添加以下内容到 `[myca]`:
|
||||
|
||||
# format: YYYYMMDDHHMMSS
|
||||
default_enddate = 20191222035911
|
||||
default_startdate = 20181222035911
|
||||
|
||||
生成一个空白 CRL(同时以 PEM 和 DER 格式):
|
||||
|
||||
openssl ca -config ca.conf -gencrl -keyfile rootca.key -cert rootca.crt -out rootca.crl.pem
|
||||
|
||||
openssl crl -inform PEM -in rootca.crl.pem -outform DER -out rootca.crl
|
||||
|
||||
### 生成末端用户证书 ###
|
||||
|
||||
我们使用这个新的中间 CA 来生成一个末端用户证书,请重复以下操作来使用该 CA 为每个用户签署。
|
||||
|
||||
mkdir enduser-certs
|
||||
|
||||
生成末端用户的私钥:
|
||||
|
||||
openssl genrsa -out enduser-certs/enduser-example.com.key 4096
|
||||
|
||||
生成末端用户的 CSR:
|
||||
|
||||
openssl req -new -sha256 -key enduser-certs/enduser-example.com.key -out enduser-certs/enduser-example.com.csr
|
||||
|
||||
样例输出:
|
||||
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [AU]:NL
|
||||
State or Province Name (full name) [Some-State]:Noord Holland
|
||||
Locality Name (eg, city) []:Amsterdam
|
||||
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Example Inc
|
||||
Organizational Unit Name (eg, section) []:IT Dept
|
||||
Common Name (e.g. server FQDN or YOUR name) []:example.com
|
||||
Email Address []:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
A challenge password []:
|
||||
An optional company name []:
|
||||
|
||||
使用中间 CA 签署末端用户的 CSR:
|
||||
|
||||
openssl ca -batch -config ca.conf -notext -in enduser-certs/enduser-example.com.csr -out enduser-certs/enduser-example.com.crt
|
||||
|
||||
样例输出:
|
||||
|
||||
Using configuration from ca.conf
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'NL'
|
||||
stateOrProvinceName :ASN.1 12:'Noord Holland'
|
||||
localityName :ASN.1 12:'Amsterdam'
|
||||
organizationName :ASN.1 12:'Example Inc'
|
||||
organizationalUnitName:ASN.1 12:'IT Dept'
|
||||
commonName :ASN.1 12:'example.com'
|
||||
Certificate is to be certified until Mar 30 15:18:26 2016 GMT (365 days)
|
||||
|
||||
Write out database with 1 new entries
|
||||
Data Base Updated
|
||||
|
||||
生成 CRL(同时以 PEM 和 DER 格式):
|
||||
|
||||
openssl ca -config ca.conf -gencrl -keyfile intermediate1.key -cert intermediate1.crt -out intermediate1.crl.pem
|
||||
|
||||
openssl crl -inform PEM -in intermediate1.crl.pem -outform DER -out intermediate1.crl
|
||||
|
||||
每次你使用该 CA 签署证书后,都需要生成 CRL。
|
||||
|
||||
如果你需要撤销该末端用户证书:
|
||||
|
||||
openssl ca -config ca.conf -revoke enduser-certs/enduser-example.com.crt -keyfile intermediate1.key -cert intermediate1.crt
|
||||
|
||||
样例输出:
|
||||
|
||||
Using configuration from ca.conf
|
||||
Revoking Certificate 1000.
|
||||
Data Base Updated
|
||||
|
||||
通过连接根证书和中间证书来创建证书链文件。
|
||||
|
||||
cat ../root/rootca.crt intermediate1.crt > enduser-certs/enduser-example.com.chain
|
||||
|
||||
发送以下文件给末端用户:
|
||||
|
||||
enduser-example.com.crt
|
||||
enduser-example.com.key
|
||||
enduser-example.com.chain
|
||||
|
||||
你也可以让末端用户提供他们自己的 CSR,而只发送给他们这个 .crt 文件。不要把它从服务器删除,否则你就不能撤销了。
|
||||
|
||||
### 校验证书 ###
|
||||
|
||||
你可以对证书链使用以下命令来验证末端用户证书:
|
||||
|
||||
openssl verify -CAfile enduser-certs/enduser-example.com.chain enduser-certs/enduser-example.com.crt
|
||||
enduser-certs/enduser-example.com.crt: OK
|
||||
|
||||
你也可以针对 CRL 来验证。首先,将 PEM 格式的 CRL 和证书链相连接:
|
||||
|
||||
cat ../root/rootca.crt intermediate1.crt intermediate1.crl.pem > enduser-certs/enduser-example.com.crl.chain
|
||||
|
||||
验证证书:
|
||||
|
||||
openssl verify -crl_check -CAfile enduser-certs/enduser-example.com.crl.chain enduser-certs/enduser-example.com.crt
|
||||
|
||||
没有撤销时的输出:
|
||||
|
||||
enduser-certs/enduser-example.com.crt: OK
|
||||
|
||||
撤销后的输出如下:
|
||||
|
||||
enduser-certs/enduser-example.com.crt: CN = example.com, ST = Noord Holland, C = NL, O = Example Inc, OU = IT Dept
|
||||
error 23 at 0 depth lookup:certificate revoked
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://raymii.org/s/tutorials/OpenSSL_command_line_Root_and_Intermediate_CA_including_OCSP_CRL%20and_revocation.html
|
||||
|
||||
作者:Remy van Elst
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,121 @@
|
||||
一个用于Gnome桌面的下拉式终端: Guake 0.7.0 发布
|
||||
================================================================================
|
||||
Linux的命令行是最好、最强大的东西,它使新手着迷,并为老手和极客的提供极其强大的功能。那些在服务器和生产环境下工作的人早已认识到了这个事实。有趣的是,Linux终端是Linus Torvald在1991年写内核时实现的第一批功能之一。
|
||||
|
||||
终端是个强大的工具,由于它没有什么可调整的部分,所以十分可靠。终端介于控制台环境和GUI环境之间。终端自身作为一个GUI程序,运行在桌面环境下。有许多终端是适用于特定的桌面环境的,其它的则是通用的。Terminator, Konsole, Gnome-Terminal, Terminology, XFCE terminal, xterm都是些常用的终端模拟器。
|
||||
|
||||
您可以从下面的链接中获得一份使用最广泛的终端模拟器的列表。
|
||||
|
||||
- [20 Useful Terminals for Linux][1]
|
||||
|
||||
前几日上网时,我偶遇了名为‘Guake’的终端程序,它是用于gnome的终端模拟器。尽管这并不是我第一次听到Guake。实际上,我在大约一年前便知道了这个应用程序,但不知怎么搞的,我那时没有写写Guake,再后来我便渐渐忘掉了Guake,直到我再一次听到Guake。所以,最终,这篇文章诞生了。我将给你讲讲Guake的功能,在Debian、Ubuntu、Fedora上的安装过程以及一些测试。
|
||||
|
||||
#### 什么是Guake? ####
|
||||
|
||||
Guake是应用于Gnome环境的下拉式终端。主要由Python编写,使用了一些C,它以GPL2+许可证发布,适用于Linux以及类似的系统。Guake的灵感来源于电脑游戏Quake(雷神之锤)中的终端,Quake的终端能通过按下特定按键(默认为F12)从屏幕上滑下来,并在按下同样的键后滑上去。
|
||||
|
||||
值得注意的是,Guake并不是第一个这样的应用。Yakuake(Yet Another Kuake)是一个运行于KDE的终端模拟器,Tilda是一个用GTK+写成的终端模拟器。它们的灵感都来自于雷神之锤那上下滑动的终端。
|
||||
|
||||
#### Guake的功能 ####
|
||||
|
||||
- 轻量级
|
||||
- 简单而优雅
|
||||
- 功能众多
|
||||
- 强大
|
||||
- 美观
|
||||
- 将终端平滑地集成于GUI中
|
||||
- 在按下预定义的键后出现/消失
|
||||
- 支持热键、标签、透明化背景,这使得它适合所有Gnome用户
|
||||
- 可配置各种方面
|
||||
- 包括许多颜色的调色板
|
||||
- 设定透明度的快捷方式
|
||||
- 通过Guake配置,可在启动时运行一个脚本
|
||||
- 可以在多个显示器上运行
|
||||
|
||||
Guake 0.7.0最近发布,它带来了一些修正以及上面提到的一些功能。完整的版本历史和源代码包可以在[这里][2]找到。
|
||||
|
||||
### 在Linux中安装Guake终端 ###
|
||||
|
||||
如果您对从源码编译Guake感兴趣,您可以从上面的链接处下载Guake,并在安装前进行编译。
|
||||
|
||||
然而Guake可以在许多的发行版中通过添加额外的仓库来安装。这里,我们将在Debian、Ubuntu、Linux Mint和Fedora下安装Guake。
|
||||
|
||||
首先从仓库获取最新的软件包列表,并从默认的仓库安装Guake,如下所示:
|
||||
|
||||
---------------- 在 Debian, Ubuntu 和 Linux Mint 上 ----------------
|
||||
$ sudo apt-get update
|
||||
$ apt-get install guake
|
||||
|
||||
----------
|
||||
|
||||
---------------- 在 Fedora 19 及其以后版本 ----------------
|
||||
# yum update
|
||||
# yum install guake
|
||||
|
||||
安装后,可以从另一个终端中启动Guake:
|
||||
|
||||
$ guake
|
||||
|
||||
在启动它后,便可以在Gnome桌面中使用F12(默认配置)来拉下、收回终端。
|
||||
|
||||
看起来非常漂亮,尤其是透明背景。滑下来...滑上去...滑下来...滑上去...执行命令,打开另一个标签,执行命令,滑上去...滑下来...(作者已沉迷其中)
|
||||
|
||||

|
||||
|
||||
*Guake实战*
|
||||
|
||||
如果您的壁纸或活动窗口的颜色和Guake的颜色有些不搭。您可以改变您的壁纸,减少透明度或者改变Guake的颜色。
|
||||
|
||||
下一步便是进入Guake的配置,根据每个人的需求修改设置。可以通过应用菜单或者下面的命令来运行Guake的配置。
|
||||
|
||||
$ guake --preferences
|
||||
|
||||

|
||||
|
||||
*Guake终端配置*
|
||||
|
||||
设置滚动
|
||||
|
||||

|
||||
|
||||
*Guake滚动配置*
|
||||
|
||||
外观设置 - 在这里您可以修改文字颜色和背景色以及透明度。
|
||||
|
||||

|
||||
|
||||
*外观设置*
|
||||
|
||||
键盘快捷键 - 在这里您可以修改Guake显示的开关快捷键。
|
||||
|
||||

|
||||
|
||||
*键盘快捷键*
|
||||
|
||||
兼容性设置 - 基本上不必设置它。
|
||||
|
||||

|
||||
|
||||
*兼容性设置*
|
||||
|
||||
### 结论 ###
|
||||
|
||||
这个项目即不是太年轻也不是太古老,因此它已经达到了一定的成熟度,足够可靠,可以开箱即用。像我这样需要在GUI和终端间频繁切换的人来说,Guake是一个福利。我不需要管理一个多余的窗口,频繁的打开和关闭,使用tab在大量打开的应用程序中寻找终端或切换到不同的工作区来管理终端,现在我需要的只有F12。
|
||||
|
||||
我认为对任何同时使用GUI和终端的Linux用户来说,Guake都是必须的工具。同样的,我会向任何想要在系统中结合使用GUI和终端的人推荐它,因为它既平滑又没有任何障碍。
|
||||
|
||||
上面就是我要说的全部了。如果在安装和使用时有任何问题,请告诉我,我们会帮助您。也请您告诉我您使用Guake的经验。在下面的评论区反馈您宝贵的经验。点赞和分享以帮助我们宣传。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-guake-terminal-ubuntu-mint-fedora/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/linux-terminal-emulators/
|
||||
[2]:https://github.com/Guake/guake/releases/tag/0.7.0
|
||||
@ -0,0 +1,115 @@
|
||||
Linux有问必答:nginx网络服务器上如何阻止特定用户代理(UA)
|
||||
================================================================================
|
||||
> **问题**: 我注意到有一些机器人经常访问我的nginx驱动的网站,并且进行一些攻击性的扫描,导致消耗掉了我的网络服务器的大量资源。我一直尝试着通过用户代理符串来阻挡这些机器人。我怎样才能在nginx网络服务器上阻挡掉特定的用户代理呢?
|
||||
|
||||
现代互联网滋生了大量各种各样的恶意机器人和网络爬虫,比如像恶意软件机器人、垃圾邮件程序或内容刮刀,这些恶意工具一直偷偷摸摸地扫描你的网站,干些诸如检测潜在网站漏洞、收获电子邮件地址,或者只是从你的网站偷取内容。大多数机器人能够通过它们的“用户代理”签名字符串来识别。
|
||||
|
||||
作为第一道防线,你可以尝试通过将这些机器人的用户代理字符串添加入robots.txt文件来阻止这些恶意软件机器人访问你的网站。但是,很不幸的是,该操作只针对那些“行为良好”的机器人,这些机器人被设计遵循robots.txt的规范。许多恶意软件机器人可以很容易地忽略掉robots.txt,然后随意扫描你的网站。
|
||||
|
||||
另一个用以阻挡特定机器人的途径,就是配置你的网络服务器,通过特定的用户代理字符串拒绝要求提供内容的请求。本文就是说明如何**在nginx网络服务器上阻挡特定的用户代理**。
|
||||
|
||||
### 在Nginx中将特定用户代理列入黑名单 ###
|
||||
|
||||
要配置用户代理阻挡列表,请打开你的网站的nginx配置文件,找到`server`定义部分。该文件可能会放在不同的地方,这取决于你的nginx配置或Linux版本(如,`/etc/nginx/nginx.conf`,`/etc/nginx/sites-enabled/<your-site>`,`/usr/local/nginx/conf/nginx.conf`,`/etc/nginx/conf.d/<your-site>`)。
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
在打开该配置文件并找到 `server` 部分后,添加以下 if 声明到该部分内的某个地方。
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
# 大小写敏感的匹配
|
||||
if ($http_user_agent ~ (Antivirx|Arian) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
#大小写无关的匹配
|
||||
if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
如你所想,这些 if 声明使用正则表达式匹配了任意不良用户字符串,并向匹配的对象返回403 HTTP状态码。
|
||||
`$http_user_agent`是HTTP请求中的一个包含有用户代理字符串的变量。‘~’操作符针对用户代理字符串进行大小写敏感匹配,而‘~*’操作符则进行大小写无关匹配。‘|’操作符是逻辑或,因此,你可以在 if 声明中放入众多的用户代理关键字,然后将它们全部阻挡掉。
|
||||
|
||||
在修改配置文件后,你必须重新加载nginx以激活阻挡:
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
你可以通过使用带有 “--user-agent” 选项的 wget 测试用户代理阻挡。
|
||||
|
||||
$ wget --user-agent "malicious bot" http://<nginx-ip-address>
|
||||
|
||||
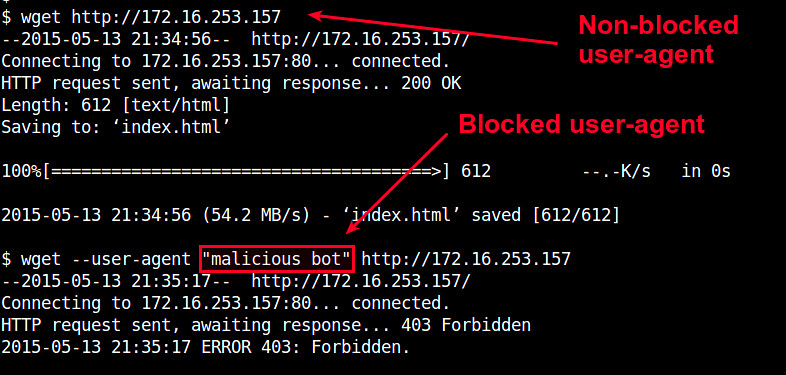
|
||||
|
||||
### 管理Nginx中的用户代理黑名单 ###
|
||||
|
||||
目前为止,我已经展示了在nginx中如何阻挡一些用户代理的HTTP请求。如果你有许多不同类型的网络爬虫机器人要阻挡,又该怎么办呢?
|
||||
|
||||
由于用户代理黑名单会增长得很大,所以将它们放在nginx的server部分不是个好点子。取而代之的是,你可以创建一个独立的文件,在该文件中列出所有被阻挡的用户代理。例如,让我们创建/etc/nginx/useragent.rules,并定义以下面的格式定义所有被阻挡的用户代理的图谱。
|
||||
|
||||
$ sudo vi /etc/nginx/useragent.rules
|
||||
|
||||
----------
|
||||
|
||||
map $http_user_agent $badagent {
|
||||
default 0;
|
||||
~*malicious 1;
|
||||
~*backdoor 1;
|
||||
~*netcrawler 1;
|
||||
~Antivirx 1;
|
||||
~Arian 1;
|
||||
~webbandit 1;
|
||||
}
|
||||
|
||||
与先前的配置类似,‘~*’将匹配以大小写不敏感的方式匹配关键字,而‘~’将使用大小写敏感的正则表达式匹配关键字。“default 0”行所表达的意思是,任何其它文件中未被列出的用户代理将被允许。
|
||||
|
||||
接下来,打开你的网站的nginx配置文件,找到里面包含 http 的部分,然后添加以下行到 http 部分某个位置。
|
||||
|
||||
http {
|
||||
.....
|
||||
include /etc/nginx/useragent.rules
|
||||
}
|
||||
|
||||
注意,该 include 声明必须出现在 server 部分之前(这就是为什么我们将它添加到了 http 部分里)。
|
||||
|
||||
现在,打开nginx配置定义你的服务器的部分,添加以下 if 声明:
|
||||
|
||||
server {
|
||||
....
|
||||
|
||||
if ($badagent) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
最后,重新加载nginx。
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
现在,任何包含有`/etc/nginx/useragent.rules`中列出的关键字的用户代理将被nginx自动禁止。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/block-specific-user-agents-nginx-web-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,33 @@
|
||||
如何修复 “fatal error: security/pam_modules.h: No such file or directory”
|
||||
================================================================================
|
||||
> **问题**: 我尝试在 [某某 Linux 发行版] 上编译程序,但是出现下面的编译错误:
|
||||
>
|
||||
> "pam_otpw.c:27:34: fatal error: security/pam_modules.h: No such file or directory"
|
||||
>
|
||||
> 我怎样才能修复这个错误?
|
||||
|
||||
缺失的头文件 'security/pam_modules.h' 是 libpam 开发版的一部分,一个 PAM(Pluggable Authentication Modules:插入式验证模块)库。因此要修复这个错误,你需要安装 libpam 开发包,如下所示。
|
||||
|
||||
对于 Debian、 Ubuntu 或者 Linux Mint:
|
||||
|
||||
$ sudo apt-get install libpam0g-dev
|
||||
|
||||
对与 CentOS、 Fedora 或者 RHEL:
|
||||
|
||||
$ sudo yum install gcc pam-devel
|
||||
|
||||
现在验证缺失的头文件是否安装到了 /usr/include/security。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fatal-error-security-pam-modules.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,26 @@
|
||||
微软开源了WCF框架
|
||||
================================================================================
|
||||
微软于今日(2015/5/20)宣布了针对 .NET Core 重大开源:WCF(Windows Communication Foundation)。
|
||||
|
||||
如[MSDN][1]中的描述:“WCF是一个构建面向服务应用的框架。使用WCF,你可以从一个服务终端给另一个发送异步消息。服务终端可以是托管在IIS中连续可用的服务的一部分,也可以是托管在某个程序上的服务。服务终端可以是请求服务端数据的客户端。消息可以是一个字符或者XML,也可以是复杂的二进制流。”
|
||||
|
||||
它的[代码放在GitHub][2],“包含了Window桌面中完整WCF框架的一部分,它支持已经可用于构建Window Store上的WCF应用的库。这些主要是基于客户端,方便移动设备和中间层服务器使用WCF进行通信。”
|
||||
|
||||
更多的关于微软开源 WCF 的细节查看[dotNETFoundation.org blog][3]的公告。
|
||||
|
||||
WCF听上去有点像Linux中用于进程/服务之间的进程间通讯的D-BUS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=Microsoft-Open-Source-WCF
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:https://msdn.microsoft.com/en-us/library/ms731082%28v=vs.110%29.aspx
|
||||
[2]:https://github.com/dotnet/wcf
|
||||
[3]:http://www.dotnetfoundation.org/blog/wcf-is-open-source
|
||||
@ -1,23 +1,23 @@
|
||||
translating by cvsher
|
||||
Linux grep command with 14 different examples
|
||||
================================================================================
|
||||
### Overview : ###
|
||||
14 个 grep 命令的例子
|
||||
===========
|
||||
|
||||
Linux like operating system provides a searching tool known as **grep (global regular expression print)**. grep command is useful for searching the content of one more files based on the pattern. A pattern may be a single character, bunch of characters, single word or a sentence.
|
||||
###概述:###
|
||||
|
||||
When we execute the grep command with specified pattern, if its is matched, then it will display the line of file containing the pattern without modifying the contents of existing file.
|
||||
所有的类linux系统都会提供一个名为**grep(global regular expression print,全局正则表达式输出)**的搜索工具。grep命令在对一个或多个文件的内容进行基于模式的搜索的情况下是非常有用的。模式可以是单个字符、多个字符、单个单词、或者是一个句子。
|
||||
|
||||
In this tutorial we will discuss 14 different examples of grep command
|
||||
当命令匹配到执行命令时指定的模式时,grep会将包含模式的一行输出,但是并不对原文件内容进行修改。
|
||||
|
||||
### Example:1 Search the pattern (word) in a file ###
|
||||
在本文中,我们将会讨论到14个grep命令的例子。
|
||||
|
||||
Search the “linuxtechi” word in the file /etc/passwd file
|
||||
###例1 在文件中查找模式(单词)###
|
||||
|
||||
在/etc/passwd文件中查找单词“linuxtechi”
|
||||
|
||||
root@Linux-world:~# grep linuxtechi /etc/passwd
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:2 Search the pattern in the multiple files. ###
|
||||
###例2 在多个文件中查找模式。###
|
||||
|
||||
root@Linux-world:~# grep linuxtechi /etc/passwd /etc/shadow /etc/gshadow
|
||||
/etc/passwd:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
@ -31,14 +31,14 @@ Search the “linuxtechi” word in the file /etc/passwd file
|
||||
/etc/gshadow:sambashare:!::linuxtechi
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:3 List the name of those files which contain a specified pattern using -l option. ###
|
||||
###例3 使用-l参数列出包含指定模式的文件的文件名。###
|
||||
|
||||
root@Linux-world:~# grep -l linuxtechi /etc/passwd /etc/shadow /etc/fstab /etc/mtab
|
||||
/etc/passwd
|
||||
/etc/shadow
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:4 Search the pattern in the file along with associated line number(s) using the -n option ###
|
||||
###例4 使用-n参数,在文件中查找指定模式并显示匹配行的行号###
|
||||
|
||||
root@Linux-world:~# grep -n linuxtechi /etc/passwd
|
||||
39:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
@ -48,34 +48,34 @@ root@Linux-world:~# grep -n root /etc/passwd /etc/shadow
|
||||
|
||||

|
||||
|
||||
### Example:5 Print the line excluding the pattern using -v option ###
|
||||
###例5 使用-v参数输出不包含指定模式的行###
|
||||
|
||||
List all the lines of the file /etc/passwd that does not contain specific word “linuxtechi”.
|
||||
输出/etc/passwd文件中所有不含单词“linuxtechi”的行
|
||||
|
||||
root@Linux-world:~# grep -v linuxtechi /etc/passwd
|
||||
|
||||
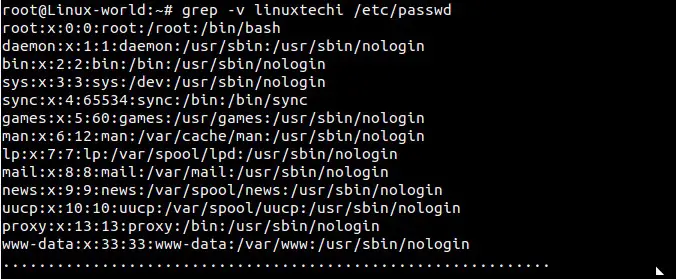
|
||||
|
||||
### Example:6 Display all the lines that starts with specified pattern using ^ symbol ###
|
||||
###例6 使用 ^ 符号输出所有以某指定模式开头的行###
|
||||
|
||||
Bash shell treats carrot symbol (^) as a special character which marks the beginning of line or a word. Let’s display the lines which starts with “root” word in the file /etc/passwd.
|
||||
Bash脚本将 ^ 符号视作特殊字符,用于指定一行或者一个单词的开始。例如输出/etc/passes文件中所有以“root”开头的行
|
||||
|
||||
root@Linux-world:~# grep ^root /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example: 7 Display all the lines that ends with specified pattern using $ symbol. ###
|
||||
###例7 使用 $ 符号输出所有以指定模式结尾的行。###
|
||||
|
||||
List all the lines of /etc/passwd that ends with “bash” word.
|
||||
输出/etc/passwd文件中所有以“bash”结尾的行。
|
||||
|
||||
root@Linux-world:~# grep bash$ /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
Bash shell treats dollar ($) symbol as a special character which marks the end of line or word.
|
||||
Bash脚本将美元($)符号视作特殊字符,用于指定一行或者一个单词的结尾。
|
||||
|
||||
### Example:8 Search the pattern recursively using -r option ###
|
||||
###例8 使用 -r 参数递归地查找特定模式###
|
||||
|
||||
root@Linux-world:~# grep -r linuxtechi /etc/
|
||||
/etc/subuid:linuxtechi:100000:65536
|
||||
@ -91,37 +91,37 @@ Bash shell treats dollar ($) symbol as a special character which marks the end o
|
||||
/etc/passwd:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
............................................................................
|
||||
|
||||
Above command will search linuxtechi in the “/etc” directory recursively.
|
||||
上面的命令将会递归的在/etc目录中查找“linuxtechi”单词
|
||||
|
||||
### Example:9 Search all the empty or blank lines of a file using grep ###
|
||||
###例9 使用 grep 查找文件中所有的空行
|
||||
|
||||
root@Linux-world:~# grep ^$ /etc/shadow
|
||||
root@Linux-world:~#
|
||||
|
||||
As there is no empty line in /etc/shadow file , so nothing is displayed.
|
||||
由于/etc/shadow文件中没有空行,所以没有任何输出
|
||||
|
||||
### Example:10 Search the pattern using ‘grep -i’ option. ###
|
||||
###例10 使用 -i 参数查找模式###
|
||||
|
||||
-i option in the grep command ignores the letter case i.e it will ignore upper case or lower case letters while searching
|
||||
grep命令的-i参数在查找时忽略字符的大小写。
|
||||
|
||||
Lets take an example , i want to search “LinuxTechi” word in the passwd file.
|
||||
我们来看一个例子,在paswd文件中查找“LinuxTechi”单词。
|
||||
|
||||
nextstep4it@localhost:~$ grep -i LinuxTechi /etc/passwd
|
||||
linuxtechi:x:1001:1001::/home/linuxtechi:/bin/bash
|
||||
nextstep4it@localhost:~$
|
||||
|
||||
### Example:11 Search multiple patterns using -e option ###
|
||||
###例11 使用 -e 参数查找多个模式###
|
||||
|
||||
For example i want to search ‘linuxtechi’ and ‘root’ word in a single grep command , then using -e option we can search multiple patterns .
|
||||
例如,我想在一条grep命令中查找‘linuxtechi’和‘root’单词,使用-e参数,我们可以查找多个模式。
|
||||
|
||||
root@Linux-world:~# grep -e "linuxtechi" -e "root" /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:12 Getting Search pattern from a file using “grep -f” ###
|
||||
###例12 使用 -f 用文件指定待查找的模式###
|
||||
|
||||
First create a search pattern file “grep_pattern” in your current working directory. In my case i have put the below contents.
|
||||
首先,在当前目录中创建一个搜索模式文件“grep_pattern”,我想文件中输入的如下内容。
|
||||
|
||||
root@Linux-world:~# cat grep_pattern
|
||||
^linuxtechi
|
||||
@ -129,35 +129,35 @@ First create a search pattern file “grep_pattern” in your current working di
|
||||
false$
|
||||
root@Linux-world:~#
|
||||
|
||||
Now try to search using grep_pattern file.
|
||||
现在,试试使用grep_pattern文件进行搜索
|
||||
|
||||
root@Linux-world:~# grep -f grep_pattern /etc/passwd
|
||||
|
||||
|
||||
|
||||
### Example:13 Count the number of matching patterns using -c option ###
|
||||
###例13 使用 -c 参数计算模式匹配到的数量###
|
||||
|
||||
Let take the above example , we can count the number of matching patterns using -c option in grep command.
|
||||
继续上面例子,我们在grep命令中使用-c命令计算匹配指定模式的数量
|
||||
|
||||
root@Linux-world:~# grep -c -f grep_pattern /etc/passwd
|
||||
22
|
||||
root@Linux-world:~#
|
||||
|
||||
### Example:14 Display N number of lines before & after pattern matching ###
|
||||
###例14 输出匹配指定模式行的前或者后面N行###
|
||||
|
||||
a) Display Four lines before patten matching using -B option
|
||||
a)使用-B参数输出匹配行的前4行
|
||||
|
||||
root@Linux-world:~# grep -B 4 "games" /etc/passwd
|
||||
|
||||
|
||||
|
||||
b) Display Four lines after pattern matching using -A option
|
||||
b)使用-A参数输出匹配行的后4行
|
||||
|
||||
root@Linux-world:~# grep -A 4 "games" /etc/passwd
|
||||
|
||||
|
||||
|
||||
c) Display Four lines around the pattern matching using -C option
|
||||
c)使用-C参数输出匹配行的前后各4行
|
||||
|
||||
root@Linux-world:~# grep -C 4 "games" /etc/passwd
|
||||
|
||||
@ -168,8 +168,8 @@ c) Display Four lines around the pattern matching using -C option
|
||||
via: http://www.linuxtechi.com/linux-grep-command-with-14-different-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,31 @@
|
||||
Ubuntu Devs Propose Stateless Persistent Network Interface Names for Ubuntu and Debian
|
||||
======================================================================================
|
||||
*Networks are detected in an unpredictable and unstable order*
|
||||
|
||||
**Martin Pitt, a renown Ubuntu and Debian developer, came with the proposal of enabling stateless persistent network interface names in the upcoming versions of the Ubuntu Linux and Debian GNU/Linux operating systems.**
|
||||
|
||||
According to Mr. Pitt, it appears that the problem lies in the automatic detection of network interfaces within the Linux kernel. As such, network interfaces are detected in an unstable and unpredictable order. However, it order to connect to a certain network interface in ifupdown or networkd users will need to identify it first using a stable name.
|
||||
|
||||
"The general schema for this is to have an udev rule which does some matches to identify a particular interface, and assings a NAME="foo" to it," says Martin Pitt in an email to the Ubuntu mailinglist. "Interfaces with an explicit NAME= get called just like this, and others just get a kernel driver default, usually ethN, wlanN, or sometimes others (some wifi drivers have their own naming schemas)."
|
||||
|
||||
**Sever solutions appeared over the years: mac, biosdevname, and ifnames**
|
||||
|
||||
Apparently, several solutions are available for this problem, including an installation of an udev rule in /lib/udev/rules.d/75-persistent-net-generator.rules that creates a MAC address at first boot and writes it to /etc/udev/rules.d/70-persistent-net.rules, which is currently used by default in Ubuntu and applies to most hardware components.
|
||||
|
||||
Other solutions include biosdevname, a package that reads port or index numbers, and slot names from the BIOS and writes them to /lib/udev/rules.d/71-biosdevname.rules, and ifnames, a persistent name generator that automatically checks the BIOS and/or firmware for index numbers or slot names, similar to biosdevname.
|
||||
|
||||
However, the difference between ifnames and biosdevname is that the latter falls back to slot names, such as PCI numbers, and then to the MAC address and writes to /lib/udev/rules.d/80-net-setup-link.rules. All of these solutions can be combined, and Martin Pitt proposes to replace the first solution that is now used by default with the ifnames one.
|
||||
|
||||
If a new solution is implemented, a lot of networking issues will be resolved in Ubuntu, especially the cloud version. In addition, it will provide for stable network interface names for all new Ubuntu installations, and resolve many other problems related to system-image, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Ubuntu-Devs-Propose-Stateless-Persistent-Network-Interface-Names-for-Ubuntu-and-Debian-480730.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
@ -0,0 +1,33 @@
|
||||
Ubuntu Community Council Asks the Kubuntu Project Leader to Step Down
|
||||
================================================================================
|
||||
> Jonathan Riddell refuses to step down as Kubuntu leader
|
||||
|
||||

|
||||
|
||||
**So this just happened. Scott Kitterman, a Debian developer and member of the Kubuntu Council, decided to make public some emails where it would appear that members of the Ubuntu Community Council asks Jonathan Riddell to step down from his position as a Kubuntu Project leader.**
|
||||
|
||||
Jonathan Riddell, which is both a KDE and Kubuntu developer, as well as an important member of the Ubuntu community for many years now, is being accused by several members of the Ubuntu and Kubuntu community about his confrontational and aggressive behavior towards them, as [the email exchanges exposed today][1] by Scott Kitterman suggest.
|
||||
|
||||
Long story short, after several email exchanges, the final decision of the Ubuntu Community Council, which is also backed by Canonical and Ubuntu founder Mark Shuttleworth, was for Jonathan Riddell to step down from all his positions as a leader within the Ubuntu and Kubuntu communities, for at least 12 months, but still being able to participate to discussions as any other member.
|
||||
|
||||
"It is with regret that we write this email to discuss an issue that we feel is negatively impacting the Ubuntu Community. Over a long period of time Jonathan Riddell has become increasingly difficult to deal with. Jonathan raised valid issues and concerns, but reacted poorly when he received answers he did not agree with," reads the first email send to the Ubuntu Community Council regarding the "nasty" behavior of Jonathan Riddell.
|
||||
|
||||
### Jonathan Riddell refuses to step down as a Kubuntu Project leader ###
|
||||
|
||||
From the email exchanges exposed today by Scott Kitterman, who decided to write a second post on his blog, suggesting that he wants to resign from its position in the Ubuntu and Kubuntu community, it would appear that Jonathan Riddell refused to step down as a Kubuntu Project leader.
|
||||
|
||||
As expected, Jonathan Riddell is being backed by members of the Kubuntu Community Council, who fired back at the Ubuntu Community Council's decision to take down the Kubuntu Project leader. "I’d like to thank all the Kubuntu members who just voted to re-affirm me on the Kubuntu Council," says Jonathan Riddell on [his blog][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Ubuntu-Community-Council-Asks-the-Kubuntu-Project-Leader-to-Step-Down-482384.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:https://skitterman.wordpress.com/
|
||||
[2]:http://jriddell.org/
|
||||
@ -1,56 +0,0 @@
|
||||
Square 2.0 Icon Pack Is Twice More Beautiful
|
||||
================================================================================
|
||||

|
||||
|
||||
Elegant, modern looking [Square icon theme][1] has recently been upgraded to version 2.0, which makes it more beautiful than ever. Square icon packs are compatible with all major desktop environments such as **Unity, GNOME, KDE, MATE** etc. Which means that you can use them for all popular Linux distributions such as Ubuntu, Fedora, Linux Mint, elementary OS etc. The vastness of this icon pack can be estimated from the fact it contains over 15,000 icons.
|
||||
|
||||
### Install and use Square icon pack 2.0 in Linux ###
|
||||
|
||||
There are two variants of Square icons, dark and light. Based on your preference, you can choose either of the two. For experimentation sake, I would advise you to download both variants of the icon theme.
|
||||
|
||||
You can download the icon pack from the link below. The files are stored in Google Drive, so don’t be suspicious if you don’t see a standard website like [SourceForge][2].
|
||||
|
||||
- [Square Dark Icons][3]
|
||||
- [Square Light Icons][4]
|
||||
|
||||
To use the icon theme, extract the downloaded files in ~/.icons directory. If this doesn’t exist, create it. Once you have the files in the right place, based on your desktop environment, use a tool to change the icon theme. I have written some small tutorials in the past on this topic. Feel free to refer to them if you need further help:
|
||||
|
||||
- [How to change themes in Ubuntu Unity][5]
|
||||
- [How to change themes in GNOME Shell][6]
|
||||
- [How to change themes in Linux Mint][7]
|
||||
- [How to change theme in Elementary OS Freya][8]
|
||||
|
||||
### Give it a try ###
|
||||
|
||||
Here is what my Ubuntu 14.04 looks like with Square icons. I am using [Ubuntu 15.04 default wallpaper][9] in the background.
|
||||
|
||||

|
||||
|
||||
A quick look at several icons in the Square theme:
|
||||
|
||||

|
||||
|
||||
How do you find it? Do you think it can be considered as one of the [best icon themes for Ubuntu 14.04][10]? Do share your thoughts and stay tuned for more articles on customizing your Linux desktop.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/square-2-0-icon-pack-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://gnome-look.org/content/show.php/Square?content=163513
|
||||
[2]:http://sourceforge.net/
|
||||
[3]:http://gnome-look.org/content/download.php?content=163513&id=1&tan=62806435
|
||||
[4]:http://gnome-look.org/content/download.php?content=163513&id=2&tan=19789941
|
||||
[5]:http://itsfoss.com/how-to-install-themes-in-ubuntu-13-10/
|
||||
[6]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[7]:http://itsfoss.com/install-icon-linux-mint/
|
||||
[8]:http://itsfoss.com/install-themes-icons-elementary-os-freya/
|
||||
[9]:http://itsfoss.com/default-wallpapers-ubuntu-1504/
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -1,41 +0,0 @@
|
||||
Synfig Studio 1.0 — Open Source Animation Gets Serious
|
||||
================================================================================
|
||||

|
||||
|
||||
**A brand new version of the free, open-source 2D animation software Synfig Studio is now available to download. **
|
||||
|
||||
The first release of the cross-platform software in well over a year, Synfig Studio 1.0 builds on its claim of offering “industrial-strength solution for creating film-quality animation” with a suite of new and improved features.
|
||||
|
||||
Among them is an improved user interface that the project developers say is ‘easier’ and ‘more intuitive’ to use. The client adds a new **single-window mode** for tidy working and has been **reworked to use the latest GTK3 libraries**.
|
||||
|
||||
On the features front there are several notable changes, including the addition of a fully-featured bone system.
|
||||
|
||||
This **joint-and-pivot ‘skeleton’ framework** is well suited to 2D cut-out animation and should prove super efficient when coupled with the complex deformations new to this release, or used with Synfig’s popular ‘automatic interpolated keyframes’ (read: frame-to-frame morphing).
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/M8zW1qCq8ng?feature=oembed"></iframe>
|
||||
|
||||
New non-destructive cutout tools, friction effects and initial support for full frame-by-frame bitmap animation, may help unlock the creativity of open-source animators, as might the addition of a sound layer for syncing the animation timeline with a soundtrack!
|
||||
|
||||
### Download Synfig Studio 1.0 ###
|
||||
|
||||
Synfig Studio is not a tool suited for everyone, though the latest batch of improvements in this latest release should help persuade some animators to give the free animation software a try.
|
||||
|
||||
If you want to find out what open-source animation software is like for yourself, you can grab an installer for Ubuntu for the latest release direct from the project’s Sourceforge page using the links below.
|
||||
|
||||
- [Download Synfig 1.0 (64bit) .deb Installer][1]
|
||||
- [Download Synfig 1.0 (32bit) .deb Installer][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/synfig-studio-new-release-features
|
||||
|
||||
作者:[oey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_amd64.deb/download
|
||||
[2]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_x86.deb/download
|
||||
@ -0,0 +1,104 @@
|
||||
sevenot Translating
|
||||
New to Linux? 5 Apps You Didn’t Know You Were Missing
|
||||
================================================================================
|
||||

|
||||
|
||||
When you moved to Linux, you went straight for the obvious browsers, cloud clients, music players, email clients, and perhaps image editors, right? As a result, you’ve missed several vital, productive tools. Here’s a roundup of five umissable Linux apps that you really need to install.
|
||||
|
||||
### [Synergy][1] ###
|
||||
|
||||
Synergy is a godsend if you use multiple desktops. It’s an open-source app that allows you to use a single mouse and keyboard across multiple computers, displays, and operating systems. Switching the mouse and keyboard functionality between the desktops is easy. Just move the mouse out the edge of one screen and into another.
|
||||
|
||||

|
||||
|
||||
When you open Synergy for the first time, it will run you through the setup wizard. The primary desktop is the one whose input devices you’ll be sharing with the other desktops. Configure that as the server. Add the remaining computers as clients.
|
||||
|
||||

|
||||
|
||||
Synergy maintains a common clipboard across all connected desktops. It also merges the lock screen setup, i.e. you need to bypass the lock screen just once to log in to all the computers together. Under **Edit > Settings**, you can make a few more tweaks such as adding a password and setting Synergy to launch on startup.
|
||||
|
||||
### [BasKet Note Pads][2] ###
|
||||
|
||||
Using BasKet Note Pads is somewhat like mapping your brain onto a computer. It helps make sense of all the ideas floating around in your head by allowing you to organize them in digestible chunks. You can use BasKet Note Pads for various tasks such as taking notes, creating idea maps and to-do lists, saving links, managing research, and keeping track of project data.
|
||||
|
||||
Each main idea or project goes into a section called a basket. To split ideas further, you can have one or more sub-baskets or sibling baskets. The baskets are further broken down into notes, which hold all the bits and pieces of a project. You can group them, tag them, and filter them.
|
||||
|
||||
The left pane in the application’s two-pane structure displays a tree-like view of all the baskets you have created.
|
||||
|
||||

|
||||
|
||||
BasKet Note Pads might seem a little complex on day one, but you’ll get the hang of it soon. When you’re not using it, the app sits in the system tray, ready for quick access.
|
||||
|
||||
Want a [simpler note-taking alternative][3] on Linux? Try [Springseed][4].
|
||||
|
||||
### [Caffeine][5]###
|
||||
|
||||
How do you ensure that your computer doesn’t go to sleep right in the middle of an [interesting movie][6]? Caffeine is the answer. No, you don’t need to brew a cup of coffee for your computer. You just need to install a lightweight indicator applet called Caffeine. It prevents the screen-saver, lock screen, or the Sleep mode from being activated when the computer is idle, only if the current window is in full-screen mode.
|
||||
|
||||
To install the applet, [download its latest version][7]. If you want to go [the ppa way][8], here’s how you can:
|
||||
|
||||
$ sudo add-apt-repository ppa:caffeine-developers/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install caffeine
|
||||
|
||||
On Ubuntu versions 14.10 and 15.04 (and their derivatives), you’ll also need to install certain dependency packages:
|
||||
|
||||
$ sudo apt-get install libappindicator3-1 gir1.2-appindicator3-0.1
|
||||
|
||||
After finishing the installation, add **caffeine-indicator** to your list of startup applications to make the indicator appear in the system tray. You can turn Caffeine’s functionality on and off via the app’s context menu, which pops up when you right-click on the tray icon.
|
||||
|
||||

|
||||
|
||||
### Easystroke ###
|
||||
|
||||
Easystroke makes an excellent [Linux mouse hack][9]. Use it to set up a series of customized mouse/touchpad/pen gestures to simulate common actions such as keystrokes, commands, and scrolls. Setting up Easystroke gestures is straightforward enough, thanks to the clear instructions that appear at all the right moments when you’re navigating the UI.
|
||||
|
||||

|
||||
|
||||
Begin by choosing the mouse button you’d like to use for performing gestures. Throw in a modifier if you like. You’ll find this setting under **Preferences > Behavior > Gesture Button**. Now head to the **Actions** tab and record strokes for your most commonly used actions.
|
||||
|
||||

|
||||
|
||||
Using the **Preferences** and **Advanced** tabs, you can make other tweaks like setting Easystroke to autostart, adding a system tray icon, and changing scroll speed.
|
||||
|
||||
### Guake ###
|
||||
|
||||
I saved my favorite Linux find for last. Guake is a dropdown command line modeled after the one in the first-person shooter video game [Quake][10]. Whether you’re [learning about terminal commands][11] or executing them on a regular basis, Guake is a great way to keep the terminal handy. You can bring it up or hide it in a single keystroke.
|
||||
|
||||
As you can see in the image below, when in action, Guake appears as an overlay on the current window. Right-click within the terminal to access the **Preferences** section, from where you can change Guake’s appearance, its scroll action, keyboard shortcuts, and more.
|
||||
|
||||

|
||||
|
||||
If KDE is your [Linux desktop of choice][12], do check out [Yakuake][13], which provides a similar functionality.
|
||||
|
||||
### Name Your Favorite Linux Discovery! ###
|
||||
|
||||
There are many more [super useful Linux apps][14] waiting to be discovered. Rest assured that we’ll keep introducing you to them.
|
||||
|
||||
Which Linux app were you happiest to learn about? Which one do you consider a must-have? Tell us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/new-linux-5-apps-didnt-know-missing/
|
||||
|
||||
作者:[Akshata][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/akshata/
|
||||
[1]:http://synergy-project.org/
|
||||
[2]:http://basket.kde.org/
|
||||
[3]:http://www.makeuseof.com/tag/try-these-3-beautiful-note-taking-apps-that-work-offline/
|
||||
[4]:http://getspringseed.com/
|
||||
[5]:https://launchpad.net/caffeine
|
||||
[6]:http://www.makeuseof.com/tag/popular-apps-movies-according-google/
|
||||
[7]:http://ppa.launchpad.net/caffeine-developers/ppa/ubuntu/pool/main/c/caffeine/
|
||||
[8]:http://www.makeuseof.com/tag/ubuntu-ppa-technology-explained/
|
||||
[9]:http://www.makeuseof.com/tag/4-astounding-linux-mouse-hacks/
|
||||
[10]:http://en.wikipedia.org/wiki/Quake_%28video_game%29
|
||||
[11]:http://www.makeuseof.com/tag/4-ways-teach-terminal-commands-linux-si/
|
||||
[12]:http://www.makeuseof.com/tag/10-top-linux-desktop-environments-available/
|
||||
[13]:https://yakuake.kde.org/
|
||||
[14]:http://www.makeuseof.com/tag/linux-treasures-x-sublime-native-linux-apps-will-make-want-switch/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wwy-hust
|
||||
|
||||
FAQ: BSD
|
||||
================================================================================
|
||||

|
||||
@ -78,4 +80,4 @@ via: http://www.linuxvoice.com/faq-bsd-2/
|
||||
[1]:http://www.openbsd.org/
|
||||
[2]:http://www.freebsd.org/
|
||||
[3]:http://www.netbsd.org/
|
||||
[4]:http://www.pcbsd.org/
|
||||
[4]:http://www.pcbsd.org/
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
[translating by KayGuoWhu]
|
||||
Open Source History: Why Did Linux Succeed?
|
||||
================================================================================
|
||||
> Why did Linux, the Unix-like operating system kernel started by Linus Torvalds in 1991 that became central to the open source world, succeed where so many similar projects, including GNU HURD and the BSDs, fail?
|
||||
|
||||

|
||||
|
||||
One of the most puzzling questions about the history of free and open source is this: Why did Linux succeed so spectacularly, whereas similar attempts to build a free or open source, Unix-like operating system kernel met with considerably less success? I don't know the answer to that question. But I have rounded up some theories, which I'd like to lay out here.
|
||||
|
||||
First, though, let me make clear what I mean when I write that Linux was a great success. I am defining it in opposition primarily to the variety of other Unix-like operating system kernels, some of them open and some not, that proliferated around the time Linux was born. [GNU][1] HURD, the free-as-in-freedom kernel whose development began in [May 1991][2], is one of them. Others include Unices that most people today have never heard of, such as various derivatives of the Unix variant developed at the University of California at Berkeley, BSD; Xenix, Microsoft's take on Unix; academic Unix clones including Minix; and the original Unix developed under the auspices of AT&T, which was vitally important in academic and commercial computing circles during earlier decades, but virtually disappeared from the scene by the 1990s.
|
||||
|
||||
#### Related ####
|
||||
|
||||
- [Open Source History: Tracing the Origins of Hacker Culture and the Hacker Ethic][3]
|
||||
- [Unix and Personal Computers: Reinterpreting the Origins of Linux][4]
|
||||
|
||||
I'd also like to make clear that I'm writing here about kernels, not complete operating systems. To a great extent, the Linux kernel owes its success to the GNU project as a whole, which produced the crucial tools, including compilers, a debugger and a BASH shell implementation, that are necessary to build a Unix-like operating system. But GNU developers never created a viable version of the the HURD kernel (although they are [still trying][5]). Instead, Linux ended up as the kernel that glued the rest of the GNU pieces together, even though that had never been in the GNU plans.
|
||||
|
||||
So it's worth asking why Linux, a kernel launched by Linus Torvalds, an obscure programmer in Finland, in 1991—the same year as HURD—endured and thrived within a niche where so many other Unix-like kernels, many of which enjoyed strong commercial backing and association with the leading Unix hackers of the day, failed to take off. To that end, here are a few theories pertaining to that question that I've come across as I've researched the history of the free and open source software worlds, along with the respective strengths and weaknesses of these various explanations.
|
||||
|
||||
### Linux Adopted a Decentralized Development Approach ###
|
||||
|
||||
This is the argument that comes out of Eric S. Raymond's essay, "[The Cathedral and the Bazaar][6]," and related works, which make the case that software develops best when a large number of contributors collaborate continuously within a relatively decentralized organizational structure. That was generally true of Linux, in contrast to, for instance, GNU HURD, which took a more centrally directed approach to code development—and, as a result, "had been evidently failing" to build a complete operating system for a decade, in Raymond's view.
|
||||
|
||||
To an extent, this explanation makes sense, but it has some significant flaws. For one, Torvalds arguably assumed a more authoritative role in directing Linux code development—deciding which contributions to include and reject—than Raymond and others have wanted to recognize. For another, this reasoning does not explain why GNU succeeded in producing so much software besides a working kernel. If only decentralized development works well in the free/open source software world, then all of GNU's programming efforts should have been a bust—which they most certainly were not.
|
||||
|
||||
### Linux is Pragmatic; GNU is Ideological ###
|
||||
|
||||
Personally, I find this explanation—which supposes that Linux grew so rapidly because its founder was a pragmatist who initially wrote the kernel just to be able to run a tailored Unix OS on his computer at home, not as part of a crusade to change the world through free software, as the GNU project aimed to do—the most compelling.
|
||||
|
||||
Still, it has some weaknesses that make it less than completely satisfying. In particular, while Torvalds himself adopted pragmatic principles, not all members of the community that coalesced around his project, then or today, have done the same. Yet, Linux has succeeded all the same.
|
||||
|
||||
Moreover, if pragmatism was the key to Linux's endurance, then why, again, was GNU successful in building so many other tools besides a kernel? If having strong political beliefs about software prevents you from pursuing successful projects, GNU should have been an outright failure, not an endeavor that produced a number of software packages that remain foundational to the IT world today.
|
||||
|
||||
Last but not least, many of the other Unix variants of the late 1980s and early 1990s, especially several BSD off-shoots, were the products of pragmatism. Their developers aimed to build Unix variants that could be more freely shared than those restricted by expensive commercial licenses, but they were not deeply ideological about programming or sharing code. Neither was Torvalds, and it is therefore difficult to explain Linux's success, and the failure of other Unix projects, in terms of ideological zeal.
|
||||
|
||||
### Operating System Design ###
|
||||
|
||||
There are technical differences between Linux and some other Unix variants that are important to keep in mind when considering the success of Linux. Richard Stallman, the founder of the GNU project, pointed to these in explaining, in an email to me, why HURD development had lagged: "It is true that the GNU Hurd is not a practical success. Part of the reason is that its basic design made it somewhat of a research project. (I chose that design thinking it was a shortcut to get a working kernel in a hurry.)"
|
||||
|
||||
Linux is also different from other Unix variants in the sense that Torvalds wrote all of the Linux code himself. Having a Unix of his own, free of other people's code, was one of his stated intentions when he [first announced Linux][7] in August 1991. This characteristic sets Linux apart from most of the other Unix variants that existed at that time, which derived their code bases from either AT&T Unix or Berkeley's BSD.
|
||||
|
||||
I'm not a computer scientist, so I'm not qualified to decide whether the Linux code was simply superior to that of the other Unices, explaining why Linux succeeded. But that's an argument someone might make—although it does not account for the disparity in culture and personnel between Linux and other Unix kernels, which, to me, seem more important than code in understanding Linux's success.
|
||||
|
||||
### The "Community" Put Its Support Behind Linux ###
|
||||
|
||||
Stallman also wrote that "mainly the reason" for Linux's success was that "Torvalds made Linux free software, and since then more of the community's effort has gone into Linux than into the Hurd." That's not exactly a complete explanation for Linux's trajectory, since it does not account for why the community of free software developers followed Torvalds instead of HURD or another Unix. But it nonetheless highlights this shift as a large part of how Linux prevailed.
|
||||
|
||||
A fuller account of the free software community's decision to endorse Linux would have to explain why developers did so even though, at first, Linux was a very obscure project—much more so, by any measure, than some of the other attempts at the time to create a freer Unix, such as NET BSD and 386/BSD—as well as one whose affinity with the goals of the free software movement was not at first clear. Originally, Torvalds released Linux under a license that simply prevented its commercial use. It was considerably later that he switched to the GNU General Public License, which protects the openness of source code.
|
||||
|
||||
So, those are the explanations I've found for Linux's success as an open source operating system kernel—a success which, to be sure, has been measured in some respects (desktop Linux never became what its proponents hoped, for instance). But Linux has also become foundational to the computing world in ways that no other Unix-like OS has. Maybe Apple OS X and iOS, which derive from BSD, come close, but they don't play such a central role as Linux in powering the Internet, among other things.
|
||||
|
||||
Have other ideas on why Linux became what it did, or why its counterparts in the Unix world have now almost all sunk into obscurity? (I know: BSD variants still have a following today, and some commercial Unices remain important enough for [Red Hat][8] (RHT) to be [courting their users][9]. But none of these Unix holdouts have conquered everything from Web servers to smartphones in the way Linux has.) I'd be delighted to hear them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/050415/open-source-history-why-did-linux-succeed
|
||||
|
||||
作者:[hristopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://gnu.org/
|
||||
[2]:http://www.gnu.org/software/hurd/history/hurd-announce
|
||||
[3]:http://thevarguy.com/open-source-application-software-companies/042915/open-source-history-tracing-origins-hacker-culture-and-ha
|
||||
[4]:http://thevarguy.com/open-source-application-software-companies/042715/unix-and-personal-computers-reinterpreting-origins-linux
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/042015/30-years-hurd-lives-gnu-updates-open-source-
|
||||
[6]:http://www.catb.org/esr/writings/cathedral-bazaar/cathedral-bazaar/
|
||||
[7]:https://groups.google.com/forum/#!topic/comp.os.minix/dlNtH7RRrGA[1-25]
|
||||
[8]:http://www.redhat.com/
|
||||
[9]:http://thevarguy.com/open-source-application-software-companies/032614/red-hat-grants-certification-award-unix-linux-migration-a
|
||||
@ -0,0 +1,57 @@
|
||||
Is Linux Better than OS X? GNU, Open Source and Apple in History
|
||||
================================================================================
|
||||
> Tensions between the free software/open source community and Apple date back to the 1980s, Linux's founder called the core of Mac OS X "a piece of crap" and other anecdotes from software history.
|
||||
|
||||

|
||||
|
||||
Open source fans have long had a rocky relationship with Microsoft. Everyone knows that. But, in many ways, the tension between Apple and supporters of free or open source software is even starker—even if it receives much less attention in the press.
|
||||
|
||||
To be sure, not all open source advocates have an aversion to Apple. Anecdotally, I've seen plenty of Linux hackers sporting iPhones and iPads. In fact, some Linux users like Apple's OS X so much that they've [created a number of Linux distributions][1] designed to look just like it. (So has the [North Korean government][2], incidentally.)
|
||||
|
||||
But relations between the Cult of Mac and the Cult of Tux—that is, the Linux community (not to mention the other, smaller segments of the free and open source software world)—have not always been completely peaceable. And that's by no means a new phenomenon, as I'm discovering as I research the history of Linux and the Free Software Foundation.
|
||||
|
||||
### GNU vs. Apple ###
|
||||
|
||||
The ill will dates to at least the late 1980s. By June 1988, [GNU][3], the project launched by Richard Stallman to build a completely free Unix-like operating system whose source code would be freely shared, was [strongly criticizing][4] Apple's lawsuit against [Hewlett-Packard][5] (HPQ) and [Microsoft][6] (MSFT) over what Apple claimed was improper copying of the "look and feel" of the Macintosh operating system. If Apple prevailed, GNU warned, the company "will use this new power over the public to put an end to free software that could substitute for commercial software."
|
||||
|
||||
At the time, GNU fought against the lawsuit (which meant, ironically, that GNU was supporting Microsoft, though those were different times) by distributing "[Keep Your Lawyers Off My Computer" buttons][7]. It also urged GNU supporters to boycott Apple, warning that, even if Macintoshes seemed like good computers, Apple's success in the lawsuit could provide the company with a monopoly in the market that would greatly increase the price of computers.
|
||||
|
||||
Apple eventually [lost the lawsuit][8], but not until 1994, after which GNU [dropped its Apple boycott][9]. In the interim, GNU remained critical of the company. In the early 1990s, even after it began promoting GNU software programs for use on other personal computing platforms, including MS-DOS PCs, [GNU affirmed][10] that, until Apple ceased pursuing a "monopoly" over computers with user interfaces similar to those of the Macintosh, "we will not provide any support for Apple machines." (It's therefore ironic that a fair amount of the software that made it into OS X, the Unix-like operating system that Apple introduced later in the 1990s, came from GNU. But that's another story.)
|
||||
|
||||
### Torvalds on Jobs ###
|
||||
|
||||
Despite his more laissez-faire attitude toward most issues, Linus Torvalds, the creator of the Linux kernel, was no less charitable in his attitudes toward Apple than Stallman and GNU had been. In his 2001 book "Just for Fun: The Story of an Accidental Revolutionary," Torvalds described meeting with Steve Jobs circa 1997, at the latter's invitation, to discuss Mac OS X, which Apple was then developing but had not yet released publicly.
|
||||
|
||||
"Basically, Jobs started off by trying to tell me that on the desktop there were just two players, Microsoft and Apple, and that he thought that the best thing I could do for Linux was to get in bed with Apple and try to get the open source people behind Mac OS X," Torvalds wrote.
|
||||
|
||||
This courting apparently turned Torvalds off quite a bit. One point of disagreement centered on Torvalds's technical disdain for Mach, the kernel on which Apple was then building its new OS X operating system, which Torvalds called "a piece of crap. It contains all the design mistakes you can make, and managed to even make up a few of its own."
|
||||
|
||||
But more off-putting, apparently, was the way Jobs was approaching open source in developing OS X (which had many open source programs at its core): "He sort of played down the flaw in the setup: Who cares if the basic operating system, the real low-core stuff, is open source if you then have the Mac layer on top, which is not open source?"
|
||||
|
||||
All in all, Torvalds concluded, Jobs "didn't use very many arguments. He just basically took it for granted that I would be interested" in collaborating with Apple. "He was clueless, unable to imagine that there could be entire segments of the human race who weren't the least bit concerned about increasing the Mac's market share. I think he was truly surprised at how little I cared about how big a market the Mac had—or how big a market Microsoft has."
|
||||
|
||||
Torvalds doesn't speak for all Linux users, of course. And his views on OS X and Apple may have softened since 2001. But the fact that, in the early 2000s, the Linux community's leading figure exhibited so much disdain for Apple and the hubris of its chief says something significant about how deeply seated tensions between the Apple world and the open source/free software world are.
|
||||
|
||||
Both of these historical tidbits offer insight into the great debate regarding the actual value of Apple's products—whether the company thrives on the quality of the hardware and software it creates, or merely benefits from exceptional marketing acumen that allows it to sell products for much more than their non-Apple functional equivalents are worth. But I'll stay out of that debate, for now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
|
||||
[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
|
||||
[3]:http://gnu.org/
|
||||
[4]:https://www.gnu.org/bulletins/bull5.html
|
||||
[5]:http://www.hp.com/
|
||||
[6]:http://www.microsoft.com/
|
||||
[7]:http://www.duntemann.com/AppleSnakeButton.jpg
|
||||
[8]:http://www.freibrun.com/articles/articl12.htm
|
||||
[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
|
||||
[10]:https://www.gnu.org/bulletins/bull12.html
|
||||
@ -1,444 +0,0 @@
|
||||
Web Caching Basics: Terminology, HTTP Headers, and Caching Strategies
|
||||
=====================================================================
|
||||
|
||||
### Introduction
|
||||
|
||||
Intelligent content caching is one of the most effective ways to improve
|
||||
the experience for your site's visitors. Caching, or temporarily storing
|
||||
content from previous requests, is part of the core content delivery
|
||||
strategy implemented within the HTTP protocol. Components throughout the
|
||||
delivery path can all cache items to speed up subsequent requests,
|
||||
subject to the caching policies declared for the content.
|
||||
|
||||
In this guide, we will discuss some of the basic concepts of web content
|
||||
caching. This will mainly cover how to select caching policies to ensure
|
||||
that caches throughout the internet can correctly process your content.
|
||||
We will talk about the benefits that caching affords, the side effects
|
||||
to be aware of, and the different strategies to employ to provide the
|
||||
best mixture of performance and flexibility.
|
||||
|
||||
What Is Caching?
|
||||
----------------
|
||||
|
||||
Caching is the term for storing reusable responses in order to make
|
||||
subsequent requests faster. There are many different types of caching
|
||||
available, each of which has its own characteristics. Application caches
|
||||
and memory caches are both popular for their ability to speed up certain
|
||||
responses.
|
||||
|
||||
Web caching, the focus of this guide, is a different type of cache. Web
|
||||
caching is a core design feature of the HTTP protocol meant to minimize
|
||||
network traffic while improving the perceived responsiveness of the
|
||||
system as a whole. Caches are found at every level of a content's
|
||||
journey from the original server to the browser.
|
||||
|
||||
Web caching works by caching the HTTP responses for requests according
|
||||
to certain rules. Subsequent requests for cached content can then be
|
||||
fulfilled from a cache closer to the user instead of sending the request
|
||||
all the way back to the web server.
|
||||
|
||||
Benefits
|
||||
--------
|
||||
|
||||
Effective caching aids both content consumers and content providers.
|
||||
Some of the benefits that caching brings to content delivery are:
|
||||
|
||||
- **Decreased network costs**: Content can be cached at various points
|
||||
in the network path between the content consumer and content origin.
|
||||
When the content is cached closer to the consumer, requests will not
|
||||
cause much additional network activity beyond the cache.
|
||||
- **Improved responsiveness**: Caching enables content to be retrieved
|
||||
faster because an entire network round trip is not necessary. Caches
|
||||
maintained close to the user, like the browser cache, can make this
|
||||
retrieval nearly instantaneous.
|
||||
- **Increased performance on the same hardware**: For the server where
|
||||
the content originated, more performance can be squeezed from the
|
||||
same hardware by allowing aggressive caching. The content owner can
|
||||
leverage the powerful servers along the delivery path to take the
|
||||
brunt of certain content loads.
|
||||
- **Availability of content during network interruptions**: With
|
||||
certain policies, caching can be used to serve content to end users
|
||||
even when it may be unavailable for short periods of time from the
|
||||
origin servers.
|
||||
|
||||
Terminology
|
||||
-----------
|
||||
|
||||
When dealing with caching, there are a few terms that you are likely to
|
||||
come across that might be unfamiliar. Some of the more common ones are
|
||||
below:
|
||||
|
||||
- **Origin server**: The origin server is the original location of the
|
||||
content. If you are acting as the web server administrator, this is
|
||||
the machine that you control. It is responsible for serving any
|
||||
content that could not be retrieved from a cache along the request
|
||||
route and for setting the caching policy for all content.
|
||||
- **Cache hit ratio**: A cache's effectiveness is measured in terms of
|
||||
its cache hit ratio or hit rate. This is a ratio of the requests
|
||||
able to be retrieved from a cache to the total requests made. A high
|
||||
cache hit ratio means that a high percentage of the content was able
|
||||
to be retrieved from the cache. This is usually the desired outcome
|
||||
for most administrators.
|
||||
- **Freshness**: Freshness is a term used to describe whether an item
|
||||
within a cache is still considered a candidate to serve to a client.
|
||||
Content in a cache will only be used to respond if it is within the
|
||||
freshness time frame specified by the caching policy.
|
||||
- **Stale content**: Items in the cache expire according to the cache
|
||||
freshness settings in the caching policy. Expired content is
|
||||
"stale". In general, expired content cannot be used to respond to
|
||||
client requests. The origin server must be re-contacted to retrieve
|
||||
the new content or at least verify that the cached content is still
|
||||
accurate.
|
||||
- **Validation**: Stale items in the cache can be validated in order
|
||||
to refresh their expiration time. Validation involves checking in
|
||||
with the origin server to see if the cached content still represents
|
||||
the most recent version of item.
|
||||
- **Invalidation**: Invalidation is the process of removing content
|
||||
from the cache before its specified expiration date. This is
|
||||
necessary if the item has been changed on the origin server and
|
||||
having an outdated item in cache would cause significant issues for
|
||||
the client.
|
||||
|
||||
There are plenty of other caching terms, but the ones above should help
|
||||
you get started.
|
||||
|
||||
What Can be Cached?
|
||||
-------------------
|
||||
|
||||
Certain content lends itself more readily to caching than others. Some
|
||||
very cache-friendly content for most sites are:
|
||||
|
||||
- Logos and brand images
|
||||
- Non-rotating images in general (navigation icons, for example)
|
||||
- Style sheets
|
||||
- General Javascript files
|
||||
- Downloadable Content
|
||||
- Media Files
|
||||
|
||||
These tend to change infrequently, so they can benefit from being cached
|
||||
for longer periods of time.
|
||||
|
||||
Some items that you have to be careful in caching are:
|
||||
|
||||
- HTML pages
|
||||
- Rotating images
|
||||
- Frequently modified Javascript and CSS
|
||||
- Content requested with authentication cookies
|
||||
|
||||
Some items that should almost never be cached are:
|
||||
|
||||
- Assets related to sensitive data (banking info, etc.)
|
||||
- Content that is user-specific and frequently changed
|
||||
|
||||
In addition to the above general rules, it's possible to specify
|
||||
policies that allow you to cache different types of content
|
||||
appropriately. For instance, if authenticated users all see the same
|
||||
view of your site, it may be possible to cache that view anywhere. If
|
||||
authenticated users see a user-sensitive view of the site that will be
|
||||
valid for some time, you may tell the user's browser to cache, but tell
|
||||
any intermediary caches not to store the view.
|
||||
|
||||
Locations Where Web Content Is Cached
|
||||
-------------------------------------
|
||||
|
||||
Content can be cached at many different points throughout the delivery
|
||||
chain:
|
||||
|
||||
- **Browser cache**: Web browsers themselves maintain a small cache.
|
||||
Typically, the browser sets a policy that dictates the most
|
||||
important items to cache. This may be user-specific content or
|
||||
content deemed expensive to download and likely to be requested
|
||||
again.
|
||||
- **Intermediary caching proxies**: Any server in between the client
|
||||
and your infrastructure can cache certain content as desired. These
|
||||
caches may be maintained by ISPs or other independent parties.
|
||||
- **Reverse Cache**: Your server infrastructure can implement its own
|
||||
cache for backend services. This way, content can be served from the
|
||||
point-of-contact instead of hitting backend servers on each request.
|
||||
|
||||
Each of these locations can and often do cache items according to their
|
||||
own caching policies and the policies set at the content origin.
|
||||
|
||||
Caching Headers
|
||||
---------------
|
||||
|
||||
Caching policy is dependent upon two different factors. The caching
|
||||
entity itself gets to decide whether or not to cache acceptable content.
|
||||
It can decide to cache less than it is allowed to cache, but never more.
|
||||
|
||||
The majority of caching behavior is determined by the caching policy,
|
||||
which is set by the content owner. These policies are mainly articulated
|
||||
through the use of specific HTTP headers.
|
||||
|
||||
Through various iterations of the HTTP protocol, a few different
|
||||
cache-focused headers have arisen with varying levels of sophistication.
|
||||
The ones you probably still need to pay attention to are below:
|
||||
|
||||
- **`Expires`**: The `Expires` header is very straight-forward,
|
||||
although fairly limited in scope. Basically, it sets a time in the
|
||||
future when the content will expire. At this point, any requests for
|
||||
the same content will have to go back to the origin server. This
|
||||
header is probably best used only as a fall back.
|
||||
- **`Cache-Control`**: This is the more modern replacement for the
|
||||
`Expires` header. It is well supported and implements a much more
|
||||
flexible design. In almost all cases, this is preferable to
|
||||
`Expires`, but it may not hurt to set both values. We will discuss
|
||||
the specifics of the options you can set with `Cache-Control` a bit
|
||||
later.
|
||||
- **`Etag`**: The `Etag` header is used with cache validation. The
|
||||
origin can provide a unique `Etag` for an item when it initially
|
||||
serves the content. When a cache needs to validate the content it
|
||||
has on-hand upon expiration, it can send back the `Etag` it has for
|
||||
the content. The origin will either tell the cache that the content
|
||||
is the same, or send the updated content (with the new `Etag`).
|
||||
- **`Last-Modified`**: This header specifies the last time that the
|
||||
item was modified. This may be used as part of the validation
|
||||
strategy to ensure fresh content.
|
||||
- **`Content-Length`**: While not specifically involved in caching,
|
||||
the `Content-Length` header is important to set when defining
|
||||
caching policies. Certain software will refuse to cache content if
|
||||
it does not know in advanced the size of the content it will need to
|
||||
reserve space for.
|
||||
- **`Vary`**: A cache typically uses the requested host and the path
|
||||
to the resource as the key with which to store the cache item. The
|
||||
`Vary` header can be used to tell caches to pay attention to an
|
||||
additional header when deciding whether a request is for the same
|
||||
item. This is most commonly used to tell caches to key by the
|
||||
`Accept-Encoding` header as well, so that the cache will know to
|
||||
differentiate between compressed and uncompressed content.
|
||||
|
||||
### An Aside about the Vary Header
|
||||
|
||||
The `Vary` header provides you with the ability to store different
|
||||
versions of the same content at the expense of diluting the entries in
|
||||
the cache.
|
||||
|
||||
In the case of `Accept-Encoding`, setting the `Vary` header allows for a
|
||||
critical distinction to take place between compressed and uncompressed
|
||||
content. This is needed to correctly serve these items to browsers that
|
||||
cannot handle compressed content and is necessary in order to provide
|
||||
basic usability. One characteristic that tells you that
|
||||
`Accept-Encoding` may be a good candidate for `Vary` is that it only has
|
||||
two or three possible values.
|
||||
|
||||
Items like `User-Agent` might at first glance seem to be a good way to
|
||||
differentiate between mobile and desktop browsers to serve different
|
||||
versions of your site. However, since `User-Agent` strings are
|
||||
non-standard, the result will likely be many versions of the same
|
||||
content on intermediary caches, with a very low cache hit ratio. The
|
||||
`Vary` header should be used sparingly, especially if you do not have
|
||||
the ability to normalize the requests in intermediate caches that you
|
||||
control (which may be possible, for instance, if you leverage a content
|
||||
delivery network).
|
||||
|
||||
How Cache-Control Flags Impact Caching
|
||||
--------------------------------------
|
||||
|
||||
Above, we mentioned how the `Cache-Control` header is used for modern
|
||||
cache policy specification. A number of different policy instructions
|
||||
can be set using this header, with multiple instructions being separated
|
||||
by commas.
|
||||
|
||||
Some of the `Cache-Control` options you can use to dictate your
|
||||
content's caching policy are:
|
||||
|
||||
- **`no-cache`**: This instruction specifies that any cached content
|
||||
must be re-validated on each request before being served to a
|
||||
client. This, in effect, marks the content as stale immediately, but
|
||||
allows it to use revalidation techniques to avoid re-downloading the
|
||||
entire item again.
|
||||
- **`no-store`**: This instruction indicates that the content cannot
|
||||
be cached in any way. This is appropriate to set if the response
|
||||
represents sensitive data.
|
||||
- **`public`**: This marks the content as public, which means that it
|
||||
can be cached by the browser and any intermediate caches. For
|
||||
requests that utilized HTTP authentication, responses are marked
|
||||
`private` by default. This header overrides that setting.
|
||||
- **`private`**: This marks the content as `private`. Private content
|
||||
may be stored by the user's browser, but must *not* be cached by any
|
||||
intermediate parties. This is often used for user-specific data.
|
||||
- **`max-age`**: This setting configures the maximum age that the
|
||||
content may be cached before it must revalidate or re-download the
|
||||
content from the origin server. In essence, this replaces the
|
||||
`Expires` header for modern browsing and is the basis for
|
||||
determining a piece of content's freshness. This option takes its
|
||||
value in seconds with a maximum valid freshness time of one year
|
||||
(31536000 seconds).
|
||||
- **`s-maxage`**: This is very similar to the `max-age` setting, in
|
||||
that it indicates the amount of time that the content can be cached.
|
||||
The difference is that this option is applied only to intermediary
|
||||
caches. Combining this with the above allows for more flexible
|
||||
policy construction.
|
||||
- **`must-revalidate`**: This indicates that the freshness information
|
||||
indicated by `max-age`, `s-maxage` or the `Expires` header must be
|
||||
obeyed strictly. Stale content cannot be served under any
|
||||
circumstance. This prevents cached content from being used in case
|
||||
of network interruptions and similar scenarios.
|
||||
- **`proxy-revalidate`**: This operates the same as the above setting,
|
||||
but only applies to intermediary proxies. In this case, the user's
|
||||
browser can potentially be used to serve stale content in the event
|
||||
of a network interruption, but intermediate caches cannot be used
|
||||
for this purpose.
|
||||
- **`no-transform`**: This option tells caches that they are not
|
||||
allowed to modify the received content for performance reasons under
|
||||
any circumstances. This means, for instance, that the cache is not
|
||||
able to send compressed versions of content it did not receive from
|
||||
the origin server compressed and is not allowed.
|
||||
|
||||
These can be combined in different ways to achieve various caching
|
||||
behavior. Some mutually exclusive values are:
|
||||
|
||||
- `no-cache`, `no-store`, and the regular caching behavior indicated
|
||||
by absence of either
|
||||
- `public` and `private`
|
||||
|
||||
The `no-store` option supersedes the `no-cache` if both are present. For
|
||||
responses to unauthenticated requests, `public` is implied. For
|
||||
responses to authenticated requests, `private` is implied. These can be
|
||||
overridden by including the opposite option in the `Cache-Control`
|
||||
header.
|
||||
|
||||
Developing a Caching Strategy
|
||||
-----------------------------
|
||||
|
||||
In a perfect world, everything could be cached aggressively and your
|
||||
servers would only be contacted to validate content occasionally. This
|
||||
doesn't often happen in practice though, so you should try to set some
|
||||
sane caching policies that aim to balance between implementing long-term
|
||||
caching and responding to the demands of a changing site.
|
||||
|
||||
### Common Issues
|
||||
|
||||
There are many situations where caching cannot or should not be
|
||||
implemented due to how the content is produced (dynamically generated
|
||||
per user) or the nature of the content (sensitive banking information,
|
||||
for example). Another problem that many administrators face when setting
|
||||
up caching is the situation where older versions of your content are out
|
||||
in the wild, not yet stale, even though new versions have been
|
||||
published.
|
||||
|
||||
These are both frequently encountered issues that can have serious
|
||||
impacts on cache performance and the accuracy of content you are
|
||||
serving. However, we can mitigate these issues by developing caching
|
||||
policies that anticipate these problems.
|
||||
|
||||
### General Recommendations
|
||||
|
||||
While your situation will dictate the caching strategy you use, the
|
||||
following recommendations can help guide you towards some reasonable
|
||||
decisions.
|
||||
|
||||
There are certain steps that you can take to increase your cache hit
|
||||
ratio before worrying about the specific headers you use. Some ideas
|
||||
are:
|
||||
|
||||
- **Establish specific directories for images, css, and shared
|
||||
content**: Placing content into dedicated directories will allow you
|
||||
to easily refer to them from any page on your site.
|
||||
- **Use the same URL to refer to the same items**: Since caches key
|
||||
off of both the host and the path to the content requested, ensure
|
||||
that you refer to your content in the same way on all of your pages.
|
||||
The previous recommendation makes this significantly easier.
|
||||
- **Use CSS image sprites where possible**: CSS image sprites for
|
||||
items like icons and navigation decrease the number of round trips
|
||||
needed to render your site and allow your site to cache that single
|
||||
sprite for a long time.
|
||||
- **Host scripts and external resources locally where possible**: If
|
||||
you utilize javascript scripts and other external resources,
|
||||
consider hosting those resources on your own servers if the correct
|
||||
headers are not being provided upstream. Note that you will have to
|
||||
be aware of any updates made to the resource upstream so that you
|
||||
can update your local copy.
|
||||
- **Fingerprint cache items**: For static content like CSS and
|
||||
Javascript files, it may be appropriate to fingerprint each item.
|
||||
This means adding a unique identifier to the filename (often a hash
|
||||
of the file) so that if the resource is modified, the new resource
|
||||
name can be requested, causing the requests to correctly bypass the
|
||||
cache. There are a variety of tools that can assist in creating
|
||||
fingerprints and modifying the references to them within HTML
|
||||
documents.
|
||||
|
||||
In terms of selecting the correct headers for different items, the
|
||||
following can serve as a general reference:
|
||||
|
||||
- **Allow all caches to store generic assets**: Static content and
|
||||
content that is not user-specific can and should be cached at all
|
||||
points in the delivery chain. This will allow intermediary caches to
|
||||
respond with the content for multiple users.
|
||||
- **Allow browsers to cache user-specific assets**: For per-user
|
||||
content, it is often acceptable and useful to allow caching within
|
||||
the user's browser. While this content would not be appropriate to
|
||||
cache on any intermediary caching proxies, caching in the browser
|
||||
will allow for instant retrieval for users during subsequent visits.
|
||||
- **Make exceptions for essential time-sensitive content**: If you
|
||||
have content that is time-sensitive, make an exception to the above
|
||||
rules so that the out-dated content is not served in critical
|
||||
situations. For instance, if your site has a shopping cart, it
|
||||
should reflect the items in the cart immediately. Depending on the
|
||||
nature of the content, the `no-cache` or `no-store` options can be
|
||||
set in the `Cache-Control` header to achieve this.
|
||||
- **Always provide validators**: Validators allow stale content to be
|
||||
refreshed without having to download the entire resource again.
|
||||
Setting the `Etag` and the `Last-Modified` headers allow caches to
|
||||
validate their content and re-serve it if it has not been modified
|
||||
at the origin, further reducing load.
|
||||
- **Set long freshness times for supporting content**: In order to
|
||||
leverage caching effectively, elements that are requested as
|
||||
supporting content to fulfill a request should often have a long
|
||||
freshness setting. This is generally appropriate for items like
|
||||
images and CSS that are pulled in to render the HTML page requested
|
||||
by the user. Setting extended freshness times, combined with
|
||||
fingerprinting, allows caches to store these resources for long
|
||||
periods of time. If the assets change, the modified fingerprint will
|
||||
invalidate the cached item and will trigger a download of the new
|
||||
content. Until then, the supporting items can be cached far into the
|
||||
future.
|
||||
- **Set short freshness times for parent content**: In order to make
|
||||
the above scheme work, the containing item must have relatively
|
||||
short freshness times or may not be cached at all. This is typically
|
||||
the HTML page that calls in the other assisting content. The HTML
|
||||
itself will be downloaded frequently, allowing it to respond to
|
||||
changes rapidly. The supporting content can then be cached
|
||||
aggressively.
|
||||
|
||||
The key is to strike a balance that favors aggressive caching where
|
||||
possible while leaving opportunities to invalidate entries in the future
|
||||
when changes are made. Your site will likely have a combination of:
|
||||
|
||||
- Aggressively cached items
|
||||
- Cached items with a short freshness time and the ability to
|
||||
re-validate
|
||||
- Items that should not be cached at all
|
||||
|
||||
The goal is to move content into the first categories when possible
|
||||
while maintaining an acceptable level of accuracy.
|
||||
|
||||
Conclusion
|
||||
----------
|
||||
|
||||
Taking the time to ensure that your site has proper caching policies in
|
||||
place can have a significant impact on your site. Caching allows you to
|
||||
cut down on the bandwidth costs associated with serving the same content
|
||||
repeatedly. Your server will also be able to handle a greater amount of
|
||||
traffic with the same hardware. Perhaps most importantly, clients will
|
||||
have a faster experience on your site, which may lead them to return
|
||||
more frequently. While effective web caching is not a silver bullet,
|
||||
setting up appropriate caching policies can give you measurable gains
|
||||
with minimal work.
|
||||
|
||||
|
||||
---
|
||||
|
||||
作者: [Justin Ellingwood](https://www.digitalocean.com/community/users/jellingwood)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
推荐:[royaso](https://github.com/royaso)
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,58 +0,0 @@
|
||||
‘Unity Greeter Badges’ Brings Missing Session Icons to Ubuntu Login Screen
|
||||
================================================================================
|
||||

|
||||
|
||||
**A new package available in Ubuntu 15.04 solves a petty gripe I have with the Unity Greeter: the lack of branded icons for alternative desktop sessions like Cinnamon.**
|
||||
|
||||
I know it’s a minor quibble; it’s a visual paper cut with minimal impact for most. But the inconsistency niggles me because Ubuntu ships with icons for a number of sessions, including Unity, GNOME and KDE. Other DEs, including some of its own flavors like Xubuntu, default to showing a plain white dot in the session switcher list and the main user pod.
|
||||
|
||||
The inconsistency these dots create jars, even if it is only for a fleeting moment, not just in design. It’s in usability too. Branded glyphs are helpful in letting us know what session we’re about to log in to.
|
||||
|
||||
For instance, can you tell what session this is?
|
||||
|
||||

|
||||
|
||||
Budgie? Maybe MATE? Could be Cinnamon…I’d have to click on it and check first.
|
||||
|
||||
It doesn’t have to be this way. The Unity Greeter is built such that the developers of desktop environments can ship badges that appear in the Greeter (and some do). But in many cases, like MATE whose packages are imported from upstream Debian, the inclination to carry an “Ubuntu-specific patch” is either not desirable or not possible.
|
||||
|
||||
### A Solution Is Badged ###
|
||||
|
||||
Experienced Debian maintainer [Doug Torrance][1] has a solution to fix this usability paper cut. Rather than rely on desktop makers themselves to add branded badges to their packages, and rather than burden Ubuntu with the responsibility of maintaining it, Torrance has created a separate ‘unity-greeter-badges’ package to house them.
|
||||
|
||||
In assuming responsibility for providing the session glyphs directly, this package ensure that new and old window managers, session and desktops alike are catered for.
|
||||
|
||||
Among the 30 or so desktop environments it bundles new session badges for are:
|
||||
|
||||
- Xubuntu
|
||||
- Cinnamon
|
||||
- MATE
|
||||
- Cairo-Dock
|
||||
- Xmonad
|
||||
- Awesome
|
||||
- OpenBox
|
||||
- Pantheon
|
||||
|
||||
The best part is that ‘**Unity-Greeter-Badges**’ has been accepted into Ubuntu 15.04. That means Torrance’s package will be available to install directly, no PPAs or downloads needed. In not being part of a core package like the Unity Greeter it can be updated with newer icons in a more efficient and timely manner.
|
||||
|
||||
If you’re running Ubuntu 15.04 you will find the package available to install from the Software Center in the coming days.
|
||||
|
||||
Don’t want to wait until 15.04? Torrance has made .deb installers for Ubuntu 14.04 LTS and Ubuntu 14.10 users.
|
||||
|
||||
- [Download unity-greeter-badges for Ubuntu 14.04][2]
|
||||
- [Download unity-greeter-badges for Ubuntu 14.10][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/unity-greeter-badges-brings-missing-session-icons-ubuntu-login-screen
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://launchpad.net/~profzoom
|
||||
[2]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.04.1_all.deb
|
||||
[3]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.10.1_all.deb
|
||||
@ -1,72 +0,0 @@
|
||||
How to make a file immutable on Linux
|
||||
================================================================================
|
||||
Suppose you want to write-protect some important files on Linux, so that they cannot be deleted or tampered with by accident or otherwise. In other cases, you may want to prevent certain configuration files from being overwritten automatically by software. While changing their ownership or permission bits on the files by using chown or chmod is one way to deal with this situation, this is not a perfect solution as it cannot prevent any action done with root privilege. That is when chattr comes in handy.
|
||||
|
||||
chattr is a Linux command which allows one to set or unset attributes on a file, which are separate from the standard (read, write, execute) file permission. A related command is lsattr which shows which attributes are set on a file. While file attributes managed by chattr and lsattr are originally supported by EXT file systems (EXT2/3/4) only, this feature is now available on many other native Linux file systems such as XFS, Btrfs, ReiserFS, etc.
|
||||
|
||||
In this tutorial, I am going to demonstrate how to use chattr to make files immutable on Linux.
|
||||
|
||||
chattr and lsattr commands are a part of e2fsprogs package which comes pre-installed on all modern Linux distributions.
|
||||
|
||||
Basic syntax of chattr is as follows.
|
||||
|
||||
$ chattr [-RVf] [operator][attribute(s)] files...
|
||||
|
||||
The operator can be '+' (which adds selected attributes to attribute list), '-' (which removes selected attributes from attribute list), or '=' (which forces selected attributes only).
|
||||
|
||||
Some of available attributes are the following.
|
||||
|
||||
- **a**: can be opened in append mode only.
|
||||
- **A**: do not update atime (file access time).
|
||||
- **c**: automatically compressed when written to disk.
|
||||
- **C**: turn off copy-on-write.
|
||||
- **i**: set immutable.
|
||||
- **s**: securely deleted with automatic zeroing.
|
||||
|
||||
### Immutable Attribute ###
|
||||
|
||||
To make a file immutable, you can add "immutable" attribute to the file as follows. For example, to write-protect /etc/passwd file:
|
||||
|
||||
$ sudo chattr +i /etc/passwd
|
||||
|
||||
Note that you must use root privilege to set or unset "immutable" attribute on a file. Now verify that "immutable" attribute is added to the file successfully.
|
||||
|
||||
$ lsattr /etc/passwd
|
||||
|
||||
Once the file is set immutable, this file is impervious to change for any user. Even the root cannot modify, remove, overwrite, move or rename the file. You will need to unset the immutable attribute before you can tamper with the file again.
|
||||
|
||||
To unset the immutable attribute, use the following command:
|
||||
|
||||
$ sudo chattr -i /etc/passwd
|
||||
|
||||

|
||||
|
||||
If you want to make a whole directory (e.g., /etc) including all its content immutable at once recursively, use "-R" option:
|
||||
|
||||
$ sudo chattr -R +i /etc
|
||||
|
||||
### Append Only Attribute ###
|
||||
|
||||
Another useful attribute is "append-only" attribute which forces a file to grow only. You cannot overwrite or delete a file with "append-only" attribute set. This attribute can be useful when you want to prevent a log file from being cleared by accident.
|
||||
|
||||
Similar to immutable attribute, you can turn a file into "append-only" mode by:
|
||||
|
||||
$ sudo chattr +a /var/log/syslog
|
||||
|
||||
Note that when you copy an immutable or append-only file to another file, those attributes will not be preserved on the newly created file.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I showed how to use chattr and lsattr commands to manage additional file attributes to prevent (accidental or otherwise) file tampering. Beware that you cannot rely on chattr as a security measure as one can easily undo immutability. One possible way to address this limitation is to restrict the availability of chattr command itself, or drop kernel capability CAP_LINUX_IMMUTABLE. For more details on chattr and available attributes, refer to its man page.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/make-file-immutable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
@ -1,63 +0,0 @@
|
||||
zBackup – A versatile deduplicating backup tool
|
||||
================================================================================
|
||||
zbackup is a globally-deduplicating backup tool, based on the ideas found in rsync. Feed a large .tar into it, and it will store duplicate regions of it only once, then compress and optionally encrypt the result. Feed another .tar file, and it will also re-use any data found in any previous backups. This way only new changes are stored, and as long as the files are not very different, the amount of storage required is very low. Any of the backup files stored previously can be read back in full at any time.
|
||||
|
||||
### zBackup Features ###
|
||||
|
||||
Parallel LZMA or LZO compression of the stored data
|
||||
Built-in AES encryption of the stored data
|
||||
Possibility to delete old backup data
|
||||
Use of a 64-bit rolling hash, keeping the amount of soft collisions to zero
|
||||
Repository consists of immutable files. No existing files are ever modified
|
||||
Written in C++ only with only modest library dependencies
|
||||
Safe to use in production
|
||||
Possibility to exchange data between repos without recompression
|
||||
|
||||
### Install zBackup in ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install zbackup
|
||||
|
||||
### Using zBackup ###
|
||||
|
||||
zbackup init initializes a backup repository for the backup files to be stored.
|
||||
|
||||
zbackup init [--non-encrypted] [--password-file ~/.my_backup_password ] /my/backup/repo
|
||||
|
||||
zbackup backup backups a tar file generated by tar c to the repository initialized using zbackup init
|
||||
|
||||
zbackup [--password-file ~/.my_backup_password ] [--threads number_of_threads ] backup /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'`
|
||||
|
||||
zbackup restore restores the backup file to a tar file.
|
||||
|
||||
zbackup [--password-file ~/.my_backup_password [--cache-size cache_size_in_mb restore /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` > /my/precious/backup-restored.tar
|
||||
|
||||
### Available Options ###
|
||||
|
||||
- -non-encrypted -- Do not encrypt the backup repository.
|
||||
- --password-file ~/.my_backup_password -- Use the password file specified at ~/.my_backup_password to encrypt the repository and backup file, or to decrypt the backup file.
|
||||
- --threads number_of_threads -- Limit the partial LZMA compression to number_of_threads needed. Recommended for 32-bit architectures.
|
||||
- --cache-size cache_size_in_mb -- Use the cache size provided by cache_size_in_mb to speed up the restoration process.
|
||||
|
||||
### zBackup files ###
|
||||
|
||||
~/.my_backup_password Used to encrypt the repository and backup file, or to decrypt the backup file. See zbackup for further details.
|
||||
|
||||
/my/backup/repo The directory used to hold the backup repository.
|
||||
|
||||
/my/precious/restored-tar The tar used for restoring the backup.
|
||||
|
||||
/my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` Specifies the backup file.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/zbackup-a-versatile-deduplicating-backup-tool.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -1,71 +0,0 @@
|
||||
Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10
|
||||
================================================================================
|
||||
|
||||
A low-overhead monitoring web dashboard for a GNU/Linux machine. Simply drop-in the app and go!.Linux Dash's interface provides a detailed overview of all vital aspects of your server, including RAM and disk usage, network, installed software, users, and running processes. All information is organized into sections, and you can jump to a specific section using the buttons in the main toolbar. Linux Dash is not the most advanced monitoring tool out there, but it might be a good fit for users looking for a slick, lightweight, and easy to deploy application.
|
||||
|
||||
### Linux-Dash Features ###
|
||||
|
||||
A beautiful web-based dashboard for monitoring server info
|
||||
|
||||
Live, on-demand monitoring of RAM, Load, Uptime, Disk Allocation, Users and many more system stats
|
||||
|
||||
Drop-in install for servers with Apache2/nginx + PHP
|
||||
|
||||
Click and drag to re-arrange widgets
|
||||
|
||||
Support for wide range of linux server flavors
|
||||
|
||||
### List of Current Widgets ###
|
||||
|
||||
- General info
|
||||
- Load Average
|
||||
- RAM
|
||||
- Disk Usage
|
||||
- Users
|
||||
- Software
|
||||
- IP
|
||||
- Internet Speed
|
||||
- Online
|
||||
- Processes
|
||||
- Logs
|
||||
|
||||
### Install Linux-dash on ubuntu server 14.10 ###
|
||||
|
||||
First you need to make sure you have [Ubuntu LAMP server 14.10][1] installed and Now you have to install the following package
|
||||
|
||||
sudo apt-get install php5-json unzip
|
||||
|
||||
After the installation this module will enable for apache2 so you need to restart the apache2 server using the following command
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
Now you need to download the linux-dash package and install
|
||||
|
||||
wget https://github.com/afaqurk/linux-dash/archive/master.zip
|
||||
|
||||
unzip master.zip
|
||||
|
||||
sudo mv linux-dash-master/ /var/www/html/linux-dash-master/
|
||||
|
||||
Now you need to change the permissions using the following command
|
||||
|
||||
sudo chmod 755 /var/www/html/linux-dash-master/
|
||||
|
||||
Now you need to go to http://serverip/linux-dash-master/ you should see similar to the following output
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-linux-dash-web-based-monitoring-tool-on-ubntu-14-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||
@ -1,115 +0,0 @@
|
||||
[translating by KayGuoWhu]
|
||||
Enjoy Android Apps on Ubuntu using ARChon Runtime
|
||||
================================================================================
|
||||
Before, we gave try to many android app emulating tools like Genymotion, Virtualbox, Android SDK, etc to try to run android apps on it. But, with this new Chrome Android Runtime, we are able to run Android Apps on our Chrome Browser. So, here are the steps we'll need to follow to install Android Apps on Ubuntu using ARChon Runtime.
|
||||
|
||||
Google had [announced the first set of Android apps is ready to run natively on Chrome OS][1], a feature made possible using a new ‘**Android Runtime**’ extension. Now, a developer named Vlad Filippov has figured out a way to bring Android Apps to Chrome on the desktop. His chromeos-apk script and ARChon Android Runtime extension work hand-in-hand to bring Android apps to Chrome browser on the Windows, Mac and Linux desktop.
|
||||
|
||||
Performance of this apps through the runtime is not pretty good. Similarly, as its both an unofficial repackaging of the official runtime and running outside of Google's Chrome OS, system integration like webcam, speakers, etc. may be patchy or non-existent.
|
||||
|
||||
### Installing Chrome ###
|
||||
|
||||
First of all, we'll need Chrome installed in our machine, Chrome version 37 or higher is required. We can download them from the [download page of Chrome Browser][2].
|
||||
|
||||
If you wanna install a Dev Channel version you'll need to follow below procedure.
|
||||
|
||||
We'll need to add repository source list for Google Chrome which can be done my using the following command.
|
||||
|
||||
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
|
||||
|
||||

|
||||
|
||||
After adding the repository source list, we'll need to update the local repository index by the command below.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Now, we'll gonna install google chrome unstable which is dev version.
|
||||
|
||||
$ sudo apt-get install google-chrome-unstable
|
||||
|
||||

|
||||
|
||||
### Installing Archon Runtime ###
|
||||
|
||||
Next we'll need to download the custom-made ergo officially not endorsed by Google or Chromium Android Runtime created by Vlad Filippov. This differs from the official version in a number of ways, the chief being it can be used on desktop versions of the browser. Here below is the runtime we need to download, please select anyone of the following according to your bit of Ubuntu installed.
|
||||
|
||||
For **32-bit** Ubuntu Distributions:
|
||||
|
||||
- [Download Archron for 32-bit Ubuntu][3]
|
||||
|
||||
For **64-bit** Ubuntu Distributions:
|
||||
|
||||
- [Download Archron for 64-bit Ubuntu][4]
|
||||
|
||||
Once the runtime has fully downloaded you will need to extract the contents from the .zip files and move the resulting directory to Home. Here is the gist commands for this steps to download and extract the contents.
|
||||
|
||||
$ wget https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_32.zip
|
||||
|
||||

|
||||
|
||||
$ unzip ARChon-v1.1-x86_32.zip ~/
|
||||
|
||||
Now to install the runtime, we'll gonna Open our latest Google Chrome and goto the url **chrome://extensions/** then, we'll need to check ‘**Enable developer mode**’. Finally, we'll gonna click on the ‘**load unpacked extension**’ button and select the folder which was placed into **~/Home**.
|
||||
|
||||
### Installing ChromeOS-APK ###
|
||||
|
||||
To convert APKs manually is something you really don’t need to do any more if you use one of the apps mentioned above — you will need to install the ‘[chromeos-apk][5]’ command line JavaScript utility. This is available to install through the Node Packaged Modules (npm) manager. To install nmp and chromeos-apk, we'll need to run the following command in a shell or terminal.
|
||||
|
||||
$ sudo apt-get install npm nodejs nodejs-legacy
|
||||
|
||||
**If you are running 64 bit OS**, you should grab the following library, to do so run the below commands in a shell or terminal.
|
||||
|
||||
$ sudo apt-get install lib32stdc++6
|
||||
|
||||
Now run the command to install the the latest chromeos-apk is:
|
||||
|
||||
$ npm install -g chromeos-apk@latest
|
||||
|
||||

|
||||
|
||||
Depending on your system configuration you may need to need to run this latter command as sudo.
|
||||
|
||||
Now, we'll gonna for Google to find an APK of an app to give it a try, bearing in mind **not all Android apps will work**, and those that do may be unstable or lack features. Most of the messenger out of the box are not working.
|
||||
|
||||
### Converting APK ###
|
||||
|
||||
Place your **Android APK in ~/Home**, then return to **Terminal** to convert it using the following command:
|
||||
|
||||
$ chromeos-apk myapp.apk --archon
|
||||
|
||||
If you want the app in fullscreen mode then run the following instead:
|
||||
|
||||
$ chromeos-apk myapp.apk --archon --tablet
|
||||
|
||||
Note: Please replace myapp.apk to the Android APK app filename you want to convert.
|
||||
|
||||
For our ease, we can also use [Twerk][6] for the conversion process if we want to skip this step.
|
||||
|
||||
### Running Android Apk ###
|
||||
|
||||
Finally, we'll need to open our chrome browser and then goto chrome://extensions page and enable developer mode then tap the ‘load unpacked extension’ button and select the folder the script above created.
|
||||
|
||||
Now, we can Open the Chrome App Launcher to run it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray! We have successfully installed Android Apk App in our favorite desktop browser ie Chrome Browser. This article is all about the popular Chrome Android Runtime called Archon created by Vlad Filippov. This runtime allows us to run converted Apk files in our Chrome browser. It has not yet supported messaging apps like Whatsapp, etc. So, if you have any questions, suggestions, feedback please write them in the comment box below. Thank you ! Enjoy Archon :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/android-apps-ubuntu-archon-runtime/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://chrome.blogspot.com/2014/09/first-set-of-android-apps-coming-to.html
|
||||
[2]:https://www.google.com/chrome/browser
|
||||
[3]:https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_32.zip
|
||||
[4]:https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_64.zip
|
||||
[5]:https://github.com/vladikoff/chromeos-apk/blob/master/README.md
|
||||
[6]:https://chrome.google.com/webstore/detail/twerk/jhdnjmjhmfihbfjdgmnappnoaehnhiaf
|
||||
@ -1,115 +0,0 @@
|
||||
5 Interesting Command Line Tips and Tricks in Linux – Part 1
|
||||
================================================================================
|
||||
Are you making most out of the Linux? There are lots of helpful features which appears to be Tips and Tricks for many of Linux Users. Sometimes Tips and Tricks become the need. It helps you get productive with the same set of commands yet with enhanced functionality.
|
||||
|
||||

|
||||
5 Command Line Tips and Tricks
|
||||
|
||||
Here we are starting a new series, where we will be writing some tips and tricks and will try to yield as more as we can in small time.
|
||||
|
||||
### 1. To audit the commands we’d run in past, we use [history command][1]. Here is a sample output of history command. ###
|
||||
|
||||
# history
|
||||
|
||||

|
||||
history command example
|
||||
|
||||
Obvious from output, the history command do not output the time stamp with the log of last executed commands. Any solution for this? Yeah! Run the below command.
|
||||
|
||||
# HISTTIMEFORMAT="%d/%m/%y %T "
|
||||
# history
|
||||
|
||||
If you want to permanently append this change, add the below line to `~/.bashrc`.
|
||||
|
||||
export HISTTIMEFORMAT="%d/%m/%y %T "
|
||||
|
||||
and then, from terminal run,
|
||||
|
||||
# source ~/.bashrc
|
||||
|
||||
Explanation of commands and switches.
|
||||
|
||||
- history – GNU History Library
|
||||
- HISTIMEFORMAT – Environmental Variable
|
||||
- %d – Day
|
||||
- %m – Month
|
||||
- %y – Year
|
||||
- %T – Time Stamp
|
||||
- source – in short send the contents of file to shell
|
||||
- .bashrc – is a shell script that BASH runs whenever it is started interactively.
|
||||
|
||||

|
||||
history Command Logs
|
||||
|
||||
### 2. The next gem in the list is – how to check disk write speed? Well one liner dd command script serves the purpose. ###
|
||||
|
||||
# dd if=/dev/zero of=/tmp/output.img bs=8k count=256k conv=fdatasync; rm -rf /tmp/output.img
|
||||
|
||||

|
||||
dd Command Example
|
||||
|
||||
Explanation of commands and switches.
|
||||
|
||||
- dd – Convert and Copy a file
|
||||
- if=/dev/zero – Read the file and not stdin
|
||||
- of=/tmp/output.img – Write to file and not stdout
|
||||
- bs – Read and Write maximum upto M bytes, at one time
|
||||
- count – Copy N input block
|
||||
- conv – Convert the file as per comma separated symbol list.
|
||||
- rm – Removes files and folder
|
||||
- -rf – (-r) removes directories and contents recursively and (-f) Force the removal without prompt.
|
||||
|
||||
### 3. How will you check the top six files that are eating out your space? A simple one liner script made from [du command][2], which is primarily used as file space usages. ###
|
||||
|
||||
# du -hsx * | sort -rh | head -6
|
||||
|
||||

|
||||
Check Disk Space Usage
|
||||
|
||||
Explanation of commands and switches.
|
||||
|
||||
- du – Estimate file space usages
|
||||
- -hsx – (-h) Human Readable Format, (-s) Summaries Output, (-x) One File Format, skip directories on other file format.
|
||||
- sort – Sort text file lines
|
||||
- -rf – (-r) Reverse the result of comparison, (-f) Ignore case
|
||||
- head – output first n lines of file.
|
||||
|
||||
### 4. The next step involves statistics in terminal of a file of every kind. We can output the statistics related to a file with the help of stat (output file/fileSystem status) command. ###
|
||||
|
||||
# stat filename_ext (viz., stat abc.pdf)
|
||||
|
||||

|
||||
Check File Statistics
|
||||
|
||||
### 5. The next and last but not the least, this one line script is for those, who are newbies. If you are an experienced user you probably don’t need it, unless you want some fun out of it. Well newbies are Linux-command-line phobic and the below one liner will generate random man pages. The benefit is as a newbie you always get something to learn and never get bored. ###
|
||||
|
||||
# man $(ls /bin | shuf | head -1)
|
||||
|
||||

|
||||
Generate Random Man Pages
|
||||
|
||||
Explanation of commands and switches.
|
||||
|
||||
- man – Linux Man pages
|
||||
- ls – Linux Listing Commands
|
||||
- /bin – System Binary file Location
|
||||
- shuf – Generate Random Permutation
|
||||
- head – Output first n line of file.
|
||||
|
||||
That’s all for now. If you know any such tips and tricks you may share with us and we will post the same in your words on our reputed Tecmint.com website.
|
||||
|
||||
If you want to share any tips and tricks that you cannot make into article you may share it at tecmint[dot]com[at]gmail[dot]com and we will include it in our article. Don’t forget to provide us with your valuable feedback in the comments below. Keep connected. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/history-command-examples/
|
||||
[2]:http://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
@ -1,144 +0,0 @@
|
||||
How to share a directory with Samba on Fedora or CentOS
|
||||
================================================================================
|
||||
Nowadays sharing data across different computers is not something new at home or many work places. Riding on this trend, modern operating systems make it easy to share and exchange data transparently across computers via network file systems. If your work environment involves a mix of Microsoft Windows and Linux computers, one way to share files and folders among them is via SMB/CIFS, a cross-platform network file sharing protocol. Windows Microsoft natively supports SMB/CIFS, while Linux offers free software implementation of SMB/CIFS network protocol in Samba.
|
||||
|
||||
In this article, we will demonstrate **how to share a directory using Samba**. The Linux platform we will use is **Fedora or CentOS**. This article is dividied into four parts. First, we will install Samba under Fedora/CentOS environment. Next, we discuss how to adjust SELinux and firewall configurations to allow file sharing with Samba. Finally, we cover how to enable Samba to share a directory.
|
||||
|
||||
### Step One: Install Samba on Fedora or CentOS ###
|
||||
|
||||
First thing first. Let's install Samba and configure basic settings.
|
||||
|
||||
Check whether Samba application is already installed on your system by running:
|
||||
|
||||
$ rpm -q samba samba-common samba-client
|
||||
|
||||
If the above command doesn't show anything at all, it means that Samba is not installed. In that case, install Samba using the command below.
|
||||
|
||||
$ sudo yum install samba samba-common samba-client
|
||||
|
||||
Next, creates a local directory which will share data over network. This directory will be exported to remote users as a Samba share. In this tutorial, we will create this directory in the top-level directory '/', so make sure that you have the privileges to do it.
|
||||
|
||||
$ sudo mkdir /shared
|
||||
|
||||
If you want to create a shared directory inside your home directory (e.g., ~/shared), you must activate Samba home directory sharing in the SELinux options, which will be described below in more detail.
|
||||
|
||||
After creating /shared directory, set the privileges of the directory so other users can access it.
|
||||
|
||||
$ sudo chmod o+rw /shared
|
||||
|
||||
If you don't want other users to be able to have write to the directory, just remove the 'w' option in chmod command as follows.
|
||||
|
||||
$ sudo chmod o+r /shared
|
||||
|
||||
Next, create one empty file as a test. This file will be used to verify that he Samba share is mounted properly.
|
||||
|
||||
$ sudo touch /shared/file1
|
||||
|
||||
### Step Two: Configure SELinux for Samba ###
|
||||
|
||||
Next, we need to re-configure SELinux which is enabled by default in Fedora and CentOS distributions. SELinux allows Samba to read and modify files or directories only when they have the right security context (e.g., labeled with the 'samba_share_t' attribute).
|
||||
|
||||
The following command adds the necessary label to file-context configuration:
|
||||
|
||||
$ sudo semanage fcontext -a -t samba_share_t "<directory>(/.*)?"
|
||||
|
||||
Replace the <directory> with the local directory we created earlier for Samba share (e.g., /shared):
|
||||
|
||||
$ sudo semanage fcontext -a -t samba_share_t "/shared(/.*)?"
|
||||
|
||||
To activate the label change, we then must run the restorecon command like below.
|
||||
|
||||
$ sudo restorecon -R -v /shared
|
||||
|
||||
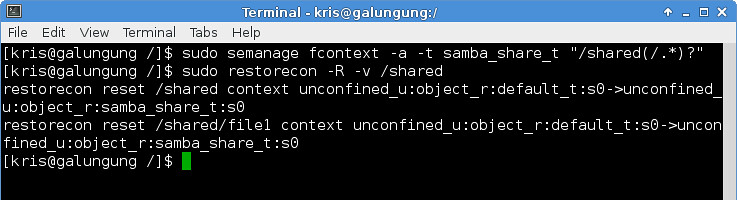
|
||||
|
||||
To share a directory inside our home directory via Samba, we must enable sharing home directory option in SELinux because it is disabled by default. The following command achieves the desired effect. Skip this step if you are not sharing your home directory.
|
||||
|
||||
$ sudo setsebool -P samba_enable_home_dirs 1
|
||||
|
||||
### Step Three: Configure Firewall for Samba ###
|
||||
|
||||
The next step is to open necessary TCP/UDP ports in the firewall settings for Samba to operate.
|
||||
|
||||
If you are using firewalld (e.g., on Fedora or CentOS 7), the following command will take care of permanent firewall rule change for Samba service.
|
||||
|
||||
$ sudo firewall-cmd --permanent --add-service=samba
|
||||
|
||||
If you are using iptables for your firewall (e.g., CentOS 6 or earlier), use the following commands to open up necessary Samba ports to the world.
|
||||
|
||||
$ sudo vi /etc/sysconfig/iptables
|
||||
|
||||
----------
|
||||
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 445 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m udp -p udp --dport 445 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m udp -p udp --dport 137 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m udp -p udp --dport 138 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 139 -j ACCEPT
|
||||
|
||||
Then restart iptables service:
|
||||
|
||||
$ sudo service iptables restart
|
||||
|
||||
### Step Four: Change Samba Configuration ###
|
||||
|
||||
The last step is to configure Samba to export a created local directory as a Samba-share.
|
||||
|
||||
Open the Samba configuration file with a text editor, and add the following lines at the bottom of the file.
|
||||
|
||||
$ sudo nano /etc/samba/smb.conf
|
||||
|
||||
----------
|
||||
|
||||
[myshare]
|
||||
comment=my shared files
|
||||
path=/shared
|
||||
public=yes
|
||||
writeable=yes
|
||||
|
||||
In the above the text inside a pair of brackets (e.g., "myshare") is the name of the Samba-shared resource, which will be used to access the Samba share from a remote host.
|
||||
|
||||
Create a Samba user account which is required to mount and export the Samba file system. To create a Samba user, use the smbpasswd tool. Note that the Samba user account must be the same as any existing Linux user. If you try to add a non-existing user with smbpasswd, it will give an error message.
|
||||
|
||||
If you don't want to use any existing Linux user as a Samba user, you can create a new dedicated user in your system. For safety, set the new user's login shell to /sbin/nologin, and do not create its home directory.
|
||||
|
||||
In this example, we are creating a new user named "sambaguest" as follows.
|
||||
|
||||
$ sudo useradd -M -s /sbin/nologin sambaguest
|
||||
$ sudo passwd sambaguest
|
||||
|
||||
|
||||
|
||||
After creating a new user, add the user as a Samba user using smbpasswd command. When this command asks a password, you can type a different password than the user's password.
|
||||
|
||||
$ sudo smbpasswd -a sambaguest
|
||||
|
||||
4. Activate the Samba service, and check whether the Samba service is running or not.
|
||||
|
||||
$ sudo systemctl enable smb.service
|
||||
$ sudo systemctl start smb.service
|
||||
$ sudo systemctl is-active smb
|
||||
|
||||

|
||||
|
||||
To see the list of shared directories in Samba, type the following command.
|
||||
|
||||
$ smbclient -U sambaguest -L localhost
|
||||
|
||||
|
||||
|
||||
The following is a screenshot of accessing the Samba-shared directory on Thunar file manager, and doing copy-paste of file1. Note that the Samba share is accessible via "smb://<samba-server-IP-address>/myshare" address on Thunar.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/share-directory-samba-fedora-centos.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/kristophorus
|
||||
@ -1,159 +0,0 @@
|
||||
Sleuth Kit - Open Source Forensic Tool to Analyze Disk Images and Recover Files
|
||||
================================================================================
|
||||
SIFT is a Ubuntu based forensics distribution provided by SANS Inc. It consist of many forensics tools such as Sleuth kit / Autopsy etc . However, Sleuth kit/Autopsy tools can be installed on Ubuntu/Fedora distribution instead of downloading complete distribution of SIFT.
|
||||
|
||||
Sleuth Kit /Autopsy is open source digital forensics investigation tool which is used for recovering the lost files from disk image and analysis of images for incident response. Autopsy tool is a web interface of sleuth kit which supports all features of sleuth kit. This tool is available for both Windows and Linux Platforms.
|
||||
|
||||
### Install Sleuth kit ###
|
||||
|
||||
First of all, download Sleuth kit software from [sleuthkit][1] website. Use wget command to download it in terminal which is shown in the figure.
|
||||
|
||||
# wget http://cznic.dl.sourceforge.net/project/sleuthkit/sleuthkit/4.1.3/sleuthkit-4.1.3.tar.gz
|
||||
|
||||

|
||||
|
||||
Extract the sleuthkit-4.1.3.tar.gz using following command and go inside the extracted directory
|
||||
|
||||
# tar -xvzf sleuthkit-4.1.3.tar.gz
|
||||
|
||||

|
||||
|
||||
Run following command which perform the requirement check before sleuth kit installation
|
||||
|
||||
#./configure
|
||||
|
||||

|
||||
|
||||
Make command compile the sleuth kit code.
|
||||
|
||||
#make
|
||||
|
||||

|
||||
|
||||
Finally following command install it under **/usr/local** path.
|
||||
|
||||
#make install
|
||||
|
||||

|
||||
|
||||
### Install Autopsy Tool ###
|
||||
|
||||
Sleuth kit installation is complete and now we will install autopsy interface. Download Autopsy software from [sleuthkit's autopsy page][2] . Use wget command to download it in terminal which is shown in the figure.
|
||||
|
||||
# wget http://kaz.dl.sourceforge.net/project/autopsy/autopsy/2.24/autopsy-2.24.tar.gz
|
||||
|
||||

|
||||
|
||||
Extract the autopsy-2.24.tar.gz using following command and go inside the extracted directory
|
||||
|
||||
# tar -xvzf autopsy-2.24.tar.gz
|
||||
|
||||

|
||||
|
||||
Configuration script of autopsy asks for NSRL (National Software Reference Library) and path of **Evidence_Locker** folder.
|
||||
|
||||
Enter "n" for NSRL prompt and create Evidence_Locker folder under **/usr/local** directory. Autopsy stores the configuration files, audit logs and output under Evidence_Locker folder.
|
||||
|
||||
#mkdir /usr/local/Evidence_Locker
|
||||
|
||||
#cd autopsy-2.24
|
||||
|
||||
#./configure
|
||||
|
||||

|
||||
|
||||
After adding Evidence_Locker path in installation process , autopsy stores configuration files in it and shows a following message to run the autopsy program.
|
||||
|
||||

|
||||
|
||||
Type **./autopsy** command in terminal to start the graphical interface of Sleuth kit tool.
|
||||
|
||||

|
||||
|
||||
Type following address in the web browser to access the interface of autopsy .
|
||||
|
||||
http://localhost:9999/autopsy
|
||||
|
||||
Main web page of autopsy plugin is shown int the following figure.
|
||||
|
||||

|
||||
|
||||
Click on the **New Case** button to start analysis in autopsy tool. Enter the case name, description about the investigation and name of agent which is shown in the following figure.
|
||||
|
||||

|
||||
|
||||
Following web page will appear after entering the details in the above page. Click on **Add Host** button to add details for the analyst machine.
|
||||
|
||||

|
||||
|
||||
Enter host name, description and time zone setting of analyst machine on the next page.
|
||||
|
||||

|
||||
|
||||
Click on the **Add Image** button to add image file for forensics analysis.
|
||||
|
||||

|
||||
|
||||
Click on the **Add Image File** button on the following web page. It opens new web page which require Path of image file and select type & importing method.
|
||||
|
||||

|
||||
|
||||
As shown in the following figure, we have entered path of Linux image file. In our case, image file is partition of disk.
|
||||
|
||||

|
||||
|
||||
Click on the next button and select **Calculate hash** option in the next page which is shown in the following figure. It also detect the file system type of the given image.
|
||||
|
||||

|
||||
|
||||
Following window shows the MD5 hash of the image file before static analysis .
|
||||
|
||||

|
||||
|
||||
On the next web page, autopsy shows following information about the image file.
|
||||
|
||||
- mount point for the image
|
||||
- name of image
|
||||
- file system type of given image
|
||||
|
||||
Click on the **details** button to get more information about the given image file. It also offer extraction of unallocated fragments and strings from the volume of image file which is shown in the following figure.
|
||||
|
||||

|
||||
|
||||
Click on **Analyze** button which is shown in the below figure to start analysis on given image . It opens another page which shows the multiple options for image analysis.
|
||||
|
||||

|
||||
|
||||
Autopsy offer following features during image analysis process.
|
||||
|
||||
- File Analysis
|
||||
- Keyword Search
|
||||
- File Type
|
||||
- Image Details
|
||||
- Data Unit
|
||||
|
||||
File Analysis on given image of Linux partition is shown in the following figure.
|
||||
|
||||

|
||||
|
||||
It extracts all files and folders from the given image . Extraction of deleted files are shown int he figure.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hopefully this article will be useful for the beginner in static forensics analysis of disk image. Autopsy is web interface for sleuth kit which provides features such as extraction of strings , recovery of deleted files, timeline analysis, extraction of web surfing history, keyword search and email analysis on windows and linux disk images.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/autopsy-sleuth-kit-installation-ubuntu/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:http://www.sleuthkit.org/sleuthkit/download.php
|
||||
[2]:http://www.sleuthkit.org/autopsy/download.php
|
||||
@ -1,163 +0,0 @@
|
||||
7 Quirky ‘ls’ Command Tricks Every Linux User Should Know
|
||||
================================================================================
|
||||
We have covered most of the things on ‘ls‘ command in last two articles of our Interview series. This article is the last part of the ‘ls command‘ series. If you have not gone through last two articles of this series you may visit the links below.
|
||||
|
||||
注:以下三篇都做过源文,看看翻译了没有,如果发布了可适当改链接地址
|
||||
- [15 Basic ‘ls’ Command Examples in Linux][]
|
||||
- [15 Interview Questions on Linux “ls” Command – Part 1][]
|
||||
- [10 Useful ‘ls’ Command Interview Questions – Part 2][]
|
||||
|
||||

|
||||
7 Quirky ls Command Tricks
|
||||
|
||||
### 1. List the contents of a directory with time using various time styles. ###
|
||||
|
||||
To list the contents of a directory with times using style, we need to choose any of the below two methods.
|
||||
|
||||
# ls -l –time-style=[STYLE] (Method A)
|
||||
|
||||
**Note** – The above switch (`--time` style must be run with switch `-l`, else it won’t serve the purpose).
|
||||
|
||||
# ls –full-time (Method B)
|
||||
|
||||
Replace `[STYLE]` with any of the below option.
|
||||
|
||||
full-iso
|
||||
long-iso
|
||||
iso
|
||||
locale
|
||||
+%H:%M:%S:%D
|
||||
|
||||
**Note** – In the above line H(Hour), M(Minute), S(Second), D(Date) can be used in any order.
|
||||
|
||||
Moreover you just choose those relevant and not all options. E.g., `ls -l --time-style=+%H` will show only hour.
|
||||
|
||||
`ls -l --time-style=+%H:%M:%D` will show Hour, Minute and date.
|
||||
|
||||
# ls -l --time-style=full-iso
|
||||
|
||||

|
||||
ls Command Full Time Style
|
||||
|
||||
# ls -l --time-style=long-iso
|
||||
|
||||

|
||||
Long Time Style Listing
|
||||
|
||||
# ls -l --time-style=iso
|
||||
|
||||

|
||||
Time Style Listing
|
||||
|
||||
# ls -l --time-style=locale
|
||||
|
||||

|
||||
Locale Time Style Listing
|
||||
|
||||
# ls -l --time-style=+%H:%M:%S:%D
|
||||
|
||||

|
||||
Date and Time Style Listing
|
||||
|
||||
# ls --full-time
|
||||
|
||||

|
||||
|
||||
Full Style Time Listing
|
||||
|
||||
### 2. Output the contents of a directory in various formats such as separated by commas, horizontal, long, vertical, across, etc. ###
|
||||
|
||||
Contents of directory can be listed using ls command in various format as suggested below.
|
||||
|
||||
- across
|
||||
- comma
|
||||
- horizontal
|
||||
- long
|
||||
- single-column
|
||||
- verbose
|
||||
- vertical
|
||||
|
||||
# ls –-format=across
|
||||
# ls --format=comma
|
||||
# ls --format=horizontal
|
||||
# ls --format=long
|
||||
# ls --format=single-column
|
||||
# ls --format=verbose
|
||||
# ls --format=vertical
|
||||
|
||||

|
||||
Listing Formats of ls Command
|
||||
|
||||
### 3. Use ls command to append indicators like (/=@|) in output to the contents of the directory. ###
|
||||
|
||||
The option `-p` with ‘ls‘ command will server the purpose. It will append one of the above indicator, based upon the type of file.
|
||||
|
||||
# ls -p
|
||||
|
||||

|
||||
Append Indicators to Content
|
||||
|
||||
### 4. Sort the contents of directory on the basis of extension, size, time and version. ###
|
||||
|
||||
We can use options like `--extension` to sort the output by extension, size by extension `--size`, time by using extension `-t` and version using extension `-v`.
|
||||
|
||||
Also we can use option `--none` which will output in general way without any sorting in actual.
|
||||
|
||||
# ls --sort=extension
|
||||
# ls --sort=size
|
||||
# ls --sort=time
|
||||
# ls --sort=version
|
||||
# ls --sort=none
|
||||
|
||||

|
||||
Sort Listing of Content by Options
|
||||
|
||||
### 5. Print numeric UID and GID for every contents of a directory using ls command. ###
|
||||
|
||||
The above scenario can be achieved using flag -n (Numeric-uid-gid) along with ls command.
|
||||
|
||||
# ls -n
|
||||
|
||||

|
||||
Print Listing of Content by UID and GID
|
||||
|
||||
### 6. Print the contents of a directory on standard output in more columns than specified by default. ###
|
||||
|
||||
Well ls command output the contents of a directory according to the size of the screen automatically.
|
||||
|
||||
We can however manually assign the value of screen width and control number of columns appearing. It can be done using switch ‘`--width`‘.
|
||||
|
||||
# ls --width 80
|
||||
# ls --width 100
|
||||
# ls --width 150
|
||||
|
||||

|
||||
List Content Based on Window Sizes
|
||||
|
||||
**Note**: You can experiment what value you should pass with width flag.
|
||||
|
||||
### 7. Include manual tab size at the contents of directory listed by ls command instead of default 8. ###
|
||||
|
||||
# ls --tabsize=[value]
|
||||
|
||||

|
||||
List Content by Table Size
|
||||
|
||||
**Note**: Specify the `[Value]=` Numeric value.
|
||||
|
||||
That’s all for now. Stay tuned to Tecmint till we come up with next article. Do not forget to provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-ls-command-tricks/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
@ -1,252 +0,0 @@
|
||||
How to set up server monitoring system with Monit
|
||||
================================================================================
|
||||
Many Linux admins rely on a centralized remote monitoring system (e.g., [Nagios][1] or [Cacti][2]) to check the health of their network infrastructure. While centralized monitoring makes an admin's life easy when dealing with many hosts and devices, a dedicated monitoring box obviously becomes a single point of failure; if the monitoring box goes down or becomes unreachable for whatever reason (e.g., bad hardware or network outage), you will lose visibility on your entire infrastructure.
|
||||
|
||||
One way to add redundancy to your monitoring system is to install standalone monitoring software (as a fallback) at least on any critical/core servers on your network. In case a centralized monitor is down, you will still be able to maintain visibility on your core servers from their backup monitor.
|
||||
|
||||
### What is Monit? ###
|
||||
|
||||
[Monit][3] is a cross-platform open-source tool for monitoring Unix/Linux systems (e.g., Linux, BSD, OSX, Solaris). Monit is extremely easy to install and reasonably lightweight (with only 500KB in size), and does not require any third-party programs, plugins or libraries. Yet, Monit lends itself to full-blown monitoring, capable of process status monitoring, filesystem change monitoring, email notification, customizable actions for core services, and so on. The combination of ease of setup, lightweight implementation and powerful features makes Monit an ideal candidate for a backup monitoring tool.
|
||||
|
||||
I have been using Monit for several years on multiple hosts, and I am very pleased how reliable it has been. Even as a full-blown monitoring system, Monit is very useful and powerful for any Linux admin. In this tutorial, let me demonstrate how to set up Monit on a local server (as a backup monitor) to monitor common services. With this setup, I will only scrach the surface of what Monit can do for us.
|
||||
|
||||
### Installation of Monit on Linux ###
|
||||
|
||||
Most Linux distributions already include Monit in their repositories.
|
||||
|
||||
Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo aptitude install monit
|
||||
|
||||
Fedora or CentOS/RHEL:
|
||||
|
||||
On CentOS/RHEL, you must enable either [EPEL][4] or [Repoforge][5] repository first.
|
||||
|
||||
# yum install monit
|
||||
|
||||
Monit comes with a very well documented configuration file with a lots of examples. The main configuration file is located in /etc/monit.conf in Fedora/CentOS/RHEL, or /etc/monit/monitrc in Debian/Ubuntu/Mint. Monit configuration has two parts: "Global" and "Services" sections.
|
||||
|
||||
Gl### ###obal Configuration: Web Status Page
|
||||
|
||||
Monit can use several mail servers for notifications, and/or an HTTP/HTTPS status page. Let's start with the web status page with the following requirements.
|
||||
|
||||
- Monit listens on port 1966.
|
||||
- Access to the web status page is encrypted with SSL.
|
||||
- Login requires monituser/romania as user/password.
|
||||
- Login is permitted from localhost, myhost.mydomain.ro, and internal LAN (192.168.0.0/16) only.
|
||||
- Monit stores an SSL certificate in a pem format.
|
||||
|
||||
For subsequent steps, I will use a Red Hat based system. Similar steps will be applicable on a Debian based system.
|
||||
|
||||
First, generate and store a self-signed certificate (monit.pem) in /var/cert.
|
||||
|
||||
# mkdir /var/certs
|
||||
# cd /etc/pki/tls/certs
|
||||
# ./make-dummy-cert monit.pem
|
||||
# cp monit.pem /var/certs
|
||||
# chmod 0400 /var/certs/monit.pem
|
||||
|
||||
Now put the following snippet in the Monit's main configuration file. You can start with an empty configuration file or make a copy of the original file.
|
||||
|
||||
set httpd port 1966 and
|
||||
SSL ENABLE
|
||||
PEMFILE /var/certs/monit.pem
|
||||
allow monituser:romania
|
||||
allow localhost
|
||||
allow 192.168.0.0/16
|
||||
allow myhost.mydomain.ro
|
||||
|
||||
### Global Configuration: Email Notification ###
|
||||
|
||||
Next, let's set up email notification in Monit. We need at least one active [SMTP server][6] which can send mails from the Monit host. Something like the following will do (adjust it for your case):
|
||||
|
||||
- Mail server hostname: smtp.monit.ro
|
||||
- Sender email address used by monit (from): monit@monit.ro
|
||||
- Who will receive mail from monit daemon: guletz@monit.ro
|
||||
- SMTP port used by mail server: 587 (default is 25)
|
||||
|
||||
With the above information, email notification would be configured like this:
|
||||
|
||||
set mailserver smtp.monit.ro port 587
|
||||
set mail-format {
|
||||
from: monit@monit.ro
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
|
||||
}
|
||||
|
||||
set alert guletz@monit.ro
|
||||
|
||||
As you can see, Monit offers several built-in variables ($DATE, $EVENT, $HOST, etc.), and you can customize your email message for your needs. If you want to send mails from the Monit host itself, you need a sendmail-compatible program (e.g., postfix or ssmtp) already installed.
|
||||
|
||||
### Global Configuration: Monit Daemon ###
|
||||
|
||||
The next part is setting up monit daemon. We will set it up as follows.
|
||||
|
||||
- Performs the first check after 120 seconds.
|
||||
- Checks services once every 3 minutes.
|
||||
- Use syslog for logging.
|
||||
|
||||
Place the following snippet to achieve the above setting.
|
||||
|
||||
set daemon 120
|
||||
with start delay 240
|
||||
set logfile syslog facility log_daemon
|
||||
|
||||
We must also define "idfile", a unique ID used by monit demon, and "eventqueue", a path where mails sent by monit but undelivered due to SMTP/network errors. Verifiy that path (/var/monit) already exists. The following configuration will do.
|
||||
|
||||
set idfile /var/monit/id
|
||||
set eventqueue
|
||||
basedir /var/monit
|
||||
|
||||
### Test Global Configuration ###
|
||||
|
||||
Now the "Global" section is finished. The Monit configuration file will look like this:
|
||||
|
||||
# Global Section
|
||||
|
||||
# status webpage and acl's
|
||||
set httpd port 1966 and
|
||||
SSL ENABLE
|
||||
PEMFILE /var/certs/monit.pem
|
||||
allow monituser:romania
|
||||
allow localhost
|
||||
allow 192.168.0.0/16
|
||||
allow myhost.mydomain.ro
|
||||
|
||||
# mail-server
|
||||
set mailserver smtp.monit.ro port 587
|
||||
# email-format
|
||||
set mail-format {
|
||||
from: monit@monit.ro
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
|
||||
}
|
||||
|
||||
set alert guletz@monit.ro
|
||||
|
||||
# delay checks
|
||||
set daemon 120
|
||||
with start delay 240
|
||||
set logfile syslog facility log_daemon
|
||||
|
||||
# idfile and mail queue path
|
||||
set idfile /var/monit/id
|
||||
set eventqueue
|
||||
basedir /var/monit
|
||||
|
||||
Now it is time to check what we have done. You can test an existing configuration file (/etc/monit.conf) by running:
|
||||
|
||||
# monit -t
|
||||
|
||||
----------
|
||||
|
||||
Control file syntax OK
|
||||
|
||||
If Monit complains about any error, please review the configuration file again. Fortunately, error/warnings messages are informative. For example:
|
||||
|
||||
monit: Cannot stat the SSL server PEM file '/var/certs/monit.pem' -- No such file or directory
|
||||
/etc/monit/monitrc:10: Warning: hostname did not resolve 'smtp.monit.ro'
|
||||
|
||||
Once you verify the syntax of configuration, start monit daemon, and wait 2 to 3 minutes:
|
||||
|
||||
# service monit start
|
||||
|
||||
If you are using systemd, run:
|
||||
|
||||
# systemctl start monit
|
||||
|
||||
Now open a browser window, and go to https://<monit_host>:1966. Replace &<monit_host> with your Monit hostname or IP address.
|
||||
|
||||
Note that if you have a self-signed SSL certificate, you will see a warning message in your browser.
|
||||
|
||||

|
||||
|
||||
After you have completed login, you must see the following page.
|
||||
|
||||
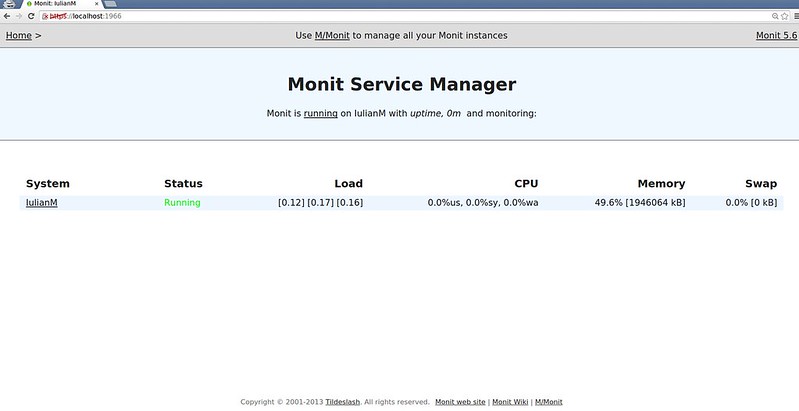
|
||||
|
||||
In the rest of the tutorial, let me show how we can monitor a local server and common services. You will see a lot of useful examples on the [official wiki page][7]. Most of them are copy-and-pastable!
|
||||
|
||||
### Service Configuration: CPU/Memory Monitoring ###
|
||||
|
||||
Let start with monitoring a local server's CPU/memory usage. Copy the following snippet in the configuration file.
|
||||
|
||||
check system localhost
|
||||
if loadavg (1min) > 10 then alert
|
||||
if loadavg (5min) > 6 then alert
|
||||
if memory usage > 75% then alert
|
||||
if cpu usage (user) > 70% then alert
|
||||
if cpu usage (system) > 60% then alert
|
||||
if cpu usage (wait) > 75% then alert
|
||||
|
||||
You can easily interpret the above configuration. The above checks are performed on local host for every monitoring cycle (which is set to 120 seconds in the Global section). If any condition is met, monit daemon will send an alert with an email.
|
||||
|
||||
If certain properties do not need to be monitored for every cycle, you can use the following format. For example, this will monitor average load every other cycle (i.e., every 240 seconds).
|
||||
|
||||
if loadavg (1min) > 10 for 2 cycles then alert
|
||||
|
||||
### Service Configuration: SSH Service Monitoring ###
|
||||
|
||||
Let's check if we have sshd binary installed in /usr/sbin/sshd:
|
||||
|
||||
check file sshd_bin with path /usr/sbin/sshd
|
||||
|
||||
We also want to check if the init script for sshd exist:
|
||||
|
||||
check file sshd_init with path /etc/init.d/sshd
|
||||
|
||||
Finally, we want to check if sshd daemon is up an running, and listens on port 22:
|
||||
|
||||
check process sshd with pidfile /var/run/sshd.pid
|
||||
start program "/etc/init.d/sshd start"
|
||||
stop program "/etc/init.d/sshd stop"
|
||||
if failed port 22 protocol ssh then restart
|
||||
if 5 restarts within 5 cycles then timeout
|
||||
|
||||
More specifically, we can interpret the above configuration as follows. We check if a process named sshd and a pidfile (/var/run/sshd.pid) exist. If either one does not exist, we restart sshd demon using init script. We check if a process listening on port 22 can speak SSH protocol. If not, we restart sshd daemon. If there are at least 5 restarts within the last 5 monitoring cycles (i.e., 5x120 seconds), sshd daemon is declared non-functional, and we do not try to check again.
|
||||
|
||||
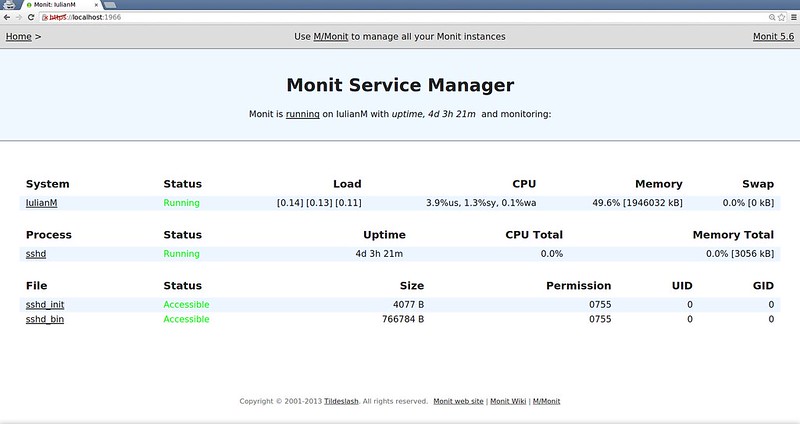
|
||||
|
||||
### Service Configuration: SMTP Service Monitoring ###
|
||||
|
||||
Now let's set up a check on a remote SMTP mail server (e.g., 192.168.111.102). Let's assume that the SMTP server is running SMTP, IMAP and SSH on its LAN interface.
|
||||
|
||||
check host MAIL with address 192.168.111.102
|
||||
if failed icmp type echo within 10 cycles then alert
|
||||
if failed port 25 protocol smtp then alert
|
||||
else if recovered then exec "/scripts/mail-script"
|
||||
if failed port 22 protocol ssh then alert
|
||||
if failed port 143 protocol imap then alert
|
||||
|
||||
We check if the remote host responds to ICMP. If we haven't received ICMP response within 10 cycles, we send out an alert. If testing for SMTP protocol on port 25 fails, we send out an alert. If testing succeeds again after a failed test, we run a script (/scripts/mail-script). If testing for SSH and IMAP protocols fail on port 22 and 143, respectively, we send out an alert.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I demonstrate how to set up Monit on a local server. What I showed here is just the tip of the iceberg, as far as Monit's capabilities are concerned. Take your time and read the man page about Monit (a very good one). Monit can do a lot for any Linux admin with a very nice and easy to understand syntax. If you put together a centralized remote monitor and Monit to work for you, you will have a more reliable monitoring system. What is your thought on Monit?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/server-monitoring-system-monit.html
|
||||
|
||||
作者:[Iulian Murgulet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/iulian
|
||||
[1]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
[2]:http://xmodulo.com/monitor-linux-servers-snmp-cacti.html
|
||||
[3]:http://mmonit.com/monit/
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
[6]:http://xmodulo.com/mail-server-ubuntu-debian.html
|
||||
[7]:http://mmonit.com/wiki/Monit/ConfigurationExamples
|
||||
@ -1,101 +0,0 @@
|
||||
How to Serve Git Repositories Using Gitblit Tool in Linux
|
||||
================================================================================
|
||||
Hi friends, today we'll be learning how to install Gitblit in your Linux Server or PC. So, lets check out what is a Git, its features and steps to install Gitblit. [Git is a distributed revision control system][1] with an emphasis on speed, data integrity, and support for distributed, non-linear workflows. It was initially designed and developed by Linus Torvalds for Linux kernel under the terms of the GNU General Public License version 2 development in 2005, and has since become the most widely adopted version control system for software development.
|
||||
|
||||
[Gitblit is a free and open source][2] built on a pure Java stack designed to handle everything from small to very large projects with speed and efficiency for serving Git repositories. It is easy to learn and has a tiny footprint with lightning fast performance. It outclasses SCM tools like Subversion, CVS, Perforce, and ClearCase with features like cheap local branching, convenient staging areas, and multiple workflows.
|
||||
|
||||
#### Features of Gitblit ####
|
||||
|
||||
- It can be used as a dumb repository viewer with no administrative controls or user accounts.
|
||||
- It can be used as a complete Git stack for cloning, pushing, and repository access control.
|
||||
- It can be used without any other Git tooling (including actual Git) or it can cooperate with your established tools.
|
||||
|
||||
### 1. Creating Gitblit install directory ###
|
||||
|
||||
First of all we'll gonna to create a directory in our server in which we'll be installing our latest gitblit in.
|
||||
|
||||
$ sudo mkdir -p /opt/gitblit
|
||||
|
||||
$ cd /opt/gitblit
|
||||
|
||||

|
||||
|
||||
### 2. Downloading and Extracting ###
|
||||
|
||||
Now, we will want to download the latest gitblit from the official site. Here, the current version of gitblit we are gonna install is 1.6.2 . So, please change it as the version you are gonna install in your system.
|
||||
|
||||
$ sudo wget http://dl.bintray.com/gitblit/releases/gitblit-1.6.2.tar.gz
|
||||
|
||||

|
||||
|
||||
Now, we'll be extracting our downloaded tarball package to our current folder ie /opt/gitblit/
|
||||
|
||||
$ sudo tar -zxvf gitblit-1.6.2.tar.gz
|
||||
|
||||

|
||||
|
||||
### 3. Configuring and Running ###
|
||||
|
||||
Now, we'll configure our Gitblit configuration. If you want to customize the behavior of Gitblit server, you can do it by modifying `gitblit/data/gitblit.properties` . Now, after you are done configuring the configuration. We finally wanna run our gitblit. We have two options on running gitblit, first is that we run it manually by the command below:
|
||||
|
||||
$ sudo java -jar gitblit.jar --baseFolder data
|
||||
|
||||
And next is to add and use gitblit as service. Here are the steps that we'll need to follow to use gitblit as service in linux.
|
||||
|
||||
So, As I am running Ubuntu, the command below will be sudo cp service-ubuntu.sh /etc/init.d/gitblit so please change the file name service-ubuntu.sh to the distribution you are currently running.
|
||||
|
||||
$ sudo ./install-service-ubuntu.sh
|
||||
|
||||
$ sudo service gitblit start
|
||||
|
||||

|
||||
|
||||
Open your browser to http://localhost:8080 or https://localhost:8443 or replace "localhost" with the ip-address of the machine depending on your system configuration. Enter the default administrator credentials: admin / admin and click the Login button.
|
||||
|
||||

|
||||
|
||||
Now, we'll wanna add a new user. First you'll need to login to the admin with default administrator credentials: username = **admin** and password = **admin** .
|
||||
|
||||
Then, Goto user icon > users > (+) new user. And create a new user like as shown in the figure below.
|
||||
|
||||

|
||||
|
||||
Now, we'll create a new repo out of the box. Go to repositories > (+) new repository . Then, add new repository as shown below.
|
||||
|
||||

|
||||
|
||||
#### Create a new repository on the command-line ####
|
||||
|
||||
touch README.md
|
||||
git init
|
||||
git add README.md
|
||||
git commit -m "first commit"
|
||||
git remote add origin ssh://arunlinoxide@localhost:29418/linoxide.com.git
|
||||
git push -u origin master
|
||||
|
||||
Please replace the username arunlinoxide with the user you add.
|
||||
|
||||
#### Push an existing repository from the command-line ####
|
||||
|
||||
git remote add origin ssh://arunlinoxide@localhost:29418/linoxide.com.git
|
||||
git push -u origin master
|
||||
|
||||
**Note**: It is highly recommended to everyone to change the password of username "admin" as it comes by default.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray, we finally installed our latest Gitblit in our Linux Computer. We can now enjoy such a beautiful version controlling system for our projects whether its small or large, no matter. With Gitblit, version controlling has been too easy. It is easy to learn and has a tiny footprint with lightning fast performance. So, if you have any questions, suggestions, feedback please write them in the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/serve-git-repositories-gitblit/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://git-scm.com/
|
||||
[2]:http://gitblit.com/
|
||||
@ -1,149 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
Conky – The Ultimate X Based System Monitor Application
|
||||
================================================================================
|
||||
Conky is a system monitor application written in ‘C’ Programming Language and released under GNU General Public License and BSD License. It is available for Linux and BSD Operating System. The application is X (GUI) based that was originally forked from [Torsmo][1].
|
||||
|
||||
#### Features ####
|
||||
|
||||
- Simple User Interface
|
||||
- Higher Degree of configuration
|
||||
- It can show System stats using built-in objects (300+) as well as external scripts either on the desktop or in it’s own container.
|
||||
- Low on Resource Utilization
|
||||
- Shows system stats for a wide range of system variables which includes but not restricted to CPU, memory, swap, Temperature, Processes, Disk, Network, Battery, email, System messages, Music player, weather, breaking news, updates and blah..blah..blah
|
||||
- Available in Default installation of OS like CrunchBang Linux and Pinguy OS.
|
||||
|
||||
#### Lesser Known Facts about Conky ####
|
||||
|
||||
- The Name conky was derived from a Canadian Television Show.
|
||||
- It has already been ported to Nokia N900.
|
||||
- It is no more maintained officially.
|
||||
|
||||
### Conky Installation and Usage in Linux ###
|
||||
|
||||
Before we install conky, we need to install packages like lm-sensors, curl and hddtemp using following command.
|
||||
|
||||
# apt-get install lm-sensors curl hddtemp
|
||||
|
||||
Time to detect-sensors.
|
||||
|
||||
# sensors-detect
|
||||
|
||||
**Note**: Answer ‘Yes‘ when prompted!
|
||||
|
||||
Check all the detected sensors.
|
||||
|
||||
# sensors
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
acpitz-virtual-0
|
||||
Adapter: Virtual device
|
||||
temp1: +49.5°C (crit = +99.0°C)
|
||||
|
||||
coretemp-isa-0000
|
||||
Adapter: ISA adapter
|
||||
Physical id 0: +49.0°C (high = +100.0°C, crit = +100.0°C)
|
||||
Core 0: +49.0°C (high = +100.0°C, crit = +100.0°C)
|
||||
Core 1: +49.0°C (high = +100.0°C, crit = +100.0°C)
|
||||
|
||||
Conky can be installed from repo as well as, can be compiled from source.
|
||||
|
||||
# yum install conky [On RedHat systems]
|
||||
# apt-get install conky-all [On Debian systems]
|
||||
|
||||
**Note**: Before you install conky on Fedora/CentOS, you must have enabled [EPEL repository][2].
|
||||
|
||||
After conky has been installed, just issue following command to start it.
|
||||
|
||||
$ conky &
|
||||
|
||||

|
||||
Conky Monitor in Action
|
||||
|
||||
It will run conky in a popup like window. It uses the basic conky configuration file located at /etc/conky/conky.conf.
|
||||
|
||||
You may need to integrate conky with the desktop and won’t like a popup like window every-time. Here is what you need to do
|
||||
|
||||
Copy the configuration file /etc/conky/conky.conf to your home directory and rename it as ‘`.conkyrc`‘. The dot (.) at the beginning ensures that the configuration file is hidden.
|
||||
|
||||
$ cp /etc/conky/conky.conf /home/$USER/.conkyrc
|
||||
|
||||
Now restart conky to take new changes.
|
||||
|
||||
$ killall -SIGUSR1 conky
|
||||
|
||||

|
||||
Conky Monitor Window
|
||||
|
||||
You may edit the conky configuration file located in your home dircetory. The configuration file is very easy to understand.
|
||||
|
||||
Here is a sample configuration of conky.
|
||||
|
||||

|
||||
Conky Configuration
|
||||
|
||||
From the above window you can modify color, borders, size, scale, background, alignment and several other properties. By setting different alignments to different conky window, we can run more than one conky script at a time.
|
||||
|
||||
**Using script other than the default for conky and where to find it?**
|
||||
|
||||
You may write your own conky script or use one that is available over Internet. We don’t suggest you to use any script you find on the web which can be potentially dangerous unless you know what you are doing. However a few famous threads and pages have conky script that you can trust as mentioned below.
|
||||
|
||||
- [http://ubuntuforums.org/showthread.php?t=281865][3]
|
||||
- [http://conky.sourceforge.net/screenshots.html][4]
|
||||
|
||||
At the above url, you will find every screenshot has a hyperlink, which will redirects to script file.
|
||||
|
||||
#### Testing Conky Script ####
|
||||
|
||||
Here I will be running a third party written conky-script on my Debian Jessie Machine, to test.
|
||||
|
||||
$ wget https://github.com/alexbel/conky/archive/master.zip
|
||||
$ unzip master.zip
|
||||
|
||||
Change current working directory to just extracted directory.
|
||||
|
||||
$ cd conky-master
|
||||
|
||||
Rename the secrets.yml.example to secrets.yml.
|
||||
|
||||
$ mv secrets.yml.example secrets.yml
|
||||
|
||||
Install Ruby before you could run this (ruby) script.
|
||||
|
||||
$ sudo apt-get install ruby
|
||||
$ ruby starter.rb
|
||||
|
||||

|
||||
Conky Fancy Look
|
||||
|
||||
**Note**: This script can be modified to show your current weather, temperature, etc.
|
||||
|
||||
If you want to start conky at boot, add the below one liner to startup Applications.
|
||||
|
||||
conky --pause 10
|
||||
save and exit.
|
||||
|
||||
And Finally…such a lightweight and useful GUI eye candy like package is not in active stage and is not maintained officially anymore. The last stable release was conky 1.9.0 released on May 03, 2012. A thread on Ubuntu forum has gone over 2k pages of users sharing configuration. (link to forum : [http://ubuntuforums.org/showthread.php?t=281865/][5])
|
||||
|
||||
- [Conky Homepage][6]
|
||||
|
||||
That’s all for now. Keep connected. Keep commenting. Share your thoughts and configuration in comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-conky-in-ubuntu-debian-fedora/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://torsmo.sourceforge.net/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://ubuntuforums.org/showthread.php?t=281865
|
||||
[4]:http://conky.sourceforge.net/screenshots.html
|
||||
[5]:http://ubuntuforums.org/showthread.php?t=281865/
|
||||
[6]:http://conky.sourceforge.net/
|
||||
@ -1,85 +0,0 @@
|
||||
How to secure BGP sessions using authentication on Quagga
|
||||
================================================================================
|
||||
The BGP protocol runs over TCP, and as such, it inherits all the vulnerabilities of a TCP connection. For example, within a BGP session, an attacker may impersonate a legitimate BGP neighbor, and convince the BGP routers on the other end to share their routing information with the attacker. The problem occurs when the attacker advertises and injects bogus routes towards neighboring routers. The unsuspecting neighboring routers may then start sending live traffic towards the attacker, which in most cases goes nowhere and simply gets dropped. Back in 2008, YouTube actually [fell victim][1] to such BGP route poisoning, and suffered major outage on their video service for more than an hour. In a far worse case, if the attacker is savvy enough, they can falsely act as a transparent transit router and sniff the transit traffic for any sensitive data. As you can imagine, this can have far reaching consequences.
|
||||
|
||||
To protect active BGP sessions against such attacks, many service providers leverage [MD5 checksum and a pre-shared key][2] for their BGP sessions. In a protected BGP session, a BGP router which sends a packet generates an MD5 hash value by using a pre-shared key, portions of the IP and TCP headers and the payload. The MD5 hash is then stored as a TCP option field. Upon receipt of the packet, a receiving router uses the same method to generate its version of the MD5 hash using a pre-shared key. It compares the hash with the one of the received packet to decide whether to accept the packet. For an attacker, it is almost impossible to guess the checksum or the key. For BGP routers, they can be assured that each packet is validated before its content is consumed.
|
||||
|
||||
In this tutorial, we will see how we can secure a BGP session between two neighbors using MD5 checksum and a pre-shared key.
|
||||
|
||||
### Preparation ###
|
||||
|
||||
Securing a BGP session is fairly straightforward. We will use the following routers.
|
||||
|
||||
注:表格
|
||||
<table id="content">
|
||||
<tbody><tr>
|
||||
<td><b>Router name</b></td>
|
||||
<td><b>AS</b></td>
|
||||
<td><b>IP address</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>router-A</td>
|
||||
<td>100</td>
|
||||
<td>10.10.12.1/30</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>router-B</td>
|
||||
<td>200</td>
|
||||
<td>10.10.12.2/30</td>
|
||||
</tr>
|
||||
</tbody></table>
|
||||
|
||||
The stock Linux kernel supports TCP MD5 option natively for IPv4 and IPv6. Thus if you built Quagga router from a brand new [Linux box][3], TCP MD5 capability will be automatically available for Quagga. It'll be just a matter of configuring Quagga to take advantage of the capability. But if you are using a FreeBSD box or built a custom kernel for Quagga, make sure that you enable TCP MD5 support on the kernel (e.g., CONFIG_TCP_MD5SIG kernel option in Linux).
|
||||
|
||||
### Configuring Router-A for Authentication ###
|
||||
|
||||
We will use the CLI shell of Quagga to configure the routers. The only new command that we will use is 'password'.
|
||||
|
||||
[root@router-a ~]# vtysh
|
||||
router-a# conf t
|
||||
router-a(config)# router bgp 100
|
||||
router-a(config-router)# network 192.168.100.0/24
|
||||
router-a(config-router)# neighbor 10.10.12.2 remote-as 200
|
||||
router-a(config-router)# neighbor 10.10.12.2 password xmodulo
|
||||
|
||||
The pre-shared key in this example is 'xmodulo'. Obviously, in a production environment you need to select a strong key.
|
||||
|
||||
**Note**: in Quagga, the 'service password-encryption’ command is supposed to encrypt all plain-text passwords (e.g., login password) in its configuration file. However, when I use this command, I notice that the pre-shared key in BGP configuration still remains in clear text. I am not sure whether it's a limitation of Quagga, or whether it's a version issue.
|
||||
|
||||
### Configuring Router-B for Authentication ###
|
||||
|
||||
We will configure router-B in a similar fashion.
|
||||
|
||||
[root@router-b ~]# vtysh
|
||||
router-b# conf t
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# network 192.168.200.0/24
|
||||
router-b(config-router)# neighbor 10.10.12.1 remote-as 100
|
||||
router-b(config-router)# neighbor 10.10.12.1 password xmodulo
|
||||
|
||||
### Verifying a BGP session ###
|
||||
|
||||
If everything has been configured correctly, the BGP session should be up, and both routers should be exchanging routes. At this point, every outgoing packet in a TCP session carries a MD5 digest of the packet contents and a secret key, and the digest is automatically validated by the other end point.
|
||||
|
||||
We can verify the active BGP session by viewing BGP summary as usual. MD5 checksum verification occurs transparently within Quagga, so you don't see it at the BGP level.
|
||||
|
||||

|
||||
|
||||
If you want to test BGP authentication, you can configure one neighbor without a password or deliberately use a wrong pre-shared key and see what happens. You can also use a packet sniffer like tcpdump or Wireshark to analyze the packets that go through the BGP session. For example, tcpdump with "-M <secret>" option will validate the MD5 digests found in TCP option field.
|
||||
|
||||
To sum up, in this tutorial we demonstrate how we can easily secure the BGP session between two routers. The process is very straightforward compared to other protocols. It is always recommended to secure your BGP session, especially if you are setting up the BGP session with another AS. The pre-shared key should also be kept safe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/bgp-authentication-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://research.dyn.com/2008/02/pakistan-hijacks-youtube-1/
|
||||
[2]:http://tools.ietf.org/html/rfc2385
|
||||
[3]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
@ -1,261 +0,0 @@
|
||||
4 Tools Send Email with Subject, Body and Attachment in Linux
|
||||
================================================================================
|
||||
In today's article we will cover a few ways you can use to send emails with attachments from the command line interface on Linux. It can have quite a few uses, for example to send an archive with an application from an application server to email or you can use the commands in scripts to automate some process. For our examples,we will use the file foo.tar.gz as our attachment.
|
||||
|
||||
There are various ways to send emails from command line using different mail clients but here I am sharing few mail client utility used by most users like mailx, mutt and swaks.
|
||||
|
||||
All the tools we will present to you are very popular and present in the repositories of most Linux distributions, you can install them using the following commands:
|
||||
|
||||
For **Debian / Ubuntu** systems
|
||||
|
||||
apt-get install mutt
|
||||
apt-get install swaks
|
||||
apt-get install mailx
|
||||
apt-get install sharutils
|
||||
|
||||
For Red Hat based systems like **CentOS** or **Fedora**
|
||||
|
||||
yum install mutt
|
||||
yum install swaks
|
||||
yum install mailx
|
||||
yum install sharutils
|
||||
|
||||
### 1) Using mail / mailx ###
|
||||
|
||||
The mailx utility found as the default mailer application in most Linux distributions now includes the support to attach file. If it is not available you can easily install using the following commands please take note that this may not be supported in older versions, to check this you can use the command:
|
||||
|
||||
$ man mail
|
||||
|
||||
And the first line should look like this:
|
||||
|
||||
mailx [-BDdEFintv~] [-s subject] [-a attachment ] [-c cc-addr] [-b bcc-addr] [-r from-addr] [-h hops] [-A account] [-S variable[=value]] to-addr . . .
|
||||
|
||||
As you can see it supports the -a attribute to add a file to the email and -s attribute to subject to the email. Use few of below examples to send mails.
|
||||
|
||||
**a) Simple Mail**
|
||||
|
||||
Run the mail command, and then mailx would wait for you to enter the message of the email. You can hit enter for new lines. When done typing the message, press Ctrl+D and mailx would display EOT.
|
||||
|
||||
After than mailx automatically delivers the email to the destination.
|
||||
|
||||
$ mail user@example.com
|
||||
|
||||
HI,
|
||||
Good Morning
|
||||
How are you
|
||||
EOT
|
||||
|
||||
**b) To send email with subject**
|
||||
|
||||
$ echo "Email text" | mail -s "Test Subject" user@example.com
|
||||
|
||||
-s is used for defining subject for email.
|
||||
|
||||
**c) To send message from a file**
|
||||
|
||||
$ mail -s "message send from file" user@example.com < /path/to/file
|
||||
|
||||
**d) To send message piped using the echo command**
|
||||
|
||||
$ echo "This is message body" | mail -s "This is Subject" user@example.com
|
||||
|
||||
**e) To send email with attachment**
|
||||
|
||||
$ echo “Body with attachment "| mail -a foo.tar.gz -s "attached file" user@example.com
|
||||
|
||||
-a is used for attachments
|
||||
|
||||
### 2) mutt ###
|
||||
|
||||
Mutt is a text-based email client for Unix-like systems. It was developed over 20 years ago and it's an important part of Linux history, one of the first clients to support scoring and threading capabilities. Use few of below examples to send email.
|
||||
|
||||
**a) Send email with subject & body message from a file**
|
||||
|
||||
$ mutt -s "Testing from mutt" user@example.com < /tmp/message.txt
|
||||
|
||||
**b) To send body message piped using the echo command**
|
||||
|
||||
$ echo "This is the body" | mutt -s "Testing mutt" user@example.com
|
||||
|
||||
**c) To send email with attachment**
|
||||
|
||||
$ echo "This is the body" | mutt -s "Testing mutt" user@example.com -a /tmp/foo.tar.gz
|
||||
|
||||
**d) To send email with multiple attachments**
|
||||
|
||||
$ echo "This is the body" | mutt -s "Testing" user@example.com -a foo.tar.gz –a bar.tar.gz
|
||||
|
||||
### 3) swaks ###
|
||||
|
||||
Swaks stands for Swiss Army Knife for SMTP and it is a featureful, flexible, scriptable, transaction-oriented SMTP test tool written and maintained by John Jetmore. You can use the following syntax to send an email with attachment:
|
||||
|
||||
$ swaks -t "foo@bar.com" --header "Subject: Subject" --body "Email Text" --attach foo.tar.gz
|
||||
|
||||
The important thing about Swaks is that it will also debug the full mail transaction for you, so it is a very useful tool if you also wish to debug the mail sending process:
|
||||
|
||||
As you can see it gives you full details about the sending process including what capabilities the receiving mail server supports, each step of the transaction between the 2 servers.
|
||||
|
||||
### 4) uuencode ###
|
||||
|
||||
Email transport systems were originally designed to transmit characters with a seven-bit encoding -- like ASCII. This meant they could send messages with plain text but not "binary" text, such as program files or image files that used all of an eight-bit byte. The program is used to solve this limitation is “uuencode”( "UNIX to UNIX encoding") which encode the mail from binary format to text format that is safe to transmit & program is used to decode the data is called “uudecode”
|
||||
|
||||
We can easily send binary text such as a program files or image files using uuencode with mailx or mutt email client is shown by following example:
|
||||
|
||||
$ uuencode example.jpeg example.jpeg | mail user@example.com
|
||||
|
||||
### Shell Script : Explain how to send email ###
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
FROM=""
|
||||
SUBJECT=""
|
||||
ATTACHMENTS=""
|
||||
TO=""
|
||||
BODY=""
|
||||
|
||||
# Function to check if entered file names are really files
|
||||
function check_files()
|
||||
{
|
||||
output_files=""
|
||||
for file in $1
|
||||
do
|
||||
if [ -s $file ]
|
||||
then
|
||||
output_files="${output_files}${file} "
|
||||
fi
|
||||
done
|
||||
echo $output_files
|
||||
}
|
||||
|
||||
echo "*********************"
|
||||
echo "E-mail sending script."
|
||||
echo "*********************"
|
||||
echo
|
||||
|
||||
# Getting the From address from user
|
||||
while [ 1 ]
|
||||
do
|
||||
if [ ! $FROM ]
|
||||
then
|
||||
echo -n -e "Enter the e-mail address you wish to send mail from:\n[Enter] "
|
||||
else
|
||||
echo -n -e "The address you provided is not valid:\n[Enter] "
|
||||
fi
|
||||
|
||||
read FROM
|
||||
echo $FROM | grep -E '^.+@.+$' > /dev/null
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
break
|
||||
fi
|
||||
done
|
||||
|
||||
echo
|
||||
|
||||
# Getting the To address from user
|
||||
while [ 1 ]
|
||||
do
|
||||
if [ ! $TO ]
|
||||
then
|
||||
echo -n -e "Enter the e-mail address you wish to send mail to:\n[Enter] "
|
||||
else
|
||||
echo -n -e "The address you provided is not valid:\n[Enter] "
|
||||
fi
|
||||
|
||||
read TO
|
||||
echo $TO | grep -E '^.+@.+$' > /dev/null
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
break
|
||||
fi
|
||||
done
|
||||
|
||||
echo
|
||||
|
||||
# Getting the Subject from user
|
||||
echo -n -e "Enter e-mail subject:\n[Enter] "
|
||||
read SUBJECT
|
||||
|
||||
echo
|
||||
|
||||
if [ "$SUBJECT" == "" ]
|
||||
then
|
||||
echo "Proceeding without the subject..."
|
||||
fi
|
||||
|
||||
# Getting the file names to attach
|
||||
echo -e "Provide the list of attachments. Separate names by space.
|
||||
If there are spaces in file name, quote file name with \"."
|
||||
read att
|
||||
|
||||
echo
|
||||
|
||||
# Making sure file names are poiting to real files
|
||||
attachments=$(check_files "$att")
|
||||
echo "Attachments: $attachments"
|
||||
|
||||
for attachment in $attachments
|
||||
do
|
||||
ATTACHMENTS="$ATTACHMENTS-a $attachment "
|
||||
done
|
||||
|
||||
echo
|
||||
|
||||
# Composing body of the message
|
||||
echo "Enter message. To mark the end of message type ;; in new line."
|
||||
read line
|
||||
|
||||
while [ "$line" != ";;" ]
|
||||
do
|
||||
BODY="$BODY$line\n"
|
||||
read line
|
||||
done
|
||||
|
||||
SENDMAILCMD="mutt -e \"set from=$FROM\" -s \"$SUBJECT\" \
|
||||
$ATTACHMENTS -- \"$TO\" <<< \"$BODY\""
|
||||
echo $SENDMAILCMD
|
||||
|
||||
mutt -e "set from=$FROM" -s "$SUBJECT" $ATTACHMENTS -- $TO <<< $BODY
|
||||
|
||||
**Script Output**
|
||||
|
||||
$ bash send_mail.sh
|
||||
*********************
|
||||
E-mail sending script.
|
||||
*********************
|
||||
|
||||
Enter the e-mail address you wish to send mail from:
|
||||
[Enter] test@gmail.com
|
||||
|
||||
Enter the e-mail address you wish to send mail to:
|
||||
[Enter] test@gmail.com
|
||||
|
||||
Enter e-mail subject:
|
||||
[Enter] Message subject
|
||||
|
||||
Provide the list of attachments. Separate names by space.
|
||||
If there are spaces in file name, quote file name with ".
|
||||
send_mail.sh
|
||||
|
||||
Attachments: send_mail.sh
|
||||
|
||||
Enter message. To mark the end of message type ;; in new line.
|
||||
This is a message
|
||||
text
|
||||
;;
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There are many ways of send emails from command line / shell script but here we have shared 4 tools available for unix / linux based distros. Hope you enjoyed reading our article and please provide your valuable comments and also let us know if you know about any new tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-shell-script/send-email-subject-body-attachment-linux/
|
||||
|
||||
作者:[Bobbin Zachariah][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bobbin/
|
||||
@ -1,237 +0,0 @@
|
||||
20 Awesome Docker Containers for a Desktop User
|
||||
================================================================================
|
||||
Greetings to everyone, today we'll list out some awesome Desktop Apps that we can run using Docker Containers in our very own Desktop running Docker. Docker is an Open Source project that provides an open platform to pack, ship and run any application as a lightweight container. It has no boundaries of Language support, Frameworks or packaging system and can be run anywhere, anytime from a small home computers to high-end servers. It makes them great building blocks for deploying and scaling web apps, databases, and back-end services without depending on a particular stack or provider. It is basically used by the developers, Ops and Engineers as it is easy, fast and handy tool for testing or deploying their products but we can also use Docker for our Desktop usage to run a desktop apps out of the box.
|
||||
|
||||
So here are some awesome 10 Desktop Application Docker images that we can run with Docker.
|
||||
|
||||
### 1. Lynx ###
|
||||
|
||||
Lynx is a all time favorite text-based web browser which is a lot familiar to most of the people running Linux. It is the oldest web browser currently in general use and development. To run Lynx, run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
--name lynx \
|
||||
jess/lynx
|
||||
|
||||
### 2. Irssi ###
|
||||
|
||||
Irssi is an awesome IRC Client which is based on Text Interface. To run Irssi using docker, we'll need to run the following commands in a docker installed desktop computer.
|
||||
|
||||
docker run -it --name my-irssi -e TERM -u $(id -u):$(id -g) \
|
||||
-v $HOME/.irssi:/home/user/.irssi:ro \
|
||||
-v /etc/localtime:/etc/localtime:ro \
|
||||
irssi
|
||||
|
||||
### 3. Chrome ###
|
||||
|
||||
Chrome is an awesome GUI-based web browser developed by Google and is based on Open Source Project Chromium. Google Chrome is widely used, fast and secure web browser that are very much familiar to most of the people who surf internet. We can run Chrome using docker by running the following command.
|
||||
|
||||
$ docker run -it \
|
||||
--net host \
|
||||
--cpuset 0 \
|
||||
--memory 512mb \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e DISPLAY=unix$DISPLAY \
|
||||
-v $HOME/Downloads:/root/Downloads \
|
||||
-v $HOME/.config/google-chrome/:/data \
|
||||
-v /dev/snd:/dev/snd --privileged \
|
||||
--name chrome \
|
||||
jess/chrome
|
||||
|
||||
### 4. Tor Browser ###
|
||||
|
||||
Tor Browser is a web browser which support anonymous features. It enables us freedom to surf website or services blocked by a particular organization or ISPs. It prevents somebody watching our Internet connection from learning what we do on internet and our exact location. To run Tor Browser, run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e DISPLAY=unix$DISPLAY \
|
||||
-v /dev/snd:/dev/snd --privileged \
|
||||
--name tor-browser \
|
||||
jess/tor-browser
|
||||
|
||||
### 5. Firefox Browser ###
|
||||
|
||||
Firefox Browser is a free and open source web browser which is developed by Mozilla Foundation. It is run by Gecko and SpiderMonkey engines. Firefox Browser has a lot of new features and is specially known for its performance and security.
|
||||
|
||||
$ docker run -d \
|
||||
--name firefox \
|
||||
-e DISPLAY=$DISPLAY \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
kennethkl/firefox
|
||||
|
||||
### 6. Rainbow Stream ###
|
||||
|
||||
Rainbow Stream is a terminal based Twitter Client featuring real time tweetstream, compose, search , favorite and much more fun directly from terminal. To run Rainbow Stream, run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /etc/localtime:/etc/localtime \
|
||||
-v $HOME/.rainbow_oauth:/root/.rainbow_oauth \
|
||||
-v $HOME/.rainbow_config.json:/root/.rainbow_config.json \
|
||||
--name rainbowstream \
|
||||
jess/rainbowstream
|
||||
|
||||
### 7. Gparted ###
|
||||
|
||||
Gparted is an open source software which allows us to partition disks. Now enjoy partitioning from a docker container. To run gparted, we'll need to run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e DISPLAY=unix$DISPLAY \
|
||||
--device /dev/sda:/dev/sda \ # mount the device to partition
|
||||
--name gparted \
|
||||
jess/gparted
|
||||
|
||||
### 8. GIMP Editor ###
|
||||
|
||||
GIMP stands for Gnu Image Manipulation Program which is an awesome tool on Linux for graphics, image editing platform. It is a freely distributed piece of software for such tasks as photo retouching, image composition and image authoring.
|
||||
|
||||
$ docker run -it \
|
||||
--rm -e DISPLAY=$DISPLAY \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
jarfil/gimp-git
|
||||
|
||||
### 9. Thunderbird ###
|
||||
|
||||
Thunderbird is also a free and open source email application which is developed and maintained by Mozilla Foundation. It has tons of features that an email application software should have. Thunderbird is really easy to setup and customize. To run Thunderbird in a Docker environment, run the following command.
|
||||
|
||||
$ docker run -d \
|
||||
-e DISPLAY \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix:ro \
|
||||
-u docker \
|
||||
-v $HOME/docker-data/thunderbird:/home/docker/.thunderbird/ \
|
||||
yantis/thunderbird thunderbird
|
||||
|
||||
### 10. Mutt ###
|
||||
|
||||
Mutt is a text based email client which has bunches of cool features including color support, IMAP, POP3, SMTP support, mail storing support and much more. To run Mutt out of the box using docker, we'll need to run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /etc/localtime:/etc/localtime \
|
||||
-e GMAIL -e GMAIL_NAME \
|
||||
-e GMAIL_PASS -e GMAIL_FROM \
|
||||
-v $HOME/.gnupg:/home/user/.gnupg \
|
||||
--name mutt \
|
||||
jess/mutt
|
||||
|
||||
### 11. Skype ###
|
||||
|
||||
Skype is an instant messaging, video calling software which is not open source but can be run awesome in linux. We can run Skype using Docker Containers too. To run Skype using a docker, run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix:ro \
|
||||
-v /dev/snd:/dev/snd --privileged \
|
||||
-e DISPLAY="unix$DISPLAY" \
|
||||
tianon/skype
|
||||
|
||||
### 12. Cathode ###
|
||||
|
||||
Cathode is a beautiful fully customizable terminal app with a look inspired by classic computers. We can run Cathode by running the below command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e DISPLAY=unix$DISPLAY \
|
||||
--name cathode \
|
||||
jess/1995
|
||||
|
||||
### 13. LibreOffice ###
|
||||
|
||||
LibreOffice is a powerful office suite which is free and open source and is maintained by The Document Foundation. It has clean interface and is a powerful tools that lets us unleash our creativity and grow our productivity. LibreOffice embeds several applications that make it the most powerful Free & Open Source Office suite on the market.
|
||||
|
||||
$docker run \
|
||||
-v $HOME/Documents:/home/libreoffice/Documents:rw \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e uid=$(id -u) -e gid=$(id -g) \
|
||||
-e DISPLAY=unix$DISPLAY --name libreoffice \
|
||||
chrisdaish/libreoffice
|
||||
|
||||
### 14. Spotify ###
|
||||
|
||||
Spotify gives us instant access to millions of songs from old favorites to the latest hits. To listen our favorite songs using docker, run the following command.
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e DISPLAY=unix$DISPLAY \
|
||||
-v /dev/snd:/dev/snd --privileged \
|
||||
--name spotify \
|
||||
jess/spotify
|
||||
|
||||
### 15. Audacity ###
|
||||
|
||||
Audacity is free and open source cross-platform software for recording and editing sounds. Audacity can be used for post-processing of all types of audio, including podcasts by adding effects such as normalization, trimming, and fading in and out. To run Audacity, we'll need to run the following command in a terminal or shell.
|
||||
|
||||
$ docker run --rm \
|
||||
-u $(id -u):$(id -g) \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix:ro \
|
||||
-v /dev/snd:/dev/snd \
|
||||
-v "$HOME:$HOME" \
|
||||
-w "$HOME" \
|
||||
-e DISPLAY="unix$DISPLAY" \
|
||||
-e HOME \
|
||||
$(find /dev/snd/ -type c | sed 's/^/--device /') \
|
||||
knickers/audacity
|
||||
|
||||
### 16. Eclipse ###
|
||||
|
||||
Eclipse is an integrated development environment (IDE). It contains a base workspace and an extensible plug-in system for customizing the environment. It is mostly used to develop Java Based Applications.
|
||||
|
||||
$ docker run -v ~/workspace/:/home/eclipse/workspace/ \
|
||||
-e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix:ro \
|
||||
-d leesah/eclipse
|
||||
|
||||
### 17. VLC Media Player ###
|
||||
|
||||
VLC is a free and open source cross-platform multimedia player and framework that plays most multimedia files as well as DVDs, Audio CDs, VCDs, and various streaming protocols. VLC Media Player is developed and maintained by VideoLAN Organization. To run VLC in docker environment, run the following command.
|
||||
|
||||
$ docker run -v\
|
||||
$HOME/Documents:/home/vlc/Documents:rw \
|
||||
-v /dev/snd:/dev/snd --privileged \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e uid=$(id -u) -e gid=$(id -g) \
|
||||
-e DISPLAY=unix$DISPLAY --name vlc \
|
||||
chrisdaish/vlc
|
||||
|
||||
### 18. Vim Editor ###
|
||||
|
||||
Vim is a highly configurable text-based text editor built to enable efficient text editing. It is an improved version of the vi editor distributed with most UNIX systems.
|
||||
|
||||
$ docker run -i -t --name my-vim -v ~/:/home/dev/src haron/vim
|
||||
|
||||
### 19. Inkscape ###
|
||||
|
||||
Inkscape is a free and open-source vector graphics editor. It can create, edit vector graphics such as illustrations, diagrams, line arts, charts, logos and even complex paintings. Inkscape's primary vector graphics format is Scalable Vector Graphics (SVG) version 1.1. It can import from or export to several other formats as well but all editing workflow must inevitably occur within the constraints of SVG format.
|
||||
|
||||
$docker build -t rasch/inkscape --rm .
|
||||
$ docker run --rm -e DISPLAY \
|
||||
-u inkscaper
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-v $HOME/.Xauthority:/home/inkscaper/.Xauthority \
|
||||
--net=host rasch/inkscape
|
||||
|
||||
### 20. Filezilla ###
|
||||
|
||||
Filezilla is a free FTP solution application software. It supports FTP, SFTP, FTPS protocols. It is a powerful file management tool for client side. It is an awesome open source FTP project which is highly reliable and easy to use.
|
||||
|
||||
$ xhost +si:localuser:$(whoami)
|
||||
$ docker run \
|
||||
-d \
|
||||
-e DISPLAY \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix:ro \
|
||||
-u docker \
|
||||
-v /:/host \
|
||||
-v $HOME/docker-data/filezilla:/home/docker/.config/filezilla/ \
|
||||
yantis/filezilla filezilla
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Running desktop application software using Docker is really an awesome experience. Docker is really an awesome platform for fast and easy development, shipping and deployment of software and packages in any place from home to office to production areas. Running desktop apps with docker is a cool way to try out the apps without really installing it into the host filesystem. So, if you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy with Docker :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/20-docker-containers-desktop-user/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,86 +0,0 @@
|
||||
KDE Plasma 5.3 Released, Here’s How To Upgrade in Kubuntu 15.04
|
||||
================================================================================
|
||||
**KDE [has announced][1] the stable release of Plasma 5.3, which comes charged with a slate of new power management features. **
|
||||
|
||||
Having impressed and excited [with an earlier beta release in April][2], the latest update to the new stable update to the Plasma 5 desktop environments is now considered stable and ready for download.
|
||||
|
||||
Plasma 5.3 continues to refine and finesse the new-look KDE desktop. It sees plenty of feature additions for desktop users to enjoy and **almost 400 bug fixes** packed in it should also improvements the performance and overall stability, too.
|
||||
|
||||
### What’s New in Plasma 5.3 ###
|
||||
|
||||
|
||||
Better Bluetooth Management in Plasma 5.3
|
||||
|
||||
While we touched on the majority of the **new features** [in Plasma 5.3 in an earlier article][3] many are worth reiterating.
|
||||
|
||||
**Enhanced power management** features and configuration options, including a **new battery applet, energy usage monitor** and **animated changes in screen brightness**, will help KDE last longer on portable devices.
|
||||
|
||||
Closing a laptop when an external monitor is connected no longer triggers ‘suspend’. This new behaviour is called ‘**cinema mode**‘ and comes enabled by default, but can be disabled using an option in power management settings.
|
||||
|
||||
**Bluetooth functionality is improved**, with a brand new panel applet making connecting and configuring paired bluetooth devices like smartphones, keyboards and speakers easier than ever.
|
||||
|
||||
Similarly, **trackpad configuration in KDE is easier** with Plasma 5.3 thanks to a new set-up and settings module.
|
||||
|
||||
|
||||
Trackpad, Touchpad. Tomato, Tomayto.
|
||||
|
||||
For Plasma widget fans there is a new **Press and Hold** gesture. When enabled this hides the settings handle that appears when on mouseover. Instead making it only appear when long-clicking on widget.
|
||||
|
||||
On the topic of widget-y things, several **old Plasmoid favourites are reintroduced** with this release, including a useful system monitor, handy hard-drive stats and a comic reader.
|
||||
|
||||
### Learning More & Trying It Out ###
|
||||
|
||||

|
||||
|
||||
A full list of everything — and I mean everything — that is new and improved in Plasma 5.3 is listed [in the official change log][4].
|
||||
|
||||
Live images that let you try Plasma 5.3 on a Kubuntu base **without affecting your own system** are available from the KDE community:
|
||||
|
||||
- [Download KDE Plasma Live Images][5]
|
||||
|
||||
If you need super stable system you can use these live images to try the features but stick with the version of KDE that comes with your distribution on your main computer.
|
||||
|
||||
However, if you’re happy to experiment — read: can handle any package conflicts or system issues resulting from attempting to upgrade your desktop environment — you can.
|
||||
|
||||
### Install Plasma 5.3 in Kubuntu 15.04 ###
|
||||
|
||||

|
||||
|
||||
To **install Plasma 5.3 in Kubuntu 15.04** you need to add the KDE Backports PPA, run the Software Updater tool and install any available updates.
|
||||
|
||||
The Kubuntu backports PPA may/will also upgrade other parts of the KDE Platform other than Plasma that are installed on your system including KDE applications, frameworks and Kubuntu specific configuration files.
|
||||
|
||||
Using the command line is by far the fastest way to upgrade to Plasma 5.3 in Kubuntu:
|
||||
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
|
||||
sudo apt-get update && sudo apt-get dist-upgrade
|
||||
|
||||
After the upgrade process has completed, and assuming everything went well, you should reboot your computer.
|
||||
|
||||
If you’re using an alternative desktop environment, like LXDE, Unity or GNOME, you will need to install the Kubuntu desktop package (you’ll find it in the Ubuntu Software Centre) after running both of the commands above.
|
||||
|
||||
To downgrade to the stock version of Plasma in 15.04 you can use the PPA-Purge tool:
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
sudo ppa-purge ppa:kubuntu-ppa/backports
|
||||
|
||||
Let us know how your upgrade/testing goes in the comments below and don’t forget to mention the features you hope to see added to the Plasma 5 desktop next.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/kde-plasma-5-3-released-heres-how-to-upgrade-in-kubuntu-15-04
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://www.kde.org/announcements/plasma-5.3.0.php
|
||||
[2]:http://www.omgubuntu.co.uk/2015/04/beta-plasma-5-3-features
|
||||
[3]:http://www.omgubuntu.co.uk/2015/04/beta-plasma-5-3-features
|
||||
[4]:https://www.kde.org/announcements/plasma-5.2.2-5.3.0-changelog.php
|
||||
[5]:https://community.kde.org/Plasma/Live_Images
|
||||
@ -1,183 +0,0 @@
|
||||
Useful Commands to Create Commandline Chat Server and Remove Unwanted Packages in Linux
|
||||
================================================================================
|
||||
Here we are with the next part of Linux Command Line Tips and Tricks. If you missed our previous post on Linux Tricks you may find it here.
|
||||
|
||||
- [5 Linux Command Line Tricks][1]
|
||||
|
||||
In this post we will be introducing 6 command Line tips namely create Linux Command line chat using Netcat command, perform addition of a column on the fly from the output of a command, remove orphan packages from Debian and CentOS, get local and remote IP from command Line, get colored output in terminal and decode various color code and last but not the least hash tags implementation in Linux command Line. Lets check them one by one.
|
||||
|
||||

|
||||
6 Useful Commandline Tricks and Tips
|
||||
|
||||
### 1. Create Linux Commandline Chat Server ###
|
||||
|
||||
We all have been using chat service since a long time. We are familiar with Google chat, Hangout, Facebook chat, Whatsapp, Hike and several other application and integrated chat services. Do you know Linux nc command can make your Linux box a chat server with just one line of command.
|
||||
What is nc command in Linux and what it does?
|
||||
|
||||
nc is the depreciation of Linux netcat command. The nc utility is often referred as Swiss army knife based upon the number of its built-in capabilities. It is used as debugging tool, investigation tool, reading and writing to network connection using TCP/UDP, DNS forward/reverse checking.
|
||||
|
||||
It is prominently used for port scanning, file transferring, backdoor and port listening. nc has the ability to use any local unused port and any local network source address.
|
||||
|
||||
Use nc command (On Server with IP address: 192.168.0.7) to create a command line messaging server instantly.
|
||||
|
||||
$ nc -l -vv -p 11119
|
||||
|
||||
Explanation of the above command switches.
|
||||
|
||||
- -v : means Verbose
|
||||
- -vv : more verbose
|
||||
- -p : The local port Number
|
||||
|
||||
You may replace 11119 with any other local port number.
|
||||
|
||||
Next on the client machine (IP address: 192.168.0.15) run the following command to initialize chat session to machine (where messaging server is running).
|
||||
|
||||
$ nc 192.168.0.7 11119
|
||||
|
||||

|
||||
|
||||
**Note**: You can terminate chat session by hitting ctrl+c key and also nc chat is one-to-one service.
|
||||
|
||||
### 2. How to Sum Values in a Column in Linux ###
|
||||
|
||||
How to sum the numerical values of a column, generated as an output of a command, on the fly in the terminal.
|
||||
|
||||
The output of the ‘ls -l‘ command.
|
||||
|
||||
$ ls -l
|
||||
|
||||

|
||||
|
||||
Notice that the second column is numerical which represents number of symbolic links and the 5th column is numerical which represents the size of he file. Say we need to sum the values of fifth column on the fly.
|
||||
|
||||
List the content of 5th column without printing anything else. We will be using ‘awk‘ command to do this. ‘$5‘ represents 5th column.
|
||||
|
||||
$ ls -l | awk '{print $5}'
|
||||
|
||||

|
||||
|
||||
Now use awk to print the sum of the output of 5th column by pipelining it.
|
||||
|
||||
$ ls -l | awk '{print $5}' | awk '{total = total + $1}END{print total}'
|
||||
|
||||

|
||||
|
||||
### How to Remove Orphan Packages in Linux? ###
|
||||
|
||||
Orphan packages are those packages that are installed as a dependency of another package and no longer required when the original package is removed.
|
||||
|
||||
Say we installed a package gtprogram which was dependent of gtdependency. We can’t install gtprogram unless gtdependency is installed.
|
||||
|
||||
When we remove gtprogram it won’t remove gtdependency by default. And if we don’t remove gtdependency, it will remain as Orpahn Package with no connection to any other package.
|
||||
|
||||
# yum autoremove [On RedHat Systems]
|
||||
|
||||

|
||||
|
||||
# apt-get autoremove [On Debian Systems]
|
||||
|
||||

|
||||
|
||||
You should always remove Orphan Packages to keep the Linux box loaded with just necessary stuff and nothing else.
|
||||
|
||||
### 4. How to Get Local and Public IP Address of Linux Server ###
|
||||
|
||||
To get you local IP address run the below one liner script.
|
||||
|
||||
$ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||
You must have installed ifconfig, if not, apt or yum the required packages. Here we will be pipelining the output of ifconfig with grep command to find the string “intel addr:”.
|
||||
|
||||
We know ifconfig command is sufficient to output local IP Address. But ifconfig generate lots of other outputs and our concern here is to generate only local IP address and nothing else.
|
||||
|
||||
# ifconfig | grep "inet addr:"
|
||||
|
||||

|
||||
|
||||
Although the output is more custom now, but we need to filter our local IP address only and nothing else. For this we will use awk to print the second column only by pipelining it with the above script.
|
||||
|
||||
# ifconfig | grep “inet addr:” | awk '{print $2}'
|
||||
|
||||

|
||||
|
||||
Clear from the above image that we have customised the output very much but still not what we want. The loopback address 127.0.0.1 is still there in the result.
|
||||
|
||||
We use use -v flag with grep that will print only those lines that don’t match the one provided in argument. Every machine have the same loopback address 127.0.0.1, so use grep -v to print those lines that don’t have this string, by pipelining it with above output.
|
||||
|
||||
# ifconfig | grep "inet addr" | awk '{print $2}' | grep -v '127.0.0.1'
|
||||
|
||||

|
||||
|
||||
We have almost generated desired output, just replace the string `(addr:)` from the beginning. We will use cut command to print only column two. The column 1 and column 2 are not separated by tab but by `(:)`, so we need to use delimiter `(-d)` by pipelining the above output.
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||

|
||||
|
||||
Finally! The desired result has been generated.
|
||||
|
||||
### 5. How to Color Linux Terminal ###
|
||||
|
||||
You might have seen colored output in terminal. Also you would be knowing to enable/disable colored output in terminal. If not you may follow the below steps.
|
||||
|
||||
In Linux every user has `'.bashrc'` file, this file is used to handle your terminal output. Open and edit this file with your choice of editor. Note that, this file is hidden (dot beginning of file means hidden).
|
||||
|
||||
$ vi /home/$USER/.bashrc
|
||||
|
||||
Make sure that the following lines below are uncommented. ie., it don’t start with a #.
|
||||
|
||||
if [ -x /usr/bin/dircolors ]; then
|
||||
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dirc$
|
||||
alias ls='ls --color=auto'
|
||||
#alias dir='dir --color=auto'
|
||||
#alias vdir='vdir --color=auto'
|
||||
|
||||
alias grep='grep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias egrep='egrep --color=auto'
|
||||
fi
|
||||
|
||||

|
||||
|
||||
Once done! Save and exit. To make the changes taken into effect logout and again login.
|
||||
|
||||
Now you will see files and folders are listed in various colors based upon type of file. To decode the color code run the below command.
|
||||
|
||||
$ dircolors -p
|
||||
|
||||
Since the output is too long, lets pipeline the output with less command so that we get output one screen at a time.
|
||||
|
||||
$ dircolors -p | less
|
||||
|
||||

|
||||
|
||||
### 6. How to Hash Tag Linux Commands and Scripts ###
|
||||
|
||||
We are using hash tags on Twitter, Facebook and Google Plus (may be some other places, I have not noticed). These hash tags make it easier for others to search for a hash tag. Very few know that we can use hash tag in Linux command Line.
|
||||
|
||||
We already know that `#` in configuration files and most of the programming languages is treated as comment line and is excluded from execution.
|
||||
|
||||
Run a command and then create a hash tag of the command so that we can find it later. Say we have a long script that was executed in point 4 above. Now create a hash tag for this. We know ifconfig can be run by sudo or root user hence acting as root.
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d: #myip
|
||||
|
||||
The script above has been hash tagged with ‘myip‘. Now search for the hash tag in reverse-i-serach (press ctrl+r), in the terminal and type ‘myip‘. You may execute it from there, as well.
|
||||
|
||||

|
||||
|
||||
You may create as many hash tags for every command and find it later using reverse-i-search.
|
||||
|
||||
That’s all for now. We have been working hard to produce interesting and knowledgeable contents for you. What do you think how we are doing? Any suggestion is welcome. You may comment in the box below. Keep connected! Kudos.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-commandline-chat-server-and-remove-unwanted-packages/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
@ -1,459 +0,0 @@
|
||||
First Step Guide for Learning Shell Scripting
|
||||
================================================================================
|
||||

|
||||
|
||||
Usually when people say "shell scripting" they have on mind bash, ksh, sh, ash or similar linux/unix scripting language. Scripting is another way to communicate with computer. Using graphic windows interface (not matter windows or linux) user can move mouse and clicking on the various objects like, buttons, lists, check boxes and so on. But it is very inconvenient way witch requires user participation and accuracy each time he would like to ask computer / server to do the same tasks (lets say to convert photos or download new movies, mp3 etc). To make all these things easy accessible and automated we could use shell scripts.
|
||||
|
||||
Some programming languages like pascal, foxpro, C, java needs to be compiled before they could be executed. They needs appropriate compiler to make our code to do some job.
|
||||
|
||||
Another programming languages like php, javascript, visualbasic do not needs compiler. So they need interpretersand we could run our program without compiling the code.
|
||||
|
||||
The shell scripts is also like interpreters, but it is usually used to call external compiled programs. Then captures the outputs, exit codes and act accordingly.
|
||||
|
||||
One of the most popular shell scripting language in the linux world is the bash. And i think (this is my own opinion) this is because bash shell allows user easily navigate through the history commands (previously executed) by default, in opposite ksh which requires some tuning in .profile or remember some "magic" key combination to walk through history and amend commands.
|
||||
|
||||
Ok, i think this is enough for introduction and i leaving for your judge which environment is most comfortable for you. Since now i will speak only about bash and scripting. In the following examples i will use the CentOS 6.6 and bash-4.1.2. Just make sure you have the same or greater version.
|
||||
|
||||
### Shell Script Streams ###
|
||||
|
||||
The shell scripting it is something similar to conversation of several persons. Just imagine that all command like the persons who able to do something if you properly ask them. Lets say you would like to write the document. First of all you need the paper, then you need to say the content to someone to write it, and finally you would like to store it somewhere. Or you would like build a house, so you will ask appropriate persons to cleanup the space. After they say "its done" then other engineers could build for you the walls. And finally, when engineers also tell "Its done" you can ask the painters to color your house. And what would happen if you ask the painters coloring your walls before they are built? I think they will start to complain. Almost all commands like the persons could speak and if they did its job without any issues they speaks to "standard output". If they can't to what you asking - they speaking to the "standard error". So finally all commands listening for you through "standard input".
|
||||
|
||||
Quick example- when you opening linux terminal and writing some text - you speaking to bash through "standard input". So ask the bash shell **who am i**
|
||||
|
||||
root@localhost ~]# who am i <--- you speaking through the standard input to bash shell
|
||||
root pts/0 2015-04-22 20:17 (192.168.1.123) <--- bash shell answering to you through the standard output
|
||||
|
||||
Now lets ask something that bash will not understand us:
|
||||
|
||||
[root@localhost ~]# blablabla <--- and again, you speaking through standard input
|
||||
-bash: blablabla: command not found <--- bash complaining through standard error
|
||||
|
||||
The first word before ":" usually is the command which complaining to you. Actually each of these streams has their own index number:
|
||||
|
||||
- standard input (**stdin**) - 0
|
||||
- standard output (**stdout**) - 1
|
||||
- standard error (**stderr**) - 2
|
||||
|
||||
If you really would like to know to witch output command said something - you need to redirect (to use "greater than ">" symbol after command and stream index) that speech to file:
|
||||
|
||||
[root@localhost ~]# blablabla 1> output.txt
|
||||
-bash: blablabla: command not found
|
||||
|
||||
In this example we tried to redirect 1 (**stdout**) stream to file named output.txt. Lets look does to the content of that file. We use the command cat for that:
|
||||
|
||||
[root@localhost ~]# cat output.txt
|
||||
[root@localhost ~]#
|
||||
|
||||
Seams that is empty. Ok now lets try to redirect 2 (**stderr**) streem:
|
||||
|
||||
[root@localhost ~]# blablabla 2> error.txt
|
||||
[root@localhost ~]#
|
||||
|
||||
Ok, we see that complains gone. Lets chec the file:
|
||||
|
||||
[root@localhost ~]# cat error.txt
|
||||
-bash: blablabla: command not found
|
||||
[root@localhost ~]#
|
||||
|
||||
Exactly! We see that all complains was recorded to the errors.txt file.
|
||||
|
||||
Sometimes commands produces **stdout** and **stderr** simultaniously. To redirect them to separate files we can use the following syntax:
|
||||
|
||||
command 1>out.txt 2>err.txt
|
||||
|
||||
To shorten this syntax a bit we can skip the "1" as by default the **stdout** stream will be redirected:
|
||||
|
||||
command >out.txt 2>err.txt
|
||||
|
||||
Ok, lets try to do something "bad". lets remove the file1 and folder1 with the rm command:
|
||||
|
||||
[root@localhost ~]# rm -vf folder1 file1 > out.txt 2>err.txt
|
||||
|
||||
Now check our output files:
|
||||
|
||||
[root@localhost ~]# cat out.txt
|
||||
removed `file1'
|
||||
[root@localhost ~]# cat err.txt
|
||||
rm: cannot remove `folder1': Is a directory
|
||||
[root@localhost ~]#
|
||||
|
||||
As we see the streams was separated to different files. Sometimes it is not handy as usually we want to see the sequence when the errors appeared - before or after some actions. For that we can redirect both streams to the same file:
|
||||
|
||||
command >>out_err.txt 2>>out_err.txt
|
||||
|
||||
Note : Please notice that i use ">>" instead of ">". It allows us to append file instead of overwrite.
|
||||
|
||||
We can redirect one stream to another:
|
||||
|
||||
command >out_err.txt 2>&1
|
||||
|
||||
Let me explain. All stdout of the command will be redirected to the out_err.txt. The errout will be redirected to the 1-st stream which (as i already explained above) will be redirected to the same file. Let see the example:
|
||||
|
||||
[root@localhost ~]# rm -fv folder2 file2 >out_err.txt 2>&1
|
||||
[root@localhost ~]# cat out_err.txt
|
||||
rm: cannot remove `folder2': Is a directory
|
||||
removed `file2'
|
||||
[root@localhost ~]#
|
||||
|
||||
Looking at the combined output we can state that first of all **rm** command tried to remove the folder2 and it was not success as linux require the **-r** key for **rm** command to allow remove folders. At the second the file2 was removed. By providing the **-v** (verbose) key for the **rm** command we asking rm command to inform as about each removed file or folder.
|
||||
|
||||
This is almost all you need to know about redirection. I say almost, because there is one more very important redirection which called "piping". By using | (pipe) symbol we usually redirecting **stdout** streem.
|
||||
|
||||
Lets say we have the text file:
|
||||
|
||||
[root@localhost ~]# cat text_file.txt
|
||||
This line does not contain H e l l o word
|
||||
This lilne contains Hello
|
||||
This also containd Hello
|
||||
This one no due to HELLO all capital
|
||||
Hello bash world!
|
||||
|
||||
and we need to find the lines in it with the words "Hello". Linux has the **grep** command for that:
|
||||
|
||||
[root@localhost ~]# grep Hello text_file.txt
|
||||
This lilne contains Hello
|
||||
This also containd Hello
|
||||
Hello bash world!
|
||||
[root@localhost ~]#
|
||||
|
||||
This is ok when we have file and would like to sech in it. But what to do if we need to find something in the output of another command? Yes, of course we can redirect the output to the file and then look in it:
|
||||
|
||||
[root@localhost ~]# fdisk -l>fdisk.out
|
||||
[root@localhost ~]# grep "Disk /dev" fdisk.out
|
||||
Disk /dev/sda: 8589 MB, 8589934592 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_root: 7205 MB, 7205814272 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_swap: 855 MB, 855638016 bytes
|
||||
[root@localhost ~]#
|
||||
|
||||
If you going to grep something with white spaces embrace that with " quotes!
|
||||
|
||||
Note : fdisk command shows information about Linux OS disk drives
|
||||
|
||||
As we see this way is not very handy as soon we will mess the space with temporary files. For that we can use the pipes. They allow us redirect one command **stdout** to another command **stdin** streams:
|
||||
|
||||
[root@localhost ~]# fdisk -l | grep "Disk /dev"
|
||||
Disk /dev/sda: 8589 MB, 8589934592 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_root: 7205 MB, 7205814272 bytes
|
||||
Disk /dev/mapper/VolGroup-lv_swap: 855 MB, 855638016 bytes
|
||||
[root@localhost ~]#
|
||||
|
||||
As we see, we get the same result without any temporary files. We have redirected **frisk stdout** to the **grep stdin**.
|
||||
|
||||
**Note** : Pipe redirection is always from left to right.
|
||||
|
||||
There are several other redirections but we will speak about them later.
|
||||
|
||||
### Displaying custom messages in the shell ###
|
||||
|
||||
As we already know usually communication with and within shell is going as dialog. So lets create some real script which also will speak with us. It will allow you to learn some simple commands and better understand the scripting concept.
|
||||
|
||||
Imagine we are working in some company as help desk manager and we would like to create some shell script to register the call information: phone number, User name and brief description about issue. We going to store it in the plain text file data.txt for future statistics. Script it self should work in dialog way to make live easy for help desk workers. So first of all we need to display the questions. For displaying any messages there is echo and printf commands. Both of them displaying messages, but printf is more powerful as we can nicely form output to align it to the right, left or leave dedicated space for message. Lets start from simple one. For file creation please use your favorite text editor (kate, nano, vi, ...) and create the file named note.sh with the command inside:
|
||||
|
||||
echo "Phone number ?"
|
||||
|
||||
### Script execution ###
|
||||
|
||||
After you have saved the file we can run it with bash command by providing our file as an argument:
|
||||
|
||||
[root@localhost ~]# bash note.sh
|
||||
Phone number ?
|
||||
|
||||
Actually to use this way for script execution is not handy. It would be more comfortable just execute the script without any **bash** command as a prefix. To make it executable we can use **chmod** command:
|
||||
|
||||
[root@localhost ~]# ls -la note.sh
|
||||
-rw-r--r--. 1 root root 22 Apr 23 20:52 note.sh
|
||||
[root@localhost ~]# chmod +x note.sh
|
||||
[root@localhost ~]# ls -la note.sh
|
||||
-rwxr-xr-x. 1 root root 22 Apr 23 20:52 note.sh
|
||||
[root@localhost ~]#
|
||||
|
||||

|
||||
|
||||
**Note** : ls command displays the files in the current folder. By adding the keys -la it will display a bit more information about files.
|
||||
|
||||
As we see, before **chmod** command execution, script has only read (r) and write (w) permissions. After **chmod +x** it got execute (x) permissions. (More details about permissions i am going to describe in next article.) Now we can simply run it:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
|
||||
Before script name i have added ./ combination. . (dot) in the unix world means current position (current folder), the / (slash) is the folder separator. (In Windows OS we use \ (backslash) for the same). So whole this combination means: "from the current folder execute the note.sh script". I think it will be more clear for you if i run this script with full path:
|
||||
|
||||
[root@localhost ~]# /root/note.sh
|
||||
Phone number ?
|
||||
[root@localhost ~]#
|
||||
|
||||
It also works.
|
||||
|
||||
Everything would be ok if all linux users would have the same default shell. If we simply execute this script default user shell will be used to parse script content and run the commands. Different shells have a bit different syntax, internal commands, etc. So to guarantee the **bash** will be used for our script we should add **#!/bin/bash** as the first line. In this way default user shell will call **/bin/bash** and only then will execute following shell commands in the script:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
|
||||
Only now we will be 100% sure that **bash** will be used to parse our script content. Lets move on.
|
||||
|
||||
### Reading the inputs ###
|
||||
|
||||
After we have displayed the message script should wait for answer from user. There is the command **read**:
|
||||
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
read phone
|
||||
|
||||
After execution script will wait for the user input until he press the [ENTER] key:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
12345 <--- here is my input
|
||||
[root@localhost ~]#
|
||||
|
||||
Everything you have input will be stored to the variable **phone**. To display the value of variable we can use the same **echo** command:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
read phone
|
||||
echo "You have entered $phone as a phone number"
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
123456
|
||||
You have entered 123456 as a phone number
|
||||
[root@localhost ~]#
|
||||
|
||||
In **bash** shell we using **$** (dollar) sign as variable indication, except when reading into variable and few other moments (will describe later).
|
||||
|
||||
Ok, now we are ready to add the rest questions:
|
||||
|
||||
#!/bin/bash
|
||||
echo "Phone number?"
|
||||
read phone
|
||||
echo "Name?"
|
||||
read name
|
||||
echo "Issue?"
|
||||
read issue
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
123
|
||||
Name?
|
||||
Jim
|
||||
Issue?
|
||||
script is not working.
|
||||
[root@localhost ~]#
|
||||
|
||||
### Using stream redirection ###
|
||||
|
||||
Perfect! There is left to redirect everything to the file data.txt. As a field separator we going to use / (slash) symbol.
|
||||
|
||||
**Note** : You can chose any which you think is the best, bat be sure that content will not have thes symbols inside. It will cause extra fields in the line.
|
||||
|
||||
Do not forget to use ">>" instead of ">" as we would like to append the output to the end of file!
|
||||
|
||||
[root@localhost ~]# tail -2 note.sh
|
||||
read issue
|
||||
echo "$phone/$name/$issue">>data.txt
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
987
|
||||
Name?
|
||||
Jimmy
|
||||
Issue?
|
||||
Keybord issue.
|
||||
[root@localhost ~]# cat data.txt
|
||||
987/Jimmy/Keybord issue.
|
||||
[root@localhost ~]#
|
||||
|
||||
**Note** : The command **tail** displays the last **-n** lines of the file.
|
||||
|
||||
Bingo. Lets run once again:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
556
|
||||
Name?
|
||||
Janine
|
||||
Issue?
|
||||
Mouse was broken.
|
||||
[root@localhost ~]# cat data.txt
|
||||
987/Jimmy/Keybord issue.
|
||||
556/Janine/Mouse was broken.
|
||||
[root@localhost ~]#
|
||||
|
||||
Our file is growing. Lets add the date in the front of each line. This will be useful later when playing with data while calculating statistic. For that we can use command date and give it some format as i do not like default one:
|
||||
|
||||
[root@localhost ~]# date
|
||||
Thu Apr 23 21:33:14 EEST 2015 <---- default output of dta command
|
||||
[root@localhost ~]# date "+%Y.%m.%d %H:%M:%S"
|
||||
2015.04.23 21:33:18 <---- formated output
|
||||
|
||||
There are several ways to read the command output to the variable. In this simple situation we will use ` (back quotes):
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
echo "Phone number?"
|
||||
read phone
|
||||
echo "Name?"
|
||||
read name
|
||||
echo "Issue?"
|
||||
read issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number?
|
||||
123
|
||||
Name?
|
||||
Jim
|
||||
Issue?
|
||||
Script hanging.
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
[root@localhost ~]#
|
||||
|
||||
Hmmm... Our script looks a bit ugly. Lets prettify it a bit. If you would read manual about **read** command you would find that read command also could display some messages. For this we should use -p key and message:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
read -p "Phone number: " phone
|
||||
read -p "Name: " name
|
||||
read -p "Issue: " issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
|
||||
You can fine a lots of interesting about each command directly from the console. Just type: **man read, man echo, man date, man ....**
|
||||
|
||||
Agree it looks much better!
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 321
|
||||
Name: Susane
|
||||
Issue: Mouse was stolen
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
[root@localhost ~]#
|
||||
|
||||
And the cursor is right after the message (not in new line) what makes a bit sense.
|
||||
Loop
|
||||
|
||||
Time to improve our script. If user works all day with the calls it is not very handy to run it each time. Lets add all these actions in the never-ending loop:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
while true
|
||||
do
|
||||
read -p "Phone number: " phone
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
read -p "Name: " name
|
||||
read -p "Issue: " issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
done
|
||||
|
||||
I have swapped **read phone** and **now=`date** lines. This is because i would like to get the time right after the phone number will be entered. If i would left it as the first line in the loop **- the** now variable will get the time right after the data was stored in the file. And it is not good as the next call could be after 20 mins or so.
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 123
|
||||
Name: Jim
|
||||
Issue: Script still not works.
|
||||
Phone number: 777
|
||||
Name: Daniel
|
||||
Issue: I broke my monitor
|
||||
Phone number: ^C
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
2015.04.23 21:47:55/123/Jim/Script still not works.
|
||||
2015.04.23 21:48:16/777/Daniel/I broke my monitor
|
||||
[root@localhost ~]#
|
||||
|
||||
NOTE: To exit from the never-ending loop you can by pressing [Ctrl]+[C] keys. Shell will display ^ as the Ctrl key.
|
||||
|
||||
### Using pipe redirection ###
|
||||
|
||||
Lets add more functionality to our "Frankenstein" I would like the script will display some statistic after each call. Lets say we want to see the how many times each number called us. For that we should cat the data.txt file:
|
||||
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
2015.04.23 21:47:55/123/Jim/Script still not works.
|
||||
2015.04.23 21:48:16/777/Daniel/I broke my monitor
|
||||
2015.04.23 22:02:14/123/Jimmy/New script also not working!!!
|
||||
[root@localhost ~]#
|
||||
|
||||
Now all this output we can redirect to the **cut** command to **cut** each line into the chunks (our delimiter "/") and print the second field:
|
||||
|
||||
[root@localhost ~]# cat data.txt | cut -d"/" -f2
|
||||
123
|
||||
321
|
||||
123
|
||||
777
|
||||
123
|
||||
[root@localhost ~]#
|
||||
|
||||
Now this output we can redirect to another command to **sort**:
|
||||
|
||||
[root@localhost ~]# cat data.txt | cut -d"/" -f2|sort
|
||||
123
|
||||
123
|
||||
123
|
||||
321
|
||||
777
|
||||
[root@localhost ~]#
|
||||
|
||||
and leave only unique lines. To count unique entries just add **-c** key for **uniq** command:
|
||||
|
||||
[root@localhost ~]# cat data.txt | cut -d"/" -f2 | sort | uniq -c
|
||||
3 123
|
||||
1 321
|
||||
1 777
|
||||
[root@localhost ~]#
|
||||
|
||||
Just add this to end of our loop:
|
||||
|
||||
#!/bin/bash
|
||||
while true
|
||||
do
|
||||
read -p "Phone number: " phone
|
||||
now=`date "+%Y.%m.%d %H:%M:%S"`
|
||||
read -p "Name: " name
|
||||
read -p "Issue: " issue
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
echo "===== We got calls from ====="
|
||||
cat data.txt | cut -d"/" -f2 | sort | uniq -c
|
||||
echo "--------------------------------"
|
||||
done
|
||||
|
||||
Run it:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 454
|
||||
Name: Malini
|
||||
Issue: Windows license expired.
|
||||
===== We got calls from =====
|
||||
3 123
|
||||
1 321
|
||||
1 454
|
||||
1 777
|
||||
--------------------------------
|
||||
Phone number: ^C
|
||||
|
||||

|
||||
|
||||
Current scenario is going through well-known steps like:
|
||||
|
||||
- Display message
|
||||
- Get user input
|
||||
- Store values to the file
|
||||
- Do something with stored data
|
||||
|
||||
But what if user has several responsibilities and he needs sometimes to input data, sometimes to do statistic calculations, or might be to find something in stored data? For that we need to implement switches / cases. In next article i will show you how to use them and how to nicely form the output. It is useful while "drawing" the tables in the shell.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-shell-script/guide-start-learning-shell-scripting-scratch/
|
||||
|
||||
作者:[Petras Liumparas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/petrasl/
|
||||
@ -1,134 +0,0 @@
|
||||
Install uGet Download Manager 2.0 in Debian, Ubuntu, Linux Mint and Fedora
|
||||
================================================================================
|
||||
After a long development period, which includes more than 11 developement releases, finally uGet project team pleased to announce the immediate availability of the latest stable version of uGet 2.0. The latest version includes numerous attractive features, such as a new setting dialog, improved BitTorrent and Metalink support added in the aria2 plugin, as well as better support for uGet RSS messages in the banner, other features include:
|
||||
|
||||
- A new “Check for Updates” button informs you about new released versions.
|
||||
- Added new languages & updated existing languages.
|
||||
- Added a new “Message Banner” that allows developers to easily provide uGet related information to all users.
|
||||
- Enhanced the Help Menu by including links to the Documentation, to submit Feedback & Bug Reports and more.
|
||||
- Integrated uGet download manager into the two major browsers on the Linux platform, Firefox and Google Chrome.
|
||||
- Improved support for Firefox Addon ‘FlashGot’.
|
||||
|
||||
### What is uGet ###
|
||||
|
||||
uGet (formerly known ad UrlGfe) is an open source, free and very powerful multi-platform GTK based download manager application was written in C language, that released and licensed under GPL. It offers large collection of features such as resuming downloads, multiple download support, categories support with an independent configuration, clipboard monitoring, download scheduler, import URLs from HTML files, integrated Flashgot plugin with Firefox and download torrent and metalink files using aria2 (a command-line download manager) that integrated with uGet.
|
||||
|
||||
I have listed down all the key features of uGet Download Manager in detailed explanation.
|
||||
|
||||
#### Key Features of uGet Download Manager ####
|
||||
|
||||
- Downloads Queue: Place all your downloads into a Queue. As downloads finishes, the remaining queue files will automatically start downloading.
|
||||
- Resume Downloads: If in case, your network connection disconnected, don’t worry you can start or resume download where it was left.
|
||||
- Download Categories: Support for unlimited categories to manage downloads.
|
||||
- Clipboard Monitor: Add the types of files to clipboard that automatically prompt you to download copied files.
|
||||
- Batch Downloads: Allows you to easily add unlimited number of files at once for downloading.
|
||||
- Multi-Protocol: Allows you to easily download files through HTTP, HTTPS, FTP, BitTorrent and Metalink using arial2 command-line plugin.
|
||||
- Multi-Connection: Support for up to 20 simultaneous connections per download using aria2 plugin.
|
||||
- FTP Login & Anonymous FTP: Added support for FTP login using username and password, as well as anonymous FTP.
|
||||
- Scheduler: Added support for scheduled downloads, now you can schedule all your downloads.
|
||||
- FireFox Integration via FlashGot: Integrated FlashGot as an independent supported Firefox extension that handles single or massive selection of files for downloading.
|
||||
- CLI / Terminal Support: Offers command line or terminal option to download files.
|
||||
- Folder Auto-Creation: If you have provided the save path for the download, but the save path doesn’t exist, uget will automatically create them.
|
||||
- Download History Management: Keeps a track of finished download and recycled entries, per list 9,999 files. Entries which are older than the custom limit will be deleted automatically.
|
||||
- Multi-Language Support: By default uGet uses English, but it support more than 23 languages.
|
||||
- Aria2 Plugin: uGet integrated with Aria2 plugin to give more user friendly GUI.
|
||||
|
||||
If you want to know a complete list of available features, see the official uGet [features page][1].
|
||||
|
||||
### Install uGet in Debian, Ubuntu, Linux Mint and Fedora ###
|
||||
|
||||
The uGet developers added latest version in various repos throughout the Linux platform, so you can able to install or upgrade uGet using supported repository under your Linux distribution.
|
||||
|
||||
Currently, a few Linux distributions are not up-to-date, but you can get the status of your distribution by going to the [uGet Download page][2] and selecting your preferred distro from there for more details.
|
||||
|
||||
#### On Debian ####
|
||||
|
||||
In Debian Testing (Jessie) and Debian Unstable (Sid), you can easily install and update using the official repository on a fairly reliable basis.
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install uget
|
||||
|
||||
#### On Ubuntu & Linux Mint ####
|
||||
|
||||
In Ubuntu and Linux Mint, you can install and update uGet using official PPA repository ‘ppa:plushuang-tw/uget-stable‘. By using this PPA, you automatically be kept up-to-date with the latest versions.
|
||||
|
||||
$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install uget
|
||||
|
||||
#### On Fedora ####
|
||||
|
||||
In Fedora 20 – 21, latest version of uGet (2.0) available from the official repositories, installing from these repo is fairly reliable.
|
||||
|
||||
$ sudo yum install uget
|
||||
|
||||
**Note**: On older versions of Debian, Ubuntu, Linux Mint and Fedora, users can also install uGet. but the available version is 1.10.4. If you are looking for updated version (i.e. 2.0) you need to upgrade your system and add uGet PPA to get latest stable version.
|
||||
|
||||
### Installing aria2 plugin ###
|
||||
|
||||
[aria2][3] is a excellent command-line download utility, that is used by uGet as a aria2 plugin to add even more great functionality such as downloading torrent files, metalinks, multi-protocol & multi-source download.
|
||||
|
||||
By default uGet uses CURL as backend in most of the today’s Linux systems, but the aria2 Plugin replaces CURL with aria2 as the backend.
|
||||
|
||||
aria2 is a separate package that needs to be installed separately. You can easily install latest version of aria2 using supported repository under your Linux distribution or you can also use [downloads-aria2][4] that explains how to install aria2 on each distro.
|
||||
|
||||
#### On Debian, Ubuntu and Linux Mint ####
|
||||
|
||||
Use the official aria2 PPA repository to install latest version of aria2 using the following commands.
|
||||
|
||||
$ sudo add-apt-repository ppa:t-tujikawa/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install aria2
|
||||
|
||||
#### On Fedora ####
|
||||
|
||||
Fedora’s official repositories already added aria2 package, so you can easily install it using the following yum command.
|
||||
|
||||
$ sudo yum install aria2
|
||||
|
||||
#### Starting uGet ####
|
||||
|
||||
To start uGet application, from the desktop “Menu” on search bar type “uget“. Refer below screenshot.
|
||||
|
||||

|
||||
Start uGet Download Manager
|
||||
|
||||

|
||||
uGet Version: 2.0
|
||||
|
||||
#### Activate aria2 Plugin in uGet ####
|
||||
|
||||
To active the aria2 plugin, from the uGet menu go to Edit –> Settings –> Plug-in tab, from the drop-down select “arial2“.
|
||||
|
||||

|
||||
Enable Aria2 Plugin for uGet
|
||||
|
||||
### uGet 2.0 Screenshot Tour ###
|
||||
|
||||

|
||||
Download Files Using Aria2
|
||||
|
||||

|
||||
Download Torrent File Using uGet
|
||||
|
||||

|
||||
Batch Downloads Using uGet
|
||||
|
||||
uGet source files and RPM packages also available for other Linux distributions and Windows at [download page][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-uget-download-manager-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://uget.visuex.com/features
|
||||
[2]:http://ugetdm.com/downloads
|
||||
[3]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
|
||||
[4]:http://ugetdm.com/downloads-aria2
|
||||
[5]:http://ugetdm.com/downloads
|
||||
@ -0,0 +1,188 @@
|
||||
How to Install Percona Server on CentOS 7
|
||||
================================================================================
|
||||
In this article we are going to learn about percona server, an opensource drop-in replacement for MySQL and also for MariaDB. The InnoDB database engine make it very attractive and a good alternative if you need performance, reliability and a cost efficient solution
|
||||
|
||||
In the following sections I am going to cover the installation of the percona server on the CentOS 7, I will also cover the steps needed to make backup of your current data, configuration and how to restore your backup.
|
||||
|
||||
### Table of contents ###
|
||||
|
||||
1. What is and why use percona
|
||||
1. Backup your databases
|
||||
1. Remove previous SQL server
|
||||
1. Installing Percona binaries
|
||||
1. Configuring Percona
|
||||
1. Securing your environment
|
||||
1. Restore your backup
|
||||
|
||||
### 1. What is and why use Percona ###
|
||||
|
||||
Percona is an opensource alternative to the MySQL and MariaDB databases, it's a fork of the MySQL with many improvements and unique features that makes it more reliable, powerful and faster than MySQL, and yet is fully compatible with it, you can even use replication between Oracle's MySQL and Percona.
|
||||
|
||||
#### Features exclusive to Percona ####
|
||||
|
||||
- Partitioned Adaptive Hash Search
|
||||
- Fast Checksum Algorithm
|
||||
- Buffer Pool Pre-Load
|
||||
- Support for FlashCache
|
||||
|
||||
#### MySQL Enterprise and Percona specific features ####
|
||||
|
||||
- Import Tables From Different Servers
|
||||
- PAM authentication
|
||||
- Audit Log
|
||||
- Threadpool
|
||||
|
||||
Now that you are pretty excited to see all these good things together, we are going show you how to install and do basic configuration of Percona Server.
|
||||
|
||||
### 2. Backup your databases ###
|
||||
|
||||
The following, command creates a mydatabases.sql file with the SQL commands to recreate/restore salesdb and employeedb databases, replace the databases names to reflect your setup, skip if this is a brand new setup
|
||||
|
||||
mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
|
||||
|
||||
Copy the current configuration file, you can also skip this in fresh setups
|
||||
|
||||
cp my.cnf my.cnf.bkp
|
||||
|
||||
### 3. Remove your previous SQL Server ###
|
||||
|
||||
Stop the MySQL/MariaDB if it's running.
|
||||
|
||||
systemctl stop mysql.service
|
||||
|
||||
Uninstall MariaDB and MySQL
|
||||
|
||||
yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
|
||||
|
||||
Move / Rename the MariaDB files in **/var/lib/mysql**, it's a safer and faster than just removing, it's like a 2nd level instant backup. :)
|
||||
|
||||
mv /var/lib/mysql /var/lib/mysql_mariadb
|
||||
|
||||
### 4. Installing Percona binaries ###
|
||||
|
||||
You can choose from a number of options on how to install Percona, in a CentOS system it's generally a better idea to use yum or RPM, so these are the way that are covered by this article, compiling and install from sources are not covered by this article.
|
||||
|
||||
Installing from Yum repository:
|
||||
|
||||
First you need to set the Percona's Yum repository with this:
|
||||
|
||||
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
|
||||
|
||||
And then install Percona with:
|
||||
|
||||
yum install Percona-Server-client-56 Percona-Server-server-56
|
||||
|
||||
The above command installs Percona server and clients, shared libraries, possibly Perl and perl modules such as DBI::MySQL, if that are not already installed, and also other dependencies as needed.
|
||||
|
||||
Installing from RPM package:
|
||||
|
||||
We can download all rpm packages with the help of wget:
|
||||
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
|
||||
And with rpm utility, you install all the packages once:
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
Note the backslash '\' on the end of the sentences on the above commands, if you install individual packages, remember that to met dependencies, the shared package must be installed before client and client before server.
|
||||
|
||||
### 5. Configuring Percona Server ###
|
||||
|
||||
#### Restoring previous configuration ####
|
||||
|
||||
As we are moving from MariaDB, you can just restore the backup of my.cnf file that you made in earlier steps.
|
||||
|
||||
cp /etc/my.cnf.bkp /etc/my.cnf
|
||||
|
||||
#### Creating a new my.cnf ####
|
||||
|
||||
If you need a new configuration file that fit your needs or if you don't have made a copy of my.cnf, you can use this wizard, it will generate for you, through simple steps.
|
||||
|
||||
Here is a sample my.cnf file that comes with Percona-Server package
|
||||
|
||||
# Percona Server template configuration
|
||||
|
||||
[mysqld]
|
||||
#
|
||||
# Remove leading # and set to the amount of RAM for the most important data
|
||||
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
|
||||
# innodb_buffer_pool_size = 128M
|
||||
#
|
||||
# Remove leading # to turn on a very important data integrity option: logging
|
||||
# changes to the binary log between backups.
|
||||
# log_bin
|
||||
#
|
||||
# Remove leading # to set options mainly useful for reporting servers.
|
||||
# The server defaults are faster for transactions and fast SELECTs.
|
||||
# Adjust sizes as needed, experiment to find the optimal values.
|
||||
# join_buffer_size = 128M
|
||||
# sort_buffer_size = 2M
|
||||
# read_rnd_buffer_size = 2M
|
||||
datadir=/var/lib/mysql
|
||||
socket=/var/lib/mysql/mysql.sock
|
||||
|
||||
# Disabling symbolic-links is recommended to prevent assorted security risks
|
||||
symbolic-links=0
|
||||
|
||||
[mysqld_safe]
|
||||
log-error=/var/log/mysqld.log
|
||||
pid-file=/var/run/mysqld/mysqld.pid
|
||||
|
||||
After making your my.cnf file fit your needs, it's time to start the service:
|
||||
|
||||
systemctl restart mysql.service
|
||||
|
||||
If everything goes fine, your server is now up and ready to ready to receive SQL commands, you can try the following command to check:
|
||||
|
||||
mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
|
||||
|
||||
If you can't start the service, you can look for a reason in **/var/log/mysql/mysqld.log** this file is set by the **log-error** option in my.cnf's **[mysqld_safe]** session.
|
||||
|
||||
tail /var/log/mysql/mysqld.log
|
||||
|
||||
You can also take a look in a file inside **/var/lib/mysql/** with name in the form of **[hostname].err** as the following example:
|
||||
|
||||
tail /var/lib/mysql/centos7.err
|
||||
|
||||
If this also fail in show what is wrong, you can also try strace:
|
||||
|
||||
yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
|
||||
|
||||
The above command is extremely verbous and it's output is quite low level but can show you the reason you can't start service in most times.
|
||||
|
||||
### 6. Securing your environment ###
|
||||
|
||||
Ok, you now have your RDBMS ready to receive SQL queries, but it's not a good idea to put your precious data on a server without minimum security, it's better to make it safer with mysql_secure_instalation, this utility helps in removing unused default features, also set the root main password and make access restrictions for using this user.
|
||||
Just invoke it by the shell and follow instructions on the screen.
|
||||
|
||||
mysql_secure_install
|
||||
|
||||
### 7. Restore your backup ###
|
||||
|
||||
If you are coming from a previous setup, now you can restore your databases, just use mysqldump once again.
|
||||
|
||||
mysqldump -u root -p < mydatabases.sql
|
||||
|
||||
Congratulations, you just installed Percona on your CentOS Linux, your server is now fully ready for use; You can now use your service as it was MySQL, and your services are fully compatible with it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There is a lot of things to configure in order to achieve better performance, but here is some straightforward options to improve your setup. When using innodb engine it's also a good idea to set the **innodb_file_per_table** option **on**, it gonna distribute table indexes in a file per table basis, it means that each table have it's own index file, it makes the overall system, more robust and easier to repair.
|
||||
|
||||
Other option to have in mind is the **innodb_buffer_pool_size** option, InnoDB should have large enough to your datasets, and some value **between 70% and 80%** of the total available memory should be reasonable.
|
||||
|
||||
By setting the **innodb-flush-method** to **O_DIRECT** you disable write cache, if you have **RAID**, this should be set to improved performance as this cache is already done in a lower level.
|
||||
|
||||
If your data is not that critical and you don't need fully **ACID** compliant transactions, you can adjust to 2 the option **innodb_flush_log_at_trx_commit**, this will also lead to improved performance.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/percona-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
@ -0,0 +1,179 @@
|
||||
Install ‘Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity
|
||||
================================================================================
|
||||
In this Internet world and the world of Internet we perform most of our task online be it Ticket booking, Money transfer, Studies, Business, Entertainment, Social Networking and what not. We spend a major part of our time online daily. It has been getting hard to remain anonymous with each passing day specially when backdoors are being planted by organizations like NSA (National Security Agency) who are putting their nose in between every thing that we come across online. We have least or no privacy online. All the searches are logged upon the basis of user Internet surfing activity and machine activity.
|
||||
|
||||
A wonderful browser from Tor project is used by millions which help us surfing the web anonymously however it is not difficult to trace your browsing habits and hence tor alone is not the guarantee of your safety online. You may like to check Tor features and installation instructions here:
|
||||
|
||||
- [Anonymous Web Browsing using Tor][1]
|
||||
|
||||
There is a operating system named Tails by Tor Projects. Tails (The Amnesic Incognito Live System) is a live operating system, based on Debian Linux distribution, which mainly focused on preserving privacy and anonymity on the web while browsing internet, means all it’s outgoing connection are forced to pass through the Tor and direct (non-anonymous) requests are blocked. The system is designed to run from any boot-able media be it USB stick or DVD.
|
||||
|
||||
The latest stable release of Tails OS is 1.4 which was released on May 12, 2015. Powered by open source Monolithic Linux Kernel and built on top of Debian GNU/Linux Tails aims at Personal Computer Market and includes GNOME 3 as default user Interface.
|
||||
|
||||
#### Features of Tails OS 1.4 ####
|
||||
|
||||
- Tails is a free operating system, free as in beer and free as in speech.
|
||||
- Built on top of Debian/GNU Linux. The most widely used OS that is Universal.
|
||||
- Security Focused Distribution.
|
||||
- Windows 8 camouflage.
|
||||
- Need not to be installed and browse Internet anonymously using Live Tails CD/DVD.
|
||||
- Leave no trace on the computer, while tails is running.
|
||||
- Advanced cryptographic tools used to encrypt everything that concerns viz., files, emails, etc.
|
||||
- Sends and Receive traffic through tor network.
|
||||
- In true sense it provides privacy for anyone, anywhere.
|
||||
- Comes with several applications ready to be used from Live Environment.
|
||||
- All the softwares comes per-configured to connect to INTERNET only through Tor network.
|
||||
- Any application that tries to connect to Internet without Tor Network is blocked, automatically.
|
||||
- Restricts someone who is watching what sites you visit and restricts sites to learn your geographical location.
|
||||
- Connect to websites that are blocked and/or censored.
|
||||
- Designed specially not to use space used by parent OS even when there is free swap space.
|
||||
- The whole OS loads on RAM and is flushed when we reboot/shutdown. Hence no trace of running.
|
||||
- Advanced security implementation by encrypting USB disk, HTTPS ans Encrypt and sign emails and documents.
|
||||
|
||||
#### What can you expect in Tails 1.4 ####
|
||||
|
||||
- Tor Browser 4.5 with a security Slider.
|
||||
- Tor Upgraded to version 0.2.6.7.
|
||||
- Several Security holes fixed.
|
||||
- Many of the bug fixed and patches applied to Applications like curl, OpenJDK 7, tor Network, openldap, etc.
|
||||
|
||||
To get a complete list of change logs you may visit [HERE][2]
|
||||
|
||||
**Note**: It is strongly recommended to upgrade to Tails 1.4, if you’re using any older version of Tails.
|
||||
|
||||
#### Why should I use Tails Operating System ####
|
||||
|
||||
You need Tails because you need:
|
||||
|
||||
- Freedom from network surveillance
|
||||
- Defend freedom, privacy and confidentiality
|
||||
- Security aka traffic analysis
|
||||
|
||||
This tutorial will walk through the installation of Tails 1.4 OS with a short review.
|
||||
|
||||
### Tails 1.4 Installation Guide ###
|
||||
|
||||
1. To download the latest Tails OS 1.4, you may use wget command to download directly.
|
||||
|
||||
$ wget http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
|
||||
Alternatively you may download Tails 1.4 Direct ISO image or use a Torrent Client to pull the iso image file for you. Here is the link to both downloads:
|
||||
|
||||
- [tails-i386-1.4.iso][3]
|
||||
- [tails-i386-1.4.torrent][4]
|
||||
|
||||
2. After downloading, verify ISO Integrity by matching SHA256 checksum with the SHA256SUM provided on the official website..
|
||||
|
||||
$ sha256sum tails-i386-1.4.iso
|
||||
|
||||
339c8712768c831e59c4b1523002b83ccb98a4fe62f6a221fee3a15e779ca65d
|
||||
|
||||
If you are interested in knowing OpenPGP, checking Tails signing key against Debian keyring and anything related to Tails cryptographic signature, you may like to point your browser [HERE][5].
|
||||
|
||||
3. Next you need to write the image to USB stick or DVD ROM. You may like to check the article, [How to Create Live Bootable USB][6] for details on how to make a flash drive bootable and write ISO to it.
|
||||
|
||||
4. Insert the Tails OS Bootable flash drive or DVD ROM in the disk and boot from it (select from BIOS to boot). The first screen – two options to select from ‘Live‘ and ‘Live (failsafe)‘. Select ‘Live‘ and press Enter.
|
||||
|
||||

|
||||
Tails Boot Menu
|
||||
|
||||
5. Just before login. You have two options. Click ‘More Options‘ if you want to configure and set advanced options else click ‘No‘.
|
||||
|
||||

|
||||
Tails Welcome Screen
|
||||
|
||||
6. After clicking Advanced option, you need to setup root password. This is important if you want to upgrade it. This root password is valid till you shutdown/reboot the machine.
|
||||
|
||||
Also you may enable Windows Camouflage, if you want to run this OS on a public place, so that it seems as you are running Windows 8 operating system. Good option indeed! Is not it? Also you have a option to configure Network and Mac Address. Click ‘Login‘ when done!.
|
||||
|
||||

|
||||
Tails OS Configuration
|
||||
|
||||
7. This is Tails GNU/Linux OS camouflaged by Windows Skin.
|
||||
|
||||

|
||||
Tails Windows Look
|
||||
|
||||
8. It will start Tor Network in the background. Check the Notification on the top-right corner of the screen – Tor is Ready / You are now connected to the Internet.
|
||||
|
||||
Also check what it contains under Internet Menu. Notice – It has Tor Browser (safe) and Unsafe Web Browser (Where incoming and outgoing data don’t pass through TOR Network) along with other applications.
|
||||
|
||||
|
||||
Tails Menu and Tools
|
||||
|
||||
9. Click Tor and check your IP Address. It confirms my physical location is not shared and my privacy is intact.
|
||||
|
||||

|
||||
Check Privacy on Tails
|
||||
|
||||
10. You may Invoke Tails Installer to clone & Install, Clone & Upgrade and Upgrade from ISO.
|
||||
|
||||

|
||||
Tails Installer Options
|
||||
|
||||
11. The other option was to select Tor without any advanced option, just before login (Check step #5 above).
|
||||
|
||||

|
||||
Tails Without Advance Option
|
||||
|
||||
12. You will get log-in to Gnome3 Desktop Environment.
|
||||
|
||||

|
||||
Tails Gnome Desktop
|
||||
|
||||
13. If you click to Launch Unsafe browser in Camouflage or without Camouflage, you will be notified.
|
||||
|
||||

|
||||
Tails Browsing Notification
|
||||
|
||||
If you do, this is what you get in a Browser.
|
||||
|
||||

|
||||
Tails Browsing Alert
|
||||
|
||||
#### Is Tails for me? ####
|
||||
|
||||
To get the above question answered, first answer a few question.
|
||||
|
||||
- Do you need your privacy to be intact while you are online?
|
||||
- Do you want to remain hidden from Identity thieves?
|
||||
- Do you want somebody to put your nose in between your private chat online?
|
||||
- Do you really want to show your geographical location to anybody there?
|
||||
- Do you carry out banking transactions online?
|
||||
- Are you happy with the censorship by government and ISP?
|
||||
|
||||
If the answer to any of the above question is ‘YES‘ you preferably need Tails. If answer to all the above question is ‘NO‘ you perhaps don’t need it.
|
||||
|
||||
To know more about Tails? Point your browser to user Documentation : [https://tails.boum.org/doc/index.en.html][7]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Tails is an OS which is must for those who work in an unsafe environment. An OS focused on security yet contains bundles of Application – Gnome Desktop, Tor, Firefox (Iceweasel), Network Manager, Pidgin, Claws mail, Liferea feed addregator, Gobby, Aircrack-ng, I2P.
|
||||
|
||||
It also contain several tools for Encryption and Privacy Under the Hood, viz., LUKS, GNUPG, PWGen, Shamir’s Secret Sharing, Virtual Keyboard (against Hardware Keylogging), MAT, KeePassX Password Manager, etc.
|
||||
|
||||
That’s all for now. Keep Connected to Tecmint. Share your thoughts on Tails GNU/Linux Operating System. What do you think about the future of the Project? Also test it Locally and let us know your experience.
|
||||
|
||||
You may run it in [Virtualbox][8] as well. Remember Tails loads the whole OS in RAM hence give enough RAM to run Tails in VM.
|
||||
|
||||
I tested in 1GB Environment and it worked without lagging. Thanks to all our readers for their Support. In making Tecmint a one place for all Linux related stuffs your co-operation is needed. Kudos!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-tails-1-4-linux-operating-system-to-preserve-privacy-and-anonymity/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
[2]:https://tails.boum.org/news/version_1.4/index.en.html
|
||||
[3]:http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
[4]:https://tails.boum.org/torrents/files/tails-i386-1.4.torrent
|
||||
[5]:https://tails.boum.org/download/index.en.html#verify
|
||||
[6]:http://www.tecmint.com/install-linux-from-usb-device/
|
||||
[7]:https://tails.boum.org/doc/index.en.html
|
||||
[8]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
|
||||
182
sources/tech/20150518 How to set up a Replica Set on MongoDB.md
Normal file
182
sources/tech/20150518 How to set up a Replica Set on MongoDB.md
Normal file
@ -0,0 +1,182 @@
|
||||
How to set up a Replica Set on MongoDB
|
||||
================================================================================
|
||||
MongoDB has become the most famous NoSQL database on the market. MongoDB is document-oriented, and its scheme-free design makes it a really attractive solution for all kinds of web applications. One of the features that I like the most is Replica Set, where multiple copies of the same data set are maintained by a group of mongod nodes for redundancy and high availability.
|
||||
|
||||
This tutorial describes how to configure a Replica Set on MonoDB.
|
||||
|
||||
The most common configuration for a Replica Set involves one primary and multiple secondary nodes. The replication will then be initiated from the primary toward the secondaries. Replica Sets can not only provide database protection against unexpected hardware failure and service downtime, but also improve read throughput of database clients as they can be configured to read from different nodes.
|
||||
|
||||
### Set up the Environment ###
|
||||
|
||||
In this tutorial, we are going to set up a Replica Set with one primary and two secondary nodes.
|
||||
|
||||

|
||||
|
||||
In order to implement this lab, we will use three virtual machines (VMs) running on VirtualBox. I am going to install Ubuntu 14.04 on the VMs, and install official packages for Mongodb.
|
||||
|
||||
I am going to set up a necessary environment on one VM instance, and then clone it to the other two VM instances. Thus pick one VM named master, and perform the following installations.
|
||||
|
||||
First, we need to add the MongoDB key for apt:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
Then we need to add the official MongoDB repository to our source.list:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
Let's update repositories and install MongoDB.
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
Now let's make some changes in /etc/mongodb.conf.
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
The first line is to make sure that we are going to have authentication on our database. keyFile is to set up a keyfile that is going to be used by MongoDB to replicate between nodes. replSet sets up the name of our replica set.
|
||||
|
||||
Now we are going to create our keyfile, so that it can be in all our instances.
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
This will create keyfile that contains a MD5 string, but it has some noise that we need to clean up before using it in MongoDB. Use the following command to clean it up:
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
What grep command does is to print MD5 string with no spaces or other characters that we don't want.
|
||||
|
||||
Now we are going to make the keyfile ready for use:
|
||||
|
||||
$ sudo cp keyFile /var/lib/mongodb
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
Now we have our Ubuntu VM ready to be cloned. Power it off, and clone it to the other VMs.
|
||||
|
||||

|
||||
|
||||
I name the cloned VMs secondary1 and secondary2. Make sure to reinitialize the MAC address of cloned VMs and clone full disks.
|
||||
|
||||

|
||||
|
||||
All three VM instances should be on the same network to communicate with each other. For this, we are going to attach all three VMs to "Internet Network".
|
||||
|
||||
It is recommended that each VM instances be assigned a static IP address, as opposed to DHCP IP address, so that the VMs will not lose connectivity among themselves when a DHCP server assigns different IP addresses to them.
|
||||
|
||||
Let's edit /etc/networks/interfaces of each VM as follows.
|
||||
|
||||
On primary:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
On secondary1:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
On secondary2:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
Another file that needs to be set up is /etc/hosts, because we don't have DNS. We need to set the hostnames in /etc/hosts.
|
||||
|
||||
On primary:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
On secondary1:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
On secondary2:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
Check connectivity among themselves by using ping command:
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
$ ping secondary2
|
||||
|
||||
### Set up a Replica Set ###
|
||||
|
||||
After verifying connectivity among VMs, we can go ahead and create the admin user so that we can start working on the Replica Set.
|
||||
|
||||
On primary node, open /etc/mongodb.conf, and comment out two lines that start with auth and replSet:
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
Restart mongod daemon.
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
Create an admin user after conencting to MongoDB:
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
$ sudo service mongod restart
|
||||
|
||||
Connect to MongoDB and use these commands to add secondary1 and secondary2 to our Replicat Set.
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
> rs.initiate()
|
||||
> rs.add ("secondary1:27017")
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
Now that we have our Replica Set, we can start working on our project. Consult the [official driver documentation][1] to see how to connect to a Replica Set. In case you want to query from shell, you have to connect to primary instance to insert or query the database. Secondary nodes will not let you do that. If you attempt to access the database on a secondary node, you will get this error message:
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
2015-05-10T03:09:24.131+0000 E QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
|
||||
at Error ()
|
||||
at Mongo.getDBs (src/mongo/shell/mongo.js:47:15)
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
I hope you find this tutorial useful. You can use Vagrant to automate your local environments and help you code faster.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
182
sources/tech/20150522 Analyzing Linux Logs.md
Normal file
182
sources/tech/20150522 Analyzing Linux Logs.md
Normal file
@ -0,0 +1,182 @@
|
||||
translating by zhangboyue
|
||||
Analyzing Linux Logs
|
||||
================================================================================
|
||||
There’s a great deal of information waiting for you within your logs, although it’s not always as easy as you’d like to extract it. In this section we will cover some examples of basic analysis you can do with your logs right away (just search what’s there). We’ll also cover more advanced analysis that may take some upfront effort to set up properly, but will save you time on the back end. Examples of advanced analysis you can do on parsed data include generating summary counts, filtering on field values, and more.
|
||||
|
||||
We’ll show you first how to do this yourself on the command line using several different tools and then show you how a log management tool can automate much of the grunt work and make this so much more streamlined.
|
||||
|
||||
### Searching with Grep ###
|
||||
|
||||
Searching for text is the most basic way to find what you’re looking for. The most common tool for searching text is [grep][1]. This command line tool, available on most Linux distributions, allows you to search your logs using regular expressions. A regular expression is a pattern written in a special language that can identify matching text. The simplest pattern is to put the string you’re searching for surrounded by quotes
|
||||
|
||||
#### Regular Expressions ####
|
||||
|
||||
Here’s an example to find authentication logs for “user hoover” on an Ubuntu system:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
It can be hard to construct regular expressions that are accurate. For example, if we searched for a number like the port “4792” it could also match timestamps, URLs, and other undesired data. In the below example for Ubuntu, it matched an Apache log that we didn’t want.
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### Surround Search ####
|
||||
|
||||
Another useful tip is that you can do surround search with grep. This will show you what happened a few lines before or after a match. It can help you debug what lead up to a particular error or problem. The B flag gives you lines before, and A gives you lines after. For example, we can see that when someone failed to login as an admin, they also failed the reverse mapping which means they might not have a valid domain name. This is very suspicious!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
You can also pair grep with [tail][2] to get the last few lines of a file, or to follow the logs and print them in real time. This is useful if you are making interactive changes like starting a server or testing a code change.
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
A full introduction on grep and regular expressions is outside the scope of this guide, but [Ryan’s Tutorials][3] include more in-depth information.
|
||||
|
||||
Log management systems have higher performance and more powerful searching abilities. They often index their data and parallelize queries so you can quickly search gigabytes or terabytes of logs in seconds. In contrast, this would take minutes or in extreme cases hours with grep. Log management systems also use query languages like [Lucene][4] which offer an easier syntax for searching on numbers, fields, and more.
|
||||
|
||||
### Parsing with Cut, AWK, and Grok ###
|
||||
|
||||
#### Command Line Tools ####
|
||||
|
||||
Linux offers several command line tools for text parsing and analysis. They are great if you want to quickly parse a small amount of data but can take a long time to process large volumes of data
|
||||
|
||||
#### Cut ####
|
||||
|
||||
The [cut][5] command allows you to parse fields from delimited logs. Delimiters are characters like equal signs or commas that break up fields or key value pairs.
|
||||
|
||||
Let’s say we want to parse the user from this log:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
We can use the cut command like this to get the text after the eighth equal sign. This example is on an Ubuntu system:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
Alternately, you can use [awk][6], which offers more powerful features to parse out fields. It offers a scripting language so you can filter out nearly everything that’s not relevant.
|
||||
|
||||
For example, let’s say we have the following log line on an Ubuntu system and we want to extract the username that failed to login:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
Here’s how you can use the awk command. First, put a regular expression /sshd.*invalid user/ to match the sshd invalid user lines. Then print the ninth field using the default delimiter of space using { print $9 }. This outputs the usernames.
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
You can read more about how to use regular expressions and print fields in the [Awk User’s Guide][7].
|
||||
|
||||
#### Log Management Systems ####
|
||||
|
||||
Log management systems make parsing easier and enable users to quickly analyze large collections of log files. They can automatically parse standard log formats like common Linux logs or web server logs. This saves a lot of time because you don’t have to think about writing your own parsing logic when troubleshooting a system problem.
|
||||
|
||||
Here you can see an example log message from sshd which has each of the fields remoteHost and user parsed out. This is a screenshot from Loggly, a cloud-based log management service.
|
||||
|
||||

|
||||
|
||||
You can also do custom parsing for non-standard formats. A common tool to use is [Grok][8] which uses a library of common regular expressions to parse raw text into structured JSON. Here is an example configuration for Grok to parse kernel log files inside Logstash:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
And here is what the parsed output looks like from Grok:
|
||||
|
||||

|
||||
|
||||
### Filtering with Rsyslog and AWK ###
|
||||
|
||||
Filtering allows you to search on a specific field value instead of doing a full text search. This makes your log analysis more accurate because it will ignore undesired matches from other parts of the log message. In order to search on a field value, you need to parse your logs first or at least have a way of searching based on the event structure.
|
||||
|
||||
#### How to Filter on One App ####
|
||||
|
||||
Often, you just want to see the logs from just one application. This is easy if your application always logs to a single file. It’s more complicated if you need to filter one application among many in an aggregated or centralized log. Here are several ways to do this:
|
||||
|
||||
1. Use the rsyslog daemon to parse and filter logs. This example writes logs from the sshd application to a file named sshd-messages, then discards the event so it’s not repeated elsewhere. You can try this example by adding it to your rsyslog.conf file.
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. Use command line tools like awk to extract the values of a particular field like the sshd username. This example is from an Ubuntu system.
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. Use a log management system that automatically parses your logs, then click to filter on the desired application name. Here is a screenshot showing the syslog fields in a log management service called Loggly. We are filtering on the appName “sshd” as indicated by the Venn diagram icon.
|
||||
|
||||

|
||||
|
||||
#### How to Filter on Errors ####
|
||||
|
||||
One of the most common thing people want to see in their logs is errors. Unfortunately, the default syslog configuration doesn’t output the severity of errors directly, making it difficult to filter on them.
|
||||
|
||||
There are two ways you can solve this problem. First, you can modify your rsyslog configuration to output the severity in the log file to make it easier to read and search. In your rsyslog configuration you can add a [template][9] with pri-text such as the following:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
This example gives you output in the following format. You can see that the severity in this message is err.
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
You can use awk or grep to search for just the error messages. In this example for Ubuntu, we’re including some surrounding syntax like the . and the > which match only this field.
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
Your second option is to use a log management system. Good log management systems automatically parse syslog messages and extract the severity field. They also allow you to filter on log messages of a certain severity with a single click.
|
||||
|
||||
Here is a screenshot from Loggly showing the syslog fields with the error severity highlighted to show we are filtering for errors:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a] [Amy Echeverri][b] [ Sadequl Hussain][c]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
300
sources/tech/20150526 20 Useful Terminal Emulators for Linux.md
Normal file
300
sources/tech/20150526 20 Useful Terminal Emulators for Linux.md
Normal file
@ -0,0 +1,300 @@
|
||||
20 Useful Terminal Emulators for Linux
|
||||
================================================================================
|
||||
A Terminal emulator is a computer program that reproduces a video terminal within some other display structure. In other words the Terminal emulator has an ability to make a dumb machine appear like a client computer networked to the server. The terminal emulator allows an end user to access console as well as its applications such as text user interface and command line interface.
|
||||
|
||||

|
||||
|
||||
20 Linux Terminal Emulators
|
||||
|
||||
You may find huge number of terminal emulators to choose from this open source world. Some of them offers large range of features while others offers less features. To give a better understanding to the quality of software that are available, we have gathered a list of marvelous terminal emulator for Linux. Each title provides its description and feature along with screenshot of the software with relevant download link.
|
||||
|
||||
### 1. Terminator ###
|
||||
|
||||
Terminator is an advanced and powerful terminal emulator which supports multiple terminals windows. This emulator is fully customizable. You can change the size, colour, give different shapes to the terminal. Its very user friendly and fun to use.
|
||||
|
||||
#### Features of Terminator ####
|
||||
|
||||
- Customize your profiles and colour schemes, set the size to fit your needs.
|
||||
- Use plugins to get even more functionality.
|
||||
- Several key-shortcuts are available to speed up common activities.
|
||||
- Split the terminal window into several virtual terminals and re-size them as needed.
|
||||
|
||||
|
||||
|
||||
Terminator Terminal
|
||||
|
||||
- [Terminator Homepage][1]
|
||||
- [Download and Installation Instructions][2]
|
||||
|
||||
### 2. Tilda ###
|
||||
|
||||
Tilda is a stylish drop-down terminal based on GTK+. With the help of a single key press you can launch a new or hide Tilda window. However, you can add colors of your choice to change the look of the text and Terminal background.
|
||||
|
||||
#### Features of Tilda ####
|
||||
|
||||
Interface with Highly customization option.
|
||||
You can set the transparency level for Tilda window.
|
||||
Excellent built-in colour schemes.
|
||||
|
||||

|
||||
|
||||
Tilda Terminal
|
||||
|
||||
- [Tilda Homepage][3]
|
||||
|
||||
### 3. Guake ###
|
||||
|
||||
Guake is a python based drop-down terminal created for the GNOME Desktop Environment. It is invoked by pressing a single keystroke, and can make it hidden by pressing same keystroke again. Its design was determined from FPS (First Person Shooter) games such as Quake and one of its main target is be easy to reach.
|
||||
|
||||
Guake is very much similar to Yakuaka and Tilda, but it’s an experiment to mix the best of them into a single GTK-based program. Guake has been written in python from scratch using a little piece in C (global hotkeys stuff).
|
||||
|
||||

|
||||
|
||||
Guake Terminal
|
||||
|
||||
- [Guake Homepage][4]
|
||||
|
||||
### 4. Yakuake ###
|
||||
|
||||
Yakuake (Yet Another Kuake) is a KDE based drop-down terminal emulator very much similar to Guake terminal emulator in functionality. It’s design was inspired from fps consoles games such as Quake.
|
||||
|
||||
Yakuake is basically a KDE application, which can be easily installed on KDE desktop, but if you try to install Yakuake in GNOME desktop, it will prompt you to install huge number of dependency packages.
|
||||
|
||||
#### Yakuake Features ####
|
||||
|
||||
- Fluently turn down from the top of your screen
|
||||
- Tabbed interface
|
||||
- Configurable dimensions and animation speed
|
||||
- Customizable
|
||||
|
||||

|
||||
|
||||
Yakuake Terminal
|
||||
|
||||
- [Yakuake Homepage][5]
|
||||
|
||||
### 5. ROXTerm ###
|
||||
|
||||
ROXterm is yet another lightweight terminal emulator designed to provide similar features to gnome-terminal. It was originally constructed to have lesser footprints and faster start-up time by not using the Gnome libraries and by using a independent applet to bring the configuration interface (GUI), but over the time it’s role has shifted to bringing a higher range of features for power users.
|
||||
|
||||
However, it is more customizable than gnome-terminal and anticipated more at “power” users who make excessive use of terminals. It is easily integrated with GNOME desktop environment and provides features like drag & drop of items into terminal.
|
||||
|
||||

|
||||
|
||||
Roxterm Terminal
|
||||
|
||||
- [ROXTerm Homepage][6]
|
||||
|
||||
### 6. Eterm ###
|
||||
|
||||
Eterm is a lightest color terminal emulator designed as a replacement for xterm. It is developed with a Freedom of Choice ideology, leaving as much power, flexibility, and freedom as workable in the hands of the user.
|
||||
|
||||

|
||||
|
||||
Eterm Terminal
|
||||
|
||||
- [Eterm Homepage][7]
|
||||
|
||||
### 7. Rxvt ###
|
||||
|
||||
Rxvt stands for extended virtual terminal is a color terminal emulator application for Linux intended as an xterm replacement for power users who don’t need to have a feature such as Tektronix 4014 emulation and toolkit-style configurability.
|
||||
|
||||

|
||||
|
||||
Rxvt Terminal
|
||||
|
||||
- [Rxvt Homepage][8]
|
||||
|
||||
### 8. Wterm ###
|
||||
|
||||
Wterm is a another light weight color terminal emulator based on rxvt project. It includes features such as background images, transparency, reverse transparency and an considerable set or runtime options are accessible resulting in a very high customizable terminal emulator.
|
||||
|
||||

|
||||
|
||||
wterm Terminal
|
||||
|
||||
- [Wterm Homepage][9]
|
||||
|
||||
### 9. LXTerminal ###
|
||||
|
||||
LXTerminal is a default VTE-based terminal emulator for LXDE (Lightweight X Desktop Environment) without any unnecessary dependency. The terminal has got some nice features such as.
|
||||
LXTerminal Features
|
||||
|
||||
- Multiple tabs support
|
||||
- Supports common commands like cp, cd, dir, mkdir, mvdir.
|
||||
- Feature to hide the menu bar for saving space
|
||||
- Change the color scheme.
|
||||
|
||||

|
||||
|
||||
lxterminal Terminal
|
||||
|
||||
- [LXTerminal Homepage][10]
|
||||
|
||||
### 10. Konsole ###
|
||||
|
||||
Konsole is yet another powerful KDE based free terminal emulator was originally created by Lars Doelle.
|
||||
Konsole Features
|
||||
|
||||
- Multiple Tabbed terminals.
|
||||
- Translucent backgrounds.
|
||||
- Support for Split-view mode.
|
||||
- Directory and SSH bookmarking.
|
||||
- Customizable color schemes.
|
||||
- Customizable key bindings.
|
||||
- Notification alerts about activity in a terminal.
|
||||
- Incremental search
|
||||
- Support for Dolphin file manager
|
||||
- Export of output in plain text or HTML format.
|
||||
|
||||

|
||||
|
||||
Konsole Terminal
|
||||
|
||||
- [Konsole Homepage][11]
|
||||
|
||||
### 11. TermKit ###
|
||||
|
||||
TermKit is a elegant terminal that aims to construct aspects of the GUI with the command line based application using WebKit rendering engine mostly used in web browsers like Google Chrome and Chromium. TermKit is originally designed for Mac and Windows, but due to TermKit fork by Floby which you can now able to install it under Linux based distributions and experience the power of TermKit.
|
||||
|
||||
|
||||
|
||||
TermKit Terminal
|
||||
|
||||
- [TermKit Homepage][12]
|
||||
|
||||
12. st
|
||||
|
||||
st is a simple terminal implementation for X Window.
|
||||
|
||||

|
||||
|
||||
st terminal
|
||||
|
||||
- [st Homepage][13]
|
||||
|
||||
### 13. Gnome-Terminal ###
|
||||
|
||||
GNOME terminal is a built-in terminal emulator for GNOME desktop environment developed by Havoc Pennington and others. It allow users to run commands using a real Linux shell while remaining on the on the GNOME environment. GNOME Terminal emulates the xterm terminal emulator and brings a few similar features.
|
||||
|
||||
The Gnome terminal supports multiple profiles, where users can able to create multiple profiles for his/her account and can customize configuration options such as fonts, colors, background image, behavior, etc. per account and define a name to each profile. It also supports mouse events, url detection, multiple tabs, etc.
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
- [Gnome Terminal][14]
|
||||
|
||||
### 14. Final Term ###
|
||||
|
||||
Final Term is a open source stylish terminal emulator that has some exciting capabilities and handy features into one single beautiful interface. It is still under development, but provides significant features such as Semantic text menus, Smart command completion, GUI terminal controls, Omnipotent keybindings, Color support and many more. The following animated screen grab demonstrates some of their features. Please click on image to view demo.
|
||||
|
||||

|
||||
|
||||
FinalTerm Terminal
|
||||
|
||||
- [Final Term][15]
|
||||
|
||||
### 15. Terminology ###
|
||||
|
||||
Terminology is yet another new modern terminal emulator created for the Enlightenment desktop, but also can be used in different desktop environments. It has some awesome unique features, which do not have in any other terminal emulator.
|
||||
|
||||
Apart features, terminology offers even more things that you wouldn’t assume from a other terminal emulators, like preview thumbnails of images, videos and documents, it also allows you to see those files directly from Terminology.
|
||||
|
||||
You can watch a following demonstrations video created by the Terminology developer (the video quality isn’t clear, but still it’s enough to get the idea about Terminology).
|
||||
|
||||
<iframe width="630" height="480" frameborder="0" allowfullscreen="" src="//www.youtube.com/embed/ibPziLRGvkg"></iframe>
|
||||
|
||||
- [Terminology][16]
|
||||
|
||||
### 16. Xfce4 terminal ###
|
||||
|
||||
Xfce terminal is a lightweight modern and easy to use terminal emulator specially designed for Xfce desktop environment. The latest release of xfce terminal has some new cool features such as search dialog, tab color changer, drop-down console like Guake or Yakuake and many more.
|
||||
|
||||

|
||||
|
||||
Xfce Terminal
|
||||
|
||||
- [Xfce4 Terminal][17]
|
||||
|
||||
### 17. xterm ###
|
||||
|
||||
The xterm application is a standard terminal emulator for the X Window System. It maintain DEC VT102 and Tektronix 4014 compatible terminals for applications that can’t use the window system directly.
|
||||
|
||||

|
||||
|
||||
xterm Terminal
|
||||
|
||||
- [xterm][18]
|
||||
|
||||
### 18. LilyTerm ###
|
||||
|
||||
The LilyTerm is a another less known open source terminal emulator based off of libvte that desire to be fast and lightweight. LilyTerm also include some key features such as:
|
||||
|
||||
- Support for tabbing, coloring and reordering tabs
|
||||
- Ability to manage tabs through keybindings
|
||||
- Support for background transparency and saturation.
|
||||
- Support for user specific profile creation.
|
||||
- Several customization options for profiles.
|
||||
- Extensive UTF-8 support.
|
||||
|
||||

|
||||
|
||||
Lilyterm Terminal
|
||||
|
||||
- [LilyTerm][19]
|
||||
|
||||
### 19. Sakura ###
|
||||
|
||||
The sakura is a another less known Unix style terminal emulator developed for command line purpose as well as text-based terminal programs. Sakura is based on GTK and livte and provides not more advanced features but some customization options such as multiple tab support, custom text color, font and background images, speedy command processing and few more.
|
||||
|
||||

|
||||
|
||||
Sakura Terminal
|
||||
|
||||
- [Sakura][20]
|
||||
|
||||
### 20. rxvt-unicode ###
|
||||
|
||||
The rxvt-unicode (also known as urxvt) is a yet another highly customizable, lightweight and fast terminal emulator with xft and unicode support was developed by Marc Lehmann. It got some outstanding features such as support for international language via Unicode, the ability to display multiple font types and support for Perl extensions.
|
||||
|
||||

|
||||
|
||||
rxvt unicode
|
||||
|
||||
- [rxvt-unicode][21]
|
||||
|
||||
If you know any other capable Linux terminal emulators that I’ve not included in the above list, please do share with me using our comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-terminal-emulators/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:https://launchpad.net/terminator
|
||||
[2]:http://www.tecmint.com/terminator-a-linux-terminal-emulator-to-manage-multiple-terminal-windows/
|
||||
[3]:http://tilda.sourceforge.net/tildaabout.php
|
||||
[4]:https://github.com/Guake/guake
|
||||
[5]:http://extragear.kde.org/apps/yakuake/
|
||||
[6]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||
[7]:http://www.eterm.org/
|
||||
[8]:http://sourceforge.net/projects/rxvt/
|
||||
[9]:http://sourceforge.net/projects/wterm/
|
||||
[10]:http://wiki.lxde.org/en/LXTerminal
|
||||
[11]:http://konsole.kde.org/
|
||||
[12]:https://github.com/unconed/TermKit
|
||||
[13]:http://st.suckless.org/
|
||||
[14]:https://help.gnome.org/users/gnome-terminal/stable/
|
||||
[15]:http://finalterm.org/
|
||||
[16]:http://www.enlightenment.org/p.php?p=about/terminology
|
||||
[17]:http://docs.xfce.org/apps/terminal/start
|
||||
[18]:http://invisible-island.net/xterm/
|
||||
[19]:http://lilyterm.luna.com.tw/
|
||||
[20]:https://launchpad.net/sakura
|
||||
[21]:http://software.schmorp.de/pkg/rxvt-unicode
|
||||
@ -1,320 +0,0 @@
|
||||
组测试: Linux 文本编辑器
|
||||
================================================================================
|
||||
> Mayank Sharma 测试了5款不仅仅是能处理字的超级文本编辑器。
|
||||
|
||||
如果你使用Linux已经有很长一段时间,你知道,不管是编辑一款app的配置文件,一起用shell脚本骇客,或者编写/查看代码,类似LobreOffice的工具并不能满足。尽管字面上看起来意思一样,你不需要一个字处理器来完成这些任务;你需要一个文本编辑器。
|
||||
|
||||
在这个组测试中,我们将着眼于5款不仅仅是能胜任繁重文本任务的简陋的文本编辑器。他们能高亮语法,像拼写检查一样轻松处理代码缩进。你可以像你复制/粘贴文本那样容易地使用他们记录宏以及管理代码片段。
|
||||
|
||||
得益于能向它们注入足以抗衡其它类型的以文本为中心的应用程序能力的插件,一些简单的文本编辑器甚至超过了它们的设计目标。它们能胜任一个源代码编辑器的任务,甚至是一个集成开发环境。
|
||||
|
||||
Emacs和Vim是两款最流行和强大的纯文本编辑器。但是,由于一些原因,我们在这个组测试中并没有包括它们。首先,如果你使用它们中的任何一个,那么恭喜你:你不需要更换了。其次,它们都有陡峭的学习曲线,尤其是那些熟悉了桌面环境的用户:他们很更愿意投入其他有图形界面的文本编辑器。
|
||||
|
||||
### 目录: ###
|
||||
|
||||
#### Gedit ####
|
||||
|
||||
- URL:http://projects.gnome.org/gedit/
|
||||
- 版本: 3.10
|
||||
- 许可证: GPL
|
||||
- Gnome的默认文本编辑器准备好挑战了?
|
||||
|
||||
#### Kate ####
|
||||
|
||||
- URL: www.kate-editor.org
|
||||
- 版本: 3.11
|
||||
- 许可证: LGPL/GPL
|
||||
- Kate会挑战命运吗?
|
||||
|
||||
#### Sublime Text ####
|
||||
|
||||
- URL: www.sublimetext.com
|
||||
- 版本: 2.0.2
|
||||
- 许可证: Proprietary
|
||||
- 在自由与黄金心脏土地上的私有软件。
|
||||
|
||||
#### UltraEdit ####
|
||||
|
||||
- URL: www.ultraedit.com
|
||||
- 版本: 4.1.0.4
|
||||
- 许可证: Proprietary
|
||||
- 它做的足够多去证明它的价值了吗?
|
||||
|
||||
#### jEdit ####
|
||||
|
||||
- URL: www.jedit.org
|
||||
- 版本: 5.1.0
|
||||
- 许可证: GPL
|
||||
- 基于Java的编辑器是否会扰乱其他编辑器的世界?
|
||||
|
||||

|
||||
在展示一个有功能的应用程序和将它们所有的东西曝光给用户之间有一个很好的平衡。Geddit隐藏了它的大部分功能。
|
||||
|
||||
### 关键标准 ###
|
||||
|
||||
除了Gedit和jEdit以外的所有工具,都是通过推荐的安装方法安装在Fedora和Ubuntu上。前者已经兼容默认的Gnome桌面,后者仍然固执地反对安装在Fedora上。由于这些是相对简单的应用程序,他们没有复杂的依赖,唯一例外的是jEdit,它要求要有Oracle Java。
|
||||
|
||||
得益于Gnome和KDE持续的努力,不论他们运行的桌面环境,所有编辑器看起来很好,功能也很正常。这不仅是作为评价的标准,也意味着你不再受制于要找到和你的桌面环境兼容的工具。
|
||||
|
||||
除了它们奇特的功能,我们也对所有候选者测试了通用文本编辑功能。然而,它们并没有被设计为模仿现代字处理器的所有功能,我们也不以此评判。
|
||||
|
||||

|
||||
|
||||
Kate能搭建为功能丰富的集成开发环境。
|
||||
|
||||
### 编程语言支持 ###
|
||||
|
||||
UltraEdit 能进行语法高亮,代码折叠以及拥有项目管理的能力。这也有一个罗列源文件中所有函数的功能列表,但并不适用于我们任何的测试代码文件。UltraEdit也支持HTML5,有能添加常用HTML标记的HTML工具栏。
|
||||
|
||||
即使Gnome的默认文本编辑器Gedit,也有几个面向编码的功能特性,例如括号匹配,自动缩进以及为包括C, C++, Java, HTML, XML, Python, Perl, 以及许多其它编程语言进行语法高亮。
|
||||
|
||||
如果你需要更多的编程辅助,看一下Sublime和Kate。Sublime支持多种编程语言并且(正如流行的那些)能为C#, D, Dylan, Erlang, Groovy, Haskell, Lisp, Lua, MATLAB, OCaml, R, 甚至 SQL 进行语法高亮。如果这还不够,你可以下载插件以支持更多的语言。
|
||||
|
||||
另外,它的语法高亮功能提供了多个可定制选项。这个应用程序也会进行括号匹配,确保代码段都正确,Sublime的自动补全功能也支持用户创建的变量。
|
||||
|
||||
正如Komodo IDE,Sublime也可滚动浏览显示完整的代码,这对于长代码文件导航和在文件中的不同部分跳转很方便。
|
||||
|
||||
Sublime最好的功能之一就是能在编辑器内部为特定语言,例如C++, Python, Ruby等运行代码,当然假设在你的电脑上安装有编译器以及其它系统工具。省时间而且不用再开终端.
|
||||
|
||||
你也可以用插件在Kate中开启构建系统功能。另外,你可以为GDB调试器添加一个简单的前端。Kate能和Git,Subversion以及Mercurial版本控制系统一起工作,也提供了一些项目管理的功能。
|
||||
|
||||
除了能为超过180中语言进行语法高亮,它支持所有的这些辅助功能,例如括号匹配,自动补全和自动缩进。它也支持代码折叠,甚至在一个程序中折叠函数。
|
||||
|
||||
唯一的遗憾的是jEdit,它声称自己是一个程序员的文本编辑器,但它缺少其他的基本功能,例如代码折叠,它甚至不能提示或者不全函数.
|
||||
|
||||
**评分:**
|
||||
|
||||
- Gedit:3/5
|
||||
- Kate:5/5
|
||||
- Sublime:5/5
|
||||
- UltraEdit3/5
|
||||
- jEdit:1/5
|
||||
|
||||

|
||||
|
||||
如果你不喜欢Sublime的Charcoal外观,你可以选择它包含的其它22中主题。
|
||||
|
||||
### 键盘控制 ###
|
||||
|
||||
高级文本编辑器用户希望能完全通过键盘控制和操作,一些应用程序甚至运行他们的用户自定义快捷方式的键盘绑定。
|
||||
|
||||
你可以轻松的使用Gedit的扩展键盘快捷键。这里有编辑文件,为普通任务,例如对一个文档进行拼写检查,唤起工具的快捷键。你可以获取应用程序内部的一系列默认快捷键,但并没有图形化的方式去自定义它们。相似的,在Sublime中自定义键绑定,你需要修改他的XML键映射文件。Sublime由于缺少定义键盘快捷键的图形化界面而饱受批评,但长期使用的用户支持当前的基于文件的机制:这给他们更多的控制能力。
|
||||
|
||||
UltraEdit为它"一切都可自定义"的座右铭感到自豪,这也包括键盘快捷键。你可以自定义菜单导航的热键,以及定义你自己的访问大量函数的多键键映射。
|
||||
|
||||
除了完全可自定义的键盘快捷键以外,jEdit也有为Emacs预定义的键映射。Kate在这方面尤其令人映像深刻。它有简单可访问的自定义键绑定窗口。你可以更改默认的键,或者定义替代的键。另外,Kate也有一个能使用户使用Vi键操作Kate的Vi模式。
|
||||
|
||||
**Verdict:**
|
||||
|
||||
- Gedit:2/5
|
||||
- Kate:5/5
|
||||
- Sublime:3/5
|
||||
- UltraEdit:4/5
|
||||
- jEdit:5/5
|
||||
|
||||
### 片段和宏 ###
|
||||
|
||||
宏通过自动化重复的步骤帮助你降低花费在编辑和组织数据上的时间,而代码片段通过创建可重用的源代码块为程序员扩展类似的功能。这两者都能节省你的时间。
|
||||
|
||||
标准的Gedit安装没有这两种功能中的任何一种,但是你可以通过独立的插件启用这些功能。片段插件随Gedit一起发布,但在Gedit内部启用宏插件之前你需要手动下载和安装(被称为gedit-macropy,托管在GitHub上)。
|
||||
|
||||
Kate也同样通过插件的形式启用片段功能。一旦加入,插件也增加了片段的PHP,Bash和Java库。你可以在侧边栏中显示片段列表以便于访问。可以通过右击片段或者快捷键组合方式编辑它的内容。然而,令人惊讶的是,它不支持宏-尽管用户从2002年开始重复要求!
|
||||
|
||||
jEdit也有一个启用片段的插件。但是它可以从用户行为中记录宏或者你也可以在BeanShell 脚本语言(BeanShell支持像Perl和JavaScript那样将脚本对象封锁为简单的方法)中写宏。jEdit也有一个可以从jEdit的网站中下载多种宏的插件。
|
||||
|
||||
Sublime有创建片段和宏的内建功能,也有为大多数编程语言经常使用的函数多种片段。
|
||||
|
||||
在UltraEdit中片段被称为智能模板,正如Sublime你可以根据正在编辑的源代码文件类型插入片段。要完成宏记录功能,UltraEdit还有一个基于JavaScript的集成脚本语言来完成自动任务。你也可以从编辑器的网站中下载用户提交的宏和脚本。
|
||||
|
||||
**Verdict:**
|
||||
|
||||
- Gedit:3/5
|
||||
- Kate:1/5
|
||||
- Sublime:5/5
|
||||
- UltraEdit:5/5
|
||||
- jEdit:5/5
|
||||
|
||||

|
||||
|
||||
UltraEdit的用户界面是高度可配置的 — 你可以正如改变其它许多方面那样简单的自定义工具栏和菜单的布局。]
|
||||
|
||||
### 易用性 ###
|
||||
|
||||
不像一个准系统文本编辑器,文本编辑器的这个功能洋溢着适应大范围用户的功能 - 从文档写作者到程序员。从应用程序剥离相反,他们的开发者在寻找添加更多功能的途径。
|
||||
|
||||
尽管第一眼看上去这次组测试中的大部分应用有一个很相似的布局,经过仔细的检查,你会发现一些可用性差异。我们通过用户界面的合理使用来介绍它们的功能和特性,而不是铺天盖地地告诉读者。
|
||||
|
||||
### Gedit: 4/5 ###
|
||||
|
||||
Gedit有很普通的外观。通过最小化菜单和按钮有一个简单的界面。但这也是一种双刃剑,因为有些用户可能不会发现它真正的潜能。
|
||||
|
||||
Gedit可以通过在窗口中能重排和移动的选项卡打开多个文件。用户可以通过使用一个插件选择性地启用旁边或者底部用来显示文件浏览和工具输出的面板。这个应用程序会检测到被其它应用程序更改的文件并可以重新加载这个文件。
|
||||
|
||||
为了适配Gnome,在应用程序的最后一个版本中考虑了大量的用户界面。然而它还并不稳定,尽管包括了所有的功能,和菜单交互的一些插件还需要升级。
|
||||
|
||||
### Kate: 5/5 ###
|
||||
|
||||
尽管用户界面的主要部分和Gedit的相似,Kate可以在两边显示选项卡并且它的菜单更加丰富。该应用程序平易近人,让用户可以挖掘其它功能。
|
||||
|
||||
Kate可以在KDE的KIO支持的所有协议上透明地打开和保存文件,包括HTTP, FTP, SSH, SMB 和 WebDAV。你可以用这个应用同时处理多个文件。但不同于大部分应用程序传统的水平选项卡选择栏,Kate在屏幕的两个方向都有选项卡。左侧的侧边栏显示打开文件的索引。需要同时查看一个文件不同部分的程序员也会感激它可以水平或者竖直分隔界面的能力。
|
||||
|
||||
### Sublime: 5/5 ###
|
||||
|
||||
|
||||
Sublime支持你在不同方式同时查看多达四个文件。当你在zone下,这里也有一个只显示文件和菜单的全屏模式。
|
||||
|
||||
这个编辑器还在右边有个小地图,这在长文件中导航非常有用。应用程序为多种编程语言提供多种流行功能的片段,这使得它对于开发者非常有用。另一个精巧的功能是,无论你使用都是文本文档或者代码,都可以交换和随机选择。
|
||||
|
||||
### UltraEdit: 3/5 ###
|
||||
|
||||
|
||||
UltraEdit在界面的顶部和底部加载了多种工具栏。由于有在文档中跳转的选项卡,两边的面板,以及复杂区别,使得只剩下一点空间给编辑窗口。
|
||||
|
||||
使用HTML的网络开发者有很多唾手可得的帮助。你可以通过FTP和SFTP访问远程文件。高级功能,例如记录一个宏以及比较文件,也简单易用。
|
||||
|
||||
使用应用程序的Preference窗口,你可以调整应用程序的多个方面,包括颜色主题和类似语法高亮的其它功能。
|
||||
|
||||
### jEdit: 3/5 ###
|
||||
|
||||
在可用性方面,首先一个不好就是jEdit不能在基于RPM的发行版上安装。导航编辑器需要一些时间来适应,因为它的菜单和其它流行的应用程序顺序不同,而且有些普通桌面用户不熟悉的名字。但是,该应用程序有详细的内部帮助,这有利于缓解学习曲线。
|
||||
|
||||
jEdit高亮你所在的当前行,并使你能一多种查看方式分隔窗口。你可以简单地从应用程序中安装和管理插件,除了全宏,jEdit也支持你记录快速临时的宏。
|
||||
|
||||

|
||||
|
||||
由于它的Java基础,jEdit在任何桌面环境中都不能给人宾至如归的感觉
|
||||
|
||||
### 可用性和支持 ###
|
||||
|
||||
在Gedit和Kate之间有很多相似性。两个应用程序都得益于他们各自的父项目,Gnome和KDE,并绑定在各种主流的发行版中。另外两个项目都是交叉平台的,有Windows和Mac OS X版本以及本来的Linux版本。
|
||||
|
||||
Gedit托管在Gnome的网络设施上并有一个简单的用户指南,关于多种插件的信息,以及包括邮件列表和IRC通道的常用保持联系方式。你也可以在其它基于Gnome的发行版,例如Ubuntu中找到使用信息。相似地,Kate得益于KDE的资源,并包括详细的用户信息以及邮件列表和IRC通道。你也可以从应用程序中获取相应的离线用户指南。
|
||||
|
||||
除了Linux,UltraEdit在Windows和Mac OS X中也可用,虽然在应用程序中并没有包括,但在启动时也有详细的用户指南。为了辅助用户,UltraEdit保存了一个常见问题的数据库,一系列关于多种特定功能的详细信息的有用提示,用户还可以在论坛版块彼此帮助。另外,付费用户也可以通过邮件从开发者中获取支持。
|
||||
|
||||
Sublime支持相同数目的平台,但是你需要单独为每种平台购买许可证。开发者通过博客使用户了解正在进行的开发,并积极参加了主持论坛。这个项目支持设施的亮点是提供免费的详细教程和视频课程。Sublime非常可爱。
|
||||
|
||||
由于是用java编写的,jEdit在多种平台中都可用。在它的网站上你可以找到一个详细的用户指南以及一些插件帮助文档的链接。然而,这里没有能使用户和其他用户或者开发者交流的途径。
|
||||
|
||||
**判定:**
|
||||
|
||||
- Gedit: 4/5
|
||||
- Kate: 4/5
|
||||
- Sublime: 5/5
|
||||
- UltraEdit: 3/5
|
||||
- jEdit: 2/5
|
||||
|
||||
### 附加和插件 ###
|
||||
|
||||
不同的用户有不同的需求,一个简单的轻量级应用程序只能做到这么多。这就是为什么需要插件的原因。应用程序依赖于这些小部件来扩展它们的功能集并让更多的用户使用。
|
||||
|
||||
UltraEdit是一个另外。它没有第三方插件,但开发者确实支出了例如HtmlTidy的第三方工具已经安装到了UltraEdit。
|
||||
|
||||
Gedit附带了好多已安装的插件,你可以从gedit-插件包下载更多的插件。基于和Gedit版本的兼容性,项目网站也有到多个第三方插件的链接。
|
||||
|
||||
三个对程序员非常有用的插件是Code Comment,在底部面板增加一个终端的Terminal Plugin以及Session Saver。当你用多个文件开发项目的时候Session Saver相当有用。你可以在选项卡中打开文件,保存会话,当你用一个单击回复的时候,可以按照你保存时的选项卡顺序打开所有的文件。
|
||||
|
||||
类似的,你可以通过用内部的插件管理器增加插件来扩展Kate。除了令人映像深刻的项目插件,一些开发者使用的插件包括嵌入式终端,能编译和调试代码,以及对数据库执行SQL查询。
|
||||
|
||||
Sublime的插件是用Python写的,文本编辑器包括了一个类似于apt-get,能使用户查找,安装,升级和移除插件包的名为Package Control的工具。通过插件,你可以在Sublime中使用Git版本控制,以及改进JavaScript的JSLint工具。Sublime Linter能指出你代码中的错误,是编码人员必备的插件。
|
||||
|
||||
jEdit拥有最令人映像深刻的插件设施。该应用有超过200个插件,可以在它们自己的专用网站中浏览。网站通过不同的类型列举了插件,例如文件管理,版本控制,文本等。你可以在每个类型下找到很多的插件。
|
||||
|
||||
一些最好的插件是Android插件,它们提供了和Android项目协同工作的工具;你可以使用TomcatSwitch插件创建和控制外部Jakarta Tomcat服务器进程;以及类似于Vi功能的Vimulator插件。你可以通过使用jEdit的插件管理器安装这些插件。
|
||||
|
||||
**评定**
|
||||
|
||||
- Gedit: 3/5
|
||||
- Kate: 4/5
|
||||
- Sublime: 4/5
|
||||
- UltraEdit: 1/5
|
||||
- jEdit: 5/5
|
||||
|
||||
### 纯文本编辑 ###
|
||||
|
||||
尽管它们强大的额外功能甚至可能会取代几个流派完全成熟的应用程序,有时候可能只需要使用这些庞大的文本编辑器读写或者编辑简单的纯文本。虽然你可以使用它们中的任何一个输入文本,我们通过普通文本编辑的方便性评价它们。
|
||||
|
||||
Gnome的默认文本编辑器Gedit,支持取消和重做机制以及搜索和替换。它可以对多种语言进行拼写检查,并能通过使用Gnome GVFS库访问和编辑远程文件。
|
||||
|
||||
你也可以使用Kate进行拼写检查,它也可以让你对任何高亮文本进行Google搜索。它还有一个能可视化告知用户文件中更改过但没有保存的行的行修改系统。另外,它通过允许用户在文件中使用书签简化长文档的导航。
|
||||
|
||||
Sublime有很多可选择的编辑命令,例如缩进文本和格式化段落。它的自动保存功能帮助防止用户丢失他们的更改。高级用户还会喜欢基于正则表达式的递归查找和替换功能,以及选择多个不连续的文本块并执行统一操作。
|
||||
|
||||
UltraEdit也允许用户在查找和替换功能中使用正则表示,并能通过FTP编辑远程文件。JEdit一个独特的功能是它支持被称为寄存器的不限数目的剪切板。你可以复制文本片段到这些寄存器中,在编辑会话过程中都可用。
|
||||
|
||||
**评定:**
|
||||
|
||||
- Gedit: 4/5
|
||||
- Kate: 5/5
|
||||
- Sublime: 5/5
|
||||
- UltraEdit: 4/5
|
||||
- jEdit: 4/5
|
||||
|
||||
### 我们的评比 ###
|
||||
|
||||
在这里的所有编辑器都足以替换你已有的文本编辑器去用来编辑文本和调整配置文件。事实上,没准它们会组合起来作为你的集成开发环境。这些应用程序都有各种各样功能,它们的开发者不会考虑剥离功能,而是增加越来越多的功能。
|
||||
|
||||
jEdit排在这次测试的最后面。因为它不仅坚持使用专有的Oracle Java运行环境,不能在你的Fedora机器上安装,而且开发者不积极的和用户交互。
|
||||
|
||||
UltraEdit做的稍微好一点。这个商业专用工具专注于网络开发者,不为非开发者高级用户提供任何功能,使得它不值得推荐为免费软件的替代品。
|
||||
|
||||
排在第三的是Gedit。作为Gnome的默认编辑器,它没有任何内在的错误,但尽管有很多积极的方面,它还是略微被Sublime和Kate超越。开诚布公地说,Kate是比Gedit更通用的编辑器,甚至考虑到他们的插件系统,评分也优于Gnome的默认编辑器。
|
||||
|
||||
Sublime和Kate都相当好。他们在我们的大多数测试中表现同样出色。由于不支持宏而落后于Sublime,但键盘友好和能简单定义自定义键绑定又使Kate找回优势。
|
||||
|
||||
Kate成功的原因可以归结为它通过最小化学习曲线提供了最大化数目的功能。尽量使用它吧,不仅作为简单文本编辑器使用,或者容易使用语法高亮编辑配置文件,甚至得益于项目管理能力能使用它协作一个复杂的编程项目。
|
||||
|
||||
我们不是选择Kate去替换一个类似[在这里插入你最喜欢的专业工具]的全面的集成开发环境。但是它是一个专业工具理想的全面的以及完美的垫脚石。
|
||||
|
||||
Kate为能快速响应你的需要而设计,它的界面并不会使你茫然,并且和那些过于复杂的应用一样的有用。
|
||||
|
||||
### 1st Kate ###
|
||||
|
||||
- Licence LGPL/GPL Version 3.11
|
||||
- www.kate-editor.org
|
||||
- 拥有超能力,最终温和的文本编辑器。
|
||||
- Kate是KDE项目中最有用的应用程序之一。
|
||||
|
||||
### 2nd Sublime Text ###
|
||||
|
||||
- Licence Proprietary Version 2.0.2
|
||||
- www.sublimetext.com
|
||||
- 值得你每分钱的专业文本编辑器 - 简单易用,功能全面而且看起来很棒。
|
||||
|
||||
### 3rd Gedit ###
|
||||
|
||||
- Licence GPL Version 3.10
|
||||
- http://projects.gnome.org/gedit
|
||||
- 从Gnome中完成。这是一个奇妙的文本编辑器,确实令人钦佩的工作,但这里的竞争实在太大了。
|
||||
|
||||
### 4th UltraEdit ###
|
||||
|
||||
- Licence Proprietary Version 4.1.0.4
|
||||
- www.ultraedit.com
|
||||
- 关注于为网络开发者绑定便利,而不为普通用户提供任何特殊功能。
|
||||
|
||||
### 5th jEdit ###
|
||||
|
||||
- Licence GPL Version 5.1.0
|
||||
- www.jedit.org
|
||||
- 缺乏支持,不支持Fedora,缺乏好看的界面,jEdit被贬低到最后。
|
||||
|
||||
### 你也许希望尝试… ###
|
||||
|
||||
随你发行版发布的默认文本编辑器也能帮助你一些高级任务。例如KDE的KWrite和Raspbian的Nano。得益于KDE的katepart组件,KWrite继承了一些Kate的功能,得益于在树莓派上的可用性,Nano也开始重现风头。
|
||||
|
||||
如果你希望跟随Linux大师的脚步,你总是可以尝试崇高的文本编辑机Emacs和Vim。想尝试Vim强大的用户首先可以考虑gVim,它通过图形界面展现了Vim的强大。
|
||||
|
||||
除了jEdit和Kate,这里还有其他模仿例如Emacs和Vim之类的老派高级编辑器的编辑器,比如JED 编辑器和Joe's Own Editor,这两者都有Emacs的模拟模式。另一方面,如果你在寻找轻量级的代码编辑器,可以看看Bluefish和Geany。他们的存在是为了填补文本编辑器和全面集成的开发平台之间的空隙。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/text-editors/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[royaso](https://github.com/royaso)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
@ -0,0 +1,43 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
Synfig Studio 1.0 —— 开源动画动真格的了
|
||||
================================================================================
|
||||

|
||||
|
||||
**现在可以下载 Synfig Studio 这个自由、开源的2D动画软件的全新版本了。 **
|
||||
|
||||
在第一次发行这个跨平台的软件一年以后,Synfig Studio 1.0 带着一套全新改和改进过的功能,实现它所承诺的“创造电影级别的动画的产业级解决方案”。
|
||||
|
||||
在众多功能之上的是一个改进过的用户界面,据工程开发者说那是个用起来‘更简单’、‘更直观’的界面。客户端添加了新的**单窗口模式**,让界面更整洁,而且**为了使用最新的 GTK3 库而被重新制作**。
|
||||
|
||||
在功能方面有几个值得注意的变化,包括新加的全功能骨骼系统。
|
||||
|
||||
这套**关节和转轴的‘骨骼’构架**非常适合2D剪纸动画,再配上这个版本新加的复杂的变形控制系统或是 Synfig 受欢迎的‘关键帧自动插入’(阅读:画面与画面间的变形)应该会变得非常有效率的。
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/M8zW1qCq8ng?feature=oembed"></iframe>
|
||||
|
||||
新的无损剪切工具,摩擦力效果和对逐帧位图动画的支持,可能会有助于释放开源动画师们的创造力,更别说新加的用于同步动画的时间线和声音的声效层!
|
||||
|
||||
### 下载 Synfig Studio 1.0 ###
|
||||
|
||||
Synfig Studio 并不是任何人都能用的工具套件,这最新发行版的最新一批改进应该能吸引一些动画制作者试一试这个软件。
|
||||
|
||||
If you want to find out what open-source animation software is like for yourself, you can grab an installer for Ubuntu for the latest release direct from the project’s page using the links below. 如果你想看看开源动画制作软件是什么样的,你可以通过下面的链接直接从工程的 Sourceforge 页下载一个适用于 Ubuntu 的最新版本的安装器。
|
||||
|
||||
- [Download Synfig 1.0 (64bit) .deb Installer][1]
|
||||
- [Download Synfig 1.0 (32bit) .deb Installer][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/synfig-studio-new-release-features
|
||||
|
||||
作者:[oey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_amd64.deb/download
|
||||
[2]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_x86.deb/download
|
||||
@ -0,0 +1,74 @@
|
||||
一个Ubuntu中给你的照片加Instagram风格滤镜的程序
|
||||
================================================================================
|
||||
**在Ubuntu中寻找一个给你的照片加Instagram风格的滤镜程序么?**
|
||||
|
||||
拿起你的自拍棒跟着这个来。
|
||||
|
||||

|
||||
XnRetro是一个照片编辑应用
|
||||
|
||||
### XnRetro 照片编辑器 ###
|
||||
|
||||
**XnRetro** 是一个可以让你快速给你照片添加“类Instagram”效果的程序。
|
||||
|
||||
你知道我说的这些效果:划痕、噪点、框架、过处理、复古和怀旧色调(因为在这个数字时代,我们必须知道无尽的自拍不能称为怀旧的自己。)
|
||||
|
||||
无论你认为这些效果是愚蠢的艺术价值或者创作的捷径,这些滤镜非常流行切可以帮助那些平平照片添加个性。
|
||||
|
||||
|
||||
#### XnRetro的功能 ####
|
||||
|
||||
**XnRetro有下面那些功能**
|
||||
|
||||
- 20色彩滤镜
|
||||
- 15中光效果(虚化、泄露等等)
|
||||
- 28框架和边框
|
||||
- 5中插图 (带力度控制)
|
||||
- Image adjustments for contrast, gamma, saturation, etc
|
||||
- 对比度、伽马、饱和度等图像调整
|
||||
- 矩形修剪选项
|
||||
|
||||

|
||||
灯光效果调整
|
||||
|
||||
你可以(理论上)编辑。jpg或者.png文件并且直接在app中等想到社交媒体上。
|
||||
|
||||
我说“理论”上的意思是保存.jpg图像无法正常在linux版的程序上工作(你可以保存.png的图像)。相似的,大多数内置的社交链接失效或者无法导出。
|
||||
|
||||
要使用**15中光影效果**你需要在XnRetro的‘light’文件夹下重新保存.jpg文件成.png文件。编辑‘light.xml’来匹配新的文件名,点击保存那没灯光效果就可以没有问题的加载进XnRetro了。
|
||||
|
||||
> ‘用户友好的XnRetro很难打败-一旦你用顺之后。’
|
||||
|
||||
**XnRetro值得安装么?**
|
||||
|
||||
XnRetro并不是完美的。它看上去很丑、很难正确的安装并且已经纪念没有更新了。
|
||||
|
||||
它还可以使用,输了保存.jpg文件外。同时也是那些像Gimp或者Shotwell的那些‘正规’图片调整工具的一个灵活替代品。
|
||||
|
||||
While web apps and Chrome Apps¹ like [Pixlr Touch Up][1] and [Polarr][2] offer similar features you may be looking for a truly native solution.
|
||||
虽然web应用和Chrome Apps¹像[Pixlr Touch Up][1] 和 [Polarr][2]提供另外相似的功能,而你也许正在寻找真正原生的解决方案。
|
||||
|
||||
对于此,用户友好带有容易使用滤镜的XnRetro很难被打败。
|
||||
|
||||
### 下载Ubuntu下的XnRetro ###
|
||||
|
||||
XnRetro没有可用的.deb安装包。它以二进制文件的形式发型,这意味着你需要每次双击程序来运行。它也只有32位的版本。
|
||||
|
||||
你可以使用下面的XnRetro下载链接。下载完成后你需要解压压缩包并进入。双击里面的‘xnretro’程序。
|
||||
|
||||
- [下载Linux版XnRetro (32位, tar.gz)][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/05/instagram-photo-filters-ubuntu-desktop-app
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgchrome.com/?s=pixlr
|
||||
[2]:http://www.omgchrome.com/the-best-chrome-apps-of-2014/
|
||||
[3]:http://www.xnview.com/en/xnretro/#downloads
|
||||
@ -0,0 +1,38 @@
|
||||
Ubuntu会在今年达到2亿用户么?
|
||||
================================================================================
|
||||
距离Mark Shuttleworth表达他的目标“在4年内Ubuntu的用户达到2亿”已经过去了四年零两周。尽管Ubuntu的用户数量在过去的四年中一直在上升,但这个目标目前并未实现,并且看起来不会在今年年底实现。
|
||||
|
||||
那是2011年5月在[UDS 布达佩斯][1],Shuttleworth表示Ubuntu将在4年内达到2亿用户。
|
||||
|
||||

|
||||
|
||||
上一次我听到Ubuntu有“1千万”用户,但是并没有任何可靠的报道表明Ubuntu的用户数接近2亿。来自Valve最近的统计表明相比于Windows和OS X的用户[使用Linux的游戏用户的比重少于1%][2]。大多数基于Web计量和其他统计方式的数据倾向于表明Linux的用户总数只占很少的部分。
|
||||
|
||||
撇开桌面版不谈,Ubuntu在过去的四年来至少在云和服务器部署方面得到了大量的占有率,并且被证明是Red Hat Enterprise的有力竞争者。Ubuntu还证明了它对基于ARM的硬件十分友好。当Mark在四年前提出他的目标时,他可能考虑到Ubuntu Phone/Touch会比目前的状况更好。可是Ubuntu Phone/Touch目前仅仅在欧洲和[中国][3]可用,并且[Ubuntu Touch软件依旧在成熟的路上][4],[仍需要大量的关键应用程序方面的工作][5]等。
|
||||
|
||||

|
||||
|
||||
距离Canonical宣布[Ubuntu不久将登陆5%的PC][6]也已过去了3年。5%的目标是全球的PC装机量,但哪怕再过3年,我依旧很难相信这个目标会实现。至少在美国和欧洲,我仍难以在实体店看到Ubuntu作为预装的系统,主要的网络零售商/OEM厂商仍倾向于在特定的PC型号中提供Linux,比如Chrome OS、Android设备。
|
||||
|
||||
另一个由开源社区提出的高傲地、落空的目标便是[GNOME将在2010年占有全球桌面市场10%的份额][7]。五年前,没有任何迹象表明他们接近了那10%的里程碑。
|
||||
|
||||
在今天,您认为Ubuntu用户有多少呢?在未来的几年里,Ubuntu(或者Linux)的用户会有多大增长呢?通过评论来与我们分享您的想法吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=2015-200-Million-Goal-Retro
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/vr.php?view=16002
|
||||
[2]:http://www.phoronix.com/scan.php?page=news_item&px=Steam-April-2015-1-Drop
|
||||
[3]:http://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-MX4-In-China
|
||||
[4]:http://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-Calculator-Reboot
|
||||
[5]:http://www.phoronix.com/scan.php?page=news_item&px=MTgzOTM
|
||||
[6]:http://www.phoronix.com/scan.php?page=news_item&px=MTA5ODM
|
||||
[7]:https://www.phoronix.com/scan.php?page=news_item&px=Nzg1Mw
|
||||
@ -1,135 +0,0 @@
|
||||
什么是Linux上实用的命令行式网络监视工具
|
||||
===============================================================================
|
||||
对任何规模的业务来说,网络监视器都是一个重要的功能。网络监视的目标可能千差万别。比如,监视活动的目标可以是保证长期的网络供应、安全保护、对性能进行排查、网络使用统计等。由于它的目标不同,网络监视器使用很多不同的方式来完成任务。比如使用包层面的嗅探,使用流层面的统计数据,向网络中注入探测的流量,分析服务器日志等。
|
||||
|
||||
尽管有许多专用的网络监视系统可以365天24小时监视,但您依旧可以在特定的情况下使用命令行式的网络监视器,某些命令行式的网络监视器在某方面很有用。如果您是系统管理员,那您就应该有亲身使用一些知名的命令行式网络监视器的经历。这里有一份**Linux上流行且实用的网络监视器**列表。
|
||||
|
||||
### 包层面的嗅探器 ###
|
||||
|
||||
在这个类别下,监视工具在链路上捕捉独立的包,分析它们的内容,展示解码后的内容或者包层面的统计数据。这些工具在最底层对网络进行监视、管理,同样的也能进行最细粒度的监视,其代价是部分网络I/O和分析的过程。
|
||||
|
||||
1. **dhcpdump**:一个命令行式的DHCP流量嗅探工具,捕捉DHCP的请求/回复流量,并以用户友好的方式显示解码的DHCP协议消息。这是一款排查DHCP相关故障的实用工具。
|
||||
|
||||
2. **[dsniff][1]**:一个基于命令行的嗅探工具集合,拥有欺骗和劫持功能,被设计用于网络审查和渗透测试。它可以嗅探多种信息,比如密码、NSF流量、email消息、网络地址等。
|
||||
|
||||
3. **[httpry][2]**:一个HTTP报文嗅探器,用于捕获、解码HTTP请求和回复报文,并以用户友好的方式显示这些信息。
|
||||
|
||||
4. **IPTraf**:基于命令行的网络统计数据查看器。它实时显示包层面、连接层面、接口层面、协议层面的报文/字节数。抓包过程由协议过滤器控制,且操作过程全部是菜单驱动的。
|
||||
|
||||

|
||||
|
||||
5. **[mysql-sniffer][3]**:一个用于抓取、解码MySQL请求相关的数据包的工具。它以可读的方式显示最频繁或全部的请求。
|
||||
|
||||
6. **[ngrep][4]**:在网络报文中执行grep。它能实时抓取报文,并用正则表达式或十六进制表达式的方式匹配报文。它是一个可以对异常流量进行检测、存储或者对实时流中特定模式报文进行抓取的实用工具。
|
||||
|
||||
7. **[p0f][5]**:一个被动的基于包嗅探的指纹采集工具,可以可靠地识别操作系统、NAT或者代理设置、网络链路类型以及许多其他与活动的TCP连接相关的属性。
|
||||
|
||||
8. **pktstat**:一个命令行式的工具,通过实时分析报文,显示连接带宽使用情况以及相关的协议(例如,HTTP GET/POST、FTP、X11)等描述信息。
|
||||
|
||||

|
||||
|
||||
13. **[iftop][7]**:一个带宽使用监测工具,可以实时显示某个网络连接的带宽使用情况。它对所有带宽使用情况排序并通过ncurses的接口来进行可视化。他可以方便的监视哪个连接消耗了最多的带宽。
|
||||
|
||||
14. **nethogs**:一个进程监视工具,提供进程相关的实时的上行/下行带宽使用信息,并基于ncurses显示。它对检测占用大量带宽的进程很有用。
|
||||
|
||||
15. **netstat**:一个显示许多TCP/UDP的网络堆栈统计信息的工具。诸如网络接口发送/接收、路由表、协议/套接字的统计信息和属性。当您诊断与网络堆栈相关的性能、资源使用时它很有用。
|
||||
|
||||
16. **[speedometer][8]**:一个可视化某个接口发送/接收的带宽使用的历史趋势,并且基于ncurses的条状图进行显示的工具。
|
||||
|
||||

|
||||
|
||||
17. **[sysdig][9]**:一个对Linux子系统拥有统一调试接口的系统级综合性debug工具。它的网络监视模块可以监视在线或离线、许多进程/主机相关的网络统计数据,例如带宽、连接/请求数等。
|
||||
|
||||
18. **tcptrack**:一个TCP连接监视工具,可以显示活动的TCP连接,包括源/目的IP地址/端口、TCP状态、带宽使用等。
|
||||
|
||||

|
||||
|
||||
19. **vnStat**:一个维护了基于接口的历史接收/发送带宽视图(例如,当前、每日、每月)的流量监视器。作为一个后台守护进程,它收集并存储统计数据,包括接口带宽使用率和传输字节总数。
|
||||
|
||||
### 主动网络监视器 ###
|
||||
|
||||
不同于前面提到的被动的监听工具,这个类别的工具们在监听时会主动的“注入”探测内容到网络中,并且会收集相应的反应。监听目标包括路由路径、可供使用的带宽、丢包率、延时、抖动、系统设置或者缺陷等。
|
||||
|
||||
20. **[dnsyo][10]**:一个DNS检测工具,能够管理多达1500个不同网络的开放解析器集群的DNS查询。它在您检查DNS传播或排查DNS设置的时候很有用。
|
||||
|
||||
21. **[iperf][11]**:一个TCP/UDP带宽测量工具,能够测量两个结点间最大可用带宽。它通过在两个主机间单向或双向的输出TCP/UDP探测流量来测量可用的带宽。它在监测网络容量、调谐网络协议栈参数时很有用。一个叫做[netperf][12]的变种拥有更多的功能及更好的统计数据。
|
||||
|
||||
22. **[netcat][13]/socat**:通用的网络debug工具,可以对TCP/UDP套接字进行读、写或监听。它通常和其他的程序或脚本结合起来在后端对网络传输或端口进行监听。
|
||||
|
||||
23. **nmap**:一个命令行端口扫描和网络发现工具。它依赖于若干基于TCP/UDP的扫描技术来查找开放的端口、活动的主机或者在本地网络存在的操作系统。它在你审查本地主机漏洞或者建立主机映射时很有用。[zmap][14]是一个类似的替代品,是一个用于互联网范围的扫描工具。
|
||||
|
||||
24. ping:一个常用的网络测试工具。通过对ICMP的echo和reply报文进行增强来实现其功能。它在测量路由的RTT、丢包率以及检测远端系统防火墙规则时很有用。ping的变种有更漂亮的界面(例如,[noping][15])、多协议支持(例如,[hping][16])或者并行探测能力(例如,[fping][17])。
|
||||
|
||||

|
||||
|
||||
25. **[sprobe][18]**:一个启发式推断本地主机和任意远端IP地址的网络带宽瓶颈的命令行工具。它使用TCP三次握手机制来评估带宽的瓶颈。它在检测大范围网络性能和路由相关的问题时很有用。
|
||||
|
||||
26. **traceroute**:一个能发现从本地到远端主机的第三层路由/转发路径的网络发现工具。它发送有限TTL的探测报文,收集中间路由的ICMP反馈信息。它在排查低速网络连接或者路由相关的问题时很有用。traceroute的变种有更好的RTT统计功能(例如,[mtr][19])。
|
||||
|
||||
### 应用日志解析器 ###
|
||||
|
||||
在这个类别下,网络监测器把特定的服务器应用程序作为目标(例如,web服务器或者数据库服务器)。由服务器程序产生或消耗的网络流量通过它的日志被分析和监测。不像前面提到的网络层的监视器,这个类别的工具能够在应用层面分析和监控网络流量。
|
||||
|
||||
27. **[GoAccess][20]**:一个针对Apache和Nginx服务器流量的交互式查看器。基于对获取到的日志的分析,它能展示包括日访问量、最多请求、客户端操作系统、客户端位置、客户端浏览器等在内的多个实时的统计信息,并以滚动方式显示。
|
||||
|
||||

|
||||
|
||||
28. **[mtop][21]**:一个面向MySQL/MariaDB服务器的命令行监视器,它可以将当前数据库服务器负载中代价最大的查询以可视化的方式进行显示。它在您优化MySQL服务器性能、调谐服务器参数时很有用。
|
||||
|
||||

|
||||
|
||||
29. **[ngxtop][22]**:一个面向Nginx和Apache服务器的流量监测工具,能够以类似top指令的方式可视化的显示Web服务器的流量。它解析web服务器的查询日志文件并收集某个目的地或请求的流量统计信息。
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
在这篇文章中,我展示了许多的命令行式监测工具,从最底层的包层面的监视器到最高层应用程序层面的网络监视器。知道那个工具的作用是一回事,选择哪个工具使用又是另外一回事。单一的一个工具不能作为您每天使用的通用的解决方案。一个好的系统管理员应该能决定哪个工具更适合当前的环境。希望这个列表对此有所帮助。
|
||||
|
||||
欢迎您通过回复来改进这个列表的内容!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.monkey.org/~dugsong/dsniff/
|
||||
[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
|
||||
[3]:https://github.com/zorkian/mysql-sniffer
|
||||
[4]:http://ngrep.sourceforge.net/
|
||||
[5]:http://lcamtuf.coredump.cx/p0f3/
|
||||
[6]:http://xmodulo.com/recommend/firewallbook
|
||||
[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
|
||||
[8]:https://excess.org/speedometer/
|
||||
[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
|
||||
[10]:http://xmodulo.com/check-dns-propagation-linux.html
|
||||
[11]:https://iperf.fr/
|
||||
[12]:http://www.netperf.org/netperf/
|
||||
[13]:http://xmodulo.com/useful-netcat-examples-linux.html
|
||||
[14]:https://zmap.io/
|
||||
[15]:http://noping.cc/
|
||||
[16]:http://www.hping.org/
|
||||
[17]:http://fping.org/
|
||||
[18]:http://sprobe.cs.washington.edu/
|
||||
[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
|
||||
[20]:http://goaccess.io/
|
||||
[21]:http://mtop.sourceforge.net/
|
||||
[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
|
||||
@ -1,77 +0,0 @@
|
||||
|
||||
iptraf:一个实用的TCP/UDP网络监控工具
|
||||
================================================================================
|
||||
|
||||
[iptraf][1]是一个基于ncurses(ncurses-based)的IP局域网监控器,用来生成包括TCP信息,UDP计数,ICMP和OSPF信息,以太网加载信息,结点状态信息,IP校验和错误等等统计数据。
|
||||
|
||||
它基于ncurses的用户界面帮助用户免于记忆繁琐的命令行开关。
|
||||
|
||||
### 特征 ###
|
||||
|
||||
- 拥有一个IP流量监控器,用来显示你的网络中的流量变化信息。包括TCP标识信息,包以及字节计数,ICMP细节,OSPF包类型。
|
||||
|
||||
- 拥有普通和详细的交互统计数据显示了IP,TCP,UDP,ICMP,非IP以及其他的IP包计数,IP校验和错误,交互活动,包尺寸计数。(这里一些专业术语拿不定)
|
||||
|
||||
- 拥有一个TCP和UDP服务监控器,能够显示普通TCP和UDP应用端口上发送的和接收的包的数量。
|
||||
|
||||
- 拥有一个局域网数据统计模块,能够检查到(discover)处于活动状态的主机,并显示其上正在运行的数据活动的统计信息。
|
||||
|
||||
- 拥有TCP,UDP,以及其他协议的显示过滤器(display filters),允许你只查看感兴趣的流量。
|
||||
|
||||
- 日志功能。
|
||||
|
||||
- 支持以太网,FDDI,ISDN,SLIP,PPP以及loopback接口类型(interface types)。
|
||||
|
||||
- 利用Linux内核内置的(built-in)原始套接字接口,允许它(指iptraf)能够用于许多种网卡上(这句话翻译不好)
|
||||
|
||||
- 全屏,菜单式驱动的操作。
|
||||
|
||||
安装方法
|
||||
|
||||
### Ubuntu以及其衍生版本 ###
|
||||
|
||||
sudo apt-get install iptraf
|
||||
|
||||
### Arch Linux以及其衍生版本 ###
|
||||
|
||||
sudo pacman -S iptra
|
||||
|
||||
### Fedora以及其衍生版本 ###
|
||||
|
||||
sudo yum install iptraf
|
||||
|
||||
### 用法 ###
|
||||
|
||||
|
||||
如果不加任何命令行选项地运行**iptraf**命令,程序将进入一种交互模式,通过主菜单可以访问多种设备(various facilities)
|
||||
|
||||

|
||||
|
||||
|
||||
简易的上手导航菜单。
|
||||
|
||||

|
||||
|
||||
为monitor选择界面(接口)?
|
||||
|
||||

|
||||
|
||||
接口 **pp0** 处的流量。
|
||||
|
||||

|
||||
|
||||
开始吧!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
|
||||
|
||||
作者:[Enock Seth Nyamador][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
@ -0,0 +1,63 @@
|
||||
zBackup——一个通用的重复数据备份工具
|
||||
================================================================================
|
||||
zbackup是一个基于rsync思想的全局重复数据备份工具。给它传入一个大的tar文件后,它会存储该文件的重复区域(仅进行一次),然后对结果进行压缩,并根据参数确定是否对其加密。传入另一个tar文件后,它会从之前的已备份文件中复用重复的数据。只有新的改动会被保存,并且只要文件变动不是很大,需要的存储空间非常少。任何时候之前的已备份文件都可以被完整地读出来。
|
||||
|
||||
### zBackup特性 ###
|
||||
|
||||
- 使用并行的LZMA或者LZO压缩算法压缩已备份数据
|
||||
- 使用内置的AES加密算法加密已备份数据
|
||||
- 可以删除旧的已备份数据
|
||||
- 使用一个64位滚动哈希,保持软碰撞数量为0
|
||||
- 已备份数据由不可更改的文件组成。任何现有文件都没有被更改过
|
||||
- 使用C++语言编写,并且只有适量的依赖库
|
||||
- 可以在生产环境安全使用
|
||||
- 可以在不同备份库中交换数据而无需重新压缩
|
||||
|
||||
### 在ubuntu中安装zBackup ###
|
||||
|
||||
打开终端并运行如下命令:
|
||||
|
||||
sudo apt-get install zbackup
|
||||
|
||||
### 使用zBackup ###
|
||||
|
||||
`zbackup init`命令会初始化一个备份库,用来存放待备份的数据。
|
||||
|
||||
zbackup init [--non-encrypted] [--password-file ~/.my_backup_password ] /my/backup/repo
|
||||
|
||||
`zbackup backup`命令备份一个由`tar c`创建的tar文件到刚才使用`zbackup init`初始化的备份库。(译注:实际使用时类似这样,tar c files | zbackup ...)
|
||||
|
||||
zbackup [--password-file ~/.my_backup_password ] [--threads number_of_threads ] backup /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'`
|
||||
|
||||
`zbackup restore`命令从备份库中恢复一个已备份文件到tar文件中。
|
||||
|
||||
zbackup [--password-file ~/.my_backup_password ] [--cache-size cache_size_in_mb ] restore /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` > /my/precious/backup-restored.tar
|
||||
|
||||
### 可用选项 ###
|
||||
|
||||
- -non-encrypted -- 不加密备份库。
|
||||
- --password-file ~/.my_backup_password -- 使用位于~/.my_backup_password的口令文件来加密备份库和待备份文件,以及解密已备份文件。
|
||||
- --threads number_of_threads -- 限制并行LZMA压缩的线程数到number_of_threads。建议在32位的系统平台使用。
|
||||
- --cache-size cache_size_in_mb -- 使用cache_size_in_mb中的缓存大小来加速恢复文件的过程。
|
||||
|
||||
### zBackup相关文件 ###
|
||||
|
||||
~/.my_backup_password 用来加密备份库和待备份文件,以及解密已备份文件。更多细节见zbackup。
|
||||
|
||||
/my/backup/repo 存放备份库的目录。
|
||||
|
||||
/my/precious/restored-tar 用来恢复已备份文件的tar文件。
|
||||
|
||||
/my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` 指定的之前已备份文件的文件名。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/zbackup-a-versatile-deduplicating-backup-tool.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -0,0 +1,113 @@
|
||||
使用ARChon环境在Ubuntu上运行Android应用
|
||||
================================================================================
|
||||
在此之前,我们尝试过在多款安卓应用模拟器工具上运行安卓应用,比如Genymotion、VirtualBox和Android SDK等。但是,有了这套全新的Chrome安卓运行环境,就可以在Chrome浏览器中运行安卓应用了。所以,下面是一些步骤来指导如何使用ARChon运行环境在Ubuntu上安装安卓应用。
|
||||
|
||||
谷歌已经公布了[首批支持原生运行在Chrome OS的安卓应用][1],而使用一个全新的“**安卓运行环境**”扩展程序使其成为可能。如今,一位名为Vlad Filippov的开发者已经找到了一种把安卓应用移植到桌面端Chrome浏览器的方法。他把chromeos-apk脚本和ARChon安卓运行环境扩展程序两者紧密结合在一起,使得安卓应用可以运行在Windows、Max和Linux系统的桌面端Chrome浏览器中。
|
||||
|
||||
应用借助这种运行环境时的性能并不是很好。同样,由于它是官方运行环境的非官方二次开发包,而且运行在Google的Chrome OS之外,因此一些如webcam和speaker等系统集成工具可能需要通过打补丁获得或者根本就没有。
|
||||
|
||||
### 安装Chrome ###
|
||||
|
||||
首先,需要在机器上安装Chrome,版本要求是Chrome 37或者更高。可以从[Chrome浏览器的下载页面][2]下载。
|
||||
|
||||
如果打算安装Dev Channel版本,按照如下操作。
|
||||
|
||||
首先,使用这个命令为Google Chrome添加软件源列表:
|
||||
|
||||
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
|
||||
|
||||

|
||||
|
||||
添加完软件源列表后,使用下列命令更新本地的软件库索引。
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
现在,就可以安装非稳定版的google chrome,即开发版。
|
||||
$ sudo apt-get install google-chrome-unstable
|
||||
|
||||

|
||||
|
||||
### 安装Archon运行时环境 ###
|
||||
|
||||
接下来,需要下载定制版的运行环境安装包,因为官方版本不被Google或Vlad Filippov创建的Chromium安卓运行环境认可。它在很多方面有别于官方版本,主要区别是它可以用于Google浏览器的各个桌面端。下面是需要下载的运行环境安装包,请根据所安装的Ubuntu系统位数选择下列的一种。
|
||||
|
||||
**32位** Ubntu发行版:
|
||||
|
||||
- [Download Archron for 32-bit Ubuntu][3]
|
||||
|
||||
**64位** Ubntu发行版:
|
||||
|
||||
- [Download Archron for 64-bit Ubuntu][4]
|
||||
|
||||
下载好运行环境安装包后,从.zip文件中解压,并将解压得到的目录移动到Home目录。操作命令如下:
|
||||
|
||||
$ wget https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_32.zip
|
||||
|
||||

|
||||
|
||||
$ unzip ARChon-v1.1-x86_32.zip ~/
|
||||
|
||||
接下来是安装运行时环境,首先打开Google Chrome浏览器,在地址栏键入**chrome://extensions**。然后,选中“**开发者模式**”。最后,点击“**载入未打包扩展程序**”,选择刚才放置在**~/Home**下面的文件夹。
|
||||
|
||||
### 安装 ChromeOS-APK ###
|
||||
|
||||
如果要用到上面提到的应用,那么手动转换这些APKs无需复杂的操作——只需要安装“[chromeos-apk][5]”命令行JavaScript工具。可以在Node Package Modules(npm)管理器中安装它。为了安装npm和chromeos-apk,在shell或终端中运行下面命令:
|
||||
|
||||
$ sudo apt-get install npm nodejs nodejs-legacy
|
||||
|
||||
如果**操作系统是64位**,需要安装下面这个库,命令如下:
|
||||
|
||||
$ sudo apt-get install lib32stdc++6
|
||||
|
||||
然后,运行这条命令来安装最新的chromeos-apk:
|
||||
|
||||
$ npm install -g chromeos-apk@latest
|
||||
|
||||

|
||||
|
||||
取决于系统配置,可能需要以sudo权限运行后一条命令。
|
||||
|
||||
现在,我们将找一个应用程序的APK来在Google浏览器上试一试,但务必牢记**并非所有的安卓应用都可以**,有一些可能不稳定或者缺少某些特性。大部分安装即用的通讯类应用都不适用这个环境。
|
||||
|
||||
### 转换APK ###
|
||||
|
||||
将**安卓APK放到~/Home**下,然后在**终端**执行下列命令进行转换:
|
||||
|
||||
$ chromeos-apk myapp.apk --archon
|
||||
|
||||
如果想以全屏模式运行应用,请替换成这条命令:
|
||||
|
||||
$ chromeos-apk myapp.apk --archon --tablet
|
||||
|
||||
注意:请将myapp.apk替换成待转换的安卓APK应用的文件名。
|
||||
|
||||
为了方便,也可以使用[Twerk][6]来进行转换,这样可以跳过这一步。
|
||||
|
||||
### 运行安卓Apk ###
|
||||
|
||||
最后,打开chrome浏览器,然后进入chrome://extensions页面,勾选开发者模式。点击“载入未打包扩展程序”按钮,选择文件夹载入刚创建的脚本。
|
||||
|
||||
至此,就可以打开Chrome应用启动器运行安卓应用了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
万岁!我们已经成功在Chrome浏览器中安装好安卓Apk应用程序了。这篇文章是关于一款由Vlad Filippov开发的、名为Archon的、时下流行的Chrome安卓运行环境。这个运行环境使用户在Chrome浏览器中运行转换过的Apk文件。目前它还不支持通讯类应用,诸如Whatsapp。因此,如果你有任何问题、建议和反馈,请在下面的评论框中写出来。非常感谢!去拥抱Archon吧!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/android-apps-ubuntu-archon-runtime/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://chrome.blogspot.com/2014/09/first-set-of-android-apps-coming-to.html
|
||||
[2]:https://www.google.com/chrome/browser
|
||||
[3]:https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_32.zip
|
||||
[4]:https://github.com/vladikoff/chromeos-apk/releases/download/v3.0.0/ARChon-v1.1-x86_64.zip
|
||||
[5]:https://github.com/vladikoff/chromeos-apk/blob/master/README.md
|
||||
[6]:https://chrome.google.com/webstore/detail/twerk/jhdnjmjhmfihbfjdgmnappnoaehnhiaf
|
||||
@ -1,314 +0,0 @@
|
||||
如何在linux上使用Trickle来限制应用程序的网络宽带使用.
|
||||
================================================================================
|
||||
有没有遇到过系统中的某个应用程序独占了你所有的网络宽带的情形?如果你有过这样的遭遇,那么你就会感受到Trickle宽带调整应用角色的价值.不管你是一个系统管理员还是仅仅Linux用户,都需要学习如何控制应用程序的上下行速度,来确保你的网络宽带不会被某个程序
|
||||
霸占.
|
||||
|
||||

|
||||
Install Trickle Bandwidth Limit in Linux
|
||||
|
||||
### 什么是 Trickle? ###
|
||||
|
||||
Trickle是一个网络宽带调整工具,可以让我们管理应用程序的网络上下行速度,使得可以避免其中的某个应用程序吃掉了全部或大部分可用的宽带.换句话说,Trickle可以让你基于单个应用程序来控制
|
||||
网络流量速率,而不是仅仅针对与单个用户--在客户端网络环境中经典的宽带调整样例,
|
||||
|
||||
### Trickle是如何工作的?###
|
||||
|
||||
另外,tricle可以帮助我们基于应用来定义优先级,所以当对整个系统进行了全局限制设定,高优先级的应用依然会自动地获取更多的宽带。为了实现这个目标,tricle设置通过TCP连接的套接字对数
|
||||
据发送、数据接收路径的流量限制。我们必须注意到,除了影响传输速率之外,tricle任何时候都不会以任何方式来改变其处理过程。
|
||||
|
||||
### Trickle不能做什么? ###
|
||||
|
||||
这么说吧,唯一的限制就是,tricle静态连接的应用或者具有SUID或SGID位设置的二进制--因为他们使用动态链接并且将其自身加载到调整过程以及其关联的网络套接字之间。 Trickle此时会在这两种软件
|
||||
组件之间扮演代理的角色。
|
||||
|
||||
由于trickle并不会需要超级用户的权限来运行,所以用户可以设置用户独立的流量限制,可能这并不是你想要的,我们会探索如何使用全局设定来限制系统中的所有用户的流量限制。也即是说,此时系统中的每个用户具有管理
|
||||
各自的流量速率,但是无论如何,都会受到系统管理员给他们设置的边界限制。
|
||||
|
||||
在这边文章中,我们会描述如何通过trickle在linux平台上管理应用程序使用的网络宽带。为了生成必要流量,在此会在客户端(CentOS 7 server – dev1: 192.168.0.17)上使用 ncftpput 和
|
||||
ncftpget, 在服务器(Debian Wheezy 7.5 – dev2: 192.168.0.15)上使用vsftpd 来进行演示。 相同的指令也可以在RedHat,Fedora和Ubuntu等系统使用。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
1. 对于 RHEL/CentOS 7/6, [开启EPEL仓库][1]。EPEL的Extra Packages是一个 有Fedora项目维护的高质量、开源的软件仓库,而且百分之百与其衍生产品相兼容,如
|
||||
企业版本Linux和CentOS. 在这个仓库中trickle和ncftp两者都是可用的。
|
||||
|
||||
2. 按照如下方式安装ncftp:
|
||||
|
||||
# yum update && sudo yum install ncftp [On RedHat based systems]
|
||||
# aptitude update && aptitude install ncftp [On Debian based systems]
|
||||
|
||||
3. 在单独的服务器上设置一个FTP服务器。需要注意的是,尽管FTP天生就不安全,但是
|
||||
仍然被广泛应用在安全性无关紧要的文件上传下载中。 在这篇文章中我们使用它来演示
|
||||
trickle的优点,同时它也会在客户端的标准输出流中显示传输速率,我们将是否在另外
|
||||
的日期时间中使用放在一边讨论。
|
||||
|
||||
# yum update && yum install vsftpd [On RedHat based systems]
|
||||
# aptitude update && aptitude install vsftpd [On Debian based systems]
|
||||
|
||||
现在,在FTP服务器上按照以下方式编辑 /etc/vsftpd/vsftpd.conf 文件。
|
||||
|
||||
anonymous_enable=NO
|
||||
local_enable=YES
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
|
||||
在此之后,确保在你的当前会话中开启了vsftpd,并在之后的启动中让其自动启动。
|
||||
|
||||
# systemctl start vsftpd [For systemd-based systems]
|
||||
# systemctl enable vsftpd
|
||||
# service vsftpd start [For init-based systems]
|
||||
# chkconfig vsftpd on
|
||||
|
||||
4. 如果你选在在一个CentOS/RHEL 7中为FTP服务器的远程访问配备SSH秘钥,你需要
|
||||
一个具有适合访问root目录之外的目录和文件内容上传下载权限并密码受保护的用户账户。
|
||||
|
||||
你可以通过在你的浏览器中输入以下的URL来浏览你的Home目录。一个登陆窗口会弹出来
|
||||
提示你输入FTP服务器中的有效的用户名和密码。
|
||||
|
||||
ftp://192.168.0.15
|
||||
|
||||
如果验证成功,你就会看到你的home目录中的内容。该教程的稍后部分中,你将可以刷新
|
||||
页面来显示在你之前上传过的文件。
|
||||
|
||||

|
||||
FTP Directory Tree
|
||||
|
||||
### 如何在Linux中安装 Tricle ###
|
||||
|
||||
1. 通过yum或aptitude来安装tricle.
|
||||
|
||||
为了确保能够成功安装,最好在安装工具之前,保证当前的安装包是最新的版本。
|
||||
|
||||
|
||||
# yum -y update && yum install trickle [On RedHat based systems]
|
||||
# aptitude -y update && aptitude install trickle [On Debian based systems]
|
||||
|
||||
2. 确认trickle是否对特定的二进制包有用。
|
||||
|
||||
之前我们解释过,trickle只对使用动态或共享包的二进制包有用。为了确认我们是否可以对某个特定的应用使用trickle,我们可以使用著名的ldd(
|
||||
列出动态依赖)工具。 特别地,我们会查看任何给定程序的动态依赖中检查其当前使用的glibc,因为其准确地定义了使用套接字交流中使用的系统调用。
|
||||
|
||||
对一个给定的二进制包执行以下命令来查看是否能对其使用trickle进行宽带调整:
|
||||
|
||||
# ldd $(which [binary]) | grep libc.so
|
||||
|
||||
例如,
|
||||
|
||||
# ldd $(which ncftp) | grep libc.so
|
||||
|
||||
其输出是:
|
||||
|
||||
# libc.so.6 => /lib64/libc.so.6 (0x00007efff2e6c000)
|
||||
|
||||
输出中的括号中的字符可能在不同的系统平台中发生改变,甚至相同的命令在不同的时候运行也会,因为其代表包加载到物理内存中的地址。
|
||||
|
||||
如果上面的命令没有返回任何的结果,就说明这个二进制包没有使用libc包,因此tricle对其不能起到宽带调整的作用。
|
||||
|
||||
### 学习如何使用Trickle###
|
||||
|
||||
最基本的用法就是使用其单模式,通过这种方式,trickle用来显示地定义给定应用程序的上传下载速率。如前所述,为了简单性,我们会使用相同的应用
|
||||
来进行上传下载测试。
|
||||
|
||||
#### 在单模式下运行trickle####
|
||||
|
||||
我们会比较在有无trickle的情况下的上传下载速率, ‘-d’选项指示下载速率(KB/s单位),而'-u'选项指示相同单位的上传速率。另外我们会使用到‘-s’
|
||||
选项来指定trickle应该以单模式运行。
|
||||
|
||||
以单模式运行trickle的基本语法如下:
|
||||
|
||||
# trickle -s -d [download rate in KB/s] -u [upload rate in KB/s]
|
||||
|
||||
为了能够让你自己运行以下样例,确保你在自己的客户端安装了trickle和ncftp(我的是192.168.0.17)。
|
||||
|
||||
**样例1:在有无trickle的情况下上传一个2.8 MB的PDF文件。**
|
||||
|
||||
我们使用一个自由发布的LInux基础知识PDF文件来进行下面的测试[文件链接][2]。
|
||||
|
||||
你可以首先使用下面的命令将这个文件下载到你当前的工作目录中:
|
||||
# wget http://linux-training.be/files/books/LinuxFun.pdf
|
||||
|
||||
下面是在没有trickle的情况下将一个文件上传到我们的FTP服务器的语法:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /remote_directory local-filename
|
||||
|
||||
其中的 /remote_directory 是相对于用户名的Home目录的上传路径,而local-filename是一个你当前工作目录中的文件。
|
||||
|
||||
特别的是,在没有trickle的情形下,我们可以得到上传峰值速率52.02MB/s(请注意,这个不是真正的平均上传速率,而是峰值开始的瞬时值),而且这个文件几乎
|
||||
在瞬间就完成了上传。
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /testdir LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 52.02 MB/s
|
||||
|
||||
在使用trickle的情况下,我们会限制上传速率在5KB/s。在第二次上传文件之前,我们需要在目标目录中删除这个文件,否则ncftp就会通知我们在目标
|
||||
目录中已经存在了与上传文件相同的文件,从而不会执行文件的传输:
|
||||
# rm /absolute/path/to/destination/directory/LinuxFun.pdf
|
||||
|
||||
然后:
|
||||
|
||||
# trickle -s -u 5 ncftpput -u username -p password 111.111.111.111 /testdir LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 4.94 kB/s
|
||||
|
||||
在上面的样例中,我们看到平均的上传速率下降到了5KB/s。
|
||||
|
||||
**样例2:在有无trickle的情况下下载相同过得2.8MB的PDF文件**
|
||||
|
||||
首先,记得从原来的源文目录中删除这个PDF:
|
||||
|
||||
# rm /absolute/path/to/source/directory/LinuxFun.pdf
|
||||
|
||||
请注意,下面的样例中将远程的文件下载到客户端机器的当前目录下,这是由FTP服务器的IP地址后面的·.·决定的。
|
||||
|
||||
没有trickle的情况下:
|
||||
|
||||
# ncftpget -u username -p password 111.111.111.111 . /testdir/LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 260.53 MB/s
|
||||
|
||||
在有trickle的情况下,限制下载速率在20KB/s:
|
||||
|
||||
# trickle -s -d 30 ncftpget -u username -p password 111.111.111.111 . /testdir/LinuxFun.pdf
|
||||
|
||||
输出:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 17.76 kB/s
|
||||
|
||||
### 在有监督的模式下运行Trickle [未管理的]###
|
||||
|
||||
Tricle也可以在未管理的模式下运行,通过跟随在/etc/tricled.conf文件中定义的一系列参数。 这个文件定义了守护线程 trickled的行为以及如何管理tricle。
|
||||
|
||||
另外,如果你想要全局设置被所有的应用程序使用的话,我们就会需要使用tricle命令。 这个命令运行守护线程并允许我们通过trickle定义所有应用程序共享的上传下载限制,不需要我们每次来进行指定。
|
||||
|
||||
例如,运行:
|
||||
|
||||
# trickled -d 50 -u 10
|
||||
|
||||
会导致任何通过tricle运行的应用程序的上传下载速率分别限制在30kb/s和10kb/s。
|
||||
|
||||
请注意,你可以在任何时间都能确认守护线程tricled是否正在运行以及其运行参数:
|
||||
|
||||
# ps -ef | grep trickled | grep -v grep
|
||||
|
||||
输出:
|
||||
|
||||
root 16475 1 0 Dec24 ? 00:00:04 trickled -d 50 -u 10
|
||||
|
||||
**样例3:在是否使用tricle的情形下上传一个 19MB 的mp4文件到我们的FTP服务器。**
|
||||
|
||||
在这个样例中,我们会使用“He is the gift”的自由分布视频,可以通过这个[链接][3]下载。
|
||||
|
||||
我们将会在开始通过以下的命令将这个文件下载到你的当前工作目录中:
|
||||
|
||||
# wget http://media2.ldscdn.org/assets/missionary/our-people-2014/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
首先,我们会使用之前列出的命令来开启守护进程trickled:
|
||||
|
||||
# trickled -d 30 -u 10
|
||||
|
||||
在没有trickle时:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /testdir 2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 36.31 MB/s
|
||||
|
||||
有trickle的时:
|
||||
|
||||
# trickle ncftpput -u username -p password 192.168.0.15 /testdir 2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 9.51 kB/s
|
||||
|
||||
我们可以看到上面的输出,上传的速率下降到了约 10KB/s。
|
||||
|
||||
** 样例4:在有无trickle的情形下下载这个相同的视频 **
|
||||
|
||||
与样例2一样,我们会将该文件下载到当前工作目录中。
|
||||
|
||||
在没有trickle时:
|
||||
|
||||
# ncftpget -u username -p password 192.168.0.15 . /testdir/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 108.34 MB/s
|
||||
|
||||
有trickle的时:
|
||||
|
||||
# trickle ncftpget -u username -p password 111.111.111.111 . /testdir/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
输出:
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 29.28 kB/s
|
||||
|
||||
上面的结果与我们之前设置的下载限速相对应(30KB/s)。
|
||||
|
||||
**注意:** 一旦守护进程开启之后,没有必要使用trickle来为每个应用程序来单独设置限制。
|
||||
|
||||
如前所述,每个人都可以进一步地通过tricled.conf来客制化tricle的宽带速率调整,该文件的一个典型的分区有以下部分组成:
|
||||
|
||||
[service]
|
||||
Priority = <value>
|
||||
Time-Smoothing = <value>
|
||||
Length-Smoothing = <value>
|
||||
|
||||
其中,
|
||||
|
||||
- [service] 用来指示我们想要对其进行宽带使用调整的应用程序名称
|
||||
- Priority 用来让我们为某个服务制定一个相对于其他服务高的优先级,这样就不允许守护进程管理中的一个单独的应用程序来占用所有的宽带。越小的数字代表更高的优先级。
|
||||
- Time-Smoothing [以秒计]: 定义了trickled让各个应用程序传输或接收数据的时间间隔。小的间隔值(0.1-1秒)对于交互式应用程序是理想的,因为这样会具有一个更加平滑的会话体验,而一个相对较大
|
||||
的时间间隔值(1-10秒)对于需要批量传输应用程序就会显得更好。如果没有指定该值,默认是5秒。
|
||||
- Length-smoothing [KB 单位]: 该想法与Time-Smoothing如出一辙,但是是基于I/O操作而言。如果没有指定值,会使用默认的10KB。
|
||||
|
||||
平滑值的改变会被翻译为将指定的服务的使用一个间隔值而不是一个固定值。不幸的是,没有一个特定的公式来计算间隔值的上下限,主要依赖于特定的应用场景。
|
||||
|
||||
下面是一个在CentOS 7 客户端中的tricled.conf 样例文件(192.168.0.17):
|
||||
|
||||
[ssh]
|
||||
Priority = 1
|
||||
Time-Smoothing = 0.1
|
||||
Length-Smoothing = 2
|
||||
|
||||
[ftp]
|
||||
Priority = 2
|
||||
Time-Smoothing = 1
|
||||
Length-Smoothing = 3
|
||||
|
||||
使用该设置,tricled会为SSH赋予比FTP较高的传输优先级。值得注意的是,一个交互进程,例如SSH,使用了一个较小的时间间隔值,然而一个处理批量数据传输的服务如FTP使用一个较大的时间
|
||||
间隔来负责之前的样例中的上传下载速率,尽管不是百分百的有trickled指定的值,但是也已经非常接近了。
|
||||
|
||||
### 总结 ###
|
||||
在该文章中,我们探索了任何使用trickle在基于Fedora发行版和Debian衍生版平台上来限制应用程序的宽带使用.也包含了其他的可能用法,但是不对以下情形进行限制:
|
||||
|
||||
- 限制系统下载工具的下载速度,例如[wget][4],或 BT客户端.
|
||||
|
||||
- 限制你的系统的包管理工具`[yun][5]`更新的速度 (如果是基于Debian系统的话,其包管理工具为`[aptitude][6]`)。
|
||||
|
||||
- 如果你的服务器是在一个代理或防火墙后面(或者其本身即是代理或防火墙的话),你可以使用trickle来同时设定下载和上传速率,或者与客户端或外部交流速率。
|
||||
|
||||
欢迎提问或留言.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-and-limit-downloadupload-bandwidth-with-trickle-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:http://linux-training.be/files/books/LinuxFun.pdf
|
||||
[3]:http://media2.ldscdn.org/assets/missionary/our-people-2014/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
[4]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]:http://www.tecmint.com/dpkg-command-examples/
|
||||
@ -1,172 +0,0 @@
|
||||
|
||||
使用Observium来监控你的网络和服务器
|
||||
================================================================================
|
||||
### 简介###
|
||||
|
||||
在监控你的服务器,交换机或者物理机器时有过问题吗?, **Observium**可以满足你的需求.作为一个免费的监控系统,可以帮助你远程监控你的服务器.它是一个由PHP编写的基于自动发现SNMP的网络监控平台,支持非常广泛的网络硬件和操作系统,包括 Cisco,Windows,Linux,HP,NetApp等.在此我会通过在Ubuntu12.04上设置一个**Observium**服务器的同时提供相应的步骤.
|
||||
|
||||

|
||||
|
||||
目前存在两种不同的**observium**版本.
|
||||
|
||||
- Observium 社区版本是一个在QPL开源许可证下的免费工具,这个版本时对于较小部署的最好解决方案. 该版本每6个月得到一次安全性更新.
|
||||
- 第2个版本是Observium Professional, 该版本在基于SVN的发布机制下的发行版. 会得到每日安全性更新. 该工具适用于服务提供商和企业级部署.
|
||||
|
||||
更多信息可以通过其官网获得[website of Observium][1].
|
||||
|
||||
### 系统需求###
|
||||
|
||||
为了安装 **Observium**, 需要具有一个最新安装的服务器。**Observium**是在Ubuntu LTS和Debian系统上进行开发的,所以推荐在Ubuntu或Debian上安装**Observium**,因为可能在别的平台上会有一些小问题。
|
||||
|
||||
该文章会知道你如何在Ubuntu12.04上进行安装**Observium**。对于小型的**Observium**安装,推荐的基础配置要有256MB内存和双核处理器。
|
||||
|
||||
### 安装需求 ###
|
||||
|
||||
在安装**Observuim**之前,你需要确认安装所有的依赖关系包。
|
||||
|
||||
首先,使用下面的命令更新的服务器:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
然后你需要安装运行Observuim 所需的全部包。
|
||||
|
||||
Observium需要使用下面所列出的软件才能正确的运行:
|
||||
|
||||
- LAMP server
|
||||
- fping
|
||||
- Net-SNMP 5.4+
|
||||
- RRDtool 1.3+
|
||||
- Graphviz
|
||||
|
||||
对于可选特性的要求:
|
||||
|
||||
- Ipmitool - 只有当你想要探寻IPMI(Intelligent Platform Management Interface智能平台管理接口)基板控制器。
|
||||
- Libvirt-bin - 只有当你想要使用libvirt进行远程VM主机监控时。
|
||||
|
||||
sudo apt-get install libapache2-mod-php5 php5-cli php5-mysql php5-gd php5-mcrypt php5-json php-pear snmp fping mysql-server mysql-client python-mysqldb rrdtool subversion whois mtr-tiny ipmitool graphviz imagemagick libvirt ipmitool
|
||||
|
||||
### 为Observium创建MySQL 数据库和用户。
|
||||
|
||||
现在你需要登录到MySQL中并为**Observium**创建数据库:
|
||||
mysql -u root -p
|
||||
|
||||
在用户验证成功之后,你需要按照下面的命令创建该数据库。
|
||||
|
||||
CREATE DATABASE observium;
|
||||
|
||||
数据库名为**Observium**,稍后你会需要这个信息。
|
||||
|
||||
现在你需要创建数据库管理员用户。
|
||||
|
||||
CREATE USER observiumadmin@localhost IDENTIFIED BY 'observiumpassword';
|
||||
|
||||
接下来,你需要给该管理员用户相应的权限来管理创建的数据库。
|
||||
|
||||
GRANT ALL PRIVILEGES ON observium.* TO observiumadmin@localhost;
|
||||
|
||||
你需要将权限信息写回到磁盘中来激活新的MySQL用户:
|
||||
|
||||
FLUSH PRIVILEGES;
|
||||
exit
|
||||
|
||||
### 下载并安装 Observium###
|
||||
|
||||
现在我们的系统已经准备好了, 可以开始Observium的安装了。
|
||||
|
||||
第一步,创建Observium将要使用的文件目录:
|
||||
mkdir -p /opt/observium && cd /opt
|
||||
|
||||
为了达到本教程的目的,我们将会使用Observium的社区/开源版本。使用下面的命令下载并解压:
|
||||
|
||||
wget http://www.observium.org/observium-community-latest.tar.gz
|
||||
tar zxvf observium-community-latest.tar.gz
|
||||
|
||||
现在进入到Observium目录。
|
||||
|
||||
cd observium
|
||||
|
||||
将默认的配置文件'**config.php.default**'复制到'**config.php**',并将数据库配置选项填充到配置文件中:
|
||||
|
||||
cp config.php.default config.php
|
||||
nano config.php
|
||||
|
||||
----------
|
||||
|
||||
/ Database config
|
||||
$config['db_host'] = 'localhost';
|
||||
$config['db_user'] = 'observiumadmin';
|
||||
$config['db_pass'] = 'observiumpassword';
|
||||
$config['db_name'] = 'observium';
|
||||
|
||||
现在为MySQL数据库设置默认的数据库模式:
|
||||
php includes/update/update.php
|
||||
|
||||
现在你需要创建一个文件目录来存储rrd文件,并修改其权限以便让apache能将写入到文件中。
|
||||
|
||||
mkdir rrd
|
||||
chown apache:apache rrd
|
||||
|
||||
为了在出现问题时进行问题修理,你需要创建日志文件。
|
||||
|
||||
mkdir -p /var/log/observium
|
||||
chown apache:apache /var/log/observium
|
||||
|
||||
现在你需要为Observium创建虚拟主机配置。
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /opt/observium/html/
|
||||
ServerName observium.domain.com
|
||||
CustomLog /var/log/observium/access_log combined
|
||||
ErrorLog /var/log/observium/error_log
|
||||
<Directory "/opt/observium/html/">
|
||||
AllowOverride All
|
||||
Options FollowSymLinks MultiViews
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
下一步你需要让你的Apache服务器的rewrite(重写)功能生效。
|
||||
|
||||
为了让'mod_rewrite'生效,输入以下命令:
|
||||
|
||||
sudo a2enmod rewrite
|
||||
|
||||
该模块在下一次Apache服务重启之后就会生效。
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
###配置Observium###
|
||||
|
||||
在登入网络接口之前,你需要为Observium创建一个管理员账户(级别10)。
|
||||
|
||||
# cd /opt/observium
|
||||
# ./adduser.php admin adminpassword 10
|
||||
User admin added successfully.
|
||||
|
||||
下一步为发现和探寻工作设置一个cron任务,创建一个新的文件‘**/etc/cron.d/observium**’ 并在其中添加以下的内容。
|
||||
|
||||
33 */6 * * * root /opt/observium/discovery.php -h all >> /dev/null 2>&1
|
||||
*/5 * * * * root /opt/observium/discovery.php -h new >> /dev/null 2>&1
|
||||
*/5 * * * * root /opt/observium/poller-wrapper.py 1 >> /dev/null 2>&1
|
||||
|
||||
重载cron进程来获取系的人物实体。
|
||||
|
||||
# /etc/init.d/cron reload
|
||||
|
||||
好啦,你已经完成了Observium服务器的安装拉! 使用你的浏览器登录到**http://<Server IP>**,然后上路巴。
|
||||
|
||||

|
||||
|
||||
尽情享受吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/monitoring-network-servers-observium/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
[1]:http://www.observium.org/
|
||||
@ -1,81 +0,0 @@
|
||||
在windows下,连接你的Linux服务器的ssh免费客户端工具列举\
|
||||
================================================================================
|
||||
你的操作系统是Windows,而你想要连接Linux服务器相互传送文件.于是你需要一个Secure Shell,简称SSH.实际上,SSH是一个网络协议,允许你通过网络连接到Linux和Unix服务器.SSH使用公钥加密来认证远程的计算机.你可以有多种途径使用SSH,要么自动地连接,或者使用密码认证登录.
|
||||
|
||||
本篇文章讲述了几种SSH客户端,供选择使用来连接你的Linux服务器.
|
||||
|
||||
我们开始.
|
||||
|
||||
### Putty ###
|
||||
|
||||
**Putty**是最有名的SSH和telnet客户端,最初由Simon Tatham为Windows平台开发.Putty是一款开源软件,有可用的源代码,和一群志愿者的发展和支持.
|
||||
|
||||

|
||||
|
||||
Putty非常易于安装和使用,通常你不需要改大部分的配置选项.你只需要输入少量基本的参赛,就可以开始最简单的对话连接[here][1].
|
||||
|
||||
### Bitvise SSH Client ###
|
||||
|
||||
**Bitvise SSH **是一款支持SSH和SFTP的Windows客户端.由Bitvise专业地提供支持和发展.这款SSH客户端性能强悍,易于安装和使用.Bitvise SSH客户端功能丰富,拥有图形界面,通过一个有自动重连能力的内置代理允许用户动态端口运行.
|
||||
|
||||

|
||||
|
||||
Bitvise SSH客户端对个人用户使用**是**免费的,同时对于在组织内部的单独商业使用也一样.你可以[在这里下载Bitvise SSH客户端][2]
|
||||
|
||||
### MobaXterm ###
|
||||
|
||||
**M偶吧Xterm**是你的**终极工具箱,解决远程计算**.在单一的Windows应用里,它提供了许多裁剪过的的功能,针对程序员,网络管理者,IT管理员和相当一部分需要在更简单界面(此处原文为in a more simple fashion,有点费解)远程作业的用户.
|
||||
|
||||

|
||||
|
||||
MobaXterm提供了所有重要的**远程网络工具** (如SSH, X11, RDP, VNC, FTP, MOSH 等等),和**Unix 命令**(bash, ls, cat, sed, grep, awk, rsync等等)适用于Windows桌面,在一个**单独便于携带的可执行文件里**,其工作独立于工具箱.MobaXterm对**个人使用免费**.你可以下载MobaXterm[在这里][3].
|
||||
|
||||
### DameWare SSH ###
|
||||
|
||||
我认为**DameWare SSH**是最好的免费SSH客户端.
|
||||
|
||||

|
||||
|
||||
这个免费工具是一个终端模拟器,可以让你实现从一个易用控制台的多种telnet和SSH连接.
|
||||
|
||||
-用一个带标签的控制台界面管理多方会话
|
||||
-在Windows文件系统中保存喜欢的会话
|
||||
-获取多个保存的证书集合,用于轻松登录不同的设备
|
||||
-使用telnet,SSH1和SSH2协议连接计算机和设备
|
||||
|
||||
你可以从[这个链接][4]下载 **DameWare SSH**
|
||||
|
||||
### SmarTTY ###
|
||||
|
||||
SmarTTY是一款免费的多标签SSH客户端,支持使用SCP命令及时复制文件和目录
|
||||
|
||||

|
||||
|
||||
大多数SSH服务器每次连接支持最多10个子会话.SmarTTY在这方面做得很好:没有烦人的多个窗口,不需要重新登录,仅仅打开一个新的标签页就可以开始了!
|
||||
|
||||
### Cygwin ###
|
||||
|
||||
Cygwin是一款GNU和开源工具的大杂烩,提供的功能近似一个Windows平台下的Linux.
|
||||
|
||||

|
||||
|
||||
**Cygwin**包括了一个Unix系统,集模拟库,cygwin.dll,GNU大量集合和其他被归类了的大量可选免费应用软件包.在这些安装包中,有高质量的编译器和其他软件开发工具,一个X11服务器,一套完整的X11开发套件,GNU emacs编辑器,Tex和LaTeX,openSSH(客户端和服务器),除此之外还有很多,包括在微软Windows下需要编译和使用PhysioToolkit软件的每一样东西.
|
||||
|
||||
读完我们的文章后,不知你中意哪一款SSH客户端?你可以留下你的评论,描述你喜欢的系统和选择的原因.当然,如果有另外的SSH客户端没有被本文列举出来,你可以帮助我们补充.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/list-free-windows-ssh-client-tools-connect-linux-server/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
[1]:http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html
|
||||
[2]:http://www.bitvise.com/download-area
|
||||
[3]:http://mobaxterm.mobatek.net/download.html
|
||||
[4]:http://www.dameware.com/downloads/registration.aspx?productType=ssh&AppID=17471&CampaignID=70150000000PcNM
|
||||
[5]:http://cygwin.com/packages/
|
||||
@ -0,0 +1,144 @@
|
||||
如何在Fedora或CentOS上使用Samba共享文件夹
|
||||
================================================================================
|
||||
如今,无论在家里或者是办公场所,不同的电脑之间共享文件夹已不是什么新鲜事了。在这种趋势下,现代操作系统通过网络文件系统的方式使得电脑间数据的交换变得简单而透明。如果您工作的环境中既有微软的Windows又有Linux,那么,一个共享文件及目录的方式便是通过一个跨平台网络文件共享协议,SMB/CIFS。Windows天然的支持SMB/CIFS,Linux也通过开源的软件Samba实现了SMB/CIFS协议。
|
||||
|
||||
在这篇文章中,我们将展示**如何使用Samba共享文件夹**。我们使用的Linux平台是**Fedora或CentOS**。这篇文章分为四部分。首先,我们在Fedora/CentOS环境下安装Sambe。接着,我们讨论如何调整SELinux和防火墙配置以允许Samba的文件共享。最后我们介绍如何使用Samba来共享文件夹。
|
||||
|
||||
### 步骤1:在Fedora和CentOS上安装Samba ###
|
||||
|
||||
首先,安装Samba以及进行一些基本的配置。
|
||||
|
||||
检验Samba是否已经安装在您的系统中:
|
||||
|
||||
$ rpm -q samba samba-common samba-client
|
||||
|
||||
如果上面的命令没有任何输出,这意味着Samba并未安装。这时,应使用下面的命令来安装Samba。
|
||||
|
||||
$ sudo yum install samba samba-common samba-client
|
||||
|
||||
接下来,创建一个用于在网络中共享的本地文件夹。这个文件夹应该以Samba共享的方式导出到远程的用户。在这个指南中,我们会在顶层文件夹'/'中创建这个文件夹,因此,请确保您有相应的权限。
|
||||
|
||||
$ sudo mkdir /shared
|
||||
|
||||
如果您想在您的home文件夹内创建共享文件夹(例如,~/shared),您必须激活SELinux中Samba的home文件夹共享选项,具体将在后面提到。
|
||||
|
||||
在创建/shared文件夹后,设置文件夹权限以保证其余用户可以访问它。
|
||||
|
||||
$ sudo chmod o+rw /shared
|
||||
|
||||
如果您不想其他用户对该文件夹拥有写权限,您需要移除命令中的'w'选项。
|
||||
|
||||
$ sudo chmod o+r /shared
|
||||
|
||||
接下来,创建一个空文件来测试。这个文件可以被用来验证Samba的共享已经被挂载。
|
||||
|
||||
$ sudo touch /shared/file1
|
||||
|
||||
### 步骤2:为Samba配置SELinux ###
|
||||
|
||||
接下来,我们需要再次配置SELinux。在Fedora和CentOS发行版中SELinux是默认开启的。SELinux仅在正确的安全配置下才允许Samba读取和修改文件或文件夹。(例如,加上'samba_share_t'属性标签)。
|
||||
|
||||
下面的命令为文件的配置添加必要的标签:
|
||||
|
||||
$ sudo semanage fcontext -a -t samba_share_t "<directory>(/.*)?"
|
||||
|
||||
将<directory>替换为我们之前为Samba共享创建的本地文件夹(例如,/shared):
|
||||
|
||||
$ sudo semanage fcontext -a -t samba_share_t "/shared(/.*)?"
|
||||
|
||||
我们必须执行restorecon命令来激活修改的标签,命令如下:
|
||||
|
||||
$ sudo restorecon -R -v /shared
|
||||
|
||||

|
||||
|
||||
为了通过Samba共享在我们home文件夹内的文件夹,我们必须在SELinux中开启共享home文件夹的选项,该选项默认被关闭。下面的命令能达到该效果。如果您并未共享您的home文件夹,那么您可以跳过该步骤。
|
||||
|
||||
$ sudo setsebool -P samba_enable_home_dirs 1
|
||||
|
||||
### 步骤3:为Samba配置防火墙 ###
|
||||
|
||||
下面的命令用来打开防火墙中Samba为共享需要的TCP/UDP端口。
|
||||
|
||||
如果您在使用firewalld(例如,在Fedora和CentOS7下),接下来的命令将会永久的修改Samba相关的防火墙规则。
|
||||
|
||||
$ sudo firewall-cmd --permanent --add-service=samba
|
||||
|
||||
如果您在防火墙中使用iptables(例如,CentOS6或者更早的版本),可以使用下面的命令来打开Samba必要的向外的端口。
|
||||
|
||||
$ sudo vi /etc/sysconfig/iptables
|
||||
|
||||
----------
|
||||
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 445 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m udp -p udp --dport 445 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m udp -p udp --dport 137 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m udp -p udp --dport 138 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 139 -j ACCEPT
|
||||
|
||||
然后重启iptables服务:
|
||||
|
||||
$ sudo service iptables restart
|
||||
|
||||
### 步骤4:更改Samba配置 ###
|
||||
|
||||
后面的步骤用来配置Samba以将本地文件夹导出为Samba共享文件夹。
|
||||
|
||||
使用文件编辑器打开Samba配置文件,并将下面的行添加到文件的末尾。
|
||||
|
||||
$ sudo nano /etc/samba/smb.conf
|
||||
|
||||
----------
|
||||
|
||||
[myshare]
|
||||
comment=my shared files
|
||||
path=/shared
|
||||
public=yes
|
||||
writeable=yes
|
||||
|
||||
上面在括号内的文本(例如,"myshare")是Samba共享的资源的名字,它被用来从远程主机存取Samba共享。
|
||||
|
||||
创建Samba用户帐户,这是挂载和导出Samba文件系统所必须的。我们可以使用smbpasswd工具来创建一个Samba用户。注意,Samba用户帐户必须是Linux用户管理中已存在的。如果您尝试使用smbpasswd添加一个不存在的用户,它会返回一个错误的消息。
|
||||
|
||||
如果您不想使用任何已存在的Linux用户作为Samba用户,您可以在您的系统中创建一个新的用户。为安全起见,设置新用户的登录脚本为/sbin/nologin,并且不创建该用户的home文件夹。
|
||||
|
||||
在这个例子中,我们正在创建一个名叫"sambaguest"的用户,如下:
|
||||
|
||||
$ sudo useradd -M -s /sbin/nologin sambaguest
|
||||
$ sudo passwd sambaguest
|
||||
|
||||

|
||||
|
||||
在创建一个新用户后,使用smbpasswd命令添加Samba用户。当这个命令询问一个密码时,您可以键入一个不同于该用户的密码。
|
||||
|
||||
$ sudo smbpasswd -a sambaguest
|
||||
|
||||
4. 激活Samba服务,并检测Samba服务是否在运行。
|
||||
|
||||
$ sudo systemctl enable smb.service
|
||||
$ sudo systemctl start smb.service
|
||||
$ sudo systemctl is-active smb
|
||||
|
||||

|
||||
|
||||
使用下面的命令来查看Samba中共享的文件夹列表。
|
||||
|
||||
$ smbclient -U sambaguest -L localhost
|
||||
|
||||

|
||||
|
||||
接下来是在Thunar文件管理器中存取Samba共享文件夹以及对file1进行拷贝复制的截图。注意,Samba的共享内容可以通过在Thunar中通过"smb://<samba-server-IP-address>/myshare"这个地址来存取。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/share-directory-samba-fedora-centos.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/kristophorus
|
||||
@ -0,0 +1,159 @@
|
||||
Sleuth Kit -- 一个用来分析磁盘映像和恢复文件的开源取证工具
|
||||
================================================================================
|
||||
SIFT 是一个由 SANS 公司提供的基于 Ubuntu 的取证发行版本。它包含许多取证工具,如 Sleuth kit/Autopsy 。但 Sleuth kit / Autopsy 可以直接在 Ubuntu 或 Fedora 发行版本上直接安装,而不必下载 SIFT 的整个发行版本。
|
||||
|
||||
Sleuth Kit/Autopsy 是一个开源的电子取证调查工具,它被用于从磁盘映像中恢复丢失的文件,基于事件响应的磁盘映像的分析。 Autopsy 工具是 sleuth kit 的一个网页接口,支持 sleuth kit 的所有功能。这个工具在 Windows 和 Linux 平台下都可获取到。
|
||||
|
||||
### 安装 Sleuth kit ###
|
||||
|
||||
首先,从 [sleuthkit][1] 的网站下载 Sleuth kit 软件。使用下面的命令在虚拟终端下使用 wget 命令来下载它,下图展示了这个过程。
|
||||
|
||||
# wget http://cznic.dl.sourceforge.net/project/sleuthkit/sleuthkit/4.1.3/sleuthkit-4.1.3.tar.gz
|
||||
|
||||

|
||||
|
||||
使用下面的命令解压 sleuthkit-4.1.3.tar.gz 并进入解压后的目录:
|
||||
|
||||
# tar -xvzf sleuthkit-4.1.3.tar.gz
|
||||
|
||||

|
||||
|
||||
在安装 sleuth kit 之前,运行下面的命令来执行所需的检查:
|
||||
|
||||
#./configure
|
||||
|
||||

|
||||
|
||||
然后使用 Make 命令来编译 sleuth kit :
|
||||
|
||||
#make
|
||||
|
||||

|
||||
|
||||
最后,使用下面的命令将它安装到 **/usr/local** 目录下:
|
||||
|
||||
#make install
|
||||
|
||||

|
||||
|
||||
### 安装 Autopsy 工具 ###
|
||||
|
||||
Sleuth kit 已经安装完毕,现在我们将为它安装 autopsy 界面。从 [sleuthkit 的 autopsy 页面][2] 下载 Autopsy 软件。使用下面的命令在虚拟终端下使用 wget 命令来下载它,下图展示了这个过程。
|
||||
|
||||
# wget http://kaz.dl.sourceforge.net/project/autopsy/autopsy/2.24/autopsy-2.24.tar.gz
|
||||
|
||||

|
||||
|
||||
使用下面的命令解压 autopsy-2.24.tar.gz 并进入解压后的目录:
|
||||
|
||||
# tar -xvzf autopsy-2.24.tar.gz
|
||||
|
||||

|
||||
|
||||
autopsy 的配置脚本将询问 NSRL (National Software Reference Library) 和 **Evidence_Locker** 文件夹的路径。
|
||||
|
||||
当弹窗问及 NSRL 时,输入 "n",并在 **/usr/local** 目录下创建名为 Evidence_Locker 的文件夹。Autopsy 将在 Evidence_Locker 文件夹下存储配置文件,审计记录和输出文件。
|
||||
|
||||
#mkdir /usr/local/Evidence_Locker
|
||||
|
||||
#cd autopsy-2.24
|
||||
|
||||
#./configure
|
||||
|
||||

|
||||
|
||||
在安装过程中添加完 Evidence_Locker 的安装路径后, autopsy 在那里存储配置文件并展现如下的信息来运行 autopsy 程序。
|
||||
|
||||

|
||||
|
||||
在虚拟终端中键入 **./autopsy** 命令来启动 Sleuth kit 工具的图形界面:
|
||||
|
||||

|
||||
|
||||
在浏览器中键入下面的地址来获取 autopsy 的界面:
|
||||
|
||||
http://localhost:9999/autopsy
|
||||
|
||||
下图展现了 autopsy 插件的主页面:
|
||||
|
||||

|
||||
|
||||
在 autopsy 工具中,点击 **新案例** 按钮来开始进行分析。键入案例名称,此次调查的描述和检查人的姓名,下图有具体的展示:
|
||||
|
||||

|
||||
|
||||
在接下来的网页中,将展示在上一个的网页中键入的详细信息。接着点击 **增加主机** 按钮来添加有关要分析的机器的详细信息。
|
||||
|
||||

|
||||
|
||||
在下一个网页中键入主机名,相关的描述和要分析的机器的时区设置。
|
||||
|
||||

|
||||
|
||||
点击 **增加映像** 按钮来为取证分析添加映像文件。
|
||||
|
||||

|
||||
|
||||
在接下来的网页中点击 **增加映像文件** 按钮。它将打开一个新的网页,来询问映像文件的路径和选择映像的类型以及导入的方法。
|
||||
|
||||

|
||||
|
||||
正如下图中展示的那样,我们已经键入了 Linux 映像文件的路径。在我们这个例子中,映像文件是磁盘的分区。
|
||||
|
||||

|
||||
|
||||
点击 下一步 按钮并在下一页中选择 **计算散列值** 的选项,这在下图中有展示。它也将检测所给映像的文件系统类型。
|
||||
|
||||

|
||||
|
||||
下面的图片展示了静态分析之前映像文件的 MD5 散列值。
|
||||
|
||||

|
||||
|
||||
在下一个网页中, autopsy 展现了有关映像文件的如下信息:
|
||||
|
||||
- 映像的挂载点
|
||||
- 映像的名称
|
||||
- 所给映像的文件系统类型
|
||||
|
||||
点击 **详情** 按钮来获取更多有关所给映像文件的信息。它还提供了从映像文件的卷中导出未分配的片段和字符串的数据信息,这在下图中有展现。
|
||||
|
||||

|
||||
|
||||
在下图中那样,点击 **分析** 按钮来开始分析所给映像。它将开启另一个页面,其中包含了映像分析的多个选项。
|
||||
|
||||

|
||||
|
||||
在映像分析过程中,Autopsy 提供了如下的功能:
|
||||
|
||||
- 文件分析
|
||||
- 关键字搜索
|
||||
- 文件类型
|
||||
- 映像详情
|
||||
- 数据单元
|
||||
|
||||
下图展示的是在给定的 Linux 分区映像上进行文件分析:
|
||||
|
||||

|
||||
|
||||
它将从所给映像中提取所有的文件和文件夹。在下图中也展示了已被删除的文件的提取:
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
希望这篇文章能够给那些进入磁盘映像的静态分析领域的新手提供帮助。Autopsy 是 sleuth kit 的网页界面,提供了在 Windows 和 Linux 磁盘映像中进行诸如字符串提取,恢复被删文件,时间线分析,网络浏览历史,关键字搜索和邮件分析等功能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/autopsy-sleuth-kit-installation-ubuntu/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:http://www.sleuthkit.org/sleuthkit/download.php
|
||||
[2]:http://www.sleuthkit.org/autopsy/download.php
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user