mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
35968581c1
@ -1,47 +1,47 @@
|
||||
使用OpenCV(C ++ / Python)进行高动态范围(HDR)成像
|
||||
使用 OpenCV 进行高动态范围(HDR)成像
|
||||
============================================================
|
||||
|
||||
在本教程中,我们将学习如何使用由不同曝光设置拍摄的多张图像创建高动态范围(HDR)图像。 我们将以C ++和Python两种形式分享代码。
|
||||
在本教程中,我们将学习如何使用由不同曝光设置拍摄的多张图像创建<ruby>高动态范围<rt>High Dynamic Range</rt></ruby>(HDR)图像。 我们将以 C++ 和 Python 两种形式分享代码。
|
||||
|
||||
### 什么是高动态范围成像?
|
||||
|
||||
大多数数码相机和显示器都是按照24位矩阵捕获或者显示彩色图像。 每个颜色通道有8位,因此每个通道的像素值在0-255范围内。 换句话说,普通的相机或者显示器的动态范围是有限的。
|
||||
大多数数码相机和显示器都是按照 24 位矩阵捕获或者显示彩色图像。 每个颜色通道有 8 位,因此每个通道的像素值在 0-255 范围内。 换句话说,普通的相机或者显示器的动态范围是有限的。
|
||||
|
||||
但是,我们周围世界动态范围极大。 在车库内关灯就会变黑,直接看着太阳就会变得非常亮。 即使不考虑这些极端,在日常情况下,8位的通道勉强可以捕捉到现场场景。 因此,相机会尝试去评估光照并且自动设置曝光,这样图像的感兴趣区就会有良好的动态范围,并且太暗和太亮的部分会被截取,取值为0和255。
|
||||
但是,我们周围世界动态范围极大。 在车库内关灯就会变黑,直接看着太阳就会变得非常亮。 即使不考虑这些极端,在日常情况下,8 位的通道勉强可以捕捉到现场场景。 因此,相机会尝试去评估光照并且自动设置曝光,这样图像的最关注区域就会有良好的动态范围,并且太暗和太亮的部分会被相应截取为 0 和 255。
|
||||
|
||||
在下图中,左侧的图像是正常曝光的图像。 请注意,由于相机决定使用拍摄主体(我的儿子)的设置,所以背景中的天空已经完全流失了,但是明亮的天空也因此被刷掉了。 右侧的图像是由iPhone生成的HDR图像。
|
||||
在下图中,左侧的图像是正常曝光的图像。 请注意,由于相机决定使用拍摄主体(我的儿子)的设置,所以背景中的天空已经完全流失了,但是明亮的天空也因此被刷掉了。 右侧的图像是由 iPhone 生成的HDR图像。
|
||||
|
||||
[][3]
|
||||
|
||||
iPhone是如何拍摄HDR图像的呢? 它实际上采用三种不同的曝光度拍摄了3张图像,3张图像拍摄非常迅速,在3张图像之间几乎没有产生位移。然后组合三幅图像来产生HDR图像。 我们将在下一节看到一些细节。
|
||||
iPhone 是如何拍摄 HDR 图像的呢? 它实际上采用三种不同的曝光度拍摄了 3 张图像,3 张图像拍摄非常迅速,在 3 张图像之间几乎没有产生位移。然后组合三幅图像来产生 HDR 图像。 我们将在下一节看到一些细节。
|
||||
|
||||
将在不同曝光设置下获取的相同场景的不同图像组合的过程称为高动态范围(HDR)成像。
|
||||
> 将在不同曝光设置下获取的相同场景的不同图像组合的过程称为高动态范围(HDR)成像。
|
||||
|
||||
### 高动态范围(HDR)成像是如何工作的?
|
||||
|
||||
在本节中,我们来看下使用OpenCV创建HDR图像的步骤。
|
||||
在本节中,我们来看下使用 OpenCV 创建 HDR 图像的步骤。
|
||||
|
||||
要想轻松学习本教程,请点击[此处][5][下载][4]C ++和Python代码还有图像。 如果您有兴趣了解更多关于人工智能,计算机视觉和机器学习的信息,请[订阅][6]我们的电子杂志。
|
||||
> 要想轻松学习本教程,请点击[此处][5][下载][4] C++ 和 Python 代码还有图像。 如果您有兴趣了解更多关于人工智能,计算机视觉和机器学习的信息,请[订阅][6]我们的电子杂志。
|
||||
|
||||
### 第1步:捕获不同曝光度的多张图像
|
||||
### 第 1 步:捕获不同曝光度的多张图像
|
||||
|
||||
当我们使用相机拍照时,每个通道只有8位来表示场景的动态范围(亮度范围)。 但是,通过改变快门速度,我们可以在不同的曝光条件下拍摄多个场景图像。 大多数单反相机SLR有一个功能称为自动包围式曝光(AEB),只需按一下按钮,我们就可以在不同的曝光下拍摄多张照片。 如果你正在使用iPhone,你可以使用这个[自动包围式HDR应用程序][7],如果你是一个Android用户,你可以尝试一个[更好的相机应用程序][8]。
|
||||
当我们使用相机拍照时,每个通道只有 8 位来表示场景的动态范围(亮度范围)。 但是,通过改变快门速度,我们可以在不同的曝光条件下拍摄多个场景图像。 大多数单反相机(SLR)有一个功能称为<ruby>自动包围式曝光<rt>Auto Exposure Bracketing</rt></ruby>(AEB),只需按一下按钮,我们就可以在不同的曝光下拍摄多张照片。 如果你正在使用 iPhone,你可以使用这个[自动包围式 HDR 应用程序][7],如果你是一个 Android 用户,你可以尝试一个[更好的相机应用程序][8]。
|
||||
|
||||
场景没有变化时,在相机上使用自动包围式曝光或在手机上使用自动包围式应用程序,我们可以一张接一张地快速拍摄多张照片。 当我们在iPhone中使用HDR模式时,会拍摄三张照片。
|
||||
场景没有变化时,在相机上使用自动包围式曝光或在手机上使用自动包围式应用程序,我们可以一张接一张地快速拍摄多张照片。 当我们在 iPhone 中使用 HDR 模式时,会拍摄三张照片。
|
||||
|
||||
1. 曝光不足的图像:该图像比正确曝光的图像更暗。 目标是捕捉非常明亮的图像部分。
|
||||
2. 正确曝光的图像:这是相机将根据其估计的照明拍摄的常规图像。
|
||||
3. 曝光过度的图像:该图像比正确曝光的图像更亮。 目标是拍摄非常黑暗的图像部分。
|
||||
|
||||
但是,如果场景的动态范围很大,我们可以拍摄三张以上的图片来合成HDR图像。 在本教程中,我们将使用曝光时间为1/30秒,0.25秒,2.5秒和15秒的4张图像。 缩略图如下所示。
|
||||
但是,如果场景的动态范围很大,我们可以拍摄三张以上的图片来合成 HDR 图像。 在本教程中,我们将使用曝光时间为1/30 秒,0.25 秒,2.5 秒和 15 秒的 4 张图像。 缩略图如下所示。
|
||||
|
||||
[][9]
|
||||
|
||||
单反相机或手机的曝光时间和其他设置的信息通常存储在JPEG文件的EXIF元数据中。 查看此[链接][10]可查看Windows和Mac中存储在JPEG文件中的EXIF元数据。 或者,您可以使用我最喜欢的名为[EXIFTOOL][11]的查看EXIF的命令行工具。
|
||||
单反相机或手机的曝光时间和其他设置的信息通常存储在 JPEG 文件的 EXIF 元数据中。 查看此[链接][10]可在 Windows 和 Mac 中查看存储在 JPEG 文件中的 EXIF 元数据。 或者,您可以使用我最喜欢的名为 [EXIFTOOL][11] 的查看 EXIF 的命令行工具。
|
||||
|
||||
我们先从读取分配到不同曝光时间的图像开始
|
||||
我们先从读取分配到不同曝光时间的图像开始。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
void readImagesAndTimes(vector<Mat> &images, vector<float> ×)
|
||||
@ -64,7 +64,7 @@ void readImagesAndTimes(vector<Mat> &images, vector<float> ×)
|
||||
}
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
def readImagesAndTimes():
|
||||
@ -81,19 +81,20 @@ def readImagesAndTimes():
|
||||
return images, times
|
||||
```
|
||||
|
||||
### 第2步:对齐图像
|
||||
|
||||
合成HDR图像时使用的图像如果未对齐可能会导致严重的伪影。 在下图中,左侧的图像是使用未对齐的图像组成的HDR图像,右侧的图像是使用对齐的图像的图像。 通过放大图像的一部分,使用红色圆圈显示的,,我们会在左侧图像中看到严重的鬼影。
|
||||
### 第 2 步:对齐图像
|
||||
|
||||
合成 HDR 图像时使用的图像如果未对齐可能会导致严重的伪影。 在下图中,左侧的图像是使用未对齐的图像组成的 HDR 图像,右侧的图像是使用对齐的图像的图像。 通过放大图像的一部分(使用红色圆圈显示的)我们会在左侧图像中看到严重的鬼影。
|
||||
|
||||
[][12]
|
||||
|
||||
在拍摄照片制作HDR图像时,专业摄影师自然是将相机安装在三脚架上。 他们还使用称为[镜像锁定][13]功能来减少额外的振动。 即使如此,图像可能仍然没有完美对齐,因为没有办法保证无振动的环境。 使用手持相机或手机拍摄图像时,对齐问题会变得更糟。
|
||||
在拍摄照片制作 HDR 图像时,专业摄影师自然是将相机安装在三脚架上。 他们还使用称为[镜像锁定][13]功能来减少额外的振动。 即使如此,图像可能仍然没有完美对齐,因为没有办法保证无振动的环境。 使用手持相机或手机拍摄图像时,对齐问题会变得更糟。
|
||||
|
||||
幸运的是,OpenCV提供了一种简单的方法,使用`AlignMTB`对齐这些图像。 该算法将所有图像转换为中值阈值位图(MTB)。 图像的MTB生成方式为将比中值亮度的更亮的分配为1,其余为0。 MTB不随曝光时间的改变而改变。 因此不需要我们指定曝光时间就可以对齐MTB。
|
||||
幸运的是,OpenCV 提供了一种简单的方法,使用 `AlignMTB` 对齐这些图像。 该算法将所有图像转换为<ruby>中值阈值位图<rt>median threshold bitmaps</rt></ruby>(MTB)。 图像的 MTB 生成方式为将比中值亮度的更亮的分配为 1,其余为 0。 MTB 不随曝光时间的改变而改变。 因此不需要我们指定曝光时间就可以对齐 MTB。
|
||||
|
||||
基于MTB的对齐方式的代码如下。
|
||||
基于 MTB 的对齐方式的代码如下。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 对齐输入图像
|
||||
@ -101,7 +102,7 @@ Ptr<AlignMTB> alignMTB = createAlignMTB();
|
||||
alignMTB->process(images, images);
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 对齐输入图像
|
||||
@ -109,21 +110,21 @@ alignMTB = cv2.createAlignMTB()
|
||||
alignMTB.process(images, images)
|
||||
```
|
||||
|
||||
### 第3步:提取相机响应函数
|
||||
### 第 3 步:提取相机响应函数
|
||||
|
||||
典型相机的响应与场景亮度不成线性关系。 那是什么意思呢? 假设有两个物体由同一个相机拍摄,在现实世界中其中一个物体是另一个物体亮度的两倍。 当您测量照片中两个物体的像素亮度时,较亮物体的像素值将不会是较暗物体的两倍。 在不估计相机响应函数(CRF)的情况下,我们将无法将图像合并到一个HDR图像中。
|
||||
典型相机的响应与场景亮度不成线性关系。 那是什么意思呢? 假设有两个物体由同一个相机拍摄,在现实世界中其中一个物体是另一个物体亮度的两倍。 当您测量照片中两个物体的像素亮度时,较亮物体的像素值将不会是较暗物体的两倍。 在不估计<ruby>相机响应函数<rt>Camera Response Function</rt></ruby>(CRF)的情况下,我们将无法将图像合并到一个HDR图像中。
|
||||
|
||||
将多个曝光图像合并为HDR图像意味着什么?
|
||||
将多个曝光图像合并为 HDR 图像意味着什么?
|
||||
|
||||
只考虑图像的某个位置(x,y)一个像素。 如果CRF是线性的,则像素值将直接与曝光时间成比例,除非像素在特定图像中太暗(即接近0)或太亮(即接近255)。 我们可以过滤出这些不好的像素(太暗或太亮),并且将像素值除以曝光时间来估计像素的亮度,然后在像素不差的(太暗或太亮)所有图像上对亮度值取平均。我们可以对所有像素进行这样的处理,并通过对“好”像素进行平均来获得所有像素的单张图像。
|
||||
只考虑图像的某个位置 `(x,y)` 一个像素。 如果 CRF 是线性的,则像素值将直接与曝光时间成比例,除非像素在特定图像中太暗(即接近 0)或太亮(即接近 255)。 我们可以过滤出这些不好的像素(太暗或太亮),并且将像素值除以曝光时间来估计像素的亮度,然后在像素不差的(太暗或太亮)所有图像上对亮度值取平均。我们可以对所有像素进行这样的处理,并通过对“好”像素进行平均来获得所有像素的单张图像。
|
||||
|
||||
但是CRF不是线性的, 我们需要评估CRF把图像强度变成线性,然后才能合并或者平均它们。
|
||||
但是 CRF 不是线性的, 我们需要评估 CRF 把图像强度变成线性,然后才能合并或者平均它们。
|
||||
|
||||
好消息是,如果我们知道每个图像的曝光时间,则可以从图像估计CRF。 与计算机视觉中的许多问题一样,找到CRF的问题本质是一个最优解问题,其目标是使由数据项和平滑项组成的目标函数最小化。 这些问题通常会降维到线性最小二乘问题,这些问题可以使用奇异值分解(SVD)来解决,奇异值分解是所有线性代数包的一部分。 CRF提取算法的细节在[从照片提取高动态范围辐射图][14]这篇论文中可以找到。
|
||||
好消息是,如果我们知道每个图像的曝光时间,则可以从图像估计 CRF。 与计算机视觉中的许多问题一样,找到 CRF 的问题本质是一个最优解问题,其目标是使由数据项和平滑项组成的目标函数最小化。 这些问题通常会降维到线性最小二乘问题,这些问题可以使用<ruby>奇异值分解<rt>Singular Value Decomposition</rt></ruby>(SVD)来解决,奇异值分解是所有线性代数包的一部分。 CRF 提取算法的细节在[从照片提取高动态范围辐射图][14]这篇论文中可以找到。
|
||||
|
||||
使用OpenCv的`CalibrateDebevec` 或者`CalibrateRobertson`就可以用2行代码找到CRF。本篇教程中我们使用 `CalibrateDebevec`
|
||||
使用 OpenCV 的 `CalibrateDebevec` 或者 `CalibrateRobertson` 就可以用 2 行代码找到 CRF。本篇教程中我们使用 `CalibrateDebevec`
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 获取图像响应函数 (CRF)
|
||||
@ -133,7 +134,7 @@ calibrateDebevec->process(images, responseDebevec, times);
|
||||
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 获取图像响应函数 (CRF)
|
||||
@ -141,15 +142,15 @@ calibrateDebevec = cv2.createCalibrateDebevec()
|
||||
responseDebevec = calibrateDebevec.process(images, times)
|
||||
```
|
||||
|
||||
下图显示了使用红绿蓝通道的图像提取的CRF。
|
||||
下图显示了使用红绿蓝通道的图像提取的 CRF。
|
||||
|
||||
[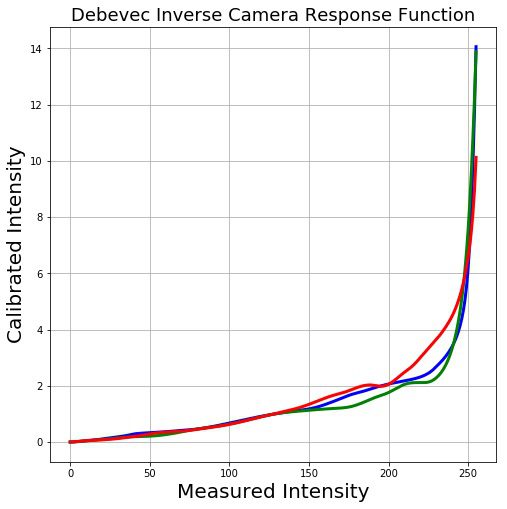][15]
|
||||
|
||||
### 第4步:合并图像
|
||||
### 第 4 步:合并图像
|
||||
|
||||
一旦CRF评估结束,我们可以使用`MergeDebevec`将曝光图像合并成一个HDR图像。 C ++和Python代码如下所示。
|
||||
一旦 CRF 评估结束,我们可以使用 `MergeDebevec` 将曝光图像合并成一个HDR图像。 C++ 和 Python 代码如下所示。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 将图像合并为HDR线性图像
|
||||
@ -160,7 +161,7 @@ mergeDebevec->process(images, hdrDebevec, times, responseDebevec);
|
||||
imwrite("hdrDebevec.hdr", hdrDebevec);
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 将图像合并为HDR线性图像
|
||||
@ -170,31 +171,33 @@ hdrDebevec = mergeDebevec.process(images, times, responseDebevec)
|
||||
cv2.imwrite("hdrDebevec.hdr", hdrDebevec)
|
||||
```
|
||||
|
||||
上面保存的HDR图像可以在Photoshop中加载并进行色调映射。示例图像如下所示。
|
||||
上面保存的 HDR 图像可以在 Photoshop 中加载并进行色调映射。示例图像如下所示。
|
||||
|
||||
[][16] HDR Photoshop 色调映射
|
||||
[][16]
|
||||
|
||||
*HDR Photoshop 色调映射*
|
||||
|
||||
### 第5步:色调映射
|
||||
### 第 5 步:色调映射
|
||||
|
||||
现在我们已经将我们的曝光图像合并到一个HDR图像中。 你能猜出这个图像的最小和最大像素值吗? 对于黑色条件,最小值显然为0。 理论最大值是什么? 无限大! 在实践中,不同情况下的最大值是不同的。 如果场景包含非常明亮的光源,那么最大值就会非常大。
|
||||
现在我们已经将我们的曝光图像合并到一个 HDR 图像中。 你能猜出这个图像的最小和最大像素值吗? 对于黑色条件,最小值显然为 0。 理论最大值是什么? 无限大! 在实践中,不同情况下的最大值是不同的。 如果场景包含非常明亮的光源,那么最大值就会非常大。
|
||||
|
||||
尽管我们已经使用多个图像恢复了相对亮度信息,但是我们现在又面临了新的挑战:将这些信息保存为24位图像用于显示。
|
||||
尽管我们已经使用多个图像恢复了相对亮度信息,但是我们现在又面临了新的挑战:将这些信息保存为 24 位图像用于显示。
|
||||
|
||||
将高动态范围(HDR)图像转换为8位单通道图像的过程称为色调映射。这个过程的同时还需要保留尽可能多的细节。
|
||||
将高动态范围(HDR)图像转换为 8 位单通道图像的过程称为色调映射。这个过程的同时还需要保留尽可能多的细节。
|
||||
|
||||
有几种色调映射算法。 OpenCV实现了其中的四个。 要记住的是没有一个绝对正确的方法来做色调映射。 通常,我们希望在色调映射图像中看到比任何一个曝光图像更多的细节。 有时色调映射的目标是产生逼真的图像,而且往往是产生超现实图像的目标。 在OpenCV中实现的算法倾向于产生现实的并不那么生动的结果。
|
||||
有几种色调映射算法。 OpenCV 实现了其中的四个。 要记住的是没有一个绝对正确的方法来做色调映射。 通常,我们希望在色调映射图像中看到比任何一个曝光图像更多的细节。 有时色调映射的目标是产生逼真的图像,而且往往是产生超现实图像的目标。 在 OpenCV 中实现的算法倾向于产生现实的并不那么生动的结果。
|
||||
|
||||
我们来看看各种选项。 以下列出了不同色调映射算法的一些常见参数。
|
||||
|
||||
1. 伽马gamma:该参数通过应用伽马gamma校正来压缩动态范围。 当gamma等于1时,不应用修正。 小于1的伽玛会使图像变暗,而大于1的伽马会使图像变亮。
|
||||
2. 饱和度saturation:该参数用于增加或减少饱和度。 饱和度高时,色彩更丰富,更浓。 饱和度值接近零,使颜色逐渐消失为灰度。
|
||||
3. 对比度contrast:控制输出图像的对比度(即log (maxPixelValue/minPixelValue))。
|
||||
1. <ruby>伽马<rt>gamma</rt></ruby>:该参数通过应用伽马校正来压缩动态范围。 当伽马等于 1 时,不应用修正。 小于 1 的伽玛会使图像变暗,而大于 1 的伽马会使图像变亮。
|
||||
2. <ruby>饱和度<rt>saturation</rt></ruby>:该参数用于增加或减少饱和度。 饱和度高时,色彩更丰富,更浓。 饱和度值接近零,使颜色逐渐消失为灰度。
|
||||
3. <ruby>对比度<rt>contrast</rt></ruby>:控制输出图像的对比度(即 `log(maxPixelValue/minPixelValue)`)。
|
||||
|
||||
让我们来探索OpenCV中可用的四种色调映射算法。
|
||||
让我们来探索 OpenCV 中可用的四种色调映射算法。
|
||||
|
||||
#### Drago 色调映射
|
||||
|
||||
Drago 色调映射的参数如下所示
|
||||
Drago 色调映射的参数如下所示:
|
||||
|
||||
```
|
||||
createTonemapDrago
|
||||
@ -205,11 +208,11 @@ float bias = 0.85f
|
||||
)
|
||||
```
|
||||
|
||||
这里,bias是[0,1]范围内偏差函数的值。 从0.7到0.9的值通常效果较好。 默认值是0.85。 有关更多技术细节,请参阅这篇[论文][17]。
|
||||
这里,`bias` 是 `[0, 1]` 范围内偏差函数的值。 从 0.7 到 0.9 的值通常效果较好。 默认值是 0.85。 有关更多技术细节,请参阅这篇[论文][17]。
|
||||
|
||||
C ++和Python代码如下所示。 参数是通过反复试验获得的。 最后的结果乘以3只是因为它给出了最令人满意的结果。
|
||||
C++ 和 Python 代码如下所示。 参数是通过反复试验获得的。 最后的结果乘以 3 只是因为它给出了最令人满意的结果。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 使用Drago色调映射算法获得24位彩色图像
|
||||
@ -220,7 +223,7 @@ ldrDrago = 3 * ldrDrago;
|
||||
imwrite("ldr-Drago.jpg", ldrDrago * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 使用Drago色调映射算法获得24位彩色图像
|
||||
@ -230,13 +233,15 @@ ldrDrago = 3 * ldrDrago
|
||||
cv2.imwrite("ldr-Drago.jpg", ldrDrago * 255)
|
||||
```
|
||||
|
||||
结果如下
|
||||
结果如下:
|
||||
|
||||
[][18] 使用Drago算法的HDR色调映射
|
||||
[][18]
|
||||
|
||||
*使用Drago算法的HDR色调映射*
|
||||
|
||||
#### Durand 色调映射
|
||||
|
||||
Durand 色调映射的参数如下所示
|
||||
Durand 色调映射的参数如下所示:
|
||||
|
||||
```
|
||||
createTonemapDurand
|
||||
@ -248,11 +253,12 @@ createTonemapDurand
|
||||
float sigma_color = 2.0f
|
||||
);
|
||||
```
|
||||
该算法基于将图像分解为基础层和细节层。 使用称为双边滤波器的边缘保留滤波器来获得基本层。 sigma_space和sigma_color是双边滤波器的参数,分别控制空间域和彩色域中的平滑量。
|
||||
|
||||
该算法基于将图像分解为基础层和细节层。 使用称为双边滤波器的边缘保留滤波器来获得基本层。 `sigma_space` 和`sigma_color` 是双边滤波器的参数,分别控制空间域和彩色域中的平滑量。
|
||||
|
||||
有关更多详细信息,请查看这篇[论文][19]。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 使用Durand色调映射算法获得24位彩色图像
|
||||
@ -262,7 +268,8 @@ tonemapDurand->process(hdrDebevec, ldrDurand);
|
||||
ldrDurand = 3 * ldrDurand;
|
||||
imwrite("ldr-Durand.jpg", ldrDurand * 255);
|
||||
```
|
||||
Python
|
||||
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 使用Durand色调映射算法获得24位彩色图像
|
||||
@ -272,9 +279,11 @@ Python
|
||||
cv2.imwrite("ldr-Durand.jpg", ldrDurand * 255)
|
||||
```
|
||||
|
||||
结果如下
|
||||
结果如下:
|
||||
|
||||
[][20] 使用Durand算法的HDR色调映射
|
||||
[][20]
|
||||
|
||||
*使用Durand算法的HDR色调映射*
|
||||
|
||||
#### Reinhard 色调映射
|
||||
|
||||
@ -289,11 +298,11 @@ float color_adapt = 0.0f
|
||||
)
|
||||
```
|
||||
|
||||
intensity 参数应在[-8, 8]范围内。 更高的亮度值会产生更明亮的结果。 light_adapt控制灯光,范围为[0, 1]。 值1表示仅基于像素值的自适应,而值0表示全局自适应。 中间值可以用于两者的加权组合。 参数color_adapt控制色彩,范围为[0, 1]。 如果值被设置为1,则通道被独立处理,如果该值被设置为0,则每个通道的适应级别相同。中间值可以用于两者的加权组合。
|
||||
`intensity` 参数应在 `[-8, 8]` 范围内。 更高的亮度值会产生更明亮的结果。 `light_adapt` 控制灯光,范围为 `[0, 1]`。 值 1 表示仅基于像素值的自适应,而值 0 表示全局自适应。 中间值可以用于两者的加权组合。 参数 `color_adapt` 控制色彩,范围为 `[0, 1]`。 如果值被设置为 1,则通道被独立处理,如果该值被设置为 0,则每个通道的适应级别相同。中间值可以用于两者的加权组合。
|
||||
|
||||
有关更多详细信息,请查看这篇[论文][21]。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 使用Reinhard色调映射算法获得24位彩色图像
|
||||
@ -303,7 +312,7 @@ tonemapReinhard->process(hdrDebevec, ldrReinhard);
|
||||
imwrite("ldr-Reinhard.jpg", ldrReinhard * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 使用Reinhard色调映射算法获得24位彩色图像
|
||||
@ -312,9 +321,11 @@ ldrReinhard = tonemapReinhard.process(hdrDebevec)
|
||||
cv2.imwrite("ldr-Reinhard.jpg", ldrReinhard * 255)
|
||||
```
|
||||
|
||||
结果如下
|
||||
结果如下:
|
||||
|
||||
[][22] 使用Reinhard算法的HDR色调映射
|
||||
[][22]
|
||||
|
||||
*使用Reinhard算法的HDR色调映射*
|
||||
|
||||
#### Mantiuk 色调映射
|
||||
|
||||
@ -327,11 +338,11 @@ float saturation = 1.0f
|
||||
)
|
||||
```
|
||||
|
||||
参数scale是对比度比例因子。 从0.7到0.9的值通常效果较好
|
||||
参数 `scale` 是对比度比例因子。 从 0.7 到 0.9 的值通常效果较好
|
||||
|
||||
有关更多详细信息,请查看这篇[论文][23]。
|
||||
|
||||
C++
|
||||
**C++**
|
||||
|
||||
```
|
||||
// 使用Mantiuk色调映射算法获得24位彩色图像
|
||||
@ -342,7 +353,7 @@ ldrMantiuk = 3 * ldrMantiuk;
|
||||
imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255);
|
||||
```
|
||||
|
||||
Python
|
||||
**Python**
|
||||
|
||||
```
|
||||
# 使用Mantiuk色调映射算法获得24位彩色图像
|
||||
@ -352,19 +363,21 @@ ldrMantiuk = 3 * ldrMantiuk
|
||||
cv2.imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255)
|
||||
```
|
||||
|
||||
结果如下
|
||||
结果如下:
|
||||
|
||||
[][24] 使用Mantiuk算法的HDR色调映射
|
||||
[][24]
|
||||
|
||||
*使用Mantiuk算法的HDR色调映射*
|
||||
|
||||
### 订阅然后下载代码
|
||||
|
||||
如果你喜欢这篇文章,并希望下载本文中使用的代码(C ++和Python)和示例图片,请[订阅][25]我们的电子杂志。 您还将获得免费的[计算机视觉资源][26]指南。 在我们的电子杂志中,我们分享了用C ++还有Python编写的OpenCV教程和例子,以及计算机视觉和机器学习的算法和新闻。
|
||||
如果你喜欢这篇文章,并希望下载本文中使用的代码(C++ 和 Python)和示例图片,请[订阅][25]我们的电子杂志。 您还将获得免费的[计算机视觉资源][26]指南。 在我们的电子杂志中,我们分享了用 C++ 还有 Python 编写的 OpenCV 教程和例子,以及计算机视觉和机器学习的算法和新闻。
|
||||
|
||||
[点此订阅][27]
|
||||
|
||||
图像学分
|
||||
图片致谢
|
||||
|
||||
本文中使用的四个曝光图像获得[CC BY-SA 3.0][28]许可,并从[维基百科的HDR页面][29]下载。 图像由Kevin McCoy拍摄。
|
||||
本文中使用的四个曝光图像获得 [CC BY-SA 3.0][28] 许可,并从[维基百科的 HDR 页面][29]下载。 图像由 Kevin McCoy拍摄。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -372,15 +385,15 @@ cv2.imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255)
|
||||
|
||||
我是一位热爱计算机视觉和机器学习的企业家,拥有十多年的实践经验(还有博士学位)。
|
||||
|
||||
2007年,在完成博士学位之后,我和我的顾问David Kriegman博士还有Kevin Barnes共同创办了TAAZ公司.。 我们的计算机视觉和机器学习算法的可扩展性和鲁棒性已经经过了试用了我们产品的超过1亿的用户的严格测试。
|
||||
2007 年,在完成博士学位之后,我和我的顾问 David Kriegman 博士还有 Kevin Barnes 共同创办了 TAAZ 公司。 我们的计算机视觉和机器学习算法的可扩展性和鲁棒性已经经过了试用了我们产品的超过 1 亿的用户的严格测试。
|
||||
|
||||
---------------------------
|
||||
|
||||
via: http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/
|
||||
|
||||
作者:[SATYA MALLICK ][a]
|
||||
作者:[SATYA MALLICK][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
使用 Stratis 从命令行管理 Linux 存储
|
||||
======
|
||||
|
||||
> 通过从命令行运行它,得到这个易于使用的 Linux 存储工具的主要用途。
|
||||
|
||||

|
||||
|
||||
正如本系列的[第一部分][1]和[第二部分][2]中所讨论的,Stratis 是一个具有与 [ZFS][3] 和 [Btrfs] [4] 相似功能的卷管理文件系统。在本文中,我们将介绍如何在命令行上使用 Stratis。
|
||||
@ -10,9 +12,9 @@
|
||||
对于非开发人员,现在尝试 Stratis 最简单的方法是在 [Fedora 28][5] 中。
|
||||
|
||||
你可以用以下命令安装 Stratis 守护进程和 Stratis 命令行工具:
|
||||
|
||||
```
|
||||
# dnf install stratis-cli stratisd
|
||||
|
||||
```
|
||||
|
||||
### 创建一个池
|
||||
@ -20,29 +22,28 @@
|
||||
Stratis 有三个概念:blockdevs、池和文件系统。 Blockdevs 是组成池的块设备,例如磁盘或磁盘分区。一旦创建池,就可以从中创建文件系统。
|
||||
|
||||
假设你的系统上有一个名为 `vdg` 的块设备,它目前没有被使用或挂载,你可以在它上面创建一个 Stratis 池:
|
||||
|
||||
```
|
||||
# stratis pool create mypool /dev/vdg
|
||||
|
||||
```
|
||||
|
||||
这假设 `vdg` 是完全清零并且是空的。如果它没有被使用,但有旧数据,则可能需要使用 `pool create` 的 ` - force` 选项。如果正在使用,请勿将它用于 Stratis。
|
||||
这假设 `vdg` 是完全清零并且是空的。如果它没有被使用,但有旧数据,则可能需要使用 `pool create` 的 `-force` 选项。如果正在使用,请勿将它用于 Stratis。
|
||||
|
||||
如果你想从多个块设备创建一个池,只需在 `pool create` 命令行中列出它们。你也可以稍后使用 `blockdev add-data` 命令添加更多的 blockdevs。请注意,Stratis 要求 blockdevs 的大小至少为 1 GiB。
|
||||
|
||||
### 创建文件系统
|
||||
|
||||
在你创建了一个名为 `mypool` 的池后,你可以从它创建文件系统:
|
||||
|
||||
```
|
||||
# stratis fs create mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
从 `mypool` 池创建一个名为 `myfs1` 的文件系统后,可以使用 Stratis 在 /dev/stratis 中创建的条目来挂载并使用它:
|
||||
从 `mypool` 池创建一个名为 `myfs1` 的文件系统后,可以使用 Stratis 在 `/dev/stratis` 中创建的条目来挂载并使用它:
|
||||
|
||||
```
|
||||
# mkdir myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
文件系统现在已被挂载在 `myfs1` 上并准备可以使用。
|
||||
@ -50,47 +51,45 @@ Stratis 有三个概念:blockdevs、池和文件系统。 Blockdevs 是组成
|
||||
### 快照
|
||||
|
||||
除了创建空文件系统之外,你还可以创建一个文件系统作为现有文件系统的快照:
|
||||
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1 myfs1-experiment
|
||||
|
||||
```
|
||||
|
||||
这样做后,你可以挂载新的 `myfs1-experiment`,它将初始包含与 `myfs1` 相同的文件内容,但它可能随着文件系统的修改而改变。无论你对 `myfs1-experiment` 所做的任何更改都不会反映到 `myfs1` 中,除非你卸载了 `myfs1` 并将其销毁:
|
||||
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
然后进行快照以重新创建并重新挂载它:
|
||||
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1-experiment myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
### 获取信息
|
||||
|
||||
Stratis 可以列出系统中的池:
|
||||
|
||||
```
|
||||
# stratis pool list
|
||||
|
||||
```
|
||||
|
||||
随着文件系统写入更多数据,你将看到 “Total Physical Used” 值的增加。当这个值接近 “Total Physical Size” 时要小心。我们仍在努力处理这个问题。
|
||||
|
||||
列出池中的文件系统:
|
||||
|
||||
```
|
||||
# stratis fs list mypool
|
||||
|
||||
```
|
||||
|
||||
列出组成池的 blockdevs:
|
||||
|
||||
```
|
||||
# stratis blockdev list mypool
|
||||
|
||||
```
|
||||
|
||||
目前只提供这些最少的信息,但它们将在未来提供更多信息。
|
||||
@ -98,17 +97,13 @@ Stratis 可以列出系统中的池:
|
||||
#### 摧毁池
|
||||
|
||||
当你了解了 Stratis 可以做什么后,要摧毁池,首先确保从它创建的所有文件系统都被卸载并销毁,然后使用 `pool destroy` 命令:
|
||||
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# umount myfs1-experiment (if you created it)
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1-experiment
|
||||
|
||||
# stratis pool destroy mypool
|
||||
|
||||
```
|
||||
|
||||
`stratis pool list` 现在应该显示没有池。
|
||||
@ -122,13 +117,13 @@ via: https://opensource.com/article/18/5/stratis-storage-linux-command-line
|
||||
作者:[Andy Grover][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/agrover
|
||||
[1]:https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux
|
||||
[2]:https://opensource.com/article/18/4/stratis-lessons-learned
|
||||
[1]:https://linux.cn/article-9736-1.html
|
||||
[2]:https://linux.cn/article-9743-1.html
|
||||
[3]:https://en.wikipedia.org/wiki/ZFS
|
||||
[4]:https://en.wikipedia.org/wiki/Btrfs
|
||||
[5]:https://fedoraproject.org/wiki/Releases/28/Schedule
|
||||
@ -1,36 +1,33 @@
|
||||
什么是 Linux 服务器以及你的业务为什么需要它?
|
||||
什么是 Linux 服务器,你的业务为什么需要它?
|
||||
=====
|
||||
|
||||
> 想寻找一个稳定、安全的基础来为您的企业应用程序的未来提供动力?Linux 服务器可能是答案。
|
||||
|
||||

|
||||
IT 组织力求通过提高生产力和提供更快速的服务来提供商业价值,同时保持足够的灵活性,将云,容器和配置自动化等创新融入其中。现代的工作负载,无论是裸机,虚拟机,容器,还是私有云或公共云,都预计是可移植且可扩展的。支持所有的这些需要一个现代且安全的平台。
|
||||
|
||||
通往创新最直接的途径并不总是一条直线。随着私有云和公共云,多种体系架构和虚拟化的日益普及,当今的数据中心就像一个球一样,基础设施的选择各不相同,从而带来了维度和深度。就像飞行员依赖空中交通管制员提供持续更新一样,数字化转型之旅应该由像 Linux 这样可信赖的操作系统来指导,以提供持续更新的技术,以及对云,容器和配置自动化等创新的最有效和安全的访问。
|
||||
IT 组织力求通过提高生产力和提供更快速的服务来提供商业价值,同时保持足够的灵活性,将云、容器和配置自动化等创新融入其中。现代的工作任务,无论是裸机、虚拟机、容器,还是私有云或公共云,都需要是可移植且可扩展的。支持所有的这些需要一个现代且安全的平台。
|
||||
|
||||
Linux 是一个家族,它围绕 Linux 内核构建的免费开源软件操作系统。最初开发的基于 Intel x86 架构的个人电脑,此后比起任何其他操作系统,Linux 被移植到更多的平台上。得益于基于 Linux 内核的 Android 操作系统在智能手机上的主导地位,Linux 拥有所有通用操作系统中最大的安装基数。Linux 也是服务器和大型计算机等“大型机”系统的主要操作系统,也是 [TOP500][1] 超级计算机上唯一使用的操作系统。
|
||||
通往创新最直接的途径并不总是一条直线。随着私有云和公共云、多种体系架构和虚拟化的日益普及,当今的数据中心就像一个球一样,基础设施的选择各不相同,从而带来了维度和深度。就像飞行员依赖空中交通管制员提供持续更新一样,数字化转型之旅应该由像 Linux 这样可信赖的操作系统来指引,以提供持续更新的技术,以及对云、容器和配置自动化等创新的最有效和安全的访问。
|
||||
|
||||
为了利用这一功能,许多企业公司已经采用具有高性能的 Linux 开源操作系统的服务器。这些旨在处理最苛刻的业务应用程序要求,如网络和系统管理,数据库管理和 Web 服务。Linux 服务器通常选择其他服务器操作系统(to 校正者:这句话望细心理解),以保证它们的稳定性,安全性和灵活性。领先的 Linux 服务器操作系统包括 [Debian][2], [Ubuntu Server][3], [CentOS][4], [Slackware][5]和[Gentoo][6]。
|
||||
Linux 是一个家族,它围绕 Linux 内核构建的自由、开源软件操作系统。最初开发的是基于 Intel x86 架构的个人电脑,此后比起任何其他操作系统,Linux 被移植到更多的平台上。得益于基于 Linux 内核的 Android 操作系统在智能手机上的主导地位,Linux 拥有所有通用操作系统中最大的安装基数。Linux 也是服务器和大型计算机等“大型机”系统的主要操作系统,也是 [TOP500][1] 超级计算机上唯一使用的操作系统。
|
||||
|
||||
在企业级工作负载中,你应该考虑企业级 Linux 服务器上的哪些功能和优势?首先,通过对 Linux 和 Windows 管理员都熟悉的接口,内置的安全控制和可管理的扩展使你可以专注于业务增长,而不是对安全漏洞和昂贵的管理配置错误担心。你选择的 Linux 服务器应提供安全技术和认证,并保持增强以抵御入侵,保护你的数据,并满足一个开放源代码项目或特定系统供应商的合规性。它应该:
|
||||
为了利用这一功能,许多企业公司已经采用具有高性能的 Linux 开源操作系统的服务器。这些旨在处理最苛刻的业务应用程序要求,如网络和系统管理、数据库管理和 Web 服务。出于其稳定性、安全性和灵活性,通常选择 Linux 服务器而不是其他服务器操作系统。位居前列的 Linux 服务器操作系统包括 [Debian][2]、 [Ubuntu Server][3]、 [CentOS][4]、[Slackware][5] 和 [Gentoo][6]。
|
||||
|
||||
* 使用集中式身份管理和[安全增强型 Linux][7](SELinux),强制访问控制(MAC)等集成控制功能来**安全地交付资源**。这是[通用的标准][8] 和 [FIPS 140-2 认证][9]。并且第一个 Linux 容器框架支持是通用的标准认证。(to 校正:这段话不怎么通顺)
|
||||
|
||||
* **自动执行法规遵从和安全配置修复** 应贯穿于你的系统和容器。通过像 OpenSCAP 的图像扫描,它应该检查,补救漏洞和配置安全基准,包括针对 [PCI-DSS][12], [DISA STIG][13] 等的[国家清单程序][11]内容。另外,它应该在整个混合环境中集中和扩展配置修复。
|
||||
在企业级工作任务中,你应该考虑企业级 Linux 服务器上的哪些功能和优势?首先,通过对 Linux 和 Windows 管理员都熟悉的界面,内置的安全控制和可管理的扩展使你可以专注于业务增长,而不是对安全漏洞和昂贵的管理配置错误担心。你选择的 Linux 服务器应提供安全技术和认证,并保持增强以抵御入侵,保护你的数据,而且满足一个开放源代码项目或特定系统供应商的合规性。它应该:
|
||||
|
||||
* 使用集中式身份管理和[安全增强型 Linux][7](SELinux)、强制访问控制(MAC)等集成控制功能来**安全地交付资源**,这是[通用标准认证][8] 和 [FIPS 140-2 认证][9],并且第一个 Linux 容器框架支持也是通用标准认证。
|
||||
* **自动执行法规遵从和安全配置修复** 应贯穿于你的系统和容器。通过像 OpenSCAP 的映像扫描,它应该可以检查、补救漏洞和配置安全基准,包括针对 [PCI-DSS][12]、 [DISA STIG][13] 等的[国家清单程序][11]内容。另外,它应该在整个混合环境中集中和扩展配置修复。
|
||||
* **持续接收漏洞安全更新**,从上游社区或特定的系统供应商,如有可能,可在下一工作日补救并提供所有关键问题,以最大限度地降低业务影响。
|
||||
|
||||
作为混合数据中心的基础,Linux 服务器应提供平台可管理性和与传统管理和自动化基础设施的灵活集成。与非付费的 Linux 基础设施相比,这将节省 IT 员工的时间并减少意外停机的情况。它应该:
|
||||
|
||||
* 通过内置功能 **加速整个数据中心的映像构建,部署和补丁管理**,并丰富系统生命周期管理,配置和增强的修补等等。
|
||||
|
||||
* 通过一个 **简单易用的 web 界面管理单个系统**,包括存储,网络,容器,服务等等。
|
||||
|
||||
* 通过使用 [Ansible][14], [Chef][15], [Salt][16], [Puppet][17] 等原生配置管理工具,可以跨异构多个环境实现 **自动化一致性和合规性**,并通过系统角色减少脚本返工。
|
||||
|
||||
* 通过内置功能 **加速整个数据中心的映像构建、部署和补丁管理**,并丰富系统生命周期管理,配置和增强的修补等等。
|
||||
* 通过一个 **简单易用的 web 界面管理单个系统**,包括存储、网络、容器、服务等等。
|
||||
* 通过使用 [Ansible][14]、 [Chef][15]、 [Salt][16]、 [Puppet][17] 等原生配置管理工具,可以跨多个异构环境实现 **自动化一致性和合规性**,并通过系统角色减少脚本返工。
|
||||
* 通过就地升级 **简化平台更新**,消除机器迁移和应用程序重建的麻烦。
|
||||
|
||||
* 通过使用预测分析工具自动识别和修复异常情况及其根本原因,在技术问题影响业务运营之前 **解决技术问题**。
|
||||
|
||||
Linux 服务器正在在全球范围内推动创新。作为一个企业工作负载的平台,Linux 服务器应该为运行当下和未来业务的应用程序提供稳定,安全和性能驱动的基础。
|
||||
Linux 服务器正在在全球范围内推动创新。作为一个企业工作任务的平台,Linux 服务器应该为运行当下和未来业务的应用程序提供稳定,安全和性能驱动的基础。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -39,7 +36,7 @@ via: https://opensource.com/article/18/5/what-linux-server
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,25 @@
|
||||
如何在 Linux 中不安装软测试一个软件包
|
||||
======
|
||||

|
||||
出于某种原因,你可能需要在将软件包安装到你的 Linux 系统之前对其进行测试。如果是这样,你很幸运!今天,我将向你展示如何在 Linux 中使用 **Nix** 包管理器来实现。Nix 包管理器的一个显著特性是它允许用户测试软件包而无需先安装它们。当你想要临时使用特定的程序时,这会很有帮助。
|
||||
|
||||

|
||||
|
||||
出于某种原因,你可能需要在将软件包安装到你的 Linux 系统之前对其进行测试。如果是这样,你很幸运!今天,我将向你展示如何在 Linux 中使用 **Nix** 包管理器来实现。Nix 包管理器的一个显著特性是它允许用户测试软件包而无需先安装它们。当你想要临时使用特定的程序时,这会很有帮助。
|
||||
|
||||
### 测试一个软件包而不在 Linux 中安装它
|
||||
|
||||
确保你先安装了 Nix 包管理器。如果尚未安装,请参阅以下指南。
|
||||
|
||||
例如,假设你想测试你的 C++ 代码。你不必安装 GCC。只需运行以下命令:
|
||||
|
||||
```
|
||||
$ nix-shell -p gcc
|
||||
|
||||
```
|
||||
|
||||
该命令会构建或下载 gcc 软件包及其依赖项,然后将其放入一个存在 **gcc** 命令的 Bash shell 中,所有这些都不会影响正常环境。
|
||||
该命令会构建或下载 gcc 软件包及其依赖项,然后将其放入一个存在 `gcc` 命令的 Bash shell 中,所有这些都不会影响正常环境。
|
||||
|
||||
```
|
||||
LANGUAGE = (unset),
|
||||
LANGUAGE = (unset),
|
||||
LC_ALL = (unset),
|
||||
LANG = "en_US.UTF-8"
|
||||
are supported and installed on your system.
|
||||
@ -51,10 +54,10 @@ Dload Upload Total Spent Left Speed
|
||||
100 8324 100 8324 0 0 6353 0 0:00:01 0:00:01 --:--:-- 6373
|
||||
|
||||
[nix-shell:~]$
|
||||
|
||||
```
|
||||
|
||||
检查GCC版本:
|
||||
|
||||
```
|
||||
[nix-shell:~]$ gcc -v
|
||||
Using built-in specs.
|
||||
@ -67,39 +70,39 @@ gcc version 5.4.0 (GCC)
|
||||
|
||||
```
|
||||
|
||||
现在,继续并测试代码。完成后,输入 **exit** 返回到控制台。
|
||||
现在,继续并测试代码。完成后,输入 `exit` 返回到控制台。
|
||||
|
||||
```
|
||||
[nix-shell:~]$ exit
|
||||
exit
|
||||
|
||||
```
|
||||
|
||||
一旦你从 nix-shell 中退出,你就不能使用 GCC。
|
||||
|
||||
这是另一个例子。
|
||||
|
||||
```
|
||||
$ nix-shell -p hello
|
||||
|
||||
```
|
||||
|
||||
这会构建或下载 GNU Hello 和它的依赖关系,然后将其放入 **hello** 命令所在的 Bash shell 中,所有这些都不会影响你的正常环境:
|
||||
这会构建或下载 GNU Hello 和它的依赖关系,然后将其放入 `hello` 命令所在的 Bash shell 中,所有这些都不会影响你的正常环境:
|
||||
|
||||
```
|
||||
[nix-shell:~]$ hello
|
||||
Hello, world!
|
||||
|
||||
```
|
||||
|
||||
输入 exit 返回到控制台。
|
||||
输入 `exit` 返回到控制台。
|
||||
|
||||
```
|
||||
[nix-shell:~]$ exit
|
||||
|
||||
```
|
||||
|
||||
现在测试你的 hello 程序是否可用。
|
||||
现在测试你的 `hello` 程序是否可用。
|
||||
|
||||
```
|
||||
$ hello
|
||||
hello: command not found
|
||||
|
||||
```
|
||||
|
||||
有关 Nix 包管理器的更多详细信息,请参阅以下指南。
|
||||
@ -117,7 +120,7 @@ via: https://www.ostechnix.com/how-to-test-a-package-without-installing-it-in-li
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,47 +0,0 @@
|
||||
Translating by FelixYFZ How DevOps helps deliver cool apps to users
|
||||
======
|
||||
|
||||

|
||||
|
||||
A long time ago, in a galaxy far, far away, before DevOps became a mainstream practice, the software development process was excruciatingly slow, tedious, and methodical. By the time an application was ready to be deployed, a ginormous laundry list of changes and fixes to the next major release had already amassed. It took months to go back and work through the entire development cycle to prepare for each new release. Keep in mind that this process would be repeated again and again to deliver updates to users.
|
||||
|
||||
Today everything is done instantaneously and in real time, and this concept seems primitive. The mobile revolution has dramatically changed the way we interact with software, and companies that were early adopters of DevOps have totally changed the expectations for software development and deployment.
|
||||
|
||||
Consider Facebook: The Facebook mobile app is updated and refreshed every two weeks, like clockwork. This is the new standard, because users now expect software to be constantly fixed and updated. Any company that takes a month or more to deploy new features or simple bug fixes would surely fade into obscurity. If you cannot deliver what users expect, they will find someone who can.
|
||||
|
||||
Facebook, along with industry giants such as Amazon, Netflix, Google, and others, have forced enterprises to become faster and more efficient to meet today's customer expectations.
|
||||
|
||||
### Why DevOps?
|
||||
|
||||
Agile and DevOps are critically important to mobile app development since deployment cycles are lightning-quick. It’s a dense, fast-paced environment in which companies must outpace, out-think, and outmaneuver the competition to survive. In the App Store, the average top ten app remains in that position for only about a month.
|
||||
|
||||
To illustrate the old-school waterfall methodology, think back to when you first learned how to drive. Initially, you focused on every individual aspect, using a methodological process: You got in the car; fastened the seat belt; adjusted the seat, mirrors, and steering wheel; started the car, placed your hands at 10 and 2 o’clock, etc. Performing a simple task such as a lane change involved a painstaking, multi-step process executed in a particular order.
|
||||
|
||||
DevOps, in contrast, is how you would drive after several years of experience. Everything occurs intuitively and simultaneously, and you can move smoothly from A to B without putting much thought into the process.
|
||||
|
||||
The world of mobile apps is too fast-paced for old methods of app development. DevOps is designed to deliver effective, stable apps quickly and without the need for extensive resources. However, you cannot buy DevOps like an ordinary product or service. DevOps is about changing the culture and dynamics of how teams work together.
|
||||
|
||||
Large organizations like Amazon and Facebook are not the only ones embracing the DevOps culture; smaller mobile app companies are signing on as well. “Shortening the release cycle while keeping number of production incidents at a low level along with the overall cost of failure is what our customers looking for,” says Oleg Reshetnyak, head of engineering at mobile product agency [Reinvently.][1]
|
||||
|
||||
### DevOps: Not _if_ , but _when_
|
||||
|
||||
In today’s fast-paced business environment, choosing DevOps is like choosing to breathe: You either [do it or die][2].
|
||||
|
||||
According to the [U.S. Small Business Administration][3], only 16% of companies starting out today will last an entire generation. Mobile app companies that do not adopt DevOps risk going the way of the dinosaurs. Furthermore, the same study found that organizations that adopt DevOps are twice as likely to exceed profitability, product goals, and market share.
|
||||
|
||||
Innovating more quickly and securely requires three things: cloud, automation, and DevOps. Depending on how you define DevOps, the lines that separate these three factors can be unclear. However, one thing is certain: DevOps unifies everyone within the organization around the common goal of delivering higher-quality software more quickly and with less risk.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/devops-delivers-cool-apps-users
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://reinvently.com/
|
||||
[2]:https://squadex.com/insights/devops-or-die/
|
||||
[3]:https://www.sba.gov/
|
||||
@ -1,3 +1,4 @@
|
||||
translating by amwps290
|
||||
How To Convert DEB Packages Into Arch Linux Packages
|
||||
======
|
||||

|
||||
|
||||
@ -1,140 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Simple Load Balancing with DNS on Linux
|
||||
======
|
||||
|
||||

|
||||
When you have server back ends built of multiple servers, such as clustered or mirrowed web or file servers, a load balancer provides a single point of entry. Large busy shops spend big money on high-end load balancers that perform a wide range of tasks: proxy, caching, health checks, SSL processing, configurable prioritization, traffic shaping, and lots more.
|
||||
|
||||
But you don't want all that. You need a simple method for distributing workloads across all of your servers and providing a bit of failover and don't care whether it is perfectly efficient. DNS round-robin and subdomain delegation with round-robin provide two simple methods to achieve this.
|
||||
|
||||
DNS round-robin is mapping multiple servers to the same hostname, so that when users visit foo.example.com multiple servers are available to handle their requests.
|
||||
|
||||
Subdomain delegation with round-robin is useful when you have multiple subdomains or when your servers are geographically dispersed. You have a primary nameserver, and then your subdomains have their own nameservers. Your primary nameserver refers all subdomain requests to their own nameservers. This usually improves response times, as the DNS protocol will automatically look for the fastest links.
|
||||
|
||||
### Round-Robin DNS
|
||||
|
||||
Round-robin has nothing to do with robins. According to my favorite librarian, it was originally a French phrase, _ruban rond_ , or round ribbon. Way back in olden times, French government officials signed grievance petitions in non-hierarchical circular, wavy, or spoke patterns to conceal whoever originated the petition.
|
||||
|
||||
Round-robin DNS is also non-hierarchical, a simple configuration that takes a list of servers and sends requests to each server in turn. It does not perform true load-balancing as it does not measure loads, and does no health checks, so if one of the servers is down, requests are still sent to that server. Its virtue lies in simplicity. If you have a little cluster of file or web servers and want to spread the load between them in the simplest way, then round-robin DNS is for you.
|
||||
|
||||
All you do is create multiple A or AAAA records, mapping multiple servers to a single host name. This BIND example uses both IPv4 and IPv6 private address classes:
|
||||
```
|
||||
fileserv.example.com. IN A 172.16.10.10
|
||||
fileserv.example.com. IN A 172.16.10.11
|
||||
fileserv.example.com. IN A 172.16.10.12
|
||||
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::10
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::11
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::12
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq uses _/etc/hosts_ for A and AAAA records:
|
||||
```
|
||||
172.16.1.10 fileserv fileserv.example.com
|
||||
172.16.1.11 fileserv fileserv.example.com
|
||||
172.16.1.12 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::10 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::11 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::12 fileserv fileserv.example.com
|
||||
|
||||
```
|
||||
|
||||
Note that these examples are simplified, and there are multiple ways to resolve fully-qualified domain names, so please study up on configuring DNS.
|
||||
|
||||
Use the `dig` command to check your work. Replace `ns.example.com` with your name server:
|
||||
```
|
||||
$ dig @ns.example.com fileserv A fileserv AAA
|
||||
|
||||
```
|
||||
|
||||
That should display both IPv4 and IPv6 round-robin records.
|
||||
|
||||
### Subdomain Delegation and Round-Robin
|
||||
|
||||
Subdomain delegation combined with round-robin is more work to set up, but it has some advantages. Use this when you have multiple subdomains or geographically-dispersed servers. Response times are often quicker, and a down server will not respond, so clients will not get hung up waiting for a reply. A short TTL, such as 60 seconds, helps this.
|
||||
|
||||
This approach requires multiple name servers. In the simplest scenario, you have a primary name server and two subdomains, each with its own name server. Configure your round-robin entries on the subdomain servers, then configure the delegations on your primary server.
|
||||
|
||||
In BIND on your primary name server, you'll need at least two additional configurations, a zone statement, and A/AAAA records in your zone data file. The delegation looks something like this on your primary name server:
|
||||
```
|
||||
ns1.sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
ns2.sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN NS ns2.sub.example.com.
|
||||
|
||||
```
|
||||
|
||||
Then each of the subdomain servers have their own zone files. The trick here is for each server to return its own IP address. The zone statement in `named.conf` is the same on both servers:
|
||||
```
|
||||
zone "sub.example.com" {
|
||||
type master;
|
||||
file "db.sub.example.com";
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
Then the data files are the same, except that the A/AAAA records use the server's own IP address. The SOA (start of authority) refers to the primary name server:
|
||||
```
|
||||
; first subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018123456 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
|
||||
; second subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018234567 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
Next, make your round-robin entries on the subdomain name servers, and you're done. Now you have multiple name servers handling requests for your subdomains. Again, BIND is complex and has multiple ways to do the same thing, so your homework is to ensure that your configuration fits with the way you use it.
|
||||
|
||||
Subdomain delegations are easier in Dnsmasq. On your primary server, add lines like this in `dnsmasq.conf` to point to the name servers for the subdomains:
|
||||
```
|
||||
server=/sub.example.com/172.16.1.20
|
||||
server=/sub.example.com/172.16.1.21
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::20
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
Then configure round-robin on the subdomain name servers in `/etc/hosts`.
|
||||
|
||||
For way more details and help, refer to these resources:
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][1]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/simple-load-balancing-dns-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,115 +0,0 @@
|
||||
translating by amwps290
|
||||
How to clean up your data in the command line
|
||||
======
|
||||

|
||||
|
||||
I work part-time as a data auditor. Think of me as a proofreader who works with tables of data rather than pages of prose. The tables are exported from relational databases and are usually fairly modest in size: 100,000 to 1,000,000 records and 50 to 200 fields.
|
||||
|
||||
I haven't seen an error-free data table, ever. The messiness isn't limited, as you might think, to duplicate records, spelling and formatting errors, and data items placed in the wrong field. I also find:
|
||||
|
||||
* broken records spread over several lines because data items had embedded line breaks
|
||||
* data items in one field disagreeing with data items in another field, in the same record
|
||||
* records with truncated data items, often because very long strings were shoehorned into fields with 50- or 100-character limits
|
||||
* character encoding failures producing the gibberish known as [mojibake][1]
|
||||
* invisible [control characters][2], some of which can cause data processing errors
|
||||
* [replacement characters][3] and mysterious question marks inserted by the last program that failed to understand the data's character encoding
|
||||
|
||||
|
||||
|
||||
Cleaning up these problems isn't hard, but there are non-technical obstacles to finding them. The first is everyone's natural reluctance to deal with data errors. Before I see a table, the data owners or managers may well have gone through all five stages of Data Grief:
|
||||
|
||||
1. There are no errors in our data.
|
||||
2. Well, maybe there are a few errors, but they're not that important.
|
||||
3. OK, there are a lot of errors; we'll get our in-house people to deal with them.
|
||||
4. We've started fixing a few of the errors, but it's time-consuming; we'll do it when we migrate to the new database software.
|
||||
5. We didn't have time to clean the data when moving to the new database; we could use some help.
|
||||
|
||||
|
||||
|
||||
The second progress-blocking attitude is the belief that data cleaning requires dedicated applications—either expensive proprietary programs or the excellent open source program [OpenRefine][4]. To deal with problems that dedicated applications can't solve, data managers might ask a programmer for help—someone good with [Python][5] or [R][6].
|
||||
|
||||
But data auditing and cleaning generally don't require dedicated applications. Plain-text data tables have been around for many decades, and so have text-processing tools. Open up a Bash shell and you have a toolbox loaded with powerful text processors like `grep`, `cut`, `paste`, `sort`, `uniq`, `tr`, and `awk`. They're fast, reliable, and easy to use.
|
||||
|
||||
I do all my data auditing on the command line, and I've put many of my data-auditing tricks on a ["cookbook" website][7]. Operations I do regularly get stored as functions and shell scripts (see the example below).
|
||||
|
||||
Yes, a command-line approach requires that the data to be audited have been exported from the database. And yes, the audit results need to be edited later within the database, or (database permitting) the cleaned data items need to be imported as replacements for the messy ones.
|
||||
|
||||
But the advantages are remarkable. `awk` will process a few million records in seconds on a consumer-grade desktop or laptop. Uncomplicated regular expressions will find all the data errors you can imagine. And all of this will happen safely outside the database structure: Command-line auditing cannot affect the database, because it works with data liberated from its database prison.
|
||||
|
||||
Readers who trained on Unix will be smiling smugly at this point. They remember manipulating data on the command line many years ago in just these ways. What's happened since then is that processing power and RAM have increased spectacularly, and the standard command-line tools have been made substantially more efficient. Data auditing has never been faster or easier. And now that Microsoft Windows 10 can run Bash and GNU/Linux programs, Windows users can appreciate the Unix and Linux motto for dealing with messy data: Keep calm and open a terminal.
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
Photo by Robert Mesibov, CC BY
|
||||
|
||||
### An example
|
||||
|
||||
Suppose I want to find the longest data item in a particular field of a big table. That's not really a data auditing task, but it will show how shell tools work. For demonstration purposes, I'll use the tab-separated table `full0`, which has 1,122,023 records (plus a header line) and 49 fields, and I'll look in field number 36. (I get field numbers with a function explained [on my cookbook site][10].)
|
||||
|
||||
The command begins by using `tail` to remove the header line from `full0`. The result is piped to `cut`, which extracts the decapitated field 36. Next in the pipeline is `awk`. Here the variable `big` is initialized to a value of 0; then `awk` tests the length of the data item in the first record. If the length is bigger than 0, `awk` resets `big` to the new length and stores the line number (NR) in the variable `line` and the whole data item in the variable `text`. `awk` then processes each of the remaining 1,122,022 records in turn, resetting the three variables when it finds a longer data item. Finally, it prints out a neatly separated list of line numbers, length of data item, and full text of the longest data item. (In the following code, the commands have been broken up for clarity onto several lines.)
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
```
|
||||
|
||||
How long does this take? About 4 seconds on my desktop (core i5, 8GB RAM):
|
||||
|
||||
|
||||
|
||||
Now for the neat part: I can pop that long command into a shell function, `longest`, which takes as its arguments the filename `($1)` and the field number `($2)`:
|
||||

|
||||
|
||||
I can then re-run the command as a function, finding longest data items in other fields and in other files without needing to remember how the command is written:
|
||||
|
||||
|
||||
As a final tweak, I can add to the output the name of the numbered field I'm searching. To do this, I use `head` to extract the header line of the table, pipe that line to `tr` to convert tabs to new lines, and pipe the resulting list to `tail` and `head` to print the `$2th` field name on the list, where `$2` is the field number argument. The field name is stored in the shell variable `field` and passed to `awk` for printing as the internal `awk` variable `fld`.
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
Note that if I'm looking for the longest data item in a number of different fields, all I have to do is press the Up Arrow key to get the last `longest` command, then backspace the field number and enter a new one.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bobmesibov
|
||||
[1]:https://en.wikipedia.org/wiki/Mojibake
|
||||
[2]:https://en.wikipedia.org/wiki/Control_character
|
||||
[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
|
||||
[4]:http://openrefine.org/
|
||||
[5]:https://www.python.org/
|
||||
[6]:https://www.r-project.org/about.html
|
||||
[7]:https://www.polydesmida.info/cookbook/index.html
|
||||
[8]:/file/399116
|
||||
[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg (Tshirt, Keep Calm and Open A Terminal)
|
||||
[10]:https://www.polydesmida.info/cookbook/functions.html#fields
|
||||
@ -0,0 +1,51 @@
|
||||
|
||||
DevOps如何帮助你将很酷的应用交付给用户
|
||||
======
|
||||
|
||||

|
||||
|
||||
在很久之前,在DevOps成为主流实践之前,软件开放的过程是极其缓慢,单调和系统性的。当一个应用准备要部署的时候,一长串为下次主要的版本迭代的工具变更已经积累起来了。每次的新版本迭代的准备都将花费数月的时间去追溯以及贯穿整个开发周期的工作。请记住这个过程将会在交付更新给用户的过程中不断的
|
||||
重复。
|
||||
|
||||
今天一切都是瞬间和实时完成的,这个概念似乎很原始。这场移动革命已经极大的改变了我们和软件之间的交互。那些早期采用DevOps的公司已经彻底改变了对
|
||||
软件开发和部署的期望。
|
||||
|
||||
考虑到脸书:脸书这个移动应用每两周更新和刷新一次,像钟表一样,这就是新的标准因为现在的用户期望软件持续的被修复和更新。任何一家要花费一个月或者更多的
|
||||
时间来部署新的功能或者修复bug的公司将会逐渐走向没落。如果你不能交付用户所期待的,他们将会去寻找那些能够满足他们需求的。
|
||||
|
||||
Facebook,以及一些工业巨头如亚马逊,Netfix,谷歌以及其他的都已经强制要求企业变得更快速更有效的来满足如天的顾客们的需求。
|
||||
|
||||
### 为什么是DevOps?
|
||||
|
||||
敏捷和DevOps在移动应用开发领域是相当重要的因为开发周期正变得越来越快。现在是一个密集快节奏的环境,公司必须加紧步伐赶超,思考的更深入,运用策略来去完成从而生存下去。在应用商店中,排名前十的应用平均能够保持的时间只有一个月左右。
|
||||
|
||||
为了说明老式的瀑布方法,回想一下你第一次学习驾驶。起先,你专注于每个独立的层面,使用一套方法论的过程:你上车;系上安全带;调整座椅,镜子,控制方向盘,发动汽车,将你的手放在10点和2点钟的方向,等等。完成一个简单的任务就像是换车道一样需要付出艰苦的努力,在一个特定的顺序下执行多个步骤。
|
||||
|
||||
DevOps,正好相反,是在你有了几年的经验之后如何去驾驶的。一切都是靠直觉同时发生的,你可以不用过多的思考就很平滑的从A移动到B。
|
||||
|
||||
移动APP的世界对越老式的APP开发环境来说太快节奏了。DevOps被设计用来有效,稳定快速的在不需要增加资源的情况下交付应用。然而你不能像购买一件普通的商品或者服务一样去购买DevOps.DevOps是用来指导改变团队如何一起工作的文化和活动的。
|
||||
|
||||
不是只有像亚马逊和脸书这样的大公司拥抱DevOps文化;小的移动应用公司也在很好的使用。“在保持生产事故处于一个较低水平的同时速度啊迭代周期以及满足顾客最求的整体的失败成本。”来自移产品代理[Reinvently][1]的工程部的负责人,Oleg Reshetnyak说道。
|
||||
|
||||
### DevOps: 不是如果,而是什么时候
|
||||
|
||||
在今天的快节奏的商业环境中,选在了DevOps就像是选择了呼吸:要么去做要么就死亡。[2]
|
||||
|
||||
根据美国小企业管理的报道,现在只有16% 的公司能够持续一代人的时间。不采用DevOps的移动应用公司将冒着逐渐走向灭绝的风险。而且,同样的研究表明采用DevOps的公司组织可能能够超过盈利能力,生产目标以及市场份额。
|
||||
|
||||
更快速更安全的革新需要做到三点:云,自动化和DevOps, 根据你对DevOps的定义的不同,这三个要点之间的界限是不清晰的。然而,有一点是确定的:DevOps围绕着更快更少风险的交付高质量的软件的共同目标将组织额内的每个人都统一起来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/devops-delivers-cool-apps-users
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://reinvently.com/
|
||||
[2]:https://squadex.com/insights/devops-or-die/
|
||||
[3]:https://www.sba.gov/
|
||||
@ -0,0 +1,139 @@
|
||||
在 Linux 上用 DNS 实现简单的负载均衡
|
||||
======
|
||||
|
||||

|
||||
如果你的后端服务器是由多台服务器构成的,比如集群化或者镜像的 Web 或者文件服务器,通过一个负载均衡器提供了单一的入口点。业务繁忙的大型电商花费大量的资金在高端负载均衡器上,用它来执行各种各样的任务:代理、缓存、状况检查、SSL 处理、可配置的优先级、流量整形等很多任务。
|
||||
|
||||
但是你并不需要做那么多工作的负载均衡器。你需要的是一个跨服务器分发负载的简单方法,它能够提供故障切换,并且不太在意它是否高效和完美。DNS 轮询和使用轮询的子域委派是实现这个目标的两种简单方法。
|
||||
|
||||
DNS 轮询是将多台服务器映射到同一个主机名上,当用户访问 `foo.example.com` 时多台服务器都可用于处理它们的请求,使用的就是这种方式。
|
||||
|
||||
当你有多个子域或者你的服务器在地理上比较分散时,使用轮询的子域委派就比较有用。你有一个主域名服务器,而子域有它们自己的域名服务器。你的主域名服务器将所有的到子域的请求指向到它们自己的域名服务器上。这将提升响应时间,因为 DNS 协议会自动查找最快的链路。
|
||||
|
||||
### DNS 轮询
|
||||
|
||||
轮询和旅鸫鸟(robins)没有任何关系,据我喜欢的图书管理员说,它最初是一个法语短语,_`ruban rond`_、或者 `round ribbon`。很久以前,法国政府官员以不分级的圆形、波浪形、或者辐条形状去签署请愿书以掩盖请愿书的发起人。
|
||||
|
||||
DNS 轮询也是不分级的,简单配置一个服务器列表,然后将请求转到每个服务器上。它并不做真正的负载均衡,因为它根本就不测量负载,也没有状况检查,因此如果一个服务器宕机,请求仍然会发送到那个宕机的服务器上。它的优点就是简单。如果你有一个小的文件或者 Web 服务器集群,想通过一个简单的方法在它们之间分散负载,那么 DNS 轮询很适合你。
|
||||
|
||||
你所做的全部配置就是创建多条 A 或者 AAAA 记录,映射多台服务器到单个的主机名。这个 BIND 示例同时使用了 IPv4 和 IPv6 私有地址类:
|
||||
```
|
||||
fileserv.example.com. IN A 172.16.10.10
|
||||
fileserv.example.com. IN A 172.16.10.11
|
||||
fileserv.example.com. IN A 172.16.10.12
|
||||
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::10
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::11
|
||||
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::12
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 在 _/etc/hosts_ 文件中保存 A 和 AAAA 记录:
|
||||
```
|
||||
172.16.1.10 fileserv fileserv.example.com
|
||||
172.16.1.11 fileserv fileserv.example.com
|
||||
172.16.1.12 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::10 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::11 fileserv fileserv.example.com
|
||||
fd02:faea:f561:8fa0:1::12 fileserv fileserv.example.com
|
||||
|
||||
```
|
||||
|
||||
请注意这些示例都是很简化的,解析完全合格域名有多种方法,因此,关于如何配置 DNS 请自行学习。
|
||||
|
||||
使用 `dig` 命令去检查你的配置能否按预期工作。将 `ns.example.com` 替换为你的域名服务器:
|
||||
```
|
||||
$ dig @ns.example.com fileserv A fileserv AAA
|
||||
|
||||
```
|
||||
|
||||
它将同时显示出 IPv4 和 IPv6 的轮询记录。
|
||||
|
||||
### 子域委派和轮询
|
||||
|
||||
子域委派结合轮询要做的配置会更多,但是这样有一些好处。当你有多个子域或者地理位置比较分散的服务器时,就应该去使用它。它的响应时间更快,并且宕机的服务器不会去响应,因此客户端不会因为等待回复而被挂住。一个短的 TTL,比如 60 秒,就能帮你做到。
|
||||
|
||||
这种方法需要多台域名服务器。在最简化的场景中,你需要一台主域名服务器和两个子域,每个子域都有它们自己的域名服务器。在子域服务器上配置你的轮询记录,然后在你的主域名服务器上配置委派。
|
||||
|
||||
在主域名服务器上的 BIND 中,你至少需要两个额外的配置,一个区声明以及在区数据文件中的 A/AAAA 记录。主域名服务器中的委派应该像如下的内容:
|
||||
```
|
||||
ns1.sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
ns2.sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN NS ns2.sub.example.com.
|
||||
|
||||
```
|
||||
|
||||
接下来的每台子域服务器上有它们自己的区文件。在这里它的关键点是每个服务器去返回它**自己的** IP 地址。在 `named.conf` 中的区声明,所有的服务上都是一样的:
|
||||
```
|
||||
zone "sub.example.com" {
|
||||
type master;
|
||||
file "db.sub.example.com";
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
然后数据文件也是相同的,除了那个 A/AAAA 记录使用的是各个服务器自己的 IP 地址。SOA 记录都指向到主域名服务器:
|
||||
```
|
||||
; first subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018123456 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.20
|
||||
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
|
||||
|
||||
; second subdomain name server
|
||||
$ORIGIN sub.example.com.
|
||||
$TTL 60
|
||||
sub.example.com IN SOA ns1.example.com. admin.example.com. (
|
||||
2018234567 ; serial
|
||||
3H ; refresh
|
||||
15 ; retry
|
||||
3600000 ; expire
|
||||
)
|
||||
|
||||
sub.example.com. IN NS ns1.sub.example.com.
|
||||
sub.example.com. IN A 172.16.1.21
|
||||
ns2.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
接下来生成子域服务器上的轮询记录,方法和前面一样。现在你已经有了多个域名服务器来处理到你的子域的请求。再说一次,BIND 是很复杂的,做同一件事情它有多种方法,因此,给你留的家庭作业是找出适合你使用的最佳配置方法。
|
||||
|
||||
在 Dnsmasq 中做子域委派很容易。在你的主域名服务器上的 `dnsmasq.conf` 文件中添加如下的行,去指向到子域的域名服务器:
|
||||
```
|
||||
server=/sub.example.com/172.16.1.20
|
||||
server=/sub.example.com/172.16.1.21
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::20
|
||||
server=/sub.example.com/fd02:faea:f561:8fa0:1::21
|
||||
|
||||
```
|
||||
|
||||
然后在子域的域名服务器上的 `/etc/hosts` 中配置轮询。
|
||||
|
||||
获取配置方法的详细内容和帮助,请参考这些资源:~~(致校对:这里的资源链接全部丢失了!!)~~
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][1] 学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/simple-load-balancing-dns-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,115 @@
|
||||
# 在命令行中整理数据
|
||||
|
||||

|
||||
|
||||
我兼职做数据审计。把我想象成一个校对者,处理数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200个字段。
|
||||
|
||||
我从来没有见过没有错误的数据表。您可能认为,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
|
||||
|
||||
* 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
|
||||
* 在同一记录中一个字段中的数据项与另一个字段中的数据项不一致
|
||||
* 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有50或100字符限制的字段中
|
||||
* 字符编码失败产生称为[乱码][1]
|
||||
* 不可见的[控制字符][2],其中一些会导致数据处理错误
|
||||
* 由上一个程序插入的[替换字符][3]和神秘的问号,这导致了不知道数据的编码是什么
|
||||
|
||||
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了数据悲伤的所有五个阶段:
|
||||
|
||||
1. 我们的数据没有错误。
|
||||
|
||||
1. 好吧,也许有一些错误,但它们并不重要。
|
||||
2. 好的,有很多错误; 我们会让我们的内部人员处理它们。
|
||||
3. 我们已经开始修复一些错误,但这很耗时间; 我们将在迁移到新的数据库软件时执行此操作。
|
||||
4. 1.移至新数据库时,我们没有时间整理数据; 我们可以使用一些帮助。
|
||||
|
||||
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 [OpenRefine][4] 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 [Python][5] 或 [R][6] 的人。
|
||||
|
||||
但是数据审计和整理通常不需要专用的应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您将拥有一个工具箱,其中装载了强大的文本处理器,如 `grep`、`cut`、`paste`、`sort`、`uniq`、`tr` 和 `awk`。它们快速、可靠、易于使用。
|
||||
|
||||
我在命令行上执行所有的数据审计工作,并且在 “[cookbook][7]” 网站上发布了许多数据审计技巧。我经常将操作存储为函数和 shell 脚本(参见下面的示例)。
|
||||
|
||||
是的,命令行方法要求将要审计的数据从数据库中导出。 是的,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)整理的数据项作为替换杂乱的数据项导入其中。
|
||||
|
||||
但其优势是显著的。awk 将在普通的台式机或笔记本电脑上以几秒钟的时间处理数百万条记录。不复杂的正则表达式将找到您可以想象的所有数据错误。所有这些都将安全地发生在数据库结构之外:命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
|
||||
|
||||
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来都不是更快或更容易的。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。
|
||||
|
||||
|
||||
![Tshirt, Keep Calm and Open A Terminal][9]
|
||||
|
||||
图片:Robert Mesibov,CC BY
|
||||
|
||||
### 例子:
|
||||
|
||||
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 `full0` ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段.(我得到字段编号的函数在我的[网站][10]上有解释)
|
||||
|
||||
首先,使用 `tail` 命令从表 `full0` 移除标题行,结果管道至 `cut` 命令,截取第 36 个字段,接下来,管道至 `awk` ,这里有一个初始化为 0 的变量 `big` ,然后 `awk` 开始检测第一行数据项的长度,如果长度大于 0 , `awk` 将会设置 `big` 变量为新的长度,同时存储行数到变量 `line` 中。整个数据项存储在变量 `text` 中。然后 `awk` 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号,数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
|
||||
|
||||
```
|
||||
<code>tail -n +2 full0 \
|
||||
|
||||
> | cut -f36 \
|
||||
|
||||
> | awk 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
> {big=length($0);line=NR;text=$0} \
|
||||
|
||||
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
|
||||
|
||||
```
|
||||
|
||||
大约花了多长时间?我的电脑大约用了 4 秒钟(core i5,8GB RAM);
|
||||
|
||||

|
||||
|
||||
现在我可以将这个长长的命令封装成一个 shell 函数,`longest`,它把第一个参数认为是文件名,第二个参数认为是字段号:
|
||||
|
||||

|
||||
|
||||
现在,我重新运行这个命令,在另一个文件中找另一个字段中最长的数据项而不需要去记忆命令是如何写的:
|
||||
|
||||

|
||||
|
||||
最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 `head` 命令抽取表格第一行的标题行,然后将结果管道至 `tr` 命令,将制表位转换为换行,然后将结果管道至 `tail` 和 `head` 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 `field` 中,然后将他传向 `awk` ,通过变量 `fld` 打印出来。(译者注:按照下面的代码,编号的方式应该是从右向左)
|
||||
|
||||
```
|
||||
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
|
||||
|
||||
tail -n +2 "$1" \
|
||||
|
||||
| cut -f"$2" | \
|
||||
|
||||
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
|
||||
|
||||
{big=length($0);line=NR;text=$0}
|
||||
|
||||
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
注意,如果我在多个不同的字段中查找最长的数据项,我所要做的就是按向上箭头来获得最后一个最长的命令,然后删除字段号并输入一个新的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/command-line-data-auditing
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bobmesibov
|
||||
[1]:https://en.wikipedia.org/wiki/Mojibake
|
||||
[2]:https://en.wikipedia.org/wiki/Control_character
|
||||
[3]:https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character
|
||||
[4]:http://openrefine.org/
|
||||
[5]:https://www.python.org/
|
||||
[6]:https://www.r-project.org/about.html
|
||||
[7]:https://www.polydesmida.info/cookbook/index.html
|
||||
[8]:/file/399116
|
||||
[9]:https://opensource.com/sites/default/files/uploads/terminal_tshirt.jpg "Tshirt, Keep Calm and Open A Terminal"
|
||||
[10]:https://www.polydesmida.info/cookbook/functions.html#fields
|
||||
Loading…
Reference in New Issue
Block a user