diff --git a/published/20171216 Sysadmin 101- Troubleshooting.md b/published/20171216 Sysadmin 101- Troubleshooting.md
new file mode 100644
index 0000000000..0beb6eeb67
--- /dev/null
+++ b/published/20171216 Sysadmin 101- Troubleshooting.md
@@ -0,0 +1,138 @@
+系统管理员入门:排除故障
+======
+
+
+
+我通常会严格保持此博客的技术性,将观察、意见等内容保持在最低限度。但是,这篇和接下来的几篇文章将介绍刚进入系统管理/SRE/系统工程师/sysops/devops-ops(无论你想称自己是什么)角色的常见的基础知识。
+
+请跟我来!
+
+> “我的网站很慢!”
+
+我只是随机选择了本文的问题类型,这也可以应用于任何与系统管理员相关的故障排除。我并不是要炫耀那些可以发现最多的信息的最聪明的“金句”。它也不是一个详尽的、一步步指导的、并在最后一个方框中导向“利润”一词的“流程图”。
+
+我会通过一些例子展示常规的方法。
+
+示例场景仅用于说明本文目的。它们有时会做一些不适用于所有情况的假设,而且肯定会有很多读者在某些时候说“哦,但我觉得你会发现……”。
+
+但那可能会让我们错失重点。
+
+十多年来,我一直在从事于支持工作,或在支持机构工作,有一件事让我一次又一次地感到震惊,这促使我写下了这篇文章。
+
+**有许多技术人员在遇到问题时的本能反应,就是不管三七二十一去尝试可能的解决方案。**
+
+*“我的网站很慢,所以”,*
+
+* 我将尝试增大 `MaxClients`/`MaxRequestWorkers`/`worker_connections`
+* 我将尝试提升 `innodb_buffer_pool_size`/`effective_cache_size`
+* 我打算尝试启用 `mod_gzip`(遗憾的是,这是真实的故事)
+
+*“我曾经看过这个问题,它是因为某种原因造成的 —— 所以我估计还是这个原因,它应该能解决这个问题。”*
+
+这浪费了很多时间,并会让你在黑暗中盲目乱撞,胡乱鼓捣。
+
+你的 InnoDB 的缓冲池也许达到 100% 的利用率,但这可能只是因为有人运行了一段时间的一次性大型报告导致的。如果没有排除这种情况,那你就是在浪费时间。
+
+### 开始之前
+
+在这里,我应该说明一下,虽然这些建议同样适用于许多角色,但我是从一般的支持系统管理员的角度来撰写的。在一个成熟的内部组织中,或与规模较大的、规范管理的或“企业级”客户合作时,你通常会对一切都进行检测、测量、绘制、整理(甚至不是文字),并发出警报。那么你的方法也往往会有所不同。让我们在这里先忽略这种情况。
+
+如果你没有这种东西,那就随意了。
+
+### 澄清问题
+
+首先确定实际上是什么问题。“慢”可以是多种形式的。是收到第一个字节的时间吗?从糟糕的 Javascript 加载和每页加载要拉取 15 MB 的静态内容,这是一个完全不同类型的问题。是慢,还是比通常慢?这是两个非常不同的解决方案!
+
+在你着手做某事之前,确保你知道实际报告和遇到的问题。找到问题的根源通常很困难,但即便找不到也必须找到问题本身。
+
+否则,这相当于系统管理员带着一把刀去参加枪战。
+
+### 唾手可得
+
+首次登录可疑服务器时,你可以查找一些常见的嫌疑对象。事实上,你应该这样做!每当我登录到服务器时,我都会发出一些命令来快速检查一些事情:我们是否发生了页交换(`free` / `vmstat`),磁盘是否繁忙(`top` / `iostat` / `iotop`),是否有丢包(`netstat` / `proc` / `net` / `dev`),是否处于连接数过多的状态(`netstat`),有什么东西占用了 CPU(`top`),谁在这个服务器上(`w` / `who`),syslog 和 `dmesg` 中是否有引人注目的消息?
+
+如果你从 RAID 控制器得到 2000 条抱怨直写式缓存没有生效的消息,那么继续进行是没有意义的。
+
+这用不了半分钟。如果什么都没有引起你的注意 —— 那么继续。
+
+### 重现问题
+
+如果某处确实存在问题,并且找不到唾手可得的信息。
+
+那么采取所有步骤来尝试重现问题。当你可以重现该问题时,你就可以观察它。**当你能观察到时,你就可以解决。**如果在第一步中尚未显现出或覆盖了问题所在,询问报告问题的人需要采取哪些确切步骤来重现问题。
+
+对于由太阳耀斑或只能运行在 OS/2 上的客户端引起的问题,重现并不总是可行的。但你的第一个停靠港应该是至少尝试一下!在一开始,你所知道的是“某人认为他们的网站很慢”。对于那些人,他们可能还在用他们的 GPRS 手机,也可能正在安装 Windows 更新。你在这里挖掘得再深也是浪费时间。
+
+尝试重现!
+
+### 检查日志
+
+我对于有必要包括这一点感到很难过。但是我曾经看到有人在运行 `tail /var/log/...` 之后几分钟就不看了。大多数 *NIX 工具都特别喜欢记录日志。任何明显的错误都会在大多数应用程序日志中显得非常突出。检查一下。
+
+### 缩小范围
+
+如果没有明显的问题,但你可以重现所报告的问题,那也很棒。所以,你现在知道网站是慢的。现在你已经把范围缩小到:浏览器的渲染/错误、应用程序代码、DNS 基础设施、路由器、防火墙、网卡(所有的)、以太网电缆、负载均衡器、数据库、缓存层、会话存储、Web 服务器软件、应用程序服务器、内存、CPU、RAID 卡、磁盘等等。
+
+根据设置添加一些其他可能的罪魁祸首。它们也可能是 SAN,也不要忘记硬件 WAF!以及…… 你明白我的意思。
+
+如果问题是接收到第一个字节的时间,你当然会开始对 Web 服务器去应用上已知的修复程序,就是它响应缓慢,你也觉得几乎就是它,对吧?但是你错了!
+
+你要回去尝试重现这个问题。只是这一次,你要试图消除尽可能多的潜在问题来源。
+
+你可以非常轻松地消除绝大多数可能的罪魁祸首:你能从服务器本地重现问题吗?恭喜,你刚刚节省了自己必须尝试修复 BGP 路由的时间。
+
+如果不能,请尝试使用同一网络上的其他计算机。如果可以的话,至少你可以将防火墙移到你的嫌疑人名单上,(但是要注意一下那个交换机!)
+
+是所有的连接都很慢吗?虽然服务器是 Web 服务器,但并不意味着你不应该尝试使用其他类型的服务进行重现问题。[netcat][1] 在这些场景中非常有用(但是你的 SSH 连接可能会一直有延迟,这可以作为线索)! 如果这也很慢,你至少知道你很可能遇到了网络问题,可以忽略掉整个 Web 软件及其所有组件的问题。用这个知识(我不收 200 美元)再次从顶部开始,按你的方式由内到外地进行!
+
+即使你可以在本地复现 —— 仍然有很多“因素”留下。让我们排除一些变量。你能用普通文件重现它吗? 如果 `i_am_a_1kb_file.html` 很慢,你就知道它不是数据库、缓存层或 OS 以外的任何东西和 Web 服务器本身的问题。
+
+你能用一个需要解释或执行的 `hello_world.(py|php|js|rb..)` 文件重现问题吗?如果可以的话,你已经大大缩小了范围,你可以专注于少数事情。如果 `hello_world` 可以马上工作,你仍然学到了很多东西!你知道了没有任何明显的资源限制、任何满的队列或在任何地方卡住的 IPC 调用,所以这是应用程序正在做的事情或它正在与之通信的事情。
+
+所有页面都慢吗?或者只是从第三方加载“实时分数数据”的页面慢?
+
+**这可以归结为:你仍然可以重现这个问题所涉及的最少量的“因素”是什么?**
+
+我们的示例是一个缓慢的网站,但这同样适用于几乎所有问题。邮件投递?你能在本地投递吗?能发给自己吗?能发给<常见的服务提供者>吗?使用小的、纯文本的消息进行测试。尝试直到遇到 2MB 拥堵时。使用 STARTTLS 和不使用 STARTTLS 呢?按你的方式由内到外地进行!
+
+这些步骤中的每一步都只需要几秒钟,远远快于实施大多数“可能的”修复方案。
+
+### 隔离观察
+
+到目前为止,当你去除特定组件时无法重现问题时,你可能已经偶然发现了问题所在。
+
+但如果你还没有,或者你仍然不知道**为什么**:一旦你找到了一种方法来重现问题,你和问题之间的“东西”(某个技术术语)最少,那么就该开始隔离和观察了。
+
+请记住,许多服务可以在前台运行和/或启用调试。对于某些类别的问题,执行此操作通常非常有帮助。
+
+这也是你的传统武器库发挥作用的地方。`strace`、`lsof`、`netstat`、`GDB`、`iotop`、`valgrind`、语言分析器(cProfile、xdebug、ruby-prof ……)那些类型的工具。
+
+一旦你走到这一步,你就很少能摆脱剖析器或调试器了。
+
+[strace][2] 通常是一个非常好的起点。
+
+你可能会注意到应用程序停留在某个连接到端口 3306 的套接字文件描述符上的特定 `read()` 调用上。你会知道该怎么做。
+
+转到 MySQL 并再次从顶部开始。显而易见:“等待某某锁”、死锁、`max_connections` ……进而:是所有查询?还是只写请求?只有某些表?还是只有某些存储引擎?等等……
+
+你可能会注意到调用外部 API 资源的 `connect()` 需要五秒钟才能完成,甚至超时。你会知道该怎么做。
+
+你可能会注意到,在同一对文件中有 1000 个调用 `fstat()` 和 `open()` 作为循环依赖的一部分。你会知道该怎么做。
+
+它可能不是那些特别的东西,但我保证,你会发现一些东西。
+
+如果你只是从这一部分学到一点,那也不错;学习使用 `strace` 吧!**真的**学习它,阅读整个手册页。甚至不要跳过历史部分。`man` 每个你还不知道它做了什么的系统调用。98% 的故障排除会话以 `strace` 而终结。
+
+---------------------------------------------------------------------
+
+via: http://northernmost.org/blog/troubleshooting-101/index.html
+
+作者:[Erik Ljungstrom][a]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://northernmost.org
+[1]:http://nc110.sourceforge.net/
+[2]:https://linux.die.net/man/1/strace
diff --git a/published/20180928 Quiet log noise with Python and machine learning.md b/published/20180928 Quiet log noise with Python and machine learning.md
new file mode 100644
index 0000000000..d6471b3969
--- /dev/null
+++ b/published/20180928 Quiet log noise with Python and machine learning.md
@@ -0,0 +1,106 @@
+Logreduce:用 Python 和机器学习去除日志噪音
+======
+
+> Logreduce 可以通过从大量日志数据中挑选出异常来节省调试时间。
+
+
+
+持续集成(CI)作业会生成大量数据。当一个作业失败时,弄清楚出了什么问题可能是一个繁琐的过程,它涉及到调查日志以发现根本原因 —— 这通常只能在全部的作业输出的一小部分中找到。为了更容易地将最相关的数据与其余数据分开,可以使用先前成功运行的作业结果来训练 [Logreduce][1] 机器学习模型,以从失败的运行日志中提取异常。
+
+此方法也可以应用于其他用例,例如,从 [Journald][2] 或其他系统级的常规日志文件中提取异常。
+
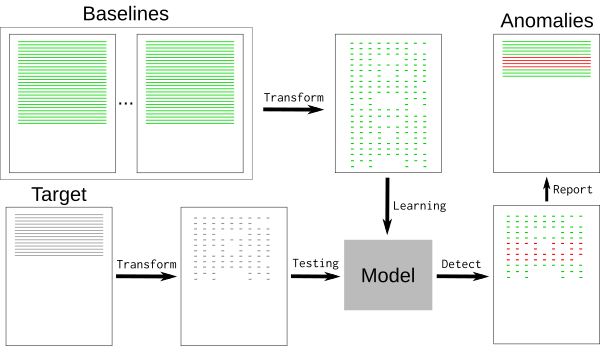
+### 使用机器学习来降低噪音
+
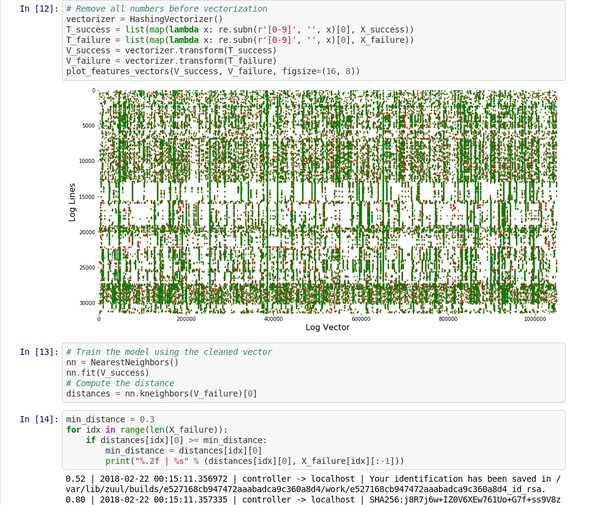
+典型的日志文件包含许多标称事件(“基线”)以及与开发人员相关的一些例外事件。基线可能包含随机元素,例如难以检测和删除的时间戳或唯一标识符。要删除基线事件,我们可以使用 [k-最近邻模式识别算法][3](k-NN)。
+
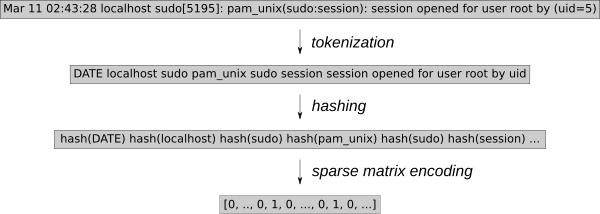
+
+
+日志事件必须转换为可用于 k-NN 回归的数值。使用通用特征提取工具 [HashingVectorizer][4] 可以将该过程应用于任何类型的日志。它散列每个单词并在稀疏矩阵中对每个事件进行编码。为了进一步减少搜索空间,这个标记化过程删除了已知的随机单词,例如日期或 IP 地址。
+
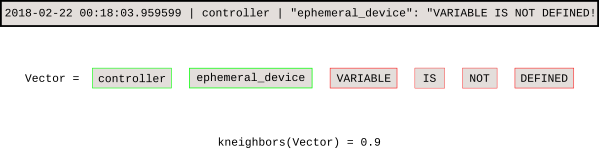
+
+
+训练模型后,k-NN 搜索可以告诉我们每个新事件与基线的距离。
+
+
+
+这个 [Jupyter 笔记本][5] 演示了该稀疏矩阵向量的处理和图形。
+
+
+
+### Logreduce 介绍
+
+Logreduce Python 软件透明地实现了这个过程。Logreduce 的最初目标是使用构建数据库来协助分析 [Zuul CI][6] 作业的失败问题,现在它已集成到 [Software Factory 开发车间][7]的作业日志处理中。
+
+最简单的是,Logreduce 会比较文件或目录并删除相似的行。Logreduce 为每个源文件构建模型,并使用以下语法输出距离高于定义阈值的任何目标行:`distance | filename:line-number: line-content`。
+
+```
+$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
+INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
+0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
+INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
+99.99% reduction (from 20015 lines to 1
+
+```
+
+更高级的 Logreduce 用法可以离线训练模型以便重复使用。可以使用基线的许多变体来拟合 k-NN 搜索树。
+
+```
+$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
+INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
+DEBUG logreduce.Classifier - audit.clf: written
+$ logreduce dir-run audit.clf /var/log/audit/audit.log
+```
+
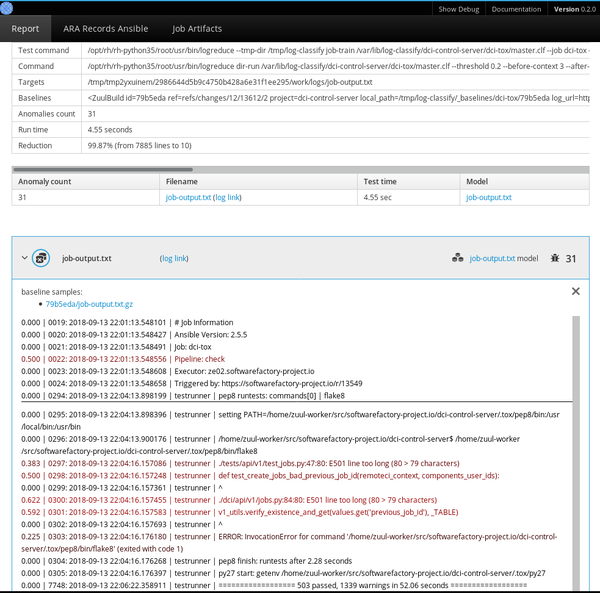
+Logreduce 还实现了接口,以发现 Journald 时间范围(天/周/月)和 Zuul CI 作业构建历史的基线。它还可以生成 HTML 报告,该报告在一个简单的界面中将在多个文件中发现的异常进行分组。
+
+
+
+### 管理基线
+
+使用 k-NN 回归进行异常检测的关键是拥有一个已知良好基线的数据库,该模型使用数据库来检测偏离太远的日志行。此方法依赖于包含所有标称事件的基线,因为基线中未找到的任何内容都将报告为异常。
+
+CI 作业是 k-NN 回归的重要目标,因为作业的输出通常是确定性的,之前的运行结果可以自动用作基线。 Logreduce 具有 Zuul 作业角色,可以将其用作失败的作业发布任务的一部分,以便发布简明报告(而不是完整作业的日志)。只要可以提前构建基线,该原则就可以应用于其他情况。例如,标称系统的 [SoS 报告][8] 可用于查找缺陷部署中的问题。
+
+
+
+### 异常分类服务
+
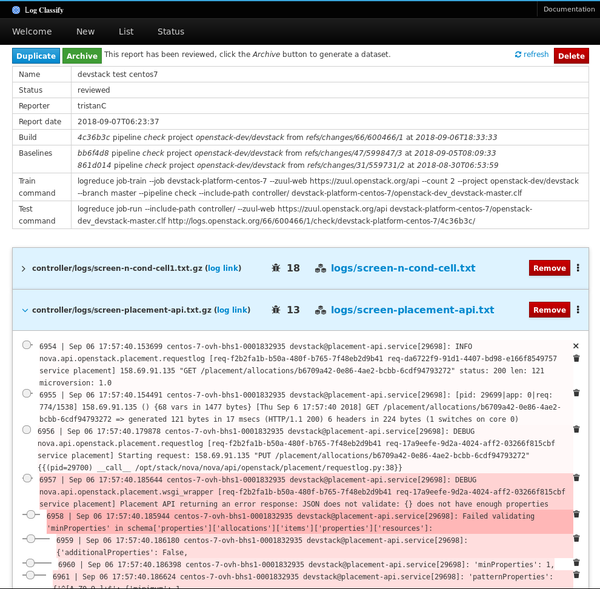
+下一版本的 Logreduce 引入了一种服务器模式,可以将日志处理卸载到外部服务,在外部服务中可以进一步分析该报告。它还支持导入现有报告和请求以分析 Zuul 构建。这些服务以异步方式运行分析,并具有 Web 界面以调整分数并消除误报。
+
+
+
+已审核的报告可以作为独立数据集存档,其中包含目标日志文件和记录在一个普通的 JSON 文件中的异常行的分数。
+
+### 项目路线图
+
+Logreduce 已经能有效使用,但是有很多机会来改进该工具。未来的计划包括:
+
+* 策划在日志文件中发现的许多带注释的异常,并生成一个公共域数据集以进行进一步研究。日志文件中的异常检测是一个具有挑战性的主题,并且有一个用于测试新模型的通用数据集将有助于识别新的解决方案。
+* 重复使用带注释的异常模型来优化所报告的距离。例如,当用户通过将距离设置为零来将日志行标记为误报时,模型可能会降低未来报告中这些日志行的得分。
+* 对存档异常取指纹特征以检测新报告何时包含已知的异常。因此,该服务可以通知用户该作业遇到已知问题,而不是报告异常的内容。解决问题后,该服务可以自动重新启动该作业。
+* 支持更多基准发现接口,用于 SOS 报告、Jenkins 构建、Travis CI 等目标。
+
+如果你有兴趣参与此项目,请通过 #log-classify Freenode IRC 频道与我们联系。欢迎反馈!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
+
+作者:[Tristan de Cacqueray][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/tristanc
+[1]: https://pypi.org/project/logreduce/
+[2]: http://man7.org/linux/man-pages/man8/systemd-journald.service.8.html
+[3]: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
+[4]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
+[5]: https://github.com/TristanCacqueray/anomaly-detection-workshop-opendev/blob/master/datasets/notebook/anomaly-detection-with-scikit-learn.ipynb
+[6]: https://zuul-ci.org
+[7]: https://www.softwarefactory-project.io
+[8]: https://sos.readthedocs.io/en/latest/
+[9]: https://www.openstack.org/summit/berlin-2018/summit-schedule/speakers/4307
+[10]: https://www.openstack.org/summit/berlin-2018/
diff --git a/published/20190304 How to Install MongoDB on Ubuntu.md b/published/20190304 How to Install MongoDB on Ubuntu.md
new file mode 100644
index 0000000000..1ba0edae1f
--- /dev/null
+++ b/published/20190304 How to Install MongoDB on Ubuntu.md
@@ -0,0 +1,235 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11175-1.html)
+[#]: subject: (How to Install MongoDB on Ubuntu)
+[#]: via: (https://itsfoss.com/install-mongodb-ubuntu)
+[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
+
+如何在 Ubuntu 上安装 MongoDB
+======
+
+> 本教程介绍了在 Ubuntu 和基于 Ubuntu 的 Linux 发行版上安装 MongoDB 的两种方法。
+
+[MongoDB][1] 是一个越来越流行的自由开源的 NoSQL 数据库,它将数据存储在类似 JSON 的灵活文档集中,这与 SQL 数据库中常见的表格形式形成对比。
+
+你很可能发现在现代 Web 应用中使用 MongoDB。它的文档模型使得使用各种编程语言能非常直观地访问和处理它。
+
+![mongodb Ubuntu][2]
+
+在本文中,我将介绍两种在 Ubuntu 上安装 MongoDB 的方法。
+
+### 在基于 Ubuntu 的发行版上安装 MongoDB
+
+1. 使用 Ubuntu 仓库安装 MongoDB。简单但不是最新版本的 MongoDB
+2. 使用其官方仓库安装 MongoDB。稍微复杂,但你能得到最新版本的 MongoDB。
+
+第一种安装方法更容易,但如果你计划使用官方支持的最新版本,那么我建议使用第二种方法。
+
+有些人可能更喜欢使用 snap 包。Ubuntu 软件中心提供了 snap,但我不建议使用它们,因为他们现在已经过期了,因此我这里不会提到。
+
+### 方法 1:从 Ubuntu 仓库安装 MongoDB
+
+这是在系统中安装 MongoDB 的简便方法,你只需输入一个命令即可。
+
+#### 安装 MongoDB
+
+首先,确保你的包是最新的。打开终端并输入:
+
+```
+sudo apt update && sudo apt upgrade -y
+```
+
+继续安装 MongoDB:
+
+```
+sudo apt install mongodb
+```
+
+这就完成了!MongoDB 现在安装到你的计算机上了。
+
+MongoDB 服务应该在安装时自动启动,但要检查服务状态:
+
+```
+sudo systemctl status mongodb
+```
+
+![Check if the MongoDB service is running.][3]
+
+你可以看到该服务是**活动**的。
+
+#### 运行 MongoDB
+
+MongoDB 目前是一个 systemd 服务,因此我们使用 `systemctl` 来检查和修改它的状态,使用以下命令:
+
+```
+sudo systemctl status mongodb
+sudo systemctl stop mongodb
+sudo systemctl start mongodb
+sudo systemctl restart mongodb
+```
+
+你也可以修改 MongoDB 是否自动随系统启动(默认:启用):
+
+```
+sudo systemctl disable mongodb
+sudo systemctl enable mongodb
+```
+
+要开始使用(创建和编辑)数据库,请输入:
+
+```
+mongo
+```
+
+这将启动 **mongo shell**。有关查询和选项的详细信息,请查看[手册][4]。
+
+**注意:**根据你计划使用 MongoDB 的方式,你可能需要调整防火墙。不过这超出了本篇的内容,并且取决于你的配置。
+
+#### 卸载 MongoDB
+
+如果你从 Ubuntu 仓库安装 MongoDB 并想要卸载它(可能要使用官方支持的方式安装),请输入:
+
+```
+sudo systemctl stop mongodb
+sudo apt purge mongodb
+sudo apt autoremove
+```
+
+这应该会完全卸载 MongoDB。确保**备份**你可能想要保留的任何集合或文档,因为它们将被删除!
+
+### 方法 2:在 Ubuntu 上安装 MongoDB 社区版
+
+这是推荐的安装 MongoDB 的方法,它使用包管理器。你需要多打几条命令,对于 Linux 新手而言,这可能会感到害怕。
+
+但没有什么可怕的!我们将一步步说明安装过程。
+
+#### 安装 MongoDB
+
+由 MongoDB Inc. 维护的包称为 `mongodb-org`,而不是 `mongodb`(这是 Ubuntu 仓库中包的名称)。在开始之前,请确保系统上未安装 `mongodb`。因为包之间会发生冲突。让我们开始吧!
+
+首先,我们必须导入公钥:
+
+```
+sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4
+```
+
+现在,你需要在源列表中添加一个新的仓库,以便你可以安装 MongoDB 社区版并获得自动更新:
+
+```
+echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu $(lsb_release -cs)/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list
+```
+
+要安装 `mongodb-org`,我们需要更新我们的包数据库,以便系统知道可用的新包:
+
+```
+sudo apt update
+```
+
+现在你可以安装**最新稳定版**的 MongoDB:
+
+```
+sudo apt install -y mongodb-org
+```
+
+或者某个**特定版本**(在 `=` 后面修改版本号)
+
+```
+sudo apt install -y mongodb-org=4.0.6 mongodb-org-server=4.0.6 mongodb-org-shell=4.0.6 mongodb-org-mongos=4.0.6 mongodb-org-tools=4.0.6
+```
+
+如果你选择安装特定版本,请确保在所有位置都修改了版本号。如果你修改了 `mongodb-org=4.0.6`,你将安装最新版本。
+
+默认情况下,使用包管理器(`apt-get`)更新时,MongoDB 将更新为最新的版本。要阻止这种情况发生(并冻结为已安装的版本),请使用:
+
+```
+echo "mongodb-org hold" | sudo dpkg --set-selections
+echo "mongodb-org-server hold" | sudo dpkg --set-selections
+echo "mongodb-org-shell hold" | sudo dpkg --set-selections
+echo "mongodb-org-mongos hold" | sudo dpkg --set-selections
+echo "mongodb-org-tools hold" | sudo dpkg --set-selections
+```
+
+你现在已经成功安装了 MongoDB!
+
+#### 配置 MongoDB
+
+默认情况下,包管理器将创建 `/var/lib/mongodb` 和 `/var/log/mongodb`,MongoDB 将使用 `mongodb` 用户帐户运行。
+
+我不会去更改这些默认设置,因为这超出了本指南的范围。有关详细信息,请查看[手册][5]。
+
+`/etc/mongod.conf` 中的设置在启动/重新启动 **mongodb** 服务实例时生效。
+
+##### 运行 MongoDB
+
+要启动 mongodb 的守护进程 `mongod`,请输入:
+
+```
+sudo service mongod start
+```
+
+现在你应该验证 `mongod` 进程是否已成功启动。此信息(默认情况下)保存在 `/var/log/mongodb/mongod.log` 中。我们来看看文件的内容:
+
+```
+sudo cat /var/log/mongodb/mongod.log
+```
+
+![Check MongoDB logs to see if the process is running properly.][6]
+
+只要你在某处看到:`[initandlisten] waiting for connections on port 27017`,就说明进程正常运行。
+
+**注意**:27017 是 `mongod` 的默认端口。
+
+要停止/重启 `mongod`,请输入:
+
+```
+sudo service mongod stop
+sudo service mongod restart
+```
+
+现在,你可以通过打开 **mongo shell** 来使用 MongoDB:
+
+```
+mongo
+```
+
+#### 卸载 MongoDB
+
+运行以下命令:
+
+```
+sudo service mongod stop
+sudo apt purge mongodb-org*
+```
+
+要删除**数据库**和**日志文件**(确保**备份**你要保留的内容!):
+
+```
+sudo rm -r /var/log/mongodb
+sudo rm -r /var/lib/mongodb
+```
+
+### 总结
+
+MongoDB 是一个很棒的 NoSQL 数据库,它易于集成到现代项目中。我希望本教程能帮助你在 Ubuntu 上安装它!在下面的评论中告诉我们你计划如何使用 MongoDB。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-mongodb-ubuntu
+
+作者:[Sergiu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/sergiu/
+[b]: https://github.com/lujun9972
+[1]: https://www.mongodb.com/
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/mongodb-ubuntu.jpeg?resize=800%2C450&ssl=1
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/mongodb_check_status.jpg?fit=800%2C574&ssl=1
+[4]: https://docs.mongodb.com/manual/tutorial/getting-started/
+[5]: https://docs.mongodb.com/manual/
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/mongodb_org_check_logs.jpg?fit=800%2C467&ssl=1
diff --git a/published/20190613 Continuous integration testing for the Linux kernel.md b/published/20190613 Continuous integration testing for the Linux kernel.md
new file mode 100644
index 0000000000..38f262eabe
--- /dev/null
+++ b/published/20190613 Continuous integration testing for the Linux kernel.md
@@ -0,0 +1,92 @@
+[#]: collector: (lujun9972)
+[#]: translator: (LazyWolfLin)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11176-1.html)
+[#]: subject: (Continuous integration testing for the Linux kernel)
+[#]: via: (https://opensource.com/article/19/6/continuous-kernel-integration-linux)
+[#]: author: (Major Hayden https://opensource.com/users/mhayden)
+
+Linux 内核的持续集成测试
+======
+
+> CKI 团队是如何防止 bug 被合并到 Linux 内核中。
+
+
+
+Linux 内核的每个发布版本包含了来自 1,700 个开发者产生的 14,000 个变更集,很显然,这使得 Linux 内核快速迭代的同时也产生了巨大的复杂性问题。内核上 Bug 有小麻烦也有大问题,有时是系统崩溃,有时是数据丢失。
+
+随着越来越多的项目对于持续集成(CI)的呼声,[内核持续集成(CKI)][2]小组秉承着一个任务目标:防止 Bug 被合并到内核当中。
+
+### Linux 测试问题
+
+许多 Linux 发行版只在需要的时候对 Linux 内核进行测试。而这种测试往往只在版本发布时或者用户发现错误时进行。
+
+有时候,出现玄学问题时,维护人员需要在包含了数万个补丁的变更中匆忙地寻找哪个补丁导致这个新的玄学 Bug。诊断 Bug 需要专业的硬件设备、一系列的触发器以及内核相关的专业知识。
+
+#### CI 和 Linux
+
+许多现代软件代码库都采用某种自动化 CI 测试机制,能够在提交进入代码存储库之前对其进行测试。这种自动化测试使得维护人员可以通过查看 CI 测试报告来发现软件质量问题以及大多数的错误。一些简单的项目,比如某个 Python 库,附带的大量工具使得整个检查过程更简单。
+
+在任何测试之前都需要配置和编译 Linux。而这么做将耗费大量的时间和计算资源。此外,Linux 内核必需在虚拟机或者裸机上启动才能进行测试。而访问某些硬件架构需要额外的开销或者非常慢的仿真。因此,人们必须确定一组能够触发错误或者验证修复的测试集。
+
+#### CKI 团队如何运作?
+
+Red Hat 公司的 CKI 团队当前正追踪来自数个内部内核分支和上游的[稳定内核分支树][3]等内核分支的更改。我们关注每个代码库的两类关键事件:
+
+ 1. 当维护人员合并 PR 或者补丁时,代码库变化后的最终结果。
+ 2. 当开发人员通过拼凑或者稳定补丁队列发起变更合并时。
+
+当这些事件发生时,自动化工具开始执行,[GitLab CI 管道][4]开始进行测试。一旦管道开始执行 [linting][5] 脚本、合并每一个补丁,并为多种硬件架构编译内核,真正的测试便开始了。我们会在六分钟内完成四种硬件架构的内核编译工作,并且通常会在两个小时或更短的时间内将反馈提交到稳定邮件列表中。(自 2019 年 1 月起)每月执行超过 100,000 次内核测试,并完成了超过 11,000 个 GitLab 管道。
+
+每个内核都会在本地硬件架构上启动,其中包含:
+
+* [aarch64][6]:64 位 [ARM][7],例如 [Cavium(当前是 Marvell)ThunderX][8]。
+* [ppc64/ppc64le][9]:大端和小端的 [IBM POWER][10] 系统。
+* [s390x][11]:[IBM Zseries][12] 大型机
+* [x86_64][13]:[Intel][14] 和 [AMD][15] 工作站、笔记本和服务器。
+
+这些内核上运行了包括 [Linux 测试项目(LTP)][16]在内的多个测试,其中包括使用常用测试工具的大量测试。我们 CKI 团队开源了超过 44 个测试并将继续开源更多测试。
+
+### 参与其中
+
+上游的内核测试工作日渐增多。包括 [Google][17]、Intel、[Linaro][18] 和 [Sony][19] 在内的许多公司为各种内核提供了测试输出。每一项工作都专注于为上游内核以及每个公司的客户群带来价值。
+
+如果你或者你的公司想要参与这一工作,请参加在 9 月份在葡萄牙里斯本举办的 [Linux Plumbers Conference 2019][20]。在会议结束后的两天加入我们的 Kernel CI hackfest 活动,并推动快速内核测试的发展。
+
+更多详细信息,[请见][21]我在 Texas Linux Fest 2019 上的演讲。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/6/continuous-kernel-integration-linux
+
+作者:[Major Hayden][a]
+选题:[lujun9972][b]
+译者:[LazyWolfLin](https://github.com/LazyWolfLin)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mhayden
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr "Linux kernel source code (C) in Visual Studio Code"
+[2]: https://cki-project.org/
+[3]: https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
+[4]: https://docs.gitlab.com/ee/ci/pipelines.html
+[5]: https://en.wikipedia.org/wiki/Lint_(software)
+[6]: https://en.wikipedia.org/wiki/ARM_architecture
+[7]: https://www.arm.com/
+[8]: https://www.marvell.com/server-processors/thunderx-arm-processors/
+[9]: https://en.wikipedia.org/wiki/Ppc64
+[10]: https://www.ibm.com/it-infrastructure/power
+[11]: https://en.wikipedia.org/wiki/Linux_on_z_Systems
+[12]: https://www.ibm.com/it-infrastructure/z
+[13]: https://en.wikipedia.org/wiki/X86-64
+[14]: https://www.intel.com/
+[15]: https://www.amd.com/
+[16]: https://github.com/linux-test-project/ltp
+[17]: https://www.google.com/
+[18]: https://www.linaro.org/
+[19]: https://www.sony.com/
+[20]: https://www.linuxplumbersconf.org/
+[21]: https://docs.google.com/presentation/d/1T0JaRA0wtDU0aTWTyASwwy_ugtzjUcw_ZDmC5KFzw-A/edit?usp=sharing
diff --git a/published/20171226 Top 10 Microsoft Visio Alternatives for Linux.md b/published/201907/20171226 Top 10 Microsoft Visio Alternatives for Linux.md
similarity index 100%
rename from published/20171226 Top 10 Microsoft Visio Alternatives for Linux.md
rename to published/201907/20171226 Top 10 Microsoft Visio Alternatives for Linux.md
diff --git a/published/20180406 MX Linux- A Mid-Weight Distro Focused on Simplicity.md b/published/201907/20180406 MX Linux- A Mid-Weight Distro Focused on Simplicity.md
similarity index 100%
rename from published/20180406 MX Linux- A Mid-Weight Distro Focused on Simplicity.md
rename to published/201907/20180406 MX Linux- A Mid-Weight Distro Focused on Simplicity.md
diff --git a/published/20180529 Manage your workstation with Ansible- Configure desktop settings.md b/published/201907/20180529 Manage your workstation with Ansible- Configure desktop settings.md
similarity index 100%
rename from published/20180529 Manage your workstation with Ansible- Configure desktop settings.md
rename to published/201907/20180529 Manage your workstation with Ansible- Configure desktop settings.md
diff --git a/published/20180620 How To Find The Port Number Of A Service In Linux.md b/published/201907/20180620 How To Find The Port Number Of A Service In Linux.md
similarity index 100%
rename from published/20180620 How To Find The Port Number Of A Service In Linux.md
rename to published/201907/20180620 How To Find The Port Number Of A Service In Linux.md
diff --git a/published/20180629 100 Best Ubuntu Apps.md b/published/201907/20180629 100 Best Ubuntu Apps.md
similarity index 100%
rename from published/20180629 100 Best Ubuntu Apps.md
rename to published/201907/20180629 100 Best Ubuntu Apps.md
diff --git a/published/20180902 Learning BASIC Like It-s 1983.md b/published/201907/20180902 Learning BASIC Like It-s 1983.md
similarity index 100%
rename from published/20180902 Learning BASIC Like It-s 1983.md
rename to published/201907/20180902 Learning BASIC Like It-s 1983.md
diff --git a/published/201907/20180924 5 ways to play old-school games on a Raspberry Pi.md b/published/201907/20180924 5 ways to play old-school games on a Raspberry Pi.md
new file mode 100644
index 0000000000..f9a55eda13
--- /dev/null
+++ b/published/201907/20180924 5 ways to play old-school games on a Raspberry Pi.md
@@ -0,0 +1,173 @@
+在树莓派上玩怀旧游戏的 5 种方法
+======
+
+> 使用这些用于树莓派的开源平台来重温游戏的黄金时代。
+
+
+
+他们使它们不像过去那样子了,对吧?我是说,电子游戏。
+
+当然,现在的设备更强大了。赛达尔公主在过去每个边只有 16 个像素,而现在的图像处理能力足够处理她头上的每根头发。今天的处理器打败 1988 年的处理器简直不费吹灰之力。
+
+但是你知道缺少什么吗?乐趣。
+
+你有数之不尽的游戏,按下一个按钮就可以完成教程任务。可能有故事情节,当然杀死坏蛋也可以不需要故事情节,你需要的只是跳跃和射击。因此,毫不奇怪,树莓派最持久的流行用途之一就是重温上世纪八九十年代的 8 位和 16 位游戏的黄金时代。但从哪里开始呢?
+
+在树莓派上有几种方法可以玩怀旧游戏。每一种都有自己的优点和缺点,我将在这里讨论这些。
+
+### RetroPie
+
+[RetroPie][1] 可能是树莓派上最受欢迎的复古游戏平台。它是一个可靠的万能选手,是模拟经典桌面和控制台游戏系统的绝佳选择。
+
+
+
+#### 介绍
+
+RetroPie 构建在 [Raspbian][2] 上运行。如果你愿意,它也可以安装在现有的 Raspbian 镜像上。它使用 [EmulationStation][3] 作为开源仿真器库(包括 [Libretro][4] 仿真器)的图形前端。
+
+不过,你要玩游戏其实并不需要理解上面的任何一个词。
+
+#### 它有什么好处
+
+入门很容易。你需要做的就是将镜像刻录到 SD 卡,配置你的控制器、复制游戏,然后开始杀死坏蛋。
+
+它的庞大用户群意味着有大量的支持和信息,活跃的在线社区也可以求助问题。
+
+除了随 RetroPie 镜像一起安装的仿真器之外,还有一个可以从包管理器安装的庞大的仿真器库,并且它一直在增长。RetroPie 还提供了用户友好的菜单系统来管理这些,可以节省你的时间。
+
+从 RetroPie 菜单中可以轻松添加 Kodi 和配备了 Chromium 浏览器的 Raspbian 桌面。这意味着你的这套复古游戏装备也适于作为家庭影院、[YouTube][5]、[SoundCloud][6] 以及所有其它“休息室电脑”产品。
+
+RetroPie 还有许多其它自定义选项:你可以更改菜单中的图形,为不同的模拟器设置不同的控制手柄配置,使你的树莓派文件系统的所有内容对你的本地 Windows 网络可见等等。
+
+RetroPie 建立在 Raspbian 上,这意味着你可以探索这个树莓派最受欢迎的操作系统。你所发现的大多数树莓派项目和教程都是为 Raspbian 编写的,因此可以轻松地自定义和安装新内容。我已经使用我的 RetroPie 装备作为无线桥接器,在上面安装了 MIDI 合成器,自学了一些 Python,更重要的是,所有这些都没有影响它作为游戏机的用途。
+
+#### 它有什么不太好的
+
+RetroPie 的安装简单和易用性在某种程度上是一把双刃剑。你可以在 RetroPie 上玩了很长时间,而甚至没有学习过哪怕像 `sudo apt-get` 这样简单的东西,但这也意味着你错过了很多树莓派的体验。
+
+但不一定必须如此;当你需要时,命令行仍然存在于底层,但是也许用户与 Bash shell 有点隔离,而使它最终并没有看上去那么可怕、另外,RetroPie 的主菜单只能通过控制手柄操作,当你没有接入手柄时,这可能很烦人,因为你一直将该系统用于游戏之外的事情。
+
+#### 它适用于谁?
+
+任何想直接玩一些游戏的人,任何想拥有最大、最好的模拟器库的人,以及任何想在不玩游戏的时候开始探索 Linux 的人。
+
+### Recalbox
+
+[Recalbox][7] 是一个较新的树莓派开源模拟器套件。它还支持其它基于 ARM 的小型计算机。
+
+
+
+#### 介绍
+
+与 Retropie 一样, Recalbox 基于 EmulationStation 和 Libretro。它的不同之处在于它不是基于 Raspbian 构建的,而是基于它自己的 Linux 发行版:RecalboxOS。
+
+#### 它有什么好处
+
+Recalbox 的设置比 RetroPie 更容易。你甚至不需要做 SD 卡镜像;只需复制一些文件即可。它还为一些游戏控制器提供开箱即用的支持,可以让你更快地开始游戏。它预装了 Kodi。这是一个现成的游戏和媒体平台。
+
+#### 它有什么不太好的
+
+Recalbox 比 RetroPie 拥有更少的仿真器、更少的自定义选项和更小的用户社区。
+
+你的 Recalbox 装备可能一直用于模拟器和 Kodi,安装成什么样就是什么样。如果你想深入了解 Linux,你可能需要为 Raspbian 提供一个新的 SD 卡。
+
+#### 它适用于谁?
+
+如果你想要绝对简单的复古游戏体验,并且不想玩一些比较少见的游戏平台模拟器,或者你害怕一些技术性工作(也没有兴趣去做),那么 Recalbox 非常适合你。
+
+对于大多数读者来说,Recalbox 可能最适合推荐给你那些不太懂技术的朋友或亲戚。它超级简单的设置和几乎没什么选项甚至可以让你免去帮助他们解决问题。
+
+### 做个你自己的
+
+好,你可能已经注意到 Retropie 和 Recalbox 都是由许多相同的开源组件构建的。那么为什么不自己把它们组合在一起呢?
+
+#### 介绍
+
+无论你想要的是什么,开源软件的本质意味着你可以使用现有的模拟器套件作为起点,或者随意使用它们。
+
+#### 它有什么好处
+
+如果你想有自己的自定义界面,我想除了亲自动手别无它法。这也是安装在 RetroPie 中没有的仿真器的方法,例如 [BeebEm][8]) 或 [ArcEm][9]。
+
+#### 它有什么不太好的
+
+嗯,工作量有点大。
+
+#### 它适用于谁?
+
+喜欢鼓捣的人,有动手能力的人,开发者,经验丰富的业余爱好者等。
+
+### 原生 RISC OS 游戏体验
+
+现在有一匹黑马:[RISC OS][10],它是 ARM 设备的原始操作系统。
+
+#### 介绍
+
+在 ARM 成为世界上最受欢迎的 CPU 架构之前,它最初是作为 Acorn Archimedes 的处理器而开发的。现在看起来这像是一种被遗忘的野兽,但是那几年,它作为世界上最强大的台式计算机独领风骚了好几年,并且吸引了大量的游戏开发项目。
+
+树莓派中的 ARM 处理器是 Archimedes 的曾孙辈的 CPU,所以我们仍然可以在其上安装 RISC OS,只要做一点工作,就可以让这些游戏运行起来。这与我们到上面所介绍的仿真器方式不同,我们是在玩为该操作系统和 CPU 架构开发的游戏。
+
+#### 它有什么好处
+
+这是 RISC OS 的完美展现,这绝对是操作系统的瑰宝,非常值得一试。
+
+事实上,你使用的是和以前几乎相同的操作系统来加载和玩你的游戏,这使得你的复古游戏装备像是一个时间机器一样,这无疑为该项目增添了一些魅力和复古价值。
+
+有一些精彩的游戏只在 Archimedes 上发布过。Archimedes 的巨大硬件优势也意味着它通常拥有许多多平台游戏大作的最佳图形和最流畅的游戏体验。这类游戏的版权持有者非常慷慨,可以合法地免费下载它们。
+
+#### 它有什么不太好的
+
+安装了 RISC OS 之后,它仍然需要一些努力才能让游戏运行起来。这是 [入门指南][11]。
+
+对于休息室来说,这绝对不是一个很好的全能选手。没有什么比 [Kodi][12] 更好的了。它有一个网络浏览器 [NetSurf][13],但它在支持现代 Web 方面还需要一些努力。你不会像使用模拟器套件那样得到大量可以玩的游戏。RISC OS Open 对于爱好者来说可以免费下载和使用,而且很多源代码已经开源,尽管由于这个名字,它不是一个 100% 的开源操作系统。
+
+#### 它适用于谁?
+
+这是专为追求新奇的人,绝对怀旧的人,想要探索一个来自上世纪 80 年代的有趣的操作系统的人,怀旧过去的 Acorn 机器的人,以及想要一个完全不同的怀旧游戏项目的人而设计的。
+
+### 终端游戏
+
+你是否真的需要安装模拟器或者一个异域风情的操作系统才能重温辉煌的日子?为什么不从命令行安装一些原生 Linux 游戏呢?
+
+#### 介绍
+
+有一系列原生的 Linux 游戏经过测试可以在 [树莓派][14] 上运行。
+
+#### 它有什么好处
+
+你可以使用命令行从程序包安装其中的大部分,然后开始玩。很容易。如果你已经有了一个跑起来的 Raspbian,那么它可能是你运行游戏的最快途径。
+
+#### 它有什么不太好的
+
+严格来说,这并不是真正的复古游戏。Linux 诞生于 1991 年,过了一段时间才成为了一个游戏平台。这些不是经典的 8 位和 16 位时代的游戏体验;后来有一些移植的游戏或受复古影响的游戏。
+
+#### 它适用于谁?
+
+如果你只是想找点乐子,这没问题。但如果你想重温过去,那就不完全是这样了。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/9/retro-gaming-raspberry-pi
+
+作者:[James Mawson][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[canhetingsky](https://github.com/canhetingsky)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dxmjames
+[1]: https://retropie.org.uk/
+[2]: https://www.raspbian.org/
+[3]: https://emulationstation.org/
+[4]: https://www.libretro.com/
+[5]: https://www.youtube.com/
+[6]: https://soundcloud.com/
+[7]: https://www.recalbox.com/
+[8]: http://www.mkw.me.uk/beebem/
+[9]: http://arcem.sourceforge.net/
+[10]: https://opensource.com/article/18/7/gentle-intro-risc-os
+[11]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
+[12]: https://kodi.tv/
+[13]: https://www.netsurf-browser.org/
+[14]: https://www.raspberrypi.org/forums/viewtopic.php?f=78&t=51794
diff --git a/published/20190211 Introducing kids to computational thinking with Python.md b/published/201907/20190211 Introducing kids to computational thinking with Python.md
similarity index 100%
rename from published/20190211 Introducing kids to computational thinking with Python.md
rename to published/201907/20190211 Introducing kids to computational thinking with Python.md
diff --git a/published/20190301 Emacs for (even more of) the win.md b/published/201907/20190301 Emacs for (even more of) the win.md
similarity index 100%
rename from published/20190301 Emacs for (even more of) the win.md
rename to published/201907/20190301 Emacs for (even more of) the win.md
diff --git a/published/20190302 Create a Custom System Tray Indicator For Your Tasks on Linux.md b/published/201907/20190302 Create a Custom System Tray Indicator For Your Tasks on Linux.md
similarity index 100%
rename from published/20190302 Create a Custom System Tray Indicator For Your Tasks on Linux.md
rename to published/201907/20190302 Create a Custom System Tray Indicator For Your Tasks on Linux.md
diff --git a/published/201907/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md b/published/201907/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md
new file mode 100644
index 0000000000..ed9c481007
--- /dev/null
+++ b/published/201907/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md
@@ -0,0 +1,295 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11147-1.html)
+[#]: subject: (ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel)
+[#]: via: (https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+ClusterShell:一个在集群节点上并行运行命令的好工具
+======
+
+
+
+我们过去曾写过两篇如何并行地在多个远程服务器上运行命令的文章:[并行 SSH(PSSH)][1] 和[分布式 Shell(DSH)][2]。今天,我们将讨论相同类型的主题,但它允许我们在集群节点上执行相同的操作。你可能会想,我可以编写一个小的 shell 脚本来实现这个目的,而不是安装这些第三方软件包。
+
+当然,你是对的,如果要在十几个远程系统中运行一些命令,那么你不需要使用它。但是,你的脚本需要一些时间来完成此任务,因为它是按顺序运行的。想想你要是在一千多台服务器上运行一些命令会是什么样子?在这种情况下,你的脚本用处不大。此外,完成任务需要很长时间。所以,要克服这种问题和情况,我们需要可以在远程计算机上并行运行命令。
+
+为此,我们需要在一个并行应用程序中使用它。我希望这个解释可以解决你对并行实用程序的疑虑。
+
+### ClusterShell
+
+[ClusterShell][3] 是一个事件驱动的开源 Python 库,旨在在服务器场或大型 Linux 集群上并行运行本地或远程命令。(`clush` 即 [ClusterShell][3])。
+
+它将处理在 HPC 集群上遇到的常见问题,例如在节点组上操作,使用优化过的执行算法运行分布式命令,以及收集结果和合并相同的输出,或检索返回代码。
+
+ClusterShell 可以利用已安装在系统上的现有远程 shell 设施,如 SSH。
+
+ClusterShell 的主要目标是通过为开发人员提供轻量级、但可扩展的 Python API 来改进高性能集群的管理。它还提供了 `clush`、`clubak` 和 `cluset`/`nodeset` 等方便的命令行工具,可以让传统的 shell 脚本利用这个库的一些功能。
+
+ClusterShell 是用 Python 编写的,它需要 Python(v2.6+ 或 v3.4+)才能在你的系统上运行。
+
+### 如何在 Linux 上安装 ClusterShell?
+
+ClusterShell 包在大多数发行版的官方包管理器中都可用。因此,使用发行版包管理器工具进行安装。
+
+对于 Fedora 系统,使用 [DNF 命令][4]来安装 clustershell。
+
+```
+$ sudo dnf install clustershell
+```
+
+如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
+
+```
+$ sudo dnf install python3-clustershell
+```
+
+在执行 clustershell 安装之前,请确保你已在系统上启用 [EPEL 存储库][5]。
+
+对于 RHEL/CentOS 系统,使用 [YUM 命令][6] 来安装 clustershell。
+
+```
+$ sudo yum install clustershell
+```
+
+如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
+
+```
+$ sudo yum install python34-clustershell
+```
+
+对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 来安装 clustershell。
+
+```
+$ sudo zypper install clustershell
+```
+
+如果系统默认是 Python 2,这会安装 Python 2 模块和工具,可以运行以下命令安装 Python 3 开发包。
+
+```
+$ sudo zypper install python3-clustershell
+```
+
+对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][8] 或 [APT 命令][9] 来安装 clustershell。
+
+```
+$ sudo apt install clustershell
+```
+
+### 如何在 Linux 使用 PIP 安装 ClusterShell?
+
+可以使用 PIP 安装 ClusterShell,因为它是用 Python 编写的。
+
+在执行 clustershell 安装之前,请确保你已在系统上启用了 [Python][10] 和 [PIP][11]。
+
+```
+$ sudo pip install ClusterShell
+```
+
+### 如何在 Linux 上使用 ClusterShell?
+
+与其他实用程序(如 `pssh` 和 `dsh`)相比,它是直接了当的优秀工具。它有很多选项可以在远程并行执行。
+
+在开始使用 clustershell 之前,请确保你已启用系统上的[无密码登录][12]。
+
+以下配置文件定义了系统范围的默认值。你不需要修改这里的任何东西。
+
+```
+$ cat /etc/clustershell/clush.conf
+```
+
+如果你想要创建一个服务器组,那也可以。默认情况下有一些示例,请根据你的要求执行相同操作。
+
+```
+$ cat /etc/clustershell/groups.d/local.cfg
+```
+
+只需按以下列格式运行 clustershell 命令即可从给定节点获取信息:
+
+```
+$ clush -w 192.168.1.4,192.168.1.9 cat /proc/version
+192.168.1.9: Linux version 4.15.0-45-generic ([email protected]) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #48-Ubuntu SMP Tue Jan 29 16:28:13 UTC 2019
+192.168.1.4: Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
+```
+
+选项:
+
+ * `-w:` 你要运行该命令的节点。
+
+你可以使用正则表达式而不是使用完整主机名和 IP:
+
+```
+$ clush -w 192.168.1.[4,9] uname -r
+192.168.1.9: 4.15.0-45-generic
+192.168.1.4: 3.10.0-957.el7.x86_64
+```
+
+或者,如果服务器位于同一 IP 系列中,则可以使用以下格式:
+
+```
+$ clush -w 192.168.1.[4-9] date
+192.168.1.6: Mon Mar 4 21:08:29 IST 2019
+192.168.1.7: Mon Mar 4 21:08:29 IST 2019
+192.168.1.8: Mon Mar 4 21:08:29 IST 2019
+192.168.1.5: Mon Mar 4 09:16:30 CST 2019
+192.168.1.9: Mon Mar 4 21:08:29 IST 2019
+192.168.1.4: Mon Mar 4 09:16:30 CST 2019
+```
+
+clustershell 允许我们以批处理模式运行命令。使用以下格式来实现此目的:
+
+```
+$ clush -w 192.168.1.4,192.168.1.9 -b
+Enter 'quit' to leave this interactive mode
+Working with nodes: 192.168.1.[4,9]
+clush> hostnamectl
+---------------
+192.168.1.4
+---------------
+ Static hostname: CentOS7.2daygeek.com
+ Icon name: computer-vm
+ Chassis: vm
+ Machine ID: 002f47b82af248f5be1d67b67e03514c
+ Boot ID: f9b37a073c534dec8b236885e754cb56
+ Virtualization: kvm
+ Operating System: CentOS Linux 7 (Core)
+ CPE OS Name: cpe:/o:centos:centos:7
+ Kernel: Linux 3.10.0-957.el7.x86_64
+ Architecture: x86-64
+---------------
+192.168.1.9
+---------------
+ Static hostname: Ubuntu18
+ Icon name: computer-vm
+ Chassis: vm
+ Machine ID: 27f6c2febda84dc881f28fd145077187
+ Boot ID: f176f2eb45524d4f906d12e2b5716649
+ Virtualization: oracle
+ Operating System: Ubuntu 18.04.2 LTS
+ Kernel: Linux 4.15.0-45-generic
+ Architecture: x86-64
+clush> free -m
+---------------
+192.168.1.4
+---------------
+ total used free shared buff/cache available
+Mem: 1838 641 217 19 978 969
+Swap: 2047 0 2047
+---------------
+192.168.1.9
+---------------
+ total used free shared buff/cache available
+Mem: 1993 352 1067 1 573 1473
+Swap: 1425 0 1425
+clush> w
+---------------
+192.168.1.4
+---------------
+ 09:21:14 up 3:21, 3 users, load average: 0.00, 0.01, 0.05
+USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
+daygeek :0 :0 06:02 ?xdm? 1:28 0.30s /usr/libexec/gnome-session-binary --session gnome-classic
+daygeek pts/0 :0 06:03 3:17m 0.06s 0.06s bash
+daygeek pts/1 192.168.1.6 06:03 52:26 0.10s 0.10s -bash
+---------------
+192.168.1.9
+---------------
+ 21:13:12 up 3:12, 1 user, load average: 0.08, 0.03, 0.00
+USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
+daygeek pts/0 192.168.1.6 20:42 29:41 0.05s 0.05s -bash
+clush> quit
+```
+
+如果要在一组节点上运行该命令,请使用以下格式:
+
+```
+$ clush -w @dev uptime
+or
+$ clush -g dev uptime
+or
+$ clush --group=dev uptime
+
+192.168.1.9: 21:10:10 up 3:09, 1 user, load average: 0.09, 0.03, 0.01
+192.168.1.4: 09:18:12 up 3:18, 3 users, load average: 0.01, 0.02, 0.05
+```
+
+如果要在多个节点组上运行该命令,请使用以下格式:
+
+```
+$ clush -w @dev,@uat uptime
+or
+$ clush -g dev,uat uptime
+or
+$ clush --group=dev,uat uptime
+
+192.168.1.7: 07:57:19 up 59 min, 1 user, load average: 0.08, 0.03, 0.00
+192.168.1.9: 20:27:20 up 1:00, 1 user, load average: 0.00, 0.00, 0.00
+192.168.1.5: 08:57:21 up 59 min, 1 user, load average: 0.00, 0.01, 0.05
+```
+
+clustershell 允许我们将文件复制到远程计算机。将本地文件或目录复制到同一个远程节点:
+
+```
+$ clush -w 192.168.1.[4,9] --copy /home/daygeek/passwd-up.sh
+```
+
+我们可以通过运行以下命令来验证它:
+
+```
+$ clush -w 192.168.1.[4,9] ls -lh /home/daygeek/passwd-up.sh
+192.168.1.4: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 09:00 /home/daygeek/passwd-up.sh
+192.168.1.9: -rwxr-xr-x 1 daygeek daygeek 159 Mar 4 20:52 /home/daygeek/passwd-up.sh
+```
+
+将本地文件或目录复制到不同位置的远程节点:
+
+```
+$ clush -g uat --copy /home/daygeek/passwd-up.sh --dest /tmp
+```
+
+我们可以通过运行以下命令来验证它:
+
+```
+$ clush --group=uat ls -lh /tmp/passwd-up.sh
+192.168.1.7: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 6 07:44 /tmp/passwd-up.sh
+```
+
+将文件或目录从远程节点复制到本地系统:
+
+```
+$ clush -w 192.168.1.7 --rcopy /home/daygeek/Documents/magi.txt --dest /tmp
+```
+
+我们可以通过运行以下命令来验证它:
+
+```
+$ ls -lh /tmp/magi.txt.192.168.1.7
+-rw-r--r-- 1 daygeek daygeek 35 Mar 6 20:24 /tmp/magi.txt.192.168.1.7
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
+[2]: https://www.2daygeek.com/dsh-run-execute-shell-commands-on-multiple-linux-servers-at-once/
+[3]: https://cea-hpc.github.io/clustershell/
+[4]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[5]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
+[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[10]: https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
+[11]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
+[12]: https://www.2daygeek.com/linux-passwordless-ssh-login-using-ssh-keygen/
diff --git a/published/20190320 4 cool terminal multiplexers.md b/published/201907/20190320 4 cool terminal multiplexers.md
similarity index 100%
rename from published/20190320 4 cool terminal multiplexers.md
rename to published/201907/20190320 4 cool terminal multiplexers.md
diff --git a/published/20190416 Can schools be agile.md b/published/201907/20190416 Can schools be agile.md
similarity index 100%
rename from published/20190416 Can schools be agile.md
rename to published/201907/20190416 Can schools be agile.md
diff --git a/published/20190501 Looking into Linux modules.md b/published/201907/20190501 Looking into Linux modules.md
similarity index 100%
rename from published/20190501 Looking into Linux modules.md
rename to published/201907/20190501 Looking into Linux modules.md
diff --git a/published/20190505 Blockchain 2.0 - Public Vs Private Blockchain Comparison -Part 7.md b/published/201907/20190505 Blockchain 2.0 - Public Vs Private Blockchain Comparison -Part 7.md
similarity index 100%
rename from published/20190505 Blockchain 2.0 - Public Vs Private Blockchain Comparison -Part 7.md
rename to published/201907/20190505 Blockchain 2.0 - Public Vs Private Blockchain Comparison -Part 7.md
diff --git a/published/20190513 When to be concerned about memory levels on Linux.md b/published/201907/20190513 When to be concerned about memory levels on Linux.md
similarity index 100%
rename from published/20190513 When to be concerned about memory levels on Linux.md
rename to published/201907/20190513 When to be concerned about memory levels on Linux.md
diff --git a/published/20190518 Best Linux Distributions for Beginners.md b/published/201907/20190518 Best Linux Distributions for Beginners.md
similarity index 100%
rename from published/20190518 Best Linux Distributions for Beginners.md
rename to published/201907/20190518 Best Linux Distributions for Beginners.md
diff --git a/published/201907/20190522 Convert Markdown files to word processor docs using pandoc.md b/published/201907/20190522 Convert Markdown files to word processor docs using pandoc.md
new file mode 100644
index 0000000000..381510d7a7
--- /dev/null
+++ b/published/201907/20190522 Convert Markdown files to word processor docs using pandoc.md
@@ -0,0 +1,129 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11160-1.html)
+[#]: subject: (Convert Markdown files to word processor docs using pandoc)
+[#]: via: (https://opensource.com/article/19/5/convert-markdown-to-word-pandoc)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez)
+
+使用 pandoc 将 Markdown 转换为格式化文档
+======
+
+> 生活在普通文本世界么?以下是无需使用文字处理器而创建别人要的格式化文档的方法。
+
+![][1]
+
+如果你生活在[普通文本][2]世界里,总会有人要求你提供格式化文档。我就经常遇到这个问题,特别是在 Day JobTM。虽然我已经给与我合作的开发团队之一介绍了用于撰写和审阅发行说明的 [Docs Like Code][3] 工作流程,但是还有少数人对 GitHub 和使用 [Markdown][4] 没有兴趣,他们更喜欢为特定的专有应用格式化的文档。
+
+好消息是,你不会被卡在将未格式化的文本复制粘贴到文字处理器的问题当中。使用 [pandoc][5],你可以快速地给人们他们想要的东西。让我们看看如何使用 pandoc 将文档从 Markdown 转换为 Linux 中的文字处理器格式。
+
+请注意,pandoc 也可用于从两种 BSD([NetBSD][7] 和 [FreeBSD][8])到 Chrome OS、MacOS 和 Windows 等的各种操作系统。
+
+### 基本转换
+
+首先,在你的计算机上[安装 pandoc][9]。然后,打开控制台终端窗口,并导航到包含要转换的文件的目录。
+
+输入此命令以创建 ODT 文件(可以使用 [LibreOffice Writer][10] 或 [AbiWord][11] 等字处理器打开):
+
+```
+pandoc -t odt filename.md -o filename.odt
+```
+
+记得用实际文件名称替换 `filename`。如果你需要为其他文字处理器(你知道我的意思)创建一个文件,替换命令行的 `odt` 为 `docx`。以下是本文转换为 ODT 文件时的内容:
+
+![Basic conversion results with pandoc.][12]
+
+这些转换结果虽然可用,但有点乏味。让我们看看如何为转换后的文档添加更多样式。
+
+### 带样式转换
+
+`pandoc` 有一个漂亮的功能,使你可以在将带标记的纯文本文件转换为字处理器格式时指定样式模板。在此文件中,你可以编辑文档中的少量样式,包括控制段落、文章标题和副标题、段落标题、说明、基本的表格和超链接的样式。
+
+让我们来看看能做什么。
+
+#### 创建模板
+
+要设置文档样式,你不能只是使用任何一个模板就行。你需要生成 pandoc 称之为引用模板的文件,这是将文本文件转换为文字处理器文档时使用的模板。要创建此文件,请在终端窗口中键入以下内容:
+
+```
+pandoc -o custom-reference.odt --print-default-data-file reference.odt
+```
+
+此命令创建一个名为 `custom-reference.odt` 的文件。如果你正在使用其他文字处理程序,请将命令行中的 “odt” 更改为 “docx”。
+
+在 LibreOffice Writer 中打开模板文件,然后按 `F11` 打开 LibreOffice Writer 的 “样式” 窗格。虽然 [pandoc 手册][13]建议不要对该文件进行其他更改,但我会在必要时更改页面大小并添加页眉和页脚。
+
+#### 使用模板
+
+那么,你要如何使用刚刚创建的模板?有两种方法可以做到这一点。
+
+最简单的方法是将模板放在家目录的 `.pandoc` 文件夹中,如果该文件夹不存在,则必须先创建该文件夹。当转换文档时,`pandoc` 会使用此模板文件。如果你需要多个模板,请参阅下一节了解如何从多个模板中进行选择。
+
+使用模板的另一种方法是在命令行键入以下转换选项:
+
+```
+pandoc -t odt file-name.md --reference-doc=path-to-your-file/reference.odt -o file-name.odt
+```
+
+如果你想知道使用自定义模板转换后的文件是什么样的,这是一个示例:
+
+![A document converted using a pandoc style template.][14]
+
+#### 选择模板
+
+很多人只需要一个 `pandoc` 模板,但是,有些人需要不止一个。
+
+例如,在我的日常工作中,我使用了几个模板:一个带有 DRAFT 水印,一个带有表示内部使用的水印,另一个用于文档的最终版本。每种类型的文档都需要不同的模板。
+
+如果你有类似的需求,可以像使用单个模板一样创建文件 `custom-reference.odt`,将生成的文件重命名为例如 `custom-reference-draft.odt` 这样的名字,然后在 LibreOffice Writer 中打开它并修改样式。对你需要的每个模板重复此过程。
+
+接下来,将文件复制到家目录中。如果你愿意,你甚至可以将它们放在 `.pandoc` 文件夹中。
+
+要在转换时选择特定模板,你需要在终端中运行此命令:
+
+```
+pandoc -t odt file-name.md --reference-doc=path-to-your-file/custom-template.odt -o file-name.odt
+```
+
+改变 `custom-template.odt` 为你的模板文件名。
+
+### 结语
+
+为了不用记住我不经常使用的一组选项,我拼凑了一些简单的、非常蹩脚的单行脚本,这些脚本封装了每个模板的选项。例如,我运行脚本 `todraft.sh` 以使用带有 DRAFT 水印的模板创建文字处理器文档。你可能也想要这样做。
+
+以下是使用包含 DRAFT 水印的模板的脚本示例:
+
+```
+pandoc -t odt $1.md -o $1.odt --reference-doc=~/Documents/pandoc-templates/custom-reference-draft.odt
+```
+
+使用 pandoc 是一种不必放弃命令行生活而以人们要求的格式提供文档的好方法。此工具也不仅适用于 Markdown。我在本文中讨论的内容还可以让你在各种标记语言之间创建和转换文档。有关更多详细信息,请参阅前面链接的 [pandoc 官网][5]。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb
+[2]: https://plaintextproject.online/
+[3]: https://www.docslikecode.com/
+[4]: https://en.wikipedia.org/wiki/Markdown
+[5]: https://pandoc.org/
+[6]: /resources/linux
+[7]: https://www.netbsd.org/
+[8]: https://www.freebsd.org/
+[9]: https://pandoc.org/installing.html
+[10]: https://www.libreoffice.org/discover/writer/
+[11]: https://www.abisource.com/
+[12]: https://opensource.com/sites/default/files/uploads/pandoc-wp-basic-conversion_600_0.png (Basic conversion results with pandoc.)
+[13]: https://pandoc.org/MANUAL.html
+[14]: https://opensource.com/sites/default/files/uploads/pandoc-wp-conversion-with-tpl_600.png (A document converted using a pandoc style template.)
diff --git a/published/20190531 Use Firefox Send with ffsend in Fedora.md b/published/201907/20190531 Use Firefox Send with ffsend in Fedora.md
similarity index 100%
rename from published/20190531 Use Firefox Send with ffsend in Fedora.md
rename to published/201907/20190531 Use Firefox Send with ffsend in Fedora.md
diff --git a/published/20190603 How to set up virtual environments for Python on MacOS.md b/published/201907/20190603 How to set up virtual environments for Python on MacOS.md
similarity index 100%
rename from published/20190603 How to set up virtual environments for Python on MacOS.md
rename to published/201907/20190603 How to set up virtual environments for Python on MacOS.md
diff --git a/published/20190604 5G will augment Wi-Fi, not replace it.md b/published/201907/20190604 5G will augment Wi-Fi, not replace it.md
similarity index 100%
rename from published/20190604 5G will augment Wi-Fi, not replace it.md
rename to published/201907/20190604 5G will augment Wi-Fi, not replace it.md
diff --git a/published/20190606 Zorin OS Becomes Even More Awesome With Zorin 15 Release.md b/published/201907/20190606 Zorin OS Becomes Even More Awesome With Zorin 15 Release.md
similarity index 100%
rename from published/20190606 Zorin OS Becomes Even More Awesome With Zorin 15 Release.md
rename to published/201907/20190606 Zorin OS Becomes Even More Awesome With Zorin 15 Release.md
diff --git a/published/20190607 4 tools to help you drive Kubernetes.md b/published/201907/20190607 4 tools to help you drive Kubernetes.md
similarity index 100%
rename from published/20190607 4 tools to help you drive Kubernetes.md
rename to published/201907/20190607 4 tools to help you drive Kubernetes.md
diff --git a/published/20190607 Free and Open Source Trello Alternative OpenProject 9 Released.md b/published/201907/20190607 Free and Open Source Trello Alternative OpenProject 9 Released.md
similarity index 100%
rename from published/20190607 Free and Open Source Trello Alternative OpenProject 9 Released.md
rename to published/201907/20190607 Free and Open Source Trello Alternative OpenProject 9 Released.md
diff --git a/published/20190609 How to set ulimit and file descriptors limit on Linux Servers.md b/published/201907/20190609 How to set ulimit and file descriptors limit on Linux Servers.md
similarity index 100%
rename from published/20190609 How to set ulimit and file descriptors limit on Linux Servers.md
rename to published/201907/20190609 How to set ulimit and file descriptors limit on Linux Servers.md
diff --git a/published/20190610 5 Easy Ways To Free Up Space (Remove Unwanted or Junk Files) on Ubuntu.md b/published/201907/20190610 5 Easy Ways To Free Up Space (Remove Unwanted or Junk Files) on Ubuntu.md
similarity index 100%
rename from published/20190610 5 Easy Ways To Free Up Space (Remove Unwanted or Junk Files) on Ubuntu.md
rename to published/201907/20190610 5 Easy Ways To Free Up Space (Remove Unwanted or Junk Files) on Ubuntu.md
diff --git a/published/20190612 BitTorrent Client Deluge 2.0 Released- Here-s What-s New.md b/published/201907/20190612 BitTorrent Client Deluge 2.0 Released- Here-s What-s New.md
similarity index 100%
rename from published/20190612 BitTorrent Client Deluge 2.0 Released- Here-s What-s New.md
rename to published/201907/20190612 BitTorrent Client Deluge 2.0 Released- Here-s What-s New.md
diff --git a/published/20190613 IPython is still the heart of Jupyter Notebooks for Python developers.md b/published/201907/20190613 IPython is still the heart of Jupyter Notebooks for Python developers.md
similarity index 100%
rename from published/20190613 IPython is still the heart of Jupyter Notebooks for Python developers.md
rename to published/201907/20190613 IPython is still the heart of Jupyter Notebooks for Python developers.md
diff --git a/published/20190617 Use ImageGlass to quickly view JPG images as a slideshow.md b/published/201907/20190617 Use ImageGlass to quickly view JPG images as a slideshow.md
similarity index 100%
rename from published/20190617 Use ImageGlass to quickly view JPG images as a slideshow.md
rename to published/201907/20190617 Use ImageGlass to quickly view JPG images as a slideshow.md
diff --git a/published/20190618 A beginner-s guide to Linux permissions.md b/published/201907/20190618 A beginner-s guide to Linux permissions.md
similarity index 100%
rename from published/20190618 A beginner-s guide to Linux permissions.md
rename to published/201907/20190618 A beginner-s guide to Linux permissions.md
diff --git a/published/20190619 Leading in the Python community.md b/published/201907/20190619 Leading in the Python community.md
similarity index 100%
rename from published/20190619 Leading in the Python community.md
rename to published/201907/20190619 Leading in the Python community.md
diff --git a/published/20190621 Three Ways to Lock and Unlock User Account in Linux.md b/published/201907/20190621 Three Ways to Lock and Unlock User Account in Linux.md
similarity index 100%
rename from published/20190621 Three Ways to Lock and Unlock User Account in Linux.md
rename to published/201907/20190621 Three Ways to Lock and Unlock User Account in Linux.md
diff --git a/published/20190624 With Upgraded Specs, Raspberry Pi 4 Takes Aim at Desktop Segment.md b/published/201907/20190624 With Upgraded Specs, Raspberry Pi 4 Takes Aim at Desktop Segment.md
similarity index 100%
rename from published/20190624 With Upgraded Specs, Raspberry Pi 4 Takes Aim at Desktop Segment.md
rename to published/201907/20190624 With Upgraded Specs, Raspberry Pi 4 Takes Aim at Desktop Segment.md
diff --git a/published/20190625 5 tiny Linux distros to try before you die.md b/published/201907/20190625 5 tiny Linux distros to try before you die.md
similarity index 100%
rename from published/20190625 5 tiny Linux distros to try before you die.md
rename to published/201907/20190625 5 tiny Linux distros to try before you die.md
diff --git a/published/20190625 The innovation delusion.md b/published/201907/20190625 The innovation delusion.md
similarity index 100%
rename from published/20190625 The innovation delusion.md
rename to published/201907/20190625 The innovation delusion.md
diff --git a/published/20190626 Tracking down library injections on Linux.md b/published/201907/20190626 Tracking down library injections on Linux.md
similarity index 100%
rename from published/20190626 Tracking down library injections on Linux.md
rename to published/201907/20190626 Tracking down library injections on Linux.md
diff --git a/published/20190627 How to use Tig to browse Git logs.md b/published/201907/20190627 How to use Tig to browse Git logs.md
similarity index 100%
rename from published/20190627 How to use Tig to browse Git logs.md
rename to published/201907/20190627 How to use Tig to browse Git logs.md
diff --git a/published/20190628 Undo releases Live Recorder 5.0 for Linux debugging.md b/published/201907/20190628 Undo releases Live Recorder 5.0 for Linux debugging.md
similarity index 100%
rename from published/20190628 Undo releases Live Recorder 5.0 for Linux debugging.md
rename to published/201907/20190628 Undo releases Live Recorder 5.0 for Linux debugging.md
diff --git a/published/20190630 Donald Trump Now Wants to Ban End-to-End Encryption.md b/published/201907/20190630 Donald Trump Now Wants to Ban End-to-End Encryption.md
similarity index 100%
rename from published/20190630 Donald Trump Now Wants to Ban End-to-End Encryption.md
rename to published/201907/20190630 Donald Trump Now Wants to Ban End-to-End Encryption.md
diff --git a/published/20190701 Ubuntu or Fedora- Which One Should You Use and Why.md b/published/201907/20190701 Ubuntu or Fedora- Which One Should You Use and Why.md
similarity index 100%
rename from published/20190701 Ubuntu or Fedora- Which One Should You Use and Why.md
rename to published/201907/20190701 Ubuntu or Fedora- Which One Should You Use and Why.md
diff --git a/published/20190702 Jupyter and data science in Fedora.md b/published/201907/20190702 Jupyter and data science in Fedora.md
similarity index 100%
rename from published/20190702 Jupyter and data science in Fedora.md
rename to published/201907/20190702 Jupyter and data science in Fedora.md
diff --git a/published/20190702 Make Linux stronger with firewalls.md b/published/201907/20190702 Make Linux stronger with firewalls.md
similarity index 100%
rename from published/20190702 Make Linux stronger with firewalls.md
rename to published/201907/20190702 Make Linux stronger with firewalls.md
diff --git a/published/20190703 How to Manually Install Security Updates on Debian-Ubuntu.md b/published/201907/20190703 How to Manually Install Security Updates on Debian-Ubuntu.md
similarity index 100%
rename from published/20190703 How to Manually Install Security Updates on Debian-Ubuntu.md
rename to published/201907/20190703 How to Manually Install Security Updates on Debian-Ubuntu.md
diff --git a/published/20190703 Parse arguments with Python.md b/published/201907/20190703 Parse arguments with Python.md
similarity index 100%
rename from published/20190703 Parse arguments with Python.md
rename to published/201907/20190703 Parse arguments with Python.md
diff --git a/published/201907/20190705 Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux.md b/published/201907/20190705 Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux.md
new file mode 100644
index 0000000000..8f06f3a6a9
--- /dev/null
+++ b/published/201907/20190705 Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux.md
@@ -0,0 +1,109 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11171-1.html)
+[#]: subject: (Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux)
+[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+在 Linux 上用 Bash 脚本监控 messages 日志
+======
+
+目前市场上有许多开源监控工具可用于监控 Linux 系统的性能。当系统达到指定的阈值限制时,它将发送电子邮件警报。它可以监视 CPU 利用率、内存利用率、交换利用率、磁盘空间利用率等所有内容。
+
+如果你只有很少的系统并且想要监视它们,那么编写一个小的 shell 脚本可以使你的任务变得非常简单。
+
+在本教程中,我们添加了一个 shell 脚本来监视 Linux 系统上的 messages 日志。
+
+我们过去添加了许多有用的 shell 脚本。如果要查看这些内容,请导航至以下链接。
+
+- [如何使用 shell 脚本监控系统的日常活动?][1]
+
+此脚本将检查 `/var/log/messages` 文件中的 “warning“、“error” 和 “critical”,如果发现任何有关的东西,就给指定电子邮件地址发邮件。
+
+如果服务器有许多匹配的字符串,我们就不能经常运行这个可能填满收件箱的脚本,我们可以在一天内运行一次。
+
+为了解决这个问题,我让脚本以不同的方式触发电子邮件。
+
+如果 `/var/log/messages` 文件中昨天的日志中找到任何给定字符串,则脚本将向给定的电子邮件地址发送电子邮件警报。
+
+**注意:**你需要更改电子邮件地址,而不是我们的电子邮件地址。
+
+```
+# vi /opt/scripts/os-log-alert.sh
+```
+
+```
+#!/bin/bash
+#Set the variable which equal to zero
+prev_count=0
+
+count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | egrep -wi 'warning|error|critical' | wc -l)
+
+if [ "$prev_count" -lt "$count" ] ; then
+ # Send a mail to given email id when errors found in log
+ SUBJECT="WARNING: Errors found in log on "`date --date='yesterday' '+%b %e'`""
+ # This is a temp file, which is created to store the email message.
+ MESSAGE="/tmp/logs.txt"
+ TO="2daygeek@gmail.com"
+ echo "ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin." >> $MESSAGE
+ echo "Hostname: `hostname`" >> $MESSAGE
+ echo -e "\n" >> $MESSAGE
+ echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
+ echo "Error messages in the log file as below" >> $MESSAGE
+ echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
+ grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | awk '{ $3=""; print}' | egrep -wi 'warning|error|critical' >> $MESSAGE
+ mail -s "$SUBJECT" "$TO" < $MESSAGE
+ #rm $MESSAGE
+fi
+```
+
+为 `os-log-alert.sh` 文件设置可执行权限。
+
+```
+$ chmod +x /opt/scripts/os-log-alert.sh
+```
+
+最后添加一个 cron 任务来自动执行此操作。它将每天 7 点钟运行。
+
+```
+# crontab -e
+```
+
+```
+0 7 * * * /bin/bash /opt/scripts/os-log-alert.sh
+```
+
+**注意:**你将在每天 7 点收到昨天日志的电子邮件提醒。
+
+**输出:**你将收到类似下面的电子邮件提醒。
+
+```
+ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin.
+
++-----------------------------------------------------+
+Error messages in the log file as below
++-----------------------------------------------------+
+Jul 3 02:40:11 ns1 kernel: php-fpm[3175]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
+Jul 3 02:50:14 ns1 kernel: lmtp[8249]: segfault at 20 ip 00007f9cc05295e4 sp 00007ffc57bca1a0 error 4 in libdovecot-storage.so.0.0.0[7f9cc04df000+148000]
+Jul 3 15:36:09 ns1 kernel: php-fpm[17846]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
+Jul 3 15:45:54 ns1 pure-ftpd: (?@5.188.62.5) [WARNING] Authentication failed for user [daygeek]
+Jul 3 16:25:36 ns1 pure-ftpd: (?@104.140.148.58) [WARNING] Sorry, cleartext sessions and weak ciphers are not accepted on this server.#012Please reconnect using TLS security mechanisms.
+Jul 3 16:44:20 ns1 kernel: php-fpm[8979]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/category/shell-script/
diff --git a/published/20190705 Copy and paste at the Linux command line with xclip.md b/published/201907/20190705 Copy and paste at the Linux command line with xclip.md
similarity index 100%
rename from published/20190705 Copy and paste at the Linux command line with xclip.md
rename to published/201907/20190705 Copy and paste at the Linux command line with xclip.md
diff --git a/published/20190705 Manage your shell environment.md b/published/201907/20190705 Manage your shell environment.md
similarity index 100%
rename from published/20190705 Manage your shell environment.md
rename to published/201907/20190705 Manage your shell environment.md
diff --git a/published/20190706 How To Delete A Repository And GPG Key In Ubuntu.md b/published/201907/20190706 How To Delete A Repository And GPG Key In Ubuntu.md
similarity index 100%
rename from published/20190706 How To Delete A Repository And GPG Key In Ubuntu.md
rename to published/201907/20190706 How To Delete A Repository And GPG Key In Ubuntu.md
diff --git a/published/201907/20190706 How to enable DNS-over-HTTPS (DoH) in Firefox.md b/published/201907/20190706 How to enable DNS-over-HTTPS (DoH) in Firefox.md
new file mode 100644
index 0000000000..7a4e915b9e
--- /dev/null
+++ b/published/201907/20190706 How to enable DNS-over-HTTPS (DoH) in Firefox.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11163-1.html)
+[#]: subject: (How to enable DNS-over-HTTPS (DoH) in Firefox)
+[#]: via: (https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/)
+[#]: author: (Catalin Cimpanu https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/)
+
+如何在 Firefox 中启用 DNS-over-HTTPS(DoH)
+======
+
+DNS-over-HTTPS(DoH)协议目前是谈论的焦点,Firefox 是唯一支持它的浏览器。但是,Firefox 默认不启用此功能,用户必须经历许多步骤并修改多个设置才能启动并运行 DoH。
+
+在开始如何在 Firefox 中启用 DoH 支持的分步教程之前,让我们先描述它的原理。
+
+### DNS-over-HTTPS 的工作原理
+
+DNS-over-HTTPS 协议通过获取用户在浏览器中输入的域名,并向 DNS 服务器发送查询,以了解托管该站点的 Web 服务器的 IP 地址。
+
+这也是正常 DNS 的工作原理。但是,DoH 通过 443 端口的加密 HTTPS 连接接受 DNS 查询将其发送到兼容 DoH 的 DNS 服务器(解析器),而不是在 53 端口上发送纯文本。这样,DoH 就会在常规 HTTPS 流量中隐藏 DNS 查询,因此第三方监听者将无法嗅探流量,并了解用户的 DNS 查询,从而推断他们将要访问的网站。
+
+此外,DNS-over-HTTPS 的第二个特性是该协议工作在应用层。应用可以带上内部硬编码的 DoH 兼容的 DNS 解析器列表,从而向它们发送 DoH 查询。这种操作模式绕过了系统级别的默认 DNS 设置,在大多数情况下,这些设置是由本地 Internet 服务提供商(ISP)设置的。这也意味着支持 DoH 的应用可以有效地绕过本地 ISP 流量过滤器并访问可能被本地电信公司或当地政府阻止的内容 —— 这也是 DoH 目前被誉为用户隐私和安全的福音的原因。
+
+这是 DoH 在推出后不到两年的时间里获得相当大的普及的原因之一,同时也是一群[英国 ISP 因为 Mozilla 计划支持 DoH 协议而提名它为 2019 年的“互联网恶棍” (Internet Villian)][1]的原因,ISP 认为 DoH 协议会阻碍他们过滤不良流量的努力。(LCTT 译注:后来这一奖项的提名被取消。)
+
+作为回应,并且由于英国政府阻止访问侵犯版权内容的复杂情况,以及 ISP 自愿阻止访问虐待儿童网站的情况,[Mozilla 已决定不为英国用户默认启用此功能][2]。
+
+下面的分步指南将向英国和世界各地的 Firefox 用户展示如何立即启用该功能,而不用等到 Mozilla 将来启用它 —— 如果它会这么做的话。在 Firefox 中有两种启用 DoH 支持的方法。
+
+### 方法 1:通过 Firefox 设置
+
+**步骤 1:**进入 Firefox 菜单,选择**工具**,然后选择**首选项**。 可选在 URL 栏中输入 `about:preferences`,然后按下回车。这将打开 Firefox 的首选项。
+
+**步骤 2:**在**常规**中,向下滚动到**网络设置**,然后按**设置**按钮。
+
+![DoH section in Firefox settings][3]
+
+**步骤3:**在弹出窗口中,向下滚动并选择“**Enable DNS over HTTPS**”,然后配置你需要的 DoH 解析器。你可以使用内置的 Cloudflare 解析器(该公司与 Mozilla [达成协议][4],记录更少的 Firefox 用户数据),或者你可以在[这个列表][4]中选择一个。
+
+![DoH section in Firefox settings][6]
+
+### 方法 2:通过 about:config
+
+**步骤 1:**在 URL 栏中输入 `about:config`,然后按回车访问 Firefox 的隐藏配置面板。在这里,用户需要启用和修改三个设置。
+
+**步骤 2:**第一个设置是 `network.trr.mode`。这打开了 DoH 支持。此设置支持四个值:
+
+* `0` - 标准 Firefox 安装中的默认值(当前为 5,表示禁用 DoH)
+* `1` - 启用 DoH,但 Firefox 依据哪个请求更快返回选择使用 DoH 或者常规 DNS
+* `2` - 启用 DoH,常规 DNS 作为备用
+* `3` - 启用 DoH,并禁用常规 DNS
+* `5` - 禁用 DoH
+
+值为 2 工作得最好
+
+![DoH in Firefox][7]
+
+**步骤3:**需要修改的第二个设置是 `network.trr.uri`。这是与 DoH 兼容的 DNS 服务器的 URL,Firefox 将向它发送 DoH DNS 查询。默认情况下,Firefox 使用 Cloudflare 的 DoH服务,地址是:。但是,用户可以使用自己的 DoH 服务器 URL。他们可以从[这个列表][8]中选择其中一个可用的。Mozilla 在 Firefox 中使用 Cloudflare 的原因是因为与这家公司[达成了协议][4],之后 Cloudflare 将收集来自 Firefox 用户的 DoH 查询的非常少的数据。
+
+[DoH in Firefox][9]
+
+**步骤4:**第三个设置是可选的,你可以跳过此设置。 但是如果设置不起作用,你可以使用此作为步骤 3 的备用。该选项名为 `network.trr.bootstrapAddress`,它是一个输入字段,用户可以输入步骤 3 中兼容 DoH 的 DNS 解析器的 IP 地址。对于 Cloudflare,它是 1.1.1.1。 对于 Google 服务,它是 8.8.8.8。 如果你使用了另一个 DoH 解析器的 URL,如果有必要的话,你需要追踪那台服务器的 IP 地址并输入。
+
+![DoH in Firefox][10]
+
+通常,在步骤 3 中输入的 URL 应该足够了。
+设置应该立即生效,但如果它们不起作用,请重新启动 Firefox。
+
+文章信息来源:[Mozilla Wiki][11]
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/
+
+作者:[Catalin Cimpanu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-11068-1.html
+[2]: https://www.zdnet.com/article/mozilla-no-plans-to-enable-dns-over-https-by-default-in-the-uk/
+[3]: https://zdnet1.cbsistatic.com/hub/i/2019/07/07/df30c7b0-3a20-4de7-8640-3dea6d249a49/121bd379b6232e1e2a97c35ea8c7764e/doh-settings-1.png
+[4]: https://developers.cloudflare.com/1.1.1.1/commitment-to-privacy/privacy-policy/firefox/
+[6]: https://zdnet3.cbsistatic.com/hub/i/2019/07/07/8608af28-2a28-4ff1-952b-9b6d2deb1ea6/b1fc322caaa2c955b1a2fb285daf0e42/doh-settings-2.png
+[7]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/0232b3a7-82c6-4a6f-90c1-faf0c090254c/6db9b36509021c460fcc7fe825bb74c5/doh-1.png
+[8]: https://github.com/curl/curl/wiki/DNS-over-HTTPS#publicly-available-servers
+[9]: https://zdnet2.cbsistatic.com/hub/i/2019/07/06/4dd1d5c1-6fa7-4f5b-b7cd-b544748edfed/baa7a70ac084861d94a744a57a3147ad/doh-2.png
+[10]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/8ec20a28-673c-4a17-8195-16579398e90a/538fe8420f9b24724aeb4a6c8d4f0f0f/doh-3.png
+[11]: https://wiki.mozilla.org/Trusted_Recursive_Resolver
diff --git a/published/20190706 Say WHAAAT- Mozilla has Been Nominated for the -Internet Villain- Award in the UK.md b/published/201907/20190706 Say WHAAAT- Mozilla has Been Nominated for the -Internet Villain- Award in the UK.md
similarity index 100%
rename from published/20190706 Say WHAAAT- Mozilla has Been Nominated for the -Internet Villain- Award in the UK.md
rename to published/201907/20190706 Say WHAAAT- Mozilla has Been Nominated for the -Internet Villain- Award in the UK.md
diff --git a/published/20190708 10 ways to get started with Linux.md b/published/201907/20190708 10 ways to get started with Linux.md
similarity index 100%
rename from published/20190708 10 ways to get started with Linux.md
rename to published/201907/20190708 10 ways to get started with Linux.md
diff --git a/published/20190708 Command line quick tips- Permissions.md b/published/201907/20190708 Command line quick tips- Permissions.md
similarity index 100%
rename from published/20190708 Command line quick tips- Permissions.md
rename to published/201907/20190708 Command line quick tips- Permissions.md
diff --git a/published/20190708 Debian 10 (Buster) Installation Steps with Screenshots.md b/published/201907/20190708 Debian 10 (Buster) Installation Steps with Screenshots.md
similarity index 100%
rename from published/20190708 Debian 10 (Buster) Installation Steps with Screenshots.md
rename to published/201907/20190708 Debian 10 (Buster) Installation Steps with Screenshots.md
diff --git a/published/20190708 Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve-s New Compiler.md b/published/201907/20190708 Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve-s New Compiler.md
similarity index 100%
rename from published/20190708 Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve-s New Compiler.md
rename to published/201907/20190708 Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve-s New Compiler.md
diff --git a/published/20190709 From BASIC to Ruby- Life lessons from first programming languages on Command Line Heroes.md b/published/201907/20190709 From BASIC to Ruby- Life lessons from first programming languages on Command Line Heroes.md
similarity index 100%
rename from published/20190709 From BASIC to Ruby- Life lessons from first programming languages on Command Line Heroes.md
rename to published/201907/20190709 From BASIC to Ruby- Life lessons from first programming languages on Command Line Heroes.md
diff --git a/published/20190709 Pipx - Install And Run Python Applications In Isolated Environments.md b/published/201907/20190709 Pipx - Install And Run Python Applications In Isolated Environments.md
similarity index 100%
rename from published/20190709 Pipx - Install And Run Python Applications In Isolated Environments.md
rename to published/201907/20190709 Pipx - Install And Run Python Applications In Isolated Environments.md
diff --git a/published/20190709 Sysadmin vs SRE- What-s the difference.md b/published/201907/20190709 Sysadmin vs SRE- What-s the difference.md
similarity index 100%
rename from published/20190709 Sysadmin vs SRE- What-s the difference.md
rename to published/201907/20190709 Sysadmin vs SRE- What-s the difference.md
diff --git a/published/20190710 32-bit life support- Cross-compiling with GCC.md b/published/201907/20190710 32-bit life support- Cross-compiling with GCC.md
similarity index 100%
rename from published/20190710 32-bit life support- Cross-compiling with GCC.md
rename to published/201907/20190710 32-bit life support- Cross-compiling with GCC.md
diff --git a/published/20190710 How To Find Virtualbox Version From Commandline In Linux.md b/published/201907/20190710 How To Find Virtualbox Version From Commandline In Linux.md
similarity index 100%
rename from published/20190710 How To Find Virtualbox Version From Commandline In Linux.md
rename to published/201907/20190710 How To Find Virtualbox Version From Commandline In Linux.md
diff --git a/published/20190710 Test 200- Linux And Unix Operating Systems Online For Free.md b/published/201907/20190710 Test 200- Linux And Unix Operating Systems Online For Free.md
similarity index 100%
rename from published/20190710 Test 200- Linux And Unix Operating Systems Online For Free.md
rename to published/201907/20190710 Test 200- Linux And Unix Operating Systems Online For Free.md
diff --git a/published/20190711 How to install Elasticsearch on MacOS.md b/published/201907/20190711 How to install Elasticsearch on MacOS.md
similarity index 100%
rename from published/20190711 How to install Elasticsearch on MacOS.md
rename to published/201907/20190711 How to install Elasticsearch on MacOS.md
diff --git a/published/20190711 Type Linux Commands In Capital Letters To Run Them As Sudo User.md b/published/201907/20190711 Type Linux Commands In Capital Letters To Run Them As Sudo User.md
similarity index 100%
rename from published/20190711 Type Linux Commands In Capital Letters To Run Them As Sudo User.md
rename to published/201907/20190711 Type Linux Commands In Capital Letters To Run Them As Sudo User.md
diff --git a/published/201907/20190712 MTTR is dead, long live CIRT.md b/published/201907/20190712 MTTR is dead, long live CIRT.md
new file mode 100644
index 0000000000..1055d9e832
--- /dev/null
+++ b/published/201907/20190712 MTTR is dead, long live CIRT.md
@@ -0,0 +1,78 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11155-1.html)
+[#]: subject: (MTTR is dead, long live CIRT)
+[#]: via: (https://opensource.com/article/19/7/measure-operational-performance)
+[#]: author: (Julie Gunderson https://opensource.com/users/juliegund/users/kearnsjd/users/ophir)
+
+MTTR 已死,CIRT 长存
+======
+
+> 通过关注影响业务的事件,CIRT 是衡量运维绩效的更准确方法。
+
+![Green graph of measurements][1]
+
+IT 运维圈子的玩法正在发生变化,这意味着过去的规则越来越不合理。机构需要适当环境中的准确的、可理解的、且可操作的指标,以衡量运维绩效并推动关键业务转型。
+
+越多的客户使用现代工具,他们管理的事件类型的变化越多,将所有这些不同事件粉碎到一个桶中以计算平均解决时间来表示运维绩效的意义就越少,这就是 IT 一直以来在做的事情。
+
+### 历史与指标
+
+历史表明,在分析信号以防止错误和误解时,背景信息是关键。例如,在 20 世纪 80 年代,瑞典建立了一个分析水听器信号的系统,以提醒他们在瑞典当地水域出现的俄罗斯潜艇。瑞典人使用了他们认为代表一类俄罗斯潜艇的声学特征 —— 但实际上是鲱鱼在遇到潜在捕食者时释放的[气泡声][2]。这种对指标的误解加剧了各国之间的紧张关系,几乎导致了战争。
+
+![Funny fish cartoon][3]
+
+平均解决时间(MTTR)是运维经理用于获得实现目标洞察力的主要运维绩效指标。这是一项基于系统可靠性工程的古老措施。MTTR 已被许多行业采用,包括制造、设施维护以及最近的 IT 运维,它代表了解决在特定时间段内创建的事件所需的平均时间。
+
+MTTR 的计算方法是将所有事件(从事件创建时间到解决时间)所需的时间除以事件总数。
+
+![MTTR formula][4]
+
+正如它所说的,MTTR 是 **所有** 事件的平均值。MTTR 将高紧急事件和低紧急事件混为一谈。它还会重复计算每个单独的、未分组的事件,并得出有效的解决时间。它包括了在相同上下文中手动解决和自动解决的事件。它将在创建了几天(或几个月)甚至完全被忽略的事件混合在一起。最后,MTTR 包括每个小的瞬态突发事件(在 120 秒内自动关闭的事件),这些突发事件要么是非问题噪音,要么已由机器快速解决。
+
+![Variability in incident types][5]
+
+MTTR 将所有事件(无论何种类型)抛入一个桶中,将它们全部混合在一起,并计算整个集合中的“平均”解决时间。这种过于简单化的方法导致运维执行方式的的噪音、错误和误导性指示。
+
+### 一种衡量绩效的新方法
+
+关键事件响应时间(CIRT)是评估运维绩效的一种更准确的新方法。PagerDuty 创立了 CIRT 的概念,但该方法可供所有人免费使用。
+
+CIRT 通过使用以下技术剔除来自信号的噪声,其重点关注最有可能影响业务的事件:
+
+1. 真正影响(或可能影响)业务的事件很少是低紧急事件,因此要排除所有低紧急事件。
+2. 真正影响业务的事件很少(如果有的话)可以无需人为干预而通过监控工具自动解决,因此要排除未由人工解决的事件。
+3. 在 120 秒内解决的短暂、爆发性和瞬态事件几乎不可能是真正影响业务的事件,因此要排除它们。
+4. 长时间未被注意、提交或忽略(未确认、未解决)的事件很少会对业务造成影响;排除它们。注意:此阈值可以是特定于客户的统计推导数字(例如,高于均值的两个标准差),以避免使用任意数字。
+5. 由单独警报产生的个别未分组事件并不代表较大的业务影响事件。因此,模拟具有非常保守的阈值(例如,两分钟)的事件分组以计算响应时间。
+
+应用这些假设对响应时间有什么影响?简而言之,效果非常非常大!
+
+通过在关键的、影响业务的事件中关注运维绩效,解决时间分布变窄并极大地向左偏移,因为现在它处理类似类型的事件而不是所有事件。
+
+由于 MTTR 计算的响应时间长得多、人为地偏差,因此它是运维绩效较差的一个指标。另一方面,CIRT 是一项有意的措施,专注于对业务最重要的事件。
+
+与 CIRT 一起使用的另一个关键措施是确认和解决事故的百分比。这很重要,因为它验证 CIRT(或 MTTA / MTTR)是否值得利用。例如,如果 MTTR 结果很低,比如 10 分钟,那听起来不错,但如果只有 42% 的事件得到解决,那么 MTTR 是可疑的。
+
+总之,CIRT 和确认、解决事件的百分比形成了一组有价值的指标,可以让你更好地了解运营的执行情况。衡量绩效是提高绩效的第一步,因此这些新措施对于实现机构的可持续、可衡量的改进周期至关重要。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/measure-operational-performance
+
+作者:[Julie Gunderson][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/juliegund/users/kearnsjd/users/ophir
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
+[2]: http://blogfishx.blogspot.com/2014/05/herring-fart-to-communicate.html
+[3]: https://opensource.com/sites/default/files/uploads/fish.png (Funny fish cartoon)
+[4]: https://opensource.com/sites/default/files/uploads/mttr.png (MTTR formula)
+[5]: https://opensource.com/sites/default/files/uploads/incidents.png (Variability in incident types)
diff --git a/published/20190712 Make an RGB cube with Python and Scribus.md b/published/201907/20190712 Make an RGB cube with Python and Scribus.md
similarity index 100%
rename from published/20190712 Make an RGB cube with Python and Scribus.md
rename to published/201907/20190712 Make an RGB cube with Python and Scribus.md
diff --git a/published/20190713 ElectronMail - a Desktop Client for ProtonMail and Tutanota.md b/published/201907/20190713 ElectronMail - a Desktop Client for ProtonMail and Tutanota.md
similarity index 100%
rename from published/20190713 ElectronMail - a Desktop Client for ProtonMail and Tutanota.md
rename to published/201907/20190713 ElectronMail - a Desktop Client for ProtonMail and Tutanota.md
diff --git a/published/20190714 Excellent- Ubuntu LTS Users Will Now Get the Latest Nvidia Driver Updates -No PPA Needed Anymore.md b/published/201907/20190714 Excellent- Ubuntu LTS Users Will Now Get the Latest Nvidia Driver Updates -No PPA Needed Anymore.md
similarity index 100%
rename from published/20190714 Excellent- Ubuntu LTS Users Will Now Get the Latest Nvidia Driver Updates -No PPA Needed Anymore.md
rename to published/201907/20190714 Excellent- Ubuntu LTS Users Will Now Get the Latest Nvidia Driver Updates -No PPA Needed Anymore.md
diff --git a/published/20190716 Become a lifelong learner and succeed at work.md b/published/201907/20190716 Become a lifelong learner and succeed at work.md
similarity index 100%
rename from published/20190716 Become a lifelong learner and succeed at work.md
rename to published/201907/20190716 Become a lifelong learner and succeed at work.md
diff --git a/published/20190716 Save and load Python data with JSON.md b/published/201907/20190716 Save and load Python data with JSON.md
similarity index 100%
rename from published/20190716 Save and load Python data with JSON.md
rename to published/201907/20190716 Save and load Python data with JSON.md
diff --git a/translated/tech/20190717 Bond WiFi and Ethernet for easier networking mobility.md b/published/201907/20190717 Bond WiFi and Ethernet for easier networking mobility.md
similarity index 63%
rename from translated/tech/20190717 Bond WiFi and Ethernet for easier networking mobility.md
rename to published/201907/20190717 Bond WiFi and Ethernet for easier networking mobility.md
index 797a9abe8b..b8528ca1dd 100644
--- a/translated/tech/20190717 Bond WiFi and Ethernet for easier networking mobility.md
+++ b/published/201907/20190717 Bond WiFi and Ethernet for easier networking mobility.md
@@ -1,28 +1,28 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11149-1.html)
[#]: subject: (Bond WiFi and Ethernet for easier networking mobility)
[#]: via: (https://fedoramagazine.org/bond-wifi-and-ethernet-for-easier-networking-mobility/)
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
-绑定 WiFi 和以太网,以便于更轻松的网络移动
+绑定 WiFi 和以太网,以使网络间移动更轻松
======
![][1]
-有时一个网络接口是不够的。网络绑定允许将多条网络连接与单个逻辑接口一起工作。你可能因为需要单条连接更多的带宽而需要这么做。或者你可能希望在有线和无线网络之间来回切换而不会丢失网络连接。
+有时一个网络接口是不够的。网络绑定允许将多条网络连接与单个逻辑接口一起工作。你可能因为需要给单条连接更多的带宽而这么做,或者你可能希望在有线和无线网络之间来回切换而不会丢失网络连接。
-我是后面一种情况。在家工作的好处之一是,当天气晴朗时,在阳光明媚的阳台而不是在室内工作是很愉快的。但每当我这样做时,我都会失去网络连接。 IRC、SSH、VPN,一切都断开了,客户端重连至少需要一会。本文介绍了如何在 Fedora 30 笔记本上设置网络绑定,以便从笔记本扩展坞的有线连接无缝切换到 WiFi。
+我是后面一种情况。在家工作的好处之一是,当天气晴朗时,在阳光明媚的阳台而不是在室内工作是很愉快的。但每当我这样做时,我都会失去网络连接。IRC、SSH、VPN,一切都断开了,客户端重连至少需要一会。本文介绍了如何在 Fedora 30 笔记本上设置网络绑定,以便从笔记本扩展坞的有线连接无缝切换到 WiFi。
-在 Linux 中,接口绑定由绑定内核模块处理。默认情况下,Fedora 没有启用此功能,但它包含在 kernel-core 软件包中。这意味着启用接口绑定只需一个命令:
+在 Linux 中,接口绑定由内核模块 `bonding` 处理。默认情况下,Fedora 没有启用此功能,但它包含在 `kernel-core` 软件包中。这意味着启用接口绑定只需一个命令:
```
sudo modprobe bonding
```
-请注意,这只会在你重启之前生效。要永久启用接口绑定,请在 _/etc/modules-load.d_ 目录中创建一个名为 _bonding.conf_ 的文件,该文件仅包含单词 “bonding”。
+请注意,这只会在你重启之前生效。要永久启用接口绑定,请在 `/etc/modules-load.d` 目录中创建一个名为 `bonding.conf` 的文件,该文件仅包含单词 `bonding`。
现在你已启用绑定,现在可以创建绑定接口了。首先,你必须获取要绑定的接口的名称。要列出可用的接口,请运行:
@@ -44,7 +44,7 @@ lo loopback unmanaged --
virbr0-nic tun unmanaged --
```
-在本例中,有两个(有线)以太网接口可用。 _enp12s0u1_ 在笔记本电脑扩展坞上,你可以通过 _STATE_ 列知道它已连接。另一个是 _enp0s31f6_,是笔记本电脑中的内置端口。还有一个名为 _wlp2s0_ 的 WiFi 连接。 _enp12s0u1_ 和 _wlp2s0_ 是我们在这里感兴趣的两个接口。(请注意,本文无需了解网络设备的命名方式,但如果你感兴趣,可以查看 [systemd.net-naming-scheme 手册页][2]。)
+在本例中,有两个(有线)以太网接口可用。 `enp12s0u1` 在笔记本电脑扩展坞上,你可以通过 `STATE` 列知道它已连接。另一个是 `enp0s31f6`,是笔记本电脑中的内置端口。还有一个名为 `wlp2s0` 的 WiFi 连接。 `enp12s0u1` 和 `wlp2s0` 是我们在这里感兴趣的两个接口。(请注意,阅读本文无需了解网络设备的命名方式,但如果你感兴趣,可以查看 [systemd.net-naming-scheme 手册页][2]。)
第一步是创建绑定接口:
@@ -52,7 +52,7 @@ virbr0-nic tun unmanaged --
sudo nmcli connection add type bond ifname bond0 con-name bond0
```
-在此示例中,绑定接口名为 _bond0_。 “_con-name bond0_” 将连接名称设置为 _bond0_。直接这样会有一个名为 _bond-bond0_ 的连接。你还可以将连接名设置得更加人性化,例如 “Docking station bond” 或 “Ben”
+在此示例中,绑定接口名为 `bond0`。`con-name bond0` 将连接名称设置为 `bond0`。直接这样做会有一个名为 `bond-bond0` 的连接。你还可以将连接名设置得更加人性化,例如 “Docking station bond” 或 “Ben”。
下一步是将接口添加到绑定接口:
@@ -61,14 +61,14 @@ sudo nmcli connection add type ethernet ifname enp12s0u1 master bond0 con-name b
sudo nmcli connection add type wifi ifname wlp2s0 master bond0 ssid Cotton con-name bond-wifi
```
-如上所示,连接名称被设置为[更具描述性][3]。请务必使用系统上相应的接口名称替换 _enp12s0u1_ 和 _wlp2s0_。对于 WiFi 接口,请使用你自己的网络名称 (SSID)替换我的 “Cotton”。如果你的 WiFi 连接有密码(这当然会有!),你也需要将其添加到配置中。以下假设你使用 [WPA2-PSK][4] 身份验证
+如上所示,连接名称被设置为[更具描述性][3]。请务必使用系统上相应的接口名称替换 `enp12s0u1` 和 `wlp2s0`。对于 WiFi 接口,请使用你自己的网络名称 (SSID)替换我的 “Cotton”。如果你的 WiFi 连接有密码(这当然会有!),你也需要将其添加到配置中。以下假设你使用 [WPA2-PSK][4] 身份验证
```
sudo nmcli connection modify bond-wifi wifi-sec.key-mgmt wpa-psk
sudo nmcli connection edit bond-wif
```
-第二条命令将进入交互式编辑器,你可以在其中输入密码,而无需将其记录在 shell 历史记录中。输入以下内容,将 _password_ 替换为你的实际密码
+第二条命令将进入交互式编辑器,你可以在其中输入密码,而无需将其记录在 shell 历史记录中。输入以下内容,将 `password` 替换为你的实际密码。
```
set wifi-sec.psk password
@@ -76,7 +76,7 @@ save
quit
```
-现在,你可以启动你的绑定接口以及你创建的辅助接口
+现在,你可以启动你的绑定接口以及你创建的辅助接口。
```
sudo nmcli connection up bond0
@@ -98,13 +98,13 @@ sudo nmcli connection down bond0
### 微调你的绑定
-默认情况下,绑定接口使用“负载平衡(round-robin)”模式。 这会在接口上平均分配负载。 但是,如果你有有线和无线连接,你可能希望更喜欢有线连接。 “active-backup” 模式能实现此功能。 你可以在创建接口时指定模式和主接口,或者之后使用此命令(绑定接口应该关闭):
+默认情况下,绑定接口使用“轮询”模式。这会在接口上平均分配负载。但是,如果你有有线和无线连接,你可能希望更喜欢有线连接。 `active-backup` 模式能实现此功能。你可以在创建接口时指定模式和主接口,或者之后使用此命令(绑定接口应该关闭):
```
sudo nmcli connection modify bond0 +bond.options "mode=active-backup,primary=enp12s0u1"
```
-[kernel 文档][5]提供了有关绑定选项的更多信息。
+[内核文档][5]提供了有关绑定选项的更多信息。
--------------------------------------------------------------------------------
@@ -113,7 +113,7 @@ via: https://fedoramagazine.org/bond-wifi-and-ethernet-for-easier-networking-mob
作者:[Ben Cotton][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20190717 How to install Kibana on MacOS.md b/published/201907/20190717 How to install Kibana on MacOS.md
similarity index 100%
rename from published/20190717 How to install Kibana on MacOS.md
rename to published/201907/20190717 How to install Kibana on MacOS.md
diff --git a/translated/tech/20190717 Mastering user groups on Linux.md b/published/201907/20190717 Mastering user groups on Linux.md
similarity index 57%
rename from translated/tech/20190717 Mastering user groups on Linux.md
rename to published/201907/20190717 Mastering user groups on Linux.md
index 6595649ea7..99c57b5d45 100644
--- a/translated/tech/20190717 Mastering user groups on Linux.md
+++ b/published/201907/20190717 Mastering user groups on Linux.md
@@ -1,26 +1,26 @@
[#]: collector: (lujun9972)
[#]: translator: (0x996)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11148-1.html)
[#]: subject: (Mastering user groups on Linux)
[#]: via: (https://www.networkworld.com/article/3409781/mastering-user-groups-on-linux.html)
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
掌握 Linux 用户组
======
-在 Linux 系统中管理用户组并不费力,但相关命令可能比你所知的更为灵活。
+
+> 在 Linux 系统中管理用户组并不费力,但相关命令可能比你所知的更为灵活。
+
![Scott 97006 \(CC BY 2.0\)][1]
在 Linux 系统中用户组起着重要作用。用户组提供了一种简单方法供一组用户互相共享文件。用户组也允许系统管理员更加有效地管理用户权限,因为管理员可以将权限分配给用户组而不是逐一分配给单个用户。
尽管通常只要在系统中添加用户账户就会创建用户组,关于用户组如何工作以及如何运用用户组还有很多需要了解的。
-**[ 两分钟 Linux 技巧:[ 观看这些 2 分钟视频学习如何精通一大批 Linux 命令 ][2] ]**
+### 一个用户一个用户组?
-### 一个用户,一个用户组?
-
-Linux 系统中多数用户账户被设为用户名与用户组名相同。用户 "jdoe" 会被赋予一个名为 "jdoe" 的用户组,且成为该新建用户组的唯一成员。如本例所示,该用户的登录名,用户 id 和用户组 id 在新建账户时会被添加到 **/etc/passwd** 和 **/etc/group** 文件中:
+Linux 系统中多数用户账户被设为用户名与用户组名相同。用户 `jdoe` 会被赋予一个名为 `jdoe` 的用户组,且成为该新建用户组的唯一成员。如本例所示,该用户的登录名,用户 id 和用户组 id 在新建账户时会被添加到 `/etc/passwd` 和 `/etc/group` 文件中:
```
$ sudo useradd jdoe
@@ -30,15 +30,15 @@ $ grep jdoe /etc/group
jdoe:x:1066:
```
-这些文件中的配置使系统得以在文本(jdoe)和数字(1066)这两种用户 id 形式之间互相转换—— jdoe 就是 1006,且 1006 就是 jdoe。
+这些文件中的配置使系统得以在文本(`jdoe`)和数字(`1066`)这两种用户 id 形式之间互相转换—— `jdoe` 就是 `1006`,且 `1006` 就是 `jdoe`。
-分配给每个用户的 UID(用户 id)和 GID(用户组 id)通常是一样的并且顺序递增。若上例中 Jane Doe 是最近添加的用户,分配给下一个新用户的用户 id 和用户组 id 很可能都是 1067。
+分配给每个用户的 UID(用户 id)和 GID(用户组 id)通常是一样的,并且顺序递增。若上例中 Jane Doe 是最近添加的用户,分配给下一个新用户的用户 id 和用户组 id 很可能都是 1067。
### GID = UID?
-UID 和 GID 可能不一致。例如,如果你用 **groupadd** 命令添加一个用户组而不指定用户组 id,系统会分配下一个可用的用户组 id(在本例中为 1067)。下一个添加到系统中的用户其 UID 会是 1067 而 GID 则为 1068。
+UID 和 GID 可能不一致。例如,如果你用 `groupadd` 命令添加一个用户组而不指定用户组 id,系统会分配下一个可用的用户组 id(在本例中为 1067)。下一个添加到系统中的用户其 UID 会是 1067 而 GID 则为 1068。
-你可以避免这个问题,方法是添加用户组的时候指定一个较小的用户组 id 而不是接受默认值。在下面的命令中我们添加一个用户组并提供一个 GID,这个 GID 小于应用于用户账户的 GID 取值范围。
+你可以避免这个问题,方法是添加用户组的时候指定一个较小的用户组 id 而不是接受默认值。在下面的命令中我们添加一个用户组并提供一个 GID,这个 GID 小于用于用户账户的 GID 取值范围。
```
$ sudo groupadd -g 500 devops
@@ -52,11 +52,11 @@ $ grep bennyg /etc/passwd
bennyg:x:1064:50::/home/bennyg:/bin/sh
```
-### 主要用户组和次要用户组
+### 主要用户组和次要用户组
-用户组实际上有两种——主要用户组和次要用户组
+用户组实际上有两种:主要用户组和次要用户组。
-**主要用户组**是保存在 /etc/passwd 文件中的用户组,该用户组在账户创建时配置。当用户创建一个文件,用户的主要用户组与此文件关联。
+主要用户组是保存在 `/etc/passwd` 文件中的用户组,该用户组在账户创建时配置。当用户创建一个文件时,用户的主要用户组与此文件关联。
```
$ whoami
@@ -74,7 +74,7 @@ $ ls -l newfile
+-------- 主要用户组
```
-用户一旦拥有账户之后被加入的那些用户组是**次要用户组**。次要用户组成员关系在 /etc/group 文件中显示。
+用户一旦拥有账户之后被加入的那些用户组是次要用户组。次要用户组成员关系在 `/etc/group` 文件中显示。
```
$ grep devops /etc/group
@@ -84,15 +84,15 @@ devops:x:500:shs,jadep
+-------- shs 和 jadep 的次要用户组
```
-**/etc/group** 文件给用户组分配组名称(例如 500 = devops)并记录次要用户组成员。
+`/etc/group` 文件给用户组分配组名称(例如 `500` = `devops`)并记录次要用户组成员。
### 首选的准则
-每个用户是他自己的主要用户组成员并可以成为任意多个次要用户组成员这样一种准则允许用户更加容易地将个人文件和需要与同事分享的文件分开。当用户创建一个文件时,用户所属的不同用户组的成员不一定有访问权限。用户必须用 **chgrp** 命令将文件和次要用户组关联起来。
+每个用户是他自己的主要用户组成员,并可以成为任意多个次要用户组成员,这样的一种准则允许用户更加容易地将个人文件和需要与同事分享的文件分开。当用户创建一个文件时,用户所属的不同用户组的成员不一定有访问权限。用户必须用 `chgrp` 命令将文件和次要用户组关联起来。
-### 哪里也不如自己的家目录
+### 哪里也不如自己的家目录
-添加新账户时一个重要的细节是 **useradd** 命令并不一定为新用户添加一个家目录。若你只有某些时候想为用户添加家目录,你可以在 useradd 命令中加入 **-m**选项(可以把它想象成“安家”选项)
+添加新账户时一个重要的细节是 `useradd` 命令并不一定为新用户添加一个家目录家目录。若你只有某些时候想为用户添加家目录,你可以在 `useradd` 命令中加入 `-m` 选项(可以把它想象成“安家”选项)。
```
$ sudo useradd -m -g devops -c "John Doe" jdoe2
@@ -100,30 +100,28 @@ $ sudo useradd -m -g devops -c "John Doe" jdoe2
此命令中的选项如下:
-* **-m** 创建家目录并在其中生成初始文件
-* **-g** 指定用户归属的用户组
-* **-c** 添加账户描述信息(通常是用户的姓名)
+* `-m` 创建家目录并在其中生成初始文件
+* `-g` 指定用户归属的用户组
+* `-c` 添加账户描述信息(通常是用户的姓名)
-
-
-若你希望总是创建家目录,你可以编辑 **/etc/login.defs** 文件来更改默认工作方式。更改或添加 CREATE_HOME 变量并将其设置为 "yes":
+若你希望总是创建家目录,你可以编辑 `/etc/login.defs` 文件来更改默认工作方式。更改或添加 `CREATE_HOME` 变量并将其设置为 `yes`:
```
$ grep CREATE_HOME /etc/login.defs
CREATE_HOME yes
```
-另一种方法是用自己的账户设置别名从而让 **useradd** 一直带有 -m 选项。
+另一种方法是用自己的账户设置别名从而让 `useradd` 一直带有 `-m` 选项。
```
$ alias useradd=’useradd -m’
```
-确保将该别名添加到你的 ~/.bashrc 文件或类似的启动文件中以使其永久生效。
+确保将该别名添加到你的 `~/.bashrc` 文件或类似的启动文件中以使其永久生效。
### 深入了解 /etc/login.defs
-下面这个命令可列出 /etc/login.defs 文件中的全部设置。**grep**命令会隐藏所有注释和空行。
+下面这个命令可列出 `/etc/login.defs` 文件中的全部设置。下面的 `grep` 命令会隐藏所有注释和空行。
```
$ cat /etc/login.defs | grep -v "^#" | grep -v "^$"
@@ -163,14 +161,14 @@ ENCRYPT_METHOD SHA512
### 如何显示用户所属的用户组
-出于各种原因用户可能是多个用户组的成员。用户组成员身份给与用户对用户组拥有的文件和目录的访问权限,有时候这种工作方式是至关重要的。要生成某个用户所属用户组的清单,用 **groups** 命令即可。
+出于各种原因用户可能是多个用户组的成员。用户组成员身份给与用户对用户组拥有的文件和目录的访问权限,有时候这种工作方式是至关重要的。要生成某个用户所属用户组的清单,用 `groups` 命令即可。
```
$ groups jdoe
jdoe : jdoe adm admin cdrom sudo dip plugdev lpadmin staff sambashare
```
-你可以键入不带任何参数的“groups”来列出你自己的用户组。
+你可以键入不带任何参数的 `groups` 命令来列出你自己的用户组。
### 如何添加用户至用户组
@@ -186,9 +184,9 @@ $ sudo usermod -a -G devops jdoe
$ sudo usermod -a -G devops,mgrs jdoe
```
-参数 **-a** 意思是“添加”,**-G** 指定用户组列表
+参数 `-a` 意思是“添加”,`-G` 指定用户组列表。
-你可以编辑 **/etc/group** 文件将用户名从用户组成员名单中删除,从而将用户从用户组中移除。usermod 命令或许也有个选项用于从用户组中删除某个成员。
+你可以编辑 `/etc/group` 文件将用户名从用户组成员名单中删除,从而将用户从用户组中移除。`usermod` 命令或许也有个选项用于从用户组中删除某个成员。
```
fish:x:16:nemo,dory,shark
@@ -201,18 +199,14 @@ fish:x:16:nemo,dory
添加和管理用户组并非特别困难,但长远来看配置账户时的一致性可使这项工作更容易些。
-**[ 延伸阅读:[必会的 Linux 命令][3] ]**
-
-加入 Network World 的 [Facebook][4] 和 [LinkedIn][5] 社区,对最重要的话题发表你的评论。
-
--------------------------------------------------------------------------------
via: https://www.networkworld.com/article/3409781/mastering-user-groups-on-linux.html
作者:[Sandra Henry-Stocker][a]
选题:[lujun9972][b]
-译者:[译者ID](https://github.com/0x996)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[0x996](https://github.com/0x996)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20190718 Epic Games Backs Blender Foundation with -1.2m Epic MegaGrants.md b/published/201907/20190718 Epic Games Backs Blender Foundation with -1.2m Epic MegaGrants.md
similarity index 100%
rename from published/20190718 Epic Games Backs Blender Foundation with -1.2m Epic MegaGrants.md
rename to published/201907/20190718 Epic Games Backs Blender Foundation with -1.2m Epic MegaGrants.md
diff --git a/published/201907/20190722 How to run virtual machines with virt-manager.md b/published/201907/20190722 How to run virtual machines with virt-manager.md
new file mode 100644
index 0000000000..32f1faea08
--- /dev/null
+++ b/published/201907/20190722 How to run virtual machines with virt-manager.md
@@ -0,0 +1,145 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11151-1.html)
+[#]: subject: (How to run virtual machines with virt-manager)
+[#]: via: (https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/)
+[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
+
+如何使用 virt-manager 运行虚拟机
+======
+
+![][1]
+
+在早些年,在同一台笔记本中运行多个操作系统只能双启动。当时,这些操作系统很难同时运行或彼此交互。许多年过去了,在普通的 PC 上,可以通过虚拟化在一个系统中运行另一个系统。
+
+最近的 PC 或笔记本(包括价格适中的笔记本电脑)都有硬件虚拟化,可以运行性能接近物理主机的虚拟机。
+
+虚拟化因此变得常见,它可以用来测试操作系统、学习新技术、创建自己的家庭云、创建自己的测试环境等等。本文将指导你使用 Fedora 上的 Virt Manager 来设置虚拟机。
+
+### 介绍 QEMU/KVM 和 Libvirt
+
+与所有其他 Linux 系统一样,Fedora 附带了虚拟化扩展支持。它由作为内核模块之一的 KVM(基于内核的虚拟机)提供支持。
+
+QEMU 是一个完整的系统仿真器,它可与 KVM 协同工作,允许你使用硬件和外部设备创建虚拟机。
+
+最后,[libvirt][2] 能让你管理基础设施的 API 层,即创建和运行虚拟机。
+
+这三个技术都是开源的,我们将在 Fedora Workstation 上安装它们。
+
+### 安装
+
+#### 步骤 1:安装软件包
+
+安装是一个相当简单的操作。 Fedora 仓库提供了 “virtualization” 软件包组,其中包含了你需要的所有包。
+
+```
+sudo dnf install @virtualization
+```
+
+#### 步骤 2:编辑 libvirtd 配置
+
+默认情况下,系统管理仅限于 root 用户,如果要启用常规用户,那么必须按以下步骤操作。
+
+打开 `/etc/libvirt/libvirtd.conf` 进行编辑:
+
+```
+sudo vi /etc/libvirt/libvirtd.conf
+```
+
+将 UNIX 域套接字组所有者设置为 libvirt:
+
+```
+unix_sock_group = "libvirt"
+```
+
+调整 UNIX 域套接字的读写权限:
+
+```
+unix_sock_rw_perms = "0770"
+```
+
+#### 步骤 3:启动并启用 libvirtd 服务
+
+```
+sudo systemctl start libvirtd
+sudo systemctl enable libvirtd
+```
+
+#### 步骤 4:将用户添加到组
+
+为了管理 libvirt 与普通用户,你必须将用户添加到 `libvirt` 组,否则每次启动 `virt-manager` 时,都会要求你输入 sudo 密码。
+
+```
+sudo usermod -a -G libvirt $(whoami)
+```
+
+这会将当前用户添加到组中。你必须注销并重新登录才能应用更改。
+
+### 开始使用 virt-manager
+
+可以通过命令行 (`virsh`) 或通过 `virt-manager` 图形界面管理 libvirt 系统。如果你想做虚拟机自动化配置,那么命令行非常有用,例如使用 [Ansible][3],但在本文中我们将专注于用户友好的图形界面。
+
+`virt-manager` 界面很简单。主窗口显示连接列表,其中包括本地系统连接。
+
+连接设置包括虚拟网络和存储定义。你可以定义多个虚拟网络,这些网络可用于在客户端系统之间以及客户端系统和主机之间进行通信。
+
+### 创建你的第一个虚拟机
+
+要开始创建新虚拟机,请按下主窗口左上角的按钮:
+
+![][4]
+
+向导的第一步需要选择安装模式。你可以选择本地安装介质、网络引导/安装或导入现有虚拟磁盘:
+
+![][5]
+
+选择本地安装介质,下一步将需要选择 ISO 镜像路径:
+
+![ ][6]
+
+随后的两个步骤能让你调整新虚拟机的 CPU、内存和磁盘大小。最后一步将要求你选择网络选项:如果你希望虚拟机通过 NAT 与外部隔离,请选择默认网络。如果你希望从外部访问虚拟机,那么选择桥接。请注意,如果选择桥接,那么虚拟机则无法与主机通信。
+
+如果要在启动设置之前查看或更改配置,请选中“安装前自定义配置”:
+
+![][7]
+
+虚拟机配置窗口能让你查看和修改硬件配置。你可以添加磁盘、网络接口、更改引导选项等。满意后按“开始安装”:
+
+![][8]
+
+此时,你将被重定向到控制台来继续安装操作系统。操作完成后,你可以从控制台访问虚拟机:
+
+![][9]
+
+刚刚创建的虚拟机将出现在主窗口的列表中,你还能看到 CPU 和内存占用率的图表:
+
+![][10]
+
+libvirt 和 `virt-manager` 是功能强大的工具,它们可以以企业级管理为你的虚拟机提供出色的自定义。如果你需要更简单的东西,请注意 Fedora Workstation [预安装的 GNOME Boxes 已经能够满足基础的虚拟化要求][11]。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
+
+作者:[Marco Sarti][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/msarti/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/virt-manager-816x346.jpg
+[2]: https://libvirt.org/
+[3]: https://fedoramagazine.org/get-the-latest-ansible-2-8-in-fedora/
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-41-45.png
+[5]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-30-53.png
+[6]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-42-39.png
+[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-43-21.png
+[8]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-44-58.png
+[9]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-55-35.png
+[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-11-09-22.png
+[11]: https://fedoramagazine.org/getting-started-with-virtualization-in-gnome-boxes/
diff --git a/sources/tech/20190723 Getting help for Linux shell built-ins.md b/published/201907/20190723 Getting help for Linux shell built-ins.md
similarity index 70%
rename from sources/tech/20190723 Getting help for Linux shell built-ins.md
rename to published/201907/20190723 Getting help for Linux shell built-ins.md
index 621ee44bed..490de661c7 100644
--- a/sources/tech/20190723 Getting help for Linux shell built-ins.md
+++ b/published/201907/20190723 Getting help for Linux shell built-ins.md
@@ -1,45 +1,45 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11158-1.html)
[#]: subject: (Getting help for Linux shell built-ins)
[#]: via: (https://www.networkworld.com/article/3410350/getting-help-for-linux-shell-built-ins.html)
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
-Getting help for Linux shell built-ins
+获取有关 Linux shell 内置命令的帮助
======
-Linux built-ins are commands that are part of a user’s shell. Here's an explanation on how to recognize them and get help on their use.
-![Sandra Henry-Stocker][1]
-Linux built-ins are commands that are built into the shell, much like shelves that are built into a wall. You won’t find them as stand-alone files the way standard Linux commands are stored in /usr/bin and you probably use quite a few of them without ever questioning how they’re different from commands such as **ls** and **pwd**.
+> Linux 内置命令属于用户 shell 的一部分,本文将告诉你如何识别它们并获取使用它们的帮助。
-Built-ins are used just like other Linux commands. They are likely to run a bit faster than similar commands that are not part of your shell. Bash built-ins include commands such as **alias**, **export** and **bg**.
+
-**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
+Linux 内置命令是内置于 shell 中的命令,很像内置于墙中的书架。与标准 Linux 命令存储在 `/usr/bin` 中的方式不同,你不会找到它们的独立文件,你可能使用过相当多的内置命令,但你不会感觉到它们与 `ls` 和 `pwd` 等命令有何不同。
-As you might suspect, because built-ins are shell-specific, they won't be supplied with man pages. Ask **man** to help with **bg** and you'll see something like this:
+内置命令与其他 Linux 命令一样使用,它们可能要比不属于 shell 的类似命令运行得快一些。Bash 内置命令包括 `alias`、`export` 和 `bg` 等。
+
+正如你担心的那样,因为内置命令是特定于 shell 的,所以它们不会提供手册页。使用 `man` 来查看 `bg`,你会看到这样的东西:
```
$ man bg
No manual entry for bg
```
-Another tip-off that a command is a built-in is when you use the **which** command to identify the source of the command. Bash's non-response will remind you that there is no file associated with the built-in:
+判断内置命令的另一个提示是当你使用 `which` 命令来识别命令的来源时,Bash 不会响应,表示没有与内置命令关联的文件:
```
$ which bg
$
```
-If your shell is **/bin/zsh**, on the other hand, you might get a slightly more illuminating response:
+另一方面,如果你的 shell 是 `/bin/zsh`,你可能会得到一个更有启发性的响应:
```
% which bg
bg: shell built-in command
```
-Additional help is available with bash, but it comes through the use of the **help** command:
+bash 提供了额外的帮助信息,但它是通过使用 `help` 命令实现的:
```
$ help bg
@@ -54,7 +54,7 @@ bg: bg [job_spec ...]
Returns success unless job control is not enabled or an error occurs.
```
-If you want to see a list of all of the built-ins that bash provides, use the **compgen -b** command. Pipe the output to column for a nicely formatted listing.
+如果你想要查看 bash 提供的所有内置命令的列表,使用 `compgen -b` 命令。通过管道将命令输出到列中,以获得较好格式的清单。
```
$ compgen -b | column
@@ -71,7 +71,7 @@ cd eval jobs readarray true
command exec kill readonly type
```
-If you use the **help** command, you’ll see a list of built-ins along with short descriptions. This list is, however, truncated (ending with the **help** command):
+如果你使用 `help` 命令,你将看到一个内置命令列表以及简短描述。但是,这个列表被截断了(以 `help` 命令结尾):
```
$ help
@@ -123,9 +123,9 @@ A star (*) next to a name means that the command is disabled.
help [-dms] [pattern ...] { COMMANDS ; }
```
-As you can see from the listings above, the **help** command is itself a built-in.
+从上面的清单中可以看出,`help` 命令本身就是内置的。
-You can get more information on any of these built-ins by providing the **help** command with the name of the built-in you're curious about — as in **help dirs**.
+你可以通过向 `help` 命令提供你感兴趣的内置命令名称来获取关于它们的更多信息,例如 `help dirs`:
```
$ help dirs
@@ -157,7 +157,7 @@ dirs: dirs [-clpv] [+N] [-N]
Returns success unless an invalid option is supplied or an error occurs.
```
-Built-ins provide much of the functionality of each shell. Any shell you use will have some built-ins, though how to get information on these built-ins may differ from shell to shell. For **zsh**, for example, you can get a description of built-in commands by using the **man zshbuiltins** command.
+内置命令提供了每个 shell 的大部分功能。你使用的任何 shell 都有一些内置命令,但是如何获取这些内置命令的信息可能因 shell 而异。例如,对于 `zsh`,你可以使用 `man zshbuiltins` 命令获得其内置命令的描述。
```
$ man zshbuiltins
@@ -177,7 +177,7 @@ SHELL BUILTIN COMMANDS
…
```
-Within this lengthy man page, you will find a list of built-ins with useful descriptions as in this excerpt.
+在这个冗长的手册页中,你将找到一个内置命令列表,其中包含有用的描述,如下摘录中所示:
```
bg [ job ... ]
@@ -194,13 +194,9 @@ break [ n ]
instead of just one.
```
-### Wrap-up
+### 最后
-Linux built-ins are essential to each shell and operate like shell-specific commands. If you use a different shell from time to time and notice that some command you often use doesn’t seem to exist or doesn’t work as you were expecting, it just might be that it's one of your normal shell's built-ins.
-
-**[ Also see: [Invaluable tips and tricks for troubleshooting Linux][3] ]**
-
-Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
+Linux 内置命令对于每个 shell 都很重要,它的操作类似特定于 shell 的命令一样。如果你经常使用不同的 shell,并注意到你经常使用的某些命令似乎不存在或者不能按预期工作,那么它可能是你使用的其他 shell 之一中的内置命令。
--------------------------------------------------------------------------------
@@ -208,8 +204,8 @@ via: https://www.networkworld.com/article/3410350/getting-help-for-linux-shell-b
作者:[Sandra Henry-Stocker][a]
选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201907/20190723 How to Create a User Account Without useradd Command in Linux.md b/published/201907/20190723 How to Create a User Account Without useradd Command in Linux.md
new file mode 100644
index 0000000000..3bc9a26c39
--- /dev/null
+++ b/published/201907/20190723 How to Create a User Account Without useradd Command in Linux.md
@@ -0,0 +1,112 @@
+[#]: collector: "lujun9972"
+[#]: translator: "hello-wn"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-11156-1.html"
+[#]: subject: "How to Create a User Account Without useradd Command in Linux?"
+[#]: via: "https://www.2daygeek.com/linux-user-account-creation-in-manual-method/"
+[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
+
+在 Linux 中不使用 useradd 命令如何创建用户账号
+========
+
+Linux 中有三个命令可以用来创建用户账号。你尝试过在 Linux 中手动创建用户吗?我的意思是不使用上面说的三个命令。
+
+如果你不知道怎么做,本文可以手把手教你,并向你展示细节部分。
+
+你可能想,这怎么可能?别担心,正如我们多次提到的那样,在 Linux 上任何事都可以搞定。这只是其中一例。
+
+是的,我们可以做到的。想了解更多吗?
+
+- [在 Linux 中创建用户的三种方法][1]
+- [在 Linux 中批量创建用户的两种方法][2]
+
+话不多说,让我们开始吧。
+
+首先,我们要找出最后创建的 UID 和 GID 信息。 掌握了这些信息之后,就可以继续下一步。
+
+```
+# cat /etc/passwd | tail -1
+tuser1:x:1153:1154:Test User:/home/tuser1:/bin/bash
+```
+
+根据以上输出,最后创建的用户 UID 是 1153,GID 是 1154。为了试验,我们将在系统中添加 `tuser2` 用户。
+
+现在,在`/etc/passwd` 文件中添加一条用户信息。 总共七个字段,你需要添加一些必要信息。
+
+```
++-----------------------------------------------------------------------+
+|username:password:UID:GID:Comments:User Home Directory:User Login Shell|
++-----------------------------------------------------------------------+
+ | | | | | | |
+ 1 2 3 4 5 6 7
+```
+
+1. 用户名:这个字段表示用户名称。字符长度必须在 1 到 32 之间。
+2. 密码(`x`):表示存储在 `/etc/shadow` 文件中的加密密码。
+3. 用户 ID:表示用户的 ID(UID),每个用户都有独一无二的 UID。UID 0 保留给 root 用户,UID 1-99 保留给系统用户,UID 100-999 保留给系统账号/组。
+4. 组 ID:表示用户组的 ID(GID),每个用户组都有独一无二的 GID,存储在 `/etc/group` 文件中。
+5. 注释/用户 ID 信息:这个字段表示备注,用于描述用户信息。
+6. 主目录(`/home/$USER`):表示用户的主目录。
+7. shell(`/bin/bash`):表示用户使用的 shell。
+
+在文件最后添加用户信息。
+
+```
+# vi /etc/passwd
+
+tuser2:x:1154:1155:Test User2:/home/tuser2:/bin/bash
+```
+
+你需要创建相同名字的用户组。同样地,在 `/etc/group` 文件中添加用户组信息。
+
+```
+# vi /etc/group
+
+tuser2:x:1155:
+```
+
+做完以上两步之后,给用户设置一个密码。
+
+```
+# passwd tuser2
+
+Changing password for user tuser2.
+New password:
+Retype new password:
+passwd: all authentication tokens updated successfully.
+```
+
+最后,试着登录新创建的用户。
+
+```
+# ssh [email protected]
+
+[email protected]'s password:
+Creating directory '/home/tuser2'.
+
+$ls -la
+
+total 16
+drwx------. 2 tuser2 tuser2 59 Jun 17 09:46 .
+drwxr-xr-x. 15 root root 4096 Jun 17 09:46 ..
+-rw-------. 1 tuser2 tuser2 18 Jun 17 09:46 .bash_logout
+-rw-------. 1 tuser2 tuser2 193 Jun 17 09:46 .bash_profile
+-rw-------. 1 tuser2 tuser2 231 Jun 17 09:46 .bashrc
+```
+
+------
+
+via: https://www.2daygeek.com/linux-user-account-creation-in-manual-method/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[hello-wn](https://github.com/hello-wn)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/
+[2]: https://www.2daygeek.com/linux-bulk-users-creation-useradd-newusers/
diff --git a/published/201907/20190724 Master the Linux -ls- command.md b/published/201907/20190724 Master the Linux -ls- command.md
new file mode 100644
index 0000000000..3744fa3906
--- /dev/null
+++ b/published/201907/20190724 Master the Linux -ls- command.md
@@ -0,0 +1,328 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11159-1.html)
+[#]: subject: (Master the Linux 'ls' command)
+[#]: via: (https://opensource.com/article/19/7/master-ls-command)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+精通 Linux 的 ls 命令
+======
+
+> Linux 的 ls 命令拥有数量惊人的选项,可以提供有关文件的重要信息。
+
+
+
+`ls` 命令可以列出一个 [POSIX][2] 系统上的文件。这是一个简单的命令,但它经常被低估,不是它能做什么(因为它确实只做了一件事),而是你该如何优化对它的使用。
+
+要知道在最重要的 10 个终端命令中,这个简单的 `ls` 命令可以排进前三,因为 `ls` 不会*只是*列出文件,它还会告诉你有关它们的重要信息。它会告诉你诸如拥有文件或目录的人、每个文件修改的时间、甚至是什么类型的文件。它的附带功能能让你了解你在哪里、附近有些什么,以及你可以用它们做什么。
+
+如果你对 `ls` 的体验仅限于你的发行版在 `.bashrc` 中的别名,那么你可能错失了它。
+
+### GNU 还是 BSD?
+
+在了解 `ls` 的隐藏能力之前,你必须确定你正在运行哪个 `ls` 命令。有两个最流行的版本:包含在 GNU coreutils 包中的 GNU 版本,以及 BSD 版本。如果你正在运行 Linux,那么你很可能已经安装了 GNU 版本的 `ls`(LCTT 译注:几乎可以完全确定)。如果你正在运行 BSD 或 MacOS,那么你有的是 BSD 版本。本文会介绍它们的不同之处。
+
+你可以使用 `--version` 选项找出你计算机上的版本:
+
+```
+$ ls --version
+```
+
+如果它返回有关 GNU coreutils 的信息,那么你拥有的是 GNU 版本。如果它返回一个错误,你可能正在运行的是 BSD 版本(运行 `man ls | head` 以确定)。
+
+你还应该调查你的发行版可能具有哪些预设选项。终端命令的自定义通常放在 `$HOME/.bashrc` 或 `$HOME/.bash_aliases` 或 `$HOME/.profile` 中,它们是通过将 `ls` 别名化为更复杂的 `ls` 命令来完成的。例如:
+
+```
+alias ls='ls --color'
+```
+
+发行版提供的预设非常有用,但它们确实很难分辨出哪些是 `ls` 本身的特性,哪些是它的附加选项提供的。你要是想要运行 `ls` 命令本身而不是它的别名,你可以用反斜杠“转义”命令:
+
+```
+$ \ls
+```
+
+### 分类
+
+单独运行 `ls` 会以适合你终端的列数列出文件:
+
+```
+$ ls ~/example
+bunko jdk-10.0.2
+chapterize otf2ttf.ff
+despacer overtar.sh
+estimate.sh pandoc-2.7.1
+fop-2.3 safe_yaml
+games tt
+```
+
+这是有用的信息,但所有这些文件看起来基本相同,没有方便的图标来快速表示出哪个是目录、文本文件或图像等等。
+
+使用 `-F`(或 GNU 上的长选项 `--classify`)以在每个条目之后显示标识文件类型的指示符:
+
+```
+$ ls ~/example
+bunko jdk-10.0.2/
+chapterize* otf2ttf.ff*
+despacer* overtar.sh*
+estimate.sh pandoc@
+fop-2.3/ pandoc-2.7.1/
+games/ tt*
+```
+
+使用此选项,终端中列出的项目使用简写符号来按文件类型分类:
+
+* 斜杠(`/`)表示目录(或“文件夹”)。
+* 星号(`*`)表示可执行文件。这包括二进制文件(编译代码)以及脚本(具有[可执行权限][3]的文本文件)。
+* 符号(`@`)表示符号链接(或“别名”)。
+* 等号(`=`)表示套接字。
+* 在 BSD 上,百分号(`%`)表示涂改(某些文件系统上的文件删除方法)。
+* 在 GNU 上,尖括号(`>`)表示门([Illumos][4] 和 Solaris上的进程间通信)。
+* 竖线(`|`)表示 [FIFO][5] 管道。
+
+这个选项的一个更简单的版本是 `-p`,它只区分文件和目录。
+
+(LCTT 译注:在支持彩色的终端上,使用 `--color` 选项可以以不同的颜色来区分文件类型,但要注意如果将输出导入到管道中,则颜色消失。)
+
+### 长列表
+
+从 `ls` 获取“长列表”的做法是如此常见,以至于许多发行版将 `ll` 别名为 `ls -l`。长列表提供了许多重要的文件属性,例如权限、拥有每个文件的用户、文件所属的组、文件大小(以字节为单位)以及文件上次更改的日期:
+
+```
+$ ls -l
+-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
+-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
+-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
+-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
+-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
+[...]
+```
+
+如果你不想以字节为单位,请添加 `-h` 标志(或 GNU 中的 `--human`)以将文件大小转换为更加人性化的表示方法:
+
+```
+$ ls --human
+-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
+-rwxrwxr-x. 1 seth seth 662 Apr 29 22:27 factorial
+-rwxrwx---. 1 seth users 20M Jun 29 2018 fop-2.3-bin.tar.gz
+-rwxrwxr-x. 1 seth seth 6.1K May 22 10:22 geteltorito
+-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
+```
+
+要看到更少的信息,你可以带有 `-o` 选项只显示所有者的列,或带有 `-g` 选项只显示所属组的列:
+
+```
+$ ls -o
+-rwxrwx---. 1 seth 455 Mar 2 2017 estimate.sh
+-rwxrwxr-x. 1 seth 662 Apr 29 22:27 factorial
+-rwxrwx---. 1 seth 20M Jun 29 2018 fop-2.3-bin.tar.gz
+-rwxrwxr-x. 1 seth 6.1K May 22 10:22 geteltorito
+-rwxrwx---. 1 seth 177 Nov 12 2018 html4mutt.sh
+```
+
+也可以将两个选项组合使用以显示两者。
+
+### 时间和日期格式
+
+`ls` 的长列表格式通常如下所示:
+
+```
+-rwxrwx---. 1 seth users 455 Mar 2 2017 estimate.sh
+-rwxrwxr-x. 1 seth users 662 Apr 29 22:27 factorial
+-rwxrwx---. 1 seth users 20697793 Jun 29 2018 fop-2.3-bin.tar.gz
+-rwxrwxr-x. 1 seth users 6210 May 22 10:22 geteltorito
+-rwxrwx---. 1 seth users 177 Nov 12 2018 html4mutt.sh
+```
+
+月份的名字不便于排序,无论是通过计算还是识别(取决于你的大脑是否倾向于喜欢字符串或整数)。你可以使用 `--time-style` 选项和格式名称更改时间戳的格式。可用格式为:
+
+* `full-iso`:ISO 完整格式(1970-01-01 21:12:00)
+* `long-iso`:ISO 长格式(1970-01-01 21:12)
+* `iso`:iso 格式(01-01 21:12)
+* `locale`:本地化格式(使用你的区域设置)
+* `posix-STYLE`:POSIX 风格(用区域设置定义替换 `STYLE`)
+
+你还可以使用 `date` 命令的正式表示法创建自定义样式。
+
+### 按时间排序
+
+通常,`ls` 命令按字母顺序排序。你可以使用 `-t` 选项根据文件的最近更改的时间(最新的文件最先列出)进行排序。
+
+例如:
+
+```
+$ touch foo bar baz
+$ ls
+bar baz foo
+$ touch foo
+$ ls -t
+foo bar baz
+```
+
+### 列出方式
+
+`ls` 的标准输出平衡了可读性和空间效率,但有时你需要按照特定方式排列的文件列表。
+
+要以逗号分隔文件列表,请使用 `-m`:
+
+```
+ls -m ~/example
+bar, baz, foo
+```
+
+要强制每行一个文件,请使用 `-1` 选项(这是数字 1,而不是小写的 L):
+
+```
+$ ls -1 ~/bin/
+bar
+baz
+foo
+```
+
+要按文件扩展名而不是文件名对条目进行排序,请使用 `-X`(这是大写 X):
+
+```
+$ ls
+bar.xfc baz.txt foo.asc
+$ ls -X
+foo.asc baz.txt bar.xfc
+```
+
+### 隐藏杂项
+
+在某些 `ls` 列表中有一些你可能不关心的条目。例如,元字符 `.` 和 `..` 分别代表“本目录”和“父目录”。如果你熟悉在终端中如何切换目录,你可能已经知道每个目录都将自己称为 `.`,并将其父目录称为 `..`,因此当你使用 `-a` 选项显示隐藏文件时并不需要它经常提醒你。
+
+要显示几乎所有隐藏文件(`.` 和 `..` 除外),请使用 `-A` 选项:
+
+```
+$ ls -a
+.
+..
+.android
+.atom
+.bash_aliases
+[...]
+$ ls -A
+.android
+.atom
+.bash_aliases
+[...]
+```
+
+有许多优秀的 Unix 工具有保存备份文件的传统,它们会在保存文件的名称后附加一些特殊字符作为备份文件。例如,在 Vim 中,备份会以在文件名后附加 `~` 字符的文件名保存。
+
+这些类型的备份文件已经多次使我免于愚蠢的错误,但是经过多年享受它们提供的安全感后,我觉得不需要用视觉证据来证明它们存在。我相信 Linux 应用程序可以生成备份文件(如果它们声称这样做的话),我很乐意相信它们存在 —— 而不用必须看到它们。
+
+要隐藏备份文件,请使用 `-B` 或 `--ignore-backups` 隐藏常用备份格式(此选项在 BSD 的 `ls` 中不可用):
+
+```
+$ ls
+bar.xfc baz.txt foo.asc~ foo.asc
+$ ls -B
+bar.xfc baz.txt foo.asc
+```
+
+当然,备份文件仍然存在;它只是过滤掉了,你不必看到它。
+
+除非另有配置,GNU Emacs 在文件名的开头和结尾添加哈希字符(`#`)来保存备份文件(`#file#`)。其他应用程序可能使用不同的样式。使用什么模式并不重要,因为你可以使用 `--hide` 选项创建自己的排除项:
+
+```
+$ ls
+bar.xfc baz.txt #foo.asc# foo.asc
+$ ls --hide="#*#"
+bar.xfc baz.txt foo.asc
+```
+
+### 递归地列出目录
+
+除非你在指定目录上运行 `ls`,否则子目录的内容不会与 `ls` 命令一起列出:
+
+```
+$ ls -F
+example/ quux* xyz.txt
+$ ls -R
+quux xyz.txt
+
+./example:
+bar.xfc baz.txt #foo.asc# foo.asc
+```
+
+### 使用别名使其永久化
+
+`ls` 命令可能是 shell 会话期间最常使用的命令。这是你的眼睛和耳朵,为你提供上下文信息和确认命令的结果。虽然有很多选项很有用,但 `ls` 之美的一部分就是简洁:两个字符和回车键,你就知道你到底在哪里以及附近有什么。如果你不得不停下思考(更不用说输入)几个不同的选项,它会变得不那么方便,所以通常情况下,即使最有用的选项也不会用了。
+
+解决方案是为你的 `ls` 命令添加别名,以便在使用它时,你可以获得最关心的信息。
+
+要在 Bash shell 中为命令创建别名,请在主目录中创建名为 `.bash_aliases` 的文件(必须在开头包含 `.`)。 在此文件中,列出要创建的别名,然后是要为其创建别名的命令。例如:
+
+```
+alias ls='ls -A -F -B --human --color'
+```
+
+这一行导致你的 Bash shell 将 `ls` 命令解释为 `ls -A -F -B --human --color`。
+
+你不必仅限于重新定义现有命令,还可以创建自己的别名:
+
+```
+alias ll='ls -l'
+alias la='ls -A'
+alias lh='ls -h'
+```
+
+要使别名起作用,shell 必须知道 `.bash_aliases` 配置文件存在。在编辑器中打开 `.bashrc` 文件(如果它不存在则创建它),并包含以下代码块:
+
+```
+if [ -e $HOME/.bash_aliases ]; then
+ source $HOME/.bash_aliases
+fi
+```
+
+每次加载 `.bashrc`(这是一个新的 Bash shell 启动的时候),Bash 会将 `.bash_aliases` 加载到你的环境中。你可以关闭并重新启动 Bash 会话,或者直接强制它执行此操作:
+
+```
+$ source ~/.bashrc
+```
+
+如果你忘了你是否有别名命令,`which` 命令可以告诉你:
+
+```
+$ which ls
+alias ls='ls -A -F -B --human --color'
+ /usr/bin/ls
+```
+
+如果你将 `ls` 命令别名为带有选项的 `ls` 命令,则可以通过将反斜杠前缀到 `ls` 前来覆盖你的别名。例如,在示例别名中,使用 `-B` 选项隐藏备份文件,这意味着无法使用 `ls` 命令显示备份文件。 可以覆盖该别名以查看备份文件:
+
+```
+$ ls
+bar baz foo
+$ \ls
+bar baz baz~ foo
+```
+
+### 做一件事,把它做好
+
+`ls` 命令有很多选项,其中许多是特定用途的或高度依赖于你所使用的终端。在 GNU 系统上查看 `info ls`,或在 GNU 或 BSD 系统上查看 `man ls` 以了解更多选项。
+
+你可能会觉得奇怪的是,一个以每个工具“做一件事,把它做好”的前提而闻名的系统会让其最常见的命令背负 50 个选项。但是 `ls` 只做一件事:它列出文件,而这 50 个选项允许你控制接收列表的方式,`ls` 的这项工作做得非常、*非常*好。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/master-ls-command
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/sambocettahttps://opensource.com/users/scottnesbitthttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/sethhttps://opensource.com/users/don-watkinshttps://opensource.com/users/sethhttps://opensource.com/users/jamesfhttps://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://opensource.com/article/19/6/understanding-linux-permissions
+[4]: https://www.illumos.org/
+[5]: https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)
diff --git a/published/201907/20190724 WPS Office on Linux is a Free Alternative to Microsoft Office.md b/published/201907/20190724 WPS Office on Linux is a Free Alternative to Microsoft Office.md
new file mode 100644
index 0000000000..1b74136442
--- /dev/null
+++ b/published/201907/20190724 WPS Office on Linux is a Free Alternative to Microsoft Office.md
@@ -0,0 +1,105 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11170-1.html)
+[#]: subject: (WPS Office on Linux is a Free Alternative to Microsoft Office)
+[#]: via: (https://itsfoss.com/wps-office-linux/)
+[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
+
+WPS Office:Linux 上的 Microsoft Office 的免费替代品
+======
+
+> 如果你在寻找 Linux 上 Microsoft Office 免费替代品,那么 WPS Office 是最佳选择之一。它可以免费使用,并兼容 MS Office 文档格式。
+
+[WPS Office][1] 是一个跨平台的办公生产力套件。它轻巧,并且与 Microsoft Office、Google Docs/Sheets/Slide 和 Adobe PDF 完全兼容。
+
+对于许多用户而言,WPS Office 足够直观,并且能够满足他们的需求。由于它在外观和兼容性方面与 Microsoft Office 非常相似,因此广受欢迎。
+
+![WPS Office 2019 All In One Mode][2]
+
+WPS office 由中国的金山公司创建。对于 Windows 用户而言,WPS Office 有免费版和高级版。对于 Linux 用户,WPS Office 可通过其[社区项目][3]免费获得。
+
+> **非 FOSS 警告!**
+
+> WPS Office 不是一个开源软件。因为它对于 Linux 用户免费使用,我们已经在这介绍过它,有时我们也会介绍即使不是开源的 Linux 软件。
+
+### Linux 上的 WPS Office
+
+![WPS Office in Linux | Image Credit: Ubuntu Handbook][4]
+
+WPS Office 有四个主要组件:
+
+ * WPS 文字
+ * WPS 演示
+ * WPS 表格
+ * WPS PDF
+
+WPS Office 与 MS Office 完全兼容,支持 .doc、.docx、.dotx、.ppt、.pptx、.xls、.xlsx、.docm、.dotm、.xml、.txt、.html、.rtf (等其他),以及它自己的格式(.wps、.wpt)。它还默认包含 Microsoft 字体(以确保兼容性),它可以导出 PDF 并提供超过 10 种语言的拼写检查功能。
+
+但是,它在 ODT、ODP 和其他开放文档格式方面表现不佳。
+
+三个主要的 WPS Office 应用都有与 Microsoft Office 非常相似的界面,都有相同的 Ribbon UI。尽管存在细微差别,但使用习惯仍然相对一致。你可以使用 WPS Office 轻松克隆任何 Microsoft Office/LibreOffice 文档。
+
+![WPS Office Writer][5]
+
+你可能唯一不喜欢的是一些默认的样式设置(一些标题下面有很多空间等),但这些可以很容易地调整。
+
+默认情况下,WPS 以 .docx、.pptx 和 .xlsx 文件类型保存文件。你还可以将文档保存到 **[WPS 云][7]**中并与他人协作。另一个不错的功能是能从[这里][8]下载大量模板。
+
+### 在 Linux 上安装 WPS Office
+
+WPS 为 Linux 发行版提供 DEB 和 RPM 安装程序。如果你使用的是 Debian/Ubuntu 或基于 Fedora 的发行版,那么安装 WPS Office 就简单了。
+
+你可以在下载区那下载 Linux 中的 WPS:
+
+- [下载 WPS Office for Linux][9]
+
+向下滚动,你将看到最新版本包的链接:
+
+![WPS Office Download][10]
+
+下载适合你发行版的文件。只需双击 DEB 或者 RPM 就能[安装它们][11]。这会打开软件中心,你将看到安装选项:
+
+![WPS Office Install Package][12]
+
+几秒钟后,应用应该成功安装到你的系统上了!
+
+你现在可以在“应用程序”菜单中搜索 **WPS**,查找 WPS Office 套件中所有的应用:
+
+![WPS Applications Menu][13]
+
+### 你是否使用 WPS Office 或其他软件?
+
+还有其他 [Microsoft Office 的开源替代方案][14],但它们与 MS Office 的兼容性很差。
+
+就个人而言,我更喜欢 LibreOffice,但如果你必须要用到 Microsoft Office,你可以尝试在 Linux 上使用 WPS Office。它看起来和 MS Office 类似,并且与 MS 文档格式具有良好的兼容性。它在 Linux 上是免费的,因此你也不必担心 Office 365 订阅。
+
+你在系统上使用什么办公套件?你曾经在 Linux 上使用过 WPS Office 吗?你的体验如何?
+
+----------------------------------------------------------------------------
+
+via: https://itsfoss.com/wps-office-linux/
+
+作者:[Sergiu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/sergiu/
+[b]: https://github.com/lujun9972
+[1]: https://www.wps.com/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps2019-all-in-one-mode.png?resize=800%2C526&ssl=1
+[3]: http://wps-community.org/
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-2019-Linux.jpg?resize=800%2C450&ssl=1
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-office-writer.png?resize=800%2C454&ssl=1
+[7]: https://account.wps.com/?cb=https%3A%2F%2Fdrive.wps.com%2F
+[8]: https://template.wps.com/
+[9]: http://wps-community.org/downloads
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_download.jpg?fit=800%2C413&ssl=1
+[11]: https://itsfoss.com/install-deb-files-ubuntu/
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_install_package.png?fit=800%2C719&ssl=1
+[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_applications_menu.jpg?fit=800%2C355&ssl=1
+[14]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
diff --git a/published/201907/20190725 How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System.md b/published/201907/20190725 How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System.md
new file mode 100644
index 0000000000..ebda41f03c
--- /dev/null
+++ b/published/201907/20190725 How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System.md
@@ -0,0 +1,141 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11152-1.html)
+[#]: subject: (How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System?)
+[#]: via: (https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+如何在 Ubuntu LTS 系统上启用 Canonical 的内核实时补丁服务
+======
+
+
+
+Canonical 在 Ubuntu 14.04 LTS 系统中引入了内核实时补丁服务。实时补丁服务允许你安装和应用关键的 Linux 内核安全更新,而无需重新启动系统。这意味着,在应用内核补丁程序后,你无需重新启动系统。而通常情况下,我们需要在安装内核补丁后重启 Linux 服务器才能供系统使用。
+
+实时修补非常快。大多数内核修复程序只需要几秒钟。Canonical 的实时补丁服务对于不超过 3 个系统的用户无需任何费用。你可以通过命令行在桌面和服务器中启用 Canonical 实时补丁服务。
+
+这个实时补丁系统旨在解决高级和关键的 Linux 内核安全漏洞。
+
+有关[支持的系统][1]和其他详细信息,请参阅下表。
+
+Ubuntu 版本 | 架构 | 内核版本 | 内核变体
+---|---|---|---
+Ubuntu 18.04 LTS | 64-bit x86 | 4.15 | 仅 GA 通用和低电压内核
+Ubuntu 16.04 LTS | 64-bit x86 | 4.4 | 仅 GA 通用和低电压内核
+Ubuntu 14.04 LTS | 64-bit x86 | 4.4 | 仅 Hardware Enablement 内核
+
+**注意**:Ubuntu 14.04 中的 Canonical 实时补丁服务 LTS 要求用户在 Trusty 中运行 Ubuntu v4.4 内核。如果你当前没有运行使用该服务,请重新启动到此内核。
+
+为此,请按照以下步骤操作。
+
+### 如何获取实时补丁令牌?
+
+导航到 [Canonical 实时补丁服务页面][2],如果要使用免费服务,请选择“Ubuntu 用户”。它适用于不超过 3 个系统的用户。如果你是 “UA 客户” 或多于 3 个系统,请选择 “Ubuntu customer”。最后,单击 “Get your Livepatch token” 按钮。
+
+![][4]
+
+确保你已经在 “Ubuntu One” 中拥有帐号。否则,可以创建一个新的。
+
+登录后,你将获得你的帐户密钥。
+
+![][5]
+
+### 在系统中安装 Snap 守护程序
+
+实时补丁系统通过快照包安装。因此,请确保在 Ubuntu 系统上安装了 snapd 守护程序。
+
+```
+$ sudo apt update
+$ sudo apt install snapd
+```
+
+### 如何系统中安装和配置实时补丁服务?
+
+通过运行以下命令安装 `canonical-livepatch` 守护程序。
+
+```
+$ sudo snap install canonical-livepatch
+canonical-livepatch 9.4.1 from Canonical* installed
+```
+
+运行以下命令以在 Ubuntu 计算机上启用实时内核补丁程序。
+
+```
+$ sudo canonical-livepatch enable xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
+
+Successfully enabled device. Using machine-token: xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
+```
+
+运行以下命令查看实时补丁机器的状态。
+
+```
+$ sudo canonical-livepatch status
+
+client-version: 9.4.1
+architecture: x86_64
+cpu-model: Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
+last-check: 2019-07-24T12:30:04+05:30
+boot-time: 2019-07-24T12:11:06+05:30
+uptime: 19m11s
+status:
+- kernel: 4.15.0-55.60-generic
+ running: true
+ livepatch:
+ checkState: checked
+ patchState: nothing-to-apply
+ version: ""
+ fixes: ""
+```
+
+使用 `--verbose` 开关运行上述相同的命令,以获取有关实时修补机器的更多信息。
+
+```
+$ sudo canonical-livepatch status --verbose
+```
+
+如果要手动运行补丁程序,请执行以下命令。
+
+```
+$ sudo canonical-livepatch refresh
+
+Before refresh:
+
+kernel: 4.15.0-55.60-generic
+fully-patched: true
+version: ""
+
+After refresh:
+
+kernel: 4.15.0-55.60-generic
+fully-patched: true
+version: ""
+```
+
+`patchState` 会有以下状态之一:
+
+* `applied`:未发现任何漏洞
+* `nothing-to-apply`:成功找到并修补了漏洞
+* `kernel-upgrade-required`:实时补丁服务无法安装补丁来修复漏洞
+
+请注意,安装内核补丁与在系统上升级/安装新内核不同。如果安装了新内核,则必须重新引导系统以激活新内核。
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://wiki.ubuntu.com/Kernel/Livepatch
+[2]: https://auth.livepatch.canonical.com/
+[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[4]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-1.jpg
+[5]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-2.jpg
diff --git a/published/201907/20190730 Is This the End of Floppy Disk in Linux- Linus Torvalds Marks Floppy Disks ‘Orphaned.md b/published/201907/20190730 Is This the End of Floppy Disk in Linux- Linus Torvalds Marks Floppy Disks ‘Orphaned.md
new file mode 100644
index 0000000000..7a4e3e0404
--- /dev/null
+++ b/published/201907/20190730 Is This the End of Floppy Disk in Linux- Linus Torvalds Marks Floppy Disks ‘Orphaned.md
@@ -0,0 +1,70 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11167-1.html)
+[#]: subject: (Is This the End of Floppy Disk in Linux? Linus Torvalds Marks Floppy Disks ‘Orphaned’)
+[#]: via: (https://itsfoss.com/end-of-floppy-disk-in-linux/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Linux 中的软盘走向终结了吗?Torvalds 将软盘的驱动标记为“孤儿”
+======
+
+> 在 Linux 内核最近的提交当中,Linus Torvalds 将软盘的驱动程序标记为孤儿。这标志着软盘在 Linux 中步入结束了吗?
+
+有可能你很多年没见过真正的软盘了。如果你正在寻找带软盘驱动器的计算机,可能需要去博物馆里看看。
+
+在二十多年前,软盘是用于存储数据和运行操作系统的流行介质。[早期的 Linux 发行版][1]使用软盘进行“分发”。软盘也广泛用于保存和传输数据。
+
+你有没有想过为什么许多应用程序中的保存图标看起来像软盘?因为它就是软盘啊!软盘常用于保存数据,因此许多应用程序将其用作保存图标,并且这个传统一直延续至今。
+
+![][2]
+
+今天我为什么要说起软盘?因为 Linus Torvalds 在一个 Linux 内核代码的提交里标记软盘的驱动程序为“孤儿”。
+
+### 在 Linux 内核中被标记为“孤儿”的软盘驱动程序
+
+正如你可以在 [GitHub 镜像上的提交][3]中看到的那样,开发人员 Jiri 不再使用带有软驱的工作计算机了。而如果没有正确的硬件,Jiri 将无法继续开发。这就是 Torvalds 将其标记为孤儿的原因。
+
+> 越来越难以找到可以实际工作的软盘的物理硬件,虽然 Willy 能够对此进行测试,但我认为从实际的硬件角度来看,这个驱动程序几乎已经死了。目前仍然销售的硬件似乎主要是基于 USB 的,根本不使用这种传统的驱动器。
+
+![][4]
+
+### “孤儿”在 Linux 内核中意味着什么?
+
+“孤儿”意味着没有开发人员能够或愿意支持这部分代码。如果没有其他人出现继续维护和开发它,孤儿模块可能会被弃用并最终删除。
+
+### 它没有被立即删除
+
+Torvalds 指出,各种虚拟环境模拟器仍在使用软盘驱动器。所以软盘的驱动程序不会被立即丢弃。
+
+> 各种 VM 环境中仍然在仿真旧的软盘控制器,因此该驱动程序不会消失,但让我们看看是否有人有兴趣进一步维护它。
+
+为什么不永远保持内核中的软盘驱动器支持呢?因为这将构成安全威胁。即使没有真正的计算机使用软盘驱动程序,虚拟机仍然拥有它,这将使虚拟机容易受到攻击。
+
+### 一个时代的终结?
+
+这将是一个时代的结束还是会有其他人出现并承担起在 Linux 中继续维护软盘驱动程序的责任?只有时间会给出答案。
+
+在 Linux 内核中,软盘驱动器成为孤儿我不觉得有什么可惜的。
+
+在过去的十五年里我没有使用过软盘,我怀疑很多人也是如此。那么你呢?你有没有用过软盘?如果是的话,你最后一次使用它的时间是什么时候?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/end-of-floppy-disk-in-linux/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/earliest-linux-distros/
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/floppy-disk-icon-of-saving.png?resize=800%2C300&ssl=1
+[3]: https://github.com/torvalds/linux/commit/47d6a7607443ea43dbc4d0f371bf773540a8f8f4
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/End-of-Floppy-in-Linux.png?resize=800%2C450&ssl=1
+[5]: https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
diff --git a/published/20191110 What is DevSecOps.md b/published/201907/20191110 What is DevSecOps.md
similarity index 100%
rename from published/20191110 What is DevSecOps.md
rename to published/201907/20191110 What is DevSecOps.md
diff --git a/published/20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md b/published/20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md
new file mode 100644
index 0000000000..85b9e0ff98
--- /dev/null
+++ b/published/20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md
@@ -0,0 +1,98 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11182-1.html)
+[#]: subject: (Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip])
+[#]: via: (https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+如何在 Ubuntu 登录屏幕上启用轻击
+======
+
+> 轻击选项在 Ubuntu 18.04 GNOME 桌面的登录屏幕上不起作用。在本教程中,你将学习如何在 Ubuntu 登录屏幕上启用“轻击”。
+
+安装 Ubuntu 后我做的第一件事就是确保启用了轻击功能。作为笔记本电脑用户,我更喜欢轻击触摸板进行左键单击。这比使用触摸板上的左键单击按钮更方便。
+
+我登录并使用操作系统时可以轻击。但是,如果你在登录屏幕上,轻击不起作用,这是一个烦恼。
+
+在 Ubuntu(或使用 GNOME 桌面的其他发行版)的 [GDM 登录屏幕][1]上,你必须单击用户名才能显示密码字段。现在,如果你习惯了轻击,即使你已启用了它并在登录系统后可以使用,它也无法在登录屏幕上运行。
+
+这是一个轻微的烦恼,但仍然是一个烦恼。好消息是你可以解决这个烦恼。让我告诉你如何在这个快速提示中做到这一点。
+
+### 在 Ubuntu 登录屏幕上启用轻击
+
+![][2]
+
+你必须在这里使用终端和一些命令。我希望你能够适应。
+
+[在 Ubuntu 中使用 Ctrl + Alt + T 快捷键打开终端][3]。由于 Ubuntu 18.04 仍在使用 X 显示服务器,因此需要启用它才能连接到 [X 服务器][4]。为此,你可以将 `gdm` 添加到访问控制列表中。
+
+首先切换到 `root` 用户。这是必需的,因为你必须稍后切换为 `gdm` 用户,而不能以非 `root` 用户身份执行此操作。
+
+```
+sudo -i
+```
+
+[在 Ubuntu 中没有为 root 用户设置密码][5]。你可以使用管理员用户帐户访问它。因此,当要求输入密码时,请使用你自己的密码。输入密码时,屏幕上不会显示任何输入内容。
+
+```
+xhost +SI:localuser:gdm
+```
+
+这是我的输出:
+
+```
+xhost +SI:localuser:gdm
+localuser:gdm being added to access control list
+```
+
+现在运行此命令,以便 `gdm` 用户具有正确的轻击设置。
+
+```
+gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click true
+```
+
+如果你看到这样的警告:`(process:6339): dconf-WARNING **: 19:52:21.217: Unable to open /root/.local/share/flatpak/exports/share/dconf/profile/user: Permission denied`。别担心。忽略它就行。
+
+[][6]
+
+这将使你能够轻击登录屏幕。为什么在系统设置中进行更改之前无法使用轻击?这是因为在登录屏幕上,你还没有选择用户名。只有在屏幕上选择用户时才能使用你的帐户。这就是你必须使用用户 `gdm` 并使用它添加正确设置的原因。
+
+重新启动 Ubuntu,你会看到现在可以使用轻击来选择你的用户帐户。
+
+#### 还原改变
+
+如果你因为某些原因不喜欢在 Ubuntu 登录界面轻击,可以还原更改。
+
+你必须执行上一节中的所有步骤:切换到 `root`,将 `gdm` 与 X 服务器连接,切换到 `gdm` 用户。但是,你需要运行此命令,而不是上一个命令:
+
+```
+gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click false
+```
+
+就是这样。
+
+正如我所说,这是一件小事。我的意思是你可以轻松地点击左键而不是轻击。这只是一次单击的问题。但是,当你在几次轻击后被迫使用左键单击时,它会打破操作“连续性”。
+
+我希望你喜欢这个快速的小调整。如果你知道其他一些很酷的调整,请与我们分享。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://wiki.archlinux.org/index.php/GDM
+[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/tap-to-click-on-ubuntu-login.jpg?ssl=1
+[3]: https://itsfoss.com/ubuntu-shortcuts/
+[4]: https://en.wikipedia.org/wiki/X.Org_Server
+[5]: https://itsfoss.com/change-password-ubuntu/
+[6]: https://itsfoss.com/change-hostname-ubuntu/
diff --git a/published/20190706 Install NetData Performance Monitoring Tool On Linux.md b/published/20190706 Install NetData Performance Monitoring Tool On Linux.md
new file mode 100644
index 0000000000..5a5dc8d958
--- /dev/null
+++ b/published/20190706 Install NetData Performance Monitoring Tool On Linux.md
@@ -0,0 +1,306 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11173-1.html)
+[#]: subject: (Install NetData Performance Monitoring Tool On Linux)
+[#]: via: (https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+在 Linux 上安装 NetData 性能监控工具
+======
+
+![][1]
+
+**NetData** 是一个用于系统和应用的分布式实时性能和健康监控工具。它提供了对系统中实时发生的所有事情的全面检测。你可以在高度互动的 Web 仪表板中查看结果。使用 Netdata,你可以清楚地了解现在发生的事情,以及之前系统和应用中发生的事情。你无需成为专家即可在 Linux 系统中部署此工具。NetData 开箱即用,零配置、零依赖。只需安装它然后坐等,之后 NetData 将负责其余部分。
+
+它有自己的内置 Web 服务器,以图形形式显示结果。NetData 非常快速高效,安装后可立即开始分析系统性能。它是用 C 编程语言编写的,所以它非常轻量。它占用的单核 CPU 使用率不到 3%,内存占用 10-15MB。我们可以轻松地在任何现有网页上嵌入图表,并且它还有一个插件 API,以便你可以监控任何应用。
+
+以下是 Linux 系统中 NetData 的监控列表。
+
+* CPU 使用率
+* RAM 使用率
+* 交换内存使用率
+* 内核内存使用率
+* 硬盘及其使用率
+* 网络接口
+* IPtables
+* Netfilter
+* DDoS 保护
+* 进程
+* 应用
+* NFS 服务器
+* Web 服务器 (Apache 和 Nginx)
+* 数据库服务器 (MySQL),
+* DHCP 服务器
+* DNS 服务器
+* 电子邮件服务
+* 代理服务器
+* Tomcat
+* PHP
+* SNP 设备
+* 等等
+
+NetData 是自由开源工具,它支持 Linux、FreeBSD 和 Mac OS。
+
+### 在 Linux 上安装 NetData
+
+Netdata 可以安装在任何安装了 Bash 的 Linux 发行版上。
+
+最简单的安装 Netdata 的方法是从终端运行以下命令:
+
+```
+$ bash <(curl -Ss https://my-netdata.io/kickstart-static64.sh)
+```
+
+这将下载并安装启动和运行 Netdata 所需的一切。
+
+有些用户可能不想在没有研究的情况下将某些东西直接注入到 Bash。如果你不喜欢此方法,可以按照以下步骤在系统上安装它。
+
+#### 在 Arch Linux 上
+
+Arch Linux 默认仓库中提供了最新版本。所以,我们可以使用以下 [pacman][2] 命令安装它:
+
+```
+$ sudo pacman -S netdata
+```
+
+#### 在基于 DEB 和基于 RPM 的系统上
+
+在基于 DEB (Ubuntu / Debian)或基于 RPM(RHEL / CentOS / Fedora) 系统的默认仓库没有 NetData。我们需要从它的 Git 仓库手动安装 NetData。
+
+首先安装所需的依赖项:
+
+```
+# Debian / Ubuntu
+$ sudo apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libjudy-dev libssl-dev libmnl-dev gcc make git autoconf autoconf-archive autogen automake pkg-config curl
+
+# Fedora
+$ sudo dnf install zlib-devel libuuid-devel libuv-devel lz4-devel Judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
+
+# CentOS / Red Hat Enterprise Linux
+$ sudo yum install epel-release
+$ sudo yum install autoconf automake curl gcc git libmnl-devel libuuid-devel openssl-devel libuv-devel lz4-devel Judy-devel lm_sensors make MySQL-python nc pkgconfig python python-psycopg2 PyYAML zlib-devel
+
+# openSUSE
+$ sudo zypper install zlib-devel libuuid-devel libuv-devel liblz4-devel judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
+```
+
+安装依赖项后,在基于 DEB 或基于 RPM 的系统上安装 NetData,如下所示。
+
+Git 克隆 NetData 仓库:
+
+```
+$ git clone https://github.com/netdata/netdata.git --depth=100
+```
+
+上面的命令将在当前工作目录中创建一个名为 `netdata` 的目录。
+
+切换到 `netdata` 目录:
+
+```
+$ cd netdata/
+```
+
+最后,使用命令安装并启动 NetData:
+
+```
+$ sudo ./netdata-installer.sh
+```
+
+**示例输出:**
+
+```
+Welcome to netdata!
+Nice to see you are giving it a try!
+
+You are about to build and install netdata to your system.
+
+It will be installed at these locations:
+
+- the daemon at /usr/sbin/netdata
+ - config files at /etc/netdata
+ - web files at /usr/share/netdata
+ - plugins at /usr/libexec/netdata
+ - cache files at /var/cache/netdata
+ - db files at /var/lib/netdata
+ - log files at /var/log/netdata
+ - pid file at /var/run
+
+This installer allows you to change the installation path.
+Press Control-C and run the same command with --help for help.
+
+Press ENTER to build and install netdata to your system > ## Press ENTER key
+```
+
+安装完成后,你将在最后看到以下输出:
+
+```
+-------------------------------------------------------------------------------
+
+OK. NetData is installed and it is running (listening to *:19999).
+
+-------------------------------------------------------------------------------
+
+INFO: Command line options changed. -pidfile, -nd and -ch are deprecated.
+If you use custom startup scripts, please run netdata -h to see the
+corresponding options and update your scripts.
+
+Hit http://localhost:19999/ from your browser.
+
+To stop netdata, just kill it, with:
+
+killall netdata
+
+To start it, just run it:
+
+/usr/sbin/netdata
+
+
+Enjoy!
+
+Uninstall script generated: ./netdata-uninstaller.sh
+```
+
+![][3]
+
+*安装 NetData*
+
+NetData 已安装并启动。
+
+要在其他 Linux 发行版上安装 Netdata,请参阅[官方安装说明页面][4]。
+
+### 在防火墙或者路由器上允许 NetData 的默认端口
+
+如果你的系统在防火墙或者路由器后面,那么必须允许默认端口 `19999` 以便从任何远程系统访问 NetData 的 web 界面。
+
+#### 在 Ubuntu/Debian 中
+
+```
+$ sudo ufw allow 19999
+```
+
+#### 在 CentOS/RHEL/Fedora 中
+
+```
+$ sudo firewall-cmd --permanent --add-port=19999/tcp
+
+$ sudo firewall-cmd --reload
+```
+
+### 启动/停止 NetData
+
+要在使用 Systemd 的系统上启用和启动 Netdata 服务,请运行:
+
+```
+$ sudo systemctl enable netdata
+$ sudo systemctl start netdata
+```
+
+要停止:
+
+```
+$ sudo systemctl stop netdata
+```
+
+要在使用 Init 的系统上启用和启动 Netdata 服务,请运行:
+
+```
+$ sudo service netdata start
+$ sudo chkconfig netdata on
+```
+
+要停止:
+
+```
+$ sudo service netdata stop
+```
+
+### 通过 Web 浏览器访问 NetData
+
+打开 Web 浏览器,然后打开 `http://127.0.0.1:19999` 或者 `http://localhost:19999/` 或者 `http://ip-address:19999`。你应该看到如下页面。
+
+![][5]
+
+*Netdata 仪表板*
+
+在仪表板中,你可以找到 Linux 系统的完整统计信息。向下滚动以查看每个部分。
+
+你可以随时打开 `http://localhost:19999/netdata.conf` 来下载和/或查看 NetData 默认配置文件。
+
+![][6]
+
+*Netdata 配置文件*
+
+### 更新 NetData
+
+在 Arch Linux 中,只需运行以下命令即可更新 NetData。如果仓库中提供了更新版本,那么就会自动安装该版本。
+
+```
+$ sudo pacman -Syyu
+```
+
+在基于 DEB 或 RPM 的系统中,只需进入已克隆它的目录(此例中是 `netdata`)。
+
+```
+$ cd netdata
+```
+
+拉取最新更新:
+
+```
+$ git pull
+```
+
+然后,使用命令重新构建并更新它:
+
+```
+$ sudo ./netdata-installer.sh
+```
+
+### 卸载 NetData
+
+进入克隆 NetData 的文件夹。
+
+```
+$ cd netdata
+```
+
+然后,使用命令卸载它:
+
+```
+$ sudo ./netdata-uninstaller.sh --force
+```
+
+在 Arch Linux 中,使用以下命令卸载它。
+
+```
+$ sudo pacman -Rns netdata
+```
+
+### 资源
+
+* [NetData 网站][7]
+* [NetData 的 GitHub 页面][8]
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2016/06/Install-netdata-720x340.png
+[2]: https://www.ostechnix.com/getting-started-pacman/
+[3]: https://www.ostechnix.com/wp-content/uploads/2016/06/Deepin-Terminal_002-6.png
+[4]: https://docs.netdata.cloud/packaging/installer/
+[5]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-dashboard.png
+[6]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-config-file.png
+[7]: http://netdata.firehol.org/
+[8]: https://github.com/firehol/netdata
diff --git a/published/20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md b/published/20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md
new file mode 100644
index 0000000000..14e36860b6
--- /dev/null
+++ b/published/20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md
@@ -0,0 +1,161 @@
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11172-1.html)
+[#]: subject: (How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line)
+[#]: via: (https://www.linuxtechi.com/upgrade-debian-9-to-debian-10-command-line/)
+[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
+
+如何通过命令行升级 Debian 9 为 Debian 10
+======
+
+我们已经在先前的文章中看到如何安装 [Debian 10(Buster)][1]。今天,我们将学习如何从 Debian 9 升级为 Debian 10,虽然我们已将看到 Debian 10 和它的特色,所以这里我们不会深入介绍。但是可能读者没有机会读到那篇文章,让我们快速了解一下 Debian 10 和它的新功能。
+
+
+
+在差不多两年的开发后,Debian 团队最终发布一个稳定版本,Debian 10 的代码名称是 Buster。Buster 是一个 LTS (长期支持支持)版本,因此未来将由 Debian 支持 5 年。
+
+### Debian 10(Buster)新的特色
+
+Debian 10(Buster)回报给大多数 Debian 爱好者大量的新特色。一些特色包括:
+
+ * GNOME 桌面 3.30
+ * 默认启用 AppArmor
+ * 支持 Linux 内核 4.19.0-4
+ * 支持 OpenJDk 11.0
+ * 从 Nodejs 4 ~ 8 升级到 Nodejs 10.15.2
+ * Iptables 替换为 NFTables
+
+等等。
+
+### 从 Debian 9 到 Debian 10 的逐步升级指南
+
+在我们开始升级 Debian 10 前,让我们看看升级需要的必备条件:
+
+#### 步骤 1) Debian 升级必备条件
+
+ * 一个良好的网络连接
+ * root 用户权限
+ * 数据备份
+
+备份你所有的应用程序代码库、数据文件、用户账号详细信息、配置文件是极其重要的,以便在升级出错时,你可以总是可以还原到先前的版本。
+
+#### 步骤 2) 升级 Debian 9 现有的软件包
+
+接下来的步骤是升级你所有现有的软件包,因为一些软件包被标志为保留不能升级,从 Debian 9 升级为 Debian 10 有失败或引发一些问题的可能性。所以,我们不冒任何风险,更好地升级软件包。使用下面的代码来升级软件包:
+
+```
+root@linuxtechi:~$ sudo apt update && sudo apt upgrade -y
+```
+
+#### 步骤 3) 修改软件包存储库文件 /etc/sources.list
+
+接下来的步骤是修改软件包存储库文件 `/etc/sources.list`,你需要用文本 `Buster` 替换 `Stretch`。
+
+但是,在你更改任何东西前,确保如下创建一个 `sources.list` 文件的备份:
+
+```
+root@linuxtechi:~$ sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
+```
+
+现在使用下面的 `sed` 命令来在软件包存储库文件中使用 `buster` 替换 `stretch`,示例如下显示:
+
+```
+root@linuxtechi:~$ sudo sed -i 's/stretch/buster/g' /etc/apt/sources.list
+root@linuxtechi:~$ sudo sed -i 's/stretch/buster/g' /etc/apt/sources.list.d/*.list
+```
+
+更新后,你需要如下更新软件包存储库索引:
+
+```
+root@linuxtechi:~$ sudo apt update
+```
+
+在开始升级你现有的 Debian 操作系统前,让我们使用下面的命令验证当前版本,
+
+```
+root@linuxtechi:~$ cat /etc/*-release
+PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
+NAME="Debian GNU/Linux"
+VERSION_ID="9"
+VERSION="9 (stretch)"
+ID=debian
+HOME_URL="https://www.debian.org/"
+SUPPORT_URL="https://www.debian.org/support"
+BUG_REPORT_URL="https://bugs.debian.org/"
+root@linuxtechi:~$
+```
+
+#### 步骤 4) 从 Debian 9 升级到 Debian 10
+
+你做完所有的更改后,是时候从 Debian 9 升级到 Debian 10 了。但是在这之前,再次如下确保更新你的软件包:
+
+```
+root@linuxtechi:~$ sudo apt update && sudo apt upgrade -y
+```
+
+在软件包升级期间,你将被提示启动服务,所以选择你较喜欢的选项。
+
+一旦你系统的所有软件包升级完成,就升级你的发行版的软件包。使用下面的代码来升级发行版:
+
+```
+root@linuxtechi:~$ sudo apt dist-upgrade -y
+```
+
+升级过程可能花费一些时间,取决于你的网络速度。记住在升级过程中,你将被询问一些问题,在软件包升级后是否需要重启服务、你是否需要保留现存的配置文件等。如果你不想进行一些自定义更改,简单地键入 “Y” ,来让升级过程继续。
+
+#### 步骤 5) 验证升级
+
+一旦升级过程完成,重启你的机器,并使用下面的方法检测版本:
+
+```
+root@linuxtechi:~$ lsb_release -a
+```
+
+如果你获得如下输出:
+
+```
+Distributor ID: Debian
+Description: Debian GNU/Linux 10 (buster)
+Release: 10
+Codename: buster
+root@linuxtechi:~$
+```
+
+是的,你已经成功地从 Debian 9 升级到 Debian 10。
+
+验证升级的备用方法:
+
+```
+root@linuxtechi:~$ cat /etc/*-release
+PRETTY_NAME="Debian GNU/Linux 10 (buster)"
+NAME="Debian GNU/Linux"
+VERSION_ID="10"
+VERSION="10 (buster)"
+VERSION_CODENAME=buster
+ID=debian
+HOME_URL="https://www.debian.org/"
+SUPPORT_URL="https://www.debian.org/support"
+BUG_REPORT_URL="https://bugs.debian.org/"
+root@linuxtechi:~$
+```
+
+### 结束
+
+希望上面的逐步指南为你提供了从 Debian 9(Stretch)简单地升级为 Debian 10(Buster)的所有信息。在评论部分,请给予你使用 Debian 10 的反馈、建议、体验。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/upgrade-debian-9-to-debian-10-command-line/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972][b]
+译者:[robsean](https://github.com/robsean)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/pradeep/
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-11083-1.html
diff --git a/published/20190724 3 types of metric dashboards for DevOps teams.md b/published/20190724 3 types of metric dashboards for DevOps teams.md
new file mode 100644
index 0000000000..8d2f7aebe5
--- /dev/null
+++ b/published/20190724 3 types of metric dashboards for DevOps teams.md
@@ -0,0 +1,78 @@
+[#]: collector: "lujun9972"
+[#]: translator: "hello-wn"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-11183-1.html"
+[#]: subject: "3 types of metric dashboards for DevOps teams"
+[#]: via: "https://opensource.com/article/19/7/dashboards-devops-teams"
+[#]: author: "Daniel Oh https://opensource.com/users/daniel-oh"
+
+DevOps 团队必备的 3 种指标仪表板
+=========
+
+> 仪表板可以帮助 DevOps 团队观测和监控系统,以提高性能。
+
+
+
+指标仪表板帮助 [DevOps][2] 团队监控整个 DevOps 平台,以便实时响应议题。在处理生产环境宕机或者应用服务中断等情况时,指标仪表板显得尤为重要。
+
+DevOps 仪表板聚合了多个监测工具的指标,为开发和运维团队生成监控报告。它还允许团队跟踪多项指标,例如服务部署时间、程序 bug、报错信息、工作项、待办事项等等。
+
+下面三种指标仪表板可以帮助 DevOps 团队监测系统,改善服务性能。
+
+### 敏捷项目管理仪表板
+
+这种类型的仪表板为 DevOps 团队的工作项提供可视化视图,优化敏捷项目的工作流。有利于提高团队协作效率,对工作进行可视化并提供灵活的视图 —— 就像我们过去在白板上使用便利贴来共享项目进度、议题和待办事项一样。
+
+- [Kanban boards][3] 允许 DevOps 团队创建卡片、标签、任务和栏目,便于持续交付敏捷项目。
+- [Burndown charts][4] 对指定时间段内未完成的工作或待办事项提供可视化视图,并记录团队当前的效率和轨迹,这些指标通常用于敏捷项目和 DevOps 项目管理。
+- [Jira boards][5] 帮助 DevOps 团队创建议题、计划迭代并生成团队总结。这些灵活的仪表板还能帮助团队综合考虑并确定个人和团队任务的优先级;实时查看、汇报和跟踪正在进行的工作;并提高团队绩效。
+- [GitHub project boards][6] 帮助确定团队任务的优先级。它们还支持拉取请求,因此团队成员可以方便地提交 DevOps 项目相关的信息。
+
+### 应用程序监控仪表板
+
+开发者负责优化应用和服务的性能,并开发新功能。应用程序监控面板则帮助开发者在持续集成/持续开发流程下,加快修复 bug、增强程序健壮性、发布安全修丁的进度。另外,这些可视化仪表板有利于查看请求模式、请求耗时、报错和网络拓扑信息。
+
+- [Jaeger][7] 帮助开发人员跟踪请求数量、请求响应时间等。对于分布式网络系统上的云原生应用程序,它还使用 [Istio 服务网格][8]加强了监控和跟踪。
+- [OpenCensus][9] 帮助团队查看运行应用程序的主机上的数据,它还提供了一个可插拔的导出系统,用于将数据导出到数据中心。
+
+### DevOps 平台监控面板
+
+你可能使用多种技术和工具在云上或本地构建 DevOps 平台,但 Linux 容器管理工具(如 Kubernetes 和 OpenShift )更利于搭建出一个成功的 DevOps 平台。因为 Linux 容器的不可变性和可移植性使得应用程序从开发环境到生产环境的编译、测试和部署变得更快更容易。
+
+DevOps 平台监控仪表板帮助运营团队从机器/节点故障和服务报错中收集各种按时序排列的数据,用于编排应用程序容器和基于软件的基础架构,如网络(SDN)和存储(SDS)。这些仪表板还能可视化多维数据格式,方便地查询数据模式。
+
+- [Prometheus dashboards][12] 从平台节点或者运行中的容器化应用中收集指标。帮助 DevOps 团队构建基于指标的监控系统和仪表板,监控微服务的客户端/服务器工作负载,及时识别出异常节点故障。
+- [Grafana boards][13] 帮助收集事件驱动的各项指标,包括服务响应持续时间、请求量、客户端/服务器工作负载、网络流量等,并提供了可视化面板。DevOps 团队可以通过多种方式分享指标面板,也可以生成编码的当前监控数据快照分享给其他团队。
+
+### 总结
+
+这些仪表板提供了可视化的工作流程,能够发现团队协作、应用程序交付和平台状态中的各种问题。它们帮助开发团队增强其在快速应用交付、安全运行和自动化 CI/CD 等领域的能力。
+
+------
+
+via: https://opensource.com/article/19/7/dashboards-devops-teams
+
+作者:[Daniel Oh][a]
+选题:[lujun9972][b]
+译者:[hello-wn](https://github.com/hello-wn)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/daniel-ohhttps://opensource.com/users/daniel-ohhttps://opensource.com/users/heronthecli
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png
+[2]: https://opensource.com/resources/devops
+[3]: https://opensource.com/article/19/1/productivity-tool-taskboard
+[4]: https://openpracticelibrary.com/practice/burndown/
+[5]: https://www.atlassian.com/software/jira
+[6]: https://opensource.com/life/15/11/short-introduction-github
+[7]: https://www.jaegertracing.io/
+[8]: https://opensource.com/article/19/3/getting-started-jaeger
+[9]: https://opencensus.io/
+[10]: https://opensource.com/article/18/11/intro-software-defined-networking
+[11]: https://opensource.com/business/14/10/sage-weil-interview-openstack-ceph
+[12]: https://opensource.com/article/18/12/introduction-prometheus
+[13]: https://opensource.com/article/17/8/linux-grafana
+
diff --git a/published/20190726 Manage your passwords with Bitwarden and Podman.md b/published/20190726 Manage your passwords with Bitwarden and Podman.md
new file mode 100644
index 0000000000..0abb8e1378
--- /dev/null
+++ b/published/20190726 Manage your passwords with Bitwarden and Podman.md
@@ -0,0 +1,126 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11181-1.html)
+[#]: subject: (Manage your passwords with Bitwarden and Podman)
+[#]: via: (https://fedoramagazine.org/manage-your-passwords-with-bitwarden-and-podman/)
+[#]: author: (Eric Gustavsson https://fedoramagazine.org/author/egustavs/)
+
+使用 Bitwarden 和 Podman 管理你的密码
+======
+
+![][1]
+
+在过去的一年中,你可能会遇到一些试图向你推销密码管理器的广告。比如 [LastPass][2]、[1Password][3] 或 [Dashlane][4]。密码管理器消除了记住所有网站密码的负担。你不再需要使用重复或容易记住的密码。相反,你只需要记住一个可以解锁所有其他密码的密码。
+
+通过使用一个强密码而不是许多弱密码,这可以使你更安全。如果你有基于云的密码管理器(例如 LastPass、1Password 或 Dashlane),你还可以跨设备同步密码。不幸的是,这些产品都不是开源的。幸运的是,还有其他开源替代品。
+
+### 开源密码管理器
+
+替代方案包括 Bitwarden、[LessPass][5] 或 [KeePass][6]。Bitwarden 是一款[开源密码管理器][7],它会将所有密码加密存储在服务器上,它的工作方式与 LastPass、1Password 或 Dashlane 相同。LessPass 有点不同,因为它专注于成为无状态密码管理器。这意味着它根据主密码、网站和用户名生成密码,而不是保存加密的密码。另一方面,KeePass 是一个基于文件的密码管理器,它的插件和应用具有很大的灵活性。
+
+这三个应用中的每一个都有其自身的缺点。Bitwarden 将所有东西保存在一个地方,并通过其 API 和网站接口暴露给网络。LessPass 无法保存自定义密码,因为它是无状态的,因此你需要使用它生成的密码。KeePass 是一个基于文件的密码管理器,因此无法在设备之间轻松同步。你可以使用云存储和 [WebDAV][8] 来解决此问题,但是有许多客户端不支持它,如果设备无法正确同步,你可能会遇到文件冲突。
+
+本文重点介绍 Bitwarden。
+
+### 运行非官方的 Bitwarden 实现
+
+有一个名为 [bitwarden_rs][9] 的服务器及其 API 的社区实现。这个实现是完全开源的,因为它可以使用 SQLite 或 MariaDB/MySQL,而不是官方服务器使用的专有 Microsoft SQL Server。
+
+有一点重要的是要认识到官方和非官方版本之间存在一些差异。例如,[官方服务器已经由第三方审核][10],而非官方服务器还没有。在实现方面,非官方版本缺少[电子邮件确认和采用 Duo 或邮件码的双因素身份验证][11]。
+
+让我们在 SELinux 中运行服务器。根据 bitwarden_rs 的文档,你可以如下构建一个 Podman 命令:
+
+```
+$ podman run -d \
+ --userns=keep-id \
+ --name bitwarden \
+ -e SIGNUPS_ALLOWED=false \
+ -e ROCKET_PORT=8080 \
+ -v /home/egustavs/Bitwarden/bw-data/:/data/:Z \
+ -p 8080:8080 \
+ bitwardenrs/server:latest
+```
+
+这将下载 bitwarden_rs 镜像并在用户命名空间下的用户容器中运行它。它使用 1024 以上的端口,以便非 root 用户可以绑定它。它还使用 `:Z` 更改卷的 SELinux 上下文,以防止在 `/data` 中的读写权限问题。
+
+如果你在某个域下托管它,建议将此服务器放在 Apache 或 Nginx 的反向代理下。这样,你可以使用 80 和 443 端口指向容器的 8080 端口,而无需以 root 身份运行容器。
+
+### 在 systemd 下运行
+
+Bitwarden 现在运行了,你可能希望保持这种状态。接下来,创建一个使容器保持运行的单元文件,如果它没有响应则自动重新启动,并在系统重启后开始运行。创建文件 `/etc/systemd/system/bitwarden.service`:
+
+```
+[Unit]
+Description=Bitwarden Podman container
+Wants=syslog.service
+
+[Service]
+User=egustavs
+Group=egustavs
+TimeoutStartSec=0
+ExecStart=/usr/bin/podman run 'bitwarden'
+ExecStop=-/usr/bin/podman stop -t 10 'bitwarden'
+Restart=always
+RestartSec=30s
+KillMode=none
+
+[Install]
+WantedBy=multi-user.target
+```
+
+现在使用 [sudo][12] 启用并启动该服务:
+
+```
+$ sudo systemctl enable bitwarden.service && sudo systemctl start bitwarden.service
+$ systemctl status bitwarden.service
+bitwarden.service - Bitwarden Podman container
+ Loaded: loaded (/etc/systemd/system/bitwarden.service; enabled; vendor preset: disabled)
+ Active: active (running) since Tue 2019-07-09 20:23:16 UTC; 1 day 14h ago
+ Main PID: 14861 (podman)
+ Tasks: 44 (limit: 4696)
+ Memory: 463.4M
+```
+
+成功了!Bitwarden 现在运行了并将继续运行。
+
+### 添加 LetsEncrypt
+
+如果你有域名,强烈建议你使用类似 LetsEncrypt 的加密证书运行你的 Bitwarden 实例。Certbot 是一个为我们创建 LetsEncrypt 证书的机器人,这里有个[在 Fedora 中操作的指南][13]。
+
+生成证书后,你可以按照 [bitwarden_rs 指南中关于 HTTPS 的部分来][14]。只要记得将 `:Z` 附加到 LetsEncrypt 来处理权限,而不用更改端口。
+
+* * *
+
+照片由 [CMDR Shane][15] 拍摄,发表在 [Unsplash][16] 上。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/manage-your-passwords-with-bitwarden-and-podman/
+
+作者:[Eric Gustavsson][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/egustavs/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/bitwarden-816x345.jpg
+[2]: https://www.lastpass.com
+[3]: https://1password.com/
+[4]: https://www.dashlane.com/
+[5]: https://lesspass.com/
+[6]: https://keepass.info/
+[7]: https://bitwarden.com/
+[8]: https://en.wikipedia.org/wiki/WebDAV
+[9]: https://github.com/dani-garcia/bitwarden_rs/
+[10]: https://blog.bitwarden.com/bitwarden-completes-third-party-security-audit-c1cc81b6d33
+[11]: https://github.com/dani-garcia/bitwarden_rs/wiki#missing-features
+[12]: https://fedoramagazine.org/howto-use-sudo/
+[13]: https://certbot.eff.org/instructions
+[14]: https://github.com/dani-garcia/bitwarden_rs/wiki/Enabling-HTTPS
+[15]: https://unsplash.com/@cmdrshane?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[16]: https://unsplash.com/search/photos/password?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/published/20190729 Command line quick tips- More about permissions.md b/published/20190729 Command line quick tips- More about permissions.md
new file mode 100644
index 0000000000..bbe0b4c66a
--- /dev/null
+++ b/published/20190729 Command line quick tips- More about permissions.md
@@ -0,0 +1,94 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11185-1.html)
+[#]: subject: (Command line quick tips: More about permissions)
+[#]: via: (https://fedoramagazine.org/command-line-quick-tips-more-about-permissions/)
+[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
+
+命令行快速提示:权限进阶
+======
+
+![][1]
+
+前一篇文章[介绍了 Fedora 系统上有关文件权限的一些基础知识][2]。本部分介绍使用权限管理文件访问和共享的其他方法。它建立在前一篇文章中的知识和示例的基础上,所以如果你还没有阅读过那篇文章,请[查看][2]它。
+
+### 符号与八进制
+
+在上一篇文章中,你了解到文件有三个不同的权限集。拥有该文件的用户有一个集合,拥有该文件的组的成员有一个集合,然后最终一个集合适用于其他所有人。在长列表(`ls -l`)中这些权限使用符号模式显示在屏幕上。
+
+每个集合都有 `r`、`w` 和 `x` 条目,表示特定用户(所有者、组成员或其他)是否可以读取、写入或执行该文件。但是还有另一种表达这些权限的方法:八进制模式。
+
+你已经习惯了[十进制][3]编号系统,它有十个不同的值(`0` 到 `9`)。另一方面,八进制系统有八个不同的值(`0` 到 `7`)。在表示权限时,八进制用作速记来显示 `r`、`w` 和 `x` 字段的值。将每个字段视为具有如下值:
+
+ * `r` = 4
+ * `w` = 2
+ * `x` = 1
+
+现在,你可以使用单个八进制值表达任何组合。例如,读取和写入权限(但没有执行权限)的值为 `6`。读取和执行权限的值仅为 `5`。文件的 `rwxr-xr-x` 符号权限的八进制值为 `755`。
+
+与符号值类似,你可以使用八进制值使用 `chmod` 命令设置文件权限。以下两个命令对文件设置相同的权限:
+
+```
+chmod u=rw,g=r,o=r myfile1
+chmod 644 myfile1
+```
+
+### 特殊权限位
+
+文件上还有几个特殊权限位。这些被称为 `setuid`(或 `suid`)、`setgid`(或 `sgid`),以及粘滞位(或阻止删除位)。 将此视为另一组八进制值:
+
+ * `setuid` = 4
+ * `setgid` = 2
+ * `sticky` = 1
+
+**除非**该文件是可执行的,否则 `setuid` 位是被忽略的。如果是可执行的这种情况,则该文件(可能是应用程序或脚本)的运行就像拥有该文件的用户启动的一样。`setuid` 的一个很好的例子是 `/bin/passwd` 实用程序,它允许用户设置或更改密码。此实用程序必须能够写入到不允许普通用户更改的文件中(LCTT 译注:此处是指 `/etc/passwd` 和 `/etc/shadow`)。因此它需要精心编写,由 `root` 用户拥有,并具有 `setuid` 位,以便它可以更改密码相关文件。
+
+`setgid` 位对于可执行文件的工作方式类似。该文件将使用拥有它的组的权限运行。但是,`setgid` 对于目录还有一个额外的用途。如果在具有 `setgid` 权限的目录中创建文件,则该文件的组所有者将设置为该目录的组所有者。
+
+最后,虽然文件粘滞位没有意义会被忽略,但它对目录很有用。在目录上设置的粘滞位将阻止用户删除其他用户拥有的该目录中的文件。
+
+在八进制模式下使用 `chmod` 设置这些位的方法是添加一个值前缀,例如 `4755`,可以将 `setuid` 添加到可执行文件中。在符号模式下,`u` 和 `g` 也可用于设置或删除 `setuid` 和 `setgid`,例如 `u+s,g+s`。粘滞位使用 `o+t` 设置。(其他的组合,如 `o+s` 或 `u+t`,是没有意义的,会被忽略。)
+
+### 共享与特殊权限
+
+回想一下前一篇文章中关于需要共享文件的财务团队的示例。可以想象,特殊权限位有助于更有效地解决问题。原来的解决方案只是创建了一个整个组可以写入的目录:
+
+```
+drwxrwx---. 2 root finance 4096 Jul 6 15:35 finance
+```
+
+此目录的一个问题是,`finance` 组成员的用户 `dwayne` 和 `jill` 可以删除彼此的文件。这对于共享空间来说不是最佳选择。它在某些情况下可能有用,但在处理财务记录时可能不会!
+
+另一个问题是此目录中的文件可能无法真正共享,因为它们将由 `dwayne` 和 `jill` 的默认组拥有 - 很可能用户私有组也命名为 `dwayne` 和 `jill`,而不是 `finance`。
+
+解决此问题的更好方法是在文件夹上设置 `setgid` 和粘滞位。这将做两件事:使文件夹中创建的文件自动归 `finance` 组所有,并防止 `dwayne` 和 `jill` 删除彼此的文件。下面这些命令中的任何一个都可以工作:
+
+```
+sudo chmod 3770 finance
+sudo chmod u+rwx,g+rwxs,o+t finance
+```
+
+该文件的长列表现在显示了所应用的新特殊权限。粘滞位显示为 `T` 而不是 `t`,因为 `finance` 组之外的用户无法搜索该文件夹。
+
+```
+drwxrws--T. 2 root finance 4096 Jul 6 15:35 finance
+```
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/command-line-quick-tips-more-about-permissions/
+
+作者:[Paul W. Frields][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/pfrields/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2018/10/commandlinequicktips-816x345.jpg
+[2]: https://linux.cn/article-11123-1.html
+[3]: https://en.wikipedia.org/wiki/Decimal
diff --git a/published/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md b/published/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md
new file mode 100644
index 0000000000..48264d8479
--- /dev/null
+++ b/published/20190729 Top 8 Things to do after Installing Debian 10 (Buster).md
@@ -0,0 +1,288 @@
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11178-1.html)
+[#]: subject: (Top 8 Things to do after Installing Debian 10 (Buster))
+[#]: via: (https://www.linuxtechi.com/things-to-do-after-installing-debian-10/)
+[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
+
+Debian 10(Buster)安装后要做的前 8 件事
+======
+
+Debian 10 的代号是 Buster,它是来自 Debian 家族的最新 LTS 发布版本,并包含大量的特色功能。因此,如果你已经在你的电脑上安装了 Debian 10,并在思考接下来该做什么,那么,请继续阅读这篇文章直到结尾,因为我们为你提供在安装 Debian 10 后要做的前 8 件事。对于还没有安装 Debian 10 的人们,请阅读这篇指南 [图解 Debian 10 (Buster) 安装步骤][1]。 让我们继续这篇文章。
+
+
+
+### 1) 安装和配置 sudo
+
+在设置完成 Debian 10 后,你需要做的第一件事是安装 sudo 软件包,因为它能够使你获得管理员权限来安装你需要的软件包。为安装和配置 sudo,请使用下面的命令:
+
+变成 root 用户,然后使用下面的命令安装 sudo 软件包,
+
+```
+root@linuxtechi:~$ su -
+Password:
+root@linuxtechi:~# apt install sudo -y
+```
+
+添加你的本地用户到 sudo 组,使用下面的 [usermod][2] 命令,
+
+```
+root@linuxtechi:~# usermod -aG sudo pkumar
+root@linuxtechi:~#
+```
+
+现在验证是否本地用户获得 sudo 权限:
+
+```
+root@linuxtechi:~$ id
+uid=1000(pkumar) gid=1000(pkumar) groups=1000(pkumar),27(sudo)
+root@linuxtechi:~$ sudo vi /etc/hosts
+[sudo] password for pkumar:
+root@linuxtechi:~$
+```
+
+### 2) 校正日期和时间
+
+在你成功配置 sudo 软件包后,接下来,你需要根据你的位置来校正日期和时间。为了校正日期和时间,
+
+转到系统 **设置** –> **详细说明** –> **日期和时间** ,然后更改为适合你的位置的时区。
+
+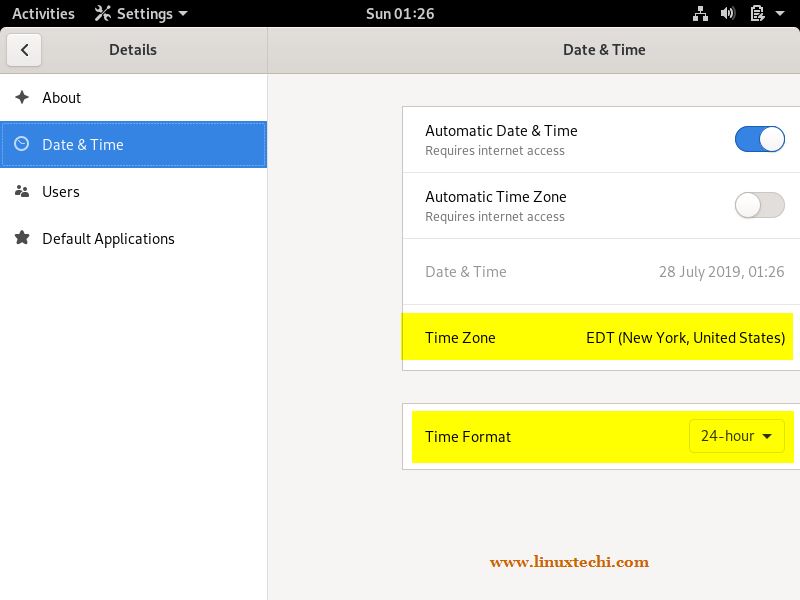
+
+一旦时区被更改,你可以看到时钟中的时间自动更改。
+
+### 3) 应用所有更新
+
+在 Debian 10 安装后,建议安装所有 Debian 10 软件包存储库中可用的更新,执行下面的 `apt` 命令:
+
+```
+root@linuxtechi:~$ sudo apt update
+root@linuxtechi:~$ sudo apt upgrade -y
+```
+
+**注意:** 如果你是 vi 编辑器的忠实粉丝,那么使用下面的 `apt` 命令安装 `vim`:
+
+```
+root@linuxtechi:~$ sudo apt install vim -y
+```
+
+### 4) 安装 Flash 播放器插件
+
+默认情况下,Debian 10(Buster)存储库不包含 Flash 插件,因此,用户需要遵循下面的介绍来在他们的系统中查找和安装 flash 播放器。
+
+为 Flash 播放器配置存储库:
+
+```
+root@linuxtechi:~$ echo "deb http://ftp.de.debian.org/debian buster main contrib" | sudo tee -a /etc/apt/sources.list
+deb http://ftp.de.debian.org/debian buster main contrib
+root@linuxtechi:~
+```
+
+现在使用下面的命令更新软件包索引:
+
+```
+root@linuxtechi:~$ sudo apt update
+```
+
+使用下面的 `apt` 命令安装 Flash 插件:
+
+```
+root@linuxtechi:~$ sudo apt install pepperflashplugin-nonfree -y
+```
+
+一旦软件包被成功安装,接下来,尝试播放 YouTube 中的视频:
+
+
+
+### 5) 安装软件,如 VLC、Skype、FileZilla 和截图工具
+
+如此,现在我们已经启用 Flash 播放器,是时候在我们的 Debian 10 系统中安装所有其它的软件,如 VLC、Skype,Filezilla 和截图工具(flameshot)。
+
+#### 安装 VLC 多媒体播放器
+
+为在你的系统中安装 VLC 播放器,使用下面的 `apt` 命令:
+
+```
+root@linuxtechi:~$ sudo apt install vlc -y
+```
+
+在成功安装 VLC 播放器后,尝试播放你喜欢的视频。
+
+
+
+#### 安装 Skype
+
+首先,下载最新的 Skype 软件包:
+
+```
+root@linuxtechi:~$ wget https://go.skype.com/skypeforlinux-64.deb
+```
+
+接下来,使用 `apt` 命令安装软件包:
+
+```
+root@linuxtechi:~$ sudo apt install ./skypeforlinux-64.deb
+```
+
+在成功安装 Skype 后,尝试访问它,并输入你的用户名和密码。
+
+
+
+#### 安装 Filezilla
+
+为在你的系统中安装 Filezilla,使用下面的 `apt` 命令,
+
+```
+root@linuxtechi:~$ sudo apt install filezilla -y
+```
+
+一旦 FileZilla 软件包被成功安装,尝试访问它。
+
+
+
+#### 安装截图工具(flameshot)
+
+使用下面的命令来安装截图工具:flameshot,
+
+```
+root@linuxtechi:~$ sudo apt install flameshot -y
+```
+
+**注意:** Shutter 工具在 Debian 10 中已被移除。
+
+
+
+### 6) 启用和启动防火墙
+
+总是建议启动防火墙来使你的网络安全。如果你希望在 Debian 10 中启用防火墙, **UFW**(简单的防火墙)是最好的控制防火墙的工具。UFW 在 Debian 存储库中可用,它非常容易安装,如下:
+
+```
+root@linuxtechi:~$ sudo apt install ufw
+```
+
+在你安装 UFW 后,接下来的步骤是设置防火墙。因此,设置防火墙,通过拒绝端口来禁用所有的传入流量,并且只允许需要的端口传出,像 ssh、http 和 https。
+
+```
+root@linuxtechi:~$ sudo ufw default deny incoming
+Default incoming policy changed to 'deny'
+(be sure to update your rules accordingly)
+root@linuxtechi:~$ sudo ufw default allow outgoing
+Default outgoing policy changed to 'allow'
+(be sure to update your rules accordingly)
+root@linuxtechi:~$
+```
+
+允许 SSH 端口:
+
+```
+root@linuxtechi:~$ sudo ufw allow ssh
+Rules updated
+Rules updated (v6)
+root@linuxtechi:~$
+```
+
+假使你在系统中已经安装 Web 服务器,那么使用下面的 `ufw` 命令来在防火墙中允许它们的端口:
+
+```
+root@linuxtechi:~$ sudo ufw allow 80
+Rules updated
+Rules updated (v6)
+root@linuxtechi:~$ sudo ufw allow 443
+Rules updated
+Rules updated (v6)
+root@linuxtechi:~$
+```
+
+最后,你可以使用下面的命令启用 UFW:
+
+```
+root@linuxtechi:~$ sudo ufw enable
+Command may disrupt existing ssh connections. Proceed with operation (y|n)? y
+Firewall is active and enabled on system startup
+root@linuxtechi:~$
+```
+
+假使你想检查你的防火墙的状态,你可以使用下面的命令检查它:
+
+```
+root@linuxtechi:~$ sudo ufw status
+```
+
+### 7) 安装虚拟化软件(VirtualBox)
+
+安装 Virtualbox 的第一步是将 Oracle VirtualBox 存储库的公钥导入到你的 Debian 10 系统:
+
+```
+root@linuxtechi:~$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
+OK
+root@linuxtechi:~$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
+OK
+root@linuxtechi:~$
+```
+
+如果导入成功,你将看到一个 “OK” 显示信息。
+
+接下来,你需要添加存储库到仓库列表:
+
+```
+root@linuxtechi:~$ sudo add-apt-repository "deb http://download.virtualbox.org/virtualbox/debian buster contrib"
+root@linuxtechi:~$
+```
+
+最后,是时候在你的系统中安装 VirtualBox 6.0:
+
+```
+root@linuxtechi:~$ sudo apt update
+root@linuxtechi:~$ sudo apt install virtualbox-6.0 -y
+```
+
+一旦 VirtualBox 软件包被成功安装,尝试访问它,并开始创建虚拟机。
+
+
+
+### 8) 安装最新的 AMD 驱动程序
+
+最后,你也可以安装需要的附加 AMD 显卡驱动程序(如 ATI 专有驱动)和 Nvidia 图形驱动程序。为安装最新的 AMD 驱动程序,首先,我们需要修改 `/etc/apt/sources.list` 文件,在包含 **main** 和 **contrib** 的行中添加 **non-free** 单词,示例如下显示:
+
+```
+root@linuxtechi:~$ sudo vi /etc/apt/sources.list
+```
+
+```
+...
+deb http://deb.debian.org/debian/ buster main non-free contrib
+deb-src http://deb.debian.org/debian/ buster main non-free contrib
+
+deb http://security.debian.org/debian-security buster/updates main contrib non-free
+deb-src http://security.debian.org/debian-security buster/updates main contrib non-free
+
+deb http://ftp.us.debian.org/debian/ buster-updates main contrib non-free
+...
+```
+
+现在,使用下面的 `apt` 命令来在 Debian 10 系统中安装最新的 AMD 驱动程序。
+
+```
+root@linuxtechi:~$ sudo apt update
+root@linuxtechi:~$ sudo apt install firmware-linux firmware-linux-nonfree libdrm-amdgpu1 xserver-xorg-video-amdgpu -y
+```
+
+这就是这篇文章的全部内容,我希望你了解在安装 Debian 10 后应该做什么。请在下面的评论区,分享你的反馈和评论。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/things-to-do-after-installing-debian-10/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972][b]
+译者:[robsean](https://github.com/robsean)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/pradeep/
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-11083-1.html
+[2]: https://www.linuxtechi.com/linux-commands-to-manage-local-accounts/
diff --git a/published/20190730 OpenHMD- Open Source Project for VR Development.md b/published/20190730 OpenHMD- Open Source Project for VR Development.md
new file mode 100644
index 0000000000..1d4ee0c1aa
--- /dev/null
+++ b/published/20190730 OpenHMD- Open Source Project for VR Development.md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11193-1.html)
+[#]: subject: (OpenHMD: Open Source Project for VR Development)
+[#]: via: (https://itsfoss.com/openhmd/)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+OpenHMD:用于 VR 开发的开源项目
+======
+
+> 在这个时代,有一些开源替代品可满足你的所有计算需求。甚至还有一个 VR 眼镜之类的开源平台。让我们快速看一下 OpenHMD 这个项目。
+
+![][5]
+
+### 什么是 OpenHMD?
+
+![][1]
+
+[OpenHMD][2] 是一个为沉浸式技术创建开源 API 及驱动的项目。这类技术包括带内置头部跟踪的头戴式显示器。
+
+它目前支持很多系统,包括 Android、FreeBSD、Linux、OpenBSD、mac OS 和 Windows。它支持的[设备][3]包括 Oculus Rift、HTC Vive、DreamWorld DreamGlass、Playstation Move 等。它还支持各种语言,包括 Go、Java、.NET、Perl、Python 和 Rust。
+
+OpenHMD 项目是在 [Boost 许可证][4]下发布的。
+
+### 新版本中的更多功能和改进功能
+
+最近,OpenHMD 项目[发布版本 0.3.0][6],代号为 Djungelvral([Djungelvral][7] 是来自瑞典的盐渍甘草)。它带来了不少变化。
+
+这次更新添加了对以下设备的支持:
+
+ * 3Glasses D3
+ * Oculus Rift CV1
+ * HTC Vive 和 HTC Vive Pro
+ * NOLO VR
+ * Windows Mixed Reality HMD 支持
+ * Deepoon E2
+ * GearVR Gen1
+
+OpenHMD 增加了一个通用扭曲着色器。这一新增功能“可以方便地在驱动程序中设置一些变量,为着色器提供有关镜头尺寸、色差、位置和 Quirks 的信息。”
+
+他们还宣布计划改变构建系统。OpenHMD 增加了对 Meson 的支持,并将在下一个 (0.4) 版本中将删除对 Autotools 的支持。
+
+OpenHMD 背后的团队还不得不删除一些功能,因为他们希望他们的系统适合所有人。由于 Windows 和 mac OS 对 HID 头的兼容问题,因此禁用了对 PlayStation VR 的支持。NOLO 有一堆固件版本,很多都会有小改动。OpenHMD 无法测试所有固件版本,因此某些版本可能无法正常工作。他们建议升级到最新的固件版本。最后,几个设备仅提供有限的支持,因此不包含在此版本中。
+
+他们预计将加快 OpenHMD 发布周期,以便更快地获得更新的功能并为用户提供更多设备支持。他们优先要做的是“让当前在主干分支中禁用的设备在下次发布补丁时能够试用,同时让支持的头戴式显示器支持位置跟踪。”
+
+### 最后总结
+
+我没有 VR 设备而且从未使用过。我相信它们有很大的潜力,甚至能超越游戏。我很兴奋(但并不惊讶)有一个开源实现会去支持许多设备。我很高兴他们专注于各种各样的设备,而不是专注于一些非品牌的 VR 的努力。
+
+我希望 OpenHMD 团队做得不错,并希望他们创建一个平台,让它们成为 VR项目。
+
+你曾经使用或看到过 OpenHMD 吗?你有没有使用 VR 进行游戏和其他用途?如果是,你是否用过任何开源硬件或软件?请在下面的评论中告诉我们。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/openhmd/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/openhmd-logo.png?resize=300%2C195&ssl=1
+[2]: http://www.openhmd.net/
+[3]: http://www.openhmd.net/index.php/devices/
+[4]: https://github.com/OpenHMD/OpenHMD/blob/master/LICENSE
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/virtual-reality-development.jpg?ssl=1
+[6]: http://www.openhmd.net/index.php/2019/07/12/openhmd-0-3-0-djungelvral-released/
+[7]: https://www.youtube.com/watch?v=byP5i6LdDXs
+[9]: http://reddit.com/r/linuxusersgroup
diff --git a/published/20190731 Bash aliases you can-t live without.md b/published/20190731 Bash aliases you can-t live without.md
new file mode 100644
index 0000000000..056c8a2006
--- /dev/null
+++ b/published/20190731 Bash aliases you can-t live without.md
@@ -0,0 +1,421 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11179-1.html)
+[#]: subject: (Bash aliases you can’t live without)
+[#]: via: (https://opensource.com/article/19/7/bash-aliases)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+不可或缺的 Bash 别名
+======
+
+> 厌倦了一遍又一遍地输入相同的长命令?你觉得在命令行上工作效率低吗?Bash 别名可以为你创造一个与众不同的世界。
+
+
+
+Bash 别名是一种用新的命令补充或覆盖 Bash 命令的方法。Bash 别名使用户可以轻松地在 [POSIX][2] 终端中自定义其体验。它们通常定义在 `$HOME/.bashrc` 或 `$HOME/bash_aliases` 中(它是由 `$HOME/.bashrc` 加载的)。
+
+大多数发行版在新用户帐户的默认 `.bashrc` 文件中至少添加了一些流行的别名。这些可以用来简单演示 Bash 别名的语法:
+
+```
+alias ls='ls -F'
+alias ll='ls -lh'
+```
+
+但并非所有发行版都附带预先添加好的别名。如果你想手动添加别名,则必须将它们加载到当前的 Bash 会话中:
+
+```
+$ source ~/.bashrc
+```
+
+否则,你可以关闭终端并重新打开它,以便重新加载其配置文件。
+
+通过 Bash 初始化脚本中定义的那些别名,你可以键入 `ll` 而得到 `ls -l` 的结果,当你键入 `ls` 时,得到也不是原来的 [ls][3] 的普通输出。
+
+那些别名很棒,但它们只是浅尝辄止。以下是十大 Bash 别名,一旦你试过它们,你会发现再也不能离开它们。
+
+### 首先设置
+
+在开始之前,创建一个名为 `~/.bash_aliases` 的文件:
+
+```
+$ touch ~/.bash_aliases
+```
+
+然后,确认这些代码出现在你的 `~/.bashrc` 文件当中:
+
+```
+if [ -e $HOME/.bash_aliases ]; then
+ source $HOME/.bash_aliases
+fi
+```
+
+如果你想亲自尝试本文中的任何别名,请将它们输入到 `.bash_aliases` 文件当中,然后使用 `source ~/.bashrc` 命令将它们加载到当前 Bash 会话中。
+
+### 按文件大小排序
+
+如果你一开始使用过 GNOME 中的 Nautilus、MacOS 中的 Finder 或 Windows 中的资源管理器等 GUI 文件管理器,那么你很可能习惯了按文件大小排序文件列表。你也可以在终端上做到这一点,但这条命令不是很简洁。
+
+将此别名添加到 GNU 系统上的配置中:
+
+```
+alias lt='ls --human-readable --size -1 -S --classify'
+```
+
+此别名将 `lt` 替换为 `ls` 命令,该命令在单个列中显示每个项目的大小,然后按大小对其进行排序,并使用符号表示文件类型。加载新别名,然后试一下:
+
+```
+$ source ~/.bashrc
+$ lt
+total 344K
+140K configure*
+ 44K aclocal.m4
+ 36K LICENSE
+ 32K config.status*
+ 24K Makefile
+ 24K Makefile.in
+ 12K config.log
+8.0K README.md
+4.0K info.slackermedia.Git-portal.json
+4.0K git-portal.spec
+4.0K flatpak.path.patch
+4.0K Makefile.am*
+4.0K dot-gitlab.ci.yml
+4.0K configure.ac*
+ 0 autom4te.cache/
+ 0 share/
+ 0 bin/
+ 0 install-sh@
+ 0 compile@
+ 0 missing@
+ 0 COPYING@
+```
+
+在 MacOS 或 BSD 上,`ls` 命令没有相同的选项,因此这个别名可以改为:
+
+```
+alias lt='du -sh * | sort -h'
+```
+
+这个版本的结果稍有不同:
+
+```
+$ du -sh * | sort -h
+0 compile
+0 COPYING
+0 install-sh
+0 missing
+4.0K configure.ac
+4.0K dot-gitlab.ci.yml
+4.0K flatpak.path.patch
+4.0K git-portal.spec
+4.0K info.slackermedia.Git-portal.json
+4.0K Makefile.am
+8.0K README.md
+12K config.log
+16K bin
+24K Makefile
+24K Makefile.in
+32K config.status
+36K LICENSE
+44K aclocal.m4
+60K share
+140K configure
+476K autom4te.cache
+```
+
+实际上,即使在 Linux上,上面这个命令也很有用,因为使用 `ls` 列出的目录和符号链接的大小为 0,这可能不是你真正想要的信息。使用哪个看你自己的喜好。
+
+*感谢 Brad Alexander 提供的这个别名的思路。*
+
+### 只查看挂载的驱动器
+
+`mount` 命令过去很简单。只需一个命令,你就可以获得计算机上所有已挂载的文件系统的列表,它经常用于概览连接到工作站有哪些驱动器。在过去看到超过三、四个条目就会令人印象深刻,因为大多数计算机没有那么多的 USB 端口,因此这个结果还是比较好查看的。
+
+现在计算机有点复杂,有 LVM、物理驱动器、网络存储和虚拟文件系统,`mount` 的结果就很难一目了然:
+
+```
+sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
+proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
+devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=8131024k,nr_inodes=2032756,mode=755)
+securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
+[...]
+/dev/nvme0n1p2 on /boot type ext4 (rw,relatime,seclabel)
+/dev/nvme0n1p1 on /boot/efi type vfat (rw,relatime,fmask=0077,dmask=0077,codepage=437,iocharset=ascii,shortname=winnt,errors=remount-ro)
+[...]
+gvfsd-fuse on /run/user/100977/gvfs type fuse.gvfsd-fuse (rw,nosuid,nodev,relatime,user_id=100977,group_id=100977)
+/dev/sda1 on /run/media/seth/pocket type ext4 (rw,nosuid,nodev,relatime,seclabel,uhelper=udisks2)
+/dev/sdc1 on /run/media/seth/trip type ext4 (rw,nosuid,nodev,relatime,seclabel,uhelper=udisks2)
+binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)
+```
+
+要解决这个问题,试试这个别名:
+
+```
+alias mnt='mount | awk -F' ' '{ printf "%s\t%s\n",$1,$3; }' | column -t | egrep ^/dev/ | sort'
+```
+
+此别名使用 `awk` 按列解析 `mount` 的输出,将输出减少到你可能想要查找的内容(挂载了哪些硬盘驱动器,而不是文件系统):
+
+```
+$ mnt
+/dev/mapper/fedora-root /
+/dev/nvme0n1p1 /boot/efi
+/dev/nvme0n1p2 /boot
+/dev/sda1 /run/media/seth/pocket
+/dev/sdc1 /run/media/seth/trip
+```
+
+在 MacOS 上,`mount` 命令不提供非常详细的输出,因此这个别名可能过度精简了。但是,如果你更喜欢简洁的报告,请尝试以下方法:
+
+```
+alias mnt='mount | grep -E ^/dev | column -t'
+```
+
+结果:
+
+```
+$ mnt
+/dev/disk1s1 on / (apfs, local, journaled)
+/dev/disk1s4 on /private/var/vm (apfs, local, noexec, journaled, noatime, nobrowse)
+```
+
+### 在你的 grep 历史中查找命令
+
+有时你好不容易弄清楚了如何在终端完成某件事,并觉得自己永远不会忘记你刚学到的东西。然后,一个小时过去之后你就完全忘记了你做了什么。
+
+搜索 Bash 历史记录是每个人不时要做的事情。如果你确切地知道要搜索的内容,可以使用 `Ctrl + R` 对历史记录进行反向搜索,但有时你无法记住要查找的确切命令。
+
+这是使该任务更容易的别名:
+
+```
+alias gh='history|grep'
+```
+
+这是如何使用的例子:
+
+```
+$ gh bash
+482 cat ~/.bashrc | grep _alias
+498 emacs ~/.bashrc
+530 emacs ~/.bash_aliases
+531 source ~/.bashrc
+```
+
+### 按修改时间排序
+
+每个星期一都会这样:你坐在你的电脑前开始工作,你打开一个终端,你发现你已经忘记了上周五你在做什么。你需要的是列出最近修改的文件的别名。
+
+你可以使用 `ls` 命令创建别名,以帮助你找到上次离开的位置:
+
+```
+alias left='ls -t -1'
+```
+
+输出很简单,但如果你愿意,可以使用 `--long` 选项扩展它。这个别名列出的显示如下:
+
+```
+$ left
+demo.jpeg
+demo.xcf
+design-proposal.md
+rejects.txt
+brainstorm.txt
+query-letter.xml
+```
+
+### 文件计数
+
+如果你需要知道目录中有多少文件,那么该解决方案是 UNIX 命令构造的最典型示例之一:使用 `ls` 命令列出文件,用`-1` 选项将其输出控制为只有一列,然后输出到 `wc`(单词计数)命令的管道,以计算有多少行。
+
+这是 UNIX 理念如何允许用户使用小型的系统组件构建自己的解决方案的精彩演示。如果你碰巧每天都要做几次,这个命令组合也要输入很多字母,如果没有使用 `-R` 选项,它就不能用于目录,这会为输出引入新行并导致无用的结果。
+
+而这个别名使这个过程变得简单:
+
+```
+alias count='find . -type f | wc -l'
+```
+
+这个别名会计算文件,忽略目录,但**不会**忽略目录的内容。如果你有一个包含两个目录的项目文件夹,每个目录包含两个文件,则该别名将返回 4,因为整个项目中有 4 个文件。
+
+```
+$ ls
+foo bar
+$ count
+4
+```
+
+### 创建 Python 虚拟环境
+
+你用 Python 编程吗?
+
+你用 Python 编写了很多程序吗?
+
+如果是这样,那么你就知道创建 Python 虚拟环境至少需要 53 次击键。
+
+这个数字里有 49 次是多余的,它很容易被两个名为 `ve` 和 `va` 的新别名所解决:
+
+```
+alias ve='python3 -m venv ./venv'
+alias va='source ./venv/bin/activate'
+```
+
+运行 `ve` 会创建一个名为 `venv` 的新目录,其中包含 Python 3 的常用虚拟环境文件系统。`va` 别名在当前 shell 中的激活该环境:
+
+```
+$ cd my-project
+$ ve
+$ va
+(venv) $
+```
+
+### 增加一个复制进度条
+
+每个人都会吐槽进度条,因为它们似乎总是不合时宜。然而,在内心深处,我们似乎都想要它们。UNIX 的 `cp` 命令没有进度条,但它有一个 `-v` 选项用于显示详细信息,它回显了复制的每个文件名到终端。这是一个相当不错的技巧,但是当你复制一个大文件并且想要了解还有多少文件尚未传输时,它的作用就没那么大了。
+
+`pv` 命令可以在复制期间提供进度条,但它并不常用。另一方面,`rsync` 命令包含在几乎所有的 POSIX 系统的默认安装中,并且它被普遍认为是远程和本地复制文件的最智能方法之一。
+
+更好的是,它有一个内置的进度条。
+
+```
+alias cpv='rsync -ah --info=progress2'
+```
+
+像使用 `cp` 命令一样使用此别名:
+
+```
+$ cpv bigfile.flac /run/media/seth/audio/
+ 3.83M 6% 213.15MB/s 0:00:00 (xfr#4, to-chk=0/4)
+```
+
+使用此命令的一个有趣的副作用是 `rsync` 无需 `-r` 标志就可以复制文件和目录,而 `cp` 则需要。
+
+### 避免意外删除
+
+你不应该使用 `rm` 命令。`rm` 手册甚至这样说:
+
+> **警告:**如果使用 `rm` 删除文件,通常可以恢复该文件的内容。如果你想要更加确保内容真正无法恢复,请考虑使用 `shred`。
+
+如果要删除文件,则应将文件移动到“废纸篓”,就像使用桌面时一样。
+
+POSIX 使这很简单,因为垃圾桶是文件系统中可访问的一个实际位置。该位置可能会发生变化,具体取决于你的平台:在 [FreeDesktop][4] 上,“垃圾桶”位于 `~/.local/share/Trash`,而在 MacOS 上则是 `~/.Trash`,但无论如何,它只是一个目录,你可以将文件藏在那个看不见的地方,直到你准备永久删除它们为止。
+
+这个简单的别名提供了一种从终端将文件扔进垃圾桶的方法:
+
+```
+alias tcn='mv --force -t ~/.local/share/Trash '
+```
+
+该别名使用一个鲜为人知的 `mv` 标志(`-t`),使你能够提供作为最终移动目标的参数,而忽略了首先列出要移动的文件的通常要求。现在,你可以使用新命令将文件和文件夹移动到系统垃圾桶:
+
+```
+$ ls
+foo bar
+$ tcn foo
+$ ls
+bar
+```
+
+现在文件已“消失”,只有在你一头冷汗的时候才意识到你还需要它。此时,你可以从系统垃圾桶中抢救该文件;这肯定可以给 Bash 和 `mv` 开发人员提供一些帮助。
+
+**注意:**如果你需要一个具有更好的 FreeDesktop 兼容性的更强大的垃圾桶命令,请参阅 [Trashy][5]。
+
+### 简化 Git 工作流
+
+每个人都有自己独特的工作流程,但无论如何,通常都会有重复的任务。如果你经常使用 Git,那么你可能会发现自己经常重复的一些操作序列。也许你会发现自己回到主分支并整天一遍又一遍地拉取最新的变化,或者你可能发现自己创建了标签然后将它们推到远端,抑或可能完全是其它的什么东西。
+
+无论让你厌倦一遍遍输入的 Git 魔咒是什么,你都可以通过 Bash 别名减轻一些痛苦。很大程度上,由于它能够将参数传递给钩子,Git 拥有着丰富的内省命令,可以让你不必在 Bash 中执行那些丑陋冗长的命令。
+
+例如,虽然你可能很难在 Bash 中找到项目的顶级目录(就 Bash 而言,它是一个完全随意的名称,因为计算机的绝对顶级是根目录),但 Git 可以通过简单的查询找到项目的顶级目录。如果你研究过 Git 钩子,你会发现自己能够找到 Bash 一无所知的各种信息,而你可以利用 Bash 别名来利用这些信息。
+
+这是一个来查找 Git 项目的顶级目录的别名,无论你当前在哪个项目中工作,都可以将目录改变为顶级目录,切换到主分支,并执行 Git 拉取:
+
+```
+alias startgit='cd `git rev-parse --show-toplevel` && git checkout master && git pull'
+```
+
+这种别名绝不是一个普遍有用的别名,但它演示了一个相对简单的别名如何能够消除大量繁琐的导航、命令和等待提示。
+
+一个更简单,可能更通用的别名将使你返回到 Git 项目的顶级目录。这个别名非常有用,因为当你在一个项目上工作时,该项目或多或少会成为你的“临时家目录”。它应该像回家一样简单,就像回你真正的家一样,这里有一个别名:
+
+```
+alias cg='cd `git rev-parse --show-toplevel`'
+```
+
+现在,命令 `cg` 将你带到 Git 项目的顶部,无论你下潜的目录结构有多深。
+
+### 切换目录并同时查看目录内容
+
+(据称)曾经一位著名科学家提出过,我们可以通过收集极客输入 `cd` 后跟 `ls` 消耗的能量来解决地球上的许多能量问题。
+
+这是一种常见的用法,因为通常当你更改目录时,你都会有查看周围的内容的冲动或需要。
+
+但是在你的计算机的目录树中移动并不一定是一个走走停停的过程。
+
+这是一个作弊,因为它根本不是别名,但它是探索 Bash 功能的一个很好的借口。虽然别名非常适合快速替换一个命令,但 Bash 也允许你在 `.bashrc` 文件中添加本地函数(或者你加载到 `.bashrc` 中的单独函数文件,就像你的别名文件一样)。
+
+为了保持模块化,创建一个名为 `~/.bash_functions` 的新文件,然后让你的 `.bashrc` 加载它:
+
+```
+if [ -e $HOME/.bash_functions ]; then
+ source $HOME/.bash_functions
+fi
+```
+
+在该函数文件中,添加这些代码:
+
+```
+function cl() {
+ DIR="$*";
+ # if no DIR given, go home
+ if [ $# -lt 1 ]; then
+ DIR=$HOME;
+ fi;
+ builtin cd "${DIR}" && \
+ # use your preferred ls command
+ ls -F --color=auto
+}
+```
+
+将函数加载到 Bash 会话中,然后尝试:
+
+```
+$ source ~/.bash_functions
+$ cl Documents
+foo bar baz
+$ pwd
+/home/seth/Documents
+$ cl ..
+Desktop Documents Downloads
+[...]
+$ pwd
+/home/seth
+```
+
+函数比别名更灵活,但有了这种灵活性,你就有责任确保代码有意义并达到你的期望。别名是简单的,所以要保持简单而有用。要正式修改 Bash 的行为,请使用保存到 `PATH` 环境变量中某个位置的函数或自定义的 shell 脚本。
+
+附注,有一些巧妙的奇技淫巧来实现 `cd` 和 `ls` 序列作为别名,所以如果你足够耐心,那么即使是一个简单的别名也永无止限。
+
+### 开始别名化和函数化吧
+
+可以定制你的环境使得 Linux 变得如此有趣,提高效率使得 Linux 可以改变生活。开始使用简单的别名,进而使用函数,并在评论中发布你必须拥有的别名!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/bash-aliases
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://opensource.com/article/19/7/master-ls-command
+[4]: https://www.freedesktop.org/wiki/
+[5]: https://gitlab.com/trashy/trashy
diff --git a/published/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md b/published/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md
new file mode 100644
index 0000000000..d721d097c0
--- /dev/null
+++ b/published/20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md
@@ -0,0 +1,80 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11187-1.html)
+[#]: subject: (The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news)
+[#]: via: (https://opensource.com/article/19/8/news-august-3)
+[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo)
+
+开源新闻综述:有史以来最快的开源 CPU、Facebook 分享对抗有害内容的 AI 算法
+======
+
+> 不要错过最近两周最大的开源新闻。
+
+![Weekly news roundup with TV][1]
+
+在本期开源新闻综述中,我们分享了 Facebook 开源了两种算法来查找有害内容,Apple 在数据传输项目中的新角色以及你应该知道的更多新闻。
+
+### Facebook 开源算法用于查找有害内容
+
+Facebook 宣布它[开源两种算法][2]用于在该平台上发现儿童剥削、恐怖主义威胁和写实暴力。在 8 月 1 日的博客文章中,Facebook 分享了 PDQ 和 TMK + PDQF 这两种将文件存储为数字哈希的技术,然后将它们与已知的有害内容示例进行比较 - [现在已放在 GitHub 上][3]。
+
+该代码是在 Facebook 要尽快将有害内容从平台上移除的压力之下发布的。三月份在新西兰的大规模谋杀案被曝光在 Facebook Live 上,澳大利亚政府[威胁][4]如果视频没有及时删除 Facebook 高管将被处以罚款和入狱。通过发布这些算法的源代码,Facebook 表示希望非营利组织、科技公司和独立开发人员都能帮助他们更快地找到并删除有害内容。
+
+### 阿里巴巴发布了最快的开源 CPU
+
+上个月,阿里巴巴的子公司平头哥半导体公司[发布了其玄铁 91 处理器][5]。它可以用于人工智能、物联网、5G 和自动驾驶汽车等基础设施。它拥有 7.1 Coremark/MHz 的基准,使其成为市场上最快的开源 CPU。
+
+平头哥宣布计划在今年 9 月在 GitHub 上提供其优质代码。分析师认为此次发布旨在帮助中国实现其目标,即到 2021 年使用本地供应商满足 40% 的处理器需求。近期美国的关税调整威胁要破坏这一目标,从而造成了对开源计算机组件的需求。
+
+### Mattermost 为开源协作应用提供了理由
+
+所有开源社区都受益于可以从一个或多个地方彼此进行通信。团队聊天应用程序的世界似乎由 Slack 和 Microsoft Teams 等极少数的强大工具主导。大多数选择都是基于云的和专有产品的;而 Mattermost 采用了不同的方法,销售开源协作应用程序的价值。
+
+“人们想要一个开源替代品,因为他们需要信任、灵活性和只有开源才能提供的创新,”Mattermost 的联合创始人兼首席执行官 Ian Tien 说。
+
+随着从优步到国防部的客户,Mattermost 走上了一个关键市场:需要开源软件的团队,他们可以信任这些软件并安装在他们自己的服务器上。对于需要协作应用程序在其内部基础架构上运行的企业,Mattermost 填补了 [Atlassian 离开后][6] 的空白。在 Computerworld 的一篇文章中,Matthew Finnegan [探讨][7]了为什么在本地部署的开源聊天工具尚未死亡。
+
+### Apple 加入了开源数据传输项目
+
+Google、Facebook、Twitter 和微软去年联合创建了数据传输项目(DTP)。DTP 被誉为通过自己的数据提升数据安全性和用户代理的一种方式,是一种罕见的技术上的团结展示。本周,Apple 宣布他们也将[加入][8]。
+
+DTP 的目标是帮助用户通过开源平台将数据从一个在线服务转移到另一个在线服务。DTP 旨在通过使用 API 和授权工具来取消中间人,以便用户将数据从一个服务转移到另一个服务。这将消除用户下载数据然后将其上传到另一个服务的需要。Apple 加入 DTP 的选择将允许用户将数据传入和传出 iCloud,这可能是隐私权拥护者的一大胜利。
+
+#### 其它新闻
+
+* [FlexiWAN 的开源 SD-WAN 可在公共测试版中下载] [9]
+* [开源的 Windows 计算器应用程序获得了永远置顶模式] [10]
+* [通过 Zowe,开源和 DevOps 正在使大型计算机民主化] [11]
+* [Mozilla 首次推出 WebThings Gateway 开源路由器固件的实现] [12]
+* [更新:向 Mozilla 代码库做成贡献][13]
+
+*谢谢 Opensource.com 的工作人员和主持人本周的帮助。*
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/news-august-3
+
+作者:[Lauren Maffeo][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lmaffeo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
+[2]: https://www.theverge.com/2019/8/1/20750752/facebook-child-exploitation-terrorism-open-source-algorithm-pdq-tmk
+[3]: https://github.com/facebook/ThreatExchange/tree/master/hashing/tmk
+[4]: https://www.buzzfeed.com/hannahryan/social-media-facebook-livestreaming-laws-christchurch
+[5]: https://hexus.net/tech/news/cpu/133229-alibabas-16-core-risc-v-fastest-open-source-cpu-yet/
+[6]: https://lab.getapp.com/atlassian-slack-on-premise-software/
+[7]: https://www.computerworld.com/article/3428679/mattermost-makes-case-for-open-source-as-team-messaging-market-booms.html
+[8]: https://www.techspot.com/news/81221-apple-joins-data-transfer-project-open-source-project.html
+[9]: https://www.fiercetelecom.com/telecom/flexiwan-s-open-source-sd-wan-available-for-download-public-beta-release
+[10]: https://mspoweruser.com/open-source-windows-calculator-app-to-get-always-on-top-mode/
+[11]: https://siliconangle.com/2019/07/29/zowe-open-source-devops-democratizing-mainframe-computer/
+[12]: https://venturebeat.com/2019/07/25/mozilla-debuts-webthings-gateway-open-source-router-firmware-for-turris-omnia/
+[13]: https://developer.mozilla.org/en-US/docs/Mozilla/Developer_guide/Introduction
diff --git a/published/20190805 How To Find Hardware Specifications On Linux.md b/published/20190805 How To Find Hardware Specifications On Linux.md
new file mode 100644
index 0000000000..453b19f74c
--- /dev/null
+++ b/published/20190805 How To Find Hardware Specifications On Linux.md
@@ -0,0 +1,341 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11194-1.html)
+[#]: subject: (How To Find Hardware Specifications On Linux)
+[#]: via: (https://www.ostechnix.com/getting-hardwaresoftware-specifications-in-linux-mint-ubuntu/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+如何在 Linux 上查找硬件规格
+======
+
+
+
+在 Linux 系统上有许多工具可用于查找硬件规格。在这里,我列出了四种最常用的工具,可以获取 Linux 系统的几乎所有硬件(和软件)细节。好在是这些工具在某些 Linux 发行版上默认预装。我在 Ubuntu 18.04 LTS 桌面上测试了这些工具,但是它们也适用于其他 Linux 发行版。
+
+### 1、LSHW
+
+lshw(硬件列表)是一个简单但功能齐全的实用程序,它提供了 Linux 系统上的硬件规格的详细信息。它可以报告确切的内存规格、固件版本、主板规格、CPU 版本和速度、缓存规格、总线速度等。信息可以以纯文本、XML 或 HTML 格式输出。
+
+它目前支持 DMI(仅限 x86 和 EFI)、Open Firmware 设备树(仅限 PowerPC)、PCI/AGP、ISA PnP(x86)、CPUID(x86)、IDE/ATA/ATAPI、PCMCIA(仅在 x86 上测试过)、USB 和 SCSI。
+
+就像我已经说过的那样,Ubuntu 默认预装了 lshw。如果它未安装在你的 Ubuntu 系统中,请使用以下命令安装它:
+
+```
+$ sudo apt install lshw lshw-gtk
+```
+
+在其他 Linux 发行版上,例如 Arch Linux,运行:
+
+```
+$ sudo pacman -S lshw lshw-gtk
+```
+
+安装后,运行 `lshw` 以查找系统硬件详细信息:
+
+```
+$ sudo lshw
+```
+
+你将看到输出详细的系统硬件。
+
+示例输出:
+
+![][2]
+
+*使用 lshw 在 Linux 上查找硬件规格*
+
+请注意,如果你没有以 `sudo` 权限运行 `lshw` 命令,则输出可能不完整或不准确。
+
+`lshw` 可以将输出显示为 HTML 页面。为此,请使用:
+
+```
+$ sudo lshw -html
+```
+
+同样,我们可以将设备树输出为 XML 和 json 格式,如下所示:
+
+```
+$ sudo lshw -xml
+$ sudo lshw -json
+```
+
+要输出显示硬件路径的设备树,请使用 `-short` 选项:
+
+```
+$ sudo lshw -short
+```
+
+![][3]
+
+*使用 lshw 显示具有硬件路径的设备树*
+
+要列出设备的总线信息、详细的 SCSI、USB、IDE 和 PCI 地址,请运行:
+
+```
+$ sudo lshw -businfo
+```
+
+默认情况下,`lshw` 显示所有硬件详细信息。你还可以使用类选项查看特定硬件详细信息的硬件信息,例如处理器、内存、显示器等。可以使用 `lshw -short` 或 `lshw -businfo` 找到类选项。
+
+要显示特定硬件详细信息,例如处理器,请执行以下操作:
+
+```
+$ sudo lshw -class processor
+```
+
+示例输出:
+
+```
+*-cpu
+description: CPU
+product: Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
+vendor: Intel Corp.
+physical id: 4
+bus info: [email protected]
+version: Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
+serial: To Be Filled By O.E.M.
+slot: CPU 1
+size: 913MHz
+capacity: 2300MHz
+width: 64 bits
+clock: 100MHz
+capabilities: x86-64 fpu fpu_exception wp vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer xsave avx lahf_lm epb pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid xsaveopt dtherm arat pln pts md_clear flush_l1d cpufreq
+configuration: cores=2 enabledcores=1 threads=2
+```
+
+类似的,你可以得到系统细节:
+
+```
+$ sudo lshw -class system
+```
+
+硬盘细节:
+
+```
+$ sudo lshw -class disk
+```
+
+网络细节:
+
+```
+$ sudo lshw -class network
+```
+
+内存细节:
+
+```
+$ sudo lshw -class memory
+```
+
+你也可以像下面这样列出多个设备的细节:
+
+```
+$ sudo lshw -class storage -class power -class volume
+```
+
+如果你想要查看带有硬件路径的细节信息,加上 `-short` 选项即可:
+
+```
+$ sudo lshw -short -class processor
+```
+
+示例输出:
+
+```
+H/W path Device Class Description
+=======================================================
+/0/4 processor Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
+```
+
+有时,你可能希望将某些硬件详细信息共享给别人,例如客户支持人员。如果是这样,你可以从输出中删除潜在的敏感信息,如 IP 地址、序列号等,如下所示。
+
+```
+$ lshw -sanitize
+```
+
+#### lshw-gtk GUI 工具
+
+如果你对 CLI 不熟悉,可以使用 `lshw-gtk`,这是 `lshw` 命令行工具的图形界面。
+
+它可以从终端或 Dash 中打开。
+
+要从终端启动它,只需执行以下操作:
+
+```
+$ sudo lshw-gtk
+```
+
+这是 `lshw` 工具的默认 GUI 界面。
+
+![][4]
+
+*使用 lshw-gtk 在 Linux 上查找硬件*
+
+只需双击“Portable Computer”即可进一步展开细节。
+
+![][5]
+
+*使用 lshw-gtk GUI 在 Linux 上查找硬件*
+
+你可以双击后续的硬件选项卡以获取详细视图。
+
+有关更多详细信息,请参阅手册页。
+
+```
+$ man lshw
+```
+
+### 2、Inxi
+
+Inxi 是我查找 Linux 系统上几乎所有内容的另一个最喜欢的工具。它是一个自由开源的、功能齐全的命令行系统信息工具。它显示了系统硬件、CPU、驱动程序、Xorg、桌面、内核、GCC 版本、进程、RAM 使用情况以及各种其他有用信息。无论是硬盘还是 CPU、主板还是整个系统的完整细节,inxi 都能在几秒钟内更准确地显示它。由于它是 CLI 工具,你可以在桌面或服务器版本中使用它。有关更多详细信息,请参阅以下指南。
+
+* [如何使用 inxi 发现系统细节][6]
+
+### 3、Hardinfo
+
+Hardinfo 将为你提供 `lshw` 中没有的系统硬件和软件详细信息。
+
+HardInfo 可以收集有关系统硬件和操作系统的信息,执行基准测试,并以 HTML 或纯文本格式生成可打印的报告。
+
+如果 Ubuntu 中未安装 Hardinfo,请使用以下命令安装:
+
+```
+$ sudo apt install hardinfo
+```
+
+安装后,Hardinfo 工具可以从终端或菜单中进行。
+
+以下是 Hardinfo 默认界面的外观。
+
+![][7]
+
+*使用 Hardinfo 在 Linux 上查找硬件*
+
+正如你在上面的屏幕截图中看到的,Hardinfo 的 GUI 简单直观。
+
+所有硬件信息分为四个主要组:计算机、设备、网络和基准。每个组都显示特定的硬件详细信息。
+
+例如,要查看处理器详细信息,请单击“设备”组下的“处理器”选项。
+
+![][8]
+
+*使用 hardinfo 显示处理器详细信息*
+
+与 `lshw` 不同,Hardinfo 可帮助你查找基本软件规范,如操作系统详细信息、内核模块、区域设置信息、文件系统使用情况、用户/组和开发工具等。
+
+![][9]
+
+*使用 hardinfo 显示操作系统详细信息*
+
+Hardinfo 的另一个显着特点是它允许我们做简单的基准测试来测试 CPU 和 FPU 功能以及一些图形用户界面功能。
+
+![][10]
+
+*使用 hardinfo 执行基准测试*
+
+建议阅读:
+
+* [Phoronix 测试套件 - 开源测试和基准测试工具][11]
+* [UnixBench - 类 Unix 系统的基准套件][12]
+* [如何从命令行对 Linux 命令和程序进行基准测试][13]
+
+我们可以生成整个系统以及各个设备的报告。要生成报告,只需单击菜单栏上的“生成报告”按钮,然后选择要包含在报告中的信息。
+
+![][14]
+
+*使用 hardinfo 生成系统报告*
+
+Hardinfo 也有几个命令行选项。
+
+例如,要生成报告并在终端中显示它,请运行:
+
+```
+$ hardinfo -r
+```
+
+列出模块:
+
+```
+$ hardinfo -l
+```
+
+更多信息请参考手册:
+
+```
+$ man hardinfo
+```
+
+### 4、Sysinfo
+
+Sysinfo 是 HardInfo 和 lshw-gtk 实用程序的另一个替代品,可用于获取下面列出的硬件和软件信息。
+
+* 系统详细信息,如发行版版本、GNOME 版本、内核、gcc 和 Xorg 以及主机名。
+* CPU 详细信息,如供应商标识、型号名称、频率、L2 缓存、型号和标志。
+* 内存详细信息,如系统全部内存、可用内存、交换空间总量和空闲、缓存、活动/非活动的内存。
+* 存储控制器,如 IDE 接口、所有 IDE 设备、SCSI 设备。
+* 硬件详细信息,如主板、图形卡、声卡和网络设备。
+
+让我们使用以下命令安装 sysinfo:
+
+```
+$ sudo apt install sysinfo
+```
+
+Sysinfo 可以从终端或 Dash 启动。
+
+要从终端启动它,请运行:
+
+```
+$ sysinfo
+```
+
+这是 Sysinfo 实用程序的默认界面。
+
+![][15]
+
+*sysinfo 界面*
+
+如你所见,所有硬件(和软件)详细信息都分为五类,即系统、CPU、内存、存储和硬件。单击导航栏上的类别以获取相应的详细信息。
+
+![][16]
+
+*使用 Sysinfo 在 Linux 上查找硬件*
+
+更多细节可以在手册页上找到。
+
+```
+$ man sysinfo
+```
+
+就这样。就像我已经提到的那样,可以有很多工具可用于显示硬件/软件规范。但是,这四个工具足以找到你的 Linux 发行版的所有软硬件规格信息。
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/getting-hardwaresoftware-specifications-in-linux-mint-ubuntu/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[2]: https://www.ostechnix.com/wp-content/uploads/2013/01/Find-Hardware-Specifications-On-Linux-using-lshw-1.png
+[3]: https://www.ostechnix.com/wp-content/uploads/2013/01/Show-device-tree-with-hardware-path-using-lshw.png
+[4]: https://www.ostechnix.com/wp-content/uploads/2013/01/Find-Hardware-Specifications-On-Linux-using-lshw-gtk-1.png
+[5]: https://www.ostechnix.com/wp-content/uploads/2013/01/Find-Hardware-Specifications-On-Linux-using-lshw-gtk-2.png
+[6]: https://www.ostechnix.com/how-to-find-your-system-details-using-inxi/
+[7]: https://www.ostechnix.com/wp-content/uploads/2013/01/Find-Hardware-Specifications-On-Linux-Using-Hardinfo.png
+[8]: https://www.ostechnix.com/wp-content/uploads/2013/01/Show-processor-details-using-hardinfo.png
+[9]: https://www.ostechnix.com/wp-content/uploads/2013/01/Show-operating-system-details-using-hardinfo.png
+[10]: https://www.ostechnix.com/wp-content/uploads/2013/01/Perform-benchmarks-using-hardinfo.png
+[11]: https://www.ostechnix.com/phoronix-test-suite-open-source-testing-benchmarking-tool/
+[12]: https://www.ostechnix.com/unixbench-benchmark-suite-unix-like-systems/
+[13]: https://www.ostechnix.com/how-to-benchmark-linux-commands-and-programs-from-commandline/
+[14]: https://www.ostechnix.com/wp-content/uploads/2013/01/Generate-system-reports-using-hardinfo.png
+[15]: https://www.ostechnix.com/wp-content/uploads/2013/01/sysinfo-interface.png
+[16]: https://www.ostechnix.com/wp-content/uploads/2013/01/Find-Hardware-Specifications-On-Linux-Using-Sysinfo.png
diff --git a/sources/news/20190619 Codethink open sources part of onboarding process.md b/sources/news/20190619 Codethink open sources part of onboarding process.md
deleted file mode 100644
index 537ded948b..0000000000
--- a/sources/news/20190619 Codethink open sources part of onboarding process.md
+++ /dev/null
@@ -1,42 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Codethink open sources part of onboarding process)
-[#]: via: (https://opensource.com/article/19/6/codethink-onboarding-process)
-[#]: author: (Laurence Urhegyi https://opensource.com/users/laurence-urhegyi)
-
-Codethink open sources part of onboarding process
-======
-In other words, how to Git going in FOSS.
-![Teacher or learner?][1]
-
-Here at [Codethink][2], we’ve recently focused our energy into enhancing the onboarding process we use for all new starters at the company. As we grow steadily in size, it’s important that we have a well-defined approach to both welcoming new employees into the company, and introducing them to the organization’s culture.
-
-As part of this overall onboarding effort, we’ve created [_How to Git going in FOSS_][3]: an introductory guide to the world of free and open source software (FOSS), and some of the common technologies, practices, and principles associated with free and open source software.
-
-This guide was initially aimed at work experience students and summer interns. However, the document is in fact equally applicable to anyone who is new to free and open source software, no matter their prior experience in software or IT in general. _How to Git going in FOSS_ is hosted on GitLab and consists of several repositories, each designed to be a self-guided walk through.
-
-Our guide begins with a general introduction to FOSS, including explanations of the history of GNU/Linux, how to use [Git][4] (as well as Git hosting services such as GitLab), and how to use a text editor. The document then moves on to exercises that show the reader how to implement some of the things they’ve just learned.
-
-_How to Git going in FOSS_ is fully public and available for anyone to try. If you’re new to FOSS or know someone who is, then please have a read-through, and see what you think. If you have any feedback, feel free to raise an issue on GitLab. And, of course, we also welcome contributions. We’re keen to keep improving the guide however possible. One future improvement we plan to make is an additional exercise that is more complex than the existing two, such as potentially introducing the reader to [Continuous Integration][5].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/6/codethink-onboarding-process
-
-作者:[Laurence Urhegyi][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/laurence-urhegyi
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead-teacher-learner.png?itok=rMJqBN5G (Teacher or learner?)
-[2]: https://www.codethink.co.uk/about.html
-[3]: https://gitlab.com/ct-starter-guide
-[4]: https://git-scm.com
-[5]: https://en.wikipedia.org/wiki/Continuous_integration
diff --git a/sources/news/20190622 Cloudflare-s random number generator, robotics data visualization, npm token scanning, and more news.md b/sources/news/20190622 Cloudflare-s random number generator, robotics data visualization, npm token scanning, and more news.md
deleted file mode 100644
index af595d310b..0000000000
--- a/sources/news/20190622 Cloudflare-s random number generator, robotics data visualization, npm token scanning, and more news.md
+++ /dev/null
@@ -1,84 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Cloudflare's random number generator, robotics data visualization, npm token scanning, and more news)
-[#]: via: (https://opensource.com/article/19/6/news-june-22)
-[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
-
-Cloudflare's random number generator, robotics data visualization, npm token scanning, and more news
-======
-Catch up on the biggest open source headlines from the past two weeks.
-![Weekly news roundup with TV][1]
-
-In this edition of our open source news roundup, we take a look Cloudflare's open source random number generator, more open source robotics data, new npm functionality, and more!
-
-### Cloudflare announces open source random number generator project
-
-Is there such a thing as a truly random number? Internet security and services provider Cloudflare things so. To prove it, the company has formed [The League of Entropy][2], an open source project to create a generator for random numbers.
-
-The League consists of Cloudflare and "five other organisations — predominantly universities and security companies." They share random numbers, using an open source tool called [Drand][3] (short for Distributed Randomness Beacon Daemon). The numbers are then "composited into one random number" on the basis that "several random numbers are more random than one random number." While the League's random number generator isn't intended "for any kind of password or cryptographic seed generation," Cloudflare's CEO Matthew Prince points out that if "you need a way of having a known random source, this is a really valuable tool."
-
-### Cruise open sources robotics data analysis tool
-
-Projects involved in creating self-driving vehicles generate petabytes of data. And with amounts of data that large comes the challenge of quickly and effectively analyzing it. To make the task easier, General Motors subsidiary Cruise has made its Webviz data visualization tool "[freely available to developers][4] in need of a modular robotics analysis solution."
-
-Webviz "takes as input any bag file (the message format used by the popular Robot Operating System) and outputs charts and graphs." It "contains a collection of general panels (which visualize data) applicable to most robotics developers," said Esther Weon, a software engineer at Cruise. The company also plans to "release a public API that’ll allow developers to build custom panels themselves."
-
-The code for Webviz is [available on GitHub][5], where you can download or contribute to the project.
-
-### npm provides more security
-
-The team behind npm, the site providing JavaScript package hosting, has a new collaboration with GitHub to automatically scan for exposed tokens that could give hackers access that doesn't belong to them. The project includes a handy automatic revoke of leaked credentials them if are still valid. This could drastically reduce vulnerabilities in the JavaScript community. For instructions on how to participate, see the [original article][6].
-
-Note that this news was found via the [Changelog news][7].
-
-### Better end of life tracking via open source
-
-A new project, [endoflife.date][8], aims to overcome the complexity of end of life (EOL) announcements for software. It's part tracker, part public announcement on what good documentation looks like for software. As the README states: "The reason this site exists is because this information is very often hidden away. If you're releasing something on a regular basis:
-
- 1. List only supported releases.
- 2. Give EoL dates/policy if possible.
- 3. Hide unsupported releases behind a few extra clicks.
- 4. Mention security/active release difference if needed."
-
-
-
-Check out the [source code][9] for more information.
-
-### In other news
-
- * [Medicine needs to embrace open source][10]
- * [Using geospatial data to create safer roads][11]
- * [Embracing open source could be a big competitive advantage for businesses][12]
-
-
-
-_Thanks, as always, to Opensource.com staff members and moderators for their help this week._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/6/news-june-22
-
-作者:[Scott Nesbitt][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/scottnesbitt
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
-[2]: https://thenextweb.com/dd/2019/06/17/cloudflares-new-open-source-project-helps-anyone-obtain-truly-random-numbers/
-[3]: https://github.com/dedis/drand
-[4]: https://venturebeat.com/2019/06/18/cruise-open-sources-webview-a-tool-for-robotics-data-analysis/
-[5]: https://github.com/cruise-automation/webviz
-[6]: https://blog.npmjs.org/post/185680936500/protecting-package-publishers-npm-token-security
-[7]: https://changelog.com/news/npm-token-scanning-extending-to-github-NAoe
-[8]: https://endoflife.date/
-[9]: https://github.com/captn3m0/endoflife.date
-[10]: https://www.zdnet.com/article/medicine-needs-to-embrace-open-source/
-[11]: https://itbrief.co.nz/story/using-geospatial-data-to-create-safer-roads
-[12]: https://www.fastcompany.com/90364152/embracing-open-source-could-be-a-big-competitive-advantage-for-businesses
diff --git a/sources/news/20190802 Linux Smartphone Librem 5 is Available for Preorder.md b/sources/news/20190802 Linux Smartphone Librem 5 is Available for Preorder.md
new file mode 100644
index 0000000000..de4e87cf2f
--- /dev/null
+++ b/sources/news/20190802 Linux Smartphone Librem 5 is Available for Preorder.md
@@ -0,0 +1,91 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Linux Smartphone Librem 5 is Available for Preorder)
+[#]: via: (https://itsfoss.com/librem-5-available/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Linux Smartphone Librem 5 is Available for Preorder
+======
+
+Purism recently [announced][1] the final specs for its [Librem 5 smartphone][2]. This is not based on Android or iOS – but built on [PureOS][3], which is an [open-source alternative to Android][4].
+
+Along with the announcement, the Librem 5 is also available for [pre-orders for $649][5] (as an early bird offer till 31st July) and it will go up by $50 following the date. It will start shipping from Q3 of 2019.
+
+![][6]
+
+Here’s what Purism mentioned about Librem 5 in its blog post:
+
+_**We believe phones should not track you nor exploit your digital life.**_
+
+_The Librem 5 represents the opportunity for you to take back control and protect your private information, your digital life through free and open source software, open governance, and transparency. The Librem 5 is_ **_a phone built on_ [_PureOS_][3]**_, a fully free, ethical and open-source operating system that is_ _**not based on Android or iOS**_ _(learn more about [why this is important][7])._
+
+_We have successfully crossed our crowdfunding goals and will be delivering on our promise. The Librem 5’s hardware and software development is advancing [at a steady pace][8], and is scheduled for an initial release in Q3 2019. You can preorder the phone at $649 until shipping begins and regular pricing comes into effect. Kits with an external monitor, keyboard and mouse, are also available for preorder._
+
+### Librem 5 Specifications
+
+From what it looks like, Librem 5 definitely aims to provide better privacy and security. In addition to this, it tries to avoid using anything from Google or Apple.
+
+While the idea is good enough – how does it hold up as a commercial smartphone under $700?
+
+![Librem 5 Smartphone][9]
+
+Let us take a look at the tech specs:
+
+![Librem 5][10]
+
+On paper the tech specs seems to be good enough. Not too great – not too bad. But, what about the performance? The user experience?
+
+Well, we can’t be too sure about it – unless we use it. So, if you are pre-ordering it – take that into consideration.
+
+[][11]
+
+Suggested read Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve's New Compiler
+
+### Lifetime software updates for Librem 5
+
+Of course, the specs aren’t very pretty when compared to the smartphones available at this price range.
+
+However, with the promise of lifetime software updates – it does look like a decent offering for open source enthusiasts.
+
+### Other Key Features
+
+Purism also highlights the fact that Librem 5 will be the first-ever [Matrix][12]-powered smartphone. This means that it will support end-to-end decentralized encrypted communications for messaging and calling.
+
+In addition to all these, the presence of headphone jack and a user-replaceable battery makes it a pretty solid deal.
+
+### Wrapping Up
+
+Even though it is tough to compete with the likes of Android/iOS smartphones, having an alternative is always good. Librem 5 may not prove to be an ideal smartphone for every user – but if you are an open-source enthusiast and looking for a simple smartphone that respects privacy and security without utilizing Google/Apple services, this is for you.
+
+Also the fact that it will receive lifetime software updates – makes it an interesting smartphone.
+
+What do you think about Librem 5? Are you thinking to pre-order it? Let us know your thoughts in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/librem-5-available/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://puri.sm/posts/librem-5-smartphone-final-specs-announced/
+[2]: https://itsfoss.com/librem-linux-phone/
+[3]: https://pureos.net/
+[4]: https://itsfoss.com/open-source-alternatives-android/
+[5]: https://shop.puri.sm/shop/librem-5/
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/librem-5-linux-smartphone.jpg?resize=800%2C450&ssl=1
+[7]: https://puri.sm/products/librem-5/pureos-mobile/
+[8]: https://puri.sm/posts/tag/phones
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/librem-5-smartphone.jpg?ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/librem-5-specs.png?ssl=1
+[11]: https://itsfoss.com/linux-games-performance-boost-amd-gpu/
+[12]: http://matrix.org
diff --git a/sources/talk/20170320 An Ubuntu User-s Review Of Dell XPS 13 Ubuntu Edition.md b/sources/talk/20170320 An Ubuntu User-s Review Of Dell XPS 13 Ubuntu Edition.md
index 61a4c4993c..5e00b887d2 100644
--- a/sources/talk/20170320 An Ubuntu User-s Review Of Dell XPS 13 Ubuntu Edition.md
+++ b/sources/talk/20170320 An Ubuntu User-s Review Of Dell XPS 13 Ubuntu Edition.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (anonymone )
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/talk/20180604 10 principles of resilience for women in tech.md b/sources/talk/20180604 10 principles of resilience for women in tech.md
index e5d6b09401..be1960d0c9 100644
--- a/sources/talk/20180604 10 principles of resilience for women in tech.md
+++ b/sources/talk/20180604 10 principles of resilience for women in tech.md
@@ -1,4 +1,3 @@
-XYenChi is translating
10 principles of resilience for women in tech
======
diff --git a/sources/talk/20180818 What Did Ada Lovelace-s Program Actually Do.md b/sources/talk/20180818 What Did Ada Lovelace-s Program Actually Do.md
index fc669a1a3c..8bbb651cfd 100644
--- a/sources/talk/20180818 What Did Ada Lovelace-s Program Actually Do.md
+++ b/sources/talk/20180818 What Did Ada Lovelace-s Program Actually Do.md
@@ -1,5 +1,3 @@
-Northurland Translating
-
What Did Ada Lovelace's Program Actually Do?
======
The story of Microsoft’s founding is one of the most famous episodes in computing history. In 1975, Paul Allen flew out to Albuquerque to demonstrate the BASIC interpreter that he and Bill Gates had written for the Altair microcomputer. Because neither of them had a working Altair, Allen and Gates tested their interpreter using an emulator that they wrote and ran on Harvard’s computer system. The emulator was based on nothing more than the published specifications for the Intel 8080 processor. When Allen finally ran their interpreter on a real Altair—in front of the person he and Gates hoped would buy their software—he had no idea if it would work. But it did. The next month, Allen and Gates officially founded their new company.
diff --git a/sources/talk/20190131 OOP Before OOP with Simula.md b/sources/talk/20190131 OOP Before OOP with Simula.md
index aca160ad2d..cae9d9bd3a 100644
--- a/sources/talk/20190131 OOP Before OOP with Simula.md
+++ b/sources/talk/20190131 OOP Before OOP with Simula.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: (warmfrog)
+[#]: translator: ( )
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/talk/20190412 Gov-t warns on VPN security bug in Cisco, Palo Alto, F5, Pulse software.md b/sources/talk/20190412 Gov-t warns on VPN security bug in Cisco, Palo Alto, F5, Pulse software.md
deleted file mode 100644
index b5d5c21ee6..0000000000
--- a/sources/talk/20190412 Gov-t warns on VPN security bug in Cisco, Palo Alto, F5, Pulse software.md
+++ /dev/null
@@ -1,76 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Gov’t warns on VPN security bug in Cisco, Palo Alto, F5, Pulse software)
-[#]: via: (https://www.networkworld.com/article/3388646/gov-t-warns-on-vpn-security-bug-in-cisco-palo-alto-f5-pulse-software.html#tk.rss_all)
-[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
-
-Gov’t warns on VPN security bug in Cisco, Palo Alto, F5, Pulse software
-======
-VPN packages from Cisco, Palo Alto, F5 and Pusle may improperly secure tokens and cookies
-![Getty Images][1]
-
-The Department of Homeland Security has issued a warning that some [VPN][2] packages from Cisco, Palo Alto, F5 and Pusle may improperly secure tokens and cookies, allowing nefarious actors an opening to invade and take control over an end user’s system.
-
-The DHS’s Cybersecurity and Infrastructure Security Agency (CISA) [warning][3] comes on the heels of a notice from Carnegie Mellon's CERT that multiple VPN applications store the authentication and/or session cookies insecurely in memory and/or log files.
-
-**[Also see:[What to consider when deploying a next generation firewall][4]. Get regularly scheduled insights by [signing up for Network World newsletters][5]]**
-
-“If an attacker has persistent access to a VPN user's endpoint or exfiltrates the cookie using other methods, they can replay the session and bypass other authentication methods,” [CERT wrote][6]. “An attacker would then have access to the same applications that the user does through their VPN session.”
-
-According to the CERT warning, the following products and versions store the cookie insecurely in log files:
-
- * Palo Alto Networks GlobalProtect Agent 4.1.0 for Windows and GlobalProtect Agent 4.1.10 and earlier for macOS0 ([CVE-2019-1573][7])
- * Pulse Secure Connect Secure prior to 8.1R14, 8.2, 8.3R6, and 9.0R2.
-
-
-
-The following products and versions store the cookie insecurely in memory:
-
- * Palo Alto Networks GlobalProtect Agent 4.1.0 for Windows and GlobalProtect Agent 4.1.10 and earlier for macOS0.
- * Pulse Secure Connect Secure prior to 8.1R14, 8.2, 8.3R6, and 9.0R2.
- * Cisco AnyConnect 4.7.x and prior.
-
-
-
-CERT says that Palo Alto Networks GlobalProtect version 4.1.1 [patches][8] this vulnerability.
-
-In the CERT warning F5 stated it has been aware of the insecure memory storage since 2013 and has not yet been patched. More information can be found [here][9]. F5 also stated it has been aware of the insecure log storage since 2017 and fixed it in version 12.1.3 and 13.1.0 and onwards. More information can be found [here][10].
-
-**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][11] ]**
-
-CERT said it is unaware of any patches at the time of publishing for Cisco AnyConnect and Pulse Secure Connect Secure.
-
-CERT credited the [National Defense ISAC Remote Access Working Group][12] for reporting the vulnerability.
-
-Join the Network World communities on [Facebook][13] and [LinkedIn][14] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3388646/gov-t-warns-on-vpn-security-bug-in-cisco-palo-alto-f5-pulse-software.html#tk.rss_all
-
-作者:[Michael Cooney][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Michael-Cooney/
-[b]: https://github.com/lujun9972
-[1]: https://images.idgesg.net/images/article/2018/10/broken-chain_metal_link_breach_security-100777433-large.jpg
-[2]: https://www.networkworld.com/article/3268744/understanding-virtual-private-networks-and-why-vpns-are-important-to-sd-wan.html
-[3]: https://www.us-cert.gov/ncas/current-activity/2019/04/12/Vulnerability-Multiple-VPN-Applications
-[4]: https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
-[5]: https://www.networkworld.com/newsletters/signup.html
-[6]: https://www.kb.cert.org/vuls/id/192371/
-[7]: https://nvd.nist.gov/vuln/detail/CVE-2019-1573
-[8]: https://securityadvisories.paloaltonetworks.com/Home/Detail/146
-[9]: https://support.f5.com/csp/article/K14969
-[10]: https://support.f5.com/csp/article/K45432295
-[11]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
-[12]: https://ndisac.org/workinggroups/
-[13]: https://www.facebook.com/NetworkWorld/
-[14]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190724 Data centers may soon recycle heat into electricity.md b/sources/talk/20190724 Data centers may soon recycle heat into electricity.md
new file mode 100644
index 0000000000..92298e1a01
--- /dev/null
+++ b/sources/talk/20190724 Data centers may soon recycle heat into electricity.md
@@ -0,0 +1,67 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Data centers may soon recycle heat into electricity)
+[#]: via: (https://www.networkworld.com/article/3410578/data-centers-may-soon-recycle-heat-into-electricity.html)
+[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
+
+Data centers may soon recycle heat into electricity
+======
+Rice University researchers are developing a system that converts waste heat into light and then that light into electricity, which could help data centers reduce computing costs.
+![Gordon Mah Ung / IDG][1]
+
+Waste heat is the scurge of computing. In fact, much of the cost of powering a computer is from creating unwanted heat. That’s because the inefficiencies in electronic circuits, caused by resistance in the materials, generates that heat. The processors, without computing anything, are essentially converting expensively produced electrical energy into waste energy.
+
+It’s a fundamental problem, and one that hasn’t been going away. But what if you could convert the unwanted heat back into electricity—recycle the heat back into its original energy form? The data center heat, instead of simply disgorging into the atmosphere to be gotten rid of with dubious eco-effects, could actually run more machines. Plus, your cooling costs would be taken care of—there’s nothing to cool because you’ve already grabbed the hot air.
+
+**[ Read also: [How server disaggregation can boost data center efficiency][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3] ]**
+
+Scientists at Rice Univeristy are trying to make that a reality by developing heat scavenging and conversion solutions.
+
+Currently, the most efficient way to convert heat into electricity is through the use of traditional turbines.
+
+Turbines “can give you nearly 50% conversion efficiency,” says Chloe Doiron, a graduate student at Rice University and co-lead on the project, in a [news article][4] on the school’s website. Turbines convert the kinetic energy of moving fluids, like steam or combustion gases, into mechanical energy. The moving steam then shifts blades mounted on a shaft, which turns a generator, thus creating the power.
+
+Not a bad solution. The problem, though, is “those systems are not easy to implement,” the researchers explain. The issue is that turbines are full of moving parts, and they’re big, noisy, and messy.
+
+### Thermal emitter better than turbines for converting heat to energy
+
+A better option would be a solid-state, thermal device that could absorb heat at the source and simply convert it, perhaps straight into attached batteries.
+
+The researchers say a thermal emitter could absorb heat, jam it into tight, easy-to-capture bandwidth and then emit it as light. Cunningly, they would then simply turn the light into electricity, as we see all the time now in solar systems.
+
+“Thermal photons are just photons emitted from a hot body,” says Rice University professor Junichiro Kono in the article. “If you look at something hot with an infrared camera, you see it glow. The camera is capturing these thermally excited photons.” Indeed, all heated surfaces, to some extent, send out light as thermal radiation.
+
+The Rice team wants to use a film of aligned carbon nanotubes to do the job. The test system will be structured as an actual solar panel. That’s because solar panels, too, lose energy through heat, so are a good environment in which to work. The concept applies to other inefficient technologies, too. “Anything else that loses energy through heat [would become] far more efficient,” the researchers say.
+
+Around 20% of industrial energy consumption is unwanted heat, Doiron says. That's a lot of wasted energy.
+
+### Other heat conversion solutions
+
+Other heat scavenging devices are making inroads, too. Now-commercially available thermoelectric technology can convert a temperature difference into power, also with no moving parts. They function by exposing a specially made material to heat. [Electrons flow when one part is cold and one is hot][5]. And the University of Utah is working on [silicon for chips that generates electricity][6] as one of two wafers heat up.
+
+Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3410578/data-centers-may-soon-recycle-heat-into-electricity.html
+
+作者:[Patrick Nelson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Patrick-Nelson/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/07/flir_20190711t191326-100801627-large.jpg
+[2]: https://www.networkworld.com/article/3266624/how-server-disaggregation-could-make-cloud-datacenters-more-efficient.html
+[3]: https://www.networkworld.com/newsletters/signup.html
+[4]: https://news.rice.edu/2019/07/12/rice-device-channels-heat-into-light/
+[5]: https://www.networkworld.com/article/2861438/how-to-convert-waste-data-center-heat-into-electricity.html
+[6]: https://unews.utah.edu/beat-the-heat/
+[7]: https://www.facebook.com/NetworkWorld/
+[8]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190724 How BMW-s new annual fee for Apple CarPlay could define the IoT.md b/sources/talk/20190724 How BMW-s new annual fee for Apple CarPlay could define the IoT.md
new file mode 100644
index 0000000000..6a73b041d5
--- /dev/null
+++ b/sources/talk/20190724 How BMW-s new annual fee for Apple CarPlay could define the IoT.md
@@ -0,0 +1,73 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How BMW’s new annual fee for Apple CarPlay could define the IoT)
+[#]: via: (https://www.networkworld.com/article/3411478/how-bmws-new-annual-fee-for-apple-carplay-could-define-the-iot.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+How BMW’s new annual fee for Apple CarPlay could define the IoT
+======
+BMW's plans to charge for Apple CarPlay access illustrates the promise—and the pitfalls—of the internet of things (IoT).
+![Apple][1]
+
+Apple calls CarPlay “[the ultimate co-pilot][2].” BMW calls it the “smart and fast way to conveniently use your iPhone features while in your car. ... You can control your iPhone and use apps with the touchscreen display, the iDrive Controller or voice commands.”
+
+However you describe it, though, Apple’s CarPlay system suddenly finds itself in the center of what could be a defining conversation about the future of the internet of things (IoT).
+
+You see, the German luxury carmaker’s plans to charge $80 a year to access CarPlay have suddenly become the talk of the internet, from [tech blogs][3] to [car sites][4]. The hue and cry makes CarPlay the perfect illustration of the promise—and the pitfalls—of the IoT.
+
+**[ [Learn more:][5] Download a PDF bundle of five essential articles about IoT in the enterprise ]**
+
+First, the facts: BMW’s website now reveals that beginning with the 2019 model year, it’s turning the CarPlay interface between iPhones and the vehicle’s infotainment system into a subscription service. While most car manufacturers that offer CarPlay make it available free of charge, owners of the “ultimate driving machine,” will get free access for only the first year. After that, [BMW drivers will need to pony up $80 a year—or $300 for 20 years][6]—to keep using it.
+
+### An “outrageous” fee?
+
+Some observers are labeling the new fee “[outrageous][7],” and it’s not yet clear what Apple thinks about BMW’s pricing policy. For me, though, it’s both a shining example of the amazing new revenue opportunities generated by the IoT, and a terrifying warning of how the IoT could add new cost and complexity to everyday activities.
+
+Look at this as a glass half full, and BMW is cleverly finding a new revenue stream by offering valuable functionality to a target market that has already demonstrated a willingness to pay for high-end functionality. The IoT and connected cars offer a new and better experience, and BMW is leveraging that to boost its business. It’s the power of capitalism at work, and if BMW drivers don’t value the CarPlay functionality, no one is forcing them to buy it.
+
+In some ways, the subscription business model is similar to that of [satellite radio][8] or GM’s [OnStar][9] system. The automaker builds in the equipment needed to offer the service, and car owners can choose to avail themselves of it if they feel it’s worthwhile. Or not.
+
+### A particular bit of usury
+
+But that’s only one perspective on what’s happening here. Look at it another way, and you could paint a very different picture. For one thing, as noted above, other car makers that offer CarPlay do not charge anything extra for it. BMWs are relatively expensive vehicles, and nickel-and-diming affluent consumers does not seem like a path to great customer loyalty. Think of the annoyance surrounding the fact that budget motels typically make Wi-Fi available for free, while luxury properties charge guests through the nose. (With the [rise of 5G networks][10], though, that particular bit of usury may not last much longer.)
+
+Making matters worse, CarPlay is really just internal connectivity between your iPhone and your car’s infotainment system. There’s no actual _service_ involved, and no real justification for a separate fee, other than the fact that BMW _can_ charge for it. It seems more like getting charged a monthly fee to connect your own phone to your own big-screen TV (like Apple’s AirPlay) or hooking up your smart light fixture to your home assistant or—I don’t know—putting your lamp on your coffee table! It just doesn’t feel right.
+
+### Dangerous long-term implications?
+
+Sure, if this kind of thing takes off in the larger world of the IoT, it could lead to a significant amount of new revenue—at least in the short run. But over time, it could easily backfire, encouraging consumers to view IoT vendors as greedy and to question the costs and benefits of everything from smart houses to connected enterprises. That could turn out to be a drag on the overall IoT market.
+
+That would be a shame, and it doesn’t have to be that way. If BMW had merely buried the CarPlay costs in the price of the equipment or options, or in the sticker cost of the car itself, nobody would be worrying about it. But just like breaking out the costs of checked baggage on airplane flights, charging a subscription for CarPlay makes it seem like a combination of bait-and-switch and price gouging. And that’s exactly what the IoT industry _doesn’t_ need. If the goal is to maximize the growth and acceptance of the IoT, vendors should strive to make IoT users feel like they’re getting great functionality at a fair price.
+
+That’s often exactly what many IoT devices and IoT-based services do, so it shouldn’t be too hard to avoid screwing it up.
+
+Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3411478/how-bmws-new-annual-fee-for-apple-carplay-could-define-the-iot.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/06/ios13-carplay-waze-100799546-large.jpg
+[2]: https://www.apple.com/ios/carplay/
+[3]: https://www.engadget.com/2019/07/24/bmw-adds-a-80-yearly-subscription-for-apples-carplay/
+[4]: https://www.caranddriver.com/news/a15530125/bmw-to-treat-apple-carplay-as-a-subscription-service-and-charge-customers-an-annual-fee/
+[5]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
+[6]: https://connecteddrive.bmwusa.com/app/index.html#/portal/store/Base_CarPlay
+[7]: https://www.cultofmac.com/640578/bmw-carplay-annual-fee/
+[8]: https://www.siriusxm.com/
+[9]: https://www.onstar.com/us/en/home/?ppc=GOOGLE_700000001302986_71700000048879287_58700004855294718_p41772767724&gclid=EAIaIQobChMIi7qn4IDO4wIVJRh9Ch1mlw6tEAAYASAAEgKQf_D_BwE&gclsrc=aw.ds
+[10]: http://www.networkworld.com/cms/article/17%20predictions%20about%205G%20networks%20and%20devices
+[11]: https://www.facebook.com/NetworkWorld/
+[12]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190724 Reports- As the IoT grows, so do its threats to DNS.md b/sources/talk/20190724 Reports- As the IoT grows, so do its threats to DNS.md
new file mode 100644
index 0000000000..d9647304b9
--- /dev/null
+++ b/sources/talk/20190724 Reports- As the IoT grows, so do its threats to DNS.md
@@ -0,0 +1,78 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Reports: As the IoT grows, so do its threats to DNS)
+[#]: via: (https://www.networkworld.com/article/3411437/reports-as-the-iot-grows-so-do-its-threats-to-dns.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+Reports: As the IoT grows, so do its threats to DNS
+======
+ICANN and IBM's security researchers separately spell out how the growth of the internet of things will increase opportunities for malicious actors to attack the Domain Name System with hyperscale botnets and worm their malware into the cloud.
+The internet of things is shaping up to be a more significant threat to the Domain Name System through larger IoT botnets, unintentional adverse effects of IoT-software updates and the continuing development of bot-herding software.
+
+The Internet Corporation for Assigned Names and Numbers (ICANN) and IBM’s X-Force security researchers have recently issued reports outlining the interplay between DNS and IoT that includes warnings about the pressure IoT botnets will put on the availability of DNS systems.
+
+**More about DNS:**
+
+ * [DNS in the cloud: Why and why not][1]
+ * [DNS over HTTPS seeks to make internet use more private][2]
+ * [How to protect your infrastructure from DNS cache poisoning][3]
+ * [ICANN housecleaning revokes old DNS security key][4]
+
+
+
+ICANN’s Security and Stability Advisory Committee (SSAC) wrote in a [report][5] that “a significant number of IoT devices will likely be IP enabled and will use the DNS to locate the remote services they require to perform their functions. As a result, the DNS will continue to play the same crucial role for the IoT that it has for traditional applications that enable human users to interact with services and content,” ICANN stated. “The role of the DNS might become even more crucial from a security and stability perspective with IoT devices interacting with people’s physical environment.”
+
+IoT represents both an opportunity and a risk to the DNS, ICANN stated. “It is an opportunity because the DNS provides functions and data that can help make the IoT more secure, stable, and transparent, which is critical given the IoT's interaction with the physical world. It is a risk because various measurement studies suggest that IoT devices may stress the DNS, for instance, because of complex DDoS attacks carried out by botnets that grow to hundreds of thousands or in the future millions of infected IoT devices within hours,” ICANN stated.
+
+Unintentional DDoS attacks
+
+One risk is that the IoT could place new burdens on the DNS. “For example, a software update for a popular IP-enabled IoT device that causes the device to use the DNS more frequently (e.g., regularly lookup random domain names to check for network availability) could stress the DNS in individual networks when millions of devices automatically install the update at the same time,” ICANN stated.
+
+While this is a programming error from the perspective of individual devices, it could result in a significant attack vector from the perspective of DNS infrastructure operators. Incidents like this have already occurred on a small scale, but they may occur more frequently in the future due to the growth of heterogeneous IoT devices from manufacturers that equip their IoT devices with controllers that use the DNS, ICANN stated.
+
+Massively larger botnets, threat to clouds
+
+The report also suggested that the scale of IoT botnets could grow from hundreds of thousands of devices to millions. The best known IoT botnet is Mirai, responsible for DDoS attacks involving 400,000 to 600,000 devices. The Hajime botnet hovers around 400K infected IoT devices but has not launched any DDoS attacks yet. But as the IoT grows, so will the botnets and as a result larger DDoS attacks.
+
+Cloud-connected IoT devices could endanger cloud resources. “IoT devices connected to cloud architecture could allow Mirai adversaries to gain access to cloud servers. They could infect a server with additional malware dropped by Mirai or expose all IoT devices connected to the server to further compromise,” wrote Charles DeBeck, a senior cyber threat intelligence strategic analyst with [IBM X-Force Incident Response][6] in a recent report.
+
+ “As organizations increasingly adopt cloud architecture to scale efficiency and productivity, disruption to a cloud environment could be catastrophic.”
+
+For enterprises that are rapidly adopting both IoT technology and cloud architecture, insufficient security controls could expose the organization to elevated risk, calling for the security committee to conduct an up-to-date risk assessment, DeBeck stated.
+
+Attackers continue malware development
+
+“Since this activity is highly automated, there remains a strong possibility of large-scale infection of IoT devices in the future,” DeBeck stated. “Additionally, threat actors are continuing to expand their targets to include new types of IoT devices and may start looking at industrial IoT devices or connected wearables to increase their footprint and profits.”
+
+Botnet bad guys are also developing new Mirai variants and IoT botnet malware outside of the Mirai family to target IoT devices, DeBeck stated.
+
+To continue reading this article register now
+
+[Get Free Access][7]
+
+[Learn More][8] Existing Users [Sign In][7]
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3411437/reports-as-the-iot-grows-so-do-its-threats-to-dns.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3273891/hybrid-cloud/dns-in-the-cloud-why-and-why-not.html
+[2]: https://www.networkworld.com/article/3322023/internet/dns-over-https-seeks-to-make-internet-use-more-private.html
+[3]: https://www.networkworld.com/article/3298160/internet/how-to-protect-your-infrastructure-from-dns-cache-poisoning.html
+[4]: https://www.networkworld.com/article/3331606/security/icann-housecleaning-revokes-old-dns-security-key.html
+[5]: https://www.icann.org/en/system/files/files/sac-105-en.pdf
+[6]: https://securityintelligence.com/posts/i-cant-believe-mirais-tracking-the-infamous-iot-malware-2/?cm_mmc=OSocial_Twitter-_-Security_Security+Brand+and+Outcomes-_-WW_WW-_-SI+TW+blog&cm_mmca1=000034XK&cm_mmca2=10009814&linkId=70790642
+[7]: javascript://
+[8]: https://www.networkworld.com/learn-about-insider/
diff --git a/sources/talk/20190724 When it comes to the IoT, Wi-Fi has the best security.md b/sources/talk/20190724 When it comes to the IoT, Wi-Fi has the best security.md
new file mode 100644
index 0000000000..2b5014dfa8
--- /dev/null
+++ b/sources/talk/20190724 When it comes to the IoT, Wi-Fi has the best security.md
@@ -0,0 +1,88 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (When it comes to the IoT, Wi-Fi has the best security)
+[#]: via: (https://www.networkworld.com/article/3410563/when-it-comes-to-the-iot-wi-fi-has-the-best-security.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+When it comes to the IoT, Wi-Fi has the best security
+======
+It’s easy to dismiss good ol’ Wi-Fi’s role in internet of things networking. But Wi-Fi has more security advantages than other IoT networking choices.
+![Ralph Gaithe / Soifer / Getty Images][1]
+
+When it comes to connecting internet of things (IoT) devices, there is a wide variety of networks to choose from, each with its own set of capabilities, advantages and disadvantages, and ideal use cases. Good ol’ Wi-Fi is often seen as a default networking choice, available in many places, but of limited range and not particularly suited for IoT implementations.
+
+According to [Aerohive Networks][2], however, Wi-Fi is “evolving to help IT address security complexities and challenges associated with IoT devices.” Aerohive sells cloud-managed networking solutions and was [acquired recently by software-defined networking company Extreme Networks for some $272 million][3]. And Aerohive's director of product marketing, Mathew Edwards, told me via email that Wi-Fi brings a number of security advantages compared to other IoT networking choices.
+
+It’s not a trivial problem. According to Gartner, in just the last three years, [approximately one in five organizations have been subject to an IoT-based attack][4]. And as more and more IoT devices come on line, the attack surface continues to grow quickly.
+
+**[ Also read: [Extreme targets cloud services, SD-WAN, Wi-Fi 6 with $210M Aerohive grab][3] and [Smart cities offer window into the evolution of enterprise IoT technology][5] ]**
+
+### What makes Wi-Fi more secure for IoT?
+
+What exactly are Wi-Fi’s IoT security benefits? Some of it is simply 20 years of technological maturity, Edwards said.
+
+“Extending beyond the physical boundaries of organizations, Wi-Fi has always had to be on the front foot when it comes to securely onboarding and monitoring a range of corporate, guest, and BYOD devices, and is now prepared with the next round of connectivity complexities with IoT,” he said.
+
+Specifically, Edwards said, “Wi-Fi has evolved … to increase the visibility, security, and troubleshooting of edge devices by combining edge security with centralized cloud intelligence.”
+
+Just as important, though, new Wi-Fi capabilities from a variety of vendors are designed to help identify and isolate IoT devices to integrate them into the wider network while limiting the potential risks. The goal is to incorporate IoT device awareness and protection mechanisms to prevent breaches and attacks through vulnerable headless devices. Edwards cited Aerohive’s work to “securely onboard IoT devices with its PPSK (private pre-shared key) technology, an authentication and encryption method providing 802.1X-equivalent role-based access, without the equivalent management complexities.”
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][6] ]**
+
+### The IoT is already here—and so is Wi-Fi
+
+Unfortunately, enterprise IoT security is not always a carefully planned and monitored operation.
+
+“Much like BYOD,” Edwards said, “many organizations are dealing with IoT without them even knowing it.” On the plus side, even as “IoT devices have infiltrated many networks , ... administrators are already leveraging some of the tools to protect against IoT threats without them even realizing it.”
+
+He noted that customers who have already deployed PPSK to secure guest and BYOD networks can easily extend those capabilities to cover IoT devices such as “smart TVs, projectors, printers, security systems, sensors and more.”
+
+In addition, Edwards said, “vendors have introduced methods to assign performance and security limits through context-based profiling, which is easily extended to IoT devices once the vendor can utilize signatures to identify an IoT device.”
+
+Once an IoT device is identified and tagged, Wi-Fi networks can assign it to a particular VLAN, set minimum and maximum data rates, data limits, application access, firewall rules, and other protections. That way, Edwards said, “if the device is lost, stolen, or launches a DDoS attack, the Wi-Fi network can kick it off, restrict it, or quarantine it.”
+
+### Wi-Fi still isn’t for every IoT deployment
+
+All that hardly turns Wi-Fi into the perfect IoT network. Relatively high costs and limited range mean it won’t find a place in many large-scale IoT implementations. But Edwards says Wi-Fi’s mature identification and control systems can help enterprises incorporate new IoT-based systems and sensors into their networks with more confidence.
+
+**More about 802.11ax (Wi-Fi 6)**
+
+ * [Why 802.11ax is the next big thing in wireless][7]
+ * [FAQ: 802.11ax Wi-Fi][8]
+ * [Wi-Fi 6 (802.11ax) is coming to a router near you][9]
+ * [Wi-Fi 6 with OFDMA opens a world of new wireless possibilities][10]
+ * [802.11ax preview: Access points and routers that support Wi-Fi 6 are on tap][11]
+
+
+
+Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3410563/when-it-comes-to-the-iot-wi-fi-has-the-best-security.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/03/hack-your-own-wi-fi_neon-wi-fi_keyboard_hacker-100791531-large.jpg
+[2]: http://www.aerohive.com/
+[3]: https://www.networkworld.com/article/3405440/extreme-targets-cloud-services-sd-wan-wifi-6-with-210m-aerohive-grab.html
+[4]: https://www.gartner.com/en/newsroom/press-releases/2018-03-21-gartner-says-worldwide-iot-security-spending-will-reach-1-point-5-billion-in-2018.
+[5]: https://www.networkworld.com/article/3409787/smart-cities-offer-window-into-the-evolution-of-enterprise-iot-technology.html
+[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[7]: https://www.networkworld.com/article/3215907/mobile-wireless/why-80211ax-is-the-next-big-thing-in-wi-fi.html
+[8]: https://%20https//www.networkworld.com/article/3048196/mobile-wireless/faq-802-11ax-wi-fi.html
+[9]: https://www.networkworld.com/article/3311921/mobile-wireless/wi-fi-6-is-coming-to-a-router-near-you.html
+[10]: https://www.networkworld.com/article/3332018/wi-fi/wi-fi-6-with-ofdma-opens-a-world-of-new-wireless-possibilities.html
+[11]: https://www.networkworld.com/article/3309439/mobile-wireless/80211ax-preview-access-points-and-routers-that-support-the-wi-fi-6-protocol-on-tap.html
+[12]: https://www.facebook.com/NetworkWorld/
+[13]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190725 How to transition into a career as a DevOps engineer.md b/sources/talk/20190725 How to transition into a career as a DevOps engineer.md
new file mode 100644
index 0000000000..05ae0f717e
--- /dev/null
+++ b/sources/talk/20190725 How to transition into a career as a DevOps engineer.md
@@ -0,0 +1,102 @@
+[#]: collector: (lujun9972)
+[#]: translator: (beamrolling)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to transition into a career as a DevOps engineer)
+[#]: via: (https://opensource.com/article/19/7/how-transition-career-devops-engineer)
+[#]: author: (Conor Delanbanque https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque)
+
+How to transition into a career as a DevOps engineer
+======
+Whether you're a recent college graduate or a seasoned IT pro looking to
+advance your career, these tips can help you get hired as a DevOps
+engineer.
+![technical resume for hiring new talent][1]
+
+DevOps engineering is a hot career with many rewards. Whether you're looking for your first job after graduating or seeking an opportunity to reskill while leveraging your prior industry experience, this guide should help you take the right steps to become a [DevOps engineer][2].
+
+### Immerse yourself
+
+Begin by learning the fundamentals, practices, and methodologies of [DevOps][3]. Understand the "why" behind DevOps before jumping into the tools. A DevOps engineer's main goal is to increase speed and maintain or improve quality across the entire software development lifecycle (SDLC) to provide maximum business value. Read articles, watch YouTube videos, and go to local Meetup groups or conferences—become part of the welcoming DevOps community, where you'll learn from the mistakes and successes of those who came before you.
+
+### Consider your background
+
+If you have prior experience working in technology, such as a software developer, systems engineer, systems administrator, network operations engineer, or database administrator, you already have broad insights and useful experience for your future role as a DevOps engineer. If you're just starting your career after finishing your degree in computer science or any other STEM field, you have some of the basic stepping-stones you'll need in this transition.
+
+The DevOps engineer role covers a broad spectrum of responsibilities. Following are the three ways enterprises are most likely to use them:
+
+ * **DevOps engineers with a dev bias** work in a software development role building applications. They leverage continuous integration/continuous delivery (CI/CD), shared repositories, cloud, and containers as part of their everyday work, but they are not necessarily responsible for building or implementing tooling. They understand infrastructure and, in a mature environment, will be able to push their own code into production.
+ * **DevOps engineers with an ops bias** could be compared to systems engineers or systems administrators. They understand software development but do not spend the core of their day building applications. Instead, they are more likely to be supporting software development teams to automate manual processes and increase efficiencies across human and technology systems. This could mean breaking down legacy code and using less cumbersome automation scripts to run the same commands, or it could mean installing, configuring, or maintaining infrastructure and tooling. They ensure the right tools are installed and available for any teams that need them. They also help to enable teams by teaching them how to leverage CI/CD and other DevOps practices.
+ * **Site reliability engineers (SRE)** are like software engineers that solve operations and infrastructure problems. SREs focus on creating scalable, highly available, and reliable software systems.
+
+
+
+In the ideal world, DevOps engineers will understand all of these areas; this is typical at mature technology companies. However, DevOps roles at top-tier banks and many Fortune 500 companies usually have biases towards dev or ops.
+
+### Technologies to learn
+
+DevOps engineers need to know a wide spectrum of technologies to do their jobs effectively. Whatever your background, start with the fundamental technologies you'll need to use and understand as a DevOps engineer.
+
+#### Operating systems
+
+The operating system is where everything runs, and having fundamental knowledge is important. [Linux is the operating system][4] you'll most likely use daily, although some organizations use Windows. To get started, you can install Linux at home, where you'll be able to break as much as you want and learn along the way.
+
+#### Scripting
+
+Next, pick a language to learn for scripting purposes. There are many to choose from ranging from Python, Go, Java, Bash, PowerShell, Ruby, and C/C++. I suggest [starting with Python][5]; it's one of the most popular for a reason, as it's relatively easy to learn and interpret. Python is often written to follow the fundamentals of object-oriented programming (OOP) and can be used for web development, software development, and creating desktop GUI and business applications.
+
+#### Cloud
+
+After [Linux][4] and [Python][5], I think the next thing to study is cloud computing. Infrastructure is no longer left to the "operations guys," so you'll need some exposure to a cloud platform such as Amazon Web Services, Azure, or Google Cloud Platform. I'd start with AWS, as it has an extensive collection of free learning tools that can take you down any track from using AWS as a developer, to operations, and even business-facing components. In fact, you might become overwhelmed by how much is on offer. Consider starting with EC2, S3, and VPC, and see where you want to go from there.
+
+#### Programming languages
+
+If you come to DevOps with a passion for software development, keep on improving your programming skills. Some good and commonly used languages in DevOps are the same as you would for scripting: Python, Go, Java, Bash, PowerShell, Ruby, and C/C++. You should also become familiar with Jenkins and Git/GitHub, which you'll use frequently within the CI/CD process.
+
+#### Containers
+
+Finally, start learning about [containerizing cod][6]e using tools such as Docker and orchestration platforms such as Kubernetes. There are extensive learning resources available for free online, and most cities will have local Meetup groups where you can learn from experienced people in a friendly environment (with pizza and beer!).
+
+#### What else?
+
+If you have less experience in development, you can still [get involved in DevOps][3] by applying your passion for automation, increasing efficiency, collaborating with others, and improving your work. I would still suggest learning the tooling described above, but with less emphasis on the coding/scripting languages. It will be useful to learn about Infrastructure-as-a-Service, Platform-as-a-Service, cloud platforms, and Linux. You'll likely be setting up the tools and learning how to build systems that are resilient and fault-tolerant, leveraging them while writing code.
+
+### Finding a DevOps job
+
+The job search process will differ depending on whether you've been working in tech and are moving into DevOps or you're a recent graduate beginning your career.
+
+#### If you're already working in technology
+
+If you're transitioning from one tech field into a DevOps role, start by exploring opportunities within your current company. Can you reskill by working with another team? Try to shadow other team members, ask for advice, and acquire new skills without leaving your current job. If this isn't possible, you may need to move to another company. If you can learn some of the practices, tools, and technologies listed above, you'll be in a good position to demonstrate relevant knowledge during interviews. The key is to be honest and not set yourself up for failure. Most hiring managers understand that you don't know all the answers; if you can show what you've been learning and explain that you're open to learning more, you should have a good chance to land a DevOps job.
+
+#### If you're starting your career
+
+Apply to open opportunities at companies hiring junior DevOps engineers. Unfortunately, many companies say they're looking for more experience and recommend you re-apply when you've gained some. It's the typical, frustrating scenario of "we want more experience," but nobody seems willing to give you the first chance.
+
+It's not all gloomy though; some companies focus on training and upskilling graduates directly out of the university. For example, [MThree][7], where I work, hires fresh graduates and trains them for eight weeks. When they complete training, participants have solid exposure to the entire SDLC and a good understanding of how it applies in a Fortune 500 environment. Graduates are hired as junior DevOps engineers with MThree's client companies—MThree pays their full-time salary and benefits for the first 18 to 24 months, after which they join the client as direct employees. This is a great way to bridge the gap from the university into a technology career.
+
+### Summary
+
+There are many ways to transition to become a DevOps engineer. It is a very rewarding career route that will likely keep you engaged and challenged—and increase your earning potential.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
+
+作者:[Conor Delanbanque][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
+[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
+[3]: https://opensource.com/resources/devops
+[4]: https://opensource.com/resources/linux
+[5]: https://opensource.com/resources/python
+[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
+[7]: https://www.mthreealumni.com/
diff --git a/sources/talk/20190725 IoT-s role in expanding drone use.md b/sources/talk/20190725 IoT-s role in expanding drone use.md
new file mode 100644
index 0000000000..a9281dcf40
--- /dev/null
+++ b/sources/talk/20190725 IoT-s role in expanding drone use.md
@@ -0,0 +1,61 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (IoT’s role in expanding drone use)
+[#]: via: (https://www.networkworld.com/article/3410564/iots-role-in-expanding-drone-use.html)
+[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
+
+IoT’s role in expanding drone use
+======
+Collision avoidance technology that uses internet of things (IoT) connectivity, AI, machine learning, and computer vision could be the key to expanding drone applications.
+![Thinkstock][1]
+
+As faithful readers of [TechWatch][2] (love you, Mom) may know, the rollout of many companies’ ambitious drone delivery services has not gone as quickly as promised. Despite recent signs of progress in Australia and the United States—not to mention [clever ideas for burger deliveries to cars stuck in traffic][3]—drone delivery remains a long way from becoming a viable option in the vast majority of use cases. And the problem affects many areas of drone usage, not just the heavily hyped drone delivery applications.
+
+According to [Grace McKenzie][4], director of operations and controller at [Iris Automation][5], one key restriction to economically viable drone deliveries is that the “skies are not safe enough for many drone use cases.”
+
+Speaking at a recent [SF New Tech “Internet of Everything” event in San Francisco][6], McKenzie said fear of collisions with manned aircraft is the big reason why the Federal Aviation Association (FAA) and international regulators typically prohibit drones from flying beyond the line of the sight of the remote pilot. Obviously, she added, that restriction greatly constrains where and how drones can make deliveries and is working to keep the market from growing test and pilot programs into full-scale commercial adoption.
+
+**[ Read also: [No, drone delivery still isn’t ready for prime time][7] | Get regularly scheduled insights: [Sign up for Network World newsletters][8] ]**
+
+### Detect and avoid technology is critical
+
+Iris Automation, not surprisingly, is in the business of creating workable collision avoidance systems for drones in an attempt to solve this issue. Variously called “detect and avoid” or “sense and avoid” technologies, these automated solutions are required for “beyond visual line of sight” (BVLOS) drone operations. There are multiple issues in play.
+
+As explained on Iris’ website, “Drone pilots are skilled aviators, but even they struggle to see and avoid obstacles and aircraft when operating drones at extended range [and] no pilot on board means low situational awareness. This risk is huge, and the potential conflicts can be extremely dangerous.”
+
+As “a software company with a hardware problem,” McKenzie said, Iris’ systems use artificial intelligence (AI), machine learning, computer vision, and IoT connectivity to identify and focus on the “small group of pixels that could be a risk.” Working together, those technologies are creating an “exponential curve” in detect-and-avoid technology improvements, she added. The result? Drones that “see better than a human pilot,” she claimed.
+
+### Bigger market and new use cases for drones
+
+It’s hardly an academic issue. “Not being able to show adequate mitigation of operational risk means regulators are forced to limit drone uses and applications to closed environments,” the company says.
+
+Solving this problem would open up a wide range of industrial and commercial applications for drones. Far beyond delivering burritos, McKenzie said that with confidence in drone “sense and avoid” capabilities, drones could be used for all kinds of aerial data gathering, from inspecting hydro-electric dams, power lines, and railways to surveying crops to fighting forest fires and conducting search-and-rescue operations.
+
+Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3410564/iots-role-in-expanding-drone-use.html
+
+作者:[Fredric Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Fredric-Paul/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/01/drone_delivery_package_future-100745961-large.jpg
+[2]: https://www.networkworld.com/blog/techwatch/
+[3]: https://www.networkworld.com/article/3396188/the-traffic-jam-whopper-project-may-be-the-coolestdumbest-iot-idea-ever.html
+[4]: https://www.linkedin.com/in/withgracetoo/
+[5]: https://www.irisonboard.com/
+[6]: https://sfnewtech.com/event/iot/
+[7]: https://www.networkworld.com/article/3390677/drone-delivery-not-ready-for-prime-time.html
+[8]: https://www.networkworld.com/newsletters/signup.html
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190725 Report- Smart-city IoT isn-t smart enough yet.md b/sources/talk/20190725 Report- Smart-city IoT isn-t smart enough yet.md
new file mode 100644
index 0000000000..da6d4ee57a
--- /dev/null
+++ b/sources/talk/20190725 Report- Smart-city IoT isn-t smart enough yet.md
@@ -0,0 +1,73 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Report: Smart-city IoT isn’t smart enough yet)
+[#]: via: (https://www.networkworld.com/article/3411561/report-smart-city-iot-isnt-smart-enough-yet.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+Report: Smart-city IoT isn’t smart enough yet
+======
+A report from Forrester Research details vulnerabilities affecting smart-city internet of things (IoT) infrastructure and offers some methods of mitigation.
+![Aleksandr Durnov / Getty Images][1]
+
+Security arrangements for smart-city IoT technology around the world are in an alarming state of disrepair, according to a report from Forrester Research that argues serious changes are needed in order to avoid widespread compromises.
+
+Much of what’s wrong has to do with a lack of understanding on the part of the people in charge of those systems and a failure to follow well-known security best practices, like centralized management, network visibility and limiting attack-surfaces.
+
+**More on IoT:**
+
+ * [What is the IoT? How the internet of things works][2]
+ * [What is edge computing and how it’s changing the network][3]
+ * [Most powerful Internet of Things companies][4]
+ * [10 Hot IoT startups to watch][5]
+ * [The 6 ways to make money in IoT][6]
+ * [What is digital twin technology? [and why it matters]][7]
+ * [Blockchain, service-centric networking key to IoT success][8]
+ * [Getting grounded in IoT networking and security][9]
+ * [Building IoT-ready networks must become a priority][10]
+ * [What is the Industrial IoT? [And why the stakes are so high]][11]
+
+
+
+Those all pose stiff challenges, according to “Making Smart Cities Safe And Secure,” the Forrester report by Merritt Maxim and Salvatore Schiano. The attack surface for a smart city is, by default, enormous, given the volume of Internet-connected hardware involved. Some device, somewhere, is likely to be vulnerable, and with the devices geographically spread out it’s difficult to secure all types of access to them.
+
+Worse still, some legacy systems can be downright impossible to manage and update in a safe way. Older technology often contains no provision for live updates, and its vulnerabilities can be severe, according to the report. Physical access to some types of devices also remains a serious challenge. The report gives the example of wastewater treatment plants in remote locations in Australia, which were sabotaged by a contractor who accessed the SCADA systems directly.
+
+In addition to the risk of compromised control systems, the generalized insecurity of smart city IoT makes the vast amounts of data that it generates highly suspect. Improperly configured devices could collect more information than they’re supposed to, including personally identifiable information, which could violate privacy regulations. Also, the data collected is analyzed to glean useful information about such things as parking patterns, water flow and electricity use, and inaccurate or compromised information can badly undercut the value of smart city technology to a given user.
+
+“Security teams are just gaining maturity in the IT environment with the necessity for data inventory, classification, and flow mapping, together with thorough risk and privacy impact assessments, to drive appropriate protection,” the report says. “In OT environments, they’re even further behind.”
+
+Yet, despite the fact that IoT planning and implementation doubled between 2017 and 2018, according to Forrester’s data, comparatively little work has been done on the security front. The report lists 13 cyberattacks on smart-city technology between 2014 and 2019 that had serious consequences, including widespread electricity outages, ransomware infections on hospital computers and emergency-service interruptions.
+
+Still, there are ways forward, according to Forrester. Careful log monitoring can keep administrators abreast of what’s normal and what’s suspicious on their networks. Asset mapping and centralizing control-plane functionality should make it much more difficult for bad actors to insert malicious devices into a smart-city network or take control of less-secure items. And intelligent alerting – the kind that provides contextual information, differentiating between “this system just got rained on and has poor connectivity” and “someone is tampering with this system” – should help cities be more responsive to security threats when they arise.
+
+Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3411561/report-smart-city-iot-isnt-smart-enough-yet.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/02/smart_city_smart_cities_iot_internet_of_things_by_aleksandr_durnov_gettyimages-971455374_2400x1600-100788363-large.jpg
+[2]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
+[3]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
+[4]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
+[5]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
+[6]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
+[7]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
+[8]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
+[9]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
+[10]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
+[11]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
+[12]: https://www.facebook.com/NetworkWorld/
+[13]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190725 Storage management a weak area for most enterprises.md b/sources/talk/20190725 Storage management a weak area for most enterprises.md
new file mode 100644
index 0000000000..859c1caa32
--- /dev/null
+++ b/sources/talk/20190725 Storage management a weak area for most enterprises.md
@@ -0,0 +1,82 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Storage management a weak area for most enterprises)
+[#]: via: (https://www.networkworld.com/article/3411400/storage-management-a-weak-area-for-most-enterprises.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+Storage management a weak area for most enterprises
+======
+Survey finds companies are adopting technology for such things as AI, machine learning, edge computing and IoT, but still use legacy storage that can't handle those workloads.
+![Miakievy / Getty Images][1]
+
+Stop me if you’ve heard this before: Companies are racing to a new technological paradigm but are using yesterday’s tech to do it.
+
+I know. Shocking.
+
+A survey of more than 300 storage professionals by storage vendor NGD Systems found only 11% of the companies they talked to would give themselves an “A” grade for their compute and storage capabilities.
+
+Why? The chief reason given is that while enterprises are rapidly deploying technologies for edge networks, real-time analytics, machine learning, and internet of things (IoT) projects, they are still using legacy storage solutions that are not designed for such data-intensive workloads. More than half — 54% — said their processing of edge applications is a bottleneck, and they want faster and more intelligent storage solutions.
+
+**[ Read also: [What is NVMe, and how is it changing enterprise storage][2] ]**
+
+### NVMe SSD use increases, but doesn't solve all needs
+
+It’s not all bad news. The study, entitled ["The State of Storage and Edge Computing"][3] and conducted by Dimensional Research, found 60% of storage professionals are using NVMe SSDs to speed up the processing of large data sets being generated at the edge.
+
+However, this has not solved their needs. As artificial intelligence (AI) and other data-intensive deployments increase, data needs to be moved over increasingly longer distances, which causes network bottlenecks and delays analytic results. And edge computing systems tend to have a smaller footprint than a traditional data center, so they are performance constrained.
+
+The solution is to process the data where it is ingested, in this case, the edge device. Separate the wheat from the chafe and only send relevant data upstream to a data center to be processed. This is called computational storage, processing data where it is stored rather than moving it around.
+
+According to the survey, 89% of respondents said they expect real value from computational storage. Conveniently, NGD is a vendor of computational storage systems. So, yes, this is a self-serving finding. This happens a lot. That doesn’t mean they don’t have a valid point, though. Processing the data where it lies is the point of edge computing.
+
+Among the survey’s findings:
+
+ * 55% use edge computing
+ * 71% use edge computing for real-time analytics
+ * 61% said the cost of traditional storage solutions continues to plague their applications
+ * 57% said faster access to storage would improve their compute abilities
+
+
+
+The study also found that [NVMe][2] is being adopted very quickly but is being hampered by price.
+
+ * 86% expect storage’s future to rely on NVMe SSDs
+ * 60% use NVMe SSDs in their work environments
+ * 63% said NVMe SSDs helped with superior storage speed
+ * 67% reported budget and cost as issues preventing the use of NVMe SSDs
+
+
+
+That last finding is why so many enterprises are hampered in their work. For whatever reason they are using old storage systems rather than new NVMe systems, and it hurts them.
+
+### GPUs won't improve workload performance
+
+One interesting finding: 70% of respondents said they are using GPUs to help improve workload performance, but NGD said those are no good.
+
+“We were not surprised to find that while more than half of respondents are actively using edge computing, more than 70% are using legacy GPUs, which will not reduce the network bandwidth, power and footprint necessary to analyze mass data-sets in real time,” said Nader Salessi, CEO and founder of NGD Systems, in a statement.
+
+That’s because GPUs lend themselves well to repetitive tasks and parallel processing jobs, while computational storage is very much a serial processing job, with the task constantly changing. So while some processing jobs will benefit from a GPU, a good number will not and the GPU is essentially wasted.
+
+Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3411400/storage-management-a-weak-area-for-most-enterprises.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/02/edge_computing_by_miakievy_gettyimages-957694592_2400x1600-100788315-large.jpg
+[2]: https://www.networkworld.com/article/3280991/what-is-nvme-and-how-is-it-changing-enterprise-storage.html
+[3]: https://ngd.dnastaging.net/brief/NGD_Systems_Storage_Edge_Computing_Survey_Report
+[4]: https://www.facebook.com/NetworkWorld/
+[5]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190726 NVMe over Fabrics enterprise storage spec enters final review process.md b/sources/talk/20190726 NVMe over Fabrics enterprise storage spec enters final review process.md
new file mode 100644
index 0000000000..f14dcd7d67
--- /dev/null
+++ b/sources/talk/20190726 NVMe over Fabrics enterprise storage spec enters final review process.md
@@ -0,0 +1,71 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (NVMe over Fabrics enterprise storage spec enters final review process)
+[#]: via: (https://www.networkworld.com/article/3411958/nvme-over-fabrics-enterprise-storage-spec-enters-final-review-process.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+NVMe over Fabrics enterprise storage spec enters final review process
+======
+The NVMe over Fabric (NVMe-oF) architecture is closer to becoming a formal specification. It's expected improve storage network fabric communications and network performance.
+![Gremlin / Getty Images][1]
+
+NVM Express Inc., the developer of the [NVMe][2] spec for enterprise SSDs, announced that its NVMe-oF architecture has entered a final 45-day review, an important step toward release of a formal specification for enterprise SSD makers.
+
+NVMe-oF stands for [NVMe over Fabrics][3], a mechanism to transfer data between a host computer and a target SSD or system over a network, such as Ethernet, Fibre Channel (FC), or InfiniBand. NVM Express first released the 1.0 spec of NVMe-oF in 2016, so this is long overdue.
+
+**[ Read also: [NVMe over Fabrics creates data-center storage disruption][3] ]**
+
+NVMe has become an important advance in enterprise storage because it allows for intra-network data sharing. Before, when PCI Express-based SSDs first started being used in servers, they could not easily share data with another physical server. The SSD was basically for the machine it was in, and moving data around was difficult.
+
+With NVMe over Fabrics, it’s possible for one machine to directly reach out to another for data and have it transmitted over a variety of high-speed fabrics rather than just Ethernet.
+
+### How NVMe-oF 1.1 improves storage network fabric communication
+
+The NVMe-oF 1.1 architecture is designed to improve storage network fabric communications in several ways:
+
+ * Adds TCP transport supports NVMe-oF on current data center TCP/IP network infrastructure.
+ * Asynchronous discovery events inform hosts of addition or removal of target ports in a fabric-independent manner.
+ * Fabric I/O Queue Disconnect enables finer-grain I/O resource management.
+ * End-to-end (command to response) flow control improves concurrency.
+
+
+
+### New enterprise features for NVMe 1.4
+
+The organization also announced the release of the NVMe 1.4 base specification with new “enterprise features” described as a further maturation of the protocol. The specification provides important benefits, such as improved quality of service (QoS), faster performance, improvements for high-availability deployments, and scalability optimizations for data centers.
+
+Among the new features:
+
+ * Rebuild Assist simplifies data recovery and migration scenarios.
+ * Persistent Event Log enables robust drive history for issue triage and debug at scale.
+ * NVM Sets and IO Determinism allow for better performance, isolation, and QoS.
+ * Multipathing enhancements or Asymmetric Namespace Access (ANA) enable optimal and redundant paths to namespaces for high availability and full multi-controller scalability.
+ * Host Memory Buffer feature reduces latency and SSD design complexity, benefiting client SSDs.
+
+
+
+The upgraded NVMe 1.4 base specification and the pending over-fabric spec will be demonstrated at the Flash Memory Summit August 6-8, 2019 in Santa Clara, California.
+
+Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3411958/nvme-over-fabrics-enterprise-storage-spec-enters-final-review-process.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/02/big_data_storage_businessman_walks_through_futuristic_data_center_by_gremlin_gettyimages-1098116540_2400x1600-100788347-large.jpg
+[2]: https://www.networkworld.com/article/3280991/what-is-nvme-and-how-is-it-changing-enterprise-storage.html
+[3]: https://www.networkworld.com/article/3394296/nvme-over-fabrics-creates-data-center-storage-disruption.html
+[4]: https://www.facebook.com/NetworkWorld/
+[5]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190729 Do you prefer a live demo to be perfect or broken.md b/sources/talk/20190729 Do you prefer a live demo to be perfect or broken.md
new file mode 100644
index 0000000000..b4b76aadd6
--- /dev/null
+++ b/sources/talk/20190729 Do you prefer a live demo to be perfect or broken.md
@@ -0,0 +1,82 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Do you prefer a live demo to be perfect or broken?)
+[#]: via: (https://opensource.com/article/19/7/live-demo-perfect-or-broken)
+[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeohttps://opensource.com/users/don-watkinshttps://opensource.com/users/jamesf)
+
+Do you prefer a live demo to be perfect or broken?
+======
+Do you learn more from flawless demos or ones the presenter de-bugs in
+real-time? Let us know by answering our poll.
+![video editing dashboard][1]
+
+At [DevFest DC][2] in June, [Sara Robinson][3], developer advocate at Google Cloud, gave the most seamless live demo I've ever witnessed.
+
+Sara live-coded a machine model from scratch using TensorFlow and Keras. Then she trained the model live, deployed it to Google's Cloud AI platform, and used the deployed model to make predictions.
+
+With the exception of perhaps one small hiccup, the whole thing went smoothly, and I learned a lot as an audience member.
+
+At that evening's reception, I congratulated Sara on the live demo's success and told her I've never seen a live demo go so well. It turns out that this subject was already on her mind; Sara asked this question on Twitter less than two hours before her live demo:
+
+> Do you prefer watching a live demo where everything works perfectly or one that breaks and the presenter has to de-bug?
+>
+> — Sara Robinson (@SRobTweets) [June 14, 2019][4]
+
+Contrary to my preference for flawless demos, two-thirds of Sara's followers prefer to watch de-bugging. The replies to her poll were equally enlightening:
+
+> I prefer ones that break once or twice, just so you know it's real. "Break" can be something small like a typo or skipping a step.
+>
+> — Seth Vargo (@sethvargo) [June 14, 2019][5]
+
+> Broken demos which are fixed in real time seem to get a better reaction from the audience. This was our experience with the All-Demo Super Session at NEXT SF. Audible gasps followed by applause from the audience when the broken demo was fixed in real-time 🤓
+>
+> — Jamie Kinney (@jamiekinney) [June 14, 2019][6]
+
+This made me reconsider my preference for perfection. When I attend live demos at events, I'm looking for tools that I'm unfamiliar with. I want to learn the basics of those tools, then see real-world applications. I don't expect magic, but I do want to see how the tools intend to work so I can gain and retain some knowledge.
+
+I've gone to several live demos that break. In my experience, this has caught most presenters off-guard; they seemed unfamiliar with the bugs at hand and, in one case, the error derailed the rest of the presentation. In short, it was like this:
+
+> Hmm, at least when the live demo fails you know it's not a video 😁
+> But I don't like when the presenter start to struggle, when everything becomes silent, it becomes so awkward (especially when I'm the one presenting)
+>
+> — Sylvain Nouts Ⓥ (@SylvainNouts) [June 14, 2019][7]
+
+Reading the replies to Sara's thread made me wonder what I'm really after when attending live demos. Is "perfection" what I seek? Or is it presenters who are more skilled at de-bugging in real-time? Upon reflection, I suspect that it's the latter.
+
+After all, "perfect" code is a lofty (if impossible) concept. Mistakes will happen, and I don't expect them not to. But I _do_ expect conference presenters to know their tools well enough that when things go sideways during live demos, they won't get so flustered that they can't keep going.
+
+Overall, this reply to Sara resonates with me the most. I attend live demos as a new coder with the goal to learn, and those that veer too far off-course aren't as effective for me:
+
+> I don’t necessarily prefer a broken demo, but I do think they show a more realistic view.
+> That said, when you are newer to coding if the error takes things too far off the rails it can make it challenging to understand the original concept.
+>
+> — April Bowler (@A_Bowler2) [June 14, 2019][8]
+
+I don't expect everyone to attend live demos with the same goals and perspective as me. That's why we want to learn what the open source community thinks.
+
+_Do you prefer for live demos to be perfect? Or do you gain more from watching presenters de-bug in real-time? Do you attend live demos primarily to learn or for other reasons? Let us know by taking our poll or leaving a comment below._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/live-demo-perfect-or-broken
+
+作者:[Lauren Maffeo][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lmaffeohttps://opensource.com/users/don-watkinshttps://opensource.com/users/jamesf
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
+[2]: https://www.devfestdc.org/
+[3]: https://twitter.com/SRobTweets
+[4]: https://twitter.com/SRobTweets/status/1139619990687162368?ref_src=twsrc%5Etfw
+[5]: https://twitter.com/sethvargo/status/1139620990546145281?ref_src=twsrc%5Etfw
+[6]: https://twitter.com/jamiekinney/status/1139636109585989632?ref_src=twsrc%5Etfw
+[7]: https://twitter.com/SylvainNouts/status/1139637154731237376?ref_src=twsrc%5Etfw
+[8]: https://twitter.com/A_Bowler2/status/1139648492953976832?ref_src=twsrc%5Etfw
diff --git a/sources/talk/20190729 Intent-Based Networking (IBN)- Bridging the gap on network complexity.md b/sources/talk/20190729 Intent-Based Networking (IBN)- Bridging the gap on network complexity.md
new file mode 100644
index 0000000000..86a3ea2b86
--- /dev/null
+++ b/sources/talk/20190729 Intent-Based Networking (IBN)- Bridging the gap on network complexity.md
@@ -0,0 +1,107 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Intent-Based Networking (IBN): Bridging the gap on network complexity)
+[#]: via: (https://www.networkworld.com/article/3428356/intent-based-networking-ibn-bridging-the-gap-on-network-complexity.html)
+[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
+
+Intent-Based Networking (IBN): Bridging the gap on network complexity
+======
+Intent-Based Networking was a result of the need for greater network automation.
+![IDG / Thinkstock][1]
+
+Networking has gone through various transformations over the last decade. In essence, the network has become complex and hard to manage using traditional mechanisms. Now there is a significant need to design and integrate devices from multiple vendors and employ new technologies, such as virtualization and cloud services.
+
+Therefore, every network is a unique snowflake. You will never come across two identical networks. The products offered by the vendors act as the building blocks for engineers to design solutions that work for them. If we all had a simple and predictable network, this would not be a problem. But there are no global references to follow and designs vary from organization to organization. These lead to network variation even while offering similar services.
+
+It is estimated that over 60% of users consider their I.T environment to be more complex than it was 2 years ago. We can only assume that network complexity is going to increase in the future.
+
+**[ Learn more about SDN: Find out [where SDN is going][2] and learn the [difference between SDN and NFV][3]. | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
+
+Large enterprises and service providers need to manage this complexity to ensure that all their traffic flows, policies and configurations are in line with requirements and objectives. You cannot manage a complex network in a manual way. Human error will always get you, eventually slowing down the network prohibiting agility.
+
+As I wrote about on Network Insight _[Disclaimer: the author is employed by Network Insight]_, the fact that the network is complex and error-prone is an [encouragement to automate][5]. How this actually happens, depends on the level of automation. Hence, a higher-level of orchestration is needed.
+
+### The need to modernize
+
+This complexity is compounded by the fact that the organizations are now looking to modernize their business processes and networks. The traditional vertically integrated monolithic networking solutions prohibit network modernization. This consequently creates a gap between the architect’s original intent and the actual runtime-behavior.
+
+If you examine, you will find that the contents of a design document are loosely coupled to the network execution. Primarily, there is no structured process as to how the design documents get translated and implemented to the actual devices. How it gets implemented is wide-open to individual interpretation.
+
+These networks were built for a different era. Therefore, we must now shift the focus from the traditional network prescriptive to Intent-Based Networking (IBN). IBN is a technology that has the capability to modernize the network and process in-line with the overall business objectives. This gives you the tight coupling of your design rules with your network.
+
+### The need for new tools
+
+Undoubtedly, we need new tools, not just from the physical device’s perspective, but also from the traffic’s perspective. Verifying the manual way will not work anymore. We have 100s of bits in the packet, meaning the traffic could be performing numerous talks at one time. Hence, tracking the end-to-end flow is impossible using the human approach.
+
+When it comes to provisioning, CLI is the most common method used to make configuration changes. But it has many drawbacks. Firstly, it offers the wrong level of abstraction. It targets the human operator and there is no validation whether the engineers will follow the correct procedures.
+
+Also, the CLI languages are not standardized across multi-vendors. The industry reacted and introduced NETCONF. However, NETCONF has many inconsistencies across the vendor operating systems. Many use their own proprietary format, making it hard to write NETCONF applications across multiple vendor networks.
+
+NETCONF was basically meant to make the automation easy but in reality, the irregularities it presented actually made the automation even more difficult. Also, the old troubleshooting tools that we use such as ping, traceroute does not provide a holistic assessment of how the network is behaving. Traceroute has problems with IP unnumbered links which is useful in the case of fully automated network environments. On the other hand, ping tells you nothing about how the network is performing. These tools were originally built for simpler times.
+
+We need to progress to a vendor-agnostic solution that can verify the intent against the configured policies. This should be regardless of the number of devices, the installed operating system, traffic rules and any other type of configured policy. We need networks to be automated and predictable. And the existing tools that are commonly used add no value.
+
+In a nutshell, we need a new model that can figure out all the device and traffic interactions, not just at the device level but the network-wide level.
+
+### IBN and SDN
+
+Software-Defined Networking (SDN) was a success in terms of interest, on the other hand, its adoption rate largely comprised of only the big players. These were the users who had the resources to build their own hardware and software, such as Google and Facebook.
+
+For example, Google’s B4 project to build an efficient Wide Area Network (WAN) in a dynamic fashion with flow-based optimization. However, this would be impossible to implement in case of a traditional WAN architecture on the production network.
+
+IBN is a natural successor to SDN as it borrows the same principles and architectures; a divide between the application and the network infrastructure. Similar to SDN, IBN is making software that controls the network as a whole, instead of device-to-device.
+
+Now the question that surfaces is can SDN, as a concept, automate as much as you want it to? Virtually, SDN uses software to configure the network, thereby driving a software-based network. But IBN is the next step where you have more of an explicit emphasis. Intent-Based systems work higher in the application level to offer true automation.
+
+### What is IBN?
+
+IBN was a result of the need for greater network automation. IBN is a technology that provides enhanced automation and network insights. It represents a paradigm shift that focuses on “what” the network is supposed to do versus “how” the network components are configured. It monitors if the network design is doing what it should be doing.
+
+IBN does this by generating the configuration for the design and device implementation. In addition, it continuously verifies and validates in real-time whether the original intent is being met. For example, if the desired intent is not being met, the system can take corrective action, such as modifying a QoS policy, VLAN or ACL. This makes the network more in-line with both; business objectives and compliance requirements.
+
+It uses declarative statements i.e. what the network should do as opposed to imperative statements that describe how it should be done. IBN has the capability to understand a large collection of heterogeneous networks which consist of a range of diverse devices that do not have one API. This substantially allows you to focus on the business needs rather than the constraints of traditional networking.
+
+### The IBN journey
+
+The first step on the road to IBN is to translate all of this into explicit logical rules which are essentially a piece of IBN software. You also need to understand the traffic to see if the reality is matching the intent. For this, the system would build a model of the network and then verify that model; this is known as formal verification in computer science. This is a method where we mathematically analyze the network to see if it's matching its intent. This involves certain calculations to encompass the logic.
+
+### Network verification
+
+Network verification is a key part of any IBN system. It requires an underlying mathematical model of the network behavior in order to analyze and reason out the targeted network design and policies. The systems need to verify all the conceivable packets flows and traffic patterns.
+
+Although there are no clear architectural guidelines for IBN a mathematical model can be used to treat every network device. This can be treated as a set of algebraic and logical operations on all the packet types and traffic flows at a per-device level. This allows the IBM system to evaluate and verify all the possible scenarios.
+
+When a device receives a packet, it can perform a number of actions. It can forward the packet to a particular port, drop the packet, or modify the packet header and then forward to a port. It’s up to the mathematical model to understand how each device responds to every possible type of packet and to evaluate the behavior at a network-wide level, not just at a device-level.
+
+Principally, the verification process must be end-to-end. It must collect the configuration files and state information from every device on the network. It then mathematically analyzes the behavior of all the possible traffic flows on a hop-by-hop basis. The IBM system builds a software model of the network infrastructure. This model first reads the Layer 2 to Layer 4 configuration details and then collects the state from each device (IP routing tables).
+
+With IBN we will see the shift from a reactive to a proactive approach. It will have a profound effect on the future of networking as we switch to a model that primarily focuses on the business needs and makes things easier. We are not as far down the road as one might think, but if you want to you can start your IBN journey today. So, the technology is there, and a phased deployment model is recommended. If you look at the deployment of IDS/IPS, you will find that most are still altering.
+
+**This article is published as part of the IDG Contributor Network. [Want to Join?][6]**
+
+Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3428356/intent-based-networking-ibn-bridging-the-gap-on-network-complexity.html
+
+作者:[Matt Conran][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Matt-Conran/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/01/nw_2018_intent-based_networking_cover_art-100747914-large.jpg
+[2]: https://www.networkworld.com/article/3209131/lan-wan/what-sdn-is-and-where-its-going.html
+[3]: https://www.networkworld.com/article/3206709/lan-wan/what-s-the-difference-between-sdn-and-nfv.html
+[4]: https://www.networkworld.com/newsletters/signup.html
+[5]: https://network-insight.net/2019/07/introducing-intent-based-networking-its-not-hype/
+[6]: https://www.networkworld.com/contributor-network/signup.html
+[7]: https://www.facebook.com/NetworkWorld/
+[8]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190730 From e-learning to m-learning- Open education-s next move.md b/sources/talk/20190730 From e-learning to m-learning- Open education-s next move.md
new file mode 100644
index 0000000000..cb5bd4baae
--- /dev/null
+++ b/sources/talk/20190730 From e-learning to m-learning- Open education-s next move.md
@@ -0,0 +1,87 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (From e-learning to m-learning: Open education's next move)
+[#]: via: (https://opensource.com/open-organization/19/7/m-learning-open-education)
+[#]: author: (Jim Hall https://opensource.com/users/jim-hallhttps://opensource.com/users/mysentimentshttps://opensource.com/users/petercheerhttps://opensource.com/users/jenkelchnerhttps://opensource.com/users/gkftii)
+
+From e-learning to m-learning: Open education's next move
+======
+"Open education" means more than teaching with open source software. It
+means being open to meeting students wherever they are.
+![A person looking at a phone][1]
+
+> "Access to computers and the Internet has become a basic need for education in our society."‒U.S. Senator Kent Conrad, 2004
+
+I spent seventeen years working in higher education, both as a campus technology leader and as an adjunct professor. Today, I continue as an adjunct professor. I know firsthand that educational technology is invaluable to the teaching and learning mission of universities—and that it changes at a rapid pace.
+
+Higher education is often an entrepreneurial space, seizing on new opportunities to deliver the best value. Too often, however, institutions spend a year or more to designing, bidding on, selecting, purchasing, building, or implementing new education technologies in the service of the teaching and learning mission. But in that yearlong interim, the technology landscape may change so much that the solution delivered no longer addresses the needs of the education community.
+
+What's more, technological solutions often re-entrench traditional educational models that aren't as effective today as they once were. The "closed" classroom featuring the model of teacher as a "sage on a stage" can no longer be the norm.
+
+Education needs to evolve and embrace new technologies and new modes of learning if we are to meet our students' needs.
+
+### Shifts in teaching and learning
+
+The next fundamental technological shift at universities will impact how students interface with teaching and learning. To understand the new learning landscape, let me first provide the context of previous methods.
+
+Learning has always been about students sitting in a classroom, pen and paper in hand, taking notes during a professor's lecture. We've experienced variations on this mode over time (such as small group breakout discussions and inverted classrooms) but most classes involve some version of this teaching model.
+
+In the 1980s, IBM introduced the IBM-PC, which put individual computing power into the hands of everyone, including students. Overnight, institutions needed to integrate the new technology into their pedagogies.
+
+The PC changed the teaching and learning landscape. Certainly students needed to learn the new software. Students previously wrote papers by hand—a methodology that directly mirrored work in the professional world. But with the introduction of the PC, modern students now needed to learn new skills.
+
+For example, writing-intensive courses could no longer expect students to use a standard typewriter to write papers. That would be like expecting handwritten papers in the era of the typewriter. "Keyboarding" became a new skill, replacing "typing" classes in most institutions. Rather than simply learning to type on a typewriter, students needed to learn the new "word processing" software available on the new PC.
+
+The thought process behind writing remains the same, only the tools change. In this case, the PC introduced an additional component to teaching and learning: Students learned the same writing _process_, but now learned new skills in the _mechanics_ of writing via word processing software.
+
+### M-learning means mobile learning
+
+Technology is changing, and will continue to evolve. How will students access information next year? Five years from now? Ten years from now? We cannot expect to rely on old models. And campuses need to look toward the technology horizon and consider how to prepare for that new landscape in the face of new technologies.
+
+Universities cannot rest on the accomplishments of e-learning. How students interface with e-learning continues to evolve, and is already changing.
+
+In response to today's ubiquitous computing trends across higher education, many institutions have already adopted electronic learning system, or "e-learning." If you have stepped into a college campus in the last few years, you'll already be familiar with central systems that provide a single place for students to turn in homework, respond to quizzes, interact with other students, ask questions of the instructor, receive grades, and track other progress in their courses. Universities that adopt e-learning are evolving to the classroom of the future.
+
+But these universities cannot rest on the accomplishments of e-learning. How students interface with e-learning continues to evolve, and is already changing.
+
+By my count, only two years ago students preferred laptops for their personal computing devices. Since then, smaller mobile devices have overtaken the classroom. Students still use laptops for _creating_ content, such as writing papers, but they increasingly use mobile devices such as phones to _consume_ content. This trend is increasing. According to research by Nielsen conducted a few years ago, [98% of surveyed Millennials aged 18 to 24 said they owned a smartphone][2].
+
+In a listening session with my campus, I heard one major concern from our students: How could they could access e-learning systems from their phones? With loud voices, students asked for e-learning interfaces that supported their smartphones. Electronic learning had shifted from "e-learning" to mobile learning, or "m-learning."
+
+In turn, this meant we needed better mobile carrier reception across campus. The focus changes again—this time, from providing high-quality, high-speed WiFi networks to every corner of campus to ensuring the mobile carriers could provide their own coverage across campus. With smartphones, and with m-learning, students now expect to "bring their network with them."
+
+### Finding the future landscape
+
+This radically changes the model of e-learning and how students access e-learning systems. M-learning is about responding to _the mobility of the student_, and recognizing that _students can continue to learn wherever they are_. Students don't want to be anchored to the four walls of a classroom.
+
+Our responsibility as stewards of education is to discover the next educational computing methods in partnership with the students we serve.
+
+How will the future unfold? The future is always changing, so I cannot give a complete picture of the future of learning. But I can describe the trends that we will see.
+
+Mobile computing and m-learning will only expand. In the next five years, campuses that have dedicated computer labs will be in the minority. Instead of dedicated spaces, students will need to access software and programs from these "labs" through a "virtual lab." If this sounds similar to today's model of a laptop connected to a virtual lab, that's to be expected. The model isn't likely to change much; education will be via m-learning and mobile devices for the foreseeable future.
+
+Even after education fully adopts m-learning, change will continue. Students won't stop discovering new ways of learning, and they'll demand those new methods from their institutions. We will move beyond m-learning to new modes we have yet to uncover. That's the reality of educational technology.
+
+Our responsibility as stewards of education is to discover the next educational computing methods _in partnership_ with the students we serve. To meet the challenges this future technology landscape presents us, we cannot expect an ivory tower to dictate how students will adopt technology. That era is long past. Instead, institutions need to work together with students—and examine how to adapt technology to serve students.
+
+_(This article is part of the_ [Open Organization Guide for Educators][3] _project.)_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/19/7/m-learning-open-education
+
+作者:[Jim Hall][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jim-hallhttps://opensource.com/users/mysentimentshttps://opensource.com/users/petercheerhttps://opensource.com/users/jenkelchnerhttps://opensource.com/users/gkftii
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_mobile_phone.png?itok=RqVtvxkd (A person looking at a phone)
+[2]: https://www.nielsen.com/us/en/insights/article/2016/millennials-are-top-smartphone-users/
+[3]: https://github.com/open-organization-ambassadors/open-org-educators-guide
diff --git a/sources/talk/20190730 Google Cloud to offer VMware data-center tools natively.md b/sources/talk/20190730 Google Cloud to offer VMware data-center tools natively.md
new file mode 100644
index 0000000000..e882248bf8
--- /dev/null
+++ b/sources/talk/20190730 Google Cloud to offer VMware data-center tools natively.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Google Cloud to offer VMware data-center tools natively)
+[#]: via: (https://www.networkworld.com/article/3428497/google-cloud-to-offer-vmware-data-center-tools-natively.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+Google Cloud to offer VMware data-center tools natively
+======
+Google is enlisting VMware and CloudSimple to serve up vSphere, NSX and vSAN software on Google Cloud to make ease the transition of enterprise workloads to the cloud.
+![Thinkstock / Google][1]
+
+Google this week said it would for the first time natively support VMware workloads in its Cloud service, giving customers more options for deploying enterprise applications.
+
+The hybrid cloud service called Google Cloud VMware Solution by CloudSimple will use VMware software-defined data center (SDCC) technologies including VMware vSphere, NSX and vSAN software deployed on a platform administered by CloudSimple for GCP.
+
+[RELATED: How to make hybrid cloud work][2]
+
+“Users will have full, native access to the full VMware stack including vCenter, vSAN and NSX-T. Google Cloud will provide the first line of support, working closely with CloudSimple to help ensure customers receive a streamlined product support experience and that their business-critical applications are supported with the SLAs that enterprise customers need,” Thomas Kurian, CEO of Google Cloud [wrote in a blog outlining the deal][3].
+
+“With VMware on Google Cloud Platform, customers will be able to leverage all of the familiarity of VMware tools and training, and protect their investments, as they execute on their cloud strategies and rapidly bring new services to market and operate them seamlessly and more securely across a hybrid cloud environment,” said Sanjay Poonen, chief operating officer, customer operations at VMware [in a statement][4].
+
+The move further integrates Google and VMware software as both have teamed up multiple times in the past including:
+
+ * Google Cloud integration for VMware NSX Service Mesh and SD-WAN by VeloCloud that lets customers deploy and gain visibility into their hybrid workloads—wherever they’re running.
+ * Google Cloud’s Anthos on VMware vSphere, including validations for vSAN, as the preferred hyperconverged infrastructure, to provide customers a multi-cloud offering and providing Kubernetes users the ability to create and manage persistent storage volumes for stateful workloads on-premises.
+ * A Google Cloud plug-in for VMware vRealize Automation providing customers with a seamless way to deploy, orchestrate and manage Google Cloud resources from within their vRealize Automation environment.
+
+
+
+Google is just one key cloud relationship VMware relies on. It has a deep integration with Amazon Web Services that began in 2017. With that flagship agreement, VMware customers can run workloads in the AWS cloud. And more recently, VMware cloud offerings can be bought directly through the AWS service.
+
+VMware also has a hybrid cloud partnership with [Microsoft’s Azure cloud service][5]. That package, called Azure VMware Solutions is built on VMware Cloud Foundation, which is a packaging of the company’s traditional compute virtualization software vSphere with its NSX network virtualization product and its VSAN software-defined storage area network product.
+
+More recently VMware bulked up its cloud offerings by [buying Avi Networks][6]' load balancing, analytics and application-delivery technology for an undisclosed amount.
+
+Founded in 2012 by a group of Cisco engineers and executives, Avi offers a variety of software-defined products and services including a software-based application delivery controller (ADC) and intelligent web-application firewall. The software already integrates with VMware vCenter and NSX, OpenStack, third party [SDN][7] controllers, as well as Amazon AWS and Google Cloud Platform, Red Hat OpenShift and container orchestration platforms such as Kubernetes and Docker.
+
+According to the company, the VMware and Avi Networks teams will work together to advance VMware’s Virtual Cloud Network plan, build out full stack Layer 2-7 services, and deliver the public-cloud experience for on-prem environments and data centers, said Tom Gillis, VMware's senior vice president and general manager of its networking and security business unit.
+
+Combining Avi Networks with [VMware NSX][8] will further enable organizations to respond to new opportunities and threats, create new business models and deliver services to all applications and data, wherever they are located, VMware stated.
+
+Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3428497/google-cloud-to-offer-vmware-data-center-tools-natively.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/07/google-cloud-services-100765812-large.jpg
+[2]: https://www.networkworld.com/article/3119362/hybrid-cloud/how-to-make-hybrid-cloud-work.html#tk.nww-fsb
+[3]: https://cloud.google.com/blog/topics/partners/vmware-cloud-foundation-comes-to-google-cloud
+[4]: https://www.vmware.com/company/news/releases/vmw-newsfeed.Google-Cloud-and-VMware-Extend-Strategic-Partnership.1893625.html
+[5]: https://www.networkworld.com/article/3113394/vmware-cloud-foundation-integrates-virtual-compute-network-and-storage-systems.html
+[6]: https://www.networkworld.com/article/3402981/vmware-eyes-avi-networks-for-data-center-software.html
+[7]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
+[8]: https://www.networkworld.com/article/3346017/vmware-preps-milestone-nsx-release-for-enterprise-cloud-push.html
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190730 IoT roundup- Connected cows, food safety sensors and tracking rent-a-bikes.md b/sources/talk/20190730 IoT roundup- Connected cows, food safety sensors and tracking rent-a-bikes.md
new file mode 100644
index 0000000000..e751d31d66
--- /dev/null
+++ b/sources/talk/20190730 IoT roundup- Connected cows, food safety sensors and tracking rent-a-bikes.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (IoT roundup: Connected cows, food safety sensors and tracking rent-a-bikes)
+[#]: via: (https://www.networkworld.com/article/3412141/iot-roundup-connected-cows-food-safety-sensors-and-tracking-rent-a-bikes.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+IoT roundup: Connected cows, food safety sensors and tracking rent-a-bikes
+======
+Farmers use LoRaWAN wireless with internet of things devices that monitor the health and location of beef cattle; restaurant chains use it to network IoT sensors that signal temperature shifts in commercial refrigerators.
+![Getty Images][1]
+
+While the public image of agriculture remains a bit antiquated, the industry is actually an increasingly sophisticated one, and farmers have been particularly enthusiastic in their embrace of the internet of things ([IoT][2]). Everything from GPS-guided precision for planting, watering and harvesting to remote soil monitoring and in-depth yield analysis is available to the modern farmer.
+
+What’s more, the technology used in agriculture continues to evolve at speed; witness the recent partnership between Quantified Ag, a University of Nebraska-backed program that, among other things, can track livestock health via a system of IoT ear tags, and Cradlepoint, a vendor that makes the NetCloud Manager product.
+
+**[ Now see: [How edge networking and IoT will reshape data centers][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
+
+Quantified Ag’s tags use [LoRaWAN][5] tech to transmit behavioral and biometric data to custom gateways installed at a farm, where the data is aggregated. Yet those gateways sometimes suffered from problems, particularly where unreliable wired connectivity and the complexities of working with an array of different rural ISPs were concerned. Enter Cradlepoint, which partnered up with an unnamed national cellular data provider to dramatically simplify the synchronization of data across a given implementation, as well as make it easier to deploy and provision new nodes.
+
+Simplicity is always a desirable quality in an IoT deployment, and single-pane-of-glass systems, provisioned by a single network, are a strong play for numerous IoT use cases.
+
+### LoRaWAN keeping food safe
+
+Even after the livestock is no longer, well, alive, IoT technology plays a role. Restaurants such as Five Guys and Shake Shack are integrating low-power WAN technology to connect temperature sensors into a network. Sort of an Internet of Burgers, if you will.
+
+According to an announcement earlier this month from Semtech, who makes the LoRaWAN devices in question, the restaurant chains join up-and-comers like Hattie B’s among those using IoT tech to improve food safety. The latter restaurant – a Nashville-based small chain noted for its spicy fried chicken – recently realized the benefits of such a system after a power outage. Instant notification that the refrigeration had died enabled the management to rescue tens of thousands of dollars’ worth of food inventory.
+
+Frankly, anything that saves fried chicken and burgers from wastage – and potentially, keeps their prices fractionally lower – is a good thing in our book, and Semtech argues (as it might be expected to) that the lower-frequency LoRa-based technology is a better choice for this application, given its ability to pass through obstacles like refrigerator and freezer doors with less attenuation than, for example, Bluetooth.
+
+### IoT tracking rental bikes**
+
+**
+
+Readers who live in urban areas will probably have noticed the rent-a-bike phenomenon spreading quickly of late. IoT connectivity provider Sigfox has, also, getting in on the action via a partnership with France-based INDIGO weel, a self-service bicycle fleet that was announced earlier this month.
+
+In this application, Sigfox’s proprietary wide area network technology is used to precisely track INDIGO’s bikes, deterring theft and damage. Sigfox also claims that the integration of its technology into the bike fleet will reduce costs, since reusable sensors can be easily transferred from one bike to another, and help users find the vehicle they need more quickly.
+
+Sigfox likes to talk about itself as an “IoT service provider,” and its large coverage footprint – the company claims to be operating in 60 countries – is a good fit for the kind of application that covers a lot of ground and might not require a great deal of bandwidth.
+
+### Vulnerability warning for IoT medical devices
+
+Per usual, several minor but alarming revelations about insecure, exploitable IoT devices have come to light this month. One advisory, [revealed by healthcare cybersecurity firm CyberMDX][6], said attackers could compromise GE Aestiva and Aespire anesthesia and respiration devices – changing the mix of gases that the patient breathes, altering the date and time on the machine or silencing alarms. (GE responded by pointing out that the compromise requires access to both the hospital’s network and an insufficiently secure terminal server, and urged users not to use such servers. Obviously, if devices don’t need to be on the network in the first place, that’s an even better solution.)
+
+Elsewhere, [an anonymous researcher at VPN Mentor][7] posted early this month that China-based smart home product maker Orvibo had (presumably by accident) opened up an enormous database to public view. The database contained 2 billion log entries, which covered email addresses, usernames, passwords and even geographic locations, based on its footprint of smart home devices installed in residences and hotels. The company has since cut off access to the database, but, still – not a great look for them.
+
+Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3412141/iot-roundup-connected-cows-food-safety-sensors-and-tracking-rent-a-bikes.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/08/nw_iot-news_internet-of-things_smart-city_smart-home7-100768495-large.jpg
+[2]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
+[3]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
+[4]: https://www.networkworld.com/newsletters/signup.html
+[5]: https://www.networkworld.com/article/3211390/lorawan-key-to-building-full-stack-production-iot-networks.html
+[6]: https://www.cybermdx.com/news/vulnerability-discovered-ge-anesthesia-respiratory-devices
+[7]: https://www.vpnmentor.com/blog/report-orvibo-leak/
+[8]: https://www.facebook.com/NetworkWorld/
+[9]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190731 Cisco simplifies Kubernetes container deployment with Microsoft Azure collaboration.md b/sources/talk/20190731 Cisco simplifies Kubernetes container deployment with Microsoft Azure collaboration.md
new file mode 100644
index 0000000000..423cd7180a
--- /dev/null
+++ b/sources/talk/20190731 Cisco simplifies Kubernetes container deployment with Microsoft Azure collaboration.md
@@ -0,0 +1,67 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Cisco simplifies Kubernetes container deployment with Microsoft Azure collaboration)
+[#]: via: (https://www.networkworld.com/article/3429116/cisco-simplifies-kubernetes-container-deployment-with-microsoft-azure-collaboration.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+Cisco simplifies Kubernetes container deployment with Microsoft Azure collaboration
+======
+Microsoft's Azure Kubernetes Service (AKS) has been added to the Kubernetes managed services that natively integrate with the Cisco Container Platform.
+![Viti / Getty Images][1]
+
+Cisco seeks to enhance container deployment with a service to let enterprise customers run containerized applications across both Cisco-based on-premises environments and in the Microsoft Azure cloud.
+
+Customers can now further simplify deploying and managing Kubernetes clusters on-premises and in Azure Kubernetes Service (AKS) with one tool, using common identify and control policies, reducing manual tasks and ultimately time-to-market for their application environments, wrote Cisco’s Kip Compton, senior vice president of the company’s Cloud Platform and Solutions group in a [blog][2] about the work.
+
+[RELATED: How to make hybrid cloud work][3]
+
+Specifically, AKS has been added to Kubernetes managed services that natively integrate with the [Cisco Container Platform][4]. Cisco introduced its Kubernetes-based Container Platform in January 2018 and said it allows for self-service deployment and management of container clusters.
+
+Cisco has added multivendor support to the platform, including support of SAP’s Data Hub to integrate large data sets that may be in public clouds, such as Amazon Web Services, Hadoop, Microsoft or Google, and integrate them with private cloud or enterprise apps such as SAP S/4 HANA.
+
+Kubernetes, originally designed by Google, is an open-source-based system for developing and orchestrating containerized applications. Containers can be deployed across multiple server hosts and Kubernetes orchestration lets customers build application services that span multiple containers, schedule those containers across a cluster, scale those containers and manage the container health.
+
+Cisco has been working to further integrate with Azure services for quite a while now. For example, the [Cisco Integrated System for Microsoft Azure Stack][5] lets organizations access development tools, data repositories, and related Azure services to reinvent applications and gain new information from secured data. Azure Stack provides the same APIs and user interface as the Azure public cloud.
+
+In future phases, the Cisco Container Platform will integrate more features to support Microsoft Windows container applications with the potential to leverage virtual-kubelet or Windows node pools in Azure, Compton stated. “In addition, we will support Azure Active Directory common identity integration for both on-prem and AKS clusters so customer/applications experience a single consistent environment across hybrid cloud.”
+
+In addition, Cisco has a substantial portfolio of offerings running in the Azure cloud and available in the Azure Marketplace. For example, the company offers its Cloud Services Router, CSV1000v, as well as Meraki vMX, Stealthwatch Cloud, the Adaptive Security Virtual Appliance and its Next Generation Firewall.
+
+The Azure work broadens Cisco’s drive into cloud. For example Cisco and [Amazon Web Services (AWS) offer][6] enterprise customers an integrated platform that promises to help them more simply build, secure and connect Kubernetes clusters across private data centers and the AWS cloud.
+
+The package, Cisco Hybrid Solution for Kubernetes on AWS, combines Cisco, AWS and open-source technologies to simplify complexity and helps eliminate challenges for customers who use Kubernetes to enable deploying applications on premises and across the AWS cloud in a secure, consistent manner. The hybrid service integrates Cisco Container Platform (CCP) and Amazon Elastic Container Service for Kubernetes (EKS), so customers can provision clusters on premises and on EKS in the cloud.
+
+Cisco [also released a cloud-service program][7] on its flagship software-defined networking (SDN) software that will let customers manage and secure applications running in the data center or in Amazon Web Service cloud environments. The service, Cisco Cloud application centric infrastructure (ACI) for AWS lets users configure inter-site connectivity, define policies and monitor the health of network infrastructure across hybrid environments, Cisco said.
+
+Meanwhile, Cisco and Google have done extensive work on their own joint cloud-development activities to help customers more easily build secure multicloud and hybrid applications everywhere from on-premises data centers to public clouds.
+
+Cisco and Google have been working closely together since October 2017, when the companies said they were working on an open hybrid cloud platform that bridges on-premises and cloud environments. That package, [Cisco Hybrid Cloud Platform for Google Cloud][8], became generally available in September 2018. It lets customer develop enterprise-grade capabilities from Google Cloud-managed Kubernetes containers that include Cisco networking and security technology as well as service mesh monitoring from Istio.
+
+Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429116/cisco-simplifies-kubernetes-container-deployment-with-microsoft-azure-collaboration.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/07/africa_guinea_conakry_harbor_harbour_shipping_containers_cranes_by_viti_gettyimages-1154922310_2400x1600-100802866-large.jpg
+[2]: https://www.networkworld.com/cms/article/%20https:/blogs.cisco.com/news/cisco-microsoft%20%E2%80%8E
+[3]: https://www.networkworld.com/article/3119362/hybrid-cloud/how-to-make-hybrid-cloud-work.html#tk.nww-fsb
+[4]: https://www.networkworld.com/article/3252810/cisco-unveils-container-management-on-hyperflex.html
+[5]: https://blogs.cisco.com/datacenter/cisco-integrated-system-for-microsoft-azure-stack-it-is-here-and-shipping
+[6]: https://www.networkworld.com/article/3319782/cisco-aws-marriage-simplifies-hybrid-cloud-app-development.html
+[7]: https://www.networkworld.com/article/3388679/cisco-taps-into-aws-for-data-center-cloud-applications.html
+[8]: https://cloud.google.com/cisco/
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190731 Remote code execution is possible by exploiting flaws in Vxworks.md b/sources/talk/20190731 Remote code execution is possible by exploiting flaws in Vxworks.md
new file mode 100644
index 0000000000..7fa6eaa226
--- /dev/null
+++ b/sources/talk/20190731 Remote code execution is possible by exploiting flaws in Vxworks.md
@@ -0,0 +1,85 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Remote code execution is possible by exploiting flaws in Vxworks)
+[#]: via: (https://www.networkworld.com/article/3428996/remote-code-execution-is-possible-by-exploiting-flaws-in-vxworks.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+Remote code execution is possible by exploiting flaws in Vxworks
+======
+
+![Thinkstock][1]
+
+Eleven zero-day vulnerabilities in WindRiver’s VxWorks, a real-time operating system in use across an advertised 2 billion connected devices have been discovered by network security vendor Armis.
+
+Six of the vulnerabilities could enable remote attackers to access unpatched systems without any user interaction, even through a firewall according to Armis.
+
+**About IoT:**
+
+ * [What is the IoT? How the internet of things works][2]
+ * [What is edge computing and how it’s changing the network][3]
+ * [Most powerful Internet of Things companies][4]
+ * [10 Hot IoT startups to watch][5]
+ * [The 6 ways to make money in IoT][6]
+ * [What is digital twin technology? [and why it matters]][7]
+ * [Blockchain, service-centric networking key to IoT success][8]
+ * [Getting grounded in IoT networking and security][9]
+ * [Building IoT-ready networks must become a priority][10]
+ * [What is the Industrial IoT? [And why the stakes are so high]][11]
+
+
+
+The vulnerabilities affect all devices running VxWorks version 6.5 and later with the exception of VxWorks 7, issued July 19, which patches the flaws. That means the attack windows may have been open for more than 13 years.
+
+Armis Labs said that affected devices included SCADA controllers, patient monitors, MRI machines, VOIP phones and even network firewalls, specifying that users in the medical and industrial fields should be particularly quick about patching the software.
+
+Thanks to remote-code-execution vulnerabilities, unpatched devices can be compromised by a maliciously crafted IP packet that doesn’t need device-specific tailoring, and every vulnerable device on a given network can be targeted more or less simultaneously.
+
+The Armis researchers said that, because the most severe of the issues targets “esoteric parts of the TCP/IP stack that are almost never used by legitimate applications,” specific rules for the open source Snort security framework can be imposed to detect exploits.
+
+VxWorks, which has been in use since the 1980s, is a popular real-time OS, used in industrial, medical and many other applications that require extremely low latency and response time. While highly reliable, the inability to install a security agent alongside the operating system makes it vulnerable, said Armis, and the proprietary source code makes it more difficult to detect problems.
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][12] ]**
+
+Armis argued that more attention has to be paid by security researchers to real-time operating systems, particularly given the explosive growth in IoT usage – for one thing, the researchers said, any software that doesn’t get thoroughly researched runs a higher risk of having serious vulnerabilities go unaddressed. For another, the critical nature of many IoT use cases means that the consequences of a compromised device are potentially very serious.
+
+“It is inconvenient to have your phone put out of use, but it’s an entirely different story to have your manufacturing plant shut down,” the Armis team wrote. “A compromised industrial controller could shut down a factory, and a pwned patient monitor could have a life-threatening effect.”
+
+In addition to the six headlining vulnerabilities, five somewhat less serious security holes were found. These could lead to consequences ranging from denial of service and leaked information to logic flaws and memory issues.
+
+More technical details and a fuller overview of the problem can be found at the Armis Labs blog post here, and there are partial lists available of companies and devices that run VxWorks available [on Wikipedia][13] and at [Wind River’s customer page][14]. Wind River itself issued a security advisory [here][15], which contains some potential mitigation techniques.
+
+Join the Network World communities on [Facebook][16] and [LinkedIn][17] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3428996/remote-code-execution-is-possible-by-exploiting-flaws-in-vxworks.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2017/09/iot-security11-100735405-large.jpg
+[2]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
+[3]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
+[4]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
+[5]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
+[6]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
+[7]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
+[8]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
+[9]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
+[10]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
+[11]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
+[12]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[13]: https://en.wikipedia.org/wiki/VxWorks#Notable_uses
+[14]: https://www.windriver.com/customers/
+[15]: https://www.windriver.com/security/announcements/tcp-ip-network-stack-ipnet-urgent11/security-advisory-ipnet/
+[16]: https://www.facebook.com/NetworkWorld/
+[17]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190731 VMware-s Bitfusion acquisition could be a game-changer for GPU computing.md b/sources/talk/20190731 VMware-s Bitfusion acquisition could be a game-changer for GPU computing.md
new file mode 100644
index 0000000000..4946824820
--- /dev/null
+++ b/sources/talk/20190731 VMware-s Bitfusion acquisition could be a game-changer for GPU computing.md
@@ -0,0 +1,58 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (VMware’s Bitfusion acquisition could be a game-changer for GPU computing)
+[#]: via: (https://www.networkworld.com/article/3429036/vmwares-bitfusion-acquisition-could-be-a-game-changer-for-gpu-computing.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+VMware’s Bitfusion acquisition could be a game-changer for GPU computing
+======
+VMware will integrate Bitfusion technology into vSphere, bolstering VMware’s strategy of supporting AI- and ML-based workloads by virtualizing hardware accelerators.
+![Vladimir Timofeev / Getty Images][1]
+
+In a low-key move that went under the radar of a lot of us, last week VMware snapped up a startup called Bitfusion, which makes virtualization software for accelerated computing. It improves performance of virtual machines by offloading processing to accelerator chips, such as GPUs, FPGAs, or other custom ASICs.
+
+Bitfusion provides sharing of GPU resources among isolated GPU compute workloads, allowing workloads to be shared across the customer’s network. This way workloads are not tied to one physical server but shared as a pool of resources, and if multiple GPUs are brought to bear, performance naturally increases.
+
+“In many ways, Bitfusion offers for hardware acceleration what VMware offered to the compute landscape several years ago. Bitfusion also aligns well with VMware’s ‘Any Cloud, Any App, Any Device’ vision with its ability to work across AI frameworks, clouds, networks, and formats such as virtual machines and containers,” said Krish Prasad, senior vice president and general manager of the Cloud Platform Business Unit at VMware, in a [blog post][2] announcing the deal.
+
+**[ Also read: [After virtualization and cloud, what's left on premises?][3] ]**
+
+When the acquisition closes, VMware will integrate Bitfusion technology into vSphere. Prasad said the inclusion of Bitfusion will bolster VMware’s strategy of supporting artificial intelligence- and machine learning-based workloads by virtualizing hardware accelerators.
+
+“Multi-vendor hardware accelerators and the ecosystem around them are key components for delivering modern applications. These accelerators can be used regardless of location in the environment—on-premises and/or in the cloud,” he wrote. The platform can be extended to support other accelerator chips, such as FGPAs and ASICs, he wrote.
+
+Prasad noted that hardware accelerators today are deployed “with bare-metal practices, which force poor utilization, poor efficiencies, and limit organizations from sharing, abstracting, and automating the infrastructure. This provides a perfect opportunity to virtualize them—providing increased sharing of resources and lowering costs.”
+
+He added: “The platform can share GPUs in a virtualized infrastructure as a pool of network-accessible resources rather than isolated resources per server.”
+
+This is a real game-changer, much the way VMware added storage virtualization and software-defined networks (SDN) to expand the use of vSphere. It gives them a major competitive advantage over Microsoft Hyper-V and Linux’s KVM now as well.
+
+By virtualizing and pooling GPUs, it lets users bring multiple GPUs to bear rather than locking one physical processor to a server and application. The same applies to FPGAs and the numerous AI processor chips either on or coming to market.
+
+### VMware also buys Uhana
+
+That wasn’t VMware’s only purchase. The company also acquired Uhana, which provides an AI engine specifically for telcos and other carriers that discovers anomalies in the network or application, prioritizes them based on their potential impact, and automatically recommends optimization strategies. That means improved network operations and operational efficiently.
+
+Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429036/vmwares-bitfusion-acquisition-could-be-a-game-changer-for-gpu-computing.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/08/clouded_view_of_data_center_server_virtualization_by_vladimir_timofeev_gettyimages-600404124_1200x800-100768156-large.jpg
+[2]: https://blogs.vmware.com/vsphere/2019/07/vmware-to-acquire-bitfusion.html
+[3]: https://https//www.networkworld.com/article/3232626/virtualization/extreme-virtualization-impact-on-enterprises.html
+[4]: https://www.facebook.com/NetworkWorld/
+[5]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190801 Cisco assesses the top enterprise SD-WAN technology drivers.md b/sources/talk/20190801 Cisco assesses the top enterprise SD-WAN technology drivers.md
new file mode 100644
index 0000000000..b6f845b4a7
--- /dev/null
+++ b/sources/talk/20190801 Cisco assesses the top enterprise SD-WAN technology drivers.md
@@ -0,0 +1,96 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Cisco assesses the top enterprise SD-WAN technology drivers)
+[#]: via: (https://www.networkworld.com/article/3429186/cisco-assesses-the-top-enterprise-sd-wan-technology-drivers.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+Cisco assesses the top enterprise SD-WAN technology drivers
+======
+Cisco SD-WAN customer National Instruments touts benefits of the technology: Speed, efficiency, security, cost savings
+![Getty Images][1]
+
+Cisco this week celebrated the [second anniversary][2] of its purchase of SD-WAN vendor Viptela and reiterated its expectation that 2019 will see the [technology change][3] enterprise networks in major ways.
+
+In a blog outlining trends in the SD-WAN world, Anand Oswal, Cisco senior vice president, engineering, in the company’s Enterprise Networking Business described how SD-WAN technology has changed the network for one of its customers, test and measurement systems vendor National Instruments.
+
+**More about SD-WAN**
+
+ * [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][4]
+ * [How to pick an off-site data-backup method][5]
+ * [SD-Branch: What it is and why you’ll need it][6]
+ * [What are the options for security SD-WAN?][7]
+
+
+
+“The existing WAN greatly constrained video conferencing, slowed large software transfers, and couldn’t provide acceptable application performance,” [Oswald wrote][8]. Implementing SD-WAN turned those issues around by:
+
+ * Reducing MPLS spending by 25% while increasing bandwidth by 3,075%
+ * Categorizing traffic by function and type, sending backup traffic over the Internet under an SLA, eliminating bandwidth bottleneck on MPLS circuits
+ * Reducing the time for software updates to replicate across the network from 8 hours to 10 minutes
+ * Adding new internet-based services used to take months, but with the agility of SD-WAN, new services can be deployed in the cloud immediately
+ * Eliminating the need for call -dmission controls and limiting video quality for conferencing
+
+
+
+National Instruments' bandwidth requirements were growing10 to 25 percent per year, overwhelming the budget, Luis Castillo, global network team manager told Cisco in a [case study][9] of the SD-WAN project. “Part of the problem was that these sites can have very different requirements. R&D shops need lots of bandwidth. One site may have a special customer that requires unique segmentation and security. Our contact centers need to support mission-critical voice services. All of that is dependent on the WAN, which means escalating complexity and constantly growing costs.”
+
+After the shift to SD-WAN, the company no longer has 80 people with diverse IT workloads copeting for a sinlge 10-Mbit circuit, Castillo says.
+
+It’s not just cost savings by supplementing or replacing MPLS with direct internet connections that is motivating the transition to software-defined WAN architecture, Oswald said. “It’s also about gaining flexibility and stability with intelligent, continuously monitored connections to multicloud resources and SaaS applications that are fueling the current SD-WAN transition.”
+
+In its most recent [SD-WAN Infrastructure Forecast][10], IDC researchers talked about a number of other factors driving SD-WAN evolution.
+
+"First, traditional enterprise WANs are increasingly not meeting the needs of today's modern digital businesses, especially as it relates to supporting SaaS apps and multi- and hybrid-cloud usage. Second, enterprises are interested in easier management of multiple connection types across their WAN to improve application performance and end-user experience," said [Rohit Mehra][11], vice president, [Network Infrastructure][12] at IDC. "Combined with the rapid embrace of SD-WAN by leading communications service providers globally, these trends continue to drive deployments of SD-WAN, providing enterprises with dynamic management of hybrid WAN connections and the ability to guarantee high levels of quality of service on a per-application basis."
+
+IDC also said that the SD-WAN infrastructure market continues to be highly competitive with sales increasing 64.9% in 2018 to $1.37 billion. IDC stated Cisco holds the largest share of the SD-WAN infrastructure market, with VMware coming in second followed by Silver Peak, Nokia-Nuage, and Riverbed.
+
+IDC also [recently wrote][13] about how security is also a key driver in recent SD-WAN deployments.
+
+“With SD-WAN, mission-critical traffic and assets can be partitioned and protected against vulnerabilities in other parts of the enterprise. This use case appears to be especially popular in verticals such as retail, healthcare, and financial,” IDC wrote.
+
+"SD-WAN can also protect application traffic from threats within the enterprise and from outside by leveraging a full stack of security solutions included in SD-WAN such as next-gen firewalls, IPS, URL filtering, malware protection, and cloud security.
+
+These security features can enable Layer 3-7 protection for WAN traffic regardless of where it's headed - to the cloud or to the data center, IDC wrote.
+
+Application traffic to the cloud straight from the branch can now be secured using an internet or cloud gateway, IDC wrote. Users, applications and their data at the branch edge can be protected by the stack of security solutions incorporated into the SD-WAN on-premises appliance, vCPE or router, which typically includes next-gen firewall, intrusion protection, malware protection and URL filtering, IDC wrote.
+
+Cisco [most recently][14] added support for its cloud-based security gateway – known as Umbrella – to its SD-WAN software offerings. According to Cisco, Umbrella can provide the first line of defense against threats on the internet. By analyzing and learning from internet activity patterns, Umbrella automatically uncovers attacker infrastructure and blocks requests to malicious destinations before a connection is even established — without adding latency for users. With Umbrella, customers can stop phishing and malware infections earlier, identify already infected devices faster and prevent data exfiltration, Cisco says.
+
+The Umbrella announcement is on top of other recent SD-WAN security enhancements the company has made. In May Cisco added support for Advanced Malware Protection (AMP) to its million-plus ISR/ASR edge routers in an effort to reinforce branch- and core-network malware protection across the SD-WAN. AMP support is added to a menu of security features already included in Cisco's SD-WAN software including support for URL filtering, Snort Intrusion Prevention, the ability to segment users across the WAN and embedded platform security, including the Cisco Trust Anchor module.
+
+Last year Cisco added its Viptela SD-WAN technology to the IOS XE version 16.9.1 software that runs its core ISR/ASR routers.
+
+Join the Network World communities on [Facebook][15] and [LinkedIn][16] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429186/cisco-assesses-the-top-enterprise-sd-wan-technology-drivers.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/08/2_networks_smart-city_iot_connected-100769196-large.jpg
+[2]: https://www.networkworld.com/article/3193888/why-cisco-needs-sd-wan-vendor-viptela.html
+[3]: https://blog.cimicorp.com/?p=3781
+[4]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
+[5]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
+[6]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
+[7]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
+[8]: https://blogs.cisco.com/author/anandoswal
+[9]: https://www.cisco.com/c/dam/en_us/services/it-case-studies/ni-case-study.pdf
+[10]: https://www.idc.com/getdoc.jsp?containerId=prUS45380319
+[11]: https://www.idc.com/getdoc.jsp?containerId=PRF003513
+[12]: https://www.idc.com/getdoc.jsp?containerId=IDC_P2
+[13]: https://www.cisco.com/c/dam/en/us/solutions/collateral/enterprise-networks/intelligent-wan/idc-tangible-benefits.pdf
+[14]: https://www.networkworld.com/article/3402079/cisco-offers-cloud-based-security-for-sd-wan-resources.html
+[15]: https://www.facebook.com/NetworkWorld/
+[16]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190801 Failure is a feature in blameless DevOps.md b/sources/talk/20190801 Failure is a feature in blameless DevOps.md
new file mode 100644
index 0000000000..d4a13a4e68
--- /dev/null
+++ b/sources/talk/20190801 Failure is a feature in blameless DevOps.md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Failure is a feature in blameless DevOps)
+[#]: via: (https://opensource.com/article/19/8/failure-feature-blameless-devops)
+[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
+
+Failure is a feature in blameless DevOps
+======
+In blameless DevOps culture, failure is more than an option; it's our
+friend.
+![failure sign at a party, celebrating failure][1]
+
+DevOps is just another term for _value stream development_. What does _value stream_ mean?
+
+Value is what arises during our interactions with customers and stakeholders. Once we get into value stream development, we quickly realize that value is not an entity. Value constantly changes. Value is a process. Value is a flow.
+
+Hence the term _stream_. Value is only value if it's a stream. And this streaming of value is what we call continuous integration (CI).
+
+### How do we generate value?
+
+No matter how carefully we specify value, its expectations tend to change. Therefore, the only realistic way to define and generate value is to solicit feedback.
+
+But it's obvious that no one is volunteering feedback. People are busy. We need to solicit feedback from our customers and stakeholders, but somehow, they always have something more pressing to do. Even if we throw a tantrum and insist that they stop what they're doing and give us much-needed feedback, at best we'd get a few lukewarm comments. Very little to go by. People are busy.
+
+We slowly learn that the most efficient and effective way to solicit feedback is to fail. Failure is a sure-fire way to make our customers and stakeholders drop everything, sit up, and pay attention. If we refuse to fail, we continue marching down the development path confidently, only to discover later that we're in the wrong.
+
+Agile DevOps culture is about dropping this arrogant stance and adopting the attitude of humility. We admit that we don't know it all, and we commit to a more humble approach to working on the value stream.
+
+It is of paramount importance to fail as soon as possible. That way, failure is not critical; it is innocuous, easy to overcome, easy to fix. But we need feedback to know how to fix it. The best feedback is reaction to failure.
+
+Let's illustrate this dynamic visually:
+
+![Value generation via feedback loop][2]
+
+Value generation via a feedback loop from continuous solicitation
+
+This figure illustrates the dynamics of producing value by soliciting feedback in a continuous, never-ending fashion.
+
+### Where does failure fit?
+
+Where in the above process do we see failure? Time for another diagram:
+
+![Failure is central to feedback loop][3]
+
+Failure is the central driving force enabling the delivery of value stream.
+
+_Failure is center stage_. Without failure, nothing useful ever gets done. From this, we conclude that failure is our friend.
+
+### How do we know we failed?
+
+In the ~~good~~ bad old days of waterfall methodology, the prime directive was "Failure is not an option." We worked under the pressure that every step must be a fully qualified success. We were going out of our way to avoid getting any feedback. Feedback was reserved for the momentous Big Bang event; the point when we all got an earful on how much the system we built missed the mark.
+
+That was, in a nutshell, the traditional way of learning that we failed. With the advent of agile and DevOps, we underwent cultural transformation and embraced incremental, iterative development processes. Each iteration starts with a mini failure, fixes it, and keeps going (mini being the keyword here). But how do we know if we failed?
+
+The only way to know for sure is to have a measurable test or goal. The measurable test will let us know if—and how—we failed.
+
+Now that we have set the stage and exposed the fundamentals of the blameless, failure-centric culture, the next article in this series will dive into a more detailed exposition on how to iterate over failed attempts to satisfy measurable tests and goals.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/failure-feature-blameless-devops
+
+作者:[Alex Bunardzic][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alex-bunardzic
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_failure_celebrate.png?itok=LbvDAEZF (failure sign at a party, celebrating failure)
+[2]: https://opensource.com/sites/default/files/uploads/valuestreamfeedbackloop.jpg (Value generation via feedback loop)
+[3]: https://opensource.com/sites/default/files/uploads/valuestreamfeedbackloopfailure.jpg (Failure is central to feedback loop)
diff --git a/sources/talk/20190801 IBM fuses its software with Red Hat-s to launch hybrid-cloud juggernaut.md b/sources/talk/20190801 IBM fuses its software with Red Hat-s to launch hybrid-cloud juggernaut.md
new file mode 100644
index 0000000000..c1c3ba375e
--- /dev/null
+++ b/sources/talk/20190801 IBM fuses its software with Red Hat-s to launch hybrid-cloud juggernaut.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (IBM fuses its software with Red Hat’s to launch hybrid-cloud juggernaut)
+[#]: via: (https://www.networkworld.com/article/3429596/ibm-fuses-its-software-with-red-hats-to-launch-hybrid-cloud-juggernaut.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+IBM fuses its software with Red Hat’s to launch hybrid-cloud juggernaut
+======
+IBM is starting a potentially huge run at hybrid cloud by tying more than 100 of its products to the Red Hat OpenShift platform.
+![Hans \(CC0\)][1]
+
+IBM has wasted no time aligning its own software with its newly acquired [Red Hat technoloogy][2],saying its portfolio would be transformed to work cloud natively and augmented to run on Red Hat’s OpenShift platform.
+
+IBM in July [finalized its $34 billion][3] purchase of Red Hat and says it will use the Linux powerhouse's open-source know-how and Linux expertise to grow larger scale hybrid-cloud customer projects and to create a web of partnerships to simplify carrying them out.
+
+**[ Check out [What is hybrid cloud computing][4] and learn [what you need to know about multi-cloud][5]. | Get regularly scheduled insights by [signing up for Network World newsletters][6]. ]**
+
+The effort has started with IBM bundling Red Hat’s Kubernetes-based OpenShift Container Platform with more than 100 IBM products in what it calls Cloud Paks. OpenShift lets enterprise customers deploy and manage containers on their choice of infrastructure of choice, be it private or public clouds, including AWS, Microsoft Azure, Google Cloud Platform, Alibaba and IBM Cloud.
+
+The prepackaged Cloud Paks include a secured Kubernetes container and containerized IBM middleware designed to let customers quickly spin-up enterprise-ready containers, the company said.
+
+Five Cloud Paks exist today: Cloud Pak for Data, Application, Integration, Automation and Multicloud Management. The Paks will ultimately include IBM’s DB2, WebSphere, [API Connect][7], Watson Studio, [Cognos Analytics][8] and more.
+
+In addition, IBM said it will bring the Red Hat OpenShift Container Platform over to IBM Z mainframes and IBM LinuxONE. Together these two platforms power about 30 billion transactions a day globally, [IBM said][9]. Some of the goals here are to increase container density and help customers build containerized applications that can scale vertically and horizontally.
+
+“The vision is for OpenShift-enabled IBM software to become the foundational building blocks clients can use to transform their organizations and build across hybrid, multicloud environments,” Hillery Hunter, VP & CTO IBM Cloud said in an [IBM blog][10] about the announcement.
+
+OpenShift is the underlying Kubernetes and Container orchestration layer that supports the containerized software, she wrote, and placing the Cloud Paks atop Red Hat OpenShift gives IBM a broad reach immediately. "OpenShift is also where the common services such as logging, metering, and security that IBM Cloud Paks leverage let businesses effectively manage and understand their workloads,” Hunter stated.
+
+Analysts said the moves were expected but still extremely important for the company to ensure this acquisition is successful.
+
+“We expect IBM and Red Hat will do the obvious stuff first, and that’s what this mostly is,” said Lee Doyle, principal analyst at Doyle Research. "The challenge will be getting deeper integrations and taking the technology to the next level. What they do in the next six months to a year will be critical.”
+
+Over the last few years IBM has been evolving its strategy to major on-cloud computing and cognitive computing. Its argument against cloud providers like AWS, Microsoft Azure, and Google Cloud is that only 20 percent of enterprise workloads have so far moved to the cloud – the easy 20 percent. The rest are the difficult 80 percent of workloads that are complex, legacy applications, often mainframe based, that have run banking and big business for decades, wrote David Terrar, executive advisor for [Bloor Research][11]. "How do you transform those?"
+
+That background gives IBM enterprise expertise and customer relationships competitors don't. “IBM has been talking hybrid cloud and multicloud to these customers for a while, and the Red Hat move is like an injection of steroids to the strategy, " Terrar wrote. "When you add in its automation and cognitive positioning with Watson, and the real-world success with enterprise-grade blockchain implementations like TradeLens and the Food Trust network, I’d argue that IBM is positioning itself as the ‘Enterprise Cloud Company’.”
+
+Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429596/ibm-fuses-its-software-with-red-hats-to-launch-hybrid-cloud-juggernaut.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2017/06/moon-2117426_1280-100726933-large.jpg
+[2]: https://www.networkworld.com/article/3317517/the-ibm-red-hat-deal-what-it-means-for-enterprises.html
+[3]: https://www.networkworld.com/article/3316960/ibm-closes-34b-red-hat-deal-vaults-into-multi-cloud.html
+[4]: https://www.networkworld.com/article/3233132/cloud-computing/what-is-hybrid-cloud-computing.html
+[5]: https://www.networkworld.com/article/3252775/hybrid-cloud/multicloud-mania-what-to-know.html
+[6]: https://www.networkworld.com/newsletters/signup.html
+[7]: https://www.ibm.com/cloud/api-connect
+[8]: https://www.ibm.com/products/cognos-analytics
+[9]: https://www.ibm.com/blogs/systems/announcing-our-direction-for-red-hat-openshift-for-ibm-z-and-linuxone/?cm_mmc=OSocial_Twitter-_-Systems_Systems+-+LinuxONE-_-WW_WW-_-OpenShift+IBM+Z+and+LinuxONE+BLOG+still+image&cm_mmca1=000001BT&cm_mmca2=10009456&linkId=71365692
+[10]: https://www.ibm.com/blogs/think/2019/08/ibm-software-on-any-cloud/
+[11]: https://www.bloorresearch.com/
+[12]: https://www.facebook.com/NetworkWorld/
+[13]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190801 Self-organizing micro robots may soon swarm the industrial IoT.md b/sources/talk/20190801 Self-organizing micro robots may soon swarm the industrial IoT.md
new file mode 100644
index 0000000000..6c2d36337b
--- /dev/null
+++ b/sources/talk/20190801 Self-organizing micro robots may soon swarm the industrial IoT.md
@@ -0,0 +1,85 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Self-organizing micro robots may soon swarm the industrial IoT)
+[#]: via: (https://www.networkworld.com/article/3429200/self-organizing-micro-robots-may-soon-swarm-the-industrial-iot.html)
+[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
+
+Self-organizing micro robots may soon swarm the industrial IoT
+======
+Masses of ant-like, self-organizing, microbots could soon perform tasks such as push objects in factories, swarm industrial production-line trouble-spots, and report environmental data.
+![Marc Delachaux / 2019 EPFL][1]
+
+Miniscule robots that can jump and crawl could soon be added to the [industrial internet of things][2]’ arsenal. The devices, a kind of printed circuit board with leg-like appendages, wouldn’t need wide networks to function but would self-organize and communicate efficiently, mainly with one another.
+
+Breakthrough inventions announced recently make the likelihood of these ant-like helpers a real possibility.
+
+**[ Also see: [What is edge computing?][3] and [How edge networking and IoT will reshape data centers][4] ]**
+
+### Vibration-powered micro robots
+
+The first invention is the ability to harness vibration from ultrasound and other sources, such as piezoelectric actuators, to get micro robots to respond to commands. The piezoelectric effect is when some kinds of materials generate an electrical charge in response to mechanical stresses.
+
+[Researchers at Georgia Tech have created 3D-printed micro robots][5] that are vibration powered. Only 0.07 inches long, the ant-like devices — which they call "micro-bristle-bots" — have four or six spindly legs and can can respond to differing quivering frequencies and move uniquely, based on their leg design.
+
+Researcher say the microbots could be used to sense environmental changes and to move materials.
+
+“As the micro-bristle-bots move up and down, the vertical motion is translated into a directional movement by optimizing the design of the legs,” says assistant professor Azadeh Ansari in a Georgia Tech article. Steering will be accomplished by frequencies and amplitudes. Jumping and swimming might also be possible, the researchers say.
+
+### Self-organizing micro robots that traverse any surface
+
+In another advancement, scientists at Ecole Polytechnique Fédérale de Lausanne (EPFL) say they have overcome limitations on locomotion and can now get [tiny, self-organizing robot devices to traverse any kind of surface][6]. Pushing objects in factories could be one use.
+
+The robots already jump, and now they self-organize. The Swiss school’s PCB-with-legs robots, en masse, figure for themselves how many fellow microbots to recruit for a particular job. Additionally, the ad hoc, swarming and self-organizing nature of the group means it can’t fail catastrophically—substitute robots get marshalled and join the work environment as necessary.
+
+Ad hoc networks are the way to go for robots. One advantage to an ad hoc network in IoT is that one can distribute the sensors randomly, and the sensors, which are basically nodes, figure out how to communicate. Routers don’t get involved. The nodes sample to find out which other nodes are nearby, including how much bandwidth is needed.
+
+The concept works on the same principal as how a marketer samples public opinion by just asking a representative group what they think, not everyone. Ants, too, size their nests like that—they bump into other ants, never really counting all of their neighbors.
+
+It’s a strong networking concept for locations where the sensor can get moved inadvertently. [I used the example of environmental sensors being strewn randomly in an active volcano][7] when I wrote about the theory some years ago.
+
+The Swiss robots (developed in conjunction with Osaka University) use the same concept. They, too, can travel to places requiring the environmental observation. Heat spots in a factory is one example. The collective intelligence also means one could conceivably eliminate GPS or visual feedback, which is unlike current aerial drone technology.
+
+### Even smaller industrial robots
+
+University of Pennsylvania professor Marc Miskin, presenting at the American Physical Society in March, said he is working on even smaller robots.
+
+“They could crawl into cellphone batteries and clean and rejuvenate them,” writes [Kenneth Chang in a New York Times article][8]. “Millions of them in a petri dish could be used to test ideas in networking and communications.”
+
+**More about edge networking:**
+
+ * [How edge networking and IoT will reshape data centers][4]
+ * [Edge computing best practices][9]
+ * [How edge computing can help secure the IoT][10]
+
+
+
+Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429200/self-organizing-micro-robots-may-soon-swarm-the-industrial-iot.html
+
+作者:[Patrick Nelson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Patrick-Nelson/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/08/epfl-robot-ants-100807019-large.jpg
+[2]: https://www.networkworld.com/article/3243928/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
+[3]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
+[4]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
+[5]: https://www.news.gatech.edu/2019/07/16/tiny-vibration-powered-robots-are-size-worlds-smallest-ant
+[6]: https://actu.epfl.ch/news/robot-ants-that-can-jump-communicate-and-work-toge/
+[7]: https://www.networkworld.com/article/3098572/how-new-ad-hoc-networks-will-organize.html
+[8]: https://www.nytimes.com/2019/04/30/science/microbots-robots-silicon-wafer.html
+[9]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
+[10]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
+[11]: https://www.facebook.com/NetworkWorld/
+[12]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20190805 Is your enterprise software committing security malpractice.md b/sources/talk/20190805 Is your enterprise software committing security malpractice.md
new file mode 100644
index 0000000000..7170e5a486
--- /dev/null
+++ b/sources/talk/20190805 Is your enterprise software committing security malpractice.md
@@ -0,0 +1,80 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Is your enterprise software committing security malpractice?)
+[#]: via: (https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+Is your enterprise software committing security malpractice?
+======
+ExtraHop discovered enterprise security and analytic software are "phoning home" and quietly uploading information to servers outside of customers' networks.
+![Getty Images][1]
+
+Back when this blog was dedicated to all things Microsoft I routinely railed against the spying aspects of Windows 10. Well, apparently that’s nothing compared to what enterprise security, analytics, and hardware management tools are doing.
+
+An analytics firm called ExtraHop examined the networks of its customers and found that their security and analytic software was quietly uploading information to servers outside of the customer's network. The company issued a [report and warning][2] last week.
+
+ExtraHop deliberately chose not to name names in its four examples of enterprise security tools that were sending out data without warning the customer or user. A spokesperson for the company told me via email, “ExtraHop wants the focus of the report to be the trend, which we have observed on multiple occasions and find alarming. Focusing on a specific group would detract from the broader point that this important issue requires more attention from enterprises.”
+
+**[ For more on IoT security, read [tips to securing IoT on your network][3] and [10 best practices to minimize IoT security vulnerabilities][4]. | Get regularly scheduled insights by [signing up for Network World newsletters][5]. ]**
+
+### Products committing security malpractice and secretly transmitting data offsite
+
+[ExtraHop's report][6] found a pretty broad range of products secretly phoning home, including endpoint security software, device management software for a hospital, surveillance cameras, and security analytics software used by a financial institution. It also noted the applications may run afoul of Europe’s [General Data Privacy Regulation (GDPR)][7].
+
+In every case, ExtraHop provided evidence that the software was transmitting data offsite. In one case, a company noticed that approximately every 30 minutes, a network-connected device was sending UDP traffic out to a known bad IP address. The device in question was a Chinese-made security camera that was phoning home to a known malicious IP address with ties to China.
+
+And the camera was likely set up independently by an employee at their office for personal security purposes, showing the downside to shadow IT.
+
+In the cases of the hospital's device management tool and the financial firm's analytics tool, those were violations of data security laws and could expose the company to legal risks even though it was happening without their knowledge.
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][8] ]**
+
+The hospital’s medical device management product was supposed to use the hospital’s Wi-Fi network to only ensure patient data privacy and HIPAA compliance. ExtraHop noticed traffic from the workstation that was managing initial device rollout was opening encrypted SSL:443 connections to vendor-owned cloud storage, a major HIPAA violation.
+
+ExtraHop notes that while there may not be any malicious activity in these examples, it is still in violation of the law, and administrators need to keep an eye on their networks to monitor traffic for unusual activity.
+
+"To be clear, we don’t know why these vendors are phoning home data. The companies are all respected security and IT vendors, and in all likelihood, their phoning home of data was either for a legitimate purpose given their architecture design or the result of a misconfiguration," the report says.
+
+### How to mitigate phoning-home security risks
+
+To address this security malpractice problem, ExtraHop suggests companies do these five things:
+
+ * Monitor for vendor activity: Watch for unexpected vendor activity on your network, whether they are an active vendor, a former vendor or even a vendor post-evaluation.
+ * Monitor egress traffic: Be aware of egress traffic, especially from sensitive assets such as domain controllers. When egress traffic is detected, always match it to approved applications and services.
+ * Track deployment: While under evaluation, track deployments of software agents.
+ * Understand regulatory considerations: Be informed about the regulatory and compliance considerations of data crossing political and geographic boundaries.
+ * Understand contract agreements: Track whether data is used in compliance with vendor contract agreements.
+
+
+
+**[ Now read this: [Network World's corporate guide to addressing IoT security][9] ]**
+
+Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2018/03/cybersecurity_eye-with-binary_face-recognition_abstract-eye-100751589-large.jpg
+[2]: https://www.extrahop.com/company/press-releases/2019/extrahop-issues-warning-about-phoning-home/
+[3]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
+[4]: https://www.networkworld.com/article/3269184/10-best-practices-to-minimize-iot-security-vulnerabilities#nww-fsb
+[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
+[6]: https://www.extrahop.com/resources/whitepapers/eh-security-advisory-calling-home-success/
+[7]: https://www.csoonline.com/article/3202771/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html
+[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[9]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
+[10]: https://www.facebook.com/NetworkWorld/
+[11]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20131228 Introduction to Clojure - Modern dialect of Lisp (Part 1).md b/sources/tech/20131228 Introduction to Clojure - Modern dialect of Lisp (Part 1).md
deleted file mode 100644
index 5e5f4df763..0000000000
--- a/sources/tech/20131228 Introduction to Clojure - Modern dialect of Lisp (Part 1).md
+++ /dev/null
@@ -1,1784 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Introduction to Clojure – Modern dialect of Lisp (Part 1))
-[#]: via: (https://www.creativeapplications.net/tutorials/introduction-to-clojure-part-1/)
-[#]: author: (Karsten Schmidt and Ricardo Sanchez https://www.creativeapplications.net/author/karstenricardo/)
-
-Introduction to Clojure – Modern dialect of Lisp (Part 1)
-======
-
-
-
-### Foreword by [Ricardo Sanchez][1]
-
-Back in March I had the pleasure to attend Karsten’s workshop at the 2013 [Resonate][2] conference in Belgrade, in it we learned how to work with audio and music while coding live using the Clojure programming language. It was great! I got so addicted to this new way of programming that it made me work on a little tutorial so I can share my experience with newcomers. After I finished my first draft I asked Karsten to do a technical review of it and he very kindly accepted. A couple of weeks months later we managed to expand & transform it into a comprehensive introductory article to Clojure and functional programming with a few very cool examples I hope you’ll enjoy. Without Karsten’s input this tutorial would never have been what it is today – so for that a big THANKS is due to him and the Resonate team for putting together such an awesome event.
-
-### Foreword by [Karsten Schmidt][3]
-
-Getting (back) into the [magical world of Lisp][4] had been on my to-do list for a long while, though my first encounter with Clojure in 2011 was through sheer coincidence (if you believe in such things!). It took me only a few hours to realise how this encounter was impeccable timing since there was this nagging feeling that I had become too accustomed to the status quo of the languages I’d been using for the last decade. Most importantly, I instinctively knew, I wanted to learn & use this language for my own work, badly & ASAP. And indeed, I’ve been fortunate enough to be able to use Clojure on several large projects since, from cloud based server apps/renderfarms to OpenGL/CL desktop apps and a [festival identity][5]. What I wasn’t quite prepared for were the many doors (of perception and inquiry) Clojure has opened wide in terms of process, thinking & learning about code from outside the boxes of our so beloved, popular languages & frameworks. Now, having been using it almost daily for 2.5 years, this tutorial, this labour of love, is largely meant to share some findings of this journey so far (though admittedly this first part is more of a crash course) – all in the hope to inspire some like-minded souls from this community, keen to help realising the untapped potential this language & its philosophy bring to the creative drafting table…
-
-Since this tutorial has grown well beyond the scope of a single article and there’s no [TL;DR][6] version, we will be releasing it in stages over the coming weeks…
-
-### Introduction
-
-This tutorial aims at giving you a taste of functional programming with [Clojure][7], a modern dialect of [Lisp][8] designed to run as an hosted language on the Java Virtual Machine (and an increasing number of other host platforms). Based on the [lambda calculus][9] theory developed by [Alonzo Church][10] in 1930s, the family of functional languages has a long history and forms one of the major branches in the big tree of available programming languages today. Largely through developments in hardware and the increasing numbers of cores in CPU chip designs, as well as through the appearance of languages like [Erlang][11], [F#][12], [Haskell][13], [Scala][14] & Clojure, the [functional philosophy][15] has been re-gaining traction in recent years, since it offers a solid and plausible approach to writing safe & scalable code on these modern hardware architectures. Core functional ideas are also slowly infiltrating long established bastions of the [Kingdom of Nouns][16], i.e. through the inclusion of lambda expressions in both the latest versions of [Java 8][17] and [C++11][18]. However, Clojure goes much further and its combined features (e.g. [immutability][19], [laziness][20], [sequence abstractions][21], extensible [protocols][22], [multimethods][23], [macros][24], [async constructs][25], choice of [concurrency primitives][26]) make it an interesting choice for approaching data intensive or distributed applications with a fresh mindset around lightweight modelling.
-
-### Sections:
-1\. Getting to know Clojure
-2\. Setting up an environment
-3\. Hello world, Hello REPL!
-4\. Clojure syntax summarized
-5\. Symbols
-6\. Vars & namespaces
-7\. Functions
-8\. Metadata
-9\. Truthiness, conditionals & predicates
-10\. Data structures
-11\. Common data manipulation functions
-12\. Sequences
-13\. Looping, iteration & recursive processing
-14\. Common sequence processing functions
-15\. Destructuring
-16\. Further reading & references
-
-### Getting to know Clojure
-
-Clojure is a young (first release in 2007) and opinionated language whose philosophy challenges/contrasts (just as much as [Rich Hickey][27], Clojure’s author, does) some commonly accepted assumptions about programming and software design. It therefore requires some serious unlearning and rethinking for anyone who’s ever only programmed in Processing, Java, C++ etc. (JavaScript programmers will find some of the ideas more familiar though, since that language too was heavily influenced by older Lisp implementations). So even if after working through this tutorial series you decide Clojure isn’t for you, the new perspectives should provide you with some food for thought and useful knowledge to continue on your journey.
-
-[As a reward for taking on this learning curve][28], you’ll gain access to ideas and tools, which (not just in our opinion) should excite anyone interested in a more “creative” computing process: a truly interactive programming environment without a write/compile/run cycle and live coding & manipulation even of long running complex systems, a language, which by design, removes an entire class of possible bugs, a super active, helpful community of thousands of users/seekers – and at the very least it will give you some alternative insights to common programming problems, regardless your chosen language. With the JVM as its current main host platform and Clojure’s seamless Java interop features, you’ll have full access to that language’s humungous ecosystem of open source libraries, often in [an easier way than Java itself][29]. Clojure’s sister project [ClojureScript][30] is equally making headway in the JavaScript world and there’re a number of efforts underway to port Clojure to other platforms (incl. [Android][31] and [native compilation via LLVM][32]).
-
-Clojure’s (and Lisp’s) syntax is a bit like [Marmite][33]: There’re probably as many people who love it as there’re who hate it, though in this case the objections are usually just caused by unfamiliarity. The seemingly large amount of parantheses present is one of the most immediately obvious and eye-grabbing aspects to any novice looking at Clojure/Lisp code. However, being a programming language, this a) is obviously by design, b) not strictly true, and c) is the result of [stripping out most other syntax][34] and special characters known from other languages: I.e. there’re no semicolons, no operator overloading, no curly brackets for defining scope etc. – even commas are optional and considered whitespace! All this leads to some concise, yet readable code and is further enhanced by the number of powerful algorithmic constructs the language offers.
-
-Whereas in a C-like language a simple function/method definition looks like this:
-
-```
-// C
-void greetings(char *fname, char *lname) {
- printf("hello %s %s\n", fname, lname);
-}
-
-// C++
-void greetings(const char *fname, const char *lname) {
- std::cout << "hello " << fname << " " << lname << std::endl;
-}
-
-// Java
-public void greetings(String fname, String lname) {
- System.out.println("hello " + name);
-}
-```
-
-...in Clojure it is:
-
-```
-(defn greetings [fname lname]
- (println "hello" fname lname))
-```
-
-Calling this function then:
-
-```
-// C-style
-greetings("Doctor", "Evil");
-
-; Clojure
-(greetings "Doctor" "Evil")
-```
-
-Clojure's philosophy to syntax is pure minimalism and boils down to the understanding that every piece of source code, as in any programming language, is merely a definition of an executable tree structure. Writing Clojure is literally defining the nested branches of that tree (identified by brackets, also called [S-expressions][35] or sexp, short for symbolic expressions). Even after a short while, you'll find these brackets seem to become automatic and mentally disappear (especially when using an appropriate text editor w/ support for [bracket matching][36], [rainbow brackets][37] and [structural editing features][38]).
-
-Also because this tutorial is more of a crash course and limited in scope, we can only provide you with a basic overview of core language features. Throughout the tutorial you will find lots of links for further reading and a list of Clojure related books at the end. Now, without much further ado, let's dive in...
-
-### Setting up an environment
-
-As with any programming language, we first need to ensure we've got some proper tooling in place, before we can begin our journey through unknown lands. Since Clojure is just a language and runtime environment, it doesn't have any specific requirements for editors and other useful tools. However, the Clojure community has developed and adopted a number of such tools, which make working with Clojure (even) more fun and the first one we introduce right away:
-
-### Leiningen
-
-These days most software projects are using a large number of open source libraries, which themselves often have further dependencies of their own. To anyone having ever worked with a language with an active community, life without a package manager seems like pure hell, trying to manage & install dependencies manually. [Leiningen][39] is the de-facto build tool used by the Clojure community, with its name being an [humorous take][40] on [Ant][41], the former de-facto build tool in the Java world. Lein calls itself a tool for "automating Clojure projects without setting your hair on fire". It's truly one of the easiest ways to get started with Clojure and is so much more than just a package manager, even though in this tutorial we'll be mainly using it as such. So please head over to the [Leiningen][39] website and follow the simple 3-step install procedure (or check your system package manager, e.g. [Homebrew][42] for OSX: `brew install leiningen`). **Regardless, you'll need to have an existing[Java installation][43] (Java 6 or newer) on your machine, before installing Leiningen...**
-
-> The Clojure community has developed integration plug-ins for several popular editors & IDEs and we will start working with one of them [Counterclockwise][44] in the next part of this tutorial. A list of other options can be found on the [Clojuredoc website][45].
-
-### Hello world, Hello REPL!
-
-As briefly mentioned in the beginning, Clojure provides us with a fully dynamic programming environment, called the REPL: The **(R)**ead, **(E)**valuate, **(P)**rint, **(L)**oop. The REPL reads input from the user, executes it, prints the result of the process, then rinse & repeat...
-
-The "read" phase converts source code into a data structure (mostly a nested list of lists). During "evaluation" this data structure is first compiled into Java byte code and then executed by the JVM. So unlike some other dynamic languages running on the JVM (e.g. [JRuby][46], [Rhino][47]), Clojure is a compiled language and in many cases can have similar performance characteristics as Java.
-
-The REPL quickly becomes the main sketch pad and development tool for many Clojure users, a space in which complex code is slowly built up from small parts, which can be immediately tested and experimented with, providing an uninterrupted experience.
-
-To start a REPL with leiningen, simply type `lein repl` on your command line and after a few moments, you should see a prompt like this:
-
-```
-$ lein repl
-nREPL server started on port 51443
-REPL-y 0.1.10
-Clojure 1.5.1
-Exit: Control+D or (exit) or (quit)
-Commands: (user/help)
- Docs: (doc function-name-here)
- (find-doc "part-of-name-here")
- Source: (source function-name-here)
- (user/sourcery function-name-here)
-Javadoc: (javadoc java-object-or-class-here)
-Examples from clojuredocs.org: [clojuredocs or cdoc]
- (user/clojuredocs name-here)
- (user/clojuredocs "ns-here" "name-here")
-user=> _
-```
-
-> Btw. The first time `lein` is run, it will download Clojure and possibly a number of other files/libraries. This only happens once and all files are stored/cached in this folder `~/.m2/repository`. REPL startup time will always take a few seconds due to the JVM initializations needed, however a REPL usually doesn't need to be restarted often, so in practice isn't an huge issue.
->
-> Should ever end up triggering an action which will make the REPL hang (e.g. trying to display an infinite sequence), you can press `Control+C` to cancel this action.
->
-> **If you don't want to (or can't) install Clojure/Leiningen, you can try out all of the examples in this part of the tutorial using the online REPL at[Try Clojure][48].**
-
-As is traditional, our first piece of Clojure code should be `(println "Hello World")`. So please go ahead and type it at the prompt. Once you hit `Enter`, the **(R)**ead phase of the REPL begins, turning our entered text into a stream of symbols. Provided there're no errors, these symbols are then **(E)**valuated according to the rules of the language, followed by **(P)**rinting the result of that code and **(L)**oop giving us a new prompt for input.
-
-```
-user=> (println "Hello World")
-Hello World
-nil
-user=> _
-```
-
-> **Input - > Process -> Output**
->
-> ...is one of the fundamental concepts in programming, especially in functional programming. If you look closely, you might be wondering where that `nil` came from? `nil` is Clojure's equivalent of `null` and here indicates that our `println` actually didn't produce any computational result. In fact, the display of "Hello World" was simply a side-effect of executing `println` (by pushing that string to your system's output stream), but the `println` function gave us no actual value back, which we might pass to another process. We will return to this important distinction later on when we'll talk about truthiness, predicates and pure functions.
-
-Some other brief examples:
-
-```
-(+ 1 2)
-; 3
-(+ (+ 1 2) (+ 3 4))
-; 10
-(+ 1 2 3 4)
-; 10
-```
-
-Looks weird, huh? At least no more `nil` is to be seen (of course we expected some results from an addition), and maybe you can already spot a pattern:
-
- 1. Operations seem to come first (this is called [prefix notation][49]) and
- 2. it seems the number of parameters/arguments doesn't matter...
-
-
-
-These are the kind of assumptions, you might make coming from an imperative programming background (Java/C etc.), where symbols like `+`, `-`, `/`, `*` or `=` actually are operators, basically symbols with pre-defined, hardcoded meanings and can only appear in certain places within the code. In Clojure however, there're no such operators and `+` is just defined as a standard function and that function accepts indeed a flexible number of params (as do all other basic math operators).
-
-### Clojure syntax summarized
-
-The syntax of Clojure/Lisp boils down to just this **one rule** and any Clojure form has this overall structure (no exceptions!):
-
-```
-(function param1 param2 ... paramN)
-```
-
-**Note:** Functions are processes and parameters (also called arguments) are their inputs. The number of params depends of course on the function, with some not requiring arguments at all.
-
-The parentheses define the scope of an S-expression (technically a list, but also a branch in the tree of our program), with its first element interpreted as a function to call. An important thing to consider at this stage is that all the elements (incl. the first) of such an expression can be (and often are) results of other function calls.
-
-Here we calculate the sum of two products, the [Pythagorean][50] (c2 = a2 + b2) of a fixed triangle with sides a = 4 and b = 8:
-
-```
-(+ (* 4 4) (* 8 8))
-; 80
-```
-
-![AST visualized][51]
-
-The image shows a visualization of the encoded tree structure we've written. The tree needs to be evaluated from the bottom to the top: The inner forms `(* 4 4)` and `(* 8 8)` are evaluated first before their sum can be computed. Clojure is read inside out. At first this might seem alien, but really just takes getting used to and doesn't prove problematic in practice, since most Clojure functions are often less than 10 lines long.
-
-### Symbols
-
-Symbols are used to name things and are at the heart of Clojure. Clojure code is evaluated as a tree of symbols, each of which can be bound to a value, but doesn't need to be. Of course in practice, it mostly means a symbol must have a bound value in order to work with it. Yet there're situations in Clojure when a symbol must remain unevaluated (as is) and we'll describe some of these in more detail when we discuss the `list` data type further below.
-
-Imagine for a moment to be in Clojure's shoes and we have to evaluate the form `(+ 1 2)`. The Reader simply provides us with a list of 3 symbols `+`, `1` and `2`. The latter two are easily identified as numbers and need no further treatment. The `+` however is a symbol we don't know and therefore need to look up first to obtain its value. Since that symbol is part of the core language, we find out it's bound to a function and then can call it with `1` and `2` as its arguments. Once the function returns, we can replace the whole form `(+ 1 2)` with its result, the value `3`. If this form was part of a larger form/computation, this result is then inserted back into it and the whole process repeats until all remaining forms & symbols have been resolved and a final value has been computed.
-
-Symbols are conceptually similar to variables in that both provide reusable, named references to data (and code). Yet, variables don't really exist in Clojure. The biggest difference to variables in other languages, is that by default a symbol is bound to a fixed value once, after which it can't be changed. This concept is called...
-
-#### Immutability
-
-[Immutability][19] isn't a well known concept among the (imperative) languages, which readers of this blog might be more familiar with. In fact, these languages are mainly built around its opposite, mutability - the ability to define data, pass it around via references/pointers and then change it (usually impacting multiple places of the codebase). The fact, that immutable data is read-only once it's been defined, provides the key feature for truly enabling safe multi-threaded applications and simplifies other programming tasks (e.g. easy comparison of nested values, general testability and the ability to safely reason over a function's behaviour). The presence of immutable data also leads to fundamental questions about the actual need for key topics in object oriented programming, e.g. the need for hiding data through encapsulation and all the resulting complexity is only required if a language doesn't provide features protecting data from direct 3rd party (i.e. user code) manipulation. This problem simply doesn't exist in Clojure! On the other hand immutability too provides one of the most challenging unlearning tasks for people coming from a world of mutable state, since it seems paradoxical to work it into any realworld system requiring constant changes to our data.
-
-Since no real application can exist without changing its internal state, throughout the course of this tutorial we will show how a) Clojure makes the most of immutability using persistent data structures, b) how actual mutable behaviour can be achieved where it is beneficial and c) show how mutable state can be easily avoided in most parts of a Clojure program. But for now please remember: **Clojure data is immutable by default.**
-
-> As an aside, unlike other functional languages like [Haskell][52] or [Scheme][53] where all data is truly 100% immutable and changing state can only be achieved through [Closures][54] & [Monads][55], Clojure takes a more pragmatic route and provides a number of mutable data types. However, each of those is intended for certain usage scenarios and we will only discuss two of them (Vars and Atoms) further below.
-
-#### Symbol bindings
-
-In most programming languages variables are based on [lexical scope][56]: Depending on the level at which a variable has been declared in a program, its binding is either global or local (e.g. local within a function or class). Clojure also provides lexical scope binding using the `let` form, giving us local, symbolic value bindings only existing within its body.
-
-The [`let`][57] form has this general structure and the last (often only) expression of its body becomes the final result:
-
-```
-(let [symbol value
- symbol value ...]
- body-expressions)
-```
-
-> Btw. The name `let` comes from mathematical texts, where we often say things like: "Let C be the sum of A and B" etc. To anyone with a previous career in BASIC, this should be familiar too...
-
-Sticking with our pythagorean example from above, we could wrap the computation inside a `let` form and introduce two symbols `a` and `b`:
-
-```
-(let [a 4 ; bind symbol a to 4
- b 8] ; bind symbol b to 8
- (+ (* a a) (* b b))) ; use symbols
-; 80
-
-a ; outside the let form symbol a is undefined
-CompilerException java.lang.RuntimeException: Unable to resolve symbol: a in this context
-```
-
-We will deal with `let` several more times throughout this tutorial.
-
-### Vars & namespaces
-
-Being restricted to only lexical scoped symbols defined with `let` is of course a painstaking way of programming, but thankfully isn't the whole truth. The basis of programming is "[Don't repeat yourself][58]" and that implies we need some form of mechanism to refer to existing values/processes defined elsewhere. In Clojure, this mechanism is implemented using Vars, named storage containers holding our data. Vars are named using symbols and can keep any datatype. They're always global within a given namespace, meaning they're visible from anywhere within that namespace and possibly others too.
-
-Namespaces are an important concept (not only) in Clojure to manage modularity and avoid naming conflicts. They're conceptually similar to [namespaces in C++][59], [packages in Java][60] or [modules in Python][61], although in Clojure have additional dynamic features. All Clojure code is evaluated as namespaced symbols and the language provides a rich set of functions to create, link and manipulate them. You can read more about them on the [Clojure website][62]. In the REPL the prompt will always show which namespace we're currently working in (default `user`).
-
-Back to Vars now, they're the closest thing to "traditional" variables in other languages, though are not equal: Whereas in many other languages a variable is a direct mapping from a named symbol to a value, in Clojure, symbols are mapped to Var objects, and only the Vars themselves provide a reference to their current values. This is an additional level of indirection, important for working in the dynamic environment of the REPL and in multi-threaded scenarios. For the latter, Vars provide a mechanism to be dynamically rebound to a new value on a per-thread basis and is one of Clojure's concurrency features we will discuss in a future part of this tutorial.
-
-![Clojure Vars explained][63]
-
-[`def`][64] is the general form used to define Vars. It is a special form which takes two arguments, but doesn't evaluate the first one and instead takes it literally to create a new Var of that name, which then holds the given value (if any). Vars can also be defined without a value, which keeps them initially unbound and is less common, but is sometimes needed to declare a Var for future reference.
-
-We used Vars a couple of times already: the `+`, `*` and `let` symbols are all bound to Vars defined in the [`clojure.core`][65] namespace. But let's define two vars ourselves and then pass their values to a process:
-
-```
-(def a 4)
-; #'user/a ; def returns the created var object
-a ; just providing a Var's name will return its value
-; 4
-(def b 8)
-; #'user/b
-b
-; 8
-(+ (* a a) (* b b)) ; Vars used in a computation
-; 80
-```
-
-> If we want to refer to a Var itself, rather than its value, we can use the `#'` prefix or the `var` function.
-
-To explain some more how Vars are used in the light of immutability, let's look at another example: In imperative languages like C, Java, JS etc. we have the `++` operator to increment a variable by one. Clojure has the [`inc`][66] function: It too takes a value and returns the value + 1. So we can apply this to our `a` and see what happens:
-
-```
-(inc a) ; returns a + 1
-; 5
-```
-
-Correct answer. But printing out `a` shows its value is still 4...
-
-```
-a
-; 4
-```
-
-This is because `inc` does not operate on the Var `a`, but only is given `a`'s current value `4`. The value returned by `inc` is entirely distinct and our `a` is never touched (apart from reading its value).
-
-**Vars should only be used to define values in the interactive programming context of the REPL or for pre-defined values in Clojure source files.** When we said that Vars are mutable, then this is only true in that they can be redefined with `def` (and some other advanced functions we won't cover here) to have new values, but practically, a Var should be considered unchangeable. Of course, one could write a function which uses `def` within its body to re-define a var with a new value, however this is considered non-idiomatic, generally bad form and is never seen in the wild. Just don't do it! If this is still confusing, we hope things will make more sense, once we've discussed Clojure's data structures and have seen how mutation of variables is actually not needed in practice.
-
-### Functions
-
-In stark contrast to object oriented languages like Java, where classes and objects are the primary unit of computation, Clojure is a functional language with functions at its heart. They're "first class", standalone entities in this language and should be considered equal to any other type of data/value. They're accepted as arguments to other functions and can also be constructed or returned as result from a function call. With functions playing such a key role in Clojure, they can be defined in different ways and be given a name, but don't need to.
-
-When defining a re-usable function, we most likely want to also give it a name so that we can easily refer to it again. To define a named function we use the built-in form [`defn`][67] (`def`'s sibling and short for "define function") and provide it with all the important things needed: a name, a list of inputs (parameters) and the body of the function (the actual code). In pseudo-code this then looks like this:
-
-```
-(defn name [parameters] body-expressions)
-```
-
-...applied to our above example this could be written like this:
-
-```
-(defn hypot
- [a b]
- (let [a (* a a)
- b (* b b)
- c (+ a b)]
- (Math/sqrt c)))
-```
-
-This implementation is not the most concise, but shows how we can use `let` to split up a computation into smaller steps and temporarily redefine symbols. We also make use of [Java interop features][68] to refer to Java's built-in [`Math`][69] class and compute the square root of that expression. According to Pythogoras, this is the actual length of the third side (the [Hypotenuse][70]) of the right-angled triangle given by `a` and `b`. A shorter alternative would be just this:
-
-```
-(defn hypot [a b] (Math/sqrt (+ (* a a) (* b b))))
-```
-
-If you're coming from a C-style language, you might wonder where we define the actual result (or return value) of this function. In Clojure this is implicitly given: **Just as with`let`, the result of the last expression in a function's path of execution is the result.**
-
-Now that we have defined our first function, we can call it like this:
-
-```
-(hypot 9 12) ; call fn with 9 & 12
-; 15.0
-(hypot a b) ; call fn with our Vars a=4 & b=8
-; 8.94427190999916
-```
-
-#### Anonymous functions
-
-A function without a name is called an anonymous function. In this case they're defined via the special form [`fn`][71], like this:
-
-```
-(fn [params] body-expressions)
-```
-
-Just like `defn`, this form takes a number of parameter names and body expressions. So another alternative would be to use `def` and the `fn` form to achieve the same function definition as above (`defn` is really just a short form of this combo):
-
-```
-(def hypot (fn [a b] (Math/sqrt (+ (* a a) (* b b)))))
-```
-
-Anonymous functions are often used with Cloure's data processing features (see further below), for callbacks or if the result of a function is another function, e.g. to pre-configure functions as explained next (readers with a JS background should also find the following familiar):
-
-Let's take another brief look at the `greetings` function we showed at the beginning of this tutorial:
-
-```
-(defn greetings [name] (println "hello" name))
-```
-
-Now, we assume such a greeting exists in other languages too, so we might want to define a German version as well:
-
-```
-(defn greetings-de [name] (println "hallo" name))
-```
-
-The only difference between the two is the first part of the greeting, so a more reusable alternative would be to redefine `greeting` to use two arguments:
-
-```
-(defn greetings [hello name] (println hello name))
-; #'user/greetings
-(greetings "hello" "toxi")
-; hello toxi
-```
-
-This is one of the situations where anonymous functions come into play, since we could define a `make-greetings` function which takes a single parameter (a greeting) and returns an anonymous function which then only requires a name, instead of a greeting **and** a name. Instead of using `println` we make use of the [`str`][72] function to concatenate values into a single string and return it as result.
-
-```
-(defn make-greetings
- [hello]
- (fn [name]
- (str hello " " name "!"))) ; str concatenates strings
-```
-
-With this in place, we can now define a couple of Vars holding such greeters for different languages and then use these directly:
-
-```
-(def greetings-es (make-greetings "Hola"))
-(def greetings-de (make-greetings "Guten Tag,"))
-```
-
-The new Vars `greetings-es` & `greetings-de` now contain the pre-configured functions returned by `make-greetings` and we can use them like this:
-
-```
-(greetings-es "Ricardo")
-; "Hola Ricardo!"
-(greetings-de "Toxi")
-; "Guten Tag, Toxi!"
-```
-
-> We call functions which consume or produce functions [Higher Order functions][73] (HOF) and they play a crucial role in the functional programming world. HOFs like the one above are used to achieve a concept called [Partial application][74] and the mechanism enabling it is called a [Closure][75], which should also explain Clojure's naming. We could also use the [`partial`][76] function to achieve what we've done here manually.
-
-#### Multiple arities & varargs
-
-Even though this isn't the place to go into details just yet, Clojure allows functions to provide multiple implementations based on the number of arguments/parameters given. This features enables a function to adjust itself to different usage contexts and also supports functions with a flexible number of parameters (also called varargs, discussed at the end of this article).
-
-#### Guards
-
-Errors are an intrinsic aspect of programming, but taking a defensive stance can help catching many of them early on during the design stage, also articulated through the "[Fail fast][77]" philosophy popular amongst software folk. Clojure supports this form of [Design-by-contract][78] approach, allowing us to specify arbitrary guard expressions for our functions and uses them to pre-validate inputs (parameters) and/or the output (post-validation). E.g. we might want to constrain the parameter to our `make-greetings` function to only allow strings with less than 10 characters and ensures the function returns a string...
-
-```
-(defn make-greetings
- [hello]
- {:pre [(string? hello) (< (count hello) 10)] ; pre-validation guards
- :post [(string? %)]} ; result validation
- (fn [name]
- (str hello " " name "!")))
-```
-
-Guards are given as a Clojure map (discussed further below) with `:pre`/`:post` keys, each containing a vector of boolean-valued expressions (also discussed further below; in our case it's a call to [`string?`][79], a so called predicate function, which only returns `true` if its argument is a string). Since the result of a function is an unnamed value, we use the `%` symbol to refer to it in the post-validatator. Attempting to call this guarded function with a non-string or too long greeting string will now result in an error even before the function executes:
-
-```
-(make-greetings nil)
-; AssertionError Assert failed: (string? hello) ...
-(make-greetings "Labas vakaras") ; apologies to Lithuanians...
-; AssertionError Assert failed: (< (count hello) 10)
-```
-
-[Mr. Fogus][80] and [Ian Rumford][81] have some further examples...
-
-### Metadata
-
-Before moving on to more exciting topics, let's briefly mention some more optional features of functions: metadata, documentation & type hints. The following function is an extended version of our `make-greetings` fn with these all of these things included:
-
-```
-(defn make-greetings
- "Takes a single argument (a greeting) and returns a fn which also
- takes a single arg (a name). When the returned fn is
- called, prints out a greeting message to stdout and returns nil."
- [^String greeting]
- (fn [^String name]
- (str greeting " " name "!")))
-```
-
-The string given between the function name and parameter list is a doc string and constitutes metadata added to the Var `make-greetings` defined by `defn`. Doc strings are defined for all built-in Clojure functions and generally can be read in the REPL using [`doc`][82]:
-
-```
-(doc make-greetings)
-; ([greeting])
-; Takes a single argument (a greeting) and returns a fn which also
-; takes a single arg (a name). When the returned fn is called,
-; prints out a greeting message to stdout and returns nil.
-```
-
-Clojure allows arbitrary metadata to be added to any datatype and this data can be created, read and manipulated with functions like [`meta`][83], [`with-meta`][84] and [`alter-meta`][85]. Please see the [Clojure website][86] for more information. E.g. to show us the complete metadata map for our `make-greetings` Var we can use:
-
-```
-(meta (var make-greetings))
-; {:arglists ([greeting]),
-; :ns #,
-; :name make-greetings,
-; :doc "Takes a single argument (a greeting)..."
-; :line 1,
-; :column 1,
-; :file "/private/var/..."}
-```
-
-Type hints attached to the function parameters were the other addition (and form of compiler metadata) used above. By specifying `^String` we indicate to the compiler that the following argument is supposed to be a String. Specifying type hints is optional and is an advanced topic, but can be very important for performance critical code. Again, we will have to refer you to the [Clojure website][87] for further details.
-
-### Truthiness, conditionals & predicates
-
-The concept of branching is one of the fundamental aspects in programming. Branching is required whenever we must make a decision at runtime based on some given fact and respond accordingly. In many programming languages, we use the Boolean values `true` and `false` to indicate the success or general "truth" value of something. These values exist in Clojure too, of course. However, in many places **Clojure applies a more general term for what constitutes truth (or "success") and considers any value apart from`false` or `nil` as `true`.** This includes **any** datatype!
-
-As you might expect, the basic boolean logic operations in Clojure are [`and`][88], [`or`][89] and [`not`][90]. The first two can take any number of arguments and each will be either `truthy` or not:
-
-```
-(or nil false true)
-; true
-(or 1 false) ; `or` bails at the first truthy value encountered
-; 1
-
-(and true nil false) ; `and` bails at the first falsy value encountered
-; nil
-(and true "foo") ; if all arguments are truthy, `and` returns the last
-; "foo"
-
-(not false)
-; true
-(not nil)
-; true
-(not 1)
-; false
-```
-
-An important aspect of `and` & `or` is that both are lazy, i.e. their arguments are only evaluated if any preceeding ones were falsy. Combined with Clojure's definition of truthiness and `and`/`or` returning not just boolean values, it's often possible avoid traditional branching in our code.
-
-For the cases where we do need proper branching, we can use the `if` and `when` forms:
-
-[`if`][91] takes a test expression and one or two body expressions of which only one will be executed based on the test result, in pseudo code:
-
-```
-(if test true-body-expression false-body-expression)
-```
-
-...in real terms:
-
-```
-(def age 16)
-
-(if (>= age 21)
- "beer"
- "lemonade")
-; "lemonade"
-```
-
-Being restricted to a single form for both the "truthy" and "falsy" branch is one important limitation of the `if` form, but is a reflection of Clojure's focus on using functions and an encouragement to limit side effects (i.e. I/O operations) to be only contained within functions. The second, falsy branch of `if` is also optional and if not needed, it is more idiomatic to use `when` instead. [`when`][92] is somewhat more flexible in these cases, since its body can contain any number of forms to be executed if the test succeeds:
-
-```
-(when (and (>= age 21) (< age 25))
- (println "Are you sure you're 21?")
- (println "Okay, here's your beer. Cheers!"))
-```
-
-To achieve a similar effect using `if` we can either wrap these two `println`'s in a function or use the [`do`][93] form, which is used as an invisible container for grouping (often side-effecting) actions and it returns the result of its last expression:
-
-```
-(do
- (expression-1)
- (expression-2)
- ...)
-```
-
-### Data structures
-
-Data lies at the heart of any application, big or small. Apart from dealing with primitive data like individual numbers, characters and strings, one of the biggest differences between programming languages (and therefore one of the most important factors for choosing one language over another) is in the ways complex data can be defined and manipulated. As we will see next, this aspect is one of Clojure's highlights, as the language not only provides a rich set of primitives (incl. ratios, big integers, arbitrary precision decimals, unicode characters, regular expressions), but also truly powerful approaches to model & process data, of which we can unfortunately only outline some in the scope of this tutorial.
-
-Before we discuss the various common data structures, we also need to point out once more that Clojure is an untyped, dynamic, yet compiled language. All of the following data structures can be fully recursive and contain any mixture of data types.
-
-For reference, a full list of Clojure data structures is available on the [Clojure Website][94]
-
-#### Lists
-
-Lists are sequential data containers of multiple values and form the heart of Clojure (and Lisp in general). In fact, the name "Lisp" is short for List Processing. We actually already know by now how lists are defined, having done so many times in the previous sections: Lists can take any number of elements and are defined with `(` and `)` or using the function [`list`][95]. We also know by now that lists are usually evaluated as a function calls, so trying to define a list of only numbers will not work as expected:
-
-```
-(1 2 3 4)
-; ClassCastException java.lang.Long cannot be cast to clojure.lang.IFn
-```
-
-Because the first element of our list is the number `1` (not a function!), Clojure will give us this error... Here's how & why:
-
-##### Homoiconicity
-
-Long story short: **In Clojure, code is data and data is (can be) code.** Languages using the same data structures for code and data are called homoiconic and all Lisps share this feature, as well as other languages like [R][96], [XSLT][97], [PostScript][98] etc.
-
-To treat code as data, we somehow need to circumvent the evaluation of our list as function call. To that purpose Clojure provides us with a `quote` mechanism to evaluate a data structure literally (as symbolic data). We can do this with any Clojure data structure to recursively stop evaluation of a form as code:
-
-```
-(quote (1 2 3 4))
-; (1 2 3 4)
-'(1 2 3 4) ; the apostrophe is a shorthand for `quote`
-; (1 2 3 4)
-'(+ 1 2)
-; (+ 1 2)
-(println "the result is" (+ 1 2))
-; the result is 3
-(println "the result of" '(+ 1 2) "is" (+ 1 2))
-; the result of (+ 1 2) is 3
-```
-
-The diagram below shows the impact of quoting and the difference of the resulting trees:
-
-![AST differences through quoting][99]
-
-We could also use the `list` function to programatically assemble a list/function (using our previously defined vars `a` and `b`) and then evaluate it with `eval`:
-
-```
-; first construct a function call using a list of individually quoted symbols
-(def a-plus-b (list '+ 'a 'b))
-; #'user/a-plus-b
-
-a-plus-b ; show resulting list
-; (+ a b)
-
-(eval a-plus-b) ; treat data as code: evaluate...
-; 12
-
-; treat code as data structure & look at the first item of that list
-(first a-plus-b)
-; # ; internal representation of `+` fn
-
-; next treat code as data: replace all occurrences of a & b w/ their square values
-; the {...} structure is a map of key => value pairs (discussed below):
-; any keys found in the original list are replaced with their values
-; so `a` is replaced with (* a a) and `b` with (* b b)
-; the map is also quoted to avoid the evaluation of its contents
-(replace '{a (* a a) b (* b b)} a-plus-b)
-; (+ (* a a) (* b b))
-
-; btw. if the map would *not* be quoted, it would be evaluated as:
-{a (* a a) b (* b b)}
-; {4 16, 8 64}
-
-(eval (replace '{a (* a a) b (* b b)} a-plus-b)) ; data as code again...
-; 80
-```
-
-> We will discuss the `first` function in more detail below.
-
-Right now, you might wonder why this is all worth pointing out. The most dramatic implication of homoiconicity is the enabling of [metaprogramming][100], the programmatic generation & manipulation of code at run time and by doing this, being able to define our own language constructs. It also opens the door to lazy evaluation of code or skipping code entirely depending on context (e.g. what happens with `and`/`or`). Unlike C's pre-processor, which only operates on the original textual representation of the source code (before the compile step and hence is severely limited and potentially more error prone), Lisps give us full access to the actual data structures as they're consumed by the machine. For example this makes Clojure an ideal candidate for [genetic programming][101] or to implement your own [domain specific language][102]. The main forms responsible for these kinds of code transformations are [macros][24] and we will leave them for another tutorial...
-
-Clojure lists have another important detail to know about: Because they're implemented as independent, linked elements, they can only be efficiently accessed at their head (the beginning of the list) and they don't provide direct, random access to any other elements. This restriction makes them less flexible than the next data structure, but still has some concrete use cases where this limitation doesn't matter: e.g. to implement [stacks][103].
-
-#### Vectors
-
-Since lists in Clojure are both limited in terms of access and are semantically overloaded (as containers of code), it's often more convenient to use another similar data type to store multiple values: vectors. Vectors are literally defined using `[` and `]` or the [`vector`][104] function and are, like lists, a sequential data structure. We already encountered vectors when defining the parameters for our functions above, but just for kicks, here we define a vector with each element using a different data type: number, string, character & keyword (the latter is explained in more detail in the next section)
-
-```
-[1 "2" \3 :4]
-; [1 "2" \3 :4]
-```
-
-Like lists, vectors can contain any number of elements. Unlike lists, but very much like arrays and vectors in others languages, they can also be accessed randomly using an element index. This can be done in multiple ways:
-
-```
-(def v [1 2 3 4])
-; #user/v
-(get v 0) ; using the `get` function with index 0
-; 1
-(get v 10 -1) ; using `get` with a default value -1 for missing items
-; -1
-(v 0) ; using the vector itself as function with index 0 as param
-; 1
-```
-
-#### Maps & keywords
-
-Maps are one of the most powerful data structures in Clojure and provide an associative mapping of key/value pairs. They're similar to [HashMaps][105] in Java or some aspects of [JavaScript objects][106], however both keys and values can of course be of any data type (incl. `nil`, functions or maps themselves). The most common data type for map keys however, are keywords.
-
-Keywords are simply symbols which evaluate to themselves (i.e. they have no other value attached). Within a given namespace only a single instance exists for each defined keyword. They can be created by prefixing a name with `:` or with the [`keyword`][107] function. Keywords can contain almost any character, but no spaces!
-
-```
-:my-key
-; :my-key
-(keyword (str "my-" "key")) ; kw built programmatically
-; :my-key
-```
-
-Back to maps now. They are defined with `{` and `}` or the [`hash-map`][108] function (plus a few other variations we will skip here). Here's a map with 3 keys (`:a :b :c`), each having a different data type as its value (also note that `:c`'s map uses strings as keys, much like [JSON][109] objects):
-
-```
-(def m {:a 23 :b [1 2 3] :c {"name" "toxi" "age" 38}})
-; {:a 23 :b [1 2 3] :c {"name" "toxi" "age" 38}}
-```
-
-Having defined a map structure, we can now lookup its values using keys. Once again many roads lead to Rome:
-
-```
-(m :a) ; use the map as function with :a as lookup key
-; 23
-(:b m) ; use key :b as function applied to m
-; [1 2 3]
-(get m :c) ; use get function with :c as key
-; {"name" "toxi", "age" 38}
-(:foo m) ; lookup a missing key returns nil
-; nil
-(get m :foo "nada") ; use get with default value for missing keys
-; "nada"
-```
-
-> Note, we can use both maps & keywords as functions, because both implement Clojure's mechanism for function calls. Depending on context, it's good to have both as an option.
-
-Since the values for `:b` and `:c` are nested data structures, we can continue this further...
-
-```
-((:b m) 2)
-; 3
-((:c m) "name")
-; "toxi"
-```
-
-Although this works, Clojure offers an alternative (nicer) approach, which becomes especially handy if our nesting increases: The [`get-in`][110] function allows us to specify a "path" (as vector) into our data structure to look up a nested value. As we saw already with `get`, this function can be applied to both vectors and maps (or a mixture of both):
-
-```
-(def db {:toxi {:name "Karsten"
- :address {:city "London"}
- :urls ["http://toxiclibs.org" "http://thi.ng"]}
- :nardove {:name "Ricardo"
- :urls ["http://nardove.com"]}})
-
-(get-in db [:toxi :address :city])
-; "London"
-(get-in db [:nardove :address :city] "I think Bournemouth")
-; "I think Bournemouth"
-(get-in db [:nardove :urls 0])
-; "http://nardove.com"
-```
-
-[`select-keys`][111] can be used to extract a sub-set of keys from a map. The new map only contains the keys listed as arguments (if present in the map):
-
-```
-(select-keys m [:a :b :foo]) ; :foo isn't present in `m` so won't be in result...
-; {:a 23 :b [1 2 3]}
-```
-
-#### Sets
-
-Sets are incredibly useful whenever we must deal with unique values, but don't care about their ordering. The name comes from [Set theory][112] in Mathematics. A Clojure set is (usually) unordered and will never contain more than a single instance of a given value. We will exploit this fact in the next part of the tutorial to build up our first full example application. Sets are defined like this:
-
-```
-#{1 2 3 4}
-; #{1 2 3 4}
-#{1 1 2 3 4}
-; IllegalArgumentException Duplicate key: 1
-```
-
-Be aware, that the literal definition syntax of sets **doesn't allow duplicate values**. However we can use it's functional equivalent:
-
-```
-(hash-set 1 1 2 3 4)
-; #{1 2 3 4}
-```
-
-...or we could use the [`set`][113] or [`into`][114] functions to convert another data structure into a set and hence filter out any duplicate values from the original (of course without destroying the original!):
-
-```
-(def lucky-numbers [1 2 3 4 4 2 1 3])
-; #user/my-vals
-(set lucky-numbers)
-; #{1 2 3 4}
-(into #{} lucky-numbers)
-; #{1 2 3 4}
-lucky-numbers
-; [1 2 3 4 4 2 1 3]
-```
-
-Since a set can be considered a special kind of map in which keys have no values, but are simply mapped to themselves, we can use the same lookup approaches to check if a value is present or not.
-
-```
-(get #{1 2 3 4} 3)
-; 3
-(#{1 2 3 4} 5)
-; nil
-(get #{1 2 3 4} 5 :nope)
-; :nope
-```
-
-As a slightly more practical example, let's define a nested set of sets to encode the following mini social graph:
-
-![Dummy undirected social graph][115]
-
-```
-(def g
- #{#{:toxi :ricardo}
- #{:mia :toxi}
- #{:filip :toxi}
- #{:filip :ricardo}})
-```
-
-Let's also define a simple lookup function (a predicate) to check if two people know each other:
-
-```
-(defn knows?
- "Takes a graph and two node names, returns true if the graph contains
- a relationship between the nodes (ignoring direction)"
- [graph a b]
- (not (nil? (graph #{a b}))))
-```
-
-> The [`nil?`][116] function returns true if its given argument is `nil`.
-
-Now we can use this function to get some answers (the order of names doesn't matter):
-
-```
-(knows? g :toxi :filip)
-; true
-(knows? g :ricardo :toxi)
-; true
-(knows? g :filip :mia)
-; false
-```
-
-### Common data manipulation functions
-
-Even in the face of immutability, what good is a data structure, if it can't be manipulated? One of the most often quoted and popular sayings amongst Clojurians is:
-
-> "It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures."
-> \-- Alan J. Perlis
-
-It neatly sums up Clojure's approach to data processing and is achieved through a number of elegant abstraction mechanisms, allowing dozens of core language functions to work polymorphically with different types of data. [Polymorphism][117] allows for a very small, but powerful API and so reduces cognitive load for the programmer. Because each of the above mentioned data structures has its own peculiarities, the concrete behaviour of the functions discussed below slightly varies and adjusts to each data type.
-
-#### Adding elements
-
-Adding new data to existing collections is one of the most common programming tasks and in Clojure is usually done with [`conj`][118].
-
-For vectors, new elements are added to the end/tail:
-
-```
-(conj [1 2 3] 4 5 6)
-; [1 2 3 4 5 6]
-```
-
-For lists, new elements are added to the beginning/head (because it's most efficient), therefore resulting in the opposite value order:
-
-```
-(conj '(1 2 3) 4 5 6)
-; (6 5 4 1 2 3)
-```
-
-Maps are unordered collections and consist of key/value pairs. To add new pairs to a map, we need to define each as vector:
-
-```
-(conj {:a 1 :b 2} [:c 3] [:d 4])
-; {:d 4, :c 3, :a 1, :b 2}
-```
-
-Sets are also unordered and don't allow duplicates, so adding duplicate values will have no effect:
-
-```
-(conj #{1 2 3} 1 2 4 5) ; only 4 and 5 are added
-; #{1 2 3 4 5}
-```
-
-Another often used alternative exists for maps and vectors, both of which are associative collections: Maps associate keys with values. Vectors associate numeric indices with values. Therefore Clojure provides us with the [`assoc`][119] function to add new or replace existing associations (`assoc` too takes a flexible number of parameters so that more than one such association can be changed in one go):
-
-```
-(assoc {:a 23} :b 42 :a 88) ; override :a, add :b
-; {:a 88 :b 42}
-(assoc [1 2 3] 0 10, 3 40) ; override 1st element, add new one (comma is optional)
-; [10 2 3 40]
-```
-
-**Important:** For vectors you can only add new indices directly at the tail position. I.e. if a vector has 3 elements we can add a new value at position 3 (with indices starting at 0, this is actually the 4th element, therefore growing the vector by one). Attempting to `assoc` a greater index will result in an error, be careful:
-
-```
-(assoc [1 2 3] 10 -1)
-; IndexOutOfBoundsException...
-```
-
-##### Nested data manipulations
-
-When dealing with nested structures we can use [`assoc-in`][120] and [`update-in`][121] to manipulate elements at any level. E.g. we might want to add Ricardo's current home town to our above mini DB map:
-
-```
-(assoc-in db [:nardove :address :city] "Bournemouth")
-; {:toxi ......
-; :nardove
-; {:name "Ricardo",
-; :urls ["http://nardove.com"],
-; :address {:city "Bournemouth"}}}
-```
-
-Like `get-in`, `assoc-in` takes a path into the datastructure and adds (or replaces) the value for that key. Whilst doing that it also creates any missing nesting levels automatically (i.e. `:nardove`'s map did not even contain an `:address` key beforehand).
-
-`update-in` is similar to `assoc-in`, however instead of a fixed value to be inserted into the collection, it takes a function (incl. any additional params) which is being applied to the current value for the key and then uses the result of that function as the new value. E.g. here we use `update-in` and `conj` to add another URL to `:toxi`'s DB entry:
-
-```
-(update-in db [:toxi :urls] conj "http://toxi.co.uk")
-; {:toxi
-; {:name "Karsten",
-; :urls ["http://toxiclibs.org" "http://thi.ng" "http://toxi.co.uk"],
-; :address {:city "London"}} ....
-```
-
-#### Removing elements
-
-To remove items from a collection, we can use [`dissoc`][122] (for maps) or [`disj`][123] (disjoin) for sets. If a key to be removed isn't present, both functions have no effect.
-
-```
-(dissoc {:a 23 :b 42} :b)
-; {:a 23}
-(disj #{10 20 30} 20)
-; #{10 30}
-```
-
-Lists and vectors only allow for the direct removal near the head or tail, but don't support removing random items: [`pop`][124] applied to a list removes the first item, for vectors the last item. If the collection is empty, `pop` will throw an exception.
-
-```
-(pop '(1 2 3))
-; (2 3)
-(pop [1 2 3])
-; [1 2]
-```
-
-#### Immutability, one more time
-
-We've just seen how we can add & remove elements from collections, thus seemingly modifying them - which technically would make them mutable, not immutable. However, as we've seen earlier, **the modified results returned by these functions are not the original collections.** To clarify:
-
-```
-(def v [1 2 3 4])
-; #'user/v
-(def v2 (conj v 5))
-; #'user/v2
-v2
-; [1 2 3 4 5]
-v
-; [1 2 3 4]
-```
-
-Our original `v` still exists even though we've added `5` to it! Under the hood Clojure has created a new data structure (bound to `v2`) which is the original collection `v` with `5` added. Thinking like a programmer, your next questions should be immediately: Isn't that incredibly inefficient? What happens if I want to add a value to a vector with 10 million elements? Doesn't it become super slow & memory hungry to copy all of them each time? The short answer is: No. And here's why:
-
-#### Persistent data structures
-
-All Clojure data structures are so called [persistent data structures][125] (largely based on the [paper by Chris Okasaki][126]). Internally they're implemented as a tree and therefore can easily provide structural sharing without the need to copy data, which would be the naive solution to achieve immutability. The following diagram illustrates what happens internally for the above example:
-
-![Structural sharing in persistent datastructures][127]
-
-Using trees as the internal data structure, our `v2` can share the original contents of `v` and simply add a new leaf to its tree, pointing to the added value `5`. This is very cheap and doesn't cause a huge loss of performance, regardless of the size of the collection. The same principle is applied to all of the mentioned data structures and it's this uniform approach which both enables & requires immutability.
-
-### Sequences
-
-This section discusses Clojure's uniform approach to data processing using sequence abstractions. A sequence is a logical view of a data structure. All Clojure data structures can be treated as sequences, but the concept is extended even further and Clojure sequences include Java collections, strings, streams, directory structures and XML trees etc. You can even build your own ones by implementing an interface. The name for sequences in Clojure is [`seq`][128] and any compatible data structure can be explicitly turned into a `seq` using the function with the same name.
-
-#### The sequence API
-
-The sequence API is a minimal, low level interface consisting largely of only these four functions: [`first`][129], [`next`][130] to read and [`cons`][131] & [`seq`][128] to create sequences. All of the following functions are built on top of these, but before we get there let's first illustrate their role using a vector and a hash map as an example:
-
-```
-(def my-vec ["1st" "2nd" "3rd"])
-(def my-map {:a "1st" :b "2nd" :c "3rd"})
-```
-
-Any Clojure collection can be turned into a seq, using the `seq` function. If the original collection is empty, `seq` will return `nil`.
-
-```
-(seq my-vec)
-; ("1st" "2nd" "3rd)
-(seq my-map)
-; ([:a "1st"] [:c "3rd"] [:b "2nd"])
-(seq "creativeapplications.net") ; a string's seq is its characters
-; (\c \r \e \a \t \i \v \e \a \p \p \l \i \c \a \t \i \o \n \s \. \n \e \t)
-(seq [])
-; nil
-```
-
-Since a map consists of key/value pairs, a map's seq is a seq of its pairs (vectors of 2 elements). And since a map is an unordered collection, the order of elements in its seq is undefined...
-
-![Sequence API][132]
-
-##### first
-
-...returns the first element of a seq (or `nil` if the sequence is empty):
-
-```
-(first my-vec)
-; "1st"
-(first my-map)
-; [:a "1st"]
-(first "hello") ; a string can be turned into a seq as well...
-; \h
-(first []) ; first of an empty vector/seq returns nil
-; nil
-```
-
-##### next & rest
-
-As you might have guessed already, `next` returns a seq of all the remaining elements, excluding the first one. Again, if there're no further elements in the seq, `next` also returns `nil`.
-
-```
-(next my-vec)
-; ("2nd" "3rd")
-(next my-map)
-; ([:c "3rd"] [:b "2nd"])
-```
-
-We could now also combine the use of `first` and `next` to retrieve other elements, e.g. the 2nd element is the first element of the seq returned by `next`:
-
-```
-(first (next my-vec))
-; "2nd"
-(first (next (next my-vec)))
-; "3rd"
-```
-
-`rest` is almost identical to `next`, however will always return a seq: If there're no more elements, it will simply return an empty seq instead of `nil`.
-
-##### cons
-
-This function is used to prepend elements to a seq. `cons` takes two arguments, a value and an existing seq (or seqable collection) and adds that value at the front. If `nil` is given as the 2nd argument, a new seq is produced:
-
-```
-(cons 1 nil)
-; (1)
-(cons 2 (cons 1 nil))
-; (2 1)
-(cons \c "ab")
-; (\c \a \b)
-```
-
-### Looping, iteration & recursive processing
-
-At this point you might be wondering what use these above functions have in practice. Since Clojure offers far more high-level approaches to work with data collections, direct use of these functions in Clojure is actually less common. Yet, before we discuss these higher level functions, please bear with us as we want to illustrate some other important core operations common to all programming languages, one to which Clojure adds its own twist (again): Iteration & recursion. Meet the `loop` construct.
-
-#### loop & recur
-
-[`loop`][133] defines a body of code which can be executed repeatedly, e.g. to iterate over the elements of a sequence. This is best illustrated by an example, a loop which takes a vector and produces a seq of the vector's elements in reverse order (Clojure actually provides the [`reverse`][134] function to do the same for us, but we're focussed on `loop` here):
-
-```
-(loop [result nil, coll [1 2 3 4]]
- (if (seq coll)
- (let [x (first coll)]
- (recur (cons x result) (rest coll)))
- ; no more elements, just return result...
- result))
-; (4 3 2 1)
-```
-
-The vector following the `loop` keyword is a binding vector just as we know from `let` and it can be used to bind any number of symbols. In our case we only require two: the initially non-existing `result` sequence (set to `nil`) and `coll`, a vector of numbers to be processed. The other code is the loop's body which is executed repeatedly: At each iteration we first check if our `coll` contains any more elements by calling `seq` (remember, `seq` returns `nil` (and is therefore falsy) when given an empty collection). If there're any elements remaining, we bind `coll`'s `first` element to `x`. What follows next is a call to [`recur`][135], the actual mechanism to trigger the recursive re-execution of the loop, however each time with new values given for the loop's `result` and `coll` symbols. These new values are the updated result sequence (with `x` prepended) and the remainder of the current collection produced via `rest`. Once `rest` returns an empty seq, the loop is finished and `result` is "returned" as final value.
-
-The combined application of `loop` & `recur` is the most low-level and verbose construct to create iterative behavior in Clojure, but because of that is also the most flexible. The most important restriction however is that `recur` can only be used at the end (tail) of a `loop`'s execution path, meaning there can be no further expressions following `recur` (hence the concept is called [Tail recursion][136]. In the above example you might think the final occurance of `result` violates this restriction, but that is not true: `recur` is the last expression of the "truth branch" of the enclosing `if`, whereas the returned `result` is on its other branch and therefore independent.
-
-#### doseq
-
-A more concise way of completely iterating the elements of a collection is offered by [`doseq`][137], however this form is designed to work with/trigger side effects and only returns `nil`. The example iterates over a vector of hashmaps and displays each person's age with some extra formatting:
-
-```
-(doseq [p [{:name "Ben" :age 42} {:name "Alex"} {:name "Boris" :age 26}]]
- (let [name (:name p)
- suffix (if (#{\s \x} (last name)) "'" "'s")
- age (or (:age p) "rather not say")]
- (println (str name suffix " age: " age))))
-; Ben's age: 42
-; Alex' age: rather not say
-; Boris' age: 26
-; nil
-```
-
-The value of `suffix` is based on the [`last`][138] letter of a person's name and is usually `'s` (unless the last letter is in the set `#{\s \x}`). We'd also like the `:age` to be optional and provide a default value if missing...
-
-#### dotimes
-
-[`dotimes`][139] is yet another looping construct used for side effects, this time just for simply binding a symbol to a number of iterations:
-
-```
-(dotimes [i 3] (println i))
-; 0
-; 1
-; 2
-```
-
-### Common sequence processing functions
-
-Now that we've discussed some of the underlying forms and mechanisms, it's time to focus on the more commonly used features of Clojure's sequence processing.
-
-Loops and iterators are the de-facto tools/patterns to process collections in many imperative languages. This is where idiomatic Clojure probably differs the most, since its functional approach is more focused on the transformation of sequences using a combination of higher order functions and so called:
-
-#### Pure functions
-
-A pure function's does not depend on any other data than its inputs and causes no side effects (i.e. I/O operations). This makes them [referentially transparent][140], meaning a function could be replaced with its result without any impact, or in other words, a function is consistently providing the same value, given the same inputs. Pure functions can also be [idempotent][141], meaning a function, if applied multiple times, has no other effects than applying it once. E.g. `(Math/abs -1)` will always provide `1` as a result and `(Math/abs (Math/abs -1))` will not change it, nor will it cause any other effect.
-
-Pure functions play a key role in functional programming. Their characteristics allow us to compose small, primitive functions into more complex constructs with predictable behaviors.
-
-##### Memoization of pure functions
-
-The caching of results of previous calls to a function is called [memoization][142]. This technique is especially useful if these results are produced by a complex/slow process. Clojure provides the [`memoize`][143] HOF to allow any function be memoized, however safe memoization requires those functions to be pure. We can demonstrate this caching effect by simulating a slow function using Java interop and [`Thread/sleep`][144]:
-
-```
-; simulate long process by sleeping for x 选题模板.txt 中文排版指北.md core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE published README.md scripts sources translated 1000 milliseconds
-(defn slow-fn [x] (Thread/sleep (* x 1000)) x)
-
-(def not-so-slow-fn (memoize slow-fn))
-
-(not-so-slow-fn 3)
-; 3
-```
-
-#### Map-Reduce
-
-Several years ago, Google published a [paper][145] about their use of the [Map-Reduce algorithm][146]. Whereas this paper was focused on the distributed application of that algorithm running in parallel on thousands of machines, the general approach itself has been around for decades and plays an important role in many functional languages, where it is the de-facto pattern to process data without the need for explicit loops.
-
-The idea of Map-Reduce is to first transform the elements of an input collection into an intermediate new collection of values, which is then passed to a reduction function, producing a single final result value. This result could be any data type, though, incl. a new collection.
-
-Even though Map-Reduce is a 2-phase process, each phase can also be applied on its own. I.e. sometimes there's no need for a later reduction or an initial mapping step.
-
-> Btw. Several modern "NoSQL" database systems (e.g. [CouchDB][147], [MongoDB][148], [Riak][149]) and distributed data processing platforms like [Hadoop][150] also heavily rely on Map-Reduce as underlying mechanism to process & create views of data. So if you ever intent to work with such, it's quite useful knowledge to work through this section, even if you have no further interest in Clojure...
-
-#### map
-
-In mathematical terms mapping is the transformation of values through the application of a function. In Clojure the [`map`][151] function is one of the most often used functions. It takes a transformation function and applies it to each element in a given collection/sequence. E.g. The example below takes the function `inc` and a seq of numbers. It then applies `inc` to each number individually and returns a new sequence of the results:
-
-```
-(map inc [1 2 3 4 5])
-; (2 3 4 5 6)
-```
-
-![map function visualized][152]
-
-The transformation function given to `map` can be anything and its also one of the situations where anonymous functions are often used. E.g. Here we produce a seq of square numbers:
-
-```
-(map (fn [x] (* x x)) [1 2 3 4 5])
-; (1 4 9 16 25)
-```
-
-As an aside, since anonymous functions are often very short, they can also be defined more concisely (though become less legible). The following is equivalent to the above expression:
-
-```
-(map #(* % %) [1 2 3 4 5])
-; (1 4 9 16 25)
-```
-
-Here we use the reader macro `#(..)` to define an anon fn and the symbol `%` to refer to the first (in this case only) argument. If such a function takes more than a single arg, then we can use `%2`, `%3` etc. to refer to these...
-
-```
-(#(* % %2) 10 2) ; call anon fn with args: 10, 2
-; 20
-```
-
-`map` can also be applied to several collections at once. In this case the transformation function needs to accept as many parameters as there are collections. Let's use `map` to build a seq of hashmaps from two vectors of point coordinates and colors. Each time our transformation fn is given a single point (a vector) and a color keyword. The fn simply combines these values into a single map with keys `:pos` and `:color`:
-
-```
-(map
- (fn [p c] {:pos p :color c}) ; transformation fn
- [[100 0] [0 -100] [0 100] [200 100]] ; points
- [:red :green :blue]) ; colors
-; ({:pos [100 0], :color :red}
-; {:pos [0 -100], :color :green}
-; {:pos [0 100], :color :blue})
-```
-
-![map builder][153]
-
-> **Important:** You might have noticed that our vector of points has one more element than there're colors. In that case, `map` will stop as soon as one of the input collections is exhausted / has no further values. In this case we only have 3 colors, so the last (4th) point is ignored.
-
-##### Laziness and lazy seqs
-
-One thing not immediately obvious when experimenting with `map` in the REPL, is that the seq returned by `map` is a so called `lazy-seq`, that is, **the transformation function is actually not applied to our original values until their results are needed**. In other words, `map` is more of a recipe for a computation, but the computation does not ever happen if we don't attempt to use its results.
-
-To illustrate this better, let's again simulate a slow transformation function which takes 1 second per value. With 5 values in the original collection, our entire processing should take approx. 5 seconds:
-
-```
-(def results
- (map
- (fn [x]
- (Thread/sleep 1000)
- (* x 10))
- [1 2 3 4 5]))
-```
-
-When this code executes, we can see the REPL **immediately** returned a result, the new Var `user/results`. It did not take 5 seconds, because at this stage we haven't yet attempted to do anything with that new Var - and hence no mapping did take place thus far. [It's plain lazy!][20].
-
-Now trying to display the contents of `results` however will force the computation and therefore will take 5 seconds until we can see the mapped values:
-
-```
-results ; takes ~5secs, world's slowest multiply
-; (20 30 40 50 60)
-```
-
-#### reduce
-
-[`reduce`][154] is Clojure's natural way of expressing an accumulation over a sequence of values. Like `map` it takes a function, an optional initial result and a sequence whose elements will be passed to the transformation function individually, for example:
-
-```
-(reduce + 0 [1 2 3 4 5 6 7 8 9 10])
-; 55
-```
-
-In this case `reduce` uses the function `+` to combine all values of our seq into the accumulated result one by one. The transformation function must always take 2 arguments: the current result (reduced value) and the next item to be processed. If no initial result is given, the first iteration will consume the first 2 items from the sequence.
-
-In our case this happens:
-
-```
-(+ 0 1) ; 0 is the initial result, returns 1
- (+ 1 2) ; 1 is current result, returns 3
- (+ 3 3) ; returns 6
- ; and so on until the seq is exhausted...
-```
-
-Clojure also provides an alternative to `reduce`, called [`reductions`][155]. Instead of the just final reduction it returns a seq of all intermediate results (here we also use [`range`][156] to create a seq of numbers from 0-9):
-
-```
-(reduce + (range 10))
-; 45
-(reductions + (range 10))
-; (0 1 3 6 10 15 21 28 36 45)
-```
-
-![reduce vs. reductions][157]
-
-#### filter
-
-[`filter`][158] takes a function and a seq, then applies the function to each element and returns a lazyseq of only the elements the function returned a "truthy" value for. These kind of functions are also called "predicates".
-
-Clojure has a number of predicate functions which rely on truthiness and they can be easily recognized by their general naming convention, a function name suffixed with `?`. E.g. [`even?`][159] can be used to filter out all even numbers from the seq of numbers 0-9:
-
-```
-(filter even? (range 10))
-; (0 2 4 6 8)
-```
-
-![filter][160]
-
-Since the function needn't strictly return `true` or `false`, we can also use a set as predicate to filter out only values which are present in the set:
-
-```
-(filter #{1 2 4 8 16 32} (range 10))
-; (1 2 4 8)
-```
-
-Again we're using data as code, since vectors, maps & sets all can be used as functions and return `nil` if a value isn't present, therefore fulfilling the general contract of a predicate function...
-
-#### take / drop
-
-Sometimes we are only interested in a chunk of values from a larger collection. We can use [`take`][161] to retrieve the first `n` elements from a collection as a lazy sequence:
-
-```
-(take 3 '(a b c d e f))
-; (a b c)
-```
-
-In contrast, we can use [`drop`][162] to ignore the first `n` elements and give us a lazy sequence of all remaining elements:
-
-```
-(drop 3 '(a b c d e f))
-; (d e f)
-```
-
-Clojure has a few other variations on that theme, most notably [`take-last`][163], [`drop-last`][164], [`butlast`][165], [`take-nth`][166], [`take-while`][167] and [`drop-while`][168]. The latter two also take a predicate function and terminate as soon as the predicate returns a "falsy" result:
-
-```
-(take-while #(< % 5) (range 10))
-; (0 1 2 3 4)
-```
-
-#### concat & mapcat
-
-[`concat`][169] splices any number of seqs together into a single new lazy seq. The new `rotate-left` function shows how we can use `concat` with `take`/`drop` to rotate elements in a sequence:
-
-```
-(concat [1 2 3] '(a b c) {:a "aa" :b "bb})
-; (1 2 3 a b c [:a "aa"] [:b "bb"])
-
-(defn rotate-left [n coll] (concat (drop n coll) (take n coll)))
-; #'users/rotate-left
-
-(rotate-left 3 '(a b c d e f g h i))
-; (d e f g h i a b c)
-```
-
-[`mapcat`][170] is a combination of `map` & `concat`. Like `map` it accepts a transformation function and a (number of) seqs. The mapping function needs to produce a collection for each step which are then concatenated using `concat`:
-
-```
-; another social graph structure as from above (only w/ more people)...
-(def g2
- #{#{:ricardo :toxi}
- #{:filip :edu}
- #{:filip :toxi}
- #{:filip :ricardo}
- #{:filip :marija}
- #{:toxi :marija}
- #{:marija :edu}
- #{:edu :toxi}})
-
-; step 1: produce a seq of all relations
-(map seq g2)
-; ((:marija :filip) (:toxi :marija) (:edu :filip) (:ricardo :filip)
-; (:toxi :edu) (:toxi :ricardo) (:marija :edu) (:toxi :filip))
-
-; step 2: combine rels into single seq
-(mapcat seq g2) ; option #1: `seq` as transform fn
-(mapcat identity g2) ; option #2: `identity` as transform (same result)
-; (:marija :filip :toxi :marija :edu :filip :ricardo :filip :toxi :edu :toxi :ricardo :marija :edu :toxi :filip)
-
-; step 3: form a set of unique nodes in the graph
-(set (mapcat identity g2))
-; #{:toxi :marija :edu :ricardo :filip}
-
-; step 4: build map of node valence/connectivity
-(frequencies (mapcat identity g2))
-; {:marija 3, :filip 4, :toxi 4, :edu 3, :ricardo 2}
-```
-
-> There're two functions we haven't dealt with so far: [`identity`][171] simply returns the value given as argument. [`frequencies`][172] consumes a seq and returns a map with the seq's unique values as keys and their number of occurrences as values, basically a [histogram][173].
-
-`take` & `drop` are also important with respect to one more (optional) property of lazy sequences we haven't mentioned so far:
-
-##### Infinite sequences
-
-The concept of infinite data in a non-lazy (i.e. eager) context is obviously unachievable on a machine with finite memory. Laziness, however does enable potential infinity, both in terms of generating and/or consuming. In fact, there're many Clojure functions which exactly do that and without the proper precautions (i.e. combined with `take`, `drop` and friends), they would bring a machine to its knees. So be careful!
-
-We already have used one of these potentially infinite sequence generators above: [`range`][156] when called without an argument produces a lazyseq of monotonically increasing numbers: `(0 1 2 3 4 ...)` **(Since the REPL always tries to print out the result, do not ever call one of these without guards in the REPL!)**
-
-Other useful infinite lazyseq generators are:
-
-[`cycle`][174] delivers a lazyseq by repeating a given seq ad infinitum:
-
-```
-(take 5 (cycle [1 2 3]))
-; (1 2 3 1 2)
-(take 10 (take-nth 3 (cycle (range 10))))
-; (0 3 6 9 2 5 8 1 4 7)
-```
-
-[`repeat`][175] produces a lazyseq of a given value:
-
-```
-(take 5 (repeat 42))
-; (42 42 42 42 42)
-(repeat 5 42)
-; (42 42 42 42 42)
-```
-
-[`repeatedly`][176] produces a lazyseq of the results of calling a function (without arguments) repeatedly:
-
-```
-(take 5 (repeatedly rand))
-; (0.07610618695828963 0.3862058886976354 0.9787365745813027 0.6499681207528709 0.5344143491834465)
-```
-
-[`iterate`][177] takes a function and a start argument and produces a lazyseq of values returned by applying the function to the previous result: so (f (f (f x)))... Here to generate powers of 2:
-
-```
-(take 5 (iterate #(* 2 %) 1))
-; (1 2 4 8 16)
-(take 5 (drop 10 (iterate #(* 2 %) 1)))
-; (1024 2048 4096 8192 16384)
-```
-
-Since infinite lazyseqs are values just like any other (but at the same time can't be exhausted) it sometimes it's helpful to think about them as high level recipes for changing program states or triggers of computations. Combined with the various sequence processing functions they provide a truly alternative approach to solving common programming problems.
-
-#### Sequence (re)combinators
-
-Here're some more core functions related to combining collections in different ways:
-
-[`interleave`][178] recombines two sequences in an alternating manner (also lazy):
-
-```
-(interleave [:clojure :lisp :scheme] [2007 1958 1970])
-; (:clojure 2007 :lisp 1958 :scheme 1970)
-```
-
-[`interpose`][179] inserts a separator between each element of the original seq:
-
-```
-(interpose "," #{"cyan" "black" "yellow" "magenta"})
-; ("cyan" "," "magenta" "," "yellow" "," "black")
-```
-
-[`zipmap`][180] combines two collections into a single hashmap, where the 1st collection is used for keys and the second as values. Let's have some [Roman Numerals][181]:
-
-```
-; first the individual pieces:
-; powers of 10
-(take 10 (iterate #(* 10 %) 1))
-; (1 10 100 1000 10000 100000 1000000 10000000 100000000 1000000000)
-
-; apply powers to 1 & 5
-(take 5 (map (fn [x] [x (* x 5)]) (iterate #(* 10 %) 1))) ; using `map`
-; ([1 5] [10 50] [100 500] [1000 5000] [10000 50000])
-(take 5 (mapcat (fn [x] [x (* x 5)]) (iterate #(* 10 %) 1))) ; using `mapcat`
-; (1 5 10 50 100)
-
-; altogether now...
-(zipmap
- [:I :V :X :L :C :D :M] ; keys
- (mapcat (fn [x] [x (* x 5)]) (iterate #(* 10 %) 1))) ; values
-; {:M 1000, :D 500, :C 100, :L 50, :X 10, :V 5, :I 1}
-```
-
-#### for
-
-Since we've just discussed sequence generators, we also must briefly mention [`for`][182]. Unlike `for` loops in other languages, Clojure's `for` is a so called [List comprehension][183], just another generator of lazyseqs, though one on crack if we may say so... `for` combines the behavior of `map` with lexical binding as we know from `let` and conditional processing. It returns its results as lazyseq. Here we iterate over the seq returned by `(range 4)` and bind `i` to each value successively, then execute `for`'s body to tell us if that current value of `i` is even:
-
-```
-(for [i (range 4)] {:i i :even (even? i)})
-; ({:i 0, :even true} {:i 1, :even false} {:i 2, :even true} {:i 3, :even false})
-(into {} (for [i (range 4)] [i (even? i)]))
-; {0 true, 1 false, 2 true, 3 false}
-```
-
-`for` can also be used to created nested seqs. This happens automatically when more than one symbol is bound, e.g. here we create positions in a 4x2 grid (the first symbol defines the outer loop, the next one(s) inner loops:
-
-```
-(for [y (range 2) ; outer loop
- x (range 4)] ; inner loop
- [x y]) ; result per iteration
-; ([0 0] [1 0] [2 0] [3 0] [0 1] [1 1] [2 1] [3 1])
-```
-
-The symbol binding part can be further customized with additional bindings to pre-compute values used in the body of `for` and/or we can specify a predicate to skip an iteration (therefore also achieving filtering a la `filter`) or cancel iteration (using `:while`). The next example creates points only along the border of a 4x4 grid (center points are skipped):
-
-```
-(for [y (range 4)
- x (range 4)
- :let [border? (or (= 0 x) (= 3 x) (= 0 y) (= 3 y))]
- :when border?] ; skip iteration when border? is false
- [x y])
-; ([0 0] [1 0] [2 0] [3 0] ; manually formatted to better visualize result...
-; [0 1] [3 1]
-; [0 2] [3 2]
-; [0 3] [1 3] [2 3] [3 3])
-```
-
-#### every? / some
-
-Sometimes we need to check if the values of a collection match certain criteria, e.g. to enforce a restriction. The [`every?`][184] function takes a validation function (predicate) and applies it to all elements of a collection. It only returns true, if the predicate returns a truthy value for all of them. Here we check if all elements in a seq have a `:name` key (remember, keywords can be used as functions!)
-
-```
-(every? :name [{:name "nardove"} {:name "toxi"} {:age 88}])
-; false
-```
-
-Or we could write our own predicate and check if all values are multiples of 3, that is a number for which the remainder, [`rem`][185], of a division by 3 is zero:
-
-```
-(every? #(zero? (rem % 3)) [666 42 99 12])
-; true
-```
-
-Alternatively, we can use [`some`][186] if we only want to ensure some of the values match a condition. `some` will return the first truthy value returned by the predicate (or `nil` if no items match). Again, we are using data (a set) as predicate fn:
-
-```
-(some #{3 6 9 12} [1 2 3 4 5 6])
-; 3
-```
-
-...or ask if some names are longer than 4 characters:
-
-```
-(some #(> (count %) 4) ["mia" "nardove" "toxi"])
-; true
-(some #(if (> (count %) 4) %) ["mia" "nardove" "toxi"])
-; "nardove"
-```
-
-#### apply
-
-So far we have used the phrase "applies a function to x" several times. In short it simply means that a function is called with `x` as its argument. Though, what should we do if we have a function accepting multiple arguments, but have our arguments only in a single collection (i.e. one built with `map` etc.)?
-
-To stick with some familiar constructs and add a concrete use case, our `hypot` function defined earlier, computes the length of the longest side in a triangle, given the lengths of the 2 other sides. At the same time we could interpret this as the calculation of the distance of a 2d point from the origin in a cartesian coordinate system: One side is the distance along the X-axis and the other the distance in Y.
-
-Imagine we have a collection of 2d points and we want to measure their distance from the origin (their [magnitude][187]):
-
-```
-(def points [[0 100] [200 100] [-300 50]])
-; #'user/points
-```
-
-Now we could use `map` and our `hypot` function to compute the distance/length for each point and produce a new sequence of the results. However, `hypot` so far requires 2 arguments `a` & `b`, but our points are defined as vectors of 2 elements and therefore each point is just a single value (the vector itself). For such situations, Clojure provides us with the `apply` function, allowing a function to accept a collection of values as individual arguments (with possibly additional ones given as well). So whereas the following will produce an error...
-
-```
-(hypot [200 100])
-; ArityException Wrong number of args (1) passed to: user$hypot
-```
-
-... using [`apply`][188] will unravel our vector into two individual arguments and call our function correctly:
-
-```
-(apply hypot [200 100])
-; 223.60679774997897
-```
-
-With this in place, we can now plug this into a `map` form and process all our points:
-
-```
-(map #(apply hypot %) points)
-; (100.0 223.60679774997897 304.138126514911)
-```
-
-To complete an earlier arc of our tutorial, we could also plug this into another `reduce` step to give us the longest distance (using `max` as the reduction function):
-
-```
-(reduce max (map #(apply hypot %) points))
-; 304.138126514911
-```
-
-### Destructuring
-
-As we've just learned with `apply`, sometimes it is required to adapt our data to a function's specifics. But we can also achieve the opposite and adapt a function to expect a specific data structure and do so without having to jump through hoops painstakingly pulling out individual values from a given collection. Clojure make this very easy using destructuring.
-
-Destructuring is a way to bind symbols to values in a collection, by replicating the overall structure of the collection and placing the symbols to be bound at the points from which we intend to get a value from in the supplied data structure. A few lines of code will illustrate this much better...
-
-#### Sequential destructuring
-
-As we know a vector is just a sequence of values, each of which can be another nested data structure:
-
-```
-(def nested-data [10 20 [30 40] {:x 1 :y 2}]) ; some test data
-```
-
-To bind the first 3 items of that input vector to symbols `a`, `b` and `c`, a naive and inelegant solution would be to bind each symbol individually, like this:
-
-```
-(let [a (nested-data 0)
- b (nested-data 1)
- c (nested-data 2)]
- (prn :a a :b b :c c))
-; :a 10 :b 20 :c [30 40]
-```
-
-Using sequential destructuring, this can be expressed much more concisely. All we need to do is telling Clojure the symbols' values are part of a sequence, by wrapping them in a vector themselves:
-
-```
-(let [[a b c] nested-data] (prn :a a :b b :c c))
-; :a 10 :b 20 :c [30 40]
-```
-
-Sometimes we might need values which are not successive in the collection e.g. say we only care about the 2nd and 4th value:
-
-```
-(let [[_ b _ d] nested-data] (prn :b b :d d))
-; :b 20 :d {:x 1 :y 2}
-```
-
-> It's idiomatic to use the `_` symbol to bind values we're not interested in (in this case the 1st and 3rd elements).
-
-The third element of `nested-data` is another vector. To also restructure its elements, we simply need to replicate the overall structure of `nested-data` and indicate that this 3rd element is a sequence itself. We combine this with another destructuring option, called `:as`, to bind the entire 3rd element to yet another symbol, `third`:
-
-```
-(let [[_ _ [c d :as third]] nested-data]
- (prn third "contains:" c d))
-; [30 40] "contains:" 30 40
-```
-
-When attempting to destructure sequences with more symbols than there are values, any symbols with missing values are bound to `nil`:
-
-```
-(let [[_ _ _ _ missing] nested-data]
- (prn "missing?" (nil? missing)))
-; "missing?" true
-```
-
-Likewise, if we're only interested in the first x elements of a seq, we don't need to specify any additional symbols/placeholders. Clojure doesn't care if there're more elements in a seq than destructuring symbols. However, in addition to the initial elements we're interested in, we might still want to hold on to the `rest` of the collection too. This can be done with `&`:
-
-```
-(let [[a b & more] nested-data]
- (println (count more) "more elements:" more))
-; 2 more elements: ([30 40] {:x 1 :y 2})
-```
-
-Destructuring can be used almost anywhere whenever Clojure expects a symbol binding form. E.g. in the symbol binding part of a `for` form or to specify the argument list(s) of a function.
-
-#### Map destructuring
-
-Maps too can be destructured, though because the lookup of values requires keys, their destructuring form needs to refer to keys as well. Since we used `[` and `]` to specify a sequential destructuring, it should also make sense that we use `{` and `}` for destructuring maps. In the following we destructure the 4th element of `nested-data` and bind this map's `:x` to symbol `a` and `:y` to `b`:
-
-```
-(let [{a :x b :y} (nested-data 4)]
- (prn :a a :b b))
-; :a 1 :b 2
-```
-
-If we wanted to use the same symbol names as the keys used in the original map, an alternative is:
-
-```
-(let [{:keys [x y] :as v} (nested-data 4)]
- (prn :x x :y y :v v))
-; :x 1 :y 2 :v {:x 1 :y 2}
-```
-
-As with sequential destructuring we can use `:as` to also bind the entire map and of course can be done recursively. You can find more examples in [Jay Field's blog post][189] about this matter.
-
-#### Destructuring and function arities
-
-A function providing more than one implementation is called a "multi-arity" function and many core Clojure functions are implemented like this to provide maximum flexibility. So finally, let's extend our earlier `hypot` function and turn it into a multi-arity fn, accepting not only two numbers, but also a single seq (w/ minimum two elements) instead:
-
-```
-(defn hypot
- ([[a b]] (hypot a b)) ; destructure the seq and then call itself with the 2 args
- ([a b] (Math/sqrt (+ (* a a) (* b b)))))
-; #'user/hypot
-
-(hypot [9 12]) ; no more need for `apply`
-; 15.0
-(= (hypot [9 12]) (hypot 9 12)) ; testing other arity...
-; true
-```
-
-> Remember to wrap each arity implementation in its own form, i.e. surround with `(` and `)`.
-
-### End of part 1
-
-Congratulations!!! You made it through to here and we're truly proud of you! Even though we could only give you glimpses of The Clojure Way™ so far, we hope you're excited enough to try out more when we will be applying some of these basics to more practical & visual examples in the next part(s) of this tutorial. In the next part we will start building our first projects and introduce you to [Quil][190], a Clojure wrapper around [Processing][191].
-
-In the meantime we recommend that you sharpen your Clojure Skillz by checking out some of the materials below, esp. the [4clojure][192] puzzles are a great way of learning.
-
-### Further reading & references
-
-+ Clojure mailing list - main community discussion (~8600 members)
-+ clojure-doc.org - great community based collection of guides & tutorials aimed at all levels (incl. setup guides for various tools & platforms)
-+ clojuredocs.org - community & example based reference for core Clojure namespaces & functions (learn by example)
-+ Clojure cheatsheets - online & PDF versions, incl. ClojureScript
-+ Stackoverflow - SO questions tagged w/ Clojure
-+ Try Clojure - online playground REPL, no installation needed
-+ 4clojure - online learning resource to solve Clojure puzzles of varying difficulties
-+ Planet Clojure (Twitter) - Clojure blog aggregator
-+ O'Reilly book - IMHO currently most comprehensive & accessible book
-+ The Joy of Clojure - another great book, also touching more on the why & how of Clojure's philosophy
-+ clojure-toolbox.com - curated list of Clojure projects, grouped by topic
-+ clojuresphere.com - autogenerated list of Clojure projects on GitHub, incl. dependency info
-+ clojars.org - community repository for open source Clojure libraries (main repo for Leiningen)
-+ ClojureWerkz - growing collection of well maintained open source libraries (mainly DB centric projects)
-
-
---------------------------------------------------------------------------------
-
-via: https://www.creativeapplications.net/tutorials/introduction-to-clojure-part-1/
-
-作者:[Karsten Schmidt and Ricardo Sanchez][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.creativeapplications.net/author/karstenricardo/
-[b]: https://github.com/lujun9972
-[1]: http://nardove.com/
-[2]: http://resonate.io/2013/education
-[3]: http://postspectacular.com/
-[4]: http://www.lisperati.com/clojure-spels/casting.html
-[5]: http://resonate.io/
-[6]: http://en.wiktionary.org/wiki/TLDR
-[7]: http://clojure.org
-[8]: http://en.wikipedia.org/wiki/Lisp_(programming_language)
-[9]: http://en.wikipedia.org/wiki/Lambda_calculus
-[10]: http://en.wikipedia.org/wiki/Alonzo_Church
-[11]: http://www.erlang.org/
-[12]: http://fsharp.org/
-[13]: http://haskell.org
-[14]: http://scala-lang.org
-[15]: http://en.wikipedia.org/wiki/Functional_programming
-[16]: http://steve-yegge.blogspot.co.uk/2006/03/execution-in-kingdom-of-nouns.html
-[17]: http://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html
-[18]: http://en.wikipedia.org/wiki/Anonymous_function#C.2B.2B
-[19]: http://en.wikipedia.org/wiki/Immutable_object
-[20]: http://en.wikipedia.org/wiki/Lazy_evaluation
-[21]: http://clojure.org/sequences
-[22]: http://clojure.org/protocols
-[23]: http://en.wikipedia.org/wiki/Multiple_dispatch
-[24]: http://clojure.org/macros
-[25]: http://clojure.com/blog/2013/06/28/clojure-core-async-channels.html
-[26]: http://clojure.org/concurrent_programming
-[27]: http://thechangelog.com/rich-hickeys-greatest-hits/
-[28]: https://twitter.com/yoavrubin/status/226419931435130880
-[29]: http://thinkrelevance.com/blog/2009/10/19/the-case-for-clojure
-[30]: https://github.com/clojure/clojurescript
-[31]: https://github.com/clojure-android/lein-droid
-[32]: https://github.com/halgari/mjolnir/
-[33]: http://en.wikipedia.org/wiki/Marmite
-[34]: https://twitter.com/puredanger/status/313507982623268865
-[35]: http://en.wikipedia.org/wiki/S-expression
-[36]: http://en.wikipedia.org/wiki/Brace_matching
-[37]: https://github.com/jlr/rainbow-delimiters
-[38]: https://www.youtube.com/watch?v=D6h5dFyyUX0
-[39]: http://leiningen.org
-[40]: http://en.wikipedia.org/wiki/Leiningen_Versus_the_Ants
-[41]: http://ant.apache.org
-[42]: http://brew.sh/
-[43]: http://www.oracle.com/technetwork/java/javase/downloads/index.html
-[44]: http://code.google.com/p/counterclockwise
-[45]: http://clojure-doc.org
-[46]: http://jruby.org/
-[47]: https://developer.mozilla.org/en/docs/Rhino
-[48]: http://tryclj.com
-[49]: http://en.wikipedia.org/wiki/Prefix_notation
-[50]: http://en.wikipedia.org/wiki/Pythagorean_theorem
-[51]: https://www.creativeapplications.net/wp-content/uploads/2013/12/hypot.png
-[52]: http://www.haskell.org/
-[53]: http://en.wikipedia.org/wiki/Scheme_(programming_language)
-[54]: http://en.wikipedia.org/wiki/Closure_(computer_science)
-[55]: http://en.wikipedia.org/wiki/Monad_(functional_programming)
-[56]: http://en.wikipedia.org/wiki/Scope_(computer_science#Lexical_scoping)
-[57]: http://clojuredocs.org/clojure_core/clojure.core/let
-[58]: http://en.wikipedia.org/wiki/Don't_Repeat_Yourself
-[59]: http://www.cplusplus.com/doc/tutorial/namespaces/
-[60]: http://en.wikipedia.org/wiki/Java_package
-[61]: http://docs.python.org/2/tutorial/modules.html
-[62]: http://clojure.org/namespaces
-[63]: https://www.creativeapplications.net/wp-content/uploads/2013/04/var.png
-[64]: http://clojuredocs.org/clojure_core/clojure.core/def
-[65]: http://clojure.github.io/clojure/clojure.core-api.html
-[66]: http://clojuredocs.org/clojure_core/clojure.core/inc
-[67]: http://clojuredocs.org/clojure_core/clojure.core/defn
-[68]: http://clojure.org/java_interop
-[69]: http://docs.oracle.com/javase/7/docs/api/java/lang/Math.html
-[70]: http://en.wikipedia.org/wiki/Hypotenuse
-[71]: http://clojuredocs.org/clojure_core/clojure.core/fn
-[72]: http://clojuredocs.org/clojure_core/clojure.core/str
-[73]: http://en.wikipedia.org/wiki/Higher-order_function
-[74]: http://rosettacode.org/wiki/Partial_function_application
-[75]: http://en.wikipedia.org/wiki/Closure_(computer_programming)
-[76]: http://clojuredocs.org/clojure_core/clojure.core/partial
-[77]: http://en.wikipedia.org/wiki/Fail-fast
-[78]: http://en.wikipedia.org/wiki/Design_by_contract
-[79]: http://clojuredocs.org/clojure_core/clojure.core/string_q
-[80]: http://blog.fogus.me/2009/12/21/clojures-pre-and-post/
-[81]: http://ianrumford.github.io/blog/2012/11/17/first-take-on-contracts-in-clojure/
-[82]: http://clojuredocs.org/clojure_core/clojure.repl/doc
-[83]: http://clojuredocs.org/clojure_core/clojure.core/meta
-[84]: http://clojuredocs.org/clojure_core/clojure.core/with-meta
-[85]: http://clojuredocs.org/clojure_core/clojure.core/alter-meta
-[86]: http://clojure.org/metadata
-[87]: http://clojure.org/java_interop#Java%20Interop-Type%20Hints
-[88]: http://clojuredocs.org/clojure_core/clojure.core/and
-[89]: http://clojuredocs.org/clojure_core/clojure.core/or
-[90]: http://clojuredocs.org/clojure_core/clojure.core/not
-[91]: http://clojuredocs.org/clojure_core/clojure.core/if
-[92]: http://clojuredocs.org/clojure_core/clojure.core/when
-[93]: http://clojuredocs.org/clojure_core/clojure.core/do
-[94]: http://clojure.org/data_structures
-[95]: http://clojuredocs.org/clojure_core/clojure.core/list
-[96]: http://www.r-project.org/
-[97]: http://en.wikipedia.org/wiki/XSLT
-[98]: http://en.wikipedia.org/wiki/PostScript
-[99]: https://www.creativeapplications.net/wp-content/uploads/2013/12/quote.png
-[100]: http://en.wikipedia.org/wiki/Metaprogramming
-[101]: https://gist.github.com/stonegao/1335696
-[102]: http://www.packtpub.com/clojure-for-domain-specific-languages/book
-[103]: http://en.wikipedia.org/wiki/Stack_(abstract_data_type)
-[104]: http://clojuredocs.org/clojure_core/clojure.core/vector
-[105]: http://en.wikipedia.org/wiki/Hash_table
-[106]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Working_with_Objects
-[107]: http://clojuredocs.org/clojure_core/clojure.core/keyword
-[108]: http://clojuredocs.org/clojure_core/clojure.core/hash-map
-[109]: http://en.wikipedia.org/wiki/JSON
-[110]: http://clojuredocs.org/clojure_core/clojure.core/get-in
-[111]: http://clojuredocs.org/clojure_core/clojure.core/select-keys
-[112]: http://en.wikipedia.org/wiki/Set_theory
-[113]: http://clojuredocs.org/clojure_core/clojure.core/set
-[114]: http://clojuredocs.org/clojure_core/clojure.core/into
-[115]: https://www.creativeapplications.net/wp-content/uploads/2013/12/socialgraph.png
-[116]: http://clojuredocs.org/clojure_core/clojure.core/nil_q
-[117]: http://en.wikipedia.org/wiki/Polymorphism_(computer_science)
-[118]: http://clojuredocs.org/clojure_core/clojure.core/conj
-[119]: http://clojuredocs.org/clojure_core/clojure.core/assoc
-[120]: http://clojuredocs.org/clojure_core/clojure.core/assoc-in
-[121]: http://clojuredocs.org/clojure_core/clojure.core/update-in
-[122]: http://clojuredocs.org/clojure_core/clojure.core/dissoc
-[123]: http://clojuredocs.org/clojure_core/clojure.core/disj
-[124]: http://clojuredocs.org/clojure_core/clojure.core/pop
-[125]: http://en.wikipedia.org/wiki/Persistent_data_structure
-[126]: http://www.cs.cmu.edu/~rwh/theses/okasaki.pdf
-[127]: https://www.creativeapplications.net/wp-content/uploads/2013/04/persistent.png
-[128]: http://clojuredocs.org/clojure_core/clojure.core/seq
-[129]: http://clojuredocs.org/clojure_core/clojure.core/first
-[130]: http://clojuredocs.org/clojure_core/clojure.core/next
-[131]: http://clojuredocs.org/clojure_core/clojure.core/cons
-[132]: https://www.creativeapplications.net/wp-content/uploads/2013/12/first-rest.png
-[133]: http://clojuredocs.org/clojure_core/clojure.core/loop
-[134]: http://clojuredocs.org/clojure_core/clojure.core/reverse
-[135]: http://clojuredocs.org/clojure_core/clojure.core/recur
-[136]: http://en.wikipedia.org/wiki/Tail_recursion
-[137]: http://clojuredocs.org/clojure_core/clojure.core/doseq
-[138]: http://clojuredocs.org/clojure_core/clojure.core/last
-[139]: http://clojuredocs.org/clojure_core/clojure.core/dotimes
-[140]: http://en.wikipedia.org/wiki/Referential_transparency_(computer_science)
-[141]: http://en.wikipedia.org/wiki/Idempotence
-[142]: http://en.wikipedia.org/wiki/Memoization
-[143]: http://clojuredocs.org/clojure_core/clojure.core/memoize
-[144]: http://docs.oracle.com/javase/7/docs/api/java/lang/Thread.html#sleep(long)
-[145]: http://research.google.com/archive/mapreduce.html
-[146]: http://en.wikipedia.org/wiki/Map_Reduce
-[147]: http://couchdb.apache.org
-[148]: http://www.mongodb.org/
-[149]: http://basho.com/riak/
-[150]: http://en.wikipedia.org/wiki/Apache_Hadoop
-[151]: http://clojuredocs.org/clojure_core/clojure.core/map
-[152]: https://www.creativeapplications.net/wp-content/uploads/2013/04/map.png
-[153]: https://www.creativeapplications.net/wp-content/uploads/2013/12/map-builder-640x259.png
-[154]: http://clojuredocs.org/clojure_core/clojure.core/reduce
-[155]: http://clojuredocs.org/clojure_core/clojure.core/reductions
-[156]: http://clojuredocs.org/clojure_core/clojure.core/range
-[157]: https://www.creativeapplications.net/wp-content/uploads/2013/12/reduce-sum.png
-[158]: http://clojuredocs.org/clojure_core/clojure.core/filter
-[159]: http://clojuredocs.org/clojure_core/clojure.core/even_q
-[160]: https://www.creativeapplications.net/wp-content/uploads/2013/12/filter-640x54.png
-[161]: http://clojuredocs.org/clojure_core/clojure.core/take
-[162]: http://clojuredocs.org/clojure_core/clojure.core/drop
-[163]: http://clojuredocs.org/clojure_core/clojure.core/take-last
-[164]: http://clojuredocs.org/clojure_core/clojure.core/drop-last
-[165]: http://clojuredocs.org/clojure_core/clojure.core/butlast
-[166]: http://clojuredocs.org/clojure_core/clojure.core/take-nth
-[167]: http://clojuredocs.org/clojure_core/clojure.core/take-while
-[168]: http://clojuredocs.org/clojure_core/clojure.core/drop-while
-[169]: http://clojuredocs.org/clojure_core/clojure.core/concat
-[170]: http://clojuredocs.org/clojure_core/clojure.core/mapcat
-[171]: http://clojuredocs.org/clojure_core/clojure.core/identity
-[172]: http://clojuredocs.org/clojure_core/clojure.core/frequencies
-[173]: http://en.wikipedia.org/wiki/Histogram
-[174]: http://clojuredocs.org/clojure_core/clojure.core/cycle
-[175]: http://clojuredocs.org/clojure_core/clojure.core/repeat
-[176]: http://clojuredocs.org/clojure_core/clojure.core/repeatedly
-[177]: http://clojuredocs.org/clojure_core/clojure.core/iterate
-[178]: http://clojuredocs.org/clojure_core/clojure.core/interleave
-[179]: http://clojuredocs.org/clojure_core/clojure.core/interpose
-[180]: http://clojuredocs.org/clojure_core/clojure.core/zipmap
-[181]: http://en.wikipedia.org/wiki/Roman_numerals
-[182]: http://clojuredocs.org/clojure_core/clojure.core/for
-[183]: http://en.wikipedia.org/wiki/List_comprehension
-[184]: http://clojuredocs.org/clojure_core/clojure.core/every_q
-[185]: http://clojuredocs.org/clojure_core/clojure.core/rem
-[186]: http://clojuredocs.org/clojure_core/clojure.core/some
-[187]: http://en.wikipedia.org/wiki/Magnitude_(vector)
-[188]: http://clojuredocs.org/clojure_core/clojure.core/apply
-[189]: http://blog.jayfields.com/2010/07/clojure-destructuring.html
-[190]: https://github.com/quil/quil
-[191]: http://processing.org
-[192]: http://www.4clojure.com/
diff --git a/sources/tech/20171114 Finding Files with mlocate- Part 2.md b/sources/tech/20171114 Finding Files with mlocate- Part 2.md
index 7a99b3793a..19c546a917 100644
--- a/sources/tech/20171114 Finding Files with mlocate- Part 2.md
+++ b/sources/tech/20171114 Finding Files with mlocate- Part 2.md
@@ -1,4 +1,3 @@
-translating by amwps290
Finding Files with mlocate: Part 2
======
diff --git a/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md b/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md
index 0b5576e3a6..c6c50d9b25 100644
--- a/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md
+++ b/sources/tech/20171116 Unleash Your Creativity – Linux Programs for Drawing and Image Editing.md
@@ -1,4 +1,3 @@
-IEAST is translating
### Unleash Your Creativity – Linux Programs for Drawing and Image Editing
By: [chabowski][1]
@@ -75,11 +74,11 @@ And indeed, the sky’s the limit on how creative a user wants to be when using
(
- _**2** votes, average: **5.00** out of 5_
+ _**2** votes, average: **5.00** out of 5_
)
- _You need to be a registered member to rate this post._
+ _You need to be a registered member to rate this post._
Tags: [drawing][19], [Getting Started with Linux][20], [GIMP][21], [image editing][22], [Images][23], [InkScape][24], [KDE][25], [Krita][26], [Leap 42.3][27], [LibreOffice][28], [Linux Magazine][29], [Okular][30], [openSUSE][31], [PDF][32] Categories: [Desktop][33], [Expert Views][34], [LibreOffice][35], [openSUSE][36]
diff --git a/sources/tech/20171216 Sysadmin 101- Troubleshooting.md b/sources/tech/20171216 Sysadmin 101- Troubleshooting.md
deleted file mode 100644
index a08081e3fd..0000000000
--- a/sources/tech/20171216 Sysadmin 101- Troubleshooting.md
+++ /dev/null
@@ -1,123 +0,0 @@
-Sysadmin 101: Troubleshooting
-======
-I typically keep this blog strictly technical, keeping observations, opinions and the like to a minimum. But this, and the next few posts will be about basics and fundamentals for starting out in system administration/SRE/system engineer/sysops/devops-ops (whatever you want to call yourself) roles more generally.
-Bear with me!
-
-"My web site is slow"
-
-I just picked the type of issue for this article at random, this can be applied to pretty much any sysadmin related troubleshooting. It's not about showing off the cleverest oneliners to find the most information. It's also not an exhaustive, step-by-step "flowchart" with the word "profit" in the last box. It's about general approach, by means of a few examples.
-The example scenarios are solely for illustrative purposes. They sometimes have a basis in assumptions that doesn't apply to all cases all of the time, and I'm positive many readers will go "oh, but I think you will find…" at some point.
-But that would be missing the point.
-
-Having worked in support, or within a support organization for over a decade, there is one thing that strikes me time and time again and that made me write this;
-**The instinctive reaction many techs have when facing a problem, is to start throwing potential solutions at it.**
-
-"My website is slow"
-
- * I'm going to try upping `MaxClients/MaxRequestWorkers/worker_connections`
- * I'm going to try to increase `innodb_buffer_pool_size/effective_cache_size`
- * I'm going to try to enable `mod_gzip` (true story, sadly)
-
-
-
-"I saw this issue once, and then it was because X. So I'm going to try to fix X again, it might work".
-
-This wastes a lot of time, and leads you down a wild goose chase. In the dark. Wearing greased mittens.
-InnoDB's buffer pool may well be at 100% utilization, but that's just because there are remnants of a large one-off report someone ran a while back in there. If there are no evictions, you've just wasted time.
-
-### Quick side-bar before we start
-
-At this point, I should mention that while it's equally applicable to many roles, I'm writing this from a general support system adminstrator's point of view. In a mature, in-house organization or when working with larger, fully managed or "enterprise" customers, you'll typically have everything instrumented, measured, graphed, thresheld (not even word) and alerted on. Then your approach will often be rather different. We're going in blind here.
-
-If you don't have that sort of thing at your disposal;
-
-### Clarify and First look
-
-Establish what the issue actually is. "Slow" can take many forms. Is it time to first byte? That's a whole different class of problem from poor Javascript loading and pulling down 15 MB of static assets on each page load. Is it slow, or just slower than it usually is? Two very different plans of attack!
-
-Make sure you know what the issue reported/experienced actually is before you go off and do something. Finding the source of the problem is often difficult enough, without also having to find the problem itself.
-That is the sysadmin equivalent of bringing a knife to a gunfight.
-
-### Low hanging fruit / gimmies
-
-You are allowed to look for a few usual suspects when you first log in to a suspect server. In fact, you should! I tend to fire off a smattering of commands whenever I log in to a server to just very quickly check a few things; Are we swapping (`free/vmstat`), are the disks busy (`top/iostat/iotop`), are we dropping packets (`netstat/proc/net/dev`), is there an undue amount of connections in an undue state (`netstat`), is something hogging the CPUs (`top`), is someone else on this server (`w/who`), any eye-catching messages in syslog and `dmesg`?
-
-There's little point to carrying on if you have 2000 messages from your RAID controller about how unhappy it is with its write-through cache.
-
-This doesn't have to take more than half a minute. If nothing catches your eye - continue.
-
-### Reproduce
-
-If there indeed is a problem somewhere, and there's no low hanging fruit to be found;
-
-Take all steps you can to try and reproduce the problem. When you can reproduce, you can observe. **When you can observe, you can solve.** Ask the person reporting the issue what exact steps to take to reproduce the issue if it isn 't already obvious or covered by the first section.
-
-Now, for issues caused by solar flares and clients running exclusively on OS/2, it's not always feasible to reproduce. But your first port of call should be to at least try! In the very beginning, all you know is "X thinks their website is slow". For all you know at that point, they could be tethered to their GPRS mobile phone and applying Windows updates. Delving any deeper than we already have at that point is, again, a waste of time.
-
-Attempt to reproduce!
-
-### Check the log!
-
-It saddens me that I felt the need to include this. But I've seen escalations that ended mere minutes after someone ran `tail /var/log/..` Most *NIX tools these days are pretty good at logging. Anything blatantly wrong will manifest itself quite prominently in most application logs. Check it.
-
-### Narrow down
-
-If there are no obvious issues, but you can reproduce the reported problem, great. So, you know the website is slow. Now you've narrowed things down to: Browser rendering/bug, application code, DNS infrastructure, router, firewall, NICs (all eight+ involved), ethernet cables, load balancer, database, caching layer, session storage, web server software, application server, RAM, CPU, RAID card, disks.
-Add a smattering of other potential culprits depending on the set-up. It could be the SAN, too. And don't forget about the hardware WAF! And.. you get my point.
-
-If the issue is time-to-first-byte you'll of course start applying known fixes to the webserver, that's the one responding slowly and what you know the most about, right? Wrong!
-You go back to trying to reproduce the issue. Only this time, you try to eliminate as many potential sources of issues as possible.
-
-You can eliminate the vast majority of potential culprits very easily: Can you reproduce the issue locally from the server(s)? Congratulations, you've just saved yourself having to try your fixes for BGP routing.
-If you can't, try from another machine on the same network. If you can - at least you can move the firewall down your list of suspects, (but do keep a suspicious eye on that switch!)
-
-Are all connections slow? Just because the server is a web server, doesn't mean you shouldn't try to reproduce with another type of service. [netcat][1] is very useful in these scenarios (but chances are your SSH connection would have been lagging this whole time, as a clue)! If that's also slow, you at least know you've most likely got a networking problem and can disregard the entire web stack and all its components. Start from the top again with this knowledge (do not collect $200). Work your way from the inside-out!
-
-Even if you can reproduce locally - there's still a whole lot of "stuff" left. Let's remove a few more variables. Can you reproduce it with a flat-file? If `i_am_a_1kb_file.html` is slow, you know it's not your DB, caching layer or anything beyond the OS and the webserver itself.
-Can you reproduce with an interpreted/executed `hello_world.(py|php|js|rb..)` file? If you can, you've narrowed things down considerably, and you can focus on just a handful of things. If `hello_world` is served instantly, you've still learned a lot! You know there aren't any blatant resource constraints, any full queues or stuck IPC calls anywhere. So it's something the application is doing or something it's communicating with.
-
-Are all pages slow? Or just the ones loading the "Live scores feed" from a third party?
-
-**What this boils down to is; What 's the smallest amount of "stuff" that you can involve, and still reproduce the issue?**
-
-Our example is a slow web site, but this is equally applicable to almost any issue. Mail delivery? Can you deliver locally? To yourself? To ? Test with small, plaintext messages. Work your way up to the 2MB campaign blast. STARTTLS and no STARTTLS. Work your way from the inside-out.
-
-Each one of these steps takes mere seconds each, far quicker than implementing most "potential" fixes.
-
-### Observe / isolate
-
-By now, you may already have stumbled across the problem by virtue of being unable to reproduce when you removed a particular component.
-
-But if you haven't, or you still don't know **why** ; Once you've found a way to reproduce the issue with the smallest amount of "stuff" (technical term) between you and the issue, it's time to start isolating and observing.
-
-Bear in mind that many services can be ran in the foreground, and/or have debugging enabled. For certain classes of issues, it is often hugely helpful to do this.
-
-Here's also where your traditional armory comes into play. `strace`, `lsof`, `netstat`, `GDB`, `iotop`, `valgrind`, language profilers (cProfile, xdebug, ruby-prof…). Those types of tools.
-
-Once you've come this far, you rarely end up having to break out profilers or debugers though.
-
-[`strace`][2] is often a very good place to start.
-You might notice that the application is stuck on a particular `read()` call on a socket file descriptor connected to port 3306 somewhere. You'll know what to do.
-Move on to MySQL and start from the top again. Low hanging fruit: "Waiting_for comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md lock", deadlocks, max_connections.. Move on to: All queries? Only writes? Only certain tables? Only certain storage engines?…
-
-You might notice that there's a `connect()` to an external API resource that takes five seconds to complete, or even times out. You'll know what to do.
-
-You might notice that there are 1000 calls to `fstat()` and `open()` on the same couple of files as part of a circular dependency somewhere. You'll know what to do.
-
-It might not be any of those particular things, but I promise you, you'll notice something.
-
-If you're only going to take one thing from this section, let it be; learn to use `strace`! **Really** learn it, read the whole man page. Don 't even skip the HISTORY section. `man` each syscall you don't already know what it does. 98% of troubleshooting sessions ends with strace.
-
---------------------------------------------------------------------------------
-
-via: http://northernmost.org/blog/troubleshooting-101/index.html
-
-作者:[Erik Ljungstrom][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://northernmost.org
-[1]:http://nc110.sourceforge.net/
-[2]:https://linux.die.net/man/1/strace
diff --git a/sources/tech/20180131 How to test Webhooks when youre developing locally.md b/sources/tech/20180131 How to test Webhooks when youre developing locally.md
index 78242caae9..a0bba59d26 100644
--- a/sources/tech/20180131 How to test Webhooks when youre developing locally.md
+++ b/sources/tech/20180131 How to test Webhooks when youre developing locally.md
@@ -1,3 +1,5 @@
+wxy is applied
+
How to test Webhooks when you’re developing locally
============================================================
@@ -219,4 +221,4 @@ via: https://medium.freecodecamp.org/testing-webhooks-while-using-vagrant-for-de
[19]:https://github.com/wernight/docker-ngrok
[20]:https://github.com/stefandoorn
[21]:https://twitter.com/stefan_doorn
-[22]:https://www.linkedin.com/in/stefandoorn
\ No newline at end of file
+[22]:https://www.linkedin.com/in/stefandoorn
diff --git a/sources/tech/20180416 Cgo and Python.md b/sources/tech/20180416 Cgo and Python.md
index 422f510949..e5688d43c8 100644
--- a/sources/tech/20180416 Cgo and Python.md
+++ b/sources/tech/20180416 Cgo and Python.md
@@ -1,4 +1,3 @@
-translating by name1e5s
Cgo and Python
============================================================
diff --git a/sources/tech/20180612 7 open source tools to make literature reviews easy.md b/sources/tech/20180612 7 open source tools to make literature reviews easy.md
index 674f4ea44b..96edb68eff 100644
--- a/sources/tech/20180612 7 open source tools to make literature reviews easy.md
+++ b/sources/tech/20180612 7 open source tools to make literature reviews easy.md
@@ -1,4 +1,3 @@
-translated by lixinyuxx
7 open source tools to make literature reviews easy
======
diff --git a/sources/tech/20180725 Best Online Linux Terminals and Online Bash Editors.md b/sources/tech/20180725 Best Online Linux Terminals and Online Bash Editors.md
deleted file mode 100644
index 7f430c3d59..0000000000
--- a/sources/tech/20180725 Best Online Linux Terminals and Online Bash Editors.md
+++ /dev/null
@@ -1,212 +0,0 @@
-Best Online Linux Terminals and Online Bash Editors
-======
-No matter whether you want to practice Linux commands or just analyze/test your shell scripts online, there’s always a couple of online Linux terminals and online bash compilers available.
-
-This is particularly helpful when you are using the Windows operating system. Though you can [install Linux inside Windows using Windows Subsystem for Linux][1], using online Linux terminals are often more convenient for a quick test.
-
-![Websites that allow to use Linux Terminal online][2]
-
-But where can you find free Linux console? Which online Linux shell should you use?
-
-Fret not, to save you the hassle, here, we have compiled a list of the best online Linux terminals and a separate list of best online bash compilers for you to look at.
-
-**Note:** All of the online terminals support several browsers that include Google Chrome, Mozilla Firefox, Opera and Microsoft Edge.
-
-### Best Online Linux Terminals To Practice Linux Commands
-
-In the first part, I’ll list the online Linux terminals. These websites allow you to run the regular Linux commands in a web browser so that you can practice or test them. Some websites may require you to register and login to save your sessions.
-
-#### 1. JSLinux
-
-![online linux terminal - jslinux][3]
-
-JSLinux is more like a complete Linux emulator instead of just offering you the terminal. As the name suggests, it has been entirely written in JavaScript. You get to choose a console-based system or a GUI-based online Linux system. However, in this case, you would want to launch the console-based system to practice Linux commands. To be able to connect your account, you need to sign up first.
-
-JSLinux also lets you upload files to the virtual machine. At its core, it utilizes [Buildroot][4] (a tool that helps you to build a complete Linux system for an embedded system).
-
-[Try JSLinux Terminal][5]
-
-#### 2. Copy.sh
-
-![copysh online linux terminal][6]
-
-Copy.sh offers one of the best online Linux terminals which is fast and reliable to test and run Linux commands.
-
-Copy.sh is also on [GitHub][7] – and it is being actively maintained, which is a good thing. It also supports other Operating Systems, which includes:
-
- * Windows 98
- * KolibriOS
- * FreeDOS
- * Windows 1.01
- * Archlinux
-
-
-
-[Try Copy.sh Terminal][8]
-
-#### 3. Webminal
-
-![webminal online linux terminal][9]
-
-Webminal is an impressive online Linux terminal – and my personal favorite when it comes to a recommendation for beginners to practice Linux commands online.
-
-The website offers several lessons to learn from while you type in the commands in the same window. So, you do not need to refer to another site for the lessons and then switch back or split the screen in order to practice commands. It’s all right there – in a single tab on the browser.
-
-[Try Webminal Terminal][10]
-
-#### 4. Tutorialspoint Unix Terminal
-
-![tutorialspoint linux terminal][11]
-
-You might be aware of Tutorialspoint – which happens to be one of the most popular websites with high quality (yet free) online tutorials for just about any programming language (and more).
-
-So, for obvious reasons, they provide a free online Linux console for you to practice commands while referring to their site as a resource at the same time. You also get the ability to upload files. It is quite simple but an effective online terminal. Also, it doesn’t stop there, it offers a lot of different online terminals as well in its [Coding Ground][12] page.
-
-[Try Unix Terminal Online][13]
-
-#### 5. JS/UIX
-
-![js uix online linux terminal][14]
-
-JS/UIX is yet another online Linux terminal which is written entirely in JavaScript without any plug-ins. It contains an online Linux virtual machine, virtual file-system, shell, and so on.
-
-You can go through its manual page for the list of commands implemented.
-
-[Try JS/UX Terminal][15]
-
-#### 6. CB.VU
-
-![online linux terminal][16]
-
-If you are in for a treat with FreeBSD 7.1 stable version, cb.vu is a quite simple solution for that.
-
-Nothing fancy, just try out the Linux commands you want and get the output. Unfortunately, you do not get the ability to upload files here.
-
-[Try CB.VU Terminal][17]
-
-#### 7. Linux Containers
-
-![online linux terminal][18]
-
-Linux Containers lets you run a demo server with a 30-minute countdown on which acts as one of the best online Linux terminals. In fact, it’s a project sponsored by Canonical.
-
-[Try Linux LXD][19]
-
-#### 8. Codeanywhere
-
-![online linux terminal][20]
-
-Codeanywhere is a service which offers cross-platform cloud IDEs. However, in order to run a free Linux virtual machine, you just need to sign up and choose the free plan. And, then, proceed to create a new connection while setting up a container with an OS of your choice. Finally, you will have a free Linux console at your disposal.
-
-[Try Codeanywhere Editor][21]
-
-### Best Online Bash Editors
-
-Wait a sec! Are the online Linux terminals not good enough for Bash scripting? They are. But creating bash scripts in terminal editors and then executing them is not as convinient as using an online Bash editor.
-
-These bash editors allow you to easily write shell scripts online and you can run them to check if it works or not.
-
-Let’s see here can you run shell scripts online.
-
-#### Tutorialspoint Bash Compiler
-
-![online bash compiler][22]
-
-As mentioned above, Tutorialspoint also offers an online Bash compiler. It is a very simple bash compiler to execute bash shell online.
-
-[Try Tutorialspoint Bash Compiler][23]
-
-#### JDOODLE
-
-![online bash compiler][24]
-
-Yet another useful online bash editor to test Bash scripts is JDOODLE. It also offers other IDEs, but we’ll focus on bash script execution here. You get to set the command line arguments and the stdin inputs, and would normally get the result of your code.
-
-[Try JDOODLE Bash Script Online Tester][25]
-
-#### Paizo.io
-
-![paizo online bash editor][26]
-
-Paizo.io is a good bash online editor that you can try for free. To utilize some of its advanced features like task scheduling, you need to first sign up. It also supports real-time collaboration, but that’s still in the experimental phase.
-
-[Try Paizo.io Bash Editor][27]
-
-#### ShellCheck
-
-![shell check bash check][28]
-
-An interesting Bash editor which lets you find bugs in your shell script. It is available on [GitHub][29] as well. In addition, you can install ShellCheck locally on [supported platforms][30].
-
-[Try ShellCheck][31]
-
-#### Rextester
-
-![rextester bash editor][32]
-
-If you only want a dead simple online bash compiler, Rextester should be your choice. It also supports other programming languages.
-
-[Try Rextester][33]
-
-#### Learn Shell
-
-![online bash shell editor][34]
-
-Just like [Webminal][35], Learnshell provides you with the content (or resource) to learn shell programming and you could also run/try your code at the same time. It covers the basics and a few advanced topics as well.
-
-[Try Learn Shell Programming][36]
-
-### Wrapping Up
-
-Now that you know of the most reliable and fast online Linux terminals & online bash editors, learn, experiment, and play with the code!
-
-We might have missed any of your favorite online Linux terminals or maybe the best online bash compiler which you happen to use? Let us know your thoughts in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/online-linux-terminals/
-
-作者:[Ankush Das][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/ankush/
-[1]:https://itsfoss.com/install-bash-on-windows/
-[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/online-linux-terminals.jpeg
-[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/jslinux-online-linux-terminal.jpg
-[4]:https://buildroot.org/
-[5]:https://bellard.org/jslinux/
-[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/copy-sh-online-linux-terminal.jpg
-[7]:https://github.com/copy/v86
-[8]:https://copy.sh/v86/?profile=linux26
-[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/webminal.jpg
-[10]:http://www.webminal.org/terminal/
-[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/coding-ground-tutorialspoint-online-linux-terminal.jpg
-[12]:https://www.tutorialspoint.com/codingground.htm
-[13]:https://www.tutorialspoint.com/unix_terminal_online.php
-[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/JS-UIX-online-linux-terminal.jpg
-[15]:http://www.masswerk.at/jsuix/index.html
-[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/cb-vu-online-linux-terminal.jpg
-[17]:http://cb.vu/
-[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/linux-containers-terminal.jpg
-[19]:https://linuxcontainers.org/lxd/try-it/
-[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/codeanywhere-terminal.jpg
-[21]:https://codeanywhere.com/editor/
-[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/tutorialspoint-bash-compiler.jpg
-[23]:https://www.tutorialspoint.com/execute_bash_online.php
-[24]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/jdoodle-online-bash-editor.jpg
-[25]:https://www.jdoodle.com/test-bash-shell-script-online
-[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/paizo-io-bash-editor.jpg
-[27]:https://paiza.io/en/projects/new?language=bash
-[28]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/shell-check-bash-analyzer.jpg
-[29]:https://github.com/koalaman/shellcheck
-[30]:https://github.com/koalaman/shellcheck#user-content-installing
-[31]:https://www.shellcheck.net/#
-[32]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/rextester-bash-editor.jpg
-[33]:http://rextester.com/l/bash_online_compiler
-[34]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/learnshell-online-bash-shell.jpg
-[35]:http://www.webminal.org/
-[36]:http://www.learnshell.org/
diff --git a/sources/tech/20180924 5 ways to play old-school games on a Raspberry Pi.md b/sources/tech/20180924 5 ways to play old-school games on a Raspberry Pi.md
deleted file mode 100644
index 539ac42082..0000000000
--- a/sources/tech/20180924 5 ways to play old-school games on a Raspberry Pi.md
+++ /dev/null
@@ -1,169 +0,0 @@
-5 ways to play old-school games on a Raspberry Pi
-======
-
-Relive the golden age of gaming with these open source platforms for Raspberry Pi.
-
-
-
-They don't make 'em like they used to, do they? Video games, I mean.
-
-Sure, there's a bit more grunt in the gear now. Princess Zelda used to be 16 pixels in each direction; there's now enough graphics power for every hair on her head. Today's processors could beat up 1988's processors in a cage-fight deathmatch without breaking a sweat.
-
-But you know what's missing? The fun.
-
-You've got a squillion and one buttons to learn just to get past the tutorial mission. There's probably a storyline, too. You shouldn't need a backstory to kill bad guys. All you need is jump and shoot. So, it's little wonder that one of the most enduring popular uses for a Raspberry Pi is to relive the 8- and 16-bit golden age of gaming in the '80s and early '90s. But where to start?
-
-There are a few ways to play old-school games on the Pi. Each has its strengths and weaknesses, which I'll discuss here.
-
-### Retropie
-
-[Retropie][1] is probably the most popular retro-gaming platform for the Raspberry Pi. It's a solid all-rounder and a great default option for emulating classic desktop and console gaming systems.
-
-#### What is it?
-
-Retropie is built to run on [Raspbian][2]. It can also be installed over an existing Raspbian image if you'd prefer. It uses [EmulationStation][3] as a graphical front-end for a library of open source emulators, including the [Libretro][4] emulators.
-
-You don't need to understand a word of that to play your games, though.
-
-#### What's great about it
-
-It's very easy to get started. All you need to do is burn the image to an SD card, configure your controllers, copy your games over, and start killing bad guys.
-
-The huge user base means that there is a wealth of support and information out there, and active online communities to turn to for questions.
-
-In addition to the emulators that come installed with the Retropie image, there's a huge library of emulators you can install from the package manager, and it's growing all the time. Retropie also offers a user-friendly menu system to manage this, saving you time.
-
-From the Retropie menu, it's easy to add Kodi and the Raspbian desktop, which comes with the Chromium web browser. This means your retro-gaming rig is also good for home theatre, [YouTube][5], [SoundCloud][6], and all those other “lounge room computer” goodies.
-
-Retropie also has a number of other customization options: You can change the graphics in the menus, set up different control pad configurations for different emulators, make your Raspberry Pi file system visible to your local Windows network—all sorts of stuff.
-
-Retropie is built on Raspbian, which means you have the Raspberry Pi's most popular operating system to explore. Most Raspberry Pi projects and tutorials you find floating around are written for Raspbian, making it easy to customize and install new things on it. I've used my Retropie rig as a wireless bridge, installed MIDI synthesizers on it, taught myself a bit of Python, and more—all without compromising its use as a gaming machine.
-
-#### What's not so great about it
-
-Retropie's simple installation and ease of use is, in a way, a double-edged sword. You can go for a long time with Retropie without ever learning simple stuff like `sudo apt-get`, which means you're missing out on a lot of the Raspberry Pi experience.
-
-It doesn't have to be this way; the command line is still there under the hood when you want it, but perhaps users are a bit too insulated from a Bash shell that's ultimately a lot less scary than it looks. Retropie's main menu is operable only with a control pad, which can be annoying when you don't have one plugged in because you've been using the system for things other than gaming.
-
-#### Who's it for?
-
-Anyone who wants to get straight into some gaming, anyone who wants the biggest and best library of emulators, and anyone who wants a great way to start exploring Linux when they're not playing games.
-
-### Recalbox
-
-[Recalbox][7] is a newer open source suite of emulators for the Raspberry Pi. It also supports other ARM-based small-board computers.
-
-#### What is it?
-
-Like Retropie, Recalbox is built on EmulationStation and Libretro. Where it differs is that it's not built on Raspbian, but on its own flavor of Linux: RecalboxOS.
-
-#### What's great about it
-
-The setup for Recalbox is even easier than for Retropie. You don't even need to image an SD card; simply copy some files over and go. It also has out-of-the-box support for some game controllers, getting you to Level 1 that little bit faster. Kodi comes preinstalled. This is a ready-to-go gaming and media rig.
-
-#### What's not so great about it
-
-Recalbox has fewer emulators than Retropie, fewer customization options, and a smaller user community.
-
-Your Recalbox rig is probably always just going to be for emulators and Kodi, the same as when you installed it. If you feel like getting deeper into Linux, you'll probably want a new SD card for Raspbian.
-
-#### Who's it for?
-
-Recalbox is great if you want the absolute easiest retro gaming experience and can happily go without some of the more obscure gaming platforms, or if you are intimidated by the idea of doing anything a bit technical (and have no interest in growing out of that).
-
-For most opensource.com readers, Recalbox will probably come in most handy to recommend to your not-so-technical friend or relative. Its super-simple setup and overall lack of options might even help you avoid having to help them with it.
-
-### Roll your own
-
-Ok, if you've been paying attention, you might have noticed that both Retropie and Recalbox are built from many of the same open source components. So what's to stop you from putting them together yourself?
-
-#### What is it?
-
-Whatever you want it to be, baby. The nature of open source software means you could use an existing emulator suite as a starting point, or pilfer from them at will.
-
-#### What's great about it
-
-If you have your own custom interface in mind, I guess there's nothing to do but roll your sleeves up and get to it. This is also a way to install emulators that haven't quite found their way into Retropie yet, such as [BeebEm][8] or [ArcEm][9].
-
-#### What's not so great about it
-
-Well, it's a bit of work, isn't it?
-
-#### Who's it for?
-
-Hackers, tinkerers, builders, seasoned hobbyists, and such.
-
-### Native RISC OS gaming
-
-Now here's a dark horse: [RISC OS][10], the original operating system for ARM devices.
-
-#### What is it?
-
-Before ARM went on to become the world's most popular CPU architecture, it was originally built to be the heart of the Acorn Archimedes. That's kind of a forgotten beast nowadays, but for a few years it was light years ahead as the most powerful desktop computer in the world, and it attracted a lot of games development.
-
-Because the ARM processor in the Pi is the great-grandchild of the one in the Archimedes, we can still install RISC OS on it, and with a little bit of work, get these games running. This is different to the emulator options we've covered so far because we're playing our games on the operating system and CPU architecture for which they were written.
-
-#### What's great about it
-
-It's the perfect introduction to RISC OS. This is an absolute gem of an operating system and well worth checking out in its own right.
-
-The fact that you're using much the same operating system as back in the day to load and play your games makes your retro gaming rig just that little bit more of a time machine. This definitely adds some charm and retro value to the project.
-
-There are a few superb games that were released only on the Archimedes. The massive hardware advantage of the Archimedes also means that it often had the best graphics and smoothest gameplay of a lot of multi-platform titles. The rights holders to many of these games have been generous enough to make them legally available for free download.
-
-#### What's not so great about it
-
-Once you have installed RISC OS, it still takes a bit of elbow grease to get the games working. Here's a [guide to getting started][11].
-
-This is definitely not a great all-rounder for the lounge room. There's nothing like [Kodi][12]. There's a web browser, [NetSurf][13], but it's struggling to catch up to the modern web. You won't get the range of titles to play as you would with an emulator suite. RISC OS Open is free for hobbyists to download and use and much of the source code has been made open. But despite the name, it's not a 100% open source operating system.
-
-#### Who's it for?
-
-This one's for novelty seekers, absolute retro heads, people who want to explore an interesting operating system from the '80s, people who are nostalgic for Acorn machines from back in the day, and people who want a totally different retro gaming project.
-
-### Command line gaming
-
-Do you really need to install an emulator or an exotic operating system just to relive the glory days? Why not just install some native linux games from the command line?
-
-#### What is it?
-
-There's a whole range of native Linux games tested to work on the [Raspberry Pi][14].
-
-#### What's great about it
-
-You can install most of these from packages using the command line and start playing. Easy. If you've already got Raspbian up and running, it's probably your fastest path to getting a game running.
-
-#### What's not so great about it
-
-This isn't, strictly speaking, actual retro gaming. Linux was born in 1991 and took a while longer to come together as a gaming platform. This isn't quite gaming from the classic 8- and 16-bit era; these are ports and retro-influenced games that were built later.
-
-#### Who's it for?
-
-If you're just after a bucket of fun, no problem. But if you're trying to relive the actual era, this isn't quite it.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/retro-gaming-raspberry-pi
-
-作者:[James Mawson][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/dxmjames
-[1]: https://retropie.org.uk/
-[2]: https://www.raspbian.org/
-[3]: https://emulationstation.org/
-[4]: https://www.libretro.com/
-[5]: https://www.youtube.com/
-[6]: https://soundcloud.com/
-[7]: https://www.recalbox.com/
-[8]: http://www.mkw.me.uk/beebem/
-[9]: http://arcem.sourceforge.net/
-[10]: https://opensource.com/article/18/7/gentle-intro-risc-os
-[11]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
-[12]: https://kodi.tv/
-[13]: https://www.netsurf-browser.org/
-[14]: https://www.raspberrypi.org/forums/viewtopic.php?f=78&t=51794
diff --git a/sources/tech/20180928 Quiet log noise with Python and machine learning.md b/sources/tech/20180928 Quiet log noise with Python and machine learning.md
deleted file mode 100644
index f1fe2f1b7f..0000000000
--- a/sources/tech/20180928 Quiet log noise with Python and machine learning.md
+++ /dev/null
@@ -1,110 +0,0 @@
-Quiet log noise with Python and machine learning
-======
-
-Logreduce saves debugging time by picking out anomalies from mountains of log data.
-
-
-
-Continuous integration (CI) jobs can generate massive volumes of data. When a job fails, figuring out what went wrong can be a tedious process that involves investigating logs to discover the root cause—which is often found in a fraction of the total job output. To make it easier to separate the most relevant data from the rest, the [Logreduce][1] machine learning model is trained using previous successful job runs to extract anomalies from failed runs' logs.
-
-This principle can also be applied to other use cases, for example, extracting anomalies from [Journald][2] or other systemwide regular log files.
-
-### Using machine learning to reduce noise
-
-A typical log file contains many nominal events ("baselines") along with a few exceptions that are relevant to the developer. Baselines may contain random elements such as timestamps or unique identifiers that are difficult to detect and remove. To remove the baseline events, we can use a [k-nearest neighbors pattern recognition algorithm][3] (k-NN).
-
-
-
-Log events must be converted to numeric values for k-NN regression. Using the generic feature extraction tool [HashingVectorizer][4] enables the process to be applied to any type of log. It hashes each word and encodes each event in a sparse matrix. To further reduce the search space, tokenization removes known random words, such as dates or IP addresses.
-
-
-
-Once the model is trained, the k-NN search tells us the distance of each new event from the baseline.
-
-
-
-This [Jupyter notebook][5] demonstrates the process and graphs the sparse matrix vectors.
-
-
-
-### Introducing Logreduce
-
-The Logreduce Python software transparently implements this process. Logreduce's initial goal was to assist with [Zuul CI][6] job failure analyses using the build database, and it is now integrated into the [Software Factory][7] development forge's job logs process.
-
-At its simplest, Logreduce compares files or directories and removes lines that are similar. Logreduce builds a model for each source file and outputs any of the target's lines whose distances are above a defined threshold by using the following syntax: **distance | filename:line-number: line-content**.
-
-```
-$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
-INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
-0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
-INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
-99.99% reduction (from 20015 lines to 1
-
-```
-
-A more advanced Logreduce use can train a model offline to be reused. Many variants of the baselines can be used to fit the k-NN search tree.
-
-```
-$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
-INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
-DEBUG logreduce.Classifier - audit.clf: written
-$ logreduce dir-run audit.clf /var/log/audit/audit.log
-```
-
-Logreduce also implements interfaces to discover baselines for Journald time ranges (days/weeks/months) and Zuul CI job build histories. It can also generate HTML reports that group anomalies found in multiple files in a simple interface.
-
-
-
-### Managing baselines
-
-The key to using k-NN regression for anomaly detection is to have a database of known good baselines, which the model uses to detect lines that deviate too far. This method relies on the baselines containing all nominal events, as anything that isn't found in the baseline will be reported as anomalous.
-
-CI jobs are great targets for k-NN regression because the job outputs are often deterministic and previous runs can be automatically used as baselines. Logreduce features Zuul job roles that can be used as part of a failed job post task in order to issue a concise report (instead of the full job's logs). This principle can be applied to other cases, as long as baselines can be constructed in advance. For example, a nominal system's [SoS report][8] can be used to find issues in a defective deployment.
-
-
-
-### Anomaly classification service
-
-The next version of Logreduce introduces a server mode to offload log processing to an external service where reports can be further analyzed. It also supports importing existing reports and requests to analyze a Zuul build. The services run analyses asynchronously and feature a web interface to adjust scores and remove false positives.
-
-
-
-Reviewed reports can be archived as a standalone dataset with the target log files and the scores for anomalous lines recorded in a flat JSON file.
-
-### Project roadmap
-
-Logreduce is already being used effectively, but there are many opportunities for improving the tool. Plans for the future include:
-
- * Curating many annotated anomalies found in log files and producing a public domain dataset to enable further research. Anomaly detection in log files is a challenging topic, and having a common dataset to test new models would help identify new solutions.
- * Reusing the annotated anomalies with the model to refine the distances reported. For example, when users mark lines as false positives by setting their distance to zero, the model could reduce the score of those lines in future reports.
- * Fingerprinting archived anomalies to detect when a new report contains an already known anomaly. Thus, instead of reporting the anomaly's content, the service could notify the user that the job hit a known issue. When the issue is fixed, the service could automatically restart the job.
- * Supporting more baseline discovery interfaces for targets such as SOS reports, Jenkins builds, Travis CI, and more.
-
-
-
-If you are interested in getting involved in this project, please contact us on the **#log-classify** Freenode IRC channel. Feedback is always appreciated!
-
-Tristan Cacqueray will present [Reduce your log noise using machine learning][9] at the [OpenStack Summit][10], November 13-15 in Berlin.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
-
-作者:[Tristan de Cacqueray][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/tristanc
-[1]: https://pypi.org/project/logreduce/
-[2]: http://man7.org/linux/man-pages/man8/systemd-journald.service.8.html
-[3]: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
-[4]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
-[5]: https://github.com/TristanCacqueray/anomaly-detection-workshop-opendev/blob/master/datasets/notebook/anomaly-detection-with-scikit-learn.ipynb
-[6]: https://zuul-ci.org
-[7]: https://www.softwarefactory-project.io
-[8]: https://sos.readthedocs.io/en/latest/
-[9]: https://www.openstack.org/summit/berlin-2018/summit-schedule/speakers/4307
-[10]: https://www.openstack.org/summit/berlin-2018/
diff --git a/sources/tech/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md b/sources/tech/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md
index 2fd085eda0..8ee4f34897 100644
--- a/sources/tech/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md
+++ b/sources/tech/20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md
@@ -1,5 +1,3 @@
-Translating by Jamskr
-
Exploring the Linux kernel: The secrets of Kconfig/kbuild
======
Dive into understanding how the Linux config/build system works.
diff --git a/sources/tech/20181011 The First Beta of Haiku is Released After 16 Years of Development.md b/sources/tech/20181011 The First Beta of Haiku is Released After 16 Years of Development.md
deleted file mode 100644
index b6daaef053..0000000000
--- a/sources/tech/20181011 The First Beta of Haiku is Released After 16 Years of Development.md
+++ /dev/null
@@ -1,87 +0,0 @@
-The First Beta of Haiku is Released After 16 Years of Development
-======
-There are a number of small operating systems out there that are designed to replicate the past. Haiku is one of those. We will look to see where Haiku came from and what the new release has to offer.
-
-![Haiku OS desktop screenshot][1]Haiku desktop
-
-### What is Haiku?
-
-Haiku’s history begins with the now defunct [Be Inc][2]. Be Inc was founded by former Apple executive [Jean-Louis Gassée][3] after he was ousted by CEO [John Sculley][4]. Gassée wanted to create a new operating system from the ground up. BeOS was created with digital media work in mind and was designed to take advantage of the most modern hardware of the time. Originally, Be Inc attempted to create their own platform encompassing both hardware and software. The result was called the [BeBox][5]. After BeBox failed to sell well, Be turned their attention to BeOS.
-
-In the 1990s, Apple was looking for a new operating system to replace the aging Classic Mac OS. The two contenders were Gassée’s BeOS and Steve Jobs’ NeXTSTEP. In the end, Apple went with NeXTSTEP. Be tried to license BeOS to hardware makers, but [in at least one case][6] Microsoft threatened to revoke a manufacturer’s Windows license if they sold BeOS machines. Eventually, Be Inc was sold to Palm in 2001 for $11 million. BeOS was subsequently discontinued.
-
-Following the news of Palm’s purchase, a number of loyal fans decided they wanted to keep the operating system alive. The original name of the project was OpenBeOS, but was changed to Haiku to avoid infringing on Palm’s trademarks. The name is a reference to reference to the [haikus][7] used as error messages by many of the applications. Haiku is completely written from scratch and is compatible with BeOS.
-
-### Why Haiku?
-
-According to the project’s website, [Haiku][8] “is a fast, efficient, simple to use, easy to learn, and yet very powerful system for computer users of all levels”. Haiku comes with a kernel that have been customized for performance. Like FreeBSD, there is a “single team writing everything from the kernel, drivers, userland services, toolkit, and graphics stack to the included desktop applications and preflets”.
-
-### New Features in Haiku Beta Release
-
-A number of new features have been introduced since the release of Alpha 4.1. (Please note that Haiku is a passion project and all the devs are part-time, so some they can’t spend as much time working on Haiku as they would like.)
-
-![Haiku OS software][9]
-HaikuDepot, Haiku’s package manager
-
-One of the biggest features is the inclusion of a complete package management system. HaikuDepot allows you to sort through many applications. Many are built specifically for Haiku, but a number have been ported to the platform, such as [LibreOffice][10], [Otter Browser][11], and [Calligra][12]. Interestingly, each Haiku package is [“a special type of compressed filesystem image, which is ‘mounted’ upon installation”][13]. There is also a command line interface for package management named `pkgman`.
-
-Another big feature is an upgraded browser. Haiku was able to hire a developer to work full-time for a year to improve the performance of WebPositive, the built-in browser. This included an update to a newer version of WebKit. WebPositive will now play Youtube videos properly.
-
-![Haiku OS WebPositive browser][14]
-WebPositive, Haiku’s built-in browser
-
-Other features include:
-
- * A completely rewritten network preflet
- * User interface cleanup
- * Media subsystem improvements, including better streaming support, HDA driver improvements, and FFmpeg decoder plugin improvements
- * Native RemoteDesktop improved
- * Add EFI bootloader and GPT support
- * Updated Ethernet & WiFi drivers
- * Updated filesystem drivers
- * General system stabilization
- * Experimental Bluetooth stack
-
-
-
-### Thoughts on Haiku OS
-
-I have been following Haiku for many years. I’ve installed and played with the nightly builds a dozen times over the last couple of years. I even took some time to start learning one of its programming languages, so that I could write apps. But I got busy with other things.
-
-I’m very conflicted about it. I like Haiku because it is a neat non-Linux project, but it is only just getting features that everyone else takes for granted, like a package manager.
-
-If you’ve got a couple of minutes, download the [ISO][15] and install it on the virtual machine of your choice. You just might like it.
-
-Have you ever used Haiku or BeOS? If so, what are your favorite features? Let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][16].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/haiku-os-release/
-
-作者:[John Paul][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[b]: https://github.com/lujun9972
-[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/haiku.jpg
-[2]: https://en.wikipedia.org/wiki/Be_Inc.
-[3]: https://en.wikipedia.org/wiki/Jean-Louis_Gass%C3%A9e
-[4]: https://en.wikipedia.org/wiki/John_Sculley
-[5]: https://en.wikipedia.org/wiki/BeBox
-[6]: https://birdhouse.org/beos/byte/30-bootloader/
-[7]: https://en.wikipedia.org/wiki/Haiku
-[8]: https://www.haiku-os.org/about/
-[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/haiku-depot.png
-[10]: https://www.libreoffice.org/
-[11]: https://itsfoss.com/otter-browser-review/
-[12]: https://www.calligra.org/
-[13]: https://www.haiku-os.org/get-haiku/release-notes/
-[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/webpositive.jpg
-[15]: https://www.haiku-os.org/get-haiku
-[16]: http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20181105 How to manage storage on Linux with LVM.md b/sources/tech/20181105 How to manage storage on Linux with LVM.md
index 9c0ee685d6..36cc8d47a0 100644
--- a/sources/tech/20181105 How to manage storage on Linux with LVM.md
+++ b/sources/tech/20181105 How to manage storage on Linux with LVM.md
@@ -1,4 +1,3 @@
-[zianglei translating]
How to manage storage on Linux with LVM
======
Create, expand, and encrypt storage pools as needed with the Linux LVM utilities.
diff --git a/sources/tech/20190304 How to Install MongoDB on Ubuntu.md b/sources/tech/20190304 How to Install MongoDB on Ubuntu.md
deleted file mode 100644
index 30d588ddba..0000000000
--- a/sources/tech/20190304 How to Install MongoDB on Ubuntu.md
+++ /dev/null
@@ -1,238 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (An-DJ)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Install MongoDB on Ubuntu)
-[#]: via: (https://itsfoss.com/install-mongodb-ubuntu)
-[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
-
-How to Install MongoDB on Ubuntu
-======
-
-**This tutorial presents two ways to install MongoDB on Ubuntu and Ubuntu-based Linux distributions.**
-
-[MongoDB][1] is an increasingly popular free and open-source NoSQL database that stores data in collections of JSON-like, flexible documents, in contrast to the usual table approach you’ll find in SQL databases.
-
-You are most likely to find MongoDB used in modern web applications. Its document model makes it very intuitive to access and handle with various programming languages.
-
-![mongodb Ubuntu][2]
-
-In this article, I’ll cover two ways you can install MongoDB on your Ubuntu system.
-
-### Installing MongoDB on Ubuntu based Distributions
-
- 1. Install MongoDB using Ubuntu’s repository. Easy but not the latest version of MongoDB
- 2. Install MongoDB using its official repository. Slightly complicated but you get the latest version of MongoDB.
-
-
-
-The first installation method is easier, but I recommend the second method if you plan on using the latest release with official support.
-
-Some people might prefer using snap packages. There are snaps available in the Ubuntu Software Center, but I wouldn’t recommend using them; they’re outdated at the moment and I won’t be covering that.
-
-#### Method 1. Install MongoDB from Ubuntu Repository
-
-This is the easy way to install MongoDB on your system, you only need to type in a simple command.
-
-##### Installing MongoDB
-
-First, make sure your packages are up-to-date. Open up a terminal and type:
-
-```
-sudo apt update && sudo apt upgrade -y
-```
-
-Go ahead and install MongoDB with:
-
-```
-sudo apt install mongodb
-```
-
-That’s it! MongoDB is now installed on your machine.
-
-The MongoDB service should automatically be started on install, but to check the status type
-
-```
-sudo systemctl status mongodb
-```
-
-![Check if the MongoDB service is running.][3]
-
-You can see that the service is **active**.
-
-##### Running MongoDB
-
-MongoDB is currently a systemd service, so we’ll use **systemctl** to check and modify it’s state, using the following commands:
-
-```
-sudo systemctl status mongodb
-sudo systemctl stop mongodb
-sudo systemctl start mongodb
-sudo systemctl restart mongodb
-```
-
-You can also change if MongoDB automatically starts when the system starts up ( **default** : enabled):
-
-```
-sudo systemctl disable mongodb
-sudo systemctl enable mongodb
-```
-
-To start working with (creating and editing) databases, type:
-
-```
-mongo
-```
-
-This will start up the **mongo shell**. Please check out the [manual][4] for detailed information on the available queries and options.
-
-**Note:** Depending on how you plan to use MongoDB, you might need to adjust your Firewall. That’s unfortunately more involved than what I can cover here and depends on your configuration.
-
-##### Uninstall MongoDB
-
-If you installed MongoDB from the Ubuntu Repository and want to uninstall it (maybe to install using the officially supported way), type:
-
-```
-sudo systemctl stop mongodb
-sudo apt purge mongodb
-sudo apt autoremove
-```
-
-This should completely get rid of your MongoDB install. Make sure to **backup** any collections or documents you might want to keep since they will be wiped out!
-
-#### Method 2. Install MongoDB Community Edition on Ubuntu
-
-This is the way the recommended way to install MongoDB, using the package manager. You’ll have to type a few more commands and it might be intimidating if you are newer to the Linux world.
-
-But there’s nothing to be afraid of! We’ll go through the installation process step by step.
-
-##### Installing MongoDB
-
-The package maintained by MongoDB Inc. is called **mongodb-org** , not **mongodb** (this is the name of the package in the Ubuntu Repository). Make sure **mongodb** is not installed on your system before applying this steps. The packages will conflict. Let’s get to it!
-
-First, we’ll have to import the public key:
-
-```
-sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4
-```
-
-Now, you need to add a new repository in your sources list so that you can install MongoDB Community Edition and also get automatic updates:
-
-```
-echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu $(lsb_release -cs)/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list
-```
-
-To be able to install **mongodb-org** , we’ll have to update our package database so that your system is aware of the new packages available:
-
-```
-sudo apt update
-```
-
-Now you can ether install the **latest stable version** of MongoDB:
-
-```
-sudo apt install -y mongodb-org
-```
-
-or a **specific version** (change the version number after **equal** sign)
-
-```
-sudo apt install -y mongodb-org=4.0.6 mongodb-org-server=4.0.6 mongodb-org-shell=4.0.6 mongodb-org-mongos=4.0.6 mongodb-org-tools=4.0.6
-```
-
-If you choose to install a specific version, make sure you change the version number everywhere. If you only change it in the **mongodb-org=4.0.6** part, the latest version will be installed.
-
-By default, when updating using the package manager ( **apt-get** ), MongoDB will be updated to the newest updated version. To stop that from happening (and freezing to the installed version), use:
-
-```
-echo "mongodb-org hold" | sudo dpkg --set-selections
-echo "mongodb-org-server hold" | sudo dpkg --set-selections
-echo "mongodb-org-shell hold" | sudo dpkg --set-selections
-echo "mongodb-org-mongos hold" | sudo dpkg --set-selections
-echo "mongodb-org-tools hold" | sudo dpkg --set-selections
-```
-
-You have now successfully installed MongoDB!
-
-##### Configuring MongoDB
-
-By default, the package manager will create **/var/lib/mongodb** and **/var/log/mongodb** and MongoDB will run using the **mongodb** user account.
-
-I won’t go into changing these default settings since that is beyond the scope of this guide. You can check out the [manual][5] for detailed information.
-
-The settings in **/etc/mongod.conf** are applied when starting/restarting the **mongodb** service instance.
-
-##### Running MongoDB
-
-To start the mongodb daemon **mongod** , type:
-
-```
-sudo service mongod start
-```
-
-Now you should verify that the **mongod** process started successfully. This information is stored (by default) at **/var/log/mongodb/mongod.log**. Let’s check the contents of that file:
-
-```
-sudo cat /var/log/mongodb/mongod.log
-```
-
-![Check MongoDB logs to see if the process is running properly.][6]
-
-As long as you get this: **[initandlisten] waiting for connections on port 27017** somewhere in there, the process is running properly.
-
-**Note: 27017** is the default port of **mongod.**
-
-To stop/restart **mongod** enter:
-
-```
-sudo service mongod stop
-sudo service mongod restart
-```
-
-Now, you can use MongoDB by opening the **mongo shell** :
-
-```
-mongo
-```
-
-##### Uninstall MongoDB
-
-Run the following commands
-
-```
-sudo service mongod stop
-sudo apt purge mongodb-org*
-```
-
-To remove the **databases** and **log files** (make sure to **backup** what you want to keep!):
-
-```
-sudo rm -r /var/log/mongodb
-sudo rm -r /var/lib/mongodb
-```
-
-**Wrapping Up**
-
-MongoDB is a great NoSQL database, easy to integrate into modern projects. I hope this tutorial helped you to set it up on your Ubuntu machine! Let us know how you plan on using MongoDB in the comments below.
-
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/install-mongodb-ubuntu
-
-作者:[Sergiu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/sergiu/
-[b]: https://github.com/lujun9972
-[1]: https://www.mongodb.com/
-[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/mongodb-ubuntu.jpeg?resize=800%2C450&ssl=1
-[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/mongodb_check_status.jpg?fit=800%2C574&ssl=1
-[4]: https://docs.mongodb.com/manual/tutorial/getting-started/
-[5]: https://docs.mongodb.com/manual/
-[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/mongodb_org_check_logs.jpg?fit=800%2C467&ssl=1
diff --git a/sources/tech/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md b/sources/tech/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md
deleted file mode 100644
index 8f69143d36..0000000000
--- a/sources/tech/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md
+++ /dev/null
@@ -1,309 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel)
-[#]: via: (https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel
-======
-
-We had written two articles in the past to run commands on multiple remote server in parallel.
-
-These are **[Parallel SSH (PSSH)][1]** or **[Distributed Shell (DSH)][2]**.
-
-Today also, we are going to discuss about the same kind of topic but it allows us to perform the same on cluster nodes as well.
-
-You may think, i can write a small shell script to archive this instead of installing these third party packages.
-
-Of course you are right and if you are going to run some commands in 10-15 remote systems then you don’t need to use this.
-
-However, the scripts take some time to complete this task as it’s running in a sequential order.
-
-Think about if you would like to run some commands on 1000+ servers what will be the options?
-
-In this case your script won’t help you. Also, it would take good amount of time to complete a task.
-
-So, to overcome this kind of issue and situation. We need to run the command in parallel on remote machines.
-
-For that, we need use in one of the Parallel applications. I hope this explanation might fulfilled your doubts about parallel utilities.
-
-### What Is ClusterShell?
-
-clush stands for [ClusterShell][3]. ClusterShell is an event-driven open source Python library, designed to run local or distant commands in parallel on server farms or on large Linux clusters.
-
-It will take care of common issues encountered on HPC clusters, such as operating on groups of nodes, running distributed commands using optimized execution algorithms, as well as gathering results and merging identical outputs, or retrieving return codes.
-
-ClusterShell takes advantage of existing remote shell facilities already installed on your systems, like SSH.
-
-ClusterShell’s primary goal is to improve the administration of high- performance clusters by providing a lightweight but scalable Python API for developers. It also provides clush, clubak and cluset/nodeset, convenient command-line tools that allow traditional shell scripts to benefit from some of the library features.
-
-ClusterShell’s written in Python and it requires Python (v2.6+ or v3.4+) to run on your system.
-
-### How To Install ClusterShell On Linux?
-
-ClusterShell package is available in most of the distribution official package manager. So, use the distribution package manager tool to install it.
-
-For **`Fedora`** system, use **[DNF Command][4]** to install clustershell.
-
-```
-$ sudo dnf install clustershell
-```
-
-Python 2 module and tools are installed and if it’s default on your system then run the following command to install Python 3 development on Fedora System.
-
-```
-$ sudo dnf install python3-clustershell
-```
-
-Make sure you should have enabled the **[EPEL repository][5]** on your system before performing clustershell installation.
-
-For **`RHEL/CentOS`** systems, use **[YUM Command][6]** to install clustershell.
-
-```
-$ sudo yum install clustershell
-```
-
-Python 2 module and tools are installed and if it’s default on your system then run the following command to install Python 3 development on CentOS/RHEL System.
-
-```
-$ sudo yum install python34-clustershell
-```
-
-For **`openSUSE Leap`** system, use **[Zypper Command][7]** to install clustershell.
-
-```
-$ sudo zypper install clustershell
-```
-
-Python 2 module and tools are installed and if it’s default on your system then run the following command to install Python 3 development on OpenSUSE System.
-
-```
-$ sudo zypper install python3-clustershell
-```
-
-For **`Debian/Ubuntu`** systems, use **[APT-GET Command][8]** or **[APT Command][9]** to install clustershell.
-
-```
-$ sudo apt install clustershell
-```
-
-### How To Install ClusterShell In Linux Using PIP?
-
-Use PIP to install ClusterShell because it’s written in Python.
-
-Make sure you should have enabled the **[Python][10]** and **[PIP][11]** on your system before performing clustershell installation.
-
-```
-$ sudo pip install ClusterShell
-```
-
-### How To Use ClusterShell On Linux?
-
-It’s straight forward and awesome tool compared with other utilities such as pssh and dsh. It has so many options to perform the remote execution in parallel.
-
-Make sure you should have enabled the **[password less login][12]** on your system before start using clustershell.
-
-The following configuration file defines system-wide default values. You no need to modify anything here.
-
-```
-$ cat /etc/clustershell/clush.conf
-```
-
-If you would like to create a servers group. Here you can go. By default some examples were available so, do the same for your requirements.
-
-```
-$ cat /etc/clustershell/groups.d/local.cfg
-```
-
-Just run the clustershell command in the following format to get the information from the given nodes.
-
-```
-$ clush -w 192.168.1.4,192.168.1.9 cat /proc/version
-192.168.1.9: Linux version 4.15.0-45-generic ([email protected]) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #48-Ubuntu SMP Tue Jan 29 16:28:13 UTC 2019
-192.168.1.4: Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
-```
-
-**Option:**
-
- * **`-w:`** nodes where to run the command.
-
-
-
-You can use the regular expressions instead of using full hostname and IPs.
-
-```
-$ clush -w 192.168.1.[4,9] uname -r
-192.168.1.9: 4.15.0-45-generic
-192.168.1.4: 3.10.0-957.el7.x86_64
-```
-
-Alternatively you can use the following format if you have the servers in the same IP series.
-
-```
-$ clush -w 192.168.1.[4-9] date
-192.168.1.6: Mon Mar 4 21:08:29 IST 2019
-192.168.1.7: Mon Mar 4 21:08:29 IST 2019
-192.168.1.8: Mon Mar 4 21:08:29 IST 2019
-192.168.1.5: Mon Mar 4 09:16:30 CST 2019
-192.168.1.9: Mon Mar 4 21:08:29 IST 2019
-192.168.1.4: Mon Mar 4 09:16:30 CST 2019
-```
-
-clustershell allow us to run the command in batch mode. Use the following format to achieve this.
-
-```
-$ clush -w 192.168.1.4,192.168.1.9 -b
-Enter 'quit' to leave this interactive mode
-Working with nodes: 192.168.1.[4,9]
-clush> hostnamectl
----------------
-192.168.1.4
----------------
- Static hostname: CentOS7.2daygeek.com
- Icon name: computer-vm
- Chassis: vm
- Machine ID: 002f47b82af248f5be1d67b67e03514c
- Boot ID: f9b37a073c534dec8b236885e754cb56
- Virtualization: kvm
- Operating System: CentOS Linux 7 (Core)
- CPE OS Name: cpe:/o:centos:centos:7
- Kernel: Linux 3.10.0-957.el7.x86_64
- Architecture: x86-64
----------------
-192.168.1.9
----------------
- Static hostname: Ubuntu18
- Icon name: computer-vm
- Chassis: vm
- Machine ID: 27f6c2febda84dc881f28fd145077187
- Boot ID: f176f2eb45524d4f906d12e2b5716649
- Virtualization: oracle
- Operating System: Ubuntu 18.04.2 LTS
- Kernel: Linux 4.15.0-45-generic
- Architecture: x86-64
-clush> free -m
----------------
-192.168.1.4
----------------
- total used free shared buff/cache available
-Mem: 1838 641 217 19 978 969
-Swap: 2047 0 2047
----------------
-192.168.1.9
----------------
- total used free shared buff/cache available
-Mem: 1993 352 1067 1 573 1473
-Swap: 1425 0 1425
-clush> w
----------------
-192.168.1.4
----------------
- 09:21:14 up 3:21, 3 users, load average: 0.00, 0.01, 0.05
-USER TTY FROM [email protected] IDLE JCPU PCPU WHAT
-daygeek :0 :0 06:02 ?xdm? 1:28 0.30s /usr/libexec/gnome-session-binary --session gnome-classic
-daygeek pts/0 :0 06:03 3:17m 0.06s 0.06s bash
-daygeek pts/1 192.168.1.6 06:03 52:26 0.10s 0.10s -bash
----------------
-192.168.1.9
----------------
- 21:13:12 up 3:12, 1 user, load average: 0.08, 0.03, 0.00
-USER TTY FROM [email protected] IDLE JCPU PCPU WHAT
-daygeek pts/0 192.168.1.6 20:42 29:41 0.05s 0.05s -bash
-clush> quit
-```
-
-If you would like to run the command on a group of nodes then use the following format.
-
-```
-$ clush -w @dev uptime
-or
-$ clush -g dev uptime
-or
-$ clush --group=dev uptime
-
-192.168.1.9: 21:10:10 up 3:09, 1 user, load average: 0.09, 0.03, 0.01
-192.168.1.4: 09:18:12 up 3:18, 3 users, load average: 0.01, 0.02, 0.05
-```
-
-If you would like to run the command on more than one group of nodes then use the following format.
-
-```
-$ clush -w @dev,@uat uptime
-or
-$ clush -g dev,uat uptime
-or
-$ clush --group=dev,uat uptime
-
-192.168.1.7: 07:57:19 up 59 min, 1 user, load average: 0.08, 0.03, 0.00
-192.168.1.9: 20:27:20 up 1:00, 1 user, load average: 0.00, 0.00, 0.00
-192.168.1.5: 08:57:21 up 59 min, 1 user, load average: 0.00, 0.01, 0.05
-```
-
-clustershell allow us to copy a file to remote machines. To copy local file or directory to the remote nodes in the same location.
-
-```
-$ clush -w 192.168.1.[4,9] --copy /home/daygeek/passwd-up.sh
-```
-
-We can verify the same by running the following command.
-
-```
-$ clush -w 192.168.1.[4,9] ls -lh /home/daygeek/passwd-up.sh
-192.168.1.4: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 09:00 /home/daygeek/passwd-up.sh
-192.168.1.9: -rwxr-xr-x 1 daygeek daygeek 159 Mar 4 20:52 /home/daygeek/passwd-up.sh
-```
-
-To copy local file or directory to the remote nodes in the different location.
-
-```
-$ clush -g uat --copy /home/daygeek/passwd-up.sh --dest /tmp
-```
-
-We can verify the same by running the following command.
-
-```
-$ clush --group=uat ls -lh /tmp/passwd-up.sh
-192.168.1.7: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 6 07:44 /tmp/passwd-up.sh
-```
-
-To copy file or directory from remote nodes to local system.
-
-```
-$ clush -w 192.168.1.7 --rcopy /home/daygeek/Documents/magi.txt --dest /tmp
-```
-
-We can verify the same by running the following command.
-
-```
-$ ls -lh /tmp/magi.txt.192.168.1.7
--rw-r--r-- 1 daygeek daygeek 35 Mar 6 20:24 /tmp/magi.txt.192.168.1.7
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
-[2]: https://www.2daygeek.com/dsh-run-execute-shell-commands-on-multiple-linux-servers-at-once/
-[3]: https://cea-hpc.github.io/clustershell/
-[4]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
-[5]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
-[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
-[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
-[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
-[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
-[10]: https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
-[11]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
-[12]: https://www.2daygeek.com/linux-passwordless-ssh-login-using-ssh-keygen/
diff --git a/sources/tech/20190315 How To Parse And Pretty Print JSON With Linux Commandline Tools.md b/sources/tech/20190315 How To Parse And Pretty Print JSON With Linux Commandline Tools.md
index 16e9c70627..1cc2f14b43 100644
--- a/sources/tech/20190315 How To Parse And Pretty Print JSON With Linux Commandline Tools.md
+++ b/sources/tech/20190315 How To Parse And Pretty Print JSON With Linux Commandline Tools.md
@@ -1,5 +1,5 @@
[#]: collector: "lujun9972"
-[#]: translator: "zhangxiangping "
+[#]: translator: " "
[#]: reviewer: " "
[#]: publisher: " "
[#]: url: " "
diff --git a/sources/tech/20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md b/sources/tech/20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md
deleted file mode 100644
index bb1d187ea4..0000000000
--- a/sources/tech/20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md
+++ /dev/null
@@ -1,88 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8])
-[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/)
-[#]: author: (editor https://www.ostechnix.com/author/editor/)
-
-Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8]
-======
-
-![Introduction To Hyperledger Project][1]
-
-Once a new technology platform reaches a threshold level of popularity in terms of active development and commercial interests, major global companies and smaller start-ups alike rush to catch a slice of the pie. **Linux** was one such platform back in the day. Once the ubiquity of its applications was realized individuals, firms, and institutions started displaying their interest in it and by 2000 the **Linux foundation** was formed.
-
-The Linux foundation aims to standardize and develop Linux as a platform by sponsoring their development team. The Linux Foundation is a non-profit organization that is supported by software and IT behemoths such as Microsoft, Oracle, Samsung, Cisco, IBM, Intel among others[1]. This is excluding the hundreds of individual developers who offer their services for the betterment of the platform. Over the years the Linux foundation has taken many projects under its roof. The **Hyperledger Project** is their fastest growing one till date.
-
-Such consortium led development have a lot of advantages when it comes to furthering tech into usable useful forms. Developing the standards, libraries and all the back-end protocols for large scale projects are expensive and resource intensive without a shred of income generating from it. Hence, it makes sense for companies to pool in their resources to develop the common “boring” parts by supporting such organizations and later upon completing work on these standard parts to simply plug & play and customize their products afterwards. Apart from the economics of the model, such collaborative efforts also yield standards allowing for easier use and integration into aspiring products and services.
-
-Other major innovations that were once or are currently being developed following the said consortium model include standards for WiFi (The Wi-Fi alliance), Mobile Telephony etc.
-
-### Introduction to Hyperledger Project (HLP)
-
-The Hyperledger project was launched in December 2015 by the Linux foundation as is currently among the fastest growing project they’ve incubated. It’s an umbrella organization for collaborative efforts into developing and advancing tools & standards for [**blockchain**][2] based distributed ledger technologies(DLT). Major industry players supporting the project include **IBM** , **Intel** and **SAP Ariba** among [**others**][3]. The HLP aims to create frameworks for individuals and companies to create shared as well as closed blockchains as required to further their own requirements. The design principles include a strong tilt toward developing a globally deployable, scalable, robust platform with a focus on privacy, and future auditability[2]. It is also important to note that most of the blockchains proposed and the frame.
-
-### Development goals and structure: Making it plug & play
-
-Although enterprise facing platforms exist from the likes of the Ethereum alliance, HLP is by definition business facing and supported by industry behemoths who contribute and further development in the many modules that come under the HLP banner. The HLP incubates projects in development after their induction into the cause and after finishing work on it and correcting the knick-knacks rolls it out for the public. Members of the Hyperledger project contribute their own work such as how IBM contributed their Fabric platform for collaborative development. The codebase is absorbed and developed in house by the group in the project and rolled out for all members equally for their use.
-
-Such processes make the modules in HLP highly flexible plug-in frameworks which will support rapid development and roll-outs in enterprise settings. Furthermore, other comparable platforms are open **permission-less blockchains** or rather **public chains** by default and even though it is possible to adapt them to specific applications, HLP modules support the feature natively.
-
-The differences and use cases of public & private blockchains are covered more [**here**][4] in this comparative primer on the same.
-
-The Hyperledger project’s mission is four-fold according to **Brian Behlendorf** , the executive director of the project.
-
-They are:
-
- 1. To create an enterprise grade DLT framework and standards which anyone can port to suit their specific industrial or personal needs.
- 2. To give rise to a robust open source community to aid the ecosystem.
- 3. To promote and further participation of industry members of the said ecosystem such as member firms.
- 4. To host a neutral unbiased infrastructure for the HLP community to gather and share updates and developments regarding the same.
-
-
-
-The original document can be accessed [**here**][5]****.
-
-### Structure of the HLP
-
-The **HLP consists of 12 projects** that are classified as independent modules, each usually structured and working independently to develop their module. These are first studied for their capabilities and viability before being incubated. Proposals for additions can be made by any member of the organization. After the project is incubated active development ensues after which it is rolled out. The interoperability between these modules are given a high priority, hence regular communication between these groups are maintained by the community. Currently 4 of these projects are categorized as active. The active tag implies these are ready for use but not ready for a major release yet. These 4 are arguably the most significant or rather fundamental modules to furthering the blockchain revolution. We’ll look at the individual modules and their functionalities at a later time in detail. However, a brief description of a the Hyperledger Fabric platform, arguably the most popular among them follows.
-
-### Hyperledger Fabric
-
-The **Hyperledger Fabric** [2] is a fully open-source, permissioned (non-public) blockchain-based DLT platform that is designed keeping enterprise uses in mind. The platform provides features and is structured to fit the enterprise environment. It is highly modular allowing its developers to choose from different consensus protocols, **chain code protocols ([smart contracts][6])** , or identity management systems etc., as they go along. **It is a permissioned blockchain based platform** that’s makes use of an identity management system, meaning participants will be aware of each other’s identities which is required in an enterprise setting. Fabric allows for smart contract ( _ **“chaincode”, is the term that the Hyperledger team uses**_ ) development in a variety of mainstream programming languages including **Java** , **Javascript** , **Go** etc. This allows institutions and enterprises to make use of their existing talent in the area without hiring or re-training developers to develop their own smart contracts. Fabric also uses an execute-order-validate system to handle smart contracts for better reliability compared to the standard order-validate system that is used by other platforms providing smart contract functionality. Pluggable performance, identity management systems, DBMS, Consensus platforms etc. are other features of Fabric that keeps it miles ahead of its competition.
-
-### Conclusion
-
-Projects such as the Hyperledger Fabric platforms enable a faster rate of adoption of blockchain technology in mainstream use-cases. The Hyperledger community structure itself supports open governance principles and since all the projects are led as open source platforms, this improves the security and accountability that the teams exhibit in pushing out commitments.
-
-Since major applications of such projects involve working with enterprises to further development of platforms and standards, the Hyperledger project is currently at a great position with respect to comparable projects by others.
-
-**References:**
-
- * **[1][Samsung takes a seat with Intel and IBM at the Linux Foundation | TheINQUIRER][7]**
- * **[2] E. Androulaki et al., “Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains,” 2018.**
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
-
-作者:[editor][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/editor/
-[b]: https://github.com/lujun9972
-[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Introduction-To-Hyperledger-Project-720x340.png
-[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
-[3]: https://www.hyperledger.org/members
-[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
-[5]: http://www.hitachi.com/rev/archive/2017/r2017_01/expert/index.html
-[6]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
-[7]: https://www.theinquirer.net/inquirer/news/2182438/samsung-takes-seat-intel-ibm-linux-foundation
diff --git a/sources/tech/20190522 Convert Markdown files to word processor docs using pandoc.md b/sources/tech/20190522 Convert Markdown files to word processor docs using pandoc.md
deleted file mode 100644
index 8fab8bfcae..0000000000
--- a/sources/tech/20190522 Convert Markdown files to word processor docs using pandoc.md
+++ /dev/null
@@ -1,119 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Convert Markdown files to word processor docs using pandoc)
-[#]: via: (https://opensource.com/article/19/5/convert-markdown-to-word-pandoc)
-[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez)
-
-Convert Markdown files to word processor docs using pandoc
-======
-Living that plaintext life? Here's how to create the word processor
-documents people ask for without having to work in a word processor
-yourself.
-![][1]
-
-If you live your life in [plaintext][2], there invariably comes a time when someone asks for a word processor document. I run into this issue frequently, especially at the Day JobTM. Although I've introduced one of the development teams I work with to a [Docs Like Code][3] workflow for writing and reviewing release notes, there are a small number of people who have no interest in GitHub or working with [Markdown][4]. They prefer documents formatted for a certain proprietary application.
-
-The good news is that you're not stuck copying and pasting unformatted text into a word processor document. Using **[pandoc][5]** , you can quickly give people what they want. Let's take a look at how to convert a document from Markdown to a word processor format in [Linux][6] using **pandoc.**
-
-Note that **pandoc** is also available for a wide variety of operating systems, ranging from two flavors of BSD ([NetBSD][7] and [FreeBSD][8]) to Chrome OS, MacOS, and Windows.
-
-### Converting basics
-
-To begin, [install **pandoc**][9] on your computer. Then, crack open a console terminal window and navigate to the directory containing the file that you want to convert.
-
-Type this command to create an ODT file (which you can open with a word processor like [LibreOffice Writer][10] or [AbiWord][11]):
-
-**pandoc -t odt filename.md -o filename.odt**
-
-Remember to replace **filename** with the file's actual name. And if you need to create a file for that other word processor (you know the one I mean), replace **odt** on the command line with **docx**. Here's what this article looks like when converted to an ODT file:
-
-![Basic conversion results with pandoc.][12]
-
-These results are serviceable, but a bit bland. Let's look at how to add a bit more style to the converted documents.
-
-### Converting with style
-
-**pandoc** has a nifty feature enabling you to specify a style template when converting a marked-up plaintext file to a word processor format. In this file, you can edit a small number of styles in the document, including those that control the look of paragraphs, headings, captions, titles and subtitles, a basic table, and hyperlinks.
-
-Let's look at the possibilities.
-
-#### Creating a template
-
-In order to style your documents, you can't just use _any_ template. You need to generate what **pandoc** calls a _reference_ template, which is the template it uses when converting text files to word processor documents. To create this file, type the following in a terminal window:
-
-**pandoc -o custom-reference.odt --print-default-data-file reference.odt**
-
-This command creates a file called **custom-reference.odt**. If you're using that other word processor, change the references to **odt** on the command line to **docx**.
-
-Open the template file in LibreOffice Writer, and then press **F11** to open LibreOffice Writer's **Styles** pane. Although the [pandoc manual][13] advises against making other changes to the file, I change the page size and add headers and footers when necessary.
-
-#### Using the template
-
-So, how do you use that template you just created? There are two ways to do this.
-
-The easiest way is to drop the template in your **/home** directory's **.pandoc** folder—you might have to create the folder first if it doesn't exist. When it's time to convert a document, **pandoc** uses this template file. See the next section on how to choose from multiple templates if you need more than one.
-
-The other way to use your template is to type this set of conversion options at the command line:
-
-**pandoc -t odt file-name.md --reference-doc=path-to-your-file/reference.odt -o file-name.odt**
-
-If you're wondering what a converted file looks like with a customized template, here's an example:
-
-![A document converted using a pandoc style template.][14]
-
-#### Choosing from multiple templates
-
-Many people only need one **pandoc** template. Some people, however, need more than one.
-
-At my day job, for example, I use several templates—one with a DRAFT watermark, one with a watermark stating FOR INTERNAL USE, and one for a document's final versions. Each type of document needs a different template.
-
-If you have similar needs, start the same way you do for a single template, by creating the file **custom-reference.odt**. Rename the resulting file—for example, to **custom-reference-draft.odt** —then open it in LibreOffice Writer and modify the styles. Repeat this process for each template you need.
-
-Next, copy the files into your **/home** directory. You can even put them in the **.pandoc** folder if you want to.
-
-To select a specific template at conversion time, you'll need to run this command in a terminal:
-
-**pandoc -t odt file-name.md --reference-doc=path-to-your-file/custom-template.odt -o file-name.odt**
-
-Change **custom-template.odt** to your template file's name.
-
-### Wrapping up
-
-To avoid having to remember a set of options I don't regularly use, I cobbled together some simple, very lame one-line scripts that encapsulate the options for each template. For example, I run the script **todraft.sh** to create a word processor document using the template with a DRAFT watermark. You might want to do the same.
-
-Here's an example of a script using the template containing a DRAFT watermark:
-
-`pandoc -t odt $1.md -o $1.odt --reference-doc=~/Documents/pandoc-templates/custom-reference-draft.odt`
-
-Using **pandoc** is a great way to provide documents in the format that people ask for, without having to give up the command line life. This tool doesn't just work with Markdown, either. What I've discussed in this article also allows you to create and convert documents between a wide variety of markup languages. See the **pandoc** site linked earlier for more details.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
-
-作者:[Scott Nesbitt][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/scottnesbitt/users/jason-van-gumster/users/kikofernandez
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb
-[2]: https://plaintextproject.online/
-[3]: https://www.docslikecode.com/
-[4]: https://en.wikipedia.org/wiki/Markdown
-[5]: https://pandoc.org/
-[6]: /resources/linux
-[7]: https://www.netbsd.org/
-[8]: https://www.freebsd.org/
-[9]: https://pandoc.org/installing.html
-[10]: https://www.libreoffice.org/discover/writer/
-[11]: https://www.abisource.com/
-[12]: https://opensource.com/sites/default/files/uploads/pandoc-wp-basic-conversion_600_0.png (Basic conversion results with pandoc.)
-[13]: https://pandoc.org/MANUAL.html
-[14]: https://opensource.com/sites/default/files/uploads/pandoc-wp-conversion-with-tpl_600.png (A document converted using a pandoc style template.)
diff --git a/sources/tech/20190613 Continuous integration testing for the Linux kernel.md b/sources/tech/20190613 Continuous integration testing for the Linux kernel.md
deleted file mode 100644
index d837cd9e67..0000000000
--- a/sources/tech/20190613 Continuous integration testing for the Linux kernel.md
+++ /dev/null
@@ -1,98 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (LazyWolfLin)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Continuous integration testing for the Linux kernel)
-[#]: via: (https://opensource.com/article/19/6/continuous-kernel-integration-linux)
-[#]: author: (Major Hayden https://opensource.com/users/mhayden)
-
-Continuous integration testing for the Linux kernel
-======
-How this team works to prevent bugs from being merged into the Linux
-kernel.
-![Linux kernel source code \(C\) in Visual Studio Code][1]
-
-With 14,000 changesets per release from over 1,700 different developers, it's clear that the Linux kernel moves quickly, and brings plenty of complexity. Kernel bugs range from small annoyances to larger problems, such as system crashes and data loss.
-
-As the call for continuous integration (CI) grows for more and more projects, the [Continuous Kernel Integration (CKI)][2] team forges ahead with a single mission: prevent bugs from being merged into the kernel.
-
-### Linux testing problems
-
-Many Linux distributions test the Linux kernel when needed. This testing often occurs around release time, or when users find a bug.
-
-Unrelated issues sometimes appear, and maintainers scramble to find which patch in a changeset full of tens of thousands of patches caused the new, unrelated bug. Diagnosing the bug may require specialized hardware, a series of triggers, and specialized knowledge of that portion of the kernel.
-
-#### CI and Linux
-
-Most modern software repositories have some sort of automated CI testing that tests commits before they find their way into the repository. This automated testing allows the maintainers to find software quality issues, along with most bugs, by reviewing the CI report. Simpler projects, such as a Python library, come with tons of tools to make this process easier.
-
-Linux must be configured and compiled prior to any testing. Doing so takes time and compute resources. In addition, that kernel must boot in a virtual machine or on a bare metal machine for testing. Getting access to certain system architectures requires additional expense or very slow emulation. From there, someone must identify a set of tests which trigger the bug or verify the fix.
-
-#### How the CKI team works
-
-The CKI team at Red Hat currently follows changes from several internal kernels, as well as upstream kernels such as the [stable kernel tree][3]. We watch for two critical events in each repository:
-
- 1. When maintainers merge pull requests or patches, and the resulting commits in the repository change.
-
- 2. When developers propose changes for merging via patchwork or the stable patch queue.
-
-
-
-
-As these events occur, automation springs into action and [GitLab CI pipelines][4] begin the testing process. Once the pipeline runs [linting][5] scripts, merges any patches, and compiles the kernel for multiple architectures, the real testing begins. We compile kernels in under six minutes for four architectures and submit feedback to the stable mailing list usually in two hours or less. Over 100,000 kernel tests run each month and over 11,000 GitLab pipelines have completed (since January 2019).
-
-Each kernel is booted on its native architecture, which includes:
-
-● [aarch64][6]: 64-bit [ARM][7], such as the [Cavium (now Marvell) ThunderX][8].
-
-● [ppc64/ppc64le][9]: Big and little endian [IBM POWER][10] systems.
-
-● [s390x][11]: [IBM Zseries][12] mainframes.
-
-● [x86_64][13]: [Intel][14] and [AMD][15] workstations, laptops, and servers.
-
-Multiple tests run on these kernels, including the [Linux Test Project (LTP)][16], which contains a myriad of tests using a common test harness. My CKI team open-sourced over 44 tests with more on the way.
-
-### Get involved
-
-The upstream kernel testing effort grows day-by-day. Many companies provide test output for various kernels, including [Google][17], Intel, [Linaro][18], and [Sony][19]. Each effort is focused on bringing value to the upstream kernel as well as each company’s customer base.
-
-If you or your company want to join the effort, please come to the [Linux Plumbers Conference 2019][20] in Lisbon, Portugal. Join us at the Kernel CI hackfest during the two days after the conference, and drive the future of rapid kernel testing.
-
-For more details, [review the slides][21] from my Texas Linux Fest 2019 talk.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/6/continuous-kernel-integration-linux
-
-作者:[Major Hayden][a]
-选题:[lujun9972][b]
-译者:[LazyWolfLin](https://github.com/LazyWolfLin)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mhayden
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr (Linux kernel source code (C) in Visual Studio Code)
-[2]: https://cki-project.org/
-[3]: https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
-[4]: https://docs.gitlab.com/ee/ci/pipelines.html
-[5]: https://en.wikipedia.org/wiki/Lint_(software)
-[6]: https://en.wikipedia.org/wiki/ARM_architecture
-[7]: https://www.arm.com/
-[8]: https://www.marvell.com/server-processors/thunderx-arm-processors/
-[9]: https://en.wikipedia.org/wiki/Ppc64
-[10]: https://www.ibm.com/it-infrastructure/power
-[11]: https://en.wikipedia.org/wiki/Linux_on_z_Systems
-[12]: https://www.ibm.com/it-infrastructure/z
-[13]: https://en.wikipedia.org/wiki/X86-64
-[14]: https://www.intel.com/
-[15]: https://www.amd.com/
-[16]: https://github.com/linux-test-project/ltp
-[17]: https://www.google.com/
-[18]: https://www.linaro.org/
-[19]: https://www.sony.com/
-[20]: https://www.linuxplumbersconf.org/
-[21]: https://docs.google.com/presentation/d/1T0JaRA0wtDU0aTWTyASwwy_ugtzjUcw_ZDmC5KFzw-A/edit?usp=sharing
diff --git a/sources/tech/20190628 How to Install and Use R on Ubuntu.md b/sources/tech/20190628 How to Install and Use R on Ubuntu.md
index abbbeef6a2..84699fbc8e 100644
--- a/sources/tech/20190628 How to Install and Use R on Ubuntu.md
+++ b/sources/tech/20190628 How to Install and Use R on Ubuntu.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: (guevaraya)
+[#]: translator: ( )
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20190705 Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux.md b/sources/tech/20190705 Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux.md
deleted file mode 100644
index d7799311d6..0000000000
--- a/sources/tech/20190705 Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux.md
+++ /dev/null
@@ -1,127 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux)
-[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux
-======
-
-There are many open source monitoring tools are currently available in market to monitor Linux systems performance.
-
-It will send an email alert when the system reaches the specified threshold limit.
-
-It monitors everything such as CPU utilization, Memory utilization, swap utilization, disk space utilization and much more.
-
-If you only have few systems and want to monitor them then writing a small shell script can make your task very easy.
-
-In this tutorial we have added a shell script to monitor Messages Log on Linux system.
-
-We had added many useful shell scripts in the past. If you want to check those, navigate to the below link.
-
- * **[How to automate day to day activities using shell scripts?][1]**
-
-
-
-This script will check **“warning, error and critical”** in the `/var/log/messages` file and trigger a mail to given email id, if it’s found anything related it.
-
-We can’t run this script frequently that may fill up your inbox if the server has many matching strings, instead we can run once in a day.
-
-To overcome this issue, i made the script to trigger an email in a different manner.
-
-If any given strings are found in the **“/var/log/messages”** file for yesterday’s date then the script will send an email alert to given email id.
-
-**Note:** You need to change the email id instead of ours. Also, you can change the Memory utilization threshold value as per your requirement.
-
-```
-# vi /opt/scripts/os-log-alert.sh
-
-#!/bin/bash
-
-#Set the variable which equal to zero
-
-prev_count=0
-
-count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | egrep -wi 'warning|error|critical' | wc -l)
-
-if [ "$prev_count" -lt "$count" ] ; then
-
-# Send a mail to given email id when errors found in log
-
-SUBJECT="WARNING: Errors found in log on "`date --date='yesterday' '+%b %e'`""
-
-# This is a temp file, which is created to store the email message.
-
-MESSAGE="/tmp/logs.txt"
-
-TO="[email protected]"
-
-echo "ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin." >> $MESSAGE
-
-echo "Hostname: `hostname`" >> $MESSAGE
-
-echo -e "\n" >> $MESSAGE
-
-echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
-
-echo "Error messages in the log file as below" >> $MESSAGE
-
-echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
-
-grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | awk '{ $3=""; print}' | egrep -wi 'warning|error|critical' >> $MESSAGE
-
-mail -s "$SUBJECT" "$TO" < $MESSAGE
-
-#rm $MESSAGE
-
-fi
-```
-
-Set an executable permission to `os-log-alert.sh` file.
-
-```
-$ chmod +x /opt/scripts/os-log-alert.sh
-```
-
-Finally add a cronjob to automate this. It will run everyday at 7'o clock.
-
-```
-# crontab -e
-0 7 * * * /bin/bash /opt/scripts/os-log-alert.sh
-```
-
-**Note:** You will be getting an email alert everyday at 7 o'clock, which is for yesterday's log.
-
-**Output:** You will be getting an email alert similar to below.
-
-```
-ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin.
-
-+-----------------------------------------------------+
-Error messages in the log file as below
-+-----------------------------------------------------+
-Jul 3 02:40:11 ns1 kernel: php-fpm[3175]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
-Jul 3 02:50:14 ns1 kernel: lmtp[8249]: segfault at 20 ip 00007f9cc05295e4 sp 00007ffc57bca1a0 error 4 in libdovecot-storage.so.0.0.0[7f9cc04df000+148000]
-Jul 3 15:36:09 ns1 kernel: php-fpm[17846]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
-Jul 3 15:45:54 ns1 pure-ftpd: ([email protected]) [WARNING] Authentication failed for user [daygeek]
-Jul 3 16:25:36 ns1 pure-ftpd: ([email protected]) [WARNING] Sorry, cleartext sessions and weak ciphers are not accepted on this server.#012Please reconnect using TLS security mechanisms.
-Jul 3 16:44:20 ns1 kernel: php-fpm[8979]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md b/sources/tech/20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md
deleted file mode 100644
index 8c62453ef7..0000000000
--- a/sources/tech/20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md
+++ /dev/null
@@ -1,100 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip])
-[#]: via: (https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip]
-======
-
-_**Brief: The tap to click option doesn’t work on the login screen in Ubuntu 18.04 GNOME desktop. In this tutorial, you’ll learn to enable the ‘tap to click’ on the Ubuntu login screen.**_
-
-One of the first few things I do after installing Ubuntu is to make sure that tap to click has been enabled. As a laptop user, I prefer to tap the touchpad for making a left click. This is more convenient than using the left click button on the touchpad all the time.
-
-This is what happens when I have logged in and using the operating system. But if you are at the login screen, the tap to click doesn’t work and that’s an annoyance.
-
-On the [GDM login screen][1] in Ubuntu (or other distributions using GNOME desktop), you have to click the username in order to bring the password field. Now if you are habitual of tap to click, it doesn’t work on the login screen even if you have it enabled and use it after logging into the system.
-
-This is a minor annoyance but an annoyance nonetheless. The good news is that you can fix this annoyance.Let me show you how to do that in this quick tip.
-
-### Enabling tap to click on Ubuntu login screen
-
-![][2]
-
-You’ll have to use the terminal and a few commands here. I hope you are comfortable with it.
-
-[Open a terminal using Ctrl+Alt+T shortcut in Ubuntu][3]. Since Ubuntu 18.04 is still using X server, you need to enable it to connect to the [x server][4]. For that, you can add gdm to access control list.
-
-Switch to root user first. It’s required because you have to switch as gdm user later and you cannot do that as a non-root user.
-
-```
-sudo -i
-```
-
-[There is no password set for root user in Ubuntu][5]. You access it with your admin user account. So when asked for password, use your own password. You won’t see anything being typed on the screen when you type in your password.
-
-```
-xhost +SI:localuser:gdm
-```
-
-Here’s the output for me:
-
-```
-xhost +SI:localuser:gdm
-localuser:gdm being added to access control list
-```
-
-Now run this command so that the the ‘user gdm’ has the correct tap to click setting.
-
-```
-gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click true
-```
-
-If you see a warning like this: (process:6339): dconf-WARNING **: 19:52:21.217: Unable to open /root/.local/share/flatpak/exports/share/dconf/profile/user: Permission denied . Don’t worry. Just ignore it.
-
-[][6]
-
-Suggested read How To Change Hostname on Ubuntu & Other Linux Distributions
-
-This will enable you to perform a tap to click on the login screen. Why were you not able to use tap to click when you made the changes in the system settings before? It’s because at the login screen, you haven’t selected your username yet. You get to use your account only when you select the user on the screen. This is why you had to use the user gdm and add the correct settings with it.
-
-Restart Ubuntu and you’ll see that you can now use the tap to select your user account now.
-
-#### Revert the changes
-
-If you are not happy with the tap to click on the Ubuntu login screen for some reason, you can revert the changes.
-
-You’ll have to perform all the steps you did in the previous section: switch to root, connect gdm with x server, switch to gdm user. But instead of the last command, you need to run this command:
-
-```
-gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click false
-```
-
-That’s it.
-
-As I said, it’s a tiny thing. I mean you can easily do a left click instead of the tap to click. It’s just a matter of one single click.However, it breaks the ‘continuity’ when you are forced to use the left click after a few taps.
-
-I hope you liked this quick little tweak. If you know some other cool tweaks, do share it with us.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://wiki.archlinux.org/index.php/GDM
-[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/tap-to-click-on-ubuntu-login.jpg?ssl=1
-[3]: https://itsfoss.com/ubuntu-shortcuts/
-[4]: https://en.wikipedia.org/wiki/X.Org_Server
-[5]: https://itsfoss.com/change-password-ubuntu/
-[6]: https://itsfoss.com/change-hostname-ubuntu/
diff --git a/sources/tech/20190705 Learn object-oriented programming with Python.md b/sources/tech/20190705 Learn object-oriented programming with Python.md
index b617517526..3d647c2041 100644
--- a/sources/tech/20190705 Learn object-oriented programming with Python.md
+++ b/sources/tech/20190705 Learn object-oriented programming with Python.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (MjSeven)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20190706 How to enable DNS-over-HTTPS (DoH) in Firefox.md b/sources/tech/20190706 How to enable DNS-over-HTTPS (DoH) in Firefox.md
deleted file mode 100644
index 1817425816..0000000000
--- a/sources/tech/20190706 How to enable DNS-over-HTTPS (DoH) in Firefox.md
+++ /dev/null
@@ -1,117 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to enable DNS-over-HTTPS (DoH) in Firefox)
-[#]: via: (https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/)
-[#]: author: (Catalin Cimpanu https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/)
-
-How to enable DNS-over-HTTPS (DoH) in Firefox
-======
-
-The DNS-over-HTTPS (DoH) protocol is currently the talk of the town, and the Firefox browser is the only one to support it.
-
-However, the feature is not enabled by default for Firefox users, who will have to go through many hoops and modify multiple settings before they can get the DoH up and running.
-
-But before we go into a step-by-step tutorial on how someone can enable DoH support in Firefox, let's describe what it does first.
-
-### How DNS-over-HTTPS works
-
-The DNS-over-HTTPS protocol works by taking a domain name that a user has typed in their browser and sending a query to a DNS server to learn the numerical IP address of the web server that hosts that specific site.
-
-This is how normal DNS works, too. However, DoH takes the DNS query and sends it to a DoH-compatible DNS server (resolver) via an encrypted HTTPS connection on port 443, rather than plaintext on port 53.
-
-This way, DoH hides DNS queries inside regular HTTPS traffic, so third-party observers won't be able to sniff traffic and tell what DNS queries users have run and infer what websites they are about to access.
-
-Further, a secondary feature of DNS-over-HTTPS is that the protocol works at the app level. Apps can come with internally hardcoded lists of DoH-compatible DNS resolvers where they can send DoH queries.
-
-This mode of operation bypasses the default DNS settings that exist at the OS level, which, in most cases are the ones set by local internet service providers (ISPs).
-
-This also means that apps that support DoH can effectively bypass local ISPs traffic filters and access content that may be blocked by a local telco or local government -- and a reason why DoH is currently hailed as a boon for users' privacy and security.
-
-This is one of the reasons that DoH has gained quite the popularity in less than two years after it launched, and a reason why a group of [UK ISPs nominated Mozilla for the award of 2019 Internet Vilain][1] for its plans to support the DoH protocol, which they said would thwart their efforts in filtering bad traffic.
-
-As a response, and due to the complex situation in the UK where the government blocks access to copyright-infringing content, and where ISPs voluntarily block access to child abuse website, [Mozilla has decided not to enable this feature by default for British users][2].
-
-The below step-by-step guide will show Firefox users in the UK and Firefox users all over the world how to enable the feature right now, and not wait until Mozilla enables it later down the road -- if it will ever do. There are two methods of enabling DoH support in Firefox.
-
-### Method 1 - via the Firefox settings
-
-**Step 1:** Go to the Firefox menu, choose **Tools** , and then **Preferences**. Optionally type **about:preferences** in the URL bar and press enter. This will open the Firefox prerences section.
-
-**Step 2:** In the **General** section, scroll down to the **Network Settings** panel, and press the **Settings** button.
-
-![DoH section in Firefox settings][3]
-
-Image: ZDNet
-
-**Step 3:** In the popup, scroll down and select " **Enable DNS over HTTPS** ," then configure your desired DoH resolver. You can use the built in Cloudflare resolver (a company with which Mozilla has [reached an agreement][4] to log less data about Firefox users), or use one of your choice, [from this list][4].
-
-![DoH section in Firefox settings][5]![DoH section in Firefox settings][6]
-
-Image: ZDNet
-
-### Method 2 - via about:config
-
-**Step 1:** Type **about:config** in the URL bar and press Enter to access Firefox's hidden configuration panel. Here users will need to enable and modify three settings.
-
-**Step 2:** The first setting is **network.trr.mode**. This turns on DoH support. This setting supports four values:
-
- * 0 - Default value in standard Firefox installations (currently is 5, which means DoH is disabled)
- * 1 - DoH is enabled, but Firefox picks if it uses DoH or regular DNS based on which returns faster query responses
- * 2 - DoH is enabled, and regular DNS works as a backup
- * 3 - DoH is enabled, and regular DNS is disabled
- * 5 - DoH is disabled
-
-
-
-A value of 2 works best.
-
-![DoH in Firefox][5]![DoH in Firefox][7]
-
-Image: ZDNet
-
-**Step 3:** The second setting that needs to be modified is **network.trr.uri**. This is the URL of the DoH-compatible DNS server where Firefox will send DoH DNS queries. By default, Firefox uses Cloudflare's DoH service located at . However, users can use their own DoH server URL. They can select one from the many available servers, [from this list, here][8]. The reason why Mozilla uses Cloudflare in Firefox is because the companies [reached an agreement][4] following which Cloudflare would collect very little data on DoH queries coming from Firefox users.
-
-![DoH in Firefox][5]![DoH in Firefox][9]
-
-Image: ZDNet
-
-**Step 4:** The third setting is optional and you can skip this one. But if things don't work, you can use this one as a backup for Step 3. The option is called **network.trr.bootstrapAddress** and is an input field where users can enter the numerical IP address of the DoH-compatible DNS resolver they entered in Step 3. For Cloudflare, that would be 1.1.1.1. For Google's service, that would be 8.8.8.8. If you used another DoH resolver's URL, you'll need to track down that server's IP and enter it here, if ever necesarry.
-
-![DoH in Firefox][5]![DoH in Firefox][10]
-
-Image: ZDNet
-
-Normally, the URL entered in Step 3 should be enough, though.
-
-Settings should apply right away, but in case they don't work, give Firefox a restart.
-
-Article source: [Mozilla Wiki][11]
-
-
---------------------------------------------------------------------------------
-
-via: https://www.zdnet.com/article/how-to-enable-dns-over-https-doh-in-firefox/
-
-作者:[Catalin Cimpanu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.zdnet.com/meet-the-team/us/catalin.cimpanu/
-[b]: https://github.com/lujun9972
-[1]: https://www.zdnet.com/article/uk-isp-group-names-mozilla-internet-villain-for-supporting-dns-over-https/
-[2]: https://www.zdnet.com/article/mozilla-no-plans-to-enable-dns-over-https-by-default-in-the-uk/
-[3]: https://zdnet1.cbsistatic.com/hub/i/2019/07/07/df30c7b0-3a20-4de7-8640-3dea6d249a49/121bd379b6232e1e2a97c35ea8c7764e/doh-settings-1.png
-[4]: https://developers.cloudflare.com/1.1.1.1/commitment-to-privacy/privacy-policy/firefox/
-[5]:
-[6]: https://zdnet3.cbsistatic.com/hub/i/2019/07/07/8608af28-2a28-4ff1-952b-9b6d2deb1ea6/b1fc322caaa2c955b1a2fb285daf0e42/doh-settings-2.png
-[7]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/0232b3a7-82c6-4a6f-90c1-faf0c090254c/6db9b36509021c460fcc7fe825bb74c5/doh-1.png
-[8]: https://github.com/curl/curl/wiki/DNS-over-HTTPS#publicly-available-servers
-[9]: https://zdnet2.cbsistatic.com/hub/i/2019/07/06/4dd1d5c1-6fa7-4f5b-b7cd-b544748edfed/baa7a70ac084861d94a744a57a3147ad/doh-2.png
-[10]: https://zdnet1.cbsistatic.com/hub/i/2019/07/06/8ec20a28-673c-4a17-8195-16579398e90a/538fe8420f9b24724aeb4a6c8d4f0f0f/doh-3.png
-[11]: https://wiki.mozilla.org/Trusted_Recursive_Resolver
diff --git a/sources/tech/20190706 Install NetData Performance Monitoring Tool On Linux.md b/sources/tech/20190706 Install NetData Performance Monitoring Tool On Linux.md
deleted file mode 100644
index a0fa775728..0000000000
--- a/sources/tech/20190706 Install NetData Performance Monitoring Tool On Linux.md
+++ /dev/null
@@ -1,312 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Install NetData Performance Monitoring Tool On Linux)
-[#]: via: (https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/)
-[#]: author: (sk https://www.ostechnix.com/author/sk/)
-
-Install NetData Performance Monitoring Tool On Linux
-======
-
-![][1]
-
-**NetData** is a distributed, real-time, performance and health monitoring tool for systems and applications. It provides unparalleled insights of everything happening on a system in real-time. You can view the results in a highly interactive web-dashboard. Using Netdata, you can get a clear idea of what is happening now, and what happened before in your systems and applications. You don’t need to be an expert to deploy this tool in your Linux systems. NetData just works fine out of the box with zero configuration, and zero dependencies. Just install this utility and sit back, NetData will take care of the rest.
-
-It has its own built-in webserver to display the result in graphical format. NetData is quite fast and efficient, and it will immediately start to analyze the performance of your system in no time after installing it. It is written using **C** programming language, so it is extremely light weight. It consumes less than 3% of a single core CPU usage and a 10-15MB of RAM. We can easily embed the charts on any existing web pages, and also it has a plugin API, so that you can monitor any application.
-
-Here is the list of things that will be monitored by NetData utility in your Linux system.
-
- * CPU usage,
- * RAM Usage,
- * Swap memory usage,
- * Kernel memory usage,
- * Hard disks and its usage,
- * Network interfaces,
- * IPtables,
- * Netfilter,
- * DDoS protection,
- * Processes,
- * Applications,
- * NFS server,
- * Web server (Apache & Nginx),
- * Database servers (MySQL),
- * DHCP server,
- * DNS server,
- * Email serve,r
- * Proxy server,
- * Tomcat,
- * PHP,
- * SNP devices,
- * And many more.
-
-
-
-NetData is free, open source tool and it supports Linux, FreeBSD and Mac OS.
-
-### Install NetData On Linux
-
-Netdata can be installed on any Linux distributions that have **Bash** installed.
-
-The easiest way to install Netdata is to run the following one-liner command from the Terminal:
-
-```
-$ bash <(curl -Ss https://my-netdata.io/kickstart-static64.sh)
-```
-
-This will download and install everything needed to up and run Netdata.
-
-Some users may not want to inject something directly into Bash without investigating it. If you don’t like this method, you can follow the steps below to install it on your system.
-
-**On Arch Linux:**
-
-The latest version is available in the Arch Linux default repositories. So, we can install it with [**pacman**][2] using command:
-
-```
-$ sudo pacman -S netdata
-```
-
-**On DEB and RPM-based systems**
-
-NetData is not available in the default repositories of DEB based (Ubuntu / Debian) or RPM based (RHEL / CentOS / Fedora) systems. We need to install NetData manually from its Git repository.
-
-First install the required dependencies:
-
-```
-# Debian / Ubuntu
-$ sudo apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libjudy-dev libssl-dev libmnl-dev gcc make git autoconf autoconf-archive autogen automake pkg-config curl
-
-# Fedora
-$ sudo dnf install zlib-devel libuuid-devel libuv-devel lz4-devel Judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
-
-# CentOS / Red Hat Enterprise Linux
-$ sudo yum install epel-release
-$ sudo yum install autoconf automake curl gcc git libmnl-devel libuuid-devel openssl-devel libuv-devel lz4-devel Judy-devel lm_sensors make MySQL-python nc pkgconfig python python-psycopg2 PyYAML zlib-devel
-
-# openSUSE
-$ sudo zypper install zlib-devel libuuid-devel libuv-devel liblz4-devel judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
-```
-
-After installing the required dependencies, install NetData on DEB or RPM based systems as shown below.
-
-Git clone the NetData repository:
-
-```
-$ git clone https://github.com/netdata/netdata.git --depth=100
-```
-
-The above command will create a directory called **‘netdata’** in the current working directory.
-
-Change to the ‘netdata’ directory:
-
-```
-$ cd netdata/
-```
-
-Finally, install and start NetData using command:
-
-```
-$ sudo ./netdata-installer.sh
-```
-
-**Sample output:**
-
-```
-Welcome to netdata!
-Nice to see you are giving it a try!
-
-You are about to build and install netdata to your system.
-
-It will be installed at these locations:
-
-- the daemon at /usr/sbin/netdata
- - config files at /etc/netdata
- - web files at /usr/share/netdata
- - plugins at /usr/libexec/netdata
- - cache files at /var/cache/netdata
- - db files at /var/lib/netdata
- - log files at /var/log/netdata
- - pid file at /var/run
-
-This installer allows you to change the installation path.
-Press Control-C and run the same command with --help for help.
-
-Press ENTER to build and install netdata to your system > ## Press ENTER key
-```
-
-After installing NetData, you will see the following output at the end:
-
-```
--------------------------------------------------------------------------------
-
-OK. NetData is installed and it is running (listening to *:19999).
-
--------------------------------------------------------------------------------
-
-INFO: Command line options changed. -pidfile, -nd and -ch are deprecated.
-If you use custom startup scripts, please run netdata -h to see the
-corresponding options and update your scripts.
-
-Hit http://localhost:19999/ from your browser.
-
-To stop netdata, just kill it, with:
-
-killall netdata
-
-To start it, just run it:
-
-/usr/sbin/netdata
-
-
-Enjoy!
-
-Uninstall script generated: ./netdata-uninstaller.sh
-```
-
-![][3]
-
-Install NetData
-
-NetData has been installed and started.
-
-To install Netdata on other Linux distributions, refer the [**official installation instructions page**][4].
-
-##### Allow NetData default port via Firewall or Router
-
-If your system stays behind any firewall or router, you must allow the default port **19999** to access the NetData web interface from any remote systems on the network,.
-
-**On Ubuntu / Debian:**
-
-```
-$ sudo ufw allow 19999
-```
-
-**On CentOS / RHEL / Fedora:**
-
-```
-$ sudo firewall-cmd --permanent --add-port=19999/tcp
-
-$ sudo firewall-cmd --reload
-```
-
-### Starting / Stopping NetData
-
-To enable and start Netdata service on systems that use **Systemd** , run:
-
-```
-$ sudo systemctl enable netdata
-
-$ sudo systemctl start netdata
-```
-
-To stop:
-
-```
-$ sudo systemctl stop netdata
-```
-
-To enable and start Netdata service on systems that use **Init** , run:
-
-```
-$ sudo service netdata start
-
-$ sudo chkconfig netdata on
-```
-
-To stop it:
-
-```
-$ sudo service netdata stop
-```
-
-### Access NetData via Web browser
-
-Open your web browser, and navigate to **** or **** or ****. You should see a screen something like below.
-
-![][5]
-
-Netdata dashboard
-
-From the dashboard, you will find the complete statistics of your Linux system. Scroll down to view each section.
-
-You can download and/or view NetData default configuration file at any time by simply navigating to ****.
-
-![][6]
-
-Netdata configuration file
-
-### Updating NetData
-
-In Arch Linux, just run the following command to update NetData. If the updated version is available in the repository, it will be automatically installed.
-
-```
-$ sudo pacman -Syyu
-```
-
-In DEB or RPM based systems, just go to the directory where you have cloned it (In our case it’s netdata).
-
-```
-$ cd netdata
-```
-
-Pull the latest update:
-
-```
-$ git pull
-```
-
-Then, rebuild and update it using command:
-
-```
-$ sudo ./netdata-installer.sh
-```
-
-### Uninstalling NetData
-
-Go to the location where you have cloned NetData.
-
-```
-$ cd netdata
-```
-
-Then, uninstall it using command:
-
-```
-$ sudo ./netdata-uninstaller.sh --force
-```
-
-In Arch Linux, the following command will uninstall it.
-
-```
-$ sudo pacman -Rns netdata
-```
-
-**Resources:**
-
- * [**NetData website**][7]
- * [**NetData GitHub page**][8]
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/
-
-作者:[sk][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[b]: https://github.com/lujun9972
-[1]: https://www.ostechnix.com/wp-content/uploads/2016/06/Install-netdata-720x340.png
-[2]: https://www.ostechnix.com/getting-started-pacman/
-[3]: https://www.ostechnix.com/wp-content/uploads/2016/06/Deepin-Terminal_002-6.png
-[4]: https://docs.netdata.cloud/packaging/installer/
-[5]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-dashboard.png
-[6]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-config-file.png
-[7]: http://netdata.firehol.org/
-[8]: https://github.com/firehol/netdata
diff --git a/sources/tech/20190711 What is a golden image.md b/sources/tech/20190711 What is a golden image.md
deleted file mode 100644
index 5bbb61e329..0000000000
--- a/sources/tech/20190711 What is a golden image.md
+++ /dev/null
@@ -1,77 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (What is a golden image?)
-[#]: via: (https://opensource.com/article/19/7/what-golden-image)
-[#]: author: (Seth Kenlon https://opensource.com/users/seth)
-
-What is a golden image?
-======
-Working on projects that will be distributed widely? Learn more about
-golden images so it's easy to revert to a "perfect" state if things go
-wrong.
-![Gold star][1]
-
-If you’re in quality assurance, system administration, or (believe it or not) media production, you might have heard some variation of the term _gold master_, _golden image_, or _master image_, and so on. It’s a term that has made its way into the collective consciousness of anyone involved in creating one _perfect_ model and then producing many duplicates from that mold. That’s what a gold master, or golden image, is: The virtual mold from which you cast your distributable models.
-
-In media production, the theory is that a crew works toward the gold master. This final product is one of a kind. It looks and sounds the best a movie or an album (or whatever it is) can possibly look and sound. Copies of this master image are made, compressed, and sent out to the eager public.
-
-In software, a similar idea is associated with the term. Once software has been compiled and tested and re-tested, the perfect build is declared _gold_. No further changes are allowed, and all distributable copies are generated from this master image (this used to actually mean something, back when software was distributed on CDs or DVDs).
-
-And in system administration, you may encounter golden images of an organization’s chosen operating system, with the important settings *baked in—*the virtual private network (VPN) certificates are already in place, incoming email servers are already set in the email client, and so on. Similarly, you might also hear this term in the world of virtual machines (VMs), where a _golden image_ of a carefully configured virtual drive is the source from which all new virtual machines are cloned.
-
-### GNOME Boxes
-
-The concept of a gold master is simple, but putting it into practice is often overlooked. Sometimes, your team is just so happy to have reached their goal that no one stops to think about designating the achievement as the authoritative version. At other times, there’s no simple mechanism for doing this.
-
-A golden image is equal parts historical preservation and a backup plan in advance. Once you craft a perfect model of whatever it is you were toiling over, you owe it to yourself to preserve that work, because it not only marks your progress, but it serves as a fallback should you stumble as you continue your work.
-
-[GNOME Boxes][2], the virtualization platform that ships with the GNOME desktop, can provide a simple demonstration. If you’ve never used GNOME Boxes, you can learn the basics from Alan Formy-Duval in his article [Getting started with GNOME Boxes][3].
-
-Imagine that you used GNOME boxes to create a virtual machine, and then installed an operating system into that VM. Now, you want to make a golden image. GNOME Boxes is one step ahead of you: It has already taken a snapshot of your install, which can serve as the golden image for a stock OS installation.
-
-With GNOME Boxes open and in the dashboard view, right-click on any virtual machine and select **Properties**. In the **Properties** window, select the **Snapshots** tab. The first snapshot, created automatically by GNOME Boxes, is **Just Installed**. As its name suggests, this is the operating system as you originally installed it onto its virtual machine.
-
-![The Just Installed snapshot, or initial golden image, in GNOME Boxes.][4]
-
-Should your virtual machine reach a state that you did not intend, you can always revert to this **Just Installed** image.
-
-Of course, reverting back to the OS after it’s just been installed would be a drastic measure if you’ve already fine-tuned the environment for yourself. That’s why it’s a common workflow with virtual machines to first install the OS, then modify it to suit your requirements or preferences, and then take a snapshot, declaring that snapshot as your configured golden image. For instance, if you are using the virtual machine for [Flatpak][5] packaging, then after your initial install you might add software and Flatpak development tools, construct your working environment, and then take a snapshot. Once the snapshot is created, you can rename the virtual machine to indicate its true purpose in life.
-
-To rename a virtual machine, right-click on its thumbnail in the dashboard view, and select **Properties**. In the **Properties** window, enter a new name:
-
-![Renaming your VM image in GNOME Boxes.][6]
-
-To make a clone of your golden image, right-click on the virtual machine in the GNOME Boxes interfaces and select **Clone**.
-
-![Cloning your golden image in GNOME Boxes.][7]
-
-You now have a clone from your golden image’s latest snapshot.
-
-### Golden
-
-There are few disciplines that can’t benefit from golden images. Whether you’re tagging releases in [Git][8], taking snapshots in Boxes, pressing a prototype vinyl, printing a book for approval, designing a screen print for mass production, or fashioning a literal mold, the archetype is everything. It’s just one more way that modern technology lets us humans work smarter rather than harder, so make a golden image for your project, and generate clones as often as you need.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/7/what-golden-image
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/origami_star_gold_best_top.jpg?itok=aEc0eutt (Gold star)
-[2]: https://wiki.gnome.org/Apps/Boxes
-[3]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
-[4]: https://opensource.com/sites/default/files/uploads/snapshots.jpg (The Just Installed snapshot, or initial golden image.)
-[5]: https://opensource.com/business/16/8/flatpak
-[6]: https://opensource.com/sites/default/files/uploads/boxes-rename_0.jpg (Renaming your virtual machine in GNOME Boxes.)
-[7]: https://opensource.com/sites/default/files/uploads/boxes-clone.jpg (Cloning your golden image in GNOME Boxes.)
-[8]: https://git-scm.com
diff --git a/sources/tech/20190712 MTTR is dead, long live CIRT.md b/sources/tech/20190712 MTTR is dead, long live CIRT.md
deleted file mode 100644
index 4ceca78067..0000000000
--- a/sources/tech/20190712 MTTR is dead, long live CIRT.md
+++ /dev/null
@@ -1,79 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (MTTR is dead, long live CIRT)
-[#]: via: (https://opensource.com/article/19/7/measure-operational-performance)
-[#]: author: (Julie Gunderson https://opensource.com/users/juliegund/users/kearnsjd/users/ophir)
-
-MTTR is dead, long live CIRT
-======
-By focusing on business-impacting incidents, CIRT is a more accurate way
-to gauge ops performance.
-![Green graph of measurements][1]
-
-The game is changing for the IT ops community, which means the rules of the past make less and less sense. Organizations need accurate, understandable, and actionable metrics in the right context to measure operations performance and drive critical business transformation.
-
-The more customers use modern tools and the more variation in the types of incidents they manage, the less sense it makes to smash all those different incidents into one bucket to compute an average resolution time that will represent ops performance, which is what IT has been doing for a long time.
-
-### History and metrics
-
-History shows that context is key when analyzing signals to prevent errors and misunderstandings. For example, during the 1980s, Sweden set up a system to analyze hydrophone signals to alert them to Russian submarines in local Sweden waters. The Swedes used an acoustic signature they thought represented a class of Russian submarines—but was actually [gas bubbles][2] released by herring when confronted by a potential predator. This misinterpretation of a metric increased tensions between the countries and almost resulted in a war.
-
-![Funny fish cartoon][3]
-
-Mean time to resolve (MTTR) is the main ops performance metric operations managers use to gain insight towards achieving their goals. It is an age-old measure based on systems reliability engineering. MTTR has been adopted across many industries, including manufacturing, facility maintenance, and, more recently, IT ops, where it represents the average time it takes to resolve incidents from the time they were created across a given period of time.
-
-MTTR is calculated by dividing the time it takes to resolve all incidents (from the time of incident creation to time of resolution) by the total number of incidents.
-
-![MTTR formula][4]
-
-MTTR is exactly what it says: It's the average across _**all**_ incidents. MTTR smears together both high- and low-urgency incidents. It also repetitively counts each separate, ungrouped incident and results in a biased resolve time. It includes manually resolved and auto-resolved incidents in the same context. It mashes together incidents that are tabled for days (or months) after creation or are even completely ignored. Finally, MTTR includes every little transient burst (incidents that are auto-closed in under 120 seconds), which are either noisy non-issues or quickly resolved by a machine.
-
-![Variability in incident types][5]
-
-MTTR takes all incidents, regardless of type, throws them into a single bucket, mashes them all together, and calculates an "average" resolution time across the entire set. This overly simplistic method results in a noisy, erroneous, and misleading indication of how operations is performing.
-
-### A new way of measuring performance
-
-Critical incident response time (CIRT) is a new, significantly more accurate method to evaluate operations performance. PagerDuty developed the concept of CIRT, but the methodology is freely available for anyone to use.
-
-CIRT focuses on the incidents that are most likely to impact business by culling noise from incoming signals using the following techniques:
-
- 1. Real business-impacting (or potentially impacting) incidents are very rarely low urgency, so rule out all low-urgency incidents.
- 2. Real business-impacting incidents are very rarely (if ever) auto-resolved by monitoring tools without the need for human intervention, so rule out incidents that were not resolved by a human.
- 3. Short, bursting, and transient incidents that are resolved within 120 seconds are highly unlikely to be real business-impacting incidents, so rule them out.
- 4. Incidents that go unnoticed, tabled, or ignored (not acknowledged, not resolved) for a very long time are rarely business-impacting; rule them out. Note: This threshold can be a statistically derived number that is customer-specific (e.g., two standard deviations above the mean) to avoid using an arbitrary number.
- 5. Individual, ungrouped incidents generated by separate alerts are not representative of the larger business-impacting incident. Therefore, simulate incident groupings with a very conservative threshold, e.g., two minutes, to calculate response time.
-
-
-
-What effect does applying these assumptions have on response times? In a nutshell, a very, very large effect!
-
-By focusing on ops performance during critical, business-impacting incidents, the resolve-time distribution narrows and shifts greatly to the left, because now it is dealing with similar types of incidents rather than all events.
-
-Because MTTR calculates a much longer, artificially skewed response time, it is a poor indicator of operations performance. CIRT, on the other hand, is an intentional measure focused on the incidents that matter most to business.
-
-An additional critical measure that is wise to use alongside CIRT is the percentage of responders who are acknowledging and resolving incidents. This is important, as it validates whether the CIRT (or MTTA/MTTR for that matter) is worth utilizing. For example, if an MTTR result is low, say 10 minutes, it sounds great, but if only 42% of your responders are resolving their incidents, then that number is suspect.
-
-In summary, CIRT and the percentage of responders who are acknowledging and resolving incidents form a valuable set of metrics that give you a much better idea of how operations is performing. Gauging performance is the first step to improving performance, so these new measures are key to achieving continuous cycles of measurable improvement for your organization.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/7/measure-operational-performance
-
-作者:[Julie Gunderson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/juliegund/users/kearnsjd/users/ophir
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
-[2]: http://blogfishx.blogspot.com/2014/05/herring-fart-to-communicate.html
-[3]: https://opensource.com/sites/default/files/uploads/fish.png (Funny fish cartoon)
-[4]: https://opensource.com/sites/default/files/uploads/mttr.png (MTTR formula)
-[5]: https://opensource.com/sites/default/files/uploads/incidents.png (Variability in incident types)
diff --git a/sources/tech/20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md b/sources/tech/20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md
deleted file mode 100644
index 6c28cfb644..0000000000
--- a/sources/tech/20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md
+++ /dev/null
@@ -1,165 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (robsean)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line)
-[#]: via: (https://www.linuxtechi.com/upgrade-debian-9-to-debian-10-command-line/)
-[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
-
-How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line
-======
-
-Hello All!!!, Good to See you! So we saw how to install [Debian 10(Buster)][1] in the previous article. Today, we are going to learn how to upgrade from Debian 9 to Debian 10. Since we have already seen about Debian 10 and its features, let’s not go deep into it. But readers who didn’t have the chance to read that article, let’s give a quick update about Debian 10 and its new features.
-
-
-
-After almost two years of development, the team at Debian has finally released a stable version of Buster, code name for Debian 10. Buster is a LTS (Long Term Support) version and hence will be supported for the next 5 years by Debian.
-
-### Debian 10 (Buster) – New Features
-
-Debian 10 (Buster) comes packed with a lot of new features which could be rewarding to most of the Debian fans out there. Some of the features include:
-
- * GNOME Desktop 3.30
- * AppArmor enabled by default
- * Supports Linux Kernel 4.19.0-4
- * Supports OpenJDk 11.0
- * Moved from Nodejs 4-8 to Nodejs 10.15.2
- * Iptables replaced by NFTables
-
-
-
-and a lot more.
-
-### Step by Step Guide to Upgrade from Debian 9 to Debian 10
-
-Before we start upgrading to Debian 10, let’s look at the prerequisites needed for the upgrade:
-
-### Step 1) Debian upgrade prerequisites
-
- * A good internet connection
- * Root user permission
- * Data backup
-
-
-
-It is extremely important to backup all your application code bases, data files, user account details, configuration files, so that you can always revert to the previous version if anything goes wrong during the upgrade.
-
-### Step 2) Upgrade Debian 9 Existing Packages
-
-Next step is to upgrade all your existing packages as any packages that are tagged as held back cannot be upgraded and there is a possibility the upgrade from Debian 9 to Debian 10 may fail or cause some issues. So, let’s not take any chances and better upgrade the packages. Use the following code to upgrade the packages:
-
-```
-root@linuxtechi:~$ sudo apt update && sudo apt upgrade -y
-```
-
-### Step 3) Modify Package Repository file (/etc/sources.list)
-
-Next step is to modify package repository file “/etc/sources.list” where you need to replace the text “Stretch” with the text “Buster”.
-
-But before you change anything, make sure to create a backup of the sources.list file as shown below:
-
-```
-root@linuxtechi:~$ sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
-```
-
-Now use below sed commands to replace the text ‘**stretch**‘ with ‘**buster**‘ in package repository file, example is shown below,
-
-```
-root@linuxtechi:~$ sudo sed -i 's/stretch/buster/g' /etc/apt/sources.list
-root@linuxtechi:~$ sudo sed -i 's/stretch/buster/g' /etc/apt/sources.list.d/*.list
-```
-
-Once the text is updated, you need to update the package index like shown below:
-
-```
-root@linuxtechi:~$ sudo apt update
-```
-
-Before start upgrading your existing Debian OS , let’s verify the current version using the following command,
-
-```
-root@linuxtechi:~$ cat /etc/*-release
-PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
-NAME="Debian GNU/Linux"
-VERSION_ID="9"
-VERSION="9 (stretch)"
-ID=debian
-HOME_URL="https://www.debian.org/"
-SUPPORT_URL="https://www.debian.org/support"
-BUG_REPORT_URL="https://bugs.debian.org/"
-root@linuxtechi:~$
-```
-
-### Step 4) Upgrade from Debian 9 to Debian 10
-
-Once you made all the changes, it is time to upgrade from Debian 9 – Debian 10. But before that, make sure to update your packages again as shown below:
-
-```
-root@linuxtechi:~$ sudo apt update && sudo apt upgrade -y
-```
-
-During packages upgrade you will be prompted to start the services, so choose your preferred option
-
-Once all the packages are updated in your system, it is time to upgrade your distribution package. Use the following code to upgrade the distribution:
-
-```
-root@linuxtechi:~$ sudo apt dist-upgrade -y
-```
-
-The upgrade process may take a few minutes depending upon your internet connection. Remember during the upgrade process, you’ll also be asked a few questions whether you need to restart the services during the packages are upgraded and whether you need to keep the existing configurations files. If you don’t want to make any custom changes, simply type “Y” and let the upgrade process continue.
-
-### Step 5) Verify Upgrade
-
-Once the upgrade process is completed, reboot your machine and check the version using the following command:
-
-```
-root@linuxtechi:~$ lsb_release -a
-```
-
-If you get the output as shown below:
-
-```
-Distributor ID: Debian
-Description: Debian GNU/Linux 10 (buster)
-Release: 10
-Codename: buster
-root@linuxtechi:~$
-```
-
-Yes, you have successfully upgraded from Debian 9 to Debian 10.
-
-Alternate way to verify upgrade
-
-```
-root@linuxtechi:~$ cat /etc/*-release
-PRETTY_NAME="Debian GNU/Linux 10 (buster)"
-NAME="Debian GNU/Linux"
-VERSION_ID="10"
-VERSION="10 (buster)"
-VERSION_CODENAME=buster
-ID=debian
-HOME_URL="https://www.debian.org/"
-SUPPORT_URL="https://www.debian.org/support"
-BUG_REPORT_URL="https://bugs.debian.org/"
-root@linuxtechi:~$
-```
-
-### Conclusion
-
-Hope the above step by step guide provided you with all the information needed to upgrade from Debian 9(Stretch) to Debian 10 (Buster) easily. Please give us your feedback, suggestions and your experiences with the all new Debian 10 in the comments section. For more such Linux tutorials and articles, keep visiting LinuxTechi.com every now and then.
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxtechi.com/upgrade-debian-9-to-debian-10-command-line/
-
-作者:[Pradeep Kumar][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linuxtechi.com/author/pradeep/
-[b]: https://github.com/lujun9972
-[1]: https://www.linuxtechi.com/debian-10-buster-installation-guide/
diff --git a/sources/tech/20190722 How to run virtual machines with virt-manager.md b/sources/tech/20190722 How to run virtual machines with virt-manager.md
deleted file mode 100644
index e9b2f14c2c..0000000000
--- a/sources/tech/20190722 How to run virtual machines with virt-manager.md
+++ /dev/null
@@ -1,169 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to run virtual machines with virt-manager)
-[#]: via: (https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/)
-[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
-
-How to run virtual machines with virt-manager
-======
-
-![][1]
-
-In the beginning there was dual boot, it was the only way to have more than one operating system on the same laptop. At the time, it was difficult for these operating systems to be run simultaneously or interact with each other. Many years passed before it was possible, on common PCs, to run an operating system inside another through virtualization.
-
-Recent PCs or laptops, including moderately-priced ones, have the hardware features to run virtual machines with performance close to the physical host machine.
-
-Virtualization has therefore become normal, to test operating systems, as a playground for learning new techniques, to create your own home cloud, to create your own test environment and much more. This article walks you through using Virt Manager on Fedora to setup virtual machines.
-
-### Introducing QEMU/KVM and Libvirt
-
-Fedora, like all other Linux systems, comes with native support for virtualization extensions. This support is given by KVM (Kernel based Virtual Machine) currently available as a kernel module.
-
-QEMU is a complete system emulator that works together with KVM and allows you to create virtual machines with hardware and peripherals.
-
-Finally [libvirt][2] is the API layer that allows you to administer the infrastructure, ie create and run virtual machines.
-
-The set of these three technologies, all open source, is what we’re going to install on our Fedora Workstation.
-
-### Installation
-
-#### Step 1: install packages
-
-Installation is a fairly simple operation. The Fedora repository provides the “virtualization” package group that contains everything you need.
-```
-
-```
-
-sudo dnf install @virtualization
-```
-
-```
-
-#### Step 2: edit the libvirtd configuration
-
-By default the system administration is limited to the root user, if you want to enable a regular user you have to proceed as follows.
-
-Open the /etc/libvirt/libvirtd.conf file for editing
-```
-
-```
-
-sudo vi /etc/libvirt/libvirtd.conf
-```
-
-```
-
-Set the domain socket group ownership to libvirt
-```
-
-```
-
-unix_sock_group = "libvirt"
-```
-
-```
-
-Adjust the UNIX socket permissions for the R/W socket
-```
-
-```
-
-unix_sock_rw_perms = "0770"
-```
-
-```
-
-#### Step 3: start and enable the libvirtd service
-```
-
-```
-
-sudo systemctl start libvirtd
-sudo systemctl enable libvirtd
-```
-
-```
-
-#### Step 4: add user to group
-
-In order to administer libvirt with the regular user you must add the user to the libvirt group, otherwise every time you start virtual-manager you will be asked for the password for sudo.
-```
-
-```
-
-sudo usermod -a -G libvirt $(whoami)
-```
-
-```
-
-This adds the current user to the group. You must log out and log in to apply the changes.
-
-### Getting started with virt-manager
-
-The libvirt system can be managed either from the command line (virsh) or via the virt-manager graphical interface. The command line can be very useful if you want to do automated provisioning of virtual machines, for example with [Ansible][3], but in this article we will concentrate on the user-friendly graphical interface.
-
-The virt-manager interface is simple. The main form shows the list of connections including the local system connection.
-
-The connection settings include virtual networks and storage definition. it is possible to define multiple virtual networks and these networks can be used to communicate between guest systems and between the guest systems and the host.
-
-### Creating your first virtual machine
-
-To start creating a new virtual machine, press the button at the top left of the main form:
-
-![][4]
-
-The first step of the wizard requires the installation mode. You can choose between a local installation media, network boot / installation or an existing virtual disk import:
-
-![][5]
-
-Choosing the local installation media the next step will require the ISO image path:
-
-![ ][6]
-
-The subsequent two steps will allow you to size the CPU, memory and disk of the new virtual machine. The last step will ask you to choose network preferences: choose the default network if you want the virtual machine to be separated from the outside world by a NAT, or bridged if you want it to be reachable from the outside. Note that if you choose bridged the virtual machine cannot communicate with the host machine.
-
-Check “Customize configuration before install” if you want to review or change the configuration before starting the setup:
-
-![][7]
-
-The virtual machine configuration form allows you to review and modify the hardware configuration. You can add disks, network interfaces, change boot options and so on. Press “Begin installation” when satisfied:
-
-![][8]
-
-At this point you will be redirected to the console where to proceed with the installation of the operating system. Once the operation is complete, you will have the working virtual machine that you can access from the console:
-
-![][9]
-
-The virtual machine just created will appear in the list of the main form, where you will also have a graph of the CPU and memory occupation:
-
-![][10]
-
-libvirt and virt-manager is a powerful tool that allows great customization to your virtual machines with enterprise level management. If something even simpler is desired, note that Fedora Workstation comes with [GNOME Boxes pre-installed and can be sufficient for basic virtualization needs][11].
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
-
-作者:[Marco Sarti][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/msarti/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/virt-manager-816x346.jpg
-[2]: https://libvirt.org/
-[3]: https://fedoramagazine.org/get-the-latest-ansible-2-8-in-fedora/
-[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-41-45.png
-[5]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-09-30-53.png
-[6]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-42-39.png
-[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-43-21.png
-[8]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-44-58.png
-[9]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-10-55-35.png
-[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/Screenshot-from-2019-07-14-11-09-22.png
-[11]: https://fedoramagazine.org/getting-started-with-virtualization-in-gnome-boxes/
diff --git a/sources/tech/20190723 How to Create a User Account Without useradd Command in Linux.md b/sources/tech/20190723 How to Create a User Account Without useradd Command in Linux.md
deleted file mode 100644
index 2f8d92bb28..0000000000
--- a/sources/tech/20190723 How to Create a User Account Without useradd Command in Linux.md
+++ /dev/null
@@ -1,119 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Create a User Account Without useradd Command in Linux?)
-[#]: via: (https://www.2daygeek.com/linux-user-account-creation-in-manual-method/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-How to Create a User Account Without useradd Command in Linux?
-======
-
-There are three commands are available in Linux to create an user account.
-
-Did you ever tried to create a user account in Linux using manual method?
-
-I mean to say without using an above three commands.
-
-If you don’t know how to do that? we are here to help you on this and will show you in details.
-
-Have you wondering, how it’s possible? If yes, don’t worry, as we have mentioned many times that anything can be done on Linux. It is one of the example.
-
-Yes, we can create it. Are you excited to know more it?
-
- * **[Three Methods To Create A User Account In Linux?][1]**
- * **[Two Methods To Create Bulk Users In Linux][2]**
-
-
-
-I don’t want to you to wait any more. Let’s do it right away.
-
-To do so, first, we need to find out last created UID and GID information. Once you have these information handy then proceed to next step.
-
-```
-# cat /etc/passwd | tail -1
-
-tuser1:x:1153:1154:Test User:/home/tuser1:/bin/bash
-```
-
-Based on the above output. Last created user UID is 1153 and GID is 1154. To experiment this, we are going to add `tuser2` in the system.
-
-Now, add an entry of user details in /etc/passwd. There are seven fields exist and you need to add required details.
-
-```
-+-----------------------------------------------------------------------+
-|username:password:UID:GID:Comments:User Home Directory:User Login Shell|
-+-----------------------------------------------------------------------+
- | | | | | | |
- 1 2 3 4 5 6 7
-
-1- Username: This field indicates the User name. Characters length should be between 1 to 32.
-2- Password (x): It indicates that encrypted password is stored at /etc/shadow file.
-3- User ID: It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
-4- Group ID (GID): It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
-5- Comment/User ID Info: It indicates the command field. This field can be used to describe the user information.
-6- Home directory (/home/$USER): It indicates the user's home directory.
-7- shell (/bin/bash): It indicates the user's shell.
-```
-
-Add the user information in end of the file.
-
-```
-# vi /etc/passwd
-
-tuser2:x:1154:1155:Test User2:/home/tuser2:/bin/bash
-```
-
-You have to create a group with same name. So, add a group details in /etc/group file as well.
-
-```
-# vi /etc/group
-
-tuser2:x:1155:
-```
-
-Once you done the above two steps, then set a password for user.
-
-```
-# passwd tuser2
-
-Changing password for user tuser2.
-New password:
-Retype new password:
-passwd: all authentication tokens updated successfully.
-```
-
-Finally, try to login with newly created user.
-
-```
-# ssh [email protected]
-
-[email protected]'s password:
-Creating directory '/home/tuser2'.
-
-$ls -la
-
-total 16
-drwx------. 2 tuser2 tuser2 59 Jun 17 09:46 .
-drwxr-xr-x. 15 root root 4096 Jun 17 09:46 ..
--rw-------. 1 tuser2 tuser2 18 Jun 17 09:46 .bash_logout
--rw-------. 1 tuser2 tuser2 193 Jun 17 09:46 .bash_profile
--rw-------. 1 tuser2 tuser2 231 Jun 17 09:46 .bashrc
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/linux-user-account-creation-in-manual-method/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/linux-user-account-creation-useradd-adduser-newusers/
-[2]: https://www.2daygeek.com/linux-bulk-users-creation-useradd-newusers/
diff --git a/sources/tech/20190724 How to make an old computer useful again.md b/sources/tech/20190724 How to make an old computer useful again.md
new file mode 100644
index 0000000000..68748a93b6
--- /dev/null
+++ b/sources/tech/20190724 How to make an old computer useful again.md
@@ -0,0 +1,192 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to make an old computer useful again)
+[#]: via: (https://opensource.com/article/19/7/how-make-old-computer-useful-again)
+[#]: author: (Howard Fosdick https://opensource.com/users/howtechhttps://opensource.com/users/don-watkinshttps://opensource.com/users/suehlehttps://opensource.com/users/aseem-sharmahttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/dragonbitehttps://opensource.com/users/don-watkinshttps://opensource.com/users/jamesfhttps://opensource.com/users/seth)
+
+How to make an old computer useful again
+======
+Refurbish an old machine with these step-by-step instructions.
+![Person typing on a 1980's computer][1]
+
+Have an old computer gathering dust in your basement? Why not put it to use? A backup machine could come in handy if your primary computer fails and you want to be online with a larger screen than your smartphone. Or it could act as a cheap secondary computer shared by the family. You could even make it into a retro gaming box.
+
+You can take any computer up to a dozen years old and—with the right software—perform many of the same tasks you can with new machines. Open source software is the key.
+
+I've refurbished computers for two decades, and in this article, I'll share how I do it. We're talking about dual-core laptops and desktops between five and 12 years old.
+
+### Verify the hardware
+
+Step one is to verify that your hardware all works. Overlooking a problem here could cause you big headaches later.
+
+Dust kills electronics, so open up the box and clean out the dirt. [Compressed air][2] comes in handy. Be careful that you're [grounded][3] whenever you touch the machine. And _don't_ rub anything with a cleaning cloth. Even a static shock so small you won't feel it can destroy circuitry.
+
+Then close the clean computer and verify that all the hardware works. Test:
+
+ * Memory
+ * Disk
+ * Motherboard
+ * Peripherals (DVD drive, USB ports, sound, etc.)
+
+
+
+Run any diagnostic tests in the computer's boot panels (the [UEFI][4] or [BIOS][5] panels). [This list][6] tells you which program function (PF) key to press to access those panels for your computer.
+
+Free resource kits like [Hirens BootCD][7] or [Ultimate Boot CD][8] enable you to test what your boot panels don't. They contain hundreds of testing programs; all are free, but not all are open source. You don't have to install anything to run these kits because they'll boot from a USB thumb drive or DVD drive.
+
+Be thorough! Run the extended tests for memory and disk—not just the short tests. Let them run overnight. That's the only way to catch transient (sporadic) errors.
+
+If you find problems, my [Quick guide to fixing hardware][9] will help you solve the most common hardware issues.
+
+### Select the software
+
+The key to refurbishing is to install software appropriate for the hardware resources you have. The three essential hardware resources are:
+
+ 1. Processor (number of cores and speed)
+ 2. Memory
+ 3. Video memory
+
+
+
+You can identify your computer's resources in its boot-time UEFI/BIOS panels. Write down your findings so that you don't forget them. Then, look up your processor at [CPU Benchmark][10]. That website gives you background on your CPU plus a CPU Mark that indicates its performance.
+
+Now that you know your hardware's power, you're ready to select software that it can efficiently run. Your software choices are divided into four critical areas:
+
+ 1. Operating system (OS)
+ 2. Desktop environment (DE)
+ 3. Browser
+ 4. Applications
+
+
+
+A good Linux distribution covers all four. Don't be tempted to run an unsupported version of Windows like 8, Vista, or XP just because it's already on the computer! The [risk][11] of malware is too great. You're much better off with a more virus-resistant, up-to-date operating system.
+
+How about Windows 7? [Extended support][12] ends January 14, 2020, meaning you get security fixes only until that date. After that, zilch. Now is the perfect time to migrate off Windows 7.
+
+Linux's big benefit is that it offers [many distros][13] specifically designed for older hardware. Plus, its design decouples [DEs][14] from the OS, so you can mix and match the two. This is important because DEs heavily impact low-end system performance. (With Windows and MacOS, the OS version you run dictates the DE.)
+
+Other Linux advantages: Its thousands of apps are free and open source, so you don't have to worry about activation and licensing. And Linux is portable. You can copy, move, or clone the OS and applications across partitions, disks, devices, or computers. (Windows binds itself to the computer it's installed on via its Registry.)
+
+### What can your refurbished computer do?
+
+We're talking dual-core machines dating from about 2006 to 2013, especially [Intel Core 2][15] CPUs and [AMD Athlon 64 X2][16] family processors. Most have a [CPU Mark][10] of between 1,000 and 4,000. You can often pick up these machines for a song, yet they're still powerful enough to run lightweight Linux software.
+
+One caution: be sure your computer has at least 2GB of memory. Upgrade the RAM if you have to. End users on my refurbished machines typically use between 0.5 and 2GB of RAM (exclusive of data buffering); rarely do they go over 2 gig. So if you can bump memory to 2GB, your system won't be forced to _swap_, or substitute disk for memory. That's critical for good performance.
+
+For example, I removed 1GB RAM from the decade-old rebuild I'm writing this article on, which dropped memory down to 1GB. The machine slowed to a crawl. Web surfing and other tasks became frustrating, even painful. I popped the memory stick back in and, with 2GB RAM, the desktop instantly reverted to its usable self.
+
+With a 2 gig dual-core computer, most people can do whatever they want, so long as they run a lightweight distro and browser. You can web surf, email, edit documents, do spreadsheets, watch YouTube videos, bid on eBay auctions, post on social media, listen to podcasts, view photo collections, manage home finance and personal scheduling, play games, and more.
+
+### Limitations
+
+What can't these older computers do? Their concurrency is less than state-of-the-art machines. So run a fast browser and block ads, because that's what slows down web surfing. If your virtual private network (VPN) can block ads for you and offload that work from your processor, that's ideal. Disable autoplay of videos, Flash, and animation. Surf with a couple of tabs open rather than 20. Install a browser extension so you can toggle JavaScript.
+
+Direct the processors to what you're working on; don't keep a ton of apps open or run lots of stuff in the background. High-end graphics and video editing may be slow. Virtual machine hosting is out.
+
+How about games? The open source software repositories offer literally thousands of games. That's why I listed video memory as one of the three essential hardware resources. If your box doesn't have a video card, it likely has only 32 or 64MB of VRAM. Bump that to 256 or 512MB by adding a video card, and you'll find that processor-intensive games run much better. [Here's how][17] to see how much VRAM your computer has. Be sure to get a card that fits your computer's [video slot][18] (AGP, PCI-Express, or PCI) and has the right [cable connector][19] (VGA, DVI, or HDMI).
+
+#### What about Windows compatibility?
+
+People often ask about Windows compatibility. First, there's a [Linux equivalent][20] for every Windows program.
+
+Second, if you really must run a specific Windows program, you can usually do that on Linux using [Wine][21]. Look up your application in the [Wine database][22] to verify it runs under Wine and learn any special install tricks. Then the auxiliary tools [Winetricks][23] or [PlayOnLinux][24] will help you with installation and setup.
+
+Wine's other benefit is that it runs programs from old Windows versions like Vista, XP, ME/98/95, and 3.1. I know a guy who set up a fantastic game box running his old XP games. You can even run thousands of [free DOS programs][25] using [DOSBox.][26] One caution: if Windows programs can run, so can Windows [viruses][27]. You must protect your Wine environment inside Linux just as you would any other Windows environment.
+
+How about compatibility with Microsoft Office? I use LibreOffice and routinely edit and exchange Word and Excel files without problems. You must, however, avoid using obscure or specialized features.
+
+### Which distro?
+
+Assuming Linux is the OS, you need to select a DE, browser, and applications. The easy way to do this is to install a distribution that bundles everything you need.
+
+Remember that you can try out different distros without installing anything by booting from a [live USB][28] thumb drive or DVD. [Here's how to create a bootable Linux][29] from within Linux or Windows.
+
+I rebuild computers for charity, so I can't assume any knowledge on the part of my users. I need a distro with these traits:
+
+ * User-friendly
+ * Lightweight interface
+ * Bundles lightweight apps
+ * Big repository
+ * Solid track record
+ * Large user community with an active forum
+ * Stability through long-term support releases (not rolling releases)
+ * Prioritizes reliability over cutting-edge features
+ * Configurable by a GUI rather than by text files
+
+
+
+Many distros fulfill these criteria. The three I've successfully deployed are [Mint/Xfce][30], [Xubuntu,][31] and [Lubuntu][32]. The first two use the Xfce desktop environment, while the latter runs LXQt. These DEs [use less][33] processor and memory resources than alternatives like GNOME, Unity, KDE, MATE, and Cinnamon.
+
+Xfce and LXQt are very easy to use. My clients have never seen Linux before, yet they have no trouble using these simple, menu-driven interfaces.
+
+It's vital to run the fastest, most efficient browser on older equipment. [Many feel][34] Chromium wins the browser race. I also install Firefox Quantum because people are familiar with it and [its performance][35] rivals [that of Chromium][36]. I toss in Opera because it's speedy and has some unique features, like integrated ad-blocking and a free [virtual private network][37]. Opera is free but not open source.
+
+Whatever browser you use, block ads and trackers! Minimize browser overhead. And don't allow videos or Flash to run without your explicit say-so.
+
+For applications, I rely on the lightweight apps bundled with Mint/Xfce, Xubuntu, and Lubuntu. They address every possible need.
+
+### Go for it
+
+Will you be happy with your rebuild? The computers I've been using lately are both over a decade old. One has an Intel dual-core processor ([eMachines T5274a][38]) while the other features an AMD Athlon 64 x2 processor ([HP dc5750][39]). Both have 2 gig memory. They're as effective for my office workload as my quad-core i5 with 16GB RAM. The only function I miss when using them is the ability to host virtual machines.
+
+We live in an amazing era. You can take a five- to 12-year-old computer and, with a little effort, restore it to practical use. What could be more fun?
+
+Having recently co-authored a book about building things with the Raspberry Pi ( Raspberry Pi Hacks...
+
+I can see the brightness of curiosity in my six year old niece Shuchi's eyes when she explores a...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/how-make-old-computer-useful-again
+
+作者:[Howard Fosdick][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/howtechhttps://opensource.com/users/don-watkinshttps://opensource.com/users/suehlehttps://opensource.com/users/aseem-sharmahttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/dragonbitehttps://opensource.com/users/don-watkinshttps://opensource.com/users/jamesfhttps://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
+[2]: https://www.amazon.com/s/ref=nb_sb_noss_1?url=search-alias%3Daps&field-keywords=compressed+air+for+computers&rh=i%3Aaps%2Ck%3Acompressed+air+for+computers
+[3]: https://www.wikihow.com/Ground-Yourself-to-Avoid-Destroying-a-Computer-with-Electrostatic-Discharge
+[4]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
+[5]: http://en.wikipedia.org/wiki/BIOS
+[6]: http://www.disk-image.com/faq-bootmenu.htm
+[7]: http://www.hirensbootcd.org/download/
+[8]: http://www.ultimatebootcd.com/
+[9]: http://www.rexxinfo.org/Quick_Guide/Quick_Guide_To_Fixing_Computer_Hardware
+[10]: http://www.cpubenchmark.net/
+[11]: https://askleo.com/unsupported-software-really-mean/
+[12]: http://home.bt.com/tech-gadgets/computing/windows-7/windows-7-support-end-11364081315419
+[13]: https://fossbytes.com/best-lightweight-linux-distros/
+[14]: http://en.wikipedia.org/wiki/Desktop_environment
+[15]: https://en.wikipedia.org/wiki/Intel_Core_2
+[16]: https://en.wikipedia.org/wiki/Athlon_64_X2
+[17]: http://www.cyberciti.biz/faq/howto-find-linux-vga-video-card-ram/
+[18]: https://www.onlinecomputertips.com/support-categories/hardware/493-pci-vs-agp-vs-pci-express-video-cards/
+[19]: https://silentpc.com/articles/video-connectors
+[20]: http://wiki.linuxquestions.org/wiki/Linux_software_equivalent_to_Windows_software
+[21]: https://en.wikipedia.org/wiki/Wine_%28software%29
+[22]: https://appdb.winehq.org/
+[23]: https://en.wikipedia.org/wiki/Winetricks
+[24]: https://en.wikipedia.org/wiki/PlayOnLinux
+[25]: https://archive.org/details/softwarelibrary_msdos
+[26]: https://en.wikipedia.org/wiki/DOSBox
+[27]: https://wiki.winehq.org/FAQ#Is_Wine_malware-compatible.3F
+[28]: https://www.howtogeek.com/howto/linux/create-a-bootable-ubuntu-usb-flash-drive-the-easy-way/
+[29]: https://unetbootin.github.io/
+[30]: https://linuxmint.com/
+[31]: https://xubuntu.org/
+[32]: https://lubuntu.me/
+[33]: https://www.makeuseof.com/tag/best-lean-linux-desktop-environment-lxde-vs-xfce-vs-mate/
+[34]: https://www.zdnet.com/article/chrome-is-the-most-popular-web-browser-of-all/
+[35]: https://www.laptopmag.com/articles/firefox-quantum-vs-chrome
+[36]: https://www.zdnet.com/article/just-how-fast-is-firefox-quantum/
+[37]: http://en.wikipedia.org/wiki/Virtual_private_network
+[38]: https://www.cnet.com/products/emachines-t5274/specs/
+[39]: https://community.spiceworks.com/products/7727-hewlett-packard-dc5750-microtower
diff --git a/sources/tech/20190724 Introducing Fedora CoreOS.md b/sources/tech/20190724 Introducing Fedora CoreOS.md
new file mode 100644
index 0000000000..070573f74e
--- /dev/null
+++ b/sources/tech/20190724 Introducing Fedora CoreOS.md
@@ -0,0 +1,120 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Introducing Fedora CoreOS)
+[#]: via: (https://fedoramagazine.org/introducing-fedora-coreos/)
+[#]: author: (Benjamin Gilbert https://fedoramagazine.org/author/bgilbert/)
+
+Introducing Fedora CoreOS
+======
+
+![The Fedora CoreOS logo on a gray background.][1]
+
+The Fedora CoreOS team is excited to [announce the first preview release][2] of Fedora CoreOS, a new Fedora edition built specifically for running containerized workloads securely and at scale. It’s the successor to both [Fedora Atomic Host][3] and [CoreOS Container Linux][4]. Fedora CoreOS combines the provisioning tools, automatic update model, and philosophy of Container Linux with the packaging technology, OCI support, and SELinux security of Atomic Host.
+
+Read on for more details about this exciting new release.
+
+### Why Fedora CoreOS?
+
+Containers allow workloads to be reproducibly deployed to production and automatically scaled to meet demand. The isolation provided by a container means that the host OS can be small. It only needs a Linux kernel, systemd, a container runtime, and a few additional services such as an SSH server.
+
+While containers can be run on a full-sized server OS, an operating system built specifically for containers can provide functionality that a general purpose OS cannot. Since the required software is minimal and uniform, the entire OS can be deployed as a unit with little customization. And, since containers are deployed across multiple nodes for redundancy, the OS can update itself automatically and then reboot without interrupting workloads.
+
+Fedora CoreOS is built to be the secure and reliable host for your compute clusters. It’s designed specifically for running containerized workloads without regular maintenance, automatically updating itself with the latest OS improvements, bug fixes, and security updates. It provisions itself with Ignition, runs containers with Podman and Moby, and updates itself atomically and automatically with rpm-ostree.
+
+### Provisioning immutable infrastructure
+
+Whether you run in the cloud, virtualized, or on bare metal, a Fedora CoreOS machine always begins from the same place: a [generic OS image][5]. Then, during the first boot, Fedora CoreOS uses _Ignition_ to provision the system. Ignition reads an _Ignition config_ from cloud user data or a remote URL, and uses it to create disk partitions and file systems, users, files and systemd units.
+
+To provision a machine:
+
+ 1. Write a [Fedora CoreOS Config][6] (FCC), a YAML document that specifies the desired configuration of a machine. FCCs support all Ignition functionality, and also provide additional syntax (“sugar”) that makes it easier to specify typical configuration changes.
+ 2. Use the [Fedora CoreOS Config Transpiler][7] to [validate your FCC and convert it to an Ignition config][8].
+ 3. Launch a Fedora CoreOS machine and [pass it the Ignition config][9]. If the machine boots successfully, provisioning has completed without errors.
+
+
+
+Fedora CoreOS is designed to be managed as _immutable infrastructure_. After a machine is provisioned, you should not modify _/etc_ or otherwise reconfigure the machine. Instead, modify the FCC and use it to provision a replacement machine.
+
+This is similar to how you’d manage a container: container images are not updated in place, but rebuilt from scratch and redeployed. This approach makes it easy to scale out when load increases. Simply use the same Ignition config to launch additional machines.
+
+### Automatic updates
+
+By default, Fedora CoreOS automatically downloads new OS releases, atomically installs them, and reboots into them. Releases roll out gradually over time. We can even stop a rollout if we discover a problem in a new release. Upgrades between Fedora releases are treated as any other update, and are automatically applied without user intervention.
+
+The Linux ecosystem evolves quickly, and software updates can bring undesired behavior changes. However, for automatic updates to be trustworthy, they cannot break existing machines. To avoid this, Fedora CoreOS takes a two-pronged approach. First, we automatically test each change to the OS. However, automatic testing can’t catch all regressions, so Fedora CoreOS also ships multiple independent _release streams_:
+
+ * The _testing_ stream is a regular snapshot of the current Fedora release, plus updates.
+ * After a _testing_ release has been available for two weeks, it is sent to the _stable_ stream. Bugs discovered in _testing_ will be fixed before a release is sent to _stable_.
+ * The _next_ stream is a regular snapshot of the upcoming Fedora release, allowing additional time for testing larger changes.
+
+
+
+All three streams receive security updates and critical bugfixes, and are intended to be safe for production use. Most machines should run the _stable_ stream, since that receives the most testing. However, users should run a few percent of their nodes on the _next_ and _testing_ streams, and report problems to the [issue tracker][10]. This helps ensure that bugs that only affect certain workloads or certain hardware are fixed before they reach _stable_.
+
+### Telemetry
+
+To help direct our development efforts, Fedora CoreOS will perform some telemetry by default. A service called _[fedora-coreos-pinger][11]_ will periodically collect non-identifying information about the machine, such as the OS version, cloud platform, and instance type, and report it to servers controlled by the Fedora project.
+
+No unique identifiers will be reported or collected, and the data will only be used in aggregate to answer questions about how Fedora CoreOS is being used. We will prominently document that this collection is occurring and how to disable it. We will also tell you how to help the project by reporting additional detail, including information that might identify the machine.
+
+### Current status of Fedora CoreOS
+
+Fedora CoreOS is still under active development, and some planned functionality is not available in the first preview release:
+
+ * Only the _testing_ stream currently exists; the _next_ and _stable_ streams are not yet available.
+ * Several cloud and virtualization platforms are not yet available. Only x86_64 is currently supported.
+ * Booting a live Fedora CoreOS system via network (PXE) or CD is not yet supported.
+ * We are actively discussing plans for closer integration with Kubernetes distributions, including OKD.
+ * Fedora CoreOS Config Transpiler will gain more sugar over time.
+ * Telemetry is not yet active.
+ * Documentation is still under development.
+
+
+
+**While Fedora CoreOS is intended for production use, preview releases should _not_ be used in production. Fedora CoreOS may change in incompatible ways during the preview period. There is no guarantee that a preview release will successfully update to a later preview release, or to a stable release.**
+
+### The future
+
+We expect the preview period to continue for about six months. At the end of the preview, we will declare Fedora CoreOS stable and encourage its use in production.
+
+CoreOS Container Linux will be maintained until about six months after Fedora CoreOS is declared stable. We’ll announce the exact timing later this year. During the preview period, we’ll publish tools and documentation to help Container Linux users migrate to Fedora CoreOS.
+
+[Fedora Atomic Host will be maintained][12] until the end of life of Fedora 29, expected in late November. Before then, Fedora Atomic Host users should migrate to Fedora CoreOS.
+
+### Getting involved in Fedora CoreOS
+
+To try out the new release, head over to the [download page][5] to get OS images or cloud image IDs. Then use the [quick start guide][13] to get a machine running quickly. Finally, get involved! You can report bugs and missing features to the [issue tracker][10]. You can also discuss Fedora CoreOS in [Fedora Discourse][14], the [development mailing list][15], or in #fedora-coreos on Freenode.
+
+Welcome to Fedora CoreOS, and let us know what you think!
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/introducing-fedora-coreos/
+
+作者:[Benjamin Gilbert][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/bgilbert/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/introducing-fedora-coreos-816x345.png
+[2]: https://getfedora.org/coreos/
+[3]: https://www.projectatomic.io/
+[4]: https://coreos.com/os/docs/latest/
+[5]: https://getfedora.org/coreos/download/
+[6]: https://github.com/coreos/fcct/blob/master/docs/configuration-v1_0.md
+[7]: https://github.com/coreos/fcct/releases
+[8]: https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/#_generating_ignition_configs
+[9]: https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/#_launching_fedora_coreos
+[10]: https://github.com/coreos/fedora-coreos-tracker/issues
+[11]: https://github.com/coreos/fedora-coreos-pinger/
+[12]: https://fedoramagazine.org/announcing-fedora-coreos/
+[13]: https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/
+[14]: https://discussion.fedoraproject.org/c/server/coreos
+[15]: https://lists.fedoraproject.org/archives/list/coreos@lists.fedoraproject.org/
diff --git a/sources/tech/20190724 WPS Office on Linux is a Free Alternative to Microsoft Office.md b/sources/tech/20190724 WPS Office on Linux is a Free Alternative to Microsoft Office.md
deleted file mode 100644
index 6d271a33cf..0000000000
--- a/sources/tech/20190724 WPS Office on Linux is a Free Alternative to Microsoft Office.md
+++ /dev/null
@@ -1,112 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (WPS Office on Linux is a Free Alternative to Microsoft Office)
-[#]: via: (https://itsfoss.com/wps-office-linux/)
-[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
-
-WPS Office on Linux is a Free Alternative to Microsoft Office
-======
-
-_**If you are looking for a free alternative of Microsoft Office on Linux, WPS Office is one of the best choice. It’s free to use and offers compatibility with MS Office document formats.**_
-
-[WPS Office][1] is a cross-platform office productivity suite. It is light and fully compatible with Microsoft Office, Google Docs/Sheets/Slide and Adobe PDF.
-
-For many users, WPS Office feels intuitive and capable enough to meet their needs. It has gained popularity because of its closeness to Microsoft Office, both in terms of looks and compatibility.
-
-![WPS Office 2019 All In One Mode][2]
-
-WPS office is created by Kingsoft Corporation based in China. For Windows users, WPS Office has both free and premium versions. For Linux users, WPS Office is available for free through its [community project][3].
-
-Non-FOSS Alert!
-
-WPS Office is not an open source software. We have covered it here because it’s available for free for Linux users and at times, we cover software created for Linux even if they are not open source.
-
-### WPS Office on Linux
-
-![WPS Office in Linux | Image Credit: Ubuntu Handbook][4]
-
-WPS Office has four main components:
-
- * WPS Writer
- * WPS Presentation
- * WPS Spreadsheet
- * WPS PDF
-
-
-
-WPS Office is fully compatible with MS Office and more, supporting .doc, .docx, .dotx, .ppt, .pptx, .xls, .xlsx, .docm, .dotm, .xml, .txt, .html, .rtf (and others), as well as its own format (.wps, .wpt). It also includes Microsoft fonts by default (to ensure compatibility), can export PDFs and provides spell checking capabilities in more than 10 languages.
-
-However, it didn’t do very well with ODT, ODP and other open document formats.
-
-All three main WPS Office applications feature a very similar interface to Microsoft Office, with the same Ribbon UI. Although there are minor differences, the usage remains relatively the same. You can easily clone any Microsoft Office/LibreOffice document using WPS Office.
-
-![WPS Office Writer][5]
-
-The only thing you might dislike are some of the default styling settings (some headers having a lot of space beneath them etc.), but these can be easily tweaked.
-
-[][6]
-
-Suggested read WPS Office: Microsoft Office Clone For Ubuntu!
-
-By default, WPS saves files in .docx, .pptx and .xlsx file types. You can also save documents to the **[WPS Cloud][7]** and collaborate on them with others. Another nice addition is the possibility to download a great number of templates from [here][8].
-
-### Install WPS Office on Linux
-
-WPS provides DEB and RPM installer files for Linux distributions. This makes installing WPS Office an easy process if you use Debian/Ubuntu or Fedora based distributions.
-
-You can download WPS for Linux from its download section:
-
-[Download WPS Office for Linux][9]
-
-Scroll down and you’ll find a link to the package for the latest version:
-
-![WPS Office Download][10]
-
-Download the appropriate file for your distribution. [Installing applications from DEB][11] or RPM file is as easy as double clicking on them. Doing so will open up a Software Center instance providing you the option to install the package:
-
-![WPS Office Install Package][12]
-
-After a few seconds, the application should successfully install on your system!
-
-You can now search for **WPS** in the Applications Menu and find all applications found in the WPS Office Suite:
-
-![WPS Applications Menu][13]
-
-**Do you use WPS Office or something else?**
-
-There are other [open source alternatives to Microsoft Office][14] but they have poor compatibility with the MS Office.
-
-Personally, I prefer LibreOffice but you have to work considerably with Microsoft Office, you may try WPS Office on Linux. It looks similar to MS Office and has good compatibility with MS document formats. It’s free on Linux so you don’t have to worry about Office 365 subscription as well.
-
-What office suite do you use on your system? Have you ever used WPS Office on Linux? How was/is your experience with it?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/wps-office-linux/
-
-作者:[Sergiu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/sergiu/
-[b]: https://github.com/lujun9972
-[1]: https://www.wps.com/
-[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps2019-all-in-one-mode.png?resize=800%2C526&ssl=1
-[3]: http://wps-community.org/
-[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-2019-Linux.jpg?resize=800%2C450&ssl=1
-[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps-office-writer.png?resize=800%2C454&ssl=1
-[6]: https://itsfoss.com/wps-office-microsoft-office-clone-for-ubuntu/
-[7]: https://account.wps.com/?cb=https%3A%2F%2Fdrive.wps.com%2F
-[8]: https://template.wps.com/
-[9]: http://wps-community.org/downloads
-[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_download.jpg?fit=800%2C413&ssl=1
-[11]: https://itsfoss.com/install-deb-files-ubuntu/
-[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_office_install_package.png?fit=800%2C719&ssl=1
-[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/wps_applications_menu.jpg?fit=800%2C355&ssl=1
-[14]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
diff --git a/sources/tech/20190725 24 sysadmin job interview questions you should know.md b/sources/tech/20190725 24 sysadmin job interview questions you should know.md
new file mode 100644
index 0000000000..c80bf8f86e
--- /dev/null
+++ b/sources/tech/20190725 24 sysadmin job interview questions you should know.md
@@ -0,0 +1,292 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (24 sysadmin job interview questions you should know)
+[#]: via: (https://opensource.com/article/19/7/sysadmin-job-interview-questions)
+[#]: author: (DirectedSoul https://opensource.com/users/directedsoul)
+
+24 sysadmin job interview questions you should know
+======
+Have a sysadmin job interview coming up? Read this article for some
+questions you might encounter and possible answers.
+![Question and answer.][1]
+
+As a geek who always played with computers, a career after my masters in IT was a natural choice. So, I decided the sysadmin path was the right one. In the process of my career, I have grown quite familiar with the job interview process. Here is a look at what to expect, the general career path, and a set of common questions and my answers to them.
+
+### Typical sysadmin tasks and duties
+
+Organizations need someone who understands the basics of how a system works so that they can keep their data safe, and keep their services running smoothly. You might ask: "Wait, isn’t there more that a sysadmin can do?"
+
+You are right. Now, in general, let’s look at what might be a typical sysadmin’s day-to-day tasks. Depending on their company’s needs and the person’s skill level, a sysadmin’s tasks vary from managing desktops, laptops, networks, and servers, to designing the organization’s IT policies. Sometimes sysadmins are even in charge of purchasing and placing orders for new IT equipment.
+
+Those seeking system administration as their career paths might find it difficult to keep their skills and knowledge up to date, as rapid changes in the IT field are inevitable. The next natural question that arises out of anyone’s mind is how IT professionals keep up with the latest updates and skills.
+
+### Low difficulty questions
+
+Here are some of the more basic questions you will encounter, and my answers:
+
+ 1. What are the first five commands you type on a *nix server after login?
+
+
+
+> * **lsblk** to see information on all block devices
+> * **who** to see who is logged into the server
+> * **top** to get a sense of what is running on the server
+> * **df -khT** to view the amount of disk space available on the server
+> * **netstat** to see what TCP network connections are active
+>
+
+
+ 2. How do you make a process run in the background, and what are the advantages of doing so?
+
+
+
+> You can make a process run in the background by adding the special character **&** at the end of the command. Generally, applications that take too long to execute, and don’t require user interaction are sent to the background so that we can continue our work in the terminal. ([Citation][2])
+
+ 3. Is running these commands as root a good or bad idea?
+
+
+
+> Running (everything) as root is bad due to two major issues. The first is _risk_. Nothing prevents you from making a careless mistake when you are logged in as **root**. If you try to change the system in a potentially harmful way, you need to use **sudo**, which introduces a pause (while you’re entering the password) to ensure that you aren’t about to make a mistake.
+>
+> The second reason is _security_. Systems are harder to hack if you don’t know the admin user’s login information. Having access to root means you already have one half of the working set of admin credentials.
+
+ 4. What is the difference between **rm** and **rm -rf**?
+
+
+
+> The **rm** command by itself only deletes the named files (and not directories). With **-rf** you add two additional features: The **-r**, **-R**, or --**recursive** flag recursively deletes the directory’s contents, including hidden files and subdirectories, and the **-f**, or --**force**, flag makes **rm** ignore nonexistent files, and never prompt for confirmation.
+
+ 5. **Compress.tgz** has a file size of approximately 15GB. How can you list its contents, and how do you list them only for a specific file?
+
+
+
+> To list the file’s contents:
+>
+> **tar tf archive.tgz**
+>
+> To extract a specific file:
+>
+> **tar xf archive.tgz filename**
+
+### Medium difficulty questions
+
+Here are some harder questions you might encounter, and my answers:
+
+ 6. What is RAID? What is RAID 0, RAID 1, RAID 5, RAID 6, and RAID 10?
+
+
+
+> A RAID (Redundant Array of Inexpensive Disks) is a technology used to increase the performance and/or reliability of data storage. The RAID levels are:
+>
+> * RAID 0: Also known as disk striping, which is a technique that breaks up a file, and spreads the data across all of the disk drives in a RAID group. There are no safeguards against failure. ([Citation][3])
+> * RAID 1: A popular disk subsystem that increases safety by writing the same data on two drives. Called _mirroring_, RAID1 does not increase write performance, but read performance may increase up to the sum of each disks’ performance. Also, if one drive fails, the second drive is used, and the failed drive is manually replaced. After replacement, the RAID controller duplicates the contents of the working drive onto the new one.
+> * RAID 5: A disk subsystem that increases safety by computing parity data and increasing speed. RAID 5 does this by interleaving data across three or more drives (striping). Upon failure of a single drive, subsequent reads can be calculated from the distributed parity such that no data is lost.
+> * RAID 6: Which extends RAID 5 by adding another parity block. This level requires a minimum of four disks, and can continue to execute read/write with any two concurrent disk failures. RAID 6 does not have a performance penalty for reading operations, but it does have a performance penalty on write operations because of the overhead associated with parity calculations.
+> * RAID 10: Also known as RAID 1+0, RAID 10 combines disk mirroring and disk striping to protect data. It requires a minimum of four disks, and stripes data across mirrored pairs. As long as one disk in each mirrored pair is functional, data can be retrieved. If two disks in the same mirrored pair fail, all data will be lost because there is no parity in the striped sets. ([Citation][4])
+>
+
+
+ 7. Which port is used for the **ping** command?
+
+
+
+> The **ping** command uses ICMP. Specifically, it uses ICMP echo requests and ICMP echo reply packets.
+>
+> ICMP does not use either UDP or TCP communication services: Instead, it uses raw IP communication services. This means that the ICMP message is carried directly in an IP datagram data field.
+
+ 8. What is the difference between a router and a gateway? What is the default gateway?
+
+
+
+> _Router_ describes the general technical function (layer 3 forwarding), or a hardware device intended for that purpose, while _gateway_ describes the function for the local segment (providing connectivity to elsewhere). You could also state that you "set up a router as a gateway." Another term is _hop_, which describes forwarding between subnets.
+>
+> The term _default gateway_ is used to mean the router on your LAN, which has the responsibility of being the first point of contact for traffic to computers outside the LAN.
+
+ 9. Explain the boot process for Linux.
+
+
+
+> BIOS -> Master Boot Record (MBR) -> GRUB -> the kernel -> init -> runlevel
+
+ 10. How do you check the error messages while the server is booting up?
+
+
+
+> Kernel messages are always stored in the kmsg buffer, visible via the **dmesg** command.
+>
+> Boot issues and errors call for a system administrator to look into certain important files, in conjunction with particular commands, which are each handled differently by different versions of Linux:
+>
+> * **/var/log/boot.log** is the system boot log, which contains all that unfolded during the system boot.
+> * **/var/log/messages** stores global system messages, including the messages logged during system boot.
+> * **/var/log/dmesg** contains kernel ring buffer information.
+>
+
+
+ 11. What is the difference between a symbolic link and a hard link?
+
+
+
+> A _symbolic_ or _soft link_ is an actual link to the original file, whereas a _hard link_ is a mirror copy of the original file. If you delete the original file, the soft link has no value, because it then points to a non-existent file. In the case of a hard link, it is entirely the opposite. If you delete the original file, the hard link still contains the data from the original file. ([Citation][5])
+
+ 12. How do you change kernel parameters? What kernel options might you need to tune?
+
+
+
+> To set the kernel parameters in Unix-like systems, first edit the file **/etc/sysctl.conf**. After making the changes, save the file and run the **sysctl -p** command. This command makes the changes permanent without rebooting the machine
+
+ 13. Explain the **/proc** filesystem.
+
+
+
+> The **/proc** filesystem is virtual, and provides detailed information about the kernel, hardware, and running processes. Since **/proc** contains virtual files, it is called the _virtual file system_. These virtual files have unique qualities. Most of them are listed as zero bytes in size.
+>
+> Virtual files such as **/proc/interrupts**, **/proc/meminfo**, **/proc/mounts** and **/proc/partitions** provide an up-to-the-moment glimpse of the system’s hardware. Others, such as **/proc/filesystems** and the **/proc/sys** directory provide system configuration information and interfaces.
+
+ 14. How do you run a script as another user without their password?
+
+
+
+> For example, if you were editing the sudoers file (such as **/private/etc/sudoers**), you might use **visudo** to add the following:
+>
+> [**user1 ALL=(user2) NOPASSWD: /opt/scripts/bin/generate.sh**][2]
+
+ 15. What is the UID 0 toor account? Have you been compromised?
+
+
+
+> The toor user is an alternative superuser account, where toor is root spelled backward. It is intended to be used with a non-standard shell, so the default shell for root does not need to change.
+>
+> This purpose is important. Shells which are not part of the base distribution, but are instead installed from ports or packages, are installed in **/usr/local/bin**; which, by default, resides on a different file system. If root’s shell is located in **/usr/local/bin** and the file system containing **/usr/local/bin** is not mounted, root could not log in to fix a problem, and the sysadmin would have to reboot into single-user mode to enter the shell’s path.
+
+### Advanced questions
+
+Here are the even more difficult questions you may encounter:
+
+ 16. How does **tracert** work and what protocol does it use?
+
+
+
+> The command **tracert**—or **traceroute** depending on the operating system—allows you to see exactly what routers you touch as you move through the chain of connections to your final destination. If you end up with a problem where you can’t connect to or **ping** your final destination, a **tracert** can help in that you can tell exactly where the chain of connections stops. ([Citation][6])
+>
+> With this information, you can contact the correct people; whether it be your own firewall, your ISP, your destination’s ISP, or somewhere in the middle. The **tracert** command—like **ping**—uses the ICMP protocol, but also can use the first step of the TCP three-way handshake to send SYN requests for a response.
+
+ 17. What is the main advantage of using **chroot**? When and why do we use it? What is the purpose of the **mount /dev**, **mount /proc**, and **mount /sys** commands in a **chroot** environment?
+
+
+
+> An advantage of having a **chroot** environment is that the filesystem is isolated from the physical host, since **chroot** has a separate filesystem inside your filesystem. The difference is that **chroot** uses a newly created root (**/**) as its root directory.
+>
+> A **chroot** jail lets you isolate a process and its children from the rest of the system. It should only be used for processes that don’t run as **root**, as **root** users can break out of the jail easily.
+>
+> The idea is that you create a directory tree where you copy or link in all of the system files needed for the process to run. You then use the **chroot()** system call to tell it the root directory now exists at the base of this new tree, and then start the process running in that **chroot**’d environment. Since the command then can’t reference paths outside the modified root directory, it can’t perform operations (read, write, etc.) maliciously on those locations. ([Citation][7])
+
+ 18. How do you protect your system from getting hacked?
+
+
+
+> By following the principle of least privileges and these practices:
+>
+> * Encrypt with public keys, which provides excellent security.
+> * Enforce password complexity.
+> * Understand why you are making exceptions to the rules above.
+> * Review your exceptions regularly.
+> * Hold someone to account for failure. (It keeps you on your toes.) ([Citation][8])
+>
+
+
+ 19. What is LVM, and what are the advantages of using it?
+
+
+
+> LVM, or Logical Volume Management, uses a storage device management technology that gives users the power to pool and abstract the physical layout of component storage devices for easier and flexible administration. Using the device mapper Linux kernel framework, the current iteration (LVM2) can be used to gather existing storage devices into groups and allocate logical units from the combined space as needed.
+
+ 20. What are sticky ports?
+
+
+
+> Sticky ports are one of the network administrator’s best friends and worst headaches. They allow you to set up your network so that each port on a switch only permits one (or a number that you specify) computer to connect on that port, by locking it to a particular MAC address.
+
+ 21. Explain port forwarding?
+
+
+
+> When trying to communicate with systems on the inside of a secured network, it can be very difficult to do so from the outside—and with good reason. Therefore, the use of a port forwarding table within the router itself, or other connection management device, can allow specific traffic to automatically forward to a particular destination. For example, if you had a web server running on your network and you wanted to grant access to it from the outside, you would set up port forwarding to port 80 on the server in question. This would mean that anyone entering your IP address in a web browser would connect to the server’s website immediately.
+>
+> Please note, it is usually not recommended to allow access to a server from the outside directly into your network.
+
+ 22. What is a false positive and false negative in the case of IDS?
+
+
+
+> When the Intrusion Detection System (IDS) device generates an alert for an intrusion which has actually not happened, this is false positive. If the device has not generated any alert and the intrusion has actually happened, this is the case of a false negative.
+
+ 23. Explain **:(){ :|:& };:** and how to stop this code if you are already logged into the system?
+
+
+
+> This is a fork bomb. It breaks down as follows:
+>
+> * **:()** defines the function, with **:** as the function name, and the empty parenthesis shows that it will not accept any arguments.
+> * **{ }** shows the beginning and end of the function definition.
+> * **:|:** loads a copy of the function **:** into memory, and pipes its output to another copy of the **:** function, which also has to be loaded into memory.
+> * **&** makes the previous item a background process, so that the child processes will not get killed even though the parent gets auto-killed.
+> * **:** at the end executes the function again, and hence the chain reaction begins.
+>
+
+>
+> The best way to protect a multi-user system is to use Privileged Access Management (PAM) to limit the number of processes a user can use.
+>
+> The biggest problem with a fork bomb is the fact it takes up so many processes. So, we have two ways of attempting to fix this if you are already logged into the system. One option is to execute a SIGSTOP command to stop the process, such as:
+>
+> **killall -STOP -u user1**
+>
+> If you can’t use the command line due to all processes being used, you will have to use **exec** to force it to run:
+>
+> **exec killall -STOP -u user1**
+>
+> With fork bombs, your best option is preventing them from becoming too big of an issue in the first place
+
+ 24. What is OOM killer and how does it decide which process to kill first?
+
+
+
+> If memory is exhaustively used up by processes to the extent that possibly threatens the system’s stability, then the out of memory (OOM) killer comes into the picture.
+>
+> An OOM killer first has to select the best process(es) to kill. _Best_ here refers to the process which will free up the maximum memory upon being killed, and is also the least important to the system. The primary goal is to kill the least number of processes to minimize the damage done, and at the same time maximize the amount of memory freed.
+>
+> To facilitate this goal, the kernel maintains an oom_score for each of the processes. You can see the oom_score of each of the processes in the **/proc** filesystem under the **pid** directory:
+>
+> **$ cat /proc/10292/oom_score**
+>
+> The higher the value of oom_score for any process, the higher its likelihood is of being killed by the OOM Killer in an out-of-memory situation. ([Citation][9])
+
+### Conclusion
+
+System administration salaries have a [wide range][10] with some sites mentioning $70,000 to $100,000 a year, depending on the location, the size of the organization, and your education level plus years of experience. In the end, the system administration career path boils down to your interest in working with servers and solving cool problems. Now, I would say go ahead and achieve your dream path.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/sysadmin-job-interview-questions
+
+作者:[DirectedSoul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/directedsoul
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_HowToFish_520x292.png?itok=DHbdxv6H (Question and answer.)
+[2]: https://github.com/trimstray/test-your-sysadmin-skills
+[3]: https://www.waytoeasylearn.com/2016/05/netapp-filer-tutorial.html
+[4]: https://searchstorage.techtarget.com/definition/RAID-10-redundant-array-of-independent-disks
+[5]: https://www.answers.com/Q/What_is_hard_link_and_soft_link_in_Linux
+[6]: https://www.wisdomjobs.com/e-university/network-administrator-interview-questions.html
+[7]: https://unix.stackexchange.com/questions/105/chroot-jail-what-is-it-and-how-do-i-use-it
+[8]: https://serverfault.com/questions/391370/how-to-prevent-zero-day-attacks
+[9]: https://unix.stackexchange.com/a/153586/8369
+[10]: https://blog.netwrix.com/2018/07/23/systems-administrator-salary-in-2018-how-much-can-you-earn/
diff --git a/sources/tech/20190725 How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System.md b/sources/tech/20190725 How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System.md
deleted file mode 100644
index d7e58a24c1..0000000000
--- a/sources/tech/20190725 How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System.md
+++ /dev/null
@@ -1,153 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System?)
-[#]: via: (https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-How to Enable Canonical Kernel Livepatch Service on Ubuntu LTS System?
-======
-
-Canonical was introduced Live patch Service in Ubuntu 14.04 LTS system.
-
-Live patching service allows you to install and apply critical Linux kernel security updates without rebooting your system.
-
-This means, you don’t need to reboot your system after applying the kernel patches.
-
-But usually, we need to reboot the Linux server after installing the kernel patches to available for the system to use.
-
-Live patching is pretty fast. Most kernel fixes apply in seconds without any issues.
-
-Canonical live patch service is available for user upto 3 systems without any cost.
-
-You can enable Canonical Live patch in both variants desktop and server, through the command line.
-
-This live patching system is intended to address high and critical Linux kernel security vulnerabilities.
-
-Refer the following table for [supported systems][1] and other details.
-
-Ubuntu Release | Arch | Kernel Version | Kernel Variants
----|---|---|---
-Ubuntu 18.04 LTS | 64-bit x86 | 4.15 | GA generic and lowlatency kernel variants only
-Ubuntu 16.04 LTS | 64-bit x86 | 4.4 | GA generic and lowlatency kernel variants only
-Ubuntu 14.04 LTS | 64-bit x86 | 4.4 | Hardware Enablement kernel only
-
-**`Note:`**` ` Canonical Livepatch Service in Ubuntu 14.04 LTS requires users to run the Ubuntu v4.4 kernel in Trusty. Please reboot into this kernel if you are not currently running to use the service.
-
-To do so, follow the below procedures.
-
-### How To Get Live patch Token?
-
-Navigate to [Canonical Live patch service page][2] and choose `Ubuntu user` if you want to use the free service.
-
-It will be applicable upto 3 systems. If you are an `UA customer`, then select Ubuntu Advantage customer. Finally click Get your Live patch token.
-[![][3]![][3]][4]
-
-Make sure you already have account in `Ubuntu One`. If no, you can create a new one.
-
-After logged in, you will get a secret key for your account.
-[![][3]![][3]][5]
-
-### Install Snap Daemon in Your System
-
-The live patching system is handled through a snap package. So, make sure you have the “snap daemon” installed on your Ubuntu system.
-
-```
-$ sudo apt update
-
-$ sudo apt install snapd
-```
-
-### How To Install & Configure Live patch Service in Your System?
-
-Install the canonical-livepatch daemon by running the below command.
-
-```
-$ sudo snap install canonical-livepatch
-
-canonical-livepatch 9.4.1 from Canonical* installed
-```
-
-Run the following command to enable live kernel patches on an Ubuntu machine.
-
-```
-$ sudo canonical-livepatch enable xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
-
-Successfully enabled device. Using machine-token: xxxxc4xxxx67xxxxbxxxxbxxxxfbxx4e
-```
-
-Run the below command to find the status of your livepatched machine.
-
-```
-$ sudo canonical-livepatch status
-
-client-version: 9.4.1
-architecture: x86_64
-cpu-model: Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
-last-check: 2019-07-24T12:30:04+05:30
-boot-time: 2019-07-24T12:11:06+05:30
-uptime: 19m11s
-status:
-- kernel: 4.15.0-55.60-generic
- running: true
- livepatch:
- checkState: checked
- patchState: nothing-to-apply
- version: ""
- fixes: ""
-```
-
-Run the above same command with the `--verbose` switch to get more information about live patched machine.
-
-```
-$ sudo canonical-livepatch status --verbose
-```
-
-Execute the below command, if you would like to run the patch manually.
-
-```
-$ sudo canonical-livepatch refresh
-
-Before refresh:
-
-kernel: 4.15.0-55.60-generic
-fully-patched: true
-version: ""
-
-After refresh:
-
-kernel: 4.15.0-55.60-generic
-fully-patched: true
-version: ""
-```
-
-You will be getting one of the below status in the `patchState` output.
-
- * **applied:** There are no vulnerabilities found
- * **nothing-to-apply:** Vulnerabilities are found and patched successfully
- * **kernel-upgrade-required:** Livepatch cannot install a patch to fix the vulnerability
-
-
-
-Make a note, installing a kernel patch is different from upgrading/installing a new kernel on system. If you have installed new kernel then you have to reboot the system to activate the new kernel.
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/enable-canonical-kernel-livepatch-service-on-ubuntu-lts-system/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://wiki.ubuntu.com/Kernel/Livepatch
-[2]: https://auth.livepatch.canonical.com/
-[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[4]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-1.jpg
-[5]: https://www.2daygeek.com/wp-content/uploads/2019/07/enable-canonical-livepatch-service-on-ubuntu-lts-system-2.jpg
diff --git a/sources/tech/20190725 Introduction to GNU Autotools.md b/sources/tech/20190725 Introduction to GNU Autotools.md
new file mode 100644
index 0000000000..5eb41ad803
--- /dev/null
+++ b/sources/tech/20190725 Introduction to GNU Autotools.md
@@ -0,0 +1,263 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Introduction to GNU Autotools)
+[#]: via: (https://opensource.com/article/19/7/introduction-gnu-autotools)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Introduction to GNU Autotools
+======
+If you're not using Autotools yet, this tutorial will change the way you
+deliver your code.
+![Linux kernel source code \(C\) in Visual Studio Code][1]
+
+Have you ever downloaded the source code for a popular software project that required you to type the almost ritualistic **./configure; make && make install** command sequence to build and install it? If so, you’ve used [GNU Autotools][2]. If you’ve ever looked into some of the files accompanying such a project, you’ve likely also been terrified at the apparent complexity of such a build system.
+
+Good news! GNU Autotools is a lot simpler to set up than you think, and it’s GNU Autotools itself that generates those 1,000-line configuration files for you. Yes, you can write 20 or 30 lines of installation code and get the other 4,000 for free.
+
+### Autotools at work
+
+If you’re a user new to Linux looking for information on how to install applications, you do not have to read this article! You’re welcome to read it if you want to research how software is built, but if you’re just installing a new application, go read my article about [installing apps on Linux][3].
+
+For developers, Autotools is a quick and easy way to manage and package source code so users can compile and install software. Autotools is also well-supported by major packaging formats, like DEB and RPM, so maintainers of software repositories can easily prepare a project built with Autotools.
+
+Autotools works in stages:
+
+ 1. First, during the **./configure** step, Autotools scans the host system (the computer it’s being run on) to discover the default settings. Default settings include where support libraries are located, and where new software should be placed on the system.
+ 2. Next, during the **make** step, Autotools builds the application, usually by converting human-readable source code into machine language.
+ 3. Finally, during the **make install** step, Autotools copies the files it built to the appropriate locations (as detected during the configure stage) on your computer.
+
+
+
+This process seems simple, and it is, as long as you use Autotools.
+
+### The Autotools advantage
+
+GNU Autotools is a big and important piece of software that most of us take for granted. Along with [GCC (the GNU Compiler Collection)][4], Autotools is the scaffolding that allows Free Software to be constructed and installed to a running system. If you’re running a [POSIX][5] system, it’s not an understatement to say that most of your operating system exists as runnable software on your computer because of these projects.
+
+In the likely event that your pet project isn’t an operating system, you might assume that Autotools is overkill for your needs. But, despite its reputation, Autotools has lots of little features that may benefit you, even if your project is a relatively simple application or series of scripts.
+
+#### Portability
+
+First of all, Autotools comes with portability in mind. While it can’t make your project work across all POSIX platforms (that’s up to you, as the coder), Autotools can ensure that the files you’ve marked for installation get installed to the most sensible locations on a known platform. And because of Autotools, it’s trivial for a power user to customize and override any non-optimal value, according to their own system.
+
+With Autotools, all you need to know is what files need to be installed to what general location. It takes care of everything else. No more custom install scripts that break on any untested OS.
+
+#### Packaging
+
+Autotools is also well-supported. Hand a project with Autotools over to a distro packager, whether they’re packaging an RPM, DEB, TGZ, or anything else, and their job is simple. Packaging tools know Autotools, so there’s likely to be no patching, hacking, or adjustments necessary. In many cases, incorporating an Autotools project into a pipeline can even be automated.
+
+### How to use Autotools
+
+To use Autotools, you must first have Autotools installed. Your distribution may provide one package meant to help developers build projects, or it may provide separate packages for each component, so you may have to do some research on your platform to discover what packages you need to install.
+
+The components of Autotools are:
+
+ * **automake**
+ * **autoconf**
+ * **automake**
+ * **make**
+
+
+
+While you likely need to install the compiler (GCC, for instance) required by your project, Autotools works just fine with scripts or binary assets that don’t need to be compiled. In fact, Autotools can be useful for such projects because it provides a **make uninstall** script for easy removal.
+
+Once you have all of the components installed, it’s time to look at the structure of your project’s files.
+
+#### Autotools project structure
+
+GNU Autotools has very specific expectations, and most of them are probably familiar if you download and build source code often. First, the source code itself is expected to be in a subdirectory called **src**.
+
+Your project doesn’t have to follow all of these expectations, but if you put files in non-standard locations (from the perspective of Autotools), then you’ll have to make adjustments for that in your Makefile later.
+
+Additionally, these files are required:
+
+ * **NEWS**
+ * **README**
+ * **AUTHORS**
+ * **ChangeLog**
+
+
+
+You don’t have to actively use the files, and they can be symlinks to a monolithic document (like **README.md**) that encompasses all of that information, but they must be present.
+
+#### Autotools configuration
+
+Create a file called **configure.ac** at your project’s root directory. This file is used by **autoconf** to create the **configure** shell script that users run before building. The file must contain, at the very least, the **AC_INIT** and **AC_OUTPUT** [M4 macros][6]. You don’t need to know anything about the M4 language to use these macros; they’re already written for you, and all of the ones relevant to Autotools are defined in the documentation.
+
+Open the file in your favorite text editor. The **AC_INIT** macro may consist of the package name, version, an email address for bug reports, the project URL, and optionally the name of the source TAR file.
+
+The **[AC_OUTPUT][7]** macro is much simpler and accepts no arguments.
+
+
+```
+AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
+AC_OUTPUT
+```
+
+If you were to run **autoconf** at this point, a **configure** script would be generated from your **configure.ac** file, and it would run successfully. That’s all it would do, though, because all you have done so far is define your project’s metadata and called for a configuration script to be created.
+
+The next macros you must invoke in your **configure.ac** file are functions to create a [Makefile][9]. A Makefile tells the **make** command what to do (usually, how to compile and link a program).
+
+The macros to create a Makefile are **AM_INIT_AUTOMAKE**, which accepts no arguments, and **AC_CONFIG_FILES**, which accepts the name you want to call your output file.
+
+Finally, you must add a macro to account for the compiler your project needs. The macro you use obviously depends on your project. If your project is written in C++, the appropriate macro is **AC_PROG_CXX**, while a project written in C requires **AC_PROG_CC**, and so on, as detailed in the [Building Programs and Libraries][10] section in the Autoconf documentation.
+
+For example, I might add the following for my C++ program:
+
+
+```
+AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
+AC_OUTPUT
+AM_INIT_AUTOMAKE
+AC_CONFIG_FILES([Makefile])
+AC_PROG_CXX
+```
+
+Save the file. It’s time to move on to the Makefile.
+
+#### Autotools Makefile generation
+
+Makefiles aren’t difficult to write manually, but Autotools can write one for you, and the one it generates will use the configuration options detected during the `./configure` step, and it will contain far more options than you would think to include or want to write yourself. However, Autotools can’t detect everything your project requires to build, so you have to add some details in the file **Makefile.am**, which in turn is used by **automake** when constructing a Makefile.
+
+**Makefile.am** uses the same syntax as a Makefile, so if you’ve ever written a Makefile from scratch, then this process will be familiar and simple. Often, a **Makefile.am** file needs only a few variable definitions to indicate what files are to be built, and where they are to be installed.
+
+Variables ending in **_PROGRAMS** identify code that is to be built (this is usually considered the _primary_ target; it’s the main reason the Makefile exists). Automake recognizes other primaries, like **_SCRIPTS**, **_DATA**, **_LIBRARIES**, and other common parts that make up a software project.
+
+If your application is literally compiled during the build process, then you identify it as a binary program with the **bin_PROGRAMS** variable, and then reference any part of the source code required to build it (these parts may be one or more files to be compiled and linked together) using the program name as the variable prefix:
+
+
+```
+bin_PROGRAMS = penguin
+penguin_SOURCES = penguin.cpp
+```
+
+The target of **bin_PROGRAMS** is installed into the **bindir**, which is user-configurable during compilation.
+
+If your application isn’t actually compiled, then your project doesn’t need a **bin_PROGRAMS** variable at all. For instance, if your project is a script written in Bash, Perl, or a similar interpreted language, then define a **_SCRIPTS** variable instead:
+
+
+```
+bin_SCRIPTS = bin/penguin
+```
+
+Automake expects sources to be located in a directory called **src**, so if your project uses an alternative directory structure for its layout, you must tell Automake to accept code from outside sources:
+
+
+```
+AUTOMAKE_OPTIONS = foreign subdir-objects
+```
+
+Finally, you can create any custom Makefile rules in **Makefile.am** and they’ll be copied verbatim into the generated Makefile. For instance, if you know that a temporary value needs to be replaced in your source code before the installation proceeds, you could make a custom rule for that process:
+
+
+```
+all-am: penguin
+ touch bin/penguin.sh
+
+penguin: bin/penguin.sh
+ @sed "s|__datadir__|@datadir@|" $< >bin/$@
+```
+
+A particularly useful trick is to extend the existing **clean** target, at least during development. The **make clean** command generally removes all generated build files with the exception of the Automake infrastructure. It’s designed this way because most users rarely want **make clean** to obliterate the files that make it easy to build their code.
+
+However, during development, you might want a method to reliably return your project to a state relatively unaffected by Autotools. In that case, you may want to add this:
+
+
+```
+clean-local:
+ @rm config.status configure config.log
+ @rm Makefile
+ @rm -r autom4te.cache/
+ @rm aclocal.m4
+ @rm compile install-sh missing Makefile.in
+```
+
+There’s a lot of flexibility here, and if you’re not already familiar with Makefiles, it can be difficult to know what your **Makefile.am** needs. The barest necessity is a primary target, whether that’s a binary program or a script, and an indication of where the source code is located (whether that’s through a **_SOURCES** variable or by using **AUTOMAKE_OPTIONS** to tell Automake where to look for source code).
+
+Once you have those variables and settings defined, you can try generating your build scripts as you see in the next section, and adjust for anything that’s missing.
+
+#### Autotools build script generation
+
+You’ve built the infrastructure, now it’s time to let Autotools do what it does best: automate your project tooling. The way the developer (you) interfaces with Autotools is different from how users building your code do.
+
+Builders generally use this well-known sequence:
+
+
+```
+$ ./configure
+$ make
+$ sudo make install
+```
+
+For that incantation to work, though, you as the developer must bootstrap the build infrastructure. First, run **autoreconf** to generate the configure script that users invoke before running **make**. Use the **–install** option to bring in auxiliary files, such as a symlink to **depcomp**, a script to generate dependencies during the compiling process, and a copy of the **compile** script, a wrapper for compilers to account for syntax variance, and so on.
+
+
+```
+$ autoreconf --install
+configure.ac:3: installing './compile'
+configure.ac:2: installing './install-sh'
+configure.ac:2: installing './missing'
+```
+
+With this development build environment, you can then create a package for source code distribution:
+
+
+```
+$ make dist
+```
+
+The **dist** target is a rule you get for "free" from Autotools.
+It’s a feature that gets built into the Makefile generated from your humble **Makefile.am** configuration. This target produces a **tar.gz** archive containing all of your source code and all of the essential Autotools infrastructure so that people downloading the package can build the project.
+
+At this point, you should review the contents of the archive carefully to ensure that it contains everything you intend to ship to your users. You should also, of course, try building from it yourself:
+
+
+```
+$ tar --extract --file penguin-0.0.1.tar.gz
+$ cd penguin-0.0.1
+$ ./configure
+$ make
+$ DESTDIR=/tmp/penguin-test-build make install
+```
+
+If your build is successful, you find a local copy of your compiled application specified by **DESTDIR** (in the case of this example, **/tmp/penguin-test-build**).
+
+
+```
+$ /tmp/example-test-build/usr/local/bin/example
+hello world from GNU Autotools
+```
+
+### Time to use Autotools
+
+Autotools is a great collection of scripts for a predictable and automated release process. This toolset may be new to you if you’re used to Python or Bash builders, but it’s likely worth learning for the structure and adaptability it provides to your project.
+
+And Autotools is not just for code, either. Autotools can be used to build [Docbook][11] projects, to keep media organized (I use Autotools for my music releases), documentation projects, and anything else that could benefit from customizable install targets.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/introduction-gnu-autotools
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr (Linux kernel source code (C) in Visual Studio Code)
+[2]: https://www.gnu.org/software/automake/faq/autotools-faq.html
+[3]: https://opensource.com/article/18/1/how-install-apps-linux
+[4]: https://en.wikipedia.org/wiki/GNU_Compiler_Collection
+[5]: https://en.wikipedia.org/wiki/POSIX
+[6]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Initializing-configure.html
+[7]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Output.html#Output
+[8]: mailto:seth@example.com
+[9]: https://www.gnu.org/software/make/manual/html_node/Introduction.html
+[10]: https://www.gnu.org/software/automake/manual/html_node/Programs.html#Programs
+[11]: https://opensource.com/article/17/9/docbook
diff --git a/sources/tech/20190726 The Future Of Red Hat At IBM.md b/sources/tech/20190726 The Future Of Red Hat At IBM.md
new file mode 100644
index 0000000000..72cfc84a65
--- /dev/null
+++ b/sources/tech/20190726 The Future Of Red Hat At IBM.md
@@ -0,0 +1,85 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Future Of Red Hat At IBM)
+[#]: via: (https://www.linux.com/blog/future-red-hat-ibm)
+[#]: author: (Swapnil Bhartiya https://www.linux.com/users/swapnil)
+
+The Future Of Red Hat At IBM
+======
+
+![][1]
+
+[Creative Commons Attribution-NonCommercial-NoDerivs][2]
+
+Swapnil Bhartiya
+
+IBM has a long history of [working with the open source community][3]. Way back in 1999, [IBM announced a $1billion investment in Linux][4]. IBM is also credited for creating one of the [most innovative advertisements about Linux.][5] But IBM’s acquisition of Red Hat raised some serious and genuine questions around IBM’s commitment to Open Source and the future of Red Hat at the big blue.
+
+Red Hat CTO, Chris Wright, took it upon himself to address some of these concerns and answer people’s questions in [an AMA (Ask Me Anything) on Reddit.][6] Wright has evolved from being a Linux kernel developer to becoming the CTO of the world’s largest open source company. He has his pulse on both the business and community sides of the open source world.
+
+**Red vs Blue:** Some of the most pressing questions asked during the AMA were around the future of open source and Red Hat at IBM. Red Hat has its unique identity and branding. You will often see people walking with their red hats on at open source events, you may even notice some permanent tattoos.
+
+One Redditor asked if there were any plans to overhaul Red Hat branding to make it blue or purple, Wright said, “No, Red Hat is Red. We just announced the evolution of our logo in May, no plans for any other changes. We like the new logo and so do the associates who already got tattoos of it!”
+
+**Kubernetes:** A Redditor asked about the future of Red Hat OpenShift and OKD (the Origin community distribution of Kubernetes). Wright assured that the acquisition doesn’t have any effect on OpenShift and OKD. Wright said that Red Hat is focused on delivering the industry’s most comprehensive enterprise Kubernetes platform – OpenShift - without changes.
+
+As far as community engagement is concerned, “…upstream first development in Kubernetes and community ecosystem development in OKD are part of our product development process. Neither of those change,” he said. “The IBM acquisition can help accelerate the adoption of OpenShift given the increasing scale and reach in sales and services that IBM has.”
+
+**Conflict of Culture:** IBM and Red Hat are two companies with different, and often conflicting cultures. While Red Hat employees are allowed and encouraged to contribute to open Source, IBMers do not have the same level of freedom. One ex-IBMer asked, “IBM has traditionally had very strict policies regarding contributing to non-IBM open source projects. I understand that Red Hat's culture is quite different in this regard; do you see IBM loosening up in this regard? Or will only the Red Hat division operate differently?”
+
+Wright said that Red Hat would continue to operate the way it does with respect to allowing Red Hatters to contribute to open source projects.
+
+IBM’s CTO of Open Source, Chris Ferris pitched in and said that for the past 5 years or so, the policy for IBMers contributing to open source on their own time was relaxed such that they could do so with their manager’s permission.
+
+“In fact, we have been on a steady trend over the past 5 years or more to reduce the process barriers to both contributing to, and consuming open source and we continue to review our policies periodically. With the acquisition now complete, IBM has chosen to adopt the same policy towards contributing to open source on one’s own time as Red Hat has had historically. This is one important way that the Red Hat culture has benefited IBM developers.”
+
+Adam Kaplan, Senior Software Engineer at Red Hat, contributed to the AMA and said that Red Hat employees are free to contribute as they see fit, even if a said contribution goes against Red Hat's business objectives.
+
+**Future of Fedora & Gnome:** Red Hat is among the leading contributors to many open source projects that are being used by the larger open source community. Some Redditors expressed fear about the future of such projects that won’t be bringing in any revenue for IBM.
+
+One user asked about Fedora, which is the upstream for Red Hat Enterprise Linux. Wright assured that Fedora and its path stays the same. “It is an important community Linux distribution and Red Hat's involvement will continue to be the same.”
+
+Red Hat is one of the major contributors to Gnome, one of the biggest desktop environments for Linux and BSD. When asked about the future of Gnome, Wright said that nothing will change. “Certainly not to what we have contributed. More importantly, our future contributions will follow the same pattern,” he said. “We contribute to open source projects that are part of our product portfolio and focus on the areas that are important to our customers, which includes not just features but also long term maintainability (this becomes important in a codebase when you talk about architectural changes).”
+
+**Sunset at Oracle:** Some Redditors drew a comparison with Oracle’s acquisition of Sun Microsystems. “I guess the biggest concern among the “Linux community” in general is that Red Hat might go down the path Solaris did after Oracle's acquisition. IBM is viewed as an old school company, a bit like Oracle in that sense. We have learned through press that IBM's plan is to use Red Hat to change IBMs perception and not the other way around. Hope it's true. How do you guys plan on addressing such concerns?
+
+Wright said that Red Hat would continue to run as an independent company and the team would continue to do what it does best: engage with customers, partners, and open source communities to build open-source solutions.
+
+“Those solutions focus on our hybrid cloud strategy. A key part of the acquisition is for IBM and Red Hat to work closely together to advance our customers’ journeys to an open hybrid cloud. You’ve seen mention of IBM’s plans to use Red Hat platforms as part of their offerings, so this is the other key piece here. We stay independent, we share a vision, and IBM is building from our core platforms,” he said.
+
+Addressing a similar question that IBM has a history of buying companies and then breaking them up, Wright said, Red Hat will remain committed to the upstream work it does across the board. “It is a fundamental part of how we develop our software products. Things like Network Manager create desktop usability, and can even be the impetus behind more core distro improvements. The IBM acquisition doesn’t change this at all. I see the future of Red Hat as staying focused on our core mission and continuing to evolve with (upstream first!) open source and our customer's needs,” he said.
+
+**IBM nukes all Open Source at Red Hat**: One Redditor asked what stops IBM from going nuclear and dismantling all of the open source work Red Hat has done?
+
+Wright said that the reality of software is that open source has become the de facto means by which software is developed. “I often refer to this historic acquisition as an acknowledgment that open source has won. So, a simple way to look at this is the $34b value is about how important open source is to IBM’s strategy...again, open source has won!” he said, “Another way to look at it is the value that we’ve created with Red Hat is synonymous with open source. We wouldn’t exist without open source, it’s core to our strategy. And we (both Red Hat and IBM) are deeply vested in Red Hat’s continued success.”
+
+**Take Away**
+
+People should remember that by design, open source is protected from any such risk. If a company gets acquired and the code is at risk of being nuked, the community can fork the project and maintain it. Life goes on. Since everything that Red Hat does is open source, people can always take the code-base and maintain it themselves. open source code has escape velocities, it doesn’t go away with the companies that built it.
+
+After reading the entire AMA, it’s fair to conclude that Red Hat is safe in the hands of IBM. It’s like a drop of color in a glass of water. The entire glass of water turns red. Red Hat has a very strong community-driven, open source culture. It’s very likely that IBM will be the one benefitting and transforming into an even more open source friendly company.
+
+Rumor has it that one day Red Hat CEO Jim Whitehurst might become the CEO of IBM. When a Redditor asked the same question, whether Whitehurst will succeed Ginni Rometty as the CEO, Wright said, “I certainly don’t have a crystal ball, but I think Jim is a great CEO!”
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/future-red-hat-ibm
+
+作者:[Swapnil Bhartiya][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/swapnil
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dsc_7800.jpg?itok=Ch1vMOHq (Jim Whitehurst)
+[2]: https://www.linux.com/licenses/category/creative-commons-attribution-noncommercial-noderivs
+[3]: https://www-03.ibm.com/press/us/en/pressrelease/2262.wss
+[4]: https://en.wikipedia.org/wiki/Linux_Technology_Center
+[5]: https://www.youtube.com/watch?v=s7dTjpvakmA
+[6]: https://www.reddit.com/r/linux/comments/cgu6aj/chris_wright_cto_of_red_hat_is_hosting_an_ama_at/
diff --git a/sources/tech/20190726 What does it mean to be a sysadmin hero.md b/sources/tech/20190726 What does it mean to be a sysadmin hero.md
new file mode 100644
index 0000000000..bc3148eb63
--- /dev/null
+++ b/sources/tech/20190726 What does it mean to be a sysadmin hero.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What does it mean to be a sysadmin hero?)
+[#]: via: (https://opensource.com/article/19/7/sysadmin-heroics-saving-day)
+[#]: author: (Opensource.com https://opensource.com/users/admin)
+
+What does it mean to be a sysadmin hero?
+======
+Two stories from the community on sysadmin heroics: What does it mean to
+you?
+![Open Force superhero characters][1]
+
+Sysadmins spend a lot of time preventing and fixing problems. There are certainly times when a sysadmin becomes a hero, whether to their team, department, company, or the general public, though the people they "saved" from trouble may never even know.
+
+Enjoy these two stories from the community on sysadmin heroics. What does it mean to you?
+
+* * *
+
+I worked as a system administrator for a contract with the Army National Guard in the early 2000s. I was involved in a project to pilot a new content management system. This system would enable distribution of online educational materials to classrooms across the country. The state of Montana was chosen for the initial pilot and test phase. I traveled to Montana and deployed several servers running Red Hat Linux plus the content management software in their data centers.
+
+A few days later, I received a call at my regular office from a worried guardsman with urgent news. One of the servers would not boot. Due to the circumstances, there was no way to easily troubleshoot.
+
+The testing was scheduled to commence the following week, which left little time to get the server back online. A delay in the project would be costly. I needed to solve the problem fast. Fortunately, we had several identical servers in our local data center. I used one of them to reinstall the operating system and applications, and then configured it identically to the problem server back in Montana. I then pulled the hard drive, packed it safely, and overnighted it to the Montana National Guard Armory.
+
+The guardsman called me the next morning to say he had the replacement drive. I instructed him on how to remove and replace the boot drive. After doing so, he pressed the power button. We waited for several silent seconds before he informed me that he could see lights and hear the sound of drive activity. I began pinging the server and after a few positive responses, I was able to SSH into it. This was a great sign!
+
+Everyone was relieved that the server was online again so that testing could get underway.
+
+If you want to know more about this program, [there is an article here][2]. (It takes a really long time to load for some reason, so I saved it as a PDF just in case.)
+
+—_Alan Formy-Duval_
+
+* * *
+
+Humans love good stories. In IT, stories about heroic feats of coding and cabling go back to the first computers and the bugs that lived inside them. They’re all loved. They’re loved more if the audience wasn’t part of the fallout of what created the story.
+
+Sysadmins tend to be left holding the bag when events turn sour. That fact affords us the often unwanted honor of being cast as the protagonist for one of these stories. Antagonists can be anything from bad weather or dug up cables, to mistyped commands, or simply human error. Because we operate in an industry built around generated conflict and drama, the legendary epics in our industry usually involve sysadmins battling the thoughtless developer. It’s an old trope, but a good one that gets lots of laughs and amazed stares when the stories are told.
+
+I’ve always been someone who’s loved to share these stories with my peers and friends. The camaraderie and the laughs are important to me. These stories are ice breakers and scene closers when on stage, in a conference room, or just when having a beer with your friends after a hard day. But this year, I’ve begun to think about our storytelling tradition a little differently. The heroes we should be talking about around the water cooler aren’t the sysadmins who fix the problem with a flourish at 3am on Sunday. The true heroes in the industry are the sysadmins who prevent the problem from ever happening at 3pm on a Tuesday.
+
+When I talk to my customers about building effective solutions, I focus the conversation around two core principles. First, I implore them to not rabbit hole themselves with shiny objects and base their solution around proven, supportable technology. Yes, shiny new tech can provide value in some use cases. But most likely it just adds complexity that drives down stability and maintainability. These factors all work together to ultimately slow down adoption by their end users.
+
+Platforms that don’t grow are platforms that don’t last. I don’t want to work on a platform that won’t be around for its first upgrade. Violating this principle creates systems that require Herculean efforts to keep alive. No one benefits from that situation, even if you do get a good story out of it.
+
+The second principle I drive home every time I get a chance is to focus on fundamental knowledge, and understand how the technology we’re implementing actually works. We’ve focused for a long time in our industry on marketing our products as fast to deploy, and easy to manage, but that’s almost always a thin veneer. Every IT system designed by humans will ultimately break at some point in its lifecycle. If you don’t understand what’s happening when that system goes sideways, you don’t have a chance of recovering without writing a new saga to talk about at lunch for weeks to come.
+
+It took me much longer than I’m comfortable with to figure out that the same hero stories we all enjoyed are a result of not sticking to the fundamental principles that I value the most in any solution I have a hand in creating. So, when Sysadmin Day rolls around this year, I won’t be lifting my glass to the heroes who built a bad system and kept it alive through extreme circumstances and too much caffeine. I’ll tip my hat and share a drink with the boring people in the middle of our industry who specialize in preventing the hero moments. A boring weekend with the on-call phone is the most heroic thing I’m ever going to ask from my sysadmin brethren from now on.
+
+_—Jamie Duncan_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/sysadmin-heroics-saving-day
+
+作者:[Opensource.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/admin
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/superhero_character_open_force.jpg?itok=cndIf6Zw (Open Force superhero characters)
+[2]: https://gcn.com/Articles/2002/01/18/National-Guard-will-test-distancelearning-standard.aspx
diff --git a/sources/tech/20190729 3 commands to reboot Linux (plus 4 more ways to do it safely).md b/sources/tech/20190729 3 commands to reboot Linux (plus 4 more ways to do it safely).md
new file mode 100644
index 0000000000..4cc9cf417e
--- /dev/null
+++ b/sources/tech/20190729 3 commands to reboot Linux (plus 4 more ways to do it safely).md
@@ -0,0 +1,262 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (3 commands to reboot Linux (plus 4 more ways to do it safely))
+[#]: via: (https://opensource.com/article/19/7/reboot-linux)
+[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/sethhttps://opensource.com/users/greg-phttps://opensource.com/users/greg-phttps://opensource.com/users/sethhttps://opensource.com/users/cldxsolutions)
+
+3 commands to reboot Linux (plus 4 more ways to do it safely)
+======
+Learn how to reboot Linux through many different methods, from the GUI
+to deep within the command line.
+![Tux with binary code background][1]
+
+Linux is fully capable of running not weeks, but years, without a reboot. In some industries, that’s exactly what Linux does, thanks to advances like **kpatch** and **kgraph**.
+
+For laptop and desktop users, though, that metric is a little extreme. While it may not be a day-to-day reality, it’s at least a weekly reality that sometimes you have a good reason to reboot your machine. And for a system that doesn’t need rebooting often, Linux offers plenty of choices for when it’s time to start over.
+
+### Understand your options
+
+Before continuing though, a note on rebooting. Rebooting is a unique process on each operating system. Even within [POSIX][2] systems, the commands to power down and reboot may behave differently due to different initialization systems or command designs.
+
+Despite this factor, two concepts are vital. First, rebooting is rarely requisite on a POSIX system. Your Linux machine can operate for weeks or months at a time without a reboot if that’s what you need. There’s no need to "freshen up" your computer with a reboot unless specifically advised to do so by a software installer or updater. Then again, it doesn’t hurt to reboot, either, so it’s up to you.
+
+Second, rebooting is meant to be a friendly process, allowing time for programs to exit, files to be saved, temporary files to be removed, filesystem journals updated, and so on. Whenever possible, reboot using the intended interfaces, whether in a GUI or a terminal. If you force your computer to shut down or reboot, you risk losing unsaved and even recently-saved data, and even corrupting important system information; you should only ever force your computer off when there’s no other option**.**
+
+### Click the button
+
+The first way to reboot or shut down Linux is the most common one, and the most intuitive for most desktop users regardless of their OS: It’s the power button in the GUI. Since powering down and rebooting are common tasks on a workstation, you can usually find the power button (typically with reboot and shut down options) in a few different places. On the GNOME desktop, it's in the system tray:
+
+![The GNOME power button.][3]
+
+It’s also in the GNOME **Activities** menu:
+
+![The GNOME Activities menu power button.][4]
+
+On the KDE desktop, the power buttons can be found in the **Applications** menu:
+
+![The KDE power buttons via the Applications menu.][5]
+
+You can also access the KDE power controls by right-clicking on the desktop and selecting the **Leave** option, which opens the window you see here:
+
+![The KDE power buttons via the Leave option.][6]
+
+Other desktops provide variations on these themes, but the general idea is the same: use your mouse to locate the power button, and then click it. You may have to select between rebooting and powering down, but in the end, the result is nearly identical: Processes are stopped, nicely, so that data is saved and temporary files are removed, then data is synchronized to drives, and then the system is powered down.
+
+### Push the physical button
+
+Most computers have a physical power button. If you press that button, your Linux desktop may display a power menu with options to shut down or reboot. This feature is provided by the [Advanced Configuration and Power Interface (ACPI)][7] subsystem, which communicates with your motherboard’s firmware to control your computer’s state.
+
+ACPI is important but it’s limited in scope, so there’s not much to configure from the user’s perspective. Usually, ACPI options are generically called **Power** and are set to a sane default. If you want to change this setup, you can do so in your system settings.
+
+On GNOME, open the system tray menu and select **Activities**, and then **Settings.** Next, select the **Power** category in the left column, which opens the following menu:
+
+![GNOME’s power button settings.][8]
+
+In the **Suspend & Power Button** section, select what you want the physical power button to do.
+
+The process is similar across desktops. For instance, on KDE, the **Power Management** panel in **System Settings** contains an option for **Button Event Handling.**
+
+* * *
+
+* * *
+
+* * *
+
+**![KDE Power Management][9]**
+
+* * *
+
+* * *
+
+* * *
+
+**opensource.com**
+
+After you configure how the button event is handled, pressing your computer’s physical power button follows whatever option you chose. Depending on your computer vendor (or parts vendors, if you build your own), a button press might be a light tap, or it may require a slightly longer push, so you might have to do some tests before you get the hang of it.
+
+Beware of an over-long press, though, since it may shut your computer down without warning.
+
+### Run the systemctl command
+
+If you operate more in a terminal than in a GUI desktop, you might prefer to reboot with a command. Broadly speaking, rebooting and powering down are processes of the _init_ system—the sequence of programs that bring a computer up or down after a power signal (either on or off, respectively) is received.
+
+On most modern Linux distributions, **systemd** is the init system, so both rebooting and powering down can be performed through the **systemd** user interface, **systemctl**. The **systemctl** command accepts, among many other options, **halt** (halts disk activity but does not cut power) **reboot** (halts disk activity and sends a reset signal to the motherboard) and **poweroff** (halts disk acitivity, and then cut power). These commands are mostly equivalent to starting the target file of the same name.
+
+For instance, to trigger a reboot:
+
+
+```
+`$ sudo systemctl start reboot.target`
+```
+
+### Run the shutdown command
+
+Traditional UNIX, before the days of **systemd** (and for some Linux distributions, like [Slackware][10], that’s _now_), there were commands specific to stopping a system. The **shutdown** command, for instance, can power down your machine, but it has several options to control exactly what that means.
+
+This command requires a time argument, in minutes, so that **shutdown** knows when to execute. To reboot immediately, append the **-r** flag:
+
+
+```
+`$ sudo shutdown -r now`
+```
+
+To power down immediately:
+
+
+```
+`$ sudo shutdown -P now`
+```
+
+Or you can use the **poweroff** command:
+
+
+```
+`$ poweroff`
+```
+
+To reboot after 10 minutes:
+
+
+```
+`$ sudo shutdown -r 10`
+```
+
+The **shutdown** command is a safe way to power off or reboot your computer, allowing disks to sync and processes to end. This command prevents new logins within the final 5 minutes of shutdown commencing, which is particularly useful on multi-user systems.
+
+On many systems today, the **shutdown** command is actually just a call to **systemctl** with the appropriate reboot or power off option.
+
+### Run the reboot command
+
+The **reboot** command, on its own, is basically a shortcut to **shutdown -r now**. From a terminal, this is the easiest and quickest reboot command:
+
+
+```
+`$ sudo reboot`
+```
+
+If your system is being blocked from shutting down (perhaps due to a runaway process), you can use the **\--force** flag to make the system shut down anyway. However, this option skips the actual shutting down process, which can be abrupt for running processes, so it should only be used when the **shutdown** command is blocking you from powering down.
+
+On many systems, **reboot** is actually a call to **systemctl** with the appropriate reboot or power off option.
+
+### Init
+
+On Linux distributions without **systemd**, there are up to 7 runlevels your computer understands. Different distributions can assign each mode uniquely, but generally, 0 initiates a halt state, and 6 initiates a reboot (the numbers in between denote states such as single-user mode, multi-user mode, a GUI prompt, and a text prompt).
+
+These modes are defined in **/etc/inittab** on systems without **systemd**. On distributions using **systemd** as the init system, the **/etc/inittab** file is either missing, or it’s just a placeholder.
+
+The **telinit** command is the front-end to your init system. If you’re using **systemd**, then this command is a link to **systemctl** with the appropriate options.
+
+To power off your computer by sending it into runlevel 0:
+
+
+```
+`$ sudo telinit 0`
+```
+
+To reboot using the same method:
+
+
+```
+`$ sudo telinit 6`
+```
+
+How unsafe this command is for your data depends entirely on your init configuration. Most distributions try to protect you from pulling the plug (or the digital equivalent of that) by mapping runlevels to friendly commands.
+
+You can see for yourself what happens at each runlevel by reading the init scripts found in **/etc/rc.d** or **/etc/init.d**, or by reading the **systemd** targets in **/lib/systemd/system/**.
+
+### Apply brute force
+
+So far I’ve covered all the _right_ ways to reboot or shut down your Linux computer. To be thorough, I include here additional methods of bringing down a Linux computer, but by no means are these methods recommended. They aren’t designed as a daily reboot or shut down command (**reboot** and **shutdown** exist for that), but they’re valid means to accomplish the task.
+
+If you try these methods, try them in a virtual machine. Otherwise, use them only in emergencies.
+
+#### Proc
+
+A step lower than the init system is the **/proc** filesystem, which is a virtual representation of nearly everything happening on your computer. For instance, you can view your CPUs as though they were text files (with **cat /proc/cpuinfo**), view how much power is left in your laptop’s battery, or, after a fashion, reboot your system.
+
+There’s a provision in the Linux kernel for system requests (**Sysrq** on most keyboards). You can communicate directly with this subsystem using key combinations, ideally regardless of what state your computer is in; it gets complex on some keyboards because the **Sysrq** key can be a special function key that requires a different key to access (such as **Fn** on many laptops).
+
+An option less likely to fail is using **echo** to insert information into **/proc**, manually. First, make sure that the Sysrq system is enabled:
+
+
+```
+`$ sudo echo 1 > /proc/sys/kernel/sysrq`
+```
+
+To reboot, you can use either **Alt**+**Sysrq**+**B** or type:
+
+
+```
+`$ sudo echo b > /proc/sysrq-trigger`
+```
+
+This method is not a reasonable way to reboot your machine on a regular basis, but it gets the job done in a pinch.
+
+#### Sysctl
+
+Kernel parameters can be managed during runtime with **sysctl**. There are lots of kernel parameters, and you can see them all with **sysctl --all**. Most probably don’t mean much to you until you know what to look for, and in this case, you’re looking for **kernel.panic**.
+
+You can query kernel parameters using the **-–value** option:
+
+
+```
+`$ sudo sysctl --value kernel.panic`
+```
+
+If you get a 0 back, then the kernel you’re running has no special setting, at least by default, to reboot upon a kernel panic. That situation is fairly typical since rebooting immediately on a catastrophic system crash makes it difficult to diagnose the cause of the crash. Then again, systems that need to stay on no matter what might benefit from an automatic restart after a kernel failure, so it’s an option that does get switched on in some cases.
+
+You can activate this feature as an experiment (if you’re following along, try this in a virtual machine rather than on your actual computer):
+
+
+```
+`$ sudo sysctl kernel.reboot=1`
+```
+
+Now, should your computer experience a kernel panic, it is set to reboot instead of waiting patiently for you to diagnose the problem. You can test this by simulating a catastrophic crash with **sysrq**. First, make sure that Sysrq is enabled:
+
+
+```
+`$ sudo echo 1 > /proc/sys/kernel/sysrq`
+```
+
+And then simulate a kernel panic:
+
+
+```
+`$ sudo echo c > /proc/sysrq-trigger`
+```
+
+Your computer reboots immediately.
+
+### Reboot responsibly
+
+Knowing all of these options doesn't mean that you should use them all. Give careful thought to what you're trying to accomplish, and what the command you've selected will do. You don't want to damage your system by being reckless. That's what virtual machines are for. However, having so many options means that you're ready for most situations.
+
+Have I left out your favorite method of rebooting or powering down a system? List what I’ve missed in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/reboot-linux
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/sethhttps://opensource.com/users/greg-phttps://opensource.com/users/greg-phttps://opensource.com/users/sethhttps://opensource.com/users/cldxsolutions
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tux_linux_penguin_code_binary.jpg?itok=TxGxW0KY (Tux with binary code background)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://opensource.com/sites/default/files/uploads/gnome-menu-power.jpg (The GNOME power button.)
+[4]: https://opensource.com/sites/default/files/uploads/gnome-screen-power.jpg (The GNOME Activities menu power button.)
+[5]: https://opensource.com/sites/default/files/uploads/kde-menu-power.jpg (The KDE power buttons via the Applications menu.)
+[6]: https://opensource.com/sites/default/files/uploads/kde-screen-power.jpg (The KDE power buttons via the Leave option.)
+[7]: https://en.wikipedia.org/wiki/Advanced_Configuration_and_Power_Interface
+[8]: https://opensource.com/sites/default/files/uploads/gnome-settings-power.jpg (GNOME’s power button settings.)
+[9]: https://opensource.com/sites/default/files/images/kde-power-management.jpg
+[10]: http://slackware.com
diff --git a/sources/tech/20190729 How to structure a multi-file C program- Part 1.md b/sources/tech/20190729 How to structure a multi-file C program- Part 1.md
new file mode 100644
index 0000000000..b4c9cd194d
--- /dev/null
+++ b/sources/tech/20190729 How to structure a multi-file C program- Part 1.md
@@ -0,0 +1,197 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to structure a multi-file C program: Part 1)
+[#]: via: (https://opensource.com/article/19/7/structure-multi-file-c-part-1)
+[#]: author: (Erik O'Shaughnessy https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions)
+
+How to structure a multi-file C program: Part 1
+======
+Grab your favorite beverage, editor, and compiler, crank up some tunes,
+and start structuring a C program composed of multiple files.
+![Programming keyboard.][1]
+
+It has often been said that the art of computer programming is part managing complexity and part naming things. I contend that this is largely true with the addition of "and sometimes it requires drawing boxes."
+
+In this article, I'll name some things and manage some complexity while writing a small C program that is loosely based on the program structure I discussed in "[How to write a good C main function][2]"—but different. This one will do something. Grab your favorite beverage, editor, and compiler, crank up some tunes, and let's write a mildly interesting C program together.
+
+### Philosophy of a good Unix program
+
+The first thing to know about this C program is that it's a [Unix][3] command-line tool. This means that it runs on (or can be ported to) operating systems that provide a Unix C runtime environment. When Unix was invented at Bell Labs, it was imbued from the beginning with a [design philosophy][4]. In my own words: _programs do one thing, do it well, and act on files_. While it makes sense to do one thing and do it well, the part about "acting on files" seems a little out of place.
+
+It turns out that the Unix abstraction of a "file" is very powerful. A Unix file is a stream of bytes that ends with an end-of-file (EOF) marker. That's it. Any other structure in a file is imposed by the application and not the operating system. The operating system provides system calls that allow a program to perform a set of standard operations on files: open, read, write, seek, and close (there are others, but those are the biggies). Standardizing access to files allows different programs to share a common abstraction and work together even when different people implement them in different programming languages.
+
+Having a shared file interface makes it possible to build programs that are _composable_. The output of one program can be the input of another program. The Unix family of operating systems provides three files by default whenever a program is executed: standard in (**stdin**), standard out (**stdout**), and standard error (**stderr**). Two of these files are opened in write-only mode: **stdout** and **stderr**, while **stdin** is opened read-only. We see this in action whenever we use file redirection in a command shell like Bash:
+
+
+```
+`$ ls | grep foo | sed -e 's/bar/baz/g' > ack`
+```
+
+This construction can be described briefly as: the output of **ls** is written to stdout, which is redirected to the stdin of **grep**, whose stdout is redirected to **sed**, whose stdout is redirected to write to a file called **ack** in the current directory.
+
+We want our program to play well in this ecosystem of equally flexible and awesome programs, so let's write a program that reads and writes files.
+
+### MeowMeow: A stream encoder/decoder concept
+
+When I was a dewy-eyed kid studying computer science in the <mumbles>s, there were a plethora of encoding schemes. Some of them were for compressing files, some were for packaging files together, and others had no purpose but to be excruciatingly silly. An example of the last is the [MooMoo encoding scheme][5].
+
+To give our program a purpose, I'll update this concept for the [2000s][6] and implement a concept called MeowMeow encoding (since the internet loves cats). The basic idea here is to take files and encode each nibble (half of a byte) with the text "meow." A lower-case letter indicates a zero, and an upper-case indicates a one. Yes, it will balloon the size of a file since we are trading 4 bits for 32 bits. Yes, it's pointless. But imagine the surprise on someone's face when this happens:
+
+
+```
+$ cat /home/your_sibling/.super_secret_journal_of_my_innermost_thoughts
+MeOWmeOWmeowMEoW...
+```
+
+This is going to be awesome.
+
+### Implementation, finally
+
+The full source for this can be found on [GitHub][7], but I'll talk through my thought process while writing it. The object is to illustrate how to structure a C program composed of multiple files.
+
+Having already established that I want to write a program that encodes and decodes files in MeowMeow format, I fired up a shell and issued the following commands:
+
+
+```
+$ mkdir meowmeow
+$ cd meowmeow
+$ git init
+$ touch Makefile # recipes for compiling the program
+$ touch main.c # handles command-line options
+$ touch main.h # "global" constants and definitions
+$ touch mmencode.c # implements encoding a MeowMeow file
+$ touch mmencode.h # describes the encoding API
+$ touch mmdecode.c # implements decoding a MeowMeow file
+$ touch mmdecode.h # describes the decoding API
+$ touch table.h # defines encoding lookup table values
+$ touch .gitignore # names in this file are ignored by git
+$ git add .
+$ git commit -m "initial commit of empty files"
+```
+
+In short, I created a directory full of empty files and committed them to git.
+
+Even though the files are empty, you can infer the purpose of each from its name. Just in case you can't, I annotated each **touch** with a brief description.
+
+Usually, a program starts as a single, simple **main.c** file, with only two or three functions that solve the problem. And then the programmer rashly shows that program to a friend or her boss, and suddenly the number of functions in the file balloons to support all the new "features" and "requirements" that pop up. The first rule of "Program Club" is don't talk about "Program Club." The second rule is to minimize the number of functions in one file.
+
+To be honest, the C compiler does not care one little bit if every function in your program is in one file. But we don't write programs for computers or compilers; we write them for other people (who are sometimes us). I know that is probably a surprise, but it's true. A program embodies a set of algorithms that solve a problem with a computer, and it's important that people understand it when the parameters of the problem change in unanticipated ways. People will have to modify the program, and they will curse your name if you have all 2,049 functions in one file.
+
+So we good and true programmers break functions out, grouping similar functions into separate files. Here I've got files **main.c**, **mmencode.c**, and **mmdecode.c**. For small programs like this, it may seem like overkill. But small programs rarely stay small, so planning for expansion is a "Good Idea."
+
+But what about those **.h** files? I'll explain them in general terms later, but in brief, those are called _header_ files, and they can contain C language type definitions and C preprocessor directives. Header files should _not_ have any functions in them. You can think of headers as a definition of the application programming interface (API) offered by the **.c** flavored file that is used by other **.c** files.
+
+### But what the heck is a Makefile?
+
+I know all you cool kids are using the "Ultra CodeShredder 3000" integrated development environment to write the next blockbuster app, and building your project consists of mashing on Ctrl-Meta-Shift-Alt-Super-B. But back in my day (and also today), lots of useful work got done by C programs built with Makefiles. A Makefile is a text file that contains recipes for working with files, and programmers use it to automate building their program binaries from source (and other stuff too!).
+
+Take, for instance, this little gem:
+
+
+```
+00 # Makefile
+01 TARGET= my_sweet_program
+02 $(TARGET): main.c
+03 cc -o my_sweet_program main.c
+```
+
+Text after an octothorpe/pound/hash is a comment, like in line 00.
+
+Line 01 is a variable assignment where the variable **TARGET** takes on the string value **my_sweet_program**. By convention, OK, my preference, all Makefile variables are capitalized and use underscores to separate words.
+
+Line 02 consists of the name of the file that the recipe creates and the files it depends on. In this case, the target is **my_sweet_program**, ****and the dependency is **main.c**.
+
+The final line, 03, is indented with a tab and not four spaces. This is the command that will be executed to create the target. In this case, we call **cc** the C compiler frontend to compile and link **my_sweet_program**.
+
+Using a Makefile is simple:
+
+
+```
+$ make
+cc -o my_sweet_program main.c
+$ ls
+Makefile main.c my_sweet_program
+```
+
+The [Makefile][8] that will build our MeowMeow encoder/decoder is considerably more sophisticated than this example, but the basic structure is the same. I'll break it down Barney-style in another article.
+
+### Form follows function
+
+My idea here is to write a program that reads a file, transforms it, and writes the transformed data to another file. The following fabricated command-line interaction is how I imagine using the program:
+
+
+```
+ $ meow < clear.txt > clear.meow
+ $ unmeow < clear.meow > meow.tx
+ $ diff clear.txt meow.tx
+ $
+```
+
+We need to write code to handle command-line parsing and managing the input and output streams. We need a function to encode a stream and write it to another stream. And finally, we need a function to decode a stream and write it to another stream. Wait a second, I've only been talking about writing one program, but in the example above, I invoke two commands: **meow** and **unmeow**? I know you are probably thinking that this is getting complex as heck.
+
+### Minor sidetrack: argv[0] and the ln command
+
+If you recall, the signature of a C main function is:
+
+
+```
+`int main(int argc, char *argv[])`
+```
+
+where **argc** is the number of command-line arguments, and **argv** is a list of character pointers (strings). The value of **argv[0]** is the path of the file containing the program being executed. Many Unix utility programs with complementary functions (e.g., compress and uncompress) look like two programs, but in fact, they are one program with two names in the filesystem. The two-name trick is accomplished by creating a filesystem "link" using the **ln** command.
+
+An example from **/usr/bin** on my laptop is:
+
+
+```
+ $ ls -li /usr/bin/git*
+3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git
+3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git-receive-pack
+...
+```
+
+Here **git** and **git-receive-pack** are the same file with different names. We can tell it's the same file because they have the same inode number (the first column). An inode is a feature of the Unix filesystem and is super outside the scope of this article.
+
+Good and/or lazy programmers can use this feature of the Unix filesystem to write less code but double the number of programs they deliver. First, we write a program that changes its behavior based on the value of **argv[0]**, then we make sure to create links with the names that cause the behavior.
+
+In our Makefile, the **unmeow** link is created using this recipe:
+
+
+```
+ # Makefile
+ ...
+ $(DECODER): $(ENCODER)
+ $(LN) -f $< $@
+ ...
+```
+
+I tend to parameterize everything in my Makefiles, rarely using a "bare" string. I group all the definitions at the top of the Makefile, which makes it easy to find and change them. This makes a big difference when you are trying to port software to a new platform and you need to change all your rules to use **xcc** instead of **cc**.
+
+The recipe should appear relatively straightforward except for the two built-in variables **$@** and **$<**. The first is a shortcut for the target of the recipe; in this case, **$(DECODER)**. (I remember this because the at-sign looks like a target to me.) The second, **$<** is the rule dependency; in this case, it resolves to **$(ENCODER)**.
+
+Things are getting complex for sure, but it's managed.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/structure-multi-file-c-part-1
+
+作者:[Erik O'Shaughnessy][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_keyboard_coding.png?itok=E0Vvam7A (Programming keyboard.)
+[2]: https://opensource.com/article/19/5/how-write-good-c-main-function
+[3]: https://en.wikipedia.org/wiki/Unix
+[4]: http://harmful.cat-v.org/cat-v/
+[5]: http://www.jabberwocky.com/software/moomooencode.html
+[6]: https://giphy.com/gifs/nyan-cat-sIIhZliB2McAo
+[7]: https://github.com/JnyJny/meowmeow
+[8]: https://github.com/JnyJny/meowmeow/blob/master/Makefile
diff --git a/sources/tech/20190730 How to create a pull request in GitHub.md b/sources/tech/20190730 How to create a pull request in GitHub.md
new file mode 100644
index 0000000000..b41dec1ee6
--- /dev/null
+++ b/sources/tech/20190730 How to create a pull request in GitHub.md
@@ -0,0 +1,144 @@
+[#]: collector: (lujun9972)
+[#]: translator: (furrybear)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to create a pull request in GitHub)
+[#]: via: (https://opensource.com/article/19/7/create-pull-request-github)
+[#]: author: (Kedar Vijay Kulkarni https://opensource.com/users/kkulkarnhttps://opensource.com/users/fontanahttps://opensource.com/users/mhanwellhttps://opensource.com/users/mysentimentshttps://opensource.com/users/greg-p)
+
+How to create a pull request in GitHub
+======
+Learn how to fork a repo, make changes, and ask the maintainers to
+review and merge it.
+![a checklist for a team][1]
+
+So, you know how to use git. You have a [GitHub][2] repo and can push to it. All is well. But how the heck do you contribute to other people's GitHub projects? That is what I wanted to know after I learned git and GitHub. In this article, I will explain how to fork a git repo, make changes, and submit a pull request.
+
+When you want to work on a GitHub project, the first step is to fork a repo.
+
+![Forking a GitHub repo][3]
+
+Use [my demo repo][4] to try it out.
+
+Once there, click on the **Fork** button in the top-right corner. This creates a new copy of my demo repo under your GitHub user account with a URL like:
+
+
+```
+`https://github.com//demo`
+```
+
+The copy includes all the code, branches, and commits from the original repo.
+
+Next, clone the repo by opening the terminal on your computer and running the command:
+
+
+```
+`git clone https://github.com//demo`
+```
+
+Once the repo is cloned, you need to do two things:
+
+ 1. Create a new branch by issuing the command:
+
+
+```
+`git checkout -b new_branch`
+```
+
+ 2. Create a new remote for the upstream repo with the command:
+
+
+```
+`git remote add upstream https://github.com/kedark3/demo`
+```
+
+
+
+
+In this case, "upstream repo" refers to the original repo you created your fork from.
+
+Now you can make changes to the code. The following code creates a new branch, makes an arbitrary change, and pushes it to **new_branch**:
+
+
+```
+$ git checkout -b new_branch
+Switched to a new branch ‘new_branch’
+$ echo “some test file” > test
+$ cat test
+Some test file
+$ git status
+On branch new_branch
+No commits yet
+Untracked files:
+ (use "git add <file>..." to include in what will be committed)
+ test
+nothing added to commit but untracked files present (use "git add" to track)
+$ git add test
+$ git commit -S -m "Adding a test file to new_branch"
+[new_branch (root-commit) 4265ec8] Adding a test file to new_branch
+ 1 file changed, 1 insertion(+)
+ create mode 100644 test
+$ git push -u origin new_branch
+Enumerating objects: 3, done.
+Counting objects: 100% (3/3), done.
+Writing objects: 100% (3/3), 918 bytes | 918.00 KiB/s, done.
+Total 3 (delta 0), reused 0 (delta 0)
+Remote: Create a pull request for ‘new_branch’ on GitHub by visiting:
+Remote:
+Remote:
+ * [new branch] new_branch -> new_branch
+```
+
+Once you push the changes to your repo, the **Compare & pull request** button will appear in GitHub.
+
+![GitHub's Compare & Pull Request button][5]
+
+Click it and you'll be taken to this screen:
+
+![GitHub's Open pull request button][6]
+
+Open a pull request by clicking the **Create pull request** button. This allows the repo's maintainers to review your contribution. From here, they can merge it if it is good, or they may ask you to make some changes.
+
+### TLDR
+
+In summary, if you want to contribute to a project, the simplest way is to:
+
+ 1. Find a project you want to contribute to
+ 2. Fork it
+ 3. Clone it to your local system
+ 4. Make a new branch
+ 5. Make your changes
+ 6. Push it back to your repo
+ 7. Click the **Compare & pull request** button
+ 8. Click **Create pull request** to open a new pull request
+
+
+
+If the reviewers ask for changes, repeat steps 5 and 6 to add more commits to your pull request.
+
+Happy coding!
+
+In a previous article , I discussed the complaints that have been leveled against GitHub during the...
+
+Arfon Smith works at GitHub and is involved in a number of activities at the intersection of open...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/create-pull-request-github
+
+作者:[Kedar Vijay Kulkarni][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/kkulkarnhttps://opensource.com/users/fontanahttps://opensource.com/users/mhanwellhttps://opensource.com/users/mysentimentshttps://opensource.com/users/greg-p
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk (a checklist for a team)
+[2]: https://github.com/
+[3]: https://opensource.com/sites/default/files/uploads/forkrepo.png (Forking a GitHub repo)
+[4]: https://github.com/kedark3/demo
+[5]: https://opensource.com/sites/default/files/uploads/compare-and-pull-request-button.png (GitHub's Compare & Pull Request button)
+[6]: https://opensource.com/sites/default/files/uploads/open-a-pull-request_crop.png (GitHub's Open pull request button)
diff --git a/sources/tech/20190730 How to manage logs in Linux.md b/sources/tech/20190730 How to manage logs in Linux.md
new file mode 100644
index 0000000000..cebfbc5f99
--- /dev/null
+++ b/sources/tech/20190730 How to manage logs in Linux.md
@@ -0,0 +1,110 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to manage logs in Linux)
+[#]: via: (https://www.networkworld.com/article/3428361/how-to-manage-logs-in-linux.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+How to manage logs in Linux
+======
+Log files on Linux systems contain a LOT of information — more than you'll ever have time to view. Here are some tips on how you can make use of it without ... drowning in it.
+![Greg Lobinski \(CC BY 2.0\)][1]
+
+Managing log files on Linux systems can be incredibly easy or painful. It all depends on what you mean by log management.
+
+If all you mean is how you can go about ensuring that your log files don’t eat up all the disk space on your Linux server, the issue is generally quite straightforward. Log files on Linux systems will automatically roll over, and the system will only maintain a fixed number of the rolled-over logs. Even so, glancing over what can easily be a group of 100 files can be overwhelming. In this post, we'll take a look at how the log rotation works and some of the most relevant log files.
+
+**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
+
+### Automatic log rotation
+
+Log files rotate frequently. What is the current log acquires a slightly different file name and a new log file is established. Take the syslog file as an example. This file is something of a catch-all for a lot of normal system messages. If you **cd** over to **/var/log** and take a look, you’ll probably see a series of syslog files like this:
+
+```
+$ ls -l syslog*
+-rw-r----- 1 syslog adm 28996 Jul 30 07:40 syslog
+-rw-r----- 1 syslog adm 71212 Jul 30 00:00 syslog.1
+-rw-r----- 1 syslog adm 5449 Jul 29 00:00 syslog.2.gz
+-rw-r----- 1 syslog adm 6152 Jul 28 00:00 syslog.3.gz
+-rw-r----- 1 syslog adm 7031 Jul 27 00:00 syslog.4.gz
+-rw-r----- 1 syslog adm 5602 Jul 26 00:00 syslog.5.gz
+-rw-r----- 1 syslog adm 5995 Jul 25 00:00 syslog.6.gz
+-rw-r----- 1 syslog adm 32924 Jul 24 00:00 syslog.7.gz
+```
+
+Rolled over at midnight each night, the older syslog files are kept for a week and then the oldest is deleted. The syslog.7.gz file will be tossed off the system and syslog.6.gz will be renamed syslog.7.gz. The remainder of the log files will follow suit until syslog becomes syslog.1 and a new syslog file is created. Some syslog files will be larger than others, but in general, none will likely ever get very large and you’ll never see more than eight of them. This gives you just over a week to review any data they collect.
+
+The number of files maintained for any particular log file depends on the log file itself. For some, you may have as many as 13. Notice how the older files – both for syslog and dpkg – are gzipped to save space. The thinking here is likely that you’ll be most interested in the recent logs. Older logs can be unzipped with **gunzip** as needed.
+
+```
+# ls -t dpkg*
+dpkg.log dpkg.log.3.gz dpkg.log.6.gz dpkg.log.9.gz dpkg.log.12.gz
+dpkg.log.1 dpkg.log.4.gz dpkg.log.7.gz dpkg.log.10.gz
+dpkg.log.2.gz dpkg.log.5.gz dpkg.log.8.gz dpkg.log.11.gz
+```
+
+Log files can be rotated based on age, as well as by size. Keep this in mind as you examine your log files.
+
+Log file rotation can be configured differently if you are so inclined, though the defaults work for most Linux sysadmins. Take a look at files like **/etc/rsyslog.conf** and **/etc/logrotate.conf** for some of the details.
+
+### Making use of your log files
+
+Managing log files should also include using them from time to time. The first step in making use of log files should probably include getting used to what each log file can tell you about how your system is working and what problems it might have run into. Reading log files from top to bottom is almost never a good option, but knowing how to pull information from them can be of great benefit when you want to get a sense of how well your system is working or need to track down a problem. This also suggests that you have a general idea what kind of information is stored in each file. For example:
+
+```
+$ who wtmp | tail -10 show the most recent logins
+$ who wtmp | grep shark show recent logins for a particular user
+$ grep "sudo:" auth.log see who is using sudo
+$ tail dmesg look at kernel messages
+$ tail dpkg.log see recently installed and updated packages
+$ more ufw.log see firewall activity (i.e., if you are using ufw)
+```
+
+Some commands that you run will also extract information from your log files. If you want to see, for example, a list of system reboots, you can use a command like this:
+
+```
+$ last reboot
+reboot system boot 5.0.0-20-generic Tue Jul 16 13:19 still running
+reboot system boot 5.0.0-15-generic Sat May 18 17:26 - 15:19 (21+21:52)
+reboot system boot 5.0.0-13-generic Mon Apr 29 10:55 - 15:34 (18+04:39)
+```
+
+### Using more advanced log managers
+
+While you can write scripts to make it easier to find interesting information in your log files, you should also be aware that there are some very sophisticated tools available for log file analysis. Some correlate information from multiple sources to get a fuller picture of what’s happening on your network. They may provide real-time monitoring, as well. Tools such as [Solarwinds Log & Event Manager][3] and [PRTG Network Monitor][4] (which includes log monitoring) come to mind.
+
+There are also some free tools that can help with analyzing log files. These include:
+
+ * **Logwatch** — program to scan system logs for interesting lines
+ * **Logcheck** — system log analyzer and reporter
+
+
+
+I'll provide some insights and help on these tools in upcoming posts.
+
+**[ Also see: [Invaluable tips and tricks for troubleshooting Linux][5] ]**
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3428361/how-to-manage-logs-in-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://images.idgesg.net/images/article/2019/07/logs-100806633-large.jpg
+[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
+[3]: https://www.esecurityplanet.com/products/solarwinds-log-event-manager-siem.html
+[4]: https://www.paessler.com/prtg
+[5]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20190730 Using Python to explore Google-s Natural Language API.md b/sources/tech/20190730 Using Python to explore Google-s Natural Language API.md
new file mode 100644
index 0000000000..b5f8611a1c
--- /dev/null
+++ b/sources/tech/20190730 Using Python to explore Google-s Natural Language API.md
@@ -0,0 +1,304 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Using Python to explore Google's Natural Language API)
+[#]: via: (https://opensource.com/article/19/7/python-google-natural-language-api)
+[#]: author: (JR Oakes https://opensource.com/users/jroakes)
+
+Using Python to explore Google's Natural Language API
+======
+Google's API can surface clues to how Google is classifying your site
+and ways to tweak your content to improve search results.
+![magnifying glass on computer screen][1]
+
+As a technical search engine optimizer, I am always looking for ways to use data in novel ways to better understand how Google ranks websites. I recently investigated whether Google's [Natural Language API][2] could better inform how Google may be classifying a site's content.
+
+Although there are [open source NLP tools][3], I wanted to explore Google's tools under the assumption it might use the same tech in other products, like Search. This article introduces Google's Natural Language API and explores common natural language processing (NLP) tasks and how they might be used to inform website content creation.
+
+### Understanding the data types
+
+To begin, it is important to understand the types of data that Google's Natural Language API returns.
+
+#### Entities
+
+Entities are text phrases that can be tied back to something in the physical world. Named entity recognition (NER) is a difficult part of NLP because tools often need to look at the full context around words to understand their usage. For example, homographs are spelled the same but have multiple meanings. Does "lead" in a sentence refer to a metal (a noun), causing someone to move (a verb), or the main character in a play (also a noun)? Google has 12 distinct types of entities, as well as a 13th catch-all category called "UNKNOWN." Some of the entities tie back to Wikipedia articles, suggesting [Knowledge Graph][4] influence on the data. Each entity returns a salience score, which is its overall relevance to the supplied text.
+
+![Entities][5]
+
+#### Sentiment
+
+Sentiment, a view of or attitude towards something, is measured at the document and sentence level and for individual entities discovered in the document. The score of the sentiment ranges from -1.0 (negative) to 1.0 (positive). The magnitude represents the non-normalized strength of emotion; it ranges between 0.0 and infinity.
+
+![Sentiment][6]
+
+#### Syntax
+
+Syntax parsing contains most of the common NLP activities found in better libraries, like [lemmatization][7], [part-of-speech tagging][8], and [dependency-tree parsing][9]. NLP mainly deals with helping machines understand text and the relationship between words. Syntax parsing is a foundational part of most language-processing or understanding tasks.
+
+![Syntax][10]
+
+#### Categories
+
+Categories assign the entire given content to a specific industry or topical category with a confidence score from 0.0 to 1.0. The categories appear to be the same audience and website categories used by other Google tools, like AdWords.
+
+![Categories][11]
+
+### Pulling some data
+
+Now I'll pull some sample data to play around with. I gathered some search queries and their corresponding URLs using Google's [Search Console API][12]. Google Search Console is a tool that reports the terms people use to find a website's pages with Google Search. This [open source Jupyter notebook][13] allows you to pull similar data about your website. For this example, I pulled Google Search Console data on a website (which I won't name) generated between January 1 and June 1, 2019, and restricted it to queries that received at least one click (as opposed to just impressions).
+
+This dataset contains information on 2,969 pages and 7,144 queries that displayed the website's pages in Google Search results. The table below shows that the vast majority of pages received very few clicks, as this site focuses on what is called long-tail (more specific and usually longer) as opposed to short-tail (very general, higher search volume) search queries.
+
+![Histogram of clicks for all pages][14]
+
+To reduce the dataset size and get only top-performing pages, I limited the dataset to pages that received at least 20 impressions over the period. This is the histogram of clicks by page for this refined dataset, which includes 723 pages:
+
+![Histogram of clicks for subset of pages][15]
+
+### Using Google's Natural Language API library in Python
+
+To test out the API, create a small script that leverages the **[google-cloud-language][16]** library in Python. The following code is Python 3.5+.
+
+First, activate a new virtual environment and install the libraries. Replace **<your-env>** with a unique name for the environment.
+
+
+```
+virtualenv <your-env>
+source <your-env>/bin/activate
+pip install --upgrade google-cloud-language
+pip install --upgrade requests
+```
+
+This script extracts HTML from a URL and feeds the HTML to the Natural Language API. It returns a dictionary of **sentiment**, **entities**, and **categories**, where the values for these keys are all lists. I used a Jupyter notebook to run this code because it makes it easier to annotate and retry code using the same kernel.
+
+
+```
+# Import needed libraries
+import requests
+import json
+
+from google.cloud import language
+from google.oauth2 import service_account
+from google.cloud.language import enums
+from google.cloud.language import types
+
+# Build language API client (requires service account key)
+client = language.LanguageServiceClient.from_service_account_json('services.json')
+
+# Define functions
+def pull_googlenlp(client, url, invalid_types = ['OTHER'], **data):
+
+ html = load_text_from_url(url, **data)
+
+ if not html:
+ return None
+
+ document = types.Document(
+ content=html,
+ type=language.enums.Document.Type.HTML )
+
+ features = {'extract_syntax': True,
+ 'extract_entities': True,
+ 'extract_document_sentiment': True,
+ 'extract_entity_sentiment': True,
+ 'classify_text': False
+ }
+
+ response = client.annotate_text(document=document, features=features)
+ sentiment = response.document_sentiment
+ entities = response.entities
+
+ response = client.classify_text(document)
+ categories = response.categories
+
+ def get_type(type):
+ return client.enums.Entity.Type(entity.type).name
+
+ result = {}
+
+ result['sentiment'] = []
+ result['entities'] = []
+ result['categories'] = []
+
+ if sentiment:
+ result['sentiment'] = [{ 'magnitude': sentiment.magnitude, 'score':sentiment.score }]
+
+ for entity in entities:
+ if get_type(entity.type) not in invalid_types:
+ result['entities'].append({'name': entity.name, 'type': get_type(entity.type), 'salience': entity.salience, 'wikipedia_url': entity.metadata.get('wikipedia_url', '-') })
+
+ for category in categories:
+ result['categories'].append({'name':category.name, 'confidence': category.confidence})
+
+
+ return result
+
+def load_text_from_url(url, **data):
+
+ timeout = data.get('timeout', 20)
+
+ results = []
+
+ try:
+
+ print("Extracting text from: {}".format(url))
+ response = requests.get(url, timeout=timeout)
+
+ text = response.text
+ status = response.status_code
+
+ if status == 200 and len(text) > 0:
+ return text
+
+ return None
+
+
+ except Exception as e:
+ print('Problem with url: {0}.'.format(url))
+ return None
+```
+
+To access the API, follow Google's [quickstart instructions][17] to create a project in Google Cloud Console, enable the API, and download a service account key. Afterward, you should have a JSON file that looks similar to this:
+
+![services.json file][18]
+
+Upload it to your project folder with the name **services.json**.
+
+Then you can pull the API data for any URL (such as Opensource.com) by running the following:
+
+
+```
+url = ""
+pull_googlenlp(client,url)
+```
+
+If it's set up correctly, you should see this output:
+
+![Output from pulling API data][19]
+
+To make it easier to get started, I created a [Jupyter Notebook][20] that you can download and use to test extracting web pages' entities, categories, and sentiment. I prefer using [JupyterLab][21], which is an extension of Jupyter Notebooks that includes a file viewer and other enhanced user experience features. If you're new to these tools, I think [Anaconda][22] is the easiest way to get started using Python and Jupyter. It makes installing and setting up Python, as well as common libraries, very easy, especially on Windows.
+
+### Playing with the data
+
+With these functions that scrape the HTML of the given page and pass it to the Natural Language API, I can run some analysis across the 723 URLs. First, I'll look at the categories relevant to the site by looking at the count of returned top categories across all pages.
+
+#### Categories
+
+![Categories data from example site][23]
+
+This seems to be a fairly accurate representation of the key themes of this particular site. Looking at a single query that one of the top-performing pages ranks for, I can compare the other ranking pages in Google's results for that same query.
+
+ * _URL 1 | Top Category: /Law & Government/Legal (0.5099999904632568) of 1 total categories._
+ * _No categories returned._
+ * _URL 3 | Top Category: /Internet & Telecom/Mobile & Wireless (0.6100000143051147) of 1 total categories._
+ * _URL 4 | Top Category: /Computers & Electronics/Software (0.5799999833106995) of 2 total categories._
+ * _URL 5 | Top Category: /Internet & Telecom/Mobile & Wireless/Mobile Apps & Add-Ons (0.75) of 1 total categories._
+ * _No categories returned._
+ * _URL 7 | Top Category: /Computers & Electronics/Software/Business & Productivity Software (0.7099999785423279) of 2 total categories._
+ * _URL 8 | Top Category: /Law & Government/Legal (0.8999999761581421) of 3 total categories._
+ * _URL 9 | Top Category: /Reference/General Reference/Forms Guides & Templates (0.6399999856948853) of 1 total categories._
+ * _No categories returned._
+
+
+
+The numbers in parentheses above represent Google's confidence that the content of the page is relevant for that category. The eighth result has much higher confidence than the first result for the same category, so this doesn't seem to be a magic bullet for defining relevance for ranking. Also, the categories are much too broad to make sense for a specific search topic.
+
+Looking at average confidence by ranking position, there doesn't seem to be a correlation between these two metrics, at least for this dataset:
+
+![Plot of average confidence by ranking position ][24]
+
+Both of these approaches make sense to review for a website at scale to ensure the content categories seem appropriate, and boilerplate or sales content isn't moving your pages out of relevance for your main expertise area. Think if you sell industrial supplies, but your pages return _Marketing_ as the main category. There doesn't seem to be a strong suggestion that category relevancy has anything to do with how well you rank, at least at a page level.
+
+#### Sentiment
+
+I won't spend much time on sentiment. Across all the pages that returned a sentiment from the API, they fell into two bins: 0.1 and 0.2, which is almost neutral sentiment. Based on the histogram, it is easy to tell that sentiment doesn't provide much value. It would be a much more interesting metric to run for a news or opinion site to measure the correlation of sentiment to median rank for particular pages.
+
+![Histogram of sentiment for unique pages][25]
+
+#### Entities
+
+Entities were the most interesting part of the API, in my opinion. This is a selection of the top entities, across all pages, by salience (or relevancy to the page). Notice that Google is inferring different types for the same terms (Bill of Sale), perhaps incorrectly. This is caused by the terms appearing in different contexts in the content.
+
+![Top entities for example site][26]
+
+Then I looked at each entity type individually and all together to see if there was any correlation between the salience of the entity and the best-ranking position of the page. For each type, I matched the salience (overall relevance to the page) of the top entity matching that type ordered by salience (descending).
+
+Some of the entity types returned zero salience across all examples, so I omitted those results from the charts below.
+
+![Correlation between salience and best ranking position][27]
+
+The **Consumer Good** entity type had the highest positive correlation, with a Pearson correlation of 0.15854, although since lower-numbered rankings are better, the **Person** entity had the best result with a -0.15483 correlation. This is an extremely small sample set, especially for individual entity types, so I can't make too much of the data. I didn't find any value with a strong correlation, but the **Person** entity makes the most sense. Sites usually have pages about their chief executive and other key employees, and these pages are very likely to do well in search results for those queries.
+
+Moving on, while looking at the site holistically, the following themes emerge based on **entity** **name** and **entity type**.
+
+![Themes based on entity name and entity type][28]
+
+I blurred a few results that seem too specific to mask the site's identity. Thematically, the name information is a good way to look topically at your (or a competitor's) site to see its core themes. This was done based only on the example site's ranking URLs and not all the site's possible URLs (Since Search Console data only reports on pages that received impressions in Google), but the results would be interesting, especially if you were to pull a site's main ranking URLs from a tool like [Ahrefs][29], which tracks many, many queries and the Google results for those queries.
+
+The other interesting piece in the entity data is that entities marked **CONSUMER_GOOD** tended to "look" like results I have seen in Knowledge Results, i.e., the Google Search results on the right-hand side of the page.
+
+![Google search results][30]
+
+Of the **Consumer Good** entity names from our data set that had three or more words, 5.8% had the same Knowledge Results as Google's results for the entity name. This means, if you searched for the term or phrase in Google, the block on the right (eg. the Knowledge Results showing Linux above), would display in the search result page. Since Google "picks" an exemplar webpage to represent the entity, it is a good opportunity to identify opportunities to be singularly featured in search results. Also of interest, of the 5.8% names that displayed these Knowledge Results in Google, none of the entities had Wikipedia URLs returned from the Natural Language API. This is interesting enough to warrant additional analysis. It would be very useful, especially for more esoteric topics that traditional global rank-tracking tools, like Ahrefs, don't have in their databases.
+
+As mentioned, the Knowledge Results can be important to site owners who want to have their content featured in Google, as they are strongly highlighted on desktop search. They are also more than likely, hypothetically, to line up with knowledge-base topics from Google [Discover][31], an offering for Android and iOS that attempts to surface content for users based on topics they are interested in but haven't searched explicitly for.
+
+### Wrapping up
+
+This article went over Google's Natural Language API, shared some code, and investigated ways this API may be useful for site owners. The key takeaways are:
+
+ * Learning to use Python and Jupyter Notebooks opens your data-gathering tasks to a world of incredible APIs and open source projects (like Pandas and NumPy) built by incredibly smart and talented people.
+ * Python allows me to quickly pull and test my hypothesis about the value of an API for a particular purpose.
+ * Passing a website's pages through Google's categorization API may be a good check to ensure its content falls into the correct thematic categories. Doing this for competitors' sites may also offer guidance on where to tune-up or create content.
+ * Google's sentiment score didn't seem to be an interesting metric for the example site, but it may be for news or opinion-based sites.
+ * Google's found entities gave a much more granular topic-level view of the website holistically and, like categorization, would be very interesting to use in competitive content analysis.
+ * Entities may help define opportunities where your content can line up with Google Knowledge blocks in search results or Google Discover results. With 5.8% of our results set for longer (word count) **Consumer Goods** entities, displaying these results, there may be opportunities, for some sites, to better optimize their page's salience score for these entities to stand a better chance of capturing this featured placement in Google search results or Google Discovers suggestions.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/python-google-natural-language-api
+
+作者:[JR Oakes][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jroakes
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
+[2]: https://cloud.google.com/natural-language/#natural-language-api-demo
+[3]: https://opensource.com/article/19/3/natural-language-processing-tools
+[4]: https://en.wikipedia.org/wiki/Knowledge_Graph
+[5]: https://opensource.com/sites/default/files/uploads/entities.png (Entities)
+[6]: https://opensource.com/sites/default/files/uploads/sentiment.png (Sentiment)
+[7]: https://en.wikipedia.org/wiki/Lemmatisation
+[8]: https://en.wikipedia.org/wiki/Part-of-speech_tagging
+[9]: https://en.wikipedia.org/wiki/Parse_tree#Dependency-based_parse_trees
+[10]: https://opensource.com/sites/default/files/uploads/syntax.png (Syntax)
+[11]: https://opensource.com/sites/default/files/uploads/categories.png (Categories)
+[12]: https://developers.google.com/webmaster-tools/
+[13]: https://github.com/MLTSEO/MLTS/blob/master/Demos.ipynb
+[14]: https://opensource.com/sites/default/files/uploads/histogram_1.png (Histogram of clicks for all pages)
+[15]: https://opensource.com/sites/default/files/uploads/histogram_2.png (Histogram of clicks for subset of pages)
+[16]: https://pypi.org/project/google-cloud-language/
+[17]: https://cloud.google.com/natural-language/docs/quickstart
+[18]: https://opensource.com/sites/default/files/uploads/json_file.png (services.json file)
+[19]: https://opensource.com/sites/default/files/uploads/output.png (Output from pulling API data)
+[20]: https://github.com/MLTSEO/MLTS/blob/master/Tutorials/Google_Language_API_Intro.ipynb
+[21]: https://github.com/jupyterlab/jupyterlab
+[22]: https://www.anaconda.com/distribution/
+[23]: https://opensource.com/sites/default/files/uploads/categories_2.png (Categories data from example site)
+[24]: https://opensource.com/sites/default/files/uploads/plot.png (Plot of average confidence by ranking position )
+[25]: https://opensource.com/sites/default/files/uploads/histogram_3.png (Histogram of sentiment for unique pages)
+[26]: https://opensource.com/sites/default/files/uploads/entities_2.png (Top entities for example site)
+[27]: https://opensource.com/sites/default/files/uploads/salience_plots.png (Correlation between salience and best ranking position)
+[28]: https://opensource.com/sites/default/files/uploads/themes.png (Themes based on entity name and entity type)
+[29]: https://ahrefs.com/
+[30]: https://opensource.com/sites/default/files/uploads/googleresults.png (Google search results)
+[31]: https://www.blog.google/products/search/introducing-google-discover/
diff --git a/sources/tech/20190731 How to structure a multi-file C program- Part 2.md b/sources/tech/20190731 How to structure a multi-file C program- Part 2.md
new file mode 100644
index 0000000000..0570214eba
--- /dev/null
+++ b/sources/tech/20190731 How to structure a multi-file C program- Part 2.md
@@ -0,0 +1,229 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to structure a multi-file C program: Part 2)
+[#]: via: (https://opensource.com/article/19/7/structure-multi-file-c-part-2)
+[#]: author: (Erik O'Shaughnessy https://opensource.com/users/jnyjny)
+
+How to structure a multi-file C program: Part 2
+======
+Dive deeper into the structure of a C program composed of multiple files
+in the second part of this article.
+![4 manilla folders, yellow, green, purple, blue][1]
+
+In [Part 1][2], I laid out the structure for a multi-file C program called [MeowMeow][3] that implements a toy [codec][4]. I also talked about the Unix philosophy of program design, laying out a number of empty files to start with a good structure from the very beginning. Lastly, I touched on what a Makefile is and what it can do for you. This article picks up where the other one left off and now I'll get to the actual implementation of our silly (but instructional) MeowMeow codec.
+
+The structure of the **main.c** file for **meow**/**unmeow** should be familiar to anyone who's read my article "[How to write a good C main function][5]." It has the following general outline:
+
+
+```
+/* main.c - MeowMeow, a stream encoder/decoder */
+
+/* 00 system includes */
+/* 01 project includes */
+/* 02 externs */
+/* 03 defines */
+/* 04 typedefs */
+/* 05 globals (but don't)*/
+/* 06 ancillary function prototypes if any */
+
+int main(int argc, char *argv[])
+{
+ /* 07 variable declarations */
+ /* 08 check argv[0] to see how the program was invoked */
+ /* 09 process the command line options from the user */
+ /* 10 do the needful */
+}
+
+/* 11 ancillary functions if any */
+```
+
+### Including project header files
+
+The second section, **/* 01 project includes /***, reads like this from the source:
+
+
+```
+/* main.c - MeowMeow, a stream encoder/decoder */
+...
+/* 01 project includes */
+#include "main.h"
+#include "mmecode.h"
+#include "mmdecode.h"
+```
+
+The **#include** directive is a C preprocessor command that causes the contents of the named file to be "included" at this point in the file. If the programmer uses double-quotes around the name of the header file, the compiler will look for that file in the current directory. If the file is enclosed in <>, it will look for the file in a set of predefined directories.
+
+The file [**main.h**][6] contains the definitions and typedefs used in [**main.c**][7]. I like to collect these things here in case I want to use those definitions elsewhere in my program.
+
+The files [**mmencode.h**][8] and [**mmdecode.h**][9] are nearly identical, so I'll break down **mmencode.h**.
+
+
+```
+ /* mmencode.h - MeowMeow, a stream encoder/decoder */
+
+ #ifndef _MMENCODE_H
+ #define _MMENCODE_H
+
+ #include <stdio.h>
+
+ int mm_encode(FILE *src, FILE *dst);
+
+ #endif /* _MMENCODE_H */
+```
+
+The **#ifdef, #define, #endif** construction is collectively known as a "guard." This keeps the C compiler from including this file more than once per file. The compiler will complain if it finds multiple definitions/prototypes/declarations, so the guard is a _must-have_ for header files.
+
+Inside the guard, there are only two things: an **#include** directive and a function prototype declaration. I include **stdio.h** here to bring in the definition of **FILE** that is used in the function prototype. The function prototype can be included by other C files to establish that function in the file's namespace. You can think of each file as a separate _namespace_, which means variables and functions in one file are not usable by functions or variables in another file.
+
+Writing header files is complex, and it is tough to manage in larger projects. Use guards.
+
+### MeowMeow encoding, finally
+
+The meat and potatoes of this program—encoding and decoding bytes into/out of **MeowMeow** strings—is actually the easy part of this project. All of our activities until now have been putting the scaffolding in place to support calling this function: parsing the command line, determining which operation to use, and opening the files that we'll operate on. Here is the encoding loop:
+
+
+```
+ /* mmencode.c - MeowMeow, a stream encoder/decoder */
+ ...
+ while (![feof][10](src)) {
+
+ if (![fgets][11](buf, sizeof(buf), src))
+ break;
+
+ for(i=0; i<[strlen][12](buf); i++) {
+ lo = (buf[i] & 0x000f);
+ hi = (buf[i] & 0x00f0) >> 4;
+ [fputs][13](tbl[hi], dst);
+ [fputs][13](tbl[lo], dst);
+ }
+ }
+```
+
+In plain English, this loop reads in a chunk of the file while there are chunks left to read (**feof(3)** and **fgets(3)**). Then it splits each byte in the chunk into **hi** and **lo** nibbles. Remember, a nibble is half of a byte, or 4 bits. The real magic here is realizing that 4 bits can encode 16 values. I use **hi** and **lo** as indices into a 16-string lookup table, **tbl**, that contains the **MeowMeow** strings that encode each nibble. Those strings are written to the destination **FILE** stream using **fputs(3)**, then we move on to the next byte in the buffer.
+
+The table is initialized with a macro defined in [**table.h**][14] for no particular reason except to demonstrate including another project local header file, and I like initialization macros. We will go further into why a future article.
+
+### MeowMeow decoding
+
+Alright, I'll admit it took me a couple of runs at this before I got it working. The decode loop is similar: read a buffer full of **MeowMeow** strings and reverse the encoding from strings to bytes.
+
+
+```
+ /* mmdecode.c - MeowMeow, a stream decoder/decoder */
+ ...
+ int mm_decode(FILE *src, FILE *dst)
+ {
+ if (!src || !dst) {
+ errno = EINVAL;
+ return -1;
+ }
+ return stupid_decode(src, dst);
+ }
+```
+
+Not what you were expecting?
+
+Here, I'm exposing the function **stupid_decode()** via the externally visible **mm_decode()** function. When I say "externally," I mean outside this file. Since **stupid_decode()** isn't in the header file, it isn't available to be called in other files.
+
+Sometimes we do this when we want to publish a solid public interface, but we aren't quite done noodling around with functions to solve a problem. In my case, I've written an I/O-intensive function that reads 8 bytes at a time from the source stream to decode 1 byte to write to the destination stream. A better implementation would work on a buffer bigger than 8 bytes at a time. A _much_ better implementation would also buffer the output bytes to reduce the number of single-byte writes to the destination stream.
+
+
+```
+ /* mmdecode.c - MeowMeow, a stream decoder/decoder */
+ ...
+ int stupid_decode(FILE *src, FILE *dst)
+ {
+ char buf[9];
+ decoded_byte_t byte;
+ int i;
+
+ while (![feof][10](src)) {
+ if (![fgets][11](buf, sizeof(buf), src))
+ break;
+ byte.field.f0 = [isupper][15](buf[0]);
+ byte.field.f1 = [isupper][15](buf[1]);
+ byte.field.f2 = [isupper][15](buf[2]);
+ byte.field.f3 = [isupper][15](buf[3]);
+ byte.field.f4 = [isupper][15](buf[4]);
+ byte.field.f5 = [isupper][15](buf[5]);
+ byte.field.f6 = [isupper][15](buf[6]);
+ byte.field.f7 = [isupper][15](buf[7]);
+
+ [fputc][16](byte.value, dst);
+ }
+ return 0;
+ }
+```
+
+Instead of using the bit-shifting technique I used in the encoder, I elected to create a custom data structure called **decoded_byte_t**.
+
+
+```
+ /* mmdecode.c - MeowMeow, a stream decoder/decoder */
+ ...
+
+ typedef struct {
+ unsigned char f7:1;
+ unsigned char f6:1;
+ unsigned char f5:1;
+ unsigned char f4:1;
+ unsigned char f3:1;
+ unsigned char f2:1;
+ unsigned char f1:1;
+ unsigned char f0:1;
+ } fields_t;
+
+ typedef union {
+ fields_t field;
+ unsigned char value;
+ } decoded_byte_t;
+```
+
+It's a little complex when viewed all at once, but hang tight. The **decoded_byte_t** is defined as a **union** of a **fields_t** and an **unsigned char**. The named members of a union can be thought of as aliases for the same region of memory. In this case, **value** and **field** refer to the same 8-bit region of memory. Setting **field.f0** to 1 would also set the least significant bit in **value**.
+
+While **unsigned char** shouldn't be a mystery, the **typedef** for **fields_t** might look a little unfamiliar. Modern C compilers allow programmers to specify "bit fields" in a **struct**. The field type needs to be an unsigned integral type, and the member identifier is followed by a colon and an integer that specifies the length of the bit field.
+
+This data structure makes it simple to access each bit in the byte by field name and then access the assembled value via the **value** field of the union. We depend on the compiler to generate the correct bit-shifting instructions to access the fields, which can save you a lot of heartburn when you are debugging.
+
+Lastly, **stupid_decode()** is _stupid_ because it only reads 8 bytes at a time from the source **FILE** stream. Usually, we try to minimize the number of reads and writes to improve performance and reduce our cost of system calls. Remember that reading or writing a bigger chunk less often is much better than reading/writing a lot of smaller chunks more frequently.
+
+### The wrap-up
+
+Writing a multi-file program in C requires a little more planning on behalf of the programmer than just a single **main.c**. But just a little effort up front can save a lot of time and headache when you refactor as you add functionality.
+
+To recap, I like to have a lot of files with a few short functions in them. I like to expose a small subset of the functions in those files via header files. I like to keep my constants in header files, both numeric and string constants. I _love_ Makefiles and use them instead of Bash scripts to automate all sorts of things. I like my **main()** function to handle command-line argument parsing and act as a scaffold for the primary functionality of the program.
+
+I know I've only touched the surface of what's going on in this simple program, and I'm excited to learn what things were helpful to you and which topics need better explanations. Share your thoughts in the comments to let me know.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/structure-multi-file-c-part-2
+
+作者:[Erik O'Shaughnessy][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jnyjny
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/file_system.jpg?itok=pzCrX1Kc (4 manilla folders, yellow, green, purple, blue)
+[2]: https://opensource.com/article/19/7/how-structure-multi-file-c-program-part-1
+[3]: https://github.com/jnyjny/MeowMeow.git
+[4]: https://en.wikipedia.org/wiki/Codec
+[5]: https://opensource.com/article/19/5/how-write-good-c-main-function
+[6]: https://github.com/JnyJny/meowmeow/blob/master/main.h
+[7]: https://github.com/JnyJny/meowmeow/blob/master/main.c
+[8]: https://github.com/JnyJny/meowmeow/blob/master/mmencode.h
+[9]: https://github.com/JnyJny/meowmeow/blob/master/mmdecode.h
+[10]: http://www.opengroup.org/onlinepubs/009695399/functions/feof.html
+[11]: http://www.opengroup.org/onlinepubs/009695399/functions/fgets.html
+[12]: http://www.opengroup.org/onlinepubs/009695399/functions/strlen.html
+[13]: http://www.opengroup.org/onlinepubs/009695399/functions/fputs.html
+[14]: https://github.com/JnyJny/meowmeow/blob/master/table.h
+[15]: http://www.opengroup.org/onlinepubs/009695399/functions/isupper.html
+[16]: http://www.opengroup.org/onlinepubs/009695399/functions/fputc.html
diff --git a/sources/tech/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md b/sources/tech/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md
new file mode 100644
index 0000000000..684a940ac8
--- /dev/null
+++ b/sources/tech/20190801 Bash Script to Send a Mail When a New User Account is Created in System.md
@@ -0,0 +1,123 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Bash Script to Send a Mail When a New User Account is Created in System)
+[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+Bash Script to Send a Mail When a New User Account is Created in System
+======
+
+There are many open source monitoring tools are currently available in market to monitor Linux systems performance.
+
+It will send an email alert when the system reaches the specified threshold limit.
+
+It monitors everything such as CPU utilization, Memory utilization, swap utilization, disk space utilization and much more.
+
+But i don’t think they have an option to monitor a new user creation activity and alert when it’s happening.
+
+If not, it doesn’t really matter as we can write our own bash script to achieve this.
+
+We had added many useful shell scripts in the past. If you want to check those, navigate to the below link.
+
+ * **[How to automate day to day activities using shell scripts?][1]**
+
+
+
+What the script does? It monitors **`/var/log/secure`**` ` file and alert admin when a new account is created in system.
+
+We can’t run this script frequently since user creation is not happening very often. However, I’m planning to run this script once in a day.
+
+So, that we can get a consolidated report about the user creation.
+
+If useradd string was found in “/var/log/secure” file for yesterday’s date, then the script will send an email alert to given email id with new users details.
+
+**Note:** You need to change the email id instead of ours.
+
+```
+# vi /opt/scripts/new-user.sh
+
+#!/bin/bash
+
+#Set the variable which equal to zero
+prev_count=0
+
+count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/secure | egrep -wi 'useradd' | wc -l)
+
+if [ "$prev_count" -lt "$count" ] ; then
+
+# Send a mail to given email id when errors found in log
+
+SUBJECT="ATTENTION: New User Account is created on server : `date --date='yesterday' '+%b %e'`"
+
+# This is a temp file, which is created to store the email message.
+
+MESSAGE="/tmp/new-user-logs.txt"
+
+TO="[email protected]"
+
+echo "Hostname: `hostname`" >> $MESSAGE
+
+echo -e "\n" >> $MESSAGE
+
+echo "The New User Details are below." >> $MESSAGE
+
+echo "+------------------------------+" >> $MESSAGE
+
+grep -i "`date --date='yesterday' '+%b %e'`" /var/log/secure | egrep -wi 'useradd' | grep -v 'failed adding'| awk '{print $4,$8}' | uniq | sed 's/,/ /' >> $MESSAGE
+
+echo "+------------------------------+" >> $MESSAGE
+
+mail -s "$SUBJECT" "$TO" < $MESSAGE
+
+rm $MESSAGE
+
+fi
+```
+
+Set an executable permission to **`new-user.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/new-user.sh
+```
+
+Finally add a cronjob to automate this. It will run everyday at 7'o clock.
+
+```
+# crontab -e
+
+0 7 * * * /bin/bash /opt/scripts/new-user.sh
+```
+
+Note: You will be getting an email alert everyday at 7 o'clock, which is for yesterday's log.
+
+**`Output:`**` ` You will be getting an email alert similar to below.
+
+```
+# cat /tmp/logs.txt
+
+Hostname: 2g.server10.com
+
+The New User Details are below.
++------------------------------+
+2g.server10.com name=magesh
+2g.server10.com name=daygeek
++------------------------------+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20190801 GitHub Pages is a CI-CD pipeline.md b/sources/tech/20190801 GitHub Pages is a CI-CD pipeline.md
new file mode 100644
index 0000000000..cad16c5512
--- /dev/null
+++ b/sources/tech/20190801 GitHub Pages is a CI-CD pipeline.md
@@ -0,0 +1,74 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (GitHub Pages is a CI/CD pipeline)
+[#]: via: (https://opensource.com/article/19/8/github-pages-cicd-pipeline)
+[#]: author: (Katie McLaughlin https://opensource.com/users/glasnt)
+
+GitHub Pages is a CI/CD pipeline
+======
+Integrating just a little bit of automation into your workflow can
+greatly improve your productivity and development velocity.
+![An intersection of pipes.][1]
+
+One of GitHub's superpowers is the ability to _magically_ turn your documentation into a website. If you configure a [GitHub Page][2] for your **docs/** folder on your AwesomeProject website, you'll end up with **yourname.github.io/awesomeproject**, showing your documentation, all for free.
+
+But it's not actually magic. Sadly, even though we have taught glass to think, we can still only thank the advanced application of technology for anything that appears to be magical.
+
+GitHub Pages is just an integrated pathway within GitHub to help you set up a Jekyll project. [Jekyll][3] is a static site generator, written in Ruby. Out of the box you can quickly generate websites using markdown files that are then merged into pre-formatted HTML templated themes. There are many [default themes][4] available for GitHub Pages, or you can use one of the many [free templates][5] out there.
+
+![Jekyll Themes screenshot][6]
+
+There are many open source licensed templates available for use.
+
+When you first set up GitHub Pages, you declare which branch you want to build from and the domain you want to use. When you merge into that branch, GitHub goes and takes your Jekyll site, renders it, and hosts it for you on that domain. You don't have to do anything else. No FTP transfers onto a server. No server costs. [No GitHub costs][7]. This is all the power of automation.
+
+### Turning it up to 11 with Netlify PR previews
+
+One of the limitations of this system is when you're working with pull requests (PRs). If you want to test your code, you have to run Jekyll locally. This isn't [terribly difficult][8], but when you're reviewing someone else's PR, say when it's related to the documentation on a project's homepage, you want to be able to see what the new website will look like if you merge the PR. Especially if there could be issues with the changes that are proposed (particularly large changes, changes to the theme/layout, etc)
+
+Normally, you'd have to go to the PR, clone the fork of the repo and check out the branch that was used for the PR, merge that code into your local master, build _that_ version of the code in Jekyll, and open the local server to look at the changes.
+
+But the great thing is, you can automate this.
+
+One such service is [Netlify][9]. You can use Netlify to host your projects, but you can also use its [Deploy Previews][10] feature to generate Jekyll sites for any PR on your project automatically.
+
+Its [continuous deployment][11] docs show how to set up Netlify to automatically build your site any time a PR is opened or updated. The results of that build are available as a temporary website that is linked in the "Checks" section at the bottom of the PR, uniquely named for the PR and project. You can have multiple active PRs and Netlify will update the previews independently!
+
+This has greatly improved the website development process for [PyCon AU][12], which is using GitHub Pages to host the [2019 event website][13]. We heavily borrowed this idea and the Netlify setup from [DjangoCon US][14], which has every [DjangoCon website][15] on GitHub. Well, [most of them][16], as there is an ongoing project to ensure that every DjangoCon conference website is archived for prosperity.
+
+### Machines do the work, so people have time to code
+
+CI and CD have many benefits, but integrating just a little bit of automation into your workflow can greatly improve your productivity and development velocity.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/github-pages-cicd-pipeline
+
+作者:[Katie McLaughlin][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/glasnt
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW-Internet_construction_9401467_520x292_0512_dc.png?itok=RPkPPtDe (An intersection of pipes.)
+[2]: https://help.github.com/en/articles/configuring-a-publishing-source-for-github-pages
+[3]: https://jekyllrb.com/
+[4]: https://pages.github.com/themes/
+[5]: http://jekyllthemes.org/
+[6]: https://opensource.com/sites/default/files/uploads/jekyll-themes.png (Jekyll Themes screenshot)
+[7]: https://github.com/pricing
+[8]: https://jekyllrb.com/docs/
+[9]: https://www.netlify.com/
+[10]: https://www.netlify.com/blog/2017/10/31/introducing-public-deploy-logs-for-open-source-sites/
+[11]: https://www.netlify.com/docs/continuous-deployment/
+[12]: http://2019.pycon-au.org
+[13]: https://github.com/pyconau/2019.pycon-au.org
+[14]: https://2019.djangocon.us/
+[15]: https://github.com/djangocon
+[16]: https://github.com/djangocon/djangocon-archive-project
diff --git a/sources/tech/20190801 Linux permissions 101.md b/sources/tech/20190801 Linux permissions 101.md
new file mode 100644
index 0000000000..cfbc3d0a29
--- /dev/null
+++ b/sources/tech/20190801 Linux permissions 101.md
@@ -0,0 +1,346 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Linux permissions 101)
+[#]: via: (https://opensource.com/article/19/8/linux-permissions-101)
+[#]: author: (Alex Juarez https://opensource.com/users/mralexjuarezhttps://opensource.com/users/marcobravohttps://opensource.com/users/greg-p)
+
+Linux permissions 101
+======
+Knowing how to control users' access to files is a fundamental system
+administration skill.
+![Penguins][1]
+
+Understanding Linux permissions and how to control which users have access to files is a fundamental skill for systems administration.
+
+This article will cover standard Linux file systems permissions, dig further into special permissions, and wrap up with an explanation of default permissions using **umask**.
+
+### Understanding the ls command output
+
+Before we can talk about how to modify permissions, we need to know how to view them. The **ls** command with the long listing argument (**-l**) gives us a lot of information about a file.
+
+
+```
+$ ls -lAh
+total 20K
+-rwxr-xr--+ 1 root root 0 Mar 4 19:39 file1
+-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file10
+-rwxrwxr--+ 1 root root 0 Mar 4 19:39 file2
+-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file8
+-rw-rw-rw-. 1 root root 0 Mar 4 19:39 file9
+drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir
+```
+
+To understand what this means, let's break down the output regarding the permissions into individual sections. It will be easier to reference each section individually.
+
+Take a look at each component of the final line in the output above:
+
+
+```
+`drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir`
+```
+
+Section 1 | Section 2 | Section 3 | Section 4 | Section 5 | Section 6 | Section 7
+---|---|---|---|---|---|---
+d | rwx | rwx | rwx | . | root | root
+
+Section 1 (on the left) reveals what type of file it is.
+
+d | Directory
+---|---
+- | Regular file
+l | A soft link
+
+The [info page][2] for **ls** has a full listing of the different file types.
+
+Each file has three modes of access:
+
+ * the owner
+ * the group
+ * all others
+
+
+
+Sections 2, 3, and 4 refer to the user, group, and "other users" permissions. And each section can include a combination of **r** (read), **w** (write), and **x** (executable) permissions.
+
+Each of the permissions is also assigned a numerical value, which is important when talking about the octal representation of permissions.
+
+Permission | Octal Value
+---|---
+Read | 4
+Write | 2
+Execute | 1
+
+Section 5 details any alternative access methods, such as SELinux or File Access Control List (FACL).
+
+Method | Character
+---|---
+No other method | -
+SELinux | .
+FACLs | +
+Any combination of methods | +
+
+Sections 6 and 7 are the names of the owner and the group, respectively.
+
+### Using chown and chmod
+
+#### The chown command
+
+The **chown** (change ownership) command is used to change a file's user and group ownership.
+
+To change both the user and group ownership of the file **foo** to **root**, we can use these commands:
+
+
+```
+$ chown root:root foo
+$ chown root: foo
+```
+
+Running the command with the user followed by a colon (**:**) sets both the user and group ownership.
+
+To set only the user ownership of the file **foo** to the **root** user, enter:
+
+
+```
+`$ chown root foo`
+```
+
+To change only the group ownership of the file **foo**, precede the group with a colon:
+
+
+```
+`$ chown :root foo`
+```
+
+#### The chmod command
+
+The **chmod** (change mode) command controls file permissions for the owner, group, and all other users who are neither the owner nor part of the group associated with the file.
+
+The **chmod** command can set permissions in both octal (e.g., 755, 644, etc.) and symbolic (e.g., u+rwx, g-rwx, o=rw) formatting.
+
+Octal notation assigns 4 "points" to **read**, 2 to **write**, and 1 to **execute**. If we want to assign the user **read** permissions, we assign 4 to the first slot, but if we want to add **write** permissions, we must add 2. If we want to add **execute**, then we add 1. We do this for each permission type: owner, group, and others.
+
+For example, if we want to assign **read**, **write**, and **execute** to the owner of the file, but only **read** and **execute** to group members and all other users, we would use 755 in octal formatting. That's all permission bits for the owner (4+2+1), but only a 4 and 1 for the group and others (4+1).
+
+> The breakdown for that is: 4+2+1=7; 4+1=5; and 4+1=5.
+
+If we wanted to assign **read** and **write** to the owner of the file but only **read** to members of the group and all other users, we could use **chmod** as follows:
+
+
+```
+`$ chmod 644 foo_file`
+```
+
+In the examples below, we use symbolic notation in different groupings. Note the letters **u**, **g**, and **o** represent **user**, **group**, and **other**. We use **u**, **g**, and **o** in conjunction with **+**, **-**, or **=** to add, remove, or set permission bits.
+
+To add the **execute** bit to the ownership permission set:
+
+
+```
+`$ chmod u+x foo_file`
+```
+
+To remove **read**, **write**, and **execute** from members of the group:
+
+
+```
+`$ chmod g-rwx foo_file`
+```
+
+To set the ownership for all other users to **read** and **write**:
+
+
+```
+`$ chmod o=rw`
+```
+
+### The special bits: Set UID, set GID, and sticky bits
+
+In addition to the standard permissions, there are a few special permission bits that have some useful benefits.
+
+#### Set user ID (suid)
+
+When **suid** is set on a file, an operation executes as the owner of the file, not the user running the file. A [good example][3] of this is the **passwd** command. It needs the **suid** bit to be set so that changing a password runs with root permissions.
+
+
+```
+$ ls -l /bin/passwd
+-rwsr-xr-x. 1 root root 27832 Jun 10 2014 /bin/passwd
+```
+
+An example of setting the **suid** bit would be:
+
+
+```
+`$ chmod u+s /bin/foo_file_name`
+```
+
+#### Set group ID (sgid)
+
+The **sgid** bit is similar to the **suid** bit in the sense that the operations are done under the group ownership of the directory instead of the user running the command.
+
+An example of using **sgid** would be if multiple users are working out of the same directory, and every file created in the directory needs to have the same group permissions. The example below creates a directory called **collab_dir**, sets the **sgid** bit, and changes the group ownership to **webdev**.
+
+
+```
+$ mkdir collab_dir
+$ chmod g+s collab_dir
+$ chown :webdev collab_dir
+```
+
+Now any file created in the directory will have the group ownership of **webdev** instead of the user who created the file.
+
+
+```
+$ cd collab_dir
+$ touch file-sgid
+$ ls -lah file-sgid
+-rw-r--r--. 1 root webdev 0 Jun 12 06:04 file-sgid
+```
+
+#### The "sticky" bit
+
+The sticky bit denotes that only the owner of a file can delete the file, even if group permissions would otherwise allow it. This setting usually makes the most sense on a common or collaborative directory such as **/tmp**. In the example below, the **t** in the **execute** column of the **all others** permission set indicates that the sticky bit has been applied.
+
+
+```
+$ ls -ld /tmp
+drwxrwxrwt. 8 root root 4096 Jun 12 06:07 /tmp/
+```
+
+Keep in mind this does not prevent somebody from editing the file; it just keeps them from deleting the contents of a directory.
+
+We set the sticky bit with:
+
+
+```
+`$ chmod o+t foo_dir`
+```
+
+On your own, try setting the sticky bit on a directory and give it full group permissions so that multiple users can read, write and execute on the directory because they are in the same group.
+
+From there, create files as each user and then try to delete them as the other.
+
+If everything is configured correctly, one user should not be able to delete users from the other user.
+
+Note that each of these bits can also be set in octal format with SUID=4, SGID=2, and Sticky=1.
+
+
+```
+$ chmod 4744
+$ chmod 2644
+$ chmod 1755
+```
+
+#### Uppercase or lowercase?
+
+If you are setting the special bits and see an uppercase **S** or **T** instead of lowercase (as we've seen until this point), it is because the underlying execute bit is not present. To demonstrate, the following example creates a file with the sticky bit set. We can then add/remove the execute bit to demonstrate the case change.
+
+
+```
+$ touch file cap-ST-demo
+$ chmod 1755 cap-ST-demo
+$ ls -l cap-ST-demo
+-rwxr-xr-t. 1 root root 0 Jun 12 06:16 cap-ST-demo
+
+$ chmod o-x cap-X-demo
+$ ls -l cap-X-demo
+-rwxr-xr-T. 1 root root 0 Jun 12 06:16 cap-ST-demo
+```
+
+#### Setting the execute bit conditionally
+
+To this point, we've set the **execute** bit using a lowercase **x**, which sets it without asking any questions. We have another option: using an uppercase **X** instead of lowercase will set the **execute** bit only if it is already present somewhere in the permission group. This can be a difficult concept to explain, but the demo below will help illustrate it. Notice here that after trying to add the **execute** bit to the group privileges, it is not applied.
+
+
+```
+$ touch cap-X-file
+$ ls -l cap-X-file
+-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
+$ chmod g+X cap-X-file
+$ ls -l cap-X-file
+-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
+```
+
+In this similar example, we add the execute bit first to the group permissions using the lowercase **x** and then use the uppercase **X** to add permissions for all other users. This time, the uppercase **X** sets the permissions.
+
+
+```
+$ touch cap-X-file
+$ ls -l cap-X-file
+-rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
+$ chmod g+x cap-X-file
+$ ls -l cap-X-file
+-rw-r-xr--. 1 root root 0 Jun 12 06:31 cap-X-file
+$ chmod g+x cap-X-file
+$ chmod o+X cap-X-file
+ls -l cap-X-file
+-rw-r-xr-x. 1 root root 0 Jun 12 06:31 cap-X-file
+```
+
+### Understanding umask
+
+The **umask** masks (or "blocks off") bits from the default permission set in order to define permissions for a file or directory. For example, a 2 in the **umask** output indicates it is blocking the **write** bit from a file, at least by default.
+
+Using the **umask** command without any arguments allows us to see the current **umask** setting. There are four columns: the first is reserved for the special suid, sgid, or sticky bit, and the remaining three represent the owner, group, and other permissions.
+
+
+```
+$ umask
+0022
+```
+
+To understand what this means, we can execute **umask** with a **-S** (as shown below) to get the result of masking the bits. For instance, because of the **2** value in the third column, the **write** bit is masked off from the group and other sections; only **read** and **execute** can be assigned for those.
+
+
+```
+$ umask -S
+u=rwx,g=rx,o=rx
+```
+
+To see what the default permission set is for files and directories, let's set our **umask** to all zeros. This means that we are not masking off any bits when we create a file.
+
+
+```
+$ umask 000
+$ umask -S
+u=rwx,g=rwx,o=rwx
+
+$ touch file-umask-000
+$ ls -l file-umask-000
+-rw-rw-rw-. 1 root root 0 Jul 17 22:03 file-umask-000
+```
+
+Now when we create a file, we see the default permissions are **read** (4) and **write** (2) for all sections, which would equate to 666 in octal representation.
+
+We can do the same for a directory and see its default permissions are 777. We need the **execute** bit on directories so we can traverse through them.
+
+
+```
+$ mkdir dir-umask-000
+$ ls -ld dir-umask-000
+drwxrwxrwx. 2 root root 4096 Jul 17 22:03 dir-umask-000/
+```
+
+### Conclusion
+
+There are many other ways an administrator can control access to files on a system. These permissions are basic to Linux, and we can build upon these fundamental aspects. If your work takes you into FACLs or SELinux, you will see that they also build upon these first rules of file access.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/linux-permissions-101
+
+作者:[Alex Juarez][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mralexjuarezhttps://opensource.com/users/marcobravohttps://opensource.com/users/greg-p
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux-penguins.png?itok=yKOpaJM_ (Penguins)
+[2]: https://www.gnu.org/software/texinfo/manual/info-stnd/info-stnd.html
+[3]: https://www.theurbanpenguin.com/using-a-simple-c-program-to-explain-the-suid-permission/
diff --git a/sources/tech/20190802 Getting started with the BBC Microbit.md b/sources/tech/20190802 Getting started with the BBC Microbit.md
new file mode 100644
index 0000000000..6e32536f04
--- /dev/null
+++ b/sources/tech/20190802 Getting started with the BBC Microbit.md
@@ -0,0 +1,92 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Getting started with the BBC Microbit)
+[#]: via: (https://opensource.com/article/19/8/getting-started-bbc-microbit)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+Getting started with the BBC Microbit
+======
+Tiny open hardware board makes it easy for anyone to learn to code with
+fun projects.
+![BBC Microbit board][1]
+
+Whether you are a maker, a teacher, or someone looking to expand your Python skillset, the [BBC:Microbit][2] has something for you. It was designed by the British Broadcasting Corporation to support computer education in the United Kingdom.
+
+The [open hardware board][3] is half the size of a credit card and packed with an ARM processor, a three-axis accelerometer, a three-axis magnetometer, a Micro USB port, a 25-pin edge connector, and 25 LEDs in a 5x5 array.
+
+I purchased my Microbit online for $19.99. It came in a small box and included a battery pack and a USB-to-Micro USB cable. It connects to my Linux laptop very easily and shows up as a USB drive.
+
+![BBC Microbit board][4]
+
+### Start coding
+
+Microbit's website offers several ways to start exploring and [coding][5] quickly, including links to [third-party code editors][6] and its two official editors: [Microsoft MakeCode][7] and [MicroPython][8], which both operate in any browser using any computer (including a Chromebook). MakeCode is a block coding editor, like the popular Scratch interface, and MicroPython is a Python 3 implementation that includes a small subset of the Python library and is designed to work on microcontrollers. Both save your created code as a HEX file, which you can download and copy to the device, just as you would with any other file you are writing to a USB drive.
+
+The [documentation][9] suggests using the [Mu Python editor][10], which I [wrote about][11] last year, because it's designed to work with the Microbit. One advantage of the Mu editor is it uses the Python REPL (read–evaluate–print loop) to enter code directly to the device, rather than having to download and copy it over.
+
+When you're writing code for the Microbit, it's important to begin each program with **From microbit import ***. This is true even when you're using the REPL in Mu because it imports all the objects and functions in the Microbit library.
+
+![Beginning a Microbit project][12]
+
+### Example projects
+
+The documentation provides a wealth of code examples and [projects][13] that got me started hacking these incredible devices right away.
+
+You can start out easy by getting the Microbit to say "Hello." Load your new code using the **Flash** button at the top of the Mu editor.
+
+![Flash button loads new code][14]
+
+There are many built-in [images][15] you can load, and you can make your own, too. To display an image, enter the code **display.show(Image.IMAGE)** where IMAGE is the name of the image you want to use. For example, **display.show(Image.HEART)** shows the built-in heart image.
+
+The **sleep** command adds time between display commands, which I found useful for making the display work a little slower.
+
+Here is a simple **for** loop with images and a scrolling banner for my favorite NFL football team, the Buffalo Bills. In the code, **display** is a Python object that controls the 25 LEDs on the front of the Microbit. The **show** method within the **display** object indicates which image to show. The **scroll** within the **display** object scrolls the string _"The Buffalo Bills are my team"_ across the LED array.
+
+![Code for Microbit to display Buffalo Bills tribute][16]
+
+The Microbit also has two buttons, Button A and Button B, that can be programmed to perform many tasks. Here is a simple example.
+
+![Code to program Microbit buttons][17]
+
+By attaching a speaker, the device can speak, beep, and play music. You can also program it to function as a compass and accelerometer and to respond to gestures and movement. Check the documentation for more information about these and other capabilities.
+
+### Get involved
+
+Research studies have found that 90% of [teachers in Denmark][18] and [students in the United Kingdom][19] learned to code by using the Microbit. As pressure mounts for programming to become a larger part of the K-12 school curriculum, inexpensive devices like the Microbit can play an important role in achieving that goal. If you want to get involved with the Microbit, be sure to join its [developer community][20].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/getting-started-bbc-microbit
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bbc_microbit_board_hardware.jpg?itok=3HiIupG- (BBC Microbit board)
+[2]: https://microbit.org/
+[3]: https://tech.microbit.org/hardware/
+[4]: https://opensource.com/sites/default/files/uploads/image-1.jpg (BBC Microbit board)
+[5]: https://microbit.org/code/
+[6]: https://microbit.org/code-alternative-editors/
+[7]: https://makecode.microbit.org/
+[8]: https://python.microbit.org/v/1.1
+[9]: https://microbit-micropython.readthedocs.io/en/latest/tutorials/introduction.html
+[10]: https://codewith.mu/en/
+[11]: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
+[12]: https://opensource.com/sites/default/files/uploads/microbit1_frommicrobitimport.png (Beginning a Microbit project)
+[13]: https://microbit.org/ideas/
+[14]: https://opensource.com/sites/default/files/uploads/microbit2_hello.png (Flash button loads new code)
+[15]: https://microbit-micropython.readthedocs.io/en/latest/tutorials/images.html
+[16]: https://opensource.com/sites/default/files/uploads/microbit3_bills.png (Code for Microbit to display Buffalo Bills tribute)
+[17]: https://opensource.com/sites/default/files/uploads/microbit4_buttons.png (Code to program Microbit buttons)
+[18]: https://microbit.org/assets/2019-03-05-ultrabit.pdf
+[19]: https://www.bbc.co.uk/mediacentre/latestnews/2017/microbit-first-year
+[20]: https://tech.microbit.org/get-involved/where-to-find/
diff --git a/sources/tech/20190802 New research article type embeds live code and data.md b/sources/tech/20190802 New research article type embeds live code and data.md
new file mode 100644
index 0000000000..a6e256f9b4
--- /dev/null
+++ b/sources/tech/20190802 New research article type embeds live code and data.md
@@ -0,0 +1,79 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (New research article type embeds live code and data)
+[#]: via: (https://opensource.com/article/19/8/reproducible-research)
+[#]: author: (Giuliano Maciocci https://opensource.com/users/gmacioccihttps://opensource.com/users/etsang)
+
+New research article type embeds live code and data
+======
+The non-profit scientific research publication platform eLife recently
+announced the Reproducible Document Stack (RDS).
+![magnifying glass on computer screen][1]
+
+While science is supposed to be about building on each other's findings to improve our understanding of the world around us, reproducing and reusing previously published results remains challenging, even in the age of the internet. The basic format of the scientific paper—the primary means through which scientists communicate their findings—has more or less remained the same since the first papers were published in the 18th century.
+
+This is particularly problematic because, thanks to the technological advancements in research over the last two decades, the richness and sophistication of the methods used by researchers have far outstripped the publishing industry's ability to publish them in full. Indeed, the Methods section in research articles remains primarily a huge section of text that does not reflect the complexity or facilitate the reuse of the methods used to obtain the published results.
+
+### Working together on a solution
+
+To counter these challenges, eLife [teamed up][2] with [Substance][3] and [Stencila][4] in 2017 to develop a stack of open source tools for authoring, compiling, and publishing computationally reproducible manuscripts online. Our vision for the project is to create a new type of research article that embeds live code, data, and interactive figures within the flow of the traditional manuscript and to provide authors and publishers with the tools to support this new format throughout the publishing lifecycle.
+
+As a result of our collaboration, we published eLife's [first computationally reproducible article][5] in February 2019. It was based on [a paper][6] in the [Reproducibility Project: Cancer Biology][7] collection. The reproducible version of the article showcases some of the possibilities with the new RDS tools: scientists can share the richness of their research more fully, telling the complete story of their work, while others can directly interact with the authors, interrogate them, and build on their code and data with minimal effort.
+
+The response from the research community to the release of our first reproducible manuscript was overwhelmingly positive. Thousands of scientists explored the paper's inline code re-execution abilities by manipulating its plots, and several authors approached us directly to ask how they might publish a reproducible version of their own manuscripts.
+
+Encouraged by this interest and feedback, [in May we announced][8] our roadmap towards an open, scalable infrastructure for the publication of computationally reproducible articles. The goal of this next phase in the RDS project is to ship researcher-centered, publisher-friendly open source solutions that will allow for the hosting and publication of reproducible documents, at scale, by anyone. This includes:
+
+ 1. Developing conversion, rendering, and authoring tools to allow researchers to compose articles from multiple starting points, including GSuite tools, Microsoft Word, and Jupyter notebooks
+ 2. Optimizing containerization tools to provide reliant and performant reproducible computing environments
+ 3. Building the backend infrastructure needed to enable the options for live-code re-execution in the browser and PDF export at the same time
+ 4. Formalizing an open, portable format (DAR) for reproducible document archives
+
+
+
+### What's next, and how can you get involved?
+
+Our first step is to publish reproducible articles as companions of already accepted papers. We will endeavor to accept submissions of reproducible manuscripts in the form of DAR files by the end of 2019. You can learn more about the key areas of innovation in this next phase of development in our article "[Reproducible Document Stack: Towards a scalable solution for reproducible articles][8]."
+
+The RDS project is being built with three core principles in mind:
+
+ * **Openness:** We prioritize building on top of existing open technologies as well as engaging and involving a community of open source technologists and researchers to create an inclusive tool stack that evolves continuously based on user needs.
+ * **Interoperability:** We want to make it easy for scientists to create and for publishers to publish reproducible documents from multiple starting points.
+ * **Modularity:** We're developing tools within the stack in such a way that they can be taken out and integrated into other publisher workflows.
+
+
+
+And you can help. We welcome all developers and researchers who wish to contribute to this exciting project. Since the release of eLife's first reproducible article, we have been actively collecting feedback from both the research and open source communities, and this has been (and will continue to be) crucial to shaping the development of the RDS.
+
+If you'd like to stay up to date on our progress, please sign up for the [RDS community newsletter][9]. For any questions or comments, please [contact us][10]. We look forward to having you with us on the journey.
+
+* * *
+
+_This article is based in part on "[Reproducible Document Stack: Towards a scalable solution for reproducible articles][8]" by Giuliano Maciocci, Emmy Tsang, Nokome Bentley, and Michael Aufreiter._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/reproducible-research
+
+作者:[Giuliano Maciocci][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gmacioccihttps://opensource.com/users/etsang
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
+[2]: https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online
+[3]: https://substance.io/
+[4]: https://stenci.la/
+[5]: https://repro.elifesciences.org/example.html
+[6]: https://elifesciences.org/articles/30274
+[7]: https://osf.io/e81xl/wiki/home/
+[8]: https://elifesciences.org/labs/b521cf4d/reproducible-document-stack-towards-a-scalable-solution-for-reproducible-articles
+[9]: https://crm.elifesciences.org/crm/RDS-updates
+[10]: mailto:innovation@elifesciences.org
diff --git a/sources/tech/20190802 Understanding file paths and how to use them in Linux.md b/sources/tech/20190802 Understanding file paths and how to use them in Linux.md
new file mode 100644
index 0000000000..1332b99161
--- /dev/null
+++ b/sources/tech/20190802 Understanding file paths and how to use them in Linux.md
@@ -0,0 +1,99 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Understanding file paths and how to use them in Linux)
+[#]: via: (https://opensource.com/article/19/8/understanding-file-paths-linux)
+[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/jrbarnett)
+
+Understanding file paths and how to use them in Linux
+======
+If you're used to drag-and-drop environments, then file paths may be
+frustrating. Learn here how they work, and some basic tricks to make
+using them easier.
+![open source button on keyboard][1]
+
+A file path is the human-readable representation of a file or folder’s location on a computer system. You’ve seen file paths, although you may not realize it, on the internet: An internet URL, despite ancient battles fought by proprietary companies like AOL and CompuServe, is actually just a path to a (sometimes dynamically created) file on someone else’s computer. For instance, when you navigate to example.com/index.html, you are actually viewing the HTML file index.html, probably located in the **var** directory on the example.com server. Files on your computer have file paths, too, and this article explains how to understand them, and why they’re important.
+
+When computers became a household item, they took on increasingly stronger analogies to real-world models. For instance, instead of accounts and directories, personal computers were said to have _desktops_ and _folders_, and eventually, people developed the latent impression that the computer was a window into a virtual version of the real world. It’s a useful analogy, because everyone is familiar with the concept of desktops and file cabinets, while fewer people understand digital storage and memory addresses.
+
+Imagine for a moment that you invented computers or operating systems. You would probably have created a way to group common files together, because humans love to classify and organize things. Since all files on a computer are on the hard drive, the biggest container you probably would have designated is the drive itself; that is, all files on a drive are in the drive.
+
+As it turns out, the creators of UNIX had the same instinct, only they called these units of organization _directories_ or _folders_. All files on your computer’s drive are in the system’s base (root) directory. Even external drives are brought into this root directory, just as you might place important related items into one container if you were organizing your office space or hobby room.
+
+Files and folders on Linux are given names containing the usual components like the letters, numbers, and other characters on a keyboard. But when a file is inside a folder, or a folder is inside another folder, the **/** character shows the relationship between them. That’s why you often see files listed in the format **/usr/bin/python3** or **/etc/os-release**. The forward slashes indicate that one item is stored inside of the item preceding it.
+
+Every file and folder on a [POSIX][2] system can be expressed as a path. If I have the file **penguin.jpg** in the **photos** folder within my home directory, and my username is **seth**, then the file path can be expressed as **/home/seth/Pictures/penguin.jpg**.
+
+Most users interact primarily with their home directory, so the tilde (**~**) character is used as a shorthand. That fact means that I can express my example penguin picture as either **/home/seth/Pictures/penguin.jpg** or as **~/Pictures/penguin.jpg**.
+
+### Practice makes perfect
+
+Computers use file paths whether you’re thinking of what that path is or not. There’s not necessarily a reason for you to have to think of files in terms of a path. However, file paths are part of a useful framework for understanding how computers work, and learning to think of files in a path can be useful if you’re looking to become a developer (you need to understand the paths to support libraries), a web designer (file paths ensure you’re pointing your HTML to the appropriate CSS), a system administrator, or just a power user.
+
+#### When in doubt, drag and drop
+
+If you’re not used to thinking of the structure of your hard drive as a path, then it can be difficult to construct a full path for an arbitrary file. On Linux, most file managers either natively display (or have the option to) the full file path to where you are, which helps reinforce the concept on a daily basis:
+
+![Dolphin file manager][3]
+
+opensource.com
+
+If you’re using a terminal, it might help to know that modern terminals, unlike the teletype machines they emulate, can accept files by way of drag-and-drop. When you copying a file to a server over SSH, for instance, and you’re not certain of how to express the file path, try dragging the file from your GUI file manager into your terminal. The GUI object representing the file gets translated into a text file path in the terminal:
+
+![Terminals accept drag and drop actions][4]
+
+opensource.com
+
+Don’t waste time typing in guesses. Just drag and drop.
+
+#### **Tab** is your friend
+
+On a system famous for eschewing three-letter commands when two or even one-letter commands will do, rest assured that no seasoned POSIX user _ever_ types out everything. In the Bash shell, the **Tab** key means _autocomplete_, and autocomplete never lies. For instance, to type the example **penguin.jpg** file’s location, you can start with:
+
+
+```
+$ ~/Pi
+```
+
+and then press the **Tab** key. As long as there is only one item starting with Pi, the folder **Pictures** autocompletes for you.
+
+If there are two or more items starting with the letters you attempt to autocomplete, then Bash displays what those items are. You manually type more until you reach a unique string that the shell can safely autocomplete. The best thing about this process isn’t necessarily that it saves you from typing (though that’s definitely a selling point), but that autocomplete is never wrong. No matter how much you fight the computer to autocomplete something that isn’t there, in the end, you’ll find that autocomplete understands paths better than anyone.
+
+Assume that you, in a fit of late-night reorganization, move **penguin.jpg** from your **~/Pictures** folder to your **~/Spheniscidae** directory. You fall asleep and wake up refreshed, but with no memory that you’ve reorganized, so you try to copy **~/Pictures/penguin.jpg** to your web server, in the terminal, using autocomplete.
+
+No matter how much you pound on the **Tab** key, Bash refuses to autocomplete. The file you want simply does not exist in the location where you think it exists. That feature can be helpful when you’re trying to point your web page to a font or CSS file _you were sure_ you’d uploaded, or when you’re pointing a compiler to a library you’re _100% positive_ you already compiled.
+
+#### This isn’t your grandma’s autocompletion
+
+If you like Bash’s autocompletion, you’ll come to scoff at it once you try the autocomplete in [Zsh][5]. The Z shell, along with the [Oh My Zsh][6] site, provides a dynamic experience filled with plugins for specific programming languages and environments, visual themes packed with useful feedback, and a vibrant community of passionate shell users:
+
+![A modest Zsh configuration.][7]
+
+If you’re a visual thinker and find the display of most terminals stagnant and numbing, Zsh may well change the way you interact with your computer.
+
+### Practice more
+
+File paths are important on any system. You might be a visual thinker who prefers to think of files as literal documents inside of literal folders, but the computer sees files and folders as named tags in a pool of data. The way it identifies one collection of data from another is by following its designated path. If you understand these paths, you can also come to visualize them, and you can speak the same language as your OS, making file operations much, much faster.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/understanding-file-paths-linux
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/jrbarnett
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/button_push_open_keyboard_file_organize.png?itok=KlAsk1gx (open source button on keyboard)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://opensource.com/sites/default/files/images/dolphin-file-path.jpg
+[4]: https://opensource.com/sites/default/files/images/terminal-drag-drop.jpg
+[5]: https://opensource.com/article/18/9/tips-productivity-zsh
+[6]: https://ohmyz.sh/
+[7]: https://opensource.com/sites/default/files/uploads/zsh-simple.jpg (A modest Zsh configuration.)
diff --git a/sources/tech/20190802 Use Postfix to get email from your Fedora system.md b/sources/tech/20190802 Use Postfix to get email from your Fedora system.md
new file mode 100644
index 0000000000..e9c4336a5b
--- /dev/null
+++ b/sources/tech/20190802 Use Postfix to get email from your Fedora system.md
@@ -0,0 +1,179 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Use Postfix to get email from your Fedora system)
+[#]: via: (https://fedoramagazine.org/use-postfix-to-get-email-from-your-fedora-system/)
+[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
+
+Use Postfix to get email from your Fedora system
+======
+
+![][1]
+
+Communication is key. Your computer might be trying to tell you something important. But if your mail transport agent ([MTA][2]) isn’t properly configured, you might not be getting the notifications. Postfix is a MTA [that’s easy to configure and known for a strong security record][3]. Follow these steps to ensure that email notifications sent from local services will get routed to your internet email account through the Postfix MTA.
+
+### Install packages
+
+Use _dnf_ to install the required packages ([you configured][4] _[sudo][4]_[, right?][4]):
+
+```
+$ sudo -i
+# dnf install postfix mailx
+```
+
+If you previously had a different MTA configured, you may need to set Postfix to be the system default. Use the _alternatives_ command to set your system default MTA:
+
+```
+$ sudo alternatives --config mta
+There are 2 programs which provide 'mta'.
+ Selection Command
+*+ 1 /usr/sbin/sendmail.sendmail
+ 2 /usr/sbin/sendmail.postfix
+Enter to keep the current selection[+], or type selection number: 2
+```
+
+### Create a _password_maps_ file
+
+You will need to create a Postfix lookup table entry containing the email address and password of the account that you want to use to for sending email:
+
+```
+# MY_EMAIL_ADDRESS=glb@gmail.com
+# MY_EMAIL_PASSWORD=abcdefghijklmnop
+# MY_SMTP_SERVER=smtp.gmail.com
+# MY_SMTP_SERVER_PORT=587
+# echo "[$MY_SMTP_SERVER]:$MY_SMTP_SERVER_PORT $MY_EMAIL_ADDRESS:$MY_EMAIL_PASSWORD" >> /etc/postfix/password_maps
+# chmod 600 /etc/postfix/password_maps
+# unset MY_EMAIL_PASSWORD
+# history -c
+```
+
+If you are using a Gmail account, you’ll need to configure an “app password” for Postfix, rather than using your gmail password. See “[Sign in using App Passwords][5]” for instructions on configuring an app password.
+
+Next, you must run the _postmap_ command against the Postfix lookup table to create or update the hashed version of the file that Postfix actually uses:
+
+```
+# postmap /etc/postfix/password_maps
+```
+
+The hashed version will have the same file name but it will be suffixed with _.db_.
+
+### Update the _main.cf_ file
+
+Update Postfix’s _main.cf_ configuration file to reference the Postfix lookup table you just created. Edit the file and add these lines.
+
+```
+relayhost = smtp.gmail.com:587
+smtp_tls_security_level = verify
+smtp_tls_mandatory_ciphers = high
+smtp_tls_verify_cert_match = hostname
+smtp_sasl_auth_enable = yes
+smtp_sasl_security_options = noanonymous
+smtp_sasl_password_maps = hash:/etc/postfix/password_maps
+```
+
+The example assumes you’re using Gmail for the _relayhost_ setting, but you can substitute the correct hostname and port for the mail host to which your system should hand off mail for sending.
+
+For the most up-to-date details about the above configuration options, see the man page:
+
+```
+$ man postconf.5
+```
+
+### Enable, start, and test Postfix
+
+After you have updated the main.cf file, enable and start the Postfix service:
+
+```
+# systemctl enable --now postfix.service
+```
+
+You can then exit your _sudo_ session as root using the _exit_ command or **Ctrl+D**. You should now be able to test your configuration with the _mail_ command:
+
+```
+$ echo 'It worked!' | mail -s "Test: $(date)" glb@gmail.com
+```
+
+### Update services
+
+If you have services like [logwatch][6], [mdadm][7], [fail2ban][8], [apcupsd][9] or [certwatch][10] installed, you can now update their configurations so that their email notifications will go to your internet email address.
+
+Optionally, you may want to configure all email that is sent to your local system’s root account to go to your internet email address. Add this line to the _/etc/aliases_ file on your system (you’ll need to use _sudo_ to edit this file, or switch to the _root_ account first):
+
+```
+root: glb+root@gmail.com
+```
+
+Now run this command to re-read the aliases:
+
+```
+# newaliases
+```
+
+ * TIP: If you are using Gmail, you can [add an alpha-numeric mark][11] between your username and the **@** symbol as demonstrated above to make it easier to identify and filter the email that you will receive from your computer(s).
+
+
+
+### Troubleshooting
+
+**View the mail queue:**
+
+```
+$ mailq
+```
+
+**Clear all email from the queues:**
+
+```
+# postsuper -d ALL
+```
+
+**Filter the configuration settings for interesting values:**
+
+```
+$ postconf | grep "^relayhost\|^smtp_"
+```
+
+**View the _postfix/smtp_ logs:**
+
+```
+$ journalctl --no-pager -t postfix/smtp
+```
+
+**Reload _postfix_ after making configuration changes:**
+
+```
+$ systemctl reload postfix
+```
+
+* * *
+
+_Photo by _[_Sharon McCutcheon_][12]_ on [Unsplash][13]_.
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/use-postfix-to-get-email-from-your-fedora-system/
+
+作者:[Gregory Bartholomew][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/glb/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/postfix-816x345.jpg
+[2]: https://en.wikipedia.org/wiki/Message_transfer_agent
+[3]: https://en.wikipedia.org/wiki/Postfix_(software)
+[4]: https://fedoramagazine.org/howto-use-sudo/
+[5]: https://support.google.com/accounts/answer/185833
+[6]: https://src.fedoraproject.org/rpms/logwatch
+[7]: https://fedoramagazine.org/mirror-your-system-drive-using-software-raid/
+[8]: https://fedoraproject.org/wiki/Fail2ban_with_FirewallD
+[9]: https://src.fedoraproject.org/rpms/apcupsd
+[10]: https://www.linux.com/learn/automated-certificate-expiration-checks-centos
+[11]: https://gmail.googleblog.com/2008/03/2-hidden-ways-to-get-more-from-your.html
+[12]: https://unsplash.com/@sharonmccutcheon?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[13]: https://unsplash.com/search/photos/envelopes?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/sources/tech/20190805 4 cool new projects to try in COPR for August 2019.md b/sources/tech/20190805 4 cool new projects to try in COPR for August 2019.md
new file mode 100644
index 0000000000..c7a54360b4
--- /dev/null
+++ b/sources/tech/20190805 4 cool new projects to try in COPR for August 2019.md
@@ -0,0 +1,105 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (4 cool new projects to try in COPR for August 2019)
+[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-august-2019/)
+[#]: author: (Dominik Turecek https://fedoramagazine.org/author/dturecek/)
+
+4 cool new projects to try in COPR for August 2019
+======
+
+![][1]
+
+COPR is a [collection][2] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
+
+Here’s a set of new and interesting projects in COPR.
+
+### Duc
+
+[Duc][3] is a collection of tools for disk usage inspection and visualization. Duc uses an indexed database to store sizes of files on your system. Once the indexing is done, you can then quickly overview your disk usage either by its command-line interface or the GUI.
+
+![][4]
+
+#### Installation instructions
+
+The [repo][5] currently provides duc for EPEL 7, Fedora 29 and 30. To install duc, use these commands:
+
+```
+sudo dnf copr enable terrywang/duc
+sudo dnf install duc
+```
+
+### MuseScore
+
+[MuseScore][6] is a software for working with music notation. With MuseScore, you can create sheet music either by using a mouse, virtual keyboard or a MIDI controller. MuseScore can then play the created music or export it as a PDF, MIDI or MusicXML. Additionally, there’s an extensive database of sheet music created by Musescore users.
+
+![][7]
+
+#### Installation instructions
+
+The [repo][8] currently provides MuseScore for Fedora 29 and 30. To install MuseScore, use these commands:
+
+```
+sudo dnf copr enable jjames/MuseScore
+sudo dnf install musescore
+```
+
+### Dynamic Wallpaper Editor
+
+[Dynamic Wallpaper Editor][9] is a tool for creating and editing a collection of wallpapers in GNOME that change in time. This can be done using XML files, however, Dynamic Wallpaper Editor makes this easy with its graphical interface, where you can simply add pictures, arrange them and set the duration of each picture and transitions between them.
+
+![][10]
+
+#### Installation instructions
+
+The [repo][11] currently provides dynamic-wallpaper-editor for Fedora 30 and Rawhide. To install dynamic-wallpaper-editor, use these commands:
+
+```
+sudo dnf copr enable atim/dynamic-wallpaper-editor
+sudo dnf install dynamic-wallpaper-editor
+```
+
+### Manuskript
+
+[Manuskript][12] is a tool for writers and is aimed to make creating large writing projects easier. It serves as an editor for writing the text itself, as well as a tool for organizing notes about the story itself, characters of the story and individual plots.
+
+![][13]
+
+#### Installation instructions
+
+The [repo][14] currently provides Manuskript for Fedora 29, 30 and Rawhide. To install Manuskript, use these commands:
+
+```
+sudo dnf copr enable notsag/manuskript
+sudo dnf install manuskript
+```
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-august-2019/
+
+作者:[Dominik Turecek][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/dturecek/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
+[2]: https://copr.fedorainfracloud.org/
+[3]: https://duc.zevv.nl/
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/duc.png
+[5]: https://copr.fedorainfracloud.org/coprs/terrywang/duc/
+[6]: https://musescore.org/
+[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/musescore-1024x512.png
+[8]: https://copr.fedorainfracloud.org/coprs/jjames/MuseScore/
+[9]: https://github.com/maoschanz/dynamic-wallpaper-editor
+[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/dynamic-walppaper-editor.png
+[11]: https://copr.fedorainfracloud.org/coprs/atim/dynamic-wallpaper-editor/
+[12]: https://www.theologeek.ch/manuskript/
+[13]: https://fedoramagazine.org/wp-content/uploads/2019/07/manuskript-1024x600.png
+[14]: https://copr.fedorainfracloud.org/coprs/notsag/manuskript/
diff --git a/sources/tech/20190805 Find The Linux Distribution Name, Version And Kernel Details.md b/sources/tech/20190805 Find The Linux Distribution Name, Version And Kernel Details.md
new file mode 100644
index 0000000000..b7f481bcb4
--- /dev/null
+++ b/sources/tech/20190805 Find The Linux Distribution Name, Version And Kernel Details.md
@@ -0,0 +1,199 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Find The Linux Distribution Name, Version And Kernel Details)
+[#]: via: (https://www.ostechnix.com/find-out-the-linux-distribution-name-version-and-kernel-details/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+Find The Linux Distribution Name, Version And Kernel Details
+======
+
+![Find The Linux Distribution Name, Version And Kernel Details][1]
+
+This guide explains how to find the Linux distribution name, version and Kernel details. If your Linux system has GUI mode, you can find these details easily from the System’s Settings. But in CLI mode, it is bit difficult for beginners to find out such details. No problem! Here I have given a few command line methods to find the Linux system information. There could be many, but these methods will work on most Linux distributions.
+
+### 1\. Find Linux distribution name, version
+
+There are many methods to find out what OS is running on in your VPS.
+
+##### Method 1:
+
+Open your Terminal and run the following command:
+
+```
+$ cat /etc/*-release
+```
+
+**Sample output from CentOS 7:**
+
+```
+CentOS Linux release 7.0.1406 (Core)
+NAME="CentOS Linux"
+VERSION="7 (Core)"
+ID="centos"
+ID_LIKE="rhel fedora"
+VERSION_ID="7"
+PRETTY_NAME="CentOS Linux 7 (Core)"
+ANSI_COLOR="0;31"
+CPE_NAME="cpe:/o:centos:centos:7"
+HOME_URL="https://www.centos.org/"
+BUG_REPORT_URL="https://bugs.centos.org/"
+
+CentOS Linux release 7.0.1406 (Core)
+CentOS Linux release 7.0.1406 (Core)
+```
+
+**Sample output from Ubuntu 18.04:**
+
+```
+DISTRIB_ID=Ubuntu
+DISTRIB_RELEASE=18.04
+DISTRIB_CODENAME=bionic
+DISTRIB_DESCRIPTION="Ubuntu 18.04.2 LTS"
+NAME="Ubuntu"
+VERSION="18.04.2 LTS (Bionic Beaver)"
+ID=ubuntu
+ID_LIKE=debian
+PRETTY_NAME="Ubuntu 18.04.2 LTS"
+VERSION_ID="18.04"
+HOME_URL="https://www.ubuntu.com/"
+SUPPORT_URL="https://help.ubuntu.com/"
+BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
+PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
+VERSION_CODENAME=bionic
+UBUNTU_CODENAME=bionic
+```
+
+##### Method 2:
+
+The following command will also get your distribution details.
+
+```
+$ cat /etc/issue
+```
+
+**Sample output from Ubuntu 18.04:**
+
+```
+Ubuntu 18.04.2 LTS \n \l
+```
+
+##### Method 3:
+
+The following command will get you the distribution details in Debian and its variants like Ubuntu, Linux Mint etc.
+
+```
+$ lsb_release -a
+```
+
+**Sample output:**
+
+```
+No LSB modules are available.
+Distributor ID: Ubuntu
+Description: Ubuntu 18.04.2 LTS
+Release: 18.04
+Codename: bionic
+```
+
+### 2\. Find Linux Kernel details
+
+##### Method 1:
+
+To find out your Linux kernel details, run the following command from your Terminal.
+
+```
+$ uname -a
+```
+
+**Sample output in CentOS 7:**
+
+```
+Linux server.ostechnix.lan 3.10.0-123.9.3.el7.x86_64 #1 SMP Thu Nov 6 15:06:03 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
+```
+
+**Sample output in Ubuntu 18.04:**
+
+```
+Linux ostechnix 4.18.0-25-generic #26~18.04.1-Ubuntu SMP Thu Jun 27 07:28:31 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
+```
+
+Or,
+
+```
+$ uname -mrs
+```
+
+**Sample output:**
+
+```
+Linux 4.18.0-25-generic x86_64
+```
+
+Where,
+
+ * **Linux** – Kernel name
+ * **4.18.0-25-generic** – Kernel version
+ * **x86_64** – System hardware architecture (i.e 64 bit system)
+
+
+
+For more details about uname command, refer the man page.
+
+```
+$ man uname
+```
+
+##### Method 2:
+
+From your Terminal, run the following command:
+
+```
+$ cat /proc/version
+```
+
+**Sample output from CentOS 7:**
+
+```
+Linux version 3.10.0-123.9.3.el7.x86_64 ([email protected]) (gcc version 4.8.2 20140120 (Red Hat 4.8.2-16) (GCC) ) #1 SMP Thu Nov 6 15:06:03 UTC 2014
+```
+
+**Sample output from Ubuntu 18.04:**
+
+```
+Linux version 4.18.0-25-generic ([email protected]) (gcc version 7.4.0 (Ubuntu 7.4.0-1ubuntu1~18.04.1)) #26~18.04.1-Ubuntu SMP Thu Jun 27 07:28:31 UTC 2019
+```
+
+* * *
+
+**Suggested read:**
+
+ * [**How To Find Linux System Details Using inxi**][2]
+ * [**Neofetch – Display Linux system Information In Terminal**][3]
+ * [**How To Find Hardware And Software Specifications In Ubuntu**][4]
+
+
+
+* * *
+
+These are few ways to find find out a Linux distribution’s name, version and Kernel details. Hope you find it useful.
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/find-out-the-linux-distribution-name-version-and-kernel-details/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2015/08/Linux-Distribution-Name-Version-Kernel-720x340.png
+[2]: https://www.ostechnix.com/how-to-find-your-system-details-using-inxi/
+[3]: https://www.ostechnix.com/neofetch-display-linux-systems-information/
+[4]: https://www.ostechnix.com/getting-hardwaresoftware-specifications-in-linux-mint-ubuntu/
diff --git a/sources/tech/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md b/sources/tech/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md
new file mode 100644
index 0000000000..abaea75707
--- /dev/null
+++ b/sources/tech/20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md
@@ -0,0 +1,117 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (GameMode – A Tool To Improve Gaming Performance On Linux)
+[#]: via: (https://www.ostechnix.com/gamemode-a-tool-to-improve-gaming-performance-on-linux/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+GameMode – A Tool To Improve Gaming Performance On Linux
+======
+
+![Gamemmode improve gaming performance on Linux][1]
+
+Ask some Linux users why they still sticks with Windows dual boot, probably the answer would be – “Games!”. It was true! Luckily, open source gaming platforms like [**Lutris**][2] and Proprietary gaming platform **Steam** have brought many games to Linux platforms and improved the Linux gaming experience significantly over the years. Today, I stumbled upon yet another Linux gaming-related, open source tool named **GameMode** , which allows the users to improve gaming performance on Linux.
+
+GameMode is basically a daemon/lib combo that lets the games optimise Linux system performance on demand. I thought GameMode is a kind of tool that would kill some resource-hungry tools running in the background. But it is different. What it does actually is just instruct the CPU to **automatically run in Performance mode when playing games** and helps the Linux users to get best possible performance out of their games.
+
+GameMode improves the gaming performance significantly by requesting a set of optimisations be temporarily applied to the host OS while playing the games. Currently, It includes support for optimisations including the following:
+
+ * CPU governor,
+ * I/O priority,
+ * Process niceness,
+ * Kernel scheduler (SCHED_ISO),
+ * Screensaver inhibiting,
+ * GPU performance mode (NVIDIA and AMD), GPU overclocking (NVIDIA),
+ * Custom scripts.
+
+
+
+GameMode is free and open source system tool developed by [**Feral Interactive**][3], a world-leading publisher of games.
+
+### Install GameMode
+
+GameMode is available for many Linux distributions.
+
+On Arch Linux and its variants, you can install it from [**AUR**][4] using any AUR helper programs, for example [**Yay**][5].
+
+```
+$ yay -S gamemode
+```
+
+On Debian, Ubuntu, Linux Mint and other Deb-based systems:
+
+```
+$ sudo apt install gamemode
+```
+
+If GameMode is not available for your system, you can manually compile and install it from source as described in its Github page under Development section.
+
+### Activate GameMode support to improve Gaming Performance on Linux
+
+Here are the list of games with GameMode integration, so we need not to do any additional configuration to activate GameMode support.
+
+ * Rise of the Tomb Raider
+ * Total War Saga: Thrones of Britannia
+ * Total War: WARHAMMER II
+ * DiRT 4
+ * Total War: Three Kingdoms
+
+
+
+Simply run these games and GameMode support will be enabled automatically.
+
+There is also an [**extension**][6] is available to integrate GameMode support with GNOME shell. It indicates when GameMode is active in the top panel.
+
+For other games, you may need to manually request GameMode support like below.
+
+```
+gamemoderun ./game
+```
+
+I am not fond of games and I haven’t played any games for years. So, I can’t share any actual benchmarks.
+
+However, I’ve found a short video tutorial on Youtube to enable GameMode support for Lutris games. It is a good start point for those who wants to try GameMode for the first time.
+
+
+
+By looking at the comments in the video, I can say that that GameMode has indeed improved gaming performance on Linux.
+
+For more details, refer the [**GameMode GitHub repository**][7].
+
+* * *
+
+**Related read:**
+
+ * [**GameHub – An Unified Library To Put All Games Under One Roof**][8]
+ * [**How To Run MS-DOS Games And Programs In Linux**][9]
+
+
+
+* * *
+
+Have you used GameMode tool? Did it really improve the Gaming performance on your Linux box? Share you thoughts in the comment section below.
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/gamemode-a-tool-to-improve-gaming-performance-on-linux/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Gamemode-720x340.png
+[2]: https://www.ostechnix.com/manage-games-using-lutris-linux/
+[3]: http://www.feralinteractive.com/en/
+[4]: https://aur.archlinux.org/packages/gamemode/
+[5]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[6]: https://github.com/gicmo/gamemode-extension
+[7]: https://github.com/FeralInteractive/gamemode
+[8]: https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/
+[9]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
diff --git a/sources/tech/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md b/sources/tech/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md
new file mode 100644
index 0000000000..53fb5a5906
--- /dev/null
+++ b/sources/tech/20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md
@@ -0,0 +1,109 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04)
+[#]: via: (https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+How To Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04
+======
+
+![Add 'New Document' Option In Right Click Context Menu In Ubuntu 18.04 GNOME desktop][1]
+
+The other day, I was collecting reference notes for [**Linux package managers**][2] on various online sources. When I tried to create a text file to save those notes, I noticed that the ‘New document’ option is missing in my Ubuntu 18.04 LTS desktop. I thought somehow the option is gone in my system. After googling a bit, It turns out to be the “new document” option is not included in Ubuntu GNOME editions. Luckily, I have found an easy solution to add ‘New Document’ option in right click context menu in Ubuntu 18.04 LTS desktop.
+
+As you can see in the following screenshot, the “New Doucment” option is missing in the right-click context menu of Nautilus file manager.
+
+![][3]
+
+new document option is missing in right-click context menu ubuntu 18.04
+
+If you want to add this option, just follow the steps given below.
+
+### Add ‘New Document’ Option In Right Click Context Menu In Ubuntu
+
+First, make sure you have **~/Templates** directory in your system. If it is not available create one like below.
+
+```
+$ mkdir ~/Templates
+```
+
+Next open the Terminal application and cd into the **~/Templates** folder using command:
+
+```
+$ cd ~/Templates
+```
+
+Create an empty file:
+
+```
+$ touch Empty\ Document
+```
+
+Or,
+
+```
+$ touch "Empty Document"
+```
+
+![][4]
+
+Now open your Nautilus file manager and check if “New Doucment” option is added in context menu.
+
+![][5]
+
+Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04
+
+As you can see in the above screenshot, the “New Document” option is back again.
+
+You can also additionally add options for different files types like below.
+
+```
+$ cd ~/Templates
+
+$ touch New\ Word\ Document.docx
+$ touch New\ PDF\ Document.pdf
+$ touch New\ Text\ Document.txt
+$ touch New\ PyScript.py
+```
+
+![][6]
+
+Add options for different files types in New Document sub-menu
+
+Please note that all files should be created inside the **~/Templates** directory.
+
+Now, open the Nautilus and check if the newly created file types are present in “New Document” sub-menu.
+
+![][7]
+
+If you want to remove any file type from the sub-menu, simply remove the appropriate file from the Templates directory.
+
+```
+$ rm ~/Templates/New\ Word\ Document.docx
+```
+
+I am wondering why this option has been removed in recent Ubuntu GNOME editions. I use it frequently. However, it is easy to re-enable this option in couple minutes.
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-1-720x340.png
+[2]: https://www.ostechnix.com/linux-package-managers-compared-appimage-vs-snap-vs-flatpak/
+[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/new-document-option-missing.png
+[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Create-empty-document-in-Templates-directory.png
+[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-In-Ubuntu.png
+[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-options-for-different-files-types.png
+[7]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu.png
diff --git a/sources/tech/20190805 How To Magnify Screen Areas On Linux Desktop.md b/sources/tech/20190805 How To Magnify Screen Areas On Linux Desktop.md
new file mode 100644
index 0000000000..cd53bf8941
--- /dev/null
+++ b/sources/tech/20190805 How To Magnify Screen Areas On Linux Desktop.md
@@ -0,0 +1,127 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Magnify Screen Areas On Linux Desktop)
+[#]: via: (https://www.ostechnix.com/how-to-magnify-screen-areas-on-linux-desktop/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+How To Magnify Screen Areas On Linux Desktop
+======
+
+Have you ever been in a situation where you wanted to magnify a particular portion of your screen? If you’re a graphic designer, you might be definitely in this situation often. Please note that I am not talking about enlarging a text. Magnifying the screen area is different than merely enlarging the text size. Magnification is the process of enlarging something (E.g. Images) only in appearance, not in physical size. Fortunately, there are many applications available to magnify screen areas on Linux systems. The magnifiers can help the artists or graphic designers for accurate graphical design and/or detail work. This can also help to those who have poor eyesight or small screen size monitor with low resolutions in general.
+
+### Magnify Screen Areas On Linux Desktop
+
+There could be several ways, applications to do this. I am aware of the following two methods as of writing this guide. I will keep looking for more ways and applications which will help to magnify, try them out and update this guide in future.
+
+##### Method 1 – Using Magnus
+
+Magnus is a small and simple desktop magnifier application for Linux. It literally follows the mouse cursor, allowing you to move around by zooming in on parts of the screen. It shows the screen areas around the mouse pointer in a separate window magnified up to five times. Magnus is free, open source application released under MIT license.
+
+Magnus is available as [**snap**][1] application. So we can install it on Linux distributions that supports snaps using command:
+
+```
+$ sudo snap install magnus
+```
+
+There is also a PPA for Magnus is available.
+
+```
+$ sudo add-apt-repository ppa:flexiondotorg/magnus
+
+$ sudo apt update
+
+$ sudo apt install magnus
+```
+
+Once Magnus is installed, launch it from menu or application launcher.
+
+You will see a small window on the top left corner of your screen. You can move it to any side of the screen and increase its size by simply dragging the hot corners windows.
+
+![][3]
+
+Magnus screen magnifier Interface
+
+Now, move the mouse pointer around the screen areas to magnify them.
+
+![][4]
+
+Magnify Screen Areas On Linux Desktop Using Magnus
+
+You can increase the zooming level (by 2x, 3x, 4x and 5x) from the drop-down box in the tool bar of Magnus app. By default, Magnus will magnify the areas in 2x size.
+
+##### Method 2 – Using Universal Access menu
+
+If you’re a GNOME user, you need not to install any external applications. GNOME desktop comes with a built-in feature called **Universal Access** which will provide many accessibility features such as,
+
+ * Magnifying screen areas,
+ * Read screen aloud,
+ * Read screen in Braille,
+ * Change text size,
+ * Adjust contrast,
+ * Adjust speed of mouse/touchpad,
+ * Use on-screen keyboard,
+ * And many.
+
+
+
+We will look into only one feature i.e magnifying screen areas.
+
+Launch Universal Access menu. It is usually found under System Settings. Or, click on a person-like icon on the top bar.
+
+There are many accessibility options available in Universal access menu as shown in the picture below. To enable magnification, click on **Zoom** tab.
+
+![][5]
+
+Universal Access menu
+
+In the Zoom options window, simply enable Zoom option. Just click the **ON/OFF slider button** to enable/disable zoom option.
+
+![][6]
+
+Magnify Screen Areas On Linux Desktop Using Universal Access menu
+
+Once you enabled the zoom option, the screen areas will simply magnify when you move the mouse pointer around them. You can increase or decrease the zooming level by simply clicking on the +/- buttons besides Magnification option.
+
+Unlike Magnus application, Universal access menu offers a few additional functionalities as listed below.
+
+ * Change mouse tracking. This setting can be applied in the **Magnifier tab** of Zoom options window.
+ * Change position of the magnified view on the screen i.e entire screen or part of the screen like top half, bottom half, left half and right half. To adjust these settings, go to **Magnifier tab**.
+ * Activate crosshairs to help you find the mouse or touchpad pointer. Also, we can adjust mouse or touchpad thickness, length and color. These settings can be changed in the **Crosshairs tab**.
+ * Adjust color effects such as brightness, contrast, color. All of these settings can be adjusted in **Color effects tab**.
+
+
+
+I tested these two methods on Ubuntu 18.04 desktop and I could easily magnify the screen areas.
+
+To be honest, I never knew that we can magnify a screen area in Linux. Before I know about this, all I would do is just screenshot the area and zoom in/out using an image viewer application. Well, not anymore! I know now how to magnify a screen area on Linux desktop and I hope this will be useful to you too.
+
+**Resources:**
+
+ * [**Magnus GitHub Repository**][7]
+ * [**Ubuntu documentation**][8]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-magnify-screen-areas-on-linux-desktop/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/introduction-ubuntus-snap-packages/
+[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/Magnus-launch.png
+[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Magnify-Screen-Areas-On-Linux-Desktop-Using-Magnus.gif
+[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Universal-Access-menu.png
+[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Magnify-Screen-Areas-On-Linux-Desktop-Using-Universal-Access-menu.png
+[7]: https://github.com/stuartlangridge/magnus
+[8]: https://help.ubuntu.com/stable/ubuntu-help/a11y-mag.html.en
diff --git a/sources/tech/20190805 How To Screenshot Right Click Context Menu On Linux.md b/sources/tech/20190805 How To Screenshot Right Click Context Menu On Linux.md
new file mode 100644
index 0000000000..17f13338dc
--- /dev/null
+++ b/sources/tech/20190805 How To Screenshot Right Click Context Menu On Linux.md
@@ -0,0 +1,74 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Screenshot Right Click Context Menu On Linux)
+[#]: via: (https://www.ostechnix.com/how-to-screenshot-right-click-context-menu-on-linux/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+How To Screenshot Right Click Context Menu On Linux
+======
+
+![How To Screenshot Right Click Context Menu On Linux][1]
+
+Taking screenshots is part of my work. I take a lot of screenshots daily to use them in my guides. The other day, I had to screenshot the right-click context menu while writing a guide to show our readers how to [**add ‘New Document’ option in right click context menu in Ubuntu 18.04 LTS desktop**][2]. Usually, I take screenshots with **Print screen** button in the keyboard and **Deepin Screenshot** application. While trying to screenshot the context menu using Deepin Screenshot app, the context menu automatically disappeared as soon as I clicked the Deepin Screenshot. Printscreen also doesn’t work when the context menu is open. If you happened to be in this situation, here are two simple workarounds to screenshot right click context menu on Linux systems with GNOME DE.
+
+### Screenshot Right-click Context Menu On Linux
+
+If you want to take the screenshot of right click context menu when it is open, simply instruct the screenshot apps to wait for a particular seconds before taking a screenshot.
+
+We can do this in two ways, the CLI way and GUI way. First, we will see the CLI way.
+
+##### 1\. Schedule screenshots using Scrot
+
+As you might already know, [**Scrot**][3] (short for **SCR** eensh **OT** ) is a command-line screenshot tool for taking screenshots in Unix-like operating systems. Scrot comes pre-installed in most Linux distributions. Just in case, if it is not installed already, you can install it using your distribution’s default package manager. For example, run the following command to install Scrot on Ubuntu and its derivatives:
+
+```
+$ sudo apt install scrot
+```
+
+Now we are going to instruct Scrot to wait for X seconds, for example 5 seconds, before taking a screenshot using command:
+
+```
+$ scrot -d 5
+```
+
+Now, right click anywhere to open the context menu and wait for 5 seconds. Scrot will take screenshot exactly after 5 seconds.
+
+![][4]
+
+Screenshot Right-click Context Menu On Linux Using Scrot
+
+You can set the timeout value as you wish.
+
+If you’re not comfortable with CLI way, no problem! We can do this in GUI way as well.
+
+##### 2\. Schedule screenshots using Gnome Screenshot
+
+Open Gnome Screenshot application. it comes pre-installed with GNOME desktop. Now, set a time (E.g. 5 seconds) after which the picture has to be taken, click **Take screenshot** button, open the right click context menu and simply wait for 5 seconds. The screenshot will be taken in 5 seconds.
+
+![][5]
+
+Screenshot Right-click Context Menu On Linux Using Gnome screenshot
+
+And, that’s all. This is how we can take screenshots when a menu is open or running. Of course, some advanced screenshot applications like **Shutter** can do this as well. But I find these two ways much easier.
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-screenshot-right-click-context-menu-on-linux/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Screenshot-Right-Click-Context-Menu-720x340.png
+[2]: https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/
+[3]: https://www.ostechnix.com/take-screenshots-command-line-using-scrot-linux/
+[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Screenshot-Right-click-Context-Menu-On-Linux.gif
+[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Screenshot-Right-click-Context-Menu-On-Linux-Using-Gnome-screenshot.gif
diff --git a/sources/tech/20190805 How To Set Up Time Synchronization On Ubuntu.md b/sources/tech/20190805 How To Set Up Time Synchronization On Ubuntu.md
new file mode 100644
index 0000000000..861cdb6bfc
--- /dev/null
+++ b/sources/tech/20190805 How To Set Up Time Synchronization On Ubuntu.md
@@ -0,0 +1,236 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Set Up Time Synchronization On Ubuntu)
+[#]: via: (https://www.ostechnix.com/how-to-set-up-time-synchronization-on-ubuntu/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+How To Set Up Time Synchronization On Ubuntu
+======
+
+![Set Up Time Synchronization On Ubuntu][1]
+
+You might have set up [**cron jobs**][2] that runs at a specific time to backup important files or perform any system related tasks. Or, you might have configured a [**log server to rotate the logs**][3] out of your system at regular interval time. If your clock is out-of-sync, these jobs will not execute at the desired time. This is why setting up a correct time zone on the Linux systems and keep the clock synchronized with Internet is important. This guide describes how to set up time synchronization on Ubuntu Linux. The steps given below have been tested on Ubuntu 18.04, however they are same for other Ubuntu-based systems that uses systemd’s **timesyncd** service.
+
+### Set Up Time Synchronization On Ubuntu
+
+Usually, we set time zone during installation. You can however change it or set different time zone if you want to.
+
+First, let us see the current time zone in our Ubuntu system using “date” command:
+
+```
+$ date
+```
+
+Sample output:
+
+```
+Tue Jul 30 11:47:39 UTC 2019
+```
+
+As you see in the above output, the “date” command shows the actual date as well as the current time. Here, my current time zone is **UTC** which stands for **Coordinated Universal Time**.
+
+Alternatively, you can look up the **/etc/timezone** file to find the current time zone.
+
+```
+$ cat /etc/timezone
+UTC
+```
+
+Now, let us see if the clock is synchronized with Internet. To do so, simply run:
+
+```
+$ timedatectl
+```
+
+Sample output:
+
+```
+Local time: Tue 2019-07-30 11:53:58 UTC
+Universal time: Tue 2019-07-30 11:53:58 UTC
+RTC time: Tue 2019-07-30 11:53:59
+Time zone: Etc/UTC (UTC, +0000)
+System clock synchronized: yes
+systemd-timesyncd.service active: yes
+RTC in local TZ: no
+```
+
+As you can see, the “timedatectl” command displays the local time, universal time, time zone and whether the system clock is synchronized with Internet servers and if the **systemd-timesyncd.service** is active or inactive. In my case, the system clock is synchronizing with Internet time servers.
+
+If the clock is out-of-sync, you would see **“System clock synchronized: no”** as shown in the below screenshot.
+
+![][4]
+
+Time synchronization is disabled.
+
+Note: The above screenshot is old one. That’s why you see the different date.
+
+If you see **“System clock synchronized:** value set as **no** , the timesyncd service might be inactive. So, simply restart the service and see if it helps.
+
+```
+$ sudo systemctl restart systemd-timesyncd.service
+```
+
+Now check the timesyncd service status:
+
+```
+$ sudo systemctl status systemd-timesyncd.service
+● systemd-timesyncd.service - Network Time Synchronization
+Loaded: loaded (/lib/systemd/system/systemd-timesyncd.service; enabled; vendor preset: enabled)
+Active: active (running) since Tue 2019-07-30 10:50:18 UTC; 1h 11min ago
+Docs: man:systemd-timesyncd.service(8)
+Main PID: 498 (systemd-timesyn)
+Status: "Synchronized to time server [2001:67c:1560:8003::c7]:123 (ntp.ubuntu.com)."
+Tasks: 2 (limit: 2319)
+CGroup: /system.slice/systemd-timesyncd.service
+└─498 /lib/systemd/systemd-timesyncd
+
+Jul 30 10:50:30 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:31 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:31 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:32 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:32 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
+Jul 30 10:51:06 ubuntuserver systemd-timesyncd[498]: Synchronized to time server [2001:67c:1560:800
+```
+
+If this service is enabled and active, your system clock should sync with Internet time servers.
+
+You can verify if the time synchronization is enabled or not using command:
+
+```
+$ timedatectl
+```
+
+If it still not works, run the following command to enable the time synchronization:
+
+```
+$ sudo timedatectl set-ntp true
+```
+
+Now your system clock will synchronize with Internet time servers.
+
+##### Change time zone using Timedatectl command
+
+What if I want to use different time zone other than UTC? It is easy!
+
+First, list of available time zones using command:
+
+```
+$ timedatectl list-timezones
+```
+
+You will see an output similar to below image.
+
+![][5]
+
+List time zones using timedatectl command
+
+You can set the desired time zone(E.g. Asia/Kolkata) using command:
+
+```
+$ sudo timedatectl set-timezone Asia/Kolkata
+```
+
+Check again if the time zone has been really changed using “date” command:
+
+**$ date**
+Tue Jul 30 17:52:33 **IST** 2019
+
+Or, use timedatectl command if you want the detailed output:
+
+```
+$ timedatectl
+Local time: Tue 2019-07-30 17:52:35 IST
+Universal time: Tue 2019-07-30 12:22:35 UTC
+RTC time: Tue 2019-07-30 12:22:36
+Time zone: Asia/Kolkata (IST, +0530)
+System clock synchronized: yes
+systemd-timesyncd.service active: yes
+RTC in local TZ: no
+```
+
+As you noticed, I have changed the time zone from UTC to IST (Indian standard time).
+
+To switch back to UTC time zone, simply run:
+
+```
+$ sudo timedatectl set-timezone UTC
+```
+
+##### Change time zone using Tzdata
+
+In older Ubuntu versions, the Timedatectl command is not available. In such cases, you can use **Tzdata** (Time zone data) to set up time synchronization.
+
+```
+$ sudo dpkg-reconfigure tzdata
+```
+
+Choose the geographic area in which you live. In my case, I chose **Asia**. Select OK and hit ENTER key.
+
+![][6]
+
+Next, select the city or region corresponding to your time zone. Here I’ve chosen **Kolkata**.
+
+![][7]
+
+Finally, you will see an output something like below in the Terminal.
+
+```
+Current default time zone: 'Asia/Kolkata'
+Local time is now: Tue Jul 30 19:29:25 IST 2019.
+Universal Time is now: Tue Jul 30 13:59:25 UTC 2019.
+```
+
+##### Configure time zone in graphical mode
+
+Some users may not be comfortable with CLI way. If you’re one of them, you can easily change do all this from system settings panel in graphical mode.
+
+Hit the **Super key** (Windows key), type **settings** in the Ubuntu dash and click on **Settings** icon.
+
+![][8]
+
+Launch System’s settings from Ubuntu dash
+
+Alternatively, click on the down arrow located at the top right corner of your Ubuntu desktop and click the Settings icon in the left corner.
+
+![][9]
+
+Launch System’s settings from top panel
+
+In the next window, choose **Details** and then Click **Date & Time** option. Turn on both **Automatic Date & Time** and **Automatic Time Zone** options.
+
+![][10]
+
+Set automatic time zone in Ubuntu
+
+Close the Settings window an you’re done! Your system clock should now sync with Internet time servers.
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-set-up-time-synchronization-on-ubuntu/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Set-Up-Time-Synchronization-On-Ubuntu-720x340.png
+[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
+[3]: https://www.ostechnix.com/manage-log-files-using-logrotate-linux/
+[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/timedatectl-command-output-ubuntu.jpeg
+[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/List-timezones-using-timedatectl-command.png
+[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/configure-time-zone-using-tzdata-1.png
+[7]: https://www.ostechnix.com/wp-content/uploads/2019/07/configure-time-zone-using-tzdata-2.png
+[8]: https://www.ostechnix.com/wp-content/uploads/2019/07/System-settings-Ubuntu-dash.png
+[9]: https://www.ostechnix.com/wp-content/uploads/2019/07/Ubuntu-system-settings.png
+[10]: https://www.ostechnix.com/wp-content/uploads/2019/07/Set-automatic-timezone-in-ubuntu.png
diff --git a/sources/tech/20190805 How To Verify ISO Images In Linux.md b/sources/tech/20190805 How To Verify ISO Images In Linux.md
new file mode 100644
index 0000000000..8d36124e10
--- /dev/null
+++ b/sources/tech/20190805 How To Verify ISO Images In Linux.md
@@ -0,0 +1,155 @@
+[#]: collector: (lujun9972)
+[#]: translator: (FSSlc)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Verify ISO Images In Linux)
+[#]: via: (https://www.ostechnix.com/how-to-verify-iso-images-in-linux/)
+[#]: author: (sk https://www.ostechnix.com/author/sk/)
+
+How To Verify ISO Images In Linux
+======
+
+![How To Verify ISO Images In Linux][1]
+
+You just downloaded an ISO image of your favorite Linux distribution from the official site or a third party site, now what? [**Create bootable medium**][2] and start installing the OS? No, wait. Before start using it, It is highly recommended to verify that the downloaded ISO in your local system is the exact copy of the ISO present in the download mirrors. Because, [**Linux Mint’s website is hacked**][3] few years ago and the hackers made a modified Linux Mint ISO, with a backdoor in it. So, It is important to check the authenticity and integrity of your Linux ISO images. If you don’t know how to verify ISO images in Linux, this brief guide will help. Read on!
+
+### Verify ISO Images In Linux
+
+We can verify ISO images using the **Checksum** values. Checksum is a sequence of letters and numbers used to check data for errors and verify the authenticity and integrity of the downloaded files. There are different types of checksums, such as SHA-0, SHA-1, SHA-2 (224, 256, 384, 512) and MD5. MD5 sums have been the most popular, but nowadays SHA-256 sums are mostly used by modern Linux distros.
+
+We are going to use two tools namely **“gpg”** and **“sha256”** to verify authenticity and integrity of the ISO images.
+
+##### Download checksums and signatures
+
+For the purpose of this guide, I am going to use Ubuntu 18.04 LTS server ISO image. However, the steps given below should work on other Linux distributions as well.
+
+Near the top of the Ubuntu download page, you will see a few extra files (checksums and signatures) as shown in the following picture.
+
+![][4]
+
+Ubuntu 18.04 checksum and signature
+
+Here, the **SHA256SUMS** file contains checksums for all the available images and the **SHA256SUMS.gpg** file is the GnuPG signature for that file. We use this signature file to **verify** the checksum file in subsequent steps.
+
+Download the Ubuntu ISO images and these two files and put them all in a directory, for example **ISO**.
+
+```
+$ ls ISO/
+SHA256SUMS SHA256SUMS.gpg ubuntu-18.04.2-live-server-amd64.iso
+```
+
+As you see in the above output, I have downloaded Ubuntu 18.04.2 LTS server image along with checksum and signature values.
+
+##### Download valid signature key
+
+Now, download the correct signature key using command:
+
+```
+$ gpg --keyid-format long --keyserver hkp://keyserver.ubuntu.com --recv-keys 0x46181433FBB75451 0xD94AA3F0EFE21092
+```
+
+Sample output:
+
+```
+gpg: key D94AA3F0EFE21092: 57 signatures not checked due to missing keys
+gpg: key D94AA3F0EFE21092: public key "Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>" imported
+gpg: key 46181433FBB75451: 105 signatures not checked due to missing keys
+gpg: key 46181433FBB75451: public key "Ubuntu CD Image Automatic Signing Key <[email protected]>" imported
+gpg: no ultimately trusted keys found
+gpg: Total number processed: 2
+gpg: imported: 2
+```
+
+##### Verify SHA-256 checksum
+
+Next verify the checksum file using the signature with command:
+
+```
+$ gpg --keyid-format long --verify SHA256SUMS.gpg SHA256SUMS
+```
+
+Sample output:
+
+```
+gpg: Signature made Friday 15 February 2019 04:23:33 AM IST
+gpg: using DSA key 46181433FBB75451
+gpg: Good signature from "Ubuntu CD Image Automatic Signing Key <[email protected]>" [unknown]
+gpg: WARNING: This key is not certified with a trusted signature!
+gpg: There is no indication that the signature belongs to the owner.
+Primary key fingerprint: C598 6B4F 1257 FFA8 6632 CBA7 4618 1433 FBB7 5451
+gpg: Signature made Friday 15 February 2019 04:23:33 AM IST
+gpg: using RSA key D94AA3F0EFE21092
+gpg: Good signature from "Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>" [unknown]
+gpg: WARNING: This key is not certified with a trusted signature!
+gpg: There is no indication that the signature belongs to the owner.
+Primary key fingerprint: 8439 38DF 228D 22F7 B374 2BC0 D94A A3F0 EFE2 1092
+```
+
+If you see “Good signature” in the output,the checksum file is created by Ubuntu developer and signed by the owner of the key file.
+
+##### Check the downloaded ISO file
+
+Next, let us go ahead and check the downloaded ISO file matches the checksum. To do so, simply run:
+
+```
+$ sha256sum -c SHA256SUMS 2>&1 | grep OK
+ubuntu-18.04.2-live-server-amd64.iso: OK
+```
+
+If the checksum values are matched, you will see the **“OK”** message. Meaning – the downloaded file is legitimate and hasn’t altered or tampered.
+
+If you don’t get any output or different than above output, the ISO file has been modified or incorrectly downloaded. You must re-download the file again from a good source.
+
+Some Linux distributions have included the checksum value in the download page itself. For example, **Pop!_os** developers have provided the SHA-256 checksum values for all ISO images in the download page itself, so you can quickly verify the ISO images.
+
+![][5]
+
+Pop os SHA256 sum value in download page
+
+After downloading the the ISO image, verify it using command:
+
+```
+$ sha256sum Soft_backup/ISOs/pop-os_18.04_amd64_intel_54.iso
+```
+
+Sample output:
+
+```
+680e1aa5a76c86843750e8120e2e50c2787973343430956b5cbe275d3ec228a6 Soft_backup/ISOs/pop-os_18.04_amd64_intel_54.iso
+```
+
+![][6]
+
+Pop os SHA256 sum value
+
+Here, the random string starting with **“680elaa…”** is the SHA-256 checksum value. Compare this value with the SHA-256 sum value provided on the downloads page. If both values are same, you’re good to go! The downloaded ISO file is legitimate and it hasn’t changed or modified from its original state.
+
+This is how we can verify the authenticity and integrity of an ISO file in Linux. Whether you download ISOs from official or third-party sources, it is always recommended to do a quick verification before using them. Hope this was useful.
+
+**Reference:**
+
+ * [**https://tutorials.ubuntu.com/tutorial/tutorial-how-to-verify-ubuntu**][7]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-verify-iso-images-in-linux/
+
+作者:[sk][a]
+选题:[lujun9972][b]
+译者:[FSSlc](https://github.com/FSSlc)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Verify-ISO-Images-In-Linux-720x340.png
+[2]: https://www.ostechnix.com/etcher-beauitiful-app-create-bootable-sd-cards-usb-drives/
+[3]: https://blog.linuxmint.com/?p=2994
+[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Ubuntu-18.04-checksum-and-signature.png
+[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Pop-os-SHA256-sum.png
+[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Pop-os-SHA256-sum-value.png
+[7]: https://tutorials.ubuntu.com/tutorial/tutorial-how-to-verify-ubuntu
diff --git a/sources/tech/20190805 How to Install and Configure PostgreSQL on Ubuntu.md b/sources/tech/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
new file mode 100644
index 0000000000..8b9677ba83
--- /dev/null
+++ b/sources/tech/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
@@ -0,0 +1,267 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Install and Configure PostgreSQL on Ubuntu)
+[#]: via: (https://itsfoss.com/install-postgresql-ubuntu/)
+[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
+
+How to Install and Configure PostgreSQL on Ubuntu
+======
+
+_**In this tutorial, you’ll learn how to install and use the open source database PostgreSQL on Ubuntu Linux.**_
+
+[PostgreSQL][1] (or Postgres) is a powerful, free and open-source relational database management system ([RDBMS][2]) that has a strong reputation for reliability, feature robustness, and performance. It is designed to handle various tasks, of any size. It is cross-platform, and the default database for [macOS Server][3].
+
+PostgreSQL might just be the right tool for you if you’re a fan of a simple to use SQL database manager. It supports SQL standards and offers additional features, while also being heavily extendable by the user as the user can add data types, functions, and do many more things.
+
+Earlier I discussed [installing MySQL on Ubuntu][4]. In this article, I’ll show you how to install and configure PostgreSQL, so that you are ready to use it to suit whatever your needs may be.
+
+![][5]
+
+### Installing PostgreSQL on Ubuntu
+
+PostgreSQL is available in Ubuntu main repository. However, like many other development tools, it may not be the latest version.
+
+First check the PostgreSQL version available in [Ubuntu repositories][6] using this [apt command][7] in the terminal:
+
+```
+apt show postgresql
+```
+
+In my Ubuntu 18.04, it showed that the available version of PostgreSQL is version 10 (10+190 means version 10) whereas PostgreSQL version 11 is already released.
+
+```
+Package: postgresql
+Version: 10+190
+Priority: optional
+Section: database
+Source: postgresql-common (190)
+Origin: Ubuntu
+```
+
+Based on this information, you can make your mind whether you want to install the version available from Ubuntu or you want to get the latest released version of PostgreSQL.
+
+I’ll show both methods to you.
+
+#### Method 1: Install PostgreSQL from Ubuntu repositories
+
+In the terminal, use the following command to install PostgreSQL
+
+```
+sudo apt update
+sudo apt install postgresql postgresql-contrib
+```
+
+Enter your password when asked and you should have it installed in a few seconds/minutes depending on your internet speed. Speaking of that, feel free to check various [network bandwidth in Ubuntu][8].
+
+What is postgresql-contrib?
+
+The postgresql-contrib or the contrib package consists some additional utilities and functionalities that are not part of the core PostgreSQL package. In most cases, it’s good to have the contrib package installed along with the PostgreSQL core.
+
+[][9]
+
+Suggested read Fix gvfsd-smb-browse Taking 100% CPU In Ubuntu 16.04
+
+#### Method 2: Installing the latest version 11 of PostgreSQL in Ubuntu
+
+To install PostgreSQL 11, you need to add the official PostgreSQL repository in your sources.list, add its certificate and then install it from there.
+
+Don’t worry, it’s not complicated. Just follow these steps.
+
+Add the GPG key first:
+
+```
+wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
+```
+
+Now add the repository with the below command. If you are using Linux Mint, you’ll have to manually replace the `lsb_release -cs` the Ubuntu version your Mint release is based on.
+
+```
+sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
+```
+
+Everything is ready now. Install PostgreSQL with the following commands:
+
+```
+sudo apt update
+sudo apt install postgresql postgresql-contrib
+```
+
+PostgreSQL GUI application
+
+You may also install a GUI application (pgAdmin) for managing PostgreSQL databases:
+
+_sudo apt install pgadmin4_
+
+### Configuring PostgreSQL
+
+You can check if **PostgreSQL** is running by executing:
+
+```
+service postgresql status
+```
+
+Via the **service** command you can also **start**, **stop** or **restart** **postgresql**. Typing in **service postgresql** and pressing **Enter** should output all options. Now, onto the users.
+
+By default, PostgreSQL creates a special user postgres that has all rights. To actually use PostgreSQL, you must first log in to that account:
+
+```
+sudo su postgres
+```
+
+Your prompt should change to something similar to:
+
+```
+[email protected]:/home/ubuntu$
+```
+
+Now, run the **PostgreSQL Shell** with the utility **psql**:
+
+```
+psql
+```
+
+You should be prompted with:
+
+```
+postgress=#
+```
+
+You can type in **\q** to **quit** and **\?** for **help**.
+
+To see all existing tables, enter:
+
+```
+\l
+```
+
+The output will look similar to this (Hit the key **q** to exit this view):
+
+![PostgreSQL Tables][10]
+
+With **\du** you can display the **PostgreSQL users**:
+
+![PostgreSQLUsers][11]
+
+You can change the password of any user (including **postgres**) with:
+
+```
+ALTER USER postgres WITH PASSWORD 'my_password';
+```
+
+**Note:** _Replace **postgres** with the name of the user and **my_password** with the wanted password._ Also, don’t forget the **;** (**semicolumn**) after every statement.
+
+It is recommended that you create another user (it is bad practice to use the default **postgres** user). To do so, use the command:
+
+```
+CREATE USER my_user WITH PASSWORD 'my_password';
+```
+
+If you run **\du**, you will see, however, that **my_user** has no attributes yet. Let’s add **Superuser** to it:
+
+```
+ALTER USER my_user WITH SUPERUSER;
+```
+
+You can **remove users** with:
+
+```
+DROP USER my_user;
+```
+
+To **log in** as another user, quit the prompt (**\q**) and then use the command:
+
+```
+psql -U my_user
+```
+
+You can connect directly to a database with the **-d** flag:
+
+```
+psql -U my_user -d my_db
+```
+
+You should call the PostgreSQL user the same as another existing user. For example, my use is **ubuntu**. To log in, from the terminal I use:
+
+```
+psql -U ubuntu -d postgres
+```
+
+**Note:** _You must specify a database (by default it will try connecting you to the database named the same as the user you are logged in as)._
+
+If you have a the error:
+
+```
+psql: FATAL: Peer authentication failed for user "my_user"
+```
+
+Make sure you are logging as the correct user and edit **/etc/postgresql/11/main/pg_hba.conf** with administrator rights:
+
+```
+sudo vim /etc/postgresql/11/main/pg_hba.conf
+```
+
+**Note:** _Replace **11** with your version (e.g. **10**)._
+
+Here, replace the line:
+
+```
+local all postgres peer
+```
+
+With:
+
+```
+local all postgres md5
+```
+
+Then restart **PostgreSQL**:
+
+```
+sudo service postgresql restart
+```
+
+Using **PostgreSQL** is the same as using any other **SQL** type database. I won’t go into the specific commands, since this article is about getting you started with a working setup. However, here is a [very useful gist][12] to reference! Also, the man page (**man psql**) and the [documentation][13] are very helpful.
+
+[][14]
+
+Suggested read [How To] Share And Sync Any Folder With Dropbox in Ubuntu
+
+**Wrapping Up**
+
+Reading this article has hopefully guided you through the process of installing and preparing PostgreSQL on an Ubuntu system. If you are new to SQL, you should read this article to know the [basic SQL commands][15]:
+
+[Basic SQL Commands][15]
+
+If you have any issues or questions, please feel free to ask in the comment section.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-postgresql-ubuntu/
+
+作者:[Sergiu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/sergiu/
+[b]: https://github.com/lujun9972
+[1]: https://www.postgresql.org/
+[2]: https://www.codecademy.com/articles/what-is-rdbms-sql
+[3]: https://www.apple.com/in/macos/server/
+[4]: https://itsfoss.com/install-mysql-ubuntu/
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-postgresql-ubuntu.png?resize=800%2C450&ssl=1
+[6]: https://itsfoss.com/ubuntu-repositories/
+[7]: https://itsfoss.com/apt-command-guide/
+[8]: https://itsfoss.com/network-speed-monitor-linux/
+[9]: https://itsfoss.com/fix-gvfsd-smb-high-cpu-ubuntu/
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/postgresql_tables.png?fit=800%2C303&ssl=1
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/postgresql_users.png?fit=800%2C244&ssl=1
+[12]: https://gist.github.com/Kartones/dd3ff5ec5ea238d4c546
+[13]: https://www.postgresql.org/docs/manuals/
+[14]: https://itsfoss.com/sync-any-folder-with-dropbox/
+[15]: https://itsfoss.com/basic-sql-commands/
diff --git a/sources/tech/20190805 Navigating the filesystem with relative paths at the command line.md b/sources/tech/20190805 Navigating the filesystem with relative paths at the command line.md
new file mode 100644
index 0000000000..f532ad8571
--- /dev/null
+++ b/sources/tech/20190805 Navigating the filesystem with relative paths at the command line.md
@@ -0,0 +1,93 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Navigating the filesystem with relative paths at the command line)
+[#]: via: (https://opensource.com/article/19/8/navigating-filesystem-relative-paths)
+[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/greg-p)
+
+Navigating the filesystem with relative paths at the command line
+======
+Learn the difference between absolute and relative paths and how to use
+them, and save yourself a lot of time and potential trouble.
+![Blue folders flying in the clouds above a city skyline][1]
+
+If you’re on your way to work, but you stop by a deli for breakfast first, you don’t go back home after breakfast so you can restart your journey. Instead, you continue from where you are because you understand where your office is located relative to your current location. Navigating your computer is the same way. If you change your working directory in a terminal to a subdirectory, such as **Pictures**, you don’t necessarily have to go home again just to make your way into **Documents**. Instead, you use a _relative_ path.
+
+Conversely, absolute paths always begin from the start of your hard drive. You know that you’ve reached the start by a lone forward slash (**/**) with nothing to its left, because your drive’s root level is the biggest container, holding all your folders and files within it. For that reason, the path **/home/seth** (and its shorthand version **~**, although that’s less clear, because it lacks the leftmost slash) is considered an absolute path. It represents your hard drive’s base level, which contains the **home** directory, which in turn contains **seth** (my username).
+
+Anything starting with a forward slash is an absolute path, which is the digital equivalent of you going 12 blocks back home just to reach a location that’s two blocks away from where you are now. That fact doesn’t mean absolute paths are bad, though. There are many valid reasons to use absolute paths, not the least of which is their clarity. If you can navigate your drive from absolute paths, then use that as a wayfinder. With auto-completion, typing a full path can be as quick as using a relative path, [especially with autocompletion][2].
+
+That said, relative paths can be convenient, and in some cases vital. For instance, you can never be sure of a web server’s absolute path. If a web designer knows they keep [web fonts in a local directory][3] and they link to those fonts on their development laptop using the absolute path **/home/webdev/Public/[www.example.com/fonts][4]**, then all of their links break when the code is pushed to **/var/www/example.com/fonts** on the server.
+
+Besides that, sometimes it really is quicker and easier to type **cd ../Documents** instead of **cd /home/seth/Documents**.
+
+Relative paths use two control sequences: the single (**.**) and the double (**..**) dot. A single dot means _don’t move_. The double dot means _take one step back_. These dots work best when you’re somewhat familiar with what’s on your drive, and provided that you can visualize the corresponding paths.
+
+It may help to visualize each directory as a room in a house. For instance, knowing that you have a home directory that contains both a **Pictures** and a **Documents** folder, you can visualize each subdirectory as a step forward from home:
+
+![Stepping into a directory.][5]
+
+To get from one room to the other, you must go back to the common area using the _step back_ control sequence, and then step forward into the other. You can get your current location at any time with the **pwd** (print working directory) command:
+
+
+```
+$ pwd
+/home/seth/Pictures
+$ cd ../Documents
+$ pwd
+/home/seth/Documents
+```
+
+Remember that a single dot means _don’t move_, and it does exactly that:
+
+
+```
+$ pwd
+/home/seth
+$ cd .
+$ pwd
+/home/seth
+```
+
+It might seem odd to have a special command representing a state of no change, but it’s a usefully explicit directive. For instance, were you to create a custom application to [list a directory’s contents][6] and save it in your home directory, foolishly naming the application **reboot**, then any time you used that custom application you would want to be careful that your computer knew _exactly_ which **reboot** command to execute.
+
+One way you can specify which version is to provide an explicit path to your custom and poorly named application. The single dot reinforces your desire not to stray from your intended path when you’re already in the directory:
+
+
+```
+$ pwd
+/home/seth
+$ ./reboot
+Documents/ Downloads/
+Music/ Pictures/
+Public/ Spheniscidae/
+Videos/ Yugolothae/
+```
+
+Sometimes the single dot can be useful as a filler character in paths that you expect to contain a number of levels. For instance, take a web developer who used several links to a **font** directory that was once three steps back. Recently, though, this developer moved the **font** directory into the same directory as their HTML. If the developer doesn’t replace all instances of **../../../fonts** with **./././fonts**, their site will break.
+
+**Note:** In the case of this example, changing **../../../fonts** to **./fonts** would work, but assume for the sake of this example that doing so would break a script that expects to see three levels before the **fonts** directory.
+
+Relative paths can be confusing at first, so stick to absolute paths when navigating your computer until you’re comfortable with the concept of relativity. Many people find them useful, while others do not use them. It’s all relative.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/navigating-filesystem-relative-paths
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sethhttps://opensource.com/users/greg-p
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_cloud21x_cc.png?itok=5UwC92dO (Blue folders flying in the clouds above a city skyline)
+[2]: https://opensource.com/article/19/7/understanding-file-paths-and-how-use-them#autocomplete
+[3]: https://opensource.com/article/19/3/webfonts
+[4]: http://www.example.com/fonts
+[5]: https://opensource.com/sites/default/files/uploads/path-layout.jpg (Stepping into a directory.)
+[6]: https://opensource.com/article/19/7/master-ls-command
diff --git a/sources/tech/20190805 What-s your favorite open source BI software.md b/sources/tech/20190805 What-s your favorite open source BI software.md
new file mode 100644
index 0000000000..b7ea3e1046
--- /dev/null
+++ b/sources/tech/20190805 What-s your favorite open source BI software.md
@@ -0,0 +1,56 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What's your favorite open source BI software?)
+[#]: via: (https://opensource.com/article/19/8/favorite-open-source-bi-software)
+[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeohttps://opensource.com/users/seth)
+
+What's your favorite open source BI software?
+======
+What business intelligence applications are you using to gather and
+share insights from your data? Please let us know in our poll.
+![Open for business][1]
+
+Open source software has come a long way since the [Open Source Initiative][2] was founded in February 1998. Back then, the thought of releasing source code anyone could change scared many commercial software vendors. Now, according to Red Hat's 2019 [State of Enterprise Open Source survey][3], 99% of IT leaders say open source software plays at least a "somewhat important" role in their enterprise IT strategy.
+
+Open source principles play an equally key role in business intelligence (BI). [Gartner's Magic Quadrant for Data Science and Machine Learning][4] said the market is in the midst of a "big bang" that's redefining the "who" and "how" of data science and ML. In this report (available for clients), the authors cite open source software as one reason for the growth of [citizen data scientists][5]—"'power users' who can perform both simple and moderately sophisticated analytical tasks that would previously have required more expertise."
+
+### What is open source BI software?
+
+Open source business intelligence (BI) software helps users upload, visualize, and make decisions based on data that is pulled from several sources. Like all open source software, its source code is public. That's because the copyright holder allows anyone to review, revise, and run the software at any time, for any reason. These benefits extend to users and non-users alike.
+
+BI involves [turning data into insights][6] that help your business make better decisions. This type of software allows users to pull data from a range of sources, then share it with colleagues and clients.
+
+[Dashboards and reports][7] are two standard features you should look for. Advanced BI tools like [Kibana][8] also offer data visualizations, while others (like [Sisense][9]) pride themselves on the ability to be set up in-house.
+
+One big benefit of open source software is having so many developers fixing code at once. Likewise, open source BI software democratizes data. With countless people working on—and within—the same tool, open source BI software gives teams the power to share data with more colleagues from one centralized resource.
+
+The quality of the data used to make decisions is a top concern for small business leaders GetApp [surveyed][10] in Spring 2019. So, before choosing which open source BI tool to adopt, it's worth weighing the pros and cons of each tool against your business needs.
+
+_Which open source BI software does your team use? What's your main goal for using it? (Boost collaboration, visualize data, use a wider range of data, etc.?) Which challenges (if any) have you encountered bringing BI software into your business? Keep this conversation going in the comments!_
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/8/favorite-open-source-bi-software
+
+作者:[Lauren Maffeo][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lmaffeohttps://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_openseries.png?itok=rCtTDz5G (Open for business)
+[2]: https://opensource.org/
+[3]: https://www.redhat.com/en/enterprise-open-source-report/2019
+[4]: https://www.gartner.com/en/documents/3899464/magic-quadrant-for-data-science-and-machine-learning-pla
+[5]: https://blogs.gartner.com/carlie-idoine/2018/05/13/citizen-data-scientists-and-why-they-matter/
+[6]: https://www.getapp.com/business-intelligence-analytics-software/business-intelligence/#guide
+[7]: https://www.getapp.com/business-intelligence-analytics-software/business-intelligence/#features-to-watch-for
+[8]: https://www.elastic.co/products/kibana
+[9]: https://www.getapp.com/business-intelligence-analytics-software/a/sisense-prism/
+[10]: https://lab.getapp.com/data-driven-decision-making/
diff --git a/sources/tech/20190806 Bash Script to Automatically Start a Services When it Goes Down on Linux.md b/sources/tech/20190806 Bash Script to Automatically Start a Services When it Goes Down on Linux.md
new file mode 100644
index 0000000000..fda3063c02
--- /dev/null
+++ b/sources/tech/20190806 Bash Script to Automatically Start a Services When it Goes Down on Linux.md
@@ -0,0 +1,545 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Bash Script to Automatically Start a Services When it Goes Down on Linux)
+[#]: via: (https://www.2daygeek.com/linux-bash-script-auto-restart-services-when-down/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+Bash Script to Automatically Start a Services When it Goes Down on Linux
+======
+
+There are many open source monitoring tools are currently available in market to monitor Linux systems performance.
+
+Those are send an email alert when the system reaches the specified threshold limit for CPU, Memory, and Disk space or any service is down.
+
+But, it doesn’t have an intelligence to auto start the services, if it crash/goes down.
+
+There are various reasons for the process to crash, which you can investigate and fix the issue but it may take a while.
+
+If you don’t want to make your service down for a while and if you would like to bring them up immediately whenever it goes down?
+
+If so, what to do in this situation? How to mitigate this?
+
+We can write our own bash script to start a service whenever it goes down. Writing a shell script is not a big deal and you have to understand few things to achieve this.
+
+Once you familiar on this, you can write your own shell script to automate the day to day activities, which will save lots of time.
+
+We had added many useful shell scripts in the past. If you want to check those, navigate to the below link.
+
+ * **[How to automate day to day activities using shell scripts?][1]**
+
+
+
+I have added totally six shell scripts for this usage and you can choose which one is suitable for you.
+
+I had applied different commands and methodology in each shell script.
+
+**`Note:`**` ` You need to change the email id instead of ours.
+
+### 1) How to Automatically Start a Service When it Goes Down on SysVinit Linux System?
+
+Use the following bash script, if you would like to start a single service in SysVinit Linux System.
+
+I have added **`httpd`**` ` service in this script but you can add the service, which you want to monitor.
+
+```
+# vi /opt/scripts/service-monitor.sh
+
+#!/bin/bash
+
+serv=httpd
+
+sstat=stopped
+
+service $serv status | grep -i 'running\|stopped' | awk '{print $3}' | while read output;
+
+do
+
+echo $output
+
+if [ "$output" == "$sstat" ]; then
+
+ service $serv start
+
+ echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+ else
+
+ echo "$serv service is running"
+
+ fi
+
+done
+```
+
+Set an executable permission to **`service-monitor.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor.sh
+```
+
+Alternatively, you can use the following script.
+
+```
+# vi /opt/scripts/service-monitor-1.sh
+
+#!/bin/bash
+
+serv=httpd
+
+sstat=$(pidof $serv | wc -l )
+
+if [ $sstat -gt 0 ]
+
+then
+
+echo "$serv is running fine!!!"
+
+else
+
+echo "$serv is down/dead"
+
+service $serv start
+
+echo "$serv service is UP now!!!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+fi
+```
+
+Set an executable permission to **`service-monitor-1.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-1.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-1.sh
+```
+
+### 2) How to Automatically Start a Service When it Goes Down on systemd Linux System?
+
+Use the following bash script, if you would like to start a single service in systemd Linux System.
+
+I have added **`httpd`**` ` service in this script but you can add the service, which you want to monitor.
+
+```
+# vi /opt/scripts/service-monitor-2.sh
+
+#!/bin/bash
+
+serv=httpd
+
+sstat=dead
+
+systemctl status $serv | grep -i 'running\|dead' | awk '{print $3}' | sed 's/[()]//g' | while read output;
+
+do
+
+echo $output
+
+if [ "$output" == "$sstat" ]; then
+
+ systemctl start $serv
+
+ echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+ else
+
+ echo "$serv service is running"
+
+ fi
+
+done
+```
+
+Set an executable permission to **`service-monitor-2.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-2.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-2.sh
+```
+
+Alternatively, you can use the following script.
+
+```
+# vi /opt/scripts/service-monitor-3.sh
+
+#!/bin/bash
+
+serv=httpd
+
+sstat=$(pidof $serv | wc -l )
+
+if [ $sstat -gt 0 ]
+
+then
+
+echo "$serv is running fine!!!"
+
+else
+
+echo "$serv is down/dead"
+
+systemctl start $serv
+
+echo "$serv service is UP now!!!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+fi
+```
+
+Set an executable permission to **`service-monitor-3.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-3.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-3.sh
+```
+
+### 3) How to Automatically Start Multiple Services When it Goes Down on SysVinit Linux System?
+
+Use the following bash script, if you would like to start multiple service in SysVinit Linux System.
+
+I have added **`httpd`**` ` and **`rsyslog`**` ` services in this script but you can add the service, which you want to monitor.
+
+```
+# vi /opt/scripts/service-monitor-4.sh
+
+#!/bin/bash
+
+sstat=stopped
+
+for serv in httpd rsyslog
+
+do
+
+service $serv status | grep -i 'running\|stopped' | awk '{print $3}' | while read output;
+
+do
+
+echo $output
+
+if [ "$output" == "$sstat" ]; then
+
+ service $serv start
+
+ echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+ else
+
+ echo "$serv service is running"
+
+ fi
+
+done
+done
+```
+
+Set an executable permission to **`service-monitor-4.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-4.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-4.sh
+```
+
+Alternatively, you can use the following script.
+
+```
+# vi /opt/scripts/service-monitor-5.sh
+
+#!/bin/bash
+
+for serv in rsyslog httpd
+
+do
+
+sstat=$(pgrep $serv | wc -l )
+
+if [ $sstat -gt 0 ]
+
+then
+
+echo "$serv is running!!!"
+
+else
+
+echo "$serv is down/dead"
+
+service $serv start
+
+echo "$serv serv is UP now!!!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+fi
+
+done
+```
+
+Set an executable permission to **`service-monitor-5.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-5.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-5.sh
+```
+
+### 4) How to Automatically Start Multiple Service When it Goes Down on systemd Linux System?
+
+Use the following bash script, if you would like to start multiple services in systemd Linux System.
+
+I have added **`httpd`**` ` and **`rsyslog`**` ` services in this script but you can add the service, which you want to monitor.
+
+```
+# vi /opt/scripts/service-monitor-6.sh
+
+#!/bin/bash
+
+sstat=dead
+
+for serv in httpd rsyslog
+
+do
+
+systemctl status $serv | grep -i 'running\|dead' | awk '{print $3}' | sed 's/[()]//g' | while read output;
+
+do
+
+echo $output
+
+if [ "$output" == "$sstat" ]; then
+
+ systemctl start $serv
+
+ echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+ else
+
+ echo "$serv service is running"
+
+ fi
+
+done
+
+done
+```
+
+Set an executable permission to **`service-monitor-6.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-6.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-6.sh
+```
+
+Alternatively, you can use the following script.
+
+```
+# vi /opt/scripts/service-monitor-7.sh
+
+#!/bin/bash
+
+for serv in rsyslog httpd
+
+do
+
+sstat=$(pgrep $serv | wc -l )
+
+if [ $sstat -gt 0 ]
+
+then
+
+echo "$serv is running!!!"
+
+else
+
+echo "$serv is down/dead"
+
+systemctl start $serv
+
+echo "$serv serv is UP now!!!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+fi
+
+done
+```
+
+Set an executable permission to **`service-monitor-7.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-7.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-7.sh
+```
+
+### 5) How to Automatically Start a Service When it Goes Down on systemd and SysVinit Linux System?
+
+Use the following bash script, if you would like to start a service in systemd and SysVinit Linux System.
+
+I have added **`httpd`**` ` service in this script but you can add the service, which you want to monitor.
+
+```
+# vi /opt/scripts/service-monitor-8.sh
+
+#!/bin/bash
+
+smanager=$(ps -p1 | grep "init\|systemd" | awk '{print $4}')
+
+serv=httpd
+
+if (( $(pidof $serv | wc -l) > 0 ))
+
+then
+
+echo "$serv is running!!!"
+
+elif [ "$smanager" == "init" ]
+
+then
+
+service $serv start
+
+echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+else
+
+systemctl start $serv
+
+echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+fi
+```
+
+Set an executable permission to **`service-monitor-8.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-8.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-8.sh
+```
+
+### 6) How to Automatically Start Multiple Services When it Goes Down on systemd and SysVinit Linux System?
+
+Use the following bash script, if you would like to start multiple services in systemd and SysVinit Linux System.
+
+I have added **`httpd`**` ` and **`rsyslog`**` ` services in this script but you can add the service, which you want to monitor.
+
+```
+# vi /opt/scripts/service-monitor-9.sh
+
+#!/bin/bash
+
+smanager=$(ps -p1 | grep "init\|systemd" | awk '{print $4}')
+
+for serv in rsyslog httpd
+
+do
+
+if (( $(pgrep $serv | wc -l) > 0 ))
+
+then
+
+echo "$serv is running!!!"
+
+elif [ "$smanager" == "init" ]
+
+then
+
+service $serv start
+
+echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+else
+
+systemctl start $serv
+
+echo "$serv service is UP now.!" | mail -s "$serv service is DOWN and restarted now On $(hostname)" [email protected]
+
+fi
+
+done
+```
+
+Set an executable permission to **`service-monitor-9.sh`**` ` file.
+
+```
+$ chmod +x /opt/scripts/service-monitor-9.sh
+```
+
+Finally add a cronjob to automate this. It will run every 5 minutes.
+
+```
+# crontab -e
+
+*/5 * * * * /bin/bash /opt/scripts/service-monitor-9.sh
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-bash-script-auto-restart-services-when-down/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20190806 Linux Mint 19.2 -Tina- Released- Here-s What-s New and How to Get it.md b/sources/tech/20190806 Linux Mint 19.2 -Tina- Released- Here-s What-s New and How to Get it.md
new file mode 100644
index 0000000000..8f9371e787
--- /dev/null
+++ b/sources/tech/20190806 Linux Mint 19.2 -Tina- Released- Here-s What-s New and How to Get it.md
@@ -0,0 +1,156 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Linux Mint 19.2 “Tina” Released: Here’s What’s New and How to Get it)
+[#]: via: (https://itsfoss.com/linux-mint-19-2-release/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Linux Mint 19.2 “Tina” Released: Here’s What’s New and How to Get it
+======
+
+_**Linux Mint 19.2 “Tina” has been released. See what’s new in it and learn how to upgrade to Linux Mint 19.2.**_
+
+Recently, the Linux Mint team [announced][1] the release of Linux Mint 19 Cinnamon with significant improvements and feature additions. I’ll show you some of the main features of the new release and how to upgrade to it.
+
+### Linux Mint 19.2: What’s new?
+
+What matters the most is that Linux Mint 19.2 is also a Long Term Support release which will be supported till 2023. The new version includes updated software and lot of improvements along with added features.
+
+What are the key highlights among the added features? Let us take a look.
+
+#### Enhanced Update Manager
+
+![][2]
+
+Now, you can easily manage kernel updates from the update manager like never before. You get to know how long the kernels are supported. It is also possible to install/remove multiple kernels in a single queue.
+
+Linux Mint 19.2 also supports multiple kernel flavors, so you can switch between them when you want.
+
+![][3]
+
+In addition to all this, you can choose to automate the removal of kernels which are no longer needed and blacklist specific update packages (without blacklisting the future updates for that).
+
+#### Revamped ‘System Tools’
+
+![][4]
+
+A new tab was added to the System Tools window – “**System Information**” – which will come in handy for users to easily copy/paste their configuration onto a forum to seek support. And, the layout has been improved.
+
+#### Other Improvements
+
+With Linux 19.2, the performance has greatly improved due to optimizations done in the window manager. Their aim was to reduce the input lag and make it feel smoother.
+
+You can now configure the scrollbar to how you want it to be. Sharing files on Linux Mint 19.2 is has improved as well with Cinnamon 4.2.
+
+Linux Mint 19.2 uses Noto fonts now instead of the Ubuntu fonts.
+
+With these, there are numerous other improvements under the hood (and some customization ability) – you can check the full details in the [blog post][5] of their official website.
+
+### Linux Mint 19 vs 19.1 vs 19.2: What’s the difference?
+
+You probably already know that Linux Mint releases are based on Ubuntu long term support releases. Linux Mint 19 series is based on Ubuntu 18.04 LTS.
+
+[][6]
+
+Suggested read Five Tiny Features of Linux Mint Cinnamon I’ve Come to Love
+
+Ubuntu LTS releases get ‘point releases’ on the interval of a few months. Point release basically consists of bug fixes and security updates that have been pushed since the last release of the LTS version. This is similar to the Service Pack concept in Windows XP, if you remember it.
+
+If you are going to download Ubuntu 18.04 which was released in April, 2018 in 2019, you’ll get Ubuntu 18.04.2. The ISO image of 18.04.2 will consists of 18.04 and the bug fixes and security updates applied till 18.04.2. Imagine if there was no point releases, then right after [installing Ubuntu 18.04][7], you’ll have to install a few gigabytes of system updates. Not very convenient, right?
+
+But Linux Mint has it slightly different. Linux Mint has a major release based on Ubuntu LTS release and then it has three minor releases based on Ubuntu LTS point releases.
+
+Mint 19 was based on Ubuntu 18.04, 19.1 was based on 18.04.1 and Mint 19.2 is based on Ubuntu 18.04.2. There should be 19.3 in the Mint 19 series before the release of Mint 20 based on Ubuntu 20.04 LTS. All Mint 19.x releases are long term support releases and will get security updates till 2023.
+
+Now, if you are using Ubuntu 18.04 and keep your system updated, you’ll automatically get updated to 18.04.1, 18.04.2 etc. That’s not the case in Linux Mint.
+
+Linux Mint minor releases also consists of _feature changes_ along with bug fixes and security updates and this is the reason why updating Linux Mint 19 won’t automatically put you on 19.1.
+
+Linux Mint gives you the option if you want the new features or not. For example, Mint 19.2 has Cinnamon 4.2 and several other visual changes. If you are happy with the existing features, you can stay on Mint 19. You’ll still get the necessary security and maintenance updates on Mint 19 till 2023.
+
+Now that you understand the concept of minor releases and want the latest minor release, let’s see how to upgrade to Mint 19.2.
+
+### Linux Mint 19.2: How to Upgrade?
+
+No matter whether you have Linux Mint 19.1 or 19, you can follow these steps to [upgrade Linux Mint version][8].
+
+[][9]
+
+Suggested read Fedora 24 released!
+
+**Note**: _You should consider making a system snapshot (just in case) for backup. In addition, the Linux Mint team advises you to disable the screensaver and upgrade Cinnamon spices (if installed) from the System settings._
+
+![][10]
+
+ 1. Launch the Update Manager.
+ 2. Now, refresh it to load up the latest available updates (or you can change the mirror if you want).
+ 3. Once done, simply click on the Edit button to find “**Upgrade to Linux Mint 19.2 Tina**” button.
+ 4. Finally, just follow the on-screen instructions to easily update it.
+
+
+
+Based on your internet connection, it should take anything between a couple of minutes to 30 minutes.
+
+#### Don’t see Mint 19.2 update yet? Here’s what you can do
+
+If you don’t see the option to upgrade to Linux Mint 19.2 Tina, don’t lose hope. Here are a couple of things you can do.
+
+**Step 1: Make sure to use mint-upgrade-info version 1.1.3**
+
+Make sure that mint-upgrade-info is updated to version 1.1.3. You can try the install command that will update it to a newer version (if there is any).
+
+```
+sudo apt install mint-upgrade-info
+```
+
+**Step 2: Switch to default software sources**
+
+Chances are that you are using a mirror closer to you to get faster software downloads. But this could cause a problem as the mirrors might not have the new upgrade info yet.
+
+Go to Software Source and change the sources to default. Now run the update manager again and see if Mint 19.2 upgrade is available.
+
+**Wrapping Up**
+
+Linux Mint 19.2 is a solid upgrade. The new feature additions are very useful and it’s always good to see them working on the performance (so that it consumes less RAM) and appears to be smoother.
+
+What do you think about the latest release – Linux Mint 19.2 “Tina”? Have you upgraded yet? If yes, how is your experience so far? Feel free to let us know in the comments below.
+
+![][11]
+
+### Ankush Das
+
+co-author
+
+![][12]
+
+### Abhishek Prakash
+
+co-author
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/linux-mint-19-2-release/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://blog.linuxmint.com/?p=3786
+[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-mint-tina-kernel.png?resize=800%2C523&ssl=1
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-mint-tina-update.png?resize=800%2C515&ssl=1
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-mint-tina.jpg?ssl=1
+[5]: https://www.linuxmint.com/rel_tina_cinnamon_whatsnew.php
+[6]: https://itsfoss.com/tiny-features-linux-mint-cinnamon/
+[7]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
+[8]: https://itsfoss.com/upgrade-linux-mint-version/
+[9]: https://itsfoss.com/fedora-24-released/
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/mintupgrade.png?ssl=1
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/ankush_das.jpg?ssl=1
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2016/11/14883680_10154845158472952_6433939564474062315_o.jpg?ssl=1
diff --git a/translated/tech/20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md b/translated/tech/20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md
new file mode 100644
index 0000000000..792de128c6
--- /dev/null
+++ b/translated/tech/20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md
@@ -0,0 +1,86 @@
+[#]: collector: (lujun9972)
+[#]: translator: (zionfuo)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8])
+[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/)
+[#]: author: (editor https://www.ostechnix.com/author/editor/)
+
+区块链2.0:Hyperledger项目简介(八)
+======
+
+![Introduction To Hyperledger Project][1]
+
+一旦,一个新技术平台在积极发展和商业利益方面达到了普及的门槛,全球的主要公司和小型的初创企业都急于抓住这块蛋糕。在当时**Linux**就是这样的平台。一旦实现了其应用程序的普及,个人、公司和机构就开始对其表现出兴趣,到2000年,**Linux基金会**成立了。
+
+Linux 基金会旨在通过赞助他们的开发团队来制定规范和开发Linux作为平台。Linux基金会是一个由软件和IT巨头(如微软、甲骨文、三星、思科、 IBM 、英特尔等[[1][7]]支持的非营利组织。这不包括为改善平台而提供服务的数百名个人开发者。多年来,Linux基金会已经开展了许多项目。**Hyperledger**项目是迄今为止发展最快的项目。
+
+在将技术推进至可用且有用的方面上,这种联合主导的开发具有很多优势。为大型项目提供开发标准、库和所有后端协议既昂贵又资源密集型,而且不会从中产生丝毫收入。因此, 对于公司来说,通过支持这些组织来汇集他们的资源来开发常见的那些 “烦人” 部分是有很意义的,以及随后完成这些标准部分的工作以简单地即插即用和定制他们的产品。除了模型的经济性之外,这种合作努力还产生了标准,使其容易使用和集成到优秀的产品和服务中。
+
+上述联盟模式,在曾经或当下使WiFi (The Wi-Fi alliance) 、移动电话等标准在制定方面得到了创新。
+
+
+### Hyperledger (HLP) 项目简介
+
+Hyperledger 项目于 2015年12月由 Linux 基金会启动,目前是其孵化的增长最快的项目之一。它是一个伞式组织(umbrella organization),用于合作开发和推进基于[区块链][2]的分布式账本技术 (DLT) 的工具和标准。支持该项目的主要行业参与者包括**IBM**、**英特尔**和**SAP Ariba**[等][3]。HLP 旨在为个人和公司创建框架,以便根据需要创建共享和封闭的区块链,以满足他们自己的需求。设计原则是开发一个专注于隐私和未来可审计性的全球可部署、可扩展、强大的区块链平台。
+
+### 开发目标和构造: 即插即用
+
+虽然面向企业的平台有以太坊联盟之类的产品,但根据定义,HLP是面向企业的,并得到行业巨头的支持,他们在HLP旗下的许多模块中做出贡献并进一步发展。还孵化开发的周边项目,并这些创意项目推向公众。Hyperledger 项目的成员贡献了他们自己的力量,例如IBM如何为协作开发贡献他们的Fabric平台。该代码库由IBM在其内部研究和开发,并开源出来供所有成员使用。
+
+这些过程使得 HLP 中的模块具有高度灵活的插件框架,这将支持企业设置中的快速开发和推出。此外,默认情况下,其他类似的平台是开放的**无需许可链**(permission-less blockchain)或是**公有链**(public blockchain),HLP模块本身就是支持通过调试可以适应特定的功能。
+
+在这篇关于[公有链和私有链][4]的比较入门文章中,更多地涵盖了公有链和私有链的差异和用例。
+
+根据项目执行董事**Brian Behlendorf**的说法,Hyperledger项目的使命有四个。
+
+分别是:
+
+ 1. 创建企业级DLT框架和标准,任何人都可以移植以满足其特定的工业或个人需求。
+ 2. 创建一个强大的开源社区来帮助生态系统。
+ 3. 促进所述生态系统的行业成员(如成员公司)的参与。
+ 4. 为HLP社区提供中立且无偏见的基础设施,以收集和分享相关的更新和发展。
+
+可以在这里访问[原始文档][5]。
+
+### HLP的架构
+
+HLP由12个项目组成,这些项目被归类为独立的模块,每个项目通常都是独立构建和工作的,以开发他们的模块。在孵化之前,首先对它们的能力和生存能力进行研究。组织的任何成员都可以提出增加的建议。在项目孵化后,就会出现积极开发,然后才会推出。这些模块之间的互操作性被赋予了很高的优先级,因此这些组之间的定期通信由社区维护。目前,这些项目中有4个被归类为活动项目。活动标签意味着这些标签已经准备好使用,但还没有准备好发布重大版本。这4个模块可以说是推动区块链革命的最重要或最基本的模块。稍后,我们将详细介绍各个模块及其功能。然而,Hyperledger Fabric平台的简要描述,可以说是其中最受欢迎的。
+
+### Hyperledger Fabric
+
+**Hyperledger Fabric**[2]是一个完全开源的、基于区块链的许可 (非公开) DLT 平台,设计时考虑了企业的使用。该平台提供了适合企业环境的功能和结构。它是高度模块化的,允许开发人员在不同的一致协议、**链码协议**([智能合约][6]) 或身份管理系统等中进行选择。这是一个基于区块链的许可平台,利用身份管理系统,这意味着参与者将知道彼此在企业环境中需要的身份。Fabric允许以各种主流编程语言 (包括Java、Javascript、Go等) 开发智能合约(“链码”,是Hyperledger团队使用的术语)。这使得机构和企业可以利用他们在该领域的现有人才,而无需雇佣或重新培训开发人员来开发他们自己的智能合约。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。可插拔性能、身份管理系统、数据库管理系统、共识平台等是Fabric的其他功能,这些功能使它在竞争中保持领先地位。
+
+
+### 结论
+
+诸如Hyperledger Fabric平台这样的项目能够在主流用例中更快地采用区块链技术。Hyperledger社区结构本身支持开放治理原则,并且由于所有项目都是作为开源平台引导的,因此这提高了团队在履行承诺时表现出来的安全性和责任感。
+
+由于此类项目的主要应用涉及与企业合作及进一步开发平台和标准,因此Hyperledger项目目前在其他类似项目前面处于有利地位。
+
+**参考资料**
+
+ * **[1][Samsung takes a seat with Intel and IBM at the Linux Foundation | TheINQUIRER][7]**
+ * **[2] E. Androulaki et al., “Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains,” 2018.**
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
+
+作者:[editor][a]
+选题:[lujun9972][b]
+译者:[zionfuo](https://github.com/zionfuo)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Introduction-To-Hyperledger-Project-720x340.png
+[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
+[3]: https://www.hyperledger.org/members
+[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
+[5]: http://www.hitachi.com/rev/archive/2017/r2017_01/expert/index.html
+[6]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
+[7]: https://www.theinquirer.net/inquirer/news/2182438/samsung-takes-seat-intel-ibm-linux-foundation
diff --git a/translated/tech/20190711 What is a golden image.md b/translated/tech/20190711 What is a golden image.md
new file mode 100644
index 0000000000..fee6d53874
--- /dev/null
+++ b/translated/tech/20190711 What is a golden image.md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What is a golden image?)
+[#]: via: (https://opensource.com/article/19/7/what-golden-image)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+什么是黄金镜像?
+======
+
+> 正在开发一个将广泛分发的项目吗?了解一下黄金镜像吧,以便在出现问题时轻松恢复到“完美”状态。
+
+![Gold star][1]
+
+如果你正在进行质量保证、系统管理或媒体制作(没想到吧),你可能听说过正式版、黄金镜像或母片等等这一术语的某些变体。这个术语已经进入了每个参与创建一个**完美**模具的人的集体意识,然后从该模具中产生许多复制品。母片或黄金镜像就是:一种虚拟模具,你可以从中打造可分发的模型。
+
+在媒体制作中,这就是全体人员努力开发母片的过程。这个最终产品是独一无二的。它看起来和听起来像是能够看和听的最好的电影或专辑(或其他任何东西)。可以制作和压缩该母片的副本并发送给急切的公众。
+
+在软件中,与该术语相关联的也是类似的思路。一旦软件经过编译和一再测试,完美的构建就会被声明为**黄金版本**。不允许对它进一步更改,并且所有可分发的副本都是从此母片生成的(当软件是用 CD 或 DVD 分发时,这实际上意味着母盘)。
+
+在系统管理中,你可能会遇到你的机构所选的操作系统的黄金镜像,其中的重要设置已经就绪,如安装好的虚拟专用网络(VPN)证书、设置好的电子邮件收件服务器的邮件客户端,等等。同样,你可能也会在虚拟机(VM)的世界中听到这个术语,其中精心配置的虚拟驱动器的黄金镜像是所有克隆的新虚拟机的源头。
+
+### GNOME Boxes
+
+正式版的概念很简单,但往往忽视将其付诸实践。有时,你的团队很高兴能够达成他们的目标,但没有人停下来考虑将这些成就指定为权威版本。在其他时候,没有简单的机制来做到这一点。
+
+黄金镜像等同于部分历史保存和提前备份计划。一旦你制作了一个完美的模型,无论你正在努力做什么,你都应该为自己保留这项工作,因为它不仅标志着你的进步,而且如果你继续工作时遇到问题,它就会成为一个后备。
+
+[GNOME Boxes][2],是随 GNOME 桌面一起提供的虚拟化平台,可以提供简单的演示。如果你从未使用过GNOME Boxes,你可以在 Alan Formy-Duval 的文章 [GNOME Boxes 入门][3]中学习它的基础知识。
+
+想象一下,你使用 GNOME Boxes 创建虚拟机,然后将操作系统安装到该 VM 中。现在,你想要制作一个黄金镜像。GNOME Boxes 已经率先摄取了你的安装快照,可以作为库存的操作系统安装的黄金镜像。
+
+打开 GNOME Boxes 并在仪表板视图中,右键单击任何虚拟机,然后选择**属性**。 在**属性**窗口中,选择**快照**选项卡。由 GNOME Boxes 自动创建的第一个快照是“Just Installed”。顾名思义,这是你最初安装到虚拟机上的操作系统。
+
+![The Just Installed snapshot, or initial golden image, in GNOME Boxes.][4]
+
+如果你的虚拟机变成了你不想要的状态,你可以随时恢复为“Just Installed”镜像。
+
+当然,如果你已经为自己调整了环境,那么在安装后恢复操作系统将是一个极大的工程。这就是为什么虚拟机的常见工作流程是:首先安装操作系统,然后根据你的要求或偏好修改它,然后拍摄快照,将该快照声明为配置好的黄金镜像。例如,如果你使用虚拟机进行 [Flatpak][5] 打包,那么在初始安装之后,你可以添加软件和 Flatpak 开发工具,构建工作环境,然后拍摄快照。创建快照后,你可以重命名该虚拟机以指示其真实用途。
+
+要重命名虚拟机,请在仪表板视图中右键单击其缩略图,然后选择**属性**。在**属性**窗口中,输入新名称:
+
+![Renaming your VM image in GNOME Boxes.][6]
+
+要克隆你的黄金映像,请右键单击 GNOME Boxes 界面中的虚拟机,然后选择**克隆**。
+
+![Cloning your golden image in GNOME Boxes.][7]
+
+你现在可以从黄金映像的最新快照中克隆了。
+
+### 黄金镜像
+
+很少有学科无法从黄金镜像中受益。无论你是在 [Git][8] 中标记版本、在 Boxes 中拍摄快照、出版原型黑胶唱片、打印书籍以进行审核、设计用于批量生产的丝网印刷、还是制作文字模具,到处都是各种原型。这只是现代技术让我们人类更聪明而不是更努力的另一种方式,因此为你的项目制作一个黄金镜像,并根据需要随时生成克隆。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/7/what-golden-image
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/origami_star_gold_best_top.jpg?itok=aEc0eutt (Gold star)
+[2]: https://wiki.gnome.org/Apps/Boxes
+[3]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
+[4]: https://opensource.com/sites/default/files/uploads/snapshots.jpg (The Just Installed snapshot, or initial golden image.)
+[5]: https://opensource.com/business/16/8/flatpak
+[6]: https://opensource.com/sites/default/files/uploads/boxes-rename_0.jpg (Renaming your virtual machine in GNOME Boxes.)
+[7]: https://opensource.com/sites/default/files/uploads/boxes-clone.jpg (Cloning your golden image in GNOME Boxes.)
+[8]: https://git-scm.com
diff --git a/translated/tech/20190801 5 Free Partition Managers for Linux.md b/translated/tech/20190801 5 Free Partition Managers for Linux.md
new file mode 100644
index 0000000000..d85a0f21f9
--- /dev/null
+++ b/translated/tech/20190801 5 Free Partition Managers for Linux.md
@@ -0,0 +1,124 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (5 Free Partition Managers for Linux)
+[#]: via: (https://itsfoss.com/partition-managers-linux/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+5 个免费的 Linux 分区管理器
+======
+
+_ **以下是我们推荐的 Linux 分区工具。它们能让你删除、添加、微调 Linux 系统上的磁盘分区或分区大小。** _
+
+通常,你在安装操作系统时决定磁盘分区。但是,如果你需要在安装后的某个时间修改分区,该怎么办?你无法会到系统安装页面。因此,这就需要分区管理器(或准确地说是磁盘分区管理器)上场了。
+
+在大多数情况下,你无需单独安装分区管理器,因为它已预先安装。此外,值得注意的是,你可以选择基于命令行或有 GUI 的分区管理器。
+
+注意!
+
+磁盘分区是一项有风险的任务。除非绝对必要,否则不要这样做。
+如果你使用的是基于命令行的分区工具,那么需要学习完成任务的命令。否则,你可能最终会擦除整个磁盘。
+
+### Linux 中的 5 个管理磁盘分区的工具
+
+![][1]
+
+下面的列表没有特定的排名顺序。大多数分区工具应该存在于 Linux 发行版的仓库中。
+
+#### GParted
+
+![GParted][2]
+
+这可能是 Linux 发行版中最流行的基于 GUI 的分区管理器。你可能已在某些发行版中预装它。如果还没有,只需在软件中心搜索它即可完成安装。
+
+它会在启动时直接提示你以 root 用户进行身份验证。所以,你根本不需要在这里使用终端。身份验证后,它会分析设备,然后让你调整磁盘分区。如果发生数据丢失或意外删除文件,你还可以找到“尝试数据救援”的选项。
+
+[GParted][3]
+
+#### GNOME Disks
+
+![Gnome Disks][4]
+
+一个基于 GUI 的分区管理器,随 Ubuntu 或任何基于 Ubuntu 的发行版(如 Zorin OS)一起出现。
+
+它能让你删除、添加、调整大小和微调分区。如果还有疑问,它甚至可以帮助你[在 Ubuntu 中格式化 USB][6]。
+
+你甚至可以借助此工具尝试修复分区。它的选项还包括编辑文件系统、创建分区镜像、还原镜像以及对分区进行基准测试。
+
+[GNOME Disks][7]
+
+#### KDE Partition Manager
+
+![Kde Partition Manager][8]
+
+KDE Partition Manager 应该预装在基于 KDE 的 Linux 发行版上。但是,如果没有,你可以在软件中心搜索并轻松安装它。
+
+
+如果你没有预装它,那么可能会在尝试启动时通知你没有管理权限。没有管理员权限,你无法做任何事情。因此,在这种情况下,请输入以下命令:
+
+```
+sudo partitionmanager
+```
+
+它将扫描你的设备,然后你就可以创建、移动、复制、删除和调整分区大小。你还可以导入/导出分区表及使用其他许多调整选项。
+
+[KDE Partition Manager][9]
+
+#### Fdisk (命令行)
+
+![Fdisk][10]
+
+[fdisk][11] 是一个命令行程序,它在每个类 Unix 的系统中都有。不要担心,即使它需要你启动终端并输入命令,但这并不是很困难。但是,如果你在使用基于文本的程序时感到困惑,那么你应该继续使用上面提到的 GUI 程序。它们都做同样的事情。
+
+要启动 fdisk,你必须是 root 用户并指定管理分区的设备。以下是该命令的示例:
+
+```
+sudo fdisk /dev/sdc
+```
+
+你可以参考 [Linux 文档项目的维基页面][12]以获取命令列表以及有关其工作原理的更多详细信息。
+
+#### GNU Parted (命令行)
+
+![Gnu Parted][13]
+
+这是另一个在你 Linux 发行版上预安装的命令行程序。你需要输入下面的命令启动:
+
+```
+sudo parted
+```
+
+**总结**
+
+我不会忘了说 [QtParted][15] 是分区管理器的替代品之一。但它已经几年没有维护,因此我不建议使用它。
+
+你如何看待这里提到的分区管理器?我有错过你最喜欢的吗?让我知道,我将根据你的建议更新这个 Linux 分区管理器列表。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/partition-managers-linux/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/disk-partitioning-tools-linux.jpg?resize=800%2C450&ssl=1
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/g-parted.png?ssl=1
+[3]: https://gparted.org/
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/gnome-disks.png?ssl=1
+[6]: https://itsfoss.com/format-usb-drive-sd-card-ubuntu/
+[7]: https://wiki.gnome.org/Apps/Disks
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/kde-partition-manager.jpg?resize=800%2C404&ssl=1
+[9]: https://kde.org/applications/system/org.kde.partitionmanager
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/fdisk.jpg?fit=800%2C496&ssl=1
+[11]: https://en.wikipedia.org/wiki/Fdisk
+[12]: https://www.tldp.org/HOWTO/Partition/fdisk_partitioning.html
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/gnu-parted.png?fit=800%2C559&ssl=1
+[15]: http://qtparted.sourceforge.net/