diff --git a/published/20190826 How RPM packages are made- the source RPM.md b/published/20190826 How RPM packages are made- the source RPM.md
new file mode 100644
index 0000000000..222ec93038
--- /dev/null
+++ b/published/20190826 How RPM packages are made- the source RPM.md
@@ -0,0 +1,235 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11527-1.html)
+[#]: subject: (How RPM packages are made: the source RPM)
+[#]: via: (https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/)
+[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
+
+RPM 包是如何从源 RPM 制作的
+======
+
+![][1]
+
+在[上一篇文章中,我们研究了什么是 RPM 软件包][2]。它们是包含文件和元数据的档案文件。当安装或卸载 RPM 时,此元数据告诉 RPM 在哪里创建或删除文件。正如你将在上一篇文章中记住的,元数据还包含有关“依赖项”的信息,它可以是“运行时”或“构建时”的依赖信息。
+
+例如,让我们来看看 `fpaste`。你可以使用 `dnf` 下载该 RPM。这将下载 Fedora 存储库中可用的 `fpaste` 最新版本。在 Fedora 30 上,当前版本为 0.3.9.2:
+
+```
+$ dnf download fpaste
+
+...
+fpaste-0.3.9.2-2.fc30.noarch.rpm
+```
+
+由于这是个构建 RPM,因此它仅包含使用 `fpaste` 所需的文件:
+
+```
+$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.noarch.rpm
+/usr/bin/fpaste
+/usr/share/doc/fpaste
+/usr/share/doc/fpaste/README.rst
+/usr/share/doc/fpaste/TODO
+/usr/share/licenses/fpaste
+/usr/share/licenses/fpaste/COPYING
+/usr/share/man/man1/fpaste.1.gz
+```
+
+### 源 RPM
+
+在此链条中的下一个环节是源 RPM。Fedora 中的所有软件都必须从其源代码构建。我们不包括预构建的二进制文件。因此,要制作一个 RPM 文件,RPM(工具)需要:
+
+* 给出必须要安装的文件,
+* 例如,如果要编译出这些文件,则告诉它们如何生成这些文件,
+* 告知必须在何处安装这些文件,
+* 该特定软件需要其他哪些依赖才能正常工作。
+
+源 RPM 拥有所有这些信息。源 RPM 与构建 RPM 相似,但顾名思义,它们不包含已构建的二进制文件,而是包含某个软件的源文件。让我们下载 `fpaste` 的源 RPM:
+
+```
+$ dnf download fpaste --source
+
+...
+fpaste-0.3.9.2-2.fc30.src.rpm
+```
+
+注意文件的结尾是 `src.rpm`。所有的 RPM 都是从源 RPM 构建的。你也可以使用 `dnf` 轻松检查“二进制” RPM 的源 RPM:
+
+```
+$ dnf repoquery --qf "%{SOURCERPM}" fpaste
+fpaste-0.3.9.2-2.fc30.src.rpm
+```
+
+另外,由于这是源 RPM,因此它不包含构建的文件。相反,它包含有关如何从中构建 RPM 的源代码和指令:
+
+```
+$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.src.rpm
+fpaste-0.3.9.2.tar.gz
+fpaste.spec
+```
+
+这里,第一个文件只是 `fpaste` 的源代码。第二个是 spec 文件。spec 文件是个配方,可告诉 RPM(工具)如何使用源 RPM 中包含的源代码创建 RPM(档案文件)— 它包含 RPM(工具)构建 RPM(档案文件)所需的所有信息。在 spec 文件中。当我们软件包维护人员添加软件到 Fedora 中时,我们大部分时间都花在编写和完善 spec 文件上。当软件包需要更新时,我们会回过头来调整 spec 文件。你可以在 的源代码存储库中查看 Fedora 中所有软件包的 spec 文件。
+
+请注意,一个源 RPM 可能包含构建多个 RPM 的说明。`fpaste` 是一款非常简单的软件,一个源 RPM 生成一个“二进制” RPM。而 Python 则更复杂。虽然只有一个源 RPM,但它会生成多个二进制 RPM:
+
+```
+$ sudo dnf repoquery --qf "%{SOURCERPM}" python3
+python3-3.7.3-1.fc30.src.rpm
+python3-3.7.4-1.fc30.src.rpm
+
+$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-devel
+python3-3.7.3-1.fc30.src.rpm
+python3-3.7.4-1.fc30.src.rpm
+
+$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-libs
+python3-3.7.3-1.fc30.src.rpm
+python3-3.7.4-1.fc30.src.rpm
+
+$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-idle
+python3-3.7.3-1.fc30.src.rpm
+python3-3.7.4-1.fc30.src.rpm
+
+$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-tkinter
+python3-3.7.3-1.fc30.src.rpm
+python3-3.7.4-1.fc30.src.rpm
+```
+
+用 RPM 行话来讲,“python3” 是“主包”,因此该 spec 文件将称为 `python3.spec`。所有其他软件包均为“子软件包”。你可以下载 python3 的源 RPM,并查看其中的内容。(提示:补丁也是源代码的一部分):
+
+```
+$ dnf download --source python3
+python3-3.7.4-1.fc30.src.rpm
+
+$ rpm -qpl ./python3-3.7.4-1.fc30.src.rpm
+00001-rpath.patch
+00102-lib64.patch
+00111-no-static-lib.patch
+00155-avoid-ctypes-thunks.patch
+00170-gc-assertions.patch
+00178-dont-duplicate-flags-in-sysconfig.patch
+00189-use-rpm-wheels.patch
+00205-make-libpl-respect-lib64.patch
+00251-change-user-install-location.patch
+00274-fix-arch-names.patch
+00316-mark-bdist_wininst-unsupported.patch
+Python-3.7.4.tar.xz
+check-pyc-timestamps.py
+idle3.appdata.xml
+idle3.desktop
+python3.spec
+```
+
+### 从源 RPM 构建 RPM
+
+现在我们有了源 RPM,并且其中有什么内容,我们可以从中重建 RPM。但是,在执行此操作之前,我们应该设置系统以构建 RPM。首先,我们安装必需的工具:
+
+```
+$ sudo dnf install fedora-packager
+```
+
+这将安装 `rpmbuild` 工具。`rpmbuild` 需要一个默认布局,以便它知道源 RPM 中每个必需组件的位置。让我们看看它们是什么:
+
+```
+# spec 文件将出现在哪里?
+$ rpm -E %{_specdir}
+/home/asinha/rpmbuild/SPECS
+
+# 源代码将出现在哪里?
+$ rpm -E %{_sourcedir}
+/home/asinha/rpmbuild/SOURCES
+
+# 临时构建目录是哪里?
+$ rpm -E %{_builddir}
+/home/asinha/rpmbuild/BUILD
+
+# 构建根目录是哪里?
+$ rpm -E %{_buildrootdir}
+/home/asinha/rpmbuild/BUILDROOT
+
+# 源 RPM 将放在哪里?
+$ rpm -E %{_srcrpmdir}
+/home/asinha/rpmbuild/SRPMS
+
+# 构建的 RPM 将放在哪里?
+$ rpm -E %{_rpmdir}
+/home/asinha/rpmbuild/RPMS
+```
+
+我已经在系统上设置了所有这些目录:
+
+```
+$ cd
+$ tree -L 1 rpmbuild/
+rpmbuild/
+├── BUILD
+├── BUILDROOT
+├── RPMS
+├── SOURCES
+├── SPECS
+└── SRPMS
+
+6 directories, 0 files
+```
+
+RPM 还提供了一个为你全部设置好的工具:
+
+```
+$ rpmdev-setuptree
+```
+
+然后,确保已安装 `fpaste` 的所有构建依赖项:
+
+```
+sudo dnf builddep fpaste-0.3.9.2-3.fc30.src.rpm
+```
+
+对于 `fpaste`,你只需要 Python,并且它肯定已经安装在你的系统上(`dnf` 也使用 Python)。还可以给 `builddep` 命令一个 spec 文件,而不是源 RPM。在手册页中了解更多信息:
+
+```
+$ man dnf.plugin.builddep
+```
+
+现在我们有了所需的一切,从源 RPM 构建一个 RPM 就像这样简单:
+
+```
+$ rpmbuild --rebuild fpaste-0.3.9.2-3.fc30.src.rpm
+..
+..
+
+$ tree ~/rpmbuild/RPMS/noarch/
+/home/asinha/rpmbuild/RPMS/noarch/
+└── fpaste-0.3.9.2-3.fc30.noarch.rpm
+
+0 directories, 1 file
+```
+
+`rpmbuild` 将安装源 RPM 并从中构建你的 RPM。现在,你可以使用 `dnf` 安装 RPM 以使用它。当然,如前所述,如果你想在 RPM 中进行任何更改,则必须修改 spec 文件,我们将在下一篇文章中介绍 spec 文件。
+
+### 总结
+
+总结一下这篇文章有两点:
+
+* 我们通常安装使用的 RPM 是包含软件的构建版本的 “二进制” RPM
+* 构建 RPM 来自于源 RPM,源 RPM 包括用于生成二进制 RPM 所需的源代码和规范文件。
+
+如果你想开始构建 RPM,并帮助 Fedora 社区维护我们提供的大量软件,则可以从这里开始:
+
+如有任何疑问,请发邮件到 [Fedora 开发人员邮件列表][3],我们随时乐意为你提供帮助!
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/
+
+作者:[Ankur Sinha "FranciscoD"][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/ankursinha/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
+[2]: https://linux.cn/article-11452-1.html
+[3]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
diff --git a/published/20190828 Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word.md b/published/20190828 Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word.md
new file mode 100644
index 0000000000..70abe7d3c9
--- /dev/null
+++ b/published/20190828 Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word.md
@@ -0,0 +1,84 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11529-1.html)
+[#]: subject: (Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word)
+[#]: via: (https://itsfoss.com/gimp-fork-glimpse/)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+由于 GIMP 是令人反感的字眼,有人将它复刻了
+======
+
+在开源应用程序世界中,当社区成员希望以与其他人不同的方向来开发应用程序时,复刻是很常见的。最新的具有新闻价值的一个复刻称为 [Glimpse][1],旨在解决用户在使用 [GNU 图像处理程序][2](通常称为 GIMP)时遇到的某些问题。
+
+### 为什么创建 GIMP 的复刻?
+
+![][3]
+
+当你访问 Glimpse 应用的[主页][1]时,它表示该项目的目标是“尝试其他设计方向并修复长期存在的错误。”这听起来并不奇怪。但是,如果你开始阅读该项目的博客文章,则是另外一种印象。
+
+根据该项目的[第一篇博客文章][4],他们创建了这个复刻是因为他们不喜欢 GIMP 这个名称。根据该帖子,“我们中的许多人不认为该软件的名称适用于所有用户,并且在拒绝该项目的 13 年后,我们决定复刻!”
+
+如果你想知道为什么这些人认为 GIMP 令人讨厌,他们在[关于页面][5]中回答该问题:
+
+> “如果英语不是你的母语,那么你可能没有意识到 ‘gimp’ 一词有问题。在某些国家,这被视为针对残疾人的侮辱和针对不受欢迎儿童的操场侮辱。它也可以与成年人同意的某些‘天黑后’活动联系起来。”
+
+他们还指出,他们并没有使这一举动脱离政治正确或过于敏感。“除了可能给边缘化社区带来的痛苦外,我们当中许多人都有过倡导自由软件的故事,比如在 GNU 图像处理程序没有被专业环境中的老板或同事视为可选项这件事上。”
+
+他们似乎在回答许多质疑,“不幸的是,我们不得不复刻整个项目来更改其名称,我们认为有关此问题的讨论陷入了僵局,而这是最积极的前进方向。 ”
+
+看起来 Glimpse 这个名称不是确定不变的。他们的 GitHub 页面上有个关于可能选择其他名称的[提案][7]。也许他们应该放弃 GNU 这个词,我认为 IMP 这个词没有不好的含义。(LCTT 译注:反讽)
+
+### 分叉之路
+
+![GIMP 2.10][8]
+
+[GIMP][6] 已经存在了 20 多年,因此任何形式的复刻都是一项艰巨的任务。当前,[他们正在计划][9]首先在 2019 年 9 月发布 Glimpse 0.1。这将是一个软复刻,这意味着在迁移到新身份时的更改将主要是装饰性的。(LCTT 译注:事实上到本译文发布时,该项目仍然处于蛋疼的 0.1 beta,也许 11 月,也许 12 月,才能发布 0.1 的正式版本。)
+
+Glimpse 1.0 将是一个硬复刻,他们将积极更改代码库并将其添加到代码库中。他们想将 1.0 移植到 GTK3 并拥有自己的文档。他们估计,直到 2020 年 GIMP 3 发布之后才能做到。
+
+除了 1.0,Glimpse 团队还计划打响自己的名声。他们计划进行“前端 UI 重写”。他们目前正在讨论[改用哪种语言][10]。D 和 Rust 似乎有很多支持者。随着时间的流逝,他们也[希望][4]“添加新功能以解决普通用户的抱怨”。
+
+### 最后的思考
+
+我过去曾经使用过一点 GIMP,但从来没有对它的名称感到困扰。老实说,我很长一段时间都不知道这意味着什么。有趣的是,当我在 Wikipedia 上搜索 GIMP 时,看到了一个 [GIMP 项目][11]的条目,这是纽约的一个现代舞蹈项目,其中包括残疾人。我想 gimp 并不是每个人视为一个贬低词汇的。
+
+对我来说,更改名称似乎需要大量工作。似乎改写 UI 的想法会使项目看起来更有价值一些。我想知道他们是否会调整它以带来更经典的 UI,例如[使用 Ctrl + S 保存到 GIMP][12] / Glimpse。让我们拭目以待。
+
+如果你对该项目感兴趣,可以在 [Twitter][14] 上关注他们,查看其 [GitHub 帐户][15],或查看其 [Patreon 页面][16]。
+
+你觉得被 GIMP 名称冒犯了吗?你是否认为值得对应用程序进行复刻,以便你可以对其进行重命名?在下面的评论中让我们知道。
+
+如果你觉得这篇文章有趣,请花一点时间在社交媒体、Hacker News 或 [Reddit][17] 上分享。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gimp-fork-glimpse/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://getglimpse.app/
+[2]: https://www.gimp.org/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/gimp-fork-glimpse.png?resize=800%2C450&ssl=1
+[4]: https://getglimpse.app/posts/so-it-begins/
+[5]: https://getglimpse.app/about/
+[6]: https://itsfoss.com/gimp-2-10-release/
+[7]: https://github.com/glimpse-editor/Glimpse/issues/92
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/gimp-screenshot.jpg?resize=800%2C508&ssl=1
+[9]: https://getglimpse.app/posts/six-week-checkpoint/
+[10]: https://github.com/glimpse-editor/Glimpse/issues/70
+[11]: https://en.wikipedia.org/wiki/The_Gimp_Project
+[12]: https://itsfoss.com/how-to-solve-gimp-2-8-does-not-save-in-jpeg-or-png-format/
+[13]: https://itsfoss.com/wps-office-2016-linux/
+[14]: https://twitter.com/glimpse_editor
+[15]: https://github.com/glimpse-editor/Glimpse
+[16]: https://www.patreon.com/glimpse
+[17]: https://reddit.com/r/linuxusersgroup
diff --git a/published/20140510 Managing Digital Files (e.g., Photographs) in Files and Folders.md b/published/201910/20140510 Managing Digital Files (e.g., Photographs) in Files and Folders.md
similarity index 100%
rename from published/20140510 Managing Digital Files (e.g., Photographs) in Files and Folders.md
rename to published/201910/20140510 Managing Digital Files (e.g., Photographs) in Files and Folders.md
diff --git a/published/201910/20180706 Building a Messenger App- OAuth.md b/published/201910/20180706 Building a Messenger App- OAuth.md
new file mode 100644
index 0000000000..62b85717d5
--- /dev/null
+++ b/published/201910/20180706 Building a Messenger App- OAuth.md
@@ -0,0 +1,444 @@
+[#]: collector: (lujun9972)
+[#]: translator: (PsiACE)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11510-1.html)
+[#]: subject: (Building a Messenger App: OAuth)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-oauth/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+构建一个即时消息应用(二):OAuth
+======
+
+[上一篇:模式](https://linux.cn/article-11396-1.html)。
+
+在这篇帖子中,我们将会通过为应用添加社交登录功能进入后端开发。
+
+社交登录的工作方式十分简单:用户点击链接,然后重定向到 GitHub 授权页面。当用户授予我们对他的个人信息的访问权限之后,就会重定向回登录页面。下一次尝试登录时,系统将不会再次请求授权,也就是说,我们的应用已经记住了这个用户。这使得整个登录流程看起来就和你用鼠标单击一样快。
+
+如果进一步考虑其内部实现的话,过程就会变得复杂起来。首先,我们需要注册一个新的 [GitHub OAuth 应用][2]。
+
+这一步中,比较重要的是回调 URL。我们将它设置为 `http://localhost:3000/api/oauth/github/callback`。这是因为,在开发过程中,我们总是在本地主机上工作。一旦你要将应用交付生产,请使用正确的回调 URL 注册一个新的应用。
+
+注册以后,你将会收到“客户端 id”和“安全密钥”。安全起见,请不要与任何人分享他们 👀
+
+顺便让我们开始写一些代码吧。现在,创建一个 `main.go` 文件:
+
+```
+package main
+
+import (
+ "database/sql"
+ "fmt"
+ "log"
+ "net/http"
+ "net/url"
+ "os"
+ "strconv"
+
+ "github.com/gorilla/securecookie"
+ "github.com/joho/godotenv"
+ "github.com/knq/jwt"
+ _ "github.com/lib/pq"
+ "github.com/matryer/way"
+ "golang.org/x/oauth2"
+ "golang.org/x/oauth2/github"
+)
+
+var origin *url.URL
+var db *sql.DB
+var githubOAuthConfig *oauth2.Config
+var cookieSigner *securecookie.SecureCookie
+var jwtSigner jwt.Signer
+
+func main() {
+ godotenv.Load()
+
+ port := intEnv("PORT", 3000)
+ originString := env("ORIGIN", fmt.Sprintf("http://localhost:%d/", port))
+ databaseURL := env("DATABASE_URL", "postgresql://root@127.0.0.1:26257/messenger?sslmode=disable")
+ githubClientID := os.Getenv("GITHUB_CLIENT_ID")
+ githubClientSecret := os.Getenv("GITHUB_CLIENT_SECRET")
+ hashKey := env("HASH_KEY", "secret")
+ jwtKey := env("JWT_KEY", "secret")
+
+ var err error
+ if origin, err = url.Parse(originString); err != nil || !origin.IsAbs() {
+ log.Fatal("invalid origin")
+ return
+ }
+
+ if i, err := strconv.Atoi(origin.Port()); err == nil {
+ port = i
+ }
+
+ if githubClientID == "" || githubClientSecret == "" {
+ log.Fatalf("remember to set both $GITHUB_CLIENT_ID and $GITHUB_CLIENT_SECRET")
+ return
+ }
+
+ if db, err = sql.Open("postgres", databaseURL); err != nil {
+ log.Fatalf("could not open database connection: %v\n", err)
+ return
+ }
+ defer db.Close()
+ if err = db.Ping(); err != nil {
+ log.Fatalf("could not ping to db: %v\n", err)
+ return
+ }
+
+ githubRedirectURL := *origin
+ githubRedirectURL.Path = "/api/oauth/github/callback"
+ githubOAuthConfig = &oauth2.Config{
+ ClientID: githubClientID,
+ ClientSecret: githubClientSecret,
+ Endpoint: github.Endpoint,
+ RedirectURL: githubRedirectURL.String(),
+ Scopes: []string{"read:user"},
+ }
+
+ cookieSigner = securecookie.New([]byte(hashKey), nil).MaxAge(0)
+
+ jwtSigner, err = jwt.HS256.New([]byte(jwtKey))
+ if err != nil {
+ log.Fatalf("could not create JWT signer: %v\n", err)
+ return
+ }
+
+ router := way.NewRouter()
+ router.HandleFunc("GET", "/api/oauth/github", githubOAuthStart)
+ router.HandleFunc("GET", "/api/oauth/github/callback", githubOAuthCallback)
+ router.HandleFunc("GET", "/api/auth_user", guard(getAuthUser))
+
+ log.Printf("accepting connections on port %d\n", port)
+ log.Printf("starting server at %s\n", origin.String())
+ addr := fmt.Sprintf(":%d", port)
+ if err = http.ListenAndServe(addr, router); err != nil {
+ log.Fatalf("could not start server: %v\n", err)
+ }
+}
+
+func env(key, fallbackValue string) string {
+ v, ok := os.LookupEnv(key)
+ if !ok {
+ return fallbackValue
+ }
+ return v
+}
+
+func intEnv(key string, fallbackValue int) int {
+ v, ok := os.LookupEnv(key)
+ if !ok {
+ return fallbackValue
+ }
+ i, err := strconv.Atoi(v)
+ if err != nil {
+ return fallbackValue
+ }
+ return i
+}
+```
+
+安装依赖项:
+
+```
+go get -u github.com/gorilla/securecookie
+go get -u github.com/joho/godotenv
+go get -u github.com/knq/jwt
+go get -u github.com/lib/pq
+ge get -u github.com/matoous/go-nanoid
+go get -u github.com/matryer/way
+go get -u golang.org/x/oauth2
+```
+
+我们将会使用 `.env` 文件来保存密钥和其他配置。请创建这个文件,并保证里面至少包含以下内容:
+
+```
+GITHUB_CLIENT_ID=your_github_client_id
+GITHUB_CLIENT_SECRET=your_github_client_secret
+```
+
+我们还要用到的其他环境变量有:
+
+ * `PORT`:服务器运行的端口,默认值是 `3000`。
+ * `ORIGIN`:你的域名,默认值是 `http://localhost:3000/`。我们也可以在这里指定端口。
+ * `DATABASE_URL`:Cockroach 数据库的地址。默认值是 `postgresql://root@127.0.0.1:26257/messenger?sslmode=disable`。
+ * `HASH_KEY`:用于为 cookie 签名的密钥。没错,我们会使用已签名的 cookie 来确保安全。
+ * `JWT_KEY`:用于签署 JSON 网络令牌的密钥。
+
+因为代码中已经设定了默认值,所以你也不用把它们写到 `.env` 文件中。
+
+在读取配置并连接到数据库之后,我们会创建一个 OAuth 配置。我们会使用 `ORIGIN` 信息来构建回调 URL(就和我们在 GitHub 页面上注册的一样)。我们的数据范围设置为 “read:user”。这会允许我们读取公开的用户信息,这里我们只需要他的用户名和头像就够了。然后我们会初始化 cookie 和 JWT 签名器。定义一些端点并启动服务器。
+
+在实现 HTTP 处理程序之前,让我们编写一些函数来发送 HTTP 响应。
+
+```
+func respond(w http.ResponseWriter, v interface{}, statusCode int) {
+ b, err := json.Marshal(v)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not marshal response: %v", err))
+ return
+ }
+ w.Header().Set("Content-Type", "application/json; charset=utf-8")
+ w.WriteHeader(statusCode)
+ w.Write(b)
+}
+
+func respondError(w http.ResponseWriter, err error) {
+ log.Println(err)
+ http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
+}
+```
+
+第一个函数用来发送 JSON,而第二个将错误记录到控制台并返回一个 `500 Internal Server Error` 错误信息。
+
+### OAuth 开始
+
+所以,用户点击写着 “Access with GitHub” 的链接。该链接指向 `/api/oauth/github`,这将会把用户重定向到 github。
+
+```
+func githubOAuthStart(w http.ResponseWriter, r *http.Request) {
+ state, err := gonanoid.Nanoid()
+ if err != nil {
+ respondError(w, fmt.Errorf("could not generte state: %v", err))
+ return
+ }
+
+ stateCookieValue, err := cookieSigner.Encode("state", state)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not encode state cookie: %v", err))
+ return
+ }
+
+ http.SetCookie(w, &http.Cookie{
+ Name: "state",
+ Value: stateCookieValue,
+ Path: "/api/oauth/github",
+ HttpOnly: true,
+ })
+ http.Redirect(w, r, githubOAuthConfig.AuthCodeURL(state), http.StatusTemporaryRedirect)
+}
+```
+
+OAuth2 使用一种机制来防止 CSRF 攻击,因此它需要一个“状态”(`state`)。我们使用 `Nanoid()` 来创建一个随机字符串,并用这个字符串作为状态。我们也把它保存为一个 cookie。
+
+### OAuth 回调
+
+一旦用户授权我们访问他的个人信息,他将会被重定向到这个端点。这个 URL 的查询字符串上将会包含状态(`state`)和授权码(`code`): `/api/oauth/github/callback?state=&code=`。
+
+```
+const jwtLifetime = time.Hour * 24 * 14
+
+type GithubUser struct {
+ ID int `json:"id"`
+ Login string `json:"login"`
+ AvatarURL *string `json:"avatar_url,omitempty"`
+}
+
+type User struct {
+ ID string `json:"id"`
+ Username string `json:"username"`
+ AvatarURL *string `json:"avatarUrl"`
+}
+
+func githubOAuthCallback(w http.ResponseWriter, r *http.Request) {
+ stateCookie, err := r.Cookie("state")
+ if err != nil {
+ http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
+ return
+ }
+
+ http.SetCookie(w, &http.Cookie{
+ Name: "state",
+ Value: "",
+ MaxAge: -1,
+ HttpOnly: true,
+ })
+
+ var state string
+ if err = cookieSigner.Decode("state", stateCookie.Value, &state); err != nil {
+ http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
+ return
+ }
+
+ q := r.URL.Query()
+
+ if state != q.Get("state") {
+ http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
+ return
+ }
+
+ ctx := r.Context()
+
+ t, err := githubOAuthConfig.Exchange(ctx, q.Get("code"))
+ if err != nil {
+ respondError(w, fmt.Errorf("could not fetch github token: %v", err))
+ return
+ }
+
+ client := githubOAuthConfig.Client(ctx, t)
+ resp, err := client.Get("https://api.github.com/user")
+ if err != nil {
+ respondError(w, fmt.Errorf("could not fetch github user: %v", err))
+ return
+ }
+
+ var githubUser GithubUser
+ if err = json.NewDecoder(resp.Body).Decode(&githubUser); err != nil {
+ respondError(w, fmt.Errorf("could not decode github user: %v", err))
+ return
+ }
+ defer resp.Body.Close()
+
+ tx, err := db.BeginTx(ctx, nil)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not begin tx: %v", err))
+ return
+ }
+
+ var user User
+ if err = tx.QueryRowContext(ctx, `
+ SELECT id, username, avatar_url FROM users WHERE github_id = $1
+ `, githubUser.ID).Scan(&user.ID, &user.Username, &user.AvatarURL); err == sql.ErrNoRows {
+ if err = tx.QueryRowContext(ctx, `
+ INSERT INTO users (username, avatar_url, github_id) VALUES ($1, $2, $3)
+ RETURNING id
+ `, githubUser.Login, githubUser.AvatarURL, githubUser.ID).Scan(&user.ID); err != nil {
+ respondError(w, fmt.Errorf("could not insert user: %v", err))
+ return
+ }
+ user.Username = githubUser.Login
+ user.AvatarURL = githubUser.AvatarURL
+ } else if err != nil {
+ respondError(w, fmt.Errorf("could not query user by github ID: %v", err))
+ return
+ }
+
+ if err = tx.Commit(); err != nil {
+ respondError(w, fmt.Errorf("could not commit to finish github oauth: %v", err))
+ return
+ }
+
+ exp := time.Now().Add(jwtLifetime)
+ token, err := jwtSigner.Encode(jwt.Claims{
+ Subject: user.ID,
+ Expiration: json.Number(strconv.FormatInt(exp.Unix(), 10)),
+ })
+ if err != nil {
+ respondError(w, fmt.Errorf("could not create token: %v", err))
+ return
+ }
+
+ expiresAt, _ := exp.MarshalText()
+
+ data := make(url.Values)
+ data.Set("token", string(token))
+ data.Set("expires_at", string(expiresAt))
+
+ http.Redirect(w, r, "/callback?"+data.Encode(), http.StatusTemporaryRedirect)
+}
+```
+
+首先,我们会尝试使用之前保存的状态对 cookie 进行解码。并将其与查询字符串中的状态进行比较。如果它们不匹配,我们会返回一个 `418 I'm teapot`(未知来源)错误。
+
+接着,我们使用授权码生成一个令牌。这个令牌被用于创建 HTTP 客户端来向 GitHub API 发出请求。所以最终我们会向 `https://api.github.com/user` 发送一个 GET 请求。这个端点将会以 JSON 格式向我们提供当前经过身份验证的用户信息。我们将会解码这些内容,一并获取用户的 ID、登录名(用户名)和头像 URL。
+
+然后我们将会尝试在数据库上找到具有该 GitHub ID 的用户。如果没有找到,就使用该数据创建一个新的。
+
+之后,对于新创建的用户,我们会发出一个将用户 ID 作为主题(`Subject`)的 JSON 网络令牌,并使用该令牌重定向到前端,查询字符串中一并包含该令牌的到期日(`Expiration`)。
+
+这一 Web 应用也会被用在其他帖子,但是重定向的链接会是 `/callback?token=&expires_at=`。在那里,我们将会利用 JavaScript 从 URL 中获取令牌和到期日,并通过 `Authorization` 标头中的令牌以 `Bearer token_here` 的形式对 `/api/auth_user` 进行 GET 请求,来获取已认证的身份用户并将其保存到 localStorage。
+
+### Guard 中间件
+
+为了获取当前已经过身份验证的用户,我们设计了 Guard 中间件。这是因为在接下来的文章中,我们会有很多需要进行身份认证的端点,而中间件将会允许我们共享这一功能。
+
+```
+type ContextKey struct {
+ Name string
+}
+
+var keyAuthUserID = ContextKey{"auth_user_id"}
+
+func guard(handler http.HandlerFunc) http.HandlerFunc {
+ return func(w http.ResponseWriter, r *http.Request) {
+ var token string
+ if a := r.Header.Get("Authorization"); strings.HasPrefix(a, "Bearer ") {
+ token = a[7:]
+ } else if t := r.URL.Query().Get("token"); t != "" {
+ token = t
+ } else {
+ http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
+ return
+ }
+
+ var claims jwt.Claims
+ if err := jwtSigner.Decode([]byte(token), &claims); err != nil {
+ http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
+ return
+ }
+
+ ctx := r.Context()
+ ctx = context.WithValue(ctx, keyAuthUserID, claims.Subject)
+
+ handler(w, r.WithContext(ctx))
+ }
+}
+```
+
+首先,我们尝试从 `Authorization` 标头或者是 URL 查询字符串中的 `token` 字段中读取令牌。如果没有找到,我们需要返回 `401 Unauthorized`(未授权)错误。然后我们将会对令牌中的申明进行解码,并使用该主题作为当前已经过身份验证的用户 ID。
+
+现在,我们可以用这一中间件来封装任何需要授权的 `http.handlerFunc`,并且在处理函数的上下文中保有已经过身份验证的用户 ID。
+
+```
+var guarded = guard(func(w http.ResponseWriter, r *http.Request) {
+ authUserID := r.Context().Value(keyAuthUserID).(string)
+})
+```
+
+### 获取认证用户
+
+```
+func getAuthUser(w http.ResponseWriter, r *http.Request) {
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+
+ var user User
+ if err := db.QueryRowContext(ctx, `
+ SELECT username, avatar_url FROM users WHERE id = $1
+ `, authUserID).Scan(&user.Username, &user.AvatarURL); err == sql.ErrNoRows {
+ http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
+ return
+ } else if err != nil {
+ respondError(w, fmt.Errorf("could not query auth user: %v", err))
+ return
+ }
+
+ user.ID = authUserID
+
+ respond(w, user, http.StatusOK)
+}
+```
+
+我们使用 Guard 中间件来获取当前经过身份认证的用户 ID 并查询数据库。
+
+这一部分涵盖了后端的 OAuth 流程。在下一篇帖子中,我们将会看到如何开始与其他用户的对话。
+
+- [源代码][3]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[PsiACE](https://github.com/PsiACE)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://github.com/settings/applications/new
+[3]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/published/20180906 What a shell dotfile can do for you.md b/published/201910/20180906 What a shell dotfile can do for you.md
similarity index 100%
rename from published/20180906 What a shell dotfile can do for you.md
rename to published/201910/20180906 What a shell dotfile can do for you.md
diff --git a/published/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md b/published/201910/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md
similarity index 100%
rename from published/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md
rename to published/201910/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md
diff --git a/published/20190301 Guide to Install VMware Tools on Linux.md b/published/201910/20190301 Guide to Install VMware Tools on Linux.md
similarity index 100%
rename from published/20190301 Guide to Install VMware Tools on Linux.md
rename to published/201910/20190301 Guide to Install VMware Tools on Linux.md
diff --git a/published/20190320 Move your dotfiles to version control.md b/published/201910/20190320 Move your dotfiles to version control.md
similarity index 100%
rename from published/20190320 Move your dotfiles to version control.md
rename to published/201910/20190320 Move your dotfiles to version control.md
diff --git a/published/20190404 How writers can get work done better with Git.md b/published/201910/20190404 How writers can get work done better with Git.md
similarity index 100%
rename from published/20190404 How writers can get work done better with Git.md
rename to published/201910/20190404 How writers can get work done better with Git.md
diff --git a/published/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md b/published/201910/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md
similarity index 100%
rename from published/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md
rename to published/201910/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md
diff --git a/published/20190614 What is a Java constructor.md b/published/201910/20190614 What is a Java constructor.md
similarity index 100%
rename from published/20190614 What is a Java constructor.md
rename to published/201910/20190614 What is a Java constructor.md
diff --git a/published/20190627 RPM packages explained.md b/published/201910/20190627 RPM packages explained.md
similarity index 100%
rename from published/20190627 RPM packages explained.md
rename to published/201910/20190627 RPM packages explained.md
diff --git a/published/20190701 Learn how to Record and Replay Linux Terminal Sessions Activity.md b/published/201910/20190701 Learn how to Record and Replay Linux Terminal Sessions Activity.md
similarity index 100%
rename from published/20190701 Learn how to Record and Replay Linux Terminal Sessions Activity.md
rename to published/201910/20190701 Learn how to Record and Replay Linux Terminal Sessions Activity.md
diff --git a/published/20190719 Buying a Linux-ready laptop.md b/published/201910/20190719 Buying a Linux-ready laptop.md
similarity index 100%
rename from published/20190719 Buying a Linux-ready laptop.md
rename to published/201910/20190719 Buying a Linux-ready laptop.md
diff --git a/published/20190805 How to Install and Configure PostgreSQL on Ubuntu.md b/published/201910/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
similarity index 100%
rename from published/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
rename to published/201910/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
diff --git a/published/20190809 Mutation testing is the evolution of TDD.md b/published/201910/20190809 Mutation testing is the evolution of TDD.md
similarity index 100%
rename from published/20190809 Mutation testing is the evolution of TDD.md
rename to published/201910/20190809 Mutation testing is the evolution of TDD.md
diff --git a/published/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md b/published/201910/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md
similarity index 100%
rename from published/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md
rename to published/201910/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md
diff --git a/published/20190823 The lifecycle of Linux kernel testing.md b/published/201910/20190823 The lifecycle of Linux kernel testing.md
similarity index 100%
rename from published/20190823 The lifecycle of Linux kernel testing.md
rename to published/201910/20190823 The lifecycle of Linux kernel testing.md
diff --git a/published/20190824 How to compile a Linux kernel in the 21st century.md b/published/201910/20190824 How to compile a Linux kernel in the 21st century.md
similarity index 100%
rename from published/20190824 How to compile a Linux kernel in the 21st century.md
rename to published/201910/20190824 How to compile a Linux kernel in the 21st century.md
diff --git a/published/20190826 Introduction to the Linux chown command.md b/published/201910/20190826 Introduction to the Linux chown command.md
similarity index 100%
rename from published/20190826 Introduction to the Linux chown command.md
rename to published/201910/20190826 Introduction to the Linux chown command.md
diff --git a/published/20190830 How to Install Linux on Intel NUC.md b/published/201910/20190830 How to Install Linux on Intel NUC.md
similarity index 100%
rename from published/20190830 How to Install Linux on Intel NUC.md
rename to published/201910/20190830 How to Install Linux on Intel NUC.md
diff --git a/published/20190901 Best Linux Distributions For Everyone in 2019.md b/published/201910/20190901 Best Linux Distributions For Everyone in 2019.md
similarity index 100%
rename from published/20190901 Best Linux Distributions For Everyone in 2019.md
rename to published/201910/20190901 Best Linux Distributions For Everyone in 2019.md
diff --git a/published/20190911 4 open source cloud security tools.md b/published/201910/20190911 4 open source cloud security tools.md
similarity index 100%
rename from published/20190911 4 open source cloud security tools.md
rename to published/201910/20190911 4 open source cloud security tools.md
diff --git a/published/20190916 Copying large files with Rsync, and some misconceptions.md b/published/201910/20190916 Copying large files with Rsync, and some misconceptions.md
similarity index 100%
rename from published/20190916 Copying large files with Rsync, and some misconceptions.md
rename to published/201910/20190916 Copying large files with Rsync, and some misconceptions.md
diff --git a/published/20190916 Linux commands to display your hardware information.md b/published/201910/20190916 Linux commands to display your hardware information.md
similarity index 100%
rename from published/20190916 Linux commands to display your hardware information.md
rename to published/201910/20190916 Linux commands to display your hardware information.md
diff --git a/published/20190918 Adding themes and plugins to Zsh.md b/published/201910/20190918 Adding themes and plugins to Zsh.md
similarity index 100%
rename from published/20190918 Adding themes and plugins to Zsh.md
rename to published/201910/20190918 Adding themes and plugins to Zsh.md
diff --git a/published/20190920 Hone advanced Bash skills by building Minesweeper.md b/published/201910/20190920 Hone advanced Bash skills by building Minesweeper.md
similarity index 100%
rename from published/20190920 Hone advanced Bash skills by building Minesweeper.md
rename to published/201910/20190920 Hone advanced Bash skills by building Minesweeper.md
diff --git a/published/20190923 Installation Guide of Manjaro 18.1 (KDE Edition) with Screenshots.md b/published/201910/20190923 Installation Guide of Manjaro 18.1 (KDE Edition) with Screenshots.md
similarity index 100%
rename from published/20190923 Installation Guide of Manjaro 18.1 (KDE Edition) with Screenshots.md
rename to published/201910/20190923 Installation Guide of Manjaro 18.1 (KDE Edition) with Screenshots.md
diff --git a/published/20190923 Mutation testing by example- How to leverage failure.md b/published/201910/20190923 Mutation testing by example- How to leverage failure.md
similarity index 100%
rename from published/20190923 Mutation testing by example- How to leverage failure.md
rename to published/201910/20190923 Mutation testing by example- How to leverage failure.md
diff --git a/published/20190924 Fedora and CentOS Stream.md b/published/201910/20190924 Fedora and CentOS Stream.md
similarity index 100%
rename from published/20190924 Fedora and CentOS Stream.md
rename to published/201910/20190924 Fedora and CentOS Stream.md
diff --git a/published/20190924 How DevOps professionals can become security champions.md b/published/201910/20190924 How DevOps professionals can become security champions.md
similarity index 100%
rename from published/20190924 How DevOps professionals can become security champions.md
rename to published/201910/20190924 How DevOps professionals can become security champions.md
diff --git a/published/20190924 Java still relevant, Linux desktop, and more industry trends.md b/published/201910/20190924 Java still relevant, Linux desktop, and more industry trends.md
similarity index 100%
rename from published/20190924 Java still relevant, Linux desktop, and more industry trends.md
rename to published/201910/20190924 Java still relevant, Linux desktop, and more industry trends.md
diff --git a/published/20190924 Mutation testing by example- Failure as experimentation.md b/published/201910/20190924 Mutation testing by example- Failure as experimentation.md
similarity index 100%
rename from published/20190924 Mutation testing by example- Failure as experimentation.md
rename to published/201910/20190924 Mutation testing by example- Failure as experimentation.md
diff --git a/published/20190925 3 quick tips for working with Linux files.md b/published/201910/20190925 3 quick tips for working with Linux files.md
similarity index 100%
rename from published/20190925 3 quick tips for working with Linux files.md
rename to published/201910/20190925 3 quick tips for working with Linux files.md
diff --git a/published/20190925 Essential Accessories for Intel NUC Mini PC.md b/published/201910/20190925 Essential Accessories for Intel NUC Mini PC.md
similarity index 100%
rename from published/20190925 Essential Accessories for Intel NUC Mini PC.md
rename to published/201910/20190925 Essential Accessories for Intel NUC Mini PC.md
diff --git a/published/20190925 Mirror your Android screen on your computer with Guiscrcpy.md b/published/201910/20190925 Mirror your Android screen on your computer with Guiscrcpy.md
similarity index 100%
rename from published/20190925 Mirror your Android screen on your computer with Guiscrcpy.md
rename to published/201910/20190925 Mirror your Android screen on your computer with Guiscrcpy.md
diff --git a/published/20190926 How to Execute Commands on Remote Linux System over SSH.md b/published/201910/20190926 How to Execute Commands on Remote Linux System over SSH.md
similarity index 100%
rename from published/20190926 How to Execute Commands on Remote Linux System over SSH.md
rename to published/201910/20190926 How to Execute Commands on Remote Linux System over SSH.md
diff --git a/published/20190926 You Can Now Use OneDrive in Linux Natively Thanks to Insync.md b/published/201910/20190926 You Can Now Use OneDrive in Linux Natively Thanks to Insync.md
similarity index 100%
rename from published/20190926 You Can Now Use OneDrive in Linux Natively Thanks to Insync.md
rename to published/201910/20190926 You Can Now Use OneDrive in Linux Natively Thanks to Insync.md
diff --git a/published/20190927 CentOS 8 Installation Guide with Screenshots.md b/published/201910/20190927 CentOS 8 Installation Guide with Screenshots.md
similarity index 100%
rename from published/20190927 CentOS 8 Installation Guide with Screenshots.md
rename to published/201910/20190927 CentOS 8 Installation Guide with Screenshots.md
diff --git a/published/20190929 Bash Script to Generate System Uptime Reports on Linux.md b/published/201910/20190929 Bash Script to Generate System Uptime Reports on Linux.md
similarity index 100%
rename from published/20190929 Bash Script to Generate System Uptime Reports on Linux.md
rename to published/201910/20190929 Bash Script to Generate System Uptime Reports on Linux.md
diff --git a/published/20190929 How to Install and Use Cockpit on CentOS 8 - RHEL 8.md b/published/201910/20190929 How to Install and Use Cockpit on CentOS 8 - RHEL 8.md
similarity index 100%
rename from published/20190929 How to Install and Use Cockpit on CentOS 8 - RHEL 8.md
rename to published/201910/20190929 How to Install and Use Cockpit on CentOS 8 - RHEL 8.md
diff --git a/published/20191002 3 command line games for learning Bash the fun way.md b/published/201910/20191002 3 command line games for learning Bash the fun way.md
similarity index 100%
rename from published/20191002 3 command line games for learning Bash the fun way.md
rename to published/201910/20191002 3 command line games for learning Bash the fun way.md
diff --git a/published/20191002 7 Bash history shortcuts you will actually use.md b/published/201910/20191002 7 Bash history shortcuts you will actually use.md
similarity index 100%
rename from published/20191002 7 Bash history shortcuts you will actually use.md
rename to published/201910/20191002 7 Bash history shortcuts you will actually use.md
diff --git a/published/20191003 How to Run the Top Command in Batch Mode.md b/published/201910/20191003 How to Run the Top Command in Batch Mode.md
similarity index 100%
rename from published/20191003 How to Run the Top Command in Batch Mode.md
rename to published/201910/20191003 How to Run the Top Command in Batch Mode.md
diff --git a/published/20191004 9 essential GNU binutils tools.md b/published/201910/20191004 9 essential GNU binutils tools.md
similarity index 100%
rename from published/20191004 9 essential GNU binutils tools.md
rename to published/201910/20191004 9 essential GNU binutils tools.md
diff --git a/published/20191004 All That You Can Do with Google Analytics, and More.md b/published/201910/20191004 All That You Can Do with Google Analytics, and More.md
similarity index 100%
rename from published/20191004 All That You Can Do with Google Analytics, and More.md
rename to published/201910/20191004 All That You Can Do with Google Analytics, and More.md
diff --git a/published/20191004 In Fedora 31, 32-bit i686 is 86ed.md b/published/201910/20191004 In Fedora 31, 32-bit i686 is 86ed.md
similarity index 100%
rename from published/20191004 In Fedora 31, 32-bit i686 is 86ed.md
rename to published/201910/20191004 In Fedora 31, 32-bit i686 is 86ed.md
diff --git a/published/201910/20191005 Use GameHub to Manage All Your Linux Games in One Place.md b/published/201910/20191005 Use GameHub to Manage All Your Linux Games in One Place.md
new file mode 100644
index 0000000000..5c4de853c5
--- /dev/null
+++ b/published/201910/20191005 Use GameHub to Manage All Your Linux Games in One Place.md
@@ -0,0 +1,161 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wenwensnow)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11504-1.html)
+[#]: subject: (Use GameHub to Manage All Your Linux Games in One Place)
+[#]: via: (https://itsfoss.com/gamehub/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+用 GameHub 集中管理你 Linux 上的所有游戏
+======
+
+你在 Linux 上是怎么[玩游戏的呢][1]? 让我猜猜,要不就是从软件中心直接安装,要不就选 Steam、GOG、Humble Bundle 等平台,对吧?但是,如果你有多个游戏启动器和客户端,又要如何管理呢?好吧,对我来说这简直令人头疼 —— 这也是我发现 [GameHub][2] 这个应用之后,感到非常高兴的原因。
+
+GameHub 是为 Linux 发行版设计的一个桌面应用,它能让你“集中管理你的所有游戏”。这听起来很有趣,是不是?下面让我来具体说明一下。
+
+![][3]
+
+### 集中管理不同平台 Linux 游戏的 GameHub
+
+让我们看看,对玩家来说,让 GameHub 成为一个[不可或缺的 Linux 应用][4]的功能,都有哪些。
+
+#### Steam、GOG & Humble Bundle 支持
+
+![][5]
+
+它支持 Steam、[GOG][6] 和 [Humble Bundle][7] 账户整合。你可以登录你的 GameHub 账号,从而在你的库管理器中管理所有游戏。
+
+对我来说,我在 Steam 上有很多游戏,Humble Bundle 上也有一些。我不能确保它支持所有平台,但可以确信的是,主流平台游戏是没有问题的。
+
+#### 支持原生游戏
+
+![][8]
+
+[有很多网站专门推荐 Linux 游戏,并支持下载][9]。你可以通过下载安装包,或者添加可执行文件,从而管理原生游戏。
+
+可惜的是,现在无法在 GameHub 内搜索 Linux 游戏。如上图所示,你需要分别下载游戏,随后再将其添加到 GameHub 中。
+
+#### 模拟器支持
+
+用模拟器,你可以在 [Linux 上玩复古游戏][10]。正如上图所示,你可以添加模拟器(并导入模拟的镜像)。
+
+你可以在 [RetroArch][11] 查看已有的模拟器,但也能根据需求添加自定义模拟器。
+
+#### 用户界面
+
+![Gamehub 界面选项][12]
+
+当然,用户体验很重要。因此,探究下用户界面都有些什么,也很有必要。
+
+我个人觉得,这一应用很容易使用,并且黑色主题是一个加分项。
+
+#### 手柄支持
+
+如果你习惯在 Linux 系统上用手柄玩游戏 —— 你可以轻松在设置里添加,启用或禁用它。
+
+#### 多个数据提供商
+
+因为它需要获取你的游戏信息(或元数据),也意味着它需要一个数据源。你可以看到下图列出的所有数据源。
+
+![Data Providers Gamehub][13]
+
+这里你什么也不用做 —— 但如果你使用的是 steam 之外的其他平台,你需要为 [IDGB 生成一个 API 密钥][14]。
+
+我建议只有出现 GameHub 中的提示/通知,或有些游戏在 GameHub 上没有任何描述/图片/状态时,再这么做。
+
+#### 兼容性选项
+
+![][15]
+
+你有不支持在 Linux 上运行的游戏吗?
+
+不用担心,GameHub 上提供了多种兼容工具,如 Wine/Proton,你可以利用它们来玩游戏。
+
+我们无法确定具体哪个兼容工具适用于你 —— 所以你需要自己亲自测试。然而,对许多游戏玩家来说,这的确是个很有用的功能。
+
+### GameHub: 如何安装它呢?
+
+![][18]
+
+首先,你可以直接在软件中心或者应用商店内搜索。 它在 “Pop!_Shop” 之下。所以,它在绝大多数官方源中都能找到。
+
+如果你在这些地方都没有找到,你可以手动添加源,并从终端上安装它,你需要输入以下命令:
+
+```
+sudo add-apt-repository ppa:tkashkin/gamehub
+sudo apt update
+sudo apt install com.github.tkashkin.gamehub
+```
+
+如果你遇到了 “add-apt-repository command not found” 这个错误,你可以看看,[add-apt-repository not found error.][19]这篇文章,它能帮你解决这一问题。
+
+这里还提供 AppImage 和 FlatPak 版本。 在[官网][2] 上,你可以针对找到其他 Linux 发行版的安装手册。
+
+同时,你还可以从它的 [GitHub 页面][20]下载之前版本的安装包.
+
+[GameHub][2]
+
+### 如何在 GameHub 上管理你的游戏?
+
+在启动程序后,你可以将自己的 Steam/GOG/Humble Bundle 账号添加进来。
+
+对于 Steam,你需要在 Linux 发行版上安装 Steam 客户端。一旦安装完成,你可以轻松将账号中的游戏导入 GameHub。
+
+![][16]
+
+对于 GOG & Humble Bundle,登录后,就能直接在 GameHub 上管理游戏了。
+
+如果你想添加模拟器或者本地安装文件,点击窗口右上角的 “+” 按钮进行添加。
+
+### 如何安装游戏?
+
+对于 Steam 游戏,它会自动启动 Steam 客户端,从而下载/安装游戏(我希望之后安装游戏,可以不用启动 Steam!)
+
+![][17]
+
+但对于 GOG/Humble Bundle,登录后就能直接、下载安装游戏。必要的话,对于那些不支持在 Linux 上运行的游戏,你可以使用兼容工具。
+
+无论是模拟器游戏,还是本地游戏,只需添加安装包或导入模拟器镜像就可以了。这里没什么其他步骤要做。
+
+### 注意
+
+GameHub 是相当灵活的一个集中游戏管理应用。 用户界面和选项设置也相当直观。
+
+你之前是否使用过这一应用呢?如果有,请在评论里写下你的感受。
+
+而且,如果你想尝试一些与此功能相似的工具/应用,请务必告诉我们。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gamehub/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wenwensnow](https://github.com/wenwensnow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/linux-gaming-guide/
+[2]: https://tkashkin.tk/projects/gamehub/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-home-1.png?ssl=1
+[4]: https://itsfoss.com/essential-linux-applications/
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-platform-support.png?ssl=1
+[6]: https://www.gog.com/
+[7]: https://www.humblebundle.com/monthly?partner=itsfoss
+[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-native-installers.png?ssl=1
+[9]: https://itsfoss.com/download-linux-games/
+[10]: https://itsfoss.com/play-retro-games-linux/
+[11]: https://www.retroarch.com/
+[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-appearance.png?ssl=1
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/data-providers-gamehub.png?ssl=1
+[14]: https://www.igdb.com/api
+[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-windows-game.png?fit=800%2C569&ssl=1
+[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-library.png?ssl=1
+[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-compatibility-layer.png?ssl=1
+[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-install.jpg?ssl=1
+[19]: https://itsfoss.com/add-apt-repository-command-not-found/
+[20]: https://github.com/tkashkin/GameHub/releases
diff --git a/published/20191006 How to Install and Configure VNC Server on Centos 8 - RHEL 8.md b/published/201910/20191006 How to Install and Configure VNC Server on Centos 8 - RHEL 8.md
similarity index 100%
rename from published/20191006 How to Install and Configure VNC Server on Centos 8 - RHEL 8.md
rename to published/201910/20191006 How to Install and Configure VNC Server on Centos 8 - RHEL 8.md
diff --git a/published/20191007 IceWM - A really cool desktop.md b/published/201910/20191007 IceWM - A really cool desktop.md
similarity index 100%
rename from published/20191007 IceWM - A really cool desktop.md
rename to published/201910/20191007 IceWM - A really cool desktop.md
diff --git a/published/20191008 7 steps to securing your Linux server.md b/published/201910/20191008 7 steps to securing your Linux server.md
similarity index 100%
rename from published/20191008 7 steps to securing your Linux server.md
rename to published/201910/20191008 7 steps to securing your Linux server.md
diff --git a/published/20191008 How to manage Go projects with GVM.md b/published/201910/20191008 How to manage Go projects with GVM.md
similarity index 100%
rename from published/20191008 How to manage Go projects with GVM.md
rename to published/201910/20191008 How to manage Go projects with GVM.md
diff --git a/published/20191009 Command line quick tips- Locate and process files with find and xargs.md b/published/201910/20191009 Command line quick tips- Locate and process files with find and xargs.md
similarity index 100%
rename from published/20191009 Command line quick tips- Locate and process files with find and xargs.md
rename to published/201910/20191009 Command line quick tips- Locate and process files with find and xargs.md
diff --git a/published/20191009 Top 10 open source video players for Linux.md b/published/201910/20191009 Top 10 open source video players for Linux.md
similarity index 100%
rename from published/20191009 Top 10 open source video players for Linux.md
rename to published/201910/20191009 Top 10 open source video players for Linux.md
diff --git a/published/20191010 DevSecOps pipelines and tools- What you need to know.md b/published/201910/20191010 DevSecOps pipelines and tools- What you need to know.md
similarity index 100%
rename from published/20191010 DevSecOps pipelines and tools- What you need to know.md
rename to published/201910/20191010 DevSecOps pipelines and tools- What you need to know.md
diff --git a/published/20191010 Viewing files and processes as trees on Linux.md b/published/201910/20191010 Viewing files and processes as trees on Linux.md
similarity index 100%
rename from published/20191010 Viewing files and processes as trees on Linux.md
rename to published/201910/20191010 Viewing files and processes as trees on Linux.md
diff --git a/published/20191011 How to Unzip a Zip File in Linux -Beginner-s Tutorial.md b/published/201910/20191011 How to Unzip a Zip File in Linux -Beginner-s Tutorial.md
similarity index 100%
rename from published/20191011 How to Unzip a Zip File in Linux -Beginner-s Tutorial.md
rename to published/201910/20191011 How to Unzip a Zip File in Linux -Beginner-s Tutorial.md
diff --git a/published/201910/20191011 How to use IoT devices to keep children safe.md b/published/201910/20191011 How to use IoT devices to keep children safe.md
new file mode 100644
index 0000000000..bf05a950f1
--- /dev/null
+++ b/published/201910/20191011 How to use IoT devices to keep children safe.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: (Morisun029)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11506-1.html)
+[#]: subject: (How to use IoT devices to keep children safe?)
+[#]: via: (https://opensourceforu.com/2019/10/how-to-use-iot-devices-to-keep-children-safe/)
+[#]: author: (Andrew Carroll https://opensourceforu.com/author/andrew-carroll/)
+
+如何使用物联网设备来确保儿童安全?
+======
+
+![][1]
+
+IoT (物联网)设备正在迅速改变我们的生活。这些设备无处不在,从我们的家庭到其它行业。根据一些预测数据,到 2020 年,将会有 100 亿个 IoT 设备。到 2025 年,该数量将增长到 220 亿。目前,物联网已经在很多领域得到了应用,包括智能家居、工业生产过程、农业甚至医疗保健领域。伴随着如此广泛的应用,物联网显然已经成为近年来的热门话题之一。
+
+多种因素促成了物联网设备在多个学科的爆炸式增长。这其中包括低成本处理器和无线连接的的可用性,以及开源平台的信息交流推动了物联网领域的创新。与传统的应用程序开发相比,物联网设备的开发成指数级增长,因为它的资源是开源的。
+
+在解释如何使用物联网设备来保护儿童之前,必须对物联网技术有基本的了解。
+
+### IoT 设备是什么?
+
+IoT 设备是指那些在没有人类参与的情况下彼此之间可以通信的设备。因此,许多专家并不将智能手机和计算机视为物联网设备。此外,物联网设备必须能够收集数据并且能将收集到的数据传送到其他设备或云端进行处理。
+
+然而,在某些领域中,我们需要探索物联网的潜力。儿童往往是脆弱的,他们很容易成为犯罪分子和其他蓄意伤害者的目标。无论在物理世界还是数字世界中,儿童都很容易面临犯罪的威胁。因为父母不能始终亲自到场保护孩子;这就是为什么需要监视工具了。
+
+除了适用于儿童的可穿戴设备外,还有许多父母监视应用程序,例如 Xnspy,可实时监控儿童并提供信息的实时更新。这些工具可确保儿童安全。可穿戴设备确保儿童身体上的安全性,而家长监控应用可确保儿童的上网安全。
+
+由于越来越多的孩子花费时间在智能手机上,毫无意外地,他们也就成为诈骗分子的主要目标。此外,由于恋童癖、网络自夸和其他犯罪在网络上的盛行,儿童也有可能成为网络欺凌的目标。
+
+这些解决方案够吗?我们需要找到物联网解决方案,以确保孩子们在网上和线下的安全。在当代,我们如何确保孩子的安全?我们需要提出创新的解决方案。 物联网可以帮助保护孩子在学校和家里的安全。
+
+### 物联网的潜力
+
+物联网设备提供的好处很多。举例来说,父母可以远程监控自己的孩子,而又不会显得太霸道。因此,儿童在拥有安全环境的同时也会有空间和自由让自己变得独立。
+
+而且,父母也不必在为孩子的安全而担忧。物联网设备可以提供 7x24 小时的信息更新。像 Xnspy 之类的监视应用程序在提供有关孩子的智能手机活动信息方面更进了一步。随着物联网设备变得越来越复杂,拥有更长使用寿命的电池只是一个时间问题。诸如位置跟踪器之类的物联网设备可以提供有关孩子下落的准确详细信息,所以父母不必担心。
+
+虽然可穿戴设备已经非常好了,但在确保儿童安全方面,这些通常还远远不够。因此,要为儿童提供安全的环境,我们还需要其他方法。许多事件表明,儿童在学校比其他任何公共场所都容易受到攻击。因此,学校需要采取安全措施,以确保儿童和教师的安全。在这一点上,物联网设备可用于检测潜在威胁并采取必要的措施来防止攻击。威胁检测系统包括摄像头。系统一旦检测到威胁,便可以通知当局,如一些执法机构和医院。智能锁等设备可用于封锁学校(包括教室),来保护儿童。除此之外,还可以告知父母其孩子的安全,并立即收到有关威胁的警报。这将需要实施无线技术,例如 Wi-Fi 和传感器。因此,学校需要制定专门用于提供教室安全性的预算。
+
+智能家居实现拍手关灯,也可以让你的家庭助手帮你关灯。同样,物联网设备也可用在屋内来保护儿童。在家里,物联网设备(例如摄像头)为父母在照顾孩子时提供 100% 的可见性。当父母不在家里时,可以使用摄像头和其他传感器检测是否发生了可疑活动。其他设备(例如连接到这些传感器的智能锁)可以锁门和窗,以确保孩子们的安全。
+
+同样,可以引入许多物联网解决方案来确保孩子的安全。
+
+### 有多好就有多坏
+
+物联网设备中的传感器会创建大量数据。数据的安全性是至关重要的一个因素。收集的有关孩子的数据如果落入不法分子手中会存在危险。因此,需要采取预防措施。IoT 设备中泄露的任何数据都可用于确定行为模式。因此,必须对提供不违反用户隐私的安全物联网解决方案投入资金。
+
+IoT 设备通常连接到 Wi-Fi,用于设备之间传输数据。未加密数据的不安全网络会带来某些风险。这样的网络很容易被窃听。黑客可以使用此类网点来入侵系统。他们还可以将恶意软件引入系统,从而使系统变得脆弱、易受攻击。此外,对设备和公共网络(例如学校的网络)的网络攻击可能导致数据泄露和私有数据盗用。 因此,在实施用于保护儿童的物联网解决方案时,保护网络和物联网设备的总体计划必须生效。
+
+物联网设备保护儿童在学校和家里的安全的潜力尚未发现有什么创新。我们需要付出更多努力来保护连接 IoT 设备的网络安全。此外,物联网设备生成的数据可能落入不法分子手中,从而造成更多麻烦。因此,这是物联网安全至关重要的一个领域。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/how-to-use-iot-devices-to-keep-children-safe/
+
+作者:[Andrew Carroll][a]
+选题:[lujun9972][b]
+译者:[Morisun029](https://github.com/Morisun029)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/andrew-carroll/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Visual-Internet-of-things_EB-May18.jpg?resize=696%2C507&ssl=1 (Visual Internet of things_EB May18)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Visual-Internet-of-things_EB-May18.jpg?fit=900%2C656&ssl=1
diff --git a/published/201910/20191013 Object-Oriented Programming and Essential State.md b/published/201910/20191013 Object-Oriented Programming and Essential State.md
new file mode 100644
index 0000000000..2847253e32
--- /dev/null
+++ b/published/201910/20191013 Object-Oriented Programming and Essential State.md
@@ -0,0 +1,98 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11519-1.html)
+[#]: subject: (Object-Oriented Programming and Essential State)
+[#]: via: (https://theartofmachinery.com/2019/10/13/oop_and_essential_state.html)
+[#]: author: (Simon Arneaud https://theartofmachinery.com)
+
+面向对象编程和根本状态
+======
+
+
+
+早在 2015 年,Brian Will 撰写了一篇有挑衅性的博客:[面向对象编程:一个灾难故事][1]。他随后发布了一个名为[面向对象编程很糟糕][2]的视频,该视频更加详细。我建议你花些时间观看视频,下面是我的一段总结:
+
+> OOP 的柏拉图式理想是一堆相互解耦的对象,它们彼此之间发送无状态消息。没有人真的像这样制作软件,Brian 指出这甚至没有意义:对象需要知道向哪个对象发送消息,这意味着它们需要相互引用。该视频大部分讲述的是这样一个痛点:人们试图将对象耦合以实现控制流,同时假装它们是通过设计解耦的。
+
+总的来说,他的想法与我自己的 OOP 经验产生了共鸣:对象没有问题,但是我一直不满意的是*面向*对象建模程序控制流,并且试图使代码“正确地”面向对象似乎总是在创建不必要的复杂性。
+
+有一件事我认为他无法完全解释。他直截了当地说“封装没有作用”,但在脚注后面加上“在细粒度的代码级别”,并继续承认对象有时可以奏效,并且在库和文件级别封装是可以的。但是他没有确切解释为什么有时会奏效,有时却没有奏效,以及如何和在何处划清界限。有人可能会说这使他的 “OOP 不好”的说法有缺陷,但是我认为他的观点是正确的,并且可以在根本状态和偶发状态之间划清界限。
+
+如果你以前从未听说过“根本”和“偶发”这两个术语的使用,那么你应该阅读 Fred Brooks 的经典文章《[没有银弹][3]》。(顺便说一句,他写了许多很棒的有关构建软件系统的文章。)我以前曾写过[关于根本和偶发的复杂性的文章][4],这里有一个简短的摘要:软件是复杂的。部分原因是因为我们希望软件能够解决混乱的现实世界问题,因此我们将其称为“根本复杂性”。“偶发复杂性”是所有其它的复杂性,因为我们正尝试使用硅和金属来解决与硅和金属无关的问题。例如,对于大多数程序而言,用于内存管理或在内存与磁盘之间传输数据或解析文本格式的代码都是“偶发的复杂性”。
+
+假设你正在构建一个支持多个频道的聊天应用。消息可以随时到达任何频道。有些频道特别有趣,当有新消息传入时,用户希望得到通知。而其他频道静音:消息被存储,但用户不会受到打扰。你需要跟踪每个频道的用户首选设置。
+
+一种实现方法是在频道和频道设置之间使用映射(也称为哈希表、字典或关联数组)。注意,映射是 Brian Will 所说的可以用作对象的抽象数据类型(ADT)。
+
+如果我们有一个调试器并查看内存中的映射对象,我们将看到什么?我们当然会找到频道 ID 和频道设置数据(或至少指向它们的指针)。但是我们还会找到其它数据。如果该映射是使用红黑树实现的,我们将看到带有红/黑标签和指向其他节点的指针的树节点对象。与频道相关的数据是根本状态,而树节点是偶发状态。不过,请注意以下几点:该映射有效地封装了它的偶发状态 —— 你可以用 AVL 树实现的另一个映射替换该映射,并且你的聊天程序仍然可以使用。另一方面,映射没有封装根本状态(仅使用 `get()` 和 `set()` 方法访问数据并不是封装)。事实上,映射与根本状态是尽可能不可知的,你可以使用基本相同的映射数据结构来存储与频道或通知无关的其他映射。
+
+这就是映射 ADT 如此成功的原因:它封装了偶发状态,并与根本状态解耦。如果你思考一下,Brian 用封装描述的问题就是尝试封装根本状态。其他描述的好处是封装偶发状态的好处。
+
+要使整个软件系统都达到这一理想状况相当困难,但扩展开来,我认为它看起来像这样:
+
+* 没有全局的可变状态
+* 封装了偶发状态(在对象或模块或以其他任何形式)
+* 无状态偶发复杂性封装在单独函数中,与数据解耦
+* 使用诸如依赖注入之类的技巧使输入和输出变得明确
+* 组件可由易于识别的位置完全拥有和控制
+
+其中有些违反了我很久以来的直觉。例如,如果你有一个数据库查询函数,如果数据库连接处理隐藏在该函数内部,并且唯一的参数是查询参数,那么接口会看起来会更简单。但是,当你使用这样的函数构建软件系统时,协调数据库的使用实际上变得更加复杂。组件不仅以自己的方式做事,而且还试图将自己所做的事情隐藏为“实现细节”。数据库查询需要数据库连接这一事实从来都不是实现细节。如果无法隐藏某些内容,那么显露它是更合理的。
+
+我对将面向对象编程和函数式编程放在对立的两极非常警惕,但我认为从函数式编程进入面向对象编程的另一极端是很有趣的:OOP 试图封装事物,包括无法封装的根本复杂性,而纯函数式编程往往会使事情变得明确,包括一些偶发复杂性。在大多数时候,这没什么问题,但有时候(比如[在纯函数式语言中构建自我指称的数据结构][5])设计更多的是为了函数编程,而不是为了简便(这就是为什么 [Haskell 包含了一些“逃生出口”][6])。我之前写过一篇[所谓“弱纯性”的中间立场][7]。
+
+Brian 发现封装对更大规模有效,原因有几个。一个是,由于大小的原因,较大的组件更可能包含偶发状态。另一个是“偶发”与你要解决的问题有关。从聊天程序用户的角度来看,“偶发的复杂性”是与消息、频道和用户等无关的任何事物。但是,当你将问题分解为子问题时,更多的事情就变得“根本”。例如,在解决“构建聊天应用”问题时,可以说频道名称和频道 ID 之间的映射是偶发的复杂性,而在解决“实现 `getChannelIdByName()` 函数”子问题时,这是根本复杂性。因此,封装对于子组件的作用比对父组件的作用要小。
+
+顺便说一句,在视频的结尾,Brian Will 想知道是否有任何语言支持*无法*访问它们所作用的范围的匿名函数。[D][8] 语言可以。 D 中的匿名 Lambda 通常是闭包,但是如果你想要的话,也可以声明匿名无状态函数:
+
+```
+import std.stdio;
+
+void main()
+{
+ int x = 41;
+
+ // Value from immediately executed lambda
+ auto v1 = () {
+ return x + 1;
+ }();
+ writeln(v1);
+
+ // Same thing
+ auto v2 = delegate() {
+ return x + 1;
+ }();
+ writeln(v2);
+
+ // Plain functions aren't closures
+ auto v3 = function() {
+ // Can't access x
+ // Can't access any mutable global state either if also marked pure
+ return 42;
+ }();
+ writeln(v3);
+}
+```
+
+--------------------------------------------------------------------------------
+
+via: https://theartofmachinery.com/2019/10/13/oop_and_essential_state.html
+
+作者:[Simon Arneaud][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://theartofmachinery.com
+[b]: https://github.com/lujun9972
+[1]: https://medium.com/@brianwill/object-oriented-programming-a-personal-disaster-1b044c2383ab
+[2]: https://www.youtube.com/watch?v=QM1iUe6IofM
+[3]: http://www.cs.nott.ac.uk/~pszcah/G51ISS/Documents/NoSilverBullet.html
+[4]: https://theartofmachinery.com/2017/06/25/compression_complexity_and_software.html
+[5]: https://wiki.haskell.org/Tying_the_Knot
+[6]: https://en.wikibooks.org/wiki/Haskell/Mutable_objects#The_ST_monad
+[7]: https://theartofmachinery.com/2016/03/28/dirtying_pure_functions_can_be_useful.html
+[8]: https://dlang.org
diff --git a/published/20191014 Use sshuttle to build a poor man-s VPN.md b/published/201910/20191014 Use sshuttle to build a poor man-s VPN.md
similarity index 100%
rename from published/20191014 Use sshuttle to build a poor man-s VPN.md
rename to published/201910/20191014 Use sshuttle to build a poor man-s VPN.md
diff --git a/published/201910/20191015 10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool.md b/published/201910/20191015 10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool.md
new file mode 100644
index 0000000000..c9adda9a5d
--- /dev/null
+++ b/published/201910/20191015 10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool.md
@@ -0,0 +1,166 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11523-1.html)
+[#]: subject: (10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool)
+[#]: via: (https://itsfoss.com/gnome-tweak-tool/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+使用 GNOME 优化工具自定义 Linux 桌面的 10 种方法
+======
+
+
+![][7]
+
+你可以通过多种方法来调整 Ubuntu,以自定义其外观和行为。我发现最简单的方法是使用 [GNOME 优化工具][2]。它也被称为 GNOME Tweak 或简单地称为 Tweak(优化)。
+
+在过去的教程中,我已经多次介绍过它。在这里,我列出了你可以使用此工具执行的所有主要优化。
+
+我在这里使用的是 Ubuntu,但是这些步骤应该适用于使用 GNOME 桌面环境的任何 Linux 发行版。
+
+### 在 Ubuntu 18.04 或其它版本上安装 GNOME 优化工具
+
+GNOME 优化工具可从 [Ubuntu 中的 Universe 存储库][3]中安装,因此请确保已在“软件和更新”工具中启用了该仓库:
+
+![在 Ubuntu 中启用 Universe 存储库][4]
+
+之后,你可以从软件中心安装 GNOME 优化工具。只需打开软件中心并搜索 “GNOME Tweaks” 并从那里安装它:
+
+![从软件中心安装 GNOME 优化工具][5]
+
+或者,你也可以使用命令行通过 [apt 命令][6]安装此软件:
+
+```
+sudo apt install gnome-tweaks
+```
+
+### 用优化工具定制 GNOME 桌面
+
+GNOME 优化工具使你可以进行许多设置更改。其中的某些更改(例如墙纸更改、启动应用程序等)也可以在官方的“系统设置”工具中找到。我将重点介绍默认情况下“设置”中不可用的优化。
+
+#### 1、改变主题
+
+你可以通过各种方式[在 Ubuntu 中安装新主题][8]。但是,如果要更改为新安装的主题,则必须安装GNOME 优化工具。
+
+你可以在“外观”部分找到主题和图标设置。你可以浏览可用的主题和图标并设置你喜欢的主题和图标。更改将立即生效。
+
+![通过 GNOME 优化更改主题][9]
+
+#### 2、禁用动画以提速你的桌面体验
+
+应用程序窗口的打开、关闭、最大化等操作都有一些细微的动画。你可以禁用这些动画以稍微加快系统的速度,因为它会稍微使用一点资源。
+
+![禁用动画以获得稍快的桌面体验][10]
+
+#### 3、控制桌面图标
+
+至少在 Ubuntu 中,你会在桌面上看到“家目录”和“垃圾箱”图标。如果你不喜欢,可以选择禁用它。你还可以选择要在桌面上显示的图标。
+
+![在 Ubuntu 中控制桌面图标][11]
+
+#### 4、管理 GNOME 扩展
+
+我想你可能知道 [GNOME 扩展][12]。这些是用于桌面的小型“插件”,可扩展 GNOME 桌面的功能。有[大量的 GNOME 扩展][13],可用于在顶部面板中查看 CPU 消耗、获取剪贴板历史记录等等。
+
+我已经写了一篇[安装和使用 GNOME 扩展][14]的详细文章。在这里,我假设你已经在使用它们,如果是这样,可以从 GNOME 优化工具中对其进行管理。
+
+![管理 GNOME 扩展][15]
+
+#### 5、改变字体和缩放比例
+
+你可以[在 Ubuntu 中安装新字体][16],并使用这个优化工具在系统范围应用字体更改。如果你认为桌面上的图标和文本太小,也可以更改缩放比例。
+
+![更改字体和缩放比例][17]
+
+#### 6、控制触摸板行为,例如在键入时禁用触摸板,使触摸板右键单击可以工作
+
+GNOME 优化工具还允许你在键入时禁用触摸板。如果你在笔记本电脑上快速键入,这将很有用。手掌底部可能会触摸触摸板,并导致光标移至屏幕上不需要的位置。
+
+在键入时自动禁用触摸板可解决此问题。
+
+![键入时禁用触摸板][18]
+
+你还会注意到[当你按下触摸板的右下角以进行右键单击时,什么也没有发生][19]。你的触摸板并没有问题。这是一项系统设置,可对没有实体右键按钮的任何触摸板(例如旧的 Thinkpad 笔记本电脑)禁用这种右键单击功能。两指点击可为你提供右键单击操作。
+
+你也可以通过在“鼠标单击模拟”下设置为“区域”中而不是“手指”来找回这项功能。
+
+![修复右键单击问题][20]
+
+你可能必须[重新启动 Ubuntu][21] 来使这项更改生效。如果你是 Emacs 爱好者,还可以强制使用 Emacs 键盘绑定。
+
+#### 7、改变电源设置
+
+电源这里只有一个设置。它可以让你在盖上盖子后将笔记本电脑置于挂起模式。
+
+![GNOME 优化工具中的电源设置][22]
+
+#### 8、决定什么显示在顶部面板
+
+桌面的顶部面板显示了一些重要的信息。在这里有日历、网络图标、系统设置和“活动”选项。
+
+你还可以[显示电池百分比][23]、添加日期及时间,并显示星期数。你还可以启用鼠标热角,以便将鼠标移至屏幕的左上角时可以获得所有正在运行的应用程序的活动视图。
+
+![GNOME 优化工具中的顶部面板设置][24]
+
+如果将鼠标焦点放在应用程序窗口上,你会注意到其菜单显示在顶部面板中。如果你不喜欢这样,可以将其关闭,然后应用程序菜单将显示应用程序本身。
+
+#### 9、配置应用窗口
+
+你可以决定是否在应用程序窗口中显示最大化和最小化选项(右上角的按钮)。你也可以改变它们的位置到左边或右边。
+
+![应用程序窗口配置][25]
+
+这里还有其他一些配置选项。我不使用它们,但你可以自行探索。
+
+#### 10、配置工作区
+
+GNOME 优化工具还允许你围绕工作区配置一些内容。
+
+![在 Ubuntu 中配置工作区][26]
+
+### 总结
+
+对于任何 GNOME 用户,GNOME 优化(Tweaks)工具都是必备工具。它可以帮助你配置桌面的外观和功能。 我感到惊讶的是,该工具甚至没有出现在 Ubuntu 的主存储库中。我认为应该默认安装它,要不,你就得在 Ubuntu 中手动安装 GNOME 优化工具。
+
+如果你在 GNOME 优化工具中发现了一些此处没有讨论的隐藏技巧,为什么不与大家分享呢?
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gnome-tweak-tool/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/gnome-tweak-tool-icon.png?ssl=1
+[2]: https://wiki.gnome.org/action/show/Apps/Tweaks?action=show&redirect=Apps%2FGnomeTweakTool
+[3]: https://itsfoss.com/ubuntu-repositories/
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/enable-repositories-ubuntu.png?ssl=1
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/install-gnome-tweaks-tool.jpg?ssl=1
+[6]: https://itsfoss.com/apt-command-guide/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/customize-gnome-with-tweak-tool.jpg?ssl=1
+[8]: https://itsfoss.com/install-themes-ubuntu/
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/change-theme-ubuntu-gnome.jpg?ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/disable-animation-ubuntu-gnome.jpg?ssl=1
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/desktop-icons-ubuntu.jpg?ssl=1
+[12]: https://extensions.gnome.org/
+[13]: https://itsfoss.com/best-gnome-extensions/
+[14]: https://itsfoss.com/gnome-shell-extensions/
+[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/manage-gnome-extension-tweaks-tool.jpg?ssl=1
+[16]: https://itsfoss.com/install-fonts-ubuntu/
+[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/change-fonts-ubuntu-gnome.jpg?ssl=1
+[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/disable-touchpad-while-typing-ubuntu.jpg?ssl=1
+[19]: https://itsfoss.com/fix-right-click-touchpad-ubuntu/
+[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/enable-right-click-ubuntu.jpg?ssl=1
+[21]: https://itsfoss.com/schedule-shutdown-ubuntu/
+[22]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/power-settings-gnome-tweaks-tool.jpg?ssl=1
+[23]: https://itsfoss.com/display-battery-ubuntu/
+[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/top-panel-settings-gnome-tweaks-tool.jpg?ssl=1
+[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/windows-configuration-ubuntu-gnome-tweaks.jpg?ssl=1
+[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/configure-workspaces-ubuntu.jpg?ssl=1
diff --git a/published/20191015 4 Free and Open Source Alternatives to Adobe Photoshop.md b/published/201910/20191015 4 Free and Open Source Alternatives to Adobe Photoshop.md
similarity index 100%
rename from published/20191015 4 Free and Open Source Alternatives to Adobe Photoshop.md
rename to published/201910/20191015 4 Free and Open Source Alternatives to Adobe Photoshop.md
diff --git a/published/20191015 Bash Script to Delete Files-Folders Older Than -X- Days in Linux.md b/published/201910/20191015 Bash Script to Delete Files-Folders Older Than -X- Days in Linux.md
similarity index 100%
rename from published/20191015 Bash Script to Delete Files-Folders Older Than -X- Days in Linux.md
rename to published/201910/20191015 Bash Script to Delete Files-Folders Older Than -X- Days in Linux.md
diff --git a/published/20191016 Linux sudo flaw can lead to unauthorized privileges.md b/published/201910/20191016 Linux sudo flaw can lead to unauthorized privileges.md
similarity index 100%
rename from published/20191016 Linux sudo flaw can lead to unauthorized privileges.md
rename to published/201910/20191016 Linux sudo flaw can lead to unauthorized privileges.md
diff --git a/translated/tech/20191018 How to Configure Rsyslog Server in CentOS 8 - RHEL 8.md b/published/201910/20191018 How to Configure Rsyslog Server in CentOS 8 - RHEL 8.md
similarity index 53%
rename from translated/tech/20191018 How to Configure Rsyslog Server in CentOS 8 - RHEL 8.md
rename to published/201910/20191018 How to Configure Rsyslog Server in CentOS 8 - RHEL 8.md
index 370c68d163..ba0505daf9 100644
--- a/translated/tech/20191018 How to Configure Rsyslog Server in CentOS 8 - RHEL 8.md
+++ b/published/201910/20191018 How to Configure Rsyslog Server in CentOS 8 - RHEL 8.md
@@ -1,27 +1,27 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11505-1.html)
[#]: subject: (How to Configure Rsyslog Server in CentOS 8 / RHEL 8)
[#]: via: (https://www.linuxtechi.com/configure-rsyslog-server-centos-8-rhel-8/)
[#]: author: (James Kiarie https://www.linuxtechi.com/author/james/)
-如何在 CentOS 8 / RHEL 8 中配置 Rsyslog 服务器
+如何在 CentOS8/RHEL8 中配置 Rsyslog 服务器
======
-**Rsyslog** 是一个免费的开源日志记录程序,默认下在 **CentOS** 8 和 **RHEL** 8 系统上存在。它提供了一种从客户端节点到单个中央服务器的“集中日志”的简单有效的方法。日志集中化有两个好处。首先,它简化了日志查看,因为系统管理员可以在一个中心节点查看远程服务器的所有日志,而无需登录每个客户端系统来检查日志。如果需要监视多台服务器,这将非常有用,其次,如果远程客户端崩溃,你不用担心丢失日志,因为所有日志都将保存在**中央 rsyslog 服务器上**。Rsyslog 取代了仅支持 **UDP** 协议的 syslog。它以优异的功能扩展了基本的 syslog 协议,例如在传输日志时支持 **UDP** 和 **TCP**协议,增强的过滤功能以及灵活的配置选项。让我们来探讨如何在 CentOS 8 / RHEL 8 系统中配置 Rsyslog 服务器。
+
-[![configure-rsyslog-centos8-rhel8][1]][2]
+Rsyslog 是一个自由开源的日志记录程序,在 CentOS 8 和 RHEL 8 系统上默认可用。它提供了一种从客户端节点到单个中央服务器的“集中日志”的简单有效的方法。日志集中化有两个好处。首先,它简化了日志查看,因为系统管理员可以在一个中心节点查看远程服务器的所有日志,而无需登录每个客户端系统来检查日志。如果需要监视多台服务器,这将非常有用,其次,如果远程客户端崩溃,你不用担心丢失日志,因为所有日志都将保存在中心的 Rsyslog 服务器上。rsyslog 取代了仅支持 UDP 协议的 syslog。它以优异的功能扩展了基本的 syslog 协议,例如在传输日志时支持 UDP 和 TCP 协议,增强的过滤功能以及灵活的配置选项。让我们来探讨如何在 CentOS 8 / RHEL 8 系统中配置 Rsyslog 服务器。
+
+![configure-rsyslog-centos8-rhel8][2]
### 预先条件
我们将搭建以下实验环境来测试集中式日志记录过程:
- * **Rsyslog 服务器** CentOS 8 Minimal IP 地址: 10.128.0.47
- * **客户端系统** RHEL 8 Minimal IP 地址: 10.128.0.48
-
-
+ * Rsyslog 服务器 CentOS 8 Minimal IP 地址: 10.128.0.47
+ * 客户端系统 RHEL 8 Minimal IP 地址: 10.128.0.48
通过上面的设置,我们将演示如何设置 Rsyslog 服务器,然后配置客户端系统以将日志发送到 Rsyslog 服务器进行监视。
@@ -35,30 +35,30 @@
$ systemctl status rsyslog
```
-示例输出
+示例输出:
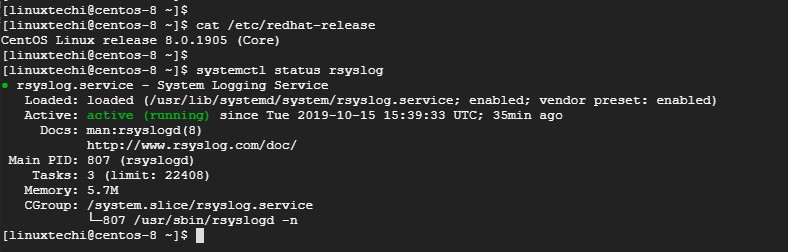
-![rsyslog-service-status-centos8][1]
+
-如果由于某种原因不存在 rsyslog,那么可以使用以下命令进行安装:
+如果由于某种原因 Rsyslog 不存在,那么可以使用以下命令进行安装:
```
$ sudo yum install rsyslog
```
-接下来,你需要修改 Rsyslog 配置文件中的一些设置。打开配置文件。
+接下来,你需要修改 Rsyslog 配置文件中的一些设置。打开配置文件:
```
$ sudo vim /etc/rsyslog.conf
```
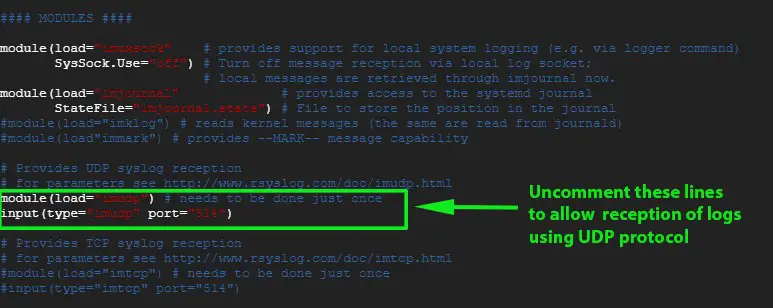
-滚动并取消注释下面的行,以允许通过 UDP 协议接收日志
+滚动并取消注释下面的行,以允许通过 UDP 协议接收日志:
```
module(load="imudp") # needs to be done just once
input(type="imudp" port="514")
```
-![rsyslog-conf-centos8-rhel8][1]
+
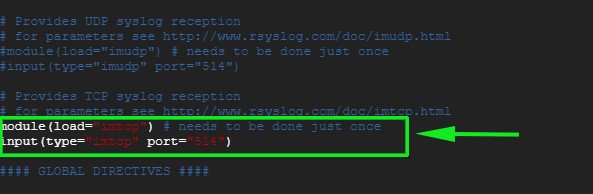
同样,如果你希望启用 TCP rsyslog 接收,请取消注释下面的行:
@@ -67,47 +67,47 @@ module(load="imtcp") # needs to be done just once
input(type="imtcp" port="514")
```
-![rsyslog-conf-tcp-centos8-rhel8][1]
+
保存并退出配置文件。
-要从客户端系统接收日志,我们需要在防火墙上打开 Rsyslog 默认端口 514。为此,请运行
+要从客户端系统接收日志,我们需要在防火墙上打开 Rsyslog 默认端口 514。为此,请运行:
```
# sudo firewall-cmd --add-port=514/tcp --zone=public --permanent
```
-接下来,重新加载防火墙保存更改
+接下来,重新加载防火墙保存更改:
```
# sudo firewall-cmd --reload
```
-示例输出
+示例输出:
-![firewall-ports-rsyslog-centos8][1]
+
-接下来,重启 Rsyslog 服务器
+接下来,重启 Rsyslog 服务器:
```
$ sudo systemctl restart rsyslog
```
-要在启动时运行 Rsyslog,运行以下命令
+要在启动时运行 Rsyslog,运行以下命令:
```
$ sudo systemctl enable rsyslog
```
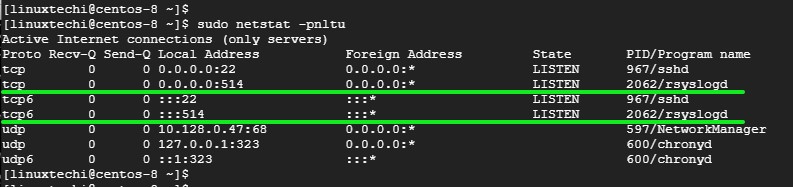
-要确认 Rsyslog 服务器正在监听 514 端口,请使用 netstat 命令,如下所示:
+要确认 Rsyslog 服务器正在监听 514 端口,请使用 `netstat` 命令,如下所示:
```
$ sudo netstat -pnltu
```
-示例输出
+示例输出:
-![netstat-rsyslog-port-centos8][1]
+
完美!我们已经成功配置了 Rsyslog 服务器来从客户端系统接收日志。
@@ -127,42 +127,42 @@ $ tail -f /var/log/messages
$ sudo systemctl status rsyslog
```
-示例输出
+示例输出:
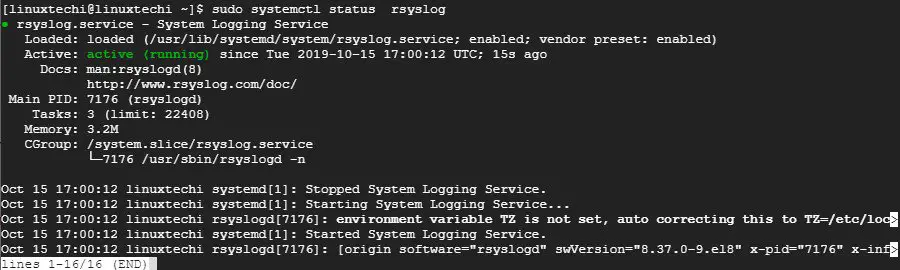
-![client-rsyslog-service-rhel8][1]
+
-接下来,打开 rsyslog 配置文件
+接下来,打开 rsyslog 配置文件:
```
$ sudo vim /etc/rsyslog.conf
```
-在文件末尾,添加以下行
+在文件末尾,添加以下行:
```
*.* @10.128.0.47:514 # Use @ for UDP protocol
*.* @@10.128.0.47:514 # Use @@ for TCP protocol
```
-保存并退出配置文件。就像 Rsyslog 服务器一样,打开 514 端口,这是防火墙上的默认 Rsyslog 端口。
+保存并退出配置文件。就像 Rsyslog 服务器一样,打开 514 端口,这是防火墙上的默认 Rsyslog 端口:
```
$ sudo firewall-cmd --add-port=514/tcp --zone=public --permanent
```
-接下来,重新加载防火墙以保存更改
+接下来,重新加载防火墙以保存更改:
```
$ sudo firewall-cmd --reload
```
-接下来,重启 rsyslog 服务
+接下来,重启 rsyslog 服务:
```
$ sudo systemctl restart rsyslog
```
-要在启动时运行 Rsyslog,请运行以下命令
+要在启动时运行 Rsyslog,请运行以下命令:
```
$ sudo systemctl enable rsyslog
@@ -178,15 +178,15 @@ $ sudo systemctl enable rsyslog
# logger "Hello guys! This is our first log"
```
-现在进入 Rsyslog 服务器并运行以下命令来实时查看日志消息
+现在进入 Rsyslog 服务器并运行以下命令来实时查看日志消息:
```
# tail -f /var/log/messages
```
-客户端系统上命令运行的输出显示在了 Rsyslog 服务器的日志中,这意味着 Rsyslog 服务器正在接收来自客户端系统的日志。
+客户端系统上命令运行的输出显示在了 Rsyslog 服务器的日志中,这意味着 Rsyslog 服务器正在接收来自客户端系统的日志:
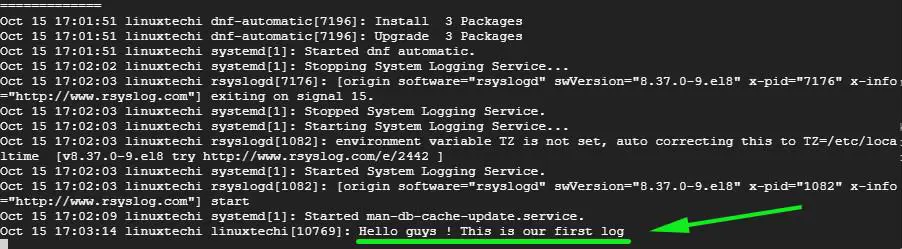
-![centralize-logs-rsyslogs-centos8][1]
+
就是这些了!我们成功设置了 Rsyslog 服务器来接收来自客户端系统的日志信息。
@@ -197,11 +197,11 @@ via: https://www.linuxtechi.com/configure-rsyslog-server-centos-8-rhel-8/
作者:[James Kiarie][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]: https://www.linuxtechi.com/author/james/
[b]: https://github.com/lujun9972
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/configure-rsyslog-centos8-rhel8.jpg
\ No newline at end of file
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/configure-rsyslog-centos8-rhel8.jpg
diff --git a/published/20191021 Kubernetes networking, OpenStack Train, and more industry trends.md b/published/201910/20191021 Kubernetes networking, OpenStack Train, and more industry trends.md
similarity index 100%
rename from published/20191021 Kubernetes networking, OpenStack Train, and more industry trends.md
rename to published/201910/20191021 Kubernetes networking, OpenStack Train, and more industry trends.md
diff --git a/published/20191021 Pylint- Making your Python code consistent.md b/published/201910/20191021 Pylint- Making your Python code consistent.md
similarity index 100%
rename from published/20191021 Pylint- Making your Python code consistent.md
rename to published/201910/20191021 Pylint- Making your Python code consistent.md
diff --git a/published/201910/20191021 Transition to Nftables.md b/published/201910/20191021 Transition to Nftables.md
new file mode 100644
index 0000000000..71aac43603
--- /dev/null
+++ b/published/201910/20191021 Transition to Nftables.md
@@ -0,0 +1,193 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11513-1.html)
+[#]: subject: (Transition to Nftables)
+[#]: via: (https://opensourceforu.com/2019/10/transition-to-nftables/)
+[#]: author: (Vijay Marcel D https://opensourceforu.com/author/vijay-marcel/)
+
+过渡到 nftables
+======
+
+
+
+> 开源世界中的每个主要发行版都在演进,逐渐将 nftables 作为了默认防火墙。换言之,古老的 iptables 现在已经消亡。本文是有关如何构建 nftables 的教程。
+
+当前,有一个与 nftables 兼容的 iptables-nft 后端,但是很快,即使是它也不再提供了。另外,正如 Red Hat 开发人员所指出的那样,有时它可能会错误地转换规则。我们需要知道如何构建自己的 nftables,而不是依赖于 iptables 到 nftables 的转换器。
+
+在 nftables 中,所有地址族都遵循一个规则。与 iptables 不同,nftables 在用户空间中运行,iptables 中的每个模块都运行在内核(空间)中。它很少需要更新内核,并带有一些新功能,例如映射、地址族和字典。
+
+### 地址族
+
+地址族确定要处理的数据包的类型。在 nftables 中有六个地址族,它们是:
+
+* ip
+* ipv6
+* inet
+* arp
+* bridge
+* netdev
+
+在 nftables 中,ipv4 和 ipv6 协议可以被合并为一个称为 inet 的单一地址族。因此,我们不需要指定两个规则:一个用于 ipv4,另一个用于 ipv6。如果未指定地址族,它将默认为 ip 协议,即 ipv4。我们感兴趣的领域是 inet 地址族,因为大多数家庭用户将使用 ipv4 或 ipv6 协议。
+
+### nftables
+
+典型的 nftables 规则包含三个部分:表、链和规则。
+
+表是链和规则的容器。它们由其地址族和名称来标识。链包含 inet/arp/bridge/netdev 等协议所需的规则,并具有三种类型:过滤器、NAT 和路由。nftables 规则可以从脚本加载,也可以在终端键入,然后另存为规则集。
+
+对于家庭用户,默认链为过滤器。inet 系列包含以下钩子:
+
+* Input
+* Output
+* Forward
+* Pre-routing
+* Post-routing
+
+### 使用脚本还是不用?
+
+最大的问题之一是我们是否可以使用防火墙脚本。答案是:这是你自己的选择。这里有一些建议:如果防火墙中有数百条规则,那么最好使用脚本,但是如果你是典型的家庭用户,则可以在终端中键入命令,然后(保存并在重启时)加载规则集。每种选择都有其自身的优缺点。在本文中,我们将在终端中键入它们以构建防火墙。
+
+nftables 使用一个名为 `nft` 的程序来添加、创建、列出、删除和加载规则。确保使用以下命令将 nftables 与 conntrackd 和 netfilter-persistent 软件包一起安装,并删除 iptables:
+
+```
+apt-get install nftables conntrackd netfilter-persistent
+apt-get purge iptables
+```
+
+`nft` 需要以 root 身份运行或使用 `sudo` 运行。使用以下命令分别列出、刷新、删除规则集和加载脚本。
+
+```
+nft list ruleset
+nft flush ruleset
+nft delete table inet filter
+/usr/sbin/nft -f /etc/nftables.conf
+```
+
+### 输入策略
+
+就像 iptables 一样,防火墙将包含三部分:输入(`input`)、转发(`forward`)和输出(`output`)。在终端中,为输入(`input`)策略键入以下命令。在开始之前,请确保已刷新规则集。我们的默认策略将会删除所有内容。我们将在防火墙中使用 inet 地址族。将以下规则以 root 身份添加或使用 `sudo` 运行:
+
+```
+nft add table inet filter
+nft add chain inet filter input { type filter hook input priority 0 \; counter \; policy drop \; }
+```
+
+你会注意到有一个名为 `priority 0` 的东西。这意味着赋予该规则更高的优先级。挂钩通常赋予负整数,这意味着更高的优先级。每个挂钩都有自己的优先级,过滤器链的优先级为 0。你可以检查 nftables Wiki 页面以查看每个挂钩的优先级。
+
+要了解你计算机中的网络接口,请运行以下命令:
+
+```
+ip link show
+```
+
+它将显示已安装的网络接口,一个是本地主机、另一个是以太网端口或无线端口。以太网端口的名称如下所示:`enpXsY`,其中 `X` 和 `Y` 是数字,无线端口也是如此。我们必须允许本地主机的流量,并且仅允许从互联网建立的传入连接。
+
+nftables 具有一项称为裁决语句的功能,用于解析规则。裁决语句为 `accept`、`drop`、`queue`、`jump`、`goto`、`continue` 和 `return`。由于这是一个很简单的防火墙,因此我们将使用 `accept` 或 `drop` 处理数据包。
+
+```
+nft add rule inet filter input iifname lo accept
+nft add rule inet filter input iifname enpXsY ct state new, established, related accept
+```
+
+接下来,我们必须添加规则以保护我们免受隐秘扫描。并非所有的隐秘扫描都是恶意的,但大多数都是。我们必须保护网络免受此类扫描。第一组规则列出了要测试的 TCP 标志。在这些标志中,第二组列出了要与第一组匹配的标志。
+
+```
+nft add rule inet filter input iifname enpXsY tcp flags \& \(syn\|fin\) == \(syn\|fin\) drop
+nft add rule inet filter input iifname enpXsY tcp flags \& \(syn\|rst\) == \(syn\|rst\) drop
+nft add rule inet filter input iifname enpXsY tcp flags \& \(fin\|rst\) == \(fin\|rst\) drop
+nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|fin\) == fin drop
+nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|psh\) == psh drop
+nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|urg\) == urg drop
+```
+
+记住,我们在终端中键入这些命令。因此,我们必须在一些特殊字符之前添加一个反斜杠,以确保终端能够正确解释该斜杠。如果你使用的是脚本,则不需要这样做。
+
+### 关于 ICMP 的警告
+
+互联网控制消息协议(ICMP)是一种诊断工具,因此不应完全丢弃该流量。完全阻止 ICMP 的任何尝试都是不明智的,因为它还会导致停止向我们提供错误消息。仅启用最重要的控制消息,例如回声请求、回声应答、目的地不可达和超时等消息,并拒绝其余消息。回声请求和回声应答是 `ping` 的一部分。在输入策略中,我们仅允许回声应答、而在输出策略中,我们仅允许回声请求。
+
+```
+nft add rule inet filter input iifname enpXsY icmp type { echo-reply, destination-unreachable, time-exceeded } limit rate 1/second accept
+nft add rule inet filter input iifname enpXsY ip protocol icmp drop
+```
+
+最后,我们记录并丢弃所有无效数据包。
+
+```
+nft add rule inet filter input iifname enpXsY ct state invalid log flags all level info prefix \”Invalid-Input: \”
+nft add rule inet filter input iifname enpXsY ct state invalid drop
+```
+
+### 转发和输出策略
+
+在转发和输出策略中,默认情况下我们将丢弃数据包,仅接受已建立连接的数据包。
+
+```
+nft add chain inet filter forward { type filter hook forward priority 0 \; counter \; policy drop \; }
+nft add rule inet filter forward ct state established, related accept
+nft add rule inet filter forward ct state invalid drop
+nft add chain inet filter output { type filter hook output priority 0 \; counter \; policy drop \; }
+```
+
+典型的桌面用户只需要端口 80 和 443 即可访问互联网。最后,允许可接受的 ICMP 协议并在记录无效数据包时丢弃它们。
+
+```
+nft add rule inet filter output oifname enpXsY tcp dport { 80, 443 } ct state established accept
+nft add rule inet filter output oifname enpXsY icmp type { echo-request, destination-unreachable, time-exceeded } limit rate 1/second accept
+nft add rule inet filter output oifname enpXsY ip protocol icmp drop
+nft add rule inet filter output oifname enpXsY ct state invalid log flags all level info prefix \”Invalid-Output: \”
+nft add rule inet filter output oifname enpXsY ct state invalid drop
+```
+
+现在我们必须保存我们的规则集,否则重新启动时它将丢失。为此,请运行以下命令:
+
+```
+sudo nft list ruleset. > /etc/nftables.conf
+```
+
+我们须在引导时加载 nftables,以下将在 systemd 中启用 nftables 服务:
+
+```
+sudo systemctl enable nftables
+```
+
+接下来,编辑 nftables 单元文件以删除 `Execstop` 选项,以避免在每次引导时刷新规则集。该文件通常位于 `/etc/systemd/system/sysinit.target.wants/nftables.service`。现在重新启动nftables:
+
+```
+sudo systemctl restart nftables
+```
+
+### 在 rsyslog 中记录日志
+
+当你记录丢弃的数据包时,它们直接进入 syslog,这使得读取该日志文件非常困难。最好将防火墙日志重定向到单独的文件。在 `/var/log` 目录中创建一个名为 `nftables` 的目录,并在其中创建两个名为 `input.log` 和 `output.log` 的文件,分别存储输入和输出日志。确保系统中已安装 rsyslog。现在转到 `/etc/rsyslog.d` 并创建一个名为 `nftables.conf` 的文件,其内容如下:
+
+```
+:msg,regex,”Invalid-Input: “ -/var/log/nftables/Input.log
+:msg,regex,”Invalid-Output: “ -/var/log/nftables/Output.log & stop
+```
+
+现在,我们必须确保日志是可管理的。为此,使用以下代码在 `/etc/logrotate.d` 中创建另一个名为 `nftables` 的文件:
+
+```
+/var/log/nftables/* { rotate 5 daily maxsize 50M missingok notifempty delaycompress compress postrotate invoke-rc.d rsyslog rotate > /dev/null endscript }
+```
+
+重新启动 nftables。现在,你可以检查你的规则集。如果你觉得在终端中键入每个命令很麻烦,则可以使用脚本来加载 nftables 防火墙。我希望本文对保护你的系统有用。
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/transition-to-nftables/
+
+作者:[Vijay Marcel D][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/vijay-marcel/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/01/REHfirewall-1.jpg?resize=696%2C481&ssl=1 (REHfirewall)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/01/REHfirewall-1.jpg?fit=900%2C622&ssl=1
diff --git a/published/20191022 How to Get the Size of a Directory in Linux.md b/published/201910/20191022 How to Get the Size of a Directory in Linux.md
similarity index 100%
rename from published/20191022 How to Get the Size of a Directory in Linux.md
rename to published/201910/20191022 How to Get the Size of a Directory in Linux.md
diff --git a/published/201910/20191023 Building container images with the ansible-bender tool.md b/published/201910/20191023 Building container images with the ansible-bender tool.md
new file mode 100644
index 0000000000..b4cd0fce3c
--- /dev/null
+++ b/published/201910/20191023 Building container images with the ansible-bender tool.md
@@ -0,0 +1,149 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11518-1.html)
+[#]: subject: (Building container images with the ansible-bender tool)
+[#]: via: (https://opensource.com/article/19/10/building-container-images-ansible)
+[#]: author: (Tomas Tomecek https://opensource.com/users/tomastomecek)
+
+使用 ansible-bender 构建容器镜像
+======
+
+> 了解如何使用 Ansible 在容器中执行命令。
+
+
+
+容器和 [Ansible][2] 可以很好地融合在一起:从管理和编排到供应和构建。在本文中,我们将重点介绍构建部分。
+
+如果你熟悉 Ansible,就会知道你可以编写一系列任务,`ansible-playbook` 命令将为你执行这些任务。你知道吗,如果你编写 Dockerfile 并运行 `podman build`,你还可以在容器环境中执行此类命令,并获得相同的结果。
+
+这是一个例子:
+
+```
+- name: Serve our file using httpd
+ hosts: all
+ tasks:
+ - name: Install httpd
+ package:
+ name: httpd
+ state: installed
+ - name: Copy our file to httpd’s webroot
+ copy:
+ src: our-file.txt
+ dest: /var/www/html/
+```
+
+你可以在 Web 服务器本地或容器中执行这个剧本,并且只要你记得先创建 `our-file.txt`,它就可以工作。
+
+但是这里缺少了一些东西。你需要启动(并配置)httpd 以便提供文件。这是容器构建和基础架构供应之间的区别:构建镜像时,你只需准备内容;而运行容器是另一项任务。另一方面,你可以将元数据附加到容器镜像,它会默认运行命令。
+
+这有个工具可以帮助。试试看 `ansible-bender` 怎么样?
+
+```
+$ ansible-bender build the-playbook.yaml fedora:30 our-httpd
+```
+
+该脚本使用 `ansible-bender` 对 Fedora 30 容器镜像执行该剧本,并将生成的容器镜像命名为 `our-httpd`。
+
+但是,当你运行该容器时,它不会启动 httpd,因为它不知道如何操作。你可以通过向该剧本添加一些元数据来解决此问题:
+
+```
+- name: Serve our file using httpd
+ hosts: all
+ vars:
+ ansible_bender:
+ base_image: fedora:30
+ target_image:
+ name: our-httpd
+ cmd: httpd -DFOREGROUND
+ tasks:
+ - name: Install httpd
+ package:
+ name: httpd
+ state: installed
+ - name: Listen on all network interfaces.
+ lineinfile:
+ path: /etc/httpd/conf/httpd.conf
+ regexp: '^Listen '
+ line: Listen 0.0.0.0:80
+ - name: Copy our file to httpd’s webroot
+ copy:
+ src: our-file.txt
+ dest: /var/www/html
+```
+
+现在你可以构建镜像(从这里开始,请以 root 用户身份运行所有命令。目前,Buildah 和 Podman 不会为无 root 容器创建专用网络):
+
+```
+# ansible-bender build the-playbook.yaml
+PLAY [Serve our file using httpd] ****************************************************
+
+TASK [Gathering Facts] ***************************************************************
+ok: [our-httpd-20191004-131941266141-cont]
+
+TASK [Install httpd] *****************************************************************
+loaded from cache: 'f053578ed2d47581307e9ba3f64f4b4da945579a082c6f99bd797635e62befd0'
+skipping: [our-httpd-20191004-131941266141-cont]
+
+TASK [Listen on all network interfaces.] *********************************************
+changed: [our-httpd-20191004-131941266141-cont]
+
+TASK [Copy our file to httpd’s webroot] **********************************************
+changed: [our-httpd-20191004-131941266141-cont]
+
+PLAY RECAP ***************************************************************************
+our-httpd-20191004-131941266141-cont : ok=3 changed=2 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
+
+Getting image source signatures
+Copying blob sha256:4650c04b851c62897e9c02c6041a0e3127f8253fafa3a09642552a8e77c044c8
+Copying blob sha256:87b740bba596291af8e9d6d91e30a01d5eba9dd815b55895b8705a2acc3a825e
+Copying blob sha256:82c21252bd87532e93e77498e3767ac2617aa9e578e32e4de09e87156b9189a0
+Copying config sha256:44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
+Writing manifest to image destination
+Storing signatures
+44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
+Image 'our-httpd' was built successfully \o/
+```
+
+镜像构建完毕,可以运行容器了:
+
+```
+# podman run our-httpd
+AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.88.2.106. Set the 'ServerName' directive globally to suppress this message
+```
+
+是否提供文件了?首先,找出你容器的 IP:
+
+```
+# podman inspect -f '{{ .NetworkSettings.IPAddress }}' 7418570ba5a0
+10.88.2.106
+```
+
+你现在可以检查了:
+
+```
+$ curl http://10.88.2.106/our-file.txt
+Ansible is ❤
+```
+
+你文件内容是什么?
+
+这只是使用 Ansible 构建容器镜像的介绍。如果你想了解有关 `ansible-bender` 可以做什么的更多信息,请查看它的 [GitHub][3] 页面。构建快乐!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/building-container-images-ansible
+
+作者:[Tomas Tomecek][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/tomastomecek
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/blocks_building.png?itok=eMOT-ire (Blocks for building)
+[2]: https://www.ansible.com/
+[3]: https://github.com/ansible-community/ansible-bender
diff --git a/published/201910/20191023 Using SSH port forwarding on Fedora.md b/published/201910/20191023 Using SSH port forwarding on Fedora.md
new file mode 100644
index 0000000000..e2a66912a4
--- /dev/null
+++ b/published/201910/20191023 Using SSH port forwarding on Fedora.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11515-1.html)
+[#]: subject: (Using SSH port forwarding on Fedora)
+[#]: via: (https://fedoramagazine.org/using-ssh-port-forwarding-on-fedora/)
+[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
+
+在 Fedora 上使用 SSH 端口转发
+======
+
+
+
+你可能已经熟悉使用 [ssh 命令][2]访问远程系统。`ssh` 命令背后所使用的协议允许终端的输入和输出流经[安全通道][3]。但是你知道也可以使用 `ssh` 来安全地发送和接收其他数据吗?一种方法是使用“端口转发”,它允许你在进行 `ssh` 会话时安全地连接网络端口。本文向你展示了它是如何工作的。
+
+### 关于端口
+
+标准 Linux 系统已分配了一组网络端口,范围是 0 - 65535。系统会保留 0 - 1023 的端口以供系统使用。在许多系统中,你不能选择使用这些低端口号。通常有几个端口用于运行特定的服务。你可以在系统的 `/etc/services` 文件中找到这些定义。
+
+你可以认为网络端口是类似的物理端口或可以连接到电缆的插孔。端口可以连接到系统上的某种服务,类似物理插孔后面的接线。一个例子是 Apache Web 服务器(也称为 `httpd`)。对于 HTTP 非安全连接,Web 服务器通常要求在主机系统上使用端口 80,对于 HTTPS 安全连接通常要求使用 443。
+
+当你连接到远程系统(例如,使用 Web 浏览器)时,你是将浏览器“连接”到你的主机上的端口。这通常是一个随机的高端口号,例如 54001。你的主机上的端口连接到远程主机上的端口(例如 443)来访问其安全的 Web 服务器。
+
+那么,当你有这么多可用端口时,为什么还要使用端口转发呢?这是 Web 开发人员生活中的几种常见情况。
+
+### 本地端口转发
+
+想象一下,你正在名为 `remote.example.com` 的远程系统上进行 Web 开发。通常,你是通过 `ssh` 进入此系统的,但是它位于防火墙后面,而且该防火墙很少允许其他类型的访问,并且会阻塞大多数其他端口。要尝试你的网络应用,能够使用浏览器访问远程系统会很有帮助。但是,由于使用了讨厌的防火墙,你无法通过在浏览器中输入 URL 的常规方法来访问它。
+
+本地转发使你可以通过 `ssh` 连接来建立可通过远程系统访问的端口。该端口在系统上显示为本地端口(因而称为“本地转发”)。
+
+假设你的网络应用在 `remote.example.com` 的 8000 端口上运行。要将那个系统的 8000 端口本地转发到你系统上的 8000 端口,请在开始会话时将 `-L` 选项与 `ssh` 结合使用:
+
+```
+$ ssh -L 8000:localhost:8000 remote.example.com
+```
+
+等等,为什么我们使用 `localhost` 作为转发目标?这是因为从 `remote.example.com` 的角度来看,你是在要求主机使用其自己的端口 8000。(回想一下,任何主机通常可以通过网络连接 `localhost` 而连接到自身。)现在那个端口连接到你系统的 8000 端口了。`ssh` 会话准备就绪后,将其保持打开状态,然后可以在浏览器中键入 `http://localhost:8000` 来查看你的 Web 应用。现在,系统之间的流量可以通过 `ssh` 隧道安全地传输!
+
+如果你有敏锐的眼睛,你可能已经注意到了一些东西。如果我们要 `remote.example.com` 转发到与 `localhost` 不同的主机名怎么办?如果它可以访问该网络上另一个系统上的端口,那么通常可以同样轻松地转发该端口。例如,假设你想访问也在该远程网络中的 `db.example.com` 的 MariaDB 或 MySQL 服务。该服务通常在端口 3306 上运行。因此,即使你无法 `ssh` 到实际的 `db.example.com` 主机,你也可以使用此命令将其转发:
+
+```
+$ ssh -L 3306:db.example.com:3306 remote.example.com
+```
+
+现在,你可以在 `localhost` 上运行 MariaDB 命令,而实际上是在使用 `db.example.com` 主机。
+
+### 远程端口转发
+
+远程转发让你可以进行相反操作。想象一下,你正在为办公室的朋友设计一个 Web 应用,并想向他们展示你的工作。不过,不幸的是,你在咖啡店里工作,并且由于网络设置,他们无法通过网络连接访问你的笔记本电脑。但是,你同时使用着办公室的 `remote.example.com` 系统,并且仍然可在这里登录。你的 Web 应用似乎在本地 5000 端口上运行良好。
+
+远程端口转发使你可以通过 `ssh` 连接从本地系统建立端口的隧道,并使该端口在远程系统上可用。在开始 `ssh` 会话时,只需使用 `-R` 选项:
+
+```
+$ ssh -R 6000:localhost:5000 remote.example.com
+```
+
+现在,当在公司防火墙内的朋友打开浏览器时,他们可以进入 `http://remote.example.com:6000` 查看你的工作。就像在本地端口转发示例中一样,通信通过 `ssh` 会话安全地进行。
+
+默认情况下,`sshd` 守护进程运行在设置的主机上,因此**只有**该主机可以连接它的远程转发端口。假设你的朋友希望能够让其他 `example.com` 公司主机上的人看到你的工作,而他们不在 `remote.example.com` 上。你需要让 `remote.example.com` 主机的所有者将以下选项**之一**添加到 `/etc/ssh/sshd_config` 中:
+
+```
+GatewayPorts yes # 或
+GatewayPorts clientspecified
+```
+
+第一个选项意味着 `remote.example.com` 上的所有网络接口都可以使用远程转发的端口。第二个意味着建立隧道的客户端可以选择地址。默认情况下,此选项设置为 `no`。
+
+使用此选项,你作为 `ssh` 客户端仍必须指定可以共享你这边转发端口的接口。通过在本地端口之前添加网络地址范围来进行此操作。有几种方法可以做到,包括:
+
+```
+$ ssh -R *:6000:localhost:5000 # 所有网络
+$ ssh -R 0.0.0.0:6000:localhost:5000 # 所有网络
+$ ssh -R 192.168.1.15:6000:localhost:5000 # 单个网络
+$ ssh -R remote.example.com:6000:localhost:5000 # 单个网络
+```
+
+### 其他注意事项
+
+请注意,本地和远程系统上的端口号不必相同。实际上,有时你甚至可能无法使用相同的端口。例如,普通用户可能不会在默认设置中转发到系统端口。
+
+另外,可以限制主机上的转发。如果你需要在联网主机上更严格的安全性,那么这你来说可能很重要。 `sshd` 守护程进程的 `PermitOpen` 选项控制是否以及哪些端口可用于 TCP 转发。默认设置为 `any`,这让上面的所有示例都能正常工作。要禁止任何端口转发,请选择 `none`,或仅允许的特定的“主机:端口”。有关更多信息,请在手册页中搜索 `PermitOpen` 来配置 `sshd` 守护进程:
+
+```
+$ man sshd_config
+```
+
+最后,请记住,只有在 `ssh` 会话处于打开状态时才会端口转发。如果需要长时间保持转发活动,请尝试使用 `-N` 选项在后台运行会话。确保控制台已锁定,以防止在你离开控制台时其被篡夺。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/using-ssh-port-forwarding-on-fedora/
+
+作者:[Paul W. Frields][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/pfrields/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/10/ssh-port-forwarding-816x345.jpg
+[2]: https://en.wikipedia.org/wiki/Secure_Shell
+[3]: https://fedoramagazine.org/open-source-ssh-clients/
diff --git a/published/201910/20191025 MX Linux 19 Released With Debian 10.1 ‘Buster- - Other Improvements.md b/published/201910/20191025 MX Linux 19 Released With Debian 10.1 ‘Buster- - Other Improvements.md
new file mode 100644
index 0000000000..1e157e106d
--- /dev/null
+++ b/published/201910/20191025 MX Linux 19 Released With Debian 10.1 ‘Buster- - Other Improvements.md
@@ -0,0 +1,96 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11509-1.html)
+[#]: subject: (MX Linux 19 Released With Debian 10.1 ‘Buster’ & Other Improvements)
+[#]: via: (https://itsfoss.com/mx-linux-19/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+随着 Debian 10.1 “Buster” 的发布,MX Linux 19 也发布了
+======
+
+MX Linux 18 是我在[最佳 Linux 发行版][1]中的主要推荐的发行版之一,特别是当你在考虑 Ubuntu 以外的发行版时。
+
+它基于 Debian 9.6 “Stretch”,具有令人难以置信的快速流畅的体验。
+
+现在,作为该发行版的主要升级版本,MX Linux 19 带来了许多重大改进和变更。在这里,我们将看一下主要亮点。
+
+### MX Linux 19 中的新功能
+
+- [视频](https://player.vimeo.com/video/368459760)
+
+#### Debian 10 “Buster”
+
+这个值得一提,因为 Debian 10 实际上是 MX Linux 18 所基于的 Debian 9.6 “Stretch” 的主要升级。
+
+如果你对 Debian 10 “Buster” 的变化感到好奇,建议你阅读有关 [Debian 10 “Buster” 的新功能][3]的文章。
+
+#### Xfce 桌面 4.14
+
+![MX Linux 19][4]
+
+[Xfce 4.14][5] 正是 Xfce 开发团队提供的最新产品。就个人而言,我不是 Xfce 桌面环境的粉丝,但是当你在 Linux 发行版(尤其是 MX Linux 19)上使用它时,它超快的性能会让你惊叹。
+
+或许你会感兴趣,我们也有一个快速指南来帮助你[自定义 Xfce][6]。
+
+#### 升级的软件包及最新的 Debian 内核 4.19
+
+除了 [GIMP][7]、MESA、Firefox 等的更新软件包之外,它还随附有 Debian “Buster” 可用的最新内核 4.19。
+
+#### 升级的 MX 系列应用
+
+如果你以前使用过 MX Linux,则可能会知道它已经预装了有用的 MX 系列应用,可以帮助你快速完成更多工作。
+
+像 MX-installer 和 MX-packageinstaller 这样的应用程序得到了显著改进。
+
+除了这两个以外,所有其他 MX 工具也已不同程度的进行了更新和修复错误、添加了新的翻译(或只是改善了用户体验)。
+
+#### 其它改进
+
+考虑到这是一次重大升级,很明显,底层的更改要多于表面(包括最新的 antiX live 系统更新)。
+
+你可以在他们的[官方公告][8]中查看更多详细信息。你还可以从开发人员那里观看以下视频,它介绍了 MX Linux 19 中的所有新功能:
+
+- [视频](https://youtu.be/4XVHA4l4Zrc)
+
+### 获取 MX Linux 19
+
+即使是你现在正在使用 MX Linux 18 版本,你也[无法][9]升级到 MX Linux 19。你需要像其他人一样进行全新安装。
+
+你可以从此页面下载 MX Linux 19:
+
+- [下载 MX Linux 19][10]
+
+### 结语
+
+在 MX Linux 18 上,我在使用 WiFi 适配器时遇到了问题,通过[论坛][11]解决了该问题,但看来 MX Linux 19 仍未解决该问题。因此,如果你在安装 MX Linux 19 之后遇到了相同的问题,你可能想要查看一下我的[论坛帖子][11]。
+
+如果你使用的是 MX Linux 18,那么这绝对是一个令人印象深刻的升级。
+
+你尝试过了吗?你对新的 MX Linux 19 版本有何想法?让我知道你在以下评论中的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/mx-linux-19/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-11411-1.html
+[2]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
+[3]: https://linux.cn/article-11071-1.html
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/mx-linux-19.jpg?ssl=1
+[5]: https://xfce.org/about/news
+[6]: https://itsfoss.com/customize-xfce/
+[7]: https://itsfoss.com/gimp-2-10-release/
+[8]: https://mxlinux.org/blog/mx-19-patito-feo-released/
+[9]: https://mxlinux.org/migration/
+[10]: https://mxlinux.org/download-links/
+[11]: https://forum.mxlinux.org/viewtopic.php?t=52201
diff --git a/published/201910/20191029 Fedora 31 is officially here.md b/published/201910/20191029 Fedora 31 is officially here.md
new file mode 100644
index 0000000000..d3af75f5cd
--- /dev/null
+++ b/published/201910/20191029 Fedora 31 is officially here.md
@@ -0,0 +1,85 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11522-1.html)
+[#]: subject: (Fedora 31 is officially here!)
+[#]: via: (https://fedoramagazine.org/announcing-fedora-31/)
+[#]: author: (Matthew Miller https://fedoramagazine.org/author/mattdm/)
+
+Fedora 31 正式发布
+======
+
+![][1]
+
+这里,我们很荣幸地宣布 Fedora 31 的发布。感谢成千上万的 Fedora 社区成员和贡献者的辛勤工作,我们现在正在庆祝又一次的准时发布。这已成为一种惯例!
+
+如果你只想立即获取它,请立即访问 。要了解详细信息,请继续阅读!
+
+### 工具箱
+
+如果你还没有使用过 [Fedora 工具箱][2],那么现在是尝试一下的好时机。这是用于启动和管理个人工作区容器的简单工具,你可以在一个单独的环境中进行开发或试验。它只需要在命令行运行 `toolbox enter` 就行。
+
+这种容器化的工作流程对于基于 ostree 的 Fedora 变体(如 CoreOS、IoT 和 Silverblue)的用户至关重要,但在任何工作站甚至服务器系统上也非常有用。在接下来的几个月中,希望对该工具及其相关的用户体验进行更多增强,非常欢迎你提供反馈。
+
+### Fedora 风味版
+
+Fedora 的“版本”是针对特定的“展示柜”用途输出的。
+
+Fedora 工作站版本专注于台式机,以及希望获得“可以工作的” Linux 操作系统体验的特定软件开发人员。此版本具有 GNOME 3.34,它带来了显著的性能增强,在功耗较低的硬件上尤其明显。
+
+Fedora 服务器版本以易于部署的方式为系统管理员带来了最新的、最先进的开源服务器软件。
+
+而且,我们还有处于预览状态下的 Fedora CoreOS(一个定义了现代容器世界分类的操作系统)和[Fedora IoT][3](用于“边缘计算”用例)。(敬请期待计划中的给该物联网版本的征集名称的活动!)
+
+当然,我们不仅仅提供的是各种版本。还有面向各种受众和用例的 [Fedora Spins][4] 和 [Labs][5],包括 [Fedora 天文学][6] 版本,为业余和专业的天文学家带来了完整的开源工具链,以及支持各种桌面环境(例如 [KDE Plasma][7] 和 [Xfce][8])。
+
+而且,请不要忘记我们的替代架构 [ARM AArch64、Power 和 S390x][9]。特别要注意的是,我们对包括 Rock960、RockPro64 和 Rock64 在内的 Rockchip 片上系统设备的支持得到了改善,并初步支持了 “[panfrost][10]”,这是一种较新的开源 3D 加速图形驱动程序 Arm Mali "midgard" GPU。
+
+不过,如果你使用的是只支持 32 位的 i686 旧系统,那么该找个替代方案了,[我们的基本系统告别了 32 位 Intel 架构][11]。
+
+### 常规改进
+
+无论你使用哪种 Fedora 版本,你都将获得开源世界所提供的最新版本。遵循 “[First][12]” 准则,我们启用了 CgroupsV2(如果你使用的是 Docker,[请确保检查一下][13])。Glibc 2.30 和 NodeJS 12 是 Fedora 31 中许多更新的软件包之一。而且,我们已经将 `python` 命令切换为 Python 3,请记住,Python 2 在[今年年底][14]生命期就终止了。
+
+我们很高兴你能试用新版本!转到 并立即下载吧。或者,如果你已经在运行 Fedora 操作系统,请遵循简单的[升级说明][15]就行。
+
+### 万一出现问题……
+
+如果遇到问题,请查看 [Fedora 31 常见错误][16]页面,如果有疑问,请访问我们的 [Ask Fedora][17] 用户支持平台。
+
+### 谢谢大家
+
+感谢在此发行周期中成千上万为 Fedora 项目做出贡献的人们,尤其是那些为使该发行版再次按时发行而付出更多努力的人。而且,如果你本周在波特兰参加 [USENIX LISA][18],请在博览会大厅,在 Red Hat、Fedora 和 CentOS 展位找到我。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/announcing-fedora-31/
+
+作者:[Matthew Miller][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/mattdm/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/10/fedora31-816x345.jpg
+[2]: https://docs.fedoraproject.org/en-US/fedora-silverblue/toolbox/
+[3]: https://iot.fedoraproject.org/
+[4]: https://spins.fedoraproject.org/
+[5]: https://labs.fedoraproject.org/
+[6]: https://labs.fedoraproject.org/en/astronomy/
+[7]: https://spins.fedoraproject.org/en/kde/
+[8]: https://spins.fedoraproject.org/en/xfce/
+[9]: https://alt.fedoraproject.org/alt/
+[10]: https://panfrost.freedesktop.org/
+[11]: https://fedoramagazine.org/in-fedora-31-32-bit-i686-is-86ed/
+[12]: https://docs.fedoraproject.org/en-US/project/#_first
+[13]: https://fedoraproject.org/wiki/Common_F31_bugs#Docker_package_no_longer_available_and_will_not_run_by_default_.28due_to_switch_to_cgroups_v2.29
+[14]: https://pythonclock.org/
+[15]: https://docs.fedoraproject.org/en-US/quick-docs/upgrading/
+[16]: https://fedoraproject.org/wiki/Common_F31_bugs
+[17]: http://ask.fedoraproject.org
+[18]: https://www.usenix.org/conference/lisa19
diff --git a/published/20191008 5 Best Password Managers For Linux Desktop.md b/published/20191008 5 Best Password Managers For Linux Desktop.md
new file mode 100644
index 0000000000..ebdda1f376
--- /dev/null
+++ b/published/20191008 5 Best Password Managers For Linux Desktop.md
@@ -0,0 +1,193 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11531-1.html)
+[#]: subject: (5 Best Password Managers For Linux Desktop)
+[#]: via: (https://itsfoss.com/password-managers-linux/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+5 个 Linux 桌面上的最佳密码管理器
+======
+
+> 密码管理器是创建唯一密码并安全存储它们的有用工具,这样你无需记住密码。了解一下适用于 Linux 桌面的最佳密码管理器。
+
+
+
+密码无处不在。网站、论坛、Web 应用等,你需要为其创建帐户和密码。麻烦在于密码,为各个帐户使用相同的密码会带来安全风险,因为[如果其中一个网站遭到入侵,黑客也会在其他网站上尝试相同的电子邮件密码组合][1]。
+
+但是,为所有新帐户设置独有的密码意味着你必须记住所有密码,这对普通人而言不太可能。这就是密码管理器可以提供帮助的地方。
+
+密码管理应用会为你建议/创建强密码,并将其存储在加密的数据库中。你只需要记住密码管理器的主密码即可。
+
+主流的现代浏览器(例如 Mozilla Firefox 和 Google Chrome)内置了密码管理器。这有帮助,但是你只能在浏览器上使用它。
+
+有一些第三方专门的密码管理器,其中一些还提供 Linux 的原生桌面应用。在本文中,我们将筛选出可用于 Linux 的最佳密码管理器。
+
+继续之前,我还建议你仔细阅读 [Linux 的免费密码生成器][2],来为你生成强大的唯一密码。
+
+### Linux 密码管理器
+
+> 可能的非 FOSS 警报!
+
+> 我们优先考虑开源软件(有一些专有软件,请不要讨厌我!),并提供适用于 Linux 的独立桌面应用(GUI)。专有软件已高亮显示。
+
+#### 1、Bitwarden
+
+![][3]
+
+主要亮点:
+
+* 开源
+* 免费供个人使用(可选付费升级)
+* 云服务器的端到端加密
+* 跨平台
+* 有浏览器扩展
+* 命令行工具
+
+Bitwarden 是 Linux 上最令人印象深刻的密码管理器之一。老实说,直到现在我才知道它。我已经从 [LastPass][4] 切换到了它。我能够轻松地从 LastPass 导入数据,而没有任何问题和困难。
+
+付费版本的价格仅为每年 10 美元。这似乎是值得的(我已经为个人使用进行了升级)。
+
+它是一个开源解决方案,因此没有任何可疑之处。你甚至可以将其托管在自己的服务器上,并为你的组织创建密码解决方案。
+
+除此之外,你还将获得所有必需的功能,例如用于登录的两步验证、导入/导出凭据、指纹短语(唯一键)、密码生成器等等。
+
+你可以免费将帐户升级为组织帐户,以便最多与 2 个用户共享你的信息。但是,如果你想要额外的加密存储以及与 5 个用户共享密码的功能,那么付费升级的费用低至每月 1 美元。我认为绝对值得一试!
+
+- [Bitwarden][5]
+
+#### 2、Buttercup
+
+![][6]
+
+主要亮点:
+
+* 开源
+* 免费,没有付费方式。
+* 跨平台
+* 有浏览器扩展
+
+这是 Linux 中的另一个开源密码管理器。Buttercup 可能不是一个非常流行的解决方案。但是,如果你在寻找一种更简单的保存凭据的方法,那么这将是一个不错的开始。
+
+与其他软件不同,你不必对怀疑其云服务器的安全,因为它只支持离线使用并支持连接 [Dropbox][7]、[OwnCloud] [8]、[Nextcloud][9] 和 [WebDAV][10] 等云服务。
+
+因此,如果需要同步数据,那么可以选择云服务。你有不同选择。
+
+- [Buttercup][11]
+
+#### 3、KeePassXC
+
+![][12]
+
+主要亮点:
+
+* 开源
+* 简单的密码管理器
+* 跨平台
+* 没有移动设备支持
+
+KeePassXC 是 [KeePassX][13] 的社区分支,它最初是 Windows 上 [KeePass][14] 的 Linux 移植版本。
+
+除非你没意识到,KeePassX 已经多年没有维护。因此,如果你在寻找简单易用的密码管理器,那么 KeePassXC 是一个不错的选择。KeePassXC 可能不是最漂亮或最好的密码管理器,但它确实可以做到该做的事。
+
+它也是安全和开源的。我认为这值得一试,你说呢?
+
+- [KeePassXC][15]
+
+#### 4、Enpass (非开源)
+
+![][16]
+
+主要亮点:
+
+* 专有软件
+* 有许多功能,包括对“可穿戴”设备支持。
+* Linux 完全免费(具有付费支持)
+
+Enpass 是非常流行的跨平台密码管理器。即使它不是开源解决方案,但还是有很多人依赖它。因此,至少可以肯定它是可行的。
+
+它提供了很多功能,如果你有可穿戴设备,它也可以支持它,这点很少见。
+
+很高兴能看到 Enpass 积极管理 Linux 发行版的软件包。另外,请注意,它仅适用于 64 位系统。你可以在它的网站上找到[官方的安装说明] [17]。它需要使用终端,但是我按照步骤进行了测试,它非常好用。
+
+- [Enpass][18]
+
+#### 5、myki (非开源)
+
+![][19]
+
+主要亮点:
+
+* 专有软件
+* 不使用云服务器存储密码
+* 专注于本地点对点同步
+* 能够在移动设备上用指纹 ID 替换密码
+
+这可能不是一个受欢迎的建议,但我发现它很有趣。它是专有软件密码管理器,它让你避免使用云服务器,而是依靠点对点同步。
+
+因此,如果你不想使用任何云服务器来存储你的信息,那么它适合你。另外值得注意的是,用于 Android 和 iOS 的程序可让你用指纹 ID 替换密码。如果你希望便于在手机上使用,又有桌面密码管理器的基本功能,这似乎是个不错的选择。
+
+但是,如果你选择升级到付费版,这有个付费计划供你判断,绝对不便宜。
+
+尝试一下,让我们知道它如何!
+
+- [myki][20]
+
+### 其他一些值得说的密码管理器
+
+即使没有为 Linux 提供独立的应用,但仍有一些密码管理器值得一提。
+
+如果你需要使用基于浏览器的(扩展)密码管理器,建议你尝试使用 [LastPass][21]、[Dashlane][22] 和 [1Password][23]。LastPass 甚至提供了 [Linux 客户端(和命令行工具)][24]。
+
+如果你正在寻找命令行密码管理器,那你应该试试 [Pass][25]。
+
+[Password Safe][26] 也是种选择,但它的 Linux 客户端还处于 beta 阶段。我不建议依靠 “beta” 程序来存储密码。还有 [Universal Password Manager][27],但它不再维护。你可能也听说过 [Password Gorilla][28],但并它没有积极维护。
+
+### 总结
+
+目前,Bitwarden 似乎是我个人的最爱。但是,在 Linux 上有几个替代品可供选择。你可以选择提供原生应用的程序,也可选择浏览器插件,选择权在你。
+
+如果我有错过值得尝试的密码管理器,请在下面的评论中告诉我们。与往常一样,我们会根据你的建议扩展列表。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/password-managers-linux/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://medium.com/@computerphonedude/one-of-my-old-passwords-was-hacked-on-6-different-sites-and-i-had-no-clue-heres-how-to-quickly-ced23edf3b62
+[2]: https://itsfoss.com/password-generators-linux/
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/bitward.png?ssl=1
+[4]: https://www.lastpass.com/
+[5]: https://bitwarden.com/
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/buttercup.png?ssl=1
+[7]: https://www.dropbox.com/
+[8]: https://owncloud.com/
+[9]: https://nextcloud.com/
+[10]: https://en.wikipedia.org/wiki/WebDAV
+[11]: https://buttercup.pw/
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/KeePassXC.png?ssl=1
+[13]: https://www.keepassx.org/
+[14]: https://keepass.info/
+[15]: https://keepassxc.org
+[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/enpass.png?ssl=1
+[17]: https://www.enpass.io/support/kb/general/how-to-install-enpass-on-linux/
+[18]: https://www.enpass.io/
+[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/myki.png?ssl=1
+[20]: https://myki.com/
+[21]: https://lastpass.com/
+[22]: https://www.dashlane.com/
+[23]: https://1password.com/
+[24]: https://lastpass.com/misc_download2.php
+[25]: https://www.passwordstore.org/
+[26]: https://pwsafe.org/
+[27]: http://upm.sourceforge.net/
+[28]: https://github.com/zdia/gorilla/wiki
diff --git a/sources/tech/20191013 How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server.md b/published/20191013 How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server.md
similarity index 57%
rename from sources/tech/20191013 How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server.md
rename to published/20191013 How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server.md
index d959b30d0c..c71aa58995 100644
--- a/sources/tech/20191013 How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server.md
+++ b/published/20191013 How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server.md
@@ -1,65 +1,63 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11535-1.html)
[#]: subject: (How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server)
[#]: via: (https://www.linuxtechi.com/enable-epel-repo-centos8-rhel8-server/)
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
-How to Enable EPEL Repository on CentOS 8 and RHEL 8 Server
+如何在 CentOS 8 和 RHEL 8 服务器上启用 EPEL 仓库
======
-**EPEL** Stands for Extra Packages for Enterprise Linux, it is a free and opensource additional packages repository available for **CentOS** and **RHEL** servers. As the name suggests, EPEL repository provides extra and additional packages which are not available in the default package repositories of [CentOS 8][1] and [RHEL 8][2].
+EPEL 代表 “Extra Packages for Enterprise Linux”,它是一个自由开源的附加软件包仓库,可用于 CentOS 和 RHEL 服务器。顾名思义,EPEL 仓库提供了额外的软件包,这些软件在 [CentOS 8][1] 和 [RHEL 8][2] 的默认软件包仓库中不可用。
-In this article we will demonstrate how to enable and use epel repository on CentOS 8 and RHEL 8 Server.
+在本文中,我们将演示如何在 CentOS 8 和 RHEL 8 服务器上启用和使用 EPEL 存储库。
-[![EPEL-Repo-CentOS8-RHEL8][3]][4]
+
-### Prerequisites of EPEL Repository
+### EPEL 仓库的先决条件
- * Minimal CentOS 8 and RHEL 8 Server
- * Root or sudo admin privileges
- * Internet Connection
+ * 最小化安装的 CentOS 8 和 RHEL 8 服务器
+ * root 或 sudo 管理员权限
+ * 网络连接
+### 在 RHEL 8.x 服务器上安装并启用 EPEL 仓库
-
-### Install and Enable EPEL Repository on RHEL 8.x Server
-
-Login or ssh to your RHEL 8.x server and execute the following dnf command to install EPEL rpm package,
+登录或 SSH 到你的 RHEL 8.x 服务器,并执行以下 `dnf` 命令来安装 EPEL rpm 包,
```
[root@linuxtechi ~]# dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm -y
```
-Output of above command would be something like below,
+上面命令的输出将如下所示,
-![dnf-install-epel-repo-rehl8][3]
+![dnf-install-epel-repo-rehl8][5]
-Once epel rpm package is installed successfully then it will automatically enable and configure its yum / dnf repository. Run following dnf or yum command to verify whether EPEL repository is enabled or not,
+EPEL rpm 包成功安装后,它将自动启用并配置其 yum/dnf 仓库。运行以下 `dnf` 或 `yum` 命令,以验证是否启用了 EPEL 仓库,
```
[root@linuxtechi ~]# dnf repolist epel
-Or
+或者
[root@linuxtechi ~]# dnf repolist epel -v
```
-![epel-repolist-rhel8][3]
+![epel-repolist-rhel8][6]
-### Install and Enable EPEL Repository on CentOS 8.x Server
+### 在 CentOS 8.x 服务器上安装并启用 EPEL 仓库
-Login or ssh to your CentOS 8 server and execute following dnf or yum command to install ‘**epel-release**‘ rpm package. In CentOS 8 server, epel rpm package is available in its default package repository.
+登录或 SSH 到你的 CentOS 8 服务器,并执行以下 `dnf` 或 `yum` 命令来安装 `epel-release` rpm 软件包。在 CentOS 8 服务器中,EPEL rpm 在其默认软件包仓库中。
```
[root@linuxtechi ~]# dnf install epel-release -y
-Or
+或者
[root@linuxtechi ~]# yum install epel-release -y
```
-Execute the following commands to verify the status of epel repository on CentOS 8 server,
+执行以下命令来验证 CentOS 8 服务器上 EPEL 仓库的状态,
```
- [root@linuxtechi ~]# dnf repolist epel
+[root@linuxtechi ~]# dnf repolist epel
Last metadata expiration check: 0:00:03 ago on Sun 13 Oct 2019 04:18:05 AM BST.
repo id repo name status
*epel Extra Packages for Enterprise Linux 8 - x86_64 1,977
@@ -82,11 +80,11 @@ Total packages: 1,977
[root@linuxtechi ~]#
```
-Above command’s output confirms that we have successfully enabled epel repo. Let’s perform some basic operations on EPEL repo.
+以上命令的输出说明我们已经成功启用了 EPEL 仓库。让我们在 EPEL 仓库上执行一些基本操作。
-### List all available packages from epel repository
+### 列出 EPEL 仓库种所有可用包
-If you want to list all the packages from epel repository then run the following dnf command,
+如果要列出 EPEL 仓库中的所有的软件包,请运行以下 `dnf` 命令,
```
[root@linuxtechi ~]# dnf repository-packages epel list
@@ -116,33 +114,35 @@ zvbi-fonts.noarch 0.2.35-9.el8 epel
[root@linuxtechi ~]#
```
-### Search a package from epel repository
+### 从 EPEL 仓库中搜索软件包
-Let’s assume if we want to search Zabbix package in epel repository, execute the following dnf command,
+假设我们要搜索 EPEL 仓库中的 Zabbix 包,请执行以下 `dnf` 命令,
```
[root@linuxtechi ~]# dnf repository-packages epel list | grep -i zabbix
```
-Output of above command would be something like below,
+上面命令的输出类似下面这样,
-![epel-repo-search-package-centos8][3]
+![epel-repo-search-package-centos8][7]
-### Install a package from epel repository
+### 从 EPEL 仓库安装软件包
-Let’s assume we want to install htop package from epel repo, then issue the following dnf command,
+假设我们要从 EPEL 仓库安装 htop 包,运行以下 `dnf` 命令,
-Syntax:
+语法:
-# dnf –enablerepo=”epel” install <pkg_name>
+```
+# dnf –enablerepo=”epel” install <包名>
+```
```
[root@linuxtechi ~]# dnf --enablerepo="epel" install htop -y
```
-**Note:** If we don’t specify the “**–enablerepo=epel**” in above command then it will look for htop package in all available package repositories.
+注意:如果我们在上面的命令中未指定 `–enablerepo=epel`,那么它将在所有可用的软件包仓库中查找 htop 包。
-That’s all from this article, I hope above steps helps you to enable and configure EPEL repository on CentOS 8 and RHEL 8 Server, please don’t hesitate to share your comments and feedback in below comments section.
+本文就是这些内容了,我希望上面的步骤能帮助你在 CentOS 8 和 RHEL 8 服务器上启用并配置 EPEL 仓库,请在下面的评论栏分享你的评论和反馈。
--------------------------------------------------------------------------------
@@ -150,8 +150,8 @@ via: https://www.linuxtechi.com/enable-epel-repo-centos8-rhel8-server/
作者:[Pradeep Kumar][a]
选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -161,3 +161,6 @@ via: https://www.linuxtechi.com/enable-epel-repo-centos8-rhel8-server/
[2]: https://www.linuxtechi.com/install-configure-kvm-on-rhel-8/
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
[4]: https://www.linuxtechi.com/wp-content/uploads/2019/10/EPEL-Repo-CentOS8-RHEL8.jpg
+[5]: https://www.linuxtechi.com/wp-content/uploads/2019/10/dnf-install-epel-repo-rehl8.jpg
+[6]: https://www.linuxtechi.com/wp-content/uploads/2019/10/epel-repolist-rhel8.jpg
+[7]: https://www.linuxtechi.com/wp-content/uploads/2019/10/epel-repo-search-package-centos8.jpg
diff --git a/published/20191022 Initializing arrays in Java.md b/published/20191022 Initializing arrays in Java.md
new file mode 100644
index 0000000000..80177952cb
--- /dev/null
+++ b/published/20191022 Initializing arrays in Java.md
@@ -0,0 +1,361 @@
+[#]: collector: (lujun9972)
+[#]: translator: (laingke)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11533-1.html)
+[#]: subject: (Initializing arrays in Java)
+[#]: via: (https://opensource.com/article/19/10/initializing-arrays-java)
+[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
+
+Java 中初始化数组
+======
+
+> 数组是一种有用的数据类型,用于管理在连续内存位置中建模最好的集合元素。下面是如何有效地使用它们。
+
+![Coffee beans and a cup of coffee][1]
+
+有使用 C 或者 FORTRAN 语言编程经验的人会对数组的概念很熟悉。它们基本上是一个连续的内存块,其中每个位置都是某种数据类型:整型、浮点型或者诸如此类的数据类型。
+
+Java 的情况与此类似,但是有一些额外的问题。
+
+### 一个数组的示例
+
+让我们在 Java 中创建一个长度为 10 的整型数组:
+
+```
+int[] ia = new int[10];
+```
+
+上面的代码片段会发生什么?从左到右依次是:
+
+ 1. 最左边的 `int[]` 将变量的*类型*声明为 `int` 数组(由 `[]` 表示)。
+ 2. 它的右边是变量的名称,当前为 `ia`。
+ 3. 接下来,`=` 告诉我们,左侧定义的变量赋值为右侧的内容。
+ 4. 在 `=` 的右侧,我们看到了 `new`,它在 Java 中表示一个对象正在*被初始化中*,这意味着已为其分配存储空间并调用了其构造函数([请参见此处以获取更多信息][2])。
+ 5. 然后,我们看到 `int[10]`,它告诉我们正在初始化的这个对象是包含 10 个整型的数组。
+
+因为 Java 是强类型的,所以变量 `ia` 的类型必须跟 `=` 右侧表达式的类型兼容。
+
+### 初始化示例数组
+
+让我们把这个简单的数组放在一段代码中,并尝试运行一下。将以下内容保存到一个名为 `Test1.java` 的文件中,使用 `javac` 编译,使用 `java` 运行(当然是在终端中):
+
+```
+import java.lang.*;
+
+public class Test1 {
+
+ public static void main(String[] args) {
+ int[] ia = new int[10]; // 见下文注 1
+ System.out.println("ia is " + ia.getClass()); // 见下文注 2
+ for (int i = 0; i < ia.length; i++) // 见下文注 3
+ System.out.println("ia[" + i + "] = " + ia[i]); // 见下文注 4
+ }
+
+}
+```
+
+让我们来看看最重要的部分。
+
+ 1. 我们声明和初始化了长度为 10 的整型数组,即 `ia`,这显而易见。
+ 2. 在下面的行中,我们看到表达式 `ia.getClass()`。没错,`ia` 是属于一个*类*的*对象*,这行代码将告诉我们是哪个类。
+ 3. 在紧接的下一行中,我们看到了一个循环 `for (int i = 0; i < ia.length; i++)`,它定义了一个循环索引变量 `i`,该变量遍历了从 0 到比 `ia.length` 小 1 的序列,这个表达式告诉我们在数组 `ia` 中定义了多少个元素。
+ 4. 接下来,循环体打印出 `ia` 的每个元素的值。
+
+当这个程序编译和运行时,它产生以下结果:
+
+```
+me@mydesktop:~/Java$ javac Test1.java
+me@mydesktop:~/Java$ java Test1
+ia is class [I
+ia[0] = 0
+ia[1] = 0
+ia[2] = 0
+ia[3] = 0
+ia[4] = 0
+ia[5] = 0
+ia[6] = 0
+ia[7] = 0
+ia[8] = 0
+ia[9] = 0
+me@mydesktop:~/Java$
+```
+
+`ia.getClass()` 的输出的字符串表示形式是 `[I`,它是“整数数组”的简写。与 C 语言类似,Java 数组以第 0 个元素开始,扩展到第 `<数组大小> - 1` 个元素。如上所见,我们可以看到数组 `ia` 的每个元素都(似乎由数组构造函数)设置为零。
+
+所以,就这些吗?声明类型,使用适当的初始化器,就完成了吗?
+
+好吧,并没有。在 Java 中有许多其它方法来初始化数组。
+
+### 为什么我要初始化一个数组,有其它方式吗?
+
+像所有好的问题一样,这个问题的答案是“视情况而定”。在这种情况下,答案取决于初始化后我们希望对数组做什么。
+
+在某些情况下,数组自然会作为一种累加器出现。例如,假设我们正在编程实现计算小型办公室中一组电话分机接收和拨打的电话数量。一共有 8 个分机,编号为 1 到 8,加上话务员的分机,编号为 0。 因此,我们可以声明两个数组:
+
+```
+int[] callsMade;
+int[] callsReceived;
+```
+
+然后,每当我们开始一个新的累计呼叫统计数据的周期时,我们就将每个数组初始化为:
+
+```
+callsMade = new int[9];
+callsReceived = new int[9];
+```
+
+在每个累计通话统计数据的最后阶段,我们可以打印出统计数据。粗略地说,我们可能会看到:
+
+```
+import java.lang.*;
+import java.io.*;
+
+public class Test2 {
+
+ public static void main(String[] args) {
+
+ int[] callsMade;
+ int[] callsReceived;
+
+ // 初始化呼叫计数器
+
+ callsMade = new int[9];
+ callsReceived = new int[9];
+
+ // 处理呼叫……
+ // 分机拨打电话:callsMade[ext]++
+ // 分机接听电话:callsReceived[ext]++
+
+ // 汇总通话统计
+
+ System.out.printf("%3s%25s%25s\n", "ext", " calls made",
+ "calls received");
+ for (int ext = 0; ext < callsMade.length; ext++) {
+ System.out.printf("%3d%25d%25d\n", ext,
+ callsMade[ext], callsReceived[ext]);
+ }
+
+ }
+
+}
+```
+
+这会产生这样的输出:
+
+```
+me@mydesktop:~/Java$ javac Test2.java
+me@mydesktop:~/Java$ java Test2
+ext calls made calls received
+ 0 0 0
+ 1 0 0
+ 2 0 0
+ 3 0 0
+ 4 0 0
+ 5 0 0
+ 6 0 0
+ 7 0 0
+ 8 0 0
+me@mydesktop:~/Java$
+```
+
+看来这一天呼叫中心不是很忙。
+
+在上面的累加器示例中,我们看到由数组初始化程序设置的零起始值可以满足我们的需求。但是在其它情况下,这个起始值可能不是正确的选择。
+
+例如,在某些几何计算中,我们可能需要将二维数组初始化为单位矩阵(除沿主对角线———左上角到右下角——以外所有全是零)。我们可以选择这样做:
+
+
+```
+double[][] m = new double[3][3];
+for (int d = 0; d < 3; d++) {
+ m[d][d] = 1.0;
+}
+```
+
+在这种情况下,我们依靠数组初始化器 `new double[3][3]` 将数组设置为零,然后使用循环将主对角线上的元素设置为 1。在这种简单情况下,我们可以使用 Java 提供的快捷方式:
+
+```
+double[][] m = {
+ {1.0, 0.0, 0.0},
+ {0.0, 1.0, 0.0},
+ {0.0, 0.0, 1.0}};
+```
+
+这种可视结构特别适用于这种应用程序,在这种应用程序中,它便于复查数组的实际布局。但是在这种情况下,行数和列数只在运行时确定时,我们可能会看到这样的东西:
+
+```
+int nrc;
+// 一些代码确定行数和列数 = nrc
+double[][] m = new double[nrc][nrc];
+for (int d = 0; d < nrc; d++) {
+ m[d][d] = 1.0;
+}
+```
+
+值得一提的是,Java 中的二维数组实际上是数组的数组,没有什么能阻止无畏的程序员让这些第二层数组中的每个数组的长度都不同。也就是说,下面这样的事情是完全合法的:
+
+```
+int [][] differentLengthRows = {
+ {1, 2, 3, 4, 5},
+ {6, 7, 8, 9},
+ {10, 11, 12},
+ {13, 14},
+ {15}};
+```
+
+在涉及不规则形状矩阵的各种线性代数应用中,可以应用这种类型的结构(有关更多信息,请参见[此 Wikipedia 文章][5])。除此之外,既然我们了解到二维数组实际上是数组的数组,那么以下内容也就不足为奇了:
+
+```
+differentLengthRows.length
+```
+
+可以告诉我们二维数组 `differentLengthRows` 的行数,并且:
+
+```
+differentLengthRows[i].length
+```
+
+告诉我们 `differentLengthRows` 第 `i` 行的列数。
+
+### 深入理解数组
+
+考虑到在运行时确定数组大小的想法,我们看到数组在实例化之前仍需要我们知道该大小。但是,如果在处理完所有数据之前我们不知道大小怎么办?这是否意味着我们必须先处理一次以找出数组的大小,然后再次处理?这可能很难做到,尤其是如果我们只有一次机会使用数据时。
+
+[Java 集合框架][6]很好地解决了这个问题。提供的其中一项是 `ArrayList` 类,它类似于数组,但可以动态扩展。为了演示 `ArrayList` 的工作原理,让我们创建一个 `ArrayList` 对象并将其初始化为前 20 个[斐波那契数字][7]:
+
+```
+import java.lang.*;
+import java.util.*;
+
+public class Test3 {
+
+ public static void main(String[] args) {
+
+ ArrayList fibos = new ArrayList();
+
+ fibos.add(0);
+ fibos.add(1);
+ for (int i = 2; i < 20; i++) {
+ fibos.add(fibos.get(i - 1) + fibos.get(i - 2));
+ }
+
+ for (int i = 0; i < fibos.size(); i++) {
+ System.out.println("fibonacci " + i + " = " + fibos.get(i));
+ }
+
+ }
+}
+```
+
+上面的代码中,我们看到:
+
+ * 用于存储多个 `Integer` 的 `ArrayList` 的声明和实例化。
+ * 使用 `add()` 附加到 `ArrayList` 实例。
+ * 使用 `get()` 通过索引号检索元素。
+ * 使用 `size()` 来确定 `ArrayList` 实例中已经有多少个元素。
+
+这里没有展示 `put()` 方法,它的作用是将一个值放在给定的索引号上。
+
+该程序的输出为:
+
+```
+fibonacci 0 = 0
+fibonacci 1 = 1
+fibonacci 2 = 1
+fibonacci 3 = 2
+fibonacci 4 = 3
+fibonacci 5 = 5
+fibonacci 6 = 8
+fibonacci 7 = 13
+fibonacci 8 = 21
+fibonacci 9 = 34
+fibonacci 10 = 55
+fibonacci 11 = 89
+fibonacci 12 = 144
+fibonacci 13 = 233
+fibonacci 14 = 377
+fibonacci 15 = 610
+fibonacci 16 = 987
+fibonacci 17 = 1597
+fibonacci 18 = 2584
+fibonacci 19 = 4181
+```
+
+`ArrayList` 实例也可以通过其它方式初始化。例如,可以给 `ArrayList` 构造器提供一个数组,或者在编译过程中知道初始元素时也可以使用 `List.of()` 和 `array.aslist()` 方法。我发现自己并不经常使用这些方式,因为我对 `ArrayList` 的主要用途是当我只想读取一次数据时。
+
+此外,对于那些喜欢在加载数据后使用数组的人,可以使用 `ArrayList` 的 `toArray()` 方法将其实例转换为数组;或者,在初始化 `ArrayList` 实例之后,返回到当前数组本身。
+
+Java 集合框架提供了另一种类似数组的数据结构,称为 `Map`(映射)。我所说的“类似数组”是指 `Map` 定义了一个对象集合,它的值可以通过一个键来设置或检索,但与数组(或 `ArrayList`)不同,这个键不需要是整型数;它可以是 `String` 或任何其它复杂对象。
+
+例如,我们可以创建一个 `Map`,其键为 `String`,其值为 `Integer` 类型,如下:
+
+```
+Map stoi = new Map();
+```
+
+然后我们可以对这个 `Map` 进行如下初始化:
+
+```
+stoi.set("one",1);
+stoi.set("two",2);
+stoi.set("three",3);
+```
+
+等类似操作。稍后,当我们想要知道 `"three"` 的数值时,我们可以通过下面的方式将其检索出来:
+
+```
+stoi.get("three");
+```
+
+在我的认知中,`Map` 对于将第三方数据集中出现的字符串转换为我的数据集中的一致代码值非常有用。作为[数据转换管道][8]的一部分,我经常会构建一个小型的独立程序,用作在处理数据之前清理数据;为此,我几乎总是会使用一个或多个 `Map`。
+
+值得一提的是,`ArrayList` 的 `ArrayList` 和 `Map` 的 `Map` 是很可能的,有时也是合理的。例如,假设我们在看树,我们对按树种和年龄范围累计树的数目感兴趣。假设年龄范围定义是一组字符串值(“young”、“mid”、“mature” 和 “old”),物种是 “Douglas fir”、“western red cedar” 等字符串值,那么我们可以将这个 `Map` 中的 `Map` 定义为:
+
+```
+Map> counter = new Map>();
+```
+
+这里需要注意的一件事是,以上内容仅为 `Map` 的*行*创建存储。因此,我们的累加代码可能类似于:
+
+```
+// 假设我们已经知道了物种和年龄范围
+if (!counter.containsKey(species)) {
+ counter.put(species,new Map());
+}
+if (!counter.get(species).containsKey(ageRange)) {
+ counter.get(species).put(ageRange,0);
+}
+```
+
+此时,我们可以这样开始累加:
+
+```
+counter.get(species).put(ageRange, counter.get(species).get(ageRange) + 1);
+```
+
+最后,值得一提的是(Java 8 中的新特性)Streams 还可以用来初始化数组、`ArrayList` 实例和 `Map` 实例。关于此特性的详细讨论可以在[此处][9]和[此处][10]中找到。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/initializing-arrays-java
+
+作者:[Chris Hermansen][a]
+选题:[lujun9972][b]
+译者:[laingke](https://github.com/laingke)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/clhermansen
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-mug.jpg?itok=Bj6rQo8r (Coffee beans and a cup of coffee)
+[2]: https://opensource.com/article/19/8/what-object-java
+[3]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
+[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
+[5]: https://en.wikipedia.org/wiki/Irregular_matrix
+[6]: https://en.wikipedia.org/wiki/Java_collections_framework
+[7]: https://en.wikipedia.org/wiki/Fibonacci_number
+[8]: https://towardsdatascience.com/data-science-for-startups-data-pipelines-786f6746a59a
+[9]: https://stackoverflow.com/questions/36885371/lambda-expression-to-initialize-array
+[10]: https://stackoverflow.com/questions/32868665/how-to-initialize-a-map-using-a-lambda
diff --git a/translated/tech/20191024 Open Source CMS Ghost 3.0 Released with New features for Publishers.md b/published/20191024 Open Source CMS Ghost 3.0 Released with New features for Publishers.md
similarity index 54%
rename from translated/tech/20191024 Open Source CMS Ghost 3.0 Released with New features for Publishers.md
rename to published/20191024 Open Source CMS Ghost 3.0 Released with New features for Publishers.md
index 6ed5b8b71a..1879697316 100644
--- a/translated/tech/20191024 Open Source CMS Ghost 3.0 Released with New features for Publishers.md
+++ b/published/20191024 Open Source CMS Ghost 3.0 Released with New features for Publishers.md
@@ -1,52 +1,46 @@
[#]: collector: (lujun9972)
-[#]: translator: ( Morisun029)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: translator: (Morisun029)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11534-1.html)
[#]: subject: (Open Source CMS Ghost 3.0 Released with New features for Publishers)
[#]: via: (https://itsfoss.com/ghost-3-release/)
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-开源 CMS Ghost 3.0发布新功能
+开源 CMS Ghost 3.0 发布,带来新功能
======
-[Ghost][1]是一个免费的开源内容管理系统(CMS)。 如果你还不了CMS,那我在此解释一下。CMS 是一款软件,用它可以构建专注于创建内容的网站,而无需了解 HTML 和其他与 Web 相关的技术。
+[Ghost][1] 是一个自由开源的内容管理系统(CMS)。如果你还不了解 CMS,那我在此解释一下。CMS 是一种软件,用它可以构建主要专注于创建内容的网站,而无需了解 HTML 和其他与 Web 相关的技术。
+事实上,Ghost 是目前[最好的开源 CMS][2] 之一。它主要聚焦于创建轻量级、快速加载、界面美观的博客。
-事实上,Ghost 是目前[最好的开源 CMS][2] 之一。 它主要聚焦于创建轻量级、快速加载、界面美观的博客。
-
-
-Ghost 系统有一个现代直观的编辑器,该编辑器内置 SEO(搜索引擎优化)功能。 你也可以用本地桌面(包括Linux 系统)和移动应用程序。 如果你喜欢终端,也可以使用其提供的 CLI(命令行界面)工具。
-
-让我们看看Ghost 3.0带来了什么新功能。
-
+Ghost 系统有一个现代直观的编辑器,该编辑器内置 SEO(搜索引擎优化)功能。你也可以用本地桌面(包括 Linux 系统)和移动应用程序。如果你喜欢终端,也可以使用其提供的 CLI(命令行界面)工具。
+让我们看看 Ghost 3.0 带来了什么新功能。
### Ghost 3.0 的新功能
![][3]
-我通常对开源的 CMS 解决方案很感兴趣。因此,在阅读了官方公告后,我继续尝试通过[Digital Ocean 云服务器][4]来安装新的 Ghost 实例。
+我通常对开源的 CMS 解决方案很感兴趣。因此,在阅读了官方公告后,我通过在 Digital Ocean 云服务器上安装新的 Ghost 实例来进一步尝试它。
+
与以前的版本相比,Ghost 3.0 在功能和用户界面上的改进给我留下了深刻的印象。
在此,我将列出一些值得一提的关键点。
-
#### 书签卡
+
![][5]
-除了编辑器的所有细微更改之外,3.0版本现在支持通过输入 URL 添加漂亮的书签卡。
-
-如果你使用过WordPress(你可能已经注意到,WordPress 需要添加一个插件才能添加类似的卡片),所以该功能绝对是Ghost 3.0 系统的一个最大改进。
+除了编辑器的所有细微更改之外,3.0 版本现在支持通过输入 URL 添加漂亮的书签卡。
+如果你使用过 WordPress(你可能已经注意到,WordPress 需要添加一个插件才能添加类似的卡片),所以该功能绝对是 Ghost 3.0 系统的一个最大改进。
#### 改进的 WordPress 迁移插件
-我还未对 WordPress 进行特别测试,但它已经对 WordPress 的迁移插件进行了更新,可以让你轻松地将帖子(带有图片)克隆到 Ghost CMS。
-
-基本上,使用该插件,你就能够创建一个存档(包含图片)并将其导入到Ghost CMS。
-
+我没有专门对此进行测试,但它更新了 WordPress 的迁移插件,可以让你轻松地将帖子(带有图片)克隆到 Ghost CMS。
+基本上,使用该插件,你就能够创建一个存档(包含图片)并将其导入到 Ghost CMS。
#### 响应式图像库和图片
@@ -54,53 +48,49 @@ Ghost 系统有一个现代直观的编辑器,该编辑器内置 SEO(搜索
此外,帖子和页面中的图片也更改为响应式的了。
-
-
#### 添加成员和订阅选项
![Ghost Subscription Model][6]
-虽然,该功能目前还处于测试阶段,但如果你是以此平台作为维持你业务关系的重要发布平台,你可以为你的博客添加成员,订阅选项。
+虽然,该功能目前还处于测试阶段,但如果你是以此平台作为维持你业务关系的重要发布平台,你可以为你的博客添加成员、订阅选项。
+
该功能可以确保只有订阅的成员才能访问你的博客,你也可以选择让未订阅者也可以访问。
+#### Stripe:集成支付功能
-#### 条纹(美国公司):支付整合
-
-默认情况下,该版本支持 Stripe 付款网关,帮助你轻松订阅(或使用任何类型的付款的付款方式),而 Ghost 不再收取任何额外费用。
+默认情况下,该版本支持 Stripe 付款网关,帮助你轻松启用订阅功能(或使用任何类型的付款的付款方式),而 Ghost 不收取任何额外费用。
#### 新的应用程序集成
![][7]
-你现在可以在 Ghost 3.0 的博客中集成各种流行的应用程序/服务。 它可以使很多事情自动化。
+你现在可以在 Ghost 3.0 的博客中集成各种流行的应用程序/服务。它可以使很多事情自动化。
#### 默认主题改进
引入的默认主题(设计)已得到改进,现在也提供了夜间模式。
+
你也可以随时选择创建自定义主题(如果没有可用的预置主题)。
#### 其他小改进
-
除了所有关键亮点以外,用于创建帖子/页面的可视编辑器也得到了改进(具有某些拖放功能)。
-我确定还有很多技术方面的更改-如果你对此感兴趣,可以在他们的[更改日志][8] 中查看。
+我确定还有很多技术方面的更改,如果你对此感兴趣,可以在他们的[更改日志][8]中查看。
+### Ghost 影响力渐增
-### Ghost 逐渐获得好的影响力
+要在以 WordPress 为主导的世界中获得认可并不是一件容易的事。但 Ghost 逐渐形成了它的一个专门的发布者社区。
-要在以 WordPress 为主导的世界中获得认可并不是一件容易的事。 但 Ghost逐渐形成了一个专门的发布者社区。
-不仅如此,它的托管服务 [Ghost Pro][9] 现在拥有像 NASA,Mozilla 和 DuckDuckGo 这样的客户。
+不仅如此,它的托管服务 [Ghost Pro][9] 现在拥有像 NASA、Mozilla 和 DuckDuckGo 这样的客户。
+在过去的六年中,Ghost 从其 Ghost Pro 客户那里获得了 500 万美元的收入。就从它是致力于开源系统解决方案的非营利组织这一点来讲,这确实是一项成就。
-在过去的六年中,Ghost 从其 Ghost Pro 客户那里获得了500万美元的收入。 就从它是致力于开源系统解决方案的非营利组织这一点来讲,这确实是一项成就。
+这些收入有助于它们保持独立,避免风险投资家的外部资金投入。Ghost CMS 的托管客户越多,投入到免费和开源的 CMS 的研发款项就越多。
-这些收入有助于它们保持独立,避免风险投资家的外部资金投入。Ghost CMS 的 托管客户越多,投入到免费和开源的 CMS 的研发款就越多。
-
-总体而言,Ghost 3.0 是迄今为止提供的最好的升级版本。 这些功能给我留下了深刻的印象。
-
-如果你拥有自己的网站,你会使用什么CMS吗? 你曾经使用过Ghost吗? 你的体验如何? 请在评论部分分享你的想法。
+总体而言,Ghost 3.0 是迄今为止提供的最好的升级版本。这些功能给我留下了深刻的印象。
+如果你拥有自己的网站,你会使用什么 CMS?你曾经使用过 Ghost 吗?你的体验如何?请在评论部分分享你的想法。
--------------------------------------------------------------------------------
@@ -108,8 +98,8 @@ via: https://itsfoss.com/ghost-3-release/
作者:[Ankush Das][a]
选题:[lujun9972][b]
-译者:[Morisun029](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[Morisun029](https://github.com/Morisun029)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20191025 4 cool new projects to try in COPR for October 2019.md b/published/20191025 4 cool new projects to try in COPR for October 2019.md
new file mode 100644
index 0000000000..73682ef6e5
--- /dev/null
+++ b/published/20191025 4 cool new projects to try in COPR for October 2019.md
@@ -0,0 +1,93 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11528-1.html)
+[#]: subject: (4 cool new projects to try in COPR for October 2019)
+[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-october-2019/)
+[#]: author: (Dominik Turecek https://fedoramagazine.org/author/dturecek/)
+
+COPR 仓库中 4 个很酷的新项目(2019.10)
+======
+
+![][1]
+
+COPR 是个人软件仓库[集合][2],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
+
+本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档][3]。
+
+### Nu
+
+[Nu][4] 也被称为 Nushell,是受 PowerShell 和现代 CLI 工具启发的 shell。通过使用基于结构化数据的方法,Nu 可轻松处理命令的输出,并通过管道传输其他命令。然后将结果显示在可以轻松排序或过滤的表中,并可以用作其他命令的输入。最后,Nu 提供了几个内置命令、多 shell 和对插件的支持。
+
+#### 安装说明
+
+该[仓库][5]目前为 Fedora 30、31 和 Rawhide 提供 Nu。要安装 Nu,请使用以下命令:
+
+```
+sudo dnf copr enable atim/nushell
+sudo dnf install nushell
+```
+
+### NoteKit
+
+[NoteKit][6] 是一个笔记程序。它支持 Markdown 来格式化笔记,并支持使用鼠标创建手绘笔记的功能。在 NoteKit 中,笔记以树状结构进行排序和组织。
+
+#### 安装说明
+
+该[仓库][7]目前为 Fedora 29、30、31 和 Rawhide 提供 NoteKit。要安装 NoteKit,请使用以下命令:
+
+```
+sudo dnf copr enable lyessaadi/notekit
+sudo dnf install notekit
+```
+
+### Crow Translate
+
+[Crow Translate][8] 是一个翻译程序。它可以翻译文本并且可以对输入和结果发音,它还提供命令行界面。对于翻译,Crow Translate 使用 Google、Yandex 或 Bing 的翻译 API。
+
+#### 安装说明
+
+该[仓库][9]目前为 Fedora 30、31 和 Rawhide 以及 Epel 8 提供 Crow Translate。要安装 Crow Translate,请使用以下命令:
+
+```
+sudo dnf copr enable faezebax/crow-translate
+sudo dnf install crow-translate
+```
+
+### dnsmeter
+
+[dnsmeter][10] 是用于测试域名服务器及其基础设施性能的命令行工具。为此,它发送 DNS 查询并计算答复数,从而测量各种统计数据。除此之外,dnsmeter 可以使用不同的加载步骤,使用 PCAP 文件中的载荷和欺骗发送者地址。
+
+#### 安装说明
+
+该仓库目前为 Fedora 29、30、31、Rawhide 以及 Epel 7 提供 dnsmeter。要安装 dnsmeter,请使用以下命令:
+
+```
+sudo dnf copr enable @dnsoarc/dnsmeter
+sudo dnf install dnsmeter
+```
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-october-2019/
+
+作者:[Dominik Turecek][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/dturecek/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
+[2]: https://copr.fedorainfracloud.org/
+[3]: https://docs.pagure.org/copr.copr/user_documentation.html#
+[4]: https://github.com/nushell/nushell
+[5]: https://copr.fedorainfracloud.org/coprs/atim/nushell/
+[6]: https://github.com/blackhole89/notekit
+[7]: https://copr.fedorainfracloud.org/coprs/lyessaadi/notekit/
+[8]: https://github.com/crow-translate/crow-translate
+[9]: https://copr.fedorainfracloud.org/coprs/faezebax/crow-translate/
+[10]: https://github.com/DNS-OARC/dnsmeter
diff --git a/published/20191028 SQLite is really easy to compile.md b/published/20191028 SQLite is really easy to compile.md
new file mode 100644
index 0000000000..54afd887f0
--- /dev/null
+++ b/published/20191028 SQLite is really easy to compile.md
@@ -0,0 +1,114 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11536-1.html)
+[#]: subject: (SQLite is really easy to compile)
+[#]: via: (https://jvns.ca/blog/2019/10/28/sqlite-is-really-easy-to-compile/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+SQLite 真的很容易编译
+======
+
+
+
+上周,我一直在做一个 SQL 网站(,一个 SQL 示例列表)。我使用 sqlite 运行网站上的所有查询,并且我想在其中一个例子([这个][1])中使用窗口函数。
+
+但是我使用的是 Ubuntu 18.04 中的 sqlite 版本,它太旧了,不支持窗口函数。所以我需要升级 sqlite!
+
+事实证明,这个过程超麻烦(如通常一样),但是非常有趣!我想起了一些有关可执行文件和共享库如何工作的信息,结论令人满意。所以我想在这里写下来。
+
+(剧透: 中解释了如何编译 SQLite,它只需花费 5 秒左右,这比我平时从源码编译的体验容易了许多。)
+
+### 尝试 1:从它的网站下载 SQLite 二进制文件
+
+[SQLite 的下载页面][2]有一个用于 Linux 的 SQLite 命令行工具的二进制文件的链接。我下载了它,它可以在笔记本电脑上运行,我以为这就完成了。
+
+但是后来我尝试在构建服务器(Netlify) 上运行它,得到了这个极其奇怪的错误消息:“File not found”。我进行了追踪,并确定 `execve` 返回错误代码 ENOENT,这意味着 “File not found”。这有点令人发狂,因为该文件确实存在,并且有正确的权限。
+
+我搜索了这个问题(通过搜索 “execve enoen”),找到了[这个 stackoverflow 中的答案][3],它指出要运行二进制文件,你不仅需要二进制文件存在!你还需要它的**加载程序**才能存在。(加载程序的路径在二进制文件内部)
+
+要查看加载程序的路径,可以使用 `ldd`,如下所示:
+
+```
+$ ldd sqlite3
+ linux-gate.so.1 (0xf7f9d000)
+ libdl.so.2 => /lib/i386-linux-gnu/libdl.so.2 (0xf7f70000)
+ libm.so.6 => /lib/i386-linux-gnu/libm.so.6 (0xf7e6e000)
+ libz.so.1 => /lib/i386-linux-gnu/libz.so.1 (0xf7e4f000)
+ libc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xf7c73000)
+ /lib/ld-linux.so.2
+```
+
+所以 `/lib/ld-linux.so.2` 是加载程序,而该文件在构建服务器上不存在,可能是因为 Xenial(Xenial 是 Ubuntu 16.04,本文应该使用的是 18.04 “Bionic Beaver”)安装程序不支持 32 位二进制文件(?),因此我需要尝试一些不同的东西。
+
+### 尝试 2:安装 Debian sqlite3 软件包
+
+好吧,我想我也许可以安装来自 [debian testing 的 sqlite 软件包][4]。尝试从另一个我不使用的 Debian 版本安装软件包并不是一个好主意,但是出于某种原因,我还是决定尝试一下。
+
+这次毫不意外地破坏了我计算机上的 sqlite(这也破坏了 git),但我设法通过 `sudo dpkg --purge --force-all libsqlite3-0` 恢复了,并使所有依赖于 sqlite 的软件再次工作。
+
+### 尝试 3:提取 Debian sqlite3 软件包
+
+我还尝试仅从 Debian sqlite 软件包中提取 sqlite3 二进制文件并运行它。毫不意外,这也行不通,但这个更容易理解:我有旧版本的 libreadline(`.so.7`),但它需要 `.so.8`。
+
+```
+$ ./usr/bin/sqlite3
+./usr/bin/sqlite3: error while loading shared libraries: libreadline.so.8: cannot open shared object file: No such file or directory
+```
+
+### 尝试 4:从源代码进行编译
+
+我花费这么多时间尝试下载 sqlite 二进制的原因是我认为从源代码编译 sqlite 既烦人又耗时。但是显然,下载随便一个 sqlite 二进制文件根本不适合我,因此我最终决定尝试自己编译它。
+
+这有指导:[如何编译 SQLite][5]。它是宇宙中最简单的东西。通常,编译的感觉是类似这样的:
+
+ * 运行 `./configure`
+ * 意识到我缺少依赖
+ * 再次运行 `./configure`
+ * 运行 `make`
+ * 编译失败,因为我安装了错误版本的依赖
+ * 去做其他事,之后找到二进制文件
+
+编译 SQLite 的方式如下:
+
+ * [从下载页面下载整合的 tarball][2]
+ * 运行 `gcc shell.c sqlite3.c -lpthread -ldl`
+ * 完成!!!
+
+所有代码都在一个文件(`sqlite.c`)中,并且没有奇怪的依赖项!太奇妙了。
+
+对我而言,我实际上并不需要线程支持或 readline 支持,因此我用编译页面上的说明来创建了一个非常简单的二进制文件,它仅使用了 libc 而没有其他共享库。
+
+```
+$ ldd sqlite3
+ linux-vdso.so.1 (0x00007ffe8e7e9000)
+ libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fbea4988000)
+ /lib64/ld-linux-x86-64.so.2 (0x00007fbea4d79000)
+```
+
+### 这很好,因为它使体验 sqlite 变得容易
+
+我认为 SQLite 的构建过程如此简单很酷,因为过去我很乐于[编辑 sqlite 的源码][6]来了解其 B 树的实现方式。
+
+鉴于我对 SQLite 的了解,这并不令人感到意外(它在受限环境/嵌入式中确实可以很好地工作,因此可以以一种非常简单/最小的方式进行编译是有意义的)。 但这真是太好了!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/10/28/sqlite-is-really-easy-to-compile/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://sql-steps.wizardzines.com/lag.html
+[2]: https://www.sqlite.org/download.html
+[3]: https://stackoverflow.com/questions/5234088/execve-file-not-found-when-stracing-the-very-same-file
+[4]: https://packages.debian.org/bullseye/amd64/sqlite3/download
+[5]: https://www.sqlite.org/howtocompile.html
+[6]: https://jvns.ca/blog/2014/10/02/how-does-sqlite-work-part-2-btrees/
diff --git a/published/20191029 Collapse OS - An OS Created to Run After the World Ends.md b/published/20191029 Collapse OS - An OS Created to Run After the World Ends.md
new file mode 100644
index 0000000000..9044248779
--- /dev/null
+++ b/published/20191029 Collapse OS - An OS Created to Run After the World Ends.md
@@ -0,0 +1,100 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-11525-1.html)
+[#]: subject: (Collapse OS – An OS Created to Run After the World Ends)
+[#]: via: (https://itsfoss.com/collapse-os/)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+Collapse OS:为世界末日创建的操作系统
+======
+
+当大多数人考虑为末日后的世界做准备时,想到的第一件事就是准备食物和其他生活必需品。最近,有一个程序员觉得,在社会崩溃之后,创建一个多功能的、且可生存的操作系统同样重要。我们今天将尽我们所能地来了解一下它。
+
+### Collapse OS:当文明被掩埋在垃圾中
+
+![][1]
+
+这里说的操作系统称为 [Collapse OS(崩溃操作系统)][2]。根据该官方网站的说法,Collapse OS 是 “z80 内核以及一系列程序、工具和文档的集合”。 它可以让你:
+
+* 可在最小的和临时拼凑的机器上运行。
+* 通过临时拼凑的方式(串行、键盘、显示)进行接口。
+* 可编辑文本文件。
+* 编译适用于各种 MCU 和 CPU 的汇编源代码文件。
+* 从各种存储设备读取和写入。
+* 自我复制。
+
+其创造者 [Virgil Dupras][3] 之所以开始这个项目,是因为[他认为][4]“我们的全球供应链在我们到达 2030 年之前就会崩溃”。他是根据巴勃罗·塞维尼的作品得出了这一结论的。他似乎也觉得并非所有人都会认可[他的观点][4],“话虽如此,我认为不相信到 2030 年可能会发生崩溃也是可以理解的,所以请不要为我的信念而感到受到了冲击。”
+
+该项目的总体目标是迅速让瓦解崩溃后的文明重新回到计算机时代。电子产品的生产取决于非常复杂的供应链。一旦供应链崩溃,人类将回到一个技术水平较低的时代。要恢复我们以前的技术水平,将需要数十年的时间。Dupras 希望通过创建一个生态系统来跨越几个步骤,该生态系统将与从各种来源搜寻到的更简单的芯片一起工作。
+
+### z80 是什么?
+
+最初的 Collapse OS 内核是为 [z80 芯片][5]编写的。作为复古计算机历史的爱好者,我对 [Zilog][6] 和 z80 芯片很熟悉。在 1970 年代后期,Zilog 公司推出了 z80,以和 [Intel 的 8080][7] CPU 竞争。z80 被用于许多早期的个人计算机中,例如 [Sinclair ZX Spectrum][8] 和 [Tandy TRS-80][9]。这些系统中的大多数使用了 [CP/M 操作系统] [10],这是当时最流行的操作系统。(有趣的是,Dupras 最初希望使用[一个开源版本的 CP/M][11],但最终决定[从头开始][12]。)
+
+在 1981 年 [IBM PC][13] 发布之后,z80 和 CP/M 的普及率开始下降。Zilog 确实发布了其它几种微处理器(Z8000 和 Z80000),但并没有获得成功。该公司将重点转移到了微控制器上。今天,更新后的 z80 后代产品可以在图形计算器、嵌入式设备和消费电子产品中找到。
+
+Dupras 在 [Reddit][14] 上说,他为 z80 编写了 Collapse OS,因为“它已经投入生产很长时间了,并且因为它被用于许多机器上,所以拾荒者有很大的机会拿到它。”
+
+### 该项目的当前状态和未来发展
+
+Collapse OS 的起步相当不错。有足够的内存和存储空间它就可以进行自我复制。它可以在 [RC2014 家用计算机][15]或世嘉 Master System / MegaDrive(Genesis)上运行。它可以读取 SD 卡。它有一个简单的文本编辑器。其内核由用粘合代码连接起来的模块组成。这是为了使系统具有灵活性和适应性。
+
+还有一个详细的[路线图][16]列出了该项目的方向。列出的目标包括:
+
+* 支持其他 CPU,例如 8080 和 [6502][17]。
+* 支持临时拼凑的外围设备,例如 LCD 屏幕、电子墨水显示器和 [ACIA 设备][18]。
+* 支持更多的存储方式,例如软盘、CD、SPI RAM/ROM 和 AVR MCU。
+* 使它可以在其他 z80 机器上工作,例如 [TI-83+][19] 和 [TI-84+][20] 图形计算器和 TRS-80s。
+
+如果你有兴趣帮助或只是想窥视一下这个项目,请访问其 [GitHub 页面][21]。
+
+### 最后的思考
+
+坦率地说,我认为 Collapse OS 与其说是一个有用的项目,倒不如说更像是一个有趣的爱好项目(对于那些喜欢构建操作系统的人来说)。当崩溃真的到来时,我认为 GitHub 也会宕机,那么 Collapse OS 将如何分发?我无法想像,得具有多少技能的人才能够从捡来的零件中创建出一个系统。到时候会有新一代的创客们,但大多数创客们会习惯于选择 Arduino 或树莓派来构建项目,而不是从头开始。
+
+与 Dupras 相反,我最担心的是[电磁脉冲炸弹(EMP)][22] 的使用。这些东西会炸毁所有的电气系统,这意味着将没有任何构建系统的可能。如果没有发生这种事情,我想我们将能够找到过去 30 年制造的那么多的 x86 组件,以保持它们运行下去。
+
+话虽如此,对于那些喜欢为奇奇怪怪的应用编写低级代码的人来说,Collapse OS 听起来是一个有趣且具有高度挑战性的项目。如果你是这样的人,去检出 [Collapse OS][2] 代码吧。
+
+让我提个假设的问题:你选择的世界末日操作系统是什么?请在下面的评论中告诉我们。
+
+如果你觉得这篇文章有趣,请花一点时间在社交媒体、Hacker News 或 [Reddit][23] 上分享。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/collapse-os/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/Collapse_OS.jpg?ssl=1
+[2]: https://collapseos.org/
+[3]: https://github.com/hsoft
+[4]: https://collapseos.org/why.html
+[5]: https://en.m.wikipedia.org/wiki/Z80
+[6]: https://en.wikipedia.org/wiki/Zilog
+[7]: https://en.wikipedia.org/wiki/Intel_8080
+[8]: https://en.wikipedia.org/wiki/ZX_Spectrum
+[9]: https://en.wikipedia.org/wiki/TRS-80
+[10]: https://en.wikipedia.org/wiki/CP/M
+[11]: https://github.com/davidgiven/cpmish
+[12]: https://github.com/hsoft/collapseos/issues/52
+[13]: https://en.wikipedia.org/wiki/IBM_Personal_Computer
+[14]: https://old.reddit.com/r/collapse/comments/dejmvz/collapse_os_bootstrap_postcollapse_technology/f2w3sid/?st=k1gujoau&sh=1b344da9
+[15]: https://rc2014.co.uk/
+[16]: https://collapseos.org/roadmap.html
+[17]: https://en.wikipedia.org/wiki/MOS_Technology_6502
+[18]: https://en.wikipedia.org/wiki/MOS_Technology_6551
+[19]: https://en.wikipedia.org/wiki/TI-83_series#TI-83_Plus
+[20]: https://en.wikipedia.org/wiki/TI-84_Plus_series
+[21]: https://github.com/hsoft/collapseos
+[22]: https://en.wikipedia.org/wiki/Electromagnetic_pulse
+[23]: https://reddit.com/r/linuxusersgroup
diff --git a/sources/news/20191023 Cisco issues critical security warning for IOS XE REST API container.md b/sources/news/20191023 Cisco issues critical security warning for IOS XE REST API container.md
new file mode 100644
index 0000000000..13bc238c2c
--- /dev/null
+++ b/sources/news/20191023 Cisco issues critical security warning for IOS XE REST API container.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Cisco issues critical security warning for IOS XE REST API container)
+[#]: via: (https://www.networkworld.com/article/3447558/cisco-issues-critical-security-warning-for-ios-xe-rest-api-container.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+Cisco issues critical security warning for IOS XE REST API container
+======
+This Cisco IOS XE REST API vulnerability could lead to attackers obtaining the token-id of an authenticated user.
+D3Damon / Getty Images
+
+Cisco this week said it issued a software update to address a vulnerability in its [Cisco REST API virtual service container for Cisco IOS XE][1] software that scored a critical 10 out of 10 on the Common Vulnerability Scoring System (CVSS) system.
+
+With the vulnerability an attacker could submit malicious HTTP requests to the targeted device and if successful, obtain the _token-id_ of an authenticated user. This _token-id_ could be used to bypass authentication and execute privileged actions through the interface of the REST API virtual service container on the affected Cisco IOS XE device, the company said.
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
+
+According to Cisco the REST API is an application that runs in a virtual services container. A virtual services container is a virtualized environment on a device and is delivered as an open virtual application (OVA). The OVA package has to be installed and enabled on a device through the device virtualization manager (VMAN) CLI.
+
+**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][3] ]**
+
+The Cisco REST API provides a set of RESTful APIs as an alternative method to the Cisco IOS XE CLI to provision selected functions on Cisco devices.
+
+Cisco said the vulnerability can be exploited under the following conditions:
+
+ * The device runs an affected Cisco IOS XE Software release.
+ * The device has installed and enabled an affected version of the Cisco REST API virtual service container.
+ * An authorized user with administrator credentials (level 15) is authenticated to the REST API interface.
+
+
+
+The REST API interface is not enabled by default. To be vulnerable, the virtual services container must be installed and activated. Deleting the OVA package from the device storage memory removes the attack vector. If the Cisco REST API virtual service container is not enabled, this operation will not impact the device's normal operating conditions, Cisco stated.
+
+This vulnerability affects Cisco devices that are configured to use a vulnerable version of Cisco REST API virtual service container. This vulnerability affected the following products:
+
+ * Cisco 4000 Series Integrated Services Routers
+ * Cisco ASR 1000 Series Aggregation Services Routers
+ * Cisco Cloud Services Router 1000V Series
+ * Cisco Integrated Services Virtual Router
+
+
+
+Cisco said it has [released a fixed version of the REST API][4] virtual service container and a hardened IOS XE release that prevents installation or activation of a vulnerable container on a device. If the device was already configured with an active vulnerable container, the IOS XE software upgrade will deactivate the container, making the device not vulnerable. In that case, to restore the REST API functionality, customers should upgrade the Cisco REST API virtual service container to a fixed software release, the company said.
+
+Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447558/cisco-issues-critical-security-warning-for-ios-xe-rest-api-container.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190828-iosxe-rest-auth-bypass
+[2]: https://www.networkworld.com/newsletters/signup.html
+[3]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
+[4]: https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html
+[5]: https://www.facebook.com/NetworkWorld/
+[6]: https://www.linkedin.com/company/network-world
diff --git a/sources/news/20191025 MX Linux 19 Released With Debian 10.1 ‘Buster- - Other Improvements.md b/sources/news/20191025 MX Linux 19 Released With Debian 10.1 ‘Buster- - Other Improvements.md
deleted file mode 100644
index df7ea64637..0000000000
--- a/sources/news/20191025 MX Linux 19 Released With Debian 10.1 ‘Buster- - Other Improvements.md
+++ /dev/null
@@ -1,94 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (MX Linux 19 Released With Debian 10.1 ‘Buster’ & Other Improvements)
-[#]: via: (https://itsfoss.com/mx-linux-19/)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-MX Linux 19 Released With Debian 10.1 ‘Buster’ & Other Improvements
-======
-
-MX Linux 18 has been one of my top recommendations for the [best Linux distributions][1], specially when considering distros other than Ubuntu.
-
-It is based on Debian 9.6 ‘Stretch’ – which was incredibly a fast and smooth experience.
-
-Now, as a major upgrade to that, MX Linux 19 brings a lot of major improvements and changes. Here, we shall take a look at the key highlights.
-
-### New features in MX Linux 19
-
-[Subscribe to our YouTube channel for more Linux videos][2]
-
-#### Debian 10 ‘Buster’
-
-This deserves a separate mention as Debian 10 is indeed a major upgrade from Debian 9.6 ‘Stretch’ on which MX Linux 18 was based on.
-
-In case you’re curious about what has changed with Debian 10 Buster, we suggest to check out our article on the [new features of Debian 10 Buster][3].
-
-#### Xfce Desktop 4.14
-
-![MX Linux 19][4]
-
-[Xfce 4.14][5] happens to be the latest offering from Xfce development team. Personally, I’m not a fan of Xfce desktop environment but it screams fast performance when you get to use it on a Linux distro (especially on MX Linux 19).
-
-Interestingly, we also have a quick guide to help you [customize Xfce][6] on your system.
-
-#### Updated Packages & Latest Debian Kernel 4.19
-
-Along with updated packages for [GIMP][7], MESA, Firefox, and so on – it also comes baked in with the latest kernel 4.19 available for Debian Buster.
-
-#### Updated MX-Apps
-
-If you’ve used MX Linux before, you might be knowing that it comes pre-installed with useful MX-Apps that help you get more things done quickly.
-
-The apps like MX-installer and MX-packageinstaller have significantly improved.
-
-In addition to these two, all other MX-tools have been updated here and there to fix bugs, add new translations (or simply to improve the user experience).
-
-#### Other Improvements
-
-Considering it a major upgrade, there’s obviously a lot of under-the-hood changes than highlighted (including the latest antiX live system updates).
-
-You can check out more details on their [official announcement post][8]. You may also watch this video from the developers explaining all the new stuff in MX Linux 19:
-
-### Getting MX Linux 19
-
-Even if you are using MX Linux 18 versions right now, you [cannot upgrade][9] to MX Linux 19. You need to go for a clean install like everyone else.
-
-You can download MX Linux 19 from this page:
-
-[Download MX Linux 19][10]
-
-**Wrapping Up**
-
-With MX Linux 18, I had a problem using my WiFi adapter due to a driver issue which I resolved through the [forum][11], it seems that it still hasn’t been fixed with MX Linux 19. So, you might want to take a look at my [forum post][11] if you face the same issue after installing MX Linux 19.
-
-If you’ve been using MX Linux 18, this definitely seems to be an impressive upgrade.
-
-Have you tried it yet? What are your thoughts on the new MX Linux 19 release? Let me know what you think in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/mx-linux-19/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://itsfoss.com/best-linux-distributions/
-[2]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
-[3]: https://itsfoss.com/debian-10-buster/
-[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/mx-linux-19.jpg?ssl=1
-[5]: https://xfce.org/about/news
-[6]: https://itsfoss.com/customize-xfce/
-[7]: https://itsfoss.com/gimp-2-10-release/
-[8]: https://mxlinux.org/blog/mx-19-patito-feo-released/
-[9]: https://mxlinux.org/migration/
-[10]: https://mxlinux.org/download-links/
-[11]: https://forum.mxlinux.org/viewtopic.php?t=52201
diff --git a/sources/news/20191026 Netflix builds a Jupyter Lab alternative, a bug bounty to fight election hacking, Raspberry Pi goes microscopic, and more open source news.md b/sources/news/20191026 Netflix builds a Jupyter Lab alternative, a bug bounty to fight election hacking, Raspberry Pi goes microscopic, and more open source news.md
new file mode 100644
index 0000000000..b50a93d8c1
--- /dev/null
+++ b/sources/news/20191026 Netflix builds a Jupyter Lab alternative, a bug bounty to fight election hacking, Raspberry Pi goes microscopic, and more open source news.md
@@ -0,0 +1,78 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Netflix builds a Jupyter Lab alternative, a bug bounty to fight election hacking, Raspberry Pi goes microscopic, and more open source news)
+[#]: via: (https://opensource.com/article/19/10/news-october-26)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
+
+Netflix builds a Jupyter Lab alternative, a bug bounty to fight election hacking, Raspberry Pi goes microscopic, and more open source news
+======
+Catch up on the biggest open source headlines from the past two weeks.
+![Weekly news roundup with TV][1]
+
+In this edition of our open source news roundup, we take a look at a machine learning tool from Netflix, Microsoft's election software bug bounty, a cost-effective microscope built with Raspberry Pi, and more!
+
+### Netflix release Polynote machine learning tool
+
+While there have been numerous advances in machine learning over the last decade, it's still a difficult, laborious, and sometimes frustrating task. To help make that task easier, Netflix has [released a machine learning notebook environment][2] called Polynote as open source.
+
+Polynote enables "data scientists and AI researchers to integrate Netflix’s JVM-based machine learning framework with Python machine learning and visualization libraries". What make Polynote unique is its reproducibility feature, which "takes cells’ positions in the notebook into account before executing them, helping prevent bad practices that make notebooks difficult to rerun from the top." It's also quite flexible—Polynote works with Apache Spark and supports languages like Python, Scala, and SQL.
+
+You can grab Polynote [off GitHub][3] or learn more about it at the Polynote website.
+
+### Microsoft announces bug bounty program for its election software
+
+Hoping that more eyeballs on its code will make bugs shallow, Microsoft announced a [a bug bounty][4] for its open source ElectionGuard software development kit for voting machines. The goal of the program is to "uncover vulnerabilities and help bolster election security."
+
+The bounty is open to "security professionals, part-time hobbyists, and students." Successful submissions, which must include proofs of concept demonstrating how bugs could compromise the security of voters, are worth up to $15,000 (USD).
+
+If you're interested in participating, you can find ElectionGuard's code on [GitHub][5], and read more about the [bug bounty][6].
+
+### microscoPI: a microscope built on Raspberry Pi
+
+It's not a stretch to say that the Raspberry Pi is one of the most flexible platforms for hardware and software hackers. Micropalaeontologist Martin Tetard saw the potential of the tiny computers in his field of study and [create the microscoPI][7].
+
+The microscoPI is a Raspberry Pi-assisted microscope that can "capture, process, and store images and image analysis results." Using an old adjustable microscope with a movable stage as a base, Tetard added a Raspberry Pi B, a Raspberry Pi camera module, and a small touchscreen to the device. The result is a compact rig that's "completely portable and measuring less than 30 cm (12 inches) in height." The entire setup cost him €159 (about $177 USD).
+
+Tetard has set up [a website][8] for the microscoPI, where you can learn more about it.
+
+#### In other news
+
+ * [Happy 15th birthday, Ubuntu][9]
+ * [Open-Source Arm Puts Robotics Within Reach][10]
+ * [Apache Rya matures open source triple store database][11]
+ * [UNICEF Launches Cryptocurrency Fund to Back Open Source Technology][12]
+ * [Open-source Delta Lake project moves to the Linux Foundation][13]
+
+
+
+_Thanks, as always, to Opensource.com staff members and moderators for their help this week._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/news-october-26
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
+[2]: https://venturebeat.com/2019/10/23/netflix-open-sources-polynote-to-simplify-data-science-and-machine-learning-workflows/
+[3]: https://github.com/polynote/polynote
+[4]: https://thenextweb.com/security/2019/10/21/microsofts-open-source-election-software-now-has-a-bug-bounty-program/
+[5]: https://github.com/microsoft/ElectionGuard-SDK
+[6]: https://www.microsoft.com/en-us/msrc/bounty
+[7]: https://www.geeky-gadgets.com/raspberry-pi-microscope-07-10-2019/
+[8]: https://microscopiproject.wordpress.com/
+[9]: https://www.omgubuntu.co.uk/2019/10/happy-birthday-ubuntu-2019
+[10]: https://hackaday.com/2019/10/17/open-source-arm-puts-robotics-within-reach/
+[11]: https://searchdatamanagement.techtarget.com/news/252472464/Apache-Rya-matures-open-source-triple-store-database
+[12]: https://www.coindesk.com/unicef-launches-cryptocurrency-fund-to-back-open-source-technology
+[13]: https://siliconangle.com/2019/10/16/open-source-delta-lake-project-moves-linux-foundation/
diff --git a/sources/talk/20190828 Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word.md b/sources/talk/20190828 Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word.md
deleted file mode 100644
index ab1ad90fe7..0000000000
--- a/sources/talk/20190828 Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word.md
+++ /dev/null
@@ -1,92 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word)
-[#]: via: (https://itsfoss.com/gimp-fork-glimpse/)
-[#]: author: (John Paul https://itsfoss.com/author/john/)
-
-Someone Forked GIMP into Glimpse Because Gimp is an Offensive Word
-======
-
-In the world of open source applications, forking is common when members of the community want to take an application in a different direction than the rest. The latest newsworthy fork is named [Glimpse][1] and is intended to fix certain issues that users have with the [GNU Image Manipulation Program][2], commonly known as GIMP.
-
-### Why create a fork of GIMP?
-
-![][3]
-
-When you visit the [homepage][1] of the Glimpse app, it says that the goal of the project is to “experiment with other design directions and fix longstanding bugs.” That doesn’t sound too much out of the ordinary. However, if you start reading the project’s blog posts, a different image appears.
-
-According to the project’s [first blog post][4], they created this fork because they did not like the GIMP name. According to the post, “A number of us disagree that the name of the software is suitable for all users, and after 13 years of the project refusing to budge on this have decided to fork!”
-
-If you are wondering why these people find the work GIMP disagreeable they answer that question on the [About page][5]:
-
-> “If English is not your first language, then you may not have realised that the word “gimp” is problematic. In some countries it is considered a slur against disabled people and a playground insult directed at unpopular children. It can also be linked to certain “after dark” activities performed by consenting adults.”
-
-They also point out that they are not making this move out of political correctness or being oversensitive. “In addition to the pain it can cause to marginalized communities many of us have our own free software advocacy stories about the GNU Image Manipulation Program not being taken seriously as an option by bosses or colleagues in professional settings.”
-
-As if to answer many questions, they also said, “It is unfortunate that we have to fork the whole project to change the name, but we feel that discussions about the issue are at an impasse and that this is the most positive way forward.”
-
-[][6]
-
-Suggested read After 6 Years, GIMP 2.10 is Here With Ravishing New Looks and Tons of New Features
-
-It looks like the Glimpse name is not written in stone. There is [an issue][7] on their GitHub page about possibly picking another name. Maybe they should just drop GNU. I don’t think the word IMP has a bad connotation.
-
-### A diverging path
-
-![GIMP 2.10][8]
-
-[GIMP][6] has been around for over twenty years, so any kind of fork is a big task. Currently, [they are planning][9] to start by releasing Glimpse 0.1 in September 2019. This will be a soft fork, meaning that changes will be mainly cosmetic as they migrate to a new identity.
-
-Glimpse 1.0 will be a hard fork where they will be actively changing the codebase and adding to it. They want 1.0 to be a port to GTK3 and have its own documentation. They estimate that this will not take place until GIMP 3 is released in 2020.
-
-Beyond the 1.0, the Glimpse team has plans to forge their own identity. They plan to work on a “front-end UI rewrite”. They are currently discussing [which language][10] they should use for the rewrite. There seems to be a lot of push for D and Rust. They also [hope to][4] “add new functionality that addresses common user complaints” as time goes on.
-
-### Final Thoughts
-
-I have used GIMP a little bit in the past but was never too bothered by the name. To be honest, I didn’t know what it meant for quite a while. Interestingly, when I searched Wikipedia for GIMP, I came across an entry for the [GIMP Project][11], which is a modern dance project in New York that includes disabled people. I guess gimp isn’t considered a derogatory term by everyone.
-
-To me, it seems like a lot of work to go through to change a name. It also seems like the idea of rewriting the UI was tacked to make the project look more worthwhile. I wonder if they will tweak it to bring a more classic UI like [using Ctrl+S to save in GIMP][12]/Glimpse. Let’s wait and watch.
-
-[][13]
-
-Suggested read Finally! WPS Office Has A New Release for Linux
-
-If you are interested in the project, you can follow them on [Twitter][14], check out their [GitHub account][15], or take a look at their [Patreon page][16].
-
-Are you offended by the GIMP name? Do you think it is worthwhile to fork an application, just so you can rename it? Let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][17].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/gimp-fork-glimpse/
-
-作者:[John Paul][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[b]: https://github.com/lujun9972
-[1]: https://getglimpse.app/
-[2]: https://www.gimp.org/
-[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/gimp-fork-glimpse.png?resize=800%2C450&ssl=1
-[4]: https://getglimpse.app/posts/so-it-begins/
-[5]: https://getglimpse.app/about/
-[6]: https://itsfoss.com/gimp-2-10-release/
-[7]: https://github.com/glimpse-editor/Glimpse/issues/92
-[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/gimp-screenshot.jpg?resize=800%2C508&ssl=1
-[9]: https://getglimpse.app/posts/six-week-checkpoint/
-[10]: https://github.com/glimpse-editor/Glimpse/issues/70
-[11]: https://en.wikipedia.org/wiki/The_Gimp_Project
-[12]: https://itsfoss.com/how-to-solve-gimp-2-8-does-not-save-in-jpeg-or-png-format/
-[13]: https://itsfoss.com/wps-office-2016-linux/
-[14]: https://twitter.com/glimpse_editor
-[15]: https://github.com/glimpse-editor/Glimpse
-[16]: https://www.patreon.com/glimpse
-[17]: https://reddit.com/r/linuxusersgroup
diff --git a/sources/talk/20191023 IT-as-a-Service Simplifies Hybrid IT.md b/sources/talk/20191023 IT-as-a-Service Simplifies Hybrid IT.md
new file mode 100644
index 0000000000..1a0b2ad9a0
--- /dev/null
+++ b/sources/talk/20191023 IT-as-a-Service Simplifies Hybrid IT.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (IT-as-a-Service Simplifies Hybrid IT)
+[#]: via: (https://www.networkworld.com/article/3447342/it-as-a-service-simplifies-hybrid-it.html)
+[#]: author: (Anne Taylor https://www.networkworld.com/author/Anne-Taylor/)
+
+IT-as-a-Service Simplifies Hybrid IT
+======
+Consumption-based model reduces complexity, improves IT infrastructure.
+iStock
+
+The data center must rapidly change. Companies are increasingly moving toward hybrid IT models, with some workloads in the cloud and others staying on premises. The burden of ever-growing apps and data is placing pressure on infrastructure in both worlds, but especially the data center.
+
+Organizations are struggling to reach the required speed and flexibility — with the same public-cloud economics — from their on-premises data centers. That’s likely because they’re dealing with legacy systems acquired over the years, possibly inherited as the result of mergers and acquisitions.
+
+These complex environments create headaches when trying to accommodate for IT capacity fluctuations. When extra storage is needed, for example, 67% of IT departments buy too much, according to [Futurum Research][1]. They don’t have the visibility into resources, nor the ability to effectively scale up and down.
+
+Meanwhile, lines of business need solutions fast, and if IT can’t deliver, they’ll go out and buy their own cloud-based services or solutions. IT must think strategically about how all this technology strings together — efficiently, securely, and cost-effectively.
+
+Enter IT-as-a-Service (ITaaS).
+
+**1) How does ITaaS work?**
+
+Unlike other as-a-service models, ITaaS is not cloud based, although the concept can be applied to cloud environments. Rather, the focus is about shifting IT operations toward managed services on an as-needed, pay-as-you-go basis. 1
+
+For example, HPE GreenLake delivers infrastructure capacity based on actual metered usage, where companies only pay for what is used. There are no upfront costs, extended purchasing and implementation timeframes, or overprovisioning headaches. Infrastructure capacity can be scaled up or down as needed.
+
+**2) What are the benefits of ITaaS?**
+
+Some of the most significant advantages include: scalable infrastructure and resources, improved workload management, greater availability, and reduced burden on IT, including network admins.
+
+ * _Infrastructure_. Resource needs are often in flux depending on business demands and market changes. Using ITaaS not only enhances infrastructure usage, it also helps network admins better plan for and manage bandwidth, switches, routers, and other network gear.
+ * _Workloads_. ITaaS can immediately tackle cloud bursting to better manage application flow. Companies might also, for example, choose to use the consumption-based model for workloads that are unpredictable in their growth — such as big data, storage, and private cloud.
+ * _Availability_. It’s critical to have zero network downtime. Using a consumption-based IT model, companies can opt to adopt services such as continuous network monitoring or expertise on-call with a 24/7 network help desk.
+ * _Reduced burden on IT_. All of the above benefits affect day-to-day operations. By simplifying network management, ITaaS frees personnel to use their expertise where it is best served.
+
+
+
+Furthermore, a consumption-based IT model helps organizations gain end-to-end visibility into storage resources, so that admins can ensure the highest levels of service, performance, and availability.
+
+**HPE GreenLake: The Answer**
+
+As hybrid IT takes hold, IT organizations must get a grip on their infrastructure resources to ensure agility and scalability for the business, while maintaining IT cost-effectiveness.
+
+HPE GreenLake enables a simplified IT environment where companies pay only for the resources they actually use, while providing the business with the speed and agility it requires.
+
+[Learn more at hpe.com/greenlake.][2]
+
+Minimum commitment may apply
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447342/it-as-a-service-simplifies-hybrid-it.html
+
+作者:[Anne Taylor][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Anne-Taylor/
+[b]: https://github.com/lujun9972
+[1]: https://h20195.www2.hpe.com/v2/Getdocument.aspx?docname=a00079768enw
+[2]: https://www.hpe.com/us/en/services/flexible-capacity.html
diff --git a/sources/talk/20191023 MPLS Migration- How a KISS Transformed the WANs of 4 IT Managers.md b/sources/talk/20191023 MPLS Migration- How a KISS Transformed the WANs of 4 IT Managers.md
new file mode 100644
index 0000000000..3e6ebc8f61
--- /dev/null
+++ b/sources/talk/20191023 MPLS Migration- How a KISS Transformed the WANs of 4 IT Managers.md
@@ -0,0 +1,92 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (MPLS Migration: How a KISS Transformed the WANs of 4 IT Managers)
+[#]: via: (https://www.networkworld.com/article/3447383/mpls-migration-how-a-kiss-transformed-the-wans-of-4-it-managers.html)
+[#]: author: (Cato Networks https://www.networkworld.com/author/Matt-Conran/)
+
+MPLS Migration: How a KISS Transformed the WANs of 4 IT Managers
+======
+WAN transformation is challenging; learning from the experiences of others can help. Here are practical insights from four IT managers who migrated to SD-WAN.
+flytosky11
+
+Back in 1960, a Lockheed engineer named Kelly Johnson coined the acronym KISS for “keep it simple stupid.” His wise—and simple—advice was that systems tend to work better when they’re simple than when they’re complex. KISS became an essential U.S. Navy design principle and captures the crux of any WAN transformation initiative.
+
+So many of the challenges of today’s WANs stem from the sheer number of components involved. Each location may require one or more routers, firewalls, WAN optimizers, VPN concentrators, and other devices just to connect safely and effectively with other locations or the cloud. The result: multiple points of failure and a potential uptime and troubleshooting nightmare. Simply understanding the state of the WAN can be difficult with information spread across so many devices and components. Managing all the updates required to protect the network from new and evolving threats can be overwhelming.
+
+Simplifying the enterprise backbone addresses those challenges. According to four IT managers, the key is to create a single global enterprise backbone that connects all users–mobile or fixed–and all locations–cloud or physical. The backbone’s software should include a complete security stack and WAN optimization to protect and enhance the performance of all “edges” everywhere. Such an approach avoids the complexity that comes with all the appliances and other solutions forming today enterprise networks.
+
+The four IT managers did not use every aspect of this approach. Some focused on the global performance benefits and cost savings, others on security. But they all gained from the agility and visibility that result. Here are their stories.
+
+**Pharmaceutical Firm Improves China Connectivity, Reduced Costs by Eliminating MPLS**
+
+For [Centrient Pharmaceuticals][1], [SD-WAN][2] looked at first as if it might be just as complex as the company’s tangled Web of global MPLS and Internet VPNs. A global leader in sustainable antibiotics, next-generation statins, and antifungals, Centrient had relied on MPLS to connect its Netherlands data center with nine manufacturing and office locations across China, India, Netherlands, Spain, and Mexico. SAP, VoIP, and other Internet applications had to be backhauled through the data center. Local Internet breakouts secured by firewall hardware provided access to the public Internet, Office 365, and some other SaaS applications. Five smaller global locations had to connect via VPN to India or the Netherlands office.
+
+Over time, MPLS became congested and performance suffered. “It took a long time for users to open documents,” said Mattheiu Cijsouw, Global IT Manager.
+
+Agility suffered as well, as it typically took three to four months to move a location. “One time we needed to move a sales office and the MPLS connection was simply not ready in time,” Cijsouw said.
+
+Cijsouw looked toward SD-WAN to simplify connectivity and cut costs but found that the typical solution of SD-WAN appliances at every location secured by firewalls and Secure Web Gateway (SWGs) was also complex, expensive, and dependent on the fickleness of the Internet middle mile. For him, the simplicity of a global, distributed, SLA-backed network of PoPS interconnected by an enterprise backbone seemed appealing. All it required was a simple, zero-touch appliance at each location to connect to the local PoP.
+
+Cijsouw went with simple. “We migrated in stages, gaining confidence along the way,” he said.
+
+The 6 Mbits/s of MPLS was replaced by 20 Mbits/s per site, burstable to 40 Mbits/s, and 50 Mbits/s burstable to 100 Mbits/s at the data center, all at lower cost than MPLS. Immediately applications became more responsive, China connectivity worked as well or better than with MPLS, and the cloud-based SD-WAN solution gave Cijsouw better visibility into the network.
+
+**Paysafe Achieves Fast Application Access at Every Location**
+
+Similarly, [Paysafe, a global provider of end-to-end payment solutions][3], had been connecting its 21 globally dispersed locations with a combination of MPLS and local Internet access at six locations and VPNs at the other 15. Depending on where staff members were, Internet connectivity could range from 25 Mbits/s to 500 Mbits/sec.
+
+“We wanted the same access everywhere,” said Stuart Gall, then PaySafe’s Infrastructure Architect in its Network and Systems Groups. “If I’m in Calgary and go to any other office, the access must be the same—no need to RDP into a machine or VPN into the network.”
+
+The lack of a fully meshed network also made Active Directory operation erratic, with users sometimes locked out of some accounts at one location but not another. Rolling out new locations took two to three months.
+
+As with Centrient, a cloud-based SD-WAN solution using global PoPS and an enterprise backbone seemed a much simpler, less expensive, and more secure approach than the typical SD-WAN services offered by competing providers.
+
+Paysafe has connected 11 sites to its enterprise backbone. “We found latency to be 45 percent less than with the public Internet,” said Gall. “New site deployment takes 30 minutes instead of weeks. Full meshing problems are no longer, as all locations instantly mesh once they connect.”
+
+**Sanne Group Cleans Up WAN and Reduces Latency in the Process**
+
+[Sanne Group, a global provider of alternative asset and corporate administrative services][4], had two data centers in Jersey and Guernsey UK connected by two 1Gbits/s fiber links, with seven locations connecting to the data centers via the public Internet. A Malta office connected via an IPsec VPN to Cape Town, which connected to Jersey via MPLS. A business continuity site in HIlgrove and two other UK locations connected to the data centers via dedicated fiber. Access for small office users consisted of a combination of Internet broadband, a small firewall appliance, and Citrix VDI.
+
+Printing PDFs took forever, according to Nathan Trevor, Sanne Group’s IT Director, and the remote desktop architectures suffered from high latency and packet loss. Traffic from the Hong Kong office took 12 to 15 hops to get to the UK.
+
+The company tried MPLS but found it too expensive. Deploying a site took up to 120 days. Trevor started looking at SD-WAN, but it was also complex.
+
+“Even with zero-touch provisioning configuration was complicated,” he said. “IT professionals new to SD-WAN would definitely need handholding.”
+
+The simplicity of the cloud-based global enterprise backbone solution was obvious. “Just looking at an early screen share I could understand how to connect my sites,” said Trevor.
+
+Sanne connected its locations big and small to the enterprise backbone, eliminating the mess of Internet and MPLS connections. Performance improved immediately, with latency down by 20 percent. All users have to do to connect is log into their computers, and the solution has saved Sanne “an absolute fortune,” according to Trevor.
+
+**Humphrey’s Eliminates MPLS and Embraces Freedom Easily**
+
+As for [Humphrey’s and Partners, an architectural services firm][5], eight regional offices connected to its Dallas headquarters via a hybrid WAN and a ninth connected over the Internet. Three offices ran SD-WAN appliances connected to MPLS and the Internet. Another three connected via MPLS only. Two connected with SD-WAN and the Internet, and an office in Vietnam had to rely on file sharing and transfer to move data across the Internet to Dallas.
+
+With MPLS, Humphrey’s needed three months to deploy at a new site. Even simple network changes took 24 hours, frequently requiring off-hours work. “Often the process involved waking me up in the middle of the night,” said IT Director Paul Burns.
+
+Burns had tried deploying SD-WAN appliances in some locations, but “the configuration pages of the SD-WAN appliance were insane,” said Burns, and it was sometimes difficult to get WAN connections working properly. “Sometimes Dallas could connect to two sites, but they couldn’t connect to each other,” he said.
+
+Burns deployed a global enterprise backbone solution at most locations, including Vietnam. Getting sites up and running took minutes or hours. “We dropped shipped devices to New Orleans, and I flew out to install the stuff. Took less than a day and the performance was great,” said Burns. “We set up Uruguay in less than 10 minutes. [The solution] gave us freedom.”
+
+MPLS and VPNs can be very complex, but so can an SD-WAN replacement if it’s not architected carefully. For many organizations, a simpler approach is to connect and secure all users and locations with a global private backbone and software providing WAN optimization and a complete security stack. Such an approach fulfills the goals of KISS: performance, agility, and low cost.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447383/mpls-migration-how-a-kiss-transformed-the-wans-of-4-it-managers.html
+
+作者:[Cato Networks][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Matt-Conran/
+[b]: https://github.com/lujun9972
+[1]: https://www.catonetworks.com/customers/pharmaceutical-leader-replaces-mpls-with-cato-cloud-cutting-costs-while-quadrupling-capacity?utm_source=idg
+[2]: https://www.catonetworks.com/sd-wan?utm_source=idg
+[3]: https://www.catonetworks.com/customers/paysafe-replaces-global-mpls-network-and-internet-vpn-with-cato-cloud?utm_source=idg
+[4]: https://www.catonetworks.com/customers/sanne-group-replaces-internet-and-mpls-simplifying-citrix-access-and-improving-performance-with-cato-cloud?utm_source=idg
+[5]: https://www.catonetworks.com/customers/humphreys-replaces-mpls-sd-wan-appliances-and-mobile-vpn-with-cato-cloud?utm_source=idg
diff --git a/sources/talk/20191023 Psst- Wanna buy a data center.md b/sources/talk/20191023 Psst- Wanna buy a data center.md
new file mode 100644
index 0000000000..26ac4617b8
--- /dev/null
+++ b/sources/talk/20191023 Psst- Wanna buy a data center.md
@@ -0,0 +1,76 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Psst! Wanna buy a data center?)
+[#]: via: (https://www.networkworld.com/article/3447657/psst-wanna-buy-a-data-center.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+Psst! Wanna buy a data center?
+======
+Data centers are being bought and sold at an increasing rate, although since they are often private transactions, solid numbers can be hard to come by.
+artisteer / Getty Images
+
+When investment bank Bear Stearns collapsed in 2008, there was nothing left of value to auction off except its [data centers][1]. JP Morgan bought the company's carcass for just $270 million, but the only thing of value was Bear's NYC headquarters and two data centers.
+
+Since then there have been numerous sales of data centers under better conditions. There are even websites ([Datacenters.com][2], [Five 9s Digital][3]) that list data centers for sale. You can buy an empty building, but in most cases, you get the equipment, too.
+
+There are several reasons why, the most common being companies want to get out of owning a data center. It's an expensive capex and opex investment, and if the cloud is a good alternative, then that's where they go.
+
+[][4]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][4]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+But there are other reasons, too, said Jon Lin, president of the Equinix Americas office. He said enterprises have overbuilt because of their initial long-term forecasts fell short, partially driven by increased use of cloud. He also said there is an increase in the amount of private equity and real estate investors interested in diversifying into data centers.
+
+But that doesn't mean Equinix takes every data center they are offered. He cited three reasons why Equinix would pass on an offer:
+
+1) It is difficult to repurpose an enterprise data center designed around a very tailored customer into a general purpose, multi-tenant data center without significant investment in order to tailor it to the company's satisfaction.
+
+2) Most of these sites were not built to Equinix standards, diminishing their value.
+
+**[ Learn more about SDN: Find out [where SDN is going][5] and learn the [difference between SDN and NFV][6]. | Get regularly scheduled insights by [signing up for Network World newsletters][7]. ]**
+
+3) Enterprise data centers are usually located where the company HQ is for convenience, and not near the interconnection points or infrastructure locations Equinix would prefer for fiber and power.
+
+Just how much buying and selling is going on is hard to tell. Most of these firms are privately held and thus no disclosure is required. Kelly Morgan, research vice president with 451 Research who tracks the data center market, put the dollar figure for data center sales in 2019 so far at $5.4 billion. That's way down from $19.5 billion just two years ago.
+
+She says that back then there were very big deals, like when Verizon sold its data centers to Equinix in 2017 for $3.6 billion while AT&T sold its data centers to Brookfield Infrastructure Partners, which buys and managed infrastructure assets, for $1.1 billion.
+
+These days, she says, the main buyers are big real estate-oriented pension funds that have a different perspective on why they buy vs. traditional real estate investors. Pension funds like the steady income, even in a recession. Private equity firms were buying data centers to buy up the assets, group them, then sell them and make a double-digit return, she said.
+
+Enterprises do look to sell their data centers, but it's a more challenging process. She echoes what Lin said about the problem with specialty data centers. "They tend to be expensive and often in not great locations for multi-tenant situations. They are often at company headquarters or the town where the company is headquartered. So they are hard to sell," she said.
+
+Enterprises want to sell their data center to get out of data center ownership, since they are often older -- the average age of corporate data centers is from 10 years to 25 years old – for the obvious reasons. "When we ask enterprises why they are selling or closing their data centers, they say they are consolidating multiple data centers into one, plus moving half their stuff to the cloud," said Morgan.
+
+There is still a good chunk of companies who build or acquire data centers, either because they are consolidating or just getting rid of older facilities. Some add space because they are moving to a new geography. However, Morgan said they almost never buy. "They lease one from someone else. Enterprise data centers for sale are not bought by other enterprises, they are bought by service providers who will lease it. Enterprises build a new one," she said.
+
+Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447657/psst-wanna-buy-a-data-center.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
+[2]: https://www.datacenters.com/real-estate/data-centers-for-sale
+[3]: https://five9sdigital.com/data-centers/
+[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[5]: https://www.networkworld.com/article/3209131/lan-wan/what-sdn-is-and-where-its-going.html
+[6]: https://www.networkworld.com/article/3206709/lan-wan/what-s-the-difference-between-sdn-and-nfv.html
+[7]: https://www.networkworld.com/newsletters/signup.html
+[8]: https://www.facebook.com/NetworkWorld/
+[9]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191023 The Protocols That Help Things to Communicate Over the Internet.md b/sources/talk/20191023 The Protocols That Help Things to Communicate Over the Internet.md
new file mode 100644
index 0000000000..349e2b7e2a
--- /dev/null
+++ b/sources/talk/20191023 The Protocols That Help Things to Communicate Over the Internet.md
@@ -0,0 +1,141 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Protocols That Help Things to Communicate Over the Internet)
+[#]: via: (https://opensourceforu.com/2019/10/the-protocols-that-help-things-to-communicate-over-the-internet-2/)
+[#]: author: (Sapna Panchal https://opensourceforu.com/author/sapna-panchal/)
+
+The Protocols That Help Things to Communicate Over the Internet
+======
+
+[![][1]][2]
+
+_The Internet of Things is a system of connected, interrelated objects. These objects transmit data to servers for processing and, in turn, receive messages from the servers. These messages are sent and received using different protocols. This article discusses some of the protocols related to the IoT._
+
+The Internet of Things (IoT) is beginning to pervade more and more aspects of our lives. Everyone everywhere is using the Internet of Things. Using the Internet, connected things are used to collect information, convey/send information back, or do both. IoT is an architecture that is a combination of available technologies. It helps to make our daily lives more pleasant and convenient.
+
+![Figure 1: IoT architecture][3]
+
+![Figure 2: Messaging Queuing Telemetry Transmit protocol][4]
+
+**IoT architecture**
+Basically, IoT architecture has four components. In this article, we will explore each component to understand the architecture better.
+
+**Sensors:** These are present everywhere. They help to collect data from any location and then share it to the IoT gateway. As an example, sensors sense the temperature at different locations, which helps to gauge the weather conditions. And this information is shared or passed to the IoT gateway. This is a basic example of how the IoT operates.
+
+**IoT gateway:** Once the information is collected from the sensors, it is passed on to the gateway. The gateway is a mediator between sensor nodes and the World Wide Web. So basically, it processes the data that is collected from sensor nodes and then transmits this to the Internet infrastructure.
+**Cloud server:** Once data is transmitted through the gateway, it is stored and processed in the cloud server.
+**Mobile app:** Using a mobile application, the user can view and access the data processed in the cloud server.
+This is the basic idea of the IoT and its architecture, along with the components. We now move on to the basic ideas behind different IoT protocols.
+
+![Figure 3: Advance Message Queuing Protocol][5]
+
+![Figure 4: CoAP][6]
+
+**IoT protocols**
+As mentioned earlier, connected things are used to collect information, convey/send information back, or do both, using the Internet. This is the fundamental basis of the IoT. To convey/send information, we need a protocol, which is a set of procedures that is used to transmit the data between electronic devices.
+Essentially, we have two types of IoT protocols — the IoT network protocols and the IoT data protocols. This article discusses the IoT data protocols.
+
+![Figure 5: Constrained Application Protocol architecture][7]
+
+**MQTT**
+The Messaging Queuing Telemetry Transmit (MQTT) protocol was primarily designed for low bandwidth networks, but is very popular today as an IoT protocol. It is used to exchange data between clients and the server. It is a lightweight messaging protocol.
+
+This protocol has many advantages:
+
+ * It is small in size and has low power usage.
+ * It is a lightweight protocol.
+ * It is based on low network usage.
+ * It works entirely in real-time.
+
+
+
+Considering all the above reasons, MQTT emerges as the perfect IoT data protocol.
+
+**How MQTT works:** MQTT is based on a client-server relationship. The server manages the requests that come from different clients and sends the required information to clients. MQTT is based on two operations.
+
+i) _Publish:_ When the client sends data to the MQTT broker, this operation is known as ‘Publish’.
+ii) _Subscribe:_ When the client receives data from the broker, this operation is known as ‘Subscribe’.
+
+The MQTT broker is the mediator that handles these operations, primarily taking messages and delivering them to the application or client.
+
+Let’s look at the example of a device temperature sensor, which sends readings to the MQTT broker, and then information is delivered to desktop or mobile applications. As stated earlier, ‘Publish’ means sending readings to the MQTT broker and ‘Subscribe’ means delivering the information to the desktop/mobile application.
+
+**AMQP**
+Advanced Message Queuing Protocol is a peer-to-peer protocol, where one peer plays the role of the client application and the other peer plays the role of the delivery service or broker. It is the combination of hard and fast components that basically routes and saves messages within the delivery service or broker carrier.
+The benefits of AMQP are:
+
+ * It helps to send messages without them getting missed out.
+ * It helps to guarantee a ‘one-time-only’ and secured delivery.
+ * It provides a secure connection.
+ * It always supports acknowledgements for message delivery or failure.
+
+
+
+**How AMQP works and its architecture:** The AMQP architecture is made up of the following parts.
+
+_**Exchange**_ – Messages that come from the publisher are accepted by Exchange, which routes them to the message queue.
+_**Message queue**_ – This is the combination of multiple queues and is helpful for processing the messages.
+_**Binding**_ – This helps to maintain the connectivity between Exchange and the message queue.
+The combination of Exchange and the message queues is known as the broker or AMQP broker.
+
+![Figure 6: Extensible Messaging and Presence Protocol][8]
+
+**Constrained Application Protocol (CoAP)**
+This was initially used as a machine-to-machine (M2M) protocol and later began to be used as an IoT protocol. It is a Web transfer protocol that is used with constrained nodes and constrained networks. CoAP uses the RESTful architecture, just like the HTTP protocol.
+The advantages CoAP offers are:
+
+ * It works as a REST model for small devices.
+ * As this is like HTTP, it’s easy for developers to work on.
+ * It is a one-to-one protocol for transferring information between the client and server, directly.
+ * It is very simple to parse.
+
+
+
+**How CoAP works and its architecture:** From Figure 4, we can understand that CoAP is the combination of ‘Request/Response and Message’. We can also say it has two layers – ‘Request/Response’and ‘Message’.
+Figure 5 clearly explains that CoAP architecture is based on the client server relationship, where…
+
+ * The client sends requests to the server.
+ * The server receives requests from the client and responds to them.
+
+
+
+**Extensible Messaging and Presence Protocol (XMPP)**
+
+This protocol is used to exchange messages in real-time. It is used not only to communicate with others, but also to get information on the status of the user (away, offline, active). This protocol is widely used in real life, like in WhatsApp.
+
+The Extensible Messaging and Presence Protocol should be used because:
+
+ * It is free, open and easy to understand. Hence, it is very popular.
+ * It has secured authentication, is extensible and flexible.
+
+
+
+**How XMPP works and its architecture:** In the XMPP architecture, each client has a unique name associated with it and communicates to other clients via the XMPP server. The XMPP client has either the same domain or a different one.
+
+In Figure 6, the XMPP client belongs to the same domain in which one XMPP client sends the information to the XMPP server. The server translates it and conveys the information to another client.
+Basically, this protocol is the backbone that provides universal connectivity between different endpoint protocols.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/the-protocols-that-help-things-to-communicate-over-the-internet-2/
+
+作者:[Sapna Panchal][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/sapna-panchal/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Internet-of-things-illustration.jpg?resize=696%2C439&ssl=1 (Internet of things illustration)
+[2]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Internet-of-things-illustration.jpg?fit=1125%2C710&ssl=1
+[3]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-1-IoT-architecture.jpg?resize=350%2C133&ssl=1
+[4]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-2-Messaging-Queuing-Telemetry-Transmit-protocol.jpg?resize=350%2C206&ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-3-Advance-Message-Queuing-Protocol.jpg?resize=350%2C160&ssl=1
+[6]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-4-CoAP.jpg?resize=350%2C84&ssl=1
+[7]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-5-Constrained-Application-Protocol-architecture.jpg?resize=350%2C224&ssl=1
+[8]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-6-Extensible-Messaging-and-Presence-Protocol.jpg?resize=350%2C46&ssl=1
diff --git a/sources/talk/20191024 4 ways developers can have a say in what agile looks like.md b/sources/talk/20191024 4 ways developers can have a say in what agile looks like.md
new file mode 100644
index 0000000000..1c247c622e
--- /dev/null
+++ b/sources/talk/20191024 4 ways developers can have a say in what agile looks like.md
@@ -0,0 +1,89 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (4 ways developers can have a say in what agile looks like)
+[#]: via: (https://opensource.com/article/19/10/ways-developers-what-agile)
+[#]: author: (Clement Verna https://opensource.com/users/cverna)
+
+4 ways developers can have a say in what agile looks like
+======
+How agile is implemented—versus imposed—plays a big role in what
+developers gain from it.
+![Person on top of a mountain, arm raise][1]
+
+Agile has become the default way of developing software; sometimes, it seems like every organization is doing (or wants to do) agile. But, instead of trying to change their culture to become agile, many companies try to impose frameworks like scrum onto developers, looking for a magic recipe to increase productivity. This has unfortunately created some bad experiences and leads developers to feel like agile is something they would rather avoid. This is a shame because, when it's done correctly, developers and their projects benefit from becoming involved in it. Here are four reasons why.
+
+### Agile, back to the basics
+
+The first way for developers to be unafraid of agile is to go back to its basics and remember what agile is really about. Many people see agile as a synonym for scrum, kanban, story points, or daily stand-ups. While these are important parts of the [agile umbrella][2], this perception takes people away from the original spirit of agile.
+
+Going back to agile's origins means looking at the [Agile Manifesto][3], and what I believe is its most important part, the introduction:
+
+> We are uncovering better ways of developing software by doing it and helping others do it.
+
+I'm a believer in continuous improvement, and this sentence resonates with me. It emphasizes the importance of having a [growth mindset][4] while being a part of an agile team. In fact, I think this outlook is a solution to most of the problems a team may face when adopting agile.
+
+Scrum is not working for your team? Right, let's discover a better way of organizing it. You are working in a distributed team across multiple timezones, and having a daily standup is not ideal? No problem, let's find a better way to communicate and share information.
+
+Agile is all about flexibility and being able to adapt to change, so be open-minded and creative to discover better ways of collaborating and developing software.
+
+### Agile metrics as a way to improve, not control
+
+Indeed, agile is about adopting and embracing change. Metrics play an important part in this process, as they help the team determine if it is heading in the right direction. As an agile developer, you want metrics to provide the data your team needs to support its decisions, including whether it should change directions. This process of learning from facts and experience is known as empiricism, and it is well-illustrated by the three pillars of agile.
+
+![Three pillars of agile][5]
+
+Unfortunately, in most of the teams I've worked with, metrics were used by project management as an indicator of the team's performance, which causes people on the team to be afraid of implementing changes or to cut corners to meet expectations.
+
+In order to avoid those outcomes, developers need to be in control of their team's metrics. They need to know exactly what is measured and, most importantly, why it's being measured. Once the team has a good understanding of those factors, it will be easier for them to try new practices and measure their impact.
+
+Rather than using metrics to measure your team's performance, engage with management to find a better way to define what success means to your team.
+
+### Developer power is in the team
+
+As a member of an agile team, you have more power than you think to help build a team that has a great impact. The [Toyota Production System][6] recognized this long ago. Indeed, Toyota considered that employees, not processes, were the key to building great products.
+
+This means that, even if a team uses the best process possible, if the people on the team are not comfortable working with each other, there is a high chance that the team will fail. As a developer, invest time to build trust inside your team and to understand what motivates its members.
+
+If you are curious about how to do this, I recommend reading Alexis Monville's book [_Changing Your Team from the Inside_][7].
+
+### Making developer work visible
+
+A big part of any agile methodology is to make information and work visible; this is often referred to as an [information radiator][8]. In his book [_Teams of Teams_][9], Gen. Stanley McChrystal explains how the US Army had to transform itself from an organization that was optimized on productivity to one optimized to adapt. What we learn from his book is that the world in which we live has changed. The problem of becoming more productive was mostly solved at the end of the 20th century, and the challenge that companies now face is how to adapt to a world in constant evolution.
+
+![A lot of sticky notes on a whiteboard][10]
+
+I particularly like Gen. McChrystal's explanation of how he created a powerful information radiator. When he took charge of the [Joint Special Operations Command][11], Gen. McChrystal began holding a daily call with his high commanders to discuss and plan future operations. He soon realized that this was not optimal and instead started running 90-minute briefings every morning for 7,000 people around the world. This allowed every task force to acquire the knowledge necessary to accomplish their missions and made them aware of other task forces' assignments and situations. Gen. McChrystal refers to this as "shared consciousness."
+
+So, as a developer, how can you help build a shared consciousness in your team? Start by simply sharing what you are working on and/or plan to work on and get curious about what your colleagues are doing.
+
+* * *
+
+If you're using agile in your development organization, what do you think are its main benefits? And if you aren't using agile, what barriers are holding your team back? Please share your thoughts in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/ways-developers-what-agile
+
+作者:[Clement Verna][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/cverna
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/developer_mountain_cloud_top_strong_win.jpg?itok=axK3EX-q (Person on top of a mountain, arm raise)
+[2]: https://confluence.huit.harvard.edu/display/WGAgile/2014/07/01/The+Agile+Umbrella
+[3]: https://agilemanifesto.org/
+[4]: https://www.edglossary.org/growth-mindset/
+[5]: https://opensource.com/sites/default/files/uploads/3pillarsofagile.png (Three pillars of agile)
+[6]: https://en.wikipedia.org/wiki/Toyota_Production_System#Respect_for_people
+[7]: https://leanpub.com/changing-your-team-from-the-inside#packages
+[8]: https://www.agilealliance.org/glossary/information-radiators/
+[9]: https://www.mcchrystalgroup.com/insights-2/teamofteams/
+[10]: https://opensource.com/sites/default/files/uploads/stickynotes.jpg (A lot of sticky notes on a whiteboard)
+[11]: https://en.wikipedia.org/wiki/Joint_Special_Operations_Command
diff --git a/sources/talk/20191024 Gartner crystal ball- Looking beyond 2020 at the top IT-changing technologies.md b/sources/talk/20191024 Gartner crystal ball- Looking beyond 2020 at the top IT-changing technologies.md
new file mode 100644
index 0000000000..76bd69c4fa
--- /dev/null
+++ b/sources/talk/20191024 Gartner crystal ball- Looking beyond 2020 at the top IT-changing technologies.md
@@ -0,0 +1,122 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Gartner crystal ball: Looking beyond 2020 at the top IT-changing technologies)
+[#]: via: (https://www.networkworld.com/article/3447759/gartner-looks-beyond-2020-to-foretell-the-top-it-changing-technologies.html)
+[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
+
+Gartner crystal ball: Looking beyond 2020 at the top IT-changing technologies
+======
+Gartner’s top strategic predictions for 2020 and beyond is heavily weighted toward the human side of technology
+[Thinkstock][1]
+
+ORLANDO – Forecasting long-range IT technology trends is a little herding cats – things can get a little crazy.
+
+But Gartner analysts have specialized in looking forwardth, boasting an 80 percent accuracy rate over the years, Daryl Plummer, distinguished vice president and Gartner Fellow told the IT crowd at this year’s [IT Symposium/XPO][2]. Some of those successful prediction have included the rise of automation, robotics, AI technology and other ongoing trends.
+
+[Now see how AI can boost data-center availability and efficiency][3]
+
+Like some of the [other predictions][4] Gartner has made at this event, this year’s package of predictions for 2020 and beyond is heavily weighted toward the human side of technology rather than technology itself.
+
+**[ [Become a Microsoft Office 365 administrator in record time with this quick start course from PluralSight.][5] ]**
+
+ “Beyond offering insights into some of the most critical areas of technology evolution, this year’s predictions help us move beyond thinking about mere notions of technology adoption and draw us more deeply into issues surrounding what it means to be human in the digital world.” Plummer said.
+
+The list this year goes like this:
+
+**By 2023, the number of people with disabilities employed will triple due to AI and emerging technologies, reducing barriers to access.**
+
+Technology is going to make it easier for people with disabilities to connect to the business world. “People with disabilities constitute an untapped pool of critically skilled talent,” Plummer said.
+
+“[Artificial intelligence (AI)][6], augmented reality (AR), virtual reality (VR) and other [emerging technologies][7] have made work more accessible for employees with disabilities. For example, select restaurants are starting to pilot AI robotics technology that enables paralyzed employees to control robotic waiters remotely. Organizations that actively employ people with disabilities will not only cultivate goodwill from their communities, but also see 89 percent higher retention rates, a 72 percent increase in employee productivity, and a 29 percent increase in profitability,” Plummer said.
+
+**By 2024, AI identification of emotions will influence more than half of the online advertisements you see.**
+
+Computer vision, which allows AI to identify and interpret physical environments, is one of the key technologies used for emotion recognition and has been ranked by Gartner as one of the most important technologies in the next three to five years. [Artificial emotional intelligence (AEI)][8] is the next frontier for AI development, Plummer said. Twenty-eight percent of marketers ranked AI and machine learning (ML) among the top three technologies that will drive future marketing impact, and 87 percent of marketing organizations are currently pursuing some level of personalization, according to Gartner. By 2022, 10 percent of personal devices will have emotion AI capabilities, Gartner predicted.
+
+“AI makes it possible for both digital and physical experiences to become hyper personalized, beyond clicks and browsing history but actually on how customers _feel_ in a specific purchasing moment. With the promise to measure and engage consumers based on something once thought to be intangible, this area of ‘empathetic marketing’ holds tremendous value for both brands and consumers when used within the proper [privacy][9] boundaries,” said Plummer.
+
+**Through 2023, 30% of IT organizations will extend BYOD policies with “bring your own enhancement” (BYOE) to address augmented humans in the workforce.**
+
+The concept of augmented workers has gained traction in social media conversations in 2019 due to advancements in wearable technology. Wearables are driving workplace productivity and safety across most verticals, including automotive, oil and gas, retail and healthcare.
+
+Wearables are only one example of physical augmentations available today, but humans will look to additional physical augmentations that will enhance their personal lives and help do their jobs. Gartner defines human augmentation as creating cognitive and physical improvements as an integral part of the human body. An example is using active control systems to create limb prosthetics with characteristics that can exceed the highest natural human performance.
+
+“IT leaders certainly see these technologies as impactful, but it is the consumers’ desire to physically enhance themselves that will drive the adoption of these technologies first,” Plummer said. “Enterprises need to balance the control of these devices in their enterprises while also enabling users to use them for the benefit of the organization.”
+
+**By 2025, 50% of people with a smartphone but without a bank account will use a mobile-accessible cryptocurrency account.**
+
+Currently 30 percent of people have no bank account and 71 percent will subscribe to mobile services by 2025. Major online marketplaces and social media platforms will start supporting cryptocurrency payments by the end of next year. By 2022, Facebook, Uber, Airbnb, eBay, PayPal and other digital e-commerce companies will support over 750 million customer, Gartner predicts.
+
+At least half the globe’s citizens who do not use a bank account will instead use these new mobile-enabled cryptocurrency account services offered by global digital platforms by 2025, Gartner said.
+
+**By 2023, a self-regulating association for oversight of AI and machine-learning designers will be established in at least four of the G7 countries.**
+
+By 2021, multiple incidents involving non-trivial AI-produced harm to hundreds or thousands of individuals can be expected, Gartner said. Public demand for protection from the consequences of malfunctioning algorithms will in turn produce pressure to assign legal liability for the harmful consequences of algorithm failure. The immediate impact of regulation of process will be to increase cycle times for AI and ML algorithm development and deployment. Enterprises can also expect to spend more for training and certification for practitioners and documentation of processes, as well as higher salaries for certified personnel.
+
+“Regulation of products as complex as AI and ML algorithms is no easy task. Consequences of algorithm failures at scale that occur within major societal functions are becoming more visible. For instance, AI-related failures in autonomous vehicles and aircraft have already killed people and attracted widespread attention in recent months,” said Plummer.
+
+**By 2023, 40% of professional workers will orchestrate their business application experiences and capabilities like they do their music streaming experience.**
+
+The human desire to have a work environment that is similar to their personal environment continues to rise — one where they can assemble their own applications to meet job and personal requirements in a [self-service fashion][10]. The consumerization of technology and introduction of new applications have elevated the expectations of employees as to what is possible from their business applications. Gartner says through 2020, the top 10 enterprise-application vendors will expose over 90 percent of their application capabilities through APIs.
+
+“Applications used to define our jobs. Nowadays, we are seeing organizations designing application experiences around the employee. For example, mobile and cloud technologies are freeing many workers from coming into an office and instead supporting a work-anywhere environment, outpacing traditional application business models,” Plummer said. “Similar to how humans customize their streaming experience, they can increasingly customize and engage with new application experiences.”
+
+**By 2023, up to 30 percent of world news and video content will be authenticated as real by blockchain countering deep fake technology.**
+
+Fake news represents deliberate disinformation, such as propaganda that is presented to viewers as real news. Its rapid proliferation in recent years can be attributed to bot-controlled accounts on social media, attracting more viewers than authentic news and manipulating human intake of information, Plummer said. Fake content, exacerbated by AI can pose an existential threat to an organization.
+
+By 2021, at least 10 major news organizations will use [blockchain][11] to track and prove the authenticity of their published content to readers and consumers. Likewise, governments, technology giants and other entities are fighting back through industry groups and proposed regulations. “The IT organization must work with content-production teams to establish and track the origin of enterprise-generated content using blockchain technology,” Plummer said.
+
+**On average, through 202, digital transformation initiatives will take large traditional enterprises twice as long and cost twice as much as anticipated.**
+
+Business leaders’ expectations for revenue growth are unlikely to be realized from digital optimization strategies, due to the cost of technology modernization and the unanticipated costs of simplifying operational interdependencies. Such operational complexity also impedes the pace of change along with the degree of innovation and adaptability required to operate as a digital business.
+
+“In most traditional organizations, the gap between digital ambition and reality is large,” Plummer said. “We expect CIOs’ budget allocation for IT modernization to grow 7 percent year-over-year through 2021 to try to close that gap.”
+
+**By 2023, individual activities will be tracked digitally by an “Internet of Behavior” to influence, benefit and service eligibility for 40% of people worldwide.**
+
+Through facial recognition, location tracking and big data, organizations are starting to monitor individual behavior and link that behavior to other digital actions, like buying a train ticket. The Internet of Things (IoT) – where physical things are directed to do a certain thing based on a set of observed operating parameters relative to a desired set of operating parameters — is now being extended to people, known as the Internet of Behavior (IoB). Through 2020 watch for examples of usage-based and behaviorally-based business models to expand into health insurance or financial services, Plummer said.
+
+“With IoB, value judgements are applied to behavioral events to create a desired state of behavior,” Plummer said. “What level of tracking will we accept? Will it be hard to get life insurance if your Fitbit tracker doesn’t see 10,000 steps a day?”
+
+“Over the long term, it is likely that almost everyone living in a modern society will be exposed to some form of IoB that melds with cultural and legal norms of our existing predigital societies,” Plummer said
+
+**By 2024, the World Health Organization will identify online shopping as an addictive disorder, as millions abuse digital commerce and encounter financial stress.**
+
+Consumer spending via digital commerce platforms will continue to grow over 10 percent year-over-year through 2022. In addition watch for an increased number of digital commerce orders predicted by, and initiated by, AI.
+
+The ease of online shopping will cause financial stress for millions of people, as online retailers increasingly use AI and personalization to effectively target consumers and prompt them to spend income that they do not have. The resulting debt and personal bankruptcies will cause depression and other health concerns caused by stress, which is capturing the attention of the WHO.
+
+“The side effects of technology that promote addictive behavior are not exclusive to consumers. CIOs must also consider the possibility of lost productivity among employees who put work aside for online shopping and other digital distractions. In addition, regulations in support of responsible online retail practices might force companies to provide warnings to prospective customers who are ready to make online purchases, similar to casinos or cigarette companies,” Plummer said.
+
+Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447759/gartner-looks-beyond-2020-to-foretell-the-top-it-changing-technologies.html
+
+作者:[Michael Cooney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Michael-Cooney/
+[b]: https://github.com/lujun9972
+[1]: http://thinkstockphotos.com
+[2]: https://www.networkworld.com/article/3447397/gartner-10-infrastructure-trends-you-need-to-know.html
+[3]: https://www.networkworld.com/article/3274654/ai-boosts-data-center-availability-efficiency.html
+[4]: https://www.networkworld.com/article/3447401/gartner-top-10-strategic-technology-trends-for-2020.html
+[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fadministering-office-365-quick-start
+[6]: https://www.gartner.com/en/newsroom/press-releases/2019-07-15-gartner-survey-reveals-leading-organizations-expect-t
+[7]: https://www.gartner.com/en/newsroom/press-releases/2018-08-20-gartner-identifies-five-emerging-technology-trends-that-will-blur-the-lines-between-human-and-machine
+[8]: https://www.gartner.com/smarterwithgartner/13-surprising-uses-for-emotion-ai-technology/
+[9]: https://www.gartner.com/smarterwithgartner/how-to-balance-personalization-with-data-privacy/
+[10]: https://www.gartner.com/en/newsroom/press-releases/2019-05-28-gartner-says-the-future-of-self-service-is-customer-l
+[11]: https://www.gartner.com/smarterwithgartner/the-cios-guide-to-blockchain/
+[12]: https://www.facebook.com/NetworkWorld/
+[13]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191024 My Linux Story- Why introduce people to the Raspberry Pi.md b/sources/talk/20191024 My Linux Story- Why introduce people to the Raspberry Pi.md
new file mode 100644
index 0000000000..c9e32f85e2
--- /dev/null
+++ b/sources/talk/20191024 My Linux Story- Why introduce people to the Raspberry Pi.md
@@ -0,0 +1,55 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (My Linux Story: Why introduce people to the Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/10/new-linux-open-source-users)
+[#]: author: (RolandBerberich https://opensource.com/users/rolandberberich)
+
+My Linux Story: Why introduce people to the Raspberry Pi
+======
+Learn why I consider the Raspberry Pi one of our best opportunities to
+invite more people to the open source community.
+![Team of people around the world][1]
+
+My first steps into Linux happened around 2003 or 2004 when I was a student. The experiment lasted an hour or two. Being used to Windows, I was confused and quickly frustrated at having to learn the most basic stuff again.
+
+By 2018, I was curious enough to try Ubuntu before settling on Fedora 29 on an unused laptop, and to get a Pi3B+ and Pi4, both currently running Raspbian. What changed? Well, first of all, Linux has certainly changed. Also, by that time I was not only curious but more patient than my younger self by that time. Reflecting on this experience, I reckon that patience to overcome the perceived usability gap is the key to Linux satisfaction. Just one year later, I can confidently say I am productive in both Windows as well as (my) Linux environments.
+
+This experience has brought up two questions. First, why are more people not using Linux (or other open source software)? Second, what can the savvier among us could do to improve these numbers? Of course, these questions assume the open source world has advantages over the more common alternatives, and that some of us would go to ends of the Earth to convince the non-believers.
+
+Believe it or not, this last issue is one of the problems. By far, I am not a Linux pro. I would rather describe myself as a "competent user" able to solve a few issues by myself. Admittedly, internet search engines are my friend, but step-by-step I accumulated the expertise and confidence to work outside the omnipresent Windows workspace.
+
+On the other hand, how technophile is the standard user? Probably not at all. The internet is full of "have you switched it on" examples to illustrate the incompetence of users. Now, imagine someone suggests you are incompetent and then offers (unsolicited) advice on how to improve. How well would you take that, especially if you consider yourself "operational" (meaning that you have no problems at work or surfing the web)?
+
+### Introduce them to the Raspberry Pi
+
+Overcoming this initial barrier is crucial, and we cannot do so with a superiority complex. Personally, I consider the Raspberry Pi one of our best opportunities to invite more people to the open source community. The Raspberry Pi’s simplicity combined with its versatility and affordability could entice more people to get and use one.
+
+I recently upgraded my Pi3B+ to the new Pi4B, and with the exception of my usual reference manager, this unit fully replaces my (Windows) desktop. My next step is to use a Pi3B+ as a media center and gaming console. The point is that if we want people to use open source software, we need to make it accessible for everyday tasks such as the above. Realizing it isn't that difficult will do more for user numbers than aloof superiority from open source advocates, or Linux clubs at university.
+
+It is one thing to keep preaching the many advantages of open source, but a more convincing experience can only be a personal one. Obviously, people will realize the cost advantage of, say, a Pi4 running Linux over a standard supermarket Windows PC. And humans are curious. An affordable gadget where mistakes are easy to correct (clone your card, it is not hard) will entice more and more users to fiddle around and get first hand IT knowledge. Maybe none of us will be an expert (I count myself among this crowd) but the least that will happen is wider use of open source software with users realizing that is is a viable alternative.
+
+With curiosity rampant, a Pi club at school or university could make younger workers competent in Linux. Some of these workers perhaps will bring their SD card to work, plug it into any Raspberry Pi provided, and start being productive. Imagine the potential savings in regards to IT. Imagine the flexibility of choosing any space in the office and having your own work environment with you.
+
+Wider use of open source solutions will not only add flexibility. Targetting mainly Windows environments, your systems will be somewhat safer from attacks, and with more demand, more resources will pour into further development. Consequently, this trend will force propriety software developers to up their game, which is also good for users of course.
+
+In summary, my point is to reflect as a community how we can improve our resource base by following my journey. We can only do so by starting early, accessibly, and affordably, and by showing that open source is a real alternative for any professional application on a daily basis.
+
+There are lots of non-code ways to contribute to open source: Here are three alternatives.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/new-linux-open-source-users
+
+作者:[RolandBerberich][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rolandberberich
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/team_global_people_gis_location.png?itok=Rl2IKo12 (Team of people around the world)
diff --git a/sources/talk/20191024 The evolution to Secure Access Service Edge (SASE) is being driven by necessity.md b/sources/talk/20191024 The evolution to Secure Access Service Edge (SASE) is being driven by necessity.md
new file mode 100644
index 0000000000..2990d249cb
--- /dev/null
+++ b/sources/talk/20191024 The evolution to Secure Access Service Edge (SASE) is being driven by necessity.md
@@ -0,0 +1,124 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The evolution to Secure Access Service Edge (SASE) is being driven by necessity)
+[#]: via: (https://www.networkworld.com/article/3448276/the-evolution-to-secure-access-service-edge-sase-is-being-driven-by-necessity.html)
+[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
+
+The evolution to Secure Access Service Edge (SASE) is being driven by necessity
+======
+The users and devices are everywhere. As a result, secure access services also need to be everywhere.
+MF3d / Getty Images
+
+The WAN consists of network and security stacks, both of which have gone through several phases of evolution. Initially, we began with the router, introduced WAN optimization, and then edge SD-WAN. From the perspective of security, we have a number of firewall generations that lead to network security-as-a-service. In today’s scenario, we have advanced to another stage that is more suited to today’s environment. This stage is the convergence of network and security in the cloud.
+
+For some, the network and security trends have been thought of in terms of silos. However, the new market category of secure access service edge (SASE) challenges this ideology and recommends a converged cloud-delivered secure access service edge.
+
+Gartner proposes that the future of the network and network security is in the cloud. This is similar to what [Cato Networks][1] has been offering for quite some time – the convergence of networking and security-as-a-service capabilities into a private, global cloud.
+
+[][2]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][2]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+We all know; when we employ anything new, there will be noise. Therefore, it's difficult to dissect the right information and understand who is doing what and if SASE actually benefits your organization. And this is the prime motive of this post. However, before we proceed, I have a question for you.
+
+Will combining the comprehensive WAN capabilities with comprehensive network security functions be the next evolution? In the following sections, I would like to discuss each of the previous network and security stages to help you answer the same question. So, first, let’s begin with networking.
+
+### The networking era
+
+### The router
+
+We started with the router at the WAN edge, configured with routing protocols. Routing protocols do not make a decision on global information and are limited to the routing loop restrictions. This restricts the number of paths that the application traffic can take.
+
+For a redundant WAN design, we need the complex BGP tuning to the load balance between the border edges along with the path attributes. This is because these path attributes may not choose the best performing path. By and large, the shortest path is not necessarily the best path.
+
+**[ Now read [20 hot jobs ambitious IT pros should shoot for][3]. ]**
+
+The WAN edge exhibited a rigid network topology that applications had to fit into. Security was provided by pushing the traffic from one appliance to another. With the passage of time, we began to see the rise of real-time voice and video traffic which are highly sensitive to latency and jitter. Hence, the WAN optimization was a welcomed feature.
+
+### WAN optimization
+
+The basic WAN optimization includes a range of TCP optimizations and basic in-line compression. The advanced WAN optimization includes deduplication, file-based caching and protocol-specific optimizations. This, indeed, helped in managing the latency-sensitive applications and applications where large amounts of data must be transferred across the WAN.
+
+However, it was a complex deployment. A WAN optimization physical appliance was needed at both ends of the connection and had to be used for all the applications. At that time, it was an all or nothing approach and you couldn’t roll out WAN optimization per application. Besides, it had no effect on the remote workers where the users were not located in the office.
+
+Subsequently, SD-WAN started to appear in 2015. During this year, I was consulting an Azure migration and attempting to [create my own DIY SD-WAN][4] _[Disclaimer: the author works for Network Insight]_ with a protocol called Tina from Barracuda. Since I was facing some challenges, so I welcomed the news of SD-WAN with open arms. For the first time, we had a decent level of abstraction in the WAN that was manageable.
+
+Deploying SD-WAN allows me to have all the available bandwidth. Contrarily, many of the WAN optimization techniques such as data compression and deduplication are not as useful.
+
+But others, such as error correction, protocol, and application acceleration could still be useful and are widely used today. Regardless of how many links you bundle, it might still result in latency and packet loss unless of course, you privatize as much as possible.
+
+### The security era
+
+### Packet filters
+
+Elementally, the firewall is classed in a number of generations. We started with the first-generation firewalls that are just simple packet filters. These packet filters match on layer 2 to 4 headers. Since most of them do not match on the TCP SYN flags it’s impossible to identify the established sessions.
+
+### Stateful devices
+
+The second-generation firewalls refer to stateful devices. Stateful firewalls keep the state connections and the return traffic is permitted if the state for that flow is in the connection table.
+
+These stateful firewalls did not inspect at an application level. The second-generation firewalls were stateful and could track the state of the session. However, they could not go deeper into the application, for example, examining the HTTP content and inspecting what users are doing.
+
+### Next-generation firewalls
+
+Just because a firewall is stateful doesn’t mean it can examine the application layer and determine what users are doing. Therefore, we switched to the third-generation firewalls.
+
+These firewall types are often termed as the next-generation firewalls because they offer layer 7 inspections combined with other network device filtering functionalities. Some examples could be an application firewall using an in-line deep packet inspection (DPI) or intrusion prevention system (IPS).
+
+Eventually, other niche devices started to emerge, called application-level firewalls. These devices are usually only concerned with the HTTP traffic, also known as web application firewalls (WAF). The WAF has similar functionality to reverse the web proxy, thereby terminating the HTTP session.
+
+From my experience, while designing the on-premises active/active firewalls with a redundant WAN, you must keep an eye on the asymmetric traffic flows. If the firewall receives a packet that does not have any connection/state information for that packet, it will drop the packet.
+
+Having an active/active design is complicated, whereas the active/passive design with an idle firewall is expensive. Anyways, if you manage to piece together a redundant design, most firewall vendors will require the management of security boxes instead of delivering policy-based security services.
+
+### Network Security-as-a-Service
+
+We then witnessed some major environmental changes. The introduction of the cloud and workload mobility changed the network and security paradigm completely. Workload fluidity and the movement of network state put pressure on the traditional physical security devices.
+
+The physical devices cannot follow workloads and you can’t move a physical appliance around the network. There is also considerable operational overhead. We have to constantly maintain these devices which literally becomes a race against time. For example, when a new patch is issued there will be a test, stage and deploy phase. All of this needs to be done before the network becomes prone to vulnerability.
+
+Network Security-as-a-Service was one solution to this problem. Network security functions, such as the CASB, FWaaS cloud SWG are now pushed to the cloud.
+
+### Converging network and security
+
+All the technologies described above have a time and a place. But these traditional networks and network security architectures are becoming increasingly ineffective.
+
+Now, we have more users, devices, applications, services and data located outside of an enterprise than inside. Hence, with the emergence of edge and cloud-based service, we need a completely different type of architecture.
+
+The SASE proposes combining the network-as-a-service capabilities (SD-WAN, WAN optimization, etc.) with the Security-as-a-Service (SWG, CASB, FWaaS, etc.) to support the dynamic secure access. It focuses extensively on the identity of the user and/or device, not the data center.
+
+Then policy can be applied to the identity and context. Following this model inverts our thinking about network and security. To be fair, we have seen the adoption of some cloud-based services including cloud-based SWG, content delivery network (CDN) and the WAF. However, the overarching design stays the same – the data center is still the center of most enterprise networks and network security architectures. Yet, the user/identity should be the new center of its operations.
+
+In the present era, we have dynamic secure access requirements. The users and devices are everywhere. As a result, secure access services need to be everywhere and distributed closer to the systems and devices that require access. When pursuing a data-centric approach to cloud security, one must follow the data everywhere it goes.
+
+**This article is published as part of the IDG Contributor Network. [Want to Join?][5]**
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3448276/the-evolution-to-secure-access-service-edge-sase-is-being-driven-by-necessity.html
+
+作者:[Matt Conran][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Matt-Conran/
+[b]: https://github.com/lujun9972
+[1]: https://www.catonetworks.com/blog/the-secure-access-service-edge-sase-as-described-in-gartners-hype-cycle-for-enterprise-networking-2019/
+[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[3]: https://www.networkworld.com/article/3276025/careers/20-hot-jobs-ambitious-it-pros-should-shoot-for.html
+[4]: https://network-insight.net/2015/07/azure-expressroute-cloud-ix-barracuda/
+[5]: https://www.networkworld.com/contributor-network/signup.html
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191025 NICT successfully demos petabit-per-second network node.md b/sources/talk/20191025 NICT successfully demos petabit-per-second network node.md
new file mode 100644
index 0000000000..0439e944c9
--- /dev/null
+++ b/sources/talk/20191025 NICT successfully demos petabit-per-second network node.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (NICT successfully demos petabit-per-second network node)
+[#]: via: (https://www.networkworld.com/article/3447857/nict-successfully-demos-petabit-per-second-network-node.html)
+[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
+
+NICT successfully demos petabit-per-second network node
+======
+One-petabit-per-second signals could send 8K resolution video to 10 million people simultaneously, researchers say. Japan’s national research agency says it has just successfully demoed a networked version of it.
+Thinkstock
+
+Petabit-class networks will support more than 100-times the capacity of existing networks, according to scientists who have just demonstrated an optical switching rig designed to handle the significant amounts of data that would pour through future petabit cables. One petabit is equal to a thousand terabits, or a million gigabits.
+
+Researchers at the [National Institute of Information and Communications Technology][1] (NICT) in Japan routed signals with capacities ranging from 10 terabits per second to 1 petabit per second through their node. Those kinds of capacities, which could send 8K resolution video to 10 million people simultaneously, are going to be needed for future broadband video streaming and Internet of Things at scale, researchers believe. In-data-center applications and backhaul could benefit.
+
+“Petabit-class transmission requires petabit-class switching technologies to manage and reliably direct large amounts of data through complex networks, NICT said in a [press release][2]. “Up to now, such technologies have been beyond reach, because the existing approaches are limited by complexity and, or performance.”
+
+[][3]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][3]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+In this case, NICT used “large-scale” spatial optical switching with spatial-division multiplexing to build its node. Three types of multicore fibers were incorporated, all with different capacities, in order to represent different scenarios, like metropolitan or regional networks. MEMS technology, too, was incorporated. That’s equipment built on micro-electro-mechanical systems, or a kind of merging of micrometer-measured, nanoscale electronics devices with moving parts.
+
+NICT says that within its testing, it was able to not only perform the one petabit optical switching, but also was able to run a redundant configuration at one petabit per second. That’s to support network failures such as breaks in the fiber. It used 22-core fiber for both of those scenarios.
+
+Additionally, NICT branched the one petabit signals into other multicore optical fibers with miscellaneous capacities. It used 22-Core Fiber, 7-Core Fiber and 3-Mode Fiber. Finally, running at a slower 10 terabits per second, it managed that lower capacity signal within the capacious one petabit per second network— NICT says that that kind of application would be most suitable for regional networks, whereas the other scenarios apply best to metro networks.
+
+Actual, straight, petabit-class transmissions over fiber have been achieved before. In 2015 NICT was involved in the successful testing of a 2.15 petabit per second signal over a single 22-core fiber. Then, it said, [in a press release][4], that it was making “progress to the practical realization of an over one petabit per second optical fiber.” (Typical [real-world limits][5], right now, include 26.2 terabits, in an experiment, over a transatlantic cable, and an 800 gigabit fiber data center solution Ciena is pitching.)
+
+**More about SD-WAN**: [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][6] • [How to pick an off-site data-backup method][7] • [SD-Branch: What it is and why you’ll need it][8] • [What are the options for security SD-WAN?][9]
+
+In 2018 NICT said, in another [news release][10], that it had tested a petabit transmission over thinner 4-core, 3-mode fiber with a diameter of 0.16 mm (0.006 inches): There’s an advantage to getting the cladding diameter as small as possible—smaller diameter fiber has less propensity to mechanical stress damage, such as bending or pulling, NICT explains. It can also be connected less problematically if it has a similar diameter to existing fiber cables, already run.
+
+“This is a major step forward towards practical petabit-class backbone networks,” NICT says of its current 22-core fiber, one petabit per second switch capacity experiments. These will end up being “backbone optical networks capable of supporting the increasing requirements of internet services,” it says.
+
+Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447857/nict-successfully-demos-petabit-per-second-network-node.html
+
+作者:[Patrick Nelson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Patrick-Nelson/
+[b]: https://github.com/lujun9972
+[1]: https://www.nict.go.jp/en/about/index.html
+[2]: https://www.nict.go.jp/en/press/2019/10/17-1.html
+[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[4]: https://www.nict.go.jp/en/press/2015/10/13-1.html
+[5]: https://www.networkworld.com/article/3374545/data-center-fiber-to-jump-to-800-gigabits-in-2019.html
+[6]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
+[7]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
+[8]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
+[9]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html
+[10]: https://www.nict.go.jp/en/press/2018/11/21-1.html
+[11]: https://www.facebook.com/NetworkWorld/
+[12]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191025 Why I made the switch from Mac to Linux.md b/sources/talk/20191025 Why I made the switch from Mac to Linux.md
new file mode 100644
index 0000000000..342a6c9bd3
--- /dev/null
+++ b/sources/talk/20191025 Why I made the switch from Mac to Linux.md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why I made the switch from Mac to Linux)
+[#]: via: (https://opensource.com/article/19/10/why-switch-mac-linux)
+[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
+
+Why I made the switch from Mac to Linux
+======
+Thanks to a lot of open source developers, it's a lot easier to use
+Linux as your daily driver than ever before.
+![Hands programming][1]
+
+I have been a huge Mac fan and power user since I started in IT in 2004. But a few months ago—for several reasons—I made the commitment to shift to Linux as my daily driver. This isn't my first attempt at fully adopting Linux, but I'm finding it easier than ever. Here is what inspired me to switch.
+
+### My first attempt at Linux on the desktop
+
+I remember looking up at the projector, and it looking back at me. Neither of us understood why it wouldn't display. VGA cords were fully seated with no bent pins to be found. I tapped every key combination I could think of to signal my laptop that it's time to get over the stage fright.
+
+I ran Linux in college as an experiment. My manager in the IT department was an advocate for the many flavors out there, and as I grew more confident in desktop support and writing scripts, I wanted to learn more about it. IT was far more interesting to me than my computer science degree program, which felt so abstract and theoretical—"who cares about binary search trees?" I thought—while our sysadmin team's work felt so tangible.
+
+This story ends with me logging into a Windows workstation to get through my presentation for class, and marks the end of my first attempt at Linux as my day-to-day OS. I admired its flexibility, but compatibility was lacking. I would occasionally write a script that SSHed into a box to run another script, but I stopped using Linux on a day-to-day basis.
+
+### A fresh look at Linux compatibility
+
+When I decided to give Linux another go a few months ago, I expected more of the same compatibility nightmare, but I couldn't be more wrong.
+
+Right after the installation process completed, I plugged in a USB-C hub to see what I'd gotten myself into. Everything worked immediately. The HDMI-connected extra-wide monitor popped up as a mirrored display to my laptop screen, and I easily adjusted it to be a second monitor. The USB-connected webcam, which is essential to my [work-from-home life][2], showed up as a video with no trouble at all. Even my Mac charger, which was already plugged into the hub since I've been using a Mac, started to charge my very-not-Mac hardware.
+
+My positive experience was probably related to some updates to USB-C, which received some needed attention in 2018 to compete with other OS experiences. As [Phoronix explained][3]:
+
+> "The USB Type-C interface offers an 'Alternate Mode' extension for non-USB signaling and the biggest user of this alternate mode in the specification is allowing DisplayPort support. Besides DP, another alternate mode is the Thunderbolt 3 support. The DisplayPort Alt Mode supports 4K and even 8Kx4K video output, including multi-channel audio.
+>
+> "While USB-C alternate modes and DisplayPort have been around for a while now and is common in the Windows space, the mainline Linux kernel hasn't supported this functionality. Fortunately, thanks to Intel, that is now changing."
+
+Thinking beyond ports, a quick scroll through the [Linux on Laptops][4] hardware options shows a much more complete set of choices than I experienced in the early 2000s.
+
+This has been a night-and-day difference from my first attempt at Linux adoption, and it's one I welcome with open arms.
+
+### Breaking out of Apple's walled garden
+
+Using Linux has added new friction to my daily workflow, and I love that it has.
+
+My Mac workflow was seamless: hop on an iPad in the morning, write down some thoughts on what my day will look like, and start to read some articles in Safari; slide over my iPhone to continue reading; then log into my MacBook where years of fine-tuning have worked out how all these pieces connect. Keyboard shortcuts are built into my brain; user experiences are as they've mostly always been. It's wildly comfortable.
+
+That comfort comes with a cost. I largely forgot how my environment functions, and I couldn't answer questions I wanted to answer. Did I customize some [PLIST files][5] to get that custom shortcut, or did I remember to check it into [my dotfiles][6]? How did I get so dependent on Safari and Chrome when Firefox has a much better mission? Or why, specifically, won't I use an Android-based phone instead of my i-things?
+
+On that note, I've often thought about shifting to an Android-based phone, but I would lose the connection I have across all these devices and the little conveniences designed into the ecosystem. For instance, I wouldn't be able to type in searches from my iPhone for the Apple TV or share a password with AirDrop with my other Apple-based friends. Those features are great benefits of homogeneous device environments, and it is remarkable engineering. That said, these conveniences come at a cost of feeling trapped by the ecosystem.
+
+I love being curious about how devices work. I want to be able to explain environmental configurations that make it fun or easy to use my systems, but I also want to see what adding some friction does for my perspective. To paraphrase [Marcel Proust][7], "The real voyage of discovery consists not in seeking new lands but seeing with new eyes." My use of technology has been so convenient that I stopped being curious about how it all works. Linux gives me an opportunity to see with new eyes again.
+
+### Inspired by you
+
+All of the above is reason enough to explore Linux, but I have also been inspired by you. While all operating systems are welcome in the open source community, Opensource.com writers' and readers' joy for Linux is infectious. It inspired me to dive back in, and I'm enjoying the journey.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/why-switch-mac-linux
+
+作者:[Matthew Broberg][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mbbroberg
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
+[2]: https://opensource.com/article/19/8/rules-remote-work-sanity
+[3]: https://www.phoronix.com/scan.php?page=news_item&px=Linux-USB-Type-C-Port-DP-Driver
+[4]: https://www.linux-laptop.net/
+[5]: https://fileinfo.com/extension/plist
+[6]: https://opensource.com/article/19/3/move-your-dotfiles-version-control
+[7]: https://www.age-of-the-sage.org/quotations/proust_having_seeing_with_new_eyes.html
diff --git a/sources/talk/20191028 6 signs you might be a Linux user.md b/sources/talk/20191028 6 signs you might be a Linux user.md
new file mode 100644
index 0000000000..d66d08cf35
--- /dev/null
+++ b/sources/talk/20191028 6 signs you might be a Linux user.md
@@ -0,0 +1,161 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (6 signs you might be a Linux user)
+[#]: via: (https://opensource.com/article/19/10/signs-linux-user)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+6 signs you might be a Linux user
+======
+If you're a heavy Linux user, you'll probably recognize these common
+tendencies.
+![Tux with binary code background][1]
+
+Linux users are a diverse bunch, but many of us share a few habits. You might not have any of the telltale signs listed in this article, and if you're a new Linux user, you may not recognize many of them... yet.
+
+Here are six signs you might be a Linux user.
+
+### 1\. As far as you know, the world began on January 1, 1970.
+
+There are many rumors about why a Unix computer clock always sets itself back to 1970-01-01 when it resets. But the mundane truth is that the Unix "epoch" serves as a common and simple reference point for synchronization. For example, Halloween is the 304th day of this year in the Julian calendar, but we commonly refer to the holiday as being "on the 31st". We know which 31st we mean because we have common reference points: We know that Halloween is celebrated in October and that October is the 10th month of the year, and we know how many days each preceding month contains. Without these values, we could use traditional methods of timekeeping, such as phases of the moon, to keep track of special seasonal events, but of course, a computer doesn't have that ability.
+
+A computer requires firm and clearly defined values, so the value 1970-01-01T00:00:00Z was chosen as the beginning of the Unix epoch. Any time a [POSIX][2] computer loses track of time, a service like the Network Time Protocol (NTP) can provide it the number of seconds since 1970-01-01T00:00:00Z, which the computer can convert to a human-friendly date.
+
+Date and time are a famously complex thing to track in computing, largely because there are exceptions to nearly standard. A month doesn't always have 30 days, a year doesn't always have 365 days, and even seconds tend to drift a little each year. If you're looking for a fun and frustrating programming exercise, try to program a reliable calendaring application!
+
+### 2\. You think it's a chore to type anything over two letters to get something done.
+
+The most common Unix commands are famously short. In addition to commands like **cd** and **ls** and **mv**, there's one command that literally can't get any shorter: **w** (which shows who is currently logged in according to the **/var/run/utmp** file).
+
+On the one hand, extremely short commands seem unintuitive. A new user probably isn't going to guess that typing **ls** would _list_ directories. Once you learn the commands, though, the shorter they are, the better. If you spend all day in a terminal, the fewer keystrokes you have to type means you can spend more time getting your work done.
+
+Luckily, single-letter commands are far and few between, which means you can use most letters for aliases. For example, I use Emacs often enough that I consider **emacs** too long to type, so I alias it to **e** by adding this line to my **.bashrc** file:
+
+
+```
+`alias e='emacs'`
+```
+
+You can also alias commands temporarily. For instance, if you find yourself running [firewall-cmd][3] repeatedly while you troubleshoot a network issue, then you can create an alias just for your current session:
+
+
+```
+$ alias f='firewall-cmd'
+$ f
+usage: see firewall-cmd man page
+No option specified.
+```
+
+As long as the terminal is open, your alias persists. Once the terminal is closed, it's forgotten.
+
+### 3\. You think it's a chore to click more than two times to get something done.
+
+Linux users are fond of efficiency. While not every Linux user is always in a hurry to get things done, there are conventions in Linux desktops that seek to reduce the number of actions required to accomplish any given task. Here are some examples.
+
+ * In the KDE file manager Dolphin, a single click opens a file or directory. It's assumed that if you want to select a file, you can either click and drag or else Ctrl+Click instead. This may confuse users who are used to double-clicking everything, but once you've tried single-click actions, you usually can't go back to laborious double-clicks.
+ * On most Linux desktops, a middle-click pastes the most recent contents of the clipboard.
+ * On many Linux desktops, drag actions can be modified by pressing the Alt, Ctrl, or Shift keys. For instance, Alt+Drag moves a window in KDE, and Ctrl+Drag in GNOME causes a file to be copied instead of moved.
+
+
+
+### 4\. You've never performed any action on a computer more than three times because you've already automated it by the third time.
+
+Pardon the hyperbole, but many Linux users expect their computer to work harder than they do. While it takes time to learn how to automate common tasks, it tends to be easier on Linux than on other platforms because the Linux terminal and the Linux operating system are so tightly integrated. The easy things to automate are the actions you already do in a terminal because commands are just strings that you type into an interpreter, and that interpreter (the terminal) doesn't care whether you typed the strings out manually or whether you're just pointing it to a script.
+
+For instance, if you find yourself frequently moving a set of files from one place to another, then you can probably use the same sequence of instructions as a script, which you can trigger with a single command. Imagine you are doing this manually each morning:
+
+
+```
+$ cd Documents
+$ trash reports-latest.txt
+$ wget myserver.local/reports/daily/report-latest.txt
+$ cp report-latest.txt reports_daily/2019-31-10.log
+```
+
+It's a simple sequence, but repeating it daily isn't the most efficient way of spending your time. With a little bit of abstraction, you could automate it with a simple script:
+
+
+```
+#!/bin/sh
+
+trash $HOME/Documents/reports-latest.txt
+
+wget myserver.local/reports/daily/report-latest.txt \
+-P $HOME/Documents/udpates_daily/`date --iso-8601`.log
+
+cp $HOME/Documents/udpates_daily/`date --iso-8601`.log \
+$HOME/Documents/reports-latest.txt
+```
+
+You could call your script **get-reports.sh** and launch it manually each morning, or you could even enter it into your crontab so that your computer performs the task without requiring any intervention from you.
+
+This can be confusing for a new user because it's not always obvious what's integrated with what. For instance, if you regularly find yourself opening images and scaling them down by 50%, then you're probably used to doing something like this:
+
+ 1. Opening up your photo viewer or editor
+ 2. Scaling the image
+ 3. Exporting the image as a modified file
+ 4. Closing the application
+
+
+
+If you did this several times a day, you would probably get tired of the repetition. However, because you perform those actions in the graphical user interface (GUI), you would need to know how to script the GUI to automate it. Some applications, like [GIMP][4], have a rich scripting interface, but the process is obviously different than just adapting a bunch of commands and dumping those into a file.
+
+Then again, sometimes there are command-line equivalents to things you do in a GUI. Converting documents from one text format to another can be done with [Pandoc][5], images can be manipulated with [Image Magick][6], music and video can be edited and converted, and so on. It's a matter of knowing what to look for, and usually learning a new (and sometimes complex) command. Scaling images down, however, is notably simpler in the terminal than in a GUI:
+
+
+```
+#!/bin/sh
+
+convert "${1}" -scale 50% `basename "${1}" .jpg`_50.jpg
+```
+
+It's worth investigating those bothersome, repetitious tasks. You never know how simple and fast your work is for a computer to do!
+
+### 5\. You distro hop
+
+I'm an ardent Slackware user at home and a RHEL user at work. Actually, that's not true; I'm a Fedora user at work now. Except when I use CentOS. And there was that time I ran [Mageia][7] for a while.
+
+![Debian on a PowerPC64 box, image CC BY SA Claudio Miranda][8]
+
+Debian on a PowerPC64 box
+
+It doesn't matter how great a distribution is; part of the guilty pleasure of being a Linux user is the freedom to be indecisive about which distro you run. At a glance, they're all basically the same, and that's refreshing. But depending on your mood, you might prefer the stability of CentOS to the constant updates of Fedora, or you might truly enjoy the centralized control center of Mageia one day and then frolic in the modularity of raw [Debian][9] configuration files another. And sometimes you turn to an alternate OS altogether.
+
+![OpenBSD, image CC BY SA Claudio Miranda][10]
+
+OpenBSD, not a Linux distro
+
+The point is, Linux distributions are passion projects, and it's fun to be a part of other people's open source passions.
+
+### 6\. You have a passion for open source.
+
+Regardless of your experience, if you're a Linux user, you undoubtedly have a passion for open source. Whether you express that on a daily basis through [Creative Commons artwork][11] or code or you sublimate it and just get your work done in a liberating (and liberated) environment, you're living in and building upon open source. It's because of you that there's an open source community, and the community is richer for having you as a member.
+
+There are lots of things I haven't mentioned. What else betrays you as a Linux user? Let us know in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/signs-linux-user
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tux_linux_penguin_code_binary.jpg?itok=TxGxW0KY (Tux with binary code background)
+[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
+[3]: https://opensource.com/article/19/7/make-linux-stronger-firewalls
+[4]: https://www.gimp.org/
+[5]: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
+[6]: https://opensource.com/article/17/8/imagemagick
+[7]: http://mageia.org
+[8]: https://opensource.com/sites/default/files/uploads/debian.png (Debian on a PowerPC64 box)
+[9]: http://debian.org
+[10]: https://opensource.com/sites/default/files/uploads/openbsd.jpg (OpenBSD)
+[11]: http://freesvg.org
diff --git a/sources/talk/20191028 Building trust in the Linux community.md b/sources/talk/20191028 Building trust in the Linux community.md
new file mode 100644
index 0000000000..d4f7e22114
--- /dev/null
+++ b/sources/talk/20191028 Building trust in the Linux community.md
@@ -0,0 +1,83 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building trust in the Linux community)
+[#]: via: (https://opensource.com/article/19/10/trust-linux-community)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+Building trust in the Linux community
+======
+Everyone should be empowered to use whatever software they wish,
+regardless of platform.
+![Tall building with windows][1]
+
+I recently listened to an interesting interview on [Linux for everyone][2]. Host [Jason Evangelho][3] interviewed [Christopher Scott][4], senior premier field engineer (open source) at Microsoft. Christopher is a Linux advocate who has a unique perspective as an avid Linux user who works for Microsoft. There was a time when there was little trust between Redmond and the Linux world. There are some who fear that Microsoft’s embrace of Linux is sinister. Christopher is trying to dispel that notion and build trust where mistrust has existed in the past. Listening to the interview invited my curiosity. Anxious to learn more, I contacted Christopher on [Twitter][5] and requested an interview (which has been lightly edited for length and clarity). He graciously agreed.
+
+**Don Watkins:** What is your background?
+
+**Christopher Scott:** In short, I’m a geek who loves technology, especially hardware. The first computer I got to spend any time with was our 486SX 20MHz 4MB RAM 171MB HDD IBM-compatible machine. My mom spent $2,500 on the setup at the time, which seemed outrageous. It wasn’t long after that I bought Comanche Maximum Overkill (PC Game) and realized I didn’t have a CD-ROM drive, nor a compatible sound card, so I bought those and installed them. That started it right there. I had to play games on our Windows 3.1 machine. That was really the focus of my interest in computers growing up: video games. I had the NES in 1984 and an SNES after, along with many other game systems since, but there was always something about PC gaming that caught my attention.
+
+My first love, however, was cars. My dad was into hot rods and such, so I read his magazines growing up. I had high aspirations of building my own first car. After finding college to not be for me and realizing that minimum wage jobs wouldn’t secure my future, I went back to school and learned a trade: automotive paint and body repair. I got a job thanks to my instructor and did this for several years, but I wasn’t satisfied that most of the jobs were insurance claim-based. I wanted to focus on the attention to detail aspects and make every job come out perfectly, but insurance companies don’t pay for that type of detail with a "just good enough" mentality.
+
+I wasn’t able to find work in a custom paint and body shop, so I looked to my second love, computers. I found a company that had training courses on Windows 2000 certification preparation. It was outrageously priced at something like $8,000, but I got a student loan (so I could carry that debt with me for many years after) and started class. I didn’t get a job immediately after, that took a number of months, but I worked my way into a temp job at Timex’s call center in the advanced products division.
+
+I had been at Timex for a year-and-a-half or so when I was able to get a job offer at a "real computer company." It wasn’t temp work and it had benefits, so it seemed perfect. This company provided managed IT services for their customers, so I started doing PC and network support over the phone and in person. I met my wife while working for this company, too. Since then, I’ve done help desk support, litigation support, SharePoint, Skype for Business, Microsoft Teams, and all of the Office 365 Suite. Today I’m a happily married father of three with two grandsons.
+
+**DW**: How did you get started with Linux and open source?
+
+**CS**: Roughly 20 years ago, while I was taking classes on Windows 2000 Server, I started acquiring parts of older machines that were slated for disposal and managed to piece together at least one fully working system with a monitor, keyboard, and mouse. The home computer at the time was running Windows 98 or ME, I can’t recall, but I didn’t have any OS to put on this older system. Somehow, I stumbled across Mandrake Linux and loaded it up. It all seemed to work okay from what I could tell, so I put an ad in the local newspaper classifieds to see if anyone needed a computer for free. I got exactly one response to that ad. I packed up the computer and took it to their house. I found out it was a family with a special needs son and they wanted to get him learning on the computer. I set it up on the little table they wanted to use as a desk, they thanked me, and I left. I sure hope it was helpful for them. At the time, all I really knew of Linux was that I could have a fully working system without having to go to a store to buy a disk.
+
+Since that point, I would consider myself a Linux hobbyist and enthusiast. I am a distro hopper, always trying out different distros and desktop environments, never making any one of them truly home. I’ve always had my heartstrings pulled between Ubuntu-based systems and Fedora. For some reason, I really like **`apt`** and **DEB**, but always loved getting faster updates from Fedora. I’ve always appreciated the way open source projects are open to the community for feedback and extra dev support, and how the code is freely available for anyone to use, reuse, and review.
+
+Until recently, I wasn’t able to make Linux my primary OS. I’ve tried over the years and often it came back to games. They would either not run at all, or ran poorly by comparison, so I ended up returning to Windows. With the improvements to Proton and tools like Lutris, that landscape has changed dramatically. I run Linux on my primary desktop and laptop now. Currently, Pop!_OS and Ubuntu 18.04 respectively, but I do have a soft spot for Manjaro (which is on a third machine).
+
+Admittedly, I do make concessions by having Linux as my primary OS for work. I mostly lean on web-based access to things I need, but I still have a VM for specific applications that won’t run outside of Windows and are required for my job. To be clear on this, I don’t hate Windows. I dislike some of the things it does and some of the things it doesn’t do. Linux, too, has things I like and dislike. My decision on what to run is based on what annoys me the least and what gives me the features and software I want or need. Some distros just don’t appeal to me or annoy me in a number of ways that I just cannot get over. Every OS has its pros and cons.
+
+**DW**: What invited you to work for Microsoft?
+
+**CS**: Short answer: A recruiter on LinkedIn. Long answer: Like many people who get into SharePoint, it fell into my lap a number of years ago. Okay, I volunteered, but no one else on the three-person IT team was going to learn it and our CEO wanted it. Fast forward about three years later, I got hired as a SharePoint admin for, what I thought, was a quite large company of 700 users. At that point, I considered Microsoft to be the top option to work for considering that’s who owns SharePoint, but I figured that I was five years or so away from being at the level I needed to be to even be considered. After working at this job for a year, I was contacted by a recruiter on LinkedIn. We chatted, I interviewed, and I got hired. Since then, I have jumped technologies to Skype/Teams and now open source software (OSS) and have gone from leading one team to over 20, all in sort of a non-traditional way.
+
+To be more to the point, I wanted to move into an OSS role to see more of what Microsoft is doing in this space, which was something I couldn’t see in other roles while supporting other technologies.
+
+**DW**: How are you building trust for the Linux community at Microsoft?
+
+**CS**: The first step is to listen. I can’t assume to know, even though I consider myself part of the Linux community, what it would take to build that trust. So, I reached out to get that feedback. My goal is to take action against that feedback as merely an employee looking to make the software landscape better for Linux users who would appreciate the option of running Microsoft software on their chosen platform (as one example).
+
+**DW**: What Microsoft products besides Visual Studio are wins for the Linux and open source community?
+
+**CS**: Honestly, it depends on which part of the community you refer to. For developers, there are other things that were released/open-sourced by Microsoft that carry great benefits, like .NET and C++ libraries. Even [Windows Subsystem for Linux][6] (WSL) and the [new Windows Terminal][7] can be seen as big wins. However, there is another component of the community that wants something that impacts their daily, personal lives (if I were to summarize). In a sense, each individual has taken the stance to decide for themselves what constitutes a win and what doesn’t. That issue makes it more difficult at times when they request that Windows or the whole software catalog be open-sourced completely before even considering that Microsoft is doing anything valid.
+
+Essentially, from how I view Microsoft’s standpoint, the company is focused on the cloud, namely Azure. Who in the Linux and open source community should be targeted that aligns with that? People who manage Linux servers, people who want to use open source software in Azure, and people who develop open source software that can run on Azure. To that market, there have been many wins. The catalog of OSS that runs in the context of Azure is huge.
+
+**DW**: Some tech writers see the Linux kernel replacing the NT kernel. Do you disagree?
+
+**CS**: I do disagree. There’s far too much incompatibility to just replace the underpinnings. It’s not realistic, in my opinion.
+
+**DW**: What is the future of Linux at Microsoft?
+
+**CS**: I’ll say what I expect and what I hope. I expect continued growth of Linux on Azure, and continued growth in open source used on Azure and written by Microsoft. I hope that this drives further investment into the Linux desktop, essentially, by bringing Windows software to run well on Linux. This topic is what the community wants to see, too, but it will take the customers, the individuals, within the enterprise speaking up to push this to reality.
+
+Would I like to see, as an example, one code base for Office that runs on all desktop platforms whether through Wine or some other compatibility layer? Yes, of course. I think this would be optimal, really. Office for Mac has never seen all the same features as the Windows versions. Everyone should be empowered to use whatever software they wish, regardless of platform. I believe that Microsoft can get there, I just don’t know if it will, so that’s where I step in to do what I can to try to make this happen. I hope that we can see Linux desktop users have the same options for software from Microsoft as Windows and macOS.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/trust-linux-community
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/windows_building_sky_scale.jpg?itok=mH6CAX29 (Tall building with windows)
+[2]: https://linuxforeveryone.fireside.fm/10-the-microsoft-linux-interview
+[3]: https://opensource.com/article/19/9/found-linux-video-gaming
+[4]: https://www.linkedin.com/in/christophersscott/
+[5]: https://twitter.com/chscott_msft
+[6]: https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux
+[7]: https://github.com/Microsoft/Terminal
diff --git a/sources/talk/20191029 5 reasons why I love Python.md b/sources/talk/20191029 5 reasons why I love Python.md
new file mode 100644
index 0000000000..5df5be960e
--- /dev/null
+++ b/sources/talk/20191029 5 reasons why I love Python.md
@@ -0,0 +1,168 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (5 reasons why I love Python)
+[#]: via: (https://opensource.com/article/19/10/why-love-python)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
+
+5 reasons why I love Python
+======
+These are a few of my favorite things about Python.
+![Snake charmer cartoon with a yellow snake and a blue snake][1]
+
+I have been using Python since it was a little-known language in 1998. It was a time when [Perl was quite popular][2] in the open source world, but I believed in Python from the moment I found it. My parents like to remind me that I used to say things like, "Python is going to be a big deal" and "I'll be able to find a job using it one day."** **It took a while, but my predictions came true.
+
+There is so much to love about the language. Here are my top 5 reasons why I continue to love Python so much (in reverse order, to build anticipation).
+
+### 5\. Python reads like executable pseudocode
+
+Pseudocode is the concept of writing out programming logic without it following the exact syntax and grammar of a specific language. I have stopped writing much pseudocode since becoming a Python programmer because its actual design meets my needs.
+
+Python can be easy to read even if you don't know the language well and that is very much by design. It is reasonably famous for whitespace requirements for code to be able to run. Whitespace is necessary for any language–it allows us to see each of the words in this sentence as distinct. Most languages have suggestions or "best practices" around whitespace usage, but Python takes a bold step by requiring standardization. For me, that makes it incredibly straightforward to read through code and see exactly what it's doing.
+
+For example, here is an implementation of the classic [bubble sort algorithm][3].
+
+
+```
+def bubble_sort(things):
+
+ needs_pass = True
+
+ while needs_pass:
+
+ needs_pass = False
+
+ for idx in range(1, len(things)):
+
+ if things[idx - 1] > things[idx]:
+
+ things[idx - 1], things[idx] = things[idx], things[idx - 1]
+
+ needs_pass = True
+```
+
+Now let's compare that with [this implementation][4] in Java.
+
+
+```
+public static int[] bubblesort(int[] numbers) {
+ boolean swapped = true;
+ for(int i = numbers.length - 1; i > 0 && swapped; i--) {
+ swapped = false;
+ for (int j = 0; j < i; j++) {
+ if (numbers[j] > numbers[j+1]) {
+ int temp = numbers[j];
+ numbers[j] = numbers[j+1];
+ numbers[j+1] = temp;
+ swapped = true;
+ }
+ }
+ }
+ return numbers;
+}
+```
+
+I appreciate that Python requires indentation to indicate nesting of blocks. While our Java example also uses indentation quite nicely, it is not required. The curly brackets are what determine the beginning and end of the block, not the spacing. Since Python uses whitespace as syntax, there is no need for beginning **{** and end **}** notation throughout the other code.
+
+Python also avoids the need for semicolons, which is a [syntactic sugar][5] needed to make other languages human-readable. Python is much easier to read on my eyes and it feels so close to pseudocode it sometimes surprises me what is runnable!
+
+### 4\. Python has powerful primitives
+
+In programming language design, a primitive is the simplest available element. The fact that Python is easy to read does _not_ mean it is not a powerful language, and that stems from its use of primitives. My favorite example of what makes Python both easy to use and advanced is its concept of **generators**.
+
+Imagine you have a simple binary tree structure with `value`, `left`, and `right`. You want to easily iterate over it in order. You usually are looking for "small" elements, in order to exit as soon as the right value is found. That sounds simple so far. However, there are many kinds of algorithms to make a decision on the element.
+
+Other languages would have you write a **visitor**, where you invert control by putting your "is this the right element?" in a function and call it via function pointers. You _can_ do this in Python. But you don't have to.
+
+
+```
+def in_order(tree):
+
+ if tree is None:
+
+ return
+
+ yield from in_order(tree.left)
+
+ yield tree.value
+
+ yield from in_order(tree.right)
+```
+
+This _generator function_ will return an iterator that, if used in a **for** loop, will only execute as much as needed but no more. That's powerful.
+
+### 3\. The Python standard library
+
+Python has a great standard library with many hidden gems I did not know about until I took the time to [walk through the list of all available][6] functions, constants, types, and much more. One of my personal favorites is the `itertools` module, which is listed under the functional programming modules (yes, [Python supports functional programming][7]!).
+
+It is great for playing jokes on your tech interviewer, for example with this nifty little solution to the classic [FizzBuzz interview question][8]:
+
+
+```
+fizz = itertools.cycle(itertools.chain(['Fizz'], itertools.repeat('', 2)))
+
+buzz = itertools.cycle(itertools.chain(['Buzz'], itertools.repeat('', 4)))
+
+fizz_buzz = map(operator.add, fizz, buzz)
+
+numbers = itertools.islice(itertools.count(), 100)
+
+combo = zip(fizz_buzz, numbers)
+
+for fzbz, n in combo:
+
+ print(fzbz or n)
+```
+
+A quick web search will show that this is not the most straight-forward way to solve for FizzBuzz, but it sure is fun!
+
+Beyond jokes, the `itertools` module, as well as the `heapq` and `functools` modules are a trove of treasures that come by default in your Python implementation.
+
+### 2\. The Python ecosystem is massive
+
+For everything that is not in the standard library, there is an enormous ecosystem to support the new Pythonista, from exciting packages to text editor plugins specifically for the language. With around 200,000 projects hosted on PyPi (at the time of writing) and growing, there is something for everyone: [data science][9], [async frameworks][10], [web frameworks][11], or just tools to make [remote automation][12] easier.
+
+### 1\. The Python community is special
+
+The Python community is amazing. It was one of the first to adopt a code of conduct, first for the [Python Software Foundation][13] and then for [PyCon][14]. There is a real commitment to diversity and inclusion: blog posts and conference talks on this theme are frequent, thoughtful, and well-read by Python community members.
+
+While the community is global, there is a lot of great activity in the local community as well. Local Python meet-ups are a great place to meet wonderful people who are smart, experienced, and eager to help. A lot of meet-ups will explicitly have time set aside for experienced people to help newcomers who want to learn a new concept or to get past an issue with their code. My local community took the time to support me as I began my Python journey, and I am privileged to continue to give back to new developers.
+
+Whether you can attend a local community meet-up or you spend time with the [online Python community][15] across IRC, Slack, and Twitter, I am sure you will meet lovely people who want to help you succeed as a developer.
+
+### Wrapping it up
+
+There is so much to love about Python, and now you know my favorite part is definitely the people.
+
+I have found kind, thoughtful Pythonistas in the community throughout the world, and the amount of community investment provide to those in need is incredibly encouraging. In addition to those I've met, the simple, clean, and powerful Python language gives any developer more than enough to master on their journey toward a career in software development or as a hobbyist enjoying playing around with a fun language. If you are interested in learning your first or a new language, consider Python and let me know how I can help.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/why-love-python
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshez
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/getting_started_with_python.png?itok=MFEKm3gl (Snake charmer cartoon with a yellow snake and a blue snake)
+[2]: https://opensource.com/article/19/8/command-line-heroes-perl
+[3]: https://en.wikipedia.org/wiki/Bubble_sort
+[4]: https://en.wikibooks.org/wiki/Algorithm_Implementation/Sorting/Bubble_sort#Java
+[5]: https://en.wikipedia.org/wiki/Syntactic_sugar
+[6]: https://docs.python.org/3/library/
+[7]: https://opensource.com/article/19/10/python-programming-paradigms
+[8]: https://en.wikipedia.org/wiki/Fizz_buzz
+[9]: https://pypi.org/project/pandas/
+[10]: https://pypi.org/project/Twisted/
+[11]: https://pypi.org/project/Django/
+[12]: https://pypi.org/project/paramiko/
+[13]: https://www.python.org/psf/conduct/
+[14]: https://us.pycon.org/2019/about/code-of-conduct/
+[15]: https://www.python.org/community/
diff --git a/sources/talk/20191029 How SD-WAN is evolving into Secure Access Service Edge.md b/sources/talk/20191029 How SD-WAN is evolving into Secure Access Service Edge.md
new file mode 100644
index 0000000000..bc841758be
--- /dev/null
+++ b/sources/talk/20191029 How SD-WAN is evolving into Secure Access Service Edge.md
@@ -0,0 +1,93 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How SD-WAN is evolving into Secure Access Service Edge)
+[#]: via: (https://www.networkworld.com/article/3449136/how-sd-wan-is-evolving-into-secure-access-service-edge.html)
+[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
+
+How SD-WAN is evolving into Secure Access Service Edge
+======
+SASE, pronounced 'sassy,' combines elements of SD-WAN and network security into a single cloud-based service.
+Anya Berkut / Getty Images
+
+SASE, pronounced "sassy," stands for secure access service edge, and it's being positioned by Gartner as the next big thing in enterprise networking. The technology category, which Gartner and other network experts first introduced earlier this year, converges the WAN edge and network security into a cloud-based, as-a-service delivery model. [According to Gartner][1], the convergence is driven by customer demands for simplicity, scalability, flexibility, low latency, and pervasive security.
+
+### SASE brings together security and networking
+
+A SASE implementation requires a comprehensive technology portfolio that only a few vendors can currently deliver. The technology is still in its infancy, with less than 1% adoption. There are a handful of existing [SD-WAN][2] providers, including Cato Networks, Juniper, Fortinet and Versa, that are expected to compete in the emerging SASE market. There will be other SD-WAN vendors jumping on this wagon, and the industry is likely to see another wave of startups.
+
+**READ MORE:** [Gartner's top 10 strategic technology trends for 2020][3]
+
+When networking and security devices are procured from different vendors, as is typical, the result is a complex network architecture that relies on the data center as the hub for enterprise applications. But with growing digital business and edge computing requirements, organizations are no longer primarily accessing their apps and services from within the data center. This approach is ineffective for organizations that are shifting to cloud services.
+
+[][4]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][4]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+### Existing network and security models to become obsolete? Not so fast
+
+An architectural transformation of the traditional data center-centric networking and security is underway to better meet the needs of today’s mobile workforces. Gartner predicts that the adoption of SASE will take place over the next five to 10 years, rendering existing network and security models obsolete.
+
+In my opinion, the term "obsolete" is a bit aggressive, but I do agree there is a need to bring networking and security together. Having them be procured and managed by separate teams is inefficient and leads to inconsistencies and blind spots. SD-WANs enable a number of new design principals, such as direct to cloud or user access, and necessitate the need for a new architecture – enter SASE.
+
+SASE combines elements of SD-WAN and network security into a single cloud-based service. It supports all types of edges, including WAN, mobile, cloud, and edge computing. So, instead of connecting a branch to the central office, it connects individual users and devices to a centralized cloud-based service. With this model, the endpoint is the individual user, device, or application, not the data center.
+
+### Cloud delivery benefits
+
+The cloud delivery-based approach benefits providers with many points of presence. Gartner highlighted a number of advantages of this approach, such as:
+
+ * There are limited endpoint functions like routing and path selection, with the rest delivered as a service from the cloud.
+ * Due to the thinner stack, functions can be provided via software without requiring dedicated hardware.
+ * New endpoints such as pop-up stores can be added quickly.
+ * Since SASE favors cloud-based delivery, vendors can add new services to the stack faster.
+ * Common policies are shared by branch offices and individual devices. The policies are also more consistent and can be managed through a cloud-based console from one vendor.
+ * The overall infrastructure is simpler and less expensive for an organization to manage.
+ * Emerging latency-sensitive apps, such as the IoT edge to edge, can be supported even if the endpoints have minimal local resources.
+ * Malware, decryption, and management is performed within SASE, and organizations can scale up or down based on their needs.
+
+
+
+### Agility is the biggest benefit SASE brings
+
+These advantages are all true, but Gartner missed the biggest advantage, and that’s increased agility to accelerate business velocity. SASE makes security intrinsic in the network and, if architected correctly, organizations should not have to hold up the rollout of new apps and services while the security implications are being figured out. Instead, with security being "baked in," companies can be as aggressive as they want and know the environment is secure. Speed is the new currency of business, and SASE lets companies move faster.
+
+### SASE is identify driven instead of location driven
+
+In addition to being cloud native, SASE is identity driven instead of location driven. An identity is attached to every person, application, service, or device within an organization. The convergence of networking and security allows an identity to follow a person or device wherever they need access and makes the experience seamless for the user.
+
+Think of this scenario: An employee working remotely on an unmanaged laptop needs to connect to Salesforce, which is hosted on its own cloud. Traditionally, an administrator would go through many steps to authenticate a user and connect them to a virtual private network (VPN). But with a single identity, a remote employee could access Salesforce or any other app seamlessly, regardless of their device, location, or network.
+
+SASE addresses new security demands networks face from a variety of sources. The core capabilities of SASE include multifactor authentication and access to applications and services controlled by firewall policies. Therefore, users can only access authorized applications without entering the general network. SASE can also detect sensitive data and stop it from leaving the network by applying specific data loss prevention rules.
+
+In the [report][1], Gartner does caution that some vendors will attempt to satisfy customers by combining separate products together or by acquiring appliance-based point products that are then hosted in the cloud, which is likely to result in higher latency and poor performance. This shouldn’t be a surprise as this is how legacy vendors have attacked new markets in the past. Industry people often refer to this as “sheet metal” integration, where a vendor essentially tosses a number of capabilities into a single appliance and makes it looks integrated – but it’s not. Buyers need to ensure the vendor is delivering an integrated, cloud-native set of services to be delivered on demand. Organizations can begin transitioning to SASE with a WAN makeover and by gradually retiring their legacy network security appliance.
+
+(Gartner defines and discusses demand for SASE in its 2019 [Hype Cycle for Enterprise Networking][1]; this post by [Cato][5] effectively summarizes SASE without having to read the entire Gartner report.)
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3449136/how-sd-wan-is-evolving-into-secure-access-service-edge.html
+
+作者:[Zeus Kerravala][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Zeus-Kerravala/
+[b]: https://github.com/lujun9972
+[1]: https://www.gartner.com/doc/3947237
+[2]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
+[3]: https://www.networkworld.com/article/3447401/gartner-top-10-strategic-technology-trends-for-2020.html
+[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[5]: https://www.catonetworks.com/blog/the-secure-access-service-edge-sase-as-described-in-gartners-hype-cycle-for-enterprise-networking-2019/
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191029 The best (and worst) ways to influence your open community.md b/sources/talk/20191029 The best (and worst) ways to influence your open community.md
new file mode 100644
index 0000000000..51cb63286c
--- /dev/null
+++ b/sources/talk/20191029 The best (and worst) ways to influence your open community.md
@@ -0,0 +1,91 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The best (and worst) ways to influence your open community)
+[#]: via: (https://opensource.com/open-organization/19/10/how-to-influence-open-community)
+[#]: author: (ldimaggi https://opensource.com/users/ldimaggi)
+
+The best (and worst) ways to influence your open community
+======
+The trick to effectively influencing your community's decisions?
+Empathy, confidence, and patience.
+![Media ladder][1]
+
+After you've established a positive reputation in an open community—hopefully, as [we discussed in our previous article][2], by being an active member in and contributing productively to that community—you'll have built up a healthy "bank balance" of credibility you can use to influence the _direction_ of that community.
+
+What does this mean in concrete terms? It means you can contribute to the decisions the community makes.
+
+In this article, we'll explain how best to do this—and how best _not_ to do it.
+
+### Understanding influence
+
+To some, the term "influence" denotes a heavy-handed approach to imposing your will over others. That _is_ one way to exercise influence. But "influencing" others over whom you have clear political or economic power and seeing them obey your commands isn't too difficult.
+
+In an organization structured such that a single leader makes decisions and simply "passes down" those decisions to followers, influence isn't _earned_; it's simply _enforced_. Decisions in this sense are mandates. Those decisions don't encourage differing views. If someone questions a decision (or raises a contrarian view) he or she will have a difficult time promoting that view, because people's employment or membership in the organization depends on following the will of the leader. Unfortunately, many hierarchical organizations around the world run this way.
+
+When it comes to influencing people who can actually exercise free will (and most people in an open organization can, to some degree), patience is both necessary and useful. Sometimes the only way to make quick progress is to go slowly and persistently.
+
+### Balancing empathy and confidence
+
+In an organization structured such that a single leader makes decisions and simply "passes down" those decisions to followers, influence isn't earned; it's simply enforced.
+
+Apart from patience and persistence, what else will you need to display in order to influence others in an open organization? We think these factors are important:
+
+#### Expressing empathy
+
+It's easy to become frustrated when you encounter a situation where you simply cannot get people to change their minds and see things your way. As human beings, we all have beliefs and opinions. And all too frequently, we base these on incorrect information or biases. A key element to success at influencing others in an open organization is understanding not only others' opinions but also the causes behind them.
+
+In this context, empathy and listening skills are more important than your ability to command (and more effective, too). For example, if you propose a change in direction for a project, and other people object, think: Are they objecting because they are carrying emotional "baggage" from a previous project that encountered problems in a similar situation? They may not be able to see your point of view unless they can be freed from carrying around that baggage.
+
+#### Having confidence (in yourself and others)
+
+In this context, to be successful in influencing others, you must have reached your own conclusions through a rigorous vetting process. In other words, must have gotten past the point of conducting internal debates with yourself. You won't influence others to think or do something you yourself don't believe in.
+
+Don't misunderstand us: This is not a matter of having blind faith in yourself. Indeed, some of the most dangerous people around do not know their own limits. For example, we all have a general understanding of dentistry, but we're not going to work on our own teeth (or anyone else's, for that matter)! The confidence you have in your opinion must be based on your ability to defend that position to both others and yourself, based on facts and evidence. You also have to have confidence in your audience. You have to have faith that when presented with facts and evidence, they have the ability to internalize that argument, understand, and eventually accept that information.
+
+### Moving forward
+
+So far we've focused almost exclusively on the _positive_ situations in which you'd want to apply your influence (i.e., to "bring people around" to your side of an issue). Unfortunately, you'll also encounter _negative_ situations where team members are in disagreement, or one or more team members are simply saying "no" to all your attempts to find common ground.
+
+Remember, in an open organization, great ideas can come from anyone, not just someone in a leadership position, and those ideas must always be reviewed to ensure they provide value.
+
+What can you do if you hit this type of brick wall? How can you move forward?
+
+The answer might be by applying patient, persistent, and empathetic escalation, along with some flexibility. For example:
+
+ * **Search for the root causes of disagreement:** Are the problems that you face technical in nature, or are they interpersonal? Technical issues can be difficult to resolve, but interpersonal problems can be much _more_ difficult, as they involve human needs and emotions (we humans love to hold grudges). Does the person with whom you're dealing feel a loss of control over the project, or are they feeling marginalized? With distributed teams (which often require us to communicate through online tools), hard feelings can grow undetected until they explode into the open. How will you spot and resolve these? You may need to invest time and effort reaching out to team members privately, on a one-to-one basis. Based on time zones, this may require some late nights or early mornings. But it can be very effective, as some people will be reluctant to discuss disagreements in group meetings or online chats.
+ * **Seek common ground:** A blanket refusal to compromise on a topic can sometimes mask areas of potential agreement. Can you sub-divide the topic you're discussing into smaller pieces, then look for areas of possible agreement or common ground? Building upon smaller agreements can have a multiplier effect, which can lead to better cooperation and ultimately agreement on larger topics. Think of this approach as emulating a sailboat facing a headwind. The only way to make forward progress is to "tack"—that is, to move forward at an angle when a straight ahead path is not possible.
+ * **Enlist allies:** Open teams and communities can feel like families. At some point in everyone's family, feuds break out, and you can only resolve them through a third party. On your team or in your community, if you're locked in a polarizing disagreement with a team member, reach out to other members of the team to provide support for your conclusions.
+
+
+
+And if all that fails, then try turning to these "last resorts":
+
+ * **Last Resort #1:** If empathetic approaches fail, then it's time to escalate. Start by staging an intervention, where the full team meets to convince a team member to adopt a team decision. It's not "do what I'm tellin' ya"; it's "do what we all are asking you to do and here's why."
+ * **Last Resort #2:** If all else fails—if you've tried _everything else_ on this list and the team is mostly in agreement, yet you cannot get the last few holdouts to agree—then it's time to move on without them. Hopefully, this will be a rare occurrence.
+
+
+
+### Conclusions
+
+In a traditional, top-down organization, a person's degree of influence springs from that person's position, title, and the economic power the position commands. In sharp contrast, many open organizations are meritocracies in which the amount of influence a person possesses is directly related to the value of the contributions that one makes to the community. In open source communities, for example, influence is _earned_ over time through contributions—and through patience and persistence—much like a virtual currency. Making slow, patient, and persistent progress can sometimes be more effective than trying to make _quick_ progress.
+
+Remember, in an open organization, great ideas can come from anyone, not just someone in a leadership position, and those ideas must always be reviewed to ensure they provide value. Influence in an open community—like happiness in life—must always be earned. And, once earned, it must be applied with patience and sensitivity to other people's views (and the reasons behind them), and with confidence in both your own judgement and others' abilities to accept occasionally unpleasant, but still critical, facts.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/19/10/how-to-influence-open-community
+
+作者:[ldimaggi][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ldimaggi
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_meritladder.png?itok=eWIDxnh2 (Media ladder)
+[2]: https://opensource.com/open-organization/19/10/gaining-influence-open-community
diff --git a/sources/talk/20191030 Watson IoT chief- AI can broaden IoT services.md b/sources/talk/20191030 Watson IoT chief- AI can broaden IoT services.md
new file mode 100644
index 0000000000..eaab58b886
--- /dev/null
+++ b/sources/talk/20191030 Watson IoT chief- AI can broaden IoT services.md
@@ -0,0 +1,64 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Watson IoT chief: AI can broaden IoT services)
+[#]: via: (https://www.networkworld.com/article/3449243/watson-iot-chief-ai-can-broaden-iot-services.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+Watson IoT chief: AI can broaden IoT services
+======
+IBM’s Kareem Yusuf talks smart maintenance systems, workforce expertise and some IoT use cases you might not have thought of.
+IBM
+
+IBM thrives on the complicated, asset-intensive part of the enterprise [IoT][1] market, according to Kareem Yusuf, GM of the company’s Watson IoT business unit. From helping seaports manage shipping traffic to keeping technical knowledge flowing within an organization, Yusuf said that the idea is to teach [artificial intelligence][2] to provide insights from the reams of data generated by such complex systems.
+
+[Predictive maintenance][3] is probably the headliner in terms of use cases around asset-intensive IoT, and Yusuf said that it’s a much more complicated task than many people might think. It isn’t simply a matter of monitoring, say, pressure levels in a pipe somewhere and throwing an alert when they move outside of norms. It’s about aggregate information on failure rates and asset planning, that a company can have replacements and contingency plans ready for potential failures.
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][4]
+
+“It’s less to do with ‘Is that thing going to fail on that day?’ more to do with, because I'm now leveraging all these technologies, I have more insights to make the decision to say, ‘this is my more optimal work-management route,’” he said. “And that’s how I save money.”
+
+For that to work, of course, AI has to be trained. Yusuf uses the example of a drone-based system to detect worrisome cracks in bridges, a process that usually involves sending technicians out to look at the bridge in person. Allowing AI to differentiate between serious and trivial damage means showing it reams of images of both types, and sourcing that kind of information isn’t always straightforward.
+
+“So when a client says they want that [service], often clients themselves will say, ‘Here's some training data sets we’d like you to start with,’” he said, noting that there are also open-source and government data sets available for some applications.
+
+IBM itself collects a huge amount of data from its various AI implementations, and, with the explicit permission of its existing clients, uses some of that information to train new systems that do similar things.
+
+“You get this kind of collaborative cohesion going on,” said Yusuf. “So when you think about, say[, machine-learning][5] models to help predict foot traffic for space planning and building usage … we can build that against data we have, because we already drive a lot of that kind of test data through our systems.”
+
+Another non-traditional use case is for the design of something fantastically complicated, like an autonomous car. There are vast amounts of engineering requirements involved in such a process, governing the software, orchestration, hardware specs, regulatory compliance and more. A system with a particular strength in natural-language processing (NLP) could automatically understand what the various requirements actually mean and relate them to one another, detecting conflicts and impossibilities, said Yusuf.
+
+“We’ve trained up Watson using discovery services and NLP to be able to tell you whether your requirements are clear,” he said. “It will find duplicates or conflicting requirements.”
+
+Nor is it simply a matter of enabling AI-based IoT systems on the back end. Helping technicians do work is a critical part of IBM’s strategy in the IoT sector, and the company has taken aim at the problem of knowledge transfer via mobility solutions.
+
+Take, for example, a newer technician dispatched to repair an elevator or other complex piece of machinery. With a mobile assistant app on his or her smartphone, the tech can do more than simply referencing error codes – an AI-driven system can cross reference an error code against the history of a specific elevator, noting what, in the past, has tended to be the root of a given problem, and what needs to be done to fix it.
+
+The key, said Yusuf, is to enable that kind of functionality without disrupting the standard workflow that’s already in place.
+
+“When we think about leveraging AI, it has to like seamlessly integrate into the [existing] way of working,” he said.
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3449243/watson-iot-chief-ai-can-broaden-iot-services.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
+[2]: https://www.networkworld.com/article/3243925/artificial-intelligence-may-not-need-networks-at-all.html
+[3]: https://www.networkworld.com/article/3340132/why-predictive-maintenance-hasn-t-taken-off-as-expected.html
+[4]: https://www.networkworld.com/newsletters/signup.html
+[5]: https://www.networkworld.com/article/3202701/the-inextricable-link-between-iot-and-machine-learning.html
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191031 A Bird-s Eye View of Big Data for Enterprises.md b/sources/talk/20191031 A Bird-s Eye View of Big Data for Enterprises.md
new file mode 100644
index 0000000000..c62169b830
--- /dev/null
+++ b/sources/talk/20191031 A Bird-s Eye View of Big Data for Enterprises.md
@@ -0,0 +1,62 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (A Bird’s Eye View of Big Data for Enterprises)
+[#]: via: (https://opensourceforu.com/2019/10/a-birds-eye-view-of-big-data-for-enterprises/)
+[#]: author: (Swapneel Mehta https://opensourceforu.com/author/swapneel-mehta/)
+
+A Bird’s Eye View of Big Data for Enterprises
+======
+
+[![][1]][2]
+
+_Entrepreneurial decisions are made using data and business acumen. Big Data is today a tool that helps to maximise revenue and customer engagement. Open source tools like Hadoop, Apache Spark and Apache Storm are the popular choices when it comes to analysing Big Data. As the volume and variety of data in the world grows by the day, there is great scope for the discovery of trends as well as for innovation in data analysis and storage._
+
+In the past five years, the spate of research focused on machine learning has resulted in a boom in the nature and quality of heterogeneous data sources that are being tapped by providers for their customers. Cheaper compute and widespread storage makes it so much easier to apply bulk data processing techniques, and derive insights from existing and unexplored sources of rich user data including logs and traces of activity whilst using software products. Business decision making and strategy has been primarily dictated by data and is usually supported by business acumen. But in recent times it has not been uncommon to see data providing conclusions seemingly in contrast with conventional business logic.
+
+One could take the simple example of the baseball movie ‘Moneyball’, in which the protagonist defies all notions of popular wisdom in looking solely at performance statistics to evaluate player viability, eventually building a winning team of players – a team that would otherwise never have come together. The advantage of Big Data for enterprises, then, becomes a no brainer for most corporate entities looking to maximise revenue and engagement. At the back-end, this is accomplished by popular combinations of existing tools specially designed for large scale, multi-purpose data analysis. Apache, Hadoop and Spark are some of the most widespread open source tools used in this space in the industry. Concomitantly, it is easy to imagine that there are a number of software providers offering B2B services to corporate clients looking to outsource specific portions of their analytics. Therefore, there is a bustling market with customisable, proprietary technological solutions in this space as well.
+
+Traditionally, Big Data refers to the large volumes of unstructured and heterogeneous data that is often subject to processing in order to provide insights and improve decision-making regarding critical business processes. The McKinsey Global institute estimates that data volumes have been growing at 40 per cent per year and will grow 44x between the years 2009 and 2020. But there is more to Big Data than just its immense volume. The rate of data production is an important factor given that smaller data streams generated at faster rates produce larger pools than their counterparts. Social media is a great example of how small networks can expand rapidly to become rich sources of information — up to massive, billion-node scales.
+
+Structure in data is a highly variable attribute given that data is now extracted from across the entire spectrum of user activity. Conventional formats of storage, including relational databases, have been virtually replaced by massively unstructured data pools designed to be leveraged in manners unique to their respective use cases. In fact, there has been a huge body of work on data storage in order to leverage various write formats, compression algorithms, access methods and data structures to arrive at the best combination for improving productivity of the workflow reliant on that data. A variety of these combinations has emerged to set the industry standards in their respective verticals, with the benefits ranging from efficient storage to faster access.
+
+Finally, we have the latent value in these data pools that remains to be exploited by the use of emerging trends in artificial intelligence and machine learning. Personalised advertising recommendations are a huge factor driving revenue for social media giants like Facebook and companies like Google that offer a suite of products and an ecosystem to use them. The well-known Silicon Valley giant started out as a search provider, but now controls a host of apps and most of the entry points for the data generated in the course of people using a variety of electronic devices across the world. Established financial institutions are now exploring the possibility of a portion of user data being put on an immutable public ledger to introduce a blockchain-like structure that can open the doors to innovation. The pace is picking up as product offerings improve in quality and expand in variety. Let’s get a bird’s eye view of this subject to understand where the market stands.
+
+The idea behind building better frameworks is increasingly turning into a race to provide more add-on features and simplify workflows for the end user to engage with. This means the categories have many blurred lines because most products and tools present themselves as end-to-end platforms to manage Big Data analytics. However, we’ll attempt to divide this broadly into a few categories and examine some providers in each of these.
+
+**Big Data storage and processing**
+Infrastructure is the key to building a reliable workflow when it comes to enterprise use cases. Earlier, relational databases were worthwhile to invest in for small and mid-sized firms. However, when the data starts pouring in, it is usually the scalability that is put to the test first. Building a flexible infrastructure comes at the cost of complexity. It is likely to have more moving parts that can cause failure in the short-term. However, if done right – something that will not be easy because it has to be tailored exactly to your company – it can result in life-changing improvements for both users and the engineers working with the said infrastructure to build and deliver state-of-the-art products.
+
+There are many alternatives to SQL, with the NoSQL paradigm being adopted and modified for building different types of systems. Cassandra, MongoDB and CouchDB are some well-known alternatives. Most emerging options can be distinguished based on their disruption, which is aimed at the fundamental ACID properties of databases. To recall, a transaction in a database system must maintain atomicity, consistency, isolation, and durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity (from Tutorialspoint). For instance, CockroachDB, an open source offshoot of Google’s Spanner database system, has gained traction due to its support for being distributed. Redis and HBase offer a sort of hybrid storage solution while Neo4j remains a flag bearer for graph structured databases. However, traditional areas aside, there are always new challenges on the horizon for building enterprise software.
+
+![Figure 1: A crowded landscape to follow \(Source: Forbes\)][3]
+
+Backups are one such area where startups have found viable disruption points to enter the market. Cloud backups for enterprise software are expensive, non-trivial procedures and offloading this work to proprietary software offers a lucrative business opportunity. Rubrik and Cohesity are two companies that originally started out in this space and evolved to offer added services atop their primary offerings. Clumio is a recent entrant, purportedly creating a data fabric that the promoters expect will serve as a foundational layer to run analytics on top of. It is interesting to follow recent developments in this burgeoning space as we see competitors enter the market and attempt to carve a niche for themselves with their product offerings.
+
+**Big Data analytics in the cloud**
+Apache Hadoop remains the popular choice for many organisations. However, many successors have emerged to offer a set of additional analytical capabilities: Apache Spark, commonly hailed as an improvement to the Hadoop ecosystem; Apache Storm that offers real-time data processing capabilities; and Google’s BigQuery, which is supposedly a full-fledged platform for Big Data analytics.
+
+Typically, cloud providers such as Amazon Web Services and Google Cloud Platform tend to build in-house products leveraging these capabilities, or replicate them entirely and offer them as hosted services to businesses. This helps them provide enterprise offerings that are closely integrated within their respective cloud computing ecosystem. There has been some discussion about the moral consequences of replicating open source products to profit off closed source versions of the same, but there has been no consensus on the topic, nor any severe consequences suffered on account of this questionable approach to boost revenue.
+
+Another hosted service offering a plethora of Big Data analytics tools is Cloudera which has an established track record in the market. It has been making waves since its merger with Hortonworks earlier this year, giving it added fuel to compete with the giants in its bid to become the leading enterprise cloud provider in the market.
+
+Overall, we’ve seen interesting developments in the Big Data storage and analysis domain and as the volume and variety of data grows, so do the opportunities to innovate in the field.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/a-birds-eye-view-of-big-data-for-enterprises/
+
+作者:[Swapneel Mehta][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/swapneel-mehta/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-1-Big-Data-analytics-and-processing-for-the-enterprise.jpg?resize=696%2C449&ssl=1 (Figure 1 Big Data analytics and processing for the enterprise)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-1-Big-Data-analytics-and-processing-for-the-enterprise.jpg?fit=900%2C580&ssl=1
+[3]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-2-A-crowded-landscape-to-follow.jpg?resize=350%2C254&ssl=1
diff --git a/sources/talk/20191031 The Best Reasons To Use Enterprise Network Management Software.md b/sources/talk/20191031 The Best Reasons To Use Enterprise Network Management Software.md
new file mode 100644
index 0000000000..654078f72a
--- /dev/null
+++ b/sources/talk/20191031 The Best Reasons To Use Enterprise Network Management Software.md
@@ -0,0 +1,67 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Best Reasons To Use Enterprise Network Management Software)
+[#]: via: (https://opensourceforu.com/2019/10/the-best-reasons-to-use-enterprise-network-management-software/)
+[#]: author: (Ruby Hamilton https://opensourceforu.com/author/ruby-hamilton/)
+
+The Best Reasons To Use Enterprise Network Management Software
+======
+
+[![][1]][2]
+
+_Your company has workers in the field all day every day. You have sent them out with tablets, phones, and minicomputers, but you need to connect these devices back to the home network. When you begin shopping for enterprise software, you will find that it should provide you with all five benefits listed below. You can reorganize your business, streamline all the things that you do, and reduce the headaches that come along with mobile device management._
+
+**1\. Increased Security**
+
+When you begin shopping for [_Micro Focus enterprise network management software_][3], you will improve security instantly. Devices that are not managed are inherently unsafe. The device becomes a security risk every time it logs on to a new WiFi network or it uses Bluetooth in a new place.
+
+If a hacker wanted access to your network, they could hack a mobile device for each access. You may have staff members who use Bluetooth, and Bluetooth could cause security concerns for you. This is especially important if your company has a lot of sensitive information on each device.
+
+**2\. Easier Workflow**
+
+Workflow improves instantly when all your mobile devices are connected. Your staff can access all their assignments, appointments, and numbers for the day. You can send messages to your staff, and you can check on their progress using the enterprise software. Your staff members can ask you questions through the system instead of sending emails that are too difficult to check. Plus, you can hand out only mobile devices so that your staff members are not carrying too many devices.
+
+If your staff members need to communicate with each other to complete a project, they can share information with ease. You can load all your manuals and pricing charts so that your staff can access this information, and you can offer fast service to each customer. Your company can use its quick service and abundance of information as selling points for customers.
+
+**3\. Your Staff Can Go Anywhere**
+
+Your staff can go anywhere while still working diligently. The phone, tablet, or computer that they are using will still receive all the information that you would get if you were in the office. You can send your staff on trips to work on behalf of the company, and they will have all the information that is required to handle big projects.
+
+When your staff members need to present information to clients, they can pull that information from the cloud on their devices. This is a much easier way for you to store information, and you do not need to carry a massive laptop around. Plus, you can give everyone on your staff a mobile device instead of filling your office with clunky computers.
+
+**4\. Lower Costs**
+
+The [_enterprise software_][4] that you use will instantly lower your costs. You save time when managing these devices because the software does so much of it for you. You do not lose money due to hacking, and you can create reports from the information on each device.
+
+Your company will spend less time selling new services or products to customers, and you will find that the devices last longer because they are consistently updated. The software is updated online when the developer builds a new version, and you can hand out just one device to everyone on your staff. There is no need for you to spend extra money on new devices, extra security software, or more man-hours.
+
+**5\. Lower IT Demands**
+
+Your IT team is not swamped by the amount of activity on your network. When your IT demands are lower, your carbon footprint drops. The servers in your office will not work as hard as they once did, and you can easily upgrade your servers without bogging them down with information.
+
+The enterprise system can clean up junk files on every device, and you will not need to hire extra people in the IT department just to manage these devices. It is very easy for you to maintain the IT network, and you will save money on hardware. If your company has a small budget, you need to use the enterprise system to cut back on costs.
+
+**Conclusion**
+
+It is very easy for you to install enterprise software when your company is using mobile devices every day. The best part of using enterprise software is that you can streamline what you do, only use mobile devices, and reduce your costs over time. You can send your staff into the field with mobile devices, and you also have the capacity to send information to your staff instead of forcing them to use papers all day every day. You can save money on devices, and you can maintain your system using the software instead of forcing your IT team to do all the work for you.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/the-best-reasons-to-use-enterprise-network-management-software/
+
+作者:[Ruby Hamilton][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/ruby-hamilton/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2016/08/Computer-network-connectivity.jpg?resize=696%2C391&ssl=1 (Computer network connectivity)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2016/08/Computer-network-connectivity.jpg?fit=800%2C449&ssl=1
+[3]: https://www.microfocus.com/en-us/products/network-operations-management-suite/overview
+[4]: https://en.wikipedia.org/wiki/Enterprise_software
diff --git a/sources/talk/20191031 Wireless noise protocol can extend IoT range.md b/sources/talk/20191031 Wireless noise protocol can extend IoT range.md
new file mode 100644
index 0000000000..bafa9c53e1
--- /dev/null
+++ b/sources/talk/20191031 Wireless noise protocol can extend IoT range.md
@@ -0,0 +1,73 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Wireless noise protocol can extend IoT range)
+[#]: via: (https://www.networkworld.com/article/3449819/wireless-noise-protocol-can-extend-iot-range.html)
+[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
+
+Wireless noise protocol can extend IoT range
+======
+On-off noise power communication (ONPC) protocol creates a long-distance carrier of noise energy in Wi-Fi to ping IoT devices.
+Thinkstock
+
+The effective range of [Wi-Fi][1], and other wireless communications used in [Internet of Things][2] networks could be increased significantly by adding wireless noise, say scientists.
+
+This counter-intuitive solution could extend the range of an off-the-shelf Wi-Fi radio by 73 yards, a group led by Brigham Young University says. Wireless noise, a disturbance in the signal, is usually unwanted.
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
+
+The remarkably simple concept sends wireless noise-energy over-the-top of Wi-Fi data traffic in an additional, unrelated channel. That second channel, or carrier, which is albeit at a much lower data rate than the native Wi-Fi, travels further, and when encoded can be used to ping a sensor, say, to find out if the device is alive when the Wi-Fi link itself may have lost association through distance-caused, poor handshaking.
+
+[][4]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][4]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+The independent, additional noise channel travels further than the native Wi-Fi. “It works beyond the range of Wi-Fi,” [the scientists say in their paper][5].
+
+Applications could be found in hard-to-reach sensor locations where the sensor might still be usefully collecting data, just be offline on the network through an iffy Wi-Fi link. Ones-and-zeroes can be encoded in the add-on channel to switch sensors on and off too.
+
+### How it works
+
+The on-off noise power communication (ONPC) protocol, as it’s called, works via a software hack on commodity Wi-Fi access points. Through software, part of the transmitter is converted to an RF power source, and then elements in the receiver are turned into a power measuring device. Noise energy, created by the power source is encoded, emitted and picked up by the measuring setup at the other end.
+
+“If the access point, [or] router hears this code, it says, ‘OK, I know the sensor is still alive and trying to reach me, it’s just out of range,’” Neal Patwari of Washington University says in a Brigham Young University (BYU) [press release][6]. “It’s basically sending one bit of information that says it’s alive.”
+
+The noise channel is much leaner than the Wi-Fi one, BYU explains. “While Wi-Fi requires speeds of at least one megabit per second to maintain a signal, ONPC can maintain a signal on as low as one bit per second—one millionth of the data speed required by Wi-Fi.” That’s enough for IoT sensor housekeeping, conceivably. Additionally, “one bit of information is sufficient for many Wi-Fi enabled devices that simply need an on [and] off message,” the school says. It uses the example of an irrigation system.
+
+Assuring up-time, though, in hard-to-reach, dynamic environments, is where the school got the idea from. Researchers found that they were continually implementing sensors for environmental IoT experiments in hard to reach spots.
+
+The team use an example of a sensor placed in a student’s bedroom where the occupant had placed a laundry basket in front of the important device. It had blocked the native Wi-Fi signal. The scientists, then, couldn’t get a site appointment for some weeks due to the vagaries of the subject student’s life, and they didn’t know if the trouble issue was sensor or link during that crucial time. ONPC would have allowed them to be reassured that data was still being collected and stored—or not—without the tricky-to-obtain site visit.
+
+The researchers reckon cellular, [Bluetooth][7] and also [LoRa][8] could use ONPC, too. “We can send and receive data regardless of what Wi-Fi is doing; all we need is the ability to transmit energy and then receive noise measurements,” Phil Lundrigan of BYU says.
+
+Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3449819/wireless-noise-protocol-can-extend-iot-range.html
+
+作者:[Patrick Nelson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Patrick-Nelson/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3258807/what-is-802-11ax-wi-fi-and-what-will-it-mean-for-802-11ac.html
+[2]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
+[3]: https://www.networkworld.com/newsletters/signup.html
+[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[5]: https://dl.acm.org/citation.cfm?id=3345436
+[6]: https://news.byu.edu/byu-created-software-could-significantly-extend-wi-fi-range-for-smart-home-devices
+[7]: https://www.networkworld.com/article/3434526/bluetooth-finds-a-role-in-the-industrial-internet-of-things.html
+[8]: https://www.networkworld.com/article/3211390/lorawan-key-to-building-full-stack-production-iot-networks.html
+[9]: https://www.facebook.com/NetworkWorld/
+[10]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191101 Big Four carriers want to rule IoT by simplifying it.md b/sources/talk/20191101 Big Four carriers want to rule IoT by simplifying it.md
new file mode 100644
index 0000000000..4194e97438
--- /dev/null
+++ b/sources/talk/20191101 Big Four carriers want to rule IoT by simplifying it.md
@@ -0,0 +1,104 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Big Four carriers want to rule IoT by simplifying it)
+[#]: via: (https://www.networkworld.com/article/3449820/big-four-carriers-want-to-rule-iot-by-simplifying-it.html)
+[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
+
+Big Four carriers want to rule IoT by simplifying it
+======
+A look at some of the pros and cons of IoT services from AT&T, Sprint, T-Mobile and Verizon
+Natalya Burova / Getty Images
+
+The [Internet of Things][1] promises a transformative impact on a wide range of industries, but along with that promise comes an enormous new level of complexity for the network and those in charge of maintaining it. For the major mobile data carriers in the U.S., that fact suggests an opportunity.
+
+The core of the carriers’ appeal for IoT users is simplicity. Opting for Verizon or AT&T instead of in-house connectivity removes a huge amount of the work involved in pulling an IoT implementation together.
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
+
+Operationally, it’s the same story. The carrier is handling the network management and security functionality, and everything involved in the connectivity piece is available through a centralized management console.
+
+[][3]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][3]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+The carriers’ approach to the IoT market is two-pronged, in that they sell connectivity services directly to end-users as well as selling connectivity wholesale to device makers. For example, one customer might buy a bunch of sensors directly from Verizon, while another might buy equipment from a specialist manufacturer that contracts with Verizon to provide connectivity.
+
+There are, experts agree, numerous advantages to simply handing off the wireless networking of an IoT project to a major carrier. Licensed networks are largely free of interference – the carriers own the exclusive rights to the RF spectrum being used in a designated area, so no one else is allowed to use it without risking the wrath of the FCC. In contrast, a company using unlicensed technologies like Wi-Fi might be competing for the same spectrum area with half a dozen other organizations.
+
+It’s also better-secured than most unlicensed technologies or at least easier to secure, according to former chair of the IEEE’s IoT [smart cities][4] working group Shawn Chandler. Buying connectivity services that will have to be managed and secured in-house can be a lot more work than letting one of the carriers take care of it.
+
+“If you’re going to use mesh networks and RF networks,” he said, “then the enterprise is looking at [buying] a full security solution.”
+
+There are, of course, downsides as well. Plenty of businesses with a lot of institutional experience on the networking side are going to have trust issues with handing over control of mission-critical networks to a third party, said 451 Research vice president Christian Renaud.
+
+“For someone to come in over the top with, ‘Oh we’ll manage everything for you,’” he said, might draw a response along the lines of, “Wait, what?” from the networking staff. Carriers promise a lot of visibility into the logical relationships between endpoints, edge modules and the cloud – but the actual topology of the network itself may be abstracted out.
+
+And despite a generally higher level of security, carrier networks aren’t completely bulletproof. Several research teams have demonstrated attack techniques that, although unlikely to be seen in the wild, at least have the potential to compromise modern LTE networks. An example: researchers at Ruhr-University Bochum in 2018 [published a paper detailing potential attack vectors][5] that could allow a bad actor to target unencrypted metadata, which details users connected to a given mobile node, in order to spoof DNS requests.
+
+Nevertheless, carriers are set to play a crucially important part in the future evolution of enterprise IoT, and each of the big four U.S. carriers has a robust suite of offerings.
+
+### T-Mobile
+
+T-Mobile’s focus is on asset tracking, smart city technology, smart buildings and vehicular fleet management, which makes sense, given that those areas are a natural fit for carrier-based IoT. All except smart buildings require a large geographical coverage area, and the ability to bring a large number of diverse endpoints from diverse sources onto the network is a strength.
+
+The company also runs the CONNECT partner program, aimed at makers of IoT solutions who want to use T-Mobile’s network for connectivity. It offers the option to sell hardware, software or specialist IoT platforms through the main T-Mobile for Business program, as well as, of course, close technical integration with T-Mobile’s network.
+
+Finally, T-Mobile offers the option of using [narrow-band IoT technology, or NB-IoT][6]. This refers to the practice of using a small slice of the network’s spectrum to provide low-throughput connectivity to a large number of devices at the same time. It’s purpose-built for IoT, and although it won’t work for something like streaming video, where a lot of data has to be moved quickly, it’s well-suited to an asset tracking system that merely has to send brief status reports. The company even sells five-dollar systems-on-a-chip in bulk for organizations that want to integrate existing hardware or sensors into T-Mobile’s network.
+
+### AT&T
+
+Like the rest of the big four, AT&T does business both by selling their own IoT services – most of it under the umbrella of the Multi-Network Connect platform, a single pane of glass offering designed to streamline the management of many types of IoT product – and by partnering with an array of hardware and other product makers who want to use the company’s network.
+
+Along with NB-IoT, AT&T provides LTE-M connectivity, a similar but slightly more capable IoT-focused network technology that adds voice support and more throughput to the NB-IoT playbook. David Allen, director of advanced product development at AT&T’s advanced mobility and enterprise solutions division, said that LTE-M and NB-IoT are powerful tools in the company’s IoT arsenal.
+
+“These are small slivers of spectrum that offer an instant national footprint,” he said.
+
+MNC is advertised as a broad-based platform that can bring together input from nearly any type of licensed network, from 2G up through satellite, and even integrate with other connectivity management platforms – so a company that uses multiple operators could bring trhem all under the roof of MNC.
+
+### Verizon
+
+Verizon’s IoT platform, and the focus of its efforts to do business in the IoT realm is Thingspace, which is similar to AT&T’s MNC in many respects. The company also offers both NB-IoT and LTE-M for flexible IoT-specific connectivity options, as well as support for traditional SIM-based networking. As with the rest of the big four, Verizon also sells connectivity services to third parties.
+
+While the company said that it doesn’t break down its IoT business into third-party/first-party sales, Verizon says it has had success in several verticals, including telematics for the energy and healthcare industries. The first use case involves using current sensors on the grid and smart meters at the home to study sustainability and track usage more closely. The second involves working on remote monitoring of patient data, and the company said it will hav announcements around that in the future.
+
+While the focus is obviously on connectivity, Verizon also does something slightly unusual for the carrier IoT market by selling a one-size-fits-most sensor of its own creation, called the Critical Asset Sensor. This is a small sensor module that contains acceleration, temperature, pressure, light, humidity and shock sensors, along with GPS and network connectivity, so that it can fit a huge variety of IoT use cases. The idea is that they can be bought in bulk for an IoT implementation direct from Verizon, obviating the need to deal with a separate sensor vendor.
+
+### Sprint
+
+Sprint’s IoT offerings are partially provided under the umbrella of the company’s IoT Factory store, and the emphasis has been on various types of sensor-based service, including restaurant and food-service storage temperatures, smart building solutions for offices and other commercial property, as well as fleet management for terrestrial and marine vehicles.
+
+Most of these are offered through Sprint via partnerships with vertical specialists in those areas, like Apptricity, CU Trak, M2M in Motion and Rently, among many others.
+
+The company also has a dedicated IoT platform offering called Curiosity IoT, which leans on [Arm’s][7] platform security and connectivity management for basic functionality, but it promises most of the same functionality as the other Big Four vendors’ platforms. It provides a single pane of glass that integrates management and monitoring for every sensor on the network and shapes data into a standardized format for analysis on the back end.
+
+Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3449820/big-four-carriers-want-to-rule-iot-by-simplifying-it.html
+
+作者:[Jon Gold][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Jon-Gold/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
+[2]: https://www.networkworld.com/newsletters/signup.html
+[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[4]: https://www.networkworld.com/article/3411561/report-smart-city-iot-isnt-smart-enough-yet.html
+[5]: https://alter-attack.net/media/breaking_lte_on_layer_two.pdf
+[6]: https://www.networkworld.com/article/3227206/faq-what-is-nb-iot.html
+[7]: https://www.networkworld.com/article/3294781/arm-flexes-flexibility-with-pelion-iot-announcement.html
+[8]: https://www.facebook.com/NetworkWorld/
+[9]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191101 Micron finally delivers its answer to Optane.md b/sources/talk/20191101 Micron finally delivers its answer to Optane.md
new file mode 100644
index 0000000000..84b63007ec
--- /dev/null
+++ b/sources/talk/20191101 Micron finally delivers its answer to Optane.md
@@ -0,0 +1,63 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Micron finally delivers its answer to Optane)
+[#]: via: (https://www.networkworld.com/article/3449576/micron-finally-delivers-its-answer-to-optane.html)
+[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
+
+Micron finally delivers its answer to Optane
+======
+New drive offers DRAM-like performance and is targeted at analytics and transaction workloads.
+Intel
+
+Micron Technology partnered with Intel back in 2015 to develop 3D XPoint, a new type of memory that has the storage capability of NAND flash but speed almost equal to DRAM. However, the two companies parted ways in 2018 before either of them could bring a product to market. They had completed the first generation, agreed to work on the second generation together, and decided to part after that and do their own thing for the third generation.
+
+Intel released its product under the [Optane][1] brand name. Now Micron is hitting the market with its own product under the QuantX brand. At its Insight 2019 show in San Francisco, Micron unveiled the X100, a new solid-state drive the company claims is the fastest in the world.
+
+On paper, this thing is fast:
+
+ * Up to 2.5 million IOPS, which it claims is the fastest in the world.
+ * More than 9GB per second bandwidth for read, write, and mixed workloads, which it claims is three times faster than comparable NAND drives.
+ * Read-write latency of less than 8 microseconds, which it claims is 11 times better than NAND-based SSDs.
+
+
+
+Micron sees the X100 serving data to the world’s most demanding analytics and transactional applications, “a role that’s befitting the world’s fastest drive,” it said in a statement.
+
+The company also launched the Micron 7300, a NVMe SSD for data center use with capacities from 400GB to 8TB, depending on the form factor. It comes in SATA and U.2 form factors, the latter of which is like the M.2 PCI Express drives that are the size of a stick of gum and mount on the motherboard.
+
+Also released is the Micron 5300, a SATA drive with capacities from 240GB to nearly 8TB. This drive is the first to use 96-layer 3D TLC NAND, hence its high capacity. It can deliver random read performance of up to 95K IOPS and random write IOPS of 75K.
+
+Micron also announced it had acquired FWDNXT, an AI startup that develop deep learning solutions. Micron says it’s integrating the compute, memory, tools, and software from FWDNXT into a “comprehensive AI development platform,” which it calls the Micron Deep Learning Accelerator (DLA).
+
+ * [Backup vs. archive: Why it’s important to know the difference][2]
+ * [How to pick an off-site data-backup method][3]
+ * [Tape vs. disk storage: Why isn’t tape dead yet?][4]
+ * [The correct levels of backup save time, bandwidth, space][5]
+
+
+
+Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3449576/micron-finally-delivers-its-answer-to-optane.html
+
+作者:[Andy Patrizio][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Andy-Patrizio/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3387117/intel-formally-launches-optane-for-data-center-memory-caching.html
+[2]: https://www.networkworld.com/article/3285652/storage/backup-vs-archive-why-its-important-to-know-the-difference.html
+[3]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
+[4]: https://www.networkworld.com/article/3315156/storage/tape-vs-disk-storage-why-isnt-tape-dead-yet.html
+[5]: https://www.networkworld.com/article/3302804/storage/the-correct-levels-of-backup-save-time-bandwidth-space.html
+[6]: https://www.facebook.com/NetworkWorld/
+[7]: https://www.linkedin.com/company/network-world
diff --git a/sources/talk/20191101 Product vs. project in open source.md b/sources/talk/20191101 Product vs. project in open source.md
new file mode 100644
index 0000000000..f4fb128368
--- /dev/null
+++ b/sources/talk/20191101 Product vs. project in open source.md
@@ -0,0 +1,85 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Product vs. project in open source)
+[#]: via: (https://opensource.com/article/19/11/product-vs-project)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+Product vs. project in open source
+======
+What's the difference between an open source product and an open source
+project? Not all open source is created (and maintained) equal.
+![Bees on a hive, connected by dots][1]
+
+Open source is a good thing. Open source is a particularly good thing for security. I've written about this before (notably in [_Disbelieving the many eyes hypothesis_][2] and [_The commonwealth of open source_][3]), and I'm going to keep writing about it. In this article, however, I want to talk a little more about a feature of open source that is arguably both a possible disadvantage and a benefit: the difference between a project and a product. I'll come down firmly on one side (spoiler alert: for organisations, it's "product"), but I'd like to start with a little disclaimer. I am employed by Red Hat, and we are a company that makes money from supporting open source. I believe this is a good thing, and I approve of the model that we use, but I wanted to flag any potential bias early in the article.
+
+The main reason that open source is good for security is that you can see what's going on when there's a problem, and you have a chance to fix it. Or, more realistically, unless you're a security professional with particular expertise in the open source project in which the problem arises, somebody _else_ has a chance to fix it. We hope that there are sufficient security folks with the required expertise to fix security problems and vulnerabilities in software projects about which we care.
+
+It's a little more complex than that, however. As an organisation, there are two main ways to consume open source:
+
+ * As a **project**: you take the code, choose which version to use, compile it yourself, test it, and then manage it.
+ * As a **product**: a vendor takes the project, chooses which version to package, compiles it, tests it, and then sells support for the package, typically including docs, patching, and updates.
+
+
+
+Now, there's no denying that consuming a project "raw" gives you more options. You can track the latest version, compiling and testing as you go, and you can take security patches more quickly than the product version may supply them, selecting those that seem most appropriate for your business and use cases. On the whole, this seems like a good thing. There are, however, downsides that are specific to security. These include:
+
+ 1. Some security fixes come with an [embargo][4], to which only a small number of organisations (typically the vendors) have access. Although you may get access to fixes at the same time as the wider ecosystem, you will need to check and test them (unless you blindly apply them—don't do that), which will already have been performed by the vendors.
+ 2. The _huge_ temptation to make changes to the code that don't necessarily—or immediately—make it into the upstream project means that you are likely to be running a fork of the code. Even if you _do_ manage to get these upstream in time, during the period that you're running the changes but they're not upstream, you run a major risk that any security patches will not be immediately applicable to your version. (This is, of course, true for non-security patches, but security patches are typically more urgent.) One option, of course, if you believe that your version is likely to consumed by others, is to make an _official_ fork of the project and try to encourage a community to grow around that; but in the end, you will still have to decide whether to support the _new_ version internally or externally.
+ 3. Unless you ensure that _all_ instances of the software are running the same version in your deployment, any back-porting of security fixes to older versions will require you to invest in security expertise equal (or close to equal) to that of the people who created the fix in the first place. In this case, you are giving up the "commonwealth" benefit of open source, as you need to pay experts who duplicate the skills of the community.
+
+
+
+What you are basically doing, by choosing to deploy a _project_ rather than a _product_ is taking the decision to do _internal productisation_ of the project. You lose not only the commonwealth benefit of security fixes but also the significant _economies of scale_ that are intrinsic to the vendor-supported product model. There may also be _economies of scope_ that you miss: many vendors will have multiple products that they support and will be able to apply security expertise across those products in ways that may not be possible for an organisation whose core focus is not on product support.
+
+These economies are reflected in another possible benefit to the commonwealth of using a vendor: The very fact that multiple customers are consuming their products means that vendors have an incentive and a revenue stream to spend on security fixes and general features. There are other types of fixes and improvements on which they may apply resources, but the relative scarcity of skilled security experts means that the [principle of comparative advantage][5] suggests that they should be in the best position to apply them for the benefit of the wider community.[1][6]
+
+What if a vendor you use to provide a productised version of an open source project goes bust or decides to drop support for that product? Well, this is a problem in the world of proprietary software as well, of course. But in the case of proprietary software, there are three likely outcomes:
+
+ * You now have no access to the software source, and therefore no way to make improvements.
+ * You _are_ provided access to the software source, but it is not available to the wider world, and therefore you are on your own.
+ * _Everyone_ is provided with the software source, but no existing community exists to improve it, and it either dies or takes significant time for a community to build around it.
+
+
+
+In the case of open source, however, if the vendor you have chosen goes out of business, there is always the option to use another vendor, encourage a new vendor to take it on, productise it yourself (and supply it to other organisations), or, if the worst comes to the worst, take the internal productisation route while you search for a scalable long-term solution.
+
+In the modern open source world, we (the community) have gotten quite good at managing these options, as the growth of open source consortia[2][7] shows. In a consortium, groups of organisations and individuals cluster around a software project or a set of related projects to encourage community growth, alignment around feature and functionality additions, general security work, and productisation for use cases that may as yet be ill-defined, all the while trying to exploit the economies of scale and scope outlined above. An example of this would be the Linux Foundation's [Confidential Computing Consortium][8], to which the [Enarx project][9] aims to be contributed.
+
+Choosing to consume open source software as a product instead of as a project involves some trade-offs, but, from a security point of view at least, the economics for organisations are fairly clear: unless you are in a position to employ ample security experts, products are most likely to suit your needs.
+
+* * *
+
+1\. Note: I'm not an economist, but I believe that this holds in this case. Happy to have comments explaining why I'm wrong (if I am…).
+
+2\. "Consortiums" if you _really_ must.
+
+* * *
+
+_This article was originally published on [Alice, Eve, and Bob][10] and is reprinted with the author's permission._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/11/product-vs-project
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_bees_network.png?itok=NFNRQpJi (Bees on a hive, connected by dots)
+[2]: https://opensource.com/article/17/10/many-eyes
+[3]: https://opensource.com/article/17/11/commonwealth-open-source
+[4]: https://aliceevebob.com/2018/01/09/meltdown-and-spectre-thinking-about-embargoes-and-disclosures/
+[5]: https://en.wikipedia.org/wiki/Comparative_advantage
+[6]: tmp.ov8Yhb4jS4#1
+[7]: tmp.ov8Yhb4jS4#2
+[8]: https://confidentialcomputing.io/
+[9]: https://enarx.io/
+[10]: https://aliceevebob.com/2019/10/15/of-projects-products-and-security-community/
diff --git a/sources/talk/20191101 Retro computing with FPGAs and MiSTer.md b/sources/talk/20191101 Retro computing with FPGAs and MiSTer.md
new file mode 100644
index 0000000000..8674863561
--- /dev/null
+++ b/sources/talk/20191101 Retro computing with FPGAs and MiSTer.md
@@ -0,0 +1,166 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Retro computing with FPGAs and MiSTer)
+[#]: via: (https://opensource.com/article/19/11/fpga-mister)
+[#]: author: (Sarah Thornton https://opensource.com/users/sarah-thornton)
+
+Retro computing with FPGAs and MiSTer
+======
+Field-programmable gate arrays are used in devices like smartphones,
+medical devices, aircraft, and—here—emulating an old-school Amiga.
+![Mesh networking connected dots][1]
+
+Another weekend rolls around, and I can spend some time working on my passion projects, including working with single-board computers, playing with emulators, and general tinkering with a soldering iron. Earlier this year, I wrote about [resurrecting the Commodore Amiga on the Raspberry Pi][2]. A colleague referred to our shared obsession with old technology as a "[passion for preserving our digital culture][3]."
+
+In my travels in the world of "digital archeology," I heard about a new way to emulate old systems by using [field-programmable gate arrays][4] (FPGAs). I was intrigued by the concept, so I dedicated a weekend to learn more. Specifically, I wanted to know if I could use an FPGA to emulate a Commodore Amiga.
+
+### What is an FPGA?
+
+When you build a circuit board, everything is literally etched in silicon. You can change the software that runs on it, but the physical circuit is immutable. So if you want to add a new component to it or modify it later, you are limited by the physical nature of the hardware. With an FPGA, you can program the hardware to simulate new components or change existing ones. This is achieved through programmable logic gates (hence the name). This provides a lot of flexibility for Internet-of-Things (IoT) devices, as they can be changed later to meet new requirements.
+
+![Terasic DE10-Nano][5]
+
+FPGAs are used in many devices today, including smartphones, medical devices, motor vehicles, and aircraft. Because FPGAs can be easily modified and generally have low power requirements, these devices are everywhere! They are also inexpensive to manufacture and can be configured for multiple uses.
+
+The Commodore Amiga was designed with chips that had specific uses and fun names. For example, "Gary" was a gate array that later became "Fat Gary" when "he" was upgraded on the A3000 and A4000. "Bridgette" was an integrated bus buffer, and the delightful "Amber" was a "flicker fixer" on the A3000. The ability to simulate these chips with programmable gates makes an ideal platform for Amiga emulation.
+
+When you use an emulator, you are tricking an application into using software to find the architecture it expects. The primary limitations are the accuracy of the emulation and the sequential nature of how the commands are processed through the CPU. With an FPGA, you can teach the hardware what chips are in play, and software can talk to each chip as if it was native and in parallel. It also means applications can thread as if they were running on the original hardware. This makes FGPAs especially good for emulating old systems.
+
+### Introducing the MiSTer project
+
+The board I have been working with is [Terasic][6]'s [DE10-Nano][7]. Out of the box, this device is excellent for learning how FPGAs work and gives you access to tools to get you started.
+
+![Terasic DE10-Nano][8]
+
+The [MiSTer project][9] is built on top of this board and employs daughter boards to provide memory expansion, SDRAM, and improved I/O, all built on a Linux-based distribution. To use it as a platform for emulation, it's expanded through the use of "cores" that define the architecture the board will emulate.
+
+Once you have flashed the device with the MiSTer distro, you can load a "core," which is a combination of a definition for the chips you want to use and the associated menus to manage the emulated system.
+
+![Terasic DE10-Nano][10]
+
+Compared to a Raspberry Pi running emulation software, these cores provide a more native experience for emulation, and often apps that don't run perfectly on software-based emulators will run fine on a MiSTer.
+
+### How to get started
+
+There are excellent resources online to help get you started. The first stop is the [documentation][11] on MiSTer's [GitHub page][12], which has step-by-step instructions on putting everything together. If you prefer a visual walkthrough of the board, check out [this video][13] from the [Retro Man Cave][14] YouTube channel. For more information on configuring the [Minimig][15] (short for mini Amiga) core to load disks or using Amiga's classic [Workbench][16] and [WHDLoad][17], check out this great [tutorial][18] from [Phil's Computer Lab][19] on YouTube.
+
+### Cores
+
+MiSTer has cores available for a multitude of systems; my main interest is in Amiga emulation, which is provided by the Minimig core. I'm also interested in the Commodore 64 and PET and the BBC microcomputer, which I used at college. I also have a soft spot for playing [Space Invaders on the Commodore PET][20], which I will admit (many years later!) was the real reason I booked time in the college computer lab at the end of the week.
+
+Once a core is loaded, you can interact with it through a connected keyboard and by pressing F12 to access the "core" menu. To access a shell, you can log in by using the F9 key, which presents you with a login prompt. You will need a [kickstart ROM][21] (the equivalent of a PC's BIOS), to get your Amiga running. You can obtain these from [Cloanto][22], which sells the [Amiga Forever][23] kickstart that contains the ROMs required to boot a system as well as games, demos, and hard drive files that can be used on your MiSTer. Store the kickstart ROM in the root of your SD card and name it "KICK.ROM."
+
+On my MiSTer board, I can run Amiga demos that don't run on my Raspberry Pi, even though my Pi has much more memory available. The emulation is more accurate and runs more efficiently. Through the expansion board, I can even use old hardware, such as an original Commodore monitor and Amiga joysticks.
+
+### Source code
+
+All code for the MiSTer project is available in its [GitHub repo][12]. You have access to the cores as well as the main MiSTer setup, associated scripts, and menu files. These are actively updated, and there is a solid community actively developing, bug fixing, and improving all contributions, so check back regularly for updates. The repo has a wealth of information available to help get you up and running.
+
+### Security considerations
+
+With the flexibility of customization comes the potential for [security vulnerabilities][24]. All MiSTer installs come with a preset password on the root account, so one of the first things you want to do is to change the password. If you are using the device to build a cabinet for a game and you have given the device access to your network, it can be exploited using the default login credentials, and that can lead to giving a third party access to your network.
+
+For non-MiSTer projects, FPGAs expose the ability for one process to be able to listen in on another process, so limiting access to the device should be one of the first things you do. When you build your application, you should isolate processes to prevent unwanted access. This is especially important if you intend to deploy your board where access is open to other users or with shared applications.
+
+### Find more information
+
+There is a lot of information about this type of project online. Here are some of the resources you may find helpful.
+
+#### Community
+
+ * [MiSTer wiki][9]
+ * [Setup guide][11]
+ * [Internet connections on supporting cores][25]
+ * [Discussion forums][26]
+ * [MiSTer add-ons][27] (public Facebook group)
+
+
+
+#### Daughter boards
+
+ * [SDRAM board][28]
+ * [I/O board][29]
+ * [RTC board][30]
+ * [USB hub][31]
+
+
+
+#### Videos and walkthroughs
+
+ * [Exploring the MiSTer and DE-10 Nano FPGA][32]: Is this the future of retro?
+ * [FPGA emulation MiSTer project on the Terasic DE10-Nano][33]
+ * [Amiga OS 3.1 on FPGA—DE10-Nano running MisTer][34]
+
+
+
+#### Where to buy the hardware
+
+##### MiSTer project
+
+ * [DE10-Nano][35] (Amazon)
+ * [Ultimate Mister][36]
+ * [MiSTer Add-ons][37]
+
+
+
+##### Other FPGAs
+
+ * [TinyFPGA BX—ICE40 FPGA development board with USB][38] (Adafruit)
+ * [Terasic][6], makers of the DE10-Nano and other high-performance FPGAs
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/11/fpga-mister
+
+作者:[Sarah Thornton][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/sarah-thornton
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mesh_networking_dots_connected.png?itok=ovINTRR3 (Mesh networking connected dots)
+[2]: https://opensource.com/article/19/3/amiga-raspberry-pi
+[3]: https://www.linkedin.com/pulse/passion-preserving-digital-culture-%C3%B8ivind-ekeberg/
+[4]: https://en.wikipedia.org/wiki/Field-programmable_gate_array
+[5]: https://opensource.com/sites/default/files/uploads/image5_0.jpg (Terasic DE10-Nano)
+[6]: https://www.terasic.com.tw/en/
+[7]: https://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English&CategoryNo=165&No=1046
+[8]: https://opensource.com/sites/default/files/uploads/image2_0.jpg (Terasic DE10-Nano)
+[9]: https://github.com/MiSTer-devel/Main_MiSTer/wiki
+[10]: https://opensource.com/sites/default/files/uploads/image1_0.jpg (Terasic DE10-Nano)
+[11]: https://github.com/MiSTer-devel/Main_MiSTer/wiki/Setup-Guide
+[12]: https://github.com/MiSTer-devel
+[13]: https://www.youtube.com/watch?v=e5yPbzD-W-I&t=2s
+[14]: https://www.youtube.com/channel/UCLEoyoOKZK0idGqSc6Pi23w
+[15]: https://github.com/MiSTer-devel/Minimig-AGA_MiSTer
+[16]: https://en.wikipedia.org/wiki/Workbench_%28AmigaOS%29
+[17]: https://en.wikipedia.org/wiki/WHDLoad
+[18]: https://www.youtube.com/watch?v=VFespp1adI0
+[19]: https://www.youtube.com/channel/UCj9IJ2QvygoBJKSOnUgXIRA
+[20]: https://www.youtube.com/watch?v=hqs6gIZbpxo
+[21]: https://en.wikipedia.org/wiki/Kickstart_(Amiga)
+[22]: https://cloanto.com/
+[23]: https://www.amigaforever.com/
+[24]: https://www.helpnetsecurity.com/2019/06/03/vulnerability-in-fpgas/
+[25]: https://github.com/MiSTer-devel/Main_MiSTer/wiki/Internet-and-console-connection-from-supported-cores
+[26]: http://www.atari-forum.com/viewforum.php?f=117
+[27]: https://www.facebook.com/groups/251655042432052/
+[28]: https://github.com/MiSTer-devel/Main_MiSTer/wiki/SDRAM-Board
+[29]: https://github.com/MiSTer-devel/Main_MiSTer/wiki/IO-Board
+[30]: https://github.com/MiSTer-devel/Main_MiSTer/wiki/RTC-board
+[31]: https://github.com/MiSTer-devel/Main_MiSTer/wiki/USB-Hub-daughter-board
+[32]: https://www.youtube.com/watch?v=e5yPbzD-W-I
+[33]: https://www.youtube.com/watch?v=1jb8YPXc8DA
+[34]: https://www.youtube.com/watch?v=tAz8VRAv7ig
+[35]: https://www.amazon.com/Terasic-Technologies-P0496-DE10-Nano-Kit/dp/B07B89YHSB/
+[36]: https://ultimatemister.com/
+[37]: https://misteraddons.com/
+[38]: https://www.adafruit.com/product/4038
diff --git a/sources/talk/20191102 6 remarkable features of the new United Nations open source initiative.md b/sources/talk/20191102 6 remarkable features of the new United Nations open source initiative.md
new file mode 100644
index 0000000000..a5394515d4
--- /dev/null
+++ b/sources/talk/20191102 6 remarkable features of the new United Nations open source initiative.md
@@ -0,0 +1,56 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (6 remarkable features of the new United Nations open source initiative)
+[#]: via: (https://opensource.com/article/19/11/united-nations-goes-open-source)
+[#]: author: (Frank Karlitschek https://opensource.com/users/frankkarlitschek)
+
+6 remarkable features of the new United Nations open source initiative
+======
+What does it mean when the UN goes open source?
+![Globe up in the clouds][1]
+
+Three months, ago the United Nations asked me to join a new advisory board to help them develop their open source strategy and policy. I’m honored to have the opportunity to work together with a group of established experts in open source licensing and policy areas.
+
+The United Nations wants to make technology, software, and intellectual property available to everyone, including developing countries. Open source and free software are great tools to achieve this goal since open source is all about empowering people and global collaboration while protecting the personal data and privacy of users. So, the United Nations and the open source community share the same values.
+
+This new open source strategy and policy is developed by the [United Nations Technology Innovation Labs][2] (UNTIL). Last month, we had our first in-person meeting in Helsinki in the UNTIL offices. I find this initiative remarkable for several reasons:
+
+ * **Sharing:** The United Nations wants to have a positive impact on everyone on this planet. For that goal, it is important that software, data, and services are available for everyone independent of their language, budget, education, or other factors. Open source is perfect to guarantee that result.
+
+ * **Contributing:** It should be possible that everyone can contribute to the software, data, and services of the United Nations. The goal is to not depend on a single software vendor alone, but instead, build a bigger ecosystem that drives innovation together.
+
+ * **Empowering:** Open source makes it possible for underdeveloped countries and regions to foster local companies and expertise by building on top of existing open source software—standing on the shoulders of giants.
+
+ * **Sustainability:** Open source guarantees more sustainable software, data, and services by not relying on a single entity to support, maintain, and develop it. Open source helps to avoid a single point of failure by creating an equal playing field for everyone.
+
+ * **Security:** Open source software is more secure than proprietary software because the code can be constantly reviewed and audited. This fact is especially important for security-sensitive applications that require [transparency and openness][3].
+
+ * **Decentralization:** An open source strategy enables decentralized hosting of software and data. This fact makes it possible to be compliant with all data protection and privacy regulations and enables a more free and open internet.
+
+
+
+
+We discussed that a fair business model like the one from Nextcloud should be encouraged and recommended. Specifically, we discussed that that 100% of the code should be placed under an [OSI-approved open source license][4]. There should be no open core, proprietary extensions, dual licensing, or other limited-access components to ensure that everyone is on the same playing field.
+
+I’m excited to have the opportunity to advise the United Nations in this matter, and I hope to have a positive influence on the future of IT, especially in developing countries.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/11/united-nations-goes-open-source
+
+作者:[Frank Karlitschek][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/frankkarlitschek
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cloud-globe.png?itok=_drXt4Tn (Globe up in the clouds)
+[2]: https://until.un.org
+[3]: https://until.un.org/content/governance
+[4]: https://opensource.org/licenses
diff --git a/sources/talk/20191102 Can Data Scientists be Replaced by Automation.md b/sources/talk/20191102 Can Data Scientists be Replaced by Automation.md
new file mode 100644
index 0000000000..89b4e8b77a
--- /dev/null
+++ b/sources/talk/20191102 Can Data Scientists be Replaced by Automation.md
@@ -0,0 +1,66 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Can Data Scientists be Replaced by Automation?)
+[#]: via: (https://opensourceforu.com/2019/11/can-data-scientists-be-replaced-by-automation/)
+[#]: author: (Preet Gandhi https://opensourceforu.com/author/preet-gandhi/)
+
+Can Data Scientists be Replaced by Automation?
+======
+
+[![][1]][2]
+
+_The advent of AI, automation and smart bots triggers the question: Is it possible that data scientists will become redundant in the future? Are they indispensable? The ideal approach appears to be automation complementing the work data scientists do. This would better utilise the tremendous data being generated throughout the world every day._
+
+Data scientists are currently very much in demand. But there is the question about whether they can automate themselves out of their jobs. Can artificial intelligence replace data scientists? If so, up to what extent can their tasks be automated? Gartner recently reported that 40 per cent of data science tasks will be automated by 2020. So what kind of skills can be efficiently handled by automation? All this speculation adds fuel to the ongoing ‘Man vs Machine’ debate.
+
+Data scientists need a strong mathematical mind, quantitative skills, computer programming skills and business acumen to make decisions. They need to gather large unstructured data and transform it into results and insights, which can be understood by laymen or business executives. The whole process is highly customised, depending on the type of application domain. Some degree of human interaction will always be needed due to the subjective nature of the process, and what percentage of the task is automated depends in the specific use case and is open to debate. To understand how much or what parts can be automated, we need to have a deep understanding of the process.
+
+Data scientists are expensive to hire and there is a shortage of this skill in the industry as it’s a relatively new field. Many companies try to look for alternative solutions. Several AI algorithms have now been developed, which can analyse data and provide insights similar to a data scientist. The algorithm has to provide the data output and make accurate predictions, which can be done by using Natural Language Processing (NLP).
+
+NLP can be used to communicate with AI in the same way that laymen interact with data scientists to put forth their demands. For example, IBM Watson has NLP facilities which interact with business intelligence (BI) tools to perform data science tasks. Microsoft’s Cortana also has a powerful BI tool, and users can process Big Data sets by just speaking to it. All these are simple forms of automation which are widely available already. Data engineering tasks such as cleansing, normalisation, skewness removal, transformation, etc, as well as modelling methods like champion model selection, feature selection, algorithm selection, fitness metric selection, etc, are tasks for which automated tools are currently available in the market.
+
+Automation in data science will squeeze some manual labour out of the workflow instead of completely replacing the data scientists. Low-level functions can be efficiently handled by AI systems. There are many technologies to do this. The Alteryx Designer tool automatically generates customised REST APIs and Docker images around machine learning models during the promotion and deployment stage.
+
+Designer workflows can also be set up to automatically retrain machine learning models, using fresh data, and then to automatically redeploy them. Data integration, model building, and optimising model hyper parameters are areas where automation can be helpful. Data integration combines data from multiple sources to provide a uniform data set. Automation here can pull trusted data from multiple sources for a data scientist to analyse. Collecting data, searching for patterns and making predictions are required for model building, which can be automated as machines can collect data to find patterns.
+
+Machines are getting smarter everyday due to the integration of AI principles that help them learn from the types of patterns they were historically trying to detect. An added advantage here is that machines will not make the kinds of errors that humans do.
+
+Automation has its own set of limitations, however. It can only go so far. Artificial intelligence can automate data engineering and machine learning processes but AI can’t automate itself. Data wrangling (data munging) consists of manually converting raw data to an easily consumable form. The process still requires human judgment to turn raw data into insights that make sense for an organisation, and take all of an organisation’s complexities into account. Even unsupervised learning is not entirely automated. Data scientists still prepare sets, clean them, specify which algorithms to use, and interpret the findings. Data visualisation, most of the time, needs a human as the findings to be presented to laymen have to be highly customised, depending on the technical knowledge of the audience. A machine can’t possibly be trained to do that.
+
+Low-level visualisations can be automated, but human intelligence would be required to interpret and explain the data. It will also be needed to write AI algorithms that can handle mundane visualisation tasks. Moreover, intangibles like human curiosity, intuition or the desire to create/validate experiments can’t be simulated by AI. This aspect of data science probably won’t be ever handled by AI in the near future as the technology hasn’t evolved to that extent.
+
+While thinking about automation, we should also consider the quality of the output. Here, output means the validity or relevance of the insights. With automation, the quantity and throughput of data science artefacts will increase, but that doesn’t translate to an increase in quality. The process of extracting insights and applying them within the context of particular data driven applications is still inherently a creative, exploratory process that demands human judgment. To get a deeper understanding of the data, feature engineering is a very essential portion of the process. It allows us to make maximum use of the data available to us. Automating feature engineering is really difficult as it requires human domain knowledge and a real-world understanding, which is tough for a machine to acquire. Even if AI is used, it can’t provide the same level of feedback that a human expert in that domain can. While automation can help identify patterns in an organisation, machines cannot truly understand what data means for an organisation and its relationships between different, unconnected operations.
+
+You can’t teach a machine to be creative. After getting results from a pipeline, a data scientist can seek further domain knowledge in order to add value and improve the pipeline.Collaborating alongside marketing, sales and engineering teams, solutions will need to be implemented and deployed based on these findings to improve the model. It’s an iterative process and after each iteration, the creativity with which data scientists plan on adding to the next phase is what differentiates them from bots. The interactions and conversations driving these initiatives, which are fuelled by abstract, creative thinking, surpass the capabilities of any modern-day machine.
+
+Current data scientists shouldn’t be worried about losing their jobs to computers due to automation, as they are an amalgamation of thought leaders, coders and statisticians. A successful data science project will always need a strong team of humans to work together and collaborate to synergistically solve a problem. AI will have a tough time collaborating, which is essential in order to transform data to actionable data. Even if automation is used to some extent, a data scientist will always have to manually validate the results of a pipeline in order to make sure it makes sense in the real world. Automation can be thought of as a supplementary tool which will help scale data science and make the work more efficient. Bots can handle lower-level tasks and leave the problem-solving tasks to human experts. The combination of automation with human problem-solving will actually empower, rather than threaten, the jobs of data scientists as bots will be like assistants to the former.
+
+Automation can never completely replace a data scientist because no amount of advanced AI can emulate the most important quality a skilful data scientist must possess – intuition.
+
+![Avatar][3]
+
+[Preet Gandhi][4]
+
+The author is an avid Big Data and data science enthusiast. You can contact her at [gandhipreet1995@gmail.com][5].
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/11/can-data-scientists-be-replaced-by-automation/
+
+作者:[Preet Gandhi][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/preet-gandhi/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/Data-Scientist-automation.jpg?resize=696%2C458&ssl=1 (Data Scientist automation)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/Data-Scientist-automation.jpg?fit=727%2C478&ssl=1
+[3]: https://secure.gravatar.com/avatar/4603e91c8ba6455d0d817c912a8985bf?s=100&r=g
+[4]: https://opensourceforu.com/author/preet-gandhi/
+[5]: mailto:gandhipreet1995@gmail.com
diff --git a/sources/tech/20190826 How RPM packages are made- the source RPM.md b/sources/tech/20190826 How RPM packages are made- the source RPM.md
deleted file mode 100644
index 4629db3580..0000000000
--- a/sources/tech/20190826 How RPM packages are made- the source RPM.md
+++ /dev/null
@@ -1,238 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How RPM packages are made: the source RPM)
-[#]: via: (https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/)
-[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
-
-How RPM packages are made: the source RPM
-======
-
-![][1]
-
-In a [previous post, we looked at what RPM packages are][2]. They are archives that contain files and metadata. This metadata tells RPM where to create or remove files from when an RPM is installed or uninstalled. The metadata also contains information on “dependencies”, which you will remember from the previous post, can either be “runtime” or “build time”.
-
-As an example, we will look at _fpaste_. You can download the RPM using _dnf_. This will download the latest version of _fpaste_ that is available in the Fedora repositories. On Fedora 30, this is currently 0.3.9.2:
-
-```
-$ dnf download fpaste
-
-...
-fpaste-0.3.9.2-2.fc30.noarch.rpm
-```
-
-Since this is the built RPM, it contains only files needed to use _fpaste_:
-
-```
-$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.noarch.rpm
-/usr/bin/fpaste
-/usr/share/doc/fpaste
-/usr/share/doc/fpaste/README.rst
-/usr/share/doc/fpaste/TODO
-/usr/share/licenses/fpaste
-/usr/share/licenses/fpaste/COPYING
-/usr/share/man/man1/fpaste.1.gz
-```
-
-### Source RPMs
-
-The next link in the chain is the source RPM. All software in Fedora must be built from its source code. We do not include pre-built binaries. So, for an RPM file to be made, RPM (the tool) needs to be:
-
- * given the files that have to be installed,
- * told how to generate these files, if they are to be compiled, for example,
- * told where these files must be installed,
- * what other dependencies this particular software needs to work properly.
-
-
-
-The source RPM holds all of this information. Source RPMs are similar archives to RPM, but as the name suggests, instead of holding the built binary files, they contain the source files for a piece of software. Let’s download the source RPM for _fpaste_:
-
-```
-$ dnf download fpaste --source
-...
-fpaste-0.3.9.2-2.fc30.src.rpm
-```
-
-Notice how the file ends with “src.rpm”. All RPMs are built from source RPMs. You can easily check what source RPM a “binary” RPM comes from using dnf too:
-
-```
-$ dnf repoquery --qf "%{SOURCERPM}" fpaste
-fpaste-0.3.9.2-2.fc30.src.rpm
-```
-
-Also, since this is the source RPM, it does not contain built files. Instead, it contains the sources and instructions on how to build the RPM from them:
-
-```
-$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.src.rpm
-fpaste-0.3.9.2.tar.gz
-fpaste.spec
-```
-
-Here, the first file is simply the source code for _fpaste_. The second is the “spec” file. The spec file is the recipe that tells RPM (the tool) how to create the RPM (the archive) using the sources contained in the source RPM—all the information that RPM (the tool) needs to build RPMs (the archives) are contained in spec files. When we package maintainers add software to Fedora, most of our time is spent writing and perfecting the individual spec files. When a software package needs an update, we go back and tweak the spec file. You can see the spec files for ALL packages in Fedora at our source repository at
-
-Note that one source RPM may contain the instructions to build multiple RPMs. _fpaste_ is a very simple piece of software, where one source RPM generates one “binary” RPM. Python, on the other hand is more complex. While there is only one source RPM, it generates multiple binary RPMs:
-
-```
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-devel
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-libs
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-idle
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-tkinter
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-```
-
-In RPM jargon, “python3” is the “main package”, and so the spec file will be called “python3.spec”. All the other packages are “sub-packages”. You can download the source RPM for python3 and see what’s in it too. (Hint: patches are also part of the source code):
-
-```
-$ dnf download --source python3
-python3-3.7.4-1.fc30.src.rpm
-
-$ rpm -qpl ./python3-3.7.4-1.fc30.src.rpm
-00001-rpath.patch
-00102-lib64.patch
-00111-no-static-lib.patch
-00155-avoid-ctypes-thunks.patch
-00170-gc-assertions.patch
-00178-dont-duplicate-flags-in-sysconfig.patch
-00189-use-rpm-wheels.patch
-00205-make-libpl-respect-lib64.patch
-00251-change-user-install-location.patch
-00274-fix-arch-names.patch
-00316-mark-bdist_wininst-unsupported.patch
-Python-3.7.4.tar.xz
-check-pyc-timestamps.py
-idle3.appdata.xml
-idle3.desktop
-python3.spec
-```
-
-### Building an RPM from a source RPM
-
-Now that we have the source RPM, and know what’s in it, we can rebuild our RPM from it. Before we do so, though, we should set our system up to build RPMs. First, we install the required tools:
-
-```
-$ sudo dnf install fedora-packager
-```
-
-This will install the rpmbuild tool. rpmbuild requires a default layout so that it knows where each required component of the source rpm is. Let’s see what they are:
-
-```
-# Where should the spec file go?
-$ rpm -E %{_specdir}
-/home/asinha/rpmbuild/SPECS
-
-# Where should the sources go?
-$ rpm -E %{_sourcedir}
-/home/asinha/rpmbuild/SOURCES
-
-# Where is temporary build directory?
-$ rpm -E %{_builddir}
-/home/asinha/rpmbuild/BUILD
-
-# Where is the buildroot?
-$ rpm -E %{_buildrootdir}
-/home/asinha/rpmbuild/BUILDROOT
-
-# Where will the source rpms be?
-$ rpm -E %{_srcrpmdir}
-/home/asinha/rpmbuild/SRPMS
-
-# Where will the built rpms be?
-$ rpm -E %{_rpmdir}
-/home/asinha/rpmbuild/RPMS
-```
-
-I have all of this set up on my system already:
-
-```
-$ cd
-$ tree -L 1 rpmbuild/
-rpmbuild/
-├── BUILD
-├── BUILDROOT
-├── RPMS
-├── SOURCES
-├── SPECS
-└── SRPMS
-
-6 directories, 0 files
-```
-
-RPM provides a tool that sets it all up for you too:
-
-```
-$ rpmdev-setuptree
-```
-
-Then we ensure that we have all the build dependencies for _fpaste_ installed:
-
-```
-sudo dnf builddep fpaste-0.3.9.2-3.fc30.src.rpm
-```
-
-For _fpaste_ you only need Python and that must already be installed on your system (dnf uses Python too). The builddep command can also be given a spec file instead of an source RPM. Read more in the man page:
-
-```
-$ man dnf.plugin.builddep
-```
-
-Now that we have all that we need, building an RPM from a source RPM is as simple as:
-
-```
-$ rpmbuild --rebuild fpaste-0.3.9.2-3.fc30.src.rpm
-..
-..
-
-$ tree ~/rpmbuild/RPMS/noarch/
-/home/asinha/rpmbuild/RPMS/noarch/
-└── fpaste-0.3.9.2-3.fc30.noarch.rpm
-
-0 directories, 1 file
-```
-
-rpmbuild will install the source RPM and build your RPM from it. You can now install the RPM to use it as you do–using dnf. Of course, as said before, if you want to change anything in the RPM, you must modify the spec file—we’ll cover spec files in next post.
-
-### Summary
-
-To summarise this post in two short points:
-
- * the RPMs we generally install to use software are “binary” RPMs that contain built versions of the software
- * these are built from source RPMs that include the source code and the spec file that are needed to generate the binary RPMs.
-
-
-
-If you’d like to get started with building RPMs, and help the Fedora community maintain the massive amount of software we provide, you can start here:
-
-For any queries, post to the [Fedora developers mailing list][3]—we’re always happy to help!
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/
-
-作者:[Ankur Sinha "FranciscoD"][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/ankursinha/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
-[2]: https://fedoramagazine.org/rpm-packages-explained/
-[3]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
diff --git a/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md b/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
index d1523f33c3..d1c4ce50a6 100644
--- a/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
+++ b/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (robsean)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20191008 5 Best Password Managers For Linux Desktop.md b/sources/tech/20191008 5 Best Password Managers For Linux Desktop.md
deleted file mode 100644
index c9a51c91e6..0000000000
--- a/sources/tech/20191008 5 Best Password Managers For Linux Desktop.md
+++ /dev/null
@@ -1,201 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (5 Best Password Managers For Linux Desktop)
-[#]: via: (https://itsfoss.com/password-managers-linux/)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-5 Best Password Managers For Linux Desktop
-======
-
-_**A password manager is a useful tool for creating unique passwords and storing them securely so that you don’t have to remember them. Check out the best password managers available for Linux desktop.**_
-
-Passwords are everywhere. Websites, forums, web apps and what not, you need to create accounts and password for them. The trouble comes with the password. Keeping the same password for various accounts poses a security risk because [if one of the websites is compromised, hackers try the same email-password combination on other websites][1] as well.
-
-But keeping unique passwords for all the new accounts means that you have to remember all of them and it’s not possible for normal humans. This is where password managers come to your help.
-
-Password managing apps suggest/create strong passwords for you and store them in an encrypted database. You just need to remember the master password for the password manager.
-
-Mainstream modern web browsers like Mozilla Firefox and Google Chrome have built in password manager. This helps but you are restricted to use it on their web browser only.
-
-There are third party, dedicated password managers and some of them also provide native desktop applications for Linux. In this article, we filter out the best password managers available for Linux.
-
-Before you see that, I would also advise going through the list of [free password generators for Linux][2] to generate strong, unique passwords for you.
-
-### Password Managers for Linux
-
-Possible non-FOSS alert!
-
-We’ve given priority to the ones which are open source (with some proprietary options, don’t hate me!) and also offer a standalone desktop app (GUI) for Linux. The proprietary options have been highlighted.
-
-#### 1\. Bitwarden
-
-![][3]
-
-Key Highlights:
-
- * Open Source
- * Free for personal use (paid options available for upgrade)
- * End-to-end encryption for Cloud servers
- * Cross-platform
- * Browser Extensions available
- * Command-line tools
-
-
-
-Bitwarden is one of the most impressive password managers for Linux. I’ll be honest that I didn’t know about this until now – and I’m already making the switch from [LastPass][4]. I was able to easily import the data from LastPass without any issues and had no trouble whatsoever.
-
-The premium version costs just $10/year – which seems to be worth it (I’ve upgraded for my personal usage).
-
-It is an open source solution – so there’s nothing shady about it. You can even host it on your own server and create a password solution for your organization.
-
-In addition to that, you get all the necessary features like 2FA for login, import/export options for your credentials, fingerprint phrase (a unique key), password generator, and more.
-
-You can upgrade your account as an organization account for free to be able to share your information with 2 users in total. However, if you want additional encrypted vault storage and the ability to share passwords with 5 users, premium upgrades are available starting from as low as $1 per month. I think it’s definitely worth a shot!
-
-[Bitwarden][5]
-
-#### 2\. Buttercup
-
-![][6]
-
-Key Highlights:
-
- * Open Source
- * Free, with no premium options.
- * Cross-platform
- * Browser Extensions available
-
-
-
-Yet another open-source password manager for Linux. Buttercup may not be a very popular solution – but if you are looking for a simpler alternative to store your credentials, this would be a good start.
-
-Unlike some others, you do not have to be skeptical about its cloud servers because it sticks to offline usage only and supports connecting cloud sources like [Dropbox][7], [OwnCloud][8], [Nextcloud][9], and [WebDAV][10].
-
-So, you can opt for the cloud source if you need to sync the data. You’ve got the choice for it.
-
-[Buttercup][11]
-
-#### 4\. KeePassXC
-
-![][12]
-
-Key Highlights:
-
- * Open Source
- * Simple password manager
- * Cross-platform
- * No mobile support
-
-
-
-KeePassXC is a community fork of [KeePassX][13] – which was originally a Linux port for [KeePass][14] on Windows.
-
-Unless you’re not aware, KeePassX hasn’t been maintained for years – so KeePassXC is a good alternative if you are looking for a dead-simple password manager. KeePassXC may not be the most prettiest or fanciest password manager, but it does the job.
-
-It is secure and open source as well. I think that makes it worth a shot, what say?
-
-[KeePassXC][15]
-
-#### 4\. Enpass (not open source)
-
-![][16]
-
-Key Highlights:
-
- * Proprietary
- * A lot of features – including ‘Wearable’ device support.
- * Completely free for Linux (with premium features)
-
-
-
-Enpass is a quite popular password manager across multiple platforms. Even though it’s not an open source solution, a lot of people rely on it – so you can be sure that it works, at least.
-
-It offers a great deal of features and if you have a wearable device, it will support that too – which is rare.
-
-It’s great to see that Enpass manages the package for Linux distros actively. Also, note that it works for 64-bit systems only. You can find the [official instructions for installation][17] on their website. It will require utilizing the terminal, but I followed the steps to test it out and it worked like a charm.
-
-[Enpass][18]
-
-#### 5\. myki (not open source)
-
-![][19]
-
-Key Highlights:
-
- * Proprietary
- * Avoids cloud servers for storing passwords
- * Focuses on local peer-to-peer syncing
- * Ability to replace passwords with Fingerprint IDs on mobile
-
-
-
-This may not be a popular recommendation – but I found it very interesting. It is a proprietary password manager which lets you avoid cloud servers and relies on peer-to-peer sync.
-
-So, if you do not want to utilize any cloud servers to store your information, this is for you. It is also interesting to note that the app available for Android and iOS helps you replace passwords with your fingerprint ID. If you want convenience on your mobile phone along with the basic functionality on a desktop password manager – this looks like a good option.
-
-However, if you are opting for a premium upgrade, the pricing plans are for you to judge, definitely not cheap.
-
-Do try it out and let us know how it goes!
-
-[myki][20]
-
-### Some Other Password Managers Worth Pointing Out
-
-Even without offering a standalone app for Linux, there are some password managers that may deserve a mention.
-
-If you need to utilize browser-based (extensions) password managers, we would recommend trying out [LastPass][21], [Dashlane][22], and [1Password][23]. LastPass even offers a [Linux client (and a command-line tool)][24].
-
-If you are looking for CLI password managers, you should check out [Pass][25].
-
-[Password Safe][26] is also an option – but the Linux client is in beta. I wouldn’t recommend relying on “beta” applications for storing passwords. [Universal Password Manager][27] exists but it’s no longer maintained. You may have also heard about [Password Gorilla][28] but it isn’t actively maintained.
-
-**Wrapping Up**
-
-Bitwarden seems to be my personal favorite for now. However, there are several options to choose from on Linux. You can either opt for something that offers a native app or just a browser extension – the choice is yours.
-
-If we missed listing out a password manager worth trying out, let us know about it in the comments below. As always, we’ll extend our list with your suggestion.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/password-managers-linux/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://medium.com/@computerphonedude/one-of-my-old-passwords-was-hacked-on-6-different-sites-and-i-had-no-clue-heres-how-to-quickly-ced23edf3b62
-[2]: https://itsfoss.com/password-generators-linux/
-[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/bitward.png?ssl=1
-[4]: https://www.lastpass.com/
-[5]: https://bitwarden.com/
-[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/buttercup.png?ssl=1
-[7]: https://www.dropbox.com/
-[8]: https://owncloud.com/
-[9]: https://nextcloud.com/
-[10]: https://en.wikipedia.org/wiki/WebDAV
-[11]: https://buttercup.pw/
-[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/KeePassXC.png?ssl=1
-[13]: https://www.keepassx.org/
-[14]: https://keepass.info/
-[15]: https://keepassxc.org
-[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/enpass.png?ssl=1
-[17]: https://www.enpass.io/support/kb/general/how-to-install-enpass-on-linux/
-[18]: https://www.enpass.io/
-[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/myki.png?ssl=1
-[20]: https://myki.com/
-[21]: https://lastpass.com/
-[22]: https://www.dashlane.com/
-[23]: https://1password.com/
-[24]: https://lastpass.com/misc_download2.php
-[25]: https://www.passwordstore.org/
-[26]: https://pwsafe.org/
-[27]: http://upm.sourceforge.net/
-[28]: https://github.com/zdia/gorilla/wiki
diff --git a/sources/tech/20191015 10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool.md b/sources/tech/20191015 10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool.md
deleted file mode 100644
index 2cf9c93596..0000000000
--- a/sources/tech/20191015 10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool.md
+++ /dev/null
@@ -1,167 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool)
-[#]: via: (https://itsfoss.com/gnome-tweak-tool/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-10 Ways to Customize Your Linux Desktop With GNOME Tweaks Tool
-======
-
-![GNOME Tweak Tool Icon][1]
-
-There are several ways you can tweak Ubuntu to customize its looks and behavior. The easiest way I find is by using the [GNOME Tweak tool][2]. It is also known as GNOME Tweaks or simply Tweaks.
-
-I have mentioned it numerous time in my tutorials in the past. Here, I list all the major tweaks you can perform with this tool.
-
-I have used Ubuntu here but the steps should be applicable to any Linux distribution using GNOME desktop environment.
-
-### Install GNOME Tweak tool in Ubuntu 18.04 and other versions
-
-Gnome Tweak tool is available in the [Universe repository in Ubuntu][3] so make sure that you have it enabled in your Software & Updates tool:
-
-![Enable Universe Repository in Ubuntu][4]
-
-After that, you can install GNOME Tweak tool from the software center. Just open the Software Center and search for GNOME Tweaks and install it from there:
-
-![Install GNOME Tweaks Tool from Software Center][5]
-
-Alternatively, you may also use command line to install software with [apt command][6]:
-
-```
-sudo apt install gnome-tweaks
-```
-
-### Customizing GNOME desktop with Tweaks tool
-
-![][7]
-
-GNOME Tweak tool enables you to do a number of settings changes. Some of these changes like wallpaper changes, startup applications etc are also available in the official System Settings tool. I am going to focus on tweaks that are not available in the Settings by default.
-
-#### 1\. Change themes
-
-You can [install new themes in Ubuntu][8] in various ways. But if you want to change to the newly installed theme, you’ll have to install GNOME Tweaks tool.
-
-You can find the theme and icon settings in Appearance section. You can browse through the available themes and icons and set the ones you like. The changes take into effect immediately.
-
-![Change Themes With GNOME Tweaks][9]
-
-#### 2\. Disable animation to speed up your desktop
-
-There are subtle animations for application window opening, closing, maximizing etc. You can disable these animations to speed up your system slightly as it will use slightly fewer resources.
-
-![Disable Animations For Slightly Faster Desktop Experience][10]
-
-#### 3\. Control desktop icons
-
-At least in Ubuntu, you’ll see the Home and Trash icons on the desktop. If you don’t like, you can choose to disable it. You can also choose which icons will be displayed on the desktop.
-
-![Control Desktop Icons in Ubuntu][11]
-
-#### 4\. Manage GNOME extensions
-
-I hope you are aware of [GNOME Extensions][12]. These are small ‘plugins’ for your desktop that extends the functionalities of the GNOME desktop. There are [plenty of GNOME extensions][13] that you can use to get CPU consumption in the top panel, get clipboard history etc.
-
-I have written in detail about [installing and using GNOME extensions][14]. Here, I assume that you are already using them and if that’s the case, you can manage them from within GNOME Tweaks.
-
-![Manage GNOME Extensions][15]
-
-#### 5\. Change fonts and scaling factor
-
-You can [install new fonts in Ubuntu][16] and apply the system wide font change using Tweaks tool. You can also change the scaling factor if you think the icons, text are way too small on your desktop.
-
-![Change Fonts and Scaling Factor][17]
-
-#### 6\. Control touchpad behavior like Disable touchpad while typing, Make right click on touchpad working
-
-The GNOME Tweaks also allows you to disable touchpad while typing. This is useful if you type fast on a laptop. The bottom of your palm may touch the touchpad and the cursor moves away to an undesired location on the screen.
-
-Automatically disabling touchpad while typing fixes this problem.
-
-![Disable Touchpad While Typing][18]
-
-You’ll also notice that [when you press the bottom right corner of your touchpad for right click, nothing happens][19]. There is nothing wrong with your touchpad. It’s a system settings that disables the right clicking this way for any touchpad that doesn’t have a real right click button (like the old Thinkpad laptops). Two finger click gives you the right click.
-
-You can also get this back by choosing Area in under Mouse Click Simulation instead of Fingers.
-
-![Fix Right Click Issue][20]
-
-You may have to [restart Ubuntu][21] in order to take the changes in effect. If you are Emacs lover, you can also force keybindings from Emacs.
-
-#### 7\. Change power settings
-
-There is only one power settings here. It allows you to put your laptop in suspend mode when the lid is closed.
-
-![Power Settings in GNOME Tweaks Tool][22]
-
-#### 8\. Decide what’s displayed in the top panel
-
-The top panel in your desktop gives shows a few important things. You have the calendar, network icon, system settings and the Activities option.
-
-You can also [display battery percentage][23], add date along with day and time and show week numbers. You can also enable hot corners so that if you take your mouse to the top left corner of the screen, you’ll get the activities view with all the running applications.
-
-![Top Panel Settings in GNOME Tweaks Tool][24]
-
-If you have the mouse focus on an application window, you’ll notice that it’s menu is displayed in the top panel. If you don’t like it, you may toggle it off and then the application menu will be available on the application itself.
-
-#### 9\. Configure application window
-
-You can decide if maximize and minimize option (the buttons on the top right corner) will be shown in the application window. You may also change their positioning between left and right.
-
-![Application Window Configuration][25]
-
-There are some other configuration options as well. I don’t use them but feel free to explore them on your own.
-
-#### 10\. Configure workspaces
-
-GNOME Tweaks tool also allows you to configure a couple of things around workspaces.
-
-![Configure Workspaces in Ubuntu][26]
-
-**In the end…**
-
-GNOME Tweaks tool is a must have utility for any GNOME user. It helps you configure looks and functionality of the desktop. I find it surprising that this tool is not even in Main repository of Ubuntu. In my opinion, it should be installed by default. Till then, you’ll have to install GNOME Tweak tool in Ubuntu manually.
-
-If you find some hidden gem in GNOME Tweaks that hasn’t been discussed here, why not share it with the rest of us?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/gnome-tweak-tool/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/gnome-tweak-tool-icon.png?ssl=1
-[2]: https://wiki.gnome.org/action/show/Apps/Tweaks?action=show&redirect=Apps%2FGnomeTweakTool
-[3]: https://itsfoss.com/ubuntu-repositories/
-[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/enable-repositories-ubuntu.png?ssl=1
-[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/install-gnome-tweaks-tool.jpg?ssl=1
-[6]: https://itsfoss.com/apt-command-guide/
-[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/customize-gnome-with-tweak-tool.jpg?ssl=1
-[8]: https://itsfoss.com/install-themes-ubuntu/
-[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/change-theme-ubuntu-gnome.jpg?ssl=1
-[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/disable-animation-ubuntu-gnome.jpg?ssl=1
-[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/desktop-icons-ubuntu.jpg?ssl=1
-[12]: https://extensions.gnome.org/
-[13]: https://itsfoss.com/best-gnome-extensions/
-[14]: https://itsfoss.com/gnome-shell-extensions/
-[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/manage-gnome-extension-tweaks-tool.jpg?ssl=1
-[16]: https://itsfoss.com/install-fonts-ubuntu/
-[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/change-fonts-ubuntu-gnome.jpg?ssl=1
-[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/disable-touchpad-while-typing-ubuntu.jpg?ssl=1
-[19]: https://itsfoss.com/fix-right-click-touchpad-ubuntu/
-[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/enable-right-click-ubuntu.jpg?ssl=1
-[21]: https://itsfoss.com/schedule-shutdown-ubuntu/
-[22]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/power-settings-gnome-tweaks-tool.jpg?ssl=1
-[23]: https://itsfoss.com/display-battery-ubuntu/
-[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/top-panel-settings-gnome-tweaks-tool.jpg?ssl=1
-[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/windows-configuration-ubuntu-gnome-tweaks.jpg?ssl=1
-[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/configure-workspaces-ubuntu.jpg?ssl=1
diff --git a/sources/tech/20191021 Transition to Nftables.md b/sources/tech/20191021 Transition to Nftables.md
deleted file mode 100644
index a6b7af0e08..0000000000
--- a/sources/tech/20191021 Transition to Nftables.md
+++ /dev/null
@@ -1,185 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Transition to Nftables)
-[#]: via: (https://opensourceforu.com/2019/10/transition-to-nftables/)
-[#]: author: (Vijay Marcel D https://opensourceforu.com/author/vijay-marcel/)
-
-Transition to Nftables
-======
-
-[![][1]][2]
-
-_Every major distribution in the open source world is moving towards nftables as the default firewall. In short, the venerable Iptables is now dead. This article is a tutorial on how to build nftables._
-
-Currently, there is an iptables-nft backend that is compatible with nftables but soon, even this will not be available. Also, as noted by Red Hat developers, sometimes it may translate the rules incorrectly. Rather than rely on an iptables-to-nftables converter, we need to know how to build our own nftables. In nftables, all the address families come under one rule. Nftables runs in the user space unlike iptables, where every module is in the kernel. It also needs less kernel updates and comes with new features such as maps, families and dictionaries.
-
-**Address families**
-Address families determine the types of packets that are processed. There are six address families in nftables and they are:
-
- * ip
- * ipv6
- * inet
- * arp
- * bridge
- * netdev
-
-
-
-In nftables, the ipv4 and ipv6 protocols are combined into one single family called inet. So we do not need to specify two rules – one for ipv4 and another for ipv6. If no address family is specified, it will default to ip protocol, i.e., ipv4. Our area of interest lies in the inet family, since most home users will use either ipv4 or ipv6 protocols (see Figure 1).
-
-**Nftables**
-A typical nftable rule contains three parts – table, chain and rules.
-Tables are containers for chains and rules. They are identified by their address families and their names. Chains contain the rules needed for the _inet/arp/bridge/netdev_ protocols and are of three types — filter, NAT and route. Nftable rules can be loaded from a script or they can be typed into a terminal and then saved as a rule-set. For home users, the default chain will be filter. The inet family contains the following hooks:
-
- * Input
- * Output
- * Forward
- * Pre-routing
- * Post-routing
-
-
-
-**To script or not to script?**
-One of the biggest questions is whether we can use a firewall script or not. The answer is: it’s your choice. Here’s some advice – if you have hundreds of rules in your firewall, then it is best to use a script, but if you are a typical home user, then you can type the commands in the terminal and then load your rule-set. Each option has its own advantages and disadvantages. In this article, we will type them in the terminal to build our firewall.
-
-Nftables uses a program called nft to add, create, list, delete and load rules. Make sure nftables is installed along with conntrackd and netfilter-persistent, and remove iptables, using the following command:
-
-```
-apt-get install nftables conntrackd netfilter-persistent
-apt-get purge iptables
-```
-
-_nft_ needs to be run as root or use sudo. Use the following commands to list, flush, delete ruleset and load the script respectively.
-
-```
-nft list ruleset
-nft flush ruleset
-nft delete table inet filter
-/usr/sbin/nft -f /etc/nftables.conf
-```
-
-**Input policy**
-The firewall will contain three parts – input, forward and output – just like in iptables. In the terminal, type the following commands for the input firewall. Make sure you have flushed your rule-set before you begin. Our default policy will be to drop everything. We will use the inet family in the firewall. Add the following rules as root or use sudo:
-
-```
-nft add table inet filter
-nft add chain inet filter input { type filter hook input priority 0 \; counter \; policy drop \; }
-```
-
-You have noticed there is something called _priority 0_. It means giving the rule higher precedence. Hooks typically give higher precedence to the negative integer. Every hook has its own precedence and the filter chain has priority 0. You can check the nftables wiki page to see the priority of each hook.
-To know the network interfaces in your computer, run the following command:
-
-```
-ip link show
-```
-
-It will show the installed network interface, one local host and other Ethernet port or your wireless port. Your Ethernet port’s name looks something like this: _enpXsY_ where X and Y are numbers, and the same goes for your wireless port. We have to allow the local host and only allow established incoming connections from the Internet.
-Nftables has a feature called verdict statements on how to parse a rule. The verdict statements are _accept, drop, queue, jump, goto, continue_ and _return_. Since the firewall is a simple one, we will use either _accept_ or _drop the packets_ (Figure 2).
-
-```
-nft add rule inet filter input iifname lo accept
-nft add rule inet filter input iifname enpXsY ct state new, established, related accept
-```
-
-Next, we have to add rules to protect us from stealth scans. Not all stealth scans are malicious but most of them are. We have to protect the network from such scans. The first set lists the TCP flags to be tested. Of these flags, the second set lists the flags to be matched with the first.
-
-```
-nft add rule inet filter input iifname enpXsY tcp flags \& \(syn\|fin\) == \(syn\|fin\) drop
-nft add rule inet filter input iifname enpXsY tcp flags \& \(syn\|rst\) == \(syn\|rst\) drop
-nft add rule inet filter input iifname enpXsY tcp flags \& \(fin\|rst\) == \(fin\|rst\) drop
-nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|fin\) == fin drop
-nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|psh\) == psh drop
-nft add rule inet filter input iifname enpXsY tcp flags \& \(ack\|urg\) == urg drop
-```
-
-Remember, we are typing these commands in the terminal. So we have to add a backslash before some special characters, to make sure the terminal interprets it as it should. If you are using a script, then this isn’t required.
-
-**A word of caution regarding ICMP**
-The Internet Control Message Protocol (ICMP) is a diagnostic tool and so should not be dropped outright. Any attempt to fully block ICMP is unwise as it will also stop giving error messages to us. Enable only the most important control messages such as echo-request, echo-reply, destination-unreachable and time-exceeded, and reject the rest. Echo-request and echo-reply are part of ping. In the input, we only allow echo reply and in the output, we only allow the echo-request.
-
-```
-nft add rule inet filter input iifname enpXsY icmp type { echo-reply, destination-unreachable, time-exceeded } limit rate 1/second accept
-nft add rule inet filter input iifname enpXsY ip protocol icmp drop
-```
-
-Finally, we are logging and dropping all the invalid packets.
-
-```
-nft add rule inet filter input iifname enpXsY ct state invalid log flags all level info prefix \”Invalid-Input: \”
-nft add rule inet filter input iifname enpXsY ct state invalid drop
-```
-
-**Forward and output policy**
-In both the forward and output policies, we will drop packets by default and only accept those that are established connections.
-
-```
-nft add chain inet filter forward { type filter hook forward priority 0 \; counter \; policy drop \; }
-nft add rule inet filter forward ct state established, related accept
-nft add rule inet filter forward ct state invalid drop
-nft add chain inet filter output { type filter hook output priority 0 \; counter \; policy drop \; }
-```
-
-A typical desktop user needs only Port 80 and 443 to be allowed to access the Internet. Finally, allow acceptable ICMP protocols and drop the invalid packets while logging them.
-
-```
-nft add rule inet filter output oifname enpXsY tcp dport { 80, 443 } ct state established accept
-nft add rule inet filter output oifname enpXsY icmp type { echo-request, destination-unreachable, time-exceeded } limit rate 1/second accept
-nft add rule inet filter output oifname enpXsY ip protocol icmp drop
-nft add rule inet filter output oifname enpXsY ct state invalid log flags all level info prefix \”Invalid-Output: \”
-nft add rule inet filter output oifname enpXsY ct state invalid drop
-```
-
-Now we have to save our rule-set, otherwise it will be lost when we reboot. To do so, run the following command:
-
-```
-sudo nft list ruleset. > /etc/nftables.conf
-```
-
-We now have to load nftables at boot, for that enables the nftables service in systemd:
-
-```
-sudo systemctl enable nftables
-```
-
-Next, edit the nftables unit file to remove the Execstop option to avoid flushing the rule-set at every boot. The file is usually located in /etc/systemd/system/sysinit.target.wants/nftables.service. Now restart the nftables:
-
-```
-sudo systemctl restart nftables
-```
-
-**Logging in rsyslog**
-When you log the dropped packets, they go straight to _syslog_, which makes reading your log file quite difficult. It is better to redirect your firewall logs to a separate file. Create a directory called nftables in
-_/var/log_ and in it, create two files called _input.log_ and _output.log_ to store the input and output logs, respectively. Make sure rsyslog is installed in your system. Now go to _/etc/rsyslog.d_ and create a file called _nftables.conf_ with the following contents:
-
-```
-:msg,regex,”Invalid-Input: “ -/var/log/nftables/Input.log
-:msg,regex,”Invalid-Output: “ -/var/log/nftables/Output.log
-& stop
-```
-
-Now we have to make sure the log is manageable. For that, create another file in _/etc/logrotate.d_ called nftables with the following code:
-
-```
-/var/log/nftables/* { rotate 5 daily maxsize 50M missingok notifempty delaycompress compress postrotate invoke-rc.d rsyslog rotate > /dev/null endscript }
-```
-
-Restart nftables. You can now check your rule-set. If you feel typing each command in the terminal is bothersome, you can use a script to load the nftables firewall. I hope this article is useful in protecting your system.
-
---------------------------------------------------------------------------------
-
-via: https://opensourceforu.com/2019/10/transition-to-nftables/
-
-作者:[Vijay Marcel D][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensourceforu.com/author/vijay-marcel/
-[b]: https://github.com/lujun9972
-[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/01/REHfirewall-1.jpg?resize=696%2C481&ssl=1 (REHfirewall)
-[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/01/REHfirewall-1.jpg?fit=900%2C622&ssl=1
diff --git a/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md b/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md
index 2d92d9a66c..024af38122 100644
--- a/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md
+++ b/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md
@@ -4,7 +4,7 @@
[#]: publisher: ( )
[#]: url: ( )
[#]: subject: (How to program with Bash: Logical operators and shell expansions)
-[#]: via: (https://opensource.com/article/19/10/programming-bash-part-2)
+[#]: via: (https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions)
[#]: author: (David Both https://opensource.com/users/dboth)
How to program with Bash: Logical operators and shell expansions
@@ -482,7 +482,7 @@ The third article in this series will explore the use of loops for performing va
--------------------------------------------------------------------------------
-via: https://opensource.com/article/19/10/programming-bash-part-2
+via: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
作者:[David Both][a]
选题:[lujun9972][b]
diff --git a/sources/tech/20191022 Initializing arrays in Java.md b/sources/tech/20191022 Initializing arrays in Java.md
deleted file mode 100644
index 7971ec104b..0000000000
--- a/sources/tech/20191022 Initializing arrays in Java.md
+++ /dev/null
@@ -1,389 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (laingke)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Initializing arrays in Java)
-[#]: via: (https://opensource.com/article/19/10/initializing-arrays-java)
-[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
-
-Initializing arrays in Java
-======
-Arrays are a helpful data type for managing collections elements best
-modeled in contiguous memory locations. Here's how to use them
-effectively.
-![Coffee beans and a cup of coffee][1]
-
-People who have experience programming in languages like C or FORTRAN are familiar with the concept of arrays. They’re basically a contiguous block of memory where each location is a certain type: integers, floating-point numbers, or what-have-you.
-
-The situation in Java is similar, but with a few extra wrinkles.
-
-### An example array
-
-Let’s make an array of 10 integers in Java:
-
-
-```
-int[] ia = new int[10];
-```
-
-What’s going on in the above piece of code? From left to right:
-
- 1. The **int[]** to the extreme left declares the _type_ of the variable as an array (denoted by the **[]**) of **int**.
-
- 2. To the right is the _name_ of the variable, which in this case is **ia**.
-
- 3. Next, the **=** tells us that the variable defined on the left side is set to what’s to the right side.
-
- 4. To the right of the **=** we see the word **new**, which in Java indicates that an object is being _initialized_, meaning that storage is allocated and its constructor is called ([see here for more information][2]).
-
- 5. Next, we see **int[10]**, which tells us that the specific object being initialized is an array of 10 integers.
-
-
-
-
-Since Java is strongly-typed, the type of the variable **ia** must be compatible with the type of the expression on the right-hand side of the **=**.
-
-### Initializing the example array
-
-Let’s put this simple array in a piece of code and try it out. Save the following in a file called **Test1.java**, use **javac** to compile it, and use **java** to run it (in the terminal of course):
-
-
-```
-import java.lang.*;
-
-public class Test1 {
-
- public static void main([String][3][] args) {
- int[] ia = new int[10]; // See note 1 below
- [System][4].out.println("ia is " + ia.getClass()); // See note 2 below
- for (int i = 0; i < ia.length; i++) // See note 3 below
- [System][4].out.println("ia[" + i + "] = " + ia[i]); // See note 4 below
- }
-
-}
-```
-
-Let’s work through the most important bits.
-
- 1. Our declaration and initialization of the array of 10 integers, **ia**, is easy to spot.
- 2. In the line just following, we see the expression **ia.getClass()**. That’s right, **ia** is an _object_ belonging to a _class_, and this code will let us know which class that is.
- 3. In the next line following that, we see the start of the loop **for (int i = 0; i < ia.length; i++)**, which defines a loop index variable **i** that runs through a sequence from zero to one less than **ia.length**, which is an expression that tells us how many elements are defined in the array **ia**.
- 4. Next, the body of the loop prints out the values of each element of **ia**.
-
-
-
-When this program is compiled and run, it produces the following results:
-
-
-```
-me@mydesktop:~/Java$ javac Test1.java
-me@mydesktop:~/Java$ java Test1
-ia is class [I
-ia[0] = 0
-ia[1] = 0
-ia[2] = 0
-ia[3] = 0
-ia[4] = 0
-ia[5] = 0
-ia[6] = 0
-ia[7] = 0
-ia[8] = 0
-ia[9] = 0
-me@mydesktop:~/Java$
-```
-
-The string representation of the output of **ia.getClass()** is **[I**, which is shorthand for "array of integer." Similar to the C programming language, Java arrays begin with element zero and extend up to element **<array size> – 1**. We can see above that each of the elements of **ia** are set to zero (by the array constructor, it seems).
-
-So, is that it? We declare the type, use the appropriate initializer, and we’re done?
-
-Well, no. There are many other ways to initialize an array in Java.
-
-### Why do I want to initialize an array, anyway?
-
-The answer to this question, like that of all good questions, is "it depends." In this case, the answer depends on what we expect to do with the array once it is initialized.
-
-In some cases, arrays emerge naturally as a type of accumulator. For example, suppose we are writing code for counting the number of calls received and made by a set of telephone extensions in a small office. There are eight extensions, numbered one through eight, plus the operator’s extension, numbered zero. So we might declare two arrays:
-
-
-```
-int[] callsMade;
-int[] callsReceived;
-```
-
-Then, whenever we start a new period of accumulating call statistics, we initialize each array as:
-
-
-```
-callsMade = new int[9];
-callsReceived = new int[9];
-```
-
-At the end of each period of accumulating call statistics, we can print out the stats. In very rough terms, we might see:
-
-
-```
-import java.lang.*;
-import java.io.*;
-
-public class Test2 {
-
- public static void main([String][3][] args) {
-
- int[] callsMade;
- int[] callsReceived;
-
- // initialize call counters
-
- callsMade = new int[9];
- callsReceived = new int[9];
-
- // process calls...
- // an extension makes a call: callsMade[ext]++
- // an extension receives a call: callsReceived[ext]++
-
- // summarize call statistics
-
- [System][4].out.printf("%3s%25s%25s\n","ext"," calls made",
- "calls received");
- for (int ext = 0; ext < callsMade.length; ext++)
- [System][4].out.printf("%3d%25d%25d\n",ext,
- callsMade[ext],callsReceived[ext]);
-
- }
-
-}
-```
-
-Which would produce output something like this:
-
-
-```
-me@mydesktop:~/Java$ javac Test2.java
-me@mydesktop:~/Java$ java Test2
-ext calls made calls received
- 0 0 0
- 1 0 0
- 2 0 0
- 3 0 0
- 4 0 0
- 5 0 0
- 6 0 0
- 7 0 0
- 8 0 0
-me@mydesktop:~/Java$
-```
-
-Not a very busy day in the call center.
-
-In the above example of an accumulator, we see that the starting value of zero as set by the array initializer is satisfactory for our needs. But in other cases, this starting value may not be the right choice.
-
-For example, in some kinds of geometric computations, we might need to initialize a two-dimensional array to the identity matrix (all zeros except for the ones along the main diagonal). We might choose to do this as:
-
-
-```
- double[][] m = new double[3][3];
- for (int d = 0; d < 3; d++)
- m[d][d] = 1.0;
-```
-
-In this case, we rely on the array initializer **new double[3][3]** to set the array to zeros, and then use a loop to set the diagonal elements to ones. In this simple case, we might use a shortcut that Java provides:
-
-
-```
- double[][] m = {
- {1.0, 0.0, 0.0},
- {0.0, 1.0, 0.0},
- {0.0, 0.0, 1.0}};
-```
-
-This type of visual structure is particularly appropriate in this sort of application, where it can be a useful double-check to see the actual layout of the array. But in the case where the number of rows and columns is only determined at run time, we might instead see something like this:
-
-
-```
- int nrc;
- // some code determines the number of rows & columns = nrc
- double[][] m = new double[nrc][nrc];
- for (int d = 0; d < nrc; d++)
- m[d][d] = 1.0;
-```
-
-It’s worth mentioning that a two-dimensional array in Java is actually an array of arrays, and there’s nothing stopping the intrepid programmer from having each one of those second-level arrays be a different length. That is, something like this is completely legitimate:
-
-
-```
-int [][] differentLengthRows = {
- { 1, 2, 3, 4, 5},
- { 6, 7, 8, 9},
- {10,11,12},
- {13,14},
- {15}};
-```
-
-There are various linear algebra applications that involve irregularly-shaped matrices, where this type of structure could be applied (for more information see [this Wikipedia article][5] as a starting point). Beyond that, now that we understand that a two-dimensional array is actually an array of arrays, it shouldn’t be too much of a surprise that:
-
-
-```
-differentLengthRows.length
-```
-
-tells us the number of rows in the two-dimensional array **differentLengthRows**, and:
-
-
-```
-differentLengthRows[i].length
-```
-
-tells us the number of columns in row **i** of **differentLengthRows**.
-
-### Taking the array further
-
-Considering this idea of array size that is determined at run time, we see that arrays still require us to know that size before instantiating them. But what if we don’t know the size until we’ve processed all of the data? Does that mean we have to process it once to figure out the size of the array, and then process it again? That could be hard to do, especially if we only get one chance to consume the data.
-
-The [Java Collections Framework][6] solves this problem in a nice way. One of the things provided there is the class **ArrayList**, which is like an array but dynamically extensible. To demonstrate the workings of **ArrayList**, let’s create one and initialize it to the first 20 [Fibonacci numbers][7]:
-
-
-```
-import java.lang.*;
-import java.util.*;
-
-public class Test3 {
-
- public static void main([String][3][] args) {
-
- ArrayList<Integer> fibos = new ArrayList<Integer>();
-
- fibos.add(0);
- fibos.add(1);
- for (int i = 2; i < 20; i++)
- fibos.add(fibos.get(i-1) + fibos.get(i-2));
-
- for (int i = 0; i < fibos.size(); i++)
- [System][4].out.println("fibonacci " + i +
- " = " + fibos.get(i));
-
- }
-}
-```
-
-Above, we see:
-
- * The declaration and instantiation of an **ArrayList** that is used to store **Integer**s.
- * The use of **add()** to append to the **ArrayList** instance.
- * The use of **get()** to retrieve an element by index number.
- * The use of **size()** to determine how many elements are already in the **ArrayList** instance.
-
-
-
-Not shown is the **put()** method, which places a value at a given index number.
-
-The output of this program is:
-
-
-```
-fibonacci 0 = 0
-fibonacci 1 = 1
-fibonacci 2 = 1
-fibonacci 3 = 2
-fibonacci 4 = 3
-fibonacci 5 = 5
-fibonacci 6 = 8
-fibonacci 7 = 13
-fibonacci 8 = 21
-fibonacci 9 = 34
-fibonacci 10 = 55
-fibonacci 11 = 89
-fibonacci 12 = 144
-fibonacci 13 = 233
-fibonacci 14 = 377
-fibonacci 15 = 610
-fibonacci 16 = 987
-fibonacci 17 = 1597
-fibonacci 18 = 2584
-fibonacci 19 = 4181
-```
-
-**ArrayList** instances can also be initialized by other techniques. For example, an array can be supplied to the **ArrayList** constructor, or the **List.of()** and **Arrays.asList()** methods can be used when the initial elements are known at compile time. I don’t find myself using these options all that often since my primary use case for an **ArrayList** is when I only want to read the data once.
-
-Moreover, an **ArrayList** instance can be converted to an array using its **toArray()** method, for those who prefer to work with an array once the data is loaded; or, returning to the current topic, once the **ArrayList** instance is initialized.
-
-The Java Collections Framework provides another kind of array-like data structure called a **Map**. What I mean by "array-like" is that a **Map** defines a collection of objects whose values can be set or retrieved by a key, but unlike an array (or an **ArrayList**), this key need not be an integer; it could be a **String** or any other complex object.
-
-For example, we can create a **Map** whose keys are **String**s and whose values are **Integer**s as follows:
-
-
-```
-Map<[String][3],Integer> stoi = new Map<[String][3],Integer>();
-```
-
-Then we can initialize this **Map** as follows:
-
-
-```
-stoi.set("one",1);
-stoi.set("two",2);
-stoi.set("three",3);
-```
-
-And so on. Later, when we want to know the numeric value of **"three"**, we can retrieve it as:
-
-
-```
-stoi.get("three");
-```
-
-In my world, a **Map** is useful for converting strings occurring in third-party datasets into coherent code values in my datasets. As a part of a [data transformation pipeline][8], I will often build a small standalone program to clean the data before processing it; for this, I will almost always use one or more **Map**s.
-
-Worth mentioning is that it’s quite possible, and sometimes reasonable, to have **ArrayLists** of **ArrayLists** and **Map**s of **Map**s. For example, let’s assume we’re looking at trees, and we’re interested in accumulating the count of the number of trees by tree species and age range. Assuming that the age range definition is a set of string values ("young," "mid," "mature," and "old") and that the species are string values like "Douglas fir," "western red cedar," and so forth, then we might define a **Map** of **Map**s as:
-
-
-```
-Map<[String][3],Map<[String][3],Integer>> counter =
- new Map<[String][3],Map<[String][3],Integer>>();
-```
-
-One thing to watch out for here is that the above only creates storage for the _rows_ of **Map**s. So, our accumulation code might look like:
-
-
-```
-// assume at this point we have figured out the species
-// and age range
-if (!counter.containsKey(species))
- counter.put(species,new Map<[String][3],Integer>());
-if (!counter.get(species).containsKey(ageRange))
- counter.get(species).put(ageRange,0);
-```
-
-At which point, we can start accumulating as:
-
-
-```
-counter.get(species).put(ageRange,
- counter.get(species).get(ageRange) + 1);
-```
-
-Finally, it’s worth mentioning that the (new in Java 8) Streams facility can also be used to initialize arrays, **ArrayList** instances, and **Map** instances. A nice discussion of this feature can be found [here][9] and [here][10].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/10/initializing-arrays-java
-
-作者:[Chris Hermansen][a]
-选题:[lujun9972][b]
-译者:[laingke](https://github.com/laingke)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/clhermansen
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-mug.jpg?itok=Bj6rQo8r (Coffee beans and a cup of coffee)
-[2]: https://opensource.com/article/19/8/what-object-java
-[3]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
-[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
-[5]: https://en.wikipedia.org/wiki/Irregular_matrix
-[6]: https://en.wikipedia.org/wiki/Java_collections_framework
-[7]: https://en.wikipedia.org/wiki/Fibonacci_number
-[8]: https://towardsdatascience.com/data-science-for-startups-data-pipelines-786f6746a59a
-[9]: https://stackoverflow.com/questions/36885371/lambda-expression-to-initialize-array
-[10]: https://stackoverflow.com/questions/32868665/how-to-initialize-a-map-using-a-lambda
diff --git a/sources/tech/20191023 Building container images with the ansible-bender tool.md b/sources/tech/20191023 Building container images with the ansible-bender tool.md
deleted file mode 100644
index 2056e4e4b7..0000000000
--- a/sources/tech/20191023 Building container images with the ansible-bender tool.md
+++ /dev/null
@@ -1,154 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Building container images with the ansible-bender tool)
-[#]: via: (https://opensource.com/article/19/10/building-container-images-ansible)
-[#]: author: (Tomas Tomecek https://opensource.com/users/tomastomecek)
-
-Building container images with the ansible-bender tool
-======
-Learn how to use Ansible to execute commands in a container.
-![Blocks for building][1]
-
-Containers and [Ansible][2] blend together so nicely—from management and orchestration to provisioning and building. In this article, we'll focus on the building part.
-
-If you are familiar with Ansible, you know that you can write a series of tasks, and the **ansible-playbook** command will execute them for you. Did you know that you can also execute such commands in a container environment and get the same result as if you'd written a Dockerfile and run **podman build**.
-
-Here is an example:
-
-
-```
-\- name: Serve our file using httpd
- hosts: all
- tasks:
- - name: Install httpd
- package:
- name: httpd
- state: installed
- - name: Copy our file to httpd’s webroot
- copy:
- src: our-file.txt
- dest: /var/www/html/
-```
-
-You could execute this playbook locally on your web server or in a container, and it would work—as long as you remember to create the **our-file.txt** file first.
-
-But something is missing. You need to start (and configure) httpd in order for your file to be served. This is a difference between container builds and infrastructure provisioning: When building an image, you just prepare the content; running the container is a different task. On the other hand, you can attach metadata to the container image that tells the command to run by default.
-
-Here's where a tool would help. How about trying **ansible-bender**?
-
-
-```
-`$ ansible-bender build the-playbook.yaml fedora:30 our-httpd`
-```
-
-This script uses the ansible-bender tool to execute the playbook against a Fedora 30 container image and names the resulting container image **our-httpd**.
-
-But when you run that container, it won't start httpd because it doesn't know how to do it. You can fix this by adding some metadata to the playbook:
-
-
-```
-\- name: Serve our file using httpd
- hosts: all
- vars:
- ansible_bender:
- base_image: fedora:30
- target_image:
- name: our-httpd
- cmd: httpd -DFOREGROUND
- tasks:
- - name: Install httpd
- package:
- name: httpd
- state: installed
- - name: Listen on all network interfaces.
- lineinfile:
- path: /etc/httpd/conf/httpd.conf
- regexp: '^Listen '
- line: Listen 0.0.0.0:80
- - name: Copy our file to httpd’s webroot
- copy:
- src: our-file.txt
- dest: /var/www/html
-```
-
-Now you can build the image (from here on, please run all the commands as root—currently, Buildah and Podman won't create dedicated networks for rootless containers):
-
-
-```
-# ansible-bender build the-playbook.yaml
-PLAY [Serve our file using httpd] ****************************************************
-
-TASK [Gathering Facts] ***************************************************************
-ok: [our-httpd-20191004-131941266141-cont]
-
-TASK [Install httpd] *****************************************************************
-loaded from cache: 'f053578ed2d47581307e9ba3f64f4b4da945579a082c6f99bd797635e62befd0'
-skipping: [our-httpd-20191004-131941266141-cont]
-
-TASK [Listen on all network interfaces.] *********************************************
-changed: [our-httpd-20191004-131941266141-cont]
-
-TASK [Copy our file to httpd’s webroot] **********************************************
-changed: [our-httpd-20191004-131941266141-cont]
-
-PLAY RECAP ***************************************************************************
-our-httpd-20191004-131941266141-cont : ok=3 changed=2 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
-
-Getting image source signatures
-Copying blob sha256:4650c04b851c62897e9c02c6041a0e3127f8253fafa3a09642552a8e77c044c8
-Copying blob sha256:87b740bba596291af8e9d6d91e30a01d5eba9dd815b55895b8705a2acc3a825e
-Copying blob sha256:82c21252bd87532e93e77498e3767ac2617aa9e578e32e4de09e87156b9189a0
-Copying config sha256:44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
-Writing manifest to image destination
-Storing signatures
-44c6dc6dda1afe28892400c825de1c987c4641fd44fa5919a44cf0a94f58949f
-Image 'our-httpd' was built successfully \o/
-```
-
-The image is built, and it's time to run the container:
-
-
-```
-# podman run our-httpd
-AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.88.2.106. Set the 'ServerName' directive globally to suppress this message
-```
-
-Is your file being served? First, find out the IP of your container:
-
-
-```
-# podman inspect -f '{{ .NetworkSettings.IPAddress }}' 7418570ba5a0
-10.88.2.106
-```
-
-And now you can check:
-
-
-```
-$ curl
-Ansible is ❤
-```
-
-What were the contents of your file?
-
-This was just an introduction to building container images with Ansible. If you want to learn more about what ansible-bender can do, please check it out on [GitHub][3]. Happy building!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/10/building-container-images-ansible
-
-作者:[Tomas Tomecek][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/tomastomecek
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/blocks_building.png?itok=eMOT-ire (Blocks for building)
-[2]: https://www.ansible.com/
-[3]: https://github.com/ansible-community/ansible-bender
diff --git a/sources/tech/20191023 How to dual boot Windows 10 and Debian 10.md b/sources/tech/20191023 How to dual boot Windows 10 and Debian 10.md
index 6bc74a6b8e..d445417c83 100644
--- a/sources/tech/20191023 How to dual boot Windows 10 and Debian 10.md
+++ b/sources/tech/20191023 How to dual boot Windows 10 and Debian 10.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (wenwensnow)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20191023 How to program with Bash- Loops.md b/sources/tech/20191023 How to program with Bash- Loops.md
index b32748b397..e582bda447 100644
--- a/sources/tech/20191023 How to program with Bash- Loops.md
+++ b/sources/tech/20191023 How to program with Bash- Loops.md
@@ -4,7 +4,7 @@
[#]: publisher: ( )
[#]: url: ( )
[#]: subject: (How to program with Bash: Loops)
-[#]: via: (https://opensource.com/article/19/10/programming-bash-part-3)
+[#]: via: (https://opensource.com/article/19/10/programming-bash-loops)
[#]: author: (David Both https://opensource.com/users/dboth)
How to program with Bash: Loops
@@ -334,7 +334,7 @@ Many years ago, despite being familiar with other shell languages and Perl, I ma
--------------------------------------------------------------------------------
-via: https://opensource.com/article/19/10/programming-bash-part-3
+via: https://opensource.com/article/19/10/programming-bash-loops
作者:[David Both][a]
选题:[lujun9972][b]
diff --git a/sources/tech/20191023 Using SSH port forwarding on Fedora.md b/sources/tech/20191023 Using SSH port forwarding on Fedora.md
deleted file mode 100644
index 5bf45983d2..0000000000
--- a/sources/tech/20191023 Using SSH port forwarding on Fedora.md
+++ /dev/null
@@ -1,106 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Using SSH port forwarding on Fedora)
-[#]: via: (https://fedoramagazine.org/using-ssh-port-forwarding-on-fedora/)
-[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
-
-Using SSH port forwarding on Fedora
-======
-
-![][1]
-
-You may already be familiar with using the _[ssh][2]_ [command][2] to access a remote system. The protocol behind _ssh_ allows terminal input and output to flow through a [secure channel][3]. But did you know that you can also use _ssh_ to send and receive other data securely as well? One way is to use _port forwarding_, which allows you to connect network ports securely while conducting your _ssh_ session. This article shows you how it works.
-
-### About ports
-
-A standard Linux system has a set of network ports already assigned, from 0-65535. Your system reserves ports up to 1023 for system use. In many systems you can’t elect to use one of these low-numbered ports. Quite a few ports are commonly expected to run specific services. You can find these defined in your system’s _/etc/services_ file.
-
-You can think of a network port like a physical port or jack to which you can connect a cable. That port may connect to some sort of service on the system, like wiring behind that physical jack. An example is the Apache web server (also known as _httpd_). The web server usually claims port 80 on the host system for HTTP non-secure connections, and 443 for HTTPS secure connections.
-
-When you connect to a remote system, such as with a web browser, you are also “wiring” your browser to a port on your host. This is usually a random high port number, such as 54001. The port on your host connects to the port on the remote host, such as 443 to reach its secure web server.
-
-So why use port forwarding when you have so many ports available? Here are a couple common cases in the life of a web developer.
-
-### Local port forwarding
-
-Imagine that you are doing web development on a remote system called _remote.example.com_. You usually reach this system via _ssh_ but it’s behind a firewall that allows very little additional access, and blocks most other ports. To try out your web app, it’s helpful to be able to use your web browser to point to the remote system. But you can’t reach it via the normal method of typing the URL in your browser, thanks to that pesky firewall.
-
-Local forwarding allows you to tunnel a port available via the remote system through your _ssh_ connection. The port appears as a local port on your system (thus “local forwarding.”)
-
-Let’s say your web app is running on port 8000 on the _remote.example.com_ box. To locally forward that system’s port 8000 to your system’s port 8000, use the _-L_ option with _ssh_ when you start your session:
-
-```
-$ ssh -L 8000:localhost:8000 remote.example.com
-```
-
-Wait, why did we use _localhost_ as the target for forwarding? It’s because from the perspective of _remote.example.com_, you’re asking the host to use its own port 8000. (Recall that any host usually can refer to itself as _localhost_ to connect to itself via a network connection.) That port now connects to your system’s port 8000. Once the _ssh_ session is ready, keep it open, and you can type __ in your browser to see your web app. The traffic between systems now travels securely over an _ssh_ tunnel!
-
-If you have a sharp eye, you may have noticed something. What if we used a different hostname than _localhost_ for the _remote.example.com_ to forward? If it can reach a port on another system on its network, it usually can forward that port just as easily. For example, say you wanted to reach a MariaDB or MySQL service on the _db.example.com_ box also on the remote network. This service typically runs on port 3306. So you could forward it with this command, even if you can’t _ssh_ to the actual _db.example.com_ host:
-
-```
-$ ssh -L 3306:db.example.com:3306 remote.example.com
-```
-
-Now you can run MariaDB commands against your _localhost_ and you’re actually using the _db.example.com_ box.
-
-### Remote port forwarding
-
-Remote forwarding lets you do things the opposite way. Imagine you’re designing a web app for a friend at the office, and want to show them your work. Unfortunately, though, you’re working in a coffee shop, and because of the network setup, they can’t reach your laptop via a network connection. However, you both use the _remote.example.com_ system at the office and you can still log in there. Your web app seems to be running well on port 5000 locally.
-
-Remote port forwarding lets you tunnel a port from your local system through your _ssh_ connection, and make it available on the remote system. Just use the _-R_ option when you start your _ssh_ session:
-
-```
-$ ssh -R 6000:localhost:5000 remote.example.com
-```
-
-Now when your friend inside the corporate firewall runs their browser, they can point it at __ and see your work. And as in the local port forwarding example, the communications travel securely over your _ssh_ session.
-
-By default the _sshd_ daemon running on a host is set so that **only** that host can connect to its remote forwarded ports. Let’s say your friend wanted to be able to let people on other _example.com_ corporate hosts see your work, and they weren’t on _remote.example.com_ itself. You’d need the owner of the _remote.example.com_ host to add **one** of these options to _/etc/ssh/sshd_config_ on that box:
-
-```
-GatewayPorts yes # OR
-GatewayPorts clientspecified
-```
-
-The first option means remote forwarded ports are available on all the network interfaces on _remote.example.com_. The second means that the client who sets up the tunnel gets to choose the address. This option is set to **no** by default.
-
-With this option, you as the _ssh_ client must still specify the interfaces on which the forwarded port on your side can be shared. Do this by adding a network specification before the local port. There are several ways to do this, including the following:
-
-```
-$ ssh -R *:6000:localhost:5000 # all networks
-$ ssh -R 0.0.0.0:6000:localhost:5000 # all networks
-$ ssh -R 192.168.1.15:6000:localhost:5000 # single network
-$ ssh -R remote.example.com:6000:localhost:5000 # single network
-```
-
-### Other notes
-
-Notice that the port numbers need not be the same on local and remote systems. In fact, at times you may not even be able to use the same port. For instance, normal users may not to forward onto a system port in a default setup.
-
-In addition, it’s possible to restrict forwarding on a host. This might be important to you if you need tighter security on a network-connected host. The _PermitOpen_ option for the _sshd_ daemon controls whether, and which, ports are available for TCP forwarding. The default setting is **any**, which allows all the examples above to work. To disallow any port fowarding, choose **none**, or choose only a specific **host:port** setting to permit. For more information, search for _PermitOpen_ in the manual page for _sshd_ daemon configuration:
-
-```
-$ man sshd_config
-```
-
-Finally, remember port forwarding only happens as long as the controlling _ssh_ session is open. If you need to keep the forwarding active for a long period, try running the session in the background using the _-N_ option. Make sure your console is locked to prevent tampering while you’re away from it.
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/using-ssh-port-forwarding-on-fedora/
-
-作者:[Paul W. Frields][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/pfrields/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/10/ssh-port-forwarding-816x345.jpg
-[2]: https://en.wikipedia.org/wiki/Secure_Shell
-[3]: https://fedoramagazine.org/open-source-ssh-clients/
diff --git a/sources/tech/20191024 Get sorted with sort at the command line.md b/sources/tech/20191024 Get sorted with sort at the command line.md
new file mode 100644
index 0000000000..ff291f39bc
--- /dev/null
+++ b/sources/tech/20191024 Get sorted with sort at the command line.md
@@ -0,0 +1,250 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get sorted with sort at the command line)
+[#]: via: (https://opensource.com/article/19/10/get-sorted-sort)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Get sorted with sort at the command line
+======
+Reorganize your data in a format that makes sense to you—right from the
+Linux, BSD, or Mac terminal—with the sort command.
+![Coding on a computer][1]
+
+If you've ever used a spreadsheet application, then you know that rows can be sorted by the contents of a column. For instance, if you have a list of expenses, you might want to sort them by date or by ascending price or by category, and so on. If you're comfortable using a terminal, you may not want to have to use a big office application just to sort text data. And that's exactly what the [**sort**][2] command is for.
+
+### Installing
+
+You don't need to install **sort** because it's invariably included on any [POSIX][3] system. On most Linux systems, the **sort** command is bundled in a collection of utilities from the GNU organization. On other POSIX systems, such as BSD and Mac, the default **sort** command is not from GNU, so some options may differ. I'll attempt to account for both GNU and BSD implementations in this article.
+
+### Sort lines alphabetically
+
+The **sort** command, by default, looks at the first character of each line of a file and outputs each line in ascending alphabetic order. In the event that two characters on multiple lines are the same, it considers the next character. For example:
+
+
+```
+$ cat distro.list
+Slackware
+Fedora
+Red Hat Enterprise Linux
+Ubuntu
+Arch
+1337
+Mint
+Mageia
+Debian
+$ sort distro.list
+1337
+Arch
+Debian
+Fedora
+Mageia
+Mint
+Red Hat Enterprise Linux
+Slackware
+Ubuntu
+```
+
+Using **sort** doesn't change the original file. Sort is a filter, so if you want to preserve your data in its sorted form, you must redirect the output using either **>** or **tee**:
+
+
+```
+$ sort distro.list | tee distro.sorted
+1337
+Arch
+Debian
+[...]
+$ cat distro.sorted
+1337
+Arch
+Debian
+[...]
+```
+
+### Sort by column
+
+Complex data sets sometimes need to be sorted by something other than the first letter of each line. Imagine, for instance, a list of animals and each one's species and genus, and each "field" (a "cell" in a spreadsheet) is defined by a predictable delimiter character. This is such a common data format for spreadsheet exports that the CSV (comma-separated values) file extension exists to identify such files (although a CSV file doesn't have to be comma-separated, nor does a delimited file have to use the CSV extension to be valid and usable). Consider this example data set:
+
+
+```
+Aptenodytes;forsteri;Miller,JF;1778;Emperor
+Pygoscelis;papua;Wagler;1832;Gentoo
+Eudyptula;minor;Bonaparte;1867;Little Blue
+Spheniscus;demersus;Brisson;1760;African
+Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+Eudyptes;chrysocome;Viellot;1816;Southern Rockhopper
+Torvaldis;linux;Ewing,L;1996;Tux
+```
+
+Given this sample data set, you can use the **\--field-separator** (use **-t** on BSD and Mac—or on GNU to reduce typing) option to set the delimiting character to a semicolon (because this example uses semicolons instead of commas, but it could use any character), and use the **\--key** (**-k** on BSD and Mac or on GNU to reduce typing) option to define which field to sort by. For example, to sort by the second field (starting at 1, not 0) of each line:
+
+
+```
+sort --field-separator=";" --key=2
+Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
+Spheniscus;demersus;Brisson;1760;African
+Aptenodytes;forsteri;Miller,JF;1778;Emperor
+Torvaldis;linux;Ewing,L;1996;Tux
+Eudyptula;minor;Bonaparte;1867;Little Blue
+Pygoscelis;papua;Wagler;1832;Gentoo
+```
+
+That's somewhat difficult to read, but Unix is famous for its _pipe_ method of constructing commands, so you can use the **column** command to "prettify" the output. Using GNU **column**:
+
+
+```
+$ sort --field-separator=";" \
+\--key=2 penguins.list | \
+column --table --separator ";"
+Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
+Eudyptes chrysocome Viellot 1816 Southern Rockhopper
+Spheniscus demersus Brisson 1760 African
+Aptenodytes forsteri Miller,JF 1778 Emperor
+Torvaldis linux Ewing,L 1996 Tux
+Eudyptula minor Bonaparte 1867 Little Blue
+Pygoscelis papua Wagler 1832 Gentoo
+```
+
+Slightly more cryptic to the new user (but shorter to type), the command options on BSD and Mac:
+
+
+```
+$ sort -t ";" \
+-k2 penguins.list | column -t -s ";"
+Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
+Eudyptes chrysocome Viellot 1816 Southern Rockhopper
+Spheniscus demersus Brisson 1760 African
+Aptenodytes forsteri Miller,JF 1778 Emperor
+Torvaldis linux Ewing,L 1996 Tux
+Eudyptula minor Bonaparte 1867 Little Blue
+Pygoscelis papua Wagler 1832 Gentoo
+```
+
+The **key** definition doesn't have to be set to **2**, of course. Any existing field may be used as the sorting key.
+
+### Reverse sort
+
+You can reverse the order of a sorted list with the **\--reverse** (**-r** on BSD or Mac or GNU for brevity):
+
+
+```
+$ sort --reverse alphabet.list
+z
+y
+x
+w
+[...]
+```
+
+You can achieve the same result by piping the output of a normal sort through [tac][4].
+
+### Sorting by month (GNU only)
+
+In a perfect world, everyone would write dates according to the ISO 8601 standard: year, month, day. It's a logical method of specifying a unique date, and it's easy for computers to understand. And yet quite often, humans use other means of identifying dates, including months with pretty arbitrary names.
+
+Fortunately, the GNU **sort** command accounts for this and is able to sort correctly by month name. Use the **\--month-sort** (**-M**) option:
+
+
+```
+$ cat month.list
+November
+October
+September
+April
+[...]
+$ sort --month-sort month.list
+January
+February
+March
+April
+May
+[...]
+November
+December
+```
+
+Months may be identified by their full name or some portion of their names.
+
+### Human-readable numeric sort (GNU only)
+
+Another common point of confusion between humans and computers is groups of numbers. For instance, humans often write "1024 kilobytes" as "1KB" because it's easier and quicker for the human brain to parse "1KB" than "1024" (and it gets easier the larger the number becomes). To a computer, though, a string such as 9KB is larger than, for instance, 1MB (even though 9KB is only a fraction of a megabyte). The GNU **sort** command provides the **\--human-numeric-sort** (**-h**) option to help parse these values correctly.
+
+
+```
+$ cat sizes.list
+2M
+12MB
+1k
+9k
+900
+7000
+$ sort --human-numeric-sort
+900
+7000
+1k
+9k
+2M
+12MB
+```
+
+There are some inconsistencies. For example, 16,000 bytes is greater than 1KB, but **sort** fails to recognize that:
+
+
+```
+$ cat sizes0.list
+2M
+12MB
+16000
+1k
+$ sort -h sizes0.list
+16000
+1k
+2M
+12MB
+```
+
+Logically, 16,000 should be written 16KB in this context, so GNU **sort** is not entirely to blame. As long as you are sure that your numbers are consistent, the **\--human-numeric-sort** can help parse human-readable numbers in a computer-friendly way.
+
+### Randomized sort (GNU only)
+
+Sometimes utilities provide the option to do the opposite of what they're meant to do. In a way, it makes no sense for a **sort** command to have the ability to "sort" a file randomly. Then again, the workflow of the command makes it a convenient feature to have. You _could_ use a different command, like [**shuf**][5], or you could just add an option to the command you're using. Whether it's bloat or ingenious UX design, the GNU **sort** command provides the means to sort a file arbitrarily.
+
+The purest form of arbitrary sorting is the **\--random-sort** or **-R** option (not to be confused with the **-r** option, which is short for **\--reverse**).
+
+
+```
+$ sort --random-sort alphabet.list
+d
+m
+p
+a
+[...]
+```
+
+You can run a random sort multiple times on a file for different results each time.
+
+### Sorted
+
+There are many more features available with the **sort** GNU and BSD commands, so spend some time getting to know the options. You'll be surprised at how flexible **sort** can be, especially when it's combined with other Unix utilities.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/get-sorted-sort
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
+[2]: https://en.wikipedia.org/wiki/Sort_(Unix)
+[3]: https://en.wikipedia.org/wiki/POSIX
+[4]: https://opensource.com/article/19/9/tac-command
+[5]: https://www.gnu.org/software/coreutils/manual/html_node/shuf-invocation.html
diff --git a/sources/tech/20191024 The Five Most Popular Operating Systems for the Internet of Things.md b/sources/tech/20191024 The Five Most Popular Operating Systems for the Internet of Things.md
new file mode 100644
index 0000000000..89d6ef1acf
--- /dev/null
+++ b/sources/tech/20191024 The Five Most Popular Operating Systems for the Internet of Things.md
@@ -0,0 +1,147 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Five Most Popular Operating Systems for the Internet of Things)
+[#]: via: (https://opensourceforu.com/2019/10/the-five-most-popular-operating-systems-for-the-internet-of-things/)
+[#]: author: (K S Kuppusamy https://opensourceforu.com/author/ks-kuppusamy/)
+
+The Five Most Popular Operating Systems for the Internet of Things
+======
+
+[![][1]][2]
+
+_Connecting every ‘thing’ that we see around us to the Internet is the fundamental idea of the Internet of Things (IoT). There are many operating systems to get the best out of the things that are connected to the Internet. This article explores four popular operating systems for IoT — Ubuntu Core, RIOT, Contiki and TinyOS._
+
+To say that life is running on the Internet these days is not an exaggeration due to the number and variety of services that we consume on the Net. These services span multiple domains such as information, financial services, social networking and entertainment. As this list grows longer, it becomes imperative that we do not restrict the types of devices that can connect to the Internet. The Internet of Things (IoT) facilitates connecting various types of ‘things’ to the Internet infrastructure. By connecting a device or thing to the Internet, these things get the ability to not only interact with the user but also between themselves. This feature of a variety of things interacting among themselves to assist users in a pervasive manner constitutes an interesting phenomenon called ambient intelligence.
+
+![Figure 1: IoT application domains][3]
+
+IoT is becoming increasingly popular as the types of devices that can be connected to it are becoming more diverse. The nature of applications is also evolving. Some of the popular domains in which IoT is getting used increasingly are listed below (Figure 1):
+
+ * Smart homes
+ * Smart cities
+ * Smart agriculture
+ * Connected automobiles
+ * Smart shopping
+ * Connected health
+
+
+
+![Figure 2: IoT operating system features][4]
+
+As the application domains become diverse, the need to manage the IoT infrastructure efficiently is also becoming more important. The operating systems in normal computers perform the primary functions such as resource management, user interaction, etc. The requirements of IoT operating systems are specialised due to the nature and size of the devices involved in the process. Some of the important characteristics/requirements of IoT operating systems are listed below (Figure 2):
+
+ * A tiny memory footprint
+ * Energy efficiency
+ * Connectivity features
+ * Hardware-agnostic operations
+ * Real-time processing requirements
+ * Security requirements
+ * Application development ecosystem
+
+
+
+As of 2019, there is a spectrum of choices for selecting the operating system (OS) for the Internet of Things. Some of these OSs are shown in Figure 3.
+
+![Figure 3: IoT operating systems][5]
+
+**Ubuntu Core**
+As Ubuntu is a popular Linux distribution, the Ubuntu Core IoT offering has also become popular. Ubuntu Core is a secure and lightweight OS for IoT, and is designed with a ‘security first’ philosophy. According to the official documentation, the entire system has been redesigned to focus on security from the first boot. There is a detailed white paper available on Ubuntu Core’s security features. It can be accessed at _ -ubuntu-core-security-whitepaper.pdf?_ga=2.74563154.1977628533. 1565098475-2022264852.1565098475_.
+
+Ubuntu Core has been made tamper-resistant. As the applications may be from diverse sources, they are given privileges for only their own data. This has been done so that one poorly designed app does not make the entire system vulnerable. Ubuntu Core is ‘built for business’, which means that the developers can focus directly on the application at hand, while the other requirements are supported by the default operating system.
+
+Another important feature of Ubuntu Core is the availability of a secure app store, which you can learn more about at __. There is a ready-to-go software ecosystem that makes using Ubuntu Core simple.
+
+The official documentation lists various successful case studies about how Ubuntu Core has been successfully used.
+
+**RIOT**
+RIOT is a user-friendly OS for the Internet of Things. This FOSS OS has been developed by a number of people from around the world.
+RIOT supports many low-power IoT devices. It has support for various microcontroller architectures. The official documentation lists the following reasons for using the RIOT OS.
+
+ * _**It is developer friendly:**_ It supports the standard environments and tools so that developers need not go through a steep learning curve. Standard programming languages such as C or C++ are supported. The hardware dependent code is very minimal. Developers can code once and then run their code on 8-bit, 16-bit and 32-bit platforms.
+ * _**RIOT is resource friendly:**_ One of the important features of RIOT is its ability to support lightweight devices. It enables maximum energy efficiency. It supports multi-threading with very little overhead for threading.
+ * _**RIOT is IoT friendly:**_ The common system support provided by RIOT makes it a very important choice for IoT. It has support for CoAP, CBOR, high resolution and long-term timers.
+
+
+
+**Contiki**
+Contiki is an important OS for IoT. It facilitates connecting tiny, low-cost and low-energy devices to the Internet.
+The prominent reasons for choosing the Contiki OS are as follows.
+
+ * _**Internet standards:**_ The Contiki OS supports the IPv6 and IPv4 standards, in addition to the low-power 6lowpan, RPL and CoAP standards.
+ * _**Support for a variety of hardware:**_ Contiki can be run on a variety of low-power devices, which are easily available online.
+ * _**Large community support:**_ One of the important advantages of using Contiki is the availability of an active community of developers. So when you have some technical issues to be solved, these community members make the problem solving process simple and effective.
+
+
+
+The major features of Contiki are listed below.
+
+ * _**Memory allocation:**_ Even the tiny systems with only a few kilobytes of memory can also use Contiki. Its memory efficiency is an important feature.
+ * _**Full IP networking:**_ The Contiki OS offers a full IP network stack. This includes major standard protocols such as UDP, TCP, HTTP, 6lowpan, RPL, CoAP, etc.
+ * _**Power awareness:**_ The ability to assess the power requirements and to use them in an optimal minimal manner is an important feature of Contiki.
+ * The Cooja network simulator makes the process of developing and debugging software easier.
+ * The availability of the Coffee Flash file system and the Contiki shell makes the file handling and command execution simpler and more effective.
+
+
+
+**TinyOS**
+TinyOS is an open source operating system designed for low-power wireless devices. It has a vibrant community of users spread across the world from both academia and industry. The popularity of TinyOS can be understood from the fact that it gets downloaded more than 35,000 times in a year.
+TinyOS is very effectively used in various scenarios such as sensor networks, smart buildings, smart meters, etc. The main repository of TinyOS is available at .
+TinyOS is written in nesC which is a dialect of C. A sample code snippet is shown below:
+
+```
+configuration Led {
+provides {
+interface LedControl;
+}
+uses {
+interface Gpio;
+}
+}
+implementation {
+
+command void LedControl.turnOn() {
+call Gpio.set();
+}
+
+command void LedControl.turnOff() {
+call Gpio.clear();
+}
+
+}
+```
+
+**Zephyr**
+Zephyr is a real-time OS that supports multiple architectures and is optimised for resource-constrained environments. Security is also given importance in the Zephyr design.
+
+The prominent features of Zephyr are listed below:
+
+ * Support for 150+ boards.
+ * Complete flexibility and freedom of choice.
+ * Can handle small footprint IoT devices.
+ * Can develop products with built-in security features.
+
+
+
+This article has introduced readers to a list of four OSs for the IoT, from which they can select the ideal one, based on individual requirements.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/the-five-most-popular-operating-systems-for-the-internet-of-things/
+
+作者:[K S Kuppusamy][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/ks-kuppusamy/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/OS-for-IoT.jpg?resize=696%2C647&ssl=1 (OS for IoT)
+[2]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/OS-for-IoT.jpg?fit=800%2C744&ssl=1
+[3]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-1-IoT-application-domains.jpg?resize=350%2C107&ssl=1
+[4]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-2-IoT-operating-system-features.jpg?resize=350%2C93&ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-3-IoT-operating-systems.jpg?resize=350%2C155&ssl=1
diff --git a/sources/tech/20191025 How I used the wget Linux command to recover lost images.md b/sources/tech/20191025 How I used the wget Linux command to recover lost images.md
new file mode 100644
index 0000000000..08dd80f053
--- /dev/null
+++ b/sources/tech/20191025 How I used the wget Linux command to recover lost images.md
@@ -0,0 +1,132 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How I used the wget Linux command to recover lost images)
+[#]: via: (https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+How I used the wget Linux command to recover lost images
+======
+The story of the rise and fall of the Open Clip Art Library and the
+birth of FreeSVG.org, a new library of communal artwork.
+![White shoes on top of an orange tribal pattern][1]
+
+In 2004, the Open Clip Art Library (OCAL) was launched as a source of free illustrations for anyone to use, for any purpose, without requiring attribution or anything in return. This site was the open source world’s answer to the big stacks of clip art CDs on the shelf of every home office in the 1990s, and to the art dumps provided by the closed-source office and artistic software titles.
+
+In the beginning, the clip art library consisted mostly of work by a few contributors, but in 2010 it went live with a brand new interactive website, allowing anyone to create and contribute clip art with a vector illustration application. The site immediately garnered contributions from around the globe, and from all manner of free software and free culture projects. A special importer for this library was even included in [Inkscape][2].
+
+However, in early 2019, the website hosting the Open Clip Art Library went offline with no warning or explanation. Its community, which had grown to number in the thousands, assumed at first that this was a temporary glitch. The site remained offline, however, for over six months without any clear explanation of what had happened.
+
+Rumors started to swell. The site was being updated ("There is years of technical debt to pay off," said site developer Jon Philips in an email). The site had fallen to rampant DDOS attacks, claimed a Twitter account. The maintainer had fallen prey to identity theft, another Twitter account claimed. Today, as of this writing, the site’s one and only remaining page declares that it is in "maintenance and protected mode," the meaning of which is unclear, except that users cannot access its content.
+
+### Recovering the commons
+
+Sites appear and disappear over the course of time, but the loss of the Open Clip Art Library was particularly surprising to its community because it was seen as a community project. Few community members understood that the site hosting the library had fallen into the hands of a single maintainer, so while the artwork in the library was owned by everyone due to its [Creative Commons 0 License][3], access to it was functionally owned by a single maintainer. And, because the site’s community kept in touch with one another through the site, that same maintainer effectively owned the community.
+
+When the site failed, the community lost access to its artwork as well as each other. And without the site, there was no community.
+
+Initially, everything on the site was blocked when it went down. After several months, though, users started recognizing that the site’s database was still online, which meant that a user could access an individual art file by entering its exact URL. In other words, you couldn’t navigate to the art file through clicking around a website, but if you already knew the address, then you could bring it up in your browser. Similarly, technical (or lazy) users realized it was also possible to "scrape" the site with an automated web browser like **wget**.
+
+The **wget** Linux command is _technically_ a web browser, although it doesn’t let you browse interactively the way you do with Firefox. Instead, **wget** goes out onto the internet and retrieves a file or a collection of files and downloads them to your hard drive. You can then open those files in Firefox or a text editor, or whatever application is most appropriate, and view the content.
+
+Usually, **wget** needs to know a specific file to fetch. If you’re on Linux or macOS with **wget** installed, you can try this process by downloading the index page for [example.com][4]:
+
+
+```
+$ wget example.org/index.html
+[...]
+$ tail index.html
+
+<body><div>
+ <h1>Example Domain</h1>
+ <p>This domain is for illustrative examples in documents.
+ You may use this domain in examples without permission.</p>
+ <p><a href="[http://www.iana.org/domains/example"\>More][5] info</a></p>
+</div></body></html>
+```
+
+To scrape the Open Clip Art Library, I used the **\--mirror** option, so that I could point **wget** to just the directory containing the artwork so it could download everything within that directory. This action resulted in four straight days (96 hours) of constant downloading, ending with an excess of 100,000 SVG files that had been contributed by over 5,000 community members. Unfortunately, the author of any file that did not have proper metadata was irrecoverable because this information was locked in inaccessible files in the database, but the CC0 license meant that this issue _technically_ didn’t matter (because no attribution is required with CC0 files).
+
+A casual analysis of the downloaded files also revealed that nearly 45,000 of them were copies of the same single file (the site’s logo). This was caused by redirects pointing to the site's logo (for reasons unknown), and careful parsing could extract the original destination. Another 96 hours, and all clip art posted on OCAL up to its last day was recovered: **a total of about 156,000 images.**
+
+SVG files tend to be small, but this is still an enormous amount of work that poses a few very real problems. First of all, several gigabytes of online storage would be needed so the artwork could be made available to its former community. Secondly, a means of searching the artwork would be necessary, because it’s just not realistic to browse through 55,000 files manually.
+
+It became apparent that what the community really needed was a platform.
+
+### Building a new platform
+
+For some time, the site [Public Domain Vectors][6] had been publishing vector art that was in the public domain. While it remains a popular site, open source users often used it only as a secondary source of art because most of the files there were in the EPS and AI formats, both of which are associated with Adobe. Both file formats can generally be converted to SVG but at a loss of features.
+
+When the Public Domain Vectors site’s maintainers (Vedran and Boris) heard about the loss of the Open Clip Art Library, they decided to create a site oriented toward the open source community. True to form, they chose the open source [Laravel][7] framework as the backend, which provided the site with an admin dashboard and user access. The framework, being robust and well-developed, also allowed them to respond quickly to bug reports and feature requests, and to upgrade the site as needed. The site they are building is called [FreeSVG.org][8], and is already a robust and thriving library of communal artwork.
+
+Since then they have been uploading all of the clip art from the Open Clip Art Library, and they're even diligently tagging and categorizing the art as they go. As creators of Public Domain Vectors, they are also contributing their own images in SVG format. Their aim is to become the primary resource for SVG images with a CC0 license on the internet.
+
+### Contributing
+
+The maintainers of [FreeSVG.org][8] are aware that they have inherited significant stewardship. They are working to title and describe all images on the site so that users can easily find artwork, and will provide this file to the community once it is ready, believing strongly that the metadata about the art belongs to the people that create and use the art as much as the art itself does. They're also aware that unforeseen circumstances can arise, so they create regular backups of their site and content, and intend to make the most recent backup available to the public, should their site fail.
+
+If you want to add to the Creative Commons content of [FreeSVG.org][9], then download [Inkscape][10] and start drawing. There’s plenty of public domain artwork out there in the world, like [historical advertisements][11], [tarot cards][12], and [storybooks][13] just waiting to be converted to SVG, so you can contribute even if you aren’t confident in your drawing skills. Visit the [FreeSVG forum][14] to connect with and support other contributors.
+
+The concept of the _commons_ is important. [Creative Commons benefits everyone][15], whether you’re a student, teacher, librarian, small business owner, or CEO. If you don’t contribute directly, then you can always help promote it.
+
+That’s a strength of free culture: It doesn’t just scale, it gets better when more people participate.
+
+### Hard lessons learned
+
+From the demise of the Open Clip Art Library to the rise of FreeSVG.org, the open culture community has learned several hard lessons. For posterity, here are the ones that I believe are most important.
+
+#### Maintain your metadata
+
+If you’re a content creator, help the archivists of the future and add metadata to your files. Most image, music, font, and video file formats can have EXIF data embedded into them, and others have metadata entry interfaces in the applications that create them. Be diligent in tagging your work with your name, website or public email, and license.
+
+#### Make copies
+
+Don’t assume that somebody else is doing backups. If you care about communal digital content, then back it up yourself, or else don’t count on having it available forever. The trope that _whatever’s uploaded to the internet is forever_ may be true, but that doesn’t mean it’s _available to you_ forever. If the Open Clip Art Library files hadn’t become secretly available again, it’s unlikely that anyone would have ever successfully uncovered all 55,000 images from random places on the web, or from personal stashes on people’s hard drives around the globe.
+
+#### Create external channels
+
+If a community is defined by a single website or physical location, then that community is as good as dissolved should it lose access to that space. If you’re a member of a community that’s driven by a single organization or site, you owe it to yourselves to share contact information with those you care about and to establish a channel for communication even when that site is not available.
+
+For example, [Opensource.com][16] itself maintains mailing lists and other off-site channels for its authors and correspondents to communicate with one another, with or without the intervention or even existence of the website.
+
+#### Free culture is worth working for
+
+The internet is sometimes seen as a lazy person’s social club. You can log on when you want and turn it off when you’re tired, and you can wander into whatever social circle you want.
+
+But in reality, free culture can be hard work. It’s not hard in the sense that it’s difficult to be a part of, but it’s something you have to work to maintain. If you ignore the community you’re in, then the community may wither and fade before you realize it.
+
+Take a moment to look around you and identify what communities you’re a part of, and if nothing else, tell someone that you appreciate what they bring to your life. And just as importantly, keep in mind that you’re contributing to the lives of your communities, too.
+
+Creative Commons held its Gl obal Summit a few weeks ago in Warsaw, with amazing international...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tribal_pattern_shoes.png?itok=e5dSf2hS (White shoes on top of an orange tribal pattern)
+[2]: https://opensource.com/article/18/1/inkscape-absolute-beginners
+[3]: https://creativecommons.org/share-your-work/public-domain/cc0/
+[4]: http://example.com
+[5]: http://www.iana.org/domains/example"\>More
+[6]: http://publicdomainvectors.org
+[7]: https://github.com/viralsolani/laravel-adminpanel
+[8]: https://freesvg.org
+[9]: http://freesvg.org
+[10]: http://inkscape.org
+[11]: https://freesvg.org/drinking-coffee-vector-drawing
+[12]: https://freesvg.org/king-of-swords-tarot-card
+[13]: https://freesvg.org/space-pioneers-135-scene-vector-image
+[14]: http://forum.freesvg.org/
+[15]: https://opensource.com/article/18/1/creative-commons-real-world
+[16]: http://Opensource.com
diff --git a/sources/tech/20191025 Understanding system calls on Linux with strace.md b/sources/tech/20191025 Understanding system calls on Linux with strace.md
new file mode 100644
index 0000000000..7628cfa545
--- /dev/null
+++ b/sources/tech/20191025 Understanding system calls on Linux with strace.md
@@ -0,0 +1,452 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Understanding system calls on Linux with strace)
+[#]: via: (https://opensource.com/article/19/10/strace)
+[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
+
+Understanding system calls on Linux with strace
+======
+Trace the thin layer between user processes and the Linux kernel with
+strace.
+![Hand putting a Linux file folder into a drawer][1]
+
+A system call is a programmatic way a program requests a service from the kernel, and **strace** is a powerful tool that allows you to trace the thin layer between user processes and the Linux kernel.
+
+To understand how an operating system works, you first need to understand how system calls work. One of the main functions of an operating system is to provide abstractions to user programs.
+
+An operating system can roughly be divided into two modes:
+
+ * **Kernel mode:** A privileged and powerful mode used by the operating system kernel
+ * **User mode:** Where most user applications run
+
+
+
+Users mostly work with command-line utilities and graphical user interfaces (GUI) to do day-to-day tasks. System calls work silently in the background, interfacing with the kernel to get work done.
+
+System calls are very similar to function calls, which means they accept and work on arguments and return values. The only difference is that system calls enter a kernel, while function calls do not. Switching from user space to kernel space is done using a special [trap][2] mechanism.
+
+Most of this is hidden away from the user by using system libraries (aka **glibc** on Linux systems). Even though system calls are generic in nature, the mechanics of issuing a system call are very much machine-dependent.
+
+This article explores some practical examples by using some general commands and analyzing the system calls made by each command using **strace**. These examples use Red Hat Enterprise Linux, but the commands should work the same on other Linux distros:
+
+
+```
+[root@sandbox ~]# cat /etc/redhat-release
+Red Hat Enterprise Linux Server release 7.7 (Maipo)
+[root@sandbox ~]#
+[root@sandbox ~]# uname -r
+3.10.0-1062.el7.x86_64
+[root@sandbox ~]#
+```
+
+First, ensure that the required tools are installed on your system. You can verify whether **strace** is installed using the RPM command below; if it is, you can check the **strace** utility version number using the **-V** option:
+
+
+```
+[root@sandbox ~]# rpm -qa | grep -i strace
+strace-4.12-9.el7.x86_64
+[root@sandbox ~]#
+[root@sandbox ~]# strace -V
+strace -- version 4.12
+[root@sandbox ~]#
+```
+
+If that doesn't work, install **strace** by running:
+
+
+```
+`yum install strace`
+```
+
+For the purpose of this example, create a test directory within **/tmp** and create two files using the **touch** command using:
+
+
+```
+[root@sandbox ~]# cd /tmp/
+[root@sandbox tmp]#
+[root@sandbox tmp]# mkdir testdir
+[root@sandbox tmp]#
+[root@sandbox tmp]# touch testdir/file1
+[root@sandbox tmp]# touch testdir/file2
+[root@sandbox tmp]#
+```
+
+(I used the **/tmp** directory because everybody has access to it, but you can choose another directory if you prefer.)
+
+Verify that the files were created using the **ls** command on the **testdir** directory:
+
+
+```
+[root@sandbox tmp]# ls testdir/
+file1 file2
+[root@sandbox tmp]#
+```
+
+You probably use the **ls** command every day without realizing system calls are at work underneath it. There is abstraction at play here; here's how this command works:
+
+
+```
+`Command-line utility -> Invokes functions from system libraries (glibc) -> Invokes system calls`
+```
+
+The **ls** command internally calls functions from system libraries (aka **glibc**) on Linux. These libraries invoke the system calls that do most of the work.
+
+If you want to know which functions were called from the **glibc** library, use the **ltrace** command followed by the regular **ls testdir/** command:
+
+
+```
+`ltrace ls testdir/`
+```
+
+If **ltrace** is not installed, install it by entering:
+
+
+```
+`yum install ltrace`
+```
+
+A bunch of output will be dumped to the screen; don't worry about it—just follow along. Some of the important library functions from the output of the **ltrace** command that are relevant to this example include:
+
+
+```
+opendir("testdir/") = { 3 }
+readdir({ 3 }) = { 101879119, "." }
+readdir({ 3 }) = { 134, ".." }
+readdir({ 3 }) = { 101879120, "file1" }
+strlen("file1") = 5
+memcpy(0x1665be0, "file1\0", 6) = 0x1665be0
+readdir({ 3 }) = { 101879122, "file2" }
+strlen("file2") = 5
+memcpy(0x166dcb0, "file2\0", 6) = 0x166dcb0
+readdir({ 3 }) = nil
+closedir({ 3 })
+```
+
+By looking at the output above, you probably can understand what is happening. A directory called **testdir** is being opened by the **opendir** library function, followed by calls to the **readdir** function, which is reading the contents of the directory. At the end, there is a call to the **closedir** function, which closes the directory that was opened earlier. Ignore the other **strlen** and **memcpy** functions for now.
+
+You can see which library functions are being called, but this article will focus on system calls that are invoked by the system library functions.
+
+Similar to the above, to understand what system calls are invoked, just put **strace** before the **ls testdir** command, as shown below. Once again, a bunch of gibberish will be dumped to your screen, which you can follow along with here:
+
+
+```
+[root@sandbox tmp]# strace ls testdir/
+execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
+brk(NULL) = 0x1f12000
+<<< truncated strace output >>>
+write(1, "file1 file2\n", 13file1 file2
+) = 13
+close(1) = 0
+munmap(0x7fd002c8d000, 4096) = 0
+close(2) = 0
+exit_group(0) = ?
++++ exited with 0 +++
+[root@sandbox tmp]#
+```
+
+The output on the screen after running the **strace** command was simply system calls made to run the **ls** command. Each system call serves a specific purpose for the operating system, and they can be broadly categorized into the following sections:
+
+ * Process management system calls
+ * File management system calls
+ * Directory and filesystem management system calls
+ * Other system calls
+
+
+
+An easier way to analyze the information dumped onto your screen is to log the output to a file using **strace**'s handy **-o** flag. Add a suitable file name after the **-o** flag and run the command again:
+
+
+```
+[root@sandbox tmp]# strace -o trace.log ls testdir/
+file1 file2
+[root@sandbox tmp]#
+```
+
+This time, no output dumped to the screen—the **ls** command worked as expected by showing the file names and logging all the output to the file **trace.log**. The file has almost 100 lines of content just for a simple **ls** command:
+
+
+```
+[root@sandbox tmp]# ls -l trace.log
+-rw-r--r--. 1 root root 7809 Oct 12 13:52 trace.log
+[root@sandbox tmp]#
+[root@sandbox tmp]# wc -l trace.log
+114 trace.log
+[root@sandbox tmp]#
+```
+
+Take a look at the first line in the example's trace.log:
+
+
+```
+`execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0`
+```
+
+ * The first word of the line, **execve**, is the name of a system call being executed.
+ * The text within the parentheses is the arguments provided to the system call.
+ * The number after the **=** sign (which is **0** in this case) is a value returned by the **execve** system call.
+
+
+
+The output doesn't seem too intimidating now, does it? And you can apply the same logic to understand other lines.
+
+Now, narrow your focus to the single command that you invoked, i.e., **ls testdir**. You know the directory name used by the command **ls**, so why not **grep** for **testdir** within your **trace.log** file and see what you get? Look at each line of the results in detail:
+
+
+```
+[root@sandbox tmp]# grep testdir trace.log
+execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
+stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0
+openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3
+[root@sandbox tmp]#
+```
+
+Thinking back to the analysis of **execve** above, can you tell what this system call does?
+
+
+```
+`execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0`
+```
+
+You don't need to memorize all the system calls or what they do, because you can refer to documentation when you need to. Man pages to the rescue! Ensure the following package is installed before running the **man** command:
+
+
+```
+[root@sandbox tmp]# rpm -qa | grep -i man-pages
+man-pages-3.53-5.el7.noarch
+[root@sandbox tmp]#
+```
+
+Remember that you need to add a **2** between the **man** command and the system call name. If you read **man**'s man page using **man man**, you can see that section 2 is reserved for system calls. Similarly, if you need information on library functions, you need to add a **3** between **man** and the library function name.
+
+The following are the manual's section numbers and the types of pages they contain:
+
+
+```
+1\. Executable programs or shell commands
+2\. System calls (functions provided by the kernel)
+3\. Library calls (functions within program libraries)
+4\. Special files (usually found in /dev)
+```
+
+Run the following **man** command with the system call name to see the documentation for that system call:
+
+
+```
+`man 2 execve`
+```
+
+As per the **execve** man page, this executes a program that is passed in the arguments (in this case, that is **ls**). There are additional arguments that can be provided to **ls**, such as **testdir** in this example. Therefore, this system call just runs **ls** with **testdir** as the argument:
+
+
+```
+'execve - execute program'
+
+'DESCRIPTION
+ execve() executes the program pointed to by filename'
+```
+
+The next system call, named **stat**, uses the **testdir** argument:
+
+
+```
+`stat("testdir/", {st_mode=S_IFDIR|0755, st_size=32, ...}) = 0`
+```
+
+Use **man 2 stat** to access the documentation. **stat** is the system call that gets a file's status—remember that everything in Linux is a file, including a directory.
+
+Next, the **openat** system call opens **testdir.** Keep an eye on the **3** that is returned. This is a file description, which will be used by later system calls:
+
+
+```
+`openat(AT_FDCWD, "testdir/", O_RDONLY|O_NONBLOCK|O_DIRECTORY|O_CLOEXEC) = 3`
+```
+
+So far, so good. Now, open the **trace.log** file and go to the line following the **openat** system call. You will see the **getdents** system call being invoked, which does most of what is required to execute the **ls testdir** command. Now, **grep getdents** from the **trace.log** file:
+
+
+```
+[root@sandbox tmp]# grep getdents trace.log
+getdents(3, /* 4 entries */, 32768) = 112
+getdents(3, /* 0 entries */, 32768) = 0
+[root@sandbox tmp]#
+```
+
+The **getdents** man page describes it as **get directory entries**, which is what you want to do. Notice that the argument for **getdents** is **3**, which is the file descriptor from the **openat** system call above.
+
+Now that you have the directory listing, you need a way to display it in your terminal. So, **grep** for another system call, **write**, which is used to write to the terminal, in the logs:
+
+
+```
+[root@sandbox tmp]# grep write trace.log
+write(1, "file1 file2\n", 13) = 13
+[root@sandbox tmp]#
+```
+
+In these arguments, you can see the file names that will be displayed: **file1** and **file2**. Regarding the first argument (**1**), remember in Linux that, when any process is run, three file descriptors are opened for it by default. Following are the default file descriptors:
+
+ * 0 - Standard input
+ * 1 - Standard out
+ * 2 - Standard error
+
+
+
+So, the **write** system call is displaying **file1** and **file2** on the standard display, which is the terminal, identified by **1**.
+
+Now you know which system calls did most of the work for the **ls testdir/** command. But what about the other 100+ system calls in the **trace.log** file? The operating system has to do a lot of housekeeping to run a process, so a lot of what you see in the log file is process initialization and cleanup. Read the entire **trace.log** file and try to understand what is happening to make the **ls** command work.
+
+Now that you know how to analyze system calls for a given command, you can use this knowledge for other commands to understand what system calls are being executed. **strace** provides a lot of useful command-line flags to make it easier for you, and some of them are described below.
+
+By default, **strace** does not include all system call information. However, it has a handy **-v verbose** option that can provide additional information on each system call:
+
+
+```
+`strace -v ls testdir`
+```
+
+It is good practice to always use the **-f** option when running the **strace** command. It allows **strace** to trace any child processes created by the process currently being traced:
+
+
+```
+`strace -f ls testdir`
+```
+
+Say you just want the names of system calls, the number of times they ran, and the percentage of time spent in each system call. You can use the **-c** flag to get those statistics:
+
+
+```
+`strace -c ls testdir/`
+```
+
+Suppose you want to concentrate on a specific system call, such as focusing on **open** system calls and ignoring the rest. You can use the **-e** flag followed by the system call name:
+
+
+```
+[root@sandbox tmp]# strace -e open ls testdir
+open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libselinux.so.1", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libacl.so.1", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libpcre.so.1", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libdl.so.2", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libattr.so.1", O_RDONLY|O_CLOEXEC) = 3
+open("/lib64/libpthread.so.0", O_RDONLY|O_CLOEXEC) = 3
+open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
+file1 file2
++++ exited with 0 +++
+[root@sandbox tmp]#
+```
+
+What if you want to concentrate on more than one system call? No worries, you can use the same **-e** command-line flag with a comma between the two system calls. For example, to see the **write** and **getdents** systems calls:
+
+
+```
+[root@sandbox tmp]# strace -e write,getdents ls testdir
+getdents(3, /* 4 entries */, 32768) = 112
+getdents(3, /* 0 entries */, 32768) = 0
+write(1, "file1 file2\n", 13file1 file2
+) = 13
++++ exited with 0 +++
+[root@sandbox tmp]#
+```
+
+The examples so far have traced explicitly run commands. But what about commands that have already been run and are in execution? What, for example, if you want to trace daemons that are just long-running processes? For this, **strace** provides a special **-p** flag to which you can provide a process ID.
+
+Instead of running a **strace** on a daemon, take the example of a **cat** command, which usually displays the contents of a file if you give a file name as an argument. If no argument is given, the **cat** command simply waits at a terminal for the user to enter text. Once text is entered, it repeats the given text until a user presses Ctrl+C to exit.
+
+Run the **cat** command from one terminal; it will show you a prompt and simply wait there (remember **cat** is still running and has not exited):
+
+
+```
+`[root@sandbox tmp]# cat`
+```
+
+From another terminal, find the process identifier (PID) using the **ps** command:
+
+
+```
+[root@sandbox ~]# ps -ef | grep cat
+root 22443 20164 0 14:19 pts/0 00:00:00 cat
+root 22482 20300 0 14:20 pts/1 00:00:00 grep --color=auto cat
+[root@sandbox ~]#
+```
+
+Now, run **strace** on the running process with the **-p** flag and the PID (which you found above using **ps**). After running **strace**, the output states what the process was attached to along with the PID number. Now, **strace** is tracing the system calls made by the **cat** command. The first system call you see is **read**, which is waiting for input from 0, or standard input, which is the terminal where the **cat** command ran:
+
+
+```
+[root@sandbox ~]# strace -p 22443
+strace: Process 22443 attached
+read(0,
+```
+
+Now, move back to the terminal where you left the **cat** command running and enter some text. I entered **x0x0** for demo purposes. Notice how **cat** simply repeated what I entered; hence, **x0x0** appears twice. I input the first one, and the second one was the output repeated by the **cat** command:
+
+
+```
+[root@sandbox tmp]# cat
+x0x0
+x0x0
+```
+
+Move back to the terminal where **strace** was attached to the **cat** process. You now see two additional system calls: the earlier **read** system call, which now reads **x0x0** in the terminal, and another for **write**, which wrote **x0x0** back to the terminal, and again a new **read**, which is waiting to read from the terminal. Note that Standard input (**0**) and Standard out (**1**) are both in the same terminal:
+
+
+```
+[root@sandbox ~]# strace -p 22443
+strace: Process 22443 attached
+read(0, "x0x0\n", 65536) = 5
+write(1, "x0x0\n", 5) = 5
+read(0,
+```
+
+Imagine how helpful this is when running **strace** against daemons to see everything it does in the background. Kill the **cat** command by pressing Ctrl+C; this also kills your **strace** session since the process is no longer running.
+
+If you want to see a timestamp against all your system calls, simply use the **-t** option with **strace**:
+
+
+```
+[root@sandbox ~]#strace -t ls testdir/
+
+14:24:47 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
+14:24:47 brk(NULL) = 0x1f07000
+14:24:47 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2530bc8000
+14:24:47 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
+14:24:47 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
+```
+
+What if you want to know the time spent between system calls? **strace** has a handy **-r** command that shows the time spent executing each system call. Pretty useful, isn't it?
+
+
+```
+[root@sandbox ~]#strace -r ls testdir/
+
+0.000000 execve("/usr/bin/ls", ["ls", "testdir/"], [/* 40 vars */]) = 0
+0.000368 brk(NULL) = 0x1966000
+0.000073 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fb6b1155000
+0.000047 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
+0.000119 open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
+```
+
+### Conclusion
+
+The **strace** utility is very handy for understanding system calls on Linux. To learn about its other command-line flags, please refer to the man pages and online documentation.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/strace
+
+作者:[Gaurav Kamathe][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gkamathe
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
+[2]: https://en.wikipedia.org/wiki/Trap_(computing)
diff --git a/sources/tech/20191026 How to Backup Configuration Files on a Remote System Using the Bash Script.md b/sources/tech/20191026 How to Backup Configuration Files on a Remote System Using the Bash Script.md
new file mode 100644
index 0000000000..c2d3b4397f
--- /dev/null
+++ b/sources/tech/20191026 How to Backup Configuration Files on a Remote System Using the Bash Script.md
@@ -0,0 +1,550 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Backup Configuration Files on a Remote System Using the Bash Script)
+[#]: via: (https://www.2daygeek.com/linux-bash-script-backup-configuration-files-remote-linux-system-server/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+How to Backup Configuration Files on a Remote System Using the Bash Script
+======
+
+It is a good practice to backup configuration files before performing any activity on a Linux system.
+
+You can use this script if you are restarting the server after several days.
+
+If you are really concerned about the backup of your configuration files, it is advisable to use this script at least once a month.
+
+If something goes wrong, you can restore the system to normal by comparing configuration files based on the error message.
+
+Three **[bash scripts][1]** are included in this article, and each **[shell script][2]** is used for specific purposes.
+
+You can choose one based on your requirements.
+
+Everything in Linux is a file. If you make some wrong changes in the configuration file, it will cause the associated service to crash.
+
+So it is a good idea to take a backup of configuration files, and you do not have to worry about disk usage as this not consume much space.
+
+### What does this script do?
+
+This script backs up specific configuration files, moves them to another server, and finally deletes the backup on the remote machine.
+
+This script has six parts, and the details are below.
+
+ * **Part-1:** Backup a General Configuration Files
+ * **Part-2:** Backup a wwn/wwpn number if the server is physical.
+ * **Part-3:** Backup an oracle related files if the system has an oracle user account.
+ * **Part-4:** Create a tar archive of backup configuration files.
+ * **Part-5:** Copy the tar archive to other server.
+ * **Part-6:** Remove Backup of configuration files on the remote system.
+
+
+
+**System details are as follows:**
+
+ * **Server-A:** Local System/ JUMP System (local.2daygeek.com)
+ * **Server-B:** Remote System-1 (CentOS6.2daygeek.com)
+ * **Server-C:** Remote System-2 (CentOS7.2daygeek.com)
+
+
+
+### 1) Bash Script to Backup Configuration files on Remote Server
+
+Two scripts are included in this example, which allow you to back up important configurations files from one server to another (that is, from a remote server to a local server).
+
+For example, if you want to back up important configuration files from **“Server-B”** to **“Server-A”**. Use the following script.
+
+This is a real bash script that takes backup of configuration files on the remote server.
+
+```
+# vi /home/daygeek/shell-script/config-file.sh
+
+#!/bin/bash
+mkdir /tmp/conf-bk-$(date +%Y%m%d)
+cd /tmp/conf-bk-$(date +%Y%m%d)
+
+For General Configuration Files
+hostname > hostname.out
+uname -a > uname.out
+uptime > uptime.out
+cat /etc/hosts > hosts.out
+/bin/df -h>df-h.out
+pvs > pvs.out
+vgs > vgs.out
+lvs > lvs.out
+/bin/ls -ltr /dev/mapper>mapper.out
+fdisk -l > fdisk.out
+cat /etc/fstab > fstab.out
+cat /etc/exports > exports.out
+cat /etc/crontab > crontab.out
+cat /etc/passwd > passwd.out
+ip link show > ip.out
+/bin/netstat -in>netstat-in.out
+/bin/netstat -rn>netstat-rn.out
+/sbin/ifconfig -a>ifconfig-a.out
+cat /etc/sysctl.conf > sysctl.out
+sleep 10s
+
+#For Physical Server
+vserver=$(lscpu | grep vendor | wc -l)
+if [ $vserver -gt 0 ]
+then
+echo "$(hostname) is a VM"
+else
+systool -c fc_host -v | egrep "(Class Device path | port_name |port_state)" > systool.out
+fi
+sleep 10s
+
+#For Oracle DB Servers
+if id oracle >/dev/null 2>&1; then
+/usr/sbin/oracleasm listdisks>asm.out
+/sbin/multipath -ll > mpath.out
+/bin/ps -ef|grep pmon > pmon.out
+else
+echo "oracle user does not exist on server"
+fi
+sleep 10s
+
+#Create a tar archive
+tar -cvf /tmp/$(hostname)-date +%Y%m%d.tar /tmp/conf-bk-$(date +%Y%m%d)
+sleep 10s
+
+#Copy a tar archive to other server
+sshpass -p 'password' scp /tmp/$(hostname)-date +%Y%m%d.tar Server-A:/home/daygeek/backup/
+
+#Remove the backup config folder
+cd ..
+rm -Rf conf-bk-$(date +%Y%m%d)
+rm $(hostname)-date +%Y%m%d.tar
+rm config-file.sh
+exit
+```
+
+This is a sub-script that pushes the above script to the target server.
+
+```
+# vi /home/daygeek/shell-script/conf-remote.sh
+
+#!/bin/bash
+echo -e "Enter the Remote Server Name: \c"
+read server
+scp /home/daygeek/shell-script/config-file.sh $server:/tmp/
+ssh [email protected]${server} sh /home/daygeek/shell-script/config-file.sh
+sleep 10s
+exit
+```
+
+Finally run the bash script to achieve this.
+
+```
+# sh /home/daygeek/shell-script/conf-remote.sh
+
+Enter the Remote Server Name: CentOS6.2daygeek.com
+config-file.sh 100% 1446 647.8KB/s 00:00
+CentOS6.2daygeek.com is a VM
+oracle user does not exist on server
+tar: Removing leading `/' from member names
+/tmp/conf-bk-20191024/
+/tmp/conf-bk-20191024/pvs.out
+/tmp/conf-bk-20191024/vgs.out
+/tmp/conf-bk-20191024/ip.out
+/tmp/conf-bk-20191024/netstat-in.out
+/tmp/conf-bk-20191024/fstab.out
+/tmp/conf-bk-20191024/ifconfig-a.out
+/tmp/conf-bk-20191024/hostname.out
+/tmp/conf-bk-20191024/crontab.out
+/tmp/conf-bk-20191024/netstat-rn.out
+/tmp/conf-bk-20191024/uptime.out
+/tmp/conf-bk-20191024/uname.out
+/tmp/conf-bk-20191024/mapper.out
+/tmp/conf-bk-20191024/lvs.out
+/tmp/conf-bk-20191024/exports.out
+/tmp/conf-bk-20191024/df-h.out
+/tmp/conf-bk-20191024/sysctl.out
+/tmp/conf-bk-20191024/hosts.out
+/tmp/conf-bk-20191024/passwd.out
+/tmp/conf-bk-20191024/fdisk.out
+```
+
+Once you run the above script, use the ls command to check the copied tar archive file.
+
+```
+# ls -ltrh /home/daygeek/backup/*.tar
+
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 11:01 /home/daygeek/backup/CentOS6.2daygeek.com-20191024.tar
+```
+
+If it is moved successfully, you can find the contents of it without extracting it using the following tar command.
+
+```
+# tar -tvf /home/daygeek/backup/CentOS6.2daygeek.com-20191024.tar
+
+drwxr-xr-x root/root 0 2019-10-25 11:00 tmp/conf-bk-20191024/
+-rw-r--r-- root/root 96 2019-10-25 11:00 tmp/conf-bk-20191024/pvs.out
+-rw-r--r-- root/root 92 2019-10-25 11:00 tmp/conf-bk-20191024/vgs.out
+-rw-r--r-- root/root 413 2019-10-25 11:00 tmp/conf-bk-20191024/ip.out
+-rw-r--r-- root/root 361 2019-10-25 11:00 tmp/conf-bk-20191024/netstat-in.out
+-rw-r--r-- root/root 785 2019-10-25 11:00 tmp/conf-bk-20191024/fstab.out
+-rw-r--r-- root/root 1375 2019-10-25 11:00 tmp/conf-bk-20191024/ifconfig-a.out
+-rw-r--r-- root/root 21 2019-10-25 11:00 tmp/conf-bk-20191024/hostname.out
+-rw-r--r-- root/root 457 2019-10-25 11:00 tmp/conf-bk-20191024/crontab.out
+-rw-r--r-- root/root 337 2019-10-25 11:00 tmp/conf-bk-20191024/netstat-rn.out
+-rw-r--r-- root/root 62 2019-10-25 11:00 tmp/conf-bk-20191024/uptime.out
+-rw-r--r-- root/root 116 2019-10-25 11:00 tmp/conf-bk-20191024/uname.out
+-rw-r--r-- root/root 210 2019-10-25 11:00 tmp/conf-bk-20191024/mapper.out
+-rw-r--r-- root/root 276 2019-10-25 11:00 tmp/conf-bk-20191024/lvs.out
+-rw-r--r-- root/root 0 2019-10-25 11:00 tmp/conf-bk-20191024/exports.out
+-rw-r--r-- root/root 236 2019-10-25 11:00 tmp/conf-bk-20191024/df-h.out
+-rw-r--r-- root/root 1057 2019-10-25 11:00 tmp/conf-bk-20191024/sysctl.out
+-rw-r--r-- root/root 115 2019-10-25 11:00 tmp/conf-bk-20191024/hosts.out
+-rw-r--r-- root/root 2194 2019-10-25 11:00 tmp/conf-bk-20191024/passwd.out
+-rw-r--r-- root/root 1089 2019-10-25 11:00 tmp/conf-bk-20191024/fdisk.out
+```
+
+### 2) Bash Script to Backup Configuration files on Remote Server
+
+There are two scripts added in this example, which do the same as the above script, but this can be very useful if you have a JUMP server in your environment.
+
+This script allows you to copy important configuration files from your client system into the JUMP box
+
+For example, since we have already set up a password-less login, you have ten clients that can be accessed from the JUMP server. If so, use this script.
+
+This is a real bash script that takes backup of configuration files on the remote server.
+
+```
+# vi /home/daygeek/shell-script/config-file-1.sh
+
+#!/bin/bash
+mkdir /tmp/conf-bk-$(date +%Y%m%d)
+cd /tmp/conf-bk-$(date +%Y%m%d)
+
+For General Configuration Files
+hostname > hostname.out
+uname -a > uname.out
+uptime > uptime.out
+cat /etc/hosts > hosts.out
+/bin/df -h>df-h.out
+pvs > pvs.out
+vgs > vgs.out
+lvs > lvs.out
+/bin/ls -ltr /dev/mapper>mapper.out
+fdisk -l > fdisk.out
+cat /etc/fstab > fstab.out
+cat /etc/exports > exports.out
+cat /etc/crontab > crontab.out
+cat /etc/passwd > passwd.out
+ip link show > ip.out
+/bin/netstat -in>netstat-in.out
+/bin/netstat -rn>netstat-rn.out
+/sbin/ifconfig -a>ifconfig-a.out
+cat /etc/sysctl.conf > sysctl.out
+sleep 10s
+
+#For Physical Server
+vserver=$(lscpu | grep vendor | wc -l)
+if [ $vserver -gt 0 ]
+then
+echo "$(hostname) is a VM"
+else
+systool -c fc_host -v | egrep "(Class Device path | port_name |port_state)" > systool.out
+fi
+sleep 10s
+
+#For Oracle DB Servers
+if id oracle >/dev/null 2>&1; then
+/usr/sbin/oracleasm listdisks>asm.out
+/sbin/multipath -ll > mpath.out
+/bin/ps -ef|grep pmon > pmon.out
+else
+echo "oracle user does not exist on server"
+fi
+sleep 10s
+
+#Create a tar archieve
+tar -cvf /tmp/$(hostname)-date +%Y%m%d.tar /tmp/conf-bk-$(date +%Y%m%d)
+sleep 10s
+
+#Remove the backup config folder
+cd ..
+rm -Rf conf-bk-$(date +%Y%m%d)
+rm config-file.sh
+exit
+```
+
+This is a sub-script that pushes the above script to the target server.
+
+```
+# vi /home/daygeek/shell-script/conf-remote-1.sh
+
+#!/bin/bash
+echo -e "Enter the Remote Server Name: \c"
+read server
+scp /home/daygeek/shell-script/config-file-1.sh $server:/tmp/
+ssh [email protected]${server} sh /home/daygeek/shell-script/config-file-1.sh
+sleep 10s
+echo -e "Re-Enter the Remote Server Name: \c"
+read server
+scp $server:/tmp/$server-date +%Y%m%d.tar /home/daygeek/backup/
+exit
+```
+
+Finally run the bash script to achieve this.
+
+```
+# sh /home/daygeek/shell-script/conf-remote-1.sh
+
+Enter the Remote Server Name: CentOS6.2daygeek.com
+config-file.sh 100% 1446 647.8KB/s 00:00
+CentOS6.2daygeek.com is a VM
+oracle user does not exist on server
+tar: Removing leading `/' from member names
+/tmp/conf-bk-20191025/
+/tmp/conf-bk-20191025/pvs.out
+/tmp/conf-bk-20191025/vgs.out
+/tmp/conf-bk-20191025/ip.out
+/tmp/conf-bk-20191025/netstat-in.out
+/tmp/conf-bk-20191025/fstab.out
+/tmp/conf-bk-20191025/ifconfig-a.out
+/tmp/conf-bk-20191025/hostname.out
+/tmp/conf-bk-20191025/crontab.out
+/tmp/conf-bk-20191025/netstat-rn.out
+/tmp/conf-bk-20191025/uptime.out
+/tmp/conf-bk-20191025/uname.out
+/tmp/conf-bk-20191025/mapper.out
+/tmp/conf-bk-20191025/lvs.out
+/tmp/conf-bk-20191025/exports.out
+/tmp/conf-bk-20191025/df-h.out
+/tmp/conf-bk-20191025/sysctl.out
+/tmp/conf-bk-20191025/hosts.out
+/tmp/conf-bk-20191025/passwd.out
+/tmp/conf-bk-20191025/fdisk.out
+Enter the Server Name Once Again: CentOS6.2daygeek.com
+CentOS6.2daygeek.com-20191025.tar
+```
+
+Once you run the above script, use the ls command to check the copied tar archive file.
+
+```
+# ls -ltrh /home/daygeek/backup/*.tar
+
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 11:44 /home/daygeek/backup/CentOS6.2daygeek.com-20191025.tar
+```
+
+If it is moved successfully, you can find the contents of it without extracting it using the following tar command.
+
+```
+# tar -tvf /home/daygeek/backup/CentOS6.2daygeek.com-20191025.tar
+
+drwxr-xr-x root/root 0 2019-10-25 11:43 tmp/conf-bk-20191025/
+-rw-r--r-- root/root 96 2019-10-25 11:43 tmp/conf-bk-20191025/pvs.out
+-rw-r--r-- root/root 92 2019-10-25 11:43 tmp/conf-bk-20191025/vgs.out
+-rw-r--r-- root/root 413 2019-10-25 11:43 tmp/conf-bk-20191025/ip.out
+-rw-r--r-- root/root 361 2019-10-25 11:43 tmp/conf-bk-20191025/netstat-in.out
+-rw-r--r-- root/root 785 2019-10-25 11:43 tmp/conf-bk-20191025/fstab.out
+-rw-r--r-- root/root 1375 2019-10-25 11:43 tmp/conf-bk-20191025/ifconfig-a.out
+-rw-r--r-- root/root 21 2019-10-25 11:43 tmp/conf-bk-20191025/hostname.out
+-rw-r--r-- root/root 457 2019-10-25 11:43 tmp/conf-bk-20191025/crontab.out
+-rw-r--r-- root/root 337 2019-10-25 11:43 tmp/conf-bk-20191025/netstat-rn.out
+-rw-r--r-- root/root 61 2019-10-25 11:43 tmp/conf-bk-20191025/uptime.out
+-rw-r--r-- root/root 116 2019-10-25 11:43 tmp/conf-bk-20191025/uname.out
+-rw-r--r-- root/root 210 2019-10-25 11:43 tmp/conf-bk-20191025/mapper.out
+-rw-r--r-- root/root 276 2019-10-25 11:43 tmp/conf-bk-20191025/lvs.out
+-rw-r--r-- root/root 0 2019-10-25 11:43 tmp/conf-bk-20191025/exports.out
+-rw-r--r-- root/root 236 2019-10-25 11:43 tmp/conf-bk-20191025/df-h.out
+-rw-r--r-- root/root 1057 2019-10-25 11:43 tmp/conf-bk-20191025/sysctl.out
+-rw-r--r-- root/root 115 2019-10-25 11:43 tmp/conf-bk-20191025/hosts.out
+-rw-r--r-- root/root 2194 2019-10-25 11:43 tmp/conf-bk-20191025/passwd.out
+-rw-r--r-- root/root 1089 2019-10-25 11:43 tmp/conf-bk-20191025/fdisk.out
+```
+
+### 3) Bash Script to Backup Configuration files on Multiple Linux Remote Systems
+
+This script allows you to copy important configuration files from multiple remote Linux systems into the JUMP box at the same time.
+
+This is a real bash script that takes backup of configuration files on the remote server.
+
+```
+# vi /home/daygeek/shell-script/config-file-2.sh
+
+#!/bin/bash
+mkdir /tmp/conf-bk-$(date +%Y%m%d)
+cd /tmp/conf-bk-$(date +%Y%m%d)
+
+For General Configuration Files
+hostname > hostname.out
+uname -a > uname.out
+uptime > uptime.out
+cat /etc/hosts > hosts.out
+/bin/df -h>df-h.out
+pvs > pvs.out
+vgs > vgs.out
+lvs > lvs.out
+/bin/ls -ltr /dev/mapper>mapper.out
+fdisk -l > fdisk.out
+cat /etc/fstab > fstab.out
+cat /etc/exports > exports.out
+cat /etc/crontab > crontab.out
+cat /etc/passwd > passwd.out
+ip link show > ip.out
+/bin/netstat -in>netstat-in.out
+/bin/netstat -rn>netstat-rn.out
+/sbin/ifconfig -a>ifconfig-a.out
+cat /etc/sysctl.conf > sysctl.out
+sleep 10s
+
+#For Physical Server
+vserver=$(lscpu | grep vendor | wc -l)
+if [ $vserver -gt 0 ]
+then
+echo "$(hostname) is a VM"
+else
+systool -c fc_host -v | egrep "(Class Device path | port_name |port_state)" > systool.out
+fi
+sleep 10s
+
+#For Oracle DB Servers
+if id oracle >/dev/null 2>&1; then
+/usr/sbin/oracleasm listdisks>asm.out
+/sbin/multipath -ll > mpath.out
+/bin/ps -ef|grep pmon > pmon.out
+else
+echo "oracle user does not exist on server"
+fi
+sleep 10s
+
+#Create a tar archieve
+tar -cvf /tmp/$(hostname)-date +%Y%m%d.tar /tmp/conf-bk-$(date +%Y%m%d)
+sleep 10s
+
+#Remove the backup config folder
+cd ..
+rm -Rf conf-bk-$(date +%Y%m%d)
+rm config-file.sh
+exit
+```
+
+This is a sub-script that pushes the above script to the target servers.
+
+```
+# vi /home/daygeek/shell-script/conf-remote-2.sh
+
+#!/bin/bash
+for server in CentOS6.2daygeek.com CentOS7.2daygeek.com
+do
+scp /home/daygeek/shell-script/config-file-2.sh $server:/tmp/
+ssh [email protected]${server} sh /tmp/config-file-2.sh
+sleep 10s
+scp $server:/tmp/$server-date +%Y%m%d.tar /home/daygeek/backup/
+done
+exit
+```
+
+Finally run the bash script to achieve this.
+
+```
+# sh /home/daygeek/shell-script/conf-remote-2.sh
+
+config-file-1.sh 100% 1444 416.5KB/s 00:00
+CentOS6.2daygeek.com is a VM
+oracle user does not exist on server
+tar: Removing leading `/' from member names
+/tmp/conf-bk-20191025/
+/tmp/conf-bk-20191025/pvs.out
+/tmp/conf-bk-20191025/vgs.out
+/tmp/conf-bk-20191025/ip.out
+/tmp/conf-bk-20191025/netstat-in.out
+/tmp/conf-bk-20191025/fstab.out
+/tmp/conf-bk-20191025/ifconfig-a.out
+/tmp/conf-bk-20191025/hostname.out
+/tmp/conf-bk-20191025/crontab.out
+/tmp/conf-bk-20191025/netstat-rn.out
+/tmp/conf-bk-20191025/uptime.out
+/tmp/conf-bk-20191025/uname.out
+/tmp/conf-bk-20191025/mapper.out
+/tmp/conf-bk-20191025/lvs.out
+/tmp/conf-bk-20191025/exports.out
+/tmp/conf-bk-20191025/df-h.out
+/tmp/conf-bk-20191025/sysctl.out
+/tmp/conf-bk-20191025/hosts.out
+/tmp/conf-bk-20191025/passwd.out
+/tmp/conf-bk-20191025/fdisk.out
+CentOS6.2daygeek.com-20191025.tar
+config-file-1.sh 100% 1444 386.2KB/s 00:00
+CentOS7.2daygeek.com is a VM
+oracle user does not exist on server
+/tmp/conf-bk-20191025/
+/tmp/conf-bk-20191025/hostname.out
+/tmp/conf-bk-20191025/uname.out
+/tmp/conf-bk-20191025/uptime.out
+/tmp/conf-bk-20191025/hosts.out
+/tmp/conf-bk-20191025/df-h.out
+/tmp/conf-bk-20191025/pvs.out
+/tmp/conf-bk-20191025/vgs.out
+/tmp/conf-bk-20191025/lvs.out
+/tmp/conf-bk-20191025/mapper.out
+/tmp/conf-bk-20191025/fdisk.out
+/tmp/conf-bk-20191025/fstab.out
+/tmp/conf-bk-20191025/exports.out
+/tmp/conf-bk-20191025/crontab.out
+/tmp/conf-bk-20191025/passwd.out
+/tmp/conf-bk-20191025/ip.out
+/tmp/conf-bk-20191025/netstat-in.out
+/tmp/conf-bk-20191025/netstat-rn.out
+/tmp/conf-bk-20191025/ifconfig-a.out
+/tmp/conf-bk-20191025/sysctl.out
+tar: Removing leading `/' from member names
+CentOS7.2daygeek.com-20191025.tar
+```
+
+Once you run the above script, use the ls command to check the copied tar archive file.
+
+```
+# ls -ltrh /home/daygeek/backup/*.tar
+
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 12:37 /home/daygeek/backup/CentOS6.2daygeek.com-20191025.tar
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 12:38 /home/daygeek/backup/CentOS7.2daygeek.com-20191025.tar
+```
+
+If it is moved successfully, you can find the contents of it without extracting it using the following tar command.
+
+```
+# tar -tvf /home/daygeek/backup/CentOS7.2daygeek.com-20191025.tar
+
+drwxr-xr-x root/root 0 2019-10-25 12:23 tmp/conf-bk-20191025/
+-rw-r--r-- root/root 21 2019-10-25 12:23 tmp/conf-bk-20191025/hostname.out
+-rw-r--r-- root/root 115 2019-10-25 12:23 tmp/conf-bk-20191025/uname.out
+-rw-r--r-- root/root 62 2019-10-25 12:23 tmp/conf-bk-20191025/uptime.out
+-rw-r--r-- root/root 228 2019-10-25 12:23 tmp/conf-bk-20191025/hosts.out
+-rw-r--r-- root/root 501 2019-10-25 12:23 tmp/conf-bk-20191025/df-h.out
+-rw-r--r-- root/root 88 2019-10-25 12:23 tmp/conf-bk-20191025/pvs.out
+-rw-r--r-- root/root 84 2019-10-25 12:23 tmp/conf-bk-20191025/vgs.out
+-rw-r--r-- root/root 252 2019-10-25 12:23 tmp/conf-bk-20191025/lvs.out
+-rw-r--r-- root/root 197 2019-10-25 12:23 tmp/conf-bk-20191025/mapper.out
+-rw-r--r-- root/root 1088 2019-10-25 12:23 tmp/conf-bk-20191025/fdisk.out
+-rw-r--r-- root/root 465 2019-10-25 12:23 tmp/conf-bk-20191025/fstab.out
+-rw-r--r-- root/root 0 2019-10-25 12:23 tmp/conf-bk-20191025/exports.out
+-rw-r--r-- root/root 451 2019-10-25 12:23 tmp/conf-bk-20191025/crontab.out
+-rw-r--r-- root/root 2748 2019-10-25 12:23 tmp/conf-bk-20191025/passwd.out
+-rw-r--r-- root/root 861 2019-10-25 12:23 tmp/conf-bk-20191025/ip.out
+-rw-r--r-- root/root 455 2019-10-25 12:23 tmp/conf-bk-20191025/netstat-in.out
+-rw-r--r-- root/root 505 2019-10-25 12:23 tmp/conf-bk-20191025/netstat-rn.out
+-rw-r--r-- root/root 2072 2019-10-25 12:23 tmp/conf-bk-20191025/ifconfig-a.out
+-rw-r--r-- root/root 449 2019-10-25 12:23 tmp/conf-bk-20191025/sysctl.out
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-bash-script-backup-configuration-files-remote-linux-system-server/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/category/bash-script/
+[2]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20191027 How to Install and Configure Nagios Core on CentOS 8 - RHEL 8.md b/sources/tech/20191027 How to Install and Configure Nagios Core on CentOS 8 - RHEL 8.md
new file mode 100644
index 0000000000..bcbf0c27ec
--- /dev/null
+++ b/sources/tech/20191027 How to Install and Configure Nagios Core on CentOS 8 - RHEL 8.md
@@ -0,0 +1,271 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Install and Configure Nagios Core on CentOS 8 / RHEL 8)
+[#]: via: (https://www.linuxtechi.com/install-nagios-core-rhel-8-centos-8/)
+[#]: author: (James Kiarie https://www.linuxtechi.com/author/james/)
+
+How to Install and Configure Nagios Core on CentOS 8 / RHEL 8
+======
+
+**Nagios** is a free and opensource network and alerting engine used to monitor various devices, such as network devices, and servers in a network. It supports both **Linux** and **Windows OS** and provides an intuitive web interface that allows you to easily monitor network resources. When professionally configured, it can alert you in the event a server or a network device goes down or malfunctions via email alerts. In this topic, we shed light on how you can install and configure Nagios core on **RHEL 8** / **CentOS 8**.
+
+[![Install-Nagios-Core-RHEL8-CentOS8][1]][2]
+
+### Prerequisites of Nagios Core
+
+Before we begin, perform a flight check and ensure you have the following:
+
+ * An instance of RHEL 8 / CentOS 8
+ * SSH access to the instance
+ * A fast and stable internet connection
+
+
+
+With the above requirements in check, let’s roll our sleeves!
+
+### Step 1: Install LAMP Stack
+
+For Nagios to work as expected, you need to install LAMP stack or any other web hosting stack since it’s going to run on a browser. To achieve this, execute the command:
+
+```
+# dnf install httpd mariadb-server php-mysqlnd php-fpm
+```
+
+![Install-LAMP-stack-CentOS8][1]
+
+You need to ensure that Apache web server is up and running. To do so, start and enable Apache server using the commands:
+
+```
+# systemctl start httpd
+# systemctl enable httpd
+```
+
+![Start-enable-httpd-centos8][1]
+
+To check the status of Apache server run
+
+```
+# systemctl status httpd
+```
+
+![Check-status-httpd-centos8][1]
+
+Next, we need to start and enable MariaDB server, run the following commands
+
+```
+# systemctl start mariadb
+# systemctl enable mariadb
+```
+
+![Start-enable-MariaDB-CentOS8][1]
+
+To check MariaDB status run:
+
+```
+# systemctl status mariadb
+```
+
+![Check-MariaDB-status-CentOS8][1]
+
+Also, you might consider hardening or securing your server and making it less susceptible to unauthorized access. To secure your server, run the command:
+
+```
+# mysql_secure_installation
+```
+
+Be sure to set a strong password for your MySQL instance. For the subsequent prompts, Type **Yes** and hit **ENTER**
+
+![Secure-MySQL-server-CentOS8][1]
+
+### Step 2: Install Required packages
+
+Apart from installing the LAMP server, some additional packages are needed for the installation and proper configuration of Nagios. Therefore, install the packages as shown below:
+
+```
+# dnf install gcc glibc glibc-common wget gd gd-devel perl postfix
+```
+
+![Install-requisite-packages-CentOS8][1]
+
+### Step 3: Create a Nagios user account
+
+Next, we need to create a user account for the Nagios user. To achieve this , run the command:
+
+```
+# adduser nagios
+# passwd nagios
+```
+
+![Create-new-user-for-Nagios][1]
+
+Now, we need to create a group for Nagios and add the Nagios user to this group.
+
+```
+# groupadd nagiosxi
+```
+
+Now add the Nagios user to the group
+
+```
+# usermod -aG nagiosxi nagios
+```
+
+Also, add Apache user to the Nagios group
+
+```
+# usermod -aG nagiosxi apache
+```
+
+![Add-Nagios-group-user][1]
+
+### Step 4: Download and install Nagios core
+
+We can now proceed and install Nagios Core. The latest stable version in Nagios 4.4.5 which was released on August 19, 2019. But first, download the Nagios tarball file from its official site.
+
+To download Nagios core, first head to the tmp directory
+
+```
+# cd /tmp
+```
+
+Next download the tarball file
+
+```
+# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.5.tar.gz
+```
+
+![Download-Nagios-CentOS8][1]
+
+After downloading the tarball file, extract it using the command:
+
+```
+# tar -xvf nagios-4.4.5.tar.gz
+```
+
+Next, navigate to the uncompressed folder
+
+```
+# cd nagios-4.4.5
+```
+
+Run the commands below in this order
+
+```
+# ./configure --with-command-group=nagcmd
+# make all
+# make install
+# make install-init
+# make install-daemoninit
+# make install-config
+# make install-commandmode
+# make install-exfoliation
+```
+
+To setup Apache configuration issue the command:
+
+```
+# make install-webconf
+```
+
+### Step 5: Configure Apache Web Server Authentication
+
+Next, we are going to setup authentication for the user **nagiosadmin**. Please be mindful not to change the username or else, you may be required to perform further configuration which may be quite tedious.
+
+To set up authentication run the command:
+
+```
+# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
+```
+
+![Configure-Apache-webserver-authentication-CentOS8][1]
+
+You will be prompted for the password of the nagiosadmin user. Enter and confirm the password as requested. This is the user that you will use to login to Nagios towards the end of this tutorial.
+
+For the changes to come into effect, restart your web server.
+
+```
+# systemctl restart httpd
+```
+
+### Step 6: Download & install Nagios Plugins
+
+Plugins will extend the functionality of the Nagios Server. They will help you monitor various services, network devices, and applications. To download the plugin tarball file run the command:
+
+```
+# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
+```
+
+Next, extract the tarball file and navigate to the uncompressed plugin folder
+
+```
+# tar -xvf nagios-plugins-2.2.1.tar.gz
+# cd nagios-plugins-2.2.1
+```
+
+To install the plugins compile the source code as shown
+
+```
+# ./configure --with-nagios-user=nagios --with-nagios-group=nagiosxi
+# make
+# make install
+```
+
+### Step 7: Verify and Start Nagios
+
+After the successful installation of Nagios plugins, verify the Nagios configuration to ensure that all is well and there is no error in the configuration:
+
+```
+# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
+```
+
+![Verify-Nagios-settings-CentOS8][1]
+
+Next, start Nagios and verify its status
+
+```
+# systemctl start nagios
+# systemctl status nagios
+```
+
+![Start-check-status-Nagios-CentOS8][1]
+
+In case Firewall is running on system then allow “80” using the following command
+
+```
+# firewall-cmd --permanent --add-port=80/tcp# firewall-cmd --reload
+```
+
+### Step 8: Access Nagios dashboard via the web browser
+
+To access Nagios, browse your server’s IP address as shown
+
+
+
+A pop-up will appear prompting for the username and the password of the user we created earlier in Step 5. Enter the credentials and hit ‘**Sign In**’
+
+![Access-Nagios-via-web-browser-CentOS8][1]
+
+This ushers you to the Nagios dashboard as shown below
+
+![Nagios-dashboard-CentOS8][1]
+
+We have finally successfully installed and configured Nagios Core on CentOS 8 / RHEL 8. Your feedback is most welcome.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/install-nagios-core-rhel-8-centos-8/
+
+作者:[James Kiarie][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/james/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/Install-Nagios-Core-RHEL8-CentOS8.jpg
diff --git a/sources/tech/20191028 Enterprise JavaBeans, infrastructure predictions, and more industry trends.md b/sources/tech/20191028 Enterprise JavaBeans, infrastructure predictions, and more industry trends.md
new file mode 100644
index 0000000000..f1d2b48d0d
--- /dev/null
+++ b/sources/tech/20191028 Enterprise JavaBeans, infrastructure predictions, and more industry trends.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: (warmfrog)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Enterprise JavaBeans, infrastructure predictions, and more industry trends)
+[#]: via: (https://opensource.com/article/19/10/enterprise-javabeans-and-more-industry-trends)
+[#]: author: (Tim Hildred https://opensource.com/users/thildred)
+
+Enterprise JavaBeans, infrastructure predictions, and more industry trends
+======
+A weekly look at open source community and industry trends.
+![Person standing in front of a giant computer screen with numbers, data][1]
+
+As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
+
+## [Gartner: 10 infrastructure trends you need to know][2]
+
+> Corporate network infrastructure is only going to get more involved over the next two to three years as automation, network challenges, and hybrid cloud become more integral to the enterprise.
+
+**The impact:** The theme running through all these predictions is the impact of increased complexity. As consumers of technology, we expect things to get easier and easier. As producers of technology, we know what's going on behind the curtains to make that simplicity possible is its opposite.
+
+## [Jakarta EE: What's in store for Enterprise JavaBeans?][3]
+
+> [Enterprise JavaBeans (EJB)][4] has been very important to the Java EE ecosystem and promoted many robust solutions to enterprise problems. Besides that, in the past when integration techniques were not so advanced, EJB did great work with remote EJB, integrating many Java EE applications. However, remote EJB is not necessary anymore, and we have many techniques and tools that are better for doing that. So, does EJB still have a place in this new cloud-native world?
+
+**The impact:** This offers some insights into how programming languages and frameworks evolve and change over time. Respond to changes in developer affinity by identifying the good stuff in a language and getting it landed somewhere else. Ideally that "somewhere else" should be an open standard so that no single vendor gets to control your technology destiny.
+
+## [From virtualization to containerization][5]
+
+> Before the telecom industry has got to grips with "step one" virtualization, many industry leaders are already moving on to the next level—containerization. This is a key part of making network software cloud-native i.e. designed, developed, and optimized to exploit cloud technology such as distributed processing and data stores.
+
+**The impact:** There are certain industries that make big technology decisions on long time horizons; I can only imagine the FOMO that the fast-moving world of infrastructure technology could cause when you've picked something and it starts to look a bit crufty next to the new hotness.
+
+## [How do you rollback deployments in Kubernetes?][6]
+
+> There are several strategies when it comes to deploying apps into production. In Kubernetes, rolling updates are the default strategy to update the running version of your app. The rolling update cycles previous Pod out and bring newer Pod in incrementally.
+
+**The impact:** What is the cloud-native distributed equivalent to **ctrl+z**? And aren't you glad there is one?
+
+## [What's a Trusted Compute Base?][7]
+
+> A few months ago, in an article called [Turtles—and chains of trust][8], I briefly mentioned Trusted Compute Bases, or TCBs, but then didn’t go any deeper. I had a bit of a search across the articles on this blog, and realised that I’ve never gone into this topic in much detail, which feels like a mistake, so I’m going to do it now.
+
+**The impact:** The issue of to what extent you can trust the computer systems that power your whole life is only going to become more prevalent and more vexing. That turns out to be a great argument for open source from the bottom turtle (hardware) all the way up.
+
+_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/enterprise-javabeans-and-more-industry-trends
+
+作者:[Tim Hildred][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/thildred
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
+[2]: https://www.networkworld.com/article/3447397/gartner-10-infrastructure-trends-you-need-to-know.html
+[3]: https://developers.redhat.com/blog/2019/10/22/jakarta-ee-whats-in-store-for-enterprise-javabeans/
+[4]: https://docs.oracle.com/cd/E13222_01/wls/docs100/ejb/deploy.html
+[5]: https://www.lightreading.com/nfv/from-virtualization-to-containerization/a/d-id/755016
+[6]: https://learnk8s.io/kubernetes-rollbacks/
+[7]: https://aliceevebob.com/2019/10/22/whats-a-trusted-compute-base/
+[8]: https://aliceevebob.com/2019/07/02/turtles-and-chains-of-trust/
diff --git a/sources/tech/20191028 How to remove duplicate lines from files with awk.md b/sources/tech/20191028 How to remove duplicate lines from files with awk.md
new file mode 100644
index 0000000000..0282a26768
--- /dev/null
+++ b/sources/tech/20191028 How to remove duplicate lines from files with awk.md
@@ -0,0 +1,243 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to remove duplicate lines from files with awk)
+[#]: via: (https://opensource.com/article/19/10/remove-duplicate-lines-files-awk)
+[#]: author: (Lazarus Lazaridis https://opensource.com/users/iridakos)
+
+How to remove duplicate lines from files with awk
+======
+Learn how to use awk '!visited[$0]++' without sorting or changing their
+order.
+![Coding on a computer][1]
+
+Suppose you have a text file and you need to remove all of its duplicate lines.
+
+### TL;DR
+
+To remove the duplicate lines while _preserving their order in the file_, use:
+
+
+```
+`awk '!visited[$0]++' your_file > deduplicated_file`
+```
+
+### How it works
+
+The script keeps an associative array with _indices_ equal to the unique lines of the file and _values_ equal to their occurrences. For each line of the file, if the line occurrences are zero, then it increases them by one and _prints the line_, otherwise, it just increases the occurrences _without printing the line_.
+
+I was not familiar with **awk**, and I wanted to understand how this can be accomplished with such a short script (**awk**ward). I did my research, and here is what is going on:
+
+ * The awk "script" **!visited[$0]++** is executed for _each line_ of the input file.
+ * **visited[]** is a variable of type [associative array][2] (a.k.a. [Map][3]). We don't have to initialize it because **awk** will do it the first time we access it.
+ * The **$0** variable holds the contents of the line currently being processed.
+ * **visited[$0]** accesses the value stored in the map with a key equal to **$0** (the line being processed), a.k.a. the occurrences (which we set below).
+ * The **!** negates the occurrences' value:
+ * In awk, [any nonzero numeric value or any nonempty string value is true][4].
+ * By default, [variables are initialized to the empty string][5], which is zero if converted to a number.
+ * That being said:
+ * If **visited[$0]** returns a number greater than zero, this negation is resolved to **false**.
+ * If **visited[$0]** returns a number equal to zero or an empty string, this negation is resolved to **true**.
+ * The **++** operation increases the variable's value (**visited[$0]**) by one.
+ * If the value is empty, **awk** converts it to **0** (number) automatically and then it gets increased.
+ * **Note:** The operation is executed after we access the variable's value.
+
+
+
+Summing up, the whole expression evaluates to:
+
+ * **true** if the occurrences are zero/empty string
+ * **false** if the occurrences are greater than zero
+
+
+
+**awk** statements consist of a [_pattern-expression_ and an _associated action_][6].
+
+
+```
+` { }`
+```
+
+If the pattern succeeds, then the associated action is executed. If we don't provide an action, **awk**, by default, **print**s the input.
+
+> An omitted action is equivalent to **{ print $0 }**.
+
+Our script consists of one **awk** statement with an expression, omitting the action. So this:
+
+
+```
+`awk '!visited[$0]++' your_file > deduplicated_file`
+```
+
+is equivalent to this:
+
+
+```
+`awk '!visited[$0]++ { print $0 }' your_file > deduplicated_file`
+```
+
+For every line of the file, if the expression succeeds, the line is printed to the output. Otherwise, the action is not executed, and nothing is printed.
+
+### Why not use the **uniq** command?
+
+The **uniq** command removes only the _adjacent duplicate lines_. Here's a demonstration:
+
+
+```
+$ cat test.txt
+A
+A
+A
+B
+B
+B
+A
+A
+C
+C
+C
+B
+B
+A
+$ uniq < test.txt
+A
+B
+A
+C
+B
+A
+```
+
+### Other approaches
+
+#### Using the sort command
+
+We can also use the following [**sort**][7] command to remove the duplicate lines, but _the line order is not preserved_.
+
+
+```
+`sort -u your_file > sorted_deduplicated_file`
+```
+
+#### Using cat, sort, and cut
+
+The previous approach would produce a de-duplicated file whose lines would be sorted based on the contents. [Piping a bunch of commands][8] can overcome this issue:
+
+
+```
+`cat -n your_file | sort -uk2 | sort -nk1 | cut -f2-`
+```
+
+##### How it works
+
+Suppose we have the following file:
+
+
+```
+abc
+ghi
+abc
+def
+xyz
+def
+ghi
+klm
+```
+
+**cat -n test.txt** prepends the order number in each line.
+
+
+```
+1 abc
+2 ghi
+3 abc
+4 def
+5 xyz
+6 def
+7 ghi
+8 klm
+```
+
+**sort -uk2** sorts the lines based on the second column (**k2** option) and keeps only the first occurrence of the lines with the same second column value (**u** option).
+
+
+```
+1 abc
+4 def
+2 ghi
+8 klm
+5 xyz
+```
+
+**sort -nk1** sorts the lines based on their first column (**k1** option) treating the column as a number (**-n** option).
+
+
+```
+1 abc
+2 ghi
+4 def
+5 xyz
+8 klm
+```
+
+Finally, **cut -f2-** prints each line starting from the second column until its end (**-f2-** option: _Note the **-** suffix, which instructs it to include the rest of the line_).
+
+
+```
+abc
+ghi
+def
+xyz
+klm
+```
+
+### References
+
+ * [The GNU awk user's guide][9]
+ * [Arrays in awk][2]
+ * [Awk—Truth values][4]
+ * [Awk expressions][5]
+ * [How can I delete duplicate lines in a file in Unix?][10]
+ * [Remove duplicate lines without sorting [duplicate]][11]
+ * [How does awk '!a[$0]++' work?][12]
+
+
+
+That's all. Cat photo.
+
+![Duplicate cat][13]
+
+* * *
+
+_This article originally appeared on the iridakos blog by [Lazarus Lazaridis][14] under a [CC BY-NC 4.0 License][15] and is republished with the author's permission._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/remove-duplicate-lines-files-awk
+
+作者:[Lazarus Lazaridis][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/iridakos
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
+[2]: http://kirste.userpage.fu-berlin.de/chemnet/use/info/gawk/gawk_12.html
+[3]: https://en.wikipedia.org/wiki/Associative_array
+[4]: https://www.gnu.org/software/gawk/manual/html_node/Truth-Values.html
+[5]: https://ftp.gnu.org/old-gnu/Manuals/gawk-3.0.3/html_chapter/gawk_8.html
+[6]: http://kirste.userpage.fu-berlin.de/chemnet/use/info/gawk/gawk_9.html
+[7]: http://man7.org/linux/man-pages/man1/sort.1.html
+[8]: https://stackoverflow.com/a/20639730/2292448
+[9]: https://www.gnu.org/software/gawk/manual/html_node/
+[10]: https://stackoverflow.com/questions/1444406/how-can-i-delete-duplicate-lines-in-a-file-in-unix
+[11]: https://stackoverflow.com/questions/11532157/remove-duplicate-lines-without-sorting
+[12]: https://unix.stackexchange.com/questions/159695/how-does-awk-a0-work/159734#159734
+[13]: https://opensource.com/sites/default/files/uploads/duplicate-cat.jpg (Duplicate cat)
+[14]: https://iridakos.com/about/
+[15]: http://creativecommons.org/licenses/by-nc/4.0/
diff --git a/sources/tech/20191029 Demystifying namespaces and containers in Linux.md b/sources/tech/20191029 Demystifying namespaces and containers in Linux.md
new file mode 100644
index 0000000000..80b505bfd0
--- /dev/null
+++ b/sources/tech/20191029 Demystifying namespaces and containers in Linux.md
@@ -0,0 +1,146 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Demystifying namespaces and containers in Linux)
+[#]: via: (https://opensource.com/article/19/10/namespaces-and-containers-linux)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Demystifying namespaces and containers in Linux
+======
+Peek behind the curtains to understand the backend of Linux container
+technology.
+![cubes coming together to create a larger cube][1]
+
+Containers have taken the world by storm. Whether you think of Kubernetes, Docker, CoreOS, Silverblue, or Flatpak when you hear the term, it's clear that modern applications are running in containers for convenience, security, and scalability.
+
+Containers can be confusing to understand, though. What does it mean to run in a container? How can processes in a container interact with the rest of the computer they're running on? Open source dislikes mystery, so this article explains the backend of container technology, just as [my article on Flatpak][2] explained a common frontend.
+
+### Namespaces
+
+Namespaces are common in the programming world. If you dwell in the highly technical places of the computer world, then you have probably seen code like this:
+
+
+```
+`using namespace std;`
+```
+
+Or you may have seen this in XML:
+
+
+```
+``
+```
+
+These kinds of phrases provide context for commands used later in a source code file. The only reason C++ knows, for instance, what programmers mean when they type **cout** is because C++ knows the **cout** namespace is a meaningful word.
+
+If that's too technical for you to picture, you may be surprised to learn that we all use namespaces every day in real life, too. We don't call them namespaces, but we use the concept all the time. For instance, the phrase "I'm a fan of the Enterprise" has one meaning in an IT company that serves large businesses (which are commonly called "enterprises"), but it may have a different meaning at a science fiction convention. The question "what engine is it running?" has one meaning in a garage and a different meaning in web development. We don't always declare a namespace in casual conversation because we're human, and our brains can adapt quickly to determine context, but for computers, the namespace must be declared explicitly.
+
+For containers, a namespace is what defines the boundaries of a process' "awareness" of what else is running around it.
+
+### lsns
+
+You may not realize it, but your Linux machine quietly maintains different namespaces specific to given processes. By using a recent version of the **util-linux** package, you can list existing namespaces on your machine:
+
+
+```
+$ lsns
+ NS TYPE NPROCS PID USER COMMAND
+4026531835 cgroup 85 1571 seth /usr/lib/systemd/systemd --user
+4026531836 pid 85 1571 seth /usr/lib/systemd/systemd --user
+4026531837 user 80 1571 seth /usr/lib/systemd/systemd --user
+4026532601 user 1 6266 seth /usr/lib64/firefox/firefox [...]
+4026532928 net 1 7164 seth /usr/lib64/firefox/firefox [...]
+[...]
+```
+
+If your version of **util-linux** doesn't provide the **lsns** command, you can see namespace entries in **/proc**:
+
+
+```
+$ ls /proc/*/ns
+1571
+6266
+7164
+[...]
+$ ls /proc/6266/ns
+ipc net pid user uts [...]
+```
+
+Each process running on your Linux machine is enumerated with a process ID (PID). Each PID is assigned a namespace. PIDs in the same namespace can have access to one another because they are programmed to operate within a given namespace. PIDs in different namespaces are unable to interact with one another by default because they are running in a different context, or _namespace_. This is why a process running in a "container" under one namespace cannot access information outside its container or information running inside a different container.
+
+### Creating a new namespace
+
+A usual feature of software dealing with containers is automatic namespace management. A human administrator starting up a new containerized application or environment doesn't have to use **lsns** to check which namespaces exist and then create a new one manually; the software using PID namespaces does that automatically with the help of the Linux kernel. However, you can mimic the process manually to gain a better understanding of what's happening behind the scenes.
+
+First, you need to identify a process that is _not_ running on your computer. For this example, I'll use the Z shell ([Zsh][3]) because I'm running the Bash shell on my machine. If you're running Zsh on your computer, then use **Bash** or **tcsh** or some other shell that you're not currently running. The goal is to find something that you can prove is not running. You can prove something is not running with the **pidof** command, which queries your system to discover the PID of any application you name:
+
+
+```
+$ pidof zsh
+$ sudo pidof zsh
+```
+
+As long as no PID is returned, the application you have queried is not running.
+
+#### Unshare
+
+The **unshare** command runs a program in a namespace _unshared_ from its parent process. There are many kinds of namespaces available, so read the **unshare** man page for all options available.
+
+To create a new namespace for your test command:
+
+
+```
+$ sudo unshare --fork --pid --mount-proc zsh
+%
+```
+
+Because Zsh is an interactive shell, it conveniently brings you into its namespace upon launch. Not all processes do that, because some processes run in the background, leaving you at a prompt in its native namespace. As long as you remain in the Zsh session, you can see that you have left the usual namespace by looking at the PID of your new forked process:
+
+
+```
+% pidof zsh
+pid 1
+```
+
+If you know anything about Linux process IDs, then you know that PID 1 is always reserved, mostly by nature of the boot process, for the initialization application (systemd on most distributions outside of Slackware, Devuan, and maybe some customized installations of Arch). It's next to impossible for Zsh, or any application that isn't a boot initialization application, to be PID 1 (because without an init system, a computer wouldn't know how to boot up). Yet, as far as your shell knows in this demonstration, Zsh occupies the PID 1 slot.
+
+Despite what your shell is now telling you, PID 1 on your system has _not_ been replaced. Open a second terminal or terminal tab on your computer and look at PID 1:
+
+
+```
+$ ps 1
+init
+```
+
+And then find the PID of Zsh:
+
+
+```
+$ pidof zsh
+7723
+```
+
+As you can see, your "host" system sees the big picture and understands that Zsh is actually running as some high-numbered PID (it probably won't be 7723 on your computer, except by coincidence). Zsh sees itself as PID 1 only because its scope is confined to (or _contained_ within) its namespace. Once you have forked a process into its own namespace, its children processes are numbered starting from 1, but only within that namespace.
+
+Namespaces, along with other technologies like **cgroups** and more, form the foundation of containerization. Understanding that namespaces exist within the context of the wider namespace of a host environment (in this demonstration, that's your computer, but in the real world the host is typically a server or a hybrid cloud) can help you understand how and why containerized applications act the way they do. For instance, a container running a Wordpress blog doesn't "know" it's not running in a container; it knows that it has access to a kernel and some RAM and whatever configuration files you've provided it, but it probably can't access your home directory or any directory you haven't specifically given it permission to access. Furthermore, a runaway process within that blog software can't affect any other process on your system, because as far as it knows, the PID "tree" only goes back to 1, and 1 is the container it's running in.
+
+Containers are a powerful Linux feature, and they're getting more popular every day. Now that you understand how they work, try exploring container technology such as Kubernetes, Silverblue, or Flatpak, and see what you can do with containerized apps. Containers are Linux, so start them up, inspect them carefully, and learn as you go.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/namespaces-and-containers-linux
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
+[2]: https://opensource.com/article/19/10/how-build-flatpak-packaging
+[3]: https://opensource.com/article/19/9/getting-started-zsh
diff --git a/sources/tech/20191029 Upgrading Fedora 30 to Fedora 31.md b/sources/tech/20191029 Upgrading Fedora 30 to Fedora 31.md
new file mode 100644
index 0000000000..e67f26d320
--- /dev/null
+++ b/sources/tech/20191029 Upgrading Fedora 30 to Fedora 31.md
@@ -0,0 +1,96 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Upgrading Fedora 30 to Fedora 31)
+[#]: via: (https://fedoramagazine.org/upgrading-fedora-30-to-fedora-31/)
+[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
+
+Upgrading Fedora 30 to Fedora 31
+======
+
+![][1]
+
+Fedora 31 [is available now][2]. You’ll likely want to upgrade your system to get the latest features available in Fedora. Fedora Workstation has a graphical upgrade method. Alternatively, Fedora offers a command-line method for upgrading Fedora 30 to Fedora 31.
+
+### Upgrading Fedora 30 Workstation to Fedora 31
+
+Soon after release time, a notification appears to tell you an upgrade is available. You can click the notification to launch the **GNOME Software** app. Or you can choose Software from GNOME Shell.
+
+Choose the _Updates_ tab in GNOME Software and you should see a screen informing you that Fedora 31 is Now Available.
+
+If you don’t see anything on this screen, try using the reload button at the top left. It may take some time after release for all systems to be able to see an upgrade available.
+
+Choose _Download_ to fetch the upgrade packages. You can continue working until you reach a stopping point, and the download is complete. Then use GNOME Software to restart your system and apply the upgrade. Upgrading takes time, so you may want to grab a coffee and come back to the system later.
+
+### Using the command line
+
+If you’ve upgraded from past Fedora releases, you are likely familiar with the _dnf upgrade_ plugin. This method is the recommended and supported way to upgrade from Fedora 30 to Fedora 31. Using this plugin will make your upgrade to Fedora 31 simple and easy.
+
+#### 1\. Update software and back up your system
+
+Before you do start the upgrade process, make sure you have the latest software for Fedora 30. This is particularly important if you have modular software installed; the latest versions of dnf and GNOME Software include improvements to the upgrade process for some modular streams. To update your software, use _GNOME Software_ or enter the following command in a terminal.
+
+```
+sudo dnf upgrade --refresh
+```
+
+Additionally, make sure you back up your system before proceeding. For help with taking a backup, see [the backup series][3] on the Fedora Magazine.
+
+#### 2\. Install the DNF plugin
+
+Next, open a terminal and type the following command to install the plugin:
+
+```
+sudo dnf install dnf-plugin-system-upgrade
+```
+
+#### 3\. Start the update with DNF
+
+Now that your system is up-to-date, backed up, and you have the DNF plugin installed, you can begin the upgrade by using the following command in a terminal:
+
+```
+sudo dnf system-upgrade download --releasever=31
+```
+
+This command will begin downloading all of the upgrades for your machine locally to prepare for the upgrade. If you have issues when upgrading because of packages without updates, broken dependencies, or retired packages, add the _‐‐allowerasing_ flag when typing the above command. This will allow DNF to remove packages that may be blocking your system upgrade.
+
+#### 4\. Reboot and upgrade
+
+Once the previous command finishes downloading all of the upgrades, your system will be ready for rebooting. To boot your system into the upgrade process, type the following command in a terminal:
+
+```
+sudo dnf system-upgrade reboot
+```
+
+Your system will restart after this. Many releases ago, the _fedup_ tool would create a new option on the kernel selection / boot screen. With the _dnf-plugin-system-upgrade_ package, your system reboots into the current kernel installed for Fedora 30; this is normal. Shortly after the kernel selection screen, your system begins the upgrade process.
+
+Now might be a good time for a coffee break! Once it finishes, your system will restart and you’ll be able to log in to your newly upgraded Fedora 31 system.
+
+![][4]
+
+### Resolving upgrade problems
+
+On occasion, there may be unexpected issues when you upgrade your system. If you experience any issues, please visit the [DNF system upgrade quick docs][5] for more information on troubleshooting.
+
+If you are having issues upgrading and have third-party repositories installed on your system, you may need to disable these repositories while you are upgrading. For support with repositories not provided by Fedora, please contact the providers of the repositories.
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/upgrading-fedora-30-to-fedora-31/
+
+作者:[Ben Cotton][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/bcotton/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/10/f30-f31-816x345.jpg
+[2]: https://fedoramagazine.org/announcing-fedora-31/
+[3]: https://fedoramagazine.org/taking-smart-backups-duplicity/
+[4]: https://cdn.fedoramagazine.org/wp-content/uploads/2016/06/Screenshot_f23-ws-upgrade-test_2016-06-10_110906-1024x768.png
+[5]: https://docs.fedoraproject.org/en-US/quick-docs/dnf-system-upgrade/#Resolving_post-upgrade_issues
diff --git a/sources/tech/20191029 What you probably didn-t know about sudo.md b/sources/tech/20191029 What you probably didn-t know about sudo.md
new file mode 100644
index 0000000000..e58c092602
--- /dev/null
+++ b/sources/tech/20191029 What you probably didn-t know about sudo.md
@@ -0,0 +1,200 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What you probably didn’t know about sudo)
+[#]: via: (https://opensource.com/article/19/10/know-about-sudo)
+[#]: author: (Peter Czanik https://opensource.com/users/czanik)
+
+What you probably didn’t know about sudo
+======
+Think you know everything about sudo? Think again.
+![Command line prompt][1]
+
+Everybody knows **sudo**, right? This tool is installed by default on most Linux systems and is available for most BSD and commercial Unix variants. Still, after talking to hundreds of **sudo** users, the most common answer I received was that **sudo** is a tool to complicate life.
+
+There is a root user and there is the **su** command, so why have yet another tool? For many, **sudo** was just a prefix for administrative commands. Only a handful mentioned that when you have multiple administrators for the same system, you can use **sudo** logs to see who did what.
+
+So, what is **sudo**? According to the [**sudo** website][2]:
+
+> _"Sudo allows a system administrator to delegate authority by giving certain users the ability to run some commands as root or another user while providing an audit trail of the commands and their arguments."_
+
+By default, **sudo** comes with a simple configuration, a single rule allowing a user or a group of users to do practically anything (more on the configuration file later in this article):
+
+
+```
+`%wheel ALL=(ALL) ALL`
+```
+
+In this example, the parameters mean the following:
+
+ * The first parameter defines the members of the group.
+ * The second parameter defines the host(s) the group members can run commands on.
+ * The third parameter defines the usernames under which the command can be executed.
+ * The last parameter defines the applications that can be run.
+
+
+
+So, in this example, the members of the **wheel** group can run all applications as all users on all hosts. Even this really permissive rule is useful because it results in logs of who did what on your machine.
+
+### Aliases
+
+Of course, once it is not just you and your best friend administering a shared box, you will start to fine-tune permissions. You can replace the items in the above configuration with lists: a list of users, a list of commands, and so on. Most likely, you will copy and paste some of these lists around in your configuration.
+
+This situation is where aliases can come handy. Maintaining the same list in multiple places is error-prone. You define an alias once and then you can use it many times. Therefore, when you lose trust in one of your administrators, you can remove them from the alias and you are done. With multiple lists instead of aliases, it is easy to forget to remove the user from one of the lists with elevated privileges.
+
+### Enable features for a certain group of users
+
+The **sudo** command comes with a huge set of defaults. Still, there are situations when you want to override some of these. This is when you use the **Defaults** statement in the configuration. Usually, these defaults are enforced on every user, but you can narrow the setting down to a subset of users based on host, username, and so on. Here is an example that my generation of sysadmins loves to hear about: insults. These are just some funny messages for when someone mistypes a password:
+
+
+```
+czanik@linux-mewy:~> sudo ls
+[sudo] password for root:
+Hold it up to the light --- not a brain in sight!
+[sudo] password for root:
+My pet ferret can type better than you!
+[sudo] password for root:
+sudo: 3 incorrect password attempts
+czanik@linux-mewy:~>
+```
+
+Because not everyone is a fan of sysadmin humor, these insults are disabled by default. The following example shows how to enable this setting only for your seasoned sysadmins, who are members of the **wheel** group:
+
+
+```
+Defaults !insults
+Defaults:%wheel insults
+```
+
+I do not have enough fingers to count how many people thanked me for bringing these messages back.
+
+### Digest verification
+
+There are, of course, more serious features in **sudo** as well. One of them is digest verification. You can include the digest of applications in your configuration:
+
+
+```
+`peter ALL = sha244:11925141bb22866afdf257ce7790bd6275feda80b3b241c108b79c88 /usr/bin/passwd`
+```
+
+In this case, **sudo** checks and compares the digest of the application to the one stored in the configuration before running the application. If they do not match, **sudo** refuses to run the application. While it is difficult to maintain this information in your configuration—there are no automated tools for this purpose—these digests can provide you with an additional layer of protection.
+
+### Session recording
+
+Session recording is also a lesser-known feature of **sudo**. After my demo, many people leave my talk with plans to implement it on their infrastructure. Why? Because with session recording, you see not just the command name, but also everything that happened in the terminal. You can see what your admins are doing even if they have shell access and logs only show that **bash** is started.
+
+There is one limitation, currently. Records are stored locally, so with enough permissions, users can delete their traces. Stay tuned for upcoming features.
+
+### Plugins
+
+Starting with version 1.8, **sudo** changed to a modular, plugin-based architecture. With most features implemented as plugins, you can easily replace or extend the functionality of **sudo** by writing your own. There are both open source and commercial plugins already available for **sudo**.
+
+In my talk, I demonstrated the **sudo_pair** plugin, which is available [on GitHub][3]. This plugin is developed in Rust, meaning that it is not so easy to compile, and it is even more difficult to distribute the results. On the other hand, the plugin provides interesting functionality, requiring a second admin to approve (or deny) running commands through **sudo**. Not just that, but sessions can be followed on-screen and terminated if there is suspicious activity.
+
+In a demo I did during a recent talk at the All Things Open conference, I had the infamous:
+
+
+```
+`czanik@linux-mewy:~> sudo rm -fr /`
+```
+
+command displayed on the screen. Everybody was holding their breath to see whether my laptop got destroyed, but it survived.
+
+### Logs
+
+As I already mentioned at the beginning, logging and alerting is an important part of **sudo**. If you do not check your **sudo** logs regularly, there is not much worth in using **sudo**. This tool alerts by email on events specified in the configuration and logs all events to **syslog**. Debug logs can be turned on and used to debug rules or report bugs.
+
+### Alerts
+
+Email alerts are kind of old-fashioned now, but if you use **syslog-ng** for collecting your log messages, your **sudo** log messages are automatically parsed. You can easily create custom alerts and send those to a wide variety of destinations, including Slack, Telegram, Splunk, or Elasticsearch. You can learn more about this feature from [my blog on syslong-ng.com][4].
+
+### Configuration
+
+We talked a lot about **sudo** features and even saw a few lines of configuration. Now, let’s take a closer look at how **sudo** is configured. The configuration itself is available in **/etc/sudoers**, which is a simple text file. Still, it is not recommended to edit this file directly. Instead, use **visudo**, as this tool also does syntax checking. If you do not like **vi**, you can change which editor to use by pointing the **EDITOR** environment variable at your preferred option.
+
+Before you start editing the **sudo** configuration, make sure that you know the root password. (Yes, even on Ubuntu, where root does not have a password by default.) While **visudo** checks the syntax, it is easy to create a syntactically correct configuration that locks you out of your system.
+
+When you have a root password at hand in case of an emergency, you can start editing your configuration. When it comes to the **sudoers** file, there is one important thing to remember: This file is read from top to bottom, and the last setting wins. What this fact means for you is that you should start with generic settings and place exceptions at the end, otherwise exceptions are overridden by the generic settings.
+
+You can find a simple **sudoers** file below, based on the one in CentOS, and add a few lines we discussed previously:
+
+
+```
+Defaults !visiblepw
+Defaults always_set_home
+Defaults match_group_by_gid
+Defaults always_query_group_plugin
+Defaults env_reset
+Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
+Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
+Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin
+root ALL=(ALL) ALL
+%wheel ALL=(ALL) ALL
+Defaults:%wheel insults
+Defaults !insults
+Defaults log_output
+```
+
+This file starts by changing a number of defaults. Then come the usual default rules: The **root** user and members of the **wheel** group have full permissions over the machine. Next, we enable insults for the **wheel** group, but disable them for everyone else. The last line enables session recording.
+
+The above configuration is syntactically correct, but can you spot the logical error? Yes, there is one: Insults are disabled for everyone since the last, generic setting overrides the previous, more specific setting. Once you switch the two lines, the setup works as expected: Members of the **wheel** group receive funny messages, but the rest of the users do not receive them.
+
+### Configuration management
+
+Once you have to maintain the **sudoers** file on multiple machines, you will most likely want to manage your configuration centrally. There are two major open source possibilities here. Both have their advantages and drawbacks.
+
+You can use one of the configuration management applications that you also use to configure the rest of your infrastructure. Red Hat Ansible, Puppet, and Chef all have modules to configure **sudo**. The problem with this approach is that updating configurations is far from real-time. Also, users can still edit the **sudoers** file locally and change settings.
+
+The **sudo** tool can also store its configuration in LDAP. In this case, configuration changes are real-time and users cannot mess with the **sudoers** file. On the other hand, this method also has limitations. For example, you cannot use aliases or use **sudo** when the LDAP server is unavailable.
+
+### New features
+
+There is a new version of **sudo** right around the corner. Version 1.9 will include many interesting new features. Here are the most important planned features:
+
+ * A recording service to collect session recordings centrally, which offers many advantages compared to local storage:
+ * It is more convenient to search in one place.
+ * Recordings are available even if the sender machine is down.
+ * Recordings cannot be deleted by someone who wants to delete their tracks.
+ * The **audit** plugin does not add new features to **sudoers**, but instead provides an API for plugins to easily access any kind of **sudo** logs. This plugin enables creating custom logs from **sudo** events using plugins.
+ * The **approval** plugin enables session approvals without using third-party plugins.
+ * And my personal favorite: Python support for plugins, which enables you to easily extend **sudo** using Python code instead of coding natively in C.
+
+
+
+### Conclusion
+
+I hope this article proved to you that **sudo** is a lot more than just a simple prefix. There are tons of possibilities to fine-tune permissions on your system. You cannot just fine-tune permissions, but also improve security by checking digests. Session recordings enable you to check what is happening on your systems. You can also extend the functionality of **sudo** using plugins, either using something already available or writing your own. Finally, given the list of upcoming features you can see that even if **sudo** is decades old, it is a living project that is constantly evolving.
+
+If you want to learn more about **sudo**, here are a few resources:
+
+ * [The **sudo** website][5]
+
+ * [The **sudo** blog][6]
+
+ * [Follow us on Twitter][7]
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/know-about-sudo
+
+作者:[Peter Czanik][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/czanik
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_prompt.png?itok=wbGiJ_yg (Command line prompt)
+[2]: https://www.sudo.ws
+[3]: https://github.com/square/sudo_pair/
+[4]: https://www.syslog-ng.com/community/b/blog/posts/alerting-on-sudo-events-using-syslog-ng
+[5]: https://www.sudo.ws/
+[6]: https://blog.sudo.ws/
+[7]: https://twitter.com/sudoproject
diff --git a/sources/tech/20191030 Getting started with awk, a powerful text-parsing tool.md b/sources/tech/20191030 Getting started with awk, a powerful text-parsing tool.md
new file mode 100644
index 0000000000..387dcf8fcd
--- /dev/null
+++ b/sources/tech/20191030 Getting started with awk, a powerful text-parsing tool.md
@@ -0,0 +1,168 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Getting started with awk, a powerful text-parsing tool)
+[#]: via: (https://opensource.com/article/19/10/intro-awk)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Getting started with awk, a powerful text-parsing tool
+======
+Let's jump in and start using it.
+![Woman programming][1]
+
+Awk is a powerful text-parsing tool for Unix and Unix-like systems, but because it has programmed functions that you can use to perform common parsing tasks, it's also considered a programming language. You probably won't be developing your next GUI application with awk, and it likely won't take the place of your default scripting language, but it's a powerful utility for specific tasks.
+
+What those tasks may be is surprisingly diverse. The best way to discover which of your problems might be best solved by awk is to learn awk; you'll be surprised at how awk can help you get more done but with a lot less effort.
+
+Awk's basic syntax is:
+
+
+```
+`awk [options] 'pattern {action}' file`
+```
+
+To get started, create this sample file and save it as **colours.txt**
+
+
+```
+name color amount
+apple red 4
+banana yellow 6
+strawberry red 3
+grape purple 10
+apple green 8
+plum purple 2
+kiwi brown 4
+potato brown 9
+pineapple yellow 5
+```
+
+This data is separated into columns by one or more spaces. It's common for data that you are analyzing to be organized in some way. It may not always be columns separated by whitespace, or even a comma or semicolon, but especially in log files or data dumps, there's generally a predictable pattern. You can use patterns of data to help awk extract and process the data that you want to focus on.
+
+### Printing a column
+
+In awk, the **print** function displays whatever you specify. There are many predefined variables you can use, but some of the most common are integers designating columns in a text file. Try it out:
+
+
+```
+$ awk '{print $2;}' colours.txt
+color
+red
+yellow
+red
+purple
+green
+purple
+brown
+brown
+yellow
+```
+
+In this case, awk displays the second column, denoted by **$2**. This is relatively intuitive, so you can probably guess that **print $1** displays the first column, and **print $3** displays the third, and so on.
+
+To display _all_ columns, use **$0**.
+
+The number after the dollar sign (**$**) is an _expression_, so **$2** and **$(1+1)** mean the same thing.
+
+### Conditionally selecting columns
+
+The example file you're using is very structured. It has a row that serves as a header, and the columns relate directly to one another. By defining _conditional_ requirements, you can qualify what you want awk to return when looking at this data. For instance, to view items in column 2 that match "yellow" and print the contents of column 1:
+
+
+```
+awk '$2=="yellow"{print $1}' file1.txt
+banana
+pineapple
+```
+
+Regular expressions work as well. This conditional looks at **$2** for approximate matches to the letter **p** followed by any number of (one or more) characters, which are in turn followed by the letter **p**:
+
+
+```
+$ awk '$2 ~ /p.+p/ {print $0}' colours.txt
+grape purple 10
+plum purple 2
+```
+
+Numbers are interpreted naturally by awk. For instance, to print any row with a third column containing an integer greater than 5:
+
+
+```
+awk '$3>5 {print $1, $2}' colours.txt
+name color
+banana yellow
+grape purple
+apple green
+potato brown
+```
+
+### Field separator
+
+By default, awk uses whitespace as the field separator. Not all text files use whitespace to define fields, though. For example, create a file called **colours.csv** with this content:
+
+
+```
+name,color,amount
+apple,red,4
+banana,yellow,6
+strawberry,red,3
+grape,purple,10
+apple,green,8
+plum,purple,2
+kiwi,brown,4
+potato,brown,9
+pineapple,yellow,5
+```
+
+Awk can treat the data in exactly the same way, as long as you specify which character it should use as the field separator in your command. Use the **\--field-separator** (or just **-F** for short) option to define the delimiter:
+
+
+```
+$ awk -F"," '$2=="yellow" {print $1}' file1.csv
+banana
+pineapple
+```
+
+### Saving output
+
+Using output redirection, you can write your results to a file. For example:
+
+
+```
+`$ awk -F, '$3>5 {print $1, $2} colours.csv > output.txt`
+```
+
+This creates a file with the contents of your awk query.
+
+You can also split a file into multiple files grouped by column data. For example, if you want to split colours.txt into multiple files according to what color appears in each row, you can cause awk to redirect _per query_ by including the redirection in your awk statement:
+
+
+```
+`$ awk '{print > $2".txt"}' colours.txt`
+```
+
+This produces files named **yellow.txt**, **red.txt**, and so on.
+
+In the next article, you'll learn more about fields, records, and some powerful awk variables.
+
+* * *
+
+This article is adapted from an episode of [Hacker Public Radio][2], a community technology podcast.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/intro-awk
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop-music-headphones.png?itok=EQZ2WKzy (Woman programming)
+[2]: http://hackerpublicradio.org/eps.php?id=2114
diff --git a/sources/tech/20191030 How to Find Out Top Memory Consuming Processes in Linux.md b/sources/tech/20191030 How to Find Out Top Memory Consuming Processes in Linux.md
new file mode 100644
index 0000000000..fe5bafeb5c
--- /dev/null
+++ b/sources/tech/20191030 How to Find Out Top Memory Consuming Processes in Linux.md
@@ -0,0 +1,218 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lnrCoder)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Find Out Top Memory Consuming Processes in Linux)
+[#]: via: (https://www.2daygeek.com/linux-find-top-memory-consuming-processes/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+How to Find Out Top Memory Consuming Processes in Linux
+======
+
+You may have seen your system consumes too much of memory many times.
+
+If that’s the case, what would be the best thing you can do to identify processes that consume too much memory on a Linux machine.
+
+I believe, you may have run one of the below commands to check it out.
+
+If not, what is the other commands you tried?
+
+I would request you to update it in the comment section, it may help other users.
+
+This can be easily identified using the **[top command][1]** and the **[ps command][2]**.
+
+I used to check both commands simultaneously, and both were given the same result.
+
+So i suggest you to use one of the command that you like.
+
+### 1) How to Find Top Memory Consuming Process in Linux Using the ps Command
+
+The ps command is used to report a snapshot of the current processes. The ps command stands for process status.
+
+This is a standard Linux application that looks for information about running processes on a Linux system.
+
+It is used to list the currently running processes and their process ID (PID), process owner name, process priority (PR), and the absolute path of the running command, etc,.
+
+The below ps command format provides you more information about top memory consumption process.
+
+```
+# ps aux --sort -rss | head
+
+USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
+mysql 1064 3.2 5.4 886076 209988 ? Ssl Oct25 62:40 /usr/sbin/mysqld
+varnish 23396 0.0 2.9 286492 115616 ? SLl Oct25 0:42 /usr/sbin/varnishd -P /var/run/varnish.pid -f /etc/varnish/default.vcl -a :82 -T 127.0.0.1:6082 -S /etc/varnish/secret -s malloc,256M
+named 1105 0.0 2.7 311712 108204 ? Ssl Oct25 0:16 /usr/sbin/named -u named -c /etc/named.conf
+nobody 23377 0.2 2.3 153096 89432 ? S Oct25 4:35 nginx: worker process
+nobody 23376 0.1 2.1 147096 83316 ? S Oct25 2:18 nginx: worker process
+root 23375 0.0 1.7 131028 66764 ? Ss Oct25 0:01 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
+nobody 23378 0.0 1.6 130988 64592 ? S Oct25 0:00 nginx: cache manager process
+root 1135 0.0 0.9 86708 37572 ? S 05:37 0:20 cwpsrv: worker process
+root 1133 0.0 0.9 86708 37544 ? S 05:37 0:05 cwpsrv: worker process
+```
+
+Use the below ps command format to include only specific information about the process of memory consumption in the output.
+
+```
+# ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%mem | head
+
+ PID PPID %MEM %CPU CMD
+ 1064 1 5.4 3.2 /usr/sbin/mysqld
+23396 23386 2.9 0.0 /usr/sbin/varnishd -P /var/run/varnish.pid -f /etc/varnish/default.vcl -a :82 -T 127.0.0.1:6082 -S /etc/varnish/secret -s malloc,256M
+ 1105 1 2.7 0.0 /usr/sbin/named -u named -c /etc/named.conf
+23377 23375 2.3 0.2 nginx: worker process
+23376 23375 2.1 0.1 nginx: worker process
+ 3625 977 1.9 0.0 /usr/local/bin/php-cgi /home/daygeekc/public_html/index.php
+23375 1 1.7 0.0 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
+23378 23375 1.6 0.0 nginx: cache manager process
+ 1135 3034 0.9 0.0 cwpsrv: worker process
+```
+
+If you want to see only the command name instead of the absolute path of the command, use the ps command format below.
+
+```
+# ps -eo pid,ppid,%mem,%cpu,comm --sort=-%mem | head
+
+ PID PPID %MEM %CPU COMMAND
+ 1064 1 5.4 3.2 mysqld
+23396 23386 2.9 0.0 cache-main
+ 1105 1 2.7 0.0 named
+23377 23375 2.3 0.2 nginx
+23376 23375 2.1 0.1 nginx
+23375 1 1.7 0.0 nginx
+23378 23375 1.6 0.0 nginx
+ 1135 3034 0.9 0.0 cwpsrv
+ 1133 3034 0.9 0.0 cwpsrv
+```
+
+### 2) How to Find Out Top Memory Consuming Process in Linux Using the top Command
+
+The Linux top command is the best and most well known command that everyone uses to monitor Linux system performance.
+
+It displays a real-time view of the system process running on the interactive interface.
+
+But if you want to find top memory consuming process then **[use the top command in the batch mode][3]**.
+
+You should properly **[understand the top command output][4]** to fix the performance issue in system.
+
+```
+# top -c -b -o +%MEM | head -n 20 | tail -15
+
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 1064 mysql 20 0 886076 209740 8388 S 0.0 5.4 62:41.20 /usr/sbin/mysqld
+23396 varnish 20 0 286492 115616 83572 S 0.0 3.0 0:42.24 /usr/sbin/varnishd -P /var/run/varnish.pid -f /etc/varnish/default.vcl -a :82 -T 127.0.0.1:6082 -S /etc/varnish/secret -s malloc,256M
+ 1105 named 20 0 311712 108204 2424 S 0.0 2.8 0:16.41 /usr/sbin/named -u named -c /etc/named.conf
+23377 nobody 20 0 153240 89432 2432 S 0.0 2.3 4:35.74 nginx: worker process
+23376 nobody 20 0 147096 83316 2416 S 0.0 2.1 2:18.09 nginx: worker process
+23375 root 20 0 131028 66764 1616 S 0.0 1.7 0:01.07 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
+23378 nobody 20 0 130988 64592 592 S 0.0 1.7 0:00.51 nginx: cache manager process
+ 1135 root 20 0 86708 37572 2252 S 0.0 1.0 0:20.18 cwpsrv: worker process
+ 1133 root 20 0 86708 37544 2212 S 0.0 1.0 0:05.94 cwpsrv: worker process
+ 3034 root 20 0 86704 36740 1452 S 0.0 0.9 0:00.09 cwpsrv: master process /usr/local/cwpsrv/bin/cwpsrv
+ 1067 nobody 20 0 1356200 31588 2352 S 0.0 0.8 0:56.06 /usr/local/apache/bin/httpd -k start
+ 977 nobody 20 0 1356088 31268 2372 S 0.0 0.8 0:30.44 /usr/local/apache/bin/httpd -k start
+ 968 nobody 20 0 1356216 30544 2348 S 0.0 0.8 0:19.95 /usr/local/apache/bin/httpd -k start
+```
+
+If you only want to see the command name instead of the absolute path of the command, use the below top command format.
+
+```
+# top -b -o +%MEM | head -n 20 | tail -15
+
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 1064 mysql 20 0 886076 210340 8388 S 6.7 5.4 62:40.93 mysqld
+23396 varnish 20 0 286492 115616 83572 S 0.0 3.0 0:42.24 cache-main
+ 1105 named 20 0 311712 108204 2424 S 0.0 2.8 0:16.41 named
+23377 nobody 20 0 153240 89432 2432 S 13.3 2.3 4:35.74 nginx
+23376 nobody 20 0 147096 83316 2416 S 0.0 2.1 2:18.09 nginx
+23375 root 20 0 131028 66764 1616 S 0.0 1.7 0:01.07 nginx
+23378 nobody 20 0 130988 64592 592 S 0.0 1.7 0:00.51 nginx
+ 1135 root 20 0 86708 37572 2252 S 0.0 1.0 0:20.18 cwpsrv
+ 1133 root 20 0 86708 37544 2212 S 0.0 1.0 0:05.94 cwpsrv
+ 3034 root 20 0 86704 36740 1452 S 0.0 0.9 0:00.09 cwpsrv
+ 1067 nobody 20 0 1356200 31588 2352 S 0.0 0.8 0:56.04 httpd
+ 977 nobody 20 0 1356088 31268 2372 S 0.0 0.8 0:30.44 httpd
+ 968 nobody 20 0 1356216 30544 2348 S 0.0 0.8 0:19.95 httpd
+```
+
+### 3) Bonus Tips: How to Find Out Top Memory Consuming Process in Linux Using the ps_mem Command
+
+The **[ps_mem utility][5]** is used to display the core memory used per program (not per process).
+
+This utility allows you to check how much memory is used per program.
+
+It calculates the amount of private and shared memory against a program and returns the total used memory in the most appropriate way.
+
+It uses the following logic to calculate RAM usage. Total RAM = sum (private RAM for program processes) + sum (shared RAM for program processes)
+
+```
+# ps_mem
+
+ Private + Shared = RAM used Program
+128.0 KiB + 27.5 KiB = 155.5 KiB agetty
+228.0 KiB + 47.0 KiB = 275.0 KiB atd
+284.0 KiB + 53.0 KiB = 337.0 KiB irqbalance
+380.0 KiB + 81.5 KiB = 461.5 KiB dovecot
+364.0 KiB + 121.5 KiB = 485.5 KiB log
+520.0 KiB + 65.5 KiB = 585.5 KiB auditd
+556.0 KiB + 60.5 KiB = 616.5 KiB systemd-udevd
+732.0 KiB + 48.0 KiB = 780.0 KiB crond
+296.0 KiB + 524.0 KiB = 820.0 KiB avahi-daemon (2)
+772.0 KiB + 51.5 KiB = 823.5 KiB systemd-logind
+940.0 KiB + 162.5 KiB = 1.1 MiB dbus-daemon
+ 1.1 MiB + 99.0 KiB = 1.2 MiB pure-ftpd
+ 1.2 MiB + 100.5 KiB = 1.3 MiB master
+ 1.3 MiB + 198.5 KiB = 1.5 MiB pickup
+ 1.3 MiB + 198.5 KiB = 1.5 MiB bounce
+ 1.3 MiB + 198.5 KiB = 1.5 MiB pipe
+ 1.3 MiB + 207.5 KiB = 1.5 MiB qmgr
+ 1.4 MiB + 198.5 KiB = 1.6 MiB cleanup
+ 1.3 MiB + 299.5 KiB = 1.6 MiB trivial-rewrite
+ 1.5 MiB + 145.0 KiB = 1.6 MiB config
+ 1.4 MiB + 291.5 KiB = 1.6 MiB tlsmgr
+ 1.4 MiB + 308.5 KiB = 1.7 MiB local
+ 1.4 MiB + 323.0 KiB = 1.8 MiB anvil (2)
+ 1.3 MiB + 559.0 KiB = 1.9 MiB systemd-journald
+ 1.8 MiB + 240.5 KiB = 2.1 MiB proxymap
+ 1.9 MiB + 322.5 KiB = 2.2 MiB auth
+ 2.4 MiB + 88.5 KiB = 2.5 MiB systemd
+ 2.8 MiB + 458.5 KiB = 3.2 MiB smtpd
+ 2.9 MiB + 892.0 KiB = 3.8 MiB bash (2)
+ 3.3 MiB + 555.5 KiB = 3.8 MiB NetworkManager
+ 4.1 MiB + 233.5 KiB = 4.3 MiB varnishd
+ 4.0 MiB + 662.0 KiB = 4.7 MiB dhclient (2)
+ 4.3 MiB + 623.5 KiB = 4.9 MiB rsyslogd
+ 3.6 MiB + 1.8 MiB = 5.5 MiB sshd (3)
+ 5.6 MiB + 431.0 KiB = 6.0 MiB polkitd
+ 13.0 MiB + 546.5 KiB = 13.6 MiB tuned
+ 22.5 MiB + 76.0 KiB = 22.6 MiB lfd - sleeping
+ 30.0 MiB + 6.2 MiB = 36.2 MiB php-fpm (6)
+ 5.7 MiB + 33.5 MiB = 39.2 MiB cwpsrv (3)
+ 20.1 MiB + 25.3 MiB = 45.4 MiB httpd (5)
+104.7 MiB + 156.0 KiB = 104.9 MiB named
+112.2 MiB + 479.5 KiB = 112.7 MiB cache-main
+ 69.4 MiB + 58.6 MiB = 128.0 MiB nginx (4)
+203.4 MiB + 309.5 KiB = 203.7 MiB mysqld
+---------------------------------
+ 775.8 MiB
+=================================
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-find-top-memory-consuming-processes/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[lnrCoder](https://github.com/lnrCoder)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/
+[2]: https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/
+[3]: https://www.2daygeek.com/linux-run-execute-top-command-in-batch-mode/
+[4]: https://www.2daygeek.com/understanding-linux-top-command-output-usage/
+[5]: https://www.2daygeek.com/ps_mem-report-core-memory-usage-accurately-in-linux/
diff --git a/sources/tech/20191030 Test automation without assertions for web development.md b/sources/tech/20191030 Test automation without assertions for web development.md
new file mode 100644
index 0000000000..7940402936
--- /dev/null
+++ b/sources/tech/20191030 Test automation without assertions for web development.md
@@ -0,0 +1,163 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Test automation without assertions for web development)
+[#]: via: (https://opensource.com/article/19/10/test-automation-without-assertions)
+[#]: author: (Jeremias Roessler https://opensource.com/users/roesslerj)
+
+Test automation without assertions for web development
+======
+Recheck-web promises the benefits of golden master-based testing without
+the drawbacks.
+![Coding on a computer][1]
+
+Graphical user interface (GUI) test automation is broken. Regression testing is not testing; it's version control for a software's behavior. Here's my assertion: test automation _without_ _assertions_ works better!
+
+In software development and test automation, an assertion is a means to check the result of a calculation, typically by comparing it to a singular expected value. While this is very well suited for unit-based test automation (i.e. testing the system from within), applying it to testing an interface (specifically the user interface) has proven to be problematic, as this post will explain.
+
+The number of tools that work according to the [golden master][2] approach to testing, characterization testing, and approval testing—such as [Approval Tests][3], [Jest][4], or [recheck-web][5] ([retest][6])—is constantly increasing. This approach promises more robust tests with less effort (for both creation and maintenance) while testing more thoroughly.
+
+The examples in this article are available on [GitHub][7].
+
+### A basic Selenium test
+
+Here's a simple example of a traditional test running against a web application's login page. Using [Selenium][8] as the testing framework, the code could look like this:
+
+
+```
+public class MySeleniumTest {
+
+ RemoteWebDriver driver;
+
+ @Before
+ public void setup() {
+ driver = new ChromeDriver();
+ }
+
+ @Test
+ public void login() throws Exception {
+ driver.get("");
+
+ driver.findElement(By.id("username")).sendKeys("Simon");
+ driver.findElement(By.id("password")).sendKeys("secret");
+ driver.findElement(By.id("sign-in")).click();
+
+ assertEquals(driver.findElement(By.tagName("h4")).getText(), "Success!");
+ }
+
+ @After
+ public void tearDown() throws InterruptedException {
+ driver.quit();
+ }
+}
+```
+
+This is a very simple test. It opens a specific URL, then finds input fields by their invisible element IDs. It enters the user name and password, then clicks the login button.
+
+As is currently best practice, this test then uses a unit-test library to check the correct outcome by means of an _assert_ statement.
+
+In this example, the test determines whether the text "Success!" is displayed.
+
+You can run the test a few times to verify success, but it's important to experience failure, as well. To create an error, change the HTML of the website being tested. You could, for instance, edit the CSS declaration:
+
+
+```
+``
+```
+
+Changing or removing as much as a single character of the URL (e.g. change "main" to "min") changes the website to display as raw HTML without a layout.
+
+![Website login form displayed as raw HTML][9]
+
+This small change is definitely an error. However, when the test is executed, it shows no problem and still passes. To outright ignore such a blatant error clearly is not what you would expect of your tests. They should guard against you involuntarily breaking your website after all.
+
+Now instead, change or remove the element IDs of the input fields. Since these IDs are invisible, this change doesn't have any impact on the website from a user's perspective. But when the test executes, it fails with a **NoSuchElementException**. This essentially means that this irrelevant change _broke the test_. Tests that ignore major changes but fail on invisible and hence irrelevant ones are the current standard in test automation. This is basically the _opposite_ of how a test should behave.
+
+Now, take the original test and wrap the driver in a RecheckDriver:
+
+
+```
+`driver = new RecheckDriver( new ChromeDriver() );`
+```
+
+Then either replace the assertion with a call to **driver.capTest();** at the end of the test or add a Junit 5 rule: **@ExtendWith(RecheckExtension.class)**. If you remove the CSS from the website, the test fails, as it should:
+
+![Failed test][10]
+
+But if you change or remove the element IDs instead, the test still passes.
+
+This surprising ability, coming from the "unbreakable" feature of recheck-web, is explained in detail below. This is how a test should behave: detect changes important to the user, and do not break on changes that are irrelevant to the user.
+
+### How it works
+
+The [recheck-web][5] project is a free, open source tool that operates on top of Selenium. It is golden master-based, which essentially means that it creates a copy of the rendered website the first time the test is executed, and subsequent runs of the test compare the current state against that copy (the golden master). This is how it can detect that the website has changed in unfavorable ways. It is also how it can still identify an element after its ID has changed: It simply peeks into the golden master (where the ID is still present) and finds the element there. Using additional properties like XPath, HTML name, and CSS classes, recheck-web identifies the element on the changed website and returns it to Selenium. The test can then interact with the element, just as before, and report the change.
+
+![recheck-web's process][11]
+
+#### Problems with golden master testing
+
+Golden master testing, in general, has two essential drawbacks:
+
+ 1. It is often difficult to ignore irrelevant changes. Many changes are not problematic (e.g., date and time changes, random IDs, etc.). For the same reason that Git features the **.gitignore** file, recheck-web features the **recheck.ignore** file. And its Git-like syntax makes it easy to specify which differences to ignore.
+ 2. It is often cumbersome to maintain redundancy. Golden masters usually have quite an overlap. Often, the same change has to be approved multiple times, nullifying the efficiency gained during the fast test creation. For that, recheck comes complete with its own [command-line interface (CLI)][12] that takes care of this annoying task. The CLI (and the [commercial GUI][13]) lets users easily apply the same change to the same element in all instances or simply apply or ignore all changes at once.
+
+
+
+The example above illustrates both drawbacks and their respective solutions: the changed ID was detected, but not reported because the ID attribute in the **recheck.ignore** file was specified to be ignored with **attribute=id**. Removing that rule makes the test fail, but it does not _break_ (the test still executes and reports the changed ID).
+
+The example test uses the implicit checking mechanism, which automatically checks the result after every action. (Note that if you prefer to do explicit checking (e.g. by calling **re.check**) this is entirely possible.) Opening the URL, entering the user name, and entering the password are three actions that are being performed on the same page, therefore three golden masters are created for the same page. The changed ID thus is reported three times. All three instances can be treated with a single call to **recheck commit --all tests.report** on the command line. Applying the change makes the recheck-web test fail because the ID is removed from the golden master. This calls for anther neat feature of recheck-web: the **retestId**.
+
+### Virtual constant IDs
+
+The basic idea of the **retestId** is to introduce an additional attribute in the copy of the website. Since this attribute lives only in the website copy, not on the live site, it can never be affected by a change (unless the element is completely removed). This is called a _virtual constant ID_.
+
+Now, this **retestId** can be referred to in the test. Simply replace the call to, for instance, **By._id_("username")** with **By._retestId_("username")**, and this problem is solved for good. This also addresses instances where elements are hard to reference because they have no ID to begin with.
+
+### Filter mechanism
+
+What would Git be without the **.gitignore** file? Filtering out irrelevant changes is one of the most important features of a version-control system. Traditional assertion-based testing ignores more than 99% of the changes. Instead, similar to Git without a **.gitignore** file, recheck-web reports any and all changes.
+
+It's up to the user to ignore changes that aren't of interest. Recheck-web can be used for cross-browser testing, cross-device testing, deep visual regression testing, and functional regression testing, depending on what you do or do not ignore.
+
+The filtering mechanism is as simple (based on the **.gitignore** file) as it is powerful. Single attributes can be filtered globally or for certain elements. Single elements—or even whole parts of the page—can be ignored. If this is not powerful enough, you can implement filter rules in JavaScript to, for example, ignore different URLs with the same base or position differences of less than five pixels.
+
+A good starting point for understanding this is the [predefined filter files][14] that are distributed with recheck-web. Ignoring element positioning is usually a good idea. If you want to learn more about how to maintain your **recheck.ignore** file or create your own filters, see the [documentation][15].
+
+### Summary
+
+Recheck-web is one of the few golden master-based testing tools available; alternatives include Approval Tests and Jest.
+
+Recheck-web provides the ability to quickly and easily create tests that are more complete and robust than traditional tests. Because it compares rendered websites (or parts of them) with each other, cross-browser testing, cross-platform testing, and other test scenarios can be realized. Also, this kind of testing is an "enabler" technology that will enable artificial intelligence to generate additional tests.
+
+Recheck-web is free and open source, so please [try it out][5]. The company's business model is to offer additional services (e.g., storing golden masters and reports as well as an AI to generate tests) and to have a commercial GUI on top of the CLI for maintaining the golden masters.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/test-automation-without-assertions
+
+作者:[Jeremias Roessler][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/roesslerj
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
+[2]: https://opensource.com/article/19/7/what-golden-image
+[3]: https://approvaltests.com
+[4]: https://jestjs.io/
+[5]: https://github.com/retest/recheck-web
+[6]: http://retest.de
+[7]: https://github.com/retest/recheck-web-example
+[8]: https://www.seleniumhq.org/
+[9]: https://opensource.com/sites/default/files/uploads/webformerror.png (Website login form displayed as raw HTML)
+[10]: https://opensource.com/sites/default/files/uploads/testfails.png (Failed test)
+[11]: https://opensource.com/sites/default/files/uploads/recheck-web-process.png (recheck-web's process)
+[12]: https://github.com/retest/recheck.cli
+[13]: https://retest.de/review/
+[14]: https://github.com/retest/recheck/tree/master/src/main/resources/filter/web
+[15]: https://docs.retest.de/recheck/usage/filter
diff --git a/sources/tech/20191030 Viewing network bandwidth usage with bmon.md b/sources/tech/20191030 Viewing network bandwidth usage with bmon.md
new file mode 100644
index 0000000000..d8d2b2e1c9
--- /dev/null
+++ b/sources/tech/20191030 Viewing network bandwidth usage with bmon.md
@@ -0,0 +1,222 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Viewing network bandwidth usage with bmon)
+[#]: via: (https://www.networkworld.com/article/3447936/viewing-network-bandwidth-usage-with-bmon.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+Viewing network bandwidth usage with bmon
+======
+Introducing bmon, a monitoring and debugging tool that captures network statistics and makes them easily digestible.
+Sandra Henry-Stocker
+
+Bmon is a monitoring and debugging tool that runs in a terminal window and captures network statistics, offering options on how and how much data will be displayed and displayed in a form that is easy to understand.
+
+To check if **bmon** is installed on your system, use the **which** command:
+
+```
+$ which bmon
+/usr/bin/bmon
+```
+
+### Getting bmon
+
+On Debian systems, use **sudo apt-get install bmon** to install the tool.
+
+[][1]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][1]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+For Red Hat and related distributions, you might be able to install with **yum install bmon** or **sudo dnf install bmon**. Alternately, you may have to resort to a more complex install with commands like these that first set up the required **libconfuse** using the root account or sudo:
+
+```
+# wget https://github.com/martinh/libconfuse/releases/download/v3.2.2/confuse-3.2.2.zip
+# unzip confuse-3.2.2.zip && cd confuse-3.2.2
+# sudo PATH=/usr/local/opt/gettext/bin:$PATH ./configure
+# make
+# make install
+# git clone https://github.com/tgraf/bmon.git &&ammp; cd bmon
+# ./autogen.sh
+# ./configure
+# make
+# sudo make install
+```
+
+The first five lines will install **libconfuse** and the second five will grab and install **bmon** itself.
+
+### Using bmon
+
+The simplest way to start **bmon** is simply to type **bmon** on the command line. Depending on the size of the window you are using, you will be able to see and bring up a variety of data.
+
+The top portion of your display will display stats on your network interfaces – the loopback (lo) and network-accessible (e.g., eth0). If you terminal window has few lines, this is all you may see, and it will look something like this:
+
+[RELATED: 11 pointless but awesome Linux terminal tricks][2]
+
+```
+lo bmon 4.0
+Interfaces x RX bps pps %x TX bps pps %
+ >lo x 4B0 x0 0 0 4B 0
+ qdisc none (noqueue) x 0 0 x 0 0
+ enp0s25 x 244B0 x1 0 0 470B 2
+ qdisc none (fq_codel) x 0 0 x 0 0 462B 2
+q Increase screen height to see graphical statistics qq
+
+
+q Press d to enable detailed statistics qq
+q Press i to enable additional information qq
+ Wed Oct 23 14:36:27 2019 Press ? for help
+```
+
+In this example, the network interface is enp0s25. Notice the helpful "Increase screen height" hint below the listed interfaces. Stretch your screen to add sufficient lines (no need to restart bmon) and you will see some graphs:
+
+```
+Interfaces x RX bps pps %x TX bps pps %
+ >lo x 0 0 x 0 0
+ qdisc none (noqueue) x 0 0 x 0 0
+ enp0s25 x 253B 3 x 2.65KiB 6
+ qdisc none (fq_codel) x 0 0 x 2.62KiB 6
+qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq
+ (RX Bytes/second)
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 1 5 10 15 20 25 30 35 40 45 50 55 60
+ (TX Bytes/second)
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 0.00 ............................................................
+ 1 5 10 15 20 25 30 35 40 45 50 55 60
+```
+
+Notice, however, that the graphs are not showing values. This is because it is displaying the loopback **>lo** interface. Arrow your way down to the public network interface and you will see some traffic.
+
+```
+Interfaces x RX bps pps %x TX bps pps %
+ lo x 0 0 x 0 0
+ qdisc none (noqueue) x 0 0 x 0 0
+ >enp0s25 x 151B 2 x 1.61KiB 3
+ qdisc none (fq_codel) x 0 0 x 1.60KiB 3
+qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqvqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq
+ B (RX Bytes/second)
+ 635.00 ...............................|............................
+ 529.17 .....|.........................|....|.......................
+ 423.33 .....|................|..|..|..|..|.|.......................
+ 317.50 .|..||.|..||.|..|..|..|..|..|..||.||||......................
+ 211.67 .|..||.|..||.|..||||.||.|||.||||||||||......................
+ 105.83 ||||||||||||||||||||||||||||||||||||||......................
+ 1 5 10 15 20 25 30 35 40 45 50 55 60
+ KiB (TX Bytes/second)
+ 4.59 .....................................|......................
+ 3.83 .....................................|......................
+ 3.06 ....................................||......................
+ 2.30 ....................................||......................
+ 1.53 |||..............|..|||.|...|.|||.||||......................
+ 0.77 ||||||||||||||||||||||||||||||||||||||......................
+ 1 5 10 15 20 25 30 35 40 45 50 55 60
+
+
+q Press d to enable detailed statistics qq
+q Press i to enable additional information qq
+ Wed Oct 23 16:42:06 2019 Press ? for help
+```
+
+The change allows you to view a graph displaying network traffic. Note, however, that the default is to display bytes per second. To display bits per second instead, you would start the tool using **bmon -b**
+
+Detailed statistics on network traffic can be displayed if your window is large enough and you press **d**. An example of the stats you will see is displayed below. This display was split into left and right portions because of its width.
+
+##### left side:
+
+```
+RX TX │ RX TX │
+ Bytes 11.26MiB 11.26MiB│ Packets 25.91K 25.91K │
+ Collisions - 0 │ Compressed 0 0 │
+ Errors 0 0 │ FIFO Error 0 0 │
+ ICMPv6 2 2 │ ICMPv6 Checksu 0 - │
+ Ip6 Broadcast 0 0 │ Ip6 Broadcast 0 0 │
+ Ip6 Delivers 8 - │ Ip6 ECT(0) Pac 0 - │
+ Ip6 Header Err 0 - │ Ip6 Multicast 0 152B │
+ Ip6 Non-ECT Pa 8 - │ Ip6 Reasm/Frag 0 0 │
+ Ip6 Reassembly 0 - │ Ip6 Too Big Er 0 - │
+ Ip6Discards 0 0 │ Ip6Octets 530B 530B │
+ Missed Error 0 - │ Multicast - 0 │
+ Window Error - 0 │ │
+```
+
+##### right side
+
+```
+│ RX TX │ RX TX
+│ Abort Error - 0 │ Carrier Error - 0
+│ CRC Error 0 - │ Dropped 0 0
+│ Frame Error 0 - │ Heartbeat Erro -
+│ ICMPv6 Errors 0 0 │ Ip6 Address Er 0 -
+│ Ip6 CE Packets 0 - │ Ip6 Checksum E 0 -
+│ Ip6 ECT(1) Pac 0 - │ Ip6 Forwarded - 0
+│ Ip6 Multicast 0 2 │ Ip6 No Route 0 0
+│ Ip6 Reasm/Frag 0 0 │ Ip6 Reasm/Frag 0 0
+│ Ip6 Truncated 0 - │ Ip6 Unknown Pr 0 -
+│ Ip6Pkts 8 8 │ Length Error 0
+│ No Handler 0 - │ Over Error 0 -
+```
+
+Additional information on the network interface will be displayed if you press **i**
+
+##### left side:
+
+```
+MTU 1500 | Flags broadcast,multicast,up |
+Address 00:1d:09:77:9d:08 | Broadcast ff:ff:ff:ff:ff:ff |
+Family unspec | Alias |
+```
+
+##### right side:
+
+```
+| Operstate up | IfIndex 2 |
+| Mode default | TXQlen 1000 |
+| Qdisc fq_codel |
+```
+
+A help menu will appear if you press **?** with brief descriptions of how to move around the screen, select data to be displayed and control the graphs.
+
+To quit **bmon**, you would type **q** and then **y** in response to the prompt to confirm your choice to exit.
+
+Some of the important things to note are that:
+
+ * **bmon** adjusts its display to the size of the terminal window
+ * some of the choices shown at the bottom of the display will only function if the window is large enough to accomodate the data
+ * the display is updated every second unless you slow this down using the **-R** (e.g., **bmon -R 5)** option
+
+
+
+Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3447936/viewing-network-bandwidth-usage-with-bmon.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[2]: https://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb
+[3]: https://www.facebook.com/NetworkWorld/
+[4]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20191031 4 Python tools for getting started with astronomy.md b/sources/tech/20191031 4 Python tools for getting started with astronomy.md
new file mode 100644
index 0000000000..79e64651b3
--- /dev/null
+++ b/sources/tech/20191031 4 Python tools for getting started with astronomy.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (4 Python tools for getting started with astronomy)
+[#]: via: (https://opensource.com/article/19/10/python-astronomy-open-data)
+[#]: author: (Gina Helfrich, Ph.D. https://opensource.com/users/ginahelfrich)
+
+4 Python tools for getting started with astronomy
+======
+Explore the universe with NumPy, SciPy, Scikit-Image, and Astropy.
+![Person looking up at the stars][1]
+
+NumFOCUS is a nonprofit charity that supports amazing open source toolkits for scientific computing and data science. As part of the effort to connect Opensource.com readers with the NumFOCUS community, we are republishing some of the most popular articles from [our blog][2]. To learn more about our mission and programs, please visit [numfocus.org][3]. If you're interested in participating in the NumFOCUS community in person, check out a local [PyData event][4] happening near you.
+
+* * *
+
+### Astronomy with Python
+
+Python is a great language for science, and specifically for astronomy. The various packages such as [NumPy][5], [SciPy][6], [Scikit-Image][7] and [Astropy][8] (to name but a few) are all a great testament to the suitability of Python for astronomy, and there are plenty of use cases. [NumPy, Astropy, and SciPy are NumFOCUS fiscally sponsored projects; Scikit-Image is an affiliated project.] Since leaving the field of astronomical research behind more than 10 years ago to start a second career as software developer, I have always been interested in the evolution of these packages. Many of my former colleagues in astronomy used most if not all of these packages for their research work. I have since worked on implementing professional astronomy software packages for instruments for the Very Large Telescope (VLT) in Chile, for example.
+
+It struck me recently that the Python packages have evolved to such an extent that it is now fairly easy for anyone to build [data reduction][9] scripts that can provide high-quality data products. Astronomical data is ubiquitous, and what is more, it is almost all publicly available—you just need to look for it.
+
+For example, ESO, which runs the VLT, offers the data for download on their site. Head over to [www.eso.org/UserPortal][10] and create a user name for their portal. If you look for data from the instrument SPHERE you can download a full dataset for any of the nearby stars that have exoplanet or proto-stellar discs. It is a fantastic and exciting project for any Pythonista to reduce that data and make the planets or discs that are deeply hidden in the noise visible.
+
+I encourage you to download the ESO or any other astronomy imaging dataset and go on that adventure. Here are a few tips:
+
+ 1. Start off with a good dataset. Have a look at papers about nearby stars with discs or exoplanets and then search, for example: . Notice that some data on this site is marked as red and some as green. The red data is not publicly available yet — it will say under “release date” when it will be available.
+ 2. Read something about the instrument you are using the data from. Try and get a basic understanding of how the data is obtained and what the standard data reduction should look like. All telescopes and instruments have publicly available documents about this.
+ 3. You will need to consider the standard problems with astronomical data and correct for them:
+ 1. Data comes in FITS files. You will need **pyfits** or **astropy** (which contains pyfits) to read them into **NumPy** arrays. In some cases the data comes in a cube and you should to use **numpy.median **along the z-axis to turn them into 2-D arrays. For some SPHERE data you get two copies of the same piece of sky on the same image (each has a different filter) which you will need to extract using **indexing and slicing.**
+ 2. The master dark and bad pixel map. All instruments will have specific images taken as “dark frames” that contain images with the shutter closed (no light at all). Use these to extract a mask of bad pixels using **NumPy masked arrays** for this. This mask of bad pixels will be very important — you need to keep track of it as you process the data to get a clean combined image in the end. In some cases it also helps to subtract this master dark from all scientific raw images.
+ 3. Instruments will typically also have a master flat frame. This is an image or series of images taken with a flat uniform light source. You will need to divide all scientific raw images by this (again, using numpy masked array makes this an easy division operation).
+ 4. For planet imaging, the fundamental technique to make planets visible against a bright star rely on using a coronagraph and a technique known as angular differential imaging. To that end, you need to identify the optical centre on the images. This is one of the most tricky steps and requires finding some artificial helper images embedded in the images using **skimage.feature.blob_dog**.
+ 4. Be patient. It can take a while to understand the data format and how to handle it. Making some plots and histograms of the pixel data can help you to understand it. It is well worth it to be persistent! You will learn a lot about imaging data and processing.
+
+
+
+Using the tools offered by NumPy, SciPy, Astropy, scikit-image and more in combination, with some patience and persistence, it is possible to analyse the vast amount of available astronomical data to produce some stunning results. And who knows, maybe you will be the first one to find a planet that was previously overlooked! Good luck!
+
+_This article was originally published on the NumFOCUS blog and is republished with permission. It is based on [a talk][11] by [Ole Moeller-Nilsson][12], CTO at Pivigo. If you want to support NumFOCUS, you can donate [here][13] or find your local [PyData event][4] happening around the world._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/python-astronomy-open-data
+
+作者:[Gina Helfrich, Ph.D.][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ginahelfrich
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/space_stars_cosmos_person.jpg?itok=XUtz_LyY (Person looking up at the stars)
+[2]: https://numfocus.org/blog
+[3]: https://numfocus.org
+[4]: https://pydata.org/
+[5]: http://numpy.scipy.org/
+[6]: http://www.scipy.org/
+[7]: http://scikit-image.org/
+[8]: http://www.astropy.org/
+[9]: https://en.wikipedia.org/wiki/Data_reduction
+[10]: http://www.eso.org/UserPortal
+[11]: https://www.slideshare.net/OleMoellerNilsson/pydata-lonon-finding-planets-with-python
+[12]: https://twitter.com/olly_mn
+[13]: https://numfocus.org/donate
diff --git a/sources/tech/20191031 Advance your awk skills with two easy tutorials.md b/sources/tech/20191031 Advance your awk skills with two easy tutorials.md
new file mode 100644
index 0000000000..f84e4ebe3a
--- /dev/null
+++ b/sources/tech/20191031 Advance your awk skills with two easy tutorials.md
@@ -0,0 +1,287 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Advance your awk skills with two easy tutorials)
+[#]: via: (https://opensource.com/article/19/10/advanced-awk)
+[#]: author: (Dave Neary https://opensource.com/users/dneary)
+
+Advance your awk skills with two easy tutorials
+======
+Go beyond one-line awk scripts with mail merge and word counting.
+![a checklist for a team][1]
+
+Awk is one of the oldest tools in the Unix and Linux user's toolbox. Created in the 1970s by Alfred Aho, Peter Weinberger, and Brian Kernighan (the A, W, and K of the tool's name), awk was created for complex processing of text streams. It is a companion tool to sed, the stream editor, which is designed for line-by-line processing of text files. Awk allows more complex structured programs and is a complete programming language.
+
+This article will explain how to use awk for more structured and complex tasks, including a simple mail merge application.
+
+### Awk program structure
+
+An awk script is made up of functional blocks surrounded by **{}** (curly brackets). There are two special function blocks, **BEGIN** and **END**, that execute before processing the first line of the input stream and after the last line is processed. In between, blocks have the format:
+
+
+```
+`pattern { action statements }`
+```
+
+Each block executes when the line in the input buffer matches the pattern. If no pattern is included, the function block executes on every line of the input stream.
+
+Also, the following syntax can be used to define functions in awk that can be called from any block:
+
+
+```
+`function name(parameter list) { statements }`
+```
+
+This combination of pattern-matching blocks and functions allows the developer to structure awk programs for reuse and readability.
+
+### How awk processes text streams
+
+Awk reads text from its input file or stream one line at a time and uses a field separator to parse it into a number of fields. In awk terminology, the current buffer is a _record_. There are a number of special variables that affect how awk reads and processes a file:
+
+ * **FS** (field separator): By default, this is any whitespace (spaces or tabs)
+ * **RS** (record separator): By default, a newline (**\n**)
+ * **NF** (number of fields): When awk parses a line, this variable is set to the number of fields that have been parsed
+ * **$0:** The current record
+ * **$1, $2, $3, etc.:** The first, second, third, etc. field from the current record
+ * **NR** (number of records): The number of records that have been parsed so far by the awk script
+
+
+
+There are many other variables that affect awk's behavior, but this is enough to start with.
+
+### Awk one-liners
+
+For a tool so powerful, it's interesting that most of awk's usage is basic one-liners. Perhaps the most common awk program prints selected fields from an input line from a CSV file, a log file, etc. For example, the following one-liner prints a list of usernames from **/etc/passwd**:
+
+
+```
+`awk -F":" '{print $1 }' /etc/passwd`
+```
+
+As mentioned above, **$1** is the first field in the current record. The **-F** option sets the FS variable to the character **:**.
+
+The field separator can also be set in a BEGIN function block:
+
+
+```
+`awk 'BEGIN { FS=":" } {print $1 }' /etc/passwd`
+```
+
+In the following example, every user whose shell is not **/sbin/nologin** can be printed by preceding the block with a pattern match:
+
+
+```
+`awk 'BEGIN { FS=":" } ! /\/sbin\/nologin/ {print $1 }' /etc/passwd`
+```
+
+### Advanced awk: Mail merge
+
+Now that you have some of the basics, try delving deeper into awk with a more structured example: creating a mail merge.
+
+A mail merge uses two files, one (called in this example **email_template.txt**) containing a template for an email you want to send:
+
+
+```
+From: Program committee <[pc@event.org][2]>
+To: {firstname} {lastname} <{email}>
+Subject: Your presentation proposal
+
+Dear {firstname},
+
+Thank you for your presentation proposal:
+ {title}
+
+We are pleased to inform you that your proposal has been successful! We
+will contact you shortly with further information about the event
+schedule.
+
+Thank you,
+The Program Committee
+```
+
+And the other is a CSV file (called **proposals.csv**) with the people you want to send the email to:
+
+
+```
+firstname,lastname,email,title
+Harry,Potter,[hpotter@hogwarts.edu][3],"Defeating your nemesis in 3 easy steps"
+Jack,Reacher,[reacher@covert.mil][4],"Hand-to-hand combat for beginners"
+Mickey,Mouse,[mmouse@disney.com][5],"Surviving public speaking with a squeaky voice"
+Santa,Claus,[sclaus@northpole.org][6],"Efficient list-making"
+```
+
+You want to read the CSV file, replace the relevant fields in the first file (skipping the first line), then write the result to a file called **acceptanceN.txt**, incrementing **N** for each line you parse.
+
+Write the awk program in a file called **mail_merge.awk**. Statements are separated by **;** in awk scripts. The first task is to set the field separator variable and a couple of other variables the script needs. You also need to read and discard the first line in the CSV, or a file will be created starting with _Dear firstname_. To do this, use the special function **getline** and reset the record counter to 0 after reading it.
+
+
+```
+BEGIN {
+ FS=",";
+ template="email_template.txt";
+ output="acceptance";
+ getline;
+ NR=0;
+}
+```
+
+The main function is very straightforward: for each line processed, a variable is set for the various fields—**firstname**, **lastname**, **email**, and **title**. The template file is read line by line, and the function **sub** is used to substitute any occurrence of the special character sequences with the value of the relevant variable. Then the line, with any substitutions made, is output to the output file.
+
+Since you are dealing with the template file and a different output file for each line, you need to clean up and close the file handles for these files before processing the next record.
+
+
+```
+{
+ # Read relevant fields from input file
+ firstname=$1;
+ lastname=$2;
+ email=$3;
+ title=$4;
+
+ # Set output filename
+ outfile=(output NR ".txt");
+
+ # Read a line from template, replace special fields, and
+ # print result to output file
+ while ( (getline ln < template) > 0 )
+ {
+ sub(/{firstname}/,firstname,ln);
+ sub(/{lastname}/,lastname,ln);
+ sub(/{email}/,email,ln);
+ sub(/{title}/,title,ln);
+ print(ln) > outfile;
+ }
+
+ # Close template and output file in advance of next record
+ close(outfile);
+ close(template);
+}
+```
+
+You're done! Run the script on the command line with:
+
+
+```
+`awk -f mail_merge.awk proposals.csv`
+```
+
+or
+
+
+```
+`awk -f mail_merge.awk < proposals.csv`
+```
+
+and you will find text files generated in the current directory.
+
+### Advanced awk: Word frequency count
+
+One of the most powerful features in awk is the associative array. In most programming languages, array entries are typically indexed by a number, but in awk, arrays are referenced by a key string. You could store an entry from the file _proposals.txt_ from the previous section. For example, in a single associative array, like this:
+
+
+```
+ proposer["firstname"]=$1;
+ proposer["lastname"]=$2;
+ proposer["email"]=$3;
+ proposer["title"]=$4;
+```
+
+This makes text processing very easy. A simple program that uses this concept is the idea of a word frequency counter. You can parse a file, break out words (ignoring punctuation) in each line, increment the counter for each word in the line, then output the top 20 words that occur in the text.
+
+First, in a file called **wordcount.awk**, set the field separator to a regular expression that includes whitespace and punctuation:
+
+
+```
+BEGIN {
+ # ignore 1 or more consecutive occurrences of the characters
+ # in the character group below
+ FS="[ .,:;()<>{}@!\"'\t]+";
+}
+```
+
+Next, the main loop function will iterate over each field, ignoring any empty fields (which happens if there is punctuation at the end of a line), and increment the word count for the words in the line.
+
+
+```
+{
+ for (i = 1; i <= NF; i++) {
+ if ($i != "") {
+ words[$i]++;
+ }
+ }
+}
+```
+
+Finally, after the text is processed, use the END function to print the contents of the array, then use awk's capability of piping output into a shell command to do a numerical sort and print the 20 most frequently occurring words:
+
+
+```
+END {
+ sort_head = "sort -k2 -nr | head -n 20";
+ for (word in words) {
+ printf "%s\t%d\n", word, words[word] | sort_head;
+ }
+ close (sort_head);
+}
+```
+
+Running this script on an earlier draft of this article produced this output:
+
+
+```
+[[dneary@dhcp-49-32.bos.redhat.com][7]]$ awk -f wordcount.awk < awk_article.txt
+the 79
+awk 41
+a 39
+and 33
+of 32
+in 27
+to 26
+is 25
+line 23
+for 23
+will 22
+file 21
+we 16
+We 15
+with 12
+which 12
+by 12
+this 11
+output 11
+function 11
+```
+
+### What's next?
+
+If you want to learn more about awk programming, I strongly recommend the book [_Sed and awk_][8] by Dale Dougherty and Arnold Robbins.
+
+One of the keys to progressing in awk programming is mastering "extended regular expressions." Awk offers several powerful additions to the sed [regular expression][9] syntax you may already be familiar with.
+
+Another great resource for learning awk is the [GNU awk user guide][10]. It has a full reference for awk's built-in function library, as well as lots of examples of simple and complex awk scripts.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/advanced-awk
+
+作者:[Dave Neary][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dneary
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk (a checklist for a team)
+[2]: mailto:pc@event.org
+[3]: mailto:hpotter@hogwarts.edu
+[4]: mailto:reacher@covert.mil
+[5]: mailto:mmouse@disney.com
+[6]: mailto:sclaus@northpole.org
+[7]: mailto:dneary@dhcp-49-32.bos.redhat.com
+[8]: https://www.amazon.com/sed-awk-Dale-Dougherty/dp/1565922255/book
+[9]: https://en.wikibooks.org/wiki/Regular_Expressions/POSIX-Extended_Regular_Expressions
+[10]: https://www.gnu.org/software/gawk/manual/gawk.html
diff --git a/sources/tech/20191031 Looping your way through bash.md b/sources/tech/20191031 Looping your way through bash.md
new file mode 100644
index 0000000000..f53d3c8089
--- /dev/null
+++ b/sources/tech/20191031 Looping your way through bash.md
@@ -0,0 +1,236 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Looping your way through bash)
+[#]: via: (https://www.networkworld.com/article/3449116/looping-your-way-through-bash.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+Looping your way through bash
+======
+There are many ways to loop through data in a bash script and on the command line. Which way is best depends on what you're trying to do.
+[Alan Levine / Flickr][1] [(CC BY 2.0)][2]
+
+There are a lot of options for looping in bash whether on the command line or in a script. The choice depends on what you're trying to do.
+
+You may want to loop indefinitely or quickly run through the days of the week. You might want to loop once for every file in a directory or for every account on a server. You might want to loop through every line in a file or have the number of loops be a choice when the script is run. Let's check out some of the options.
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
+
+### Simple loops
+
+Probably the simplest loop is a **for** loop like the one below. It loops as many times as there are pieces of text on the line. We could as easily loop through the words **cats are smart** as the numbers 1, 2, 3 and 4.
+
+[][4]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][4]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+```
+#!/bin/bash
+
+for num in 1 2 3 4
+do
+ echo $num
+done
+```
+
+And, to prove it, here's a similar loop run on the command line:
+
+```
+$ for word in cats are smart
+> do
+> echo $word
+> done
+cats
+are
+smart
+```
+
+### for vs while
+
+Bash provides both a **for** and a **while** looping command. In **while** loops, some condition is tested each time through the loop to determine whether the loop should continue. This example is practically the same as the one before in how it works, but imagine what a difference it would make if we wanted to loop 444 times instead of just 4.
+
+```
+#!/bin/bash
+
+n=1
+
+while [ $n -le 4 ]
+do
+ echo $n
+ ((n++))
+done
+```
+
+### Looping through value ranges
+
+If you want to loop through every letter of the alphabet or some more restricted range of letters, you can use syntax like this:
+
+```
+#!/bin/bash
+
+for x in {a..z}
+do
+ echo $x
+done
+```
+
+If you used **{d..f}**, you would only loop three times.
+
+### Looping inside loops
+
+There's also nothing stopping you from looping inside a loop. In this example, we're using a **for** loop inside a **while** loop.
+
+```
+#!/bin/bash
+
+n=1
+
+while [ $n -lt 6 ]
+do
+ for l in {a..d}
+ do
+ echo $n$l
+ done
+ ((n++))
+done
+```
+
+The output would in this example include 1a, 1b, 1c, 1d, 2a and so on, ending at 5d. Note that **((n++))** is used to increment the value of $n so that **while** has a stopping point.
+
+### Looping through variable data
+
+If you want to loop through every account on the system, every file in a directory or some other kind of variable data, you can issue a command within your loop to generate the list of values to loop through. In this example, we loop through every account (actually every file) in **/home** – assuming, as we should expect, that there are no other files or directories in **/home**.
+
+```
+#!/bin/bash
+
+for user in `ls /home`
+do
+ echo $user
+done
+```
+
+If the command were **date** instead of **ls /home**, we'd run through each of the 7 pieces of text in the output of the date command.
+
+```
+$ for word in `date`
+> do
+> echo $word
+> done
+Thu
+31
+Oct
+2019
+11:59:59
+PM
+EDT
+```
+
+### Looping by request
+
+It's also very easy to allow the person running the script to determine how many times a loop should run. If you want to do this, however, you should test the response provided to be sure that it's numeric. This example shows three ways to do that.
+
+```
+#!/bin/bash
+
+echo -n "How many times should I say hello? "
+read ans
+
+if [ "$ans" -eq "$ans" ]; then
+ echo ok1
+fi
+
+if [[ $ans = *[[:digit:]]* ]]; then
+ echo ok2
+fi
+
+if [[ "$ans" =~ ^[0-9]+$ ]]; then
+ echo ok3
+fi
+```
+
+The first option above shown might look a little odd, but it works because the **-eq** test only works if the values being compared are numeric. If the test came down to asking if **"f" -eq "f"**, it would fail. The second test uses the bash character class for digits. The third tests the variable to ensure that it contains only digits.
+
+Of course, once you've selected how you prefer to test a user response to be sure that it's numeric, you need to follow through on the loop. In this next example, we'll print "hello" as many times as the user wants to see it. The **le** does a "less than or equal" test.
+
+```
+#!/bin/bash
+
+echo -n "How many times should I say hello? "
+read ans
+
+if [ "$ans" -eq "$ans" ]; then
+ n=1
+ while [ $n -le $ans ]
+ do
+ echo hello
+ ((n++))
+ done
+fi
+```
+
+### Looping through the lines in a file
+
+If you want to loop through the contents of a file line by line (i.e., NOT word by word), you can use a loop like this one:
+
+```
+#!/bin/bash
+
+echo -n "File> "
+read file
+n=0
+
+while read line; do
+ ((n++))
+ echo "$n: $line"
+done < $file
+```
+
+The word "line" used in the above script is for clarity, but you could use any variable name. The **while read** and the redirection of the file content on the last line of the script is what provides the line-by-line reading.
+
+### Looping forever
+
+If you want to loop forever or until, well, someone gets tired of seeing the script's output and decides to kill it, you can simple use the **while true** syntax.
+
+```
+#!/bin/bash
+
+while true
+do
+ echo -n "Still running at "
+ date
+ sleep 10
+done
+```
+
+The examples shown above are basically only (excuse the pun) "shells" for the kind of real work that you might need to do and are meant simply to provide the basic syntax for running undoubtedly far more useful commands.
+
+### Now see:
+
+Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3449116/looping-your-way-through-bash.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.flickr.com/photos/cogdog/7778741378/in/photolist-cRo5NE-8HFUGG-e1kzG-4TFXrc-D3mM8-Lzx7h-LzGRB-fN3CY-LzwRo-8mWuUB-2jJ2j8-AABU8-eNrDET-eND7Nj-eND6Co-pNq3ZR-3bndB2-dNobDn-3brHfC-eNrSXv-4z4dNn-R1i2P5-eNDvyQ-agaw5-eND55q-4KQnc9-eXg6mo-eNscpF-eNryR6-dTGEqg-8uq9Wm-eND54j-eNrKD2-cynYp-eNrJsk-eNCSSj-e9uAD5-25xTWb-eNrJ3e-eNCW8s-7nKXtJ-5URF1j-8Y253Z-oaNVEQ-4AUK9b-6SJiLP-7GL54w-25yEqLa-fN3gL-dEgidW
+[2]: https://creativecommons.org/licenses/by/2.0/legalcode
+[3]: https://www.networkworld.com/newsletters/signup.html
+[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[5]: https://www.facebook.com/NetworkWorld/
+[6]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20191101 Awk one-liners and scripts to help you sort text files.md b/sources/tech/20191101 Awk one-liners and scripts to help you sort text files.md
new file mode 100644
index 0000000000..2ce53e1d7e
--- /dev/null
+++ b/sources/tech/20191101 Awk one-liners and scripts to help you sort text files.md
@@ -0,0 +1,254 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Awk one-liners and scripts to help you sort text files)
+[#]: via: (https://opensource.com/article/19/11/how-sort-awk)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Awk one-liners and scripts to help you sort text files
+======
+Awk is a powerful tool for doing tasks that might otherwise be left to
+other common utilities, including sort.
+![Green graph of measurements][1]
+
+Awk is the ubiquitous Unix command for scanning and processing text containing predictable patterns. However, because it features functions, it's also justifiably called a programming language.
+
+Confusingly, there is more than one awk. (Or, if you believe there can be only one, then there are several clones.) There's **awk**, the original program written by Aho, Weinberger, and Kernighan, and then there's **nawk**, **mawk**, and the GNU version, **gawk**. The GNU version of awk is a highly portable, free software version of the utility with several unique features, so this article is about GNU awk.
+
+While its official name is gawk, on GNU+Linux systems it's aliased to awk and serves as the default version of that command. On other systems that don't ship with GNU awk, you must install it and refer to it as gawk, rather than awk. This article uses the terms awk and gawk interchangeably.
+
+Being both a command and a programming language makes awk a powerful tool for tasks that might otherwise be left to **sort**, **cut**, **uniq**, and other common utilities. Luckily, there's lots of room in open source for redundancy, so if you're faced with the question of whether or not to use awk, the answer is probably a solid "maybe."
+
+The beauty of awk's flexibility is that if you've already committed to using awk for a task, then you can probably stay in awk no matter what comes up along the way. This includes the eternal need to sort data in a way other than the order it was delivered to you.
+
+### Sample set
+
+Before exploring awk's sorting methods, generate a sample dataset to use. Keep it simple so that you don't get distracted by edge cases and unintended complexity. This is the sample set this article uses:
+
+
+```
+Aptenodytes;forsteri;Miller,JF;1778;Emperor
+Pygoscelis;papua;Wagler;1832;Gentoo
+Eudyptula;minor;Bonaparte;1867;Little Blue
+Spheniscus;demersus;Brisson;1760;African
+Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
+Torvaldis;linux;Ewing,L;1996;Tux
+```
+
+It's a small dataset, but it offers a good variety of data types:
+
+ * A genus and species name, which are associated with one another but considered separate
+ * A surname, sometimes with first initials after a comma
+ * An integer representing a date
+ * An arbitrary term
+ * All fields separated by semi-colons
+
+
+
+Depending on your educational background, you may consider this a 2D array or a table or just a line-delimited collection of data. How you think of it is up to you, because awk doesn't expect anything more than text. It's up to you to tell awk how you want to parse it.
+
+### The sort cheat
+
+If you just want to sort a text dataset by a specific, definable field (think of a "cell" in a spreadsheet), then you can use the [sort command][2].
+
+### Fields and records
+
+Regardless of the format of your input, you must find patterns in it so that you can focus on the parts of the data that are important to you. In this example, the data is delimited by two factors: lines and fields. Each new line represents a new _record_, as you would likely see in a spreadsheet or database dump. Within each line, there are distinct _fields_ (think of them as cells in a spreadsheet) that are separated by semicolons (;).
+
+Awk processes one record at a time, so while you're structuring the instructions you will give to awk, you can focus on just one line. Establish what you want to do with one line, then test it (either mentally or with awk) on the next line and a few more. You'll end up with a good hypothesis on what your awk script must do in order to provide you with the data structure you want.
+
+In this case, it's easy to see that each field is separated by a semicolon. For simplicity's sake, assume you want to sort the list by the very first field of each line.
+
+Before you can sort, you must be able to focus awk on just the first field of each line, so that's the first step. The syntax of an awk command in a terminal is **awk**, followed by relevant options, followed by your awk command, and ending with the file of data you want to process.
+
+
+```
+$ awk --field-separator=";" '{print $1;}' penguins.list
+Aptenodytes
+Pygoscelis
+Eudyptula
+Spheniscus
+Megadyptes
+Eudyptes
+Torvaldis
+```
+
+Because the field separator is a character that has special meaning to the Bash shell, you must enclose the semicolon in quotes or precede it with a backslash. This command is useful only to prove that you can focus on a specific field. You can try the same command using the number of another field to view the contents of another "column" of your data:
+
+
+```
+$ awk --field-separator=";" '{print $3;}' penguins.list
+Miller,JF
+Wagler
+Bonaparte
+Brisson
+Milne-Edwards
+Viellot
+Ewing,L
+```
+
+Nothing has been sorted yet, but this is good groundwork.
+
+### Scripting
+
+Awk is more than just a command; it's a programming language with indices and arrays and functions. That's significant because it means you can grab a list of fields you want to sort by, store the list in memory, process it, and then print the resulting data. For a complex series of actions such as this, it's easier to work in a text file, so create a new file called **sort.awk** and enter this text:
+
+
+```
+#!/bin/gawk -f
+
+BEGIN {
+ FS=";";
+}
+```
+
+This establishes the file as an awk script that executes the lines contained in the file.
+
+The **BEGIN** statement is a special setup function provided by awk for tasks that need to occur only once. Defining the built-in variable **FS**, which stands for _field separator_ and is the same value you set in your awk command with **\--field-separator**, only needs to happen once, so it's included in the **BEGIN** statement.
+
+#### Arrays in awk
+
+You already know how to gather the values of a specific field by using the **$** notation along with the field number, but in this case, you need to store it in an array rather than print it to the terminal. This is done with an awk array. The important thing about an awk array is that it contains keys and values. Imagine an array about this article; it would look something like this: **author:"seth",title:"How to sort with awk",length:1200**. Elements like **author** and **title** and **length** are keys, with the following contents being values.
+
+The advantage to this in the context of sorting is that you can assign any field as the key and any record as the value, and then use the built-in awk function **asorti()** (sort by index) to sort by the key. For now, assume arbitrarily that you _only_ want to sort by the second field.
+
+Awk statements _not_ preceded by the special keywords **BEGIN** or **END** are loops that happen at each record. This is the part of the script that scans the data for patterns and processes it accordingly. Each time awk turns its attention to a record, statements in **{}** (unless preceded by **BEGIN** or **END**) are executed.
+
+To add a key and value to an array, create a variable (in this example script, I call it **ARRAY**, which isn't terribly original, but very clear) containing an array, and then assign it a key in brackets and a value with an equals sign (**=**).
+
+
+```
+{ # dump each field into an array
+ ARRAY[$2] = $R;
+}
+```
+
+In this statement, the contents of the second field (**$2**) are used as the key term, and the current record (**$R**) is used as the value.
+
+### The asorti() function
+
+In addition to arrays, awk has several basic functions that you can use as quick and easy solutions for common tasks. One of the functions introduced in GNU awk, **asorti()**, provides the ability to sort an array by key (or _index_) or value.
+
+You can only sort the array once it has been populated, meaning that this action must not occur with every new record but only the final stage of your script. For this purpose, awk provides the special **END** keyword. The inverse of **BEGIN**, an **END** statement happens only once and only after all records have been scanned.
+
+Add this to your script:
+
+
+```
+END {
+ asorti(ARRAY,SARRAY);
+ # get length
+ j = length(SARRAY);
+
+ for (i = 1; i <= j; i++) {
+ printf("%s %s\n", SARRAY[i],ARRAY[SARRAY[i]])
+ }
+}
+```
+
+The **asorti()** function takes the contents of **ARRAY**, sorts it by index, and places the results in a new array called **SARRAY** (an arbitrary name I invented for this article, meaning _Sorted ARRAY_).
+
+Next, the variable **j** (another arbitrary name) is assigned the results of the **length()** function, which counts the number of items in **SARRAY**.
+
+Finally, use a **for** loop to iterate through each item in **SARRAY** using the **printf()** function to print each key, followed by the corresponding value of that key in **ARRAY**.
+
+### Running the script
+
+To run your awk script, make it executable:
+
+
+```
+`$ chmod +x sorter.awk`
+```
+
+And then run it against the **penguin.list** sample data:
+
+
+```
+$ ./sorter.awk penguins.list
+antipodes Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+chrysocome Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
+demersus Spheniscus;demersus;Brisson;1760;African
+forsteri Aptenodytes;forsteri;Miller,JF;1778;Emperor
+linux Torvaldis;linux;Ewing,L;1996;Tux
+minor Eudyptula;minor;Bonaparte;1867;Little Blue
+papua Pygoscelis;papua;Wagler;1832;Gentoo
+```
+
+As you can see, the data is sorted by the second field.
+
+This is a little restrictive. It would be better to have the flexibility to choose at runtime which field you want to use as your sorting key so you could use this script on any dataset and get meaningful results.
+
+### Adding command options
+
+You can add a command variable to an awk script by using the literal value **var** in your script. Change your script so that your iterative clause uses **var** when creating your array:
+
+
+```
+{ # dump each field into an array
+ ARRAY[$var] = $R;
+}
+```
+
+Try running the script so that it sorts by the third field by using the **-v var** option when you execute it:
+
+
+```
+$ ./sorter.awk -v var=3 penguins.list
+Bonaparte Eudyptula;minor;Bonaparte;1867;Little Blue
+Brisson Spheniscus;demersus;Brisson;1760;African
+Ewing,L Torvaldis;linux;Ewing,L;1996;Tux
+Miller,JF Aptenodytes;forsteri;Miller,JF;1778;Emperor
+Milne-Edwards Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+Viellot Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
+Wagler Pygoscelis;papua;Wagler;1832;Gentoo
+```
+
+### Fixes
+
+This article has demonstrated how to sort data in pure GNU awk. The script can be improved so, if it's useful to you, spend some time researching [awk functions][3] on gawk's man page and customizing the script for better output.
+
+Here is the complete script so far:
+
+
+```
+#!/usr/bin/awk -f
+# GPLv3 appears here
+# usage: ./sorter.awk -v var=NUM FILE
+
+BEGIN { FS=";"; }
+
+{ # dump each field into an array
+ ARRAY[$var] = $R;
+}
+
+END {
+ asorti(ARRAY,SARRAY);
+ # get length
+ j = length(SARRAY);
+
+ for (i = 1; i <= j; i++) {
+ printf("%s %s\n", SARRAY[i],ARRAY[SARRAY[i]])
+ }
+}
+```
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/11/how-sort-awk
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
+[2]: https://opensource.com/article/19/10/get-sorted-sort
+[3]: https://www.gnu.org/software/gawk/manual/html_node/Built_002din.html#Built_002din
diff --git a/sources/tech/20191101 Keyboard Shortcuts to Speed Up Your Work in Linux.md b/sources/tech/20191101 Keyboard Shortcuts to Speed Up Your Work in Linux.md
new file mode 100644
index 0000000000..9151c9eb84
--- /dev/null
+++ b/sources/tech/20191101 Keyboard Shortcuts to Speed Up Your Work in Linux.md
@@ -0,0 +1,107 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Keyboard Shortcuts to Speed Up Your Work in Linux)
+[#]: via: (https://opensourceforu.com/2019/11/keyboard-shortcuts-to-speed-up-your-work-in-linux/)
+[#]: author: (S Sathyanarayanan https://opensourceforu.com/author/s-sathyanarayanan/)
+
+Keyboard Shortcuts to Speed Up Your Work in Linux
+======
+
+[![Google Keyboard][1]][2]
+
+_Manipulating the mouse, keyboard and menus takes up a lot of our time, which could be saved by using keyboard shortcuts. These not only save time, but also make the computer user more efficient._
+
+Did you realise that switching from the keyboard to the mouse while typing takes up to two seconds each time? If a person works for eight hours every day, switching from the keyboard to the mouse once a minute, and there are around 240 working days in a year, the amount of time wasted (as per calculations done by Brainscape) is:
+_[2 wasted seconds/min] x [480 minutes per day] x 240 working days per year = 64 wasted hours per year_
+This is equal to eight working days lost and hence learning keyboard shortcuts will increase productivity by 3.3 per cent (__).
+
+Keyboard shortcuts provide a quicker way to do a task, which otherwise would have had to be done in multiple steps using the mouse and/or the menu. Figure 1 gives a list of a few most frequently used shortcuts in Ubuntu 18.04 Linux OS and the Web browsers. I am omitting the very well-known shortcuts like copy, paste, etc, and the ones which are not used frequently. The readers can refer to online resources for a comprehensive list of shortcuts. Note that the Windows key is renamed as Super key in Linux.
+
+**General shortcuts**
+A list of general shortcuts is given below.
+
+[![][3]][4]
+**Print Screen and video recording of the screen**
+The following shortcuts can be used to print the screen or take a video recording of the screen.
+[![][5]][6]**Switching between applications**
+The shortcut keys listed here can be used to switch between applications.
+
+[![][7]][8]
+**Tile windows**
+The windows can be tiled in different ways using the shortcuts given below.
+
+[![][9]][10]
+
+**Browser shortcuts**
+The most frequently used shortcuts for browsers are listed here. Most of the shortcuts are common to the Chrome/Firefox browsers.
+
+**Key combination** | **Action**
+---|---
+Ctrl + T | Opens a new tab.
+Ctrl + Shift + T | Opens the most recently closed tab.
+Ctrl + D | Adds a new bookmark.
+Ctrl + W | Closes the browser tab.
+Alt + D | Positions the cursor in the browser’s address bar.
+F5 or Ctrl-R | Refreshes a page.
+Ctrl + Shift + Del | Clears private data and history.
+Ctrl + N | Opens a new window.
+Home | Scrolls to the top of the page.
+End | Scrolls to the bottom of the page.
+Ctrl + J | Opens the Downloads folder
+(in Chrome)
+F11 | Full-screen view (toggle effect)
+
+**Terminal shortcuts**
+Here is a list of terminal shortcuts.
+[![][11]][12]You can also configure your own custom shortcuts in Ubuntu, as follows:
+
+ * Click on Settings in Ubuntu Dash.
+ * Select the Devices tab in the left menu of the Settings window.
+ * Select the Keyboard tab in the Devices menu.
+ * The ‘+’ button is displayed at the bottom of the right panel. Click on the ‘+’ sign to open the custom shortcut dialogue box and configure a new shortcut.
+
+
+
+Learning three shortcuts mentioned in this article can save a lot of time and make you more productive.
+
+**Reference**
+_Cohen, Andrew. How keyboard shortcuts could revive America’s economy; [www.brainscape.com][13]. [Online] Brainscape, 26 May 2017; _
+
+![Avatar][14]
+
+[S Sathyanarayanan][15]
+
+The author is currently working with Sri Sathya Sai University for Human Excellence, Gulbarga. He has more than 25 years of experience in systems management and in teaching IT courses. He is an enthusiastic promoter of FOSS and can be reached at [sathyanarayanan.brn@gmail.com][16].
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/11/keyboard-shortcuts-to-speed-up-your-work-in-linux/
+
+作者:[S Sathyanarayanan][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/s-sathyanarayanan/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2016/12/Google-Keyboard.jpg?resize=696%2C418&ssl=1 (Google Keyboard)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2016/12/Google-Keyboard.jpg?fit=750%2C450&ssl=1
+[3]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/11/1.png?resize=350%2C319&ssl=1
+[4]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/11/1.png?ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/NW.png?resize=350%2C326&ssl=1
+[6]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/NW.png?ssl=1
+[7]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/2.png?resize=350%2C264&ssl=1
+[8]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/2.png?ssl=1
+[9]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/3.png?resize=350%2C186&ssl=1
+[10]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/11/3.png?ssl=1
+[11]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/11/7.png?resize=350%2C250&ssl=1
+[12]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/11/7.png?ssl=1
+[13]: http://www.brainscape.com
+[14]: https://secure.gravatar.com/avatar/736684a2707f2ed7ae72675edf7bb3ee?s=100&r=g
+[15]: https://opensourceforu.com/author/s-sathyanarayanan/
+[16]: mailto:sathyanarayanan.brn@gmail.com
diff --git a/sources/tech/20191104 How To Update a Fedora Linux System -Beginner-s Tutorial.md b/sources/tech/20191104 How To Update a Fedora Linux System -Beginner-s Tutorial.md
new file mode 100644
index 0000000000..d102d5b89f
--- /dev/null
+++ b/sources/tech/20191104 How To Update a Fedora Linux System -Beginner-s Tutorial.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Update a Fedora Linux System [Beginner’s Tutorial])
+[#]: via: (https://itsfoss.com/update-fedora/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+How To Update a Fedora Linux System [Beginner’s Tutorial]
+======
+
+_**This quick tutorial shows various ways to update a Fedora Linux install.**_
+
+So, the other day, I installed the [newly released Fedora 31][1]. I’ll be honest with you, it was my first time with a [non-Ubuntu distribution][2].
+
+The first thing I did after installing Fedora was to try and install some software. I opened the software center and found that the software center was ‘broken’. I couldn’t install any application from it.
+
+I wasn’t sure what went wrong with my installation. Discussing within the team, Abhishek advised me to update the system first. I did that and poof! everything was back to normal. After updating the [Fedora][3] system, the software center worked as it should.
+
+Sometimes we just ignore the updates and keep troubleshooting the issue we face. No matter how big/small the issue is – to avoid them, you should keep your system up-to-date.
+
+In this article, I’ll show you various possible methods to update your Fedora Linux system.
+
+ * [Update Fedora using software center][4]
+ * [Update Fedora using command line][5]
+ * [Update Fedora from system settings][6]
+
+
+
+Keep in mind that updating Fedora means installing the security patches, kernel updates and software updates. If you want to update from one version of Fedora to another, it is called version upgrade and you can [read about Fedora version upgrade procedure here][7].
+
+### Updating Fedora From The Software Center
+
+![Software Center][8]
+
+You will most likely be notified that you have some system updates to look at, you should end up launching the software center when you click on that notification.
+
+All you have to do is – hit ‘Update’ and verify the root password to start updating.
+
+In case you did not get a notification for the available updates, you can simply launch the software center and head to the “Updates” tab. Now, you just need to proceed with the updates listed.
+
+### Updating Fedora Using The Terminal
+
+If you cannot load up the software center for some reason, you can always utilize the dnf package managing commands to easily update your system.
+
+Simply launch the terminal and type in the following command to start updating (you should be prompted to verify the root password):
+
+```
+sudo dnf upgrade
+```
+
+**dnf update vs dnf upgrade
+**
+You’ll find that there are two dnf commands available: dnf update and dnf upgrade.
+Both command do the same job and that is to install all the updates provided by Fedora.
+Then why there is dnf update and dnf upgrade and which one should you use?
+Well, dnf update is basically an alias to dnf upgrade. While dnf update may still work, the good practice is to use dnf upgrade because that is the real command.
+
+### Updating Fedora From System Settings
+
+![][9]
+
+If nothing else works (or if you’re already in the System settings for a reason), navigate your way to the “Details” option at the bottom of your settings.
+
+This should show up the details of your OS and hardware along with a “Check for Updates” button as shown in the image above. You just need to click on it and provide the root/admin password to proceed to install the available updates.
+
+**Wrapping Up**
+
+As explained above, it is quite easy to update your Fedora installation. You’ve got three available methods to choose from – so you have nothing to worry about.
+
+If you notice any issue in following the instructions mentioned above, feel free to let me know in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/update-fedora/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/fedora-31-release/
+[2]: https://itsfoss.com/non-ubuntu-beginner-linux/
+[3]: https://getfedora.org/
+[4]: tmp.Lqr0HBqAd9#software-center
+[5]: tmp.Lqr0HBqAd9#command-line
+[6]: tmp.Lqr0HBqAd9#system-settings
+[7]: https://itsfoss.com/upgrade-fedora-version/
+[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/11/software-center.png?ssl=1
+[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/11/system-settings-fedora-1.png?ssl=1
diff --git a/translated/talk/20191011 How to use IoT devices to keep children safe.md b/translated/talk/20191011 How to use IoT devices to keep children safe.md
deleted file mode 100644
index f85cd46dd7..0000000000
--- a/translated/talk/20191011 How to use IoT devices to keep children safe.md
+++ /dev/null
@@ -1,66 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (Morisun029)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to use IoT devices to keep children safe?)
-[#]: via: (https://opensourceforu.com/2019/10/how-to-use-iot-devices-to-keep-children-safe/)
-[#]: author: (Andrew Carroll https://opensourceforu.com/author/andrew-carroll/)
-
-如何使用物联网设备来确保儿童安全?
-======
-
-[![][1]][2]
-
-IoT (物联网)设备正在迅速改变我们的生活。这些设备无处不在,从我们的家庭到其它行业。根据一些预测数据,到2020年,将会有100亿个 IoT 设备。到2025年,该数量将增长到220亿。目前,物联网已经在很多领域得到了应用,包括智能家居,工业生产过程,农业甚至医疗保健领域。伴随着如此广泛的应用,物联网显然已经成为近年来的热门话题之一。
-多种因素促成了物联网设备在多个学科的爆炸式增长。这其中包括低成本处理器和无线连接的的可用性, 以及开源平台的信息交流推动了物联网领域的创新。与传统的应用程序开发相比,物联网设备的开发成指数级增长,因为它的资源是开源的。
-在解释如何使用物联网设备来保护儿童之前,必须对物联网技术有基本的了解。
-
-
-**IOT 设备是什么?**
-IOT 设备是指那些在没有人类参与的情况下彼此之间可以通信的设备。 因此,许多专家并不将智能手机和计算机视为物联网设备。 此外,物联网设备必须能够收集数据并且能将收集到的数据传送到其他设备或云端进行处理。
-
-然而,在某些领域中,我们需要探索物联网的潜力。 儿童往往是脆弱的,他们很容易成为犯罪分子和其他蓄意伤害者的目标。 无论在物理世界还是数字世界中,儿童都很容易犯罪。 因为父母不能始终亲自到场保护孩子; 这就是为什么需要监视工具了。
-
-除了适用于儿童的可穿戴设备外,还有许多父母监视应用程序,例如Xnspy,可实时监控儿童并提供信息的实时更新。 这些工具可确保儿童安全。 可穿戴设备确保儿童身体上的安全性,而家长监控应用可确保儿童的上网安全。
-
-由于越来越多的孩子花费时间在智能手机上,毫无意外地,他们也就成为诈骗分子的主要目标。 此外,由于恋童癖,网络自夸和其他犯罪在网络上的盛行,儿童也有可能成为网络欺凌的目标。
-
-这些解决方案够吗? 我们需要找到物联网解决方案,以确保孩子们在网上和线下的安全。 在当代,我们如何确保孩子的安全? 我们需要提出创新的解决方案。 物联网可以帮助保护孩子在学校和家里的安全。
-
-
-**物联网的潜力**
-物联网设备提供的好处很多。 举例来说,父母可以远程监控自己的孩子,而又不会显得太霸道。 因此,儿童在拥有安全环境的同时也会有空间和自由让自己变得独立。
-而且,父母也不必在为孩子的安全而担忧。物联网设备可以提供7x24小时的信息更新。像 Xnspy 之类的监视应用程序在提供有关孩子的智能手机活动信息方面更进了一步。随着物联网设备变得越来越复杂,拥有更长使用寿命的电池只是一个时间问题。诸如位置跟踪器之类的物联网设备可以提供有关孩子下落的准确详细信息,所以父母不必担心。
-
-虽然可穿戴设备已经非常好了,但在确保儿童安全方面,这些通常还远远不够。因此,要为儿童提供安全的环境,我们还需要其他方法。许多事件表明,学校比其他任何公共场所都容易受到攻击。因此,学校需要采取安全措施,以确保儿童和教师的安全。在这一点上,物联网设备可用于检测潜在威胁并采取必要的措施来防止攻击。威胁检测系统包括摄像头。系统一旦检测到威胁,便可以通知当局,如一些执法机构和医院。智能锁等设备可用于封锁学校(包括教室),来保护儿童。除此之外,还可以告知父母其孩子的安全,并立即收到有关威胁的警报。这将需要实施无线技术,例如 Wi-Fi 和传感器。因此,学校需要制定专门用于提供教室安全性的预算。
-
-智能家居实现拍手关灯,也可以让你的家庭助手帮你关灯。 同样,物联网设备也可用在屋内来保护儿童。 在家里,物联网设备(例如摄像头)为父母在照顾孩子时提供100%的可见性。 当父母不在家里时,可以使用摄像头和其他传感器检测是否发生了可疑活动。 其他设备(例如连接到这些传感器的智能锁)可以锁门和窗,以确保孩子们的安全。
-
-同样,可以引入许多物联网解决方案来确保孩子的安全。
-
-
-
-**有多好就有多坏**
-物联网设备中的传感器会创建大量数据。 数据的安全性是至关重要的一个因素。 收集的有关孩子的数据如果落入不法分子手中会存在危险。 因此,需要采取预防措施。 IoT 设备中泄露的任何数据都可用于确定行为模式。 因此,必须投资提供不违反用户隐私的安全物联网解决方案。
-
-IoT 设备通常连接到 Wi-Fi,用于设备之间传输数据。未加密数据的不安全网络会带来某些风险。 这样的网络很容易被窃听。 黑客可以使用此类网点来入侵系统。 他们还可以将恶意软件引入系统,从而使系统变得脆弱,易受攻击。 此外,对设备和公共网络(例如学校的网络)的网络攻击可能导致数据泄露和私有数据盗用。 因此,在实施用于保护儿童的物联网解决方案时,保护网络和物联网设备的总体计划必须生效。
-
-物联网设备保护儿童在学校和家里的安全的潜力尚未发现有什么创新。 我们需要付出更多努力来保护连接 IoT 设备的网络安全。 此外,物联网设备生成的数据可能落入不法分子手中,从而造成更多麻烦。 因此,这是物联网安全至关重要的一个领域。
-
-
---------------------------------------------------------------------------------
-
-via: https://opensourceforu.com/2019/10/how-to-use-iot-devices-to-keep-children-safe/
-
-作者:[Andrew Carroll][a]
-选题:[lujun9972][b]
-译者:[Morisun029](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensourceforu.com/author/andrew-carroll/
-[b]: https://github.com/lujun9972
-[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Visual-Internet-of-things_EB-May18.jpg?resize=696%2C507&ssl=1 (Visual Internet of things_EB May18)
-[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Visual-Internet-of-things_EB-May18.jpg?fit=900%2C656&ssl=1
diff --git a/translated/talk/20191031 Why you don-t have to be afraid of Kubernetes.md b/translated/talk/20191031 Why you don-t have to be afraid of Kubernetes.md
new file mode 100644
index 0000000000..940b2279b2
--- /dev/null
+++ b/translated/talk/20191031 Why you don-t have to be afraid of Kubernetes.md
@@ -0,0 +1,105 @@
+[#]: collector: (lujun9972)
+[#]: translator: (laingke)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why you don't have to be afraid of Kubernetes)
+[#]: via: (https://opensource.com/article/19/10/kubernetes-complex-business-problem)
+[#]: author: (Scott McCarty https://opensource.com/users/fatherlinux)
+
+为什么你不必害怕 Kubernetes
+======
+Kubernetes 绝对是满足复杂 web 应用程序需求的最简单,最容易的方法。
+![Digital creative of a browser on the internet][1]
+
+在 90 年代末和 00 年代初,在大型网络媒体资源上工作很有趣。我的经历让我想起了 American Greetings Interactive,在情人节那天,我们拥有互联网上排名前 10 位之一的网站(以网络访问量衡量)。我们为 [AmericanGreetings.com][2],[BlueMountain.com][3] 等公司提供了电子贺卡,并为 MSN 和 AOL 等合作伙伴提供了电子贺卡。该组织的老员工仍然深切地记得与 Hallmark 等其它电子贺卡网站进行大战的史诗般的故事。 顺便说一句,我还为 Holly Hobbie,Care Bears 和 Strawberry Shortcake 经营大型网站。
+
+我记得就像那是昨天发生的一样,这是我们第一次遇到真正的问题。通常,我们的前门(路由器,防火墙和负载均衡器)有大约 200Mbps 的流量进入。但是,突然之间,Multi Router Traffic Grapher(MRTG)图示突然在几分钟内飙升至 2Gbps。我疯了似地东奔西跑。我了解了我们的整个技术堆栈,从路由器,交换机,防火墙和负载平衡器,到 Linux/Apache web 服务器,到我们的 Python 堆栈(FastCGI 的元版本),以及网络文件系统(NFS)服务器。我知道所有配置文件在哪里,我可以访问所有管理界面,并且我是一位经验丰富的,经验丰富的系统管理员,具有多年解决复杂问题的经验。
+
+但是,我无法弄清楚发生了什么……
+
+当你在一千个 Linux 服务器上疯狂地键入命令时,五分钟的感觉就像是永恒。我知道站点可能会在任何时候崩溃,因为当它被划分成更小的集群时,压垮上千个节点的集群是那么的容易。
+
+我迅速 _跑到_ 老板的办公桌前,解释了情况。他几乎没有从电子邮件中抬头,这使我感到沮丧。他抬头看了看,笑了笑,说道:“是的,市场营销可能会开展广告活动。有时会发生这种情况。”他告诉我在应用程序中设置一个特殊标志,以减轻 Akamai 的访问量。 我跑回我的办公桌,在上千台 web 服务器上设置了标志,几分钟后,该站点恢复正常。灾难也就被避免了。
+
+我可以再分享 50 个类似的故事,但你脑海中可能会有一点好奇:“这种运维方式将走向何方?”
+
+关键是,我们遇到了业务问题。当技术问题使你无法开展业务时,它们就变成了业务问题。换句话说,如果你的网站无法访问,你就不能处理客户交易。
+
+那么,所有这些与 Kubernetes 有什么关系?一切。世界已经改变。早在 90 年代末和 00 年代初,只有大型网站才出现大型网络规模级的问题。现在,有了微服务和数字化转型,每个企业都面临着一个大型的网络规模级的问题——可能是多个大型的网络规模级的问题。
+
+你的企业需要能够通过许多不同的人构建的许多不同的,通常是复杂的服务来管理复杂的网络规模的资产。你的网站需要动态地处理流量,并且它们必须是安全的。这些属性需要在所有层(从基础结构到应用程序层)上由 API 驱动。
+
+### 进入 Kubernetes
+
+Kubernetes 并不复杂;你的业务问题才是。当你想在生产环境中运行应用程序时,要满足性能(伸缩性,抖动等)和安全性要求,就需要最低程度的复杂性。诸如高可用性(HA),容量要求(N+1,N+2,N+100)以及保证最终一致性的数据技术等就会成为必需。这些是每家进行数字化转型的公司的生产要求,而不仅仅是 Google,Facebook 和 Twitter 这样的大型网站。
+
+在旧时代,我还在 American Greetings 任职时,每次我们加入一个新的服务,它看起来像这样:所有这些都是由网络运营团队来处理的,没有一个是通过标签系统转移给其他团队来处理的。这是在 DevOps 出现之前的 DevOps:
+
+ 1. 配置DNS(通常是内部服务层和面向外部的公众)
+ 2. 配置负载均衡器(通常是内部服务和面向公众的)
+ 3. 配置对文件的共享访问(大型 NFS 服务器,群集文件系统等)
+ 4. 配置集群软件(数据库,服务层等)
+ 5. 配置 web 服务器群集(可以是 10 或 50 个服务器)
+
+
+
+大多数配置是通过配置管理自动完成的,但是配置仍然很复杂,因为每个系统和服务都有不同的配置文件,而且格式完全不同。我们研究了像 [Augeas][4] 这样的工具来简化它,但是我们认为使用转换器来尝试和标准化一堆不同的配置文件是一种反模式。
+
+如今,借助Kubernetes,启动一项新服务本质上看起来如下:
+
+ 1. 配置 Kubernetes YAML/JSON。
+ 2. 提交给 Kubernetes API(```kubectl create -f service.yaml```)。
+
+
+
+Kubernetes 大大简化了服务的启动和管理。服务所有者(无论是系统管理员,开发人员还是架构师)都可以创建 Kubernetes 格式的 YAML/JSON 文件。使用 Kubernetes,每个系统和每个用户都说相同的语言。所有用户都可以在同一 Git 存储库中提交这些文件,从而启用 GitOps。
+
+而且,可以弃用和删除服务。从历史上看,删除 DNS 条目,负载平衡器条目,web 服务器配置等是非常可怕的,因为你几乎肯定会破坏某些东西。使用 Kubernetes,所有内容都被命名为名称空间,因此可以通过单个命令删除整个服务。尽管你仍然需要确保其它应用程序不使用它(微服务和功能即服务(FaaS)的缺点),但你可以更加确信:删除服务不会破坏基础架构环境。
+
+### 构建,管理和使用 Kubernetes
+
+太多的人专注于构建和管理 Kubernetes 而不是使用它(详见 [_Kubernetes 是一辆翻斗车_][5]).
+
+在单个节点上构建一个简单的 Kubernetes 环境并不比安装 LAMP 堆栈复杂得多,但是我们无休止地争论着构建与购买的问题。不是Kubernetes很难;它以高可用性大规模运行应用程序。建立一个复杂的,高可用性的 Kubernetes 集群很困难,因为要建立如此规模的任何集群都是很困难的。它需要规划和大量软件。建造一辆简单的翻斗车并不复杂,但是建造一辆可以运载 [10 吨灰尘并能以 200mph 的速度稳定行驶的卡车][6]则很复杂。
+
+管理 Kubernetes 可能很复杂,因为管理大型网络规模的集群可能很复杂。有时,管理此基础架构很有意义;而有时不是。由于 Kubernetes 是一个社区驱动的开源项目,它使行业能够以多种不同方式对其进行管理。供应商可以出售托管版本,而用户可以根据需要自行决定对其进行管理。(但是你应该质疑是否确实需要。)
+
+使用 Kubernetes 是迄今为止运行大规模网络资源的最简单方法。Kubernetes 正在普及运行一组大型、复杂的 Web 服务的能力——就像当年 Linux 在 Web 1.0 中所做的那样。
+
+由于时间和金钱是一个零和游戏,因此我建议将重点放在使用 Kubernetes 上。将你的时间和金钱花费在[掌握 Kubernetes 原语][7]或处理[活跃度和就绪性探针][8]的最佳方法上(另一个例子表明大型、复杂的服务很难)。不要专注于构建和管理 Kubernetes。(在构建和管理上)许多供应商可以为你提供帮助。
+
+### 结论
+
+我记得对无数的问题进行了故障排除,比如我在这篇文章的开头所描述的问题——当时 Linux 内核中的 NFS,我们自产的 CFEngine,仅在某些 web 服务器上出现的重定向问题等)。开发人员无法帮助我解决所有这些问题。实际上,除非开发人员具备高级系统管理员的技能,否则他们甚至不可能进入系统并作为第二组眼睛提供帮助。没有带有图形或“可观察性”的控制台——可观察性在我和其他系统管理员的大脑中。如今,有了 Kubernetes,Prometheus,Grafana 等,一切都改变了。
+
+关键是:
+
+ 1. 时代不一样了。现在,所有 web 应用程序都是大型的分布式系统。就像 AmericanGreetings.com 过去一样复杂,现在每个网站都需要该站点的扩展性和 HA 要求。
+ 2. 运行大型的分布式系统是很困难的。(维护)周期,这是业务需求,不是 Kubernetes 的。使用更简单的协调器并不是解决方案。
+
+
+
+Kubernetes绝对是满足复杂Web应用程序需求的最简单,最简单的方法。这是我们生活的时代,而 Kubernetes 擅长于此。你可以讨论是否应该自己构建或管理 Kubernetes。有很多供应商可以帮助你构建和管理它,但是很难否认这是大规模运行复杂 web 应用程序的最简单方法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/kubernetes-complex-business-problem
+
+作者:[Scott McCarty][a]
+选题:[lujun9972][b]
+译者:[laingke](https://github.com/laingke)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/fatherlinux
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_web_internet_website.png?itok=g5B_Bw62 (Digital creative of a browser on the internet)
+[2]: http://AmericanGreetings.com
+[3]: http://BlueMountain.com
+[4]: http://augeas.net/
+[5]: https://linux.cn/article-11011-1.html
+[6]: http://crunchtools.com/kubernetes-10-ton-dump-truck-handles-pretty-well-200-mph/
+[7]: https://linux.cn/article-11036-1.html
+[8]: https://srcco.de/posts/kubernetes-liveness-probes-are-dangerous.html
diff --git a/translated/tech/20180706 Building a Messenger App- OAuth.md b/translated/tech/20180706 Building a Messenger App- OAuth.md
deleted file mode 100644
index 044df1e174..0000000000
--- a/translated/tech/20180706 Building a Messenger App- OAuth.md
+++ /dev/null
@@ -1,446 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (PsiACE)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Building a Messenger App: OAuth)
-[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-oauth/)
-[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
-
-构建一个即时消息应用(二):OAuth
-======
-
-[上一篇:模式](https://linux.cn/article-11396-1.html),[原文][1]。
-
-在这篇帖子中,我们将会通过为应用添加社交登录功能进入后端开发。
-
-社交登录的工作方式十分简单:用户点击链接,然后重定向到 GitHub 授权页面。当用户授予我们对他的个人信息的访问权限之后,就会重定向回登录页面。下一次尝试登录时,系统将不会再次请求授权,也就是说,我们的应用已经记住了这个用户。这使得整个登录流程看起来就和你用鼠标单击一样快。
-
-如果进一步考虑其内部实现的话,过程就会变得复杂起来。首先,我们需要注册一个新的 [GitHub OAuth 应用][2]。
-
-这一步中,比较重要的是回调 URL。我们将它设置为 `http://localhost:3000/api/oauth/github/callback`。这是因为,在开发过程中,我们总是在本地主机上工作。一旦你要将应用交付生产,请使用正确的回调 URL 注册一个新的应用。
-
-注册以后,你将会收到「客户端 id」和「安全密钥」。安全起见,请不要与任何人分享他们 👀
-
-顺便让我们开始写一些代码吧。现在,创建一个 `main.go` 文件:
-
-```
-package main
-
-import (
- "database/sql"
- "fmt"
- "log"
- "net/http"
- "net/url"
- "os"
- "strconv"
-
- "github.com/gorilla/securecookie"
- "github.com/joho/godotenv"
- "github.com/knq/jwt"
- _ "github.com/lib/pq"
- "github.com/matryer/way"
- "golang.org/x/oauth2"
- "golang.org/x/oauth2/github"
-)
-
-var origin *url.URL
-var db *sql.DB
-var githubOAuthConfig *oauth2.Config
-var cookieSigner *securecookie.SecureCookie
-var jwtSigner jwt.Signer
-
-func main() {
- godotenv.Load()
-
- port := intEnv("PORT", 3000)
- originString := env("ORIGIN", fmt.Sprintf("http://localhost:%d/", port))
- databaseURL := env("DATABASE_URL", "postgresql://root@127.0.0.1:26257/messenger?sslmode=disable")
- githubClientID := os.Getenv("GITHUB_CLIENT_ID")
- githubClientSecret := os.Getenv("GITHUB_CLIENT_SECRET")
- hashKey := env("HASH_KEY", "secret")
- jwtKey := env("JWT_KEY", "secret")
-
- var err error
- if origin, err = url.Parse(originString); err != nil || !origin.IsAbs() {
- log.Fatal("invalid origin")
- return
- }
-
- if i, err := strconv.Atoi(origin.Port()); err == nil {
- port = i
- }
-
- if githubClientID == "" || githubClientSecret == "" {
- log.Fatalf("remember to set both $GITHUB_CLIENT_ID and $GITHUB_CLIENT_SECRET")
- return
- }
-
- if db, err = sql.Open("postgres", databaseURL); err != nil {
- log.Fatalf("could not open database connection: %v\n", err)
- return
- }
- defer db.Close()
- if err = db.Ping(); err != nil {
- log.Fatalf("could not ping to db: %v\n", err)
- return
- }
-
- githubRedirectURL := *origin
- githubRedirectURL.Path = "/api/oauth/github/callback"
- githubOAuthConfig = &oauth2.Config{
- ClientID: githubClientID,
- ClientSecret: githubClientSecret,
- Endpoint: github.Endpoint,
- RedirectURL: githubRedirectURL.String(),
- Scopes: []string{"read:user"},
- }
-
- cookieSigner = securecookie.New([]byte(hashKey), nil).MaxAge(0)
-
- jwtSigner, err = jwt.HS256.New([]byte(jwtKey))
- if err != nil {
- log.Fatalf("could not create JWT signer: %v\n", err)
- return
- }
-
- router := way.NewRouter()
- router.HandleFunc("GET", "/api/oauth/github", githubOAuthStart)
- router.HandleFunc("GET", "/api/oauth/github/callback", githubOAuthCallback)
- router.HandleFunc("GET", "/api/auth_user", guard(getAuthUser))
-
- log.Printf("accepting connections on port %d\n", port)
- log.Printf("starting server at %s\n", origin.String())
- addr := fmt.Sprintf(":%d", port)
- if err = http.ListenAndServe(addr, router); err != nil {
- log.Fatalf("could not start server: %v\n", err)
- }
-}
-
-func env(key, fallbackValue string) string {
- v, ok := os.LookupEnv(key)
- if !ok {
- return fallbackValue
- }
- return v
-}
-
-func intEnv(key string, fallbackValue int) int {
- v, ok := os.LookupEnv(key)
- if !ok {
- return fallbackValue
- }
- i, err := strconv.Atoi(v)
- if err != nil {
- return fallbackValue
- }
- return i
-}
-```
-
-安装依赖项:
-
-```
-go get -u github.com/gorilla/securecookie
-go get -u github.com/joho/godotenv
-go get -u github.com/knq/jwt
-go get -u github.com/lib/pq
-ge get -u github.com/matoous/go-nanoid
-go get -u github.com/matryer/way
-go get -u golang.org/x/oauth2
-```
-
-我们将会使用 `.env` 文件来保存密钥和其他配置。请创建这个文件,并保证里面至少包含以下内容:
-
-```
-GITHUB_CLIENT_ID=your_github_client_id
-GITHUB_CLIENT_SECRET=your_github_client_secret
-```
-
-我们还要用到的其他环境变量有:
-
- * `PORT`:服务器运行的端口,默认值是 `3000`。
- * `ORIGIN`:你的域名,默认值是 `http://localhost:3000/`。我们也可以在这里指定端口。
- * `DATABASE_URL`:Cockroach 数据库的地址。默认值是 `postgresql://root@127.0.0.1:26257/messenger?sslmode=disable`。
- * `HASH_KEY`:用于为 cookies 签名的密钥。没错,我们会使用已签名的 cookies 来确保安全。
- * `JWT_KEY`:用于签署 JSON 网络令牌(Json Web Token)的密钥。
-
-因为代码中已经设定了默认值,所以你也不用把它们写到 `.env` 文件中。
-
-在读取配置并连接到数据库之后,我们会创建一个 OAuth 配置。我们会使用 `ORIGIN` 来构建回调 URL(就和我们在 GitHub 页面上注册的一样)。我们的数据范围设置为 “read:user”。这会允许我们读取公开的用户信息,这里我们只需要他的用户名和头像就够了。然后我们会初始化 cookie 和 JWT 签名器。定义一些端点并启动服务器。
-
-在实现 HTTP 处理程序之前,让我们编写一些函数来发送 HTTP 响应。
-
-```
-func respond(w http.ResponseWriter, v interface{}, statusCode int) {
- b, err := json.Marshal(v)
- if err != nil {
- respondError(w, fmt.Errorf("could not marshal response: %v", err))
- return
- }
- w.Header().Set("Content-Type", "application/json; charset=utf-8")
- w.WriteHeader(statusCode)
- w.Write(b)
-}
-
-func respondError(w http.ResponseWriter, err error) {
- log.Println(err)
- http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
-}
-```
-
-第一个函数用来发送 JSON,而第二个将错误记录到控制台并返回一个 `500 Internal Server Error` 错误信息。
-
-### OAuth 开始
-
-所以,用户点击写着 “Access with GitHub” 的链接。该链接指向 `/api/oauth/github`,这将会把用户重定向到 github。
-
-```
-func githubOAuthStart(w http.ResponseWriter, r *http.Request) {
- state, err := gonanoid.Nanoid()
- if err != nil {
- respondError(w, fmt.Errorf("could not generte state: %v", err))
- return
- }
-
- stateCookieValue, err := cookieSigner.Encode("state", state)
- if err != nil {
- respondError(w, fmt.Errorf("could not encode state cookie: %v", err))
- return
- }
-
- http.SetCookie(w, &http.Cookie{
- Name: "state",
- Value: stateCookieValue,
- Path: "/api/oauth/github",
- HttpOnly: true,
- })
- http.Redirect(w, r, githubOAuthConfig.AuthCodeURL(state), http.StatusTemporaryRedirect)
-}
-```
-
-OAuth2 使用一种机制来防止 CSRF 攻击,因此它需要一个「状态」 "state"。我们使用 `Nanoid()` 来创建一个随机字符串,并用这个字符串作为状态。我们也把它保存为一个 cookie。
-
-### OAuth 回调
-
-一旦用户授权我们访问他的个人信息,他将会被重定向到这个端点。这个 URL 的查询字符串上将会包含状态(state)和授权码(code) `/api/oauth/github/callback?state=&code=`
-
-```
-const jwtLifetime = time.Hour * 24 * 14
-
-type GithubUser struct {
- ID int `json:"id"`
- Login string `json:"login"`
- AvatarURL *string `json:"avatar_url,omitempty"`
-}
-
-type User struct {
- ID string `json:"id"`
- Username string `json:"username"`
- AvatarURL *string `json:"avatarUrl"`
-}
-
-func githubOAuthCallback(w http.ResponseWriter, r *http.Request) {
- stateCookie, err := r.Cookie("state")
- if err != nil {
- http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
- return
- }
-
- http.SetCookie(w, &http.Cookie{
- Name: "state",
- Value: "",
- MaxAge: -1,
- HttpOnly: true,
- })
-
- var state string
- if err = cookieSigner.Decode("state", stateCookie.Value, &state); err != nil {
- http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
- return
- }
-
- q := r.URL.Query()
-
- if state != q.Get("state") {
- http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
- return
- }
-
- ctx := r.Context()
-
- t, err := githubOAuthConfig.Exchange(ctx, q.Get("code"))
- if err != nil {
- respondError(w, fmt.Errorf("could not fetch github token: %v", err))
- return
- }
-
- client := githubOAuthConfig.Client(ctx, t)
- resp, err := client.Get("https://api.github.com/user")
- if err != nil {
- respondError(w, fmt.Errorf("could not fetch github user: %v", err))
- return
- }
-
- var githubUser GithubUser
- if err = json.NewDecoder(resp.Body).Decode(&githubUser); err != nil {
- respondError(w, fmt.Errorf("could not decode github user: %v", err))
- return
- }
- defer resp.Body.Close()
-
- tx, err := db.BeginTx(ctx, nil)
- if err != nil {
- respondError(w, fmt.Errorf("could not begin tx: %v", err))
- return
- }
-
- var user User
- if err = tx.QueryRowContext(ctx, `
- SELECT id, username, avatar_url FROM users WHERE github_id = $1
- `, githubUser.ID).Scan(&user.ID, &user.Username, &user.AvatarURL); err == sql.ErrNoRows {
- if err = tx.QueryRowContext(ctx, `
- INSERT INTO users (username, avatar_url, github_id) VALUES ($1, $2, $3)
- RETURNING id
- `, githubUser.Login, githubUser.AvatarURL, githubUser.ID).Scan(&user.ID); err != nil {
- respondError(w, fmt.Errorf("could not insert user: %v", err))
- return
- }
- user.Username = githubUser.Login
- user.AvatarURL = githubUser.AvatarURL
- } else if err != nil {
- respondError(w, fmt.Errorf("could not query user by github ID: %v", err))
- return
- }
-
- if err = tx.Commit(); err != nil {
- respondError(w, fmt.Errorf("could not commit to finish github oauth: %v", err))
- return
- }
-
- exp := time.Now().Add(jwtLifetime)
- token, err := jwtSigner.Encode(jwt.Claims{
- Subject: user.ID,
- Expiration: json.Number(strconv.FormatInt(exp.Unix(), 10)),
- })
- if err != nil {
- respondError(w, fmt.Errorf("could not create token: %v", err))
- return
- }
-
- expiresAt, _ := exp.MarshalText()
-
- data := make(url.Values)
- data.Set("token", string(token))
- data.Set("expires_at", string(expiresAt))
-
- http.Redirect(w, r, "/callback?"+data.Encode(), http.StatusTemporaryRedirect)
-}
-```
-
-首先,我们会尝试使用之前保存的状态对 cookie 进行解码。并将其与查询字符串中的状态进行比较。如果它们不匹配,我们会返回一个 `418 I'm teapot`(未知来源)错误。
-
-接着,我们使用授权码生成一个令牌。这个令牌被用于创建 HTTP 客户端来向 GitHub API 发出请求。所以最终我们会向 `https://api.github.com/user` 发送一个 GET 请求。这个端点将会以 JSON 格式向我们提供当前经过身份验证的用户信息。我们将会解码这些内容,一并获取用户的 ID,登录名(用户名)和头像 URL。
-
-然后我们将会尝试在数据库上找到具有该 GitHub ID 的用户。如果没有找到,就使用该数据创建一个新的。
-
-之后,对于新创建的用户,我们会发出一个用户 ID 为主题(subject)的 JSON 网络令牌,并使用该令牌重定向到前端,查询字符串中一并包含该令牌的到期日(the expiration date)。
-
-这一 Web 应用也会被用在其他帖子,但是重定向的链接会是 `/callback?token=&expires_at=`。在那里,我们将会利用 JavaScript 从 URL 中获取令牌和到期日,并通过 `Authorization` 标头中的令牌以`Bearer token_here` 的形式对 `/ api / auth_user` 进行GET请求,来获取已认证的身份用户并将其保存到 localStorage。
-
-### Guard 中间件
-
-为了获取当前已经过身份验证的用户,我们设计了 Guard 中间件。这是因为在接下来的文章中,我们会有很多需要进行身份认证的端点,而中间件将会允许我们共享这一功能。
-
-```
-type ContextKey struct {
- Name string
-}
-
-var keyAuthUserID = ContextKey{"auth_user_id"}
-
-func guard(handler http.HandlerFunc) http.HandlerFunc {
- return func(w http.ResponseWriter, r *http.Request) {
- var token string
- if a := r.Header.Get("Authorization"); strings.HasPrefix(a, "Bearer ") {
- token = a[7:]
- } else if t := r.URL.Query().Get("token"); t != "" {
- token = t
- } else {
- http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
- return
- }
-
- var claims jwt.Claims
- if err := jwtSigner.Decode([]byte(token), &claims); err != nil {
- http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
- return
- }
-
- ctx := r.Context()
- ctx = context.WithValue(ctx, keyAuthUserID, claims.Subject)
-
- handler(w, r.WithContext(ctx))
- }
-}
-```
-
-首先,我们尝试从 `Authorization` 标头或者是 URL 查询字符串中的 `token` 字段中读取令牌。如果没有找到,我们需要返回 `401 Unauthorized`(未授权)错误。然后我们将会对令牌中的申明进行解码,并使用该主题作为当前已经过身份验证的用户 ID。
-
-现在,我们可以用这一中间件来封装任何需要授权的 `http.handlerFunc`,并且在处理函数的上下文中保有已经过身份验证的用户 ID。
-
-```
-var guarded = guard(func(w http.ResponseWriter, r *http.Request) {
- authUserID := r.Context().Value(keyAuthUserID).(string)
-})
-```
-
-### 获取认证用户
-
-```
-func getAuthUser(w http.ResponseWriter, r *http.Request) {
- ctx := r.Context()
- authUserID := ctx.Value(keyAuthUserID).(string)
-
- var user User
- if err := db.QueryRowContext(ctx, `
- SELECT username, avatar_url FROM users WHERE id = $1
- `, authUserID).Scan(&user.Username, &user.AvatarURL); err == sql.ErrNoRows {
- http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
- return
- } else if err != nil {
- respondError(w, fmt.Errorf("could not query auth user: %v", err))
- return
- }
-
- user.ID = authUserID
-
- respond(w, user, http.StatusOK)
-}
-```
-
-我们使用 Guard 中间件来获取当前经过身份认证的用户 ID 并查询数据库。
-
-* * *
-
-这一部分涵盖了后端的 OAuth 流程。在下一篇帖子中,我们将会看到如何开始与其他用户的对话。
-
-[源代码][3]
-
---------------------------------------------------------------------------------
-
-via: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
-
-作者:[Nicolás Parada][a]
-选题:[lujun9972][b]
-译者:[PsiACE](https://github.com/PsiACE)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://nicolasparada.netlify.com/
-[b]: https://github.com/lujun9972
-[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
-[2]: https://github.com/settings/applications/new
-[3]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/translated/tech/20191005 Use GameHub to Manage All Your Linux Games in One Place.md b/translated/tech/20191005 Use GameHub to Manage All Your Linux Games in One Place.md
deleted file mode 100644
index 383cebb174..0000000000
--- a/translated/tech/20191005 Use GameHub to Manage All Your Linux Games in One Place.md
+++ /dev/null
@@ -1,161 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (wenwensnow)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Use GameHub to Manage All Your Linux Games in One Place)
-[#]: via: (https://itsfoss.com/gamehub/)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-用GameHub集中管理你Linux上的所有游戏
-======
-
-你在Linux 上打算怎么[玩游戏呢][1]? 让我猜猜, 要不就是从软件中心直接安装,要不就选Steam,GOG, Humble Bundle 等平台,对吧?但是,如果你有多个游戏启动器和客户端,又要如何管理呢?好吧,对我来说这简直令人头疼 —— 这也是我发现[GameHub][2]这个应用之后,感到非常高兴的原因。
-
-GameHub是为Linux发行版设计的一个桌面应用,它能让你“集中管理你的所有游戏”。这听起来很有趣,是不是?下面让我来具体说明一下。
-
-![][3]
-### 集中管理不同平台Linux游戏的GameHub功能
-
-让我们看看,对玩家来说,让GameHub成为一个[不可或缺的Linux应用][4]的功能,都有哪些。
-
-#### Steam, GOG & Humble Bundle 支持
-![][5]
-
-它支持Steam, [GOG][6], 和 [Humble Bundle][7] 账户整合。你可以登录你的GameHub账号,从而在库管理器中管理所有游戏。
-
-对我来说,我在Steam上有很多游戏,Humble Bundle上也有一些。我不能确保它支持所有平台。但可以确信的是,主流平台游戏是没有问题的。
-
-#### 本地游戏支持
-![][8]
-
-有很多网站专门推荐Linux游戏,并[支持下载][9]。你可以通过下载安装包,或者添加可执行文件,从而管理本地游戏。
-
-可惜的是,在GameHub内,无法在线搜索Linux游戏。如上图所示,你需要将各平台游戏分开下载,随后再添加到自己的GameHub账号中。
-
-#### 模拟器支持
-
-在模拟器方面,你可以玩[Linux上的retro game][10]。正如上图所示,你可以添加模拟器(或导入模拟器镜像)。
-
-你可以在[RetroArch][11]查看可添加的模拟器,但也能根据需求,添加自定义模拟器。
-
-#### 用户界面
-
-![Gamehub 界面选项][12]
-
-当然,用户体验很重要。因此,探究下用户界面都有些什么,也很有必要。
-
-我个人觉得,这一应用很容易使用,并且黑色主题是一个加分项。
-
-#### 手柄支持
-
-如果你习惯在Linux系统上用手柄玩游戏 —— 你可以轻松在设置里添加,启用或禁用它。
-
-#### 多个数据提供商
-
-
-因为它需要获取你的游戏信息(或元数据),也意味着它需要一个数据源。你可以看到上图列出的所有数据源。
-
-![Data Providers Gamehub][13]
-
-这里你什么也不用做 —— 但如果你使用的是其他平台,而不是steam的话,你需要为[IDGB生成一个API密钥][14]。
-
-我建议只有出现提示/通知,或有些游戏在GameHub上没有任何描述/图片/状态时,再这么做。
-
-#### 兼容性选项
-
-![][15]
-
-你有不支持在Linux上运行的游戏吗?
-
-不用担心,GameHub上提供了多种兼容工具,如 Wine/Proton,你可以利用它们让游戏得以运行。
-
-我们无法确定具体哪个兼容工具适用于你 —— 所以你需要自己亲自测试。 然而,对许多游戏玩家来说,这的确是个很有用的功能。
-
-### 如何在GameHub上管理你的游戏?
-
-在启动程序后,你可以将自己的Steam/GOG/Humble Bundle 账号添加进来。
-
-对于Steam, 你需要在Linux 发行版上安装Steam 客户端。一旦安装完成,你可以轻松将账号中的游戏导入GameHub.
-
-
-![][16]
-
-对于GOG & Humble Bundle, 登录后,就能直接在GameHub上管理游戏了。
-
-如果你想添加模拟器或者本地安装文件,点击窗口右上角的 “**+**” 按钮进行添加。
-
-
-### 如何安装游戏?
-
-对于Steam游戏,它会自动启动Steam 客户端,从而下载/安装游戏(我希望之后安装游戏,可以不用启动Steam!)
-
-![][17]
-
-但对于GOG/Humble Bundle, 登录后就能直接、下载安装游戏。必要的话,对于那些不支持在Linux上运行的游戏,你可以使用兼容工具。
-
-无论是模拟器游戏,还是本地游戏,只需添加安装包或导入模拟器镜像就可以了。这里没什么其他步骤要做。
-
-### GameHub: 如何安装它呢?
-
-![][18]
-
-首先,你可以直接在软件中心或者应用商店内搜索。 它在 **Pop!_Shop** 分类下可见。所以,它在绝大多数官方源中都能找到。
-
-如果你在这些地方都没有找到,你可以手动添加源,并从终端上安装它,你需要输入以下命令:
-
-```
-sudo add-apt-repository ppa:tkashkin/gamehub
-sudo apt update
-sudo apt install com.github.tkashkin.gamehub
-```
-
-如果你遇到了 “**add-apt-repository command not found**” 这个错误,你可以看看,[add-apt-repository not found error.][19]这篇文章,它能帮你解决这一问题。
-
-这里还提供AppImage 和 FlatPak版本。 在[官网][2] 上,你可以针对找到其他Linux发行版的安装手册。
-
-同时,你还可以从它的 [GitHub页面][20]下载之前版本的安装包.
-
-[GameHub][2]
-
-**注意**
-
-GameHub 是相当灵活的一个集中游戏管理应用。 用户界面和选项设置也相当直观。
-
-你之前是否使用过这一应用呢?如果有,请在评论里写下你的感受。
-
-而且,如果你想尝试一些与此功能相似的工具/应用,请务必告诉我们。
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/gamehub/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://itsfoss.com/linux-gaming-guide/
-[2]: https://tkashkin.tk/projects/gamehub/
-[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-home-1.png?ssl=1
-[4]: https://itsfoss.com/essential-linux-applications/
-[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-platform-support.png?ssl=1
-[6]: https://www.gog.com/
-[7]: https://www.humblebundle.com/monthly?partner=itsfoss
-[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-native-installers.png?ssl=1
-[9]: https://itsfoss.com/download-linux-games/
-[10]: https://itsfoss.com/play-retro-games-linux/
-[11]: https://www.retroarch.com/
-[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-appearance.png?ssl=1
-[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/data-providers-gamehub.png?ssl=1
-[14]: https://www.igdb.com/api
-[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-windows-game.png?fit=800%2C569&ssl=1
-[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-library.png?ssl=1
-[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-compatibility-layer.png?ssl=1
-[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/10/gamehub-install.jpg?ssl=1
-[19]: https://itsfoss.com/add-apt-repository-command-not-found/
-[20]: https://github.com/tkashkin/GameHub/releases
diff --git a/translated/tech/20191013 Object-Oriented Programming and Essential State.md b/translated/tech/20191013 Object-Oriented Programming and Essential State.md
deleted file mode 100644
index caacee3372..0000000000
--- a/translated/tech/20191013 Object-Oriented Programming and Essential State.md
+++ /dev/null
@@ -1,99 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Object-Oriented Programming and Essential State)
-[#]: via: (https://theartofmachinery.com/2019/10/13/oop_and_essential_state.html)
-[#]: author: (Simon Arneaud https://theartofmachinery.com)
-
-面向对象编程和根本状态
-======
-
-早在 2015 年,Brian Will 撰写了一篇有挑衅性的博客:[面向对象编程:一个灾难故事][1]。他随后发布了一个名为[面向对象编程很糟糕][2]的视频,该视频更加详细。我建议你花些时间观看视频,但这是我的一小段摘要:
-
-OOP 的柏拉图式理想是一堆相互解耦的对象,它们彼此之间发送无状态消息。没有人真的像这样制作软件,Brian 指出这甚至没有意义:对象需要知道向哪个对象发送消息,这意味着它们需要相互引用。视频大部分讲述的是人们试图将对象耦合以实现控制流,同时假装它们是通过设计解耦的。
-
-总的来说,他的想法与我自己的 OOP 经验产生了共鸣:对象没有问题,但是我从来没有对_面向_对象建立程序控制流满意,而试图使代码“正确地”面向对象似乎总是在创建不必要的复杂性。
-
-我认为他无法完全解释一件事。他直截了当地说“封装没有作用”,但在脚注后面加上“在细粒度的代码级别”,并继续承认对象有时可以奏效,并且在库和文件级别可以封装。但是他没有确切解释为什么有时会奏效,有时却没有奏效,以及如何/在何处划清界限。有人可能会说这使他的“ OOP不好”的说法有缺陷,但是我认为他的观点是正确的,并且可以在根本状态和偶发状态之间划清界限。
-
-如果你以前从未听说过“根本”和“偶发”这两个术语的使用,那么你应该阅读 Fred Brooks 的经典文章[没有银弹][3]。 (顺便说一句,他写了许多有关构建软件系统的很棒的文章。)我以前曾写过[关于根本和偶发的复杂性的文章][4],但是这里有一个简短的摘要:软件很复杂。部分原因是因为我们希望软件能够解决混乱的现实世界问题,因此我们将其称为“根本复杂性”。“偶发复杂性”是所有其他复杂性,因为我们正尝试使用硅和金属来解决与硅和金属无关的问题。例如,对于大多数程序而言,用于内存管理或在内存与磁盘之间传输数据或解析文本格式的代码都是“偶发的复杂性”。
-
-假设你正在构建一个支持多个频道的聊天应用。消息可以随时到达任何频道。有些频道特别有趣,当有新消息传入时,用户希望得到通知。其他频道静音:消息被存储,但用户不会受到打扰。你需要跟踪每个频道的用户首选设置。
-
-一种实现方法是在频道和频道设置之间使用映射(也称为哈希表,字典或关联数组)。注意,映射是 Brian Will 所说的可以用作对象的抽象数据类型(ADT)。
-
-如果我们有一个调试器并查看内存中的 map 对象,我们将看到什么?我们当然会找到频道 ID 和频道设置数据(或至少指向它们的指针)。但是我们还会找到其他数据。如果 map 是使用红黑树实现的,我们将看到带有红/黑标签和指向其他节点的指针的树节点对象。与频道相关的数据是根本状态,而树节点是偶发状态。不过,请注意以下几点:该映射有效地封装了它的偶发状态-你可以用 AVL 树实现的另一个映射替换该映射,并且你的聊天程序仍然可以使用。另一方面,映射没有封装根本状态(仅使用 `get()` 和 `set()`方法访问数据不是封装)。事实上,映射与根本状态是尽可能不可知的,你可以使用基本相同的映射数据结构来存储与频道或通知无关的其他映射。
-
-
-这就是映射 ADT 如此成功的原因:它封装了偶发状态,并与根本状态解耦。如果你考虑一下,Brian 描述的封装问题就是尝试封装根本状态。其他描述的好处是封装偶发状态的好处。
-
-要使整个软件系统都达到这一理想相当困难,但扩展开来,我认为它看起来像这样:
-
- * 没有全局的可变状态
- * 封装了偶发状态(在对象或模块或以其他任何形式)
- * 无状态偶发复杂性封装在单独函数中,与数据解耦
- * 使用诸如依赖注入之类的技巧使输入和输出变得明确
- * 完全拥有组件,并从易于识别的位置进行控制
-
-
-
-其中有些违反了我很久以前的本能。例如,如果你有一个数据库查询函数,如果数据库连接处理隐藏在该函数内部,并且唯一的参数是查询参数,那么接口会看起来会更简单。但是,当你使用这样的函数构建软件系统时,协调数据库的使用实际上变得更加复杂。组件不仅以自己的方式做事,而且还试图将自己所做的事情隐藏为“实现细节”。数据库查询需要数据库连接这一事实从来都不是实现细节。如果无法隐藏某些内容,那么显露它是更合理的。
-
-我警惕将面向对象编程和函数式编程放在两极,但我认为从函数式编程进入面向对象编程的另一极端是很有趣的:OOP 试图封装事物,包括无法封装的根本复杂性,而纯函数式编程往往会使事情变得明确,包括一些偶发复杂性。在大多数时候,没什么问题,但有时候(比如[在纯函数式语言中构建自我指称的数据结构][5])设计更多的是为了函数编程,而不是为了简便(这就是为什么 [Haskell 包含了一些“逃生出口”( escape hatches)][6])。我之前写过一篇[中立的所谓的“弱纯性” (weak purity)][7]
-
-Brian 发现封装对更大规模有效,原因有几个。一个是,由于大小的原因,较大的组件更可能包含偶发状态。另一个是“偶发”与你要解决的问题有关。从聊天程序用户的角度来看,“偶发的复杂性”是与消息,频道和用户等无关的任何事物。但是,当你将问题分解为子问题时,更多的事情就变得重要。例如,在解决“构建聊天应用”问题时,可以说频道名称和频道 ID 之间的映射是偶发的复杂性,而在解决“实现 `getChannelIdByName()` 函数”子问题时,这是根本复杂性。因此,封装对于子组件的作用比对父组件的作用要小。
-
-顺便说一句,在影片的结尾,Brian Will 想知道是否有任何语言支持_无法_访问它们所作用的范围的匿名函数。[D][8] 语言可以。 D 中的匿名 Lambda 通常是闭包,但是如果你想要的话,也可以声明匿名无状态函数:
-
-```
-import std.stdio;
-
-void main()
-{
- int x = 41;
-
- // Value from immediately executed lambda
- auto v1 = () {
- return x + 1;
- }();
- writeln(v1);
-
- // Same thing
- auto v2 = delegate() {
- return x + 1;
- }();
- writeln(v2);
-
- // Plain functions aren't closures
- auto v3 = function() {
- // Can't access x
- // Can't access any mutable global state either if also marked pure
- return 42;
- }();
- writeln(v3);
-}
-```
-
---------------------------------------------------------------------------------
-
-via: https://theartofmachinery.com/2019/10/13/oop_and_essential_state.html
-
-作者:[Simon Arneaud][a]
-选题:[lujun9972][b]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://theartofmachinery.com
-[b]: https://github.com/lujun9972
-[1]: https://medium.com/@brianwill/object-oriented-programming-a-personal-disaster-1b044c2383ab
-[2]: https://www.youtube.com/watch?v=QM1iUe6IofM
-[3]: http://www.cs.nott.ac.uk/~pszcah/G51ISS/Documents/NoSilverBullet.html
-[4]: https://theartofmachinery.com/2017/06/25/compression_complexity_and_software.html
-[5]: https://wiki.haskell.org/Tying_the_Knot
-[6]: https://en.wikibooks.org/wiki/Haskell/Mutable_objects#The_ST_monad
-[7]: https://theartofmachinery.com/2016/03/28/dirtying_pure_functions_can_be_useful.html
-[8]: https://dlang.org