mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
34d971cce2
@ -1,13 +1,13 @@
|
||||
用 GNOME Boxes 下载一个镜像
|
||||
用 GNOME Boxes 下载一个操作系统镜像
|
||||
======
|
||||
|
||||

|
||||
|
||||
Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性,使得它在运行不同的 Linux 发行版时更加容易。你现在可以在 Boxes 中自动安装列表中这些发行版。该列表甚至包括红帽企业 Linux。红帽开发人员计划包括[免费订阅红帽企业版 Linux][1]。 使用[红帽开发者][2]帐户,Boxes 可以自动设置一个名为 Developer Suite 订阅的 RHEL 虚拟机。 下面是它的工作原理。
|
||||
Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性,使得它在运行不同的 Linux 发行版时更加容易。你现在可以在 Boxes 中自动安装那些发行版以及像 FreeBSD 和 FreeDOS 这样的操作系统,甚至还包括红帽企业 Linux。红帽开发者计划包括了一个[红帽企业版 Linux 的免费订阅][1]。 使用[红帽开发者][2]帐户,Boxes 可以自动设置一个名为 Developer Suite 订阅的 RHEL 虚拟机。 下面是它的工作原理。
|
||||
|
||||
### 红帽企业版 Linux
|
||||
### 红帽企业版 Linux
|
||||
|
||||
要创建一个红帽企业版 Linux 的虚拟机,启动 Boxes,点击新建。从源选择列表中选择下载一个镜像。在顶部,点击红帽企业版 Linux。这将会打开网址为 [developers.redhat.com][2] 的一个网络表单。使用已有的红帽开发者账号登录,或是新建一个。
|
||||
要创建一个红帽企业版 Linux 的虚拟机,启动 Boxes,点击“新建”。从源选择列表中选择“下载一个镜像”。在顶部,点击“红帽企业版 Linux”。这将会打开网址为 [developers.redhat.com][2] 的一个 Web 表单。使用已有的红帽开发者账号登录,或是新建一个。
|
||||
|
||||
![][3]
|
||||
|
||||
@ -15,11 +15,11 @@ Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性
|
||||
|
||||
![][5]
|
||||
|
||||
点击提交,然后就会开始下载安装磁盘镜像。下载需要的时间取决于你的网络状况。在这期间你可以去喝杯茶或者咖啡歇息一下。
|
||||
点击“提交”,然后就会开始下载安装磁盘镜像。下载需要的时间取决于你的网络状况。在这期间你可以去喝杯茶或者咖啡歇息一下。
|
||||
|
||||
![][6]
|
||||
|
||||
等媒体下载完成(一般位于 ~/Downloads ),Boxes 会有一个快速安装的显示。填入账号和密码然后点击继续,当你确认了虚拟机的信息之后点击创建。快速安装会自动完成接下来的整个安装!(现在你可以去享受你的第二杯茶或者咖啡了)
|
||||
等介质下载完成(一般位于 `~/Downloads` ),Boxes 会有一个“快速安装”的显示。填入账号和密码然后点击“继续”,当你确认了虚拟机的信息之后点击“创建”。“快速安装”会自动完成接下来的整个安装!(现在你可以去享受你的第二杯茶或者咖啡了)
|
||||
|
||||
![][7]
|
||||
|
||||
@ -27,7 +27,7 @@ Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性
|
||||
|
||||
![][9]
|
||||
|
||||
等到安装结束,虚拟机会直接重启并登录到桌面。在虚拟机里,在应用菜单的系统工具一栏启动红帽订阅管理。这一步需要输入管理员密码。
|
||||
等到安装结束,虚拟机会直接重启并登录到桌面。在虚拟机里,在应用菜单的“系统工具”一栏启动“红帽订阅管理”。这一步需要输入 root 密码。
|
||||
|
||||
![][10]
|
||||
|
||||
@ -37,13 +37,13 @@ Boxes 是 GNOME 上的虚拟机应用。最近 Boxes 添加了一个新的特性
|
||||
|
||||
![][12]
|
||||
|
||||
现在你可以通过任何一种更新方法,像是 yum 或是 GNOME Software 进行下载和更新了。
|
||||
现在你可以通过任何一种更新方法,像是 `yum` 或是 GNOME Software 进行下载和更新了。
|
||||
|
||||
![][13]
|
||||
|
||||
### FreeDOS 或是其他
|
||||
|
||||
Boxes 可以安装很多的 Linux 发行版,而不仅仅只是红帽企业版。 作为 KVM 和 qemu 的前端,Boxes 支持各种操作系统。 使用 [libosinfo][14],Boxes 可以自动下载(在某些情况下安装)相当多不同操作系统。
|
||||
Boxes 可以安装很多操作系统,而不仅仅只是红帽企业版。 作为 KVM 和 qemu 的前端,Boxes 支持各种操作系统。使用 [libosinfo][14],Boxes 可以自动下载(在某些情况下安装)相当多不同操作系统。
|
||||
|
||||
![][15]
|
||||
|
||||
@ -53,13 +53,23 @@ Boxes 可以安装很多的 Linux 发行版,而不仅仅只是红帽企业版
|
||||
|
||||
![][17]
|
||||
|
||||
### 在 Boxes 上受欢迎的操作系统
|
||||
### Boxes 上流行的操作系统
|
||||
|
||||
这里仅仅是一些目前在它上面比较受欢迎的选择。
|
||||
|
||||
![][18]![][19]![][20]![][21]![][22]![][23]
|
||||
![][18]
|
||||
|
||||
Fedora 会定期更新它的操作系统信息数据库。确保你会经常检查是否有新的操作系统选项。
|
||||
![][19]
|
||||
|
||||
![][20]
|
||||
|
||||
![][21]
|
||||
|
||||
![][22]
|
||||
|
||||
![][23]
|
||||
|
||||
Fedora 会定期更新它的操作系统信息数据库(osinfo-db)。确保你会经常检查是否有新的操作系统选项。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -69,7 +79,7 @@ via: https://fedoramagazine.org/download-os-gnome-boxes/
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,166 +0,0 @@
|
||||
LuuMing translating
|
||||
Setting Up a Timer with systemd in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Previously, we saw how to enable and disable systemd services [by hand][1], [at boot time and on power down][2], [when a certain device is activated][3], and [when something changes in the filesystem][4].
|
||||
|
||||
Timers add yet another way of starting services, based on... well, time. Although similar to cron jobs, systemd timers are slightly more flexible. Let's see how they work.
|
||||
|
||||
### "Run when"
|
||||
|
||||
Let's expand the [Minetest][5] [service you set up][1] in [the first two articles of this series][2] as our first example on how to use timer units. If you haven't read those articles yet, you may want to go and give them a look now.
|
||||
|
||||
So you will "improve" your Minetest set up by creating a timer that will run the game's server 1 minute after boot up has finished instead of right away. The reason for this could be that, as you want your service to do other stuff, like send emails to the players telling them the game is available, you will want to make sure other services (like the network) are fully up and running before doing anything fancy.
|
||||
|
||||
Jumping in at the deep end, your _minetest.timer_ unit will look like this:
|
||||
```
|
||||
# minetest.timer
|
||||
[Unit]
|
||||
Description=Runs the minetest.service 1 minute after boot up
|
||||
|
||||
[Timer]
|
||||
OnBootSec=1 m
|
||||
Unit=minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
Not hard at all.
|
||||
|
||||
As usual, you have a `[Unit]` section with a description of what the unit does. Nothing new there. The `[Timer]` section is new, but it is pretty self-explanatory: it contains information on when the service will be triggered and the service to trigger. In this case, the `OnBootSec` is the directive you need to tell systemd to run the service after boot has finished.
|
||||
|
||||
Other directives you could use are:
|
||||
|
||||
* `OnActiveSec=`, which tells systemd how long to wait after the timer itself is activated before starting the service.
|
||||
* `OnStartupSec=`, on the other hand, tells systemd how long to wait after systemd was started before starting the service.
|
||||
* `OnUnitActiveSec=` tells systemd how long to wait after the service the timer is activating was last activated.
|
||||
* `OnUnitInactiveSec=` tells systemd how long to wait after the service the timer is activating was last deactivated.
|
||||
|
||||
|
||||
|
||||
Continuing down the _minetest.timer_ unit, the `basic.target` is usually used as a synchronization point for late boot services. This means it makes _minetest.timer_ wait until local mount points and swap devices are mounted, sockets, timers, path units and other basic initialization processes are running before letting _minetest.timer_ start. As we explained in [the second article on systemd units][2], _targets_ are like the old run levels and can be used to put your machine into one state or another, or, like here, to tell your service to wait until a certain state has been reached.
|
||||
|
||||
The _minetest.service_ you developed in the first two articles [ended up][2] looking like this:
|
||||
```
|
||||
# minetest.service
|
||||
[Unit]
|
||||
Description= Minetest server
|
||||
Documentation= https://wiki.minetest.net/Main_Page
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User=
|
||||
|
||||
ExecStart= /usr/games/minetest --server
|
||||
ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
|
||||
|
||||
TimeoutStopSec= 180
|
||||
ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
|
||||
ExecStop= /bin/sleep 120
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.target
|
||||
|
||||
```
|
||||
|
||||
There’s nothing you need to change here. But you do have to change _mtsendmail.sh_ (your email sending script) from this:
|
||||
```
|
||||
#!/bin/bash
|
||||
# mtsendmail
|
||||
sleep 20
|
||||
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
|
||||
sleep 10
|
||||
|
||||
```
|
||||
|
||||
to this:
|
||||
```
|
||||
#!/bin/bash
|
||||
# mtsendmail.sh
|
||||
echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
|
||||
|
||||
```
|
||||
|
||||
What you are doing is stripping out those hacky pauses in the Bash script. Systemd does the waiting now.
|
||||
|
||||
### Making it work
|
||||
|
||||
To make sure things work, disable _minetest.service_ :
|
||||
```
|
||||
sudo systemctl disable minetest
|
||||
|
||||
```
|
||||
|
||||
so it doesn't get started when the system starts; and, instead, enable _minetest.timer_ :
|
||||
```
|
||||
sudo systemctl enable minetest.timer
|
||||
|
||||
```
|
||||
|
||||
Now you can reboot you server machine and, when you run `sudo journalctl -u minetest.*` you will see how, first the _minetest.timer_ unit gets executed and then the _minetest.service_ starts up after a minute... more or less.
|
||||
|
||||
![minetest timer][7]
|
||||
|
||||
Figure 1: The minetest.service gets started one minute after the minetest.timer... more or less.
|
||||
|
||||
[Used with permission][8]
|
||||
|
||||
### A Matter of Time
|
||||
|
||||
A couple of clarifications about why the _minetest.timer_ entry in the systemd's Journal shows its start time as 09:08:33, while the _minetest.service_ starts at 09:09:18, that is less than a minute later: First, remember we said that the `OnBootSec=` directive calculates when to start a service from when boot is complete. By the time _minetest.timer_ comes along, boot has finished a few seconds ago.
|
||||
|
||||
The other thing is that systemd gives itself a margin of error (by default, 1 minute) to run stuff. This helps distribute the load when several resource-intensive processes are running at the same time: by giving itself a minute, systemd can wait for some processes to power down. This also means that _minetest.service_ will start somewhere between the 1 minute and 2 minute mark after boot is completed, but when exactly within that range is anybody's guess.
|
||||
|
||||
For the record, [you can change the margin of error with `AccuracySec=` directive][9].
|
||||
|
||||
Another thing you can do is check when all the timers on your system are scheduled to run or the last time the ran:
|
||||
```
|
||||
systemctl list-timers --all
|
||||
|
||||
```
|
||||
|
||||
![check timer][11]
|
||||
|
||||
Figure 2: Check when your timers are scheduled to fire or when they fired last.
|
||||
|
||||
[Used with permission][8]
|
||||
|
||||
The final thing to take into consideration is the format you should use to express the periods of time. Systemd is very flexible in that respect: `2 h`, `2 hours` or `2hr` will all work to express a 2 hour delay. For seconds, you can use `seconds`, `second`, `sec`, and `s`, the same way as for minutes you can use `minutes`, `minute`, `min`, and `m`. You can see a full list of time units systemd understands by checking `man systemd.time`.
|
||||
|
||||
### Next Time
|
||||
|
||||
You'll see how to use calendar dates and times to run services at regular intervals and how to combine timers and device units to run services at defined point in time after you plug in some hardware.
|
||||
|
||||
See you then!
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||
[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://www.minetest.net/
|
||||
[6]:/files/images/minetest-timer-1png
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-1.png?itok=TG0xJvYM (minetest timer)
|
||||
[8]:/licenses/category/used-permission
|
||||
[9]:https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=
|
||||
[10]:/files/images/minetest-timer-2png
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-2.png?itok=pYxyVx8- (check timer)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Quiet log noise with Python and machine learning
|
||||
======
|
||||
|
||||
|
||||
@ -1,81 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
5 tips for choosing the right open source database
|
||||
======
|
||||
When selecting a mission-critical application, you can't afford to make mistakes.
|
||||
|
||||

|
||||
|
||||
So, your company has a directive to adopt more open source database technologies, and they've recruited you to select the right direction. Whether you are an open source technology veteran or a newcomer, this is a daunting and overwhelming task.
|
||||
|
||||
Over the past several years, open source technology adoption has steadily increased in the enterprise space. With its popularity comes a crowded marketplace with open source software companies promising that their solution will solve every problem and fit every workload. Be wary of these promises. Choosing the right open source technology—especially a database—is an important and difficult decision you can't make lightly.
|
||||
|
||||
In my experience as an IT professional at [Percona][1] and other companies, I've been fortunate to work hands-on in adopting open source technologies and guiding others in making the right decisions. There are many important factors to consider; hopefully, this article will shine a light on a few.
|
||||
|
||||
### 1. Have a goal.
|
||||
|
||||
This may seem simple, but based on my many conversations with people exploring MySQL, MongoDB, or PostgreSQL, it is top of the list in importance.
|
||||
|
||||
To avoid getting overwhelmed by the unlimited combinations of open source database software in the market, have a specific goal in mind. Maybe your goal is to provide your internal developers with a standardized, open source database backend that is managed by your internal database team. Perhaps your goal is to rip and replace the entire functionality of a legacy application and database backend with new open source technology.
|
||||
|
||||
Once you have defined a goal, you can focus your efforts. This will lead to better conversations internally as well as externally with open source database software vendors and advocates.
|
||||
|
||||
### 2. Understand your workload.
|
||||
|
||||
Despite the increasing ability of database technologies to wear many hats, each specializes in certain areas, e.g., MongoDB is now transactional, MySQL now has JSON storage. A growing trend in open source databases involves providing check boxes claiming certain features are available. One of the biggest mistakes is not using the right tool for the right job. Something leads a company down the wrong path—perhaps an overzealous developer or a manager with tunnel vision. The unfortunate thing is that the wrong tool can work fine for smaller volumes of transactions and data, but later there will be bottlenecks that can be solved only by using a different tool.
|
||||
|
||||
If you want a data analytics warehouse, an open source relational database is probably not the right choice. If you want a transaction-processing app with rigid data integrity and consistency, NoSQL options may not be the right option.
|
||||
|
||||
### 3. Don't reinvent the wheel.
|
||||
|
||||
Open source database technologies have rapidly grown, expanded, and hardened over the past several decades. We've seen a transformation from new, questionably production-ready databases to proven, enterprise-grade database backends. It's no longer necessary to be a bleeding edge, early adopter to choose open source database technologies. Organizations have grown around these communities to provide production support and tooling in the open source database space for a growing number of startups, midsized businesses, and Fortune 500 companies.
|
||||
|
||||
Battery Ventures, a tech-focused investment firm, recently introduced its [BOSS Index][2] for tracking the most popular open source projects. It's not perfect, but it provides great insight into some of the most widely adopted and active open source projects. Not surprisingly, database technologies dominate the list, comprising five of the top 10 technologies. This is a great starting point for someone new to the open source database space. A lot of times, vendors have already produced suitable architectures for solving specific problems.
|
||||
|
||||
My point is that someone has probably already done what you are trying to do. Learn from their successes and failures. Even if it is not a perfect fit, a solution can likely be modified to suit your needs. For example, Amazon provides a [CloudFormation script][3] for deploying MongoDB in its EC2 environment.
|
||||
|
||||
If you are a bleeding-edge early adopter, that doesn't mean you can't explore. If you have a unique challenge or workload that seems to fit a new open source database technology, go for it. Keep in mind that there are inherent risks (and rewards!) to being an early adopter.
|
||||
|
||||
### 4\. Start simple
|
||||
|
||||
|
||||
How many [nines][4] does your database truly need? "Achieving high availability" is often a nebulous goal for many companies. Of course, the most common answer is "it's mission-critical, and we cannot afford any downtime."
|
||||
|
||||
The more complicated your database environment, the more difficult and costly it is to manage. You can theoretically achieve higher uptime, but the tradeoffs will be the feasibility of management and performance. When in doubt, start simple. There are always options to scale out when the need arises.
|
||||
|
||||
For example, Booking.com is a widely known travel reservation site. It might be less widely known that it uses MySQL as a database backend. Nicolai Plum, a Booking.com senior systems architect, gave [a talk][5] outlining the evolution of the company's MySQL database. One of the takeaways was that the database started simple. It had to evolve over time, but in the beginning, simple master–replica architecture sufficed. As the workload and dataset increased, it introduced load balancers, multiple read replicas, archiving to Hadoop for analytics, etc. However, the early architecture was extremely simple.
|
||||
|
||||
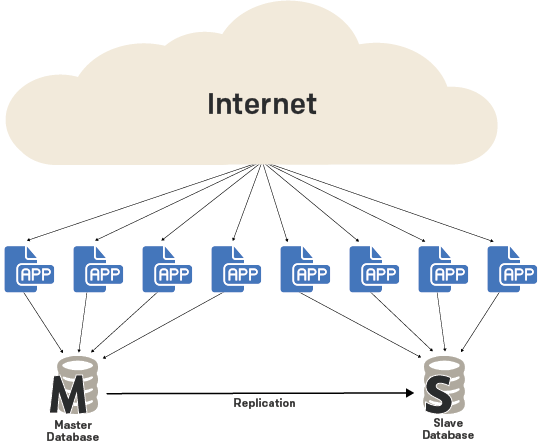
|
||||
|
||||
### 5. When in doubt, ask an expert.
|
||||
|
||||
If you're unsure whether a database would be a good fit, reach out on forums, websites, or to vendors and strike up a conversation. This can be exciting as you research which database technologies meet your requirements and which do not. Often there are suitable alternatives that you haven't considered. The open source community is all about sharing knowledge.
|
||||
|
||||
There is one important thing to be aware of when reaching out to open source software and services vendors. Many have open-core business models that incentivize adopting their database software. Take their advice or guidance with a grain of salt and use your own ability to research, create proofs of concept, and explore alternatives.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Choosing the right open source database is an important decision. Start by asking the right questions. All too often, people put the cart before the horse, making decisions before really understanding their needs.
|
||||
|
||||
Barrett Chambers will present [Choosing the Right Open Source Database][6] at [All Things Open][7], October 21-23 in Raleigh, N.C.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/tips-choosing-right-open-source-database
|
||||
|
||||
作者:[Barrett Chambers][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barrettc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.percona.com/
|
||||
[2]: https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/
|
||||
[3]: https://docs.aws.amazon.com/quickstart/latest/mongodb/welcome.html
|
||||
[4]: https://en.wikipedia.org/wiki/Five_nines
|
||||
[5]: https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design
|
||||
[6]: https://allthingsopen.org/talk/choosing-the-right-open-source-database/
|
||||
[7]: https://allthingsopen.org/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Getting started with functional programming in Python using the toolz library
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,167 @@
|
||||
在 Linux 上使用 systemd 设置定时器
|
||||
======
|
||||
|
||||

|
||||
|
||||
之前,我们看到了如何[手动的][1]、[在开机与关机时][2]、[在启用某个设备时][3]、[在文件系统发生改变时][4]启用与禁用 systemd 服务。
|
||||
|
||||
定时器增加了另一种启动服务的方式,基于...时间。尽管与定时任务很相似,但 systemd 定时器稍微地灵活一些。让我们看看它是怎么工作的。
|
||||
|
||||
### “定时运行”
|
||||
|
||||
让我们展开[本系列前两篇文章][2]中[你所设置的 ][1] [Minetest][5] 服务器作为如何使用定时器单元的第一个例子。如果你还没有读过那几篇文章,可以现在去看看。
|
||||
|
||||
你将通过创建一个定时器来改进 Minetest 服务器,使得在定时器启动 1 分钟后运行游戏服务器而不是立即运行。这样做的原因可能是,在启动之前可能会用到其他的服务,例如发邮件给其他玩家告诉他们游戏已经准备就绪,你要确保其他的服务(例如网络)在开始前完全启动并运行。
|
||||
|
||||
跳到最底下,你的 `_minetest.timer_` 单元看起来就像这样:
|
||||
|
||||
```
|
||||
# minetest.timer
|
||||
[Unit]
|
||||
Description=Runs the minetest.service 1 minute after boot up
|
||||
|
||||
[Timer]
|
||||
OnBootSec=1 m
|
||||
Unit=minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
一点也不难吧。
|
||||
|
||||
通常,开头是 `[Unit]` 和一段描述单元作用的信息,这儿没什么新东西。`[Timer]` 这一节是新出现的,但它的作用不言自明:它包含了何时启动服务,启动哪个服务的信息。在这个例子当中,`OnBootSec` 是告诉 systemd 在系统启动后运行服务的指令。
|
||||
|
||||
其他的指令有:
|
||||
|
||||
* `OnActiveSec=`,告诉 systemd 在定时器启动后多长时间运行服务。
|
||||
* `OnStartupSec=`,同样的,它告诉 systemd 在 systemd 进程启动后多长时间运行服务。
|
||||
* `OnUnitActiveSec=`,告诉 systemd 在上次由定时器激活的服务启动后多长时间运行服务。
|
||||
* `OnUnitInactiveSec=`,告诉 systemd 在上次由定时器激活的服务停用后多长时间运行服务。
|
||||
|
||||
继续 `_minetest.timer_` 单元,`basic.target` 通常用作<ruby>后期引导服务<rt>late boot services</rt></ruby>的<ruby>同步点<rt>synchronization point</rt></ruby>。这就意味着它可以让 `_minetest.timer_` 单元运行在安装完<ruby>本地挂载点<rt>local mount points</rt></ruby>或交换设备,套接字、定时器、路径单元和其他基本的初始化进程之后。就像在[第二篇文章中 systemd 单元][2]里解释的那样,`_targets_` 就像<ruby>旧的运行等级<rt>old run levels</rt></ruby>,可以将你的计算机置于某个状态,或像这样告诉你的服务在达到某个状态后开始运行。
|
||||
|
||||
在前两篇文章中你配置的`_minetest.service_`文件[最终][2]看起来就像这样:
|
||||
|
||||
```
|
||||
# minetest.service
|
||||
[Unit]
|
||||
Description= Minetest server
|
||||
Documentation= https://wiki.minetest.net/Main_Page
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User=
|
||||
|
||||
ExecStart= /usr/games/minetest --server
|
||||
ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
|
||||
|
||||
TimeoutStopSec= 180
|
||||
ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
|
||||
ExecStop= /bin/sleep 120
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.target
|
||||
|
||||
```
|
||||
|
||||
这儿没什么需要修改的。但是你需要将 `_mtsendmail.sh_`(发送你的 email 的脚本)从:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# mtsendmail
|
||||
sleep 20
|
||||
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
|
||||
sleep 10
|
||||
|
||||
```
|
||||
|
||||
改成:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# mtsendmail.sh
|
||||
echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
|
||||
|
||||
```
|
||||
|
||||
你做的事是去除掉 Bash 脚本中那些蹩脚的停顿。Systemd 现在正在等待。
|
||||
|
||||
### 让它运行起来
|
||||
|
||||
确保一切运作正常,禁用 `_minetest.service_`:
|
||||
```
|
||||
sudo systemctl disable minetest
|
||||
|
||||
```
|
||||
|
||||
这使得系统启动时它不会一同启动;然后,相反地,启用 `_minetest.timer_`:
|
||||
```
|
||||
sudo systemctl enable minetest.timer
|
||||
|
||||
```
|
||||
|
||||
现在你就可以重启服务器了,当运行`sudo journalctl -u minetest.*`后,你就会看到 `_minetest.timer_` 单元执行后大约一分钟,`_minetest.service_` 单元开始运行。
|
||||
|
||||
![minetest timer][7]
|
||||
|
||||
图 1:minetest.timer 运行大约 1 分钟后 minetest.service 开始运行
|
||||
|
||||
[经许可使用][8]
|
||||
|
||||
### 时间的问题
|
||||
|
||||
`_minetest.timer_` 在 systemd 的日志里显示的启动时间为 09:08:33 而 `_minetest.service` 启动时间是 09:09:18,它们之间少于 1 分钟,关于这件事有几点需要说明一下:首先,请记住我们说过 `OnBootSec=` 指令是从引导完成后开始计算服务启动的时间。当 `_minetest.timer_` 的时间到来时,引导已经在几秒之前完成了。
|
||||
|
||||
另一件事情是 systemd 给自己设置了一个<ruby>误差幅度<rt>margin of error</rt></ruby>(默认是 1 分钟)来运行东西。这有助于在多个<ruby>资源密集型进程<rt>resource-intensive processes</rt></ruby>同时运行时分配负载:通过分配 1 分钟的时间,systemd 可以等待某些进程关闭。这也意味着 `_minetest.service_`会在引导完成后的 1~2 分钟之间启动。但精确的时间谁也不知道。
|
||||
|
||||
作为记录,你可以用 `AccuracySec=` 指令[修改误差幅度][9]。
|
||||
|
||||
你也可以检查系统上所有的定时器何时运行或是上次运行的时间:
|
||||
|
||||
```
|
||||
systemctl list-timers --all
|
||||
```
|
||||
|
||||
![check timer][11]
|
||||
|
||||
图 2:检查定时器何时运行或上次运行的时间
|
||||
|
||||
[经许可使用][8]
|
||||
|
||||
最后一件值得思考的事就是你应该用怎样的格式去表示一段时间。Systemd 在这方面非常灵活:`2 h`,`2 hours` 或 `2hr` 都可以用来表示 2 个小时。对于“秒”,你可以用 `seconds`,`second`,`sec` 和 `s`。“分”也是同样的方式:`minutes`,`minute`,`min` 和 `m`。你可以检查 `man systemd.time` 来查看 systemd 能够理解的所有时间单元。
|
||||
|
||||
### 下一次
|
||||
|
||||
下次你会看到如何使用日历中的日期和时间来定期运行服务,以及如何通过组合定时器与设备单元在插入某些硬件时运行服务。
|
||||
|
||||
回头见!
|
||||
|
||||
在 Linux 基金会和 edx 上通过免费课程 [“Introduction to Linux”][12] 学习更多关于 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||
[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://www.minetest.net/
|
||||
[6]:/files/images/minetest-timer-1png
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-1.png?itok=TG0xJvYM (minetest timer)
|
||||
[8]:/licenses/category/used-permission
|
||||
[9]:https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=
|
||||
[10]:/files/images/minetest-timer-2png
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-2.png?itok=pYxyVx8- (check timer)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,78 @@
|
||||
正确选择开源数据库的 5 个技巧
|
||||
======
|
||||
> 对关键应用的选择不容许丝毫错误。
|
||||
|
||||

|
||||
|
||||
你或许会遇到需要选择适合的开源数据库的情况。但这无论对于开源方面的老手或是新手,都是一项艰巨的任务。
|
||||
|
||||
在过去的几年中,采用开源技术的企业越来越多。面对这样的趋势,众多开源应用公司都纷纷承诺自己提供的解决方案能够各种问题、适应各种负载。但这些承诺不能轻信,在开源应用上的选择是重要而艰难的,尤其是数据库这种关键的应用。
|
||||
|
||||
凭借我在 [Percona][1] 和其它公司担任 IT 专家的经验,我很幸运能够指导其他人在开源技术的选择上做出正确的决策,因为需要考虑的重要因素太多了。希望通过这篇文章能够向大家分享这方面的一些技巧。
|
||||
|
||||
### 有一个明确的目标
|
||||
|
||||
这一点看似简单,但在和很多人聊过 MySQL、MongoDB、PostgreSQL 之后,我觉得这一点才是最重要的。
|
||||
|
||||
面对繁杂的开源数据库,更需要明确自己的目标。无论这个数据库是作为开发用的标准化数据库后端,抑或是用于替换遗留代码中的原有数据库,这都是一个明确的目标。
|
||||
|
||||
目标一旦确定,就可以集中精力与开源软件的提供方商讨更多细节了。
|
||||
|
||||
### 了解你的工作负载
|
||||
|
||||
尽管开源数据库技术的功能越来越丰富,但这些新加入的功能都不太具有普适性。譬如 MongoDB 新增了事务的支持、MySQL 新增了 JSON 存储的功能等等。目前开源数据库的普遍趋势是不断加入新的功能,但很多人的误区却在于没有选择最适合的工具来完成自己的工作——这样的人或许是一个自大的开发者,又或许是一个视野狭窄的主管——最终导致公司业务上的损失。最致命的是,在业务初期,使用了不适合的工具往往也可以顺利地完成任务,但随着业务的增长,很快就会到达瓶颈,尽管这个时候还可以替换更合适的工具,但成本就比较高了。
|
||||
|
||||
例如,如果你需要的是数据分析仓库,关系数据库可能不是一个适合的选择;如果你处理事务的应用要求严格的数据完整性和一致性,就不要考虑 NoSQL 了。
|
||||
|
||||
### 不要重新发明轮子
|
||||
|
||||
在过去的数十年,开源数据库技术迅速发展壮大。开源数据库从新生,到受到质疑,再到受到认可,现在已经成为很多企业生产环境的数据库。企业不再需要担心选择开源数据库技术会产生风险,因为开源数据库通常都有活跃的社区,可以为越来越多的初创公司、中型企业甚至 500 强公司提供开源数据库领域的支持和第三方工具。
|
||||
|
||||
Battery Ventures 是一家专注于技术的投资公司,最近推出了一个用于跟踪最受欢迎开源项目的 [BOSS 指数][2] 。它提供了对一些被广泛采用的开源项目和活跃的开源项目的详细情况。其中,数据库技术毫无悬念地占据了榜单的主导地位,在前十位之中占了一半。这个 BOSS 指数对于刚接触开源数据库领域的人来说,这是一个很好的切入点。当然,开源技术的提供者也会针对很多常见的典型问题给出对应的解决方案。
|
||||
|
||||
我认为,你想要做的事情很可能已经有人解决过了。即使这些先行者的解决方案不一定完全契合你的需求,但也可以从他们成功或失败案例中根据你自己的需求修改得出合适的解决方案。
|
||||
|
||||
如果你采用了一个最前沿的技术,这就是你探索的好机会了。如果你的工作负载刚好适合新的开源数据库技术,放胆去尝试吧。第一个吃螃蟹的人总是会得到意外的挑战和收获。
|
||||
|
||||
### 先从简单开始
|
||||
|
||||
你的数据库实际上需要达到多少个 [9][4] 的可用性?对许多公司来说,“实现高可用性”仅仅只是一个模糊的目标。当然,最常见的答案都会是“它是关键应用,我们无论多短的停机时间都是无法忍受的”。
|
||||
|
||||
数据库环境越复杂,管理的难度就越大,成本也会越高。理论上你总可以将数据库的可用性提得更高,但代价将会是大大增加的管理难度和性能下降。所以,先从简单开始,直到有需要时再逐步扩展。
|
||||
|
||||
例如,Booking.com 是一个有名的旅游预订网站。但少有人知的是,它使用 MySQL 作为数据库后端。 Booking.com 高级系统架构师 Nicolai Plum 曾经发表过一次[演讲][5],讲述了他们公司使用 MySQL 数据库的历程。其中一个重点就是,在初始阶段数据库可以被配置得很简单,然后逐渐变得复杂。对于早期的数据库需求,一个简单的主从架构就足够了,但随着工作负载和数据量的增加,数据库引入了负载均衡、多个读取副本,还使用 Hadoop 进行分析。尽管如此,早期的架构仍然是非常简单的。
|
||||
|
||||

|
||||
|
||||
### 有疑问,找专家
|
||||
|
||||
如果你仍然不确定数据库选择得是否合适,可以在论坛、网站或者与软件的提供者处商讨。研究各种开源数据库是否满足自己的需求是一件很有意义的事,因为总会发现你从不知道的技术。而开源社区就是分享这些信息的地方。
|
||||
|
||||
当你接触到开源软件和软件提供者时,有一件重要的事情需要注意。很多公司都有开放的核心业务模式,鼓励采用他们的数据库软件。你可以只接受他们的部分建议和指导,然后用你自己的能力去研究和探索替代方案。
|
||||
|
||||
### 总结
|
||||
|
||||
选择正确的开源数据库是一个重要的过程。很多时候,人们都会在真正理解需求之前就做出决定,这是本末倒置的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/tips-choosing-right-open-source-database
|
||||
|
||||
作者:[Barrett Chambers][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barrettc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.percona.com/
|
||||
[2]: https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/
|
||||
[3]: https://docs.aws.amazon.com/quickstart/latest/mongodb/welcome.html
|
||||
[4]: https://en.wikipedia.org/wiki/Five_nines
|
||||
[5]: https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design
|
||||
[6]: https://allthingsopen.org/talk/choosing-the-right-open-source-database/
|
||||
[7]: https://allthingsopen.org/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user