mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'upstream/master'
Merge the origin
This commit is contained in:
commit
3499f36ad2
2
.gitignore
vendored
2
.gitignore
vendored
@ -3,3 +3,5 @@ members.md
|
||||
*.html
|
||||
*.bak
|
||||
.DS_Store
|
||||
sources/*/.*
|
||||
translated/*/.*
|
||||
@ -234,7 +234,7 @@ clear
|
||||
输入下面的命令来挂载主分区以开始系统安装:
|
||||
|
||||
```
|
||||
mount /dev/sda1 / mnt
|
||||
mount /dev/sda1 /mnt
|
||||
```
|
||||
|
||||
[
|
||||
@ -282,7 +282,7 @@ arch-chroot /mnt /bin/bash
|
||||
现在来更改语言配置:
|
||||
|
||||
```
|
||||
nano /etc/local.gen
|
||||
nano /etc/locale.gen
|
||||
```
|
||||
|
||||
[
|
||||
@ -328,7 +328,7 @@ LANG=en_US.UTF-8
|
||||
输入下面的命令来同步时区:
|
||||
|
||||
```
|
||||
ls user/share/zoneinfo
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
下面你将看到整个世界的时区列表。
|
||||
@ -352,7 +352,7 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
使用下面的命令来设置标准时间:
|
||||
|
||||
```
|
||||
hwclock --systohc –utc
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
硬件时钟已同步。
|
||||
|
||||
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
@ -0,0 +1,125 @@
|
||||
DevOps 时代的 7 个领导力准则
|
||||
======
|
||||
|
||||
> DevOps 是一种持续性的改变和提高:那么也准备改变你所珍视的领导力准则吧。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps] 最终更多的是一种文化而非某种技术或者平台,那么请记住:它没有终点线。而是一种持续性的改变和提高——而且最高管理层并不及格。
|
||||
|
||||
然而,如果期望 DevOps 能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]。让我们考虑 7 个在 DevOps 时代更有效的 IT 领导的想法。
|
||||
|
||||
### 1、 向失败说“是的”
|
||||
|
||||
“失败”这个词在 IT 领域中一直包含着非常具体的意义,而且通常是糟糕的意思:服务器失败、备份失败、硬盘驱动器失败——你的印象就是如此。
|
||||
|
||||
然而一个健康的 DevOps 文化取决于如何重新定义失败——IT 领导者应该在他们的字典里重新定义这个单词,使这个词的含义和“机会”对等起来。
|
||||
|
||||
“在 DevOps 之前,我们曾有一种惩罚失败者的文化,”[Datical][3] 的首席技术官兼联合创始人罗伯特·里夫斯说,“我们学到的仅仅是去避免错误。在 IT 领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
|
||||
|
||||
那是一个旧时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞实际上是失败。
|
||||
|
||||
“那些缓慢的发布周期并逃避云的公司被恐惧所麻痹——他们将会走向失败,”里夫斯说道。“IT 领导者必须拥抱失败,并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从别人的错误中学习。开放和[安全心理][4]的文化促进学习和提高。”
|
||||
|
||||
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义][5]]**
|
||||
|
||||
### 2、 在管理层渗透开发运营的理念
|
||||
|
||||
尽管 DevOps 文化可以在各个方向有机的发展,那些正在从单体、孤立的 IT 实践中转变出来的公司,以及可能遭遇逆风的公司——需要高管层的全面支持。如果缺少了它,你就会传达模糊的信息,而且可能会鼓励那些宁愿被推着走的人,但这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到高管层完全投入进去并且知道改变已经实际发生了。
|
||||
|
||||
“高层管理必须全力支持 DevOps,才能成功的实现收益”,来自 [Rainforest QA][7] 的首席信息官德里克·蔡说道。
|
||||
|
||||
成为一个 DevOps 商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
|
||||
|
||||
“没有高层管理的统一赞助支持,DevOps 的实施将很难成功,”德里克说道,“因此,在转变到 DevOps 之前在高层中保持一致是很重要的。”
|
||||
|
||||
### 3、 不要只是声明 “DevOps”——要明确它
|
||||
|
||||
即使 IT 公司也已经开始张开双臂拥抱 DevOps,也可能不是每个人都在同一个步调上。
|
||||
|
||||
**[参考我们的相关文章,[3 阐明了DevOps和首席技术官们必须在同一进程上][8]]**
|
||||
|
||||
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
|
||||
|
||||
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道,“对高管层和副总裁层来说,要执行明确的 DevOps 的目标,清楚地声明期望的成果,充分理解带来的成果将如何使公司的商业受益,并且能够衡量和报告成功的过程。”
|
||||
|
||||
事实上,在基线定义和远景之外,DevOps 要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT 领导者必须将它设置为优先。
|
||||
|
||||
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道,“领导者们需要清楚的将这个过程向公司的其他人阐述清楚,告诉他们他们作为这个过程的一份子能够期待的结果。”
|
||||
|
||||
### 4、 DevOps 对于商业和技术同样重要
|
||||
|
||||
IT 领导者们成功的将 DevOps 商店的这种文化和实践当做一项商业策略,以及构建和运营软件的方法。DevOps 是将 IT 从支持部门转向战略部门的推动力。
|
||||
|
||||
IT 领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且 DevOps 的文化能够通过自动化和强大的协作加速这些成果,来自 [CYBRIC][9] 的首席技术官和联合创始人迈克·凯尔说道。
|
||||
|
||||
事实上,这是一个强烈的趋势,贯穿这些新“规则”,在 DevOps 时代走在前沿。
|
||||
|
||||
“促进创新并且鼓励团队成员去聪明的冒险是 DevOps 文化的一个关键部分,IT 领导者们需要在一个持续的基础上清楚的和他们交流”,凯尔说道。
|
||||
|
||||
“一个高效的 IT 领导者需要比以往任何时候都要积极的参与到业务中去,”来自 [West Monroe Partners][10] 的性能服务部门的主任埃文说道,“每年或季度回顾的日子一去不复返了——[你需要欢迎每两周一次的挤压整理][11],你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
|
||||
|
||||
### 5、 改变妨碍 DevOps 目标的任何事情
|
||||
|
||||
虽然 DevOps 的老兵们普遍认为 DevOps 更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个 DevOps 商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用了 20 年的引擎,每次转动钥匙都会冒烟。
|
||||
|
||||
展览 A: [自动化][12]。这是 DevOps 成功的重要并行策略。
|
||||
|
||||
“IT 领导者需要重点强调自动化,”卡伦德说,“这将是 DevOps 的前期投资,但是如果没有它,DevOps 将会很容易被低效吞噬,而且将会无法完整交付。”
|
||||
|
||||
自动化是基石,但改变不止于此。
|
||||
|
||||
“领导者们需要推动自动化、监控和持续交付过程。这意着对现有的实践、过程、团队架构以及规则的很多改变,” 德里克说。“领导者们需要改变一切会阻碍团队去实现完全自动化的因素。”
|
||||
|
||||
### 6、 重新思考团队架构和能力指标
|
||||
|
||||
当你想改变时……如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
|
||||
|
||||
“在这个 DevOps 的新时代文化中,IT 执行者需要采取一个全新的方法来组织架构。”凯尔说,“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织、敏捷管理。”
|
||||
|
||||
凯尔告诉我们在 DevOps 时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
|
||||
|
||||
“根据业务成果和总体的积极影响来衡量主动性,”凯尔建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
|
||||
|
||||
注意很容易收集的到测量值不是 DevOps 真正的指标,[Red Hat] 的技术专家戈登·哈夫写到,“DevOps 应该把指标以某种形式和商业成果绑定在一起”,他指出,“你可能并不真正在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
|
||||
|
||||
### 7、 丢弃传统的智慧
|
||||
|
||||
如果 DevOps 时代要求关于 IT 领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
|
||||
|
||||
“说实话,是全部”,凯尔说道,“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到 DevOps 文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
|
||||
|
||||
事实上,IT 领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
|
||||
|
||||
West Monroe Partners 的卡伦德分享了一个阻碍 DevOps 的领导力的例子:未能拥抱 IT 混合模型和现代的基础架构比如说容器和微服务。
|
||||
|
||||
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
|
||||
|
||||
**领导者们,想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,30 +1,32 @@
|
||||
如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习
|
||||
============================================================
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
> 探索如何将 Android Things 与 Tensorflow 集成起来,以及如何应用机器学习到物联网系统上。学习如何在装有 Android Things 的树莓派上使用 Tensorflow 进行图片分类。
|
||||
|
||||
这个项目探索了如何将机器学习应用到物联网上。具体来说,物联网平台我们将使用 **Android Things**,而机器学习引擎我们将使用 **Google TensorFlow**。
|
||||
|
||||

|
||||
现如今,Android Things 处于名为 Android Things 1.0 的稳定版本,已经可以用在生产系统中了。如你可能已经知道的,树莓派是一个可以支持 Android Things 1.0 做开发和原型设计的平台。本教程将使用 Android Things 1.0 和树莓派,当然,你可以无需修改代码就能换到其它所支持的平台上。这个教程是关于如何将机器学习应用到物联网的,这个物联网平台就是 Android Things Raspberry Pi。
|
||||
|
||||
现如今,机器学习是物联网上使用的最热门的主题之一。给机器学习的最简单的定义,可能就是 [维基百科上的定义][13]:机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
|
||||
物联网上的机器学习是最热门的话题之一。要给机器学习一个最简单的定义,可能就是 [维基百科上的定义][13]:
|
||||
|
||||
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中一个前景看好的领域就是如何在物联网上应用机器学习,构建专业的系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。
|
||||
> 机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
|
||||
|
||||
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个感兴趣的领域,它们是:
|
||||
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中前景最看好的领域之一就是如何在物联网上应用机器学习,构建专家系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。在深入了解 Android Things 的细节之前,你应该先将其安装在你的设备上。如果你是第一次使用 Android Things,你可以阅读一下这篇[如何在你的设备上安装 Android Things][14] 的教程。
|
||||
|
||||
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个有趣的领域,它们是:
|
||||
|
||||
* 在工业物联网(IIoT)中的预见性维护
|
||||
|
||||
* 消费物联网中,机器学习可以让设备更智能,它通过调整使设备更适应我们的习惯
|
||||
|
||||
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
|
||||
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)并控制其道路方向的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
|
||||
|
||||
这个机器学习和物联网项目包含如下的主题:
|
||||
|
||||
* 如何使用 Docker 配置 TensorFlow 环境
|
||||
|
||||
* 如何训练 TensorFlow 系统
|
||||
|
||||
* 如何使用 Android Things 去集成 TensorFlow
|
||||
|
||||
* 如何使用 TensorFlow 的成果去控制无人驾驶汽车
|
||||
|
||||
这个项目起源于 [Android Things TensorFlow 图像分类器][6]。
|
||||
@ -33,59 +35,55 @@
|
||||
|
||||
### 如何使用 Tensorflow 图像识别
|
||||
|
||||
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要快速找到并且准备去使用一些东西,因此,我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
|
||||
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要找到一些快速而能用的东西,以便我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
|
||||
|
||||
1. 克隆 TensorFlow 仓库:
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
1、 克隆 TensorFlow 仓库:
|
||||
|
||||
2. 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
|
||||
3. 运行 Docker:
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
2、 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
|
||||
|
||||
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以在使用项目期间挂载一些目录。
|
||||
3、 运行 Docker:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
|
||||
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以挂载一些在使用项目期间使用的目录。
|
||||
|
||||
### 如何训练 TensorFlow 去识别图像
|
||||
|
||||
在 Android Things 系统能够识别图像之前,我们需要去训练 TensorFlow 引擎,以使它能够构建它的模型。为此,我们需要去收集一些图像。正如前面所言,我们需要使用箭头来控制 Android Things 无人驾驶汽车,因此,我们至少要收集四种类型的箭头:
|
||||
|
||||
* 向上的箭头
|
||||
|
||||
* 向下的箭头
|
||||
|
||||
* 向左的箭头
|
||||
|
||||
* 向右的箭头
|
||||
|
||||
为训练这个系统,需要使用这四类不同的图像去创建一个“知识库”。在 `/tf-data` 目录下创建一个名为 `images` 的目录,然后在它下面创建如下名字的四个子目录:
|
||||
|
||||
* up-arrow
|
||||
|
||||
* down-arrow
|
||||
|
||||
* left-arrow
|
||||
|
||||
* right-arrow
|
||||
* `up-arrow`
|
||||
* `down-arrow`
|
||||
* `left-arrow`
|
||||
* `right-arrow`
|
||||
|
||||
现在,我们去找图片。我使用的是 Google 图片搜索,你也可以使用其它的方法。为了简化图片下载过程,你可以安装一个 Chrome 下载插件,这样你只需要点击就可以下载选定的图片。别忘了多下载一些图片,这样训练效果更好,当然,这样创建模型的时间也会相应增加。
|
||||
|
||||
**扩展阅读**
|
||||
[如何使用 API 去集成 Android Things][2]
|
||||
[如何与 Firebase 一起使用 Android Things][3]
|
||||
|
||||
- [如何使用 API 去集成 Android Things][2]
|
||||
- [如何与 Firebase 一起使用 Android Things][3]
|
||||
|
||||
打开浏览器,开始去查找四种箭头的图片:
|
||||
|
||||

|
||||
[Save][7]
|
||||
|
||||
每个类别我下载了 80 张图片。不用管图片文件的扩展名。
|
||||
|
||||
@ -102,9 +100,8 @@ python /tensorflow/examples/image_retraining/retrain.py \
|
||||
|
||||
这个过程你需要耐心等待,它需要花费很长时间。结束之后,你将在 `/tf-data` 目录下发现如下的两个文件:
|
||||
|
||||
1. retrained_graph.pb
|
||||
|
||||
2. retrained_labels.txt
|
||||
1. `retrained_graph.pb`
|
||||
2. `retrained_labels.txt`
|
||||
|
||||
第一个文件包含了 TensorFlow 训练过程产生的结果模型,而第二个文件包含了我们的四个图片类相关的标签。
|
||||
|
||||
@ -139,7 +136,6 @@ python /tensorflow/python/tools/optimize_for_inference.py \
|
||||
TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将 Android Things 与 TensorFlow 集成到一起。为此,我们将这个任务分为两步来完成:
|
||||
|
||||
1. 硬件部分,我们将把电机和其它部件连接到 Android Things 开发板上
|
||||
|
||||
2. 实现这个应用程序
|
||||
|
||||
### Android Things 示意图
|
||||
@ -147,13 +143,9 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
在深入到如何连接外围部件之前,先列出在这个 Android Things 项目中使用到的组件清单:
|
||||
|
||||
1. Android Things 开发板(树莓派 3)
|
||||
|
||||
2. 树莓派摄像头
|
||||
|
||||
3. 一个 LED 灯
|
||||
|
||||
4. LN298N 双 H 桥电机驱动模块(连接控制电机)
|
||||
|
||||
5. 一个带两个轮子的无人驾驶汽车底盘
|
||||
|
||||
我不再重复 [如何使用 Android Things 去控制电机][9] 了,因为在以前的文章中已经讲过了。
|
||||
@ -161,12 +153,10 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
下面是示意图:
|
||||
|
||||

|
||||
[Save][10]
|
||||
|
||||
上图中没有展示摄像头。最终成果如下图:
|
||||
|
||||

|
||||
[Save][11]
|
||||
|
||||
### 使用 TensorFlow 实现 Android Things 应用程序
|
||||
|
||||
@ -175,11 +165,8 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
这个 Android Things 应用程序与原始的应用程序是不一样的,因为:
|
||||
|
||||
1. 它不使用按钮去开启摄像头图像捕获
|
||||
|
||||
2. 它使用了不同的模型
|
||||
|
||||
3. 它使用一个闪烁的 LED 灯来提示,摄像头将在 LED 停止闪烁后拍照
|
||||
|
||||
4. 当 TensorFlow 检测到图像时(箭头)它将控制电机。此外,在第 3 步的循环开始之前,它将打开电机 5 秒钟。
|
||||
|
||||
为了让 LED 闪烁,使用如下的代码:
|
||||
@ -264,7 +251,7 @@ public void onImageAvailable(ImageReader reader) {
|
||||
|
||||
在这个方法中,当 TensorFlow 返回捕获的图片匹配到的可能的标签之后,应用程序将比较这个结果与可能的方向,并因此来控制电机。
|
||||
|
||||
最后,将去使用前面创建的模型了。拷贝 _assets_ 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
|
||||
最后,将去使用前面创建的模型了。拷贝 `assets` 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
|
||||
|
||||
打开 `Helper.java` 并修改如下的行:
|
||||
|
||||
@ -289,9 +276,9 @@ public static final String OUTPUT_NAME = "final_result";
|
||||
|
||||
via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html
|
||||
|
||||
作者:[Francesco Azzola ][a]
|
||||
作者:[Francesco Azzola][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -309,3 +296,4 @@ via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-usi
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Integrating%20Android%20Things%20with%20TensorFlow
|
||||
[12]:https://github.com/androidthings/sample-tensorflow-imageclassifier
|
||||
[13]:https://en.wikipedia.org/wiki/Machine_learning
|
||||
[14]:https://www.survivingwithandroid.com/2017/01/android-things-android-internet-of-things.html
|
||||
55
published/20180627 CIP- Keeping the Lights On with Linux.md
Normal file
55
published/20180627 CIP- Keeping the Lights On with Linux.md
Normal file
@ -0,0 +1,55 @@
|
||||
CIP:延续 Linux 之光
|
||||
======
|
||||
|
||||
> CIP 的目标是创建一个基本的系统,使用开源软件来为我们现代社会的基础设施提供动力。
|
||||
|
||||

|
||||
|
||||
|
||||
现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
|
||||
|
||||
并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,<ruby>[民用基础设施平台][1]<rt>Civil Infrastructure Platform</rt></ruby>(CIP)最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
|
||||
|
||||
担任 CIP 的技术指导委员会主席的 Yoshitake Kobayashi 说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都面临同样的问题,即能够长时间地使用 Linux。”
|
||||
|
||||
CIP 的架构是创建一个非常基础的系统,以在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
|
||||
|
||||
### 合作
|
||||
|
||||
由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP 聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings 以他在 Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
|
||||
|
||||
在新的合作下,CIP 将使用 Debian LTS 版本作为构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的互操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
|
||||
|
||||
Debian 项目负责人 Chris Lamb 表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
|
||||
|
||||
### 安全性
|
||||
|
||||
Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),但也存在其他风险。
|
||||
|
||||
仅仅是系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
|
||||
|
||||
因此,至关重要的是保持运行在这些控制器上的所有软件是最新的并且完全修补的。为了确保安全性,CIP 还向后移植了<ruby>内核自我保护<rt>Kernel Self Protection</rt></ruby>(KSP)项目的许多组件。CIP 还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
|
||||
|
||||
### 展望未来
|
||||
|
||||
随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP 最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
|
||||
|
||||
Cybertrust 与其他行业领军者合作,如西门子、东芝、Codethink、日立、Moxa、Plat'Home 和瑞萨,致力于为未来数十年打造一个可靠、安全的基于 Linux 的嵌入式软件平台。
|
||||
|
||||
这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
|
||||
|
||||
想要了解更多信息,请访问 [民用基础设施官网][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -1,49 +1,45 @@
|
||||
使用 Ftrace 跟踪内核
|
||||
使用 ftrace 跟踪内核
|
||||
============================================================
|
||||
|
||||
标签: [ftrace][8],[kernel][9],[kernel profiling][10],[kernel tracing][11],[linux][12],[tracepoints][13]
|
||||
|
||||

|
||||
|
||||
在内核级别上分析事件有很多的工具:[SystemTap][14],[ktap][15],[Sysdig][16],[LTTNG][17]等等,并且你也可以在网络上找到关于这些工具的大量介绍文章和资料。
|
||||
在内核层面上分析事件有很多的工具:[SystemTap][14]、[ktap][15]、[Sysdig][16]、[LTTNG][17] 等等,你也可以在网络上找到关于这些工具的大量介绍文章和资料。
|
||||
|
||||
而对于使用 Linux 原生机制去跟踪系统事件以及检索/分析故障信息的方面的资料却很少找的到。这就是 [ftrace][18],它是添加到内核中的第一款跟踪工具,今天我们来看一下它都能做什么,让我们从它的一些重要术语开始吧。
|
||||
|
||||
### 内核跟踪和分析
|
||||
|
||||
内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 一个事件的总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
|
||||
<ruby>内核分析<rt>Kernel profiling</rt></ruby>可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个<ruby>概述<rt>profile</rt></ruby> — 这是一个事件总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
|
||||
|
||||
瓶颈经常发生在无法通过分析来识别的情况下。去推断出为什么会发生事件,去保存发生事件时的相关上下文,这就需要去跟踪。
|
||||
瓶颈经常发生在无法通过分析来识别的情况下。要推断出为什么会发生事件,就必须保存发生事件时的相关上下文,这就需要去<ruby>跟踪<rt>tracing</rt></ruby>。
|
||||
|
||||
跟踪可以理解为在一个正常工作的系统上活动的信息收集进程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种注册的系统事件。
|
||||
跟踪可以理解为在一个正常工作的系统上活动的信息收集过程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种系统事件。
|
||||
|
||||
跟踪程序能够同时跟踪应用级和操作系统级的事件。它们收集的信息能够用于诊断多种系统问题。
|
||||
|
||||
有时候会将跟踪与日志比较。它们两者确时很相似,但是也有不同的地方。
|
||||
|
||||
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登陆系统、应用程序错误、数据库事务等等。
|
||||
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登录系统、应用程序错误、数据库事务等等。
|
||||
|
||||
就像日志一样,跟踪数据可以被原样读取,但是用特定的应用程序提取的信息更有用。所有的跟踪程序都能这样做。
|
||||
|
||||
在内核跟踪和分析方面,Linux 内核有三个主要的机制:
|
||||
|
||||
* 跟踪点 —— 一种基于静态测试代码的工作机制
|
||||
|
||||
* 探针 —— 一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回。
|
||||
|
||||
* perf_events —— 一个访问 PMU(性能监视单元)的接口
|
||||
* <ruby>跟踪点<rt>tracepoint</rt></ruby>:一种基于静态测试代码的工作机制
|
||||
* <ruby>探针<rt>kprobe</rt></ruby>:一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回
|
||||
* perf_events —— 一个访问 PMU(<ruby>性能监视单元<rt>Performance Monitoring Unit</rt></ruby>)的接口
|
||||
|
||||
我并不想在这里写关于这些机制方面的内容,任何对它们感兴趣的人可以去访问 [Brendan Gregg 的博客][19]。
|
||||
|
||||
使用 ftrace,我们可以与这些机制进行交互,并可以从用户空间直接得到调试信息。下面我们将讨论这方面的详细内容。示例中的所有命令行都是在内核版本为 3.13.0-24 的 Ubuntu 14.04 中运行的。
|
||||
|
||||
### Ftrace:常用信息
|
||||
### ftrace:常用信息
|
||||
|
||||
Ftrace 是函数 Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
|
||||
ftrace 是 Function Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
|
||||
|
||||
Ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 `Ring` 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
|
||||
ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 Ring 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
|
||||
|
||||
Ftrace 工作在 debugfs 文件系统上,这是在大多数现代 Linux 分发版中默认挂载的文件系统。为开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
|
||||
ftrace 工作在 debugfs 文件系统上,在大多数现代 Linux 发行版中都默认挂载了。要开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
|
||||
|
||||
```
|
||||
# cd /sys/kernel/debug/tracing
|
||||
@ -70,16 +66,13 @@ kprobe_profile stack_max_size uprobe_profile
|
||||
我不想去描述这些文件和子目录;它们的描述在 [官方文档][20] 中已经写的很详细了。我只想去详细介绍与我们这篇文章相关的这几个文件:
|
||||
|
||||
* available_tracers —— 可用的跟踪程序
|
||||
|
||||
* current_tracer —— 正在运行的跟踪程序
|
||||
|
||||
* tracing_on —— 负责启用或禁用数据写入到 `Ring` 缓冲区的系统文件(如果启用它,在文件中添加数字 1,禁用它,添加数字 0)
|
||||
|
||||
* tracing_on —— 负责启用或禁用数据写入到 Ring 缓冲区的系统文件(如果启用它,数字 1 被添加到文件中,禁用它,数字 0 被添加)
|
||||
* trace —— 以人类友好格式保存跟踪数据的文件
|
||||
|
||||
### 可用的跟踪程序
|
||||
|
||||
我们可以使用如下的命令去查看可用的跟踪程序的一个列表
|
||||
我们可以使用如下的命令去查看可用的跟踪程序的一个列表:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing#: cat available_tracers
|
||||
@ -89,18 +82,14 @@ blk mmiotrace function_graph wakeup_rt wakeup function nop
|
||||
我们来快速浏览一下每个跟踪程序的特性:
|
||||
|
||||
* function —— 一个无需参数的函数调用跟踪程序
|
||||
|
||||
* function_graph —— 一个使用子调用的函数调用跟踪程序
|
||||
|
||||
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 的用途)
|
||||
|
||||
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 使用的)
|
||||
* mmiotrace —— 一个内存映射 I/O 操作跟踪程序
|
||||
|
||||
* nop —— 简化的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
|
||||
* nop —— 最简单的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
|
||||
|
||||
### 函数跟踪程序
|
||||
|
||||
在开始介绍函数跟踪程序 ftrace 之前,我们先看一下测试脚本:
|
||||
在开始介绍函数跟踪程序 ftrace 之前,我们先看一个测试脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
@ -117,7 +106,7 @@ less ${dir}/trace
|
||||
|
||||
这个脚本是非常简单的,但是还有几个需要注意的地方。命令 `sysctl ftrace.enabled=1` 启用了函数跟踪程序。然后我们通过写它的名字到 `current_tracer` 文件来启用 `current tracer`。
|
||||
|
||||
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 `Ring` 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
|
||||
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 Ring 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo 1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
|
||||
|
||||
我们为什么这样做呢?在两个 `echo` 命令之间,我们看到了命令 `sleep 1`。我们启用了缓冲区,运行了这个命令,然后禁用它。这将使跟踪程序采集了这个命令运行期间发生的所有系统调用的信息。
|
||||
|
||||
@ -156,21 +145,18 @@ less ${dir}/trace
|
||||
trace.sh-1295 [000] d... 90.502879: __acct_update_integrals <-acct_account_cputime
|
||||
```
|
||||
|
||||
这个输出以缓冲区中的信息条目数量和写入的条目数量开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
|
||||
这个输出以“缓冲区中的信息条目数量”和“写入的全部条目数量”开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
|
||||
|
||||
在这里有一个包含下列信息的函数列表:
|
||||
|
||||
* 进程标识符(PID)
|
||||
|
||||
* 运行这个进程的 CPU(CPU#)
|
||||
|
||||
* 进程开始时间(TIMESTAMP)
|
||||
|
||||
* 被跟踪函数的名字以及调用它的父级函数;例如,在我们输出的第一行,`rb_simple_write` 调用了 `mutex-unlock` 函数。
|
||||
|
||||
### Function_graph 跟踪程序
|
||||
### function_graph 跟踪程序
|
||||
|
||||
`function_graph` 跟踪程序的工作和函数一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
|
||||
function_graph 跟踪程序的工作和函数跟踪程序一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
|
||||
|
||||
我们来编辑一下最后一个示例的脚本:
|
||||
|
||||
@ -215,11 +201,11 @@ less ${dir}/trace
|
||||
0) ! 208.154 us | } /* ip_local_deliver_finish */
|
||||
```
|
||||
|
||||
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(+)意思是这个函数花费的时间超过 10 毫秒;而感叹号(!)意思是这个函数花费的时间超过了 100 毫秒。
|
||||
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(`+`)意思是这个函数花费的时间超过 10 毫秒;而感叹号(`!`)意思是这个函数花费的时间超过了 100 毫秒。
|
||||
|
||||
在 `FUNCTION_CALLS` 下面,我们可以看到每个函数调用的信息。
|
||||
|
||||
和 C 语言一样使用了花括号({)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(;)标记。
|
||||
和 C 语言一样使用了花括号(`{`)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(`;`)标记。
|
||||
|
||||
### 函数过滤器
|
||||
|
||||
@ -249,13 +235,13 @@ ftrace 还有很多过滤选项。对于它们更详细的介绍,你可以去
|
||||
|
||||
### 跟踪事件
|
||||
|
||||
我们在上面提到到跟踪点机制。跟踪点是插入的由系统事件触发的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
|
||||
我们在上面提到到跟踪点机制。跟踪点是插入的触发系统事件的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
|
||||
|
||||
静态跟踪点不会对系统有任何影响;它们只是增加几个字节用于调用测试函数以及在一个独立的节上增加一个数据结构。
|
||||
静态跟踪点不会对系统有任何影响;它们只是在测试的函数末尾增加几个字节的函数调用以及在一个独立的节上增加一个数据结构。
|
||||
|
||||
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 `Ring` 缓冲区。
|
||||
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 Ring 缓冲区。
|
||||
|
||||
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(它在 [这里][22]):
|
||||
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(取自 [这里][22]):
|
||||
|
||||
```
|
||||
{
|
||||
@ -294,7 +280,7 @@ fs kvm power scsi vfs
|
||||
ftrace kvmmmu printk signal vmscan
|
||||
```
|
||||
|
||||
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 `Ring` 缓冲区写入:
|
||||
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 Ring 缓冲区写入:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# cat tracing_on
|
||||
@ -306,25 +292,25 @@ root@andrei:/sys/kernel/debug/tracing# cat tracing_on
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 1 > tracing_on
|
||||
```
|
||||
|
||||
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。为了跟踪,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
|
||||
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。对于我们的跟踪程序,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo nop > current_tracer
|
||||
```
|
||||
|
||||
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出多个系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
|
||||
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出各种系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 1 > events/syscalls/sys_enter_chroot/enable
|
||||
```
|
||||
|
||||
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息出现在输出中:
|
||||
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [之前这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息不会出现在输出中:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 0 > tracing_on
|
||||
```
|
||||
|
||||
然后,我们去查看 `Ring` 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
|
||||
然后,我们去查看 Ring 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# сat trace
|
||||
@ -343,15 +329,10 @@ root@andrei:/sys/kernel/debug/tracing# сat trace
|
||||
在这篇文篇中,我们做了一个 ftrace 的功能概述。我们非常感谢你的任何意见或者补充。如果你想深入研究这个主题,我们为你推荐下列的资源:
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/tracepoints.txt][1] — 一个跟踪点机制的详细描述
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/events.txt][2] — 在 Linux 中跟踪系统事件的指南
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/ftrace.txt][3] — ftrace 的官方文档
|
||||
|
||||
* [https://lttng.org/files/thesis/desnoyers-dissertation-2009-12-v27.pdf][4] — Mathieu Desnoyers(作者是跟踪点和 LTTNG 的创建者)的关于内核跟踪和分析的学术论文。
|
||||
|
||||
* [https://lwn.net/Articles/370423/][5] — Steven Rostedt 的关于 ftrace 功能的文章
|
||||
|
||||
* [http://alex.dzyoba.com/linux/profiling-ftrace.html][6] — 用 ftrace 分析实际案例的一个概述
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -360,7 +341,7 @@ via:https://blog.selectel.com/kernel-tracing-ftrace/
|
||||
|
||||
作者:[Andrej Yemelianov][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
|
||||
|
||||
* 安装、删除、更新包
|
||||
* 更新和升级软件源
|
||||
* 安装主线内核
|
||||
* 删除旧的和不再使用的内核
|
||||
* 系统整体更新
|
||||
* 将系统升级到下一个可用的版本
|
||||
* 将系统升级到最新的开发版本
|
||||
* 清理系统垃圾文件
|
||||
* 在不输入密码的情况下启用或者禁用 `sudo` 权限
|
||||
* 当你在终端输入密码时使 `sudo` 密码可见
|
||||
* 启用或禁用系统休眠
|
||||
* 启用或禁用防火墙
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
|
||||
* 显示或者隐藏启动项
|
||||
* 启用或禁用登录音效
|
||||
* 配置双启动
|
||||
* 启用或禁用锁屏
|
||||
* 智能系统更新
|
||||
* 使用脚本管理器更新/一次性执行脚本
|
||||
* 从 `git` 执行常规用户安装脚本
|
||||
* 检查系统完整性和缺失的 GPG 密钥
|
||||
* 修复网络
|
||||
* 修复已破损的包
|
||||
* 还有更多功能在开发中
|
||||
|
||||
**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
|
||||
|
||||
### 安装 Ubunsys
|
||||
|
||||
Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
|
||||
|
||||
逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
sudo apt-get update
|
||||
sudo apt-get install ubunsys
|
||||
```
|
||||
|
||||
如果 PPA 无法使用,你可以在[发布页面][1]根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
|
||||
|
||||
### 用途
|
||||
|
||||
一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。
|
||||
|
||||
![][3]
|
||||
|
||||
你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
|
||||
|
||||
**Packages**
|
||||
|
||||
这一部分允许你安装、删除和更新包。
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
在这一部分,我们可以对系统进行多种调整,例如:
|
||||
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
|
||||
* 配置双启动;
|
||||
* 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
|
||||
* 在终端中输入密码时可见(禁用星号)。
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
|
||||
|
||||
**Normal user** 这一标签下的选项可以:
|
||||
|
||||
* 更新、升级包和软件源
|
||||
* 清理系统
|
||||
* 执行常规用户安装脚本
|
||||
|
||||
**Advanced user** 这一标签下的选项可以:
|
||||
|
||||
* 清理旧的/无用的内核
|
||||
* 安装主线内核
|
||||
* 智能包更新
|
||||
* 升级系统
|
||||
|
||||
**Developer** 这一部分可以将系统升级到最新的开发版本。
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。
|
||||
|
||||
![][7]
|
||||
|
||||
正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
### 参考资源
|
||||
|
||||
- [Ubunsys GitHub Repository][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
[8]:https://github.com/adgellida/ubunsys
|
||||
@ -0,0 +1,183 @@
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
======
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理][1]) ,也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
|
||||
|
||||
有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
|
||||
列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
|
||||
|
||||
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
|
||||
|
||||
\<forkfork> 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费组<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性<ruby>向后移植<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
|
||||
|
||||
### 教程:欢迎使用 Redis 的 streams
|
||||
|
||||
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到<ruby>从服务器<rt>slave server</rt></ruby>和 <ruby>AOF<rt>append-only file</rt></ruby> 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
|
||||
|
||||
正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
|
||||
|
||||
```
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;<ruby>流播<rt>streaming</rt></ruby>,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
|
||||
|
||||
### 使用 XREAD 处理流播:阻塞新的数据
|
||||
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的<ruby>汇聚池<rt>pooling</rt></ruby>。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
|
||||
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
|
||||
|
||||
这里有一个典型的 `XREAD` 调用示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
```
|
||||
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
|
||||
|
||||
如果我从另一个客户端发送这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
```
|
||||
|
||||
在 `XREAD` 侧会出现什么情况呢?
|
||||
|
||||
```
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
|
||||
### 流封顶
|
||||
|
||||
目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
```
|
||||
|
||||
这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
### 消费组(开发中)
|
||||
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,能够指定一个 `RETRY <milliseconds>` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
|
||||
### 内存使用和节省加载时间
|
||||
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
|
||||
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
### 关于最终发布时间的结论
|
||||
|
||||
Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
|
||||
|
||||
如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
---
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://antirez.com/
|
||||
[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
|
||||
@ -1,40 +1,41 @@
|
||||
通过构建一个区块链来学习区块链技术
|
||||
想学习区块链?那就用 Python 构建一个
|
||||
======
|
||||
|
||||
> 了解区块链是如何工作的最快的方法是构建一个。
|
||||
|
||||

|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
|
||||
|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
|
||||
|
||||
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
|
||||
|
||||
我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
|
||||
### 开始之前 …
|
||||
|
||||
记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
记住,区块链是一个 _不可更改的、有序的_ 记录(被称为区块)的链。它们可以包括<ruby>交易<rt>transaction</rt></ruby>、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
|
||||
如果你不知道哈希是什么,[这里有解释][1]。
|
||||
|
||||
**_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
**_本指南的目标读者是谁?_** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
|
||||
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
|
||||
|
||||
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 1 步:构建一个区块链
|
||||
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
|
||||
#### 描述一个区块链
|
||||
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -58,15 +59,16 @@ class Blockchain(object):
|
||||
@property
|
||||
def last_block(self):
|
||||
# Returns the last Block in the chain
|
||||
pass
|
||||
pass
|
||||
```
|
||||
|
||||
*我们的 Blockchain 类的原型*
|
||||
|
||||
我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
|
||||
我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
|
||||
|
||||
#### 一个区块是什么样子的?
|
||||
#### 区块是什么样子的?
|
||||
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
|
||||
单个区块的示例应该是下面的样子:
|
||||
|
||||
@ -86,13 +88,15 @@ block = {
|
||||
}
|
||||
```
|
||||
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
|
||||
*我们的区块链中的块示例*
|
||||
|
||||
这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
|
||||
|
||||
#### 添加事务到一个区块
|
||||
*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
|
||||
|
||||
我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
#### 添加交易到一个区块
|
||||
|
||||
我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -113,14 +117,14 @@ class Blockchain(object):
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
|
||||
在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
|
||||
|
||||
#### 创建新区块
|
||||
|
||||
当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
|
||||
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
|
||||
|
||||
@ -190,18 +194,18 @@ class Blockchain(object):
|
||||
|
||||
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
|
||||
block_string = json.dumps(block, sort_keys=True).encode()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
|
||||
|
||||
#### 理解工作量证明
|
||||
|
||||
一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
<ruby>工作量证明<rt>Proof of Work</rt></ruby>(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
|
||||
我们来看一个非常简单的示例来帮助你了解它。
|
||||
|
||||
我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
|
||||
我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
@ -215,19 +219,21 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
|
||||
在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
在比特币中,工作量证明算法被称之为 [Hashcash][10]。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
|
||||
|
||||
网络上的任何人都可以很容易地去核验它的答案。
|
||||
|
||||
#### 实现基本的 PoW
|
||||
|
||||
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
|
||||
|
||||
> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
|
||||
> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -266,25 +272,21 @@ class Blockchain(object):
|
||||
|
||||
guess = f'{last_proof}{proof}'.encode()
|
||||
guess_hash = hashlib.sha256(guess).hexdigest()
|
||||
return guess_hash[:4] == "0000"
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
|
||||
|
||||
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 2 步:以 API 方式去访问我们的区块链
|
||||
|
||||
我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
|
||||
我们将创建三个方法:
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新事务
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新交易
|
||||
* `/mine` 告诉我们的服务器去挖矿一个新区块
|
||||
|
||||
* `/chain` 返回完整的区块链
|
||||
|
||||
#### 配置 Flask
|
||||
@ -332,33 +334,33 @@ def full_chain():
|
||||
return jsonify(response), 200
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
对上面的代码,我们做添加一些详细的解释:
|
||||
|
||||
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
|
||||
|
||||
* Line 18:为我们的节点创建一个随机的名字。
|
||||
|
||||
* Line 21:实例化我们的区块链类。
|
||||
|
||||
* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
|
||||
|
||||
* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
|
||||
* Line 32–38:创建 /chain 端点,它返回全部区块链。
|
||||
|
||||
* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
|
||||
* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
|
||||
* Line 40–41:在 5000 端口上运行服务器。
|
||||
|
||||
#### 事务端点
|
||||
#### 交易端点
|
||||
|
||||
这就是对一个事务的请求,它是用户发送给服务器的:
|
||||
这就是对一个交易的请求,它是用户发送给服务器的:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
{
|
||||
"sender": "my address",
|
||||
"recipient": "someone else's address",
|
||||
"amount": 5
|
||||
}
|
||||
```
|
||||
|
||||
因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
@ -383,18 +385,17 @@ def new_transaction():
|
||||
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
|
||||
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
return jsonify(response), 201
|
||||
```
|
||||
创建事务的方法
|
||||
|
||||
*创建交易的方法*
|
||||
|
||||
#### 挖矿端点
|
||||
|
||||
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
|
||||
|
||||
1. 计算工作量证明
|
||||
|
||||
2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
|
||||
|
||||
2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
|
||||
3. 通过将它添加到链上而打造一个新区块
|
||||
|
||||
```
|
||||
@ -434,10 +435,10 @@ def mine():
|
||||
'proof': block['proof'],
|
||||
'previous_hash': block['previous_hash'],
|
||||
}
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
|
||||
|
||||
### 第 3 步:与我们的区块链去交互
|
||||
|
||||
@ -447,24 +448,33 @@ return jsonify(response), 200
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
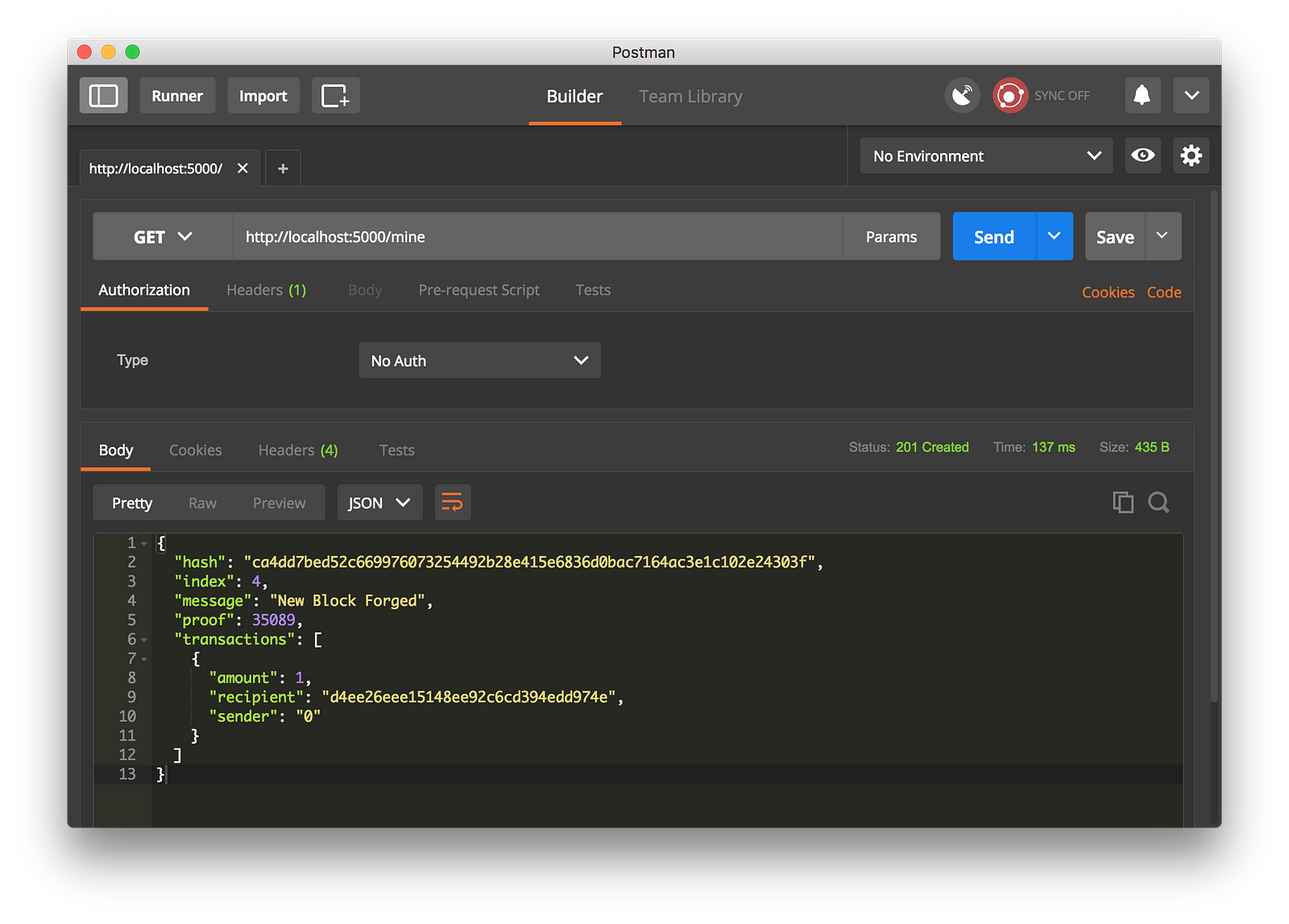
我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
|
||||
我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:
|
||||
|
||||
|
||||
使用 Postman 去生成一个 GET 请求
|
||||
|
||||
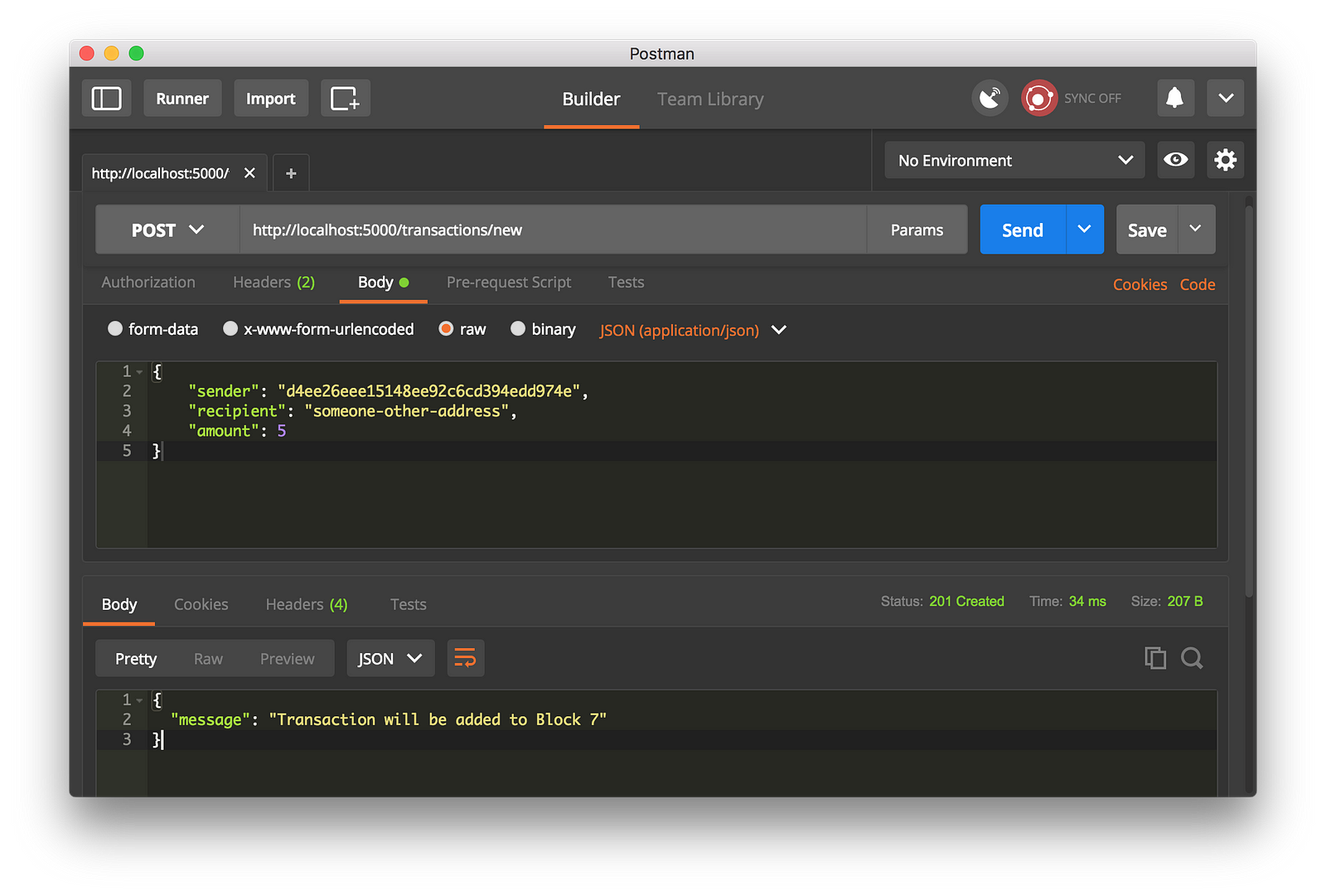
我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
|
||||
*使用 Postman 去生成一个 GET 请求*
|
||||
|
||||
我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:
|
||||
|
||||
|
||||
使用 Postman 去生成一个 POST 请求
|
||||
|
||||
*使用 Postman 去生成一个 POST 请求*
|
||||
|
||||
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{
|
||||
"sender": "d4ee26eee15148ee92c6cd394edd974e",
|
||||
"recipient": "someone-other-address",
|
||||
"amount": 5
|
||||
}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
|
||||
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
|
||||
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
@ -503,18 +513,18 @@ $ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee151
|
||||
}
|
||||
],
|
||||
"length": 3
|
||||
}
|
||||
```
|
||||
### 第 4 步:共识
|
||||
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是<ruby>去中心化的<rt>decentralized</rt></ruby>。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是<ruby>共识<rt>Consensus</rt></ruby>问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
|
||||
#### 注册新节点
|
||||
|
||||
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
|
||||
|
||||
1. /nodes/register 以 URLs 的形式去接受一个新节点列表
|
||||
|
||||
2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
|
||||
2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
|
||||
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
|
||||
|
||||
@ -538,11 +548,12 @@ class Blockchain(object):
|
||||
"""
|
||||
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
一个添加邻居节点到我们的网络的方法
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
*一个添加邻居节点到我们的网络的方法*
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是<ruby>幂等<rt>idempotent</rt></ruby>的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
|
||||
#### 实现共识算法
|
||||
|
||||
@ -615,12 +626,12 @@ class Blockchain(object)
|
||||
self.chain = new_chain
|
||||
return True
|
||||
|
||||
return False
|
||||
return False
|
||||
```
|
||||
|
||||
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
|
||||
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
|
||||
|
||||
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
|
||||
|
||||
@ -658,18 +669,20 @@ def consensus():
|
||||
'chain': blockchain.chain
|
||||
}
|
||||
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
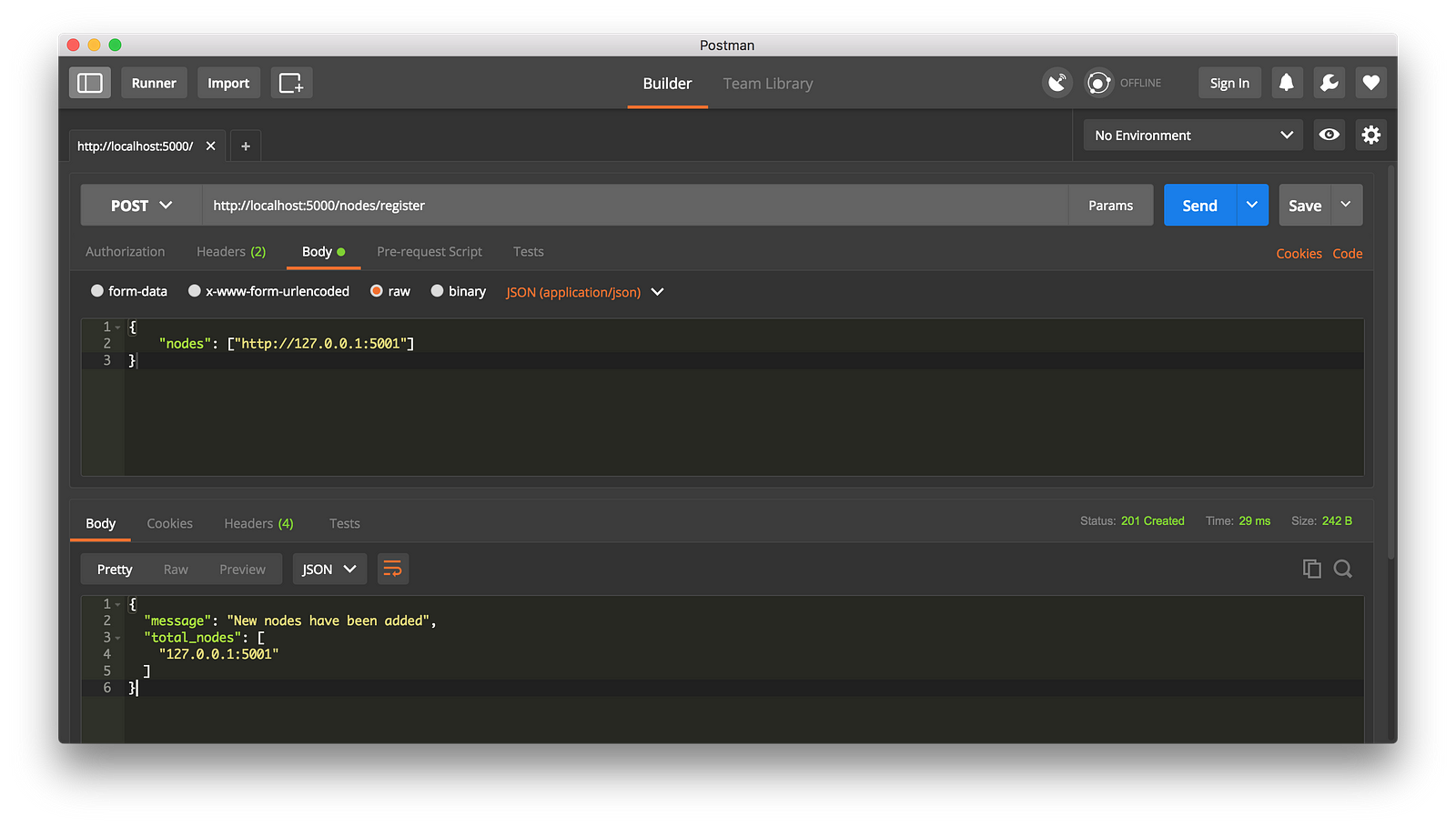
这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
|
||||
这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。
|
||||
|
||||
|
||||
注册一个新节点
|
||||
|
||||
*注册一个新节点*
|
||||
|
||||
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
|
||||
|
||||
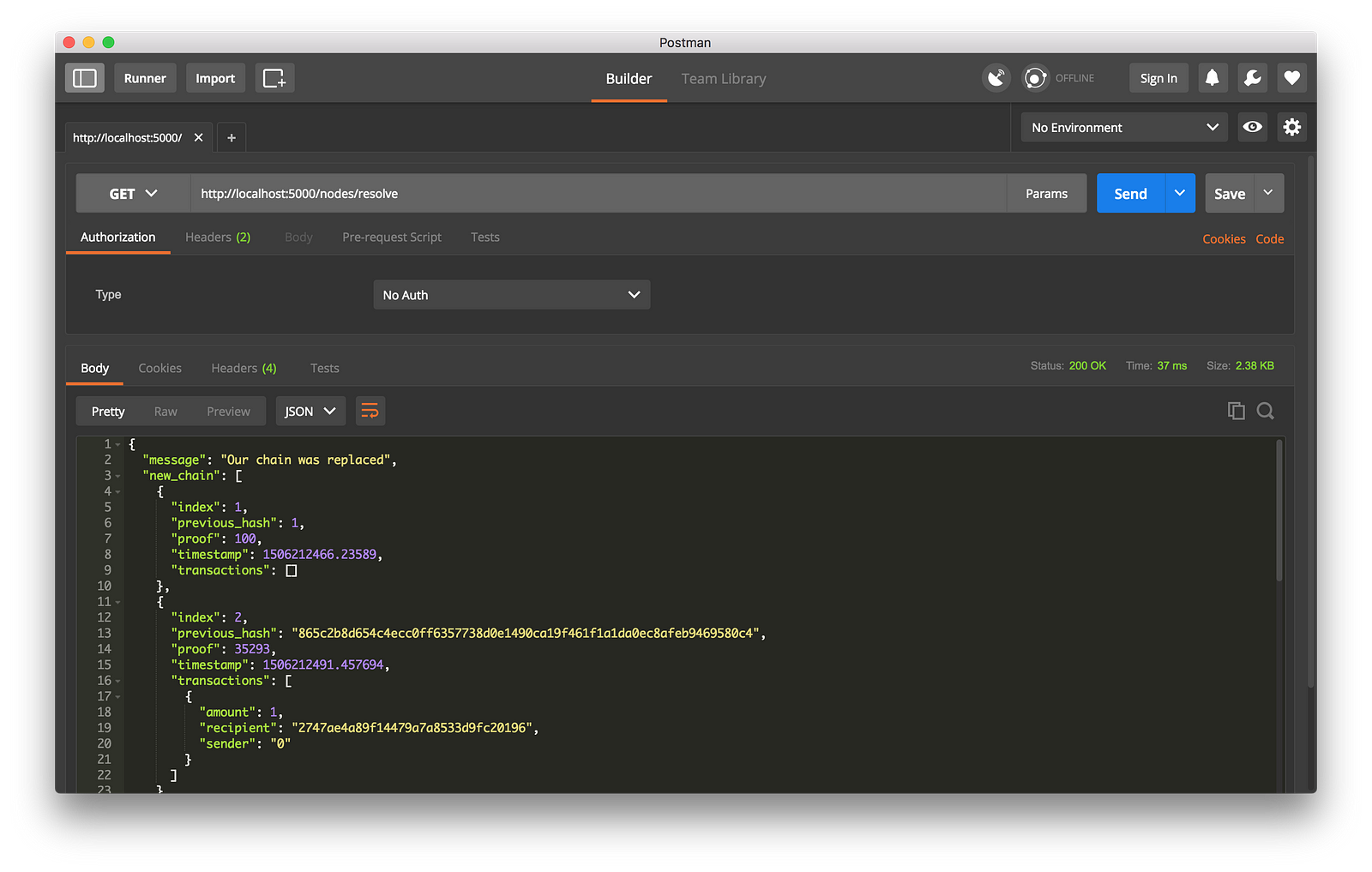
|
||||
工作中的共识算法
|
||||
|
||||
*工作中的共识算法*
|
||||
|
||||
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
|
||||
|
||||
@ -677,7 +690,7 @@ return jsonify(response), 200
|
||||
|
||||
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
|
||||
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -685,7 +698,7 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -699,3 +712,4 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
|
||||
[8]:http://localhost:5000/transactions/new
|
||||
[9]:http://localhost:5000
|
||||
[10]:https://en.wikipedia.org/wiki/Hashcash
|
||||
@ -1,12 +1,15 @@
|
||||
如何提升自动化的 ROI:4 个小提示
|
||||
======
|
||||
|
||||
> 想要在你的自动化项目上达成强 RIO?采取如下步骤来规避失败。
|
||||
|
||||

|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
|
||||
|
||||
机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
<ruby>机器人流程自动化<rt>Robotic Process Automation</rt></ruby>(RPA)似乎预示着运营的<ruby>圣杯<rt>Holy Grail</rt></ruby>:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
|
||||
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
|
||||
|
||||
@ -14,7 +17,7 @@
|
||||
|
||||
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
|
||||
|
||||
## 你是不是自动化了错误的东西?
|
||||
### 你是不是自动化了错误的东西?
|
||||
|
||||
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
|
||||
|
||||
@ -26,7 +29,7 @@
|
||||
|
||||
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
|
||||
|
||||
## 1. 教育团队
|
||||
### 1. 教育团队
|
||||
|
||||
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
|
||||
|
||||
@ -36,23 +39,23 @@
|
||||
|
||||
“实施自动化的第一步是更好地理解你的流程。”
|
||||
|
||||
## 2. 审查内部流程
|
||||
### 2. 审查内部流程
|
||||
|
||||
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
|
||||
|
||||
这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
|
||||
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
|
||||
|
||||
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
|
||||
|
||||
## 3. 为优先业务提供强有力的指导
|
||||
### 3. 为优先业务提供强有力的指导
|
||||
|
||||
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
|
||||
|
||||
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
|
||||
|
||||
## 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
### 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
|
||||
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
|
||||
|
||||
@ -68,7 +71,7 @@ via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-
|
||||
|
||||
作者:[Rajesh Kamath][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,15 @@
|
||||
调试器到底怎样工作
|
||||
======
|
||||
|
||||
> 你也许用过调速器检查过你的代码,但你知道它们是如何做到的吗?
|
||||
|
||||

|
||||
|
||||
供图:opensource.com
|
||||
|
||||
调试器是那些大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器...使用 [Rust][2]!
|
||||
调试器是大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的那些软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器……使用 [Rust][2]!
|
||||
|
||||
在本文中,术语调试器/跟踪器可以互换。 “被跟踪者”是指正在被跟踪者跟踪的进程。
|
||||
在本文中,术语<ruby>调试器<rt>debugger</rt></ruby>和<ruby>跟踪器<rt>tracer</rt></ruby>可以互换。 “<ruby>被跟踪者<rt>Tracee</rt></ruby>”是指正在被跟踪器跟踪的进程。
|
||||
|
||||
### ptrace 系统调用
|
||||
|
||||
@ -17,59 +19,46 @@
|
||||
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
|
||||
```
|
||||
|
||||
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是......我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
|
||||
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是……我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
|
||||
|
||||
现在被跟踪者可以被调试器追踪,重要的变化发生了:
|
||||
|
||||
* 每当一个信号被传送到被调试者时,它就会停止,并且一个可以被 `wait` 系列系统调用捕获的等待事件被传送给跟踪器。
|
||||
* 每当一个信号被传送到被跟踪者时,它就会停止,并且一个可以被 `wait` 系列的系统调用捕获的等待事件被传送给跟踪器。
|
||||
* 每个 `execve` 系统调用都会导致 `SIGTRAP` 被传递给被跟踪者。(与之前的项目相结合,这意味着被跟踪者在一个 `execve` 完全发生之前停止。)
|
||||
|
||||
这意味着,一旦我们发出 `PTRACE_TRACEME` 请求并调用 `execve` 系统调用来实际在被跟踪者(进程上下文)中启动程序时,被跟踪者将立即停止,因为 `execve` 会传递一个 `SIGTRAP`,并且会被跟踪器中的等待事件捕获。我们如何继续?正如人们所期望的那样,`ptrace` 有大量的请求可以用来告诉被跟踪者可以继续:
|
||||
|
||||
|
||||
* `PTRACE_CONT`:这是最简单的。 被跟踪者运行,直到它接收到一个信号,此时等待事件被传递给跟踪器。这是最常见的实现真实世界调试器的“继续直至断点”和“永远继续”选项的方式。断点将在下面介绍。
|
||||
* `PTRACE_SYSCALL`:与 `PTRACE_CONT` 非常相似,但在进入系统调用之前以及在系统调用返回到用户空间之前停止。它可以与其他请求(我们将在本文后面介绍)结合使用来监视和修改系统调用的参数或返回值。系统调用追踪程序 `strace` 很大程度上使用这个请求来获知进程发起了哪些系统调用。
|
||||
* `PTRACE_SINGLESTEP`:这个很好理解。如果您之前使用过调试器(你会知道),此请求会执行下一条指令,然后立即停止。
|
||||
|
||||
|
||||
|
||||
我们可以通过各种各样的请求停止进程,但我们如何获得被调试者的状态?进程的状态大多是通过其寄存器捕获的,所以当然 `ptrace` 有一个请求来获得(或修改)寄存器:
|
||||
|
||||
* `PTRACE_GETREGS`:这个请求将给出被跟踪者刚刚被停止时的寄存器的状态。
|
||||
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值并使用 `PTRACE_SETREGS` 将寄存器设为新值。
|
||||
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值,并使用 `PTRACE_SETREGS` 将寄存器设为新值。
|
||||
* `PTRACE_PEEKUSER` 和 `PTRACE_POKEUSER`:这些允许从被跟踪者的 `USER` 区读取信息,这里保存了寄存器和其他有用的信息。 这可以用来修改单一寄存器,而避免使用更重的 `PTRACE_{GET,SET}REGS` 请求。
|
||||
|
||||
|
||||
|
||||
在调试器仅仅修改寄存器是不够的。调试器有时需要读取一部分内存,甚至对其进行修改。GDB 可以使用 `print` 得到一个内存位置或变量的值。`ptrace` 通过下面的方法实现这个功能:
|
||||
|
||||
* `PTRACE_PEEKTEXT` 和 `PTRACE_POKETEXT`:这些允许读取和写入被跟踪者地址空间中的一个字。当然,使用这个功能时被跟踪者要被暂停。
|
||||
|
||||
|
||||
|
||||
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑x86。
|
||||
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑 x86。
|
||||
|
||||
### 体系结构的支持
|
||||
|
||||
`ptrace` 很酷,但它是如何工作? 在前面的部分中,我们已经看到 `ptrace` 跟信号有很大关系:`SIGTRAP` 可以在单步跟踪、`execve` 之前以及系统调用前后被传送。信号可以通过一些方式产生,但我们将研究两个具体的例子,以展示信号可以被调试器用来在给定的位置停止程序(有效地创建一个断点!):
|
||||
|
||||
|
||||
* **未定义的指令**:当一个进程尝试执行一个未定义的指令,CPU 将产生一个异常。此异常通过 CPU 中断处理,内核中相应的中断处理程序被调用。这将导致一个 `SIGILL` 信号被发送给进程。 这依次导致进程被停止,跟踪器通过一个等待事件被通知,然后它可以决定后面做什么。在 x86 上,指令 `ud2` 被确保始终是未定义的。
|
||||
|
||||
* **调试中断**:前面的方法的问题是,`ud2` 指令需要占用两个字节的机器码。存在一条特殊的单字节指令能够触发一个中断,它是 `int $3`,机器码是 `0xCC`。 当该中断发出时,内核向进程发送一个 `SIGTRAP`,如前所述,跟踪器被通知。
|
||||
|
||||
|
||||
|
||||
这很好,但如何做我们胁迫的被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
|
||||
这很好,但如何我们才能胁迫被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
|
||||
|
||||
好吧,我们已经讲过了断点,那观察点呢? 当一个特定的内存位置被读或写,调试器如何停止程序? 当然你不可能为了能够读或写内存而去把每一个指令都覆盖为 `int $3`。有一组调试寄存器为了更有效的满足这个目的而被设计出来:
|
||||
|
||||
|
||||
* `DR0` 到 `DR3`:这些寄存器中的每个都包含一个地址(内存位置),调试器因为某种原因希望被跟踪者在那些地址那里停止。 其原因以掩码方式被设定在 `DR7` 寄存器中。
|
||||
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7`过时的别名。
|
||||
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7` 过时的别名。
|
||||
* `DR6`:调试状态。包含有关 `DR0` 到 `DR3` 中的哪个寄存器导致调试异常被引发的信息。这被 Linux 用来计算与 `SIGTRAP` 信号一起传递给被跟踪者的信息。
|
||||
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释DR0至DR3中指定的地址。位掩码控制监视点的尺寸(监视1,2,4或8个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
|
||||
|
||||
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释 `DR0` 至 `DR3` 中指定的地址。位掩码控制监视点的尺寸(监视1、2、4 或 8 个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
|
||||
|
||||
由于调试寄存器是进程的 `USER` 区域的一部分,调试器可以使用 `PTRACE_POKEUSER` 将值写入调试寄存器。调试寄存器只与特定进程相关,因此在进程抢占并重新获得 CPU 控制权之前,调试寄存器会被恢复。
|
||||
|
||||
@ -88,7 +77,7 @@ via: https://opensource.com/article/18/1/how-debuggers-really-work
|
||||
|
||||
作者:[Levente Kurusa][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,87 @@
|
||||
为什么 DevSecOps 对 IT 领导来说如此重要
|
||||
======
|
||||
|
||||
> DevSecOps 也许不是一个优雅的词汇,但是其结果很吸引人:更强的安全、提前出现在开发周期中。来看看一个 IT 领导与 Meltdown 的拼搏。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
|
||||
|
||||
而到了术语 “DevSecOps”,就像任何其他 IT 术语一样,DevSecOps —— 一个更成熟的 DevOps 的后代 ——可能容易受到炒作和盗用。但这个术语对那些拥抱了 DevOps 文化的领导者们来说具有重要的意义,并且其实践和工具可以帮助他们实现其承诺。
|
||||
|
||||
说道这里:“DevSecOps”是什么意思?
|
||||
|
||||
“DevSecOps 是开发、安全、运营的混合,”来自 [Datical][2] 的首席技术官和联合创始人 Robert 说。“这提醒我们,对我们的应用程序来说安全和创建并部署应用到生产中一样重要。”
|
||||
|
||||
**[想阅读其他首席技术官的 DevOps 文章吗?查阅我们丰富的资源,[DevOps:IT 领导者指南][3]]**
|
||||
|
||||
向非技术人员解释 DevSecOps 的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
|
||||
|
||||
“安全团队从历史上一直都被孤立于开发团队——每个团队在 IT 的不同领域都发展了很强的专业能力”,来自红帽安全策的专家 Kirsten 最近告诉我们。“不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个 CI/CD 管道中集成安全实践、工具和自动化来采用 DevSecOps。”
|
||||
|
||||
“为了能够做的更好,他们正在整合他们的团队——专业的安全人员从开始设计到部署到生产中都融入到了开发团队中了,”她说,“双方都收获了价值——每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。 DevOps 做的很正确——或者说 DevSecOps——提高了 IT 的安全性。”
|
||||
|
||||
IT 团队比任何以往都要求要快速频繁的交付服务。DevOps 在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
|
||||
|
||||
“我们已经采用了 DevOps,因为它已经被证明通过移除开发和运营之间的阻碍来提高 IT 的绩效,”Reevess 说,“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
|
||||
|
||||
### 为什么 DevSecOps 必然出现
|
||||
|
||||
或许会把 DevSecOps 看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一层面的要素,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
|
||||
|
||||
“DevSecOps 不只是一个时髦的术语——因为多种原因它是现在和未来 IT 将呈现的状态”,来自 [Sumo Logic] 的安全和合规副总裁 George 说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
|
||||
|
||||
此外,DevSecOps 的出现可能是 DevOps 自身逐渐成熟并扎根于 IT 之中的一个征兆。
|
||||
|
||||
“企业中的 DevOps 文化已成定局,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织会对合作和衡量的结果更加满意”,来自 [CYBRIC] 的首席技术官和联合创始人 Mike 说道。
|
||||
|
||||
在实施 DevOps 的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
|
||||
|
||||
“现在的手工的安全测试方法会继续远远被甩在后面。”
|
||||
|
||||
“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动 DevSecOps 的文化是 IT 领导者们为增加整体的灵活性提供安全保证的唯一途径”,Kail 说。
|
||||
|
||||
转移安全测试也使开发者受益:他们能够在开放的较早的阶段验证并解决潜在的问题——这样很少需要或者甚至不需要安全人员的介入,而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞。
|
||||
|
||||
“做的正确,DevSecOps 能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全”,来自 [SAS][8] 的首席信息安全员 Wilson 说道。
|
||||
|
||||
Wilson 指出静态(SAST)和源组合分析(SCA)工具,集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈来使之逐渐成为可能。
|
||||
|
||||
“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。” Wilson 说。他同时指出 DevSecOps 能够帮助开发者简化更新和打补丁。
|
||||
|
||||
DevSecOps 并不意味着你不再需要安全组的意见了,就如同 DevOps 并不意味着你不再需要基础架构专家;它只是帮助你减少在生产中发现缺陷的可能性,或者减少导致降低部署速度的阻碍,因为缺陷已经在开发周期中被发现解决了。
|
||||
|
||||
“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson 说道。
|
||||
|
||||
### DevSecOps 遇到 Meltdown
|
||||
|
||||
Sumo Locic 的 Gerchow 向我们分享了一个在运转中的 DevSecOps 文化的一个及时案例:当最近 [Meltdown 和 Spectre] 的消息传来的时候,团队的 DevSecOps 方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow 所说的这点对原生云、高监管的公司来说特别的重要。
|
||||
|
||||
第一步:Gerchow 的小型安全团队都具有一定的开发能力,能够通过 Slack 和它的主要云供应商协同工作来确保它的基础架构能够在 24 小时之内完成修复。
|
||||
|
||||
“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开工单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过 Slack 的自动 jira 票据进行,通过我们的日志监控和分析解决方案”,Gerchow 解释道。
|
||||
|
||||
在本质上,它听起来非常像 DevOps 文化,匹配正确的人员、过程和工具,但它明确的将安全作为文化中的一部分进行了混合。
|
||||
|
||||
“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发、运维和安全三者是相互独立的”,Gerchow 说道,“通过一个 DevSecOps 的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.datical.com/
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
[6]:https://www.sumologic.com/
|
||||
[7]:https://www.cybric.io/
|
||||
[8]:https://www.sas.com/en_us/home.html
|
||||
[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
|
||||
@ -1,28 +1,24 @@
|
||||
在 Kubernetes 上运行一个 Python 应用程序
|
||||
============================================================
|
||||
|
||||
### 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
|
||||
> 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
|
||||
|
||||

|
||||
图片来源:opensource.com
|
||||
|
||||
Kubernetes 是一个具备部署、维护、和可伸缩特性的开源平台。它在提供可移植性、可扩展性、以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
|
||||
Kubernetes 是一个具备部署、维护和可伸缩特性的开源平台。它在提供可移植性、可扩展性以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
|
||||
|
||||
不论你的 Python 应用程序是简单还是复杂,Kubernetes 都可以帮你高效地部署和伸缩它们,在有限的资源范围内滚动升级新特性。
|
||||
|
||||
在本文中,我将描述在 Kubernetes 上部署一个简单的 Python 应用程序的过程,它包括:
|
||||
|
||||
* 创建 Python 容器镜像
|
||||
|
||||
* 发布容器镜像到镜像注册中心
|
||||
|
||||
* 使用持久卷
|
||||
|
||||
* 在 Kubernetes 上部署 Python 应用程序
|
||||
|
||||
### 必需条件
|
||||
|
||||
你需要 Docker、kubectl、以及这个 [源代码][10]。
|
||||
你需要 Docker、`kubectl` 以及这个 [源代码][10]。
|
||||
|
||||
Docker 是一个构建和承载已发布的应用程序的开源平台。可以参照 [官方文档][11] 去安装 Docker。运行如下的命令去验证你的系统上运行的 Docker:
|
||||
|
||||
@ -40,7 +36,7 @@ WARNING: No memory limit support
|
||||
WARNING: No swap limit support
|
||||
```
|
||||
|
||||
kubectl 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 kubectl:
|
||||
`kubectl` 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 `kubectl`:
|
||||
|
||||
```
|
||||
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
@ -56,9 +52,9 @@ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s
|
||||
|
||||
### 创建一个 Python 容器镜像
|
||||
|
||||
为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 `Docker file` 中的指令来自动化构建镜像。
|
||||
为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 Dockerfile 中的指令来自动化构建镜像。
|
||||
|
||||
这是我们的 Python 应用程序的 `Docker file`:
|
||||
这是我们的 Python 应用程序的 Dockerfile:
|
||||
|
||||
```
|
||||
FROM python:3.6
|
||||
@ -90,7 +86,7 @@ VOLUME ["/app-data"]
|
||||
CMD ["python", "app.py"]
|
||||
```
|
||||
|
||||
这个 `Docker file` 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
|
||||
这个 Dockerfile 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
|
||||
|
||||
### 构建一个 Python Docker 镜像
|
||||
|
||||
@ -128,45 +124,45 @@ Kubernetes 支持许多的持久存储提供商,包括 AWS EBS、CephFS、Glus
|
||||
|
||||
为使用 CephFS 存储 Kubernetes 的容器数据,我们将创建两个文件:
|
||||
|
||||
persistent-volume.yml
|
||||
`persistent-volume.yml` :
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: PersistentVolume
|
||||
metadata:
|
||||
name: app-disk1
|
||||
namespace: k8s_python_sample_code
|
||||
name: app-disk1
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
capacity:
|
||||
storage: 50Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
cephfs:
|
||||
monitors:
|
||||
- "172.17.0.1:6789"
|
||||
user: admin
|
||||
secretRef:
|
||||
name: ceph-secret
|
||||
readOnly: false
|
||||
capacity:
|
||||
storage: 50Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
cephfs:
|
||||
monitors:
|
||||
- "172.17.0.1:6789"
|
||||
user: admin
|
||||
secretRef:
|
||||
name: ceph-secret
|
||||
readOnly: false
|
||||
```
|
||||
|
||||
persistent_volume_claim.yaml
|
||||
`persistent_volume_claim.yaml`:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: appclaim1
|
||||
namespace: k8s_python_sample_code
|
||||
name: appclaim1
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Gi
|
||||
```
|
||||
|
||||
现在,我们将使用 kubectl 去添加持久卷并声明到 Kubernetes 集群中:
|
||||
现在,我们将使用 `kubectl` 去添加持久卷并声明到 Kubernetes 集群中:
|
||||
|
||||
```
|
||||
$ kubectl create -f persistent-volume.yml
|
||||
@ -185,16 +181,16 @@ $ kubectl create -f persistent-volume-claim.yml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
k8s-app: k8s_python_sample_code
|
||||
name: k8s_python_sample_code
|
||||
namespace: k8s_python_sample_code
|
||||
labels:
|
||||
k8s-app: k8s_python_sample_code
|
||||
name: k8s_python_sample_code
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
type: NodePort
|
||||
ports:
|
||||
- port: 5035
|
||||
selector:
|
||||
k8s-app: k8s_python_sample_code
|
||||
type: NodePort
|
||||
ports:
|
||||
- port: 5035
|
||||
selector:
|
||||
k8s-app: k8s_python_sample_code
|
||||
```
|
||||
|
||||
使用下列的内容创建部署文件并将它命名为 `k8s_python_sample_code.deployment.yml`:
|
||||
@ -227,7 +223,7 @@ spec:
|
||||
claimName: appclaim1
|
||||
```
|
||||
|
||||
最后,我们使用 kubectl 将应用程序部署到 Kubernetes:
|
||||
最后,我们使用 `kubectl` 将应用程序部署到 Kubernetes:
|
||||
|
||||
```
|
||||
$ kubectl create -f k8s_python_sample_code.deployment.yml $ kubectl create -f k8s_python_sample_code.service.yml
|
||||
@ -248,15 +244,15 @@ kubectl get services
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Joannah Nanjekye - Straight Outta 256 , 只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
|
||||
[][13] Joannah Nanjekye - Straight Outta 256,只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/running-python-application-kubernetes
|
||||
|
||||
作者:[Joannah Nanjekye ][a]
|
||||
作者:[Joannah Nanjekye][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
95
published/201807/20180128 Being open about data privacy.md
Normal file
95
published/201807/20180128 Being open about data privacy.md
Normal file
@ -0,0 +1,95 @@
|
||||
对数据隐私持开放的态度
|
||||
======
|
||||
|
||||
> 尽管有包括 GDPR 在内的法规,数据隐私对于几乎所有的人来说都是很重要的事情。
|
||||
|
||||

|
||||
|
||||
今天(LCTT 译注:本文发表于 2018/1/28)是<ruby>[数据隐私日][1]<rt>Data Privacy Day</rt></ruby>,(在欧洲叫“<ruby>数据保护日<rt>Data Protection Day</rt></ruby>”),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该是自由的,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
|
||||
|
||||
1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些例子[3])
|
||||
2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
|
||||
|
||||
所以实际上,数据隐私对于每个人来说是很重要的。
|
||||
|
||||
事实证明,在美国和欧洲之间,人们和政府认为让组织使用哪些数据的出发点是有些不同的。前者通常为商业实体(特别是愤世嫉俗的人们会指出是大型的商业实体)利用他们所收集到的关于我们的数据提供了更多的自由度。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在 5 月 25 日,欧洲的观点可以说取得了胜利。
|
||||
|
||||
### 通用数据保护条例(GDPR)的影响
|
||||
|
||||
那是一个相当全面的声明,其实事实上这是 2016 年欧盟通过的一项称之为<ruby>通用数据保护条例<rt>General Data Protection Regulation</rt></ruby>(GDPR)的立法的日期。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据——而且涉及的条目范围非常广泛,从你的姓名、家庭住址到你的医疗记录以及接通你电脑的 IP 地址。
|
||||
|
||||
通用数据保护条例的重要之处是它并不仅仅适用于欧洲的公司,如果你是阿根廷人、日本人、美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
|
||||
|
||||
“哼!” 你可能会这样说^注1 ,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简单:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你的全球总收入百分之四的惩罚。是的,你没听错,是全球总收入,而不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的 IT 团队,确保你的行为在相当短的时间内合规。
|
||||
|
||||
看上去这和非欧盟公民没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是仅针对欧盟公民实施,这将会是一件很有利的事情。^注2
|
||||
|
||||
然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好^注3 :事实并非如此,我们一直在丢弃关于我们自己的信息——而且允许公司去使用它。
|
||||
|
||||
有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。你有付费使用 Facebook、推特、谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客——只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
|
||||
|
||||
有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(例如,亚马逊正在努力让 Alexa 发广告),除非我们想要开始为这些所有的免费服务付费,我们需要清楚我们所放弃的,而且在我们暴露的和不想暴露的之间做一些选择。
|
||||
|
||||
### 谁是顾客?
|
||||
|
||||
关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门^注4 ——而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去挖掘这些数据。
|
||||
|
||||
然而他们面临的是,随着数据的增长和存储量无法跟上该怎么办。幸运的是——而且我是带有讽刺意味的使用了这个词^注5 ,大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司^注6 的一个极具代表性的例子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
|
||||
|
||||
不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售给第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方,以及在他们如何使用上能有发言权吗?我将把这个问题当做一个练习留给读者去思考。^注7
|
||||
|
||||
### 开放和积极
|
||||
|
||||
然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励各个部门免费开放大量他们的数据给公众或者其他组织。在某些情况下,这是专门立法的。许多志愿组织——尤其是那些接受公共资金的——正在开始这样做。甚至商业组织也有感兴趣的苗头。而且,有一些技术已经可行了,例如围绕不同的隐私和多方计算上,正在允许跨越多个数据集挖掘数据,而不用太多披露个人的信息——这个计算问题从未如现在比你想象的更容易。
|
||||
|
||||
这些对我们来说意味着什么呢?我之前在网站 Opensource.com 上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件、组织,和这次讨论有关的,数据。让我们假设一下你是 A 公司要提向另一家公司客户 B^注8 提供一项服务 。在此有四种不同类型的数据:
|
||||
|
||||
1. 数据完全开放:对 A 和 B 都是可得到的,世界上任何人都可以得到
|
||||
2. 数据是已知的、共享的,和机密的:A 和 B 可得到,但其他人不能得到
|
||||
3. 数据是公司级别上保密的:A 公司可以得到,但 B 顾客不能
|
||||
4. 数据是顾客级别保密的:B 顾客可以得到,但 A 公司不能
|
||||
|
||||
首先,也许我们对数据应该更开放些,将数据默认放到选项 1 中。如果那些数据对所有人开放——在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的。^注9 如果我们能够找到方法将数据放到选项 2、3 和 4 中,不是很好吗?——或者至少它们中的一些——在选项 1 中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
|
||||
然而有很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
|
||||
|
||||
### 一些具体的措施
|
||||
|
||||
我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
|
||||
|
||||
* 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
|
||||
* 要默认加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉——除非数据正在被处理使用,否则没有任何借口让数据清晰可见。
|
||||
* 当你注册了一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
|
||||
* 和你的非技术朋友讨论这个话题。
|
||||
* 教育你的孩子、你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师谈谈在他们的学校中展示。
|
||||
* 鼓励你所服务和志愿贡献的组织,或者和他们沟通一些推动数据的默认开放。不是去思考为什么我要使数据开放,而是从我为什么不让数据开放开始。
|
||||
* 尝试去访问一些开源数据。挖掘使用它、开发应用来使用它,进行数据分析,画漂亮的图,^注10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
|
||||
|
||||
**注:**
|
||||
|
||||
1. 我承认你可能尽管不会。
|
||||
2. 假设你坚信你的个人数据应该被保护。
|
||||
3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
|
||||
4. 事实上这些机构能够有多开放取决于你所居住的地方。
|
||||
5. 假设我是英国人,那是非常非常大的剂量。
|
||||
6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
|
||||
7. 不,答案是“不”。
|
||||
8. 尽管这个例子也同样适用于个人。看看:A 可能是 Alice,B 可能是 BOb……
|
||||
9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然——不是那类的数据。
|
||||
10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/being-open-about-data-privacy
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
|
||||
[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
|
||||
[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
|
||||
[4]:https://opensource.com/article/17/11/commonwealth-open-source
|
||||
[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
|
||||
@ -1,23 +1,25 @@
|
||||
供应链管理方面的 5 个开源软件工具
|
||||
======
|
||||
|
||||
> 跟踪您的库存和您需要的材料,用这些供应链管理工具制造产品。
|
||||
|
||||

|
||||
|
||||
本文最初发表于 2016 年 1 月 14 日,最后的更新日期为 2018 年 3 月 2 日。
|
||||
|
||||
如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
|
||||
如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数以百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
|
||||
|
||||
保持对货品、供应商、客户的持续跟踪,并且所有与它们相关的变动部分都会从中受益,并且,在某些情况下完全依赖专门的软件来帮助管理这些工作流。在本文中,我们将去了解一些免费的和开源的供应链管理方面的软件,以及它们的其中一些功能。
|
||||
保持对货品、供应商、客户的持续跟踪,而且所有与它们相关的变动部分都会受益于这些用来帮助管理工作流的专门软件,而在某些情况下需要完全依赖这些软件。在本文中,我们将去了解一些自由及开源的供应链管理方面的软件,以及它们的其中一些功能。
|
||||
|
||||
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是合法性、最低品质要求、还是社会和环境的合规性。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
|
||||
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是否是出于法律要求、最低品质要求、还是社会和环境责任。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
|
||||
|
||||
由于它的本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
|
||||
由于其本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,目录、电子商务网站、帐户、和销售点,它在供应链管理方面的主要功能关注于仓库管理、履行、订单、和生产管理。它的可定制性很强,但是,它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层、和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
|
||||
[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,分类、电子商务网站、会计和 POS,它在供应链管理方面的主要功能关注于仓库管理、履行、订单和生产管理。它的可定制性很强,但是,对应的它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
|
||||
|
||||
Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 license][6] 授权的。
|
||||
Apache OFBiz 的源代码在其 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 许可证][6] 授权的。
|
||||
|
||||
如果你对它感兴趣,你也可以去查看 [opentaps][7],它是在 OFBiz 之上构建的。Opentaps 强化了 OFBiz 的用户界面,并且添加了 ERP 和 CRM 的核心功能,包括仓库管理、采购和计划。它是按 [AGPL 3.0][8] 授权使用的,对于不接受开源授权的组织,它也提供了商业授权。
|
||||
|
||||
@ -25,25 +27,25 @@ Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz
|
||||
|
||||
[OpenBoxes][9] 是一个供应链管理和存货管理项目,最初的主要设计目标是为了医疗行业中的药品跟踪管理,但是,它可以通过修改去跟踪任何类型的货品和相关的业务流。它有一个需求预测工具,可以基于历史订单数量、存储跟踪、支持多种场所、过期日期跟踪、销售点支持等进行预测,并且它还有许多其它功能,这使它成为医疗行业的理想选择,但是,它也可以用于其它行业。
|
||||
|
||||
它在 [Eclipse Public License][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
|
||||
它在 [Eclipse 公开许可证][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
|
||||
|
||||
### OpenLMIS
|
||||
|
||||
与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由络克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达 盖茨基金会。
|
||||
与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由洛克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达·盖茨基金会。
|
||||
|
||||
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 license][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
|
||||
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 许可证][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
|
||||
|
||||
### Odoo
|
||||
|
||||
你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和销售点连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
|
||||
你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和 POS 连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
|
||||
|
||||
Odoo 既有软件即服务的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
|
||||
Odoo 既有软件即服务(SaaS)的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
|
||||
|
||||
### xTuple
|
||||
|
||||
[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是帐务、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
|
||||
[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了其传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是会计、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
|
||||
|
||||
xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去 fork 它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
|
||||
xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去复刻它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
|
||||
|
||||
就这些,当然了,还有其它的可以帮你处理供应链管理的开源软件。如果你知道还有更好的软件,请在下面的评论区告诉我们。
|
||||
|
||||
@ -53,14 +55,14 @@ via: https://opensource.com/tools/supply-chain-management
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://en.wikipedia.org/wiki/Supply_chain_management
|
||||
[2]:https://opensource.com/business/14/7/top-5-open-source-crm-tools
|
||||
[3]:https://opensource.com/resources/top-4-open-source-erp-systems
|
||||
[3]:https://linux.cn/article-9785-1.html
|
||||
[4]:http://ofbiz.apache.org/
|
||||
[5]:http://ofbiz.apache.org/source-repositories.html
|
||||
[6]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
@ -0,0 +1,132 @@
|
||||
IT 自动化的下一步是什么: 6 大趋势
|
||||
======
|
||||
|
||||
> 自动化专家分享了一点对 [自动化][6]不远的将来的看法。请将这些保留在你的视线之内。
|
||||
|
||||

|
||||
|
||||
我们最近讨论了 [推动 IT 自动化的因素][1],可以看到[当前趋势][2]正在增长,以及那些给刚开始使用自动化部分流程的组织的 [有用的技巧][3] 。
|
||||
|
||||
噢,我们也分享了如何在贵公司[进行自动化的案例][4]及 [长期成功的关键][5]的专家建议。
|
||||
|
||||
现在,只有一个问题:自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来的看法。 以下是他们建议 IT 领域领导需密切关注的六大趋势。
|
||||
|
||||
### 1、 机器学习的成熟
|
||||
|
||||
对于关于 [机器学习][7](与“自我学习系统”相似的定义)的讨论,对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次 IT 自动化浪潮中将扮演着至关重要的角色。
|
||||
|
||||
[Advanced Systems Concepts, Inc.][8] 公司的工程总监 Mehul Amin 指出机器学习是 IT 自动化下一个关键增长领域之一。
|
||||
|
||||
“随着数据化的发展,自动化软件理应可以自我决策,否则这就是开发人员的责任了”,Amin 说。 “例如,开发者构建了需要执行的内容,但通过使用来自系统内部分析的软件,可以确定执行该流程的最佳系统。”
|
||||
|
||||
假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或 SLA,同样在不需要资源以及其他的可能性的时候退出。
|
||||
|
||||
显然不只有 Amin 一个人这样认为。
|
||||
|
||||
“IT 自动化正在走向自我学习的方向” ,[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
|
||||
|
||||
Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
|
||||
|
||||
### 2、 人工智能催生的自动化
|
||||
|
||||
上述原则同样适合与相关的(但是独立的) [人工智能][10]的领域。根据对人工智能的定义,机器学习在短时间内可能会对 IT 领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。假定新兴的人工智能技术将也会产生新的自动化机会。
|
||||
|
||||
[SolarWinds][11] 公司技术负责人 Patrick Hubbard 说,“人工智能和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
|
||||
|
||||
### 3、 这并不意味着不再需要人力
|
||||
|
||||
让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
|
||||
|
||||
这很可能意味着各种角色的改变,以及[全新角色][12]的创造。
|
||||
|
||||
但是在可预见的将来,至少,你不必需要对机器人鞠躬。
|
||||
|
||||
“一台机器只能运行在给定的环境变量中——它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于 IT 专业人员来说,这将需要培养 AI 和自动化技能,如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
|
||||
|
||||
Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
|
||||
|
||||
“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
|
||||
|
||||
即使你把机器学习和 AI 先放在一边,看待一般的 IT 自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
|
||||
|
||||
[Juniper Networks][13] 公司自动化首席架构师 Matthew Oswalt ,指出 IT 自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
|
||||
|
||||
> 在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。
|
||||
|
||||
“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt 解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨 IT 频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
|
||||
|
||||
### 4、 对自动化的焦虑将会减少
|
||||
|
||||
SolarWinds 公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在 IT 领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至与科技产业本身共存。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的第 3 项时,我们将看到第 4 项的出现。
|
||||
|
||||
“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard 说。“自动化历史上为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
|
||||
|
||||
自动化还将减少令 IT 领导者神经紧张的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助 IT 部门降低与维护任务相关的安全风险。
|
||||
|
||||
他的建议是:“首先在维护活动期间记录和自动化 IT 资产之间的交互。通过依靠自动化,您不仅可以消除之前需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的 IT 组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
|
||||
|
||||
**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
|
||||
|
||||
### 5、 脚本和自动化工具将持续发展
|
||||
|
||||
许多组织看到了增加自动化的第一步,通常以脚本或自动化工具(有时称为配置管理工具)的形式作为“早期”工作。
|
||||
|
||||
但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
|
||||
|
||||
[DataVision][18] 首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17] 等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交付时间。”
|
||||
|
||||
**[想了解更多关于 Ansible 这个方面的知识吗?阅读相关文章:[使用 Ansible 时的成功秘诀][19]。 ]**
|
||||
|
||||
另一个因素是:工具本身将继续变得更先进。
|
||||
|
||||
“使用先进的 IT 自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的、预先测试过的拖放式集成,API 作业,丰富的变量使用,参考功能和对象修订历史记录。”
|
||||
|
||||
### 6、 自动化开创了新的指标机会
|
||||
|
||||
正如我们在此前所说的那样,IT 自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
|
||||
|
||||
**[ 参见我们的相关文章 [DevOps 指标:你在衡量什么重要吗?][20] ]**
|
||||
|
||||
实际上,自动化应该打开了新的机会。
|
||||
|
||||
[Janeiro Digital][21] 公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 —— 源代码管理、DevOps 管道、工作项目跟踪等转向 API 驱动的平台,将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
|
||||
|
||||
Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测 IT 所做的一切。
|
||||
|
||||
“无论是衡量个人资源还是整体团队,这些指标都可以很强大 —— 但应该用大量的背景来衡量。”Collins 说,“将这些数据用于高层次趋势并确认定性观察 —— 而不是临床评级你的团队。”
|
||||
|
||||
**想要更多这样知识, IT 领导者?[注册我们的每周电子邮件通讯][22]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
|
||||
[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
|
||||
[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
|
||||
[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
|
||||
[6]:https://enterprisersproject.com/tags/automation
|
||||
[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
|
||||
[8]:https://www.advsyscon.com/en-us/
|
||||
[9]:https://www.sungardas.com/en/
|
||||
[10]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[11]:https://www.solarwinds.com/
|
||||
[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
|
||||
[13]:https://www.juniper.net/
|
||||
[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
|
||||
[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://opensource.com/tags/ansible
|
||||
[18]:https://datavision.com/
|
||||
[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
|
||||
[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
|
||||
[21]:https://www.janeirodigital.com/
|
||||
[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,9 +1,11 @@
|
||||
Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
Kubernetes 分布式应用部署实战:以人脸识别应用为例
|
||||
============================================================
|
||||
|
||||
# 简介
|
||||

|
||||
|
||||
伙计们,请做好准备,下面将是一段漫长的旅程,期望你能够乐在其中。
|
||||
## 简介
|
||||
|
||||
伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
|
||||
|
||||
我将基于 [Kubernetes][5] 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
|
||||
|
||||
@ -11,17 +13,17 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
# 应用
|
||||
## 应用
|
||||
|
||||
### TL;DR
|
||||
|
||||
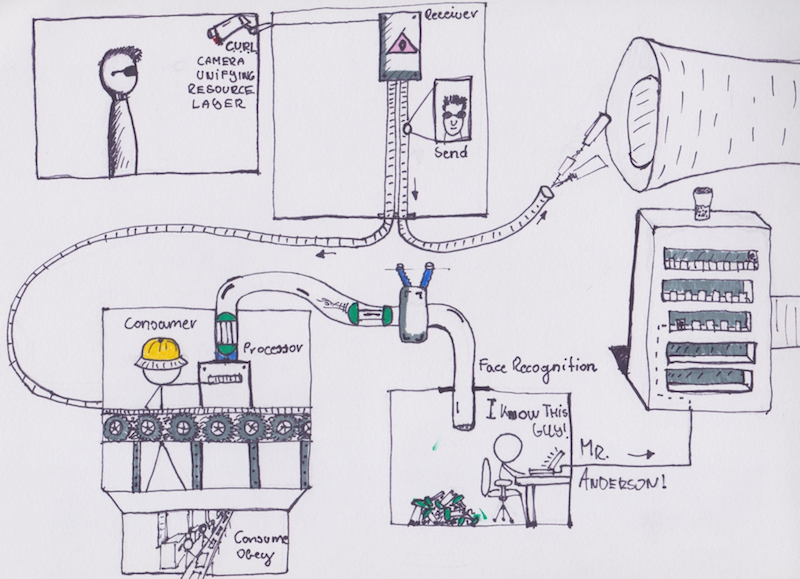
|
||||
|
||||
应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
|
||||
该应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
|
||||
|
||||
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 [接收器][6] 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 [NSQ][8] 建立队列。
|
||||
|
||||
[图片处理][9]服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的[人脸识别][10]后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
|
||||
[图片处理][9] 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的 [人脸识别][10] 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
|
||||
|
||||
标记为失败的图片可以通过计划任务等方式进行重试。
|
||||
|
||||
@ -33,39 +35,31 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
|
||||
```
|
||||
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
|
||||
|
||||
```
|
||||
|
||||
此时,接收器将<ruby>路径<rt>path</rt></ruby>存储到共享数据库集群中,对应的条目包括数据库服务提供的 ID。本应用采用”持久层提供条目对象唯一标识“的模型。获得条目 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
|
||||
此时,接收器将<ruby>路径<rt>path</rt></ruby>存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“<ruby>实体对象<rt>Entity Object</rt></ruby>的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
|
||||
|
||||
### 图片处理器
|
||||
|
||||
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go routines,具体为:
|
||||
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go <ruby>协程<rt>routine</rt></ruby>,具体为:
|
||||
|
||||
### Consume
|
||||
|
||||
这是一个 NSQ 消费者,需要完成三项任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个 routine 处理。最后,告知第二个 routine 处理新任务,方法为 [sync.Condition][12]。
|
||||
这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 [sync.Condition][12]。
|
||||
|
||||
### ProcessImages
|
||||
|
||||
该 routine 会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该 routine 并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
|
||||
该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
|
||||
|
||||
* 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
|
||||
|
||||
* 从数据库获取图片对应的条目
|
||||
|
||||
* 从数据库获取图片对应的实体
|
||||
* 为 [断路器][1] 准备两个函数
|
||||
* 函数 1: 用于 RPC 方法调用的主函数
|
||||
|
||||
* 函数 2: 基于 ping 的断路器健康检查
|
||||
|
||||
* 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
|
||||
|
||||
* 如果调用失败,将图片条目状态更新为 FAILEDPROCESSING
|
||||
|
||||
* 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
|
||||
* 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
|
||||
|
||||
* 将数据库中的图片条目状态更新为 PROCESSED,更新图片被识别成的个人的 ID
|
||||
* 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
|
||||
|
||||
这个服务可以复制多份同时运行。
|
||||
|
||||
@ -89,7 +83,7 @@ curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image
|
||||
|
||||
注意:我曾经试图使用 [GoCV][14],这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
|
||||
|
||||
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg, hannibal_2.jpg, gergely_1.jpg, john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person, person_images`,具体如下:
|
||||
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg`、 `hannibal_2.jpg`、 `gergely_1.jpg`、 `john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person`、 `person_images`,具体如下:
|
||||
|
||||
```
|
||||
+----+----------+
|
||||
@ -126,13 +120,13 @@ NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ
|
||||
|
||||
### 配置
|
||||
|
||||
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 .env 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
|
||||
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 `.env` 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
|
||||
|
||||
### 应用小结
|
||||
|
||||
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
|
||||
|
||||
# 使用 Kubernetes 部署应用
|
||||
## 使用 Kubernetes 部署应用
|
||||
|
||||
### 基础知识
|
||||
|
||||
@ -144,55 +138,51 @@ Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管
|
||||
|
||||
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
|
||||
|
||||
Kubernetes 使用标签和注释标记组件,包括服务,部署,副本组,守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与 应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
|
||||
Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
|
||||
|
||||
### Kubernetes 集群
|
||||
|
||||
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求 Nodes 并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
|
||||
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
|
||||
|
||||
### 节点 (Nodes)
|
||||
### 节点
|
||||
|
||||
节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
|
||||
<ruby>节点<rt>node</rt></ruby>是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
|
||||
|
||||
### Pods
|
||||
### Pod
|
||||
|
||||
Pods 是本地容器组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和 虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
|
||||
Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
|
||||
|
||||
### 部署 (Deployments)
|
||||
### 部署
|
||||
|
||||
在 Kubernetes 中创建任何类型的资源时,后台使用一个部署,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
|
||||
在 Kubernetes 中创建任何类型的资源时,后台使用一个<ruby>部署<rt>deployment</rt></ruby>组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
|
||||
|
||||
### 服务 (Services)
|
||||
### 服务
|
||||
|
||||
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,mysql,内部 API 或前端,都需要长期运行并使用保持不变的 IP 或 更佳的 DNS 记录。
|
||||
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
|
||||
|
||||
为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡,简单 IP 或 内部 DNS。
|
||||
为解决这个问题,Kubernetes 提供了<ruby>服务<rt>service</rt></ruby>组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
|
||||
|
||||
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别<ruby>接口<rt>endpoint</rt></ruby>。
|
||||
|
||||
由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络,服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
|
||||
由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
|
||||
|
||||
### DNS / 服务发现
|
||||
|
||||
在 Kubernetes 集群中创建服务后,该服务会从名为 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中获取一个 DNS 记录。他们两个用于提供集群内的服务发现。如果你有一个正在运行的 mysql 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
|
||||
在 Kubernetes 集群中创建服务后,该服务会从名为 `kube-proxy` 和 `kube-dns` 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
|
||||
|
||||
* `mysql` – 服务的名称
|
||||
|
||||
* `default` – 命名空间的名称
|
||||
|
||||
* `svc` – 对应服务分类
|
||||
|
||||
* `cluster.local` – 本地集群的域名
|
||||
|
||||
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 提供程序并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
|
||||
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
|
||||
|
||||
* 节点端口方式 – `kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
|
||||
|
||||
* 负载均衡方式 – `kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
|
||||
|
||||
### 模板文件
|
||||
|
||||
类似 Docker Compose, TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
|
||||
类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
|
||||
|
||||
以 Nginx 部署为例,查看下面的 yaml 模板:
|
||||
|
||||
@ -218,26 +208,26 @@ spec: #(4)
|
||||
image: nginx:1.7.9
|
||||
ports:
|
||||
- containerPort: 80
|
||||
|
||||
```
|
||||
|
||||
在这个示例部署中,我们做了如下操作:
|
||||
|
||||
* (1) 使用 kind 关键字定义模板类型
|
||||
* (2) 使用 metadata 关键字,增加该部署的识别信息,使用 labels 标记每个需要创建的资源 (3)
|
||||
* (4) 然后使用 spec 关键字描述所需的状态
|
||||
* (5) nginx 应用需要 3 个副本
|
||||
* (6) Pod 中容器的模板定义部分
|
||||
* 容器名称为 nginx
|
||||
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
|
||||
* (1) 使用 `kind` 关键字定义模板类型
|
||||
* (2) 使用 `metadata` 关键字,增加该部署的识别信息
|
||||
* (3) 使用 `labels` 标记每个需要创建的资源
|
||||
* (4) 然后使用 `spec` 关键字描述所需的状态
|
||||
* (5) nginx 应用需要 3 个副本
|
||||
* (6) Pod 中容器的模板定义部分
|
||||
* 容器名称为 nginx
|
||||
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
|
||||
|
||||
### 副本组 (ReplicaSet)
|
||||
### 副本组
|
||||
|
||||
副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
|
||||
<ruby>副本组<rt>ReplicaSet</rt></ruby>是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
|
||||
|
||||
### 守护进程组 (DaemonSet)
|
||||
### 守护进程组
|
||||
|
||||
上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
|
||||
上面提到 Kubernetes 始终使用标签,还有印象吗?<ruby>守护进程组<rt>DaemonSet</rt></ruby>是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
|
||||
|
||||
例如,你将所有节点增加 `logger` 或 `mission_critical` 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 `logger` 或 `mission_critical` 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
|
||||
|
||||
@ -253,7 +243,7 @@ spec: #(4)
|
||||
|
||||
### Kubernetes 部分小结
|
||||
|
||||
Kubernetes 是容器编排的便捷工具,工作单元为 Pods,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
|
||||
Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
|
||||
|
||||
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:[GitHub 上的 Kubernetes 项目][22]。
|
||||
|
||||
@ -272,7 +262,7 @@ kubectl get nodes -o yaml
|
||||
|
||||
### 构建容器
|
||||
|
||||
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python,NSQ 和 MySQL 使用对应的容器。
|
||||
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
|
||||
|
||||
### 上下文
|
||||
|
||||
@ -293,9 +283,9 @@ Switched to context "kube-face-cluster".
|
||||
```
|
||||
此后,所有 `kubectl` 命令都会使用 `face` 命名空间。
|
||||
|
||||
(译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
|
||||
(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
|
||||
|
||||
### 应用部署
|
||||
## 应用部署
|
||||
|
||||
Pods 和 服务概览:
|
||||
|
||||
@ -318,7 +308,6 @@ type: Opaque
|
||||
data:
|
||||
mysql_password: base64codehere
|
||||
mysql_userpassword: base64codehere
|
||||
|
||||
```
|
||||
|
||||
其中 base64 编码通过如下命令生成:
|
||||
@ -326,10 +315,9 @@ data:
|
||||
```
|
||||
echo -n "ubersecurepassword" | base64
|
||||
echo -n "root:ubersecurepassword" | base64
|
||||
|
||||
```
|
||||
|
||||
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 mysql_password, 仅包含密码;另一条对应 mysql_userpassword,包含用户和密码。后文会用到 mysql_userpassword,但没有提及相应的生成)
|
||||
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
|
||||
|
||||
我的部署 yaml 对应部分如下:
|
||||
|
||||
@ -362,13 +350,12 @@ echo -n "root:ubersecurepassword" | base64
|
||||
|
||||
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储][27]。
|
||||
|
||||
(LCTT 译注:使用 presistentVolumeClain 之前需要创建 presistentVolume,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
|
||||
(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
|
||||
|
||||
使用如下命令部署 MySQL 服务:
|
||||
|
||||
```
|
||||
kubectl apply -f mysql.yaml
|
||||
|
||||
```
|
||||
|
||||
这里比较一下 `create` 和 `apply`。`apply` 是一种<ruby>宣告式<rt>declarative</rt></ruby>的对象配置命令,而 `create` 是<ruby>命令式<rt>imperative</rt>的命令。当下我们需要知道的是,`create` 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 `apply` 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 `mysql` 的服务,当我执行 `apply -f mysql.yaml` 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 `create`,Kubernetes 会报错,告知服务已经创建。
|
||||
@ -460,7 +447,7 @@ volumes:
|
||||
|
||||
```
|
||||
|
||||
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,person_images 表中的 person_id 列数字都小 1,作者默认 id 从 0 开始,但应该是从 1 开始)
|
||||
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,`person_images` 表中的 `person_id` 列数字都小 1,作者默认 `id` 从 0 开始,但应该是从 1 开始)
|
||||
|
||||
运行如下命令查看引导脚本是否正确执行:
|
||||
|
||||
@ -489,7 +476,6 @@ mysql>
|
||||
|
||||
```
|
||||
kubectl logs deployment/mysql -f
|
||||
|
||||
```
|
||||
|
||||
### NSQ 查询
|
||||
@ -505,7 +491,7 @@ NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这
|
||||
|
||||
```
|
||||
|
||||
那么,内部 DNS 对应的条目类似于:`nsqlookup.default.svc.cluster.local`。
|
||||
那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
|
||||
|
||||
无头服务的更多细节,可以参考:[无头服务][32]。
|
||||
|
||||
@ -517,7 +503,7 @@ args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
|
||||
|
||||
```
|
||||
|
||||
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,nsqlookup 使用 `hostname` (LCTT 译注:这里是指容器的主机名,而不是 hostname 字符串本身)作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
|
||||
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
|
||||
|
||||
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
|
||||
|
||||
@ -533,6 +519,7 @@ NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsq
|
||||
```
|
||||
|
||||
服务模板:
|
||||
|
||||
```
|
||||
spec:
|
||||
ports:
|
||||
@ -592,13 +579,13 @@ NSQ 守护进程也需要一些调整的参数配置:
|
||||
|
||||
```
|
||||
|
||||
其中我们配置了 lookup-tcp-address 和 broadcast-address 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
|
||||
其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
|
||||
|
||||
#### 对外公开
|
||||
|
||||
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
|
||||
|
||||
但由于我使用的本地集群只有一个节点,那么使用 `节点端口` 的方式就足够了。`节点端口` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
|
||||
但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
|
||||
|
||||
更多信息,请参考文档:[服务发布][33]。
|
||||
|
||||
@ -643,7 +630,7 @@ spec:
|
||||
|
||||
### 图片处理器
|
||||
|
||||
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd, mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
|
||||
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
|
||||
|
||||
```
|
||||
---
|
||||
@ -781,7 +768,7 @@ curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/
|
||||
|
||||
```
|
||||
|
||||
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 known_foler 文件中找到 unknown220.jpg 对应个人的图片,最后返回匹配图片的名称。
|
||||
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 `known_folder` 文件中找到 `unknown220.jpg` 对应个人的图片,最后返回匹配图片的名称。
|
||||
|
||||
查看日志,大致信息如下:
|
||||
|
||||
@ -861,9 +848,9 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
|
||||
|
||||
```
|
||||
|
||||
### 滚动更新 (Rolling Update)
|
||||
## 滚动更新
|
||||
|
||||
滚动更新过程中会发生什么呢?
|
||||
<ruby>滚动更新<rt>Rolling Update</rt></ruby>过程中会发生什么呢?
|
||||
|
||||
|
||||
|
||||
@ -871,7 +858,7 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
|
||||
|
||||
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
|
||||
|
||||
#### 代码
|
||||
### 代码
|
||||
|
||||
目前,我们使用下面的代码段处理单个图片的情形:
|
||||
|
||||
@ -900,7 +887,7 @@ func main() {
|
||||
|
||||
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
|
||||
|
||||
#### 新的 Endpoint
|
||||
### 新的接口
|
||||
|
||||
让我们添加新的路由方法:
|
||||
|
||||
@ -941,7 +928,7 @@ func PostImage(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
```
|
||||
|
||||
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片 PR][34] 中可以找到更多的修改方式。
|
||||
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片的 PR][34] 中可以找到更多的修改方式。
|
||||
|
||||
至此,我们使用两种方法调用接收器:
|
||||
|
||||
@ -958,7 +945,7 @@ curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/po
|
||||
|
||||
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
|
||||
|
||||
#### 新镜像
|
||||
### 新镜像
|
||||
|
||||
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
|
||||
|
||||
@ -969,11 +956,11 @@ docker build -t skarlso/kube-receiver-alpine:v1.1 .
|
||||
|
||||
新镜像创建后,我们可以开始滚动更新了。
|
||||
|
||||
#### 滚动更新
|
||||
### 滚动更新
|
||||
|
||||
在 Kubernetes 中,可以使用多种方式完成滚动更新。
|
||||
|
||||
##### 手动更新
|
||||
#### 手动更新
|
||||
|
||||
不妨假设在我配置文件中使用的容器版本为 `v1.0`,那么实现滚动更新只需运行如下命令:
|
||||
|
||||
@ -991,7 +978,7 @@ kubectl rolling-update receiver --rollback
|
||||
|
||||
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
|
||||
|
||||
##### 应用新的配置文件
|
||||
#### 应用新的配置文件
|
||||
|
||||
手动更新的不足在于无法版本管理。
|
||||
|
||||
@ -1051,7 +1038,7 @@ kubectl delete services -all
|
||||
|
||||
```
|
||||
|
||||
# 写在最后的话
|
||||
## 写在最后的话
|
||||
|
||||
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
|
||||
|
||||
@ -1065,9 +1052,9 @@ Gergely 感谢你阅读本文。
|
||||
|
||||
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
|
||||
|
||||
作者:[hannibal ][a]
|
||||
作者:[hannibal][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,15 @@
|
||||
我们能否建立一个服务于用户而非广告商的社交网络?
|
||||
=====
|
||||
|
||||
> 找出 Human Connection 是如何将透明度和社区放在首位的。
|
||||
|
||||

|
||||
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的,中立的,透明的在线平台来迎接我们这个时代的挑战。
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
|
||||
|
||||
开放的原则可能会成为让我们到达那里的方法(to 校正者:这句上下文没有理解)。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们自然倾向,于乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
|
||||
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
|
||||
|
||||
@ -15,31 +17,28 @@
|
||||
|
||||
### 首先是透明
|
||||
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript, Vue, nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些对让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team (to 校正者:这里如果可以,请翻译得稍微优雅,我想不出来一个词)活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
|
||||
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
|
||||
|
||||
一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章(UN Charter)][4]和“世界人权宣言(Universal Declaration of Human Rights)”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (译者注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用<ruby>[联合国宪章][4]<rt>UN Charter</rt></ruby>和“<ruby>世界人权宣言<rt>Universal Declaration of Human Rights</rt></ruby>”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
|
||||
### 一个合作的社会
|
||||
|
||||
以一种[以社区为中心的协作方法][5]来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
|
||||
|
||||
一个抛弃了以利润为导向的算法,为广告商而不是最终用户服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并破坏(to 校正:这里译为改变较好)现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学(University Sorbonne)的国家东方语言与文明研究所(National Institute for Oriental Languages and Civilizations (INALCO) )和德国斯图加特媒体大学(Stuttgart Media University )合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动(Take Action)”领域,每个人都可以实现。
|
||||
|
||||
* “Versus” 功能是另一个定义结果的方式(to 校正者:这句话稍微注意一下)。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎<ruby>索邦大学<rt>University Sorbonne</rt></ruby>的<ruby>国家东方语言与文明研究所<rt>National Institute for Oriental Languages and Civilizations</rt></ruby>(INALCO)和德国<ruby>斯图加特媒体大学<rt>Stuttgart Media University</rt></ruby>合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“<ruby>采取行动<rt>Take Action</rt></ruby>”领域,每个人都可以实现。
|
||||
* “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
|
||||
|
||||
|
||||
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
|
||||
|
||||
[订阅我们的每周时事通讯][12]以了解有关开放组织的更多信息。
|
||||
@ -51,7 +50,7 @@ via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,406 @@
|
||||
日常 Python 编程优雅之道
|
||||
======
|
||||
|
||||
> 3 个可以使你的 Python 代码更优雅、可读、直观和易于维护的工具。
|
||||
|
||||

|
||||
|
||||
Python 提供了一组独特的工具和语言特性来使你的代码更加优雅、可读和直观。为正确的问题选择合适的工具,你的代码将更易于维护。在本文中,我们将研究其中的三个工具:魔术方法、迭代器和生成器,以及方法魔术。
|
||||
|
||||
### 魔术方法
|
||||
|
||||
魔术方法可以看作是 Python 的管道。它们被称为“底层”方法,用于某些内置的方法、符号和操作。你可能熟悉的常见魔术方法是 `__init__()`,当我们想要初始化一个类的新实例时,它会被调用。
|
||||
|
||||
你可能已经看过其他常见的魔术方法,如 `__str__` 和 `__repr__`。Python 中有一整套魔术方法,通过实现其中的一些方法,我们可以修改一个对象的行为,甚至使其行为类似于内置数据类型,例如数字、列表或字典。
|
||||
|
||||
让我们创建一个 `Money` 类来示例:
|
||||
|
||||
```
|
||||
class Money:
|
||||
|
||||
currency_rates = {
|
||||
'$': 1,
|
||||
'€': 0.88,
|
||||
}
|
||||
|
||||
def __init__(self, symbol, amount):
|
||||
self.symbol = symbol
|
||||
self.amount = amount
|
||||
|
||||
def __repr__(self):
|
||||
return '%s%.2f' % (self.symbol, self.amount)
|
||||
|
||||
def convert(self, other):
|
||||
""" Convert other amount to our currency """
|
||||
new_amount = (
|
||||
other.amount / self.currency_rates[other.symbol]
|
||||
* self.currency_rates[self.symbol])
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
```
|
||||
|
||||
该类定义为给定的货币符号和汇率定义了一个货币汇率,指定了一个初始化器(也称为构造函数),并实现 `__repr__`,因此当我们打印这个类时,我们会看到一个友好的表示,例如 `$2.00` ,这是一个带有货币符号和金额的 `Money('$', 2.00)` 实例。最重要的是,它定义了一种方法,允许你使用不同的汇率在不同的货币之间进行转换。
|
||||
|
||||
打开 Python shell,假设我们已经定义了使用两种不同货币的食品的成本,如下所示:
|
||||
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
>>> soda_cost
|
||||
$5.25
|
||||
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
>>> pizza_cost
|
||||
€7.99
|
||||
```
|
||||
|
||||
我们可以使用魔术方法使得这个类的实例之间可以相互交互。假设我们希望能够将这个类的两个实例一起加在一起,即使它们是不同的货币。为了实现这一点,我们可以在 `Money` 类上实现 `__add__` 这个魔术方法:
|
||||
|
||||
```
|
||||
class Money:
|
||||
|
||||
# ... previously defined methods ...
|
||||
|
||||
def __add__(self, other):
|
||||
""" Add 2 Money instances using '+' """
|
||||
new_amount = self.amount + self.convert(other).amount
|
||||
return Money(self.symbol, new_amount)
|
||||
```
|
||||
|
||||
现在我们可以以非常直观的方式使用这个类:
|
||||
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
>>> soda_cost + pizza_cost
|
||||
$14.33
|
||||
>>> pizza_cost + soda_cost
|
||||
€12.61
|
||||
```
|
||||
|
||||
当我们将两个实例加在一起时,我们得到以第一个定义的货币符号所表示的结果。所有的转换都是在底层无缝完成的。如果我们想的话,我们也可以为减法实现 `__sub__`,为乘法实现 `__mul__` 等等。阅读[模拟数字类型][1]或[魔术方法指南][2]来获得更多信息。
|
||||
|
||||
我们学习到 `__add__` 映射到内置运算符 `+`。其他魔术方法可以映射到像 `[]` 这样的符号。例如,在字典中通过索引或键来获得一项,其实是使用了 `__getitem__` 方法:
|
||||
|
||||
```
|
||||
>>> d = {'one': 1, 'two': 2}
|
||||
>>> d['two']
|
||||
2
|
||||
>>> d.__getitem__('two')
|
||||
2
|
||||
```
|
||||
|
||||
一些魔术方法甚至映射到内置函数,例如 `__len__()` 映射到 `len()`。
|
||||
|
||||
```
|
||||
class Alphabet:
|
||||
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
|
||||
|
||||
def __len__(self):
|
||||
return len(self.letters)
|
||||
|
||||
>>> my_alphabet = Alphabet()
|
||||
>>> len(my_alphabet)
|
||||
26
|
||||
```
|
||||
|
||||
### 自定义迭代器
|
||||
|
||||
对于新的和经验丰富的 Python 开发者来说,自定义迭代器是一个非常强大的但令人迷惑的主题。
|
||||
|
||||
许多内置类型,例如列表、集合和字典,已经实现了允许它们在底层迭代的协议。这使我们可以轻松地遍历它们。
|
||||
|
||||
```
|
||||
>>> for food in ['Pizza', 'Fries']:
|
||||
|
||||
print(food + '. Yum!')
|
||||
|
||||
Pizza. Yum!
|
||||
Fries. Yum!
|
||||
```
|
||||
|
||||
我们如何迭代我们自己的自定义类?首先,让我们来澄清一些术语。
|
||||
|
||||
* 要成为一个可迭代对象,一个类需要实现 `__iter__()`
|
||||
* `__iter__()` 方法需要返回一个迭代器
|
||||
* 要成为一个迭代器,一个类需要实现 `__next__()`(或[在 Python 2][3]中是 `next()`),当没有更多的项要迭代时,必须抛出一个 `StopIteration` 异常。
|
||||
|
||||
呼!这听起来很复杂,但是一旦你记住了这些基本概念,你就可以在任何时候进行迭代。
|
||||
|
||||
我们什么时候想使用自定义迭代器?让我们想象一个场景,我们有一个 `Server` 实例在不同的端口上运行不同的服务,如 `http` 和 `ssh`。其中一些服务处于 `active` 状态,而其他服务则处于 `inactive` 状态。
|
||||
|
||||
```
|
||||
class Server:
|
||||
|
||||
services = [
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
{'active': True, 'protocol': 'http', 'port': 80},
|
||||
]
|
||||
```
|
||||
|
||||
当我们遍历 `Server` 实例时,我们只想遍历那些处于 `active` 的服务。让我们创建一个 `IterableServer` 类:
|
||||
|
||||
```
|
||||
class IterableServer:
|
||||
def __init__(self):
|
||||
self.current_pos = 0
|
||||
def __next__(self):
|
||||
pass # TODO: 实现并记得抛出 StopIteration
|
||||
```
|
||||
|
||||
首先,我们将当前位置初始化为 `0`。然后,我们定义一个 `__next__()` 方法来返回下一项。我们还将确保在没有更多项返回时抛出 `StopIteration`。到目前为止都很好!现在,让我们实现这个 `__next__()` 方法。
|
||||
|
||||
```
|
||||
class IterableServer:
|
||||
def __init__(self):
|
||||
self.current_pos = 0. # 我们初始化当前位置为 0
|
||||
def __iter__(self): # 我们可以在这里返回 self,因为实现了 __next__
|
||||
return self
|
||||
def __next__(self):
|
||||
while self.current_pos < len(self.services):
|
||||
service = self.services[self.current_pos]
|
||||
self.current_pos += 1
|
||||
if service['active']:
|
||||
return service['protocol'], service['port']
|
||||
raise StopIteration
|
||||
next = __next__ # 可选的 Python2 兼容性
|
||||
```
|
||||
|
||||
我们对列表中的服务进行遍历,而当前的位置小于服务的个数,但只有在服务处于活动状态时才返回。一旦我们遍历完服务,就会抛出一个 `StopIteration` 异常。
|
||||
|
||||
|
||||
因为我们实现了 `__next__()` 方法,当它耗尽时,它会抛出 `StopIteration`。我们可以从 `__iter__()` 返回 `self`,因为 `IterableServer` 类遵循 `iterable` 协议。
|
||||
|
||||
现在我们可以遍历一个 `IterableServer` 实例,这将允许我们查看每个处于活动的服务,如下所示:
|
||||
|
||||
```
|
||||
>>> for protocol, port in IterableServer():
|
||||
|
||||
print('service %s is running on port %d' % (protocol, port))
|
||||
|
||||
service ssh is running on port 22
|
||||
|
||||
service http is running on port 21
|
||||
|
||||
```
|
||||
|
||||
太棒了,但我们可以做得更好!在这样类似的实例中,我们的迭代器不需要维护大量的状态,我们可以简化代码并使用 [generator(生成器)][4] 来代替。
|
||||
|
||||
```
|
||||
class Server:
|
||||
services = [
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
{'active': True, 'protocol': 'http', 'port': 21},
|
||||
]
|
||||
def __iter__(self):
|
||||
for service in self.services:
|
||||
if service['active']:
|
||||
yield service['protocol'], service['port']
|
||||
```
|
||||
|
||||
`yield` 关键字到底是什么?在定义生成器函数时使用 yield。这有点像 `return`,虽然 `return` 在返回值后退出函数,但 `yield` 会暂停执行直到下次调用它。这允许你的生成器的功能在它恢复之前保持状态。查看 [yield 的文档][5]以了解更多信息。使用生成器,我们不必通过记住我们的位置来手动维护状态。生成器只知道两件事:它现在需要做什么以及计算下一个项目需要做什么。一旦我们到达执行点,即 `yield` 不再被调用,我们就知道停止迭代。
|
||||
|
||||
这是因为一些内置的 Python 魔法。在 [Python 关于 `__iter__()` 的文档][6]中我们可以看到,如果 `__iter__()` 是作为一个生成器实现的,它将自动返回一个迭代器对象,该对象提供 `__iter__()` 和 `__next__()` 方法。阅读这篇很棒的文章,深入了解[迭代器,可迭代对象和生成器][7]。
|
||||
|
||||
### 方法魔法
|
||||
|
||||
由于其独特的方面,Python 提供了一些有趣的方法魔法作为语言的一部分。
|
||||
|
||||
其中一个例子是别名功能。因为函数只是对象,所以我们可以将它们赋值给多个变量。例如:
|
||||
|
||||
```
|
||||
>>> def foo():
|
||||
return 'foo'
|
||||
>>> foo()
|
||||
'foo'
|
||||
>>> bar = foo
|
||||
>>> bar()
|
||||
'foo'
|
||||
```
|
||||
|
||||
我们稍后会看到它的作用。
|
||||
|
||||
Python 提供了一个方便的内置函数[称为 `getattr()`][8],它接受 `object, name, default` 参数并在 `object` 上返回属性 `name`。这种编程方式允许我们访问实例变量和方法。例如:
|
||||
|
||||
```
|
||||
>>> class Dog:
|
||||
sound = 'Bark'
|
||||
def speak(self):
|
||||
print(self.sound + '!', self.sound + '!')
|
||||
|
||||
>>> fido = Dog()
|
||||
|
||||
>>> fido.sound
|
||||
'Bark'
|
||||
>>> getattr(fido, 'sound')
|
||||
'Bark'
|
||||
|
||||
>>> fido.speak
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
>>> getattr(fido, 'speak')
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
|
||||
|
||||
>>> fido.speak()
|
||||
Bark! Bark!
|
||||
>>> speak_method = getattr(fido, 'speak')
|
||||
>>> speak_method()
|
||||
Bark! Bark!
|
||||
```
|
||||
|
||||
这是一个很酷的技巧,但是我们如何在实际中使用 `getattr` 呢?让我们看一个例子,我们编写一个小型命令行工具来动态处理命令。
|
||||
|
||||
```
|
||||
class Operations:
|
||||
def say_hi(self, name):
|
||||
print('Hello,', name)
|
||||
def say_bye(self, name):
|
||||
print ('Goodbye,', name)
|
||||
def default(self, arg):
|
||||
print ('This operation is not supported.')
|
||||
|
||||
if __name__ == '__main__':
|
||||
operations = Operations()
|
||||
# 假设我们做了错误处理
|
||||
command, argument = input('> ').split()
|
||||
func_to_call = getattr(operations, command, operations.default)
|
||||
func_to_call(argument)
|
||||
```
|
||||
|
||||
脚本的输出是:
|
||||
|
||||
```
|
||||
$ python getattr.py
|
||||
> say_hi Nina
|
||||
Hello, Nina
|
||||
> blah blah
|
||||
This operation is not supported.
|
||||
```
|
||||
|
||||
接下来,我们来看看 `partial`。例如,`functool.partial(func, *args, **kwargs)` 允许你返回一个新的 [partial 对象][9],它的行为类似 `func`,参数是 `args` 和 `kwargs`。如果传入更多的 `args`,它们会被附加到 `args`。如果传入更多的 `kwargs`,它们会扩展并覆盖 `kwargs`。让我们通过一个简短的例子来看看:
|
||||
|
||||
```
|
||||
>>> from functools import partial
|
||||
>>> basetwo = partial(int, base=2)
|
||||
>>> basetwo
|
||||
<functools.partial object at 0x1085a09f0>
|
||||
>>> basetwo('10010')
|
||||
18
|
||||
|
||||
# 这等同于
|
||||
>>> int('10010', base=2)
|
||||
```
|
||||
|
||||
让我们看看在我喜欢的一个[名为 `agithub`][10] 的库中的一些示例代码中,这个方法魔术是如何结合在一起的,这是一个(名字起得很 low 的) REST API 客户端,它具有透明的语法,允许你以最小的配置快速构建任何 REST API 原型(不仅仅是 GitHub)。我发现这个项目很有趣,因为它非常强大,但只有大约 400 行 Python 代码。你可以在大约 30 行配置代码中添加对任何 REST API 的支持。`agithub` 知道协议所需的一切(`REST`、`HTTP`、`TCP`),但它不考虑上游 API。让我们深入到它的实现中。
|
||||
|
||||
以下是我们如何为 GitHub API 和任何其他相关连接属性定义端点 URL 的简化版本。在这里查看[完整代码][11]。
|
||||
|
||||
```
|
||||
class GitHub(API):
|
||||
def __init__(self, token=None, *args, **kwargs):
|
||||
props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
|
||||
self.setClient(Client(*args, **kwargs))
|
||||
self.setConnectionProperties(props)
|
||||
```
|
||||
|
||||
然后,一旦配置了[访问令牌][12],就可以开始使用 [GitHub API][13]。
|
||||
|
||||
```
|
||||
>>> gh = GitHub('token')
|
||||
>>> status, data = gh.user.repos.get(visibility='public', sort='created')
|
||||
>>> # ^ 映射到 GET /user/repos
|
||||
>>> data
|
||||
... ['tweeter', 'snipey', '...']
|
||||
```
|
||||
|
||||
请注意,你要确保 URL 拼写正确,因为我们没有验证 URL。如果 URL 不存在或出现了其他任何错误,将返回 API 抛出的错误。那么,这一切是如何运作的呢?让我们找出答案。首先,我们将查看一个 [`API` 类][14]的简化示例:
|
||||
|
||||
```
|
||||
class API:
|
||||
# ... other methods ...
|
||||
def __getattr__(self, key):
|
||||
return IncompleteRequest(self.client).__getattr__(key)
|
||||
__getitem__ = __getattr__
|
||||
```
|
||||
|
||||
在 `API` 类上的每次调用都会调用 [`IncompleteRequest` 类][15]作为指定的 `key`。
|
||||
|
||||
```
|
||||
class IncompleteRequest:
|
||||
# ... other methods ...
|
||||
def __getattr__(self, key):
|
||||
if key in self.client.http_methods:
|
||||
htmlMethod = getattr(self.client, key)
|
||||
return partial(htmlMethod, url=self.url)
|
||||
else:
|
||||
self.url += '/' + str(key)
|
||||
return self
|
||||
__getitem__ = __getattr__
|
||||
|
||||
class Client:
|
||||
http_methods = ('get') # 还有 post, put, patch 等等。
|
||||
def get(self, url, headers={}, **params):
|
||||
return self.request('GET', url, None, headers)
|
||||
```
|
||||
|
||||
如果最后一次调用不是 HTTP 方法(如 `get`、`post` 等),则返回带有附加路径的 `IncompleteRequest`。否则,它从[`Client` 类][16]获取 HTTP 方法对应的正确函数,并返回 `partial`。
|
||||
|
||||
如果我们给出一个不存在的路径会发生什么?
|
||||
|
||||
```
|
||||
>>> status, data = this.path.doesnt.exist.get()
|
||||
>>> status
|
||||
... 404
|
||||
```
|
||||
|
||||
因为 `__getattr__` 别名为 `__getitem__`:
|
||||
|
||||
```
|
||||
>>> owner, repo = 'nnja', 'tweeter'
|
||||
>>> status, data = gh.repos[owner][repo].pulls.get()
|
||||
>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
|
||||
>>> data
|
||||
.... # {....}
|
||||
```
|
||||
|
||||
这真心是一些方法魔术!
|
||||
|
||||
### 了解更多
|
||||
|
||||
Python 提供了大量工具,使你的代码更优雅,更易于阅读和理解。挑战在于找到合适的工具来完成工作,但我希望本文为你的工具箱添加了一些新工具。而且,如果你想更进一步,你可以在我的博客 [nnja.io][17] 上阅读有关装饰器、上下文管理器、上下文生成器和命名元组的内容。随着你成为一名更好的 Python 开发人员,我鼓励你到那里阅读一些设计良好的项目的源代码。[Requests][18] 和 [Flask][19] 是两个很好的起步的代码库。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems
|
||||
|
||||
作者:[Nina Zakharenko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nnja
|
||||
[1]:https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types
|
||||
[2]:https://rszalski.github.io/magicmethods/
|
||||
[3]:https://docs.python.org/2/library/stdtypes.html#iterator.next
|
||||
[4]:https://docs.python.org/3/library/stdtypes.html#generator-types
|
||||
[5]:https://docs.python.org/3/reference/expressions.html#yieldexpr
|
||||
[6]:https://docs.python.org/3/reference/datamodel.html#object.__iter__
|
||||
[7]:http://nvie.com/posts/iterators-vs-generators/
|
||||
[8]:https://docs.python.org/3/library/functions.html#getattr
|
||||
[9]:https://docs.python.org/3/library/functools.html#functools.partial
|
||||
[10]:https://github.com/mozilla/agithub
|
||||
[11]:https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py
|
||||
[12]:https://github.com/settings/tokens
|
||||
[13]:https://developer.github.com/v3/repos/#list-your-repositories
|
||||
[14]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58
|
||||
[15]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100
|
||||
[16]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231
|
||||
[17]:http://nnja.io
|
||||
[18]:https://github.com/requests/requests
|
||||
[19]:https://github.com/pallets/flask
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/164/
|
||||
[21]:https://us.pycon.org/2018/
|
||||
@ -0,0 +1,134 @@
|
||||
如何轻松地检查 Ubuntu 版本以及其它系统信息
|
||||
======
|
||||
|
||||
> 摘要:想知道你正在使用的 Ubuntu 具体是什么版本吗?这篇文档将告诉你如何检查你的 Ubuntu 版本、桌面环境以及其他相关的系统信息。
|
||||
|
||||
通常,你能非常容易的通过命令行或者图形界面获取你正在使用的 Ubuntu 的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的 Ubuntu 确切的版本号、桌面环境以及其他的系统信息将是尤为重要的。
|
||||
|
||||
在这篇简短的文章中,作者将展示各种检查 [Ubuntu][1] 版本以及其他常用的系统信息的方法。
|
||||
|
||||
### 如何在命令行检查 Ubuntu 版本
|
||||
|
||||
这个是获得 Ubuntu 版本的最好的办法。我本想先展示如何用图形界面做到这一点,但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何[桌面环境][2]。 你可以在 Ubuntu 的任何变种系统上使用这种方法。
|
||||
|
||||
打开你的命令行终端 (`Ctrl+Alt+T`), 键入下面的命令:
|
||||
|
||||
```
|
||||
lsb_release -a
|
||||
```
|
||||
|
||||
上面命令的输出应该如下:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.4 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][3]
|
||||
|
||||
正像你所看到的,当前我的系统安装的 Ubuntu 版本是 Ubuntu 16.04, 版本代号: Xenial。
|
||||
|
||||
且慢!为什么版本描述中显示的是 Ubuntu 16.04.4 而发行版本是 16.04?到底哪个才是正确的版本?16.04 还是 16.04.4? 这两者之间有什么区别?
|
||||
|
||||
如果言简意赅的回答这个问题的话,那么答案应该是你正在使用 Ubuntu 16.04。这个是基准版本,而 16.04.4 进一步指明这是 16.04 的第四个补丁版本。你可以将补丁版本理解为 Windows 世界里的服务包。在这里,16.04 和 16.04.4 都是正确的版本号。
|
||||
|
||||
那么输出的 Xenial 又是什么?那正是 Ubuntu 16.04 的版本代号。你可以阅读下面这篇文章获取更多信息:[了解 Ubuntu 的命名惯例][4]。
|
||||
|
||||
#### 其他一些获取 Ubuntu 版本的方法
|
||||
|
||||
你也可以使用下面任意的命令得到 Ubuntu 的版本:
|
||||
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
```
|
||||
|
||||
输出如下信息:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][5]
|
||||
|
||||
|
||||
你还可以使用下面的命令来获得 Ubuntu 版本:
|
||||
|
||||
```
|
||||
cat /etc/issue
|
||||
```
|
||||
|
||||
|
||||
命令行的输出将会如下:
|
||||
|
||||
```
|
||||
Ubuntu 16.04.4 LTS \n \l
|
||||
```
|
||||
|
||||
不要介意输出末尾的\n \l. 这里 Ubuntu 版本就是 16.04.4,或者更加简单:16.04。
|
||||
|
||||
|
||||
### 如何在图形界面下得到 Ubuntu 版本
|
||||
|
||||
在图形界面下获取 Ubuntu 版本更是小事一桩。这里我使用了 Ubuntu 18.04 的图形界面系统 GNOME 的屏幕截图来展示如何做到这一点。如果你在使用 Unity 或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
|
||||
|
||||
下面我来展示如何在桌面环境获取 Ubuntu 版本。
|
||||
|
||||
进入‘系统设置’并点击下面的‘详细信息’栏。
|
||||
|
||||
![Finding Ubuntu version graphically][6]
|
||||
|
||||
你将会看到系统的 Ubuntu 版本和其他和桌面系统有关的系统信息 这里的截图来自 [GNOME][7] 。
|
||||
|
||||
![Finding Ubuntu version graphically][8]
|
||||
|
||||
### 如何知道桌面环境以及其他的系统信息
|
||||
|
||||
你刚才学习的是如何得到 Ubuntu 的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的 Linux 内核版本呢?
|
||||
|
||||
有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做 [Neofetch][9]。 这个工具能在命令行完美展示系统信息,包括 Ubuntu 或者其他 Linux 发行版的系统图标。
|
||||
|
||||
用下面的命令安装 Neofetch:
|
||||
|
||||
```
|
||||
sudo apt install neofetch
|
||||
```
|
||||
|
||||
安装成功后,运行 `neofetch` 将会优雅的展示系统的信息如下。
|
||||
|
||||
![System information in Linux terminal][10]
|
||||
|
||||
如你所见,`neofetch` 完全展示了 Linux 内核版本、Ubuntu 的版本、桌面系统版本以及环境、主题和图标等等信息。
|
||||
|
||||
|
||||
希望我如上展示方法能帮到你更快的找到你正在使用的 Ubuntu 版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
|
||||
|
||||
再见。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
|
||||
[4]:https://itsfoss.com/linux-code-names/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
|
||||
[7]:https://www.gnome.org/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
|
||||
[9]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
|
||||
@ -2,7 +2,8 @@ Android 工程师的一年
|
||||
============================================================
|
||||
|
||||

|
||||
>妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
> 这幅妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
我的技术生涯,从两年前算起。开始是 QA 测试员,一年后就转入开发人员角色。没怎么努力,也没有投入过多的个人时间。
|
||||
|
||||
@ -12,7 +13,7 @@ Android 工程师的一年
|
||||
|
||||
我的第一个职位角色, Android 开发者,开始于一年前。我工作的这家公司,可以花一半的时间去尝试其它角色的工作,这给我从 QA 职位转到 Android 开发者职位创造了机会。
|
||||
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了[ Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了[ Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了 [Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了 [Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
|
||||
两个月后,公司雇佣了另一位 QA,我转向全职工作。挑战从此开始!
|
||||
|
||||
@ -46,29 +47,27 @@ Android 工程师的一年
|
||||
|
||||
一个例子就是拉取代码进行公开展示和代码审查。有是我会请同事私下检查我的代码,并不想被公开拉取,向任何人展示。
|
||||
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着"批准"按纽犹豫不决,在担心审查通过的会被其他同事找出毛病。
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着“批准”按纽犹豫不决,在担心审查通过的代码会被其他同事找出毛病。
|
||||
|
||||
当我在一些事上持反对意见时,由于缺乏相关知识,担心被坐冷板凳,从来没有大声说出来过。
|
||||
|
||||
> 某些时间我会请同事私下[...]检查我的代码,以避免被公开展示。
|
||||
|
||||
* * *
|
||||
|
||||
### 新的公司,新的挑战
|
||||
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被[ Babbel ][7]邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被 [Babbel][7] 邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
|
||||
我见到了他们的团队,同时自告奋勇的在他们办公室主持了一次本地会议。此事让我下定决心要申请这个职位。我喜欢公司的箴言:全民学习。其次,公司每个人都非常友善,在那儿工作看起来很愉快!但我没有马上申请,因为我认为自己不够好,所以为什么能申请呢?
|
||||
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的应该程序来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的程序的形式来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
|
||||
#### 招聘过程
|
||||
|
||||
我用周未的时间来完成编码挑战的项目,并在周一就立即发送过去。不久就受邀去当场面试。
|
||||
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的地方、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
|
||||
最后,通过面试,得到 offer, 我授受了!
|
||||
最后,通过面试,得到 offer,我授受了!
|
||||
|
||||
我的 Android 工程师生涯的第一年,有九个月在一个公司,后面三个月在当前的公司。
|
||||
|
||||
@ -88,7 +87,7 @@ Android 工程师的一年
|
||||
|
||||
两次三次后,压力就堵到胸口。为什么我还不知道?为什么就那么难理解?这种状态让我焦虑万分。
|
||||
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有是,仅仅需要的就是更多的时间、更多的练习,最终会"在大脑中完全演绎" :-)
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有时,仅仅需要的就是更多的时间、更多的练习,最终会“在大脑中完全演绎” :-)
|
||||
|
||||
例如,我常常为 Java 的接口类和抽象类所困扰,不管看了多少的例子,还是不能完全明白他们之间的区别。但一旦我使用后,即使还不能解释其工作原理,也知道了怎么使用以及什么时候使用。
|
||||
|
||||
@ -102,19 +101,13 @@ Android 工程师的一年
|
||||
|
||||
工程师的角色不仅仅是编码,而是广泛的技能。 我仍然处于旅程的起点,在掌握它的道路上,我想着重于以下几点:
|
||||
|
||||
* 交流:因为英文不是我的母语,所以有的时候我会努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
|
||||
* 提有建设性的反馈意见: 我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
|
||||
* 为我的成就感到骄傲: 我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
|
||||
* 不要着迷于不知道的事情: 当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
|
||||
* 多和同事分享知识。我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
|
||||
* 耐心和持续学习: 和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
|
||||
* 自我保健: 随时注意休息,不要为难自己。 放松也富有成效。
|
||||
* 交流:因为英文不是我的母语,所以有的时候我需要努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
* 提有建设性的反馈意见:我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
* 为我的成就感到骄傲:我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
* 不要着迷于不知道的事情:当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
* 多和同事分享知识:我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
* 耐心和持续学习:和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
* 自我保健:随时注意休息,不要为难自己。 放松也富有成效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -122,7 +115,7 @@ via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
|
||||
|
||||
作者:[Lara Martín][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,90 @@
|
||||
使用 Xenlism 主题对你的 Linux 桌面进行令人惊叹的改造
|
||||
============================================================
|
||||
|
||||
> 简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约的壁纸,将你的 Linux 桌面转变为引人注目的操作系统。
|
||||
|
||||
除非我找到一些非常棒的东西,否则我不会每天都把整篇文章献给一个主题。我曾经经常发布主题和图标。但最近,我更喜欢列出[最佳 GTK 主题][6]和图标主题。这对我和你来说都更方便,你可以在一个地方看到许多美丽的主题。
|
||||
|
||||
在 [Pop OS 主题][7]套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。
|
||||
|
||||

|
||||
|
||||
Xenlism GTK 主题基于 Arc 主题,其得益于许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既不特别喜欢,也没有特别不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
|
||||
|
||||
Xenlism 套件中有两个图标主题。Xenlism Wildfire 是以前的,已经进入我们的[最佳图标主题][8]列表。
|
||||
|
||||

|
||||
|
||||
*Xenlism Wildfire 图标*
|
||||
|
||||
Xenlsim Storm 是一个相对较新的图标主题,但同样美观。
|
||||
|
||||

|
||||
|
||||
*Xenlism Storm 图标*
|
||||
|
||||
Xenlism 主题在 GPL 许可下开源。
|
||||
|
||||
### 如何在 Ubuntu 18.04 上安装 Xenlism 主题包
|
||||
|
||||
Xenlism 开发提供了一种通过 PPA 安装主题包的更简单方法。尽管 PPA 可用于 Ubuntu 16.04,但我发现 GTK 主题不适用于 Unity。它适用于 Ubuntu 18.04 中的 GNOME 桌面。
|
||||
|
||||
打开终端(`Ctrl+Alt+T`)并逐个使用以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:xenatt/xenlism
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
该 PPA 提供四个包:
|
||||
|
||||
* xenlism-finewalls:一组壁纸,可直接在 Ubuntu 的壁纸中使用。截图中使用了其中一个壁纸。
|
||||
* xenlism-minimalism-theme:GTK 主题
|
||||
* xenlism-storm:一个图标主题(见前面的截图)
|
||||
* xenlism-wildfire-icon-theme:具有多种颜色变化的另一个图标主题(文件夹颜色在变体中更改)
|
||||
|
||||
你可以自己决定要安装的主题组件。就个人而言,我认为安装所有组件没有任何损害。
|
||||
|
||||
```
|
||||
sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
|
||||
```
|
||||
|
||||
你可以使用 GNOME Tweaks 来更改主题和图标。如果你不熟悉该过程,我建议你阅读本教程以学习[如何在 Ubuntu 18.04 GNOME 中安装主题][9]。
|
||||
|
||||
### 在其他 Linux 发行版中获取 Xenlism 主题
|
||||
|
||||
你也可以在其他 Linux 发行版上安装 Xenlism 主题。各种 Linux 发行版的安装说明可在其网站上找到:
|
||||
|
||||
[安装 Xenlism 主题][10]
|
||||
|
||||
### 你怎么看?
|
||||
|
||||
我知道不是每个人都会同意我,但我喜欢这个主题。我想你将来会在 It's FOSS 的教程中会看到 Xenlism 主题的截图。
|
||||
|
||||
你喜欢 Xenlism 主题吗?如果不喜欢,你最喜欢什么主题?在下面的评论部分分享你的意见。
|
||||
|
||||
### 关于作者
|
||||
|
||||
我是一名专业软件开发人员,也是 It's FOSS 的创始人。我是一名狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信分享知识。除了Linux,我喜欢经典侦探之谜。我是 Agatha Christie 作品的忠实粉丝。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/xenlism-theme/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/xenlism-theme/#comments
|
||||
[3]:https://itsfoss.com/category/desktop/
|
||||
[4]:https://itsfoss.com/tag/themes/
|
||||
[5]:https://itsfoss.com/tag/xenlism/
|
||||
[6]:https://itsfoss.com/best-gtk-themes/
|
||||
[7]:https://itsfoss.com/pop-icon-gtk-theme-ubuntu/
|
||||
[8]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[9]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[10]:http://xenlism.github.io/minimalism/#install
|
||||
246
published/201807/20180522 How to Run Your Own Git Server.md
Normal file
246
published/201807/20180522 How to Run Your Own Git Server.md
Normal file
@ -0,0 +1,246 @@
|
||||
搭建属于你自己的 Git 服务器
|
||||
======
|
||||
|
||||
|
||||
|
||||
> 在本文中,我们的目的是让你了解如何设置属于自己的Git服务器。
|
||||
|
||||
[Git][1] 是由 [Linux Torvalds 开发][2]的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。[根据报道,GitHub 是现如今全世界最大的代码托管网站][3]。GitHub 宣称已经有 920 万用户和 2180 万个仓库。许多大型公司现如今也将代码迁移到 GitHub 上。[甚至于谷歌,一家搜索引擎公司,也正将代码迁移到 GitHub 上][4]。
|
||||
|
||||
### 运行你自己的 Git 服务器
|
||||
|
||||
GitHub 能提供极佳的服务,但却有一些限制,尤其是你是单人或是一名 coding 爱好者。GitHub 其中之一的限制就是其中免费的服务没有提供代码私有托管业务。[你不得不支付每月 7 美金购买 5 个私有仓库][5],并且想要更多的私有仓库则要交更多的钱。
|
||||
|
||||
万一你想要私有仓库或需要更多权限控制,最好的方法就是在你的服务器上运行 Git。不仅你能够省去一笔钱,你还能够在你的服务器有更多的操作。在大多数情况下,大多数高级 Linux 用户已经拥有自己的服务器,并且在这些服务器上方式 Git 就像“啤酒一样免费”(LCTT 译注:指免费软件)。
|
||||
|
||||
在这篇教程中,我们主要讲在你的服务器上,使用两种代码管理的方法。一种是运行一个纯 Git 服务器,另一个是使用名为 [GitLab][6] 的 GUI 工具。在本教程中,我在 VPS 上运行的操作系统是 Ubuntu 14.04 LTS。
|
||||
|
||||
### 在你的服务器上安装 Git
|
||||
|
||||
在本篇教程中,我们考虑一个简单案例,我们有一个远程服务器和一台本地服务器,现在我们需要使用这两台机器来工作。为了简单起见,我们就分别叫它们为远程服务器和本地服务器。
|
||||
|
||||
首先,在两边的机器上安装 Git。你可以从依赖包中安装 Git,在本文中,我们将使用更简单的方法:
|
||||
|
||||
```
|
||||
sudo apt-get install git-core
|
||||
```
|
||||
|
||||
为 Git 创建一个用户。
|
||||
|
||||
```
|
||||
sudo useradd git
|
||||
passwd git
|
||||
```
|
||||
|
||||
为了容易的访问服务器,我们设置一个免密 ssh 登录。首先在你本地电脑上创建一个 ssh 密钥:
|
||||
|
||||
```
|
||||
ssh-keygen -t rsa
|
||||
```
|
||||
|
||||
这时会要求你输入保存密钥的路径,这时只需要点击回车保存在默认路径。第二个问题是输入访问远程服务器所需的密码。它生成两个密钥——公钥和私钥。记下您在下一步中需要使用的公钥的位置。
|
||||
|
||||
现在您必须将这些密钥复制到服务器上,以便两台机器可以相互通信。在本地机器上运行以下命令:
|
||||
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
现在,用 `ssh` 登录进服务器并为 Git 创建一个项目路径。你可以为你的仓库设置一个你想要的目录。
|
||||
|
||||
现在跳转到该目录中:
|
||||
|
||||
```
|
||||
cd /home/swapnil/project-1.git
|
||||
```
|
||||
|
||||
现在新建一个空仓库:
|
||||
|
||||
```
|
||||
git init --bare
|
||||
Initialized empty Git repository in /home/swapnil/project-1.git
|
||||
```
|
||||
|
||||
现在我们需要在本地机器上新建一个基于 Git 版本控制仓库:
|
||||
|
||||
```
|
||||
mkdir -p /home/swapnil/git/project
|
||||
```
|
||||
|
||||
进入我们创建仓库的目录:
|
||||
|
||||
```
|
||||
cd /home/swapnil/git/project
|
||||
```
|
||||
|
||||
现在在该目录中创建项目所需的文件。留在这个目录并启动 `git`:
|
||||
|
||||
```
|
||||
git init
|
||||
Initialized empty Git repository in /home/swapnil/git/project
|
||||
```
|
||||
|
||||
把所有文件添加到仓库中:
|
||||
|
||||
```
|
||||
git add .
|
||||
```
|
||||
|
||||
现在,每次添加文件或进行更改时,都必须运行上面的 `add` 命令。 您还需要为每个文件更改都写入提交消息。提交消息基本上说明了我们所做的更改。
|
||||
|
||||
```
|
||||
git commit -m "message" -a
|
||||
[master (root-commit) 57331ee] message
|
||||
2 files changed, 2 insertions(+)
|
||||
create mode 100644 GoT.txt
|
||||
create mode 100644 writing.txt
|
||||
```
|
||||
|
||||
在这种情况下,我有一个名为 GoT(《权力的游戏》的点评)的文件,并且我做了一些更改,所以当我运行命令时,它指定对文件进行更改。 在上面的命令中 `-a` 选项意味着提交仓库中的所有文件。 如果您只更改了一个,则可以指定该文件的名称而不是使用 `-a`。
|
||||
|
||||
举一个例子:
|
||||
|
||||
```
|
||||
git commit -m "message" GoT.txt
|
||||
[master e517b10] message
|
||||
1 file changed, 1 insertion(+)
|
||||
```
|
||||
|
||||
到现在为止,我们一直在本地服务器上工作。现在我们必须将这些更改推送到远程服务器上,以便通过互联网访问,并且可以与其他团队成员进行协作。
|
||||
|
||||
```
|
||||
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
|
||||
```
|
||||
|
||||
现在,您可以使用 `pull` 或 `push` 选项在服务器和本地计算机之间推送或拉取:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
如果有其他团队成员想要使用该项目,则需要将远程服务器上的仓库克隆到其本地计算机上:
|
||||
|
||||
```
|
||||
git clone git@remote-server:/home/swapnil/project.git
|
||||
```
|
||||
|
||||
这里 `/home/swapnil/project.git` 是远程服务器上的项目路径,在你本机上则会改变。
|
||||
|
||||
然后进入本地计算机上的目录(使用服务器上的项目名称):
|
||||
|
||||
```
|
||||
cd /project
|
||||
```
|
||||
|
||||
现在他们可以编辑文件,写入提交更改信息,然后将它们推送到服务器:
|
||||
|
||||
```
|
||||
git commit -m 'corrections in GoT.txt story' -a
|
||||
```
|
||||
|
||||
然后推送改变:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
我认为这足以让一个新用户开始在他们自己的服务器上使用 Git。 如果您正在寻找一些 GUI 工具来管理本地计算机上的更改,则可以使用 GUI 工具,例如 QGit 或 GitK for Linux。
|
||||
|
||||
|
||||
|
||||
### 使用 GitLab
|
||||
|
||||
这是项目所有者和协作者的纯命令行解决方案。这当然不像使用 GitHub 那么简单。不幸的是,尽管 GitHub 是全球最大的代码托管商,但是它自己的软件别人却无法使用。因为它不是开源的,所以你不能获取源代码并编译你自己的 GitHub。这与 WordPress 或 Drupal 不同,您无法下载 GitHub 并在您自己的服务器上运行它。
|
||||
|
||||
像往常一样,在开源世界中,是没有终结的尽头。GitLab 是一个非常优秀的项目。这是一个开源项目,允许用户在自己的服务器上运行类似于 GitHub 的项目管理系统。
|
||||
|
||||
您可以使用 GitLab 为团队成员或公司运行类似于 GitHub 的服务。您可以使用 GitLab 在公开发布之前开发私有项目。
|
||||
|
||||
GitLab 采用传统的开源商业模式。他们有两种产品:免费的开源软件,用户可以在自己的服务器上安装,以及类似于 GitHub 的托管服务。
|
||||
|
||||
可下载版本有两个版本,免费的社区版和付费企业版。企业版基于社区版,但附带针对企业客户的其他功能。它或多或少与 WordPress.org 或 Wordpress.com 提供的服务类似。
|
||||
|
||||
社区版具有高度可扩展性,可以在单个服务器或群集上支持 25000 个用户。GitLab 的一些功能包括:Git 仓库管理,代码评论,问题跟踪,活动源和维基。它配备了 GitLab CI,用于持续集成和交付。
|
||||
|
||||
Digital Ocean 等许多 VPS 提供商会为用户提供 GitLab 服务。 如果你想在你自己的服务器上运行它,你可以手动安装它。GitLab 为不同的操作系统提供了软件包。 在我们安装 GitLab 之前,您可能需要配置 SMTP 电子邮件服务器,以便 GitLab 可以在需要时随时推送电子邮件。官方推荐使用 Postfix。所以,先在你的服务器上安装 Postfix:
|
||||
|
||||
```
|
||||
sudo apt-get install postfix
|
||||
```
|
||||
|
||||
在安装 Postfix 期间,它会问你一些问题,不要跳过它们。 如果你一不小心跳过,你可以使用这个命令来重新配置它:
|
||||
|
||||
```
|
||||
sudo dpkg-reconfigure postfix
|
||||
```
|
||||
|
||||
运行此命令时,请选择 “Internet Site”并为使用 Gitlab 的域名提供电子邮件 ID。
|
||||
|
||||
我是这样输入的:
|
||||
|
||||
```
|
||||
xxx@x.com
|
||||
```
|
||||
|
||||
用 Tab 键并为 postfix 创建一个用户名。接下来将会要求你输入一个目标邮箱。
|
||||
|
||||
在剩下的步骤中,都选择默认选项。当我们安装且配置完成后,我们继续安装 GitLab。
|
||||
|
||||
我们使用 `wget` 来下载软件包(用 [最新包][7] 替换下载链接):
|
||||
|
||||
```
|
||||
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
```
|
||||
|
||||
然后安装这个包:
|
||||
|
||||
```
|
||||
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
```
|
||||
|
||||
现在是时候配置并启动 GitLab 了。
|
||||
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
```
|
||||
|
||||
您现在需要在配置文件中配置域名,以便您可以访问 GitLab。打开文件。
|
||||
|
||||
```
|
||||
nano /etc/gitlab/gitlab.rb
|
||||
```
|
||||
|
||||
在这个文件中编辑 `external_url` 并输入服务器域名。保存文件,然后从 Web 浏览器中打开新建的一个 GitLab 站点。
|
||||
|
||||
|
||||
|
||||
默认情况下,它会以系统管理员的身份创建 `root`,并使用 `5iveL!fe` 作为密码。 登录到 GitLab 站点,然后更改密码。
|
||||
|
||||
|
||||
|
||||
密码更改后,登录该网站并开始管理您的项目。
|
||||
|
||||

|
||||
|
||||
GitLab 有很多选项和功能。最后,我借用电影“黑客帝国”中的经典台词:“不幸的是,没有人知道 GitLab 可以做什么。你必须亲自尝试一下。”
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/how-run-your-own-git-server
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://github.com/git/git
|
||||
[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
|
||||
[3]:https://github.com/about/press
|
||||
[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
|
||||
[5]:https://github.com/pricing
|
||||
[6]:https://about.gitlab.com/
|
||||
[7]:https://about.gitlab.com/downloads/
|
||||
@ -1,9 +1,11 @@
|
||||
你不知道的 Bash:关于 Bash 数组的介绍
|
||||
你所不了解的 Bash:关于 Bash 数组的介绍
|
||||
======
|
||||
|
||||
> 进入这个古怪而神奇的 Bash 数组的世界。
|
||||
|
||||

|
||||
|
||||
尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然没有正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash][1] 数组其实是非常有用的。
|
||||
尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然不像正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash][1] 数组其实是非常有用的。
|
||||
|
||||
### 稍等,这是为什么?
|
||||
|
||||
@ -15,26 +17,21 @@
|
||||
|
||||
### 基础
|
||||
|
||||
我们将要测试的 `--threads` 参数:
|
||||
我们首先要做的事是定义一个数组,用来容纳我们想要测试的 `--threads` 参数:
|
||||
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
```
|
||||
|
||||
我们首先要做的事是定义一个数组,用来容纳我们想要测试的参数:
|
||||
|
||||
本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的 数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
|
||||
本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
|
||||
|
||||
现在我们初始化了数组,让我们解析它其中的一些元素。仅仅输入 `echo $allThreads` ,你能发现,它只会输出第一个元素。
|
||||
|
||||
要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出 变量。考虑以下场景:
|
||||
要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出变量。考虑以下场景:
|
||||
|
||||
```
|
||||
type="article"
|
||||
|
||||
echo "Found 42 $type"
|
||||
|
||||
```
|
||||
|
||||
假如我们得到的变量 `$type` 是一个单词,我们想要添加在句子结尾一个 `s`。我们无法直接把 `s` 加到 `$type` 里面,因为这会把它变成另一个变量,`$types`。尽管我们可以利用像 `echo "Found 42 "$type"s"` 这样的代码形变,但解决这个问题的最好方法是用一个花括号:`echo "Found 42 ${type}s"`,这让我们能够告诉 Bash 变量名的起止位置(有趣的是,JavaScript/ES6 在 [template literals][2] 中注入变量和表达式的语法和这里是一样的)
|
||||
@ -49,37 +46,31 @@ echo "Found 42 $type"
|
||||
|
||||
#### 遍历数组元素
|
||||
|
||||
记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动 pipeline:
|
||||
记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动管线:
|
||||
|
||||
```
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
./pipeline --threads $t
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### 遍历数组索引
|
||||
|
||||
接下来,考虑一个稍稍不同的方法。不是遍历所有的数组元素,我们可以遍历所有的索引:
|
||||
接下来,考虑一个稍稍不同的方法。不遍历所有的数组元素,我们可以遍历所有的索引:
|
||||
|
||||
```
|
||||
for i in ${!allThreads[@]}; do
|
||||
|
||||
./pipeline --threads ${allThreads[$i]}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
一步一步看:如之前所见,`${allThreads[@]}` 表示数组中的所有元素。前面加了个感叹号,变成 `${!allThreads[@]}`,这会返回数组索引列表(这里是 0 到 7)。换句话说。`for` 循环就遍历所有的索引 `$i` 并从 `$allThreads` 中读取第 `$i` 个元素,当作 `--threads` 选项的参数。
|
||||
|
||||
这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引避免创建要在循环中累加的额外变量。
|
||||
这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引可以避免额外创建在循环中累加的变量。
|
||||
|
||||
### 填充数组
|
||||
|
||||
到目前为止,我们已经能够用给定的 `--threads` 选项启动 pipeline 了。现在假设按秒计时的运行时间输出到 pipeline。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
|
||||
到目前为止,我们已经能够用给定的 `--threads` 选项启动管线了。现在假设按秒计时的运行时间输出到管线。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
|
||||
|
||||
#### 一些有用的语法
|
||||
|
||||
@ -89,7 +80,6 @@ done
|
||||
|
||||
```
|
||||
myArray+=( "newElement1" "newElement2" )
|
||||
|
||||
```
|
||||
|
||||
#### 参数扫描
|
||||
@ -98,24 +88,18 @@ myArray+=( "newElement1" "newElement2" )
|
||||
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
allRuntimes=()
|
||||
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
runtime=$(./pipeline --threads $t)
|
||||
|
||||
allRuntimes+=( $runtime )
|
||||
|
||||
runtime=$(./pipeline --threads $t)
|
||||
allRuntimes+=( $runtime )
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
就是这个了!
|
||||
|
||||
### 还有什么能做的?
|
||||
|
||||
这篇文章中,我们讲过使用数组进行参数扫描的场景。我担保有很多理由要使用 Bash 数组,这里就有两个例子:
|
||||
这篇文章中,我们讲过使用数组进行参数扫描的场景。我敢保证有很多理由要使用 Bash 数组,这里就有两个例子:
|
||||
|
||||
#### 日志警告
|
||||
|
||||
@ -123,81 +107,49 @@ done
|
||||
|
||||
```
|
||||
# 日志列表,发生问题时应该通知的人
|
||||
|
||||
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
|
||||
|
||||
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
|
||||
|
||||
|
||||
|
||||
# 在每个日志中查找问题标志
|
||||
|
||||
for i in ${!logPaths[@]};
|
||||
|
||||
do
|
||||
|
||||
log=${logPaths[$i]}
|
||||
|
||||
stakeholder=${logEmails[$i]}
|
||||
|
||||
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
|
||||
|
||||
|
||||
|
||||
# 如果近期发现超过 5 个错误,就警告负责人
|
||||
|
||||
if [[ "$numErrors" -gt 5 ]];
|
||||
|
||||
then
|
||||
|
||||
emailRecipient="$stakeholder"
|
||||
|
||||
emailSubject="WARNING: ${log} showing unusual levels of errors"
|
||||
|
||||
emailBody="${numErrors} errors found in log ${log}"
|
||||
|
||||
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
|
||||
|
||||
fi
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### API 查询
|
||||
|
||||
如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,毫无疑问要用 SQL,但我们可以用 APIs!
|
||||
如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,SQL 不在我们考虑范围,但我们可以用 API!
|
||||
|
||||
为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder][3] 作为我们的目的,这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
|
||||
为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder][3],这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出每个评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
|
||||
|
||||
```
|
||||
endpoint="https://jsonplaceholder.typicode.com/comments"
|
||||
|
||||
allEmails=()
|
||||
|
||||
|
||||
|
||||
# 查询前 10 个帖子
|
||||
|
||||
for postId in {1..10};
|
||||
|
||||
do
|
||||
|
||||
# 执行 API 调用,获取该帖子评论者的邮箱
|
||||
|
||||
response=$(curl "${endpoint}?postId=${postId}")
|
||||
|
||||
|
||||
|
||||
|
||||
# 使用 jq 把 JSON 响应解析成数组
|
||||
|
||||
allEmails+=( $( jq '.[].email' <<< "$response" ) )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
注意这里我是用 [`jq` 工具][4] 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
|
||||
注意这里我是用 [jq 工具][4] 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
|
||||
|
||||
你可能已经想到,使用 Bash 数组在数不胜数的场景中很有帮助,我希望这篇文章中的示例可以给你思维的启发。如果你从自己的工作中找到其它的例子想要分享出来,请在帖子下方评论。
|
||||
|
||||
@ -209,17 +161,15 @@ done
|
||||
|:--|:--|
|
||||
| `arr=()` | 创建一个空数组 |
|
||||
| `arr=(1 2 3)` | 初始化数组 |
|
||||
| `${arr[2]}` | 解析第三个元素 |
|
||||
| `${arr[@]}` | 解析所有元素 |
|
||||
| `${!arr[@]}` | 解析数组索引 |
|
||||
| `${arr[2]}` | 取得第三个元素 |
|
||||
| `${arr[@]}` | 取得所有元素 |
|
||||
| `${!arr[@]}` | 取得数组索引 |
|
||||
| `${#arr[@]}` | 计算数组长度 |
|
||||
| `arr[0]=3` | 重写第 1 个元素 |
|
||||
| `arr[0]=3` | 覆盖第 1 个元素 |
|
||||
| `arr+=(4)` | 添加值 |
|
||||
| `str=$(ls)` | 把 `ls` 输出保存到字符串 |
|
||||
| `arr=( $(ls) )` | 把 `ls` 输出的文件保存到数组里 |
|
||||
| `${arr[@]:s:n}` | 解析索引在 `n` 到 `s+n` 之间的元素|
|
||||
|
||||
>译者注: `${arr[@]:s:n}` 应该是解析索引在 `s` 到 `s+n-1` 之间的元素
|
||||
| `${arr[@]:s:n}` | 取得从索引 `s` 开始的 `n` 个元素 |
|
||||
|
||||
### 最后一点思考
|
||||
|
||||
@ -236,37 +186,24 @@ done
|
||||
```
|
||||
import subprocess
|
||||
|
||||
|
||||
|
||||
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
|
||||
|
||||
all_runtimes = []
|
||||
|
||||
|
||||
|
||||
# 用不同的线程数字启动 pipeline
|
||||
|
||||
# 用不同的线程数字启动管线
|
||||
for t in all_threads:
|
||||
|
||||
cmd = './pipeline --threads {}'.format(t)
|
||||
|
||||
|
||||
|
||||
# 使用子线程模块获得返回的输出
|
||||
|
||||
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
|
||||
|
||||
output = p.communicate()[0]
|
||||
|
||||
all_runtimes.append(output)
|
||||
|
||||
```
|
||||
|
||||
由于本例中没法避免使用命令行,所以可以优先使用 Bash。
|
||||
|
||||
#### 羞耻的宣传时间
|
||||
|
||||
如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON][5],2018 年 7 月 17 号我会在这做一个主题为 [你不知道的 Bash][6] 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
|
||||
如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON][5],2018 年 7 月 17 号我会在这做一个主题为 [你所不了解的 Bash][6] 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
|
||||
|
||||
本文章由 [Medium] 首发,再发布时已获得授权。
|
||||
|
||||
@ -277,7 +214,7 @@ via: https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
|
||||
作者:[Robert Aboukhalil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,33 +1,38 @@
|
||||
2018 年 6 月 COPR 中值得尝试的 4 个很酷的新项目
|
||||
======
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中携带。某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。Fedora 基础设施不支持 COPR 中的软件或没有项目签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||

|
||||
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
[Ghostwriter][2] 是 [Markdown][3] 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中擦除被禁用,迫使用户现在编写并稍后编辑。![][4]
|
||||
[Ghostwriter][2] 是 [Markdown][3] 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中删除被禁用,迫使用户现在智能编写,而在稍后编辑。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 Ghostwriter。要安装 Ghostwriter,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable scx/ghostwriter
|
||||
sudo dnf install ghostwriter
|
||||
|
||||
```
|
||||
|
||||
### Lector
|
||||
|
||||
[Lector][5] 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 - 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。![][6]
|
||||
[Lector][5] 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 —— 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。![][6]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 26、27、28 和 Rawhide 提供Lector。要安装 Lector,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable bugzy/lector
|
||||
sudo dnf install lector
|
||||
|
||||
```
|
||||
|
||||
### Ranger
|
||||
@ -37,24 +42,25 @@ Ranerger 是一个基于文本的文件管理器,它带有 Vim 键绑定。它
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28 和 Rawhide 提供 Ranger。要安装 Ranger,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable fszymanski/ranger
|
||||
sudo dnf install ranger
|
||||
|
||||
```
|
||||
|
||||
### PrestoPalette
|
||||
|
||||
PrestoPeralette 是一款帮助创建平衡调色板的工具。PrestoPalette 的一个很好的功能是能够使用光照来影响调色板的亮度和饱和度。你可以将创建的调色板导出为 PNG 或 JSON。
|
||||
|
||||
![][8]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 PrestoPalette。要安装 PrestoPalette,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable dagostinelli/prestopalette
|
||||
sudo dnf install prestopalette
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -65,7 +71,7 @@ via: https://fedoramagazine.org/4-try-copr-june-2018/
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
GitLab 的付费套餐现在可以免费用于开源项目
|
||||
======
|
||||
|
||||
最近在开源社区发生了很多事情。首先,[微软收购了 GitHub][1],然后人们开始寻找 [GitHub 替代套餐][2],甚至在 Linus Torvalds 发布 [Linux Kernel 4.17][3] 时没有花一点时间考虑它。好吧,如果你一直关注我们,我认为你知道这一切。
|
||||
|
||||
但是,如今,GitLab 做出了一个明智的举措,为教育机构和开源项目免费提供高级套餐。当许多开发人员有兴趣将他们的开源项目迁移到 GitLab 时,没有更好的时机来提供这些了。
|
||||
|
||||
### GitLab 的高级套餐现在对开源项目和教育机构免费
|
||||
|
||||
![GitLab Logo][4]
|
||||
|
||||
在今天(2018/6/7)[发布的博客][5]中,GitLab 宣布其**旗舰**和黄金套餐现在对教育机构和开源项目免费。虽然我们已经知道为什么 GitLab 做出这个举动(一个完美的时机!),但他们还是解释了他们让它免费的动机:
|
||||
|
||||
> 我们让 GitLab 对教育机构免费,因为我们希望学生使用我们最先进的功能。许多大学已经运行了 GitLab。如果学生使用 GitLab 旗舰和黄金套餐的高级功能,他们将把这些高级功能的经验带到他们的工作场所。
|
||||
>
|
||||
> 我们希望有更多的开源项目使用 GitLab。GitLab.com 上的公共项目已经拥有 GitLab 旗舰套餐的所有功能。像 [Gnome][6] 和 [Debian][7] 这样的项目已经在自己的服务器运行开源版 GitLab 。随着今天的宣布,在专有软件上运行的开源项目可以使用 GitLab 提供的所有功能,同时我们通过向非开源组织收费来建立可持续的业务模式。
|
||||
|
||||
### GitLab 提供的这些“免费”套餐是什么?
|
||||
|
||||
![GitLab Pricing][8]
|
||||
|
||||
GitLab 有两类产品。一个是你可以在自己的云托管服务如 [Digital Ocean][9] 上运行的软件。另一个是 Gitlab 软件既服务,其中托管由 GitLab 本身管理,你在 GitLab.com 上获得一个帐户。
|
||||
|
||||
![GitLab Pricing for hosted service][10]
|
||||
|
||||
黄金套餐是托管类别中最高的产品,而旗舰套餐是自托管类别中的最高产品。
|
||||
|
||||
你可以在 GitLab 定价页面上获得有关其功能的更多详细信息。请注意,支持服务不包括在套餐中。你必须单独购买。
|
||||
|
||||
### 你必须符合某些条件才能使用此优惠
|
||||
|
||||
GitLab 还提到 —— 该优惠对谁有效。以下是他们在博客文章中写的内容:
|
||||
|
||||
> 1. **教育机构:**任何为了学习、教育的机构,并且/或者由合格的教育机构、教职人员、学生训练。教育目的不包括商业,专业或任何其他营利目的。
|
||||
>
|
||||
> 2. **开源项目:**任何使用[标准开源许可证][11]且非商业性的项目。它不应该有付费支持或付费贡献者。
|
||||
>
|
||||
|
||||
|
||||
虽然免费套餐不包括支持,但是当你迫切需要专家帮助解决问题时,你仍然可以支付每用户每月 4.95 美元的额外费用 —— 当你特别需要一个专家来解决问题时,这是一个非常合理的价格。
|
||||
|
||||
GitLab 还为学生们添加了一条说明:
|
||||
|
||||
> 为减轻 GitLab 的管理负担,只有教育机构才能代表学生申请。如果你是学生并且你的教育机构不申请,你可以在 GitLab.com 上使用公共项目的所有功能,使用私人项目的免费功能,或者自己付费。
|
||||
|
||||
### 总结
|
||||
|
||||
现在 GitLab 正在加快脚步,你如何看待它?
|
||||
|
||||
你有 [GitHub][12] 上的项目吗?你会切换么?或者,幸运的是,你从一开始就碰巧使用 GitLab?
|
||||
|
||||
请在下面的评论栏告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gitlab-free-open-source/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/microsoft-github/
|
||||
[2]:https://itsfoss.com/github-alternatives/
|
||||
[3]:https://itsfoss.com/linux-kernel-4-17/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/GitLab-logo-800x450.png
|
||||
[5]:https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/
|
||||
[6]:https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/
|
||||
[7]:https://salsa.debian.org/public
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-pricing.jpeg
|
||||
[9]:https://m.do.co/c/d58840562553
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-hosted-service-800x273.jpeg
|
||||
[11]:https://itsfoss.com/open-source-licenses-explained/
|
||||
[12]:https://github.com/
|
||||
@ -0,0 +1,59 @@
|
||||
BLUI:创建游戏 UI 的简单方法
|
||||
======
|
||||
|
||||
> 开源游戏开发插件运行虚幻引擎的用户使用基于 Web 的编程方式创建独特的用户界面元素。
|
||||
|
||||

|
||||
|
||||
游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>,允许独立开发者使用 AAA 发行商相同达到行业标准的工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
|
||||
|
||||
这些引擎中可以包含插件以允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
|
||||
|
||||
### 什么是 BLUI?
|
||||
|
||||
作为独立游戏开发工作室的一员,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>(我们选择的引擎)有一个实现了类似目的的内置 UI 编辑器,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
|
||||
|
||||
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的虚幻引擎集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
|
||||
|
||||
在商业产品和虚幻引擎的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过 web 语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
|
||||
|
||||
### 安装和使用 BLUI
|
||||
|
||||
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括<ruby>自举<rt>bootstrapped</rt> JavaScript 代码、外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何虚幻引擎插件那样安装它,并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在虚幻引擎 UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
*将 BLUI 集成到虚幻 4 图纸中。*
|
||||
|
||||
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
*使用 BLUI 将 UI 元素与音轨同步。*
|
||||
|
||||
通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个轻松的过程。还有一个由支持虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
|
||||
|
||||
### 开源优势
|
||||
|
||||
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内的机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -0,0 +1,122 @@
|
||||
可代替 Dropbox 的 5 个开源软件
|
||||
=====
|
||||
|
||||
> 寻找一个不会破坏你的安全、自由或银行资产的文件共享应用。
|
||||
|
||||

|
||||
|
||||
Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
|
||||
|
||||
也行你出于各种好的理由,包括安全和自由,这使你决定用[开源方式][1]。亦或是你已经被数据泄露吓坏了,或者定价计划不能满足你实际需要的存储量。
|
||||
|
||||
幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
|
||||
|
||||
这里有 5 个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
|
||||
|
||||
### ownCloud
|
||||
|
||||
|
||||
|
||||
[ownCloud][2] 发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据该公司统计,有超过 150 万用户),并且由由 1100 个参与者的社区积极维护,定期发布更新。
|
||||
|
||||
它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议][3])是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
|
||||
|
||||
使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过带有密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它的 [市场][4] 中的各种各样的第三方应用来扩展它的功能。当然,它也提供付费的、商业许可的企业版本。
|
||||
|
||||
ownCloud 提供了详尽的[文档][5],包括安装指南和针对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码][6]。
|
||||
|
||||
### NextCloud
|
||||
|
||||
|
||||
|
||||
[NextCloud][7] 在 2016 年从 ownCloud 分裂出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵从性作为它的一个独特的[推崇的卖点][8]。它具有 HIPAA (医疗) 和 GDPR (隐私)法规遵从功能,并提供广泛的数据策略约束、加密、用户管理和审核功能。它还在传输和存储期间对数据进行加密,并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
|
||||
|
||||
像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,该公司与几个[提供商][9]达成了伙伴合作,提供安装和托管,并销售服务器、设备和服务支持。在[市场][10]中提供了大量的apps 来扩展它的功能。
|
||||
|
||||
NextCloud 的[文档][11]为用户、管理员和开发者提供了详细的信息,并且它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码、报告一个错误、查看它的 AGPLv3 许可,或者想了解更多,请访问它的[GitHub 项目主页][12]。
|
||||
|
||||
### Seafile
|
||||
|
||||
|
||||
|
||||
与 ownCloud 或 NextCloud 相比,[Seafile][13] 或许没有花里胡哨的卖点(app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器,以扩展你的桌面存储,并允许你使用密码保护和各种级别的权限(即只读或读写) 有选择地共享文件。
|
||||
|
||||
它的协作功能包括文件夹权限控制,密码保护的下载链接和像 Git 一样的版本控制和记录。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护,并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
|
||||
|
||||
更多详细信息, 请访问 Seafile 的 [GitHub 仓库][14]、[服务手册][15]、[wiki][16] 和[论坛][17]。请注意, Seafile 的社区版在 [GPLv2][18] 下获得许可,但其专业版不是开源的。
|
||||
|
||||
### OnionShare
|
||||
|
||||
|
||||
|
||||
[OnionShare][19] 是一个很酷的应用:如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装][20],无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时,OnionShare 创建一个 web 服务器,使其可作为 Tor 洋葱服务访问,并生成一个不可猜测的 .onion URL,这个 URL 允许收件人通过 [Tor 浏览器][21]获取文件。
|
||||
|
||||
你可以设置文件共享的限制,例如限制可以下载的次数或使用自动停止计时器,这会设置一个严格的过期日期/时间,超过这个期限便不可访问(即使尚未访问该文件)。
|
||||
|
||||
OnionShare 在 [GPLv3][22] 之下被许可;有关详细信息,请查阅其 [GitHub 仓库][22],其中还包括[文档][23],介绍了这个易用的文件共享软件的特点。
|
||||
|
||||
### Pydio Cells
|
||||
|
||||
|
||||
|
||||
[Pydio Cells][24] 在 2018 年 5 月推出了稳定版,是对 Pydio 共享应用程序的核心服务器代码的彻底大修。由于 Pydio 的基于 PHP 的后端的限制,开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
|
||||
|
||||
Pydio Cells 包括通常的共享和版本控制功能,以及应用程序中的消息接受、移动应用程序(Android 和 iOS),以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能,但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
|
||||
|
||||
您可以 在 Linux 和 MacOS 里[下载][25] Pydio Cells。有关详细信息, 请查阅 [文档常见问题][26]、[源码库][27] 和 [AGPLv3 许可证][28]
|
||||
|
||||
### 其他
|
||||
|
||||
如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
|
||||
|
||||
* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing][29]。
|
||||
* 如果你是一个 Git 的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare][30]。
|
||||
* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy][31]。
|
||||
* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review][32]——一个罕为人知的工具。
|
||||
|
||||
哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/dropbox
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/open-source-way
|
||||
[2]:https://owncloud.org/
|
||||
[3]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[4]:https://marketplace.owncloud.com/
|
||||
[5]:https://doc.owncloud.com/
|
||||
[6]:https://github.com/owncloud
|
||||
[7]:https://nextcloud.com/
|
||||
[8]:https://nextcloud.com/secure/
|
||||
[9]:https://nextcloud.com/providers/
|
||||
[10]:https://apps.nextcloud.com/
|
||||
[11]:https://nextcloud.com/support/
|
||||
[12]:https://github.com/nextcloud
|
||||
[13]:https://www.seafile.com/en/home/
|
||||
[14]:https://github.com/haiwen/seafile
|
||||
[15]:https://manual.seafile.com/
|
||||
[16]:https://seacloud.cc/group/3/wiki/
|
||||
[17]:https://forum.seafile.com/
|
||||
[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
|
||||
[19]:https://onionshare.org/
|
||||
[20]:https://onionshare.org/#downloads
|
||||
[21]:https://www.torproject.org/
|
||||
[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
|
||||
[23]:https://github.com/micahflee/onionshare/wiki
|
||||
[24]:https://pydio.com/en
|
||||
[25]:https://pydio.com/download/
|
||||
[26]:https://pydio.com/en/docs/faq
|
||||
[27]:https://github.com/pydio/cells
|
||||
[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
|
||||
[29]:https://syncthing.net/
|
||||
[30]:http://www.sparkleshare.org/
|
||||
[31]:https://cozy.io/en/
|
||||
[32]:https://opensource.com/article/17/3/file-sharing-tools
|
||||
@ -0,0 +1,160 @@
|
||||
如何在 Linux 上检查用户所属组
|
||||
======
|
||||
|
||||
将用户添加到现有组是 Linux 管理员的常规活动之一。这是一些在大环境中工作的管理员的日常活动。
|
||||
|
||||
甚至我会因为业务需求而在我的环境中每天都在进行这样的活动。它是帮助你识别环境中现有组的重要命令之一。
|
||||
|
||||
此外,这些命令还可以帮助你识别用户所属的组。所有用户都列在 `/etc/passwd` 中,组列在 `/etc/group` 中。
|
||||
|
||||
无论我们使用什么命令,都将从这些文件中获取信息。此外,每个命令都有其独特的功能,可帮助用户单独获取所需的信息。
|
||||
|
||||
### 什么是 /etc/passwd?
|
||||
|
||||
`/etc/passwd` 是一个文本文件,其中包含登录 Linux 系统所必需的每个用户信息。它维护有用的用户信息,如用户名、密码、用户 ID、组 ID、用户 ID 信息、家目录和 shell。passwd 每行包含了用户的详细信息,共有如上所述的 7 个字段。
|
||||
|
||||
```
|
||||
$ grep "daygeek" /etc/passwd
|
||||
daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
|
||||
```
|
||||
|
||||
### 什么是 /etc/group?
|
||||
|
||||
`/etc/group` 是一个文本文件,用于定义用户所属的组。我们可以将多个用户添加到单个组中。它允许用户访问其他用户文件和文件夹,因为 Linux 权限分为三类:用户、组和其他。它维护有关组的有用信息,例如组名、组密码,组 ID(GID)和成员列表。每个都在一个单独的行。组文件每行包含了每个组的详细信息,共有 4 个如上所述字段。
|
||||
|
||||
这可以通过使用以下方法来执行。
|
||||
|
||||
* `groups`: 显示一个组的所有成员。
|
||||
* `id`: 打印指定用户名的用户和组信息。
|
||||
* `lid`: 显示用户的组或组的用户。
|
||||
* `getent`: 从 Name Service Switch 库中获取条目。
|
||||
* `grep`: 代表“<ruby>全局正则表达式打印<rt>global regular expression print</rt></ruby>”,它能打印匹配的模式。
|
||||
|
||||
### 什么是 groups 命令?
|
||||
|
||||
`groups` 命令打印每个给定用户名的主要组和任何补充组的名称。
|
||||
|
||||
```
|
||||
$ groups daygeek
|
||||
daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
```
|
||||
|
||||
如果要检查与当前用户关联的组列表。只需运行 `groups` 命令,无需带任何用户名。
|
||||
|
||||
```
|
||||
$ groups
|
||||
daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
```
|
||||
|
||||
### 什么是 id 命令?
|
||||
|
||||
id 代表 “<ruby>身份<rt>identity</rt></ruby>”。它打印真实有效的用户和组 ID。打印指定用户或当前用户的用户和组信息。
|
||||
|
||||
```
|
||||
$ id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
```
|
||||
|
||||
如果要检查与当前用户关联的组列表。只运行 `id` 命令,无需带任何用户名。
|
||||
|
||||
```
|
||||
$ id
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
```
|
||||
|
||||
### 什么是 lid 命令?
|
||||
|
||||
它显示用户的组或组的用户。显示有关包含用户名的组或组名称中包含的用户的信息。此命令需要管理员权限。
|
||||
|
||||
```
|
||||
$ sudo lid daygeek
|
||||
adm(gid=4)
|
||||
cdrom(gid=24)
|
||||
sudo(gid=27)
|
||||
dip(gid=30)
|
||||
plugdev(gid=46)
|
||||
lpadmin(gid=108)
|
||||
daygeek(gid=1000)
|
||||
sambashare(gid=124)
|
||||
```
|
||||
|
||||
### 什么是 getent 命令?
|
||||
|
||||
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目,它们在 `/etc/nsswitch.conf` 中配置。
|
||||
|
||||
```
|
||||
$ getent group | grep daygeek
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
```
|
||||
|
||||
如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
|
||||
|
||||
```
|
||||
$ getent group | grep daygeek | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
```
|
||||
|
||||
运行以下命令仅打印主群组信息。
|
||||
|
||||
```
|
||||
$ getent group daygeek
|
||||
daygeek:x:1000:
|
||||
|
||||
```
|
||||
|
||||
### 什么是 grep 命令?
|
||||
|
||||
`grep` 代表 “<ruby>全局正则表达式打印<rt>global regular expression print</rt></ruby>”,它能打印文件匹配的模式。
|
||||
|
||||
```
|
||||
$ grep "daygeek" /etc/group
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
```
|
||||
|
||||
如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
|
||||
|
||||
```
|
||||
$ grep "daygeek" /etc/group | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
@ -0,0 +1,120 @@
|
||||
如何在 Linux 中使用一个命令升级所有软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
众所周知,让我们的 Linux 系统保持最新状态会用到多种包管理器。比如说,在 Ubuntu 中,你无法使用 `sudo apt update` 和 `sudo apt upgrade` 命令升级所有软件。此命令仅升级使用 APT 包管理器安装的应用程序。你有可能使用 `cargo`、[pip][1]、`npm`、`snap` 、`flatpak` 或 [Linuxbrew][2] 包管理器安装了其他软件。你需要使用相应的包管理器才能使它们全部更新。
|
||||
|
||||
再也不用这样了!跟 `topgrade` 打个招呼,这是一个可以一次性升级系统中所有软件的工具。
|
||||
|
||||
你无需运行每个包管理器来更新包。这个 `topgrade` 工具通过检测已安装的软件包、工具、插件并运行相应的软件包管理器来更新 Linux 中的所有软件,用一条命令解决了这个问题。它是自由而开源的,使用 **rust 语言**编写。它支持 GNU/Linux 和 Mac OS X.
|
||||
|
||||
### 在 Linux 中使用一个命令升级所有软件
|
||||
|
||||
`topgrade` 存在于 AUR 中。因此,你可以在任何基于 Arch 的系统中使用 [Yay][3] 助手程序安装它。
|
||||
|
||||
```
|
||||
$ yay -S topgrade
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,你可以使用 `cargo` 包管理器安装 `topgrade`。要安装 cargo 包管理器,请参阅以下链接:
|
||||
|
||||
- [在 Linux 安装 rust 语言][12]
|
||||
|
||||
然后,运行以下命令来安装 `topgrade`。
|
||||
|
||||
```
|
||||
$ cargo install topgrade
|
||||
```
|
||||
|
||||
安装完成后,运行 `topgrade` 以升级 Linux 系统中的所有软件。
|
||||
|
||||
```
|
||||
$ topgrade
|
||||
```
|
||||
|
||||
一旦调用了 `topgrade`,它将逐个执行以下任务。如有必要,系统会要求输入 root/sudo 用户密码。
|
||||
|
||||
1、 运行系统的包管理器:
|
||||
|
||||
* Arch:运行 `yay` 或者回退到 [pacman][4]
|
||||
* CentOS/RHEL:运行 `yum upgrade`
|
||||
* Fedora :运行 `dnf upgrade`
|
||||
* Debian/Ubuntu:运行 `apt update` 和 `apt dist-upgrade`
|
||||
* Linux/macOS:运行 `brew update` 和 `brew upgrade`
|
||||
|
||||
2、 检查 Git 是否跟踪了以下路径。如果有,则拉取它们:
|
||||
|
||||
* `~/.emacs.d` (无论你使用 Spacemacs 还是自定义配置都应该可用)
|
||||
* `~/.zshrc`
|
||||
* `~/.oh-my-zsh`
|
||||
* `~/.tmux`
|
||||
* `~/.config/fish/config.fish`
|
||||
* 自定义路径
|
||||
|
||||
3、 Unix:运行 `zplug` 更新
|
||||
|
||||
4、 Unix:使用 TPM 升级 `tmux` 插件
|
||||
|
||||
5、 运行 `cargo install-update`
|
||||
|
||||
6、 升级 Emacs 包
|
||||
|
||||
7、 升级 Vim 包。对以下插件框架均可用:
|
||||
|
||||
* NeoBundle
|
||||
* [Vundle][5]
|
||||
* Plug
|
||||
|
||||
8、 升级 [npm][6] 全局安装的包
|
||||
|
||||
9、 升级 Atom 包
|
||||
|
||||
10、 升级 [Flatpak][7] 包
|
||||
|
||||
11、 升级 [snap][8] 包
|
||||
|
||||
12、 Linux:运行 `fwupdmgr` 显示固件升级。 (仅查看。实际不会执行升级)
|
||||
|
||||
13、 运行自定义命令。
|
||||
|
||||
最后,`topgrade` 将运行 `needrestart` 以重新启动所有服务。在 Mac OS X 中,它会升级 App Store 程序。
|
||||
|
||||
我的 Ubuntu 18.04 LTS 测试环境的示例输出:
|
||||
|
||||
![][10]
|
||||
|
||||
好处是如果一个任务失败,它将自动运行下一个任务并完成所有其他后续任务。最后,它将显示摘要,其中包含运行的任务数量,成功的数量和失败的数量等详细信息。
|
||||
|
||||
![][11]
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
就个人而言,我喜欢创建一个像 `topgrade` 程序的想法,并使用一个命令升级使用各种包管理器安装的所有软件。我希望你也觉得它有用。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
|
||||
[12]:https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
@ -0,0 +1,100 @@
|
||||
区块链进化简史:为什么开源是其核心所在
|
||||
======
|
||||
|
||||
> 从比特币到下一代区块链。
|
||||
|
||||

|
||||
|
||||
当开源项目开发下一个新版本时,用后缀 “-ng” 表示 “下一代”的情况并不鲜见。幸运的是,到目前为止,快速演进的区块链成功地避开了这个命名陷阱。但是在这个开源生态系统的演进过程中,改变是不断发生的,而好的创意以典型的开源方式在许多不同的项目中被采用、交融和演进。
|
||||
|
||||
在本文中,我将审视不同代次的区块链,并且看一看在处理这个生态系统遇到的问题时出现什么创意。当然,任何对生态系统进行分类的尝试都有其局限性的 —— 和不同意见者的 —— 但是这也将为混乱的区块链项目提供了一个粗略的指南。
|
||||
|
||||
### 始作俑者:比特币
|
||||
|
||||
第一代的区块链起源于 <ruby>[比特币][1]<rt>Bitcoin</rt></ruby> 区块链,这是以去中心化、点对点加密货币为基础的<ruby>总帐<rt>ledger</rt></ruby>,它从 [Slashdot][2] 网站上的杂谈变成了一个主流话题。
|
||||
|
||||
这个区块链是一个分布式总帐,它对所有用户的<ruby>交易<rt>transaction</rt></ruby>保持跟踪,以避免他们<ruby>双重支付<rt>double-spending</rt></ruby>(双花)货币(在历史上,这个任务是委托给第三方—— 银行 ——来做的)。为防范攻击者在系统上捣乱,总帐被复制到每个参与到比特币网络的计算机上,并且每次只允许一台计算机去更新总帐。为决定哪台计算机能够获得更新总帐的权力,系统安排在比特币网络上的计算机之间每 10 分钟进行一场竞赛,这将消耗它们的(许多)能源才能参与竞赛。赢家将获得将前 10 分钟发生的交易写入到总帐(区块链中的“区块”)的权力,并且为赢家写入区块链的工作给予一些比特币奖励。这种方式被称为<ruby>工作量证明<rt>proof of work</rt></ruby>(PoW)共识机制。
|
||||
|
||||
这就是区块链最有趣的地方。比特币以[开源项目][3]的方式发布于 2009 年 1 月 。在 2010 年,由于意识到这些元素中的许多是可以调整的,围绕比特币聚集起了一个社区 —— [bitcointalk 论坛][4],来开始各种实验。
|
||||
|
||||
起初,看到的比特币区块链是一个分布式数据库的形式, [Namecoin][5] 项目出现后,建议去保存任意数据到它的事务数据库中。如果区块链能够记录金钱的转移,那么它也应该能够记录其它资产的转移,比如域名。这正是 Namecoin 的主要使用场景,它上线于 2011 年 4 月 —— 也就是比特币出现两年后。
|
||||
|
||||
Namecoin 调整的地方是区块链的内容,<ruby>[莱特币][6]<rt>Litecoin</rt></ruby> 调整的是两个技术部分:一是将两个区块的时间间隔从 10 分钟减少到 2.5 分钟,二是改变了竞赛方式(用 [scrypt][7] 来替换了 SHA-256 安全哈希算法)。这是能够做到的,因为比特币是以开源软件的方式来发布的,而莱特币本质上与比特币在其它部分是完全相同的。莱特币是修改了比特币共识机制的第一个分叉,这也为其它的更多“币”铺平了道路。
|
||||
|
||||
沿着这条道路,基于比特币代码库的各种变种越来越多。其中一些扩展了比特币的用途,比如 [Zerocash][8] 协议,它专注于提供交易的匿名性和可替换性,但它最终分拆为它自己的货币 —— [Zcash][9]。
|
||||
|
||||
虽然 Zcash 带来了它自己的创新,使用了最近被称为“<ruby>零知识证明<rt>zero-knowledge proof</rt></ruby>”的加密技术,但它维持着与大多数主要的比特币代码库的兼容性,这意味着它能够从上游的比特币创新中获益。
|
||||
|
||||
另外的项目 —— [CryptoNote][10],它萌芽于相同的社区,但是并没有使用相同的代码,它以比特币为背景来构建的,但又与之不同。它发布于 2012 年 12 月,由于它的出现,导致了几种加密货币的诞生,最著名的 <ruby>[门罗币][11]<rt>Monero</rt></ruby> (2014)就是其中之一。门罗币与 Zcash 使用了不同的方法,但解决了相同的问题:隐私性和可替换性。
|
||||
|
||||
就像在开源世界中经常出现的案例一样,做同样的工作有不止一个的工具可用。
|
||||
|
||||
### 下一代:“Blockchain-ng”
|
||||
|
||||
但是,到目前为止,所有的这些变体只是改进加密货币或者扩展它们去支持其它类型的事务。因此,这就引出了第二代区块链。
|
||||
|
||||
一旦社区开始去修改区块链的用法和调整技术部分时,对于一些想去扩展和重新思考它们未来的人来说,这种调整花费不了多长时间的。比特币的长期追随者 —— [Vitalik Buterin][12] 在 2013 年底建议,区域链的事务应该能够表示一个状态机的状态变化,将区域链视为能够运行应用程序(“<ruby>智能合约<rt>smart contract</rt></ruby>”)的分布式计算机。这个项目 —— <ruby>[以太坊][13]<rt>Ethereum</rt></ruby>,上线于 2015 年 4 月。它在运行分布式应用程序方面取得了巨大的成功,它的一些非常流行的分布式应用程序(<ruby>[加密猫][14]<rt>CryptoKitties</rt></ruby>)甚至导致以太坊区块链变慢。
|
||||
|
||||
这证明了目前的区块链存在一个很大的局限性:速度和容量。(速度通常用每秒事务数来测量,简称 TPS)有几个提议都建议去解决这个速度问题,从<ruby>分片<rt>sharding</rt></ruby>到<ruby>侧链<rt>sidechain</rt></ruby>,以及一个被称为“<ruby>第二层<rt>second-layer</rt></ruby>”的解决方案。这里需要更多的创新。
|
||||
|
||||
随着“智能合约”这个词开始流行起来,并且用已经被证实仍然很慢的技术去运行它们,那么就需要实现其它的思路:<ruby>许可区块链<rt>Permissioned blockchain</rt></ruby>。到目前为止,我们所介绍的所有区块链网络有两个没有明说的特征:一是它们是公开的(任何人都可以看到它们的功能),二是它们不需要许可(任何人都可以加入它们)。这两个部分是运行一个分布式的、非基于第三方的货币应该具有的和必需具有的条件。
|
||||
|
||||
随着区块链被认为出现与加密货币越来越明显的分离趋势,开始去考虑一些隐私、许可场景是很有意义的。一个有业务关系但不需要彼此完全信任的财团类型的参与者,能够从这些区块链类型中获益 —— 比如,物流链上的参与者,定期进行双边结算或者使用一个清算中心的金融、保险、或医疗保健机构。
|
||||
|
||||
一旦你将设置从“任何人都可以加入”变为“仅邀请者方可加入”,进一步对区块链构建区块的方式进行改变和调整将变得可能,那么对一些人来说,结果将变得非常有趣。
|
||||
|
||||
首先,设计用来保护网络不受恶意或者垃圾参与者的影响的工作量证明(PoW)可以被替换为更简单的和更少资源消耗的一些东西,比如,基于 [Raft][15] 的共识协议。在更高级别的安全性和更快的速度之间进行权衡,采用更简单的共识算法。对于更多群体来说这样更理想,因为他们可以用基于加密技术的担保来取代其它的基于法律关系的担保,例如为避免由于竞争而产生的大量能源消耗,而工作量证明就是这种情况。另外一个创新的地方是,使用 <ruby>[股权证明][16]<rt>Proof of Stake</rt></ruby>(PoS),它是公共网络共识机制的一个重量级的竞争者。它将可能像许可链网络一样找到它自己的实现方式。
|
||||
|
||||
有几个项目可以让创建许可区块链变得更简单,包括 [Quorum][17] (以太坊的一个分叉)和 [Hyperledger][18] 的 [Fabric][19] 和 [Sawtooth][20],这是基于新代码的两个开源项目。
|
||||
|
||||
许可区块链可以避免公共的、非许可方式的区块链中某些错综复杂的问题,但是它自己也存在一些问题。正确地管理参与者是其中的一个问题:谁可以加入?如何辨别他们?如何将他们从网络上移除?网络上的一个实体是否去管理一个中央公共密钥基础设施(PKI)?
|
||||
|
||||
### 区块链的开放本质
|
||||
|
||||
到目前为止的所有案例中,有一件事情是很明确的:使用一个区块链的目标是去提升网络中的参与者和它产生的数据的信任水平,理想情况下,不需要做进一步的工作即可足以使用它。
|
||||
|
||||
只有为这个网络提供动力的软件是自由和开源的,才能达到这种信任水平。即便是一个正确的、专用的、分布式区块链,它的本质仍然是运行着相同的第三方代码的私有代理的集合。从本质上来说,区块链的源代码必须是开源的,但仅是开源还不够。随着生态系统持续成长,这既是最低限度的担保也是进一步创新的源头。
|
||||
|
||||
最后,值得一提的是,虽然区块链的开放本质被认为是创新和变化的源头,它也被认为是一种治理形式:代码治理,用户期望运行的任何一个特定版本,都应该包含他们认为的整个网络应该包含的功能和方法。在这方面,需要说明的一点是,一些区块链的开放本质正在“变味”。但是这一问题正在解决。
|
||||
|
||||
### 第三和第四代:治理
|
||||
|
||||
接下来,我正在考虑第三代和第四代区块链:区块链将内置治理工具,并且项目将去解决棘手的大量不同区块链之间互连互通的问题,以便于它们之间可以交换信息和价值。
|
||||
|
||||
---
|
||||
关于作者
|
||||
|
||||
axel simon: 长期的自由及开源软件爱好者,就职于 Red Hat ,关注安全和区块链技术,以及分布式系统和协议。致力于保护互联网及其成就(知识分享、信息访问、去中心化和网络中立)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blockchain-guide-next-generation
|
||||
|
||||
作者:[Axel Simon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/axel
|
||||
[1]:https://bitcoin.org
|
||||
[2]:https://slashdot.org/
|
||||
[3]:https://github.com/bitcoin/bitcoin
|
||||
[4]:https://bitcointalk.org/
|
||||
[5]:https://www.namecoin.org/
|
||||
[6]:https://litecoin.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Scrypt
|
||||
[8]:http://zerocash-project.org/index
|
||||
[9]:https://z.cash
|
||||
[10]:https://cryptonote.org/
|
||||
[11]:https://en.wikipedia.org/wiki/Monero_(cryptocurrency)
|
||||
[12]:https://en.wikipedia.org/wiki/Vitalik_Buterin
|
||||
[13]:https://ethereum.org
|
||||
[14]:http://cryptokitties.co/
|
||||
[15]:https://en.wikipedia.org/wiki/Raft_(computer_science)
|
||||
[16]:https://www.investopedia.com/terms/p/proof-stake-pos.asp
|
||||
[17]:https://www.jpmorgan.com/global/Quorum
|
||||
[18]:https://hyperledger.org/
|
||||
[19]:https://www.hyperledger.org/projects/fabric
|
||||
[20]:https://www.hyperledger.org/projects/sawtooth
|
||||
43
published/201807/20180702 My first sysadmin mistake.md
Normal file
43
published/201807/20180702 My first sysadmin mistake.md
Normal file
@ -0,0 +1,43 @@
|
||||
我的第一个系统管理员错误
|
||||
======
|
||||
|
||||
> 如何在崩溃的局面中集中精力寻找解决方案。
|
||||
|
||||

|
||||
|
||||
如果你在 IT 领域工作,你知道事情永远不会像你想象的那样完好。在某些时候,你会遇到错误或出现问题,你最终必须解决问题。这就是系统管理员的工作。
|
||||
|
||||
作为人类,我们都会犯错误。我们不是已经犯错,就是即将犯错。结果,我们最终还必须解决自己的错误。总是这样。我们都会失误、敲错字母或犯错。
|
||||
|
||||
作为一名年轻的系统管理员,我艰难地学到了这一课。我犯了一个大错。但是多亏了上级的指导,我学会了不去纠缠于我的错误,而是制定一个“错误策略”来做正确的事情。从错误中吸取教训。克服它,继续前进。
|
||||
|
||||
我的第一份工作是一家小公司的 Unix 系统管理员。真的,我是一名生嫩的系统管理员,但我大部分时间都独自工作。我们是一个小型 IT 团队,只有我们三个人。我是 20 或 30 台 Unix 工作站和服务器的唯一系统管理员。另外两个支持 Windows 服务器和桌面。
|
||||
|
||||
任何阅读这篇文章的系统管理员都不会对此感到意外,作为一个不成熟的初级系统管理员,我最终在错误的目录中运行了 `rm` 命令——作为 root 用户。我以为我正在为我们的某个程序删除一些陈旧的缓存文件。相反,我错误地清除了 `/etc` 目录中的所有文件。糟糕。
|
||||
|
||||
我意识到犯了错误是看到了一条错误消息,“`rm` 无法删除某些子目录”。但缓存目录应该只包含文件!我立即停止了 `rm` 命令,看看我做了什么。然后我惊慌失措。一下子,无数个想法涌入了我的脑中。我刚刚销毁了一台重要的服务器吗?系统会怎么样?我会被解雇吗?
|
||||
|
||||
幸运的是,我运行的是 `rm *` 而不是 `rm -rf *`,因此我只删除了文件。子目录仍在那里。但这并没有让我感觉更好。
|
||||
|
||||
我立刻去找我的主管告诉她我做了什么。她看到我对自己的错误感到愚蠢,但这是我犯的。尽管紧迫,她花了几分钟时间跟我做了一些指导。她说:“你不是第一个这样做的人,在你这种情况下,别人会怎么做?”这帮助我平静下来并专注。我开始更少考虑我刚刚做的愚蠢事情,而更多地考虑我接下来要做的事情。
|
||||
|
||||
我做了一个简单的策略:不要重启服务器。使用相同的系统作为模板,并重建 `/etc` 目录。
|
||||
|
||||
制定了行动计划后,剩下的就很容易了。只需运行正确的命令即可从另一台服务器复制 `/etc` 文件并编辑配置,使其与系统匹配。多亏了我对所有东西都做记录的习惯,我使用已有的文档进行最后的调整。我避免了完全恢复服务器,这意味着一个巨大的宕机事件。
|
||||
|
||||
可以肯定的是,我从这个错误中吸取了教训。在接下来作为系统管理员的日子中,我总是在运行任何命令之前确认我所在的目录。
|
||||
|
||||
我还学习了构建“错误策略”的价值。当事情出错时,恐慌并思考接下来可能发生的所有坏事是很自然的。这是人性。但是制定一个“错误策略”可以帮助我不再担心出了什么问题,而是专注于让事情变得更好。我仍然会想一下,但是知道我接下来的步骤可以让我“克服它”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
@ -0,0 +1,147 @@
|
||||
如何在绝大部分类型的机器上安装 NVIDIA 显卡驱动
|
||||
======
|
||||
|
||||

|
||||
|
||||
无论是研究还是娱乐,安装一个最新的显卡驱动都能提升你的计算机性能,并且使你能全方位地实现新功能。本安装指南使用 Fedora 28 的新的第三方仓库来安装 NVIDIA 驱动。它将引导您完成硬件和软件两方面的安装,并且涵盖需要让你的 NVIDIA 显卡启动和运行起来的一切知识。这个流程适用于任何支持 UEFI 的计算机和任意新的 NVIDIA 显卡。
|
||||
|
||||
### 准备
|
||||
|
||||
本指南依赖于下面这些材料:
|
||||
|
||||
* 一台使用 [UEFI][1] 的计算机,如果你不确定你的电脑是否有这种固件,请运行 `sudo dmidecode -t 0`。如果输出中出现了 “UEFI is supported”,你的安装过程就可以继续了。不然的话,虽然可以在技术上更新某些电脑来支持 UEFI,但是这个过程的要求很苛刻,我们通常不建议你这么使用。
|
||||
* 一个现代的、支持 UEFI 的 NVIDIA 的显卡
|
||||
* 一个满足你的 NVIDIA 显卡的功率和接线要求的电源(有关详细信息,请参考“硬件和修改”的章节)
|
||||
* 网络连接
|
||||
* Fedora 28 系统
|
||||
|
||||
### 安装实例
|
||||
|
||||
这个安装示例使用的是:
|
||||
|
||||
* 一台 Optiplex 9010 的主机(一台相当老的机器)
|
||||
* [NVIDIA GeForce GTX 1050 Ti XLR8 游戏超频版 4 GB GDDR5 PCI Express 3.0 显卡][2]
|
||||
* 为了满足新显卡的电源要求,电源升级为 [EVGA – 80 PLUS 600 W ATX 12V/EPS 12V][3],这个最新的电源(PSU)比推荐的最低要求高了 300 W,但在大部分情况下,满足推荐的最低要求就足够了。
|
||||
* 然后,当然的,Fedora 28 也别忘了.
|
||||
|
||||
### 硬件和修改
|
||||
|
||||
#### 电源(PSU)
|
||||
|
||||
打开你的台式机的机箱,检查印刷在电源上的最大输出功率。然后,查看你的 NVIDIA 显卡的文档,确定推荐的最小电源功率要求(以瓦特为单位)。除此之外,检查你的显卡,看它是否需要额外的接线,例如 6 针连接器,大多数的入门级显卡只从主板获取电力,但是有一些显卡需要额外的电力,如果出现以下情况,你需要升级你的电源:
|
||||
|
||||
1. 你的电源的最大输出功率低于显卡建议的最小电源功率。注意:根据一些显卡厂家的说法,比起推荐的功率,预先构建的系统可能会需要更多或更少的功率,而这取决于系统的配置。如果你使用的是一个特别耗电或者特别节能的配置,请灵活决定你的电源需求。
|
||||
2. 你的电源没有提供必须的接线口来为你的显卡供电。
|
||||
|
||||
电源的更换很容易,但是在你拆除你当前正在使用的电源之前,请务必注意你的接线布局。除此之外,请确保你选择的电源适合你的机箱。
|
||||
|
||||
#### CPU
|
||||
|
||||
虽然在大多数老机器上安装高性能的 NVIDIA 显卡是可能的,但是一个缓慢或受损的 CPU 会阻碍显卡性能的发挥,如果要计算在你的机器上瓶颈效果的影响,请点击[这里][4]。了解你的 CPU 性能来避免高性能的显卡和 CPU 无法保持匹配是很重要的。升级你的 CPU 是一个潜在的考虑因素。
|
||||
|
||||
#### 主板
|
||||
|
||||
在继续进行之前,请确认你的主板和你选择的显卡是兼容的。你的显卡应该插在最靠近散热器的 PCI-E x16 插槽中。确保你的设置为显卡预留了足够的空间。此外,请注意,现在大部分的显卡使用的都是 PCI-E 3.0 技术。虽然这些显卡如果插在 PCI-E 3.0 插槽上会运行地最好,但如果插在一个旧版的插槽上的话,性能也不会受到太大的影响。
|
||||
|
||||
### 安装
|
||||
|
||||
1、 首先,打开终端更新你的包管理器(如果没有更新的话):
|
||||
|
||||
```
|
||||
sudo dnf update
|
||||
```
|
||||
|
||||
2、 然后,使用这条简单的命令进行重启:
|
||||
|
||||
```
|
||||
reboot
|
||||
```
|
||||
|
||||
3、 在重启之后,安装 Fedora 28 的工作站的仓库:
|
||||
|
||||
```
|
||||
sudo dnf install fedora-workstation-repositories
|
||||
```
|
||||
|
||||
4、 接着,设置 NVIDIA 驱动的仓库:
|
||||
|
||||
```
|
||||
sudo dnf config-manager --set-enabled rpmfusion-nonfree-nvidia-driver
|
||||
```
|
||||
|
||||
5、 然后,再次重启。
|
||||
|
||||
6、 在这次重启之后,通过下面这条命令验证是否添加了仓库:
|
||||
|
||||
```
|
||||
sudo dnf repository-packages rpmfusion-nonfree-nvidia-driver info
|
||||
```
|
||||
|
||||
如果加载了多个 NVIDIA 工具和它们各自的 spec 文件,请继续进行下一步。如果没有,你可能在添加新仓库的时候遇到了一个错误。你应该再试一次。
|
||||
|
||||
7、 登录,连接到互联网,然后打开“软件”应用程序。点击“加载项>硬件驱动> NVIDIA Linux 图形驱动>安装”。
|
||||
|
||||
如果你使用更老的显卡或者想使用多个显卡,请进一步查看 [RPMFusion 指南][8]。最后,要确保启动成功,设置 `/etc/gdm/custom.conf` 中的 `WaylandEnable=false`,确认避免使用安全启动。
|
||||
接着,再一次重启。
|
||||
|
||||
8、这个过程完成后,关闭所有的应用并**关机**。拔下电源插头,然后按下电源按钮以释放余电,避免你被电击。如果你对电源有开关,关闭它。
|
||||
|
||||
9、 最后,安装显卡,拔掉老的显卡并将新的显卡插入到正确的 PCI-E x16 插槽中。成功安装新的显卡之后,关闭你的机箱,插入电源 ,然后打开计算机,它应该会成功启动。
|
||||
|
||||
**注意:** 要禁用此安装中使用的 NVIDIA 驱动仓库,或者要禁用所有的 Fedora 工作站仓库,请参考这个 [Fedora Wiki 页面][6]。
|
||||
|
||||
### 验证
|
||||
|
||||
1、 如果你新安装的 NVIDIA 显卡已连接到你的显示器并显示正确,则表明你的 NVIDIA 驱动程序已成功和显卡建立连接。
|
||||
|
||||
如果你想去查看你的设置,或者验证驱动是否在正常工作(这里,主板上安装了两块显卡),再次打开 “NVIDIA X 服务器设置应用程序”。这次,你应该不会得到错误信息提示,并且系统会给出有关 X 的设置文件和你的 NVIDIA 显卡的信息。(请参考下面的屏幕截图)
|
||||
|
||||
![NVIDIA X Server Settings][7]
|
||||
|
||||
通过这个应用程序,你可以根据你的需要需改 X 配置文件,并可以监控显卡的性能,时钟速度和温度信息。
|
||||
|
||||
2、 为确保新显卡以满功率运行,显卡性能测试是非常必要的。GL Mark 2,是一个提供后台处理、构建、照明、纹理等等有关信息的标准工具。它提供了一个优秀的解决方案。GL Mark 2 记录了各种各样的图形测试的帧速率,然后输出一个总体的性能评分(这被称为 glmark2 分数)。
|
||||
|
||||
**注意:** glxgears 只会测试你的屏幕或显示器的性能,不会测试显卡本身,请使用 GL Mark 2。
|
||||
|
||||
要运行 GLMark2:
|
||||
|
||||
1. 打开终端并关闭其他所有的应用程序
|
||||
2. 运行 `sudo dnf install glmark2` 命令
|
||||
3. 运行 `glmark2` 命令
|
||||
4. 允许运行完整的测试来得到最好的结果。检查帧速率是否符合你对这块显卡的预期。如果你想要额外的验证,你可以查阅网站来确认是否已有你这块显卡的 glmark2 测试评分被公布到网上,你可以比较这个分数来评估你这块显卡的性能。
|
||||
5. 如果你的帧速率或者 glmark2 评分低于预期,请思考潜在的因素。CPU 造成的瓶颈?其他问题导致?
|
||||
|
||||
|
||||
如果诊断的结果很好,就开始享受你的新显卡吧。
|
||||
|
||||
### 参考链接
|
||||
|
||||
- [How to benchmark your GPU on Linux][9]
|
||||
- [How to install a graphics card][10]
|
||||
- [The Fedora Wiki Page][6]
|
||||
- [The Bottlenecker][4]
|
||||
- [What Is Unified Extensible Firmware Interface (UEFI)][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/install-nvidia-gpu/
|
||||
|
||||
作者:[Justice del Castillo][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/justice/
|
||||
[1]:https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI
|
||||
[2]:https://www.cnet.com/products/pny-geforce-gtx-xlr8-gaming-1050-ti-overclocked-edition-graphics-card-gf-gtx-1050-ti-4-gb/specs/
|
||||
[3]:https://www.evga.com/products/product.aspx?pn=100-B1-0600-KR
|
||||
[4]:http://thebottlenecker.com (Home: The Bottle Necker)
|
||||
[5]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/nvidia_xserver_error.jpg?token=c6a7effe35f1c592a155a4a46a068a19fd060a91 (NVIDIA X Sever Prompt)
|
||||
[6]:https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories
|
||||
[7]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/NVIDIA_XCONFIG.png?token=64e1a7be21e5e9ba157f029b65e24e4eef54d88f (NVIDIA X Server Settings)
|
||||
[8]:https://rpmfusion.org/Howto/NVIDIA?highlight=%28CategoryHowto%29
|
||||
[9]: https://www.howtoforge.com/tutorial/linux-gpu-benchmark/
|
||||
[10]: https://www.pcworld.com/article/2913370/components-graphics/how-to-install-a-graphics-card.html
|
||||
@ -0,0 +1,60 @@
|
||||
macOS 和 Linux 的内核有什么区别
|
||||
======
|
||||
|
||||
有些人可能会认为 macOS 和 Linux 内核之间存在相似之处,因为它们可以处理类似的命令和类似的软件。有些人甚至认为苹果公司的 macOS 是基于 Linux 的。事实上是,两个内核有着截然不同的历史和特征。今天,我们来看看 macOS 和 Linux 的内核之间的区别。
|
||||
|
||||
![macOS vs Linux][1]
|
||||
|
||||
### macOS 内核的历史
|
||||
|
||||
我们将从 macOS 内核的历史开始。1985 年,由于与首席执行官 John Sculley 和董事会不和,<ruby>史蒂夫·乔布斯<rt>Steve Jobs</rt></ruby>离开了苹果公司。然后,他成立了一家名为 [NeXT][2] 的新电脑公司。乔布斯希望将一款(带有新操作系统的)新计算机快速推向市场。为了节省时间,NeXT 团队使用了卡耐基梅隆大学的 [Mach 内核][3] 和部分 BSD 代码库来创建 [NeXTSTEP 操作系统][4]。
|
||||
|
||||
NeXT 从来没有取得过财务上的成功,部分归因于乔布斯花钱的习惯,就像他还在苹果公司一样。与此同时,苹果公司曾多次试图更新其操作系统,甚至与 IBM 合作,但从未成功。1997年,苹果公司以 4.29 亿美元收购了 NeXT。作为交易的一部分,史蒂夫·乔布斯回到了苹果公司,同时 NeXTSTEP 成为了 macOS 和 iOS 的基础。
|
||||
|
||||
### Linux 内核的历史
|
||||
|
||||
与 macOS 内核不同,Linux 的创建并非源于商业尝试。相反,它是由[芬兰计算机科学专业学生<ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>于 1991 年创建的][5]。最初,内核是按照林纳斯自己的计算机的规格编写的,因为他想利用其新的 80386 处理器(的特性)。林纳斯[于 1991 年 8 月在 Usenet 上][6]发布了他的新内核代码。很快,他就收到了来自世界各地的代码和功能建议。次年,Orest Zborowski 将 X Window 系统移植到 Linux,使其能够支持图形用户界面。
|
||||
|
||||
在过去的 27 年中,Linux 已经慢慢成长并增加了不少功能。这不再是一个学生的小型项目。现在它运行在[世界上][7]大多数的[计算设备][8]和[超级计算机][9]上。不错!
|
||||
|
||||
### macOS 内核的特性
|
||||
|
||||
macOS 内核被官方称为 XNU。这个[首字母缩写词][10]代表“XNU is Not Unix”。根据 [苹果公司的 Github 页面][10],XNU 是“将卡耐基梅隆大学开发的 Mach 内核和 FreeBSD 组件整合而成的混合内核,加上用于编写驱动程序的 C++ API”。代码的 BSD 子系统部分[“在微内核系统中通常实现为用户空间的服务”][11]。Mach 部分负责底层工作,例如多任务、内存保护、虚拟内存管理、内核调试支持和控制台 I/O。
|
||||
|
||||
### Linux 内核的特性
|
||||
|
||||
虽然 macOS 内核结合了微内核([Mach][12])和宏内核([BSD][13])的特性,但 Linux 只是一个宏内核。[宏内核][14]负责管理 CPU、内存、进程间通信、设备驱动程序、文件系统和系统服务调用( LCTT 译注:原文为 system server calls,但结合 Linux 内核的构成,译者认为这里翻译成系统服务调用更合适,即 system service calls)。
|
||||
|
||||
### 用一句话总结 Linux 和 Mac 的区别
|
||||
|
||||
macOS 内核(XNU)比 Linux 历史更悠久,并且基于两个更古老一些的代码库的结合;另一方面,Linux 新一些,是从头开始编写的,并且在更多设备上使用。
|
||||
|
||||
如果您发现这篇文章很有趣,请花一点时间在社交媒体,黑客新闻或 [Reddit][15] 上分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mac-linux-difference/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
|
||||
[2]:https://en.wikipedia.org/wiki/NeXT
|
||||
[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
|
||||
[4]:https://en.wikipedia.org/wiki/NeXTSTEP
|
||||
[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
|
||||
[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
|
||||
[8]:https://www.linuxinsider.com/story/31855.html
|
||||
[9]:https://itsfoss.com/linux-supercomputers-2017/
|
||||
[10]:https://github.com/apple/darwin-xnu
|
||||
[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
|
||||
[12]:https://en.wikipedia.org/wiki/Mach_(kernel
|
||||
[13]:https://en.wikipedia.org/wiki/FreeBSD
|
||||
[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
|
||||
[15]:http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,97 @@
|
||||
如何在 Linux 系统中使用 dd 命令而不会损毁你的磁盘
|
||||
===========
|
||||
|
||||
> 使用 Linux 中的 dd 工具安全、可靠地制作一个驱动器、分区和文件系统的完整镜像。
|
||||
|
||||

|
||||
|
||||
*这篇文章节选自 Manning 出版社出版的图书 [Linux in Action][1]的第 4 章。*
|
||||
|
||||
你是否正在从一个即将损坏的存储驱动器挽救数据,或者要把本地归档进行远程备份,或者要把一个别处的活动分区做个完整的副本,那么你需要懂得如何安全而可靠的复制驱动器和文件系统。幸运的是,`dd` 是一个可以使用的简单而又功能强大的镜像复制命令,从现在到未来很长的时间内,也许直到永远都不会出现比 `dd` 更好的工具了。
|
||||
|
||||
### 对驱动器和分区做个完整的副本
|
||||
|
||||
仔细研究后,你会发现你可以使用 `dd` 做各种任务,但是它最重要的功能是处理磁盘分区。当然,你可以使用 `tar` 命令或者 `scp` 命令从一台计算机复制整个文件系统的文件,然后把这些文件原样粘贴在另一台刚刚安装好 Linux 操作系统的计算机中。但是,因为那些文件系统归档不是完整的映像文件,所以在复制文件的过程中需要计算机操作系统的运行作为基础。
|
||||
|
||||
另一方面,使用 `dd` 可以对任何数字信息完美的进行逐个字节的镜像。但是不论何时何地,当你要对分区进行操作时,我要告诉你早期的 Unix 管理员曾开过这样的玩笑:“ dd 的意思是<ruby>磁盘毁灭者<rt>disk destroyer</rt></ruby>”(LCTT 译注:`dd` 原意是<ruby>磁盘复制<rt>disk dump</rt></ruby>)。 在使用 `dd` 命令的时候,如果你输入了哪怕是一个字母,也可能立即永久性的擦除掉整个磁盘驱动器里的所有重要的数据。因此,一定要注意命令的拼写格式规范。
|
||||
|
||||
**记住:** 在按下回车键执行 `dd` 命令之前,暂时停下来仔细的认真思考一下。
|
||||
|
||||
### dd 命令的基本操作
|
||||
|
||||
现在你已经得到了适当的提醒,我们将从简单的事情开始。假设你要对代号为 `/dev/sda` 的整个磁盘数据创建精确的映像,你已经插入了一块空的磁盘驱动器 (理想情况下具有与代号为 `/dev/sda` 的磁盘驱动器相同的容量)。语法很简单: `if=` 定义源驱动器,`of=` 定义你要将数据保存到的文件或位置:
|
||||
|
||||
```
|
||||
# dd if=/dev/sda of=/dev/sdb
|
||||
```
|
||||
|
||||
接下来的例子将要对 `/dev/sda` 驱动器创建一个 .img 的映像文件,然后把该文件保存的你的用户帐号家目录:
|
||||
|
||||
```
|
||||
# dd if=/dev/sda of=/home/username/sdadisk.img
|
||||
```
|
||||
|
||||
上面的命令针对整个驱动器创建映像文件,你也可以针对驱动器上的单个分区进行操作。下面的例子针对驱动器的单个分区进行操作,同时使用了一个 `bs` 参数用于设置单次拷贝的字节数量 (此例中是 4096)。设定 `bs` 参数值可能会影响 `dd` 命令的整体操作速度,该参数的理想设置取决于你的硬件配置和其它考虑。
|
||||
|
||||
```
|
||||
# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
|
||||
```
|
||||
|
||||
数据的恢复非常简单:通过颠倒 `if` 和 `of` 参数可以有效的完成任务。在此例中,`if=` 使用你要恢复的映像,`of=` 使用你想要写入映像的目标驱动器:
|
||||
|
||||
```
|
||||
# dd if=sdadisk.img of=/dev/sdb
|
||||
```
|
||||
|
||||
你也可以在一条命令中同时完成创建和拷贝任务。下面的例子中将使用 SSH 从远程驱动器创建一个压缩的映像文件,并把该文件保存到你的本地计算机中:
|
||||
|
||||
```
|
||||
# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
|
||||
```
|
||||
|
||||
你应该经常测试你的归档,确保它们可正常使用。如果它是你创建的启动驱动器,将它粘贴到计算机中,看看它是否能够按预期启动。如果它是普通分区的数据,挂载该分区,确保文件都存在而且可以正常的访问。
|
||||
|
||||
### 使用 dd 擦除磁盘数据
|
||||
|
||||
多年以前,我的一个负责政府海外大使馆安全的朋友曾经告诉我,在他当时在任的时候, 政府会给每一个大使馆提供一个官方版的锤子。为什么呢? 一旦大使馆设施可能被不友善的人员侵占,就会使用这个锤子毁坏所有的硬盘.
|
||||
|
||||
为什么要那样做?为什么不是删除数据就好了?你在开玩笑,对吧?所有人都知道从存储设备中删除包含敏感信息的文件实际上并没有真正移除这些数据。除非使用锤子彻底的毁坏这些存储介质,否则,只要有足够的时间和动机, 几乎所有的内容都可以从几乎任何数字存储介质重新获取。
|
||||
|
||||
但是,你可以使用 `dd` 命令让坏人非常难以获得你的旧数据。这个命令需要花费一些时间在 `/dev/sda1` 分区的每个扇区写入数百万个 `0`(LCTT 译注:是指 0x0 字节,意即 NUL ,而不是数字 0 ):
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=/dev/sda1
|
||||
```
|
||||
|
||||
还有更好的方法。通过使用 `/dev/urandom` 作为源文件,你可以在磁盘上写入随机字符:
|
||||
|
||||
```
|
||||
# dd if=/dev/urandom of=/dev/sda1
|
||||
```
|
||||
|
||||
### 监控 dd 的操作
|
||||
|
||||
由于磁盘或磁盘分区的归档可能需要很长的时间,因此你可能需要在命令中添加进度查看器。安装管道查看器(在 Ubuntu 系统上安装命令为 `sudo apt install pv`),然后把 `pv` 命令和 `dd` 命令结合在一起。使用 `pv`,最终的命令是这样的:
|
||||
|
||||
```
|
||||
# dd if=/dev/urandom | pv | dd of=/dev/sda1
|
||||
|
||||
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
|
||||
```
|
||||
|
||||
想要推迟备份和磁盘管理工作?有了 `dd` 工具,你不会有太多的借口。它真的非常简单,但是要小心。祝你好运!
|
||||
|
||||
----------------
|
||||
|
||||
via:https://opensource.com/article/18/7/how-use-dd-linux
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
@ -0,0 +1,79 @@
|
||||
6 个可以帮你理解互联网工作原理的 RFC
|
||||
======
|
||||
|
||||
> 以及 3 个有趣的 RFC。
|
||||
|
||||

|
||||
|
||||
阅读源码是开源软件的重要组成部分。这意味着用户可以查看代码并了解做了什么。
|
||||
|
||||
但“阅读源码”并不仅适用于代码。理解代码实现的标准同样重要。这些标准编写在由<ruby>[互联网工程任务组][1]<rt>Internet Engineering Task Force</rt></ruby>(IETF)发布的称为“<ruby>意见征集<rt>Requests for Comment</rt></ruby>”(RFC)的文档中。多年来已经发布了数以千计的 RFC,因此我们收集了一些我们的贡献者认为必读的内容。
|
||||
|
||||
### 6 个必读的 RFC
|
||||
|
||||
#### RFC 2119 - 在 RFC 中用于指示需求级别的关键字
|
||||
|
||||
这是一个快速阅读,但它对了解其它 RFC 非常重要。 [RFC 2119][2] 定义了后续 RFC 中使用的需求级别。 “MAY” 究竟意味着什么?如果标准说 “SHOULD”,你*真的*必须这样做吗?通过为需求提供明确定义的分类,RFC 2119 有助于避免歧义。
|
||||
|
||||
#### RFC 3339 - 互联网上的日期和时间:时间戳
|
||||
|
||||
时间是全世界程序员的祸根。 [RFC 3339][3] 定义了如何格式化时间戳。基于 [ISO 8601][4] 标准,3339 为我们提供了一种表达时间的常用方法。例如,像星期几这样的冗余信息不应该包含在存储的时间戳中,因为它很容易计算。
|
||||
|
||||
#### RFC 1918 - 私有互联网的地址分配
|
||||
|
||||
有属于每个人的互联网,也有只属于你的互联网。私有网络一直在使用,[RFC 1918][5] 定义了这些网络。当然,你可以在路由器上设置在内部使用公网地址,但这是一个坏主意。或者,你可以将未使用的公共 IP 地址视为内部网络。在任何一种情况下都表明你从未阅读过 RFC 1918。
|
||||
|
||||
#### RFC 1912 - 常见的 DNS 操作和配置错误
|
||||
|
||||
一切都是 #@%@ 的 DNS 问题,对吧? [RFC 1912][6] 列出了管理员在试图保持互联网运行时所犯的错误。虽然它是在 1996 年发布的,但 DNS(以及人们犯的错误)并没有真正改变这么多。为了理解我们为什么首先需要 DNS,如今我们再来看看 [RFC 289 - 我们希望正式的主机列表是什么样子的][7] 就知道了。
|
||||
|
||||
#### RFC 2822 — 互联网邮件格式
|
||||
|
||||
想想你知道什么是有效的电子邮件地址么?如果你知道有多少个站点不接受我邮件地址中 “+” 的话,你就知道你知道不知道了。 [RFC 2822][8] 定义了有效的电子邮件地址。它还详细介绍了电子邮件的其余部分。
|
||||
|
||||
#### RFC 7231 - 超文本传输协议(HTTP/1.1):语义和内容
|
||||
|
||||
想想看,几乎我们在网上做的一切都依赖于 HTTP。 [RFC 7231][9] 是该协议的最新更新。它有超过 100 页,定义了方法、请求头和状态代码。
|
||||
|
||||
### 3 个应该阅读的 RFC
|
||||
|
||||
好吧,并非每个 RFC 都是严肃的。
|
||||
|
||||
#### RFC 1149 - 在禽类载体上传输 IP 数据报的标准
|
||||
|
||||
网络以多种不同方式传递数据包。 [RFC 1149][10] 描述了鸽子载体的使用。当我距离州际高速公路一英里以外时,它们的可靠性不会低于我的移动提供商。
|
||||
|
||||
#### RFC 2324 — 超文本咖啡壶控制协议(HTCPCP/1.0)
|
||||
|
||||
咖啡对于完成工作非常重要,当然,我们需要一个用于管理咖啡壶的程序化界面。 [RFC 2324][11] 定义了一个用于与咖啡壶交互的协议,并添加了 HTTP 418(“我是一个茶壶”)。
|
||||
|
||||
#### RFC 69 — M.I.T.的分发列表更改
|
||||
|
||||
[RFC 69][12] 是否是第一个误导取消订阅请求的发布示例?
|
||||
|
||||
你必须阅读的 RFC 是什么(无论它们是否严肃)?在评论中分享你的列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/requests-for-comments-to-know
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://www.ietf.org
|
||||
[2]:https://www.rfc-editor.org/rfc/rfc2119.txt
|
||||
[3]:https://www.rfc-editor.org/rfc/rfc3339.txt
|
||||
[4]:https://www.iso.org/iso-8601-date-and-time-format.html
|
||||
[5]:https://www.rfc-editor.org/rfc/rfc1918.txt
|
||||
[6]:https://www.rfc-editor.org/rfc/rfc1912.txt
|
||||
[7]:https://www.rfc-editor.org/rfc/rfc289.txt
|
||||
[8]:https://www.rfc-editor.org/rfc/rfc2822.txt
|
||||
[9]:https://www.rfc-editor.org/rfc/rfc7231.txt
|
||||
[10]:https://www.rfc-editor.org/rfc/rfc1149.txt
|
||||
[11]:https://www.rfc-editor.org/rfc/rfc2324.txt
|
||||
[12]:https://www.rfc-editor.org/rfc/rfc69.txt
|
||||
@ -0,0 +1,127 @@
|
||||
如何在 Android 上借助 Wine 来运行 Windows Apps
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine(一种 Linux 上的程序,不是你喝的葡萄酒)是在类 Unix 操作系统上运行 Windows 程序的一个自由开源的兼容层。创建于 1993 年,借助它你可以在 Linux 和 macOS 操作系统上运行很多 Windows 程序,虽然有时可能还需要做一些小修改。现在,Wine 项目已经发布了 3.0 版本,这个版本兼容 Android 设备。
|
||||
|
||||
在本文中,我们将向你展示,在你的 Android 设备上如何借助 Wine 来运行 Windows Apps。
|
||||
|
||||
**相关阅读** : [如何使用 Winepak 在 Linux 上轻松安装 Windows 游戏][1]
|
||||
|
||||
### 在 Wine 上你可以运行什么?
|
||||
|
||||
Wine 只是一个兼容层,而不是一个全功能的仿真器,因此,你需要一个 x86 的 Android 设备才能完全发挥出它的优势。但是,大多数消费者手中的 Android 设备都是基于 ARM 的。
|
||||
|
||||
因为大多数人使用的是基于 ARM 的 Android 设备,所以有一个限制,只有适配在 Windows RT 上运行的那些 App 才能够使用 Wine 在基于 ARM 的 Android 上运行。但是随着发展,能够在 ARM 设备上运行的 App 数量越来越多。你可以在 XDA 开发者论坛上的这个 [帖子][2] 中找到兼容的这些 App 的清单。
|
||||
|
||||
在 ARM 上能够运行的一些 App 的例子如下:
|
||||
|
||||
* [Keepass Portable][3]: 一个密码钱包
|
||||
* [Paint.NET][4]: 一个图像处理程序
|
||||
* [SumatraPDF][5]: 一个 PDF 文档阅读器,也能够阅读一些其它的文档类型
|
||||
* [Audacity][6]: 一个数字录音和编辑程序
|
||||
|
||||
也有一些再度流行的开源游戏,比如,[Doom][7] 和 [Quake 2][8],以及它们的开源克隆,比如 [OpenTTD][9] 和《运输大亨》的一个版本。
|
||||
|
||||
随着 Wine 在 Android 上越来越普及,能够在基于 ARM 的 Android 设备上的 Wine 中运行的程序越来越多。Wine 项目致力于在 ARM 上使用 QEMU 去仿真 x86 的 CPU 指令,在该项目完成后,能够在 Android 上运行的 App 将会迅速增加。
|
||||
|
||||
### 安装 Wine
|
||||
|
||||
在安装 Wine 之前,你首先需要去确保你的设备的设置 “允许从 Play 商店之外的其它源下载和安装 APK”。对于本文的用途,你需要去许可你的设备从未知源下载 App。
|
||||
|
||||
1、 打开你手机上的设置,然后选择安全选项。
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2、 向下拉并点击 “Unknown Sources” 的开关。
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3、 接受风险警告。
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4、 打开 [Wine 安装站点][13],并点选列表中的第一个选择框。下载将自动开始。
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5、 下载完成后,从下载目录中打开它,或者下拉通知菜单并点击这里的已完成的下载。
|
||||
|
||||
6、 开始安装程序。它将提示你它需要访问和记录音频,并去修改、删除、和读取你的 SD 卡。你也可为程序中使用的一些 App 授予访问音频的权利。
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7、 安装完成后,点击程序图标去打开它。
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
当你打开 Wine 后,它模仿的是 Windows 7 的桌面。
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
Wine 有一个缺点是,你得有一个外接键盘去进行输入。如果你在一个小屏幕上运行它,并且触摸非常小的按钮很困难,你也可以使用一个外接鼠标。
|
||||
|
||||
你可以通过触摸 “开始” 按钮去打开两个菜单 —— “控制面板”和“运行”。
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### 使用 Wine 来工作
|
||||
|
||||
当你触摸 “控制面板” 后你将看到三个选项 —— 添加/删除程序、游戏控制器、和 Internet 设定。
|
||||
|
||||
使用 “运行”,你可以打开一个对话框去运行命令。例如,通过输入 `iexplore` 来启动 “Internet Explorer”。
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### 在 Wine 中安装程序
|
||||
|
||||
1、 在你的 Android 设备上下载应用程序(或通过云来同步)。一定要记住下载的程序保存的位置。
|
||||
|
||||
2、 打开 Wine 命令提示符窗口。
|
||||
|
||||
3、 输入程序的位置路径。如果你把下载的文件保存在 SD 卡上,输入:
|
||||
|
||||
```
|
||||
cd sdcard/Download/[filename.exe]
|
||||
```
|
||||
|
||||
4、 在 Android 上运行 Wine 中的文件,只需要简单地输入 EXE 文件的名字即可。
|
||||
|
||||
如果这个支持 ARM 的文件是兼容的,它将会运行。如果不兼容,你将看到一大堆错误信息。在这种情况下,在 Android 上的 Wine 中安装的 Windows 软件可能会损坏或丢失。
|
||||
|
||||
这个在 Android 上使用的新版本的 Wine 仍然有许多问题。它并不能在所有的 Android 设备上正常工作。它可以在我的 Galaxy S6 Edge 上运行的很好,但是在我的 Galaxy Tab 4 上却不能运行。许多游戏也不能正常运行,因为图形驱动还不支持 Direct3D。因为触摸屏还不是全扩展的,所以你需要一个外接的键盘和鼠标才能很轻松地操作它。
|
||||
|
||||
即便是在早期阶段的发布版本中存在这样那样的问题,但是这种技术还是值得深思的。当然了,你要想在你的 Android 智能手机上运行 Windows 程序而不出问题,可能还需要等待一些时日。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ "How to Easily Install Windows Games on Linux with Winepak"
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&amp;d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&amp;postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png "wine-android-security"
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg "wine-android-unknown-sources"
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png "wine-android-unknown-sources-warning"
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png "wine-android-download-button"
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg "wine-android-app-access"
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg "wine-android-icon-small"
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png "wine-android-desktop"
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png "wine-android-start-button"
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png "wine-android-run"
|
||||
@ -0,0 +1,215 @@
|
||||
Debian 打包入门
|
||||
======
|
||||
|
||||
> 创建 CardBook 软件包、本地 Debian 仓库,并修复错误。
|
||||
|
||||

|
||||
|
||||
我在 GSoC(LCTT 译注:Google Summer Of Code,一项针对学生进行的开源项目训练营,一般在夏季进行。)的任务中有一项是为用户构建 Thunderbird <ruby>扩展<rt>add-ons</rt></ruby>。一些非常流行的扩展,比如 [Lightning][1] (日历行事历)已经拥有了 deb 包。
|
||||
|
||||
另外一个重要的用于管理基于 CardDav 和 vCard 标准的联系人的扩展 [Cardbook][2] ,还没有一个 deb 包。
|
||||
|
||||
我的导师, [Daniel][3] 鼓励我去为它制作一个包,并上传到 [mentors.debian.net][4]。因为这样就可以使用 `apt-get` 来安装,简化了安装流程。这篇博客描述了我是如何从头开始学习为 CardBook 创建一个 Debian 包的。
|
||||
|
||||
首先,我是第一次接触打包,我在从源码构建包的基础上进行了大量研究,并检查它的协议是是否与 [DFSG][5] 兼容。
|
||||
|
||||
我从多个 Debian Wiki 中的指南中进行学习,比如 [打包介绍][6]、 [构建一个包][7],以及一些博客。
|
||||
|
||||
我还研究了包含在 [Lightning 扩展包][8]的 amd64 文件。
|
||||
|
||||
我创建的包可以在[这里][9]找到。
|
||||
|
||||
![Debian Package!][10]
|
||||
|
||||
*Debian 包*
|
||||
|
||||
### 创建一个空的包
|
||||
|
||||
我从使用 `dh_make` 来创建一个 `debian` 目录开始。
|
||||
|
||||
```
|
||||
# Empty project folder
|
||||
$ mkdir -p Debian/cardbook
|
||||
```
|
||||
|
||||
```
|
||||
# create files
|
||||
$ dh_make\
|
||||
> --native \
|
||||
> --single \
|
||||
> --packagename cardbook_1.0.0 \
|
||||
> --email minkush@example.com
|
||||
```
|
||||
|
||||
一些重要的文件,比如 `control`、`rules`、`changelog`、`copyright` 等文件被初始化其中。
|
||||
|
||||
所创建的文件的完整列表如下:
|
||||
|
||||
```
|
||||
$ find /debian
|
||||
debian/
|
||||
debian/rules
|
||||
debian/preinst.ex
|
||||
debian/cardbook-docs.docs
|
||||
debian/manpage.1.ex
|
||||
debian/install
|
||||
debian/source
|
||||
debian/source/format
|
||||
debian/cardbook.debhelper.lo
|
||||
debian/manpage.xml.ex
|
||||
debian/README.Debian
|
||||
debian/postrm.ex
|
||||
debian/prerm.ex
|
||||
debian/copyright
|
||||
debian/changelog
|
||||
debian/manpage.sgml.ex
|
||||
debian/cardbook.default.ex
|
||||
debian/README
|
||||
debian/cardbook.doc-base.EX
|
||||
debian/README.source
|
||||
debian/compat
|
||||
debian/control
|
||||
debian/debhelper-build-stamp
|
||||
debian/menu.ex
|
||||
debian/postinst.ex
|
||||
debian/cardbook.substvars
|
||||
debian/files
|
||||
```
|
||||
|
||||
我了解了 Debian 系统中 [Dpkg][11] 包管理器及如何用它安装、删除和管理包。
|
||||
|
||||
我使用 `dpkg` 命令创建了一个空的包。这个命令创建一个空的包文件以及四个名为 `.changes`、`.deb`、 `.dsc`、 `.tar.gz` 的文件。
|
||||
|
||||
- `.dsc` 文件包含了所发生的修改和签名
|
||||
- `.deb` 文件是用于安装的主要包文件。
|
||||
- `.tar.gz` (tarball)包含了源代码
|
||||
|
||||
这个过程也在 `/usr/share` 目录下创建了 `README` 和 `changelog` 文件。它们包含了关于这个包的基本信息比如描述、作者、版本。
|
||||
|
||||
我安装这个包,并检查这个包安装的内容。我的新包中包含了版本、架构和描述。
|
||||
|
||||
```
|
||||
$ dpkg -L cardbook
|
||||
/usr
|
||||
/usr/share
|
||||
/usr/share/doc
|
||||
/usr/share/doc/cardbook
|
||||
/usr/share/doc/cardbook/README.Debian
|
||||
/usr/share/doc/cardbook/changelog.gz
|
||||
/usr/share/doc/cardbook/copyright
|
||||
```
|
||||
|
||||
### 包含 CardBook 源代码
|
||||
|
||||
在成功的创建了一个空包以后,我在包中添加了实际的 CardBook 扩展文件。 CardBook 的源代码托管在 [Gitlab][12] 上。我将所有的源码文件包含在另外一个目录,并告诉打包命令哪些文件需要包含在这个包中。
|
||||
|
||||
我使用 `vi` 编辑器创建一个 `debian/install` 文件并列举了需要被安装的文件。在这个过程中,我花费了一些时间去学习基于 Linux 终端的文本编辑器,比如 `vi` 。这让我熟悉如何在 `vi` 中编辑、创建文件和快捷方式。
|
||||
|
||||
当这些完成后,我在变更日志中更新了包的版本并记录了我所做的改变。
|
||||
|
||||
```
|
||||
$ dpkg -l | grep cardbook
|
||||
ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
|
||||
```
|
||||
|
||||
![Changelog][13]
|
||||
|
||||
*更新完包的变更日志*
|
||||
|
||||
在重新构建完成后,重要的依赖和描述信息可以被加入到包中。 Debian 的 `control` 文件可以用来添加额外的必须项目和依赖。
|
||||
|
||||
### 本地 Debian 仓库
|
||||
|
||||
在不创建本地存储库的情况下,CardBook 可以使用如下的命令来安装:
|
||||
|
||||
```
|
||||
$ sudo dpkg -i cardbook_1.1.0.deb
|
||||
```
|
||||
|
||||
为了实际测试包的安装,我决定构建一个本地 Debian 存储库。没有它,`apt-get` 命令将无法定位包,因为它没有在 Debian 的包软件列表中。
|
||||
|
||||
为了配置本地 Debian 存储库,我复制我的包 (.deb)为放在 `/tmp` 目录中的 `Packages.gz` 文件。
|
||||
|
||||
![Packages-gz][14]
|
||||
|
||||
*本地 Debian 仓库*
|
||||
|
||||
为了使它工作,我了解了 `apt` 的配置和它查找文件的路径。
|
||||
|
||||
我研究了一种在 `apt-config` 中添加文件位置的方法。最后,我通过在 APT 中添加 `*.list` 文件来添加包的路径,并使用 `apt-cache` 更新APT缓存来完成我的任务。
|
||||
|
||||
因此,最新的 CardBook 版本可以成功的通过 `apt-get install cardbook` 来安装了。
|
||||
|
||||
![Package installation!][15]
|
||||
|
||||
*使用 apt-get 安装 CardBook*
|
||||
|
||||
### 修复打包错误和 Bugs
|
||||
|
||||
我的导师 Daniel 在这个过程中帮了我很多忙,并指导我如何进一步进行打包。他告诉我使用 [Lintian][16] 来修复打包过程中出现的常见错误和最终使用 [dput][17] 来上传 CardBook 包。
|
||||
|
||||
> Lintian 是一个用于发现策略问题和 Bug 的包检查器。它是 Debian 维护者们在上传包之前广泛使用的自动化检查 Debian 策略的工具。
|
||||
|
||||
我上传了该软件包的第二个更新版本到 Debian 目录中的 [Salsa 仓库][18] 的一个独立分支中。
|
||||
|
||||
我从 Debian backports 上安装 Lintian 并学习在一个包上用它来修复错误。我研究了它用在其错误信息中的缩写,和如何查看 Lintian 命令返回的详细内容。
|
||||
|
||||
```
|
||||
$ lintian -i -I --show-overrides cardbook_1.2.0.changes
|
||||
```
|
||||
|
||||
最初,在 `.changes` 文件上运行命令时,我惊讶地看到显示出来了大量错误、警告和注释!
|
||||
|
||||
![Package Error Brief!][19]
|
||||
|
||||
*在包上运行 Lintian 时看到的大量报错*
|
||||
|
||||
![Lintian error1!][20]
|
||||
|
||||
*详细的 Lintian 报错*
|
||||
|
||||
![Lintian error2!][23]
|
||||
|
||||
*详细的 Lintian 报错 (2) 以及更多*
|
||||
|
||||
我花了几天时间修复与 Debian 包策略违例相关的一些错误。为了消除一个简单的错误,我必须仔细研究每一项策略和 Debian 的规则。为此,我参考了 [Debian 策略手册][21] 以及 [Debian 开发者参考][22]。
|
||||
|
||||
我仍然在努力使它变得完美无暇,并希望很快可以将它上传到 mentors.debian.net!
|
||||
|
||||
如果 Debian 社区中使用 Thunderbird 的人可以帮助修复这些报错就太感谢了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://minkush.me/cardbook-debian-package/
|
||||
|
||||
作者:[Minkush Jain][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://minkush.me/cardbook-debian-package/#
|
||||
[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
|
||||
[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
|
||||
[3]:https://danielpocock.com/
|
||||
[4]:https://mentors.debian.net/
|
||||
[5]:https://wiki.debian.org/DFSGLicenses
|
||||
[6]:https://wiki.debian.org/Packaging/Intro
|
||||
[7]:https://wiki.debian.org/BuildingAPackage
|
||||
[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
|
||||
[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
|
||||
[10]:http://minkush.me/img/posts/13.png
|
||||
[11]:https://packages.debian.org/stretch/dpkg
|
||||
[12]:https://gitlab.com/CardBook/CardBook
|
||||
[13]:http://minkush.me/img/posts/15.png
|
||||
[14]:http://minkush.me/img/posts/14.png
|
||||
[15]:http://minkush.me/img/posts/11.png
|
||||
[16]:https://packages.debian.org/stretch/lintian
|
||||
[17]:https://packages.debian.org/stretch/dput
|
||||
[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
|
||||
[19]:http://minkush.me/img/posts/16.png (Running Lintian on package)
|
||||
[20]:http://minkush.me/img/posts/10.png
|
||||
[21]:https://www.debian.org/doc/debian-policy/
|
||||
[22]:https://www.debian.org/doc/manuals/developers-reference/
|
||||
[23]:http://minkush.me/img/posts/17.png
|
||||
@ -0,0 +1,67 @@
|
||||
在 Fedora 28 Workstation 使用 emoji 加速输入
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,这种可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一图胜千言”。这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多 emoji,在最近的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
|
||||
|
||||
很高兴看到 emoji 的数量在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
|
||||
|
||||
[**编者注:**本文是对此主题以前发表过的文章的更新]。
|
||||
|
||||
### 在 Fedora 28 Workstation 上启用 emoji 输入
|
||||
|
||||
新的 emoji 输入法默认出现在 Fedora 28 Workstation 中。要使用它,必须使用“区域和语言设置”对话框启用它。从 Fedora Workstation 设置打开“区域和语言”对话框,或在“概要”中搜索它。
|
||||
|
||||
[![Region & Language settings tool][1]][2]
|
||||
|
||||
选择 `+` 控件添加输入源。出现以下对话框:
|
||||
|
||||
[![Adding an input source][3]][4]
|
||||
|
||||
选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“Other”并选择它:
|
||||
|
||||
[![Selecting other input sources][5]][6]
|
||||
|
||||
在下面的对话框中,找到 “Typing Booster” 选项并选择它:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
这个高级输入法由 iBus 在背后支持。该高级输入法可通过列表右侧的齿轮图标在列表中识别。
|
||||
|
||||
输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 —— 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
|
||||
|
||||
[![Input method dropdown in Shell top bar][9]][10]
|
||||
|
||||
### 使用新的表情符号输入法
|
||||
|
||||
现在 emoji 输入法启用了,按键盘快捷键 `Ctrl+Shift+E` 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 “smile” 来查找匹配的符号。
|
||||
|
||||
[![Searching for smile emoji][11]][12]
|
||||
|
||||
使用箭头键翻页列表。然后按回车进行选择,字形将替换输入内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
|
||||
@ -0,0 +1,40 @@
|
||||
在 Arch 用户仓库(AUR)中发现恶意软件
|
||||
======
|
||||
|
||||
7 月 7 日,有一个 AUR 软件包被改入了一些恶意代码,提醒 [Arch Linux][1] 用户(以及一般的 Linux 用户)在安装之前应该尽可能检查所有由用户生成的软件包。
|
||||
|
||||
[AUR][3](即 Arch(Linux)用户仓库)包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全的,并且用户应尽可能在使用之前检查其内容。毕竟,AUR 在网页中以粗体显示 “**AUR 包是用户制作的内容。任何使用该提供的文件的风险由你自行承担。**”
|
||||
|
||||
这次[发现][4]包含恶意代码的 AUR 包证明了这一点。[acroread][5] 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了一个 systemd 单元以定期运行该脚本。
|
||||
|
||||
**看来有[另外两个][2] AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(它们注册在更新软件包的同一天)。**
|
||||
|
||||
这些恶意代码没有做任何真正有害的事情 —— 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单元信息)的输出到 pastebin.com。我说“试图”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
|
||||
|
||||
此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们真的不明白他们在做什么。(LCTT 译注:意即这是一个菜鸟“黑客”,还不懂得如何有经验地隐藏自己。)
|
||||
|
||||
尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
|
||||
|
||||
**更新:** Reddit用户 u/xanaxdroid_ [提及][6]同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月][7]前的一些 Ubuntu Snap 软件包也是如此)。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
|
||||
|
||||
**另一个更新:**你究竟应该在那些用户生成的软件包检查什么(如 AUR 中发现的)?情况各有不同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学做法”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须懂得 Debian 如何打包,并且这些源代码是可以直接更改的,因为它托管在 PPA 中并由用户上传的。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我觉得你应该只安装你信任的用户/打包器生成的软件包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -0,0 +1,74 @@
|
||||
15 个适用于 MacOS 的开源应用程序
|
||||
======
|
||||
|
||||
> 钟爱开源的用户不会觉得在非 Linux 操作系统上使用他们喜爱的应用有多难。
|
||||
|
||||

|
||||
|
||||
只要有可能的情况下,我都会去选择使用开源工具。不久之前,我回到大学去攻读教育领导学硕士学位。即便是我将喜欢的 Linux 笔记本电脑换成了一台 MacBook Pro(因为我不能确定校园里能够接受 Linux),我还是决定继续使用我喜欢的工具,哪怕是在 MacOS 上也是如此。
|
||||
|
||||
幸运的是,它很容易,并且没有哪个教授质疑过我用的是什么软件。即然如此,我就不能秘而不宣。
|
||||
|
||||
我知道,我的一些同学最终会在学区担任领导职务,因此,我与我的那些使用 MacOS 或 Windows 的同学分享了关于下面描述的这些开源软件。毕竟,开源软件是真正地自由和友好的。我也希望他们去了解它,并且愿意以很少的一些成本去提供给他们的学生去使用这些世界级的应用程序。他们中的大多数人都感到很惊讶,因为,众所周知,开源软件除了有像你和我这样的用户之外,压根就没有销售团队。
|
||||
|
||||
### 我的 MacOS 学习曲线
|
||||
|
||||
虽然大多数的开源工具都能像以前我在 Linux 上使用的那样工作,只是需要不同的安装方法。但是,经过这个过程,我学习了这些工具在 MacOS 上的一些细微差别。像 [yum][1]、[DNF][2]、和 [APT][3] 在 MacOS 的世界中压根不存在 —— 我真的很怀念它们。
|
||||
|
||||
一些 MacOS 应用程序要求依赖项,并且安装它们要比我在 Linux 上习惯的方法困难很多。尽管如此,我仍然没有放弃。在这个过程中,我学会了如何在我的新平台上保留最好的软件。即便是 MacOS 大部分的核心也是 [开源的][4]。
|
||||
|
||||
此外,我的 Linux 的知识背景让我使用 MacOS 的命令行很轻松很舒适。我仍然使用命令行去创建和拷贝文件、添加用户、以及使用其它的像 `cat`、`tac`、`more`、`less` 和 `tail` 这样的 [实用工具][5]。
|
||||
|
||||
### 15 个适用于 MacOS 的非常好的开源应用程序
|
||||
|
||||
* 在大学里,要求我使用 DOCX 的电子版格式来提交我的工作,而这其实很容易,最初我使用的是 [OpenOffice][6],而后来我使用的是 [LibreOffice][7] 去完成我的论文。
|
||||
* 当我因为演示需要去做一些图像时,我使用的是我最喜欢的图像应用程序 [GIMP][8] 和 [Inkscape][9]。
|
||||
* 我喜欢的播客创建工具是 [Audacity][10]。它比起 Mac 上搭载的专有应用程序更加简单。我使用它去录制访谈和为视频演示创建配乐。
|
||||
* 在 MacOS 上我最早发现的多媒体播放器是 [VideoLan][11] (VLC)。
|
||||
* MacOS 内置的专有视频创建工具是一个非常好的产品,但是你也可以很轻松地去安装和使用 [OpenShot][12],它是一个非常好的内容创建工具。
|
||||
* 当我需要在我的客户端上分析网络时,我在我的 Mac 上使用了易于安装的 [Nmap][13] (Network Mapper) 和 [Wireshark][14] 工具。
|
||||
* 当我为图书管理员和其它教育工作者提供培训时,我在 MacOS 上使用 [VirtualBox][15] 去做 Raspbian、Fedora、Ubuntu 和其它 Linux 发行版的示范操作。
|
||||
* 我使用 [Etcher.io][16] 在我的 MacBook 上制作了一个引导盘,下载 ISO 文件,将它刻录到一个 U 盘上。
|
||||
* 我认为 [Firefox][17] 比起 MacBook Pro 自带的专有浏览器更易用更安全,并且它允许我跨操作系统去同步我的书签。
|
||||
* 当我使用电子书阅读器时,[Calibre][18] 是当之无愧的选择。它很容易去下载和安装,你甚至只需要几次点击就能将它配置为一台 [教室中使用的电子书服务器][19]。
|
||||
* 最近我给中学的学生教 Python 课程,我发现它可以很容易地从 [Python.org][20] 上下载和安装 Python 3 及 IDLE3 编辑器。我也喜欢学习数据科学,并与学生分享。不论你是对 Python 还是 R 感兴趣,我都建议你下载和 [安装][21] [Anaconda 发行版][22]。它包含了非常好的 iPython 编辑器、RStudio、Jupyter Notebooks、和 JupyterLab,以及其它一些应用程序。
|
||||
* [HandBrake][23] 是一个将你家里的旧的视频 DVD 转成 MP4 的工具,这样你就可以将它们共享到 YouTube、Vimeo、或者你的 MacOS 上的 [Kodi][24] 服务器上。
|
||||
|
||||
现在轮到你了:你在 MacOS(或 Windows)上都使用什么样的开源软件?在下面的评论区共享出来吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/open-source-tools-macos
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Yum_(software)
|
||||
[2]:https://en.wikipedia.org/wiki/DNF_(software)
|
||||
[3]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[4]:https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html
|
||||
[5]:https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[6]:https://www.openoffice.org/
|
||||
[7]:https://www.libreoffice.org/
|
||||
[8]:https://www.gimp.org/
|
||||
[9]:https://inkscape.org/en/
|
||||
[10]:https://www.audacityteam.org/
|
||||
[11]:https://www.videolan.org/index.html
|
||||
[12]:https://www.openshot.org/
|
||||
[13]:https://nmap.org/
|
||||
[14]:https://www.wireshark.org/
|
||||
[15]:https://www.virtualbox.org/
|
||||
[16]:https://etcher.io/
|
||||
[17]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[18]:https://calibre-ebook.com/
|
||||
[19]:https://opensource.com/article/17/6/raspberrypi-ebook-server
|
||||
[20]:https://www.python.org/downloads/release/python-370/
|
||||
[21]:https://opensource.com/article/18/4/getting-started-anaconda-python
|
||||
[22]:https://www.anaconda.com/download/#macos
|
||||
[23]:https://handbrake.fr/
|
||||
[24]:https://kodi.tv/download
|
||||
@ -0,0 +1,94 @@
|
||||
6 个开源的数字货币钱包
|
||||
======
|
||||
|
||||
> 想寻找一个可以存储和交易你的比特币、以太坊和其它数字货币的软件吗?这里有 6 个开源的软件可以选择。
|
||||
|
||||

|
||||
|
||||
没有数字货币钱包,像比特币和以太坊这样的数字货币只不过是又一个空想罢了。这些钱包对于保存、发送、以及接收数字货币来说是必需的东西。
|
||||
|
||||
迅速成长的 [数字货币][1] 之所以是革命性的,都归功于它的去中心化,该网络中没有中央权威,每个人都享有平等的权力。开源技术是数字货币和 [区块链][2] 网络的核心所在。它使得这个充满活力的新兴行业能够从去中心化中获益 —— 比如,不可改变、透明和安全。
|
||||
|
||||
如果你正在寻找一个自由开源的数字货币钱包,请继续阅读,并开始去探索以下的选择能否满足你的需求。
|
||||
|
||||
### 1、 Copay
|
||||
|
||||
[Copay][3] 是一个能够很方便地存储比特币的开源数字货币钱包。这个软件以 [MIT 许可证][4] 发布。
|
||||
|
||||
Copay 服务器也是开源的。因此,开发者和比特币爱好者可以在服务器上部署他们自己的应用程序来完全控制他们的活动。
|
||||
|
||||
Copay 钱包能让你手中的比特币更加安全,而不是去信任不可靠的第三方。它允许你使用多重签名来批准交易,并且支持在同一个 app 钱包内支持存储多个独立的钱包。
|
||||
|
||||
Copay 可以在多种平台上使用,比如 Android、Windows、MacOS、Linux、和 iOS。
|
||||
|
||||
### 2、 MyEtherWallet
|
||||
|
||||
正如它的名字所示,[MyEtherWallet][5] (缩写为 MEW) 是一个以太坊钱包。它是开源的(遵循 [MIT 许可证][6])并且是完全在线的,可以通过 web 浏览器来访问它。
|
||||
|
||||
这个钱包的客户端界面非常简洁,它可以让你自信而安全地参与到以太坊区块链中。
|
||||
|
||||
### 3、 mSIGNA
|
||||
|
||||
[mSIGNA][7] 是一个功能强大的桌面版应用程序,用于在比特币网络上完成交易。它遵循 [MIT 许可证][8] 并且在 MacOS、Windows、和 Linux 上可用。
|
||||
|
||||
这个区块链钱包可以让你完全控制你存储的比特币。其中一些特性包括用户友好性、灵活性、去中心化的离线密钥生成能力、加密的数据备份,以及多设备同步功能。
|
||||
|
||||
### 4、 Armory
|
||||
|
||||
[Armory][9] 是一个在你的计算机上产生和保管比特币私钥的开源钱包(遵循 [GNU AGPLv3][10])。它通过使用冷存储和支持多重签名的能力增强了安全性。
|
||||
|
||||
使用 Armory,你可以在完全离线的计算机上设置一个钱包;你将通过<ruby>仅查看<rt>watch-only</rt></ruby>功能在因特网上查看你的比特币具体信息,这样有助于改善安全性。这个钱包也允许你去创建多个地址,并使用它们去完成不同的事务。
|
||||
|
||||
Armory 可用于 MacOS、Windows、和几个比较有特色的 Linux 平台上(包括树莓派)。
|
||||
|
||||
### 5、 Electrum
|
||||
|
||||
[Electrum][11] 是一个既对新手友好又具备专家功能的比特币钱包。它遵循 [MIT 许可证][12] 来发行。
|
||||
|
||||
Electrum 可以在你的本地机器上使用较少的资源来实现本地加密你的私钥,支持冷存储,并且提供多重签名能力。
|
||||
|
||||
它在各种操作系统和设备上都可以使用,包括 Windows、MacOS、Android、iOS 和 Linux,并且也可以在像 [Trezor][13] 这样的硬件钱包中使用。
|
||||
|
||||
### 6、 Etherwall
|
||||
|
||||
[Etherwall][14] 是第一款可以在桌面计算机上存储和发送以太坊的钱包。它是一个遵循 [GPLv3 许可证][15] 的开源钱包。
|
||||
|
||||
Etherwall 非常直观而且速度很快。更重要的是,它增加了你的私钥安全性,你可以在一个全节点或瘦节点上来运行它。它作为全节点客户端运行时,可以允许你在本地机器上下载整个以太坊区块链。
|
||||
|
||||
Etherwall 可以在 MacOS、Linux 和 Windows 平台上运行,并且它也支持 Trezor 硬件钱包。
|
||||
|
||||
### 智者之言
|
||||
|
||||
自由开源的数字钱包在让更多的人快速上手数字货币方面扮演至关重要的角色。
|
||||
|
||||
在你使用任何数字货币软件钱包之前,你一定要确保你的安全,而且一定要记住并完全遵循确保你的资金安全的最佳实践。
|
||||
|
||||
如果你喜欢的开源数字货币钱包不在以上的清单中,请在下面的评论区共享出你所知道的开源钱包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/crypto-wallets
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drmjg
|
||||
[1]:https://www.liveedu.tv/guides/cryptocurrency/
|
||||
[2]:https://opensource.com/tags/blockchain
|
||||
[3]:https://copay.io/
|
||||
[4]:https://github.com/bitpay/copay/blob/master/LICENSE
|
||||
[5]:https://www.myetherwallet.com/
|
||||
[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
|
||||
[7]:https://ciphrex.com/
|
||||
[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
|
||||
[9]:https://www.bitcoinarmory.com/
|
||||
[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
|
||||
[11]:https://electrum.org/#home
|
||||
[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
|
||||
[13]:https://trezor.io/
|
||||
[14]:https://www.etherwall.com/
|
||||
[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
|
||||
@ -0,0 +1,110 @@
|
||||
使用 Wttr.in 在你的终端中显示天气预报
|
||||
======
|
||||
|
||||
|
||||
|
||||
[wttr.in][1] 是一个功能丰富的天气预报服务,它支持在命令行显示天气。它可以(根据你的 IP 地址)自动检测你的位置,也支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 —— 你只需要使用 cURL 或 Wget**(见下文)。
|
||||
|
||||
wttr.in 功能包括:
|
||||
|
||||
* **显示当前天气以及 3 天内的天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
|
||||
* **可以显示月相**
|
||||
* **基于你的 IP 地址自动检测位置**
|
||||
* **允许指定城市名称、3 字母的机场代码、区域代码、GPS 坐标、IP 地址或域名**。你还可以指定地理位置,如湖泊、山脉、地标等)
|
||||
* **支持多语言位置名称**(查询字符串必须以 Unicode 指定)
|
||||
* **支持指定**天气预报显示的语言(它支持超过 50 种语言)
|
||||
* **来自美国的查询使用 USCS 单位用于,世界其他地方使用公制系统**,但你可以通过附加 `?u` 使用 USCS,附加 `?m` 使用公制系统。 )
|
||||
* **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**
|
||||
|
||||
就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以在你的服务器上[安装它][3]。 或者你可以安装 [wego][4],这是一个使用 wtter.in 的终端气候应用,虽然 wego 要求注册一个 API 密钥来安装。
|
||||
|
||||
**在使用 wttr.in 之前,请确保已安装 cURL。**在 Debian、Ubuntu 或 Linux Mint(以及其他基于 Debian 或 Ubuntu 的 Linux 发行版)中,使用以下命令安装 cURL:
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
```
|
||||
|
||||
### wttr.in 命令行示例
|
||||
|
||||
获取你所在位置的天气(wttr.in 会根据你的 IP 地址猜测你的位置):
|
||||
|
||||
```
|
||||
curl wttr.in
|
||||
```
|
||||
|
||||
通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你用 IPv6 访问 wttr.in 有问题):
|
||||
|
||||
```
|
||||
curl -4 wttr.in
|
||||
```
|
||||
|
||||
如果你想检索天气预报保存为 png,**还可以使用 Wget**(而不是 cURL),或者你想这样使用它:
|
||||
|
||||
```
|
||||
wget -O- -q wttr.in
|
||||
```
|
||||
|
||||
如果相对 cURL 你更喜欢 Wget ,可以在下面的所有命令中用 `wget -O- -q` 替换 `curl`。
|
||||
|
||||
指定位置:
|
||||
|
||||
```
|
||||
curl wttr.in/Dublin
|
||||
```
|
||||
|
||||
显示地标的天气信息(本例中为艾菲尔铁塔):
|
||||
|
||||
```
|
||||
curl wttr.in/~Eiffel+Tower
|
||||
```
|
||||
|
||||
获取 IP 地址位置的天气信息(以下 IP 属于 GitHub):
|
||||
|
||||
```
|
||||
curl wttr.in/@192.30.253.113
|
||||
```
|
||||
|
||||
使用 USCS 单位检索天气:
|
||||
|
||||
```
|
||||
curl wttr.in/Paris?u
|
||||
```
|
||||
|
||||
如果你在美国,强制 wttr.in 使用公制系统(SI):
|
||||
|
||||
```
|
||||
curl wttr.in/New+York?m
|
||||
```
|
||||
|
||||
使用 Wget 将当前天气和 3 天预报下载为 PNG 图像:
|
||||
|
||||
```
|
||||
wget wttr.in/Istanbul.png
|
||||
```
|
||||
|
||||
你可以指定 PNG 的[透明度][5],这在你要使用一个脚本自动添加天气信息到某些图片(比如墙纸)上有用。
|
||||
|
||||
**对于其他示例,请查看 wttr.in [项目页面][2]或在终端中输入:**
|
||||
|
||||
```
|
||||
curl wttr.in/:help
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://wttr.in/
|
||||
[2]:https://github.com/chubin/wttr.in
|
||||
[3]:https://github.com/chubin/wttr.in#installation
|
||||
[4]:https://github.com/schachmat/wego
|
||||
[5]:https://github.com/chubin/wttr.in#supported-formats
|
||||
88
published/201807/20180710 Getting started with Perlbrew.md
Normal file
88
published/201807/20180710 Getting started with Perlbrew.md
Normal file
@ -0,0 +1,88 @@
|
||||
Perlbrew 入门
|
||||
======
|
||||
|
||||
> 用 Perlbrew 在你系统上安装多个版本的 Perl。
|
||||
|
||||

|
||||
|
||||
有比在系统上安装了 Perl 更好的事情吗?那就是在系统中安装了多个版本的 Perl。使用 [Perlbrew][1] 你可以做到这一点。但是为什么呢,除了让你包围在 Perl 下之外,有什么好处吗?
|
||||
|
||||
简短的回答是,不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它能否工作。
|
||||
|
||||
### 安装 Perlbrew
|
||||
|
||||
另一个好处是 Perlbrew 会安装 Perl 到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
|
||||
|
||||
第一步是在你的系统上安装 Perlbrew。许多 Linux 发行版已经在包仓库中拥有它,因此你只需要 `dnf install perlbrew`(或者适用于你的发行版的命令)。你还可以使用 `cpan App::perlbrew` 从 CPAN 安装 `App::perlbrew` 模块。或者你可以在 [install.perlbrew.pl][2] 下载并运行安装脚本。
|
||||
|
||||
要开始使用 Perlbrew,请运行 `perlbrew init`。
|
||||
|
||||
### 安装新的 Perl 版本
|
||||
|
||||
假设你想尝试最新的开发版本(撰写本文时为 5.27.11)。首先,你需要安装包:
|
||||
|
||||
```
|
||||
perlbrew install 5.27.11
|
||||
```
|
||||
|
||||
### 切换 Perl 版本
|
||||
|
||||
现在你已经安装了新版本,你可以将它用于该 shell:
|
||||
|
||||
```
|
||||
perlbrew use 5.27.11
|
||||
```
|
||||
|
||||
或者你可以将其设置为你帐户的默认 Perl 版本(假设你按照 `perlbrew init` 的输出设置了你的配置文件):
|
||||
|
||||
```
|
||||
perlbrew switch 5.27.11
|
||||
```
|
||||
|
||||
### 运行单个脚本
|
||||
|
||||
你也可以用特定版本的 Perl 运行单个命令:
|
||||
|
||||
```
|
||||
perlberew exec 5.27.11 myscript.pl
|
||||
```
|
||||
|
||||
或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请指定版本为 `perl`:
|
||||
|
||||
```
|
||||
plperlbrew exec perl myscriptpl
|
||||
```
|
||||
|
||||
### 安装 CPAN 模块
|
||||
|
||||
如果你想安装 CPAN 模块,`cpanm` 包是一个易于使用的界面,可以很好地与 Perlbrew 一起使用。用下面命令安装它:
|
||||
|
||||
```
|
||||
perlbrew install-cpanm
|
||||
```
|
||||
|
||||
然后,你可以使用 `cpanm` 命令安装 CPAN 模块:
|
||||
|
||||
```
|
||||
cpanm CGI::simple
|
||||
```
|
||||
|
||||
### 但是等下,还有更多!
|
||||
|
||||
本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[App::perlbrew 文档][3]。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/perlbrew
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://perlbrew.pl/
|
||||
[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
|
||||
[3]:https://metacpan.org/pod/App::perlbrew
|
||||
366
published/201807/20180710 Python Sets What Why and How.md
Normal file
366
published/201807/20180710 Python Sets What Why and How.md
Normal file
@ -0,0 +1,366 @@
|
||||
Python 集合是什么,为什么应该使用以及如何使用?
|
||||
=====
|
||||
|
||||

|
||||
|
||||
Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表、字典、元组和集合。
|
||||
|
||||
根据 Python 3 文档:
|
||||
|
||||
> 集合是一个*无序*集合,没有*重复元素*。基本用途包括*成员测试*和*消除重复的条目*。集合对象还支持数学运算,如*并集*、*交集*、*差集*和*对等差分*。
|
||||
|
||||
在本文中,我们将回顾并查看上述定义中列出的每个要素的示例。让我们马上开始,看看如何创建它。
|
||||
|
||||
### 初始化一个集合
|
||||
|
||||
有两种方法可以创建一个集合:一个是给内置函数 `set()` 提供一个元素列表,另一个是使用花括号 `{}`。
|
||||
|
||||
使用内置函数 `set()` 来初始化一个集合:
|
||||
|
||||
```
|
||||
>>> s1 = set([1, 2, 3])
|
||||
>>> s1
|
||||
{1, 2, 3}
|
||||
>>> type(s1)
|
||||
<class 'set'>
|
||||
```
|
||||
|
||||
使用 `{}`:
|
||||
|
||||
|
||||
```
|
||||
>>> s2 = {3, 4, 5}
|
||||
>>> s2
|
||||
{3, 4, 5}
|
||||
>>> type(s2)
|
||||
<class 'set'>
|
||||
>>>
|
||||
```
|
||||
|
||||
如你所见,这两种方法都是有效的。但问题是,如果我们想要一个空的集合呢?
|
||||
|
||||
```
|
||||
>>> s = {}
|
||||
>>> type(s)
|
||||
<class 'dict'>
|
||||
```
|
||||
|
||||
没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。=)
|
||||
|
||||
值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 <ruby>[可哈希的][6]<rt>hashable</rt></ruby> 数据类型。换句话说,即整数、字符串和元组,而不是*列表*或*字典*这样的可变类型。
|
||||
|
||||
```
|
||||
>>> s = {1, 'coffee', [4, 'python']}
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: unhashable type: 'list'
|
||||
```
|
||||
|
||||
既然你知道了如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看*为什么*我们总是应该把它放在我们的工具箱中。
|
||||
|
||||
### 为什么你需要使用它
|
||||
|
||||
写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的、简洁的和可维护的,或者是 “<ruby>[Python 式的][7]<rt>pythonic</rt></ruby>”。
|
||||
|
||||
根据 [Hitchhiker 对 Python 的建议][8]:
|
||||
|
||||
> 当一个经验丰富的 Python 开发人员(<ruby>Python 人<rt>Pythonista</rt></ruby>)调用一些不够 “<ruby>Python 式的<rt>pythonic</rt></ruby>” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
|
||||
|
||||
让我们开始探索 Python 集合那些不仅可以帮助我们提高可读性,还可以加快程序执行时间的方式。
|
||||
|
||||
#### 无序的集合元素
|
||||
|
||||
首先你需要明白的是:你无法使用索引访问集合中的元素。
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s[0]
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: 'set' object does not support indexing
|
||||
```
|
||||
|
||||
或者使用切片修改它们:
|
||||
|
||||
```
|
||||
>>> s[0:2]
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: 'set' object is not subscriptable
|
||||
```
|
||||
|
||||
但是,如果我们需要删除重复项,或者进行组合列表(与)之类的数学运算,那么我们可以,并且*应该*始终使用集合。
|
||||
|
||||
我不得不提一下,在迭代时,集合的表现优于列表。所以,如果你需要它,那就加深对它的喜爱吧。为什么?好吧,这篇文章并不打算解释集合的内部工作原理,但是如果你感兴趣的话,这里有几个链接,你可以阅读它:
|
||||
|
||||
* [时间复杂度][1]
|
||||
* [set() 是如何实现的?][2]
|
||||
* [Python 集合 vs 列表][3]
|
||||
* [在列表中使用集合是否有任何优势或劣势,以确保独一无二的列表条目?][4]
|
||||
|
||||
#### 没有重复项
|
||||
|
||||
写这篇文章的时候,我总是不停地思考,我经常使用 `for` 循环和 `if` 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
>>> no_duplicate_list = []
|
||||
>>> for item in my_list:
|
||||
... if item not in no_duplicate_list:
|
||||
... no_duplicate_list.append(item)
|
||||
...
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
```
|
||||
|
||||
或者使用列表解析:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
>>> no_duplicate_list = []
|
||||
>>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list]
|
||||
[None, None, None, None]
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
```
|
||||
|
||||
但没关系,因为我们现在有了武器装备,没有什么比这更重要的了:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
>>> no_duplicate_list = list(set(my_list))
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
>>>
|
||||
```
|
||||
|
||||
现在让我们使用 `timeit` 模块,查看列表和集合在删除重复项时的执行时间:
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> def no_duplicates(list):
|
||||
... no_duplicate_list = []
|
||||
... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
|
||||
... return no_duplicate_list
|
||||
...
|
||||
>>> # 首先,让我们看看列表的执行情况:
|
||||
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
|
||||
0.0018683355819786227
|
||||
```
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> # 使用集合:
|
||||
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
|
||||
0.0010220493243764395
|
||||
>>> # 快速而且干净 =)
|
||||
```
|
||||
|
||||
使用集合而不是列表推导不仅让我们编写*更少的代码*,而且还能让我们获得*更具可读性*和*高性能*的代码。
|
||||
|
||||
注意:请记住集合是无序的,因此无法保证在将它们转换回列表时,元素的顺序不变。
|
||||
|
||||
[Python 之禅][9]:
|
||||
|
||||
> <ruby>优美胜于丑陋<rt>Beautiful is better than ugly.</rt></ruby>
|
||||
|
||||
> <ruby>明了胜于晦涩<rt>Explicit is better than implicit.</rt></ruby>
|
||||
|
||||
> <ruby>简洁胜于复杂<rt>Simple is better than complex.</rt></ruby>
|
||||
|
||||
> <ruby>扁平胜于嵌套<rt>Flat is better than nested.</rt></ruby>
|
||||
|
||||
集合不正是这样美丽、明了、简单且扁平吗?
|
||||
|
||||
#### 成员测试
|
||||
|
||||
每次我们使用 `if` 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
|
||||
|
||||
```
|
||||
my_list = [1, 2, 3]
|
||||
>>> if 2 in my_list:
|
||||
... print('Yes, this is a membership test!')
|
||||
...
|
||||
Yes, this is a membership test!
|
||||
```
|
||||
|
||||
在执行这些操作时,集合比列表更高效:
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> def in_test(iterable):
|
||||
... for i in range(1000):
|
||||
... if i in iterable:
|
||||
... pass
|
||||
...
|
||||
>>> timeit('in_test(iterable)',
|
||||
... setup="from __main__ import in_test; iterable = list(range(1000))",
|
||||
... number=1000)
|
||||
12.459663048726043
|
||||
```
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> def in_test(iterable):
|
||||
... for i in range(1000):
|
||||
... if i in iterable:
|
||||
... pass
|
||||
...
|
||||
>>> timeit('in_test(iterable)',
|
||||
... setup="from __main__ import in_test; iterable = set(range(1000))",
|
||||
... number=1000)
|
||||
.12354438152988223
|
||||
```
|
||||
|
||||
注意:上面的测试来自于[这个][10] StackOverflow 话题。
|
||||
|
||||
因此,如果你在巨大的列表中进行这样的比较,尝试将该列表转换为集合,它应该可以加快你的速度。
|
||||
|
||||
### 如何使用
|
||||
|
||||
现在你已经了解了集合是什么以及为什么你应该使用它,现在让我们快速浏览一下,看看我们如何修改和操作它。
|
||||
|
||||
#### 添加元素
|
||||
|
||||
根据要添加的元素数量,我们要在 `add()` 和 `update()` 方法之间进行选择。
|
||||
|
||||
`add()` 适用于添加单个元素:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.add(4)
|
||||
>>> s
|
||||
{1, 2, 3, 4}
|
||||
```
|
||||
|
||||
`update()` 适用于添加多个元素:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.update([2, 3, 4, 5, 6])
|
||||
>>> s
|
||||
{1, 2, 3, 4, 5, 6}
|
||||
```
|
||||
|
||||
请记住,集合会移除重复项。
|
||||
|
||||
#### 移除元素
|
||||
|
||||
如果你希望在代码中尝试删除不在集合中的元素时收到警报,请使用 `remove()`。否则,`discard()` 提供了一个很好的选择:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.remove(3)
|
||||
>>> s
|
||||
{1, 2}
|
||||
>>> s.remove(3)
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
KeyError: 3
|
||||
```
|
||||
|
||||
`discard()` 不会引起任何错误:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.discard(3)
|
||||
>>> s
|
||||
{1, 2}
|
||||
>>> s.discard(3)
|
||||
>>> # 什么都不会发生
|
||||
```
|
||||
|
||||
我们也可以使用 `pop()` 来随机丢弃一个元素:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3, 4, 5}
|
||||
>>> s.pop() # 删除一个任意的元素
|
||||
1
|
||||
>>> s
|
||||
{2, 3, 4, 5}
|
||||
```
|
||||
|
||||
或者 `clear()` 方法来清空一个集合:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3, 4, 5}
|
||||
>>> s.clear() # 清空集合
|
||||
>>> s
|
||||
set()
|
||||
```
|
||||
|
||||
#### union()
|
||||
|
||||
`union()` 或者 `|` 将创建一个新集合,其中包含我们提供集合中的所有元素:
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {3, 4, 5}
|
||||
>>> s1.union(s2) # 或者 's1 | s2'
|
||||
{1, 2, 3, 4, 5}
|
||||
```
|
||||
|
||||
#### intersection()
|
||||
|
||||
`intersection` 或 `&` 将返回一个由集合共同元素组成的集合:
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s3 = {3, 4, 5}
|
||||
>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
|
||||
{3}
|
||||
```
|
||||
|
||||
#### difference()
|
||||
|
||||
使用 `diference()` 或 `-` 创建一个新集合,其值在 “s1” 中但不在 “s2” 中:
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s1.difference(s2) # 或者 's1 - s2'
|
||||
{1}
|
||||
```
|
||||
|
||||
#### symmetric_diference()
|
||||
|
||||
`symetric_difference` 或 `^` 将返回集合之间的不同元素。
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
|
||||
{1, 4}
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
我希望在阅读本文之后,你会知道集合是什么,如何操纵它的元素以及它可以执行的操作。知道何时使用集合无疑会帮助你编写更清晰的代码并加速你的程序。
|
||||
|
||||
如果你有任何疑问,请发表评论,我很乐意尝试回答。另外,不要忘记,如果你已经理解了集合,它们在 [Python Cheatsheet][12] 中有自己的[一席之地][11],在那里你可以快速参考并重新认知你已经知道的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.pythoncheatsheet.org/blog/python-sets-what-why-how
|
||||
|
||||
作者:[wilfredinni][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.pythoncheatsheet.org/author/wilfredinni
|
||||
[1]:https://wiki.python.org/moin/TimeComplexity
|
||||
[2]:https://stackoverflow.com/questions/3949310/how-is-set-implemented
|
||||
[3]:https://stackoverflow.com/questions/2831212/python-sets-vs-lists
|
||||
[4]:https://mail.python.org/pipermail/python-list/2011-June/606738.html
|
||||
[5]:https://www.pythoncheatsheet.org/author/wilfredinni
|
||||
[6]:https://docs.python.org/3/glossary.html#term-hashable
|
||||
[7]:http://docs.python-guide.org/en/latest/writing/style/
|
||||
[8]:http://docs.python-guide.org/en/latest/
|
||||
[9]:https://www.python.org/dev/peps/pep-0020/
|
||||
[10]:https://stackoverflow.com/questions/2831212/python-sets-vs-lists
|
||||
[11]:https://www.pythoncheatsheet.org/#sets
|
||||
[12]:https://www.pythoncheatsheet.org/
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
4 个提高你在 Thunderbird 上隐私的加载项
|
||||
======
|
||||
|
||||

|
||||
|
||||
Thunderbird 是由 [Mozilla][1] 开发的流行的免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
|
||||
|
||||
### Enigmail
|
||||
|
||||
使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在这里的入门介绍][2]。
|
||||
|
||||
[Enigmail][3] 是使用 OpenPGP 和 Thunderbird 的首选加载项。实际上,Enigmail 与 Thunderbird 集成良好,可让你加密、解密、数字签名和验证电子邮件。
|
||||
|
||||
### Paranoia
|
||||
|
||||
[Paranoia][4] 可让你查看有关收到的电子邮件的重要信息。用一个表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
|
||||
|
||||
黄色、快乐的表情告诉你所有连接都已加密。蓝色、悲伤的表情意味着有一个连接未加密。最后,红色的、害怕的表情表示在多个连接上该消息未加密。
|
||||
|
||||
还有更多有关这些连接的详细信息,你可以用来检查哪台服务器用于投递邮件。
|
||||
|
||||
### Sensitivity Header
|
||||
|
||||
[Sensitivity Header][5] 是一个简单的加载项,可让你选择外发电子邮件的隐私级别。使用选项菜单,你可以选择敏感度:正常、个人、隐私和机密。
|
||||
|
||||
添加此标头不会为电子邮件添加额外的安全性。但是,某些电子邮件客户端或邮件传输/用户代理(MTA/MUA)可以使用此标头根据敏感度以不同方式处理邮件。
|
||||
|
||||
请注意,开发人员将此加载项标记为实验性的。
|
||||
|
||||
### TorBirdy
|
||||
|
||||
如果你真的担心自己的隐私,[TorBirdy][6] 就是给你设计的加载项。它将 Thunderbird 配置为使用 [Tor][7] 网络。
|
||||
|
||||
据其[文档][8]所述,TorBirdy 为以前没有使用 Tor 的电子邮件帐户提供了少量隐私保护。
|
||||
|
||||
> 请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 —— 你经常旅行并且不想通过发送电子邮件来披露你的所有位置 —— TorBirdy 非常有效!
|
||||
|
||||
请注意,要使用此加载项,必须在系统上安装 Tor。
|
||||
|
||||
照片由 [Braydon Anderson][9] 在 [Unsplash][10] 上发布。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-addons-privacy-thunderbird/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://www.mozilla.org/en-US/
|
||||
[2]:https://fedoramagazine.org/gnupg-a-fedora-primer/
|
||||
[3]:https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/
|
||||
[4]:https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users
|
||||
[5]:https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users
|
||||
[6]:https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users
|
||||
[7]:https://www.torproject.org/
|
||||
[8]:https://trac.torproject.org/projects/tor/wiki/torbirdy
|
||||
[9]:https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[10]:https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,174 @@
|
||||
在 Ubuntu 18.04 LTS 上安装 Microsoft Windows 字体
|
||||
======
|
||||
|
||||

|
||||
|
||||
大多数教育机构仍在使用 Microsoft 字体, 我不清楚其他国家是什么情况。但在泰米尔纳德邦(印度的一个州), **Times New Roman** 和 **Arial** 字体主要被用于大学和学校的几乎所有文档工作、项目和作业。不仅是教育机构,而且一些小型组织、办公室和商店仍在使用 MS Windows 字体。以防万一,如果你需要在 Ubuntu 桌面版上使用 Microsoft 字体,请按照以下步骤安装。
|
||||
|
||||
**免责声明**: Microsoft 已免费发布其核心字体。 但**请注意 Microsoft 字体是禁止使用在其他操作系统中**。在任何 Linux 操作系统中安装 MS 字体之前请仔细阅读 EULA 。我们不负责这种任何种类的盗版行为。
|
||||
|
||||
(LCTT 译注:本文只做技术探讨,并不代表作者、译者和本站鼓励任何行为。)
|
||||
|
||||
### 在 Ubuntu 18.04 LTS 桌面版上安装 MS 字体
|
||||
|
||||
如下所示安装 MS TrueType 字体:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install ttf-mscorefonts-installer
|
||||
```
|
||||
|
||||
然后将会出现 Microsoft 的最终用户协议向导,点击 **OK** 以继续。
|
||||
|
||||
![][2]
|
||||
|
||||
点击 **Yes** 已接受 Microsoft 的协议:
|
||||
|
||||
![][3]
|
||||
|
||||
安装字体之后, 我们需要使用命令行来更新字体缓存:
|
||||
|
||||
```
|
||||
$ sudo fc-cache -f -v
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
/usr/share/fonts: caching, new cache contents: 0 fonts, 6 dirs
|
||||
/usr/share/fonts/X11: caching, new cache contents: 0 fonts, 4 dirs
|
||||
/usr/share/fonts/X11/Type1: caching, new cache contents: 8 fonts, 0 dirs
|
||||
/usr/share/fonts/X11/encodings: caching, new cache contents: 0 fonts, 1 dirs
|
||||
/usr/share/fonts/X11/encodings/large: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/X11/misc: caching, new cache contents: 89 fonts, 0 dirs
|
||||
/usr/share/fonts/X11/util: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cMap: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap: caching, new cache contents: 0 fonts, 5 dirs
|
||||
/usr/share/fonts/cmap/adobe-cns1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-gb1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-japan1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-japan2: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-korea1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/opentype: caching, new cache contents: 0 fonts, 2 dirs
|
||||
/usr/share/fonts/opentype/malayalam: caching, new cache contents: 3 fonts, 0 dirs
|
||||
/usr/share/fonts/opentype/noto: caching, new cache contents: 24 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 46 dirs
|
||||
/usr/share/fonts/truetype/Gargi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Gubbi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Nakula: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Navilu: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Sahadeva: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Sarai: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/abyssinica: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/dejavu: caching, new cache contents: 6 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/droid: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-beng-extra: caching, new cache contents: 6 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-deva-extra: caching, new cache contents: 3 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-gujr-extra: caching, new cache contents: 5 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-guru-extra: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-kalapi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-orya-extra: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-telu-extra: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/freefont: caching, new cache contents: 12 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/kacst: caching, new cache contents: 15 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/kacst-one: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lao: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/liberation2: caching, new cache contents: 12 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-assamese: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-bengali: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-devanagari: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-gujarati: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-kannada: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-malayalam: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-oriya: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-punjabi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-tamil: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-tamil-classical: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-telugu: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/malayalam: caching, new cache contents: 11 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/msttcorefonts: caching, new cache contents: 60 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/noto: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/openoffice: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/padauk: caching, new cache contents: 4 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/pagul: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/samyak: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/samyak-fonts: caching, new cache contents: 3 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/sinhala: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/tibetan-machine: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/tlwg: caching, new cache contents: 58 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/ttf-khmeros-core: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/ubuntu: caching, new cache contents: 13 fonts, 0 dirs
|
||||
/usr/share/fonts/type1: caching, new cache contents: 0 fonts, 1 dirs
|
||||
/usr/share/fonts/type1/gsfonts: caching, new cache contents: 35 fonts, 0 dirs
|
||||
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/home/sk/.local/share/fonts: skipping, no such directory
|
||||
/home/sk/.fonts: skipping, no such directory
|
||||
/var/cache/fontconfig: cleaning cache directory
|
||||
/home/sk/.cache/fontconfig: cleaning cache directory
|
||||
/home/sk/.fontconfig: not cleaning non-existent cache directory
|
||||
fc-cache: succeeded
|
||||
```
|
||||
|
||||
### 在 Linux 和 Windows 双启动的机器上安装 MS 字体
|
||||
|
||||
如果你有 Linux 和 Windows 的双启动系统,你可以轻松地从 Windows C 驱动器上安装 MS 字体。
|
||||
你所要做的就是挂载 Windows 分区(C:/windows)。
|
||||
|
||||
我假设你已经在 Linux 中将 `C:\Windows` 分区挂载在了 `/Windowsdrive` 目录下。
|
||||
|
||||
现在,将字体位置链接到你的 Linux 系统的字体文件夹,如下所示:
|
||||
|
||||
```
|
||||
ln -s /Windowsdrive/Windows/Fonts /usr/share/fonts/WindowsFonts
|
||||
```
|
||||
|
||||
链接字体文件之后,使用命令行重新生成 fontconfig 缓存:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
或者,将所有的 Windows 字体复制到 `/usr/share/fonts` 目录下并使用一下命令安装字体:
|
||||
|
||||
```
|
||||
mkdir /usr/share/fonts/WindowsFonts
|
||||
cp /Windowsdrive/Windows/Fonts/* /usr/share/fonts/WindowsFonts
|
||||
chmod 755 /usr/share/fonts/WindowsFonts/*
|
||||
```
|
||||
|
||||
最后,使用命令行重新生成 fontconfig 缓存:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
|
||||
### 测试 Windows 字体
|
||||
|
||||
安装 MS 字体后打开 LibreOffice 或 GIMP。 现在,你将会看到 Microsoft coretype 字体。
|
||||
|
||||
![][4]
|
||||
|
||||
就是这样, 希望这本指南有用。我再次警告你,在其他操作系统中使用 MS 字体是被禁止的。在安装 MS 字体之前请先阅读 Microsoft 许可协议。
|
||||
|
||||
如果你觉得我们的指南有用,请在你的社区、专业网络上分享并支持我们。还有更多好东西在等着我们。持续访问!
|
||||
|
||||
庆祝吧!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-3.png
|
||||
@ -0,0 +1,157 @@
|
||||
如何强制用户在下次登录 Linux 时更改密码
|
||||
======
|
||||
|
||||
当你使用默认密码创建用户时,你必须强制用户在下一次登录时更改密码。
|
||||
|
||||
当你在一个组织中工作时,此选项是强制性的。因为老员工可能知道默认密码,他们可能会也可能不会尝试不当行为。
|
||||
|
||||
这是安全投诉之一,所以,确保你必须以正确的方式处理此事而无任何失误。即使是你的团队成员也要一样做。
|
||||
|
||||
大多数用户都很懒,除非你强迫他们更改密码,否则他们不会这样做。所以要做这个实践。
|
||||
|
||||
出于安全原因,你需要经常更改密码,或者至少每个月更换一次。
|
||||
|
||||
确保你使用的是难以猜测的密码(大小写字母,数字和特殊字符的组合)。它至少应该为 10-15 个字符。
|
||||
|
||||
我们运行了一个 shell 脚本来在 Linux 服务器中创建一个用户账户,它会自动为用户附加一个密码,密码是实际用户名和少量数字的组合。
|
||||
|
||||
我们可以通过使用以下两种方法来实现这一点:
|
||||
|
||||
* passwd 命令
|
||||
* chage 命令
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
- [如何在 Linux 上检查用户所属的组][1]
|
||||
- [如何在 Linux 上检查创建用户的日期][2]
|
||||
- [如何在 Linux 中重置/更改用户密码][3]
|
||||
- [如何使用 passwd 命令管理密码过期和老化][4]
|
||||
|
||||
### 方法 1:使用 passwd 命令
|
||||
|
||||
`passwd` 的意思是“密码”。它用于更新用户的身份验证令牌。`passwd` 命令/实用程序用于设置、修改或更改用户的密码。
|
||||
|
||||
普通的用户只能更改自己的账户,但超级用户可以更改任何账户的密码。
|
||||
|
||||
此外,我们还可以使用其他选项,允许用户执行其他活动,例如删除用户密码、锁定或解锁用户账户、设置用户账户的密码过期时间等。
|
||||
|
||||
在 Linux 中这可以通过调用 Linux-PAM 和 Libuser API 执行。
|
||||
|
||||
在 Linux 中创建用户时,用户详细信息将存储在 `/etc/passwd` 文件中。`passwd` 文件将每个用户的详细信息保存为带有七个字段的单行。
|
||||
|
||||
此外,在 Linux 系统中创建新用户时,将更新以下四个文件。
|
||||
|
||||
* `/etc/passwd`: 用户详细信息将在此文件中更新。
|
||||
* `/etc/shadow`: 用户密码信息将在此文件中更新。
|
||||
* `/etc/group`: 新用户的组详细信息将在此文件中更新。
|
||||
* `/etc/gshadow`: 新用户的组密码信息将在此文件中更新。
|
||||
|
||||
#### 如何使用 passwd 命令执行此操作
|
||||
|
||||
我们可以使用 `passwd` 命令并添加 `-e` 选项来执行此操作。
|
||||
|
||||
为了测试这一点,让我们创建一个新用户账户,看看它是如何工作的。
|
||||
|
||||
```
|
||||
# useradd -c "2g Admin - Magesh M" magesh && passwd magesh
|
||||
Changing password for user magesh.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
使用户账户的密码失效,那么在下次登录尝试期间,用户将被迫更改密码。
|
||||
|
||||
```
|
||||
# passwd -e magesh
|
||||
Expiring password for user magesh.
|
||||
passwd: Success
|
||||
```
|
||||
|
||||
当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
|
||||
|
||||
```
|
||||
login as: magesh
|
||||
[email protected]'s password:
|
||||
You are required to change your password immediately (root enforced)
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for user magesh.
|
||||
Changing password for magesh.
|
||||
(current) UNIX password:
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Connection to localhost closed.
|
||||
```
|
||||
|
||||
### 方法 2:使用 chage 命令
|
||||
|
||||
`chage` 意即“改变时间”。它会更改用户密码过期信息。
|
||||
|
||||
`chage` 命令会改变上次密码更改日期之后需要修改密码的天数。系统使用此信息来确定用户何时必须更改他/她的密码。
|
||||
|
||||
它允许用户执行其他活动,例如设置帐户到期日期,到期后设置密码失效,显示帐户过期信息,设置密码更改前的最小和最大天数以及设置到期警告天数。
|
||||
|
||||
#### 如何使用 chage 命令执行此操作
|
||||
|
||||
让我们在 `chage` 命令的帮助下,通过添加 `-d` 选项执行此操作。
|
||||
|
||||
为了测试这一点,让我们创建一个新用户帐户,看看它是如何工作的。我们将创建一个名为 `thanu` 的用户帐户。
|
||||
|
||||
```
|
||||
# useradd -c "2g Editor - Thanisha M" thanu && passwd thanu
|
||||
Changing password for user thanu.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
要实现这一点,请使用 `chage` 命令将用户的上次密码更改日期设置为 0。
|
||||
|
||||
```
|
||||
# chage -d 0 thanu
|
||||
|
||||
# chage -l thanu
|
||||
Last password change : Jul 18, 2018
|
||||
Password expires : never
|
||||
Password inactive : never
|
||||
Account expires : never
|
||||
Minimum number of days between password change : 0
|
||||
Maximum number of days between password change : 99999
|
||||
Number of days of warning before password expires : 7
|
||||
```
|
||||
|
||||
当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
|
||||
|
||||
```
|
||||
login as: thanu
|
||||
[email protected]'s password:
|
||||
You are required to change your password immediately (root enforced)
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for user thanu.
|
||||
Changing password for thanu.
|
||||
(current) UNIX password:
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Connection to localhost closed.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
[2]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
|
||||
[3]:https://www.2daygeek.com/passwd-command-examples/
|
||||
[4]:https://www.2daygeek.com/passwd-command-examples-part-l/
|
||||
@ -0,0 +1,71 @@
|
||||
如何检查 Linux 中的可用磁盘空间
|
||||
======
|
||||
|
||||
> 用这里列出的方便的工具来跟踪你的磁盘利用率。
|
||||
|
||||

|
||||
|
||||
跟踪磁盘利用率信息是系统管理员(和其他人)的日常待办事项列表之一。Linux 有一些内置的使用程序来帮助提供这些信息。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令意思是 “disk-free”,显示 Linux 系统上可用和已使用的磁盘空间。
|
||||
|
||||
`df -h` 以人类可读的格式显示磁盘空间。
|
||||
|
||||
`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0。
|
||||
|
||||
|
||||
|
||||
`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs、ext2、ext3、btrfs 等)。
|
||||
|
||||
`df -i` 显示已使用和未使用的 inode。
|
||||
|
||||
|
||||
|
||||
### du
|
||||
|
||||
`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示。
|
||||
|
||||
`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况。
|
||||
|
||||
`du -a` 显示所有文件的磁盘使用情况。
|
||||
|
||||
`du -s` 提供特定文件或目录使用的总磁盘空间。
|
||||
|
||||
|
||||
|
||||
### ls -al
|
||||
|
||||
`ls -al` 列出了特定目录的全部内容及大小。
|
||||
|
||||
|
||||
|
||||
### stat
|
||||
|
||||
`stat <文件/目录> `显示文件/目录或文件系统的大小和其他统计信息。
|
||||
|
||||
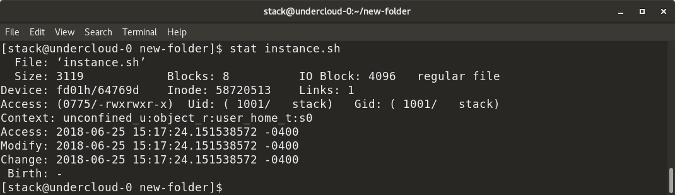
|
||||
|
||||
### fdisk -l
|
||||
|
||||
`fdisk -l` 显示磁盘大小以及磁盘分区信息。
|
||||
|
||||
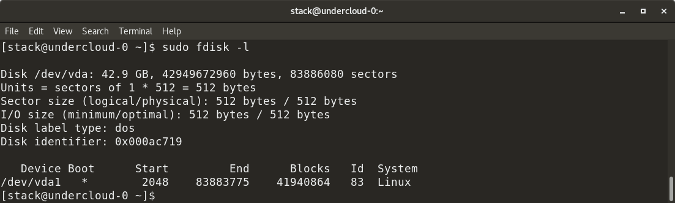
|
||||
|
||||
这些是用于检查 Linux 文件空间的大多数内置实用程序。有许多类似的工具,如 [Disks][1](GUI 工具),[Ncdu][2] 等,它们也显示磁盘空间的利用率。你有你最喜欢的工具而它不在这个列表上吗?请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://wiki.gnome.org/Apps/Disks
|
||||
[2]:https://dev.yorhel.nl/ncdu
|
||||
@ -0,0 +1,137 @@
|
||||
学习如何使用 Python 构建你自己的 Twitter 机器人
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter 允许用户将博客帖子和文章[分享][1]给全世界。使用 Python 和 Tweepy 库使得创建一个 Twitter 机器人来接管你的所有的推特变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
|
||||
|
||||
### 开始
|
||||
|
||||
[tweepy][2] 库可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口。
|
||||
|
||||
下面这些命令使用 `pipenv` 在一个虚拟环境中安装 tweepy。如果你没有安装 `pipenv`,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv][3]。
|
||||
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
```
|
||||
|
||||
### Tweepy —— 开始
|
||||
|
||||
要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 <https://apps.twitter.com/> 创建一个新的应用来获取到凭证。
|
||||
|
||||
|
||||
#### 创建一个新的 Twitter 应用
|
||||
|
||||
当你填完了表格并点击了“<ruby>创建你自己的 Twitter 应用<rt>Create your Twitter application</rt></ruby>”的按钮后,你可以获取到该应用的凭证。 Tweepy 需要<ruby>用户密钥<rt>API Key</rt></ruby>和<ruby>用户密码<rt>API Secret</rt></ruby>,这些都可以在 “<ruby>密钥和访问令牌<rt>Keys and Access Tokens</rt></ruby>” 中找到。
|
||||
|
||||
![][4]
|
||||
|
||||
向下滚动页面,使用“<ruby>创建我的访问令牌<rt>Create my access token</rt></ruby>”按钮生成一个“<ruby>访问令牌<rt>Access Token</rt></ruby>” 和一个“<ruby>访问令牌密钥<rt>Access Token Secret</rt></ruby>”。
|
||||
|
||||
#### 使用 Tweppy —— 输出你的时间线
|
||||
|
||||
现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
api = tweepy.API(auth)
|
||||
public_tweets = api.home_timeline()
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
```
|
||||
|
||||
在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序。
|
||||
|
||||
```
|
||||
$ python tweet.py
|
||||
```
|
||||
|
||||
上述程序调用了 `home_timeline` 方法来获取到你时间线中的 20 条最近的推特。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
|
||||
|
||||
#### 使用 Tweepy —— 发送一条推特
|
||||
|
||||
要发送一条推特 ,有一个容易上手的 API 方法 `update_status` 。它的用法很简单:
|
||||
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
```
|
||||
|
||||
Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。要获取 API 的详细信息,请查看[文档][5]。
|
||||
|
||||
|
||||
### 一个杂志机器人
|
||||
|
||||
接下来我们来创建一个搜索 Fedora Magazine 的推特并转推这些的机器人。
|
||||
|
||||
为了避免多次转推相同的内容,这个机器人存放了最近一条转推的推特的 ID 。 两个助手函数 `store_last_id` 和 `get_last_id` 将会帮助存储和保存这个 ID。
|
||||
|
||||
然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的推特并存储这个 ID。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Stores a tweet id in text file """
|
||||
with open('lastid', 'w') as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Retrieve the list of tweets that were
|
||||
already retweeted """
|
||||
|
||||
with open('lastid') as fp:
|
||||
return fp.read()
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
#tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted')
|
||||
```
|
||||
|
||||
为了只转推 Fedora Magazine 的推特 ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的推特。
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中你看到了如何使用 tweepy 的 Python 库来创建一个自动阅读、发送和搜索推特的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
|
||||
|
||||
这篇文章的演示源码可以在 [Github][6] 找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://linux.cn/article-9827-1.html
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
@ -0,0 +1,74 @@
|
||||
为什么 Arch Linux 如此“难弄”又有何优劣?
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Arch Linux][1] 于 **2002** 年发布,由 **Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单、最小化且优雅的体验,但它的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
|
||||
|
||||
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
|
||||
|
||||
### 1、优点: 定制属于你自己的 Linux 操作系统
|
||||
|
||||
大多数热门的 Linux 发行版(比如 **Ubuntu** 和 **Fedora**)很像一般我们会看到的预装系统,和 **Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置的符合你的品味。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
|
||||
|
||||
#### 缺点: 安装过程让人头疼
|
||||
|
||||
[Arch Linux 的安装 ][2] 别辟蹊径——因为你要花些时间来微调你的操作系统。你会在过程中了解到不少终端命令和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
|
||||
|
||||
### 2、优点: 没有预装垃圾
|
||||
|
||||
鉴于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要、甚至卸载之前都不知道它们存在的东西。
|
||||
|
||||
总而言之,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
|
||||
|
||||
### 3、优点: 无需繁琐系统升级
|
||||
|
||||
**Arch Linux** 采用滚动升级模型,简直妙极了。这意味着你不需要操心升级了。一旦你用上了 Arch,持续的更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
|
||||
|
||||
#### 缺点: 一些升级可能会滚坏你的系统
|
||||
|
||||
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(LCTT 译注:别担心,你可以‘滚’回来 ;D )
|
||||
|
||||
### 4、优点: Arch 有一个社区基因
|
||||
|
||||
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但也并非没有。比如 基于 **Ubuntu** 的衍生版本们不得不受到 Canonical 公司决策的影响。
|
||||
|
||||
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
|
||||
|
||||
### 5、优点: Arch Wiki 无敌
|
||||
|
||||
[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
|
||||
|
||||
### 6、优点: 别忘了 Arch 用户软件库 (AUR)
|
||||
|
||||
<ruby>[Arch 用户软件库][5]<rt>Arch User Repository</rt></ruby> (AUR)是一个来自社区的超大软件仓库。如果你找了一个还没有 Arch 的官方仓库里出现的软件,那你肯定能在 AUR 里找到社区为你准备好的包。
|
||||
|
||||
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
|
||||
|
||||
#### 最后: Arch Linux 适合你吗?
|
||||
|
||||
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
|
||||
|
||||
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
|
||||
|
||||
当你从零开始搭建完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
|
||||
|
||||
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
182
published/20180709 A sysadmin-s guide to network management.md
Normal file
182
published/20180709 A sysadmin-s guide to network management.md
Normal file
@ -0,0 +1,182 @@
|
||||
面向系统管理员的网络管理指南
|
||||
======
|
||||
|
||||
> 一个使管理服务器和网络更轻松的 Linux 工具和命令的参考列表。
|
||||
|
||||

|
||||
|
||||
如果你是一位系统管理员,那么你的日常工作应该包括管理服务器和数据中心的网络。以下的 Linux 实用工具和命令 —— 从基础的到高级的 —— 将帮你更轻松地管理你的网络。
|
||||
|
||||
在几个命令中,你将会看到 `<fqdn>`,它是“完全合格域名”的全称。当你看到它时,你应该用你的网站 URL 或你的服务器来代替它(比如,`server-name.company.com`),具体要视情况而定。
|
||||
|
||||
### Ping
|
||||
|
||||
正如它的名字所表示的那样,`ping` 是用于去检查从你的系统到你想去连接的系统之间端到端的连通性。当一个 ping 成功时,它使用的 [ICMP][1] 的 echo 包将会返回到你的系统中。它是检查系统/网络连通性的一个良好开端。你可以在 IPv4 和 IPv6 地址上使用 `ping` 命令。(阅读我的文章 "[如何在 Linux 系统上找到你的 IP 地址][2]" 去学习更多关于 IP 地址的知识)
|
||||
|
||||
**语法:**
|
||||
|
||||
* IPv4: `ping <ip address>/<fqdn>`
|
||||
* IPv6: `ping6 <ip address>/<fqdn>`
|
||||
|
||||
你也可以使用 `ping` 去解析出网站所对应的 IP 地址,如下图所示:
|
||||
|
||||
|
||||
|
||||
### Traceroute
|
||||
|
||||
`ping` 是用于检查端到端的连通性,`traceroute` 实用工具将告诉你到达对端系统、网站、或服务器所经过的路径上所有路由器的 IP 地址。`traceroute` 在网络连接调试中经常用于在 `ping` 之后的第二步。
|
||||
|
||||
这是一个跟踪从你的系统到其它对端的全部网络路径的非常好的工具。在检查端到端的连通性时,这个实用工具将告诉你到达对端系统、网站、或服务器上所经历的路径上的全部路由器的 IP 地址。通常用于网络连通性调试的第二步。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `traceroute <ip address>/<fqdn>`
|
||||
|
||||
### Telnet
|
||||
|
||||
**语法:**
|
||||
|
||||
* `telnet <ip address>/<fqdn>` 是用于 [telnet][3] 进入任何支持该协议的服务器。
|
||||
|
||||
### Netstat
|
||||
|
||||
这个网络统计(`netstat`)实用工具是用于去分析解决网络连接问题和检查接口/端口统计数据、路由表、协议状态等等的。它是任何管理员都应该必须掌握的工具。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `netstat -l` 显示所有处于监听状态的端口列表。
|
||||
* `netstat -a` 显示所有端口;如果去指定仅显示 TCP 端口,使用 `-at`(指定信显示 UDP 端口,使用 `-au`)。
|
||||
* `netstat -r` 显示路由表。
|
||||
|
||||
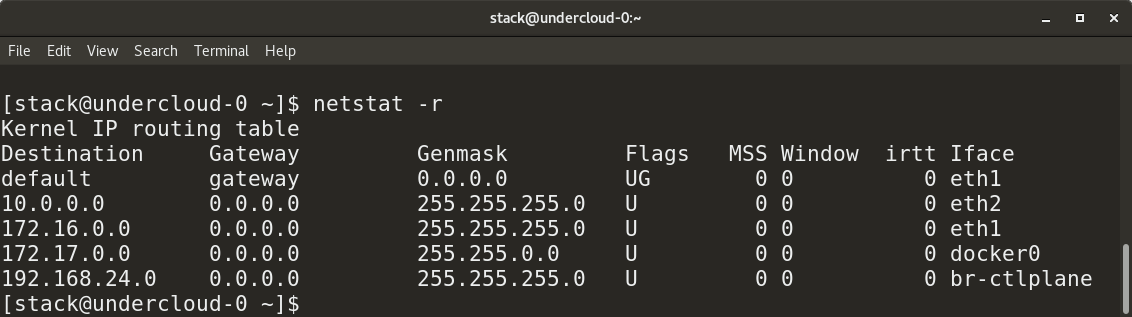
|
||||
|
||||
* `netstat -s` 显示每个协议的状态总结。
|
||||
|
||||
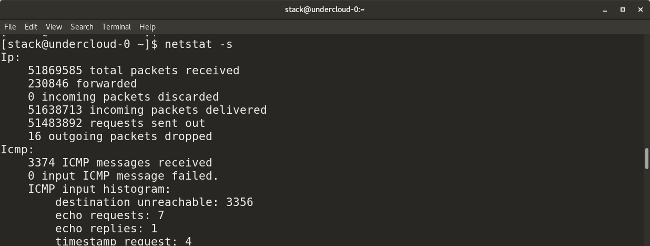
|
||||
|
||||
* `netstat -i` 显示每个接口传输/接收(TX/RX)包的统计数据。
|
||||
|
||||
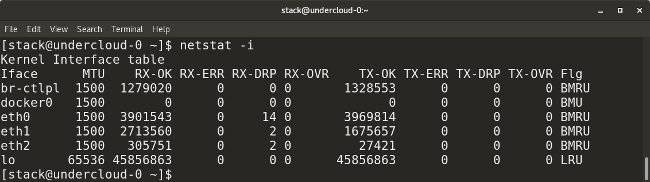
|
||||
|
||||
### Nmcli
|
||||
|
||||
`nmcli` 是一个管理网络连接、配置等工作的非常好的实用工具。它能够去管理网络管理程序和修改任何设备的网络配置详情。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `nmcli device` 列出网络上的所有设备。
|
||||
* `nmcli device show <interface>` 显示指定接口的网络相关的详细情况。
|
||||
* `nmcli connection` 检查设备的连接情况。
|
||||
* `nmcli connection down <interface>` 关闭指定接口。
|
||||
* `nmcli connection up <interface>` 打开指定接口。
|
||||
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` 在特定的接口上使用指定的 VLAN 号添加一个虚拟局域网(VLAN)接口、IP 地址、和网关。
|
||||
|
||||
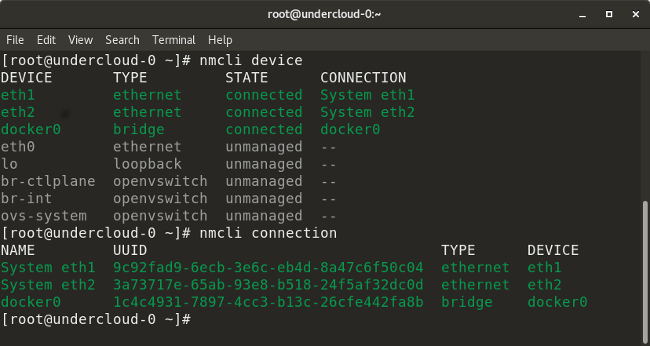
|
||||
|
||||
### 路由
|
||||
|
||||
检查和配置路由的命令很多。下面是其中一些比较有用的:
|
||||
|
||||
**语法:**
|
||||
|
||||
* `ip route` 显示各自接口上所有当前的路由配置。
|
||||
|
||||
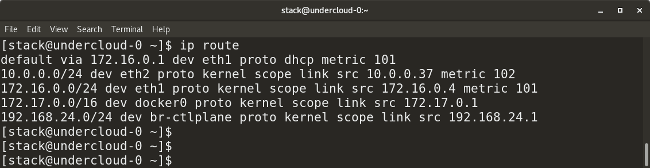
|
||||
|
||||
* `route add default gw <gateway-ip>` 在路由表中添加一个默认的网关。
|
||||
* `route add -net <network ip/cidr> gw <gateway ip> <interface>` 在路由表中添加一个新的网络路由。还有许多其它的路由参数,比如,添加一个默认路由,默认网关等等。
|
||||
* `route del -net <network ip/cidr>` 从路由表中删除一个指定的路由条目。
|
||||
|
||||
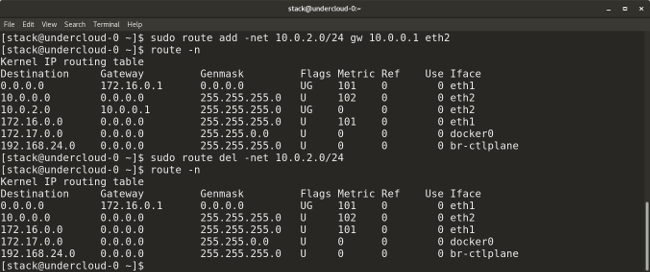
|
||||
|
||||
* `ip neighbor` 显示当前的邻接表和用于去添加、改变、或删除新的邻居。
|
||||
|
||||
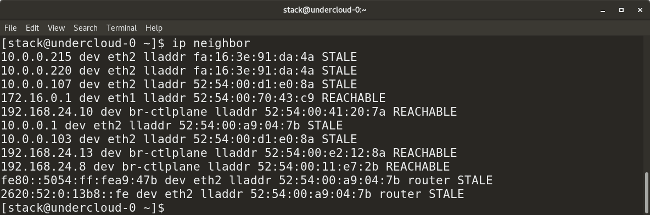
|
||||
|
||||
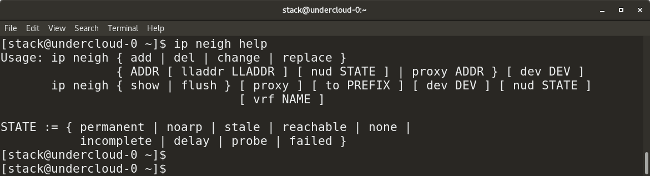
|
||||
|
||||
* `arp` (它的全称是 “地址解析协议”)类似于 `ip neighbor`。`arp` 映射一个系统的 IP 地址到它相应的 MAC(介质访问控制)地址。
|
||||
|
||||
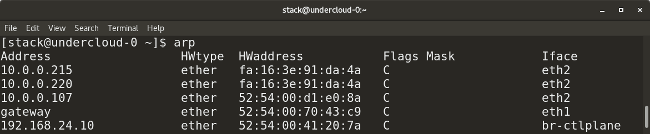
|
||||
|
||||
### Tcpdump 和 Wireshark
|
||||
|
||||
Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark` 等等。它们被用于去捕获传输/接收的网络流量中的数据包,因此它们对于系统管理员去诊断丢包或相关问题时非常有用。对于热衷于命令行操作的人来说,`tcpdump` 是一个非常好的工具,而对于喜欢 GUI 操作的用户来说,`wireshark` 是捕获和分析数据包的不二选择。`tcpdump` 是一个 Linux 内置的用于去捕获网络流量的实用工具。它能够用于去捕获/显示特定端口、协议等上的流量。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `tcpdump -i <interface-name>` 显示指定接口上实时通过的数据包。通过在命令中添加一个 `-w` 标志和输出文件的名字,可以将数据包保存到一个文件中。例如:`tcpdump -w <output-file.> -i <interface-name>`。
|
||||
|
||||
|
||||
|
||||
* `tcpdump -i <interface> src <source-ip>` 从指定的源 IP 地址上捕获数据包。
|
||||
* `tcpdump -i <interface> dst <destination-ip>` 从指定的目标 IP 地址上捕获数据包。
|
||||
* `tcpdump -i <interface> port <port-number>` 从一个指定的端口号(比如,53、80、8080 等等)上捕获数据包。
|
||||
* `tcpdump -i <interface> <protocol>` 捕获指定协议的数据包,比如:TCP、UDP、等等。
|
||||
|
||||
|
||||
|
||||
### Iptables
|
||||
|
||||
`iptables` 是一个包过滤防火墙工具,它能够允许或阻止某些流量。这个实用工具的应用范围非常广泛;下面是它的其中一些最常用的使用命令。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `iptables -L` 列出所有已存在的 `iptables` 规则。
|
||||
* `iptables -F` 删除所有已存在的规则。
|
||||
|
||||
下列命令允许流量从指定端口到指定接口:
|
||||
|
||||
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
|
||||
|
||||
下列命令允许<ruby>环回<rt>loopback</rt></ruby>接口访问系统:
|
||||
|
||||
* `iptables -A INPUT -i lo -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o lo -j ACCEPT`
|
||||
|
||||
### Nslookup
|
||||
|
||||
`nslookup` 工具是用于去获得一个网站或域名所映射的 IP 地址。它也能用于去获得你的 DNS 服务器的信息,比如,一个网站的所有 DNS 记录(具体看下面的示例)。与 `nslookup` 类似的一个工具是 `dig`(Domain Information Groper)实用工具。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `nslookup <website-name.com>` 显示你的服务器组中 DNS 服务器的 IP 地址,它后面就是你想去访问网站的 IP 地址。
|
||||
* `nslookup -type=any <website-name.com>` 显示指定网站/域中所有可用记录。
|
||||
|
||||
|
||||
### 网络/接口调试
|
||||
|
||||
下面是用于接口连通性或相关网络问题调试所需的命令和文件的汇总。
|
||||
|
||||
**语法:**
|
||||
|
||||
* `ss` 是一个转储套接字统计数据的实用工具。
|
||||
* `nmap <ip-address>`,它的全称是 “Network Mapper”,它用于扫描网络端口、发现主机、检测 MAC 地址,等等。
|
||||
* `ip addr/ifconfig -a` 提供一个系统上所有接口的 IP 地址和相关信息。
|
||||
* `ssh -vvv user@<ip/domain>` 允许你使用指定的 IP/域名和用户名通过 SSH 协议登入到其它服务器。`-vvv` 标志提供 SSH 登入到服务器过程中的 "最详细的" 信息。
|
||||
* `ethtool -S <interface>` 检查指定接口上的统计数据。
|
||||
* `ifup <interface>` 启动指定的接口。
|
||||
* `ifdown <interface>` 关闭指定的接口
|
||||
* `systemctl restart network` 重启动系统上的一个网络服务。
|
||||
* `/etc/sysconfig/network-scripts/<interface-name>` 是一个对指定的接口设置 IP 地址、网络、网关等等的接口配置文件。DHCP 模式也可以在这里设置。
|
||||
* `/etc/hosts` 这个文件包含自定义的主机/域名到 IP 地址的映射。
|
||||
* `/etc/resolv.conf` 指定系统上的 DNS 服务器的 IP 地址。
|
||||
* `/etc/ntp.conf` 指定 NTP 服务器域名。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[2]:https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[3]:https://en.wikipedia.org/wiki/Telnet
|
||||
@ -0,0 +1,525 @@
|
||||
Linux 下 cut 命令的 4 个基础实用的示例
|
||||
============================================================
|
||||
|
||||
`cut` 命令是用来从文本文件中移除“某些列”的经典工具。在本文中的“一列”可以被定义为按照一行中位置区分的一系列字符串或者字节,或者是以某个分隔符为间隔的某些域。
|
||||
|
||||
先前我已经介绍了[如何使用 AWK 命令][13]。在本文中,我将解释 linux 下 `cut` 命令的 4 个本质且实用的例子,有时这些例子将帮你节省很多时间。
|
||||
|
||||

|
||||
|
||||
### Linux 下 cut 命令的 4 个实用示例
|
||||
|
||||
假如你想,你可以观看下面的视频,视频中解释了本文中我列举的 cut 命令的使用例子。
|
||||
|
||||
- https://www.youtube.com/PhE_cFLzVFw
|
||||
|
||||
### 1、 作用在一系列字符上
|
||||
|
||||
当启用 `-c` 命令行选项时,`cut` 命令将移除一系列字符。
|
||||
|
||||
和其他的过滤器类似, `cut` 命令不会直接改变输入的文件,它将复制已修改的数据到它的标准输出里去。你可以通过重定向命令的结果到一个文件中来保存修改后的结果,或者使用管道将结果送到另一个命令的输入中,这些都由你来负责。
|
||||
|
||||
假如你已经下载了上面视频中的[示例测试文件][26],你将看到一个名为 `BALANCE.txt` 的数据文件,这些数据是直接从我妻子在她工作中使用的某款会计软件中导出的:
|
||||
|
||||
```
|
||||
sh$ head BALANCE.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
|
||||
4 1012017 623477 TIDE SCHEDULE ALNEENRE-4701-LOC 00000001615,00
|
||||
4 1012017 445452 VAT BS/ENC ALNEENRE-4701-LOC 00000000323,00
|
||||
4 1012017 4356 PAYABLES ALNEENRE-4701-LOC 00000001938,00
|
||||
5 1012017 623372 ACCOMODATION GUIDE ALNEENRE-4771-LOC 00000001333,00
|
||||
5 1012017 445452 VAT BS/ENC ALNEENRE-4771-LOC 00000000266,60
|
||||
5 1012017 4356 PAYABLES ALNEENRE-4771-LOC 00000001599,60
|
||||
6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
|
||||
6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
|
||||
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
|
||||
```
|
||||
|
||||
上述文件是一个固定宽度的文本文件,因为对于每一项数据,都使用了不定长的空格做填充,使得它看起来是一个对齐的列表。
|
||||
|
||||
这样一来,每一列数据开始和结束的位置都是一致的。从 `cut` 命令的字面意思去理解会给我们带来一个小陷阱:`cut` 命令实际上需要你指出你想_保留_的数据范围,而不是你想_移除_的范围。所以,假如我_只_需要上面文件中的 `ACCOUNTNUM` 和 `ACCOUNTLIB` 列,我需要这么做:
|
||||
|
||||
```
|
||||
sh$ cut -c 25-59 BALANCE.txt | head
|
||||
ACCOUNTNUM ACCOUNTLIB
|
||||
623477 TIDE SCHEDULE
|
||||
445452 VAT BS/ENC
|
||||
4356 /accountPAYABLES
|
||||
623372 ACCOMODATION GUIDE
|
||||
445452 VAT BS/ENC
|
||||
4356 PAYABLES
|
||||
4356 PAYABLES
|
||||
445452 VAT BS/ENC
|
||||
623795 TOURIST GUIDE BOOK
|
||||
```
|
||||
|
||||
#### 范围如何定义?
|
||||
|
||||
正如我们上面看到的那样, `cut` 命令需要我们特别指定需要保留的数据的_范围_。所以,下面我将更正式地介绍如何定义范围:对于 `cut` 命令来说,范围是由连字符(`-`)分隔的起始和结束位置组成,范围是基于 1 计数的,即每行的第一项是从 1 开始计数的,而不是从 0 开始。范围是一个闭区间,开始和结束位置都将包含在结果之中,正如它们之间的所有字符那样。如果范围中的结束位置比起始位置小,则这种表达式是错误的。作为快捷方式,你可以省略起始_或_结束值,正如下面的表格所示:
|
||||
|
||||
|
||||
| 范围 | 含义 |
|
||||
|---|---|
|
||||
| `a-b` | a 和 b 之间的范围(闭区间) |
|
||||
|`a` | 与范围 `a-a` 等价 |
|
||||
| `-b` | 与范围 `1-a` 等价 |
|
||||
| `b-` | 与范围 `b-∞` 等价 |
|
||||
|
||||
`cut` 命令允许你通过逗号分隔多个范围,下面是一些示例:
|
||||
|
||||
```
|
||||
# 保留 1 到 24 之间(闭区间)的字符
|
||||
cut -c -24 BALANCE.txt
|
||||
|
||||
# 保留 1 到 24(闭区间)以及 36 到 59(闭区间)之间的字符
|
||||
cut -c -24,36-59 BALANCE.txt
|
||||
|
||||
# 保留 1 到 24(闭区间)、36 到 59(闭区间)和 93 到该行末尾之间的字符
|
||||
cut -c -24,36-59,93- BALANCE.txt
|
||||
```
|
||||
|
||||
`cut` 命令的一个限制(或者是特性,取决于你如何看待它)是它将 _不会对数据进行重排_。所以下面的命令和先前的命令将产生相同的结果,尽管范围的顺序做了改变:
|
||||
|
||||
```
|
||||
cut -c 93-,-24,36-59 BALANCE.txt
|
||||
```
|
||||
|
||||
你可以轻易地使用 `diff` 命令来验证:
|
||||
|
||||
```
|
||||
diff -s <(cut -c -24,36-59,93- BALANCE.txt) \
|
||||
<(cut -c 93-,-24,36-59 BALANCE.txt)
|
||||
Files /dev/fd/63 and /dev/fd/62 are identical
|
||||
```
|
||||
|
||||
类似的,`cut` 命令 _不会重复数据_:
|
||||
|
||||
```
|
||||
# 某人或许期待这可以第一列三次,但并不会……
|
||||
cut -c -10,-10,-10 BALANCE.txt | head -5
|
||||
ACCDOC
|
||||
4
|
||||
4
|
||||
4
|
||||
5
|
||||
```
|
||||
|
||||
值得提及的是,曾经有一个提议,建议使用 `-o` 选项来去除上面提到的两个限制,使得 `cut` 工具可以重排或者重复数据。但这个提议被 [POSIX 委员会拒绝了][14],_“因为这类增强不属于 IEEE P1003.2b 草案标准的范围”_。
|
||||
|
||||
据我所知,我还没有见过哪个版本的 `cut` 程序实现了上面的提议,以此来作为扩展,假如你知道某些例外,请使用下面的评论框分享给大家!
|
||||
|
||||
### 2、 作用在一系列字节上
|
||||
|
||||
当使用 `-b` 命令行选项时,`cut` 命令将移除字节范围。
|
||||
|
||||
咋一看,使用_字符_范围和使用_字节_没有什么明显的不同:
|
||||
|
||||
```
|
||||
sh$ diff -s <(cut -b -24,36-59,93- BALANCE.txt) \
|
||||
<(cut -c -24,36-59,93- BALANCE.txt)
|
||||
Files /dev/fd/63 and /dev/fd/62 are identical
|
||||
```
|
||||
|
||||
这是因为我们的示例数据文件使用的是 [US-ASCII 编码][27](字符集),使用 `file -i` 便可以正确地猜出来:
|
||||
|
||||
```
|
||||
sh$ file -i BALANCE.txt
|
||||
BALANCE.txt: text/plain; charset=us-ascii
|
||||
```
|
||||
|
||||
在 US-ASCII 编码中,字符和字节是一一对应的。理论上,你只需要使用一个字节就可以表示 256 个不同的字符(数字、字母、标点符号和某些符号等)。实际上,你能表达的字符数比 256 要更少一些,因为字符编码中为某些特定值做了规定(例如 32 或 65 就是[控制字符][28])。即便我们能够使用上述所有的字节范围,但对于存储种类繁多的人类手写符号来说,256 是远远不够的。所以如今字符和字节间的一一对应更像是某种例外,并且几乎总是被无处不在的 UTF-8 多字节编码所取代。下面让我们看看如何来处理多字节编码的情形。
|
||||
|
||||
#### 作用在多字节编码的字符上
|
||||
|
||||
正如我前面提到的那样,示例数据文件来源于我妻子使用的某款会计软件。最近好像她升级了那个软件,然后呢,导出的文本就完全不同了,你可以试试和上面的数据文件相比,找找它们之间的区别:
|
||||
|
||||
```
|
||||
sh$ head BALANCE-V2.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
|
||||
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
|
||||
4 1012017 445452 VAT BS/ENC ALNÉENRE-4701-LOC 00000000323,00
|
||||
4 1012017 4356 PAYABLES ALNÉENRE-4701-LOC 00000001938,00
|
||||
5 1012017 623372 ACCOMODATION GUIDE ALNÉENRE-4771-LOC 00000001333,00
|
||||
5 1012017 445452 VAT BS/ENC ALNÉENRE-4771-LOC 00000000266,60
|
||||
5 1012017 4356 PAYABLES ALNÉENRE-4771-LOC 00000001599,60
|
||||
6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
|
||||
6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
|
||||
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
|
||||
```
|
||||
|
||||
上面的标题栏或许能够帮助你找到什么被改变了,但无论你找到与否,现在让我们看看上面的更改过后的结果:
|
||||
|
||||
```
|
||||
sh$ cut -c 93-,-24,36-59 BALANCE-V2.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
4 1012017 TIDE SCHEDULE 00000001615,00
|
||||
4 1012017 VAT BS/ENC 00000000323,00
|
||||
4 1012017 PAYABLES 00000001938,00
|
||||
5 1012017 ACCOMODATION GUIDE 00000001333,00
|
||||
5 1012017 VAT BS/ENC 00000000266,60
|
||||
5 1012017 PAYABLES 00000001599,60
|
||||
6 1012017 PAYABLES 00000001837,20
|
||||
6 1012017 VAT BS/ENC 00000000306,20
|
||||
6 1012017 TOURIST GUIDE BOOK 00000001531,00
|
||||
19 1012017 SEMINAR FEES 00000000080,00
|
||||
19 1012017 PAYABLES 00000000080,00
|
||||
28 1012017 MAINTENANCE 00000000746,58
|
||||
28 1012017 VAT BS/ENC 00000000149,32
|
||||
28 1012017 PAYABLES 00000000895,90
|
||||
31 1012017 PAYABLES 00000000240,00
|
||||
31 1012017 VAT BS/DEBIT 00000000040,00
|
||||
31 1012017 ADVERTISEMENTS 00000000200,00
|
||||
32 1012017 WATER 00000000202,20
|
||||
32 1012017 VAT BS/DEBIT 00000000020,22
|
||||
32 1012017 WATER 00000000170,24
|
||||
32 1012017 VAT BS/DEBIT 00000000009,37
|
||||
32 1012017 PAYABLES 00000000402,03
|
||||
34 1012017 RENTAL COSTS 00000000018,00
|
||||
34 1012017 PAYABLES 00000000018,00
|
||||
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
|
||||
35 1012017 VAT BS/DEBIT 00000000003,00
|
||||
35 1012017 PAYABLES 00000000018,00
|
||||
36 1012017 LANDLINE TELEPHONE 00000000069,14
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
我_毫无删减地_复制了上面命令的输出。所以可以很明显地看出列对齐那里有些问题。
|
||||
|
||||
对此我的解释是原来的数据文件只包含 US-ASCII 编码的字符(符号、标点符号、数字和没有发音符号的拉丁字母)。
|
||||
|
||||
但假如你仔细地查看经软件升级后产生的文件,你可以看到新导出的数据文件保留了带发音符号的字母。例如现在合理地记录了名为 “ALNÉENRE” 的公司,而不是先前的 “ALNEENRE”(没有发音符号)。
|
||||
|
||||
`file -i` 正确地识别出了改变,因为它报告道现在这个文件是 [UTF-8 编码][15] 的。
|
||||
|
||||
```
|
||||
sh$ file -i BALANCE-V2.txt
|
||||
BALANCE-V2.txt: text/plain; charset=utf-8
|
||||
```
|
||||
|
||||
如果想看看 UTF-8 文件中那些带发音符号的字母是如何编码的,我们可以使用 `[hexdump][12]`,它可以让我们直接以字节形式查看文件:
|
||||
|
||||
```
|
||||
# 为了减少输出,让我们只关注文件的第 2 行
|
||||
sh$ sed '2!d' BALANCE-V2.txt
|
||||
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
|
||||
sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
|
||||
00000000 34 20 20 20 20 20 20 20 20 20 31 30 31 32 30 31 |4 101201|
|
||||
00000010 37 20 20 20 20 20 20 20 36 32 33 34 37 37 20 20 |7 623477 |
|
||||
00000020 20 20 20 54 49 44 45 20 53 43 48 45 44 55 4c 45 | TIDE SCHEDULE|
|
||||
00000030 20 20 20 20 20 20 20 20 20 20 20 41 4c 4e c3 89 | ALN..|
|
||||
00000040 45 4e 52 45 2d 34 37 30 31 2d 4c 4f 43 20 20 20 |ENRE-4701-LOC |
|
||||
00000050 20 20 20 20 20 20 20 20 20 20 20 20 20 30 30 30 | 000|
|
||||
00000060 30 30 30 30 31 36 31 35 2c 30 30 20 20 20 20 20 |00001615,00 |
|
||||
00000070 20 20 20 20 20 20 20 20 20 20 20 0a | .|
|
||||
0000007c
|
||||
```
|
||||
|
||||
在 `hexdump` 输出的 00000030 那行,在一系列的空格(字节 `20`)之后,你可以看到:
|
||||
|
||||
* 字母 `A` 被编码为 `41`,
|
||||
* 字母 `L` 被编码为 `4c`,
|
||||
* 字母 `N` 被编码为 `4e`。
|
||||
|
||||
但对于大写的[带有注音的拉丁大写字母 E][16] (这是它在 Unicode 标准中字母 _É_ 的官方名称),则是使用 _2_ 个字节 `c3 89` 来编码的。
|
||||
|
||||
这样便出现问题了:对于使用固定宽度编码的文件, 使用字节位置来表示范围的 `cut` 命令工作良好,但这并不适用于使用变长编码的 UTF-8 或者 [Shift JIS][17] 编码。这种情况在下面的 [POSIX 标准的非规范性摘录][18] 中被明确地解释过:
|
||||
|
||||
> 先前版本的 `cut` 程序将字节和字符视作等同的环境下运作(正如在某些实现下对退格键 `<backspace>` 和制表键 `<tab>` 的处理)。在针对多字节字符的情况下,特别增加了 `-b` 选项。
|
||||
|
||||
嘿,等一下!我并没有在上面“有错误”的例子中使用 '-b' 选项,而是 `-c` 选项呀!所以,难道_不应该_能够成功处理了吗!?
|
||||
|
||||
是的,确实_应该_:但是很不幸,即便我们现在已身处 2018 年,GNU Coreutils 的版本为 8.30 了,`cut` 程序的 GNU 版本实现仍然不能很好地处理多字节字符。引用 [GNU 文档][19] 的话说,_`-c` 选项“现在和 `-b` 选项是相同的,但对于国际化的情形将有所不同[...]”_。需要提及的是,这个问题距今已有 10 年之久了!
|
||||
|
||||
另一方面,[OpenBSD][20] 的实现版本和 POSIX 相吻合,这将归功于当前的本地化(`locale`)设定来合理地处理多字节字符:
|
||||
|
||||
```
|
||||
# 确保随后的命令知晓我们现在处理的是 UTF-8 编码的文本文件
|
||||
openbsd-6.3$ export LC_CTYPE=en_US.UTF-8
|
||||
|
||||
# 使用 `-c` 选项, `cut` 能够合理地处理多字节字符
|
||||
openbsd-6.3$ cut -c -24,36-59,93- BALANCE-V2.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
4 1012017 TIDE SCHEDULE 00000001615,00
|
||||
4 1012017 VAT BS/ENC 00000000323,00
|
||||
4 1012017 PAYABLES 00000001938,00
|
||||
5 1012017 ACCOMODATION GUIDE 00000001333,00
|
||||
5 1012017 VAT BS/ENC 00000000266,60
|
||||
5 1012017 PAYABLES 00000001599,60
|
||||
6 1012017 PAYABLES 00000001837,20
|
||||
6 1012017 VAT BS/ENC 00000000306,20
|
||||
6 1012017 TOURIST GUIDE BOOK 00000001531,00
|
||||
19 1012017 SEMINAR FEES 00000000080,00
|
||||
19 1012017 PAYABLES 00000000080,00
|
||||
28 1012017 MAINTENANCE 00000000746,58
|
||||
28 1012017 VAT BS/ENC 00000000149,32
|
||||
28 1012017 PAYABLES 00000000895,90
|
||||
31 1012017 PAYABLES 00000000240,00
|
||||
31 1012017 VAT BS/DEBIT 00000000040,00
|
||||
31 1012017 ADVERTISEMENTS 00000000200,00
|
||||
32 1012017 WATER 00000000202,20
|
||||
32 1012017 VAT BS/DEBIT 00000000020,22
|
||||
32 1012017 WATER 00000000170,24
|
||||
32 1012017 VAT BS/DEBIT 00000000009,37
|
||||
32 1012017 PAYABLES 00000000402,03
|
||||
34 1012017 RENTAL COSTS 00000000018,00
|
||||
34 1012017 PAYABLES 00000000018,00
|
||||
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
|
||||
35 1012017 VAT BS/DEBIT 00000000003,00
|
||||
35 1012017 PAYABLES 00000000018,00
|
||||
36 1012017 LANDLINE TELEPHONE 00000000069,14
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
正如期望的那样,当使用 `-b` 选项而不是 `-c` 选项后, OpenBSD 版本的 `cut` 实现和传统的 `cut` 表现是类似的:
|
||||
|
||||
```
|
||||
openbsd-6.3$ cut -b -24,36-59,93- BALANCE-V2.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
4 1012017 TIDE SCHEDULE 00000001615,00
|
||||
4 1012017 VAT BS/ENC 00000000323,00
|
||||
4 1012017 PAYABLES 00000001938,00
|
||||
5 1012017 ACCOMODATION GUIDE 00000001333,00
|
||||
5 1012017 VAT BS/ENC 00000000266,60
|
||||
5 1012017 PAYABLES 00000001599,60
|
||||
6 1012017 PAYABLES 00000001837,20
|
||||
6 1012017 VAT BS/ENC 00000000306,20
|
||||
6 1012017 TOURIST GUIDE BOOK 00000001531,00
|
||||
19 1012017 SEMINAR FEES 00000000080,00
|
||||
19 1012017 PAYABLES 00000000080,00
|
||||
28 1012017 MAINTENANCE 00000000746,58
|
||||
28 1012017 VAT BS/ENC 00000000149,32
|
||||
28 1012017 PAYABLES 00000000895,90
|
||||
31 1012017 PAYABLES 00000000240,00
|
||||
31 1012017 VAT BS/DEBIT 00000000040,00
|
||||
31 1012017 ADVERTISEMENTS 00000000200,00
|
||||
32 1012017 WATER 00000000202,20
|
||||
32 1012017 VAT BS/DEBIT 00000000020,22
|
||||
32 1012017 WATER 00000000170,24
|
||||
32 1012017 VAT BS/DEBIT 00000000009,37
|
||||
32 1012017 PAYABLES 00000000402,03
|
||||
34 1012017 RENTAL COSTS 00000000018,00
|
||||
34 1012017 PAYABLES 00000000018,00
|
||||
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
|
||||
35 1012017 VAT BS/DEBIT 00000000003,00
|
||||
35 1012017 PAYABLES 00000000018,00
|
||||
36 1012017 LANDLINE TELEPHONE 00000000069,14
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
### 3、 作用在域上
|
||||
|
||||
从某种意义上说,使用 `cut` 来处理用特定分隔符隔开的文本文件要更加容易一些,因为只需要确定好每行中域之间的分隔符,然后复制域的内容到输出就可以了,而不需要烦恼任何与编码相关的问题。
|
||||
|
||||
下面是一个用分隔符隔开的示例文本文件:
|
||||
|
||||
```
|
||||
sh$ head BALANCE.csv
|
||||
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;ACCDOCLIB;DEBIT;CREDIT
|
||||
4;1012017;623477;TIDE SCHEDULE;ALNEENRE-4701-LOC;00000001615,00;
|
||||
4;1012017;445452;VAT BS/ENC;ALNEENRE-4701-LOC;00000000323,00;
|
||||
4;1012017;4356;PAYABLES;ALNEENRE-4701-LOC;;00000001938,00
|
||||
5;1012017;623372;ACCOMODATION GUIDE;ALNEENRE-4771-LOC;00000001333,00;
|
||||
5;1012017;445452;VAT BS/ENC;ALNEENRE-4771-LOC;00000000266,60;
|
||||
5;1012017;4356;PAYABLES;ALNEENRE-4771-LOC;;00000001599,60
|
||||
6;1012017;4356;PAYABLES;FACT FA00006253 - BIT QUIROBEN;;00000001837,20
|
||||
6;1012017;445452;VAT BS/ENC;FACT FA00006253 - BIT QUIROBEN;00000000306,20;
|
||||
6;1012017;623795;TOURIST GUIDE BOOK;FACT FA00006253 - BIT QUIROBEN;00000001531,00;
|
||||
```
|
||||
|
||||
你可能知道上面文件是一个 [CSV][29] 格式的文件(它以逗号来分隔),即便有时候域分隔符不是逗号。例如分号(`;`)也常被用来作为分隔符,并且对于那些总使用逗号作为 [十进制分隔符][30]的国家(例如法国,所以上面我的示例文件中选用了他们国家的字符),当导出数据为 “CSV” 格式时,默认将使用分号来分隔数据。另一种常见的情况是使用 [tab 键][32] 来作为分隔符,从而生成叫做 [tab 分隔的值][32] 的文件。最后,在 Unix 和 Linux 领域,冒号 (`:`) 是另一种你能找到的常见分隔符号,例如在标准的 `/etc/passwd` 和 `/etc/group` 这两个文件里。
|
||||
|
||||
当处理使用分隔符隔开的文本文件格式时,你可以向带有 `-f` 选项的 `cut` 命令提供需要保留的域的范围,并且你也可以使用 `-d` 选项来指定分隔符(当没有使用 `-d` 选项时,默认以 tab 字符来作为分隔符):
|
||||
|
||||
```
|
||||
sh$ cut -f 5- -d';' BALANCE.csv | head
|
||||
ACCDOCLIB;DEBIT;CREDIT
|
||||
ALNEENRE-4701-LOC;00000001615,00;
|
||||
ALNEENRE-4701-LOC;00000000323,00;
|
||||
ALNEENRE-4701-LOC;;00000001938,00
|
||||
ALNEENRE-4771-LOC;00000001333,00;
|
||||
ALNEENRE-4771-LOC;00000000266,60;
|
||||
ALNEENRE-4771-LOC;;00000001599,60
|
||||
FACT FA00006253 - BIT QUIROBEN;;00000001837,20
|
||||
FACT FA00006253 - BIT QUIROBEN;00000000306,20;
|
||||
FACT FA00006253 - BIT QUIROBEN;00000001531,00;
|
||||
```
|
||||
|
||||
#### 处理不包含分隔符的行
|
||||
|
||||
但要是输入文件中的某些行没有分隔符又该怎么办呢?很容易地认为可以将这样的行视为只包含第一个域。但 `cut` 程序并 _不是_ 这样做的。
|
||||
|
||||
默认情况下,当使用 `-f` 选项时,`cut` 将总是原样输出不包含分隔符的那一行(可能假设它是非数据行,就像表头或注释等):
|
||||
|
||||
```
|
||||
sh$ (echo "# 2018-03 BALANCE"; cat BALANCE.csv) > BALANCE-WITH-HEADER.csv
|
||||
|
||||
sh$ cut -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
|
||||
# 2018-03 BALANCE
|
||||
DEBIT;CREDIT
|
||||
00000001615,00;
|
||||
00000000323,00;
|
||||
;00000001938,00
|
||||
```
|
||||
|
||||
使用 `-s` 选项,你可以做出相反的行为,这样 `cut` 将总是忽略这些行:
|
||||
|
||||
```
|
||||
sh$ cut -s -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
|
||||
DEBIT;CREDIT
|
||||
00000001615,00;
|
||||
00000000323,00;
|
||||
;00000001938,00
|
||||
00000001333,00;
|
||||
```
|
||||
|
||||
假如你好奇心强,你还可以探索这种特性,来作为一种相对隐晦的方式去保留那些只包含给定字符的行:
|
||||
|
||||
```
|
||||
# 保留含有一个 `e` 的行
|
||||
sh$ printf "%s\n" {mighty,bold,great}-{condor,monkey,bear} | cut -s -f 1- -d'e'
|
||||
```
|
||||
|
||||
#### 改变输出的分隔符
|
||||
|
||||
作为一种扩展, GNU 版本实现的 `cut` 允许通过使用 `--output-delimiter` 选项来为结果指定一个不同的域分隔符:
|
||||
|
||||
```
|
||||
sh$ cut -f 5,6- -d';' --output-delimiter="*" BALANCE.csv | head
|
||||
ACCDOCLIB*DEBIT*CREDIT
|
||||
ALNEENRE-4701-LOC*00000001615,00*
|
||||
ALNEENRE-4701-LOC*00000000323,00*
|
||||
ALNEENRE-4701-LOC**00000001938,00
|
||||
ALNEENRE-4771-LOC*00000001333,00*
|
||||
ALNEENRE-4771-LOC*00000000266,60*
|
||||
ALNEENRE-4771-LOC**00000001599,60
|
||||
FACT FA00006253 - BIT QUIROBEN**00000001837,20
|
||||
FACT FA00006253 - BIT QUIROBEN*00000000306,20*
|
||||
FACT FA00006253 - BIT QUIROBEN*00000001531,00*
|
||||
```
|
||||
|
||||
需要注意的是,在上面这个例子中,所有出现域分隔符的地方都被替换掉了,而不仅仅是那些在命令行中指定的作为域范围边界的分隔符。
|
||||
|
||||
### 4、 非 POSIX GNU 扩展
|
||||
|
||||
说到非 POSIX GNU 扩展,它们中的某些特别有用。特别需要提及的是下面的扩展也同样对字节、字符或者域范围工作良好(相对于当前的 GNU 实现来说)。
|
||||
|
||||
`--complement`:
|
||||
|
||||
想想在 sed 地址中的感叹符号(`!`),使用它,`cut` 将只保存**没有**被匹配到的范围:
|
||||
|
||||
```
|
||||
# 只保留第 5 个域
|
||||
sh$ cut -f 5 -d';' BALANCE.csv |head -3
|
||||
ACCDOCLIB
|
||||
ALNEENRE-4701-LOC
|
||||
ALNEENRE-4701-LOC
|
||||
|
||||
# 保留除了第 5 个域之外的内容
|
||||
sh$ cut --complement -f 5 -d';' BALANCE.csv |head -3
|
||||
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;DEBIT;CREDIT
|
||||
4;1012017;623477;TIDE SCHEDULE;00000001615,00;
|
||||
4;1012017;445452;VAT BS/ENC;00000000323,00;
|
||||
```
|
||||
|
||||
`--zero-terminated (-z)`:
|
||||
|
||||
使用 [NUL 字符][6] 来作为行终止符,而不是 [<ruby>新行<rt>newline</rt></ruby>字符][7]。当你的数据包含 新行字符时, `-z` 选项就特别有用了,例如当处理文件名的时候(因为在文件名中新行字符是可以使用的,而 NUL 则不可以)。
|
||||
|
||||
为了展示 `-z` 选项,让我们先做一点实验。首先,我们将创建一个文件名中包含换行符的文件:
|
||||
|
||||
```
|
||||
bash$ touch $'EMPTY\nFILE\nWITH FUNKY\nNAME'.txt
|
||||
bash$ ls -1 *.txt
|
||||
BALANCE.txt
|
||||
BALANCE-V2.txt
|
||||
EMPTY?FILE?WITH FUNKY?NAME.txt
|
||||
```
|
||||
|
||||
现在假设我想展示每个 `*.txt` 文件的前 5 个字符。一个想当然的解决方法将会失败:
|
||||
|
||||
```
|
||||
sh$ ls -1 *.txt | cut -c 1-5
|
||||
BALAN
|
||||
BALAN
|
||||
EMPTY
|
||||
FILE
|
||||
WITH
|
||||
NAME.
|
||||
```
|
||||
|
||||
你可以已经知道 [ls][21] 是为了[方便人类使用][33]而特别设计的,并且在一个命令管道中使用它是一个反模式(确实是这样的)。所以让我们用 [find][22] 来替换它:
|
||||
|
||||
```
|
||||
sh$ find . -name '*.txt' -printf "%f\n" | cut -c 1-5
|
||||
BALAN
|
||||
EMPTY
|
||||
FILE
|
||||
WITH
|
||||
NAME.
|
||||
BALAN
|
||||
```
|
||||
|
||||
上面的命令基本上产生了与先前类似的结果(尽管以不同的次序,因为 `ls` 会隐式地对文件名做排序,而 `find` 则不会)。
|
||||
|
||||
在上面的两个例子中,都有一个相同的问题,`cut` 命令不能区分 新行 字符是数据域的一部分(即文件名),还是作为最后标记的 新行 记号。但使用 NUL 字节(`\0`)来作为行终止符就将排除掉这种混淆的情况,使得我们最后可以得到期望的结果:
|
||||
|
||||
```
|
||||
# 我被告知在某些旧版的 `tr` 程序中需要使用 `\000` 而不是 `\0` 来代表 NUL 字符(假如你需要这种改变请让我知晓!)
|
||||
sh$ find . -name '*.txt' -printf "%f\0" | cut -z -c 1-5| tr '\0' '\n'
|
||||
BALAN
|
||||
EMPTY
|
||||
BALAN
|
||||
```
|
||||
|
||||
通过上面最后的例子,我们就达到了本文的最后部分了,所以我将让你自己试试 `-printf` 后面那个有趣的 `"%f\0"` 参数或者理解为什么我在管道的最后使用了 [tr][23] 命令。
|
||||
|
||||
### 使用 cut 命令可以实现更多功能
|
||||
|
||||
我只是列举了 `cut` 命令的最常见且在我眼中最基础的使用方式。你甚至可以将它以更加实用的方式加以运用,这取决于你的逻辑和想象。
|
||||
|
||||
不要再犹豫了,请使用下面的评论框贴出你的发现。最后一如既往的,假如你喜欢这篇文章,请不要忘记将它分享到你最喜爱网站和社交媒体中!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxhandbook.com/cut-command/
|
||||
|
||||
作者:[Sylvain Leroux][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxhandbook.com/author/sylvain/
|
||||
[1]:https://linuxhandbook.com/cut-command/#_what_s_a_range
|
||||
[2]:https://linuxhandbook.com/cut-command/#_working_with_multibyte_characters
|
||||
[3]:https://linuxhandbook.com/cut-command/#_handling_lines_not_containing_the_delimiter
|
||||
[4]:https://linuxhandbook.com/cut-command/#_changing_the_output_delimiter
|
||||
[5]:http://click.linksynergy.com/deeplink?id=IRL8ozn3lq8&type=10&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fyes-i-know-the-bash-linux-command-line-tools%2F
|
||||
[6]:https://en.wikipedia.org/wiki/Null_character
|
||||
[7]:https://en.wikipedia.org/wiki/Newline
|
||||
[8]:https://linuxhandbook.com/cut-command/#_working_with_character_ranges
|
||||
[9]:https://linuxhandbook.com/cut-command/#_working_with_byte_ranges
|
||||
[10]:https://linuxhandbook.com/cut-command/#_working_with_fields
|
||||
[11]:https://linuxhandbook.com/cut-command/#_non_posix_gnu_extensions
|
||||
[12]:https://linux.die.net/man/1/hexdump
|
||||
[13]:https://linuxhandbook.com/awk-command-tutorial/
|
||||
[14]:http://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_18
|
||||
[15]:https://en.wikipedia.org/wiki/UTF-8#Codepage_layout
|
||||
[16]:https://www.fileformat.info/info/unicode/char/00c9/index.htm
|
||||
[17]:https://en.wikipedia.org/wiki/Shift_JIS#Shift_JIS_byte_map
|
||||
[18]:http://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_16
|
||||
[19]:https://www.gnu.org/software/coreutils/manual/html_node/cut-invocation.html#cut-invocation
|
||||
[20]:https://www.openbsd.org/
|
||||
[21]:https://linux.die.net/man/1/ls
|
||||
[22]:https://linux.die.net/man/1/find
|
||||
[23]:https://linux.die.net/man/1/tr
|
||||
[24]:https://linuxhandbook.com/author/sylvain/
|
||||
[25]:https://linuxhandbook.com/cut-command/#comments
|
||||
[26]:https://static.yesik.it/EP22/Yes_I_Know_IT-EP22.tar.gz
|
||||
[27]:https://en.wikipedia.org/wiki/ASCII#Character_set
|
||||
[28]:https://en.wikipedia.org/wiki/Control_character
|
||||
[29]:https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[30]:https://en.wikipedia.org/wiki/Decimal_separator
|
||||
[31]:https://en.wikipedia.org/wiki/Tab_key#Tab_characters
|
||||
[32]:https://en.wikipedia.org/wiki/Tab-separated_values
|
||||
[33]:http://lists.gnu.org/archive/html/coreutils/2014-02/msg00005.html
|
||||
@ -0,0 +1,78 @@
|
||||
针对 Bash 的不完整路径展开(补全)功能
|
||||
======
|
||||
|
||||
|
||||

|
||||
|
||||
[bash-complete-partial-path][1] 通过添加不完整的路径展开(类似于 Zsh)来增强 Bash(它在 Linux 上,macOS 使用 gnu-sed,Windows 使用 MSYS)中的路径补全。如果你想在 Bash 中使用这个省时特性,而不必切换到 Zsh,它将非常有用。
|
||||
|
||||
这是它如何工作的。当按下 `Tab` 键时,bash-complete-partial-path 假定每个部分都不完整并尝试展开它。假设你要进入 `/usr/share/applications` 。你可以输入 `cd /u/s/app`,按下 `Tab`,bash-complete-partial-path 应该把它展开成 `cd /usr/share/applications` 。如果存在冲突,那么按 `Tab` 仅补全没有冲突的路径。例如,Ubuntu 用户在 `/usr/share` 中应该有很多以 “app” 开头的文件夹,在这种情况下,输入 `cd /u/s/app` 只会展开 `/usr/share/` 部分。
|
||||
|
||||
另一个更深层不完整文件路径展开的例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
|
||||
|
||||
功能包括:
|
||||
|
||||
* 转义特殊字符
|
||||
* 如果用户路径开头使用引号,则不转义字符转义,而是在展开路径后使用匹配字符结束引号
|
||||
* 正确展开 `~` 表达式
|
||||
* 如果正在使用 bash-completion 包,则此代码将安全地覆盖其 `_filedir` 函数。无需额外配置,只需确保在主 bash-completion 后引入此项目。
|
||||
|
||||
查看[项目页面][2]以获取更多信息和演示截图。
|
||||
|
||||
### 安装 bash-complete-partial-path
|
||||
|
||||
bash-complete-partial-path 安装说明指定直接下载 bash_completion 脚本。我更喜欢从 Git 仓库获取,这样我可以用一个简单的 `git pull` 来更新它,因此下面的说明将使用这种安装 bash-complete-partial-path。如果你喜欢,可以使用[官方][3]说明。
|
||||
|
||||
1、 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 等中,使用此命令安装 Git:
|
||||
|
||||
```
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
2、 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
|
||||
|
||||
```
|
||||
cd ~/.config && git clone https://github.com/sio/bash-complete-partial-path
|
||||
```
|
||||
|
||||
3、 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
|
||||
|
||||
用文本编辑器打开 ~/.bashrc。例如你可以使用 Gedit:
|
||||
|
||||
```
|
||||
gedit ~/.bashrc
|
||||
```
|
||||
|
||||
在 `~/.bashrc` 的末尾添加以下内容(在一行中):
|
||||
|
||||
```
|
||||
[ -s "$HOME/.config/bash-complete-partial-path/bash_completion" ] && source "$HOME/.config/bash-complete-partial-path/bash_completion"
|
||||
```
|
||||
|
||||
我提到在文件的末尾添加它,因为这需要包含在你的 `~/.bashrc` 文件的主 bash-completion 下面(之后)。因此,请确保不要将其添加到原始 bash-completion 之上,因为它会导致问题。
|
||||
|
||||
4、 引入 `~/.bashrc`:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
这样就好了,现在应该安装完 bash-complete-partial-path 并可以使用了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/sio/bash-complete-partial-path
|
||||
[2]:https://github.com/sio/bash-complete-partial-path
|
||||
[3]:https://github.com/sio/bash-complete-partial-path#installation-and-updating
|
||||
@ -0,0 +1,192 @@
|
||||
列出 Linux 系统上所有用户的 3 种方法
|
||||
=======
|
||||
|
||||
> 通过使用 `/etc/passwd` 文件,`getent` 命令,`compgen` 命令这三种方法查看系统中用户的信息
|
||||
|
||||
大家都知道,Linux 系统中用户信息存放在 `/etc/passwd` 文件中。
|
||||
|
||||
这是一个包含每个用户基本信息的文本文件。当我们在系统中创建一个用户,新用户的详细信息就会被添加到这个文件中。
|
||||
|
||||
`/etc/passwd` 文件将每个用户的基本信息记录为文件中的一行,一行中包含 7 个字段。
|
||||
|
||||
`/etc/passwd` 文件的一行代表一个单独的用户。该文件将用户的信息分为 3 个部分。
|
||||
|
||||
* 第 1 部分:`root` 用户信息
|
||||
* 第 2 部分:系统定义的账号信息
|
||||
* 第 3 部分:真实用户的账户信息
|
||||
|
||||
第一部分是 `root` 账户,这代表管理员账户,对系统的每个方面都有完全的权力。
|
||||
|
||||
第二部分是系统定义的群组和账户,这些群组和账号是正确安装和更新系统软件所必需的。
|
||||
|
||||
第三部分在最后,代表一个使用系统的真实用户。
|
||||
|
||||
在创建新用户时,将修改以下 4 个文件。
|
||||
|
||||
* `/etc/passwd`: 用户账户的详细信息在此文件中更新。
|
||||
* `/etc/shadow`: 用户账户密码在此文件中更新。
|
||||
* `/etc/group`: 新用户群组的详细信息在此文件中更新。
|
||||
* `/etc/gshadow`: 新用户群组密码在此文件中更新。
|
||||
|
||||
** 建议阅读 : **
|
||||
|
||||
- [ 如何在 Linux 上查看创建用户的日期 ][1]
|
||||
- [ 如何在 Linux 上查看 A 用户所属的群组 ][2]
|
||||
- [ 如何强制用户在下一次登录 Linux 系统时修改密码 ][3]
|
||||
|
||||
### 方法 1 :使用 `/etc/passwd` 文件
|
||||
|
||||
使用任何一个像 `cat`、`more`、`less` 等文件操作命令来打印 Linux 系统上创建的用户列表。
|
||||
|
||||
`/etc/passwd` 是一个文本文件,其中包含了登录 Linux 系统所必需的每个用户的信息。它保存用户的有用信息,如用户名、密码、用户 ID、群组 ID、用户 ID 信息、用户的家目录和 Shell 。
|
||||
|
||||
`/etc/passwd` 文件将每个用户的详细信息写为一行,其中包含七个字段,每个字段之间用冒号 `:` 分隔:
|
||||
|
||||
```
|
||||
# cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
||||
sync:x:5:0:sync:/sbin:/bin/sync
|
||||
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
|
||||
halt:x:7:0:halt:/sbin:/sbin/halt
|
||||
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
|
||||
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
|
||||
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
|
||||
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
|
||||
tcpdump:x:72:72::/:/sbin/nologin
|
||||
2gadmin:x:500:10::/home/viadmin:/bin/bash
|
||||
apache:x:48:48:Apache:/var/www:/sbin/nologin
|
||||
zabbix:x:498:499:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
|
||||
mysql:x:497:502::/home/mysql:/bin/bash
|
||||
zend:x:502:503::/u01/zend/zend/gui/lighttpd:/sbin/nologin
|
||||
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
|
||||
2daygeek:x:503:504::/home/2daygeek:/bin/bash
|
||||
named:x:25:25:Named:/var/named:/sbin/nologin
|
||||
mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
|
||||
|
||||
```
|
||||
7 个字段的详细信息如下。
|
||||
|
||||
* **用户名** (`magesh`): 已创建用户的用户名,字符长度 1 个到 12 个字符。
|
||||
* **密码**(`x`):代表加密密码保存在 `/etc/shadow 文件中。
|
||||
* **用户 ID(`506`):代表用户的 ID 号,每个用户都要有一个唯一的 ID 。UID 号为 0 的是为 `root` 用户保留的,UID 号 1 到 99 是为系统用户保留的,UID 号 100-999 是为系统账户和群组保留的。
|
||||
* **群组 ID (`507`):代表群组的 ID 号,每个群组都要有一个唯一的 GID ,保存在 `/etc/group` 文件中。
|
||||
* **用户信息(`2g Admin - Magesh M`):代表描述字段,可以用来描述用户的信息(LCTT 译注:此处原文疑有误)。
|
||||
* **家目录(`/home/mageshm`):代表用户的家目录。
|
||||
* **Shell(`/bin/bash`):代表用户使用的 shell 类型。
|
||||
|
||||
你可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
|
||||
|
||||
```
|
||||
# awk -F':' '{ print $1}' /etc/passwd
|
||||
or
|
||||
# cut -d: -f1 /etc/passwd
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
ftp
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
2gadmin
|
||||
apache
|
||||
zabbix
|
||||
mysql
|
||||
zend
|
||||
rpc
|
||||
2daygeek
|
||||
named
|
||||
mageshm
|
||||
```
|
||||
### 方法 2 :使用 `getent` 命令
|
||||
|
||||
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目。这些库的配置文件为 `/etc/nsswitch.conf`。
|
||||
|
||||
`getent` 命令显示类似于 `/etc/passwd` 文件的用户详细信息,它将每个用户详细信息显示为包含七个字段的单行。
|
||||
|
||||
```
|
||||
# getent passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
bin:x:1:1:bin:/bin:/sbin/nologin
|
||||
daemon:x:2:2:daemon:/sbin:/sbin/nologin
|
||||
adm:x:3:4:adm:/var/adm:/sbin/nologin
|
||||
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
|
||||
sync:x:5:0:sync:/sbin:/bin/sync
|
||||
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
|
||||
halt:x:7:0:halt:/sbin:/sbin/halt
|
||||
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
|
||||
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
|
||||
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
|
||||
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
|
||||
tcpdump:x:72:72::/:/sbin/nologin
|
||||
2gadmin:x:500:10::/home/viadmin:/bin/bash
|
||||
apache:x:48:48:Apache:/var/www:/sbin/nologin
|
||||
zabbix:x:498:499:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
|
||||
mysql:x:497:502::/home/mysql:/bin/bash
|
||||
zend:x:502:503::/u01/zend/zend/gui/lighttpd:/sbin/nologin
|
||||
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
|
||||
2daygeek:x:503:504::/home/2daygeek:/bin/bash
|
||||
named:x:25:25:Named:/var/named:/sbin/nologin
|
||||
mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
|
||||
```
|
||||
|
||||
7 个字段的详细信息如上所述。(LCTT 译注:此处内容重复,删节)
|
||||
|
||||
你同样可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
|
||||
|
||||
### 方法 3 :使用 `compgen` 命令
|
||||
|
||||
`compgen` 是 `bash` 的内置命令,它将显示所有可用的命令,别名和函数。
|
||||
|
||||
```
|
||||
# compgen -u
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
ftp
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
2gadmin
|
||||
apache
|
||||
zabbix
|
||||
mysql
|
||||
zend
|
||||
rpc
|
||||
2daygeek
|
||||
named
|
||||
mageshm
|
||||
```
|
||||
|
||||
------------------------
|
||||
|
||||
via: https://www.2daygeek.com/3-methods-to-list-all-the-users-in-linux-system/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
|
||||
[2]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
[3]:https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
|
||||
|
||||
|
||||
@ -0,0 +1,93 @@
|
||||
2018 年 7 月 COPR 中 4 个值得尝试很酷的新项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Hledger
|
||||
|
||||
[Hledger][2] 是用于跟踪货币或其他商品的命令行程序。它使用简单的纯文本格式日志来存储数据和复式记帐。除了命令行界面,hledger 还提供终端界面和 Web 客户端,可以显示帐户余额图。
|
||||
|
||||
![][3]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28 和 Rawhide 提供了 hledger。要安装 hledger,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable kefah/HLedger
|
||||
sudo dnf install hledger
|
||||
```
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][4] 是一个命令行工具,可显示有关操作系统、软件和硬件的信息。其主要目的是以紧凑的方式显示数据来截图。你可以使用命令行标志和配置文件将 Neofetch 配置为完全按照你希望的方式显示。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 28 提供 Neofetch。要安装 Neofetch,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable sysek/neofetch
|
||||
sudo dnf install neofetch
|
||||
|
||||
```
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][6]是 Markdown 文本编辑器,它使用类似 GitHub 的 Markdown 风格。它提供了文档的预览,以及导出为 PDF 和 HTML 的选项。Markdown 有几种可用的样式,包括使用 CSS 创建自己的样式的选项。此外,Remarkable 支持用于编写方程的 LaTeX 语法和源代码的语法高亮。
|
||||
|
||||
![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 28 和 Rawhide 提供 Remarkable。要安装 Remarkable,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable neteler/remarkable
|
||||
sudo dnf install remarkable
|
||||
```
|
||||
|
||||
### Aha
|
||||
|
||||
[Aha][8](即 ANSI HTML Adapter)是一个命令行工具,可将终端转义成 HTML 代码。这允许你将 git diff 或 htop 的输出共享为静态 HTML 页面。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
[仓库][10] 目前为 Fedora 26、27、28 和 Rawhide、EPEL 6 和 7 以及其他发行版提供 aha。要安装 aha,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable scx/aha
|
||||
sudo dnf install aha
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-july-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://hledger.org/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/hledger.png
|
||||
[4]:https://github.com/dylanaraps/neofetch
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/neofetch.png
|
||||
[6]:https://remarkableapp.github.io/linux.html
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/remarkable.png
|
||||
[8]:https://github.com/theZiz/aha
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/aha.png
|
||||
[10]:https://copr.fedorainfracloud.org/coprs/scx/aha/
|
||||
58
published/20180720 Convert video using Handbrake.md
Normal file
58
published/20180720 Convert video using Handbrake.md
Normal file
@ -0,0 +1,58 @@
|
||||
使用 Handbrake 转换视频
|
||||
======
|
||||
|
||||
> 这个开源工具可以很简单地将老视频转换为新格式。
|
||||
|
||||

|
||||
|
||||
最近,当我的儿子让我数字化他的高中篮球比赛的一些旧 DVD 时,我马上就想到了 [Handbrake][1]。它是一个开源软件包,可轻松将视频转换为可在 MacOS、Windows、Linux、iOS、Android 和其他平台上播放的格式所需的所有工具。
|
||||
|
||||
Handbrake 是开源的,并在 [GPLv2 许可证][2]下分发。它很容易在 MacOS、Windows 和 Linux 包括 [Fedora][3] 和 [Ubuntu][4] 上安装。在 Linux 中,安装后就可以从命令行使用 `$ handbrake` 或从图形用户界面中选择它。(我的情况是 GNOME 3)
|
||||
|
||||

|
||||
|
||||
Handbrake 的菜单系统易于使用。单击 “Open Source” 选择要转换的视频源。对于我儿子的篮球视频,它是我的 Linux 笔记本中的 DVD 驱动器。将 DVD 插入驱动器后,软件会识别磁盘的内容。
|
||||
|
||||
|
||||
|
||||
正如你在上面截图中的 “Source” 旁边看到的那样,Handbrake 将其识别为 720x480 的 DVD,宽高比为 4:3,以每秒 29.97 帧的速度录制,有一个音轨。该软件还能预览视频。
|
||||
|
||||
如果默认转换设置可以接受,只需按下 “Start Encoding” 按钮(一段时间后,根据处理器的速度),DVD 的内容将被转换并以默认格式 [M4V][5] 保存(可以改变)。
|
||||
|
||||
如果你不喜欢文件名,很容易改变它。
|
||||
|
||||

|
||||
|
||||
Handbrake 有各种格式、大小和配置的输出选项。例如,它可以生成针对 YouTube、Vimeo 和其他网站以及 iPod、iPad、Apple TV、Amazon Fire TV、Roku、PlayStation 等设备优化的视频。
|
||||
|
||||
|
||||
|
||||
你可以在 “Dimensions” 选项卡中更改视频输出大小。其他选项卡允许你应用过滤器、更改视频质量和编码、添加或修改音轨,包括字幕和修改章节。“Tags” 选项卡可让你识别输出视频文件中的作者、演员、导演、发布日期等。
|
||||
|
||||
|
||||
|
||||
如果使用 Handbrake 为特定平台输出,可以使用包含的预设。
|
||||
|
||||
|
||||
|
||||
你还可以使用菜单选项创建自己的格式,具体取决于你需要的功能。
|
||||
|
||||
Handbrake 是一款非常强大的软件,但它并不是唯一的开源视频转换工具。你有其他喜欢的吗?如果有,请分享评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/handbrake
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://handbrake.fr/
|
||||
[2]:https://github.com/HandBrake/HandBrake/blob/master/LICENSE
|
||||
[3]:https://fedora.pkgs.org/28/rpmfusion-free-x86_64/HandBrake-1.1.0-1.fc28.x86_64.rpm.html
|
||||
[4]:https://launchpad.net/~stebbins/+archive/ubuntu/handbrake-releases
|
||||
[5]:https://en.wikipedia.org/wiki/M4V
|
||||
@ -0,0 +1,42 @@
|
||||
Textricator:让数据提取变得简单
|
||||
======
|
||||
|
||||
> 这个新的开源工具可以从 PDF 文档中提取复杂的数据,而无需编程技能。
|
||||
|
||||

|
||||
|
||||
你可能知道这种感觉:你请求得到数据并得到积极的响应,只打开电子邮件并发现一大堆附加的 PDF。数据——中断。
|
||||
|
||||
我们理解你的挫败感,并为此做了一些事情:让我们介绍下 [Textricator][1],这是我们的第一个开源产品。
|
||||
|
||||
我们是 “Measures for Justice”(MFJ),一个刑事司法研究和透明度组织。我们的使命是为整个司法系统从逮捕到定罪后提供数据透明度。我们通过制定一系列多达 32 项指标来实现这一目标,涵盖每个县的整个刑事司法系统。我们以多种方式获取数据 —— 当然,所有这些都是合法的 —— 虽然许多州和县机构都掌握数据,可以为我们提供 CSV 格式的高质量格式化数据,但这些数据通常捆绑在软件中,没有简单的方法可以提取。PDF 报告是他们能提供的最佳报告。
|
||||
|
||||
开发者 Joe Hale 和 Stephen Byrne 在过去两年中一直在开发 Textricator,它用来提取数万页数据供我们内部使用。Textricator 可以处理几乎任何基于文本的 PDF 格式 —— 不仅仅是表格,还包括复杂的报表,其中包含从 Crystal Reports 等工具生成的文本和细节部分。只需告诉 Textricator 你要收集的字段的属性,它就会整理文档,收集并写出你的记录。
|
||||
|
||||
不是软件工程师?Textricator 不需要编程技巧。相反,用户描述 PDF 的结构,Textricator 处理其余部分。大多数用户通过命令行运行它。但是,你可以使用基于浏览器的 GUI。
|
||||
|
||||
我们评估了其他很好的开源解决方案,如 [Tabula][2],但它们无法处理我们需要抓取的一些 PDF 的结构。技术总监 Andrew Branch 说:“Textricator 既灵活又强大,缩短了我们花费大量时间处理大型数据集的时间。”
|
||||
|
||||
在 MFJ,我们致力于透明度和知识共享,其中包括向任何人提供我们的软件,特别是那些试图公开自由共享数据的人。Textricator 可以在 [GitHub][3] 上找到,并在 [GNU Affero 通用公共许可证第 3 版][4]下发布。
|
||||
|
||||
你可以在我们的免费[在线数据门户][5]上查看我们的工作成果,包括通过 Textricator 处理的数据。Textricator 是我们流程的重要组成部分,我们希望民间技术机构和政府组织都可以使用这个新工具解锁更多数据。
|
||||
|
||||
如果你使用 Textricator,请告诉我们它如何帮助你解决数据问题。想要改进吗?提交一个拉取请求。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/textricator
|
||||
|
||||
作者:[Stephen Byrne][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stephenbyrne-mfj
|
||||
[1]:https://textricator.mfj.io/
|
||||
[2]:https://tabula.technology/
|
||||
[3]:https://github.com/measuresforjustice/textricator
|
||||
[4]:https://www.gnu.org/licenses/agpl-3.0.en.html
|
||||
[5]:https://www.measuresforjustice.org/portal/
|
||||
116
published/20180727 Three Graphical Clients for Git on Linux.md
Normal file
116
published/20180727 Three Graphical Clients for Git on Linux.md
Normal file
@ -0,0 +1,116 @@
|
||||
三款 Linux 下的 Git 图形客户端
|
||||
======
|
||||
|
||||
> 了解这三个 Git 图形客户端工具如何增强你的开发流程。
|
||||
|
||||

|
||||
|
||||
在 Linux 下工作的人们对 [Git][1] 非常熟悉。一个理所当然的原因是,Git 是我们这个星球上最广为人知也是使用最广泛的版本控制工具。不过大多数情况下,Git 需要学习繁杂的终端命令。毕竟,我们的大多数开发工作可能是基于命令行的,那么没理由不以同样的方式与 Git 交互。
|
||||
|
||||
但在某些情况下,使用带图形界面的工具可能使你的工作更高效一点(起码对那些更倾向于使用图形界面的人们来说)。那么,有哪些 Git 图形客户端可供选择呢?幸运的是,我们找到一些客户端值得你花费时间和金钱(一些情况下)去尝试一下。在此,我主要推荐三种可以运行在 Linux 操作系统上的 Git 客户端。在这几种中,你可以找到一款满足你所有要求的客户端。
|
||||
|
||||
在这里我假设你理解如何使用 Git 和具有 GitHub 类似功能的代码仓库,[使用方法我之前讲过了][2],因此我不再花费时间讲解如何使用这些工具。本篇文章主要是一篇介绍,介绍几种可以用在开发任务中的工具。
|
||||
|
||||
提前说明一下:这些工具并不都是免费的,它们中的一些可能需要商业授权。不过,它们都在 Linux 下运行良好并且可以轻而易举的和 GitHub 相结合。
|
||||
|
||||
就说这些了,快让我们看看这些出色的 Git 图形客户端吧。
|
||||
|
||||
### SmartGit
|
||||
|
||||
[SmartGit][3] 是一个商业工具,不过如果你在非商业环境下使用是免费的。如果你打算在商业环境下使用的话,一个许可证每人每年需要 99 美元,或者 5.99 美元一个月。还有一些其它升级功能(比如<ruby>分布式评审<rt>Distributed Reviews</rt></ruby>和<ruby>智能同步<rt>SmartSynchronize</rt></ruby>),这两个工具每个许可证需要另加 15 美元。你也能通过下载源码或者 deb 安装包进行安装。我在 Ubuntu 18.04 下测试,发现 SmartGit 运行良好,没有出现一点问题。
|
||||
|
||||
不过,我们为什么要用 SmartGit 呢?有许多原因,最重要的一点是,SmartGit 可以非常方便的和 GitHub 以及 Subversion 等版本控制工具整合。不需要你花费宝贵的时间去配置各种远程账号,SmartGit 的这些功能开箱即用。SmartGit 的界面(图 1)设计的也很好,整洁直观。
|
||||
|
||||
![SmartGit][5]
|
||||
|
||||
*图 1: SmartGit 帮助简化工作*
|
||||
|
||||
安装完 SmartGit 后,我马上就用它连接到了我的 GitHub 账户。默认的工具栏是和仓库操作相关联的,非常简洁。推送、拉取、检出、合并、添加分支、cherry pick、撤销、变基、重置 —— 这些 Git 的的流行功能都支持。除了支持标准 Git 和 GitHub 的大部分功能,SmartGit 运行也非常稳定。至少当你在 Ubuntu上使用时,你会觉得这一款软件是专门为 Linux 设计和开发的。
|
||||
|
||||
SmartGit 可能是使各个水平的 Git 用户都可以非常轻松的使用 Git,甚至 Git 高级功能的最好工具。为了了解更多 SmartGit 相关知识,你可以查看一下其[丰富的文档][7]。
|
||||
|
||||
### GitKraken
|
||||
|
||||
[GitKraken][8] 是另外一款商业 Git 图形客户端,它可以使你感受到一种绝不会后悔的使用 Git 或者 GitHub 的美妙体验。SmartGit 具有非常简洁的界面,而 GitKraken 拥有非常华丽的界面,它一开始就给你展现了很多特色。GitKraken 有一个免费版(你也可以使用完整版 15 天)。试用期过了,你也可以继续使用免费版,不过不能用于商业用途。
|
||||
|
||||
对那些想让其开发工作流发挥最大功效的人们来说,GitKraken 可能是一个比较好的选择。界面上具有的功能包括:可视化交互、可缩放的提交图、拖拽、与 Github、GitLab 和 BitBucked 的无缝整合、简单的应用内任务清单、应用内置的合并工具、模糊查找、支持 Gitflow、一键撤销与重做、快捷键、文件历史与追责、子模块、亮色和暗色主题、Git 钩子支持和 Git LFS 等许多功能。不过用户倍加赞赏的还是精美的界面(图 2)。
|
||||
|
||||
![GitKraken][10]
|
||||
|
||||
*图 2: GitKraken的界面非常出色*
|
||||
|
||||
除了令人惊艳的图形界面,另一个使 GitKraken 在 Git 图形客户端竞争中脱颖而出的功能是:GitKraken 使得使用多个远程仓库和多套配置变得非常简单。不过有一个告诫,使用 GitKraken 需要花钱(它是专有的)。如果你想商业使用,许可证的价钱如下:
|
||||
|
||||
* 一人一年 49 美元
|
||||
* 10 人以上团队,39 美元每人每年
|
||||
* 100 人以上团队, 29 美元每人每年
|
||||
|
||||
专业版账户不但可以在商业环境使用 Git 相关功能,还可以使用 Glo Boards(GitKraken 的项目管理工具)。Glo Boards 的一个吸引人的功能是可以将数据同步到 GitHub <ruby>工单<rt>Issues</rt></ruby>。Glo Boards 具有分享功能还具有搜索过滤、问题跟踪、Markdown 支持、附件、@ 功能、清单卡片等许多功能。所有的这些功能都可以在 GitKraken 界面里进行操作。
|
||||
|
||||
GitKraken 可以通过 deb 文件或者源码进行安装。
|
||||
|
||||
### Git Cola
|
||||
|
||||
[Git Cola][11] 是我们推荐列表中一款自由开源的 Git 图像客户端。不像 GitKraken 和 SmartGit,Git Cola是一款比较难啃的骨头,一款比较实用的 Git 客户端。Git Cola 是用 Python 写成的,使用的是 GTK 界面,因此无论你用的是什么 Linux 发行版和桌面,都可以无缝支持。并且因为它是开源的,你可以在你使用的发行版的包管理器中找到它。因此安装过程无非是打开应用商店,搜索 “Git Cola” 安装即可。你也可以通过下面的命令进行安装:
|
||||
|
||||
```
|
||||
sudo apt install git-cola
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
sudo dnf install git-cola
|
||||
```
|
||||
|
||||
Git Cola 看起来相对比较简单(图 3)。事实上,你无法找到更复杂的东西,因为 Git Cola 是非常基础的。
|
||||
|
||||
![Git Cola][13]
|
||||
|
||||
*图 3:Git Cola 界面是非常简单的*
|
||||
|
||||
因为 Git Cola 看起来回归自然,所以很多时间你必须同终端打交道。不过这并不是什么难事儿(因为大多数开发人员需要经常使用终端)。Git Cola 包含以下特性:
|
||||
|
||||
* 支持多个子命令
|
||||
* 自定义窗口设置
|
||||
* 可设置环境变量
|
||||
* 语言设置
|
||||
* 支持自定义 GUI 设置
|
||||
* 支持快捷键
|
||||
|
||||
尽管 Git Cola 支持连接到远程仓库,但和像 GitHub 这样的仓库整合看起来也没有 GitKraken 和 SmartGit 直观。不过如果你的大部分工作是在本地进行的,Git Cola 并不失为一个出色的工具。
|
||||
|
||||
Git Cola 也带有有一个高级的 DAG(有向无环图)可视化工具,叫做 Git DAG。这个工具可以使你获得分支的可视化展示。你可以独立使用 Git DAG,也可以在 Git Cola 内通过 “view->DAG” 菜单来打开。正是 Git DAG 这个威力巨大的工具使用 Git Cola 跻身于应用商店中 Git 图形客户端前列。
|
||||
|
||||
### 更多的客户端
|
||||
|
||||
还有更多的 Git 图形客户端。不过,从上面介绍的这几款中,你已经可以做很多事情了。无论你在寻找一款更有丰富功能的 Git 客户端(不管许可证的话)还是你本身是一名坚定的 GPL 支持者,都可以从上面找到适合自己的一款。
|
||||
|
||||
如果想学习更多关于 Linux 的知识,可以通过学习Linux基金会的[走进 Linux][14]课程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[tarepanda1024](https://github.com/tarepanda1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
|
||||
[3]:https://www.syntevo.com/smartgit/
|
||||
[4]:/files/images/gitgui1jpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_1.jpg?itok=LEZ_PYIf (SmartGit)
|
||||
[6]:/licenses/category/used-permission
|
||||
[7]:http://www.syntevo.com/doc/display/SG/Manual
|
||||
[8]:https://www.gitkraken.com/
|
||||
[9]:/files/images/gitgui2jpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_2.jpg?itok=Y8crSLhf (GitKraken)
|
||||
[11]:https://git-cola.github.io/
|
||||
[12]:/files/images/gitgui3jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_3.jpg?itok=bS9OYPQo (Git Cola)
|
||||
[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ynmlml
|
||||
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by aiwhj
|
||||
3 tips for organizing your open source project's workflow on GitHub
|
||||
======
|
||||
|
||||
|
||||
@ -1,52 +0,0 @@
|
||||
CIP: Keeping the Lights On with Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Modern civil infrastructure is all around us -- in power plants, radar systems, traffic lights, dams, weather systems, and so on. Many of these infrastructure projects exist for decades, if not longer, so security and longevity are paramount.
|
||||
|
||||
And, many of these systems are powered by Linux, which offers technology providers more control over these issues. However, if every provider is building their own solution, this can lead to fragmentation and duplication of effort. Thus, the primary goal of [Civil Infrastructure Platform (CIP)][1] is to create an open source base layer for industrial use-cases in these systems, such as embedded controllers and gateway devices.
|
||||
|
||||
“We have a very conservative culture in this area because once we create a system, it has to be supported for more than ten years; in some cases for over 60 years. That’s why this project was created, because every player in this industry had the same issue of being able to use Linux for a long time,” says Yoshitake Kobayashi is Technical Steering Committee Chair of CIP.
|
||||
|
||||
CIP’s concept is to create a very fundamental system to use open source software on controllers. This base layer comprises the Linux kernel and a small set of common open source software like libc, busybox, and so on. Because longevity of software is a primary concern, CIP chose Linux kernel 4.4, which is the LTS release of the kernel maintained by Greg Kroah-Hartman.
|
||||
|
||||
### Collaboration
|
||||
|
||||
Since CIP has an upstream first policy, the code that they want in the project must be in the upstream kernel. To create a proactive feedback loop with the kernel community, CIP hired Ben Hutchings as the official maintainer of CIP. Hutchings is known for the work he has done on Debian LTS release, which also led to an official collaboration between CIP and the Debian project.
|
||||
|
||||
Under the newly forged collaboration, CIP will use Debian LTS to build the platform. CIP will also help Debian Long Term Support (LTS) to extend the lifetime of all Debian stable releases. CIP will work closely with Freexian, a company that offers commercial services around Debian LTS. The two organizations will focus on interoperability, security, and support for open source software for embedded systems. CIP will also provide funding for some of the Debian LTS activities.
|
||||
|
||||
“We are excited about this collaboration as well as the CIP’s support of the Debian LTS project, which aims to extend the support lifetime to more than five years. Together, we are committed to long-term support for our users and laying the ‘foundation’ for the cities of the future.” said Chris Lamb, Debian Project Leader.
|
||||
|
||||
### Security
|
||||
|
||||
Security is the biggest concern, said Kobayashi. Although most of the civil infrastructure is not connected to the Internet for obvious security reasons (you definitely don’t want a nuclear power plant to be connected to the Internet), there are many other risks.
|
||||
|
||||
Just because the system itself is not connected to the Internet, that doesn’t mean it’s immune to all threats. Other systems -- like user’s laptops -- may connect to the Internet and then be plugged into the local systems. If someone receives a malicious file as an attachment with email, it can “contaminate” the internal infrastructure.
|
||||
|
||||
Thus, it’s critical to keep all software running on such controllers up to date and fully patched. To ensure security, CIP has also backported many components of the Kernel Self Protection project. CIP also follows one of the strictest cybersecurity standards -- IEC 62443 -- which defines processes and tests to ensure the system is more secure.
|
||||
|
||||
### Going forward
|
||||
|
||||
As CIP is maturing, it's extending its collaboration with providers of Linux. In addition to collaboration with Debian and freexian, CIP recently added Cybertrust Japan Co, Ltd., a supplier of enterprise Linux operating system, as a new Silver member.
|
||||
|
||||
Cybertrust joins other industry leaders, such as Siemens, Toshiba, Codethink, Hitachi, Moxa, Plat’Home, and Renesas, in their work to create a reliable and secure Linux-based embedded software platform that is sustainable for decades to come.
|
||||
|
||||
The ongoing work of these companies under the umbrella of CIP will ensure the integrity of the civil infrastructure that runs our modern society.
|
||||
|
||||
Learn more at the [Civil Infrastructure Platform][1] website.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -1,44 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
My first sysadmin mistake
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you work in IT, you know that things never go completely as you think they will. At some point, you'll hit an error or something will go wrong, and you'll end up having to fix things. That's the job of a systems administrator.
|
||||
|
||||
As humans, we all make mistakes. Sometimes, we are the error in the process, or we are what went wrong. As a result, we end up having to fix our own mistakes. That happens. We all make mistakes, typos, or errors.
|
||||
|
||||
As a young systems administrator, I learned this lesson the hard way. I made a huge blunder. But thanks to some coaching from my supervisor, I learned not to dwell on my errors, but to create a "mistake strategy" to set things right. Learn from your mistakes. Get over it, and move on.
|
||||
|
||||
My first job was a Unix systems administrator for a small company. Really, I was a junior sysadmin, but I worked alone most of the time. We were a small IT team, just the three of us. I was the only sysadmin for 20 or 30 Unix workstations and servers. The other two supported the Windows servers and desktops.
|
||||
|
||||
Any systems administrators reading this probably won't be surprised to know that, as an unseasoned, junior sysadmin, I eventually ran the `rm` command in the wrong directory. As root. I thought I was deleting some stale cache files for one of our programs. Instead, I wiped out all files in the `/etc` directory by mistake. Ouch.
|
||||
|
||||
My clue that I'd done something wrong was an error message that `rm` couldn't delete certain subdirectories. But the cache directory should contain only files! I immediately stopped the `rm` command and looked at what I'd done. And then I panicked. All at once, a million thoughts ran through my head. Did I just destroy an important server? What was going to happen to the system? Would I get fired?
|
||||
|
||||
Fortunately, I'd run `rm *` and not `rm -rf *` so I'd deleted only files. The subdirectories were still there. But that didn't make me feel any better.
|
||||
|
||||
Immediately, I went to my supervisor and told her what I'd done. She saw that I felt really dumb about my mistake, but I owned it. Despite the urgency, she took a few minutes to do some coaching with me. "You're not the first person to do this," she said. "What would someone else do in your situation?" That helped me calm down and focus. I started to think less about the stupid thing I had just done, and more about what I was going to do next.
|
||||
|
||||
I put together a simple strategy: Don't reboot the server. Use an identical system as a template, and re-create the `/etc` directory.
|
||||
|
||||
Once I had my plan of action, the rest was easy. It was just a matter of running the right commands to copy the `/etc` files from another server and edit the configuration so it matched the system. Thanks to my practice of documenting everything, I used my existing documentation to make any final adjustments. I avoided having to completely restore the server, which would have meant a huge disruption.
|
||||
|
||||
To be sure, I learned from that mistake. For the rest of my years as a systems administrator, I always confirmed what directory I was in before running any command.
|
||||
|
||||
I also learned the value of building a "mistake strategy." When things go wrong, it's natural to panic and think about all the bad things that might happen next. That's human nature. But creating a "mistake strategy" helps me stop worrying about what just went wrong and focus on making things better. I may still think about it, but knowing my next steps allows me to "get over it."
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
218
sources/talk/20180710 How I Fully Quit Google And You Can Too.md
Normal file
218
sources/talk/20180710 How I Fully Quit Google And You Can Too.md
Normal file
@ -0,0 +1,218 @@
|
||||
martin2011qi is translating
|
||||
|
||||
How I Fully Quit Google (And You Can, Too)
|
||||
============================================================
|
||||
|
||||
>My enlightening quest to break free of a tech giant
|
||||
|
||||
Over the past six months, I have gone on a surprisingly tough, time-intensive, and enlightening quest — to quit using, entirely, the products of just one company — Google. What should be a simple task was, in reality, many hours of research and testing. But I did it. Today, I am Google free, part of the western world’s ultimate digital minority, someone who does not use products from the world’s two most valuable technology companies (yes, I don’t use [Facebook either][6]).
|
||||
|
||||
This guide is to show you how I quit the Googleverse, and the alternatives I choose based on my own research and personal needs. I’m not a technologist or a coder, but my work as a journalist requires me to be aware of security and privacy issues.
|
||||
|
||||
I chose all of these alternatives based solely on their merit, usability, cost, and whether or not they had the functionality I desired. My choices are not universal as they reflect my own needs and desires. Nor do they reflect any commercial interests. None of the alternatives listed below paid me or are giving me any commission whatsoever for citing their services.
|
||||
|
||||
### But First: Why?
|
||||
|
||||
Here’s the thing. I don’t hate Google. In fact, not too long ago, I was a huge fan of Google. I remember the moment when I first discovered one amazing search engine back in the late 1990’s, when I was still in high school. Google was light years ahead of alternatives such as Yahoo, Altavista, or Ask Jeeves. It really did help users find what they were seeking on a web that was, at that time, a mess of broken websites and terrible indexes.
|
||||
|
||||
Google soon moved from just search to providing other services, many of which I embraced. I was an early adopter of Gmail back in 2005, when you could only join [via invites][7]. It introduced threaded conversations, archiving, labels, and was without question the best email service I had ever used. When Google introduced its Calendar tool in 2006, it was revolutionary in how easy it was to color code different calendars, search for events, and send shareable invites. And Google Docs, launched in 2007, was similarly amazing. During my first full time job, I pushed my team to do everything as a Google spreadsheet, document, or presentation that could be edited by many of us simultaneously.
|
||||
|
||||
Like many, I was a victim of Google creep. Search led to email, to documents, to analytics, photos, and dozens of other services all built on top of and connected to each other. Google turned from a company releasing useful products to one that has ensnared us, and the internet as a whole, into its money-making, data gathering apparatus. Google is pervasive in our digital lives in a way no other corporation is or ever has been. It’s relatively easy to quit using the products of other tech giants. With Apple, you’re either in the iWorld, or out. Same with Amazon, and even Facebook owns only a few platforms and quitting is more of a [psychological challenge][8] than actually difficult.
|
||||
|
||||
Google, however, is embedded everywhere. No matter what laptop, smartphone, or tablet you have, chances are you have at least one Google app on there. Google is synonymous for search, maps, email, our browser, the operating system on most of our smartphones. It even provides the “[services][9]” and analytics that other apps and websites rely on, such as Uber’s use of Google Maps to operate its ride-hailing service.
|
||||
|
||||
Google is now a word in many languages, and its global dominance means there are not many well-known, or well-used alternatives to its behemoth suite of tools — especially if you are privacy minded. We all started using Google because it, in many ways, provided better alternatives to existing products. But now, we can’t quit because either Google has become a default, or because its dominance means that alternatives can’t get enough traction.
|
||||
|
||||
The truth is, alternatives do exist, many of which have launched in the years since Edward Snowden revealed Google’s participation in [Prism][10]. I embarked on this project late last year. After six months of research, testing, and a lot of trial and error, I was able to find privacy minded alternatives to all the Google products I was using. Some, to my surprise, were even better.
|
||||
|
||||
### A Few Caveats
|
||||
|
||||
One of the biggest challenges to quitting is the fact that most alternatives, particularly those in the open source of privacy space, are really not user friendly. I’m not a techie. I have a website, understand how to manage Wordpress, and can do some basic troubleshooting, but I can’t use Command Line or do anything that requires coding.
|
||||
|
||||
These alternatives are ones you can easily use with most, if not all, the functionality of their Google alternatives. For some, though, you’ll need your own web host or access to a server.
|
||||
|
||||
Also, [Google Takeout][11] is your friend. Being able to download my entire email history and upload it on my computer to access via Thunderbird meant I have easy access to over a decade of emails. The same can be said about Calendar or Docs, the latter of which I converted to ODT format and now keep on my cloud alternative, further detailed below.
|
||||
|
||||
### The Easy Ones
|
||||
|
||||
#### Search
|
||||
|
||||
[DuckDuckGo][12] and [Startpage][13] are both privacy-centric search engines that do not collect any of your search data. Together, they take care of everything I was previously using Google search for.
|
||||
|
||||
_Other Alternatives: _ Really not many when Google has 74% global market share, with the remainder mostly due to it’s being blocked in China. Ask.com is still around. And there’s Bing…
|
||||
|
||||
#### Chrome
|
||||
|
||||
[Mozilla Firefox][14] — it recently got [a big upgrade][15], which is a huge improvement from earlier versions. It’s created by a non-profit foundation that actively works to protect privacy. There’s really no reason at all to use Chrome.
|
||||
|
||||
_Other Alternatives: _ Avoid Opera and Vivaldi, as they use Chrome as their base. [Brave][16] is my secondary browser.
|
||||
|
||||
#### Hangouts and Google Chat
|
||||
|
||||
[Jitsi Meet][17] — an open source, free alternative to Google Hangouts. You can use it directly from a browser or download the app. It’s fast, secure, and works on nearly every platform.
|
||||
|
||||
_Other Alternatives: Z_ oom has become popular among those in the professional space, but requires you to pay for most features. [Signal][18], an open source, secure messaging app, also has a call function but only on mobile. Avoid Skype, as it’s both a data hog and has a terrible interface.
|
||||
|
||||
#### Google Maps
|
||||
|
||||
Desktop: [Here WeGo][19] — it loads faster and can find nearly everything that Google Maps can. For some reason, they’re missing some countries, like Japan.
|
||||
|
||||
Mobile: [Maps.me][20] — here Maps was my initial choice here too, but became less useful once they modified the app to focus on driver navigation. Maps.me is pretty good, and has far better offline functionality than Google, something very useful to a frequent traveler like me.
|
||||
|
||||
_Other alternatives_ : [OpenStreetMap][21] is a project I wholeheartedly support, but it’s functionality was severely lacking. It couldn’t even find my home address in Oakland.
|
||||
|
||||
### Easy but Not Free
|
||||
|
||||
Some of this was self-inflicted. For example, when looking for an alternative to Gmail, I did not just want to switch to an alternative from another tech giant. That meant no Yahoo Mail, or Microsoft Outlook as that would not address my privacy concerns.
|
||||
|
||||
Remember, the fact that so many of Google’s services are free (not to mention those of its competitors including Facebook) is because they are actively monetizing our data. For alternatives to survive without this level of data monetization, they have to charge us. I am willing to pay to protect my privacy, but do understand that not everyone is able to make this choice.
|
||||
|
||||
Think of it this way: Remember when you used to send letters and had to pay for stamps? Or when you bought weekly planners from the store? Essentially, this is the cost to use a privacy-focused email or calendar app. It’s not that bad.
|
||||
|
||||
#### Gmail
|
||||
|
||||
[ProtonMail][22] — it was founded by former CERN scientists and is based in Switzerland, a country with strong privacy protections. But what really appealed to me about ProtonMail was that it, unlike most other privacy minded email programs, was user friendly. The interface is similar to Gmail, with labels, filters, and folders, and you don’t need to know anything about security or privacy to use it.
|
||||
|
||||
The free version only gives you 500MB of storage space. I opted for a paid 5GB account along with their VPN service.
|
||||
|
||||
_Other alternatives_ : [Fastmail][23] is not as privacy oriented but also has a great interface. There’s also [Hushmail][24] and [Tutanota][25], both with similar features to ProtonMail.
|
||||
|
||||
#### Calendar
|
||||
|
||||
[Fastmail][26] Calendar — this was surprisingly tough, and brings up another issue. Google products have become so ubiquitous in so many spaces that start-ups don’t even bother to create alternatives anymore. After trying a few other mediocre options, I ended getting a recommendation and choose Fastmail as a dual second-email and calendar option.
|
||||
|
||||
### More Technical
|
||||
|
||||
These require some technical knowledge or access to your web host service. I do include simpler alternatives that I researched but did not end up choosing.
|
||||
|
||||
#### Google Docs, Drive, Photos, and Contacts
|
||||
|
||||
[NextCloud ][27]— a fully featured, secure, open source cloud suite with an intuitive, user-friendly interface. The catch is that you’ll need your own host to use Nextcloud. I already had one for my own website and was able to quickly install NextCloud using Softaculous on my host’s C-Panel. You’ll need a HTTPS certificate, which I got for free from[ Let’s Encrypt][28]. Not as easy as opening a Google Drive account but not too challenging either.
|
||||
|
||||
I also use Nextcloud as an alternative for Google’s photo storage and contacts, which I sync with my phone using CalDev.
|
||||
|
||||
_Other alternative_ s: There are other open source options such as [OwnCloud][29] or [Openstack][30]. Some for-profit options are good too, as top choices Dropbox and Box are independent entities that don’t profit off of your data.
|
||||
|
||||
#### Google Analytics
|
||||
|
||||
[Matomo ][31]— formally called Piwic, this is a self-hosted analytics platform. While not as feature rich as Google Analytics, it is plenty fine for understanding basic website traffic, with the added bonus that you aren’t gifting that traffic data to Google.
|
||||
|
||||
_Other alternatives: _ Not much really. [OpenWebAnalytics][32] is another open source option, and there are some for-profit alternatives too, such as GoStats and Clicky.
|
||||
|
||||
#### Android
|
||||
|
||||
[LineageOS][33] + [F-Droid App Store][34]. Sadly, the smartphone world has become a literal duopoly, with Google’s Android and Apple’s iOS controlling the entire market. The few usable alternatives that existed a few years ago, such as Blackberry OS or Mozilla’s Firefox OS, are no longer being maintained.
|
||||
|
||||
So the next best option is Lineage OS: a privacy minded, open source version of Android that can be installed without Google services or Apps. It requires some technical knowledge as the installation process is not completely straightforward, but it works really well, and lacks the bloatware that comes with most Android installations.
|
||||
|
||||
_Other alternatives: _ Ummm…Windows 10 Mobile? [PureOS][35] looks promising, as does [UbuntuTouch][36].
|
||||
|
||||
### Unexpected Challenges
|
||||
|
||||
Firstly, this took much longer than I planned due to the lack of good resources about usable alternatives, and the challenge in moving data from Google to other platforms.
|
||||
|
||||
But the toughest thing was email, and it has nothing to do with ProtonMail or Google.
|
||||
|
||||
Before I joined Gmail in 2004, I probably switched emails once a year. My first account was with Hotmail, and I then used Mail.com, Yahoo Mail, and long-forgotten services like Bigfoot. I never recall having an issue when I changed email providers. I would just tell all my friends to update their address books and change the email address on other web accounts. It used to be necessary to change email addresses regularly — remember how spam would take over older inboxes?
|
||||
|
||||
In fact, one of Gmail’s best innovations was its ability to filter out spam. That meant no longer needing to change emails.
|
||||
|
||||
Email is key to using the internet. You need it to open a Facebook account, to use online banking, to post on message boards, and many more. So when you switch accounts, you need to update your email address on all these different services.
|
||||
|
||||
To my surprise, changing from Gmail today is a major hassle because of all the places that require email addresses to set up an account. Several sites no longer let you do it from the backend on your own. One service actually required me to close my account and open a new one as they were unable to change my email, and then they transferred over my account data manually. Others forced me to call customer service and request an email account change, meaning time wasted on hold.
|
||||
|
||||
Even more amazingly, others accepted my change, and then continued to send messages to my old Gmail account, requiring another phone call. Others were even more annoying, sending some messages to my new email, but still using my old account for other emails. This became such a cumbersome process that I ended up leaving my Gmail account open for several months alongside my new ProtonMail account just to make sure important emails did not get lost. This was the main reason this took me six months.
|
||||
|
||||
People so rarely change their emails these days that most companies’ platforms are not designed to deal with the possibility. It’s a telling sign of the sad state of the web today that it was easier to change your email back in 2002 than it is in 2018\. Technology does not always move forward.
|
||||
|
||||
### So, Are These Google Alternatives Any Good?
|
||||
|
||||
Some are actually better! Jitsi Meet runs smoother, requires less bandwidth, and is more platform friendly than Hangouts. Firefox is more stable and less of a memory suck than Chrome. Fastmail’s Calendar has far better time zone integration.
|
||||
|
||||
Others are adequate equivalents. ProtonMail has most of the features of Gmail but lacks some useful integrations, such as the Boomerang email scheduler I was using before. It also has a lacking Contacts interface, but I’m using Nextcloud for that. Speaking of Nextcloud, it’s great for hosting files, contacts, and has a nifty notes tool (and lots of other plug-ins). But it does not have the rich multi-editing features of Google Docs. I’ve not yet found a workable alternative in my budget. There is Collabora Office, but it requires me to upgrade my server, something that is not feasible for me.
|
||||
|
||||
Some depend on location. Maps.me is actually better than Google Maps in some countries (such as Indonesia) and far worse in others (including America).
|
||||
|
||||
Others require me to sacrifice some features or functionality. Piwic is a poor man’s Google Analytics, and lacks many of the detailed reports or search functions of the former. DuckDuckGo is fine for general searches but has issues with specific searches, and both it and StartPage sometimes fail when I’m searching for non-English language content.
|
||||
|
||||
### In the End, I Don’t Miss Google at All
|
||||
|
||||
In fact, I feel liberated. To be so dependent on a single company for so many products is a form of servitude, especially when your data is what you’re often paying with. Moreover, many of these alternatives are, in fact, better. And there is real comfort in knowing you are in control of your data.
|
||||
|
||||
If we have no choice but to use Google products, then we lose what little power we have as consumers.
|
||||
|
||||
I want Google, Facebook, Apple, and other tech giants to stop taking users for granted, to stop trying to force us inside their all-encompassing ecosystems. I also want new players to be able to emerge and compete, just as, once upon a time, Google’s new search tool could compete with the then-industry giants Altavista and Yahoo, or Facebook’s social network was able to compete with MySpace and Friendster. The internet was a better place because Google gave us the opportunity to have a better search. Choice is good. As is portability.
|
||||
|
||||
Today, few of us even try other products because we’re just so used to Googling. We don’t change emails cause it’s hard. We don’t even try to use a Facebook alternative because all of our friends are on Facebook. I understand.
|
||||
|
||||
You don’t have to quit Google entirely. But give other alternatives a chance. You might be surprised, and remember why you loved the web way back when.
|
||||
|
||||
* * *
|
||||
|
||||
#### Other Resources
|
||||
|
||||
I created this resource not to be an all-encompassing guide but a story of how I was able to quit Google. Here are some resources that show other alternatives. Some are far too technical for me, and others I just didn’t have time to explore.
|
||||
|
||||
* [Localization Lab][2] has a detailed list of open source or privacy-tech projects — some highly technical, others quite user friendly.
|
||||
|
||||
* [Framasoft ][3]has an entire suite of mostly open-source Google alternatives, though many are just in French.
|
||||
|
||||
* Restore Privacy has also [collected a list of alternatives][4].
|
||||
|
||||
Your turn. Please share your favorite Google alternatives in the responses or via Twitter. I am sure there are many that I missed and would love to try. I don’t plan to stick with the alternatives listed above forever.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nithin Coca
|
||||
|
||||
Freelance journalist covering politics, environment & human rights + social impacts of tech globally. For more http://www.nithincoca.com
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/s/story/how-i-fully-quit-google-and-you-can-too-4c2f3f85793a
|
||||
|
||||
作者:[Nithin Coca][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@excinit
|
||||
[1]:https://medium.com/@excinit
|
||||
[2]:https://www.localizationlab.org/projects/
|
||||
[3]:https://framasoft.org/?l=en
|
||||
[4]:https://restoreprivacy.com/google-alternatives/
|
||||
[5]:https://medium.com/@excinit
|
||||
[6]:https://www.nithincoca.com/2011/11/20/7-months-no-facebook/
|
||||
[7]:https://www.quora.com/How-long-was-Gmail-in-private-%28invitation-only%29-beta
|
||||
[8]:https://www.theverge.com/2018/4/28/17293056/facebook-deletefacebook-social-network-monopoly
|
||||
[9]:https://en.wikipedia.org/wiki/Google_Play_Services
|
||||
[10]:https://www.theguardian.com/world/2013/jun/06/us-tech-giants-nsa-data
|
||||
[11]:https://takeout.google.com/settings/takeout
|
||||
[12]:https://duckduckgo.com/
|
||||
[13]:https://www.startpage.com/
|
||||
[14]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[15]:https://www.seattletimes.com/business/firefox-is-back-and-its-time-to-give-it-a-try/
|
||||
[16]:https://brave.com/
|
||||
[17]:https://jitsi.org/jitsi-meet/
|
||||
[18]:https://signal.org/
|
||||
[19]:https://wego.here.com/
|
||||
[20]:https://maps.me/
|
||||
[21]:https://www.openstreetmap.org/
|
||||
[22]:https://protonmail.com/
|
||||
[23]:https://www.fastmail.com/
|
||||
[24]:https://www.hushmail.com/
|
||||
[25]:https://tutanota.com/
|
||||
[26]:https://www.fastmail.com/
|
||||
[27]:https://nextcloud.com/
|
||||
[28]:https://letsencrypt.org/
|
||||
[29]:https://owncloud.org/
|
||||
[30]:https://www.openstack.org/
|
||||
[31]:https://matomo.org/
|
||||
[32]:http://www.openwebanalytics.com/
|
||||
[33]:https://lineageos.org/
|
||||
[34]:https://f-droid.org/en/
|
||||
[35]:https://puri.sm/posts/tag/pureos/
|
||||
[36]:https://ubports.com/
|
||||
@ -0,0 +1,81 @@
|
||||
What's the difference between a fork and a distribution?
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you've been around open source software for any length of time, you'll hear the terms fork and distribution thrown around casually in conversation. For many people, the distinction between the two isn't clear, so here I'll try to clear up the confusion.
|
||||
|
||||
### First, some definitions
|
||||
|
||||
Before explaining the nuances of a fork vs. a distribution and the pitfalls thereof, let's define key concepts.
|
||||
|
||||
**[Open source software][1]** is software that:
|
||||
|
||||
* Is freely available to distribute under certain [license][2] restraints
|
||||
* Permits its source code to be viewable and modified under certain license restraints
|
||||
|
||||
|
||||
|
||||
Open source software can be **consumed** in the following ways:
|
||||
|
||||
* Downloaded in binary or source code format, often at no charge (e.g., the [Eclipse developer environment][3])
|
||||
* As a distribution (product) by a vendor, sometimes at a cost to the user (e.g., [Red Hat products][4])
|
||||
* Embedded into proprietary software solutions (e.g., some smartphones and browsers display fonts using the open source [freetype software][5])
|
||||
|
||||
|
||||
|
||||
**Free and open source (FOSS)** is not necessarily "free" as in "zero cost." Free and open source simply means the software is free to distribute, modify, study, and use, subject to the software's licensing. The software distributor may attach a purchase price to it. For example, Linux is available at no cost as Fedora, CentOS, Gentoo, etc. or as a paid distribution as Red Hat Enterprise Linux, SUSE, etc.
|
||||
|
||||
**Community** refers to the organizations and individuals that collaboratively work on an open source project. Any individual or organization can contribute to the project by writing or reviewing code, documentation, test suites, managing meetings, updating websites, etc., provided they abide by the license. For example, at [Openhub.net][6], we see government, nonprofit, commercial, and education organizations [contributing to some open source projects][7].
|
||||
|
||||
**project** is the result of this collaborative development, documentation, and testing. Most projects have a central repository where code, documentation, testing, and so forth are developed.
|
||||
|
||||
An open sourceis the result of this collaborative development, documentation, and testing. Most projects have a central repository where code, documentation, testing, and so forth are developed.
|
||||
|
||||
A **distribution** is a copy, in binary or source code format, of an open source project. For example, CentOS, Fedora, Red Hat Enterprise Linux, SUSE, Ubuntu, and others are distributions of the Linux project. Tectonic, Google Kubernetes Engine, Amazon Container Service, and Red Hat OpenShift are distributions of the Kubernetes project.
|
||||
|
||||
Vendor distributions of open source projects are often called **products** , thus Red Hat OpenStack Platform is the Red Hat OpenStack product that is a distribution of the OpenStack upstream project—and it is still 100% open source.
|
||||
|
||||
The **trunk** is the main workstream in the community where the open source project is developed.
|
||||
|
||||
An open source **fork** is a version of the open source project that is developed along a separate workstream from the main trunk.
|
||||
|
||||
Thus, **a distribution is not the same as a fork**. A distribution is a packaging of the upstream project that is made available by vendors, often as products. However, the core code and documentation in the distribution adhere to the version in the upstream project. A fork—and any distribution based on the fork—results in a version of the code and documentation that are different from the upstream project. Users who have forked upstream open source code have to maintain it on their own, meaning they lose the benefit of the collaboration that takes place in the upstream community.
|
||||
|
||||
To further explain a software fork, let's use the analogy of migrating animals. Whales and sea lions migrate from the Arctic to California and Mexico; Monarch butterflies migrate from Alaska to Mexico; and (in the Northern Hemisphere) swallows and many other birds fly south for the winter. The key to a successful migration is that all animals in the group stick together, follow the leaders, find food and shelter, and don't get lost.
|
||||
|
||||
### Risks of going it on your own
|
||||
|
||||
A bird, butterfly, or whale that strays from the group loses the benefit of remaining with the group and knowing where to find food, shelter, and the desired destination.
|
||||
|
||||
Similarly, users or organizations that fork and modify an upstream project and maintain it on their own run the following risks:
|
||||
|
||||
1. **They cannot update their code based on the upstream because their code differs.** This is known as technical debt; the more changes made to forked code, the more it costs in time and money to rebase the fork to the upstream project.
|
||||
2. **They potentially run less secure code.** If a vulnerability is found in open source code and fixed by the community in the upstream, a forked version of the code may not benefit from this fix because it is different from the upstream.
|
||||
3. **They might not benefit from new features.** The upstream community, using input from many organizations and individuals, creates new features for the benefit of all users of the upstream project. If an organization forks the upstream, they potentially cannot incorporate the new features because their code differs.
|
||||
4. **They might not integrate with other software packages.** Open source projects are rarely developed as single entities; rather they often are packaged together with other projects to create a solution. Forked code may not be able to be integrated with other projects because the developers of the forked code are not collaborating in the upstream with other participants.
|
||||
5. **They might not certify on hardware platforms.** Software packages are often certified to run on hardware platforms so, if problems arise, the hardware and software vendors can collaborate to find the root cause or problem.
|
||||
|
||||
|
||||
|
||||
In summary, an open source distribution is simply a packaging of an upstream, multi-organizational, collaborative open source project sold and supported by a vendor. A fork is a separate development workstream of an open source project and risks not being able to benefit from the collaborative efforts of the upstream community.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/forks-vs-distributions
|
||||
|
||||
作者:[Jonathan Gershater][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jgershat
|
||||
[1]:https://opensource.com/resources/what-open-source
|
||||
[2]:https://opensource.com/tags/licensing
|
||||
[3]:https://www.eclipse.org/che/getting-started/download/
|
||||
[4]:https://access.redhat.com/downloads
|
||||
[5]:https://www.freetype.org/
|
||||
[6]:http://openhub.net
|
||||
[7]:https://www.openhub.net/explore/orgs
|
||||
@ -0,0 +1,64 @@
|
||||
Open Source Certification: Preparing for the Exam
|
||||
======
|
||||
Open source is the new normal in tech today, with open components and platforms driving mission-critical processes at organizations everywhere. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening, making it ever more difficult to hire people][1] with much needed job skills. That’s why open source training and certification are more important than ever, and this series aims to help you learn more and achieve your own certification goals.
|
||||
|
||||
In the [first article in the series][2], we explored why certification matters so much today. In the [second article][3], we looked at the kinds of certifications that are making a difference. This story will focus on preparing for exams, what to expect during an exam, and how testing for open source certification differs from traditional types of testing.
|
||||
|
||||
Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, stated, “For many of you, if you take the exam, it may well be the first time that you've taken a performance-based exam and it is quite different from what you might have been used to with multiple choice, where the answer is on screen and you can identify it. In performance-based exams, you get what's called a prompt.”
|
||||
|
||||
As a matter of fact, many Linux-focused certification exams literally prompt test takers at the command line. The idea is to demonstrate skills in real time in a live environment, and the best preparation for this kind of exam is practice, backed by training.
|
||||
|
||||
### Know the requirements
|
||||
|
||||
"Get some training," Seepersad emphasized. "Get some help to make sure that you're going to do well. We sometimes find folks have very deep skills in certain areas, but then they're light in other areas. If you go to the website for [Linux Foundation training and certification][4], for the [LFCS][5] and the [LFCE][6] certifications, you can scroll down the page and see the details of the domains and tasks, which represent the knowledge areas you're supposed to know.”
|
||||
|
||||
Once you’ve identified the skills you need, “really spend some time on those and try to identify whether you think there are areas where you have gaps. You can figure out what the right training or practice regimen is going to be to help you get prepared to take the exam," Seepersad said.
|
||||
|
||||
### Practice, practice, practice
|
||||
|
||||
"Practice is important, of course, for all exams," he added. "We deliver the exams in a bit of a unique way -- through your browser. We're using a terminal emulator on your browser and you're being proctored, so there's a live human who is watching you via video cam, your screen is being recorded, and you're having to work through the exam console using the browser window. You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task"
|
||||
|
||||
What if you run out of time on your exam, or simply don’t pass because you couldn’t perform the required skills? “I like the phrase, exam insurance,” Seepersad said. “The way we take the stress out is by offering a ‘no questions asked’ retake. If you take either exam, LFCS, LFCE and you do not pass on your first attempt, you are automatically eligible to have a free second attempt.”
|
||||
|
||||
The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
|
||||
|
||||
### Free certification guide
|
||||
|
||||
Becoming a Linux Foundation Certified System Administrator or Engineer is no small feat, so the Foundation has created [this free certification guide][7] to help you with your preparation. In this guide, you’ll find:
|
||||
|
||||
* Critical things to keep in mind on test day
|
||||
|
||||
|
||||
* An array of both free and paid study resources to help you be as prepared as possible
|
||||
|
||||
* A few tips and tricks that could make the difference at exam time
|
||||
|
||||
* A checklist of all the domains and competencies covered in the exam
|
||||
|
||||
|
||||
|
||||
|
||||
With certification playing a more important role in securing a rewarding long-term career, careful planning and preparation are key. Stay tuned for the next article in this series that will answer frequently asked questions pertaining to open source certification and training.
|
||||
|
||||
[Learn more about Linux training and certification.][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/sysadmin-cert/2018/7/open-source-certification-preparing-exam
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/blog/os-jobs-report/2017/9/demand-open-source-skills-rise
|
||||
[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
|
||||
[3]:https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
|
||||
[4]:https://training.linuxfoundation.org/
|
||||
[5]:https://training.linuxfoundation.org/certification/linux-foundation-certified-sysadmin-lfcs/
|
||||
[6]:https://training.linuxfoundation.org/certification/linux-foundation-certified-engineer-lfce/
|
||||
[7]:https://training.linuxfoundation.org/download-free-certification-prep-guide
|
||||
[8]:https://training.linuxfoundation.org/certification/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user