diff --git a/.gitignore b/.gitignore
index 7b56441580..b5bb51a97a 100644
--- a/.gitignore
+++ b/.gitignore
@@ -3,3 +3,5 @@ members.md
*.html
*.bak
.DS_Store
+sources/*/.*
+translated/*/.*
\ No newline at end of file
diff --git a/published/201703/20170223 How to install Arch Linux on VirtualBox.md b/published/201703/20170223 How to install Arch Linux on VirtualBox.md
index 58a094b048..cdd68a0642 100644
--- a/published/201703/20170223 How to install Arch Linux on VirtualBox.md
+++ b/published/201703/20170223 How to install Arch Linux on VirtualBox.md
@@ -104,10 +104,10 @@ Arch Linux 也因其丰富的 Wiki 帮助文档而大受推崇。该系统基于
][23]
输入下面的命令来检查网络连接。
-
+
```
ping google.com
-```
+```
这个单词 ping 表示网路封包搜寻。你将会看到下面的返回信息,表明 Arch Linux 已经连接到外网了。这是执行安装过程中的很关键的一点。(LCTT 译注:或许你 ping 不到那个不存在的网站,你选个存在的吧。)
@@ -117,8 +117,8 @@ ping google.com
输入如下命令清屏:
-```
-clear
+```
+clear
```
在开始安装之前,你得先为硬盘分区。输入 `fdisk -l` ,你将会看到当前系统的磁盘分区情况。注意一开始你给 Arch Linux 系统分配的 20 GB 存储空间。
@@ -137,8 +137,8 @@ clear
输入下面的命令:
-```
-cfdisk
+```
+cfdisk
```
你将看到 `gpt`、`dos`、`sgi` 和 `sun` 类型,选择 `dos` 选项,然后按回车。
@@ -185,8 +185,8 @@ cfdisk
以同样的方式创建逻辑分区。在“退出(quit)”选项按回车键,然后输入下面的命令来清屏:
-```
-clear
+```
+clear
```
[
@@ -195,21 +195,21 @@ clear
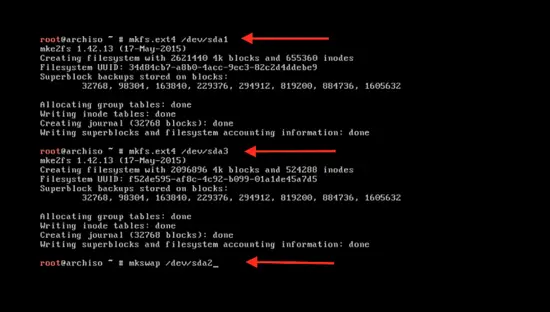
输入下面的命令来格式化新建的分区:
-```
+```
mkfs.ext4 /dev/sda1
-```
+```
这里的 `sda1` 是分区名。使用同样的命令来格式化第二个分区 `sda3` :
-```
+```
mkfs.ext4 /dev/sda3
-```
+```
格式化 swap 分区:
-```
+```
mkswap /dev/sda2
-```
+```
[
@@ -217,14 +217,14 @@ mkswap /dev/sda2
使用下面的命令来激活 swap 分区:
-```
-swapon /dev/sda2
+```
+swapon /dev/sda2
```
输入 clear 命令清屏:
-```
-clear
+```
+clear
```
[
@@ -233,9 +233,9 @@ clear
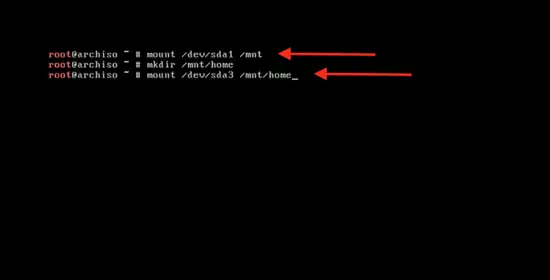
输入下面的命令来挂载主分区以开始系统安装:
-```
-mount /dev/sda1 / mnt
-```
+```
+mount /dev/sda1 /mnt
+```
[
@@ -245,9 +245,9 @@ mount /dev/sda1 / mnt
输入下面的命令来引导系统启动:
-```
+```
pacstrap /mnt base base-devel
-```
+```
可以看到系统正在同步数据包。
@@ -263,9 +263,9 @@ pacstrap /mnt base base-devel
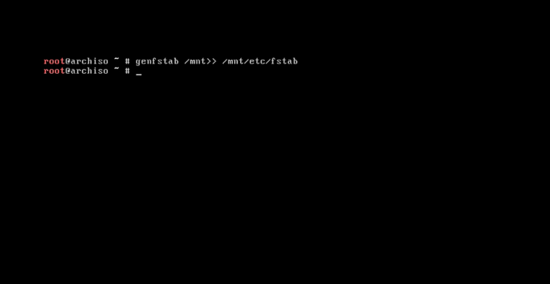
系统基本软件安装完成后,输入下面的命令来创建 fstab 文件:
-```
+```
genfstab /mnt>> /mnt/etc/fstab
-```
+```
[
@@ -275,14 +275,14 @@ genfstab /mnt>> /mnt/etc/fstab
输入下面的命令来更改系统的根目录为 Arch Linux 的安装目录:
-```
+```
arch-chroot /mnt /bin/bash
-```
+```
现在来更改语言配置:
-```
-nano /etc/local.gen
+```
+nano /etc/locale.gen
```
[
@@ -297,9 +297,9 @@ nano /etc/local.gen
输入下面的命令来激活它:
-```
+```
locale-gen
-```
+```
按回车。
@@ -309,8 +309,8 @@ locale-gen
使用下面的命令来创建 `/etc/locale.conf` 配置文件:
-```
-nano /etc/locale.conf
+```
+nano /etc/locale.conf
```
然后按回车。现在你就可以在配置文件中输入下面一行内容来为系统添加语言:
@@ -326,9 +326,9 @@ LANG=en_US.UTF-8
][44]
输入下面的命令来同步时区:
-
+
```
-ls user/share/zoneinfo
+ls /usr/share/zoneinfo
```
下面你将看到整个世界的时区列表。
@@ -339,9 +339,9 @@ ls user/share/zoneinfo
输入下面的命令来选择你所在的时区:
-```
+```
ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
-```
+```
或者你可以从下面的列表中选择其它名称。
@@ -351,8 +351,8 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
使用下面的命令来设置标准时间:
-```
-hwclock --systohc –utc
+```
+hwclock --systohc --utc
```
硬件时钟已同步。
@@ -363,8 +363,8 @@ hwclock --systohc –utc
设置 root 帐号密码:
-```
-passwd
+```
+passwd
```
按回车。 然而输入你想设置的密码,按回车确认。
@@ -377,9 +377,9 @@ passwd
使用下面的命令来设置主机名:
-```
+```
nano /etc/hostname
-```
+```
然后按回车。输入你想设置的主机名称,按 `control + x` ,按 `y` ,再按回车 。
@@ -389,9 +389,9 @@ nano /etc/hostname
启用 dhcpcd :
-```
+```
systemctl enable dhcpcd
-```
+```
这样在下一次系统启动时, dhcpcd 将会自动启动,并自动获取一个 IP 地址:
@@ -403,9 +403,9 @@ systemctl enable dhcpcd
最后一步,输入以下命令来初始化 grub 安装。输入以下命令:
-```
+```
pacman –S grub os-rober
-```
+```
然后按 `y` ,将会下载相关程序。
@@ -415,14 +415,14 @@ pacman –S grub os-rober
使用下面的命令来将启动加载程序安装到硬盘上:
-```
+```
grub-install /dev/sda
-```
+```
然后进行配置:
-```
-grub-mkconfig -o /boot/grub/grub.cfg
+```
+grub-mkconfig -o /boot/grub/grub.cfg
```
[
@@ -431,9 +431,9 @@ grub-mkconfig -o /boot/grub/grub.cfg
最后重启系统:
-```
+```
reboot
-```
+```
然后按回车 。
@@ -459,7 +459,7 @@ reboot
via: https://www.howtoforge.com/tutorial/install-arch-linux-on-virtualbox/
-译者简介:
+译者简介:
rusking:春城初春/春水初生/春林初盛/春風十裏不如妳
diff --git a/published/20180107 7 leadership rules for the DevOps age.md b/published/20180107 7 leadership rules for the DevOps age.md
new file mode 100644
index 0000000000..884aa54eaa
--- /dev/null
+++ b/published/20180107 7 leadership rules for the DevOps age.md
@@ -0,0 +1,125 @@
+DevOps 时代的 7 个领导力准则
+======
+
+> DevOps 是一种持续性的改变和提高:那么也准备改变你所珍视的领导力准则吧。
+
+
+
+如果 [DevOps] 最终更多的是一种文化而非某种技术或者平台,那么请记住:它没有终点线。而是一种持续性的改变和提高——而且最高管理层并不及格。
+
+然而,如果期望 DevOps 能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]。让我们考虑 7 个在 DevOps 时代更有效的 IT 领导的想法。
+
+### 1、 向失败说“是的”
+
+“失败”这个词在 IT 领域中一直包含着非常具体的意义,而且通常是糟糕的意思:服务器失败、备份失败、硬盘驱动器失败——你的印象就是如此。
+
+然而一个健康的 DevOps 文化取决于如何重新定义失败——IT 领导者应该在他们的字典里重新定义这个单词,使这个词的含义和“机会”对等起来。
+
+“在 DevOps 之前,我们曾有一种惩罚失败者的文化,”[Datical][3] 的首席技术官兼联合创始人罗伯特·里夫斯说,“我们学到的仅仅是去避免错误。在 IT 领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
+
+那是一个旧时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞实际上是失败。
+
+“那些缓慢的发布周期并逃避云的公司被恐惧所麻痹——他们将会走向失败,”里夫斯说道。“IT 领导者必须拥抱失败,并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从别人的错误中学习。开放和[安全心理][4]的文化促进学习和提高。”
+
+**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义][5]]**
+
+### 2、 在管理层渗透开发运营的理念
+
+尽管 DevOps 文化可以在各个方向有机的发展,那些正在从单体、孤立的 IT 实践中转变出来的公司,以及可能遭遇逆风的公司——需要高管层的全面支持。如果缺少了它,你就会传达模糊的信息,而且可能会鼓励那些宁愿被推着走的人,但这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到高管层完全投入进去并且知道改变已经实际发生了。
+
+“高层管理必须全力支持 DevOps,才能成功的实现收益”,来自 [Rainforest QA][7] 的首席信息官德里克·蔡说道。
+
+成为一个 DevOps 商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
+
+“没有高层管理的统一赞助支持,DevOps 的实施将很难成功,”德里克说道,“因此,在转变到 DevOps 之前在高层中保持一致是很重要的。”
+
+### 3、 不要只是声明 “DevOps”——要明确它
+
+即使 IT 公司也已经开始张开双臂拥抱 DevOps,也可能不是每个人都在同一个步调上。
+
+**[参考我们的相关文章,[3 阐明了DevOps和首席技术官们必须在同一进程上][8]]**
+
+造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
+
+“DevOps 对不同的人可能意味着不同的含义,”德里克解释道,“对高管层和副总裁层来说,要执行明确的 DevOps 的目标,清楚地声明期望的成果,充分理解带来的成果将如何使公司的商业受益,并且能够衡量和报告成功的过程。”
+
+事实上,在基线定义和远景之外,DevOps 要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT 领导者必须将它设置为优先。
+
+“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道,“领导者们需要清楚的将这个过程向公司的其他人阐述清楚,告诉他们他们作为这个过程的一份子能够期待的结果。”
+
+### 4、 DevOps 对于商业和技术同样重要
+
+IT 领导者们成功的将 DevOps 商店的这种文化和实践当做一项商业策略,以及构建和运营软件的方法。DevOps 是将 IT 从支持部门转向战略部门的推动力。
+
+IT 领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且 DevOps 的文化能够通过自动化和强大的协作加速这些成果,来自 [CYBRIC][9] 的首席技术官和联合创始人迈克·凯尔说道。
+
+事实上,这是一个强烈的趋势,贯穿这些新“规则”,在 DevOps 时代走在前沿。
+
+“促进创新并且鼓励团队成员去聪明的冒险是 DevOps 文化的一个关键部分,IT 领导者们需要在一个持续的基础上清楚的和他们交流”,凯尔说道。
+
+“一个高效的 IT 领导者需要比以往任何时候都要积极的参与到业务中去,”来自 [West Monroe Partners][10] 的性能服务部门的主任埃文说道,“每年或季度回顾的日子一去不复返了——[你需要欢迎每两周一次的挤压整理][11],你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
+
+### 5、 改变妨碍 DevOps 目标的任何事情
+
+虽然 DevOps 的老兵们普遍认为 DevOps 更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个 DevOps 商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用了 20 年的引擎,每次转动钥匙都会冒烟。
+
+展览 A: [自动化][12]。这是 DevOps 成功的重要并行策略。
+
+“IT 领导者需要重点强调自动化,”卡伦德说,“这将是 DevOps 的前期投资,但是如果没有它,DevOps 将会很容易被低效吞噬,而且将会无法完整交付。”
+
+自动化是基石,但改变不止于此。
+
+“领导者们需要推动自动化、监控和持续交付过程。这意着对现有的实践、过程、团队架构以及规则的很多改变,” 德里克说。“领导者们需要改变一切会阻碍团队去实现完全自动化的因素。”
+
+### 6、 重新思考团队架构和能力指标
+
+当你想改变时……如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
+
+“在这个 DevOps 的新时代文化中,IT 执行者需要采取一个全新的方法来组织架构。”凯尔说,“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织、敏捷管理。”
+
+凯尔告诉我们在 DevOps 时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
+
+“根据业务成果和总体的积极影响来衡量主动性,”凯尔建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
+
+注意很容易收集的到测量值不是 DevOps 真正的指标,[Red Hat] 的技术专家戈登·哈夫写到,“DevOps 应该把指标以某种形式和商业成果绑定在一起”,他指出,“你可能并不真正在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
+
+### 7、 丢弃传统的智慧
+
+如果 DevOps 时代要求关于 IT 领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
+
+“说实话,是全部”,凯尔说道,“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到 DevOps 文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
+
+事实上,IT 领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
+
+West Monroe Partners 的卡伦德分享了一个阻碍 DevOps 的领导力的例子:未能拥抱 IT 混合模型和现代的基础架构比如说容器和微服务。
+
+“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
+
+**领导者们,想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15]。**
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
+
+作者:[Kevin Casey][a]
+译者:[FelixYFZ](https://github.com/FelixYFZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/kevin-casey
+[1]:https://enterprisersproject.com/tags/devops
+[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
+[3]:https://www.datical.com/
+[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
+[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
+[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
+[7]:https://www.rainforestqa.com/
+[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
+[9]:https://www.cybric.io/
+[10]:http://www.westmonroepartners.com/
+[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
+[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
+[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
+[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
+[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
diff --git a/translated/tech/20180306 How to apply Machine Learning to IoT using Android Things and TensorFlow.md b/published/20180306 How to apply Machine Learning to IoT using Android Things and TensorFlow.md
similarity index 79%
rename from translated/tech/20180306 How to apply Machine Learning to IoT using Android Things and TensorFlow.md
rename to published/20180306 How to apply Machine Learning to IoT using Android Things and TensorFlow.md
index 6905e64f39..7b3e113546 100644
--- a/translated/tech/20180306 How to apply Machine Learning to IoT using Android Things and TensorFlow.md
+++ b/published/20180306 How to apply Machine Learning to IoT using Android Things and TensorFlow.md
@@ -1,30 +1,32 @@
如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习
-============================================================
+=============================
+
+
+
+> 探索如何将 Android Things 与 Tensorflow 集成起来,以及如何应用机器学习到物联网系统上。学习如何在装有 Android Things 的树莓派上使用 Tensorflow 进行图片分类。
这个项目探索了如何将机器学习应用到物联网上。具体来说,物联网平台我们将使用 **Android Things**,而机器学习引擎我们将使用 **Google TensorFlow**。
-
+现如今,Android Things 处于名为 Android Things 1.0 的稳定版本,已经可以用在生产系统中了。如你可能已经知道的,树莓派是一个可以支持 Android Things 1.0 做开发和原型设计的平台。本教程将使用 Android Things 1.0 和树莓派,当然,你可以无需修改代码就能换到其它所支持的平台上。这个教程是关于如何将机器学习应用到物联网的,这个物联网平台就是 Android Things Raspberry Pi。
-现如今,机器学习是物联网上使用的最热门的主题之一。给机器学习的最简单的定义,可能就是 [维基百科上的定义][13]:机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
+物联网上的机器学习是最热门的话题之一。要给机器学习一个最简单的定义,可能就是 [维基百科上的定义][13]:
-换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中一个前景看好的领域就是如何在物联网上应用机器学习,构建专业的系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。
+> 机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
-这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个感兴趣的领域,它们是:
+换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中前景最看好的领域之一就是如何在物联网上应用机器学习,构建专家系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。在深入了解 Android Things 的细节之前,你应该先将其安装在你的设备上。如果你是第一次使用 Android Things,你可以阅读一下这篇[如何在你的设备上安装 Android Things][14] 的教程。
+
+这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个有趣的领域,它们是:
* 在工业物联网(IIoT)中的预见性维护
-
* 消费物联网中,机器学习可以让设备更智能,它通过调整使设备更适应我们的习惯
-在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
+在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)并控制其道路方向的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
这个机器学习和物联网项目包含如下的主题:
* 如何使用 Docker 配置 TensorFlow 环境
-
* 如何训练 TensorFlow 系统
-
* 如何使用 Android Things 去集成 TensorFlow
-
* 如何使用 TensorFlow 的成果去控制无人驾驶汽车
这个项目起源于 [Android Things TensorFlow 图像分类器][6]。
@@ -33,59 +35,55 @@
### 如何使用 Tensorflow 图像识别
-在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要快速找到并且准备去使用一些东西,因此,我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
+在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要找到一些快速而能用的东西,以便我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
-1. 克隆 TensorFlow 仓库:
- ```
- git clone https://github.com/tensorflow/tensorflow.git
- cd /tensorflow
- git checkout v1.5.0
- ```
+1、 克隆 TensorFlow 仓库:
-2. 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
+```
+git clone https://github.com/tensorflow/tensorflow.git
+cd /tensorflow
+git checkout v1.5.0
+```
-3. 运行 Docker:
- ```
- docker run -it \
- --volume /tf-data:/tf-data \
- --volume /tensorflow:/tensorflow \
- --workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
- ```
+2、 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
- 使用这个命令,我们运行一个交互式 TensorFlow 环境,可以在使用项目期间挂载一些目录。
+3、 运行 Docker:
+
+```
+docker run -it \
+--volume /tf-data:/tf-data \
+--volume /tensorflow:/tensorflow \
+--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
+```
+
+使用这个命令,我们运行一个交互式 TensorFlow 环境,可以挂载一些在使用项目期间使用的目录。
### 如何训练 TensorFlow 去识别图像
在 Android Things 系统能够识别图像之前,我们需要去训练 TensorFlow 引擎,以使它能够构建它的模型。为此,我们需要去收集一些图像。正如前面所言,我们需要使用箭头来控制 Android Things 无人驾驶汽车,因此,我们至少要收集四种类型的箭头:
* 向上的箭头
-
* 向下的箭头
-
* 向左的箭头
-
* 向右的箭头
为训练这个系统,需要使用这四类不同的图像去创建一个“知识库”。在 `/tf-data` 目录下创建一个名为 `images` 的目录,然后在它下面创建如下名字的四个子目录:
-* up-arrow
-
-* down-arrow
-
-* left-arrow
-
-* right-arrow
+* `up-arrow`
+* `down-arrow`
+* `left-arrow`
+* `right-arrow`
现在,我们去找图片。我使用的是 Google 图片搜索,你也可以使用其它的方法。为了简化图片下载过程,你可以安装一个 Chrome 下载插件,这样你只需要点击就可以下载选定的图片。别忘了多下载一些图片,这样训练效果更好,当然,这样创建模型的时间也会相应增加。
**扩展阅读**
-[如何使用 API 去集成 Android Things][2]
-[如何与 Firebase 一起使用 Android Things][3]
+
+- [如何使用 API 去集成 Android Things][2]
+- [如何与 Firebase 一起使用 Android Things][3]
打开浏览器,开始去查找四种箭头的图片:

-[Save][7]
每个类别我下载了 80 张图片。不用管图片文件的扩展名。
@@ -102,9 +100,8 @@ python /tensorflow/examples/image_retraining/retrain.py \
这个过程你需要耐心等待,它需要花费很长时间。结束之后,你将在 `/tf-data` 目录下发现如下的两个文件:
-1. retrained_graph.pb
-
-2. retrained_labels.txt
+1. `retrained_graph.pb`
+2. `retrained_labels.txt`
第一个文件包含了 TensorFlow 训练过程产生的结果模型,而第二个文件包含了我们的四个图片类相关的标签。
@@ -139,7 +136,6 @@ python /tensorflow/python/tools/optimize_for_inference.py \
TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将 Android Things 与 TensorFlow 集成到一起。为此,我们将这个任务分为两步来完成:
1. 硬件部分,我们将把电机和其它部件连接到 Android Things 开发板上
-
2. 实现这个应用程序
### Android Things 示意图
@@ -147,13 +143,9 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
在深入到如何连接外围部件之前,先列出在这个 Android Things 项目中使用到的组件清单:
1. Android Things 开发板(树莓派 3)
-
2. 树莓派摄像头
-
3. 一个 LED 灯
-
4. LN298N 双 H 桥电机驱动模块(连接控制电机)
-
5. 一个带两个轮子的无人驾驶汽车底盘
我不再重复 [如何使用 Android Things 去控制电机][9] 了,因为在以前的文章中已经讲过了。
@@ -161,12 +153,10 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
下面是示意图:

-[Save][10]
上图中没有展示摄像头。最终成果如下图:

-[Save][11]
### 使用 TensorFlow 实现 Android Things 应用程序
@@ -175,11 +165,8 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
这个 Android Things 应用程序与原始的应用程序是不一样的,因为:
1. 它不使用按钮去开启摄像头图像捕获
-
2. 它使用了不同的模型
-
3. 它使用一个闪烁的 LED 灯来提示,摄像头将在 LED 停止闪烁后拍照
-
4. 当 TensorFlow 检测到图像时(箭头)它将控制电机。此外,在第 3 步的循环开始之前,它将打开电机 5 秒钟。
为了让 LED 闪烁,使用如下的代码:
@@ -264,7 +251,7 @@ public void onImageAvailable(ImageReader reader) {
在这个方法中,当 TensorFlow 返回捕获的图片匹配到的可能的标签之后,应用程序将比较这个结果与可能的方向,并因此来控制电机。
-最后,将去使用前面创建的模型了。拷贝 _assets_ 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
+最后,将去使用前面创建的模型了。拷贝 `assets` 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
打开 `Helper.java` 并修改如下的行:
@@ -289,9 +276,9 @@ public static final String OUTPUT_NAME = "final_result";
via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html
-作者:[Francesco Azzola ][a]
+作者:[Francesco Azzola][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -309,3 +296,4 @@ via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-usi
[11]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Integrating%20Android%20Things%20with%20TensorFlow
[12]:https://github.com/androidthings/sample-tensorflow-imageclassifier
[13]:https://en.wikipedia.org/wiki/Machine_learning
+[14]:https://www.survivingwithandroid.com/2017/01/android-things-android-internet-of-things.html
\ No newline at end of file
diff --git a/published/20180627 CIP- Keeping the Lights On with Linux.md b/published/20180627 CIP- Keeping the Lights On with Linux.md
new file mode 100644
index 0000000000..739fba2da0
--- /dev/null
+++ b/published/20180627 CIP- Keeping the Lights On with Linux.md
@@ -0,0 +1,55 @@
+CIP:延续 Linux 之光
+======
+
+> CIP 的目标是创建一个基本的系统,使用开源软件来为我们现代社会的基础设施提供动力。
+
+
+
+
+现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
+
+并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,[民用基础设施平台][1](CIP)最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
+
+担任 CIP 的技术指导委员会主席的 Yoshitake Kobayashi 说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都面临同样的问题,即能够长时间地使用 Linux。”
+
+CIP 的架构是创建一个非常基础的系统,以在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
+
+### 合作
+
+由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP 聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings 以他在 Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
+
+在新的合作下,CIP 将使用 Debian LTS 版本作为构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的互操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
+
+Debian 项目负责人 Chris Lamb 表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
+
+### 安全性
+
+Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),但也存在其他风险。
+
+仅仅是系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
+
+因此,至关重要的是保持运行在这些控制器上的所有软件是最新的并且完全修补的。为了确保安全性,CIP 还向后移植了内核自我保护(KSP)项目的许多组件。CIP 还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
+
+### 展望未来
+
+随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP 最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
+
+Cybertrust 与其他行业领军者合作,如西门子、东芝、Codethink、日立、Moxa、Plat'Home 和瑞萨,致力于为未来数十年打造一个可靠、安全的基于 Linux 的嵌入式软件平台。
+
+这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
+
+想要了解更多信息,请访问 [民用基础设施官网][1]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
+
+作者:[Swapnil Bhartiya][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/arnieswap
+[1]:https://www.cip-project.org/
diff --git a/published/20141127 Keeping (financial) score with Ledger .md b/published/201807/20141127 Keeping (financial) score with Ledger .md
similarity index 100%
rename from published/20141127 Keeping (financial) score with Ledger .md
rename to published/201807/20141127 Keeping (financial) score with Ledger .md
diff --git a/published/20170309 How To Record Everything You Do In Terminal.md b/published/201807/20170309 How To Record Everything You Do In Terminal.md
similarity index 100%
rename from published/20170309 How To Record Everything You Do In Terminal.md
rename to published/201807/20170309 How To Record Everything You Do In Terminal.md
diff --git a/translated/tech/20170404 Kernel Tracing with Ftrace.md b/published/201807/20170404 Kernel Tracing with Ftrace.md
similarity index 75%
rename from translated/tech/20170404 Kernel Tracing with Ftrace.md
rename to published/201807/20170404 Kernel Tracing with Ftrace.md
index 6ed3a87bf9..6c209d4e0d 100644
--- a/translated/tech/20170404 Kernel Tracing with Ftrace.md
+++ b/published/201807/20170404 Kernel Tracing with Ftrace.md
@@ -1,49 +1,45 @@
-使用 Ftrace 跟踪内核
+使用 ftrace 跟踪内核
============================================================
-标签: [ftrace][8],[kernel][9],[kernel profiling][10],[kernel tracing][11],[linux][12],[tracepoints][13]
-

-在内核级别上分析事件有很多的工具:[SystemTap][14],[ktap][15],[Sysdig][16],[LTTNG][17]等等,并且你也可以在网络上找到关于这些工具的大量介绍文章和资料。
+在内核层面上分析事件有很多的工具:[SystemTap][14]、[ktap][15]、[Sysdig][16]、[LTTNG][17] 等等,你也可以在网络上找到关于这些工具的大量介绍文章和资料。
而对于使用 Linux 原生机制去跟踪系统事件以及检索/分析故障信息的方面的资料却很少找的到。这就是 [ftrace][18],它是添加到内核中的第一款跟踪工具,今天我们来看一下它都能做什么,让我们从它的一些重要术语开始吧。
### 内核跟踪和分析
-内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 一个事件的总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
+内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 这是一个事件总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
-瓶颈经常发生在无法通过分析来识别的情况下。去推断出为什么会发生事件,去保存发生事件时的相关上下文,这就需要去跟踪。
+瓶颈经常发生在无法通过分析来识别的情况下。要推断出为什么会发生事件,就必须保存发生事件时的相关上下文,这就需要去跟踪。
-跟踪可以理解为在一个正常工作的系统上活动的信息收集进程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种注册的系统事件。
+跟踪可以理解为在一个正常工作的系统上活动的信息收集过程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种系统事件。
跟踪程序能够同时跟踪应用级和操作系统级的事件。它们收集的信息能够用于诊断多种系统问题。
有时候会将跟踪与日志比较。它们两者确时很相似,但是也有不同的地方。
-对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登陆系统、应用程序错误、数据库事务等等。
+对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登录系统、应用程序错误、数据库事务等等。
就像日志一样,跟踪数据可以被原样读取,但是用特定的应用程序提取的信息更有用。所有的跟踪程序都能这样做。
在内核跟踪和分析方面,Linux 内核有三个主要的机制:
-* 跟踪点 —— 一种基于静态测试代码的工作机制
-
-* 探针 —— 一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回。
-
-* perf_events —— 一个访问 PMU(性能监视单元)的接口
+* 跟踪点:一种基于静态测试代码的工作机制
+* 探针:一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回
+* perf_events —— 一个访问 PMU(性能监视单元)的接口
我并不想在这里写关于这些机制方面的内容,任何对它们感兴趣的人可以去访问 [Brendan Gregg 的博客][19]。
使用 ftrace,我们可以与这些机制进行交互,并可以从用户空间直接得到调试信息。下面我们将讨论这方面的详细内容。示例中的所有命令行都是在内核版本为 3.13.0-24 的 Ubuntu 14.04 中运行的。
-### Ftrace:常用信息
+### ftrace:常用信息
-Ftrace 是函数 Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
+ftrace 是 Function Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
-Ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 `Ring` 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
+ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 Ring 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
-Ftrace 工作在 debugfs 文件系统上,这是在大多数现代 Linux 分发版中默认挂载的文件系统。为开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
+ftrace 工作在 debugfs 文件系统上,在大多数现代 Linux 发行版中都默认挂载了。要开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
```
# cd /sys/kernel/debug/tracing
@@ -70,16 +66,13 @@ kprobe_profile stack_max_size uprobe_profile
我不想去描述这些文件和子目录;它们的描述在 [官方文档][20] 中已经写的很详细了。我只想去详细介绍与我们这篇文章相关的这几个文件:
* available_tracers —— 可用的跟踪程序
-
* current_tracer —— 正在运行的跟踪程序
-
-* tracing_on —— 负责启用或禁用数据写入到 `Ring` 缓冲区的系统文件(如果启用它,在文件中添加数字 1,禁用它,添加数字 0)
-
+* tracing_on —— 负责启用或禁用数据写入到 Ring 缓冲区的系统文件(如果启用它,数字 1 被添加到文件中,禁用它,数字 0 被添加)
* trace —— 以人类友好格式保存跟踪数据的文件
### 可用的跟踪程序
-我们可以使用如下的命令去查看可用的跟踪程序的一个列表
+我们可以使用如下的命令去查看可用的跟踪程序的一个列表:
```
root@andrei:/sys/kernel/debug/tracing#: cat available_tracers
@@ -89,18 +82,14 @@ blk mmiotrace function_graph wakeup_rt wakeup function nop
我们来快速浏览一下每个跟踪程序的特性:
* function —— 一个无需参数的函数调用跟踪程序
-
* function_graph —— 一个使用子调用的函数调用跟踪程序
-
-* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 的用途)
-
+* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 使用的)
* mmiotrace —— 一个内存映射 I/O 操作跟踪程序
-
-* nop —— 简化的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
+* nop —— 最简单的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
### 函数跟踪程序
-在开始介绍函数跟踪程序 ftrace 之前,我们先看一下测试脚本:
+在开始介绍函数跟踪程序 ftrace 之前,我们先看一个测试脚本:
```
#!/bin/sh
@@ -117,7 +106,7 @@ less ${dir}/trace
这个脚本是非常简单的,但是还有几个需要注意的地方。命令 `sysctl ftrace.enabled=1` 启用了函数跟踪程序。然后我们通过写它的名字到 `current_tracer` 文件来启用 `current tracer`。
-接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 `Ring` 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
+接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 Ring 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo 1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
我们为什么这样做呢?在两个 `echo` 命令之间,我们看到了命令 `sleep 1`。我们启用了缓冲区,运行了这个命令,然后禁用它。这将使跟踪程序采集了这个命令运行期间发生的所有系统调用的信息。
@@ -156,21 +145,18 @@ less ${dir}/trace
trace.sh-1295 [000] d... 90.502879: __acct_update_integrals <-acct_account_cputime
```
-这个输出以缓冲区中的信息条目数量和写入的条目数量开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
+这个输出以“缓冲区中的信息条目数量”和“写入的全部条目数量”开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
在这里有一个包含下列信息的函数列表:
* 进程标识符(PID)
-
* 运行这个进程的 CPU(CPU#)
-
* 进程开始时间(TIMESTAMP)
-
* 被跟踪函数的名字以及调用它的父级函数;例如,在我们输出的第一行,`rb_simple_write` 调用了 `mutex-unlock` 函数。
-### Function_graph 跟踪程序
+### function_graph 跟踪程序
-`function_graph` 跟踪程序的工作和函数一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
+function_graph 跟踪程序的工作和函数跟踪程序一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
我们来编辑一下最后一个示例的脚本:
@@ -215,11 +201,11 @@ less ${dir}/trace
0) ! 208.154 us | } /* ip_local_deliver_finish */
```
-在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(+)意思是这个函数花费的时间超过 10 毫秒;而感叹号(!)意思是这个函数花费的时间超过了 100 毫秒。
+在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(`+`)意思是这个函数花费的时间超过 10 毫秒;而感叹号(`!`)意思是这个函数花费的时间超过了 100 毫秒。
在 `FUNCTION_CALLS` 下面,我们可以看到每个函数调用的信息。
-和 C 语言一样使用了花括号({)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(;)标记。
+和 C 语言一样使用了花括号(`{`)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(`;`)标记。
### 函数过滤器
@@ -249,13 +235,13 @@ ftrace 还有很多过滤选项。对于它们更详细的介绍,你可以去
### 跟踪事件
-我们在上面提到到跟踪点机制。跟踪点是插入的由系统事件触发的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
+我们在上面提到到跟踪点机制。跟踪点是插入的触发系统事件的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
-静态跟踪点不会对系统有任何影响;它们只是增加几个字节用于调用测试函数以及在一个独立的节上增加一个数据结构。
+静态跟踪点不会对系统有任何影响;它们只是在测试的函数末尾增加几个字节的函数调用以及在一个独立的节上增加一个数据结构。
-当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 `Ring` 缓冲区。
+当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 Ring 缓冲区。
-跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(它在 [这里][22]):
+跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(取自 [这里][22]):
```
{
@@ -294,7 +280,7 @@ fs kvm power scsi vfs
ftrace kvmmmu printk signal vmscan
```
-所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 `Ring` 缓冲区写入:
+所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 Ring 缓冲区写入:
```
root@andrei:/sys/kernel/debug/tracing# cat tracing_on
@@ -306,25 +292,25 @@ root@andrei:/sys/kernel/debug/tracing# cat tracing_on
root@andrei:/sys/kernel/debug/tracing# echo 1 > tracing_on
```
-在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。为了跟踪,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
+在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。对于我们的跟踪程序,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
```
root@andrei:/sys/kernel/debug/tracing# echo nop > current_tracer
```
-所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出多个系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
+所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出各种系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
```
root@andrei:/sys/kernel/debug/tracing# echo 1 > events/syscalls/sys_enter_chroot/enable
```
-然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息出现在输出中:
+然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [之前这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息不会出现在输出中:
```
root@andrei:/sys/kernel/debug/tracing# echo 0 > tracing_on
```
-然后,我们去查看 `Ring` 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
+然后,我们去查看 Ring 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
```
root@andrei:/sys/kernel/debug/tracing# сat trace
@@ -343,15 +329,10 @@ root@andrei:/sys/kernel/debug/tracing# сat trace
在这篇文篇中,我们做了一个 ftrace 的功能概述。我们非常感谢你的任何意见或者补充。如果你想深入研究这个主题,我们为你推荐下列的资源:
* [https://www.kernel.org/doc/Documentation/trace/tracepoints.txt][1] — 一个跟踪点机制的详细描述
-
* [https://www.kernel.org/doc/Documentation/trace/events.txt][2] — 在 Linux 中跟踪系统事件的指南
-
* [https://www.kernel.org/doc/Documentation/trace/ftrace.txt][3] — ftrace 的官方文档
-
* [https://lttng.org/files/thesis/desnoyers-dissertation-2009-12-v27.pdf][4] — Mathieu Desnoyers(作者是跟踪点和 LTTNG 的创建者)的关于内核跟踪和分析的学术论文。
-
* [https://lwn.net/Articles/370423/][5] — Steven Rostedt 的关于 ftrace 功能的文章
-
* [http://alex.dzyoba.com/linux/profiling-ftrace.html][6] — 用 ftrace 分析实际案例的一个概述
--------------------------------------------------------------------------------
@@ -360,7 +341,7 @@ via:https://blog.selectel.com/kernel-tracing-ftrace/
作者:[Andrej Yemelianov][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201807/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md b/published/201807/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md
new file mode 100644
index 0000000000..07b851caf2
--- /dev/null
+++ b/published/201807/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md
@@ -0,0 +1,129 @@
+Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具
+======
+
+
+
+
+**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
+
+ * 安装、删除、更新包
+ * 更新和升级软件源
+ * 安装主线内核
+ * 删除旧的和不再使用的内核
+ * 系统整体更新
+ * 将系统升级到下一个可用的版本
+ * 将系统升级到最新的开发版本
+ * 清理系统垃圾文件
+ * 在不输入密码的情况下启用或者禁用 `sudo` 权限
+ * 当你在终端输入密码时使 `sudo` 密码可见
+ * 启用或禁用系统休眠
+ * 启用或禁用防火墙
+ * 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
+ * 显示或者隐藏启动项
+ * 启用或禁用登录音效
+ * 配置双启动
+ * 启用或禁用锁屏
+ * 智能系统更新
+ * 使用脚本管理器更新/一次性执行脚本
+ * 从 `git` 执行常规用户安装脚本
+ * 检查系统完整性和缺失的 GPG 密钥
+ * 修复网络
+ * 修复已破损的包
+ * 还有更多功能在开发中
+
+**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
+
+### 安装 Ubunsys
+
+Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
+
+逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
+
+```
+sudo add-apt-repository ppa:adgellida/ubunsys
+sudo apt-get update
+sudo apt-get install ubunsys
+```
+
+如果 PPA 无法使用,你可以在[发布页面][1]根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
+
+### 用途
+
+一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。
+
+![][3]
+
+你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
+
+**Packages**
+
+这一部分允许你安装、删除和更新包。
+
+![][4]
+
+**Tweaks**
+
+在这一部分,我们可以对系统进行多种调整,例如:
+
+ * 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
+ * 配置双启动;
+ * 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
+ * 在终端中输入密码时可见(禁用星号)。
+
+![][5]
+
+**System**
+
+这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
+
+**Normal user** 这一标签下的选项可以:
+
+ * 更新、升级包和软件源
+ * 清理系统
+ * 执行常规用户安装脚本
+
+**Advanced user** 这一标签下的选项可以:
+
+* 清理旧的/无用的内核
+* 安装主线内核
+* 智能包更新
+* 升级系统
+
+**Developer** 这一部分可以将系统升级到最新的开发版本。
+
+![][6]
+
+**Repair**
+
+这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。
+
+![][7]
+
+正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
+
+谢谢阅读!
+
+### 参考资源
+
+- [Ubunsys GitHub Repository][8]
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[wenwensnow](https://github.com/wenwensnow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://github.com/adgellida/ubunsys/releases
+[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
+[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
+[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
+[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
+[8]:https://github.com/adgellida/ubunsys
\ No newline at end of file
diff --git a/published/201807/20171003 Streams a new general purpose data structure in Redis.md b/published/201807/20171003 Streams a new general purpose data structure in Redis.md
new file mode 100644
index 0000000000..92933058bb
--- /dev/null
+++ b/published/201807/20171003 Streams a new general purpose data structure in Redis.md
@@ -0,0 +1,183 @@
+Streams:一个新的 Redis 通用数据结构
+======
+
+直到几个月以前,对于我来说,在消息传递的环境中,流只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理][1]) ,也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
+
+然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis 列表、有序集、发布/订阅功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
+
+有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
+
+列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
+
+对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
+
+我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
+
+### 起源
+
+在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
+
+ \ 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
+ \ 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
+
+他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
+
+当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在对数时间内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka 消费组的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
+
+### 让我们写一些代码吧
+
+从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
+
+结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性向后移植到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
+
+### 教程:欢迎使用 Redis 的 streams
+
+在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个字段和值组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以阻塞等待比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
+
+```
+> XADD mystream * sensor-id 1234 temperature 10.5
+1506871964177.0
+```
+
+这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到从服务器和 AOF 文件。
+
+这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
+
+正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
+
+```
+> MULTI
+OK
+> XADD mystream * foo 10
+QUEUED
+> XADD mystream * bar 20
+QUEUED
+> EXEC
+1) 1506872463535.0
+2) 1506872463535.1
+```
+
+在上面的示例中,也展示了无需指定任何初始模式的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
+
+为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;流播,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
+
+```
+> XRANGE mystream 1506871964177.0 1506871964177.0
+1) 1) 1506871964177.0
+ 2) 1) "sensor-id"
+ 2) "1234"
+ 3) "temperature"
+ 4) "10.5"
+```
+
+不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
+
+```
+> XRANGE mystream - + COUNT 2
+1) 1) 1506871964177.0
+ 2) 1) "sensor-id"
+ 2) "1234"
+ 3) "temperature"
+ 4) "10.5"
+2) 1) 1506872463535.0
+ 2) 1) "foo"
+ 2) "10"
+```
+
+这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
+
+```
+127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
+1) 1) 1506872463535.0
+ 2) 1) "foo"
+ 2) "10"
+2) 1) 1506872463535.1
+ 2) 1) "bar"
+ 2) "20"
+```
+
+关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
+
+### 使用 XREAD 处理流播:阻塞新的数据
+
+当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的汇聚池。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
+
+`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
+
+这里有一个典型的 `XREAD` 调用示例:
+
+```
+> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
+```
+
+它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
+
+如果我从另一个客户端发送这样的命令:
+
+```
+> XADD otherstream * message “Hi There”
+```
+
+在 `XREAD` 侧会出现什么情况呢?
+
+```
+1) 1) "otherstream"
+ 2) 1) 1) 1506935385635.0
+ 2) 1) "message"
+ 2) "Hi There"
+```
+
+与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
+
+```
+> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
+```
+
+依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
+
+### 流封顶
+
+目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
+
+```
+> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
+```
+
+它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
+
+```
+> XADD mystream MAXLEN ~ 1000000 * foo bar
+```
+
+这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
+
+### 消费组(开发中)
+
+这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP ` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
+
+当指定组时,能够指定一个 `RETRY ` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
+
+### 内存使用和节省加载时间
+
+因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
+
+我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
+
+### 关于最终发布时间的结论
+
+Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
+
+如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
+
+---
+
+via: http://antirez.com/news/114
+
+作者:[antirez][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://antirez.com/
+[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
diff --git a/translated/tech/20171024 Learn Blockchains by Building One.md b/published/201807/20171024 Learn Blockchains by Building One.md
similarity index 70%
rename from translated/tech/20171024 Learn Blockchains by Building One.md
rename to published/201807/20171024 Learn Blockchains by Building One.md
index 23135eeec9..acbcaed1de 100644
--- a/translated/tech/20171024 Learn Blockchains by Building One.md
+++ b/published/201807/20171024 Learn Blockchains by Building One.md
@@ -1,40 +1,41 @@
-通过构建一个区块链来学习区块链技术
+想学习区块链?那就用 Python 构建一个
======
+> 了解区块链是如何工作的最快的方法是构建一个。
+

-你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
+
+你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
-我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
+我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
### 开始之前 …
-记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
+记住,区块链是一个 _不可更改的、有序的_ 记录(被称为区块)的链。它们可以包括交易、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
如果你不知道哈希是什么,[这里有解释][1]。
- **_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
+ **_本指南的目标读者是谁?_** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
```
- pip install Flask==0.12.2 requests==2.18.4
+pip install Flask==0.12.2 requests==2.18.4
```
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
-* * *
-
### 第 1 步:构建一个区块链
-打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
+打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码][6]。
#### 描述一个区块链
-我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
+我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
```
class Blockchain(object):
@@ -58,15 +59,16 @@ class Blockchain(object):
@property
def last_block(self):
# Returns the last Block in the chain
-pass
+ pass
```
+*我们的 Blockchain 类的原型*
-我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
+我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
-#### 一个区块是什么样子的?
+#### 区块是什么样子的?
-每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
+每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
单个区块的示例应该是下面的样子:
@@ -86,13 +88,15 @@ block = {
}
```
-此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
+*我们的区块链中的块示例*
-这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
+此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
-#### 添加事务到一个区块
+*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
-我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
+#### 添加交易到一个区块
+
+我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
```
class Blockchain(object):
@@ -113,14 +117,14 @@ class Blockchain(object):
'amount': amount,
})
-return self.last_block['index'] + 1
+ return self.last_block['index'] + 1
```
-在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
+在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
#### 创建新区块
-当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
+当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
@@ -190,18 +194,18 @@ class Blockchain(object):
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
block_string = json.dumps(block, sort_keys=True).encode()
-return hashlib.sha256(block_string).hexdigest()
+ return hashlib.sha256(block_string).hexdigest()
```
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
#### 理解工作量证明
-一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
+工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
我们来看一个非常简单的示例来帮助你了解它。
-我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
+我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
```
from hashlib import sha256
@@ -215,19 +219,21 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
print(f'The solution is y = {y}')
```
-在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
+在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
```
hash(5 * 21) = 1253e9373e...5e3600155e860
```
+在比特币中,工作量证明算法被称之为 [Hashcash][10]。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
+
网络上的任何人都可以很容易地去核验它的答案。
#### 实现基本的 PoW
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
-> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
+> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
```
import hashlib
@@ -266,25 +272,21 @@ class Blockchain(object):
guess = f'{last_proof}{proof}'.encode()
guess_hash = hashlib.sha256(guess).hexdigest()
-return guess_hash[:4] == "0000"
+ return guess_hash[:4] == "0000"
```
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
-* * *
-
### 第 2 步:以 API 方式去访问我们的区块链
-我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
+我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
我们将创建三个方法:
-* `/transactions/new` 在一个区块上创建一个新事务
-
+* `/transactions/new` 在一个区块上创建一个新交易
* `/mine` 告诉我们的服务器去挖矿一个新区块
-
* `/chain` 返回完整的区块链
#### 配置 Flask
@@ -332,33 +334,33 @@ def full_chain():
return jsonify(response), 200
if __name__ == '__main__':
-app.run(host='0.0.0.0', port=5000)
+ app.run(host='0.0.0.0', port=5000)
```
对上面的代码,我们做添加一些详细的解释:
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
-
* Line 18:为我们的节点创建一个随机的名字。
-
* Line 21:实例化我们的区块链类。
-
-* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
-
-* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
-
-* Line 32–38:创建 /chain 端点,它返回全部区块链。
-
+* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
+* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
+* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
* Line 40–41:在 5000 端口上运行服务器。
-#### 事务端点
+#### 交易端点
-这就是对一个事务的请求,它是用户发送给服务器的:
+这就是对一个交易的请求,它是用户发送给服务器的:
```
-{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
+{
+ "sender": "my address",
+ "recipient": "someone else's address",
+ "amount": 5
+}
```
+因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
+
```
import hashlib
import json
@@ -383,18 +385,17 @@ def new_transaction():
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
response = {'message': f'Transaction will be added to Block {index}'}
-return jsonify(response), 201
+ return jsonify(response), 201
```
-创建事务的方法
+
+*创建交易的方法*
#### 挖矿端点
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
1. 计算工作量证明
-
-2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
-
+2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
3. 通过将它添加到链上而打造一个新区块
```
@@ -434,10 +435,10 @@ def mine():
'proof': block['proof'],
'previous_hash': block['previous_hash'],
}
-return jsonify(response), 200
+ return jsonify(response), 200
```
-注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
+注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
### 第 3 步:与我们的区块链去交互
@@ -447,24 +448,33 @@ return jsonify(response), 200
```
$ python blockchain.py
+* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
```
-我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
+我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:
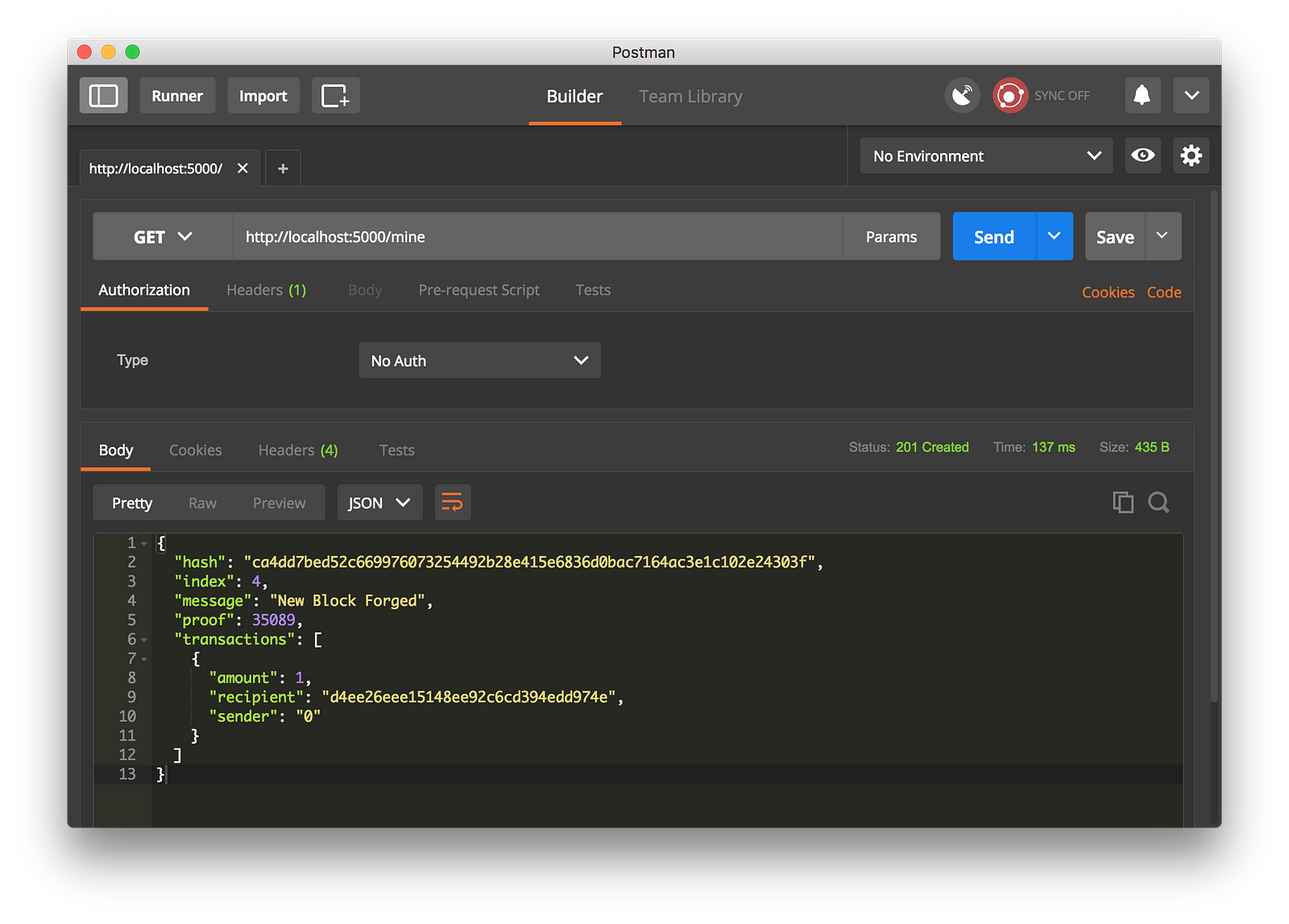
-使用 Postman 去生成一个 GET 请求
-我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
+*使用 Postman 去生成一个 GET 请求*
+
+我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:
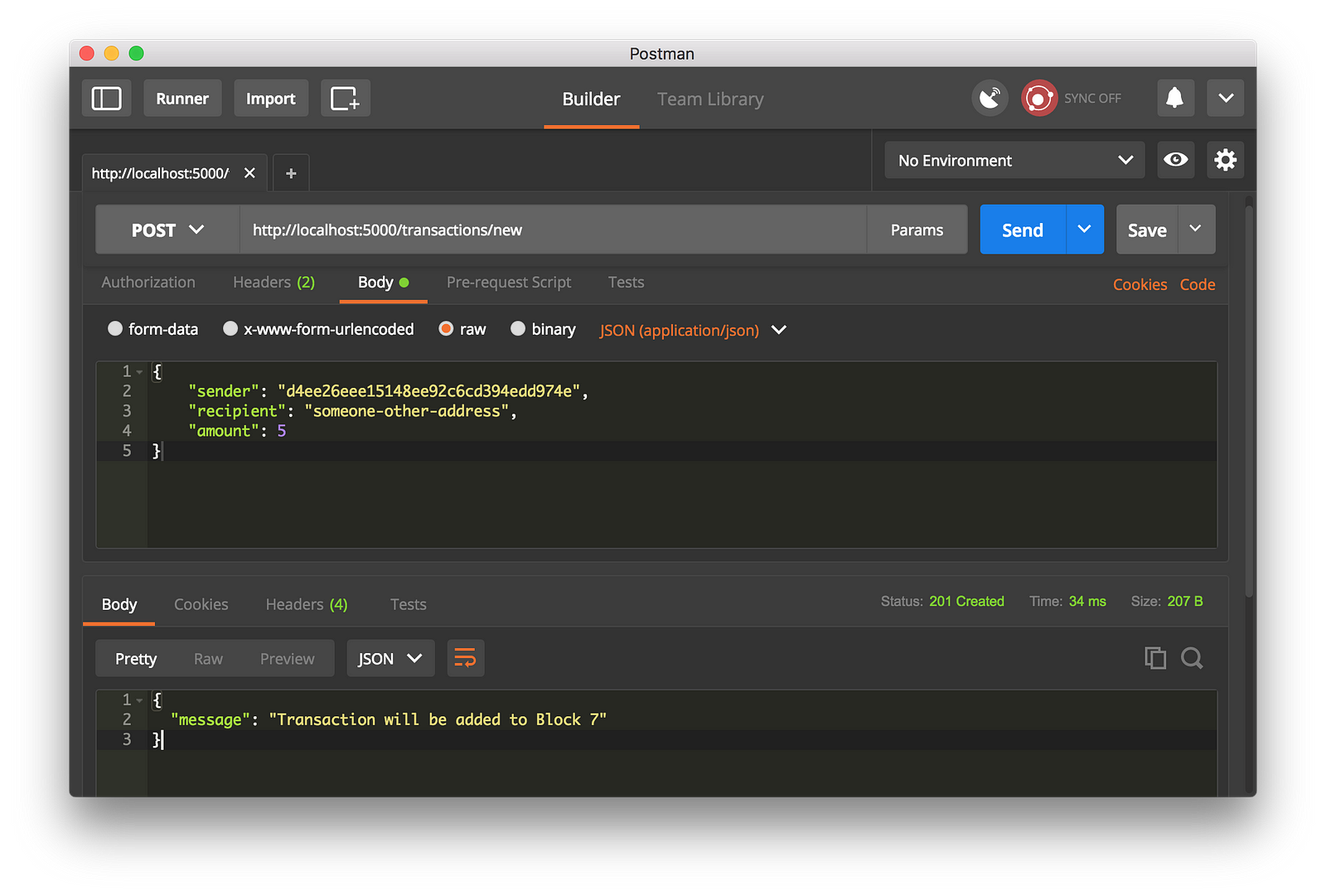
-使用 Postman 去生成一个 POST 请求
+
+*使用 Postman 去生成一个 POST 请求*
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
```
-$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
+$ curl -X POST -H "Content-Type: application/json" -d '{
+ "sender": "d4ee26eee15148ee92c6cd394edd974e",
+ "recipient": "someone-other-address",
+ "amount": 5
+}' "http://localhost:5000/transactions/new"
```
-我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
+
+我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
+
```
{
"chain": [
@@ -503,18 +513,18 @@ $ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee151
}
],
"length": 3
+}
```
### 第 4 步:共识
-这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
+这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
#### 注册新节点
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
-1. /nodes/register 以 URLs 的形式去接受一个新节点列表
-
-2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
+1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
+2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
@@ -538,11 +548,12 @@ class Blockchain(object):
"""
parsed_url = urlparse(address)
-self.nodes.add(parsed_url.netloc)
+ self.nodes.add(parsed_url.netloc)
```
-一个添加邻居节点到我们的网络的方法
-注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
+*一个添加邻居节点到我们的网络的方法*
+
+注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
#### 实现共识算法
@@ -615,12 +626,12 @@ class Blockchain(object)
self.chain = new_chain
return True
-return False
+ return False
```
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
-`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
+`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
@@ -658,18 +669,20 @@ def consensus():
'chain': blockchain.chain
}
-return jsonify(response), 200
+ return jsonify(response), 200
```
-这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
+这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。
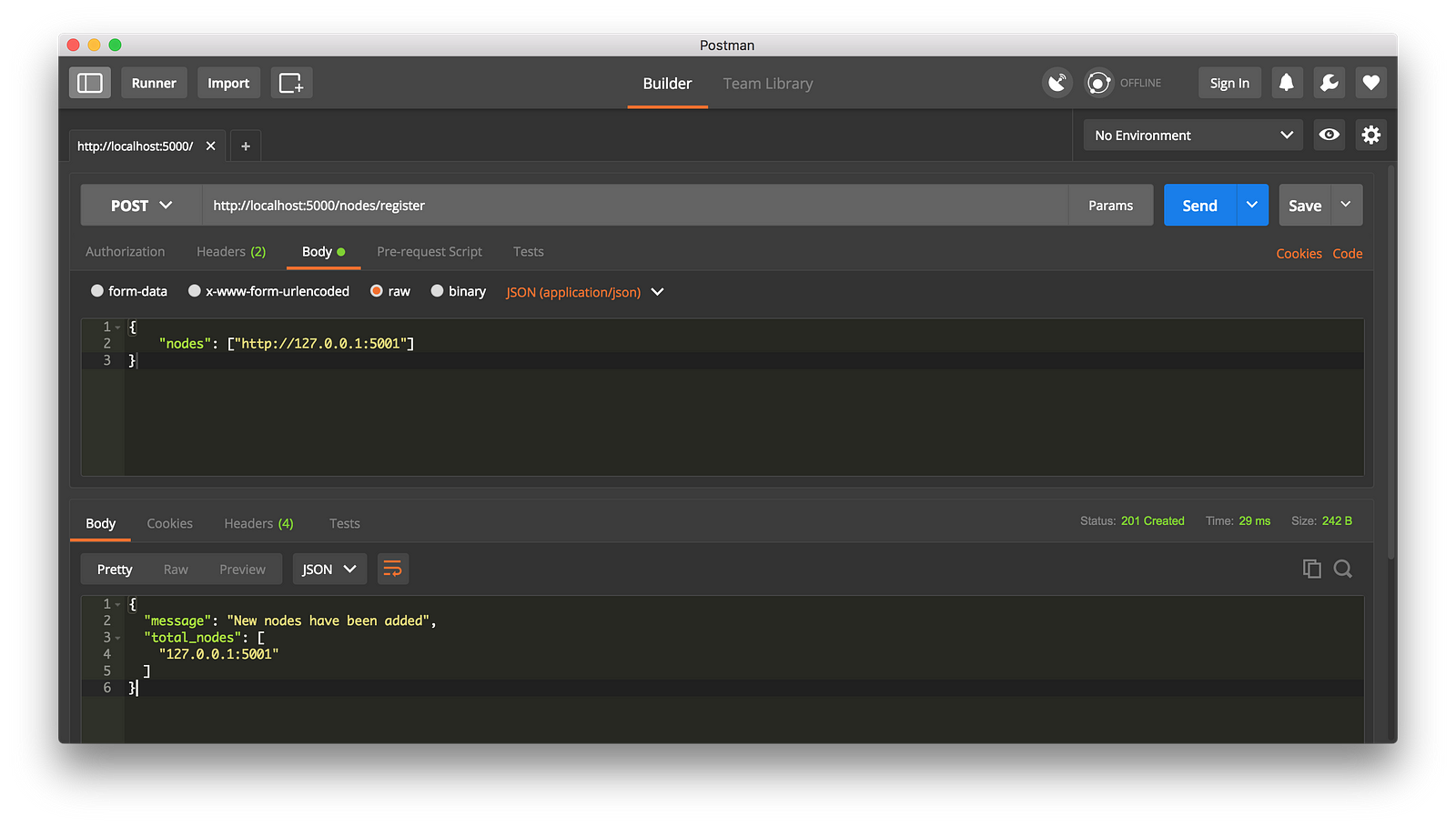
-注册一个新节点
+
+*注册一个新节点*
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
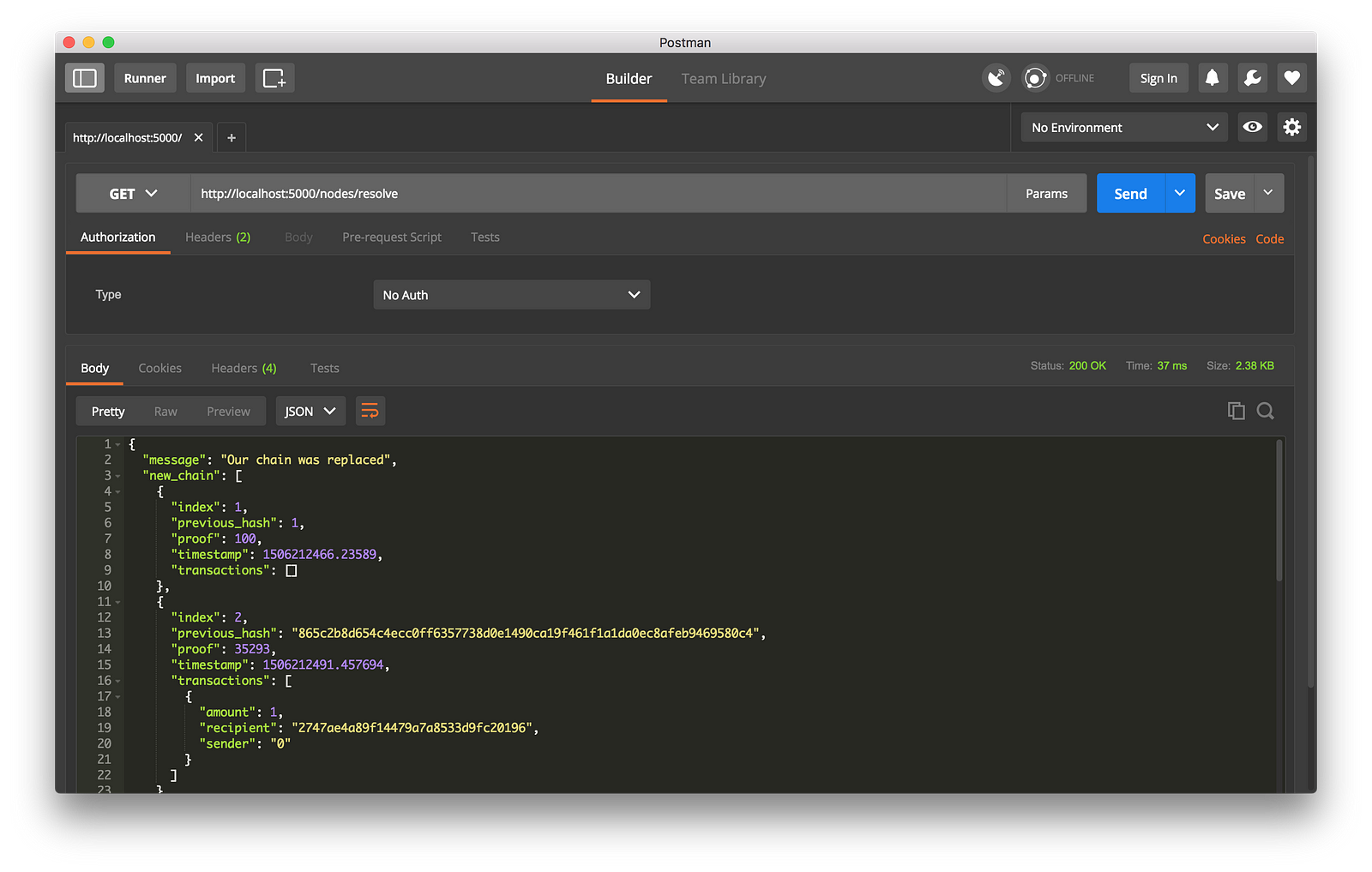
-工作中的共识算法
+
+*工作中的共识算法*
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
@@ -677,7 +690,7 @@ return jsonify(response), 200
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
-**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
+**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
--------------------------------------------------------------------------------
@@ -685,7 +698,7 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
作者:[Daniel van Flymen][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -699,3 +712,4 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
[8]:http://localhost:5000/transactions/new
[9]:http://localhost:5000
+[10]:https://en.wikipedia.org/wiki/Hashcash
\ No newline at end of file
diff --git a/translated/tech/20171116 How to improve ROI on automation- 4 tips.md b/published/201807/20171116 How to improve ROI on automation- 4 tips.md
similarity index 87%
rename from translated/tech/20171116 How to improve ROI on automation- 4 tips.md
rename to published/201807/20171116 How to improve ROI on automation- 4 tips.md
index edce4dcdb2..2139c43c64 100644
--- a/translated/tech/20171116 How to improve ROI on automation- 4 tips.md
+++ b/published/201807/20171116 How to improve ROI on automation- 4 tips.md
@@ -1,12 +1,15 @@
如何提升自动化的 ROI:4 个小提示
======
+> 想要在你的自动化项目上达成强 RIO?采取如下步骤来规避失败。
+

-在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
-机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
+在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
-低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
+机器人流程自动化(RPA)似乎预示着运营的圣杯:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
+
+低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
@@ -14,7 +17,7 @@
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
-## 你是不是自动化了错误的东西?
+### 你是不是自动化了错误的东西?
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
@@ -26,7 +29,7 @@
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
-## 1. 教育团队
+### 1. 教育团队
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
@@ -36,23 +39,23 @@
“实施自动化的第一步是更好地理解你的流程。”
-## 2. 审查内部流程
+### 2. 审查内部流程
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
-这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
+这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
-## 3. 为优先业务提供强有力的指导
+### 3. 为优先业务提供强有力的指导
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
-## 4. 应该推动 CIO 和 COO 的紧密合作
+### 4. 应该推动 CIO 和 COO 的紧密合作
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
@@ -68,7 +71,7 @@ via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-
作者:[Rajesh Kamath][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20171228 Container Basics- Terms You Need to Know.md b/published/201807/20171228 Container Basics- Terms You Need to Know.md
similarity index 100%
rename from published/20171228 Container Basics- Terms You Need to Know.md
rename to published/201807/20171228 Container Basics- Terms You Need to Know.md
diff --git a/published/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md b/published/201807/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
similarity index 100%
rename from published/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
rename to published/201807/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
diff --git a/translated/tech/20180115 How debuggers really work.md b/published/201807/20180115 How debuggers really work.md
similarity index 85%
rename from translated/tech/20180115 How debuggers really work.md
rename to published/201807/20180115 How debuggers really work.md
index b4b5740fe1..e7f2772948 100644
--- a/translated/tech/20180115 How debuggers really work.md
+++ b/published/201807/20180115 How debuggers really work.md
@@ -1,13 +1,15 @@
调试器到底怎样工作
======
+> 你也许用过调速器检查过你的代码,但你知道它们是如何做到的吗?
+

供图:opensource.com
-调试器是那些大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器...使用 [Rust][2]!
+调试器是大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的那些软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器……使用 [Rust][2]!
-在本文中,术语调试器/跟踪器可以互换。 “被跟踪者”是指正在被跟踪者跟踪的进程。
+在本文中,术语调试器和跟踪器可以互换。 “被跟踪者”是指正在被跟踪器跟踪的进程。
### ptrace 系统调用
@@ -17,59 +19,46 @@
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
```
-这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是......我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
+这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是……我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
现在被跟踪者可以被调试器追踪,重要的变化发生了:
- * 每当一个信号被传送到被调试者时,它就会停止,并且一个可以被 `wait` 系列系统调用捕获的等待事件被传送给跟踪器。
+ * 每当一个信号被传送到被跟踪者时,它就会停止,并且一个可以被 `wait` 系列的系统调用捕获的等待事件被传送给跟踪器。
* 每个 `execve` 系统调用都会导致 `SIGTRAP` 被传递给被跟踪者。(与之前的项目相结合,这意味着被跟踪者在一个 `execve` 完全发生之前停止。)
这意味着,一旦我们发出 `PTRACE_TRACEME` 请求并调用 `execve` 系统调用来实际在被跟踪者(进程上下文)中启动程序时,被跟踪者将立即停止,因为 `execve` 会传递一个 `SIGTRAP`,并且会被跟踪器中的等待事件捕获。我们如何继续?正如人们所期望的那样,`ptrace` 有大量的请求可以用来告诉被跟踪者可以继续:
-
* `PTRACE_CONT`:这是最简单的。 被跟踪者运行,直到它接收到一个信号,此时等待事件被传递给跟踪器。这是最常见的实现真实世界调试器的“继续直至断点”和“永远继续”选项的方式。断点将在下面介绍。
* `PTRACE_SYSCALL`:与 `PTRACE_CONT` 非常相似,但在进入系统调用之前以及在系统调用返回到用户空间之前停止。它可以与其他请求(我们将在本文后面介绍)结合使用来监视和修改系统调用的参数或返回值。系统调用追踪程序 `strace` 很大程度上使用这个请求来获知进程发起了哪些系统调用。
* `PTRACE_SINGLESTEP`:这个很好理解。如果您之前使用过调试器(你会知道),此请求会执行下一条指令,然后立即停止。
-
-
我们可以通过各种各样的请求停止进程,但我们如何获得被调试者的状态?进程的状态大多是通过其寄存器捕获的,所以当然 `ptrace` 有一个请求来获得(或修改)寄存器:
* `PTRACE_GETREGS`:这个请求将给出被跟踪者刚刚被停止时的寄存器的状态。
- * `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值并使用 `PTRACE_SETREGS` 将寄存器设为新值。
+ * `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值,并使用 `PTRACE_SETREGS` 将寄存器设为新值。
* `PTRACE_PEEKUSER` 和 `PTRACE_POKEUSER`:这些允许从被跟踪者的 `USER` 区读取信息,这里保存了寄存器和其他有用的信息。 这可以用来修改单一寄存器,而避免使用更重的 `PTRACE_{GET,SET}REGS` 请求。
-
-
在调试器仅仅修改寄存器是不够的。调试器有时需要读取一部分内存,甚至对其进行修改。GDB 可以使用 `print` 得到一个内存位置或变量的值。`ptrace` 通过下面的方法实现这个功能:
* `PTRACE_PEEKTEXT` 和 `PTRACE_POKETEXT`:这些允许读取和写入被跟踪者地址空间中的一个字。当然,使用这个功能时被跟踪者要被暂停。
-
-
-真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑x86。
+真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑 x86。
### 体系结构的支持
`ptrace` 很酷,但它是如何工作? 在前面的部分中,我们已经看到 `ptrace` 跟信号有很大关系:`SIGTRAP` 可以在单步跟踪、`execve` 之前以及系统调用前后被传送。信号可以通过一些方式产生,但我们将研究两个具体的例子,以展示信号可以被调试器用来在给定的位置停止程序(有效地创建一个断点!):
-
* **未定义的指令**:当一个进程尝试执行一个未定义的指令,CPU 将产生一个异常。此异常通过 CPU 中断处理,内核中相应的中断处理程序被调用。这将导致一个 `SIGILL` 信号被发送给进程。 这依次导致进程被停止,跟踪器通过一个等待事件被通知,然后它可以决定后面做什么。在 x86 上,指令 `ud2` 被确保始终是未定义的。
-
* **调试中断**:前面的方法的问题是,`ud2` 指令需要占用两个字节的机器码。存在一条特殊的单字节指令能够触发一个中断,它是 `int $3`,机器码是 `0xCC`。 当该中断发出时,内核向进程发送一个 `SIGTRAP`,如前所述,跟踪器被通知。
-
-
-这很好,但如何做我们胁迫的被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
+这很好,但如何我们才能胁迫被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
好吧,我们已经讲过了断点,那观察点呢? 当一个特定的内存位置被读或写,调试器如何停止程序? 当然你不可能为了能够读或写内存而去把每一个指令都覆盖为 `int $3`。有一组调试寄存器为了更有效的满足这个目的而被设计出来:
-
* `DR0` 到 `DR3`:这些寄存器中的每个都包含一个地址(内存位置),调试器因为某种原因希望被跟踪者在那些地址那里停止。 其原因以掩码方式被设定在 `DR7` 寄存器中。
- * `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7`过时的别名。
+ * `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7` 过时的别名。
* `DR6`:调试状态。包含有关 `DR0` 到 `DR3` 中的哪个寄存器导致调试异常被引发的信息。这被 Linux 用来计算与 `SIGTRAP` 信号一起传递给被跟踪者的信息。
- * `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释DR0至DR3中指定的地址。位掩码控制监视点的尺寸(监视1,2,4或8个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
-
+ * `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释 `DR0` 至 `DR3` 中指定的地址。位掩码控制监视点的尺寸(监视1、2、4 或 8 个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
由于调试寄存器是进程的 `USER` 区域的一部分,调试器可以使用 `PTRACE_POKEUSER` 将值写入调试寄存器。调试寄存器只与特定进程相关,因此在进程抢占并重新获得 CPU 控制权之前,调试寄存器会被恢复。
@@ -88,7 +77,7 @@ via: https://opensource.com/article/18/1/how-debuggers-really-work
作者:[Levente Kurusa][a]
译者:[stephenxs](https://github.com/stephenxs)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201807/20180115 Why DevSecOps matters to IT leaders.md b/published/201807/20180115 Why DevSecOps matters to IT leaders.md
new file mode 100644
index 0000000000..3ca2d5d3ea
--- /dev/null
+++ b/published/201807/20180115 Why DevSecOps matters to IT leaders.md
@@ -0,0 +1,87 @@
+为什么 DevSecOps 对 IT 领导来说如此重要
+======
+
+> DevSecOps 也许不是一个优雅的词汇,但是其结果很吸引人:更强的安全、提前出现在开发周期中。来看看一个 IT 领导与 Meltdown 的拼搏。
+
+
+
+如果 [DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
+
+而到了术语 “DevSecOps”,就像任何其他 IT 术语一样,DevSecOps —— 一个更成熟的 DevOps 的后代 ——可能容易受到炒作和盗用。但这个术语对那些拥抱了 DevOps 文化的领导者们来说具有重要的意义,并且其实践和工具可以帮助他们实现其承诺。
+
+说道这里:“DevSecOps”是什么意思?
+
+“DevSecOps 是开发、安全、运营的混合,”来自 [Datical][2] 的首席技术官和联合创始人 Robert 说。“这提醒我们,对我们的应用程序来说安全和创建并部署应用到生产中一样重要。”
+
+**[想阅读其他首席技术官的 DevOps 文章吗?查阅我们丰富的资源,[DevOps:IT 领导者指南][3]]**
+
+向非技术人员解释 DevSecOps 的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
+
+“安全团队从历史上一直都被孤立于开发团队——每个团队在 IT 的不同领域都发展了很强的专业能力”,来自红帽安全策的专家 Kirsten 最近告诉我们。“不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个 CI/CD 管道中集成安全实践、工具和自动化来采用 DevSecOps。”
+
+“为了能够做的更好,他们正在整合他们的团队——专业的安全人员从开始设计到部署到生产中都融入到了开发团队中了,”她说,“双方都收获了价值——每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。 DevOps 做的很正确——或者说 DevSecOps——提高了 IT 的安全性。”
+
+IT 团队比任何以往都要求要快速频繁的交付服务。DevOps 在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
+
+“我们已经采用了 DevOps,因为它已经被证明通过移除开发和运营之间的阻碍来提高 IT 的绩效,”Reevess 说,“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
+
+### 为什么 DevSecOps 必然出现
+
+或许会把 DevSecOps 看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一层面的要素,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
+
+“DevSecOps 不只是一个时髦的术语——因为多种原因它是现在和未来 IT 将呈现的状态”,来自 [Sumo Logic] 的安全和合规副总裁 George 说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
+
+此外,DevSecOps 的出现可能是 DevOps 自身逐渐成熟并扎根于 IT 之中的一个征兆。
+
+“企业中的 DevOps 文化已成定局,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织会对合作和衡量的结果更加满意”,来自 [CYBRIC] 的首席技术官和联合创始人 Mike 说道。
+
+在实施 DevOps 的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
+
+“现在的手工的安全测试方法会继续远远被甩在后面。”
+
+“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动 DevSecOps 的文化是 IT 领导者们为增加整体的灵活性提供安全保证的唯一途径”,Kail 说。
+
+转移安全测试也使开发者受益:他们能够在开放的较早的阶段验证并解决潜在的问题——这样很少需要或者甚至不需要安全人员的介入,而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞。
+
+“做的正确,DevSecOps 能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全”,来自 [SAS][8] 的首席信息安全员 Wilson 说道。
+
+Wilson 指出静态(SAST)和源组合分析(SCA)工具,集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈来使之逐渐成为可能。
+
+“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。” Wilson 说。他同时指出 DevSecOps 能够帮助开发者简化更新和打补丁。
+
+DevSecOps 并不意味着你不再需要安全组的意见了,就如同 DevOps 并不意味着你不再需要基础架构专家;它只是帮助你减少在生产中发现缺陷的可能性,或者减少导致降低部署速度的阻碍,因为缺陷已经在开发周期中被发现解决了。
+
+“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson 说道。
+
+### DevSecOps 遇到 Meltdown
+
+Sumo Locic 的 Gerchow 向我们分享了一个在运转中的 DevSecOps 文化的一个及时案例:当最近 [Meltdown 和 Spectre] 的消息传来的时候,团队的 DevSecOps 方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow 所说的这点对原生云、高监管的公司来说特别的重要。
+
+第一步:Gerchow 的小型安全团队都具有一定的开发能力,能够通过 Slack 和它的主要云供应商协同工作来确保它的基础架构能够在 24 小时之内完成修复。
+
+“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开工单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过 Slack 的自动 jira 票据进行,通过我们的日志监控和分析解决方案”,Gerchow 解释道。
+
+在本质上,它听起来非常像 DevOps 文化,匹配正确的人员、过程和工具,但它明确的将安全作为文化中的一部分进行了混合。
+
+“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发、运维和安全三者是相互独立的”,Gerchow 说道,“通过一个 DevSecOps 的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。”
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
+
+作者:[Kevin Casey][a]
+译者:[FelixYFZ](https://github.com/FelixYFZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/kevin-casey
+[1]:https://enterprisersproject.com/tags/devops
+[2]:https://www.datical.com/
+[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
+[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
+[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
+[6]:https://www.sumologic.com/
+[7]:https://www.cybric.io/
+[8]:https://www.sas.com/en_us/home.html
+[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
diff --git a/translated/tech/20180126 Running a Python application on Kubernetes.md b/published/201807/20180126 Running a Python application on Kubernetes.md
similarity index 81%
rename from translated/tech/20180126 Running a Python application on Kubernetes.md
rename to published/201807/20180126 Running a Python application on Kubernetes.md
index 85ba815931..a6b709a22c 100644
--- a/translated/tech/20180126 Running a Python application on Kubernetes.md
+++ b/published/201807/20180126 Running a Python application on Kubernetes.md
@@ -1,28 +1,24 @@
在 Kubernetes 上运行一个 Python 应用程序
============================================================
-### 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
+> 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。

-图片来源:opensource.com
-Kubernetes 是一个具备部署、维护、和可伸缩特性的开源平台。它在提供可移植性、可扩展性、以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
+Kubernetes 是一个具备部署、维护和可伸缩特性的开源平台。它在提供可移植性、可扩展性以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
不论你的 Python 应用程序是简单还是复杂,Kubernetes 都可以帮你高效地部署和伸缩它们,在有限的资源范围内滚动升级新特性。
在本文中,我将描述在 Kubernetes 上部署一个简单的 Python 应用程序的过程,它包括:
* 创建 Python 容器镜像
-
* 发布容器镜像到镜像注册中心
-
* 使用持久卷
-
* 在 Kubernetes 上部署 Python 应用程序
### 必需条件
-你需要 Docker、kubectl、以及这个 [源代码][10]。
+你需要 Docker、`kubectl` 以及这个 [源代码][10]。
Docker 是一个构建和承载已发布的应用程序的开源平台。可以参照 [官方文档][11] 去安装 Docker。运行如下的命令去验证你的系统上运行的 Docker:
@@ -40,7 +36,7 @@ WARNING: No memory limit support
WARNING: No swap limit support
```
-kubectl 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 kubectl:
+`kubectl` 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 `kubectl`:
```
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
@@ -56,9 +52,9 @@ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s
### 创建一个 Python 容器镜像
-为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 `Docker file` 中的指令来自动化构建镜像。
+为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 Dockerfile 中的指令来自动化构建镜像。
-这是我们的 Python 应用程序的 `Docker file`:
+这是我们的 Python 应用程序的 Dockerfile:
```
FROM python:3.6
@@ -90,7 +86,7 @@ VOLUME ["/app-data"]
CMD ["python", "app.py"]
```
-这个 `Docker file` 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
+这个 Dockerfile 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
### 构建一个 Python Docker 镜像
@@ -128,45 +124,45 @@ Kubernetes 支持许多的持久存储提供商,包括 AWS EBS、CephFS、Glus
为使用 CephFS 存储 Kubernetes 的容器数据,我们将创建两个文件:
-persistent-volume.yml
+`persistent-volume.yml` :
```
apiVersion: v1
kind: PersistentVolume
metadata:
- name: app-disk1
- namespace: k8s_python_sample_code
+ name: app-disk1
+ namespace: k8s_python_sample_code
spec:
- capacity:
- storage: 50Gi
- accessModes:
- - ReadWriteMany
- cephfs:
- monitors:
- - "172.17.0.1:6789"
- user: admin
- secretRef:
- name: ceph-secret
- readOnly: false
+ capacity:
+ storage: 50Gi
+ accessModes:
+ - ReadWriteMany
+ cephfs:
+ monitors:
+ - "172.17.0.1:6789"
+ user: admin
+ secretRef:
+ name: ceph-secret
+ readOnly: false
```
-persistent_volume_claim.yaml
+`persistent_volume_claim.yaml`:
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
- name: appclaim1
- namespace: k8s_python_sample_code
+ name: appclaim1
+ namespace: k8s_python_sample_code
spec:
- accessModes:
- - ReadWriteMany
- resources:
- requests:
- storage: 10Gi
+ accessModes:
+ - ReadWriteMany
+ resources:
+ requests:
+ storage: 10Gi
```
-现在,我们将使用 kubectl 去添加持久卷并声明到 Kubernetes 集群中:
+现在,我们将使用 `kubectl` 去添加持久卷并声明到 Kubernetes 集群中:
```
$ kubectl create -f persistent-volume.yml
@@ -185,16 +181,16 @@ $ kubectl create -f persistent-volume-claim.yml
apiVersion: v1
kind: Service
metadata:
- labels:
- k8s-app: k8s_python_sample_code
- name: k8s_python_sample_code
- namespace: k8s_python_sample_code
+ labels:
+ k8s-app: k8s_python_sample_code
+ name: k8s_python_sample_code
+ namespace: k8s_python_sample_code
spec:
- type: NodePort
- ports:
- - port: 5035
- selector:
- k8s-app: k8s_python_sample_code
+ type: NodePort
+ ports:
+ - port: 5035
+ selector:
+ k8s-app: k8s_python_sample_code
```
使用下列的内容创建部署文件并将它命名为 `k8s_python_sample_code.deployment.yml`:
@@ -227,7 +223,7 @@ spec:
claimName: appclaim1
```
-最后,我们使用 kubectl 将应用程序部署到 Kubernetes:
+最后,我们使用 `kubectl` 将应用程序部署到 Kubernetes:
```
$ kubectl create -f k8s_python_sample_code.deployment.yml $ kubectl create -f k8s_python_sample_code.service.yml
@@ -248,15 +244,15 @@ kubectl get services
### 关于作者
- [][13] Joannah Nanjekye - Straight Outta 256 , 只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
+ [][13] Joannah Nanjekye - Straight Outta 256,只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
--------------------------------------------------------------------------------
via: https://opensource.com/article/18/1/running-python-application-kubernetes
-作者:[Joannah Nanjekye ][a]
+作者:[Joannah Nanjekye][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201807/20180128 Being open about data privacy.md b/published/201807/20180128 Being open about data privacy.md
new file mode 100644
index 0000000000..d927af148d
--- /dev/null
+++ b/published/201807/20180128 Being open about data privacy.md
@@ -0,0 +1,95 @@
+对数据隐私持开放的态度
+======
+
+> 尽管有包括 GDPR 在内的法规,数据隐私对于几乎所有的人来说都是很重要的事情。
+
+
+
+今天(LCTT 译注:本文发表于 2018/1/28)是[数据隐私日][1],(在欧洲叫“数据保护日”),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该是自由的,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
+
+1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些例子[3])
+2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
+
+所以实际上,数据隐私对于每个人来说是很重要的。
+
+事实证明,在美国和欧洲之间,人们和政府认为让组织使用哪些数据的出发点是有些不同的。前者通常为商业实体(特别是愤世嫉俗的人们会指出是大型的商业实体)利用他们所收集到的关于我们的数据提供了更多的自由度。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在 5 月 25 日,欧洲的观点可以说取得了胜利。
+
+### 通用数据保护条例(GDPR)的影响
+
+那是一个相当全面的声明,其实事实上这是 2016 年欧盟通过的一项称之为通用数据保护条例(GDPR)的立法的日期。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据——而且涉及的条目范围非常广泛,从你的姓名、家庭住址到你的医疗记录以及接通你电脑的 IP 地址。
+
+通用数据保护条例的重要之处是它并不仅仅适用于欧洲的公司,如果你是阿根廷人、日本人、美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
+
+“哼!” 你可能会这样说^注1 ,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简单:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你的全球总收入百分之四的惩罚。是的,你没听错,是全球总收入,而不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的 IT 团队,确保你的行为在相当短的时间内合规。
+
+看上去这和非欧盟公民没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是仅针对欧盟公民实施,这将会是一件很有利的事情。^注2
+
+然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好^注3 :事实并非如此,我们一直在丢弃关于我们自己的信息——而且允许公司去使用它。
+
+有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。你有付费使用 Facebook、推特、谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客——只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
+
+有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(例如,亚马逊正在努力让 Alexa 发广告),除非我们想要开始为这些所有的免费服务付费,我们需要清楚我们所放弃的,而且在我们暴露的和不想暴露的之间做一些选择。
+
+### 谁是顾客?
+
+关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门^注4 ——而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去挖掘这些数据。
+
+然而他们面临的是,随着数据的增长和存储量无法跟上该怎么办。幸运的是——而且我是带有讽刺意味的使用了这个词^注5 ,大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司^注6 的一个极具代表性的例子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
+
+不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售给第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方,以及在他们如何使用上能有发言权吗?我将把这个问题当做一个练习留给读者去思考。^注7
+
+### 开放和积极
+
+然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励各个部门免费开放大量他们的数据给公众或者其他组织。在某些情况下,这是专门立法的。许多志愿组织——尤其是那些接受公共资金的——正在开始这样做。甚至商业组织也有感兴趣的苗头。而且,有一些技术已经可行了,例如围绕不同的隐私和多方计算上,正在允许跨越多个数据集挖掘数据,而不用太多披露个人的信息——这个计算问题从未如现在比你想象的更容易。
+
+这些对我们来说意味着什么呢?我之前在网站 Opensource.com 上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件、组织,和这次讨论有关的,数据。让我们假设一下你是 A 公司要提向另一家公司客户 B^注8 提供一项服务 。在此有四种不同类型的数据:
+
+ 1. 数据完全开放:对 A 和 B 都是可得到的,世界上任何人都可以得到
+ 2. 数据是已知的、共享的,和机密的:A 和 B 可得到,但其他人不能得到
+ 3. 数据是公司级别上保密的:A 公司可以得到,但 B 顾客不能
+ 4. 数据是顾客级别保密的:B 顾客可以得到,但 A 公司不能
+
+首先,也许我们对数据应该更开放些,将数据默认放到选项 1 中。如果那些数据对所有人开放——在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的。^注9 如果我们能够找到方法将数据放到选项 2、3 和 4 中,不是很好吗?——或者至少它们中的一些——在选项 1 中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
+然而有很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
+
+### 一些具体的措施
+
+我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
+
+ * 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
+ * 要默认加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉——除非数据正在被处理使用,否则没有任何借口让数据清晰可见。
+ * 当你注册了一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
+ * 和你的非技术朋友讨论这个话题。
+ * 教育你的孩子、你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师谈谈在他们的学校中展示。
+ * 鼓励你所服务和志愿贡献的组织,或者和他们沟通一些推动数据的默认开放。不是去思考为什么我要使数据开放,而是从我为什么不让数据开放开始。
+ * 尝试去访问一些开源数据。挖掘使用它、开发应用来使用它,进行数据分析,画漂亮的图,^注10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
+
+**注:**
+
+1. 我承认你可能尽管不会。
+2. 假设你坚信你的个人数据应该被保护。
+3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
+4. 事实上这些机构能够有多开放取决于你所居住的地方。
+5. 假设我是英国人,那是非常非常大的剂量。
+6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
+7. 不,答案是“不”。
+8. 尽管这个例子也同样适用于个人。看看:A 可能是 Alice,B 可能是 BOb……
+9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然——不是那类的数据。
+10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/being-open-about-data-privacy
+
+作者:[Mike Bursell][a]
+译者:[FelixYFZ](https://github.com/FelixYFZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mikecamel
+[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
+[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
+[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
+[4]:https://opensource.com/article/17/11/commonwealth-open-source
+[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
diff --git a/published/20180228 Why Python devs should use Pipenv.md b/published/201807/20180228 Why Python devs should use Pipenv.md
similarity index 100%
rename from published/20180228 Why Python devs should use Pipenv.md
rename to published/201807/20180228 Why Python devs should use Pipenv.md
diff --git a/published/20180301 The Cost of Cloud Computing.md b/published/201807/20180301 The Cost of Cloud Computing.md
similarity index 100%
rename from published/20180301 The Cost of Cloud Computing.md
rename to published/201807/20180301 The Cost of Cloud Computing.md
diff --git a/translated/tech/20180302 5 open source software tools for supply chain management.md b/published/201807/20180302 5 open source software tools for supply chain management.md
similarity index 56%
rename from translated/tech/20180302 5 open source software tools for supply chain management.md
rename to published/201807/20180302 5 open source software tools for supply chain management.md
index 8ead3394de..3c000a2717 100644
--- a/translated/tech/20180302 5 open source software tools for supply chain management.md
+++ b/published/201807/20180302 5 open source software tools for supply chain management.md
@@ -1,23 +1,25 @@
供应链管理方面的 5 个开源软件工具
======
+> 跟踪您的库存和您需要的材料,用这些供应链管理工具制造产品。
+

本文最初发表于 2016 年 1 月 14 日,最后的更新日期为 2018 年 3 月 2 日。
-如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
+如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数以百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
-保持对货品、供应商、客户的持续跟踪,并且所有与它们相关的变动部分都会从中受益,并且,在某些情况下完全依赖专门的软件来帮助管理这些工作流。在本文中,我们将去了解一些免费的和开源的供应链管理方面的软件,以及它们的其中一些功能。
+保持对货品、供应商、客户的持续跟踪,而且所有与它们相关的变动部分都会受益于这些用来帮助管理工作流的专门软件,而在某些情况下需要完全依赖这些软件。在本文中,我们将去了解一些自由及开源的供应链管理方面的软件,以及它们的其中一些功能。
-供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是合法性、最低品质要求、还是社会和环境的合规性。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
+供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是否是出于法律要求、最低品质要求、还是社会和环境责任。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
-由于它的本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
+由于其本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
### Apache OFBiz
-[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,目录、电子商务网站、帐户、和销售点,它在供应链管理方面的主要功能关注于仓库管理、履行、订单、和生产管理。它的可定制性很强,但是,它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层、和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
+[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,分类、电子商务网站、会计和 POS,它在供应链管理方面的主要功能关注于仓库管理、履行、订单和生产管理。它的可定制性很强,但是,对应的它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
-Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 license][6] 授权的。
+Apache OFBiz 的源代码在其 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 许可证][6] 授权的。
如果你对它感兴趣,你也可以去查看 [opentaps][7],它是在 OFBiz 之上构建的。Opentaps 强化了 OFBiz 的用户界面,并且添加了 ERP 和 CRM 的核心功能,包括仓库管理、采购和计划。它是按 [AGPL 3.0][8] 授权使用的,对于不接受开源授权的组织,它也提供了商业授权。
@@ -25,25 +27,25 @@ Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz
[OpenBoxes][9] 是一个供应链管理和存货管理项目,最初的主要设计目标是为了医疗行业中的药品跟踪管理,但是,它可以通过修改去跟踪任何类型的货品和相关的业务流。它有一个需求预测工具,可以基于历史订单数量、存储跟踪、支持多种场所、过期日期跟踪、销售点支持等进行预测,并且它还有许多其它功能,这使它成为医疗行业的理想选择,但是,它也可以用于其它行业。
-它在 [Eclipse Public License][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
+它在 [Eclipse 公开许可证][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
### OpenLMIS
-与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由络克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达 盖茨基金会。
+与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由洛克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达·盖茨基金会。
-OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 license][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
+OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 许可证][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
### Odoo
-你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和销售点连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
+你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和 POS 连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
-Odoo 既有软件即服务的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
+Odoo 既有软件即服务(SaaS)的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
### xTuple
-[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是帐务、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
+[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了其传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是会计、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
-xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去 fork 它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
+xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去复刻它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
就这些,当然了,还有其它的可以帮你处理供应链管理的开源软件。如果你知道还有更好的软件,请在下面的评论区告诉我们。
@@ -53,14 +55,14 @@ via: https://opensource.com/tools/supply-chain-management
作者:[Jason Baker][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:https://opensource.com/users/jason-baker
[1]:https://en.wikipedia.org/wiki/Supply_chain_management
[2]:https://opensource.com/business/14/7/top-5-open-source-crm-tools
-[3]:https://opensource.com/resources/top-4-open-source-erp-systems
+[3]:https://linux.cn/article-9785-1.html
[4]:http://ofbiz.apache.org/
[5]:http://ofbiz.apache.org/source-repositories.html
[6]:http://www.apache.org/licenses/LICENSE-2.0
diff --git a/published/201807/20180305 What-s next in IT automation- 6 trends to watch.md b/published/201807/20180305 What-s next in IT automation- 6 trends to watch.md
new file mode 100644
index 0000000000..d907efbf41
--- /dev/null
+++ b/published/201807/20180305 What-s next in IT automation- 6 trends to watch.md
@@ -0,0 +1,132 @@
+IT 自动化的下一步是什么: 6 大趋势
+======
+
+> 自动化专家分享了一点对 [自动化][6]不远的将来的看法。请将这些保留在你的视线之内。
+
+
+
+我们最近讨论了 [推动 IT 自动化的因素][1],可以看到[当前趋势][2]正在增长,以及那些给刚开始使用自动化部分流程的组织的 [有用的技巧][3] 。
+
+噢,我们也分享了如何在贵公司[进行自动化的案例][4]及 [长期成功的关键][5]的专家建议。
+
+现在,只有一个问题:自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来的看法。 以下是他们建议 IT 领域领导需密切关注的六大趋势。
+
+### 1、 机器学习的成熟
+
+对于关于 [机器学习][7](与“自我学习系统”相似的定义)的讨论,对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次 IT 自动化浪潮中将扮演着至关重要的角色。
+
+[Advanced Systems Concepts, Inc.][8] 公司的工程总监 Mehul Amin 指出机器学习是 IT 自动化下一个关键增长领域之一。
+
+“随着数据化的发展,自动化软件理应可以自我决策,否则这就是开发人员的责任了”,Amin 说。 “例如,开发者构建了需要执行的内容,但通过使用来自系统内部分析的软件,可以确定执行该流程的最佳系统。”
+
+假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或 SLA,同样在不需要资源以及其他的可能性的时候退出。
+
+显然不只有 Amin 一个人这样认为。
+
+“IT 自动化正在走向自我学习的方向” ,[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
+
+Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
+
+### 2、 人工智能催生的自动化
+
+上述原则同样适合与相关的(但是独立的) [人工智能][10]的领域。根据对人工智能的定义,机器学习在短时间内可能会对 IT 领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。假定新兴的人工智能技术将也会产生新的自动化机会。
+
+[SolarWinds][11] 公司技术负责人 Patrick Hubbard 说,“人工智能和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
+
+### 3、 这并不意味着不再需要人力
+
+让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
+
+这很可能意味着各种角色的改变,以及[全新角色][12]的创造。
+
+但是在可预见的将来,至少,你不必需要对机器人鞠躬。
+
+“一台机器只能运行在给定的环境变量中——它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于 IT 专业人员来说,这将需要培养 AI 和自动化技能,如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
+
+Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
+
+“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
+
+即使你把机器学习和 AI 先放在一边,看待一般的 IT 自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
+
+[Juniper Networks][13] 公司自动化首席架构师 Matthew Oswalt ,指出 IT 自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
+
+> 在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。
+
+“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt 解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨 IT 频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
+
+### 4、 对自动化的焦虑将会减少
+
+SolarWinds 公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在 IT 领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至与科技产业本身共存。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的第 3 项时,我们将看到第 4 项的出现。
+
+“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard 说。“自动化历史上为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
+
+自动化还将减少令 IT 领导者神经紧张的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助 IT 部门降低与维护任务相关的安全风险。
+
+他的建议是:“首先在维护活动期间记录和自动化 IT 资产之间的交互。通过依靠自动化,您不仅可以消除之前需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的 IT 组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
+
+**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
+
+### 5、 脚本和自动化工具将持续发展
+
+许多组织看到了增加自动化的第一步,通常以脚本或自动化工具(有时称为配置管理工具)的形式作为“早期”工作。
+
+但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
+
+[DataVision][18] 首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17] 等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交付时间。”
+
+**[想了解更多关于 Ansible 这个方面的知识吗?阅读相关文章:[使用 Ansible 时的成功秘诀][19]。 ]**
+
+另一个因素是:工具本身将继续变得更先进。
+
+“使用先进的 IT 自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的、预先测试过的拖放式集成,API 作业,丰富的变量使用,参考功能和对象修订历史记录。”
+
+### 6、 自动化开创了新的指标机会
+
+正如我们在此前所说的那样,IT 自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
+
+**[ 参见我们的相关文章 [DevOps 指标:你在衡量什么重要吗?][20] ]**
+
+实际上,自动化应该打开了新的机会。
+
+[Janeiro Digital][21] 公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 —— 源代码管理、DevOps 管道、工作项目跟踪等转向 API 驱动的平台,将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
+
+Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测 IT 所做的一切。
+
+“无论是衡量个人资源还是整体团队,这些指标都可以很强大 —— 但应该用大量的背景来衡量。”Collins 说,“将这些数据用于高层次趋势并确认定性观察 —— 而不是临床评级你的团队。”
+
+**想要更多这样知识, IT 领导者?[注册我们的每周电子邮件通讯][22]。**
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
+
+作者:[Kevin Casey][a]
+译者:[MZqk](https://github.com/MZqk)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/kevin-casey
+[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
+[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
+[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
+[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
+[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
+[6]:https://enterprisersproject.com/tags/automation
+[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
+[8]:https://www.advsyscon.com/en-us/
+[9]:https://www.sungardas.com/en/
+[10]:https://enterprisersproject.com/tags/artificial-intelligence
+[11]:https://www.solarwinds.com/
+[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
+[13]:https://www.juniper.net/
+[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
+[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
+[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
+[17]:https://opensource.com/tags/ansible
+[18]:https://datavision.com/
+[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
+[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
+[21]:https://www.janeirodigital.com/
+[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
diff --git a/published/20180313 Migrating to Linux- Using Sudo.md b/published/201807/20180313 Migrating to Linux- Using Sudo.md
similarity index 100%
rename from published/20180313 Migrating to Linux- Using Sudo.md
rename to published/201807/20180313 Migrating to Linux- Using Sudo.md
diff --git a/translated/tech/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md b/published/201807/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
similarity index 81%
rename from translated/tech/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
rename to published/201807/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
index a05307301a..612b84c53d 100644
--- a/translated/tech/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
+++ b/published/201807/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
@@ -1,9 +1,11 @@
-Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
+Kubernetes 分布式应用部署实战:以人脸识别应用为例
============================================================
-# 简介
+
-伙计们,请做好准备,下面将是一段漫长的旅程,期望你能够乐在其中。
+## 简介
+
+伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
我将基于 [Kubernetes][5] 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
@@ -11,17 +13,17 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
让我们开始吧。
-# 应用
+## 应用
### TL;DR
-应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
+该应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 [接收器][6] 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 [NSQ][8] 建立队列。
-[图片处理][9]服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的[人脸识别][10]后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
+[图片处理][9] 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的 [人脸识别][10] 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
标记为失败的图片可以通过计划任务等方式进行重试。
@@ -33,39 +35,31 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
```
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
-
```
-此时,接收器将路径存储到共享数据库集群中,对应的条目包括数据库服务提供的 ID。本应用采用”持久层提供条目对象唯一标识“的模型。获得条目 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
+此时,接收器将路径存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“实体对象的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
### 图片处理器
-从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go routines,具体为:
+从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go 协程,具体为:
### Consume
-这是一个 NSQ 消费者,需要完成三项任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个 routine 处理。最后,告知第二个 routine 处理新任务,方法为 [sync.Condition][12]。
+这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 [sync.Condition][12]。
### ProcessImages
-该 routine 会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该 routine 并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
+该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
* 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
-
-* 从数据库获取图片对应的条目
-
+* 从数据库获取图片对应的实体
* 为 [断路器][1] 准备两个函数
* 函数 1: 用于 RPC 方法调用的主函数
-
* 函数 2: 基于 ping 的断路器健康检查
-
* 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
-
-* 如果调用失败,将图片条目状态更新为 FAILEDPROCESSING
-
+* 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
* 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
-
-* 将数据库中的图片条目状态更新为 PROCESSED,更新图片被识别成的个人的 ID
+* 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
这个服务可以复制多份同时运行。
@@ -89,7 +83,7 @@ curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image
注意:我曾经试图使用 [GoCV][14],这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
-这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg, hannibal_2.jpg, gergely_1.jpg, john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person, person_images`,具体如下:
+这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg`、 `hannibal_2.jpg`、 `gergely_1.jpg`、 `john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person`、 `person_images`,具体如下:
```
+----+----------+
@@ -126,13 +120,13 @@ NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ
### 配置
-为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 .env 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
+为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 `.env` 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
### 应用小结
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
-# 使用 Kubernetes 部署应用
+## 使用 Kubernetes 部署应用
### 基础知识
@@ -144,55 +138,51 @@ Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
-Kubernetes 使用标签和注释标记组件,包括服务,部署,副本组,守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与 应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
+Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
### Kubernetes 集群
-要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求 Nodes 并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
+要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
-### 节点 (Nodes)
+### 节点
-节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
+节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
-### Pods
+### Pod
-Pods 是本地容器组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和 虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
+Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
-### 部署 (Deployments)
+### 部署
-在 Kubernetes 中创建任何类型的资源时,后台使用一个部署,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
+在 Kubernetes 中创建任何类型的资源时,后台使用一个部署组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
-### 服务 (Services)
+### 服务
-默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,mysql,内部 API 或前端,都需要长期运行并使用保持不变的 IP 或 更佳的 DNS 记录。
+默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
-为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡,简单 IP 或 内部 DNS。
+为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别接口。
-由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络,服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
+由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
### DNS / 服务发现
-在 Kubernetes 集群中创建服务后,该服务会从名为 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中获取一个 DNS 记录。他们两个用于提供集群内的服务发现。如果你有一个正在运行的 mysql 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
+在 Kubernetes 集群中创建服务后,该服务会从名为 `kube-proxy` 和 `kube-dns` 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
* `mysql` – 服务的名称
-
* `default` – 命名空间的名称
-
* `svc` – 对应服务分类
-
* `cluster.local` – 本地集群的域名
-可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 提供程序并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
+可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
* 节点端口方式 – `kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
-
* 负载均衡方式 – `kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
### 模板文件
-类似 Docker Compose, TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
+类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
以 Nginx 部署为例,查看下面的 yaml 模板:
@@ -218,26 +208,26 @@ spec: #(4)
image: nginx:1.7.9
ports:
- containerPort: 80
-
```
在这个示例部署中,我们做了如下操作:
-* (1) 使用 kind 关键字定义模板类型
-* (2) 使用 metadata 关键字,增加该部署的识别信息,使用 labels 标记每个需要创建的资源 (3)
-* (4) 然后使用 spec 关键字描述所需的状态
- * (5) nginx 应用需要 3 个副本
- * (6) Pod 中容器的模板定义部分
- * 容器名称为 nginx
- * 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
+* (1) 使用 `kind` 关键字定义模板类型
+* (2) 使用 `metadata` 关键字,增加该部署的识别信息
+* (3) 使用 `labels` 标记每个需要创建的资源
+* (4) 然后使用 `spec` 关键字描述所需的状态
+* (5) nginx 应用需要 3 个副本
+* (6) Pod 中容器的模板定义部分
+* 容器名称为 nginx
+* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
-### 副本组 (ReplicaSet)
+### 副本组
-副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
+副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
-### 守护进程组 (DaemonSet)
+### 守护进程组
-上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
+上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
例如,你将所有节点增加 `logger` 或 `mission_critical` 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 `logger` 或 `mission_critical` 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
@@ -253,7 +243,7 @@ spec: #(4)
### Kubernetes 部分小结
-Kubernetes 是容器编排的便捷工具,工作单元为 Pods,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
+Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:[GitHub 上的 Kubernetes 项目][22]。
@@ -272,7 +262,7 @@ kubectl get nodes -o yaml
### 构建容器
-Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python,NSQ 和 MySQL 使用对应的容器。
+Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
### 上下文
@@ -293,9 +283,9 @@ Switched to context "kube-face-cluster".
```
此后,所有 `kubectl` 命令都会使用 `face` 命名空间。
-(译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
+(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
-### 应用部署
+## 应用部署
Pods 和 服务概览:
@@ -318,7 +308,6 @@ type: Opaque
data:
mysql_password: base64codehere
mysql_userpassword: base64codehere
-
```
其中 base64 编码通过如下命令生成:
@@ -326,10 +315,9 @@ data:
```
echo -n "ubersecurepassword" | base64
echo -n "root:ubersecurepassword" | base64
-
```
-(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 mysql_password, 仅包含密码;另一条对应 mysql_userpassword,包含用户和密码。后文会用到 mysql_userpassword,但没有提及相应的生成)
+(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
我的部署 yaml 对应部分如下:
@@ -362,13 +350,12 @@ echo -n "root:ubersecurepassword" | base64
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储][27]。
-(LCTT 译注:使用 presistentVolumeClain 之前需要创建 presistentVolume,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
+(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
使用如下命令部署 MySQL 服务:
```
kubectl apply -f mysql.yaml
-
```
这里比较一下 `create` 和 `apply`。`apply` 是一种宣告式的对象配置命令,而 `create` 是命令式的命令。当下我们需要知道的是,`create` 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 `apply` 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 `mysql` 的服务,当我执行 `apply -f mysql.yaml` 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 `create`,Kubernetes 会报错,告知服务已经创建。
@@ -460,7 +447,7 @@ volumes:
```
-(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,person_images 表中的 person_id 列数字都小 1,作者默认 id 从 0 开始,但应该是从 1 开始)
+(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,`person_images` 表中的 `person_id` 列数字都小 1,作者默认 `id` 从 0 开始,但应该是从 1 开始)
运行如下命令查看引导脚本是否正确执行:
@@ -489,7 +476,6 @@ mysql>
```
kubectl logs deployment/mysql -f
-
```
### NSQ 查询
@@ -505,7 +491,7 @@ NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这
```
-那么,内部 DNS 对应的条目类似于:`nsqlookup.default.svc.cluster.local`。
+那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
无头服务的更多细节,可以参考:[无头服务][32]。
@@ -517,7 +503,7 @@ args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
```
-你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,nsqlookup 使用 `hostname` (LCTT 译注:这里是指容器的主机名,而不是 hostname 字符串本身)作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
+你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
@@ -533,6 +519,7 @@ NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsq
```
服务模板:
+
```
spec:
ports:
@@ -592,13 +579,13 @@ NSQ 守护进程也需要一些调整的参数配置:
```
-其中我们配置了 lookup-tcp-address 和 broadcast-address 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
+其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
#### 对外公开
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
-但由于我使用的本地集群只有一个节点,那么使用 `节点端口` 的方式就足够了。`节点端口` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `:` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
+但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `:` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
更多信息,请参考文档:[服务发布][33]。
@@ -643,7 +630,7 @@ spec:
### 图片处理器
-图片处理器用于将图片传送至识别组件。它需要访问 nslookupd, mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
+图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
```
---
@@ -781,7 +768,7 @@ curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/
```
-图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 known_foler 文件中找到 unknown220.jpg 对应个人的图片,最后返回匹配图片的名称。
+图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 `known_folder` 文件中找到 `unknown220.jpg` 对应个人的图片,最后返回匹配图片的名称。
查看日志,大致信息如下:
@@ -861,9 +848,9 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
```
-### 滚动更新 (Rolling Update)
+## 滚动更新
-滚动更新过程中会发生什么呢?
+滚动更新过程中会发生什么呢?
@@ -871,7 +858,7 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
-#### 代码
+### 代码
目前,我们使用下面的代码段处理单个图片的情形:
@@ -900,7 +887,7 @@ func main() {
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
-#### 新的 Endpoint
+### 新的接口
让我们添加新的路由方法:
@@ -941,7 +928,7 @@ func PostImage(w http.ResponseWriter, r *http.Request) {
```
-当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片 PR][34] 中可以找到更多的修改方式。
+当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片的 PR][34] 中可以找到更多的修改方式。
至此,我们使用两种方法调用接收器:
@@ -958,7 +945,7 @@ curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/po
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
-#### 新镜像
+### 新镜像
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
@@ -969,11 +956,11 @@ docker build -t skarlso/kube-receiver-alpine:v1.1 .
新镜像创建后,我们可以开始滚动更新了。
-#### 滚动更新
+### 滚动更新
在 Kubernetes 中,可以使用多种方式完成滚动更新。
-##### 手动更新
+#### 手动更新
不妨假设在我配置文件中使用的容器版本为 `v1.0`,那么实现滚动更新只需运行如下命令:
@@ -991,7 +978,7 @@ kubectl rolling-update receiver --rollback
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
-##### 应用新的配置文件
+#### 应用新的配置文件
手动更新的不足在于无法版本管理。
@@ -1051,7 +1038,7 @@ kubectl delete services -all
```
-# 写在最后的话
+## 写在最后的话
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
@@ -1065,9 +1052,9 @@ Gergely 感谢你阅读本文。
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
-作者:[hannibal ][a]
+作者:[hannibal][a]
译者:[pinewall](https://github.com/pinewall)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/talk/20180320 Can we build a social network that serves users rather than advertisers.md b/published/201807/20180320 Can we build a social network that serves users rather than advertisers.md
similarity index 56%
rename from translated/talk/20180320 Can we build a social network that serves users rather than advertisers.md
rename to published/201807/20180320 Can we build a social network that serves users rather than advertisers.md
index bd279216ca..f7d378580b 100644
--- a/translated/talk/20180320 Can we build a social network that serves users rather than advertisers.md
+++ b/published/201807/20180320 Can we build a social network that serves users rather than advertisers.md
@@ -1,13 +1,15 @@
我们能否建立一个服务于用户而非广告商的社交网络?
=====
+> 找出 Human Connection 是如何将透明度和社区放在首位的。
+

-如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的,中立的,透明的在线平台来迎接我们这个时代的挑战。
+如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
-开放的原则可能会成为让我们到达那里的方法(to 校正者:这句上下文没有理解)。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
+开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
-这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们自然倾向,于乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
+这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
@@ -15,31 +17,28 @@
### 首先是透明
-透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript, Vue, nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
+透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
-但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些对让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
+但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
-为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team (to 校正者:这里如果可以,请翻译得稍微优雅,我想不出来一个词)活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
+为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
-一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章(UN Charter)][4]和“世界人权宣言(Universal Declaration of Human Rights)”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (译者注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
+有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章][4]和“世界人权宣言”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
### 一个合作的社会
以一种[以社区为中心的协作方法][5]来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
-一个抛弃了以利润为导向的算法,为广告商而不是最终用户服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并破坏(to 校正:这里译为改变较好)现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
+一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
-我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学(University Sorbonne)的国家东方语言与文明研究所(National Institute for Oriental Languages and Civilizations (INALCO) )和德国斯图加特媒体大学(Stuttgart Media University )合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
-
- * 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动(Take Action)”领域,每个人都可以实现。
-
- * “Versus” 功能是另一个定义结果的方式(to 校正者:这句话稍微注意一下)。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
+我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学的国家东方语言与文明研究所(INALCO)和德国斯图加特媒体大学合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
+ * 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动”领域,每个人都可以实现。
+ * “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
-
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
[订阅我们的每周时事通讯][12]以了解有关开放组织的更多信息。
@@ -51,7 +50,7 @@ via: https://opensource.com/open-organization/18/3/open-social-human-connection
作者:[Dennis Hack][a]
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180320 Migrating to Linux- Installing Software.md b/published/201807/20180320 Migrating to Linux- Installing Software.md
similarity index 100%
rename from published/20180320 Migrating to Linux- Installing Software.md
rename to published/201807/20180320 Migrating to Linux- Installing Software.md
diff --git a/published/20180411 Make your first contribution to an open source project.md b/published/201807/20180411 Make your first contribution to an open source project.md
similarity index 100%
rename from published/20180411 Make your first contribution to an open source project.md
rename to published/201807/20180411 Make your first contribution to an open source project.md
diff --git a/published/20180418 The Linux Filesystem Explained.md b/published/201807/20180418 The Linux Filesystem Explained.md
similarity index 100%
rename from published/20180418 The Linux Filesystem Explained.md
rename to published/201807/20180418 The Linux Filesystem Explained.md
diff --git a/published/20180423 An introduction to Python bytecode.md b/published/201807/20180423 An introduction to Python bytecode.md
similarity index 100%
rename from published/20180423 An introduction to Python bytecode.md
rename to published/201807/20180423 An introduction to Python bytecode.md
diff --git a/published/20180425 JavaScript Router.md b/published/201807/20180425 JavaScript Router.md
similarity index 100%
rename from published/20180425 JavaScript Router.md
rename to published/201807/20180425 JavaScript Router.md
diff --git a/published/20180428 How to get a core dump for a segfault on Linux.md b/published/201807/20180428 How to get a core dump for a segfault on Linux.md
similarity index 100%
rename from published/20180428 How to get a core dump for a segfault on Linux.md
rename to published/201807/20180428 How to get a core dump for a segfault on Linux.md
diff --git a/published/20180429 Passwordless Auth- Client.md b/published/201807/20180429 Passwordless Auth- Client.md
similarity index 100%
rename from published/20180429 Passwordless Auth- Client.md
rename to published/201807/20180429 Passwordless Auth- Client.md
diff --git a/published/201807/20180430 3 practical Python tools- magic methods, iterators and generators, and method magic.md b/published/201807/20180430 3 practical Python tools- magic methods, iterators and generators, and method magic.md
new file mode 100644
index 0000000000..7ddd3f33cc
--- /dev/null
+++ b/published/201807/20180430 3 practical Python tools- magic methods, iterators and generators, and method magic.md
@@ -0,0 +1,406 @@
+日常 Python 编程优雅之道
+======
+
+> 3 个可以使你的 Python 代码更优雅、可读、直观和易于维护的工具。
+
+
+
+Python 提供了一组独特的工具和语言特性来使你的代码更加优雅、可读和直观。为正确的问题选择合适的工具,你的代码将更易于维护。在本文中,我们将研究其中的三个工具:魔术方法、迭代器和生成器,以及方法魔术。
+
+### 魔术方法
+
+魔术方法可以看作是 Python 的管道。它们被称为“底层”方法,用于某些内置的方法、符号和操作。你可能熟悉的常见魔术方法是 `__init__()`,当我们想要初始化一个类的新实例时,它会被调用。
+
+你可能已经看过其他常见的魔术方法,如 `__str__` 和 `__repr__`。Python 中有一整套魔术方法,通过实现其中的一些方法,我们可以修改一个对象的行为,甚至使其行为类似于内置数据类型,例如数字、列表或字典。
+
+让我们创建一个 `Money` 类来示例:
+
+```
+class Money:
+
+ currency_rates = {
+ '$': 1,
+ '€': 0.88,
+ }
+
+ def __init__(self, symbol, amount):
+ self.symbol = symbol
+ self.amount = amount
+
+ def __repr__(self):
+ return '%s%.2f' % (self.symbol, self.amount)
+
+ def convert(self, other):
+ """ Convert other amount to our currency """
+ new_amount = (
+ other.amount / self.currency_rates[other.symbol]
+ * self.currency_rates[self.symbol])
+
+ return Money(self.symbol, new_amount)
+```
+
+该类定义为给定的货币符号和汇率定义了一个货币汇率,指定了一个初始化器(也称为构造函数),并实现 `__repr__`,因此当我们打印这个类时,我们会看到一个友好的表示,例如 `$2.00` ,这是一个带有货币符号和金额的 `Money('$', 2.00)` 实例。最重要的是,它定义了一种方法,允许你使用不同的汇率在不同的货币之间进行转换。
+
+打开 Python shell,假设我们已经定义了使用两种不同货币的食品的成本,如下所示:
+
+```
+>>> soda_cost = Money('$', 5.25)
+>>> soda_cost
+ $5.25
+
+>>> pizza_cost = Money('€', 7.99)
+>>> pizza_cost
+ €7.99
+```
+
+我们可以使用魔术方法使得这个类的实例之间可以相互交互。假设我们希望能够将这个类的两个实例一起加在一起,即使它们是不同的货币。为了实现这一点,我们可以在 `Money` 类上实现 `__add__` 这个魔术方法:
+
+```
+class Money:
+
+ # ... previously defined methods ...
+
+ def __add__(self, other):
+ """ Add 2 Money instances using '+' """
+ new_amount = self.amount + self.convert(other).amount
+ return Money(self.symbol, new_amount)
+```
+
+现在我们可以以非常直观的方式使用这个类:
+
+```
+>>> soda_cost = Money('$', 5.25)
+>>> pizza_cost = Money('€', 7.99)
+>>> soda_cost + pizza_cost
+ $14.33
+>>> pizza_cost + soda_cost
+ €12.61
+```
+
+当我们将两个实例加在一起时,我们得到以第一个定义的货币符号所表示的结果。所有的转换都是在底层无缝完成的。如果我们想的话,我们也可以为减法实现 `__sub__`,为乘法实现 `__mul__` 等等。阅读[模拟数字类型][1]或[魔术方法指南][2]来获得更多信息。
+
+我们学习到 `__add__` 映射到内置运算符 `+`。其他魔术方法可以映射到像 `[]` 这样的符号。例如,在字典中通过索引或键来获得一项,其实是使用了 `__getitem__` 方法:
+
+```
+>>> d = {'one': 1, 'two': 2}
+>>> d['two']
+2
+>>> d.__getitem__('two')
+2
+```
+
+一些魔术方法甚至映射到内置函数,例如 `__len__()` 映射到 `len()`。
+
+```
+class Alphabet:
+ letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
+
+ def __len__(self):
+ return len(self.letters)
+
+>>> my_alphabet = Alphabet()
+>>> len(my_alphabet)
+ 26
+```
+
+### 自定义迭代器
+
+对于新的和经验丰富的 Python 开发者来说,自定义迭代器是一个非常强大的但令人迷惑的主题。
+
+许多内置类型,例如列表、集合和字典,已经实现了允许它们在底层迭代的协议。这使我们可以轻松地遍历它们。
+
+```
+>>> for food in ['Pizza', 'Fries']:
+
+ print(food + '. Yum!')
+
+Pizza. Yum!
+Fries. Yum!
+```
+
+我们如何迭代我们自己的自定义类?首先,让我们来澄清一些术语。
+
+ * 要成为一个可迭代对象,一个类需要实现 `__iter__()`
+ * `__iter__()` 方法需要返回一个迭代器
+ * 要成为一个迭代器,一个类需要实现 `__next__()`(或[在 Python 2][3]中是 `next()`),当没有更多的项要迭代时,必须抛出一个 `StopIteration` 异常。
+
+呼!这听起来很复杂,但是一旦你记住了这些基本概念,你就可以在任何时候进行迭代。
+
+我们什么时候想使用自定义迭代器?让我们想象一个场景,我们有一个 `Server` 实例在不同的端口上运行不同的服务,如 `http` 和 `ssh`。其中一些服务处于 `active` 状态,而其他服务则处于 `inactive` 状态。
+
+```
+class Server:
+
+ services = [
+ {'active': False, 'protocol': 'ftp', 'port': 21},
+ {'active': True, 'protocol': 'ssh', 'port': 22},
+ {'active': True, 'protocol': 'http', 'port': 80},
+ ]
+```
+
+当我们遍历 `Server` 实例时,我们只想遍历那些处于 `active` 的服务。让我们创建一个 `IterableServer` 类:
+
+```
+class IterableServer:
+ def __init__(self):
+ self.current_pos = 0
+ def __next__(self):
+ pass # TODO: 实现并记得抛出 StopIteration
+```
+
+首先,我们将当前位置初始化为 `0`。然后,我们定义一个 `__next__()` 方法来返回下一项。我们还将确保在没有更多项返回时抛出 `StopIteration`。到目前为止都很好!现在,让我们实现这个 `__next__()` 方法。
+
+```
+class IterableServer:
+ def __init__(self):
+ self.current_pos = 0. # 我们初始化当前位置为 0
+ def __iter__(self): # 我们可以在这里返回 self,因为实现了 __next__
+ return self
+ def __next__(self):
+ while self.current_pos < len(self.services):
+ service = self.services[self.current_pos]
+ self.current_pos += 1
+ if service['active']:
+ return service['protocol'], service['port']
+ raise StopIteration
+ next = __next__ # 可选的 Python2 兼容性
+```
+
+我们对列表中的服务进行遍历,而当前的位置小于服务的个数,但只有在服务处于活动状态时才返回。一旦我们遍历完服务,就会抛出一个 `StopIteration` 异常。
+
+
+因为我们实现了 `__next__()` 方法,当它耗尽时,它会抛出 `StopIteration`。我们可以从 `__iter__()` 返回 `self`,因为 `IterableServer` 类遵循 `iterable` 协议。
+
+现在我们可以遍历一个 `IterableServer` 实例,这将允许我们查看每个处于活动的服务,如下所示:
+
+```
+>>> for protocol, port in IterableServer():
+
+ print('service %s is running on port %d' % (protocol, port))
+
+service ssh is running on port 22
+
+service http is running on port 21
+
+```
+
+太棒了,但我们可以做得更好!在这样类似的实例中,我们的迭代器不需要维护大量的状态,我们可以简化代码并使用 [generator(生成器)][4] 来代替。
+
+```
+class Server:
+ services = [
+ {'active': False, 'protocol': 'ftp', 'port': 21},
+ {'active': True, 'protocol': 'ssh', 'port': 22},
+ {'active': True, 'protocol': 'http', 'port': 21},
+ ]
+ def __iter__(self):
+ for service in self.services:
+ if service['active']:
+ yield service['protocol'], service['port']
+```
+
+`yield` 关键字到底是什么?在定义生成器函数时使用 yield。这有点像 `return`,虽然 `return` 在返回值后退出函数,但 `yield` 会暂停执行直到下次调用它。这允许你的生成器的功能在它恢复之前保持状态。查看 [yield 的文档][5]以了解更多信息。使用生成器,我们不必通过记住我们的位置来手动维护状态。生成器只知道两件事:它现在需要做什么以及计算下一个项目需要做什么。一旦我们到达执行点,即 `yield` 不再被调用,我们就知道停止迭代。
+
+这是因为一些内置的 Python 魔法。在 [Python 关于 `__iter__()` 的文档][6]中我们可以看到,如果 `__iter__()` 是作为一个生成器实现的,它将自动返回一个迭代器对象,该对象提供 `__iter__()` 和 `__next__()` 方法。阅读这篇很棒的文章,深入了解[迭代器,可迭代对象和生成器][7]。
+
+### 方法魔法
+
+由于其独特的方面,Python 提供了一些有趣的方法魔法作为语言的一部分。
+
+其中一个例子是别名功能。因为函数只是对象,所以我们可以将它们赋值给多个变量。例如:
+
+```
+>>> def foo():
+ return 'foo'
+>>> foo()
+'foo'
+>>> bar = foo
+>>> bar()
+'foo'
+```
+
+我们稍后会看到它的作用。
+
+Python 提供了一个方便的内置函数[称为 `getattr()`][8],它接受 `object, name, default` 参数并在 `object` 上返回属性 `name`。这种编程方式允许我们访问实例变量和方法。例如:
+
+```
+>>> class Dog:
+ sound = 'Bark'
+ def speak(self):
+ print(self.sound + '!', self.sound + '!')
+
+>>> fido = Dog()
+
+>>> fido.sound
+'Bark'
+>>> getattr(fido, 'sound')
+'Bark'
+
+>>> fido.speak
+>
+>>> getattr(fido, 'speak')
+>
+
+
+>>> fido.speak()
+Bark! Bark!
+>>> speak_method = getattr(fido, 'speak')
+>>> speak_method()
+Bark! Bark!
+```
+
+这是一个很酷的技巧,但是我们如何在实际中使用 `getattr` 呢?让我们看一个例子,我们编写一个小型命令行工具来动态处理命令。
+
+```
+class Operations:
+ def say_hi(self, name):
+ print('Hello,', name)
+ def say_bye(self, name):
+ print ('Goodbye,', name)
+ def default(self, arg):
+ print ('This operation is not supported.')
+
+if __name__ == '__main__':
+ operations = Operations()
+ # 假设我们做了错误处理
+ command, argument = input('> ').split()
+ func_to_call = getattr(operations, command, operations.default)
+ func_to_call(argument)
+```
+
+脚本的输出是:
+
+```
+$ python getattr.py
+> say_hi Nina
+Hello, Nina
+> blah blah
+This operation is not supported.
+```
+
+接下来,我们来看看 `partial`。例如,`functool.partial(func, *args, **kwargs)` 允许你返回一个新的 [partial 对象][9],它的行为类似 `func`,参数是 `args` 和 `kwargs`。如果传入更多的 `args`,它们会被附加到 `args`。如果传入更多的 `kwargs`,它们会扩展并覆盖 `kwargs`。让我们通过一个简短的例子来看看:
+
+```
+>>> from functools import partial
+>>> basetwo = partial(int, base=2)
+>>> basetwo
+
+>>> basetwo('10010')
+18
+
+# 这等同于
+>>> int('10010', base=2)
+```
+
+让我们看看在我喜欢的一个[名为 `agithub`][10] 的库中的一些示例代码中,这个方法魔术是如何结合在一起的,这是一个(名字起得很 low 的) REST API 客户端,它具有透明的语法,允许你以最小的配置快速构建任何 REST API 原型(不仅仅是 GitHub)。我发现这个项目很有趣,因为它非常强大,但只有大约 400 行 Python 代码。你可以在大约 30 行配置代码中添加对任何 REST API 的支持。`agithub` 知道协议所需的一切(`REST`、`HTTP`、`TCP`),但它不考虑上游 API。让我们深入到它的实现中。
+
+以下是我们如何为 GitHub API 和任何其他相关连接属性定义端点 URL 的简化版本。在这里查看[完整代码][11]。
+
+```
+class GitHub(API):
+ def __init__(self, token=None, *args, **kwargs):
+ props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
+ self.setClient(Client(*args, **kwargs))
+ self.setConnectionProperties(props)
+```
+
+然后,一旦配置了[访问令牌][12],就可以开始使用 [GitHub API][13]。
+
+```
+>>> gh = GitHub('token')
+>>> status, data = gh.user.repos.get(visibility='public', sort='created')
+>>> # ^ 映射到 GET /user/repos
+>>> data
+... ['tweeter', 'snipey', '...']
+```
+
+请注意,你要确保 URL 拼写正确,因为我们没有验证 URL。如果 URL 不存在或出现了其他任何错误,将返回 API 抛出的错误。那么,这一切是如何运作的呢?让我们找出答案。首先,我们将查看一个 [`API` 类][14]的简化示例:
+
+```
+class API:
+ # ... other methods ...
+ def __getattr__(self, key):
+ return IncompleteRequest(self.client).__getattr__(key)
+ __getitem__ = __getattr__
+```
+
+在 `API` 类上的每次调用都会调用 [`IncompleteRequest` 类][15]作为指定的 `key`。
+
+```
+class IncompleteRequest:
+ # ... other methods ...
+ def __getattr__(self, key):
+ if key in self.client.http_methods:
+ htmlMethod = getattr(self.client, key)
+ return partial(htmlMethod, url=self.url)
+ else:
+ self.url += '/' + str(key)
+ return self
+ __getitem__ = __getattr__
+
+class Client:
+ http_methods = ('get') # 还有 post, put, patch 等等。
+ def get(self, url, headers={}, **params):
+ return self.request('GET', url, None, headers)
+```
+
+如果最后一次调用不是 HTTP 方法(如 `get`、`post` 等),则返回带有附加路径的 `IncompleteRequest`。否则,它从[`Client` 类][16]获取 HTTP 方法对应的正确函数,并返回 `partial`。
+
+如果我们给出一个不存在的路径会发生什么?
+
+```
+>>> status, data = this.path.doesnt.exist.get()
+>>> status
+... 404
+```
+
+因为 `__getattr__` 别名为 `__getitem__`:
+
+```
+>>> owner, repo = 'nnja', 'tweeter'
+>>> status, data = gh.repos[owner][repo].pulls.get()
+>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
+>>> data
+.... # {....}
+```
+
+这真心是一些方法魔术!
+
+### 了解更多
+
+Python 提供了大量工具,使你的代码更优雅,更易于阅读和理解。挑战在于找到合适的工具来完成工作,但我希望本文为你的工具箱添加了一些新工具。而且,如果你想更进一步,你可以在我的博客 [nnja.io][17] 上阅读有关装饰器、上下文管理器、上下文生成器和命名元组的内容。随着你成为一名更好的 Python 开发人员,我鼓励你到那里阅读一些设计良好的项目的源代码。[Requests][18] 和 [Flask][19] 是两个很好的起步的代码库。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems
+
+作者:[Nina Zakharenko][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/nnja
+[1]:https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types
+[2]:https://rszalski.github.io/magicmethods/
+[3]:https://docs.python.org/2/library/stdtypes.html#iterator.next
+[4]:https://docs.python.org/3/library/stdtypes.html#generator-types
+[5]:https://docs.python.org/3/reference/expressions.html#yieldexpr
+[6]:https://docs.python.org/3/reference/datamodel.html#object.__iter__
+[7]:http://nvie.com/posts/iterators-vs-generators/
+[8]:https://docs.python.org/3/library/functions.html#getattr
+[9]:https://docs.python.org/3/library/functools.html#functools.partial
+[10]:https://github.com/mozilla/agithub
+[11]:https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py
+[12]:https://github.com/settings/tokens
+[13]:https://developer.github.com/v3/repos/#list-your-repositories
+[14]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58
+[15]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100
+[16]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231
+[17]:http://nnja.io
+[18]:https://github.com/requests/requests
+[19]:https://github.com/pallets/flask
+[20]:https://us.pycon.org/2018/schedule/presentation/164/
+[21]:https://us.pycon.org/2018/
diff --git a/published/20180502 Customizing your text colors on the Linux command line.md b/published/201807/20180502 Customizing your text colors on the Linux command line.md
similarity index 100%
rename from published/20180502 Customizing your text colors on the Linux command line.md
rename to published/201807/20180502 Customizing your text colors on the Linux command line.md
diff --git a/published/201807/20180508 How To Check Ubuntu Version and Other System Information Easily.md b/published/201807/20180508 How To Check Ubuntu Version and Other System Information Easily.md
new file mode 100644
index 0000000000..48c5f617ed
--- /dev/null
+++ b/published/201807/20180508 How To Check Ubuntu Version and Other System Information Easily.md
@@ -0,0 +1,134 @@
+如何轻松地检查 Ubuntu 版本以及其它系统信息
+======
+
+> 摘要:想知道你正在使用的 Ubuntu 具体是什么版本吗?这篇文档将告诉你如何检查你的 Ubuntu 版本、桌面环境以及其他相关的系统信息。
+
+通常,你能非常容易的通过命令行或者图形界面获取你正在使用的 Ubuntu 的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的 Ubuntu 确切的版本号、桌面环境以及其他的系统信息将是尤为重要的。
+
+在这篇简短的文章中,作者将展示各种检查 [Ubuntu][1] 版本以及其他常用的系统信息的方法。
+
+### 如何在命令行检查 Ubuntu 版本
+
+这个是获得 Ubuntu 版本的最好的办法。我本想先展示如何用图形界面做到这一点,但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何[桌面环境][2]。 你可以在 Ubuntu 的任何变种系统上使用这种方法。
+
+打开你的命令行终端 (`Ctrl+Alt+T`), 键入下面的命令:
+
+```
+lsb_release -a
+```
+
+上面命令的输出应该如下:
+
+```
+No LSB modules are available.
+Distributor ID: Ubuntu
+Description: Ubuntu 16.04.4 LTS
+Release: 16.04
+Codename: xenial
+```
+
+![How to check Ubuntu version in command line][3]
+
+正像你所看到的,当前我的系统安装的 Ubuntu 版本是 Ubuntu 16.04, 版本代号: Xenial。
+
+且慢!为什么版本描述中显示的是 Ubuntu 16.04.4 而发行版本是 16.04?到底哪个才是正确的版本?16.04 还是 16.04.4? 这两者之间有什么区别?
+
+如果言简意赅的回答这个问题的话,那么答案应该是你正在使用 Ubuntu 16.04。这个是基准版本,而 16.04.4 进一步指明这是 16.04 的第四个补丁版本。你可以将补丁版本理解为 Windows 世界里的服务包。在这里,16.04 和 16.04.4 都是正确的版本号。
+
+那么输出的 Xenial 又是什么?那正是 Ubuntu 16.04 的版本代号。你可以阅读下面这篇文章获取更多信息:[了解 Ubuntu 的命名惯例][4]。
+
+#### 其他一些获取 Ubuntu 版本的方法
+
+你也可以使用下面任意的命令得到 Ubuntu 的版本:
+
+```
+cat /etc/lsb-release
+```
+
+输出如下信息:
+
+```
+DISTRIB_ID=Ubuntu
+DISTRIB_RELEASE=16.04
+DISTRIB_CODENAME=xenial
+DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
+```
+
+![How to check Ubuntu version in command line][5]
+
+
+你还可以使用下面的命令来获得 Ubuntu 版本:
+
+```
+cat /etc/issue
+```
+
+
+命令行的输出将会如下:
+
+```
+Ubuntu 16.04.4 LTS \n \l
+```
+
+不要介意输出末尾的\n \l. 这里 Ubuntu 版本就是 16.04.4,或者更加简单:16.04。
+
+
+### 如何在图形界面下得到 Ubuntu 版本
+
+在图形界面下获取 Ubuntu 版本更是小事一桩。这里我使用了 Ubuntu 18.04 的图形界面系统 GNOME 的屏幕截图来展示如何做到这一点。如果你在使用 Unity 或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
+
+下面我来展示如何在桌面环境获取 Ubuntu 版本。
+
+进入‘系统设置’并点击下面的‘详细信息’栏。
+
+![Finding Ubuntu version graphically][6]
+
+你将会看到系统的 Ubuntu 版本和其他和桌面系统有关的系统信息 这里的截图来自 [GNOME][7] 。
+
+![Finding Ubuntu version graphically][8]
+
+### 如何知道桌面环境以及其他的系统信息
+
+你刚才学习的是如何得到 Ubuntu 的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的 Linux 内核版本呢?
+
+有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做 [Neofetch][9]。 这个工具能在命令行完美展示系统信息,包括 Ubuntu 或者其他 Linux 发行版的系统图标。
+
+用下面的命令安装 Neofetch:
+
+```
+sudo apt install neofetch
+```
+
+安装成功后,运行 `neofetch` 将会优雅的展示系统的信息如下。
+
+![System information in Linux terminal][10]
+
+如你所见,`neofetch` 完全展示了 Linux 内核版本、Ubuntu 的版本、桌面系统版本以及环境、主题和图标等等信息。
+
+
+希望我如上展示方法能帮到你更快的找到你正在使用的 Ubuntu 版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
+
+再见。:)
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[DavidChenLiang](https://github.com/davidchenliang)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[1]:https://www.ubuntu.com/
+[2]:https://en.wikipedia.org/wiki/Desktop_environment
+[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
+[4]:https://itsfoss.com/linux-code-names/
+[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
+[7]:https://www.gnome.org/
+[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
+[9]:https://itsfoss.com/display-linux-logo-in-ascii/
+[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
diff --git a/translated/talk/20180514 A year as Android Engineer.md b/published/201807/20180514 A year as Android Engineer.md
similarity index 79%
rename from translated/talk/20180514 A year as Android Engineer.md
rename to published/201807/20180514 A year as Android Engineer.md
index 940d479d98..573b0ef825 100644
--- a/translated/talk/20180514 A year as Android Engineer.md
+++ b/published/201807/20180514 A year as Android Engineer.md
@@ -2,7 +2,8 @@ Android 工程师的一年
============================================================

->妙绝的绘画来自 [Miquel Beltran][0]
+
+> 这幅妙绝的绘画来自 [Miquel Beltran][0]
我的技术生涯,从两年前算起。开始是 QA 测试员,一年后就转入开发人员角色。没怎么努力,也没有投入过多的个人时间。
@@ -12,7 +13,7 @@ Android 工程师的一年
我的第一个职位角色, Android 开发者,开始于一年前。我工作的这家公司,可以花一半的时间去尝试其它角色的工作,这给我从 QA 职位转到 Android 开发者职位创造了机会。
-这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了[ Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了[ Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
+这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了 [Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了 [Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
两个月后,公司雇佣了另一位 QA,我转向全职工作。挑战从此开始!
@@ -46,29 +47,27 @@ Android 工程师的一年
一个例子就是拉取代码进行公开展示和代码审查。有是我会请同事私下检查我的代码,并不想被公开拉取,向任何人展示。
-其他时候,当我做代码审查时,会花好几分钟盯着"批准"按纽犹豫不决,在担心审查通过的会被其他同事找出毛病。
+其他时候,当我做代码审查时,会花好几分钟盯着“批准”按纽犹豫不决,在担心审查通过的代码会被其他同事找出毛病。
当我在一些事上持反对意见时,由于缺乏相关知识,担心被坐冷板凳,从来没有大声说出来过。
> 某些时间我会请同事私下[...]检查我的代码,以避免被公开展示。
-* * *
-
### 新的公司,新的挑战
-后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被[ Babbel ][7]邀请去参加初级 Android 工程师职位的招聘流程。
+后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被 [Babbel][7] 邀请去参加初级 Android 工程师职位的招聘流程。
我见到了他们的团队,同时自告奋勇的在他们办公室主持了一次本地会议。此事让我下定决心要申请这个职位。我喜欢公司的箴言:全民学习。其次,公司每个人都非常友善,在那儿工作看起来很愉快!但我没有马上申请,因为我认为自己不够好,所以为什么能申请呢?
-还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的应该程序来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
+还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的程序的形式来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
#### 招聘过程
我用周未的时间来完成编码挑战的项目,并在周一就立即发送过去。不久就受邀去当场面试。
-技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
+技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的地方、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
-最后,通过面试,得到 offer, 我授受了!
+最后,通过面试,得到 offer,我授受了!
我的 Android 工程师生涯的第一年,有九个月在一个公司,后面三个月在当前的公司。
@@ -88,7 +87,7 @@ Android 工程师的一年
两次三次后,压力就堵到胸口。为什么我还不知道?为什么就那么难理解?这种状态让我焦虑万分。
-我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有是,仅仅需要的就是更多的时间、更多的练习,最终会"在大脑中完全演绎" :-)
+我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有时,仅仅需要的就是更多的时间、更多的练习,最终会“在大脑中完全演绎” :-)
例如,我常常为 Java 的接口类和抽象类所困扰,不管看了多少的例子,还是不能完全明白他们之间的区别。但一旦我使用后,即使还不能解释其工作原理,也知道了怎么使用以及什么时候使用。
@@ -102,19 +101,13 @@ Android 工程师的一年
工程师的角色不仅仅是编码,而是广泛的技能。 我仍然处于旅程的起点,在掌握它的道路上,我想着重于以下几点:
-* 交流:因为英文不是我的母语,所以有的时候我会努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
-
-* 提有建设性的反馈意见: 我想给同事有意义的反馈,这样我们一起共同发展。
-
-* 为我的成就感到骄傲: 我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
-
-* 不要着迷于不知道的事情: 当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
-
-* 多和同事分享知识。我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
-
-* 耐心和持续学习: 和现在一样的保持不断学习,但对自己要有更多耐心。
-
-* 自我保健: 随时注意休息,不要为难自己。 放松也富有成效。
+* 交流:因为英文不是我的母语,所以有的时候我需要努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
+* 提有建设性的反馈意见:我想给同事有意义的反馈,这样我们一起共同发展。
+* 为我的成就感到骄傲:我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
+* 不要着迷于不知道的事情:当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
+* 多和同事分享知识:我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
+* 耐心和持续学习:和现在一样的保持不断学习,但对自己要有更多耐心。
+* 自我保健:随时注意休息,不要为难自己。 放松也富有成效。
--------------------------------------------------------------------------------
@@ -122,7 +115,7 @@ via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
作者:[Lara Martín][a]
译者:[runningwater](https://github.com/runningwater)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201807/20180515 Give Your Linux Desktop a Stunning Makeover With Xenlism Themes.md b/published/201807/20180515 Give Your Linux Desktop a Stunning Makeover With Xenlism Themes.md
new file mode 100644
index 0000000000..07dc338eb2
--- /dev/null
+++ b/published/201807/20180515 Give Your Linux Desktop a Stunning Makeover With Xenlism Themes.md
@@ -0,0 +1,90 @@
+使用 Xenlism 主题对你的 Linux 桌面进行令人惊叹的改造
+============================================================
+
+> 简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约的壁纸,将你的 Linux 桌面转变为引人注目的操作系统。
+
+除非我找到一些非常棒的东西,否则我不会每天都把整篇文章献给一个主题。我曾经经常发布主题和图标。但最近,我更喜欢列出[最佳 GTK 主题][6]和图标主题。这对我和你来说都更方便,你可以在一个地方看到许多美丽的主题。
+
+在 [Pop OS 主题][7]套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。
+
+
+
+Xenlism GTK 主题基于 Arc 主题,其得益于许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既不特别喜欢,也没有特别不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
+
+Xenlism 套件中有两个图标主题。Xenlism Wildfire 是以前的,已经进入我们的[最佳图标主题][8]列表。
+
+
+
+*Xenlism Wildfire 图标*
+
+Xenlsim Storm 是一个相对较新的图标主题,但同样美观。
+
+
+
+*Xenlism Storm 图标*
+
+Xenlism 主题在 GPL 许可下开源。
+
+### 如何在 Ubuntu 18.04 上安装 Xenlism 主题包
+
+Xenlism 开发提供了一种通过 PPA 安装主题包的更简单方法。尽管 PPA 可用于 Ubuntu 16.04,但我发现 GTK 主题不适用于 Unity。它适用于 Ubuntu 18.04 中的 GNOME 桌面。
+
+打开终端(`Ctrl+Alt+T`)并逐个使用以下命令:
+
+```
+sudo add-apt-repository ppa:xenatt/xenlism
+sudo apt update
+```
+
+该 PPA 提供四个包:
+
+* xenlism-finewalls:一组壁纸,可直接在 Ubuntu 的壁纸中使用。截图中使用了其中一个壁纸。
+* xenlism-minimalism-theme:GTK 主题
+* xenlism-storm:一个图标主题(见前面的截图)
+* xenlism-wildfire-icon-theme:具有多种颜色变化的另一个图标主题(文件夹颜色在变体中更改)
+
+你可以自己决定要安装的主题组件。就个人而言,我认为安装所有组件没有任何损害。
+
+```
+sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
+```
+
+你可以使用 GNOME Tweaks 来更改主题和图标。如果你不熟悉该过程,我建议你阅读本教程以学习[如何在 Ubuntu 18.04 GNOME 中安装主题][9]。
+
+### 在其他 Linux 发行版中获取 Xenlism 主题
+
+你也可以在其他 Linux 发行版上安装 Xenlism 主题。各种 Linux 发行版的安装说明可在其网站上找到:
+
+[安装 Xenlism 主题][10]
+
+### 你怎么看?
+
+我知道不是每个人都会同意我,但我喜欢这个主题。我想你将来会在 It's FOSS 的教程中会看到 Xenlism 主题的截图。
+
+你喜欢 Xenlism 主题吗?如果不喜欢,你最喜欢什么主题?在下面的评论部分分享你的意见。
+
+### 关于作者
+
+我是一名专业软件开发人员,也是 It's FOSS 的创始人。我是一名狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信分享知识。除了Linux,我喜欢经典侦探之谜。我是 Agatha Christie 作品的忠实粉丝。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/xenlism-theme/
+
+作者:[Abhishek Prakash][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/abhishek/
+[1]:https://itsfoss.com/author/abhishek/
+[2]:https://itsfoss.com/xenlism-theme/#comments
+[3]:https://itsfoss.com/category/desktop/
+[4]:https://itsfoss.com/tag/themes/
+[5]:https://itsfoss.com/tag/xenlism/
+[6]:https://itsfoss.com/best-gtk-themes/
+[7]:https://itsfoss.com/pop-icon-gtk-theme-ubuntu/
+[8]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
+[9]:https://itsfoss.com/install-themes-ubuntu/
+[10]:http://xenlism.github.io/minimalism/#install
diff --git a/published/20180519 Python Debugging Tips.md b/published/201807/20180519 Python Debugging Tips.md
similarity index 100%
rename from published/20180519 Python Debugging Tips.md
rename to published/201807/20180519 Python Debugging Tips.md
diff --git a/published/201807/20180522 How to Run Your Own Git Server.md b/published/201807/20180522 How to Run Your Own Git Server.md
new file mode 100644
index 0000000000..ca438b25a4
--- /dev/null
+++ b/published/201807/20180522 How to Run Your Own Git Server.md
@@ -0,0 +1,246 @@
+搭建属于你自己的 Git 服务器
+======
+
+
+
+> 在本文中,我们的目的是让你了解如何设置属于自己的Git服务器。
+
+[Git][1] 是由 [Linux Torvalds 开发][2]的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。[根据报道,GitHub 是现如今全世界最大的代码托管网站][3]。GitHub 宣称已经有 920 万用户和 2180 万个仓库。许多大型公司现如今也将代码迁移到 GitHub 上。[甚至于谷歌,一家搜索引擎公司,也正将代码迁移到 GitHub 上][4]。
+
+### 运行你自己的 Git 服务器
+
+GitHub 能提供极佳的服务,但却有一些限制,尤其是你是单人或是一名 coding 爱好者。GitHub 其中之一的限制就是其中免费的服务没有提供代码私有托管业务。[你不得不支付每月 7 美金购买 5 个私有仓库][5],并且想要更多的私有仓库则要交更多的钱。
+
+万一你想要私有仓库或需要更多权限控制,最好的方法就是在你的服务器上运行 Git。不仅你能够省去一笔钱,你还能够在你的服务器有更多的操作。在大多数情况下,大多数高级 Linux 用户已经拥有自己的服务器,并且在这些服务器上方式 Git 就像“啤酒一样免费”(LCTT 译注:指免费软件)。
+
+在这篇教程中,我们主要讲在你的服务器上,使用两种代码管理的方法。一种是运行一个纯 Git 服务器,另一个是使用名为 [GitLab][6] 的 GUI 工具。在本教程中,我在 VPS 上运行的操作系统是 Ubuntu 14.04 LTS。
+
+### 在你的服务器上安装 Git
+
+在本篇教程中,我们考虑一个简单案例,我们有一个远程服务器和一台本地服务器,现在我们需要使用这两台机器来工作。为了简单起见,我们就分别叫它们为远程服务器和本地服务器。
+
+首先,在两边的机器上安装 Git。你可以从依赖包中安装 Git,在本文中,我们将使用更简单的方法:
+
+```
+sudo apt-get install git-core
+```
+
+为 Git 创建一个用户。
+
+```
+sudo useradd git
+passwd git
+```
+
+为了容易的访问服务器,我们设置一个免密 ssh 登录。首先在你本地电脑上创建一个 ssh 密钥:
+
+```
+ssh-keygen -t rsa
+```
+
+这时会要求你输入保存密钥的路径,这时只需要点击回车保存在默认路径。第二个问题是输入访问远程服务器所需的密码。它生成两个密钥——公钥和私钥。记下您在下一步中需要使用的公钥的位置。
+
+现在您必须将这些密钥复制到服务器上,以便两台机器可以相互通信。在本地机器上运行以下命令:
+
+```
+cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
+```
+
+现在,用 `ssh` 登录进服务器并为 Git 创建一个项目路径。你可以为你的仓库设置一个你想要的目录。
+
+现在跳转到该目录中:
+
+```
+cd /home/swapnil/project-1.git
+```
+
+现在新建一个空仓库:
+
+```
+git init --bare
+Initialized empty Git repository in /home/swapnil/project-1.git
+```
+
+现在我们需要在本地机器上新建一个基于 Git 版本控制仓库:
+
+```
+mkdir -p /home/swapnil/git/project
+```
+
+进入我们创建仓库的目录:
+
+```
+cd /home/swapnil/git/project
+```
+
+现在在该目录中创建项目所需的文件。留在这个目录并启动 `git`:
+
+```
+git init
+Initialized empty Git repository in /home/swapnil/git/project
+```
+
+把所有文件添加到仓库中:
+
+```
+git add .
+```
+
+现在,每次添加文件或进行更改时,都必须运行上面的 `add` 命令。 您还需要为每个文件更改都写入提交消息。提交消息基本上说明了我们所做的更改。
+
+```
+git commit -m "message" -a
+[master (root-commit) 57331ee] message
+ 2 files changed, 2 insertions(+)
+ create mode 100644 GoT.txt
+ create mode 100644 writing.txt
+```
+
+在这种情况下,我有一个名为 GoT(《权力的游戏》的点评)的文件,并且我做了一些更改,所以当我运行命令时,它指定对文件进行更改。 在上面的命令中 `-a` 选项意味着提交仓库中的所有文件。 如果您只更改了一个,则可以指定该文件的名称而不是使用 `-a`。
+
+举一个例子:
+
+```
+git commit -m "message" GoT.txt
+[master e517b10] message
+ 1 file changed, 1 insertion(+)
+```
+
+到现在为止,我们一直在本地服务器上工作。现在我们必须将这些更改推送到远程服务器上,以便通过互联网访问,并且可以与其他团队成员进行协作。
+
+```
+git remote add origin ssh://git@remote-server/repo->path-on-server..git
+```
+
+现在,您可以使用 `pull` 或 `push` 选项在服务器和本地计算机之间推送或拉取:
+
+```
+git push origin master
+```
+
+如果有其他团队成员想要使用该项目,则需要将远程服务器上的仓库克隆到其本地计算机上:
+
+```
+git clone git@remote-server:/home/swapnil/project.git
+```
+
+这里 `/home/swapnil/project.git` 是远程服务器上的项目路径,在你本机上则会改变。
+
+然后进入本地计算机上的目录(使用服务器上的项目名称):
+
+```
+cd /project
+```
+
+现在他们可以编辑文件,写入提交更改信息,然后将它们推送到服务器:
+
+```
+git commit -m 'corrections in GoT.txt story' -a
+```
+
+然后推送改变:
+
+```
+git push origin master
+```
+
+我认为这足以让一个新用户开始在他们自己的服务器上使用 Git。 如果您正在寻找一些 GUI 工具来管理本地计算机上的更改,则可以使用 GUI 工具,例如 QGit 或 GitK for Linux。
+
+
+
+### 使用 GitLab
+
+这是项目所有者和协作者的纯命令行解决方案。这当然不像使用 GitHub 那么简单。不幸的是,尽管 GitHub 是全球最大的代码托管商,但是它自己的软件别人却无法使用。因为它不是开源的,所以你不能获取源代码并编译你自己的 GitHub。这与 WordPress 或 Drupal 不同,您无法下载 GitHub 并在您自己的服务器上运行它。
+
+像往常一样,在开源世界中,是没有终结的尽头。GitLab 是一个非常优秀的项目。这是一个开源项目,允许用户在自己的服务器上运行类似于 GitHub 的项目管理系统。
+
+您可以使用 GitLab 为团队成员或公司运行类似于 GitHub 的服务。您可以使用 GitLab 在公开发布之前开发私有项目。
+
+GitLab 采用传统的开源商业模式。他们有两种产品:免费的开源软件,用户可以在自己的服务器上安装,以及类似于 GitHub 的托管服务。
+
+可下载版本有两个版本,免费的社区版和付费企业版。企业版基于社区版,但附带针对企业客户的其他功能。它或多或少与 WordPress.org 或 Wordpress.com 提供的服务类似。
+
+社区版具有高度可扩展性,可以在单个服务器或群集上支持 25000 个用户。GitLab 的一些功能包括:Git 仓库管理,代码评论,问题跟踪,活动源和维基。它配备了 GitLab CI,用于持续集成和交付。
+
+Digital Ocean 等许多 VPS 提供商会为用户提供 GitLab 服务。 如果你想在你自己的服务器上运行它,你可以手动安装它。GitLab 为不同的操作系统提供了软件包。 在我们安装 GitLab 之前,您可能需要配置 SMTP 电子邮件服务器,以便 GitLab 可以在需要时随时推送电子邮件。官方推荐使用 Postfix。所以,先在你的服务器上安装 Postfix:
+
+```
+sudo apt-get install postfix
+```
+
+在安装 Postfix 期间,它会问你一些问题,不要跳过它们。 如果你一不小心跳过,你可以使用这个命令来重新配置它:
+
+```
+sudo dpkg-reconfigure postfix
+```
+
+运行此命令时,请选择 “Internet Site”并为使用 Gitlab 的域名提供电子邮件 ID。
+
+我是这样输入的:
+
+```
+xxx@x.com
+```
+
+用 Tab 键并为 postfix 创建一个用户名。接下来将会要求你输入一个目标邮箱。
+
+在剩下的步骤中,都选择默认选项。当我们安装且配置完成后,我们继续安装 GitLab。
+
+我们使用 `wget` 来下载软件包(用 [最新包][7] 替换下载链接):
+
+```
+wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
+```
+
+然后安装这个包:
+
+```
+sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
+```
+
+现在是时候配置并启动 GitLab 了。
+
+```
+sudo gitlab-ctl reconfigure
+```
+
+您现在需要在配置文件中配置域名,以便您可以访问 GitLab。打开文件。
+
+```
+nano /etc/gitlab/gitlab.rb
+```
+
+在这个文件中编辑 `external_url` 并输入服务器域名。保存文件,然后从 Web 浏览器中打开新建的一个 GitLab 站点。
+
+
+
+默认情况下,它会以系统管理员的身份创建 `root`,并使用 `5iveL!fe` 作为密码。 登录到 GitLab 站点,然后更改密码。
+
+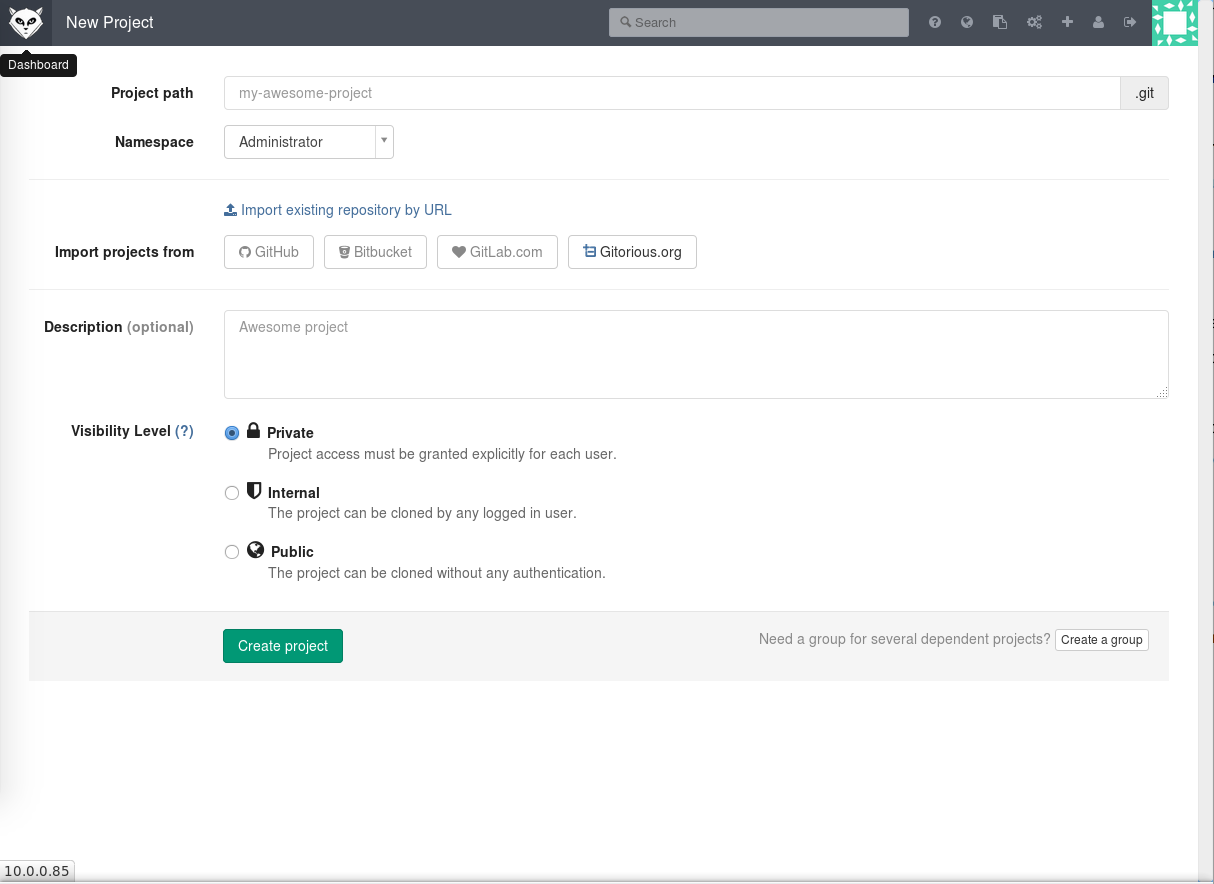
+
+密码更改后,登录该网站并开始管理您的项目。
+
+
+
+GitLab 有很多选项和功能。最后,我借用电影“黑客帝国”中的经典台词:“不幸的是,没有人知道 GitLab 可以做什么。你必须亲自尝试一下。”
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/how-run-your-own-git-server
+
+作者:[Swapnil Bhartiya][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[wyxplus](https://github.com/wyxplus)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/arnieswap
+[1]:https://github.com/git/git
+[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
+[3]:https://github.com/about/press
+[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
+[5]:https://github.com/pricing
+[6]:https://about.gitlab.com/
+[7]:https://about.gitlab.com/downloads/
diff --git a/published/20180529 5 trending open source machine learning JavaScript frameworks.md b/published/201807/20180529 5 trending open source machine learning JavaScript frameworks.md
similarity index 100%
rename from published/20180529 5 trending open source machine learning JavaScript frameworks.md
rename to published/201807/20180529 5 trending open source machine learning JavaScript frameworks.md
diff --git a/published/20180530 3 Python command-line tools.md b/published/201807/20180530 3 Python command-line tools.md
similarity index 100%
rename from published/20180530 3 Python command-line tools.md
rename to published/201807/20180530 3 Python command-line tools.md
diff --git a/translated/tech/20180531 You don-t know Bash- An introduction to Bash arrays.md b/published/201807/20180531 You don-t know Bash- An introduction to Bash arrays.md
similarity index 79%
rename from translated/tech/20180531 You don-t know Bash- An introduction to Bash arrays.md
rename to published/201807/20180531 You don-t know Bash- An introduction to Bash arrays.md
index a5466e3802..48bf345327 100644
--- a/translated/tech/20180531 You don-t know Bash- An introduction to Bash arrays.md
+++ b/published/201807/20180531 You don-t know Bash- An introduction to Bash arrays.md
@@ -1,9 +1,11 @@
-你不知道的 Bash:关于 Bash 数组的介绍
+你所不了解的 Bash:关于 Bash 数组的介绍
======
+> 进入这个古怪而神奇的 Bash 数组的世界。
+

-尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然没有正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash][1] 数组其实是非常有用的。
+尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然不像正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash][1] 数组其实是非常有用的。
### 稍等,这是为什么?
@@ -15,26 +17,21 @@
### 基础
-我们将要测试的 `--threads` 参数:
+我们首先要做的事是定义一个数组,用来容纳我们想要测试的 `--threads` 参数:
```
allThreads=(1 2 4 8 16 32 64 128)
-
```
-我们首先要做的事是定义一个数组,用来容纳我们想要测试的参数:
-
-本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的 数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
+本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
现在我们初始化了数组,让我们解析它其中的一些元素。仅仅输入 `echo $allThreads` ,你能发现,它只会输出第一个元素。
-要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出 变量。考虑以下场景:
+要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出变量。考虑以下场景:
```
type="article"
-
echo "Found 42 $type"
-
```
假如我们得到的变量 `$type` 是一个单词,我们想要添加在句子结尾一个 `s`。我们无法直接把 `s` 加到 `$type` 里面,因为这会把它变成另一个变量,`$types`。尽管我们可以利用像 `echo "Found 42 "$type"s"` 这样的代码形变,但解决这个问题的最好方法是用一个花括号:`echo "Found 42 ${type}s"`,这让我们能够告诉 Bash 变量名的起止位置(有趣的是,JavaScript/ES6 在 [template literals][2] 中注入变量和表达式的语法和这里是一样的)
@@ -49,37 +46,31 @@ echo "Found 42 $type"
#### 遍历数组元素
-记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动 pipeline:
+记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动管线:
```
for t in ${allThreads[@]}; do
-
./pipeline --threads $t
-
done
-
```
#### 遍历数组索引
-接下来,考虑一个稍稍不同的方法。不是遍历所有的数组元素,我们可以遍历所有的索引:
+接下来,考虑一个稍稍不同的方法。不遍历所有的数组元素,我们可以遍历所有的索引:
```
for i in ${!allThreads[@]}; do
-
./pipeline --threads ${allThreads[$i]}
-
done
-
```
一步一步看:如之前所见,`${allThreads[@]}` 表示数组中的所有元素。前面加了个感叹号,变成 `${!allThreads[@]}`,这会返回数组索引列表(这里是 0 到 7)。换句话说。`for` 循环就遍历所有的索引 `$i` 并从 `$allThreads` 中读取第 `$i` 个元素,当作 `--threads` 选项的参数。
-这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引避免创建要在循环中累加的额外变量。
+这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引可以避免额外创建在循环中累加的变量。
### 填充数组
-到目前为止,我们已经能够用给定的 `--threads` 选项启动 pipeline 了。现在假设按秒计时的运行时间输出到 pipeline。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
+到目前为止,我们已经能够用给定的 `--threads` 选项启动管线了。现在假设按秒计时的运行时间输出到管线。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
#### 一些有用的语法
@@ -89,7 +80,6 @@ done
```
myArray+=( "newElement1" "newElement2" )
-
```
#### 参数扫描
@@ -98,24 +88,18 @@ myArray+=( "newElement1" "newElement2" )
```
allThreads=(1 2 4 8 16 32 64 128)
-
allRuntimes=()
-
for t in ${allThreads[@]}; do
-
- runtime=$(./pipeline --threads $t)
-
- allRuntimes+=( $runtime )
-
+ runtime=$(./pipeline --threads $t)
+ allRuntimes+=( $runtime )
done
-
```
就是这个了!
### 还有什么能做的?
-这篇文章中,我们讲过使用数组进行参数扫描的场景。我担保有很多理由要使用 Bash 数组,这里就有两个例子:
+这篇文章中,我们讲过使用数组进行参数扫描的场景。我敢保证有很多理由要使用 Bash 数组,这里就有两个例子:
#### 日志警告
@@ -123,81 +107,49 @@ done
```
# 日志列表,发生问题时应该通知的人
-
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
-
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
-
-
# 在每个日志中查找问题标志
-
for i in ${!logPaths[@]};
-
do
-
log=${logPaths[$i]}
-
stakeholder=${logEmails[$i]}
-
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
-
-
# 如果近期发现超过 5 个错误,就警告负责人
-
if [[ "$numErrors" -gt 5 ]];
-
then
-
emailRecipient="$stakeholder"
-
emailSubject="WARNING: ${log} showing unusual levels of errors"
-
emailBody="${numErrors} errors found in log ${log}"
-
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
-
fi
-
done
-
```
#### API 查询
-如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,毫无疑问要用 SQL,但我们可以用 APIs!
+如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,SQL 不在我们考虑范围,但我们可以用 API!
-为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder][3] 作为我们的目的,这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
+为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder][3],这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出每个评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
```
endpoint="https://jsonplaceholder.typicode.com/comments"
-
allEmails=()
-
-
# 查询前 10 个帖子
-
for postId in {1..10};
-
do
-
# 执行 API 调用,获取该帖子评论者的邮箱
-
response=$(curl "${endpoint}?postId=${postId}")
-
-
-
+
# 使用 jq 把 JSON 响应解析成数组
-
allEmails+=( $( jq '.[].email' <<< "$response" ) )
-
done
-
```
-注意这里我是用 [`jq` 工具][4] 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
+注意这里我是用 [jq 工具][4] 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
你可能已经想到,使用 Bash 数组在数不胜数的场景中很有帮助,我希望这篇文章中的示例可以给你思维的启发。如果你从自己的工作中找到其它的例子想要分享出来,请在帖子下方评论。
@@ -209,17 +161,15 @@ done
|:--|:--|
| `arr=()` | 创建一个空数组 |
| `arr=(1 2 3)` | 初始化数组 |
-| `${arr[2]}` | 解析第三个元素 |
-| `${arr[@]}` | 解析所有元素 |
-| `${!arr[@]}` | 解析数组索引 |
+| `${arr[2]}` | 取得第三个元素 |
+| `${arr[@]}` | 取得所有元素 |
+| `${!arr[@]}` | 取得数组索引 |
| `${#arr[@]}` | 计算数组长度 |
-| `arr[0]=3` | 重写第 1 个元素 |
+| `arr[0]=3` | 覆盖第 1 个元素 |
| `arr+=(4)` | 添加值 |
| `str=$(ls)` | 把 `ls` 输出保存到字符串 |
| `arr=( $(ls) )` | 把 `ls` 输出的文件保存到数组里 |
-| `${arr[@]:s:n}` | 解析索引在 `n` 到 `s+n` 之间的元素|
-
->译者注: `${arr[@]:s:n}` 应该是解析索引在 `s` 到 `s+n-1` 之间的元素
+| `${arr[@]:s:n}` | 取得从索引 `s` 开始的 `n` 个元素 |
### 最后一点思考
@@ -236,37 +186,24 @@ done
```
import subprocess
-
-
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
-
all_runtimes = []
-
-
-# 用不同的线程数字启动 pipeline
-
+# 用不同的线程数字启动管线
for t in all_threads:
-
cmd = './pipeline --threads {}'.format(t)
-
-
# 使用子线程模块获得返回的输出
-
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
-
output = p.communicate()[0]
-
all_runtimes.append(output)
-
```
由于本例中没法避免使用命令行,所以可以优先使用 Bash。
#### 羞耻的宣传时间
-如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON][5],2018 年 7 月 17 号我会在这做一个主题为 [你不知道的 Bash][6] 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
+如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON][5],2018 年 7 月 17 号我会在这做一个主题为 [你所不了解的 Bash][6] 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
本文章由 [Medium] 首发,再发布时已获得授权。
@@ -277,7 +214,7 @@ via: https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
作者:[Robert Aboukhalil][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[BriFuture](https://github.com/BriFuture)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180604 4 cool new projects to try in COPR for June 2018.md b/published/201807/20180604 4 cool new projects to try in COPR for June 2018.md
similarity index 77%
rename from translated/tech/20180604 4 cool new projects to try in COPR for June 2018.md
rename to published/201807/20180604 4 cool new projects to try in COPR for June 2018.md
index ace9b2d7a0..2dad998bbb 100644
--- a/translated/tech/20180604 4 cool new projects to try in COPR for June 2018.md
+++ b/published/201807/20180604 4 cool new projects to try in COPR for June 2018.md
@@ -1,33 +1,38 @@
2018 年 6 月 COPR 中值得尝试的 4 个很酷的新项目
======
-COPR 是个人软件仓库[集合][1],它不在 Fedora 中携带。某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。Fedora 基础设施不支持 COPR 中的软件或没有项目签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
+
+
+
+COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
这是 COPR 中一组新的有趣项目。
### Ghostwriter
-[Ghostwriter][2] 是 [Markdown][3] 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中擦除被禁用,迫使用户现在编写并稍后编辑。![][4]
+[Ghostwriter][2] 是 [Markdown][3] 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中删除被禁用,迫使用户现在智能编写,而在稍后编辑。
+
+![][4]
#### 安装说明
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 Ghostwriter。要安装 Ghostwriter,请使用以下命令:
+
```
sudo dnf copr enable scx/ghostwriter
sudo dnf install ghostwriter
-
```
### Lector
-[Lector][5] 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 - 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。![][6]
+[Lector][5] 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 —— 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。![][6]
#### 安装说明
该仓库目前为 Fedora 26、27、28 和 Rawhide 提供Lector。要安装 Lector,请使用以下命令:
+
```
sudo dnf copr enable bugzy/lector
sudo dnf install lector
-
```
### Ranger
@@ -37,24 +42,25 @@ Ranerger 是一个基于文本的文件管理器,它带有 Vim 键绑定。它
#### 安装说明
该仓库目前为 Fedora 27、28 和 Rawhide 提供 Ranger。要安装 Ranger,请使用以下命令:
+
```
sudo dnf copr enable fszymanski/ranger
sudo dnf install ranger
-
```
### PrestoPalette
PrestoPeralette 是一款帮助创建平衡调色板的工具。PrestoPalette 的一个很好的功能是能够使用光照来影响调色板的亮度和饱和度。你可以将创建的调色板导出为 PNG 或 JSON。
+
![][8]
#### 安装说明
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 PrestoPalette。要安装 PrestoPalette,请使用以下命令:
+
```
sudo dnf copr enable dagostinelli/prestopalette
sudo dnf install prestopalette
-
```
@@ -65,7 +71,7 @@ via: https://fedoramagazine.org/4-try-copr-june-2018/
作者:[Dominik Turecek][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180606 6 Open Source AI Tools to Know.md b/published/201807/20180606 6 Open Source AI Tools to Know.md
similarity index 100%
rename from published/20180606 6 Open Source AI Tools to Know.md
rename to published/201807/20180606 6 Open Source AI Tools to Know.md
diff --git a/published/20180606 Getting started with Buildah.md b/published/201807/20180606 Getting started with Buildah.md
similarity index 100%
rename from published/20180606 Getting started with Buildah.md
rename to published/201807/20180606 Getting started with Buildah.md
diff --git a/published/20180606 Intel and AMD Reveal New Processor Designs.md b/published/201807/20180606 Intel and AMD Reveal New Processor Designs.md
similarity index 100%
rename from published/20180606 Intel and AMD Reveal New Processor Designs.md
rename to published/201807/20180606 Intel and AMD Reveal New Processor Designs.md
diff --git a/published/20180607 3 journaling applications for the Linux desktop.md b/published/201807/20180607 3 journaling applications for the Linux desktop.md
similarity index 100%
rename from published/20180607 3 journaling applications for the Linux desktop.md
rename to published/201807/20180607 3 journaling applications for the Linux desktop.md
diff --git a/published/201807/20180607 GitLab-s Ultimate - Gold Plans Are Now Free For Open-Source Projects.md b/published/201807/20180607 GitLab-s Ultimate - Gold Plans Are Now Free For Open-Source Projects.md
new file mode 100644
index 0000000000..fb1f925c0a
--- /dev/null
+++ b/published/201807/20180607 GitLab-s Ultimate - Gold Plans Are Now Free For Open-Source Projects.md
@@ -0,0 +1,77 @@
+GitLab 的付费套餐现在可以免费用于开源项目
+======
+
+最近在开源社区发生了很多事情。首先,[微软收购了 GitHub][1],然后人们开始寻找 [GitHub 替代套餐][2],甚至在 Linus Torvalds 发布 [Linux Kernel 4.17][3] 时没有花一点时间考虑它。好吧,如果你一直关注我们,我认为你知道这一切。
+
+但是,如今,GitLab 做出了一个明智的举措,为教育机构和开源项目免费提供高级套餐。当许多开发人员有兴趣将他们的开源项目迁移到 GitLab 时,没有更好的时机来提供这些了。
+
+### GitLab 的高级套餐现在对开源项目和教育机构免费
+
+![GitLab Logo][4]
+
+在今天(2018/6/7)[发布的博客][5]中,GitLab 宣布其**旗舰**和黄金套餐现在对教育机构和开源项目免费。虽然我们已经知道为什么 GitLab 做出这个举动(一个完美的时机!),但他们还是解释了他们让它免费的动机:
+
+> 我们让 GitLab 对教育机构免费,因为我们希望学生使用我们最先进的功能。许多大学已经运行了 GitLab。如果学生使用 GitLab 旗舰和黄金套餐的高级功能,他们将把这些高级功能的经验带到他们的工作场所。
+>
+> 我们希望有更多的开源项目使用 GitLab。GitLab.com 上的公共项目已经拥有 GitLab 旗舰套餐的所有功能。像 [Gnome][6] 和 [Debian][7] 这样的项目已经在自己的服务器运行开源版 GitLab 。随着今天的宣布,在专有软件上运行的开源项目可以使用 GitLab 提供的所有功能,同时我们通过向非开源组织收费来建立可持续的业务模式。
+
+### GitLab 提供的这些“免费”套餐是什么?
+
+![GitLab Pricing][8]
+
+GitLab 有两类产品。一个是你可以在自己的云托管服务如 [Digital Ocean][9] 上运行的软件。另一个是 Gitlab 软件既服务,其中托管由 GitLab 本身管理,你在 GitLab.com 上获得一个帐户。
+
+![GitLab Pricing for hosted service][10]
+
+黄金套餐是托管类别中最高的产品,而旗舰套餐是自托管类别中的最高产品。
+
+你可以在 GitLab 定价页面上获得有关其功能的更多详细信息。请注意,支持服务不包括在套餐中。你必须单独购买。
+
+### 你必须符合某些条件才能使用此优惠
+
+GitLab 还提到 —— 该优惠对谁有效。以下是他们在博客文章中写的内容:
+
+> 1. **教育机构:**任何为了学习、教育的机构,并且/或者由合格的教育机构、教职人员、学生训练。教育目的不包括商业,专业或任何其他营利目的。
+>
+> 2. **开源项目:**任何使用[标准开源许可证][11]且非商业性的项目。它不应该有付费支持或付费贡献者。
+>
+
+
+虽然免费套餐不包括支持,但是当你迫切需要专家帮助解决问题时,你仍然可以支付每用户每月 4.95 美元的额外费用 —— 当你特别需要一个专家来解决问题时,这是一个非常合理的价格。
+
+GitLab 还为学生们添加了一条说明:
+
+> 为减轻 GitLab 的管理负担,只有教育机构才能代表学生申请。如果你是学生并且你的教育机构不申请,你可以在 GitLab.com 上使用公共项目的所有功能,使用私人项目的免费功能,或者自己付费。
+
+### 总结
+
+现在 GitLab 正在加快脚步,你如何看待它?
+
+你有 [GitHub][12] 上的项目吗?你会切换么?或者,幸运的是,你从一开始就碰巧使用 GitLab?
+
+请在下面的评论栏告诉我们你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/gitlab-free-open-source/
+
+作者:[Ankush Das][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/ankush/
+[1]:https://itsfoss.com/microsoft-github/
+[2]:https://itsfoss.com/github-alternatives/
+[3]:https://itsfoss.com/linux-kernel-4-17/
+[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/GitLab-logo-800x450.png
+[5]:https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/
+[6]:https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/
+[7]:https://salsa.debian.org/public
+[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-pricing.jpeg
+[9]:https://m.do.co/c/d58840562553
+[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-hosted-service-800x273.jpeg
+[11]:https://itsfoss.com/open-source-licenses-explained/
+[12]:https://github.com/
diff --git a/published/20180607 Mesos and Kubernetes- It-s Not a Competition.md b/published/201807/20180607 Mesos and Kubernetes- It-s Not a Competition.md
similarity index 100%
rename from published/20180607 Mesos and Kubernetes- It-s Not a Competition.md
rename to published/201807/20180607 Mesos and Kubernetes- It-s Not a Competition.md
diff --git a/published/20180611 Turn Your Raspberry Pi into a Tor Relay Node.md b/published/201807/20180611 Turn Your Raspberry Pi into a Tor Relay Node.md
similarity index 100%
rename from published/20180611 Turn Your Raspberry Pi into a Tor Relay Node.md
rename to published/201807/20180611 Turn Your Raspberry Pi into a Tor Relay Node.md
diff --git a/published/20180615 4 tools for building embedded Linux systems.md b/published/201807/20180615 4 tools for building embedded Linux systems.md
similarity index 100%
rename from published/20180615 4 tools for building embedded Linux systems.md
rename to published/201807/20180615 4 tools for building embedded Linux systems.md
diff --git a/published/201807/20180615 BLUI- An easy way to create game UI.md b/published/201807/20180615 BLUI- An easy way to create game UI.md
new file mode 100644
index 0000000000..f6514e9578
--- /dev/null
+++ b/published/201807/20180615 BLUI- An easy way to create game UI.md
@@ -0,0 +1,59 @@
+BLUI:创建游戏 UI 的简单方法
+======
+
+> 开源游戏开发插件运行虚幻引擎的用户使用基于 Web 的编程方式创建独特的用户界面元素。
+
+
+
+游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的虚幻引擎,允许独立开发者使用 AAA 发行商相同达到行业标准的工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
+
+这些引擎中可以包含插件以允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
+
+### 什么是 BLUI?
+
+作为独立游戏开发工作室的一员,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管虚幻引擎(我们选择的引擎)有一个实现了类似目的的内置 UI 编辑器,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
+
+在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的虚幻引擎集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
+
+在商业产品和虚幻引擎的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过 web 语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
+
+### 安装和使用 BLUI
+
+使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括自举 JavaScript 代码、外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何虚幻引擎插件那样安装它,并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在虚幻引擎 UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
+
+![Integrating BLUI into Unreal Engine 4 blueprints][4]
+
+*将 BLUI 集成到虚幻 4 图纸中。*
+
+在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
+
+![Using BLUI to sync UI elements with the soundtrack.][6]
+
+*使用 BLUI 将 UI 元素与音轨同步。*
+
+通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个轻松的过程。还有一个由支持虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
+
+### 开源优势
+
+开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内的机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/6/blui-game-development-plugin
+
+作者:[Uwana lkaiddi][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/uwikaiddi
+[1]:https://github.com/AaronShea/BLUI
+[2]:https://bitbucket.org/chromiumembedded/cef
+[3]:/file/400616
+[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
+[5]:/file/400621
+[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
+[7]:https://github.com/AaronShea/BLUI/wiki
+[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
diff --git a/published/201807/20180618 5 open source alternatives to Dropbox.md b/published/201807/20180618 5 open source alternatives to Dropbox.md
new file mode 100644
index 0000000000..e181b37ca5
--- /dev/null
+++ b/published/201807/20180618 5 open source alternatives to Dropbox.md
@@ -0,0 +1,122 @@
+可代替 Dropbox 的 5 个开源软件
+=====
+
+> 寻找一个不会破坏你的安全、自由或银行资产的文件共享应用。
+
+
+
+Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
+
+也行你出于各种好的理由,包括安全和自由,这使你决定用[开源方式][1]。亦或是你已经被数据泄露吓坏了,或者定价计划不能满足你实际需要的存储量。
+
+幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
+
+这里有 5 个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
+
+### ownCloud
+
+
+
+[ownCloud][2] 发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据该公司统计,有超过 150 万用户),并且由由 1100 个参与者的社区积极维护,定期发布更新。
+
+它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议][3])是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
+
+使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过带有密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它的 [市场][4] 中的各种各样的第三方应用来扩展它的功能。当然,它也提供付费的、商业许可的企业版本。
+
+ownCloud 提供了详尽的[文档][5],包括安装指南和针对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码][6]。
+
+### NextCloud
+
+
+
+[NextCloud][7] 在 2016 年从 ownCloud 分裂出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵从性作为它的一个独特的[推崇的卖点][8]。它具有 HIPAA (医疗) 和 GDPR (隐私)法规遵从功能,并提供广泛的数据策略约束、加密、用户管理和审核功能。它还在传输和存储期间对数据进行加密,并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
+
+像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,该公司与几个[提供商][9]达成了伙伴合作,提供安装和托管,并销售服务器、设备和服务支持。在[市场][10]中提供了大量的apps 来扩展它的功能。
+
+NextCloud 的[文档][11]为用户、管理员和开发者提供了详细的信息,并且它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码、报告一个错误、查看它的 AGPLv3 许可,或者想了解更多,请访问它的[GitHub 项目主页][12]。
+
+### Seafile
+
+
+
+与 ownCloud 或 NextCloud 相比,[Seafile][13] 或许没有花里胡哨的卖点(app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器,以扩展你的桌面存储,并允许你使用密码保护和各种级别的权限(即只读或读写) 有选择地共享文件。
+
+它的协作功能包括文件夹权限控制,密码保护的下载链接和像 Git 一样的版本控制和记录。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护,并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
+
+更多详细信息, 请访问 Seafile 的 [GitHub 仓库][14]、[服务手册][15]、[wiki][16] 和[论坛][17]。请注意, Seafile 的社区版在 [GPLv2][18] 下获得许可,但其专业版不是开源的。
+
+### OnionShare
+
+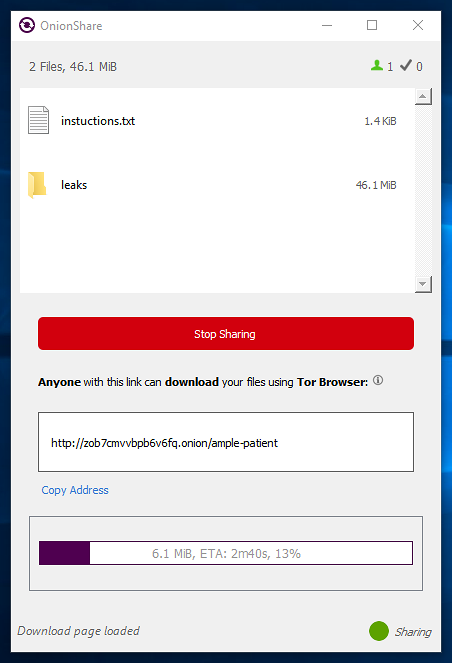
+
+[OnionShare][19] 是一个很酷的应用:如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装][20],无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时,OnionShare 创建一个 web 服务器,使其可作为 Tor 洋葱服务访问,并生成一个不可猜测的 .onion URL,这个 URL 允许收件人通过 [Tor 浏览器][21]获取文件。
+
+你可以设置文件共享的限制,例如限制可以下载的次数或使用自动停止计时器,这会设置一个严格的过期日期/时间,超过这个期限便不可访问(即使尚未访问该文件)。
+
+OnionShare 在 [GPLv3][22] 之下被许可;有关详细信息,请查阅其 [GitHub 仓库][22],其中还包括[文档][23],介绍了这个易用的文件共享软件的特点。
+
+### Pydio Cells
+
+
+
+[Pydio Cells][24] 在 2018 年 5 月推出了稳定版,是对 Pydio 共享应用程序的核心服务器代码的彻底大修。由于 Pydio 的基于 PHP 的后端的限制,开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
+
+Pydio Cells 包括通常的共享和版本控制功能,以及应用程序中的消息接受、移动应用程序(Android 和 iOS),以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能,但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
+
+您可以 在 Linux 和 MacOS 里[下载][25] Pydio Cells。有关详细信息, 请查阅 [文档常见问题][26]、[源码库][27] 和 [AGPLv3 许可证][28]
+
+### 其他
+
+如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
+
+* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing][29]。
+* 如果你是一个 Git 的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare][30]。
+* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy][31]。
+* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review][32]——一个罕为人知的工具。
+
+哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/alternatives/dropbox
+
+作者:[Opensource.com][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[distant1219](https://github.com/distant1219)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com
+[1]:https://opensource.com/open-source-way
+[2]:https://owncloud.org/
+[3]:https://www.gnu.org/licenses/agpl-3.0.html
+[4]:https://marketplace.owncloud.com/
+[5]:https://doc.owncloud.com/
+[6]:https://github.com/owncloud
+[7]:https://nextcloud.com/
+[8]:https://nextcloud.com/secure/
+[9]:https://nextcloud.com/providers/
+[10]:https://apps.nextcloud.com/
+[11]:https://nextcloud.com/support/
+[12]:https://github.com/nextcloud
+[13]:https://www.seafile.com/en/home/
+[14]:https://github.com/haiwen/seafile
+[15]:https://manual.seafile.com/
+[16]:https://seacloud.cc/group/3/wiki/
+[17]:https://forum.seafile.com/
+[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
+[19]:https://onionshare.org/
+[20]:https://onionshare.org/#downloads
+[21]:https://www.torproject.org/
+[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
+[23]:https://github.com/micahflee/onionshare/wiki
+[24]:https://pydio.com/en
+[25]:https://pydio.com/download/
+[26]:https://pydio.com/en/docs/faq
+[27]:https://github.com/pydio/cells
+[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
+[29]:https://syncthing.net/
+[30]:http://www.sparkleshare.org/
+[31]:https://cozy.io/en/
+[32]:https://opensource.com/article/17/3/file-sharing-tools
diff --git a/published/20180619 Getting started with Open edX to host your course.md b/published/201807/20180619 Getting started with Open edX to host your course.md
similarity index 100%
rename from published/20180619 Getting started with Open edX to host your course.md
rename to published/201807/20180619 Getting started with Open edX to host your course.md
diff --git a/published/201807/20180619 How To Check Which Groups A User Belongs To On Linux.md b/published/201807/20180619 How To Check Which Groups A User Belongs To On Linux.md
new file mode 100644
index 0000000000..97ceab20e2
--- /dev/null
+++ b/published/201807/20180619 How To Check Which Groups A User Belongs To On Linux.md
@@ -0,0 +1,160 @@
+如何在 Linux 上检查用户所属组
+======
+
+将用户添加到现有组是 Linux 管理员的常规活动之一。这是一些在大环境中工作的管理员的日常活动。
+
+甚至我会因为业务需求而在我的环境中每天都在进行这样的活动。它是帮助你识别环境中现有组的重要命令之一。
+
+此外,这些命令还可以帮助你识别用户所属的组。所有用户都列在 `/etc/passwd` 中,组列在 `/etc/group` 中。
+
+无论我们使用什么命令,都将从这些文件中获取信息。此外,每个命令都有其独特的功能,可帮助用户单独获取所需的信息。
+
+### 什么是 /etc/passwd?
+
+`/etc/passwd` 是一个文本文件,其中包含登录 Linux 系统所必需的每个用户信息。它维护有用的用户信息,如用户名、密码、用户 ID、组 ID、用户 ID 信息、家目录和 shell。passwd 每行包含了用户的详细信息,共有如上所述的 7 个字段。
+
+```
+$ grep "daygeek" /etc/passwd
+daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
+```
+
+### 什么是 /etc/group?
+
+`/etc/group` 是一个文本文件,用于定义用户所属的组。我们可以将多个用户添加到单个组中。它允许用户访问其他用户文件和文件夹,因为 Linux 权限分为三类:用户、组和其他。它维护有关组的有用信息,例如组名、组密码,组 ID(GID)和成员列表。每个都在一个单独的行。组文件每行包含了每个组的详细信息,共有 4 个如上所述字段。
+
+这可以通过使用以下方法来执行。
+
+ * `groups`: 显示一个组的所有成员。
+ * `id`: 打印指定用户名的用户和组信息。
+ * `lid`: 显示用户的组或组的用户。
+ * `getent`: 从 Name Service Switch 库中获取条目。
+ * `grep`: 代表“全局正则表达式打印”,它能打印匹配的模式。
+
+### 什么是 groups 命令?
+
+`groups` 命令打印每个给定用户名的主要组和任何补充组的名称。
+
+```
+$ groups daygeek
+daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
+```
+
+如果要检查与当前用户关联的组列表。只需运行 `groups` 命令,无需带任何用户名。
+
+```
+$ groups
+daygeek adm cdrom sudo dip plugdev lpadmin sambashare
+```
+
+### 什么是 id 命令?
+
+id 代表 “身份”。它打印真实有效的用户和组 ID。打印指定用户或当前用户的用户和组信息。
+
+```
+$ id daygeek
+uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
+```
+
+如果要检查与当前用户关联的组列表。只运行 `id` 命令,无需带任何用户名。
+
+```
+$ id
+uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
+```
+
+### 什么是 lid 命令?
+
+它显示用户的组或组的用户。显示有关包含用户名的组或组名称中包含的用户的信息。此命令需要管理员权限。
+
+```
+$ sudo lid daygeek
+ adm(gid=4)
+ cdrom(gid=24)
+ sudo(gid=27)
+ dip(gid=30)
+ plugdev(gid=46)
+ lpadmin(gid=108)
+ daygeek(gid=1000)
+ sambashare(gid=124)
+```
+
+### 什么是 getent 命令?
+
+`getent` 命令显示 Name Service Switch 库支持的数据库中的条目,它们在 `/etc/nsswitch.conf` 中配置。
+
+```
+$ getent group | grep daygeek
+adm:x:4:syslog,daygeek
+cdrom:x:24:daygeek
+sudo:x:27:daygeek
+dip:x:30:daygeek
+plugdev:x:46:daygeek
+lpadmin:x:118:daygeek
+daygeek:x:1000:
+sambashare:x:128:daygeek
+```
+
+如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
+
+```
+$ getent group | grep daygeek | awk -F: '{print $1}'
+adm
+cdrom
+sudo
+dip
+plugdev
+lpadmin
+daygeek
+sambashare
+```
+
+运行以下命令仅打印主群组信息。
+
+```
+$ getent group daygeek
+daygeek:x:1000:
+
+```
+
+### 什么是 grep 命令?
+
+`grep` 代表 “全局正则表达式打印”,它能打印文件匹配的模式。
+
+```
+$ grep "daygeek" /etc/group
+adm:x:4:syslog,daygeek
+cdrom:x:24:daygeek
+sudo:x:27:daygeek
+dip:x:30:daygeek
+plugdev:x:46:daygeek
+lpadmin:x:118:daygeek
+daygeek:x:1000:
+sambashare:x:128:daygeek
+```
+
+如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
+
+```
+$ grep "daygeek" /etc/group | awk -F: '{print $1}'
+adm
+cdrom
+sudo
+dip
+plugdev
+lpadmin
+daygeek
+sambashare
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/prakash/
diff --git a/published/20180620 Stop merging your pull requests manually.md b/published/201807/20180620 Stop merging your pull requests manually.md
similarity index 100%
rename from published/20180620 Stop merging your pull requests manually.md
rename to published/201807/20180620 Stop merging your pull requests manually.md
diff --git a/published/20180622 Automatically Change Wallpapers in Linux with Little Simple Wallpaper Changer.md b/published/201807/20180622 Automatically Change Wallpapers in Linux with Little Simple Wallpaper Changer.md
similarity index 100%
rename from published/20180622 Automatically Change Wallpapers in Linux with Little Simple Wallpaper Changer.md
rename to published/201807/20180622 Automatically Change Wallpapers in Linux with Little Simple Wallpaper Changer.md
diff --git a/published/201807/20180625 How To Upgrade Everything Using A Single Command In Linux.md b/published/201807/20180625 How To Upgrade Everything Using A Single Command In Linux.md
new file mode 100644
index 0000000000..8ef6fb9ff8
--- /dev/null
+++ b/published/201807/20180625 How To Upgrade Everything Using A Single Command In Linux.md
@@ -0,0 +1,120 @@
+如何在 Linux 中使用一个命令升级所有软件
+======
+
+
+
+众所周知,让我们的 Linux 系统保持最新状态会用到多种包管理器。比如说,在 Ubuntu 中,你无法使用 `sudo apt update` 和 `sudo apt upgrade` 命令升级所有软件。此命令仅升级使用 APT 包管理器安装的应用程序。你有可能使用 `cargo`、[pip][1]、`npm`、`snap` 、`flatpak` 或 [Linuxbrew][2] 包管理器安装了其他软件。你需要使用相应的包管理器才能使它们全部更新。
+
+再也不用这样了!跟 `topgrade` 打个招呼,这是一个可以一次性升级系统中所有软件的工具。
+
+你无需运行每个包管理器来更新包。这个 `topgrade` 工具通过检测已安装的软件包、工具、插件并运行相应的软件包管理器来更新 Linux 中的所有软件,用一条命令解决了这个问题。它是自由而开源的,使用 **rust 语言**编写。它支持 GNU/Linux 和 Mac OS X.
+
+### 在 Linux 中使用一个命令升级所有软件
+
+`topgrade` 存在于 AUR 中。因此,你可以在任何基于 Arch 的系统中使用 [Yay][3] 助手程序安装它。
+
+```
+$ yay -S topgrade
+```
+
+在其他 Linux 发行版上,你可以使用 `cargo` 包管理器安装 `topgrade`。要安装 cargo 包管理器,请参阅以下链接:
+
+- [在 Linux 安装 rust 语言][12]
+
+然后,运行以下命令来安装 `topgrade`。
+
+```
+$ cargo install topgrade
+```
+
+安装完成后,运行 `topgrade` 以升级 Linux 系统中的所有软件。
+
+```
+$ topgrade
+```
+
+一旦调用了 `topgrade`,它将逐个执行以下任务。如有必要,系统会要求输入 root/sudo 用户密码。
+
+1、 运行系统的包管理器:
+
+ * Arch:运行 `yay` 或者回退到 [pacman][4]
+ * CentOS/RHEL:运行 `yum upgrade`
+ * Fedora :运行 `dnf upgrade`
+ * Debian/Ubuntu:运行 `apt update` 和 `apt dist-upgrade`
+ * Linux/macOS:运行 `brew update` 和 `brew upgrade`
+
+2、 检查 Git 是否跟踪了以下路径。如果有,则拉取它们:
+
+ * `~/.emacs.d` (无论你使用 Spacemacs 还是自定义配置都应该可用)
+ * `~/.zshrc`
+ * `~/.oh-my-zsh`
+ * `~/.tmux`
+ * `~/.config/fish/config.fish`
+ * 自定义路径
+
+3、 Unix:运行 `zplug` 更新
+
+4、 Unix:使用 TPM 升级 `tmux` 插件
+
+5、 运行 `cargo install-update`
+
+6、 升级 Emacs 包
+
+7、 升级 Vim 包。对以下插件框架均可用:
+
+ * NeoBundle
+ * [Vundle][5]
+ * Plug
+
+8、 升级 [npm][6] 全局安装的包
+
+9、 升级 Atom 包
+
+10、 升级 [Flatpak][7] 包
+
+11、 升级 [snap][8] 包
+
+12、 Linux:运行 `fwupdmgr` 显示固件升级。 (仅查看。实际不会执行升级)
+
+13、 运行自定义命令。
+
+最后,`topgrade` 将运行 `needrestart` 以重新启动所有服务。在 Mac OS X 中,它会升级 App Store 程序。
+
+我的 Ubuntu 18.04 LTS 测试环境的示例输出:
+
+![][10]
+
+好处是如果一个任务失败,它将自动运行下一个任务并完成所有其他后续任务。最后,它将显示摘要,其中包含运行的任务数量,成功的数量和失败的数量等详细信息。
+
+![][11]
+
+**建议阅读:**
+
+就个人而言,我喜欢创建一个像 `topgrade` 程序的想法,并使用一个命令升级使用各种包管理器安装的所有软件。我希望你也觉得它有用。还有更多的好东西。敬请关注!
+
+干杯!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
+[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
+[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[4]:https://www.ostechnix.com/getting-started-pacman/
+[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
+[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
+[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
+[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
+[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
+[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
+[12]:https://www.ostechnix.com/install-rust-programming-language-in-linux/
\ No newline at end of file
diff --git a/published/20180625 How to install Pipenv on Fedora.md b/published/201807/20180625 How to install Pipenv on Fedora.md
similarity index 100%
rename from published/20180625 How to install Pipenv on Fedora.md
rename to published/201807/20180625 How to install Pipenv on Fedora.md
diff --git a/published/20180626 5 open source puzzle games for Linux.md b/published/201807/20180626 5 open source puzzle games for Linux.md
similarity index 100%
rename from published/20180626 5 open source puzzle games for Linux.md
rename to published/201807/20180626 5 open source puzzle games for Linux.md
diff --git a/published/20180626 TrueOS Doesnt Want to Be BSD for Desktop Anymore.md b/published/201807/20180626 TrueOS Doesnt Want to Be BSD for Desktop Anymore.md
similarity index 100%
rename from published/20180626 TrueOS Doesnt Want to Be BSD for Desktop Anymore.md
rename to published/201807/20180626 TrueOS Doesnt Want to Be BSD for Desktop Anymore.md
diff --git a/published/20180627 Historical inventory of collaborative editors.md b/published/201807/20180627 Historical inventory of collaborative editors.md
similarity index 100%
rename from published/20180627 Historical inventory of collaborative editors.md
rename to published/201807/20180627 Historical inventory of collaborative editors.md
diff --git a/published/20180627 World Cup football on the command line.md b/published/201807/20180627 World Cup football on the command line.md
similarity index 100%
rename from published/20180627 World Cup football on the command line.md
rename to published/201807/20180627 World Cup football on the command line.md
diff --git a/published/201807/20180628 Blockchain evolution- A quick guide and why open source is at the heart of it.md b/published/201807/20180628 Blockchain evolution- A quick guide and why open source is at the heart of it.md
new file mode 100644
index 0000000000..a91a1d4cda
--- /dev/null
+++ b/published/201807/20180628 Blockchain evolution- A quick guide and why open source is at the heart of it.md
@@ -0,0 +1,100 @@
+区块链进化简史:为什么开源是其核心所在
+======
+
+> 从比特币到下一代区块链。
+
+
+
+当开源项目开发下一个新版本时,用后缀 “-ng” 表示 “下一代”的情况并不鲜见。幸运的是,到目前为止,快速演进的区块链成功地避开了这个命名陷阱。但是在这个开源生态系统的演进过程中,改变是不断发生的,而好的创意以典型的开源方式在许多不同的项目中被采用、交融和演进。
+
+在本文中,我将审视不同代次的区块链,并且看一看在处理这个生态系统遇到的问题时出现什么创意。当然,任何对生态系统进行分类的尝试都有其局限性的 —— 和不同意见者的 —— 但是这也将为混乱的区块链项目提供了一个粗略的指南。
+
+### 始作俑者:比特币
+
+第一代的区块链起源于 [比特币][1] 区块链,这是以去中心化、点对点加密货币为基础的总帐,它从 [Slashdot][2] 网站上的杂谈变成了一个主流话题。
+
+这个区块链是一个分布式总帐,它对所有用户的交易保持跟踪,以避免他们双重支付(双花)货币(在历史上,这个任务是委托给第三方—— 银行 ——来做的)。为防范攻击者在系统上捣乱,总帐被复制到每个参与到比特币网络的计算机上,并且每次只允许一台计算机去更新总帐。为决定哪台计算机能够获得更新总帐的权力,系统安排在比特币网络上的计算机之间每 10 分钟进行一场竞赛,这将消耗它们的(许多)能源才能参与竞赛。赢家将获得将前 10 分钟发生的交易写入到总帐(区块链中的“区块”)的权力,并且为赢家写入区块链的工作给予一些比特币奖励。这种方式被称为工作量证明(PoW)共识机制。
+
+这就是区块链最有趣的地方。比特币以[开源项目][3]的方式发布于 2009 年 1 月 。在 2010 年,由于意识到这些元素中的许多是可以调整的,围绕比特币聚集起了一个社区 —— [bitcointalk 论坛][4],来开始各种实验。
+
+起初,看到的比特币区块链是一个分布式数据库的形式, [Namecoin][5] 项目出现后,建议去保存任意数据到它的事务数据库中。如果区块链能够记录金钱的转移,那么它也应该能够记录其它资产的转移,比如域名。这正是 Namecoin 的主要使用场景,它上线于 2011 年 4 月 —— 也就是比特币出现两年后。
+
+Namecoin 调整的地方是区块链的内容,[莱特币][6] 调整的是两个技术部分:一是将两个区块的时间间隔从 10 分钟减少到 2.5 分钟,二是改变了竞赛方式(用 [scrypt][7] 来替换了 SHA-256 安全哈希算法)。这是能够做到的,因为比特币是以开源软件的方式来发布的,而莱特币本质上与比特币在其它部分是完全相同的。莱特币是修改了比特币共识机制的第一个分叉,这也为其它的更多“币”铺平了道路。
+
+沿着这条道路,基于比特币代码库的各种变种越来越多。其中一些扩展了比特币的用途,比如 [Zerocash][8] 协议,它专注于提供交易的匿名性和可替换性,但它最终分拆为它自己的货币 —— [Zcash][9]。
+
+虽然 Zcash 带来了它自己的创新,使用了最近被称为“零知识证明”的加密技术,但它维持着与大多数主要的比特币代码库的兼容性,这意味着它能够从上游的比特币创新中获益。
+
+另外的项目 —— [CryptoNote][10],它萌芽于相同的社区,但是并没有使用相同的代码,它以比特币为背景来构建的,但又与之不同。它发布于 2012 年 12 月,由于它的出现,导致了几种加密货币的诞生,最著名的 [门罗币][11] (2014)就是其中之一。门罗币与 Zcash 使用了不同的方法,但解决了相同的问题:隐私性和可替换性。
+
+就像在开源世界中经常出现的案例一样,做同样的工作有不止一个的工具可用。
+
+### 下一代:“Blockchain-ng”
+
+但是,到目前为止,所有的这些变体只是改进加密货币或者扩展它们去支持其它类型的事务。因此,这就引出了第二代区块链。
+
+一旦社区开始去修改区块链的用法和调整技术部分时,对于一些想去扩展和重新思考它们未来的人来说,这种调整花费不了多长时间的。比特币的长期追随者 —— [Vitalik Buterin][12] 在 2013 年底建议,区域链的事务应该能够表示一个状态机的状态变化,将区域链视为能够运行应用程序(“智能合约”)的分布式计算机。这个项目 —— [以太坊][13],上线于 2015 年 4 月。它在运行分布式应用程序方面取得了巨大的成功,它的一些非常流行的分布式应用程序([加密猫][14])甚至导致以太坊区块链变慢。
+
+这证明了目前的区块链存在一个很大的局限性:速度和容量。(速度通常用每秒事务数来测量,简称 TPS)有几个提议都建议去解决这个速度问题,从分片到侧链,以及一个被称为“第二层”的解决方案。这里需要更多的创新。
+
+随着“智能合约”这个词开始流行起来,并且用已经被证实仍然很慢的技术去运行它们,那么就需要实现其它的思路:许可区块链。到目前为止,我们所介绍的所有区块链网络有两个没有明说的特征:一是它们是公开的(任何人都可以看到它们的功能),二是它们不需要许可(任何人都可以加入它们)。这两个部分是运行一个分布式的、非基于第三方的货币应该具有的和必需具有的条件。
+
+随着区块链被认为出现与加密货币越来越明显的分离趋势,开始去考虑一些隐私、许可场景是很有意义的。一个有业务关系但不需要彼此完全信任的财团类型的参与者,能够从这些区块链类型中获益 —— 比如,物流链上的参与者,定期进行双边结算或者使用一个清算中心的金融、保险、或医疗保健机构。
+
+一旦你将设置从“任何人都可以加入”变为“仅邀请者方可加入”,进一步对区块链构建区块的方式进行改变和调整将变得可能,那么对一些人来说,结果将变得非常有趣。
+
+首先,设计用来保护网络不受恶意或者垃圾参与者的影响的工作量证明(PoW)可以被替换为更简单的和更少资源消耗的一些东西,比如,基于 [Raft][15] 的共识协议。在更高级别的安全性和更快的速度之间进行权衡,采用更简单的共识算法。对于更多群体来说这样更理想,因为他们可以用基于加密技术的担保来取代其它的基于法律关系的担保,例如为避免由于竞争而产生的大量能源消耗,而工作量证明就是这种情况。另外一个创新的地方是,使用 [股权证明][16](PoS),它是公共网络共识机制的一个重量级的竞争者。它将可能像许可链网络一样找到它自己的实现方式。
+
+有几个项目可以让创建许可区块链变得更简单,包括 [Quorum][17] (以太坊的一个分叉)和 [Hyperledger][18] 的 [Fabric][19] 和 [Sawtooth][20],这是基于新代码的两个开源项目。
+
+许可区块链可以避免公共的、非许可方式的区块链中某些错综复杂的问题,但是它自己也存在一些问题。正确地管理参与者是其中的一个问题:谁可以加入?如何辨别他们?如何将他们从网络上移除?网络上的一个实体是否去管理一个中央公共密钥基础设施(PKI)?
+
+### 区块链的开放本质
+
+到目前为止的所有案例中,有一件事情是很明确的:使用一个区块链的目标是去提升网络中的参与者和它产生的数据的信任水平,理想情况下,不需要做进一步的工作即可足以使用它。
+
+只有为这个网络提供动力的软件是自由和开源的,才能达到这种信任水平。即便是一个正确的、专用的、分布式区块链,它的本质仍然是运行着相同的第三方代码的私有代理的集合。从本质上来说,区块链的源代码必须是开源的,但仅是开源还不够。随着生态系统持续成长,这既是最低限度的担保也是进一步创新的源头。
+
+最后,值得一提的是,虽然区块链的开放本质被认为是创新和变化的源头,它也被认为是一种治理形式:代码治理,用户期望运行的任何一个特定版本,都应该包含他们认为的整个网络应该包含的功能和方法。在这方面,需要说明的一点是,一些区块链的开放本质正在“变味”。但是这一问题正在解决。
+
+### 第三和第四代:治理
+
+接下来,我正在考虑第三代和第四代区块链:区块链将内置治理工具,并且项目将去解决棘手的大量不同区块链之间互连互通的问题,以便于它们之间可以交换信息和价值。
+
+---
+关于作者
+
+axel simon: 长期的自由及开源软件爱好者,就职于 Red Hat ,关注安全和区块链技术,以及分布式系统和协议。致力于保护互联网及其成就(知识分享、信息访问、去中心化和网络中立)。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/6/blockchain-guide-next-generation
+
+作者:[Axel Simon][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/axel
+[1]:https://bitcoin.org
+[2]:https://slashdot.org/
+[3]:https://github.com/bitcoin/bitcoin
+[4]:https://bitcointalk.org/
+[5]:https://www.namecoin.org/
+[6]:https://litecoin.org/
+[7]:https://en.wikipedia.org/wiki/Scrypt
+[8]:http://zerocash-project.org/index
+[9]:https://z.cash
+[10]:https://cryptonote.org/
+[11]:https://en.wikipedia.org/wiki/Monero_(cryptocurrency)
+[12]:https://en.wikipedia.org/wiki/Vitalik_Buterin
+[13]:https://ethereum.org
+[14]:http://cryptokitties.co/
+[15]:https://en.wikipedia.org/wiki/Raft_(computer_science)
+[16]:https://www.investopedia.com/terms/p/proof-stake-pos.asp
+[17]:https://www.jpmorgan.com/global/Quorum
+[18]:https://hyperledger.org/
+[19]:https://www.hyperledger.org/projects/fabric
+[20]:https://www.hyperledger.org/projects/sawtooth
diff --git a/published/20180628 Sosreport - A Tool To Collect System Logs And Diagnostic Information.md b/published/201807/20180628 Sosreport - A Tool To Collect System Logs And Diagnostic Information.md
similarity index 100%
rename from published/20180628 Sosreport - A Tool To Collect System Logs And Diagnostic Information.md
rename to published/201807/20180628 Sosreport - A Tool To Collect System Logs And Diagnostic Information.md
diff --git a/published/201807/20180702 My first sysadmin mistake.md b/published/201807/20180702 My first sysadmin mistake.md
new file mode 100644
index 0000000000..3d9c64b3f0
--- /dev/null
+++ b/published/201807/20180702 My first sysadmin mistake.md
@@ -0,0 +1,43 @@
+我的第一个系统管理员错误
+======
+
+> 如何在崩溃的局面中集中精力寻找解决方案。
+
+
+
+如果你在 IT 领域工作,你知道事情永远不会像你想象的那样完好。在某些时候,你会遇到错误或出现问题,你最终必须解决问题。这就是系统管理员的工作。
+
+作为人类,我们都会犯错误。我们不是已经犯错,就是即将犯错。结果,我们最终还必须解决自己的错误。总是这样。我们都会失误、敲错字母或犯错。
+
+作为一名年轻的系统管理员,我艰难地学到了这一课。我犯了一个大错。但是多亏了上级的指导,我学会了不去纠缠于我的错误,而是制定一个“错误策略”来做正确的事情。从错误中吸取教训。克服它,继续前进。
+
+我的第一份工作是一家小公司的 Unix 系统管理员。真的,我是一名生嫩的系统管理员,但我大部分时间都独自工作。我们是一个小型 IT 团队,只有我们三个人。我是 20 或 30 台 Unix 工作站和服务器的唯一系统管理员。另外两个支持 Windows 服务器和桌面。
+
+任何阅读这篇文章的系统管理员都不会对此感到意外,作为一个不成熟的初级系统管理员,我最终在错误的目录中运行了 `rm` 命令——作为 root 用户。我以为我正在为我们的某个程序删除一些陈旧的缓存文件。相反,我错误地清除了 `/etc` 目录中的所有文件。糟糕。
+
+我意识到犯了错误是看到了一条错误消息,“`rm` 无法删除某些子目录”。但缓存目录应该只包含文件!我立即停止了 `rm` 命令,看看我做了什么。然后我惊慌失措。一下子,无数个想法涌入了我的脑中。我刚刚销毁了一台重要的服务器吗?系统会怎么样?我会被解雇吗?
+
+幸运的是,我运行的是 `rm *` 而不是 `rm -rf *`,因此我只删除了文件。子目录仍在那里。但这并没有让我感觉更好。
+
+我立刻去找我的主管告诉她我做了什么。她看到我对自己的错误感到愚蠢,但这是我犯的。尽管紧迫,她花了几分钟时间跟我做了一些指导。她说:“你不是第一个这样做的人,在你这种情况下,别人会怎么做?”这帮助我平静下来并专注。我开始更少考虑我刚刚做的愚蠢事情,而更多地考虑我接下来要做的事情。
+
+我做了一个简单的策略:不要重启服务器。使用相同的系统作为模板,并重建 `/etc` 目录。
+
+制定了行动计划后,剩下的就很容易了。只需运行正确的命令即可从另一台服务器复制 `/etc` 文件并编辑配置,使其与系统匹配。多亏了我对所有东西都做记录的习惯,我使用已有的文档进行最后的调整。我避免了完全恢复服务器,这意味着一个巨大的宕机事件。
+
+可以肯定的是,我从这个错误中吸取了教训。在接下来作为系统管理员的日子中,我总是在运行任何命令之前确认我所在的目录。
+
+我还学习了构建“错误策略”的价值。当事情出错时,恐慌并思考接下来可能发生的所有坏事是很自然的。这是人性。但是制定一个“错误策略”可以帮助我不再担心出了什么问题,而是专注于让事情变得更好。我仍然会想一下,但是知道我接下来的步骤可以让我“克服它”。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
+
+作者:[Jim Hall][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jim-hall
diff --git a/published/201807/20180704 Install an NVIDIA GPU on almost any machine.md b/published/201807/20180704 Install an NVIDIA GPU on almost any machine.md
new file mode 100644
index 0000000000..4731d0ae8f
--- /dev/null
+++ b/published/201807/20180704 Install an NVIDIA GPU on almost any machine.md
@@ -0,0 +1,147 @@
+如何在绝大部分类型的机器上安装 NVIDIA 显卡驱动
+======
+
+
+
+无论是研究还是娱乐,安装一个最新的显卡驱动都能提升你的计算机性能,并且使你能全方位地实现新功能。本安装指南使用 Fedora 28 的新的第三方仓库来安装 NVIDIA 驱动。它将引导您完成硬件和软件两方面的安装,并且涵盖需要让你的 NVIDIA 显卡启动和运行起来的一切知识。这个流程适用于任何支持 UEFI 的计算机和任意新的 NVIDIA 显卡。
+
+### 准备
+
+本指南依赖于下面这些材料:
+
+ * 一台使用 [UEFI][1] 的计算机,如果你不确定你的电脑是否有这种固件,请运行 `sudo dmidecode -t 0`。如果输出中出现了 “UEFI is supported”,你的安装过程就可以继续了。不然的话,虽然可以在技术上更新某些电脑来支持 UEFI,但是这个过程的要求很苛刻,我们通常不建议你这么使用。
+ * 一个现代的、支持 UEFI 的 NVIDIA 的显卡
+ * 一个满足你的 NVIDIA 显卡的功率和接线要求的电源(有关详细信息,请参考“硬件和修改”的章节)
+ * 网络连接
+ * Fedora 28 系统
+
+### 安装实例
+
+这个安装示例使用的是:
+
+ * 一台 Optiplex 9010 的主机(一台相当老的机器)
+ * [NVIDIA GeForce GTX 1050 Ti XLR8 游戏超频版 4 GB GDDR5 PCI Express 3.0 显卡][2]
+ * 为了满足新显卡的电源要求,电源升级为 [EVGA – 80 PLUS 600 W ATX 12V/EPS 12V][3],这个最新的电源(PSU)比推荐的最低要求高了 300 W,但在大部分情况下,满足推荐的最低要求就足够了。
+ * 然后,当然的,Fedora 28 也别忘了.
+
+### 硬件和修改
+
+#### 电源(PSU)
+
+打开你的台式机的机箱,检查印刷在电源上的最大输出功率。然后,查看你的 NVIDIA 显卡的文档,确定推荐的最小电源功率要求(以瓦特为单位)。除此之外,检查你的显卡,看它是否需要额外的接线,例如 6 针连接器,大多数的入门级显卡只从主板获取电力,但是有一些显卡需要额外的电力,如果出现以下情况,你需要升级你的电源:
+
+ 1. 你的电源的最大输出功率低于显卡建议的最小电源功率。注意:根据一些显卡厂家的说法,比起推荐的功率,预先构建的系统可能会需要更多或更少的功率,而这取决于系统的配置。如果你使用的是一个特别耗电或者特别节能的配置,请灵活决定你的电源需求。
+ 2. 你的电源没有提供必须的接线口来为你的显卡供电。
+
+电源的更换很容易,但是在你拆除你当前正在使用的电源之前,请务必注意你的接线布局。除此之外,请确保你选择的电源适合你的机箱。
+
+#### CPU
+
+虽然在大多数老机器上安装高性能的 NVIDIA 显卡是可能的,但是一个缓慢或受损的 CPU 会阻碍显卡性能的发挥,如果要计算在你的机器上瓶颈效果的影响,请点击[这里][4]。了解你的 CPU 性能来避免高性能的显卡和 CPU 无法保持匹配是很重要的。升级你的 CPU 是一个潜在的考虑因素。
+
+#### 主板
+
+在继续进行之前,请确认你的主板和你选择的显卡是兼容的。你的显卡应该插在最靠近散热器的 PCI-E x16 插槽中。确保你的设置为显卡预留了足够的空间。此外,请注意,现在大部分的显卡使用的都是 PCI-E 3.0 技术。虽然这些显卡如果插在 PCI-E 3.0 插槽上会运行地最好,但如果插在一个旧版的插槽上的话,性能也不会受到太大的影响。
+
+### 安装
+
+1、 首先,打开终端更新你的包管理器(如果没有更新的话):
+
+```
+sudo dnf update
+```
+
+2、 然后,使用这条简单的命令进行重启:
+
+```
+reboot
+```
+
+3、 在重启之后,安装 Fedora 28 的工作站的仓库:
+
+```
+sudo dnf install fedora-workstation-repositories
+```
+
+4、 接着,设置 NVIDIA 驱动的仓库:
+
+```
+sudo dnf config-manager --set-enabled rpmfusion-nonfree-nvidia-driver
+```
+
+5、 然后,再次重启。
+
+6、 在这次重启之后,通过下面这条命令验证是否添加了仓库:
+
+```
+sudo dnf repository-packages rpmfusion-nonfree-nvidia-driver info
+```
+
+如果加载了多个 NVIDIA 工具和它们各自的 spec 文件,请继续进行下一步。如果没有,你可能在添加新仓库的时候遇到了一个错误。你应该再试一次。
+
+7、 登录,连接到互联网,然后打开“软件”应用程序。点击“加载项>硬件驱动> NVIDIA Linux 图形驱动>安装”。
+
+如果你使用更老的显卡或者想使用多个显卡,请进一步查看 [RPMFusion 指南][8]。最后,要确保启动成功,设置 `/etc/gdm/custom.conf` 中的 `WaylandEnable=false`,确认避免使用安全启动。
+接着,再一次重启。
+
+8、这个过程完成后,关闭所有的应用并**关机**。拔下电源插头,然后按下电源按钮以释放余电,避免你被电击。如果你对电源有开关,关闭它。
+
+9、 最后,安装显卡,拔掉老的显卡并将新的显卡插入到正确的 PCI-E x16 插槽中。成功安装新的显卡之后,关闭你的机箱,插入电源 ,然后打开计算机,它应该会成功启动。
+
+**注意:** 要禁用此安装中使用的 NVIDIA 驱动仓库,或者要禁用所有的 Fedora 工作站仓库,请参考这个 [Fedora Wiki 页面][6]。
+
+### 验证
+
+1、 如果你新安装的 NVIDIA 显卡已连接到你的显示器并显示正确,则表明你的 NVIDIA 驱动程序已成功和显卡建立连接。
+
+如果你想去查看你的设置,或者验证驱动是否在正常工作(这里,主板上安装了两块显卡),再次打开 “NVIDIA X 服务器设置应用程序”。这次,你应该不会得到错误信息提示,并且系统会给出有关 X 的设置文件和你的 NVIDIA 显卡的信息。(请参考下面的屏幕截图)
+
+![NVIDIA X Server Settings][7]
+
+通过这个应用程序,你可以根据你的需要需改 X 配置文件,并可以监控显卡的性能,时钟速度和温度信息。
+
+2、 为确保新显卡以满功率运行,显卡性能测试是非常必要的。GL Mark 2,是一个提供后台处理、构建、照明、纹理等等有关信息的标准工具。它提供了一个优秀的解决方案。GL Mark 2 记录了各种各样的图形测试的帧速率,然后输出一个总体的性能评分(这被称为 glmark2 分数)。
+
+**注意:** glxgears 只会测试你的屏幕或显示器的性能,不会测试显卡本身,请使用 GL Mark 2。
+
+要运行 GLMark2:
+
+ 1. 打开终端并关闭其他所有的应用程序
+ 2. 运行 `sudo dnf install glmark2` 命令
+ 3. 运行 `glmark2` 命令
+ 4. 允许运行完整的测试来得到最好的结果。检查帧速率是否符合你对这块显卡的预期。如果你想要额外的验证,你可以查阅网站来确认是否已有你这块显卡的 glmark2 测试评分被公布到网上,你可以比较这个分数来评估你这块显卡的性能。
+ 5. 如果你的帧速率或者 glmark2 评分低于预期,请思考潜在的因素。CPU 造成的瓶颈?其他问题导致?
+
+
+如果诊断的结果很好,就开始享受你的新显卡吧。
+
+### 参考链接
+
+- [How to benchmark your GPU on Linux][9]
+- [How to install a graphics card][10]
+- [The Fedora Wiki Page][6]
+- [The Bottlenecker][4]
+- [What Is Unified Extensible Firmware Interface (UEFI)][1]
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/install-nvidia-gpu/
+
+作者:[Justice del Castillo][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[hopefully2333](https://github.com/hopefully2333)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org/author/justice/
+[1]:https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI
+[2]:https://www.cnet.com/products/pny-geforce-gtx-xlr8-gaming-1050-ti-overclocked-edition-graphics-card-gf-gtx-1050-ti-4-gb/specs/
+[3]:https://www.evga.com/products/product.aspx?pn=100-B1-0600-KR
+[4]:http://thebottlenecker.com (Home: The Bottle Necker)
+[5]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/nvidia_xserver_error.jpg?token=c6a7effe35f1c592a155a4a46a068a19fd060a91 (NVIDIA X Sever Prompt)
+[6]:https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories
+[7]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/NVIDIA_XCONFIG.png?token=64e1a7be21e5e9ba157f029b65e24e4eef54d88f (NVIDIA X Server Settings)
+[8]:https://rpmfusion.org/Howto/NVIDIA?highlight=%28CategoryHowto%29
+[9]: https://www.howtoforge.com/tutorial/linux-gpu-benchmark/
+[10]: https://www.pcworld.com/article/2913370/components-graphics/how-to-install-a-graphics-card.html
\ No newline at end of file
diff --git a/published/201807/20180704 What is the Difference Between the macOS and Linux Kernels.md b/published/201807/20180704 What is the Difference Between the macOS and Linux Kernels.md
new file mode 100644
index 0000000000..bfade197ad
--- /dev/null
+++ b/published/201807/20180704 What is the Difference Between the macOS and Linux Kernels.md
@@ -0,0 +1,60 @@
+macOS 和 Linux 的内核有什么区别
+======
+
+有些人可能会认为 macOS 和 Linux 内核之间存在相似之处,因为它们可以处理类似的命令和类似的软件。有些人甚至认为苹果公司的 macOS 是基于 Linux 的。事实上是,两个内核有着截然不同的历史和特征。今天,我们来看看 macOS 和 Linux 的内核之间的区别。
+
+![macOS vs Linux][1]
+
+### macOS 内核的历史
+
+我们将从 macOS 内核的历史开始。1985 年,由于与首席执行官 John Sculley 和董事会不和,史蒂夫·乔布斯离开了苹果公司。然后,他成立了一家名为 [NeXT][2] 的新电脑公司。乔布斯希望将一款(带有新操作系统的)新计算机快速推向市场。为了节省时间,NeXT 团队使用了卡耐基梅隆大学的 [Mach 内核][3] 和部分 BSD 代码库来创建 [NeXTSTEP 操作系统][4]。
+
+NeXT 从来没有取得过财务上的成功,部分归因于乔布斯花钱的习惯,就像他还在苹果公司一样。与此同时,苹果公司曾多次试图更新其操作系统,甚至与 IBM 合作,但从未成功。1997年,苹果公司以 4.29 亿美元收购了 NeXT。作为交易的一部分,史蒂夫·乔布斯回到了苹果公司,同时 NeXTSTEP 成为了 macOS 和 iOS 的基础。
+
+### Linux 内核的历史
+
+与 macOS 内核不同,Linux 的创建并非源于商业尝试。相反,它是由[芬兰计算机科学专业学生林纳斯·托瓦兹于 1991 年创建的][5]。最初,内核是按照林纳斯自己的计算机的规格编写的,因为他想利用其新的 80386 处理器(的特性)。林纳斯[于 1991 年 8 月在 Usenet 上][6]发布了他的新内核代码。很快,他就收到了来自世界各地的代码和功能建议。次年,Orest Zborowski 将 X Window 系统移植到 Linux,使其能够支持图形用户界面。
+
+在过去的 27 年中,Linux 已经慢慢成长并增加了不少功能。这不再是一个学生的小型项目。现在它运行在[世界上][7]大多数的[计算设备][8]和[超级计算机][9]上。不错!
+
+### macOS 内核的特性
+
+macOS 内核被官方称为 XNU。这个[首字母缩写词][10]代表“XNU is Not Unix”。根据 [苹果公司的 Github 页面][10],XNU 是“将卡耐基梅隆大学开发的 Mach 内核和 FreeBSD 组件整合而成的混合内核,加上用于编写驱动程序的 C++ API”。代码的 BSD 子系统部分[“在微内核系统中通常实现为用户空间的服务”][11]。Mach 部分负责底层工作,例如多任务、内存保护、虚拟内存管理、内核调试支持和控制台 I/O。
+
+### Linux 内核的特性
+
+虽然 macOS 内核结合了微内核([Mach][12])和宏内核([BSD][13])的特性,但 Linux 只是一个宏内核。[宏内核][14]负责管理 CPU、内存、进程间通信、设备驱动程序、文件系统和系统服务调用( LCTT 译注:原文为 system server calls,但结合 Linux 内核的构成,译者认为这里翻译成系统服务调用更合适,即 system service calls)。
+
+### 用一句话总结 Linux 和 Mac 的区别
+
+macOS 内核(XNU)比 Linux 历史更悠久,并且基于两个更古老一些的代码库的结合;另一方面,Linux 新一些,是从头开始编写的,并且在更多设备上使用。
+
+如果您发现这篇文章很有趣,请花一点时间在社交媒体,黑客新闻或 [Reddit][15] 上分享。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/mac-linux-difference/
+
+作者:[John Paul][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[stephenxs](https://github.com/stephenxs)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
+[2]:https://en.wikipedia.org/wiki/NeXT
+[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
+[4]:https://en.wikipedia.org/wiki/NeXTSTEP
+[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
+[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
+[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
+[8]:https://www.linuxinsider.com/story/31855.html
+[9]:https://itsfoss.com/linux-supercomputers-2017/
+[10]:https://github.com/apple/darwin-xnu
+[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
+[12]:https://en.wikipedia.org/wiki/Mach_(kernel
+[13]:https://en.wikipedia.org/wiki/FreeBSD
+[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
+[15]:http://reddit.com/r/linuxusersgroup
diff --git a/published/201807/20180705 How to use dd in Linux without destroying your disk.md b/published/201807/20180705 How to use dd in Linux without destroying your disk.md
new file mode 100644
index 0000000000..1af60d4593
--- /dev/null
+++ b/published/201807/20180705 How to use dd in Linux without destroying your disk.md
@@ -0,0 +1,97 @@
+如何在 Linux 系统中使用 dd 命令而不会损毁你的磁盘
+===========
+
+> 使用 Linux 中的 dd 工具安全、可靠地制作一个驱动器、分区和文件系统的完整镜像。
+
+
+
+*这篇文章节选自 Manning 出版社出版的图书 [Linux in Action][1]的第 4 章。*
+
+你是否正在从一个即将损坏的存储驱动器挽救数据,或者要把本地归档进行远程备份,或者要把一个别处的活动分区做个完整的副本,那么你需要懂得如何安全而可靠的复制驱动器和文件系统。幸运的是,`dd` 是一个可以使用的简单而又功能强大的镜像复制命令,从现在到未来很长的时间内,也许直到永远都不会出现比 `dd` 更好的工具了。
+
+### 对驱动器和分区做个完整的副本
+
+仔细研究后,你会发现你可以使用 `dd` 做各种任务,但是它最重要的功能是处理磁盘分区。当然,你可以使用 `tar` 命令或者 `scp` 命令从一台计算机复制整个文件系统的文件,然后把这些文件原样粘贴在另一台刚刚安装好 Linux 操作系统的计算机中。但是,因为那些文件系统归档不是完整的映像文件,所以在复制文件的过程中需要计算机操作系统的运行作为基础。
+
+另一方面,使用 `dd` 可以对任何数字信息完美的进行逐个字节的镜像。但是不论何时何地,当你要对分区进行操作时,我要告诉你早期的 Unix 管理员曾开过这样的玩笑:“ dd 的意思是磁盘毁灭者”(LCTT 译注:`dd` 原意是磁盘复制)。 在使用 `dd` 命令的时候,如果你输入了哪怕是一个字母,也可能立即永久性的擦除掉整个磁盘驱动器里的所有重要的数据。因此,一定要注意命令的拼写格式规范。
+
+**记住:** 在按下回车键执行 `dd` 命令之前,暂时停下来仔细的认真思考一下。
+
+### dd 命令的基本操作
+
+现在你已经得到了适当的提醒,我们将从简单的事情开始。假设你要对代号为 `/dev/sda` 的整个磁盘数据创建精确的映像,你已经插入了一块空的磁盘驱动器 (理想情况下具有与代号为 `/dev/sda` 的磁盘驱动器相同的容量)。语法很简单: `if=` 定义源驱动器,`of=` 定义你要将数据保存到的文件或位置:
+
+```
+# dd if=/dev/sda of=/dev/sdb
+```
+
+接下来的例子将要对 `/dev/sda` 驱动器创建一个 .img 的映像文件,然后把该文件保存的你的用户帐号家目录:
+
+```
+# dd if=/dev/sda of=/home/username/sdadisk.img
+```
+
+上面的命令针对整个驱动器创建映像文件,你也可以针对驱动器上的单个分区进行操作。下面的例子针对驱动器的单个分区进行操作,同时使用了一个 `bs` 参数用于设置单次拷贝的字节数量 (此例中是 4096)。设定 `bs` 参数值可能会影响 `dd` 命令的整体操作速度,该参数的理想设置取决于你的硬件配置和其它考虑。
+
+```
+# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
+```
+
+数据的恢复非常简单:通过颠倒 `if` 和 `of` 参数可以有效的完成任务。在此例中,`if=` 使用你要恢复的映像,`of=` 使用你想要写入映像的目标驱动器:
+
+```
+# dd if=sdadisk.img of=/dev/sdb
+```
+
+你也可以在一条命令中同时完成创建和拷贝任务。下面的例子中将使用 SSH 从远程驱动器创建一个压缩的映像文件,并把该文件保存到你的本地计算机中:
+
+```
+# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
+```
+
+你应该经常测试你的归档,确保它们可正常使用。如果它是你创建的启动驱动器,将它粘贴到计算机中,看看它是否能够按预期启动。如果它是普通分区的数据,挂载该分区,确保文件都存在而且可以正常的访问。
+
+### 使用 dd 擦除磁盘数据
+
+多年以前,我的一个负责政府海外大使馆安全的朋友曾经告诉我,在他当时在任的时候, 政府会给每一个大使馆提供一个官方版的锤子。为什么呢? 一旦大使馆设施可能被不友善的人员侵占,就会使用这个锤子毁坏所有的硬盘.
+
+为什么要那样做?为什么不是删除数据就好了?你在开玩笑,对吧?所有人都知道从存储设备中删除包含敏感信息的文件实际上并没有真正移除这些数据。除非使用锤子彻底的毁坏这些存储介质,否则,只要有足够的时间和动机, 几乎所有的内容都可以从几乎任何数字存储介质重新获取。
+
+但是,你可以使用 `dd` 命令让坏人非常难以获得你的旧数据。这个命令需要花费一些时间在 `/dev/sda1` 分区的每个扇区写入数百万个 `0`(LCTT 译注:是指 0x0 字节,意即 NUL ,而不是数字 0 ):
+
+```
+# dd if=/dev/zero of=/dev/sda1
+```
+
+还有更好的方法。通过使用 `/dev/urandom` 作为源文件,你可以在磁盘上写入随机字符:
+
+```
+# dd if=/dev/urandom of=/dev/sda1
+```
+
+### 监控 dd 的操作
+
+由于磁盘或磁盘分区的归档可能需要很长的时间,因此你可能需要在命令中添加进度查看器。安装管道查看器(在 Ubuntu 系统上安装命令为 `sudo apt install pv`),然后把 `pv` 命令和 `dd` 命令结合在一起。使用 `pv`,最终的命令是这样的:
+
+```
+# dd if=/dev/urandom | pv | dd of=/dev/sda1
+
+4,14MB 0:00:05 [ 98kB/s] [ <=> ]
+```
+
+想要推迟备份和磁盘管理工作?有了 `dd` 工具,你不会有太多的借口。它真的非常简单,但是要小心。祝你好运!
+
+----------------
+
+via:https://opensource.com/article/18/7/how-use-dd-linux
+
+作者:[David Clinton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[SunWave](https://github.com/SunWave)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+
+[a]: https://opensource.com/users/remyd
+[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
diff --git a/published/201807/20180706 6 RFCs for understanding how the internet works.md b/published/201807/20180706 6 RFCs for understanding how the internet works.md
new file mode 100644
index 0000000000..12413c0770
--- /dev/null
+++ b/published/201807/20180706 6 RFCs for understanding how the internet works.md
@@ -0,0 +1,79 @@
+6 个可以帮你理解互联网工作原理的 RFC
+======
+
+> 以及 3 个有趣的 RFC。
+
+
+
+阅读源码是开源软件的重要组成部分。这意味着用户可以查看代码并了解做了什么。
+
+但“阅读源码”并不仅适用于代码。理解代码实现的标准同样重要。这些标准编写在由[互联网工程任务组][1](IETF)发布的称为“意见征集”(RFC)的文档中。多年来已经发布了数以千计的 RFC,因此我们收集了一些我们的贡献者认为必读的内容。
+
+### 6 个必读的 RFC
+
+#### RFC 2119 - 在 RFC 中用于指示需求级别的关键字
+
+这是一个快速阅读,但它对了解其它 RFC 非常重要。 [RFC 2119][2] 定义了后续 RFC 中使用的需求级别。 “MAY” 究竟意味着什么?如果标准说 “SHOULD”,你*真的*必须这样做吗?通过为需求提供明确定义的分类,RFC 2119 有助于避免歧义。
+
+#### RFC 3339 - 互联网上的日期和时间:时间戳
+
+时间是全世界程序员的祸根。 [RFC 3339][3] 定义了如何格式化时间戳。基于 [ISO 8601][4] 标准,3339 为我们提供了一种表达时间的常用方法。例如,像星期几这样的冗余信息不应该包含在存储的时间戳中,因为它很容易计算。
+
+#### RFC 1918 - 私有互联网的地址分配
+
+有属于每个人的互联网,也有只属于你的互联网。私有网络一直在使用,[RFC 1918][5] 定义了这些网络。当然,你可以在路由器上设置在内部使用公网地址,但这是一个坏主意。或者,你可以将未使用的公共 IP 地址视为内部网络。在任何一种情况下都表明你从未阅读过 RFC 1918。
+
+#### RFC 1912 - 常见的 DNS 操作和配置错误
+
+一切都是 #@%@ 的 DNS 问题,对吧? [RFC 1912][6] 列出了管理员在试图保持互联网运行时所犯的错误。虽然它是在 1996 年发布的,但 DNS(以及人们犯的错误)并没有真正改变这么多。为了理解我们为什么首先需要 DNS,如今我们再来看看 [RFC 289 - 我们希望正式的主机列表是什么样子的][7] 就知道了。
+
+#### RFC 2822 — 互联网邮件格式
+
+想想你知道什么是有效的电子邮件地址么?如果你知道有多少个站点不接受我邮件地址中 “+” 的话,你就知道你知道不知道了。 [RFC 2822][8] 定义了有效的电子邮件地址。它还详细介绍了电子邮件的其余部分。
+
+#### RFC 7231 - 超文本传输协议(HTTP/1.1):语义和内容
+
+想想看,几乎我们在网上做的一切都依赖于 HTTP。 [RFC 7231][9] 是该协议的最新更新。它有超过 100 页,定义了方法、请求头和状态代码。
+
+### 3 个应该阅读的 RFC
+
+好吧,并非每个 RFC 都是严肃的。
+
+#### RFC 1149 - 在禽类载体上传输 IP 数据报的标准
+
+网络以多种不同方式传递数据包。 [RFC 1149][10] 描述了鸽子载体的使用。当我距离州际高速公路一英里以外时,它们的可靠性不会低于我的移动提供商。
+
+#### RFC 2324 — 超文本咖啡壶控制协议(HTCPCP/1.0)
+
+咖啡对于完成工作非常重要,当然,我们需要一个用于管理咖啡壶的程序化界面。 [RFC 2324][11] 定义了一个用于与咖啡壶交互的协议,并添加了 HTTP 418(“我是一个茶壶”)。
+
+#### RFC 69 — M.I.T.的分发列表更改
+
+[RFC 69][12] 是否是第一个误导取消订阅请求的发布示例?
+
+你必须阅读的 RFC 是什么(无论它们是否严肃)?在评论中分享你的列表。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/requests-for-comments-to-know
+
+作者:[Ben Cotton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bcotton
+[1]:https://www.ietf.org
+[2]:https://www.rfc-editor.org/rfc/rfc2119.txt
+[3]:https://www.rfc-editor.org/rfc/rfc3339.txt
+[4]:https://www.iso.org/iso-8601-date-and-time-format.html
+[5]:https://www.rfc-editor.org/rfc/rfc1918.txt
+[6]:https://www.rfc-editor.org/rfc/rfc1912.txt
+[7]:https://www.rfc-editor.org/rfc/rfc289.txt
+[8]:https://www.rfc-editor.org/rfc/rfc2822.txt
+[9]:https://www.rfc-editor.org/rfc/rfc7231.txt
+[10]:https://www.rfc-editor.org/rfc/rfc1149.txt
+[11]:https://www.rfc-editor.org/rfc/rfc2324.txt
+[12]:https://www.rfc-editor.org/rfc/rfc69.txt
diff --git a/published/201807/20180706 How to Run Windows Apps on Android with Wine.md b/published/201807/20180706 How to Run Windows Apps on Android with Wine.md
new file mode 100644
index 0000000000..ca6eeadcfd
--- /dev/null
+++ b/published/201807/20180706 How to Run Windows Apps on Android with Wine.md
@@ -0,0 +1,127 @@
+如何在 Android 上借助 Wine 来运行 Windows Apps
+======
+
+
+
+Wine(一种 Linux 上的程序,不是你喝的葡萄酒)是在类 Unix 操作系统上运行 Windows 程序的一个自由开源的兼容层。创建于 1993 年,借助它你可以在 Linux 和 macOS 操作系统上运行很多 Windows 程序,虽然有时可能还需要做一些小修改。现在,Wine 项目已经发布了 3.0 版本,这个版本兼容 Android 设备。
+
+在本文中,我们将向你展示,在你的 Android 设备上如何借助 Wine 来运行 Windows Apps。
+
+**相关阅读** : [如何使用 Winepak 在 Linux 上轻松安装 Windows 游戏][1]
+
+### 在 Wine 上你可以运行什么?
+
+Wine 只是一个兼容层,而不是一个全功能的仿真器,因此,你需要一个 x86 的 Android 设备才能完全发挥出它的优势。但是,大多数消费者手中的 Android 设备都是基于 ARM 的。
+
+因为大多数人使用的是基于 ARM 的 Android 设备,所以有一个限制,只有适配在 Windows RT 上运行的那些 App 才能够使用 Wine 在基于 ARM 的 Android 上运行。但是随着发展,能够在 ARM 设备上运行的 App 数量越来越多。你可以在 XDA 开发者论坛上的这个 [帖子][2] 中找到兼容的这些 App 的清单。
+
+在 ARM 上能够运行的一些 App 的例子如下:
+
+ * [Keepass Portable][3]: 一个密码钱包
+ * [Paint.NET][4]: 一个图像处理程序
+ * [SumatraPDF][5]: 一个 PDF 文档阅读器,也能够阅读一些其它的文档类型
+ * [Audacity][6]: 一个数字录音和编辑程序
+
+也有一些再度流行的开源游戏,比如,[Doom][7] 和 [Quake 2][8],以及它们的开源克隆,比如 [OpenTTD][9] 和《运输大亨》的一个版本。
+
+随着 Wine 在 Android 上越来越普及,能够在基于 ARM 的 Android 设备上的 Wine 中运行的程序越来越多。Wine 项目致力于在 ARM 上使用 QEMU 去仿真 x86 的 CPU 指令,在该项目完成后,能够在 Android 上运行的 App 将会迅速增加。
+
+### 安装 Wine
+
+在安装 Wine 之前,你首先需要去确保你的设备的设置 “允许从 Play 商店之外的其它源下载和安装 APK”。对于本文的用途,你需要去许可你的设备从未知源下载 App。
+
+1、 打开你手机上的设置,然后选择安全选项。
+
+![wine-android-security][10]
+
+2、 向下拉并点击 “Unknown Sources” 的开关。
+
+![wine-android-unknown-sources][11]
+
+3、 接受风险警告。
+
+![wine-android-unknown-sources-warning][12]
+
+4、 打开 [Wine 安装站点][13],并点选列表中的第一个选择框。下载将自动开始。
+
+![wine-android-download-button][14]
+
+5、 下载完成后,从下载目录中打开它,或者下拉通知菜单并点击这里的已完成的下载。
+
+6、 开始安装程序。它将提示你它需要访问和记录音频,并去修改、删除、和读取你的 SD 卡。你也可为程序中使用的一些 App 授予访问音频的权利。
+
+![wine-android-app-access][15]
+
+7、 安装完成后,点击程序图标去打开它。
+
+![wine-android-icon-small][16]
+
+当你打开 Wine 后,它模仿的是 Windows 7 的桌面。
+
+![wine-android-desktop][17]
+
+Wine 有一个缺点是,你得有一个外接键盘去进行输入。如果你在一个小屏幕上运行它,并且触摸非常小的按钮很困难,你也可以使用一个外接鼠标。
+
+你可以通过触摸 “开始” 按钮去打开两个菜单 —— “控制面板”和“运行”。
+
+![wine-android-start-button][18]
+
+### 使用 Wine 来工作
+
+当你触摸 “控制面板” 后你将看到三个选项 —— 添加/删除程序、游戏控制器、和 Internet 设定。
+
+使用 “运行”,你可以打开一个对话框去运行命令。例如,通过输入 `iexplore` 来启动 “Internet Explorer”。
+
+![wine-android-run][19]
+
+### 在 Wine 中安装程序
+
+1、 在你的 Android 设备上下载应用程序(或通过云来同步)。一定要记住下载的程序保存的位置。
+
+2、 打开 Wine 命令提示符窗口。
+
+3、 输入程序的位置路径。如果你把下载的文件保存在 SD 卡上,输入:
+
+```
+cd sdcard/Download/[filename.exe]
+```
+
+4、 在 Android 上运行 Wine 中的文件,只需要简单地输入 EXE 文件的名字即可。
+
+如果这个支持 ARM 的文件是兼容的,它将会运行。如果不兼容,你将看到一大堆错误信息。在这种情况下,在 Android 上的 Wine 中安装的 Windows 软件可能会损坏或丢失。
+
+这个在 Android 上使用的新版本的 Wine 仍然有许多问题。它并不能在所有的 Android 设备上正常工作。它可以在我的 Galaxy S6 Edge 上运行的很好,但是在我的 Galaxy Tab 4 上却不能运行。许多游戏也不能正常运行,因为图形驱动还不支持 Direct3D。因为触摸屏还不是全扩展的,所以你需要一个外接的键盘和鼠标才能很轻松地操作它。
+
+即便是在早期阶段的发布版本中存在这样那样的问题,但是这种技术还是值得深思的。当然了,你要想在你的 Android 智能手机上运行 Windows 程序而不出问题,可能还需要等待一些时日。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
+
+作者:[Tracey Rosenberger][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/traceyrosenberger/
+[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ "How to Easily Install Windows Games on Linux with Winepak"
+[2]:https://forum.xda-developers.com/showthread.php?t=2092348
+[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
+[4]:http://forum.xda-developers.com/showthread.php?t=2411497
+[5]:http://forum.xda-developers.com/showthread.php?t=2098594
+[6]:http://forum.xda-developers.com/showthread.php?t=2103779
+[7]:http://forum.xda-developers.com/showthread.php?t=2175449
+[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&d=1358070370
+[9]:http://forum.xda-developers.com/showpost.php?p=36674868&postcount=151
+[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png "wine-android-security"
+[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg "wine-android-unknown-sources"
+[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png "wine-android-unknown-sources-warning"
+[13]:https://dl.winehq.org/wine-builds/android/
+[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png "wine-android-download-button"
+[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg "wine-android-app-access"
+[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg "wine-android-icon-small"
+[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png "wine-android-desktop"
+[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png "wine-android-start-button"
+[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png "wine-android-run"
diff --git a/published/201807/20180708 Getting Started with Debian Packaging.md b/published/201807/20180708 Getting Started with Debian Packaging.md
new file mode 100644
index 0000000000..108dd69a97
--- /dev/null
+++ b/published/201807/20180708 Getting Started with Debian Packaging.md
@@ -0,0 +1,215 @@
+Debian 打包入门
+======
+
+> 创建 CardBook 软件包、本地 Debian 仓库,并修复错误。
+
+
+
+我在 GSoC(LCTT 译注:Google Summer Of Code,一项针对学生进行的开源项目训练营,一般在夏季进行。)的任务中有一项是为用户构建 Thunderbird 扩展。一些非常流行的扩展,比如 [Lightning][1] (日历行事历)已经拥有了 deb 包。
+
+另外一个重要的用于管理基于 CardDav 和 vCard 标准的联系人的扩展 [Cardbook][2] ,还没有一个 deb 包。
+
+我的导师, [Daniel][3] 鼓励我去为它制作一个包,并上传到 [mentors.debian.net][4]。因为这样就可以使用 `apt-get` 来安装,简化了安装流程。这篇博客描述了我是如何从头开始学习为 CardBook 创建一个 Debian 包的。
+
+首先,我是第一次接触打包,我在从源码构建包的基础上进行了大量研究,并检查它的协议是是否与 [DFSG][5] 兼容。
+
+我从多个 Debian Wiki 中的指南中进行学习,比如 [打包介绍][6]、 [构建一个包][7],以及一些博客。
+
+我还研究了包含在 [Lightning 扩展包][8]的 amd64 文件。
+
+我创建的包可以在[这里][9]找到。
+
+![Debian Package!][10]
+
+*Debian 包*
+
+### 创建一个空的包
+
+我从使用 `dh_make` 来创建一个 `debian` 目录开始。
+
+```
+# Empty project folder
+$ mkdir -p Debian/cardbook
+```
+
+```
+# create files
+$ dh_make\
+> --native \
+> --single \
+> --packagename cardbook_1.0.0 \
+> --email minkush@example.com
+```
+
+一些重要的文件,比如 `control`、`rules`、`changelog`、`copyright` 等文件被初始化其中。
+
+所创建的文件的完整列表如下:
+
+```
+$ find /debian
+debian/
+debian/rules
+debian/preinst.ex
+debian/cardbook-docs.docs
+debian/manpage.1.ex
+debian/install
+debian/source
+debian/source/format
+debian/cardbook.debhelper.lo
+debian/manpage.xml.ex
+debian/README.Debian
+debian/postrm.ex
+debian/prerm.ex
+debian/copyright
+debian/changelog
+debian/manpage.sgml.ex
+debian/cardbook.default.ex
+debian/README
+debian/cardbook.doc-base.EX
+debian/README.source
+debian/compat
+debian/control
+debian/debhelper-build-stamp
+debian/menu.ex
+debian/postinst.ex
+debian/cardbook.substvars
+debian/files
+```
+
+我了解了 Debian 系统中 [Dpkg][11] 包管理器及如何用它安装、删除和管理包。
+
+我使用 `dpkg` 命令创建了一个空的包。这个命令创建一个空的包文件以及四个名为 `.changes`、`.deb`、 `.dsc`、 `.tar.gz` 的文件。
+
+- `.dsc` 文件包含了所发生的修改和签名
+- `.deb` 文件是用于安装的主要包文件。
+- `.tar.gz` (tarball)包含了源代码
+
+这个过程也在 `/usr/share` 目录下创建了 `README` 和 `changelog` 文件。它们包含了关于这个包的基本信息比如描述、作者、版本。
+
+我安装这个包,并检查这个包安装的内容。我的新包中包含了版本、架构和描述。
+
+```
+$ dpkg -L cardbook
+/usr
+/usr/share
+/usr/share/doc
+/usr/share/doc/cardbook
+/usr/share/doc/cardbook/README.Debian
+/usr/share/doc/cardbook/changelog.gz
+/usr/share/doc/cardbook/copyright
+```
+
+### 包含 CardBook 源代码
+
+在成功的创建了一个空包以后,我在包中添加了实际的 CardBook 扩展文件。 CardBook 的源代码托管在 [Gitlab][12] 上。我将所有的源码文件包含在另外一个目录,并告诉打包命令哪些文件需要包含在这个包中。
+
+我使用 `vi` 编辑器创建一个 `debian/install` 文件并列举了需要被安装的文件。在这个过程中,我花费了一些时间去学习基于 Linux 终端的文本编辑器,比如 `vi` 。这让我熟悉如何在 `vi` 中编辑、创建文件和快捷方式。
+
+当这些完成后,我在变更日志中更新了包的版本并记录了我所做的改变。
+
+```
+$ dpkg -l | grep cardbook
+ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
+```
+
+![Changelog][13]
+
+*更新完包的变更日志*
+
+在重新构建完成后,重要的依赖和描述信息可以被加入到包中。 Debian 的 `control` 文件可以用来添加额外的必须项目和依赖。
+
+### 本地 Debian 仓库
+
+在不创建本地存储库的情况下,CardBook 可以使用如下的命令来安装:
+
+```
+$ sudo dpkg -i cardbook_1.1.0.deb
+```
+
+为了实际测试包的安装,我决定构建一个本地 Debian 存储库。没有它,`apt-get` 命令将无法定位包,因为它没有在 Debian 的包软件列表中。
+
+为了配置本地 Debian 存储库,我复制我的包 (.deb)为放在 `/tmp` 目录中的 `Packages.gz` 文件。
+
+![Packages-gz][14]
+
+*本地 Debian 仓库*
+
+为了使它工作,我了解了 `apt` 的配置和它查找文件的路径。
+
+我研究了一种在 `apt-config` 中添加文件位置的方法。最后,我通过在 APT 中添加 `*.list` 文件来添加包的路径,并使用 `apt-cache` 更新APT缓存来完成我的任务。
+
+因此,最新的 CardBook 版本可以成功的通过 `apt-get install cardbook` 来安装了。
+
+![Package installation!][15]
+
+*使用 apt-get 安装 CardBook*
+
+### 修复打包错误和 Bugs
+
+我的导师 Daniel 在这个过程中帮了我很多忙,并指导我如何进一步进行打包。他告诉我使用 [Lintian][16] 来修复打包过程中出现的常见错误和最终使用 [dput][17] 来上传 CardBook 包。
+
+> Lintian 是一个用于发现策略问题和 Bug 的包检查器。它是 Debian 维护者们在上传包之前广泛使用的自动化检查 Debian 策略的工具。
+
+我上传了该软件包的第二个更新版本到 Debian 目录中的 [Salsa 仓库][18] 的一个独立分支中。
+
+我从 Debian backports 上安装 Lintian 并学习在一个包上用它来修复错误。我研究了它用在其错误信息中的缩写,和如何查看 Lintian 命令返回的详细内容。
+
+```
+$ lintian -i -I --show-overrides cardbook_1.2.0.changes
+```
+
+最初,在 `.changes` 文件上运行命令时,我惊讶地看到显示出来了大量错误、警告和注释!
+
+![Package Error Brief!][19]
+
+*在包上运行 Lintian 时看到的大量报错*
+
+![Lintian error1!][20]
+
+*详细的 Lintian 报错*
+
+![Lintian error2!][23]
+
+*详细的 Lintian 报错 (2) 以及更多*
+
+我花了几天时间修复与 Debian 包策略违例相关的一些错误。为了消除一个简单的错误,我必须仔细研究每一项策略和 Debian 的规则。为此,我参考了 [Debian 策略手册][21] 以及 [Debian 开发者参考][22]。
+
+我仍然在努力使它变得完美无暇,并希望很快可以将它上传到 mentors.debian.net!
+
+如果 Debian 社区中使用 Thunderbird 的人可以帮助修复这些报错就太感谢了。
+
+--------------------------------------------------------------------------------
+
+via: http://minkush.me/cardbook-debian-package/
+
+作者:[Minkush Jain][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[Bestony](https://github.com/bestony)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://minkush.me/cardbook-debian-package/#
+[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
+[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
+[3]:https://danielpocock.com/
+[4]:https://mentors.debian.net/
+[5]:https://wiki.debian.org/DFSGLicenses
+[6]:https://wiki.debian.org/Packaging/Intro
+[7]:https://wiki.debian.org/BuildingAPackage
+[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
+[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
+[10]:http://minkush.me/img/posts/13.png
+[11]:https://packages.debian.org/stretch/dpkg
+[12]:https://gitlab.com/CardBook/CardBook
+[13]:http://minkush.me/img/posts/15.png
+[14]:http://minkush.me/img/posts/14.png
+[15]:http://minkush.me/img/posts/11.png
+[16]:https://packages.debian.org/stretch/lintian
+[17]:https://packages.debian.org/stretch/dput
+[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
+[19]:http://minkush.me/img/posts/16.png (Running Lintian on package)
+[20]:http://minkush.me/img/posts/10.png
+[21]:https://www.debian.org/doc/debian-policy/
+[22]:https://www.debian.org/doc/manuals/developers-reference/
+[23]:http://minkush.me/img/posts/17.png
\ No newline at end of file
diff --git a/published/201807/20180709 Boost your typing with emoji in Fedora 28 Workstation.md b/published/201807/20180709 Boost your typing with emoji in Fedora 28 Workstation.md
new file mode 100644
index 0000000000..0419275816
--- /dev/null
+++ b/published/201807/20180709 Boost your typing with emoji in Fedora 28 Workstation.md
@@ -0,0 +1,67 @@
+在 Fedora 28 Workstation 使用 emoji 加速输入
+======
+
+
+
+Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,这种可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一图胜千言”。这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多 emoji,在最近的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
+
+很高兴看到 emoji 的数量在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
+
+[**编者注:**本文是对此主题以前发表过的文章的更新]。
+
+### 在 Fedora 28 Workstation 上启用 emoji 输入
+
+新的 emoji 输入法默认出现在 Fedora 28 Workstation 中。要使用它,必须使用“区域和语言设置”对话框启用它。从 Fedora Workstation 设置打开“区域和语言”对话框,或在“概要”中搜索它。
+
+[![Region & Language settings tool][1]][2]
+
+选择 `+` 控件添加输入源。出现以下对话框:
+
+[![Adding an input source][3]][4]
+
+选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“Other”并选择它:
+
+[![Selecting other input sources][5]][6]
+
+在下面的对话框中,找到 “Typing Booster” 选项并选择它:
+
+[![][7]][8]
+
+这个高级输入法由 iBus 在背后支持。该高级输入法可通过列表右侧的齿轮图标在列表中识别。
+
+输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 —— 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
+
+[![Input method dropdown in Shell top bar][9]][10]
+
+### 使用新的表情符号输入法
+
+现在 emoji 输入法启用了,按键盘快捷键 `Ctrl+Shift+E` 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 “smile” 来查找匹配的符号。
+
+[![Searching for smile emoji][11]][12]
+
+使用箭头键翻页列表。然后按回车进行选择,字形将替换输入内容。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
+
+作者:[Paul W. Frields][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org/author/pfrields/
+[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
+[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
+[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
+[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
+[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
+[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
+[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
+[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
+[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
+[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
+[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
+[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
diff --git a/published/201807/20180709 Malware Found On The Arch User Repository (AUR).md b/published/201807/20180709 Malware Found On The Arch User Repository (AUR).md
new file mode 100644
index 0000000000..6e10a14fc5
--- /dev/null
+++ b/published/201807/20180709 Malware Found On The Arch User Repository (AUR).md
@@ -0,0 +1,40 @@
+在 Arch 用户仓库(AUR)中发现恶意软件
+======
+
+7 月 7 日,有一个 AUR 软件包被改入了一些恶意代码,提醒 [Arch Linux][1] 用户(以及一般的 Linux 用户)在安装之前应该尽可能检查所有由用户生成的软件包。
+
+[AUR][3](即 Arch(Linux)用户仓库)包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全的,并且用户应尽可能在使用之前检查其内容。毕竟,AUR 在网页中以粗体显示 “**AUR 包是用户制作的内容。任何使用该提供的文件的风险由你自行承担。**”
+
+这次[发现][4]包含恶意代码的 AUR 包证明了这一点。[acroread][5] 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了一个 systemd 单元以定期运行该脚本。
+
+**看来有[另外两个][2] AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(它们注册在更新软件包的同一天)。**
+
+这些恶意代码没有做任何真正有害的事情 —— 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单元信息)的输出到 pastebin.com。我说“试图”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
+
+此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们真的不明白他们在做什么。(LCTT 译注:意即这是一个菜鸟“黑客”,还不懂得如何有经验地隐藏自己。)
+
+尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
+
+**更新:** Reddit用户 u/xanaxdroid_ [提及][6]同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月][7]前的一些 Ubuntu Snap 软件包也是如此)。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
+
+**另一个更新:**你究竟应该在那些用户生成的软件包检查什么(如 AUR 中发现的)?情况各有不同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学做法”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须懂得 Debian 如何打包,并且这些源代码是可以直接更改的,因为它托管在 PPA 中并由用户上传的。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我觉得你应该只安装你信任的用户/打包器生成的软件包。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://www.archlinux.org/
+[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
+[3]:https://aur.archlinux.org/
+[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
+[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
+[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
+[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
diff --git a/published/201807/20180710 15 open source applications for MacOS.md b/published/201807/20180710 15 open source applications for MacOS.md
new file mode 100644
index 0000000000..9d4c9e1c0a
--- /dev/null
+++ b/published/201807/20180710 15 open source applications for MacOS.md
@@ -0,0 +1,74 @@
+15 个适用于 MacOS 的开源应用程序
+======
+
+> 钟爱开源的用户不会觉得在非 Linux 操作系统上使用他们喜爱的应用有多难。
+
+
+
+只要有可能的情况下,我都会去选择使用开源工具。不久之前,我回到大学去攻读教育领导学硕士学位。即便是我将喜欢的 Linux 笔记本电脑换成了一台 MacBook Pro(因为我不能确定校园里能够接受 Linux),我还是决定继续使用我喜欢的工具,哪怕是在 MacOS 上也是如此。
+
+幸运的是,它很容易,并且没有哪个教授质疑过我用的是什么软件。即然如此,我就不能秘而不宣。
+
+我知道,我的一些同学最终会在学区担任领导职务,因此,我与我的那些使用 MacOS 或 Windows 的同学分享了关于下面描述的这些开源软件。毕竟,开源软件是真正地自由和友好的。我也希望他们去了解它,并且愿意以很少的一些成本去提供给他们的学生去使用这些世界级的应用程序。他们中的大多数人都感到很惊讶,因为,众所周知,开源软件除了有像你和我这样的用户之外,压根就没有销售团队。
+
+### 我的 MacOS 学习曲线
+
+虽然大多数的开源工具都能像以前我在 Linux 上使用的那样工作,只是需要不同的安装方法。但是,经过这个过程,我学习了这些工具在 MacOS 上的一些细微差别。像 [yum][1]、[DNF][2]、和 [APT][3] 在 MacOS 的世界中压根不存在 —— 我真的很怀念它们。
+
+一些 MacOS 应用程序要求依赖项,并且安装它们要比我在 Linux 上习惯的方法困难很多。尽管如此,我仍然没有放弃。在这个过程中,我学会了如何在我的新平台上保留最好的软件。即便是 MacOS 大部分的核心也是 [开源的][4]。
+
+此外,我的 Linux 的知识背景让我使用 MacOS 的命令行很轻松很舒适。我仍然使用命令行去创建和拷贝文件、添加用户、以及使用其它的像 `cat`、`tac`、`more`、`less` 和 `tail` 这样的 [实用工具][5]。
+
+### 15 个适用于 MacOS 的非常好的开源应用程序
+
+ * 在大学里,要求我使用 DOCX 的电子版格式来提交我的工作,而这其实很容易,最初我使用的是 [OpenOffice][6],而后来我使用的是 [LibreOffice][7] 去完成我的论文。
+ * 当我因为演示需要去做一些图像时,我使用的是我最喜欢的图像应用程序 [GIMP][8] 和 [Inkscape][9]。
+ * 我喜欢的播客创建工具是 [Audacity][10]。它比起 Mac 上搭载的专有应用程序更加简单。我使用它去录制访谈和为视频演示创建配乐。
+ * 在 MacOS 上我最早发现的多媒体播放器是 [VideoLan][11] (VLC)。
+ * MacOS 内置的专有视频创建工具是一个非常好的产品,但是你也可以很轻松地去安装和使用 [OpenShot][12],它是一个非常好的内容创建工具。
+ * 当我需要在我的客户端上分析网络时,我在我的 Mac 上使用了易于安装的 [Nmap][13] (Network Mapper) 和 [Wireshark][14] 工具。
+ * 当我为图书管理员和其它教育工作者提供培训时,我在 MacOS 上使用 [VirtualBox][15] 去做 Raspbian、Fedora、Ubuntu 和其它 Linux 发行版的示范操作。
+ * 我使用 [Etcher.io][16] 在我的 MacBook 上制作了一个引导盘,下载 ISO 文件,将它刻录到一个 U 盘上。
+ * 我认为 [Firefox][17] 比起 MacBook Pro 自带的专有浏览器更易用更安全,并且它允许我跨操作系统去同步我的书签。
+ * 当我使用电子书阅读器时,[Calibre][18] 是当之无愧的选择。它很容易去下载和安装,你甚至只需要几次点击就能将它配置为一台 [教室中使用的电子书服务器][19]。
+ * 最近我给中学的学生教 Python 课程,我发现它可以很容易地从 [Python.org][20] 上下载和安装 Python 3 及 IDLE3 编辑器。我也喜欢学习数据科学,并与学生分享。不论你是对 Python 还是 R 感兴趣,我都建议你下载和 [安装][21] [Anaconda 发行版][22]。它包含了非常好的 iPython 编辑器、RStudio、Jupyter Notebooks、和 JupyterLab,以及其它一些应用程序。
+ * [HandBrake][23] 是一个将你家里的旧的视频 DVD 转成 MP4 的工具,这样你就可以将它们共享到 YouTube、Vimeo、或者你的 MacOS 上的 [Kodi][24] 服务器上。
+
+现在轮到你了:你在 MacOS(或 Windows)上都使用什么样的开源软件?在下面的评论区共享出来吧。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/open-source-tools-macos
+
+作者:[Don Watkins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/don-watkins
+[1]:https://en.wikipedia.org/wiki/Yum_(software)
+[2]:https://en.wikipedia.org/wiki/DNF_(software)
+[3]:https://en.wikipedia.org/wiki/APT_(Debian)
+[4]:https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html
+[5]:https://www.gnu.org/software/coreutils/coreutils.html
+[6]:https://www.openoffice.org/
+[7]:https://www.libreoffice.org/
+[8]:https://www.gimp.org/
+[9]:https://inkscape.org/en/
+[10]:https://www.audacityteam.org/
+[11]:https://www.videolan.org/index.html
+[12]:https://www.openshot.org/
+[13]:https://nmap.org/
+[14]:https://www.wireshark.org/
+[15]:https://www.virtualbox.org/
+[16]:https://etcher.io/
+[17]:https://www.mozilla.org/en-US/firefox/new/
+[18]:https://calibre-ebook.com/
+[19]:https://opensource.com/article/17/6/raspberrypi-ebook-server
+[20]:https://www.python.org/downloads/release/python-370/
+[21]:https://opensource.com/article/18/4/getting-started-anaconda-python
+[22]:https://www.anaconda.com/download/#macos
+[23]:https://handbrake.fr/
+[24]:https://kodi.tv/download
diff --git a/published/201807/20180710 6 open source cryptocurrency wallets.md b/published/201807/20180710 6 open source cryptocurrency wallets.md
new file mode 100644
index 0000000000..2b5aee97e6
--- /dev/null
+++ b/published/201807/20180710 6 open source cryptocurrency wallets.md
@@ -0,0 +1,94 @@
+6 个开源的数字货币钱包
+======
+
+> 想寻找一个可以存储和交易你的比特币、以太坊和其它数字货币的软件吗?这里有 6 个开源的软件可以选择。
+
+
+
+没有数字货币钱包,像比特币和以太坊这样的数字货币只不过是又一个空想罢了。这些钱包对于保存、发送、以及接收数字货币来说是必需的东西。
+
+迅速成长的 [数字货币][1] 之所以是革命性的,都归功于它的去中心化,该网络中没有中央权威,每个人都享有平等的权力。开源技术是数字货币和 [区块链][2] 网络的核心所在。它使得这个充满活力的新兴行业能够从去中心化中获益 —— 比如,不可改变、透明和安全。
+
+如果你正在寻找一个自由开源的数字货币钱包,请继续阅读,并开始去探索以下的选择能否满足你的需求。
+
+### 1、 Copay
+
+[Copay][3] 是一个能够很方便地存储比特币的开源数字货币钱包。这个软件以 [MIT 许可证][4] 发布。
+
+Copay 服务器也是开源的。因此,开发者和比特币爱好者可以在服务器上部署他们自己的应用程序来完全控制他们的活动。
+
+Copay 钱包能让你手中的比特币更加安全,而不是去信任不可靠的第三方。它允许你使用多重签名来批准交易,并且支持在同一个 app 钱包内支持存储多个独立的钱包。
+
+Copay 可以在多种平台上使用,比如 Android、Windows、MacOS、Linux、和 iOS。
+
+### 2、 MyEtherWallet
+
+正如它的名字所示,[MyEtherWallet][5] (缩写为 MEW) 是一个以太坊钱包。它是开源的(遵循 [MIT 许可证][6])并且是完全在线的,可以通过 web 浏览器来访问它。
+
+这个钱包的客户端界面非常简洁,它可以让你自信而安全地参与到以太坊区块链中。
+
+### 3、 mSIGNA
+
+[mSIGNA][7] 是一个功能强大的桌面版应用程序,用于在比特币网络上完成交易。它遵循 [MIT 许可证][8] 并且在 MacOS、Windows、和 Linux 上可用。
+
+这个区块链钱包可以让你完全控制你存储的比特币。其中一些特性包括用户友好性、灵活性、去中心化的离线密钥生成能力、加密的数据备份,以及多设备同步功能。
+
+### 4、 Armory
+
+[Armory][9] 是一个在你的计算机上产生和保管比特币私钥的开源钱包(遵循 [GNU AGPLv3][10])。它通过使用冷存储和支持多重签名的能力增强了安全性。
+
+使用 Armory,你可以在完全离线的计算机上设置一个钱包;你将通过仅查看功能在因特网上查看你的比特币具体信息,这样有助于改善安全性。这个钱包也允许你去创建多个地址,并使用它们去完成不同的事务。
+
+Armory 可用于 MacOS、Windows、和几个比较有特色的 Linux 平台上(包括树莓派)。
+
+### 5、 Electrum
+
+[Electrum][11] 是一个既对新手友好又具备专家功能的比特币钱包。它遵循 [MIT 许可证][12] 来发行。
+
+Electrum 可以在你的本地机器上使用较少的资源来实现本地加密你的私钥,支持冷存储,并且提供多重签名能力。
+
+它在各种操作系统和设备上都可以使用,包括 Windows、MacOS、Android、iOS 和 Linux,并且也可以在像 [Trezor][13] 这样的硬件钱包中使用。
+
+### 6、 Etherwall
+
+[Etherwall][14] 是第一款可以在桌面计算机上存储和发送以太坊的钱包。它是一个遵循 [GPLv3 许可证][15] 的开源钱包。
+
+Etherwall 非常直观而且速度很快。更重要的是,它增加了你的私钥安全性,你可以在一个全节点或瘦节点上来运行它。它作为全节点客户端运行时,可以允许你在本地机器上下载整个以太坊区块链。
+
+Etherwall 可以在 MacOS、Linux 和 Windows 平台上运行,并且它也支持 Trezor 硬件钱包。
+
+### 智者之言
+
+自由开源的数字钱包在让更多的人快速上手数字货币方面扮演至关重要的角色。
+
+在你使用任何数字货币软件钱包之前,你一定要确保你的安全,而且一定要记住并完全遵循确保你的资金安全的最佳实践。
+
+如果你喜欢的开源数字货币钱包不在以上的清单中,请在下面的评论区共享出你所知道的开源钱包。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/crypto-wallets
+
+作者:[Dr.Michael J.Garbade][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/drmjg
+[1]:https://www.liveedu.tv/guides/cryptocurrency/
+[2]:https://opensource.com/tags/blockchain
+[3]:https://copay.io/
+[4]:https://github.com/bitpay/copay/blob/master/LICENSE
+[5]:https://www.myetherwallet.com/
+[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
+[7]:https://ciphrex.com/
+[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
+[9]:https://www.bitcoinarmory.com/
+[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
+[11]:https://electrum.org/#home
+[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
+[13]:https://trezor.io/
+[14]:https://www.etherwall.com/
+[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
diff --git a/published/201807/20180710 Display Weather Forecast In Your Terminal With Wttr.in.md b/published/201807/20180710 Display Weather Forecast In Your Terminal With Wttr.in.md
new file mode 100644
index 0000000000..e97d5afdd1
--- /dev/null
+++ b/published/201807/20180710 Display Weather Forecast In Your Terminal With Wttr.in.md
@@ -0,0 +1,110 @@
+使用 Wttr.in 在你的终端中显示天气预报
+======
+
+
+
+[wttr.in][1] 是一个功能丰富的天气预报服务,它支持在命令行显示天气。它可以(根据你的 IP 地址)自动检测你的位置,也支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 —— 你只需要使用 cURL 或 Wget**(见下文)。
+
+wttr.in 功能包括:
+
+ * **显示当前天气以及 3 天内的天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
+ * **可以显示月相**
+ * **基于你的 IP 地址自动检测位置**
+ * **允许指定城市名称、3 字母的机场代码、区域代码、GPS 坐标、IP 地址或域名**。你还可以指定地理位置,如湖泊、山脉、地标等)
+ * **支持多语言位置名称**(查询字符串必须以 Unicode 指定)
+ * **支持指定**天气预报显示的语言(它支持超过 50 种语言)
+ * **来自美国的查询使用 USCS 单位用于,世界其他地方使用公制系统**,但你可以通过附加 `?u` 使用 USCS,附加 `?m` 使用公制系统。 )
+ * **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**
+
+就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以在你的服务器上[安装它][3]。 或者你可以安装 [wego][4],这是一个使用 wtter.in 的终端气候应用,虽然 wego 要求注册一个 API 密钥来安装。
+
+**在使用 wttr.in 之前,请确保已安装 cURL。**在 Debian、Ubuntu 或 Linux Mint(以及其他基于 Debian 或 Ubuntu 的 Linux 发行版)中,使用以下命令安装 cURL:
+
+```
+sudo apt install curl
+```
+
+### wttr.in 命令行示例
+
+获取你所在位置的天气(wttr.in 会根据你的 IP 地址猜测你的位置):
+
+```
+curl wttr.in
+```
+
+通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你用 IPv6 访问 wttr.in 有问题):
+
+```
+curl -4 wttr.in
+```
+
+如果你想检索天气预报保存为 png,**还可以使用 Wget**(而不是 cURL),或者你想这样使用它:
+
+```
+wget -O- -q wttr.in
+```
+
+如果相对 cURL 你更喜欢 Wget ,可以在下面的所有命令中用 `wget -O- -q` 替换 `curl`。
+
+指定位置:
+
+```
+curl wttr.in/Dublin
+```
+
+显示地标的天气信息(本例中为艾菲尔铁塔):
+
+```
+curl wttr.in/~Eiffel+Tower
+```
+
+获取 IP 地址位置的天气信息(以下 IP 属于 GitHub):
+
+```
+curl wttr.in/@192.30.253.113
+```
+
+使用 USCS 单位检索天气:
+
+```
+curl wttr.in/Paris?u
+```
+
+如果你在美国,强制 wttr.in 使用公制系统(SI):
+
+```
+curl wttr.in/New+York?m
+```
+
+使用 Wget 将当前天气和 3 天预报下载为 PNG 图像:
+
+```
+wget wttr.in/Istanbul.png
+```
+
+你可以指定 PNG 的[透明度][5],这在你要使用一个脚本自动添加天气信息到某些图片(比如墙纸)上有用。
+
+**对于其他示例,请查看 wttr.in [项目页面][2]或在终端中输入:**
+
+```
+curl wttr.in/:help
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://wttr.in/
+[2]:https://github.com/chubin/wttr.in
+[3]:https://github.com/chubin/wttr.in#installation
+[4]:https://github.com/schachmat/wego
+[5]:https://github.com/chubin/wttr.in#supported-formats
diff --git a/published/201807/20180710 Getting started with Perlbrew.md b/published/201807/20180710 Getting started with Perlbrew.md
new file mode 100644
index 0000000000..8d85de4527
--- /dev/null
+++ b/published/201807/20180710 Getting started with Perlbrew.md
@@ -0,0 +1,88 @@
+Perlbrew 入门
+======
+
+> 用 Perlbrew 在你系统上安装多个版本的 Perl。
+
+
+
+有比在系统上安装了 Perl 更好的事情吗?那就是在系统中安装了多个版本的 Perl。使用 [Perlbrew][1] 你可以做到这一点。但是为什么呢,除了让你包围在 Perl 下之外,有什么好处吗?
+
+简短的回答是,不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它能否工作。
+
+### 安装 Perlbrew
+
+另一个好处是 Perlbrew 会安装 Perl 到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
+
+第一步是在你的系统上安装 Perlbrew。许多 Linux 发行版已经在包仓库中拥有它,因此你只需要 `dnf install perlbrew`(或者适用于你的发行版的命令)。你还可以使用 `cpan App::perlbrew` 从 CPAN 安装 `App::perlbrew` 模块。或者你可以在 [install.perlbrew.pl][2] 下载并运行安装脚本。
+
+要开始使用 Perlbrew,请运行 `perlbrew init`。
+
+### 安装新的 Perl 版本
+
+假设你想尝试最新的开发版本(撰写本文时为 5.27.11)。首先,你需要安装包:
+
+```
+perlbrew install 5.27.11
+```
+
+### 切换 Perl 版本
+
+现在你已经安装了新版本,你可以将它用于该 shell:
+
+```
+perlbrew use 5.27.11
+```
+
+或者你可以将其设置为你帐户的默认 Perl 版本(假设你按照 `perlbrew init` 的输出设置了你的配置文件):
+
+```
+perlbrew switch 5.27.11
+```
+
+### 运行单个脚本
+
+你也可以用特定版本的 Perl 运行单个命令:
+
+```
+perlberew exec 5.27.11 myscript.pl
+```
+
+或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请指定版本为 `perl`:
+
+```
+plperlbrew exec perl myscriptpl
+```
+
+### 安装 CPAN 模块
+
+如果你想安装 CPAN 模块,`cpanm` 包是一个易于使用的界面,可以很好地与 Perlbrew 一起使用。用下面命令安装它:
+
+```
+perlbrew install-cpanm
+```
+
+然后,你可以使用 `cpanm` 命令安装 CPAN 模块:
+
+```
+cpanm CGI::simple
+```
+
+### 但是等下,还有更多!
+
+本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[App::perlbrew 文档][3]。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/perlbrew
+
+作者:[Ben Cotton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bcotton
+[1]:https://perlbrew.pl/
+[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
+[3]:https://metacpan.org/pod/App::perlbrew
diff --git a/published/201807/20180710 Python Sets What Why and How.md b/published/201807/20180710 Python Sets What Why and How.md
new file mode 100644
index 0000000000..26100e251b
--- /dev/null
+++ b/published/201807/20180710 Python Sets What Why and How.md
@@ -0,0 +1,366 @@
+Python 集合是什么,为什么应该使用以及如何使用?
+=====
+
+
+
+Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表、字典、元组和集合。
+
+根据 Python 3 文档:
+
+> 集合是一个*无序*集合,没有*重复元素*。基本用途包括*成员测试*和*消除重复的条目*。集合对象还支持数学运算,如*并集*、*交集*、*差集*和*对等差分*。
+
+在本文中,我们将回顾并查看上述定义中列出的每个要素的示例。让我们马上开始,看看如何创建它。
+
+### 初始化一个集合
+
+有两种方法可以创建一个集合:一个是给内置函数 `set()` 提供一个元素列表,另一个是使用花括号 `{}`。
+
+使用内置函数 `set()` 来初始化一个集合:
+
+```
+>>> s1 = set([1, 2, 3])
+>>> s1
+{1, 2, 3}
+>>> type(s1)
+
+```
+
+使用 `{}`:
+
+
+```
+>>> s2 = {3, 4, 5}
+>>> s2
+{3, 4, 5}
+>>> type(s2)
+
+>>>
+```
+
+如你所见,这两种方法都是有效的。但问题是,如果我们想要一个空的集合呢?
+
+```
+>>> s = {}
+>>> type(s)
+
+```
+
+没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。=)
+
+值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 [可哈希的][6] 数据类型。换句话说,即整数、字符串和元组,而不是*列表*或*字典*这样的可变类型。
+
+```
+>>> s = {1, 'coffee', [4, 'python']}
+Traceback (most recent call last):
+ File "", line 1, in
+TypeError: unhashable type: 'list'
+```
+
+既然你知道了如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看*为什么*我们总是应该把它放在我们的工具箱中。
+
+### 为什么你需要使用它
+
+写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的、简洁的和可维护的,或者是 “[Python 式的][7]”。
+
+根据 [Hitchhiker 对 Python 的建议][8]:
+
+> 当一个经验丰富的 Python 开发人员(Python 人)调用一些不够 “Python 式的” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
+
+让我们开始探索 Python 集合那些不仅可以帮助我们提高可读性,还可以加快程序执行时间的方式。
+
+#### 无序的集合元素
+
+首先你需要明白的是:你无法使用索引访问集合中的元素。
+
+```
+>>> s = {1, 2, 3}
+>>> s[0]
+Traceback (most recent call last):
+ File "", line 1, in
+TypeError: 'set' object does not support indexing
+```
+
+或者使用切片修改它们:
+
+```
+>>> s[0:2]
+Traceback (most recent call last):
+ File "", line 1, in
+TypeError: 'set' object is not subscriptable
+```
+
+但是,如果我们需要删除重复项,或者进行组合列表(与)之类的数学运算,那么我们可以,并且*应该*始终使用集合。
+
+我不得不提一下,在迭代时,集合的表现优于列表。所以,如果你需要它,那就加深对它的喜爱吧。为什么?好吧,这篇文章并不打算解释集合的内部工作原理,但是如果你感兴趣的话,这里有几个链接,你可以阅读它:
+
+* [时间复杂度][1]
+* [set() 是如何实现的?][2]
+* [Python 集合 vs 列表][3]
+* [在列表中使用集合是否有任何优势或劣势,以确保独一无二的列表条目?][4]
+
+#### 没有重复项
+
+写这篇文章的时候,我总是不停地思考,我经常使用 `for` 循环和 `if` 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
+
+```
+>>> my_list = [1, 2, 3, 2, 3, 4]
+>>> no_duplicate_list = []
+>>> for item in my_list:
+... if item not in no_duplicate_list:
+... no_duplicate_list.append(item)
+...
+>>> no_duplicate_list
+[1, 2, 3, 4]
+```
+
+或者使用列表解析:
+
+```
+>>> my_list = [1, 2, 3, 2, 3, 4]
+>>> no_duplicate_list = []
+>>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list]
+[None, None, None, None]
+>>> no_duplicate_list
+[1, 2, 3, 4]
+```
+
+但没关系,因为我们现在有了武器装备,没有什么比这更重要的了:
+
+```
+>>> my_list = [1, 2, 3, 2, 3, 4]
+>>> no_duplicate_list = list(set(my_list))
+>>> no_duplicate_list
+[1, 2, 3, 4]
+>>>
+```
+
+现在让我们使用 `timeit` 模块,查看列表和集合在删除重复项时的执行时间:
+
+```
+>>> from timeit import timeit
+>>> def no_duplicates(list):
+... no_duplicate_list = []
+... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
+... return no_duplicate_list
+...
+>>> # 首先,让我们看看列表的执行情况:
+>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
+0.0018683355819786227
+```
+
+```
+>>> from timeit import timeit
+>>> # 使用集合:
+>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
+0.0010220493243764395
+>>> # 快速而且干净 =)
+```
+
+使用集合而不是列表推导不仅让我们编写*更少的代码*,而且还能让我们获得*更具可读性*和*高性能*的代码。
+
+注意:请记住集合是无序的,因此无法保证在将它们转换回列表时,元素的顺序不变。
+
+[Python 之禅][9]:
+
+> 优美胜于丑陋
+
+> 明了胜于晦涩
+
+> 简洁胜于复杂
+
+> 扁平胜于嵌套
+
+集合不正是这样美丽、明了、简单且扁平吗?
+
+#### 成员测试
+
+每次我们使用 `if` 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
+
+```
+my_list = [1, 2, 3]
+>>> if 2 in my_list:
+... print('Yes, this is a membership test!')
+...
+Yes, this is a membership test!
+```
+
+在执行这些操作时,集合比列表更高效:
+
+```
+>>> from timeit import timeit
+>>> def in_test(iterable):
+... for i in range(1000):
+... if i in iterable:
+... pass
+...
+>>> timeit('in_test(iterable)',
+... setup="from __main__ import in_test; iterable = list(range(1000))",
+... number=1000)
+12.459663048726043
+```
+
+```
+>>> from timeit import timeit
+>>> def in_test(iterable):
+... for i in range(1000):
+... if i in iterable:
+... pass
+...
+>>> timeit('in_test(iterable)',
+... setup="from __main__ import in_test; iterable = set(range(1000))",
+... number=1000)
+.12354438152988223
+```
+
+注意:上面的测试来自于[这个][10] StackOverflow 话题。
+
+因此,如果你在巨大的列表中进行这样的比较,尝试将该列表转换为集合,它应该可以加快你的速度。
+
+### 如何使用
+
+现在你已经了解了集合是什么以及为什么你应该使用它,现在让我们快速浏览一下,看看我们如何修改和操作它。
+
+#### 添加元素
+
+根据要添加的元素数量,我们要在 `add()` 和 `update()` 方法之间进行选择。
+
+`add()` 适用于添加单个元素:
+
+```
+>>> s = {1, 2, 3}
+>>> s.add(4)
+>>> s
+{1, 2, 3, 4}
+```
+
+`update()` 适用于添加多个元素:
+
+```
+>>> s = {1, 2, 3}
+>>> s.update([2, 3, 4, 5, 6])
+>>> s
+{1, 2, 3, 4, 5, 6}
+```
+
+请记住,集合会移除重复项。
+
+#### 移除元素
+
+如果你希望在代码中尝试删除不在集合中的元素时收到警报,请使用 `remove()`。否则,`discard()` 提供了一个很好的选择:
+
+```
+>>> s = {1, 2, 3}
+>>> s.remove(3)
+>>> s
+{1, 2}
+>>> s.remove(3)
+Traceback (most recent call last):
+ File "", line 1, in
+KeyError: 3
+```
+
+`discard()` 不会引起任何错误:
+
+```
+>>> s = {1, 2, 3}
+>>> s.discard(3)
+>>> s
+{1, 2}
+>>> s.discard(3)
+>>> # 什么都不会发生
+```
+
+我们也可以使用 `pop()` 来随机丢弃一个元素:
+
+```
+>>> s = {1, 2, 3, 4, 5}
+>>> s.pop() # 删除一个任意的元素
+1
+>>> s
+{2, 3, 4, 5}
+```
+
+或者 `clear()` 方法来清空一个集合:
+
+```
+>>> s = {1, 2, 3, 4, 5}
+>>> s.clear() # 清空集合
+>>> s
+set()
+```
+
+#### union()
+
+`union()` 或者 `|` 将创建一个新集合,其中包含我们提供集合中的所有元素:
+
+```
+>>> s1 = {1, 2, 3}
+>>> s2 = {3, 4, 5}
+>>> s1.union(s2) # 或者 's1 | s2'
+{1, 2, 3, 4, 5}
+```
+
+#### intersection()
+
+`intersection` 或 `&` 将返回一个由集合共同元素组成的集合:
+
+```
+>>> s1 = {1, 2, 3}
+>>> s2 = {2, 3, 4}
+>>> s3 = {3, 4, 5}
+>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
+{3}
+```
+
+#### difference()
+
+使用 `diference()` 或 `-` 创建一个新集合,其值在 “s1” 中但不在 “s2” 中:
+
+```
+>>> s1 = {1, 2, 3}
+>>> s2 = {2, 3, 4}
+>>> s1.difference(s2) # 或者 's1 - s2'
+{1}
+```
+
+#### symmetric_diference()
+
+`symetric_difference` 或 `^` 将返回集合之间的不同元素。
+
+```
+>>> s1 = {1, 2, 3}
+>>> s2 = {2, 3, 4}
+>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
+{1, 4}
+```
+
+### 结论
+
+我希望在阅读本文之后,你会知道集合是什么,如何操纵它的元素以及它可以执行的操作。知道何时使用集合无疑会帮助你编写更清晰的代码并加速你的程序。
+
+如果你有任何疑问,请发表评论,我很乐意尝试回答。另外,不要忘记,如果你已经理解了集合,它们在 [Python Cheatsheet][12] 中有自己的[一席之地][11],在那里你可以快速参考并重新认知你已经知道的内容。
+
+--------------------------------------------------------------------------------
+
+via: https://www.pythoncheatsheet.org/blog/python-sets-what-why-how
+
+作者:[wilfredinni][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.pythoncheatsheet.org/author/wilfredinni
+[1]:https://wiki.python.org/moin/TimeComplexity
+[2]:https://stackoverflow.com/questions/3949310/how-is-set-implemented
+[3]:https://stackoverflow.com/questions/2831212/python-sets-vs-lists
+[4]:https://mail.python.org/pipermail/python-list/2011-June/606738.html
+[5]:https://www.pythoncheatsheet.org/author/wilfredinni
+[6]:https://docs.python.org/3/glossary.html#term-hashable
+[7]:http://docs.python-guide.org/en/latest/writing/style/
+[8]:http://docs.python-guide.org/en/latest/
+[9]:https://www.python.org/dev/peps/pep-0020/
+[10]:https://stackoverflow.com/questions/2831212/python-sets-vs-lists
+[11]:https://www.pythoncheatsheet.org/#sets
+[12]:https://www.pythoncheatsheet.org/
+
diff --git a/published/201807/20180711 4 add-ons to improve your privacy on Thunderbird.md b/published/201807/20180711 4 add-ons to improve your privacy on Thunderbird.md
new file mode 100644
index 0000000000..3fb7d3f7a8
--- /dev/null
+++ b/published/201807/20180711 4 add-ons to improve your privacy on Thunderbird.md
@@ -0,0 +1,64 @@
+4 个提高你在 Thunderbird 上隐私的加载项
+======
+
+
+
+Thunderbird 是由 [Mozilla][1] 开发的流行的免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
+
+### Enigmail
+
+使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在这里的入门介绍][2]。
+
+[Enigmail][3] 是使用 OpenPGP 和 Thunderbird 的首选加载项。实际上,Enigmail 与 Thunderbird 集成良好,可让你加密、解密、数字签名和验证电子邮件。
+
+### Paranoia
+
+[Paranoia][4] 可让你查看有关收到的电子邮件的重要信息。用一个表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
+
+黄色、快乐的表情告诉你所有连接都已加密。蓝色、悲伤的表情意味着有一个连接未加密。最后,红色的、害怕的表情表示在多个连接上该消息未加密。
+
+还有更多有关这些连接的详细信息,你可以用来检查哪台服务器用于投递邮件。
+
+### Sensitivity Header
+
+[Sensitivity Header][5] 是一个简单的加载项,可让你选择外发电子邮件的隐私级别。使用选项菜单,你可以选择敏感度:正常、个人、隐私和机密。
+
+添加此标头不会为电子邮件添加额外的安全性。但是,某些电子邮件客户端或邮件传输/用户代理(MTA/MUA)可以使用此标头根据敏感度以不同方式处理邮件。
+
+请注意,开发人员将此加载项标记为实验性的。
+
+### TorBirdy
+
+如果你真的担心自己的隐私,[TorBirdy][6] 就是给你设计的加载项。它将 Thunderbird 配置为使用 [Tor][7] 网络。
+
+据其[文档][8]所述,TorBirdy 为以前没有使用 Tor 的电子邮件帐户提供了少量隐私保护。
+
+> 请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 —— 你经常旅行并且不想通过发送电子邮件来披露你的所有位置 —— TorBirdy 非常有效!
+
+请注意,要使用此加载项,必须在系统上安装 Tor。
+
+照片由 [Braydon Anderson][9] 在 [Unsplash][10] 上发布。
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-addons-privacy-thunderbird/
+
+作者:[Clément Verna][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org
+[1]:https://www.mozilla.org/en-US/
+[2]:https://fedoramagazine.org/gnupg-a-fedora-primer/
+[3]:https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/
+[4]:https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users
+[5]:https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users
+[6]:https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users
+[7]:https://www.torproject.org/
+[8]:https://trac.torproject.org/projects/tor/wiki/torbirdy
+[9]:https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[10]:https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/published/201807/20180711 Install Microsoft Windows Fonts In Ubuntu 18.04 LTS.md b/published/201807/20180711 Install Microsoft Windows Fonts In Ubuntu 18.04 LTS.md
new file mode 100644
index 0000000000..767db534c6
--- /dev/null
+++ b/published/201807/20180711 Install Microsoft Windows Fonts In Ubuntu 18.04 LTS.md
@@ -0,0 +1,174 @@
+在 Ubuntu 18.04 LTS 上安装 Microsoft Windows 字体
+======
+
+
+
+大多数教育机构仍在使用 Microsoft 字体, 我不清楚其他国家是什么情况。但在泰米尔纳德邦(印度的一个州), **Times New Roman** 和 **Arial** 字体主要被用于大学和学校的几乎所有文档工作、项目和作业。不仅是教育机构,而且一些小型组织、办公室和商店仍在使用 MS Windows 字体。以防万一,如果你需要在 Ubuntu 桌面版上使用 Microsoft 字体,请按照以下步骤安装。
+
+**免责声明**: Microsoft 已免费发布其核心字体。 但**请注意 Microsoft 字体是禁止使用在其他操作系统中**。在任何 Linux 操作系统中安装 MS 字体之前请仔细阅读 EULA 。我们不负责这种任何种类的盗版行为。
+
+(LCTT 译注:本文只做技术探讨,并不代表作者、译者和本站鼓励任何行为。)
+
+### 在 Ubuntu 18.04 LTS 桌面版上安装 MS 字体
+
+如下所示安装 MS TrueType 字体:
+
+```
+$ sudo apt update
+$ sudo apt install ttf-mscorefonts-installer
+```
+
+然后将会出现 Microsoft 的最终用户协议向导,点击 **OK** 以继续。
+
+![][2]
+
+点击 **Yes** 已接受 Microsoft 的协议:
+
+![][3]
+
+安装字体之后, 我们需要使用命令行来更新字体缓存:
+
+```
+$ sudo fc-cache -f -v
+```
+
+**示例输出:**
+
+```
+/usr/share/fonts: caching, new cache contents: 0 fonts, 6 dirs
+/usr/share/fonts/X11: caching, new cache contents: 0 fonts, 4 dirs
+/usr/share/fonts/X11/Type1: caching, new cache contents: 8 fonts, 0 dirs
+/usr/share/fonts/X11/encodings: caching, new cache contents: 0 fonts, 1 dirs
+/usr/share/fonts/X11/encodings/large: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/X11/misc: caching, new cache contents: 89 fonts, 0 dirs
+/usr/share/fonts/X11/util: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/cMap: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/cmap: caching, new cache contents: 0 fonts, 5 dirs
+/usr/share/fonts/cmap/adobe-cns1: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/cmap/adobe-gb1: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/cmap/adobe-japan1: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/cmap/adobe-japan2: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/cmap/adobe-korea1: caching, new cache contents: 0 fonts, 0 dirs
+/usr/share/fonts/opentype: caching, new cache contents: 0 fonts, 2 dirs
+/usr/share/fonts/opentype/malayalam: caching, new cache contents: 3 fonts, 0 dirs
+/usr/share/fonts/opentype/noto: caching, new cache contents: 24 fonts, 0 dirs
+/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 46 dirs
+/usr/share/fonts/truetype/Gargi: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/Gubbi: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/Nakula: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/Navilu: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/Sahadeva: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/Sarai: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/abyssinica: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/dejavu: caching, new cache contents: 6 fonts, 0 dirs
+/usr/share/fonts/truetype/droid: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-beng-extra: caching, new cache contents: 6 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-deva-extra: caching, new cache contents: 3 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-gujr-extra: caching, new cache contents: 5 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-guru-extra: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-kalapi: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-orya-extra: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/fonts-telu-extra: caching, new cache contents: 2 fonts, 0 dirs
+/usr/share/fonts/truetype/freefont: caching, new cache contents: 12 fonts, 0 dirs
+/usr/share/fonts/truetype/kacst: caching, new cache contents: 15 fonts, 0 dirs
+/usr/share/fonts/truetype/kacst-one: caching, new cache contents: 2 fonts, 0 dirs
+/usr/share/fonts/truetype/lao: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
+/usr/share/fonts/truetype/liberation2: caching, new cache contents: 12 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-assamese: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-bengali: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-devanagari: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-gujarati: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-kannada: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-malayalam: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-oriya: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-punjabi: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-tamil: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-tamil-classical: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/lohit-telugu: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/malayalam: caching, new cache contents: 11 fonts, 0 dirs
+/usr/share/fonts/truetype/msttcorefonts: caching, new cache contents: 60 fonts, 0 dirs
+/usr/share/fonts/truetype/noto: caching, new cache contents: 2 fonts, 0 dirs
+/usr/share/fonts/truetype/openoffice: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/padauk: caching, new cache contents: 4 fonts, 0 dirs
+/usr/share/fonts/truetype/pagul: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/samyak: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/samyak-fonts: caching, new cache contents: 3 fonts, 0 dirs
+/usr/share/fonts/truetype/sinhala: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/tibetan-machine: caching, new cache contents: 1 fonts, 0 dirs
+/usr/share/fonts/truetype/tlwg: caching, new cache contents: 58 fonts, 0 dirs
+/usr/share/fonts/truetype/ttf-khmeros-core: caching, new cache contents: 2 fonts, 0 dirs
+/usr/share/fonts/truetype/ubuntu: caching, new cache contents: 13 fonts, 0 dirs
+/usr/share/fonts/type1: caching, new cache contents: 0 fonts, 1 dirs
+/usr/share/fonts/type1/gsfonts: caching, new cache contents: 35 fonts, 0 dirs
+/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
+/home/sk/.local/share/fonts: skipping, no such directory
+/home/sk/.fonts: skipping, no such directory
+/var/cache/fontconfig: cleaning cache directory
+/home/sk/.cache/fontconfig: cleaning cache directory
+/home/sk/.fontconfig: not cleaning non-existent cache directory
+fc-cache: succeeded
+```
+
+### 在 Linux 和 Windows 双启动的机器上安装 MS 字体
+
+如果你有 Linux 和 Windows 的双启动系统,你可以轻松地从 Windows C 驱动器上安装 MS 字体。
+你所要做的就是挂载 Windows 分区(C:/windows)。
+
+我假设你已经在 Linux 中将 `C:\Windows` 分区挂载在了 `/Windowsdrive` 目录下。
+
+现在,将字体位置链接到你的 Linux 系统的字体文件夹,如下所示:
+
+```
+ln -s /Windowsdrive/Windows/Fonts /usr/share/fonts/WindowsFonts
+```
+
+链接字体文件之后,使用命令行重新生成 fontconfig 缓存:
+
+```
+fc-cache
+```
+
+或者,将所有的 Windows 字体复制到 `/usr/share/fonts` 目录下并使用一下命令安装字体:
+
+```
+mkdir /usr/share/fonts/WindowsFonts
+cp /Windowsdrive/Windows/Fonts/* /usr/share/fonts/WindowsFonts
+chmod 755 /usr/share/fonts/WindowsFonts/*
+```
+
+最后,使用命令行重新生成 fontconfig 缓存:
+
+```
+fc-cache
+```
+
+
+### 测试 Windows 字体
+
+安装 MS 字体后打开 LibreOffice 或 GIMP。 现在,你将会看到 Microsoft coretype 字体。
+
+![][4]
+
+就是这样, 希望这本指南有用。我再次警告你,在其他操作系统中使用 MS 字体是被禁止的。在安装 MS 字体之前请先阅读 Microsoft 许可协议。
+
+如果你觉得我们的指南有用,请在你的社区、专业网络上分享并支持我们。还有更多好东西在等着我们。持续访问!
+
+庆祝吧!!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[Auk7F7](https://github.com/Auk7F7)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-1.png
+[3]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-2.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-3.png
diff --git a/published/201807/20180718 How To Force User To Change Password On Next Login In Linux.md b/published/201807/20180718 How To Force User To Change Password On Next Login In Linux.md
new file mode 100644
index 0000000000..5608feb816
--- /dev/null
+++ b/published/201807/20180718 How To Force User To Change Password On Next Login In Linux.md
@@ -0,0 +1,157 @@
+如何强制用户在下次登录 Linux 时更改密码
+======
+
+当你使用默认密码创建用户时,你必须强制用户在下一次登录时更改密码。
+
+当你在一个组织中工作时,此选项是强制性的。因为老员工可能知道默认密码,他们可能会也可能不会尝试不当行为。
+
+这是安全投诉之一,所以,确保你必须以正确的方式处理此事而无任何失误。即使是你的团队成员也要一样做。
+
+大多数用户都很懒,除非你强迫他们更改密码,否则他们不会这样做。所以要做这个实践。
+
+出于安全原因,你需要经常更改密码,或者至少每个月更换一次。
+
+确保你使用的是难以猜测的密码(大小写字母,数字和特殊字符的组合)。它至少应该为 10-15 个字符。
+
+我们运行了一个 shell 脚本来在 Linux 服务器中创建一个用户账户,它会自动为用户附加一个密码,密码是实际用户名和少量数字的组合。
+
+我们可以通过使用以下两种方法来实现这一点:
+
+ * passwd 命令
+ * chage 命令
+
+**建议阅读:**
+
+- [如何在 Linux 上检查用户所属的组][1]
+- [如何在 Linux 上检查创建用户的日期][2]
+- [如何在 Linux 中重置/更改用户密码][3]
+- [如何使用 passwd 命令管理密码过期和老化][4]
+
+### 方法 1:使用 passwd 命令
+
+`passwd` 的意思是“密码”。它用于更新用户的身份验证令牌。`passwd` 命令/实用程序用于设置、修改或更改用户的密码。
+
+普通的用户只能更改自己的账户,但超级用户可以更改任何账户的密码。
+
+此外,我们还可以使用其他选项,允许用户执行其他活动,例如删除用户密码、锁定或解锁用户账户、设置用户账户的密码过期时间等。
+
+在 Linux 中这可以通过调用 Linux-PAM 和 Libuser API 执行。
+
+在 Linux 中创建用户时,用户详细信息将存储在 `/etc/passwd` 文件中。`passwd` 文件将每个用户的详细信息保存为带有七个字段的单行。
+
+此外,在 Linux 系统中创建新用户时,将更新以下四个文件。
+
+ * `/etc/passwd`: 用户详细信息将在此文件中更新。
+ * `/etc/shadow`: 用户密码信息将在此文件中更新。
+ * `/etc/group`: 新用户的组详细信息将在此文件中更新。
+ * `/etc/gshadow`: 新用户的组密码信息将在此文件中更新。
+
+#### 如何使用 passwd 命令执行此操作
+
+我们可以使用 `passwd` 命令并添加 `-e` 选项来执行此操作。
+
+为了测试这一点,让我们创建一个新用户账户,看看它是如何工作的。
+
+```
+# useradd -c "2g Admin - Magesh M" magesh && passwd magesh
+Changing password for user magesh.
+New password:
+Retype new password:
+passwd: all authentication tokens updated successfully.
+```
+
+使用户账户的密码失效,那么在下次登录尝试期间,用户将被迫更改密码。
+
+```
+# passwd -e magesh
+Expiring password for user magesh.
+passwd: Success
+```
+
+当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
+
+```
+login as: magesh
+[email protected]'s password:
+You are required to change your password immediately (root enforced)
+WARNING: Your password has expired.
+You must change your password now and login again!
+Changing password for user magesh.
+Changing password for magesh.
+(current) UNIX password:
+New password:
+Retype new password:
+passwd: all authentication tokens updated successfully.
+Connection to localhost closed.
+```
+
+### 方法 2:使用 chage 命令
+
+`chage` 意即“改变时间”。它会更改用户密码过期信息。
+
+`chage` 命令会改变上次密码更改日期之后需要修改密码的天数。系统使用此信息来确定用户何时必须更改他/她的密码。
+
+它允许用户执行其他活动,例如设置帐户到期日期,到期后设置密码失效,显示帐户过期信息,设置密码更改前的最小和最大天数以及设置到期警告天数。
+
+#### 如何使用 chage 命令执行此操作
+
+让我们在 `chage` 命令的帮助下,通过添加 `-d` 选项执行此操作。
+
+为了测试这一点,让我们创建一个新用户帐户,看看它是如何工作的。我们将创建一个名为 `thanu` 的用户帐户。
+
+```
+# useradd -c "2g Editor - Thanisha M" thanu && passwd thanu
+Changing password for user thanu.
+New password:
+Retype new password:
+passwd: all authentication tokens updated successfully.
+```
+
+要实现这一点,请使用 `chage` 命令将用户的上次密码更改日期设置为 0。
+
+```
+# chage -d 0 thanu
+
+# chage -l thanu
+Last password change : Jul 18, 2018
+Password expires : never
+Password inactive : never
+Account expires : never
+Minimum number of days between password change : 0
+Maximum number of days between password change : 99999
+Number of days of warning before password expires : 7
+```
+
+当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
+
+```
+login as: thanu
+[email protected]'s password:
+You are required to change your password immediately (root enforced)
+WARNING: Your password has expired.
+You must change your password now and login again!
+Changing password for user thanu.
+Changing password for thanu.
+(current) UNIX password:
+New password:
+Retype new password:
+passwd: all authentication tokens updated successfully.
+Connection to localhost closed.
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/prakash/
+[1]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
+[2]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
+[3]:https://www.2daygeek.com/passwd-command-examples/
+[4]:https://www.2daygeek.com/passwd-command-examples-part-l/
diff --git a/published/201807/20180718 How to check free disk space in Linux.md b/published/201807/20180718 How to check free disk space in Linux.md
new file mode 100644
index 0000000000..88a9d7ae73
--- /dev/null
+++ b/published/201807/20180718 How to check free disk space in Linux.md
@@ -0,0 +1,71 @@
+如何检查 Linux 中的可用磁盘空间
+======
+
+> 用这里列出的方便的工具来跟踪你的磁盘利用率。
+
+
+
+跟踪磁盘利用率信息是系统管理员(和其他人)的日常待办事项列表之一。Linux 有一些内置的使用程序来帮助提供这些信息。
+
+### df
+
+`df` 命令意思是 “disk-free”,显示 Linux 系统上可用和已使用的磁盘空间。
+
+`df -h` 以人类可读的格式显示磁盘空间。
+
+`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0。
+
+
+
+`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs、ext2、ext3、btrfs 等)。
+
+`df -i` 显示已使用和未使用的 inode。
+
+
+
+### du
+
+`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示。
+
+`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况。
+
+`du -a` 显示所有文件的磁盘使用情况。
+
+`du -s` 提供特定文件或目录使用的总磁盘空间。
+
+
+
+### ls -al
+
+`ls -al` 列出了特定目录的全部内容及大小。
+
+
+
+### stat
+
+`stat <文件/目录> `显示文件/目录或文件系统的大小和其他统计信息。
+
+
+
+### fdisk -l
+
+`fdisk -l` 显示磁盘大小以及磁盘分区信息。
+
+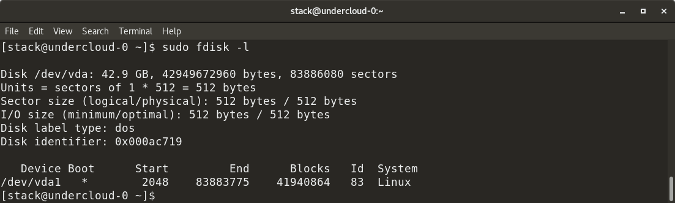
+
+这些是用于检查 Linux 文件空间的大多数内置实用程序。有许多类似的工具,如 [Disks][1](GUI 工具),[Ncdu][2] 等,它们也显示磁盘空间的利用率。你有你最喜欢的工具而它不在这个列表上吗?请在评论中分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
+
+作者:[Archit Modi][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/architmodi
+[1]:https://wiki.gnome.org/Apps/Disks
+[2]:https://dev.yorhel.nl/ncdu
diff --git a/published/201807/20180724 Learn how to build your own Twitter bot with Python.md b/published/201807/20180724 Learn how to build your own Twitter bot with Python.md
new file mode 100644
index 0000000000..4b96a80563
--- /dev/null
+++ b/published/201807/20180724 Learn how to build your own Twitter bot with Python.md
@@ -0,0 +1,137 @@
+学习如何使用 Python 构建你自己的 Twitter 机器人
+======
+
+
+
+Twitter 允许用户将博客帖子和文章[分享][1]给全世界。使用 Python 和 Tweepy 库使得创建一个 Twitter 机器人来接管你的所有的推特变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
+
+### 开始
+
+[tweepy][2] 库可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口。
+
+下面这些命令使用 `pipenv` 在一个虚拟环境中安装 tweepy。如果你没有安装 `pipenv`,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv][3]。
+
+```
+$ mkdir twitterbot
+$ cd twitterbot
+$ pipenv --three
+$ pipenv install tweepy
+$ pipenv shell
+```
+
+### Tweepy —— 开始
+
+要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 创建一个新的应用来获取到凭证。
+
+
+#### 创建一个新的 Twitter 应用
+
+当你填完了表格并点击了“创建你自己的 Twitter 应用”的按钮后,你可以获取到该应用的凭证。 Tweepy 需要用户密钥和用户密码,这些都可以在 “密钥和访问令牌” 中找到。
+
+![][4]
+
+向下滚动页面,使用“创建我的访问令牌”按钮生成一个“访问令牌” 和一个“访问令牌密钥”。
+
+#### 使用 Tweppy —— 输出你的时间线
+
+现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
+
+```
+import tweepy
+auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
+auth.set_access_token("your_access_token", "your_access_token_secret")
+api = tweepy.API(auth)
+public_tweets = api.home_timeline()
+for tweet in public_tweets:
+ print(tweet.text)
+```
+
+在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序。
+
+```
+$ python tweet.py
+```
+
+上述程序调用了 `home_timeline` 方法来获取到你时间线中的 20 条最近的推特。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
+
+#### 使用 Tweepy —— 发送一条推特
+
+要发送一条推特 ,有一个容易上手的 API 方法 `update_status` 。它的用法很简单:
+
+```
+api.update_status("The awesome text you would like to tweet")
+```
+
+Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。要获取 API 的详细信息,请查看[文档][5]。
+
+
+### 一个杂志机器人
+
+接下来我们来创建一个搜索 Fedora Magazine 的推特并转推这些的机器人。
+
+为了避免多次转推相同的内容,这个机器人存放了最近一条转推的推特的 ID 。 两个助手函数 `store_last_id` 和 `get_last_id` 将会帮助存储和保存这个 ID。
+
+然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的推特并存储这个 ID。
+
+```
+import tweepy
+
+def store_last_id(tweet_id):
+ """ Stores a tweet id in text file """
+ with open('lastid', 'w') as fp:
+ fp.write(str(tweet_id))
+
+
+def get_last_id():
+ """ Retrieve the list of tweets that were
+ already retweeted """
+
+ with open('lastid') as fp:
+ return fp.read()
+
+if __name__ == '__main__':
+
+ auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
+ auth.set_access_token("your_access_token", "your_access_token_secret")
+
+ api = tweepy.API(auth)
+
+ try:
+ last_id = get_last_id()
+ except FileNotFoundError:
+ print("No retweet yet")
+ last_id = None
+
+ for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
+ if tweet.user.name == 'Fedora Project':
+ store_last_id(tweet.id)
+ #tweet.retweet()
+ print(f'"{tweet.text}" was retweeted')
+```
+
+为了只转推 Fedora Magazine 的推特 ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的推特。
+
+### 结论
+
+在这篇文章中你看到了如何使用 tweepy 的 Python 库来创建一个自动阅读、发送和搜索推特的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
+
+这篇文章的演示源码可以在 [Github][6] 找到。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/learn-build-twitter-bot-python/
+
+作者:[Clément Verna][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[Bestony](https://github.com/bestony)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org
+[1]:https://twitter.com
+[2]:https://tweepy.readthedocs.io/en/v3.5.0/
+[3]:https://linux.cn/article-9827-1.html
+[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
+[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
+[6]:https://github.com/cverna/magabot
diff --git a/published/20180703 Why is Arch Linux So Challenging and What are Its Pros - Cons.md b/published/20180703 Why is Arch Linux So Challenging and What are Its Pros - Cons.md
new file mode 100644
index 0000000000..c41d1cd867
--- /dev/null
+++ b/published/20180703 Why is Arch Linux So Challenging and What are Its Pros - Cons.md
@@ -0,0 +1,74 @@
+为什么 Arch Linux 如此“难弄”又有何优劣?
+======
+
+
+
+[Arch Linux][1] 于 **2002** 年发布,由 **Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单、最小化且优雅的体验,但它的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
+
+很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
+
+### 1、优点: 定制属于你自己的 Linux 操作系统
+
+大多数热门的 Linux 发行版(比如 **Ubuntu** 和 **Fedora**)很像一般我们会看到的预装系统,和 **Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置的符合你的品味。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
+
+#### 缺点: 安装过程让人头疼
+
+[Arch Linux 的安装 ][2] 别辟蹊径——因为你要花些时间来微调你的操作系统。你会在过程中了解到不少终端命令和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
+
+### 2、优点: 没有预装垃圾
+
+鉴于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要、甚至卸载之前都不知道它们存在的东西。
+
+总而言之,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
+
+### 3、优点: 无需繁琐系统升级
+
+**Arch Linux** 采用滚动升级模型,简直妙极了。这意味着你不需要操心升级了。一旦你用上了 Arch,持续的更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
+
+#### 缺点: 一些升级可能会滚坏你的系统
+
+虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(LCTT 译注:别担心,你可以‘滚’回来 ;D )
+
+### 4、优点: Arch 有一个社区基因
+
+所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但也并非没有。比如 基于 **Ubuntu** 的衍生版本们不得不受到 Canonical 公司决策的影响。
+
+如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
+
+### 5、优点: Arch Wiki 无敌
+
+[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
+
+### 6、优点: 别忘了 Arch 用户软件库 (AUR)
+
+[Arch 用户软件库][5] (AUR)是一个来自社区的超大软件仓库。如果你找了一个还没有 Arch 的官方仓库里出现的软件,那你肯定能在 AUR 里找到社区为你准备好的包。
+
+AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
+
+#### 最后: Arch Linux 适合你吗?
+
+**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
+
+**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
+
+当你从零开始搭建完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
+
+欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
+
+--------------------------------------------------------------------------------
+
+via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
+
+作者:[Martins D. Okoi][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[Moelf](https://github.com/Moelf)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.fossmint.com/author/dillivine/
+[1]:https://www.archlinux.org/
+[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
+[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
+[4]:https://wiki.archlinux.org/
+[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
diff --git a/published/20180709 A sysadmin-s guide to network management.md b/published/20180709 A sysadmin-s guide to network management.md
new file mode 100644
index 0000000000..70b7d0bcc0
--- /dev/null
+++ b/published/20180709 A sysadmin-s guide to network management.md
@@ -0,0 +1,182 @@
+面向系统管理员的网络管理指南
+======
+
+> 一个使管理服务器和网络更轻松的 Linux 工具和命令的参考列表。
+
+
+
+如果你是一位系统管理员,那么你的日常工作应该包括管理服务器和数据中心的网络。以下的 Linux 实用工具和命令 —— 从基础的到高级的 —— 将帮你更轻松地管理你的网络。
+
+在几个命令中,你将会看到 ``,它是“完全合格域名”的全称。当你看到它时,你应该用你的网站 URL 或你的服务器来代替它(比如,`server-name.company.com`),具体要视情况而定。
+
+### Ping
+
+正如它的名字所表示的那样,`ping` 是用于去检查从你的系统到你想去连接的系统之间端到端的连通性。当一个 ping 成功时,它使用的 [ICMP][1] 的 echo 包将会返回到你的系统中。它是检查系统/网络连通性的一个良好开端。你可以在 IPv4 和 IPv6 地址上使用 `ping` 命令。(阅读我的文章 "[如何在 Linux 系统上找到你的 IP 地址][2]" 去学习更多关于 IP 地址的知识)
+
+**语法:**
+
+ * IPv4: `ping /`
+ * IPv6: `ping6 /`
+
+你也可以使用 `ping` 去解析出网站所对应的 IP 地址,如下图所示:
+
+
+
+### Traceroute
+
+`ping` 是用于检查端到端的连通性,`traceroute` 实用工具将告诉你到达对端系统、网站、或服务器所经过的路径上所有路由器的 IP 地址。`traceroute` 在网络连接调试中经常用于在 `ping` 之后的第二步。
+
+这是一个跟踪从你的系统到其它对端的全部网络路径的非常好的工具。在检查端到端的连通性时,这个实用工具将告诉你到达对端系统、网站、或服务器上所经历的路径上的全部路由器的 IP 地址。通常用于网络连通性调试的第二步。
+
+**语法:**
+
+ * `traceroute /`
+
+### Telnet
+
+**语法:**
+
+ * `telnet /` 是用于 [telnet][3] 进入任何支持该协议的服务器。
+
+### Netstat
+
+这个网络统计(`netstat`)实用工具是用于去分析解决网络连接问题和检查接口/端口统计数据、路由表、协议状态等等的。它是任何管理员都应该必须掌握的工具。
+
+**语法:**
+
+ * `netstat -l` 显示所有处于监听状态的端口列表。
+ * `netstat -a` 显示所有端口;如果去指定仅显示 TCP 端口,使用 `-at`(指定信显示 UDP 端口,使用 `-au`)。
+ * `netstat -r` 显示路由表。
+
+ 
+
+ * `netstat -s` 显示每个协议的状态总结。
+
+ 
+
+ * `netstat -i` 显示每个接口传输/接收(TX/RX)包的统计数据。
+
+ 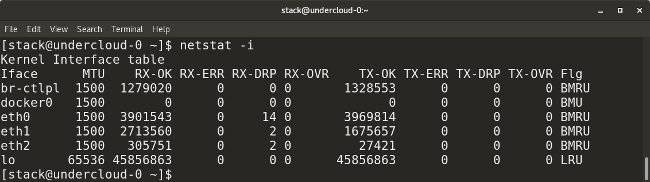
+
+### Nmcli
+
+`nmcli` 是一个管理网络连接、配置等工作的非常好的实用工具。它能够去管理网络管理程序和修改任何设备的网络配置详情。
+
+**语法:**
+
+ * `nmcli device` 列出网络上的所有设备。
+ * `nmcli device show ` 显示指定接口的网络相关的详细情况。
+ * `nmcli connection` 检查设备的连接情况。
+ * `nmcli connection down ` 关闭指定接口。
+ * `nmcli connection up ` 打开指定接口。
+ * `nmcli con add type vlan con-name dev id ipv4 gw4 ` 在特定的接口上使用指定的 VLAN 号添加一个虚拟局域网(VLAN)接口、IP 地址、和网关。
+
+ 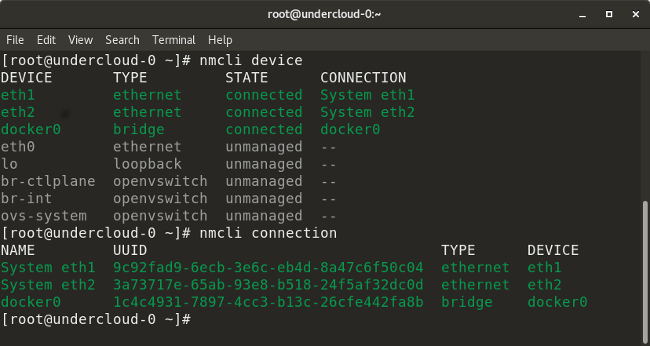
+
+### 路由
+
+检查和配置路由的命令很多。下面是其中一些比较有用的:
+
+**语法:**
+
+ * `ip route` 显示各自接口上所有当前的路由配置。
+
+ 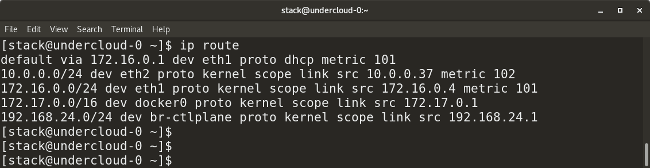
+
+ * `route add default gw ` 在路由表中添加一个默认的网关。
+ * `route add -net gw ` 在路由表中添加一个新的网络路由。还有许多其它的路由参数,比如,添加一个默认路由,默认网关等等。
+ * `route del -net ` 从路由表中删除一个指定的路由条目。
+
+ 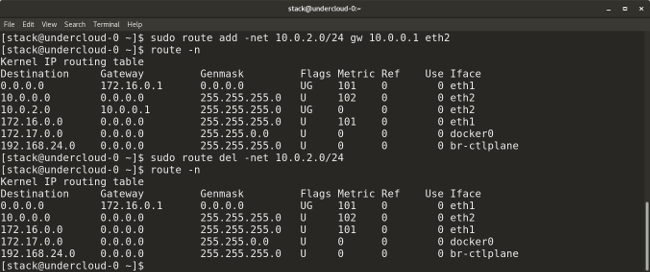
+
+ * `ip neighbor` 显示当前的邻接表和用于去添加、改变、或删除新的邻居。
+
+ 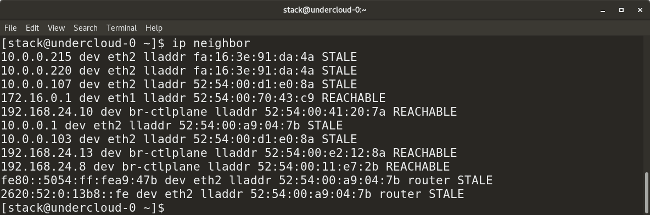
+
+ 
+
+ * `arp` (它的全称是 “地址解析协议”)类似于 `ip neighbor`。`arp` 映射一个系统的 IP 地址到它相应的 MAC(介质访问控制)地址。
+
+ 
+
+### Tcpdump 和 Wireshark
+
+Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark` 等等。它们被用于去捕获传输/接收的网络流量中的数据包,因此它们对于系统管理员去诊断丢包或相关问题时非常有用。对于热衷于命令行操作的人来说,`tcpdump` 是一个非常好的工具,而对于喜欢 GUI 操作的用户来说,`wireshark` 是捕获和分析数据包的不二选择。`tcpdump` 是一个 Linux 内置的用于去捕获网络流量的实用工具。它能够用于去捕获/显示特定端口、协议等上的流量。
+
+**语法:**
+
+ * `tcpdump -i ` 显示指定接口上实时通过的数据包。通过在命令中添加一个 `-w` 标志和输出文件的名字,可以将数据包保存到一个文件中。例如:`tcpdump -w -i `。
+
+ 
+
+ * `tcpdump -i src ` 从指定的源 IP 地址上捕获数据包。
+ * `tcpdump -i dst ` 从指定的目标 IP 地址上捕获数据包。
+ * `tcpdump -i port ` 从一个指定的端口号(比如,53、80、8080 等等)上捕获数据包。
+ * `tcpdump -i ` 捕获指定协议的数据包,比如:TCP、UDP、等等。
+
+
+
+### Iptables
+
+`iptables` 是一个包过滤防火墙工具,它能够允许或阻止某些流量。这个实用工具的应用范围非常广泛;下面是它的其中一些最常用的使用命令。
+
+**语法:**
+
+ * `iptables -L` 列出所有已存在的 `iptables` 规则。
+ * `iptables -F` 删除所有已存在的规则。
+
+下列命令允许流量从指定端口到指定接口:
+
+ * `iptables -A INPUT -i -p tcp –dport -m state –state NEW,ESTABLISHED -j ACCEPT`
+ * `iptables -A OUTPUT -o -p tcp -sport -m state – state ESTABLISHED -j ACCEPT`
+
+下列命令允许环回接口访问系统:
+
+ * `iptables -A INPUT -i lo -j ACCEPT`
+ * `iptables -A OUTPUT -o lo -j ACCEPT`
+
+### Nslookup
+
+`nslookup` 工具是用于去获得一个网站或域名所映射的 IP 地址。它也能用于去获得你的 DNS 服务器的信息,比如,一个网站的所有 DNS 记录(具体看下面的示例)。与 `nslookup` 类似的一个工具是 `dig`(Domain Information Groper)实用工具。
+
+**语法:**
+
+ * `nslookup ` 显示你的服务器组中 DNS 服务器的 IP 地址,它后面就是你想去访问网站的 IP 地址。
+ * `nslookup -type=any ` 显示指定网站/域中所有可用记录。
+
+
+### 网络/接口调试
+
+下面是用于接口连通性或相关网络问题调试所需的命令和文件的汇总。
+
+**语法:**
+
+ * `ss` 是一个转储套接字统计数据的实用工具。
+ * `nmap `,它的全称是 “Network Mapper”,它用于扫描网络端口、发现主机、检测 MAC 地址,等等。
+ * `ip addr/ifconfig -a` 提供一个系统上所有接口的 IP 地址和相关信息。
+ * `ssh -vvv user@` 允许你使用指定的 IP/域名和用户名通过 SSH 协议登入到其它服务器。`-vvv` 标志提供 SSH 登入到服务器过程中的 "最详细的" 信息。
+ * `ethtool -S ` 检查指定接口上的统计数据。
+ * `ifup ` 启动指定的接口。
+ * `ifdown ` 关闭指定的接口
+ * `systemctl restart network` 重启动系统上的一个网络服务。
+ * `/etc/sysconfig/network-scripts/` 是一个对指定的接口设置 IP 地址、网络、网关等等的接口配置文件。DHCP 模式也可以在这里设置。
+ * `/etc/hosts` 这个文件包含自定义的主机/域名到 IP 地址的映射。
+ * `/etc/resolv.conf` 指定系统上的 DNS 服务器的 IP 地址。
+ * `/etc/ntp.conf` 指定 NTP 服务器域名。
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
+
+作者:[Archit Modi][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/architmodi
+[1]:https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
+[2]:https://opensource.com/article/18/5/how-find-ip-address-linux
+[3]:https://en.wikipedia.org/wiki/Telnet
diff --git a/published/20180710 4 Essential and Practical Usage of Cut Command in Linux.md b/published/20180710 4 Essential and Practical Usage of Cut Command in Linux.md
new file mode 100644
index 0000000000..0071db3e5c
--- /dev/null
+++ b/published/20180710 4 Essential and Practical Usage of Cut Command in Linux.md
@@ -0,0 +1,525 @@
+Linux 下 cut 命令的 4 个基础实用的示例
+============================================================
+
+`cut` 命令是用来从文本文件中移除“某些列”的经典工具。在本文中的“一列”可以被定义为按照一行中位置区分的一系列字符串或者字节,或者是以某个分隔符为间隔的某些域。
+
+先前我已经介绍了[如何使用 AWK 命令][13]。在本文中,我将解释 linux 下 `cut` 命令的 4 个本质且实用的例子,有时这些例子将帮你节省很多时间。
+
+
+
+### Linux 下 cut 命令的 4 个实用示例
+
+假如你想,你可以观看下面的视频,视频中解释了本文中我列举的 cut 命令的使用例子。
+
+- https://www.youtube.com/PhE_cFLzVFw
+
+### 1、 作用在一系列字符上
+
+当启用 `-c` 命令行选项时,`cut` 命令将移除一系列字符。
+
+和其他的过滤器类似, `cut` 命令不会直接改变输入的文件,它将复制已修改的数据到它的标准输出里去。你可以通过重定向命令的结果到一个文件中来保存修改后的结果,或者使用管道将结果送到另一个命令的输入中,这些都由你来负责。
+
+假如你已经下载了上面视频中的[示例测试文件][26],你将看到一个名为 `BALANCE.txt` 的数据文件,这些数据是直接从我妻子在她工作中使用的某款会计软件中导出的:
+
+```
+sh$ head BALANCE.txt
+ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
+4 1012017 623477 TIDE SCHEDULE ALNEENRE-4701-LOC 00000001615,00
+4 1012017 445452 VAT BS/ENC ALNEENRE-4701-LOC 00000000323,00
+4 1012017 4356 PAYABLES ALNEENRE-4701-LOC 00000001938,00
+5 1012017 623372 ACCOMODATION GUIDE ALNEENRE-4771-LOC 00000001333,00
+5 1012017 445452 VAT BS/ENC ALNEENRE-4771-LOC 00000000266,60
+5 1012017 4356 PAYABLES ALNEENRE-4771-LOC 00000001599,60
+6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
+6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
+6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
+```
+
+上述文件是一个固定宽度的文本文件,因为对于每一项数据,都使用了不定长的空格做填充,使得它看起来是一个对齐的列表。
+
+这样一来,每一列数据开始和结束的位置都是一致的。从 `cut` 命令的字面意思去理解会给我们带来一个小陷阱:`cut` 命令实际上需要你指出你想_保留_的数据范围,而不是你想_移除_的范围。所以,假如我_只_需要上面文件中的 `ACCOUNTNUM` 和 `ACCOUNTLIB` 列,我需要这么做:
+
+```
+sh$ cut -c 25-59 BALANCE.txt | head
+ACCOUNTNUM ACCOUNTLIB
+623477 TIDE SCHEDULE
+445452 VAT BS/ENC
+4356 /accountPAYABLES
+623372 ACCOMODATION GUIDE
+445452 VAT BS/ENC
+4356 PAYABLES
+4356 PAYABLES
+445452 VAT BS/ENC
+623795 TOURIST GUIDE BOOK
+```
+
+#### 范围如何定义?
+
+正如我们上面看到的那样, `cut` 命令需要我们特别指定需要保留的数据的_范围_。所以,下面我将更正式地介绍如何定义范围:对于 `cut` 命令来说,范围是由连字符(`-`)分隔的起始和结束位置组成,范围是基于 1 计数的,即每行的第一项是从 1 开始计数的,而不是从 0 开始。范围是一个闭区间,开始和结束位置都将包含在结果之中,正如它们之间的所有字符那样。如果范围中的结束位置比起始位置小,则这种表达式是错误的。作为快捷方式,你可以省略起始_或_结束值,正如下面的表格所示:
+
+
+| 范围 | 含义 |
+|---|---|
+| `a-b` | a 和 b 之间的范围(闭区间) |
+|`a` | 与范围 `a-a` 等价 |
+| `-b` | 与范围 `1-a` 等价 |
+| `b-` | 与范围 `b-∞` 等价 |
+
+`cut` 命令允许你通过逗号分隔多个范围,下面是一些示例:
+
+```
+# 保留 1 到 24 之间(闭区间)的字符
+cut -c -24 BALANCE.txt
+
+# 保留 1 到 24(闭区间)以及 36 到 59(闭区间)之间的字符
+cut -c -24,36-59 BALANCE.txt
+
+# 保留 1 到 24(闭区间)、36 到 59(闭区间)和 93 到该行末尾之间的字符
+cut -c -24,36-59,93- BALANCE.txt
+```
+
+`cut` 命令的一个限制(或者是特性,取决于你如何看待它)是它将 _不会对数据进行重排_。所以下面的命令和先前的命令将产生相同的结果,尽管范围的顺序做了改变:
+
+```
+cut -c 93-,-24,36-59 BALANCE.txt
+```
+
+你可以轻易地使用 `diff` 命令来验证:
+
+```
+diff -s <(cut -c -24,36-59,93- BALANCE.txt) \
+ <(cut -c 93-,-24,36-59 BALANCE.txt)
+Files /dev/fd/63 and /dev/fd/62 are identical
+```
+
+类似的,`cut` 命令 _不会重复数据_:
+
+```
+# 某人或许期待这可以第一列三次,但并不会……
+cut -c -10,-10,-10 BALANCE.txt | head -5
+ACCDOC
+4
+4
+4
+5
+```
+
+值得提及的是,曾经有一个提议,建议使用 `-o` 选项来去除上面提到的两个限制,使得 `cut` 工具可以重排或者重复数据。但这个提议被 [POSIX 委员会拒绝了][14],_“因为这类增强不属于 IEEE P1003.2b 草案标准的范围”_。
+
+据我所知,我还没有见过哪个版本的 `cut` 程序实现了上面的提议,以此来作为扩展,假如你知道某些例外,请使用下面的评论框分享给大家!
+
+### 2、 作用在一系列字节上
+
+当使用 `-b` 命令行选项时,`cut` 命令将移除字节范围。
+
+咋一看,使用_字符_范围和使用_字节_没有什么明显的不同:
+
+```
+sh$ diff -s <(cut -b -24,36-59,93- BALANCE.txt) \
+ <(cut -c -24,36-59,93- BALANCE.txt)
+Files /dev/fd/63 and /dev/fd/62 are identical
+```
+
+这是因为我们的示例数据文件使用的是 [US-ASCII 编码][27](字符集),使用 `file -i` 便可以正确地猜出来:
+
+```
+sh$ file -i BALANCE.txt
+BALANCE.txt: text/plain; charset=us-ascii
+```
+
+在 US-ASCII 编码中,字符和字节是一一对应的。理论上,你只需要使用一个字节就可以表示 256 个不同的字符(数字、字母、标点符号和某些符号等)。实际上,你能表达的字符数比 256 要更少一些,因为字符编码中为某些特定值做了规定(例如 32 或 65 就是[控制字符][28])。即便我们能够使用上述所有的字节范围,但对于存储种类繁多的人类手写符号来说,256 是远远不够的。所以如今字符和字节间的一一对应更像是某种例外,并且几乎总是被无处不在的 UTF-8 多字节编码所取代。下面让我们看看如何来处理多字节编码的情形。
+
+#### 作用在多字节编码的字符上
+
+正如我前面提到的那样,示例数据文件来源于我妻子使用的某款会计软件。最近好像她升级了那个软件,然后呢,导出的文本就完全不同了,你可以试试和上面的数据文件相比,找找它们之间的区别:
+
+```
+sh$ head BALANCE-V2.txt
+ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
+4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
+4 1012017 445452 VAT BS/ENC ALNÉENRE-4701-LOC 00000000323,00
+4 1012017 4356 PAYABLES ALNÉENRE-4701-LOC 00000001938,00
+5 1012017 623372 ACCOMODATION GUIDE ALNÉENRE-4771-LOC 00000001333,00
+5 1012017 445452 VAT BS/ENC ALNÉENRE-4771-LOC 00000000266,60
+5 1012017 4356 PAYABLES ALNÉENRE-4771-LOC 00000001599,60
+6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
+6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
+6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
+```
+
+上面的标题栏或许能够帮助你找到什么被改变了,但无论你找到与否,现在让我们看看上面的更改过后的结果:
+
+```
+sh$ cut -c 93-,-24,36-59 BALANCE-V2.txt
+ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
+4 1012017 TIDE SCHEDULE 00000001615,00
+4 1012017 VAT BS/ENC 00000000323,00
+4 1012017 PAYABLES 00000001938,00
+5 1012017 ACCOMODATION GUIDE 00000001333,00
+5 1012017 VAT BS/ENC 00000000266,60
+5 1012017 PAYABLES 00000001599,60
+6 1012017 PAYABLES 00000001837,20
+6 1012017 VAT BS/ENC 00000000306,20
+6 1012017 TOURIST GUIDE BOOK 00000001531,00
+19 1012017 SEMINAR FEES 00000000080,00
+19 1012017 PAYABLES 00000000080,00
+28 1012017 MAINTENANCE 00000000746,58
+28 1012017 VAT BS/ENC 00000000149,32
+28 1012017 PAYABLES 00000000895,90
+31 1012017 PAYABLES 00000000240,00
+31 1012017 VAT BS/DEBIT 00000000040,00
+31 1012017 ADVERTISEMENTS 00000000200,00
+32 1012017 WATER 00000000202,20
+32 1012017 VAT BS/DEBIT 00000000020,22
+32 1012017 WATER 00000000170,24
+32 1012017 VAT BS/DEBIT 00000000009,37
+32 1012017 PAYABLES 00000000402,03
+34 1012017 RENTAL COSTS 00000000018,00
+34 1012017 PAYABLES 00000000018,00
+35 1012017 MISCELLANEOUS CHARGES 00000000015,00
+35 1012017 VAT BS/DEBIT 00000000003,00
+35 1012017 PAYABLES 00000000018,00
+36 1012017 LANDLINE TELEPHONE 00000000069,14
+36 1012017 VAT BS/ENC 00000000013,83
+```
+
+我_毫无删减地_复制了上面命令的输出。所以可以很明显地看出列对齐那里有些问题。
+
+对此我的解释是原来的数据文件只包含 US-ASCII 编码的字符(符号、标点符号、数字和没有发音符号的拉丁字母)。
+
+但假如你仔细地查看经软件升级后产生的文件,你可以看到新导出的数据文件保留了带发音符号的字母。例如现在合理地记录了名为 “ALNÉENRE” 的公司,而不是先前的 “ALNEENRE”(没有发音符号)。
+
+`file -i` 正确地识别出了改变,因为它报告道现在这个文件是 [UTF-8 编码][15] 的。
+
+```
+sh$ file -i BALANCE-V2.txt
+BALANCE-V2.txt: text/plain; charset=utf-8
+```
+
+如果想看看 UTF-8 文件中那些带发音符号的字母是如何编码的,我们可以使用 `[hexdump][12]`,它可以让我们直接以字节形式查看文件:
+
+```
+# 为了减少输出,让我们只关注文件的第 2 行
+sh$ sed '2!d' BALANCE-V2.txt
+4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
+sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
+00000000 34 20 20 20 20 20 20 20 20 20 31 30 31 32 30 31 |4 101201|
+00000010 37 20 20 20 20 20 20 20 36 32 33 34 37 37 20 20 |7 623477 |
+00000020 20 20 20 54 49 44 45 20 53 43 48 45 44 55 4c 45 | TIDE SCHEDULE|
+00000030 20 20 20 20 20 20 20 20 20 20 20 41 4c 4e c3 89 | ALN..|
+00000040 45 4e 52 45 2d 34 37 30 31 2d 4c 4f 43 20 20 20 |ENRE-4701-LOC |
+00000050 20 20 20 20 20 20 20 20 20 20 20 20 20 30 30 30 | 000|
+00000060 30 30 30 30 31 36 31 35 2c 30 30 20 20 20 20 20 |00001615,00 |
+00000070 20 20 20 20 20 20 20 20 20 20 20 0a | .|
+0000007c
+```
+
+在 `hexdump` 输出的 00000030 那行,在一系列的空格(字节 `20`)之后,你可以看到:
+
+* 字母 `A` 被编码为 `41`,
+* 字母 `L` 被编码为 `4c`,
+* 字母 `N` 被编码为 `4e`。
+
+但对于大写的[带有注音的拉丁大写字母 E][16] (这是它在 Unicode 标准中字母 _É_ 的官方名称),则是使用 _2_ 个字节 `c3 89` 来编码的。
+
+这样便出现问题了:对于使用固定宽度编码的文件, 使用字节位置来表示范围的 `cut` 命令工作良好,但这并不适用于使用变长编码的 UTF-8 或者 [Shift JIS][17] 编码。这种情况在下面的 [POSIX 标准的非规范性摘录][18] 中被明确地解释过:
+
+> 先前版本的 `cut` 程序将字节和字符视作等同的环境下运作(正如在某些实现下对退格键 `` 和制表键 `` 的处理)。在针对多字节字符的情况下,特别增加了 `-b` 选项。
+
+嘿,等一下!我并没有在上面“有错误”的例子中使用 '-b' 选项,而是 `-c` 选项呀!所以,难道_不应该_能够成功处理了吗!?
+
+是的,确实_应该_:但是很不幸,即便我们现在已身处 2018 年,GNU Coreutils 的版本为 8.30 了,`cut` 程序的 GNU 版本实现仍然不能很好地处理多字节字符。引用 [GNU 文档][19] 的话说,_`-c` 选项“现在和 `-b` 选项是相同的,但对于国际化的情形将有所不同[...]”_。需要提及的是,这个问题距今已有 10 年之久了!
+
+另一方面,[OpenBSD][20] 的实现版本和 POSIX 相吻合,这将归功于当前的本地化(`locale`)设定来合理地处理多字节字符:
+
+```
+# 确保随后的命令知晓我们现在处理的是 UTF-8 编码的文本文件
+openbsd-6.3$ export LC_CTYPE=en_US.UTF-8
+
+# 使用 `-c` 选项, `cut` 能够合理地处理多字节字符
+openbsd-6.3$ cut -c -24,36-59,93- BALANCE-V2.txt
+ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
+4 1012017 TIDE SCHEDULE 00000001615,00
+4 1012017 VAT BS/ENC 00000000323,00
+4 1012017 PAYABLES 00000001938,00
+5 1012017 ACCOMODATION GUIDE 00000001333,00
+5 1012017 VAT BS/ENC 00000000266,60
+5 1012017 PAYABLES 00000001599,60
+6 1012017 PAYABLES 00000001837,20
+6 1012017 VAT BS/ENC 00000000306,20
+6 1012017 TOURIST GUIDE BOOK 00000001531,00
+19 1012017 SEMINAR FEES 00000000080,00
+19 1012017 PAYABLES 00000000080,00
+28 1012017 MAINTENANCE 00000000746,58
+28 1012017 VAT BS/ENC 00000000149,32
+28 1012017 PAYABLES 00000000895,90
+31 1012017 PAYABLES 00000000240,00
+31 1012017 VAT BS/DEBIT 00000000040,00
+31 1012017 ADVERTISEMENTS 00000000200,00
+32 1012017 WATER 00000000202,20
+32 1012017 VAT BS/DEBIT 00000000020,22
+32 1012017 WATER 00000000170,24
+32 1012017 VAT BS/DEBIT 00000000009,37
+32 1012017 PAYABLES 00000000402,03
+34 1012017 RENTAL COSTS 00000000018,00
+34 1012017 PAYABLES 00000000018,00
+35 1012017 MISCELLANEOUS CHARGES 00000000015,00
+35 1012017 VAT BS/DEBIT 00000000003,00
+35 1012017 PAYABLES 00000000018,00
+36 1012017 LANDLINE TELEPHONE 00000000069,14
+36 1012017 VAT BS/ENC 00000000013,83
+```
+
+正如期望的那样,当使用 `-b` 选项而不是 `-c` 选项后, OpenBSD 版本的 `cut` 实现和传统的 `cut` 表现是类似的:
+
+```
+openbsd-6.3$ cut -b -24,36-59,93- BALANCE-V2.txt
+ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
+4 1012017 TIDE SCHEDULE 00000001615,00
+4 1012017 VAT BS/ENC 00000000323,00
+4 1012017 PAYABLES 00000001938,00
+5 1012017 ACCOMODATION GUIDE 00000001333,00
+5 1012017 VAT BS/ENC 00000000266,60
+5 1012017 PAYABLES 00000001599,60
+6 1012017 PAYABLES 00000001837,20
+6 1012017 VAT BS/ENC 00000000306,20
+6 1012017 TOURIST GUIDE BOOK 00000001531,00
+19 1012017 SEMINAR FEES 00000000080,00
+19 1012017 PAYABLES 00000000080,00
+28 1012017 MAINTENANCE 00000000746,58
+28 1012017 VAT BS/ENC 00000000149,32
+28 1012017 PAYABLES 00000000895,90
+31 1012017 PAYABLES 00000000240,00
+31 1012017 VAT BS/DEBIT 00000000040,00
+31 1012017 ADVERTISEMENTS 00000000200,00
+32 1012017 WATER 00000000202,20
+32 1012017 VAT BS/DEBIT 00000000020,22
+32 1012017 WATER 00000000170,24
+32 1012017 VAT BS/DEBIT 00000000009,37
+32 1012017 PAYABLES 00000000402,03
+34 1012017 RENTAL COSTS 00000000018,00
+34 1012017 PAYABLES 00000000018,00
+35 1012017 MISCELLANEOUS CHARGES 00000000015,00
+35 1012017 VAT BS/DEBIT 00000000003,00
+35 1012017 PAYABLES 00000000018,00
+36 1012017 LANDLINE TELEPHONE 00000000069,14
+36 1012017 VAT BS/ENC 00000000013,83
+```
+
+### 3、 作用在域上
+
+从某种意义上说,使用 `cut` 来处理用特定分隔符隔开的文本文件要更加容易一些,因为只需要确定好每行中域之间的分隔符,然后复制域的内容到输出就可以了,而不需要烦恼任何与编码相关的问题。
+
+下面是一个用分隔符隔开的示例文本文件:
+
+```
+sh$ head BALANCE.csv
+ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;ACCDOCLIB;DEBIT;CREDIT
+4;1012017;623477;TIDE SCHEDULE;ALNEENRE-4701-LOC;00000001615,00;
+4;1012017;445452;VAT BS/ENC;ALNEENRE-4701-LOC;00000000323,00;
+4;1012017;4356;PAYABLES;ALNEENRE-4701-LOC;;00000001938,00
+5;1012017;623372;ACCOMODATION GUIDE;ALNEENRE-4771-LOC;00000001333,00;
+5;1012017;445452;VAT BS/ENC;ALNEENRE-4771-LOC;00000000266,60;
+5;1012017;4356;PAYABLES;ALNEENRE-4771-LOC;;00000001599,60
+6;1012017;4356;PAYABLES;FACT FA00006253 - BIT QUIROBEN;;00000001837,20
+6;1012017;445452;VAT BS/ENC;FACT FA00006253 - BIT QUIROBEN;00000000306,20;
+6;1012017;623795;TOURIST GUIDE BOOK;FACT FA00006253 - BIT QUIROBEN;00000001531,00;
+```
+
+你可能知道上面文件是一个 [CSV][29] 格式的文件(它以逗号来分隔),即便有时候域分隔符不是逗号。例如分号(`;`)也常被用来作为分隔符,并且对于那些总使用逗号作为 [十进制分隔符][30]的国家(例如法国,所以上面我的示例文件中选用了他们国家的字符),当导出数据为 “CSV” 格式时,默认将使用分号来分隔数据。另一种常见的情况是使用 [tab 键][32] 来作为分隔符,从而生成叫做 [tab 分隔的值][32] 的文件。最后,在 Unix 和 Linux 领域,冒号 (`:`) 是另一种你能找到的常见分隔符号,例如在标准的 `/etc/passwd` 和 `/etc/group` 这两个文件里。
+
+当处理使用分隔符隔开的文本文件格式时,你可以向带有 `-f` 选项的 `cut` 命令提供需要保留的域的范围,并且你也可以使用 `-d` 选项来指定分隔符(当没有使用 `-d` 选项时,默认以 tab 字符来作为分隔符):
+
+```
+sh$ cut -f 5- -d';' BALANCE.csv | head
+ACCDOCLIB;DEBIT;CREDIT
+ALNEENRE-4701-LOC;00000001615,00;
+ALNEENRE-4701-LOC;00000000323,00;
+ALNEENRE-4701-LOC;;00000001938,00
+ALNEENRE-4771-LOC;00000001333,00;
+ALNEENRE-4771-LOC;00000000266,60;
+ALNEENRE-4771-LOC;;00000001599,60
+FACT FA00006253 - BIT QUIROBEN;;00000001837,20
+FACT FA00006253 - BIT QUIROBEN;00000000306,20;
+FACT FA00006253 - BIT QUIROBEN;00000001531,00;
+```
+
+#### 处理不包含分隔符的行
+
+但要是输入文件中的某些行没有分隔符又该怎么办呢?很容易地认为可以将这样的行视为只包含第一个域。但 `cut` 程序并 _不是_ 这样做的。
+
+默认情况下,当使用 `-f` 选项时,`cut` 将总是原样输出不包含分隔符的那一行(可能假设它是非数据行,就像表头或注释等):
+
+```
+sh$ (echo "# 2018-03 BALANCE"; cat BALANCE.csv) > BALANCE-WITH-HEADER.csv
+
+sh$ cut -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
+# 2018-03 BALANCE
+DEBIT;CREDIT
+00000001615,00;
+00000000323,00;
+;00000001938,00
+```
+
+使用 `-s` 选项,你可以做出相反的行为,这样 `cut` 将总是忽略这些行:
+
+```
+sh$ cut -s -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
+DEBIT;CREDIT
+00000001615,00;
+00000000323,00;
+;00000001938,00
+00000001333,00;
+```
+
+假如你好奇心强,你还可以探索这种特性,来作为一种相对隐晦的方式去保留那些只包含给定字符的行:
+
+```
+# 保留含有一个 `e` 的行
+sh$ printf "%s\n" {mighty,bold,great}-{condor,monkey,bear} | cut -s -f 1- -d'e'
+```
+
+#### 改变输出的分隔符
+
+作为一种扩展, GNU 版本实现的 `cut` 允许通过使用 `--output-delimiter` 选项来为结果指定一个不同的域分隔符:
+
+```
+sh$ cut -f 5,6- -d';' --output-delimiter="*" BALANCE.csv | head
+ACCDOCLIB*DEBIT*CREDIT
+ALNEENRE-4701-LOC*00000001615,00*
+ALNEENRE-4701-LOC*00000000323,00*
+ALNEENRE-4701-LOC**00000001938,00
+ALNEENRE-4771-LOC*00000001333,00*
+ALNEENRE-4771-LOC*00000000266,60*
+ALNEENRE-4771-LOC**00000001599,60
+FACT FA00006253 - BIT QUIROBEN**00000001837,20
+FACT FA00006253 - BIT QUIROBEN*00000000306,20*
+FACT FA00006253 - BIT QUIROBEN*00000001531,00*
+```
+
+需要注意的是,在上面这个例子中,所有出现域分隔符的地方都被替换掉了,而不仅仅是那些在命令行中指定的作为域范围边界的分隔符。
+
+### 4、 非 POSIX GNU 扩展
+
+说到非 POSIX GNU 扩展,它们中的某些特别有用。特别需要提及的是下面的扩展也同样对字节、字符或者域范围工作良好(相对于当前的 GNU 实现来说)。
+
+`--complement`:
+
+想想在 sed 地址中的感叹符号(`!`),使用它,`cut` 将只保存**没有**被匹配到的范围:
+
+```
+# 只保留第 5 个域
+sh$ cut -f 5 -d';' BALANCE.csv |head -3
+ACCDOCLIB
+ALNEENRE-4701-LOC
+ALNEENRE-4701-LOC
+
+# 保留除了第 5 个域之外的内容
+sh$ cut --complement -f 5 -d';' BALANCE.csv |head -3
+ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;DEBIT;CREDIT
+4;1012017;623477;TIDE SCHEDULE;00000001615,00;
+4;1012017;445452;VAT BS/ENC;00000000323,00;
+```
+
+`--zero-terminated (-z)`:
+
+使用 [NUL 字符][6] 来作为行终止符,而不是 [新行字符][7]。当你的数据包含 新行字符时, `-z` 选项就特别有用了,例如当处理文件名的时候(因为在文件名中新行字符是可以使用的,而 NUL 则不可以)。
+
+为了展示 `-z` 选项,让我们先做一点实验。首先,我们将创建一个文件名中包含换行符的文件:
+
+```
+bash$ touch $'EMPTY\nFILE\nWITH FUNKY\nNAME'.txt
+bash$ ls -1 *.txt
+BALANCE.txt
+BALANCE-V2.txt
+EMPTY?FILE?WITH FUNKY?NAME.txt
+```
+
+现在假设我想展示每个 `*.txt` 文件的前 5 个字符。一个想当然的解决方法将会失败:
+
+```
+sh$ ls -1 *.txt | cut -c 1-5
+BALAN
+BALAN
+EMPTY
+FILE
+WITH
+NAME.
+```
+
+你可以已经知道 [ls][21] 是为了[方便人类使用][33]而特别设计的,并且在一个命令管道中使用它是一个反模式(确实是这样的)。所以让我们用 [find][22] 来替换它:
+
+```
+sh$ find . -name '*.txt' -printf "%f\n" | cut -c 1-5
+BALAN
+EMPTY
+FILE
+WITH
+NAME.
+BALAN
+```
+
+上面的命令基本上产生了与先前类似的结果(尽管以不同的次序,因为 `ls` 会隐式地对文件名做排序,而 `find` 则不会)。
+
+在上面的两个例子中,都有一个相同的问题,`cut` 命令不能区分 新行 字符是数据域的一部分(即文件名),还是作为最后标记的 新行 记号。但使用 NUL 字节(`\0`)来作为行终止符就将排除掉这种混淆的情况,使得我们最后可以得到期望的结果:
+
+```
+# 我被告知在某些旧版的 `tr` 程序中需要使用 `\000` 而不是 `\0` 来代表 NUL 字符(假如你需要这种改变请让我知晓!)
+sh$ find . -name '*.txt' -printf "%f\0" | cut -z -c 1-5| tr '\0' '\n'
+BALAN
+EMPTY
+BALAN
+```
+
+通过上面最后的例子,我们就达到了本文的最后部分了,所以我将让你自己试试 `-printf` 后面那个有趣的 `"%f\0"` 参数或者理解为什么我在管道的最后使用了 [tr][23] 命令。
+
+### 使用 cut 命令可以实现更多功能
+
+我只是列举了 `cut` 命令的最常见且在我眼中最基础的使用方式。你甚至可以将它以更加实用的方式加以运用,这取决于你的逻辑和想象。
+
+不要再犹豫了,请使用下面的评论框贴出你的发现。最后一如既往的,假如你喜欢这篇文章,请不要忘记将它分享到你最喜爱网站和社交媒体中!
+
+--------------------------------------------------------------------------------
+
+via: https://linuxhandbook.com/cut-command/
+
+作者:[Sylvain Leroux][a]
+译者:[FSSlc](https://github.com/FSSlc)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://linuxhandbook.com/author/sylvain/
+[1]:https://linuxhandbook.com/cut-command/#_what_s_a_range
+[2]:https://linuxhandbook.com/cut-command/#_working_with_multibyte_characters
+[3]:https://linuxhandbook.com/cut-command/#_handling_lines_not_containing_the_delimiter
+[4]:https://linuxhandbook.com/cut-command/#_changing_the_output_delimiter
+[5]:http://click.linksynergy.com/deeplink?id=IRL8ozn3lq8&type=10&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fyes-i-know-the-bash-linux-command-line-tools%2F
+[6]:https://en.wikipedia.org/wiki/Null_character
+[7]:https://en.wikipedia.org/wiki/Newline
+[8]:https://linuxhandbook.com/cut-command/#_working_with_character_ranges
+[9]:https://linuxhandbook.com/cut-command/#_working_with_byte_ranges
+[10]:https://linuxhandbook.com/cut-command/#_working_with_fields
+[11]:https://linuxhandbook.com/cut-command/#_non_posix_gnu_extensions
+[12]:https://linux.die.net/man/1/hexdump
+[13]:https://linuxhandbook.com/awk-command-tutorial/
+[14]:http://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_18
+[15]:https://en.wikipedia.org/wiki/UTF-8#Codepage_layout
+[16]:https://www.fileformat.info/info/unicode/char/00c9/index.htm
+[17]:https://en.wikipedia.org/wiki/Shift_JIS#Shift_JIS_byte_map
+[18]:http://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_16
+[19]:https://www.gnu.org/software/coreutils/manual/html_node/cut-invocation.html#cut-invocation
+[20]:https://www.openbsd.org/
+[21]:https://linux.die.net/man/1/ls
+[22]:https://linux.die.net/man/1/find
+[23]:https://linux.die.net/man/1/tr
+[24]:https://linuxhandbook.com/author/sylvain/
+[25]:https://linuxhandbook.com/cut-command/#comments
+[26]:https://static.yesik.it/EP22/Yes_I_Know_IT-EP22.tar.gz
+[27]:https://en.wikipedia.org/wiki/ASCII#Character_set
+[28]:https://en.wikipedia.org/wiki/Control_character
+[29]:https://en.wikipedia.org/wiki/Comma-separated_values
+[30]:https://en.wikipedia.org/wiki/Decimal_separator
+[31]:https://en.wikipedia.org/wiki/Tab_key#Tab_characters
+[32]:https://en.wikipedia.org/wiki/Tab-separated_values
+[33]:http://lists.gnu.org/archive/html/coreutils/2014-02/msg00005.html
diff --git a/published/20180719 Incomplete Path Expansion (Completion) For Bash.md b/published/20180719 Incomplete Path Expansion (Completion) For Bash.md
new file mode 100644
index 0000000000..4a47c998fb
--- /dev/null
+++ b/published/20180719 Incomplete Path Expansion (Completion) For Bash.md
@@ -0,0 +1,78 @@
+针对 Bash 的不完整路径展开(补全)功能
+======
+
+
+
+
+[bash-complete-partial-path][1] 通过添加不完整的路径展开(类似于 Zsh)来增强 Bash(它在 Linux 上,macOS 使用 gnu-sed,Windows 使用 MSYS)中的路径补全。如果你想在 Bash 中使用这个省时特性,而不必切换到 Zsh,它将非常有用。
+
+这是它如何工作的。当按下 `Tab` 键时,bash-complete-partial-path 假定每个部分都不完整并尝试展开它。假设你要进入 `/usr/share/applications` 。你可以输入 `cd /u/s/app`,按下 `Tab`,bash-complete-partial-path 应该把它展开成 `cd /usr/share/applications` 。如果存在冲突,那么按 `Tab` 仅补全没有冲突的路径。例如,Ubuntu 用户在 `/usr/share` 中应该有很多以 “app” 开头的文件夹,在这种情况下,输入 `cd /u/s/app` 只会展开 `/usr/share/` 部分。
+
+另一个更深层不完整文件路径展开的例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
+
+功能包括:
+
+* 转义特殊字符
+* 如果用户路径开头使用引号,则不转义字符转义,而是在展开路径后使用匹配字符结束引号
+* 正确展开 `~` 表达式
+* 如果正在使用 bash-completion 包,则此代码将安全地覆盖其 `_filedir` 函数。无需额外配置,只需确保在主 bash-completion 后引入此项目。
+
+查看[项目页面][2]以获取更多信息和演示截图。
+
+### 安装 bash-complete-partial-path
+
+bash-complete-partial-path 安装说明指定直接下载 bash_completion 脚本。我更喜欢从 Git 仓库获取,这样我可以用一个简单的 `git pull` 来更新它,因此下面的说明将使用这种安装 bash-complete-partial-path。如果你喜欢,可以使用[官方][3]说明。
+
+1、 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
+
+在 Debian、Ubuntu、Linux Mint 等中,使用此命令安装 Git:
+
+```
+sudo apt install git
+```
+
+2、 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
+
+```
+cd ~/.config && git clone https://github.com/sio/bash-complete-partial-path
+```
+
+3、 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
+
+用文本编辑器打开 ~/.bashrc。例如你可以使用 Gedit:
+
+```
+gedit ~/.bashrc
+```
+
+在 `~/.bashrc` 的末尾添加以下内容(在一行中):
+
+```
+[ -s "$HOME/.config/bash-complete-partial-path/bash_completion" ] && source "$HOME/.config/bash-complete-partial-path/bash_completion"
+```
+
+我提到在文件的末尾添加它,因为这需要包含在你的 `~/.bashrc` 文件的主 bash-completion 下面(之后)。因此,请确保不要将其添加到原始 bash-completion 之上,因为它会导致问题。
+
+4、 引入 `~/.bashrc`:
+
+```
+source ~/.bashrc
+```
+
+这样就好了,现在应该安装完 bash-complete-partial-path 并可以使用了。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://github.com/sio/bash-complete-partial-path
+[2]:https://github.com/sio/bash-complete-partial-path
+[3]:https://github.com/sio/bash-complete-partial-path#installation-and-updating
diff --git a/published/20180720 3 Methods to List All The Users in Linux System.md b/published/20180720 3 Methods to List All The Users in Linux System.md
new file mode 100644
index 0000000000..f2cd524935
--- /dev/null
+++ b/published/20180720 3 Methods to List All The Users in Linux System.md
@@ -0,0 +1,192 @@
+列出 Linux 系统上所有用户的 3 种方法
+=======
+
+> 通过使用 `/etc/passwd` 文件,`getent` 命令,`compgen` 命令这三种方法查看系统中用户的信息
+
+大家都知道,Linux 系统中用户信息存放在 `/etc/passwd` 文件中。
+
+这是一个包含每个用户基本信息的文本文件。当我们在系统中创建一个用户,新用户的详细信息就会被添加到这个文件中。
+
+`/etc/passwd` 文件将每个用户的基本信息记录为文件中的一行,一行中包含 7 个字段。
+
+`/etc/passwd` 文件的一行代表一个单独的用户。该文件将用户的信息分为 3 个部分。
+
+ * 第 1 部分:`root` 用户信息
+ * 第 2 部分:系统定义的账号信息
+ * 第 3 部分:真实用户的账户信息
+
+第一部分是 `root` 账户,这代表管理员账户,对系统的每个方面都有完全的权力。
+
+第二部分是系统定义的群组和账户,这些群组和账号是正确安装和更新系统软件所必需的。
+
+第三部分在最后,代表一个使用系统的真实用户。
+
+在创建新用户时,将修改以下 4 个文件。
+
+ * `/etc/passwd`: 用户账户的详细信息在此文件中更新。
+ * `/etc/shadow`: 用户账户密码在此文件中更新。
+ * `/etc/group`: 新用户群组的详细信息在此文件中更新。
+ * `/etc/gshadow`: 新用户群组密码在此文件中更新。
+
+** 建议阅读 : **
+
+- [ 如何在 Linux 上查看创建用户的日期 ][1]
+- [ 如何在 Linux 上查看 A 用户所属的群组 ][2]
+- [ 如何强制用户在下一次登录 Linux 系统时修改密码 ][3]
+
+### 方法 1 :使用 `/etc/passwd` 文件
+
+使用任何一个像 `cat`、`more`、`less` 等文件操作命令来打印 Linux 系统上创建的用户列表。
+
+`/etc/passwd` 是一个文本文件,其中包含了登录 Linux 系统所必需的每个用户的信息。它保存用户的有用信息,如用户名、密码、用户 ID、群组 ID、用户 ID 信息、用户的家目录和 Shell 。
+
+`/etc/passwd` 文件将每个用户的详细信息写为一行,其中包含七个字段,每个字段之间用冒号 `:` 分隔:
+
+```
+# cat /etc/passwd
+root:x:0:0:root:/root:/bin/bash
+bin:x:1:1:bin:/bin:/sbin/nologin
+daemon:x:2:2:daemon:/sbin:/sbin/nologin
+adm:x:3:4:adm:/var/adm:/sbin/nologin
+lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
+sync:x:5:0:sync:/sbin:/bin/sync
+shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
+halt:x:7:0:halt:/sbin:/sbin/halt
+mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
+ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
+postfix:x:89:89::/var/spool/postfix:/sbin/nologin
+sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
+tcpdump:x:72:72::/:/sbin/nologin
+2gadmin:x:500:10::/home/viadmin:/bin/bash
+apache:x:48:48:Apache:/var/www:/sbin/nologin
+zabbix:x:498:499:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
+mysql:x:497:502::/home/mysql:/bin/bash
+zend:x:502:503::/u01/zend/zend/gui/lighttpd:/sbin/nologin
+rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
+2daygeek:x:503:504::/home/2daygeek:/bin/bash
+named:x:25:25:Named:/var/named:/sbin/nologin
+mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
+
+```
+7 个字段的详细信息如下。
+
+* **用户名** (`magesh`): 已创建用户的用户名,字符长度 1 个到 12 个字符。
+* **密码**(`x`):代表加密密码保存在 `/etc/shadow 文件中。
+* **用户 ID(`506`):代表用户的 ID 号,每个用户都要有一个唯一的 ID 。UID 号为 0 的是为 `root` 用户保留的,UID 号 1 到 99 是为系统用户保留的,UID 号 100-999 是为系统账户和群组保留的。
+* **群组 ID (`507`):代表群组的 ID 号,每个群组都要有一个唯一的 GID ,保存在 `/etc/group` 文件中。
+* **用户信息(`2g Admin - Magesh M`):代表描述字段,可以用来描述用户的信息(LCTT 译注:此处原文疑有误)。
+* **家目录(`/home/mageshm`):代表用户的家目录。
+* **Shell(`/bin/bash`):代表用户使用的 shell 类型。
+
+你可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
+
+```
+# awk -F':' '{ print $1}' /etc/passwd
+or
+# cut -d: -f1 /etc/passwd
+root
+bin
+daemon
+adm
+lp
+sync
+shutdown
+halt
+mail
+ftp
+postfix
+sshd
+tcpdump
+2gadmin
+apache
+zabbix
+mysql
+zend
+rpc
+2daygeek
+named
+mageshm
+```
+### 方法 2 :使用 `getent` 命令
+
+`getent` 命令显示 Name Service Switch 库支持的数据库中的条目。这些库的配置文件为 `/etc/nsswitch.conf`。
+
+`getent` 命令显示类似于 `/etc/passwd` 文件的用户详细信息,它将每个用户详细信息显示为包含七个字段的单行。
+
+```
+# getent passwd
+root:x:0:0:root:/root:/bin/bash
+bin:x:1:1:bin:/bin:/sbin/nologin
+daemon:x:2:2:daemon:/sbin:/sbin/nologin
+adm:x:3:4:adm:/var/adm:/sbin/nologin
+lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
+sync:x:5:0:sync:/sbin:/bin/sync
+shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
+halt:x:7:0:halt:/sbin:/sbin/halt
+mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
+ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
+postfix:x:89:89::/var/spool/postfix:/sbin/nologin
+sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
+tcpdump:x:72:72::/:/sbin/nologin
+2gadmin:x:500:10::/home/viadmin:/bin/bash
+apache:x:48:48:Apache:/var/www:/sbin/nologin
+zabbix:x:498:499:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
+mysql:x:497:502::/home/mysql:/bin/bash
+zend:x:502:503::/u01/zend/zend/gui/lighttpd:/sbin/nologin
+rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
+2daygeek:x:503:504::/home/2daygeek:/bin/bash
+named:x:25:25:Named:/var/named:/sbin/nologin
+mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
+```
+
+7 个字段的详细信息如上所述。(LCTT 译注:此处内容重复,删节)
+
+你同样可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
+
+### 方法 3 :使用 `compgen` 命令
+
+`compgen` 是 `bash` 的内置命令,它将显示所有可用的命令,别名和函数。
+
+```
+# compgen -u
+root
+bin
+daemon
+adm
+lp
+sync
+shutdown
+halt
+mail
+ftp
+postfix
+sshd
+tcpdump
+2gadmin
+apache
+zabbix
+mysql
+zend
+rpc
+2daygeek
+named
+mageshm
+```
+
+------------------------
+
+via: https://www.2daygeek.com/3-methods-to-list-all-the-users-in-linux-system/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[SunWave](https://github.com/SunWave)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/magesh/
+[1]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
+[2]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
+[3]:https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
+
+
diff --git a/published/20180720 4 cool new projects to try in COPR for July 2018.md b/published/20180720 4 cool new projects to try in COPR for July 2018.md
new file mode 100644
index 0000000000..e87b107b92
--- /dev/null
+++ b/published/20180720 4 cool new projects to try in COPR for July 2018.md
@@ -0,0 +1,93 @@
+2018 年 7 月 COPR 中 4 个值得尝试很酷的新项目
+======
+
+
+
+COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
+
+这是 COPR 中一组新的有趣项目。
+
+### Hledger
+
+[Hledger][2] 是用于跟踪货币或其他商品的命令行程序。它使用简单的纯文本格式日志来存储数据和复式记帐。除了命令行界面,hledger 还提供终端界面和 Web 客户端,可以显示帐户余额图。
+
+![][3]
+
+#### 安装说明
+
+该仓库目前为 Fedora 27、28 和 Rawhide 提供了 hledger。要安装 hledger,请使用以下命令:
+
+```
+sudo dnf copr enable kefah/HLedger
+sudo dnf install hledger
+```
+
+### Neofetch
+
+[Neofetch][4] 是一个命令行工具,可显示有关操作系统、软件和硬件的信息。其主要目的是以紧凑的方式显示数据来截图。你可以使用命令行标志和配置文件将 Neofetch 配置为完全按照你希望的方式显示。
+
+![][5]
+
+#### 安装说明
+
+仓库目前为 Fedora 28 提供 Neofetch。要安装 Neofetch,请使用以下命令:
+
+```
+sudo dnf copr enable sysek/neofetch
+sudo dnf install neofetch
+
+```
+
+### Remarkable
+
+[Remarkable][6]是 Markdown 文本编辑器,它使用类似 GitHub 的 Markdown 风格。它提供了文档的预览,以及导出为 PDF 和 HTML 的选项。Markdown 有几种可用的样式,包括使用 CSS 创建自己的样式的选项。此外,Remarkable 支持用于编写方程的 LaTeX 语法和源代码的语法高亮。
+
+![][7]
+
+#### 安装说明
+
+该仓库目前为 Fedora 28 和 Rawhide 提供 Remarkable。要安装 Remarkable,请使用以下命令:
+
+```
+sudo dnf copr enable neteler/remarkable
+sudo dnf install remarkable
+```
+
+### Aha
+
+[Aha][8](即 ANSI HTML Adapter)是一个命令行工具,可将终端转义成 HTML 代码。这允许你将 git diff 或 htop 的输出共享为静态 HTML 页面。
+
+![][9]
+
+#### 安装说明
+
+[仓库][10] 目前为 Fedora 26、27、28 和 Rawhide、EPEL 6 和 7 以及其他发行版提供 aha。要安装 aha,请使用以下命令:
+
+```
+sudo dnf copr enable scx/aha
+sudo dnf install aha
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-try-copr-july-2018/
+
+作者:[Dominik Turecek][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org
+[1]:https://copr.fedorainfracloud.org/
+[2]:http://hledger.org/
+[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/hledger.png
+[4]:https://github.com/dylanaraps/neofetch
+[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/neofetch.png
+[6]:https://remarkableapp.github.io/linux.html
+[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/remarkable.png
+[8]:https://github.com/theZiz/aha
+[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/aha.png
+[10]:https://copr.fedorainfracloud.org/coprs/scx/aha/
diff --git a/published/20180720 Convert video using Handbrake.md b/published/20180720 Convert video using Handbrake.md
new file mode 100644
index 0000000000..51b1618311
--- /dev/null
+++ b/published/20180720 Convert video using Handbrake.md
@@ -0,0 +1,58 @@
+使用 Handbrake 转换视频
+======
+
+> 这个开源工具可以很简单地将老视频转换为新格式。
+
+
+
+最近,当我的儿子让我数字化他的高中篮球比赛的一些旧 DVD 时,我马上就想到了 [Handbrake][1]。它是一个开源软件包,可轻松将视频转换为可在 MacOS、Windows、Linux、iOS、Android 和其他平台上播放的格式所需的所有工具。
+
+Handbrake 是开源的,并在 [GPLv2 许可证][2]下分发。它很容易在 MacOS、Windows 和 Linux 包括 [Fedora][3] 和 [Ubuntu][4] 上安装。在 Linux 中,安装后就可以从命令行使用 `$ handbrake` 或从图形用户界面中选择它。(我的情况是 GNOME 3)
+
+
+
+Handbrake 的菜单系统易于使用。单击 “Open Source” 选择要转换的视频源。对于我儿子的篮球视频,它是我的 Linux 笔记本中的 DVD 驱动器。将 DVD 插入驱动器后,软件会识别磁盘的内容。
+
+
+
+正如你在上面截图中的 “Source” 旁边看到的那样,Handbrake 将其识别为 720x480 的 DVD,宽高比为 4:3,以每秒 29.97 帧的速度录制,有一个音轨。该软件还能预览视频。
+
+如果默认转换设置可以接受,只需按下 “Start Encoding” 按钮(一段时间后,根据处理器的速度),DVD 的内容将被转换并以默认格式 [M4V][5] 保存(可以改变)。
+
+如果你不喜欢文件名,很容易改变它。
+
+
+
+Handbrake 有各种格式、大小和配置的输出选项。例如,它可以生成针对 YouTube、Vimeo 和其他网站以及 iPod、iPad、Apple TV、Amazon Fire TV、Roku、PlayStation 等设备优化的视频。
+
+
+
+你可以在 “Dimensions” 选项卡中更改视频输出大小。其他选项卡允许你应用过滤器、更改视频质量和编码、添加或修改音轨,包括字幕和修改章节。“Tags” 选项卡可让你识别输出视频文件中的作者、演员、导演、发布日期等。
+
+
+
+如果使用 Handbrake 为特定平台输出,可以使用包含的预设。
+
+
+
+你还可以使用菜单选项创建自己的格式,具体取决于你需要的功能。
+
+Handbrake 是一款非常强大的软件,但它并不是唯一的开源视频转换工具。你有其他喜欢的吗?如果有,请分享评论。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/handbrake
+
+作者:[Don Watkins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/don-watkins
+[1]:https://handbrake.fr/
+[2]:https://github.com/HandBrake/HandBrake/blob/master/LICENSE
+[3]:https://fedora.pkgs.org/28/rpmfusion-free-x86_64/HandBrake-1.1.0-1.fc28.x86_64.rpm.html
+[4]:https://launchpad.net/~stebbins/+archive/ubuntu/handbrake-releases
+[5]:https://en.wikipedia.org/wiki/M4V
diff --git a/published/20180724 Textricator- Data extraction made simple.md b/published/20180724 Textricator- Data extraction made simple.md
new file mode 100644
index 0000000000..ad003defd1
--- /dev/null
+++ b/published/20180724 Textricator- Data extraction made simple.md
@@ -0,0 +1,42 @@
+Textricator:让数据提取变得简单
+======
+
+> 这个新的开源工具可以从 PDF 文档中提取复杂的数据,而无需编程技能。
+
+
+
+你可能知道这种感觉:你请求得到数据并得到积极的响应,只打开电子邮件并发现一大堆附加的 PDF。数据——中断。
+
+我们理解你的挫败感,并为此做了一些事情:让我们介绍下 [Textricator][1],这是我们的第一个开源产品。
+
+我们是 “Measures for Justice”(MFJ),一个刑事司法研究和透明度组织。我们的使命是为整个司法系统从逮捕到定罪后提供数据透明度。我们通过制定一系列多达 32 项指标来实现这一目标,涵盖每个县的整个刑事司法系统。我们以多种方式获取数据 —— 当然,所有这些都是合法的 —— 虽然许多州和县机构都掌握数据,可以为我们提供 CSV 格式的高质量格式化数据,但这些数据通常捆绑在软件中,没有简单的方法可以提取。PDF 报告是他们能提供的最佳报告。
+
+开发者 Joe Hale 和 Stephen Byrne 在过去两年中一直在开发 Textricator,它用来提取数万页数据供我们内部使用。Textricator 可以处理几乎任何基于文本的 PDF 格式 —— 不仅仅是表格,还包括复杂的报表,其中包含从 Crystal Reports 等工具生成的文本和细节部分。只需告诉 Textricator 你要收集的字段的属性,它就会整理文档,收集并写出你的记录。
+
+不是软件工程师?Textricator 不需要编程技巧。相反,用户描述 PDF 的结构,Textricator 处理其余部分。大多数用户通过命令行运行它。但是,你可以使用基于浏览器的 GUI。
+
+我们评估了其他很好的开源解决方案,如 [Tabula][2],但它们无法处理我们需要抓取的一些 PDF 的结构。技术总监 Andrew Branch 说:“Textricator 既灵活又强大,缩短了我们花费大量时间处理大型数据集的时间。”
+
+在 MFJ,我们致力于透明度和知识共享,其中包括向任何人提供我们的软件,特别是那些试图公开自由共享数据的人。Textricator 可以在 [GitHub][3] 上找到,并在 [GNU Affero 通用公共许可证第 3 版][4]下发布。
+
+你可以在我们的免费[在线数据门户][5]上查看我们的工作成果,包括通过 Textricator 处理的数据。Textricator 是我们流程的重要组成部分,我们希望民间技术机构和政府组织都可以使用这个新工具解锁更多数据。
+
+如果你使用 Textricator,请告诉我们它如何帮助你解决数据问题。想要改进吗?提交一个拉取请求。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/textricator
+
+作者:[Stephen Byrne][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/stephenbyrne-mfj
+[1]:https://textricator.mfj.io/
+[2]:https://tabula.technology/
+[3]:https://github.com/measuresforjustice/textricator
+[4]:https://www.gnu.org/licenses/agpl-3.0.en.html
+[5]:https://www.measuresforjustice.org/portal/
diff --git a/published/20180727 Three Graphical Clients for Git on Linux.md b/published/20180727 Three Graphical Clients for Git on Linux.md
new file mode 100644
index 0000000000..ef1ed9bebe
--- /dev/null
+++ b/published/20180727 Three Graphical Clients for Git on Linux.md
@@ -0,0 +1,116 @@
+三款 Linux 下的 Git 图形客户端
+======
+
+> 了解这三个 Git 图形客户端工具如何增强你的开发流程。
+
+
+
+在 Linux 下工作的人们对 [Git][1] 非常熟悉。一个理所当然的原因是,Git 是我们这个星球上最广为人知也是使用最广泛的版本控制工具。不过大多数情况下,Git 需要学习繁杂的终端命令。毕竟,我们的大多数开发工作可能是基于命令行的,那么没理由不以同样的方式与 Git 交互。
+
+但在某些情况下,使用带图形界面的工具可能使你的工作更高效一点(起码对那些更倾向于使用图形界面的人们来说)。那么,有哪些 Git 图形客户端可供选择呢?幸运的是,我们找到一些客户端值得你花费时间和金钱(一些情况下)去尝试一下。在此,我主要推荐三种可以运行在 Linux 操作系统上的 Git 客户端。在这几种中,你可以找到一款满足你所有要求的客户端。
+
+在这里我假设你理解如何使用 Git 和具有 GitHub 类似功能的代码仓库,[使用方法我之前讲过了][2],因此我不再花费时间讲解如何使用这些工具。本篇文章主要是一篇介绍,介绍几种可以用在开发任务中的工具。
+
+提前说明一下:这些工具并不都是免费的,它们中的一些可能需要商业授权。不过,它们都在 Linux 下运行良好并且可以轻而易举的和 GitHub 相结合。
+
+就说这些了,快让我们看看这些出色的 Git 图形客户端吧。
+
+### SmartGit
+
+[SmartGit][3] 是一个商业工具,不过如果你在非商业环境下使用是免费的。如果你打算在商业环境下使用的话,一个许可证每人每年需要 99 美元,或者 5.99 美元一个月。还有一些其它升级功能(比如分布式评审和智能同步),这两个工具每个许可证需要另加 15 美元。你也能通过下载源码或者 deb 安装包进行安装。我在 Ubuntu 18.04 下测试,发现 SmartGit 运行良好,没有出现一点问题。
+
+不过,我们为什么要用 SmartGit 呢?有许多原因,最重要的一点是,SmartGit 可以非常方便的和 GitHub 以及 Subversion 等版本控制工具整合。不需要你花费宝贵的时间去配置各种远程账号,SmartGit 的这些功能开箱即用。SmartGit 的界面(图 1)设计的也很好,整洁直观。
+
+![SmartGit][5]
+
+*图 1: SmartGit 帮助简化工作*
+
+安装完 SmartGit 后,我马上就用它连接到了我的 GitHub 账户。默认的工具栏是和仓库操作相关联的,非常简洁。推送、拉取、检出、合并、添加分支、cherry pick、撤销、变基、重置 —— 这些 Git 的的流行功能都支持。除了支持标准 Git 和 GitHub 的大部分功能,SmartGit 运行也非常稳定。至少当你在 Ubuntu上使用时,你会觉得这一款软件是专门为 Linux 设计和开发的。
+
+SmartGit 可能是使各个水平的 Git 用户都可以非常轻松的使用 Git,甚至 Git 高级功能的最好工具。为了了解更多 SmartGit 相关知识,你可以查看一下其[丰富的文档][7]。
+
+### GitKraken
+
+[GitKraken][8] 是另外一款商业 Git 图形客户端,它可以使你感受到一种绝不会后悔的使用 Git 或者 GitHub 的美妙体验。SmartGit 具有非常简洁的界面,而 GitKraken 拥有非常华丽的界面,它一开始就给你展现了很多特色。GitKraken 有一个免费版(你也可以使用完整版 15 天)。试用期过了,你也可以继续使用免费版,不过不能用于商业用途。
+
+对那些想让其开发工作流发挥最大功效的人们来说,GitKraken 可能是一个比较好的选择。界面上具有的功能包括:可视化交互、可缩放的提交图、拖拽、与 Github、GitLab 和 BitBucked 的无缝整合、简单的应用内任务清单、应用内置的合并工具、模糊查找、支持 Gitflow、一键撤销与重做、快捷键、文件历史与追责、子模块、亮色和暗色主题、Git 钩子支持和 Git LFS 等许多功能。不过用户倍加赞赏的还是精美的界面(图 2)。
+
+![GitKraken][10]
+
+*图 2: GitKraken的界面非常出色*
+
+除了令人惊艳的图形界面,另一个使 GitKraken 在 Git 图形客户端竞争中脱颖而出的功能是:GitKraken 使得使用多个远程仓库和多套配置变得非常简单。不过有一个告诫,使用 GitKraken 需要花钱(它是专有的)。如果你想商业使用,许可证的价钱如下:
+
+ * 一人一年 49 美元
+ * 10 人以上团队,39 美元每人每年
+ * 100 人以上团队, 29 美元每人每年
+
+专业版账户不但可以在商业环境使用 Git 相关功能,还可以使用 Glo Boards(GitKraken 的项目管理工具)。Glo Boards 的一个吸引人的功能是可以将数据同步到 GitHub 工单。Glo Boards 具有分享功能还具有搜索过滤、问题跟踪、Markdown 支持、附件、@ 功能、清单卡片等许多功能。所有的这些功能都可以在 GitKraken 界面里进行操作。
+
+GitKraken 可以通过 deb 文件或者源码进行安装。
+
+### Git Cola
+
+[Git Cola][11] 是我们推荐列表中一款自由开源的 Git 图像客户端。不像 GitKraken 和 SmartGit,Git Cola是一款比较难啃的骨头,一款比较实用的 Git 客户端。Git Cola 是用 Python 写成的,使用的是 GTK 界面,因此无论你用的是什么 Linux 发行版和桌面,都可以无缝支持。并且因为它是开源的,你可以在你使用的发行版的包管理器中找到它。因此安装过程无非是打开应用商店,搜索 “Git Cola” 安装即可。你也可以通过下面的命令进行安装:
+
+```
+sudo apt install git-cola
+```
+
+或者
+
+```
+sudo dnf install git-cola
+```
+
+Git Cola 看起来相对比较简单(图 3)。事实上,你无法找到更复杂的东西,因为 Git Cola 是非常基础的。
+
+![Git Cola][13]
+
+*图 3:Git Cola 界面是非常简单的*
+
+因为 Git Cola 看起来回归自然,所以很多时间你必须同终端打交道。不过这并不是什么难事儿(因为大多数开发人员需要经常使用终端)。Git Cola 包含以下特性:
+
+ * 支持多个子命令
+ * 自定义窗口设置
+ * 可设置环境变量
+ * 语言设置
+ * 支持自定义 GUI 设置
+ * 支持快捷键
+
+尽管 Git Cola 支持连接到远程仓库,但和像 GitHub 这样的仓库整合看起来也没有 GitKraken 和 SmartGit 直观。不过如果你的大部分工作是在本地进行的,Git Cola 并不失为一个出色的工具。
+
+Git Cola 也带有有一个高级的 DAG(有向无环图)可视化工具,叫做 Git DAG。这个工具可以使你获得分支的可视化展示。你可以独立使用 Git DAG,也可以在 Git Cola 内通过 “view->DAG” 菜单来打开。正是 Git DAG 这个威力巨大的工具使用 Git Cola 跻身于应用商店中 Git 图形客户端前列。
+
+### 更多的客户端
+
+还有更多的 Git 图形客户端。不过,从上面介绍的这几款中,你已经可以做很多事情了。无论你在寻找一款更有丰富功能的 Git 客户端(不管许可证的话)还是你本身是一名坚定的 GPL 支持者,都可以从上面找到适合自己的一款。
+
+如果想学习更多关于 Linux 的知识,可以通过学习Linux基金会的[走进 Linux][14]课程。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[tarepanda1024](https://github.com/tarepanda1024)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/jlwallen
+[1]:https://git-scm.com/
+[2]:https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
+[3]:https://www.syntevo.com/smartgit/
+[4]:/files/images/gitgui1jpg
+[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_1.jpg?itok=LEZ_PYIf (SmartGit)
+[6]:/licenses/category/used-permission
+[7]:http://www.syntevo.com/doc/display/SG/Manual
+[8]:https://www.gitkraken.com/
+[9]:/files/images/gitgui2jpg
+[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_2.jpg?itok=Y8crSLhf (GitKraken)
+[11]:https://git-cola.github.io/
+[12]:/files/images/gitgui3jpg
+[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_3.jpg?itok=bS9OYPQo (Git Cola)
+[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/talk/20180127 Write Dumb Code.md b/sources/talk/20180127 Write Dumb Code.md
index acc647b0e5..505e8198df 100644
--- a/sources/talk/20180127 Write Dumb Code.md
+++ b/sources/talk/20180127 Write Dumb Code.md
@@ -1,3 +1,5 @@
+translating by ynmlml
+
Write Dumb Code
======
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
diff --git a/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md b/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md
index 29e4ea2f48..1f9b80cd13 100644
--- a/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md
+++ b/sources/talk/20180419 3 tips for organizing your open source project-s workflow on GitHub.md
@@ -1,3 +1,4 @@
+translating by aiwhj
3 tips for organizing your open source project's workflow on GitHub
======
diff --git a/sources/talk/20180627 CIP- Keeping the Lights On with Linux.md b/sources/talk/20180627 CIP- Keeping the Lights On with Linux.md
deleted file mode 100644
index 73b9c14be6..0000000000
--- a/sources/talk/20180627 CIP- Keeping the Lights On with Linux.md
+++ /dev/null
@@ -1,52 +0,0 @@
-CIP: Keeping the Lights On with Linux
-======
-
-
-
-Modern civil infrastructure is all around us -- in power plants, radar systems, traffic lights, dams, weather systems, and so on. Many of these infrastructure projects exist for decades, if not longer, so security and longevity are paramount.
-
-And, many of these systems are powered by Linux, which offers technology providers more control over these issues. However, if every provider is building their own solution, this can lead to fragmentation and duplication of effort. Thus, the primary goal of [Civil Infrastructure Platform (CIP)][1] is to create an open source base layer for industrial use-cases in these systems, such as embedded controllers and gateway devices.
-
-“We have a very conservative culture in this area because once we create a system, it has to be supported for more than ten years; in some cases for over 60 years. That’s why this project was created, because every player in this industry had the same issue of being able to use Linux for a long time,” says Yoshitake Kobayashi is Technical Steering Committee Chair of CIP.
-
-CIP’s concept is to create a very fundamental system to use open source software on controllers. This base layer comprises the Linux kernel and a small set of common open source software like libc, busybox, and so on. Because longevity of software is a primary concern, CIP chose Linux kernel 4.4, which is the LTS release of the kernel maintained by Greg Kroah-Hartman.
-
-### Collaboration
-
-Since CIP has an upstream first policy, the code that they want in the project must be in the upstream kernel. To create a proactive feedback loop with the kernel community, CIP hired Ben Hutchings as the official maintainer of CIP. Hutchings is known for the work he has done on Debian LTS release, which also led to an official collaboration between CIP and the Debian project.
-
-Under the newly forged collaboration, CIP will use Debian LTS to build the platform. CIP will also help Debian Long Term Support (LTS) to extend the lifetime of all Debian stable releases. CIP will work closely with Freexian, a company that offers commercial services around Debian LTS. The two organizations will focus on interoperability, security, and support for open source software for embedded systems. CIP will also provide funding for some of the Debian LTS activities.
-
-“We are excited about this collaboration as well as the CIP’s support of the Debian LTS project, which aims to extend the support lifetime to more than five years. Together, we are committed to long-term support for our users and laying the ‘foundation’ for the cities of the future.” said Chris Lamb, Debian Project Leader.
-
-### Security
-
-Security is the biggest concern, said Kobayashi. Although most of the civil infrastructure is not connected to the Internet for obvious security reasons (you definitely don’t want a nuclear power plant to be connected to the Internet), there are many other risks.
-
-Just because the system itself is not connected to the Internet, that doesn’t mean it’s immune to all threats. Other systems -- like user’s laptops -- may connect to the Internet and then be plugged into the local systems. If someone receives a malicious file as an attachment with email, it can “contaminate” the internal infrastructure.
-
-Thus, it’s critical to keep all software running on such controllers up to date and fully patched. To ensure security, CIP has also backported many components of the Kernel Self Protection project. CIP also follows one of the strictest cybersecurity standards -- IEC 62443 -- which defines processes and tests to ensure the system is more secure.
-
-### Going forward
-
-As CIP is maturing, it's extending its collaboration with providers of Linux. In addition to collaboration with Debian and freexian, CIP recently added Cybertrust Japan Co, Ltd., a supplier of enterprise Linux operating system, as a new Silver member.
-
-Cybertrust joins other industry leaders, such as Siemens, Toshiba, Codethink, Hitachi, Moxa, Plat’Home, and Renesas, in their work to create a reliable and secure Linux-based embedded software platform that is sustainable for decades to come.
-
-The ongoing work of these companies under the umbrella of CIP will ensure the integrity of the civil infrastructure that runs our modern society.
-
-Learn more at the [Civil Infrastructure Platform][1] website.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
-
-作者:[Swapnil Bhartiya][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/arnieswap
-[1]:https://www.cip-project.org/
diff --git a/sources/talk/20180702 My first sysadmin mistake.md b/sources/talk/20180702 My first sysadmin mistake.md
deleted file mode 100644
index 702a70fe8d..0000000000
--- a/sources/talk/20180702 My first sysadmin mistake.md
+++ /dev/null
@@ -1,44 +0,0 @@
-translating---geekpi
-
-My first sysadmin mistake
-======
-
-
-
-If you work in IT, you know that things never go completely as you think they will. At some point, you'll hit an error or something will go wrong, and you'll end up having to fix things. That's the job of a systems administrator.
-
-As humans, we all make mistakes. Sometimes, we are the error in the process, or we are what went wrong. As a result, we end up having to fix our own mistakes. That happens. We all make mistakes, typos, or errors.
-
-As a young systems administrator, I learned this lesson the hard way. I made a huge blunder. But thanks to some coaching from my supervisor, I learned not to dwell on my errors, but to create a "mistake strategy" to set things right. Learn from your mistakes. Get over it, and move on.
-
-My first job was a Unix systems administrator for a small company. Really, I was a junior sysadmin, but I worked alone most of the time. We were a small IT team, just the three of us. I was the only sysadmin for 20 or 30 Unix workstations and servers. The other two supported the Windows servers and desktops.
-
-Any systems administrators reading this probably won't be surprised to know that, as an unseasoned, junior sysadmin, I eventually ran the `rm` command in the wrong directory. As root. I thought I was deleting some stale cache files for one of our programs. Instead, I wiped out all files in the `/etc` directory by mistake. Ouch.
-
-My clue that I'd done something wrong was an error message that `rm` couldn't delete certain subdirectories. But the cache directory should contain only files! I immediately stopped the `rm` command and looked at what I'd done. And then I panicked. All at once, a million thoughts ran through my head. Did I just destroy an important server? What was going to happen to the system? Would I get fired?
-
-Fortunately, I'd run `rm *` and not `rm -rf *` so I'd deleted only files. The subdirectories were still there. But that didn't make me feel any better.
-
-Immediately, I went to my supervisor and told her what I'd done. She saw that I felt really dumb about my mistake, but I owned it. Despite the urgency, she took a few minutes to do some coaching with me. "You're not the first person to do this," she said. "What would someone else do in your situation?" That helped me calm down and focus. I started to think less about the stupid thing I had just done, and more about what I was going to do next.
-
-I put together a simple strategy: Don't reboot the server. Use an identical system as a template, and re-create the `/etc` directory.
-
-Once I had my plan of action, the rest was easy. It was just a matter of running the right commands to copy the `/etc` files from another server and edit the configuration so it matched the system. Thanks to my practice of documenting everything, I used my existing documentation to make any final adjustments. I avoided having to completely restore the server, which would have meant a huge disruption.
-
-To be sure, I learned from that mistake. For the rest of my years as a systems administrator, I always confirmed what directory I was in before running any command.
-
-I also learned the value of building a "mistake strategy." When things go wrong, it's natural to panic and think about all the bad things that might happen next. That's human nature. But creating a "mistake strategy" helps me stop worrying about what just went wrong and focus on making things better. I may still think about it, but knowing my next steps allows me to "get over it."
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
-
-作者:[Jim Hall][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jim-hall
diff --git a/sources/talk/20180710 How I Fully Quit Google And You Can Too.md b/sources/talk/20180710 How I Fully Quit Google And You Can Too.md
new file mode 100644
index 0000000000..b284fa916d
--- /dev/null
+++ b/sources/talk/20180710 How I Fully Quit Google And You Can Too.md
@@ -0,0 +1,218 @@
+martin2011qi is translating
+
+How I Fully Quit Google (And You Can, Too)
+============================================================
+
+>My enlightening quest to break free of a tech giant
+
+Over the past six months, I have gone on a surprisingly tough, time-intensive, and enlightening quest — to quit using, entirely, the products of just one company — Google. What should be a simple task was, in reality, many hours of research and testing. But I did it. Today, I am Google free, part of the western world’s ultimate digital minority, someone who does not use products from the world’s two most valuable technology companies (yes, I don’t use [Facebook either][6]).
+
+This guide is to show you how I quit the Googleverse, and the alternatives I choose based on my own research and personal needs. I’m not a technologist or a coder, but my work as a journalist requires me to be aware of security and privacy issues.
+
+I chose all of these alternatives based solely on their merit, usability, cost, and whether or not they had the functionality I desired. My choices are not universal as they reflect my own needs and desires. Nor do they reflect any commercial interests. None of the alternatives listed below paid me or are giving me any commission whatsoever for citing their services.
+
+### But First: Why?
+
+Here’s the thing. I don’t hate Google. In fact, not too long ago, I was a huge fan of Google. I remember the moment when I first discovered one amazing search engine back in the late 1990’s, when I was still in high school. Google was light years ahead of alternatives such as Yahoo, Altavista, or Ask Jeeves. It really did help users find what they were seeking on a web that was, at that time, a mess of broken websites and terrible indexes.
+
+Google soon moved from just search to providing other services, many of which I embraced. I was an early adopter of Gmail back in 2005, when you could only join [via invites][7]. It introduced threaded conversations, archiving, labels, and was without question the best email service I had ever used. When Google introduced its Calendar tool in 2006, it was revolutionary in how easy it was to color code different calendars, search for events, and send shareable invites. And Google Docs, launched in 2007, was similarly amazing. During my first full time job, I pushed my team to do everything as a Google spreadsheet, document, or presentation that could be edited by many of us simultaneously.
+
+Like many, I was a victim of Google creep. Search led to email, to documents, to analytics, photos, and dozens of other services all built on top of and connected to each other. Google turned from a company releasing useful products to one that has ensnared us, and the internet as a whole, into its money-making, data gathering apparatus. Google is pervasive in our digital lives in a way no other corporation is or ever has been. It’s relatively easy to quit using the products of other tech giants. With Apple, you’re either in the iWorld, or out. Same with Amazon, and even Facebook owns only a few platforms and quitting is more of a [psychological challenge][8] than actually difficult.
+
+Google, however, is embedded everywhere. No matter what laptop, smartphone, or tablet you have, chances are you have at least one Google app on there. Google is synonymous for search, maps, email, our browser, the operating system on most of our smartphones. It even provides the “[services][9]” and analytics that other apps and websites rely on, such as Uber’s use of Google Maps to operate its ride-hailing service.
+
+Google is now a word in many languages, and its global dominance means there are not many well-known, or well-used alternatives to its behemoth suite of tools — especially if you are privacy minded. We all started using Google because it, in many ways, provided better alternatives to existing products. But now, we can’t quit because either Google has become a default, or because its dominance means that alternatives can’t get enough traction.
+
+The truth is, alternatives do exist, many of which have launched in the years since Edward Snowden revealed Google’s participation in [Prism][10]. I embarked on this project late last year. After six months of research, testing, and a lot of trial and error, I was able to find privacy minded alternatives to all the Google products I was using. Some, to my surprise, were even better.
+
+### A Few Caveats
+
+One of the biggest challenges to quitting is the fact that most alternatives, particularly those in the open source of privacy space, are really not user friendly. I’m not a techie. I have a website, understand how to manage Wordpress, and can do some basic troubleshooting, but I can’t use Command Line or do anything that requires coding.
+
+These alternatives are ones you can easily use with most, if not all, the functionality of their Google alternatives. For some, though, you’ll need your own web host or access to a server.
+
+Also, [Google Takeout][11] is your friend. Being able to download my entire email history and upload it on my computer to access via Thunderbird meant I have easy access to over a decade of emails. The same can be said about Calendar or Docs, the latter of which I converted to ODT format and now keep on my cloud alternative, further detailed below.
+
+### The Easy Ones
+
+#### Search
+
+[DuckDuckGo][12] and [Startpage][13] are both privacy-centric search engines that do not collect any of your search data. Together, they take care of everything I was previously using Google search for.
+
+ _Other Alternatives: _ Really not many when Google has 74% global market share, with the remainder mostly due to it’s being blocked in China. Ask.com is still around. And there’s Bing…
+
+#### Chrome
+
+[Mozilla Firefox][14] — it recently got [a big upgrade][15], which is a huge improvement from earlier versions. It’s created by a non-profit foundation that actively works to protect privacy. There’s really no reason at all to use Chrome.
+
+ _Other Alternatives: _ Avoid Opera and Vivaldi, as they use Chrome as their base. [Brave][16] is my secondary browser.
+
+#### Hangouts and Google Chat
+
+[Jitsi Meet][17] — an open source, free alternative to Google Hangouts. You can use it directly from a browser or download the app. It’s fast, secure, and works on nearly every platform.
+
+ _Other Alternatives: Z_ oom has become popular among those in the professional space, but requires you to pay for most features. [Signal][18], an open source, secure messaging app, also has a call function but only on mobile. Avoid Skype, as it’s both a data hog and has a terrible interface.
+
+#### Google Maps
+
+Desktop: [Here WeGo][19] — it loads faster and can find nearly everything that Google Maps can. For some reason, they’re missing some countries, like Japan.
+
+Mobile: [Maps.me][20] — here Maps was my initial choice here too, but became less useful once they modified the app to focus on driver navigation. Maps.me is pretty good, and has far better offline functionality than Google, something very useful to a frequent traveler like me.
+
+ _Other alternatives_ : [OpenStreetMap][21] is a project I wholeheartedly support, but it’s functionality was severely lacking. It couldn’t even find my home address in Oakland.
+
+### Easy but Not Free
+
+Some of this was self-inflicted. For example, when looking for an alternative to Gmail, I did not just want to switch to an alternative from another tech giant. That meant no Yahoo Mail, or Microsoft Outlook as that would not address my privacy concerns.
+
+Remember, the fact that so many of Google’s services are free (not to mention those of its competitors including Facebook) is because they are actively monetizing our data. For alternatives to survive without this level of data monetization, they have to charge us. I am willing to pay to protect my privacy, but do understand that not everyone is able to make this choice.
+
+Think of it this way: Remember when you used to send letters and had to pay for stamps? Or when you bought weekly planners from the store? Essentially, this is the cost to use a privacy-focused email or calendar app. It’s not that bad.
+
+#### Gmail
+
+[ProtonMail][22] — it was founded by former CERN scientists and is based in Switzerland, a country with strong privacy protections. But what really appealed to me about ProtonMail was that it, unlike most other privacy minded email programs, was user friendly. The interface is similar to Gmail, with labels, filters, and folders, and you don’t need to know anything about security or privacy to use it.
+
+The free version only gives you 500MB of storage space. I opted for a paid 5GB account along with their VPN service.
+
+ _Other alternatives_ : [Fastmail][23] is not as privacy oriented but also has a great interface. There’s also [Hushmail][24] and [Tutanota][25], both with similar features to ProtonMail.
+
+#### Calendar
+
+[Fastmail][26] Calendar — this was surprisingly tough, and brings up another issue. Google products have become so ubiquitous in so many spaces that start-ups don’t even bother to create alternatives anymore. After trying a few other mediocre options, I ended getting a recommendation and choose Fastmail as a dual second-email and calendar option.
+
+### More Technical
+
+These require some technical knowledge or access to your web host service. I do include simpler alternatives that I researched but did not end up choosing.
+
+#### Google Docs, Drive, Photos, and Contacts
+
+[NextCloud ][27]— a fully featured, secure, open source cloud suite with an intuitive, user-friendly interface. The catch is that you’ll need your own host to use Nextcloud. I already had one for my own website and was able to quickly install NextCloud using Softaculous on my host’s C-Panel. You’ll need a HTTPS certificate, which I got for free from[ Let’s Encrypt][28]. Not as easy as opening a Google Drive account but not too challenging either.
+
+I also use Nextcloud as an alternative for Google’s photo storage and contacts, which I sync with my phone using CalDev.
+
+ _Other alternative_ s: There are other open source options such as [OwnCloud][29] or [Openstack][30]. Some for-profit options are good too, as top choices Dropbox and Box are independent entities that don’t profit off of your data.
+
+#### Google Analytics
+
+[Matomo ][31]— formally called Piwic, this is a self-hosted analytics platform. While not as feature rich as Google Analytics, it is plenty fine for understanding basic website traffic, with the added bonus that you aren’t gifting that traffic data to Google.
+
+ _Other alternatives: _ Not much really. [OpenWebAnalytics][32] is another open source option, and there are some for-profit alternatives too, such as GoStats and Clicky.
+
+#### Android
+
+[LineageOS][33] + [F-Droid App Store][34]. Sadly, the smartphone world has become a literal duopoly, with Google’s Android and Apple’s iOS controlling the entire market. The few usable alternatives that existed a few years ago, such as Blackberry OS or Mozilla’s Firefox OS, are no longer being maintained.
+
+So the next best option is Lineage OS: a privacy minded, open source version of Android that can be installed without Google services or Apps. It requires some technical knowledge as the installation process is not completely straightforward, but it works really well, and lacks the bloatware that comes with most Android installations.
+
+ _Other alternatives: _ Ummm…Windows 10 Mobile? [PureOS][35] looks promising, as does [UbuntuTouch][36].
+
+### Unexpected Challenges
+
+Firstly, this took much longer than I planned due to the lack of good resources about usable alternatives, and the challenge in moving data from Google to other platforms.
+
+But the toughest thing was email, and it has nothing to do with ProtonMail or Google.
+
+Before I joined Gmail in 2004, I probably switched emails once a year. My first account was with Hotmail, and I then used Mail.com, Yahoo Mail, and long-forgotten services like Bigfoot. I never recall having an issue when I changed email providers. I would just tell all my friends to update their address books and change the email address on other web accounts. It used to be necessary to change email addresses regularly — remember how spam would take over older inboxes?
+
+In fact, one of Gmail’s best innovations was its ability to filter out spam. That meant no longer needing to change emails.
+
+Email is key to using the internet. You need it to open a Facebook account, to use online banking, to post on message boards, and many more. So when you switch accounts, you need to update your email address on all these different services.
+
+To my surprise, changing from Gmail today is a major hassle because of all the places that require email addresses to set up an account. Several sites no longer let you do it from the backend on your own. One service actually required me to close my account and open a new one as they were unable to change my email, and then they transferred over my account data manually. Others forced me to call customer service and request an email account change, meaning time wasted on hold.
+
+Even more amazingly, others accepted my change, and then continued to send messages to my old Gmail account, requiring another phone call. Others were even more annoying, sending some messages to my new email, but still using my old account for other emails. This became such a cumbersome process that I ended up leaving my Gmail account open for several months alongside my new ProtonMail account just to make sure important emails did not get lost. This was the main reason this took me six months.
+
+People so rarely change their emails these days that most companies’ platforms are not designed to deal with the possibility. It’s a telling sign of the sad state of the web today that it was easier to change your email back in 2002 than it is in 2018\. Technology does not always move forward.
+
+### So, Are These Google Alternatives Any Good?
+
+Some are actually better! Jitsi Meet runs smoother, requires less bandwidth, and is more platform friendly than Hangouts. Firefox is more stable and less of a memory suck than Chrome. Fastmail’s Calendar has far better time zone integration.
+
+Others are adequate equivalents. ProtonMail has most of the features of Gmail but lacks some useful integrations, such as the Boomerang email scheduler I was using before. It also has a lacking Contacts interface, but I’m using Nextcloud for that. Speaking of Nextcloud, it’s great for hosting files, contacts, and has a nifty notes tool (and lots of other plug-ins). But it does not have the rich multi-editing features of Google Docs. I’ve not yet found a workable alternative in my budget. There is Collabora Office, but it requires me to upgrade my server, something that is not feasible for me.
+
+Some depend on location. Maps.me is actually better than Google Maps in some countries (such as Indonesia) and far worse in others (including America).
+
+Others require me to sacrifice some features or functionality. Piwic is a poor man’s Google Analytics, and lacks many of the detailed reports or search functions of the former. DuckDuckGo is fine for general searches but has issues with specific searches, and both it and StartPage sometimes fail when I’m searching for non-English language content.
+
+### In the End, I Don’t Miss Google at All
+
+In fact, I feel liberated. To be so dependent on a single company for so many products is a form of servitude, especially when your data is what you’re often paying with. Moreover, many of these alternatives are, in fact, better. And there is real comfort in knowing you are in control of your data.
+
+If we have no choice but to use Google products, then we lose what little power we have as consumers.
+
+I want Google, Facebook, Apple, and other tech giants to stop taking users for granted, to stop trying to force us inside their all-encompassing ecosystems. I also want new players to be able to emerge and compete, just as, once upon a time, Google’s new search tool could compete with the then-industry giants Altavista and Yahoo, or Facebook’s social network was able to compete with MySpace and Friendster. The internet was a better place because Google gave us the opportunity to have a better search. Choice is good. As is portability.
+
+Today, few of us even try other products because we’re just so used to Googling. We don’t change emails cause it’s hard. We don’t even try to use a Facebook alternative because all of our friends are on Facebook. I understand.
+
+You don’t have to quit Google entirely. But give other alternatives a chance. You might be surprised, and remember why you loved the web way back when.
+
+* * *
+
+#### Other Resources
+
+I created this resource not to be an all-encompassing guide but a story of how I was able to quit Google. Here are some resources that show other alternatives. Some are far too technical for me, and others I just didn’t have time to explore.
+
+* [Localization Lab][2] has a detailed list of open source or privacy-tech projects — some highly technical, others quite user friendly.
+
+* [Framasoft ][3]has an entire suite of mostly open-source Google alternatives, though many are just in French.
+
+* Restore Privacy has also [collected a list of alternatives][4].
+
+Your turn. Please share your favorite Google alternatives in the responses or via Twitter. I am sure there are many that I missed and would love to try. I don’t plan to stick with the alternatives listed above forever.
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Nithin Coca
+
+Freelance journalist covering politics, environment & human rights + social impacts of tech globally. For more http://www.nithincoca.com
+
+--------------------------------------------------------------------------------
+
+via: https://medium.com/s/story/how-i-fully-quit-google-and-you-can-too-4c2f3f85793a
+
+作者:[Nithin Coca][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://medium.com/@excinit
+[1]:https://medium.com/@excinit
+[2]:https://www.localizationlab.org/projects/
+[3]:https://framasoft.org/?l=en
+[4]:https://restoreprivacy.com/google-alternatives/
+[5]:https://medium.com/@excinit
+[6]:https://www.nithincoca.com/2011/11/20/7-months-no-facebook/
+[7]:https://www.quora.com/How-long-was-Gmail-in-private-%28invitation-only%29-beta
+[8]:https://www.theverge.com/2018/4/28/17293056/facebook-deletefacebook-social-network-monopoly
+[9]:https://en.wikipedia.org/wiki/Google_Play_Services
+[10]:https://www.theguardian.com/world/2013/jun/06/us-tech-giants-nsa-data
+[11]:https://takeout.google.com/settings/takeout
+[12]:https://duckduckgo.com/
+[13]:https://www.startpage.com/
+[14]:https://www.mozilla.org/en-US/firefox/new/
+[15]:https://www.seattletimes.com/business/firefox-is-back-and-its-time-to-give-it-a-try/
+[16]:https://brave.com/
+[17]:https://jitsi.org/jitsi-meet/
+[18]:https://signal.org/
+[19]:https://wego.here.com/
+[20]:https://maps.me/
+[21]:https://www.openstreetmap.org/
+[22]:https://protonmail.com/
+[23]:https://www.fastmail.com/
+[24]:https://www.hushmail.com/
+[25]:https://tutanota.com/
+[26]:https://www.fastmail.com/
+[27]:https://nextcloud.com/
+[28]:https://letsencrypt.org/
+[29]:https://owncloud.org/
+[30]:https://www.openstack.org/
+[31]:https://matomo.org/
+[32]:http://www.openwebanalytics.com/
+[33]:https://lineageos.org/
+[34]:https://f-droid.org/en/
+[35]:https://puri.sm/posts/tag/pureos/
+[36]:https://ubports.com/
diff --git a/sources/talk/20180713 What-s the difference between a fork and a distribution.md b/sources/talk/20180713 What-s the difference between a fork and a distribution.md
new file mode 100644
index 0000000000..f7f50e014b
--- /dev/null
+++ b/sources/talk/20180713 What-s the difference between a fork and a distribution.md
@@ -0,0 +1,81 @@
+What's the difference between a fork and a distribution?
+======
+
+
+
+If you've been around open source software for any length of time, you'll hear the terms fork and distribution thrown around casually in conversation. For many people, the distinction between the two isn't clear, so here I'll try to clear up the confusion.
+
+### First, some definitions
+
+Before explaining the nuances of a fork vs. a distribution and the pitfalls thereof, let's define key concepts.
+
+**[Open source software][1]** is software that:
+
+ * Is freely available to distribute under certain [license][2] restraints
+ * Permits its source code to be viewable and modified under certain license restraints
+
+
+
+Open source software can be **consumed** in the following ways:
+
+ * Downloaded in binary or source code format, often at no charge (e.g., the [Eclipse developer environment][3])
+ * As a distribution (product) by a vendor, sometimes at a cost to the user (e.g., [Red Hat products][4])
+ * Embedded into proprietary software solutions (e.g., some smartphones and browsers display fonts using the open source [freetype software][5])
+
+
+
+**Free and open source (FOSS)** is not necessarily "free" as in "zero cost." Free and open source simply means the software is free to distribute, modify, study, and use, subject to the software's licensing. The software distributor may attach a purchase price to it. For example, Linux is available at no cost as Fedora, CentOS, Gentoo, etc. or as a paid distribution as Red Hat Enterprise Linux, SUSE, etc.
+
+**Community** refers to the organizations and individuals that collaboratively work on an open source project. Any individual or organization can contribute to the project by writing or reviewing code, documentation, test suites, managing meetings, updating websites, etc., provided they abide by the license. For example, at [Openhub.net][6], we see government, nonprofit, commercial, and education organizations [contributing to some open source projects][7].
+
+**project** is the result of this collaborative development, documentation, and testing. Most projects have a central repository where code, documentation, testing, and so forth are developed.
+
+An open sourceis the result of this collaborative development, documentation, and testing. Most projects have a central repository where code, documentation, testing, and so forth are developed.
+
+A **distribution** is a copy, in binary or source code format, of an open source project. For example, CentOS, Fedora, Red Hat Enterprise Linux, SUSE, Ubuntu, and others are distributions of the Linux project. Tectonic, Google Kubernetes Engine, Amazon Container Service, and Red Hat OpenShift are distributions of the Kubernetes project.
+
+Vendor distributions of open source projects are often called **products** , thus Red Hat OpenStack Platform is the Red Hat OpenStack product that is a distribution of the OpenStack upstream project—and it is still 100% open source.
+
+The **trunk** is the main workstream in the community where the open source project is developed.
+
+An open source **fork** is a version of the open source project that is developed along a separate workstream from the main trunk.
+
+Thus, **a distribution is not the same as a fork**. A distribution is a packaging of the upstream project that is made available by vendors, often as products. However, the core code and documentation in the distribution adhere to the version in the upstream project. A fork—and any distribution based on the fork—results in a version of the code and documentation that are different from the upstream project. Users who have forked upstream open source code have to maintain it on their own, meaning they lose the benefit of the collaboration that takes place in the upstream community.
+
+To further explain a software fork, let's use the analogy of migrating animals. Whales and sea lions migrate from the Arctic to California and Mexico; Monarch butterflies migrate from Alaska to Mexico; and (in the Northern Hemisphere) swallows and many other birds fly south for the winter. The key to a successful migration is that all animals in the group stick together, follow the leaders, find food and shelter, and don't get lost.
+
+### Risks of going it on your own
+
+A bird, butterfly, or whale that strays from the group loses the benefit of remaining with the group and knowing where to find food, shelter, and the desired destination.
+
+Similarly, users or organizations that fork and modify an upstream project and maintain it on their own run the following risks:
+
+ 1. **They cannot update their code based on the upstream because their code differs.** This is known as technical debt; the more changes made to forked code, the more it costs in time and money to rebase the fork to the upstream project.
+ 2. **They potentially run less secure code.** If a vulnerability is found in open source code and fixed by the community in the upstream, a forked version of the code may not benefit from this fix because it is different from the upstream.
+ 3. **They might not benefit from new features.** The upstream community, using input from many organizations and individuals, creates new features for the benefit of all users of the upstream project. If an organization forks the upstream, they potentially cannot incorporate the new features because their code differs.
+ 4. **They might not integrate with other software packages.** Open source projects are rarely developed as single entities; rather they often are packaged together with other projects to create a solution. Forked code may not be able to be integrated with other projects because the developers of the forked code are not collaborating in the upstream with other participants.
+ 5. **They might not certify on hardware platforms.** Software packages are often certified to run on hardware platforms so, if problems arise, the hardware and software vendors can collaborate to find the root cause or problem.
+
+
+
+In summary, an open source distribution is simply a packaging of an upstream, multi-organizational, collaborative open source project sold and supported by a vendor. A fork is a separate development workstream of an open source project and risks not being able to benefit from the collaborative efforts of the upstream community.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/forks-vs-distributions
+
+作者:[Jonathan Gershater][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jgershat
+[1]:https://opensource.com/resources/what-open-source
+[2]:https://opensource.com/tags/licensing
+[3]:https://www.eclipse.org/che/getting-started/download/
+[4]:https://access.redhat.com/downloads
+[5]:https://www.freetype.org/
+[6]:http://openhub.net
+[7]:https://www.openhub.net/explore/orgs
diff --git a/sources/talk/20180724 Open Source Certification- Preparing for the Exam.md b/sources/talk/20180724 Open Source Certification- Preparing for the Exam.md
new file mode 100644
index 0000000000..2abcaa7693
--- /dev/null
+++ b/sources/talk/20180724 Open Source Certification- Preparing for the Exam.md
@@ -0,0 +1,64 @@
+Open Source Certification: Preparing for the Exam
+======
+Open source is the new normal in tech today, with open components and platforms driving mission-critical processes at organizations everywhere. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening, making it ever more difficult to hire people][1] with much needed job skills. That’s why open source training and certification are more important than ever, and this series aims to help you learn more and achieve your own certification goals.
+
+In the [first article in the series][2], we explored why certification matters so much today. In the [second article][3], we looked at the kinds of certifications that are making a difference. This story will focus on preparing for exams, what to expect during an exam, and how testing for open source certification differs from traditional types of testing.
+
+Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, stated, “For many of you, if you take the exam, it may well be the first time that you've taken a performance-based exam and it is quite different from what you might have been used to with multiple choice, where the answer is on screen and you can identify it. In performance-based exams, you get what's called a prompt.”
+
+As a matter of fact, many Linux-focused certification exams literally prompt test takers at the command line. The idea is to demonstrate skills in real time in a live environment, and the best preparation for this kind of exam is practice, backed by training.
+
+### Know the requirements
+
+"Get some training," Seepersad emphasized. "Get some help to make sure that you're going to do well. We sometimes find folks have very deep skills in certain areas, but then they're light in other areas. If you go to the website for [Linux Foundation training and certification][4], for the [LFCS][5] and the [LFCE][6] certifications, you can scroll down the page and see the details of the domains and tasks, which represent the knowledge areas you're supposed to know.”
+
+Once you’ve identified the skills you need, “really spend some time on those and try to identify whether you think there are areas where you have gaps. You can figure out what the right training or practice regimen is going to be to help you get prepared to take the exam," Seepersad said.
+
+### Practice, practice, practice
+
+"Practice is important, of course, for all exams," he added. "We deliver the exams in a bit of a unique way -- through your browser. We're using a terminal emulator on your browser and you're being proctored, so there's a live human who is watching you via video cam, your screen is being recorded, and you're having to work through the exam console using the browser window. You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task"
+
+What if you run out of time on your exam, or simply don’t pass because you couldn’t perform the required skills? “I like the phrase, exam insurance,” Seepersad said. “The way we take the stress out is by offering a ‘no questions asked’ retake. If you take either exam, LFCS, LFCE and you do not pass on your first attempt, you are automatically eligible to have a free second attempt.”
+
+The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
+
+### Free certification guide
+
+Becoming a Linux Foundation Certified System Administrator or Engineer is no small feat, so the Foundation has created [this free certification guide][7] to help you with your preparation. In this guide, you’ll find:
+
+ * Critical things to keep in mind on test day
+
+
+ * An array of both free and paid study resources to help you be as prepared as possible
+
+ * A few tips and tricks that could make the difference at exam time
+
+ * A checklist of all the domains and competencies covered in the exam
+
+
+
+
+With certification playing a more important role in securing a rewarding long-term career, careful planning and preparation are key. Stay tuned for the next article in this series that will answer frequently asked questions pertaining to open source certification and training.
+
+[Learn more about Linux training and certification.][8]
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/sysadmin-cert/2018/7/open-source-certification-preparing-exam
+
+作者:[Sam Dean][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/sam-dean
+[1]:https://www.linux.com/blog/os-jobs-report/2017/9/demand-open-source-skills-rise
+[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
+[3]:https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
+[4]:https://training.linuxfoundation.org/
+[5]:https://training.linuxfoundation.org/certification/linux-foundation-certified-sysadmin-lfcs/
+[6]:https://training.linuxfoundation.org/certification/linux-foundation-certified-engineer-lfce/
+[7]:https://training.linuxfoundation.org/download-free-certification-prep-guide
+[8]:https://training.linuxfoundation.org/certification/
diff --git a/sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md b/sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md
new file mode 100644
index 0000000000..1d97805178
--- /dev/null
+++ b/sources/talk/20180724 Why moving all your workloads to the cloud is a bad idea.md
@@ -0,0 +1,71 @@
+Why moving all your workloads to the cloud is a bad idea
+======
+
+
+
+As we've been exploring in this series, cloud hype is everywhere, telling you that migrating your applications to the cloud—including hybrid cloud and multicloud—is the way to ensure a digital future for your business. This hype rarely dives into the pitfalls of moving to the cloud, nor considers the daily work of enhancing your customer's experience and agile delivery of new and legacy applications.
+
+In [part one][1] of this series, we covered basic definitions (to level the playing field). We outlined our views on hybrid cloud and multi-cloud, making sure to show the dividing lines between the two. This set the stage for [part two][2], where we discussed the first of three pitfalls: Why cost is not always the obvious motivator for moving to the cloud.
+
+In part three, we'll look at the second pitfall: Why moving all your workloads to the cloud is a bad idea.
+
+### Everything's better in the cloud?
+
+There's a misconception that everything will benefit from running in the cloud. All workloads are not equal, and not all workloads will see a measurable effect on the bottom line from moving to the cloud.
+
+As [InformationWeek wrote][3], "Not all business applications should migrate to the cloud, and enterprises must determine which apps are best suited to a cloud environment." This is a hard fact that the utility company in part two of this series learned when labor costs rose while trying to move applications to the cloud. Discovering this was not a viable solution, the utility company backed up and reevaluated its applications. It found some applications were not heavily used and others had data ownership and compliance issues. Some of its applications were not certified for use in a cloud environment.
+
+Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
+
+Imagine a fictional online travel company. As its business grew, it expanded its on-premises hosting capacity to over 40,000 servers. It eventually became a question of expanding resources by purchasing a data center at a time, not a rack at a time. Its business consumes bandwidth at such volumes that cloud pricing models based on bandwidth usage remain prohibitive.
+
+### Get a baseline
+
+Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
+
+As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
+
+As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
+
+Understanding your baseline–each application's current situation and performance requirements (network, storage, CPU, memory, application and infrastructure behavior under load, etc.)–gives you the tools to make the right decision.
+
+If you're running servers with single-digit CPU utilization due to complex acquisition processes, a cloud with on-demand resourcing might be a great idea. However, first ask these questions:
+
+ * How long did this low-utilization exist?
+ * Why wasn't it caught earlier?
+ * Isn't there a process or effective monitoring in place?
+ * Do you really need a cloud to fix this? Or just a better process for both getting and managing your resources?
+ * Will you have a better process in the cloud?
+
+
+
+### Are containers necessary?
+
+Many believe you need containers to be successful in the cloud. This popular [catchphrase][4] sums it up nicely, "We crammed this monolith into a container and called it a microservice."
+
+Containers are a means to an end, and using containers doesn't mean your organization is capable of running maturely in the cloud. It's not about the technology involved, it's about applications that often were written in days gone by with technology that's now outdated. If you put a tire fire into a container and then put that container on a container platform to ship, it's still functionality that someone is using.
+
+Is that fire easier to extinguish now? These container fires just create more challenges for your DevOps teams, who are already struggling to keep up with all the changes being pushed through an organization moving everything into the cloud.
+
+Note, it's not necessarily a bad decision to move legacy workloads into the cloud, nor is it a bad idea to containerize them. It's about weighing the benefits and the downsides, assessing the options available, and making the right choices for each of your workloads.
+
+### Coming up
+
+In part four of this series, we'll describe the third and final pitfall everyone should avoid with hybrid multi-cloud. Find out what the cloud means for your data.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
+
+作者:[Eric D.Schabell][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/eschabell
+[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
+[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
+[3]:https://www.informationweek.com/cloud/10-cloud-migration-mistakes-to-avoid/d/d-id/1318829
+[4]:https://speakerdeck.com/caseywest/containercon-north-america-cloud-anti-patterns?slide=22
diff --git a/sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md b/sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md
new file mode 100644
index 0000000000..def2701a78
--- /dev/null
+++ b/sources/talk/20180726 Tech jargon- The good, the bad, and the ugly.md
@@ -0,0 +1,108 @@
+Tech jargon: The good, the bad, and the ugly
+======
+
+
+One enduring and complex piece of jargon is the use of "free" in relation to software. In fact, the term is so ambiguous that different terms have evolved to describe some of the variants—open source, FOSS, and even phrases such as "free as in speech, not as in beer." But surely this is a good thing, right? We know what we mean; we're sharing shorthand by using a particular word in a particular way. Some people might not understand, and there's some ambiguity. But does that matter?
+
+### A couple of definitions
+
+I was involved in an interesting discussion with colleagues recently about the joys (or otherwise) of jargon. It stemmed from a section I wrote in a recent article, [How to talk to security people: a guide for the rest of us][1], where I said:
+
+> "Jargon has at least two uses:
+>
+> 1. as an exclusionary mechanism for groups to keep non-members in the dark;
+> 2. as a short-hand to exchange information between 'in-the-know' people so that they don't need to explain everything in exhaustive detail every time."
+>
+
+
+Given the discussion that arose, I thought it was worth delving more deeply into this question. It's more than an idle interest, as I think there are important lessons around our use of jargon that impact how we interact with our colleagues and peers that deserve some careful thought. These lessons apply particularly to my chosen field, security.
+
+Before we start, we should define "jargon". It's always nice to have two conflicting versions, so here we go:
+
+ * "Special words or expressions used by a profession or group that are difficult for others to understand." ([Oxford Living Dictionaries][2])
+ * "Without a qualifier, denotes informal 'slangy' language peculiar to or predominantly found among hackers." ([The Jargon File][3])
+
+
+
+I should start by pointing out that The Jargon File, which was published in paper form in at least [two versions][4] as The Hacker's Dictionary (ed. Steele) and The New Hacker's Dictionary (ed. Raymond), has a pretty special place in my heart. When I decided that I wanted to properly "take up" geekery,1,2 I read The New Hacker's Dictionary from cover to cover, several times, and when a new edition came out, I bought that and did the same.
+
+In fact, for more technical readers, I suspect that a fair amount of your cultural background is expressed within its covers (paper or virtual), even if you're not aware of it. If you're interested in delving deeper and like the feel of paper in your hands, I encourage you to purchase a copy—but be careful to get the right one. There are some expensive versions that seem just to be printouts of The Jargon File, rather than properly typeset and edited versions.3
+
+But let's get onto the meat of this article: is jargon a force for good or ill?
+
+### First: Why jargon is good
+
+The case for jargon is quite simple. We need jargon to enable us to discuss concepts and the use of terms in normal language—like scheduling—as jargon leads to some interesting metaphors that guide us in our practice.4 We absolutely need shared practice, and for that we need shared language—and some of that language is bound to become jargon over time. But consider a lexicon, or an FAQ, or other ways to allow your colleagues to participate: be inclusive, not exclusive. That's the good. The problem, however, is the bad.
+
+### The case against jargon: Ambiguity
+
+You would think jargon would serve to provide agreed terms within a particular discipline and help prevent ambiguity around contexts. It may be a surprise, then, that the first problem we often run into with jargon is namespace clashes. Consider the following. There's an old joke about how to distinguish an electrical engineer from a humanities5 graduate: ask them how many syllables are in the word "coax." The point here, of course, is that they come from different disciplines. But there are lots of words—and particularly abbreviations—that have different meanings or expansions depending on context and where disciplines and contexts may collide.
+
+What do these words mean to you?6
+
+ * Scheduling: kernel-level CPU allocation to processes OR placement of workloads by an orchestration component
+ * Comms: I/O in a computer system OR marketing/analyst communications
+ * Layer: OSI model OR IP suite layer OR another architectural abstraction layer such as host or workload
+ * SME: subject matter expert OR small/medium enterprise
+ * SMB: small/medium business OR small message block
+ * TLS: transport layer security OR Times Literary Supplement
+ * IP: internet protocol OR intellectual property OR intellectual property as expressed as a silicon component block
+ * FFS for further study OR …7
+
+
+
+One of the interesting things is that quite a lot of my background is betrayed by the various options that present themselves to me. I wonder how many readers will have thought of the Times Literary Supplement, for example. I'm also more likely to think of SME as the term relating to organisations, because that's the favoured form in Europe, whereas I believe that the US tends to SMB. I'm sure your experiences will all be different—which rather makes my point for me.
+
+That's the first problem. In a context where jargon is often praised as a way of shortcutting lengthy explanations, it can actually be a significant ambiguating force.
+
+### The case against jargon: Exclusion
+
+Intentionally or not—and sometimes it is intentional—groups define themselves through the use of specific terminology. Once this terminology becomes opaque to those outside the group, it becomes "jargon," as per our first definition above. "Good" use of jargon generally allows those within the group to converse using shared context around concepts that do not need to be explained in detail every time they are used.
+
+An example would be a "smoke test"—a quick test to check that basic functionality is performing correctly (see the Jargon File's [definition][5] for more). If everyone in the group understands what this means, then why go into more detail? But if you are joined at a stand-up meeting8 by a member of marketing who wants to know whether a particular build is ready for release, and you say "well, no—it's only been smoke-tested so far," then it's likely you'll need to explain.
+
+The problem is that there are occasions when jargon can exclude others, whether that usage is intended or not. There have been times for most of us, I'm sure, when we want to show we're part of a group, so we use terms that we know another person won't understand. On other occasions, the term may be so ingrained in our practice that we use it without thinking, and the other person is unintentionally excluded. I would argue that we need to be careful to avoid both of these uses.
+
+Intentional exclusion is rarely helpful, but unintentional exclusion can be just as damaging—in some ways more so, as it is typically unremarked and therefore difficult to remedy.
+
+### What to do?
+
+First, be aware when you're using jargon, and try to foster an environment where people feel happy to query what you mean. If you see people's eyes glazing over, take a step back and explain the context and the term. Second, be on the lookout for ambiguity: if you're on a project where something can mean more than one thing, disambiguate somewhere in a file or diagram that everyone can access and is easily discoverable. And last, don't use jargon to exclude. We need all the people we can get, so let's bring them in, not push them out.
+
+1\. "Properly"—really? Although I'm not sure "improperly" is any better.
+
+2\. I studied English Literature and Theology at university, so this was a conscious decision to embrace a rather different culture.
+
+3\. The most recent "real" edition of which I'm aware is Raymond, Eric S., 1996, [The New Hacker's Dictionary][6], 3rd ed., MIT University Press, Cambridge, Mass.
+
+4\. Although metaphors can themselves be constraining as they tend to push us to think in a particular way, even if that way isn't entirely applicable in this context.
+
+5\. Or "liberal arts".
+
+6\. I've added the first options that spring to mind when I come across them—I'm aware there are almost certainly others.
+
+7\. Believe me, when I saw this abbreviation in a research paper for the first time, I was most confused and had to look it up.
+
+8\. Oh, look: jargon…
+
+This article originally appeared on [Alice, Eve, and Bob – a security blog][7] and is republished with permission.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/tech-jargon
+
+作者:[Mike Bursell][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mikecamel
+[1]:http://aliceevebob.com/2018/05/08/how-to-talk-to-security-people-a-guide-for-the-rest-of-us/
+[2]:https://en.oxforddictionaries.com/definition/jargon
+[3]:http://catb.org/jargon/html/distinctions.html
+[4]:https://en.wikipedia.org/wiki/Jargon_File
+[5]:http://catb.org/jargon/html/S/smoke-test.html
+[6]:https://www.amazon.com/New-Hackers-Dictionary-3rd/dp/0262680920
+[7]:https://aliceevebob.com/2018/06/26/jargon-a-force-for-good-or-ill/
diff --git a/sources/talk/20180731 How to be the lazy sysadmin.md b/sources/talk/20180731 How to be the lazy sysadmin.md
new file mode 100644
index 0000000000..25024a20bd
--- /dev/null
+++ b/sources/talk/20180731 How to be the lazy sysadmin.md
@@ -0,0 +1,110 @@
+How to be the lazy sysadmin
+======
+
+
+The job of a Linux SysAdmin is always complex and often fraught with various pitfalls and obstacles. Ranging from never having enough time to do everything, to having the Pointy-Haired Boss (PHB) staring over your shoulder while you try to work on the task that she or he just gave you, to having the most critical server in your care crash at the most inopportune time, problems and challenges abound. I have found that becoming the Lazy Sysadmin can help.
+
+I discuss how to be a lazy SysAdmin in detail in my forthcoming book, [The Linux Philosophy for SysAdmins][1], (Apress), which is scheduled to be available in September. Parts of this article are taken from that book, especially Chapter 9, "Be a Lazy SysAdmin." Let's take a brief look at what it means to be a Lazy SysAdmin before we discuss how to do it.
+
+### Real vs. fake productivity
+
+#### Fake productivity
+
+At one place I worked, the PHB believed in the management style called "management by walking around," the supposition being that anyone who wasn't typing something on their keyboard, or at least examining something on their display, was not being productive. This was a horrible place to work. It had high administrative walls between departments that created many, tiny silos, a heavy overburden of useless paperwork, and excruciatingly long wait times to obtain permission to do anything. For these and other reasons, it was impossible to do anything efficiently—if at all—so we were incredibly non-productive. To look busy, we all had our Look Busy Kits (LBKs), which were just short Bash scripts that showed some activity, or programs like `top`, `htop`, `iotop`, or any monitoring tool that constantly displayed some activity. The ethos of this place made it impossible to be truly productive, and I hated both the place and the fact that it was nearly impossible to accomplish anything worthwhile.
+
+That horrible place was a nightmare for real SysAdmins. None of us was happy. It took four or five months to accomplish what took only a single morning in other places. We had little real work to do but spent a huge amount of time working to look busy. We had an unspoken contest going to create the best LBK, and that is where we spent most of our time. I only managed to last a few months at that job, but it seemed like a lifetime. If you looked only at the surface of that dungeon, you could say we were lazy because we accomplished almost zero real work.
+
+This is an extreme example, and it is totally the opposite of what I mean when I say I am a Lazy SysAdmin and being a Lazy SysAdmin is a good thing.
+
+#### Real productivity
+
+I am fortunate to have worked for some true managers—they were people who understood that the productivity of a SysAdmin is not measured by how many hours per day are spent banging on a keyboard. After all, even a monkey can bang on a keyboard, but that is no indication of the value of the results.
+
+As I say in my book:
+
+> "I am a lazy SysAdmin and yet I am also a very productive SysAdmin. Those two seemingly contradictory statements are not mutually exclusive, rather they are complementary in a very positive way. …
+>
+> "A SysAdmin is most productive when thinking—thinking about how to solve existing problems and about how to avoid future problems; thinking about how to monitor Linux computers in order to find clues that anticipate and foreshadow those future problems; thinking about how to make their work more efficient; thinking about how to automate all of those tasks that need to be performed whether every day or once a year.
+>
+> "This contemplative aspect of the SysAdmin job is not well known or understood by those who are not SysAdmins—including many of those who manage the SysAdmins, the Pointy Haired Bosses. SysAdmins all approach the contemplative parts of their job in different ways. Some of the SysAdmins I have known found their best ideas at the beach, cycling, participating in marathons, or climbing rock walls. Others think best when sitting quietly or listening to music. Still others think best while reading fiction, studying unrelated disciplines, or even while learning more about Linux. The point is that we all stimulate our creativity in different ways, and many of those creativity boosters do not involve typing a single keystroke on a keyboard. Our true productivity may be completely invisible to those around the SysAdmin."
+
+There are some simple secrets to being the Lazy SysAdmin—the SysAdmin who accomplishes everything that needs to be done and more, all the while keeping calm and collected while others are running around in a state of panic. Part of this is working efficiently, and part is about preventing problems in the first place.
+
+### Ways to be the Lazy SysAdmin
+
+#### Thinking
+
+I believe the most important secret about being the Lazy SysAdmin is thinking. As in the excerpt above, great SysAdmins spend a significant amount of time thinking about things we can do to work more efficiently, locate anomalies before they become problems, and work smarter, all while considering how to accomplish all of those things and more.
+
+For example, right now—in addition to writing this article—I am thinking about a project I intend to start as soon as the new parts arrive from Amazon and the local computer store. The motherboard on one of my less critical computers is going bad, and it has been crashing more frequently recently. But my very old and minimal server—the one that handles my email and external websites, as well as providing DHCP and DNS services for the rest of my network—isn't failing but has to deal with intermittent overloads due to external attacks of various types.
+
+I started by thinking I would just replace the motherboard and its direct components—memory, CPU, and possibly the power supply—in the failing unit. But after thinking about it for a while, I decided I should put the new components into the server and move the old (but still serviceable) ones from the server into the failing system. This would work and take only an hour, or perhaps two, to remove the old components from the server and install the new ones. Then I could take my time replacing the components in the failing computer. Great. So I started generating a mental list of tasks to do to accomplish this.
+
+However, as I worked the list, I realized that about the only components of the server I wouldn't replace were the case and the hard drive, and the two computers' cases are almost identical. After having this little revelation, I started thinking about replacing the failing computer's components with the new ones and making it my server. Then, after some testing, I would just need to remove the hard drive from my current server and install it in the case with all the new components, change a couple of network configuration items, change the hostname on the KVM switch port, and change the hostname labels on the case, and it should be good to go. This will produce far less server downtime and significantly less stress for me. Also, if something fails, I can simply move the hard drive back to the original server until I can fix the problem with the new one.
+
+So now I have created a mental list of the tasks I need to do to accomplish this. And—I hope you were watching closely—my fingers never once touched the keyboard while I was working all of this out in my head. My new mental action plan is low risk and involves a much smaller amount of server downtime compared to my original plan.
+
+When I worked for IBM, I used to see signs all over that said "THINK" in many languages. Thinking can save time and stress and is the main hallmark of a Lazy SysAdmin.
+
+#### Doing preventative maintenance
+
+In the mid-1970s, I was hired as a customer engineer at IBM, and my territory consisted of a fairly large number of [unit record machines][2]. That just means that they were heavily mechanical devices that processed punched cards—a few dated from the 1930s. Because these machines were primarily mechanical, their parts often wore out or became maladjusted. Part of my job was to fix them when they broke. The main part of my job—the most important part—was to prevent them from breaking in the first place. The preventative maintenance was intended to replace worn parts before they broke and to lubricate and adjust the moving components to ensure that they were working properly.
+
+As I say in The Linux Philosophy for SysAdmins:
+
+> "My managers at IBM understood that was only the tip of the iceberg; they—and I—knew my job was customer satisfaction. Although that usually meant fixing broken hardware, it also meant reducing the number of times the hardware broke. That was good for the customer because they were more productive when their machines were working. It was good for me because I received far fewer calls from those happier customers. I also got to sleep more due to the resultant fewer emergency off-hours callouts. I was being the Lazy [Customer Engineer]. By doing the extra work upfront, I had to do far less work in the long run.
+>
+> "This same tenet has become one of the functional tenets of the Linux Philosophy for SysAdmins. As SysAdmins, our time is best spent doing those tasks that minimize future workloads."
+
+Looking for problems to fix in a Linux computer is the equivalent of project management. I review the system logs looking for hints of problems that might become critical later. If something appears to be a little amiss, or I notice my workstation or a server is not responding as it should, or if the logs show something unusual—all of these can be indicative of an underlying problem that has not generated symptoms obvious to users or the PHB.
+
+I do frequent checks of the files in `/var/log/`, especially messages and security. One of my more common problems is the many script kiddies who try various types of attacks on my firewall system. And, no, I do not rely on the alleged firewall in the modem/router provided by my ISP. These logs contain a lot of information about the source of the attempted attack and can be very valuable. But it takes a lot of work to scan the logs on various hosts and put solutions into place. So I turn to automation.
+
+#### Automating
+
+I have found that a very large percentage of my work can be performed by some form of automation. One of the tenets of the Linux Philosophy for SysAdmins is "automate everything," and this includes boring, drudge tasks like scanning logfiles every day.
+
+Programs like [Logwatch][3] can monitor your logfiles for anomalous entries and notify you when they occur. Logwatch usually runs as a cron job once a day and sends an email to root on the localhost. You can run Logwatch from the command line and view the results immediately on your display. Now I just need to look at the Logwatch email notification every day.
+
+But the reality is just getting a notification is not enough, because we can't sit and watch for problems all the time. Sometimes an immediate response is required. Another program I like, one that does all of the work for me—see, this is the real Lazy Admin—is [Fail2Ban][4]. Fail2Ban scans designated logfiles for various types of hacking and intrusion attempts, and if it sees enough sustained activity of a specific type from a particular IP address, it adds an entry to the firewall that blocks any further hacking attempts from that IP address for a specified time. The defaults tend to be around 10 minutes, but I like to specify 12 or 24 hours for most types of attacks. Each type of hacking attack is configured separately, such as those trying to log in via SSH and those attacking a web server.
+
+#### Writing scripts
+
+Automation is one of the key components of the Philosophy. Everything that can be automated should be, and the rest should be automated as much as possible. So, I also write a lot of scripts to solve problems, which also means I write scripts to do most of my work for me.
+
+My scripts save me huge amounts of time because they contain the commands to perform specific tasks, which significantly reduces the amount of typing I need to do. For example, I frequently restart my email server and my spam-fighting software (which needs restarted when configuration changes are made to SpamAssassin's `local.cf` file). Those services must be stopped and restarted in a specific order. So, I wrote a short script with a few commands and stored it in `/usr/local/bin`, where it is accessible. Now, instead of typing several commands and waiting for each to finish before typing the next one—not to mention remembering the correct sequence of commands and the proper syntax of each—I type in a three-character command and leave the rest to my script.
+
+#### Reducing typing
+
+Another way to be the Lazy SysAdmin is to reduce the amount of typing we need to do. Besides, my typing skills are really horrible (that is to say I have none—a few clumsy fingers at best). One possible cause for errors is my poor typing, so I try to keep typing to a minimum.
+
+The vast majority of GNU and Linux core utilities have very short names. They are, however, names that have some meaning. Tools like `cd` for change directory, `ls` for list (the contents of a directory), and `dd` for disk dump are pretty obvious. Short names mean less typing and fewer opportunities for errors to creep in. I think the short names are usually easier to remember.
+
+When I write shell scripts, I like to keep the names short but meaningful (to me at least) like `rsbu` for Rsync BackUp. In some cases, I like the names a bit longer, such as `doUpdates` to perform system updates. In the latter case, the longer name makes the script's purpose obvious. This saves time because it's easy to remember the script's name.
+
+Other methods to reduce typing are command line aliases and command line recall and editing. Aliases are simply substitutions that are made by the Bash shell when you type a command. Type the `alias` command and look at the list of aliases that are configured by default. For example, when you enter the command `ls`, the entry `alias ls='ls –color=auto'` substitutes the longer command, so you only need to type two characters instead of 14 to get a listing with colors. You can also use the `alias` command to add your own aliases.
+
+Command line recall allows you to use the keyboard's Up and Down arrow keys to scroll through your command history. If you need to use the same command again, you can just press the Enter key when you find the one you need. If you need to change the command once you have found it, you can use standard command line editing features to make the changes.
+
+### Parting thoughts
+
+It is actually quite a lot of work being the Lazy SysAdmin. But we work smart, rather than working hard. We spend time exploring the hosts we are responsible for and dealing with any little problems long before they become large problems. We spend a lot of time thinking about the best ways to resolve problems, and we think a lot about discovering new ways to work smarter at being the Lazy SysAdmin.
+
+There are many other ways to be the Lazy SysAdmin besides the few described here. I'm sure you have some of your own; please share them with the rest of us in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/how-be-lazy-sysadmin
+
+作者:[David Both][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/dboth
+[1]:https://www.apress.com/us/book/9781484237298
+[2]:https://en.wikipedia.org/wiki/Unit_record_equipment
+[3]:https://www.techrepublic.com/article/how-to-install-and-use-logwatch-on-linux/
+[4]:https://www.fail2ban.org/wiki/index.php/Main_Page
diff --git a/sources/talk/20180802 How blockchain will influence open source.md b/sources/talk/20180802 How blockchain will influence open source.md
new file mode 100644
index 0000000000..707f4fe033
--- /dev/null
+++ b/sources/talk/20180802 How blockchain will influence open source.md
@@ -0,0 +1,185 @@
+How blockchain will influence open source
+======
+
+
+
+What [Satoshi Nakamoto][1] started as Bitcoin a decade ago has found a lot of followers and turned into a movement for decentralization. For some, blockchain technology is a religion that will have the same impact on humanity as the Internet has had. For others, it is hype and technology suitable only for Ponzi schemes. While blockchain is still evolving and trying to find its place, one thing is for sure: It is a disruptive technology that will fundamentally transform certain industries. And I'm betting open source will be one of them.
+
+### The open source model
+
+Open source is a collaborative software development and distribution model that allows people with common interests to gather and produce something that no individual can create on their own. It allows the creation of value that is bigger than the sum of its parts. Open source is enabled by distributed collaboration tools (IRC, email, git, wiki, issue trackers, etc.), distributed and protected by an open source licensing model and often governed by software foundations such as the [Apache Software Foundation][2] (ASF), [Cloud Native Computing Foundation][3] (CNCF), etc.
+
+One interesting aspect of the open source model is the lack of financial incentives in its core. Some people believe open source work should remain detached from money and remain a free and voluntary activity driven only by intrinsic motivators (such as "common purpose" and "for the greater good”). Others believe open source work should be rewarded directly or indirectly through extrinsic motivators (such as financial incentive). While the idea of open source projects prospering only through voluntary contributions is romantic, in reality, the majority of open source contributions are done through paid development. Yes, we have a lot of voluntary contributions, but these are on a temporary basis from contributors who come and go, or for exceptionally popular projects while they are at their peak. Creating and sustaining open source projects that are useful for enterprises requires developing, documenting, testing, and bug-fixing for prolonged periods, even when the software is no longer shiny and exciting. It is a boring activity that is best motivated through financial incentives.
+
+### Commercial open source
+
+Software foundations such as ASF survive on donations and other income streams such as sponsorships, conference fees, etc. But those funds are primarily used to run the foundations, to provide legal protection for the projects, and to ensure there are enough servers to run builds, issue trackers, mailing lists, etc.
+
+Similarly, CNCF has member fees and other income streams, which are used to run the foundation and provide resources for the projects. These days, most software is not built on laptops; it is run and tested on hundreds of machines on the cloud, and that requires money. Creating marketing campaigns, brand designs, distributing stickers, etc. takes money, and some foundations can assist with that as well. At its core, foundations implement the right processes to interact with users, developers, and control mechanisms and ensure distribution of available financial resources to open source projects for the common good.
+
+If users of open source projects can donate money and the foundations can distribute it in a fair way, what is missing?
+
+What is missing is a direct, transparent, trusted, decentralized, automated bidirectional link for transfer of value between the open source producers and the open source consumer. Currently, the link is either unidirectional or indirect:
+
+ * **Unidirectional** : A developer (think of a "developer" as any role that is involved in the production, maintenance, and distribution of software) can use their brain juice and devote time to do a contribution and share that value with all open source users. But there is no reverse link.
+
+ * **Indirect** : If there is a bug that affects a specific user/company, the options are:
+
+ * To have in-house developers to fix the bug and do a pull request. That is ideal, but it not always possible to hire in-house developers who are knowledgeable about hundreds of open source projects used daily.
+
+ * To hire a freelancer specializing in that specific open source project and pay for the services. Ideally, the freelancer is also a committer for the open source project and can directly change the project code quickly. Otherwise, the fix might not ever make it to the project.
+
+ * To approach a company providing services around the open source project. Such companies typically employ open source committers to influence and gain credibility in the community and offer products, expertise, and professional services.
+
+
+
+
+The third option has been a successful [model][4] for sustaining many open source projects. Whether they provide services (training, consulting, workshops), support, packaging, open core, or SaaS, there are companies that employ hundreds of staff members who work on open source full time. There is a long [list of companies][5] that have managed to build a successful open source business model over the years, and that list is growing steadily.
+
+The companies that back open source projects play an important role in the ecosystem: They are the catalyst between the open source projects and the users. The ones that add real value do more than just package software nicely; they can identify user needs and technology trends, and they create a full stack and even an ecosystem of open source projects to address these needs. They can take a boring project and support it for years. If there is a missing piece in the stack, they can start an open source project from scratch and build a community around it. They can acquire a closed source software company and open source the projects (here I got a little carried away, but yes, I'm talking about my employer, [Red Hat][6]).
+
+To summarize, with the commercial open source model, projects are officially or unofficially managed and controlled by a very few individuals or companies that monetize them and give back to the ecosystem by ensuring the project is successful. It is a win-win-win for open source developers, managing companies, and end users. The alternative is inactive projects and expensive closed source software.
+
+### Self-sustaining, decentralized open source
+
+For a project to become part of a reputable foundation, it must conform to certain criteria. For example, ASF and CNCF require incubation and graduation processes, respectively, where apart from all the technical and formal requirements, a project must have a healthy number of active committer and users. And that is the essence of forming a sustainable open source project. Having source code on GitHub is not the same thing as having an active open source project. The latter requires committers who write the code and users who use the code, with both groups enforcing each other continuously by exchanging value and forming an ecosystem where everybody benefits. Some project ecosystems might be tiny and short-lived, and some may consist of multiple projects and competing service providers, with very complex interactions lasting for many years. But as long as there is an exchange of value and everybody benefits from it, the project is developed, maintained, and sustained.
+
+If you look at ASF [Attic][7], you will find projects that have reached their end of life. When a project is no longer technologically fit for its purpose, it is usually its natural end. Similarly, in the ASF [Incubator][8], you will find tons of projects that never graduated but were instead retired. Typically, these projects were not able to build a large enough community because they are too specialized or there are better alternatives available.
+
+But there are also cases where projects with high potential and superior technology cannot sustain themselves because they cannot form or maintain a functioning ecosystem for the exchange of value. The open source model and the foundations do not provide a framework and mechanisms for developers to get paid for their work or for users to get their requests heard. There isn’t a common value commitment framework for either party. As a result, some projects can sustain themselves only in the context of commercial open source, where a company acts as an intermediary and value adder between developers and users. That adds another constraint and requires a service provider company to sustain some open source projects. Ideally, users should be able to express their interest in a project and developers should be able to show their commitment to the project in a transparent and measurable way, which forms a community with common interest and intent for the exchange of value.
+
+Imagine there is a model with mechanisms and tools that enable direct interaction between open source users and developers. This includes not only code contributions through pull requests, questions over the mailing lists, GitHub stars, and stickers on laptops, but also other ways that allow users to influence projects' destinies in a richer, more self-controlled and transparent manner.
+
+This model could include incentives for actions such as:
+
+ * Funding open source projects directly rather than through software foundations
+
+ * Influencing the direction of projects through voting (by token holders)
+
+ * Feature requests driven by user needs
+
+ * On-time pull request merges
+
+ * Bounties for bug hunts
+
+ * Better test coverage incentives
+
+ * Up-to-date documentation rewards
+
+ * Long-term support guarantees
+
+ * Timely security fixes
+
+ * Expert assistance, support, and services
+
+ * Budget for evangelism and promotion of the projects
+
+ * Budget for regular boring activities
+
+ * Fast email and chat assistance
+
+ * Full visibility of the overall project findings, etc.
+
+
+
+
+If you haven't guessed, I'm talking about using blockchain and [smart contracts][9] to allow such interactions between users and developers—smart contracts that will give power to the hand of token holders to influence projects.
+
+![blockchain_in_open_source_ecosystem.png][11]
+
+The usage of blockchain in the open source ecosystem
+
+Existing channels in the open source ecosystem provide ways for users to influence projects through financial commitments to service providers or other limited means through the foundations. But the addition of blockchain-based technology to the open source ecosystem could open new channels for interaction between users and developers. I'm not saying this will replace the commercial open source model; most companies working with open source do many things that cannot be replaced by smart contracts. But smart contracts can spark a new way of bootstrapping new open source projects, giving a second life to commodity projects that are a burden to maintain. They can motivate developers to apply boring pull requests, write documentation, get tests to pass, etc., providing a direct value exchange channel between users and open source developers. Blockchain can add new channels to help open source projects grow and become self-sustaining in the long term, even when company backing is not feasible. It can create a new complementary model for self-sustaining open source projects—a win-win.
+
+### Tokenizing open source
+
+There are already a number of initiatives aiming to tokenize open source. Some focus only on an open source model, and some are more generic but apply to open source development as well:
+
+ * [Gitcoin][12] \- grow open source, one of the most promising ones in this area.
+
+ * [Oscoin][13] \- cryptocurrency for open source
+
+ * [Open collective][14] \- a platform for supporting open source projects.
+
+ * [FundYourselfNow][15] \- Kickstarter and ICOs for projects.
+
+ * [Kauri][16] \- support for open source project documentation.
+
+ * [Liberapay][17] \- a recurrent donations platform.
+
+ * [FundRequest][18] \- a decentralized marketplace for open source collaboration.
+
+ * [CanYa][19] \- recently acquired [Bountysource][20], now the world’s largest open source P2P bounty platform.
+
+ * [OpenGift][21] \- a new model for open source monetization.
+
+ * [Hacken][22] \- a white hat token for hackers.
+
+ * [Coinlancer][23] \- a decentralized job market.
+
+ * [CodeFund][24] \- an open source ad platform.
+
+ * [IssueHunt][25] \- a funding platform for open source maintainers and contributors.
+
+ * [District0x 1Hive][26] \- a crowdfunding and curation platform.
+
+ * [District0x Fixit][27] \- github bug bounties.
+
+
+
+
+This list is varied and growing rapidly. Some of these projects will disappear, others will pivot, but a few will emerge as the [SourceForge][28], the ASF, the GitHub of the future. That doesn't necessarily mean they'll replace these platforms, but they'll complement them with token models and create a richer open source ecosystem. Every project can pick its distribution model (license), governing model (foundation), and incentive model (token). In all cases, this will pump fresh blood to the open source world.
+
+### The future is open and decentralized
+
+ * Software is eating the world.
+
+ * Every company is a software company.
+
+ * Open source is where innovation happens.
+
+
+
+
+Given that, it is clear that open source is too big to fail and too important to be controlled by a few or left to its own destiny. Open source is a shared-resource system that has value to all, and more importantly, it must be managed as such. It is only a matter of time until every company on earth will want to have a stake and a say in the open source world. Unfortunately, we don't have the tools and the habits to do it yet. Such tools would allow anybody to show their appreciation or ignorance of software projects. It would create a direct and faster feedback loop between producers and consumers, between developers and users. It will foster innovation—innovation driven by user needs and expressed through token metrics.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/open-source-tokenomics
+
+作者:[Bilgin lbryam][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bibryam
+[1]:https://en.wikipedia.org/wiki/Satoshi_Nakamoto
+[2]:https://www.apache.org/
+[3]:https://www.cncf.io/
+[4]:https://medium.com/open-consensus/3-oss-business-model-progressions-dafd5837f2d
+[5]:https://docs.google.com/spreadsheets/d/17nKMpi_Dh5slCqzLSFBoWMxNvWiwt2R-t4e_l7LPLhU/edit#gid=0
+[6]:http://jobs.redhat.com/
+[7]:https://attic.apache.org/
+[8]:http://incubator.apache.org/
+[9]:https://en.wikipedia.org/wiki/Smart_contract
+[10]:/file/404421
+[11]:https://opensource.com/sites/default/files/uploads/blockchain_in_open_source_ecosystem.png (blockchain_in_open_source_ecosystem.png)
+[12]:https://gitcoin.co/
+[13]:http://oscoin.io/
+[14]:https://opencollective.com/opensource
+[15]:https://www.fundyourselfnow.com/page/about
+[16]:https://kauri.io/
+[17]:https://liberapay.com/
+[18]:https://fundrequest.io/
+[19]:https://canya.io/
+[20]:https://www.bountysource.com/
+[21]:https://opengift.io/pub/
+[22]:https://hacken.io/
+[23]:https://www.coinlancer.com/home
+[24]:https://codefund.io/
+[25]:https://issuehunt.io/
+[26]:https://blog.district0x.io/district-proposal-spotlight-1hive-283957f57967
+[27]:https://github.com/district0x/district-proposals/issues/177
+[28]:https://sourceforge.net/
diff --git a/sources/tech/20170721 Arch Linux Applications Automatic Installation Script.md b/sources/tech/20170721 Arch Linux Applications Automatic Installation Script.md
new file mode 100644
index 0000000000..f95ecea277
--- /dev/null
+++ b/sources/tech/20170721 Arch Linux Applications Automatic Installation Script.md
@@ -0,0 +1,151 @@
+fuowang 翻译中
+
+Arch Linux Applications Automatic Installation Script
+======
+
+
+
+Howdy Archers! Today, I have stumbled upon an useful utility called **“ArchI0”** , a CLI menu-based Arch Linux applications automatic installation script. This script provides an easiest way to install all essential applications for your Arch-based distribution. Please note that **this script is meant for noobs only**. Intermediate and advanced users can easily figure out [**how to use pacman**][1] to get things done. If you want to learn how Arch Linux works, I suggest you to manually install all software one by one. For those who are still noobs and wanted an easy and quick way to install all essential applications for their Arch-based systems, make use of this script.
+
+### ArchI0 – Arch Linux Applications Automatic Installation Script
+
+The developer of this script has created two scripts namely **ArchI0live** and **ArchI0**. You can use ArchI0live script to test without installing it. This might be helpful to know what actually is in this script before installing it on your system.
+
+### Install ArchI0
+
+To install this script, Git cone the ArchI0 script repository using command:
+```
+$ git clone https://github.com/SifoHamlaoui/ArchI0.git
+
+```
+
+The above command will clone the ArchI0 GtiHub repository contents in a folder called ArchI0 in your current directory. Go to the directory using command:
+```
+$ cd ArchI0/
+
+```
+
+Make the script executable using command:
+```
+$ chmod +x ArchI0live.sh
+
+```
+
+Run the script with command:
+```
+$ sudo ./ArchI0live.sh
+
+```
+
+We need to run this script as root or sudo user, because installing applications requires root privileges.
+
+> **Note:** For those wondering what all are those commands for at the beginning of the script, the first command downloads **figlet** , because the script logo is shown using figlet. The 2nd command install **Leafpad** which is used to open and read the license file. The 3rd command install **wget** to download files from sourceforge. The 4th and 5th commands are to download and open the License File on leafpad. And, the final and 6th command is used to close the license file after reading it.
+
+Type your Arch Linux system’s architecture and hit ENTER key. When it asks to install the script, type y and hit ENTER.
+
+![][3]
+
+Once it is installed, you will be redirected to the main menu.
+
+![][4]
+
+As you see in the above screenshot, ArchI0 has 13 categories and contains 90 easy-to-install programs under those categories. These 90 programs are just enough to setup a full-fledged Arch Linux desktop to perform day-to-day activities. To know about this script, type **a** and to exit this script type **q**.
+
+After installing it, you don’t need to run the ArchI0live script. You can directly launch it using the following command:
+```
+$ sudo ArchI0
+
+```
+
+It will ask you each time to choose your Arch Linux distribution architecture.
+```
+This script Is under GPLv3 License
+
+Preparing To Run Script
+ Checking For ROOT: PASSED
+ What Is Your OS Architecture? {32/64} 64
+
+```
+
+From now on, you can install the program of your choice from the categories listed in the main menu. To view the list of available programs under a specific category, enter the category number. Say for example, to view the list of available programs under **Text Editors** category, type **1** and hit ENTER.
+```
+This script Is under GPLv3 License
+
+[ R00T MENU ]
+Make A Choice
+ 1) Text Editors
+ 2) FTP/Torrent Applications
+ 3) Download Managers
+ 4) Network managers
+ 5) VPN clients
+ 6) Chat Applications
+ 7) Image Editors
+ 8) Video editors/Record
+ 9) Archive Handlers
+ 10) Audio Applications
+ 11) Other Applications
+ 12) Development Environments
+ 13) Browser/Web Plugins
+ 14) Dotfiles
+ 15) Usefull Links
+ ------------------------
+ a) About ArchI0 Script
+ q) Leave ArchI0 Script
+
+Choose An Option: 1
+
+```
+
+Next, choose the application you want to install. To return to main menu, type **q** and hit ENTER.
+
+I want to install Emacs, so I type **3**.
+```
+This script Is under GPLv3 License
+
+[ TEXT EDITORS ]
+ [ Option ] [ Description ]
+ 1) GEdit
+ 2) Geany
+ 3) Emacs
+ 4) VIM
+ 5) Kate
+ ---------------------------
+ q) Return To Main Menu
+
+Choose An Option: 3
+
+```
+
+Now, Emacs will be installed on your Arch Linux system.
+
+![][5]
+
+Press ENTER key to return to main menu after installing the applications of your choice.
+
+### Conclusion
+
+Undoubtedly, this script makes the Arch Linux user’s life easier, particularly the beginner’s. If you are looking for a fast and easy way to install applications without using pacman, then this script might be a good choice. Give it a try and let us know what you think about this script in the comment section below.
+
+And, that’s all. Hope this tool helps. We will be posting useful guides every day. If you find our guides useful, please share them on your social, professional networks and support OSTechNix.
+
+Cheers!!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installation-script/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:http://www.ostechnix.com/getting-started-pacman/
+[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_003.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_004-1.png
+[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/pacman-as-superuser_005.png
diff --git a/sources/tech/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md b/sources/tech/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md
index 10bb70fe72..e7457ba7dd 100644
--- a/sources/tech/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md
+++ b/sources/tech/20180203 API Star- Python 3 API Framework - Polyglot.Ninja().md
@@ -1,3 +1,6 @@
+Translating by MjSeven
+
+
API Star: Python 3 API Framework – Polyglot.Ninja()
======
For building quick APIs in Python, I have mostly depended on [Flask][1]. Recently I came across a new API framework for Python 3 named “API Star” which seemed really interesting to me for several reasons. Firstly the framework embraces modern Python features like type hints and asyncio. And then it goes ahead and uses these features to provide awesome development experience for us, the developers. We will get into those features soon but before we begin, I would like to thank Tom Christie for all the work he has put into Django REST Framework and now API Star.
diff --git a/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md b/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
index f846e9486d..5367ccf9db 100644
--- a/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
+++ b/sources/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
@@ -1,3 +1,4 @@
+## sober-wang 翻译中
Linux Virtual Machines vs Linux Live Images
======
I'll be the first to admit that I tend to try out new [Linux distros][1] on a far too frequent basis. Yet the method I use to test them, does vary depending on my goals for each instance. In this article, we're going to look at both running Linux virtual machines and running Linux live images. There are advantages to each method, but there are some hurdles with each method as well.
diff --git a/sources/tech/20180425 Understanding metrics and monitoring with Python - Opensource.com.md b/sources/tech/20180425 Understanding metrics and monitoring with Python - Opensource.com.md
index f181016aba..0982ec8b9d 100644
--- a/sources/tech/20180425 Understanding metrics and monitoring with Python - Opensource.com.md
+++ b/sources/tech/20180425 Understanding metrics and monitoring with Python - Opensource.com.md
@@ -1,3 +1,4 @@
+Translating by qhwdw
# Understanding metrics and monitoring with Python

diff --git a/sources/tech/20180427 An Official Introduction to the Go Compiler.md b/sources/tech/20180427 An Official Introduction to the Go Compiler.md
index 65c35fee64..78dbe23cd7 100644
--- a/sources/tech/20180427 An Official Introduction to the Go Compiler.md
+++ b/sources/tech/20180427 An Official Introduction to the Go Compiler.md
@@ -1,3 +1,4 @@
+
// Copyright 2018 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
diff --git a/sources/tech/20180430 3 practical Python tools- magic methods, iterators and generators, and method magic.md b/sources/tech/20180430 3 practical Python tools- magic methods, iterators and generators, and method magic.md
deleted file mode 100644
index ef3099218e..0000000000
--- a/sources/tech/20180430 3 practical Python tools- magic methods, iterators and generators, and method magic.md
+++ /dev/null
@@ -1,636 +0,0 @@
-Translating by MjSeven
-
-
-3 practical Python tools: magic methods, iterators and generators, and method magic
-======
-
-
-Python offers a unique set of tools and language features that help make your code more elegant, readable, and intuitive. By selecting the right tool for the right problem, your code will be easier to maintain. In this article, we'll examine three of those tools: magic methods, iterators and generators, and method magic.
-
-### Magic methods
-
-
-Magic methods can be considered the plumbing of Python. They're the methods that are called "under the hood" for certain built-in methods, symbols, and operations. A common magic method you may be familiar with is, `__init__()`,which is called when we want to initialize a new instance of a class.
-
-You may have seen other common magic methods, like `__str__` and `__repr__`. There is a whole world of magic methods, and by implementing a few of them, we can greatly modify the behavior of an object or even make it behave like a built-in datatype, such as a number, list, or dictionary.
-
-Let's take this `Money` class for example:
-```
-class Money:
-
-
-
- currency_rates = {
-
- '$': 1,
-
- '€': 0.88,
-
- }
-
-
-
- def __init__(self, symbol, amount):
-
- self.symbol = symbol
-
- self.amount = amount
-
-
-
- def __repr__(self):
-
- return '%s%.2f' % (self.symbol, self.amount)
-
-
-
- def convert(self, other):
-
- """ Convert other amount to our currency """
-
- new_amount = (
-
- other.amount / self.currency_rates[other.symbol]
-
- * self.currency_rates[self.symbol])
-
-
-
- return Money(self.symbol, new_amount)
-
-```
-
-The class defines a currency rate for a given symbol and exchange rate, specifies an initializer (also known as a constructor), and implements `__repr__`, so when we print out the class, we see a nice representation such as `$2.00` for an instance `Money('$', 2.00)` with the currency symbol and amount. Most importantly, it defines a method that allows you to convert between different currencies with different exchange rates.
-
-Using a Python shell, let's say we've defined the costs for two food items in different currencies, like so:
-```
->>> soda_cost = Money('$', 5.25)
-
->>> soda_cost
-
- $5.25
-
-
-
->>> pizza_cost = Money('€', 7.99)
-
->>> pizza_cost
-
- €7.99
-
-```
-
-We could use magic methods to help instances of this class interact with each other. Let's say we wanted to be able to add two instances of this class together, even if they were in different currencies. To make that a reality, we could implement the `__add__` magic method on our `Money` class:
-```
-class Money:
-
-
-
- # ... previously defined methods ...
-
-
-
- def __add__(self, other):
-
- """ Add 2 Money instances using '+' """
-
- new_amount = self.amount + self.convert(other).amount
-
- return Money(self.symbol, new_amount)
-
-```
-
-Now we can use this class in a very intuitive way:
-```
->>> soda_cost = Money('$', 5.25)
-
-
-
->>> pizza_cost = Money('€', 7.99)
-
-
-
->>> soda_cost + pizza_cost
-
- $14.33
-
-
-
->>> pizza_cost + soda_cost
-
- €12.61
-
-```
-
-When we add two instances together, we get a result in the first defined currency. All the conversion is done seamlessly under the hood. If we wanted to, we could also implement `__sub__` for subtraction, `__mul__` for multiplication, and many more. Read about [emulating numeric types][1], or read this [guide to magic methods][2] for others.
-
-We learned that `__add__` maps to the built-in operator `+`. Other magic methods can map to symbols like `[]`. For example, to access an item by index or key (in the case of a dictionary), use the `__getitem__` method:
-```
->>> d = {'one': 1, 'two': 2}
-
-
-
->>> d['two']
-
-2
-
->>> d.__getitem__('two')
-
-2
-
-```
-
-Some magic methods even map to built-in functions, such as `__len__()`, which maps to `len()`.
-```
-class Alphabet:
-
- letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
-
-
-
- def __len__(self):
-
- return len(self.letters)
-
-
-
-
-
->>> my_alphabet = Alphabet()
-
->>> len(my_alphabet)
-
- 26
-
-```
-
-### Custom iterators
-
-Custom iterators are an incredibly powerful but unfortunately confusing topic to new and seasoned Pythonistas alike.
-
-Many built-in types, such as lists, sets, and dictionaries, already implement the protocol that allows them to be iterated over under the hood. This allows us to easily loop over them.
-```
->>> for food in ['Pizza', 'Fries']:
-
- print(food + '. Yum!')
-
-
-
-Pizza. Yum!
-
-Fries. Yum!
-
-```
-
-How can we iterate over our own custom classes? First, let's clear up some terminology.
-
- * To be iterable, a class needs to implement `__iter__()`
- * The `__iter__()` method needs to return an iterator
- * To be an iterator, a class needs to implement `__next__()` (or `next()` [in Python 2][3]), which must raise a `StopIteration` exception when there are no more items to iterate over.
-
-
-
-Whew! It sounds complicated, but once you remember these fundamental concepts, you'll be able to iterate in your sleep.
-
-When might we want to use a custom iterator? Let's imagine a scenario where we have a `Server` instance running different services such as `http` and `ssh` on different ports. Some of these services have an `active` state while others are `inactive`.
-```
-class Server:
-
-
-
- services = [
-
- {'active': False, 'protocol': 'ftp', 'port': 21},
-
- {'active': True, 'protocol': 'ssh', 'port': 22},
-
- {'active': True, 'protocol': 'http', 'port': 80},
-
- ]
-
-```
-
-When we loop over our `Server` instance, we only want to loop over `active` services. Let's create a new class, an `IterableServer`:
-```
-class IterableServer:
-
-
-
- def __init__(self):
-
- self.current_pos = 0
-
-
-
- def __next__(self):
-
- pass # TODO: Implement and remember to raise StopIteration
-
-```
-
-First, we initialize our current position to `0`. Then, we define a `__next__()` method, which will return the next item. We'll also ensure that we raise `StopIteration` when there are no more items to return. So far so good! Now, let's implement this `__next__()` method.
-```
-class IterableServer:
-
-
-
- def __init__(self):
-
- self.current_pos = 0. # we initialize our current position to zero
-
-
-
- def __iter__(self): # we can return self here, because __next__ is implemented
-
- return self
-
-
-
- def __next__(self):
-
- while self.current_pos < len(self.services):
-
- service = self.services[self.current_pos]
-
- self.current_pos += 1
-
- if service['active']:
-
- return service['protocol'], service['port']
-
- raise StopIteration
-
-
-
- next = __next__ # optional python2 compatibility
-
-```
-
-We keep looping over the services in our list while our current position is less than the length of the services but only returning if the service is active. Once we run out of services to iterate over, we raise a `StopIteration` exception.
-
-Because we implement a `__next__()` method that raises `StopIteration` when it is exhausted, we can return `self` from `__iter__()` because the `IterableServer` class adheres to the `iterable` protocol.
-
-Now we can loop over an instance of `IterableServer`, which will allow us to look at each active service, like so:
-```
->>> for protocol, port in IterableServer():
-
- print('service %s is running on port %d' % (protocol, port))
-
-
-
-service ssh is running on port 22
-
-service http is running on port 21
-
-```
-
-That's pretty great, but we can do better! In an instance like this, where our iterator doesn't need to maintain a lot of state, we can simplify our code and use a [generator][4] instead.
-```
-class Server:
-
-
-
- services = [
-
- {'active': False, 'protocol': 'ftp', 'port': 21},
-
- {'active': True, 'protocol': 'ssh', 'port': 22},
-
- {'active': True, 'protocol': 'http', 'port': 21},
-
- ]
-
-
-
- def __iter__(self):
-
- for service in self.services:
-
- if service['active']:
-
- yield service['protocol'], service['port']
-
-```
-
-What exactly is the `yield` keyword? Yield is used when defining a generator function. It's sort of like a `return`. While a `return` exits the function after returning the value, `yield` suspends execution until the next time it's called. This allows your generator function to maintain state until it resumes. Check out [yield's documentation][5] to learn more. With a generator, we don't have to manually maintain state by remembering our position. A generator knows only two things: what it needs to do right now and what it needs to do to calculate the next item. Once we reach a point of execution where `yield` isn't called again, we know to stop iterating.
-
-This works because of some built-in Python magic. In the [Python documentation for `__iter__()`][6] we can see that if `__iter__()` is implemented as a generator, it will automatically return an iterator object that supplies the `__iter__()` and `__next__()` methods. Read this great article for a deeper dive of [iterators, iterables, and generators][7].
-
-### Method magic
-
-Due to its unique aspects, Python provides some interesting method magic as part of the language.
-
-One example of this is aliasing functions. Since functions are just objects, we can assign them to multiple variables. For example:
-```
->>> def foo():
-
- return 'foo'
-
-
-
->>> foo()
-
-'foo'
-
-
-
->>> bar = foo
-
-
-
->>> bar()
-
-'foo'
-
-```
-
-We'll see later on how this can be useful.
-
-Python provides a handy built-in, [called `getattr()`][8], that takes the `object, name, default` parameters and returns the attribute `name` on `object`. This programmatically allows us to access instance variables and methods. For example:
-```
->>> class Dog:
-
- sound = 'Bark'
-
- def speak(self):
-
- print(self.sound + '!', self.sound + '!')
-
-
-
->>> fido = Dog()
-
-
-
->>> fido.sound
-
-'Bark'
-
->>> getattr(fido, 'sound')
-
-'Bark'
-
-
-
->>> fido.speak
-
->
-
->>> getattr(fido, 'speak')
-
->
-
-
-
-
-
->>> fido.speak()
-
-Bark! Bark!
-
->>> speak_method = getattr(fido, 'speak')
-
->>> speak_method()
-
-Bark! Bark!
-
-```
-
-Cool trick, but how could we practically use `getattr`? Let's look at an example that allows us to write a tiny command-line tool to dynamically process commands.
-```
-class Operations:
-
- def say_hi(self, name):
-
- print('Hello,', name)
-
-
-
- def say_bye(self, name):
-
- print ('Goodbye,', name)
-
-
-
- def default(self, arg):
-
- print ('This operation is not supported.')
-
-
-
-if __name__ == '__main__':
-
- operations = Operations()
-
-
-
- # let's assume we do error handling
-
- command, argument = input('> ').split()
-
- func_to_call = getattr(operations, command, operations.default)
-
- func_to_call(argument)
-
-```
-
-The output of our script is:
-```
-$ python getattr.py
-
-
-
-> say_hi Nina
-
-Hello, Nina
-
-
-
-> blah blah
-
-This operation is not supported.
-
-```
-
-Next, we'll look at `partial`. For example, **`functool.partial(func, *args, **kwargs)`** allows you to return a new [partial object][9] that behaves like `func` called with `args` and `kwargs`. If more `args` are passed in, they're appended to `args`. If more `kwargs` are passed in, they extend and override `kwargs`. Let's see it in action with a brief example:
-```
->>> from functools import partial
-
->>> basetwo = partial(int, base=2)
-
->>> basetwo
-
-
-
-
-
->>> basetwo('10010')
-
-18
-
-
-
-# This is the same as
-
->>> int('10010', base=2)
-
-```
-
-Let's see how this method magic ties together in some sample code from a library I enjoy using [called][10]`agithub`, which is a (poorly named) REST API client with transparent syntax that allows you to rapidly prototype any REST API (not just GitHub) with minimal configuration. I find this project interesting because it's incredibly powerful yet only about 400 lines of Python. You can add support for any REST API in about 30 lines of configuration code. `agithub` knows everything it needs to about protocol (`REST`, `HTTP`, `TCP`), but it assumes nothing about the upstream API. Let's dive into the implementation.
-
-Here's a simplified version of how we'd define an endpoint URL for the GitHub API and any other relevant connection properties. View the [full code][11] instead.
-```
-class GitHub(API):
-
-
-
- def __init__(self, token=None, *args, **kwargs):
-
- props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
-
- self.setClient(Client(*args, **kwargs))
-
- self.setConnectionProperties(props)
-
-```
-
-Then, once your [access token][12] is configured, you can start using the [GitHub API][13].
-```
->>> gh = GitHub('token')
-
->>> status, data = gh.user.repos.get(visibility='public', sort='created')
-
->>> # ^ Maps to GET /user/repos
-
->>> data
-
-... ['tweeter', 'snipey', '...']
-
-```
-
-Note that it's up to you to spell things correctly. There's no validation of the URL. If the URL doesn't exist or anything else goes wrong, the error thrown by the API will be returned. So, how does this all work? Let's figure it out. First, we'll check out a simplified example of the [`API` class][14]:
-```
-class API:
-
-
-
- # ... other methods ...
-
-
-
- def __getattr__(self, key):
-
- return IncompleteRequest(self.client).__getattr__(key)
-
- __getitem__ = __getattr__
-
-```
-
-Each call on the `API` class ferries the call to the [`IncompleteRequest` class][15] for the specified `key`.
-```
-class IncompleteRequest:
-
-
-
- # ... other methods ...
-
-
-
- def __getattr__(self, key):
-
- if key in self.client.http_methods:
-
- htmlMethod = getattr(self.client, key)
-
- return partial(htmlMethod, url=self.url)
-
- else:
-
- self.url += '/' + str(key)
-
- return self
-
- __getitem__ = __getattr__
-
-
-
-
-
-class Client:
-
- http_methods = ('get') # ... and post, put, patch, etc.
-
-
-
- def get(self, url, headers={}, **params):
-
- return self.request('GET', url, None, headers)
-
-```
-
-If the last call is not an HTTP method (like 'get', 'post', etc.), it returns an `IncompleteRequest` with an appended path. Otherwise, it gets the right function for the specified HTTP method from the [`Client` class][16] and returns a `partial` .
-
-What happens if we give a non-existent path?
-```
->>> status, data = this.path.doesnt.exist.get()
-
->>> status
-
-... 404
-
-```
-
-And because `__getitem__` is aliased to `__getattr__`:
-```
->>> owner, repo = 'nnja', 'tweeter'
-
->>> status, data = gh.repos[owner][repo].pulls.get()
-
->>> # ^ Maps to GET /repos/nnja/tweeter/pulls
-
->>> data
-
-.... # {....}
-
-```
-
-Now that's some serious method magic!
-
-### Learn more
-
-Python provides plenty of tools that allow you to make your code more elegant and easier to read and understand. The challenge is finding the right tool for the job, but I hope this article added some new ones to your toolbox. And, if you'd like to take this a step further, you can read about decorators, context managers, context generators, and `NamedTuple`s on my blog [nnja.io][17]. As you become a better Python developer, I encourage you to get out there and read some source code for well-architected projects. [Requests][18] and [Flask][19] are two great codebases to start with.
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems
-
-作者:[Nina Zakharenko][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/nnja
-[1]:https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types
-[2]:https://rszalski.github.io/magicmethods/
-[3]:https://docs.python.org/2/library/stdtypes.html#iterator.next
-[4]:https://docs.python.org/3/library/stdtypes.html#generator-types
-[5]:https://docs.python.org/3/reference/expressions.html#yieldexpr
-[6]:https://docs.python.org/3/reference/datamodel.html#object.__iter__
-[7]:http://nvie.com/posts/iterators-vs-generators/
-[8]:https://docs.python.org/3/library/functions.html#getattr
-[9]:https://docs.python.org/3/library/functools.html#functools.partial
-[10]:https://github.com/mozilla/agithub
-[11]:https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py
-[12]:https://github.com/settings/tokens
-[13]:https://developer.github.com/v3/repos/#list-your-repositories
-[14]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58
-[15]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100
-[16]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231
-[17]:http://nnja.io
-[18]:https://github.com/requests/requests
-[19]:https://github.com/pallets/flask
-[20]:https://us.pycon.org/2018/schedule/presentation/164/
-[21]:https://us.pycon.org/2018/
diff --git a/sources/tech/20180508 Everything old is new again- Microservices - DXC Blogs.md b/sources/tech/20180508 Everything old is new again- Microservices - DXC Blogs.md
deleted file mode 100644
index 1e9922643f..0000000000
--- a/sources/tech/20180508 Everything old is new again- Microservices - DXC Blogs.md
+++ /dev/null
@@ -1,58 +0,0 @@
-Everything old is new again: Microservices – DXC Blogs
-======
-
-
-If I told you about a software architecture in which components of an application provided services to other components via a communications protocol over a network you would say it was…
-
-Well, it depends. If you got your start programming in the 90s, you’d say I just defined a [Service-Oriented Architecture (SOA)][1]. But, if you’re younger and cut your developer teeth on the cloud, you’d say: “Oh, you’re talking about [microservices][2].”
-
-You’d both be right. To really understand the differences, you need to dive deeper into these architectures.
-
-In SOA, a service is a function, which is well-defined, self-contained, and doesn’t depend on the context or state of other services. There are two kinds of services. A service consumer, which requests a service from the other type, a service provider. An SOA service can play both roles.
-
-SOA services can trade data with each other. Two or more services can also coordinate with each other. These services carry out basic jobs such as creating a user account, providing login functionality, or validating a payment.
-
-SOA isn’t so much about modularizing an application as it is about composing an application by integrating distributed, separately-maintained and deployed components. These components run on servers.
-
-Early versions of SOA used object-oriented protocols to communicate with each other. For example, Microsoft’s [Distributed Component Object Model (DCOM)][3] and [Object Request Brokers (ORBs)][4] use the [Common Object Request Broker Architecture (CORBA)][5] specification.
-
-Later versions used messaging services such as [Java Message Service (JMS)][6] or [Advanced Message Queuing Protocol (AMQP)][7]. These service connections are called Enterprise Service Buses (ESB). Over these buses, data, almost always in eXtensible Markup Language (XML) format, is transmitted and received.
-
-[Microservices][2] is an architectural style where applications are made up from loosely coupled services or modules. It lends itself to the Continuous Integration/Continuous Deployment (CI/CD) model of developing large, complex applications. An application is the sum of its modules.
-
-Each microservice provides an application programming interface (API) endpoint. These are connected by lightweight protocols such as [REpresentational State Transfer (REST)][8], or [gRPC][9]. Data tends to be represented by [JavaScript Object Notation (JSON)][10] or [Protobuf][11].
-
-Both architectures stand as an alternative to the older, monolithic style of architecture where applications are built as single, autonomous units. For example, in a client-server model, a typical Linux, Apache, MySQL, PHP/Python/Perl (LAMP) server-side application would deal with HTTP requests, run sub-programs and retrieves/updates from the underlying MySQL database. These are all tied closely together. When you change anything, you must build and deploy a new version.
-
-With SOA, you may need to change several components, but never the entire application. With microservices, though, you can make changes one service at a time. With microservices, you’re working with a true decoupled architecture.
-
-Microservices are also lighter than SOA. While SOA services are deployed to servers and virtual machines (VMs), microservices are deployed in containers. The protocols are also lighter. This makes microservices more flexible than SOA. Hence, it works better with Agile shops.
-
-So what does this mean? The long and short of it is that microservices are an SOA variation for container and cloud computing.
-
-Old style SOA isn’t going away, but as we continue to move applications to containers, the microservice architecture will only grow more popular.
-
-
---------------------------------------------------------------------------------
-
-via: https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/
-
-作者:[Cloudy Weather][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://blogs.dxc.technology/author/steven-vaughan-nichols/
-[1]:https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html
-[2]:http://microservices.io/
-[3]:https://technet.microsoft.com/en-us/library/cc958799.aspx
-[4]:https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB
-[5]:http://www.corba.org/
-[6]:https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html
-[7]:https://www.amqp.org/
-[8]:https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html
-[9]:https://grpc.io/
-[10]:https://www.json.org/
-[11]:https://github.com/google/protobuf/
diff --git a/sources/tech/20180508 How To Check Ubuntu Version and Other System Information Easily.md b/sources/tech/20180508 How To Check Ubuntu Version and Other System Information Easily.md
deleted file mode 100644
index 9395b7708a..0000000000
--- a/sources/tech/20180508 How To Check Ubuntu Version and Other System Information Easily.md
+++ /dev/null
@@ -1,127 +0,0 @@
-How To Check Ubuntu Version and Other System Information Easily
-======
-**Brief: Wondering which Ubuntu version are you using? Here’s how to check Ubuntu version, desktop environment and other relevant system information.**
-
-You can easily find the Ubuntu version you are using in the command line or via the graphical interface. Knowing the exact Ubuntu version, desktop environment and other system information helps a lot when you are trying to follow a tutorial from the web or seeking help in various forums.
-
-In this quick tip, I’ll show you various ways to check [Ubuntu][1] version and other common system information.
-
-### How to check Ubuntu version in terminal
-
-This is the best way to find Ubuntu version. I could have mentioned the graphical way first but then I chose this method because this one doesn’t depend on the [desktop environment][2] you are using. You can use it on any Ubuntu variant.
-
-Open a terminal (Ctrl+Alt+T) and type the following command:
-```
-lsb_release -a
-
-```
-
-The output of the above command should be like this:
-```
-No LSB modules are available.
-Distributor ID: Ubuntu
-Description: Ubuntu 16.04.4 LTS
-Release: 16.04
-Codename: xenial
-
-```
-
-![How to check Ubuntu version in command line][3]
-
-As you can see, the current Ubuntu installed in my system is Ubuntu 16.04 and its code name is Xenial.
-
-Wait! Why does it say Ubuntu 16.04.4 in Description and 16.04 in the Release? Which one is it, 16.04 or 16.04.4? What’s the difference between the two?
-
-The short answer is that you are using Ubuntu 16.04. That’s the base image. 16.04.4 signifies the fourth point release of 16.04. A point release can be thought of as a service pack in Windows era. Both 16.04 and 16.04.4 will be the correct answer here.
-
-What’s Xenial in the output? That’s the codename of the Ubuntu 16.04 release. You can read this [article to know about Ubuntu naming convention][4].
-
-#### Some alternate ways to find Ubuntu version
-
-Alternatively, you can use either of the following commands to find Ubuntu version:
-```
-cat /etc/lsb-release
-
-```
-
-The output of the above command would look like this:
-```
-DISTRIB_ID=Ubuntu
-DISTRIB_RELEASE=16.04
-DISTRIB_CODENAME=xenial
-DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
-
-```
-
-![How to check Ubuntu version in command line][5]
-
-You can also use this command to know Ubuntu version
-```
-cat /etc/issue
-
-```
-
-The output of this command will be like this:
-```
-Ubuntu 16.04.4 LTS \n \l
-
-```
-
-Forget the \n \l. The Ubuntu version is 16.04.4 in this case or simply Ubuntu 16.04.
-
-### How to check Ubuntu version graphically
-
-Checking Ubuntu version graphically is no big deal either. I am going to use screenshots from Ubuntu 18.04 GNOME here. Things may look different if you are using Unity or some other desktop environment. This is why I recommend the command line version discussed in the previous sections because that doesn’t depend on the desktop environment.
-
-I’ll show you how to find the desktop environment in the next section.
-
-For now, go to System Settings and look under the Details segment.
-
-![Finding Ubuntu version graphically][6]
-
-You should see the Ubuntu version here along with the information about the desktop environment you are using, [GNOME][7] being the case here.
-
-![Finding Ubuntu version graphically][8]
-
-### How to know the desktop environment and other system information in Ubuntu
-
-So you just learned how to find Ubuntu version. What about the desktop environment in use? Which Linux kernel version is being used?
-
-Of course, there are various commands you can use to get all those information but I’ll recommend a command line utility called [Neofetch][9]. This will show you essential system information in the terminal beautifully with the logo of Ubuntu or any other Linux distribution you are using.
-
-Install Neofetch using the command below:
-```
-sudo apt install neofetch
-
-```
-
-Once installed, simply run the command `neofetch` in the terminal and see a beautiful display of system information.
-
-![System information in Linux terminal][10]
-
-As you can see, Neofetch shows you the Linux kernel version, Ubuntu version, desktop environment in use along with its version, themes and icons in use etc.
-
-I hope it helps you to find Ubuntu version and other system information. If you have suggestions to improve this article, feel free to drop it in the comment section. Ciao :)
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[1]:https://www.ubuntu.com/
-[2]:https://en.wikipedia.org/wiki/Desktop_environment
-[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
-[4]:https://itsfoss.com/linux-code-names/
-[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
-[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
-[7]:https://www.gnome.org/
-[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
-[9]:https://itsfoss.com/display-linux-logo-in-ascii/
-[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
diff --git a/sources/tech/20180510 Splicing the Cloud Native Stack, One Floor at a Time.md b/sources/tech/20180510 Splicing the Cloud Native Stack, One Floor at a Time.md
index 6515b3e193..b9ec11efba 100644
--- a/sources/tech/20180510 Splicing the Cloud Native Stack, One Floor at a Time.md
+++ b/sources/tech/20180510 Splicing the Cloud Native Stack, One Floor at a Time.md
@@ -1,3 +1,4 @@
+Translating by qhwdw
Splicing the Cloud Native Stack, One Floor at a Time
======
At Packet, our value (automated infrastructure) is super fundamental. As such, we spend an enormous amount of time looking up at the players and trends in all the ecosystems above us - as well as the very few below!
diff --git a/sources/tech/20180515 Give Your Linux Desktop a Stunning Makeover With Xenlism Themes.md b/sources/tech/20180515 Give Your Linux Desktop a Stunning Makeover With Xenlism Themes.md
deleted file mode 100644
index f76a483199..0000000000
--- a/sources/tech/20180515 Give Your Linux Desktop a Stunning Makeover With Xenlism Themes.md
+++ /dev/null
@@ -1,92 +0,0 @@
-Give Your Linux Desktop a Stunning Makeover With Xenlism Themes
-============================================================
-
-
- _Brief: Xenlism theme pack provides an aesthetically pleasing GTK theme, colorful icons, and minimalist wallpapers to transform your Linux desktop into an eye-catching setup._
-
-It’s not every day that I dedicate an entire article to a theme unless I find something really awesome. I used to cover themes and icons regularly. But lately, I preferred having lists of [best GTK themes][6] and icon themes. This is more convenient for me and for you as well as you get to see many beautiful themes in one place.
-
-After [Pop OS theme][7] suit, Xenlism is another theme that has left me awestruck by its look.
-
-
-
-Xenlism GTK theme is based on the Arc theme, an inspiration behind so many themes these days. The GTK theme provides Windows buttons similar to macOS which I neither like nor dislike. The GTK theme has a flat, minimalist layout and I like that.
-
-There are two icon themes in the Xenlism suite. Xenlism Wildfire is an old one and had already made to our list of [best icon themes][8].
-
-
-Xenlism Wildfire Icons
-
-Xenlsim Storm is the relatively new icon theme but is equally beautiful.
-
-
-Xenlism Storm Icons
-
-Xenlism themes are open source under GPL license.
-
-### How to install Xenlism theme pack on Ubuntu 18.04
-
-Xenlism dev provides an easier way of installing the theme pack through a PPA. Though the PPA is available for Ubuntu 16.04, I found the GTK theme wasn’t working with Unity. It works fine with the GNOME desktop in Ubuntu 18.04.
-
-Open a terminal (Ctrl+Alt+T) and use the following commands one by one:
-
-```
-sudo add-apt-repository ppa:xenatt/xenlism
-sudo apt update
-```
-
-This PPA offers four packages:
-
-* xenlism-finewalls: for a set of wallpapers that will be available directly in the wallpaper section of Ubuntu. One of the wallpapers has been used in the screenshot.
-
-* xenlism-minimalism-theme: GTK theme
-
-* xenlism-storm: an icon theme (see previous screenshots)
-
-* xenlism-wildfire-icon-theme: another icon theme with several color variants (folder colors get changed in the variants)
-
-You can decide on your own what theme component you want to install. Personally, I don’t see any harm in installing all the components.
-
-```
-sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
-```
-
-You can use GNOME Tweaks for changing the theme and icons. If you are not familiar with the procedure already, I suggest reading this tutorial to learn [how to install themes in Ubuntu 18.04 GNOME][9].
-
-### Getting Xenlism themes in other Linux distributions
-
-You can install Xenlism themes on other Linux distributions as well. Installation instructions for various Linux distributions can be found on its website:
-
-[Install Xenlism Themes][10]
-
-### What do you think?
-
-I know not everyone would agree with me but I loved this theme. I think you are going to see the glimpse of Xenlism theme in the screenshots in future tutorials on It’s FOSS.
-
-Did you like Xenlism theme? If not, what theme do you like the most? Share your opinion in the comment section below.
-
-#### 关于作者
-
-I am a professional software developer, and founder of It's FOSS. I am an avid Linux lover and Open Source enthusiast. I use Ubuntu and believe in sharing knowledge. Apart from Linux, I love classic detective mysteries. I'm a huge fan of Agatha Christie's work.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/xenlism-theme/
-
-作者:[Abhishek Prakash ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/abhishek/
-[1]:https://itsfoss.com/author/abhishek/
-[2]:https://itsfoss.com/xenlism-theme/#comments
-[3]:https://itsfoss.com/category/desktop/
-[4]:https://itsfoss.com/tag/themes/
-[5]:https://itsfoss.com/tag/xenlism/
-[6]:https://itsfoss.com/best-gtk-themes/
-[7]:https://itsfoss.com/pop-icon-gtk-theme-ubuntu/
-[8]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
-[9]:https://itsfoss.com/install-themes-ubuntu/
-[10]:http://xenlism.github.io/minimalism/#install
diff --git a/sources/tech/20180516 How Graphics Cards Work.md b/sources/tech/20180516 How Graphics Cards Work.md
deleted file mode 100644
index 653ec5ef5d..0000000000
--- a/sources/tech/20180516 How Graphics Cards Work.md
+++ /dev/null
@@ -1,74 +0,0 @@
-How Graphics Cards Work
-======
-![AMD-Polaris][1]
-
-Ever since 3dfx debuted the original Voodoo accelerator, no single piece of equipment in a PC has had as much of an impact on whether your machine could game as the humble graphics card. While other components absolutely matter, a top-end PC with 32GB of RAM, a $500 CPU, and PCIe-based storage will choke and die if asked to run modern AAA titles on a ten year-old card at modern resolutions and detail levels. Graphics cards (also commonly referred to as GPUs, or graphics processing units) are critical to game performance and we cover them extensively. But we don’t often dive into what makes a GPU tick and how the cards function.
-
-By necessity, this will be a high-level overview of GPU functionality and cover information common to AMD, Nvidia, and Intel’s integrated GPUs, as well as any discrete cards Intel might build in the future. It should also be common to the mobile GPUs built by Apple, Imagination Technologies, Qualcomm, ARM, and other vendors.
-
-### Why Don’t We Run Rendering With CPUs?
-
-The first point I want to address is why we don’t use CPUs for rendering workloads in gaming in the first place. The honest answer to this question is that you can run rendering workloads directly on a CPU, at least in theory. Early 3D games that predate the widespread availability of graphics cards, like Ultima Underworld, ran entirely on the CPU. UU is a useful reference case for multiple reasons — it had a more advanced rendering engine than games like Doom, with full support for looking up and down, as well as then-advanced features like texture mapping. But this kind of support came at a heavy price — many people lacked a PC that could actually run the game.
-
-
-
-In the early days of 3D gaming, many titles like Half Life and Quake II featured a software renderer to allow players without 3D accelerators to play the title. But the reason we dropped this option from modern titles is simple: CPUs are designed to be general-purpose microprocessors, which is another way of saying they lack the specialized hardware and capabilities that GPUs offer. A modern CPU could easily handle titles that tended to stutter when run in software 18 years ago, but no CPU on Earth could easily handle a modern AAA game from today if run in that mode. Not, at least, without some drastic changes to the scene, resolution, and various visual effects.
-
-### What’s a GPU?
-
-A GPU is a device with a set of specific hardware capabilities that are intended to map well to the way that various 3D engines execute their code, including geometry setup and execution, texture mapping, memory access, and shaders. There’s a relationship between the way 3D engines function and the way GPU designers build hardware. Some of you may remember that AMD’s HD 5000 family used a VLIW5 architecture, while certain high-end GPUs in the HD 6000 family used a VLIW4 architecture. With GCN, AMD changed its approach to parallelism, in the name of extracting more useful performance per clock cycle.
-
-
-
-Nvidia first coined the term “GPU” with the launch of the original GeForce 256 and its support for performing hardware transform and lighting calculations on the GPU (this corresponded, roughly to the launch of Microsoft’s DirectX 7). Integrating specialized capabilities directly into hardware was a hallmark of early GPU technology. Many of those specialized technologies are still employed (in very different forms), because it’s more power efficient and faster to have dedicated resources on-chip for handling specific types of workloads than it is to attempt to handle all of the work in a single array of programmable cores.
-
-There are a number of differences between GPU and CPU cores, but at a high level, you can think about them like this. CPUs are typically designed to execute single-threaded code as quickly and efficiently as possible. Features like SMT / Hyper-Threading improve on this, but we scale multi-threaded performance by stacking more high-efficiency single-threaded cores side-by-side. AMD’s 32-core / 64-thread Epyc CPUs are the largest you can buy today. To put that in perspective, the lowest-end Pascal GPU from Nvidia has 384 cores. A “core” in GPU parlance refers to a much smaller unit of processing capability than in a typical CPU.
-
-**Note:** You cannot compare or estimate relative gaming performance between AMD and Nvidia simply by comparing the number of GPU cores. Within the same GPU family (for example, Nvidia’s GeForce GTX 10 series, or AMD’s RX 4xx or 5xx family), a higher GPU core count means that GPU is more powerful than a lower-end card.
-
-The reason you can’t draw immediate conclusions on GPU performance between manufacturers or core families based solely on core counts is because different architectures are more and less efficient. Unlike CPUs, GPUs are designed to work in parallel. Both AMD and Nvidia structure their cards into blocks of computing resources. Nvidia calls these blocks an SM (Streaming Multiprocessor), while AMD refers to them as a Compute Unit.
-
-
-
-Each block contains a group of cores, a scheduler, a register file, instruction cache, texture and L1 cache, and texture mapping units. The SM / CU can be thought of as the smallest functional block of the GPU. It doesn’t contain literally everything — video decode engines, render outputs required for actually drawing an image on-screen, and the memory interfaces used to communicate with onboard VRAM are all outside its purview — but when AMD refers to an APU as having 8 or 11 Vega Compute Units, this is the (equivalent) block of silicon they’re talking about. And if you look at a block diagram of a GPU, any GPU, you’ll notice that it’s the SM/CU that’s duplicated a dozen or more times in the image.
-
-
-
-The higher the number of SM/CU units in a GPU, the more work it can perform in parallel per clock cycle. Rendering is a type of problem that’s sometimes referred to as “embarrassingly parallel,” meaning it has the potential to scale upwards extremely well as core counts increase.
-
-When we discuss GPU designs, we often use a format that looks something like this: 4096:160:64. The GPU core count is the first number. The larger it is, the faster the GPU, provided we’re comparing within the same family (GTX 970 versus GTX 980 versus GTX 980 Ti, RX 560 versus RX 580, and so on).
-
-### Texture Mapping and Render Outputs
-
-There are two other major components of a GPU: texture mapping units and render outputs. The number of texture mapping units in a design dictates its maximum texel output and how quickly it can address and map textures on to objects. Early 3D games used very little texturing, because the job of drawing 3D polygonal shapes was difficult enough. Textures aren’t actually required for 3D gaming, though the list of games that don’t use them in the modern age is extremely small.
-
-The number of texture mapping units in a GPU is signified by the second figure in the 4096:160:64 metric. AMD, Nvidia, and Intel typically shift these numbers equivalently as they scale a GPU family up and down. In other words, you won’t really find a scenario where one GPU has a 4096:160:64 configuration while a GPU above or below it in the stack is a 4096:320:64 configuration. Texture mapping can absolutely be a bottleneck in games, but the next-highest GPU in the product stack will typically offer at least more GPU cores and texture mapping units (whether higher-end cards have more ROPs depends on the GPU family and the card configuration).
-
-Render outputs (also sometimes called raster operations pipelines) are where the GPU’s output is assembled into an image for display on a monitor or television. The number of render outputs multiplied by the clock speed of the GPU controls the pixel fill rate. A higher number of ROPs means that more pixels can be output simultaneously. ROPs also handle antialiasing, and enabling AA — especially supersampled AA — can result in a game that’s fill-rate limited.
-
-### Memory Bandwidth, Memory Capacity
-
-The last components we’ll discuss are memory bandwidth and memory capacity. Memory bandwidth refers to how much data can be copied to and from the GPU’s dedicated VRAM buffer per second. Many advanced visual effects (and higher resolutions more generally) require more memory bandwidth to run at reasonable frame rates because they increase the total amount of data being copied into and out of the GPU core.
-
-In some cases, a lack of memory bandwidth can be a substantial bottleneck for a GPU. AMD’s APUs like the Ryzen 5 2400G are heavily bandwidth-limited, which means increasing your DDR4 clock rate can have a substantial impact on overall performance. The choice of game engine can also have a substantial impact on how much memory bandwidth a GPU needs to avoid this problem, as can a game’s target resolution.
-
-The total amount of on-board memory is another critical factor in GPUs. If the amount of VRAM needed to run at a given detail level or resolution exceeds available resources, the game will often still run, but it’ll have to use the CPU’s main memory for storing additional texture data — and it takes the GPU vastly longer to pull data out of DRAM as opposed to its onboard pool of dedicated VRAM. This leads to massive stuttering as the game staggers between pulling data from a quick pool of local memory and general system RAM.
-
-One thing to be aware of is that GPU manufacturers will sometimes equip a low-end or midrange card with more VRAM than is otherwise standard as a way to charge a bit more for the product. We can’t make an absolute prediction as to whether this makes the GPU more attractive because honestly, the results vary depending on the GPU in question. What we can tell you is that in many cases, it isn’t worth paying more for a card if the only difference is a larger RAM buffer. As a rule of thumb, lower-end GPUs tend to run into other bottlenecks before they’re choked by limited available memory. When in doubt, check reviews of the card and look for comparisons of whether a 2GB version is outperformed by the 4GB flavor or whatever the relevant amount of RAM would be. More often than not, assuming all else is equal between the two solutions, you’ll find the higher RAM loadout not worth paying for.
-
-Check out our [ExtremeTech Explains][2] series for more in-depth coverage of today’s hottest tech topics.
-
---------------------------------------------------------------------------------
-
-via: https://www.extremetech.com/gaming/269335-how-graphics-cards-work
-
-作者:[Joel Hruska][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.extremetech.com/author/jhruska
-[1]:https://www.extremetech.com/wp-content/uploads/2016/07/AMD-Polaris-640x353.jpg
-[2]:http://www.extremetech.com/tag/extremetech-explains
diff --git a/sources/tech/20180522 How to Run Your Own Git Server.md b/sources/tech/20180522 How to Run Your Own Git Server.md
deleted file mode 100644
index 9a1ee8509a..0000000000
--- a/sources/tech/20180522 How to Run Your Own Git Server.md
+++ /dev/null
@@ -1,233 +0,0 @@
-translating by wyxplus
-How to Run Your Own Git Server
-======
-**Learn how to set up your own Git server in this tutorial from our archives.**
-
-[Git ][1]is a versioning system [developed by Linus Torvalds][2], that is used by millions of users around the globe. Companies like GitHub offer code hosting services based on Git. [According to reports, GitHub, a code hosting site, is the world's largest code hosting service.][3] The company claims that there are 9.2M people collaborating right now across 21.8M repositories on GitHub. Big companies are now moving to GitHub. [Even Google, the search engine giant, is shutting it's own Google Code and moving to GitHub.][4]
-
-### Run your own Git server
-
-GitHub is a great service, however there are some limitations and restrictions, especially if you are an individual or a small player. One of the limitations of GitHub is that the free service doesn’t allow private hosting of the code. [You have to pay a monthly fee of $7 to host 5 private repositories][5], and the expenses go up with more repos.
-
-In cases like these or when you want more control, the best path is to run Git on your own server. Not only do you save costs, you also have more control over your server. In most cases a majority of advanced Linux users already have their own servers and pushing Git on those servers is like ‘free as in beer’.
-
-In this tutorial we are going to talk about two methods of managing your code on your own server. One is running a bare, basic Git server and and the second one is via a GUI tool called [GitLab][6]. For this tutorial I used a fully patched Ubuntu 14.04 LTS server running on a VPS.
-
-### Install Git on your server
-
-In this tutorial we are considering a use-case where we have a remote server and a local server and we will work between these machines. For the sake of simplicity we will call them remote-server and local-server.
-
-First, install Git on both machines. You can install Git from the packages already available via the repos or your distros, or you can do it manually. In this article we will use the simpler method:
-```
-sudo apt-get install git-core
-
-```
-
-Then add a user for Git.
-```
-sudo useradd git
-passwd git
-
-```
-
-In order to ease access to the server let's set-up a password-less ssh login. First create ssh keys on your local machine:
-```
-ssh-keygen -t rsa
-
-```
-
-It will ask you to provide the location for storing the key, just hit Enter to use the default location. The second question will be to provide it with a pass phrase which will be needed to access the remote server. It generates two keys - a public key and a private key. Note down the location of the public key which you will need in the next step.
-
-Now you have to copy these keys to the server so that the two machines can talk to each other. Run the following command on your local machine:
-```
-cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
-
-```
-
-Now ssh into the server and create a project directory for Git. You can use the desired path for the repo.
-
-Then change to this directory:
-```
-cd /home/swapnil/project-1.git
-
-```
-
-Then create an empty repo:
-```
-git init --bare
-Initialized empty Git repository in /home/swapnil/project-1.git
-
-```
-
-We now need to create a Git repo on the local machine.
-```
-mkdir -p /home/swapnil/git/project
-
-```
-
-And change to this directory:
-```
-cd /home/swapnil/git/project
-
-```
-
-Now create the files that you need for the project in this directory. Stay in this directory and initiate git:
-```
-git init
-Initialized empty Git repository in /home/swapnil/git/project
-
-```
-
-Now add files to the repo:
-```
-git add .
-
-```
-
-Now every time you add a file or make changes you have to run the add command above. You also need to write a commit message with every change in a file. The commit message basically tells what changes were made.
-```
-git commit -m "message" -a
-[master (root-commit) 57331ee] message
- 2 files changed, 2 insertions(+)
- create mode 100644 GoT.txt
- create mode 100644 writing.txt
-
-```
-
-In this case I had a file called GoT (Game of Thrones review) and I made some changes, so when I ran the command it specified that changes were made to the file. In the above command '-a' option means commits for all files in the repo. If you made changes to only one you can specify the name of that file instead of using '-a'.
-
-An example:
-```
-git commit -m "message" GoT.txt
-[master e517b10] message
- 1 file changed, 1 insertion(+)
-
-```
-
-Until now we have been working on the local server. Now we have to push these changes to the server so the work is accessible over the Internet and you can collaborate with other team members.
-```
-git remote add origin ssh://git@remote-server/repo->path-on-server..git
-
-```
-
-Now you can push or pull changes between the server and local machine using the 'push' or 'pull' option:
-```
-git push origin master
-
-```
-
-If there are other team members who want to work with the project they need to clone the repo on the server to their local machine:
-```
-git clone git@remote-server:/home/swapnil/project.git
-
-```
-
-Here /home/swapnil/project.git is the project path on the remote server, exchange the values for your own server.
-
-Then change directory on the local machine (exchange project with the name of project on your server):
-```
-cd /project
-
-```
-
-Now they can edit files, write commit change messages and then push them to the server:
-```
-git commit -m 'corrections in GoT.txt story' -a
-And then push changes:
-
-git push origin master
-
-```
-
-I assume this is enough for a new user to get started with Git on their own servers. If you are looking for some GUI tools to manage changes on local machines, you can use GUI tools such as QGit or GitK for Linux.
-
-### Using GitLab
-
-This was a pure command line solution for project owner and collaborator. It's certainly not as easy as using GitHub. Unfortunately, while GitHub is the world's largest code hosting service; its own software is not available for others to use. It's not open source so you can't grab the source code and compile your own GitHub. Unlike WordPress or Drupal you can't download GitHub and run it on your own servers.
-
-As usual in the open source world there is no end to the options. GitLab is a nifty project which does exactly that. It's an open source project which allows users to run a project management system similar to GitHub on their own servers.
-
-You can use GitLab to run a service similar to GitHub for your team members or your company. You can use GitLab to work on private projects before releasing them for public contributions.
-
-GitLab employs the traditional Open Source business model. They have two products: free of cost open source software, which users can install on their own servers, and a hosted service similar to GitHub.
-
-The downloadable version has two editions - the free of cost community edition and the paid enterprise edition. The enterprise edition is based on the community edition but comes with additional features targeted at enterprise customers. It’s more or less similar to what WordPress.org or Wordpress.com offer.
-
-The community edition is highly scalable and can support 25,000 users on a single server or cluster. Some of the features of GitLab include: Git repository management, code reviews, issue tracking, activity feeds, and wikis. It comes with GitLab CI for continuous integration and delivery.
-
-Many VPS providers such as Digital Ocean offer GitLab droplets for users. If you want to run it on your own server, you can install it manually. GitLab offers an Omnibus package for different operating systems. Before we install GitLab, you may want to configure an SMTP email server so that GitLab can push emails as and when needed. They recommend Postfix. So, install Postfix on your server:
-```
-sudo apt-get install postfix
-
-```
-
-During installation of Postfix it will ask you some questions; don't skip them. If you did miss it you can always re-configure it using this command:
-```
-sudo dpkg-reconfigure postfix
-
-```
-
-When you run this command choose "Internet Site" and provide the email ID for the domain which will be used by Gitlab.
-
-In my case I provided it with:
-```
-This e-mail address is being protected from spambots. You need JavaScript enabled to view it
-
-
-```
-
-Use Tab and create a username for postfix. The Next page will ask you to provide a destination for mail.
-
-In the rest of the steps, use the default options. Once Postfix is installed and configured, let's move on to install GitLab.
-
-Download the packages using wget (replace the download link with the [latest packages from here][7]) :
-```
-wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
-
-```
-
-Then install the package:
-```
-sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
-
-```
-
-Now it's time to configure and start GitLabs.
-```
-sudo gitlab-ctl reconfigure
-
-```
-
-You now need to configure the domain name in the configuration file so you can access GitLab. Open the file.
-```
-nano /etc/gitlab/gitlab.rb
-
-```
-
-In this file edit the 'external_url' and give the server domain. Save the file and then open the newly created GitLab site from a web browser.
-
-By default it creates 'root' as the system admin and uses '5iveL!fe' as the password. Log into the GitLab site and then change the password.
-
-Once the password is changed, log into the site and start managing your project.
-
-GitLab is overflowing with features and options. I will borrow popular lines from the movie, The Matrix: "Unfortunately, no one can be told what all GitLab can do. You have to try it for yourself."
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/how-run-your-own-git-server
-
-作者:[Swapnil Bhartiya][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/arnieswap
-[1]:https://github.com/git/git
-[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
-[3]:https://github.com/about/press
-[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
-[5]:https://github.com/pricing
-[6]:https://about.gitlab.com/
-[7]:https://about.gitlab.com/downloads/
diff --git a/sources/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md b/sources/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md
deleted file mode 100644
index e14f5ac850..0000000000
--- a/sources/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md
+++ /dev/null
@@ -1,287 +0,0 @@
-A Set Of Useful Utilities For Debian And Ubuntu Users
-======
-
-
-
-Are you using a Debian-based system? Great! I am here today with a good news for you. Say hello to **“Debian-goodies”** , a collection of useful utilities for Debian-based systems, like Ubuntu, Linux Mint. These set of utilities provides some additional useful commands which are not available by default in the Debian-based systems. Using these tools, the users can find which programs are consuming more disk space, which services need to be restarted after updating the system, search for a file matching a pattern in a package, list the installed packages based on the search string and a lot more. In this brief guide, we will be discussing some useful Debian goodies.
-
-### Debian-goodies – Useful Utilities For Debian And Ubuntu Users
-
-The debian-goodies package is available in the official repositories of Debian and its derivative Ubuntu and other Ubuntu variants such as Linux Mint. To install debian-goodies package, simply run:
-```
-$ sudo apt-get install debian-goodies
-
-```
-
-Debian-goodies has just been installed. Let us go ahead and see some useful utilities.
-
-#### **1. Checkrestart**
-
-Let me start from one of my favorite, the **“checkrestart”** utility. When installing security updates, some running applications might still use the old libraries. In order to apply the security updates completely, you need to find and restart all of them. This is where Checkrestart comes in handy. This utility will find which processes are still using the old versions of libs. You can then restart the services.
-
-To check which daemons need to be restarted after library upgrades, run:
-```
-$ sudo checkrestart
-[sudo] password for sk:
-Found 0 processes using old versions of upgraded files
-
-```
-
-Since I didn’t perform any security updates lately, it shows nothing.
-
-Please note that Checkrestart utility does work well. However, there is a new similar tool named “needrestart” available latest Debian systems. The needrestart is inspired by the checkrestart utility and it does exactly the same job. Needrestart is actively maintained and supports newer technologies such as containers (LXC, Docker).
-
-Here are the features of Needrestart:
-
- * supports (but does not require) systemd
- * binary blacklisting (i.e. display managers)
- * tries to detect pending kernel upgrades
- * tries to detect required restarts of interpreter based daemons (supports Perl, Python, Ruby)
- * fully integrated into apt/dpkg using hooks
-
-
-
-It is available in the default repositories too. so, you can install it using command:
-```
-$ sudo apt-get install needrestart
-
-```
-
-Now you can check the list of daemons need to be restarted after updating your system using command:
-```
-$ sudo needrestart
-Scanning processes...
-Scanning linux images...
-
-Running kernel seems to be up-to-date.
-
-Failed to check for processor microcode upgrades.
-
-No services need to be restarted.
-
-No containers need to be restarted.
-
-No user sessions are running outdated binaries.
-
-```
-
-The good thing is Needrestart works on other Linux distributions too. For example, you can install on Arch Linux and its variants from AUR using any AUR helper programs like below.
-```
-$ yaourt -S needrestart
-
-```
-
-On fedora:
-```
-$ sudo dnf install needrestart
-
-```
-
-#### 2. Check-enhancements
-
-The check-enhancements utility is used to find packages which enhance the installed packages. This utility will list all packages that enhances other packages but are not strictly necessary to run it. You can find enhancements for a single package or all installed installed packages using “-ip” or “–installed-packages” flag.
-
-For example, I am going to list the enhancements for gimp package.
-```
-$ check-enhancements gimp
-gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
-gimp => gimp-gmic: Installed: (none) Candidate: 1.7.9+zart-4build3
-gimp => gimp-gutenprint: Installed: (none) Candidate: 5.2.13-2
-gimp => gimp-help-ca: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-de: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-el: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-en: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-es: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-fr: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-it: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-ja: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-ko: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-nl: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-nn: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-pt: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-ru: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
-gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
-gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
-
-```
-
-To list the enhancements for all installed packages, run:
-```
-$ check-enhancements -ip
-autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
-btrfs-progs => snapper: Installed: (none) Candidate: 0.5.4-3
-ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
-cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
-dpkg => debsig-verify: Installed: (none) Candidate: 0.18
-[...]
-
-```
-
-#### 3. dgrep
-
-As the name implies, dgrep is used to search all files in specified packages based on the given regex. For instance, I am going to search for files that contains the regex “text” in Vim package.
-```
-$ sudo dgrep "text" vim
-Binary file /usr/bin/vim.tiny matches
-/usr/share/doc/vim-tiny/copyright: that they must include this license text. You can also distribute
-/usr/share/doc/vim-tiny/copyright: include this license text. You are also allowed to include executables
-/usr/share/doc/vim-tiny/copyright: 1) This license text must be included unmodified.
-/usr/share/doc/vim-tiny/copyright: text under a) applies to those changes.
-/usr/share/doc/vim-tiny/copyright: context diff. You can choose what license to use for new code you
-/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
-/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
-[...]
-
-```
-
-The dgrep supports most of grep’s options. Refer the following guide to learn grep commands.
-
-#### 4 dglob
-
-The dglob utility generates a list of package names which match a pattern. For example, find the list of packages that matches the string “vim”.
-```
-$ sudo dglob vim
-vim-tiny:amd64
-vim:amd64
-vim-common:all
-vim-runtime:all
-
-```
-
-By default, dglob will display only the installed packages. If you want to list all packages (installed and not installed), use **-a** flag.
-```
-$ sudo dglob vim -a
-
-```
-
-#### 5. debget
-
-The **debget** utility will download a .deb for a package in APT’s database. Please note that it will only download the given package, not the dependencies.
-```
-$ debget nano
-Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
-Fetched 231 kB in 2s (113 kB/s)
-
-```
-
-#### 6. dpigs
-
-This is another useful utility in this collection. The **dpigs** utility will find and show you which installed packages occupy the most disk space.
-```
-$ dpigs
-260644 linux-firmware
-167195 linux-modules-extra-4.15.0-20-generic
-75186 linux-headers-4.15.0-20
-64217 linux-modules-4.15.0-20-generic
-55620 snapd
-31376 git
-31070 libicu60
-28420 vim-runtime
-25971 gcc-7
-24349 g++-7
-
-```
-
-As you can see, the linux-firmware packages occupies the most disk space. By default, it will display the **top 10** packages that occupies the most disk space. If you want to display more packages, for example 20, run the following command:
-```
-$ dpigs -n 20
-
-```
-
-#### 7. debman
-
-The **debman** utility allows you to easily view man pages from a binary **.deb** without extracting it. You don’t even need to install the .deb package. The following command displays the man page of nano package.
-```
-$ debman -f nano_2.9.3-2_amd64.deb nano
-
-```
-
-If you don’t have a local copy of the .deb package, use **-p** flag to download and view package’s man page.
-```
-$ debman -p nano nano
-
-```
-
-**Suggested read:**
-
-#### 8. debmany
-
-An installed Debian package has not only a man page, but also includes other files such as acknowledgement, copy right, and read me etc. The **debmany** utility allows you to view and read those files.
-```
-$ debmany vim
-
-```
-
-![][1]
-
-Choose the file you want to view using arrow keys and hit ENTER to view the selected file. Press **q** to go back to the main menu.
-
-If the specified package is not installed, debmany will download it from the APT database and display the man pages. The **dialog** package should be installed to read the man pages.
-
-#### 9. popbugs
-
-If you’re a developer, the **popbugs** utility will be quite useful. It will display a customized release-critical bug list based on packages you use (using popularity-contest data). For those who don’t know, the popularity-contest package sets up a cron job that will periodically anonymously submit to the Debian developers statistics about the most used Debian packages on this system. This information helps Debian make decisions such as which packages should go on the first CD. It also lets Debian improve future versions of the distribution so that the most popular packages are the ones which are installed automatically for new users.
-
-To generate a list of critical bugs and display the result in your default web browser, run:
-```
-$ popbugs
-
-```
-
-Also, you can save the result in a file as shown below.
-```
-$ popbugs --output=bugs.txt
-
-```
-
-#### 10. which-pkg-broke
-
-This command will display all the dependencies of the given package and when each dependency was installed. By using this information, you can easily find which package might have broken another at what time after upgrading the system or a package.
-```
-$ which-pkg-broke vim
-Package has no install time info
-debconf Wed Apr 25 08:08:40 2018
-gcc-8-base:amd64 Wed Apr 25 08:08:41 2018
-libacl1:amd64 Wed Apr 25 08:08:41 2018
-libattr1:amd64 Wed Apr 25 08:08:41 2018
-dpkg Wed Apr 25 08:08:41 2018
-libbz2-1.0:amd64 Wed Apr 25 08:08:41 2018
-libc6:amd64 Wed Apr 25 08:08:42 2018
-libgcc1:amd64 Wed Apr 25 08:08:42 2018
-liblzma5:amd64 Wed Apr 25 08:08:42 2018
-libdb5.3:amd64 Wed Apr 25 08:08:42 2018
-[...]
-
-```
-
-#### 11. dhomepage
-
-The dhomepage utility will display the official website of the given package in your default web browser. For example, the following command will open Vim editor’s home page.
-```
-$ dhomepage vim
-
-```
-
-And, that’s all for now. Debian-goodies is a must-have tool in your arsenal. Even though, we don’t use all those utilities often, they are worth to learn and I am sure they will be really helpful at times.
-
-I hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:http://www.ostechnix.com/wp-content/uploads/2018/05/debmany.png
diff --git a/sources/tech/20180524 How CERN Is Using Linux and Open Source.md b/sources/tech/20180524 How CERN Is Using Linux and Open Source.md
deleted file mode 100644
index 958a255997..0000000000
--- a/sources/tech/20180524 How CERN Is Using Linux and Open Source.md
+++ /dev/null
@@ -1,67 +0,0 @@
-How CERN Is Using Linux and Open Source
-============================================================
-
-
->CERN relies on open source technology to handle huge amounts of data generated by the Large Hadron Collider. The ATLAS (shown here) is a general-purpose detector that probes for fundamental particles. (Image courtesy: CERN)[Used with permission][2]
-
-[CERN][3]
-
-[CERN][6] really needs no introduction. Among other things, the European Organization for Nuclear Research created the World Wide Web and the Large Hadron Collider (LHC), the world’s largest particle accelerator, which was used in discovery of the [Higgs boson][7]. Tim Bell, who is responsible for the organization’s IT Operating Systems and Infrastructure group, says the goal of his team is “to provide the compute facility for 13,000 physicists around the world to analyze those collisions, understand what the universe is made of and how it works.”
-
-CERN is conducting hardcore science, especially with the LHC, which [generates massive amounts of data][8] when it’s operational. “CERN currently stores about 200 petabytes of data, with over 10 petabytes of data coming in each month when the accelerator is running. This certainly produces extreme challenges for the computing infrastructure, regarding storing this large amount of data, as well as the having the capability to process it in a reasonable timeframe. It puts pressure on the networking and storage technologies and the ability to deliver an efficient compute framework,” Bell said.
-
-### [tim-bell-cern.png][4]
-
-
-Tim Bell, CERN[Used with permission][1]Swapnil Bhartiya
-
-The scale at which LHC operates and the amount of data it generates pose some serious challenges. But CERN is not new to such problems. Founded in 1954, CERN has been around for about 60 years. “We've always been facing computing challenges that are difficult problems to solve, but we have been working with open source communities to solve them,” Bell said. “Even in the 90s, when we invented the World Wide Web, we were looking to share this with the rest of humanity in order to be able to benefit from the research done at CERN and open source was the right vehicle to do that.”
-
-### Using OpenStack and CentOS
-
-Today, CERN is a heavy user of OpenStack, and Bell is one of the Board Members of the OpenStack Foundation. But CERN predates OpenStack. For several years, they have been using various open source technologies to deliver services through Linux servers.
-
-“Over the past 10 years, we've found that rather than taking our problems ourselves, we find upstream open source communities with which we can work, who are facing similar challenges and then we contribute to those projects rather than inventing everything ourselves and then having to maintain it as well,” said Bell.
-
-A good example is Linux itself. CERN used to be a Red Hat Enterprise Linux customer. But, back in 2004, they worked with Fermilab to build their own Linux distribution called [Scientific Linux][9]. Eventually they realized that, because they were not modifying the kernel, there was no point in spending time spinning up their own distribution; so they migrated to CentOS. Because CentOS is a fully open source and community driven project, CERN could collaborate with the project and contribute to how CentOS is built and distributed.
-
-CERN helps CentOS with infrastructure and they also organize CentOS DoJo at CERN where engineers can get together to improve the CentOS packaging.
-
-In addition to OpenStack and CentOS, CERN is a heavy user of other open source projects, including Puppet for configuration management, Grafana and influxDB for monitoring, and is involved in many more.
-
-“We collaborate with around 170 labs around the world. So every time that we find an improvement in an open source project, other labs can easily take that and use it,” said Bell, “At the same time, we also learn from others. When large scale installations like eBay and Rackspace make changes to improve scalability of solutions, it benefits us and allows us to scale.”
-
-### Solving realistic problems
-
-Around 2012, CERN was looking at ways to scale computing for the LHC, but the challenge was people rather than technology. The number of staff that CERN employs is fixed. “We had to find ways in which we can scale the compute without requiring a large number of additional people in order to administer that,” Bell said. “OpenStack provided us with an automated API-driven, software-defined infrastructure.” OpenStack also allowed CERN to look at problems related to the delivery of services and then automate those, without having to scale the staff.
-
-“We're currently running about 280,000 cores and 7,000 servers across two data centers in Geneva and in Budapest. We are using software-defined infrastructure to automate everything, which allows us to continue to add additional servers while remaining within the same envelope of staff,” said Bell.
-
-As time progresses, CERN will be dealing with even bigger challenges. Large Hadron Collider has a roadmap out to 2035, including a number of significant upgrades. “We run the accelerator for three to four years and then have a period of 18 months or two years when we upgrade the infrastructure. This maintenance period allows us to also do some computing planning,” said Bell. CERN is also planning High Luminosity Large Hadron Collider upgrade, which will allow for beams with higher luminosity. The upgrade would mean about 60 times more compute requirement compared to what CERN has today.
-
-“With Moore's Law, we will maybe get one quarter of the way there, so we have to find ways under which we can be scaling the compute and the storage infrastructure correspondingly and finding automation and solutions such as OpenStack will help that,” said Bell.
-
-“When we started off the large Hadron collider and looked at how we would deliver the computing, it was clear that we couldn't put everything into the data center at CERN, so we devised a distributed grid structure, with tier zero at CERN and then a cascading structure around that,” said Bell. “There are around 12 large tier one centers and then 150 small universities and labs around the world. They receive samples at the data from the LHC in order to assist the physicists to understand and analyze the data.”
-
-That structure means CERN is collaborating internationally, with hundreds of countries contributing toward the analysis of that data. It boils down to the fundamental principle that open source is not just about sharing code, it’s about collaboration among people to share knowledge and achieve what no single individual, organization, or company can achieve alone. That’s the Higgs boson of the open source world.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source
-
-作者:[SWAPNIL BHARTIYA ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/arnieswap
-[1]:https://www.linux.com/licenses/category/used-permission
-[2]:https://www.linux.com/licenses/category/used-permission
-[3]:https://home.cern/about/experiments/atlas
-[4]:https://www.linux.com/files/images/tim-bell-cernpng
-[5]:https://www.linux.com/files/images/atlas-cernjpg
-[6]:https://home.cern/
-[7]:https://home.cern/topics/higgs-boson
-[8]:https://home.cern/about/computing
-[9]:https://www.scientificlinux.org/
diff --git a/sources/tech/20180604 BootISO - A Simple Bash Script To Securely Create A Bootable USB Device From ISO File.md b/sources/tech/20180604 BootISO - A Simple Bash Script To Securely Create A Bootable USB Device From ISO File.md
new file mode 100644
index 0000000000..f716a164a5
--- /dev/null
+++ b/sources/tech/20180604 BootISO - A Simple Bash Script To Securely Create A Bootable USB Device From ISO File.md
@@ -0,0 +1,172 @@
+BootISO – A Simple Bash Script To Securely Create A Bootable USB Device From ISO File
+======
+Most of us (including me) very often create a bootable USB device from ISO file for OS installation.
+
+There are many applications freely available in Linux for this purpose. Even we wrote few of the utility in the past.
+
+Every one uses different application and each application has their own features and functionality.
+
+In that few of applications are belongs to CLI and few of them associated with GUI.
+
+Today we are going to discuss about similar kind of utility called BootISO. It’s a simple bash script, which allow users to create a USB device from ISO file.
+
+Many of the Linux admin uses dd command to create bootable ISO, which is one of the native and famous method but the same time, it’s one of the very dangerous command. So, be careful, when you performing any action with dd command.
+
+**Suggested Read :**
+**(#)** [Etcher – Easy way to Create a bootable USB drive & SD card from an ISO image][1]
+**(#)** [Create a bootable USB drive from an ISO image using dd command on Linux][2]
+
+### What IS BootISO
+
+[BootIOS][3] is a simple bash script, which allow users to securely create a bootable USB device from one ISO file. It’s written in bash.
+
+It doesn’t offer any GUI but in the same time it has vast of options, which allow newbies to create a bootable USB device in Linux without any issues. Since it’s a intelligent tool that automatically choose if any USB device is connected on the system.
+
+It will print the list when the system has more than one USB device connected. When you choose manually another hard disk manually instead of USB, this will safely exit without writing anything on it.
+
+This script will also check for dependencies and prompt user for installation, it works with all package managers such as apt-get, yum, dnf, pacman and zypper.
+
+### BootISO Features
+
+ * It checks whether the selected ISO has the correct mime-type or not. If no then it exit.
+ * BootISO will exit automatically, if you selected any other disks (local hard drive) except USB drives.
+ * BootISO allow users to select the desired USB drives when you have more than one.
+ * BootISO prompts the user for confirmation before erasing and paritioning USB device.
+ * BootISO will handle any failure from a command properly and exit.
+ * BootISO will call a cleanup routine on exit with trap.
+
+
+
+### How To Install BootISO In Linux
+
+There are few ways are available to install BootISO in Linux but i would advise users to install using the following method.
+```
+$ curl -L https://git.io/bootiso -O
+$ chmod +x bootiso
+$ sudo mv bootiso /usr/local/bin/
+
+```
+
+Once BootISO installed, run the following command to list the available USB devices.
+```
+$ bootiso -l
+
+Listing USB drives available in your system:
+NAME HOTPLUG SIZE STATE TYPE
+sdd 1 32G running disk
+
+```
+
+If you have only one USB device, then simple run the following command to create a bootable USB device from ISO file.
+```
+$ bootiso /path/to/iso file
+
+$ bootiso /opt/iso_images/archlinux-2018.05.01-x86_64.iso
+Granting root privileges for bootiso.
+Listing USB drives available in your system:
+NAME HOTPLUG SIZE STATE TYPE
+sdd 1 32G running disk
+Autoselecting `sdd' (only USB device candidate)
+The selected device `/dev/sdd' is connected through USB.
+Created ISO mount point at `/tmp/iso.vXo'
+`bootiso' is about to wipe out the content of device `/dev/sdd'.
+Are you sure you want to proceed? (y/n)>y
+Erasing contents of /dev/sdd...
+Creating FAT32 partition on `/dev/sdd1'...
+Created USB device mount point at `/tmp/usb.0j5'
+Copying files from ISO to USB device with `rsync'
+Synchronizing writes on device `/dev/sdd'
+`bootiso' took 250 seconds to write ISO to USB device with `rsync' method.
+ISO succesfully unmounted.
+USB device succesfully unmounted.
+USB device succesfully ejected.
+You can safely remove it !
+
+```
+
+Mention your device name, when you have more than one USB device using `--device` option.
+```
+$ bootiso -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
+
+```
+
+By default bootios uses `rsync` command to perform all the action and if you want to use `dd` command instead of, use the following format.
+```
+$ bootiso --dd -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
+
+```
+
+If you want to skip `mime-type` check, include the following option with bootios utility.
+```
+$ bootiso --no-mime-check -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
+
+```
+
+Add the below option with bootios to skip user for confirmation before erasing and partitioning USB device.
+```
+$ bootiso -y -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
+
+```
+
+Enable autoselecting USB devices in conjunction with -y option.
+```
+$ bootiso -y -a /opt/iso_images/archlinux-2018.05.01-x86_64.iso
+
+```
+
+To know more all the available option for bootiso, run the following command.
+```
+$ bootiso -h
+Create a bootable USB from any ISO securely.
+Usage: bootiso [...]
+
+Options
+
+-h, --help, help Display this help message and exit.
+-v, --version Display version and exit.
+-d, --device Select block file as USB device.
+ If is not connected through USB, `bootiso' will fail and exit.
+ Device block files are usually situated in /dev/sXX or /dev/hXX.
+ You will be prompted to select a device if you don't use this option.
+-b, --bootloader Install a bootloader with syslinux (safe mode) for non-hybrid ISOs. Does not work with `--dd' option.
+-y, --assume-yes `bootiso' won't prompt the user for confirmation before erasing and partitioning USB device.
+ Use at your own risks.
+-a, --autoselect Enable autoselecting USB devices in conjunction with -y option.
+ Autoselect will automatically select a USB drive device if there is exactly one connected to the system.
+ Enabled by default when neither -d nor --no-usb-check options are given.
+-J, --no-eject Do not eject device after unmounting.
+-l, --list-usb-drives List available USB drives.
+-M, --no-mime-check `bootiso' won't assert that selected ISO file has the right mime-type.
+-s, --strict-mime-check Disallow loose application/octet-stream mime type in ISO file.
+-- POSIX end of options.
+--dd Use `dd' utility instead of mounting + `rsync'.
+ Does not allow bootloader installation with syslinux.
+--no-usb-check `bootiso' won't assert that selected device is a USB (connected through USB bus).
+ Use at your own risks.
+
+Readme
+
+ Bootiso v2.5.2.
+ Author: Jules Samuel Randolph
+ Bugs and new features: https://github.com/jsamr/bootiso/issues
+ If you like bootiso, please help the community by making it visible:
+ * star the project at https://github.com/jsamr/bootiso
+ * upvote those SE post: https://goo.gl/BNRmvm https://goo.gl/YDBvFe
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/prakash/
+[1]:https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
+[2]:https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
+[3]:https://github.com/jsamr/bootiso
diff --git a/sources/tech/20180607 GitLab-s Ultimate - Gold Plans Are Now Free For Open-Source Projects.md b/sources/tech/20180607 GitLab-s Ultimate - Gold Plans Are Now Free For Open-Source Projects.md
deleted file mode 100644
index 1a7e3ca5e6..0000000000
--- a/sources/tech/20180607 GitLab-s Ultimate - Gold Plans Are Now Free For Open-Source Projects.md
+++ /dev/null
@@ -1,77 +0,0 @@
-GitLab’s Ultimate & Gold Plans Are Now Free For Open-Source Projects
-======
-A lot has happened in the open-source community recently. First, [Microsoft acquired GitHub][1] and then people started to look for [GitHub alternatives][2] without even taking a second to think about it while Linus Torvalds released the [Linux Kernel 4.17][3]. Well, if you’ve been following us, I assume that you know all that.
-
-But, today, GitLab made a smart move by making some of its high-tier plans free for educational institutes and open-source projects. There couldn’t be a better time to offer something like this when a lot of developers are interested in migrating their open-source projects to GitLab.
-
-### GitLab’s premium plans are now free for open source projects and educational institutes
-
-![GitLab Logo][4]
-
-In a [blog post][5] today, GitLab announced that the **Ultimate** and Gold plans are now free for educational institutes and open-source projects. While we already know why GitLab made this move (a darn perfect timing!), they did explain their motive to make it free:
-
-> We make GitLab free for education because we want students to use our most advanced features. Many universities already run GitLab. If the students use the advanced features of GitLab Ultimate and Gold they will take their experiences with these advanced features to their workplaces.
->
-> We would love to have more open source projects use GitLab. Public projects on GitLab.com already have all the features of GitLab Ultimate. And projects like [Gnome][6] and [Debian][7] already run their own server with the open source version of GitLab. With today’s announcement, open source projects that are comfortable running on proprietary software can use all the features GitLab has to offer while allowing us to have a sustainable business model by charging non-open-source organizations.
-
-### What are these ‘free’ plans offered by GitLab?
-
-![GitLab Pricing][8]
-
-GitLab has two categories of offerings. One is the software that you could host on your own cloud hosting service like [Digital Ocean][9]. The other is providing GitLab software as a service where the hosting is managed by GitLab itself and you get an account on GitLab.com.
-
-![GitLab Pricing for hosted service][10]
-
-Gold is the highest offering in the hosted category while Ultimate is the highest offering in the self-hosted category.
-
-You can get more details about their features on GitLab pricing page. Do note that the support is not included in this offer. You have to purchase it separately.
-
-### You have to match certain criteria to avail this offer
-
-GitLab also mentioned – to whom the offer will be valid for. Here’s what they wrote in their blog post:
-
-> 1. **Educational institutions:** any institution whose purposes directly relate to learning, teaching, and/or training by a qualified educational institution, faculty, or student. Educational purposes do not include commercial, professional, or any other for-profit purposes.
->
-> 2. **Open source projects:** any project that uses a [standard open source license][11] and is non-commercial. It should not have paid support or paid contributors.
->
->
-
-
-Although the free plan does not include support, you can still pay an additional fee of 4.95 USD per user per month – which is a very fair price, when you are in the dire need of an expert to help resolve an issue.
-
-GitLab also added a note for the students:
-
-> To reduce the administrative burden for GitLab, only educational institutions can apply on behalf of their students. If you’re a student and your educational institution does not apply, you can use public projects on GitLab.com with all functionality, use private projects with the free functionality, or pay yourself.
-
-### Wrapping Up
-
-Now that GitLab is stepping up its game, what do you think about it?
-
-Do you have a project hosted on [GitHub][12]? Will you be switching over? Or, luckily, you already happen to use GitLab from the start?
-
-Let us know your thoughts in the comments section below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/gitlab-free-open-source/
-
-作者:[Ankush Das][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/ankush/
-[1]:https://itsfoss.com/microsoft-github/
-[2]:https://itsfoss.com/github-alternatives/
-[3]:https://itsfoss.com/linux-kernel-4-17/
-[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/GitLab-logo-800x450.png
-[5]:https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/
-[6]:https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/
-[7]:https://salsa.debian.org/public
-[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-pricing.jpeg
-[9]:https://m.do.co/c/d58840562553
-[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-hosted-service-800x273.jpeg
-[11]:https://itsfoss.com/open-source-licenses-explained/
-[12]:https://github.com/
diff --git a/sources/tech/20180607 Using MQTT to send and receive data for your next project.md b/sources/tech/20180607 Using MQTT to send and receive data for your next project.md
deleted file mode 100644
index 7005aee93f..0000000000
--- a/sources/tech/20180607 Using MQTT to send and receive data for your next project.md
+++ /dev/null
@@ -1,311 +0,0 @@
-pinewall translating
-
-Using MQTT to send and receive data for your next project
-======
-
-
-
-Last November we bought an electric car, and it raised an interesting question: When should we charge it? I was concerned about having the lowest emissions for the electricity used to charge the car, so this is a specific question: What is the rate of CO2 emissions per kWh at any given time, and when during the day is it at its lowest?
-
-### Finding the data
-
-I live in New York State. About 80% of our electricity comes from in-state generation, mostly through natural gas, hydro dams (much of it from Niagara Falls), nuclear, and a bit of wind, solar, and other fossil fuels. The entire system is managed by the [New York Independent System Operator][1] (NYISO), a not-for-profit entity that was set up to balance the needs of power generators, consumers, and regulatory bodies to keep the lights on in New York.
-
-Although there is no official public API, as part of its mission, NYISO makes [a lot of open data][2] available for public consumption. This includes reporting on what fuels are being consumed to generate power, at five-minute intervals, throughout the state. These are published as CSV files on a public archive and updated throughout the day. If you know the number of megawatts coming from different kinds of fuels, you can make a reasonable approximation of how much CO2 is being emitted at any given time.
-
-We should always be kind when building tools to collect and process open data to avoid overloading those systems. Instead of sending everyone to their archive service to download the files all the time, we can do better. We can create a low-overhead event stream that people can subscribe to and get updates as they happen. We can do that with [MQTT][3]. The target for my project ([ny-power.org][4]) was inclusion in the [Home Assistant][5] project, an open source home automation platform that has hundreds of thousands of users. If all of these users were hitting this CSV server all the time, NYISO might need to restrict access to it.
-
-### What is MQTT?
-
-MQTT is a publish/subscribe (pubsub) wire protocol designed with small devices in mind. Pubsub systems work like a message bus. You send a message to a topic, and any software with a subscription for that topic gets a copy of your message. As a sender, you never really know who is listening; you just provide your information to a set of topics and listen for any other topics you might care about. It's like walking into a party and listening for interesting conversations to join.
-
-This can make for extremely efficient applications. Clients subscribe to a narrow selection of topics and only receive the information they are looking for. This saves both processing time and network bandwidth.
-
-As an open standard, MQTT has many open source implementations of both clients and servers. There are client libraries for every language you could imagine, even a library you can embed in Arduino for making sensor networks. There are many servers to choose from. My go-to is the [Mosquitto][6] server from Eclipse, as it's small, written in C, and can handle tens of thousands of subscribers without breaking a sweat.
-
-### Why I like MQTT
-
-Over the past two decades, we've come up with tried and true models for software applications to ask questions of services. Do I have more email? What is the current weather? Should I buy this thing now? This pattern of "ask/receive" works well much of the time; however, in a world awash with data, there are other patterns we need. The MQTT pubsub model is powerful where lots of data is published inbound to the system. Clients can subscribe to narrow slices of data and receive updates instantly when that data comes in.
-
-MQTT also has additional interesting features, such as "last-will-and-testament" messages, which make it possible to distinguish between silence because there is no relevant data and silence because your data collectors have crashed. MQTT also has retained messages, which provide the last message on a topic to clients when they first connect. This is extremely useful for topics that update slowly.
-
-In my work with the Home Assistant project, I've found this message bus model works extremely well for heterogeneous systems. If you dive into the Internet of Things space, you'll quickly run into MQTT everywhere.
-
-### Our first MQTT stream
-
-One of NYSO's CSV files is the real-time fuel mix. Every five minutes, it's updated with the fuel sources and power generated (in megawatts) during that time period.
-
-The CSV file looks something like this:
-
-| Time Stamp | Time Zone | Fuel Category | Gen MW |
-| 05/09/2018 00:05:00 | EDT | Dual Fuel | 1400 |
-| 05/09/2018 00:05:00 | EDT | Natural Gas | 2144 |
-| 05/09/2018 00:05:00 | EDT | Nuclear | 4114 |
-| 05/09/2018 00:05:00 | EDT | Other Fossil Fuels | 4 |
-| 05/09/2018 00:05:00 | EDT | Other Renewables | 226 |
-| 05/09/2018 00:05:00 | EDT | Wind | 1 |
-| 05/09/2018 00:05:00 | EDT | Hydro | 3229 |
-| 05/09/2018 00:10:00 | EDT | Dual Fuel | 1307 |
-| 05/09/2018 00:10:00 | EDT | Natural Gas | 2092 |
-| 05/09/2018 00:10:00 | EDT | Nuclear | 4115 |
-| 05/09/2018 00:10:00 | EDT | Other Fossil Fuels | 4 |
-| 05/09/2018 00:10:00 | EDT | Other Renewables | 224 |
-| 05/09/2018 00:10:00 | EDT | Wind | 40 |
-| 05/09/2018 00:10:00 | EDT | Hydro | 3166 |
-
-The only odd thing in the table is the dual-fuel category. Most natural gas plants in New York can also burn other fossil fuel to generate power. During cold snaps in the winter, the natural gas supply gets constrained, and its use for home heating is prioritized over power generation. This happens at a low enough frequency that we can consider dual fuel to be natural gas (for our calculations).
-
-The file is updated throughout the day. I created a simple data pump that polls for the file every minute and looks for updates. It publishes any new entries out to the MQTT server into a set of topics that largely mirror this CSV file. The payload is turned into a JSON object that is easy to parse from nearly any programming language.
-```
-ny-power/upstream/fuel-mix/Hydro {"units": "MW", "value": 3229, "ts": "05/09/2018 00:05:00"}
-
-ny-power/upstream/fuel-mix/Dual Fuel {"units": "MW", "value": 1400, "ts": "05/09/2018 00:05:00"}
-
-ny-power/upstream/fuel-mix/Natural Gas {"units": "MW", "value": 2144, "ts": "05/09/2018 00:05:00"}
-
-ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts": "05/09/2018 00:05:00"}
-
-ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
-
-ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
-
-ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
-
-```
-
-This direct reflection is a good first step in turning open data into open events. We'll be converting this into a CO2 intensity, but other applications might want these raw feeds to do other calculations with them.
-
-### MQTT topics
-
-Topics and topic structures are one of MQTT's major design points. Unlike more "enterprisey" message buses, in MQTT topics are not preregistered. A sender can create topics on the fly, the only limit being that they are less than 220 characters. The `/` character is special; it's used to create topic hierarchies. As we'll soon see, you can subscribe to slices of data in these hierarchies.
-
-Out of the box with Mosquitto, every client can publish to any topic. While it's great for prototyping, before going to production you'll want to add an access control list (ACL) to restrict writing to authorized applications. For example, my app's tree is accessible to everyone in read-only format, but only clients with specific credentials can publish to it.
-
-There is no automatic schema around topics nor a way to discover all the possible topics that clients will publish to. You'll have to encode that understanding directly into any application that consumes the MQTT bus.
-
-So how should you design your topics? The best practice is to start with an application-specific root name, in our case, `ny-power`. After that, build a hierarchy as deep as you need for efficient subscription. The `upstream` tree will contain data that comes directly from an upstream source without any processing. Our `fuel-mix` category is a specific type of data. We may add others later.
-
-### Subscribing to topics
-
-Subscriptions in MQTT are simple string matches. For processing efficiency, only two wildcards are allowed:
-
- * `#` matches everything recursively to the end
- * `+` matches only until the next `/` character
-
-
-
-It's easiest to explain this with some examples:
-```
-ny-power/# - match everything published by the ny-power app
-
-ny-power/upstream/# - match all raw data
-
-ny-power/upstream/fuel-mix/+ - match all fuel types
-
-ny-power/+/+/Hydro - match everything about Hydro power that's
-
- nested 2 deep (even if it's not in the upstream tree)
-
-```
-
-A wide subscription like `ny-power/#` is common for low-volume applications. Just get everything over the network and handle it in your own application. This works poorly for high-volume applications, as most of the network bandwidth will be wasted as you drop most of the messages on the floor.
-
-To stay performant at higher volumes, applications will do some clever topic slides like `ny-power/+/+/Hydro` to get exactly the cross-section of data they need.
-
-### Adding our next layer of data
-
-From this point forward, everything in the application will work off existing MQTT streams. The first additional layer of data is computing the power's CO2 intensity.
-
-Using the 2016 [U.S. Energy Information Administration][7] numbers for total emissions and total power by fuel type in New York, we can come up with an [average emissions rate][8] per megawatt hour of power.
-
-This is encapsulated in a dedicated microservice. This has a subscription on `ny-power/upstream/fuel-mix/+`, which matches all upstream fuel-mix entries from the data pump. It then performs the calculation and publishes out to a new topic tree:
-```
-ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}
-
-```
-
-In turn, there is another process that subscribes to this topic tree and archives that data into an [InfluxDB][9] instance. It then publishes a 24-hour time series to `ny-power/archive/co2/24h`, which makes it easy to graph the recent changes.
-
-This layer model works well, as the logic for each of these programs can be distinct from each other. In a more complicated system, they may not even be in the same programming language. We don't care, because the interchange format is MQTT messages, with well-known topics and JSON payloads.
-
-### Consuming from the command line
-
-To get a feel for MQTT in action, it's useful to just attach it to a bus and see the messages flow. The `mosquitto_sub` program included in the `mosquitto-clients` package is a simple way to do that.
-
-After you've installed it, you need to provide a server hostname and the topic you'd like to listen to. The `-v` flag is important if you want to see the topics being posted to. Without that, you'll see only the payloads.
-```
-mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
-
-```
-
-Whenever I'm writing or debugging an MQTT application, I always have a terminal with `mosquitto_sub` running.
-
-### Accessing MQTT directly from the web
-
-We now have an application providing an open event stream. We can connect to it with our microservices and, with some command-line tooling, it's on the internet for all to see. But the web is still king, so it's important to get it directly into a user's browser.
-
-The MQTT folks thought about this one. The protocol specification is designed to work over three transport protocols: [TCP][10], [UDP][11], and [WebSockets][12]. WebSockets are supported by all major browsers as a way to retain persistent connections for real-time applications.
-
-The Eclipse project has a JavaScript implementation of MQTT called [Paho][13], which can be included in your application. The pattern is to connect to the host, set up some subscriptions, and then react to messages as they are received.
-```
-// ny-power web console application
-
-var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random());
-
-
-
-// set callback handlers
-
-client.onMessageArrived = onMessageArrived;
-
-
-
-// connect the client
-
-client.reconnect = true;
-
-client.connect({onSuccess: onConnect});
-
-
-
-// called when the client connects
-
-function onConnect() {
-
- // Once a connection has been made, make a subscription and send a message.
-
- console.log("onConnect");
-
- client.subscribe("ny-power/computed/co2");
-
- client.subscribe("ny-power/archive/co2/24h");
-
- client.subscribe("ny-power/upstream/fuel-mix/#");
-
-}
-
-
-
-// called when a message arrives
-
-function onMessageArrived(message) {
-
- console.log("onMessageArrived:"+message.destinationName + message.payloadString);
-
- if (message.destinationName == "ny-power/computed/co2") {
-
- var data = JSON.parse(message.payloadString);
-
- $("#co2-per-kwh").html(Math.round(data.value));
-
- $("#co2-units").html(data.units);
-
- $("#co2-updated").html(data.ts);
-
- }
-
- if (message.destinationName.startsWith("ny-power/upstream/fuel-mix")) {
-
- fuel_mix_graph(message);
-
- }
-
- if (message.destinationName == "ny-power/archive/co2/24h") {
-
- var data = JSON.parse(message.payloadString);
-
- var plot = [
-
- {
-
- x: data.ts,
-
- y: data.values,
-
- type: 'scatter'
-
- }
-
- ];
-
- var layout = {
-
- yaxis: {
-
- title: "g CO2 / kWh",
-
- }
-
- };
-
- Plotly.newPlot('co2_graph', plot, layout);
-
- }
-
-```
-
-This application subscribes to a number of topics because we're going to display a few different kinds of data. The `ny-power/computed/co2` topic provides us a topline number of current intensity. Whenever we receive that topic, we replace the related contents on the site.
-
-
-![NY ISO Grid CO2 Intensity][15]
-
-NY ISO Grid CO2 Intensity graph from [ny-power.org][4].
-
-The `ny-power/archive/co2/24h` topic provides a time series that can be loaded into a [Plotly][16] line graph. And `ny-power/upstream/fuel-mix` provides the data needed to provide a nice bar graph of the current fuel mix.
-
-
-![Fuel mix on NYISO grid][18]
-
-Fuel mix on NYISO grid, [ny-power.org][4].
-
-This is a dynamic website that is not polling the server. It is attached to the MQTT bus and listening on its open WebSocket. The webpage is a pub/sub client just like the data pump and the archiver. This one just happens to be executing in your browser instead of a microservice in the cloud.
-
-You can see the page in action at . That includes both the graphics and a real-time MQTT console to see the messages as they come in.
-
-### Diving deeper
-
-The entire ny-power.org application is [available as open source on GitHub][19]. You can also check out [this architecture overview][20] to see how it was built as a set of Kubernetes microservices deployed with [Helm][21]. You can see another interesting MQTT application example with [this code pattern][22] using MQTT and OpenWhisk to translate text messages in real time.
-
-MQTT is used extensively in the Internet of Things space, and many more examples of MQTT use can be found at the [Home Assistant][23] project.
-
-And if you want to dive deep into the protocol, [mqtt.org][3] has all the details for this open standard.
-
-To learn more, attend Sean Dague's talk, [Adding MQTT to your toolkit][24], at [OSCON][25], which will be held July 16-19 in Portland, Oregon.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/mqtt
-
-作者:[Sean Dague][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/sdague
-[1]:http://www.nyiso.com/public/index.jsp
-[2]:http://www.nyiso.com/public/markets_operations/market_data/reports_info/index.jsp
-[3]:http://mqtt.org/
-[4]:http://ny-power.org/#
-[5]:https://www.home-assistant.io
-[6]:https://mosquitto.org/
-[7]:https://www.eia.gov/
-[8]:https://github.com/IBM/ny-power/blob/master/src/nypower/calc.py#L1-L60
-[9]:https://www.influxdata.com/
-[10]:https://en.wikipedia.org/wiki/Transmission_Control_Protocol
-[11]:https://en.wikipedia.org/wiki/User_Datagram_Protocol
-[12]:https://en.wikipedia.org/wiki/WebSocket
-[13]:https://www.eclipse.org/paho/
-[14]:/file/400041
-[15]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso-co2intensity.png (NY ISO Grid CO2 Intensity)
-[16]:https://plot.ly/
-[17]:/file/400046
-[18]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso_fuel-mix.png (Fuel mix on NYISO grid)
-[19]:https://github.com/IBM/ny-power
-[20]:https://developer.ibm.com/code/patterns/use-mqtt-stream-real-time-data/
-[21]:https://helm.sh/
-[22]:https://developer.ibm.com/code/patterns/deploy-serverless-multilingual-conference-room/
-[23]:https://www.home-assistant.io/
-[24]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/77317
-[25]:https://conferences.oreilly.com/oscon/oscon-or
diff --git a/sources/tech/20180609 Anatomy of a Linux DNS Lookup – Part I.md b/sources/tech/20180609 Anatomy of a Linux DNS Lookup – Part I.md
new file mode 100644
index 0000000000..d65bf40edc
--- /dev/null
+++ b/sources/tech/20180609 Anatomy of a Linux DNS Lookup – Part I.md
@@ -0,0 +1,285 @@
+pinewall is translating
+
+Anatomy of a Linux DNS Lookup – Part I
+============================================================
+
+Since I [work][3] [a][4] [lot][5] [with][6] [clustered][7] [VMs][8], I’ve ended up spending a lot of time trying to figure out how [DNS lookups][9] work. I applied ‘fixes’ to my problems from StackOverflow without really understanding why they work (or don’t work) for some time.
+
+Eventually I got fed up with this and decided to figure out how it all hangs together. I couldn’t find a complete guide for this anywhere online, and talking to colleagues they didn’t know of any (or really what happens in detail)
+
+So I’m writing the guide myself.
+
+ _If you’re looking for Part II, click [here][1]_
+
+Turns out there’s quite a bit in the phrase ‘Linux does a DNS lookup’…
+
+* * *
+
+
+
+ _“How hard can it be?”_
+
+* * *
+
+These posts are intended to break down how a program decides how it gets an IP address on a Linux host, and the components that can get involved. Without understanding how these pieces fit together, debugging and fixing problems with (for example) `dnsmasq`, `vagrant landrush`, or `resolvconf` can be utterly bewildering.
+
+It’s also a valuable illustration of how something so simple can get so very complex over time. I’ve looked at over a dozen different technologies and their archaeologies so far while trying to grok what’s going on.
+
+I even wrote some [automation code][10] to allow me to experiment in a VM. Contributions/corrections are welcome.
+
+Note that this is not a post on ‘how DNS works’. This is about everything up to the call to the actual DNS server that’s configured on a linux host (assuming it even calls a DNS server – as you’ll see, it need not), and how it might find out which one to go to, or how it gets the IP some other way.
+
+* * *
+
+### 1) There is no such thing as a ‘DNS Lookup’ call
+
+* * *
+
+
+
+ _This is NOT how it works_
+
+* * *
+
+The first thing to grasp is that there is no single method of getting a DNS lookup done on Linux. It’s not a core system call with a clean interface.
+
+There is, however, a standard C library call called which many programs use: `[getaddrinfo][2]`. But not all applications use this!
+
+Let’s just take two simple standard programs: `ping` and `host`:
+
+```
+root@linuxdns1:~# ping -c1 bbc.co.uk | head -1
+PING bbc.co.uk (151.101.192.81) 56(84) bytes of data.
+```
+
+```
+root@linuxdns1:~# host bbc.co.uk | head -1
+bbc.co.uk has address 151.101.192.81
+```
+
+They both get the same result, so they must be doing the same thing, right?
+
+Wrong.
+
+Here’s the files that `ping` looks at on my host that are relevant to DNS:
+
+```
+root@linuxdns1:~# strace -e trace=open -f ping -c1 google.com
+open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
+open("/lib/x86_64-linux-gnu/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
+open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
+open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
+open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
+open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 4
+open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
+open("/lib/x86_64-linux-gnu/libnss_files.so.2", O_RDONLY|O_CLOEXEC) = 4
+open("/etc/host.conf", O_RDONLY|O_CLOEXEC) = 4
+open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
+open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
+open("/lib/x86_64-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4
+open("/lib/x86_64-linux-gnu/libresolv.so.2", O_RDONLY|O_CLOEXEC) = 4
+PING google.com (216.58.204.46) 56(84) bytes of data.
+open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
+64 bytes from lhr25s12-in-f14.1e100.net (216.58.204.46): icmp_seq=1 ttl=63 time=13.0 ms
+[...]
+```
+
+and the same for `host`:
+
+```
+$ strace -e trace=open -f host google.com
+[...]
+[pid 9869] open("/usr/share/locale/en_US.UTF-8/LC_MESSAGES/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
+[pid 9869] open("/usr/share/locale/en/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
+[pid 9869] open("/usr/share/locale/en/LC_MESSAGES/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
+[pid 9869] open("/usr/lib/ssl/openssl.cnf", O_RDONLY) = 6
+[pid 9869] open("/usr/lib/x86_64-linux-gnu/openssl-1.0.0/engines/libgost.so", O_RDONLY|O_CLOEXEC) = 6[pid 9869] open("/etc/resolv.conf", O_RDONLY) = 6
+google.com has address 216.58.204.46
+[...]
+```
+
+You can see that while my `ping` looks at `nsswitch.conf`, `host` does not. And they both look at `/etc/resolv.conf`.
+
+We’re going to take these two `.conf` files in turn.
+
+* * *
+
+### 2) NSSwitch, and `/etc/nsswitch.conf`
+
+We’ve established that applications can do what they like when they decide which DNS server to go to. Many apps (like `ping`) above can refer (depending on the implementation (*)) to NSSwitch via its config file `/etc/nsswitch.conf`.
+
+###### (*) There’s a surprising degree of variation in
+ping implementations. That’s a rabbit-hole I
+ _didn’t_ want to get lost in.
+
+NSSwitch is not just for DNS lookups. It’s also used for passwords and user lookup information (for example).
+
+NSSwitch was originally created as part of the Solaris OS to allow applications to not have to hard-code which file or service they look these things up on, but defer them to this other configurable centralised place they didn’t have to worry about.
+
+Here’s my `nsswitch.conf`:
+
+```
+passwd: compat
+group: compat
+shadow: compat
+gshadow: files
+hosts: files dns myhostname
+networks: files
+protocols: db files
+services: db files
+ethers: db files
+rpc: db files
+netgroup: nis
+```
+
+The ‘hosts’ line is the one we’re interested in. We’ve shown that `ping` cares about `nsswitch.conf` so let’s fiddle with it and see how we can mess with `ping`.
+
+* ### Set `nsswitch.conf` to only look at ‘files’
+
+If you set the `hosts` line in `nsswitch.conf` to be ‘just’ `files`:
+
+`hosts: files`
+
+Then a `ping` to google.com will now fail:
+
+```
+$ ping -c1 google.com
+ping: unknown host google.com
+```
+
+but `localhost` still works:
+
+```
+$ ping -c1 localhost
+PING localhost (127.0.0.1) 56(84) bytes of data.
+64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.039 ms
+```
+
+and using `host` still works fine:
+
+```
+$ host google.com
+google.com has address 216.58.206.110
+```
+
+since, as we saw, it doesn’t care about `nsswitch.conf`
+
+* ### Set `nsswitch.conf` to only look at ‘dns’
+
+If you set the `hosts` line in `nsswitch.conf` to be ‘just’ dns:
+
+`hosts: dns`
+
+Then a `ping` to google.com will now succeed again:
+
+```
+$ ping -c1 google.com
+PING google.com (216.58.198.174) 56(84) bytes of data.
+64 bytes from lhr25s10-in-f174.1e100.net (216.58.198.174): icmp_seq=1 ttl=63 time=8.01 ms
+```
+
+But `localhost` is not found this time:
+
+```
+$ ping -c1 localhost
+ping: unknown host localhost
+```
+
+Here’s a diagram of what’s going on with NSSwitch by default wrt `hosts` lookup:
+
+* * *
+
+
+
+ _My default ‘`hosts:`‘ configuration in `nsswitch.conf`_
+
+* * *
+
+### 3) `/etc/resolv.conf`
+
+We’ve seen now that `host` and `ping` both look at this `/etc/resolv.conf` file.
+
+Here’s what my `/etc/resolv.conf` looks like:
+
+```
+# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
+# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
+nameserver 10.0.2.3
+```
+
+Ignore the first two lines – we’ll come back to those (they are significant, but you’re not ready for that ball of wool yet).
+
+The `nameserver` lines specify the DNS servers to look up the host for.
+
+If you hash out that line:
+
+```
+#nameserver 10.0.2.3
+```
+
+and run:
+
+```
+$ ping -c1 google.com
+ping: unknown host google.com
+```
+
+it fails, because there’s no nameserver to go to (*).
+
+###### * Another rabbit hole: `host` appears to fall back to
+127.0.0.1:53 if there’s no nameserver specified.
+
+This file takes other options too. For example, if you add this line to the `resolv.conf` file:
+
+```
+search com
+```
+
+and then `ping google` (sic)
+
+```
+$ ping google
+PING google.com (216.58.204.14) 56(84) bytes of data.
+```
+
+it will try the `.com` domain automatically for you.
+
+### End of Part I
+
+That’s the end of Part I. The next part will start by looking at how that resolv.conf gets created and updated.
+
+Here’s what you covered above:
+
+* There’s no ‘DNS lookup’ call in the OS
+
+* Different programs figure out the IP of an address in different ways
+ * For example, `ping` uses `nsswitch`, which in turn uses (or can use) `/etc/hosts`, `/etc/resolv.conf` and its own hostname to get the result
+
+* `/etc/resolv.conf` helps decide:
+ * which addresses get called
+
+ * which DNS server to look up
+
+If you thought that was complicated, buckle up…
+
+--------------------------------------------------------------------------------
+
+via: https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
+
+作者:[dmatech][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://twitter.com/dmatech2
+[1]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
+[2]:http://man7.org/linux/man-pages/man3/getaddrinfo.3.html
+[3]:https://zwischenzugs.com/2017/10/31/a-complete-chef-infrastructure-on-your-laptop/
+[4]:https://zwischenzugs.com/2017/03/04/a-complete-openshift-cluster-on-vagrant-step-by-step/
+[5]:https://zwischenzugs.com/2017/03/04/migrating-an-openshift-etcd-cluster/
+[6]:https://zwischenzugs.com/2017/03/04/1-minute-multi-node-vm-setup/
+[7]:https://zwischenzugs.com/2017/03/18/clustered-vm-testing-how-to/
+[8]:https://zwischenzugs.com/2017/10/27/ten-things-i-wish-id-known-before-using-vagrant/
+[9]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
+[10]:https://github.com/ianmiell/shutit-linux-dns/blob/master/linux_dns.py
diff --git a/sources/tech/20180615 5 Commands for Checking Memory Usage in Linux.md b/sources/tech/20180615 5 Commands for Checking Memory Usage in Linux.md
deleted file mode 100644
index 05c3da4f6c..0000000000
--- a/sources/tech/20180615 5 Commands for Checking Memory Usage in Linux.md
+++ /dev/null
@@ -1,195 +0,0 @@
-5 Commands for Checking Memory Usage in Linux
-======
-
-
-The Linux operating system includes a plethora of tools, all of which are ready to help you administer your systems. From simple file and directory tools to very complex security commands, there’s not much you can’t do on Linux. And, although regular desktop users may not need to become familiar with these tools at the command line, they’re mandatory for Linux admins. Why? First, you will have to work with a GUI-less Linux server at some point. Second, command-line tools often offer far more power and flexibility than their GUI alternative.
-
-Determining memory usage is a skill you might need should a particular app go rogue and commandeer system memory. When that happens, it’s handy to know you have a variety of tools available to help you troubleshoot. Or, maybe you need to gather information about a Linux swap partition or detailed information about your installed RAM? There are commands for that as well. Let’s dig into the various Linux command-line tools to help you check into system memory usage. These tools aren’t terribly hard to use, and in this article, I’ll show you five different ways to approach the problem.
-
-I’ll be demonstrating on the [Ubuntu Server 18.04 platform][1]. You should, however, find all of these commands available on your distribution of choice. Even better, you shouldn’t need to install a single thing (as most of these tools are included).
-
-With that said, let’s get to work.
-
-### top
-
-I want to start out with the most obvious tool. The top command provides a dynamic, real-time view of a running system. Included in that system summary is the ability to check memory usage on a per-process basis. That’s very important, as you could easily have multiple iterations of the same command consuming different amounts of memory. Although you won’t find this on a headless server, say you’ve opened Chrome and noticed your system slowing down. Issue the top command to see that Chrome has numerous processes running (one per tab - Figure 1).
-
-![top][3]
-
-Figure 1: Multiple instances of Chrome appearing in the top command.
-
-[Used with permission][4]
-
-Chrome isn’t the only app to show multiple processes. You see the Firefox entry in Figure 1? That’s the primary process for Firefox, whereas the Web Content processes are the open tabs. At the top of the output, you’ll see the system statistics. On my machine (a [System76 Leopard Extreme][5]), I have a total of 16GB of RAM available, of which just over 10GB is in use. You can then comb through the list and see what percentage of memory each process is using.
-
-One of the things top is very good for is discovering Process ID (PID) numbers of services that might have gotten out of hand. With those PIDs, you can then set about to troubleshoot (or kill) the offending tasks.
-
-If you want to make top a bit more memory-friendly, issue the command top -o %MEM, which will cause top to sort all processes by memory used (Figure 2).
-
-![top][7]
-
-Figure 2: Sorting process by memory used in top.
-
-[Used with permission][4]
-
-The top command also gives you a real-time update on how much of your swap space is being used.
-
-### free
-
-Sometimes, however, top can be a bit much for your needs. You may only need to see the amount of free and used memory on your system. For that, there is the free command. The free command displays:
-
- * Total amount of free and used physical memory
-
- * Total amount of swap memory in the system
-
- * Buffers and caches used by the kernel
-
-
-
-
-From your terminal window, issue the command free. The output of this command is not in real time. Instead, what you’ll get is an instant snapshot of the free and used memory in that moment (Figure 3).
-
-![free][9]
-
-Figure 3: The output of the free command is simple and clear.
-
-[Used with permission][4]
-
-You can, of course, make free a bit more user-friendly by adding the -m option, like so: free -m. This will report the memory usage in MB (Figure 4).
-
-![free][11]
-
-Figure 4: The output of the free command in a more human-readable form.
-
-[Used with permission][4]
-
-Of course, if your system is even remotely modern, you’ll want to use the -g option (gigabytes), as in free -g.
-
-If you need memory totals, you can add the t option like so: free -mt. This will simply total the amount of memory in columns (Figure 5).
-
-![total][13]
-
-Figure 5: Having free total your memory columns for you.
-
-[Used with permission][4]
-
-### vmstat
-
-Another very handy tool to have at your disposal is vmstat. This particular command is a one-trick pony that reports virtual memory statistics. The vmstat command will report stats on:
-
- * Processes
-
- * Memory
-
- * Paging
-
- * Block IO
-
- * Traps
-
- * Disks
-
- * CPU
-
-
-
-
-The best way to issue vmstat is by using the -s switch, like vmstat -s. This will report your stats in a single column (which is so much easier to read than the default report). The vmstat command will give you more information than you need (Figure 6), but more is always better (in such cases).
-
-![vmstat][15]
-
-Figure 6: Using the vmstat command to check memory usage.
-
-[Used with permission][4]
-
-### dmidecode
-
-What if you want to find out detailed information about your installed system RAM? For that, you could use the dmidecode command. This particular tool is the DMI table decoder, which dumps a system’s DMI table contents into a human-readable format. If you’re unsure as to what the DMI table is, it’s a means to describe what a system is made of (as well as possible evolutions for a system).
-
-To run the dmidecode command, you do need sudo privileges. So issue the command sudo dmidecode -t 17. The output of the command (Figure 7) can be lengthy, as it displays information for all memory-type devices. So if you don’t have the ability to scroll, you might want to send the output of that command to a file, like so: sudo dmidecode -t 17 > dmi_infoI, or pipe it to the less command, as in sudo dmidecode | less.
-
-![dmidecode][17]
-
-Figure 7: The output of the dmidecode command.
-
-[Used with permission][4]
-
-### /proc/meminfo
-
-You might be asking yourself, “Where do these commands get this information from?”. In some cases, they get it from the /proc/meminfo file. Guess what? You can read that file directly with the command less /proc/meminfo. By using the less command, you can scroll up and down through that lengthy output to find exactly what you need (Figure 8).
-
-![/proc/meminfo][19]
-
-Figure 8: The output of the less /proc/meminfo command.
-
-[Used with permission][4]
-
-One thing you should know about /proc/meminfo: This is not a real file. Instead /pro/meminfo is a virtual file that contains real-time, dynamic information about the system. In particular, you’ll want to check the values for:
-
- * MemTotal
-
- * MemFree
-
- * MemAvailable
-
- * Buffers
-
- * Cached
-
- * SwapCached
-
- * SwapTotal
-
- * SwapFree
-
-
-
-
-If you want to get fancy with /proc/meminfo you can use it in conjunction with the egrep command like so: egrep --color 'Mem|Cache|Swap' /proc/meminfo. This will produce an easy to read listing of all entries that contain Mem, Cache, and Swap ... with a splash of color (Figure 9).
-
-![/proc/meminfo][21]
-
-Figure 9: Making /proc/meminfo easier to read.
-
-[Used with permission][4]
-
-### Keep learning
-
-One of the first things you should do is read the manual pages for each of these commands (so man top, man free, man vmstat, man dmidecode). Starting with the man pages for commands is always a great way to learn so much more about how a tool works on Linux.
-
-Learn more about Linux through the free ["Introduction to Linux" ][22]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/5-commands-checking-memory-usage-linux
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://www.ubuntu.com/download/server
-[2]:/files/images/memory1jpg
-[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_1.jpg?itok=fhhhUL_l (top)
-[4]:/licenses/category/used-permission
-[5]:https://system76.com/desktops/leopard
-[6]:/files/images/memory2jpg
-[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_2.jpg?itok=zuVkQfvv (top)
-[8]:/files/images/memory3jpg
-[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_3.jpg?itok=rvuQp3t0 (free)
-[10]:/files/images/memory4jpg
-[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_4.jpg?itok=K_luLLPt (free)
-[12]:/files/images/memory5jpg
-[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_5.jpg?itok=q50atcsX (total)
-[14]:/files/images/memory6jpg
-[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_6.jpg?itok=bwFnUVmy (vmstat)
-[16]:/files/images/memory7jpg
-[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_7.jpg?itok=UNHIT_P6 (dmidecode)
-[18]:/files/images/memory8jpg
-[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_8.jpg?itok=t87jvmJJ (/proc/meminfo)
-[20]:/files/images/memory9jpg
-[21]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_9.jpg?itok=t-iSMEKq (/proc/meminfo)
-[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180618 5 open source alternatives to Dropbox.md b/sources/tech/20180618 5 open source alternatives to Dropbox.md
deleted file mode 100644
index 88ac17e3f6..0000000000
--- a/sources/tech/20180618 5 open source alternatives to Dropbox.md
+++ /dev/null
@@ -1,124 +0,0 @@
-**Translating by distant1219**
-
-5 open source alternatives to Dropbox
-======
-
-
-
-Dropbox is the 800-pound gorilla of filesharing applications. Even though it's a massively popular tool, you may choose to use an alternative.
-
-Maybe that's because you're dedicated to the [open source way][1] for all the good reasons, including security and freedom, or possibly you've been spooked by data breaches. Or perhaps the pricing plan doesn't work out in your favor for the amount of storage you actually need.
-
-Fortunately, there are a variety of open source filesharing applications out there that give you more storage, security, and control over your data at a far lower price than Dropbox charges. How much lower? Try free, if you're a bit tech savvy and have a Linux server to use.
-
-Here are five of the best open source alternatives to Dropbox, plus a few others that you might want to consider.
-
-### ownCloud
-
-
-
-[ownCloud][2], launched in 2010, is the oldest application on this list, but don't let that fool you: It's still very popular (with over 1.5 million users, according to the company) and actively maintained by a community of 1,100 contributors, with updates released regularly.
-
-Its primary features—file and folding sharing, document collaboration—are similar to Dropbox's. Its primary difference (aside from its [open source license][3]) is that your files are hosted on your private Linux server or cloud, giving users complete control over your data. (Self-hosting is a common thread among the apps on this list.)
-
-With ownCloud, you can sync and access files through clients for Linux, MacOS, or Windows computers or mobile apps for Android and iOS devices, and provide password-protected links to others for collaboration or file upload/download. Data transfers are secured by end-to-end encryption (E2EE) and SSL encryption. You can also expand its functionality with a wide variety of third-party apps available in its [marketplace][4], and there is also a paid, commercially licensed enterprise edition.
-
-ownCloud offers comprehensive [documentation][5], including an installation guide and manuals for users, admins, and developers, and you can access its [source code][6] in its GitHub repository.
-
-### NextCloud
-
-
-
-[NextCloud][7] spun out of ownCloud in 2016 and shares much of the same functionality. Nextcloud [touts][8] its high security and regulatory compliance as a distinguishing feature. It has HIPAA (healthcare) and GDPR (privacy) compliance features and offers extensive data-policy enforcement, encryption, user management, and auditing capabilities. It also encrypts data during transfer and at rest and integrates with mobile device management and authentication mechanisms (including LDAP/AD, single-sign-on, two-factor authentication, etc.).
-
-Like the other solutions on this list, NextCloud is self-hosted, but if you don't want to roll your own NextCloud server on Linux, the company partners with several [providers][9] for setup and hosting and sells servers, appliances, and support. A [marketplace][10] offers numerous apps to extend its features.
-
-NextCloud's [documentation][11] page offers thorough information for users, admins, and developers as well as links to its forums, IRC channel, and social media pages for community-based support. If you'd like to contribute, access its source code, report a bug, check out its (AGPLv3) license, or just learn more, visit the project's [GitHub repository][12].
-
-### Seafile
-
-
-
-[Seafile][13] may not have the bells and whistles (or app ecosystem) of ownCloud or Nextcloud, but it gets the job done. Essentially, it acts as a virtual drive on your Linux server to extend your desktop storage and allow you to share files selectively with password protection and various levels of permission (i.e., read-only or read/write).
-
-Its collaboration features include per-folder access control, password-protected download links, and Git-like version control and retention. Files are secured with two-factor authentication, file encryption, and AD/LDAP integration, and they're accessible from Windows, MacOS, Linux, iOS, or Android devices.
-
-For more information, visit Seafile's [GitHub repository][14], [server manual][15], [wiki][16], and [forums][17]. Note that Seafile's community edition is licensed under [GPLv2][18], but its professional edition is not open source.
-
-### OnionShare
-
-
-
-[OnionShare][19] is a cool app that does one thing: It allows you to share individual files or folders securely and, if you want, anonymously. There's no server to set up or maintain—all you need to do is [download and install][20] the app on MacOS, Windows, or Linux. Files are always hosted on your own computer; when you share a file, OnionShare creates a web server, makes it accessible as a Tor Onion service, and generates an unguessable .onion URL that allows the recipient to access the file via [Tor browser][21].
-
-You can set limits on your fileshare, such as limiting the number of times it can be downloaded or using an auto-stop timer, which sets a strict expiration date/time after which the file is inaccessible (even if it hasn't been accessed yet).
-
-OnionShare is licensed under [GPLv3][22]; for more information, check out its GitHub [repository][22], which also includes [documentation][23] that covers the features in this easy-to-use filesharing application.
-
-### Pydio Cells
-
-
-
-[Pydio Cells][24], which achieved stability in May 2018, is a complete overhaul of the Pydio filesharing application's core server code. Due to limitations with Pydio's PHP-based backend, the developers decided to rewrite the backend in the Go server language with a microservices architecture. (The frontend is still based on PHP.)
-
-Pydio Cells includes the usual filesharing and version control features, as well as in-app messaging, mobile apps (Android and iOS), and a social network-style approach to collaboration. Security includes OpenID Connect-based authentication, encryption at rest, security policies, and more. Advanced features are included in the enterprise distribution, but there's plenty of power for most small and midsize businesses and home users in the community (or "Home") version.
-
-You can [download][25] Pydio Cells for Linux and MacOS. For more information, check out the [documentation FAQ][26], [source code][27] repository, and [AGPLv3 license][28].
-
-### Others to consider
-
-If these choices don't meet your needs, you may want to consider these open source filesharing-type applications.
-
- * If your main goal is to sync files between devices, rather than to share files, check out [Syncthing][29]).
- * If you're a Git fan and don't need a mobile app, you might appreciate [SparkleShare][30].
- * If you primarily want a place to aggregate all your personal data, take a look at [Cozy][31].
- * And, if you're looking for a lightweight or dedicated filesharing tool, peruse [Scott Nesbitt's review][32] of some lesser-known options.
-
-
-
-What is your favorite open source filesharing application? Let us know in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/alternatives/dropbox
-
-作者:[OPensource.com][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com
-[1]:https://opensource.com/open-source-way
-[2]:https://owncloud.org/
-[3]:https://www.gnu.org/licenses/agpl-3.0.html
-[4]:https://marketplace.owncloud.com/
-[5]:https://doc.owncloud.com/
-[6]:https://github.com/owncloud
-[7]:https://nextcloud.com/
-[8]:https://nextcloud.com/secure/
-[9]:https://nextcloud.com/providers/
-[10]:https://apps.nextcloud.com/
-[11]:https://nextcloud.com/support/
-[12]:https://github.com/nextcloud
-[13]:https://www.seafile.com/en/home/
-[14]:https://github.com/haiwen/seafile
-[15]:https://manual.seafile.com/
-[16]:https://seacloud.cc/group/3/wiki/
-[17]:https://forum.seafile.com/
-[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
-[19]:https://onionshare.org/
-[20]:https://onionshare.org/#downloads
-[21]:https://www.torproject.org/
-[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
-[23]:https://github.com/micahflee/onionshare/wiki
-[24]:https://pydio.com/en
-[25]:https://pydio.com/download/
-[26]:https://pydio.com/en/docs/faq
-[27]:https://github.com/pydio/cells
-[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
-[29]:https://syncthing.net/
-[30]:http://www.sparkleshare.org/
-[31]:https://cozy.io/en/
-[32]:https://opensource.com/article/17/3/file-sharing-tools
diff --git a/sources/tech/20180618 Twitter Sentiment Analysis using NodeJS.md b/sources/tech/20180618 Twitter Sentiment Analysis using NodeJS.md
new file mode 100644
index 0000000000..4cef7ec7f5
--- /dev/null
+++ b/sources/tech/20180618 Twitter Sentiment Analysis using NodeJS.md
@@ -0,0 +1,218 @@
+BriFuture is translating
+
+Twitter Sentiment Analysis using NodeJS
+============================================================
+
+
+
+
+If you want to know how people feel about something, there is no better place than Twitter. It is a continuous stream of opinion, with around 6,000 new tweets being created every second. The internet is quick to react to events and if you want to be updated with the latest and hottest, Twitter is the place to be.
+
+Now, we live in an age where data is king and companies put Twitter's data to good use. From gauging the reception of their new products to trying to predict the next market trend, analysis of Twitter data has many uses. Businesses use it to market their product that to the right customers, to gather feedback on their brand and improve or to assess the reasons for the failure of a product or promotional campaign. Not only businesses, many political and economic decisions are made based on observation of people's opinion. Today, I will try and give you a taste of simple [sentiment analysis][1] of tweets to determine whether a tweet is positive, negative or neutral. It won't be as sophisticated as those used by professionals, but nonetheless, it will give you an idea about opinion mining.
+
+We will be using NodeJs since JavaScript is ubiquitous nowadays and is one of the easiest languages to get started with.
+
+### Prerequisite:
+
+* NodeJs and NPM installed
+
+* A little experience with NodeJs and NPM packages
+
+* some familiarity with the command line.
+
+Alright, that's it. Let's get started.
+
+### Getting Started
+
+Make a new directory for your project and go inside the directory. Open a terminal (or command line). Go inside the newly created directory and run the `npm init -y` command. This will create a `package.json` in your directory. Now we can install the npm packages we need. We just need to create a new file named `index.js` and then we are all set to start coding.
+
+### Getting the tweets
+
+Well, we want to analyze tweets and for that, we need programmatic access to Twitter. For this, we will use the [twit][2] package. So, let's install it with the `npm i twit` command. We also need to register an App through our account to gain access to the Twitter API. Head over to this [link][3], fill in all the details and copy ‘Consumer Key’, ‘Consumer Secret’, ‘Access token’ and ‘Access Token Secret’ from 'Keys and Access Token' tabs in a `.env` file like this:
+
+```
+# .env
+# replace the stars with values you copied
+CONSUMER_KEY=************
+CONSUMER_SECRET=************
+ACCESS_TOKEN=************
+ACCESS_TOKEN_SECRET=************
+
+```
+
+Now, let's begin.
+
+Open `index.js` in your favorite code editor. We need to install the `dotenv`package to read from `.env` file with the command `npm i dotenv`. Alright, let's create an API instance.
+
+```
+const Twit = require('twit');
+const dotenv = require('dotenv');
+
+dotenv.config();
+
+const { CONSUMER_KEY
+ , CONSUMER_SECRET
+ , ACCESS_TOKEN
+ , ACCESS_TOKEN_SECRET
+ } = process.env;
+
+const config_twitter = {
+ consumer_key: CONSUMER_KEY,
+ consumer_secret: CONSUMER_SECRET,
+ access_token: ACCESS_TOKEN,
+ access_token_secret: ACCESS_TOKEN_SECRET,
+ timeout_ms: 60*1000
+};
+
+let api = new Twit(config_twitter);
+
+```
+
+Here we have established a connection to the Twitter with the required configuration. But we are not doing anything with it. Let's define a function to get tweets.
+
+```
+async function get_tweets(q, count) {
+ let tweets = await api.get('search/tweets', {q, count, tweet_mode: 'extended'});
+ return tweets.data.statuses.map(tweet => tweet.full_text);
+}
+
+```
+
+This is an async function because of the `api.get` the function returns a promise and instead of chaining `then`s, I wanted an easy way to extract the text of the tweets. It accepts two arguments -q and count, `q` being the query or keyword we want to search for and `count` is the number of tweets we want the `api` to return.
+
+So now we have an easy way to get the full texts from the tweets. But we still have a problem, the text that we will get now may contain some links or may be truncated if it's a retweet. So we will write another function that will extract and return the text of the tweets, even for retweets and remove the links if any.
+
+```
+function get_text(tweet) {
+ let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
+ return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
+ }
+
+async function get_tweets(q, count) {
+ let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
+ return tweets.data.statuses.map(get_text);
+}
+
+```
+
+So, now we have the text of tweets. Our next step is getting the sentiment from the text. For this, we will use another package from `npm` - [`sentiment`][4]package. Let's install it like the other packages and add to our script.
+
+```
+const sentiment = require('sentiment')
+
+```
+
+Using `sentiment` is very easy. We will just have to call the `sentiment`function on the text that we want to analyze and it will return us the comparative score of the text. If the score is below 0, it expresses a negative sentiment, a score above 0 is positive and 0, as you may have guessed, is neutral. So based on this, we will print the tweets in different colors - green for positive, red for negative and blue for neutral. For this, we will use the [`colors`][5] package. Let's install it like the other packages and add to our script.
+
+```
+const colors = require('colors/safe');
+
+```
+
+Alright, now let us bring it all together in a `main` function.
+
+```
+async function main() {
+ let keyword = \* define the keyword that you want to search for *\;
+ let count = \* define the count of tweets you want *\;
+ let tweets = await get_tweets(keyword, count);
+ for (tweet of tweets) {
+ let score = sentiment(tweet).comparative;
+ tweet = `${tweet}\n`;
+ if (score > 0) {
+ tweet = colors.green(tweet);
+ } else if (score < 0) {
+ tweet = colors.red(tweet);
+ } else {
+ tweet = colors.blue(tweet);
+ }
+ console.log(tweet);
+ }
+}
+
+```
+
+And finally, execute the `main` function.
+
+```
+main();
+
+```
+
+There you have it, a short script of analyzing the basic sentiments of a tweet.
+
+```
+\\ full script
+const Twit = require('twit');
+const dotenv = require('dotenv');
+const sentiment = require('sentiment');
+const colors = require('colors/safe');
+
+dotenv.config();
+
+const { CONSUMER_KEY
+ , CONSUMER_SECRET
+ , ACCESS_TOKEN
+ , ACCESS_TOKEN_SECRET
+ } = process.env;
+
+const config_twitter = {
+ consumer_key: CONSUMER_KEY,
+ consumer_secret: CONSUMER_SECRET,
+ access_token: ACCESS_TOKEN,
+ access_token_secret: ACCESS_TOKEN_SECRET,
+ timeout_ms: 60*1000
+};
+
+let api = new Twit(config_twitter);
+
+function get_text(tweet) {
+ let txt = tweet.retweeted_status ? tweet.retweeted_status.full_text : tweet.full_text;
+ return txt.split(/ |\n/).filter(v => !v.startsWith('http')).join(' ');
+ }
+
+async function get_tweets(q, count) {
+ let tweets = await api.get('search/tweets', {q, count, 'tweet_mode': 'extended'});
+ return tweets.data.statuses.map(get_text);
+}
+
+async function main() {
+ let keyword = 'avengers';
+ let count = 100;
+ let tweets = await get_tweets(keyword, count);
+ for (tweet of tweets) {
+ let score = sentiment(tweet).comparative;
+ tweet = `${tweet}\n`;
+ if (score > 0) {
+ tweet = colors.green(tweet);
+ } else if (score < 0) {
+ tweet = colors.red(tweet);
+ } else {
+ tweet = colors.blue(tweet)
+ }
+ console.log(tweet)
+ }
+}
+
+main();
+```
+
+--------------------------------------------------------------------------------
+
+via: https://boostlog.io/@anshulc95/twitter-sentiment-analysis-using-nodejs-5ad1331247018500491f3b6a
+
+作者:[Anshul Chauhan][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://boostlog.io/@anshulc95
+[1]:https://en.wikipedia.org/wiki/Sentiment_analysis
+[2]:https://github.com/ttezel/twit
+[3]:https://boostlog.io/@anshulc95/apps.twitter.com
+[4]:https://www.npmjs.com/package/sentiment
+[5]:https://www.npmjs.com/package/colors
+[6]:https://boostlog.io/tags/nodejs
+[7]:https://boostlog.io/tags/twitter
+[8]:https://boostlog.io/@anshulc95
diff --git a/sources/tech/20180619 How To Check Which Groups A User Belongs To On Linux.md b/sources/tech/20180619 How To Check Which Groups A User Belongs To On Linux.md
deleted file mode 100644
index 8a7c0d2eec..0000000000
--- a/sources/tech/20180619 How To Check Which Groups A User Belongs To On Linux.md
+++ /dev/null
@@ -1,161 +0,0 @@
-translating---geekpi
-
-How To Check Which Groups A User Belongs To On Linux
-======
-Adding a user into existing group is one of the regular activity for Linux admin. This is daily activity for some of the administrator who’s working one big environments.
-
-Even i am performing such a activity on daily in my environment due to business requirement. It’s one of the important command which helps you to identify existing groups on your environment.
-
-Also these commands helps you to identify which groups a user belongs to. All the users are listed in `/etc/passwd` file and groups are listed in `/etc/group`.
-
-Whatever command we use, that will fetch the information from these files. Also, each command has their unique feature which helps user to get the required information alone.
-
-### What Is /etc/passwd?
-
-`/etc/passwd` is a text file that contains each user information, which is necessary to login Linux system. It maintain useful information about users such as username, password, user ID, group ID, user ID info, home directory and shell. The passwd file contain every user details as a single line with seven fields as described above.
-```
-$ grep "daygeek" /etc/passwd
-daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
-
-```
-
-### What Is /etc/group?
-
-`/etc/group` is a text file that defines which groups a user belongs to. We can add multiple users into single group. It allows user to access other users files and folders as Linux permissions are organized into three classes, user, group, and others. It maintain useful information about group such as Group name, Group password, Group ID (GID) and Member list. each on a separate line. The group file contain every group details as a single line with four fields as described above.
-
-This can be performed by using below methods.
-
- * `groups:`Show All Members of a Group.
- * `id:`Print user and group information for the specified username.
- * `lid:`It display user’s groups or group’s users.
- * `getent:`get entries from Name Service Switch libraries.
- * `grep`grep stands for “global regular expression print” which prints matching pattern.
-
-
-
-### What Is groups Command?
-
-groups command prints the names of the primary and any supplementary groups for each given username.
-```
-$ groups daygeek
-daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
-
-```
-
-If you would like to check list of groups associated with current user. Just run **“group”** command alone without any username.
-```
-$ groups
-daygeek adm cdrom sudo dip plugdev lpadmin sambashare
-
-```
-
-### What Is id Command?
-
-id stands for identity. print real and effective user and group IDs. To print user and group information for the specified user, or for the current user.
-```
-$ id daygeek
-uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
-
-```
-
-If you would like to check list of groups associated with current user. Just run **“id”** command alone without any username.
-```
-$ id
-uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
-
-```
-
-### What Is lid Command?
-
-It display user’s groups or group’s users. Displays information about groups containing user name, or users contained in group name. This command required privileges to run.
-```
-$ sudo lid daygeek
- adm(gid=4)
- cdrom(gid=24)
- sudo(gid=27)
- dip(gid=30)
- plugdev(gid=46)
- lpadmin(gid=108)
- daygeek(gid=1000)
- sambashare(gid=124)
-
-```
-
-### What Is getent Command?
-
-The getent command displays entries from databases supported by the Name Service Switch libraries, which are configured in /etc/nsswitch.conf.
-```
-$ getent group | grep daygeek
-adm:x:4:syslog,daygeek
-cdrom:x:24:daygeek
-sudo:x:27:daygeek
-dip:x:30:daygeek
-plugdev:x:46:daygeek
-lpadmin:x:118:daygeek
-daygeek:x:1000:
-sambashare:x:128:daygeek
-
-```
-
-If you would like to print only associated groups name then include **“awk”** command along with above command.
-```
-$ getent group | grep daygeek | awk -F: '{print $1}'
-adm
-cdrom
-sudo
-dip
-plugdev
-lpadmin
-daygeek
-sambashare
-
-```
-
-Run the below command to print only primary group information.
-```
-$ getent group daygeek
-daygeek:x:1000:
-
-```
-
-### What Is grep Command?
-
-grep stands for “global regular expression print” which prints matching pattern from the file.
-```
-$ grep "daygeek" /etc/group
-adm:x:4:syslog,daygeek
-cdrom:x:24:daygeek
-sudo:x:27:daygeek
-dip:x:30:daygeek
-plugdev:x:46:daygeek
-lpadmin:x:118:daygeek
-daygeek:x:1000:
-sambashare:x:128:daygeek
-
-```
-
-If you would like to print only associated groups name then include **“awk”** command along with above command.
-```
-$ grep "daygeek" /etc/group | awk -F: '{print $1}'
-adm
-cdrom
-sudo
-dip
-plugdev
-lpadmin
-daygeek
-sambashare
-
-```
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
-
-作者:[Prakash Subramanian][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/prakash/
diff --git a/sources/tech/20180619 How to reset, revert, and return to previous states in Git.md b/sources/tech/20180619 How to reset, revert, and return to previous states in Git.md
deleted file mode 100644
index 3532681888..0000000000
--- a/sources/tech/20180619 How to reset, revert, and return to previous states in Git.md
+++ /dev/null
@@ -1,253 +0,0 @@
-How to reset, revert, and return to previous states in Git
-======
-
-
-
-One of the lesser understood (and appreciated) aspects of working with Git is how easy it is to get back to where you were before—that is, how easy it is to undo even major changes in a repository. In this article, we'll take a quick look at how to reset, revert, and completely return to previous states, all with the simplicity and elegance of individual Git commands.
-
-### Reset
-
-Let's start with the Git command `reset`. Practically, you can think of it as a "rollback"—it points your local environment back to a previous commit. By "local environment," we mean your local repository, staging area, and working directory.
-
-Take a look at Figure 1. Here we have a representation of a series of commits in Git. A branch in Git is simply a named, movable pointer to a specific commit. In this case, our branch master is a pointer to the latest commit in the chain.
-
-![Local Git environment with repository, staging area, and working directory][2]
-
-Fig. 1: Local Git environment with repository, staging area, and working directory
-
-If we look at what's in our master branch now, we can see the chain of commits made so far.
-```
-$ git log --oneline
-b764644 File with three lines
-7c709f0 File with two lines
-9ef9173 File with one line
-```
-
-`reset` command to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
-
-What happens if we want to roll back to a previous commit. Simple—we can just move the branch pointer. Git supplies thecommand to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
-
-`$ git reset 9ef9173` (using an absolute commit SHA1 value 9ef9173)
-
-or
-
-`$ git reset current~2` (using a relative value -2 before the "current" tag)
-
-Figure 2 shows the results of this operation. After this, if we execute a `git log` command on the current branch (master), we'll see just the one commit.
-```
-$ git log --oneline
-
-9ef9173 File with one line
-
-```
-
-![After reset][4]
-
-Fig. 2: After `reset`
-
-The `git reset` command also includes options to update the other parts of your local environment with the contents of the commit where you end up. These options include: `hard` to reset the commit being pointed to in the repository, populate the working directory with the contents of the commit, and reset the staging area; `soft` to only reset the pointer in the repository; and `mixed` (the default) to reset the pointer and the staging area.
-
-Using these options can be useful in targeted circumstances such as `git reset --hard ``.` This overwrites any local changes you haven't committed. In effect, it resets (clears out) the staging area and overwrites content in the working directory with the content from the commit you reset to. Before you use the `hard` option, be sure that's what you really want to do, since the command overwrites any uncommitted changes.
-
-### Revert
-
-The net effect of the `git revert` command is similar to reset, but its approach is different. Where the `reset` command moves the branch pointer back in the chain (typically) to "undo" changes, the `revert` command adds a new commit at the end of the chain to "cancel" changes. The effect is most easily seen by looking at Figure 1 again. If we add a line to a file in each commit in the chain, one way to get back to the version with only two lines is to reset to that commit, i.e., `git reset HEAD~1`.
-
-Another way to end up with the two-line version is to add a new commit that has the third line removed—effectively canceling out that change. This can be done with a `git revert` command, such as:
-```
-$ git revert HEAD
-
-```
-
-Because this adds a new commit, Git will prompt for the commit message:
-```
-Revert "File with three lines"
-
-This reverts commit b764644bad524b804577684bf74e7bca3117f554.
-
-# Please enter the commit message for your changes. Lines starting
-# with '#' will be ignored, and an empty message aborts the commit.
-# On branch master
-# Changes to be committed:
-# modified: file1.txt
-#
-```
-
-Figure 3 (below) shows the result after the `revert` operation is completed.
-
-If we do a `git log` now, we'll see a new commit that reflects the contents before the previous commit.
-```
-$ git log --oneline
-11b7712 Revert "File with three lines"
-b764644 File with three lines
-7c709f0 File with two lines
-9ef9173 File with one line
-```
-
-Here are the current contents of the file in the working directory:
-```
-$ cat
-Line 1
-Line 2
-```
-
-#### Revert or reset?
-
-Why would you choose to do a `revert` over a `reset` operation? If you have already pushed your chain of commits to the remote repository (where others may have pulled your code and started working with it), a revert is a nicer way to cancel out changes for them. This is because the Git workflow works well for picking up additional commits at the end of a branch, but it can be challenging if a set of commits is no longer seen in the chain when someone resets the branch pointer back.
-
-This brings us to one of the fundamental rules when working with Git in this manner: Making these kinds of changes in your local repository to code you haven't pushed yet is fine. But avoid making changes that rewrite history if the commits have already been pushed to the remote repository and others may be working with them.
-
-In short, if you rollback, undo, or rewrite the history of a commit chain that others are working with, your colleagues may have a lot more work when they try to merge in changes based on the original chain they pulled. If you must make changes against code that has already been pushed and is being used by others, consider communicating before you make the changes and give people the chance to merge their changes first. Then they can pull a fresh copy after the infringing operation without needing to merge.
-
-You may have noticed that the original chain of commits was still there after we did the reset. We moved the pointer and reset the code back to a previous commit, but it did not delete any commits. This means that, as long as we know the original commit we were pointing to, we can "restore" back to the previous point by simply resetting back to the original head of the branch:
-```
-git reset
-
-```
-
-A similar thing happens in most other operations we do in Git when commits are replaced. New commits are created, and the appropriate pointer is moved to the new chain. But the old chain of commits still exists.
-
-### Rebase
-
-Now let's look at a branch rebase. Consider that we have two branches—master and feature—with the chain of commits shown in Figure 4 below. Master has the chain `C4->C2->C1->C0` and feature has the chain `C5->C3->C2->C1->C0`.
-
-![Chain of commits for branches master and feature][6]
-
-Fig. 4: Chain of commits for branches master and feature
-
-If we look at the log of commits in the branches, they might look like the following. (The `C` designators for the commit messages are used to make this easier to understand.)
-```
-$ git log --oneline master
-6a92e7a C4
-259bf36 C2
-f33ae68 C1
-5043e79 C0
-
-$ git log --oneline feature
-79768b8 C5
-000f9ae C3
-259bf36 C2
-f33ae68 C1
-5043e79 C0
-```
-
-I tell people to think of a rebase as a "merge with history" in Git. Essentially what Git does is take each different commit in one branch and attempt to "replay" the differences onto the other branch.
-
-So, we can rebase a feature onto master to pick up `C4` (e.g., insert it into feature's chain). Using the basic Git commands, it might look like this:
-```
-$ git checkout feature
-$ git rebase master
-
-First, rewinding head to replay your work on top of it...
-Applying: C3
-Applying: C5
-```
-
-Afterward, our chain of commits would look like Figure 5.
-
-![Chain of commits after the rebase command][8]
-
-Fig. 5: Chain of commits after the `rebase` command
-
-Again, looking at the log of commits, we can see the changes.
-```
-$ git log --oneline master
-6a92e7a C4
-259bf36 C2
-f33ae68 C1
-5043e79 C0
-
-$ git log --oneline feature
-c4533a5 C5
-64f2047 C3
-6a92e7a C4
-259bf36 C2
-f33ae68 C1
-5043e79 C0
-```
-
-Notice that we have `C3'` and `C5'`—new commits created as a result of making the changes from the originals "on top of" the existing chain in master. But also notice that the "original" `C3` and `C5` are still there—they just don't have a branch pointing to them anymore.
-
-If we did this rebase, then decided we didn't like the results and wanted to undo it, it would be as simple as:
-```
-$ git reset 79768b8
-
-```
-
-With this simple change, our branch would now point back to the same set of commits as before the `rebase` operation—effectively undoing it (Figure 6).
-
-![After undoing rebase][10]
-
-Fig. 6: After undoing the `rebase` operation
-
-What happens if you can't recall what commit a branch pointed to before an operation? Fortunately, Git again helps us out. For most operations that modify pointers in this way, Git remembers the original commit for you. In fact, it stores it in a special reference named `ORIG_HEAD `within the `.git` repository directory. That path is a file containing the most recent reference before it was modified. If we `cat` the file, we can see its contents.
-```
-$ cat .git/ORIG_HEAD
-79768b891f47ce06f13456a7e222536ee47ad2fe
-```
-
-We could use the `reset` command, as before, to point back to the original chain. Then the log would show this:
-```
-$ git log --oneline feature
-79768b8 C5
-000f9ae C3
-259bf36 C2
-f33ae68 C1
-5043e79 C0
-```
-
-Another place to get this information is in the reflog. The reflog is a play-by-play listing of switches or changes to references in your local repository. To see it, you can use the `git reflog` command:
-```
-$ git reflog
-79768b8 HEAD@{0}: reset: moving to 79768b
-c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
-c4533a5 HEAD@{2}: rebase: C5
-64f2047 HEAD@{3}: rebase: C3
-6a92e7a HEAD@{4}: rebase: checkout master
-79768b8 HEAD@{5}: checkout: moving from feature to feature
-79768b8 HEAD@{6}: commit: C5
-000f9ae HEAD@{7}: checkout: moving from master to feature
-6a92e7a HEAD@{8}: commit: C4
-259bf36 HEAD@{9}: checkout: moving from feature to master
-000f9ae HEAD@{10}: commit: C3
-259bf36 HEAD@{11}: checkout: moving from master to feature
-259bf36 HEAD@{12}: commit: C2
-f33ae68 HEAD@{13}: commit: C1
-5043e79 HEAD@{14}: commit (initial): C0
-```
-
-You can then reset to any of the items in that list using the special relative naming format you see in the log:
-```
-$ git reset HEAD@{1}
-
-```
-
-Once you understand that Git keeps the original chain of commits around when operations "modify" the chain, making changes in Git becomes much less scary. This is one of Git's core strengths: being able to quickly and easily try things out and undo them if they don't work.
-
-Brent Laster will present [Power Git: Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, and More][11] at the 20th annual [OSCON][12] event, July 16-19 in Portland, Ore. For more tips and explanations about using Git at any level, checkout Brent's book "[Professional Git][13]," available on Amazon.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
-
-作者:[Brent Laster][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/bclaster
-[1]:/file/401126
-[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png (Local Git environment with repository, staging area, and working directory)
-[3]:/file/401131
-[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png (After reset)
-[5]:/file/401141
-[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png (Chain of commits for branches master and feature)
-[7]:/file/401146
-[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png (Chain of commits after the rebase command)
-[9]:/file/401151
-[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png (After undoing rebase)
-[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
-[12]:https://conferences.oreilly.com/oscon/oscon-or
-[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
diff --git a/sources/tech/20180621 Bitcoin is a Cult - Adam Caudill.md b/sources/tech/20180621 Bitcoin is a Cult - Adam Caudill.md
deleted file mode 100644
index 44bc8fbc90..0000000000
--- a/sources/tech/20180621 Bitcoin is a Cult - Adam Caudill.md
+++ /dev/null
@@ -1,102 +0,0 @@
-Bitcoin is a Cult — Adam Caudill
-======
-The Bitcoin community has changed greatly over the years; from technophiles that could explain a [Merkle tree][1] in their sleep, to speculators driven by the desire for a quick profit & blockchain startups seeking billion dollar valuations led by people who don’t even know what a Merkle tree is. As the years have gone on, a zealotry has been building around Bitcoin and other cryptocurrencies driven by people who see them as something far grander than they actually are; people who believe that normal (or fiat) currencies are becoming a thing of the past, and the cryptocurrencies will fundamentally change the world’s economy.
-
-Every year, their ranks grow, and their perception of cryptocurrencies becomes more grandiose, even as [novel uses][2] of the technology brings it to its knees. While I’m a firm believer that a well designed cryptocurrency could ease the flow of money across borders, and provide a stable option in areas of mass inflation, the reality is that we aren’t there yet. In fact, it’s the substantial instability in value that allows speculators to make money. Those that preach that the US Dollar and Euro are on their deathbed have utterly abandoned an objective view of reality.
-
-### A little background…
-
-I read the Bitcoin white-paper the day it was released – an interesting use of [Merkle trees][1] to create a public ledger and a fairly reasonable consensus protocol – it got the attention of many in the cryptography sphere for its novel properties. In the years since that paper was released, Bitcoin has become rather valuable, attracted many that see it as an investment, and a loyal (and vocal) following of people who think it’ll change everything. This discussion is about the latter.
-
-Yesterday, someone on Twitter posted the hash of a recent Bitcoin block, the thousands of Tweets and other conversations that followed have convinced me that Bitcoin has crossed the line into true cult territory.
-
-It all started with this Tweet by Mark Wilcox:
-
-> #00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a
-> — Mark Wilcox (@mwilcox) June 19, 2018
-
-The value posted is the hash of [Bitcoin block #528249][3]. The leading zeros are a result of the mining process; to mine a block you combine the contents of the block with a nonce (and other data), hash it, and it has to have at least a certain number of leading zeros to be considered valid. If it doesn’t have the correct number, you change the nonce and try again. Repeat this until the number of leading zeros is the right number, and you now have a valid block. The part that people got excited about is what follows, 21e800.
-
-Some are claiming this is an intentional reference, that whoever mined this block actually went well beyond the current difficulty to not just bruteforce the leading zeros, but also the next 24 bits – which would require some serious computing power. If someone had the ability to bruteforce this, it could indicate something rather serious, such as a substantial breakthrough in computing or cryptography.
-
-You must be asking yourself, what’s so important about 21e800 – a question you would surely regret. Some are claiming it’s a reference to [E8 Theory][4] (a widely criticized paper that presents a standard field theory), or to the 21,000,000 total Bitcoins that will eventually exist (despite the fact that `21 x 10^8` would be 2,100,000,000). There are others, they are just too crazy to write about. Another important fact is that a block is mined on average on once a year that has 21e8 following the leading zeros – those were never seen as anything important.
-
-This leads to where things get fun: the [theories][5] that are circulating about how this happened.
-
- * A quantum computer, that is somehow able to hash at unbelievable speed. This is despite the fact that there’s no indication in theories around quantum computers that they’ll be able to do this; hashing is one thing that’s considered safe from quantum computers.
- * Time travel. Yes, people are actually saying that someone came back from the future to mine this block. I think this is crazy enough that I don’t need to get into why this is wrong.
- * Satoshi Nakamoto is back. Despite the fact that there has been no activity with his private keys, some theorize that he has returned, and is somehow able to do things that nobody can. These theories don’t explain how he could do it.
-
-
-
-> So basically (as i understand) Satoshi, in order to have known and computed the things that he did, according to modern science he was either:
->
-> A) Using a quantum computer
-> B) Fom the future
-> C) Both
->
-> — Crypto Randy Marsh [REKT] (@nondualrandy) [June 21, 2018][6]
-
-If all this sounds like [numerology][7] to you, you aren’t alone.
-
-All this discussion around special meaning in block hashes also reignited the discussion around something that is, at least somewhat, interesting. The Bitcoin genesis block, the first bitcoin block, does have an unusual property: the early Bitcoin blocks required that the first 32 bits of the hash be zero; however the genesis block had 43 leading zero bits. As the code that produced the genesis block was never released, it’s not known how it was produced, nor is it known what type of hardware was used to produce it. Satoshi had an academic background, so may have had access to more substantial computing power than was common at the time via a university. At this point, the oddities of the genesis block are a historical curiosity, nothing more.
-
-### A brief digression on hashing
-
-This hullabaloo started with the hash of a Bitcoin block; so it’s important to understand just what a hash is, and understand one very important property they have. A hash is a one-way cryptographic function that creates a pseudo-random output based on the data that it’s given.
-
-What this means, for the purposes of this discussion, is that for each input you get a random output. Random numbers have a way of sometimes looking interesting, simply as a result of being random and the human brain’s affinity to find order in everything. When you start looking for order in random data, you find interesting things – that are yet meaningless, as it’s simply random. When people ascribe significant meaning to random data, it tells you far more about the mindset of those involved rather than the data itself.
-
-### Cult of the Coin
-
-First, let us define a couple of terms:
-
- * Cult: a system of religious veneration and devotion directed toward a particular figure or object.
- * Religion: a pursuit or interest to which someone ascribes supreme importance.
-
-
-
-The Cult of the Coin has many saints, perhaps none greater than Satoshi Nakamoto, the pseudonym used by the person(s) that created Bitcoin. Vigorously defended, ascribed with ability and understanding far above that of a normal researcher, seen as a visionary beyond compare that is leading the world to a new economic order. When combined with Satoshi’s secretive nature and unknown true identify, adherents to the Cult view Satoshi as a truly venerated figure.
-
-That is, of course, with the exception of adherents that follow a different saint, who is unquestionably correct, and any criticism is seen as not only an attack on their saint, but on themselves as well. Those that follow EOS for example, may see Satoshi has a hack that developed a failed project, yet will react fiercely to the slightest criticism of EOS, a reaction so strong that it’s reserved only for an attack on one’s deity. Those that follow IOTA react with equal fierceness; and there are many others.
-
-These adherents have abandoned objectivity and reasonable discourse, and allowed their zealotry to cloud their vision. Any discussion of these projects and the people behind them that doesn’t include glowing praise inevitably ends with a level of vitriolic speech that is beyond reason for a discussion of technology.
-
-This is dangerous, for many reasons:
-
- * Developers & researchers are blinded to flaws. Due to the vast quantities of praise by adherents, those involved develop a grandiose view of their own abilities, and begin to view criticism as unjustified attacks – as they couldn’t possibly have been wrong.
- * Real problems are attacked. Instead of technical issues being seen as problems to be solved and opportunities to improve, they are seen as attacks from people who must be motivated to destroy the project.
- * One coin to rule them all. Adherents are often aligned to one, and only one, saint. Acknowledging the qualities of another project means acceptance of flaws or deficiencies in their own, which they will not do.
- * Preventing real progress. Evolution is brutal, it requires death, it requires projects to fail and that the reasons for those failures to be acknowledged. If lessons from failure are ignored, if things that should die aren’t allowed to, progress stalls.
-
-
-
-Discussions around many of the cryptocurrencies and related blockchain projects are becoming more and more toxic, becoming impossible for well-intentioned people to have real technical discussions without being attacked. With discussions of real flaws, flaws that would doom a design in any other environment, being instantly treated as heretical without any analysis to determine the factual claims becoming routine, the cost for the well-intentioned to get involved has become extremely high. There are at least some that are aware of significant security flaws that have opted to remain silent due to the highly toxic environment.
-
-What was once driven by curiosity, a desire to learn and improve, to determine the viability of ideas, is now driven by blind greed, religious zealotry, self-righteousness, and self-aggrandizement.
-
-I have precious little hope for the future of projects that inspire this type of zealotry, and its continuous spread will likely harm real research in this area for many years to come. These are technical projects, some projects succeed, some fail – this is how technology evolves. Those designing these systems are human, just as flawed as the rest of us, and so too are the projects flawed. Some are well suited to certain use cases and not others, some aren’t suited to any use case, none yet are suited to all. The discussions about these projects should be focused on the technical aspects, and done so to evolve this field of research; adding a religious to these projects harms all.
-
-[Note: There are many examples of this behavior that could be cited, however in the interest of protecting those that have been targeted for criticizing projects, I have opted to minimize such examples. I have seen too many people who I respect, too many that I consider friends, being viciously attacked – I have no desire to draw attention to those attacks, and risk restarting them.]
-
-
-
---------------------------------------------------------------------------------
-
-via: https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/
-
-作者:[Adam Caudill][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://adamcaudill.com/author/adam/
-[1]:https://en.wikipedia.org/wiki/Merkle_tree
-[2]:https://hackernoon.com/how-crypto-kitties-disrupted-the-ethereum-network-845c22aa1e6e
-[3]:https://blockchain.info/block-height/528249
-[4]:https://en.wikipedia.org/wiki/An_Exceptionally_Simple_Theory_of_Everything
-[5]:https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be
-[6]:https://twitter.com/nondualrandy/status/1009609117768605696?ref_src=twsrc%5Etfw
-[7]:https://en.wikipedia.org/wiki/Numerology
diff --git a/sources/tech/20180622 How to Check Disk Space on Linux from the Command Line.md b/sources/tech/20180622 How to Check Disk Space on Linux from the Command Line.md
deleted file mode 100644
index c69e6459fc..0000000000
--- a/sources/tech/20180622 How to Check Disk Space on Linux from the Command Line.md
+++ /dev/null
@@ -1,181 +0,0 @@
-How to Check Disk Space on Linux from the Command Line
-======
-
-
-
-Quick question: How much space do you have left on your drives? A little or a lot? Follow up question: Do you know how to find out? If you happen to use a GUI desktop (e.g., GNOME, KDE, Mate, Pantheon, etc.), the task is probably pretty simple. But what if you’re looking at a headless server, with no GUI? Do you need to install tools for the task? The answer is a resounding no. All the necessary bits are already in place to help you find out exactly how much space remains on your drives. In fact, you have two very easy-to-use options at the ready.
-
-In this article, I’ll demonstrate these tools. I’ll be using [Elementary OS][1], which also includes a GUI option, but we’re going to limit ourselves to the command line. The good news is these command-line tools are readily available for every Linux distribution. On my testing system, there are a number of attached drives (both internal and external). The commands used are agnostic to where a drive is plugged in; they only care that the drive is mounted and visible to the operating system.
-
-With that said, let’s take a look at the tools.
-
-### df
-
-The df command is the tool I first used to discover drive space on Linux, way back in the 1990s. It’s very simple in both usage and reporting. To this day, df is my go-to command for this task. This command has a few switches but, for basic reporting, you really only need one. That command is df -H. The -H switch is for human-readable format. The output of df -H will report how much space is used, available, percentage used, and the mount point of every disk attached to your system (Figure 1).
-
-
-![df output][3]
-
-Figure 1: The output of df -H on my Elementary OS system.
-
-[Used with permission][4]
-
-What if your list of drives is exceedingly long and you just want to view the space used on a single drive? With df, that is possible. Let’s take a look at how much space has been used up on our primary drive, located at /dev/sda1. To do that, issue the command:
-```
-df -H /dev/sda1
-
-```
-
-The output will be limited to that one drive (Figure 2).
-
-
-![disk usage][6]
-
-Figure 2: How much space is on one particular drive?
-
-[Used with permission][4]
-
-You can also limit the reported fields shown in the df output. Available fields are:
-
- * source — the file system source
-
- * size — total number of blocks
-
- * used — spaced used on a drive
-
- * avail — space available on a drive
-
- * pcent — percent of used space, divided by total size
-
- * target — mount point of a drive
-
-
-
-
-Let’s display the output of all our drives, showing only the size, used, and avail (or availability) fields. The command for this would be:
-```
-df -H --output=size,used,avail
-
-```
-
-The output of this command is quite easy to read (Figure 3).
-
-
-![output][8]
-
-Figure 3: Specifying what output to display for our drives.
-
-[Used with permission][4]
-
-The only caveat here is that we don’t know the source of the output, so we’d want to include source like so:
-```
-df -H --output=source,size,used,avail
-
-```
-
-Now the output makes more sense (Figure 4).
-
-![source][10]
-
-Figure 4: We now know the source of our disk usage.
-
-[Used with permission][4]
-
-### du
-
-Our next command is du. As you might expect, that stands for disk usage. The du command is quite different to the df command, in that it reports on directories and not drives. Because of this, you’ll want to know the names of directories to be checked. Let’s say I have a directory containing virtual machine files on my machine. That directory is /media/jack/HALEY/VIRTUALBOX. If I want to find out how much space is used by that particular directory, I’d issue the command:
-```
-du -h /media/jack/HALEY/VIRTUALBOX
-
-```
-
-The output of the above command will display the size of every file in the directory (Figure 5).
-
-![du command][12]
-
-Figure 5: The output of the du command on a specific directory.
-
-[Used with permission][4]
-
-So far, this command isn’t all that helpful. What if we want to know the total usage of a particular directory? Fortunately, du can handle that task. On the same directory, the command would be:
-```
-du -sh /media/jack/HALEY/VIRTUALBOX/
-
-```
-
-Now we know how much total space the files are using up in that directory (Figure 6).
-
-![space used][14]
-
-Figure 6: My virtual machine files are using 559GB of space.
-
-[Used with permission][4]
-
-You can also use this command to see how much space is being used on all child directories of a parent, like so:
-```
-du -h /media/jack/HALEY
-
-```
-
-The output of this command (Figure 7) is a good way to find out what subdirectories are hogging up space on a drive.
-
-![directories][16]
-
-Figure 7: How much space are my subdirectories using?
-
-[Used with permission][4]
-
-The du command is also a great tool to use in order to see a list of directories that are using the most disk space on your system. The way to do this is by piping the output of du to two other commands: sort and head. The command to find out the top 10 directories eating space on a drive would look something like this:
-```
-du -a /media/jack | sort -n -r | head -n 10
-
-```
-
-The output would list out those directories, from largest to least offender (Figure 8).
-
-![top users][18]
-
-Figure 8: Our top ten directories using up space on a drive.
-
-[Used with permission][4]
-
-### Not as hard as you thought
-
-Finding out how much space is being used on your Linux-attached drives is quite simple. As long as your drives are mounted to the Linux system, both df and du will do an outstanding job of reporting the necessary information. With df you can quickly see an overview of how much space is used on a disk and with du you can discover how much space is being used by specific directories. These two tools in combination should be considered must-know for every Linux administrator.
-
-And, in case you missed it, I recently showed how to [determine your memory usage on Linux][19]. Together, these tips will go a long way toward helping you successfully manage your Linux servers.
-
-Learn more about Linux through the free ["Introduction to Linux"][20]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
-
-作者:[Jack Wallen][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/jlwallen
-[1]:https://elementary.io/
-[2]:/files/images/diskspace1jpg
-[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_1.jpg?itok=aJa8AZAM (df output)
-[4]:https://www.linux.com/licenses/category/used-permission
-[5]:/files/images/diskspace2jpg
-[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_2.jpg?itok=_PAq3kxC (disk usage)
-[7]:/files/images/diskspace3jpg
-[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_3.jpg?itok=51m8I-Vu (output)
-[9]:/files/images/diskspace4jpg
-[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_4.jpg?itok=SuwgueN3 (source)
-[11]:/files/images/diskspace5jpg
-[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_5.jpg?itok=XfS4s7Zq (du command)
-[13]:/files/images/diskspace6jpg
-[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_6.jpg?itok=r71qICyG (space used)
-[15]:/files/images/diskspace7jpg
-[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_7.jpg?itok=PtDe4q5y (directories)
-[17]:/files/images/diskspace8jpg
-[18]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_8.jpg?itok=v9E1SFcC (top users)
-[19]:https://www.linux.com/learn/5-commands-checking-memory-usage-linux
-[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180623 Don-t Install Yaourt- Use These Alternatives for AUR in Arch Linux.md b/sources/tech/20180623 Don-t Install Yaourt- Use These Alternatives for AUR in Arch Linux.md
index b2e4eed821..b75b94c78e 100644
--- a/sources/tech/20180623 Don-t Install Yaourt- Use These Alternatives for AUR in Arch Linux.md
+++ b/sources/tech/20180623 Don-t Install Yaourt- Use These Alternatives for AUR in Arch Linux.md
@@ -1,3 +1,4 @@
+[Moelf](https://github.com/moelf/) Translating
Don’t Install Yaourt! Use These Alternatives for AUR in Arch Linux
======
**Brief: Yaourt had been the most popular AUR helper, but it is not being developed anymore. In this article, we list out some of the best alternatives to Yaourt for Arch based Linux distributions. **
diff --git a/sources/tech/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md b/sources/tech/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md
deleted file mode 100644
index 660e71642f..0000000000
--- a/sources/tech/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md
+++ /dev/null
@@ -1,294 +0,0 @@
-Translating by qhwdw
-Intercepting and Emulating Linux System Calls with Ptrace « null program
-======
-
-The `ptrace(2)` (“process trace”) system call is usually associated with debugging. It’s the primary mechanism through which native debuggers monitor debuggees on unix-like systems. It’s also the usual approach for implementing [strace][1] — system call trace. With Ptrace, tracers can pause tracees, [inspect and set registers and memory][2], monitor system calls, or even intercept system calls.
-
-By intercept, I mean that the tracer can mutate system call arguments, mutate the system call return value, or even block certain system calls. Reading between the lines, this means a tracer can fully service system calls itself. This is particularly interesting because it also means **a tracer can emulate an entire foreign operating system**. This is done without any special help from the kernel beyond Ptrace.
-
-The catch is that a process can only have one tracer attached at a time, so it’s not possible emulate a foreign operating system while also debugging that process with, say, GDB. The other issue is that emulated systems calls will have higher overhead.
-
-For this article I’m going to focus on [Linux’s Ptrace][3] on x86-64, and I’ll be taking advantage of a few Linux-specific extensions. For the article I’ll also be omitting error checks, but the full source code listings will have them.
-
-You can find runnable code for the examples in this article here:
-
-****
-
-### strace
-
-Before getting into the really interesting stuff, let’s start by reviewing a bare bones implementation of strace. It’s [no DTrace][4], but strace is still incredibly useful.
-
-Ptrace has never been standardized. Its interface is similar across different operating systems, especially in its core functionality, but it’s still subtly different from system to system. The `ptrace(2)` prototype generally looks something like this, though the specific types may be different.
-```
-long ptrace(int request, pid_t pid, void *addr, void *data);
-
-```
-
-The `pid` is the tracee’s process ID. While a tracee can have only one tracer attached at a time, a tracer can be attached to many tracees.
-
-The `request` field selects a specific Ptrace function, just like the `ioctl(2)` interface. For strace, only two are needed:
-
- * `PTRACE_TRACEME`: This process is to be traced by its parent.
- * `PTRACE_SYSCALL`: Continue, but stop at the next system call entrance or exit.
- * `PTRACE_GETREGS`: Get a copy of the tracee’s registers.
-
-
-
-The other two fields, `addr` and `data`, serve as generic arguments for the selected Ptrace function. One or both are often ignored, in which case I pass zero.
-
-The strace interface is essentially a prefix to another command.
-```
-$ strace [strace options] program [arguments]
-
-```
-
-My minimal strace doesn’t have any options, so the first thing to do — assuming it has at least one argument — is `fork(2)` and `exec(2)` the tracee process on the tail of `argv`. But before loading the target program, the new process will inform the kernel that it’s going to be traced by its parent. The tracee will be paused by this Ptrace system call.
-```
-pid_t pid = fork();
-switch (pid) {
- case -1: /* error */
- FATAL("%s", strerror(errno));
- case 0: /* child */
- ptrace(PTRACE_TRACEME, 0, 0, 0);
- execvp(argv[1], argv + 1);
- FATAL("%s", strerror(errno));
-}
-
-```
-
-The parent waits for the child’s `PTRACE_TRACEME` using `wait(2)`. When `wait(2)` returns, the child will be paused.
-```
-waitpid(pid, 0, 0);
-
-```
-
-Before allowing the child to continue, we tell the operating system that the tracee should be terminated along with its parent. A real strace implementation may want to set other options, such as `PTRACE_O_TRACEFORK`.
-```
-ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
-
-```
-
-All that’s left is a simple, endless loop that catches on system calls one at a time. The body of the loop has four steps:
-
- 1. Wait for the process to enter the next system call.
- 2. Print a representation of the system call.
- 3. Allow the system call to execute and wait for the return.
- 4. Print the system call return value.
-
-
-
-The `PTRACE_SYSCALL` request is used in both waiting for the next system call to begin, and waiting for that system call to exit. As before, a `wait(2)` is needed to wait for the tracee to enter the desired state.
-```
-ptrace(PTRACE_SYSCALL, pid, 0, 0);
-waitpid(pid, 0, 0);
-
-```
-
-When `wait(2)` returns, the registers for the thread that made the system call are filled with the system call number and its arguments. However, the operating system has not yet serviced this system call. This detail will be important later.
-
-The next step is to gather the system call information. This is where it gets architecture specific. On x86-64, [the system call number is passed in `rax`][5], and the arguments (up to 6) are passed in `rdi`, `rsi`, `rdx`, `r10`, `r8`, and `r9`. Reading the registers is another Ptrace call, though there’s no need to `wait(2)` since the tracee isn’t changing state.
-```
-struct user_regs_struct regs;
-ptrace(PTRACE_GETREGS, pid, 0, ®s);
-long syscall = regs.orig_rax;
-
-fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
- syscall,
- (long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
- (long)regs.r10, (long)regs.r8, (long)regs.r9);
-
-```
-
-There’s one caveat. For [internal kernel purposes][6], the system call number is stored in `orig_rax` rather than `rax`. All the other system call arguments are straightforward.
-
-Next it’s another `PTRACE_SYSCALL` and `wait(2)`, then another `PTRACE_GETREGS` to fetch the result. The result is stored in `rax`.
-```
-ptrace(PTRACE_GETREGS, pid, 0, ®s);
-fprintf(stderr, " = %ld\n", (long)regs.rax);
-
-```
-
-The output from this simple program is very crude. There is no symbolic name for the system call and every argument is printed numerically, even if it’s a pointer to a buffer. A more complete strace would know which arguments are pointers and use `process_vm_readv(2)` to read those buffers from the tracee in order to print them appropriately.
-
-However, this does lay the groundwork for system call interception.
-
-### System call interception
-
-Suppose we want to use Ptrace to implement something like OpenBSD’s [`pledge(2)`][7], in which [a process pledges to use only a restricted set of system calls][8]. The idea is that many programs typically have an initialization phase where they need lots of system access (opening files, binding sockets, etc.). After initialization they enter a main loop in which they processing input and only a small set of system calls are needed.
-
-Before entering this main loop, a process can limit itself to the few operations that it needs. If [the program has a flaw][9] allowing it to be exploited by bad input, the pledge significantly limits what the exploit can accomplish.
-
-Using the same strace model, rather than print out all system calls, we could either block certain system calls or simply terminate the tracee when it misbehaves. Termination is easy: just call `exit(2)` in the tracer. Since it’s configured to also terminate the tracee. Blocking the system call and allowing the child to continue is a little trickier.
-
-The tricky part is that **there’s no way to abort a system call once it’s started**. When tracer returns from `wait(2)` on the entrance to the system call, the only way to stop a system call from happening is to terminate the tracee.
-
-However, not only can we mess with the system call arguments, we can change the system call number itself, converting it to a system call that doesn’t exist. On return we can report a “friendly” `EPERM` error in `errno` [via the normal in-band signaling][10].
-```
-for (;;) {
- /* Enter next system call */
- ptrace(PTRACE_SYSCALL, pid, 0, 0);
- waitpid(pid, 0, 0);
-
- struct user_regs_struct regs;
- ptrace(PTRACE_GETREGS, pid, 0, ®s);
-
- /* Is this system call permitted? */
- int blocked = 0;
- if (is_syscall_blocked(regs.orig_rax)) {
- blocked = 1;
- regs.orig_rax = -1; // set to invalid syscall
- ptrace(PTRACE_SETREGS, pid, 0, ®s);
- }
-
- /* Run system call and stop on exit */
- ptrace(PTRACE_SYSCALL, pid, 0, 0);
- waitpid(pid, 0, 0);
-
- if (blocked) {
- /* errno = EPERM */
- regs.rax = -EPERM; // Operation not permitted
- ptrace(PTRACE_SETREGS, pid, 0, ®s);
- }
-}
-
-```
-
-This simple example only checks against a whitelist or blacklist of system calls. And there’s no nuance, such as allowing files to be opened (`open(2)`) read-only but not as writable, allowing anonymous memory maps but not non-anonymous mappings, etc. There’s also no way to the tracee to dynamically drop privileges.
-
-How could the tracee communicate to the tracer? Use an artificial system call!
-
-### Creating an artificial system call
-
-For my new pledge-like system call — which I call `xpledge()` to distinguish it from the real thing — I picked system call number 10000, a nice high number that’s unlikely to ever be used for a real system call.
-```
-#define SYS_xpledge 10000
-
-```
-
-Just for demonstration purposes, I put together a minuscule interface that’s not good for much in practice. It has little in common with OpenBSD’s `pledge(2)`, which uses a [string interface][11]. Actually designing robust and secure sets of privileges is really complicated, as the `pledge(2)` manpage shows. Here’s the entire interface and implementation of the system call for the tracee:
-```
-#define _GNU_SOURCE
-#include
-
-#define XPLEDGE_RDWR (1 << 0)
-#define XPLEDGE_OPEN (1 << 1)
-
-#define xpledge(arg) syscall(SYS_xpledge, arg)
-
-```
-
-If it passes zero for the argument, only a few basic system calls are allowed, including those used to allocate memory (e.g. `brk(2)`). The `PLEDGE_RDWR` bit allows [various][12] read and write system calls (`read(2)`, `readv(2)`, `pread(2)`, `preadv(2)`, etc.). The `PLEDGE_OPEN` bit allows `open(2)`.
-
-To prevent privileges from being escalated back, `pledge()` blocks itself — though this also prevents dropping more privileges later down the line.
-
-In the xpledge tracer, I just need to check for this system call:
-```
-/* Handle entrance */
-switch (regs.orig_rax) {
- case SYS_pledge:
- register_pledge(regs.rdi);
- break;
-}
-
-```
-
-The operating system will return `ENOSYS` (Function not implemented) since this isn’t a real system call. So on the way out I overwrite this with a success (0).
-```
-/* Handle exit */
-switch (regs.orig_rax) {
- case SYS_pledge:
- ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
- break;
-}
-
-```
-
-I wrote a little test program that opens `/dev/urandom`, makes a read, tries to pledge, then tries to open `/dev/urandom` a second time, then confirms it can read from the original `/dev/urandom` file descriptor. Running without a pledge tracer, the output looks like this:
-```
-$ ./example
-fread("/dev/urandom")[1] = 0xcd2508c7
-XPledging...
-XPledge failed: Function not implemented
-fread("/dev/urandom")[2] = 0x0be4a986
-fread("/dev/urandom")[1] = 0x03147604
-
-```
-
-Making an invalid system call doesn’t crash an application. It just fails, which is a rather convenient fallback. When run under the tracer, it looks like this:
-```
-$ ./xpledge ./example
-fread("/dev/urandom")[1] = 0xb2ac39c4
-XPledging...
-fopen("/dev/urandom")[2]: Operation not permitted
-fread("/dev/urandom")[1] = 0x2e1bd1c4
-
-```
-
-The pledge succeeds but the second `fopen(3)` does not since the tracer blocked it with `EPERM`.
-
-This concept could be taken much further, to, say, change file paths or return fake results. A tracer could effectively chroot its tracee, prepending some chroot path to the root of any path passed through a system call. It could even lie to the process about what user it is, claiming that it’s running as root. In fact, this is exactly how the [Fakeroot NG][13] program works.
-
-### Foreign system emulation
-
-Suppose you don’t just want to intercept some system calls, but all system calls. You’ve got [a binary intended to run on another operating system][14], so none of the system calls it makes will ever work.
-
-You could manage all this using only what I’ve described so far. The tracer would always replace the system call number with a dummy, allow it to fail, then service the system call itself. But that’s really inefficient. That’s essentially three context switches for each system call: one to stop on the entrance, one to make the always-failing system call, and one to stop on the exit.
-
-The Linux version of PTrace has had a more efficient operation for this technique since 2005: `PTRACE_SYSEMU`. PTrace stops only once per a system call, and it’s up to the tracer to service that system call before allowing the tracee to continue.
-```
-for (;;) {
- ptrace(PTRACE_SYSEMU, pid, 0, 0);
- waitpid(pid, 0, 0);
-
- struct user_regs_struct regs;
- ptrace(PTRACE_GETREGS, pid, 0, ®s);
-
- switch (regs.orig_rax) {
- case OS_read:
- /* ... */
-
- case OS_write:
- /* ... */
-
- case OS_open:
- /* ... */
-
- case OS_exit:
- /* ... */
-
- /* ... and so on ... */
- }
-}
-
-```
-
-To run binaries for the same architecture from any system with a stable (enough) system call ABI, you just need this `PTRACE_SYSEMU` tracer, a loader (to take the place of `exec(2)`), and whatever system libraries the binary needs (or only run static binaries).
-
-In fact, this sounds like a fun weekend project.
-
---------------------------------------------------------------------------------
-
-via: http://nullprogram.com/blog/2018/06/23/
-
-作者:[Chris Wellons][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://nullprogram.com
-[1]:https://blog.plover.com/Unix/strace-groff.html
-[2]:http://nullprogram.com/blog/2016/09/03/
-[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
-[4]:http://nullprogram.com/blog/2018/01/17/
-[5]:http://nullprogram.com/blog/2015/05/15/
-[6]:https://stackoverflow.com/a/6469069
-[7]:https://man.openbsd.org/pledge.2
-[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
-[9]:http://nullprogram.com/blog/2017/07/19/
-[10]:http://nullprogram.com/blog/2016/09/23/
-[11]:https://www.tedunangst.com/flak/post/string-interfaces
-[12]:http://nullprogram.com/blog/2017/03/01/
-[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
-[14]:http://nullprogram.com/blog/2017/11/30/
diff --git a/sources/tech/20180625 How To Upgrade Everything Using A Single Command In Linux.md b/sources/tech/20180625 How To Upgrade Everything Using A Single Command In Linux.md
deleted file mode 100644
index 599185befb..0000000000
--- a/sources/tech/20180625 How To Upgrade Everything Using A Single Command In Linux.md
+++ /dev/null
@@ -1,125 +0,0 @@
-translating-----geekpi
-
-How To Upgrade Everything Using A Single Command In Linux
-======
-
-
-
-As we all know already, keeping our Linux system up-to-date involves invoking more than one package manager. Say for instance, in Ubuntu you can’t upgrade everything using “sudo apt update && sudo apt upgrade” command. This command will only upgrade the applications which are installed using APT package manager. There are chances that you might have installed some other applications using **cargo** , [**pip**][1], **npm** , **snap** , **flatpak** or [**Linuxbrew**][2] package managers. You need to use the respective package manager in order to keep them all updated. Not anymore! Say hello to **“topgrade”** , an utility to upgrade all the things in your system in one go.
-
-You need not to run every package manager to update the packages. The topgrade tool resolves this problem by detecting the installed packages, tools, plugins and run their appropriate package manager to update everything in your Linux box with a single command. It is free, open source and written using **rust programming language**. It supports GNU/Linux and Mac OS X.
-
-### Upgrade Everything Using A Single Command In Linux
-
-The topgrade is available in AUR. So, you can install it using [**Yay**][3] helper program in any Arch-based systems.
-```
-$ yay -S topgrade
-
-```
-
-On other Linux distributions, you can install topgrade utility using **cargo** package manager. To install cargo package manager, refer the following link.
-
-And, then run the following command to install topgrade.
-```
-$ cargo install topgrade
-
-```
-
-Once installed, run the topgrade to upgrade all the things in your Linux system.
-```
-$ topgrade
-
-```
-
-Once topgrade is invoked, it will perform the following tasks one by one. You will be asked to enter root/sudo user password wherever necessary.
-
-1 Run your system’s package manager:
-
- * Arch: Run **yay** or fall back to [**pacman**][4]
- * CentOS/RHEL: Run `yum upgrade`
- * Fedora – Run `dnf upgrade`
- * Debian/Ubuntu: Run `apt update && apt dist-upgrade`
- * Linux/macOS: Run `brew update && brew upgrade`
-
-
-
-2\. Check if the following paths are tracked by Git. If so, pull them:
-
- * ~/.emacs.d (Should work whether you use **Spacemacs** or a custom configuration)
- * ~/.zshrc
- * ~/.oh-my-zsh
- * ~/.tmux
- * ~/.config/fish/config.fish
- * Custom defined paths
-
-
-
-3\. Unix: Run **zplug** update
-
-4\. Unix: Upgrade **tmux** plugins with **TPM**
-
-5\. Run **Cargo install-update**
-
-6\. Upgrade **Emacs** packages
-
-7\. Upgrade Vim packages. Works with the following plugin frameworks:
-
- * NeoBundle
- * [**Vundle**][5]
- * Plug
-
-
-
-8\. Upgrade [**NPM**][6] globally installed packages
-
-9\. Upgrade **Atom** packages
-
-10\. Update [**Flatpak**][7] packages
-
-11\. Update [**snap**][8] packages
-
-12\. **Linux:** Run **fwupdmgr** to show firmware upgrade. (View only. No upgrades will actually be performed)
-
-13\. Run custom defined commands.
-
-Finally, topgrade utility will run **needrestart** to restart all services. In Mac OS X, it will upgrade App Store applications.
-
-Sample output from my Ubuntu 18.04 LTS test box:
-
-![][10]
-
-The good thing is if one task is failed, it will automatically run the next task and complete all other subsequent tasks. Finally, it will display the summary with details such as how many tasks did it run, how many succeeded and how many failed etc.
-
-![][11]
-
-**Suggested read:**
-
-Personally, I liked this idea of creating an utility like topgrade and upgrade everything installed with various package managers with a single command. I hope you find it useful too. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
-[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
-[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
-[4]:https://www.ostechnix.com/getting-started-pacman/
-[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
-[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
-[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
-[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
-[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
-[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
diff --git a/sources/tech/20180628 Blockchain evolution- A quick guide and why open source is at the heart of it.md b/sources/tech/20180628 Blockchain evolution- A quick guide and why open source is at the heart of it.md
deleted file mode 100644
index 01f9abb44a..0000000000
--- a/sources/tech/20180628 Blockchain evolution- A quick guide and why open source is at the heart of it.md
+++ /dev/null
@@ -1,98 +0,0 @@
-Translating by qhwdw
-Blockchain evolution: A quick guide and why open source is at the heart of it
-======
-
-
-
-It isn't uncommon, when working on a new version of an open source project, to suffix it with "-ng", for "next generation." Fortunately, in their rapid evolution blockchains have so far avoided this naming pitfall. But in this evolutionary open source ecosystem, changes have been abundant, and good ideas have been picked up, remixed, and evolved between many different projects in a typical open source fashion.
-
-In this article, I will look at the different generations of blockchains and what ideas have emerged to address the problems the ecosystem has encountered. Of course, any attempt at classifying an ecosystem will have limits—and objectors—but it should provide a rough guide to the jungle of blockchain projects.
-
-### The beginning: Bitcoin
-
-The first generation of blockchains stems from the [Bitcoin][1] blockchain, the ledger underpinning the decentralized, peer-to-peer cryptocurrency that has gone from [Slashdot][2] miscellanea to a mainstream topic.
-
-This blockchain is a distributed ledger that keeps track of all users' transactions to prevent them from double-spending their coins (a task historically entrusted to third parties: banks). To prevent attackers from gaming the system, the ledger is replicated to every computer participating in the Bitcoin network and can be updated by only one computer in the network at a time. To decide which computer earns the right to update the ledger, the system organizes every 10 minutes a race between the computers, which costs them (a lot of) energy to enter. The winner wins the right to commit the last 10 minutes of transactions to the ledger (the "block" in blockchain) and some Bitcoin as a reward for their efforts. This setup is called a _proof of work_ consensus mechanism.
-
-The goal of using a blockchain is to raise the level of trust participants have in the network.
-
-This is where it gets interesting. Bitcoin was released as an [open source project][3] in January 2009. In 2010, realizing that quite a few of these elements can be tweaked, the community that had aggregated around Bitcoin, often on the [bitcointalk forums][4], started experimenting with them.
-
-First, seeing that the Bitcoin blockchain is a form of a distributed database, the [Namecoin][5] project emerged, suggesting to store arbitrary data in its transaction database. If the blockchain can record the transfer of money, it could also record the transfer of other assets, such as domain names. This is exactly Namecoin's main use case, which went live in April 2011, two years after Bitcoin's introduction.
-
-Where Namecoin tweaked the content of the blockchain, [Litecoin][6] tweaked two technical aspects: reducing the time between two blocks from 10 to 2.5 minutes and changing how the race is run (replacing the SHA-256 secure hashing algorithm with [scrypt][7]). This was possible because Bitcoin was released as open source software and Litecoin is essentially identical to Bitcoin in all other places. Litecoin was the first fork to modify the consensus mechanism, paving the way for many more.
-
-Along the way, many more variations of the Bitcoin codebase have appeared. Some started as proposed extensions to Bitcoin, such as the [Zerocash][8] protocol, which aimed to provide transaction anonymity and fungibility but was eventually spun off into its own currency, [Zcash][9].
-
-While Zcash has brought its own innovations, using recent cryptographic advances known as zero-knowledge proofs, it maintains compatibility with the vast majority of the Bitcoin code base, meaning it too can benefit from upstream Bitcoin innovations.
-
-Another project, [CryptoNote][10], didn't use the same code base but sprouted from the same community, building on (and against) Bitcoin and again, on older ideas. Published in December 2012, it led to the creation of several cryptocurrencies, of which [Monero][11] (2014) is the best-known. Monero takes a different approach to Zcash but aims to solve the same issues: privacy and fungibility.
-
-As is often the case in the open source world, there is more than one tool for the job.
-
-### The next generations: "Blockchain-ng"
-
-So far, however, all these variations have only really been about refining cryptocurrencies or extending them to support another type of transaction. This brings us to the second generation of blockchains.
-
-Once the community started modifying what a blockchain could be used for and tweaking technical aspects, it didn't take long for some people to expand and rethink them further. A longtime follower of Bitcoin, [Vitalik Buterin][12] suggested in late 2013 that a blockchain's transactions could represent the change of states of a state machine, conceiving the blockchain as a distributed computer capable of running applications ("smart contracts"). The project, [Ethereum][13], went live in July 2015. It has seen fair success in running distributed apps, and the popularity of some of its better-known distributed apps ([CryptoKitties][14]) have even caused the Ethereum blockchain to slow down.
-
-This demonstrates one of the big limitations of current blockchains: speed and capacity. (Speed is often measured in transactions per second, or TPS.) Several approaches have been suggested to solve this, from sharding to sidechains and so-called "second-layer" solutions. The need for more innovation here is strong.
-
-With the words "smart contract" in the air and a proved—if still slow—technology to run them, another idea came to fruition: permissioned blockchains. So far, all the blockchain networks we've described have had two unsaid characteristics: They are public (anyone can see them function), and they are without permission (anyone can join them). These two aspects are both desirable and necessary to run a distributed, non-third-party-based currency.
-
-As blockchains were being considered more and more separately from cryptocurrencies, it started to make sense to consider them in some private, permissioned settings. A consortium-type group of actors that have business relationships but don't necessarily trust each other fully can benefit from these types of blockchains—for example, actors along a logistics chain, financial or insurance institutions that regularly do bilateral settlements or use a clearinghouse, idem for healthcare institutions.
-
-Once you change the setting from "anyone can join" to "invitation-only," further changes and tweaks to the blockchain building blocks become possible, yielding interesting results for some.
-
-For a start, proof of work, designed to protect the network from malicious and spammy actors, can be replaced by something simpler and less resource-hungry, such as a [Raft][15]-based consensus protocol. A tradeoff appears between a high level of security or faster speed, embodied by the option of simpler consensus algorithms. This is highly desirable to many groups, as they can trade some cryptography-based assurance for assurance based on other means—legal relationships, for instance—and avoid the energy-hungry arms race that proof of work often leads to. This is another area where innovation is ongoing, with [Proof of Stake][16] a notable contender for the public network consensus mechanism of choice. It would likely also find its way to permissioned networks too.
-
-Several projects make it simple to create permissioned blockchains, including [Quorum][17] (a fork of Ethereum) and [Hyperledger][18]'s [Fabric][19] and [Sawtooth][20], two open source projects based on new code.
-
-Permissioned blockchains can avoid certain complexities that public, non-permissioned ones can't, but they still have their own set of issues. Proper management of participants is one: Who can join? How do they identify? How can they be removed from the network? Does one entity on the network manage a central public key infrastructure (PKI)?
-
-The open nature of blockchains is seen as a form of governance.
-
-### Open nature of blockchains
-
-In all of the cases so far, one thing is clear: The goal of using a blockchain is to raise the level of trust participants have in the network and the data it produces—ideally, enough to be able to use it as is, without further work.
-
-Reaching this level of trust is possible only if the software that powers the network is free and open source. Even a correctly distributed proprietary blockchain is essentially a collection of independent agents running the same third party's code. By nature, it's necessary—but not sufficient—for a blockchain's source code to be open source. This has both been a minimum guarantee and the source of further innovation as the ecosystem keeps growing.
-
-Finally, it is worth mentioning that while the open nature of blockchains has been a source of innovation and variation, it has also been seen as a form of governance: governance by code, where users are expected to run whichever specific version of the code contains a function or approach they think the whole network should embrace. In this respect, one can say the open nature of some blockchains has also become a cop-out regarding governance. But this is being addressed.
-
-### Third and fourth generations: governance
-
-Next, I will look at what I am currently considering the third and fourth generations of blockchains: blockchains with built-in governance tools and projects to solve the tricky question of interconnecting the multitude of different blockchain projects to let them exchange information and value with each other.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/blockchain-guide-next-generation
-
-作者:[Axel Simon][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/axel
-[1]:https://bitcoin.org
-[2]:https://slashdot.org/
-[3]:https://github.com/bitcoin/bitcoin
-[4]:https://bitcointalk.org/
-[5]:https://www.namecoin.org/
-[6]:https://litecoin.org/
-[7]:https://en.wikipedia.org/wiki/Scrypt
-[8]:http://zerocash-project.org/index
-[9]:https://z.cash
-[10]:https://cryptonote.org/
-[11]:https://en.wikipedia.org/wiki/Monero_(cryptocurrency)
-[12]:https://en.wikipedia.org/wiki/Vitalik_Buterin
-[13]:https://ethereum.org
-[14]:http://cryptokitties.co/
-[15]:https://en.wikipedia.org/wiki/Raft_(computer_science)
-[16]:https://www.investopedia.com/terms/p/proof-stake-pos.asp
-[17]:https://www.jpmorgan.com/global/Quorum
-[18]:https://hyperledger.org/
-[19]:https://www.hyperledger.org/projects/fabric
-[20]:https://www.hyperledger.org/projects/sawtooth
diff --git a/sources/tech/20180702 How to edit Adobe InDesign files with Scribus and Gedit.md b/sources/tech/20180702 How to edit Adobe InDesign files with Scribus and Gedit.md
deleted file mode 100644
index 3e8d2022c2..0000000000
--- a/sources/tech/20180702 How to edit Adobe InDesign files with Scribus and Gedit.md
+++ /dev/null
@@ -1,128 +0,0 @@
-How to edit Adobe InDesign files with Scribus and Gedit
-======
-
-
-
-To be a good graphic designer, you must be adept at using the profession's tools, which for most designers today are the ones in the proprietary Adobe Creative Suite.
-
-However, there are times that open source tools will get you out of a jam. For example, imagine you're a commercial printer tasked with printing a file created in Adobe InDesign. You need to make a simple change (e.g., fixing a small typo) to the file, but you don't have immediate access to the Adobe suite. While these situations are admittedly rare, open source tools like desktop publishing software [Scribus][1] and text editor [Gedit][2] can save the day.
-
-In this article, I'll show you how I edit Adobe InDesign files with Scribus and Gedit. Note that there are many open source graphic design solutions that can be used instead of or in conjunction with Adobe InDesign. For more on this subject, check out my articles: [Expensive tools aren't the only option for graphic design (and never were)][3] and [2 open][4][source][4][Adobe InDesign scripts][4].
-
-When developing this solution, I read a few blogs on how to edit InDesign files with open source software but did not find what I was looking for. One suggestion I found was to create an EPS from InDesign and open it as an editable file in Scribus, but that did not work. Another suggestion was to create an IDML (an older InDesign file format) document from InDesign and open that in Scribus. That worked much better, so that's the workaround I used in the following examples.
-
-### Editing a business card
-
-Opening and editing my InDesign business card file in Scribus worked fairly well. The only issue I had was that the tracking (the space between letters) was a bit off and the upside-down "J" I used to create the lower-case "f" in "Jeff" was flipped. Otherwise, the styles and colors were all intact.
-
-
-![Business card in Adobe InDesign][6]
-
-Business card designed in Adobe InDesign.
-
-![InDesign IDML file opened in Scribus][8]
-
-InDesign IDML file opened in Scribus.
-
-### Deleting copy in a paginated book
-
-The book conversion didn't go as well. The main body of the text was OK, but the table of contents and some of the drop caps and footers were messed up when I opened the InDesign file in Scribus. Still, it produced an editable document. One problem was some of my blockquotes defaulted to Arial font because a character style (apparently carried over from the original Word file) was on top of the paragraph style. This was simple to fix.
-
-![Book layout in InDesign][10]
-
-Book layout in InDesign.
-
-![InDesign IDML file of book layout opened in Scribus][12]
-
-InDesign IDML file of book layout opened in Scribus.
-
-Trying to select and delete a page of text produced surprising results. I placed the cursor in the text and hit Command+A (the keyboard shortcut for "select all"). It looked like one page was highlighted. However, that wasn't really true.
-
-![Selecting text in Scribus][14]
-
-Selecting text in Scribus.
-
-When I hit the Delete key, the entire text string (not just the highlighted page) disappeared.
-
-![Both pages of text deleted in Scribus][16]
-
-Both pages of text deleted in Scribus.
-
-Then something even more interesting happened… I hit Command+Z to undo the deletion. When the text came back, the formatting was messed up.
-
-![Undo delete restored the text, but with bad formatting.][18]
-
-Command+Z (undo delete) restored the text, but the formatting was bad.
-
-### Opening a design file in a text editor
-
-If you open a Scribus file and an InDesign file in a standard text editor (e.g., TextEdit on a Mac), you will see that the Scribus file is very readable whereas the InDesign file is not.
-
-You can use TextEdit to make changes to either type of file and save it, but the resulting file is useless. Here's the error I got when I tried re-opening the edited file in InDesign.
-
-![InDesign error message][20]
-
-InDesign error message.
-
-I got much better results when I used Gedit on my Linux Ubuntu machine to edit the Scribus file. I launched Gedit from the command line and voilà, the Scribus file opened, and the changes I made in Gedit were retained.
-
-![Editing Scribus file in Gedit][22]
-
-Editing a Scribus file in Gedit.
-
-![Result of the Gedit edit in Scribus][24]
-
-Result of the Gedit edit opened in Scribus.
-
-This could be very useful to a printer that receives a call from a client about a small typo in a project. Instead of waiting to get a new file, the printer could open the Scribus file in Gedit, make the change, and be good to go.
-
-### Dropping images into a file
-
-I converted an InDesign doc to an IDML file so I could try dropping in some PDFs using Scribus. It seems Scribus doesn't do this as well as InDesign, as it failed. Instead, I converted my PDFs to JPGs and imported them into Scribus. That worked great. However, when I exported my document as a PDF, I found that the files size was rather large.
-
-![Huge PDF file][26]
-
-Exporting Scribus to PDF produced a huge file.
-
-I'm not sure why this happened—I'll have to investigate it later.
-
-Do you have any tips for using open source software to edit graphics files? If so, please share them in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
-
-作者:[Jeff Macharyas][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/rikki-endsley
-[1]:https://www.scribus.net/
-[2]:https://wiki.gnome.org/Apps/Gedit
-[3]:https://opensource.com/life/16/8/open-source-alternatives-graphic-design
-[4]:https://opensource.com/article/17/3/scripts-adobe-indesign
-[5]:/file/402516
-[6]:https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png (Business card in Adobe InDesign)
-[7]:/file/402521
-[8]:https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png (InDesign IDML file opened in Scribus)
-[9]:/file/402531
-[10]:https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png (Book layout in InDesign)
-[11]:/file/402536
-[12]:https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png (InDesign IDML file of book layout opened in Scribus)
-[13]:/file/402541
-[14]:https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png (Selecting text in Scribus)
-[15]:/file/402546
-[16]:https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png (Both pages of text deleted in Scribus)
-[17]:/file/402551
-[18]:https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png (Undo delete restored the text, but with bad formatting.)
-[19]:/file/402556
-[20]:https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png (InDesign error message)
-[21]:/file/402561
-[22]:https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png (Editing Scribus file in Gedit)
-[23]:/file/402566
-[24]:https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png (Result of the Gedit edit in Scribus)
-[25]:/file/402571
-[26]:https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png (Huge PDF file)
diff --git a/sources/tech/20180703 Why is Arch Linux So Challenging and What are Its Pros - Cons.md b/sources/tech/20180703 Why is Arch Linux So Challenging and What are Its Pros - Cons.md
deleted file mode 100644
index 23ceb85dbe..0000000000
--- a/sources/tech/20180703 Why is Arch Linux So Challenging and What are Its Pros - Cons.md
+++ /dev/null
@@ -1,74 +0,0 @@
-Why is Arch Linux So Challenging and What are Its Pros & Cons?
-======
-
-
-
-[Arch Linux][1] is among the most popular Linux distributions and it was first released in **2002** , being spear-headed by **Aaron Grifin**. Yes, it aims to provide simplicity, minimalism, and elegance to the OS user but its target audience is not the faint of hearts. Arch encourages community involvement and a user is expected to put in some effort to better comprehend how the system operates.
-
-Many old-time Linux users know a good amount about **Arch Linux** but you probably don’t if you are new to it considering using it for your everyday computing tasks. I’m no authority on the distro myself but from my experience with it, here are the pros and cons you will experience while using it.
-
-### 1\. Pro: Build Your Own Linux OS
-
-Other popular Linux Operating Systems like **Fedora** and **Ubuntu** ship with computers, same as **Windows** and **MacOS**. **Arch** , on the other hand, allows you to develop your OS to your taste. If you are able to achieve this, you will end up with a system that will be able to do exactly as you wish.
-
-#### Con: Installation is a Hectic Process
-
-[Installing Arch Linux][2] is far from a walk in a park and since you will be fine-tuning the OS, it will take a while. You will need to have an understanding of various terminal commands and the components you will be working with since you are to pick them yourself. By now, you probably already know that this requires quite a bit of reading.
-
-### 2\. Pro: No Bloatware and Unnecessary Services
-
-Since **Arch** allows you to choose your own components, you no longer have to deal with a bunch of software you don’t want. In contrast, OSes like **Ubuntu** come with a huge number of pre-installed desktop and background apps which you may not need and might not be able to know that they exist in the first place, before going on to remove them.
-
-To put simply, **Arch Linux** saves you post-installation time. **Pacman** , an awesome utility app, is the package manager Arch Linux uses by default. There is an alternative to **Pacman** , called [Pamac][3].
-
-### 3\. Pro: No System Upgrades
-
-**Arch Linux** uses the rolling release model and that is awesome. It means that you no longer have to worry about upgrading every now and then. Once you install Arch, say goodbye to upgrading to a new version as updates occur continuously. By default, you will always be using the latest version.
-
-#### Con: Some Updates Can Break Your System
-
-While updates flow in continuously, you have to consciously track what comes in. Nobody knows your software’s specific configuration and it’s not tested by anyone but you. So, if you are not careful, things on your machine could break.
-
-### 4\. Pro: Arch is Community Based
-
-Linux users generally have one thing in common: The need for independence. Although most Linux distros have less corporate ties, there are still a few you cannot ignore. For instance, a distro based on **Ubuntu** is influenced by whatever decisions Canonical makes.
-
-If you are trying to become even more independent with the use of your computer, then **Arch Linux** is the way to go. Unlike most systems, Arch has no commercial influence and focuses on the community.
-
-### 5\. Pro: Arch Wiki is Awesome
-
-The [Arch Wiki][4] is a super library of everything you need to know about the installation and maintenance of every component in the Linux system. The great thing about this site is that even if you are using a different Linux distro from Arch, you would still find its information relevant. That’s simply because Arch uses the same components as many other Linux distros and its guides and fixes sometimes apply to all.
-
-### 6\. Pro: Check Out the Arch User Repository
-
-The [Arch User Repository (AUR)][5] is a huge collection of software packages from members of the community. If you are looking for a Linux program that is not yet available on Arch’s repositories, you can find it on the **AUR** for sure.
-
-The **AUR** is maintained by users who compile and install packages from source. Users are also allowed to vote on packages which give them (the packages i.e.) higher rankings that make them more visible to potential users.
-
-#### Ultimately: Is Arch Linux for You?
-
-**Arch Linux** has way more **pros** than **cons** including the ones that aren’t on this list. The installation process is long and probably too technical for a non-Linux savvy user, but with enough time on your hands and the ability to maximize productivity using wiki guides and the like, you should be good to go.
-
-**Arch Linux** is a great Linux distro – not in spite of its complexity, but because of it. And it appeals most to those who are ready to do what needs to be done – given that you will have to do your homework and exercise a good amount of patience.
-
-By the time you build this Operating System from scratch, you would have learned many details about GNU/Linux and would never be ignorant of what’s going on with your PC again.
-
-What are the **pros** and **cons** of using **Arch Linux** in your experience? And on the whole, why is using it so challenging? Drop your comments in the discussion section below.
-
---------------------------------------------------------------------------------
-
-via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
-
-作者:[Martins D. Okoi][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.fossmint.com/author/dillivine/
-[1]:https://www.archlinux.org/
-[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
-[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
-[4]:https://wiki.archlinux.org/
-[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
diff --git a/sources/tech/20180704 Install an NVIDIA GPU on almost any machine.md b/sources/tech/20180704 Install an NVIDIA GPU on almost any machine.md
deleted file mode 100644
index f7d0b1af51..0000000000
--- a/sources/tech/20180704 Install an NVIDIA GPU on almost any machine.md
+++ /dev/null
@@ -1,157 +0,0 @@
-translated by hopefully2333
-
-Install an NVIDIA GPU on almost any machine
-======
-
-
-
-Whether for research or recreation, installing a new GPU can bolster your computer’s performance and enable new functionality across the board. This installation guide uses Fedora 28’s brand-new third-party repositories to install NVIDIA drivers. It walks you through the installation of both software and hardware, and covers everything you need to get your NVIDIA card up and running. This process works for any UEFI-enabled computer, and any modern NVIDIA GPU.
-
-### Preparation
-
-This guide relies on the following materials:
-
- * A machine that is [UEFI][1] capable. If you’re uncertain whether your machine has this firmware, run sudo dmidecode -t 0. If “UEFI is supported” appears anywhere in the output, you are all set to continue. Otherwise, while it’s technically possible to update some computers to support UEFI, the process is often finicky and generally not recommended.
- * A modern, UEFI-enabled NVIDIA card
- * A power source that meets the wattage and wiring requirements for your NVIDIA card (see the Hardware & Modifications section for details)
- * Internet connection
- * Fedora 28
-
-
-
-### Example setup
-
-This example installation uses:
-
- * An Optiplex 9010 (a fairly old machine)
- * NVIDIA [GeForce GTX 1050 Ti XLR8 Gaming Overclocked Edition 4GB GDDR5 PCI Express 3.0][2] graphics card
- * In order to meet the power requirements of the new GPU, the power supply was upgraded to an [EVGA – 80 PLUS 600W ATX 12V/EPS 12V][3]. This new PSU was 300W above the minimum recommendation, but simply meeting the minimum recommendation is sufficient in most cases.
- * And, of course, Fedora 28.
-
-
-
-### Hardware and modifications
-
-#### PSU
-
-Open up your desktop case and check the maximum power output printed on your power supply. Next, check the documentation on your NVIDIA GPU and determine the minimum recommended power (in watts). Further, take a look at your GPU and see if it requires additional wiring, such as a 6-pin connector. Most entry-level GPUs only draw power directly from the motherboard, but some require extra juice. You’ll need to upgrade your PSU if:
-
- 1. Your power supply’s max power output is below the GPU’s suggested minimum power. **Note:** According to some NVIDIA card manufacturers, pre-built systems may require more or less power than recommended, depending on the system’s configuration. Use your discretion to determine your requirements if you’re using a particularly power-efficient or power-hungry setup.
- 2. Your power supply does not provide the necessary wiring to power your card.
-
-
-
-PSUs are straightforward to replace, but make sure to take note of the wiring layout before detaching your current power supply. Additionally, make sure to select a PSU that fits your desktop case.
-
-#### CPU
-
-Although installing a high-quality NVIDIA GPU is possible in many old machines, a slow or damaged CPU can “bottleneck” the performance of the GPU. To calculate the impact of the bottlenecking effect for your machine, click [here][4]. It’s important to know your CPU’s performance to avoid pairing a high-powered GPU with a CPU that can’t keep up. Upgrading your CPU is a potential consideration.
-
-#### Motherboard
-
-Before proceeding, ensure your motherboard is compatible with your GPU of choice. Your graphics card should be inserted into the PCI-E x16 slot closest to the heat-sink. Ensure that your setup contains enough space for the GPU. In addition, note that most GPUs today employ PCI-E 3.0 technology. Though these GPUs will run best if mounted on a PCI-E 3.0 x16 slot, performance should not suffer significantly with an older version slot.
-
-### Installation
-```
-sudo dnf update
-
-```
-
-2\. Next, reboot with the simple command:
-```
-reboot
-
-```
-
-3\. After reboot, install the Fedora 28 workstation repositories:
-```
-sudo dnf install fedora-workstation-repositories
-
-```
-
-4\. Next, enable the NVIDIA driver repository:
-```
-sudo dnf config-manager --set-enabled rpmfusion-nonfree-nvidia-driver
-
-```
-
-5\. Then, reboot again.
-
-6\. After the reboot, verify the addition of the repository via the following command:
-```
-sudo dnf repository-packages rpmfusion-nonfree-nvidia-driver info
-
-```
-
-If several NVIDIA tools and their respective specs are loaded, then proceed to the next step. If not, you may have encountered an error when adding the new repository and you should give it another shot.
-
-7\. Login, connect to the internet, and open the software app. Click Add-ons> Hardware Drivers> NVIDIA Linux Graphics Driver> Install.
-
-Then, reboot once again.
-
-8\. After reboot, go to ‘Show Applications’ on the side bar, and open up the newly added NVIDIA X Server Settings application. A GUI should open up, and a dialog box will appear with the following message:
-
-![NVIDIA X Server Prompt][5]
-
-Take the application’s advice, but before doing so, ensure you have your NVIDIA GPU on-hand and are ready to install. **Please note** that running nvidia xconfig as root and powering off without installing your GPU immediately may cause drastic damage. Doing so may prevent your computer from booting, and force you to repair the system through the reboot screen. A fresh install of Fedora may fix these issues, but the effects can be much worse.
-
-If you’re ready to proceed, enter the command:
-```
-sudo nvidia-xconfig
-
-```
-
-If the system prompts you to perform any downloads, accept them and proceed.
-
-9\. Once this process is complete, close all applications and **shut down** the computer. Unplug the power supply to your machine. Then, press the power button once to drain any residual power to protect yourself from electric shock. If your PSU has a power switch, switch it off.
-
-10\. Finally, install the graphics card. Remove the old GPU and insert your new NVIDIA graphics card into the proper PCI-E x16 slot, with the fans facing down. If there is no space for the fans to ventilate in this position, place the graphics card face up instead, if possible. When you have successfully installed the new GPU, close your case, plug in the PSU, and turn the computer on. It should successfully boot up.
-
-**NOTE:** To disable the NVIDIA driver repository used in this installation, or to disable all fedora workstation repositories, consult [The Fedora Wiki Page][6].
-
-### Verification
-
-1\. If your newly installed NVIDIA graphics card is connected to your monitor and displaying correctly, then your NVIDIA driver has successfully established a connection to the GPU.
-
-If you’d like to view your settings, or verify the driver is working (in the case that you have two GPUs installed on the motherboard), open up the NVIDIA X Server Settings app again. This time, you should not be prompted with an error message, and information on the X configuration file and your NVIDIA GPU should be available (see screenshot below).
-
-![NVIDIA X Server Settings][7]
-
-Through this app, you may alter your X configuration file should you please, and may monitor the GPU’s performance, clock speed, and thermal information.
-
-2\. To ensure the new card is working at capacity, a GPU performance test is needed. GL Mark 2, a benchmarking tool that provides information on buffering, building, lighting, texturing, etc, offers an excellent solution. GL Mark 2 records frame rates for a variety of different graphical tests, and outputs an overall performance score (called the glmark2 score).
-
-**Note:** glxgears will only test the performance of your screen or monitor, not the graphics card itself. Use GL Mark 2 instead.
-
-To run GLMark2:
-
- 1. Open up a terminal and close all other applications
- 2. sudo dnf install glmark2
- 3. glmark2
- 4. Allow the test to run to completion for best results. Check to see if the frame rates match your expectation for your NVIDA card. If you’d like additional verification, consult the web to determine if a glmark2 benchmark has been previously conducted on your NVIDA card model and published to the web. Compare scores to assess your GPUs performance.
- 5. If your framerates and/or glmark2 score are below expected, consider potential causes. CPU-induced bottlenecking? Other issues?
-
-
-
-Assuming the diagnostics look good, enjoy using your new GPU.
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/install-nvidia-gpu/
-
-作者:[Justice del Castillo][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/justice/
-[1]:https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI
-[2]:https://www.cnet.com/products/pny-geforce-gtx-xlr8-gaming-1050-ti-overclocked-edition-graphics-card-gf-gtx-1050-ti-4-gb/specs/
-[3]:https://www.evga.com/products/product.aspx?pn=100-B1-0600-KR
-[4]:http://thebottlenecker.com (Home: The Bottle Necker)
-[5]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/nvidia_xserver_error.jpg?token=c6a7effe35f1c592a155a4a46a068a19fd060a91 (NVIDIA X Sever Prompt)
-[6]:https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories
-[7]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/NVIDIA_XCONFIG.png?token=64e1a7be21e5e9ba157f029b65e24e4eef54d88f (NVIDIA X Server Settings)
diff --git a/sources/tech/20180704 What is the Difference Between the macOS and Linux Kernels.md b/sources/tech/20180704 What is the Difference Between the macOS and Linux Kernels.md
deleted file mode 100644
index 750666fe55..0000000000
--- a/sources/tech/20180704 What is the Difference Between the macOS and Linux Kernels.md
+++ /dev/null
@@ -1,59 +0,0 @@
-tranWhat is the Difference Between the macOS and Linux Kernels
-======
-Some people might think that there are similarities between the macOS and the Linux kernel because they can handle similar commands and similar software. Some people even think that Apple’s macOS is based on Linux. The truth is that both kernels have very different histories and features. Today, we will take a look at the difference between macOS and Linux kernels.
-
-![macOS vs Linux][1]
-
-### History of macOS Kernel
-
-We will start with the history of the macOS kernel. In 1985, Steve Jobs left Apple due to a falling out with CEO John Sculley and the Apple board of directors. He then founded a new computer company named [NeXT][2]. Jobs wanted to get a new computer (with a new operating system) to market quickly. To save time, the NeXT team used the [Mach kernel][3] from Carnegie Mellon and parts of the BSD code base to created the [NeXTSTEP operating system][4].
-
-NeXT never became a financial success, due in part to Jobs’ habit of spending money like he was still at Apple. Meanwhile, Apple had tried unsuccessfully on several occasions to update their operating system, even going so far as to partner with IBM. In 1997, Apple purchased NeXT for $429 million. As part of the deal, Steve Jobs returned to Apple and NeXTSTEP became the foundation of macOS and iOS.
-
-### History of Linux Kernel
-
-Unlike the macOS kernel, Linux was not created as part of a commercial endeavor. Instead, it was [created in 1991 by Finnish computer science student Linus Torvalds][5]. Originally, the kernel was written to the specifications of Linus’ computer because he wanted to take advantage of its new 80386 processor. Linus posted the code for his new kernel to [the Usenet in August of 1991][6]. Soon, he was receiving code and feature suggestions from all over the world. The following year Orest Zborowski ported the X Window System to Linux, giving it the ability to support a graphical user interface.
-
-Over the last 27 years, Linux has slowly grown and gained features. It’s no longer a student’s small-time project. Now it runs most of the [world’s][7] [computing devices][8] and the [world’s supercomputers][9]. Not too shabby.
-
-### Features of the macOS Kernel
-
-The macOS kernel is officially known as XNU. The [acronym][10] stands for “XNU is Not Unix.” According to [Apple’s Github page][10], XNU is “a hybrid kernel combining the Mach kernel developed at Carnegie Mellon University with components from FreeBSD and C++ API for writing drivers”. The BSD subsystem part of the code is [“typically implemented as user-space servers in microkernel systems”][11]. The Mach part is responsible for low-level work, such as multitasking, protected memory, virtual memory management, kernel debugging support, and console I/O.
-
-### Features of Linux Kernel
-
-While the macOS kernel combines the feature of a microkernel ([Mach][12])) and a monolithic kernel ([BSD][13]), Linux is solely a monolithic kernel. A [monolithic kernel][14] is responsible for managing the CPU, memory, inter-process communication, device drivers, file system, and system server calls.
-
-### Difference between Mac and Linux kernel in one line
-
-The macOS kernel (XNU) has been around longer than Linux and was based on a combination of two even older code bases. On the other hand, Linux is newer, written from scratch, and is used on many more devices.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][15].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/mac-linux-difference/
-
-作者:[John Paul][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
-[2]:https://en.wikipedia.org/wiki/NeXT
-[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
-[4]:https://en.wikipedia.org/wiki/NeXTSTEP
-[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
-[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
-[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
-[8]:https://www.linuxinsider.com/story/31855.html
-[9]:https://itsfoss.com/linux-supercomputers-2017/
-[10]:https://github.com/apple/darwin-xnu
-[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
-[12]:https://en.wikipedia.org/wiki/Mach_(kernel
-[13]:https://en.wikipedia.org/wiki/FreeBSD
-[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
-[15]:http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20180705 5 Reasons Open Source Certification Matters More Than Ever.md b/sources/tech/20180705 5 Reasons Open Source Certification Matters More Than Ever.md
new file mode 100644
index 0000000000..dace150f39
--- /dev/null
+++ b/sources/tech/20180705 5 Reasons Open Source Certification Matters More Than Ever.md
@@ -0,0 +1,49 @@
+5 Reasons Open Source Certification Matters More Than Ever
+======
+
+
+In today’s technology landscape, open source is the new normal, with open source components and platforms driving mission-critical processes and everyday tasks at organizations of all sizes. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening][1], making it ever more difficult to hire people with much needed job skills. In response, the [demand for training and certification is growing][2].
+
+In a recent webinar, Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, discussed the growing need for certification and some of the benefits of obtaining open source credentials. “As open source has become the new normal in everything from startups to Fortune 2000 companies, it is important to start thinking about the career road map, the paths that you can take and how Linux and open source in general can help you reach your career goals,” Seepersad said.
+
+With all this in mind, this is the first article in a weekly series that will cover: why it is important to obtain certification; what to expect from training options that lead to certification; and how to prepare for exams and understand what your options are if you don’t initially pass them.
+
+Seepersad pointed to these five reasons for pursuing certification:
+
+ * **Demand for Linux and open source talent.** “Year after year, we do the Linux jobs report, and year after year we see the same story, which is that the demand for Linux professionals exceeds the supply. This is true for the open source market in general,” Seepersad said. For example, certifications such as the [LFCE, LFCS,][3] and [OpenStack administrator exam][4] have made a difference for many people.
+
+ * **Getting the interview.** “One of the challenges that recruiters always reference, especially in the age of open source, is that it can be hard to decide who you want to have come in to the interview,” Seepersad said. “Not everybody has the time to do reference checks. One of the beautiful things about certification is that it independently verifies your skillset.”
+
+ * **Confirming your skills.** “Certification programs allow you to step back, look across what we call the domains and topics, and find those areas where you might be a little bit rusty,” Seepersad said. “Going through that process and then being able to demonstrate skills on the exam shows that you have a very broad skillset, not just a deep skillset in certain areas.”
+
+ * **Confidence.** This is the beauty of performance-based exams,” Seepersad said. “You're working on our live system. You're being monitored and recorded. Your timer is counting down. This really puts you on the spot to demonstrate that you can troubleshoot.” The inevitable result of successfully navigating the process is confidence.
+
+ * **Making hiring decisions.** “As you become more senior in your career, you're going to find the tables turned and you are in the role of making a hiring decision,” Seepersad said. “You're going to want to have candidates who are certified, because you recognize what that means in terms of the skillsets.”
+
+
+
+
+Although Linux has been around for more than 25 years, “it's really only in the past few years that certification has become a more prominent feature,” Seepersad noted. As a matter of fact, 87 percent of hiring managers surveyed for the [2018 Open Source Jobs Report][5] cite difficulty in finding the right open source skills and expertise. The Jobs Report also found that hiring open source talent is a priority for 83 percent of hiring managers, and half are looking for candidates holding certifications.
+
+With certification playing a more important role in securing a rewarding long-term career, are you interested in learning about options for gaining credentials? If so, stay tuned for more information in this series.
+
+[Learn more about Linux training and certification.][6]
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
+
+作者:[Sam Dean][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/sam-dean
+[1]:https://www.linuxfoundation.org/blog/open-source-skills-soar-in-demand-according-to-2018-jobs-report/
+[2]:https://www.linux.com/blog/os-jobs-report/2018/7/certification-plays-big-role-open-source-hiring
+[3]:https://www.linux.com/learn/certification/2018/5/linux-foundation-lfcs-lfce-maja-kraljic
+[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/openstack-administration-fundamentals
+[5]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
+[6]:https://training.linuxfoundation.org/certification
diff --git a/sources/tech/20180705 How to use dd in Linux without destroying your disk.md b/sources/tech/20180705 How to use dd in Linux without destroying your disk.md
deleted file mode 100644
index ddcce8e34f..0000000000
--- a/sources/tech/20180705 How to use dd in Linux without destroying your disk.md
+++ /dev/null
@@ -1,96 +0,0 @@
-How to use dd in Linux without destroying your disk
-======
-
-
-
-This article is excerpted from chapter 4 of [Linux in Action][1], published by Manning.
-
-Whether you're trying to rescue data from a dying storage drive, backing up archives to remote storage, or making a perfect copy of an active partition somewhere else, you'll need to know how to safely and reliably copy drives and filesystems. Fortunately, `dd` is a simple and powerful image-copying tool that's been around, well, pretty much forever. And in all that time, nothing's come along that does the job better.
-
-### Making perfect copies of drives and partitions
-
-`dd` if you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, use `tar` or even `scp` to replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
-
-There's all kinds of stuff you can do withif you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, useor evento replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
-
-Using `dd`, on the other hand, can make perfect byte-for-byte images of, well, just about anything digital. But before you start flinging partitions from one end of the earth to the other, I should mention that there's some truth to that old Unix admin joke: "dd stands for disk destroyer." If you type even one wrong character in a `dd` command, you can instantly and permanently wipe out an entire drive of valuable data. And yes, spelling counts.
-
-**Remember:** Before pressing that Enter key to invoke `dd`, pause and think very carefully!
-
-### Basic dd operations
-
-Now that you've been suitably warned, we'll start with something straightforward. Suppose you want to create an exact image of an entire disk of data that's been designated as `/dev/``sda`. You've plugged in an empty drive (ideally having the same capacity as your `/dev/``sda` system). The syntax is simple: `if=` defines the source drive and `of=` defines the file or location where you want your data saved:
-```
-# dd if=/dev/sda of=/dev/sdb
-
-```
-
-The next example will create an .img archive of the `/dev/``sda` drive and save it to the home directory of your user account:
-```
-# dd if=/dev/sda of=/home/username/sdadisk.img
-
-```
-
-Those commands created images of entire drives. You could also focus on a single partition from a drive. The next example does that and also uses `bs` to set the number of bytes to copy at a single time (4,096, in this case). Playing with the `bs` value can have an impact on the overall speed of a `dd` operation, although the ideal setting will depend on your hardware profile and other considerations.
-```
-# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
-
-```
-
-Restoring is simple: Effectively, you reverse the values of `if` and `of`. In this case, `if=` takes the image you want to restore, and `of=` takes the target drive to which you want to write the image:
-```
-# dd if=sdadisk.img of=/dev/sdb
-
-```
-
-You can also perform both the create and copy operations in one command. This example, for instance, will create a compressed image of a remote drive using SSH and save the resulting archive to your local machine:
-```
-# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
-
-```
-
-You should always test your archives to confirm they're working. If it's a boot drive you've created, stick it into a computer and see if it launches as expected. If it's a normal data partition, mount it to make sure the files both exist and are appropriately accessible.
-
-### Wiping disks with dd
-
-Years ago, I had a friend who was responsible for security at his government's overseas embassies. He once told me that each embassy under his watch was provided with an official government-issue hammer. Why? In case the facility was ever at risk of being overrun by unfriendlies, the hammer was to be used to destroy all their hard drives.
-
-What's that? Why not just delete the data? You're kidding, right? Everyone knows that deleting files containing sensitive data from storage devices doesn't actually remove the data. Given enough time and motivation, nearly anything can be retrieved from virtually any digital media, with the possible exception of the ones that have been well and properly hammered.
-
-You can, however, use `dd` to make it a whole lot more difficult for the bad guys to get at your old data. This command will spend some time writing millions and millions of zeros over every nook and cranny of the `/dev/sda1` partition:
-```
-# dd if=/dev/zero of=/dev/sda1
-
-```
-
-But it gets better. Using `/dev/``urandom` file as your source, you can write over a disk with random characters:
-```
-# dd if=/dev/urandom of=/dev/sda1
-
-```
-
-### Monitoring dd operations
-
-Since disk or partition archiving can take a very long time, you might want to add a progress monitor to your command. Install Pipe Viewer (`sudo apt install pv` on Ubuntu) and insert it into `dd`. With `pv`, that last command might look something like this:
-```
-# dd if=/dev/urandom | pv | dd of=/dev/sda1
-
-4,14MB 0:00:05 [ 98kB/s] [ <=> ]
-
-```
-
-Putting off backups and disk management? With dd, you aren't left with too many excuses. It's really not difficult, but be careful. Good luck!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/how-use-dd-linux
-
-作者:[David Clinton][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/remyd
-[1]:https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
diff --git a/sources/tech/20180706 6 RFCs for understanding how the internet works.md b/sources/tech/20180706 6 RFCs for understanding how the internet works.md
deleted file mode 100644
index aefdad8882..0000000000
--- a/sources/tech/20180706 6 RFCs for understanding how the internet works.md
+++ /dev/null
@@ -1,77 +0,0 @@
-translating---geekpi
-
-6 RFCs for understanding how the internet works
-======
-
-
-
-Reading the source is an important part of open source software. It means users have the ability to look at the code and see what it does.
-
-But "read the source" doesn't apply only to code. Understanding the standards the code implements can be just as important. These standards are codified in documents called "Requests for Comments" (RFCs) published by the [Internet Engineering Task Force][1] (IETF). Thousands of RFCs have been published over the years, so we collected a few that our contributors consider must-reads.
-
-### 6 must-read RFCs
-
-#### RFC 2119—Key words for use in RFCs to indicate requirement levels
-
-This is a quick read, but it's important to understanding other RFCs. [RFC 2119][2] defines the requirement levels used in subsequent RFCs. What does "MAY" really mean? If the standard says "SHOULD," do you really have to do it? By giving the requirements a well-defined taxonomy, RFC 2119 helps avoid ambiguity.
-
-Time is the bane of programmers the world over. [RFC 3339][3] defines how timestamps are to be formatted. Based on the [ISO 8601][4] standard, 3339 gives us a common way to represent time and its relentless march. For example, redundant information like the day of the week should not be included in a stored timestamp since it is easy to compute.
-
-#### RFC 1918—Address allocation for private internets
-
-There's the internet that's everyone's and then there's the internet that's just yours. Private networks are used all the time, and [RFC 1918][5] defines those networks. Sure, you could set up your router to route public spaces internally, but that's a bad idea. Alternately, you could take your unused public IP addresses and treat them as an internal network. In either case, you're making it clear you've never read RFC 1918.
-
-#### RFC 1912—Common DNS operational and configuration errors
-
-Everything is a #@%@ DNS problem, right? [RFC 1912][6] lays out mistakes that admins make when they're just trying to keep the internet running. Although it was published in 1996, DNS (and the mistakes people make with it) hasn't really changed all that much. To understand why we need DNS in the first place, consider what [RFC 289—What we hope is an official list of host names][7] would look like today.
-
-#### RFC 2822—Internet message format
-
-Think you know what a valid email address looks like? If the number of sites that won't accept a "+" in my address is any indication, you don't. [RFC 2822][8] defines what a valid email address looks like. It also goes into detail about the rest of an email message.
-
-#### RFC 7231—Hypertext Transfer Protocol (HTTP/1.1): Semantics and content
-
-When you stop to think about it, almost everything we do online relies on HTTP. [RFC 7231][9] is among the most recent updates to that protocol. Weighing in at just over 100 pages, it defines methods, headers, and status codes.
-
-### 3 should-read RFCs
-
-Okay, not every RFC is serious business.
-
-#### RFC 1149—A standard for the transmission of IP datagrams on avian carriers
-
-Networks pass packets in many different ways. [RFC 1149][10] describes the use of carrier pigeons. They can't be any less reliable than my mobile provider when I'm more than a mile away from an interstate highway.
-
-#### RFC 2324—Hypertext coffee pot control protocol (HTCPCP/1.0)
-
-Coffee is very important to getting work done, so of course, we need a programmatic interface for managing our coffee pots. [RFC 2324][11] defines a protocol for interacting with coffee pots and adds HTTP 418 ("I am a teapot").
-
-#### RFC 69—Distribution list change for M.I.T.
-
-Is [RFC 69][12] the first published example of a misdirected unsubscribe request?
-
-What are your must-read RFCs (whether they're serious or not)? Share your list in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/requests-for-comments-to-know
-
-作者:[Ben Cotton][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/bcotton
-[1]:https://www.ietf.org
-[2]:https://www.rfc-editor.org/rfc/rfc2119.txt
-[3]:https://www.rfc-editor.org/rfc/rfc3339.txt
-[4]:https://www.iso.org/iso-8601-date-and-time-format.html
-[5]:https://www.rfc-editor.org/rfc/rfc1918.txt
-[6]:https://www.rfc-editor.org/rfc/rfc1912.txt
-[7]:https://www.rfc-editor.org/rfc/rfc289.txt
-[8]:https://www.rfc-editor.org/rfc/rfc2822.txt
-[9]:https://www.rfc-editor.org/rfc/rfc7231.txt
-[10]:https://www.rfc-editor.org/rfc/rfc1149.txt
-[11]:https://www.rfc-editor.org/rfc/rfc2324.txt
-[12]:https://www.rfc-editor.org/rfc/rfc69.txt
diff --git a/sources/tech/20180706 How to Run Windows Apps on Android with Wine.md b/sources/tech/20180706 How to Run Windows Apps on Android with Wine.md
deleted file mode 100644
index 054f0082f3..0000000000
--- a/sources/tech/20180706 How to Run Windows Apps on Android with Wine.md
+++ /dev/null
@@ -1,126 +0,0 @@
-How to Run Windows Apps on Android with Wine
-======
-
-
-
-Wine (on Linux, not the one you drink) is a free and open-source compatibility layer for running Windows programs on Unix-like operating systems. Begun in 1993, it could run a wide variety of Windows programs on Linux and macOS, although sometimes with modification. Now the Wine Project has rolled out version 3.0 which is compatible with your Android devices.
-
-In this article we will show you how you can run Windows apps on your Android device with WINE.
-
-**Related** : [How to Easily Install Windows Games on Linux with Winepak][1]
-
-### What can you run on Wine?
-
-Wine is only a compatibility layer, not a full-blown emulator, so you need an x86 Android device to take full advantage of it. However, most Androids in the hands of consumers are ARM-based.
-
-Since most of you are using an ARM-based Android device, you will only be able to use Wine to run apps that have been adapted to run on Windows RT. There is a limited, but growing, list of software available for ARM devices. You can find a list of these apps that are compatible in this [thread][2] on XDA Developers Forums.
-
-Some examples of apps you will be able to run on ARM are:
-
- * [Keepass Portable][3]: A password storage wallet
- * [Paint.NET][4]: An image manipulation program
- * [SumatraPDF][5]: A document reader for PDFs and possibly some other document types
- * [Audacity][6]: A digital audio recording and editing program
-
-
-
-There are also some open-source retro games available like [Doom][7] and [Quake 2][8], as well as the open-source clone, [OpenTTD][9], a version of Transport Tycoon.
-
-The list of programs that Wine can run on Android ARM devices is bound to grow as the popularity of Wine on Android expands. The Wine project is working on using QEMU to emulate x86 CPU instructions on ARM, and when that is complete, the number of apps your Android will be able to run should grow rapidly.
-
-### Installing Wine
-
-To install Wine you must first make sure that your device’s settings allow it to download and install APKs from other sources than the Play Store. To do this you’ll need to give your device permission to download apps from unknown sources.
-
-1\. Open Settings on your phone and select your Security options.
-
-
-![wine-android-security][10]
-
-2\. Scroll down and click on the switch next to “Unknown Sources.”
-
-![wine-android-unknown-sources][11]
-
-3\. Accept the risks in the warning.
-
-![wine-android-unknown-sources-warning][12]
-
-4\. Open the [Wine installation site][13], and tap the first checkbox in the list. The download will automatically begin.
-
-![wine-android-download-button][14]
-
-5\. Once the download completes, open it from your Downloads folder, or pull down the notifications menu and click on the completed download there.
-
-6\. Install the program. It will notify you that it needs access to recording audio and to modify, delete, and read the contents of your SD card. You may also need to give access for audio recording for some apps you will use in the program.
-
-![wine-android-app-access][15]
-
-7\. When the installation completes, click on the icon to open the program.
-
-![wine-android-icon-small][16]
-
-When you open Wine, the desktop mimics Windows 7.
-
-![wine-android-desktop][17]
-
-One drawback of Wine is that you have to have an external keyboard available to type. An external mouse may also be useful if you are running it on a small screen and find it difficult to tap small buttons.
-
-You can tap the Start button to open two menus – Control Panel and Run.
-
-![wine-android-start-button][18]
-
-### Working with Wine
-
-When you tap “Control panel” you will see three choices – Add/Remove Programs, Game Controllers, and Internet Settings.
-
-Using “Run,” you can open a dialogue box to issue commands. For instance, launch Internet Explorer by entering `iexplore`.
-
-![wine-android-run][19]
-
-### Installing programs on Wine
-
-1\. Download the application (or sync via the cloud) to your Android device. Take note of where you save it.
-
-2\. Open the Wine Command Prompt window.
-
-3\. Type the path to the location of the program. If you have saved it to the Download folder on your SD card, type:
-
-4\. To run the file in Wine for Android, simply input the name of the EXE file.
-
-If the ARM-ready file is compatible, it should run. If not, you’ll see a bunch of error messages. At this stage, installing Windows software on Android in Wine can be hit or miss.
-
-There are still a lot of issues with this new version of Wine for Android. It doesn’t work on all Android devices. It worked on my Galaxy S6 Edge but not on my Galaxy Tab 4. Many games won’t work because the graphics driver doesn’t support Direct3D yet. You need an external keyboard and mouse to be able to easily manipulate the screen because touch-screen is not fully developed yet.
-
-Even with these issues in the early stages of release, the possibilities for this technology are thought-provoking. It’s certainly likely that it will take some time yet before you can launch Windows programs on your Android smartphone using Wine without a hitch.
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
-
-作者:[Tracey Rosenberger][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com/author/traceyrosenberger/
-[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ (How to Easily Install Windows Games on Linux with Winepak)
-[2]:https://forum.xda-developers.com/showthread.php?t=2092348
-[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
-[4]:http://forum.xda-developers.com/showthread.php?t=2411497
-[5]:http://forum.xda-developers.com/showthread.php?t=2098594
-[6]:http://forum.xda-developers.com/showthread.php?t=2103779
-[7]:http://forum.xda-developers.com/showthread.php?t=2175449
-[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&d=1358070370
-[9]:http://forum.xda-developers.com/showpost.php?p=36674868&postcount=151
-[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png (wine-android-security)
-[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg (wine-android-unknown-sources)
-[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png (wine-android-unknown-sources-warning)
-[13]:https://dl.winehq.org/wine-builds/android/
-[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png (wine-android-download-button)
-[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg (wine-android-app-access)
-[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg (wine-android-icon-small)
-[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png (wine-android-desktop)
-[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png (wine-android-start-button)
-[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png (wine-android-run)
diff --git a/sources/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md b/sources/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
index f00496a6b6..8bca52e1af 100644
--- a/sources/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
+++ b/sources/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
@@ -1,3 +1,5 @@
+translating---geekpi
+
Revisiting wallabag, an open source alternative to Instapaper
======
diff --git a/sources/tech/20180708 Getting Started with Debian Packaging.md b/sources/tech/20180708 Getting Started with Debian Packaging.md
deleted file mode 100644
index a7387ecf09..0000000000
--- a/sources/tech/20180708 Getting Started with Debian Packaging.md
+++ /dev/null
@@ -1,212 +0,0 @@
-Getting Started with Debian Packaging
-======
-
-
-
-One of my tasks in GSoC involved set up of Thunderbird extensions for the user. Some of the more popular add-ons like [‘Lightning’][1] (calendar organiser) already has a Debian package.
-
-Another important add on is ‘[Cardbook][2]’ which is used to manage contacts for the user based on CardDAV and vCard standards. But it doesn’t have a package yet.
-
-My mentor, [Daniel][3] motivated me to create a package for it and upload it to [mentors.debian.net][4]. It would ease the installation process as it could get installed through `apt-get`. This blog describes how I learned and created a Debian package for CardBook from scratch.
-
-Since, I was new to packaging, I did extensive research on basics of building a package from the source code and checked if the license was [DFSG][5] compatible.
-
-I learned from various Debian wiki guides like ‘[Packaging Intro][6]’, ‘[Building a Package][7]’ and blogs.
-
-I also studied the amd64 files included in [Lightning extension package][8].
-
-The package I created could be found [here][9].
-
-![Debian Package!][10]
-
-Debian Package
-
-### Creating an empty package
-
-I started by creating a `debian` directory by using `dh_make` command
-```
-# Empty project folder
-$ mkdir -p Debian/cardbook
-
-```
-```
-# create files
-$ dh_make\
-> --native \
-> --single \
-> --packagename cardbook_1.0.0 \
-> --email minkush@example.com
-
-```
-
-Some important files like control, rules, changelog, copyright are initialized with it.
-
-The list of all the files created:
-```
-$ find /debian
-debian/
-debian/rules
-debian/preinst.ex
-debian/cardbook-docs.docs
-debian/manpage.1.ex
-debian/install
-debian/source
-debian/source/format
-debian/cardbook.debhelper.lo
-debian/manpage.xml.ex
-debian/README.Debian
-debian/postrm.ex
-debian/prerm.ex
-debian/copyright
-debian/changelog
-debian/manpage.sgml.ex
-debian/cardbook.default.ex
-debian/README
-debian/cardbook.doc-base.EX
-debian/README.source
-debian/compat
-debian/control
-debian/debhelper-build-stamp
-debian/menu.ex
-debian/postinst.ex
-debian/cardbook.substvars
-debian/files
-
-```
-
-I gained an understanding of [Dpkg][11] package management program in Debian and its use to install, remove and manage packages.
-
-I build an empty package with `dpkg` commands. This created an empty package with four files namely `.changes`, `.deb`, `.dsc`, `.tar.gz`
-
-`.dsc` file contains the changes made and signature
-
-`.deb` is the main package file which can be installed
-
-`.tar.gz` (tarball) contains the source package
-
-The process also created the README and changelog files in `/usr/share`. They contain the essential notes about the package like description, author and version.
-
-I installed the package and checked the installed package contents. My new package mentions the version, architecture and description!
-```
-$ dpkg -L cardbook
-/usr
-/usr/share
-/usr/share/doc
-/usr/share/doc/cardbook
-/usr/share/doc/cardbook/README.Debian
-/usr/share/doc/cardbook/changelog.gz
-/usr/share/doc/cardbook/copyright
-
-```
-
-### Including CardBook source files
-
-After successfully creating an empty package, I added the actual CardBook add-on files inside the package. The CardBook’s codebase is hosted [here][12] on Gitlab. I included all the source files inside another directory and told the build package command which files to include in the package.
-
-I did this by creating a file `debian/install` using vi editor and listed the directories that should be installed. In this process I spent some time learning to use Linux terminal based text editors like vi. It helped me become familiar with editing, creating new files and shortcuts in vi.
-
-Once, this was done, I updated the package version in the changelog file to document the changes that I have made.
-```
-$ dpkg -l | grep cardbook
-ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
-
-```
-
-![Changelog][13]
-
-Changelog file after updating Package
-
-After rebuilding it, dependencies and detailed description can be added if necessary. The Debian control file can be edited to add the additional package requirements and dependencies.
-
-### Local Debian Repository
-
-Without creating a local repository, CardBook could be installed with:
-```
-$ sudo dpkg -i cardbook_1.1.0.deb
-
-```
-
-To actually test the installation for the package, I decided to build a local Debian repository. Without it, the `apt-get` command would not locate the package, as it is not in uploaded in Debian packages on net.
-
-For configuring a local Debian repository, I copied my packages (.deb) to `Packages.gz` file placed in a `/tmp` location.
-
-![Packages-gz][14]
-
-Local Debian Repo
-
-To make it work, I learned about the apt configuration and where it looks for files.
-
-I researched for a way to add my file location in apt-config. Finally I could accomplish the task by adding `*.list` file with package’s path in APT and updating ‘apt-cache’ afterwards.
-
-Hence, the latest CardBook version could be successfully installed by `apt-get install cardbook`
-
-![Package installation!][15]
-
-CardBook Installation through apt-get
-
-### Fixing Packaging errors and bugs
-
-My mentor, Daniel helped me a lot during this process and guided me how to proceed further with the package. He told me to use [Lintian][16] for fixing common packaging error and then using [dput][17] to finally upload the CardBook package.
-
-> Lintian is a Debian package checker which finds policy violations and bugs. It is one of the most widely used tool by Debian Maintainers to automate checks for Debian policies before uploading the package.
-
-I have uploaded the second updated version of the package in a separate branch of the repository on Salsa [here][18] inside Debian directory.
-
-I installed Lintian from backports and learned to use it on a package to fix errors. I researched on the abbreviations used in its errors and how to show detailed response from lintian commands
-```
-$ lintian -i -I --show-overrides cardbook_1.2.0.changes
-
-```
-
-Initially on running the command on the `.changes` file, I was surprised to see that a large number of errors, warnings and notes were displayed!
-
-![Package Error Brief!][19]
-
-Brief errors after running Lintian on Package
-
-![Lintian error1!][20]
-
-Detailed Lintian errors
-
-Detailed Lintian errostyle=”width:200px;”rs
-
-I spend some days to fix some errors related to Debian package policy violations. I had to dig into every policy and Debian rules carefully to eradicate a simple error. For this I referred various sections on [Debian Policy Manual][21] and [Debian Developer’s Reference][22].
-
-I am still working on making it flawless and hope to upload it on mentors.debian.net soon!
-
-It would be grateful if people from the Debian community who use Thunderbird could help fix these errors.
-
---------------------------------------------------------------------------------
-
-via: http://minkush.me/cardbook-debian-package/
-
-作者:[Minkush Jain][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://minkush.me/cardbook-debian-package/#
-[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
-[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
-[3]:https://danielpocock.com/
-[4]:https://mentors.debian.net/
-[5]:https://wiki.debian.org/DFSGLicenses
-[6]:https://wiki.debian.org/Packaging/Intro
-[7]:https://wiki.debian.org/BuildingAPackage
-[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
-[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
-[10]:/img/posts/13.png
-[11]:https://packages.debian.org/stretch/dpkg
-[12]:https://gitlab.com/CardBook/CardBook
-[13]:/img/posts/15.png
-[14]:/img/posts/14.png
-[15]:/img/posts/11.png
-[16]:https://packages.debian.org/stretch/lintian
-[17]:https://packages.debian.org/stretch/dput
-[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
-[19]:/img/posts/16.png (Running Lintian on package)
-[20]:/img/posts/10.png
-[21]:https://www.debian.org/doc/debian-policy/
-[22]:https://www.debian.org/doc/manuals/developers-reference/
diff --git a/sources/tech/20180709 A sysadmin-s guide to network management.md b/sources/tech/20180709 A sysadmin-s guide to network management.md
deleted file mode 100644
index 3c512ad0bc..0000000000
--- a/sources/tech/20180709 A sysadmin-s guide to network management.md
+++ /dev/null
@@ -1,200 +0,0 @@
-A sysadmin's guide to network management
-======
-
-
-
-If you're a sysadmin, your daily tasks include managing servers and the data center's network. The following Linux utilities and commands—from basic to advanced—will help make network management easier.
-
-In several of these commands, you'll see ``, which stands for "fully qualified domain name." When you see this, substitute your website URL or your server (e.g., `server-name.company.com`), as the case may be.
-
-### Ping
-
-As the name suggests, `ping` is used to check the end-to-end connectivity from your system to the one you are trying to connect to. It uses [ICMP][1] echo packets that travel back to your system when a ping is successful. It's also a good first step to check system/network connectivity. You can use the `ping` command with IPv4 and IPv6 addresses. (Read my article "[How to find your IP address in Linux][2]" to learn more about IP addresses.)
-
-**Syntax:**
-
- * IPv4: `ping /`
- * IPv6: `ping6 /`
-
-
-
-You can also use `ping` to resolve names of websites to their corresponding IP address, as shown below:
-
-
-
-### Traceroute
-
-`ping` checks end-to-end connectivity, the `traceroute` utility tells you all the router IPs on the path you travel to reach the end system, website, or server. `traceroute` is usually is the second step after `ping` for network connection debugging.
-
-This is a nice utility for tracing the full network path from your system to another. Wherechecks end-to-end connectivity, theutility tells you all the router IPs on the path you travel to reach the end system, website, or server.is usually is the second step afterfor network connection debugging.
-
-**Syntax:**
-
- * `traceroute /`
-
-
-
-### Telnet
-
-**Syntax:**
-
- * `telnet /` is used to [telnet][3] into any server.
-
-
-
-### Netstat
-
-The network statistics (`netstat`) utility is used to troubleshoot network-connection problems and to check interface/port statistics, routing tables, protocol stats, etc. It's any sysadmin's must-have tool.
-
-**Syntax:**
-
- * `netstat -l` shows the list of all the ports that are in listening mode.
- * `netstat -a` shows all ports; to specify only TCP, use `-at` (for UDP use `-au`).
- * `netstat -r` provides a routing table.
-
- 
-
- * `netstat -s` provides a summary of statistics for each protocol.
-
- 
-
- * `netstat -i` displays transmission/receive (TX/RX) packet statistics for each interface.
-
- 
-
-### Nmcli
-
-`nmcli` is a good utility for managing network connections, configurations, etc. It can be used to control Network Manager and modify any device's network configuration details.
-
-**Syntax:**
-
- * `nmcli device` lists all devices on the system.
-
- * `nmcli device show ` shows network-related details of the specified interface.
-
- * `nmcli connection` checks a device's connection.
-
- * `nmcli connection down ` shuts down the specified interface.
-
- * `nmcli connection up ` starts the specified interface.
-
- * `nmcli con add type vlan con-name dev id ipv4 gw4 ` adds a virtual LAN (VLAN) interface with the specified VLAN number, IP address, and gateway to a particular interface.
-
- 
-
-
-### Routing
-
-There are many commands you can use to check and configure routing. Here are some useful ones:
-
-**Syntax:**
-
- * `ip route` shows all the current routes configured for the respective interfaces.
-
- 
-
- * `route add default gw ` adds a default gateway to the routing table.
- * `route add -net gw ` adds a new network route to the routing table. There are many other routing parameters, such as adding a default route, default gateway, etc.
- * `route del -net ` deletes a particular route entry from the routing table.
-
- 
-
- * `ip neighbor` shows the current neighbor table and can be used to add, change, or delete new neighbors.
-
-
-
-
-
- * `arp` (which stands for address resolution protocol) is similar to `ip neighbor`. `arp` maps a system's IP address to its corresponding MAC (media access control) address.
-
-
-
-### Tcpdump and Wireshark
-
-Linux provides many packet-capturing tools like `tcpdump`, `wireshark`, `tshark`, etc. They are used to capture network traffic in packets that are transmitted/received and hence are very useful for a sysadmin to debug any packet losses or related issues. For command-line enthusiasts, `tcpdump` is a great tool, and for GUI users, `wireshark` is a great utility to capture and analyze packets. `tcpdump` is a built-in Linux utility to capture network traffic. It can be used to capture/show traffic on specific ports, protocols, etc.
-
-**Syntax:**
-
- * `tcpdump -i ` shows live packets from the specified interface. Packets can be saved in a file by adding the `-w` flag and the name of the output file to the command, for example: `tcpdump -w -i `.
-
-
-
- * `tcpdump -i src ` captures packets from a particular source IP.
- * `tcpdump -i dst ` captures packets from a particular destination IP.
- * `tcpdump -i port ` captures traffic for a specific port number like 53, 80, 8080, etc.
- * `tcpdump -i ` captures traffic for a particular protocol, like TCP, UDP, etc.
-
-
-
-### Iptables
-
-`iptables` is a firewall-like packet-filtering utility that can allow or block certain traffic. The scope of this utility is very wide; here are some of its most common uses.
-
-**Syntax:**
-
- * `iptables -L` lists all existing `iptables` rules.
- * `iptables -F` deletes all existing rules.
-
-
-
-The following commands allow traffic from the specified port number to the specified interface:
-
- * `iptables -A INPUT -i -p tcp –dport -m state –state NEW,ESTABLISHED -j ACCEPT`
- * `iptables -A OUTPUT -o -p tcp -sport -m state – state ESTABLISHED -j ACCEPT`
-
-
-
-The following commands allow loopback access to the system:
-
- * `iptables -A INPUT -i lo -j ACCEPT`
- * `iptables -A OUTPUT -o lo -j ACCEPT`
-
-
-
-### Nslookup
-
-The `nslookup` tool is used to obtain IP address mapping of a website or domain. It can also be used to obtain information on your DNS server, such as all DNS records on a website (see the example below). A similar tool to `nslookup` is the `dig` (Domain Information Groper) utility.
-
-**Syntax:**
-
- * `nslookup ` shows the IP address of your DNS server in the Server field, and, below that, gives the IP address of the website you are trying to reach.
- * `nslookup -type=any ` shows all the available records for the specified website/domain.
-
-
-
-### Network/interface debugging
-
-Here is a summary of the necessary commands and files used to troubleshoot interface connectivity or related network issues.
-
-**Syntax:**
-
- * `ss` is a utility for dumping socket statistics.
- * `nmap `, which stands for Network Mapper, scans network ports, discovers hosts, detects MAC addresses, and much more.
- * `ip addr/ifconfig -a` provides IP addresses and related info on all the interfaces of a system.
- * `ssh -vvv user@` enables you to SSH to another server with the specified IP/domain and username. The `-vvv` flag provides "triple-verbose" details of the processes going on while SSH'ing to the server.
- * `ethtool -S ` checks the statistics for a particular interface.
- * `ifup ` starts up the specified interface.
- * `ifdown ` shuts down the specified interface.
- * `systemctl restart network` restarts a network service for the system.
- * `/etc/sysconfig/network-scripts/` is an interface configuration file used to set IP, network, gateway, etc. for the specified interface. DHCP mode can be set here.
- * `/etc/hosts` this file contains custom host/domain to IP mappings.
- * `/etc/resolv.conf` specifies the DNS nameserver IP of the system.
- * `/etc/ntp.conf` specifies the NTP server domain.
-
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
-
-作者:[Archit Modi][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/architmodi
-[1]:https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
-[2]:https://opensource.com/article/18/5/how-find-ip-address-linux
-[3]:https://en.wikipedia.org/wiki/Telnet
diff --git a/sources/tech/20180709 Boost your typing with emoji in Fedora 28 Workstation.md b/sources/tech/20180709 Boost your typing with emoji in Fedora 28 Workstation.md
deleted file mode 100644
index 47c3412f28..0000000000
--- a/sources/tech/20180709 Boost your typing with emoji in Fedora 28 Workstation.md
+++ /dev/null
@@ -1,68 +0,0 @@
-Boost your typing with emoji in Fedora 28 Workstation
-======
-
-
-
-Fedora 28 Workstation ships with a feature that allows you to quickly search, select and input emoji using your keyboard. Emoji, cute ideograms that are part of Unicode, are used fairly widely in messaging and especially on mobile devices. You may have heard the idiom “A picture is worth a thousand words.” This is exactly what emoji provide: simple images for you to use in communication. Each release of Unicode adds more, with over 200 new ones added in past releases of Unicode. This article shows you how to make them easy to use in your Fedora system.
-
-It’s great to see emoji numbers growing. But at the same time it brings the challenge of how to input them in a computing device. Many people already use these symbols for input in mobile devices or social networking sites.
-
-[**Editors’ note: **This article is an update to a previously published piece on this topic.]
-
-### Enabling Emoji input on Fedora 28 Workstation
-
-The new emoji input method ships by default in Fedora 28 Workstation. To use it, you must enable it using the Region and Language settings dialog. Open the Region and Language dialog from the main Fedora Workstation settings, or search for it in the Overview.
-
-[![Region & Language settings tool][1]][2]
-
-Choose the + control to add an input source. The following dialog appears:
-
-[![Adding an input source][3]][4]
-
-Choose the final option (three dots) to expand the selections fully. Then, find Other at the bottom of the list and select it:
-
-[![Selecting other input sources][5]][6]
-
-In the next dialog, find the Typing booster choice and select it:
-
-[![][7]][8]
-
-This advanced input method is powered behind the scenes by iBus. The advanced input methods are identifiable in the list by the cogs icon on the right of the list.
-
-The Input Method drop-down automatically appears in the GNOME Shell top bar. Ensure your default method — in this example, English (US) — is selected as the current method, and you’ll be ready to input.
-
-[![Input method dropdown in Shell top bar][9]][10]
-
-## Using the new Emoji input method
-
-Now the Emoji input method is enabled, search for emoji by pressing the keyboard shortcut **Ctrl+Shift+E**. A pop-over dialog appears where you can type a search term, such as smile, to find matching symbols.
-
-[![Searching for smile emoji][11]][12]
-
-Use the arrow keys to navigate the list. Then, hit **Enter** to make your selection, and the glyph will be placed as input.
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
-
-作者:[Paul W. Frields][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/pfrields/
-[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
-[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
-[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
-[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
-[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
-[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
-[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
-[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
-[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
-[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
-[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
-[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
diff --git a/sources/tech/20180709 Malware Found On The Arch User Repository (AUR).md b/sources/tech/20180709 Malware Found On The Arch User Repository (AUR).md
deleted file mode 100644
index cadb92bfd8..0000000000
--- a/sources/tech/20180709 Malware Found On The Arch User Repository (AUR).md
+++ /dev/null
@@ -1,43 +0,0 @@
-Malware Found On The Arch User Repository (AUR)
-======
-
-On July 7, an AUR package was modified with some malicious code, reminding [Arch Linux][1] users (and Linux users in general) that all user-generated packages should be checked (when possible) before installation.
-
-[AUR][3] , or the Arch (Linux) User Repository contains package descriptions, also known as PKGBUILDs, which make compiling packages from source easier. While these packages are very useful, they should never be treated as safe, and users should always check their contents before using them, when possible. After all, the AUR webpage states in bold that "AUR packages are user produced content. Any use of the provided files is at your own risk."
-
-The [discovery][4] of an AUR package containing malicious code proves this. [acroread][5] was modified on July 7 (it appears it was previously "orphaned", meaning it had no maintainer) by an user named "xeactor" to include a `curl` command that downloaded a script from a pastebin. The script then downloaded another script and installed a systemd unit to run that script periodically.
-
-**It appears [two other][2] AUR packages were modified in the same way. All the offending packages were removed and the user account (which was registered in the same day those packages were updated) that was used to upload them was suspended.**
-
-The malicious code didn't do anything truly harmful - it only tried to upload some system information, like the machine ID, the output of `uname -a` (which includes the kernel version, architecture, etc.), CPU information, pacman information, and the output of `systemctl list-units` (which lists systemd units information) to pastebin.com. I'm saying "tried" because no system information was actually uploaded due to an error in the second script (the upload function is called "upload", but the script tried to call it using a different name, "uploader").
-
-Also, the person adding these malicious scripts to AUR left the personal Pastebin API key in the script in cleartext, proving once again that they don't know exactly what they are doing.
-
-The purpose for trying to upload this information to Pastebin is not clear, especially since much more sensitive data could have been uploaded, like GPG / SSH keys.
-
-**Update:** Reddit user u/xanaxdroid_ [mentions][6] that the same user named "xeactor" also had some cryptocurrency mining packages posted, so he speculates that "xeactor" was probably planning on adding some hidden cryptocurrency mining software to AUR (this was also the case with some Ubuntu Snap packages [two months ago][7]). That's why "xeactor" was probably trying to obtain various system information. All the packages uploaded by this AUR user have been removed so I cannot check this.
-
-**Another update:**
-
-What exactly should you check in user-generated packages such as those found in AUR? This varies and I can't tell you exactly but you can start by looking for anything that tries to download something using `curl` , `wget` and other similar tools, and see what exactly they are attempting to download. Also check the server from which the package source is downloaded from and make sure it's the official source. Unfortunately this is not an exact 'science'. For Launchpad PPAs for example, things get more complicated as you must know how Debian packaging works, and the source can be altered directly as it's hosted in the PPA and uploaded by the user. It gets even more complicated with Snap packages, because you cannot check such packages before installation (as far as I know). In these latter cases, and as a generic solution, I guess you should only install user-generated packages if you trust the uploader / packager.
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/118280394805678839070
-[1]:https://www.archlinux.org/
-[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
-[3]:https://aur.archlinux.org/
-[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
-[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
-[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
-[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
diff --git a/sources/tech/20180710 15 open source applications for MacOS.md b/sources/tech/20180710 15 open source applications for MacOS.md
deleted file mode 100644
index 25992ce35b..0000000000
--- a/sources/tech/20180710 15 open source applications for MacOS.md
+++ /dev/null
@@ -1,74 +0,0 @@
-15 open source applications for MacOS
-======
-
-
-
-I use open source tools whenever and wherever I can. I returned to college a while ago to earn a master's degree in educational leadership. Even though I switched from my favorite Linux laptop to a MacBook Pro (since I wasn't sure Linux would be accepted on campus), I decided I would keep using my favorite tools, even on MacOS, as much as I could.
-
-Fortunately, it was easy, and no professor ever questioned what software I used. Even so, I couldn't keep a secret.
-
-I knew some of my classmates would eventually assume leadership positions in school districts, so I shared information about the open source applications described below with many of my MacOS or Windows-using classmates. After all, open source software is really about freedom and goodwill. I also wanted them to know that it would be easy to provide their students with world-class applications at little cost. Most of them were surprised and amazed because, as we all know, open source software doesn't have a marketing team except users like you and me.
-
-### My MacOS learning curve
-
-Through this process, I learned some of the nuances of MacOS. While most of the open source tools worked as I was used to, others required different installation methods. Tools like [yum][1], [DNF][2], and [APT][3] do not exist in the MacOS world—and I really missed them.
-
-Some MacOS applications required dependencies and installations that were more difficult than what I was accustomed to with Linux. Nonetheless, I persisted. In the process, I learned how I could keep the best software on my new platform. Even much of MacOS's core is [open source][4].
-
-Also, my Linux background made it easy to get comfortable with the MacOS command line. I still use it to create and copy files, add users, and use other [utilities][5]like cat, tac, more, less, and tail.
-
-### 15 great open source applications for MacOS
-
- * The college required that I submit most of my work electronically in DOCX format, and I did that easily, first with [OpenOffice][6] and later using [LibreOffice][7] to produce my papers.
- * When I needed to produce graphics for presentations, I used my favorite graphics applications, [GIMP][8] and [Inkscape][9].
- * My favorite podcast creation tool is [Audacity][10]. It's much simpler to use than the proprietary application that ships with the Mac. I use it to record interviews and create soundtracks for video presentations.
- * I discovered early on that I could use the [VideoLan][11] (VLC) media player on MacOS.
- * MacOS's built-in proprietary video creation tool is a good product, but you can easily install and use [OpenShot][12], which is a great content creation tool.
- * When I need to analyze networks for my clients, I use the easy-to-install [Nmap][13] (Network Mapper) and [Wireshark][14] tools on my Mac.
- * I use [VirtualBox][15] for MacOS to demonstrate Raspbian, Fedora, Ubuntu, and other Linux distributions, as well as Moodle, WordPress, Drupal, and Koha when I provide training for librarians and other educators.
- * I make boot drives on my MacBook using [Etcher.io][16]. I just download the ISO file and burn it on a USB stick drive.
- * I think [Firefox][17] is easier and more secure to use than the proprietary browser that comes with the MacBook Pro, and it allows me to synchronize my bookmarks across operating systems.
- * When it comes to eBook readers, [Calibre][18] cannot be beaten. It is easy to download and install, and you can even configure it for a [classroom eBook server][19] with a few clicks.
- * Recently I have been teaching Python to middle school students, I have found it is easy to download and install Python 3 and the IDLE3 editor from [Python.org][20]. I have also enjoyed learning about data science and sharing that with students. Whether you're interested in Python or R, I recommend you download and [install][21] the [Anaconda distribution][22]. It contains the great iPython editor, RStudio, Jupyter Notebooks, and JupyterLab, along with some other applications.
- * [HandBrake][23] is a great way to turn your old home video DVDs into MP4s, which you can share on YouTube, Vimeo, or your own [Kodi][24] server on MacOS.
-
-
-
-Now it's your turn: What open source software are you using on MacOS (or Windows)? Share your favorites in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/open-source-tools-macos
-
-作者:[Don Watkins][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/don-watkins
-[1]:https://en.wikipedia.org/wiki/Yum_(software)
-[2]:https://en.wikipedia.org/wiki/DNF_(software)
-[3]:https://en.wikipedia.org/wiki/APT_(Debian)
-[4]:https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html
-[5]:https://www.gnu.org/software/coreutils/coreutils.html
-[6]:https://www.openoffice.org/
-[7]:https://www.libreoffice.org/
-[8]:https://www.gimp.org/
-[9]:https://inkscape.org/en/
-[10]:https://www.audacityteam.org/
-[11]:https://www.videolan.org/index.html
-[12]:https://www.openshot.org/
-[13]:https://nmap.org/
-[14]:https://www.wireshark.org/
-[15]:https://www.virtualbox.org/
-[16]:https://etcher.io/
-[17]:https://www.mozilla.org/en-US/firefox/new/
-[18]:https://calibre-ebook.com/
-[19]:https://opensource.com/article/17/6/raspberrypi-ebook-server
-[20]:https://www.python.org/downloads/release/python-370/
-[21]:https://opensource.com/article/18/4/getting-started-anaconda-python
-[22]:https://www.anaconda.com/download/#macos
-[23]:https://handbrake.fr/
-[24]:https://kodi.tv/download
diff --git a/sources/tech/20180710 6 open source cryptocurrency wallets.md b/sources/tech/20180710 6 open source cryptocurrency wallets.md
deleted file mode 100644
index 57db5f254c..0000000000
--- a/sources/tech/20180710 6 open source cryptocurrency wallets.md
+++ /dev/null
@@ -1,92 +0,0 @@
-6 open source cryptocurrency wallets
-======
-
-
-
-Without crypto wallets, cryptocurrencies like Bitcoin and Ethereum would just be another pie-in-the-sky idea. These wallets are essential for keeping, sending, and receiving cryptocurrencies.
-
-The revolutionary growth of [cryptocurrencies][1] is attributed to the idea of decentralization, where a central authority is absent from the network and everyone has a level playing field. Open source technology is at the heart of cryptocurrencies and [blockchain][2] networks. It has enabled the vibrant, nascent industry to reap the benefits of decentralization—such as immutability, transparency, and security.
-
-If you're looking for a free and open source cryptocurrency wallet, read on to start exploring whether any of the following options meet your needs.
-
-### 1\. Copay
-
-[Copay][3] is an open source Bitcoin crypto wallet that promises convenient storage. The software is released under the [MIT License][4].
-
-The Copay server is also open source. Therefore, developers and Bitcoin enthusiasts can assume complete control of their activities by deploying their own applications on the server.
-
-The Copay wallet empowers you to take the security of your Bitcoin in your own hands, instead of trusting unreliable third parties. It allows you to use multiple signatories for approving transactions and supports the storage of multiple, separate wallets within the same app.
-
-Copay is available for a range of platforms, such as Android, Windows, MacOS, Linux, and iOS.
-
-### 2\. MyEtherWallet
-
-As the name implies, [MyEtherWallet][5] (abbreviated MEW) is a wallet for Ethereum transactions. It is open source (under the [MIT License][6]) and is completely online, accessible through a web browser.
-
-The wallet has a simple client-side interface, which allows you to participate in the Ethereum blockchain confidently and securely.
-
-### 3\. mSIGNA
-
-[mSIGNA][7] is a powerful desktop application for completing transactions on the Bitcoin network. It is released under the [MIT License][8] and is available for MacOS, Windows, and Linux.
-
-The blockchain wallet provides you with complete control over your Bitcoin stash. Some of its features include user-friendliness, versatility, decentralized offline key generation capabilities, encrypted data backups, and multi-device synchronization.
-
-### 4\. Armory
-
-[Armory][9] is an open source wallet (released under the [GNU AGPLv3][10]) for producing and keeping Bitcoin private keys on your computer. It enhances security by providing users with cold storage and multi-signature support capabilities.
-
-With Armory, you can set up a wallet on a computer that is completely offline; you'll use the watch-only feature for observing your Bitcoin details on the internet, which improves security. The wallet also allows you to create multiple addresses and use them to complete different transactions.
-
-Armory is available for MacOS, Windows, and several flavors of Linux (including Raspberry Pi).
-
-### 5\. Electrum
-
-[Electrum][11] is a Bitcoin wallet that navigates the thin line between beginner user-friendliness and expert functionality. The open source wallet is released under the [MIT License][12].
-
-Electrum encrypts your private keys locally, supports cold storage, and provides multi-signature capabilities with minimal resource usage on your machine.
-
-It is available for a wide range of operating systems and devices, including Windows, MacOS, Android, iOS, and Linux, and hardware wallets such as [Trezor][13].
-
-### 6\. Etherwall
-
-[Etherwall][14] is the first wallet for storing and sending Ethereum on the desktop. The open source wallet is released under the [GPLv3 License][15].
-
-Etherwall is intuitive and fast. What's more, to enhance the security of your private keys, you can operate it on a full node or a thin node. Running it as a full-node client will enable you to download the whole Ethereum blockchain on your local machine.
-
-Etherwall is available for MacOS, Linux, and Windows, and it also supports the Trezor hardware wallet.
-
-### Words to the wise
-
-Open source and free crypto wallets are playing a vital role in making cryptocurrencies easily available to more people.
-
-Before using any digital currency software wallet, make sure to do your due diligence to protect your security, and always remember to comply with best practices for safeguarding your finances.
-
-If your favorite open source cryptocurrency wallet is not on this list, please share what you know in the comment section below.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/crypto-wallets
-
-作者:[Dr.Michael J.Garbade][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/drmjg
-[1]:https://www.liveedu.tv/guides/cryptocurrency/
-[2]:https://opensource.com/tags/blockchain
-[3]:https://copay.io/
-[4]:https://github.com/bitpay/copay/blob/master/LICENSE
-[5]:https://www.myetherwallet.com/
-[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
-[7]:https://ciphrex.com/
-[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
-[9]:https://www.bitcoinarmory.com/
-[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
-[11]:https://electrum.org/#home
-[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
-[13]:https://trezor.io/
-[14]:https://www.etherwall.com/
-[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
diff --git a/sources/tech/20180710 Display Weather Forecast In Your Terminal With Wttr.in.md b/sources/tech/20180710 Display Weather Forecast In Your Terminal With Wttr.in.md
deleted file mode 100644
index 0fdd9389e4..0000000000
--- a/sources/tech/20180710 Display Weather Forecast In Your Terminal With Wttr.in.md
+++ /dev/null
@@ -1,117 +0,0 @@
-Display Weather Forecast In Your Terminal With Wttr.in
-======
-**[wttr.in][1] is a feature-packed weather forecast service that supports displaying the weather from the command line**. It can automatically detect your location (based on your IP address), supports specifying the location or searching for a geographical location (like a site in a city, a mountain and so on), and much more. Oh, and **you don't have to install it - all you need to use it is cURL or Wget** (see below).
-
-wttr.in features include:
-
- * **displays the current weather as well as a 3-day weather forecast, split into morning, noon, evening and night** (includes temperature range, wind speed and direction, viewing distance, precipitation amount and probability)
-
- * **can display Moon phases**
-
- * **automatic location detection based on your IP address**
-
- * **allows specifying a location using the city name, 3-letter airport code, area code, GPS coordinates, IP address, or domain name**. You can also specify a geographical location like a lake, mountain, landmark, and so on)
-
- * **supports multilingual location names** (the query string must be specified in Unicode)
-
- * **supports specifying the language** in which the weather forecast should be displayed in (it supports more than 50 languages)
-
- * **it uses USCS units for queries from the USA and the metric system for the rest of the world** , but you can change this by appending `?u` for USCS, and `?m` for the metric system (SI)
-
- * **3 output formats: ANSI for the terminal, HTML for the browser, and PNG**.
-
-
-
-
-Like I mentioned in the beginning of the article, to use wttr.in, all you need is cURL or Wget, but you can also
-
-**Before using wttr.in, make sure cURL is installed.** In Debian, Ubuntu or Linux Mint (and other Debian or Ubuntu-based Linux distributions), install cURL using this command:
-```
-sudo apt install curl
-
-```
-
-### wttr.in command line examples
-
-Get the weather for your location (wttr.in tries to guess your location based on your IP address):
-```
-curl wttr.in
-
-```
-
-Force cURL to resolve names to IPv4 addresses (in case you're having issues with IPv6 and wttr.in) by adding `-4` after `curl` :
-```
-curl -4 wttr.in
-
-```
-
-**Wget also works** (instead of cURL) if you want to retrieve the current weather and forecast as a png, or if you use it like this:
-```
-wget -O- -q wttr.in
-
-```
-
-You can replace `curl` with `wget -O- -q` in all the commands below if you prefer Wget over cURL.
-
-Specify the location:
-```
-curl wttr.in/Dublin
-
-```
-
-Display weather information for a landmark (the Eiffel Tower in this example):
-```
-curl wttr.in/~Eiffel+Tower
-
-```
-
-Get the weather information for an IP address' location (the IP below belongs to GitHub):
-```
-curl wttr.in/@192.30.253.113
-
-```
-
-Retrieve the weather using USCS units:
-```
-curl wttr.in/Paris?u
-
-```
-
-Force wttr.in to use the metric system (SI) if you're in the USA:
-```
-curl wttr.in/New+York?m
-
-```
-
-Use Wget to download the current weather and 3-day forecast as a PNG image:
-```
-wget wttr.in/Istanbul.png
-
-```
-
-You can specify the PNG
-
-**For many other examples, check out the wttr.in[project page][2] or type this in a terminal:**
-```
-curl wttr.in/:help
-
-```
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/118280394805678839070
-[1]:https://wttr.in/
-[2]:https://github.com/chubin/wttr.in
-[3]:https://github.com/chubin/wttr.in#installation
-[4]:https://github.com/schachmat/wego
-[5]:https://github.com/chubin/wttr.in#supported-formats
diff --git a/sources/tech/20180710 Getting started with Perlbrew.md b/sources/tech/20180710 Getting started with Perlbrew.md
deleted file mode 100644
index 9128ca77a1..0000000000
--- a/sources/tech/20180710 Getting started with Perlbrew.md
+++ /dev/null
@@ -1,86 +0,0 @@
-Getting started with Perlbrew
-======
-
-
-
-What's better than having Perl installed on your system? Having multiple Perls installed on your system! With [Perlbrew][1] you can do just that. But why—apart from surrounding yourself in Perl—would you want to do that?
-
-The short answer is that different versions of Perl are… different. Application A may depend on behavior deprecated in a newer release, while Application B needs new features that weren't available last year. If you have multiple versions of Perl installed, each script can use the version that best suits it. This also comes in handy if you're a developer—you can test your application against multiple versions of Perl so that, no matter what your users are running, you know it works.
-
-### Install Perlbrew
-
-The other benefit is that Perlbrew installs to the user's home directory. That means each user can manage their Perl versions (and the associated CPAN packages) without having to involve the system administrators. Self-service means quicker installation for the users and gives sysadmins more time to work on the hard problems.
-
-The first step is to install Perlbrew on your system. Many Linux distributions have it in the package repo already, so you're just a `dnf install perlbrew` (or whatever is the appropriate command for your distribution) away. You can also install the `App::perlbrew` module from CPAN with `cpan App::perlbrew`. Or you can download and run the installation script at [install.perlbrew.pl][2].
-
-To begin using Perlbrew, run `perlbrew init`.
-
-### Install a new Perl version
-
-Let's say you want to try the latest development release (5.27.11 as of this writing). First, you need to install the package:
-```
-perlbrew install 5.27.11
-
-```
-
-### Switch Perl version
-
-Now that you have a new version installed, you can use it for just that shell:
-```
-perlbrew use 5.27.11
-
-```
-
-Or you can make it the default Perl version for your account (assuming you set up your profile as instructed by the output of `perlbrew init`):
-```
-perlbrew switch 5.27.11
-
-```
-
-### Run a single script
-
-You can run a single command against a specific version of Perl, too:
-```
-perlberew exec 5.27.11 myscript.pl
-
-```
-
-Or you can run a command against all your installed versions. This is particularly handy if you want to run tests against a variety of versions. In this case, specify Perl as the version:
-```
-.plperlbrew exec perl myscriptpl
-
-```
-
-### Install CPAN modules
-
-If you want to install CPAN modules, the `cpanm` package is an easy-to-use interface that works well with Perlbrew. Install it with:
-```
-perlbrew install-cpamn
-
-```
-
-You can then install CPAN modules with the `cpanm` command:
-```
-cpanm CGI::simple
-
-```
-
-### But wait, there's more!
-
-This article covers basic Perlbrew usage. There are many more features and options available. Look at the output of `perlbrew help` as a starting point, or check out the [App::perlbrew documentation][3]. What other features do you love in Perlbrew? Let us know in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/7/perlbrew
-
-作者:[Ben Cotton][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/bcotton
-[1]:https://perlbrew.pl/
-[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
-[3]:https://metacpan.org/pod/App::perlbrew
diff --git a/sources/tech/20180710 How To View Detailed Information About A Package In Linux.md b/sources/tech/20180710 How To View Detailed Information About A Package In Linux.md
new file mode 100644
index 0000000000..86ba067463
--- /dev/null
+++ b/sources/tech/20180710 How To View Detailed Information About A Package In Linux.md
@@ -0,0 +1,408 @@
+Translating by DavidChenLiang
+
+
+
+How To View Detailed Information About A Package In Linux
+======
+This is know topic and we can write so many articles because most of the time we would stick with package managers for many reasons.
+
+Each distribution clones has their own package manager, each has comes with their unique features that allow users to perform many actions such as installing new software packages, removing unnecessary software packages, updating the existing software packages, searching for specific software packages, and updating the system to latest available version, etc.
+
+Whoever is sticking with command-line most of the time they would preferring the CLI based package managers. The major CLI package managers for Linux are Yum, Dnf, Rpm,Apt, Apt-Get, Deb, pacman and zypper.
+
+**Suggested Read :**
+**(#)** [List of Command line Package Managers For Linux & Usage][1]
+**(#)** [A Graphical frontend tool for Linux Package Manager][2]
+**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][3]
+**(#)** [How To Add, Enable And Disable A Repository By Using The DNF/YUM Config Manager Command On Linux][4]
+
+As a system administrator you should aware of from where packages are coming, which repository, version of the package, size of the package, release, package source url, license info, etc,.
+
+This will help you to understand the package usage in simple way since it’s coming with package summary & Description. Run the below commands based on your distribution to get detailed information about given package.
+
+### [YUM Command][5] : View Package Information On RHEL & CentOS Systems
+
+YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
+
+Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
+```
+# yum info python
+Loaded plugins: fastestmirror, security
+Loading mirror speeds from cached hostfile
+ * epel: epel.mirror.constant.com
+Installed Packages
+Name : python
+Arch : x86_64
+Version : 2.6.6
+Release : 66.el6_8
+Size : 78 k
+Repo : installed
+From repo : updates
+Summary : An interpreted, interactive, object-oriented programming language
+URL : http://www.python.org/
+License : Python
+Description : Python is an interpreted, interactive, object-oriented programming
+ : language often compared to Tcl, Perl, Scheme or Java. Python includes
+ : modules, classes, exceptions, very high level dynamic data types and
+ : dynamic typing. Python supports interfaces to many system calls and
+ : libraries, as well as to various windowing systems (X11, Motif, Tk,
+ : Mac and MFC).
+ :
+ : Programmers can write new built-in modules for Python in C or C++.
+ : Python can be used as an extension language for applications that need
+ : a programmable interface.
+ :
+ : Note that documentation for Python is provided in the python-docs
+ : package.
+ :
+ : This package provides the "python" executable; most of the actual
+ : implementation is within the "python-libs" package.
+
+```
+
+### YUMDB Command : View Package Information On RHEL & CentOS Systems
+
+Yumdb info provides information similar to yum info but additionally it provides package checksum data, type, user info (who installed the package). Since yum 3.2.26 yum has started storing additional information outside of the rpmdatabase (where user indicates it was installed by the user, and dep means it was brought in as a dependency).
+```
+# yumdb info python
+Loaded plugins: fastestmirror
+python-2.6.6-66.el6_8.x86_64
+ changed_by = 4294967295
+ checksum_data = 53c75a1756e5b4f6564c5229a37948c9b4561e0bf58076bd7dab7aff85a417f2
+ checksum_type = sha256
+ command_line = update -y
+ from_repo = updates
+ from_repo_revision = 1488370672
+ from_repo_timestamp = 1488371100
+ installed_by = 4294967295
+ reason = dep
+ releasever = 6
+
+
+```
+
+### [RPM Command][6] : View Package Information On RHEL/CentOS/Fedora Systems
+
+RPM stands for Red Hat Package Manager is a powerful, command line Package Management utility for Red Hat based system such as (RHEL, CentOS, Fedora, openSUSE & Mageia) distributions. The utility allow you to install, upgrade, remove, query & verify the software on your Linux system/server. RPM files comes with .rpm extension. RPM package built with required libraries and dependency which will not conflicts other packages were installed on your system.
+```
+# rpm -qi nano
+Name : nano Relocations: (not relocatable)
+Version : 2.0.9 Vendor: CentOS
+Release : 7.el6 Build Date: Fri 12 Nov 2010 02:18:36 AM EST
+Install Date: Fri 03 Mar 2017 08:57:47 AM EST Build Host: c5b2.bsys.dev.centos.org
+Group : Applications/Editors Source RPM: nano-2.0.9-7.el6.src.rpm
+Size : 1588347 License: GPLv3+
+Signature : RSA/8, Sun 03 Jul 2011 12:46:50 AM EDT, Key ID 0946fca2c105b9de
+Packager : CentOS BuildSystem
+URL : http://www.nano-editor.org
+Summary : A small text editor
+Description :
+GNU nano is a small and friendly text editor.
+
+```
+
+### [DNF Command][7] : View Package Information On Fedora System
+
+DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally. Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
+```
+$ dnf info tilix
+Last metadata expiration check: 27 days, 10:00:23 ago on Wed 04 Oct 2017 06:43:27 AM IST.
+Installed Packages
+Name : tilix
+Version : 1.6.4
+Release : 1.fc26
+Arch : x86_64
+Size : 3.6 M
+Source : tilix-1.6.4-1.fc26.src.rpm
+Repo : @System
+From repo : @commandline
+Summary : Tiling terminal emulator
+URL : https://github.com/gnunn1/tilix
+License : MPLv2.0 and GPLv3+ and CC-BY-SA
+Description : Tilix is a tiling terminal emulator with the following features:
+ :
+ : - Layout terminals in any fashion by splitting them horizontally or vertically
+ : - Terminals can be re-arranged using drag and drop both within and between
+ : windows
+ : - Terminals can be detached into a new window via drag and drop
+ : - Input can be synchronized between terminals so commands typed in one
+ : terminal are replicated to the others
+ : - The grouping of terminals can be saved and loaded from disk
+ : - Terminals support custom titles
+ : - Color schemes are stored in files and custom color schemes can be created by
+ : simply creating a new file
+ : - Transparent background
+ : - Supports notifications when processes are completed out of view
+ :
+ : The application was written using GTK 3 and an effort was made to conform to
+ : GNOME Human Interface Guidelines (HIG).
+
+```
+
+### [Zypper Command][8] : View Package Information On openSUSE System
+
+Zypper is a command line package manager which makes use of libzypp. Zypper provides functions like repository access, dependency solving, package installation, etc.
+```
+$ zypper info nano
+
+Loading repository data...
+Reading installed packages...
+
+
+Information for package nano:
+-----------------------------
+Repository : Main Repository (OSS)
+Name : nano
+Version : 2.4.2-5.3
+Arch : x86_64
+Vendor : openSUSE
+Installed Size : 1017.8 KiB
+Installed : No
+Status : not installed
+Source package : nano-2.4.2-5.3.src
+Summary : Pico editor clone with enhancements
+Description :
+ GNU nano is a small and friendly text editor. It aims to emulate
+ the Pico text editor while also offering a few enhancements.
+
+```
+
+### [pacman Command][9] : View Package Information On Arch Linux & Manjaro Systems
+
+Pacman stands for package manager utility. pacman is a simple command-line utility to install, build, remove and manage Arch Linux packages. Pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
+```
+$ pacman -Qi bash
+Name : bash
+Version : 4.4.012-2
+Description : The GNU Bourne Again shell
+Architecture : x86_64
+URL : http://www.gnu.org/software/bash/bash.html
+Licenses : GPL
+Groups : base
+Provides : sh
+Depends On : readline>=7.0 glibc ncurses
+Optional Deps : bash-completion: for tab completion
+Required By : autoconf automake bison bzip2 ca-certificates-utils db
+ dhcpcd diffutils e2fsprogs fakeroot figlet findutils
+ flex freetype2 gawk gdbm gettext gmp grub gzip icu
+ iptables keyutils libgpg-error libksba libpcap libpng
+ libtool lvm2 m4 man-db mkinitcpio nano neofetch nspr
+ nss openresolv os-prober pacman pcre pcre2 shadow
+ systemd texinfo vte-common which xdg-user-dirs xdg-utils
+ xfsprogs xorg-mkfontdir xorg-xpr xz
+Optional For : None
+Conflicts With : None
+Replaces : None
+Installed Size : 7.13 MiB
+Packager : Jan Alexander Steffens (heftig)
+Build Date : Tue 14 Feb 2017 01:16:51 PM UTC
+Install Date : Thu 24 Aug 2017 06:08:12 AM UTC
+Install Reason : Explicitly installed
+Install Script : No
+Validated By : Signature
+
+```
+
+### [Apt-Cache Command][10] : View Package Information On Debian/Ubuntu/Mint Systems
+
+The apt-cache command can display much of the information stored in APT’s internal database. This information is a sort of cache since it is gathered from the different sources listed in the sources.list file. This happens during the apt update operation.
+```
+$ sudo apt-cache show apache2
+Package: apache2
+Priority: optional
+Section: web
+Installed-Size: 473
+Maintainer: Ubuntu Developers
+Original-Maintainer: Debian Apache Maintainers
+Architecture: amd64
+Version: 2.4.12-2ubuntu2
+Replaces: apache2.2-common
+Provides: httpd, httpd-cgi
+Depends: lsb-base, procps, perl, mime-support, apache2-bin (= 2.4.12-2ubuntu2), apache2-utils (>= 2.4), apache2-data (= 2.4.12-2ubuntu2)
+Pre-Depends: dpkg (>= 1.17.14)
+Recommends: ssl-cert
+Suggests: www-browser, apache2-doc, apache2-suexec-pristine | apache2-suexec-custom, ufw
+Conflicts: apache2.2-common (<< 2.3~)
+Filename: pool/main/a/apache2/apache2_2.4.12-2ubuntu2_amd64.deb
+Size: 91348
+MD5sum: ab0ee0b0d1c6b3d19bd87aa2a9537125
+SHA1: 350c9a1a954906088ed032aebb77de3d5bb24004
+SHA256: 03f515f7ebc3b67b050b06e82ebca34b5e83e34a528868498fce020bf1dbbe34
+Description-en: Apache HTTP Server
+ The Apache HTTP Server Project's goal is to build a secure, efficient and
+ extensible HTTP server as standards-compliant open source software. The
+ result has long been the number one web server on the Internet.
+ .
+ Installing this package results in a full installation, including the
+ configuration files, init scripts and support scripts.
+Description-md5: d02426bc360345e5acd45367716dc35c
+Homepage: http://httpd.apache.org/
+Bugs: https://bugs.launchpad.net/ubuntu/+filebug
+Origin: Ubuntu
+Supported: 9m
+Task: lamp-server, mythbuntu-frontend, mythbuntu-desktop, mythbuntu-backend-slave, mythbuntu-backend-master, mythbuntu-backend-master
+
+```
+
+### [APT Command][11] : View Package Information On Debian/Ubuntu/Mint Systems
+
+APT stands for Advanced Packaging Tool (APT) which is replacement for apt-get, like how DNF came to picture instead of YUM. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features. For example we can easily install .dpkg packages through APT but we can’t do through Apt-Get similar more features are included into APT command. APT-GET replaced by APT Due to lock of futures missing in apt-get which was not solved.
+```
+$ apt show nano
+Package: nano
+Version: 2.8.6-3
+Priority: standard
+Section: editors
+Origin: Ubuntu
+Maintainer: Ubuntu Developers
+Original-Maintainer: Jordi Mallach
+Bugs: https://bugs.launchpad.net/ubuntu/+filebug
+Installed-Size: 766 kB
+Depends: libc6 (>= 2.14), libncursesw5 (>= 6), libtinfo5 (>= 6)
+Suggests: spell
+Conflicts: pico
+Breaks: nano-tiny (<< 2.8.6-2)
+Replaces: nano-tiny (<< 2.8.6-2), pico
+Homepage: https://www.nano-editor.org/
+Task: standard, ubuntu-touch-core, ubuntu-touch
+Supported: 9m
+Download-Size: 222 kB
+APT-Manual-Installed: yes
+APT-Sources: http://in.archive.ubuntu.com/ubuntu artful/main amd64 Packages
+Description: small, friendly text editor inspired by Pico
+ GNU nano is an easy-to-use text editor originally designed as a replacement
+ for Pico, the ncurses-based editor from the non-free mailer package Pine
+ (itself now available under the Apache License as Alpine).
+ .
+ However, GNU nano also implements many features missing in pico, including:
+ - undo/redo
+ - line numbering
+ - syntax coloring
+ - soft-wrapping of overlong lines
+ - selecting text by holding Shift
+ - interactive search and replace (with regular expression support)
+ - a go-to line (and column) command
+ - support for multiple file buffers
+ - auto-indentation
+ - tab completion of filenames and search terms
+ - toggling features while running
+ - and full internationalization support
+
+```
+
+### [dpkg Command][12] : View Package Information On Debian/Ubuntu/Mint Systems
+
+dpkg stands for Debian package manager (dpkg). dpkg is a command-line tool to install, build, remove and manage Debian packages. dpkg uses Aptitude (primary and more user-friendly) as a front-end to perform all the actions. Other utility such as dpkg-deb and dpkg-query uses dpkg as a front-end to perform some action. Now a days most of the administrator using Apt, Apt-Get & Aptitude to manage packages easily without headache and its robust management too. Even though still we need to use dpkg to perform some software installation where it’s necessary.
+```
+$ dpkg -s python
+Package: python
+Status: install ok installed
+Priority: optional
+Section: python
+Installed-Size: 626
+Maintainer: Ubuntu Developers
+Architecture: amd64
+Multi-Arch: allowed
+Source: python-defaults
+Version: 2.7.14-2ubuntu1
+Replaces: python-dev (<< 2.6.5-2)
+Provides: python-ctypes, python-email, python-importlib, python-profiler, python-wsgiref
+Depends: python2.7 (>= 2.7.14-1~), libpython-stdlib (= 2.7.14-2ubuntu1)
+Pre-Depends: python-minimal (= 2.7.14-2ubuntu1)
+Suggests: python-doc (= 2.7.14-2ubuntu1), python-tk (>= 2.7.14-1~)
+Breaks: update-manager-core (<< 0.200.5-2)
+Conflicts: python-central (<< 0.5.5)
+Description: interactive high-level object-oriented language (default version)
+ Python, the high-level, interactive object oriented language,
+ includes an extensive class library with lots of goodies for
+ network programming, system administration, sounds and graphics.
+ .
+ This package is a dependency package, which depends on Debian's default
+ Python version (currently v2.7).
+Homepage: http://www.python.org/
+Original-Maintainer: Matthias Klose
+
+```
+
+Alternatively we can use `-p` option with dpkg that provides information similar to `dpkg -s` info but additionally it provides package checksum data and type.
+```
+$ dpkg -p python3
+Package: python3
+Priority: important
+Section: python
+Installed-Size: 67
+Origin: Ubuntu
+Maintainer: Ubuntu Developers
+Bugs: https://bugs.launchpad.net/ubuntu/+filebug
+Architecture: amd64
+Multi-Arch: allowed
+Source: python3-defaults
+Version: 3.6.3-0ubuntu2
+Replaces: python3-minimal (<< 3.1.2-2)
+Provides: python3-profiler
+Depends: python3.6 (>= 3.6.3-1~), libpython3-stdlib (= 3.6.3-0ubuntu2), dh-python
+Pre-Depends: python3-minimal (= 3.6.3-0ubuntu2)
+Suggests: python3-doc (>= 3.6.3-0ubuntu2), python3-tk (>= 3.6.3-1~), python3-venv (>= 3.6.3-0ubuntu2)
+Filename: pool/main/p/python3-defaults/python3_3.6.3-0ubuntu2_amd64.deb
+Size: 8712
+MD5sum: a8bae494c6e5d1896287675faf40d373
+Description: interactive high-level object-oriented language (default python3 version)
+Original-Maintainer: Matthias Klose
+SHA1: 2daec885cea7d4dc83c284301c3bebf42b23e095
+SHA256: 865e509c91d2504a16c4b573dbe27e260c36fceec2add3fa43a30c1751d7e9bb
+Homepage: http://www.python.org/
+Task: minimal, ubuntu-core, ubuntu-core
+Description-md5: 950ebd8122c0a7340f0a740c295b9eab
+Supported: 9m
+
+```
+
+### Aptitude Command : View Package Information On Debian/Ubuntu/Mint Systems
+
+aptitude is a text-based interface to the Debian GNU/Linux package system. It allows the user to view the list of packages and to perform package management tasks such as installing, upgrading, and removing packages. Actions may be performed from a visual interface or from the command-line.
+```
+$ aptitude show htop
+Package: htop
+Version: 2.0.2-1
+State: installed
+Automatically installed: no
+Priority: optional
+Section: universe/utils
+Maintainer: Ubuntu Developers
+Architecture: amd64
+Uncompressed Size: 216 k
+Depends: libc6 (>= 2.15), libncursesw5 (>= 6), libtinfo5 (>= 6)
+Suggests: lsof, strace
+Conflicts: htop:i386
+Description: interactive processes viewer
+ Htop is an ncursed-based process viewer similar to top, but it allows one to scroll the list vertically and horizontally to see all processes and their full command lines.
+
+ Tasks related to processes (killing, renicing) can be done without entering their PIDs.
+Homepage: http://hisham.hm/htop/
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-in-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/prakash/
+[1]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
+[2]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
+[3]:https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
+[4]:https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
+[5]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[6]:https://www.2daygeek.com/rpm-command-examples/
+[7]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[8]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[9]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+[10]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[11]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[12]:https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
diff --git a/sources/tech/20180710 Users, Groups, and Other Linux Beasts.md b/sources/tech/20180710 Users, Groups, and Other Linux Beasts.md
new file mode 100644
index 0000000000..6083111a32
--- /dev/null
+++ b/sources/tech/20180710 Users, Groups, and Other Linux Beasts.md
@@ -0,0 +1,153 @@
+Users, Groups, and Other Linux Beasts
+======
+
+
+
+Having reached this stage, [after seeing how to manipulate folders/directories][1], but before flinging ourselves headlong into fiddling with files, we have to brush up on the matter of _permissions_ , _users_ and _groups_. Luckily, [there is already an excellent and comprehensive tutorial on this site that covers permissions][2], so you should go and read that right now. In a nutshell: you use permissions to establish who can do stuff to files and directories and what they can do with each file and directory -- read from it, write to it, move it, erase it, etc.
+
+To try everything this tutorial covers, you'll need to create a new user on your system. Let's be practical and make a user for anybody who needs to borrow your computer, that is, what we call a _guest account_.
+
+**WARNING:** _Creating and especially deleting users, along with home directories, can seriously damage your system if, for example, you remove your own user and files by mistake. You may want to practice on another machine which is not your main work machine or on a virtual machine. Regardless of whether you want to play it safe, or not, it is always a good idea to back up your stuff frequently, check the backups have worked correctly, and save yourself a lot of gnashing of teeth later on._
+
+### A New User
+
+You can create a new user with the `useradd` command. Run `useradd` with superuser/root privileges, that is using `sudo` or `su`, depending on your system, you can do:
+```
+sudo useradd -m guest
+
+```
+
+... and input your password. Or do:
+```
+su -c "useradd -m guest"
+
+```
+
+... and input the password of root/the superuser.
+
+( _For the sake of brevity, we'll assume from now on that you get superuser/root privileges by using`sudo`_ ).
+
+By including the `-m` argument, `useradd` will create a home directory for the new user. You can see its contents by listing _/home/guest_.
+
+Next you can set up a password for the new user with
+```
+sudo passwd guest
+
+```
+
+Or you could also use `adduser`, which is interactive and asks you a bunch of questions, including what shell you want to assign the user (yes, there are more than one), where you want their home directory to be, what groups you want them to belong to (more about that in a second) and so on. At the end of running `adduser`, you get to set the password. Note that `adduser` is not installed by default on many distributions, while `useradd` is.
+
+Incidentally, you can get rid of a user with `userdel`:
+```
+sudo userdel -r guest
+
+```
+
+With the `-r` option, `userdel` not only removes the _guest_ user, but also deletes their home directory and removes their entry in the mailing spool, if they had one.
+
+### Skeletons at Home
+
+Talking of users' home directories, depending on what distro you're on, you may have noticed that when you use the `-m` option, `useradd` populates a user's directory with subdirectories for music, documents, and whatnot as well as an assortment of hidden files. To see everything in you guest's home directory run `sudo ls -la /home/guest`.
+
+What goes into a new user's directory is determined by a skeleton directory which is usually _/etc/skel_. Sometimes it may be a different directory, though. To check which directory is being used, run:
+```
+useradd -D
+GROUP=100
+HOME=/home
+INACTIVE=-1
+EXPIRE=
+SHELL=/bin/bash
+SKEL=/etc/skel
+CREATE_MAIL_SPOOL=no
+
+```
+
+This gives you some extra interesting information, but what you're interested in right now is the `SKEL=/etc/skel` line. In this case, and as is customary, it is pointing to _/etc/skel/_.
+
+As everything is customizable in Linux, you can, of course, change what gets put into a newly created user directory. Try this: Create a new directory in _/etc/skel/_ :
+```
+sudo mkdir /etc/skel/Documents
+
+```
+
+And create a file containing a welcome text and copy it over:
+```
+sudo cp welcome.txt /etc/skel/Documents
+
+```
+
+Now delete the guest account:
+```
+sudo userdel -r guest
+
+```
+
+And create it again:
+```
+sudo useradd -m guest
+
+```
+
+Hey presto! Your _Documents/_ directory and _welcome.txt_ file magically appear in the guest's home directory.
+
+You can also modify other things when you create a user by editing _/etc/default/useradd_. Mine looks like this:
+```
+GROUP=users
+HOME=/home
+INACTIVE=-1
+EXPIRE=
+SHELL=/bin/bash
+SKEL=/etc/skel
+CREATE_MAIL_SPOOL=no
+
+```
+
+Most of these options are self-explanatory, but let's take a closer look at the `GROUP` option.
+
+### Herd Mentality
+
+Instead of assigning permissions and privileges to users one by one, Linux and other Unix-like operating systems rely on _groups_. A group is a what you imagine it to be: a bunch of users that are related in some way. On your system you may have a group of users that are allowed to use the printer. They would belong to the _lp_ (for " _line printer_ ") group. The members of the _wheel_ group were traditionally the only ones who could become superuser/root by using _su_. The _network_ group of users can bring up and power down the network. And so on and so forth.
+
+Different distributions have different groups and groups with the same or similar names have different privileges also depending on the distribution you are using. So don't be surprised if what you read in the prior paragraph doesn't match what is going on in your system.
+
+Either way, to see which groups are on your system you can use:
+```
+getent group
+
+```
+
+The `getent` command lists the contents of some of the system's databases.
+
+To find out which groups your current user belongs to, try:
+```
+groups
+
+```
+
+When you create a new user with `useradd`, unless you specify otherwise, the user will only belong to one group: their own. A _guest_ user will belong to a _guest_ group and the group gives the user the power to administer their own stuff and that is about it.
+
+You can create new groups and then add users to them at will with the `groupadd` command:
+```
+sudo groupadd photos
+
+```
+
+will create the _photos_ group, for example. Next time, we’ll use this to build a shared directory all members of the group can read from and write to, and we'll learn even more about permissions and privileges. Stay tuned!
+
+Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts
+
+作者:[Paul Brown][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/bro66
+[1]:https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
+[2]:https://www.linux.com/learn/understanding-linux-file-permissions
+[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180711 5 open source racing and flying games for Linux.md b/sources/tech/20180711 5 open source racing and flying games for Linux.md
new file mode 100644
index 0000000000..c2b540f498
--- /dev/null
+++ b/sources/tech/20180711 5 open source racing and flying games for Linux.md
@@ -0,0 +1,102 @@
+5 open source racing and flying games for Linux
+======
+
+
+
+Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games often are not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
+
+So, can someone who uses only free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely to ever rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website to install and play it.
+
+This article looks at racing and flying games. I have already written about [arcade-style games][1], [board and card games][2], and [puzzle games][3]. In future articles, I plan to cover role-playing games and strategy & simulation games.
+
+### Extreme Tux Racer
+
+
+
+Race down snow and ice-covered mountains as Tux or other characters in [Extreme Tux Racer][4]. In this racing game, the goal is to collect herrings and earn the best time. There are many different tracks to choose from, and tracks can be customized by altering the time of day, wind, and weather conditions. While the game has a few rough edges compared to modern, commercial racing games, it is still an enjoyable game to play. The controls and gameplay are straightforward and simple to learn, making this a great choice for kids.
+
+To install Extreme Tux Racer, run the following command:
+
+ * On Fedora: `dnf install extremetuxracer`
+ * On Debian/Ubuntu: `apt install extremetuxracer`
+
+
+
+### FlightGear
+
+
+
+[FlightGear][5] is a full-fledged, open source flight simulator. Multiple aircraft types are available, and 20,000 airports are included in the full world scenery set. That means the player can fly to most parts of the world and have realistic airports and scenery. The full world scenery data is large enough to fill three DVDs. Even the developers are jokingly not sure if that counts as "a feature or a problem," so be aware that a complete installation of FlightGear and all its scenery data is huge. While certainly not the right game for everyone, FlightGear provides a very complete and complex flight simulator experience for players looking to explore the skies on their own computer.
+
+To install FlightGear, run the following command:
+
+ * On Fedora: `dnf install FlightGear`
+ * On Debian/Ubuntu: `apt install flightgear`
+
+
+
+### SuperTuxKart
+
+
+
+[SuperTuxKart][6] takes the basic formula used by Nintendo in the Mario Kart series and applies it to open source mascots. Players race around a variety of tracks in go-karts driven by the mascots for a plethora of open source projects. Character choices include the mascots for open source operating systems and applications of varying familiarity, with options ranging from Tux and Beastie to Gavroche, the mascot for [GNU MediaGoblin][7]. There are several gameplay modes to choose from, including multi-player modes, but many of the tracks are unavailable until they are unlocked by playing the game's single-player story mode. SuperTuxKart's graphics settings can be tweaked to run on everything from older computers with built-in graphics to modern hardware with high-end graphics cards. There is also a version of [SuperTuxKart for Android][8] available. SuperTuxKart is a very good game and great for players of all ages.
+
+To install SuperTuxKart, run the following command:
+
+ * On Fedora: `dnf install supertuxkart`
+ * On Debian/Ubuntu: `apt install supertuxkart`
+
+
+
+### Torcs
+
+
+
+[Torcs][9] is a fairly standard racing game with some extra features for the tech-savvy. Torcs can be played as just a standard racing game, where the player drives around a track trying to get the best time, but an alternative usage is as a platform to develop an artificial intelligence driver that can drive itself through Torcs' tracks. The cars and tracks included with the game vary in style, ranging from stock car racing to rally racing, but the gameplay is pretty typical for a racing game. Keyboard, mouse, joystick, and steering wheel input are all supported, but keyboard and mouse input modes are a little hard to get used to. Single-player races range from practice runs to championships, and there is a [split-screen multi-player mode][10] for up to four players.
+
+To install Torcs, run the following command:
+
+ * On Fedora: `dnf install torcs`
+ * On Debian/Ubuntu: `apt install torcs`
+
+
+
+### Trigger Rally
+
+
+
+[Trigger Rally][11] is an off-road, single-player rally racing game. The player needs to make it to each checkpoint in time to complete the race, which is standard racing game fare, but still enjoyable. The gameplay is more arcade-like than a strict racing simulator like Torcs but more realistic than cartoonish racing games like SuperTuxKart. The tracks are interesting and the controls are responsive, but a little too sensitive when playing with a keyboard. Joystick controls are available by changing an option in a configuration file. Unfortunately, development on the game is slow going, with the latest release in 2016, but the gameplay that is already there is fun.
+
+To install Trigger Rally, run the following command:
+
+ * On Debian/Ubuntu: `apt install trigger-rally`
+
+
+
+Unfortunately, Trigger Rally is not packaged for Fedora.
+
+Did I miss one of your favorite open source racing or flying games? Share it in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/racing-flying-games-linux
+
+作者:[About The Author;Joshua Allen Holm;Mlis;Med;Is One Of Opensource.Com'S Community Moderators. Joshua'S Main Interests Are Digital Humanities;Open Access;Open Educational Resources. He Can Reached At][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/holmja
+[1]:https://opensource.com/article/18/1/arcade-games-linux
+[2]:https://opensource.com/article/18/3/card-board-games-linux
+[3]:https://opensource.com/article/18/6/puzzle-games-linux
+[4]:https://extremetuxracer.sourceforge.io/
+[5]:http://home.flightgear.org/
+[6]:https://supertuxkart.net/Main_Page
+[7]:https://mediagoblin.org
+[8]:https://play.google.com/store/apps/details?id=org.supertuxkart.stk
+[9]:http://torcs.sourceforge.net/index.php
+[10]:http://torcs.sourceforge.net/?name=Sections&op=viewarticle&artid=30#c4_4_4
+[11]:http://trigger-rally.sf.net/
diff --git a/sources/tech/20180711 Becoming a senior developer 9 experiences you ll encounter.md b/sources/tech/20180711 Becoming a senior developer 9 experiences you ll encounter.md
new file mode 100644
index 0000000000..1ca6e94ef3
--- /dev/null
+++ b/sources/tech/20180711 Becoming a senior developer 9 experiences you ll encounter.md
@@ -0,0 +1,143 @@
+bestony is translating
+
+Becoming a senior developer: 9 experiences you'll encounter
+============================================================
+
+
+
+Plenty of career guides suggest appropriate steps to take if you want a management track. But what if you want to stay technical—and simply become the best possible programmer? These non-obvious markers let you know you’re on the right path.
+
+Many programming career guidelines stress the skills a software developer is expected to acquire. Such general advice suggests that someone who wants to focus on a technical track—as opposed to, say, [taking a management path to CIO][5]—should go after the skills needed to mentor junior developers, design future application features, build out release engineering systems, and set company standards.
+
+That isn’t this article.
+
+Being a developer—a good one—isn't just about writing code. To be successful, you do a lot of planning, you deal with catastrophes, and you prevent catastrophes. Not to mention you spend plenty of time [working with other humans][6] about what your code should do.
+
+Following are a number of markers you’ll likely encounter as your career progresses and you become a more accomplished developer. You’ll have highs that boost you up and remind you how awesome you are. You'll also encounter lows that keep you humble and give you wisdom—at least in retrospect, if you respond to them appropriately.
+
+These experiences may feel good, they may be uncomfortable, or they may be downright scary. They're all learning experiences—at least for those developers who sincerely want to move forward, in both skills and professional ambition. These experiences often change the way developers look at their job or how they approach the next problem. It's why an experienced developer's value to a company is more than just a list of technology buzzwords.
+
+Here, in no particular order, is a sampling of what you'll run into on your way to becoming a senior developer—not in terms of a specific job title but being confident about creating quality code that serves users.
+
+### You write your first big bug into production
+
+Probably your initial step into the big leagues is the first bug you write into production. It's a sickening feeling. You know that the software you're working on is now broken in some significant way because of something you did, code you wrote, or a test you didn't run.
+
+No matter how good a programmer you are, you'll make mistakes. You're a human, and that's part of what we do.
+
+Most developers learn from the “bug that went live” experience. You promise never to make the same bug again. You analyze what happened, and you think about how the bug could have been prevented. For me, one effect of discovering I let a bug into production code is that it reinforced my belief that compiler warnings and static analysis tools are a programmer's best friend.
+
+You repeat the process when it happens again. It _will_ happen again, but as your programming skill improves, it happens less frequently.
+
+### You delete production data for the first time
+
+It might be a `DROP TABLE` in production or [a mistaken `rm -rf`][7]. Maybe you clicked on the wrong volume to format. You get an uneasy feeling that "this is taking longer to run than I would expect. It's not running on... oh, no!" followed by a mad scramble to fix it.
+
+Data loss has long-term effects on a growing-wiser developer much like the production bug. Afterward, you re-examine how you work. It teaches you to take more safeguards than you did previously. Maybe you decide to create a more rigorous rotation schedule for backups, or even start having a backup schedule at all.
+
+As with the bug in production, you learn that you can survive making a mistake, and it's not the end of the world.
+
+### You automate away part of your job
+
+There's an old saying that you can't get promoted if you can't be replaced. Anything that ties you to a specific job or task is an anchor on your ability to move up in the company or be assigned newer and more interesting tasks.
+
+When good programmers find themselves doing drudgework as part of their job, they find a way to let a machine do it. If they are stuck [scanning server logs][8] every Monday looking for problems, they'll install a tool like Logwatch to summarize the results. When there are many servers to be monitored, a good programmer will turn to a more capable tool that analyzes logs on multiple servers.
+
+Unsure how to get started with containers? Yes, we have a guide for that. Get Containers for Dummies.
+
+[Download now][4]
+
+In each case, wise programmers provide more value to their company, because an automated system is much cheaper than a senior programmer’s salary. They also grow personally by eliminating drudgery, leaving them more time to work on more challenging tasks.
+
+### You use existing code instead of writing your own
+
+A senior programmer knows that code that doesn't get written doesn't have bugs, and that many problems, both common and uncommon, have already been solved—in many cases, multiple times.
+
+Senior programmers know that the chances are very low that they can write, test, and debug their own code for a task faster or cheaper than existing code that does what they want. It doesn't have to be perfect to make it worth their while.
+
+It might take a little bit of turning down your ego to make it happen, but that's an excellent skill for senior programmers to have, too.
+
+### You are publicly recognized for achievements
+
+Many people aren't comfortable with public recognition. It's embarrassing. We have these amazing skills, and we like the feeling of helping others, but we can be embarrassed when it's called out.
+
+Praise comes in many forms and many sizes. Maybe it's winning an "employee of the quarter" award for a project you drove and being presented a plaque onstage. It could be as low-key as your team leader saying, "Thanks to Cheryl for implementing that new microservice."
+
+Whatever it is, accept it graciously and appreciatively, even if you're embarrassed by the attention. Don't diminish the praise you receive with, "Oh, it was nothing" or anything similar. Accept credit for the things that users and co-workers appreciate. Thank the speaker and say you were glad you could be of service.
+
+First, this is the polite thing to do. When people praise you, they want it to be acknowledged. In addition, that warm recognition helps you in the future. Remembering it gets you through those crappy days, such as when you uncover bugs in your code.
+
+### You turn down a user request
+
+As much as we love being superheroes who can do amazing things with computers, sometimes turning down a request is best for the organization. Part of being a senior programmer is knowing when not to write code. A senior programmer knows that every bit of code in a codebase is a chance for things to go wrong and a potential future cost for maintenance.
+
+You might be uncomfortable the first time you tell a user that you won’t be incorporating his maybe-even-useful suggestion. But this is a notable occasion. It means you understand the application and its role in a larger context. It also means you “own” the software, in a positive, confident way.
+
+The organization need not be an employer, either. Open source project managers deal with this all the time, when they have to tell a user, "Sorry, it doesn't fit with where the project is going.”
+
+### You know when to fight for what's right and when it really doesn't matter
+
+Rookie programmers are full of knowledge straight from school, having learned all the right ways to do things. They're eager to apply their knowledge and make amazing things happen for their employers. However, they're often surprised to find that out in the business world, things sometimes don't get done the "right" way.
+
+There's an old military saying: No plan survives contact with the enemy. It's the same with new programmers and project plans. Sometimes in the heat of the battle of business, the purist computer science techniques learned in school fall by the wayside.
+
+Maybe the database schema gets slapped together in a way that isn't perfect [fifth normal form][9]. Sometimes code gets cut and pasted rather than refactored out into a new function or library. Plenty of production systems run on shell scripts and prayers. The wise programmer knows when to push for the right way to do things and when to take the cheap way out.
+
+The first time you do it, it feels like you're selling out your principles. It’s not. The balance between academic purism and the realities of getting work done can be a delicate one, and that knowledge of when to do things less than perfectly is part of the wisdom you’ll acquire.
+
+### You are asked what to do
+
+After a while, you'll have earned a reputation in your organization for getting things done. It won’t be just for having expertise in a certain area—it’ll be wisdom. Someone will come to you and ask for guidance with a project or a problem.
+
+That person isn't just asking you for help with a problem. You are being asked to lead.
+
+A common situation is when you are asked to help a team of less-experienced developers that's navigating difficult new terrain or needs shepherding on a project. That's when you'll be called on to help not just do things but show people how to improve their own skills.
+
+It might also be leadership from a technical point of view. Your boss might say, "We need a new indexing solution. Find out what you can about FooIndex and BarSearch, and let me know what you propose." That's the sort of responsibility given only to someone who has demonstrated wisdom and experience.
+
+### You are seriously headhunted for the first time
+
+Recruiting professionals are always looking for talent. Most recruiters seem to do random emailing and LinkedIn harvesting. But every so often, they find out about talented performers and hunt them down.
+
+When that happens, it's a feather in your cap. Maybe a former colleague spoke to a recruiter friend trying to place a developer at a company that needs the skills you have. If you get a personal recommendation for a position—even if you don’t want the job—it means you've really arrived. You're recognized as an expert, or someone who brings value to an organization, enough to recommend you to others.
+
+### Onward
+
+I hope that my little list helps prompt some thought about [where you are in your career][10] or [where you might be headed][11]. Markers and milestones can help you understand what’s around you and what to expect.
+
+This list is far from complete, of course. Everyone has their own story. In fact, one of the ways to know you’ve hit a milestone is when you find yourself telling a story about it to others. When you do find yourself looking back at a tough situation, make sure to reflect on what it means to you and why. Experience is a great teacher—if you listen to it.
+
+What are your markers? How did you know you had finally become a senior programmer? Tweet at [@enterprisenxt][12] and let me know.
+
+This article/content was written by the individual writer identified and does not necessarily reflect the view of Hewlett Packard Enterprise Company.
+
+ [][13]
+
+### 作者简介
+
+Andy Lester has been a programmer and developer since the 1980s, when COBOL walked the earth. He is the author of the job-hunting guide [Land the Tech Job You Love][2] (2009, Pragmatic Bookshelf). Andy has been an active contributor to the open source community for decades, most notably as the creator of the grep-like code search tool [ack][3].
+
+--------------------------------------------------------------------------------
+
+via: https://www.hpe.com/us/en/insights/articles/becoming-a-senior-developer-9-experiences-youll-encounter-1807.html
+
+作者:[Andy Lester ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
+[1]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
+[2]:https://pragprog.com/book/algh/land-the-tech-job-you-love
+[3]:https://beyondgrep.com/
+[4]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_seniordev0718
+[5]:https://www.hpe.com/us/en/insights/articles/7-career-milestones-youll-meet-on-the-cio-and-it-management-track-1805.html
+[6]:https://www.hpe.com/us/en/insights/articles/how-to-succeed-in-it-without-social-skills-1705.html
+[7]:https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html
+[8]:https://www.hpe.com/us/en/insights/articles/back-to-basics-what-sysadmins-must-know-about-logging-and-monitoring-1805.html
+[9]:http://www.bkent.net/Doc/simple5.htm
+[10]:https://www.hpe.com/us/en/insights/articles/career-interventions-when-your-it-career-needs-a-swift-kick-1806.html
+[11]:https://www.hpe.com/us/en/insights/articles/how-to-avoid-an-it-career-dead-end-1806.html
+[12]:https://twitter.com/enterprisenxt
+[13]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
diff --git a/sources/tech/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md b/sources/tech/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md
new file mode 100644
index 0000000000..f6a348980d
--- /dev/null
+++ b/sources/tech/20180711 Open hardware meets open science in a multi-microphone hearing aid project.md
@@ -0,0 +1,69 @@
+Open hardware meets open science in a multi-microphone hearing aid project
+======
+
+
+
+Since [Opensource.com][1] first published the story of the [GNU/Linux hearing aid][2] research platform in 2010, there has been an explosion in the availability of miniature system boards, including the original BeagleBone in 2011 and the Raspberry Pi in 2012. These ARM processor devices built from cellphone chips differ from the embedded system reference boards of the past—not only by being far less expensive and more widely available—but also because they are powerful enough to run familiar GNU/Linux distributions and desktop applications.
+
+What took a laptop to accomplish in 2010 can now be achieved with a pocket-sized board costing a fraction as much. Because a hearing aid does not need a screen and a small ARM board's power consumption is far less than a typical laptop's, field trials can potentially run all day. Additionally, the system's lower weight is easier for the end user to wear.
+
+The [openMHA project][3]—from the [Carl von Ossietzky Universität Oldenburg][4] in Germany, [BatAndCat Sound Labs][5] in Palo Alto, California, and [HörTech gGmbH][6]—is an open source platform for improving hearing aids using real-time audio signal processing. For the next iteration of the research platform, openMHA is using the US$ 55 [BeagleBone Black][7] board with its 1GHz Cortex A8 CPU.
+
+The BeagleBone family of boards enjoys guaranteed long-term availability, thanks to its open hardware design that can be produced by anyone with the requisite knowledge. For example, BeagleBone hardware variations are available from community members including [SeeedStudio][8] and [SanCloud][9].
+
+![BeagleBone Black][11]
+
+The BeagleBone Black is open hardware finding its way into research labs.
+
+Spatial filtering techniques, including [beamforming][12] and [directional microphone arrays][13], can suppress distracting noise, focusing audio amplification on the point in space where the hearing aid wearer is looking, rather than off to the side where a truck might be thundering past. These neat tricks can use two or three microphones per ear, yet typical sound cards for embedded devices support only one or two input channels in total.
+
+Fortunately, the [McASP][14] communication peripheral in Texas Instruments chips offers multiple channels and support for the [I2S protocol][15], originally devised by Philips for short digital audio interconnects inside CD players. This means an add-on "cape" board can hook directly into the BeagleBone's audio system without using USB or other external interfaces. The direct approach helps reduce the signal processing delay into the range where it is undetectable by the hearing aid wearer.
+
+The openMHA project uses an audio cape developed by the [Hearing4all][16] project, which combines three stereo codecs to provide up to six input channels. Like the BeagleBone, the Cape4all is open hardware with design files available on [GitHub][17].
+
+The Cape4all, [presented recently][18] at the Linux Audio Conference in Berlin, Germany, runs at a sample rate from 24kHz to 96Khz with as few as 12 samples per period, leading to internal latencies in the sub-millisecond range. With hearing enhancement algorithms running, the complete round-trip latency from a microphone to an earpiece has been measured at 3.6 milliseconds (at 48KHz sample rate with 16 samples per period). Using the speed of sound for comparison, this latency is similar to listening to someone just over four feet away without a hearing aid.
+
+![Cape4all ][20]
+
+The Cape4all might be the first multi-microphone hearing aid on an open hardware platform.
+
+The next step for the openMHA project is to develop a [Bluetooth Low Energy][21] module that will enable remote control of the research device from a smartphone and perhaps route phone calls and media playback to the hearing aid. Consumer hearing aids support Bluetooth, so the openMHA research platform must do so, too.
+
+Also, instructions for running a [stereo hearing aid on the Raspberry Pi][22] were released by an openMHA user-project.
+
+As evidenced by the openMHA project, open source innovation has transformed digital hearing aid research from an esoteric branch of audiology into an accessible open science.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/open-hearing-aid-platform
+
+作者:[Daniel James,Christopher Obbard][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/daniel-james
+[1]:http://Opensource.com
+[2]:https://opensource.com/life/10/9/open-source-designing-next-generation-digital-hearing-aids
+[3]:http://www.openmha.org/
+[4]:https://www.uni-oldenburg.de/
+[5]:http://batandcat.com/
+[6]:http://www.hoertech.de/
+[7]:https://beagleboard.org/black
+[8]:https://www.seeedstudio.com/
+[9]:http://www.sancloud.co.uk
+[10]:/file/403046
+[11]:https://opensource.com/sites/default/files/uploads/1-beagleboneblack-600.jpg (BeagleBone Black)
+[12]:https://en.wikipedia.org/wiki/Beamforming
+[13]:https://en.wikipedia.org/wiki/Microphone_array
+[14]:https://en.wikipedia.org/wiki/McASP
+[15]:https://en.wikipedia.org/wiki/I%C2%B2S
+[16]:http://hearing4all.eu/EN/
+[17]:https://github.com/HoerTech-gGmbH/Cape4all
+[18]:https://lac.linuxaudio.org/2018/pages/event/35/
+[19]:/file/403051
+[20]:https://opensource.com/sites/default/files/uploads/2-beaglebone-wireless-with-cape4all-labelled-600.jpg (Cape4all )
+[21]:https://en.wikipedia.org/wiki/Bluetooth_Low_Energy
+[22]:http://www.openmha.org/userproject/2017/12/21/openMHA-on-raspberry-pi.html
diff --git a/sources/tech/20180711 netdev-day-1--ipsec.md b/sources/tech/20180711 netdev-day-1--ipsec.md
new file mode 100644
index 0000000000..86132a4592
--- /dev/null
+++ b/sources/tech/20180711 netdev-day-1--ipsec.md
@@ -0,0 +1,121 @@
+
+FSSlc is translating
+
+netdev day 1: IPsec!
+============================================================
+
+Hello! This year, like last year, I’m at the [netdev conference][3]. (here are my [notes from last year][4]).
+
+Today at the conference I learned a lot about IPsec, so we’re going to talk about IPsec! There was an IPsec workshop given by Sowmini Varadhan and [Paul Wouters][5]. All of the mistakes in this post are 100% my fault though :).
+
+### what’s IPsec?
+
+IPsec is a protocol used to encrypt IP packets. Some VPNs are implemented with IPsec. One big thing I hadn’t really realized until today is that there isn’t just one protocol used for VPNs – I think VPN is just a general term meaning “your IP packets get encrypted and sent through another server” and VPNs can be implemented using a bunch of different protocols (OpenVPN, PPTP, SSTP, IPsec, etc) in a bunch of different ways.
+
+Why is IPsec different from other VPN protocols? (like, why was there a tutorial about it at netdev and not the other protocols?) My understanding is that there are 2 things that make it different:
+
+* It’s an IETF standard, documented in eg [RFC 6071][1] (did you know the IETF is the group that makes RFCs? I didn’t until today!)
+
+* it’s implemented in the Linux kernel (so it makes sense that there was a netdev tutorial on it, since netdev is a Linux kernel networking conference :))
+
+### How does IPsec work?
+
+So let’s say your laptop is using IPsec to encrypt its packets and send them through another device. How does that work? There are 2 parts to IPsec: a userspace part, and a kernel part.
+
+The userspace part of IPsec is responsible for key exchange, using a protocol called [IKE][6] (“internet key exchange”). Basically when you open a new VPN connection, you need to talk to the VPN server and negotiate a key to do encryption.
+
+The kernel part of IPsec is responsible for the actual encryption of packets – once a key is generated using IKE, the userspace part of IPsec will tell the kernel which encryption key to use. Then the kernel will use that key to encrypt packets!
+
+### Security Policy & Security Associations
+
+The kernel part of IPSec has two databases: the security policy database(SPD) and the security association database (SAD).
+
+The security policy database has IP ranges and rules for what to do to packets for that IP range (“do IPsec to it”, “drop the packet”, “let it through”). I find this a little confusing because I’m used to rules about what to do to packets in various IP ranges being in the route table (`sudo ip route list`), but apparently you can have IPsec rules too and they’re in a different place!
+
+The security association database I think has the encryption keys to use for various IPs.
+
+The way you inspect these databases is, extremely unintuitively, using a command called `ip xfrm`. What does xfrm mean? I don’t know!
+
+```
+# security policy database
+$ sudo ip xfrm policy
+$ sudo ip x p
+
+# security association database
+$ sudo ip xfrm state
+$ sudo ip x s
+
+```
+
+### Why is IPsec implemented in the Linux kernel and TLS isn’t?
+
+For both TLS and IPsec, you need to do a key exchange when opening the connection (using Diffie-Hellman or something). For some reason that might be obvious but that I don’t understand yet (??) people don’t want to do key exchange in the kernel.
+
+The reason IPsec is easier to implement in the kernel is that with IPsec, you need to negotiate key exchanges much less frequently (once for every IP address you want to open a VPN connection with), and IPsec sessions are much longer lived. So it’s easy for userspace to do a key exchange, get the key, and hand it off to the kernel which will then use that key for every IP packet.
+
+With TLS, there are a couple of problems:
+
+a. you’re constantly doing new key exchanges every time you open a new TLS connection, and TLS connections are shorter-lived b. there isn’t a natural protocol boundary where you need to start doing encryption – with IPsec, you just encrypt every IP packet in a given IP range, but with TLS you need to look at your TCP stream, recognize whether the TCP packet is a data packet or not, and decide to encrypt it
+
+There’s actually a patch [implementing TLS in the Linux kernel][7] which lets userspace do key exchange and then pass the kernel the keys, so this obviously isn’t impossible, but it’s a much newer thing and I think it’s more complicated with TLS than with IPsec.
+
+### What software do you use to do IPsec?
+
+The ones I know about are Libreswan and Strongswan. Today’s tutorial focused on Libreswan.
+
+Somewhat confusingly, even though Libreswan and Strongswan are different software packages, they both install a binary called `ipsec` for managing IPsec connections, and the two `ipsec` binaries are not the same program (even though they do have the same role).
+
+Strongswan and Libreswan do what’s described in the “how does IPsec work” section above – they do key exchange with IKE and tell the kernel about keys to configure it to do encryption.
+
+### IPsec isn’t only for VPNs!
+
+At the beginning of this post I said “IPsec is a VPN protocol”, which is true, but you don’t have to use IPsec to implement VPNs! There are actually two ways to use IPsec:
+
+1. “transport mode”, where the IP header is unchanged and only the contents of the IP packet are encrypted. This mode is a little more like using TLS – you talk to the server you’re communicating with directly (not through a VPN server or something), it’s just that the contents of the IP packet get encrypted
+
+2. “tunnel mode”, where the IP header and its contents are all encrypted and encapsulated into another UDP packet. This is the mode that’s used for VPNs – you take your packet that you’re sending to secret_site.com, encrypt it, send it to your VPN server, and the VPN server passes it on for you.
+
+### opportunistic IPsec
+
+An interesting application of “transport mode” IPsec I learned about today (where you open an IPsec connection directly with the host you’re communicating with instead of some other intermediary server) is this thing called “opportunistic IPsec”. There’s an opportunistic IPsec server here:[http://oe.libreswan.org/][8].
+
+I think the idea is that if you set up Libreswan and unbound up on your computer, then when you connect to [http://oe.libreswan.org][9], what happens is:
+
+1. `unbound` makes a DNS query for the IPSECKEY record of oe.libreswan.org (`dig ipseckey oe.libreswan.org`) to get a public key to use for that domain. (this requires DNSSEC to be secure which when I learn about it will be a whole other blog post, but you can just run that DNS query with dig and it will work if you want to see the results)
+
+2. `unbound` gives the public key to libreswan, which uses it to do a key exchange with the IKE server running on oe.libreswan.org
+
+3. `libreswan` finishes the key exchange, gives the encryption key to the kernel, and tells the kernel to use that encryption key when talking to `oe.libreswan.org`
+
+4. Your connection is now encrypted! Even though it’s a HTTP connection! so interesting!
+
+### IPsec and TLS learn from each other
+
+One interesting tidbit from the tutorial today was that the IPsec and TLS protocols have actually learned from each other over time – like they said IPsec’s IKE protocol had perfect forward secrecy before TLS, and IPsec has also learned some things from TLS. It’s neat to hear about how different internet protocols are learning & changing over time!
+
+### IPsec is interesting!
+
+I’ve spent quite a lot of time learning about TLS, which is obviously a super important networking protocol (let’s encrypt the internet! :D). But IPsec is an important internet encryption protocol too, and it has a different role from TLS! Apparently some mobile phone protocols (like 5G/LTE) use IPsec to encrypt their network traffic!
+
+I’m happy I know a little more about it now! As usual several things in this post are probably wrong, but hopefully not too wrong :)
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/
+
+作者:[ Julia Evans][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca/about
+[1]:https://tools.ietf.org/html/rfc6071
+[2]:https://jvns.ca/categories/netdev
+[3]:https://www.netdevconf.org/0x12/
+[4]:https://jvns.ca/categories/netdev/
+[5]:https://nohats.ca/
+[6]:https://en.wikipedia.org/wiki/Internet_Key_Exchange
+[7]:https://blog.filippo.io/playing-with-kernel-tls-in-linux-4-13-and-go/
+[8]:http://oe.libreswan.org/
+[9]:http://oe.libreswan.org/
diff --git a/sources/tech/20180712 A sysadmins guide to SELinux 42 answers to the big questions.md b/sources/tech/20180712 A sysadmins guide to SELinux 42 answers to the big questions.md
new file mode 100644
index 0000000000..996fdcdf59
--- /dev/null
+++ b/sources/tech/20180712 A sysadmins guide to SELinux 42 answers to the big questions.md
@@ -0,0 +1,283 @@
+FSSlc is translating
+
+A sysadmin's guide to SELinux: 42 answers to the big questions
+============================================================
+
+> Get answers to the big questions about life, the universe, and everything else about Security-Enhanced Linux.
+
+
+Image credits : [JanBaby][13], via Pixabay [CC0][14].
+
+> "It is an important and popular fact that things are not always what they seem…"
+> ―Douglas Adams, _The Hitchhiker's Guide to the Galaxy_
+
+Security. Hardening. Compliance. Policy. The Four Horsemen of the SysAdmin Apocalypse. In addition to our daily tasks—monitoring, backup, implementation, tuning, updating, and so forth—we are also in charge of securing our systems. Even those systems where the third-party provider tells us to disable the enhanced security. It seems like a job for _Mission Impossible_ 's [Ethan Hunt][15].
+
+Faced with this dilemma, some sysadmins decide to [take the blue pill][16] because they think they will never know the answer to the big question of life, the universe, and everything else. And, as we all know, that answer is **[42][2]**.
+
+In the spirit of _The Hitchhiker's Guide to the Galaxy_ , here are the 42 answers to the big questions about managing and using [SELinux][17] with your systems.
+
+1. SELinux is a LABELING system, which means every process has a LABEL. Every file, directory, and system object has a LABEL. Policy rules control access between labeled processes and labeled objects. The kernel enforces these rules.
+
+1. The two most important concepts are: _Labeling_ (files, process, ports, etc.) and _Type enforcement_ (which isolates processes from each other based on types).
+
+1. The correct Label format is `user:role:type:level` ( _optional_ ).
+
+1. The purpose of _Multi-Level Security (MLS) enforcement_ is to control processes ( _domains_ ) based on the security level of the data they will be using. For example, a secret process cannot read top-secret data.
+
+1. _Multi-Category Security (MCS) enforcement_ protects similar processes from each other (like virtual machines, OpenShift gears, SELinux sandboxes, containers, etc.).
+
+1. Kernel parameters for changing SELinux modes at boot:
+ * `autorelabel=1` → forces the system to relabel
+
+ * `selinux=0` → kernel doesn't load any part of the SELinux infrastructure
+
+ * `enforcing=0` → boot in permissive mode
+
+1. If you need to relabel the entire system:
+ `# touch /.autorelabel
+ #reboot`
+ If the system labeling contains a large amount of errors, you might need to boot in permissive mode in order for the autorelabel to succeed.
+
+1. To check if SELinux is enabled: `# getenforce`
+
+1. To temporarily enable/disable SELinux: `# setenforce [1|0]`
+
+1. SELinux status tool: `# sestatus`
+
+1. Configuration file: `/etc/selinux/config`
+
+1. How does SELinux work? Here's an example of labeling for an Apache Web Server:
+ * Binary: `/usr/sbin/httpd`→`httpd_exec_t`
+
+ * Configuration directory: `/etc/httpd`→`httpd_config_t`
+
+ * Logfile directory: `/var/log/httpd` → `httpd_log_t`
+
+ * Content directory: `/var/www/html` → `httpd_sys_content_t`
+
+ * Startup script: `/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
+
+ * Process: `/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
+
+ * Ports: `80/tcp, 443/tcp` → `httpd_t, http_port_t`
+
+A process running in the `httpd_t` context can interact with an object with the `httpd_something_t` label.
+
+1. Many commands accept the argument `-Z` to view, create, and modify context:
+ * `ls -Z`
+
+ * `id -Z`
+
+ * `ps -Z`
+
+ * `netstat -Z`
+
+ * `cp -Z`
+
+ * `mkdir -Z`
+
+Contexts are set when files are created based on their parent directory's context (with a few exceptions). RPMs can set contexts as part of installation.
+
+1. There are four key causes of SELinux errors, which are further explained in items 15-21 below:
+ * Labeling problems
+
+ * Something SELinux needs to know
+
+ * A bug in an SELinux policy/app
+
+ * Your information may be compromised
+
+1. _Labeling problem:_ If your files in `/srv/myweb` are not labeled correctly, access might be denied. Here are some ways to fix this:
+ * If you know the label:
+ `# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
+
+ * If you know the file with the equivalent labeling:
+ `# semanage fcontext -a -e /srv/myweb /var/www`
+
+ * Restore the context (for both cases):
+ `# restorecon -vR /srv/myweb`
+
+1. _Labeling problem:_ If you move a file instead of copying it, the file keeps its original context. To fix these issues:
+ * Change the context command with the label:
+ `# chcon -t httpd_system_content_t /var/www/html/index.html`
+
+ * Change the context command with the reference label:
+ `# chcon --reference /var/www/html/ /var/www/html/index.html`
+
+ * Restore the context (for both cases): `# restorecon -vR /var/www/html/`
+
+1. If _SELinux needs to know_ HTTPD listens on port 8585, tell SELinux:
+ `# semanage port -a -t http_port_t -p tcp 8585`
+
+1. _SELinux needs to know_ booleans allow parts of SELinux policy to be changed at runtime without any knowledge of SELinux policy writing. For example, if you want httpd to send email, enter: `# setsebool -P httpd_can_sendmail 1`
+
+1. _SELinux needs to know_ booleans are just off/on settings for SELinux:
+ * To see all booleans: `# getsebool -a`
+
+ * To see the description of each one: `# semanage boolean -l`
+
+ * To set a boolean execute: `# setsebool [_boolean_] [1|0]`
+
+ * To configure it permanently, add `-P`. For example:
+ `# setsebool httpd_enable_ftp_server 1 -P`
+
+1. SELinux policies/apps can have bugs, including:
+ * Unusual code paths
+
+ * Configurations
+
+ * Redirection of `stdout`
+
+ * Leaked file descriptors
+
+ * Executable memory
+
+ * Badly built libraries
+ Open a ticket (do not file a Bugzilla report; there are no SLAs with Bugzilla).
+
+1. _Your information may be compromised_ if you have confined domains trying to:
+ * Load kernel modules
+
+ * Turn off the enforcing mode of SELinux
+
+ * Write to `etc_t/shadow_t`
+
+ * Modify iptables rules
+
+1. SELinux tools for the development of policy modules:
+ `# yum -y install setroubleshoot setroubleshoot-server`
+ Reboot or restart `auditd` after you install.
+
+1. Use `journalctl` for listing all logs related to `setroubleshoot`:
+ `# journalctl -t setroubleshoot --since=14:20`
+
+1. Use `journalctl` for listing all logs related to a particular SELinux label. For example:
+ `# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
+
+1. Use `setroubleshoot` log when an SELinux error occurs and suggest some possible solutions. For example, from `journalctl`:
+ ```
+ Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
+
+ # sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
+ SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
+
+ ***** Plugin restorecon (99.5 confidence) suggests ************************
+
+ If you want to fix the label,
+ /var/www/html/index.html default label should be httpd_syscontent_t.
+ Then you can restorecon.
+ Do
+ # /sbin/restorecon -v /var/www/html/index.html
+ ```
+
+1. Logging: SELinux records information all over the place:
+ * `/var/log/messages`
+
+ * `/var/log/audit/audit.log`
+
+ * `/var/lib/setroubleshoot/setroubleshoot_database.xml`
+
+1. Logging: Looking for SELinux errors in the audit log:
+ `# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
+
+1. To search for SELinux Access Vector Cache (AVC) messages for a particular service:
+ `# ausearch -m avc -c httpd`
+
+1. The `audit2allow` utility gathers information from logs of denied operations and then generates SELinux policy-allow rules. For example:
+ * To produce a human-readable description of why the access was denied: `# audit2allow -w -a`
+
+ * To view the type enforcement rule that allows the denied access: `# audit2allow -a`
+
+ * To create a custom module: `# audit2allow -a -M mypolicy`
+ The `-M` option creates a type enforcement file (.te) with the name specified and compiles the rule into a policy package (.pp): `mypolicy.pp mypolicy.te`
+
+ * To install the custom module: `# semodule -i mypolicy.pp`
+
+1. To configure a single process (domain) to run permissive: `# semanage permissive -a httpd_t`
+
+1. If you no longer want a domain to be permissive: `# semanage permissive -d httpd_t`
+
+1. To disable all permissive domains: `# semodule -d permissivedomains`
+
+1. Enabling SELinux MLS policy: `# yum install selinux-policy-mls`
+ In `/etc/selinux/config:`
+ `SELINUX=permissive`
+ `SELINUXTYPE=mls`
+ Make sure SELinux is running in permissive mode: `# setenforce 0`
+ Use the `fixfiles` script to ensure that files are relabeled upon the next reboot:
+ `# fixfiles -F onboot # reboot`
+
+1. Create a user with a specific MLS range: `# useradd -Z staff_u john`
+ Using the `useradd` command, map the new user to an existing SELinux user (in this case, `staff_u`).
+
+1. To view the mapping between SELinux and Linux users: `# semanage login -l`
+
+1. Define a specific range for a user: `# semanage login --modify --range s2:c100 john`
+
+1. To correct the label on the user's home directory (if needed): `# chcon -R -l s2:c100 /home/john`
+
+1. To list the current categories: `# chcat -L`
+
+1. To modify the categories or to start creating your own, modify the file as follows:
+ `/etc/selinux/__/setrans.conf`
+
+1. To run a command or script in a specific file, role, and user context:
+ `# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
+ * `-t` is the _file context_
+
+ * `-r` is the _role context_
+
+ * `-u` is the _user context_
+
+1. Containers running with SELinux disabled:
+ * With Podman: `# podman run --security-opt label=disable` …
+
+ * With Docker: `# docker run --security-opt label=disable` …
+
+1. If you need to give a container full access to the system:
+ * With Podman: `# podman run --privileged` …
+
+ * With Docker: `# docker run --privileged` …
+
+And with this, you already know the answer. So please: **Don't panic, and turn on SELinux**.
+
+
+### About the author
+
+Alex Callejas - Alex Callejas is a Technical Account Manager of Red Hat in the LATAM region, based in Mexico City. With more than 10 years of experience as SysAdmin, he has strong expertise on Infrastructure Hardening. Enthusiast of the Open Source, supports the community sharing his knowledge in different events of public access and universities. Geek by nature, Linux by choice, Fedora of course.[More about me][11]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/sysadmin-guide-selinux
+
+作者:[ Alex Callejas][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/darkaxl
+[1]:https://opensource.com/article/18/7/sysadmin-guide-selinux?rate=hR1QSlwcImXNksBPPrLOeP6ooSoOU7PZaR07aGFuYVo
+[2]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
+[3]:https://fedorapeople.org/~dwalsh/SELinux/SELinux
+[4]:https://opensource.com/users/rhatdan
+[5]:https://opensource.com/business/13/11/selinux-policy-guide
+[6]:http://people.redhat.com/tcameron/Summit2018/selinux/SELinux_for_Mere_Mortals_Summit_2018.pdf
+[7]:http://twitter.com/thomasdcameron
+[8]:http://blog.linuxgrrl.com/2014/04/16/the-selinux-coloring-book/
+[9]:https://opensource.com/users/mairin
+[10]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/selinux_users_and_administrators_guide/index
+[11]:https://opensource.com/users/darkaxl
+[12]:https://opensource.com/user/219886/feed
+[13]:https://pixabay.com/en/security-secure-technology-safety-2168234/
+[14]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
+[15]:https://en.wikipedia.org/wiki/Ethan_Hunt
+[16]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
+[17]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
+[18]:https://opensource.com/users/darkaxl
+[19]:https://opensource.com/users/darkaxl
+[20]:https://opensource.com/article/18/7/sysadmin-guide-selinux#comments
+[21]:https://opensource.com/tags/security
+[22]:https://opensource.com/tags/linux
+[23]:https://opensource.com/tags/sysadmin
diff --git a/sources/tech/20180712 netdev day 2 moving away from as fast as possible in networking code.md b/sources/tech/20180712 netdev day 2 moving away from as fast as possible in networking code.md
new file mode 100644
index 0000000000..26c78551e7
--- /dev/null
+++ b/sources/tech/20180712 netdev day 2 moving away from as fast as possible in networking code.md
@@ -0,0 +1,124 @@
+FSSlc is translating
+
+
+netdev day 2: moving away from "as fast as possible" in networking code
+============================================================
+
+Hello! Today was day 2 of netdev. I only made it to the morning of the conference, but the morning was VERY EXCITING. The highlight of this morning was a keynote by [Van Jacobson][1] about the future of congestion control on the internet (!!!) called “Evolving from As Fast As Possible: Teaching NICs about time”
+
+I’m going to try to summarize what I learned from this talk. I almost certainly have some things wrong, but let’s go!
+
+This talk was about how the internet has changed since 1988, why we need new algorithms today, and how we can change Linux’s networking stack to implement those algorithms more easily.
+
+### what’s congestion control?
+
+Everyone on the internet is sending packets all at once, all the time. The links on the internet are of dramatically different speeds (some are WAY slower than others), and sometimes they get full! When a device on the internet receives packets at a rate faster than it can handle, it drops the packets.
+
+The most naive you way you could imagine sending packets is:
+
+1. Send all the packets you have to send all at once
+
+2. If you discover any of those packets got dropped, resend the packet right away
+
+It turns out that if you implemented TCP that way, the internet would collapse and grind to a halt. We know that it would collapse because it did kinda collapse, in 1986\. To fix this, folks invented congestion control algorithms – the original paper describing how they avoided collapsing the internet is [Congestion Avoidance and Control][2], by Van Jacobson from 1988\. (30 years ago!)
+
+### How has the internet changed since 1988?
+
+The main thing he said has changed about the internet is – it used to be that switches would always have faster network cards than servers on the internet. So the servers in the middle of the internet would be a lot faster than the clients, and it didn’t matter as much how fast clients sent packets.
+
+Today apparently that’s not true! As we all know, computers today aren’t really faster than computers 5 years ago (we ran into some problems with the speed of light). So what happens (I think) is that the big switches in routers are not really that much faster than the NICs on servers in datacenters.
+
+This is bad because it means that clients are much more easily able to saturate the links in the middle, which results in the internet getting slower. (and there’s [buffer bloat][3] which results in high latency)
+
+So to improve performance on the internet and not saturate all the queues on every router, clients need to be a little better behaved and to send packets a bit more slowly.
+
+### sending more packets more slowly results in better performance
+
+Here’s an idea that was really surprising to me – sending packets more slowly often actually results in better performance (even if you are the only one doing it). Here’s why!
+
+Suppose you’re trying to send 10MB of data, and there’s a link somewhere in the middle between you and the client you’re trying to talk to that is SLOW, like 1MB/s or something. Assuming that you can tell the speed of this slow link (more on that later), you have 2 choices:
+
+1. Send the entire 10MB of data at once and see what happens
+
+2. Slow it down so you send it at 1MB/s
+
+Now – either way, you’re probably going to end up with some packet loss. So it seems like you might as well just send all the data at once if you’re going to end up with packet loss either way, right? No!! The key observation is that packet loss in the middle of your stream is much better than packet loss at the end of your stream. If a few packets in the middle are dropped, the client you’re sending to will realize, tell you, and you can just resend them. No big deal! But if packets at the END are dropped, the client has no way of knowing you sent those packets at all! So you basically need to time out at some point when you don’t get an ACK for those packets and resend it. And timeouts typically take a long time to happen!
+
+So why is sending data more slowly better? Well, if you send data faster than the bottleneck for the link, what will happen is that all the packets will pile up in a queue somewhere, the queue will get full, and then the packets at the END of your stream will get dropped. And, like we just explained, the packets at the end of the stream are the worst packets to drop! So then you have all these timeouts, and sending your 10MB of data will take way longer than if you’d just sent your packets at the correct speed in the first place.
+
+I thought this was really cool because it doesn’t require cooperation from anybody else on the internet – even if everybody else is sending all their packets really fast, it’s _still_ more advantageous for you to send your packets at the correct rate (the rate of the bottleneck in the middle)
+
+### how to tell the right speed to send data at: BBR!
+
+Earlier I said “assuming that you can tell the speed of the slow link between your client and server…“. How do you do that? Well, some folks from Google (where Jacobson works) came up with an algorithm for measuring the speed of bottlenecks! It’s called BBR. This post is already long enough, but for more about BBR, see [BBR: Congestion-based congestion control][4] and [the summary from the morning paper][5].
+
+(as an aside, [https://blog.acolyer.org][6]’s daily “the morning paper” summaries are basically the only way I learn about / understand CS papers, it’s possibly the greatest blog on the internet)
+
+### networking code is designed to run “as fast as possible”
+
+So! Let’s say we believe we want to send data a little more slowly, at the speed of the bottleneck in our connection. This is all very well, but networking software isn’t really designed to send data at a controlled rate! This (as far as I understand it) is how most networking stuff is designed:
+
+1. There’s a queue of packets coming in
+
+2. It reads off the queue and sends the packets out as as fast as possible
+
+3. That’s it
+
+This is pretty inflexible! Like – suppose I have one really fast connection I’m sending packets on, and one really slow connection. If all I have is a queue to put packets on, I don’t get that much control over when the packets I’m sending actually get sent out. I can’t slow down the queue!
+
+### a better way: give every packet an “earliest departure time”
+
+His proposal was to modify the skb data structure in the Linux kernel (which is the data structure used to represent network packets) to have a TIMESTAMP on it representing the earliest time that packet should go out.
+
+I don’t know a lot about the Linux network stack, but the interesting thing to me about this proposal is that it doesn’t sound like a huge change! It’s just an extra timestamp.
+
+### replace queues with timing wheels!!!
+
+Once we have all these packets with times on them, how do we get them sent out at the right time? TIMING WHEELS!
+
+At Papers We Love a while back ([some good links in the meetup description][7]) there was a talk about timing wheels. Timing wheels are the algorithm the Linux process scheduler decides when to run processes.
+
+He said that timing wheels actually perform better than queues for scheduling work – they both offer constant time operations, but the timing wheels constant is smaller because of some stuff to do with cache performance. I didn’t really follow the performance arguments.
+
+One point he made about timing wheels is that you can easily implement a queue with a timing wheel (though not vice versa!) – if every time you add a new packet, you say that you want it to be sent RIGHT NOW at the earliest, then you effectively end up with a queue. So this timing wheel approach is backwards compatible, but it makes it much easier to implement more complex traffic shaping algorithms where you send out different packets at different rates.
+
+### maybe we can fix the internet by improving Linux!
+
+With any internet-scale problem, the tricky thing about making progress on it is that you need cooperation from SO MANY different parties to change how internet protocols are implemented. You have Linux machines, BSD machines, Windows machines, different kinds of phones, Juniper/Cisco routers, and lots of other devices!
+
+But Linux is in kind of an interesting position in the networking landscape!
+
+* Android phones run Linux
+
+* Most consumer wifi routers run Linux
+
+* Lots of servers run Linux
+
+So in any given network connection, you’re actually relatively likely to have a Linux machine at both ends (a linux server, and either a Linux router or Android device).
+
+So the point is that if you want to improve congestion on the internet in general, it would make a huge difference to just change the Linux networking stack. (and maybe the iOS networking stack too) Which is why there was a keynote at this Linux networking conference about it!
+
+### the internet is still changing! Cool!
+
+I usually think of TCP/IP as something that we figured out in the 80s, so it was really fascinating to hear that folks think that there are still serious issues with how we’re designing our networking protocols, and that there’s work to do to design them differently.
+
+And of course it makes sense – the landscape of networking hardware and the relative speeds of everything and the kinds of things people are using the internet for (netflix!) is changing all the time, so it’s reasonable that at some point we need to start designing our algorithms differently for the internet of 2018 instead of the internet of 1998.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/07/12/netdev-day-2--moving-away-from--as-fast-as-possible/
+
+作者:[Julia Evans][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca/about
+[1]:https://en.wikipedia.org/wiki/Van_Jacobson
+[2]:https://cs162.eecs.berkeley.edu/static/readings/jacobson-congestion.pdf
+[3]:https://apenwarr.ca/log/?m=201101#10
+[4]:https://queue.acm.org/detail.cfm?id=3022184
+[5]:https://blog.acolyer.org/2017/03/31/bbr-congestion-based-congestion-control/
+[6]:https://blog.acolyer.org/
+[7]:https://www.meetup.com/Papers-We-Love-Montreal/events/235100825/
diff --git a/sources/tech/20180719 Building tiny container images.md b/sources/tech/20180719 Building tiny container images.md
new file mode 100644
index 0000000000..bdaef5f08c
--- /dev/null
+++ b/sources/tech/20180719 Building tiny container images.md
@@ -0,0 +1,362 @@
+Building tiny container images
+======
+
+
+
+When [Docker][1] exploded onto the scene a few years ago, it brought containers and container images to the masses. Although Linux containers existed before then, Docker made it easy to get started with a user-friendly command-line interface and an easy-to-understand way to build images using the Dockerfile format. But while it may be easy to jump in, there are still some nuances and tricks to building container images that are usable, even powerful, but still small in size.
+
+### First pass: Clean up after yourself
+
+Some of these examples involve the same kind of cleanup you would use with a traditional server, but more rigorously followed. Smaller image sizes are critical for quickly moving images around, and storing multiple copies of unnecessary data on disk is a waste of resources. Consequently, these techniques should be used more regularly than on a server with lots of dedicated storage.
+
+An example of this kind of cleanup is removing cached files from an image to recover space. Consider the difference in size between a base image with [Nginx][2] installed by `dnf` with and without the metadata and yum cache cleaned up:
+```
+# Dockerfile with cache
+
+FROM fedora:28
+
+LABEL maintainer Chris Collins
+
+
+
+RUN dnf install -y nginx
+
+
+
+-----
+
+
+
+# Dockerfile w/o cache
+
+FROM fedora:28
+
+LABEL maintainer Chris Collins
+
+
+
+RUN dnf install -y nginx \
+
+ && dnf clean all \
+
+ && rm -rf /var/cache/yum
+
+
+
+-----
+
+
+
+[chris@krang] $ docker build -t cache -f Dockerfile .
+
+[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
+
+| head -n 1
+
+cache: 464 MB
+
+
+
+[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
+
+[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
+
+no-cache: 271 MB
+
+```
+
+That is a significant difference in size. The version with the `dnf` cache is almost twice the size of the image without the metadata and cache. Package manager cache, Ruby gem temp files, `nodejs` cache, even downloaded source tarballs are all perfect candidates for cleaning up.
+
+### Layers—a potential gotcha
+
+Unfortunately (or fortunately, as you’ll see later), based on the way layers work with containers, you cannot simply add a `RUN rm -rf /var/cache/yum` line to your Dockerfile and call it a day. Each instruction of a Dockerfile is stored in a layer, with changes between layers applied on top. So even if you were to do this:
+```
+RUN dnf install -y nginx
+
+RUN dnf clean all
+
+RUN rm -rf /var/cache/yum
+
+```
+
+...you’d still end up with three layers, one of which contains all the cache, and two intermediate layers that "remove" the cache from the image. But the cache is actually still there, just as when you mount a filesystem over the top of another one, the files are there—you just can’t see or access them.
+
+You’ll notice that the example in the previous section chains the cache cleanup in the same Dockerfile instruction where the cache is generated:
+```
+RUN dnf install -y nginx \
+
+ && dnf clean all \
+
+ && rm -rf /var/cache/yum
+
+```
+
+This is a single instruction and ends up being a single layer within the image. You’ll lose a bit of the Docker (*ahem*) cache this way, making a rebuild of the image slightly longer, but the cached data will not end up in your final image. As a nice compromise, just chaining related commands (e.g., `yum install` and `yum clean all`, or downloading, extracting and removing a source tarball, etc.) can save a lot on your final image size while still allowing you to take advantage of the Docker cache for quicker development.
+
+This layer "gotcha" is more subtle than it first appears, though. Because the image layers document the _changes_ to each layer, one upon another, it’s not just the existence of files that add up, but any change to the file. For example, _even changing the mode_ of the file creates a copy of that file in the new layer.
+
+For example, the output of `docker images` below shows information about two images. The first, `layer_test_1`, was created by adding a single 1GB file to a base CentOS image. The second image, `layer_test_2`, was created `FROM layer_test_1` and did nothing but change the mode of the 1GB file with `chmod u+x`.
+```
+layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
+
+layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
+
+```
+
+As you can see, the new image is more than 1GB larger than the first. Despite the fact that `layer_test_1` is only the first two layers of `layer_test_2`, there’s still an extra 1GB file floating around hidden inside the second image. This is true anytime you remove, move, or change any file during the image build process.
+
+### Purpose-built images vs. flexible images
+
+An anecdote: As my office heavily invested in [Ruby on Rails][3] applications, we began to embrace the use of containers. One of the first things we did was to create an official Ruby base image for all of our teams to use. For simplicity’s sake (and suffering under “this is the way we did it on our servers”), we used [rbenv][4] to install the latest four versions of Ruby into the image, allowing our developers to migrate all of their applications into containers using a single image. This resulted in a very large but flexible (we thought) image that covered all the bases of the various teams we were working with.
+
+This turned out to be wasted work. The effort required to maintain separate, slightly modified versions of a particular image was easy to automate, and selecting a specific image with a specific version actually helped to identify applications approaching end-of-life before a breaking change was introduced, wreaking havoc downstream. It also wasted resources: When we started to split out the different versions of Ruby, we ended up with multiple images that shared a single base and took up very little extra space if they coexisted on a server, but were considerably smaller to ship around than a giant image with multiple versions installed.
+
+That is not to say building flexible images is not helpful, but in this case, creating purpose-build images from a common base ended up saving both storage space and maintenance time, and each team could modify their setup however they needed while maintaining the benefit of the common base image.
+
+### Start without the cruft: Add what you need to a blank image
+
+As friendly and easy-to-use as the _Dockerfile_ is, there are tools available that offer the flexibility to create very small Docker-compatible container images without the cruft of a full operating system—even those as small as the standard Docker base images.
+
+[I’ve written about Buildah before][5], and I’ll mention it again because it is flexible enough to create an image from scratch using tools from your host to install packaged software and manipulate the image. Those tools then never need to be included in the image itself.
+
+Buildah replaces the `docker build` command. With it, you can mount the filesystem of your container image to your host machine and interact with it using tools from the host.
+
+Let’s try Buildah with the Nginx example from above (ignoring caches for now):
+```
+#!/usr/bin/env bash
+
+set -o errexit
+
+
+
+# Create a container
+
+container=$(buildah from scratch)
+
+
+
+# Mount the container filesystem
+
+mountpoint=$(buildah mount $container)
+
+
+
+# Install a basic filesystem and minimal set of packages, and nginx
+
+dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
+
+
+
+# Save the container to an image
+
+buildah commit --format docker $container nginx
+
+
+
+# Cleanup
+
+buildah unmount $container
+
+
+
+# Push the image to the Docker daemon’s storage
+
+buildah push nginx:latest docker-daemon:nginx:latest
+
+```
+
+You’ll notice we’re no longer using a Dockerfile to build the image, but a simple Bash script, and we’re building it from a scratch (or blank) image. The Bash script mounts the container’s root filesystem to a mount point on the host, and then uses the hosts’ command to install the packages. This way the package manager doesn’t even have to exist inside the container.
+
+Without extra cruft—all the extra stuff in the base image, like `dnf`, for example—the image weighs in at only 304 MB, more than 100 MB smaller than the Nginx image built with a Dockerfile above.
+```
+[chris@krang] $ docker images |grep nginx
+
+docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
+
+```
+
+_Note: The image name has`docker.io` appended to it due to the way the image is pushed into the Docker daemon’s namespace, but it is still the image built locally with the build script above._
+
+That 100 MB is already a huge savings when you consider a base image is already around 300 MB on its own. Installing Nginx with a package manager brings in a ton of dependencies, too. For something compiled from source using tools from the host, the savings can be even greater because you can choose the exact dependencies and not pull in any extra files you don’t need.
+
+If you’d like to try this route, [Tom Sweeney][6] wrote a much more in-depth article, [Creating small containers with Buildah][7], which you should check out.
+
+Using Buildah to build images without a full operating system and included build tools can enable much smaller images than you would otherwise be able to create. For some types of images, we can take this approach even further and create images with _only_ the application itself included.
+
+### Create images with only statically linked binaries
+
+Following the same philosophy that leads us to ditch administrative and build tools inside images, we can go a step further. If we specialize enough and abandon the idea of troubleshooting inside of production containers, do we need Bash? Do we need the [GNU core utilities][8]? Do we _really_ need the basic Linux filesystem? You can do this with any compiled language that allows you to create binaries with [statically linked libraries][9]—where all the libraries and functions needed by the program are copied into and stored within the binary itself.
+
+This is a relatively popular way of doing things within the [Golang][10] community, so we’ll use a Go application to demonstrate.
+
+The Dockerfile below takes a small Go Hello-World application and compiles it in an image `FROM golang:1.8`:
+```
+FROM golang:1.8
+
+
+
+ENV GOOS=linux
+
+ENV appdir=/go/src/gohelloworld
+
+
+
+COPY ./ /go/src/goHelloWorld
+
+WORKDIR /go/src/goHelloWorld
+
+
+
+RUN go get
+
+RUN go build -o /goHelloWorld -a
+
+
+
+CMD ["/goHelloWorld"]
+
+```
+
+The resulting image, containing the binary, the source code, and the base image layer comes in at 716 MB. The only thing we actually need for our application is the compiled binary, however. Everything else is unused cruft that gets shipped around with our image.
+
+If we disable `cgo` with `CGO_ENABLED=0` when we compile, we can create a binary that doesn’t wrap C libraries for some of its functions:
+```
+GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go
+
+```
+
+The resulting binary can be added to an empty, or "scratch" image:
+```
+FROM scratch
+
+COPY goHelloWorld /
+
+CMD ["/goHelloWorld"]
+
+```
+
+Let’s compare the difference in image size between the two:
+```
+[ chris@krang ] $ docker images
+
+REPOSITORY TAG IMAGE ID CREATED SIZE
+
+goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
+
+goHello builder 980290a100db 14 seconds ago 716 MB
+
+```
+
+That’s a huge difference. The image built from `golang:1.8` with the `goHelloWorld` binary in it (tagged "builder" above) is _460_ times larger than the scratch image with just the binary. The entirety of the scratch image with the binary is only 1.55 MB. That means we’d be shipping around 713 MB of unnecessary data if we used the builder image.
+
+As mentioned above, this method of creating small images is used often in the Golang community, and there is no shortage of blog posts on the subject. [Kelsey Hightower][11] wrote [an article on the subject][12] that goes into more detail, including dealing with dependencies other than just C libraries.
+
+### Consider squashing, if it works for you
+
+There’s an alternative to chaining all the commands into layers in an attempt to save space: Squashing your image. When you squash an image, you’re really exporting it, removing all the intermediate layers, and saving a single layer with the current state of the image. This has the advantage of reducing that image to a much smaller size.
+
+Squashing layers used to require some creative workarounds to flatten an image—exporting the contents of a container and re-importing it as a single layer image, or using tools like `docker-squash`. Starting in version 1.13, Docker introduced a handy flag, `--squash`, to accomplish the same thing during the build process:
+```
+FROM fedora:28
+
+LABEL maintainer Chris Collins
+
+
+
+RUN dnf install -y nginx
+
+RUN dnf clean all
+
+RUN rm -rf /var/cache/yum
+
+
+
+[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
+
+[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
+
+squash: 271 MB
+
+```
+
+Using `docker squash` with this multi-layer Dockerfile, we end up with another 271MB image, as we did with the chained instruction example. This works great for this use case, but there’s a potential gotcha.
+
+“What? ANOTHER gotcha?”
+
+Well, sort of—it’s the same issue as before, causing problems in another way.
+
+### Going too far: Too squashed, too small, too specialized
+
+Images can share layers. The base may be _x_ megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images sharing layers is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
+
+This is a drawback with squashing or specializing too much. When you squash an image into a single layer, you lose any opportunity to share layers with other images. Each image ends up being as large as the total size of its single layer. This might work well for you if you use only a few images and run many containers from them, but if you have many diverse images, it could end up costing you space in the long run.
+
+Revisiting the Nginx squash example, we can see it’s not a big deal for this case. We end up with Fedora, Nginx installed, no cache, and squashing that is fine. Nginx by itself is not incredibly useful, though. You generally need customizations to do anything interesting—e.g., configuration files, other software packages, maybe some application code. Each of these would end up being more instructions in the Dockerfile.
+
+With a traditional image build, you would have a single base image layer with Fedora, a second layer with Nginx installed (with or without cache), and then each customization would be another layer. Other images with Fedora and Nginx could share these layers.
+
+Need an image:
+```
+[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
+
+[ Nginx Layer ( 21 MB) ] ------------------^
+
+[ Fedora Layer (249 MB) ]
+
+```
+
+But if you squash the image, then even the Fedora base layer is squashed. Any squashed image based on Fedora has to ship around its own Fedora content, adding another 249 MB for _each image!_
+```
+[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ]
+
+```
+
+This also becomes a problem if you build lots of highly specialized, super-tiny images.
+
+As with everything in life, moderation is key. Again, thanks to how layers work, you will find diminishing returns as your container images become smaller and more specialized and can no longer share base layers with other related images.
+
+Images with small customizations can share base layers. As explained above, the base may be _x_ megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
+```
+[ specific app ] [ specific app 2 ]
+
+[ customizations ]--------------^
+
+[ base layer ]
+
+```
+
+If you go too far with your image shrinking and you have too many variations or specializations, you can end up with many images, none of which share base layers and all of which take up their own space on disk.
+```
+ [ specific app 1 ] [ specific app 2 ] [ specific app 3 ]
+
+```
+
+### Conclusion
+
+There are a variety of different ways to reduce the amount of storage space and bandwidth you spend working with container images, but the most effective way is to reduce the size of the images themselves. Whether you simply clean up your caches (avoiding leaving them orphaned in intermediate layers), squash all your layers into one, or add only static binaries in an empty image, it’s worth spending some time looking at where bloat might exist in your container images and slimming them down to an efficient size.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/building-container-images
+
+作者:[Chris Collins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/clcollins
+[1]:https://www.docker.com/
+[2]:https://www.nginx.com/
+[3]:https://rubyonrails.org/
+[4]:https://github.com/rbenv/rbenv
+[5]:https://opensource.com/article/18/6/getting-started-buildah
+[6]:https://twitter.com/TSweeneyRedHat
+[7]:https://opensource.com/article/18/5/containers-buildah
+[8]:https://www.gnu.org/software/coreutils/coreutils.html
+[9]:https://en.wikipedia.org/wiki/Static_library
+[10]:https://golang.org/
+[11]:https://twitter.com/kelseyhightower
+[12]:https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07
diff --git a/sources/tech/20180720 A brief history of text-based games and open source.md b/sources/tech/20180720 A brief history of text-based games and open source.md
new file mode 100644
index 0000000000..2b8728fb39
--- /dev/null
+++ b/sources/tech/20180720 A brief history of text-based games and open source.md
@@ -0,0 +1,142 @@
+A brief history of text-based games and open source
+======
+
+
+
+The [Interactive Fiction Technology Foundation][1] (IFTF) is a non-profit organization dedicated to the preservation and improvement of technologies enabling the digital art form we call interactive fiction. When a Community Moderator for Opensource.com suggested an article about IFTF, the technologies and services it supports, and how it all intersects with open source, I found it a novel angle to the decades-long story I’ve so often told. The history of IF is longer than—but quite enmeshed with—the modern FOSS movement. I hope you’ll enjoy my sharing it here.
+
+### Definitions and history
+
+To me, the term interactive fiction includes any video game or digital artwork whose audience interacts with it primarily through text. The term originated in the 1980s when parser-driven text adventure games—epitomized in the United States by [Zork][2], [The Hitchhiker’s Guide to the Galaxy][3], and the rest of [Infocom][4]’s canon—defined home-computer entertainment. Its mainstream commercial viability had guttered by the 1990s, but online hobbyist communities carried on the tradition, releasing both games and game-creation tools.
+
+After a quarter century, interactive fiction now comprises a broad and sparkling variety of work, from puzzle-laden text adventures to sprawling and introspective hypertexts. Regular online competitions and festivals provide a great place to peruse and play new work: The English-language IF world enjoys annual events including [Spring Thing][5] and [IFComp][6], the latter a centerpiece of modern IF since 1995—which also makes it the longest-lived continually running game showcase event of its kind in any genre. [IFComp’s crop of judged-and-ranked entries from 2017][7] shows the amazing diversity in form, style, and subject matter that text-based games boast today.
+
+(I specify "English-language" above because IF communities tend to self-segregate by language, perhaps due to the technology's focus on writing. There are also annual IF events in [French][8] and [Italian][9], for example, and I've heard of at least one Chinese IF festival. Happily, these borders are porous; during the four years I managed IFComp, it has welcomed English-translated work from all international communities.)
+
+![counterfeit monkey game screenshot][11]
+
+Starting a new game of Emily Short's "Counterfeit Monkey," running on the interpreter Lectrote (both open source software).
+
+Also due to its focus on text, IF presents some of the most accessible platforms for both play and authorship. Almost anyone who can read digital text—including users of assistive technology such as text-to-speech software—can play most IF works. Likewise, IF creation is open to all writers willing to learn and work with its tools and techniques.
+
+This brings us to IF’s long relationship with open source, which has helped enable the art form’s availability since its commercial heyday. I'll provide an overview of contemporary open-source IF creation tools, and then discuss the ancient and sometimes curious tradition of IF works that share their source code.
+
+### The world of open source IF tools
+
+A number of development platforms, most of which are open source, are available to create traditional parser-driven IF in which the user types commands—for example, `go north,` `get lamp`, `pet the cat`, or `ask Zoe about quantum mechanics`—to interact with the game’s world. The early 1990s saw the emergence of several hacker-friendly parser-game development kits; those still in use today include [TADS][12], [Alan][13], and [Quest][14]—all open, with the latter two bearing FOSS licenses.
+
+But by far the most prominent of these is [Inform][15], first released by Graham Nelson in 1993 and now maintained by a team Nelson still leads. Inform source is semi-open, in an unusual fashion: Inform 6, the previous major version, [makes its source available through the Artistic License][16]. This has more immediate relevance than may be obvious, since the otherwise proprietary Inform 7 holds Inform 6 at its core, translating its [remarkable natural-language syntax][17] into its predecessor’s more C-like code before letting it compile the work down into machine code.
+
+![inform 7 IDE screenshot][19]
+
+The Inform 7 IDE, loaded up with documentation and a sample project.
+
+Inform games run on a virtual machine, a relic of the Infocom era when that publisher targeted a VM so that it could write a single game that would run on Apple II, Commodore 64, Atari 800, and other flavors of the "[home computer][20]." Fewer popular operating systems exist today, but Inform’s virtual machines—the relatively modern [Glulx][21] or the charmingly antique [Z-machine][22], a reverse-engineered clone of Infocom’s historical VM—let Inform-created work run on any computer with an Inform interpreter. Currently, popular cross-platform interpreters include desktop programs like [Lectrote][23] and [Gargoyle][24] or browser-based ones like [Quixe][25] and [Parchment][26]. All are open source.
+
+If the pace of Inform’s development has slowed in its maturity, it remains vital through an active and transparent ecosystem—just like any other popular open source project. In Inform’s case, this includes the aforementioned interpreters, [a collection of language extensions][27] (usually written in a mix of Inform 6 and 7), and of course, all the work created with it and shared with the world, sometimes with source included (I’ll return to that topic later in this article).
+
+IF creation tools invented in the 21st century tend to explore player interactions outside of the traditional parser, generating hypertext-driven work that any modern web browser can load. Chief among these is [Twine][28], originally developed by Chris Klimas in 2009 and under active development by many contributors today as [a GNU-licensed open source project][29]. (In fact, [Twine][30] can trace its OSS lineage back to [TiddlyWiki][31], the project from which Klimas initially derived it.)
+
+Twine represents a sort of maximally [open and accessible approach][30] to IF development: Beyond its own FOSS nature, it renders its output as self-contained websites, relying not on machine code requiring further specialized interpretation but the open and well-exercised standards of HTML, CSS, and JavaScript. As a creative tool, Twine can match its own exposed complexity to the creator’s skill level. Users with little or no programming knowledge can create simple but playable IF work, while those with more coding and design skills—including those developing these skills by making Twine games—can develop more sophisticated projects. Little wonder that Twine’s visibility and popularity in educational contexts has grown quite a bit in recent years.
+
+Other noteworthy open source IF development projects include the MIT-licensed [Undum][32] by Ian Millington, and [ChoiceScript][33] by Dan Fabulich and the [Choice of Games][34] team—both of which also target the web browser as the gameplay platform. Looking beyond strict development systems like these, web-based IF gives us a rich and ever-churning ecosystem of open source work, such as furkle’s [collection of Twine-extending tools][35] and Liza Daly’s [Windrift][36], a JavaScript framework purpose-built for her own IF games.
+
+### Programs, games, and game-programs
+
+Twine benefits from [a standing IFTF program dedicated to its support][37], allowing the public to help fund its maintenance and development. IFTF also directly supports two long-time public services, IFComp and the IF Archive, both of which depend upon and contribute back into open software and technologies.
+
+![Harmonia opening screen shot][39]
+
+The opening of Liza Daly's "Harmonia," created with the Windrift open source IF-creation framework.
+
+The Perl- and JavaScript-based application that runs the IFComp’s website has been [a shared-source project][40] since 2014, and it reflects [the stew of FOSS licenses used by its IF-specific sub-components][41], including the various code libraries that allow parser-driven competition entries to run in a web browser. [The IF Archive][42]—online since 1992 and [an IFTF project since 2017][43]—is a set of mirrored repositories based entirely on ancient and stable internet standards, with [a little open source Python script][44] to handle indexing.
+
+### At last, the fun part: Let's talk about open source text games
+
+The bulk of the archive [comprises games][45], of course—years and years of games, reflecting decades of evolving game-design trends and IF tool development.
+
+Lots of IF work shares its source code, and the community’s quick-start solution for finding it is simple: [Search the IFDB for the tag "source available"][46]. (The IFDB is yet another long-running IF community service, run privately by TADS creator Mike Roberts.) Users who are comfortable with a more bare-bones interface may also wish to browse [the `/games/source` directory][47] of the IF Archive, which groups content by development platform and written language (there's also a lot of work either too miscellaneous or too ancient to categorize floating at the top).
+
+A little bit of random sampling of these code-sharing games reveals an interesting dilemma: Unlike the wider world of open source software, the IF community lacks a generally agreed-upon way of licensing all the code that it generates. Unlike a software tool—including all the tools we use to build IF—an interactive fiction game is a work of art in the most literal sense, meaning that an open source license intended for software would fit it no better than it would any other work of prose or poetry. But then again, an IF game is also a piece of software, and it exhibits source-code patterns and techniques that its creator may legitimately wish to share with the world. What is an open source-aware IF creator to do?
+
+Some games address this by passing their code into the public domain, either through explicit license or—as in the case of [the original 42-year-old Adventure by Crowther and Woods][48]—through community fiat. Some try to split the difference, rolling their own license that allows for free re-use of a game’s exposed business logic but prohibits the creation of work derived specifically from its prose. This is the tack I took when I opened up the source of my own game, [The Warbler’s Nest][49]. Lord knows how well that’d stand up in court, but I didn’t have any better ideas at the time.
+
+Naturally, you can find work that simply puts everything under a single common license and never mind the naysayers. A prominent example is [Emily Short’s epic Counterfeit Monkey][50], released in its entirety under a Creative Commons 4.0 license. [CC frowns at its application to code][51], but you could argue that [the strangely prose-like nature of Inform 7 source][52] makes it at least a little more compatible with a CC license than a more traditional software project would be.
+
+### What now, adventurer?
+
+If you are eager to start exploring the world of interactive fiction, here are a few links to check out:
+
+
++ As mentioned above, IFDB and the IF Archive both present browsable interfaces to more than 40 years worth of collected interactive fiction work. Much of this is playable in a web browser, but some require additional interpreter programs. IFDB can help you find and install these.
+
+ IFComp’s annual results pages provide another view into the best of this free and archive-available work.
+
++ The Interactive Fiction Technology Foundation is a charitable non-profit organization that helps support Twine, IFComp, and the IF Archive, as well as improve the accessibility of IF, explore IF’s use in education, and more. Join its mailing list to receive IFTF’s monthly newsletter, peruse its blog, and browse some thematic merchandise.
+
++ John Paul Wohlscheid wrote this article about open-source IF tools earlier this year. It covers some platforms not mentioned here, so if you’re still hungry for more, have a look.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/interactive-fiction-tools
+
+作者:[Jason Mclntosh][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/jmac
+[1]:http://iftechfoundation.org/
+[2]:https://en.wikipedia.org/wiki/Zork
+[3]:https://en.wikipedia.org/wiki/The_Hitchhiker%27s_Guide_to_the_Galaxy_(video_game)
+[4]:https://en.wikipedia.org/wiki/Infocom
+[5]:http://www.springthing.net/
+[6]:http://ifcomp.org/
+[7]:https://ifcomp.org/comp/2017
+[8]:http://www.fiction-interactive.fr/
+[9]:http://www.oldgamesitalia.net/content/marmellata-davventura-2018
+[10]:/file/403396
+[11]:https://opensource.com/sites/default/files/uploads/monkey.png (counterfeit monkey game screenshot)
+[12]:http://tads.org/
+[13]:https://www.alanif.se/
+[14]:http://textadventures.co.uk/quest/
+[15]:http://inform7.com/
+[16]:https://github.com/DavidKinder/Inform6
+[17]:http://inform7.com/learn/man/RB_4_1.html#e307
+[18]:/file/403386
+[19]:https://opensource.com/sites/default/files/uploads/inform.png (inform 7 IDE screenshot)
+[20]:https://www.youtube.com/watch?v=bu55q_3YtOY
+[21]:http://ifwiki.org/index.php/Glulx
+[22]:http://ifwiki.org/index.php/Z-machine
+[23]:https://github.com/erkyrath/lectrote
+[24]:https://github.com/garglk/garglk/
+[25]:http://eblong.com/zarf/glulx/quixe/
+[26]:https://github.com/curiousdannii/parchment
+[27]:https://github.com/i7/extensions
+[28]:http://twinery.org/
+[29]:https://github.com/klembot/twinejs
+[30]:/article/18/7/twine-vs-renpy-interactive-fiction
+[31]:https://tiddlywiki.com/
+[32]:https://github.com/idmillington/undum
+[33]:https://github.com/dfabulich/choicescript
+[34]:https://www.choiceofgames.com/
+[35]:https://github.com/furkle
+[36]:https://github.com/lizadaly/windrift
+[37]:http://iftechfoundation.org/committees/twine/
+[38]:/file/403391
+[39]:https://opensource.com/sites/default/files/uploads/harmonia.png (Harmonia opening screen shot)
+[40]:https://github.com/iftechfoundation/ifcomp
+[41]:https://github.com/iftechfoundation/ifcomp/blob/master/LICENSE.md
+[42]:https://www.ifarchive.org/
+[43]:http://blog.iftechfoundation.org/2017-06-30-iftf-is-adopting-the-if-archive.html
+[44]:https://github.com/iftechfoundation/ifarchive-ifmap-py
+[45]:https://www.ifarchive.org/indexes/if-archiveXgames
+[46]:http://ifdb.tads.org/search?sortby=ratu&searchfor=%22source+available%22
+[47]:https://www.ifarchive.org/indexes/if-archiveXgamesXsource.html
+[48]:http://ifdb.tads.org/viewgame?id=fft6pu91j85y4acv
+[49]:https://github.com/jmacdotorg/warblers-nest/
+[50]:https://github.com/i7/counterfeit-monkey
+[51]:https://creativecommons.org/faq/#can-i-apply-a-creative-commons-license-to-software
+[52]:https://github.com/i7/counterfeit-monkey/blob/master/Counterfeit%20Monkey.materials/Extensions/Counterfeit%20Monkey/Liquids.i7x
diff --git a/sources/tech/20180720 An Introduction to Using Git.md b/sources/tech/20180720 An Introduction to Using Git.md
new file mode 100644
index 0000000000..2a91406721
--- /dev/null
+++ b/sources/tech/20180720 An Introduction to Using Git.md
@@ -0,0 +1,193 @@
+translating by distant1219
+
+An Introduction to Using Git
+======
+
+If you’re a developer, then you know your way around development tools. You’ve spent years studying one or more programming languages and have perfected your skills. You can develop with GUI tools or from the command line. On your own, nothing can stop you. You code as if your mind and your fingers are one to create elegant, perfectly commented, source for an app you know will take the world by storm.
+
+But what happens when you’re tasked with collaborating on a project? Or what about when that app you’ve developed becomes bigger than just you? What’s the next step? If you want to successfully collaborate with other developers, you’ll want to make use of a distributed version control system. With such a system, collaborating on a project becomes incredibly efficient and reliable. One such system is [Git][1]. Along with Git comes a handy repository called [GitHub][2], where you can house your projects, such that a team can check out and check in code.
+
+I will walk you through the very basics of getting Git up and running and using it with GitHub, so the development on your game-changing app can be taken to the next level. I’ll be demonstrating on Ubuntu 18.04, so if your distribution of choice is different, you’ll only need to modify the Git install commands to suit your distribution’s package manager.
+
+### Git and GitHub
+
+The first thing to do is create a free GitHub account. Head over to the [GitHub signup page][3] and fill out the necessary information. Once you’ve done that, you’re ready to move on to installing Git (you can actually do these two steps in any order).
+
+Installing Git is simple. Open up a terminal window and issue the command:
+```
+sudo apt install git-all
+
+```
+
+This will include a rather large number of dependencies, but you’ll wind up with everything you need to work with Git and GitHub.
+
+On a side note: I use Git quite a bit to download source for application installation. There are times when a piece of software isn’t available via the built-in package manager. Instead of downloading the source files from a third-party location, I’ll often go the project’s Git page and clone the package like so:
+```
+git clone ADDRESS
+
+```
+
+Where ADDRESS is the URL given on the software’s Git page.
+Doing this most always ensures I am installing the latest release of a package.
+
+Create a local repository and add a file
+
+The next step is to create a local repository on your system (we’ll call it newproject and house it in ~/). Open up a terminal window and issue the commands:
+```
+cd ~/
+
+mkdir newproject
+
+cd newproject
+
+```
+
+Now we must initialize the repository. In the ~/newproject folder, issue the command git init. When the command completes, you should see that the empty Git repository has been created (Figure 1).
+
+![new repository][5]
+
+Figure 1: Our new repository has been initialized.
+
+[Used with permission][6]
+
+Next we need to add a file to the project. From within the root folder (~/newproject) issue the command:
+```
+touch readme.txt
+
+```
+
+You will now have an empty file in your repository. Issue the command git status to verify that Git is aware of the new file (Figure 2).
+
+![readme][8]
+
+Figure 2: Git knows about our readme.txt file.
+
+[Used with permission][6]
+
+Even though Git is aware of the file, it hasn’t actually been added to the project. To do that, issue the command:
+```
+git add readme.txt
+
+```
+
+Once you’ve done that, issue the git status command again to see that readme.txt is now considered a new file in the project (Figure 3).
+
+![file added][10]
+
+Figure 3: Our file now has now been added to the staging environment.
+
+[Used with permission][6]
+
+### Your first commit
+
+With the new file in the staging environment, you are now ready to create your first commit. What is a commit? Easy: A commit is a record of the files you’ve changed within the project. Creating the commit is actually quite simple. It is important, however, that you include a descriptive message for the commit. By doing this, you are adding notes about what the commit contains (such as what changes you’ve made to the file). Before we do this, however, we have to inform Git who we are. To do this, issue the command:
+```
+git config --global user.email EMAIL
+
+git config --global user.name “FULL NAME”
+
+```
+
+Where EMAIL is your email address and FULL NAME is your name.
+
+Now we can create the commit by issuing the command:
+```
+git commit -m “Descriptive Message”
+
+```
+
+Where Descriptive Message is your message about the changes within the commit. For example, since this is the first commit for the readme.txt file, the commit could be:
+```
+git commit -m “First draft of readme.txt file”
+
+```
+
+You should see output indicating that 1 file has changed and a new mode was created for readme.txt (Figure 4).
+
+![success][12]
+
+Figure 4: Our commit was successful.
+
+[Used with permission][6]
+
+### Create a branch and push it to GitHub
+
+Branches are important, as they allow you to move between project states. Let’s say you want to create a new feature for your game-changing app. To do that, create a new branch. Once you’ve completed work on the feature you can merge this feature from the branch to the master branch. To create the new branch, issue the command:
+
+git checkout -b BRANCH
+
+where BRANCH is the name of the new branch. Once the command completes, issue the command git branch to see that it has been created (Figure 5).
+
+![featureX][14]
+
+Figure 5: Our new branch, called featureX.
+
+[Used with permission][6]
+
+Next we need to create a repository on GitHub. If you log into your GitHub account, click the New Repository button from your account main page. Fill out the necessary information and click Create repository (Figure 6).
+
+![new repository][16]
+
+Figure 6: Creating the new repository on GitHub.
+
+[Used with permission][6]
+
+After creating the repository, you will be presented with a URL to use for pushing our local repository. To do this, go back to the terminal window (still within ~/newproject) and issue the commands:
+```
+git remote add origin URL
+
+git push -u origin master
+
+```
+
+Where URL is the url for our new GitHub repository.
+
+You will be prompted for your GitHub username and password. Once you successfully authenticate, the project will be pushed to your GitHub repository and you’re ready to go.
+
+### Pulling the project
+
+Say your collaborators make changes to the code on the GitHub project and have merged those changes. You will then need to pull the project files to your local machine, so the files you have on your system match those on the remote account. To do this, issue the command (from within ~/newproject):
+```
+git pull origin master
+
+```
+
+The above command will pull down any new or changed files to your local repository.
+
+### The very basics
+
+And that is the very basics of using Git from the command line to work with a project stored on GitHub. There is quite a bit more to learn, so I highly recommend you issue the commands man git, man git-push, and man git-pull to get a more in-depth understanding of what the git command can do.
+
+Happy developing!
+
+Learn more about Linux through the free ["Introduction to Linux" ][17]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/jlwallen
+[1]:https://git-scm.com/
+[2]:https://github.com/
+[3]:https://github.com/join?source=header-home
+[4]:/files/images/git1jpg
+[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_1.jpg?itok=FKkr5Mrk (new repository)
+[6]:https://www.linux.com/licenses/category/used-permission
+[7]:/files/images/git2jpg
+[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_2.jpg?itok=54G9KBHS (readme)
+[9]:/files/images/git3jpg
+[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_3.jpg?itok=KAJwRJIB (file added)
+[11]:/files/images/git4jpg
+[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_4.jpg?itok=qR0ighDz (success)
+[13]:/files/images/git5jpg
+[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_5.jpg?itok=6m9RTWg6 (featureX)
+[15]:/files/images/git6jpg
+[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/git_6.jpg?itok=d2toRrUq (new repository)
+[17]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180720 How to build a URL shortener with Apache.md b/sources/tech/20180720 How to build a URL shortener with Apache.md
new file mode 100644
index 0000000000..ede90814af
--- /dev/null
+++ b/sources/tech/20180720 How to build a URL shortener with Apache.md
@@ -0,0 +1,82 @@
+How to build a URL shortener with Apache
+======
+
+
+
+Long ago, folks started sharing links on Twitter. The 140-character limit meant that URLs might consume most (or all) of a tweet, so people turned to URL shorteners. Eventually, Twitter added a built-in URL shortener ([t.co][1]).
+
+Character count isn't as important now, but there are still other reasons to shorten links. For one, the shortening service may provide analytics—you can see how popular the links are that you share. It also simplifies making easy-to-remember URLs. For example, [bit.ly/INtravel][2] is much easier to remember than . And URL shorteners can come in handy if you want to pre-share a link but don't know the final destination yet.
+
+Like any technology, URL shorteners aren't all positive. By masking the ultimate destination, shortened links can be used to direct people to malicious or offensive content. But if you surf carefully, URL shorteners are a useful tool.
+
+We [covered shorteners previously][3] on this site, but maybe you want to run something simple that's powered by a text file. In this article, we'll show how to use the Apache HTTP server's mod_rewrite feature to set up your own URL shortener. If you're not familiar with the Apache HTTP server, check out David Both's article on [installing and configuring][4] it.
+
+### Create a VirtualHost
+
+In this tutorial, I'm assuming you bought a cool domain that you'll use exclusively for the URL shortener. For example, my website is [funnelfiasco.com][5] , so I bought [funnelfias.co][6] to use for my URL shortener (okay, it's not exactly short, but it feeds my vanity). If you won't run the shortener as a separate domain, skip to the next section.
+
+The first step is to set up the VirtualHost that will be used for the URL shortener. For more information on VirtualHosts, see [David Both's article][7]. This setup requires just a few basic lines:
+```
+
+
+ ServerName funnelfias.co
+
+
+
+```
+
+### Create the rewrites
+
+This service uses HTTPD's rewrite engine to rewrite the URLs. If you created a VirtualHost in the section above, the configuration below goes into your VirtualHost section. Otherwise, it goes in the VirtualHost or main HTTPD configuration for your server.
+```
+ RewriteEngine on
+
+ RewriteMap shortlinks txt:/data/web/shortlink/links.txt
+
+ RewriteRule ^/(.+)$ ${shortlinks:$1} [R=temp,L]
+
+```
+
+The first line simply enables the rewrite engine. The second line builds a map of the short links from a text file. The path above is only an example; you will need to use a valid path on your system (make sure it's readable by the user account that runs HTTPD). The last line rewrites the URL. In this example, it takes any characters and looks them up in the rewrite map. You may want to have your rewrites use a particular string at the beginning. For example, if you wanted all your shortened links to be of the form "slX" (where X is a number), you would replace `(.+)` above with `(sl\d+)`.
+
+I used a temporary (HTTP 302) redirect here. This allows me to update the destination URL later. If you want the short link to always point to the same target, you can use a permanent (HTTP 301) redirect instead. Replace `temp` on line three with `permanent`.
+
+### Build your map
+
+Edit the file you specified on the `RewriteMap` line of the configuration. The format is a space-separated key-value store. Put one link on each line:
+```
+ osdc https://opensource.com/users/bcotton
+
+ twitter https://twitter.com/funnelfiasco
+
+ swody1 https://www.spc.noaa.gov/products/outlook/day1otlk.html
+
+```
+
+### Restart HTTPD
+
+The last step is to restart the HTTPD process. This is done with `systemctl restart httpd` or similar (the command and daemon name may differ by distribution). Your link shortener is now up and running. When you're ready to edit your map, you don't need to restart the web server. All you have to do is save the file, and the web server will pick up the differences.
+
+### Future work
+
+This example gives you a basic URL shortener. It can serve as a good starting point if you want to develop your own management interface as a learning project. Or you can just use it to share memorable links to forgettable URLs.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/apache-url-shortener
+
+作者:[Ben Cotton][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bcotton
+[1]:http://t.co
+[2]:http://bit.ly/INtravel
+[3]:https://opensource.com/article/17/3/url-link-shortener
+[4]:https://opensource.com/article/18/2/how-configure-apache-web-server
+[5]:http://funnelfiasco.com
+[6]:http://funnelfias.co
+[7]:https://opensource.com/article/18/3/configuring-multiple-web-sites-apache
diff --git a/sources/tech/20180723 4 open source media conversion tools for the Linux desktop.md b/sources/tech/20180723 4 open source media conversion tools for the Linux desktop.md
new file mode 100644
index 0000000000..16b78303a0
--- /dev/null
+++ b/sources/tech/20180723 4 open source media conversion tools for the Linux desktop.md
@@ -0,0 +1,73 @@
+translating---geekpi
+
+4 open source media conversion tools for the Linux desktop
+======
+
+
+
+Ah, so many file formats—especially audio and video ones—can make for fun times if you get a file with an extension you don't recognize, if your media player doesn't play a file in that format, or if you want to use an open format.
+
+So, what can a Linux user do? Turn to one of the many open source media conversion tools for the Linux desktop, of course. Let's take a look at four of them.
+
+### Gnac
+
+
+
+[Gnac][1] is one of my favorite audio converters and has been for years. It's easy to use, it's powerful, and it does one thing well—as any top-notch utility should.
+
+How easy? You click a toolbar button to add one or more files to convert, choose a format to convert to, and then click **Convert**. The conversions are quick, and they're clean.
+
+How powerful? Gnac can handle all the audio formats that the [GStreamer][2] multimedia framework supports. Out of the box, you can convert between Ogg, FLAC, AAC, MP3, WAV, and SPX. You can also change the conversion options for each format or add new ones.
+
+### SoundConverter
+
+
+
+If simplicity with a few extra features is your thing, then give [SoundConverter][3] a look. As its name states, SoundConverter works its magic only on audio files. Like Gnac, it can read the formats that GStreamer supports, and it can spit out Ogg Vorbis, MP3, FLAC, WAV, AAC, and Opus files.
+
+Load individual files or an entire folder by either clicking **Add File** or dragging and dropping it into the SoundConverter window. Click **Convert** , and the software powers through the conversion. It's fast, too—I've converted a folder containing a couple dozen files in about a minute.
+
+SoundConverter has options for setting the quality of your converted files. You can change the way files are named (for example, include a track number or album name in the title) and create subfolders for the converted files.
+
+### WinFF
+
+
+
+[WinFF][4], on its own, isn't a converter. It's a graphical frontend to FFmpeg, which [Tim Nugent looked at][5] for Opensource.com. While WinFF doesn't have all the flexibility of FFmpeg, it makes FFmpeg easier to use and gets the job done quickly and fairly easily.
+
+Although it's not the prettiest application out there, WinFF doesn't need to be. It's more than usable. You can choose what formats to convert to from a dropdown list and select several presets. On top of that, you can specify options like bitrates and frame rates, the number of audio channels to use, and even the size at which to crop videos.
+
+The conversions, especially video, take a bit of time, but the results are generally quite good. Once in a while, the conversion gets a bit mangled—but not often enough to be a concern. And, as I said earlier, using WinFF can save me a bit of time.
+
+### Miro Video Converter
+
+
+
+Not all video files are created equally. Some are in proprietary formats. Others look great on a monitor or TV screen but aren't optimized for a mobile device. That's where [Miro Video Converter][6] comes to the rescue.
+
+Miro Video Converter has a heavy emphasis on mobile. It can convert video that you can play on Android phones, Apple devices, the PlayStation Portable, and the Kindle Fire. It will convert most common video formats to MP4, [WebM][7] , and [Ogg Theora][8] . You can find a full list of supported devices and formats [on Miro's website][6]
+
+To use it, either drag and drop a file into the window or select the file that you want to convert. Then, click the Format menu to choose the format for the conversion. You can also click the Apple, Android, or Other menus to choose a device for which you want to convert the file. Miro Video Converter resizes the video for the device's screen resolution.
+
+Do you have a favorite Linux media conversion application? Feel free to share it by leaving a comment.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/media-conversion-tools-linux
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/scottnesbitt
+[1]:http://gnac.sourceforge.net
+[2]:http://www.gstreamer.net/
+[3]:http://soundconverter.org/
+[4]:https://www.biggmatt.com/winff/
+[5]:https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
+[6]:http://www.mirovideoconverter.com/
+[7]:https://en.wikipedia.org/wiki/WebM
+[8]:https://en.wikipedia.org/wiki/Ogg_theora
diff --git a/sources/tech/20180723 Setting Up a Timer with systemd in Linux.md b/sources/tech/20180723 Setting Up a Timer with systemd in Linux.md
new file mode 100644
index 0000000000..27841dec61
--- /dev/null
+++ b/sources/tech/20180723 Setting Up a Timer with systemd in Linux.md
@@ -0,0 +1,165 @@
+Setting Up a Timer with systemd in Linux
+======
+
+
+
+Previously, we saw how to enable and disable systemd services [by hand][1], [at boot time and on power down][2], [when a certain device is activated][3], and [when something changes in the filesystem][4].
+
+Timers add yet another way of starting services, based on... well, time. Although similar to cron jobs, systemd timers are slightly more flexible. Let's see how they work.
+
+### "Run when"
+
+Let's expand the [Minetest][5] [service you set up][1] in [the first two articles of this series][2] as our first example on how to use timer units. If you haven't read those articles yet, you may want to go and give them a look now.
+
+So you will "improve" your Minetest set up by creating a timer that will run the game's server 1 minute after boot up has finished instead of right away. The reason for this could be that, as you want your service to do other stuff, like send emails to the players telling them the game is available, you will want to make sure other services (like the network) are fully up and running before doing anything fancy.
+
+Jumping in at the deep end, your _minetest.timer_ unit will look like this:
+```
+# minetest.timer
+[Unit]
+Description=Runs the minetest.service 1 minute after boot up
+
+[Timer]
+OnBootSec=1 m
+Unit=minetest.service
+
+[Install]
+WantedBy=basic.target
+
+```
+
+Not hard at all.
+
+As usual, you have a `[Unit]` section with a description of what the unit does. Nothing new there. The `[Timer]` section is new, but it is pretty self-explanatory: it contains information on when the service will be triggered and the service to trigger. In this case, the `OnBootSec` is the directive you need to tell systemd to run the service after boot has finished.
+
+Other directives you could use are:
+
+ * `OnActiveSec=`, which tells systemd how long to wait after the timer itself is activated before starting the service.
+ * `OnStartupSec=`, on the other hand, tells systemd how long to wait after systemd was started before starting the service.
+ * `OnUnitActiveSec=` tells systemd how long to wait after the service the timer is activating was last activated.
+ * `OnUnitInactiveSec=` tells systemd how long to wait after the service the timer is activating was last deactivated.
+
+
+
+Continuing down the _minetest.timer_ unit, the `basic.target` is usually used as a synchronization point for late boot services. This means it makes _minetest.timer_ wait until local mount points and swap devices are mounted, sockets, timers, path units and other basic initialization processes are running before letting _minetest.timer_ start. As we explained in [the second article on systemd units][2], _targets_ are like the old run levels and can be used to put your machine into one state or another, or, like here, to tell your service to wait until a certain state has been reached.
+
+The _minetest.service_ you developed in the first two articles [ended up][2] looking like this:
+```
+# minetest.service
+[Unit]
+Description= Minetest server
+Documentation= https://wiki.minetest.net/Main_Page
+
+[Service]
+Type= simple
+User=
+
+ExecStart= /usr/games/minetest --server
+ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
+
+TimeoutStopSec= 180
+ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
+ExecStop= /bin/sleep 120
+ExecStop= /bin/kill -2 $MAINPID
+
+[Install]
+WantedBy= multi-user.target
+
+```
+
+There’s nothing you need to change here. But you do have to change _mtsendmail.sh_ (your email sending script) from this:
+```
+#!/bin/bash
+# mtsendmail
+sleep 20
+echo $1 | mutt -F /home//.muttrc -s "$2" my_minetest@mailing_list.com
+sleep 10
+
+```
+
+to this:
+```
+#!/bin/bash
+# mtsendmail.sh
+echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
+
+```
+
+What you are doing is stripping out those hacky pauses in the Bash script. Systemd does the waiting now.
+
+### Making it work
+
+To make sure things work, disable _minetest.service_ :
+```
+sudo systemctl disable minetest
+
+```
+
+so it doesn't get started when the system starts; and, instead, enable _minetest.timer_ :
+```
+sudo systemctl enable minetest.timer
+
+```
+
+Now you can reboot you server machine and, when you run `sudo journalctl -u minetest.*` you will see how, first the _minetest.timer_ unit gets executed and then the _minetest.service_ starts up after a minute... more or less.
+
+![minetest timer][7]
+
+Figure 1: The minetest.service gets started one minute after the minetest.timer... more or less.
+
+[Used with permission][8]
+
+### A Matter of Time
+
+A couple of clarifications about why the _minetest.timer_ entry in the systemd's Journal shows its start time as 09:08:33, while the _minetest.service_ starts at 09:09:18, that is less than a minute later: First, remember we said that the `OnBootSec=` directive calculates when to start a service from when boot is complete. By the time _minetest.timer_ comes along, boot has finished a few seconds ago.
+
+The other thing is that systemd gives itself a margin of error (by default, 1 minute) to run stuff. This helps distribute the load when several resource-intensive processes are running at the same time: by giving itself a minute, systemd can wait for some processes to power down. This also means that _minetest.service_ will start somewhere between the 1 minute and 2 minute mark after boot is completed, but when exactly within that range is anybody's guess.
+
+For the record, [you can change the margin of error with `AccuracySec=` directive][9].
+
+Another thing you can do is check when all the timers on your system are scheduled to run or the last time the ran:
+```
+systemctl list-timers --all
+
+```
+
+![check timer][11]
+
+Figure 2: Check when your timers are scheduled to fire or when they fired last.
+
+[Used with permission][8]
+
+The final thing to take into consideration is the format you should use to express the periods of time. Systemd is very flexible in that respect: `2 h`, `2 hours` or `2hr` will all work to express a 2 hour delay. For seconds, you can use `seconds`, `second`, `sec`, and `s`, the same way as for minutes you can use `minutes`, `minute`, `min`, and `m`. You can see a full list of time units systemd understands by checking `man systemd.time`.
+
+### Next Time
+
+You'll see how to use calendar dates and times to run services at regular intervals and how to combine timers and device units to run services at defined point in time after you plug in some hardware.
+
+See you then!
+
+Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
+
+作者:[Paul Brown][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/bro66
+[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
+[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
+[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
+[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
+[5]:https://www.minetest.net/
+[6]:/files/images/minetest-timer-1png
+[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-1.png?itok=TG0xJvYM (minetest timer)
+[8]:/licenses/category/used-permission
+[9]:https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=
+[10]:/files/images/minetest-timer-2png
+[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-2.png?itok=pYxyVx8- (check timer)
+[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180724 Building a network attached storage device with a Raspberry Pi.md b/sources/tech/20180724 Building a network attached storage device with a Raspberry Pi.md
new file mode 100644
index 0000000000..4083023ca4
--- /dev/null
+++ b/sources/tech/20180724 Building a network attached storage device with a Raspberry Pi.md
@@ -0,0 +1,285 @@
+translating by wyxplus
+Building a network attached storage device with a Raspberry Pi
+======
+
+
+
+In this three-part series, I'll explain how to set up a simple, useful NAS (network attached storage) system. I use this kind of setup to store my files on a central system, creating incremental backups automatically every night. To mount the disk on devices that are located in the same network, NFS is installed. To access files offline and share them with friends, I use [Nextcloud][1].
+
+This article will cover the basic setup of software and hardware to mount the data disk on a remote device. In the second article, I will discuss a backup strategy and set up a cron job to create daily backups. In the third and last article, we will install Nextcloud, a tool for easy file access to devices synced offline as well as online using a web interface. It supports multiple users and public file-sharing so you can share pictures with friends, for example, by sending a password-protected link.
+
+The target architecture of our system looks like this:
+
+
+### Hardware
+
+Let's get started with the hardware you need. You might come up with a different shopping list, so consider this one an example.
+
+The computing power is delivered by a [Raspberry Pi 3][2], which comes with a quad-core CPU, a gigabyte of RAM, and (somewhat) fast ethernet. Data will be stored on two USB hard drives (I use 1-TB disks); one is used for the everyday traffic, the other is used to store backups. Be sure to use either active USB hard drives or a USB hub with an additional power supply, as the Raspberry Pi will not be able to power two USB drives.
+
+### Software
+
+The operating system with the highest visibility in the community is [Raspbian][3] , which is excellent for custom projects. There are plenty of [guides][4] that explain how to install Raspbian on a Raspberry Pi, so I won't go into details here. The latest official supported version at the time of this writing is [Raspbian Stretch][5] , which worked fine for me.
+
+At this point, I will assume you have configured your basic Raspbian and are able to connect to the Raspberry Pi by `ssh`.
+
+### Prepare the USB drives
+
+To achieve good performance reading from and writing to the USB hard drives, I recommend formatting them with ext4. To do so, you must first find out which disks are attached to the Raspberry Pi. You can find the disk devices in `/dev/sd/`. Using the command `fdisk -l`, you can find out which two USB drives you just attached. Please note that all data on the USB drives will be lost as soon as you follow these steps.
+```
+pi@raspberrypi:~ $ sudo fdisk -l
+
+
+
+<...>
+
+
+
+Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
+
+Units: sectors of 1 * 512 = 512 bytes
+
+Sector size (logical/physical): 512 bytes / 512 bytes
+
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+Disklabel type: dos
+
+Disk identifier: 0xe8900690
+
+
+
+Device Boot Start End Sectors Size Id Type
+
+/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
+
+
+
+
+
+Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
+
+Units: sectors of 1 * 512 = 512 bytes
+
+Sector size (logical/physical): 512 bytes / 512 bytes
+
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+Disklabel type: dos
+
+Disk identifier: 0x6aa4f598
+
+
+
+Device Boot Start End Sectors Size Id Type
+
+/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
+
+```
+
+As those devices are the only 1TB disks attached to the Raspberry Pi, we can easily see that `/dev/sda` and `/dev/sdb` are the two USB drives. The partition table at the end of each disk shows how it should look after the following steps, which create the partition table and format the disks. To do this, repeat the following steps for each of the two devices by replacing `sda` with `sdb` the second time (assuming your devices are also listed as `/dev/sda` and `/dev/sdb` in `fdisk`).
+
+First, delete the partition table of the disk and create a new one containing only one partition. In `fdisk`, you can use interactive one-letter commands to tell the program what to do. Simply insert them after the prompt `Command (m for help):` as follows (you can also use the `m` command anytime to get more information):
+```
+pi@raspberrypi:~ $ sudo fdisk /dev/sda
+
+
+
+Welcome to fdisk (util-linux 2.29.2).
+
+Changes will remain in memory only, until you decide to write them.
+
+Be careful before using the write command.
+
+
+
+
+
+Command (m for help): o
+
+Created a new DOS disklabel with disk identifier 0x9c310964.
+
+
+
+Command (m for help): n
+
+Partition type
+
+ p primary (0 primary, 0 extended, 4 free)
+
+ e extended (container for logical partitions)
+
+Select (default p): p
+
+Partition number (1-4, default 1):
+
+First sector (2048-1953525167, default 2048):
+
+Last sector, +sectors or +size{K,M,G,T,P} (2048-1953525167, default 1953525167):
+
+
+
+Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
+
+
+
+Command (m for help): p
+
+
+
+Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
+
+Units: sectors of 1 * 512 = 512 bytes
+
+Sector size (logical/physical): 512 bytes / 512 bytes
+
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+Disklabel type: dos
+
+Disk identifier: 0x9c310964
+
+
+
+Device Boot Start End Sectors Size Id Type
+
+/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
+
+
+
+Command (m for help): w
+
+The partition table has been altered.
+
+Syncing disks.
+
+```
+
+Now we will format the newly created partition `/dev/sda1` using the ext4 filesystem:
+```
+pi@raspberrypi:~ $ sudo mkfs.ext4 /dev/sda1
+
+mke2fs 1.43.4 (31-Jan-2017)
+
+Discarding device blocks: done
+
+
+
+<...>
+
+
+
+Allocating group tables: done
+
+Writing inode tables: done
+
+Creating journal (1024 blocks): done
+
+Writing superblocks and filesystem accounting information: done
+
+```
+
+After repeating the above steps, let's label the new partitions according to their usage in your system:
+```
+pi@raspberrypi:~ $ sudo e2label /dev/sda1 data
+
+pi@raspberrypi:~ $ sudo e2label /dev/sdb1 backup
+
+```
+
+Now let's get those disks mounted to store some data. My experience, based on running this setup for over a year now, is that USB drives are not always available to get mounted when the Raspberry Pi boots up (for example, after a power outage), so I recommend using autofs to mount them when needed.
+
+First install autofs and create the mount point for the storage:
+```
+pi@raspberrypi:~ $ sudo apt install autofs
+
+pi@raspberrypi:~ $ sudo mkdir /nas
+
+```
+
+Then mount the devices by adding the following line to `/etc/auto.master`:
+```
+/nas /etc/auto.usb
+
+```
+
+Create the file `/etc/auto.usb` if not existing with the following content, and restart the autofs service:
+```
+data -fstype=ext4,rw :/dev/disk/by-label/data
+
+backup -fstype=ext4,rw :/dev/disk/by-label/backup
+
+pi@raspberrypi3:~ $ sudo service autofs restart
+
+```
+
+Now you should be able to access the disks at `/nas/data` and `/nas/backup`, respectively. Clearly, the content will not be too thrilling, as you just erased all the data from the disks. Nevertheless, you should be able to verify the devices are mounted by executing the following commands:
+```
+pi@raspberrypi3:~ $ cd /nas/data
+
+pi@raspberrypi3:/nas/data $ cd /nas/backup
+
+pi@raspberrypi3:/nas/backup $ mount
+
+<...>
+
+/etc/auto.usb on /nas type autofs (rw,relatime,fd=6,pgrp=463,timeout=300,minproto=5,maxproto=5,indirect)
+
+<...>
+
+/dev/sda1 on /nas/data type ext4 (rw,relatime,data=ordered)
+
+/dev/sdb1 on /nas/backup type ext4 (rw,relatime,data=ordered)
+
+```
+
+First move into the directories to make sure autofs mounts the devices. Autofs tracks access to the filesystems and mounts the needed devices on the go. Then the `mount` command shows that the two devices are actually mounted where we wanted them.
+
+Setting up autofs is a bit fault-prone, so do not get frustrated if mounting doesn't work on the first try. Give it another chance, search for more detailed resources (there is plenty of documentation online), or leave a comment.
+
+### Mount network storage
+
+Now that you have set up the basic network storage, we want it to be mounted on a remote Linux machine. We will use the network file system (NFS) for this. First, install the NFS server on the Raspberry Pi:
+```
+pi@raspberrypi:~ $ sudo apt install nfs-kernel-server
+
+```
+
+Next we need to tell the NFS server to expose the `/nas/data` directory, which will be the only device accessible from outside the Raspberry Pi (the other one will be used for backups only). To export the directory, edit the file `/etc/exports` and add the following line to allow all devices with access to the NAS to mount your storage:
+```
+/nas/data *(rw,sync,no_subtree_check)
+
+```
+
+For more information about restricting the mount to single devices and so on, refer to `man exports`. In the configuration above, anyone will be able to mount your data as long as they have access to the ports needed by NFS: `111` and `2049`. I use the configuration above and allow access to my home network only for ports 22 and 443 using the routers firewall. That way, only devices in the home network can reach the NFS server.
+
+To mount the storage on a Linux computer, run the commands:
+```
+you@desktop:~ $ sudo mkdir /nas/data
+
+you@desktop:~ $ sudo mount -t nfs :/nas/data /nas/data
+
+```
+
+Again, I recommend using autofs to mount this network device. For extra help, check out [How to use autofs to mount NFS shares][6].
+
+Now you are able to access files stored on your own RaspberryPi-powered NAS from remote devices using the NFS mount. In the next part of this series, I will cover how to automatically back up your data to the second hard drive using `rsync`. To save space on the device while still doing daily backups, you will learn how to create incremental backups with `rsync`.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
+
+作者:[Manuel Dewald][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/ntlx
+[1]:https://nextcloud.com/
+[2]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
+[3]:https://www.raspbian.org/
+[4]:https://www.raspberrypi.org/documentation/installation/installing-images/
+[5]:https://www.raspberrypi.org/blog/raspbian-stretch/
+[6]:https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
diff --git a/sources/tech/20180724 How To Mount Google Drive Locally As Virtual File System In Linux.md b/sources/tech/20180724 How To Mount Google Drive Locally As Virtual File System In Linux.md
new file mode 100644
index 0000000000..3f804ffe9e
--- /dev/null
+++ b/sources/tech/20180724 How To Mount Google Drive Locally As Virtual File System In Linux.md
@@ -0,0 +1,265 @@
+How To Mount Google Drive Locally As Virtual File System In Linux
+======
+
+
+
+[**Google Drive**][1] is the one of the popular cloud storage provider on the planet. As of 2017, over 800 million users are actively using this service worldwide. Even though the number of users have dramatically increased, Google haven’t released a Google drive client for Linux yet. But it didn’t stop the Linux community. Every now and then, some developers had brought few google drive clients for Linux operating system. In this guide, we will see three unofficial google drive clients for Linux. Using these clients, you can mount Google drive locally as a virtual file system and access your drive files in your Linux box. Read on.
+
+### 1. Google-drive-ocamlfuse
+
+The **google-drive-ocamlfuse** is a FUSE filesystem for Google Drive, written in OCaml. For those wondering, FUSE, stands for **F** ilesystem in **Use** rspace, is a project that allows the users to create virtual file systems in user level. **google-drive-ocamlfuse** allows you to mount your Google Drive on Linux system. It features read/write access to ordinary files and folders, read-only access to Google docks, sheets, and slides, support for multiple google drive accounts, duplicate file handling, access to your drive trash directory, and more.
+
+#### Installing google-drive-ocamlfuse
+
+google-drive-ocamlfuse is available in the [**AUR**][2], so you can install it using any AUR helper programs, for example [**Yay**][3].
+```
+$ yay -S google-drive-ocamlfuse
+
+```
+
+On Ubuntu:
+```
+$ sudo add-apt-repository ppa:alessandro-strada/ppa
+$ sudo apt-get update
+$ sudo apt-get install google-drive-ocamlfuse
+
+```
+
+To install latest beta version, do:
+```
+$ sudo add-apt-repository ppa:alessandro-strada/google-drive-ocamlfuse-beta
+$ sudo apt-get update
+$ sudo apt-get install google-drive-ocamlfuse
+
+```
+
+#### Usage
+
+Once installed, run the following command to launch **google-drive-ocamlfuse** utility from your Terminal:
+```
+$ google-drive-ocamlfuse
+
+```
+
+When you run this first time, the utility will open your web browser and ask your permission to authorize your google drive files. Once you gave authorization, all necessary config files and folders it needs to mount your google drive will be automatically created.
+
+![][5]
+
+After successful authentication, you will see the following message in your Terminal.
+```
+Access token retrieved correctly.
+
+```
+
+You’re good to go now. Close the web browser and then create a mount point to mount your google drive files.
+```
+$ mkdir ~/mygoogledrive
+
+```
+
+Finally, mount your google drive using command:
+```
+$ google-drive-ocamlfuse ~/mygoogledrive
+
+```
+
+Congratulations! You can access access your files either from Terminal or file manager.
+
+From **Terminal** :
+```
+$ ls ~/mygoogledrive
+
+```
+
+From **File manager** :
+
+![][6]
+
+If you have more than one account, use **label** option to distinguish different accounts like below.
+```
+$ google-drive-ocamlfuse -label label [mountpoint]
+
+```
+
+Once you’re done, unmount the FUSE flesystem using command:
+```
+$ fusermount -u ~/mygoogledrive
+
+```
+
+For more details, refer man pages.
+```
+$ google-drive-ocamlfuse --help
+
+```
+
+Also, do check the [**official wiki**][7] and the [**project GitHub repository**][8] for more details.
+
+### 2. GCSF
+
+**GCSF** is a FUSE filesystem based on Google Drive, written using **Rust** programming language. The name GCSF has come from the Romanian word “ **G** oogle **C** onduce **S** istem de **F** ișiere”, which means “Google Drive Filesystem” in English. Using GCSF, you can mount your Google drive as a local virtual file system and access the contents from the Terminal or file manager. You might wonder how it differ from other Google Drive FUSE projects, for example **google-drive-ocamlfuse**. The developer of GCSF replied to a similar [comment on Reddit][9] “GCSF tends to be faster in several cases (listing files recursively, reading large files from Drive). The caching strategy it uses also leads to very fast reads (x4-7 improvement compared to google-drive-ocamlfuse) for files that have been cached, at the cost of using more RAM“.
+
+#### Installing GCSF
+
+GCSF is available in the [**AUR**][10], so the Arch Linux users can install it using any AUR helper, for example [**Yay**][3].
+```
+$ yay -S gcsf-git
+
+```
+
+For other distributions, do the following.
+
+Make sure you have installed Rust on your system.
+
+Make sure **pkg-config** and the **fuse** packages are installed. They are available in the default repositories of most Linux distributions. For example, on Ubuntu and derivatives, you can install them using command:
+```
+$ sudo apt-get install -y libfuse-dev pkg-config
+
+```
+
+Once all dependencies installed, run the following command to install GCSF:
+```
+$ cargo install gcsf
+
+```
+
+#### Usage
+
+First, we need to authorize our google drive. To do so, simply run:
+```
+$ gcsf login ostechnix
+
+```
+
+You must specify a session name. Replace **ostechnix** with your own session name. You will see an output something like below with an URL to authorize your google drive account.
+
+![][11]
+
+Just copy and navigate to the above URL from your browser and click **allow** to give permission to access your google drive contents. Once you gave the authentication you will see an output like below.
+```
+Successfully logged in. Credentials saved to "/home/sk/.config/gcsf/ostechnix".
+
+```
+
+GCSF will create a configuration file in **$XDG_CONFIG_HOME/gcsf/gcsf.toml** , which is usually defined as **$HOME/.config/gcsf/gcsf.toml**. Credentials are stored in the same directory.
+
+Next, create a directory to mount your google drive contents.
+```
+$ mkdir ~/mygoogledrive
+
+```
+
+Then, edit **/etc/fuse.conf** file:
+```
+$ sudo vi /etc/fuse.conf
+
+```
+
+Uncomment the following line to allow non-root users to specify the allow_other or allow_root mount options.
+```
+user_allow_other
+
+```
+
+Save and close the file.
+
+Finally, mount your google drive using command:
+```
+$ gcsf mount ~/mygoogledrive -s ostechnix
+
+```
+
+Sample output:
+```
+INFO gcsf > Creating and populating file system...
+INFO gcsf > File sytem created.
+INFO gcsf > Mounting to /home/sk/mygoogledrive
+INFO gcsf > Mounted to /home/sk/mygoogledrive
+INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
+INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
+
+```
+
+Again, replace **ostechnix** with your session name. You can view the existing sessions using command:
+```
+$ gcsf list
+Sessions:
+- ostechnix
+
+```
+
+You can now access your google drive contents either from the Terminal or from File manager.
+
+From **Terminal** :
+```
+$ ls ~/mygoogledrive
+
+```
+
+From **File manager** :
+
+![][12]
+
+If you don’t know where your Google drive is mounted, use **df** or **mount** command as shown below.
+```
+$ df -h
+Filesystem Size Used Avail Use% Mounted on
+udev 968M 0 968M 0% /dev
+tmpfs 200M 1.6M 198M 1% /run
+/dev/sda1 20G 7.5G 12G 41% /
+tmpfs 997M 0 997M 0% /dev/shm
+tmpfs 5.0M 4.0K 5.0M 1% /run/lock
+tmpfs 997M 0 997M 0% /sys/fs/cgroup
+tmpfs 200M 40K 200M 1% /run/user/1000
+GCSF 15G 857M 15G 6% /home/sk/mygoogledrive
+
+$ mount | grep GCSF
+GCSF on /home/sk/mygoogledrive type fuse (rw,nosuid,nodev,relatime,user_id=1000,group_id=1000,allow_other)
+
+```
+
+Once done, unmount the google drive using command:
+```
+$ fusermount -u ~/mygoogledrive
+
+```
+
+Check the [**GCSF GitHub repository**][13] for more details.
+
+### 3. Tuxdrive
+
+**Tuxdrive** is yet another unofficial google drive client for Linux. We have written a detailed guide about Tuxdrive a while ago. Please check the following link.
+
+Of course, there were few other unofficial google drive clients available in the past, such as Grive2, Syncdrive. But it seems that they are discontinued now. I will keep updating this list when I come across any active google drive clients.
+
+And, that’s all for now, folks. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.google.com/drive/
+[2]:https://aur.archlinux.org/packages/google-drive-ocamlfuse/
+[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive.png
+[6]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-2.png
+[7]:https://github.com/astrada/google-drive-ocamlfuse/wiki/Configuration
+[8]:https://github.com/astrada/google-drive-ocamlfuse
+[9]:https://www.reddit.com/r/DataHoarder/comments/8vlb2v/google_drive_as_a_file_system/e1oh9q9/
+[10]:https://aur.archlinux.org/packages/gcsf-git/
+[11]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-3.png
+[12]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-4.png
+[13]:https://github.com/harababurel/gcsf
diff --git a/sources/tech/20180725 Best Online Linux Terminals and Online Bash Editors.md b/sources/tech/20180725 Best Online Linux Terminals and Online Bash Editors.md
new file mode 100644
index 0000000000..7f430c3d59
--- /dev/null
+++ b/sources/tech/20180725 Best Online Linux Terminals and Online Bash Editors.md
@@ -0,0 +1,212 @@
+Best Online Linux Terminals and Online Bash Editors
+======
+No matter whether you want to practice Linux commands or just analyze/test your shell scripts online, there’s always a couple of online Linux terminals and online bash compilers available.
+
+This is particularly helpful when you are using the Windows operating system. Though you can [install Linux inside Windows using Windows Subsystem for Linux][1], using online Linux terminals are often more convenient for a quick test.
+
+![Websites that allow to use Linux Terminal online][2]
+
+But where can you find free Linux console? Which online Linux shell should you use?
+
+Fret not, to save you the hassle, here, we have compiled a list of the best online Linux terminals and a separate list of best online bash compilers for you to look at.
+
+**Note:** All of the online terminals support several browsers that include Google Chrome, Mozilla Firefox, Opera and Microsoft Edge.
+
+### Best Online Linux Terminals To Practice Linux Commands
+
+In the first part, I’ll list the online Linux terminals. These websites allow you to run the regular Linux commands in a web browser so that you can practice or test them. Some websites may require you to register and login to save your sessions.
+
+#### 1. JSLinux
+
+![online linux terminal - jslinux][3]
+
+JSLinux is more like a complete Linux emulator instead of just offering you the terminal. As the name suggests, it has been entirely written in JavaScript. You get to choose a console-based system or a GUI-based online Linux system. However, in this case, you would want to launch the console-based system to practice Linux commands. To be able to connect your account, you need to sign up first.
+
+JSLinux also lets you upload files to the virtual machine. At its core, it utilizes [Buildroot][4] (a tool that helps you to build a complete Linux system for an embedded system).
+
+[Try JSLinux Terminal][5]
+
+#### 2. Copy.sh
+
+![copysh online linux terminal][6]
+
+Copy.sh offers one of the best online Linux terminals which is fast and reliable to test and run Linux commands.
+
+Copy.sh is also on [GitHub][7] – and it is being actively maintained, which is a good thing. It also supports other Operating Systems, which includes:
+
+ * Windows 98
+ * KolibriOS
+ * FreeDOS
+ * Windows 1.01
+ * Archlinux
+
+
+
+[Try Copy.sh Terminal][8]
+
+#### 3. Webminal
+
+![webminal online linux terminal][9]
+
+Webminal is an impressive online Linux terminal – and my personal favorite when it comes to a recommendation for beginners to practice Linux commands online.
+
+The website offers several lessons to learn from while you type in the commands in the same window. So, you do not need to refer to another site for the lessons and then switch back or split the screen in order to practice commands. It’s all right there – in a single tab on the browser.
+
+[Try Webminal Terminal][10]
+
+#### 4. Tutorialspoint Unix Terminal
+
+![tutorialspoint linux terminal][11]
+
+You might be aware of Tutorialspoint – which happens to be one of the most popular websites with high quality (yet free) online tutorials for just about any programming language (and more).
+
+So, for obvious reasons, they provide a free online Linux console for you to practice commands while referring to their site as a resource at the same time. You also get the ability to upload files. It is quite simple but an effective online terminal. Also, it doesn’t stop there, it offers a lot of different online terminals as well in its [Coding Ground][12] page.
+
+[Try Unix Terminal Online][13]
+
+#### 5. JS/UIX
+
+![js uix online linux terminal][14]
+
+JS/UIX is yet another online Linux terminal which is written entirely in JavaScript without any plug-ins. It contains an online Linux virtual machine, virtual file-system, shell, and so on.
+
+You can go through its manual page for the list of commands implemented.
+
+[Try JS/UX Terminal][15]
+
+#### 6. CB.VU
+
+![online linux terminal][16]
+
+If you are in for a treat with FreeBSD 7.1 stable version, cb.vu is a quite simple solution for that.
+
+Nothing fancy, just try out the Linux commands you want and get the output. Unfortunately, you do not get the ability to upload files here.
+
+[Try CB.VU Terminal][17]
+
+#### 7. Linux Containers
+
+![online linux terminal][18]
+
+Linux Containers lets you run a demo server with a 30-minute countdown on which acts as one of the best online Linux terminals. In fact, it’s a project sponsored by Canonical.
+
+[Try Linux LXD][19]
+
+#### 8. Codeanywhere
+
+![online linux terminal][20]
+
+Codeanywhere is a service which offers cross-platform cloud IDEs. However, in order to run a free Linux virtual machine, you just need to sign up and choose the free plan. And, then, proceed to create a new connection while setting up a container with an OS of your choice. Finally, you will have a free Linux console at your disposal.
+
+[Try Codeanywhere Editor][21]
+
+### Best Online Bash Editors
+
+Wait a sec! Are the online Linux terminals not good enough for Bash scripting? They are. But creating bash scripts in terminal editors and then executing them is not as convinient as using an online Bash editor.
+
+These bash editors allow you to easily write shell scripts online and you can run them to check if it works or not.
+
+Let’s see here can you run shell scripts online.
+
+#### Tutorialspoint Bash Compiler
+
+![online bash compiler][22]
+
+As mentioned above, Tutorialspoint also offers an online Bash compiler. It is a very simple bash compiler to execute bash shell online.
+
+[Try Tutorialspoint Bash Compiler][23]
+
+#### JDOODLE
+
+![online bash compiler][24]
+
+Yet another useful online bash editor to test Bash scripts is JDOODLE. It also offers other IDEs, but we’ll focus on bash script execution here. You get to set the command line arguments and the stdin inputs, and would normally get the result of your code.
+
+[Try JDOODLE Bash Script Online Tester][25]
+
+#### Paizo.io
+
+![paizo online bash editor][26]
+
+Paizo.io is a good bash online editor that you can try for free. To utilize some of its advanced features like task scheduling, you need to first sign up. It also supports real-time collaboration, but that’s still in the experimental phase.
+
+[Try Paizo.io Bash Editor][27]
+
+#### ShellCheck
+
+![shell check bash check][28]
+
+An interesting Bash editor which lets you find bugs in your shell script. It is available on [GitHub][29] as well. In addition, you can install ShellCheck locally on [supported platforms][30].
+
+[Try ShellCheck][31]
+
+#### Rextester
+
+![rextester bash editor][32]
+
+If you only want a dead simple online bash compiler, Rextester should be your choice. It also supports other programming languages.
+
+[Try Rextester][33]
+
+#### Learn Shell
+
+![online bash shell editor][34]
+
+Just like [Webminal][35], Learnshell provides you with the content (or resource) to learn shell programming and you could also run/try your code at the same time. It covers the basics and a few advanced topics as well.
+
+[Try Learn Shell Programming][36]
+
+### Wrapping Up
+
+Now that you know of the most reliable and fast online Linux terminals & online bash editors, learn, experiment, and play with the code!
+
+We might have missed any of your favorite online Linux terminals or maybe the best online bash compiler which you happen to use? Let us know your thoughts in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/online-linux-terminals/
+
+作者:[Ankush Das][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/ankush/
+[1]:https://itsfoss.com/install-bash-on-windows/
+[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/online-linux-terminals.jpeg
+[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/jslinux-online-linux-terminal.jpg
+[4]:https://buildroot.org/
+[5]:https://bellard.org/jslinux/
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/copy-sh-online-linux-terminal.jpg
+[7]:https://github.com/copy/v86
+[8]:https://copy.sh/v86/?profile=linux26
+[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/webminal.jpg
+[10]:http://www.webminal.org/terminal/
+[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/coding-ground-tutorialspoint-online-linux-terminal.jpg
+[12]:https://www.tutorialspoint.com/codingground.htm
+[13]:https://www.tutorialspoint.com/unix_terminal_online.php
+[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/JS-UIX-online-linux-terminal.jpg
+[15]:http://www.masswerk.at/jsuix/index.html
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/cb-vu-online-linux-terminal.jpg
+[17]:http://cb.vu/
+[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/linux-containers-terminal.jpg
+[19]:https://linuxcontainers.org/lxd/try-it/
+[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/codeanywhere-terminal.jpg
+[21]:https://codeanywhere.com/editor/
+[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/tutorialspoint-bash-compiler.jpg
+[23]:https://www.tutorialspoint.com/execute_bash_online.php
+[24]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/jdoodle-online-bash-editor.jpg
+[25]:https://www.jdoodle.com/test-bash-shell-script-online
+[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/paizo-io-bash-editor.jpg
+[27]:https://paiza.io/en/projects/new?language=bash
+[28]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/shell-check-bash-analyzer.jpg
+[29]:https://github.com/koalaman/shellcheck
+[30]:https://github.com/koalaman/shellcheck#user-content-installing
+[31]:https://www.shellcheck.net/#
+[32]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/rextester-bash-editor.jpg
+[33]:http://rextester.com/l/bash_online_compiler
+[34]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/learnshell-online-bash-shell.jpg
+[35]:http://www.webminal.org/
+[36]:http://www.learnshell.org/
diff --git a/sources/tech/20180725 Build an interactive CLI with Node.js.md b/sources/tech/20180725 Build an interactive CLI with Node.js.md
new file mode 100644
index 0000000000..6ec13f1cfc
--- /dev/null
+++ b/sources/tech/20180725 Build an interactive CLI with Node.js.md
@@ -0,0 +1,531 @@
+Build an interactive CLI with Node.js
+======
+
+
+
+Node.js can be very useful when it comes to building command-line interfaces (CLIs). In this post, I'll teach you how to use [Node.js][1] to build a CLI that asks some questions and creates a file based on the answers.
+
+### Get started
+
+Let's start by creating a brand new [npm][2] package. (Npm is the JavaScript package manager.)
+```
+mkdir my-script
+
+cd my-script
+
+npm init
+
+```
+
+Npm will ask some questions. After that, we need to install some packages.
+```
+npm install --save chalk figlet inquirer shelljs
+
+```
+
+Here's what these packages do:
+
+ * **Chalk:** Terminal string styling done right
+ * **Figlet:** A program for making large letters out of ordinary text
+ * **Inquirer:** A collection of common interactive command-line user interfaces
+ * **ShellJS:** Portable Unix shell commands for Node.js
+
+
+
+### Make an index.js file
+
+Now we'll create an `index.js` file with the following content:
+```
+#!/usr/bin/env node
+
+
+
+const inquirer = require("inquirer");
+
+const chalk = require("chalk");
+
+const figlet = require("figlet");
+
+const shell = require("shelljs");
+
+```
+
+### Plan the CLI
+
+It's always good to plan what a CLI needs to do before writing any code. This CLI will do just one thing: **create a file**.
+
+The CLI will ask two questions—what is the filename and what is the extension?—then create the file, and show a success message with the created file path.
+```
+// index.js
+
+
+
+const run = async () => {
+
+ // show script introduction
+
+ // ask questions
+
+ // create the file
+
+ // show success message
+
+};
+
+
+
+run();
+
+```
+
+The first function is the script introduction. Let's use `chalk` and `figlet` to get the job done.
+```
+const init = () => {
+
+ console.log(
+
+ chalk.green(
+
+ figlet.textSync("Node JS CLI", {
+
+ font: "Ghost",
+
+ horizontalLayout: "default",
+
+ verticalLayout: "default"
+
+ })
+
+ )
+
+ );
+
+}
+
+
+
+const run = async () => {
+
+ // show script introduction
+
+ init();
+
+
+
+ // ask questions
+
+ // create the file
+
+ // show success message
+
+};
+
+
+
+run();
+
+```
+
+Second, we'll write a function that asks the questions.
+```
+const askQuestions = () => {
+
+ const questions = [
+
+ {
+
+ name: "FILENAME",
+
+ type: "input",
+
+ message: "What is the name of the file without extension?"
+
+ },
+
+ {
+
+ type: "list",
+
+ name: "EXTENSION",
+
+ message: "What is the file extension?",
+
+ choices: [".rb", ".js", ".php", ".css"],
+
+ filter: function(val) {
+
+ return val.split(".")[1];
+
+ }
+
+ }
+
+ ];
+
+ return inquirer.prompt(questions);
+
+};
+
+
+
+// ...
+
+
+
+const run = async () => {
+
+ // show script introduction
+
+ init();
+
+
+
+ // ask questions
+
+ const answers = await askQuestions();
+
+ const { FILENAME, EXTENSION } = answers;
+
+
+
+ // create the file
+
+ // show success message
+
+};
+
+```
+
+Notice the constants FILENAME and EXTENSIONS that came from `inquirer`.
+
+The next step will create the file.
+```
+const createFile = (filename, extension) => {
+
+ const filePath = `${process.cwd()}/${filename}.${extension}`
+
+ shell.touch(filePath);
+
+ return filePath;
+
+};
+
+
+
+// ...
+
+
+
+const run = async () => {
+
+ // show script introduction
+
+ init();
+
+
+
+ // ask questions
+
+ const answers = await askQuestions();
+
+ const { FILENAME, EXTENSION } = answers;
+
+
+
+ // create the file
+
+ const filePath = createFile(FILENAME, EXTENSION);
+
+
+
+ // show success message
+
+};
+
+```
+
+And last but not least, we'll show the success message along with the file path.
+```
+const success = (filepath) => {
+
+ console.log(
+
+ chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
+
+ );
+
+};
+
+
+
+// ...
+
+
+
+const run = async () => {
+
+ // show script introduction
+
+ init();
+
+
+
+ // ask questions
+
+ const answers = await askQuestions();
+
+ const { FILENAME, EXTENSION } = answers;
+
+
+
+ // create the file
+
+ const filePath = createFile(FILENAME, EXTENSION);
+
+
+
+ // show success message
+
+ success(filePath);
+
+};
+
+```
+
+Let's test the script by running `node index.js`. Here's what we get:
+
+### The full code
+
+Here is the final code:
+```
+#!/usr/bin/env node
+
+
+
+const inquirer = require("inquirer");
+
+const chalk = require("chalk");
+
+const figlet = require("figlet");
+
+const shell = require("shelljs");
+
+
+
+const init = () => {
+
+ console.log(
+
+ chalk.green(
+
+ figlet.textSync("Node JS CLI", {
+
+ font: "Ghost",
+
+ horizontalLayout: "default",
+
+ verticalLayout: "default"
+
+ })
+
+ )
+
+ );
+
+};
+
+
+
+const askQuestions = () => {
+
+ const questions = [
+
+ {
+
+ name: "FILENAME",
+
+ type: "input",
+
+ message: "What is the name of the file without extension?"
+
+ },
+
+ {
+
+ type: "list",
+
+ name: "EXTENSION",
+
+ message: "What is the file extension?",
+
+ choices: [".rb", ".js", ".php", ".css"],
+
+ filter: function(val) {
+
+ return val.split(".")[1];
+
+ }
+
+ }
+
+ ];
+
+ return inquirer.prompt(questions);
+
+};
+
+
+
+const createFile = (filename, extension) => {
+
+ const filePath = `${process.cwd()}/${filename}.${extension}`
+
+ shell.touch(filePath);
+
+ return filePath;
+
+};
+
+
+
+const success = filepath => {
+
+ console.log(
+
+ chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
+
+ );
+
+};
+
+
+
+const run = async () => {
+
+ // show script introduction
+
+ init();
+
+
+
+ // ask questions
+
+ const answers = await askQuestions();
+
+ const { FILENAME, EXTENSION } = answers;
+
+
+
+ // create the file
+
+ const filePath = createFile(FILENAME, EXTENSION);
+
+
+
+ // show success message
+
+ success(filePath);
+
+};
+
+
+
+run();
+
+```
+
+### Use the script anywhere
+
+To execute this script anywhere, add a `bin` section in your `package.json` file and run `npm link`.
+```
+{
+
+ "name": "creator",
+
+ "version": "1.0.0",
+
+ "description": "",
+
+ "main": "index.js",
+
+ "scripts": {
+
+ "test": "echo \"Error: no test specified\" && exit 1",
+
+ "start": "node index.js"
+
+ },
+
+ "author": "",
+
+ "license": "ISC",
+
+ "dependencies": {
+
+ "chalk": "^2.4.1",
+
+ "figlet": "^1.2.0",
+
+ "inquirer": "^6.0.0",
+
+ "shelljs": "^0.8.2"
+
+ },
+
+ "bin": {
+
+ "creator": "./index.js"
+
+ }
+
+}
+
+```
+
+Running `npm link` makes this script available anywhere.
+
+That's what happens when you run this command:
+```
+/usr/bin/creator -> /usr/lib/node_modules/creator/index.js
+
+/usr/lib/node_modules/creator -> /home/hugo/code/creator
+
+```
+
+It links the `index.js` file as an executable. This is only possible because of the first line of the CLI script: `#!/usr/bin/env node`.
+
+Now we can run this script by calling:
+```
+$ creator
+
+```
+
+### Wrapping up
+
+As you can see, Node.js makes it very easy to build nice command-line tools! If you want to go even further, check this other packages:
+
+ * [meow][3] – a simple command-line helper
+ * [yargs][4] – a command-line opt-string parser
+ * [pkg][5] – package your Node.js project into an executable
+
+
+
+Tell us about your experience building a CLI in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/node-js-interactive-cli
+
+作者:[Hugo Dias][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/hugodias
+[1]:https://nodejs.org/en/
+[2]:https://www.npmjs.com/
+[3]:https://github.com/sindresorhus/meow
+[4]:https://github.com/yargs/yargs
+[5]:https://github.com/zeit/pkg
diff --git a/sources/tech/20180725 How do private keys work in PKI and cryptography.md b/sources/tech/20180725 How do private keys work in PKI and cryptography.md
new file mode 100644
index 0000000000..bc73101560
--- /dev/null
+++ b/sources/tech/20180725 How do private keys work in PKI and cryptography.md
@@ -0,0 +1,101 @@
+How do private keys work in PKI and cryptography?
+======
+
+
+
+In [a previous article][1], I gave an overview of cryptography and discussed the core concepts of confidentiality (keeping data secret), integrity (protecting data from tampering), and authentication (knowing the identity of the data's source). Since authentication relates so closely to all the messiness of identity in the real world, a complex technological ecosystem has evolved around establishing that someone is who they claim to be. In this article, I'll describe in broad strokes how these systems work.
+
+### A quick review of public key cryptography and digital signatures
+
+Authentication in the online world relies on public key cryptography where a key has two parts: a private key kept secret by the owner and a public key shared with the world. After the public key encrypts data, only the private key can decrypt it. This feature is useful if a whistleblower wanted to establish contact with a [journalist][2], for example. More importantly for this article, a private key can be combined with a message to create a digital signature that provides integrity and authentication.
+
+In practice, what is signed is not the actual message, but a digest of a message attained by sending the message through a cryptographic hash function. Instead of signing an entire zip file of source code, the sender signs the 256-bit [SHA-256][3] digest of that zip file and sends the zip file in the clear. Recipients independently calculate the SHA-256 digest of the file they received. They input their digest, the signature they received, and the sender's public key into a signature verification algorithm. The verification process varies depending on the encryption algorithm, and there are enough subtleties that signature verification [vulnerabilities][4] still [pop up][5] . If the verification succeeds, the file has not been modified in transit and must have originated from the sender since only the sender has the private key that created the signature.
+
+### The missing piece of the puzzle
+
+There's one major detail missing from this scenario. Where do we get the sender's public key? The sender could send the public key along with a message, but then we have no proof of their identity beyond their own assertion. Imagine being a bank teller and a customer walks up and says, "Hello, I'm Jane Doe, and I'd like to make a withdrawal." When you ask for identification, she points to a name tag sticker on her shirt that says "Jane Doe." Personally, I would politely turn "Jane" away.
+
+If you already know the sender, you could meet in person and exchange public keys. If you don't, you could meet in person, examine their passport, and once you are satisfied it is authentic, accept their public key. To make the process more efficient, you could throw a [party][6], invite a bunch of people, examine all their passports, and accept all their public keys. Building off that, if you know Jane Doe and trust her (despite her unusual banking practices), Jane could go to the party, get the public keys, and give them to you. In fact, Jane could just sign the other public keys using her own private key, and then you could use [an online repository][7] of public keys, trusting the ones signed by Jane. If a person's public key is signed by multiple people you trust, then you might decide to trust that person as well (even though you don't know them). In this fashion, you can build a [web of trust][8].
+
+But now things have gotten complicated: We need to decide on a standard way to encode a key and the identity associated with that key into a digital bundle we can sign. More properly, these digital bundles are called certificates. We'll also need tooling that can create, use, and manage these certificates. The way we solve these and other requirements is what constitutes a public key infrastructure (PKI).
+
+### Beyond the web of trust
+
+You can think of the web of trust as a network of people. A network with many interconnections between the people makes it easy to find a short path of trust: a social circle, for example. [GPG][9]-encrypted email relies on a web of trust, and it functions ([in theory][10]) since most of us communicate primarily with a relatively small group of friends, family, and co-workers.
+
+In practice, the web of trust has some [significant problems][11], many of them around scaling. When the network starts to get larger and there are few connections between people, the web of trust starts to break down. If the path of trust is attenuated across a long chain of people, you face a higher chance of encountering someone who carelessly or maliciously signed a key. And if there is no path at all, you have to create one by contacting the other party and verifying their key to your satisfaction. Imagine going to an online store that you and your friends have never used. Before you establish a secure communications channel to place an order, you'd need to verify the site's public key belongs to the company and not an impostor. That vetting would entail going to a physical store, making telephone calls, or some other laborious process. Online shopping would be a lot less convenient (or a lot less secure since many people would cut corners and accept the key without verifying it).
+
+What if the world had some exceptionally trustworthy people constantly verifying and signing keys for websites? You could just trust them, and browsing the internet would be much smoother. At a high level, that's how things work today. These "exceptionally trustworthy people" are companies called certificate authorities (CAs). When a website wants to get its public key signed, it submits a certificate signing request (CSR) to the CA.
+
+CSRs are like stub certificates that contain a public key and an identity (in this case, the hostname of the server), but are not signed by a CA. Before signing, the CA performs some verification steps. In some cases, the CA merely verifies that the requester controls the domain for the hostname listed in the CSR (via a challenge-and-response email exchange with the address in the WHOIS entry, for example). [In other cases][12], the CA inspects legal documents, like business licenses. Once the CA is satisfied (and usually after the requester has paid a fee), it takes the data from the CSR and signs it with its own private key to create a certificate. The CA then sends the certificate to the requester. The requester installs the certificate on their site's web server, and the certificate is delivered to users when they connect over HTTPS (or any other protocol secured with [TLS][13]).
+
+When users connect to the site, their browser looks at the certificate, checks that the hostname in the certificate is the same as the hostname it is connected to (more on this in a moment), and verifies the CA's signature. If any of these steps fail, the browser will show a warning and break off the connection. Otherwise, the browser uses the public key in the certificate to verify some signed information sent from the server to ensure that the server possesses the certificate's private key. These messages also serve as steps in one of several algorithms used to establish a shared secret key that will encrypt subsequent messages. Key exchange algorithms are beyond the scope of this article, but there's a good discussion of one of them in [this video][14].
+
+### Creating trust
+
+You're probably wondering, "If the CA's private key signs a certificate, that means to verify a certificate we need the CA's public key. Where does it come from and who signs it?" The answer is the CA signs for itself! A certificate can be signed using the private key associated with the same certificate's public key. These certificates are said to be self-signed; they are the PKI equivalent of saying, "Trust me." (People often say, as a form of shorthand, that a certificate has signed something even though it's the private key—which isn't in the certificate at all—doing the actual signing.)
+
+By adhering to policies established by [web browser][15] and [operating system][16] vendors, CAs demonstrate they are trustworthy enough to be placed into a group of self-signed certificates built into the browser or operating system. These certificates are called trust anchors or root CA certificates, and they are placed in a root certificate store where they are trusted implicitly.
+
+A CA can also issue a certificate endowed with the ability to act as a CA itself. In this way, they can create a chain of certificates. To verify the chain, a program starts at the trust anchor and verifies (among other things) the signature on the next certificate using the public key of the current certificate. It continues down the chain, verifying each link until it reaches the end. If there are no problems along the way, a chain of trust is established. When a website pays a CA to sign a certificate for it, they are paying for the privilege of being placed at the end of that chain. CAs mark certificates sold to websites as not being allowed to sign subsequent certificates; this is so they can terminate the chain of trust at the appropriate place.
+
+Why would a chain ever be more than two links long? After all, a site just needs its certificate signed by a CA's root certificate. In practice, CAs create intermediate CA certificates for convenience (among other reasons). The private keys for a CA's root certificates are so valuable that they reside in a specialized device, a [hardware security module][17] (HSM), that requires multiple people to unlock it, is completely offline, and is kept inside a [vault][18] wired with alarms and cameras.
+
+CAB Forum, the association that governs CAs, [requires][19] any interaction with a CA's root certificate to be performed directly by a human. Issuing certificates for dozens of websites a day would be tedious if every certificate request required an employee to place the request on secure media, enter a vault, unlock the HSM with a coworker, sign the certificate, exit the vault, and then copy the signed certificate off the media. Instead, CAs create internal, intermediate CAs used to sign certificates automatically.
+
+You can see this chain in Firefox by clicking the lock icon in the URL bar, opening up the page information, and clicking the "View Certificate" button on the "Security" tab. As of this writing, [opensource.com][20] had the following chain:
+```
+DigiCert High Assurance EV Root CA
+
+ DigiCert SHA2 High Assurance Server CA
+
+ opensource.com
+
+```
+
+### The man in the middle
+
+I mentioned earlier that a browser needs to check that the hostname in the certificate is the same as the hostname it connected to. Why? The answer has to do with what's called a [man-in-the-middle (MITM) attack][21]. These are [network attacks][22] that allow an attacker to insert itself between a client and a server, masquerading as the server to the client and vice versa. If the traffic is over HTTPS, it's encrypted and eavesdropping is fruitless. Instead, the attacker can create a proxy that will accept HTTPS connections from the victim, decrypt the information, and then form an HTTPS connection with the original destination. To create the phony HTTPS connection, the proxy must return a certificate that our attacker has the private key for. Our attacker could generate self-signed certificates, but the victim's browser won't trust anything not signed by a CA's root certificate in the browser's root certificate store. What if instead, the attacker uses a certificate signed by a trusted CA for a domain it owns?
+
+Imagine we're back to our job in the bank. A man walks in and asks to withdraw money from Jane Doe's account. When asked for identification, the man hands us a valid driver's license for Joe Smith. We would be rightfully fired if we allowed the transaction to continue. If a browser detects a mismatch between the certificate hostname and the connection hostname, it will show a warning that says something like "Your connection is not secure" and an option to show additional details. In Firefox, this error is called SSL_ERROR_BAD_CERT_DOMAIN.
+
+If there's one lesson I want you to remember from this article, it's: If you see these warnings, **do not disregard them**! They signal that the site is either configured so erroneously that you shouldn't use it or that you're the potential victim of a MITM attack.
+
+### Final thoughts
+
+I've only scratched the surface of the PKI world in this article, but I hope that I've given you a map that you can use to guide your further explorations. Cryptography and PKI are fractal-like in their beauty and complexity. The further you dive in, the more there is to discover.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/private-keys
+
+作者:[Alex Wood][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/awood
+[1]:https://opensource.com/article/18/5/cryptography-pki
+[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
+[3]:https://en.wikipedia.org/wiki/SHA-2
+[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
+[5]:https://www.imperialviolet.org/2014/09/26/pkcs1.html
+[6]:https://en.wikipedia.org/wiki/Key_signing_party
+[7]:https://en.wikipedia.org/wiki/Key_server_(cryptographic)
+[8]:https://en.wikipedia.org/wiki/Web_of_trust
+[9]:https://www.gnupg.org/gph/en/manual/x547.html
+[10]:https://blog.cryptographyengineering.com/2014/08/13/whats-matter-with-pgp/
+[11]:https://lists.torproject.org/pipermail/tor-talk/2013-September/030235.html
+[12]:https://en.wikipedia.org/wiki/Extended_Validation_Certificate
+[13]:https://en.wikipedia.org/wiki/Transport_Layer_Security
+[14]:https://www.youtube.com/watch?v=YEBfamv-_do
+[15]:https://www.mozilla.org/en-US/about/governance/policies/security-group/certs/policy/
+[16]:https://technet.microsoft.com/en-us/library/cc751157.aspx
+[17]:https://en.wikipedia.org/wiki/Hardware_security_module
+[18]:https://arstechnica.com/information-technology/2012/11/inside-symantecs-ssl-certificate-vault/
+[19]:https://cabforum.org/baseline-requirements-documents/
+[20]:http://opensource.com
+[21]:https://en.wikipedia.org/wiki/Man-in-the-middle_attack
+[22]:http://www.shortestpathfirst.net/2010/11/18/man-in-the-middle-mitm-attacks-explained-arp-poisoining/
diff --git a/sources/tech/20180726 4 cool apps for your terminal.md b/sources/tech/20180726 4 cool apps for your terminal.md
new file mode 100644
index 0000000000..b86d47be79
--- /dev/null
+++ b/sources/tech/20180726 4 cool apps for your terminal.md
@@ -0,0 +1,123 @@
+translating---geekpi
+
+4 cool apps for your terminal
+======
+
+
+
+Many Linux users think that working in a terminal is either too complex or boring, and try to escape it. Here is a fix, though — four great open source apps for your terminal. They’re fun and easy to use, and may even brighten up your life when you need to spend a time in the command line.
+
+### No More Secrets
+
+This is a simple command line tool that recreates the famous data decryption effect seen in the 1992 movie [Sneakers][1]. The project lets you compile the nms command, which works with piped data and prints the output in the form of messed characters. Once it does so, you can press any key, and see the live “deciphering” of the output with a cool Hollywood-style effect.
+
+![][2]
+
+#### Installation instructions
+
+A fresh Fedora Workstation system already includes everything you need to build No More Secrets from source. Just enter the following command in your terminal:
+```
+git clone https://github.com/bartobri/no-more-secrets.git
+cd ./no-more-secrets
+make nms
+make sneakers ## Optional
+sudo make install
+
+```
+
+The sneakers command is a little bonus for those who remember the original movie, but the main hero is nms. Use a pipe to redirect any Linux command to nms, like this:
+```
+systemctl list-units --type=target | nms
+
+```
+
+Once the text stops flickering, hit any key to “decrypt” it. The systemctl command above is only an example — you can replace it with virtually anything!
+
+### Lolcat
+
+Here’s a command that colorizes the terminal output with rainbows. Nothing can be more useless, but boy, it looks awesome!
+
+![][3]
+
+#### Installation instructions
+
+Lolcat is a Ruby package available from the official Ruby Gems hosting. So, you’ll need the gem client first:
+```
+sudo dnf install -y rubygems
+
+```
+
+And then install Lolcat itself:
+```
+gem install lolcat
+
+```
+
+Again, use the lolcat command in for piping any other command and enjoy rainbows (and unicorns!) right in your Fedora terminal.
+
+### Chafa
+
+![][4]
+
+Chafa is a [command line image converter and viewer][5]. It helps you enjoy your images without leaving your lovely terminal. The syntax is very straightforward:
+```
+chafa /path/to/your/image
+
+```
+
+You can throw almost any sort of image to Chafa, including JPG, PNG, TIFF, BMP or virtually anything that ImageMagick supports — this is the engine that Chafa uses for parsing input files. The coolest part is that Chafa can also show very smooth and fluid GIF animations right inside your terminal!
+
+#### Installation instructions
+
+Chafa isn’t packaged for Fedora yet, but it’s quite easy to build it from source. First, get the necessary build dependencies:
+```
+sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
+
+```
+
+Next, clone the code or download a snapshot from the project’s Github page and cd to the Chafa directory. After that, you’re ready to go:
+```
+git clone https://github.com/hpjansson/chafa
+./autogen.sh
+make
+sudo make install
+
+```
+
+Large images can take a while to process at the first run, but Chafa caches everything you load with it. Next runs will be nearly instantaneous.
+
+### Browsh
+
+Browsh is a fully-fledged web browser for the terminal. It’s more powerful than Lynx and certainly more eye-catching. Browsh launches the Firefox web browser in a headless mode (so that you can’t see it) and connects it with your terminal with the help of special web extension. Therefore, Browsh renders all rich media content just like Firefox, only in a bit pixelated style.
+
+![][6]
+
+#### Installation instructions
+
+The project provides packages for various Linux distributions, including Fedora. Install it this way:
+```
+sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
+
+```
+
+After that, launch the browsh command and give it a couple of seconds to load up. Press Ctrl+L to switch focus to the address bar and start browsing the Web like you never did before! Use Ctrl+Q to get back to your terminal.
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-apps-for-your-terminal/
+
+作者:[atolstoy][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org/author/atolstoy/
+[1]:https://www.imdb.com/title/tt0105435/
+[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/nms.gif
+[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/lolcat.png
+[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/sir.gif
+[5]:https://hpjansson.org/chafa/
+[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/browsh.png
diff --git a/sources/tech/20180726 The evolution of package managers.md b/sources/tech/20180726 The evolution of package managers.md
new file mode 100644
index 0000000000..62859d8110
--- /dev/null
+++ b/sources/tech/20180726 The evolution of package managers.md
@@ -0,0 +1,601 @@
+Translating by DavidChenLiang
+
+The evolution of package managers
+======
+
+
+
+Every computerized device uses some form of software to perform its intended tasks. In the early days of software, products were stringently tested for bugs and other defects. For the last decade or so, software has been released via the internet with the intent that any bugs would be fixed by applying new versions of the software. In some cases, each individual application has its own updater. In others, it is left up to the user to figure out how to obtain and upgrade software.
+
+Linux adopted early the practice of maintaining a centralized location where users could find and install software. In this article, I'll discuss the history of software installation on Linux and how modern operating systems are kept up to date against the never-ending torrent of [CVEs][1].
+
+### How was software on Linux installed before package managers?
+
+Historically, software was provided either via FTP or mailing lists (eventually this distribution would grow to include basic websites). Only a few small files contained the instructions to create a binary (normally in a tarfile). You would untar the files, read the readme, and as long as you had GCC or some other form of C compiler, you would then typically run a `./configure` script with some list of attributes, such as pathing to library files, location to create new binaries, etc. In addition, the `configure` process would check your system for application dependencies. If any major requirements were missing, the configure script would exit and you could not proceed with the installation until all the dependencies were met. If the configure script completed successfully, a `Makefile` would be created.
+
+Once a `Makefile` existed, you would then proceed to run the `make` command (this command is provided by whichever compiler you were using). The `make` command has a number of options called make flags, which help optimize the resulting binaries for your system. In the earlier days of computing, this was very important because hardware struggled to keep up with modern software demands. Today, compilation options can be much more generic as most hardware is more than adequate for modern software.
+
+Finally, after the `make` process had been completed, you would need to run `make install` (or `sudo make install`) in order to actually install the software. As you can imagine, doing this for every single piece of software was time-consuming and tedious—not to mention the fact that updating software was a complicated and potentially very involved process.
+
+### What is a package?
+
+Packages were invented to combat this complexity. Packages collect multiple data files together into a single archive file for easier portability and storage, or simply compress files to reduce storage space. The binaries included in a package are precompiled with according to the sane defaults the developer chosen. Packages also contain metadata, such as the software's name, a description of its purpose, a version number, and a list of dependencies necessary for the software to run properly.
+
+Several flavors of Linux have created their own package formats. Some of the most commonly used package formats include:
+
+ * .deb: This package format is used by Debian, Ubuntu, Linux Mint, and several other derivatives. It was the first package type to be created.
+ * .rpm: This package format was originally called Red Hat Package Manager. It is used by Red Hat, Fedora, SUSE, and several other smaller distributions.
+ * .tar.xz: While it is just a compressed tarball, this is the format that Arch Linux uses.
+
+
+
+While packages themselves don't manage dependencies directly, they represented a huge step forward in Linux software management.
+
+### What is a software repository?
+
+A few years ago, before the proliferation of smartphones, the idea of a software repository was difficult for many users to grasp if they were not involved in the Linux ecosystem. To this day, most Windows users still seem to be hardwired to open a web browser to search for and install new software. However, those with smartphones have gotten used to the idea of a software "store." The way smartphone users obtain software and the way package managers work are not dissimilar. While there have been several attempts at making an attractive UI for software repositories, the vast majority of Linux users still use the command line to install packages. Software repositories are a centralized listing of all of the available software for any repository the system has been configured to use. Below are some examples of searching a repository for a specifc package (note that these have been truncated for brevity):
+
+Arch Linux with aurman
+```
+user@arch ~ $ aurman -Ss kate
+
+extra/kate 18.04.2-2 (kde-applications kdebase)
+ Advanced Text Editor
+aur/kate-root 18.04.0-1 (11, 1.139399)
+ Advanced Text Editor, patched to be able to run as root
+aur/kate-git r15288.15d26a7-1 (1, 1e-06)
+ An advanced editor component which is used in numerous KDE applications requiring a text editing component
+```
+
+CentOS 7 using YUM
+```
+[user@centos ~]$ yum search kate
+
+kate-devel.x86_64 : Development files for kate
+kate-libs.x86_64 : Runtime files for kate
+kate-part.x86_64 : Kate kpart plugin
+```
+
+Ubuntu using APT
+```
+user@ubuntu ~ $ apt search kate
+Sorting... Done
+Full Text Search... Done
+
+kate/xenial 4:15.12.3-0ubuntu2 amd64
+ powerful text editor
+
+kate-data/xenial,xenial 4:4.14.3-0ubuntu4 all
+ shared data files for Kate text editor
+
+kate-dbg/xenial 4:15.12.3-0ubuntu2 amd64
+ debugging symbols for Kate
+
+kate5-data/xenial,xenial 4:15.12.3-0ubuntu2 all
+ shared data files for Kate text editor
+```
+
+### What are the most prominent package managers?
+
+As suggested in the above output, package managers are used to interact with software repositories. The following is a brief overview of some of the most prominent package managers.
+
+#### RPM-based package managers
+
+Updating RPM-based systems, particularly those based on Red Hat technologies, has a very interesting and detailed history. In fact, the current versions of [yum][2] (for enterprise distributions) and [DNF][3] (for community) combine several open source projects to provide their current functionality.
+
+Initially, Red Hat used a package manager called [RPM][4] (Red Hat Package Manager), which is still in use today. However, its primary use is to install RPMs, which you have locally, not to search software repositories. The package manager named `up2date` was created to inform users of updates to packages and enable them to search remote repositories and easily install dependencies. While it served its purpose, some community members felt that `up2date` had some significant shortcomings.
+
+The current incantation of yum came from several different community efforts. Yellowdog Updater (YUP) was developed in 1999-2001 by folks at Terra Soft Solutions as a back-end engine for a graphical installer of [Yellow Dog Linux][5]. Duke University liked the idea of YUP and decided to improve upon it. They created [Yellowdog Updater, Modified (yum)][6] which was eventually adapted to help manage the university's Red Hat Linux systems. Yum grew in popularity, and by 2005 it was estimated to be used by more than half of the Linux market. Today, almost every distribution of Linux that uses RPMs uses yum for package management (with a few notable exceptions).
+
+#### Working with yum
+
+In order for yum to download and install packages out of an internet repository, files must be located in `/etc/yum.repos.d/` and they must have the extension `.repo`. Here is an example repo file:
+```
+[local_base]
+name=Base CentOS (local)
+baseurl=http://7-repo.apps.home.local/yum-repo/7/
+enabled=1
+gpgcheck=0
+```
+
+This is for one of my local repositories, which explains why the GPG check is off. If this check was on, each package would need to be signed with a cryptographic key and a corresponding key would need to be imported into the system receiving the updates. Because I maintain this repository myself, I trust the packages and do not bother signing them.
+
+Once a repository file is in place, you can start installing packages from the remote repository. The most basic command is `yum update`, which will update every package currently installed. This does not require a specific step to refresh the information about repositories; this is done automatically. A sample of the command is shown below:
+```
+[user@centos ~]$ sudo yum update
+Loaded plugins: fastestmirror, product-id, search-disabled-repos, subscription-manager
+local_base | 3.6 kB 00:00:00
+local_epel | 2.9 kB 00:00:00
+local_rpm_forge | 1.9 kB 00:00:00
+local_updates | 3.4 kB 00:00:00
+spideroak-one-stable | 2.9 kB 00:00:00
+zfs | 2.9 kB 00:00:00
+(1/6): local_base/group_gz | 166 kB 00:00:00
+(2/6): local_updates/primary_db | 2.7 MB 00:00:00
+(3/6): local_base/primary_db | 5.9 MB 00:00:00
+(4/6): spideroak-one-stable/primary_db | 12 kB 00:00:00
+(5/6): local_epel/primary_db | 6.3 MB 00:00:00
+(6/6): zfs/x86_64/primary_db | 78 kB 00:00:00
+local_rpm_forge/primary_db | 125 kB 00:00:00
+Determining fastest mirrors
+Resolving Dependencies
+--> Running transaction check
+```
+
+If you are sure you want yum to execute any command without stopping for input, you can put the `-y` flag in the command, such as `yum update -y`.
+
+Installing a new package is just as easy. First, search for the name of the package with `yum search`:
+```
+[user@centos ~]$ yum search kate
+
+artwiz-aleczapka-kates-fonts.noarch : Kates font in Artwiz family
+ghc-highlighting-kate-devel.x86_64 : Haskell highlighting-kate library development files
+kate-devel.i686 : Development files for kate
+kate-devel.x86_64 : Development files for kate
+kate-libs.i686 : Runtime files for kate
+kate-libs.x86_64 : Runtime files for kate
+kate-part.i686 : Kate kpart plugin
+```
+
+Once you have the name of the package, you can simply install the package with `sudo yum install kate-devel -y`. If you installed a package you no longer need, you can remove it with `sudo yum remove kate-devel -y`. By default, yum will remove the package plus its dependencies.
+
+There may be times when you do not know the name of the package, but you know the name of the utility. For example, suppose you are looking for the utility `updatedb`, which creates/updates the database used by the `locate` command. Attempting to install `updatedb` returns the following results:
+```
+[user@centos ~]$ sudo yum install updatedb
+Loaded plugins: fastestmirror, langpacks
+Loading mirror speeds from cached hostfile
+No package updatedb available.
+Error: Nothing to do
+```
+
+You can find out what package the utility comes from by running:
+```
+[user@centos ~]$ yum whatprovides *updatedb
+Loaded plugins: fastestmirror, langpacks
+Loading mirror speeds from cached hostfile
+
+bacula-director-5.2.13-23.1.el7.x86_64 : Bacula Director files
+Repo : local_base
+Matched from:
+Filename : /usr/share/doc/bacula-director-5.2.13/updatedb
+
+mlocate-0.26-8.el7.x86_64 : An utility for finding files by name
+Repo : local_base
+Matched from:
+Filename : /usr/bin/updatedb
+```
+
+The reason I have used an asterisk `*` in front of the command is because `yum whatprovides` uses the path to the file in order to make a match. Since I was not sure where the file was located, I used an asterisk to indicate any path.
+
+There are, of course, many more options available to yum. I encourage you to view the man page for yum for additional options.
+
+[Dandified Yum (DNF)][7] is a newer iteration on yum. Introduced in Fedora 18, it has not yet been adopted in the enterprise distributions, and as such is predominantly used in Fedora (and derivatives). Its usage is almost exactly the same as that of yum, but it was built to address poor performance, undocumented APIs, slow/broken dependency resolution, and occasional high memory usage. DNF is meant as a drop-in replacement for yum, and therefore I won't repeat the commands—wherever you would use `yum`, simply substitute `dnf`.
+
+#### Working with Zypper
+
+[Zypper][8] is another package manager meant to help manage RPMs. This package manager is most commonly associated with [SUSE][9] (and [openSUSE][10]) but has also seen adoption by [MeeGo][11], [Sailfish OS][12], and [Tizen][13]. It was originally introduced in 2006 and has been iterated upon ever since. There is not a whole lot to say other than Zypper is used as the back end for the system administration tool [YaST][14] and some users find it to be faster than yum.
+
+Zypper's usage is very similar to that of yum. To search for, update, install or remove a package, simply use the following:
+```
+zypper search kate
+zypper update
+zypper install kate
+zypper remove kate
+```
+Some major differences come into play in how repositories are added to the system with `zypper`. Unlike the package managers discussed above, `zypper` adds repositories using the package manager itself. The most common way is via a URL, but `zypper` also supports importing from repo files.
+```
+suse:~ # zypper addrepo http://download.videolan.org/pub/vlc/SuSE/15.0 vlc
+Adding repository 'vlc' [done]
+Repository 'vlc' successfully added
+
+Enabled : Yes
+Autorefresh : No
+GPG Check : Yes
+URI : http://download.videolan.org/pub/vlc/SuSE/15.0
+Priority : 99
+```
+
+You remove repositories in a similar manner:
+```
+suse:~ # zypper removerepo vlc
+Removing repository 'vlc' ...................................[done]
+Repository 'vlc' has been removed.
+```
+
+Use the `zypper repos` command to see what the status of repositories are on your system:
+```
+suse:~ # zypper repos
+Repository priorities are without effect. All enabled repositories share the same priority.
+
+# | Alias | Name | Enabled | GPG Check | Refresh
+---|---------------------------|-----------------------------------------|---------|-----------|--------
+ 1 | repo-debug | openSUSE-Leap-15.0-Debug | No | ---- | ----
+ 2 | repo-debug-non-oss | openSUSE-Leap-15.0-Debug-Non-Oss | No | ---- | ----
+ 3 | repo-debug-update | openSUSE-Leap-15.0-Update-Debug | No | ---- | ----
+ 4 | repo-debug-update-non-oss | openSUSE-Leap-15.0-Update-Debug-Non-Oss | No | ---- | ----
+ 5 | repo-non-oss | openSUSE-Leap-15.0-Non-Oss | Yes | ( p) Yes | Yes
+ 6 | repo-oss | openSUSE-Leap-15.0-Oss | Yes | ( p) Yes | Yes
+```
+
+`zypper` even has a similar ability to determine what package name contains files or binaries. Unlike YUM, it uses a hyphen in the command (although this method of searching is deprecated):
+```
+localhost:~ # zypper what-provides kate
+Command 'what-provides' is replaced by 'search --provides --match-exact'.
+See 'help search' for all available options.
+Loading repository data...
+Reading installed packages...
+
+S | Name | Summary | Type
+---|------|----------------------|------------
+i+ | Kate | Advanced Text Editor | application
+i | kate | Advanced Text Editor | package
+```
+
+As with YUM and DNF, Zypper has a much richer feature set than covered here. Please consult with the official documentation for more in-depth information.
+
+#### Debian-based package managers
+
+One of the oldest Linux distributions currently maintained, Debian's system is very similar to RPM-based systems. They use `.deb` packages, which can be managed by a tool called dpkg. dpkg is very similar to rpm in that it was designed to manage packages that are available locally. It does no dependency resolution (although it does dependency checking), and has no reliable way to interact with remote repositories. In order to improve the user experience and ease of use, the Debian project commissioned a project called Deity. This codename was eventually abandoned and changed to [Advanced Package Tool (APT)][15].
+
+Released as test builds in 1998 (before making an appearance in Debian 2.1 in 1999), many users consider APT one of the defining features of Debian-based systems. It makes use of repositories in a similar fashion to RPM-based systems, but instead of individual `.repo` files that `yum` uses, `apt` has historically used `/etc/apt/sources.list` to manage repositories. More recently, it also ingests files from `/etc/apt/sources.d/`. Following the examples in the RPM-based package managers, to accomplish the same thing on Debian-based distributions you have a few options. You can edit/create the files manually in the aforementioned locations from the terminal, or in some cases, you can use a UI front end (such as `Software & Updates` provided by Ubuntu et al.). To provide the same treatment to all distributions, I will cover only the command-line options. To add a repository without directly editing a file, you can do something like this:
+```
+user@ubuntu:~$ sudo apt-add-repository "deb http://APT.spideroak.com/ubuntu-spideroak-hardy/ release restricted"
+
+```
+
+This will create a `spideroakone.list` file in `/etc/apt/sources.list.d`. Obviously, these lines change depending on the repository being added. If you are adding a Personal Package Archive (PPA), you can do this:
+```
+user@ubuntu:~$ sudo apt-add-repository ppa:gnome-desktop
+
+```
+
+NOTE: Debian does not support PPAs natively.
+
+After a repository has been added, Debian-based systems need to be made aware that there is a new location to search for packages. This is done via the `apt-get update` command:
+```
+user@ubuntu:~$ sudo apt-get update
+Get:1 http://security.ubuntu.com/ubuntu xenial-security InRelease [107 kB]
+Hit:2 http://APT.spideroak.com/ubuntu-spideroak-hardy release InRelease
+Hit:3 http://ca.archive.ubuntu.com/ubuntu xenial InRelease
+Get:4 http://ca.archive.ubuntu.com/ubuntu xenial-updates InRelease [109 kB]
+Get:5 http://security.ubuntu.com/ubuntu xenial-security/main amd64 Packages [517 kB]
+Get:6 http://security.ubuntu.com/ubuntu xenial-security/main i386 Packages [455 kB]
+Get:7 http://security.ubuntu.com/ubuntu xenial-security/main Translation-en [221 kB]
+...
+
+Fetched 6,399 kB in 3s (2,017 kB/s)
+Reading package lists... Done
+```
+
+Now that the new repository is added and updated, you can search for a package using the `apt-cache` command:
+```
+user@ubuntu:~$ apt-cache search kate
+aterm-ml - Afterstep XVT - a VT102 emulator for the X window system
+frescobaldi - Qt4 LilyPond sheet music editor
+gitit - Wiki engine backed by a git or darcs filestore
+jedit - Plugin-based editor for programmers
+kate - powerful text editor
+kate-data - shared data files for Kate text editor
+kate-dbg - debugging symbols for Kate
+katepart - embeddable text editor component
+```
+
+To install `kate`, simply run the corresponding install command:
+```
+user@ubuntu:~$ sudo apt-get install kate
+
+```
+
+To remove a package, use `apt-get remove`:
+```
+user@ubuntu:~$ sudo apt-get remove kate
+
+```
+
+When it comes to package discovery, APT does not provide any functionality that is similar to `yum whatprovides`. There are a few ways to get this information if you are trying to find where a specific file on disk has come from.
+
+Using dpkg
+```
+user@ubuntu:~$ dpkg -S /bin/ls
+coreutils: /bin/ls
+```
+
+Using apt-file
+```
+user@ubuntu:~$ sudo apt-get install apt-file -y
+
+user@ubuntu:~$ sudo apt-file update
+
+user@ubuntu:~$ apt-file search kate
+```
+
+The problem with `apt-file search` is that it, unlike `yum whatprovides`, it is overly verbose unless you know the exact path, and it automatically adds a wildcard search so that you end up with results for anything with the word kate in it:
+```
+kate: /usr/bin/kate
+kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebacktracebrowserplugin.so
+kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebuildplugin.so
+kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katecloseexceptplugin.so
+kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katectagsplugin.so
+```
+
+Most of these examples have used `apt-get`. Note that most of the current tutorials for Ubuntu specifically have taken to simply using `apt`. The single `apt` command was designed to implement only the most commonly used commands in the APT arsenal. Since functionality is split between `apt-get`, `apt-cache`, and other commands, `apt` looks to unify these into a single command. It also adds some niceties such as colorization, progress bars, and other odds and ends. Most of the commands noted above can be replaced with `apt`, but not all Debian-based distributions currently receiving security patches support using `apt` by default, so you may need to install additional packages.
+
+#### Arch-based package managers
+
+[Arch Linux][16] uses a package manager called [pacman][17]. Unlike `.deb` or `.rpm` files, pacman uses a more traditional tarball with the LZMA2 compression (`.tar.xz`). This enables Arch Linux packages to be much smaller than other forms of compressed archives (such as gzip). Initially released in 2002, pacman has been steadily iterated and improved. One of the major benefits of pacman is that it supports the [Arch Build System][18], a system for building packages from source. The build system ingests a file called a PKGBUILD, which contains metadata (such as version numbers, revisions, dependencies, etc.) as well as a shell script with the required flags for compiling a package conforming to the Arch Linux requirements. The resulting binaries are then packaged into the aforementioned `.tar.xz` file for consumption by pacman.
+
+This system led to the creation of the [Arch User Repository][19] (AUR) which is a community-driven repository containing PKGBUILD files and supporting patches or scripts. This allows for a virtually endless amount of software to be available in Arch. The obvious advantage of this system is that if a user (or maintainer) wishes to make software available to the public, they do not have to go through official channels to get it accepted in the main repositories. The downside is that it relies on community curation similar to [Docker Hub][20], Canonical's Snap packages, or other similar mechanisms. There are numerous AUR-specific package managers that can be used to download, compile, and install from the PKGBUILD files in the AUR (we will look at this later).
+
+#### Working with pacman and official repositories
+
+Arch's main package manager, pacman, uses flags instead of command words like `yum` and `apt`. For example, to search for a package, you would use `pacman -Ss`. As with most commands on Linux, you can find both a `manpage` and inline help. Most of the commands for `pacman `use the sync (-S) flag. For example:
+```
+user@arch ~ $ pacman -Ss kate
+
+extra/kate 18.04.2-2 (kde-applications kdebase)
+ Advanced Text Editor
+extra/libkate 0.4.1-6 [installed]
+ A karaoke and text codec for embedding in ogg
+extra/libtiger 0.3.4-5 [installed]
+ A rendering library for Kate streams using Pango and Cairo
+extra/ttf-cheapskate 2.0-12
+ TTFonts collection from dustimo.com
+community/haskell-cheapskate 0.1.1-100
+ Experimental markdown processor.
+```
+
+Arch also uses repositories similar to other package managers. In the output above, search results are prefixed with the repository they are found in (`extra/` and `community/` in this case). Similar to both Red Hat and Debian-based systems, Arch relies on the user to add the repository information into a specific file. The location for these repositories is `/etc/pacman.conf`. The example below is fairly close to a stock system. I have enabled the `[multilib]` repository for Steam support:
+```
+[options]
+Architecture = auto
+
+Color
+CheckSpace
+
+SigLevel = Required DatabaseOptional
+LocalFileSigLevel = Optional
+
+[core]
+Include = /etc/pacman.d/mirrorlist
+
+[extra]
+Include = /etc/pacman.d/mirrorlist
+
+[community]
+Include = /etc/pacman.d/mirrorlist
+
+[multilib]
+Include = /etc/pacman.d/mirrorlist
+```
+
+It is possible to specify a specific URL in `pacman.conf`. This functionality can be used to make sure all packages come from a specific point in time. If, for example, a package has a bug that affects you severely and it has several dependencies, you can roll back to a specific point in time by adding a specific URL into your `pacman.conf` and then running the commands to downgrade the system:
+```
+[core]
+Server=https://archive.archlinux.org/repos/2017/12/22/$repo/os/$arch
+```
+
+Like Debian-based systems, Arch does not update its local repository information until you tell it to do so. You can refresh the package database by issuing the following command:
+```
+user@arch ~ $ sudo pacman -Sy
+
+:: Synchronizing package databases...
+ core 130.2 KiB 851K/s 00:00 [##########################################################] 100%
+ extra 1645.3 KiB 2.69M/s 00:01 [##########################################################] 100%
+ community 4.5 MiB 2.27M/s 00:02 [##########################################################] 100%
+ multilib is up to date
+```
+
+As you can see in the above output, `pacman` thinks that the multilib package database is up to date. You can force a refresh if you think this is incorrect by running `pacman -Syy`. If you want to update your entire system (excluding packages installed from the AUR), you can run `pacman -Syu`:
+```
+user@arch ~ $ sudo pacman -Syu
+
+:: Synchronizing package databases...
+ core is up to date
+ extra is up to date
+ community is up to date
+ multilib is up to date
+:: Starting full system upgrade...
+resolving dependencies...
+looking for conflicting packages...
+
+Packages (45) ceph-13.2.0-2 ceph-libs-13.2.0-2 debootstrap-1.0.105-1 guile-2.2.4-1 harfbuzz-1.8.2-1 harfbuzz-icu-1.8.2-1 haskell-aeson-1.3.1.1-20
+ haskell-attoparsec-0.13.2.2-24 haskell-tagged-0.8.6-1 imagemagick-7.0.8.4-1 lib32-harfbuzz-1.8.2-1 lib32-libgusb-0.3.0-1 lib32-systemd-239.0-1
+ libgit2-1:0.27.2-1 libinput-1.11.2-1 libmagick-7.0.8.4-1 libmagick6-6.9.10.4-1 libopenshot-0.2.0-1 libopenshot-audio-0.1.6-1 libosinfo-1.2.0-1
+ libxfce4util-4.13.2-1 minetest-0.4.17.1-1 minetest-common-0.4.17.1-1 mlt-6.10.0-1 mlt-python-bindings-6.10.0-1 ndctl-61.1-1 netctl-1.17-1
+ nodejs-10.6.0-1
+
+Total Download Size: 2.66 MiB
+Total Installed Size: 879.15 MiB
+Net Upgrade Size: -365.27 MiB
+
+:: Proceed with installation? [Y/n]
+```
+
+In the scenario mentioned earlier regarding downgrading a system, you can force a downgrade by issuing `pacman -Syyuu`. It is important to note that this should not be undertaken lightly. This should not cause a problem in most cases; however, there is a chance that downgrading of a package or several packages will cause a cascading failure and leave your system in an inconsistent state. USE WITH CAUTION!
+
+To install a package, simply use `pacman -S kate`:
+```
+user@arch ~ $ sudo pacman -S kate
+
+resolving dependencies...
+looking for conflicting packages...
+
+Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
+ kate-18.04.2-2
+
+Total Download Size: 10.94 MiB
+Total Installed Size: 38.91 MiB
+
+:: Proceed with installation? [Y/n]
+```
+
+To remove a package, you can run `pacman -R kate`. This removes only the package and not its dependencies:
+```
+user@arch ~ $ sudo pacman -S kate
+
+checking dependencies...
+
+Packages (1) kate-18.04.2-2
+
+Total Removed Size: 20.30 MiB
+
+:: Do you want to remove these packages? [Y/n]
+```
+
+If you want to remove the dependencies that are not required by other packages, you can run `pacman -Rs:`
+```
+user@arch ~ $ sudo pacman -Rs kate
+
+checking dependencies...
+
+Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
+ kate-18.04.2-2
+
+Total Removed Size: 38.91 MiB
+
+:: Do you want to remove these packages? [Y/n]
+```
+
+Pacman, in my opinion, offers the most succinct way of searching for the name of a package for a given utility. As shown above, `yum` and `apt` both rely on pathing in order to find useful results. Pacman makes some intelligent guesses as to which package you are most likely looking for:
+```
+user@arch ~ $ sudo pacman -Fs updatedb
+core/mlocate 0.26.git.20170220-1
+ usr/bin/updatedb
+
+user@arch ~ $ sudo pacman -Fs kate
+extra/kate 18.04.2-2
+ usr/bin/kate
+```
+
+#### Working with the AUR
+
+There are several popular AUR package manager helpers. Of these, `yaourt` and `pacaur` are fairly prolific. However, both projects are listed as discontinued or problematic on the [Arch Wiki][21]. For that reason, I will discuss `aurman`. It works almost exactly like `pacman,` except it searches the AUR and includes some helpful, albeit potentially dangerous, options. Installing a package from the AUR will initiate use of the package maintainer's build scripts. You will be prompted several times for permission to continue (I have truncated the output for brevity):
+```
+aurman -S telegram-desktop-bin
+~~ initializing aurman...
+~~ the following packages are neither in known repos nor in the aur
+...
+~~ calculating solutions...
+
+:: The following 1 package(s) are getting updated:
+ aur/telegram-desktop-bin 1.3.0-1 -> 1.3.9-1
+
+?? Do you want to continue? Y/n: Y
+
+~~ looking for new pkgbuilds and fetching them...
+Cloning into 'telegram-desktop-bin'...
+
+remote: Counting objects: 301, done.
+remote: Compressing objects: 100% (152/152), done.
+remote: Total 301 (delta 161), reused 286 (delta 147)
+Receiving objects: 100% (301/301), 76.17 KiB | 639.00 KiB/s, done.
+Resolving deltas: 100% (161/161), done.
+?? Do you want to see the changes of telegram-desktop-bin? N/y: N
+
+[sudo] password for user:
+
+...
+==> Leaving fakeroot environment.
+==> Finished making: telegram-desktop-bin 1.3.9-1 (Thu 05 Jul 2018 11:22:02 AM EDT)
+==> Cleaning up...
+loading packages...
+resolving dependencies...
+looking for conflicting packages...
+
+Packages (1) telegram-desktop-bin-1.3.9-1
+
+Total Installed Size: 88.81 MiB
+Net Upgrade Size: 5.33 MiB
+
+:: Proceed with installation? [Y/n]
+```
+
+Sometimes you will be prompted for more input, depending on the complexity of the package you are installing. To avoid this tedium, `aurman` allows you to pass both the `--noconfirm` and `--noedit` options. This is equivalent to saying "accept all of the defaults, and trust that the package maintainers scripts will not be malicious." **USE THIS OPTION WITH EXTREME CAUTION!** While these options are unlikely to break your system on their own, you should never blindly accept someone else's scripts.
+
+### Conclusion
+
+This article, of course, only scratches the surface of what package managers can do. There are also many other package managers available that I could not cover in this space. Some distributions, such as Ubuntu or Elementary OS, have gone to great lengths to provide a graphical approach to package management.
+
+If you are interested in some of the more advanced functions of package managers, please post your questions or comments below and I would be glad to write a follow-up article.
+
+### Appendix
+```
+# search for packages
+yum search
+dnf search
+zypper search
+apt-cache search
+apt search
+pacman -Ss
+
+# install packages
+yum install
+dnf install
+zypper install
+apt-get install
+apt install
+pacman -Ss
+
+# update package database, not required by yum, dnf and zypper
+apt-get update
+apt update
+pacman -Sy
+
+# update all system packages
+yum update
+dnf update
+zypper update
+apt-get upgrade
+apt upgrade
+pacman -Su
+
+# remove an installed package
+yum remove
+dnf remove
+apt-get remove
+apt remove
+pacman -R
+pacman -Rs
+
+# search for the package name containing specific file or folder
+yum whatprovides *
+dnf whatprovides *
+zypper what-provides
+zypper search --provides
+apt-file search
+pacman -Sf
+```
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/evolution-package-managers
+
+作者:[Steve Ovens][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/stratusss
+[1]:https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures
+[2]:https://en.wikipedia.org/wiki/Yum_(software)
+[3]:https://fedoraproject.org/wiki/DNF
+[4]:https://en.wikipedia.org/wiki/Rpm_(software)
+[5]:https://en.wikipedia.org/wiki/Yellow_Dog_Linux
+[6]:https://searchdatacenter.techtarget.com/definition/Yellowdog-Updater-Modified-YUM
+[7]:https://en.wikipedia.org/wiki/DNF_(software)
+[8]:https://en.opensuse.org/Portal:Zypper
+[9]:https://www.suse.com/
+[10]:https://www.opensuse.org/
+[11]:https://en.wikipedia.org/wiki/MeeGo
+[12]:https://sailfishos.org/
+[13]:https://www.tizen.org/
+[14]:https://en.wikipedia.org/wiki/YaST
+[15]:https://en.wikipedia.org/wiki/APT_(Debian)
+[16]:https://www.archlinux.org/
+[17]:https://wiki.archlinux.org/index.php/pacman
+[18]:https://wiki.archlinux.org/index.php/Arch_Build_System
+[19]:https://aur.archlinux.org/
+[20]:https://hub.docker.com/
+[21]:https://wiki.archlinux.org/index.php/AUR_helpers#Discontinued_or_problematic
diff --git a/sources/tech/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md b/sources/tech/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md
new file mode 100644
index 0000000000..c4372724f7
--- /dev/null
+++ b/sources/tech/20180727 4 Ways to Customize Xfce and Give it a Modern Look.md
@@ -0,0 +1,145 @@
+4 Ways to Customize Xfce and Give it a Modern Look
+======
+**Brief: Xfce is a great lightweight desktop environment with one drawback. It looks sort of old. But you don’t have to stick with the default looks. Let’s see various ways you can customize Xfce to give it a modern and beautiful look.**
+
+![Customize Xfce desktop envirnment][1]
+
+To start with, Xfce is one of the most [popular desktop environments][2]. Being a lightweight DE, you can run Xfce on very low resource and it still works great. This is one of the reasons why many [lightweight Linux distributions][3] use Xfce by default.
+
+Some people prefer it even on a high-end device stating its simplicity, easy of use and non-resource hungry nature as the main reasons.
+
+[Xfce][4] is in itself minimal and provides just what you need. The one thing that bothers is its look and feel which feel old. However, you can easily customize Xfce to look modern and beautiful without reaching the limit where a Unity/GNOME session eats up system resources.
+
+### 4 ways to Customize Xfce desktop
+
+Let’s see some of the ways by which we can improve the look and feel of your Xfce desktop environment.
+
+The default Xfce desktop environment looks something like this :
+
+![Xfce default screen][5]
+
+As you can see, the default Xfce desktop is kinda boring. We will use some themes, icon packs and change the default dock to make it look fresh and a bit revealing.
+
+#### 1. Change themes in Xfce
+
+The first thing we will do is pick up a theme from [xfce-look.org][6]. My favorite Xfce theme is [XFCE-D-PRO][7].
+
+You can download the theme from [here][8] and extract it somewhere.
+
+You can copy this extracted file to **.theme** folder in your home directory. If the folder is not present by default, you can create one and the same goes for icons which needs a **.icons** folder in the home directory.
+
+Open **Settings > Appearance > Style** to select the theme, log out and login to see the change. Adwaita-dark from default is also a nice one.
+
+![Appearance Xfce][9]
+
+You can use any [good GTK theme][10] on Xfce.
+
+#### 2. Change icons in Xfce
+
+Xfce-look.org also provides icon themes which you can download, extract and put it in your home directory under **.icons** directory. Once you have added the icon theme in the .icons directory, go to **Settings > Appearance > Icons** to select that icon theme.
+
+![Moka icon theme][11]
+
+I have installed [Moka icon set][12] that looks awesome.
+
+![Moka theme][13]
+
+You can also refer to our list of [awesome icon themes][14].
+
+##### **Optional: Installing themes through Synaptic**
+
+If you want to avoid the manual search and copying of the files, install Synaptic Manager in your system. You can look for some best themes over web and icon sets, and using synaptic manager you can search and install it.
+```
+sudo apt-get install synaptic
+
+```
+
+**Searching and installing theme/icons through Synaptic**
+
+Open synaptic and click on **Search**. Enter your desired theme, and it will display the list of matching items. Mark all the additional required changes and click on **Apply**. This will download the theme and then install it.
+
+![Arc Theme][15]
+
+Once done, you can open the **Appearance** option to select the desired theme.
+
+In my opinion, this is not the best way to install themes in Xfce.
+
+#### 3. Change wallpapers in Xfce
+
+Again, the default Xfce wallpaper is not bad at all. But you can change the wallpaper to something that matches with your icons and themes.
+
+To change wallpapers in Xfce, right click on the desktop and click on Desktop Settings. You can change the desktop background from your custom collection or the defaults one given.
+
+Right click on the desktop and click on **Desktop Settings**. Choose **Background** from the folder option, and choose any one of the default backgrounds or a custom one.
+
+![Changing desktop wallpapers][16]
+
+#### 4. Change the dock in Xfce
+
+The default dock is nice and pretty much does what it is for. But again, it looks a bit boring.
+
+![Docky][17]
+
+However, if you want your dock to be better and with a little more customization options, you can install another dock.
+
+Plank is one of the simplest and lightweight docks and is highly configurable.
+
+To install Plank use the command below:
+
+`sudo apt-get install plank`
+
+If Plank is not available in the default repository, you can install it from this PPA.
+```
+sudo add-apt-repository ppa:ricotz/docky
+sudo apt-get update
+sudo apt-get install plank
+
+```
+
+Before you use Plank, you should remove the default dock by right-clicking in it and under Panel Settings, clicking on delete.
+
+Once done, go to **Accessory > Plank** to launch Plank dock.
+
+![Plank][18]
+
+Plank picks up icons from the one you are using. So if you change the icon themes, you’ll see the change is reflected in the dock also.
+
+### Wrapping Up
+
+XFCE is a lightweight, fast and highly customizable. If you are limited on system resource, it serves good and you can easily customize it to look better. Here’s how my screen looks after applying these steps.
+
+![XFCE desktop][19]
+
+This is just with half an hour of effort. You can make it look much better with different themes/icons customization. Feel free to share your customized XFCE desktop screen in the comments and the combination of themes and icons you are using.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/customize-xfce/
+
+作者:[Ambarish Kumar][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/ambarish/
+[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/xfce-customization.jpeg
+[2]:https://itsfoss.com/best-linux-desktop-environments/
+[3]:https://itsfoss.com/lightweight-linux-beginners/
+[4]:https://xfce.org/
+[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/1-1-800x410.jpg
+[6]:http://xfce-look.org
+[7]:https://www.xfce-look.org/p/1207818/XFCE-D-PRO
+[8]:https://www.xfce-look.org/p/1207818/startdownload?file_id=1523730502&file_name=XFCE-D-PRO-1.6.tar.xz&file_type=application/x-xz&file_size=105328&url=https%3A%2F%2Fdl.opendesktop.org%2Fapi%2Ffiles%2Fdownloadfile%2Fid%2F1523730502%2Fs%2F6019b2b57a1452471eac6403ae1522da%2Ft%2F1529360682%2Fu%2F%2FXFCE-D-PRO-1.6.tar.xz
+[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/4.jpg
+[10]:https://itsfoss.com/best-gtk-themes/
+[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/6.jpg
+[12]:https://snwh.org/moka
+[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/11-800x547.jpg
+[14]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
+[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/5-800x531.jpg
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/7-800x546.jpg
+[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/8.jpg
+[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/9.jpg
+[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/10-800x447.jpg
diff --git a/sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md b/sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md
new file mode 100644
index 0000000000..9d4c7fedd7
--- /dev/null
+++ b/sources/tech/20180727 Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py.md
@@ -0,0 +1,221 @@
+Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py
+======
+**If you're looking for a quick way to download subtitles from OpenSubtitles.org from your Linux desktop or server, give[OpenSubtitlesDownload.py][1] a try. This neat Python tool can be used as a Nautilus, Nemo or Caja script, or from the command line.**
+
+
+
+The Python script **searches for subtitles on OpenSubtitles.org using the video hash sum to find exact matches** , and thus avoid out of sync subtitles. In case no match is found, it then tries to perform a search based on the video file name, although such subtitles may not always be in sync.
+
+OpenSubtitlesDownload.py has quite a few cool features, including **support for more than 60 languages,** and it can query both multiple subtitle languages and videos in the same time (so it **supports mass subtitle search and download** ).
+
+The **optional graphical user interface** (uses Zenity for Gnome and Kdialog for KDE) can display multiple subtitle matches and by digging into its settings you can enable the display of some extra information, like the subtitles download count, rating, language, and more.
+
+Other OpenSubtitlesDownload.py features include:
+
+ * Option to download subtitles automatically if only one is available, choose the one you want otherwise.
+ * Option to rename downloaded subtitles to match source video file. Possibility to append the language code to the file name (ex: movie_en.srt).
+
+
+
+The Python tool does not yet support downloading subtitles for movies within a directory recursively, but this is a planned feature.
+
+In case you encounter errors when downloading a large number of subtitles, you should be aware that OpenSubtitles has a daily subtitle download limit (it appears it was 200 subtitles downloads / day a while back, I'm not sure if it changed). For VIP users it's 1000 subtitles per day, but OpenSubtitlesDownload.py does not allow logging it to an OpenSubtitles account and thus, you can't take advantage of a VIP account while using this tool.
+
+### Installing and using OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script
+
+The instructions below explain how to install OpenSubtitlesDownload.py as a script for Caja, Nemo or Nautilus file managers. Thanks to this you'll be able to right click (context menu) one or multiple video files in your file manager, select `Scripts > OpenSubtitlesDownload.py` and the script will search for and download subtitles from OpenSubtitles.org for your video files.
+
+This is OpenSubtitlesDownload.py used as a Nautilus script:
+
+
+
+And as a Nemo script:
+
+
+
+To install OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script, see the instructions below.
+
+1\. Install the dependencies required by OpenSubtitlesDownload.py
+
+You'll need to install `gzip` , `wget` and `zenity` before using OpenSubtitlesDownload.py. The instructions below assume you already have Python (both Python 2 and 3 will do it), as well as `ps` and `grep` available.
+
+In Debian, Ubuntu, or Linux Mint, install `gzip` , `wget` and `zenity` using this command:
+```
+sudo apt install gzip wget zenity
+
+```
+
+2\. Now you can download the OpenSubtitlesDownload.py
+```
+wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
+
+```
+
+3\. Use the commands below to move the downloaded OpenSubtitlesDownload.py script to the file manager scripts folder and make it executable (use the commands for your current file manager - Nautilus, Nemo or Caja):
+
+ * Nautilus (default Gnome, Unity and Solus OS file manager):
+
+
+```
+mkdir -p ~/.local/share/nautilus/scripts
+mv OpenSubtitlesDownload.py ~/.local/share/nautilus/scripts/
+chmod u+x ~/.local/share/nautilus/scripts/OpenSubtitlesDownload.py
+
+```
+
+ * Nemo (default Cinnamon file manager):
+
+
+```
+mkdir -p ~/.local/share/nemo/scripts
+mv OpenSubtitlesDownload.py ~/.local/share/nemo/scripts/
+chmod u+x ~/.local/share/nemo/scripts/OpenSubtitlesDownload.py
+
+```
+
+ * Caja (default MATE file manager):
+
+
+```
+mkdir -p ~/.config/caja/scripts
+mv OpenSubtitlesDownload.py ~/.config/caja/scripts/
+chmod u+x ~/.config/caja/scripts/OpenSubtitlesDownload.py
+
+```
+
+4\. Configure OpenSubtitlesDownload.py
+
+Since it's running as a file manager script, without any arguments, you'll need to modify the script if you want to change some of its settings, like enabling the GUI, changing the subtitles language, and so on. These are optional of course, and you can use it directly to automatically download subtitles using its default settings.
+
+To Configure OpenSubtitlesDownload.py, you'll need to open it with a text editor. The script path should now be:
+
+ * Nautilus:
+
+`~/.local/share/nautilus/scripts`
+
+ * Nemo:
+
+`~/.local/share/nemo/scripts`
+
+ * Caja:
+
+`~/.config/caja/scripts`
+
+
+
+
+Navigate to that folder using your file manager and open the OpenSubtitlesDownload.py file with a text editor.
+
+Here's what you may want to change in this file:
+
+ * To change the subtitle language, search for `opt_languages = ['eng']` and change the language from `['eng']` (English) to `['fre']` (French), or whatever language you want to use. The ISO codes for each language supported by OpenSubtitles.org are available on [this][2] page (use the code in the first column).
+
+ * If you want a GUI to present you with all subtitles options and let you choose which to download, find the `opt_selection_mode = 'default'` setting and change it to `'manual'` . You'll not want to change this to 'manual' (or better yet, change it to 'auto') if you want to download multiple subtitles in the same time and avoid having a window popup for each video!
+
+ * To force the Gnome GUI to be used, search for `opt_gui = 'auto'` and change `'auto'` to `'gnome'`
+
+ * You can also enable multiple info columns in the GUI:
+
+ * Search for `opt_selection_rating = 'off'` and change it to `'auto'` to display user ratings if available
+
+ * Search for `opt_selection_count = 'off'` and change it to `'auto'` to display the subtitle number of downloads if available
+
+
+**You can find a list of OpenSubtitlesDownload.py settings with explanations by visiting[this page][3].**
+
+And you're done. OpenSubtitlesDownload.py should now appear in Nautilus, Nemo or Caja, when right clicking a file and selecting Scripts. Clicking OpenSubtitlesDownload.py should search and download subtitles for the selected video(s).
+
+### Installing and using OpenSubtitlesDownload.py from the command line
+
+1\. Install the dependencies required by OpenSubtitlesDownload.py (command line only)
+
+You'll need to install `gzip` and `wget` . On Debian, Ubuntu or Linux Mint you can install these packages by using this command:
+```
+sudo apt install wget gzip
+
+```
+
+2\. Install the `/usr/local/bin/` and set it so it uses the command line interface by default:
+```
+wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py -O opensubtitlesdownload
+sed -i "s/opt_gui = 'auto'/opt_gui = 'cli'/" opensubtitlesdownload
+sudo install opensubtitlesdownload /usr/local/bin/
+
+```
+
+Now you can start using it. To use the script with automatic selection and download of the best available subtitle, type:
+```
+opensubtitlesdownload --auto /path/to/video.mkv
+
+```
+
+You can specify the language by appending `--lang LANG` , where `LANG` is the ISO code for a language supported by OpenSubtitles.org, available on
+```
+opensubtitlesdownload --lang SPA /home/logix/Videos/Sintel.2010.720p.mkv
+
+```
+
+Which provides this output (it allows you to choose the best subtitle since we didn't use `--auto` only, nor did we append `--select manual` to allow manual selection):
+```
+>> Title: Sintel
+>> Filename: Sintel.2010.720p.mkv
+>> Available subtitles:
+[1] "Sintel (2010).spa.srt" > "Language: Spanish"
+[2] "sintel_es.srt" > "Language: Spanish"
+[3] "Sintel.2010.720p.x264-VODO-spa.srt" > "Language: Spanish"
+[0] Cancel search
+>> Enter your choice (0-3): 1
+>> Downloading 'Spanish' subtitles for 'Sintel'
+2018-07-27 14:37:04 URL:http://dl.opensubtitles.org/en/download/src-api/vrf-19c10c57/sid-8rL5O0xhUw2BgKG6lvsVBM0p00f/filead/1955318590.gz [936/936] -> "-" [1]
+
+```
+
+These are all the available options:
+```
+$ opensubtitlesdownload --help
+usage: OpenSubtitlesDownload.py [-h] [-g GUI] [--cli] [-s SEARCH] [-t SELECT]
+ [-a] [-v] [-l [LANG]]
+ filePathListArg [filePathListArg ...]
+
+This software is designed to help you find and download subtitles for your favorite videos!
+
+
+ -h, --help show this help message and exit
+ -g GUI, --gui GUI Select the GUI you want from: auto, kde, gnome, cli (default: auto)
+ --cli Force CLI mode
+ -s SEARCH, --search SEARCH
+ Search mode: hash, filename, hash_then_filename, hash_and_filename (default: hash_then_filename)
+ -t SELECT, --select SELECT
+ Selection mode: manual, default, auto
+ -a, --auto Force automatic selection and download of the best subtitles found
+ -v, --verbose Force verbose output
+ -l [LANG], --lang [LANG]
+ Specify the language in which the subtitles should be downloaded (default: eng).
+ Syntax:
+ -l eng,fre: search in both language
+ -l eng -l fre: download both language
+
+```
+
+**The theme used for the screenshots in this article is called[Canta][4].**
+
+**You may also be interested in:[How To Replace Nautilus With Nemo File Manager On Ubuntu 18.04 Gnome Desktop (Complete Guide)][5]**
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxuprising.com/2018/07/download-subtitles-via-right-click-from.html
+
+作者:[Logix][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/118280394805678839070
+[1]:https://emericg.github.io/OpenSubtitlesDownload/
+[2]:http://www.opensubtitles.org/addons/export_languages.php
+[3]:https://github.com/emericg/OpenSubtitlesDownload/wiki/Adjust-settings
+[4]:https://www.linuxuprising.com/2018/04/canta-is-amazing-material-design-gtk.html
+[5]:https://www.linuxuprising.com/2018/07/how-to-replace-nautilus-with-nemo-file.html
+[6]:https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
diff --git a/sources/tech/20180727 How to analyze your system with perf and Python.md b/sources/tech/20180727 How to analyze your system with perf and Python.md
new file mode 100644
index 0000000000..c1be98cc0e
--- /dev/null
+++ b/sources/tech/20180727 How to analyze your system with perf and Python.md
@@ -0,0 +1,1479 @@
+How to analyze your system with perf and Python
+======
+
+
+
+Modern computers are ever increasing in performance and capacity. This matters little if that increasing capacity is not well utilized. Following is a description of the motivation and work behind "curt," a new tool for Linux systems for measuring and breaking down system utilization by process, by task, and by CPU using the `perf` command's Python scripting capabilities.
+
+I had the privilege of presenting this topic at [Texas Linux Fest 2018][1], and here I've gone a bit deeper into the details, included links to further information, and expanded the scope of my talk.
+
+### System utilization
+
+In discussing computation, let's begin with some assertions:
+
+ 1. Every computational system is equally fast at doing nothing.
+ 2. Computational systems were created to do things.
+ 3. A computational system is better at doing things when it is doing something than when it is doing nothing.
+
+
+
+Modern computational systems have many streams of execution:
+
+ * Often, very large systems are created by literally wiring together smaller systems. At IBM, these smaller systems are sometimes called CECs (short for Central Electronics Complexes and pronounced "keks").
+ * There are multiple sockets for processor modules in each system.
+ * There are sometimes multiple chips per socket (in the form of dual-chip modules—DCMs—or multi-chip modules—MCMs).
+ * There are multiple cores per chip.
+ * There are multiple threads per core.
+
+
+
+In sum, there are potentially thousands of execution threads across a single computational system.
+
+Ideally, all these execution streams are 100% busy doing useful work. One measure of **utilization** for an individual execution stream (CPU thread) is the percentage of time that thread has tasks scheduled and running. (Note that I didn't say "doing useful work." Creating a tool that measures useful work is left as an exercise for the reader.) By extension, **system utilization** is the overall percentage of time that all execution streams of a system have tasks scheduled and running. Similarly, utilization can be defined with respect to an individual task. **Task utilization** is the percentage of the lifetime of the task that was spent actively running on any CPU thread. By extension, **process utilization** is the collective utilization of its tasks.
+
+### Utilization measurement tools
+
+There are tools that measure system utilization: `uptime`, `vmstat`, `mpstat`, `nmon`, etc. There are tools that measure individual process utilization: `time`. There are not many tools that measure system-wide per-process and per-task utilization. One such command is `curt` on AIX. According to [IBM's Knowledge Center][2]: "The `curt` command takes an AIX trace file as input and produces a number of statistics related to processor (CPU) utilization and process/thread/pthread activity."
+
+The AIX `curt` command reports system-wide, per-processor, per-process, and per-task statistics for application processing (user time), system calls (system time), hypervisor calls, kernel threads, interrupts, and idle time.
+
+This seems like a good model for a similar command for a Linux system.
+
+### Utilization data
+
+Before starting to create any tools for utilization analysis, it is important to know what data is required. Since utilization is directly related to whether a task is actively running or not, related scheduling events are required: When is the task made to run, and when is it paused? Tracking on which CPU the task runs is important, so migration events are required for implicit migrations. There are also certain system calls that force explicit migrations. Creation and deletion of tasks are obviously important. Since we want to understand user time, system time, hypervisor time, and interrupt time, events that show the transitions between those task states are required.
+
+The Linux kernel contains "tracepoints" for all those events. It is possible to enable tracing for those events directly in the kernel's `debugfs` filesystem, usually mounted at `/sys/kernel/debug`, in the `tracing` directory (`/sys/kernel/debug/tracing`).
+
+An easier way to record tracing data is with the Linux `perf` command.
+
+### The perf command
+
+`perf` is a very powerful userspace command for tracing or counting both hardware and software events.
+
+Software events are predefined in the kernel, can be predefined in userspace code, and can be dynamically created (as "probes") in kernel or userspace code.
+
+`perf` can do much more than just trace and count, though.
+
+#### perf stat
+
+The `stat` subcommand of `perf` will run a command, count some events commonly found interesting, and produce a simple report:
+```
+Performance counter stats for './load 100000':
+
+ 90537.006424 task-clock:u (msec) # 1.000 CPUs utilized
+ 0 context-switches:u # 0.000 K/sec
+ 0 cpu-migrations:u # 0.000 K/sec
+ 915 page-faults:u # 0.010 K/sec
+ 386,836,206,133 cycles:u # 4.273 GHz (66.67%)
+ 3,488,523,420 stalled-cycles-frontend:u # 0.90% frontend cycles idle (50.00%)
+ 287,222,191,827 stalled-cycles-backend:u # 74.25% backend cycles idle (50.00%)
+ 291,102,378,513 instructions:u # 0.75 insn per cycle
+ # 0.99 stalled cycles per insn (66.67%)
+ 43,730,320,236 branches:u # 483.010 M/sec (50.00%)
+ 822,030,340 branch-misses:u # 1.88% of all branches (50.00%)
+
+ 90.539972837 seconds time elapsed
+```
+
+#### perf record, perf report, and perf annotate
+
+For much more interesting analysis, the `perf` command can also be used to record events and information associated with the task state at the time the event occurred:
+```
+$ perf record ./some-command
+[ perf record: Woken up 55 times to write data ]
+[ perf record: Captured and wrote 13.973 MB perf.data (366158 samples) ]
+$ perf report --stdio --show-nr-samples --percent-limit 4
+# Samples: 366K of event 'cycles:u'
+# Event count (approx.): 388851358382
+#
+# Overhead Samples Command Shared Object Symbol
+# ........ ............ ....... ................. ................................................
+#
+ 62.31% 228162 load load [.] main
+ 19.29% 70607 load load [.] sum_add
+ 18.33% 67117 load load [.] sum_sub
+```
+
+This example shows a program that spends about 60% of its running time in the function `main` and about 20% each in subfunctions `sum_sub` and `sum_add`. Note that the default event used by `perf record` is "cycles." Later examples will show how to use `perf record` with other events.
+
+`perf report` can further report runtime statistics by source code line (if the compilation was performed with the `-g` flag to produce debug information):
+```
+$ perf report --stdio --show-nr-samples --percent-limit 4 --sort=srcline
+# Samples: 366K of event 'cycles:u'
+# Event count (approx.): 388851358382
+#
+# Overhead Samples Source:Line
+# ........ ............ ...................................
+#
+ 19.40% 71031 load.c:58
+ 16.16% 59168 load.c:18
+ 15.11% 55319 load.c:14
+ 13.30% 48690 load.c:66
+ 13.23% 48434 load.c:70
+ 4.58% 16767 load.c:62
+ 4.01% 14677 load.c:56
+```
+
+Further, `perf annotate` can show statistics for each instruction of the program:
+```
+$ perf annotate --stdio
+Percent | Source code & Disassembly of load for cycles:u (70607 samples)
+------------------------------------------------------------------------------
+ : 0000000010000774 :
+ : int sum_add(int sum, int value) {
+ 12.60 : 10000774: std r31,-8(r1)
+ 0.02 : 10000778: stdu r1,-64(r1)
+ 0.00 : 1000077c: mr r31,r1
+ 41.90 : 10000780: mr r10,r3
+ 0.00 : 10000784: mr r9,r4
+ 0.05 : 10000788: stw r10,32(r31)
+ 23.78 : 1000078c: stw r9,36(r31)
+ : return (sum + value);
+ 0.76 : 10000790: lwz r10,32(r31)
+ 0.00 : 10000794: lwz r9,36(r31)
+ 14.75 : 10000798: add r9,r10,r9
+ 0.00 : 1000079c: extsw r9,r9
+ : }
+ 6.09 : 100007a0: mr r3,r9
+ 0.02 : 100007a4: addi r1,r31,64
+ 0.03 : 100007a8: ld r31,-8(r1)
+ 0.00 : 100007ac: blr
+```
+
+(Note: this code is not optimized.)
+
+#### perf top
+
+Similar to the `top` command, which displays (at a regular update interval) the processes using the most CPU time, `perf top` will display the functions using the most CPU time among all processes on the system, a nice leap in granularity.
+
+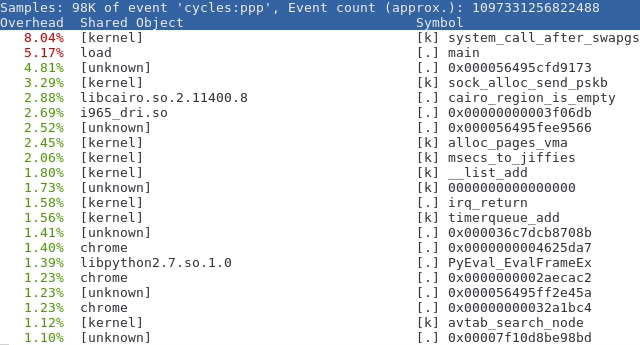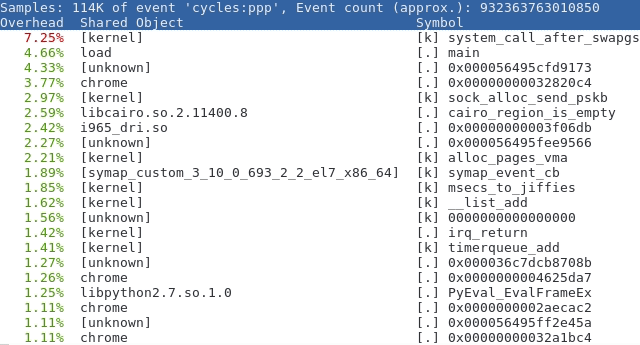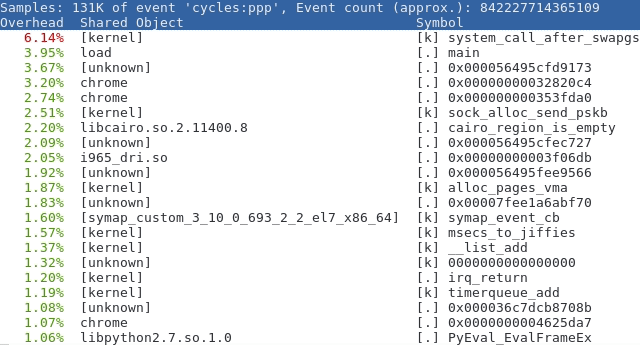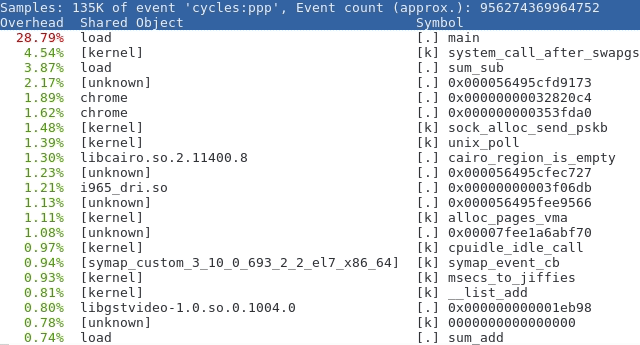
+
+#### perf list
+
+The examples thus far have used the default event, run cycles. There are hundreds and perhaps thousands of events of different types. `perf list` will show them all. Following are just a few examples:
+```
+$ perf list
+ instructions [Hardware event]
+ context-switches OR cs [Software event]
+ L1-icache-loads [Hardware cache event]
+ mem_access OR cpu/mem_access/ [Kernel PMU event]
+cache:
+ pm_data_from_l2
+ [The processor's data cache was reloaded from local core's L2 due to a demand load]
+floating point:
+ pm_fxu_busy
+ [fxu0 busy and fxu1 busy]
+frontend:
+ pm_br_mpred_cmpl
+ [Number of Branch Mispredicts]
+memory:
+ pm_data_from_dmem
+ [The processor's data cache was reloaded from another chip's memory on the same Node or Group (Distant) due to a demand load]
+ pm_data_from_lmem
+ [The processor's data cache was reloaded from the local chip's Memory due to a demand load]
+ rNNN [Raw hardware event descriptor]
+ raw_syscalls:sys_enter [Tracepoint event]
+ syscalls:sys_enter_chmod [Tracepoint event]
+ sdt_libpthread:pthread_create [SDT event]
+```
+
+Events labeled as `Hardware event`, `Hardware cache event`, `Kernel PMU event`, and most (if not all) of the events under the categories like `cache`, `floating point`, `frontend`, and `memory` are hardware events counted by the hardware and triggered each time a certain count is reached. Once triggered, an entry is made into the kernel trace buffer with the current state of the associated task. `Raw hardware event` codes are alphanumeric encodings of the hardware events. These are mostly needed when the hardware is newer than the kernel and the user needs to enable events that are new for that hardware. Users will rarely, if ever, need to use raw event codes.
+
+Events labeled `Tracepoint event` are embedded in the kernel. These are triggered when that section of code is executed by the kernel. There are "syscalls" events for every system call supported by the kernel. `raw_syscalls` events are triggered for every system call. Since there is a limit to the number of events being actively traced, the `raw_syscalls` events may be more practical when a large number of system calls need to be traced.
+
+Events labeled `SDT event` are for software-defined tracepoints (SDTs). These can be embedded in application or library code and enabled as needed. When enabled, they behave just like other events: When that section of code is executed (by any task being traced on the system), an entry is made in the kernel trace buffer with the current state of the associated task. This is a very powerful capability that can prove very useful.
+
+#### perf buildid-cache and perf probe
+
+Enabling SDTs is easy. First, make the SDTs for a certain library known to `perf`:
+```
+$ perf buildid-cache -v --add /lib/powerpc64le-linux-gnu/libpthread.so.0
+$ perf list | grep libpthread
+[…]
+ sdt_libpthread:pthread_create [SDT event]
+[…]
+```
+
+Then, turn SDT definitions into available tracepoints:
+```
+$ /usr/bin/sudo perf probe sdt_libpthread:pthread_create
+Added new event:
+ sdt_libpthread:pthread_create (on %pthread_create in /lib/powerpc64le-linux-gnu/libpthread-2.27.so)
+You can now use it in all perf tools, such as:
+ perf record -e sdt_libpthread:pthread_create -aR sleep 1
+$ perf record -a -e sdt_libpthread:pthread_create ./test
+[ perf record: Woken up 1 times to write data ]
+[ perf record: Captured and wrote 0.199 MB perf.data (9 samples) ]
+```
+
+Note that any location in an application or library can be made into a tracepoint. To find functions in an application that can be made into tracepoints, use `perf probe` with `–funcs`:
+```
+$ perf probe –x ./load --funcs
+[…]
+main
+sum_add
+sum_sub
+```
+
+To enable the function `main` of the `./load` application as a tracepoint:
+```
+/usr/bin/sudo perf probe –x ./load main
+Added new event:
+ probe_load:main (on main in /home/pc/projects/load-2.1pc/load)
+You can now use it in all perf tools, such as:
+ perf record –e probe_load:main –aR sleep 1
+$ perf list | grep load:main
+ probe_load:main [Tracepoint event]
+$ perf record –e probe_load:main ./load
+[ perf record: Woken up 1 times to write data ]
+[ perf record: Captured and wrote 0.024 MB perf.data (1 samples) ]
+```
+
+#### perf script
+
+Continuing the previous example, `perf script` can be used to walk through the `perf.data` file and output the contents of each record:
+```
+$ perf script
+ Load 16356 [004] 80526.760310: probe_load:main: (4006a2)
+```
+
+### Processing perf trace data
+
+The preceding discussion and examples show that `perf` can collect the data required for system utilization analysis. However, how can that data be processed to produce the desired results?
+
+#### perf eBPF
+
+A relatively new and emerging technology with `perf` is called [eBPF][3]. BPF is an acronym for Berkeley Packet Filter, and it is a C-like language originally for, not surprisingly, network packet filtering in the kernel. eBPF is an acronym for extended BPF, a similar, but more robust C-like language based on BPF.
+
+Recent versions of `perf` can be used to incorporate compiled eBPF code into the kernel to securely and intelligently handle events for any number of purposes, with some limitations.
+
+The capability is very powerful and quite useful for real-time, continuous updates of event-related data and statistics.
+
+However, as this capability is emerging, support is mixed on current releases of Linux distributions. It's a bit complicated (or, put differently, I have not figured it out yet). It's also only for online use; there is no offline capability. For these reasons, I won't cover it further here.
+
+#### perf data file
+
+`perf record` produces a `perf.data` file. The file is a structured binary file, is not particularly well documented, has no programming interface for access, and is unclear on what compatibility guarantees exist. For these reasons, I chose not to directly use the `perf.data` file.
+
+#### perf script
+
+One of the last examples above showed how `perf script` is used for walking through the `perf.data` file and emitting basic information about each record there. This is an appropriate model for what would be needed to process the file and track the state changes and compute the statistics required for system utilization analysis.
+
+`perf script` has several modes of operation, including several higher-level scripts that come with `perf` that produce statistics based on the trace data in a `perf.data` file.
+```
+$ perf script -l
+List of available trace scripts:
+ rw-by-pid system-wide r/w activity
+ rwtop [interval] system-wide r/w top
+ wakeup-latency system-wide min/max/avg wakeup latency
+ failed-syscalls [comm] system-wide failed syscalls
+ rw-by-file r/w activity for a program, by file
+ failed-syscalls-by-pid [comm] system-wide failed syscalls, by pid
+ intel-pt-events print Intel PT Power Events and PTWRITE
+ syscall-counts-by-pid [comm] system-wide syscall counts, by pid
+ export-to-sqlite [database name] [columns] [calls] export perf data to a sqlite3 database
+ futex-contention futext contention measurement
+ sctop [comm] [interval] syscall top
+ event_analyzing_sample analyze all perf samples
+ net_dropmonitor display a table of dropped frames
+ compaction-times [-h] [-u] [-p|-pv] [-t | [-m] [-fs] [-ms]] [pid|pid-range|comm-regex] display time taken by mm compaction
+ export-to-postgresql [database name] [columns] [calls] export perf data to a postgresql database
+ stackcollapse produce callgraphs in short form for scripting use
+ netdev-times [tx] [rx] [dev=] [debug] display a process of packet and processing time
+ syscall-counts [comm] system-wide syscall counts
+ sched-migration sched migration overview
+$ perf script failed-syscalls-by-pid /bin/ls
+
+syscall errors:
+
+comm [pid] count
+------------------------------ ----------
+
+ls [18683]
+ syscall: access
+ err = ENOENT 1
+ syscall: statfs
+ err = ENOENT 1
+ syscall: ioctl
+ err = ENOTTY 3
+```
+
+What do these scripts look like? Let's find out.
+```
+$ locate failed-syscalls-by-pid
+/usr/libexec/perf-core/scripts/python/failed-syscalls-by-pid.py
+[…]
+$ rpm –qf /usr/libexec/perf-core/scripts/python/failed-syscalls-by-pid.py
+perf-4.14.0-46.el7a.x86_64
+$ $ ls /usr/libexec/perf-core/scripts
+perl python
+$ perf script -s lang
+
+Scripting language extensions (used in perf script -s [spec:]script.[spec]):
+
+ Perl [Perl]
+ pl [Perl]
+ Python [Python]
+ py [Python]
+```
+
+So, these scripts come with `perf`, and both Python and Perl are supported languages.
+
+Note that for the entirety of this content, I will refer exclusively to Python.
+
+#### perf scripts
+
+How do these scripts do what they do? Here are important extracts from `/usr/libexec/perf-core/scripts/python/failed-syscalls-by-pid.py`:
+```
+def raw_syscalls__sys_exit(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, id, ret):
+[…]
+ if ret < 0:
+[…]
+ syscalls[common_comm][common_pid][id][ret] += 1
+```
+
+The function `raw_syscalls__sys_exit` has parameters for all the data for the associated event. The rest of the function only increments a counter associated with the command, process ID, and system call. The rest of the code doesn't do that much. Most of the complexity is in the function signature for the event-handling routine.
+
+Fortunately, `perf` makes it easy to figure out the proper signatures for various tracepoint event-handling functions.
+
+#### perf script –gen-script
+
+For the `raw_syscalls` events, we can generate a trace containing just those events:
+```
+$ perf list | grep raw_syscalls
+ raw_syscalls:sys_enter [Tracepoint event]
+ raw_syscalls:sys_exit [Tracepoint event]
+$ perf record -e 'raw_syscalls:*' /bin/ls >/dev/null
+[ perf record: Woken up 1 times to write data ]
+[ perf record: Captured and wrote 0.025 MB perf.data (176 samples) ]
+```
+
+We can then have `perf` generate a script that contains sample implementations of event-handling functions for the events in the `perf.data` file:
+```
+$ perf script --gen-script python
+generated Python script: perf-script.py
+```
+
+What do we find in the script?
+```
+def raw_syscalls__sys_exit(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, id, ret):
+[…]
+def raw_syscalls__sys_enter(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, id, args):
+```
+
+Both event-handling functions are specified with their signatures. Nice!
+
+Note that this script works with `perf script –s`:
+```
+$ perf script -s ./perf-script.py
+in trace_begin
+raw_syscalls__sys_exit 7 94571.445908134 21117 ls id=0, ret=0
+raw_syscalls__sys_enter 7 94571.445942946 21117 ls id=45, args=���?bc���?�
+[…]
+```
+
+Now we have a template on which to base writing a Python script to parse the events of interest for reporting system utilization.
+
+### perf scripting
+
+The Python scripts generated by `perf script –gen-script` are not directly executable. They must be invoked by `perf`:
+```
+$ perf script –s ./perf-script.py
+```
+
+What's really going on here?
+
+ 1. First, `perf` starts. The `script` subcommand's `-s` option indicates that an external script will be used.
+
+ 2. `perf` establishes a Python runtime environment.
+
+ 3. `perf` loads the specified script.
+
+ 4. `perf` runs the script. The script can perform normal initialization and even handle command line arguments, although passing the arguments is slightly awkward, requiring a `--` separator between the arguments for `perf` and for the script:
+ ```
+ $ perf script -s ./perf-script.py -- --script-arg1 [...]
+
+ ```
+
+ 5. `perf` processes each record of the trace file, calling the appropriate event-handling function in the script. Those event-handling functions can do whatever they need to do.
+
+
+
+
+### Utilization
+
+It appears that `perf` scripting has sufficient capabilities for a workable solution. What sort of information is required to generate the statistics for system utilization?
+
+ * Task creation (`fork`, `pthread_create`)
+ * Task termination (`exit`)
+ * Task replacement (`exec`)
+ * Task migration, explicit or implicit, and current CPU
+ * Task scheduling
+ * System calls
+ * Hypervisor calls
+ * Interrupts
+
+
+
+It can be helpful to understand what portion of time a task spends in various system calls, handling interrupts, or making explicit calls out to the hypervisor. Each of these categories of time can be considered a "state" for the task, and the methods of transitioning from one state to another need to be tracked:
+
+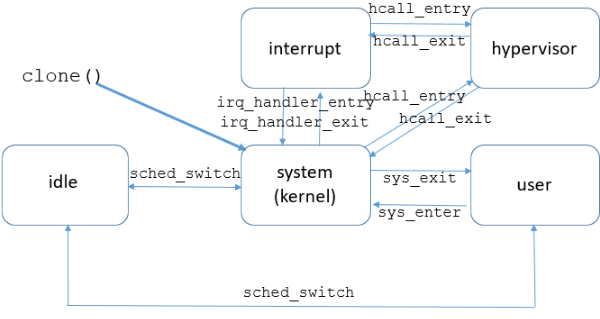
+
+The most important point of the diagram is that there are events for each state transition.
+
+ * Task creation: `clone` system call
+ * Task termination: `sched:sched_process_exit`
+ * Task replacement: `sched:sched_process_exec`
+ * Task migration: `sched_setaffinity` system call (explicit), `sched:sched_migrate_task` (implicit)
+ * Task scheduling: `sched:sched_switch`
+ * System calls: `raw_syscalls:sys_enter`, `raw_syscalls:sys_exit`
+ * Hypervisor calls: (POWER-specific) `powerpc:hcall_entry`, `powerpc:hcall_exit`
+ * Interrupts: `irq:irq_handler_entry`, `irq:irq_handler_exit`
+
+
+
+### The curt command for Linux
+
+`perf` provides a suitable infrastructure with which to capture the necessary data for system utilization. There are a sufficient set of events available for tracing in the Linux kernel. The Python scripting capabilities permit a powerful and flexible means of processing the trace data. It's time to write the tool.
+
+#### High-level design
+
+In processing each event, the relevant state of the affected tasks must be updated:
+
+ * New task? Create and initialize data structures to track the task's state
+ * Command
+ * Process ID
+ * Task ID
+ * Migration count (0)
+ * Current CPU
+ * New CPU for this task? Create and initialize data structures for CPU-specific data
+ * User time (0)
+ * System time (0)
+ * Hypervisor time (0)
+ * Interrupt time (0)
+ * Idle time (0)
+ * New transaction for this task? Create and initialize data structures for transaction-specific data
+ * Elapsed time (0)
+ * Count (0)
+ * Minimum (maxint), maximum (0)
+ * Existing task?
+ * Accumulate time for the previous state
+ * Transaction ending? Accumulate time for the transaction, adjust minimum, maximum values
+ * Set new state
+ * Save current time (time current state entered)
+ * Migration? Increment migration count
+
+
+
+#### High-level example
+
+For a `raw_syscalls:sys_enter` event:
+
+ * If this task has not been seen before, allocate and initialize a new task data structure
+ * If the CPU is new for this task, allocate and initialize a new CPU data structure
+ * If this system call is new for this task, allocate and initialize a new call data structure
+ * In the task data structure:
+ * Accumulate the time since the last state change in a bucket for the current state ("user")
+ * Set the new state ("system")
+ * Save the current timestamp as the start of this time period for the new state
+
+
+
+#### Edge cases
+
+##### sys_exit as a task's first event
+
+If the first event in the trace for a task is `raw_syscalls:sys_exit`:
+
+ * There is no matching `raw_syscalls:sys_enter` with which to determine the start time of this system call.
+ * The accumulated time since the start of the trace was all spent in the system call and needs to be added to the overall elapsed time spent in all calls to this system call.
+ * The elapsed time of this system call is unknown.
+ * It would be inaccurate to account for this elapsed time in the average, minimum, or maximum statistics for this system call.
+
+
+
+In this case, the tool creates a separate bucket called "pending" for time spent in the system call that cannot be accounted for in the average, minimum, or maximum.
+
+A "pending" bucket is required for all transactional events (system calls, hypervisor calls, and interrupts).
+
+##### sys_enter as a task's last event
+
+Similarly, If the last event in the trace for a task is `raw_syscalls:sys_enter`:
+
+ * There is no matching `raw_syscalls:sys_exit` with which to determine the end time of this system call.
+ * The accumulated time from the start of the system call to the end of the trace was all spent in the system call and needs to be added to the overall elapsed time spent in all calls to this system call.
+ * The elapsed time of this system call is unknown.
+ * It would be inaccurate to account for this elapsed time in the average, minimum, or maximum statistics for this system call.
+
+
+
+This elapsed time is also accumulated in the "pending" bucket.
+
+A "pending" bucket is required for all transactional events (system calls, hypervisor calls, and interrupts).
+
+Since this condition can only be discovered at the end of the trace, a final "wrap-up" step is required in the tool where the statistics for all known tasks are completed based on their final states.
+
+##### Indeterminable state
+
+It is possible that a very busy task (or a short trace) will never see an event for a task from which the task's state can be determined. For example, if only `sched:sched_switch` or `sched:sched_task_migrate` events are seen for a task, it is impossible to determine that task's state. However, the task is known to exist and to be running.
+
+Since the actual state cannot be determined, the runtime for the task is accumulated in a separate bucket, arbitrarily called "busy-unknown." For completeness, this time is also displayed in the final report.
+
+##### Invisible tasks
+
+For very, very busy tasks (or a short trace), it is possible that a task was actively running during the entire time the trace was being collected, but no events for that task appear in the trace. It was never migrated, paused, or forced to wait.
+
+Such tasks cannot be known to exist by the tool and will not appear in the report.
+
+#### curt.py Python classes
+
+##### Task
+
+ * One per task
+ * Holds all task-specific data (command, process ID, state, CPU, list of CPU data structures [see below], migration count, lists of per-call data structures [see below])
+ * Maintains task state
+
+
+
+##### Call
+
+ * One per unique transaction, per task (for example, one for the "open" system call, one for the "close" system call, one for IRQ 27, etc.)
+ * Holds call-specific data (e.g., start timestamp, count, elapsed time, minimum, maximum)
+ * Allocated as needed (lazy allocation)
+ * Stored within a task in a Python dictionary indexed by the unique identifier of the call (e.g., system call code, IRQ number, etc.)
+
+
+
+##### CPU
+
+ * One per CPU on which this task has been observed to be running
+ * Holds per-CPU task data (e.g., user time, system time, hypervisor call time, interrupt time)
+ * Allocated as needed (lazy allocation)
+ * Stored within a task in a Python dictionary indexed by the CPU number
+
+
+
+#### curt.py event processing example
+
+As previously discussed, `perf script` will iterate over all events in the trace and call the appropriate event-handling function for each event.
+
+A first attempt at an event-handling function for `sys_exit`, given the high-level example above, might be:
+```
+tasks = {}
+
+def raw_syscalls__sys_enter(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, args):
+
+ # convert the multiple timestamp values into a single value
+ timestamp = nsecs(common_secs, common_nsecs)
+
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+
+ if common_cpu not in task.cpus:
+ # new CPU!
+ task.cpu = common_cpu
+ task.cpus[common_cpu] = CPU()
+
+ # compute time spent in the previous state ('user')
+ delta = timestamp – task.timestamp
+ # accumulate 'user' time for this task/CPU
+ task.cpus[task.cpu].user += delta
+ if id not in task.syscalls:
+ # new system call for this task!
+ task.syscalls[id] = Call()
+
+ # change task's state
+ task.mode = 'sys'
+
+ # save the timestamp for the last event (this one) for this task
+ task.timestamp = timestamp
+
+def raw_syscalls__sys_exit(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, ret):
+
+ # convert the multiple timestamp values into a single value
+ timestamp = nsecs(common_secs, common_nsecs)
+
+ # get the task data structure
+ task = tasks[common_pid]
+
+ # compute elapsed time for this system call
+ delta = task.timestamp - timestamp
+
+ # accumulate time for this task/system call
+ task.syscalls[id].elapsed += delta
+ # increment the tally for this task/system call
+ task.syscalls[id].count += 1
+ # adjust statistics
+ if delta < task.syscalls[id].min:
+ task.syscalls[id].min = delta
+ if delta > task.syscalls[id].max:
+ task.syscalls[id].max = delta
+
+ # accumulate time for this task's state on this CPU
+ task.cpus[common_cpu].system += delta
+
+ # change task's state
+ task.mode = 'user'
+
+ # save the timestamp for the last event (this one) for this task
+ task.timestamp = timestamp
+```
+
+### Handling the edge cases
+
+Following are some of the edge cases that are possible and must be handled.
+
+#### Sys_exit as first event
+
+As a system-wide trace can be started at an arbitrary time, it is certainly possible that the first event for a task is `raw_syscalls:sys_exit`. This requires adding the same code for new task discovery from the event-handling function for `raw_syscalls:sys_enter` to the handler for `raw_syscalls:sys_exit`. This:
+```
+ # get the task data structure
+ task = tasks[common_pid]
+```
+
+becomes this:
+```
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+```
+
+Another issue is that it is impossible to properly accumulate the data for this system call since there is no timestamp for the start of the system call. The time from the start of the trace until this event has been spent by this task in the system call. It would be inaccurate to ignore this time. It would also be inaccurate to incorporate this time such that it is used to compute the average, minimum, or maximum. The only reasonable option is to accumulate this separately, calling it "pending" system time. To accurately compute this time, the timestamp of the first event of the trace must be known. Since any event could be the first event in the trace, every event must conditionally save its timestamp if it is the first event. A global variable is required:
+```
+start_timestamp = 0
+
+```
+
+And every event-handling function must conditionally save its timestamp:
+```
+ # convert the multiple timestamp values into a single value
+ timestamp = nsecs(common_secs, common_nsecs)
+
+ If start_timestamp = 0:
+ start_timestamp = timestamp
+```
+
+So, the event-handling function for `raw_syscalls:sys_exit` becomes:
+```
+def raw_syscalls__sys_exit(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, ret):
+
+ # convert the multiple timestamp values into a single value
+ timestamp = nsecs(common_secs, common_nsecs)
+
+ If start_timestamp = 0:
+ start_timestamp = timestamp
+
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+
+ # compute elapsed time for this system call
+ delta = task.timestamp - timestamp
+
+ # accumulate time for this task/system call
+ task.syscalls[id].elapsed += delta
+ # increment the tally for this task/system call
+ task.syscalls[id].count += 1
+ # adjust statistics
+ if delta < task.syscalls[id].min:
+ task.syscalls[id].min = delta
+ if delta > task.syscalls[id].max:
+ task.syscalls[id].max = delta
+
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+
+ # compute elapsed time for this system call
+ delta = start_timestamp - timestamp
+
+ # accumulate time for this task/system call
+ task.syscalls[id].pending += delta
+
+ # accumulate time for this task's state on this CPU
+ task.cpus[common_cpu].system += delta
+
+ # change task's state
+ task.mode = 'user'
+
+ # save the timestamp for the last event (this one) for this task
+ task.timestamp = timestamp
+```
+### Sys_enter as last event
+
+A similar issue to having `sys_exit` as the first event for a task is when `sys_enter` is the last event seen for a task. The time spent in the system call must be accumulated for completeness but can't accurately impact the average, minimum, nor maximum. This time will also be accumulated in for a separate "pending" state.
+
+To accurately determine the elapsed time of the pending system call, from `sys_entry` to the end of the trace period, the timestamp of the final event in the trace file is required. Unfortunately, there is no way to know which event is the last event until that event has already been processed. So, all events must save their respective timestamps in a global variable.
+
+It may be that many tasks are in the state where the last event seen for them was `sys_enter`. Thus, after the last event is processed, a final "wrap up" step is required to complete the statistics for those tasks. Fortunately, there is a `trace_end` function which is called by `perf` after the final event has been processed.
+
+Last, we need to save the `id` of the system call in every `sys_enter`.
+```
+curr_timestamp = 0
+
+def raw_syscalls__sys_enter(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, args):
+
+ # convert the multiple timestamp values into a single value
+ curr_timestamp = nsecs(common_secs, common_nsecs)
+[…]
+ task.syscall = id
+[…]
+
+def trace_end():
+ for tid in tasks.keys():
+ task = tasks[tid]
+ # if this task ended while executing a system call
+ if task.mode == 'sys':
+ # compute the time from the entry to the system call to the end of the trace period
+ delta = curr_timestamp - task.timestamp
+ # accumulate the elapsed time for this system call
+ task.syscalls[task.syscall].pending += delta
+ # accumulate the system time for this task/CPU
+ task.cpus[task.cpu].sys += delta
+```
+
+### Migrations
+
+A task migration is when a task running on one CPU is moved to another CPU. This can happen by either:
+
+ 1. Explicit request (e.g., a call to `sched_setaffinity`), or
+ 2. Implicitly by the kernel (e.g., load balancing or vacating a CPU being taken offline)
+
+
+
+When detected:
+
+ * The migration count for the task should be incremented
+ * The statistics for the previous CPU should be updated
+ * A new CPU data structure may need to be updated and initialized if the CPU is new for the task
+ * The task's current CPU is set to the new CPU
+
+
+
+For accurate statistics, task migrations must be detected as soon as possible. The first case, explicit request, happens within a system call and can be detected in the `sys_exit` event for that system call. The second case has its own event, `sched:sched_migrate_task`, so it will need a new event-handling function.
+```
+def raw_syscalls__sys_exit(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, ret):
+
+ # convert the multiple timestamp values into a single value
+ timestamp = nsecs(common_secs, common_nsecs)
+
+ If start_timestamp = 0:
+ start_timestamp = timestamp
+
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+
+ # compute elapsed time for this system call
+ delta = task.timestamp - timestamp
+
+ # accumulate time for this task/system call
+ task.syscalls[id].elapsed += delta
+ # increment the tally for this task/system call
+ task.syscalls[id].count += 1
+ # adjust statistics
+ if delta < task.syscalls[id].min:
+ task.syscalls[id].min = delta
+ if delta > task.syscalls[id].max:
+ task.syscalls[id].max = delta
+
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+
+ task.cpu = common_cpu
+
+ # compute elapsed time for this system call
+ delta = start_timestamp - timestamp
+
+ # accumulate time for this task/system call
+ task.syscalls[id].pending += delta
+
+ If common_cpu != task.cpu:
+ task.migrations += 1
+ # divide the time spent in this syscall in half...
+ delta /= 2
+ # and give have to the previous CPU, below, and half to the new CPU, later
+ task.cpus[task.cpu].system += delta
+
+ # accumulate time for this task's state on this CPU
+ task.cpus[common_cpu].system += delta
+
+ # change task's state
+ task.mode = 'user'
+
+ # save the timestamp for the last event (this one) for this task
+ task.timestamp = timestamp
+
+def sched__sched_migrate_task(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, comm, pid, prio, orig_cpu,
+ dest_cpu, perf_sample_dict):
+
+ If start_timestamp = 0:
+ start_timestamp = timestamp
+
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+
+ task.cpu = common_cpu
+
+ If common_cpu not in task.cpus:
+ task.cpus[common_cpu] = CPU()
+
+ task.migrations += 1
+```
+
+### Task creation
+
+To accurately collect statistics for a task, it is essential to know when the task is created. Tasks can be created with `fork()`, which creates a new process, or `pthread_create()`, which creates a new task within the same process. Fortunately, both are manifested by a `clone` system call and made evident by a `sched:sched_process_fork` event. The lifetime of the task starts at the `sched_process_fork` event. The edge case that arises is that the first likely events for the new task are:
+
+ 1. `sched_switch` when the new task starts running. The new task should be considered idle at creation until this event occurs
+ 2. `sys_exit` for the `clone` system call. The initial state of the new task needs to be based on the state of the task that creates it, including being within the `clone` system call.
+
+
+
+One edge case that must be handled is if the creating task (parent) is not yet known, it must be created and initialized, and the presumption is that it has been actively running since the start of the trace.
+```
+def sched__sched_process_fork(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, parent_comm, parent_pid, child_comm, child_pid):
+ global start_timestamp, curr_timestamp
+ curr_timestamp = self.timestamp
+ if (start_timestamp == 0):
+ start_timestamp = curr_timestamp
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+ try:
+ parent = tasks[self.parent_tid]
+ except:
+ # need to create parent task here!
+ parent = Task(start_timestamp, self.command, 'sys', self.pid)
+ parent.sched_stat = True # ?
+ parent.cpu = self.cpu
+ parent.cpus[parent.cpu] = CPU()
+ tasks[self.parent_tid] = parent
+
+ task.resume_mode = parent.mode
+ task.syscall = parent.syscall
+ task.syscalls[task.syscall] = Call()
+ task.syscalls[task.syscall].timestamp = self.timestamp
+```
+
+### Task exit
+
+Similarly, for complete and accurate task statistics, it is essential to know when a task has terminated. There's an event for that: `sched:sched_process_exit`. This one is pretty easy to handle, in that the effort is just to close out the statistics and set the mode appropriately, so any end-of-trace processing will not think the task is still active:
+```
+def sched__sched_process_exit_old(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, comm, pid, prio):
+ global start_timestamp, curr_timestamp
+ curr_timestamp = self.timestamp
+ if (start_timestamp == 0):
+ start_timestamp = curr_timestamp
+
+ # find this task's data structure
+ try:
+ task = tasks[common_pid]
+ except:
+ # new task!
+ task = Task()
+ # save the command string
+ task.comm = common_comm
+ task.timestamp = curr_timestamp
+ # save the new task in the global list (dictionary) of tasks
+ tasks[common_pid] = task
+
+ delta = timestamp – task.timestamp
+ task.sys += delta
+ task.mode = 'exit'
+```
+
+### Output
+
+What follows is an example of the report displayed by `curt`, slightly reformatted to fit on a narrower page width and with the idle-time classification data (which makes the output very wide) removed, and for brevity. Seen are two processes, 1497 and 2857. Process 1497 has two tasks, 1497 and 1523. Each task has a per-CPU summary and system-wide ("ALL" CPUs) summary. Each task's data is followed by the system call data for that task (if any), hypervisor call data (if any), and interrupt data (if any). After each process's respective tasks is a per-process summary. Process 2857 has a task 2857-0 that is the previous task image before an exec() system call replaced the process image. After all processes is a system-wide summary.
+```
+1497:
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [ 1497] X 2 0.076354 0.019563 0.000000 0.000000 0.000000 15.818719 | 0.6%
+ [ 1497] X ALL 0.076354 0.019563 0.000000 0.000000 0.000000 15.818719 | 0.6% 0
+
+ -- ( ID)name count elapsed pending average minimum maximum
+ ( 0)read 2 0.004699 0.000000 0.002350 0.002130 0.002569
+ (232)epoll_wait 1 9.968375 5.865208 9.968375 9.968375 9.968375
+
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [ 1523] InputThread 1 0.052598 0.037073 0.000000 0.000000 0.000000 15.824965 | 0.6%
+ [ 1523] InputThread ALL 0.052598 0.037073 0.000000 0.000000 0.000000 15.824965 | 0.6% 0
+
+ -- ( ID)name count elapsed pending average minimum maximum
+ ( 0)read 14 0.011773 0.000000 0.000841 0.000509 0.002185
+ ( 1)write 2 0.010763 0.000000 0.005381 0.004974 0.005789
+ (232)epoll_wait 1 9.966649 5.872853 9.966649 9.966649 9.966649
+
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [ ALL] ALL 0.128952 0.056636 0.000000 0.000000 0.000000 31.643684 | 0.6% 0
+
+2857:
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [ 2857] execs.sh 1 0.257617 0.249685 0.000000 0.000000 0.000000 0.266200 | 65.6%
+ [ 2857] execs.sh 2 0.000000 0.023951 0.000000 0.000000 0.000000 0.005728 | 80.7%
+ [ 2857] execs.sh 5 0.313509 0.062271 0.000000 0.000000 0.000000 0.344279 | 52.2%
+ [ 2857] execs.sh 6 0.136623 0.128883 0.000000 0.000000 0.000000 0.533263 | 33.2%
+ [ 2857] execs.sh 7 0.527347 0.194014 0.000000 0.000000 0.000000 0.990625 | 42.1%
+ [ 2857] execs.sh ALL 1.235096 0.658804 0.000000 0.000000 0.000000 2.140095 | 46.9% 4
+
+ -- ( ID)name count elapsed pending average minimum maximum
+ ( 9)mmap 15 0.059388 0.000000 0.003959 0.001704 0.017919
+ ( 14)rt_sigprocmask 12 0.006391 0.000000 0.000533 0.000431 0.000711
+ ( 2)open 9 2.253509 0.000000 0.250390 0.008589 0.511953
+ ( 3)close 9 0.017771 0.000000 0.001975 0.000681 0.005245
+ ( 5)fstat 9 0.007911 0.000000 0.000879 0.000683 0.001182
+ ( 10)mprotect 8 0.052198 0.000000 0.006525 0.003913 0.018073
+ ( 13)rt_sigaction 8 0.004281 0.000000 0.000535 0.000458 0.000751
+ ( 0)read 7 0.197772 0.000000 0.028253 0.000790 0.191028
+ ( 12)brk 5 0.003766 0.000000 0.000753 0.000425 0.001618
+ ( 8)lseek 3 0.001766 0.000000 0.000589 0.000469 0.000818
+
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [2857-0] perf 6 0.053925 0.191898 0.000000 0.000000 0.000000 0.827263 | 22.9%
+ [2857-0] perf 7 0.000000 0.656423 0.000000 0.000000 0.000000 0.484107 | 57.6%
+ [2857-0] perf ALL 0.053925 0.848321 0.000000 0.000000 0.000000 1.311370 | 40.8% 1
+
+ -- ( ID)name count elapsed pending average minimum maximum
+ ( 0)read 0 0.000000 0.167845 -- -- --
+ ( 59)execve 0 0.000000 0.000000 -- -- --
+
+ALL:
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [ ALL] ALL 10.790803 29.633170 0.160165 0.000000 0.137747 54.449823 | 7.4% 50
+
+ -- ( ID)name count elapsed pending average minimum maximum
+ ( 1)write 2896 1.623985 0.000000 0.004014 0.002364 0.041399
+ (102)getuid 2081 3.523861 0.000000 0.001693 0.000488 0.025157
+ (142)sched_setparam 691 7.222906 32.012841 0.024925 0.002024 0.662975
+ ( 13)rt_sigaction 383 0.235087 0.000000 0.000614 0.000434 0.014402
+ ( 8)lseek 281 0.169157 0.000000 0.000602 0.000452 0.013404
+ ( 0)read 133 2.782795 0.167845 0.020923 0.000509 1.864439
+ ( 7)poll 96 8.583354 131.889895 0.193577 0.000626 4.596280
+ ( 4)stat 93 7.036355 1.058719 0.183187 0.000981 3.661659
+ ( 47)recvmsg 85 0.146644 0.000000 0.001725 0.000646 0.019067
+ ( 3)close 79 0.171046 0.000000 0.002165 0.000428 0.020659
+ ( 9)mmap 78 0.311233 0.000000 0.003990 0.001613 0.017919
+ (186)gettid 74 0.067315 0.000000 0.000910 0.000403 0.014075
+ ( 2)open 71 3.081589 0.213059 0.184248 0.001921 0.937946
+ (202)futex 62 5.145112 164.286154 0.405566 0.000597 11.587437
+
+ -- ( ID)name count elapsed pending average minimum maximum
+ ( 12)i8042 10 0.160165 0.000000 0.016016 0.010920 0.032805
+
+Total Trace Time: 15.914636 ms
+```
+
+### Hurdles and issues
+
+Following are some of the issues encountered in the development of `curt`.
+
+#### Out-of-order events
+
+One of the more challenging issues is the discovery that events in a `perf.data` file can be out of time order. For a program trying to monitor state transitions carefully, this is a serious issue. For example, a trace could include the following sequence of events, displayed as they appear in the trace file:
+```
+time 0000: sys_enter syscall1
+time 0007: sys_enter syscall2
+time 0006: sys_exit syscall1
+time 0009: sys_exit syscall2
+```
+
+Just blindly processing these events in the order they are presented to their respective event-handling functions (in the wrong time order) will result in incorrect statistics (or worse).
+
+The most user-friendly ways to handle out-of-order events include:
+
+ * Prevent traces from having out-of-order events in the first place by changing the way `perf record` works
+ * Providing a means to reorder events in a trace file, perhaps by enhancing `perf inject`
+ * Modifying how `perf script` works to present the events to the event-handling functions in time order
+
+
+
+But user-friendly is not the same as straightforward, nor easy. Also, none of the above are in the user's control.
+
+I chose to implement a queue for incoming events that would be sufficiently deep to allow for proper reordering of all events. This required a significant redesign of the code, including implementation of classes for each event, and moving the event processing for each event type into a method in that event's class.
+
+In the redesigned code, the actual event handlers' only job is to save the relevant data from the event into an instance of the event class, queue it, then process the top (oldest in time) event from the queue:
+```
+def raw_syscalls__sys_enter(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, args):
+ event = Event_sys_enter(nsecs(common_secs,common_nsecs), common_cpu, common_pid, common_comm, id)
+ process_event(event)
+```
+
+The simple reorderable queuing mechanism is in a common function:
+```
+events = []
+n_events = 0
+def process_event(event):
+ global events,n_events,curr_timestamp
+ i = n_events
+ while i > 0 and events[i-1].timestamp > event.timestamp:
+ i = i-1
+ events.insert(i,event)
+ if n_events < params.window:
+ n_events = n_events+1
+ else:
+ event = events[0]
+ # need to delete from events list now,
+ # because event.process() could reenter here
+ del events[0]
+ if event.timestamp < curr_timestamp:
+ sys.stderr.write("Error: OUT OF ORDER events detected.\n Try increasing the size of the look-ahead window with --window=\n")
+ event.process()
+```
+
+Note that the size of the queue is configurable, primarily for performance and to limit memory consumption. The function will report when that queue size is insufficient to eliminate out-of-order events. It is worth considering whether to consider this case a catastrophic failure and elect to terminate the program.
+
+Implementing a class for each event type led to some consideration for refactoring, such that common code could coalesce into a base class:
+```
+class Event (object):
+
+ def __init__(self):
+ self.timestamp = 0
+ self.cpu = 0
+ self.tid = 0
+ self.command = 'unknown'
+ self.mode = 'unknown'
+ self.pid = 0
+
+ def process(self):
+ global start_timestamp
+
+ try:
+ task = tasks[self.tid]
+ if task.pid == 'unknown':
+ tasks[self.tid].pid = self.pid
+ except:
+ task = Task(start_timestamp, self.command, self.mode, self.pid)
+ tasks[self.tid] = task
+
+ if self.cpu not in task.cpus:
+ task.cpus[self.cpu] = CPU()
+ if task.cpu == 'unknown':
+ task.cpu = self.cpu
+
+ if self.cpu != task.cpu:
+ task.cpu = self.cpu
+ task.migrations += 1
+
+ return task
+```
+
+Then a class for each event type would be similarly constructed:
+```
+class Event_sys_enter ( Event ):
+
+ def __init__(self, timestamp, cpu, tid, comm, id, pid):
+ self.timestamp = timestamp
+ self.cpu = cpu
+ self.tid = tid
+ self.command = comm
+ self.id = id
+ self.pid = pid
+ self.mode = 'busy-unknown'
+
+ def process(self):
+ global start_timestamp, curr_timestamp
+ curr_timestamp = self.timestamp
+ if (start_timestamp == 0):
+ start_timestamp = curr_timestamp
+
+ task = super(Event_sys_enter, self).process()
+
+ if task.mode == 'busy-unknown':
+ task.mode = 'user'
+ for cpu in task.cpus:
+ task.cpus[cpu].user = task.cpus[cpu].busy_unknown
+ task.cpus[cpu].busy_unknown = 0
+
+ task.syscall = self.id
+ if self.id not in task.syscalls:
+ task.syscalls[self.id] = Call()
+
+ task.syscalls[self.id].timestamp = curr_timestamp
+ task.change_mode(curr_timestamp, 'sys')
+```
+
+Further refactoring is evident above, as well, moving the common code that updates relevant statistics based on a task's state change and the state change itself into a `change_mode` method of the `Task` class.
+
+### Start-of-trace timestamp
+
+As mentioned above, for scripts that depend on elapsed time, there should be an easier way to get the first timestamp in the trace other than forcing every event-handling function to conditionally save its timestamp as the start-of-trace timestamp.
+
+### Awkward invocation
+
+The syntax for invoking a `perf` Python script, including script parameters, is slightly awkward:
+```
+$ perf script –s ./curt.py -- --window=80
+```
+
+Also, it's awkward that `perf` Python scripts are not themselves executable.
+
+The `curt.py` script was made directly executable and will invoke `perf`, which will in turn invoke the script. Implementation is a bit confusing but it's easy to use:
+```
+$ ./curt.py --window=80
+```
+
+This script must detect when it has been directly invoked. The Python environment established by `perf` is a virtual module from which the `perf` Python scripts import:
+```
+try:
+ from perf_trace_context import *
+```
+
+If this import fails, the script was directly invoked. In this case, the script will `exec perf`, specifying itself as the script to run, and passing along any command line parameters:
+```
+except:
+ if len(params.file_or_command) == 0:
+ params.file_or_command = [ "perf.data" ]
+ sys.argv = ['perf', 'script', '-i' ] + params.file_or_command + [ '-s', sys.argv[0] ]
+ sys.argv.append('--')
+ sys.argv += ['--window', str(params.window)]
+ if params.debug:
+ sys.argv.append('--debug')
+ sys.argv += ['--api', str(params.api)]
+ if params.debug:
+ print sys.argv
+ os.execvp("perf", sys.argv)
+ sys.exit(1)
+```
+
+In this way, the script can not only be run directly, it can still be run by using the `perf script` command.
+
+#### Simultaneous event registration required
+
+An artifact of the way `perf` enables events can lead to unexpected trace data. For example, specifying:
+```
+$ perf record –a –e raw_syscalls:sys_enter –e raw_syscalls:sys_exit ./command
+```
+
+Will result in a trace file that begins with the following series of events for a single task (the `perf` command itself):
+```
+sys_enter
+sys_enter
+sys_enter
+…
+
+```
+
+This happens because `perf` will register the `sys_enter` event for every CPU on the system (because of the `-a` argument), then it will register the `sys_exit` event for every CPU. In the latter case, since the `sys_enter` event has already been enabled for each CPU, that event shows up in the trace; but since the `sys_exit` has not been enabled on each CPU until after the call returns, the `sys_exit` call does not show up in the trace. The reverse issue happens at the end of the trace file, with a series of `sys_exit` events in the trace because the `sys_enter` event has already been disabled.
+
+The solution to this issue is to group the events, which is not well documented:
+```
+$ perf record –e '{raw_syscalls:sys_enter,raw_syscalls:sys_exit}' ./command
+```
+
+With this syntax, the `sys_enter` and `sys_exit` events are enabled simultaneously.
+
+#### Awkward recording step
+
+There are a lot of different events required for computation of the full set of statistics for tasks. This leads to a very long, complicated command for recording:
+```
+$ perf record -e '{raw_syscalls:*,sched:sched_switch,sched:sched_migrate_task,sched:sched_process_exec,sched:sched_process_fork,sched:sched_process_exit,sched:sched_stat_runtime,sched:sched_stat_wait,sched:sched_stat_sleep,sched:sched_stat_blocked,sched:sched_stat_iowait,powerpc:hcall_entry,powerpc:hcall_exit}' -a *command --args*
+
+```
+
+The solution to this issue is to enable the script to perform the record step itself, by itself invoking `perf`. A further enhancement is to proceed after the recording is complete and report the statistics from that recording:
+```
+if params.record:
+ # [ed. Omitting here the list of events for brevity]
+ eventlist = '{' + eventlist + '}' # group the events
+ command = ['perf', 'record', '--quiet', '--all-cpus',
+ '--event', eventlist ] + params.file_or_command
+ if params.debug:
+ print command
+ subprocess.call(command)
+```
+
+The command syntax required to record and report becomes:
+```
+$ ./curt.py --record ./command
+```
+
+### Process IDs and perf API change
+
+Process IDs are treated a bit cavalierly by `perf` scripting. Note well above that one of the common parameters for the generated event-handling functions is named `common_pid`. This is not the process ID, but the task ID. In fact, on many current Linux-based distributions, there is no way to determine a task's process ID from within a `perf` Python script. This presents a serious problem for a script that wants to compute statistics for a process.
+
+Fortunately, in Linux kernel v4.14, an additional parameter was provided to each of the event-handling functions—`perf_sample_dict`—a dictionary from which the process ID could be extracted: (`perf_sample_dict['sample']['pid']`).
+
+Unfortunately, current Linux distributions may not have that version of the Linux kernel. If the script is written to expect that extra parameter, the script will fail and report an error:
+```
+TypeError: irq__irq_handler_exit_new() takes exactly 11 arguments (10 given)
+```
+
+Ideally, a means to automatically discover if the additional parameter is passed would be available to permit a script to easily run with both the old and new APIs and to take advantage of the new API if it is available. Unfortunately, such a means is not readily apparent.
+
+Since there is clearly value in using the new API to determine process-wide statistics, `curt` provides a command line option to use the new API. `curt` then takes advantage of Python's lazy function binding to adjust, at run-time, which API to use:
+```
+if params.api == 1:
+ dummy_dict = {}
+ dummy_dict['sample'] = {}
+ dummy_dict['sample']['pid'] = 'unknown'
+ raw_syscalls__sys_enter = raw_syscalls__sys_enter_old
+ […]
+else:
+ raw_syscalls__sys_enter = raw_syscalls__sys_enter_new
+ […]
+```
+
+This requires two functions for each event:
+```
+def raw_syscalls__sys_enter_new(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, args, perf_sample_dict):
+
+ event = Event_sys_enter(nsecs(common_secs,common_nsecs), common_cpu, common_pid, common_comm, id, perf_sample_dict['sample']['pid'])
+ process_event(event)
+
+def raw_syscalls__sys_enter_old(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, args):
+ global dummy_dict
+ raw_syscalls__sys_enter_new(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, id, args, dummy_dict)
+```
+
+Note that the event-handling function for the older API will make use of the function for the newer API, passing a statically defined dictionary containing just enough data such that accessing it as `perf_sample_dict['sample']['pid']` will work (resulting in `'unknown'`).
+
+#### Events reported on other CPUs
+
+Not all events that refer to a task are reported from a CPU on which the task is running. This could result in an artificially high migration count and other incorrect statistics. For these types of events (`sched_stat`), the event CPU is ignored.
+
+#### Explicit migrations (no sched_migrate event)
+
+While there is conveniently an event for when the kernel decides to migrate a task from one CPU to another, there is no event for when the task requests a migration on its own. These are effected by system calls (`sched_setaffinity`), so the `sys_exit` event handler must compare the event CPU to the task's CPU, and if different, presume a migration has occurred. (This is described above, but repeated here in the "issues" section for completeness.)
+
+#### Mapping system call IDs to names is architecture-specific
+
+System calls are identified in events only as unique numeric identifiers. These identifiers are not readily interpreted by humans in the report. These numeric identifiers are not readily mapped to their mnemonics because they are architecture-specific, and new system calls can be added in newer kernels. Fortunately, `perf` provides a means to map system call numeric identifiers to system call names. A simple example follows:
+```
+from Util import syscall_name
+def raw_syscalls__sys_enter(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, id, args, perf_sample_dict):
+ print "%s id=%d" % (syscall_name(id), id)
+```
+
+Unfortunately, using syscall_name introduces a dependency on the `audit` python bindings. This dependency is being removed in upstream versions of perf.
+
+#### Mapping hypervisor call IDs to names is non-existent
+
+Similar to system calls, hypervisor calls are also identified only with numeric identifiers. For IBM's POWER hypervisor, they are statically defined. Unfortunately, `perf` does not provide a means to map hypervisor call identifiers to mnemonics. `curt` includes a (hardcoded) function to do just that:
+```
+hcall_to_name = {
+ '0x4':'H_REMOVE',
+ '0x8':'H_ENTER',
+ '0xc':'H_READ',
+ '0x10':'H_CLEAR_MOD',
+[…]
+}
+
+def hcall_name(opcode):
+ try:
+ return hcall_to_name[hex(opcode)]
+ except:
+ return str(opcode)
+```
+
+### Command strings as bytearrays
+
+`perf` stores command names and string arguments in Python bytearrays. Unfortunately, printing bytearrays in Python prints every character in the bytearray—even if the string is null-terminated. For example:
+```
+$ perf record –a –e 'sched:sched_switch' sleep 3
+$ perf script –g Python
+generated Python script: perf-script.py
+$ perf script -s ./perf-script.py
+in trace_begin
+sched__sched_switch 3 664597.912692243 21223 perf prev_comm=perf^@-terminal-^@, prev_pid=21223, prev_prio=120, prev_state=, next_comm=migration/3^@^@^@^@^@, next_pid=23, next_prio=0
+[…]
+```
+
+One solution is to truncate the length of these bytearrays based on null termination, as needed before printing:
+```
+def null(ba):
+ null = ba.find('\x00')
+ if null >= 0:
+ ba = ba[0:null]
+ return ba
+
+def sched__sched_switch(event_name, context, common_cpu,
+ common_secs, common_nsecs, common_pid, common_comm,
+ common_callchain, prev_comm, prev_pid, prev_prio, prev_state,
+ next_comm, next_pid, next_prio, perf_sample_dict):
+
+ print "prev_comm=%s, prev_pid=%d, prev_prio=%d, " \
+ "prev_state=%s, next_comm=%s, next_pid=%d, " \
+ "next_prio=%d" % \
+ (null(prev_comm), prev_pid, prev_prio,
+ flag_str("sched__sched_switch", "prev_state", prev_state),
+ null(next_comm), next_pid, next_prio)
+```
+
+Which nicely cleans up the output:
+```
+sched__sched_switch 3 664597.912692243 21223 perf prev_comm=perf, prev_pid=21223, prev_prio=120, prev_state=, next_comm=migration/3, next_pid=23, next_prio=0
+```
+
+### Dynamic mappings, like IRQ number to name
+
+Dissimilar to system calls and hypervisor calls, interrupt numbers (IRQs) are dynamically assigned by the kernel on demand, so there can't be a static table mapping an IRQ number to a name. Fortunately, `perf` passes the name to the event's `irq_handler_entry` routine. This allows a script to create a dictionary that maps the IRQ number to a name:
+```
+irq_to_name = {}
+def irq__irq_handler_entry_new(event_name, context, common_cpu, common_secs, common_nsecs, common_pid, common_comm, common_callchain, irq, name, perf_sample_dict):
+ irq_to_name[irq] = name
+ event = Event_irq_handler_entry(nsecs(common_secs,common_nsecs), common_cpu, common_pid, common_comm, irq, name, getpid(perf_sample_dict))
+ process_event(event)
+```
+
+Somewhat oddly, `perf` does not pass the name to the `irq_handler_exit` routine. So, it is possible that a trace may only see an `irq_handler_exit` for an IRQ and must be able to tolerate that. Here, instead of mapping the IRQ to a name, the IRQ number is returned as a string instead:
+```
+def irq_name(irq):
+ if irq in irq_to_name:
+ return irq_to_name[irq]
+ return str(irq)
+```
+#### Task 0
+Task 0 shows up everywhere. It's not a real task. It's a substitute for the "idle" state. It's the task ID given to the `sched_switch` event handler when the CPU is going to (or coming from) the "idle" state. It's often the task that is "interrupted" by interrupts. Tracking the statistics for task 0 as if it were a real task would not make sense. Currently, `curt` ignores task 0. However, this loses some information, like some time spent in interrupt processing. `curt` should, but currently doesn't, track interesting (non-idle) time for task 0.
+
+#### Spurious sched_migrate_task events (same CPU)
+
+Rarely, a `sched_migrate_task` event occurs in which the source and target CPUs are the same. In other words, the task is not migrated. To avoid artificially inflated migration counts, this case must be explicitly ignored:
+```
+class Event_sched_migrate_task (Event):
+ def process(self):
+[…]
+ if self.cpu == self.dest_cpu:
+ return
+```
+
+#### exec
+
+The semantics of the `exec` system call are that the image of the current process is replaced by a completely new process image without changing the process ID. This is awkward for tracking the statistics of a process (really, a task) based on the process (task) ID. The change is significant enough that the statistics for each task should be accumulated separately, so the current task's statistics need to be closed out and a new set of statistics should be initialized. The challenge is that both the old and new tasks have the same process (task) ID. `curt` addresses this by tagging the task's task ID with a numeric suffix:
+```
+class Event_sched_process_exec (Event):
+ def process(self):
+ global start_timestamp, curr_timestamp
+ curr_timestamp = self.timestamp
+ if (start_timestamp == 0):
+ start_timestamp = curr_timestamp
+
+ task = super(Event_sched_process_exec, self).process()
+
+ new_task = Task(self.timestamp, self.command, task.mode, self.pid)
+ new_task.sched_stat = True
+ new_task.syscall = task.syscall
+ new_task.syscalls[task.syscall] = Call()
+ new_task.syscalls[task.syscall].timestamp = self.timestamp
+
+ task.change_mode(curr_timestamp, 'exit')
+
+ suffix=0
+ while True:
+ old_tid = str(self.tid)+"-"+str(suffix)
+ if old_tid in tasks:
+ suffix += 1
+ else:
+ break
+
+ tasks[old_tid] = tasks[self.tid]
+
+ del tasks[self.tid]
+
+ tasks[self.tid] = new_task
+```
+
+This will clearly separate the statistics for the different process images. In the example below, the `perf` command (task "9614-0") `exec`'d `exec.sh` (task "9614-1"), which in turn `exec`'d itself (task "9614"):
+```
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [ 9614] execs.sh 4 1.328238 0.485604 0.000000 0.000000 0.000000 2.273230 | 44.4%
+ [ 9614] execs.sh 7 0.000000 0.201266 0.000000 0.000000 0.000000 0.003466 | 98.3%
+ [ 9614] execs.sh ALL 1.328238 0.686870 0.000000 0.000000 0.000000 2.276696 | 47.0% 1
+
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [9614-0] perf 3 0.000000 0.408588 0.000000 0.000000 0.000000 2.298722 | 15.1%
+ [9614-0] perf 4 0.059079 0.028269 0.000000 0.000000 0.000000 0.611355 | 12.5%
+ [9614-0] perf 5 0.000000 0.067626 0.000000 0.000000 0.000000 0.004702 | 93.5%
+ [9614-0] perf ALL 0.059079 0.504483 0.000000 0.000000 0.000000 2.914779 | 16.2% 2
+
+-- [ task] command cpu user sys irq hv busy idle | util% moves
+ [9614-1] execs.sh 3 1.207972 0.987433 0.000000 0.000000 0.000000 2.435908 | 47.4%
+ [9614-1] execs.sh 4 0.000000 0.341152 0.000000 0.000000 0.000000 0.004147 | 98.8%
+ [9614-1] execs.sh ALL 1.207972 1.328585 0.000000 0.000000 0.000000 2.440055 | 51.0% 1
+```
+
+#### Distribution support
+
+Surprisingly, there is currently no support for `perf`'s Python bindings in Ubuntu. [Follow the saga][4] for more detail.
+
+#### Limit on number of traced events
+
+As `curt` gets more sophisticated, it is likely that more and more events may be required to be included in the trace file. `perf` currently requires one file descriptor per event per CPU. This becomes a problem when the maximum number of open file descriptors is not a large multiple of the number of CPUs on the system. On systems with large numbers of CPUs, this quickly becomes a problem. For example, the default maximum number of open file descriptors is often 1,024. An IBM POWER8 system with four sockets may have 12 cores per socket and eight threads (CPUs) per core. Such a system has 4 * 12 * 8 = 392 CPUs. In that case, `perf` could trace only about two events! A workaround is to (significantly) increase the maximum number of open file descriptors (`ulimit –n` if the system administrator has configured the hard limits high enough; or the administrator can set the limits higher in `/etc/security/limits.conf` for `nofile`).
+
+### Summary
+
+I hope this article shows the power of `perf`—and specifically the utility and flexibility of the Python scripting enabled with `perf`—to perform sophisticated processing of kernel trace data. Also, it shows some of the issues and edge cases that can be encountered when the boundaries of such technologies are tested.
+
+Please feel free to download and make use of the `curt` tool described here, report problems, suggest improvements, or contribute code of your own on the [`curt` GitHub page][5].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/fun-perf-and-python
+
+作者:[Paul Clarke][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/thinkopenly
+[1]:https://2018.texaslinuxfest.org/
+[2]:https://www.ibm.com/support/knowledgecenter/en/ssw_aix_72/com.ibm.aix.cmds1/curt.htm
+[3]:https://opensource.com/article/17/9/intro-ebpf
+[4]:https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1707875
+[5]:https://github.com/open-power-sdk/curt
diff --git a/sources/tech/20180730 7 Python libraries for more maintainable code.md b/sources/tech/20180730 7 Python libraries for more maintainable code.md
new file mode 100644
index 0000000000..24b3daa886
--- /dev/null
+++ b/sources/tech/20180730 7 Python libraries for more maintainable code.md
@@ -0,0 +1,121 @@
+7 Python libraries for more maintainable code
+======
+
+
+
+> Readability counts.
+> — [The Zen of Python][1], Tim Peters
+
+It's easy to let readability and coding standards fall by the wayside when a software project moves into "maintenance mode." (It's also easy to never establish those standards in the first place.) But maintaining consistent style and testing standards across a codebase is an important part of decreasing the maintenance burden, ensuring that future developers are able to quickly grok what's happening in a new-to-them project and safeguarding the health of the app over time.
+
+### Check your code style
+
+A great way to protect the future maintainability of a project is to use external libraries to check your code health for you. These are a few of our favorite libraries for [linting code][2] (checking for PEP 8 and other style errors), enforcing a consistent style, and ensuring acceptable test coverage as a project reaches maturity.
+
+[PEP 8][3] is the Python code style guide, and it sets out rules for things like line length, indentation, multi-line expressions, and naming conventions. Your team might also have your own style rules that differ slightly from PEP 8. The goal of any code style guide is to enforce consistent standards across a codebase to make it more readable, and thus more maintainable. Here are three libraries to help prettify your code.
+
+#### 1\. Pylint
+
+[Pylint][4] is a library that checks for PEP 8 style violations and common errors. It integrates well with several popular [editors and IDEs][5] and can also be run from the command line.
+
+To install, run `pip install pylint`.
+
+To use Pylint from the command line, run `pylint [options] path/to/dir` or `pylint [options] path/to/module.py`. Pylint will output warnings about style violations and other errors to the console.
+
+You can customize what errors Pylint checks for with a [configuration file][6] called `pylintrc`.
+
+#### 2\. Flake8
+
+[Flake8][7] is a "Python tool that glues together PEP8, Pyflakes (similar to Pylint), McCabe (code complexity checker), and third-party plugins to check the style and quality of some Python code."
+
+To use Flake8, run `pip install flake8`. Then run `flake8 [options] path/to/dir` or `flake8 [options] path/to/module.py` to see its errors and warnings.
+
+Like Pylint, Flake8 permits some customization for what it checks for with a [configuration file][8]. It has very clear docs, including some on useful [commit hooks][9] to automatically check your code as part of your development workflow.
+
+Flake8 integrates with popular editors and IDEs, but those instructions generally aren't found in the docs. To integrate Flake8 with your favorite editor or IDE, search online for plugins (for example, [Flake8 plugin for Sublime Text][10]).
+
+#### 3\. Isort
+
+[Isort][11] is a library that sorts your imports alphabetically and breaks them up into [appropriate sections][12] (e.g., standard library imports, third-party library imports, imports from your own project, etc.). This increases readability and makes it easier to locate imports if you have a lot of them in your module.
+
+Install isort with `pip install isort`, and run it with `isort path/to/module.py`. More configuration options are in the [documentation][13]. For example, you can [configure][14] how isort handles multi-line imports from one library in an `.isort.cfg` file.
+
+Like Flake8 and Pylint, isort also provides plugins that integrate it with popular [editors and IDEs][15].
+
+### Outsource your code style
+
+Remembering to run linters manually from the command line for each file you change is a pain, and you might not like how a particular plugin behaves with your IDE. Also, your colleagues might prefer different linters or might not have plugins for their favorite editors, or you might be less meticulous about always running the linter and correcting the warnings. Over time, the codebase you all share will get messy and harder to read.
+
+A great solution is to use a library that automatically reformats your code into something that passes PEP 8 for you. The three libraries we recommend all have different levels of customization and different defaults for how they format code. Some of these are more opinionated than others, so like with Pylint and Flake8, you'll want to test these out to see which offers the customizations you can't live without… and the unchangeable defaults you can live with.
+
+#### 4\. Autopep8
+
+[Autopep8][16] automatically formats the code in the module you specify. It will re-indent lines, fix indentation, remove extraneous whitespace, and refactor common comparison mistakes (like with booleans and `None`). See a full [list of corrections][17] in the docs.
+
+To install, run `pip install --upgrade autopep8`. To reformat code in place, run `autopep8 --in-place --aggressive --aggressive `. The `aggressive` flags (and the number of them) indicate how much control you want to give autopep8 over your code style. Read more about [aggressive][18] options.
+
+#### 5\. Yapf
+
+[Yapf][19] is yet another option for reformatting code that comes with its own list of [configuration options][20]. It differs from autopep8 in that it doesn't just address PEP 8 violations. It also reformats code that doesn't violate PEP 8 specifically but isn't styled consistently or could be formatted better for readability.
+
+To install, run `pip install yapf`. To reformat code, run, `yapf [options] path/to/dir` or `yapf [options] path/to/module.py`. There is also a full list of [customization options][20].
+
+#### 6\. Black
+
+[Black][21] is the new kid on the block for linters that reformat code in place. It's similar to autopep8 and Yapf, but way more opinionated. It has very few options for customization, which is kind of the point. The idea is that you shouldn't have to make decisions about code style; the only decision to make is to let Black decide for you. You can read about [limited customization options][22] and instructions on [storing them in a configuration file][23].
+
+Black requires Python 3.6+ but can format Python 2 code. To use, run `pip install black`. To prettify your code, run: `black path/to/dir` or `black path/to/module.py`.
+
+### Check your test coverage
+
+You're writing tests, right? Then you will want to make sure new code committed to your codebase is tested and doesn't drop your overall amount of test coverage. While percentage of test coverage is not the only metric you should use to measure the effectiveness and sufficiency of your tests, it is one way to ensure basic testing standards are being followed in your project. For measuring test coverage, we have one recommendation: Coverage.
+
+#### 7\. Coverage
+
+[Coverage][24] has several options for the way it reports your test coverage to you, including outputting results to the console or to an HTML page and indicating which line numbers are missing test coverage. You can set up a [configuration file][25] to customize what Coverage checks for and make it easier to run.
+
+To install, run `pip install coverage`. To run a program and see its output, run `coverage run [path/to/module.py] [args]`, and you will see your program's output. To see a report of which lines of code are missing coverage, run `coverage report -m`.
+
+Continuous integration (CI) is a series of processes you can run to automatically check for linter errors and test coverage minimums before you merge and deploy code. There are lots of free or paid tools to automate this process, and a thorough walkthrough is beyond the scope of this article. But because setting up a CI process is an important step in removing blocks to more readable and maintainable code, you should investigate continuous integration tools in general; check out [Travis CI][26] and [Jenkins][27] in particular.
+
+These are only a handful of the libraries available to check your Python code. If you have a favorite that's not on this list, please share it in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-code
+
+作者:[Jeff Triplett][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/laceynwilliams
+[1]:https://www.python.org/dev/peps/pep-0020/
+[2]:https://en.wikipedia.org/wiki/Lint_(software)
+[3]:https://www.python.org/dev/peps/pep-0008/
+[4]:https://www.pylint.org/
+[5]:https://pylint.readthedocs.io/en/latest/user_guide/ide-integration.html
+[6]:https://pylint.readthedocs.io/en/latest/user_guide/run.html#command-line-options
+[7]:http://flake8.pycqa.org/en/latest/
+[8]:http://flake8.pycqa.org/en/latest/user/configuration.html#configuration-locations
+[9]:http://flake8.pycqa.org/en/latest/user/using-hooks.html
+[10]:https://github.com/SublimeLinter/SublimeLinter-flake8
+[11]:https://github.com/timothycrosley/isort
+[12]:https://github.com/timothycrosley/isort#how-does-isort-work
+[13]:https://github.com/timothycrosley/isort#using-isort
+[14]:https://github.com/timothycrosley/isort#configuring-isort
+[15]:https://github.com/timothycrosley/isort/wiki/isort-Plugins
+[16]:https://github.com/hhatto/autopep8
+[17]:https://github.com/hhatto/autopep8#id4
+[18]:https://github.com/hhatto/autopep8#id5
+[19]:https://github.com/google/yapf
+[20]:https://github.com/google/yapf#usage
+[21]:https://github.com/ambv/black
+[22]:https://github.com/ambv/black#command-line-options
+[23]:https://github.com/ambv/black#pyprojecttoml
+[24]:https://coverage.readthedocs.io/en/latest/
+[25]:https://coverage.readthedocs.io/en/latest/config.html
+[26]:https://travis-ci.org/
+[27]:https://jenkins.io/
diff --git a/sources/tech/20180730 A single-user, lightweight OS for your next home project - Opensource.com.md b/sources/tech/20180730 A single-user, lightweight OS for your next home project - Opensource.com.md
new file mode 100644
index 0000000000..a4dbfb9e12
--- /dev/null
+++ b/sources/tech/20180730 A single-user, lightweight OS for your next home project - Opensource.com.md
@@ -0,0 +1,65 @@
+A single-user, lightweight OS for your next home project | Opensource.com
+======
+
+
+What on earth is RISC OS? Well, it's not a new kind of Linux. And it's not someone's take on Windows. In fact, released in 1987, it's older than either of these. But you wouldn't necessarily realize it by looking at it.
+
+The point-and-click graphic user interface features a pinboard and an icon bar across the bottom for your active applications. So, it looks eerily like Windows 95, eight years before it happened.
+
+This OS was originally written for the [Acorn Archimedes][1] . The Acorn RISC Machines CPU in this computer was completely new hardware that needed completely new software to run on it. This was the original operating system for the ARM chip, long before anyone had thought of Android or [Armbian][2]
+
+And while the Acorn desktop eventually faded to obscurity, the ARM chip went on to conquer the world. And here, RISC OS has always had a niche—often in embedded devices, where you'd never actually know it was there. RISC OS was, for a long time, a completely proprietary operating system. But in recent years, the owners have started releasing the source code to a project called [RISC OS Open][3].
+
+### 1\. You can install it on your Raspberry Pi
+
+The Raspberry Pi's official operating system, [Raspbian][4], is actually pretty great (but if you aren't interested in tinkering with novel and different things in tech, you probably wouldn't be fiddling with a Raspberry Pi in the first place). Because RISC OS is written specifically for ARM, it can run on all kinds of small-board computers, including every model of Raspberry Pi.
+
+### 2\. It's super lightweight
+
+The RISC OS installation on my Raspberry Pi takes up a few hundred megabytes—and that's after I've loaded dozens of utilities and games. Most of these are well under a megabyte.
+
+If you're really on a diet, the RISC OS Pico will fit on a 16MB SD card. This is perfect if you're hacking something to go in an embedded system or IoT project. Of course, 16MB is actually a fair bit more than the 512KB ROM chip squeezed into the old Archimedes. But I guess with 30 years of progress in memory technology, it's okay to stretch your legs just a little a bit.
+
+### 3\. It's excellent for retro gaming
+
+When the Archimedes was in its prime, the ARM CPU was several times faster than the Motorola 68000 in the Apple Macintosh and Commodore Amiga, and it totally smoked that new 386, too. This made it an attractive platform for game developers who wanted to strut their stuff with the most powerful desktop computer on the planet.
+
+Many of the rights holders to these games have been generous enough to give permission for hobbyists to download their old work for free. And while RISC OS and the hardware has moved on, with a very small amount of fiddling you can get them to run.
+
+If you're interested in exploring this, [here's a guide][5] to getting these games working on your Raspberry Pi.
+
+### 4\. It's got BBC BASIC
+
+Press F12 to go to the command line, type `*BASIC`, and you get a full BBC BASIC interpreter, just like the old days.
+
+For those who weren't around for it in the 80s, let me explain: BBC BASIC was the first ever programming language for so many of us back in the day, for the excellent reason that it was specifically designed to teach children how to code. There were mountains of books and magazine articles that taught us to code our own simple but highly playable games.
+
+Decades later, coding your own game in BBC BASIC is still a great project for a technically minded kid who wants something to do during school holidays. But few kids have a BBC micro at home anymore. So what should they run it on?
+
+Well, there are interpreters you can run on just about every home computer, but that's not helpful when someone else needs to use it. So why not a Raspberry Pi with RISC OS installed?
+
+### 5\. It's a simple, single-user operating system
+
+RISC OS is not like Linux, with its user and superuser access. It has one user who has full access to the whole machine. So it's probably not the best daily driver to deploy across an enterprise, or even to give to granddad to do his banking. But if you're looking for something to hack and tinker with, it's absolutely fantastic. There isn't all that much between you and the bare metal, so you can just tuck right in.
+
+### Further reading
+
+If you want to learn more about this operating system, check out [RISC OS Open][3], or just flash an image to a card and start using it.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/gentle-intro-risc-os
+
+作者:[James Mawson][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/dxmjames
+[1]:https://en.wikipedia.org/wiki/Acorn_Archimedes
+[2]:https://www.armbian.com/
+[3]:https://www.riscosopen.org/content/
+[4]:https://www.raspbian.org/
+[5]:https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS
diff --git a/sources/tech/20180731 A sysadmin-s guide to Bash.md b/sources/tech/20180731 A sysadmin-s guide to Bash.md
new file mode 100644
index 0000000000..73572b32fb
--- /dev/null
+++ b/sources/tech/20180731 A sysadmin-s guide to Bash.md
@@ -0,0 +1,197 @@
+A sysadmin's guide to Bash
+======
+
+
+
+Each trade has a tool that masters in that trade wield most often. For many sysadmins, that tool is their [shell][1]. On the majority of Linux and other Unix-like systems out there, the default shell is Bash.
+
+Bash is a fairly old program—it originated in the late 1980s—but it builds on much, much older shells, like the C shell ([csh][2]), which is easily 10 years its senior. Because the concept of a shell is that old, there is an enormous amount of arcane knowledge out there waiting to be consumed to make any sysadmin guy's or gal's life a lot easier.
+
+Let's take a look at some of the basics.
+
+Who has, at some point, unintentionally ran a command as root and caused some kind of issue? raises hand
+
+I'm pretty sure a lot of us have been that guy or gal at one point. Very painful. Here are some very simple tricks to prevent you from hitting that stone a second time.
+
+### Use aliases
+
+First, set up aliases for commands like **`mv`** and **`rm`** that point to `mv -I` and `rm -I`. This will make sure that running `rm -f /boot` at least asks you for confirmation. In Red Hat Enterprise Linux, these aliases are set up by default if you use the root account.
+
+If you want to set those aliases for your normal user account as well, just drop these two lines into a file called .bashrc in your home directory (these will also work with sudo):
+```
+alias mv='mv -i'
+
+alias rm='rm -i'
+
+```
+
+### Make your root prompt stand out
+
+Another thing you can do to prevent mishaps is to make sure you are aware when you are using the root account. I usually do that by making the root prompt stand out really well from the prompt I use for my normal, everyday work.
+
+If you drop the following into the .bashrc file in root's home directory, you will have a root prompt that is red on black, making it crystal clear that you (or anyone else) should tread carefully.
+```
+export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
+
+```
+
+In fact, you should refrain from logging in as root as much as possible and instead run the majority of your sysadmin commands through sudo, but that's a different story.
+
+Having implemented a couple of minor tricks to help prevent "unintentional side-effects" of using the root account, let's look at a couple of nice things Bash can help you do in your daily work.
+
+### Control your history
+
+You probably know that when you press the Up arrow key in Bash, you can see and reuse all (well, many) of your previous commands. That is because those commands have been saved to a file called .bash_history in your home directory. That history file comes with a bunch of settings and commands that can be very useful.
+
+First, you can view your entire recent command history by typing **`history`** , or you can limit it to your last 30 commands by typing **`history 30`**. But that's pretty vanilla. You have more control over what Bash saves and how it saves it.
+
+For example, if you add the following to your .bashrc, any commands that start with a space will not be saved to the history list:
+```
+HISTCONTROL=ignorespace
+
+```
+
+This can be useful if you need to pass a password to a command in plaintext. (Yes, that is horrible, but it still happens.)
+
+If you don't want a frequently executed command to show up in your history, use:
+```
+HISTCONTROL=ignorespace:erasedups
+
+```
+
+With this, every time you use a command, all its previous occurrences are removed from the history file, and only the last invocation is saved to your history list.
+
+A history setting I particularly like is the **`HISTTIMEFORMAT`** setting. This will prepend all entries in your history file with a timestamp. For example, I use:
+```
+HISTTIMEFORMAT="%F %T "
+
+```
+
+When I type **`history 5`** , I get nice, complete information, like this:
+```
+1009 2018-06-11 22:34:38 cat /etc/hosts
+
+1010 2018-06-11 22:34:40 echo $foo
+
+1011 2018-06-11 22:34:42 echo $bar
+
+1012 2018-06-11 22:34:44 ssh myhost
+
+1013 2018-06-11 22:34:55 vim .bashrc
+
+```
+
+That makes it a lot easier to browse my command history and find the one I used two days ago to set up an SSH tunnel to my home lab (which I forget again, and again, and again…).
+
+### Best Bash practices
+
+I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
+
+ 11. Bash scripts can become complicated and comments are cheap. If you wonder whether to add a comment, add a comment. If you return after the weekend and have to spend time figuring out what you were trying to do last Friday, you forgot to add a comment.
+
+
+ 10. Wrap all your variable names in curly braces, like **`${myvariable}`**. Making this a habit makes things like `${variable}_suffix` possible and improves consistency throughout your scripts.
+
+
+ 9. Do not use backticks when evaluating an expression; use the **`$()`** syntax instead. So use:
+```
+ for file in $(ls); do
+```
+
+
+not
+```
+ for file in `ls`; do
+
+```
+
+The former option is nestable, more easily readable, and keeps the general sysadmin population happy. Do not use backticks.
+
+
+
+ 8. Consistency is good. Pick one style of doing things and stick with it throughout your script. Obviously, I would prefer if people picked the **`$()`** syntax over backticks and wrapped their variables in curly braces. I would prefer it if people used two or four spaces—not tabs—to indent, but even if you choose to do it wrong, do it wrong consistently.
+
+
+ 7. Use the proper shebang for a Bash script. As I'm writing Bash scripts with the intention of only executing them with Bash, I most often use **`#!/usr/bin/bash`** as my shebang. Do not use **`#!/bin/sh`** or **`#!/usr/bin/sh`**. Your script will execute, but it'll run in compatibility mode—potentially with lots of unintended side effects. (Unless, of course, compatibility mode is what you want.)
+
+
+ 6. When comparing strings, it's a good idea to quote your variables in if-statements, because if your variable is empty, Bash will throw an error for lines like these:
+```
+ if [ ${myvar} == "foo" ]; then
+
+ echo "bar"
+
+ fi
+
+```
+
+And will evaluate to false for a line like this:
+```
+ if [ "${myvar}" == "foo" ]; then
+
+ echo "bar"
+
+ fi
+```
+
+Also, if you are unsure about the contents of a variable (e.g., when you are parsing user input), quote your variables to prevent interpretation of some special characters and make sure the variable is considered a single word, even if it contains whitespace.
+
+
+
+ 5. This is a matter of taste, I guess, but I prefer using the double equals sign ( **`==`** ) even when comparing strings in Bash. It's a matter of consistency, and even though—for string comparisons only—a single equals sign will work, my mind immediately goes "single equals is an assignment operator!"
+
+
+ 4. Use proper exit codes. Make sure that if your script fails to do something, you present the user with a written failure message (preferably with a way to fix the problem) and send a non-zero exit code:
+```
+ # we have failed
+
+ echo "Process has failed to complete, you need to manually restart the whatchamacallit"
+
+ exit 1
+
+```
+
+This makes it easier to programmatically call your script from yet another script and verify its successful completion.
+
+
+
+ 3. Use Bash's built-in mechanisms to provide sane defaults for your variables or throw errors if variables you expect to be defined are not defined:
+```
+ # this sets the value of $myvar to redhat, and prints 'redhat'
+
+ echo ${myvar:=redhat}
+
+ # this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
+
+ ${myvar:?The variable myvar is undefined, dear reader}
+
+```
+
+
+
+ 2. Especially if you are writing a large script, and especially if you work on that large script with others, consider using the **`local`** keyword when defining variables inside functions. The **`local`** keyword will create a local variable, that is one that's visible only within that function. This limits the possibility of clashing variables.
+
+
+ 1. Every sysadmin must do it sometimes: debug something on a console, either a real one in a data center or a virtual one through a virtualization platform. If you have to debug a script that way, you will thank yourself for remembering this: Do not make the lines in your scripts too long!
+
+On many systems, the default width of a console is still 80 characters. If you need to debug a script on a console and that script has very long lines, you'll be a sad panda. Besides, a script with shorter lines—the default is still 80 characters—is a lot easier to read and understand in a normal editor, too!
+
+
+
+
+I truly love Bash. I can spend hours writing about it or exchanging nice tricks with fellow enthusiasts. Make sure you drop your favorites in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/admin-guide-bash
+
+作者:[Maxim Burgerhout][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/wzzrd
+[1]:http://www.catb.org/jargon/html/S/shell.html
+[2]:https://en.wikipedia.org/wiki/C_shell
diff --git a/sources/tech/20180731 How To Use Pbcopy And Pbpaste Commands On Linux.md b/sources/tech/20180731 How To Use Pbcopy And Pbpaste Commands On Linux.md
new file mode 100644
index 0000000000..c54361b5fb
--- /dev/null
+++ b/sources/tech/20180731 How To Use Pbcopy And Pbpaste Commands On Linux.md
@@ -0,0 +1,136 @@
+How To Use Pbcopy And Pbpaste Commands On Linux
+======
+
+
+
+Since Linux and Mac OS X are *Nix based systems, many commands would work on both platforms. However, some commands may not available in on both platforms, for example **pbcopy** and **pbpaste**. These commands are exclusively available only on Mac OS X platform. The Pbcopy command will copy the standard input into clipboard. You can then paste the clipboard contents using Pbpaste command wherever you want. Of course, there could be some Linux alternatives to the above commands, for example **Xclip**. The Xclip will do exactly same as Pbcopy. But, the distro-hoppers who switched to Linux from Mac OS would miss this command-pair and still prefer to use them. No worries! This brief tutorial describes how to use Pbcopy and Pbpaste commands on Linux.
+
+### Install Xclip / Xsel
+
+Like I already said, Pbcopy and Pbpaste commands are not available in Linux. However, we can replicate the functionality of pbcopy and pbpaste commands using Xclip and/or Xsel commands via shell aliasing. Both Xclip and Xsel packages available in the default repositories of most Linux distributions. Please note that you need not to install both utilities. Just install any one of the above utilities.
+
+To install them on Arch Linux and its derivatives, run:
+```
+$ sudo pacman xclip xsel
+
+```
+
+On Fedora:
+```
+$ sudo dnf xclip xsel
+
+```
+
+On Debian, Ubuntu, Linux Mint:
+```
+$ sudo apt install xclip xsel
+
+```
+
+Once installed, you need create aliases for pbcopy and pbpaste commands. To do so, edit your **~/.bashrc** file:
+```
+$ vi ~/.bashrc
+
+```
+
+If you want to use Xclip, paste the following lines:
+```
+alias pbcopy='xclip -selection clipboard'
+alias pbpaste='xclip -selection clipboard -o'
+
+```
+
+If you want to use xsel, paste the following lines in your ~/.bashrc file.
+```
+alias pbcopy='xsel --clipboard --input'
+alias pbpaste='xsel --clipboard --output'
+
+```
+
+Save and close the file.
+
+Next, run the following command to update the changes in ~/.bashrc file.
+```
+$ source ~/.bashrc
+
+```
+
+The ZSH users paste the above lines in **~/.zshrc** file.
+
+### Use Pbcopy And Pbpaste Commands On Linux
+
+Let us see some examples.
+
+The pbcopy command will copy the text from stdin into clipboard buffer. For example, have a look at the following example.
+```
+$ echo "Welcome To OSTechNix!" | pbcopy
+
+```
+
+The above command will copy the text “Welcome To OSTechNix” into clipboard. You can access this content later and paste them anywhere you want using Pbpaste command like below.
+```
+$ echo `pbpaste`
+Welcome To OSTechNix!
+
+```
+
+
+
+Here are some other use cases.
+
+I have a file named **file.txt** with the following contents.
+```
+$ cat file.txt
+Welcome To OSTechNix!
+
+```
+
+You can directly copy the contents of a file into a clipboard as shown below.
+```
+$ pbcopy < file.txt
+
+```
+
+Now, the contents of the file is available in the clipboard as long as you updated with another file’s contents.
+
+To retrieve the contents from clipboard, simply type:
+```
+$ pbpaste
+Welcome To OSTechNix!
+
+```
+
+You can also send the output of any Linux command to clip board using pipeline character. Have a look at the following example.
+```
+$ ps aux | pbcopy
+
+```
+
+Now, type “pbpaste” command at any time to display the output of “ps aux” command from the clipboard.
+```
+$ pbpaste
+
+```
+
+
+
+There is much more you can do with Pbcopy and Pbpaste commands. I hope you now got a basic idea about these commands.
+
+And, that’s all for now. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
diff --git a/sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md b/sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md
new file mode 100644
index 0000000000..dafb058a42
--- /dev/null
+++ b/sources/tech/20180731 What-s in a container image- Meeting the legal challenges.md
@@ -0,0 +1,64 @@
+What's in a container image: Meeting the legal challenges
+======
+
+
+[Container][1] technology has, for many years, been transforming how workloads in data centers are managed and speeding the cycle of application development and deployment.
+
+In addition, container images are increasingly used as a distribution format, with container registries a mechanism for software distribution. Isn't this just like packages distributed using package management tools? Not quite. While container image distribution is similar to RPMs, DEBs, and other package management systems (for example, storing and distributing archives of files), the implications of container image distribution are more complicated. It is not the fault of container technology itself; rather, it's because container distribution is used differently than package management systems.
+
+Talking about the challenges of license compliance for container images, [Dirk Hohndel][2], chief open source officer at VMware, pointed out that the content of a container image is more complex than most people expect, and many readily available images have been built in surprisingly cavalier ways. (See the [LWN.net article][3] by Jake Edge about a talk Dirk gave in April.)
+
+Why is it hard to understand the licensing of container images? Shouldn't there just be a label for the image ("the license is X")? In the [Open Container Image Format Specification][4] , one of the pre-defined annotation keys is "org.opencontainers.image.licenses," which is described as "License(s) under which contained software is distributed as an SPDX License Expression." But that doesn't contemplate the complexity of a container image–while very simple images are built from tens of components, images are often built from hundreds of components. An [SPDX License Expression][5] is most frequently used to convey the licensing for a single source file. Such expressions can handle more than one license, such as "GPL-2.0 OR BSD-3-Clause" (see, for example, [Appendix IV][6] of version 2.1 of the SPDX specification). But the licensing for a typical container image is, typically, much more complicated.
+
+In talking about container-related technology, the term "[container][7]" can lead to confusion. A container does not refer to the containment of files for storing or transferring. Rather, it refers to using features built into the kernel (such as cgroups and namespaces) to present a sort of "contained" experience to code running on the kernel. In other words, the containment to which "container" refers is an execution experience, not a distribution experience. The set of files to be laid out in a file system as the basis for an executing container is typically distributed in what is known as a "container image," sometimes confusingly referred to simply as a container, thereby awkwardly overloading the term "container."
+
+In understanding software distribution via container images, I believe it is useful to consider two separate factors:
+
+ * **Diversity of content:** The basic unit of software distribution (a container image) includes a larger quantity and diversity of content than in the basic unit of distribution in typical software distribution mechanisms.
+ * **Use model:** The nature of widely used tooling fosters the use of a registry, which is often publicly available, in the typical workflow.
+
+
+
+### Diversity of content
+
+When talking about a particular container image, the focus of attention is often on a particular software component (for example, a database or the code that implements one specific service). However, the container image includes a much larger collection of software. In fact, even the developer who created the image may have only a superficial understanding of and/or interest in most of the components in the image. With other distribution mechanisms, those other pieces of software would be identified as dependencies, and users of the software might be directed elsewhere for expertise on those components. In a container, the individual who acquires the container image isn't aware of those additional components that play supporting roles to the featured component.
+
+#### The unit of distribution: user-driven vs. factory-driven
+
+For container images, the distribution unit is user-driven, not factory-driven. Container images are a great tool for reducing the burden on software consumers. With a container image, the image's consumer can focus on the application of interest; the image's builder can take care of the dependencies and configuration. This simplification can be a huge benefit.
+
+When the unit of software is driven by the "factory," the user bears a greater responsibility for building a platform on which to run the software of interest, assembling the correct versions of the dependencies, and getting all the configuration details right. The unit of distribution in a package management system is a modular unit, rather than a complete solution. This unit facilitates building and maintaining a flow of components that are flexible enough to be assembled into myriad solutions. Note that because of this unit, a package maintainer will typically be far more familiar with the content of the packages than someone who builds containers. A person building a container may have a detailed understanding of the container's featured components, but limited familiarity with the image's supporting components.
+
+Packages, package management system tools, package maintenance processes, and package maintainers are incredibly underappreciated. They have been central to delivery of a large variety of software over the last two decades. While container images are playing a growing role, I don't expect the importance of package management systems to fade anytime soon. In fact, the bulk of the content in container images benefits from being built from such packages.
+
+In understanding container images, it is important to appreciate how distribution via such images has different properties than distribution of packages. Much of the content in images is built from packages, but the image's consumer may not know what packages are included or other package-level information. In the future, a variety of techniques may be used to build containers, e.g., directly from source without involvement of a package maintainer.
+
+### Use models
+
+What about reports that so many container images are poorly built? In part, the volume of casually built images is because of container tools that facilitate a workflow to make images publicly available. When experimenting with container tools and moving to a workflow that extends beyond a laptop, the tools expect you to have a repository where multiple machines can pull container images (a container registry). You could spin up your own. Some widely used tools make it easy to use an existing registry that is available at no cost, provided the images are publicly available. This makes many casually built images visible, even those that were never intended to be maintained or updated.
+
+By comparison, how often do you see developers publishing RPMs of their early explorations? RPMs resulting from experimentation by random developers are not ending up in the major package repositories.
+
+Or consider someone experimenting with the latest machine learning frameworks. In the past, a researcher might have shared only analysis results. Now, they can share a full analytical software configuration by publishing a container image. This could be a great benefit to other researchers. However, those browsing a container registry could be confused by the ready-to-run nature of such images. It is important to distinguish between an image built for one individual's exploration and an image that was assembled and tested with broad use in mind.
+
+Be aware that container images include supporting software, not just the featured software; a container image distributes a collection of software. If you are building upon or otherwise using images built by others, be aware of how that image was built and consider your level of confidence in the image's source.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/whats-container-image-meeting-legal-challenges
+
+作者:[Scott Peterson][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/skpeterson
+[1]:https://opensource.com/resources/what-are-linux-containers
+[2]:https://www.linkedin.com/in/dirkhohndel
+[3]:https://lwn.net/Articles/752982/
+[4]:https://github.com/opencontainers/image-spec/blob/master/spec.md
+[5]:https://spdx.org/
+[6]:https://spdx.org/spdx-specification-21-web-version#h.jxpfx0ykyb60
+[7]:https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing
diff --git a/sources/tech/20180801 5 of the Best Linux Games to Play in 2018.md b/sources/tech/20180801 5 of the Best Linux Games to Play in 2018.md
new file mode 100644
index 0000000000..a0580434ec
--- /dev/null
+++ b/sources/tech/20180801 5 of the Best Linux Games to Play in 2018.md
@@ -0,0 +1,83 @@
+5 of the Best Linux Games to Play in 2018
+======
+
+
+
+Linux may not be establishing itself as the gamer’s platform of choice any time soon – the lack of success with Valve’s Steam Machines seems a poignant reminder of that – but that doesn’t mean that the platform isn’t steadily growing with its fair share of great games.
+
+From indie hits to glorious RPGs, 2018 has already been a solid year for Linux games. Here we’ve listed our five favourites so far.
+
+Looking for great Linux games but don’t want to splash the cash? Look to our list of the best [free Linux games][1] for guidance!
+
+### 1. Pillars of Eternity II: Deadfire
+
+![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
+
+One of the titles that best represents the cRPG revival of recent years makes your typical Bethesda RPG look like a facile action-adventure. The latest entry in the majestic Pillars of Eternity series has a more buccaneering slant as you sail with a crew around islands filled with adventures and peril.
+
+Adding naval combat to the mix, Deadfire continues with the rich storytelling and excellent writing of its predecessor while building on those beautiful graphics and hand-painted backgrounds of the original game.
+
+This is a deep and unquestionably hardcore RPG that may cause some to bounce off it, but those who take to it will be absorbed in its world for months.
+
+### 2. Slay the Spire
+
+![best-linux-games-2018-slay-the-spire][3]
+
+Still in early access, but already one of the best games of the year, Slay the Spire is a deck-building card game that’s embellished by a vibrant visual style and rogue-like mechanics that’ll leave you coming back for more after each infuriating (but probably deserved) death.
+
+With endless card combinations and a different layout each time you play, Slay the Spire feels like the realisation of all the best systems that have been rocking the indie scene in recent years – card games and a permadeath adventure rolled into one.
+
+And we repeat that it’s still in early access, so it’s only going to get better!
+
+### 3. Battletech
+
+![best-linux-games-2018-battletech][4]
+
+As close as we get on this list to a “blockbuster” game, Battletech is an intergalactic wargame (based on a tabletop game) where you load up a team of Mechs and guide them through a campaign of rich, turn-based battles.
+
+The action takes place across a range of terrain – from frigid wastelands to golden sun-soaked climes – as you load your squad of four with hulking hot weaponry, taking on rival squads. If this sounds a little “MechWarrior” to you, then you’re thinking along the right track, albeit this one’s more focused on the tactics than outright action.
+
+Alongside a campaign that sees you navigate your way through a cosmic conflict, the multiplayer mode is also likely to consume untold hours of your life.
+
+### 4. Dead Cells
+
+![best-linux-games-2018-dead-cells][5]
+
+This one deserves highlighting as the combat-platformer of the year. With its rogue-lite structure, Dead Cells throws you into a dark (yet gorgeously coloured) world where you slash and dodge your way through procedurally-generated levels. It’s a bit like a 2D Dark Souls, if Dark Souls were saturated in vibrant neon colours.
+
+Dead Cells can be merciless, but its precise and responsive controls ensure that you only ever have yourself to blame for failure, and its upgrades system that carries over between runs ensures that you always have some sense of progress.
+
+Dead Cells is a zenith of pixel-game graphics, animations and mechanics, a timely reminder of just how much can be achieved without the excesses of 3D graphics.
+
+### 5. Iconoclasts
+
+![best-linux-games-2018-iconoclasts][6]
+
+A little less known than some of the above, this is still a lovely game that could be seen as a less foreboding, more cutesy alternative to Dead Cells. It casts you as Robin, a girl who’s cast out as a fugitive after finding herself at the wrong end of the twisted politics of an alien world.
+
+It’s a good plot, even though your role in it is mainly blasting your way through the non-linear levels. Robin acquires all kinds of imaginative upgrades, the most crucial of which is her wrench, which you use to do everything from deflecting projectiles to solving the clever little environmental puzzles.
+
+Iconoclasts is a joyful, vibrant platformer, borrowing from greats like Megaman for its combat and Metroid for its exploration. You can do a lot worse than take inspiration from those two classics.
+
+### Conclusion
+
+That’s it for our picks of the best Linux games to have come out in 2018. Have you dug up any gaming gems that we’ve missed? Let us know in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/best-linux-games/
+
+作者:[Robert Zak][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.maketecheasier.com/author/robzak/
+[1]:https://www.maketecheasier.com/open-source-linux-games/
+[2]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-pillars-of-eternity-2-deadfire.jpg (best-linux-games-2018-pillars-of-eternity-2-deadfire)
+[3]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-slay-the-spire.jpg (best-linux-games-2018-slay-the-spire)
+[4]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-battletech.jpg (best-linux-games-2018-battletech)
+[5]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-dead-cells.jpg (best-linux-games-2018-dead-cells)
+[6]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-iconoclasts.jpg (best-linux-games-2018-iconoclasts)
diff --git a/sources/tech/20180801 Cross-Site Request Forgery.md b/sources/tech/20180801 Cross-Site Request Forgery.md
new file mode 100644
index 0000000000..71804aeb52
--- /dev/null
+++ b/sources/tech/20180801 Cross-Site Request Forgery.md
@@ -0,0 +1,53 @@
+Cross-Site Request Forgery
+======
+
+Security is a major concern when designing web apps. And I am not talking about DDOS protection, using a strong password or 2 step verification. I am talking about the biggest threat to a web app. It is known as **CSRF** short for **Cross Site Resource Forgery**.
+
+### What is CSRF?
+
+ [][1]
+
+First thing first, **CSRF** is short for Cross Site Resource Forgery. It is commonly pronounced as sea-surf and often referred to as XSRF. CSRF is a type of attack where various actions are performed on the web app where the victim is logged in without the victim's knowledge. These actions could be anything ranging from simply liking or commenting on a social media post to sending abusive messages to people or even transferring money from the victim’s bank account.
+
+### How CSRF works?
+
+**CSRF** attacks try to bank upon a simple common vulnerability in all browsers. Every time, we authenticate or log in to a website, session cookies are stored in the browser. So whenever we make a request to the website these cookies are automatically sent to the server where the server identifies us by matching the cookie we sent with the server’s records. So that way it knows it’s us.
+
+ [][2]
+
+This means that any request made by me, knowingly or unknowingly, will be fulfilled. Since the cookies are being sent and they will match the records on the server, the server thinks I am making that request.
+
+
+
+CSRF attacks usually come in form of links. We may click them on other websites or receive them as email. On clicking these links, an unwanted request is made to the server. And as I previously said, the server thinks we made the request and authenticates it.
+
+#### A Real World Example
+
+To put things into perspective, imagine you are logged into your bank’s website. And you fill up a form on the page at **yourbank.com/transfer** . You fill in the account number of the receiver as 1234 and the amount of 5,000 and you click on the submit button. Now, a request will be made to **yourbank.com/transfer/send?to=1234&amount=5000** . So the server will act upon the request and make the transfer. Now just imagine you are on another website and you click on a link that opens up the above URL with the hacker’s account number. That money is now transferred to the hacker and the server thinks you made the transaction. Even though you didn’t.
+
+ [][3]
+
+#### Protection against CSRF
+
+CSRF protection is very easy to implement. It usually involves sending a token called the CSRF token to the webpage. This token is sent and verified on the server with every new request made. So malicious requests made by the server will pass cookie authentication but fail CSRF authentication. Most web frameworks provide out of the box support for preventing CSRF attacks and CSRF attacks are not as commonly seen today as they were some time back.
+
+### Conclusion
+
+CSRF attacks were a big thing 10 years back but today we don’t see too many of them. In the past, famous sites such as Youtube, The New York Times and Netflix have been vulnerable to CSRF. However, popularity and occurrence of CSRF attacks have decreased lately. Nevertheless, CSRF attacks are still a threat and it is important, you protect your website or app from it.
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery
+
+作者:[linuxandubuntu][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxandubuntu.com
+[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-what-is-cross-site-forgery_orig.jpg
+[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/cookies-set-by-website-chrome_orig.jpg
+[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-hacking-bank-account_orig.jpg
diff --git a/sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md b/sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md
new file mode 100644
index 0000000000..a2845eef65
--- /dev/null
+++ b/sources/tech/20180801 Getting started with Standard Notes for encrypted note-taking.md
@@ -0,0 +1,299 @@
+Getting started with Standard Notes for encrypted note-taking
+======
+
+
+
+[Standard Notes][1] is a simple, encrypted notes app that aims to make dealing with your notes the easiest thing you'll do all day. When you sign up for a free sync account, your notes are automatically encrypted and seamlessly synced with all your devices.
+
+There are two key factors that differentiate Standard Notes from other, commercial software solutions:
+
+ 1. The server and client are both completely open source.
+ 2. The company is built on sustainable business practices and focuses on product development.
+
+
+
+When you combine open source with ethical business practices, you get a software product that has the potential to serve you for decades. You start to feel ownership in the product rather than feeling like just another transaction for an IPO-bound company.
+
+In this article, I’ll describe how to deploy your own Standard Notes open source syncing server on a Linux machine. You’ll then be able to use your server with our published applications for Linux, Windows, Android, Mac, iOS, and the web.
+
+If you don’t want to host your own server and are ready to start using Standard Notes right away, you can use our public syncing server. Simply head on over to [Standard Notes][1] to get started.
+
+### Hosting your own Standard Notes server
+
+Get the [Standard File Rails app][2] running on your Linux box and expose it via [NGINX][3] or any other web server.
+
+### Getting started
+
+These instructions are based on setting up our syncing server on a fresh [CentOS][4]-like installation. You can use a hosting service like [AWS][5] or [DigitalOcean][6] to launch your server, or even run it locally on your own machine.
+
+ 1. Update your system:
+
+```
+ sudo yum update
+
+```
+
+ 2. Install [RVM][7] (Ruby Version Manager):
+
+```
+ gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
+ \curl -sSL https://get.rvm.io | bash -s stable
+
+```
+
+ 3. Begin using RVM in current session:
+```
+ source /home/ec2-user/.rvm/scripts/rvm
+
+```
+
+ 4. Install [Ruby][8]:
+
+```
+ rvm install ruby
+
+```
+
+This should install the latest version of Ruby (2.3 at the time of this writing.)
+
+Note that at least Ruby 2.2.2 is required for Rails 5.
+
+ 5. Use Ruby:
+```
+ rvm use ruby
+
+```
+
+ 6. Install [Bundler][9]:
+
+```
+ gem install bundler --no-ri --no-rdoc
+
+```
+
+ 7. Install [mysql-devel][10]:
+```
+ sudo yum install mysql-devel
+
+```
+
+ 8. Install [MySQL][11] (optional; you can also use a hosted db through [Amazon RDS][12], which is recommended):
+```
+ sudo yum install mysql56-server
+
+ sudo service mysqld start
+
+ sudo mysql_secure_installation
+
+ sudo chkconfig mysqld on
+
+```
+
+Create a database:
+
+```
+ mysql -u root -p
+
+ > create database standard_file;
+
+ > quit;
+
+```
+
+ 9. Install [Passenger][13]:
+```
+ sudo yum install rubygems
+
+ gem install rubygems-update --no-rdoc --no-ri
+
+ update_rubygems
+
+ gem install passenger --no-rdoc --no-ri
+
+```
+
+ 10. Remove system NGINX installation if installed (you’ll use Passenger’s instead):
+```
+ sudo yum remove nginx
+ sudo rm -rf /etc/nginx
+```
+
+ 11. Configure Passenger:
+```
+ sudo chmod o+x "/home/ec2-user"
+
+ sudo yum install libcurl-devel
+
+ rvmsudo passenger-install-nginx-module
+
+ rvmsudo passenger-config validate-install
+
+```
+
+ 12. Install Git:
+```
+ sudo yum install git
+
+```
+
+ 13. Set up HTTPS/SSL for your server (free using [Let'sEncrypt][14]; required if using the secure client on [https://app.standardnotes.org][15]):
+```
+ sudo chown ec2-user /opt
+
+ cd /opt
+
+ git clone https://github.com/letsencrypt/letsencrypt
+
+ cd letsencrypt
+
+```
+
+Run the setup wizard:
+```
+ ./letsencrypt-auto certonly --standalone --debug
+
+```
+
+Note the location of the certificates, typically `/etc/letsencrypt/live/domain.com/fullchain.pem`
+
+ 14. Configure NGINX:
+```
+ sudo vim /opt/nginx/conf/nginx.conf
+
+```
+
+Add this to the bottom of the file, inside the last curly brace:
+```
+ server {
+
+ listen 443 ssl default_server;
+
+ ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
+
+ ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
+
+ server_name domain.com;
+
+ passenger_enabled on;
+
+ passenger_app_env production;
+
+ root /home/ec2-user/ruby-server/public;
+
+ }
+
+```
+
+ 15. Make sure you are in your home directory and clone the Standard File [ruby-server][2] project:
+```
+ cd ~
+
+ git clone https://github.com/standardfile/ruby-server.git
+
+ cd ruby-server
+
+```
+
+ 16. Set up project:
+```
+ bundle install
+
+ bower install
+
+ rails assets:precompile
+
+```
+
+ 17. Create a .env file for your environment variables. The Rails app will automatically load these when it starts.
+
+```
+ vim .env
+
+```
+
+Insert:
+```
+ RAILS_ENV=production
+
+ SECRET_KEY_BASE=use "bundle exec rake secret"
+
+
+
+ DB_HOST=localhost
+
+ DB_PORT=3306
+
+ DB_DATABASE=standard_file
+
+ DB_USERNAME=root
+
+ DB_PASSWORD=
+
+```
+
+ 18. Setup database:
+```
+ rails db:migrate
+
+```
+
+ 19. Start NGINX:
+```
+ sudo /opt/nginx/sbin/nginx
+
+```
+
+Tip: you will need to restart NGINX whenever you make changes to your environment variables or the NGINX configuration:
+```
+ sudo /opt/nginx/sbin/nginx -s reload
+
+```
+
+ 20. You’re done!
+
+
+
+
+### Using your new server
+
+Now that you have your server running, you can plug it into any of the Standard Notes applications and sign into it.
+
+**On the Standard Notes web or desktop app:**
+
+Click Account, then Register. Choose "Advanced Options" and you’ll see a field for Sync Server. Enter your server’s URL here.
+
+**On the Standard Notes Android or iOS app:**
+
+Open the Settings window, click "Advanced Options" when signing in or registering, and enter your server URL in the Sync Server field.
+
+For help or questions with your Standard Notes server, join our [Slack group][16] in the #dev channel, or visit our [help page][17] for frequently asked questions and other topics.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/getting-started-standard-notes
+
+作者:[Mo Bitar][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mobitar
+[1]:https://standardnotes.org/
+[2]:https://github.com/standardfile/ruby-server
+[3]:https://www.nginx.com/
+[4]:https://www.centos.org/
+[5]:https://aws.amazon.com/
+[6]:https://www.digitalocean.com/
+[7]:https://rvm.io/
+[8]:https://www.ruby-lang.org/en/
+[9]:https://bundler.io/
+[10]:https://rpmfind.net/linux/rpm2html/search.php?query=mysql-devel
+[11]:https://www.mysql.com/
+[12]:https://aws.amazon.com/rds/
+[13]:https://www.phusionpassenger.com/
+[14]:https://letsencrypt.org/
+[15]:https://app.standardnotes.org/
+[16]:https://standardnotes.org/slack
+[17]:https://standardnotes.org/help
diff --git a/sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md b/sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md
new file mode 100644
index 0000000000..dbe5d042f9
--- /dev/null
+++ b/sources/tech/20180801 Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange.md
@@ -0,0 +1,114 @@
+Hiri is a Linux Email Client Exclusively Created for Microsoft Exchange
+======
+Previously, I have written about the email services [Protonmail][1] and [Tutanota][2] on It’s FOSS. And though I liked both of those email providers very much, some of us couldn’t possibly use these email services exclusively. If you are like me and you have an email address provided for you by your work, then you understand what I am talking about.
+
+Some of us use [Thunderbird][3] for these types of use cases, while others of us use something like [Geary][4] or even [Mailspring][5]. But for those of us who have to deal with [Microsoft Exchange Servers][6], none of these offer seamless solutions on Linux for our work needs.
+
+This is where [Hiri][7] comes in. We have already featured Hiri on our list of [best email clients for Linux][8], but we thought it was about time for an in-depth review.
+
+FYI, Hiri is neither free nor open source software.
+
+### Reviewing Hiri email client on Linux
+
+![Hiri email client review][9]
+
+According to their website, Hiri not only supports Microsoft Exchange and Office 365 accounts, it was exclusively “built for the Microsoft email ecosystem.”
+
+Based in Dublin, Ireland, Hiri has raised $2 million in funding. They have been in the business for almost five years but started supporting Linux only last year. The support for Linux has brought Hiri a considerable amount of success.
+
+I have been using Hiri for a week as of yesterday, and I have to say, I have been very pleased with my experience…for the most part.
+
+#### Hiri features
+
+Some of the main features of Hiri are:
+
+ * Cross-platform application available for Linux, macOS and Windows
+ * **Supports only Office 365, Outlook and Microsoft Exchange for now**
+ * Clean and intuitive UI
+ * Action filters
+ * Reminders
+ * [Skills][10]: Plugins to make you more productive with your emails
+ * Office 365 and Exchange and other Calendar Sync
+ * Compatible with [Active Directory][11]
+ * Offline email access
+ * Secure (it doesn’t send data to any third party server, it’s just an email client)
+ * Compatible with Microsoft’s archiving tool
+
+
+
+#### Taking a look at Hiri Features
+
+![][12]
+
+Hiri can either be compiled manually or [installed easily as Snap][13] and comes jam-packed with useful features. But, if you knew me at all, you would know that usually, a robust feature list is not a huge selling point for me. As a self-proclaimed minimalist, I tend to believe the simpler option is often the better option, and the less “fluff” there is surrounding a product, the easier it is to get to the part that really matters. Admittedly, this is not always the case. For example, KDE’s [Plasma][14] desktop is known for its excessive amount of tweaks and features and I am still a huge Plasma fan. But in Hiri’s case, it has what feels like the perfect feature set and in no way feels convoluted or confusing.
+
+That is partially due to the way that Hiri works. If I had to put it into my own words, I would say that Hiri feels almost modular. It does this by utilizing what Hiri calls the Skill Center. Here you can add or remove functionality in Hiri at the flip of a switch. This includes the ability to add tasks, delegate action items to other people, set reminders, and even enables the user to create better subject lines. None of which are required, but each of which adds something to Hiri that no other email client has done as well.
+
+Using these features can help you organize your email like never before. The Dashboard feature allows you to monitor your time spent working on emails, the Task List enables you to stay on track, the Action/FYI feature allows you to tag your emails as needed to help you cipher through a messy inbox, and the Zero Inbox feature helps the user keep their inbox count at a minimum once they have sorted through the nonsense. And as someone who is an avid Inbox Zeroer (if that is even a thing), this to me was incredibly useful.
+
+Hiri also syncs with your associated calendars as you would expect, and it even allows a global search for all of the other accounts associated with your office. Need to email Frank Smith in Human Resources but can’t remember his email address? No big deal! Hiri will auto-fill the email address once you start typing in his name just like in a native Outlook client.
+
+Multiple account support is also available in Hiri. The support for IMAP will be added in a few months.
+
+In short, Hiri’s feature-set allows for what feels like a truly native Microsoft offering on Linux. It is clean, simple enough, and allows someone with my productivity workflow to thrive. I really dig what Hiri has to offer, and it’s as simple as that.
+
+#### Experiencing the Hiri UI
+
+As far as design goes, Hiri gets a solid A from me. I never felt like I was using something outdated looking like [Evolution][15] (I know people like Evolution a lot, but to say it is clean and modern is a lie), it never felt overly complicated like [KMail][16], and it felt less cramped than Thunderbird. Though I love Thunderbird dearly, the inbox list is just a little too small to feel like I can really cipher through my emails in a decent amount of time. Hiri seemingly fixes this but adds another issue that may be even worse.
+
+![][17]
+
+Geary is an email client that I think does layouts just right. It is spacious, but not in a wasteful way, it is clean, simple, and allows me to get from point A to point B quickly. Hiri, on the other hand, falls just shy of layout heaven. Though the inbox list looks fantastic, when you click to read an email it takes up the whole screen. Whereas Geary or Thunderbird can be set up to have the user’s list of emails on the left and opened emails in the same window on the right, which is my preferred way to read email, Hiri does not allow this functionality. The layout either looks and functions like it belongs on a mobile device, or the email preview is below the email list instead of to the right. This isn’t a make or break issue for me, but I will be honest and say I really don’t like it.
+
+In my opinion, Hiri could work even better with a couple of tweaks. But that opinion is just that, an opinion. Hiri is modern, clean, and intuitive enough, I am just obnoxiously picky. Other than that, the color palette is beautiful, the soft edges are pretty stunning, and Hiri’s overall design language is a breath of fresh air in the, at times, outdated feel that is oh so common in the Linux application world.
+
+Also, this isn’t Hiri’s fault but since I installed the Hiri snap it still has the same cursor theme issue that many other snaps suffer from, which drives me UP A WALL when I move in and out of the application, so there’s that.
+
+#### How much does Hiri cost?
+
+![Hiri is compatible with Microsoft Active Directory][18]
+
+Hiri is neither free nor open source software. [Hiri costs][19] either up to $39 a year or $119 for a lifetime license. However, it does provide a free seven day trial period.
+
+Considering the features it provides, Hiri is a good product even if you don’t have to deal with Microsoft Exchange Servers. Don’t take my word for it. Give Hiri a try for free for the seven day trial and see for yourself if it is worth paying or not.
+
+And if you decide to purchase it, I have further good news for you. Hiri team has agreed to provide an exclusive 60% discount to It’s FOSS readers. All you have to do is to use coupon code ITSFOSS60 at checkout.
+
+[Get 60% Off with ITSFOSS60 Coupon Code][20]
+
+#### Conclusion
+
+In the end, Hiri is an amazingly beautiful piece of software that checks so many boxes for me. That being said, the three marks that it misses for me are collectively too big to overlook: the layout, the cost, and the freedom (or lack thereof). If you are someone who is really in need of a native client, the layout does not bother you, you can justify spending some money, and you don’t want or need it to be FOSS, then you may have just found your new email client!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/hiri-email-review/
+
+作者:[Phillip Prado][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/phillip/
+[1]:https://itsfoss.com/protonmail/
+[2]:https://itsfoss.com/tutanota-review/
+[3]:https://www.thunderbird.net/en-US/
+[4]:https://wiki.gnome.org/Apps/Geary
+[5]:http://getmailspring.com/
+[6]:https://en.wikipedia.org/wiki/Microsoft_Exchange_Server
+[7]:https://www.hiri.com/
+[8]:https://itsfoss.com/best-email-clients-linux/
+[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/hiri-email-client-review.jpeg
+[10]:https://www.hiri.com/skills/
+[11]:https://en.wikipedia.org/wiki/Active_Directory
+[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri2-e1533106054811.png
+[13]:https://snapcraft.io/hiri
+[14]:https://www.kde.org/plasma-desktop
+[15]:https://wiki.gnome.org/Apps/Evolution
+[16]:https://www.kde.org/applications/internet/kmail/
+[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri3-e1533106099642.png
+[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/Hiri1-e1533106238745.png
+[19]:https://www.hiri.com/pricing/
+[20]:https://www.hiri.com/download/
diff --git a/sources/tech/20180801 Migrating Perl 5 code to Perl 6.md b/sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
new file mode 100644
index 0000000000..0399fd7a62
--- /dev/null
+++ b/sources/tech/20180801 Migrating Perl 5 code to Perl 6.md
@@ -0,0 +1,77 @@
+Migrating Perl 5 code to Perl 6
+======
+
+
+
+Whether you are a programmer who is taking the first steps to convert your Perl 5 code to Perl 6 and encountering some issues or you're just interested in learning about what might happen if you try to port Perl 5 programs to Perl 6, this article should answer your questions.
+
+The [Perl 6 documentation][1] already contains most (if not all) the [documentation you need][2] to deal with the issues you will confront in migrating Perl 5 code to Perl 6. But, as documentation goes, the focus is on the factual differences. I will try to go a little more in-depth about specific issues and provide a little more hands-on information based on my experience porting quite a lot of Perl 5 code to Perl 6.
+
+### How is Perl 6 anyway?
+
+Very well, thank you! Since its first official release in December 2015, Rakudo Perl 6 has seen an order of magnitude of improvement and quite a few bug fixes (more than 14,000 commits in total). Seven books about Perl 6 have been published so far. [Learning Perl 6][3] by Brian D. Foy will soon be published by O'Reilly, having been re-worked from the seminal [Learning Perl][4] (aka "The Llama Book") that many people have come to know and love.
+
+The user distribution [Rakudo Star][5] is on a three-month release cycle, and more than 1,100 modules are available in the [Perl 6 ecosystem][6]. The Rakudo Compiler Release is on a monthly release cycle and typically contains contributions by more than 30 people. Perl 6 modules are uploaded to the Perl programming Authors Upload Server ([PAUSE][7]) and distributed all over the world using the Comprehensive Perl Archive Network ([CPAN][8]).
+
+The online [Perl 6 Introduction][9] document has been translated into 12 languages, teaching over 3 billion people about Perl 6 in their native language. The most recent incarnation of [Perl 6 Weekly][10] has been reporting on all things Perl 6 every week since February 2014.
+
+[Cro][11], a microservices framework, uses all of Perl 6's features from the ground up, providing HTTP 1.1 persistent connections, HTTP 2.0 with request multiplexing, and HTTPS with optional certificate authority out of the box. And a [Perl 6 IDE][12] is now in (paid) beta (think of it as a Kickstarter with immediate deliverables).
+
+### Using Perl 5 features in Perl 6
+
+Perl 5 code can be seamlessly integrated with Perl 6 using the [`Inline::Perl5`][13] module, making all of [CPAN][14] available to any Perl 6 program. This could be considered cheating, as it will embed a Perl 5 interpreter and therefore continues to have a dependency on the `perl` (5) runtime. But it does make it easy to get your Perl 6 code running (if you need access to modules that have not yet been ported) simply by adding `:from` to your `use` statement, like `use DBI:from;`.
+
+In January 2018, I proposed a [CPAN Butterfly Plan][15] to convert Perl 5 functionality to Perl 6 as closely as possible to the original API. I stated this as a goal because Perl 5 (as a programming language) is so much more than syntax alone. Ask anyone what Perl's unique selling point is, and they will most likely tell you it is CPAN. Therefore, I think it's time to move from this view of the Perl universe:
+
+
+
+to a more modern view:
+
+
+
+In other words: put CPAN, as the most important element of Perl, in the center.
+
+### Converting semantics
+
+To run Perl 5 code natively in Perl 6, you also need a lot of Perl 5 semantics. Having (optional) support for Perl 5 semantics available in Perl 6 lowers the conceptual threshold that Perl 5 programmers perceive when trying to program in Perl 6. It's easier to feel at home!
+
+Since the publication of the CPAN Butterfly Plan, more than 100 built-in Perl 5 functions are now supported in Perl 6 with the same API. Many functions already exist in Perl 6 but have slightly different semantics, e.g., `shift` in Perl 5 magically shifts from `@_` (or `@ARGV`) if no parameter is specified; in Perl 6 the parameter is obligatory.
+
+More than 50 Perl 5 CPAN distributions have also been ported to Perl 6 while adhering to the original Perl 5 API. These include core modules such as [Scalar::Util][16] and [List::Util][17], but also non-core modules such as [Text::CSV][18] and [Memoize][19]. Distributions that are upstream on the [River of CPAN][20] are targeted to have as much effect on the ecosystem as possible.
+
+### Summary
+
+Rakudo Perl 6 has matured in such a way that using Perl 6 is now a viable approach to creating new, interactive projects. Being able to use reliable and proven Perl 5 language components aids in lowering the threshold for developers to use Perl 6, and it builds towards a situation where the sum of Perl 5 and Perl 6 becomes greater than its parts.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/migrating-perl-5-perl-6
+
+作者:[Elizabeth Mattijsen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/lizmat
+[1]:https://docs.perl6.org/
+[2]:https://docs.perl6.org/language/5to6-overview
+[3]:https://www.learningperl6.com
+[4]:http://shop.oreilly.com/product/0636920049517.do
+[5]:https://rakudo.org/files
+[6]:https://modules.perl6.org
+[7]:https://pause.perl.org/pause/query?ACTION=pause_04about
+[8]:https://www.cpan.org
+[9]:https://perl6intro.com
+[10]:https://p6weekly.wordpress.com
+[11]:https://cro.services
+[12]:https://commaide.com
+[13]:http://modules.perl6.org/dist/Inline::Perl5:cpan:NINE
+[14]:https://metacpan.org
+[15]:https://www.perl.com/article/an-open-letter-to-the-perl-community/
+[16]:https://modules.perl6.org/dist/Scalar::Util
+[17]:https://modules.perl6.org/dist/List::Util
+[18]:https://modules.perl6.org/dist/Text::CSV
+[19]:https://modules.perl6.org/dist/Memoize
+[20]:http://neilb.org/2015/04/20/river-of-cpan.html
diff --git a/sources/tech/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md b/sources/tech/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
new file mode 100644
index 0000000000..d089637650
--- /dev/null
+++ b/sources/tech/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
@@ -0,0 +1,370 @@
+6 Easy Ways to Check User Name And Other Information in Linux
+======
+This is very basic topic, everyone knows how to find a user information in Linux using **id** command. Some of the users are filtering a user information from **/etc/passwd** file.
+
+We also using these commands to get a user information.
+
+You may ask, Why are you discussing this basic topic? Even i thought the same, there is no other ways except this two but we are having some good alternatives too.
+
+Those are giving more detailed information compared with those two, which is very helpful for newbies.
+
+This is one of the basic command which helps admin to find out a user information in Linux. Everything is file in Linux, even user information were stored in a file.
+
+**Suggested Read :**
+**(#)** [How To Check User Created Date On Linux][1]
+**(#)** [How To Check Which Groups A User Belongs To On Linux][2]
+**(#)** [How To Force User To Change Password On Next Login In Linux][3]
+
+All the users are added in `/etc/passwd` file. This keep user name and other related details. Users details will be stored in /etc/passwd file when you created a user in Linux. The passwd file contain each/every user details as a single line with seven fields.
+
+We can find a user information using the below six methods.
+
+ * `id :`Print user and group information for the specified username.
+ * `getent :`Get entries from Name Service Switch libraries.
+ * `/etc/passwd file :`The /etc/passwd file contain each/every user details as a single line with seven fields.
+ * `finger :`User information lookup program
+ * `lslogins :`lslogins display information about known users in the system
+ * `compgen :`compgen is bash built-in command and it will show all available commands for the user.
+
+
+
+### 1) Using id Command
+
+id stands for identity. print real and effective user and group IDs. To print user and group information for the specified user, or for the current user.
+```
+# id daygeek
+uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
+
+```
+
+Below are the detailed information for the above output.
+
+ * **`uid (1000/daygeek):`** It displays user ID & Name
+ * **`gid (1000/daygeek):`** It displays user’s primary group ID & Name
+ * **`groups:`** It displays user’s secondary groups ID & Name
+
+
+
+### 2) Using getent Command
+
+The getent command displays entries from databases supported by the Name Service Switch libraries, which are configured in /etc/nsswitch.conf.
+
+getent command shows user details similar to /etc/passwd file, it shows every user details as a single line with seven fields.
+```
+# getent passwd
+root:x:0:0:root:/root:/bin/bash
+bin:x:1:1:bin:/bin:/sbin/nologin
+daemon:x:2:2:daemon:/sbin:/sbin/nologin
+adm:x:3:4:adm:/var/adm:/sbin/nologin
+lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
+sync:x:5:0:sync:/sbin:/bin/sync
+shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
+halt:x:7:0:halt:/sbin:/sbin/halt
+mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
+uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
+operator:x:11:0:operator:/root:/sbin/nologin
+games:x:12:100:games:/usr/games:/sbin/nologin
+gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
+ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
+nobody:x:99:99:Nobody:/:/sbin/nologin
+dbus:x:81:81:System message bus:/:/sbin/nologin
+vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
+abrt:x:173:173::/etc/abrt:/sbin/nologin
+haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
+ntp:x:38:38::/etc/ntp:/sbin/nologin
+saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
+postfix:x:89:89::/var/spool/postfix:/sbin/nologin
+sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
+tcpdump:x:72:72::/:/sbin/nologin
+centos:x:500:500:Cloud User:/home/centos:/bin/bash
+prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
+apache:x:48:48:Apache:/var/www:/sbin/nologin
+nagios:x:498:498::/var/spool/nagios:/sbin/nologin
+rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
+nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
+magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
+thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
+sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
+
+```
+
+Below are the detailed information about seven fields.
+```
+magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
+
+```
+
+ * **`Username (magesh):`** Username of created user. Characters length should be between 1 to 32.
+ * **`Password (x):`** It indicates that encrypted password is stored at /etc/shadow file.
+ * **`User ID (UID-502):`** It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
+ * **`Group ID (GID-503):`** It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
+ * **`User ID Info (2g Admin - Magesh M):`** It indicates the command field. This field can be used to describe the user information.
+ * **`Home Directory (/home/magesh):`** It indicates the user home directory.
+ * **`shell (/bin/bash):`** It indicates the user’s bash shell.
+
+
+
+If you would like to display only user names from the getent command output, use the below format.
+```
+# getent passwd | cut -d: -f1
+root
+bin
+daemon
+adm
+lp
+sync
+shutdown
+halt
+mail
+uucp
+operator
+games
+gopher
+ftp
+nobody
+dbus
+vcsa
+abrt
+haldaemon
+ntp
+saslauth
+postfix
+sshd
+tcpdump
+centos
+prakash
+apache
+nagios
+rpc
+nrpe
+magesh
+thanu
+sudha
+
+```
+
+To display only home directory users, use the below format.
+```
+# getent passwd | grep '/home' | cut -d: -f1
+centos
+prakash
+magesh
+thanu
+sudha
+
+```
+
+### 3) Using /etc/passwd file
+
+The `/etc/passwd` is a text file that contains each user information, which is necessary to login Linux system. It maintain useful information about users such as username, password, user ID, group ID, user ID info, home directory and shell. The /etc/passwd file contain every user details as a single line with seven fields as described below.
+```
+# cat /etc/passwd
+root:x:0:0:root:/root:/bin/bash
+bin:x:1:1:bin:/bin:/sbin/nologin
+daemon:x:2:2:daemon:/sbin:/sbin/nologin
+adm:x:3:4:adm:/var/adm:/sbin/nologin
+lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
+sync:x:5:0:sync:/sbin:/bin/sync
+shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
+halt:x:7:0:halt:/sbin:/sbin/halt
+mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
+uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
+operator:x:11:0:operator:/root:/sbin/nologin
+games:x:12:100:games:/usr/games:/sbin/nologin
+gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
+ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
+nobody:x:99:99:Nobody:/:/sbin/nologin
+dbus:x:81:81:System message bus:/:/sbin/nologin
+vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
+abrt:x:173:173::/etc/abrt:/sbin/nologin
+haldaemon:x:68:68:HAL daemon:/:/sbin/nologin
+ntp:x:38:38::/etc/ntp:/sbin/nologin
+saslauth:x:499:76:Saslauthd user:/var/empty/saslauth:/sbin/nologin
+postfix:x:89:89::/var/spool/postfix:/sbin/nologin
+sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
+tcpdump:x:72:72::/:/sbin/nologin
+centos:x:500:500:Cloud User:/home/centos:/bin/bash
+prakash:x:501:501:2018/04/12:/home/prakash:/bin/bash
+apache:x:48:48:Apache:/var/www:/sbin/nologin
+nagios:x:498:498::/var/spool/nagios:/sbin/nologin
+rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
+nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
+magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
+thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
+sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
+
+```
+
+Below are the detailed information about seven fields.
+```
+magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
+
+```
+
+ * **`Username (magesh):`** Username of created user. Characters length should be between 1 to 32.
+ * **`Password (x):`** It indicates that encrypted password is stored at /etc/shadow file.
+ * **`User ID (UID-502):`** It indicates the user ID (UID) each user should be contain unique UID. UID (0-Zero) is reserved for root, UID (1-99) reserved for system users and UID (100-999) reserved for system accounts/groups
+ * **`Group ID (GID-503):`** It indicates the group ID (GID) each group should be contain unique GID is stored at /etc/group file.
+ * **`User ID Info (2g Admin - Magesh M):`** It indicates the command field. This field can be used to describe the user information.
+ * **`Home Directory (/home/magesh):`** It indicates the user home directory.
+ * **`shell (/bin/bash):`** It indicates the user’s bash shell.
+
+
+
+If you would like to display only user names from the /etc/passwd file, use the below format.
+```
+# cut -d: -f1 /etc/passwd
+root
+bin
+daemon
+adm
+lp
+sync
+shutdown
+halt
+mail
+uucp
+operator
+games
+gopher
+ftp
+nobody
+dbus
+vcsa
+abrt
+haldaemon
+ntp
+saslauth
+postfix
+sshd
+tcpdump
+centos
+prakash
+apache
+nagios
+rpc
+nrpe
+magesh
+thanu
+sudha
+
+```
+
+To display only home directory users, use the below format.
+```
+# cat /etc/passwd | grep '/home' | cut -d: -f1
+centos
+prakash
+magesh
+thanu
+sudha
+
+```
+
+### 4) Using finger Command
+
+The finger comamnd displays information about the system users. It displays the user’s real name, terminal name and write status (as a ‘‘*’’ after the terminal name if write permission is denied), idle time and login time.
+```
+# finger magesh
+Login: magesh Name: 2g Admin - Magesh M
+Directory: /home/magesh Shell: /bin/bash
+Last login Tue Jul 17 22:46 (EDT) on pts/2 from 103.5.134.167
+No mail.
+No Plan.
+
+```
+
+Below are the detailed information for the above output.
+
+ * **`Login:`** User’s login name
+ * **`Name:`** Additional/Other information about the user
+ * **`Directory:`** User home directory information
+ * **`Shell:`** User’s shell information
+ * **`LAST-LOGIN:`** Date of last login and other information
+
+
+
+### 5) Using lslogins Command
+
+It displays information about known users in the system. By default it will list information about all the users in the system.
+
+The lslogins utility is inspired by the logins utility, which first appeared in FreeBSD 4.10.
+```
+# lslogins -u
+UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
+ 0 root 0 0 00:17:28 root
+500 centos 0 1 Cloud User
+501 prakash 0 0 Apr12/04:08 2018/04/12
+502 magesh 0 0 Jul17/22:46 2g Admin - Magesh M
+503 thanu 0 0 Jul18/00:40 2g Editor - Thanisha M
+504 sudha 0 0 Jul18/01:18 2g Editor - Sudha M
+
+```
+
+Below are the detailed information for the above output.
+
+ * **`UID:`** User id
+ * **`USER:`** Name of the user
+ * **`PWD-LOCK:`** password defined, but locked
+ * **`PWD-DENY:`** login by password disabled
+ * **`LAST-LOGIN:`** Date of last login
+ * **`GECOS:`** Other information about the user
+
+
+
+### 6) Using compgen Command
+
+compgen is bash built-in command and it will show all available commands, aliases, and functions for you.
+```
+# compgen -u
+root
+bin
+daemon
+adm
+lp
+sync
+shutdown
+halt
+mail
+uucp
+operator
+games
+gopher
+ftp
+nobody
+dbus
+vcsa
+abrt
+haldaemon
+ntp
+saslauth
+postfix
+sshd
+tcpdump
+centos
+prakash
+apache
+nagios
+rpc
+nrpe
+magesh
+thanu
+sudha
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/6-easy-ways-to-check-user-name-and-other-information-in-linux/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/prakash/
+[1]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
+[2]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
+[3]:https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
diff --git a/sources/tech/20180802 Getting started with Mu, a Python editor for beginners.md b/sources/tech/20180802 Getting started with Mu, a Python editor for beginners.md
new file mode 100644
index 0000000000..2465a9a106
--- /dev/null
+++ b/sources/tech/20180802 Getting started with Mu, a Python editor for beginners.md
@@ -0,0 +1,69 @@
+Getting started with Mu, a Python editor for beginners
+======
+
+
+
+Mu is a Python editor for beginning programmers, designed to make the learning experience more pleasant. It gives students the ability to experience success early on, which is important anytime you're learning something new.
+
+If you have ever tried to teach young people how to program, you will immediately grasp the importance of [Mu][1]. Most programming tools are written by developers for developers and aren't well-suited for beginning programmers, regardless of their age. Mu, however, was written by a teacher for students.
+
+### Mu's origins
+
+Mu is the brainchild of [Nicholas Tollervey][2] (who I heard speak at PyCon2018 in May). Nicholas is a classically trained musician who became interested in Python and development early in his career while working as a music teacher. He also wrote [Python in Education][3], a free book you can download from O'Reilly.
+
+Nicholas was looking for a simpler interface for Python programming. He wanted something without the complexity of other editors—even the IDLE3 editor that comes with Python—so he worked with [Carrie Ann Philbin][4] , director of education at the Raspberry Pi Foundation (which sponsored his work), to develop Mu.
+
+Mu is an open source application (licensed under [GNU GPLv3][5]) written in Python. It was originally developed to work with the [Micro:bit][6] mini-computer, but feedback and requests from other teachers spurred him to rewrite Mu into a generic Python editor.
+
+### Inspired by music
+
+Nicholas' inspiration for Mu came from his approach to teaching music. He wondered what would happen if we taught programming the way we teach music and immediately saw the disconnect. Unlike with programming, we don't have music boot camps and we don't learn to play an instrument from a book on, say, how to play the flute.
+
+Nicholas says, Mu "aims to be the real thing," because no one can learn Python in 30 minutes. As he developed Mu, he worked with teachers, observed coding clubs, and watched secondary school students as they worked with Python. He found that less is more and keeping things simple improves the finished product's functionality. Mu is only about 3,000 lines of code, Nicholas says.
+
+### Using Mu
+
+To try it out, [download][7] Mu and follow the easy installation instructions for [Linux, Windows, and Mac OS][8]. If, like me, you want to [install it on Raspberry Pi][9], enter the following in the terminal:
+```
+$ sudo apt-get update
+
+$ sudo apt-get install mu
+
+```
+
+Launch Mu from the Programming menu. Then you'll have a choice about how you will use Mu.
+
+
+
+I chose Python 3, which launches an environment to write code; the Python shell is directly below, which allows you to see the code execution.
+
+
+
+The menu is very simple to use and understand, which achieves Mu's purpose—making coding easy for beginning programmers.
+
+[Tutorials][10] and other resources are available on the Mu users' website. On the site, you can also see names of some of the [volunteers][11] who helped develop Mu. If you would like to become one of them and [contribute to Mu's development][12], you are most welcome.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
+
+作者:[Don Watkins][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/don-watkins
+[1]:https://codewith.mu
+[2]:https://us.pycon.org/2018/speaker/profile/194/
+[3]:https://www.oreilly.com/programming/free/python-in-education.csp
+[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
+[5]:https://mu.readthedocs.io/en/latest/license.html
+[6]:http://microbit.org/
+[7]:https://codewith.mu/en/download
+[8]:https://codewith.mu/en/howto/install_with_python
+[9]:https://codewith.mu/en/howto/install_raspberry_pi
+[10]:https://codewith.mu/en/tutorials/
+[11]:https://codewith.mu/en/thanks
+[12]:https://mu.readthedocs.io/en/latest/contributing.html
diff --git a/sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md b/sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
new file mode 100644
index 0000000000..f4c9790df9
--- /dev/null
+++ b/sources/tech/20180802 Walkthrough On How To Use GNOME Boxes.md
@@ -0,0 +1,117 @@
+Walkthrough On How To Use GNOME Boxes
+======
+
+
+
+Boxes or GNOME Boxes is a virtualization software for GNOME Desktop Environment. It is similar to Oracle VirtualBox but features a simple user interface. Boxes also pose some challenge for newbies and VirtualBox users, for instance, on VirtualBox, it is easy to install guest addition image through menu bar but the same is not true for Boxes. Rather, users are encouraged to install additional guest tools from the terminal program within the guest session.
+
+This article will provide a walkthrough on how to use GNOME Boxes by installing the software and actually setting a guest session on the machine. It will also take you through the steps for installing the guest tools and provide some additional tips for Boxes configuration.
+
+### Purpose of virtualization
+
+If you are wondering what is the purpose of virtualization and why most computer experts and developers use them a lot. There is usually a common reason for this: **TESTING**.
+
+Developers who use Linux and writes software for Windows has to test his program on an actual Windows environment before deploying it to the end users. Virtualization makes it possible for him to install and set up a Windows guest session on his Linux computer.
+
+Virtualization is also used by ordinary users who wish to get hands-on with their favorite Linux distro that is still in beta release, without installing it on their physical computer. So in the event the virtual machine crashes, the host is not affected and the important files & documents stored on the physical disk remain intact.
+
+Virtualization allows you to test a software built for another platform/architecture which may include ARM, MIPS, SPARC, etc on your computer equipped with another architecture such as Intel or AMD.
+
+### Installing GNOME Boxes
+
+Launch Ubuntu Software and key in " gnome boxes ". Click the application name to load its installer page and then select the Install button. [][1]
+
+### Extra setup for Ubuntu 18.04
+
+There's a bug in GNOME Boxes on Ubuntu 18.04; it fails to start the Virtual Machine (VM). To remedy that, perform the below two steps on a terminal program:
+
+1. Add the line "group=kvm" to the qemu config file sudo gedit /etc/modprobe.d/qemu-system-x86.conf
+
+2. Add your user account to kvm group sudo usermod -a -G kvm
+
+ [][2]
+
+ After that, logout and re-login again for the changes to take effect.
+
+#### Downloading an image file
+
+You can download an image file/Operating System (OS) from the Internet or within the GNOME Boxes setup itself. However, for this article we'll proceed with the realistic method ie., downloading an image file from the Internet. We'll be configuring Lubuntu on Boxes so head over to this website to download the Linux distro.
+
+[Download][3]
+
+#### To burn or not to burn
+
+If you have no intention to distribute Lubuntu to your friends or install it on a physical machine then it's best not to burn the image file to a blank disc or portable USB drive. Instead just leave it as it is, we'll use it for creating a VM afterward.
+
+#### Starting GNOME Boxes
+
+Below is the interface of GNOME Boxes on Ubuntu - [][4]
+
+The interface is simple and intuitive for newbies to get familiar right away without much effort. Boxes don't feature a menu bar or toolbar, unlike Oracle VirtualBox. On the top left is the New button to create a VM and on the right houses buttons for VM options; delete list or grid view, and configuration (they'll become available when a VM is created).
+
+### Installing an Operating System
+
+Click the New button and choose "Select a file". Select the downloaded Lubuntu image file on the Downloads library and then click Create button.
+
+ [][5]
+
+In case this is your first time installing an OS on a VM, do not panic when the installer pops up a window asking you to erase the disk partition. It's safe, your physical computer hard drive won't be erased, only that the storage space would be allocated for your VM. So on a 1TB hard drive, if you allocate 30 GB for your VM, performing erase partition operation on Boxes would only erase that virtual 30 GB storage drive and not the physical storage.
+
+ _Usually, computer students find virtualization a useful tool for practicing advanced partitioning using UNIX based OS. You can too since there is no risk that would tamper the main OS files._
+
+After installing Lubuntu, you'll be prompted to reboot the computer (VM) to finish the installation process and actually boot from the hard drive. Confirm the operation.
+
+
+
+Sometimes, certain Linux distros hang in the reboot process after installation. The trick is to force shutdown the VM from the options button found on the top right side of the tile bar and then power it on again.
+
+#### Set up Guest tools
+
+By now you might have noticed Lubuntu's screen resolution is small with extra black spaces on the left and right side, and folder sharing is not enabled too. This brings up the need to install guest tools on Lubuntu.
+
+
+
+Launch terminal program from the guest session (not your host terminal program) and install the guest tools using the below command:
+
+sudo apt install spice-vdagent spice-webdavd
+
+After that, reboot Lubuntu and the next boot will set the VM to its appropriate screen resolution; no more extra black spaces on the left and right side. You can resize Boxes window and the guest screen resolution will automatically resize itself.
+
+ [][6]
+
+To share a folder between the host and guest, open Boxes options while the guest is still running and choose Properties. On the Devices & Shares category, click the + button and set up the name. By default, Public folder from the host will be shared with the guest OS. You can configure the directory of your choice. After that is done, launch Lubuntu's file manager program (it's called PCManFM) and click Go menu on the menu bar. Select Network and choose Spice Client Folder. The first time you try to open it a dialog box will pop up asking you which program should handle the network, select PCManFM under Accessories category and the network will be mounted on the desktop. Launch it and there you'll see your shared folder name.
+
+Now you can share files and folders between host and guest computer. Subsequent launch of the network will directly open the shared folder so you don't have to open the folder manually the next time.
+
+ [][7]
+
+#### Where's the OS installed?
+
+Lubuntu is installed as a VM using **GNOME Boxes** but where does it store the disk image?
+
+This question is of particular interest for those who wish to move the huge image file to another partition where there is sufficient storage. The trick is using symlinks which is efficient as it saves more space for Linux root partition and or home partition, depending on how the user set it up during installation. Boxes stores the disk image files to ~/.local/share/gnome-boxes/images folder
+
+### Conclusion
+
+We've successfully set up Lubuntu as a guest OS on our Ubuntu. You can try other variants of Ubuntu such as Kubuntu, Ubuntu MATE, Xubuntu, etc or some random Linux distros which in my opinion would be quite challenging due to varying package management. But there's no harm in wanting to :) You can also try installing other platforms like Microsoft Windows, OpenBSD, etc on your computer as a VM. And by the way, don't forget to leave your opinions in the comment section below.
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
+
+作者:[linuxandubuntu][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxandubuntu.com
+[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-gnome-boxes_orig.jpg
+[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-extras-for-ubuntu-18-04_orig.jpg
+[3]:https://lubuntu.net/
+[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-gnome-boxes_orig.jpg
+[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-os-on-ubuntu-guest-box_orig.jpg
+[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lubuntu-on-gnome-boxes_orig.jpg
+[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-boxes-guest-addition_orig.jpg
diff --git a/translated/talk/20180107 7 leadership rules for the DevOps age.md b/translated/talk/20180107 7 leadership rules for the DevOps age.md
deleted file mode 100644
index 587d7761fb..0000000000
--- a/translated/talk/20180107 7 leadership rules for the DevOps age.md
+++ /dev/null
@@ -1,119 +0,0 @@
-DevOps时代的7个领导准则
-======
-
-
-
-如果[DevOps]最终更多的是关于文化而不是任何其他的技术或者平台,那么请记住:没有终点线。而是继续改变和提高--而且最高管理层并没有通过。
-
-然而,如果期望DevOps能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]让我们考虑7个在DevOps时代更有效的IT领导的想法。
-
-### 1. 向失败说“是的”
-
-“失败”这个词在IT领域中一直包含着特殊的内涵,而且通常是糟糕的意思:服务器失败,备份失败,硬盘驱动器失败-你得了解这些情况。
-
-然而一种健康的DevOps文化取决于重新定义失败-IT领导者在他们的字典里应该重新定义这个单词将它的含义和“机会”对等起来。
-
-“在DevOps之前,我们曾有一种惩罚失败者的文化,”罗伯特·里夫斯说,[Datical][3]的首席技术官兼联合创始人。“我们学到的仅仅是去避免错误。在IT领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
-
-那是过去的一个时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞是失败的。
-
-“那些缓慢的释放并逃避云的公司被恐惧所麻痹-他们将会走向失败,”里夫斯说道。“IT领导者必须拥抱失败并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从其他的错误中学习。一种开放和[安全心里][4]的文化促进学习和提高”
-**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义]]
-### 2. 在管理层渗透开发运营的理念
-
-尽管DevOps文化可以在各个方向有机的发展,那些正在从整体中转变,孤立的IT实践,而且可能遭遇逆风的公司-需要执行领导层的全面支持。你正在传达模糊的信息
-而且可能会鼓励那些愿意推一把的人,这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到领导层完全投入进去并且知道改变已经实际发生了。
-
-“为了成功的实现利益的兑现高层管理必须全力支持DevOps,”来自[Rainforest QA][7]的首席技术官说道。
-
-成为一个DevOps商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
-
-"没有高层管理的统一赞助支持,DevOps的实施将很难成功,"德里克说道。"因此,在转变到DevOps之前在高层中有支持的领导同盟是很重要的。"
-
-### 3. 不要只是声明“DevOps”-要明确它
-即使IT公司也已经开始拥抱欢迎DevOps,每个人可能不是在同一个进程上。
-**[参考我们的相关文章,**][**3 阐明了DevOps和首席技术官们必须在同一进程上**][8] **.]**
-
-造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
-
-“DevOps 对不同的人可能意味着不同的含义,”德里克解释道。“对高管层和副总裁层来说,执行明确的DevOps的目标,清楚的声明期望的成果,充分理解带来的成果将如何使公司的商业受益并且能够衡量和报告成功的过程。”
-
-事实上,在基线和视野之上,DevOps要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT领导者必须为它设置优先级。
-
-“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道。“领导者名需要清楚的将这个过程向公司的其他人阐述清楚告诉他们他们作为这个过程的一份子能够期待的结果。”
-
-### 4. DevOps和技术同样重要
-
-IT领导者们成功的将DevOps商店的这种文化和实践当做一项商业策略,与构建和运营软件的方法相结合。DevOps是将IT从支持部门转向战略部门的推动力。
-
-IT领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且DevOps的文化能够通过自动化和强大的协作加速收益。来自[CYBRIC][9]的首席技术官和联合创始人迈克说道。
-
-事实上,这是一个强烈的趋势通过更多的这些规则在DevOps时代走在前沿。
-
-“促进创新并且鼓励团队成员去聪明的冒险是DevOps文化的一个关键部分,IT领导者们需要在一个持续的基础上清楚的和他们交流,”凯尔说道。
-
-“一个高效的IT领导者需要比以往任何时候都要积极的参与到商业中去,”来自[West Monroe Partners][10]的性能服务部门的主任埃文说道。“每年或季度回顾的日子一去不复返了-你需要欢迎每两周一次的待办事项。[11]你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
-
-### 5. 改变妨碍DevOps目标的任何事情
-
-虽然DevOps的老兵们普遍认为DevOps更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个DevOps商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用过20年的引擎,每次转动钥匙都会冒烟。
-
-展览 A: [自动化][12].这是DevOps成功的重要并行策略。
-
-“IT领导者需要重点强调自动化,”卡伦德说。“这将是DevOps的前期投资,但是如果没有它,DevOps将会很容易被低效吞噬自己而且将会无法完整交付。”
-
-自动化是基石,但改变不止于此。
-
-“领导者们需要推动自动化,监控和持续的交付过程。这意着对现有的实践,过程,团队架构以及规则的很多改变,”Choy说。“领导者们需要改变一切会阻碍隐藏团队去全利实现自动化的因素。”
-
-### 6. 重新思考团队架构和能力指标
-
-当你想改变时...如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
-
-“在这个DevOps的新时代文化中,IT执行者需要采取一个全新的方法来组织架构。”Kail说。“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织,敏捷管理。”
-
-Kail告诉我们在DevOps时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
-
-“根据业务成果和总体的积极影响来衡量主动性,”Kail建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
-
-注意很容易收集的到测量值不是DevOps真正的指标,[Red Hat]的技术专员Gardon Half写到,“DevOps应该把指标以某种形式和商业成果绑定在一起,”他指出。“你可能真的不在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
-
-### 7. 丢弃传统的智慧
-
-如果DevOps时代要求关于IT领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
-
-“是实话,是全部,”Kail说道。“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到DevOps文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
-
-事实上,IT领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
-
-West Monroe Partners的卡伦德分享了一个阻碍DevOps的领导力的例子:未能拥抱IT混合模型和现代的基础架构比如说容器和微服务
-
-“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
-
-**想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15].**
---------------------------------------------------------------------------------
-
-via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
-
-作者:[Kevin Casey][a]
-译者:[译者FelixYFZ](https://github.com/FelixYFZ)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://enterprisersproject.com/user/kevin-casey
-[1]:https://enterprisersproject.com/tags/devops
-[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
-[3]:https://www.datical.com/
-[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
-[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
-[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
-[7]:https://www.rainforestqa.com/
-[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
-[9]:https://www.cybric.io/
-[10]:http://www.westmonroepartners.com/
-[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
-[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
-[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
-[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
-[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
diff --git a/translated/talk/20180115 Why DevSecOps matters to IT leaders.md b/translated/talk/20180115 Why DevSecOps matters to IT leaders.md
deleted file mode 100644
index aaf03510a7..0000000000
--- a/translated/talk/20180115 Why DevSecOps matters to IT leaders.md
+++ /dev/null
@@ -1,86 +0,0 @@
-为什么DevSecOps对领导来说如此重要
-======
-
-
-
-如果[DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
-
-输入术语“DevSecOps.”像任何其他IT术语一样,DevSecOps - 一个整容后的DevOps的后代 -可能容易被炒作和盗用。但这个术语对那些拥抱DevOps文化的领导者们,帮助他们实现其承诺的实践和工具来说具有重要的意义。
-
-说道这里:“DevSecOps”是什么意思?
-
-“DevSecOps是开发、安全、运营的混合,”来自[Datical][2]的首席技术官和联合创始人罗伯特说。“这提醒我们安全对我们的应用程序来说和创建并部署应用到生产中一样重要。”
-**[想阅读其他首席技术官的DevOps文章吗?查阅我们广泛的资源,[DevOps:IT领导者的指南][3].]**
-
-向非技术人员解释DevSecOps的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
-
-”安全团队从历史上一直都被从开发团队中所孤立-每个团队在IT的不同领域都开发了很强的专业能力,”来自红帽安全策的专家Kirsten最近告诉我们。“它不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个CI/CD管道中集成安全实践,工具和自动化来采用DevSecOps.”
-
-"为了能够做的更好,他们正在整合他们的团队-专业的安全人员从开始设计到部署到生产中都嵌入到了应开发团队中了,"她说。“双方都收获了价值-每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。DevOps做的很正确-或者说DevSecOps-提高了IT的安全性。”
-
-IT团队比任何以往都要求要快速频繁的交付服务。DevOps在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
-
-“我们已经采用了DevOps因为它已经被证明通过移除开发和运营之间的阻碍来提高IT的绩效,”Reevess说。“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
-
-### 为什么DevSecOps在此停留
-或许会把DevSecOps看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一流的公民,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
-
-“DevSecOps不只是一个时髦的术语-因为多种原因它是现在和未来IT将呈现的状态,”来自[Sumo Logic]的安全和合规副总裁George说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
-
-此外,DevSecOps的出现可能是DevOps自身逐渐成熟并扎根于IT之中的一个征兆。
-
-“企业中的DevOps文化就在这里,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织对合作和衡量的结果更加满意时,”来自[CYBRIC]
-的首席技术官和联合创始人Mike说道。
-
-在实施DevOps的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
-
-“现在的手工的安全测试方法会继续远远被甩在后面。”
-
-“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动DevSecOps的文化是IT领导者们增加整体的灵活性提供安全保证的唯一途径,”Kail说。
-
-转移安全测试也使开发者受益:而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞,他们能够在开放的较早的阶段验证并解决潜在的问题-经常
-是很少需要或者甚至不需要安全人员的介入。
-
-“做的正确,DevSecOps能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全,”来自[SAS][8]的首席信息安全员Wilson说道。
-
-Wilson指出静态(SAST)和源组合工具(SCA),集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈
-来使之逐渐成为可能。
-
-“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。”Wilson说。他同时指出DevSecOps能够帮助开发者简化更新和打补丁。
-
-DevSecOps并不意味着你不再需要安全组的意见了,就如同DevOps并不意味着你不再需要基础架构专家;它只是帮助减少在生产中发现缺陷的可能性,或者减少导致是降低部署的速度的阻碍,因为缺陷已经在开放周期中被发现解决了。
-
-“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson说道。
-
-### DevSecOps 遇到危机
-
-Sumo Locic's的Gerchow向我们分享了一个在运转中的DevSecOps文化的一个及时的案列:当最近[危机和幽灵]的消息传来的时候,团队的DevSecOps方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow所说的这点对原生云高监管的公司来说特别的重要。
-
-第一步:Gerchow的小的安全团队,都具有一定的开发能力,能够通过Slack和它的主要云供应商协同工作来确保它的基础架构能够在24小时之内完成修复。
-
-“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过Slack自动jira票据进行,通过我们的日志监控和分析解决方案,”Gerchow解释道。
-
-在本质上,它听起来非常像DevOps的文化,匹配正确的人员,进程和工具,但它明确的包括了安全作为文化中的一部分进行混合。
-
-“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发,运维和安全三者是相互独立的,”Gerchow说道."通过一个DevSecOps的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。"
-
---------------------------------------------------------------------------------
-
-via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
-
-作者:[Kevin Casey][a]
-译者:[FelixYFZ](https://github.com/FelixYFZ)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://enterprisersproject.com/user/kevin-casey
-[1]:https://enterprisersproject.com/tags/devops
-[2]:https://www.datical.com/
-[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
-[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
-[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
-[6]:https://www.sumologic.com/
-[7]:https://www.cybric.io/
-[8]:https://www.sas.com/en_us/home.html
-[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
diff --git a/translated/talk/20180128 Being open about data privacy.md b/translated/talk/20180128 Being open about data privacy.md
deleted file mode 100644
index 9d7e4bd87b..0000000000
--- a/translated/talk/20180128 Being open about data privacy.md
+++ /dev/null
@@ -1,95 +0,0 @@
-对数据隐私持开放的态度
-======
-
-
-
-Image by : opensource.com
-
-今天是[数据隐私日][1],(在欧洲叫"数据保护日"),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该免费,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
-1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些列子[3])
-2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
-
-所以实际上,数据隐私对于每个人来说是很重要的。
-
-事实证明,在美国和欧洲之间,人们和政府认为让组织使用的数据的起点是有些不同的。前者通常为实体提供更多的自由度,更愤世嫉俗的是--大型的商业体利用他们收集到的关于我们的数据。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在5月25日,欧洲的观点可以说取得了胜利。
-
-## 通用数据保护条例的影响
-
-那是一个相当全面的声明,其实事实上就是欧盟在2016年通过的一项关于通用数据保护的立法,使它变得可实施。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据--而且涉及的条目范围非常广泛,从你的姓名家庭住址到你的医疗记录以及接通你电脑的IP地址。
-
-通用数据保护条例的重要之处是他并不仅仅适用于欧洲的公司,如果你是阿根廷人,日本人,美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
-
-“哼!” 你可能会这样说,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简答:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你全球总收入百分之四的惩罚。是的,你没听错,是全球总收入不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的IT团队,确保你的行为相当短的时间内是符合要求的。
-
-看上去这和欧盟之外的城市没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是只是在欧盟的城市实施,这将会是一件很有利的事情。2
-
-然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好:事实并非如此,我们一直在丢弃关于我们自己的信息--而且允许公司去使用它。
-
-有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。
-你有付费使用Facebook、推特?谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客-只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
-
-有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(列如,亚马逊正在允许通过Alexa广告)除非我们想要开始为这些所有的免费服务付费,我们需要清除我们所放弃的,而且在我们想要揭发和不想的里面做一些选择。
-
-### 谁是顾客?
-
-关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门4--
-而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去开采这些数据。
-
-然而他们面临的是,随着数据的增长和存储量的不足他们是如何处理的。幸运--而且我是带有讽刺意味的使用了这个词,5大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司的一个极具代表性的列子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
-
-不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售非第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方在他们如何使用上面能有发言权吗?我将把这个问题当做一个练习留给读者去思考。7
-
-### 开放和积极
-
-然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励部门能够将免费开放他们的数据给公众或者其他组织。这项行动目前正在被实施立法。许多
-支援组织--尤其是那些收到公共基金的--正在开始推动同样的活动。即使商业组织也有些许的兴趣。而且,在技术上已经可行了,例如围绕不同的隐私和多方计算上,正在允许我们根据数据设置和不揭露太多关于个人的前提下开采数据--一个历史性的计算问题比你想象的要容易处理的多。
-
-这些对我们来说意味着什么呢?我之前在网站Opensource.com上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件,组织,和这次讨论有关的,数据。让我们假设一下你是A公司要提向另一家公司提供一项服务,客户B。在游戏中有四种不同类型的数据:
- 1. 数据完全开放:对A和B都是可得到的,世界上任何人都可以得到
- 2. 数据是已知的,共享的,和机密的:A和B可得到,但其他人不能得到。
- 3. 数据是公司级别上保密的:A公司可以得到,但B顾客不能
- 4. 数据是顾客级别保密的:B顾客可以得到,但A公司不能
-
-首先,也许我们对数据应该更开放些,将数据默认放到选项一中。如果那些数据对所有人开放--在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的,9
-如果我们能够找到方法将数据放到选项2,3和4中,不是很好嘛--或者至少它们中的一些--在选项一中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
-然而又很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
-
-### 一些具体的措施
-
-我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
- * 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
- * 要默认去加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉--除非数据正在被处理使用否则没有任何借口让数据清晰可见。
- * 当你注册一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
- * 和你的非技术朋友讨论这个话题。
- * 教育你的孩子,你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师交谈在他们的学校中展示。
- * 鼓励你工作志愿服务的组织,或者和他们互动推动数据的默认开放。不是去思考为什么我要使数据开放而是以我为什么不让数据开放开始。
- * 尝试去访问一些开源数据。开采使用它。开发应用来使用它,进行数据分析,画漂亮的图,10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
-
-
-
-1. 我承认你可能尽管不会
-2. 假设你坚信你的个人数据应该被保护。
-3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
-4. 事实上这些机构能够有多开放取决于你所居住的地方。
-5. 假设我是英国人,那是非常非常大的剂量。
-6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
-7. 不,答案是“不”。
-8. 尽管这个列子也同样适用于个人。看看:A可能是Alice,B 可能是BOb...
-9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然--不是那类的数据。
-10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/being-open-about-data-privacy
-
-作者:[Mike Bursell][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者FelixYFZ](https://github.com/FelixYFZ)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/mikecamel
-[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
-[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
-[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
-[4]:https://opensource.com/article/17/11/commonwealth-open-source
-[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
diff --git a/translated/talk/20180305 What-s next in IT automation- 6 trends to watch.md b/translated/talk/20180305 What-s next in IT automation- 6 trends to watch.md
deleted file mode 100644
index f5e93d0a0c..0000000000
--- a/translated/talk/20180305 What-s next in IT automation- 6 trends to watch.md
+++ /dev/null
@@ -1,130 +0,0 @@
-IT自动化的下一步是什么: 6 大趋势
-======
-
-
-
-我们最近介绍了 [促进自动化的因素][1] ,目前正在被人们采用的 [趋势][2], 以及那些刚开始使用自动化部分流程组织 [有用的技巧][3] 。
-
-噢, 我们也分享了在你的公司[如何使用自动化的案例][4] , 以及 [长期成功的关键][5].
-
-现在, 只有一个问题: 自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来。 以下是他们建议IT领域领导需密切关注的六大趋势。
-
-### 1. 机器学习的成熟
-
-对于关于 [机器学习][7]的讨论 (与“自我学习系统”相似的定义),对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次IT自动化浪潮中将扮演着至关重要的角色。
-
-[Advanced Systems Concepts, Inc.][8]公司工程总监 Mehul Amin 指出机器学习是IT自动化下一个关键增长领域之一。
-
-“随着数据化的发展, 自动化软件理应可以自我决策,否则这就是开发人员的责任了”, Amin 说。 “例如, 开发者需要执行构建内容, 但是识别系统最佳执行流程的,可能是由系统内软件分析完成。”
-
-假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或SLA,同样在不需要资源的时候退出以及其他的可能性。
-
-显然不只有 Amin 一个人这样认为。
-
-[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“IT自动化正在走向自我学习的方向” 。“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
-
-Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
-
-### 2. 人工智能催生的自动化
-
-上述原则同样适合 [人工智能][10](但是为独立)的领域。假定新兴的人工智能技术将也会产生新的自动化机会。根据对人工智能的定义,机器学习在短时间内可能会对IT领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。
-
-[SolarWinds][11]公司技术负责人 Patrick Hubbard说,“人工智能(AI)和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
-
-### 3. 这并不意味着不再需要人力
-
-让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
-
-这很可能意味着各种角色的改变以及[全新角色][12]的创造。
-
-但是在可预见的将来,至少,你不必需要机器人鞠躬。
-
-“一台机器只能运行在给定的环境变量中它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于IT专业人员来说,这将是需要培养AI和自动化技能的时代。如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
-
-Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
-
-“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
-
-即使你把机器学习和AI先放在一边,看待一般地IT自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
-
-[Juniper Networks][13]公司自动化首席架构师 Matthew Oswalt ,指出IT自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
-
-在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨3点来应对基础设施的问题。
-
-“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨IT频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨3点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
-
-### 4. 对自动化的焦虑将会减少
-
-SolarWinds公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在IT领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至是科技产业本身。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的“3”时,我们将看到“4”的出现。
-
-“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard说。“自动化历史上的今天为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
-
-自动化还将减少IT领导者神经紧张主题的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助IT部门降低与维护任务相关的安全风险。
-
-他的建议是:“首先在维护活动期间记录和自动化IT资产之间的交互。通过依靠自动化,您不仅可以消除历史上需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的IT组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
-
-**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
-
-### 5. 脚本和自动化工具将持续发展
-
-看到许多组织增加自动化的第一步 - 通常以脚本或自动化工具(有时称为配置管理工具)的形式 - 作为“早期”工作。
-
-但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
-
-[DataVision][18]首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17]等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交货时间。”
-
-**[想了解更多关于Ansible这个方面的知识吗?阅读相关文章:[使用Ansible时的成功秘诀][19]。 ]**
-
-另一个因素是:工具本身将继续变得更先进。
-
-“使用先进的IT自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的,预先测试过的拖放式集成,API作业,丰富的变量使用,参考功能和对象修订历史记录。”
-
-### 6. 自动化开创了新的指标机会
-
-正如我们在此前所说的那样,IT自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
-
-**[ 参见我们的相关文章 [DevOps指标:你在衡量什么重要吗?][20] ]**
-
-实际上,自动化应该打开新的机会。
-
-[Janeiro Digital][21]公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 - 源代码管理,DevOps管道,工作项目跟踪 - 转向API驱动的平台 - 将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
-
-Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测IT所做的一切。
-
-“无论是衡量个人资源还是整体团队,这些指标都可以很强大 - 但应该用大量的背景来衡量。”Collins说,“将这些数据用于高层次趋势并确认定性观察 - 而不是临床评级你的团队。”
-
-**想要更多这样知识, IT领导者?[注册我们的每周电子邮件通讯][22]。**
-
---------------------------------------------------------------------------------
-
-via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
-
-作者:[Kevin Casey][a]
-译者:[MZqk](https://github.com/MZqk)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://enterprisersproject.com/user/kevin-casey
-[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
-[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
-[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
-[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
-[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
-[6]:https://enterprisersproject.com/tags/automation
-[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
-[8]:https://www.advsyscon.com/en-us/
-[9]:https://www.sungardas.com/en/
-[10]:https://enterprisersproject.com/tags/artificial-intelligence
-[11]:https://www.solarwinds.com/
-[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
-[13]:https://www.juniper.net/
-[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
-[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
-[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
-[17]:https://opensource.com/tags/ansible
-[18]:https://datavision.com/
-[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
-[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
-[21]:https://www.janeirodigital.com/
-[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
diff --git a/translated/tech/20170706 Docker Guide Dockerizing Python Django Application.md b/translated/tech/20170706 Docker Guide Dockerizing Python Django Application.md
new file mode 100644
index 0000000000..98fd65b47d
--- /dev/null
+++ b/translated/tech/20170706 Docker Guide Dockerizing Python Django Application.md
@@ -0,0 +1,415 @@
+Docker 指南:Docker 化 Python Django 应用程序
+======
+
+### 目录
+
+1. [我们要做什么?][6]
+
+2. [步骤 1 - 安装 Docker-ce][7]
+
+3. [步骤 2 - 安装 Docker-compose][8]
+
+4. [步骤 3 - 配置项目环境][9]
+ 1. [创建一个新的 requirements.txt 文件][1]
+
+ 2. [创建 Nginx 虚拟主机文件 django.conf][2]
+
+ 3. [创建 Dockerfile][3]
+
+ 4. [创建 Docker-compose 脚本][4]
+
+ 5. [配置 Django 项目][5]
+
+5. [步骤 4 - 构建并运行 Docker 镜像][10]
+
+6. [步骤 5 - 测试][11]
+
+7. [参考][12]
+
+
+Docker 是一个开源项目,为开发人员和系统管理员提供了一个开放平台,作为一个轻量级容器,它可以在任何地方构建,打包和运行应用程序。Docker 在软件容器中自动部署应用程序。
+
+Django 是一个用 Python 编写的 Web 应用程序框架,遵循 MVC(模型-视图-控制器)架构。它是免费的,并在开源许可下发布。它速度很快,旨在帮助开发人员尽快将他们的应用程序上线。
+
+在本教程中,我将逐步向你展示在 Ubuntu 16.04 如何为现有的 Django 应用程序创建 docker 镜像。我们将学习如何 docker 化一个 Python Django 应用程序,然后使用一个 docker-compose 脚本将应用程序作为容器部署到 docker 环境。
+
+为了部署我们的 Python Django 应用程序,我们需要其他 docker 镜像:一个用于 Web 服务器的 nginx docker 镜像和用于数据库的 PostgreSQL 镜像。
+
+### 我们要做什么?
+
+1. 安装 Docker-ce
+
+2. 安装 Docker-compose
+
+3. 配置项目环境
+
+4. 构建并运行
+
+5. 测试
+
+### 步骤 1 - 安装 Docker-ce
+
+在本教程中,我们将重 docker 仓库安装 docker-ce 社区版。我们将安装 docker-ce 社区版和 docker-compose,其支持 compose 文件版本 3(to 校正者:此处不太明白具体意思)。
+
+在安装 docker-ce 之前,先使用 apt 命令安装所需的 docker 依赖项。
+
+```
+sudo apt install -y \
+ apt-transport-https \
+ ca-certificates \
+ curl \
+ software-properties-common
+```
+
+现在通过运行以下命令添加 docker 密钥和仓库。
+
+```
+curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
+sudo add-apt-repository \
+ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \
+ $(lsb_release -cs) \
+ stable"
+```
+
+ [][14]
+
+更新仓库并安装 docker-ce。
+
+```
+sudo apt update
+sudo apt install -y docker-ce
+```
+
+安装完成后,启动 docker 服务并使其能够在每次系统引导时启动。
+
+```
+systemctl start docker
+systemctl enable docker
+```
+
+接着,我们将添加一个名为 'omar' 的新用户并将其添加到 docker 组。
+
+```
+useradd -m -s /bin/bash omar
+usermod -a -G docker omar
+```
+
+ [][15]
+
+以 omar 用户身份登录并运行 docker 命令,如下所示。
+
+```
+su - omar
+docker run hello-world
+```
+
+确保你能从 Docker 获得 hello-world 消息。
+
+ [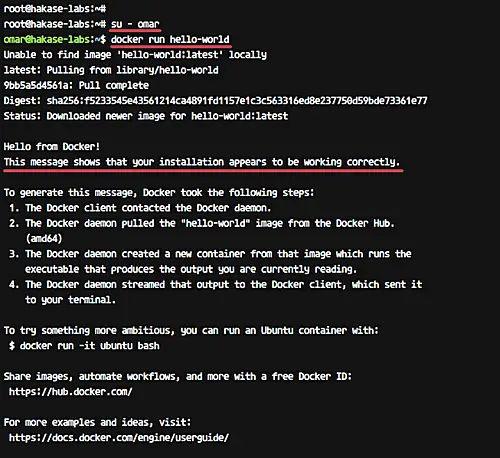][16]
+
+ Docker-ce 安装已经完成。
+
+ ### 步骤 2 - 安装 Docker-compose
+
+在本教程中,我们将使用最新的 docker-compose 支持 compose 文件版本 3。我们将手动安装 docker-compose。
+
+使用 curl 命令将最新版本的 docker-compose 下载到 `/usr/local/bin` 目录,并使用 chmod 命令使其有执行权限。
+
+运行以下命令:
+
+```
+sudo curl -L https://github.com/docker/compose/releases/download/1.21.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
+sudo chmod +x /usr/local/bin/docker-compose
+```
+
+现在检查 docker-compose 版本。
+
+```
+docker-compose version
+```
+
+确保你安装的是最新版本的 docker-compose 1.21。
+
+ [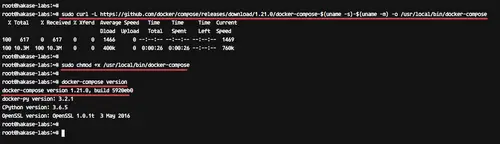][17]
+
+已安装支持 compose 文件版本 3 的 docker-compose 最新版本。
+
+### 步骤 3 - 配置项目环境
+
+在这一步中,我们将配置 Python Django 项目环境。我们将创建新目录 'guide01',并使其成为我们项目文件的主目录,例如 Dockerfile,Django 项目,nginx 配置文件等。
+
+登录到 'omar' 用户。
+
+```
+su - omar
+```
+
+创建一个新目录 'guide01',并进入目录。
+
+```
+mkdir -p guide01
+cd guide01/
+```
+
+现在在 'guide01' 目录下,创建两个新目录 'project' 和 'config'。
+
+```
+mkdir project/ config/
+```
+
+注意:
+
+* 'project' 目录:我们所有的 python Django 项目文件都将放在该目录中。
+
+* 'config' 目录:项目配置文件的目录,包括 nginx 配置文件,python pip requirements 文件等。
+
+### 创建一个新的 requirements.txt 文件
+
+接下来,使用 vim 命令在 'config' 目录中创建一个新的 requirements.txt 文件
+
+```
+vim config/requirements.txt
+```
+
+粘贴下面的配置。
+
+```
+Django==2.0.4
+ gunicorn==19.7.0
+ psycopg2==2.7.4
+```
+
+保存并退出。
+
+### 创建 Dockerfile
+
+在 'guide01' 目录下创建新文件 'Dockerfile'。
+
+运行以下命令。
+
+```
+vim Dockerfile
+```
+
+现在粘贴下面的 Dockerfile 脚本。
+
+```
+FROM python:3.5-alpine
+ ENV PYTHONUNBUFFERED 1
+
+ RUN apk update && \
+ apk add --virtual build-deps gcc python-dev musl-dev && \
+ apk add postgresql-dev bash
+
+ RUN mkdir /config
+ ADD /config/requirements.txt /config/
+ RUN pip install -r /config/requirements.txt
+ RUN mkdir /src
+ WORKDIR /src
+```
+
+保存并退出。
+
+注意:
+
+我们想要为我们的 Django 项目构建基于 Alpine Linux 的 Docker 镜像,Alpine 是最小的 Linux 版本。我们的 Django 项目将运行在带有 Python3.5 的 Alpine Linux 上,并添加 postgresql-dev 包以支持 PostgreSQL 数据库。然后,我们将使用 python pip 命令安装在 'requirements.txt' 上列出的所有 Python 包,并为我们的项目创建新目录 '/src'。
+
+### 创建 Docker-compose 脚本
+
+使用 [vim][18] 命令在 'guide01' 目录下创建 'docker-compose.yml' 文件。
+
+```
+vim docker-compose.yml
+```
+
+粘贴以下配置内容。
+
+```
+version: '3'
+ services:
+ db:
+ image: postgres:10.3-alpine
+ container_name: postgres01
+ nginx:
+ image: nginx:1.13-alpine
+ container_name: nginx01
+ ports:
+ - "8000:8000"
+ volumes:
+ - ./project:/src
+ - ./config/nginx:/etc/nginx/conf.d
+ depends_on:
+ - web
+ web:
+ build: .
+ container_name: django01
+ command: bash -c "python manage.py makemigrations && python manage.py migrate && python manage.py collectstatic --noinput && gunicorn hello_django.wsgi -b 0.0.0.0:8000"
+ depends_on:
+ - db
+ volumes:
+ - ./project:/src
+ expose:
+ - "8000"
+ restart: always
+```
+
+保存并退出。
+
+注意:
+
+使用这个 docker-compose 文件脚本,我们将创建三个服务。使用 PostgreSQL alpine Linux 创建名为 'db' 的数据库服务,再次使用 Nginx alpine Linux 创建 'nginx' 服务,并使用从 Dockerfile 生成的自定义 docker 镜像创建我们的 python Django 容器。
+
+ [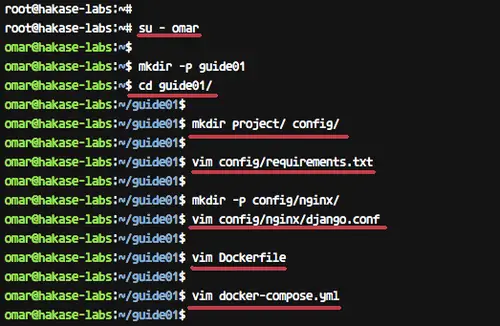][19]
+
+ ### 配置 Django 项目
+
+将 Django 项目文件复制到 'project' 目录。
+
+```
+cd ~/django
+cp -r * ~/guide01/project/
+```
+
+进入 'project' 目录并编辑应用程序设置 'settings.py'。
+
+```
+cd ~/guide01/project/
+vim hello_django/settings.py
+```
+
+注意:
+
+我们将部署名为 'hello_django' 的简单 Django 应用程序。
+
+在 'ALLOW_HOSTS' 行中,添加服务名称 'web'。
+
+```
+ALLOW_HOSTS = ['web']
+```
+
+现在更改数据库设置,我们将使用 PostgreSQL 数据库,'db' 数据库作为服务运行,使用默认用户和密码。
+
+```
+DATABASES = {
+ 'default': {
+ 'ENGINE': 'django.db.backends.postgresql_psycopg2',
+ 'NAME': 'postgres',
+ 'USER': 'postgres',
+ 'HOST': 'db',
+ 'PORT': 5432,
+ }
+ }
+```
+
+至于 'STATIC_ROOT' 配置目录,将此行添加到文件行的末尾。
+
+```
+STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
+```
+
+保存并退出。
+
+ [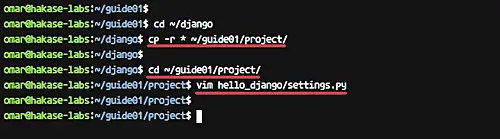][20]
+
+现在我们准备在 docker 容器下构建和运行 Django 项目。
+
+### 步骤 4 - 构建并运行 Docker 镜像
+
+在这一步中,我们想要使用 'guide01' 目录中的配置为我们的 Django 项目构建一个 Docker 镜像。
+
+进入 'guide01' 目录。
+
+```
+cd ~/guide01/
+```
+
+现在使用 docker-compose 命令构建 docker 镜像。
+
+```
+docker-compose build
+```
+
+[][21]
+
+启动 docker-compose 脚本中的所有服务。
+
+```
+docker-compose up -d
+```
+
+等待几分钟让 Docker 构建我们的 Python 镜像并下载 nginx 和 postgresql docker 镜像。
+
+[][22]
+
+完成后,使用以下命令检查运行容器并在系统上列出 docker 镜像。
+
+```
+docker-compose ps
+docker-compose images
+```
+
+现在,你将在系统上运行三个容器并列出 Docker 镜像,如下所示。
+
+[][23]
+
+我们的 Python Django 应用程序现在在 docker 容器内运行,并且已经创建了为我们服务的 docker 镜像。
+
+### 步骤 5 - 测试
+
+打开 Web 浏览器并使用端口 8000 键入服务器地址,我的是:http://ovh01:8000/
+
+现在你将获得默认的 Django 主页。
+
+[][24]
+
+接下来,通过在 URL 上添加 “/admin” 路径来测试管理页面。
+
+http://ovh01:8000/admin/
+
+然后你将会看到 Django admin 登录页面。
+
+[][25]
+
+Docker 化 Python Django 应用程序已成功完成。
+
+### 参考
+
+* [https://docs.docker.com/][13]
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
+
+作者:[Muhammad Arul][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/
+[1]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-a-new-requirementstxt-file
+[2]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-nginx-virtual-host-file-djangoconf
+[3]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-the-dockerfile
+[4]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#create-dockercompose-script
+[5]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#configure-django-project
+[6]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#what-we-will-do
+[7]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockerce
+[8]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-install-dockercompose
+[9]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-configure-project-environment
+[10]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-build-and-run-the-docker-image
+[11]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#step-testing
+[12]:https://www.howtoforge.com/tutorial/docker-guide-dockerizing-python-django-application/#reference
+[13]:https://docs.docker.com/
+[14]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/1.png
+[15]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/2.png
+[16]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/3.png
+[17]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/4.png
+[18]:https://www.howtoforge.com/vim-basics
+[19]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/5.png
+[20]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/6.png
+[21]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/7.png
+[22]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/8.png
+[23]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/9.png
+[24]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/10.png
+[25]:https://www.howtoforge.com/images/docker_guide_dockerizing_python_django_application/big/11.png
diff --git a/translated/tech/20170709 The Extensive Guide to Creating Streams in RxJS.md b/translated/tech/20170709 The Extensive Guide to Creating Streams in RxJS.md
new file mode 100644
index 0000000000..66b0e920e9
--- /dev/null
+++ b/translated/tech/20170709 The Extensive Guide to Creating Streams in RxJS.md
@@ -0,0 +1,1029 @@
+在 RxJS 中创建流的延伸教程
+============================================================
+
+
+
+对大多数开发者来说,RxJS 是以库的形式与之接触,就像 Angular。一些函数会返回流,要使用它们就得把注意力放在操作符上。
+
+有些时候,混用响应式和非响应式代码似乎很有用。然后大家就开始热衷流的创造。不论是在编写异步代码或者是数据处理时,流都是一个不错的方案。
+
+RxJS 提供很多方式来创建流。不管你遇到的是什么情况,都会有一个完美的创建流的方式。你可能根本用不上它们,但了解它们可以节省你的时间,让你少码一些代码。
+
+我把所有可能的方法,按它们的主要目的,分放在四个目录中:
+
+* 流式化现有数据
+
+* 生成数据
+
+* 使用现有 APIs 进行交互
+
+* 选择现有的流,并结合起来
+
+注意:示例用的是 RxJS 6,可能会以前的版本有所不同。已知的区别是你导入函数的方式不同了。
+
+RxJS 6
+
+```
+import {of, from} from 'rxjs';
+```
+
+```
+of(...);
+from(...);
+```
+
+RxJS < 6
+
+```
+import { Observable } from 'rxjs/Observable';
+import 'rxjs/add/observable/of';
+import 'rxjs/add/observable/from';
+```
+
+```
+Observable.of(...);
+Observable.from(...);
+```
+
+```
+//or
+```
+
+```
+import { of } from 'rxjs/observable/of';
+import { from } from 'rxjs/observable/from';
+```
+
+```
+of(...);
+from(...);
+```
+
+流的图示中的标记:
+
+* | 表示流结束了
+
+* X 表示流出现错误并被终结
+
+* … 表示流的走向不定
+
+* * *
+
+### 流式化已有数据
+
+你有一些数据,想把它们放到流中。有三种方式,并且都允许你把调度器当作最后一个参数传入(你如果想深入了解调度器,可以看看我的 [上一篇文章][5])。这些生成的流都是静态的。
+
+#### of
+
+如果只有一个或者一些不同的元素,使用 _of_ :
+
+```
+of(1,2,3)
+ .subscribe();
+```
+
+```
+// 结果
+// 1 2 3 |
+```
+
+#### from
+
+如果有一个数组或者 _可迭代的_ 对象,而且你想要其中的所有元素发送到流中,使用 _from_。你也可以用它来把一个 promise 对象变成可观测的。
+
+```
+const foo = [1,2,3];
+```
+
+```
+from(foo)
+ .subscribe();
+```
+
+```
+// 结果
+// 1 2 3 |
+```
+
+#### pairs
+
+流式化一个对象的键/值对。用这个对象表示字典时特别有用。
+
+```
+const foo = { a: 1, b: 2};
+```
+
+```
+pairs(foo)
+ .subscribe();
+```
+
+```
+// 结果
+// [a,1] [b,2] |
+```
+
+#### 那么其他的数据结构呢?
+
+也许你的数据存储在自定义的结构中,而它又没有实现 _Iterable_ 接口,又或者说你的结构是递归的,树状的。也许下面某种选择适合这些情况:
+
+* 先将数据提取到数组里
+
+* 使用下一节将会讲到的 _generate_ 函数,遍历所有数据
+
+* 创建一个自定义流(见下一节)
+
+* 创建一个迭代器
+
+稍后会讲到选项 2 和 3 ,因此这里的重点是创建一个迭代器。我们可以对一个 _iterable_ 对象调用 _from_ 创建一个流。 _iterable_ 是一个对象,可以产生一个迭代器(如果你对细节感兴趣,参考 [这篇 mdn 文章][6])。
+
+创建一个迭代器的简单方式是 [generator function][7]。当你调用一个生成函数(generator function)时,它返回一个对象,该对象同时遵循 _iterable_ 接口和 _iterator_ 接口。
+
+```
+// 自定义的数据结构
+class List {
+ add(element) ...
+ get(index) ...
+ get size() ...
+ ...
+}
+```
+
+```
+function* listIterator(list) {
+ for (let i = 0; i console.log("foo");
+// 5 秒后打印 foo
+```
+
+大多数定时器将会用来周期性的处理数据:
+
+```
+interval(10000).pipe(
+ flatMap(i => fetch("https://server/stockTicker")
+).subscribe(updateChart)
+```
+
+这段代码每 10 秒获取一次数据,更新屏幕。
+
+#### generate
+
+这是个更加复杂的函数,允许你发送一系列任意类型的对象。它有一些重载,这里你看到的是最有意思的部分:
+
+```
+generate(
+ 0, // 从这个值开始
+ x => x < 10, // 条件:只要值小于 10,就一直发送
+ x => x*2 // 迭代:前一个值加倍
+).subscribe();
+```
+
+```
+// 结果
+// 1 2 4 8 |
+```
+
+你也可以用它来迭代值,如果一个结构没有实现 _Iterable_ 接口。我们用前面的 list 例子来进行演示:
+
+```
+const myList = new List();
+myList.add(1);
+myList.add(3);
+```
+
+```
+generate(
+ 0, // 从这个值开始
+ i => i < list.size, // 条件:发送数据,直到遍历完整个列表
+ i => ++i, // 迭代:获取下一个索引
+ i => list.get(i) // 选择器:从列表中取值
+).subscribe();
+```
+
+```
+// 结果
+// 1 3 |
+```
+
+如你所见,我添加了另一个参数:选择器(selector)。它和 _map_ 操作符作用类似,将生成的值转换为更有用的东西。
+
+* * *
+
+### 空的流
+
+有时候你要传递或返回一个不用发送任何数据的流。有三个函数分别用于不同的情况。你可以给这三个函数传递调度器。_empty_ 和 _throwError_ 接收一个调度器参数。
+
+#### empty
+
+创建一个空的流,一个值也不发送。
+
+```
+empty()
+ .subscribe();
+```
+
+```
+// 结果
+// |
+```
+
+#### never
+
+创建一个永远不会结束的流,仍然不发送值。
+
+```
+never()
+ .subscribe();
+```
+
+```
+// 结果
+// ...
+```
+
+#### throwError
+
+创建一个流,流出现错误,不发送数据。
+
+```
+throwError('error')
+ .subscribe();
+```
+
+```
+// 结果
+// X
+```
+
+* * *
+
+### 挂钩已有的 API
+
+不是所有的库和所有你之前写的代码使用或者支持流。幸运的是 RxJS 提供函数用来桥接非响应式和响应式代码。这一节仅仅讨论 RxJS 为桥接代码提供的模版。
+
+你可能还对这篇出自 [Ben Lesh][9] 的 [延伸阅读][8] 感兴趣,这篇文章讲了几乎所有能与 promises 交互操作的方式。
+
+#### from
+
+我们已经用过它,把它列在这里是因为,它可以封装一个含有 observable 对象的 promise 对象。
+
+```
+from(new Promise(resolve => resolve(1)))
+ .subscribe();
+```
+
+```
+// 结果
+// 1 |
+```
+
+#### fromEvent
+
+fromEvent 为 DOM 元素添加一个事件监听器,我确定你知道这个。但你可能不知道的是,也可以通过其它类型来添加事件监听器,例如,一个 jQuery 对象。
+
+```
+const element = $('#fooButton'); // 从 DOM 元素中创建一个 jQuery 对象
+```
+
+```
+from(element, 'click')
+ .subscribe();
+```
+
+```
+// 结果
+// clickEvent ...
+```
+
+#### fromEventPattern
+
+要理解为什么有 fromEvent 了还需要 fromEventPattern,我们得先理解 fromEvent 是如何工作的。看这段代码:
+
+```
+from(document, 'click')
+ .subscribe();
+```
+
+这告诉 RxJS 我们想要监听 document 中的点击事件。在提交过程中,RxJS 发现 document 是一个 _EventTarget_ 类型,因此它可以调用它的 _addEventListener_ 方法。如果我们传入的是一个 jQuery 对象而非 document,那么 RxJs 知道它得调用 _on_ 方法。
+
+这个例子用的是 _fromEventPattern_,和 _fromEvent_ 的工作基本上一样:
+
+```
+function addClickHandler(handler) {
+ document.addEventListener('click', handler);
+}
+```
+
+```
+function removeClickHandler(handler) {
+ document.removeEventListener('click', handler);
+}
+```
+
+```
+fromEventPattern(
+ addClickHandler,
+ removeClickHandler,
+)
+.subscribe(console.log);
+```
+
+```
+// 等效于
+fromEvent(document, 'click')
+```
+
+RxJS 自动创建实际的监听器( _handler_ )你的工作是添加或者移除监听器。_fromEventPattern_ 的目的基本上是告诉 RxJS 如何注册和移除事件监听器。
+
+现在想象一下你使用了一个库,你可以调用一个叫做 _registerListener_ 的方法。我们不能再用 _fromEvent_,因为它并不知道该怎么处理这个对象。
+
+```
+const listeners = [];
+```
+
+```
+class Foo {
+ registerListener(listener) {
+ listeners.push(listener);
+ }
+```
+
+```
+ emit(value) {
+ listeners.forEach(listener => listener(value));
+ }
+}
+```
+
+```
+const foo = new Foo();
+```
+
+```
+fromEventPattern(listener => foo.registerListener(listener))
+ .subscribe();
+```
+
+```
+foo.emit(1);
+```
+
+```
+// Produces
+// 1 ...
+```
+
+当我们调用 foo.emit(1) 时,RxJS 中的监听器将被调用,然后它就能把值发送到流中。
+
+你也可以用它来监听多个事件类型,或者结合所有可以通过回调进行通讯的 API,例如,WebWorker API:
+
+```
+const myWorker = new Worker('worker.js');
+```
+
+```
+fromEventPattern(
+ handler => { myWorker.onmessage = handler },
+ handler => { myWorker.onmessage = undefined }
+)
+.subscribe();
+```
+
+```
+// 结果
+// workerMessage ...
+```
+
+#### bindCallback
+
+它和 fromEventPattern 相似,但它能用于单个值。就在回调函数被调用时,流就结束了。用法当然也不一样 —— 你可以用 bindCallBack 封装函数,然后它就会在调用时魔术般的返回一个流:
+
+```
+function foo(value, callback) {
+ callback(value);
+}
+```
+
+```
+// 没有流
+foo(1, console.log); //prints 1 in the console
+```
+
+```
+// 有流
+const reactiveFoo = bindCallback(foo);
+// 当我们调用 reactiveFoo 时,它返回一个 observable 对象
+```
+
+```
+reactiveFoo(1)
+ .subscribe(console.log); // 在控制台打印 1
+```
+
+```
+// 结果
+// 1 |
+```
+
+#### websocket
+
+是的,你完全可以创建一个 websocket 连接然后把它暴露给流:
+
+```
+import { webSocket } from 'rxjs/webSocket';
+```
+
+```
+let socket$ = webSocket('ws://localhost:8081');
+```
+
+```
+// 接收消息
+socket$.subscribe(
+ (msg) => console.log('message received: ' + msg),
+ (err) => console.log(err),
+ () => console.log('complete') * );
+```
+
+```
+// 发送消息
+socket$.next(JSON.stringify({ op: 'hello' }));
+```
+
+把 websocket 功能添加到你的应用中真的很简单。_websocket_ 创建一个 subject。这意味着你可以订阅它,通过调用 _next_ 来获得消息和发送消息。
+
+#### ajax
+
+如你所知:类似于 websocket,提供 AJAX 查询的功能。你可能用了一个带有 AJAX 功能的库或者框架。或者你没有用,那么我建议使用 fetch(或者必要的话用 polyfill),把返回的 promise 封装到一个 observable 对象中(参考稍后会讲到的 _defer_ 函数)。
+
+* * *
+
+### Custom Streams
+
+有时候已有的函数用起来并不是足够灵活。或者你需要对订阅有更强的控制。
+
+#### Subject
+
+subject 是一个特殊的对象,它使得你的能够把数据发送到流中,并且能够控制数据。subject 本身就是一个 observable 对象,但如果你想要把流暴露给其它代码,建议你使用 _asObservable_ 方法。这样你就不能意外调用原始方法。
+
+```
+const subject = new Subject();
+const observable = subject.asObservable();
+```
+
+```
+observable.subscribe();
+```
+
+```
+subject.next(1);
+subject.next(2);
+subject.complete();
+```
+
+```
+// 结果
+// 1 2 |
+```
+
+注意在订阅前发送的值将会“丢失”:
+
+```
+const subject = new Subject();
+const observable = subject.asObservable();
+```
+
+```
+subject.next(1);
+```
+
+```
+observable.subscribe(console.log);
+```
+
+```
+subject.next(2);
+subject.complete();
+```
+
+```
+// 结果
+// 2
+```
+
+除了常规的 subject,RxJS 还提供了三种特殊的版本。
+
+_AsyncSubject_ 在结束后只发送最后的一个值。
+
+```
+const subject = new AsyncSubject();
+const observable = subject.asObservable();
+```
+
+```
+observable.subscribe(console.log);
+```
+
+```
+subject.next(1);
+subject.next(2);
+subject.complete();
+```
+
+```
+// 输出
+// 2
+```
+
+_BehaviorSubject_ 使得你能够提供一个(默认的)值,如果当前没有其它值发送的话,这个值会被发送给每个订阅者。否则订阅者收到最后一个发送的值。
+
+```
+const subject = new BehaviorSubject(1);
+const observable = subject.asObservable();
+```
+
+```
+const subscription1 = observable.subscribe(console.log);
+```
+
+```
+subject.next(2);
+subscription1.unsubscribe();
+```
+
+```
+// 输出
+// 1
+// 2
+```
+
+```
+const subscription2 = observable.subscribe(console.log);
+```
+
+```
+// 输出
+// 2
+```
+
+The _ReplaySubject_ 存储一定数量、或一定时间或所有的发送过的值。所有新的订阅者将会获得所有存储了的值。
+
+```
+const subject = new ReplaySubject();
+const observable = subject.asObservable();
+```
+
+```
+subject.next(1);
+```
+
+```
+observable.subscribe(console.log);
+```
+
+```
+subject.next(2);
+subject.complete();
+```
+
+```
+// 输出
+// 1
+// 2
+```
+
+你可以在 [ReactiveX documentation][10](它提供了一些其它的连接) 里面找到更多关于 subjects 的信息。[Ben Lesh][11] 在 [On The Subject Of Subjects][12] 上面提供了一些关于 subjects 的理解,[Nicholas Jamieson][13] 在 [in RxJS: Understanding Subjects][14] 上也提供了一些理解。
+
+#### Observable
+
+你可以简单地用 new 操作符创建一个 observable 对象。通过你传入的函数,你可以控制流,只要有人订阅了或者它接收到一个可以当成 subject 使用的 observer,这个函数就会被调用,比如,调用 next,complet 和 error。
+
+让我们回顾一下列表示例:
+
+```
+const myList = new List();
+myList.add(1);
+myList.add(3);
+```
+
+```
+new Observable(observer => {
+ for (let i = 0; i {
+ // 流式化
+```
+
+```
+ return () => {
+ //clean up
+ };
+})
+.subscribe();
+```
+
+#### 继承 Observable
+
+在有可用的操作符前,这是一种实现自定义操作符的方式。RxJS 在内部扩展了 _Observable_。_Subject_ 就是一个例子,另一个是 _publisher_ 操作符。它返回一个 _ConnectableObservable_ 对象,该对象提供额外的方法 _connect_。
+
+#### 实现 Subscribable 接口
+
+有时候你已经用一个对象来保存状态,并且能够发送值。如果你实现了 Subscribable 接口,你可以把它转换成一个 observable 对象。Subscribable 接口中只有一个 subscribe 方法。
+
+```
+interface Subscribable { subscribe(observerOrNext?: PartialObserver | ((value: T) => void), error?: (error: any) => void, complete?: () => void): Unsubscribable}
+```
+
+* * *
+
+### 结合和选择现有的流
+
+知道怎么创建一个独立的流还不够。有时候你有好几个流但其实只需要一个。有些函数也可作为操作符,所以我不打算在这里深入展开。推荐看看 [Max NgWizard K][16] 所写的一篇 [文章][15],它还包含一些有趣的动画。
+
+还有一个建议:你可以通过拖拽元素的方式交互式的使用结合操作,参考 [RxMarbles][17]。
+
+#### ObservableInput 类型
+
+期望接收流的操作符和函数通常不单独和 observables 一起工作。相反,他们实际上期望的参数类型是 ObservableInput,定义如下:
+
+```
+type ObservableInput = SubscribableOrPromise | ArrayLike | Iterable;
+```
+
+这意味着你可以传递一个 promises 或者数组却不需要事先把他们转换成 observables。
+
+#### defer
+
+主要的目的是把一个 observable 对象的创建延迟(defer)到有人想要订阅的时间。在以下情况,这很有用:
+
+* 创建 observable 对象的开销较大
+
+* 你想要给每个订阅者新的 observable 对象
+
+* 你想要在订阅时候选择不同的 observable 对象
+
+* 有些代码必须在订阅之后执行
+
+最后一点包含了一个并不起眼的用例:Promises(defer 也可以返回一个 promise 对象)。看看这个用到了 fetch API 的例子:
+
+```
+function getUser(id) {
+ console.log("fetching data");
+ return fetch(`https://server/user/${id}`);
+}
+```
+
+```
+const userPromise = getUser(1);
+console.log("I don't want that request now");
+```
+
+```
+// 其它地方
+userPromise.then(response => console.log("done");
+```
+
+```
+// 输出
+// fetching data
+// I don't want that request now
+// done
+```
+
+只要流在你订阅的时候执行了,promise 就会立即执行。我们调用 getUser 的瞬间,就发送了一个请求,哪怕我们这个时候不想发送请求。当然,我们可以使用 from 来把一个 promise 对象转换成 observable 对象,但我们传递的 promise 对象已经创建或执行了。defer 让我们能够等到订阅才发送这个请求:
+
+```
+const user$ = defer(() => getUser(1));
+```
+
+```
+console.log("I don't want that request now");
+```
+
+```
+// 其它地方
+user$.subscribe(response => console.log("done");
+```
+
+```
+// 输出
+// I don't want that request now
+// fetching data
+// done
+```
+
+#### iif
+
+ _iif 包含了一个关于 _defer_ 的特殊用例:在订阅时选择两个流中的一个:
+
+```
+iif(
+ () => new Date().getHours() < 12,
+ of("AM"),
+ of("PM")
+)
+.subscribe();
+```
+
+```
+// 结果
+// AM before noon, PM afterwards
+```
+
+引用了文档:
+
+> 实际上 `[iif][3]` 能够轻松地用 `[defer][4]` 实现,它仅仅是出于方便和可读性的目的。
+
+#### onErrorResumeNext
+
+开启第一个流并且在失败的时候继续进行下一个流。错误被忽略掉。
+
+```
+const stream1$ = of(1, 2).pipe(
+ tap(i => { if(i>1) throw 'error'}) //fail after first element
+);
+```
+
+```
+const stream2$ = of(3,4);
+```
+
+```
+onErrorResumeNext(stream1$, stream2$)
+ .subscribe(console.log);
+```
+
+```
+// 结果
+// 1 3 4 |
+```
+
+如果你有多个 web 服务,这就很有用了。万一主服务器开启失败,那么备份的服务就能自动调用。
+
+#### forkJoin
+
+它让流并行运行,当流结束时发送存在数组中的最后的值。由于每个流只有最后一个值被发送,它一般用在只发送一个元素的流的情况,就像 HTTP 请求。你让请求并行运行,在所有流收到响应时执行某些任务。
+
+```
+function handleResponses([user, account]) {
+ // 执行某些任务
+}
+```
+
+```
+forkJoin(
+ fetch("https://server/user/1"),
+ fetch("https://server/account/1")
+)
+.subscribe(handleResponses);
+```
+
+#### merge / concat
+
+发送每一个从源 observables 对象中发出的值。
+
+ _merge_ 接收一个参数,让你定义有多少流能被同时订阅。默认是无限制的。设为 1 就意味着监听一个源流,在它结束的时候订阅下一个。由于这是一个常见的场景,RxJS 为你提供了一个显示的函数:_concat_。
+
+```
+merge(
+ interval(1000).pipe(mapTo("Stream 1"), take(2)),
+ interval(1200).pipe(mapTo("Stream 2"), take(2)),
+ timer(0, 1000).pipe(mapTo("Stream 3"), take(2)),
+ 2 //two concurrent streams
+)
+.subscribe();
+```
+
+```
+// 只订阅流 1 和流 2
+```
+
+```
+// 输出
+// Stream 1 -> after 1000ms
+// Stream 2 -> after 1200ms
+// Stream 1 -> after 2000ms
+```
+
+```
+// 流 1 结束后,开始订阅流 3
+```
+
+```
+// 输出
+// Stream 3 -> after 0 ms
+// Stream 2 -> after 400 ms (2400ms from beginning)
+// Stream 3 -> after 1000ms
+```
+
+```
+
+merge(
+ interval(1000).pipe(mapTo("Stream 1"), take(2)),
+ interval(1200).pipe(mapTo("Stream 2"), take(2))
+ 1
+)
+// 等效于
+concat(
+ interval(1000).pipe(mapTo("Stream 1"), take(2)),
+ interval(1200).pipe(mapTo("Stream 2"), take(2))
+)
+```
+
+```
+// 输出
+// Stream 1 -> after 1000ms
+// Stream 1 -> after 2000ms
+// Stream 2 -> after 3200ms
+// Stream 2 -> after 4400ms
+```
+
+#### zip / combineLatest
+
+ _merge_ 和 _concat_ 一个接一个的发送所有从源流中读到的值,而 zip 和 combineLatest 是把每个流中的一个值结合起来一起发送。_zip_ 结合所有源流中发送的第一个值。如果流的内容相关联,那么这就很有用。
+
+```
+zip(
+ interval(1000),
+ interval(1200),
+)
+.subscribe();
+```
+
+```
+// 结果
+// [0, 0] [1, 1] [2, 2] ...
+```
+
+_combineLatest_ 与之类似,但结合的是源流中发送的最后一个值。直到所有源流至少发送一个值之后才会触发事件。这之后每次源流发送一个值,它都会把这个值与其他流发送的最后一个值结合起来。
+
+```
+combineLatest(
+ interval(1000),
+ interval(1200),
+)
+.subscribe();
+```
+
+```
+// 结果
+// [0, 0] [1, 0] [1, 1] [2, 1] ...
+```
+
+两个函数都让允许传递一个选择器函数,把元素结合成其它对象而不是数组:
+
+```
+zip(
+ interval(1000),
+ interval(1200),
+ (e1, e2) -> e1 + e2
+)
+.subscribe();
+```
+
+```
+// 结果
+// 0 2 4 6 ...
+```
+
+#### race
+
+选择第一个发送数据的流。产生的流基本是最快的。
+
+```
+race(
+ interval(1000),
+ of("foo")
+)
+.subscribe();
+```
+
+```
+// 结果
+// foo |
+```
+
+由于 _of_ 立即产生一个值,因此它是最快的流,然而这个流就被选中了。
+
+* * *
+
+### 总结
+
+已经有很多创建 observables 对象的方式了。如果你想要创造响应式的 APIs 或者想用响应式的 API 结合传统 APIs,那么了解这些方法很重要。
+
+我已经向你展示了所有可用的方法,但它们其实还有很多内容可以讲。如果你想更加深入地了解,我极力推荐你查阅 [documentation][20] 或者阅读相关文章。
+
+[RxViz][21] 是另一种值得了解的有意思的方式。你编写 RxJS 代码,产生的流可以用图形或动画进行显示。
+
+--------------------------------------------------------------------------------
+
+via: https://blog.angularindepth.com/the-extensive-guide-to-creating-streams-in-rxjs-aaa02baaff9a
+
+作者:[Oliver Flaggl][a]
+译者:[BriFuture](https://github.com/BriFuture)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://blog.angularindepth.com/@abetteroliver
+[1]:https://rxjs-dev.firebaseapp.com/api/index/Subscribable
+[2]:https://rxjs-dev.firebaseapp.com/api/index/Subscribable#subscribe
+[3]:https://rxjs-dev.firebaseapp.com/api/index/iif
+[4]:https://rxjs-dev.firebaseapp.com/api/index/defer
+[5]:https://itnext.io/concurrency-and-asynchronous-behavior-with-rxjs-11b0c4b22597
+[6]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols
+[7]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/function*
+[8]:https://medium.com/@benlesh/rxjs-observable-interop-with-promises-and-async-await-bebb05306875
+[9]:https://medium.com/@benlesh
+[10]:http://reactivex.io/documentation/subject.html
+[11]:https://medium.com/@benlesh
+[12]:https://medium.com/@benlesh/on-the-subject-of-subjects-in-rxjs-2b08b7198b93
+[13]:https://medium.com/@cartant
+[14]:https://blog.angularindepth.com/rxjs-understanding-subjects-5c585188c3e1
+[15]:https://blog.angularindepth.com/learn-to-combine-rxjs-sequences-with-super-intuitive-interactive-diagrams-20fce8e6511
+[16]:https://medium.com/@maximus.koretskyi
+[17]:http://rxmarbles.com/#merge
+[18]:https://rxjs-dev.firebaseapp.com/api/index/ObservableInput
+[19]:https://rxjs-dev.firebaseapp.com/api/index/SubscribableOrPromise
+[20]:http://reactivex.io/documentation/operators.html#creating
+[21]:https://rxviz.com/
diff --git a/sources/tech/20170805 How to use Fio (Flexible I-O Tester) to Measure Disk Performance in Linux.md b/translated/tech/20170805 How to use Fio (Flexible I-O Tester) to Measure Disk Performance in Linux.md
similarity index 66%
rename from sources/tech/20170805 How to use Fio (Flexible I-O Tester) to Measure Disk Performance in Linux.md
rename to translated/tech/20170805 How to use Fio (Flexible I-O Tester) to Measure Disk Performance in Linux.md
index c2659f3664..d811ebad20 100644
--- a/sources/tech/20170805 How to use Fio (Flexible I-O Tester) to Measure Disk Performance in Linux.md
+++ b/translated/tech/20170805 How to use Fio (Flexible I-O Tester) to Measure Disk Performance in Linux.md
@@ -1,47 +1,41 @@
-How to use Fio (Flexible I/O Tester) to Measure Disk Performance in Linux
+
+如何在 Linux 中使用 Fio 来测评硬盘性能
======

-Fio which stands for Flexible I/O Tester [is a free and open source][1] disk I/O tool used both for benchmark and stress/hardware verification developed by Jens Axboe.
+Fio(Flexible I/O Tester) 是一款由 Jens Axboe 开发的用于测评和压力/硬件验证的[免费开源][1]的软件
-It has support for 19 different types of I/O engines (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, and more), I/O priorities (for newer Linux kernels), rate I/O, forked or threaded jobs, and much more. It can work on block devices as well as files.
+它支持 19 种不同类型的 I/O 引擎 (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, 以及更多), I/O 优先级(针对较新的 Linux 内核),I/O 速度,复刻或线程任务,和其他更多的东西。它能够在块设备和文件上工作。
-Fio accepts job descriptions in a simple-to-understand text format. Several example job files are included. Fio displays all sorts of I/O performance information, including complete IO latencies and percentiles.
+Fio 接受一种非常简单易于理解的文本格式作为任务描述。软件默认包含了许多示例任务文件。 Fio 展示了所有类型的 I/O 性能信息,包括完整的 IO 延迟和百分比。
-It is in wide use in many places, for both benchmarking, QA, and verification purposes. It supports Linux, FreeBSD, NetBSD, OpenBSD, OS X, OpenSolaris, AIX, HP-UX, Android, and Windows.
+它被广泛的应用在非常多的地方,包括测评、QA,以及验证用途。它支持 Linux 、 FreeBSD 、 NetBSD、 OpenBSD、 OS X、 OpenSolaris、 AIX、 HP-UX、 Android 以及 Windows。
-In this tutorial, we will be using Ubuntu 16 and you are required to have sudo or root privileges to the computer. We will go over the installation and use of fio.
+在这个教程,我们将使用 Ubuntu 16 ,你需要拥有这台电脑的 sudo 或 root 权限。我们将完整的进行安装和 Fio 的使用。
-### Installing fio from Source
+### 使用源码安装 Fio
+
+我们要去克隆 Github 上的仓库。安装所需的依赖,然后我们将会从源码构建应用。首先,确保我们安装了 Git 。
-We are going to clone the repo on GitHub. Install the prerequisites, and then we will build the packages from the source code. Lets' start by making sure we have git installed.
```
-
sudo apt-get install git
-
-
```
-For centOS users you can use:
+CentOS 用户可以执行下述命令:
```
-
sudo yum install git
-
-
```
-Now we change directory to /opt and clone the repo from Github:
-```
+现在,我们切换到 /opt 目录,并从 Github 上克隆仓库:
+```
cd /opt
git clone https://github.com/axboe/fio
-
-
```
-You should see the output below:
-```
+你应该会看到下面这样的输出
+```
Cloning into 'fio'...
remote: Counting objects: 24819, done.
remote: Compressing objects: 100% (44/44), done.
@@ -49,72 +43,59 @@ remote: Total 24819 (delta 39), reused 62 (delta 32), pack-reused 24743
Receiving objects: 100% (24819/24819), 16.07 MiB | 0 bytes/s, done.
Resolving deltas: 100% (16251/16251), done.
Checking connectivity... done.
-
-
```
-Now, we change directory into the fio codebase by typing the command below inside the opt folder:
-```
+现在,我们通过在 opt 目录下输入下方的命令切换到 Fio 的代码目录:
+```
cd fio
-
-
```
-We can finally build fio from source using the `make` build utility bu using the commands below:
-```
+最后,我们可以使用下面的命令来使用 `make` 从源码构建软件:
+```
# ./configure
# make
# make install
-
-
```
-### Installing fio on Ubuntu
+### 在 Ubuntu 上安装 Fio
-For Ubuntu and Debian, fio is available on the main repository. You can easily install fio using the standard package managers such as yum and apt-get.
+对于 Ubuntu 和 Debian 来说, Fio 已经在主仓库内。你可以很容易的使用类似 yum 和 apt-get 的标准包管理器来安装 Fio。
+
+对于 Ubuntu 和 Debian ,你只需要简单的执行下述命令:
-For Ubuntu and Debian you can simple use:
```
-
sudo apt-get install fio
-
-
```
-For CentOS/Redhat you can simple use:
-On CentOS, you might need to install EPEL repository to your system before you can have access to fio. You can install it by running the following command:
-```
+对于 CentOS/Redhat 你只需要简单执行下述命令:
+在 CentOS ,你可能在你能安装 Fio 前需要去安装 EPEL 仓库到你的系统中。你可以通过执行下述命令来安装它:
+```
sudo yum install epel-release -y
-
-
```
-You can then install fio using the command below:
-```
+你可以执行下述命令来安装 Fio:
+```
sudo yum install fio -y
-
-
```
-### Disk Performace testing with Fio
+### 使用 Fio 进行磁盘性能测试
-With Fio is installed on your system. It's time to see how to use Fio with some examples below. We are going to perform a random write, read and read and write test.
-### Performing a Random Write Test
+现在 Fio 已经安装到了你的系统中。现在是时候看一些如何使用 Fio 的例子了。我们将进行随机写、读和读写测试。
+
+### 执行随机写测试
+
+执行下面的命令来开始。这个命令将要同一时间执行两个进程,写入共计 4GB( 4 个任务 x 512MB = 2GB) 文件:
-Let's start by running the following command. This command will write a total 4GB file [4 jobs x 512 MB = 2GB] running 2 processes at a time:
```
-
sudo fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=0 --size=512M --numjobs=2 --runtime=240 --group_reporting
-
-
-```
```
+```
...
fio-2.2.10
Starting 2 processes
@@ -147,9 +128,9 @@ Disk stats (read/write):
```
-### Performing a Random Read Test
+### 执行随机读测试
-We are going to perform a random read test now, we will be trying to read a random 2Gb file
+我们将要执行一个随机读测试,我们将会尝试读取一个随机的 2GB 文件。
```
sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --direct=0 --size=512M --numjobs=4 --runtime=240 --group_reporting
@@ -157,7 +138,7 @@ sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --
```
-You should see the output below:
+你应该会看到下面这样的输出
```
...
@@ -199,21 +180,18 @@ Disk stats (read/write):
```
-Finally, we want to show a sample read-write test to see how the kind out output that fio returns.
+最后,我们想要展示一个简单的随机读-写测试来看一看 Fio 返回的输出类型。
-### Read Write Performance Test
+### 读写性能测试
+
+下述命令将会测试 USB Pen 驱动器 (/dev/sdc1) 的随机读写性能:
-The command below will measure random read/write performance of USB Pen drive (/dev/sdc1):
```
-
sudo fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75
-
-
```
-Below is the outout we get from the command above.
+下面的内容是我们从上面的命令得到的输出:
```
-
fio-2.2.10
Starting 1 process
Jobs: 1 (f=1): [m(1)] [100.0% done] [217.8MB/74452KB/0KB /s] [55.8K/18.7K/0 iops] [eta 00m:00s]
@@ -233,19 +211,19 @@ Run status group 0 (all jobs):
Disk stats (read/write):
sda: ios=774141/258944, merge=1463/899, ticks=748800/150316, in_queue=900720, util=99.35%
-
-
```
We hope you enjoyed this tutorial and enjoyed following along, Fio is a very useful tool and we hope you can use it in your next debugging activity. If you enjoyed reading this post feel free to leave a comment of questions. Go ahead and clone the repo and play around with the code.
+我们希望你能喜欢这个教程并且享受接下来的内容,Fio 是一个非常有用的工具,并且我们希望你能在你下一次 Debugging 活动中使用到它。如果你喜欢这个文章,欢迎留下评论和问题。
+
--------------------------------------------------------------------------------
via: https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/
作者:[Alex Pearson][a]
-译者:[译者ID](https://github.com/译者ID)
+译者:[Bestony](https://github.com/bestony)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md b/translated/tech/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md
deleted file mode 100644
index 420d9ed9f9..0000000000
--- a/translated/tech/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md
+++ /dev/null
@@ -1,146 +0,0 @@
-对Ubuntu标准用户的一个高级系统配置程序
-======
-
-
-
-
-**Ubunsys** 是一个基于Qt 的高级系统程序,可以在Ubuntu和其他Ubuntu系列衍生系统上使用.大多数情况下,高级用户可以使用命令行轻松完成大多数配置.
-不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如Linux Mint,Elementary OS 等. Ubunsys 可用来修改系统配置,安装,删除,更新包和旧内核,启用或禁用sudo 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的Ubuntu 系统升级到最新版本等等
-以上提到的所有功能都可以通过鼠标点击完成.你不需要再依赖于命令行模式,下面是你能用Ubunsys 做到的事:
-
-
- * 安装,删除,更新包
- * 更新和升级软件源
- * 安装主线内核
- * 删除旧的和不再使用的内核
- * 系统整体更新
- * 将系统升级到下一个可用的版本
- * 将系统升级到最新的开发版本
- * 清理系统垃圾文件
- * 在不输入密码的情况下启用或者禁用sudo 权限
- * 当你在terminal输入密码时使Sudo 密码可见
- * 启用或禁用系统冬眠
- * 启用或禁用防火墙
- * 打开,备份和导入 sources.list.d 和sudoers 文件.
- * 显示或者隐藏启动项
- * 启用或禁用登录音效
- * 配置双启动
- * 启用或禁用锁屏
- * 智能系统更新
- * 使用脚本管理器更新/一次性执行脚本
- * 从git执行常规用户安装脚本
- * 检查系统完整性和缺失的GPG keys.
- * 修复网络
- * 修复已破损的包
- * 还有更多功能在开发中
-
-**重要提示:** Ubunsys 不适用于Ubuntu 新手.它很危险并且没有一个稳定的版本.它可能会使你的系统崩溃.如果你刚接触Ubuntu不久,不要使用.但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险.在使用这一应用之前记着备份你自己的重要数据
-
-### Ubunsys - 对Ubuntu标准用户的一个高级系统配置程序
-
-#### 安装 Ubunsys
-
-
-Ubunusys 开发者制作了一个ppa 来简化安装过程,Ubunusys现在可以在Ubuntu 16.04 LTS, Ubuntu 17.04 64 位版本上使用.
-
-逐条执行下面的命令,将Ubunsys的PPA 添加进去,并安装它
-```
-sudo add-apt-repository ppa:adgellida/ubunsys
-
-sudo apt-get update
-
-sudo apt-get install ubunsys
-
-```
-
-
-如果ppa 无法使用,你可以在[**发布页面**][1]根据你自己当前系统,选择正确的安装包,直接下载并安装Ubunsys
-
-#### 用途
-
-一旦安装完成,从菜单栏启动Ubunsys.下图是Ubunsys 主界面
-
-![][3]
-
-你可以看到,Ubunusys 有四个主要部分,分别是 **Packages** , **Tweaks** , **System** ,和**Repair**. 在每一个标签项下面都有一个或多个子标签项以对应不同的操作
-
-
-**Packages**
-
-这一部分允许你安装,删除和更新包
-
-![][4]
-
-**Tweaks**
-
-在这一部分,我们可以对系统进行多种调整,例如,
-
- * 打开,备份和导入 sources.list.d 和sudoers 文件;
- * 配置双启动;
- * 启用或禁用登录音效,防火墙,锁屏,系统冬眠,sudo 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用sudo 权限(在不需要密码的情况下)
- * 在terminal 中输入密码时可见(禁用Asterisk).
-
-
-
-![][5]
-
-**System**
-
-这一部分被进一步分成3个部分,每个都是针对某一特定用户.
-
-**Normal user** 这一标签下的选项可以,
-
- * 更新,升级包和软件源
- * 清理系统
- * 执行常规用户安装脚本
-
-
-
-**Advanced user** 这一标签下的选项可以,
-
-* 清理旧的/无用的内核
-* 安装主线内核
-* 智能包更新
-* 升级系统
-
-
-
-
-**Developer** 这一部分可以将系统升级到最新的开发版本
-
-![][6]
-
-**Repair**
-
-这是Ubunsys 的第四个也是最后一个部分.正如名字所示,这一部分能让我们修复我们的系统,网络,缺失的GPG keys,和已经缺失的包
-
-![][7]
-
-
-正如你所见,Ubunsys可以在几次点击下就能完成诸如系统配置,系统维护和软件维护之类的任务.你不需要一直依赖于Terminal. Ubunsys 能帮你完成任何高级任务.再次声明,我警告你,这个应用不适合新手,而且它并不稳定.所以当你使用的时候,可能会出现bug或者系统崩溃.在仔细研究过每一个选项的影响之后再使用它.
-
-谢谢阅读!
-
-**参考资源:**
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
-
-作者:[SK][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://github.com/adgellida/ubunsys/releases
-[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
-[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
-[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
-[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
-[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
diff --git a/translated/tech/20171003 Streams a new general purpose data structure in Redis.md b/translated/tech/20171003 Streams a new general purpose data structure in Redis.md
deleted file mode 100644
index 39da54d0cf..0000000000
--- a/translated/tech/20171003 Streams a new general purpose data structure in Redis.md
+++ /dev/null
@@ -1,165 +0,0 @@
-streams:一个新的 Redis 通用数据结构
-==================================
-
-直到几个月以前,对于我来说,在消息传递的环境中,streams 只是一个有趣且相对简单的概念。在 Kafka 流行这个概念之后,我主要研究它们在 Disque 实例中的用途。Disque 是一个将会转化为 Redis 4.2 的模块的消息队列。后来我发现 Disque 全都是 AP 消息,它将在不需要客户端过多参与的情况下实现容错和保证送达,因此,我认为 streams 的概念在那种情况下并不适用。
-
-但是,在 Redis 中有一个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis 列表、排序集和发布/订阅(Pub/Sub)能力上有某些缺陷。你可以合适地使用这些工具去模拟一个消息或事件的序列,而有所权衡。排序集是大量耗费内存的,不能自然的模拟一次又一次的相同消息的传递,客户端不能阻塞新消息。因为一个排序集并不是一个序列化的数据结构,它是一个根据它们量的变化而移动的元素集:它不是很像时间系列一样的东西。列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中部是什么,因为在那种情况下,访问时间是线性的。此外,没有任何的指定输出功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。对于一到多的工作负载,这里有发布/订阅,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:保留一个历史是很重要的,而不是断开之后重新获得消息,也因为某些消息列表,像时间系列,在用范围查询浏览时,是非常重要的:在这 10 秒范围内我的温度读数是多少?
-
-这有一种方法可以尝试处理上面的问题,我计划对排序集进行通用化,并列入一个唯一的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而结束。一个关于 Redis 数据结构导出的更好的想法是,让它更像天然的计算机科学的数据结构,而不是,“Salvatore 发明的 API”。因此,在最后我停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许,我将为发布/订阅增加一些历史信息,或者将来对列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说“你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
-
-### 起源
-
-在将 Redis 4.0 中的模块介绍完之后,用户开始去看他们自己怎么去修复这些问题。他们之一,Timothy Downs,通过 IRC 写信给我:
-
- 这个模块,我计划去增加一个事务日志式的数据类型 - 这意味着大量的订阅者可以在没有大量的内存增加的情况下做一些像发布/订阅那样的事情
- 订阅者保持他在消息队列中的位置,而不是在 Redis 上维护每个客户和复制消息的每个订阅者
-
-这激发了我的想像力。我想了几天,并且意识到这可能是我们立刻同时解决上面的问题的契机。我需要去重新想像 “日志” 的概念是什么。它是个基本的编程元素,每个人都使用到它,因为它是非常简单地在追加模式中打开一个文件并以一定的格式写入数据,数据结构必须是抽象的。然而 Redis ,它们在内存中,并且我们使用 RAM 并不是因为我们懒,但是,因为使用一些指针,我们可以概念化数据结构并让他们抽象,并允许他们去摆脱明显的限制。对于实例,正常的日志有几个问题:偏移不是逻辑的,但是,它是一个真实的字节偏移,如果你想逻辑偏移是什么,那是与条目插入的时间相关的,我们有范围查询可用。同样的,一个日志通常很难收集:在一个只追加的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只是说,我想要最大的条目数,而旧的元素一个也不要,等等。
-
-当我从 Timothy 的想法,去尝试着写一个规范的时候,我使用了 radix 树去实现,它是用于 Redis 集群的,去优化它内部的某些部分。这为实现一个有效的空间日志提供了基础。它在对数的时间(logarithmic time)内得到范围是仍然可访问的。同时,我开始去读关于 Kafka 流,去得到另外的创意,它也非常适合我的设计,并且产生了一个 Kafka 客户组的概念,并且,将它理想化用于 Redis 和内存中(in-memory)使用的案例。然而,该规范仅保留了几个月,在一段时间后,我积累了与别人讨论的即将增加到 Redis 中的内容,为了升级它,使用了许多提示(hint)几乎从头到尾重写了一遍。我想 Redis 流尤其对于时间系列是非常有用的,而不仅是用于事件和消息类的应用程序。
-
-让我们写一些代码
-=====================
-
-从 Redis 会议回来后,在整个夏天,我实现了一个称为 “listpack” 的库。这个库是 ziplist.c 的继承者,那是一个表示在单个分配中字符串元素的列表的数据结构。它是一个非常专业的序列化格式,有在相反的顺序中可解析的特性,从右到左: 在所有的用户案例中用于替代 ziplists 中所需的某些东西。
-
-结合 radix 树 + listpacks,它可以很容易地去构建一个日志,它同时也是非常高效的,并且是索引化的,意味着,允许通过 IDs 和时间进行随机访问。自从实现这个方法后,为了实现流数据结构,我开始去写一些代码。我直到完成实现,不管怎样,在这个时候,在 Github 上的 Redis 内部的 “streams” 分支,去启动共同开发并接受订阅已经足够了。我并没有声称那个 API 是最终版本,但是,这有两个有趣的事实:一是,在那时,仅客户组是缺失的,加上一些不那么重要的命令去操作流,但是,所有的大的方面都已经实现了。二是,一旦各个方面比较稳定了之后 ,决定将所有的流的工作移植到 4.0 分支,它大约两个月后发布。这意味着 Redis 用户为了使用流,不用等待 Redis 4.2,它们将对生产使用的 ASAP 可用。这是可能的,因为有一个新的数据结构,几乎所有的代码改变都是独立于新代码的。除了阻塞列表操作之外 :代码都重构了,因此,我们和流共享了相同的代码,并且,列表阻塞操作在 Redis 内部进行了大量的简化。
-
-教程:欢迎使用 Redis 流
-==================================
-
-在某种程序上,你应该感谢流作为 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,它们更多是一个域(fields)和值(values)组成的对象。范围查询更适用而且更快。流中的每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以阻塞等待(blocking-wait)比指定的 IDs 更大的元素。Redis 流的一个基本的命令是 XADD。是的,所有的 Redis 命令都是以一个“X”为前缀的。
-
-> XADD mystream * sensor-id 1234 temperature 10.5
-1506871964177.0
-
-这个 XADD 命令将追加指定的条目作为一个新元素到一个指定的流 “mystream” 中。在上面的示例中的这个条目有两个域:sensor-id 和 temperature,然而,每个条目在同一个流中可以有不同的域。使用相同的域名字将导致更多的内存使用。一个有趣的事情是,域的排序是保证保存的。XADD 仅返回插入的条目的 ID,因为在第三个参数中有星号(*),我们请求命令去自动生成 ID。这几乎总是你想要的,但是,它也可能去强制指定一个 ID,实例为了去复制这个命令到被动服务器和 AOF 文件。
-
-这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。1506871964177 是毫秒时间,它仅是一个使用毫秒解决方案的 UNIX 时间。圆点(.)后面的数字 0,是一个序列号,它是为了区分相同毫秒数的条目增加上去的。所有的数字都是 64 位的无符号整数。这意味着在流中,我们可以增加所有我们想要的条目,在相同毫秒数中的事件。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目之间的最大值来获取。因此,对实例来说,即使是计算机时间向后跳,这个 IDs 仍然是增加的。在某些情况下,你可能想流条目的 IDs 作为完整的 128 位数字。然而,现实是,它们与被添加的实例的本地时间有关,意味着我们有毫秒级的精确的范围查询。
-
-如你想像的那样,以一个快速的方式去添加两个条目,结果是仅序列号增加。我可以使用一个 MULTI/EXEC 块去简单模拟“快速插入”,如下:
-
-> MULTI
-OK
-> XADD mystream * foo 10
-QUEUED
-> XADD mystream * bar 20
-QUEUED
-> EXEC
-1) 1506872463535.0
-2) 1506872463535.1
-
-在上面的示例中,也展示了无需在开始时指定任何模式(schema)的情况下,对不同的条目,使用不同的域。会发生什么呢?每个块(它通常包含 50 - 150 个消息范围的内容)的每一个信息被用作参考。并且,有相同域的连续条目被使用一个标志进行压缩,这个标志表明“这个块中的第一个条目的相同域”。因此,对于连续消息使用相同域可以节省许多内存,即使是域的集合随着时间发生缓慢变化。
-
-为了从流中检索数据,这里有两种方法:范围查询,它是通过 XRANGE 命令实现的,并且对于正在变化的流,通过 XREAD 命令去实现。XRANGE 命令仅取得包括从开始到停止范围内的条目。因此,对于实例,如果我知道它的 ID,我可以取得单个条目,像这样:
-
-> XRANGE mystream 1506871964177.0 1506871964177.0
-1) 1) 1506871964177.0
- 2) 1) "sensor-id"
- 2) "1234"
- 3) "temperature"
- 4) "10.5"
-
-然而,你可以使用指定的开始符号 “-” 和停止符号 “+” 去表示可能的最小和最大 ID。为了限制返回条目的数量,它也可以使用 COUNT 选项。下面是一个更复杂的 XRANGE 示例:
-
-> XRANGE mystream - + COUNT 2
-1) 1) 1506871964177.0
- 2) 1) "sensor-id"
- 2) "1234"
- 3) "temperature"
- 4) "10.5"
-2) 1) 1506872463535.0
- 2) 1) "foo"
- 2) "10"
-
-这里我们讲的是 IDs 的范围,然后,为了在一个给定时间范围内取得特定元素的范围,你可以使用 XRANGE,因为你可以省略 IDs 的“序列” 部分。因此,你可以做的仅是指定“毫秒”时间,下面的命令的意思是: “从 UNIX 时间 1506872463 开始给我 10 个条目”:
-
-127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
-1) 1) 1506872463535.0
- 2) 1) "foo"
- 2) "10"
-2) 1) 1506872463535.1
- 2) 1) "bar"
- 2) "20"
-
-关于 XRANGE 注意的最重要的事情是,由于我们在回复中收到了 IDs,并且连续 ID 是无法直接获得的,因为 ID 的序列部分是增加的,它可以使用 XRANGE 去遍历整个流,接收每个调用的元素的特定个数。在 Redis 中的*SCAN*系列命令之后,那是允许 Redis 数据结构迭代的,尽管事实上它们不是为迭代设计的,我以免再次产生相同的错误。
-
-使用 XREAD 处理变化的流:阻塞新的数据
-===========================================
-
-XRANGE 用于,当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去得到单个元素时,是非常完美的。然而,在当数据到达时,不同的客户端必须同时使用流的情况下,它就不是一个很好的解决方案,并且它是需要某种形式的“池”的。(对于*某些*应用程序来说,这可能是个好主意,因为它们仅是偶尔连接取数的)。
-
-XREAD 命令是为读设计的,同时从多个流中仅指定我们得到的流中的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,去解除阻塞。类似于阻塞列表操作产生的效果,但是,这里的数据是从流中得到的。并且多个客户端可以在同时访问相同的数据。
-
-这里有一个关于 XREAD 调用的规范示例:
-
-> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
-
-它的意思是:从 “mystream” 和 “otherstream” 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。之后我们用关键字 STREAMS 指定我们想要监听的流,和最后的 ID,指定的 ID “$” 意思是:假设我现在已经有了流中的所有元素,因此,从下一个到达的元素开始给我。
-
-如果,从另外一个客户端,我发出这样的命令:
-
-> XADD otherstream * message “Hi There”
-
-在 XREAD 侧会出现什么情况呢?
-
-1) 1) "otherstream"
- 2) 1) 1) 1506935385635.0
- 2) 1) "message"
- 2) "Hi There"
-
-和到过的数据一起,我们得到了最新到达的数据的 key,在下次的调用中,我们将使用接收到的最新消息的 ID:
-
-> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
-
-依次类推。然而需要注意的是使用方式,有可能客户端在一个非常大的延迟(因为它处理消息需要时间,或者其它什么原因)之后再次连接。在这种情况下,同时会有很多消息堆积,为了确保客户端不被消息淹没,并且服务器不会丢失太多时间的提供给单个客户端的大量消息,所以,总是使用 XREAD 的 COUNT 选项是明智的。
-
-流封顶
-==============
-
-到现在为止,一直还都不错… 然而,有些时候,流需要去删除一些旧的消息。幸运的是,这可以使用 XADD 命令的 MAXLEN 选项去做:
-
-> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
-
-它是基本意思是,如果流添加的新元素被发现超过 1000000 个消息,那么,删除旧的消息,以便于长度回到 1000000 个元素以内。它很像是使用 RPUSH + LTRIM 的列表,但是,这是我们使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将使用一些 CPU 资源,所以,在计算 MAXLEN 的之前,尽可能使用 “~” 符号,为了表明我们不是要求非常*精确*的 1000000 个消息。但是,这里有很多,它还不是一个大的问题:
-
-> XADD mystream MAXLEN ~ 1000000 * foo bar
-
-这种方式的 XADD 删除消息,仅用于当它可以删除整个节点的时候。相比 vanilla XADD,这种方式几乎可以自由地对流进行封顶。
-
-(进程内工作的)客户组
-==================================
-
-这是不在 Redis 中实现的第一个特性,但是,它是在进程内工作的。它也是来自 Kafka 的灵感,尽管在这里以不同的方式去实现的。重点是使用了 XREAD,客户端也可以增加一个 “GROUP ” 选项。 在相同组的所有客户端自动调用,以得到*不同的*消息。当然,这里不能从同一个流中被多个组读。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在不同的组,消息是不会重复的。
-
-当指定组时,尽可能指定一个 “RETRY ” 选项去扩展组:在这种情况下,如果消息没有使用 XACK 去进行确认,它将在指定的毫秒数后进行再次投递。这种情况下,客户端没有私有的方法去标记已处理的消息,这也是一项正在进行中的工作。
-
-内存使用和节省的加载时间
-=====================================
-
-因为被设计用来模拟 Redis 流,所以,根据它们的域的数量、值和长度,内存使用是显著降低的。但对于简单的消息,每 100 MB 内存使用可以有几百万条消息,此外,设想中的格式去需要极少的系列化:是存储为 radix 树节点的 listpack 块,在磁盘上和内存中是用同一个来表示的,因此,它们被琐碎地存储和读取。在一个实例中,Redis 能在 0.3 秒内可以从 RDB 文件中读取 500 万个条目。这使的流的复制和持久存储是非常高效的。
-
-它也被计划允许从条目中间删除。现在仅部分实现,策略是整个条目标记中删除的条目被标记为已删除条目,并且,当达到设置的已删除条目占全部条目的比例时,这个块将被回收重写,并且,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
-
-最终发布时间的结论
-===================
-
-Redis 流将包含在年底前推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,为了用于解决很多现在很难去解决的情况:那意味着你需要创造性地滥用当前提供的数据结构去解决那些问题。一个非常重要的使用情况是时间系列,但是,我的感觉是,对于其它案例来说,通过 TREAD 来传递消息将是非常有趣的,因为它可以替代那些需要更高可靠性的发布/订阅的应用程序,而不是“即用即弃”,以及全新的使用案例。现在,如果你想在你的有问题的环境中,去评估新的数据结构的能力,可以在 GitHub 上去获得 “streams” 分支,开始去玩吧。欢迎向我们报告所有的 bug 。 :-)
-
-如果你喜欢这个视频,展示这个 streams 的实时会话在这里: https://www.youtube.com/watch?v=ELDzy9lCFHQ
-
-
---------------------------------------------------------------------------------
-
-via: http://antirez.com/news/114
-
-作者:[antirez ][a]
-译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://antirez.com/
-[1]:http://antirez.com/news/114
-[2]:http://antirez.com/user/antirez
-[3]:https://www.youtube.com/watch?v=ELDzy9lCFHQ
diff --git a/translated/tech/20171009 Considering Pythons Target Audience.md b/translated/tech/20171009 Considering Pythons Target Audience.md
index 60cf84ca5e..b7eed6ff8f 100644
--- a/translated/tech/20171009 Considering Pythons Target Audience.md
+++ b/translated/tech/20171009 Considering Pythons Target Audience.md
@@ -1,242 +1,186 @@
-[谁是 Python 的目标受众?][40]
+盘点 Python 的目标受众
============================================================
Python 是为谁设计的?
-* [Python 使用情况的参考][8]
-
+* [Python 的参考解析器使用情况][8]
* [CPython 主要服务于哪些受众?][9]
-
* [这些相关问题的原因是什么?][10]
-
* [适合进入 PyPI 规划的方面有哪些?][11]
-
-* [当增加它到标准库中时,为什么一些 APIs 会被改变?][12]
-
-* [为什么一些 API 是以临时(provisional)的形式被增加的?][13]
-
-* [为什么只有一些标准库 APIs 被升级?][14]
-
+* [当添加它们到标准库中时,为什么一些 API 会被改变?][12]
+* [为什么一些 API 是以临时的形式被添加的?][13]
+* [为什么只有一些标准库 API 被升级?][14]
* [标准库任何部分都有独立的版本吗?][15]
-
* [这些注意事项为什么很重要?][16]
-几年前, 我在 python-dev 邮件列表中、活跃的 CPython 核心开发人员、以及决定参与该过程的人员中[强调][38]说,“CPython 的动作太快了也太慢了”,作为这种冲突的一个主要原因是,它们不能有效地使用他们的个人时间和精力。
+几年前,我在 python-dev 邮件列表中,以及在活跃的 CPython 核心开发人员和认为参与这一过程不是有效利用他们个人时间和精力的人中[强调][38]说,“CPython 的发展太快了也太慢了”是很多冲突的原因之一。
-我一直在考虑这种情况,在参与的这几年,我也花费了一些时间去思考这一点,在我写那篇文章的时候,我还在波音防务澳大利亚公司(Boeing Defence Australia)工作。下个月,我将离开波音进入红帽亚太(Red Hat Asia-Pacific),并且开始在大企业的[开源供应链管理][39]上获得重分发者(redistributor)级别的观点。
+我一直认为事实确实如此,但这也是一个要点,在这几年中我也花费了一些时间去反思它。在我写那篇文章的时候,我还在波音防务澳大利亚公司工作。下个月,我将离开波音进入红帽亚太,并且开始在大企业的[开源供应链管理][39]上获得再分发者层面的视角。
-### [Python 使用情况的参考][17]
+### Python 的参考解析器使用情况
-我将分解 CPython 的使用情况如下,它虽然有些过于简化(注意,这些分类并不是很清晰,他们仅关注影响新软件特性和版本的部署不同因素):
+我尝试将 CPython 的使用情况分解如下,它虽然有些过于简化(注意,这些分类的界线并不是很清晰,他们仅关注于思考新软件特性和版本发布后不同因素的影响):
-* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不_ 写或维护软件产品。例如:
+* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不会去_ 写或维护生产级别的软件。例如:
* 澳大利亚的 [数字课程][1]
-
* Lorena A. Barba 的 [AeroPython][2]
-
-* 个人的自动化爱好者的项目:主要的是软件,经常是只有软件,而且用户通常是写它的人。例如:
- * my Digital Blasphemy [image download notebook][3]
-
- * Paul Fenwick's (Inter)National [Rick Astley Hotline][4]
-
-* 组织(organisational)过程的自动化:主要是软件,经常是只有软件,用户是为了利益而编写它的组织。例如:
- * CPython 的 [核发工作流工具][5]
-
- * Linux 发行版的开发、构建&发行工具
-
-* “一劳永逸(Set-and-forget)” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中软件几乎不会升级,但是,在底层平台可能会升级。例如:
- * 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这是让人非常不安的)
-
+* 个人级的自动化和爱好者的项目:主要的是软件,而且经常是只有软件,用户通常是写它的人。例如:
+ * my Digital Blasphemy [图片下载器][3]
+ * Paul Fenwick 的 (Inter)National [Rick Astley Hotline][4]
+* 组织过程自动化:主要是软件,而且经常是只有软件,用户是为了利益而编写它的组织。例如:
+ * CPython 的 [核心工作流工具][5]
+ * Linux 发行版的开发、构建 & 发行管理工具
+* “一劳永逸” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中该软件几乎不会升级,但是,在底层平台可能会升级。例如:
+ * 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这种情况是让人非常不安的)
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
-
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规更新来说要昂贵很多)
-
* 没有自动升级功能的嵌入式软件系统
-
-* 持续升级的基础设施:具有健壮的持续工程化模型的软件,对于依赖和平台升级被认为是例行的,而不去关心其它的代码改变。例如:
+* 持续升级的基础设施:具有健壮支撑的工程学模型的软件,对于依赖和平台升级通常是例行的,而不去关心其它的代码改变。例如:
* Facebook 的 Python 服务基础设施
-
* 滚动发布的 Linux 分发版
-
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions等等)
-
-* 间歇性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
+* 间隔性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
* [VFX 平台][6]
-
* 长周期支持的 Linux 分发版
-
* CPython 和 Python 标准库
-
- * 基础设施管理 & 业务流程工具(比如 OpenStack、 Ansible)
-
+ * 基础设施管理 & 编排工具(比如 OpenStack、 Ansible)
* 硬件控制系统
-
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
- * 临时(Ad hoc)自动脚本
-
+ * 临时自动脚本
* 被确定为 “终止” 的单用户游戏(你玩它们一次后,甚至都忘了去卸载它,或许在一个新的设备上都不打算再去安装它)
-
* 短暂的或非持久状态的单用户游戏(如果你卸载并重安装它们,你的游戏体验也不会有什么大的变化)
-
* 特定事件的应用程序(这些应用程序与特定的物理事件捆绑,一旦事件结束,这些应用程序就不再有用了)
-
-* 定期使用的应用程序:部署后定期升级的软件。例如:
+* 频繁使用的应用程序:部署后定期升级的软件。例如:
* 业务管理软件
-
* 个人 & 专业的生产力应用程序(比如,Blender)
-
* 开发工具 & 服务(比如,Mercurial、 Buildbot、 Roundup)
-
* 多用户游戏,和其它明显的处于持续状态的还没有被定义为 “终止” 的游戏
-
* 有自动升级功能的嵌入式软件系统
-
-* 共享的抽象层:软件组件的设计使它能够在特定的问题域有效地工作,即使你没有亲自掌握该领域的所有错综复杂的东西。例如:
+* 共享的抽象层:在一个特定的问题领域中,设计用于让工作更高效的软件组件。即便是你没有亲自掌握该领域的所有错综复杂的东西。例如:
* 大多数的运行时库和归入这一类的框架(比如,Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
-
- * 也适合归入这里的许多测试和类型引用工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
-
+ * 适合归入这一类的许多测试和类型推断工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
* 其它应用程序的插件(比如,Blender plugins、OpenStack hardware adapters)
+ * 本身就代表了 “Python 世界” 基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
- * 本身就代表了 “Python 世界” 的基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
+### CPython 主要服务于哪些受众?
-### [CPython 主要服务于哪些受众?][18]
+从根本上说,CPython 和标准库的主要受众是哪些呢,是那些不管出于什么原因,将有限的标准库和从 PyPI 显式声明安装的第三方库组合起来所提供的服务,还不能够满足需求的那些人。
-最终,CPython 和标准库的主要受众是哪些,不论什么原因,一个更多的有限的标准库和从 PyPI 安装的显式声明的第三方库的组合,提供的服务是不够的。
+为了更进一步简化上面回顾的不同用法和部署模型,尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些感兴趣的环境中将 Python 作为一种_脚本语言_使用的那些人;另外一种是将它用作一个_应用程序开发语言_的那些人,他们最终发布的是一种产品而不是他们的脚本。
-为了更一步简化上面回顾的不同用法和部署模式,为了尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些环境中将 Python 作为一种_脚本语言_使用的,另外一种是将它用作一个_应用程序开发语言_,最终发布的是一种产品而不是他们的脚本。
-
-当把 Python 作为一种脚本语言来使用时,它们典型的开发者特性包括:
-
-* 主要的处理单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 目录和元数据文件
-
-* 没有任何形式的单独的构建步骤 - 是_作为_一个脚本分发的,类似于分发一个单独的 shell 脚本的方法。
-
-* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境
+把 Python 作为一种脚本语言来使用的开发者的典型特性包括:
+* 主要的工作单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 和元数据文件的目录
+* 没有任何形式的单独的构建步骤 —— 是_作为_一个脚本分发的,类似于分发一个独立的 shell 脚本的方式
+* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境外
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
-
-* 没有单独的测试套件,使用 "通过你给定的输入,这个脚本是否给出了你期望的结果?" 这种方式来进行测试
-
-* 如果在执行前需要测试,它将以 “dry run” 和 “预览” 模式来向用户展示软件_将_怎样运行
-
+* 没有单独的测试套件,使用“通过你给定的输入,这个脚本是否给出了你期望的结果?” 这种方式来进行测试
+* 如果在执行前需要测试,它将以 “试运行” 和 “预览” 模式来向用户展示软件_将_怎样运行
* 如果可以完全使用静态代码分析工具,它是通过集成进用户的软件开发环境的,而不是为个别的脚本单独设置的。
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
-* 主要的工作单元是由 Python 的目录和元数据文件组成的,而不是单个 Python 文件
-
-* 在发布之前有一个单独的构建步骤去预处理应用程序,即使是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档
-
+* 主要的工作单元是由 Python 和元数据文件组成的目录,而不是单个 Python 文件
+* 在发布之前有一个单独的构建步骤去预处理应用程序,哪怕是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档中
* 是否有独立的安装步骤去预处理将要使用的应用程序,取决于应用程序是如何打包的,和支持的目标环境
+* 外部的依赖明确表示为项目目录中的一个元数据文件中,要么是直接在项目的目录中(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),要么是作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
+* 存在一个独立的测试套件,或者作为一个 Python API 的一个单元测试,或者作为功能接口的集成测试,或者是两者的一个结合
+* 静态分析工具的使用是在项目级配置的,并作为测试管理的一部分,而不是取决于环境
-* 外部的依赖直接在项目目录中的一个元数据文件中表示(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),或作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
+作为以上分类的一个结果,CPython 和标准库的主要用途是,在相应的 CPython 特性发布后,为教育和临时的 Python 脚本环境,最终提供的是定义重分发者假定功能的独立基准 3- 5 年。
-* 存在一个独立的测试套件,或者作为一个 Python API 的一个测试单元、功能接口的集成测试、或者是两者的一个结合
+对于临时脚本使用的情况,这个 3 - 5 年的延迟是由于重分发者给用户制作新版本的延迟造成的,以及那些重分发版本的用户们花在修改他们的标准操作环境上的时间。
-* 静态分析工具的使用是在项目级配置的,作为测试管理的一部分,而不是依赖
+在教育环境中的情况是,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
-作为以上分类的一个结果,CPython 和标准库最终提供的主要用途是,在合适的 CPython 特性发布后3 - 5年,为教育和临时(ad hoc)的 Python 脚本环境的呈现的功能,定义重新分发的独立基准。
+### 这些相关问题的原因是什么?
-对于临时(ad hoc)脚本使用的情况,这个 3-5 年的延迟是由于新版本重分发给用户的延迟组成的,以及那些重分发版的用户花在修改他们的标准操作环境上的时间。
+这篇文章很大程度上是受 Twitter 上对 [我的这个评论][20] 的讨论鼓舞的,它援引了定义在 [PEP 411][21] 中临时 API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
-在教育环境中的情况,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
+这些回复包括一些在更高级别的库中支持临时 API 的困难程度的一些沮丧性表述、没有这些库做临时状态的传递、以及因此而被限制为只有临时 API 的最新版本才支持这些相关特性,而不是任何早期版本的迭代。
-### [这些相关问题的原因是什么?][19]
+我的 [主要回应][22] 是,建议开源提供者应该强制实施有限支持,通过这种强制的有限支持可以让个人的维护努力变得可持续。这意味着,如果对临时 API 的老版本提供迭代支持是非常痛苦的,到那时,只有在项目开发人员自己需要、或有人为此支付费用时,他们才会去提供支持。这与我的这个观点是类似的,那就是,志愿者提供的项目是否应该免费支持老的、商业性质的、长周期的 Python 版本,这对他们来说是非常麻烦的事,我[不认为他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的、习以为常的惯性,而不是真正的需求(真正的需求,应该去支付费用来解决问题)。
-这篇文章很大程序上是受 Twitter 上 [我的评论][20] 的讨论鼓舞的,定义在 [PEP 411][21] 中引用临时(Provisional)的 API 的情形,作为一个开源项目发行的例子,一个真实的被邀请用户,作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
+而我的[第二个回应][24]是去实现这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中最早在 2011 年的一篇的文章中,以及在 Python 3 问答的回复中的 [这里][25]、[这里][26]、和[这里][27],以及去年的这篇文章 [Python 包生态系统][28] 中也提到了一些),但我从来没有真实地尝试直接去解释它在标准库设计过程中的影响。
-这些回复包括一些在更高级别的库中支持的临时(Provisional) API 的一些相关的沮丧的表述,这些库没有临时(Provisional)状态的传递,以及因此而被限制为只有最新版本的临时(Provisional) API 支持这些相关特性,而不是任何的早期迭代版本。
+如果没有这些背景,设计过程中的一部分,比如临时 API 的引入,或者是受启发而不同于它的引入,看起来似乎是完全没有意义的,因为他们看起来似乎是在尝试对 API 进行标准化,而实际上并没有。
-我的 [主要反应][22] 是去建议,开源提供者应该努力加强他们需要的有限支持,以加强他们的维护工作的可持续性。这意味着,如果支持老版本的临时(Provisional) API 是非常痛苦的,然后,只有项目开发人员自己需要时,或者,有人为此支付费用时,他们才会去提供支持。这类似于我的观点,志愿者提供的项目是否应该免费支持老的商业的长周期支持的 Python 发行版,这对他们来说是非常麻烦的事,我[不认他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的习以为常的惯性,而不是真正的需求(真正的需求,它应该去支付费用来解决问题)
+### 适合进入 PyPI 规划的方面有哪些?
-然而,我的[第二个反应][24]是,去认识到这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中 2011 的一篇年的文章中,以及在 Python 3 问答的回答中 [在这里][25]、[这里][26]、和[这里][27],和在去年的 [Python 包生态系统][28]上的一篇文章中的一小部分),我从来没有真实尝试直接去解释过它对标准库设计过程中的影响。
-
-如果没有这些背景,设计过程中的一些方面,如临时(Provisional) API 的介绍,或者是受到不同的启发(inspired-by-not-the-same-as)的介绍,看起来似乎是很荒谬的,因为它们似乎是在试图标准化 API,而实际上并没有对 API 进行标准化。
-
-### [适合进入 PyPI 规划的方面有哪些?][29]
-
-提交给 python-ideas 或 python-dev 的_任何_建议的第一个门槛就是,清楚地回答这个问题,“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,但通过他们得到了几个共同的主题:
-
-* 大多数新手可能经常是从互联网上去 “复制粘贴” 错误的建议,而不是去下载一个合适的第三方库。(比如,这就是为什么存在 `secrets` 库的原因:使得很少的人去使用 `random` 模块,因为安全敏感的原因,这是用于游戏和统计模拟的)
-
-* 这个模块是用于提供一个实现的参考,并去允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
-
-* 这个模块是用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
+提交给 python-ideas 或 python-dev 的_任何_建议所面临的第一个门槛就是清楚地回答这个问题:“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,为了通过这一步,这里有几个常见的话题:
+* 与其去下载一个合适的第三方库,新手一般可能更倾向于从互联网上 “复制粘贴” 错误的指导。(比如,这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,由于安全敏感的原因,它预期用于游戏和统计模拟的)
+* 这个模块是打算去提供一个实现的参考,并允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
+* 这个模块是预期用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
* 这个模块是被设计去支持语言之外的一些语法(比如,`contextlib`、`asyncio` 和 `typing` 模块,就是这种情况)
+* 这个模块只是普通的临时的脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
+* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你可能根本就不会用它来做全部的统计分析)
-* 这个模块只是普通的临时(ad hoc)脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
+通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足以转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的入门级 Python 开发人员的经验有所提升?”
-* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你不会用它来做全部的统计分析)
+标准库中的 `ensurepip` 和 `venv` 模块的引入也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
-通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足够转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的 Python 开发人员的经验有所改提升?”
+### 当添加它们到标准库中时,为什么一些 API 会被改变?
-标准库中的 `ensurepip` 和 `venv` 模块的介绍也明确地告诉分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
+现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上添加的是吸收了用户对现有 API 体验之后,进行重新设计和重新实现的 API,但是,会根据另外的设计考虑和已经成为其中一部分的语言实现参考来进行一些删除或细节修改。
-### [当增加它到标准库中时,为什么一些 APIs 会被改变?][30]
+例如,不像广受欢迎的第三方库的前身 `path.py`,`pathlib` 并_没有_定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许使用文件系统路径的接口去使用更多的对象。
-现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上增加进行的是重新设计和重新实现的 API,只是它参照了现有 API 的用户体验,但是,根据另外的设计参考,删除或修改了一些细节,和附属于语言参考实现部分的权限。
+为了在“IP 地址” 这个概念的教学上提供一个更好的工具,为 `ipaddress` 模块设计的 API,将地址和网络的定义调整为显式的、独立定义的主机接口(IP 地址被关联到特定的 IP 网络),而最原始的 `ipaddr` 模块中,在网络术语的使用方式上不那么严格。
-例如,不像广受欢迎的第三方库的前身 `path.py`,`pathlib` 并_不_规定字符串子类,而是独立的类型。作为解决文件互操作性问题的结果,是定义了文件系统路径协议,它允许与文件系统路径一起使用的接口,去使用更大范围的对象。
+另外的情况是,标准库将综合多种现有的方法的来构建,以及为早已存在的库定义 API 时,还有可能依靠不存在的语法特性。比如,`asyncio` 和 `typing` 模块就全部考虑了这些因素,虽然在 PEP 557 中正在考虑将后者所考虑的因素应用到 `dataclasses` API 上。(它可以被总结为 “像属性一样,但是使用可变注释作为字段声明”)。
-为 `ipaddress` 模块设计的 API 是为教学 IP 地址概念,从定义的地址和网络中,为显式的单独主机接口调整的(IP 地址关联到特定的 IP 网络),为了提供一个最佳的教学工具,而最原始的 “ipaddr” 模块中,使用网络术语的方式不那么严谨。
+这类改变的原理是,这类库不会消失,并且它们的维护者对标准库维护相关的那些限制通常并不感兴趣(特别是,相对缓慢的发行节奏)。在这种情况下,在标准库文档的更新版本中,很常见的做法是使用 “See Also” 链接指向原始模块,尤其是在第三方版本提供了额外的特性以及标准库模块中忽略的那些特性时。
-在其它情况下,标准库被构建为多种现有方法的一个综合,而且,还有可能依赖于定义现有库的 API 时不存在的特性。应用于 `asyncio` 和 `typing` 模块的所有的这些考虑,虽然后来考虑适用于 `dataclasses` 的 API 被认为是 PEP 557 (它可以被总结为 “像属性一样,但是使用变量注释作为字段声明”)。
+### 为什么一些 API 是以临时的形式被添加的?
-这类改变的工作原理是,这类库不会消失,而且,它们的维护者经常并不关心与标准库相关的限制(特别是,相对缓慢的发行节奏)。在这种情况下,对于标准库版本的文档来说,使用 “See Also” 链接指向原始模块是很常见的,特别是,如果第三方版本提供了标准库模块中忽略的其他特性和灵活性时。
+虽然 CPython 维护了 API 的弃用策略,但在没有正当理由的情况下,我们通常不会去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
-### [为什么一些 API 是以临时(provisional)的形式被增加的?][31]
+然而在实践中,当添加这种受已有的第三方启发而不是直接精确拷贝第三方设计的新 API 时,所承担的风险要高于一些正常设计决定可能出现问题的风险。
-虽然 CPython 确实设置了 API 的弃用策略,但我们通常不希望在没有令人信服的理由的情况下去使用它(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
+当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时,表示保守的终端用户要避免完全依赖它们,而共享抽象层的开发者可能希望,对他们准备去支持的那个临时 API 的版本,考虑实施比平时更严格的限制。
-然而,当增加一个受已有的第三方启发去设计的而不是去拷贝的新的 API 时,在设计实践中,有些设计实践可能会出现问题,这比平常的风险要高。
+### 为什么只有一些标准库 API 被升级?
-当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时(provisional),表示保守的终端用户可以希望避免完全依赖他们,并且,共享抽象层的开发者可能希望考虑,对他们准备支持的临时(provisional) API 的版本实施比平时更严格的限制。
-
-### [为什么只有一些标准库 APIs 被升级?][32]
-
-这里简短的回答升级的主要 APIs 有哪些?:
-
-* 不适合外部因素驱动的补充更新
-
-* 无论是临时(ad hoc)脚本使用情况,还是为促进将来的多个第三方解决方案之间的互操作性,都有明显好外的
+这里简短的回答得到升级的主要 API 有哪些?:
+* 不太可能有大量的外部因素干扰的附加更新
+* 无论是对临时脚本使用案例还是对促进将来多个第三方解决方案之间的互操作性,都有明显好处的
* 对这方面感兴趣的人提交了一个可接受的建议
-如果一个用于应用程序开发的模块存在一个非常明显的限制(limitations),比如,`datetime`,如果重分发版通过替代一个现成的第三方模块有所改善,比如,`requests`,或者,如果标准库的发布节奏与需要的有问题的包之间有真正的冲突,比如,`certifi`,那么,计划对标准库版本进行改变的因素将显著减少。
+如果一个用于应用程序开发的模块存在一个非常明显的限制,比如,`datetime`,如果重分发者通过可供替代的第三方选择很容易地实现了改善,比如,`requests`,或者,如果标准库的发布节奏与所需要的包之间真的存在冲突,比如,`certifi`,那么,建议对标准库版本进行改变的因素将显著减少。
-从本质上说,这和关于 PyPI 上面的问题是相反的:因为,PyPI 分发机制对增强应用程序开发人员经验来说,通常_是_足够好的,这样的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为缺省提供的一部分。
+从本质上说,这和上面的关于 PyPI 问题正好相反:因为,从应用程序开发人员体验改善的角度来说,PyPI 分发机制通常_是_足够好的,这种分发方式的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为他们缺省提供的一部分。
-当改变后的能力(capabilities)假设在 3-5 年内缺省出现时被认为是有价值的,才会将这些改变进入到 CPython 和标准库中。
+假设在 3-5 年时间内,缺省出现了被认为是改变带来的可感知的价值时,才会将这些改变纳入到 CPython 和标准库中。
-### [标准库任何部分都有独立的版本吗?][33]
+### 标准库任何部分都有独立的版本吗?
-是的,它就像是 `ensurepip` 使用的捆绑模式( CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
+是的,它就像是 `ensurepip` 使用的捆绑模式(CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
-这种处理方式的其它可能的候选对象是 Tcl/Tk graphics 捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成安装可选项。
+这种处理方式的其它的可能候选者是 Tcl/Tk 图形捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成可选安装项。
-### [这些注意事项为什么很重要?][34]
+### 这些注意事项为什么很重要?
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
-写一些临时(ad hoc)脚本和为学生设计一些教学习题的人,通常不会认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师、等等。
+那些写一些临时脚本或为学生设计一些教学习题的人,通常不认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师等等。
-当所有我们的担心是,语言是开发人员的经验时,那么,我们可以简单假设人们知道一些什么,他们使用的工具,所遵循的开发流程,以及构建和部署他们软件的方法。
+对于一种语言,当我们全部的担心都是开发人员的经验时,那么我们就可以根据人们所知道的内容、他们使用的工具种类、他们所遵循的开发流程种类、构建和部署他们软件的方法等假定,来做大量的简化。
-当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在一个项目中去平衡两种需求,就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
+当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在同一个项目中去平衡两种受众的需求,将就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
-这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是指出添加到 Python 标准库中的看上去很荒谬的特性的最合理的反应(reaction),它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此,它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
+这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是去合理地回应那些对添加到 Python 标准库中的看上去很荒谬的特性的质疑,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
--------------------------------------------------------------------------------
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
-作者:[Nick Coghlan ][a]
+作者:[Nick Coghlan][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180226 Linux Virtual Machines vs Linux Live Images.md b/translated/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
new file mode 100644
index 0000000000..9b927bb348
--- /dev/null
+++ b/translated/tech/20180226 Linux Virtual Machines vs Linux Live Images.md
@@ -0,0 +1,66 @@
+## sober-wang 翻译中
+
+Linux Virtual Machines vs Linux Live Images
+Linxu 虚拟机 vs Linux 实体机
+======
+I'll be the first to admit(认可) that I tend(照顾) to try out new [Linux distros(发行版本)][1] on a far(远) too frequent(频繁) basis. Yet the method(方法) I use to test them, does vary depending(依赖) on my goals(目标) for each instance(每一个). In this article(文章), we're going to look at both(两个) running Linux virtual machines and running Linux live images. There are advantages(优势/促进/有利于) to each method(方法), but there are some hurdles(障碍) with each method(方法/函数) as well(同样的).
+
+首先我得承认,我非常倾向于频繁尝试新的[ linux 发行版本 ][1],我的目标是为了解决每一个 Linux 发行版的依赖,所以我用一些方法来测试它们。在一些文章中,我们将会看到两种运行 Linux 的模式,虚拟机或实体机。每一种方式都存在优势,但是有一些障碍会伴随着这两种方式。
+
+### Testing out a new Linux distro for the first time
+### 第一时间测试一个新的 Linux 发行版
+
+When I test out a brand new Linux distro for the first time, the method I use depends heavily(沉重的) on the resources(资源) of the PC I'm currently(目前的) on. If I have access to my desktop PC, I'm going to run the distro to be tested in a virtual machine. The reason(理由) for this approach(靠近) is that I can download and test the distro in not only a live environment(环境), but also(也) as an installed product with persistent(稳定的) storage abilities(能力).
+
+为了第一时间去做 Linux 发型版本的依赖测试,我把它们运行在我目前所拥有的所有类型的 PC 上。如果我用我的台式机,我将运行一个 Linux 虚拟机做测试。
+
+On the other hand, if I am working with much less robust hardware on a PC, then testing out a distro with a virtual machine installation of Linux is counter-productive. I'd be pushing that PC to its limits and honestly would be better off using a live Linux image instead running from a flash drive.
+
+### Touring software on a new Linux distro
+
+If you're interested in checking out a distro's desktop environment or the available software, you can't go wrong with a live image of the distro. A live environment provides you with a birds eye view of what to expect in terms of overall layout, applications provided and how the user experience flows overall.
+
+To be fair, you could do the same thing with a virtual machine installation, but it may be a bit overkill if you would rather avoid filling up hard drive space with yet more data. After all, this is a simple tour of the distro. Remember what I said in the first section – I like to run Linux in a virtual machine to test it. This means I'm going to see how it installs, what the partition options look like and other elements you wouldn't see from using a live image of any given distro.
+
+Touring usually indicates that you're only looking to take a quick look at a distro, so in this case the method that can be done with the least amount of resistance and time investment is a good course of action.
+
+### Taking a Linux distro with you
+
+While it's not as common as it was a few years ago, the ability to take a Linux distro with you may be a consideration for some users. Obviously, virtual machine installations don't necessarily lend themselves favorably to portability. However a live image of a Linux distro is actually quite portable. A live image can be written to a DVD or copied onto a flash drive for easy traveling.
+
+Expanding on this concept of Linux portability, it's also beneficial to have a live image on a flash drive when showing off how Linux works on a friend's computer. This empowers you to demonstrate how Linux can enrich their life while not relying on running a virtual machine on their PC. It's a bit of a win-win in favor of using a live image.
+
+### Alternative to dual-booting Linux
+
+This next item is a huge one. Consider this – perhaps you're a Windows user. You like playing with Linux, but would rather not take the plunge. Dual-booting is out of the question in case something goes wrong or perhaps you're not comfortable identifying individual partitions. Whatever the case may be, both using Linux in a virtual machine or from a live image might be a great option for you.
+
+Now I'm going to take a rather odd stance on something. I think you'll get far more value in the long term running Linux on a flash drive using a live image than with a virtual machine. There are two reasons for this. First of all, you'll get used to truly running Linux vs running it inside of a virtual machine on top of Windows. Second, you can setup your flash drive to contain user data with persistent storage.
+
+I'll grant you the same could be said with a virtual machine running Linux, however you will never have an update break anything using the live image approach. Why? Because you're not updating a host OS or the guest OS. Remember there are entire distros that are designed to be nothing more than persistent storage Linux distros. Puppy Linux is one great example. Not only can it run on PCs that would otherwise be recycled or thrown away, it allows you to never be bothered again with tedious system updates thanks to the way the distro handles security. It's not a normal Linux distro and it's walled off in such a way that the persistent live image is free from anything scary.
+
+### When a Linux virtual machine is absolutely the best option
+
+As I bring this article to a close, let me leave you with this. There is one instance where using a virtual machine such as Virtual Box is absolutely better than using a live image – recording the desktop environment of any Linux distro.
+
+For example, I make videos that provide a tour and review of a variety of Linux distros. Doing this with live images would require me to capture the screen with a hardware device or install a software capture device from the live image's repositories. Clearly, a virtual machine is better suited for this job than a live image of a Linux distro.
+
+Once you toss audio capture into the mix, there is no question that if you're going to use software to capture your review, you really want to have a host OS that has all the basic needs covered for a reasonably decent capture environment. Again, you could do all of this with a hardware device...but that might be cost prohibitive if you're only do video/audio capturing as a part time endeavor.
+
+### A Linux virtual machine vs a Linux live image
+
+What is your preferred method of trying out new distros? Perhaps you're someone who is fine with formatting their hard drive and throwing caution to the wind, thus, making the idea of any of this unneeded?
+
+Most people I've interacted with online tend to follow much of the methodology I've touched on above, but I'd love to hear what approach works best for you. Hit the comments, let me know which method you prefer when checking out the greatest and latest from the Linux distro world.
+
+--------------------------------------------------------------------------------
+
+via: https://www.datamation.com/open-source/linux-virtual-machines-vs-linux-live-images.html
+
+作者:[Matt Hartley][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
+[1]:https://www.datamation.com/open-source/best-linux-distro.html
diff --git a/sources/tech/20180306 How To Check All Running Services In Linux.md b/translated/tech/20180306 How To Check All Running Services In Linux.md
similarity index 79%
rename from sources/tech/20180306 How To Check All Running Services In Linux.md
rename to translated/tech/20180306 How To Check All Running Services In Linux.md
index 7baf3c3e14..b9e136a5fc 100644
--- a/sources/tech/20180306 How To Check All Running Services In Linux.md
+++ b/translated/tech/20180306 How To Check All Running Services In Linux.md
@@ -1,516 +1,516 @@
-How To Check All Running Services In Linux
-======
-
-There are many ways and tools to check and list all running services in Linux. Usually most of the administrator use `service service-name status` or `/etc/init.d/service-name status` for sysVinit system and `systemctl status service-name` for systemd systems.
-
-The above command clearly shows that the mentioned service is running on server or not. It is very simple and basic command that should known by every Linux administrator.
-
-If you are new to your environment and you don’t know what services are running on the system. How do you check?
-
-Yes, we can check this. This will will help us to understand what are the services are running on the system and whether it’s necessary or need to disable.
-
-### What Is SysVinit
-
-init (short for initialization) is the first process started during booting of the computer system. Init is a daemon process that continues running until the system is shut down.
-
-SysVinit is an old and traditional init system and system manager for old systems. Most of the latest distributions were adapted to systemd system due to some of the long pending issues on sysVinit system.
-
-### What Is systemd
-
-systemd is a new init system and system manager which is become very popular and widely adapted new standard init system by most of Linux distributions. Systemctl is a systemd utility which is help us to manage systemd system.
-
-### Method-1: How To Check Running Services In sysVinit System
-
-The below command helps us to check and list all running services in sysVinit system.
-
-If you have many number of services, i would advise you to use file view commands such as less, more, etc commands for clear view.
-```
-# service --status-all
-or
-# service --status-all | more
-or
-# service --status-all | less
-
-abrt-ccpp hook is installed
-abrtd (pid 2131) is running...
-abrt-dump-oops is stopped
-acpid (pid 1958) is running...
-atd (pid 2164) is running...
-auditd (pid 1731) is running...
-Frequency scaling enabled using ondemand governor
-crond (pid 2153) is running...
-hald (pid 1967) is running...
-htcacheclean is stopped
-httpd is stopped
-Table: filter
-Chain INPUT (policy ACCEPT)
-num target prot opt source destination
-1 ACCEPT all ::/0 ::/0 state RELATED,ESTABLISHED
-2 ACCEPT icmpv6 ::/0 ::/0
-3 ACCEPT all ::/0 ::/0
-4 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:80
-5 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:21
-6 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:22
-7 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:25
-8 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2082
-9 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2086
-10 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2083
-11 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2087
-12 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:10000
-13 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
-
-Chain FORWARD (policy ACCEPT)
-num target prot opt source destination
-1 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
-
-Chain OUTPUT (policy ACCEPT)
-num target prot opt source destination
-
-iptables: Firewall is not running.
-irqbalance (pid 1826) is running...
-Kdump is operational
-lvmetad is stopped
-mdmonitor is stopped
-messagebus (pid 1929) is running...
- SUCCESS! MySQL running (24376)
-rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
-named is stopped
-netconsole module not loaded
-Usage: startup.sh { start | stop }
-Configured devices:
-lo eth0 eth1
-Currently active devices:
-lo eth0
-ntpd is stopped
-portreserve (pid 1749) is running...
-master (pid 2107) is running...
-Process accounting is disabled.
-quota_nld is stopped
-rdisc is stopped
-rngd is stopped
-rpcbind (pid 1840) is running...
-rsyslogd (pid 1756) is running...
-sandbox is stopped
-saslauthd is stopped
-smartd is stopped
-openssh-daemon (pid 9859) is running...
-svnserve is stopped
-vsftpd (pid 4008) is running...
-xinetd (pid 2031) is running...
-zabbix_agentd (pid 2150 2149 2148 2147 2146 2140) is running...
-
-```
-
-Run the following command to view only running services in the system.
-```
-# service --status-all | grep running
-
-crond (pid 535) is running...
-httpd (pid 627) is running...
-mysqld (pid 911) is running...
-rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
-rsyslogd (pid 449) is running...
-saslauthd (pid 492) is running...
-sendmail (pid 509) is running...
-sm-client (pid 519) is running...
-openssh-daemon (pid 478) is running...
-xinetd (pid 485) is running...
-
-```
-
-Run the following command to view the particular service status.
-```
-# service --status-all | grep httpd
-httpd (pid 627) is running...
-
-```
-
-Alternatively use the following command to view the particular service status.
-```
-# service httpd status
-
-httpd (pid 627) is running...
-
-```
-
-Use the following command to view the list of running services enabled in boot.
-```
-# chkconfig --list
-crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-htcacheclean 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-httpd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
-ip6tables 0:off 1:off 2:on 3:off 4:on 5:on 6:off
-iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-modules_dep 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-named 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-netfs 0:off 1:off 2:off 3:off 4:on 5:on 6:off
-network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-nmb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-nscd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-portreserve 0:off 1:off 2:on 3:off 4:on 5:on 6:off
-quota_nld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-rdisc 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-restorecond 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-rpcbind 0:off 1:off 2:on 3:off 4:on 5:on 6:off
-rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-saslauthd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
-sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-snmpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-snmptrapd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
-udev-post 0:off 1:on 2:on 3:off 4:on 5:on 6:off
-winbind 0:off 1:off 2:off 3:off 4:off 5:off 6:off
-xinetd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
-
-xinetd based services:
- chargen-dgram: off
- chargen-stream: off
- daytime-dgram: off
- daytime-stream: off
- discard-dgram: off
- discard-stream: off
- echo-dgram: off
- echo-stream: off
- finger: off
- ntalk: off
- rsync: off
- talk: off
- tcpmux-server: off
- time-dgram: off
- time-stream: off
-
-```
-
-### Method-2: How To Check Running Services In systemd System
-
-The below command helps us to check and list all running services in “systemd” system.
-```
-# systemctl
-
- UNIT LOAD ACTIVE SUB DESCRIPTION
- sys-devices-virtual-block-loop0.device loaded active plugged /sys/devices/virtual/block/loop0
- sys-devices-virtual-block-loop1.device loaded active plugged /sys/devices/virtual/block/loop1
- sys-devices-virtual-block-loop2.device loaded active plugged /sys/devices/virtual/block/loop2
- sys-devices-virtual-block-loop3.device loaded active plugged /sys/devices/virtual/block/loop3
- sys-devices-virtual-block-loop4.device loaded active plugged /sys/devices/virtual/block/loop4
- sys-devices-virtual-misc-rfkill.device loaded active plugged /sys/devices/virtual/misc/rfkill
- sys-devices-virtual-tty-ttyprintk.device loaded active plugged /sys/devices/virtual/tty/ttyprintk
- sys-module-fuse.device loaded active plugged /sys/module/fuse
- sys-subsystem-net-devices-enp0s3.device loaded active plugged 82540EM Gigabit Ethernet Controller (PRO/1000 MT Desktop Adapter)
- -.mount loaded active mounted Root Mount
- dev-hugepages.mount loaded active mounted Huge Pages File System
- dev-mqueue.mount loaded active mounted POSIX Message Queue File System
- run-user-1000-gvfs.mount loaded active mounted /run/user/1000/gvfs
- run-user-1000.mount loaded active mounted /run/user/1000
- snap-core-3887.mount loaded active mounted Mount unit for core
- snap-core-4017.mount loaded active mounted Mount unit for core
- snap-core-4110.mount loaded active mounted Mount unit for core
- snap-gping-13.mount loaded active mounted Mount unit for gping
- snap-termius\x2dapp-8.mount loaded active mounted Mount unit for termius-app
- sys-fs-fuse-connections.mount loaded active mounted FUSE Control File System
- sys-kernel-debug.mount loaded active mounted Debug File System
- acpid.path loaded active running ACPI Events Check
- cups.path loaded active running CUPS Scheduler
- systemd-ask-password-plymouth.path loaded active waiting Forward Password Requests to Plymouth Directory Watch
- systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Directory Watch
- init.scope loaded active running System and Service Manager
- session-c2.scope loaded active running Session c2 of user magi
- accounts-daemon.service loaded active running Accounts Service
- acpid.service loaded active running ACPI event daemon
- anacron.service loaded active running Run anacron jobs
- apache2.service loaded active running The Apache HTTP Server
- apparmor.service loaded active exited AppArmor initialization
- apport.service loaded active exited LSB: automatic crash report generation
- aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
- atop.service loaded active running Atop advanced performance monitor
- atopacct.service loaded active running Atop process accounting daemon
- avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
- colord.service loaded active running Manage, Install and Generate Color Profiles
- console-setup.service loaded active exited Set console font and keymap
- cron.service loaded active running Regular background program processing daemon
- cups-browsed.service loaded active running Make remote CUPS printers available locally
- cups.service loaded active running CUPS Scheduler
- dbus.service loaded active running D-Bus System Message Bus
- postfix.service loaded active exited Postfix Mail Transport Agent
-
-```
-
- * **`UNIT`** Unit describe about the corresponding systemd unit name.
- * **`LOAD`** This describes whether the corresponding unit currently loaded in memory or not.
- * **`ACTIVE`** It’s indicate whether the unit is active or not.
- * **`SUB`** It’s indicate whether the unit is running state or not.
- * **`DESCRIPTION`** A short description about the unit.
-
-
-
-The below option help you to list units based on the type.
-```
-# systemctl list-units --type service
- UNIT LOAD ACTIVE SUB DESCRIPTION
- accounts-daemon.service loaded active running Accounts Service
- acpid.service loaded active running ACPI event daemon
- anacron.service loaded active running Run anacron jobs
- apache2.service loaded active running The Apache HTTP Server
- apparmor.service loaded active exited AppArmor initialization
- apport.service loaded active exited LSB: automatic crash report generation
- aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
- atop.service loaded active running Atop advanced performance monitor
- atopacct.service loaded active running Atop process accounting daemon
- avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
- colord.service loaded active running Manage, Install and Generate Color Profiles
- console-setup.service loaded active exited Set console font and keymap
- cron.service loaded active running Regular background program processing daemon
- cups-browsed.service loaded active running Make remote CUPS printers available locally
- cups.service loaded active running CUPS Scheduler
- dbus.service loaded active running D-Bus System Message Bus
- fwupd.service loaded active running Firmware update daemon
- [email protected] loaded active running Getty on tty1
- grub-common.service loaded active exited LSB: Record successful boot for GRUB
- irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
- keyboard-setup.service loaded active exited Set the console keyboard layout
- kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
-
-```
-
-The below option help you to list units based on the state. It’s similar to the above output but straight forward.
-```
-# systemctl list-unit-files --type service
-
-UNIT FILE STATE
-accounts-daemon.service enabled
-acpid.service disabled
-alsa-restore.service static
-alsa-state.service static
-alsa-utils.service masked
-anacron-resume.service enabled
-anacron.service enabled
-apache-htcacheclean.service disabled
-[email protected] disabled
-apache2.service enabled
-[email protected] disabled
-apparmor.service enabled
-[email protected] static
-apport.service generated
-apt-daily-upgrade.service static
-apt-daily.service static
-aptik-battery-monitor.service generated
-atop.service enabled
-atopacct.service enabled
-[email protected] enabled
-avahi-daemon.service enabled
-bluetooth.service enabled
-
-```
-
-Run the following command to view the particular service status.
-```
-# systemctl | grep apache2
- apache2.service loaded active running The Apache HTTP Server
-
-```
-
-Alternatively use the following command to view the particular service status.
-```
-# systemctl status apache2
-● apache2.service - The Apache HTTP Server
- Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
- Drop-In: /lib/systemd/system/apache2.service.d
- └─apache2-systemd.conf
- Active: active (running) since Tue 2018-03-06 12:34:09 IST; 8min ago
- Process: 2786 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
- Main PID: 1171 (apache2)
- Tasks: 55 (limit: 4915)
- CGroup: /system.slice/apache2.service
- ├─1171 /usr/sbin/apache2 -k start
- ├─2790 /usr/sbin/apache2 -k start
- └─2791 /usr/sbin/apache2 -k start
-
-Mar 06 12:34:08 magi-VirtualBox systemd[1]: Starting The Apache HTTP Server...
-Mar 06 12:34:09 magi-VirtualBox apachectl[1089]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.0.2.15. Set the 'ServerName' directive globally to suppre
-Mar 06 12:34:09 magi-VirtualBox systemd[1]: Started The Apache HTTP Server.
-Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloading The Apache HTTP Server.
-Mar 06 12:39:10 magi-VirtualBox apachectl[2786]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using fe80::7929:4ed1:279f:4d65. Set the 'ServerName' directive gl
-Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloaded The Apache HTTP Server.
-
-```
-
-Run the following command to view only running services in the system.
-```
-# systemctl | grep running
- acpid.path loaded active running ACPI Events Check
- cups.path loaded active running CUPS Scheduler
- init.scope loaded active running System and Service Manager
- session-c2.scope loaded active running Session c2 of user magi
- accounts-daemon.service loaded active running Accounts Service
- acpid.service loaded active running ACPI event daemon
- apache2.service loaded active running The Apache HTTP Server
- aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
- atop.service loaded active running Atop advanced performance monitor
- atopacct.service loaded active running Atop process accounting daemon
- avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
- colord.service loaded active running Manage, Install and Generate Color Profiles
- cron.service loaded active running Regular background program processing daemon
- cups-browsed.service loaded active running Make remote CUPS printers available locally
- cups.service loaded active running CUPS Scheduler
- dbus.service loaded active running D-Bus System Message Bus
- fwupd.service loaded active running Firmware update daemon
- [email protected] loaded active running Getty on tty1
- irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
- lightdm.service loaded active running Light Display Manager
- ModemManager.service loaded active running Modem Manager
- NetworkManager.service loaded active running Network Manager
- polkit.service loaded active running Authorization Manager
-
-```
-
-Use the following command to view the list of running services enabled in boot.
-```
-# systemctl list-unit-files | grep enabled
-acpid.path enabled
-cups.path enabled
-accounts-daemon.service enabled
-anacron-resume.service enabled
-anacron.service enabled
-apache2.service enabled
-apparmor.service enabled
-atop.service enabled
-atopacct.service enabled
-[email protected] enabled
-avahi-daemon.service enabled
-bluetooth.service enabled
-console-setup.service enabled
-cron.service enabled
-cups-browsed.service enabled
-cups.service enabled
-display-manager.service enabled
-dns-clean.service enabled
-friendly-recovery.service enabled
-[email protected] enabled
-gpu-manager.service enabled
-keyboard-setup.service enabled
-lightdm.service enabled
-ModemManager.service enabled
-network-manager.service enabled
-networking.service enabled
-NetworkManager-dispatcher.service enabled
-NetworkManager-wait-online.service enabled
-NetworkManager.service enabled
-
-```
-
-systemd-cgtop show top control groups by their resource usage such as tasks, CPU, Memory, Input, and Output.
-```
-# systemd-cgtop
-
-Control Group Tasks %CPU Memory Input/s Output/s
-/ - - 1.5G - -
-/init.scope 1 - - - -
-/system.slice 153 - - - -
-/system.slice/ModemManager.service 3 - - - -
-/system.slice/NetworkManager.service 4 - - - -
-/system.slice/accounts-daemon.service 3 - - - -
-/system.slice/acpid.service 1 - - - -
-/system.slice/apache2.service 55 - - - -
-/system.slice/aptik-battery-monitor.service 1 - - - -
-/system.slice/atop.service 1 - - - -
-/system.slice/atopacct.service 1 - - - -
-/system.slice/avahi-daemon.service 2 - - - -
-/system.slice/colord.service 3 - - - -
-/system.slice/cron.service 1 - - - -
-/system.slice/cups-browsed.service 3 - - - -
-/system.slice/cups.service 2 - - - -
-/system.slice/dbus.service 6 - - - -
-/system.slice/fwupd.service 5 - - - -
-/system.slice/irqbalance.service 1 - - - -
-/system.slice/lightdm.service 7 - - - -
-/system.slice/polkit.service 3 - - - -
-/system.slice/repowerd.service 14 - - - -
-/system.slice/rsyslog.service 4 - - - -
-/system.slice/rtkit-daemon.service 3 - - - -
-/system.slice/snapd.service 8 - - - -
-/system.slice/system-getty.slice 1 - - - -
-
-```
-
-Also we can check the running services using pstree command (Output from SysVinit system).
-```
-# pstree
-init-|-crond
- |-httpd---2*[httpd]
- |-kthreadd/99149---khelper/99149
- |-2*[mingetty]
- |-mysqld_safe---mysqld---9*[{mysqld}]
- |-rsyslogd---3*[{rsyslogd}]
- |-saslauthd---saslauthd
- |-2*[sendmail]
- |-sshd---sshd---bash---pstree
- |-udevd
- `-xinetd
-
-```
-
-Also we can check the running services using pstree command (Output from systemd system).
-```
-# pstree
-systemd─┬─ModemManager─┬─{gdbus}
- │ └─{gmain}
- ├─NetworkManager─┬─dhclient
- │ ├─{gdbus}
- │ └─{gmain}
- ├─accounts-daemon─┬─{gdbus}
- │ └─{gmain}
- ├─acpid
- ├─agetty
- ├─anacron
- ├─apache2───2*[apache2───26*[{apache2}]]
- ├─aptd───{gmain}
- ├─aptik-battery-m
- ├─atop
- ├─atopacctd
- ├─avahi-daemon───avahi-daemon
- ├─colord─┬─{gdbus}
- │ └─{gmain}
- ├─cron
- ├─cups-browsed─┬─{gdbus}
- │ └─{gmain}
- ├─cupsd
- ├─dbus-daemon
- ├─fwupd─┬─{GUsbEventThread}
- │ ├─{fwupd}
- │ ├─{gdbus}
- │ └─{gmain}
- ├─gnome-keyring-d─┬─{gdbus}
- │ ├─{gmain}
- │ └─{timer}
-
-```
-
-### Method-3: How To Check Running Services In systemd System using chkservice
-
-chkservice is a new tool for managing systemd units in terminal. It requires super user privileges to manage the units.
-```
-# chkservice
-
-```
-
-![][1]
-
-To view help page, hit `?` button. This will shows you available options to manage the systemd services.
-![][2]
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
-
-作者:[Magesh Maruthamuthu][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.2daygeek.com/author/magesh/
-[1]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-1.png
-[2]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-2.png
+如何查看 Linux 中所有正在运行的服务
+======
+
+
+有许多方法和工具可以查看 Linux 中所有正在运行的服务。大多数管理员会在 sysVinit 系统中使用 `service service-name status` 或 `/etc/init.d/service-name status`,而在 systemd 系统中使用 `systemctl status service-name`。
+
+以上命令可以清楚地显示该服务是否在服务器上运行,这也是每个 Linux 管理员都该知道的非常简单和基础的命令。
+
+如果你对系统环境并不熟悉,也不清楚系统在运行哪些服务,你会如何检查?
+
+是的,我们的确有必要这样检查一下。这将有助于我们了解系统上运行了什么服务,以及哪些是必要的、哪些需要被禁用。
+
+### 什么是 SysVinit
+
+init(初始化 initialization 的简称)是在系统启动期间运行的第一个进程。Init 是一个守护进程,它将持续运行直至关机。
+
+SysVinit 是早期传统的 init 系统和系统管理器。由于 sysVinit 系统上一些长期悬而未决的问题,大多数最新的发行版都适用于 systemd 系统。
+
+### 什么是 systemd
+
+systemd 是一个新的 init 系统以及系统管理器,它已成为大多数 Linux 发行版中非常流行且广泛适应的新的标准 init 系统。Systemctl 是一个 systemd 管理工具,它可以帮助我们管理 systemd 系统。
+
+### 方法一:如何在 sysVinit 系统中查看运行的服务
+
+以下命令可以帮助我们列出 sysVinit 系统中所有正在运行的服务。
+
+如果服务很多,我建议使用文件视图命令,如 less、more 等,以便得到清晰的结果。
+```
+# service --status-all
+or
+# service --status-all | more
+or
+# service --status-all | less
+
+abrt-ccpp hook is installed
+abrtd (pid 2131) is running...
+abrt-dump-oops is stopped
+acpid (pid 1958) is running...
+atd (pid 2164) is running...
+auditd (pid 1731) is running...
+Frequency scaling enabled using ondemand governor
+crond (pid 2153) is running...
+hald (pid 1967) is running...
+htcacheclean is stopped
+httpd is stopped
+Table: filter
+Chain INPUT (policy ACCEPT)
+num target prot opt source destination
+1 ACCEPT all ::/0 ::/0 state RELATED,ESTABLISHED
+2 ACCEPT icmpv6 ::/0 ::/0
+3 ACCEPT all ::/0 ::/0
+4 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:80
+5 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:21
+6 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:22
+7 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:25
+8 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2082
+9 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2086
+10 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2083
+11 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2087
+12 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:10000
+13 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
+
+Chain FORWARD (policy ACCEPT)
+num target prot opt source destination
+1 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
+
+Chain OUTPUT (policy ACCEPT)
+num target prot opt source destination
+
+iptables: Firewall is not running.
+irqbalance (pid 1826) is running...
+Kdump is operational
+lvmetad is stopped
+mdmonitor is stopped
+messagebus (pid 1929) is running...
+ SUCCESS! MySQL running (24376)
+rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
+named is stopped
+netconsole module not loaded
+Usage: startup.sh { start | stop }
+Configured devices:
+lo eth0 eth1
+Currently active devices:
+lo eth0
+ntpd is stopped
+portreserve (pid 1749) is running...
+master (pid 2107) is running...
+Process accounting is disabled.
+quota_nld is stopped
+rdisc is stopped
+rngd is stopped
+rpcbind (pid 1840) is running...
+rsyslogd (pid 1756) is running...
+sandbox is stopped
+saslauthd is stopped
+smartd is stopped
+openssh-daemon (pid 9859) is running...
+svnserve is stopped
+vsftpd (pid 4008) is running...
+xinetd (pid 2031) is running...
+zabbix_agentd (pid 2150 2149 2148 2147 2146 2140) is running...
+
+```
+
+执行以下命令,可以只查看正在运行的服务。
+```
+# service --status-all | grep running
+
+crond (pid 535) is running...
+httpd (pid 627) is running...
+mysqld (pid 911) is running...
+rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
+rsyslogd (pid 449) is running...
+saslauthd (pid 492) is running...
+sendmail (pid 509) is running...
+sm-client (pid 519) is running...
+openssh-daemon (pid 478) is running...
+xinetd (pid 485) is running...
+
+```
+
+运行以下命令以查看指定服务的状态。
+```
+# service --status-all | grep httpd
+httpd (pid 627) is running...
+
+```
+
+或者,使用以下命令也可以查看指定服务的状态。
+```
+# service httpd status
+
+httpd (pid 627) is running...
+
+```
+
+使用以下命令查看系统启动时哪些服务会被启用。
+```
+# chkconfig --list
+crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+htcacheclean 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+httpd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
+ip6tables 0:off 1:off 2:on 3:off 4:on 5:on 6:off
+iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+modules_dep 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+named 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+netfs 0:off 1:off 2:off 3:off 4:on 5:on 6:off
+network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+nmb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+nscd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+portreserve 0:off 1:off 2:on 3:off 4:on 5:on 6:off
+quota_nld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+rdisc 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+restorecond 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+rpcbind 0:off 1:off 2:on 3:off 4:on 5:on 6:off
+rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+saslauthd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
+sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+snmpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+snmptrapd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
+udev-post 0:off 1:on 2:on 3:off 4:on 5:on 6:off
+winbind 0:off 1:off 2:off 3:off 4:off 5:off 6:off
+xinetd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
+
+xinetd based services:
+ chargen-dgram: off
+ chargen-stream: off
+ daytime-dgram: off
+ daytime-stream: off
+ discard-dgram: off
+ discard-stream: off
+ echo-dgram: off
+ echo-stream: off
+ finger: off
+ ntalk: off
+ rsync: off
+ talk: off
+ tcpmux-server: off
+ time-dgram: off
+ time-stream: off
+
+```
+
+### 方法二:如何在 systemd 系统中查看运行的服务
+
+以下命令帮助我们列出 systemd 系统中所有服务。
+```
+# systemctl
+
+ UNIT LOAD ACTIVE SUB DESCRIPTION
+ sys-devices-virtual-block-loop0.device loaded active plugged /sys/devices/virtual/block/loop0
+ sys-devices-virtual-block-loop1.device loaded active plugged /sys/devices/virtual/block/loop1
+ sys-devices-virtual-block-loop2.device loaded active plugged /sys/devices/virtual/block/loop2
+ sys-devices-virtual-block-loop3.device loaded active plugged /sys/devices/virtual/block/loop3
+ sys-devices-virtual-block-loop4.device loaded active plugged /sys/devices/virtual/block/loop4
+ sys-devices-virtual-misc-rfkill.device loaded active plugged /sys/devices/virtual/misc/rfkill
+ sys-devices-virtual-tty-ttyprintk.device loaded active plugged /sys/devices/virtual/tty/ttyprintk
+ sys-module-fuse.device loaded active plugged /sys/module/fuse
+ sys-subsystem-net-devices-enp0s3.device loaded active plugged 82540EM Gigabit Ethernet Controller (PRO/1000 MT Desktop Adapter)
+ -.mount loaded active mounted Root Mount
+ dev-hugepages.mount loaded active mounted Huge Pages File System
+ dev-mqueue.mount loaded active mounted POSIX Message Queue File System
+ run-user-1000-gvfs.mount loaded active mounted /run/user/1000/gvfs
+ run-user-1000.mount loaded active mounted /run/user/1000
+ snap-core-3887.mount loaded active mounted Mount unit for core
+ snap-core-4017.mount loaded active mounted Mount unit for core
+ snap-core-4110.mount loaded active mounted Mount unit for core
+ snap-gping-13.mount loaded active mounted Mount unit for gping
+ snap-termius\x2dapp-8.mount loaded active mounted Mount unit for termius-app
+ sys-fs-fuse-connections.mount loaded active mounted FUSE Control File System
+ sys-kernel-debug.mount loaded active mounted Debug File System
+ acpid.path loaded active running ACPI Events Check
+ cups.path loaded active running CUPS Scheduler
+ systemd-ask-password-plymouth.path loaded active waiting Forward Password Requests to Plymouth Directory Watch
+ systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Directory Watch
+ init.scope loaded active running System and Service Manager
+ session-c2.scope loaded active running Session c2 of user magi
+ accounts-daemon.service loaded active running Accounts Service
+ acpid.service loaded active running ACPI event daemon
+ anacron.service loaded active running Run anacron jobs
+ apache2.service loaded active running The Apache HTTP Server
+ apparmor.service loaded active exited AppArmor initialization
+ apport.service loaded active exited LSB: automatic crash report generation
+ aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
+ atop.service loaded active running Atop advanced performance monitor
+ atopacct.service loaded active running Atop process accounting daemon
+ avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
+ colord.service loaded active running Manage, Install and Generate Color Profiles
+ console-setup.service loaded active exited Set console font and keymap
+ cron.service loaded active running Regular background program processing daemon
+ cups-browsed.service loaded active running Make remote CUPS printers available locally
+ cups.service loaded active running CUPS Scheduler
+ dbus.service loaded active running D-Bus System Message Bus
+ postfix.service loaded active exited Postfix Mail Transport Agent
+
+```
+
+ * **`UNIT`** 相应的 systemd 单元名称
+ * **`LOAD`** 相应的单元是否被加载到内存中
+ * **`ACTIVE`** 该单元是否处于活动状态
+ * **`SUB`** 该单元是否处于运行状态(LCTT 译者注:是较于 ACTIVE 更加详细的状态描述,不同的单元类型有不同的状态。)
+ * **`DESCRIPTION`** 关于该单元的简短描述
+
+
+以下选项可根据类型列出单元。
+```
+# systemctl list-units --type service
+ UNIT LOAD ACTIVE SUB DESCRIPTION
+ accounts-daemon.service loaded active running Accounts Service
+ acpid.service loaded active running ACPI event daemon
+ anacron.service loaded active running Run anacron jobs
+ apache2.service loaded active running The Apache HTTP Server
+ apparmor.service loaded active exited AppArmor initialization
+ apport.service loaded active exited LSB: automatic crash report generation
+ aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
+ atop.service loaded active running Atop advanced performance monitor
+ atopacct.service loaded active running Atop process accounting daemon
+ avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
+ colord.service loaded active running Manage, Install and Generate Color Profiles
+ console-setup.service loaded active exited Set console font and keymap
+ cron.service loaded active running Regular background program processing daemon
+ cups-browsed.service loaded active running Make remote CUPS printers available locally
+ cups.service loaded active running CUPS Scheduler
+ dbus.service loaded active running D-Bus System Message Bus
+ fwupd.service loaded active running Firmware update daemon
+ [email protected] loaded active running Getty on tty1
+ grub-common.service loaded active exited LSB: Record successful boot for GRUB
+ irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
+ keyboard-setup.service loaded active exited Set the console keyboard layout
+ kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
+
+```
+
+以下选项可帮助您根据状态列出单位,输出与前例类似但更直截了当。
+```
+# systemctl list-unit-files --type service
+
+UNIT FILE STATE
+accounts-daemon.service enabled
+acpid.service disabled
+alsa-restore.service static
+alsa-state.service static
+alsa-utils.service masked
+anacron-resume.service enabled
+anacron.service enabled
+apache-htcacheclean.service disabled
+[email protected] disabled
+apache2.service enabled
+[email protected] disabled
+apparmor.service enabled
+[email protected] static
+apport.service generated
+apt-daily-upgrade.service static
+apt-daily.service static
+aptik-battery-monitor.service generated
+atop.service enabled
+atopacct.service enabled
+[email protected] enabled
+avahi-daemon.service enabled
+bluetooth.service enabled
+
+```
+
+运行以下命令以查看指定服务的状态。
+```
+# systemctl | grep apache2
+ apache2.service loaded active running The Apache HTTP Server
+
+```
+
+或者,使用以下命令也可查看指定服务的状态。
+```
+# systemctl status apache2
+● apache2.service - The Apache HTTP Server
+ Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
+ Drop-In: /lib/systemd/system/apache2.service.d
+ └─apache2-systemd.conf
+ Active: active (running) since Tue 2018-03-06 12:34:09 IST; 8min ago
+ Process: 2786 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
+ Main PID: 1171 (apache2)
+ Tasks: 55 (limit: 4915)
+ CGroup: /system.slice/apache2.service
+ ├─1171 /usr/sbin/apache2 -k start
+ ├─2790 /usr/sbin/apache2 -k start
+ └─2791 /usr/sbin/apache2 -k start
+
+Mar 06 12:34:08 magi-VirtualBox systemd[1]: Starting The Apache HTTP Server...
+Mar 06 12:34:09 magi-VirtualBox apachectl[1089]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.0.2.15. Set the 'ServerName' directive globally to suppre
+Mar 06 12:34:09 magi-VirtualBox systemd[1]: Started The Apache HTTP Server.
+Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloading The Apache HTTP Server.
+Mar 06 12:39:10 magi-VirtualBox apachectl[2786]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using fe80::7929:4ed1:279f:4d65. Set the 'ServerName' directive gl
+Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloaded The Apache HTTP Server.
+
+```
+
+执行以下命令,只查看正在运行的服务。
+```
+# systemctl | grep running
+ acpid.path loaded active running ACPI Events Check
+ cups.path loaded active running CUPS Scheduler
+ init.scope loaded active running System and Service Manager
+ session-c2.scope loaded active running Session c2 of user magi
+ accounts-daemon.service loaded active running Accounts Service
+ acpid.service loaded active running ACPI event daemon
+ apache2.service loaded active running The Apache HTTP Server
+ aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
+ atop.service loaded active running Atop advanced performance monitor
+ atopacct.service loaded active running Atop process accounting daemon
+ avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
+ colord.service loaded active running Manage, Install and Generate Color Profiles
+ cron.service loaded active running Regular background program processing daemon
+ cups-browsed.service loaded active running Make remote CUPS printers available locally
+ cups.service loaded active running CUPS Scheduler
+ dbus.service loaded active running D-Bus System Message Bus
+ fwupd.service loaded active running Firmware update daemon
+ [email protected] loaded active running Getty on tty1
+ irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
+ lightdm.service loaded active running Light Display Manager
+ ModemManager.service loaded active running Modem Manager
+ NetworkManager.service loaded active running Network Manager
+ polkit.service loaded active running Authorization Manager
+
+```
+
+使用以下命令查看系统启动时会被启用的服务列表。
+```
+# systemctl list-unit-files | grep enabled
+acpid.path enabled
+cups.path enabled
+accounts-daemon.service enabled
+anacron-resume.service enabled
+anacron.service enabled
+apache2.service enabled
+apparmor.service enabled
+atop.service enabled
+atopacct.service enabled
+[email protected] enabled
+avahi-daemon.service enabled
+bluetooth.service enabled
+console-setup.service enabled
+cron.service enabled
+cups-browsed.service enabled
+cups.service enabled
+display-manager.service enabled
+dns-clean.service enabled
+friendly-recovery.service enabled
+[email protected] enabled
+gpu-manager.service enabled
+keyboard-setup.service enabled
+lightdm.service enabled
+ModemManager.service enabled
+network-manager.service enabled
+networking.service enabled
+NetworkManager-dispatcher.service enabled
+NetworkManager-wait-online.service enabled
+NetworkManager.service enabled
+
+```
+
+systemd-cgtop 按资源使用情况(任务、CPU、内存、输入和输出)列出控制组。
+```
+# systemd-cgtop
+
+Control Group Tasks %CPU Memory Input/s Output/s
+/ - - 1.5G - -
+/init.scope 1 - - - -
+/system.slice 153 - - - -
+/system.slice/ModemManager.service 3 - - - -
+/system.slice/NetworkManager.service 4 - - - -
+/system.slice/accounts-daemon.service 3 - - - -
+/system.slice/acpid.service 1 - - - -
+/system.slice/apache2.service 55 - - - -
+/system.slice/aptik-battery-monitor.service 1 - - - -
+/system.slice/atop.service 1 - - - -
+/system.slice/atopacct.service 1 - - - -
+/system.slice/avahi-daemon.service 2 - - - -
+/system.slice/colord.service 3 - - - -
+/system.slice/cron.service 1 - - - -
+/system.slice/cups-browsed.service 3 - - - -
+/system.slice/cups.service 2 - - - -
+/system.slice/dbus.service 6 - - - -
+/system.slice/fwupd.service 5 - - - -
+/system.slice/irqbalance.service 1 - - - -
+/system.slice/lightdm.service 7 - - - -
+/system.slice/polkit.service 3 - - - -
+/system.slice/repowerd.service 14 - - - -
+/system.slice/rsyslog.service 4 - - - -
+/system.slice/rtkit-daemon.service 3 - - - -
+/system.slice/snapd.service 8 - - - -
+/system.slice/system-getty.slice 1 - - - -
+
+```
+
+同时,我们可以使用 pstree 命令(输出来自 SysVinit 系统)查看正在运行的服务。
+```
+# pstree
+init-|-crond
+ |-httpd---2*[httpd]
+ |-kthreadd/99149---khelper/99149
+ |-2*[mingetty]
+ |-mysqld_safe---mysqld---9*[{mysqld}]
+ |-rsyslogd---3*[{rsyslogd}]
+ |-saslauthd---saslauthd
+ |-2*[sendmail]
+ |-sshd---sshd---bash---pstree
+ |-udevd
+ `-xinetd
+
+```
+
+我们还可以使用 pstree 命令(输出来自 systemd 系统)查看正在运行的服务。
+```
+# pstree
+systemd─┬─ModemManager─┬─{gdbus}
+ │ └─{gmain}
+ ├─NetworkManager─┬─dhclient
+ │ ├─{gdbus}
+ │ └─{gmain}
+ ├─accounts-daemon─┬─{gdbus}
+ │ └─{gmain}
+ ├─acpid
+ ├─agetty
+ ├─anacron
+ ├─apache2───2*[apache2───26*[{apache2}]]
+ ├─aptd───{gmain}
+ ├─aptik-battery-m
+ ├─atop
+ ├─atopacctd
+ ├─avahi-daemon───avahi-daemon
+ ├─colord─┬─{gdbus}
+ │ └─{gmain}
+ ├─cron
+ ├─cups-browsed─┬─{gdbus}
+ │ └─{gmain}
+ ├─cupsd
+ ├─dbus-daemon
+ ├─fwupd─┬─{GUsbEventThread}
+ │ ├─{fwupd}
+ │ ├─{gdbus}
+ │ └─{gmain}
+ ├─gnome-keyring-d─┬─{gdbus}
+ │ ├─{gmain}
+ │ └─{timer}
+
+```
+
+### 方法三:如何使用 chkservice 在 systemd 系统中查看正在运行的服务
+
+chkservice 是一个管理系统单元的终端工具,需要超级用户权限。
+```
+# chkservice
+
+```
+
+![][1]
+
+要查看帮助页面,请单击 `?` 按钮,它将显示管理 systemd 服务的可用选项。
+![][2]
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+译者:[jessie-pang](https://github.com/jessie-pang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/magesh/
+[1]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-1.png
+[2]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-2.png
\ No newline at end of file
diff --git a/sources/tech/20180429 Asynchronous Processing with Go using Kafka and MongoDB.md b/translated/tech/20180429 Asynchronous Processing with Go using Kafka and MongoDB.md
similarity index 58%
rename from sources/tech/20180429 Asynchronous Processing with Go using Kafka and MongoDB.md
rename to translated/tech/20180429 Asynchronous Processing with Go using Kafka and MongoDB.md
index ba57e40be3..baa4e1fa3e 100644
--- a/sources/tech/20180429 Asynchronous Processing with Go using Kafka and MongoDB.md
+++ b/translated/tech/20180429 Asynchronous Processing with Go using Kafka and MongoDB.md
@@ -1,33 +1,33 @@
-Asynchronous Processing with Go using Kafka and MongoDB
+使用 Kafka 和 MongoDB 进行 Go 异步处理
============================================================
-In my previous blog post ["My First Go Microservice using MongoDB and Docker Multi-Stage Builds"][9], I created a Go microservice sample which exposes a REST http endpoint and saves the data received from an HTTP POST to a MongoDB database.
+在我前面的博客文章 ["使用 MongoDB 和 Docker 多阶段构建我的第一个 Go 微服务][9] 中,我创建了一个 Go 微服务示例,它发布一个 REST 式的 http 端点,并将从 HTTP POST 中接收到的数据保存到 MongoDB 数据库。
-In this example, I decoupled the saving of data to MongoDB and created another microservice to handle this. I also added Kafka to serve as the messaging layer so the microservices can work on its own concerns asynchronously.
+在这个示例中,我将保存数据到 MongoDB 和创建另一个微服务去处理它解耦了。我还添加了 Kafka 为消息层服务,这样微服务就可以异步地处理它自己关心的东西了。
-> In case you have time to watch, I recorded a walkthrough of this blog post in the [video below][1] :)
+> 如果你有时间去看,我将这个博客文章的整个过程录制到 [这个视频中了][1] :)
-Here is the high-level architecture of this simple asynchronous processing example wtih 2 microservices.
+下面是这个使用了两个微服务的简单的异步处理示例的高级架构。

-Microservice 1 - is a REST microservice which receives data from a /POST http call to it. After receiving the request, it retrieves the data from the http request and saves it to Kafka. After saving, it responds to the caller with the same data sent via /POST
+微服务 1 —— 是一个 REST 式微服务,它从一个 /POST http 调用中接收数据。接收到请求之后,它从 http 请求中检索数据,并将它保存到 Kafka。保存之后,它通过 /POST 发送相同的数据去响应调用者。
-Microservice 2 - is a microservice which subscribes to a topic in Kafka where Microservice 1 saves the data. Once a message is consumed by the microservice, it then saves the data to MongoDB.
+微服务 2 —— 是一个在 Kafka 中订阅一个主题的微服务,在这里就是微服务 1 保存的数据。一旦消息被微服务消费之后,它接着保存数据到 MongoDB 中。
-Before you proceed, we need a few things to be able to run these microservices:
+在你继续之前,我们需要能够去运行这些微服务的几件东西:
-1. [Download Kafka][2] - I used version kafka_2.11-1.1.0
+1. [下载 Kafka][2] —— 我使用的版本是 kafka_2.11-1.1.0
-2. Install [librdkafka][3] - Unfortunately, this library should be present in the target system
+2. 安装 [librdkafka][3] —— 不幸的是,这个库应该在目标系统中
-3. Install the [Kafka Go Client by Confluent][4]
+3. 安装 [Kafka Go 客户端][4]
-4. Run MongoDB. You can check my [previous blog post][5] about this where I used a MongoDB docker image.
+4. 运行 MongoDB。你可以去看我的 [以前的文章][5] 中关于这一块的内容,那篇文章中我使用了一个 MongoDB docker 镜像。
-Let's get rolling!
+我们开始吧!
-Start Kafka first, you need Zookeeper running before you run the Kafka server. Here's how
+首先,启动 Kafka,在你运行 Kafka 服务器之前,你需要运行 Zookeeper。下面是示例:
```
$ cd //kafka_2.11-1.1.0
@@ -35,14 +35,14 @@ $ bin/zookeeper-server-start.sh config/zookeeper.properties
```
-Then run Kafka - I am using port 9092 to connect to Kafka. If you need to change the port, just configure it in config/server.properties. If you are just a beginner like me, I suggest to just use default ports for now.
+接着运行 Kafka —— 我使用 9092 端口连接到 Kafka。如果你需要改变端口,只需要在 `config/server.properties` 中配置即可。如果你像我一样是个新手,我建议你现在还是使用默认端口。
```
$ bin/kafka-server-start.sh config/server.properties
```
-After running Kafka, we need MongoDB. To make it simple, just use this docker-compose.yml.
+Kafka 跑起来之后,我们需要 MongoDB。它很简单,只需要使用这个 `docker-compose.yml` 即可。
```
version: '3'
@@ -64,14 +64,14 @@ networks:
```
-Run the MongoDB docker container using Docker Compose
+使用 Docker Compose 去运行 MongoDB docker 容器。
```
docker-compose up
```
-Here is the relevant code of Microservice 1. I just modified my previous example to save to Kafka rather than MongoDB.
+这里是微服务 1 的相关代码。我只是修改了我前面的示例去保存到 Kafka 而不是 MongoDB。
[rest-to-kafka/rest-kafka-sample.go][10]
@@ -136,7 +136,7 @@ func saveJobToKafka(job Job) {
```
-Here is the code of Microservice 2. What is important in this code is the consumption from Kafka, the saving part I already discussed in my previous blog post. Here are the important parts of the code which consumes the data from Kafka.
+这里是微服务 2 的代码。在这个代码中最重要的东西是从 Kafka 中消耗数据,保存部分我已经在前面的博客文章中讨论过了。这里代码的重点部分是从 Kafka 中消费数据。
[kafka-to-mongo/kafka-mongo-sample.go][11]
@@ -209,51 +209,51 @@ func saveJobToMongo(jobString string) {
```
-Let's get down to the demo, run Microservice 1\. Make sure Kafka is running.
+ 我们来演示一下,运行微服务 1。确保 Kafka 已经运行了。
```
$ go run rest-kafka-sample.go
```
-I used Postman to send data to Microservice 1
+我使用 Postman 向微服务 1 发送数据。

-Here is the log you will see in Microservice 1\. Once you see this, it means data has been received from Postman and saved to Kafka
+这里是日志,你可以在微服务 1 中看到。当你看到这些的时候,说明已经接收到了来自 Postman 发送的数据,并且已经保存到了 Kafka。

-Since we are not running Microservice 2 yet, the data saved by Microservice 1 will just be in Kafka. Let's consume it and save to MongoDB by running Microservice 2.
+因为我们尚未运行微服务 2,数据被微服务 1 只保存在了 Kafka。我们来消费它并通过运行的微服务 2 来将它保存到 MongoDB。
```
$ go run kafka-mongo-sample.go
```
-Now you'll see that Microservice 2 consumes the data and saves it to MongoDB
+现在,你将在微服务 2 上看到消费的数据,并将它保存到了 MongoDB。

-Check if data is saved in MongoDB. If it is there, we're good!
+检查一下数据是否保存到了 MongoDB。如果有数据,我们成功了!

-Complete source code can be found here
+完整的源代码可以在这里找到
[https://github.com/donvito/learngo/tree/master/rest-kafka-mongo-microservice][12]
-Shameless plug! If you like this blog post, please follow me in Twitter [@donvito][6]. I tweet about Docker, Kubernetes, GoLang, Cloud, DevOps, Agile and Startups. Would love to connect in [GitHub][7] and [LinkedIn][8]
+现在是广告时间:如果你喜欢这篇文章,请在 Twitter [@donvito][6] 上关注我。我的 Twitter 上有关于 Docker、Kubernetes、GoLang、Cloud、DevOps、Agile 和 Startups 的内容。欢迎你们在 [GitHub][7] 和 [LinkedIn][8] 关注我。
-[VIDEO](https://youtu.be/xa0Yia1jdu8)
+[视频](https://youtu.be/xa0Yia1jdu8)
-Enjoy!
+开心地玩吧!
--------------------------------------------------------------------------------
via: https://www.melvinvivas.com/developing-microservices-using-kafka-and-mongodb/
作者:[Melvin Vivas ][a]
-译者:[译者ID](https://github.com/译者ID)
+译者:[qhwdw](https://github.com/qhwdw)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180508 Everything old is new again- Microservices - DXC Blogs.md b/translated/tech/20180508 Everything old is new again- Microservices - DXC Blogs.md
new file mode 100644
index 0000000000..bc8c557339
--- /dev/null
+++ b/translated/tech/20180508 Everything old is new again- Microservices - DXC Blogs.md
@@ -0,0 +1,57 @@
+老树发新芽:微服务 – DXC Blogs
+======
+
+
+如果我告诉你有这样一种软件架构,一个应用程序的组件通过基于网络的通讯协议为其它组件提供服务,我估计你可能会说它是 …
+
+是的,确实是。如果你从上世纪九十年代就开始了你的编程生涯,那么你肯定会说它是 [面向服务的架构 (SOA)][1]。但是,如果你是个年青人,并且在云上获得初步的经验,那么,你将会说:“哦,你说的是 [微服务][2]。”
+
+你们都没错。如果想真正地了解它们的差别,你需要深入地研究这两种架构。
+
+在 SOA 中,一个服务是一个功能,它是定义好的、自包含的、并且是不依赖上下文和其它服务的状态的功能。总共有两种服务。一种是消费者服务,它从另外类型的服务 —— 提供者服务 —— 中请求一个服务。一个 SOA 服务可以同时扮演这两种角色。
+
+SOA 服务可以与其它服务交换数据。两个或多个服务也可以彼此之间相互协调。这些服务执行基本的任务,比如创建一个用户帐户、提供登陆功能、或验证支付。
+
+与其说 SOA 是模块化一个应用程序,还不如说它是把分布式的、独立维护和部署的组件,组合成一个应用程序。然后在服务器上运行这些组件。
+
+早期版本的 SOA 使用面向对象的协议进行组件间通讯。例如,微软的 [分布式组件对象模型 (DCOM)][3] 和使用 [通用对象请求代理架构 (CORBA)][5] 规范的 [对象请求代理 (ORBs)][4]。
+
+用于消息服务的最新版本,比如 [Java 消息服务 (JMS)][6] 或者 [高级消息队列协议 (AMQP)][7]。这些服务通过企业服务总线 (ESB) 进行连接。基于这些总线,来传递和接收可扩展标记语言(XML)格式的数据。
+
+[微服务][2] 是一个架构样式,其中的应用程序以松散耦合的服务或模块组成。它适用于开发大型的、复杂的应用程序的持续集成/持续部署(CI/CD)模型。一个应用程序就是一堆模块的汇总。
+
+每个微服务提供一个应用程序编程接口(API)端点。它们通过轻量级协议连接,比如,[表述性状态转移 (REST)][8],或 [gRPC][9]。数据倾向于使用 [JavaScript 对象标记 (JSON)][10] 或 [Protobuf][11] 来表示。
+
+这两种架构都可以用于去替代以前老的整体式架构,整体式架构的应用程序被构建为单个自治的单元。例如,在一个客户机 - 服务器模式中,一个典型的 Linux、Apache、MySQL、PHP/Python/Perl (LAMP) 服务器端应用程序将去处理 HTTP 请求、运行子程序、以及从底层的 MySQL 数据库中检索/更新数据。所有这些应用程序”绑“在一起提供服务。当你改变了任何一个东西,你都必须去构建和部署一个新版本。
+
+使用 SOA,你可以只改变需要的几个组件,而不是整个应用程序。使用微服务,你可以做到一次只改变一个服务。使用微服务,你才能真正做到一个解耦架构。
+
+微服务也比 SOA 更轻量级。不过 SOA 服务是部署到服务器和虚拟机上,而微服务是部署在容器中。协议也更轻量级。这使得微服务比 SOA 更灵活。因此,它更适合于要求敏捷性的电商网站。
+
+说了这么多,到底意味着什么呢?微服务就是 SOA 在容器和云计算上的变种。
+
+老式的 SOA 并没有离我们远去,但是,因为我们持续将应用程序搬迁到容器中,所以微服务架构将越来越流行。
+
+--------------------------------------------------------------------------------
+
+via: https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/
+
+作者:[Cloudy Weather][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://blogs.dxc.technology/author/steven-vaughan-nichols/
+[1]:https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html
+[2]:http://microservices.io/
+[3]:https://technet.microsoft.com/en-us/library/cc958799.aspx
+[4]:https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB
+[5]:http://www.corba.org/
+[6]:https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html
+[7]:https://www.amqp.org/
+[8]:https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html
+[9]:https://grpc.io/
+[10]:https://www.json.org/
+[11]:https://github.com/google/protobuf/
diff --git a/sources/tech/20180508 UKTools - Easy Way To Install Latest Linux Kernel.md b/translated/tech/20180508 UKTools - Easy Way To Install Latest Linux Kernel.md
similarity index 85%
rename from sources/tech/20180508 UKTools - Easy Way To Install Latest Linux Kernel.md
rename to translated/tech/20180508 UKTools - Easy Way To Install Latest Linux Kernel.md
index c85d9c35d4..dbbc077508 100644
--- a/sources/tech/20180508 UKTools - Easy Way To Install Latest Linux Kernel.md
+++ b/translated/tech/20180508 UKTools - Easy Way To Install Latest Linux Kernel.md
@@ -1,38 +1,40 @@
-UKTools - Easy Way To Install Latest Linux Kernel
+UKTools - 安装最新 Linux 内核的简便方法
======
-There are multiple utilities is available for Ubuntu to upgrade Linux kernel to latest stable version. We had already wrote about those utility in the past such as Linux Kernel Utilities (LKU), Ubuntu Kernel Upgrade Utility (UKUU) and Ubunsys.
-Also few utilities are available and we will be planning to include in the further article like, ubuntu-mainline-kernel.sh and manual method from mainline kernel.
+Ubuntu 中有许多实用程序可以将 Linux 内核升级到最新的稳定版本。我们之前已经写过关于这些实用程序的文章,例如 Linux Kernel Utilities (LKU), Ubuntu Kernel Upgrade Utility (UKUU) 和 Ubunsys。
-Today also we are going to teach you the similar utility called UKTools. You can try any one of these utilities to get your Linux kernels to the latest releases.
-Latest kernel release comes with security bug fixes and some improvements so, better to keep latest one to get reliable, secure and better hardware performance.
+另外还有一些其它实用程序可供使用。我们计划在其它文章中包含这些,例如 ubuntu-mainline-kernel.sh 和 manual method from mainline kernel.
-Some times the latest kernel version might be buggy and can crash your system so, it’s your own risk. I would like to advise you to not to install on production environment.
+今天我们还会教你类似的使用工具 -- UKTools。你可以尝试使用这些实用程序中的任何一个来将 Linux 内核升级至最新版本。
-**Suggested Read :**
-**(#)** [Linux Kernel Utilities (LKU) – A Set Of Shell Scripts To Compile, Install & Update Latest Kernel In Ubuntu/LinuxMint][1]
-**(#)** [Ukuu – An Easy Way To Install/Upgrade Linux Kernel In Ubuntu based Systems][2]
-**(#)** [6 Methods To Check The Running Linux Kernel Version On System][3]
+最新的内核版本附带了安全漏洞修复和一些改进,因此,最好保持最新的内核版本以获得可靠,安全和更好的硬件性能。
-### What Is UKTools
+有时候最新的内核版本可能会有一些漏洞,并且会导致系统崩溃,这是你的风险。我建议你不要在生产环境中安装它。
-[UKTools][4] stands for Ubuntu Kernel Tools, that contains two shell scripts `ukupgrade` and `ukpurge`.
+**建议阅读:**
+**(#)** [Linux 内核实用程序(LKU)- 在 Ubuntu/LinuxMint 中编译,安装和更新最新内核的一组 Shell 脚本][1]
+**(#)** [Ukuu - 在基于 Ubuntu 的系统中安装或升级 Linux 内核的简便方法][2]
+**(#)** [6 种检查系统上正在运行的 Linux 内核版本的方法][3]
-ukupgrade stands for “Ubuntu Kernel Upgrade”, which allows user to upgrade Linux kernel to latest stable version for Ubuntu/Mint and derivatives based on [kernel.ubuntu.com][5].
+### 什么是 UKTools
-ukpurge stands for “Ubuntu Kernel Purge”, which allows user to remove old Linux kernel images/headers in machine for Ubuntu/ Mint and derivatives. It will keep only three kernel versions.
+[UKTools][4] 意思是 Ubuntu 内核工具,它包含两个 shell 脚本 `ukupgrade` 和 `ukpurge`。
-There is no GUI for this utility, however it looks very simple and straight forward so, newbie can perform the upgrade without any issues.
+ukupgrade 意思是 “Ubuntu Kernel Upgrade”,它允许用户将 Linux 内核升级到 Ubuntu/Mint 的最新稳定版本以及基于 [kernel.ubuntu.com][5] 的衍生版本。
-I’m running Ubuntu 17.10 and the current kernel version is below.
+ukpurge 意思是 “Ubuntu Kernel Purge”,它允许用户在机器中删除旧的 Linux 内核镜像或头文件,用于 Ubuntu/Mint 和其衍生版本。它将只保留三个内核版本。
+
+此实用程序没有 GUI,但它看起来非常简单直接,因此,新手可以在没有任何问题的情况下进行升级。
+
+我正在运行 Ubuntu 17.10,目前的内核版本如下:
```
$ uname -a
Linux ubuntu 4.13.0-39-generic #44-Ubuntu SMP Thu Apr 5 14:25:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
```
-Run the following command to get the list of installed kernel on your system (Ubuntu and derivatives). Currently i’m holding `seven` kernels.
+运行以下命令来获取系统上已安装内核的列表(Ubuntu 及其衍生产品)。目前我持有 `7` 个内核。
```
$ dpkg --list | grep linux-image
ii linux-image-4.13.0-16-generic 4.13.0-16.19 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
@@ -53,23 +55,23 @@ ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
```
-### How To Install UKTools
+### 如何安装 UKTools
-Just run the below commands to install UKTools on Ubuntu and derivatives.
+在 Ubuntu 及其衍生产品上,只需运行以下命令来安装 UKTools 即可。
-Run the below command to clone UKTools repository on your system.
+在你的系统上运行以下命令来克隆 UKTools 仓库:
```
$ git clone https://github.com/usbkey9/uktools
```
-Navigate to uktools directory.
+进入 uktools 目录:
```
$ cd uktools
```
-Run the Makefile to generate the necessary files. Also this will automatically install latest available kernel. Just reboot the system in order to use the latest kernel.
+运行 Makefile 以生成必要的文件。此外,这将自动安装最新的可用内核。只需重新启动系统即可使用最新的内核。
```
$ sudo make
[sudo] password for daygeek:
@@ -189,27 +191,27 @@ Give it a star: https://github.com/MarauderXtreme/uktools
```
-Restart the system to activate the latest kernel.
+重新启动系统以激活最新的内核。
```
$ sudo shutdown -r now
```
-Once the system back to up, re-check the kernel version.
+一旦系统重新启动,重新检查内核版本。
```
$ uname -a
Linux ubuntu 4.16.7-041607-generic #201805021131 SMP Wed May 2 15:34:55 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
```
-This make command will drop the below files into `/usr/local/bin` directory.
+此 make 命令会将下面的文件放到 `/usr/local/bin` 目录中。
```
do-kernel-upgrade
do-kernel-purge
```
-To remove old kernels, run the following command.
+要移除旧内核,运行以下命令:
```
$ do-kernel-purge
@@ -365,7 +367,7 @@ Thanks for using this script!!!
```
-Re-check the list of installed kernels using the below command. This will keep only old three kernels.
+使用以下命令重新检查已安装内核的列表。它将只保留三个旧的内核。
```
$ dpkg --list | grep linux-image
ii linux-image-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
@@ -377,14 +379,15 @@ ii linux-image-unsigned-4.16.7-041607-generic 4.16.7-041607.201805021131 amd64 L
```
-For next time you can call `do-kernel-upgrade` utility for new kernel installation. If any new kernel is available then it will install. If no, it will report no kernel update is available at the moment.
+下次你可以调用 `do-kernel-upgrade` 实用程序来安装新的内核。如果有任何新内核可用,那么它将安装。如果没有,它将报告当前没有可用的内核更新。
```
$ do-kernel-upgrade
Kernel up to date. Finishing
```
-Run the `do-kernel-purge` command once again to confirm on this. If this found more than three kernels then it will remove. If no, it will report nothing to remove message.
+再次运行 `do-kernel-purge` 命令以确认。如果发现超过三个内核,那么它将移除。如果不是,它将报告没有删除消息。
+
```
$ do-kernel-purge
@@ -400,13 +403,14 @@ Thanks for using this script!!!
```
+
--------------------------------------------------------------------------------
via: https://www.2daygeek.com/uktools-easy-way-to-install-latest-stable-linux-kernel-on-ubuntu-mint-and-derivatives/
作者:[Prakash Subramanian][a]
选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
+译者:[MjSeven](https://github.com/MjSeven)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180516 How Graphics Cards Work.md b/translated/tech/20180516 How Graphics Cards Work.md
new file mode 100644
index 0000000000..172b0d1166
--- /dev/null
+++ b/translated/tech/20180516 How Graphics Cards Work.md
@@ -0,0 +1,74 @@
+显卡工作原理简介
+======
+![AMD-Polaris][1]
+
+自从 sdfx 推出最初的 Voodoo 加速器以来,不起眼的显卡对你的 PC 是否可以玩游戏起到决定性作用,PC 上任何其它设备都无法与其相比。其它组件当然也很重要,但对于一个拥有 32GB 内存、价值 500 美金的 CPU 和 基于 PCIe 的存储设备的高端 PC,如果使用 10 年前的显卡,都无法以最高分辨率和细节质量运行当前最高品质的游戏,会发生卡顿甚至无响应。显卡(也常被称为 GPU, 或图形处理单元)对游戏性能影响极大,我们反复强调这一点;但我们通常并不会深入了解显卡的工作原理。
+
+出于实际考虑,本文将概述 GPU 的上层功能特性,内容包括 AMD 显卡、Nvidia 显卡、Intel 集成显卡以及 Intel 后续可能发布的独立显卡之间共同的部分。也应该适用于 Apple, Imagination Technologies, Qualcomm, ARM 和 其它显卡生产商发布的移动平台 GPU。
+
+### 我们为何不使用 CPU 进行渲染?
+
+我要说明的第一点是我们为何不直接使用 CPU 完成游戏中的渲染工作。坦率的说,在理论上你确实可以直接使用 CPU 完成渲染工作。在显卡没有广泛普及之前,早期的 3D 游戏就是完全基于 CPU 运行的,例如 Ultima Underworld(LCTT 译注:中文名为 _地下创世纪_ ,下文中简称 UU)。UU 是一个很特别的例子,原因如下:与 Doom (LCTT 译注:中文名 _毁灭战士_)相比,UU 具有一个更高级的渲染引擎,全面支持向上或向下查找以及一些在当时比较高级的特性,例如纹理映射。但为支持这些高级特性,需要付出高昂的代价,很少有人可以拥有真正能运行起 UU 的 PC。
+
+
+
+对于早期的 3D 游戏,包括 Half Life 和 Quake II 在内的很多游戏,内部包含一个软件渲染器,让没有 3D 加速器的玩家也可以玩游戏。但现代游戏都弃用了这种方式,原因很简单:CPU 是设计用于通用任务的微处理器,意味着缺少 GPU 提供的专用硬件和功能。对于 18 年前使用软件渲染的那些游戏,当代 CPU 可以轻松胜任;但对于当代最高品质的游戏,除非明显降低景象质量、分辨率和各种虚拟特效,否则现有的 CPU 都无法胜任。
+
+### 什么是 GPU ?
+
+GPU 是一种包含一系列专用硬件特性的设备,其中这些特性可以让各种 3D 引擎更好地执行代码,包括形状构建,纹理映射,访存和着色器等。3D 引擎的功能特性影响着设计者如何设计 GPU。可能有人还记得,AMD HD5000 系列使用 VLIW5 架构;但在更高端的 HD 6000 系列中使用了 VLIW4 架构。通过 GCN (LCTT 译注:GCN 是 Graphics Core Next 的缩写,字面意思是下一代图形核心,既是若干代微体系结构的代号,也是指令集的名称),AMD 改变了并行化的实现方法,提高了每个时钟周期的有效性能。
+
+
+
+Nvidia 在发布首款 GeForce 256 时(大致对应 Microsoft 推出 DirectX7 的时间点)提出了 GPU 这个术语,这款 GPU 支持在硬件上执行转换和光照计算。将专用功能直接集成到硬件中是早期 GPU 的显著技术特点。很多专用功能还在(以一种极为不同的方式)使用,毕竟对于特定类型的工作任务,使用片上专用计算资源明显比使用一组可编程单元要更加高效和快速。
+
+GPU 和 CPU 的核心有很多差异,但我们可以按如下方式比较其上层特性。CPU 一般被设计成尽可能快速和高效的执行单线程代码。虽然 同时多线程 或 超线程在这方面有所改进,但我们实际上通过堆叠众多高效率的单线程核心来扩展多线程性能。AMD 的 32 核心/64 线程 Epyc CPU 已经是我们能买到的核心数最多的 CPU;相比而言,Nvidia 最低端的 Pascal GPU 都拥有 384 个核心。但相比 CPU 的核心,GPU 所谓的核心是处理能力低得多的的处理单元。
+
+**注意:** 简单比较 GPU 核心数,无法比较或评估 AMD 与 Nvidia 的相对游戏性能。在同样 GPU 系列(例如 Nvidia 的 GeForce GTX 10 系列,或 AMD 的 RX 4xx 或 5xx 系列)的情况下,更高的 GPU 核心数往往意味着更高的性能。
+
+你无法只根据核心数比较不同供应商或核心系列的 GPU 之间的性能,这是因为不同的架构对应的效率各不相同。与 CPU 不同,GPU 被设计用于并行计算。AMD 和 Nvidia 在结构上都划分为计算资源块。Nvidia 将这些块称之为流处理器,而 AMD 则称之为计算单元。
+
+
+
+每个块都包含如下组件:一组核心,一个调度器,一个寄存器文件,指令缓存,纹理和 L1 缓存以及纹理映射单元。SM/CU 可以被认为是 GPU 中最小的可工作块。SM/CU 没有涵盖全部的功能单元,例如视频解码引擎,实际在屏幕绘图所需的渲染输出,以及与板载显存通信相关的内存接口都不在 SM/CU 的范围内;但当 AMD 提到一个 APU 拥有 8 或 11 个 Vega 计算单元时,所指的是(等价的)硅晶块数目。如果你查看任意一款 GPU 的模块设计图,你会发现图中 SM/CU 是反复出现很多次的部分。
+
+
+
+GPU 中的 SM/CU 数目越多,每个时钟周期内可以并行完成的工作也越多。渲染是一种通常被认为是“高度并行”的计算问题,意味着随着核心数增加带来的可扩展性很高。
+
+当我们讨论 GPU 设计时,我们通常会使用一种形如 4096:160:64 的格式,其中第一个数字代表核心数。在核心系列(如 GTX970/GTX 980/GTX 980 Ti, 如 RX 560/RX 580 等等)一致的情况下,核心数越高,GPU 也就相对更快。
+
+### 纹理映射和渲染输出
+
+GPU 的另外两个主要组件是纹理映射单元和渲染输出。设计中的纹理映射单元数目决定了最大的纹素输出以及可以多快的处理并将纹理映射到对象上。早期的 3D 游戏很少用到纹理,这是因为绘制 3D 多边形形状的工作有较大的难度。纹理其实并不是 3D 游戏必须的,但不使用纹理的现代游戏屈指可数。
+
+GPU 中的纹理映射单元数目用 4096:160:64 指标中的第二个数字表示。AMD,Nvidia 和 Intel 一般都等比例变更指标中的数字。换句话说,如果你找到一个指标为 4096:160:64 的 GPU,同系列中不会出现指标为 4096:320:64 的 GPU。纹理映射绝对有可能成为游戏的瓶颈,但产品系列中次高级别的 GPU 往往提供更多的核心和纹理映射单元(是否拥有更高的渲染输出单元取决于 GPU 系列和显卡的指标)。
+
+渲染输出单元(有时也叫做光栅操作管道是 GPU 输出汇集成图像的场所,图像最终会在显示器或电视上呈现。渲染输出单元的数目乘以 GPU 的时钟频率决定了像素填充速率。渲染输出单元数目越多意味着可以同时输出的像素越多。渲染输出单元还处理抗锯齿,启用抗锯齿(尤其是超级采样抗锯齿)会导致游戏填充速率受限。
+
+### 显存带宽与显存容量
+
+我们最后要讨论的是显存带宽和显存容量。显存带宽是指一秒时间内可以从 GPU 专用的显存缓冲区内拷贝进或拷贝出多少数据。很多高级视觉特效(以及更常见的高分辨率)需要更高的显存带宽,以便保证足够的帧率,因为需要拷贝进和拷贝出 GPU 核心的数据总量增大了。
+
+在某些情况下,显存带宽不足会成为 GPU 的显著瓶颈。以 Ryzen 5 2400G 为例的 AMD APU 就是严重带宽受限的,以至于提高 DDR4 的时钟频率可以显著提高整体性能。导致瓶颈的显存带宽阈值,也与游戏引擎和游戏使用的分辨率相关。
+
+板载内存大小也是 GPU 的重要指标。如果按指定细节级别或分辨率运行所需的显存量超过了可用的资源量,游戏通常仍可以运行,但会使用 CPU 的主存存储额外的纹理数据;而从 DRAM 中提取数据比从板载显存中提取数据要慢得多。这会导致游戏在板载的快速访问内存池和系统内存中共同提取数据时出现明显的卡顿。
+
+有一点我们需要留意,GPU 生产厂家通常为一款低端或中端 GPU 配置比通常更大的显存,这是他们为产品提价的一种常用手段。很难说大显存是否更具有吸引力,毕竟需要具体问题具体分析。大多数情况下,用更高的价格购买一款仅显存更高的显卡是不划算的。经验规律告诉我们,低端显卡遇到显存瓶颈之前就会碰到其它瓶颈。如果存在疑问,可以查看相关评论,例如 4G 版本或其它数目的版本是否性能超过 2G 版本。更多情况下,如果其它指标都相同,购买大显存版本并不值得。
+
+查看我们的[极致技术讲解][2]系列,深入了解更多当前最热的技术话题。
+
+--------------------------------------------------------------------------------
+
+via: https://www.extremetech.com/gaming/269335-how-graphics-cards-work
+
+作者:[Joel Hruska][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[pinewall](https://github.com/pinewall)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.extremetech.com/author/jhruska
+[1]:https://www.extremetech.com/wp-content/uploads/2016/07/AMD-Polaris-640x353.jpg
+[2]:http://www.extremetech.com/tag/extremetech-explains
diff --git a/translated/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md b/translated/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md
new file mode 100644
index 0000000000..3d1e00376a
--- /dev/null
+++ b/translated/tech/20180523 A Set Of Useful Utilities For Debian And Ubuntu Users.md
@@ -0,0 +1,290 @@
+献给 Debian 和 Ubuntu 用户的一组实用程序
+======
+
+
+
+你使用的是基于 Debian 的系统吗?如果是,太好了!我今天在这里给你带来了一个好消息。先向 **“Debian-goodies”** 打个招呼,这是一组基于 Debian 系统(比如:Ubuntu, Linux Mint)的有用工具。这些实用工具提供了一些额外的有用的命令,这些命令在基于 Debian 的系统中默认不可用。通过使用这些工具,用户可以找到哪些程序占用更多磁盘空间,更新系统后需要重新启动哪些服务,在一个包中搜索与模式匹配的文件,根据搜索字符串列出已安装的包等等。在这个简短的指南中,我们将讨论一些有用的 Debian 的好东西。
+
+### Debian-goodies – 给 Debian 和 Ubuntu 用户的实用程序
+
+debian-goodies 包可以在 Debian 和其衍生的 Ubuntu 以及其它 Ubuntu 变体(如 Linux Mint)的官方仓库中找到。要安装 debian-goodies,只需简单运行:
+```
+$ sudo apt-get install debian-goodies
+
+```
+
+debian-goodies 安装完成后,让我们继续看一看一些有用的实用程序。
+
+#### **1. Checkrestart**
+
+让我从我最喜欢的 **“checkrestart”** 实用程序开始。安装某些安全更新时,某些正在运行的应用程序可能仍然会使用旧库。要彻底应用安全更新,你需要查找并重新启动所有这些更新。这就是 Checkrestart 派上用场的地方。该实用程序将查找哪些进程仍在使用旧版本的库,然后,你可以重新启动服务。
+
+在进行库更新后,要检查哪些守护进程应该被重新启动,运行:
+```
+$ sudo checkrestart
+[sudo] password for sk:
+Found 0 processes using old versions of upgraded files
+
+```
+
+由于我最近没有执行任何安全更新,因此没有显示任何内容。
+
+请注意,Checkrestart 实用程序确实运行良好。但是,有一个名为 “needrestart” 的类似工具可用于最新的 Debian 系统。Needrestart 的灵感来自 checkrestart 实用程序,它完成了同样的工作。 Needrestart 得到了积极维护,并支持容器(LXC, Docker)等新技术。
+
+以下是 Needrestart 的特点:
+
+ * 支持(当不要求)systemd
+ * 二进制黑名单(即显示管理员)
+ * 试图检测挂起的内核升级
+ * 尝试检测基于解释器的守护进程所需的重启(支持 Perl, Python, Ruby)
+ * 使用钩子完全集成到 apt/dpkg 中
+
+它在默认仓库中也可以使用。所以,你可以使用如下命令安装它:
+```
+$ sudo apt-get install needrestart
+
+```
+
+现在,你可以使用以下命令检查更新系统后需要重新启动的守护程序列表:
+```
+$ sudo needrestart
+Scanning processes...
+Scanning linux images...
+
+Running kernel seems to be up-to-date.
+
+Failed to check for processor microcode upgrades.
+
+No services need to be restarted.
+
+No containers need to be restarted.
+
+No user sessions are running outdated binaries.
+
+```
+
+好消息是 Needrestart 同样也适用于其它 Linux 发行版。例如,你可以从 Arch Linux 及其衍生版的 AUR 或者其它任何 AUR 帮助程序来安装,就像下面这样:
+```
+$ yaourt -S needrestart
+
+```
+
+在 fedora:
+```
+$ sudo dnf install needrestart
+
+```
+
+#### 2. Check-enhancements
+
+Check-enhancements 实用程序用于查找那些用于增强已安装的包的软件包。此实用程序将列出增强其它包但不是必须运行它的包。你可以通过 “-ip” 或 “–installed-packages” 选项来查找增强单个包或所有已安装包的软件包。
+
+例如,我将列出增强 gimp 包功能的包:
+```
+$ check-enhancements gimp
+gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
+gimp => gimp-gmic: Installed: (none) Candidate: 1.7.9+zart-4build3
+gimp => gimp-gutenprint: Installed: (none) Candidate: 5.2.13-2
+gimp => gimp-help-ca: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-de: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-el: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-en: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-es: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-fr: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-it: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-ja: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-ko: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-nl: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-nn: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-pt: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-ru: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
+gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
+gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
+
+```
+
+要列出增强所有已安装包的,请运行:
+```
+$ check-enhancements -ip
+autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
+btrfs-progs => snapper: Installed: (none) Candidate: 0.5.4-3
+ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
+cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
+dpkg => debsig-verify: Installed: (none) Candidate: 0.18
+[...]
+
+```
+
+#### 3. dgrep
+
+顾名思义,dgrep 用于根据给定的正则表达式搜索制指定包的所有文件。例如,我将在 Vim 包中搜索包含正则表达式 “text” 的文件。
+```
+$ sudo dgrep "text" vim
+Binary file /usr/bin/vim.tiny matches
+/usr/share/doc/vim-tiny/copyright: that they must include this license text. You can also distribute
+/usr/share/doc/vim-tiny/copyright: include this license text. You are also allowed to include executables
+/usr/share/doc/vim-tiny/copyright: 1) This license text must be included unmodified.
+/usr/share/doc/vim-tiny/copyright: text under a) applies to those changes.
+/usr/share/doc/vim-tiny/copyright: context diff. You can choose what license to use for new code you
+/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
+/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
+[...]
+
+```
+
+dgrep 支持大多数 grep 的选项。参阅以下指南以了解 grep 命令。
+
+ * [献给初学者的 Grep 命令教程][2]
+
+#### 4 dglob
+
+dglob 实用程序生成与给定模式匹配的包名称列表。例如,找到与字符串 “vim” 匹配的包列表。
+```
+$ sudo dglob vim
+vim-tiny:amd64
+vim:amd64
+vim-common:all
+vim-runtime:all
+
+```
+
+默认情况下,dglob 将仅显示已安装的软件包。如果要列出所有包(包括已安装的和未安装的),使用 **-a** 标志。
+```
+$ sudo dglob vim -a
+
+```
+
+#### 5. debget
+
+**debget** 实用程序将在 APT 的数据库中下载一个包的 .deb 文件。请注意,它只会下载给定的包,不包括依赖项。
+```
+$ debget nano
+Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
+Fetched 231 kB in 2s (113 kB/s)
+
+```
+
+#### 6. dpigs
+
+这是此次集合中另一个有用的实用程序。**dpigs** 实用程序将查找并显示那些占用磁盘空间最多的已安装包。
+```
+$ dpigs
+260644 linux-firmware
+167195 linux-modules-extra-4.15.0-20-generic
+75186 linux-headers-4.15.0-20
+64217 linux-modules-4.15.0-20-generic
+55620 snapd
+31376 git
+31070 libicu60
+28420 vim-runtime
+25971 gcc-7
+24349 g++-7
+
+```
+
+如你所见,linux-firmware 包占用的磁盘空间最多。默认情况下,它将显示占用磁盘空间的 **前 10 个**包。如果要显示更多包,例如 20 个,运行以下命令:
+```
+$ dpigs -n 20
+
+```
+
+#### 7. debman
+
+**debman** 实用程序允许你轻松查看二进制文件 **.deb** 中的手册页而不提取它。你甚至不需要安装 .deb 包。以下命令显示 nano 包的手册页。
+```
+$ debman -f nano_2.9.3-2_amd64.deb nano
+
+```
+如果你没有 .deb 软件包的本地副本,使用 **-p** 标志下载并查看包的手册页。
+```
+$ debman -p nano nano
+
+```
+
+**建议阅读:**
+[每个 Linux 用户都应该知道的 3 个 man 的替代品][3]
+
+#### 8. debmany
+
+安装的 Debian 包不仅包含手册页,还包括其它文件,如确认,版权和 read me (自述文件)等。**debmany** 实用程序允许你查看和读取那些文件。
+```
+$ debmany vim
+
+```
+
+![][1]
+
+使用方向键选择要查看的文件,然后按 ENTER 键查看所选文件。按 **q** 返回主菜单。
+
+如果未安装指定的软件包,debmany 将从 APT 数据库下载并显示手册页。应安装 **dialog** 包来阅读手册页。
+
+#### 9. popbugs
+
+如果你是开发人员,**popbugs** 实用程序将非常有用。它将根据你使用的包显示一个定制的发布关键 bug 列表(使用热门竞赛数据)。对于那些不关心的人,Popular-contest 包设置了一个 cron (定时)任务,它将定期匿名向 Debian 开发人员提交有关该系统上最常用的 Debian 软件包的统计信息。这些信息有助于 Debian 做出决定,例如哪些软件包应该放在第一张 CD 上。它还允许 Debian 改进未来的发行版本,以便为新用户自动安装最流行的软件包。
+
+要生成严重 bug 列表并在默认 Web 浏览器中显示结果,运行:
+```
+$ popbugs
+
+```
+
+此外,你可以将结果保存在文件中,如下所示。
+```
+$ popbugs --output=bugs.txt
+
+```
+
+#### 10. which-pkg-broke
+
+此命令将显示给定包的所有依赖项以及安装每个依赖项的时间。通过使用此信息,你可以在升级系统或软件包之后轻松找到哪个包可能会在什么时间损坏另一个包。
+```
+$ which-pkg-broke vim
+Package has no install time info
+debconf Wed Apr 25 08:08:40 2018
+gcc-8-base:amd64 Wed Apr 25 08:08:41 2018
+libacl1:amd64 Wed Apr 25 08:08:41 2018
+libattr1:amd64 Wed Apr 25 08:08:41 2018
+dpkg Wed Apr 25 08:08:41 2018
+libbz2-1.0:amd64 Wed Apr 25 08:08:41 2018
+libc6:amd64 Wed Apr 25 08:08:42 2018
+libgcc1:amd64 Wed Apr 25 08:08:42 2018
+liblzma5:amd64 Wed Apr 25 08:08:42 2018
+libdb5.3:amd64 Wed Apr 25 08:08:42 2018
+[...]
+
+```
+
+#### 11. dhomepage
+
+dhomepage 实用程序将在默认 Web 浏览器中显示给定包的官方网站。例如,以下命令将打开 Vim 编辑器的主页。
+```
+$ dhomepage vim
+
+```
+
+这就是全部了。Debian-goodies 是你武器库中必备的工具。即使我们不经常使用所有这些实用程序,但它们值得学习,我相信它们有时会非常有用。
+
+我希望这很有用。更多好东西要来了。敬请关注!
+
+干杯!
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:http://www.ostechnix.com/wp-content/uploads/2018/05/debmany.png
+[2]:
+https://www.ostechnix.com/the-grep-command-tutorial-with-examples-for-beginners/
+[3]:
+https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
diff --git a/translated/tech/20180524 How CERN Is Using Linux and Open Source.md b/translated/tech/20180524 How CERN Is Using Linux and Open Source.md
new file mode 100644
index 0000000000..76c8f611d4
--- /dev/null
+++ b/translated/tech/20180524 How CERN Is Using Linux and Open Source.md
@@ -0,0 +1,67 @@
+欧洲核子研究组织(CERN)是如何使用 Linux 和开源的
+============================================================
+
+
+>欧洲核子研究组织(简称 CERN)依靠开源技术处理大型强子对撞机生成的大量数据。ATLAS(超环面仪器,如图所示)是一种探测基本粒子的通用探测器。(图片来源:CERN)[经许可使用][2]
+
+[CERN][3]
+
+[CERN][6] 无需过多介绍了吧。CERN 创建了万维网和大型强子对撞机(LHC),这是世界上最大的粒子加速器,就是通过它发现了 [希格斯玻色子][7]。负责该组织 IT 操作系统和基础架构的 Tim Bell 表示,他的团队的目标是“为全球 13000 名物理学家提供计算设施,以分析这些碰撞、了解宇宙的构成以及是如何运转的。”
+
+CERN 正在进行硬核科学研究,尤其是大型强子对撞机,它在运行时 [生成大量数据][8]。“CERN 目前存储大约 200 PB 的数据,当加速器运行时,每月有超过 10 PB 的数据产生。这必然会给计算基础架构带来极大的挑战,包括存储大量数据,以及能够在合理的时间范围内处理数据,对于网络、存储技术和高效计算架构都是很大的压力。“Bell 说到。
+
+### [tim-bell-cern.png][4]
+
+
+Tim Bell, CERN [经许可使用][1] Swapnil Bhartiya
+
+大型强子对撞机的运作规模和它产生的数据量带来了严峻的挑战,但 CERN 对这些问题并不陌生。CERN 成立于 1954 年,已经 60 余年了。“我们一直面临着难以解决的计算能力挑战,但我们一直在与开源社区合作解决这些问题。”Bell 说,“即使在 90 年代,当我们发明万维网时,我们也希望与人们共享,使其能够从 CERN 的研究中受益,开源是做这件事的再合适不过的工具了。”
+
+### 使用 OpenStack 和 CentOS
+
+时至今日,CERN 是 OpenStack 的深度用户,而 Bell 则是 OpenStack 基金会的董事会成员之一。不过 CERN 比 OpenStack 出现的要早,多年来,他们一直在使用各种开源技术通过 Linux 服务器提供服务。
+
+“在过去的十年中,我们发现,与其自己解决问题,不如找到面临类似挑战的上游开源社区进行合作,然后我们一同为这些项目做出贡献,而不是一切都由自己来创造和维护。“Bell 说。
+
+一个很好的例子是 Linux 本身。CERN 曾经是 Red Hat Enterprise Linux 的客户。其实,早在 2004 年,他们就与 Fermilab 合作一起建立了自己的 Linux 发行版,名为 [Scientific Linux][9]。最终他们意识到,因为没有修改内核,耗费时间建立自己的发行版是没有意义的,所以他们迁移到了 CentOS 上。由于 CentOS 是一个完全开源和社区驱使的项目,CERN 可以与该项目合作,并为 CentOS 的构建和分发做出贡献。
+
+CERN 帮助 CentOS 提供基础架构,他们还组织了 CentOS DoJo 活动(LCTT 译者注:CentOS Dojo 是为期一日的活动,汇聚来自 CentOS 社群的人分享系统管理、最佳实践及新兴科技。),工程师可以汇聚在此共同改进 CentOS 的封装。
+
+除了 OpenStack 和 CentOS 之外,CERN 还是其他开源项目的深度用户,包括用于配置管理的 Puppet、用于监控的 Grafana 和 InfluxDB,等等。
+
+“我们与全球约 170 个实验室合作。因此,每当我们发现一个开源项目的可完善之处,其他实验室便可以很容易地采纳使用。“Bell 说,”与此同时,我们也向其他项目学习。当像 eBay 和 Rackspace 这样大规模的安装提高了解决方案的可扩展性时,我们也从中受益,也可以扩大规模。“
+
+### 解决现实问题
+
+2012 年左右,CERN 正在研究如何为大型强子对撞机扩展计算能力,但难点是人员而不是技术。CERN 雇用的员工人数是固定的。“我们必须找到一种方法来扩展计算能力,而不需要大量额外的人来管理。”Bell 说,“OpenStack 为我们提供了一个自动的 API 驱动和软件定义的基础架构。”OpenStack 还帮助 CERN 检查与服务交付相关的问题,然后使其自动化,而无需增加员工。
+
+“我们目前在日内瓦和布达佩斯的两个数据中心运行大约 280000 个核心(cores)和 7000 台服务器。我们正在使用软件定义的基础架构使一切自动化,这使我们能够在保持员工数量不变的同时继续添加更多的服务器。“Bell 说。
+
+随着时间的推移,CERN 将面临更大的挑战。大型强子对撞机有一个到 2035 年的蓝图,包括一些重要的升级。“我们的加速器运转三到四年,然后会用 18 个月或两年的时间来升级基础架构。在这维护期间我们会做一些计算能力的规划。“Bell 说。CERN 还计划升级高亮度大型强子对撞机,会允许更高光度的光束。与目前的 CERN 的规模相比,升级意味着计算需求需增加约 60 倍。
+
+“根据摩尔定律,我们可能只能满足需求的四分之一,因此我们必须找到相应的扩展计算能力和存储基础架构的方法,并找到自动化和解决方案,例如 OpenStack,将有助于此。”Bell 说。
+
+“当我们开始使用大型强子对撞机并观察我们如何提供计算能力时,很明显我们无法将所有内容都放入 CERN 的数据中心,因此我们设计了一个分布式网格结构:位于中心的 CERN 和围绕着它的级联结构。“Bell 说,“全世界约有 12 个大型一级数据中心,然后是 150 所小型大学和实验室。他们从大型强子对撞机的数据中收集样本,以帮助物理学家理解和分析数据。“
+
+这种结构意味着 CERN 正在进行国际合作,数百个国家正致力于分析这些数据。归结为一个基本原则,即开源不仅仅是共享代码,还包括人们之间的协作、知识共享,以实现个人、组织或公司无法单独实现的目标。这就是开源世界的希格斯玻色子。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source
+
+作者:[SWAPNIL BHARTIYA ][a]
+译者:[jessie-pang](https://github.com/jessie-pang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/arnieswap
+[1]:https://www.linux.com/licenses/category/used-permission
+[2]:https://www.linux.com/licenses/category/used-permission
+[3]:https://home.cern/about/experiments/atlas
+[4]:https://www.linux.com/files/images/tim-bell-cernpng
+[5]:https://www.linux.com/files/images/atlas-cernjpg
+[6]:https://home.cern/
+[7]:https://home.cern/topics/higgs-boson
+[8]:https://home.cern/about/computing
+[9]:https://www.scientificlinux.org/
\ No newline at end of file
diff --git a/translated/tech/20180607 Using MQTT to send and receive data for your next project.md b/translated/tech/20180607 Using MQTT to send and receive data for your next project.md
new file mode 100644
index 0000000000..59e9e92ac9
--- /dev/null
+++ b/translated/tech/20180607 Using MQTT to send and receive data for your next project.md
@@ -0,0 +1,256 @@
+使用 MQTT 实现项目数据收发
+======
+
+
+
+去年 11 月我们购买了一辆电动汽车,同时也引发了有趣的思考:我们应该什么时候为电动汽车充电?对于电动汽车充电所用的电,我希望能够对应最小的二氧化碳排放,归结为一个特定的问题:对于任意给定时刻,每千瓦时对应的二氧化碳排放量是多少,一天中什么时间这个值最低?
+
+
+### 寻找数据
+
+我住在纽约州,大约 80% 的电力消耗可以自给自足,主要来自天然气、水坝(大部分来自于尼亚加拉大瀑布)、核能发电,少部分来自风力、太阳能和其它化石燃料发电。非盈利性组织 [纽约独立电网运营商][1] (NYISO) 负责整个系统的运作,实现发电机组发电与用电之间的平衡,同时也是纽约路灯系统的监管部门。
+
+尽管没有为公众提供公开 API,NYISO 还是尽责提供了[不少公开数据][2]供公众使用。每隔 5 分钟汇报全州各个发电机组消耗的燃料数据。数据以 CSV 文件的形式发布于公开的档案库中,全天更新。如果你了解不同燃料对发电瓦数的贡献比例,你可以比较准确的估计任意时刻的二氧化碳排放情况。
+
+在构建收集处理公开数据的工具时,我们应该时刻避免过度使用这些资源。相比将这些数据打包并发送给所有人,我们有更好的方案。我们可以创建一个低开销的事件流,人们可以订阅并第一时间得到消息。我们可以使用 [MQTT][3] 实现该方案。我的 ([ny-power.org][4]) 项目目标是收录到 [Home Assistant][5] 项目中;后者是一个开源的家庭自动化平台,拥有数十万用户。如果所有用户同时访问 CSV 文件服务器,估计 NYISO 不得不增加访问限制。
+
+### MQTT 是什么?
+
+MQTT 是一个发布订阅线协议,为小规模设备设计。发布订阅系统工作原理类似于消息总线。你将一条消息发布到一个主题上,那么所有订阅了该主题的客户端都可以获得该消息的一份拷贝。对于消息发送者而言,无需知道哪些人在订阅消息;你只需将消息发布到一系列主题,同时订阅一些你感兴趣的主题。就像参加了一场聚会,你选取并加入感兴趣的对话。
+
+MQTT 可应用构建极为高效的应用。客户端订阅有限的几个主题,也只收到他们感兴趣的内容。不仅节省了处理时间,还降低了网络带宽使用。
+
+作为一个开放标准,MQTT 有很多开源的客户端和服务端实现。对于你能想到的每种编程语言,都有对应的客户端库;甚至有嵌入到 Arduino 的库,可以构建传感器网络。服务端可供选择的也很多,我的选择是 Eclipse 项目提供的 [Mosquitto][6] 服务端,这是因为它体积小、用 C 编写,可以承载数以万计的订阅者。
+
+### 为何我喜爱 MQTT
+
+在过去二十年间,我们为软件应用设计了可靠且准确的模型,用于解决服务遇到的问题。我还有其它邮件吗?当前的天气情况如何?我应该此刻购买这种产品吗?在绝大多数情况下,这种问答式的模型工作良好;但对于一个数据爆炸的世界,我们需要其它的模型。MQTT 的发布订阅模型十分强大,可以将大量数据发送到系统中。客户可以订阅数据中的一小部分并在订阅数据发布的第一时间收到更新。
+
+MQTT 还有一些有趣的特性,其中之一是遗嘱消息,可以用于区分两种不同的静默,一种是没有主题相关数据推送,另一种是你的数据接收器出现故障。MQTT 还包括保留消息,当客户端初次连接时会提供相关主题的最后一条消息。这对那些更新缓慢的主题来说很有必要。
+
+我在 Home Assistant 项目开发过程中,发现这种消息总线模型对异构系统尤为适合。如果你深入物联网领域,你会发现 MQTT 无处不在。
+
+### 我们的第一个 MQTT 流
+
+NYSO 公布的 CSV 文件中有一个是实时的燃料混合使用情况。每 5 分钟,NYSO 发布这 5 分钟内发电使用的燃料类型和相应的发电量(以兆瓦为单位)。
+
+The CSV file looks something like this:
+
+| 时间戳 | 时区 | 燃料类型 | 兆瓦为单位的发电量 |
+| --- | --- | --- | --- |
+| 05/09/2018 00:05:00 | EDT | 混合燃料 | 1400 |
+| 05/09/2018 00:05:00 | EDT | 天然气 | 2144 |
+| 05/09/2018 00:05:00 | EDT | 核能 | 4114 |
+| 05/09/2018 00:05:00 | EDT | 其它化石燃料 | 4 |
+| 05/09/2018 00:05:00 | EDT | 其它可再生资源 | 226 |
+| 05/09/2018 00:05:00 | EDT | 风力 | 1 |
+| 05/09/2018 00:05:00 | EDT | 水力 | 3229 |
+| 05/09/2018 00:10:00 | EDT | 混合燃料 | 1307 |
+| 05/09/2018 00:10:00 | EDT | 天然气 | 2092 |
+| 05/09/2018 00:10:00 | EDT | 核能 | 4115 |
+| 05/09/2018 00:10:00 | EDT | 其它化石燃料 | 4 |
+| 05/09/2018 00:10:00 | EDT | 其它可再生资源 | 224 |
+| 05/09/2018 00:10:00 | EDT | 风力 | 40 |
+| 05/09/2018 00:10:00 | EDT | 水力 | 3166 |
+
+表中唯一令人不解就是燃料类别中的混合燃料。纽约的大多数天然气工厂也通过燃烧其它类型的化石燃料发电。在冬季寒潮到来之际,家庭供暖的优先级高于发电;但这种情况出现的次数不多,(在我们计算中)可以将混合燃料类型看作天然气类型。
+
+CSV 文件全天更新。我编写了一个简单的数据泵,每隔 1 分钟检查是否有数据更新,并将新条目发布到 MQTT 服务器的一系列主题上,主题名称基本与 CSV 文件有一定的对应关系。数据内容被转换为 JSON 对象,方便各种编程语言处理。
+
+```
+ny-power/upstream/fuel-mix/Hydro {"units": "MW", "value": 3229, "ts": "05/09/2018 00:05:00"}
+ny-power/upstream/fuel-mix/Dual Fuel {"units": "MW", "value": 1400, "ts": "05/09/2018 00:05:00"}
+ny-power/upstream/fuel-mix/Natural Gas {"units": "MW", "value": 2144, "ts": "05/09/2018 00:05:00"}
+ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts": "05/09/2018 00:05:00"}
+ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
+ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
+ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
+
+```
+
+这种直接的转换是种不错的尝试,可将公开数据转换为公开事件。我们后续会继续将数据转换为二氧化碳排放强度,但这些原始数据还可被其它应用使用,用于其它计算用途。
+
+### MQTT 主题
+
+主题和主题结构是 MQTT 的一个主要特色。与其它标准的企业级消息总线不同,MQTT 的主题无需事先注册。发送者可以凭空创建主题,唯一的限制是主题的长度,不超过 220 字符。其中 `/` 字符有特殊含义,用于创建主题的层次结构。我们即将看到,你可以订阅这些层次中的一些分片。
+
+基于开箱即用的 Mosquitto,任何一个客户端都可以向任何主题发布消息。在原型设计过程中,这种方式十分便利;但一旦部署到生产环境,你需要增加访问控制列表只允许授权的应用发布消息。例如,任何人都能以只读的方式访问我的应用的主题层级,但只有那些具有特定凭证的客户端可以发布内容。
+
+主题中不包含自动样式,也没有方法查找客户端可以发布的全部主题。因此,对于那些从 MQTT 总线消费数据的应用,你需要让其直接使用已知的主题和消息格式样式。
+
+那么应该如何设计主题呢?最佳实践包括使用应用相关的根名称,例如在我的应用中使用 `ny-power`。接着,为提高订阅效率,构建足够深的层次结构。`upstream` 层次结构包含了直接从数据源获取的、不经处理的原始数据,而 `fuel-mix` 层次结构包含特定类型的数据;我们后续还可以增加其它的层次结构。
+
+### 订阅主题
+
+在 MQTT 中,订阅仅仅是简单的字符串匹配。为提高处理效率,只允许如下两种通配符:
+
+ * `#` 以递归方式匹配,直到字符串结束
+ * `+` 匹配下一个 `/` 之前的内容
+
+
+为便于理解,下面给出几个例子:
+```
+ny-power/# - 匹配 ny-power 应用发布的全部主题
+ny-power/upstream/# - 匹配全部原始数据的主题
+ny-power/upstream/fuel-mix/+ - 匹配全部燃料类型的主题
+ny-power/+/+/Hydro - 匹配全部两次层级之后为 Hydro 类型的主题(即使不位于 upstream 层次结构下)
+```
+
+类似 `ny-power/#` 的大范围订阅适用于低数据量的应用,应用从网络获取全部数据并处理。但对高数据量应用而言则是一个灾难,由于绝大多数消息并不会被使用,大部分的网络带宽被白白浪费了。
+
+在大数据量情况下,为确保性能,应用需要使用恰当的主题筛选(如 `ny-power/+/+/Hydro`)尽量准确获取业务所需的数据。
+
+### 增加我们自己的数据层次
+
+接下来,应用中的一切都依赖于已有的 MQTT 流并构建新流。第一个额外的数据层用于计算发电对应的二氧化碳排放。
+
+利用[美国能源情报署][7] 给出的 2016 年纽约各类燃料发电及排放情况,我们可以给出各类燃料的[平均排放率][8],单位为克/兆瓦时。
+
+上述结果被封装到一个专用的微服务中。该微服务订阅 `ny-power/upstream/fuel-mix/+`,即数据泵中燃料组成情况的原始数据,接着完成计算并将结果(单位为克/千瓦时)发布到新的主题层次结构上:
+```
+ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}
+```
+
+接着,另一个服务会订阅该主题层次结构并将数据打包到 [InfluxDB][9] 进程中;同时,发布 24 小时内的时间序列数据到 `ny-power/archive/co2/24h` 主题,这样可以大大简化当前变化数据的绘制。
+
+这种层次结构的主题模型效果不错,可以将上述程序之间的逻辑解耦合。在复杂系统中,各个组件可能使用不同的编程语言,但这并不重要,因为交换格式都是 MQTT 消息,即主题和 JSON 格式的消息内容。
+
+### 从终端消费数据
+
+为了更好的了解 MQTT 完成了什么工作,将其绑定到一个消息总线并查看消息流是个不错的方法。`mosquitto-clients` 包中的 `mosquitto_sub` 可以让我们轻松实现该目标。
+
+安装程序后,你需要提供服务器名称以及你要订阅的主题。如果有需要,使用参数 `-v` 可以让你看到有新消息发布的那些主题;否则,你只能看到主题内的消息数据。
+
+```
+mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
+
+```
+
+只要我编写或调试 MQTT 应用,我总会在一个终端中运行 `mosquitto_sub`。
+
+### 从网页直接访问 MQTT
+
+到目前为止,我们已经有提供公开事件流的应用,可以用微服务或命令行工具访问该应用。但考虑到互联网仍占据主导地位,因此让用户可以从浏览器直接获取事件流是很重要。
+
+MQTT 的设计者已经考虑到了这一点。协议标准支持三种不同的传输协议:[TCP][10],[UDP][11] 和 [WebSockets][12]。主流浏览器都支持 WebSockets,可以维持持久连接,用于实时应用。
+
+Eclipse 项目提供了 MQTT 的一个 JavaScript 实现,叫做 [Paho][13],可包含在你的应用中。工作模式为与服务器建立连接、建立一些订阅,然后根据接收到的消息进行响应。
+
+```
+// ny-power web console application
+
+var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random());
+
+// set callback handlers
+client.onMessageArrived = onMessageArrived;
+
+// connect the client
+client.reconnect = true;
+client.connect({onSuccess: onConnect});
+
+// called when the client connects
+function onConnect() {
+ // Once a connection has been made, make a subscription and send a message.
+ console.log("onConnect");
+ client.subscribe("ny-power/computed/co2");
+ client.subscribe("ny-power/archive/co2/24h");
+ client.subscribe("ny-power/upstream/fuel-mix/#");
+}
+
+// called when a message arrives
+function onMessageArrived(message) {
+ console.log("onMessageArrived:"+message.destinationName + message.payloadString);
+ if (message.destinationName == "ny-power/computed/co2") {
+ var data = JSON.parse(message.payloadString);
+ $("#co2-per-kwh").html(Math.round(data.value));
+ $("#co2-units").html(data.units);
+ $("#co2-updated").html(data.ts);
+ }
+
+ if (message.destinationName.startsWith("ny-power/upstream/fuel-mix")) {
+ fuel_mix_graph(message);
+ }
+
+ if (message.destinationName == "ny-power/archive/co2/24h") {
+ var data = JSON.parse(message.payloadString);
+ var plot = [
+ {
+ x: data.ts,
+ y: data.values,
+ type: 'scatter'
+ }
+ ];
+ var layout = {
+ yaxis: {
+ title: "g CO2 / kWh",
+ }
+ };
+ Plotly.newPlot('co2_graph', plot, layout);
+ }
+
+```
+
+上述应用订阅了不少主题,因为我们将要呈现若干种不同类型的数据;其中 `ny-power/computed/co2` 主题为我们提供当前二氧化碳排放的参考值。一旦收到该主题的新消息,网站上的相应内容会被相应替换。
+
+
+![NYISO 二氧化碳排放图][15]
+
+[ny-power.org][4] 网站提供的 NYISO 二氧化碳排放图。
+
+`ny-power/archive/co2/24h` 主题提供了时间序列数据,用于为 [Plotly][16] 线表提供数据。`ny-power/upstream/fuel-mix` 主题提供当前燃料组成情况,为漂亮的柱状图提供数据。
+
+![NYISO 燃料组成情况][18]
+
+[ny-power.org][4] 网站提供的燃料组成情况。
+
+这是一个动态网站,数据不从服务器拉取,而是结合 MQTT 消息总线,监听对外开放的 WebSocket。就像数据泵和打包器程序那样,网站页面也是一个发布订阅客户端,只不过是在你的浏览器中执行,而不是在公有云的微服务上。
+
+你可以在 站点点看到动态变更,包括图像和可以看到消息到达的实时 MQTT 终端。
+
+### 继续深入
+
+ny-power.org 应用的完整内容开源在 [GitHub][19] 中。你也可以查阅 [架构简介][20],学习如何使用 [Helm][21] 部署一系列 Kubernetes 微服务构建应用。另一个有趣的 MQTT 示例使用 MQTT 和 OpenWhisk 进行实时文本消息翻译,代码模式参考[链接][22]。
+
+MQTT 被广泛应用于物联网领域,更多关于 MQTT 用途的例子可以在 [Home Assistant][23] 项目中找到。
+
+如果你希望深入了解协议内容,可以从 [mqtt.org][3] 获得该公开标准的全部细节。
+
+想了解更多,可以参加 Sean Dague 在 [OSCON][25] 上的演讲,主题为 [将 MQTT 加入到你的工具箱][24],会议将于 7 月 16-19 日在奥尔良州波特兰举办。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/6/mqtt
+
+作者:[Sean Dague][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/sdague
+[1]:http://www.nyiso.com/public/index.jsp
+[2]:http://www.nyiso.com/public/markets_operations/market_data/reports_info/index.jsp
+[3]:http://mqtt.org/
+[4]:http://ny-power.org/#
+[5]:https://www.home-assistant.io
+[6]:https://mosquitto.org/
+[7]:https://www.eia.gov/
+[8]:https://github.com/IBM/ny-power/blob/master/src/nypower/calc.py#L1-L60
+[9]:https://www.influxdata.com/
+[10]:https://en.wikipedia.org/wiki/Transmission_Control_Protocol
+[11]:https://en.wikipedia.org/wiki/User_Datagram_Protocol
+[12]:https://en.wikipedia.org/wiki/WebSocket
+[13]:https://www.eclipse.org/paho/
+[14]:/file/400041
+[15]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso-co2intensity.png (NY ISO Grid CO2 Intensity)
+[16]:https://plot.ly/
+[17]:/file/400046
+[18]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso_fuel-mix.png (Fuel mix on NYISO grid)
+[19]:https://github.com/IBM/ny-power
+[20]:https://developer.ibm.com/code/patterns/use-mqtt-stream-real-time-data/
+[21]:https://helm.sh/
+[22]:https://developer.ibm.com/code/patterns/deploy-serverless-multilingual-conference-room/
+[23]:https://www.home-assistant.io/
+[24]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/77317
+[25]:https://conferences.oreilly.com/oscon/oscon-or
diff --git a/translated/tech/20180615 5 Commands for Checking Memory Usage in Linux.md b/translated/tech/20180615 5 Commands for Checking Memory Usage in Linux.md
new file mode 100644
index 0000000000..08cabe84c7
--- /dev/null
+++ b/translated/tech/20180615 5 Commands for Checking Memory Usage in Linux.md
@@ -0,0 +1,190 @@
+用以检查 Linux 内存使用的 5 个命令
+======
+
+
+Linux 操作系统包含大量工具,所有这些工具都可以帮助你管理系统。从简单的文件和目录工具到非常复杂的安全命令,在 Linux 中没有多少是你做不了的。而且,尽管普通桌面用户可能不需要在命令行熟悉这些工具,但对于 Linux 管理员来说,它们是必需的。为什么?首先,你在某些时候不得不使用没有 GUI 的 Linux 服务器。其次,命令行工具通常比 GUI 替代工具提供更多的功能和灵活性。
+
+确定内存使用情况是你可能需要的技能,尤其是特定应用程序变为流氓和占用系统内存时。当发生这种情况时,知道有多种工具可以帮助你进行故障排除十分方便的。或者,你可能需要收集有关 Linux 交换分区的信息,或者有关安装的 RAM 的详细信息?对于这些也有相应的命令。让我们深入了解各种 Linux 命令行工具,以帮助你检查系统内存使用情况。这些工具并不是非常难以使用,在本文中,我将向你展示五种不同的方法来解决这个问题。
+
+我将在 [Ubuntu 18.04 服务器平台][1]上进行演示,但是你应该在你选择的发行版中找到对应的所有命令。更妙的是,你不需要安装任何东西(因为大多数这些工具都包含 Linux 系统中)。
+
+话虽如此,让我们开始工作吧。
+
+### top
+
+我想从最明显的工具开始。top 命令提供正在运行的系统的动态实时视图,它检查每个进程的内存使用情况。这非常重要,因为你可以轻松地对同一命令的多次迭代消耗不同的内存量。虽然你无法在没有外设的服务器上找到它,但是你已经注意到打开 Chrome 使你的系统速度变慢了。发出 top 命令以查看 Chrome 有多个进程在运行(每个选项卡一个 - 图 1)。
+
+![top][3]
+
+图1:top 命令中出现多个 Chrome 进程。
+
+(to 校正者:不知道这句话什么意思,难道是是否允许转载的?)
+[Used with permission][4]
+
+Chrome 并不是唯一显示多个进程的应用。你看到图 1 中的 Firefox 了吗?那是 Firefox 的主进程,而 Web Content 进程是其打开的选项卡。在输出的顶部,你将看到系统统计信息。在我的机器上([System76 Leopard Extreme][5]),我总共有 16GB 可用 RAM,其中只有超过 10GB 的 RAM 正在使用中。然后,你可以整理列表,查看每个进程使用的内存百分比。
+
+top 最好的事情之一就是发现可能已经失控的进程 ID(PID)服务数量。有了这些 PID,你可以对有问题的任务进行故障排除(或 kill)。
+
+如果你想让 top 显示更友好的内存信息,使用命令 top -o%MEM,这会使 top 按进程所用内存对所有进程进行排序(图 2)。
+
+
+![top][7]
+
+图 2:在 top 命令中按使用内存对进程排序
+
+[Used with permission][4]
+
+top 命令还为你提供有关使用了多少交换空间的实时更新。
+
+### free
+
+然而有时候,top 命令可能不会满足你的需求。你可能只需要查看系统的可用和已用内存。对此,Linux 还有 free 命令。free 命令显示:
+(to 校正者:以下这种可能翻译得不太准确,望纠正)
+* 可用和已使用的物理内存总量
+
+* 系统中交换内存的总量
+
+* 内核使用的缓冲区和缓存
+
+在终端窗口中,输入 free 命令。它的输出不是实时的,相反,你将获得的是当前空闲和已用内存的即时快照(图 3)。
+
+![free][9]
+
+图 3 :free 命令的输出简单明了。
+
+[Used with permission][4]
+
+当然,你可以通过添加 -m 选项来让 free 显示得更友好一点,就像这样:free -m。这将显示内存的使用情况,以 MB 为单位(图 4)。
+
+![free][11]
+
+图 4:free 命令以一种更易于阅读的形式输出。
+
+[Used with permission][4]
+
+当然,如果你的系统是远程的,你将希望使用 -g 选项(以 GB 为单位),比如 free -g。
+
+如果你需要内存总量,你可以添加 t 选项,比如:free -mt。这将简单地计算每列中的内存总量(图 5)。
+
+![total][13]
+
+图 5:为你提供空闲的内存列。
+
+[Used with permission][4]
+
+### vmstat
+
+另一个非常方便的工具是 vmstat。这个特殊的命令是一个报告虚拟内存统计信息的小技巧。vmstat 命令将报告关于:
+
+* 进程
+
+* 内存
+
+* 页
+
+* 阻塞 IO
+
+* traps
+
+* 磁盘
+
+* CPU
+
+使用 vmstat 的最佳方法是使用 -s 选项,如 vmstat -s。这将在单列中报告统计信息(这比默认报告更容易阅读)。vmstat 命令将提供比你需要的更多的信息(图 6),但更多的总是更好的(在这种情况下)。
+
+![vmstat][15]
+
+图 6:使用 vmstat 命令来检查内存使用情况。
+
+[Used with permission][4]
+
+### dmidecode
+
+如果你想找到关于已安装的系统 RAM 的详细信息,该怎么办?为此,你可以使用 dmidecode 命令。这个特殊的工具是 DMI 表解码器,它将系统的 DMI 表内容转储成人类可读的格式。如果你不清楚 DMI 表是什么,那么可以这样说,(to 校正者:这句话可以不加)它是可以用来描述系统的构成(以及系统的演变)。
+
+要运行 dmidecode 命令,你需要 sudo 权限。因此输入命令 sudo dmidecode -t 17。该命令的输出(图 7)可能很长,因为它显示所有内存类型设备的信息。因此,如果你无法上下滚动,则可能需要将该命令的输出发送到一个文件中,比如:sudo dmidecode -t 17> dmi_infoI,或将其传递给 less 命令,如 sudo dmidecode | less。
+
+![dmidecode][17]
+
+图 7:dmidecode 命令的输出。
+
+[Used with permission][4]
+
+### /proc/meminfo
+
+你可能会问自己:“这些命令从哪里获取这些信息?”在某些情况下,它们从 /proc/meminfo 文件中获取。你猜猜?你可以使用命令 less /proc/meminfo 直接读取该文件。通过使用 less 命令,你可以在长长的输出中向上和向下滚动,以准确找到你需要的内容(图 8)。
+
+![/proc/meminfo][19]
+
+图 8:less /proc/meminfo 命令的输出。
+
+[Used with permission][4]
+
+关于 /proc/meminfo 你应该知道:这不是一个真实的文件。相反 /pro/meminfo 是一个虚拟文件,包含有关系统的实时动态信息。特别是,你需要检查以下值:
+
+ * 全部内存
+
+ * 空闲内存
+
+ * 可用内存
+
+ * 缓冲区
+
+ * 文件缓存
+
+ * 交换缓存
+
+ * 全部交换区
+
+ * 空闲交换区
+
+如果你想使用 /proc/meminfo,你可以用连词像 egrep 命令一样使用它:egrep --color'Mem | Cache | Swap'/proc/meminfo。这将生成一个易于阅读的列表,其中包含 Mem, Cache 和 Swap 等所有包含颜色的条目(图 9)。
+
+![/proc/meminfo][21]
+
+图 9:让 /proc/meminfo 更容易阅读。
+
+[Used with permission][4]
+
+### 继续学习
+
+你要做的第一件事就是阅读每个命令的手册页(例如 man top, man free, man vmstat, man dmidecode)。从命令的手册页开始,对于如何在 Linux 上使用一个工具,它总是一个很好的学习方法。
+
+通过 Linux 基金会和 edX 的免费 [“Linux 简介”][22]课程了解有关 Linux 的更多知识。
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/5-commands-checking-memory-usage-linux
+
+作者:[Jack Wallen][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/jlwallen
+[1]:https://www.ubuntu.com/download/server
+[2]:/files/images/memory1jpg
+[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_1.jpg?itok=fhhhUL_l (top)
+[4]:/licenses/category/used-permission
+[5]:https://system76.com/desktops/leopard
+[6]:/files/images/memory2jpg
+[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_2.jpg?itok=zuVkQfvv (top)
+[8]:/files/images/memory3jpg
+[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_3.jpg?itok=rvuQp3t0 (free)
+[10]:/files/images/memory4jpg
+[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_4.jpg?itok=K_luLLPt (free)
+[12]:/files/images/memory5jpg
+[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_5.jpg?itok=q50atcsX (total)
+[14]:/files/images/memory6jpg
+[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_6.jpg?itok=bwFnUVmy (vmstat)
+[16]:/files/images/memory7jpg
+[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_7.jpg?itok=UNHIT_P6 (dmidecode)
+[18]:/files/images/memory8jpg
+[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_8.jpg?itok=t87jvmJJ (/proc/meminfo)
+[20]:/files/images/memory9jpg
+[21]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/memory_9.jpg?itok=t-iSMEKq (/proc/meminfo)
+[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20180615 BLUI- An easy way to create game UI.md b/translated/tech/20180615 BLUI- An easy way to create game UI.md
deleted file mode 100644
index 5fdb1e5094..0000000000
--- a/translated/tech/20180615 BLUI- An easy way to create game UI.md
+++ /dev/null
@@ -1,57 +0,0 @@
-BLUI:创建游戏 UI 的简单方法
-======
-
-
-
-游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的 Unreal,允许独立开发者使用 AAA 发布商使用的相同行业标准工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
-
-这些引擎中包含的插件允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
-
-### 什么是 BLUI?
-
-作为独立游戏开发工作室的一部分,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管虚幻引擎(我们选择的引擎)有一个内置的 UI 编辑器实现了类似目的,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
-
-在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的 Unreal 集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,要么对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
-
-在商业产品和 Unreal 的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过网络语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
-
-### 安装和使用 BLUI
-
-使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括自举 JavaScript 代码,外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何 Unreal 插件那样安装它并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在 Unreal UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
-
-![Integrating BLUI into Unreal Engine 4 blueprints][4]
-
-将 BLUI 集成到虚幻 4 图纸中。
-
-在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
-
-![Using BLUI to sync UI elements with the soundtrack.][6]
-
-使用 BLUI 将 UI 元素与音轨同步。
-
-通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个微不足道的过程。还有一个由支援虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
-
-### 开源优势
-
-开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/6/blui-game-development-plugin
-
-作者:[Uwana lkaiddi][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/uwikaiddi
-[1]:https://github.com/AaronShea/BLUI
-[2]:https://bitbucket.org/chromiumembedded/cef
-[3]:/file/400616
-[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
-[5]:/file/400621
-[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
-[7]:https://github.com/AaronShea/BLUI/wiki
-[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
diff --git a/translated/tech/20180619 How to reset, revert, and return to previous states in Git.md b/translated/tech/20180619 How to reset, revert, and return to previous states in Git.md
new file mode 100644
index 0000000000..eba0dec60b
--- /dev/null
+++ b/translated/tech/20180619 How to reset, revert, and return to previous states in Git.md
@@ -0,0 +1,253 @@
+如何在 Git 中重置、恢复、和返回到以前的状态
+======
+
+
+
+使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何很容易地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复、和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
+
+### reset
+
+我们从 Git 的 `reset` 命令开始。确实,你应该能够想到它就是一个 "回滚" — 它将你本地环境返回到前面的提交。这里的 "本地环境" 一词,我们指的是你的本地仓库、暂存区、以及工作目录。
+
+先看一下图 1。在这里我们有一个在 Git 中表示一系列状态的提交。在 Git 中一个分支就是简单的一个命名的、可移动指针到一个特定的提交。在这种情况下,我们的 master 分支是链中指向最新提交的一个指针。
+
+![Local Git environment with repository, staging area, and working directory][2]
+
+图 1:有仓库、暂存区、和工作目录的本地环境
+
+如果看一下我们的 master 分支是什么,可以看一下到目前为止我们产生的提交链。
+```
+$ git log --oneline
+b764644 File with three lines
+7c709f0 File with two lines
+9ef9173 File with one line
+```
+
+如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
+
+`$ git reset 9ef9173`(使用一个绝对的提交 SHA1 值 9ef9173)
+
+或
+
+`$ git reset current~2`(在 “current” 标签之前,使用一个相对值 -2)
+
+图 2 展示了操作的结果。在这之后,如果我们在当前分支(master)上运行一个 `git log` 命令,我们将看到只有一个提交。
+```
+$ git log --oneline
+
+9ef9173 File with one line
+
+```
+
+![After reset][4]
+
+图 2:在 `reset` 之后
+
+`git reset` 命令也包含使用一个你最终满意的提交内容去更新本地环境的其它部分的选项。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
+
+这些选项在特定情况下非常有用,比如,`git reset --hard ` 这个命令将覆盖本地任何未提交的更改。实际上,它重置了(清除掉)暂存区,并用你重置的提交内容去覆盖了工作区中的内容。在你使用 `hard` 选项之前,一定要确保这是你真正地想要做的操作,因为这个命令会覆盖掉任何未提交的更改。
+
+### revert
+
+`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令是在(默认)链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
+
+另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 — 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
+```
+$ git revert HEAD
+
+```
+
+因为它添加了一个新的提交,Git 将提示如下的提交信息:
+```
+Revert "File with three lines"
+
+This reverts commit b764644bad524b804577684bf74e7bca3117f554.
+
+# Please enter the commit message for your changes. Lines starting
+# with '#' will be ignored, and an empty message aborts the commit.
+# On branch master
+# Changes to be committed:
+# modified: file1.txt
+#
+```
+
+图 3(在下面)展示了 `revert` 操作完成后的结果。
+
+如果我们现在运行一个 `git log` 命令,我们将看到前面的提交之前的一个新提交。
+```
+$ git log --oneline
+11b7712 Revert "File with three lines"
+b764644 File with three lines
+7c709f0 File with two lines
+9ef9173 File with one line
+```
+
+这里是工作目录中这个文件当前的内容:
+```
+$ cat
+Line 1
+Line 2
+```
+
+
+
+#### Revert 或 reset 如何选择?
+
+为什么要优先选择 `revert` 而不是 `reset` 操作?如果你已经将你的提交链推送到远程仓库(其它人可以已经拉取了你的代码并开始工作),一个 `revert` 操作是让他们去获得更改的非常友好的方式。这是因为 Git 工作流可以非常好地在分支的末端添加提交,但是当有人 `reset` 分支指针之后,一组提交将再也看不见了,这可能会是一个挑战。
+
+当我们以这种方式使用 Git 工作时,我们的基本规则之一是:在你的本地仓库中使用这种方式去更改还没有推送的代码是可以的。如果提交已经推送到了远程仓库,并且可能其它人已经使用它来工作了,那么应该避免这些重写提交历史的更改。
+
+总之,如果你想回滚、撤销、或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在没有需要去合并的侵入操作之后,他们再拉取最新的副本。
+
+你可能注意到了,在我们做了 `reset` 操作之后,原始的链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始头部来“恢复”指针到前面的位置:
+```
+git reset
+
+```
+
+当提交被替换之后,我们在 Git 中做的大量其它操作也会发生类似的事情。新提交被创建,有关的指针被移动到一个新的链,但是老的提交链仍然存在。
+
+### Rebase
+
+现在我们来看一个分支变基。假设我们有两个分支 — master 和 feature — 提交链如下图 4 所示。Master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`.
+
+![Chain of commits for branches master and feature][6]
+
+图 4:master 和 feature 分支的提交链
+
+如果我们在分支中看它的提交记录,它们看起来应该像下面的这样。(为了易于理解,`C` 表示提交信息)
+```
+$ git log --oneline master
+6a92e7a C4
+259bf36 C2
+f33ae68 C1
+5043e79 C0
+
+$ git log --oneline feature
+79768b8 C5
+000f9ae C3
+259bf36 C2
+f33ae68 C1
+5043e79 C0
+```
+
+我给人讲,在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
+
+因此,我们使用基本的 Git 命令,可以 rebase 一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
+```
+$ git checkout feature
+$ git rebase master
+
+First, rewinding head to replay your work on top of it...
+Applying: C3
+Applying: C5
+```
+
+完成以后,我们的提交链将变成如下图 5 的样子。
+
+![Chain of commits after the rebase command][8]
+
+图 5:`rebase` 命令完成后的提交链
+
+接着,我们看一下提交历史,它应该变成如下的样子。
+```
+$ git log --oneline master
+6a92e7a C4
+259bf36 C2
+f33ae68 C1
+5043e79 C0
+
+$ git log --oneline feature
+c4533a5 C5
+64f2047 C3
+6a92e7a C4
+259bf36 C2
+f33ae68 C1
+5043e79 C0
+```
+
+注意那个 `C3'` 和 `C5'`— 在 master 分支上已处于提交链的“顶部”,由于产生了更改而创建了新提交。但是也要注意的是,rebase 后“原始的” `C3` 和 `C5` 仍然在那里 — 只是再没有一个分支指向它们而已。
+
+如果我们做了这个 rebase,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
+```
+$ git reset 79768b8
+
+```
+
+由于这个简单的变更,现在我们的分支将重新指向到做 `rebase` 操作之前一模一样的位置 —— 完全等效于撤销操作(图 6)。
+
+![After undoing rebase][10]
+
+图 6:撤销 `rebase` 操作之后
+
+如果你想不起来之前一个操作指向的一个分支上提交了什么内容怎么办?幸运的是,Git 命令依然可以帮助你。用这种方式可以修改大多数操作的指针,Git 会记住你的原始提交。事实上,它是在 `.git` 仓库目录下,将它保存为一个特定的名为 `ORIG_HEAD ` 的文件中。在它被修改之前,那个路径是一个包含了大多数最新引用的文件。如果我们 `cat` 这个文件,我们可以看到它的内容。
+```
+$ cat .git/ORIG_HEAD
+79768b891f47ce06f13456a7e222536ee47ad2fe
+```
+
+我们可以使用 `reset` 命令,正如前面所述,它返回指向到原始的链。然后它的历史将是如下的这样:
+```
+$ git log --oneline feature
+79768b8 C5
+000f9ae C3
+259bf36 C2
+f33ae68 C1
+5043e79 C0
+```
+
+在 reflog 中是获取这些信息的另外一个地方。这个 reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
+```
+$ git reflog
+79768b8 HEAD@{0}: reset: moving to 79768b
+c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
+c4533a5 HEAD@{2}: rebase: C5
+64f2047 HEAD@{3}: rebase: C3
+6a92e7a HEAD@{4}: rebase: checkout master
+79768b8 HEAD@{5}: checkout: moving from feature to feature
+79768b8 HEAD@{6}: commit: C5
+000f9ae HEAD@{7}: checkout: moving from master to feature
+6a92e7a HEAD@{8}: commit: C4
+259bf36 HEAD@{9}: checkout: moving from feature to master
+000f9ae HEAD@{10}: commit: C3
+259bf36 HEAD@{11}: checkout: moving from master to feature
+259bf36 HEAD@{12}: commit: C2
+f33ae68 HEAD@{13}: commit: C1
+5043e79 HEAD@{14}: commit (initial): C0
+```
+
+你可以使用日志中列出的、你看到的相关命名格式,去 reset 任何一个东西:
+```
+$ git reset HEAD@{1}
+
+```
+
+一旦你理解了当“修改”链的操作发生后,Git 是如何跟踪原始提交链的基本原理,那么在 Git 中做一些更改将不再是那么可怕的事。这就是强大的 Git 的核心能力之一:能够很快速、很容易地尝试任何事情,并且如果不成功就撤销它们。
+
+Brent Laster 将在 7 月 16 日至 19 日在俄勒冈州波特兰举行的第 20 届 OSCON 年度活动上,展示 [强大的 Git:Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, 等等][11]。想了解在任何水平上使用 Git 的一些技巧和缘由,请查阅 Brent 的书 ——"[Professional Git][13]",它在 Amazon 上有售。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
+
+作者:[Brent Laster][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/bclaster
+[1]:/file/401126
+[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png "Local Git environment with repository, staging area, and working directory"
+[3]:/file/401131
+[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png "After reset"
+[5]:/file/401141
+[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png "Chain of commits for branches master and feature"
+[7]:/file/401146
+[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png "Chain of commits after the rebase command"
+[9]:/file/401151
+[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png "After undoing rebase"
+[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
+[12]:https://conferences.oreilly.com/oscon/oscon-or
+[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
diff --git a/translated/tech/20180621 Bitcoin is a Cult - Adam Caudill.md b/translated/tech/20180621 Bitcoin is a Cult - Adam Caudill.md
new file mode 100644
index 0000000000..1902ea274a
--- /dev/null
+++ b/translated/tech/20180621 Bitcoin is a Cult - Adam Caudill.md
@@ -0,0 +1,102 @@
+比特币是一个邪教 — Adam Caudill
+======
+经过这些年,比特币社区已经发生了非常大的变化;社区成员从闭着眼睛都能讲解 [Merkle 树][1] 的技术迷们,变成了被一夜爆富欲望驱使的投机者和由一些连什么是 Merkle 树都不懂的人所领导的企图寻求 10 亿美元估值的区块链初创公司。随着时间的流逝,围绕比特币和其它加密货币形成了一个狂热,他们认为比特币和其它加密货币远比实际的更重要;他们相信常见的货币(法定货币)正在成为过去,而加密货币将从根本上改变世界经济。
+
+每一年他们的队伍都在壮大,而他们对加密货币的看法也在变得更加宏伟,那怕是因为[使用新技术][2]而使它陷入困境的情况下。虽然我坚信设计优良的加密货币可以使金钱的跨境流动更容易,并且在大规模通胀的领域提供一个更稳定的选择,但现实情况是,我们并没有做到这些。实际上,正是价值的巨大不稳定性才使得投机者赚钱。那些宣扬美元和欧元即将死去的人,已经完全抛弃了对现实世界客观公正的看法。
+
+### 一点点背景 …
+
+比特币发行那天,我读了它的白皮书 —— 它使用有趣的 [Merkle 树][1] 去创建一个公共账簿和一个非常合理的共识协议 —— 由于它新颖的特性引起了密码学领域中许多人的注意。在白皮书发布后的几年里,比特币变得非常有价值,并由此吸引了许多人将它视为是一种投资,和那些认为它将改变一切的忠实追随者(和发声者)。这篇文章将讨论的正是后者。
+
+昨天,有人在推特上发布了一个最近的比特币区块的哈希,下面成千上万的推文和其它讨论让我相信,比特币已经跨越界线进入了真正的邪教领域。
+
+一切都源于 Mark Wilcox 的这个推文:
+
+> #00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a
+> — Mark Wilcox (@mwilcox) June 19, 2018
+
+张贴的这个值是 [比特币 #528249 号区块][3] 的哈希值。前导零是挖矿过程的结果;挖掘一个区块就是把区块内容与一个 nonce(和其它数据)组合起来,然后做哈希运算,并且它至少有一定数量的前导零才能被验证为有效区块。如果它不是正确的数字,你可以更换 nonce 再试。重复这个过程直到哈希值的前导零数量是正确的数字之后,你就有了一个有效的区块。让人们感到很兴奋的部分是接下来的 21e800。
+
+一些人说这是一个有意义的编号,挖掘出这个区块的人实际上的难度远远超出当前所看到的,不仅要调整前导零的数量,还要匹配接下来的 24 位 —— 它要求非常强大的计算能力。如果有人能够以蛮力去实现它,这将表明有些事情很严重,比如,在计算或密码学方面的重大突破。
+
+你一定会有疑问,为什么 21e800 如此重要 —— 一个你问了肯定会后悔的问题。有人说它是参考了 [E8 理论][4](一个广受批评的提出标准场理论的论文),或是表示总共存在 2100000000 枚比特币(`21 x 10^8` 就是 2,100,000,000)。还有其它说法,因为太疯狂了而没有办法写出来。另一个重要的事实是,在前导零后面有 21e8 的区块平均每年被挖掘出一次 —— 这些从来没有人认为是很重要的。
+
+这就引出了有趣的地方:关于这是如何发生的[理论][5]。
+
+ * 一台量子计算机,它能以某种方式用不可思议的速度做哈希运算。尽管在量子计算机的理论中还没有迹象表明它能够做这件事。哈希是量子计算机认为很安全的东西之一。
+ * 时间旅行。是的,真的有人这么说,有人从未来穿梭回到现在去挖掘这个区块。我认为这种说法太荒谬了,都懒得去解释它为什么是错误的。
+ * 中本聪回来了。尽管事实上他的私钥没有任何活动,一些人从理论上认为他回来了,他能做一些没人能做的事情。这些理论是无法解释他如何做到的。
+
+
+
+> 因此,总的来说(按我的理解)中本聪,为了知道和计算他做的事情,根据现代科学,他可能是以下之一:
+>
+> A) 使用了一台量子计算机
+> B) 来自未来
+> C) 两者都是
+>
+> — Crypto Randy Marsh [REKT] (@nondualrandy) [June 21, 2018][6]
+
+如果你觉得所有的这一切听起来像 [命理学][7],不止你一个人是这样想的。
+
+所有围绕有特殊意义的区块哈希的讨论,也引发了对在某种程度上比较有趣的东西的讨论。比特币的创世区块,它是第一个比特币区块,有一个不寻常的属性:早期的比特币要求哈希值的前 32 位是零;而创始区块的前导零有 43 位。因为由代码产生的创世区块从不会发布,它不知道它是如何产生的,也不知道是用什么类型的硬件产生的。中本聪有学术背景,因此可能他有比那个时候大学中常见设备更强大的计算能力。从这一点上说,只是对古怪的创世区块的历史有点好奇,仅此而已。
+
+### 关于哈希运算的简单题外话
+
+这种喧嚣始于比特币区块的哈希运算;因此理解哈希是什么很重要,并且要理解一个非常重要的属性,一个哈希是单向加密函数,它能够基于给定的数据创建一个伪随机输出。
+
+这意味着什么呢?基于本文讨论的目的,对于每个给定的输入你将得到一个随机的输出。随机数有时看起来很有趣,很简单,因为它是随机的结果,并且人类大脑可以很容易从任何东西中找到顺序。当你从随机数据中开始查看顺序时,你就会发现有趣的事情 —— 这些东西毫无意义,因为它们只是简单地随机数。当人们把重要的意义归属到随机数据上时,它将告诉你很多这些参与者观念相关的东西,而不是数据本身。
+
+### 币的邪教
+
+首先,我们来定义一组术语:
+
+ * 邪教:一个宗教崇拜和直接向一个特定的人或物虔诚的体系。
+ * 宗教:有人认为是至高无上的追求或兴趣。
+
+
+
+币的狂热追捧者中的许多圣人,或许没有人比中本聪更伟大,他是比特币创始人的假名。强力的护卫、赋予能力和理解力远超过一般的研究人员,认为他的远见卓视无人能比,他影响了世界新经济的秩序。当将中本聪的神秘本质和未知的真实身份结合起来时,狂热的追随着们将中本聪视为一个真正的值的尊敬的人物。
+
+当然,除了追随其他圣人的追捧者之外,毫无疑问这些追捧者认为自己是正确的。任何对他们的圣人的批评都被认为也是对他们的批评。例如,那些追捧 EOS 的人,可能会认为中本聪是开发了一个失败项目的黑客,而对 EOS 那怕是最轻微的批评,他们也会作出激烈的反应,之所以反应如此强烈,仅仅是因为攻击了他们心目中的神。那些追捧 IOTA 的人的反应也一样;还有更多这样的例子。
+
+这些追随着在讨论问题时已经失去了理性和客观,他们的狂热遮盖了他们的视野。任何对这些项目和项目背后的人的讨论,如果不是溢美之词,必然以某种程序的刻薄言辞结束,对于一个技术的讨论那种做法是毫无道理的。
+
+这很危险,原因很多:
+
+ * 开发者 & 研究者对缺陷视而不见。由于追捧者的大量赞美,这些参与开发的人对自己的能力开始膨胀,并将一些批评看作是无端的攻击 —— 因为他们认为自己是不可能错的。
+ * 真正的问题是被攻击。技术问题不再被看作是需要去解决的问题和改进的机会,他们认为是来自那些想去破坏项目的人的攻击。
+ * 用一枚币来控制他们。追随者们通常会结盟,而圣人仅有一个。承认其它项目的优越,意味着认同自己项目的缺陷或不足,而这是他们不愿意做的事情。
+ * 阻止真实的进步。进化是很残酷的,它要求死亡,项目失败,以及承认这些失败的原因。如果忽视失败的教训,如果不允许那些应该去死亡的事情发生,进步就会停止。
+
+
+
+许多围绕加密货币和相关区块链项目的讨论已经开始变得越来越”有毒“,善意的人想在不受攻击的情况下进行技术性讨论越来越不可能。随着对真正缺陷的讨论,那些在其它环境中注定要失败的缺陷,在没有做任何的事实分析的情况下即刻被判定为异端已经成为了惯例,善意的人参与其中的代价变得极其昂贵。至少有些人已经意识到极其严重的安全漏洞,由于高“毒性”的环境,他们选择保持沉默。
+
+曾经被好奇、学习和改进的期望、创意可行性所驱动的东西,现在被盲目的贪婪、宗教般的狂热、自以为是和自我膨胀所驱动。
+
+我对受这种狂热激励的项目的未来不抱太多的希望,而它持续地传播,可能会损害多年来在这个领域中真正的研究者。这些技术项目中,一些项目成功了,一些项目失败了 —— 这就是技术演进的方式。设计这些系统的人,就和你我一样都有缺点,同样这些项目也有缺陷。有些项目非常适合某些使用场景而不适合其它场景,有些项目不适合任何使用场景,没有一个项目适合所有使用场景。关于这些项目的讨论应该关注于技术方面,这样做是为了让这一研究领域得以发展;在这些项目中掺杂宗教般狂热必将损害所有人。
+
+[注意:这种行为有许多例子可以引用,但是为了保护那些因批评项目而成为被攻击目标的人,我选择尽可能少的列出这种例子。我看到许多我很尊敬的人、许多我认为是朋友的人成为这种恶毒攻击的受害者 —— 我不想引起人们对这些攻击的注意和重新引起对他们的攻击。]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/
+
+作者:[Adam Caudill][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://adamcaudill.com/author/adam/
+[1]:https://en.wikipedia.org/wiki/Merkle_tree
+[2]:https://hackernoon.com/how-crypto-kitties-disrupted-the-ethereum-network-845c22aa1e6e
+[3]:https://blockchain.info/block-height/528249
+[4]:https://en.wikipedia.org/wiki/An_Exceptionally_Simple_Theory_of_Everything
+[5]:https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be
+[6]:https://twitter.com/nondualrandy/status/1009609117768605696?ref_src=twsrc%5Etfw
+[7]:https://en.wikipedia.org/wiki/Numerology
diff --git a/translated/tech/20180622 How to Check Disk Space on Linux from the Command line.md b/translated/tech/20180622 How to Check Disk Space on Linux from the Command line.md
new file mode 100644
index 0000000000..a872fb15cd
--- /dev/null
+++ b/translated/tech/20180622 How to Check Disk Space on Linux from the Command line.md
@@ -0,0 +1,138 @@
+如何使用命令行检查 Linux 上的磁盘空间
+========
+
+>通过使用 `df` 命令和 `du` 命令查看 Linux 系统上挂载的驱动器的空间使用情况
+
+
+
+-----------------------------
+
+*** 快速提问: ***你的驱动器剩余多少剩余空间?一点点还是很多?接下来的提问是:你知道如何找出这些剩余空间吗?如果你使用的是 GUI 桌面( 例如 GNOME,KDE,Mate,Pantheon 等 ),则任务可能非常简单。但是,当你要在一个没有 GUI 桌面的服务器上查询剩余空间,你该如何去做呢?你是否要为这个任务安装相应的软件工具?答案是绝对不是。在 Linux 中,具备查找驱动器上的剩余磁盘空间的所有工具。事实上,有两个非常容易使用的工具。
+
+在本文中,我将演示这些工具。我将使用 Elementary OS( LCTT译注:Elementary OS 是基于 Ubuntu 精心打磨美化的桌面 Linux 发行版 ),它还包括一个 GUI 选项,但我们将限制自己仅使用命令行。好消息是这些命令行工具随时可用于每个 Linux 发行版。在我的测试系统中,连接了许多的驱动器( 内部的和外部的 )。使用的命令与连接驱动器的位置无关,仅仅与驱动器是否已经挂载好并且对操作系统可见。
+
+话虽如此,让我们来试试这些工具。
+
+### df
+
+`df` 命令是我第一次用于在 Linux 上查询驱动器空间的工具,时间可以追溯到20世纪90年代。它的使用和报告结果非常简单。直到今天,`df` 还是我执行此任务的首选命令。此命令有几个选项开关,对于基本的报告,你实际上只需要一个选项。该命令是 `df -H` 。`-H` 选项开关用于将df的报告结果以人类可读的格式进行显示。`df -H` 的输出包括:已经使用了的空间量,可用空间,空间使用的百分比,以及每个磁盘连接到系统的挂载点( 图 1 )。
+
+
+
+图 1:Elementary OS 系统上 `df -H` 命令的输出结果
+
+如果你的驱动器列表非常长并且你只想查看单个驱动器上使用的空间,该怎么办?有了 `df`,就可以做到。我们来看一下位于 `/dev/sda1` 的主驱动器已经使用了多少空间。为此,执行如下命令:
+```
+ df -H /dev/sda1
+```
+输出将限于该驱动器( 图 2 )。
+
+
+图 2:一个单独驱动器空间情况
+
+你还可以限制 `df` 命令结果报告中显示指定的字段。可用的字段包括:
+
+- source — 文件系统的来源( LCTT译注:通常为一个设备,如 `/dev/sda1` )
+- size — 块总数
+- used — 驱动器已使用的空间
+- avail — 可以使用的剩余空间
+- pcent — 驱动器已经使用的空间占驱动器总空间的百分比
+- target —驱动器的挂载点
+
+让我们显示所有驱动器的输出,仅显示 `size` ,`used` ,`avail` 字段。对此的命令是:
+```
+ df -H --output=size,used,avail
+```
+该命令的输出非常简单( 图 3 )。
+
+
+图 3:显示我们驱动器的指定输出
+
+这里唯一需要注意的是我们不知道输出的来源,因此,我们要把来源加入命令中:
+```
+ df -H --output=source,size,used,avail
+```
+现在输出的信息更加全面有意义( 图 4 )。
+
+
+图 4:我们现在知道了磁盘使用情况的来源
+
+
+### du
+
+我们的下一个命令是 `du` 。 正如您所料,这代表磁盘使用情况( disk usage )。 `du` 命令与 `df` 命令完全不同,因为它报告目录而不是驱动器的空间使用情况。 因此,您需要知道要检查的目录的名称。 假设我的计算机上有一个包含虚拟机文件的目录。 那个目录是 `/media/jack/HALEY/VIRTUALBOX` 。 如果我想知道该特定目录使用了多少空间,我将运行如下命令:
+```
+ du -h /media/jack/HALEY/VIRTUALBOX
+```
+上面命令的输出将显示目录中每个文件占用的空间( 图 5 )。
+
+
+图 5 在特定目录上运行 `du` 命令的输出
+
+到目前为止,这个命令并没有那么有用。如果我们想知道特定目录的总使用量怎么办?幸运的是,`du` 可以处理这项任务。对于同一目录,命令将是:
+```
+ du -sh /media/jack/HALEY/VIRTUALBOX/
+```
+现在我们知道了上述目录使用存储空间的总和( 图 6 )。
+
+
+图 6:我的虚拟机文件使用存储空间的总和是 559GB
+
+您还可以使用此命令查看父项的所有子目录使用了多少空间,如下所示:
+```
+ du -h /media/jack/HALEY
+```
+此命令的输出见( 图 7 ),是一个用于查看各子目录占用的驱动器空间的好方法。
+
+
+图 7:子目录的存储空间使用情况
+
+`du` 命令也是一个很好的工具,用于查看使用系统磁盘空间最多的目录列表。执行此任务的方法是将 `du` 命令的输出通过管道传递给另外两个命令:`sort` 和 `head` 。下面的命令用于找出驱动器上占用存储空间最大的前10各目录:
+```
+ du -a /media/jack | sort -n -r |head -n 10
+```
+输出将以从大到小的顺序列出这些目录( 图 8 )。
+
+
+图 8:使用驱动器空间最多的 10 个目录
+
+### 没有你想像的那么难
+
+查看 Linux 系统上挂载的驱动器的空间使用情况非常简单。只要你将你的驱动器挂载在 Linux 系统上,使用 `df` 命令或 `du` 命令在报告必要信息方面都会非常出色。使用 `df` 命令,您可以快速查看磁盘上总的空间使用量,使用 `du` 命令,可以查看特定目录的空间使用情况。对于每一个 Linux 系统的管理员来说,这两个命令的结合使用是必须掌握的。
+
+而且,如果你不需要使用 `du` 或 `df` 命令查看驱动器空间的使用情况,我最近介绍了查看 Linux 上内存使用情况的方法。总之,这些技巧将大力帮助你成功管理 Linux 服务器。
+
+通过 Linux Foundation 和 edX 免费提供的 “ Linux 简介 ” 课程,了解更多有关 Linux 的信息。
+
+--------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
+
+作者:Jack Wallen 选题:lujun9972 译者:SunWave 校对:校对者ID
+
+本文由 LCTT 原创编译,Linux中国 荣誉推出
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/translated/tech/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md b/translated/tech/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md
new file mode 100644
index 0000000000..dca23047e8
--- /dev/null
+++ b/translated/tech/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md
@@ -0,0 +1,293 @@
+使用 Ptrace 去监听和仿真 Linux 系统调用 « null program
+======
+
+`ptrace(2)`(”进程跟踪“)系统调用通常都与调试有关。它是类 Unix 系统上通过原生调试器监测调试进程的主要机制。它也是实现 [strace][1](系统调用跟踪)的常见方法。使用 Ptrace,跟踪器可以暂停跟踪过程,[检查和设置寄存器和内存][2],监视系统调用,甚至可以监听系统调用。
+
+通过监听功能,意味着跟踪器可以修改系统调用参数,修改系统调用的返回值,甚至监听某些系统调用。言外之意就是,一个跟踪器可以完全服务于系统调用本身。这是件非常有趣的事,因为这意味着**一个跟踪器可以仿真一个完整的外部操作系统**,而这些都是在没有得到内核任何帮助的情况下由 Ptrace 实现的。
+
+问题是,在同一时间一个进程只能被一个跟踪器附着,因此在那个进程的调试期间,不可能再使用诸如 GDB 这样的工具去仿真一个外部操作系统。另外的问题是,仿真系统调用的开销非常高。
+
+在本文中,我们将专注于 x86-64 [Linux 的 Ptrace][3],并将使用一些 Linux 专用的扩展。同时,在本文中,我们将忽略掉一些错误检查,但是完整的源代码仍然会包含这些错误检查。
+
+本文中的可直接运行的示例代码在这里:
+
+****
+
+### strace
+
+在进入到最有趣的部分之前,我们先从回顾 strace 的基本实现来开始。它不是 [DTrace][4],但 strace 仍然非常有用。
+
+Ptrace 还没有被标准化。它的界面在不同的操作系统上非常类似,尤其是在核心功能方面,但是在不同的系统之间仍然存在细微的差别。`ptrace(2)` 的样子看起来应该像下面这样,但特定的类型可能有些差别。
+```
+long ptrace(int request, pid_t pid, void *addr, void *data);
+
+```
+
+`pid` 是跟踪的进程 ID。虽然**同一个时间**只有一个跟踪器可以附着到进程上,但是一个跟踪器可以附着跟踪多个进程。
+
+`request` 字段选择一个具体的 Ptrace 函数,比如 `ioctl(2)` 接口。对于 strace,只需要两个:
+
+ * `PTRACE_TRACEME`:这个进程被它的父进程跟踪。
+ * `PTRACE_SYSCALL`:继续跟踪,但是在下一下系统调用入口或出口时停止。
+ * `PTRACE_GETREGS`:取得被跟踪进程的寄存器内容副本。
+
+
+
+另外两个字段,`addr` 和 `data`,作为所选的 Ptrace 函数的一般参数。一般情况下,可以忽略一个或全部忽略,在那种情况下,传递零个参数。
+
+strace 接口实质上是另一个命令的前缀。
+```
+$ strace [strace options] program [arguments]
+
+```
+
+最小化的 strace 不需要任何选项,因此需要做的第一件事情是 — 假设它至少有一个参数 — 在 `argv` 尾部的 `fork(2)` 和 `exec(2)` 被跟踪进程。但是在加载目标程序之前,新的进程将告知内核,目标程序将被它的父进程继续跟踪。被跟踪进程将被这个 Ptrace 系统调用暂停。
+```
+pid_t pid = fork();
+switch (pid) {
+ case -1: /* error */
+ FATAL("%s", strerror(errno));
+ case 0: /* child */
+ ptrace(PTRACE_TRACEME, 0, 0, 0);
+ execvp(argv[1], argv + 1);
+ FATAL("%s", strerror(errno));
+}
+
+```
+
+父进程使用 `wait(2)` 等待子进程的 `PTRACE_TRACEME`,当 `wait(2)` 返回后,子进程将被暂停。
+```
+waitpid(pid, 0, 0);
+
+```
+
+在允许子进程继续运行之前,我们告诉操作系统,被跟踪进程被它的父进程的跟踪应该被终止。一个真实的 strace 实现可能会设置其它的选择,比如: `PTRACE_O_TRACEFORK`。
+```
+ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
+
+```
+
+剩余部分就是一个简单的、无休止的循环了,每循环一次捕获一个系统调用。循环体总共有四步:
+
+ 1. 等待进程进入下一个系统调用。
+ 2. 输出一个系统调用的描述。
+ 3. 允许系统调用去运行和等待返回。
+ 4. 输出系统调用返回值。
+
+
+
+`PTRACE_SYSCALL` 要求用于等待下一个系统调用时开始,和等待那个系统调用去退出。和前面一样,需要一个 `wait(2)` 去等待跟踪进入期望的状态。
+```
+ptrace(PTRACE_SYSCALL, pid, 0, 0);
+waitpid(pid, 0, 0);
+
+```
+
+当 `wait(2)` 返回时,线程寄存器中写入了被系统调用所产生的系统调用号和它的参数。尽管如此,操作系统将不再为这个系统调用提供服务。线程寄存器中的详细内容对后续操作很重要。
+
+接下来的一步是采集系统调用信息。这是得到特定系统架构的地方。在 x86-64 上,[系统调用号是在 `rax` 中传递的][5],而参数(最多 6 个)是在 `rdi`、`rsi`、`rdx`、`r10`、`r8`、和 `r9` 中传递的。另外的 Ptrace 调用将读取这些寄存器,不过这里再也不需要 `wait(2)` 了,因为跟踪状态再也不会发生变化了。
+```
+struct user_regs_struct regs;
+ptrace(PTRACE_GETREGS, pid, 0, ®s);
+long syscall = regs.orig_rax;
+
+fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
+ syscall,
+ (long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
+ (long)regs.r10, (long)regs.r8, (long)regs.r9);
+
+```
+
+这里有一个敬告。由于 [内核的内部用途][6],系统调用号是保存在 `orig_rax` 中而不是 `rax` 中。而所有的其它系统调用参数都是非常简单明了的。
+
+接下来是它的另一个 `PTRACE_SYSCALL` 和 `wait(2)`,然后是另一个 `PTRACE_GETREGS` 去获取结果。结果保存在 `rax` 中。
+```
+ptrace(PTRACE_GETREGS, pid, 0, ®s);
+fprintf(stderr, " = %ld\n", (long)regs.rax);
+
+```
+
+这个简单程序的输出也是非常粗糙的。这里的系统调用都没有符号名,并且所有的参数都是以数字形式输出,甚至是一个指向缓冲区的指针。更完整的 strace 输出将能知道哪个参数是指针,以及 `process_vm_readv(2)` 为了从跟踪中正确输出内容而读取了哪些缓冲区。
+
+然后,这些仅仅是系统调用监听的基础工作。
+
+### 系统调用监听
+
+假设我们想使用 Ptrace 去实现如 OpenBSD 的 [`pledge(2)`][7] 这样的功能,它是 [一个进程承诺只使用一套受限的系统调用][8]。初步想法是,许多程序一般都有一个初始化阶段,这个阶段它们都需要进行许多的系统访问(比如,打开文件、绑定套接字、等等)。初始化完成以后,它们进行一个主循环,在主循环中它们处理输入,并且仅使用所需的、很少的一套系统调用。
+
+在进入主循环之前,可以限制一个进程只能运行它自己所需要的几个操作。如果 [程序有 Bug][9],允许通过恶意的输入去利用这个 Bug,这个承诺可以有效地限制漏洞利用的实现。
+
+使用与 strace 相同的模型,但不是输出所有的系统调用,我们既能够拦截某些系统调用,也可以在它的行为异常时简单地终止被跟踪进程。终止它很容易:只需要在跟踪器中调用 `exit(2)`。因此,它也可以被设置为去终止被跟踪进程。拦截系统调用和允许子进程继续运行都只是些雕虫小技而已。
+
+最棘手的部分是**当系统调用启动后没有办法去中断它**。进入系统调用之后,当跟踪器从 `wait(2)` 中返回,停止一个系统调用的仅有方式是,发生被跟踪进程终止的情况。
+
+然而,我们不仅可以“搞乱”系统调用的参数,也可以改变系统调用号本身,将它修改为一个不存在的系统调用。返回时,在 `errno` 中 [通过正常的内部信号][10],我们就可以报告一个“友好的”错误信息。
+```
+for (;;) {
+ /* Enter next system call */
+ ptrace(PTRACE_SYSCALL, pid, 0, 0);
+ waitpid(pid, 0, 0);
+
+ struct user_regs_struct regs;
+ ptrace(PTRACE_GETREGS, pid, 0, ®s);
+
+ /* Is this system call permitted? */
+ int blocked = 0;
+ if (is_syscall_blocked(regs.orig_rax)) {
+ blocked = 1;
+ regs.orig_rax = -1; // set to invalid syscall
+ ptrace(PTRACE_SETREGS, pid, 0, ®s);
+ }
+
+ /* Run system call and stop on exit */
+ ptrace(PTRACE_SYSCALL, pid, 0, 0);
+ waitpid(pid, 0, 0);
+
+ if (blocked) {
+ /* errno = EPERM */
+ regs.rax = -EPERM; // Operation not permitted
+ ptrace(PTRACE_SETREGS, pid, 0, ®s);
+ }
+}
+
+```
+
+这个简单的示例只是检查了系统调用是否违反白名单或黑名单。而它们在这里并没有差别,比如,允许文件以只读而不是读写方式打开(`open(2)`),允许匿名内存映射但不允许非匿名映射等等。但是这里仍然没有办法去动态撤销被跟踪进程的权限。
+
+跟踪器与被跟踪进程如何沟通?使用人为的系统调用!
+
+### 创建一个人为的系统调用
+
+对于我的这个类似于 pledge 的系统调用 — 我可以通过调用 `xpledge()` 将它与真实的系统调用区分开 — 我设置 10000 作为它的系统调用号,这是一个非常大的数字,真实的系统调用中从来不会用到它。
+```
+#define SYS_xpledge 10000
+
+```
+
+为演示需要,我同时构建了一个非常小的界面,这在实践中并不是个好主意。它与 OpenBSD 的 `pledge(2)` 稍有一些相似之处,它使用了一个 [字符串界面][11]。事实上,设计一个健壮且安全的权限集是非常复杂的,正如在 `pledge(2)` 的手册页面上所显示的那样。下面是对被跟踪进程的完整界面和系统调用的实现:
+```
+#define _GNU_SOURCE
+#include
+
+#define XPLEDGE_RDWR (1 << 0)
+#define XPLEDGE_OPEN (1 << 1)
+
+#define xpledge(arg) syscall(SYS_xpledge, arg)
+
+```
+
+如果给它传递零个参数,仅允许一些基本的系统调用,包括那些用于去分配内存的系统调用(比如 `brk(2)`)。 `PLEDGE_RDWR` 位允许 [各种][12] 读和写的系统调用(`read(2)`、`readv(2)`、`pread(2)`、`preadv(2)` 等等)。`PLEDGE_OPEN` 位允许 `open(2)`。
+
+为防止发生提升权限的行为,`pledge()` 会拦截它自己 — 但这样也防止了权限撤销,以后再细说这方面内容。
+
+在 xpledge 跟踪器中,我需要去检查这个系统调用:
+```
+/* Handle entrance */
+switch (regs.orig_rax) {
+ case SYS_pledge:
+ register_pledge(regs.rdi);
+ break;
+}
+
+```
+
+操作系统将返回 `ENOSYS`(因为函数还没有实现),因此它不是一个真实的系统调用。为此在退出时我用一个 `success (0)` 去覆写它。
+```
+/* Handle exit */
+switch (regs.orig_rax) {
+ case SYS_pledge:
+ ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
+ break;
+}
+
+```
+
+我写了一小段测试程序去打开 `/dev/urandom`,做一个读操作,尝试去承诺后,我第二次打开 `/dev/urandom`,然后确认它能够读取原始的 `/dev/urandom` 文件描述符。在没有承诺跟踪器的情况下运行,输出如下:
+```
+$ ./example
+fread("/dev/urandom")[1] = 0xcd2508c7
+XPledging...
+XPledge failed: Function not implemented
+fread("/dev/urandom")[2] = 0x0be4a986
+fread("/dev/urandom")[1] = 0x03147604
+
+```
+
+做一个无效的系统调用并不会让应用程序崩溃。它只是失败,这是一个很方便的返回方式。当它在跟踪器下运行时,它的输出如下:
+```
+$ ./xpledge ./example
+fread("/dev/urandom")[1] = 0xb2ac39c4
+XPledging...
+fopen("/dev/urandom")[2]: Operation not permitted
+fread("/dev/urandom")[1] = 0x2e1bd1c4
+
+```
+
+这个承诺很成功,第二次的 `fopen(3)` 并没有实现,因为跟踪器用一个 `EPERM` 拦截了它。
+
+可以将这种思路进一步发扬光大,比如,改变文件路径或返回一个假的结果。一个跟踪器可以很高效地 chroot 它的被跟踪进程,通过一个系统调用将任意路径传递给 root 从而实现 chroot 路径。它甚至可以对用户进行欺骗,告诉用户它以 root 运行。事实上,这些就是 [Fakeroot NG][13] 程序所做的事情。
+
+### 仿真外部系统
+
+假设你不满足于仅监听一些系统调用,而是想监听全部系统调用。你收到 [一个打算在其它操作系统上运行的二进制程序][14],因为没有系统调用,这个二进制程序将无法正常运行。
+
+使用我在前面所描述的这些内容你就可以管理这一切。跟踪器可以使用一个假冒的东西去代替系统调用号,允许它去失败,以及为系统调用本身提供服务。但那样做的效率很低。其实质上是对每个系统调用做了三个上下文切换:一个是在入口上停止,一个是让系统调用总是以失败告终,还有一个是在系统调用退出时停止。
+
+从 2005 年以后,对于这个技术,PTrace 的 Linux 版本有更高效的操作:`PTRACE_SYSEMU`。PTrace 仅在每个系统调用发出时停止一次,在允许被跟踪进程继续运行之前,由跟踪器为系统调用提供服务。
+```
+for (;;) {
+ ptrace(PTRACE_SYSEMU, pid, 0, 0);
+ waitpid(pid, 0, 0);
+
+ struct user_regs_struct regs;
+ ptrace(PTRACE_GETREGS, pid, 0, ®s);
+
+ switch (regs.orig_rax) {
+ case OS_read:
+ /* ... */
+
+ case OS_write:
+ /* ... */
+
+ case OS_open:
+ /* ... */
+
+ case OS_exit:
+ /* ... */
+
+ /* ... and so on ... */
+ }
+}
+
+```
+
+从任何使用(足够)稳定的系统调用 ABI(译注:应用程序二进制接口),在相同架构的机器上运行一个二进制程序时,你只需要 `PTRACE_SYSEMU` 跟踪器,一个加载器(用于代替 `exec(2)`),和这个二进制程序所需要(或仅运行静态的二进制程序)的任何系统库即可。
+
+事实上,这听起来有点像一个有趣的周末项目。
+
+--------------------------------------------------------------------------------
+
+via: http://nullprogram.com/blog/2018/06/23/
+
+作者:[Chris Wellons][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://nullprogram.com
+[1]:https://blog.plover.com/Unix/strace-groff.html
+[2]:http://nullprogram.com/blog/2016/09/03/
+[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
+[4]:http://nullprogram.com/blog/2018/01/17/
+[5]:http://nullprogram.com/blog/2015/05/15/
+[6]:https://stackoverflow.com/a/6469069
+[7]:https://man.openbsd.org/pledge.2
+[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
+[9]:http://nullprogram.com/blog/2017/07/19/
+[10]:http://nullprogram.com/blog/2016/09/23/
+[11]:https://www.tedunangst.com/flak/post/string-interfaces
+[12]:http://nullprogram.com/blog/2017/03/01/
+[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
+[14]:http://nullprogram.com/blog/2017/11/30/
diff --git a/translated/tech/20180702 How to edit Adobe InDesign files with Scribus and Gedit.md b/translated/tech/20180702 How to edit Adobe InDesign files with Scribus and Gedit.md
new file mode 100644
index 0000000000..f4cc53bc50
--- /dev/null
+++ b/translated/tech/20180702 How to edit Adobe InDesign files with Scribus and Gedit.md
@@ -0,0 +1,127 @@
+# 如何用 Scribus 和 Gedit 编辑 Adobe InDesign 文件
+
+
+
+要想成为一名优秀的平面设计师,您必须善于使用各种各样专业的工具。现在,对大多数设计师来说,最常用的工具是 Adobe 全家桶。
+
+但是,有时候使用开源工具能够帮您摆脱困境。比如,您正在使用一台公共打印机打印一份用 Adobe InDesign 创建的文件。这时,您需要对文件做一些简单的改动(比如,改正一个错别字),但您无法立刻使用 Adobe 套件。虽然这种情况很少见,但电子杂志制作软件 [Scribus][1] 和文本编辑器 [Gedit][2] 等开源工具可以节约您的时间。
+
+在本文中,我将向您展示如何使用 Scribus 和 Gedit 编辑 Adobe InDesign 文件。请注意,还有许多其他开源平面设计软件可以用来代替 Adobe InDesign 或者结合使用。详情请查看我的文章:[昂贵的工具(从来!)不是平面设计的唯一选择][3] 以及 [开源 Adobe InDesign 脚本][4].
+
+在编写本文的时候,我阅读了一些关于如何使用开源软件编辑 InDesign 文件的博客,但没有找到有用的文章。我尝试了两个解决方案。一个是:创建一个 EPS 并在文本编辑器 Scribus 中将其打开为可编辑文件,但这不起作用。另一个是:从 InDesign 中创建一个 IDML(一种旧的 InDesign 文件格式)文件,并在 Scribus 中打开它。第二种方法效果更好,也是我在下文中使用的解决方法。
+
+### 编辑个人名片
+
+我尝试在 Scribus 中打开和编辑 InDesign 名片文件的效果很好。唯一的问题是字母间的间距有些偏移,以及 “Jeff” 中的 ‘f’ 被翻转、‘J’ 被上下颠倒。其他部分,像样式和颜色等都完好无损。
+
+![Business card in Adobe InDesign][6]
+
+图:在 Adobe InDesign 中编辑个人名片。
+
+![InDesign IDML file opened in Scribus][8]
+
+图:在 Scribus 中打开 InDesign IDML 文件。
+
+### 删除书籍中的文本
+
+这本书籍的更改并不顺利。书籍的正文还 OK,但当我用 Scribus 打开 InDesign 文件,目录、页脚和一些首字下沉的段落都出现问题。不过至少,它是一个可编辑的文档。其中一个问题是一些文本框中的文字变成了默认的 Arial 字体,这是因为字体样式的优先级比段落样式高。这个问题容易解决。
+
+![Book layout in InDesign][10]
+
+图:InDesign 中的书籍布局。
+
+![InDesign IDML file of book layout opened in Scribus][12]
+
+图:用 Scribus 打开 InDesign IDML 文件的书籍布局。
+
+当我试图选择并删除一页文本的时候,发生了奇异事件。我把光标放在文本中,按下 ``Command + A``(“全选”的快捷键)。表面看起来一整页文本都高亮显示了,但事实并非如此!
+
+![Selecting text in Scribus][14]
+
+图:Scribus 中被选中的文本。
+
+当我按下“删除”键,整个文本(不只是高亮的部分)都消失了。
+
+![Both pages of text deleted in Scribus][16]
+
+图:两页文本都被删除了。
+
+然后,更奇异的事情发生了……我按下 ``Command + Z`` 键来撤回删除操作,文本恢复,但文本格式全乱套了。
+
+![Undo delete restored the text, but with bad formatting.][18]
+
+图:Command+Z (撤回删除操作) 恢复了文本,但格式乱套了。
+
+### 用文本编辑器打开 InDesign 文件
+
+当您用记事本(比如,Mac 中的 TextEdit)分别打开 Scribus 文件和 InDesign 文件,会发现 Scribus 文件是可读的,而 InDesign 文件全是乱码。
+
+您可以用 TextEdit 对两者进行更改并成功保存,但得到的文件是损坏的。下图是当我用 InDesign 打开编辑后的文件时的报错。
+
+![InDesign error message][20]
+
+图:InDesign 的报错。
+
+我在 Ubuntu 系统上用文本编辑器 Gedit 编辑 Scribus 时得到了更好的结果。我从命令行启动了 Gedit,然后打开并编辑 Scribus 文件,保存后,再次使用 Scribus 打开文件时,我在 Gedit 中所做的更改都成功显示在 Scribus 中。
+
+![Editing Scribus file in Gedit][22]
+
+图:用 Gedit 编辑 Scribus 文件。
+
+![Result of the Gedit edit in Scribus][24]
+
+图:用 Scribus 打开 Gedit 编辑过的文件。
+
+当您正准备打印的时候,客户打来电话说有一个错别字需要更改,此时您不需要苦等客户爸爸发来新的文件,只需要用 Gedit 打开 Scribus 文件,改正错别字,继续打印。
+
+### 把图像拖拽到 ID 文件中
+
+我将 InDesign 文档另存为 IDML 文件,这样我就可以用 Scribus 往其中拖进一些 PDF 文档。似乎 Scribus 并不能像 InDesign 一样把 PDF 文档 拖拽进去。于是,我把 PDF 文档转换成 JPG 格式的图片然后导入到 Scribus 中,成功了。但这么做的结果是,将 IDML 文档转换成 PDF 格式后,文件大小非常大。
+
+![Huge PDF file][26]
+
+图:把 Scribus 转换成 PDF 时得到一个非常大的文件。
+
+我不确定为什么会这样——这个坑留着以后再填吧。
+
+您是否有使用开源软件编辑平面图形文件的技巧?如果有,请在评论中分享哦。
+
+------
+
+via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
+
+作者:[Jeff Macharyas][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[XiatianSummer](https://github.com/XiatianSummer)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rikki-endsley
+[1]: https://www.scribus.net/
+[2]: https://wiki.gnome.org/Apps/Gedit
+[3]: https://opensource.com/life/16/8/open-source-alternatives-graphic-design
+[4]: https://opensource.com/article/17/3/scripts-adobe-indesign
+[5]: /file/402516
+[6]: https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png "Business card in Adobe InDesign"
+[7]: /file/402521
+[8]: https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png "InDesign IDML file opened in Scribus"
+[9]: /file/402531
+[10]: https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png "Book layout in InDesign"
+[11]: /file/402536
+[12]: https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png "InDesign IDML file of book layout opened in Scribus"
+[13]: /file/402541
+[14]: https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png "Selecting text in Scribus"
+[15]: /file/402546
+[16]: https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png "Both pages of text deleted in Scribus"
+[17]: /file/402551
+[18]: https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png "Undo delete restored the text, but with bad formatting."
+[19]: /file/402556
+[20]: https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png "InDesign error message"
+[21]: /file/402561
+[22]: https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png "Editing Scribus file in Gedit"
+[23]: /file/402566
+[24]: https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png "Result of the Gedit edit in Scribus"
+[25]: /file/402571
+[26]: https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png "Huge PDF file"
+
diff --git a/translated/tech/20180703 Understanding Python Dataclasses — Part 1.md b/translated/tech/20180703 Understanding Python Dataclasses — Part 1.md
new file mode 100644
index 0000000000..d038a4d5bf
--- /dev/null
+++ b/translated/tech/20180703 Understanding Python Dataclasses — Part 1.md
@@ -0,0 +1,513 @@
+理解 Python 的 Dataclasses -- 第一部分
+======
+
+
+
+如果你正在阅读本文,那么你已经意识到了 Python 3.7 以及它所包含的新特性。就我个人而言,我对 `Dataclasses` 感到非常兴奋,因为我有一段时间在等待它了。
+
+本系列包含两部分:
+1\. Dataclass 特点概述
+2\. 在下一篇文章概述 Dataclass 的 `fields`
+
+### 介绍
+
+`Dataclasses` 是 Python 的类(译注:更准确的说,它是一个模块),适用于存储数据对象。你可能会问什么是数据对象?下面是定义数据对象的一个不太详细的特性列表:
+
+ * 它们存储数据并代表某种数据类型。例如:一个数字。对于熟悉 ORM 的人来说,模型实例是一个数据对象。它代表一种特定的实体。它包含那些定义或表示实体的属性。
+
+ * 它们可以与同一类型的其他对象进行比较。例如:一个数字可以是 `greater than(大于)`, `less than(小于)` 或 `equal(等于)` 另一个数字。
+
+当然还有更多的特性,但是这个列表足以帮助你理解问题的关键。
+
+为了理解 `Dataclasses`,我们将实现一个包含数字的简单类,并允许我们执行上面提到的操作。
+首先,我们将使用普通类,然后我们再使用 `Dataclasses` 来实现相同的结果。
+
+但在我们开始之前,先来谈谈 `dataclasses` 的用法。
+
+Python 3.7 提供了一个装饰器 [dataclass][2],用于将类转换为 `dataclass`。
+
+你所要做的就是将类包在装饰器中:
+
+```
+from dataclasses import dataclass
+
+@dataclass
+class A:
+ …
+```
+
+现在,让我们深入了解一下 `dataclass` 带给我们的变化和用途。
+
+### 初始化
+
+通常是这样:
+
+```
+class Number:
+
+ def __init__(self, val):
+ self.val = val
+
+>>> one = Number(1)
+>>> one.val
+>>> 1
+```
+
+用 `dataclass` 是这样:
+
+```
+@dataclass
+class Number:
+ val:int
+
+>>> one = Number(1)
+>>> one.val
+>>> 1
+```
+
+以下是 dataclass 装饰器带来的变化:
+
+1\. 无需定义 `__init__`,然后将值赋给 `self.d` 负责处理它(to 校正:这里真不知道 d 在哪里)
+2\. 我们以更加易读的方式预先定义了成员属性,以及[类型提示][3]。我们现在立即能知道 `val` 是 `int` 类型。这无疑比一般定义类成员的方式更具可读性。
+
+> Python 之禅: 可读性很重要
+
+它也可以定义默认值:
+
+```
+@dataclass
+class Number:
+ val:int = 0
+```
+
+### 表示
+
+对象表示指的是对象的一个有意义的字符串表示,它在调试时非常有用。
+
+默认的 Python 对象表示不是很直观:
+
+```
+class Number:
+ def __init__(self, val = 0):
+ self.val = val
+
+>>> a = Number(1)
+>>> a
+>>> <__main__.Number object at 0x7ff395b2ccc0>
+```
+
+这让我们无法知悉对象的作用,并且会导致糟糕的调试体验。
+
+一个有意义的表示可以通过在类中定义一个 `__repr__` 方法来实现。
+
+```
+def __repr__(self):
+ return self.val
+```
+
+现在我们得到这个对象有意义的表示:
+
+```
+>>> a = Number(1)
+>>> a
+>>> 1
+```
+
+`dataclass` 会自动添加一个 `__repr__ ` 函数,这样我们就不必手动实现它了。
+
+```
+@dataclass
+class Number:
+ val: int = 0
+```
+
+```
+>>> a = Number(1)
+>>> a
+>>> Number(val = 1)
+```
+
+### 数据比较
+
+通常,数据对象之间需要相互比较。
+
+两个对象 `a` 和 `b` 之间的比较通常包括以下操作:
+
+* a < b
+
+* a > b
+
+* a == b
+
+* a >= b
+
+* a <= b
+
+在 Python 中,能够在可以执行上述操作的类中定义[方法][4]。为了简单起见,不让这篇文章过于冗长,我将只展示 `==` 和 `<` 的实现。
+
+通常这样写:
+
+```
+class Number:
+ def __init__( self, val = 0):
+ self.val = val
+
+ def __eq__(self, other):
+ return self.val == other.val
+
+ def __lt__(self, other):
+ return self.val < other.val
+```
+
+使用 `dataclass`:
+
+```
+@dataclass(order = True)
+class Number:
+ val: int = 0
+```
+
+是的,就是这样简单。
+
+我们不需要定义 `__eq__` 和 `__lt__` 方法,因为当 `order = True` 被调用时,`dataclass` 装饰器会自动将它们添加到我们的类定义中。
+
+那么,它是如何做到的呢?
+
+当你使用 `dataclass` 时,它会在类定义中添加函数 `__eq__` 和 `__lt__` 。我们已经知道这点了。那么,这些函数是怎样知道如何检查相等并进行比较呢?
+
+生成 `__eq__` 函数的 `dataclass` 类会比较两个属性构成的元组,一个由自己属性构成的,另一个由同类的其他实例的属性构成。在我们的例子中,`自动`生成的 `__eq__` 函数相当于:
+
+```
+def __eq__(self, other):
+ return (self.val,) == (other.val,)
+```
+
+让我们来看一个更详细的例子:
+
+我们会编写一个 `dataclass` 类 `Person` 来保存 `name` 和 `age`。
+
+```
+@dataclass(order = True)
+class Person:
+ name: str
+ age:int = 0
+```
+
+自动生成的 `__eq__` 方法等同于:
+
+```
+def __eq__(self, other):
+ return (self.name, self.age) == ( other.name, other.age)
+```
+
+请注意属性的顺序。它们总是按照你在 dataclass 类中定义的顺序生成。
+
+同样,等效的 `__le__` 函数类似于:
+
+```
+def __le__(self, other):
+ return (self.name, self.age) <= (other.name, other.age)
+```
+
+当你需要对数据对象列表进行排序时,通常会出现像 `__le__` 这样的函数的定义。Python 内置的 [sorted][5] 函数依赖于比较两个对象。
+
+```
+>>> import random
+
+>>> a = [Number(random.randint(1,10)) for _ in range(10)] #generate list of random numbers
+
+>>> a
+
+>>> [Number(val=2), Number(val=7), Number(val=6), Number(val=5), Number(val=10), Number(val=9), Number(val=1), Number(val=10), Number(val=1), Number(val=7)]
+
+>>> sorted_a = sorted(a) #Sort Numbers in ascending order
+
+>>> [Number(val=1), Number(val=1), Number(val=2), Number(val=5), Number(val=6), Number(val=7), Number(val=7), Number(val=9), Number(val=10), Number(val=10)]
+
+>>> reverse_sorted_a = sorted(a, reverse = True) #Sort Numbers in descending order
+
+>>> reverse_sorted_a
+
+>>> [Number(val=10), Number(val=10), Number(val=9), Number(val=7), Number(val=7), Number(val=6), Number(val=5), Number(val=2), Number(val=1), Number(val=1)]
+
+```
+
+### `dataclass` 作为一个可调用的装饰器
+
+定义所有的 `dunder`(译注:这是指双下划线方法,即魔法方法)方法并不总是值得的。你的用例可能只包括存储值和检查相等性。因此,你只需定义 `__init__` 和 `__eq__` 方法。如果我们可以告诉装饰器不生成其他方法,那么它会减少一些开销,并且我们将在数据对象上有正确的操作。
+
+幸运的是,这可以通过将 `dataclass` 装饰器作为可调用对象来实现。
+
+从官方[文档][6]来看,装饰器可以用作具有如下参数的可调用对象:
+
+```
+@dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
+class C:
+ …
+```
+
+1. `init`:默认将生成 `__init__` 方法。如果传入 `False`,那么该类将不会有 `__init__` 方法。
+
+2. `repr`:`__repr__` 方法默认生成。如果传入 `False`,那么该类将不会有 `__repr__` 方法。
+
+3. `eq`:默认将生成 `__eq__` 方法。如果传入 `False`,那么 `__eq__` 方法将不会被 `dataclass` 添加,但默认为 `object.__eq__`。
+
+4. `order`:默认将生成 `__gt__`、`__ge__`、`__lt__`、`__le__` 方法。如果传入 `False`,则省略它们。
+
+我们在接下来会讨论 `frozen`。由于 `unsafe_hash` 参数复杂的用例,它值得单独发布一篇文章。
+
+现在回到我们的用例,以下是我们需要的:
+
+1. `__init__`
+2. `__eq__`
+
+默认会生成这些函数,因此我们需要的是不生成其他函数。那么我们该怎么做呢?很简单,只需将相关参数作为 false 传入给生成器即可。
+
+```
+@dataclass(repr = False) # order, unsafe_hash and frozen are False
+class Number:
+ val: int = 0
+
+
+>>> a = Number(1)
+
+>>> a
+
+>>> <__main__.Number object at 0x7ff395afe898>
+
+>>> b = Number(2)
+
+>>> c = Number(1)
+
+>>> a == b
+
+>>> False
+
+>>> a < b
+
+>>> Traceback (most recent call last):
+ File “”, line 1, in
+TypeError: ‘<’ not supported between instances of ‘Number’ and ‘Number’
+```
+
+### Frozen(不可变) 实例
+
+Frozen 实例是在初始化对象后无法修改其属性的对象。
+
+> 无法创建真正不可变的 Python 对象
+
+在 Python 中创建对象的不可变属性是一项艰巨的任务,我将不会在本篇文章中深入探讨。
+
+以下是我们期望不可变对象能够做到的:
+
+```
+>>> a = Number(10) #Assuming Number class is immutable
+
+>>> a.val = 10 # Raises Error
+```
+
+有了 `dataclass`,就可以通过使用 `dataclass` 装饰器作为可调用对象配合参数 `frozen=True` 来定义一个 `frozen` 对象。
+
+当实例化一个 `frozen` 对象时,任何企图修改对象属性的行为都会引发 `FrozenInstanceError`。
+
+```
+@dataclass(frozen = True)
+class Number:
+ val: int = 0
+
+>>> a = Number(1)
+
+>>> a.val
+
+>>> 1
+
+>>> a.val = 2
+
+>>> Traceback (most recent call last):
+ File “”, line 1, in
+ File “”, line 3, in __setattr__
+dataclasses.FrozenInstanceError: cannot assign to field ‘val’
+```
+
+因此,一个 `frozen` 实例是一种很好方式来存储:
+
+* 常数
+
+* 设置
+
+这些通常不会在应用程序的生命周期内发生变化,任何企图修改它们的行为都应该被禁止。
+
+### 后期初始化处理
+
+有了 `dataclass`,需要定义一个 `__init__` 方法来将变量赋给 `self` 这种初始化操作已经得到了处理。但是我们失去了在变量被赋值之后立即需要的函数调用或处理的灵活性。
+
+让我们来讨论一个用例,在这个用例中,我们定义一个 `Float` 类来包含浮点数,然后在初始化之后立即计算整数和小数部分。
+
+通常是这样:
+
+```
+import math
+
+class Float:
+ def __init__(self, val = 0):
+ self.val = val
+ self.process()
+
+ def process(self):
+ self.decimal, self.integer = math.modf(self.val)
+
+>>> a = Float( 2.2)
+
+>>> a.decimal
+
+>>> 0.2000
+
+>>> a.integer
+
+>>> 2.0
+```
+
+幸运的是,使用 [__post_init__][9] 方法已经能够处理后期初始化操作。
+
+生成的 `__init__` 方法在返回之前调用 `__post_init__` 返回。因此,可以在函数中进行任何处理。
+
+```
+import math
+
+@dataclass
+class FloatNumber:
+ val: float = 0.0
+
+ def __post_init__(self):
+ self.decimal, self.integer = math.modf(self.val)
+
+>>> a = Number(2.2)
+
+>>> a.val
+
+>>> 2.2
+
+>>> a.integer
+
+>>> 2.0
+
+>>> a.decimal
+
+>>> 0.2
+```
+
+多么方便!
+
+### 继承
+
+`Dataclasses` 支持继承,就像普通的 Python 类一样。
+
+因此,父类中定义的属性将在子类中可用。
+
+```
+@dataclass
+class Person:
+ age: int = 0
+ name: str
+
+@dataclass
+class Student(Person):
+ grade: int
+
+>>> s = Student(20, "John Doe", 12)
+
+>>> s.age
+
+>>> 20
+
+>>> s.name
+
+>>> "John Doe"
+
+>>> s.grade
+
+>>> 12
+```
+
+请注意,`Student` 的参数是在类中定义的字段的顺序。
+
+继承过程中 `__post_init__` 的行为是怎样的?
+
+由于 `__post_init__` 只是另一个函数,因此必须以传统方式调用它:
+
+```
+@dataclass
+class A:
+ a: int
+
+ def __post_init__(self):
+ print("A")
+
+@dataclass
+class B(A):
+ b: int
+
+ def __post_init__(self):
+ print("B")
+
+>>> a = B(1,2)
+
+>>> B
+```
+
+在上面的例子中,只有 `B` 的 `__post_init__` 被调用,那么我们如何调用 `A` 的 `__post_init__` 呢?
+
+因为它是父类的函数,所以可以用 `super` 来调用它。
+
+```
+@dataclass
+class B(A):
+ b: int
+
+ def __post_init__(self):
+ super().__post_init__() # 调用 A 的 post init
+ print("B")
+
+>>> a = B(1,2)
+
+>>> A
+ B
+```
+
+### 结论
+
+因此,以上是 dataclasses 使 Python 开发人员变得更轻松的几种方法。
+
+我试着彻底覆盖大部分的用例,但是,没有人是完美的。如果你发现了错误,或者想让我注意相关的用例,请联系我。
+
+我将在另一篇文章中介绍 [dataclasses.field][10] 和 `unsafe_hash`。
+
+在 [Github][11] 和 [Twitter][12] 关注我。
+
+更新:`dataclasses.field` 的文章可以在[这里][13]找到。
+
+
+--------------------------------------------------------------------------------
+
+via: https://medium.com/mindorks/understanding-python-dataclasses-part-1-c3ccd4355c34
+
+作者:[Shikhar Chauhan][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://medium.com/@xsschauhan?source=post_header_lockup
+[1]:https://medium.com/@xsschauhan/understanding-python-dataclasses-part-2-660ecc11c9b8
+[2]:https://docs.python.org/3.7/library/dataclasses.html#dataclasses.dataclass
+[3]:https://stackoverflow.com/q/32557920/4333721
+[4]:https://docs.python.org/3/reference/datamodel.html#object.__lt__
+[5]:https://docs.python.org/3.7/library/functions.html#sorted
+[6]:https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass
+[7]:http://twitter.com/dataclass
+[8]:http://twitter.com/dataclass
+[9]:https://docs.python.org/3/library/dataclasses.html#post-init-processing
+[10]:https://docs.python.org/3/library/dataclasses.html#dataclasses.field
+[11]:http://github.com/xssChauhan/
+[12]:https://twitter.com/xssChauhan
+[13]:https://medium.com/@xsschauhan/understanding-python-dataclasses-part-2-660ecc11c9b8
diff --git a/translated/tech/20180705 Testing Node.js in 2018.md b/translated/tech/20180705 Testing Node.js in 2018.md
new file mode 100644
index 0000000000..4fd74b74cb
--- /dev/null
+++ b/translated/tech/20180705 Testing Node.js in 2018.md
@@ -0,0 +1,320 @@
+测试 Node.js,2018
+============================================================
+
+
+
+超过 3 亿用户正在使用 [Stream][4]。这些用户全都依赖我们的框架,而我们十分擅长测试要放到生产环境中的任何东西。我们大部分的代码库是用 Go 语言编写的,剩下的部分则是用 Python 编写。
+
+我们最新的展示应用,[Winds 2.0][5],是用 Node.js 构建的,很快我们就了解到测试 Go 和 Python 的常规方法并不适合它。而且,创造一个好的测试套件需要用 Node.js 做很多额外的工作,因为我们正在使用的框架没有提供任何内建的测试功能。
+
+不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示在使用 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
+
+### 为什么测试如此重要
+
+我们都向生产环境中推送过糟糕的提交,并且经历过结果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够自由的重构代码,重构之后的代码仍然正常运行会让你信心倍增。这在你刚刚开始编写代码的时候尤为重要。
+
+如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(ouch)。
+
+编写测试同时促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
+
+最后,没有测试,你的基本代码还不如一堆纸片。基本不能保证你的代码是稳定的。
+
+### 困难的部分
+
+在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统总是在变大。例如,如果你用的是 macOS,运行 "brew upgrade"(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
+
+以下是一些要记在心上的痛点:
+
+1. 在 Node.js 中进行测试是固执又不是固执的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
+
+2. 有一堆框架能够在你的应用里使用。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你们最终会想要从零开始编写自己的测试执行平台。
+
+3. 几乎能保证你 _需要_ 编写自己的测试执行平台(马上就会讲到这一节)。
+
+以上列出的情况不是理想的,而且这是 Node.js 社区应该尽管处理的事情。如果其他语言解决了这些问题,我认为也是作为广泛使用的语言, Node.js 解决这些问题的时候。
+
+### 编写你自己的测试执行平台
+
+所以...你可能会好奇测试执行平台 _是_ 什么,它并不复杂。测试执行平台在测试套件中是最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?没那么快呢。
+
+我们所学到的是,尽管现在就有足够数量的测试框架了,没有一个关于 Node.js 的测试框架提供标准的方式能构建你的测试执行平台。很难受,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
+
+* 能够加载不同的配置(比如,本地的,测试的,开发的),能够确保你 _永远不会_ 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
+
+* 支持数据库,生成种子数据库,产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
+
+* 能够加载配置(带有用于开发环境的种子数据的文件)。
+
+做 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
+
+为了进行测试,我们注册了自己的 Babel 模块引导器。这为我们提供了更细的粒度,更强大的控制,在 Babel 覆盖掉 Node.js 模块加载过程前,对导入的模块进行控制,让我们有机会在所有测试运行前对模块进行模拟。
+
+此外,我们还使用了 Mocha 的测试执行平台特性,预先把特定的请求赋给 HTTP 管理器。我们这么做是因为常规的初始化代码在测试中不会运行(服务器交互是用 Chai HTTP 插件模拟的),还要做一些安全性检查来确保我们不会连接到生产环境数据库。
+
+尽管这不是测试执行平台的一部分,有一个固定加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
+
+### Winds 中用到的工具
+
+尽管过程很冗长,我们还是能够合理使用框架和工具,使得针对后台 API 进行的适当测试变成现实。这里是我们选择使用的工具:
+
+### Mocha ☕
+
+[Mocha][6], 被称为 “在 Node.js 上运行的特性丰富的测试框架”,是我们完成任务的首选。拥有超过 15K 的 stars,很多支持者和贡献者,我们指定这是正确的框架。
+
+### Chai 🥃
+
+然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— [Chai][7]。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 _期望_ 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
+
+```
+describe('retrieve user', () => {
+ let user;
+
+ before(async () => {
+ await loadFixture('user');
+ user = await User.findOne({email: authUser.email});
+ expect(user).to.not.be.null;
+ });
+
+ after(async () => {
+ await User.remove().exec();
+ });
+
+ describe('valid request', () => {
+ it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
+ const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
+
+ expect(response).to.have.status(200);
+ expect(response.body._id).to.equal(user._id.toString());
+ });
+
+ it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
+ const anotherUser = await User.findOne({email: 'another_user@email.com'});
+
+ const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
+
+ expect(response).to.have.status(200);
+ expect(response.body._id).to.equal(anotherUser._id.toString());
+ expect(response.body).to.not.have.an('email');
+ });
+
+ });
+
+ describe('invalid requests', () => {
+
+ it('should return 404 if requested user does not exist', async () => {
+ const nonExistingId = '5b10e1c601e9b8702ccfb974';
+ expect(await User.findOne({_id: nonExistingId})).to.be.null;
+
+ const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
+ expect(response).to.have.status(404);
+ });
+ });
+
+});
+```
+
+### Sinon 🧙
+
+拥有与任何测试框架相适应的能力,[Sinon][8] 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成简单的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
+
+### Nock 🔮
+
+For all external HTTP requests, we use [nock][9], a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API][10]). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization][11] engine for Stream:
+对于所有外部的 HTTP 请求,我们使用稳定的 HTTP 模拟库 [nock][9],在你要和第三方 API 交互时非常易用(比如说 [Stream's REST API][10])。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 [personalization][11]:
+
+```
+nock(config.stream.baseUrl)
+ .get(/winds_article_recommendations/)
+ .reply(200, { results: [{foreign_id:`article:${article.id}`}] });
+```
+
+### Mock-require 🎩
+
+[mock-require][12] 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们还是它的粉丝。
+
+### Istanbul 🔭
+
+[Istanbul][13] 是 JavaScript 代码覆盖工具,在运行测试的时候,通过模块钩子自动添加覆盖率,可以计算语句,行数,函数和分支覆盖率。尽管我们有相似功能的 CodeCov(见下一节),进行本地测试时,这仍然是一个很棒的工具。
+
+### 最终结果 — 运行测试
+
+ _有了这些库,还有之前提过的测试执行平台,现在让我们看看什么是完整的测试(你可以在 [_这里_][14] 看看我们完整的测试套件):_
+
+```
+import nock from 'nock';
+import { expect, request } from 'chai';
+
+import api from '../../src/server';
+import Article from '../../src/models/article';
+import config from '../../src/config';
+import { dropDBs, loadFixture, withLogin } from '../utils.js';
+
+describe('Article controller', () => {
+ let article;
+
+ before(async () => {
+ await dropDBs();
+ await loadFixture('initial-data', 'articles');
+ article = await Article.findOne({});
+ expect(article).to.not.be.null;
+ expect(article.rss).to.not.be.null;
+ });
+
+ describe('get', () => {
+ it('should return the right article via /articles/:articleId', async () => {
+ let response = await withLogin(request(api).get(`/articles/${article.id}`));
+ expect(response).to.have.status(200);
+ });
+ });
+
+ describe('get parsed article', () => {
+ it('should return the parsed version of the article', async () => {
+ const response = await withLogin(
+ request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
+ );
+ expect(response).to.have.status(200);
+ });
+ });
+
+ describe('list', () => {
+ it('should return the list of articles', async () => {
+ let response = await withLogin(request(api).get('/articles'));
+ expect(response).to.have.status(200);
+ });
+ });
+
+ describe('list from personalization', () => {
+ after(function () {
+ nock.cleanAll();
+ });
+
+ it('should return the list of articles', async () => {
+ nock(config.stream.baseUrl)
+ .get(/winds_article_recommendations/)
+ .reply(200, { results: [{foreign_id:`article:${article.id}`}] });
+
+ const response = await withLogin(
+ request(api).get('/articles').query({
+ type: 'recommended',
+ })
+ );
+ expect(response).to.have.status(200);
+ expect(response.body.length).to.be.at.least(1);
+ expect(response.body[0].url).to.eq(article.url);
+ });
+ });
+});
+```
+
+### 持续集成
+
+有很多可用的持续集成服务,但我们钟爱 [Travis CI][15],因为他们和我们一样喜爱开源环境。考虑到 Winds 是开源的,它再合适不过了。
+
+我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 [npm][17] 命令进行测试。测试覆盖率反馈给 Github,在 Github 上我们通过明了的图片能够看出我们最新的代码或者 PR 是不是通过了测试。Github 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 Github 上查看 PR (经过测试)的简单截图:
+
+
+
+除了 Travis CI,我们还用到了叫做 [CodeCov][18] 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们 查看代码覆盖率,文件变动,行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。
+
+### 我们学到了什么
+
+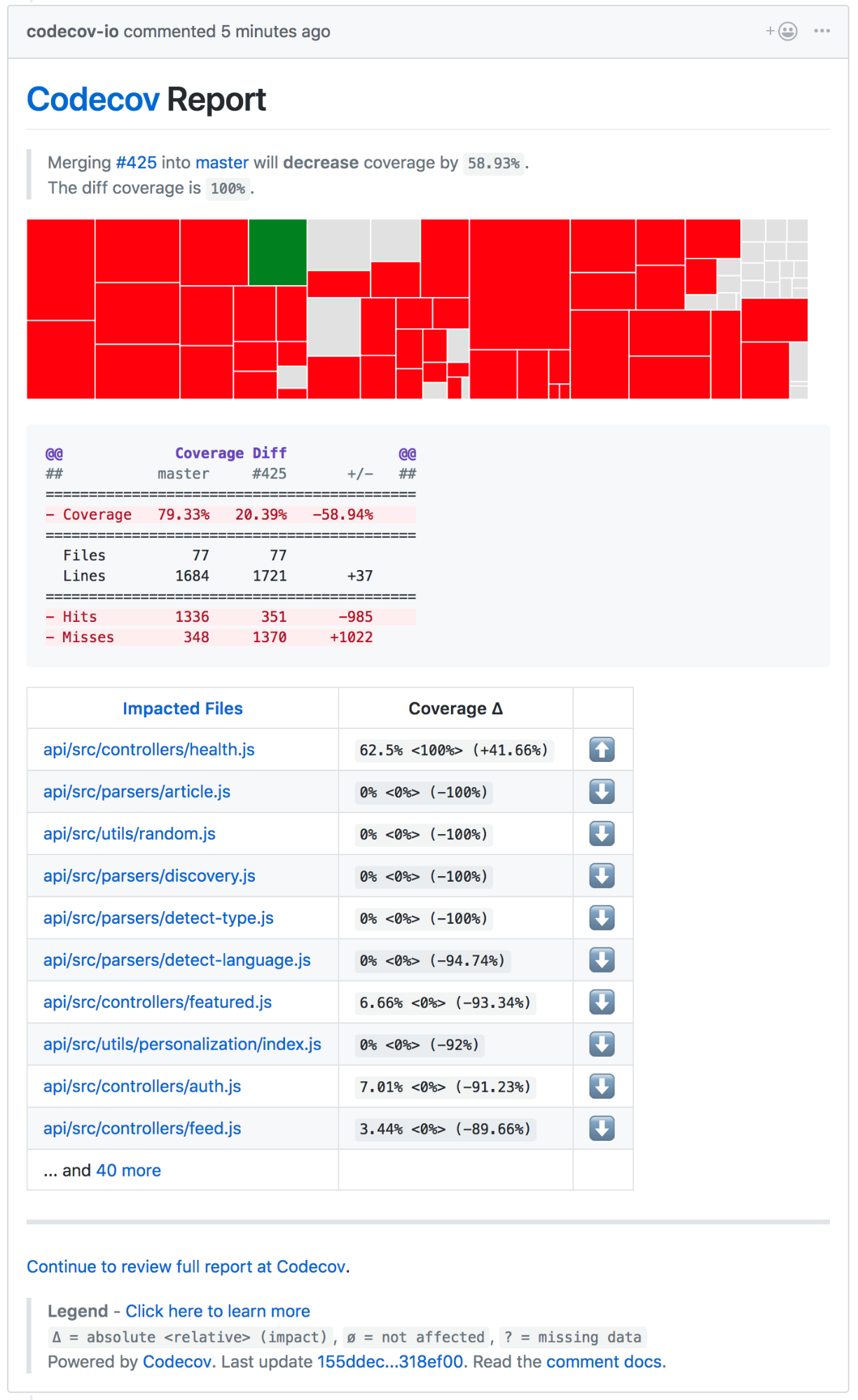
+
+在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
+
+最终我们学到的是,在 Node.js 中进行测试不是听上去那么简单。还好,随着 Node.js 持续完善,社区将会聚集力量,构建一个坚固稳健的库,可以用“正确”的方式处理所有和测试相关的东西。
+
+直到那时,我们还会接着用自己的测试套件,也就是开源的 [Winds Github repository][20]。
+
+### 局限
+
+#### 创建配置没有简单的方法
+
+框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
+
+以下命令会把整个数据库导出到 db.json 文件中:
+./manage.py dumpdata > db.json
+
+以下命令仅导出 django 中 admin.logentry 表里的内容:
+./manage.py dumpdata admin.logentry > logentry.json
+
+以下命令会导出 auth.user 表中的内容:
+./manage.py dumpdata auth.user > user.json
+
+Node.js 里面没有简单的方式来创建配置。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):
+
+
+
+#### 使用 Babel,模拟模块和 Mocha 测试执行平台时,模块加载不直观
+
+为了支持多种 node 版本,能够获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
+
+Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用模拟访问来介入模块的加载,所以我们干的是经历奇怪的模块加载边角情况,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
+
+#### 在使用 ES6 模块时声明的函数,模块内部的函数,都无法模拟
+
+当一个模块导出多个函数,其中一个函数调用了其他的函数,就不可能模拟使用在模块内部的函数。原因在于当你引用一个 ES6 模块时,你得到的引用集合和模块内部的是不同的。任何重新绑定引用,将其指向新值的尝试都无法真正影响模块内部的函数,内部函数仍然使用的是原始的函数。
+
+### 最后的思考
+
+测试 Node.js 应用是复杂的过程,因为它的生态系统总在发展。掌握最新和最好的工具很重要,这样你就不会掉队了。
+
+如今有很多路径获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 [JavaScript Weekly][21] 和 [Node Weekly][22] 是良好的开始。还有,关注一些子模块如 [/r/node][23] 也不错。如果你喜欢了解最新的趋势,[State of JS][24] 在帮助开发者可视化测试世界的趋势方便就做的很好。
+
+最后,这里是一些我喜欢的博客,我经常在这上面发文章:
+
+* [Hacker Noon][1]
+
+* [Free Code Camp][2]
+
+* [Bits and Pieces][3]
+
+觉得我遗漏了某些重要的东西?在评论区或者 Twitter [@NickParsons][25] 让我知道。
+
+还有,如果你想要了解 Stream,我们的网站上有很棒的 5 分钟教程。点 [这里][26] 进行查看。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Nick Parsons
+
+Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
+
+--------------------------------------------------------------------------------
+
+via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
+
+作者:[Nick Parsons][a]
+译者:[BriFuture](https://github.com/BriFuture)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://hackernoon.com/@nparsons08?source=post_header_lockup
+[1]:https://hackernoon.com/
+[2]:https://medium.freecodecamp.org/
+[3]:https://blog.bitsrc.io/
+[4]:https://getstream.io/
+[5]:https://getstream.io/winds
+[6]:https://github.com/mochajs/mocha
+[7]:http://www.chaijs.com/
+[8]:http://sinonjs.org/
+[9]:https://github.com/node-nock/nock
+[10]:https://getstream.io/docs_rest/
+[11]:https://getstream.io/personalization
+[12]:https://github.com/boblauer/mock-require
+[13]:https://github.com/gotwarlost/istanbul
+[14]:https://github.com/GetStream/Winds/tree/master/api/test
+[15]:https://travis-ci.org/
+[16]:https://github.com/GetStream/Winds/blob/master/.travis.yml
+[17]:https://www.npmjs.com/
+[18]:https://codecov.io/#features
+[19]:https://github.com/gotwarlost/istanbul
+[20]:https://github.com/GetStream/Winds/tree/master/api/test
+[21]:https://javascriptweekly.com/
+[22]:https://nodeweekly.com/
+[23]:https://www.reddit.com/r/node/
+[24]:https://stateofjs.com/2017/testing/results/
+[25]:https://twitter.com/@nickparsons
+[26]:https://getstream.io/try-the-api
diff --git a/translated/tech/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md b/translated/tech/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
new file mode 100644
index 0000000000..c069ca1785
--- /dev/null
+++ b/translated/tech/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
@@ -0,0 +1,214 @@
+Javascript 框架对比及案例(React、Vue 及 Hyperapp)
+============================================================
+在[我的上一片文章中][5],我试图解释为什么我认为[Hyperapp][6]是一个可用的 [React][7] 或 [Vue][8] 的替代品,我发现当我开始用它时,会容易的找到这个原因。许多人批评这篇文章,认为它自以为是,并没有给其他框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示他们的能力。
+
+#### 臭名昭著计时器例子
+
+计时器可能是响应式编程中最常用最容易理解的例子之一:
+
+* 你需要一个变量 `count` 保持对计数器的追踪。
+
+* 你需要两个方法来增加或减少 `count` 变量的值。
+
+* 你需要一种方法来渲染 `count` 变量,并将其呈现给用户。
+
+* 你需要两个挂载到两个方法上的按钮,以便在用户和它们产生交互时变更 `count` 变量。
+
+下述代码是上述所有三个框架的实现:
+
+
+
+使用 React、Vue 和 Hyperapp 实现的计数器
+
+
+这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个的时候,因此,我们来一步一步解构这些代码:
+
+* 这三个框架的顶部都有一些 `import` 语句
+
+* React 更推崇面向对象的范式,就是创建一个 `Counter` 组件的 `class`,Vue 遵循类似的范式,并通过创建一个新的 `Vue` 类的实例并将信息传递给它来实现。 最后,Hyperapp 坚持函数范式,同时完全分离 `view`、`state`和`action` 。
+
+* 就 `count` 变量而言, React 在组件的构造函数内对其进行实例化,而 Vue 和 Hyperapp 则分别是在它们的 `data` 和 `state` 中设置这些属性。
+
+* 继续看,你可能注意到 React 和 Vue 有相同的方法来于 `count` 变量进行交互。 React 使用继承自 `React.Component` 的 `setState` 方法来修改它的状态,而 Vue 直接修改 `this.count`。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,并且,据我所知,这是唯一一个更推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用 `this`。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。
+
+* 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数 `h` 作为参数传递给渲染器,事实上 Hyperapp 使用 `onclick` 替代 `onClick` 以及基于每个框架中实现状态的方式引用 `count` 变量的方式。
+
+* 最后,所有的三个框架都被挂载到了 `#app` 元素上。每个框架都有稍微不同的语法,Vue 则使用了最直接的语法,通过使用元素选择器而不是使用元素来提供最大的通用性。
+
+#### 计数器案例对比意见
+
+
+同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且他是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的安装是一个很好的补充。React 的代码看起来最多,但是并不意味着代码不好理解。
+
+* * *
+
+#### 使用异步代码
+
+偶尔你可能要不得不处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API]以及一些假数据来渲染一个文章的列表。必须做的事情如下:
+
+* 在状态里保存一个 `posts` 的数组
+
+* 使用一个方法和正确的 URL 来调用 `fetch()` ,等待返回数据,转化为 JSON,最终使用接收到的数据更新 `posts` 变量。
+
+* 渲染一个按钮,这个按钮将调用抓取文章的方法。
+
+* 渲染有主键的 `posts` 列表。
+
+
+
+从一个 RESTFul API 抓取数据
+
+让我们分解上面的代码,并比较三个框架:
+
+* 与上面的技术里例子类似,这三个框架之间的存储状态、渲染试图和挂载非常相似。这些差异与上面的讨论相同。
+
+* 在三个框架中使用 `fetch()` 抓取数据都非常简单并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其他两种框架有些不同。当数据被接收到并转换为JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。
+
+* 就代码长度而言, Hyperapp 依然需要最少的代码行数来实现相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
+
+#### 异步代码对比意见
+
+无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的路径。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
+
+* * *
+
+#### To-Do List 组件案例
+
+在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do List。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何帮助创建更小的可复用的块来协助构建应用程序。
+
+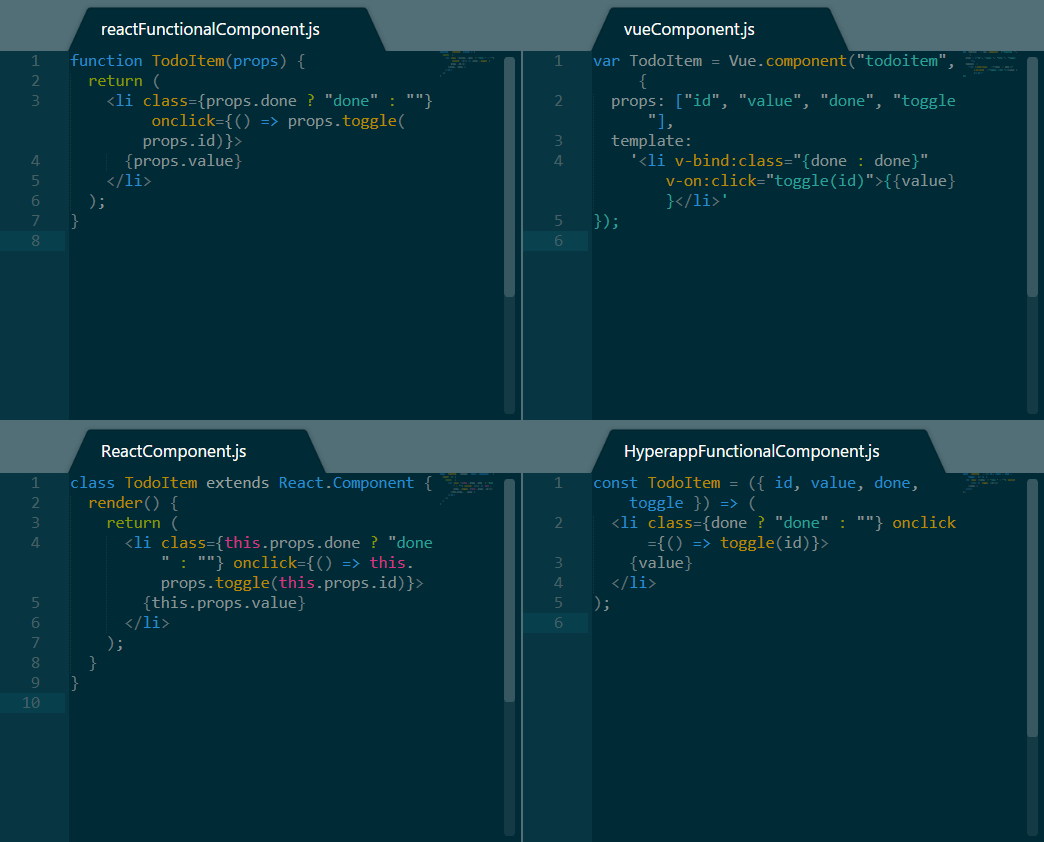
+演示 TodoItem 实现
+
+上面的图片展示了每一个框架一个例子,并为 React 提供了一个额外的例子。接下来是我们从它们四个中看到的:
+
+* React 在编程范式上最为灵活。它支持函数组件以及类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
+
+* Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有实验的空间。
+
+* 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个很有经验的人,也不能马上理解其含义。
+
+* 在长度方面,所有的案例代码长度非常相似,在 React 的一些方法中稍微冗长一些。
+
+#### To-Do List 项目对比意见
+
+Vue 需要花费一些时间来熟悉,因为它的模板和其他两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
+
+* * *
+
+#### 生命周期方法比较
+
+
+另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理这些时间。下面是我根据各框架的 API 参考手册创建的表格:
+
+
+Lifecycle method comparison
+
+* Vue 提供了最多的生命周期钩子,提供了处理生命周期时间之前或之后发生任何时间的机会。这能有效帮助管理复杂的组件。
+
+* React 和 Hyperapp 的生命周期钩子非常类似,React 将 `unmount` 和 `destory` 绑定在了一切,而 Hyperapp 则将 `create` 和 `mount` 绑定在了一起。两者在处理生命周期事件方面都提供了相当数量的控制。
+
+* Vue 根本没有处理 `unmount` (据我所理解),而是依赖于 `destroy` 事件在组件稍后的生命周期进行处理。 React 不处理 `destory` 事件,而是选择只处理 `unmount` 事件。最终,HyperApp 不处理 `create` 事件,取而代之的是只依赖 `mount` 事件。
+
+#### 生命周期对比意见
+
+总的来说,每个框架都提供了生命周期组件,它们帮助你处理组件生命周期中的许多事情。这三个框架都为它们的生命周期提供了钩子,其之间的细微差别,可能源自于实现和方案上的根本差异。通过提供更细粒度的时间处理,Vue 可以更进一步的允许你在开始或结束之后处理生命周期事件。
+
+* * *
+
+#### 性能比较
+
+除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。[js-framework-benchmark][10]是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
+
+
+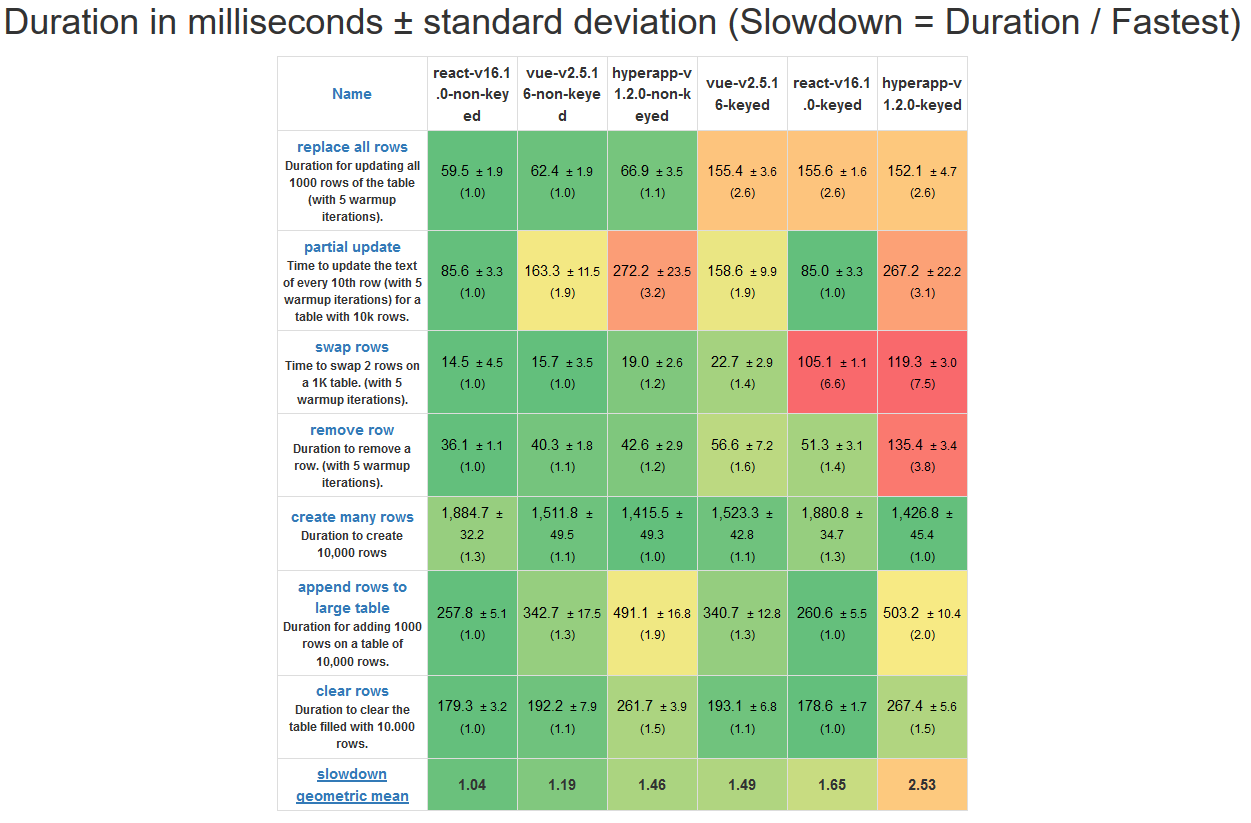
+测评操作表
+
+* 与三个框架的有主键操作相比,无主键操作更快。
+
+* 无主键的 React 在所有六种对比中拥有最强的性能,他在所有测试上都有令人深刻的表现。
+
+* 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能差。
+
+* Vue 和 Hyperapp 在进行局部更新性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
+
+
+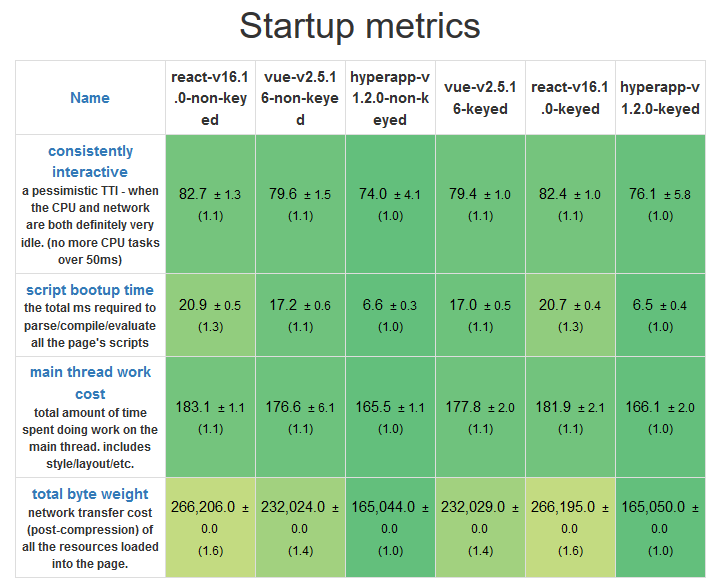
+
+启动测试
+
+* Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小尺度的差异。
+
+* Hyperapp 具有最快的启动时间,这得益于他极小的大小和极简的API
+
+* Vue 在启动上比 React 好一些,但是非常小。
+
+
+
+内存分配测试
+
+* Hyperapp 是三者中对资源依赖最小的一个,与其他两者相比,任何一个操作都需要更少的内存。
+
+* 资源消耗不是跟高,三者应该在现代硬件上进行类似的操作。
+
+#### 性能对比意见
+
+如果性能是一个问题,你应该考虑你正在使用什么样的应用程序以及你的需求是什么。看起来 Vue 和 React 用于更复杂的应用程序更好,而 Hyperapp 更适合于更小的应用程序、更少的数据处理和需要快速启动的应用程序,以及需要在低端硬件上工作的应用程序。
+
+但是,要记住,这些测试远不能代表一般用例,所以在现实场景中可能会看到不同的结果。
+
+* * *
+
+#### 额外备注
+
+Comparing React, Vue and Hyperapp might feel like comparing apples and oranges in many ways. There are some additional considerations concerning these frameworks that could very well help you decide on one over the other two:
+
+比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其他的考虑,它们可以帮助你决定使用另一个框架。
+
+* React 通过引入片段,避免了相邻的JSX元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向DOM添加额外的节点。
+
+* Read还为你提供更高级别的组件,而VUE为你提供重用组件功能的MIXIN。
+
+* Vue 允许使用[模板][4]来分离结构和功能,从而更好的分离关注点。
+
+* 与其他两个相比,Hyperapp 感觉像是一个较低级别的API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
+
+* * *
+
+#### 结论
+
+我认为如果你已经阅读了这么多,你已经知道哪种工具更适合你的需求。毕竟,这不是讨论哪一个更好,而是讨论哪一个更适合每种情况。总而言之:
+
+
+* React 是一个非常强大的工具,他的周围有大量的开发者,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
+
+* 如果你过去曾使用过另外一个 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的 ,那么它可能是一个可行的值得学习的选择。
+
+* 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你编写的许多代码都和其他两个框架兼容,或者是稍做更改,你可以在对它们中另外一个有信心时切换框架。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Web developer who loves to code, creator of 30 seconds of code (https://30secondsofcode.org/) and the mini.css framework (http://minicss.org).
+
+--------------------------------------------------------------------------------
+
+via: https://hackernoon.com/javascript-framework-comparison-with-examples-react-vue-hyperapp-97f064fb468d
+
+作者:[Angelos Chalaris ][a]
+译者:[Bestony](https://github.com/bestony)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://hackernoon.com/@chalarangelo?source=post_header_lockup
+[1]:https://reactjs.org/docs/fragments.html
+[2]:https://reactjs.org/docs/higher-order-components.html
+[3]:https://vuejs.org/v2/guide/mixins.html
+[4]:https://vuejs.org/v2/guide/syntax.html
+[5]:https://hackernoon.com/i-abandonded-react-in-favor-of-hyperapp-heres-why-df65638f8a79
+[6]:https://hyperapp.js.org/
+[7]:https://reactjs.org/
+[8]:https://vuejs.org/
+[9]:https://jsonplaceholder.typicode.com/
+[10]:https://github.com/krausest/js-framework-benchmark
diff --git a/translated/tech/20180712 A sysadmin-s guide to SELinux- 42 answers to the big questions.md b/translated/tech/20180712 A sysadmin-s guide to SELinux- 42 answers to the big questions.md
new file mode 100644
index 0000000000..23f878f804
--- /dev/null
+++ b/translated/tech/20180712 A sysadmin-s guide to SELinux- 42 answers to the big questions.md
@@ -0,0 +1,273 @@
+系统管理员的 SELinux 指南:这个大问题的 42 个答案
+======
+
+
+
+> "一个重要而普遍的事实是,事情并不总是你看上去的那样 …"
+> ―Douglas Adams,银河系漫游指南
+
+安全、坚固、遵从性、策略 —— 系统管理员启示录的四骑士。除了我们的日常任务之外 —— 监视、备份、实施、调优、更新等等 —— 我们还负责我们的系统安全。甚至是那些第三方提供给我们的禁用了安全增强的系统。这看起来像《碟中碟》中 [Ethan Hunt][1] 的工作一样。
+
+面对这种窘境,一些系统管理员决定去[服用蓝色小药丸][2],因为他们认为他们永远也不会知道如生命、宇宙、以及其它一些大问题的答案。而我们都知道,它的答案就是这 **[42][3]** 个。
+
+按《银河系漫游指南》的精神,这里是关于在你的系统上管理和使用 [SELinux][4] 这个大问题的 42 个答案。
+
+ 1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录、以及系统对象都有一个标签。策略规则负责控制标签化进程和标签化对象之间的访问。由内核强制执行这些规则。
+
+
+ 2. 两个最重要的概念是:标签化(文件、进程、端口等等)和强制类型(它将基于类型对每个进程进行隔离)。
+
+
+ 3. 正确的标签格式是 `user:role:type:level`(可选)。
+
+
+ 4. 多级别安全(MLS)的目的是基于它们所使用数据的安全级别,对进程(域)强制实施控制。比如,一个秘密级别的进程是不能读取极机密级别的数据。
+
+
+ 5. 多类别安全(MCS)从每个其它类(如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)中强制保护类似的进程。
+
+
+ 6. 在引导时内核参数可以改变 SELinux 模式:
+ * `autorelabel=1` → 强制给系统标签化
+ * `selinux=0` → 内核不加载 SELinux 基础设施的任何部分
+ * `enforcing=0` → 引导为 permissive 模式
+
+
+ 7. 如果给整个系统标签化:
+`# touch /.autorelabel #reboot`
+如果系统标签中有大量的错误,为了能够让 autorelabel 成功,你可以用 permissive 模式引导系统。
+
+
+ 8. 检查 SELinux 是否启用:`# getenforce`
+
+
+ 9. 临时启用/禁用 SELinux:`# setenforce [1|0]`
+
+
+ 10. SELinux 状态工具:`# sestatus`
+
+
+ 11. 配置文件:`/etc/selinux/config`
+
+
+ 12. SELinux 是如何工作的?这是一个为 Apache Web Server 标签化的示例:
+ * 二进制文件:`/usr/sbin/httpd`→`httpd_exec_t`
+ * 配置文件目录:`/etc/httpd`→`httpd_config_t`
+ * 日志文件目录:`/var/log/httpd` → `httpd_log_t`
+ * 内容目录:`/var/www/html` → `httpd_sys_content_t`
+ * 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
+ * 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
+ * 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`
+
+
+
+在 `httpd_t` 环境中运行的一个进程可以与具有 `httpd_something_t` 标签的对象交互。
+
+ 13. 许多命令都可以接收一个 `-Z` 参数去查看、创建、和修改环境:
+ * `ls -Z`
+ * `id -Z`
+ * `ps -Z`
+ * `netstat -Z`
+ * `cp -Z`
+ * `mkdir -Z`
+
+
+
+当文件基于它们的父级目录的环境(有一些例外)创建后,它的环境就已经被设置。RPM 包可以在安装时设置环境。
+
+ 14. 这里有导致 SELinux 出错的四个关键原因,它们将在下面的 15 - 21 号问题中展开描述:
+ * 标签化问题
+ * SELinux 需要知道一些东西
+ * 在一个 SELinux 策略/app 中有 bug
+ * 你的信息可能被损坏
+
+
+ 15. 标签化问题:如果在 `/srv/myweb` 中你的文件没有正确的标签,访问可能会被拒绝。这里有一些修复这类问题的方法:
+ * 如果你知道标签:
+`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
+ * 如果你知道使用等价标签的文件:
+`# semanage fcontext -a -e /srv/myweb /var/www`
+ * 恢复环境(对于以上两种情况):
+`# restorecon -vR /srv/myweb`
+
+
+ 16. 标签化问题:如果你是移动了一个文件,而不是去复制它,那么这个文件将保持原始的环境。修复这类问题:
+ * 用标签改变环境的命令:
+ `# chcon -t httpd_system_content_t /var/www/html/index.html`
+
+ * 用引用标签改变环境的命令:
+ `# chcon --reference /var/www/html/ /var/www/html/index.html`
+
+ * 恢复环境(对于以上两种情况):
+
+ `# restorecon -vR /var/www/html/`
+
+
+ 17. 如果 SELinux 需要知道 HTTPD 是在 8585 端口上监听,告诉 SELinux:
+`# semanage port -a -t http_port_t -p tcp 8585`
+
+
+ 18. SELinux 需要知道是否允许在运行时无需重写 SELinux 策略而改变 SELinux 策略部分的布尔值。例如,如果希望 httpd 去发送邮件,输入:`# setsebool -P httpd_can_sendmail 1`
+
+
+ 19. SELinux 需要知道 SELinux 设置的 off/on 的布尔值:
+ * 查看所有的布尔值:`# getsebool -a`
+ * 查看每个布尔值的描述:`# semanage boolean -l`
+ * 设置布尔值:`# setsebool [_boolean_] [1|0]`
+ * 将它配置为永久值,添加 `-P` 标志。例如:
+`# setsebool httpd_enable_ftp_server 1 -P`
+
+
+ 20. SELinux 策略/apps 可能有 bug,包括:
+ * 与众不同的代码路径
+ * 配置
+ * 重定向 `stdout`
+ * 文件描述符漏洞
+ * 可运行内存
+ * 错误构建的库打开了一个 ticket(不要提交 Bugzilla 报告;这里没有使用 Bugzilla 的 SLAs)
+
+
+ 21. 如果你定义了域,你的信息可能被损坏:
+ * 加载内核模块
+ * 关闭 SELinux 的强制模式
+ * 写入 `etc_t/shadow_t`
+ * 修改 iptables 规则
+
+
+ 22. 开发策略模块的 SELinux 工具:
+`# yum -y install setroubleshoot setroubleshoot-server`
+安装完成之后重引导机器或重启 `auditd` 服务。
+
+
+ 23. 使用 `journalctl` 去列出所有与 `setroubleshoot` 相关的日志:
+`# journalctl -t setroubleshoot --since=14:20`
+
+
+ 24. 使用 `journalctl` 去列出所有与特定 SELinux 标签相关的日志。例如:
+`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
+
+
+ 25. 当 SELinux 发生错误以及建议一些可能的解决方案时,使用 `setroubleshoot` 日志。例如:从 `journalctl` 中:
+[code] Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
+
+
+
+ # sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
+
+ SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
+
+
+
+ ***** Plugin restorecon (99.5 confidence) suggests ************************
+
+
+
+ If you want to fix the label,
+
+ /var/www/html/index.html default label should be httpd_syscontent_t.
+
+ Then you can restorecon.
+
+ Do
+
+ # /sbin/restorecon -v /var/www/html/index.html
+
+
+
+
+ 26. 日志:SELinux 记录的信息全部在这些地方:
+ * `/var/log/messages`
+ * `/var/log/audit/audit.log`
+ * `/var/lib/setroubleshoot/setroubleshoot_database.xml`
+
+
+ 27. 日志:在审计日志中查找 SELinux 错误:
+`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
+
+
+ 28. 为特定的服务去搜索 SELinux 的访问向量缓存(AVC)信息:
+`# ausearch -m avc -c httpd`
+
+
+ 29. `audit2allow` 实用工具从拒绝的操作的日志中采集信息,然后生成 SELinux policy-allow 规则。例如:
+ * 产生一个人类可读的关于为什么拒绝访问的描述:`# audit2allow -w -a`
+ * 查看已允许的拒绝访问的强制类型规则:`# audit2allow -a`
+ * 创建一个自定义模块:`# audit2allow -a -M mypolicy`
+`-M` 选项使用一个指定的名字去创建一个类型强制文件(.te)并编译这个规则到一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
+ * 安装自定义模块:`# semodule -i mypolicy.pp`
+
+
+ 30. 配置单个进程(域)运行在 permissive 模式:`# semanage permissive -a httpd_t`
+
+
+ 31. 如果不再希望一个域在 permissive 模式中:`# semanage permissive -d httpd_t`
+
+
+ 32. 禁用所有的 permissive 域:`# semodule -d permissivedomains`
+
+
+ 33. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`
+在 `/etc/selinux/config` 中:
+`SELINUX=permissive`
+`SELINUXTYPE=mls`
+确保 SELinux 运行在 permissive 模式:`# setenforce 0`
+使用 `fixfiles` 脚本去确保那个文件在下次重引导后重打标签:
+`# fixfiles -F onboot # reboot`
+
+
+ 34. 使用一个特定的 MLS 范围创建用户:`# useradd -Z staff_u john`
+使用 `useradd` 命令,映射新用户到一个已存在的 SELinux 用户(上面例子中是 `staff_u`)。
+
+
+ 35. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
+
+
+ 36. 为用户定义一个指定的范围:`# semanage login --modify --range s2:c100 john`
+
+
+ 37. 调整用户 home 目录上的标签(如果需要的话):`# chcon -R -l s2:c100 /home/john`
+
+
+ 38. 列出当前分类:`# chcat -L`
+
+
+ 39. 修改分类或者开始去创建你自己的分类、修改文件:
+`/etc/selinux/__/setrans.conf`
+
+
+ 40. 在指定的文件、角色、和用户环境中运行一个命令或脚本:
+`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
+ * `-t` 是文件环境
+ * `-r` 是角色环境
+ * `-u` 是用户环境
+
+
+ 41. 在容器中禁用 SELinux:
+ * 使用 Podman:`# podman run --security-opt label=disable` …
+ * 使用 Docker:`# docker run --security-opt label=disable` …
+
+
+ 42. 如果需要给容器提供完全访问系统的权限:
+ * 使用 Podman:`# podman run --privileged` …
+ * 使用 Docker:`# docker run --privileged` …
+
+
+
+就这些了,你已经知道了答案。因此请相信我:**不用恐慌,去打开 SELinux 吧**。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/sysadmin-guide-selinux
+
+作者:[Alex Callejas][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/darkaxl
+[1]:https://en.wikipedia.org/wiki/Ethan_Hunt
+[2]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
+[3]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
+[4]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
\ No newline at end of file
diff --git a/translated/tech/20180712 Slices from the ground up.md b/translated/tech/20180712 Slices from the ground up.md
new file mode 100644
index 0000000000..1e76eb515b
--- /dev/null
+++ b/translated/tech/20180712 Slices from the ground up.md
@@ -0,0 +1,260 @@
+Slices from the ground up
+============================================================
+
+这篇文章最初的灵感来源于我与一个使用切片作栈的同事的一次聊天。那次聊天,话题最后拓展到了 Go 语言中的切片是如何工作的。我认为把这些知识记录下来会帮到别人。
+
+### 数组
+
+任何关于 Go 语言的切片的讨论都要从另一个数据结构,也就是 Go 语言的数组开始。Go 语言的数组有两个特性:
+
+1. 数组的长度是固定的;`[5]int` 是由 5 个 `unt` 构成的数组,和`[3]int` 不同。
+
+2. 数组是值类型。考虑如下示例:
+ ```
+ package main
+
+ import "fmt"
+
+ func main() {
+ var a [5]int
+ b := a
+ b[2] = 7
+ fmt.Println(a, b) // prints [0 0 0 0 0] [0 0 7 0 0]
+ }
+ ```
+
+ 语句 `b := a` 定义了一个新的变量 `b`,类型是 `[5]int`,然后把 `a` 中的内容_复制_到 `b` 中。改变 `b` 中的值对 `a` 中的内容没有影响,因为 `a` 和 `b` 是相互独立的值。 [1][1]
+
+### 切片
+
+Go 语言的切片和数组的主要有如下两个区别:
+
+1. 切片没有一个固定的长度。切片的长度不是它类型定义的一部分,而是由切片内部自己维护的。我们可以使用内置的 `len` 函数知道他的长度。
+
+2. 将一个切片赋值给另一个切片时 _不会_ 将切片进行复制操作。这是因为切片没有直接保存它的内部数据,而是保留了一个指向 _底层数组_ [3][3]的指针。数据都保留在底层数组里。
+
+基于第二个特性,两个切片可以享有共同的底层数组。考虑如下示例:
+
+1. 对切片取切片
+ ```
+ package main
+
+ import "fmt"
+
+ func main() {
+ var a = []int{1,2,3,4,5}
+ b := a[2:]
+ b[0] = 0
+ fmt.Println(a, b) // prints [1 2 0 4 5] [0 4 5]
+ }
+ ```
+
+ 在这个例子里,`a` 和 `b` 享有共同的底层数组 —— 尽管 `b` 的起始值在数组里的偏移不同,两者的长度也不同。通过 `b` 修改底层数组的值也会导致 `a` 里的值的改变。
+
+2. 将切片传进函数
+ ```
+ package main
+
+ import "fmt"
+
+ func negate(s []int) {
+ for i := range s {
+ s[i] = -s[i]
+ }
+ }
+
+ func main() {
+ var a = []int{1, 2, 3, 4, 5}
+ negate(a)
+ fmt.Println(a) // prints [-1 -2 -3 -4 -5]
+ }
+ ```
+
+ 在这个例子里,`a` 作为形参 `s` 的实参传进了 `negate` 函数,这个函数遍历 `s` 内的元素并改变其符号。尽管 `nagate` 没有返回值,且没有接触到 `main` 函数里的 `a`。但是当将之传进 `negate` 函数内时,`a` 里面的值却被改变了。
+
+大多数程序员都能直观地了解 Go 语言切片的底层数组是如何工作的,因为它与其他语言中类似数组的工作方式类似。比如下面就是使用 Python 重写的这一小节的第一个示例:
+
+```
+Python 2.7.10 (default, Feb 7 2017, 00:08:15)
+[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.34)] on darwin
+Type "help", "copyright", "credits" or "license" for more information.
+>>> a = [1,2,3,4,5]
+>>> b = a
+>>> b[2] = 0
+>>> a
+[1, 2, 0, 4, 5]
+```
+
+以及使用 Ruby 重写的版本:
+
+```
+irb(main):001:0> a = [1,2,3,4,5]
+=> [1, 2, 3, 4, 5]
+irb(main):002:0> b = a
+=> [1, 2, 3, 4, 5]
+irb(main):003:0> b[2] = 0
+=> 0
+irb(main):004:0> a
+=> [1, 2, 0, 4, 5]
+```
+
+在大多数将数组视为对象或者是引用类型的语言也是如此。[4][8]
+
+### 切片头
+
+让切片得以同时拥有值和指针的特性的魔法来源于切片实际上是一个结构体类型。这个结构体通常叫做 _切片头_,这里是 [反射包内的相关定义][20]。且片头的定义大致如下:
+
+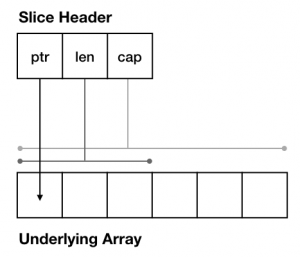
+
+```
+package runtime
+
+type slice struct {
+ ptr unsafe.Pointer
+ len int
+ cap int
+}
+```
+
+这个头很重要,因为和[ `map` 以及 `chan` 这两个类型不同][21],切片是值类型,当被赋值或者被作为函数的参数时候会被复制过去。
+
+程序员们都能理解 `square` 的形参 `v` 和 `main` 中声明的 `v` 的是相互独立的,我们一次为例。
+
+```
+package main
+
+import "fmt"
+
+func square(v int) {
+ v = v * v
+}
+
+func main() {
+ v := 3
+ square(v)
+ fmt.Println(v) // prints 3, not 9
+}
+```
+
+因此 `square` 对自己的形参 `v` 的操作没有影响到 `main` 中的 `v`。下面这个示例中的 `s` 也是 `main` 中声明的切片 `s` 的独立副本,_而不是_指向 `main` 的 `s` 的指针。
+
+```
+package main
+
+import "fmt"
+
+func double(s []int) {
+ s = append(s, s...)
+}
+
+func main() {
+ s := []int{1, 2, 3}
+ double(s)
+ fmt.Println(s, len(s)) // prints [1 2 3] 3
+}
+```
+
+Go 语言的切片是作为值传递的这一点很是不寻常。当你在 Go 语言内定义一个结构体时,90% 的时间里传递的都是这个结构体的指针。[5][9] 切片的传递方式真的很不寻常,我能想到的唯一与之相同的例子只有 `time.Time`。
+
+切片作为值传递而不是作为指针传递这一点会让很多想要理解切片的工作原理的 Go 程序员感到困惑,这是可以理解的。你只需要记住,当你对切片进行赋值,取切片,传参或者作为返回值等操作时,你是在复制结构体内的三个位域:指针,长度,以及容量。
+
+### 总结
+
+我们来用我们引出这一话题的切片作为栈的例子来总结下本文的内容:
+
+```
+package main
+
+import "fmt"
+
+func f(s []string, level int) {
+ if level > 5 {
+ return
+ }
+ s = append(s, fmt.Sprint(level))
+ f(s, level+1)
+ fmt.Println("level:", level, "slice:", s)
+}
+
+func main() {
+ f(nil, 0)
+}
+```
+
+在 `main` 函数的最开始我们把一个 `nil` 切片以及 `level` 0传给了函数 `f`。在函数 `f` 里我们把当前的 `level` 添加到切片的后面,之后增加 `level` 的值并进行递归。一旦 `level` 大于 5,函数返回,打印出当前的 `level` 以及他们复制到的 `s` 的内容。
+
+```
+level: 5 slice: [0 1 2 3 4 5]
+level: 4 slice: [0 1 2 3 4]
+level: 3 slice: [0 1 2 3]
+level: 2 slice: [0 1 2]
+level: 1 slice: [0 1]
+level: 0 slice: [0]
+```
+
+你可以注意到在每一个 `level` 内 `s` 的值没有被别的 `f` 的调用影响,尽管当计算更高阶的 `level` 时作为 `append` 的副产品,调用栈内的四个 `f` 函数创建了四个底层数组,但是没有影响到当前各自的切片。
+
+### 了解更多
+
+如果你想要了解更多 Go 语言内切片运行的原理,我建议看看 Go 博客里的这些文章:
+
+* [Go Slices: usage and internals][11] (blog.golang.org)
+
+* [Arrays, slices (and strings): The mechanics of ‘append’][12] (blog.golang.org)
+
+### 注释
+
+1. 这不是数组才有的特性,在 Go 语言里,_一切_ 赋值都是复制过去的,
+
+2. 你可以在对数组使用 `len` 函数,但是得到的结果是多少人尽皆知。[][14]
+
+3. 也叫做后台数组,以及更不严谨的说法是后台切片。[][15]
+
+4. Go 语言里我们倾向于说值类型以及指针类型,因为 C++ 的引用会使使用引用类型这个词产生误会。但是在这里我说引用类型是没有问题的。[][16]
+
+5. 如果你的结构体有[定义在其上的方法或者实现了什么接口][17],那么这个比率可以飙升到接近 100%。[][18]
+
+6. 证明留做习题。
+
+### 相关文章:
+
+1. [If a map isn’t a reference variable, what is it?][4]
+
+2. [What is the zero value, and why is it useful ?][5]
+
+3. [The empty struct][6]
+
+4. [Should methods be declared on T or *T][7]
+
+--------------------------------------------------------------------------------
+
+via: https://dave.cheney.net/2018/07/12/slices-from-the-ground-up
+
+作者:[Dave Cheney][a]
+译者:[name1e5s](https://github.com/name1e5s)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://dave.cheney.net/
+[1]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-1-3265
+[2]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-2-3265
+[3]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-3-3265
+[4]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
+[5]:https://dave.cheney.net/2013/01/19/what-is-the-zero-value-and-why-is-it-useful
+[6]:https://dave.cheney.net/2014/03/25/the-empty-struct
+[7]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
+[8]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-4-3265
+[9]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-5-3265
+[10]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-6-3265
+[11]:https://blog.golang.org/go-slices-usage-and-internals
+[12]:https://blog.golang.org/slices
+[13]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-1-3265
+[14]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-2-3265
+[15]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-3-3265
+[16]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-4-3265
+[17]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
+[18]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-5-3265
+[19]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-6-3265
+[20]:https://golang.org/pkg/reflect/#SliceHeader
+[21]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it