mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
3436643279
@ -1,18 +1,20 @@
|
||||
如何使用 Arduino 制作一个绘图仪
|
||||
======
|
||||
|
||||

|
||||
在上学时,科学系的壁橱里藏着一台惠普绘图仪。虽然我在上学期间可以经常使用它,但我还是想拥有一台属于自己的绘图仪。许多年之后,步进电机已经很容易获得了,我又在从事电子产品和微控制器方面的工作,最近,我看到有人用丙烯酸塑料(acrylic)制作了一个显示器。这件事启发了我,并最终制作了我自己的绘图仪。
|
||||
> 使用开源硬件和软件的 DIY 绘图仪可以自动地绘制、雕刻。
|
||||
|
||||

|
||||
|
||||
在上学时,科学系的壁橱里藏着一台惠普绘图仪。虽然我在上学的期间可以经常使用它,但我还是想拥有一台属于自己的绘图仪。许多年之后,步进电机已经很容易获得了,我又在从事电子产品和微控制器方面的工作,最近,我看到有人用丙烯酸塑料(acrylic)制作了一个显示器。这件事启发了我,并最终制作了我自己的绘图仪。
|
||||
|
||||
![The plotter in action ][2]
|
||||
|
||||
我 DIY 的绘图仪;在这里看它工作的[视频][3]。
|
||||
*我 DIY 的绘图仪;在这里看它工作的[视频][3]。*
|
||||
|
||||
由于我是一个很怀旧的人,我真的很喜欢最初的 [Arduino Uno][4]。下面是我用到的其它东西的一个清单(仅供参考,其中一些我也不是很满意):
|
||||
|
||||
* [FabScan shield][5]:承载步进电机驱动器。
|
||||
* [SilentStepSticks][6]:步进电机驱动器,因为 Arduino 自身不能处理步进电机所需的电压和电流。因此我使用了一个 Trinamic TMC2130 芯片,但它是工作在单独模式。这些都是为替换 Pololu 4988,但是它们运转更安静。
|
||||
* [SilentStepSticks][6]:步进电机驱动器,因为 Arduino 自身不能处理步进电机所需的电压和电流。因此我使用了一个 Trinamic TMC2130 芯片,但它是工作在单独模式。这些替换为 Pololu 4988,但是它们运转更安静。
|
||||
* [SilentStepStick 保护装置][7]:一个防止你的电机驱动器转动过快的二极管(相信我,你肯定会需要它的)。
|
||||
* 步进电机:我选择的是使用 12 V 电压的 NEMA 17 电机(如,来自 [Watterott][8] 和 [SparkFun][9] 的型号)。
|
||||
* [直线导杆][10]
|
||||
@ -21,32 +23,27 @@
|
||||
* GT2 皮带
|
||||
* [GT2 同步滑轮][11]
|
||||
|
||||
|
||||
|
||||
这是我作为个人项目而设计的。如果你想找到一个现成的工具套件,你可以从 German Make 杂志上找到 [MaXYposi][12]。
|
||||
|
||||
### 硬件安装
|
||||
|
||||
正如你所看到的,我刚开始做的太大了。这个绘图仪并不合适放在我的桌子上。但是,没有关系,我只是为了学习它(并且,我也将一些东西进行重新制作,下次我将使用一个更小的横梁)。
|
||||
|
||||
|
||||
![Plotter base plate with X-axis and Y-axis rails][14]
|
||||
|
||||
带 X 轴和 Y 轴轨道的绘图仪基板
|
||||
*带 X 轴和 Y 轴轨道的绘图仪基板*
|
||||
|
||||
皮带安装在轨道的侧面,并且用它将一些辅助轮和电机挂在一起:
|
||||
|
||||
|
||||
![The belt routing on the motor][16]
|
||||
|
||||
电机上的皮带路由
|
||||
*电机上的皮带路由*
|
||||
|
||||
我在 Arduino 上堆叠了几个组件。Arduino 在最下面,它之上是 FabScan shield,接着是一个安装在 1 和 2 号电机槽上的 StepStick 保护装置,SilentStepStick 在最上面。注意,SCK 和 SDI 针脚没有连接。
|
||||
|
||||
|
||||
![Arduino and Shield][18]
|
||||
|
||||
Arduino 堆叠配置([高清大图][19])
|
||||
*Arduino 堆叠配置([高清大图][19])*
|
||||
|
||||
注意将电机的连接线接到正确的针脚上。如果有疑问,就去查看它的数据表,或者使用欧姆表去找出哪一对线是正确的。
|
||||
|
||||
@ -57,21 +54,19 @@ Arduino 堆叠配置([高清大图][19])
|
||||
虽然像 [grbl][20] 这样的软件可以解释诸如像装置移动和其它一些动作的 G-codes,并且,我也可以将它刷进 Arduino 中,但是我很好奇,想更好地理解它是如何工作的。(我的 X-Y 绘图仪软件可以在 [GitHub][21] 上找到,不过我不提供任何保修。)
|
||||
|
||||
使用 StepStick(或者其它兼容的)驱动器去驱动步进电机,基本上只需要发送一个高电平信号或者低电平信号到各自的针脚即可。或者使用 Arduino 的术语:
|
||||
|
||||
```
|
||||
digitalWrite(stepPin, HIGH);
|
||||
|
||||
delayMicroseconds(30);
|
||||
|
||||
digitalWrite(stepPin, LOW);
|
||||
|
||||
```
|
||||
|
||||
在 `stepPin` 的位置上是步进电机的针脚编号:3 是 1 号电机,而 6 是 2 号电机。
|
||||
|
||||
在步进电机能够工作之前,它必须先被启用。
|
||||
|
||||
```
|
||||
digitalWrite(enPin, LOW);
|
||||
|
||||
```
|
||||
|
||||
实际上,StepStick 能够理解针脚的三个状态:
|
||||
@ -80,68 +75,51 @@ digitalWrite(enPin, LOW);
|
||||
* High:电机已禁用
|
||||
* Pin 未连接:电机已启用,但在一段时间后进入节能模式
|
||||
|
||||
|
||||
|
||||
电机启用后,它的线圈已经有了力量并用来保持位置。这时候几乎不可能用手来转动它的轴。这样可以保证很好的精度,但是也意味着电机和驱动器芯片都“充满着”力量,并且也因此会发热。
|
||||
|
||||
最后,也是很重要的,我们需要一个决定绘图仪方向的方法:
|
||||
|
||||
```
|
||||
digitalWrite(dirPin, direction);
|
||||
|
||||
```
|
||||
|
||||
下面的表列出了功能和针脚~~(致核对:下面的表格式错误)~~
|
||||
下面的表列出了功能和针脚:
|
||||
|
||||
Function Motor1 Motor2 Enable 2 5 Direction 4 7 Step 3 6
|
||||
| 功能 | 1 号电机 | 2 号电机 |
|
||||
|---|---|---|
|
||||
| 启用 | 2 | 5 |
|
||||
| 方向 | 4 | 7 |
|
||||
| 步进 | 3 | 6 |
|
||||
|
||||
在我们使用这些针脚之前,我们需要在代码的 `setup()` 节中设置它的 `OUTPUT` 模式。
|
||||
|
||||
```
|
||||
pinMode(enPin1, OUTPUT);
|
||||
|
||||
pinMode(stepPin1, OUTPUT);
|
||||
|
||||
pinMode(dirPin1, OUTPUT);
|
||||
|
||||
digitalWrite(enPin1, LOW);
|
||||
|
||||
```
|
||||
|
||||
了解这些知识后,我们可以很容易地让步进电机四处移动:
|
||||
|
||||
```
|
||||
totalRounds = ...
|
||||
|
||||
for (int rounds =0 ; rounds < 2*totalRounds; rounds++) {
|
||||
|
||||
if (dir==0){ // set direction
|
||||
|
||||
digitalWrite(dirPin2, LOW);
|
||||
|
||||
} else {
|
||||
|
||||
digitalWrite(dirPin2, HIGH);
|
||||
|
||||
}
|
||||
|
||||
delay(1); // give motors some breathing time
|
||||
|
||||
dir = 1-dir; // reverse direction
|
||||
|
||||
for (int i=0; i < 6400; i++) {
|
||||
|
||||
int t = abs(3200-i) / 200;
|
||||
|
||||
digitalWrite(stepPin2, HIGH);
|
||||
|
||||
delayMicroseconds(70 + t);
|
||||
|
||||
digitalWrite(stepPin2, LOW);
|
||||
|
||||
delayMicroseconds(70 + t);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
totalRounds = ...
|
||||
for (int rounds =0 ; rounds < 2*totalRounds; rounds++) {
|
||||
if (dir==0){ // set direction
|
||||
digitalWrite(dirPin2, LOW);
|
||||
} else {
|
||||
digitalWrite(dirPin2, HIGH);
|
||||
}
|
||||
delay(1); // give motors some breathing time
|
||||
dir = 1-dir; // reverse direction
|
||||
for (int i=0; i < 6400; i++) {
|
||||
int t = abs(3200-i) / 200;
|
||||
digitalWrite(stepPin2, HIGH);
|
||||
delayMicroseconds(70 + t);
|
||||
digitalWrite(stepPin2, LOW);
|
||||
delayMicroseconds(70 + t);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这将使滑块向左和向右移动。这些代码只操纵一个步进电机,但是,对于一个 X-Y 绘图仪,我们要考虑两个轴。
|
||||
@ -149,9 +127,9 @@ digitalWrite(enPin1, LOW);
|
||||
#### 命令解释器
|
||||
|
||||
我开始做一个简单的命令解释器去使用规范的路径,比如:
|
||||
|
||||
```
|
||||
"X30|Y30|X-30 Y-30|X-20|Y-20|X20|Y20|X-40|Y-25|X40 Y25
|
||||
|
||||
```
|
||||
|
||||
用毫米来描述相对移动(1 毫米等于 80 步)。
|
||||
@ -166,54 +144,39 @@ digitalWrite(enPin1, LOW);
|
||||
|
||||
![Servo to raise/lower the pen ][24]
|
||||
|
||||
图中的特写镜头就是伺服器臂提起笔的图像
|
||||
*图中的特写镜头就是伺服器臂提起笔的图像*
|
||||
|
||||
笔是用一个小夹具固定住的(图上展示的是一个大小为 8 的夹具,它一般用于将线缆固定在墙上)。伺服器臂能够提起笔;当伺服器臂放下来的时候,笔就会被放下来。
|
||||
|
||||
#### 驱动伺服器
|
||||
|
||||
驱动伺服器是非常简单的:只需要提供位置,伺服器就可以完成所有的工作。
|
||||
|
||||
```
|
||||
#include <Servo.h>
|
||||
|
||||
|
||||
|
||||
// Servo pin
|
||||
|
||||
#define servoData PIN_A1
|
||||
|
||||
|
||||
|
||||
// Positions
|
||||
|
||||
#define PEN_UP 10
|
||||
|
||||
#define PEN_DOWN 50
|
||||
|
||||
|
||||
|
||||
Servo penServo;
|
||||
|
||||
|
||||
|
||||
void setup() {
|
||||
|
||||
// Attach to servo and raise pen
|
||||
|
||||
penServo.attach(servoData);
|
||||
|
||||
penServo.write(PEN_UP);
|
||||
|
||||
// Attach to servo and raise pen
|
||||
penServo.attach(servoData);
|
||||
penServo.write(PEN_UP);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我把伺服器接头连接在 FabScan shield 的 4 号电机上,因此,我将用 1 号模拟针脚。
|
||||
|
||||
放下笔也很容易:
|
||||
|
||||
```
|
||||
penServo.write(PEN_DOWN);
|
||||
|
||||
```
|
||||
|
||||
### 进一步扩展
|
||||
@ -230,7 +193,7 @@ via: https://opensource.com/article/18/3/diy-plotter-arduino
|
||||
|
||||
作者:[Heiko W.Rupp][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,33 +1,29 @@
|
||||
Go 程序的持续分析
|
||||
============================================================
|
||||
|
||||
Google 最有趣的部分之一就是我们的持续分析服务。我们可以看到谁在使用 CPU 和内存,我们可以持续地监控我们的生产服务以争用和阻止配置文件,并且我们可以生成分析和报告,并轻松地告诉我们可以进行哪些有重要影响的优化。
|
||||
Google 最有趣的部分之一就是我们规模庞大的持续分析服务。我们可以看到谁在使用 CPU 和内存,我们可以持续地监控我们的生产服务以争用和阻止配置文件,并且我们可以生成分析和报告,并轻松地告诉我们可以进行哪些有重要影响的优化。
|
||||
|
||||
我简单研究了 [Stackdriver Profiler][2],这是我们的新产品,它填补了针对云端用户云端分析服务的空白。请注意,你无需在 Google 云平台上运行你的代码即可使用它。实际上,我现在每天都在开发时使用它。它也支持 Java 和 Node.js。
|
||||
我简单研究了 [Stackdriver Profiler][2],这是我们的新产品,它填补了针对云端用户在云服务范围内分析服务的空白。请注意,你无需在 Google 云平台上运行你的代码即可使用它。实际上,我现在每天都在开发时使用它。它也支持 Java 和 Node.js。
|
||||
|
||||
#### 在生产中分析
|
||||
### 在生产中分析
|
||||
|
||||
pprof 可安全地用于生产。我们针对 CPU 和堆分配分析的额外开销会增加 5%。一个实例中每分钟收集 10 秒。如果你有一个 Kubernetes Pod 的多个副本,我们确保进行分摊收集。例如,如果你拥有一个 pod 的 10 个副本,模式,那么开销将变为 0.5%。这使用户可以始终进行分析。
|
||||
pprof 可安全地用于生产。我们针对 CPU 和堆分配分析的额外会增加 5% 的开销。一个实例中每分钟收集 10 秒。如果你有一个 Kubernetes Pod 的多个副本,我们确保进行分摊收集。例如,如果你拥有一个 pod 的 10 个副本,模式,那么开销将变为 0.5%。这使用户可以一直进行分析。
|
||||
|
||||
我们目前支持 Go 程序的 CPU、堆、互斥和线程分析。
|
||||
|
||||
#### 为什么?
|
||||
### 为什么?
|
||||
|
||||
在解释如何在生产中使用分析器之前,先解释为什么你想要在生产中进行分析将有所帮助。一些非常常见的情况是:
|
||||
|
||||
* 调试仅在生产中可见的性能问题。
|
||||
|
||||
* 了解 CPU 使用率以减少费用。
|
||||
|
||||
* 了解争用的累积和优化的地方。
|
||||
|
||||
* 了解新版本的影响,例如看到 canary 和生产之间的区别。
|
||||
|
||||
* 了解新版本的影响,例如看到 canary 和产品级之间的区别。
|
||||
* 通过[关联][1]分析样本以了解延迟的根本原因来丰富你的分布式经验。
|
||||
|
||||
#### 启用
|
||||
### 启用
|
||||
|
||||
Stackdriver Profiler 不能与 _net/http/pprof_ 处理程序一起使用,并要求你在程序中安装和配置一个一行的代理。
|
||||
Stackdriver Profiler 不能与 `net/http/pprof` 处理程序一起使用,并要求你在程序中安装和配置一个一行的代理。
|
||||
|
||||
```
|
||||
go get cloud.google.com/go/profiler
|
||||
@ -45,56 +41,49 @@ if err := profiler.Start(profiler.Config{
|
||||
}
|
||||
```
|
||||
|
||||
当你运行你的程序后,profiler 包将每分钟报告给 profiler 10 秒钟。
|
||||
当你运行你的程序后,profiler 包将每分钟报告给分析器 10 秒钟。
|
||||
|
||||
#### 可视化
|
||||
|
||||
当分析报告给后端后,你将在 [https://console.cloud.google.com/profiler][4] 上看到火焰图。你可以按标签过滤并更改时间范围,也可以按服务名称和版本进行细分。数据将会长达 30 天。
|
||||
### 可视化
|
||||
|
||||
当分析被报告给后端后,你将在 [https://console.cloud.google.com/profiler][4] 上看到火焰图。你可以按标签过滤并更改时间范围,也可以按服务名称和版本进行细分。数据将会长达 30 天。
|
||||
|
||||
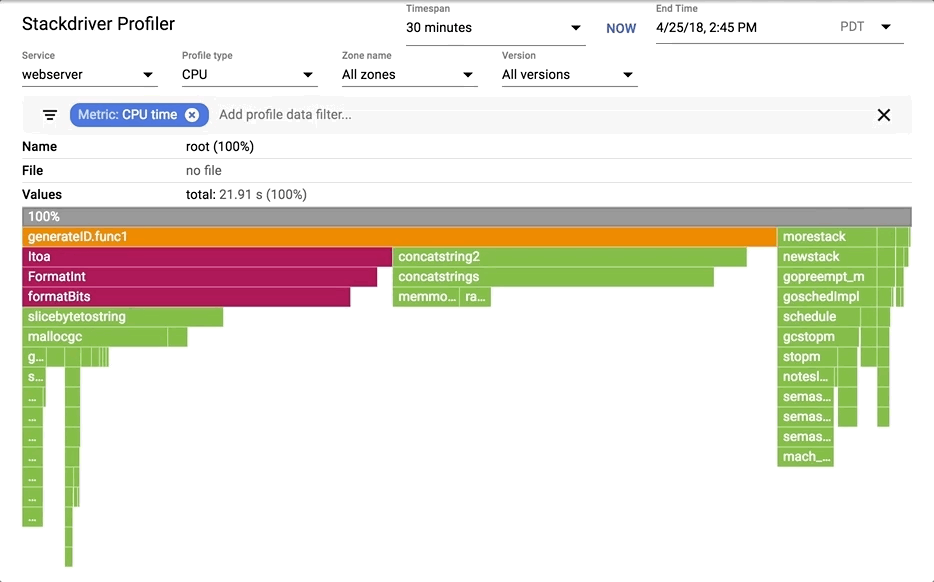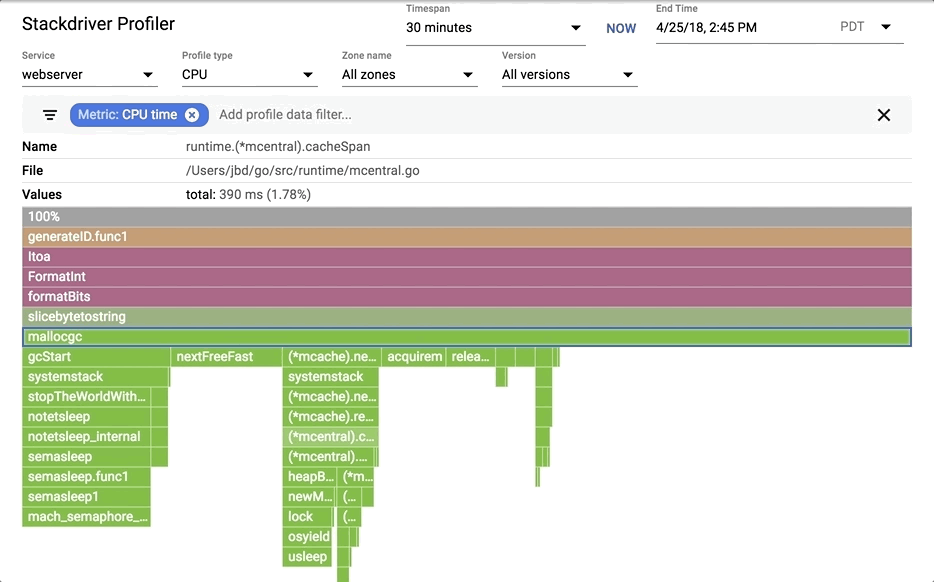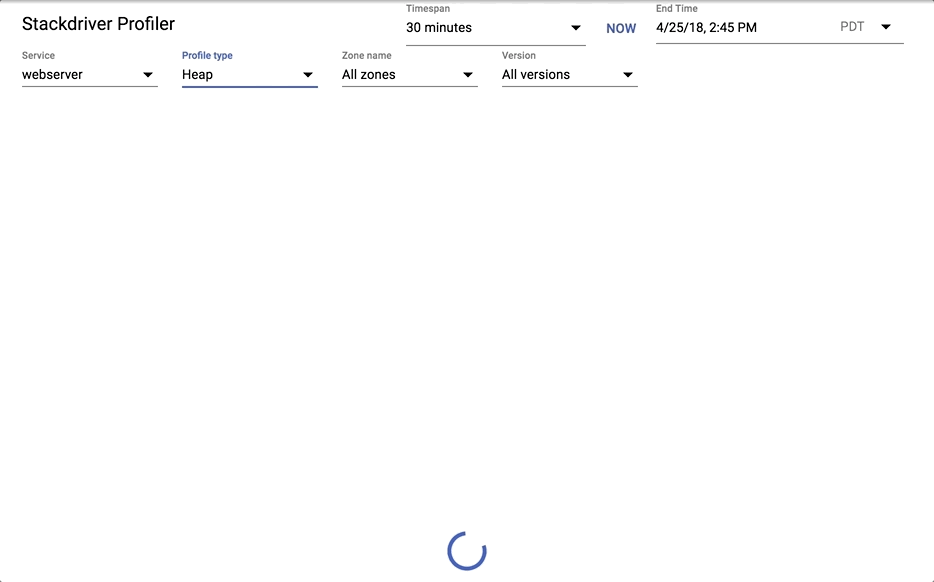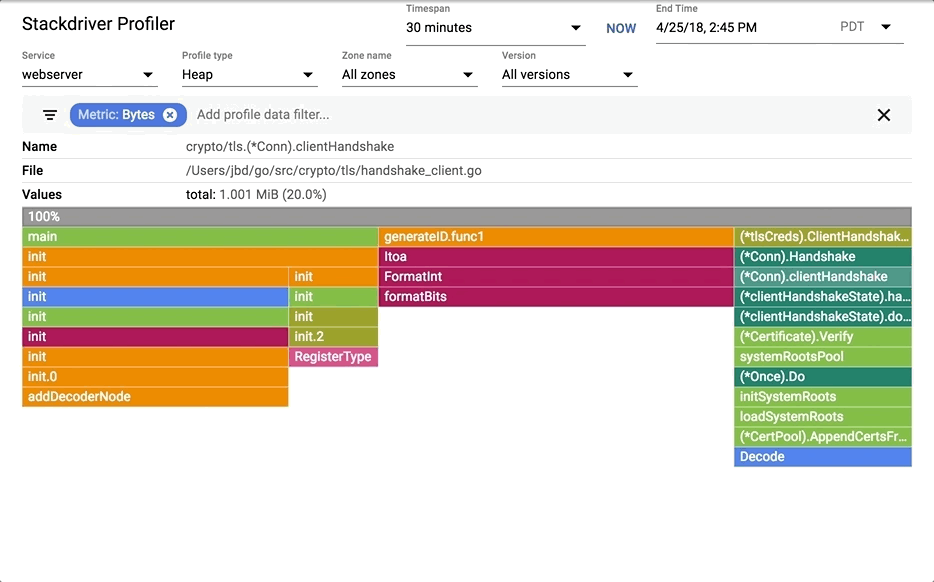
|
||||
|
||||
你可以选择其中一个分析,按服务,区域和版本分解。你可以在火焰中移动并通过标签进行过滤。
|
||||
|
||||
#### 阅读火焰图
|
||||
|
||||
火焰图可视化由 [Brendan Gregg][5] 非常全面地解释了。Stackdriver Profiler 增加了一点它自己的特点。
|
||||
### 阅读火焰图
|
||||
|
||||
[Brendan Gregg][5] 非常全面地解释了火焰图可视化。Stackdriver Profiler 增加了一点它自己的特点。
|
||||
|
||||

|
||||
|
||||
我们将查看一个 CPU 分析,但这也适用于其他分析。
|
||||
|
||||
1. 最上面的 x 轴表示整个程序。火焰上的每个框表示调用路径上的一帧。框的宽度与执行该函数花费的 CPU 时间成正比。
|
||||
|
||||
2. 框从左到右排序,左边是花费最多的调用路径。
|
||||
|
||||
3. 来自同一包的帧具有相同的颜色。这里所有运行时功能均以绿色表示。
|
||||
|
||||
4. 你可以单击任何框进一步展开执行树。
|
||||
|
||||
|
||||
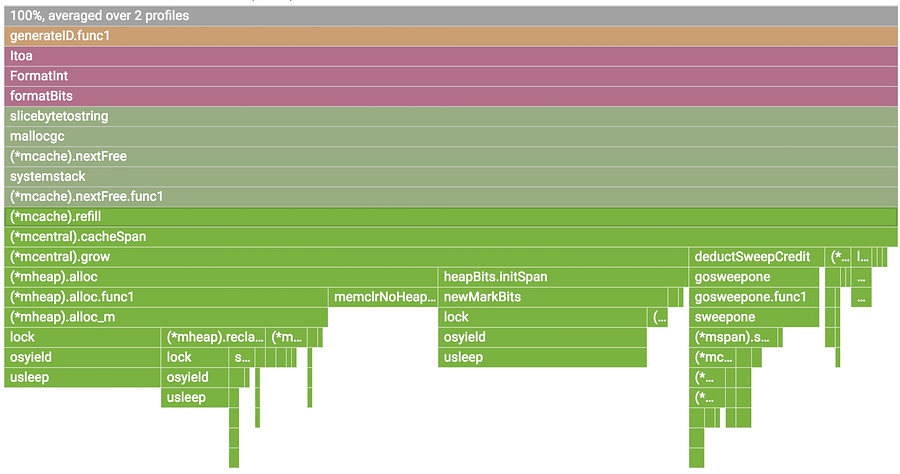
|
||||
|
||||
你可以将鼠标悬停在任何框上查看任何帧的详细信息。
|
||||
|
||||
#### 过滤
|
||||
### 过滤
|
||||
|
||||
你可以显示,隐藏和高亮符号名称。如果你特别想了解某个特定调用或包的消耗,这些信息非常有用。
|
||||
你可以显示、隐藏和高亮符号名称。如果你特别想了解某个特定调用或包的消耗,这些信息非常有用。
|
||||
|
||||
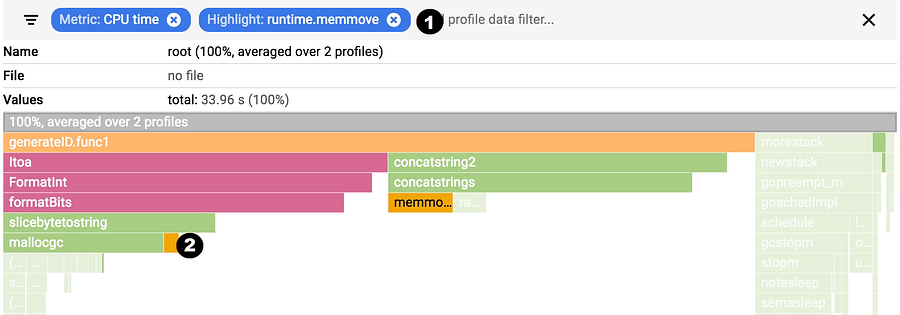
|
||||
|
||||
1. 选择你的过滤器。你可以组合多个过滤器。在这里,我们将高亮显示 runtime.memmove。
|
||||
|
||||
2. 火焰将使用过滤器过滤帧并可视化过滤后的框。在这种情况下,它高亮显示所有 runtime.memmove 框。
|
||||
1. 选择你的过滤器。你可以组合多个过滤器。在这里,我们将高亮显示 `runtime.memmove`。
|
||||
2. 火焰将使用过滤器过滤帧并可视化过滤后的框。在这种情况下,它高亮显示所有 `runtime.memmove` 框。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b
|
||||
|
||||
作者:[JBD ][a]
|
||||
作者:[JBD][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
如何在 Linux 系统中结束结束进程或是中止程序
|
||||
======
|
||||
|
||||
> 在 Linux 中有几种使用命令行或图形界面终止一个程序的方式。
|
||||
|
||||

|
||||
|
||||
进程出错的时候,您可能会想要中止或是杀掉这个进程。在本文中,我们将探索在命令行和图形界面中终止进程或是应用程序,这里我们使用 [gedit][1] 作为样例程序。
|
||||
|
||||
### 使用命令行或字符终端界面
|
||||
|
||||
#### Ctrl + C
|
||||
|
||||
在命令行中调用 `gedit` (如果您没有使用 `gedit &` 命令)程序的一个问题是 shell 会话被阻塞,没法释放命令行提示符。在这种情况下,`Ctrl + C` (`Ctrl` 和 `C` 的组合键) 会很管用。这会终止 `gedit` ,并且所有的工作都将丢失(除非文件已经被保存)。`Ctrl + C` 会给 `gedit` 发送了 `SIGINT` 信号。这是一个默认终止进程的停止信号,它将指示 shell 停止 `gedit` 的运行,并返回到主函数的循环中,您将返回到提示符。
|
||||
|
||||
```
|
||||
$ gedit
|
||||
^C
|
||||
```
|
||||
|
||||
#### Ctrl + Z
|
||||
|
||||
它被称为挂起字符。它会发送 `SIGTSTP` 信号给进程。它也是一个停止信号,但是默认行为不是杀死进程,而是挂起进程。
|
||||
|
||||
下面的命令将会停止(杀死/中断) `gedit` 的运行,并返回到 shell 提示符。
|
||||
|
||||
```
|
||||
$ gedit
|
||||
^Z
|
||||
[1]+ Stopped gedit
|
||||
$
|
||||
```
|
||||
|
||||
一旦进程被挂起(以 `gedit` 为例),将不能在 `gedit` 中写入或做任何事情。而在后台,该进程变成了一个作业,可以使用 `jsbs` 命令验证。
|
||||
|
||||
```
|
||||
$ jobs
|
||||
[1]+ Stopped gedit
|
||||
```
|
||||
|
||||
`jobs` 允许您在单个 shell 会话中控制多个进程。您可以终止,恢复作业,或是根据需要将作业移动到前台或是后台。
|
||||
|
||||
让我们在后台恢复 `gedit`,释放提示符以运行其它命令。您可以通过 `bg` 命令来做到,后跟作业 ID(注意上面的 `jobs` 命令显示出来的 `[1]`,这就是作业 ID)。
|
||||
|
||||
```
|
||||
$ bg 1
|
||||
[1]+ gedit &
|
||||
```
|
||||
|
||||
这和直接使用 `gedit &` 启动程序效果差不多:
|
||||
|
||||
```
|
||||
$ gedit &
|
||||
```
|
||||
|
||||
### 使用 kill
|
||||
|
||||
`kill` 命令提供信号的精确控制,允许您通过指定信号名或是信号数字为进程发送信号,后跟进程 ID 或是 PID。
|
||||
|
||||
我喜欢 `kill` 命令的一点是它也能够根据作业 ID 控制进程。让我们使用 `gedit &` 命令在后台开启 `gedit` 服务。假设通过 `jobs` 命令我得到了一个 `gedit` 的作业 ID,让我们为 `gedit` 发送 `SIGINT` 信号:
|
||||
|
||||
```
|
||||
$ kill -s SIGINT %1
|
||||
```
|
||||
|
||||
作业 ID 需要使用 `%` 前缀,不然 `kill` 会将其视作 PID。
|
||||
|
||||
不明确指定信号,`kill` 仍然可以工作。此时,默认会发送能中断进程的 `SIGTERM` 信号。执行 `kill -l` 可以查看信号名列表,使用 `man kill` 命令阅读手册。
|
||||
|
||||
### 使用 killall
|
||||
|
||||
如果您不想使用特定的工作 ID 或者 PID,`killall` 允许您使用特定的进程名。中断 `gedit` 最简单的 `killall` 使用方式是:
|
||||
|
||||
```
|
||||
$ killall gedit
|
||||
```
|
||||
|
||||
它将终止所有名为 `gedit` 的进程。和 `kill` 相似,默认发送的信号是 `SIGTERM`。使用 `-I` 选项忽略进程名的大小写。
|
||||
|
||||
```
|
||||
$ gedit &
|
||||
[1] 14852
|
||||
|
||||
$ killall -I GEDIT
|
||||
[1]+ Terminated gedit
|
||||
```
|
||||
|
||||
查看手册学习更多 `killall` 命令选项(如 `-u`)。
|
||||
|
||||
### 使用 xkill
|
||||
|
||||
您是否遇见过播放器崩溃,比如 [VLC][2] 灰屏或挂起?现在你可以像上面一样获得进程的 PID 来杀掉它,或者使用 `xkill` 命令终止应用程序。
|
||||
|
||||
![Using xkill][3]
|
||||
|
||||
`xkill` 允许您使用鼠标关闭窗口。仅需在终端执行 `xkill` 命令,它将会改变鼠标光标为一个 **X** 或是一个小骷髅图标。在你想关闭的进程窗口上点击 **x**。小心使用 `xkill`,如手册描述的一致,它很危险。我已经提醒过您了!
|
||||
|
||||
参阅手册,了解上述命令更多信息。您还可以接续探索 `pkill` 和 `pgrep` 命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/how-kill-process-stop-program-linux
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://wiki.gnome.org/Apps/Gedit
|
||||
[2]:https://www.videolan.org/vlc/index.html
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/xkill_gedit.png?itok=TBvMw0TN (Using xkill)
|
||||
@ -1,74 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Best Websites For Programmers
|
||||
======
|
||||
![][1]
|
||||
|
||||
As a programmer, you will often find yourself as a permanent visitor of some websites. These can be tutorial, reference or forums websites. So here in this article let us have a look at the best websites for programmers.
|
||||
|
||||
### W3Schools
|
||||
W3Schools is one of the best websites for beginners as well as experienced web developers to learn various programming languages. You can learn HTML5, CSS3, PHP. JavaScript, ASP etc.
|
||||
|
||||
More importantly, the website holds a lot of resources and references for web developers.
|
||||
|
||||
[![w3schools logo][2]][3]
|
||||
|
||||
You can quickly see various keywords and what they do. The website is very interactive and it allows you to try and practice the code in an embedded editor on the website itself. The website is one of those few that you will frequently visit as a web developer.
|
||||
|
||||
### GeeksforGeeks
|
||||
GeeksforGeeks is a website mostly focused on computer science. It has a huge collection of algorithms, solutions and programming questions.
|
||||
|
||||
[![geeksforgeeks programming support][4]][5]
|
||||
|
||||
The website also has a good stock of most frequently asked questions in interviews. Since the website is more about computer science in general, you will find a solution to all programming solutions in most famous languages.
|
||||
|
||||
### TutorialsPoint
|
||||
The de facto place for learning anything. Tutorials point has some of the finest and easiest tutorials that can teach you any programming language. What I really love about this website is that it is not just limited to generic programming languages.
|
||||
|
||||

|
||||
|
||||
You can find tutorials for almost all frameworks of all languages on the planet.
|
||||
|
||||
### StackOverflow
|
||||
You probably already know this that stack is the place where programmers meet. You ever get stuck solving some of your code, just ask a question on stack and programmers from all over the internet will be there to help you.
|
||||
|
||||
[![stackoverflow linux programming website][6]][7]
|
||||
|
||||
The best part about stack overflow is that almost all questions get answered. You might as well receive answers from several different points of views of other programmers.
|
||||
|
||||
### HackerRank
|
||||
Hacker rank is a website where you can participate in various coding competitions and check your competitive abilities.
|
||||
|
||||
[![hackerrank programming forums][8]][9]There are various contests organized in various programming languages and winning in them increases your score. This score can get you in the top ranks and increase your chance of getting noticed by some software company.
|
||||
|
||||
### Codebeautify
|
||||
Since we are programmers, beauty isn’t something we look after. Many a time our code can be difficult to read by someone else. Codebeautify can make your code easy to read.
|
||||
|
||||

|
||||
|
||||
The website has most languages that it can beautify. Alternatively, if you wish to make your code not readable by someone you can also do that.
|
||||
|
||||
So these were some of my picks for the best websites for programmers. If you frequently visit a site that I haven’t mentioned, do let me know in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/best-websites-programmers
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/12/best-websites-for-programmers.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo-550x110.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support-550x152.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support.png
|
||||
[6]:http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website-550x178.png
|
||||
[7]:http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website.png
|
||||
[8]:http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums-550x118.png
|
||||
[9]:http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums.png
|
||||
@ -0,0 +1,526 @@
|
||||
Command Line Tricks For Data Scientists • kade killary
|
||||
======
|
||||
|
||||

|
||||
|
||||
For many data scientists, data manipulation begins and ends with Pandas or the Tidyverse. In theory, there is nothing wrong with this notion. It is, after all, why these tools exist in the first place. Yet, these options can often be overkill for simple tasks like delimiter conversion.
|
||||
|
||||
Aspiring to master the command line should be on every developer’s list, especially data scientists. Learning the ins and outs of your shell will undeniably make you more productive. Beyond that, the command line serves as a great history lesson in computing. For instance, awk - a data-driven scripting language. Awk first appeared in 1977 with the help of [Brian Kernighan][1], the K in the legendary [K&R book][2]. Today, some near 50 years later, awk remains relevant with [new books][3] still appearing every year! Thus, it’s safe to assume that an investment in command line wizardry won’t depreciate any time soon.
|
||||
|
||||
### What We’ll Cover
|
||||
|
||||
* ICONV
|
||||
* HEAD
|
||||
* TR
|
||||
* WC
|
||||
* SPLIT
|
||||
* SORT & UNIQ
|
||||
* CUT
|
||||
* PASTE
|
||||
* JOIN
|
||||
* GREP
|
||||
* SED
|
||||
* AWK
|
||||
|
||||
|
||||
|
||||
### ICONV
|
||||
|
||||
File encodings can be tricky. For the most part files these days are all UTF-8 encoded. To understand some of the magic behind UTF-8, check out this [excellent video][4]. Nonetheless, there are times where we receive a file that isn’t in this format. This can lead to some wonky attempts at swapping the encoding schema. Here, `iconv` is a life saver. Iconv is a simple program that will take text in one encoding and output the text in another.
|
||||
```
|
||||
# Converting -f (from) latin1 (ISO-8859-1)
|
||||
# -t (to) standard UTF_8
|
||||
|
||||
iconv -f ISO-8859-1 -t UTF-8 < input.txt > output.txt
|
||||
|
||||
```
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `iconv -l` list all known encodings
|
||||
* `iconv -c` silently discard characters that cannot be converted
|
||||
|
||||
|
||||
|
||||
### HEAD
|
||||
|
||||
If you are a frequent Pandas user then `head` will be familiar. Often when dealing with new data the first thing we want to do is get a sense of what exists. This leads to firing up Pandas, reading in the data and then calling `df.head()` \- strenuous, to say the least. Head, without any flags, will print out the first 10 lines of a file. The true power of `head` lies in testing out cleaning operations. For instance, if we wanted to change the delimiter of a file from commas to pipes. One quick test would be: `head mydata.csv | sed 's/,/|/g'`.
|
||||
```
|
||||
# Prints out first 10 lines
|
||||
|
||||
head filename.csv
|
||||
|
||||
# Print first 3 lines
|
||||
|
||||
head -n 3 filename.csv
|
||||
|
||||
```
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `head -n` print a specific number of lines
|
||||
* `head -c` print a specific number of bytes
|
||||
|
||||
|
||||
|
||||
### TR
|
||||
|
||||
Tr is analogous to translate. This powerful utility is a workhorse for basic file cleaning. An ideal use case is for swapping out the delimiters within a file.
|
||||
```
|
||||
# Converting a tab delimited file into commas
|
||||
|
||||
cat tab_delimited.txt | tr "\t" "," comma_delimited.csv
|
||||
|
||||
```
|
||||
|
||||
Another feature of `tr` is all the built in `[:class:]` variables at your disposal. These include:
|
||||
```
|
||||
[:alnum:] all letters and digits
|
||||
[:alpha:] all letters
|
||||
[:blank:] all horizontal whitespace
|
||||
[:cntrl:] all control characters
|
||||
[:digit:] all digits
|
||||
[:graph:] all printable characters, not including space
|
||||
[:lower:] all lower case letters
|
||||
[:print:] all printable characters, including space
|
||||
[:punct:] all punctuation characters
|
||||
[:space:] all horizontal or vertical whitespace
|
||||
[:upper:] all upper case letters
|
||||
[:xdigit:] all hexadecimal digits
|
||||
|
||||
```
|
||||
|
||||
You can chain a variety of these together to compose powerful programs. The following is a basic word count program you could use to check your READMEs for overuse.
|
||||
```
|
||||
cat README.md | tr "[:punct:][:space:]" "\n" | tr "[:upper:]" "[:lower:]" | grep . | sort | uniq -c | sort -nr
|
||||
|
||||
```
|
||||
|
||||
Another example using basic regex:
|
||||
```
|
||||
# Converting all upper case letters to lower case
|
||||
|
||||
cat filename.csv | tr '[A-Z]' '[a-z]'
|
||||
|
||||
```
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `tr -d` delete characters
|
||||
* `tr -s` squeeze characters
|
||||
* `\b` backspace
|
||||
* `\f` form feed
|
||||
* `\v` vertical tab
|
||||
* `\NNN` character with octal value NNN
|
||||
|
||||
|
||||
|
||||
### WC
|
||||
|
||||
Word count. Its value is primarily derived from the `-l` flag, which will give you the line count.
|
||||
```
|
||||
# Will return number of lines in CSV
|
||||
|
||||
wc -l gigantic_comma.csv
|
||||
|
||||
```
|
||||
|
||||
This tool comes in handy to confirm the output of various commands. So, if we were to convert the delimiters within a file and then run `wc -l` we would expect the total lines to be the same. If not, then we know something went wrong.
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `wc -c` print the byte counts
|
||||
* `wc -m` print the character counts
|
||||
* `wc -L` print length of longest line
|
||||
* `wc -w` print word counts
|
||||
|
||||
|
||||
|
||||
### SPLIT
|
||||
|
||||
File sizes can range dramatically. And depending on the job, it could be beneficial to split up the file - thus `split`. The basic syntax for split is:
|
||||
```
|
||||
# We will split our CSV into new_filename every 500 lines
|
||||
|
||||
split -l 500 filename.csv new_filename_
|
||||
|
||||
# filename.csv
|
||||
# ls output
|
||||
# new_filename_aaa
|
||||
# new_filename_aab
|
||||
# new_filename_aac
|
||||
|
||||
```
|
||||
|
||||
Two quirks are the naming convention and lack of file extensions. The suffix convention can be numeric via the `-d` flag. To add file extensions, you’ll need to run the following `find` command. It will change the names of ALL files within the current directory by appending `.csv`, so be careful.
|
||||
```
|
||||
find . -type f -exec mv '{}' '{}'.csv \;
|
||||
|
||||
# ls output
|
||||
# filename.csv.csv
|
||||
# new_filename_aaa.csv
|
||||
# new_filename_aab.csv
|
||||
# new_filename_aac.csv
|
||||
|
||||
```
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `split -b` split by certain byte size
|
||||
* `split -a` generate suffixes of length N
|
||||
* `split -x` split using hex suffixes
|
||||
|
||||
|
||||
|
||||
### SORT & UNIQ
|
||||
|
||||
The preceding commands are obvious: they do what they say they do. These two provide the most punch in tandem (i.e. unique word counts). This is due to `uniq`, which only operates on duplicate adjacent lines. Thus, the reason to `sort` before piping the output through. One interesting note is that `sort -u` will achieve the same results as the typical `sort file.txt | uniq` pattern.
|
||||
|
||||
Sort does have a sneakily useful ability for data scientists: the ability to sort an entire CSV based on a particular column.
|
||||
```
|
||||
# Sorting a CSV file by the second column alphabetically
|
||||
|
||||
sort -t"," -k2,2 filename.csv
|
||||
|
||||
# Numerically
|
||||
|
||||
sort -t"," -k2n,2 filename.csv
|
||||
|
||||
# Reverse order
|
||||
|
||||
sort -t"," -k2nr,2 filename.csv
|
||||
|
||||
```
|
||||
|
||||
The `-t` option here is to specify the comma as our delimiter. More often than not spaces or tabs are assumed. Furthermore, the `-k` flag is for specifying our key. The syntax for this is `-km,n`, with `m` being the starting field and `n` being the last.
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `sort -f` ignore case
|
||||
* `sort -r` reverse sort order
|
||||
* `sort -R` scramble order
|
||||
* `uniq -c` count number of occurrences
|
||||
* `uniq -d` only print duplicate lines
|
||||
|
||||
|
||||
|
||||
### CUT
|
||||
|
||||
Cut is for removing columns. To illustrate, if we only wanted the first and third columns.
|
||||
```
|
||||
cut -d, -f 1,3 filename.csv
|
||||
|
||||
```
|
||||
|
||||
To select every column other than the first.
|
||||
```
|
||||
cut -d, -f 2- filename.csv
|
||||
|
||||
```
|
||||
|
||||
In combination with other commands, `cut` serves as a filter.
|
||||
```
|
||||
# Print first 10 lines of column 1 and 3, where "some_string_value" is present
|
||||
|
||||
head filename.csv | grep "some_string_value" | cut -d, -f 1,3
|
||||
|
||||
```
|
||||
|
||||
Finding out the number of unique values within the second column.
|
||||
```
|
||||
cat filename.csv | cut -d, -f 2 | sort | uniq | wc -l
|
||||
|
||||
# Count occurences of unique values, limiting to first 10 results
|
||||
|
||||
cat filename.csv | cut -d, -f 2 | sort | uniq -c | head
|
||||
|
||||
```
|
||||
|
||||
### PASTE
|
||||
|
||||
Paste is a niche command with an interesting function. If you have two files that you need merged, and they are already sorted, `paste` has you covered.
|
||||
```
|
||||
# names.txt
|
||||
adam
|
||||
john
|
||||
zach
|
||||
|
||||
# jobs.txt
|
||||
lawyer
|
||||
youtuber
|
||||
developer
|
||||
|
||||
# Join the two into a CSV
|
||||
|
||||
paste -d ',' names.txt jobs.txt > person_data.txt
|
||||
|
||||
# Output
|
||||
adam,lawyer
|
||||
john,youtuber
|
||||
zach,developer
|
||||
|
||||
```
|
||||
|
||||
For a more SQL_-esque variant, see below.
|
||||
|
||||
### JOIN
|
||||
|
||||
Join is a simplistic, quasi-tangential, SQL. The largest differences being that `join` will return all columns and matches can only be on one field. By default, `join` will try and use the first column as the match key. For a different result, the following syntax is necessary:
|
||||
```
|
||||
# Join the first file (-1) by the second column
|
||||
# and the second file (-2) by the first
|
||||
|
||||
join -t"," -1 2 -2 1 first_file.txt second_file.txt
|
||||
|
||||
```
|
||||
|
||||
The standard join is an inner join. However, an outer join is also viable through the `-a` flag. Another noteworthy quirk is the `-e` flag, which can be used to substitute a value if a missing field is found.
|
||||
```
|
||||
# Outer join, replace blanks with NULL in columns 1 and 2
|
||||
# -o which fields to substitute - 0 is key, 1.1 is first column, etc...
|
||||
|
||||
join -t"," -1 2 -a 1 -a2 -e ' NULL' -o '0,1.1,2.2' first_file.txt second_file.txt
|
||||
|
||||
```
|
||||
|
||||
Not the most user-friendly command, but desperate times, desperate measures.
|
||||
|
||||
* Useful options:
|
||||
|
||||
* `join -a` print unpairable lines
|
||||
* `join -e` replace missing input fields
|
||||
* `join -j` equivalent to `-1 FIELD -2 FIELD`
|
||||
|
||||
|
||||
|
||||
### GREP
|
||||
|
||||
Global search for a regular expression and print, or `grep`; likely, the most well known command, and with good reason. Grep has a lot of power, especially for finding your way around large codebases. Within the realm of data science, it acts as a refining mechanism for other commands. Although its standard usage is valuable as well.
|
||||
```
|
||||
# Recursively search and list all files in directory containing 'word'
|
||||
|
||||
grep -lr 'word' .
|
||||
|
||||
# List number of files containing word
|
||||
|
||||
grep -lr 'word' . | wc -l
|
||||
|
||||
```
|
||||
|
||||
Count total number of lines containing word / pattern.
|
||||
```
|
||||
grep -c 'some_value' filename.csv
|
||||
|
||||
# Same thing, but in all files in current directory by file name
|
||||
|
||||
grep -c 'some_value' *
|
||||
|
||||
```
|
||||
|
||||
Grep for multiple values using the or operator - `\|`.
|
||||
```
|
||||
grep "first_value\|second_value" filename.csv
|
||||
|
||||
```
|
||||
|
||||
* Useful options
|
||||
|
||||
* `alias grep="grep --color=auto"` make grep colorful
|
||||
* `grep -E` use extended regexps
|
||||
* `grep -w` only match whole words
|
||||
* `grep -l` print name of files with match
|
||||
* `grep -v` inverted matching
|
||||
|
||||
|
||||
|
||||
### THE BIG GUNS
|
||||
|
||||
Sed and Awk are the two most powerful commands in this article. For brevity, I’m not going to go into exhausting detail about either. Instead, I will cover a variety of commands that prove their impressive might. If you want to know more, [there is a book][5] just for that.
|
||||
|
||||
### SED
|
||||
|
||||
At its core `sed` is a stream editor. It excels at substitutions, but can also be leveraged for all out refactoring.
|
||||
|
||||
The most basic `sed` command consists of `s/old/new/g`. This translates to search for old value, replace with new globally. Without the `/g` our command would terminate after the first occurrence.
|
||||
|
||||
To get a quick taste of the power lets dive into an example. In this scenario you’ve been given the following file:
|
||||
```
|
||||
balance,name
|
||||
$1,000,john
|
||||
$2,000,jack
|
||||
|
||||
```
|
||||
|
||||
The first thing we may want to do is remove the dollar signs. The `-i` flag indicates in-place. The `''` is to indicate a zero-length file extension, thus overwriting our initial file. Ideally, you would test each of these individually and then output to a new file.
|
||||
```
|
||||
sed -i '' 's/\$//g' data.txt
|
||||
|
||||
# balance,name
|
||||
# 1,000,john
|
||||
# 2,000,jack
|
||||
|
||||
```
|
||||
|
||||
Next up, the commas in our `balance` column values.
|
||||
```
|
||||
sed -i '' 's/\([0-9]\),\([0-9]\)/\1\2/g' data.txt
|
||||
|
||||
# balance,name
|
||||
# 1000,john
|
||||
# 2000,jack
|
||||
|
||||
```
|
||||
|
||||
Lastly, Jack up and decided to quit one day. So, au revoir, mon ami.
|
||||
```
|
||||
sed -i '' '/jack/d' data.txt
|
||||
|
||||
# balance,name
|
||||
# 1000,john
|
||||
|
||||
```
|
||||
|
||||
As you can see, `sed` packs quite a punch, but the fun doesn’t stop there.
|
||||
|
||||
### AWK
|
||||
|
||||
The best for last. Awk is much more than a simple command: it is a full-blown language. Of everything covered in this article, `awk` is by far the coolest. If you find yourself impressed there are loads of great resources - see [here][6], [here][7] and [here][8].
|
||||
|
||||
Common use cases for `awk` include:
|
||||
|
||||
* Text processing
|
||||
* Formatted text reports
|
||||
* Performing arithmetic operations
|
||||
* Performing string operations
|
||||
|
||||
|
||||
|
||||
Awk can parallel `grep` in its most nascent form.
|
||||
```
|
||||
awk '/word/' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Or with a little more magic the combination of `grep` and `cut`. Here, `awk` prints the third and fourth column, tab separated, for all lines with our word. `-F,` merely changes our delimiter to a comma.
|
||||
```
|
||||
awk -F, '/word/ { print $3 "\t" $4 }' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Awk comes with a lot of nifty variables built-in. For instance, `NF` \- number of fields - and `NR` \- number of records. To get the fifty-third record in a file:
|
||||
```
|
||||
awk -F, 'NR == 53' filename.csv
|
||||
|
||||
```
|
||||
|
||||
An added wrinkle is the ability to filter based off of one or more values. The first example, below, will print the line number and columns for records where the first column equals string.
|
||||
```
|
||||
awk -F, ' $1 == "string" { print NR, $0 } ' filename.csv
|
||||
|
||||
# Filter based off of numerical value in second column
|
||||
|
||||
awk -F, ' $2 == 1000 { print NR, $0 } ' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Multiple numerical expressions:
|
||||
```
|
||||
# Print line number and columns where column three greater
|
||||
# than 2005 and column five less than one thousand
|
||||
|
||||
awk -F, ' $3 >= 2005 && $5 <= 1000 { print NR, $0 } ' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Sum the third column:
|
||||
```
|
||||
awk -F, '{ x+=$3 } END { print x }' filename.csv
|
||||
|
||||
```
|
||||
|
||||
The sum of the third column, for values where the first column equals “something”.
|
||||
```
|
||||
awk -F, '$1 == "something" { x+=$3 } END { print x }' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Get the dimensions of a file:
|
||||
```
|
||||
awk -F, 'END { print NF, NR }' filename.csv
|
||||
|
||||
# Prettier version
|
||||
|
||||
awk -F, 'BEGIN { print "COLUMNS", "ROWS" }; END { print NF, NR }' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Print lines appearing twice:
|
||||
```
|
||||
awk -F, '++seen[$0] == 2' filename.csv
|
||||
|
||||
```
|
||||
|
||||
Remove duplicate lines:
|
||||
```
|
||||
# Consecutive lines
|
||||
awk 'a !~ $0; {a=$0}']
|
||||
|
||||
# Nonconsecutive lines
|
||||
awk '! a[$0]++' filename.csv
|
||||
|
||||
# More efficient
|
||||
awk '!($0 in a) {a[$0];print}
|
||||
|
||||
```
|
||||
|
||||
Substitute multiple values using built-in function `gsub()`.
|
||||
```
|
||||
awk '{gsub(/scarlet|ruby|puce/, "red"); print}'
|
||||
|
||||
```
|
||||
|
||||
This `awk` command will combine multiple CSV files, ignoring the header and then append it at the end.
|
||||
```
|
||||
awk 'FNR==1 && NR!=1{next;}{print}' *.csv > final_file.csv
|
||||
|
||||
```
|
||||
|
||||
Need to downsize a massive file? Welp, `awk` can handle that with help from `sed`. Specifically, this command breaks one big file into multiple smaller ones based on a line count. This one-liner will also add an extension.
|
||||
```
|
||||
sed '1d;$d' filename.csv | awk 'NR%NUMBER_OF_LINES==1{x="filename-"++i".csv";}{print > x}'
|
||||
|
||||
# Example: splitting big_data.csv into data_(n).csv every 100,000 lines
|
||||
|
||||
sed '1d;$d' big_data.csv | awk 'NR%100000==1{x="data_"++i".csv";}{print > x}'
|
||||
|
||||
```
|
||||
|
||||
### CLOSING
|
||||
|
||||
The command line boasts endless power. The commands covered in this article are enough to elevate you from zero to hero in no time. Beyond those covered, there are many utilities to consider for daily data operations. [Csvkit][9], [xsv][10] and [q][11] are three of note. If you’re looking to take an even deeper dive into command line data science, then look no further than [this book][12]. It’s also available online [for free][13]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kadekillary.work/post/cli-4-ds/
|
||||
|
||||
作者:[Kade Killary][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kadekillary.work/authors/kadekillary
|
||||
[1]:https://en.wikipedia.org/wiki/Brian_Kernighan
|
||||
[2]:https://en.wikipedia.org/wiki/The_C_Programming_Language
|
||||
[3]:https://www.amazon.com/Learning-AWK-Programming-cutting-edge-text-processing-ebook/dp/B07BT98HDS
|
||||
[4]:https://www.youtube.com/watch?v=MijmeoH9LT4
|
||||
[5]:https://www.amazon.com/sed-awk-Dale-Dougherty/dp/1565922255/ref=sr_1_1?ie=UTF8&qid=1524381457&sr=8-1&keywords=sed+and+awk
|
||||
[6]:https://www.amazon.com/AWK-Programming-Language-Alfred-Aho/dp/020107981X/ref=sr_1_1?ie=UTF8&qid=1524388936&sr=8-1&keywords=awk
|
||||
[7]:http://www.grymoire.com/Unix/Awk.html
|
||||
[8]:https://www.tutorialspoint.com/awk/index.htm
|
||||
[9]:http://csvkit.readthedocs.io/en/1.0.3/
|
||||
[10]:https://github.com/BurntSushi/xsv
|
||||
[11]:https://github.com/harelba/q
|
||||
[12]:https://www.amazon.com/Data-Science-Command-Line-Time-Tested/dp/1491947853/ref=sr_1_1?ie=UTF8&qid=1524390894&sr=8-1&keywords=data+science+at+the+command+line
|
||||
[13]:https://www.datascienceatthecommandline.com/
|
||||
@ -1,136 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Using Stratis to manage Linux storage from the command line
|
||||
======
|
||||
|
||||

|
||||
|
||||
As discussed in [Part 1][1] and [Part 2][2] of this series, Stratis is a volume-managing filesystem with functionality similar to that of [ZFS][3] and [Btrfs][4]. In this article, we'll walk through how to use Stratis on the command line.
|
||||
|
||||
### Getting Stratis
|
||||
|
||||
For non-developers, the easiest way to try Stratis now is in [Fedora 28][5].
|
||||
|
||||
Once you're running this, you can install the Stratis daemon and the Stratis command-line tool with:
|
||||
```
|
||||
# dnf install stratis-cli stratisd
|
||||
|
||||
```
|
||||
|
||||
### Creating a pool
|
||||
|
||||
Stratis has three concepts: blockdevs, pools, and filesystems. Blockdevs are the block devices, such as a disk or a disk partition, that make up a pool. Once a pool is created, filesystems can be created from it.
|
||||
|
||||
Assuming you have a block device called `vdg` on your system that is not currently in use or mounted, you can create a Stratis pool on it with:
|
||||
```
|
||||
# stratis pool create mypool /dev/vdg
|
||||
|
||||
```
|
||||
|
||||
This assumes `vdg` is completely zeroed and empty. If it is not in use but has old data on it, it may be necessary to use `pool create`'s `- force` option. If it is in use, don't use it for Stratis.
|
||||
|
||||
If you want to create a pool from more than one block device, just list them all on the `pool create` command line. You can also add more blockdevs later using the `blockdev add-data` command. Note that Stratis requires blockdevs to be at least 1 GiB in size.
|
||||
|
||||
### Creating filesystems
|
||||
|
||||
Once you've created a pool called `mypool`, you can create filesystems from it:
|
||||
```
|
||||
# stratis fs create mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
After creating a filesystem called `myfs1` from pool `mypool`, you can mount and use it, using the entries Stratis has created within /dev/stratis:
|
||||
```
|
||||
# mkdir myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
The filesystem is now mounted on `myfs1` and ready to use.
|
||||
|
||||
### Snapshots
|
||||
|
||||
In addition to creating empty filesystems, you can also create a filesystem as a snapshot of an existing filesystem:
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1 myfs1-experiment
|
||||
|
||||
```
|
||||
|
||||
After doing so, you could mount the new `myfs1-experiment`, which will initially contain the same file contents as `myfs1`, but could change as the filesystem is modified. Whatever changes you made to `myfs1-experiment` would not be reflected in `myfs1` unless you unmounted `myfs1` and destroyed it with:
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
and then snapshotted the snapshot to recreate it and remounted it:
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1-experiment myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
### Getting information
|
||||
|
||||
Stratis can list pools on the system:
|
||||
```
|
||||
# stratis pool list
|
||||
|
||||
```
|
||||
|
||||
As filesystems have more data written to them, you will see the "Total Physical Used" value increase. Be careful when this approaches "Total Physical Size"; we're still working on handling this correctly.
|
||||
|
||||
To list filesystems within a pool:
|
||||
```
|
||||
# stratis fs list mypool
|
||||
|
||||
```
|
||||
|
||||
To list the blockdevs that make up a pool:
|
||||
```
|
||||
# stratis blockdev list mypool
|
||||
|
||||
```
|
||||
|
||||
These give only minimal information currently, but they will provide more in the future.
|
||||
|
||||
#### Destroying a pool
|
||||
|
||||
Once you have an idea of what Stratis can do, to destroy the pool, first make sure all filesystems created from it are unmounted and destroyed, then use the `pool destroy` command:
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# umount myfs1-experiment (if you created it)
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1-experiment
|
||||
|
||||
# stratis pool destroy mypool
|
||||
|
||||
```
|
||||
|
||||
`stratis pool list` should now show no pools.
|
||||
|
||||
That's it! For more information, please see the manpage: `man stratis`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/stratis-storage-linux-command-line
|
||||
|
||||
作者:[Andy Grover][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/agrover
|
||||
[1]:https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux
|
||||
[2]:https://opensource.com/article/18/4/stratis-lessons-learned
|
||||
[3]:https://en.wikipedia.org/wiki/ZFS
|
||||
[4]:https://en.wikipedia.org/wiki/Btrfs
|
||||
[5]:https://fedoraproject.org/wiki/Releases/28/Schedule
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Set up zsh on your Fedora system
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
A Bittorrent Filesystem Based On FUSE
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekp
|
||||
|
||||
The Source Code Line Counter And Analyzer
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,190 @@
|
||||
How to load or unload a Linux kernel module
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article is excerpted from chapter 15 of [Linux in Action][1], published by Manning.
|
||||
|
||||
Linux manages hardware peripherals using kernel modules. Here's how that works.
|
||||
|
||||
A running Linux kernel is one of those things you don't want to upset. After all, the kernel is the software that drives everything your computer does. Considering how many details have to be simultaneously managed on a live system, it's better to leave the kernel to do its job with as few distractions as possible. But if it's impossible to make even small changes to the compute environment without rebooting the whole system, then plugging in a new webcam or printer could cause a painful disruption to your workflow. Having to reboot each time you add a device to get the system to recognize it is hardly efficient.
|
||||
|
||||
To create an effective balance between the opposing virtues of stability and usability, Linux isolates the kernel, but lets you add specific functionality on the fly through loadable kernel modules (LKMs). As shown in the figure below, you can think of a module as a piece of software that tells the kernel where to find a device and what to do with it. In turn, the kernel makes the device available to users and processes and oversees its operation.
|
||||
|
||||
![Kernel modules][3]
|
||||
|
||||
Kernel modules act as translators between devices and the Linux kernel.
|
||||
|
||||
There's nothing stopping you from writing your own module to support a device exactly the way you'd like it, but why bother? The Linux module library is already so robust that there's usually no need to roll your own. And the vast majority of the time, Linux will automatically load a new device's module without you even knowing it.
|
||||
|
||||
Still, there are times when, for some reason, it doesn't happen by itself. (You don't want to leave that hiring manager impatiently waiting for your smiling face to join the video conference job interview for too long.) To help things along, you'll want to understand a bit more about kernel modules and, in particular, how to find the actual module that will run your peripheral and then how to manually activate it.
|
||||
|
||||
### Finding kernel modules
|
||||
|
||||
By accepted convention, modules are files with a .ko (kernel object) extension that live beneath the `/lib/modules/` directory. Before you navigate all the way down to those files, however, you'll probably have to make a choice. Because you're given the option at boot time of loading one from a list of releases, the specific software needed to support your choice (including the kernel modules) has to exist somewhere. Well, `/lib/modules`/ is one of those somewheres. And that's where you'll find directories filled with the modules for each available Linux kernel release; for example:
|
||||
```
|
||||
$ ls /lib/modules
|
||||
|
||||
4.4.0-101-generic
|
||||
|
||||
4.4.0-103-generic
|
||||
|
||||
4.4.0-104-generic
|
||||
|
||||
```
|
||||
|
||||
In my case, the active kernel is the version with the highest release number (4.4.0-104-generic), but there's no guarantee that that'll be the same for you (kernels are frequently updated). If you're going to be doing some work with modules that you'd like to use on a live system, you need to be sure you've got the right directory tree.
|
||||
|
||||
`uname -r` (the `-r` specifies the kernel release number from within the system information that would normally be displayed):
|
||||
```
|
||||
$ uname -r
|
||||
|
||||
4.4.0-104-generic
|
||||
|
||||
```
|
||||
|
||||
Good news: there's a reliable trick. Rather than identifying the directory by name and hoping you'll get the right one, use the system variable that always points to the name of the active kernel. You can invoke that variable using(thespecifies the kernel release number from within the system information that would normally be displayed):
|
||||
|
||||
With that information, you can incorporate `uname` into your filesystem references using a process known as command substitution. To navigate to the right directory, for instance, you'd add it to `/lib/modules`. To tell Linux that "uname" isn't a filesystem location, enclose the `uname` part in backticks, like this:
|
||||
```
|
||||
$ ls /lib/modules/`uname -r`
|
||||
|
||||
build modules.alias modules.dep modules.softdep
|
||||
|
||||
initrd modules.alias.bin modules.dep.bin modules.symbols
|
||||
|
||||
kernel modules.builtin modules.devname modules.symbols.bin
|
||||
|
||||
misc modules.builtin.bin modules.order vdso
|
||||
|
||||
```
|
||||
|
||||
You'll find most of the modules organized within their subdirectories beneath the `kernel/` directory. Take a few minutes to browse through those directories to get an idea of how things are arranged and what's available. The filenames usually give you a good idea of what you're looking at.
|
||||
```
|
||||
$ ls /lib/modules/`uname -r`/kernel
|
||||
|
||||
arch crypto drivers fs kernel lib mm
|
||||
|
||||
net sound ubuntu virt zfs
|
||||
|
||||
```
|
||||
|
||||
That's one way to locate kernel modules; actually, it's the quick and dirty way to go about it. But it's not the only way. If you want to get the complete set, you can list all currently loaded modules, along with some basic information, by using `lsmod`. The first column of this truncated output (there would be far too many to list here) is the module name, followed by the file size and number, and then the names of other modules on which each is dependent:
|
||||
```
|
||||
$ lsmod
|
||||
|
||||
[...]
|
||||
|
||||
vboxdrv 454656 3 vboxnetadp,vboxnetflt,vboxpci
|
||||
|
||||
rt2x00usb 24576 1 rt2800usb
|
||||
|
||||
rt2800lib 94208 1 rt2800usb
|
||||
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
How many are far too many? Well, let's run `lsmod` once again, but this time piping the output to `wc -l` to get a count of the lines:
|
||||
```
|
||||
$ lsmod | wc -l
|
||||
|
||||
113
|
||||
|
||||
```
|
||||
|
||||
Those are the loaded modules. How many are available in total? Running `modprobe -c` and counting the lines will give us that number:
|
||||
```
|
||||
$ modprobe -c | wc -l
|
||||
|
||||
33350
|
||||
|
||||
```
|
||||
|
||||
There are 33,350 available modules!?! It looks like someone's been working hard over the years to provide us with the software to run our physical devices.
|
||||
|
||||
Note: On some systems, you might encounter customized modules that are referenced either with their unique entries in the `/etc/modules` file or as a configuration file saved to `/etc/modules-load.d/`. The odds are that such modules are the product of local development projects, perhaps involving cutting-edge experiments. Either way, it's good to have some idea of what it is you're looking at.
|
||||
|
||||
That's how you find modules. Your next job is to figure out how to manually load an inactive module if, for some reason, it didn't happen on its own.
|
||||
|
||||
### Manually loading kernel modules
|
||||
|
||||
Before you can load a kernel module, logic dictates that you'll have to confirm it exists. And before you can do that, you'll need to know what it's called. Getting that part sometimes requires equal parts magic and luck and some help from of the hard work of online documentation authors.
|
||||
|
||||
I'll illustrate the process by describing a problem I ran into some time back. One fine day, for a reason that still escapes me, the WiFi interface on a laptop stopped working. Just like that. Perhaps a software update knocked it out. Who knows? I ran `lshw -c network` and was treated to this very strange information:
|
||||
```
|
||||
network UNCLAIMED
|
||||
|
||||
AR9485 Wireless Network Adapter
|
||||
|
||||
```
|
||||
|
||||
Linux recognized the interface (the Atheros AR9485) but listed it as unclaimed. Well, as they say, "When the going gets tough, the tough search the internet." I ran a search for atheros ar9 linux module and, after sifting through pages and pages of five- and even 10-year-old results advising me to either write my own module or just give up, I finally discovered that (with Ubuntu 16.04, at least) a working module existed. Its name is ath9k.
|
||||
|
||||
Yes! The battle's as good as won! Adding a module to the kernel is a lot easier than it sounds. To double check that it's available, you can run `find` against the module's directory tree, specify `-type f` to tell Linux you're looking for a file, and then add the string `ath9k` along with a glob asterisk to include all filenames that start with your string:
|
||||
```
|
||||
$ find /lib/modules/$(uname -r) -type f -name ath9k*
|
||||
|
||||
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_common.ko
|
||||
|
||||
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k.ko
|
||||
|
||||
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_htc.ko
|
||||
|
||||
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_hw.ko
|
||||
|
||||
```
|
||||
|
||||
Just one more step, load the module:
|
||||
```
|
||||
# modprobe ath9k
|
||||
|
||||
```
|
||||
|
||||
That's it. No reboots. No fuss.
|
||||
|
||||
Here's one more example to show you how to work with active modules that have become corrupted. There was a time when using my Logitech webcam with a particular piece of software would make the camera inaccessible to any other programs until the next system boot. Sometimes I needed to open the camera in a different application but didn't have the time to shut down and start up again. (I run a lot of applications, and getting them all in place after booting takes some time.)
|
||||
|
||||
Because this module is presumably active, using `lsmod` to search for the word video should give me a hint about the name of the relevant module. In fact, it's better than a hint: The only module described with the word video is uvcvideo (as you can see in the following):
|
||||
```
|
||||
$ lsmod | grep video
|
||||
|
||||
uvcvideo 90112 0
|
||||
|
||||
videobuf2_vmalloc 16384 1 uvcvideo
|
||||
|
||||
videobuf2_v4l2 28672 1 uvcvideo
|
||||
|
||||
videobuf2_core 36864 2 uvcvideo,videobuf2_v4l2
|
||||
|
||||
videodev 176128 4 uvcvideo,v4l2_common,videobuf2_core,videobuf2_v4l2
|
||||
|
||||
media 24576 2 uvcvideo,videodev
|
||||
|
||||
```
|
||||
|
||||
There was probably something I could have controlled for that was causing the crash, and I guess I could have dug a bit deeper to see if I could fix things the right way. But you know how it is; sometimes you don't care about the theory and just want your device working. So I used `rmmod` to kill the uvcvideo module and `modprobe` to start it up again all nice and fresh:
|
||||
```
|
||||
# rmmod uvcvideo
|
||||
|
||||
# modprobe uvcvideo
|
||||
|
||||
```
|
||||
|
||||
Again: no reboots. No stubborn blood stains.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/how-load-or-unload-linux-kernel-module
|
||||
|
||||
作者:[David Clinto][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dbclinton
|
||||
[1]:https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
[2]:/file/397906
|
||||
[3]:https://opensource.com/sites/default/files/uploads/kernels.png (Kernel modules)
|
||||
@ -0,0 +1,374 @@
|
||||
How to Build an Amazon Echo with Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
|
||||
Many people today are using assistant software in their homes and offices to help with everyday tasks. There are many different models to purchase, but did you know you can build your own? [Amazon Developer][1] allows you to use the Alexa software to create your own [Amazon Echo][2] with [Raspberry Pi][3].
|
||||
|
||||
### Materials
|
||||
|
||||
For this project, you’ll need:
|
||||
|
||||
* The Raspberry Pi 3 or Pi 2 Model B and Micro-USB power cable
|
||||
* Micro SD Card (Minimum 8 GB) – If you don’t have an operating system installed, there’s an easy-to-use operating system called NOOBS (New Out of the Box Software). The simplest way to get NOOBS is to buy an SD card with NOOBS pre-loaded.
|
||||
* USB 2.0 Mini Microphone
|
||||
* External speaker and 3.5mm audio cable
|
||||
* USB Keyboard and Mouse and external HDMI Monitor
|
||||
* Internet connection (Ethernet or WiFi)
|
||||
* For a Pi 2 to connect to the Internet wirelessly, you need a WiFi Wireless Adapter. The Pi 3 has built-in WiFi.
|
||||
|
||||
|
||||
|
||||
**Related** : [5 Essential Tips & Tricks to Personalize Your Amazon Echo][4]
|
||||
|
||||
### Register for an Amazon Developer account
|
||||
|
||||
If you need an Amazon Developer account, create a free one on their [page][1]. Read the AVS (Alexa Voice Service) Terms and Agreements [here][5].
|
||||
|
||||
![raspberrypi-echo-amazon-developer-account][6]
|
||||
|
||||
![raspberrypi-echo-amazon-developer-account][6]
|
||||
|
||||
Complete your profile information.
|
||||
|
||||
![raspberrypi-echo-register-profile-info][7]
|
||||
|
||||
![raspberrypi-echo-register-profile-info][7]
|
||||
|
||||
Read and accept the App Distribution Agreement.
|
||||
|
||||
![raspberrypi-echo-register-app-distribution-agree][8]
|
||||
|
||||
![raspberrypi-echo-register-app-distribution-agree][8]
|
||||
|
||||
Select whether you are choosing to monetize your apps.
|
||||
|
||||
![raspberrypi-echo-register-payments][9]
|
||||
|
||||
![raspberrypi-echo-register-payments][9]
|
||||
|
||||
### Create your device on Amazon Developer
|
||||
|
||||
After registering your Amazon Developer account, create an Alexa device and Security profile. Make careful note of the following parameters as you go through the setup – ProductID, ClientID, and ClientSecret, because you need to enter these again later.
|
||||
|
||||
From the top menu, select “Alexa Voice Service.”
|
||||
|
||||
![raspberrypi-echo-alexa-voice-service][10]
|
||||
|
||||
![raspberrypi-echo-alexa-voice-service][10]
|
||||
|
||||
The “Welcome to Developer” screen will appear.
|
||||
|
||||
![raspberrypi-echo-developer-welcome][11]
|
||||
|
||||
![raspberrypi-echo-developer-welcome][11]
|
||||
|
||||
The first screen asks about the product you are building.
|
||||
|
||||
1\. First, name your device.
|
||||
|
||||
![raspberrypi-echo-product-name][12]
|
||||
|
||||
![raspberrypi-echo-product-name][12]
|
||||
|
||||
2\. Next, type a Product ID with no spaces or special characters.
|
||||
|
||||
**Note** : You need this later. Record it somewhere.
|
||||
|
||||
![raspberrypi-echo-product-id][13]
|
||||
|
||||
![raspberrypi-echo-product-id][13]
|
||||
|
||||
3\. Select Alexa-Enabled Device for the product type.
|
||||
|
||||
![raspberrypi-echo-product-type][14]
|
||||
|
||||
![raspberrypi-echo-product-type][14]
|
||||
|
||||
4\. Alexa needs a companion app. Select yes for this question.
|
||||
|
||||
![raspberrypi-echo-companion-app][15]
|
||||
|
||||
![raspberrypi-echo-companion-app][15]
|
||||
|
||||
5\. Choose Wireless Speakers from the dropdown menu.
|
||||
|
||||
6\. Enter “Raspberry Pi Project on Github” into the description box. This is information for AVS and isn’t visible to others.
|
||||
|
||||
7\. Check both the “Touch-initiated” and “Hands-free” options.
|
||||
|
||||
![raspberrypi-echo-product-options][16]
|
||||
|
||||
![raspberrypi-echo-product-options][16]
|
||||
|
||||
8\. You can upload an image for your device, but let’s skip this step for now.
|
||||
|
||||
9\. Check “no” for commercial distribution and children’s product questions.
|
||||
|
||||
![raspberrypi-echo-product-options-2][17]
|
||||
|
||||
![raspberrypi-echo-product-options-2][17]
|
||||
|
||||
10\. Click “Next.”
|
||||
|
||||
### Create your security profile
|
||||
|
||||
On this page, you create a new LWA (Login with Amazon) security profile to identify the user data and security credentials with this project.
|
||||
|
||||
1\. Click “Create new profile.”
|
||||
|
||||
![raspberrypi-echo-lwa-security-profile2][18]
|
||||
|
||||
![raspberrypi-echo-lwa-security-profile2][18]
|
||||
|
||||
2\. Create a name for the profile. It could be something like, “Alexa Security Profile.”
|
||||
|
||||
![raspberrypi-echo-security-profile-name][19]
|
||||
|
||||
![raspberrypi-echo-security-profile-name][19]
|
||||
|
||||
3\. Type a description for the profile. You can choose “Alexa Security Profile Description.”
|
||||
|
||||
![raspberrypi-echo-security-description][20]
|
||||
|
||||
![raspberrypi-echo-security-description][20]
|
||||
|
||||
4\. Click “Next.”
|
||||
|
||||
5\. Amazon generates a Client ID and Client Secret for you. These are the other two values you need later. Keep them nearby.
|
||||
|
||||
![raspberrypi-echo-id-and-secret1][21]
|
||||
|
||||
![raspberrypi-echo-id-and-secret1][21]
|
||||
|
||||
6\. Enter your Allowed origins and Allowed return URLs. We’re setting up http and https routes for this project, so type the following into your “Allowed Origins” field — “<http://localhost:3000.”>
|
||||
|
||||
7\. Click “Add.”
|
||||
|
||||
8\. Type “<https://localhost:3000”> into the same box where you typed the first one.
|
||||
|
||||
![raspberrypi-echo-allowed-origins-2][22]
|
||||
|
||||
![raspberrypi-echo-allowed-origins-2][22]
|
||||
|
||||
9\. Click “Add” again.
|
||||
|
||||
10\. Do the same thing to the Allowed Return URLs, except enter the following two URLs:
|
||||
|
||||
11\. The page should look like this before you click Finish. Make sure none of your URLs are still in the field where you typed them. They are displayed on a grey background after you add them.
|
||||
|
||||
![raspberrypi-echo-all-origins][23]
|
||||
|
||||
![raspberrypi-echo-all-origins][23]
|
||||
|
||||
12\. Once you click “Finish,” this screen appears. Your project has been created and is ready to install.
|
||||
|
||||
![raspberrypi-echo-product-screen][24]
|
||||
|
||||
![raspberrypi-echo-product-screen][24]
|
||||
|
||||
### Clone the Alexa sample app
|
||||
|
||||
1\. Open Terminal.
|
||||
|
||||
![raspberrypi-echo-open-terminal2][25]
|
||||
|
||||
![raspberrypi-echo-open-terminal2][25]
|
||||
|
||||
2\. Type the following:
|
||||
```
|
||||
cd Desktop
|
||||
git clone https://github.com/alexa/alexa-avs-sample-app.git
|
||||
```
|
||||
|
||||
### Update the install script by adding your credentials
|
||||
|
||||
Before you run the install script, update the script with the credentials that you recorded from Amazon — ProductID, ClientID, ClientSecret.
|
||||
|
||||
1\. Type the following in Terminal:
|
||||
```
|
||||
cd ~/Desktop/alexa-avs-sample-app
|
||||
nano automated_install.sh
|
||||
```
|
||||
|
||||
2\. When it runs, this screen appears. Use the arrows on your keyboard to navigate, and replace the fields for ProductID, ClientID, and ClientSecret with your values.
|
||||
|
||||
![raspberrypi-echo-insert-device-data][26]
|
||||
|
||||
![raspberrypi-echo-insert-device-data][26]
|
||||
|
||||
The changes should look like this:
|
||||
```
|
||||
ProductID="Your Device Name"
|
||||
ClientID="amzn.xxxxx.xxxxxxxxx"
|
||||
ClientSecret="4e8cb14xxxxxxxxxxxxxxxxxxxxxxxxxxxxx6b4f9"
|
||||
```
|
||||
|
||||
3\. Type Ctrl + X to exit the script. Type Y and then Enter to save your changes.
|
||||
|
||||
### Run the install script
|
||||
|
||||
To run the script, open Terminal and run the following commands.
|
||||
```
|
||||
cd ~/Desktop/alexa-avs-sample-app
|
||||
. automated_install.sh
|
||||
```
|
||||
|
||||
While this script is running, you will be asked to answer some simple questions. These are to make sure you’ve completed all of the necessary setup on Amazon before you install the program.
|
||||
|
||||
![raspberrypi-echo-setup-questions][27]
|
||||
|
||||
![raspberrypi-echo-setup-questions][27]
|
||||
|
||||
The installation is about thirty minutes, so go grab a snack.
|
||||
|
||||
When installed correctly, your terminal window will look like the following image.
|
||||
|
||||
![raspberrypi-echo-end-install2][28]
|
||||
|
||||
![raspberrypi-echo-end-install2][28]
|
||||
|
||||
### The Three Terminals
|
||||
|
||||
You must complete three steps to run the Alexa app. Each of them must run in a separate Terminal window, and you must do them in the correct order.
|
||||
|
||||
There were some programs that I needed but didn’t have. I installed these programs as I went. In case you have the same problem, I included a side note about this in each step.
|
||||
|
||||
#### Terminal 1
|
||||
|
||||
This window runs the web service to authorize your app with AVS (Alexa Voice Service)
|
||||
|
||||
Open Terminal and type in the following commands:
|
||||
```
|
||||
cd ~/Desktop/alexa-avs-sample-app/samples
|
||||
cd companionService && npm start
|
||||
```
|
||||
|
||||
**Note** : npm is a package manager for the JavaScript programming language. If it is not available when you run the command, you can get it [here][29].
|
||||
|
||||
When the scripts finish, the window looks like this, showing that Pi is listening on port 3000.
|
||||
|
||||
![raspberrypi-echo-port-3000][30]
|
||||
|
||||
![raspberrypi-echo-port-3000][30]
|
||||
|
||||
Don’t close this window. It needs to remain open while completing the next steps.
|
||||
|
||||
#### Terminal 2
|
||||
|
||||
This window communicates with AVS.
|
||||
|
||||
Type the following into another Terminal window.
|
||||
```
|
||||
cd ~/Desktop/alexa-avs-sample-app/samples
|
||||
cd javaclient && mvn exec:exec
|
||||
```
|
||||
|
||||
**Note** : mvn is short for Apache Maven. If you don’t have it, click [here][31] to get started.
|
||||
|
||||
When you run the client, a dialog box appears saying, “Please register your device by …”
|
||||
|
||||
Click Yes.
|
||||
|
||||
![raspberrypi-echo-open-site][32]
|
||||
|
||||
![raspberrypi-echo-open-site][32]
|
||||
|
||||
With some browsers, you’ll get a warning that the connection is not safe. Dismiss this by clicking the “advanced” button. Then on the next screen, click on “Proceed to localhost (unsafe).”
|
||||
|
||||
Now, log into Amazon using your developer credentials.
|
||||
|
||||
The next screen asks for permission to use the security profile you created earlier for the device you are registering. Click Okay.
|
||||
|
||||
![raspberrypi-echo-use-security-profile][33]
|
||||
|
||||
![raspberrypi-echo-use-security-profile][33]
|
||||
|
||||
You will be redirected to a URL beginning with “<https://localhost:3000/authresponse”> that looks like the following image.
|
||||
|
||||
![raspberrypi-echo-device-tokens-ready][34]
|
||||
|
||||
![raspberrypi-echo-device-tokens-ready][34]
|
||||
|
||||
Go back to the open dialog box and click the OK button. The client is now able to accept requests from your Alexa device.
|
||||
|
||||
Keep the terminal open as well as the Voice Service Dialog box.
|
||||
|
||||
![raspberrypi-echo-voice-service-box][35]
|
||||
|
||||
![raspberrypi-echo-voice-service-box][35]
|
||||
|
||||
#### Terminal 3
|
||||
|
||||
This window installs the application that wakes up Alexa by using her wake word. Skip this if you don’t want to use voice to initiate Alexa.
|
||||
|
||||
Open a new terminal window and use one of the following commands to bring up a wake word engine using Sensory or KITT.AI.
|
||||
|
||||
To use the Sensory wake word engine, type:
|
||||
```
|
||||
cd ~/Desktop/alexa-avs-sample-app/samples
|
||||
cd wakeWordAgent/src && ./wakeWordAgent -e sensory
|
||||
```
|
||||
|
||||
To use KITT.AI’s wake word engine, type:
|
||||
```
|
||||
cd ~/Desktop/alexa-avs-sample-app/samples
|
||||
cd wakeWordAgent/src && ./wakeWordAgent -e kitt_ai
|
||||
```
|
||||
|
||||
### Test it out
|
||||
|
||||
Talk to Alexa by saying the wake word, “Alexa.” Wait for the beep before giving your command. For example, try it by saying, “Alexa.” Wait for the beep, and then ask, “What’s the time?”
|
||||
|
||||
If she responds correctly, you have a working Alexa device!
|
||||
|
||||
Check out Amazon’s Alexa [webpage][36] for more ideas. This Alexa can do everything an Echo can do!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/build-amazon-echo-with-raspberry-pi/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:http://developer.amazon.com
|
||||
[2]:https://www.amazon.com/dp/B06XCM9LJ4/?tag=maketecheas08-20
|
||||
[3]:https://www.maketecheasier.com/tag/raspberry-pi
|
||||
[4]:https://www.maketecheasier.com/essential-amazon-echo-tips-tricks/ (5 Essential Tips & Tricks to Personalize Your Amazon Echo)
|
||||
[5]:https://developer.amazon.com/support/legal/alexa/alexa-voice-service/terms-and-agreements
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Amazon-developer-account.jpg (raspberrypi-echo-amazon-developer-account)
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Register-Profile-info.jpg (raspberrypi-echo-register-profile-info)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Register-App-Distribution-Agree.jpg (raspberrypi-echo-register-app-distribution-agree)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Register-Payments.jpg (raspberrypi-echo-register-payments)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Alexa-voice-service.jpg (raspberrypi-echo-alexa-voice-service)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-developer-welcome.jpg (raspberrypi-echo-developer-welcome)
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-name.jpg (raspberrypi-echo-product-name)
|
||||
[13]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-ID.jpg (raspberrypi-echo-product-id)
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-type.jpg (raspberrypi-echo-product-type)
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-companion-app.jpg (raspberrypi-echo-companion-app)
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-options.jpg (raspberrypi-echo-product-options)
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-options-2.jpg (raspberrypi-echo-product-options-2)
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-LWA-Security-Profile2.jpg (raspberrypi-echo-lwa-security-profile2)
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-security-profile-name.jpg (raspberrypi-echo-security-profile-name)
|
||||
[20]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-security-description.jpg (raspberrypi-echo-security-description)
|
||||
[21]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-ID-and-secret1.jpg (raspberrypi-echo-id-and-secret1)
|
||||
[22]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-allowed-origins-2.jpg (raspberrypi-echo-allowed-origins-2)
|
||||
[23]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-all-origins.jpg (raspberrypi-echo-all-origins)
|
||||
[24]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-product-screen.jpg (raspberrypi-echo-product-screen)
|
||||
[25]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-open-terminal2.jpg (raspberrypi-echo-open-terminal2)
|
||||
[26]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-insert-device-data.jpg (raspberrypi-echo-insert-device-data)
|
||||
[27]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-setup-questions.jpg (raspberrypi-echo-setup-questions)
|
||||
[28]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-end-install2.jpg (raspberrypi-echo-end-install2)
|
||||
[29]:https://www.npmjs.com/
|
||||
[30]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Port-3000.jpg (raspberrypi-echo-port-3000)
|
||||
[31]:https://maven.apache.org/
|
||||
[32]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-open-site.jpg (raspberrypi-echo-open-site)
|
||||
[33]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-use-security-profile.jpg (raspberrypi-echo-use-security-profile)
|
||||
[34]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-device-tokens-ready.jpg (raspberrypi-echo-device-tokens-ready)
|
||||
[35]:https://www.maketecheasier.com/assets/uploads/2018/03/RaspberryPi-Echo-Voice-service-box.jpg (raspberrypi-echo-voice-service-box)
|
||||
[36]:https://www.amazon.com/meet-alexa/b?ie=UTF8&node=16067214011&tag=maketecheas08-20
|
||||
@ -0,0 +1,125 @@
|
||||
Qalculate! – The Best Calculator Application in The Entire Universe
|
||||
======
|
||||
I have been a GNU-Linux user and a [Debian][1] user for more than a decade. As I started using the desktop more and more, it seemed to me that apart from few web-based services most of my needs were being met with [desktop applications][2] within Debian itself.
|
||||
|
||||
One of such applications was the need for me to calculate between different measurements of units. While there are and were many web-services which can do the same, I wanted something which could do all this and more on my desktop for both privacy reasons as well as not having to hunt for a web service for doing one thing or the other. My search ended when I found Qalculate!.
|
||||
|
||||
### Qalculate! The most versatile calculator application
|
||||
|
||||
![Qalculator is the best calculator app][3]
|
||||
|
||||
This is what aptitude says about [Qalculate!][4] and I cannot put it in better terms:
|
||||
|
||||
> Powerful and easy to use desktop calculator – GTK+ version
|
||||
>
|
||||
> Qalculate! is small and simple to use but with much power and versatility underneath. Features include customizable functions, units, arbitrary precision, plotting, and a graphical interface that uses a one-line fault-tolerant expression entry (although it supports optional traditional buttons).
|
||||
|
||||
It also did have a KDE interface as well as in its previous avatar, but at least in Debian testing, it just shows only the GTK+ version which can be seen from the github [repo][5] as well.
|
||||
|
||||
Needless to say that Qalculate! is available in Debian repository and hence can easily be installed [using apt command][6] or through software center in Debian based distributions like Ubuntu. It is also availale for Windows and macOS.
|
||||
|
||||
#### Features of Qalculate!
|
||||
|
||||
Now while it would be particularly long to go through the whole list of functionality it allows – allow me to list some of the functionality to be followed by a few screenshots of just a couple of functionalities that Qalculate! provides. The idea is basically to familiarize you with a couple of basic methods and then leave it up to you to enjoy exploring what all Qalculate! can do.
|
||||
|
||||
* Algebra
|
||||
* Calculus
|
||||
* Combinatorics
|
||||
* Complex_Numbers
|
||||
* Data_Sets
|
||||
* Date_&_Time
|
||||
* Economics
|
||||
* Exponents_&_Logarithms
|
||||
* Geometry
|
||||
* Logical
|
||||
* Matrices_&_Vectors
|
||||
* Miscellaneous
|
||||
* Number_Theory
|
||||
* Statistics
|
||||
* Trigonometry
|
||||
|
||||
|
||||
|
||||
#### Using Qalculate!
|
||||
|
||||
Using Qalculate! is not complicated. You can even write in the simple natural language. However, I recommend [reading the manual][7] to utilize the full potential of Qalculate!
|
||||
|
||||
![qalculate byte to gibibyte conversion ][8]
|
||||
|
||||
![conversion from celcius degrees to fahreneit][9]
|
||||
|
||||
#### qalc is the command line version of Qalculate!
|
||||
|
||||
You can achieve the same results as Qalculate! with its command-line brethren qalc
|
||||
```
|
||||
$ qalc 62499836 byte to gibibyte
|
||||
62499836 * byte = approx. 0.058207508 gibibyte
|
||||
|
||||
$ qalc 40 degree celsius to fahrenheit
|
||||
(40 * degree) * celsius = 104 deg*oF
|
||||
|
||||
```
|
||||
|
||||
I shared the command-line interface so that people who don’t like GUI interfaces and prefer command-line (CLI) or have headless nodes (no GUI) could also use qalculate, pretty common in server environments.
|
||||
|
||||
If you want to use it in scripts, I guess libqalculate would be the way to go and seeing how qalculate-gtk, qalc depend on it seems it should be good enough.
|
||||
|
||||
Just to share, you could also explore how to use plotting of series data but that and other uses will leave to you. Don’t forget to check the /usr/share/doc/qalculate/index.html to see all the different functionalities that Qalculate! has.
|
||||
|
||||
Note:- Do note that though Debian prefers [gnuplot][10] to showcase the pretty graphs that can come out of it.
|
||||
|
||||
#### Bonus Tip: You can thank the developer via command line in Debian
|
||||
|
||||
If you use Debian and like any package, you can quickly thank the Debian Developer or maintainer maintaining the said package using:
|
||||
```
|
||||
reportbug --kudos $PACKAGENAME
|
||||
|
||||
```
|
||||
|
||||
Since I liked QaIculate!, I would like to give a big shout-out to the Debian developer and maintainer Vincent Legout for the fantastic work he has done.
|
||||
```
|
||||
reportbug --kudos qalculate
|
||||
|
||||
```
|
||||
|
||||
I would also suggest reading my detailed article on using reportbug tool for [bug reporting in Debian][11].
|
||||
|
||||
#### The opinion of a Polymer Chemist on Qalculate!
|
||||
|
||||
Through my fellow author [Philip Prado][12], we contacted a Mr. Timothy Meyers, currently a student working in a polymer lab as a Polymer Chemist.
|
||||
|
||||
His professional opinion on Qaclulate! is –
|
||||
|
||||
> This looks like almost any scientist to use as any type of data calculations statistics could use this program issue would be do you know the commands and such to make it function
|
||||
>
|
||||
> I feel like there’s some Physics constants that are missing but off the top of my head I can’t think of what they are but I feel like there’s not very many [fluid dynamics][13] stuff in there and also some different like [light absorption][14] coefficients for different compounds but that’s just a chemist in me I don’t know if those are super necessary. [Free energy][15] might be one
|
||||
|
||||
In the end, I just want to share this is a mere introduction to what Qalculate! can do and is limited by what you want to get done and your imagination. I hope you like Qalculate!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/qalculate/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/shirish/
|
||||
[1]:https://www.debian.org/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/qalculate-app-featured-1-800x450.jpeg
|
||||
[4]:https://qalculate.github.io/
|
||||
[5]:https://github.com/Qalculate
|
||||
[6]:https://itsfoss.com/apt-command-guide/
|
||||
[7]:https://qalculate.github.io/manual/index.html
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/qalculate-byte-conversion.png
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/qalculate-gtk-weather-conversion.png
|
||||
[10]:http://www.gnuplot.info/
|
||||
[11]:https://itsfoss.com/bug-report-debian/
|
||||
[12]:https://itsfoss.com/author/phillip/
|
||||
[13]:https://en.wikipedia.org/wiki/Fluid_dynamics
|
||||
[14]:https://en.wikipedia.org/wiki/Absorption_(electromagnetic_radiation)
|
||||
[15]:https://en.wikipedia.org/wiki/Gibbs_free_energy
|
||||
128
sources/tech/20180601 3 open source music players for Linux.md
Normal file
128
sources/tech/20180601 3 open source music players for Linux.md
Normal file
@ -0,0 +1,128 @@
|
||||
3 open source music players for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
As I described [in my last article][1], when I'm using a Linux-based computer to listen to music, I pass that music through a dedicated digital-analog converter, or DAC. To make sure the bits in the music file get through to the DAC without any unnecessary fiddling on the part of intermediate software on my computer (like audio mixers), I like to aim the music player directly at the [hw interface][2] (or, if necessary, the plughw interface) that ALSA provides to the external equipment.
|
||||
|
||||
So, when I hear about a new music player, the first thing I do is figure out how to configure the output device. In the process of reviewing quite a few Linux-based music players, I'm beginning to see a pattern.
|
||||
|
||||
First, a sizable group of players depends on [GStreamer][3] to play the audio. As its website says, GStreamer is a multimedia framework that allows construction of arbitrary pipelines of media-processing components. In my case, [the alsasink plugin][4] can be used in a pipeline, like this:
|
||||
```
|
||||
gst-launch-1.0 -v uridecodebin uri=file:///path/to/my.flac ! audioconvert ! audioresample ! autoaudiosink
|
||||
|
||||
```
|
||||
|
||||
to play back the file `/path/to/my.flac` on the default ALSA audio output device. Note the use of the `audioresample` component in the pipeline—that's one of the things I don't want! Also, I don't want to use the ALSA default output—I want to select the device.
|
||||
|
||||
GStreamer-based music players vary in the configurability of their outputs. At the one extreme, players like [QuodLibet][5] provide the ability to precisely configure the output. At the other extreme, players like [Rhythmbox][6] use the default audio device, meaning—as far as I can tell, anyway—that mixing and resampling are going to happen. For example, the [PulseAudio Perfect Setup Guide][7] explains:
|
||||
|
||||
> Applications using the modern GStreamer media framework such as Rhythmbox or Totem can make use of the PulseAudio through gst-pulse, the PulseAudio plugin for GStreamer…
|
||||
|
||||
and then shows how to use `gconftool` to enable that:
|
||||
```
|
||||
gconftool -t string --set /system/gstreamer/0.10/default/audiosink pulsesink
|
||||
|
||||
```
|
||||
|
||||
So far, I've only found a few GStreamer-based music players that let me build the dedicated output connection I want: QuodLibet, [Guayadeque][8], and [Gmusicbrowser][9]. All three of these are great music players, but for my use—once configured—[I prefer Guayadeque][10].
|
||||
|
||||
Second, there is a different group of players that don't use GStreamer, instead taking a different route to getting data to the output device. A subgroup of these players are clients for [the MPD music server backend][11]. Of the players that use the MPD backend, [Cantata][12] is [my favorite, by far][13]. Of course, the nice thing about MPD being a server is that it can be controlled by other devices, such as Android-based phones or tablets. Therefore, for a music player hooked up to the home stereo or AV center, MPD is my go-to.
|
||||
|
||||
Of the non-MPD, non-GStreamer music players I've tried that support my use case, I really like [Goggles Music Manager][14].
|
||||
|
||||
With that background, let's take a look at some new (to me) players.
|
||||
|
||||
### Museeks music player
|
||||
|
||||
The [Museeks][15] music player is available on GitHub in source or binary (.deb, .AppImage,.rpm, amd64, or i386). Taking a quick look at the code, I see that Museeks is an Electron application, which I find kind of intriguing. The .deb installed without problems, and upon startup I was greeted with the Museeks user interface, which I find to be simple but attractive.
|
||||
|
||||
|
||||
|
||||
After clicking on the Audio tab, the only option I saw changes the playback rate, which is not of interest to me. After further online searching, I opened an issue on GitHub to ask about this and was encouraged by a quick and friendly response from Pierre de la Martinière saying he thought it interesting and that he would look into it. So, for now, without the ability to configure output, I'm going to put this otherwise interesting-looking player on pause.
|
||||
|
||||
### LPlayer music player
|
||||
|
||||
The [LPlayer][16] music player is also available on GitHub and as an Ubuntu PPA. I used the latter to install the current version, which proceeded without issue. LPlayer offers a very simple user interface: audio files (music or whatever) are loaded from the filesystem into the current playlist, reminiscent of [VLC][17]. I don't mind this kind of organization, but I like a more extensive, tag-based music browser. However, a lightweight player has its own charms, so I continued with the evaluation.
|
||||
|
||||
Here is LPlayer's main screen with two tracks loaded:
|
||||
|
||||
|
||||
|
||||
The Settings control offers the playing track's current position, the playback speed, options to "remove silence" and "play continuously," and a graphical equalizer, but no output device configuration.
|
||||
|
||||
|
||||
|
||||
A bit of source code investigation showed that LPlayer uses GStreamer. I decided to contact the author, Lorenzo Carbonell, to see if he had any thoughts about the idea of configuring the GStreamer playback pipeline within the application. Until I hear back from him, I'll keep this little player on the shelf. (By the way, Linux fans, Sr. Carbonell has a pretty great-looking Spanish-language Linux blog, [El Atareao-Linux para Legos][18]).
|
||||
|
||||
### Elisa music player
|
||||
|
||||
According to the KDE community website, the [Elisa][19] music player is intended to provide "very good integration with the Plasma desktop of the KDE community without compromising the support for other platforms." One of these days, I need to set up a KDE desktop so I can try some of this stuff in the native environment, but that's not in the cards for this review.
|
||||
|
||||
I took a look at the [Try It][20] instructions to get an idea of how I might, well, try it. According to that page, my options were: 1) try a [Flatpak][21], 2) install ArchLinux and use the AUR available, or 3) install Fedora for which "the releases are usually packaged." Based on these options, I thought it was time I tried a Flatpak…
|
||||
```
|
||||
me@mymachine:~/Downloads$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
|
||||
me@mymachine:~/Downloads$ sudo flatpak remote-add --if-not-exists kdeapps --from https://distribute.kde.org/kdeapps.flatpakrepo
|
||||
|
||||
flatpak install kdeapps org.kde.elisa
|
||||
|
||||
Required runtime for org.kde.elisa/x86_64/master (org.kde.Platform/x86_64/5.9) is not installed, searching...
|
||||
|
||||
Found in remote flathub, do you want to install it? [y/n]:
|
||||
|
||||
```
|
||||
|
||||
Hmmm let's see, `org.kde.Platform`… maybe I don't want to bring all that in. I think I'm going to press pause on this player, too, until I can take the time to set up a KDE environment.
|
||||
|
||||
### Conclusions for this round
|
||||
|
||||
Well, really there aren't many, except that Museeks and LPlayer reinforce my impression that being able to pass music data to the DAC without tampering is not a primary design goal for a lot of Linux music players. This is too bad, really, because there are plenty of decent-to-excellent, low-cost DACs that are compatible with Linux and do a great job of converting those digits to sweet, sweet analog.
|
||||
|
||||
### Let's not forget the music
|
||||
|
||||
I've been shopping for music downloads again, this time on 7digital's Linux-friendly store. I picked up three great albums by [Fela Kuti][22], in CD-quality FLAC format: [Opposite People][23], [Roforofo Fight][24], and [Unnecessary Begging][25]. This man made so much great music! The sound quality on these files is generally quite decent, which is a nice treat. Opposite People dates back to 1977, Roforofo Fight to 1972, and Unnecessary Begging to 1982.
|
||||
|
||||
I also bought [Trentemøller][26]'s 2016 album, [Fixion][27]. I've liked his stuff since I first bumped into [The Last Resort][28]. This [video documentary][29] provides an interesting perspective on Trentemøller and his music, which is quite distinctive; I like his use of guitars, which can sometimes hint at '60s surfer music. The version on 7digital was available in 96KHz/24bit, so that's what I bought.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/open-source-music-players
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/article/18/3/phono-preamplifier-project
|
||||
[2]:https://en.wikipedia.org/wiki/Advanced_Linux_Sound_Architecture#Concepts
|
||||
[3]:https://gstreamer.freedesktop.org/
|
||||
[4]:https://gstreamer.freedesktop.org/data/doc/gstreamer/head/gst-plugins-base-plugins/html/gst-plugins-base-plugins-alsasink.html
|
||||
[5]:https://quodlibet.readthedocs.io/en/latest/
|
||||
[6]:https://help.gnome.org/users/rhythmbox/stable/
|
||||
[7]:https://www.freedesktop.org/wiki/Software/PulseAudio/Documentation/User/PerfectSetup/
|
||||
[8]:http://www.guayadeque.org/
|
||||
[9]:https://gmusicbrowser.org/
|
||||
[10]:https://opensource.com/article/16/12/soundtrack-open-source-music-players
|
||||
[11]:https://www.musicpd.org/
|
||||
[12]:https://github.com/CDrummond/cantata
|
||||
[13]:https://opensource.com/article/17/8/cantata-music-linux
|
||||
[14]:https://gogglesmm.github.io/
|
||||
[15]:https://github.com/KeitIG/Museeks/releases/tag/0.9.4
|
||||
[16]:https://github.com/atareao/lplayer
|
||||
[17]:https://www.videolan.org/vlc/index.es.html
|
||||
[18]:https://www.atareao.es/
|
||||
[19]:https://community.kde.org/Elisa
|
||||
[20]:https://community.kde.org/Elisa#Try_It
|
||||
[21]:https://flatpak.org/
|
||||
[22]:https://en.wikipedia.org/wiki/Fela_Kuti
|
||||
[23]:https://youtu.be/PeH4xziCHQs
|
||||
[24]:https://youtu.be/XvX_iNFcKho
|
||||
[25]:https://www.youtube.com/watch?v=614ZdP8SIbg
|
||||
[26]:http://www.trentemoller.com/
|
||||
[27]:http://www.trentemoller.com/music/fixion-0
|
||||
[28]:https://en.wikipedia.org/wiki/The_Last_Resort_(album)
|
||||
[29]:https://youtu.be/avatsxJazA0
|
||||
159
sources/tech/20180601 Get Started with Snap Packages in Linux.md
Normal file
159
sources/tech/20180601 Get Started with Snap Packages in Linux.md
Normal file
@ -0,0 +1,159 @@
|
||||
Get Started with Snap Packages in Linux
|
||||
======
|
||||
|
||||

|
||||
Chances are you’ve heard about Snap packages. These universal packages were brought into the spotlight with the release of Ubuntu 16.04 and have continued to draw attention as a viable solution for installing applications on Linux. What makes Snap packages so attractive to the end user? The answer is really quite easy: Simplicity. In this article, I’ll answer some common questions that arise when learning about Snaps and show how to start using them.
|
||||
|
||||
Exactly what are Snap packages? And why are they needed? Considering there are already multiple ways to install software on Linux, doesn’t this complicate the issue? Not in the slightest. Snaps actually makes installing/updating/removing applications on Linux incredibly easy.
|
||||
|
||||
How does it accomplish this? Essentially, a Snap package is a self-contained application that bundles most of the libraries and runtimes (necessary to successfully run an application) into a single, universal package. Because of this, Snaps can be installed, updated, and reverted without affecting the rest of the host system, and without having to first install dependencies. Snap packages are also confined from the OS (via various security mechanisms), yet can still function as if it were installed by the standard means (exchanging data with the host OS and other installed applications).
|
||||
|
||||
Are Snaps challenging to work with? In a word, no. In fact, Snaps make short work of installing apps that might otherwise challenge your Linux admin skills. Since Snap packages are self-contained, you only need to install one package to get an app up and running.
|
||||
|
||||
Although Snap packages were created by Ubuntu developers, they can be installed on most modern Linux distributions. Because the necessary tool for Snap packages is installed on the latest releases of Ubuntu out of the box, I’m going to walk you through the process of installing and using Snap packages on Fedora. Once installed, using Snap is the same, regardless of distribution.
|
||||
|
||||
### Installation
|
||||
|
||||
The first thing you must do is install the Snap system, aka snapd. To do this on Fedora, open up the terminal window and issue the command:
|
||||
```
|
||||
sudo dnf install snapd
|
||||
|
||||
```
|
||||
|
||||
The above command will catch any necessary dependencies and install the system for Snap. That’s all there is to is. You’re ready to install your first Snap package.
|
||||
|
||||
### Installing with Snap: Command-line edition
|
||||
|
||||
The first thing you’ll want to do is find out what packages are available to install via Snap. Although Snap has begun to gain significant momentum, not every application can be installed via Snap. Let’s say you want to install GIMP. First you might want to find out what GIMP-relate packages are available as Snaps. Back at the terminal window, issue the command:
|
||||
```
|
||||
sudo snap find gimp
|
||||
|
||||
```
|
||||
|
||||
The command should report only one package available for GIMP (Figure 1).
|
||||
|
||||
|
||||
![Snap][2]
|
||||
|
||||
Figure 1: GIMP is available to install via Snap.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
To get a better idea as to what the find option can do for you, issue the command:
|
||||
```
|
||||
sudo snap find nextcloud
|
||||
|
||||
```
|
||||
|
||||
The output of that command (Figure 2) will report Snap packages related to Nextcloud.
|
||||
|
||||
|
||||
![searching][5]
|
||||
|
||||
Figure 2: Searching for Nextcloud-related Snap packages.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Let’s say you want to go ahead and install GIMP via Snap. To do this, issue the command:
|
||||
```
|
||||
sudo snap install gimp
|
||||
|
||||
```
|
||||
|
||||
The above command will download and install the Snap package. After the command completes, you’ll find GIMP in your desktop menu, ready to use.
|
||||
|
||||
### Updating Snap packages
|
||||
|
||||
Once a Snap package is installed, it will not be updated by the normal method of system updating (via apt, yum, or dnf). To update a Snap package, the refresh option is used. Say you want to update GIMP, you would issue the command:
|
||||
```
|
||||
sudo snap refresh gimp
|
||||
|
||||
```
|
||||
|
||||
If an updated Snap package is available, it will be downloaded and installed. Say, however, you have a number of Snap packages installed, and you want to update them all. This is done with the command:
|
||||
```
|
||||
sudo snap refresh
|
||||
|
||||
```
|
||||
|
||||
The snapd system will check all installed Snap packages against what’s available. If there are newer versions, the installed Snap package will be updated. One thing to note is that Snap packages are automatically updated daily, so you don’t have to manually issue the refresh command, unless you want to do this manually.
|
||||
|
||||
### Listing installed Snap packages
|
||||
|
||||
What if you’re not sure which Snap packages you’ve installed? Easy. Issue the command sudo snap list and all of your installed Snap packages will be listed for you (Figure 3).
|
||||
|
||||
|
||||
![installed packages][7]
|
||||
|
||||
Figure 3: Listing installed Snap packages.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### Removing Snap packages
|
||||
|
||||
Removing a Snap package is just as simple as installing. We’ll stick with our GIMP example. To remove GIMP, issue the command:
|
||||
```
|
||||
sudo snap remove gimp
|
||||
|
||||
```
|
||||
|
||||
One thing you’ll notice is that removing a Snap package takes significantly less time than uninstalling via the standard method (i.e., sudo apt remove gimp or sudo dnf remove gimp). In fact, on my test Fedora system, installing, updating, and removing GIMP was quite a bit faster than doing so with dnf.
|
||||
|
||||
### Installing with Snap: GUI edition
|
||||
|
||||
You can enable Snap support in GNOME Software with a quick dnf install command. That command is:
|
||||
```
|
||||
sudo dnf install gnome-software-snap
|
||||
|
||||
```
|
||||
|
||||
Once the command finishes, reboot your system and open up GNOME Software. You will be prompted to enable third party repositories (Figure 4). Click Enable and Snap packages are now ready to be installed.
|
||||
|
||||
|
||||
![Snap repo][9]
|
||||
|
||||
Figure 4: Enabling the Snap repositories in GNOME Software.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
If you now search for GIMP, you will see two versions available. Click on one and if you see Snap Store as the source (Figure 5), you know that’s the Snap version of GIMP.
|
||||
|
||||
|
||||
![installing Snap package][11]
|
||||
|
||||
Figure 5: Installing a Snap package through GNOME Software.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
Although I cannot imagine a reason for doing so, you can install both the standard and Snap version of the package. You might find it difficult to know which is which, however. Just remember, if you use a mixture of Snap and non-Snap packages, you must update them separately (which, in the case of Snap packages, happens automatically).
|
||||
|
||||
### Get your Snap on
|
||||
|
||||
Snap packages are here to stay, of that there is no doubt. No matter if you administer or use Linux on the server or desktop, Snap packages help make that task significantly easier. Get your Snap on today and see if you don’t start defaulting to this universal package format, over the standard installation fare.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/5/get-started-snap-packages-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:/files/images/snap1jpg
|
||||
[2]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_1.jpg?itok=QklXruAe (Snap)
|
||||
[3]:/licenses/category/used-permission
|
||||
[4]:/files/images/snap2jpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_2.jpg?itok=F-wxfikN (searching)
|
||||
[6]:/files/images/snap3jpg
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_3.jpg?itok=xFMHy93a (installed packages)
|
||||
[8]:/files/images/snap4jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_4.jpg?itok=smr4xmUp (Snap repo)
|
||||
[10]:/files/images/snap5jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/snap_5.jpg?itok=dK7U2Qfv (installing Snap package)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -6,7 +6,7 @@
|
||||
|
||||

|
||||
|
||||
企业投入了大量时间、精力和金钱来保障系统的安全性。最强的安全意识可能就是有一个安全运营中心,肯定用上了防火墙以及反病毒软件,可能花费大量时间监控他们的网络,寻找可能表明违规的异常信号,就像 IDS、SIEM 和 NGFW 一样,他们部署了一个名副其实的防御阵列。
|
||||
企业投入了大量时间、精力和金钱来保障系统的安全性。最强的安全意识可能就是有一个安全的网络运行中心,肯定用上了防火墙以及反病毒软件,可能花费大量时间监控他们的网络,寻找可能表明违规的异常信号,就像 IDS、SIEM 和 NGFW 一样,他们部署了一个名副其实的防御阵列。
|
||||
|
||||
然而又有多少人想过数字化操作的基础之一:部署在员工的个人电脑上的操作系统?当选择桌面操作系统时,安全性是一个考虑的因素吗?
|
||||
|
||||
|
||||
74
translated/tech/20180301 Best Websites For Programmers.md
Normal file
74
translated/tech/20180301 Best Websites For Programmers.md
Normal file
@ -0,0 +1,74 @@
|
||||
程序员最佳网站
|
||||
======
|
||||
![][1]
|
||||
|
||||
作为程序员,你经常会发现自己是某些网站的永久访问者。它们可以是教程、参考或论坛。因此,在这篇文章中,让我们看看给程序员的最佳网站。
|
||||
|
||||
### W3Schools
|
||||
W3Schools 是为初学者和有经验的 Web 开发人员学习各种编程语言的最佳网站之一。你可以学习 HTML5、CSS3、PHP、 JavaScript、ASP 等。
|
||||
|
||||
更重要的是,该网站为网页开发人员提供了大量资源和参考资料。
|
||||
|
||||
[![w3schools logo][2]][3]
|
||||
|
||||
你可以快速浏览各种关键字及其功能。该网站非常具有互动性,它允许你在网站本身的嵌入式编辑器中尝试和练习代码。该网站是你作为网页开发人员经常访问的少数网站之一。
|
||||
|
||||
### GeeksforGeeks
|
||||
GeeksforGeeks 是一个主要专注于计算机科学的网站。它有大量的算法,解决方案和编程问题。
|
||||
|
||||
[![geeksforgeeks programming support][4]][5]
|
||||
|
||||
该网站也有很多面试中经常问到的问题。由于该网站更多地涉及计算机科学,因此你可以找到很多编程问题在大多数著名语言下的解决方案。
|
||||
|
||||
### TutorialsPoint
|
||||
一个学习任何东西的地方。TutorialsPoint 有一些又好又简单的教程,它可以教你任何编程语言。我真的很喜欢这个网站,它不仅限于通用编程语言。
|
||||
|
||||

|
||||
|
||||
你可以在这里上找到几乎所有语言框架的教程。
|
||||
|
||||
### StackOverflow
|
||||
你可能已经知道 StackOverflow 是遇到程序员的地方。你在代码中遇到问题,只要在 StackOverflow 问一个问题,来自互联网的程序员将会在那里帮助你。
|
||||
|
||||
[![stackoverflow linux programming website][6]][7]
|
||||
|
||||
关于 StackOverflow 最好的部分是几乎所有的问题都得到了答案。你可能会从其他程序员的几个不同观点获得答案。
|
||||
|
||||
### HackerRank
|
||||
HackerRank 是一个你可以参与各种编码竞赛并检测你的竞争能力的网站。
|
||||
|
||||
[![hackerrank programming forums][8]][9]
|
||||
|
||||
这里有以各种编程语言举办的各种比赛,赢得比赛将增加你的分数。这个分数可以让你处于最高级别,并增加你获得一些软件公司注意的机会。
|
||||
|
||||
### Codebeautify
|
||||
由于我们是程序员,所以美不是我们所关心的。很多时候,我们的代码很难被其他人阅读。Codebeautify 可以使你的代码易于阅读。
|
||||
|
||||

|
||||
|
||||
该网站有大多数可以美化的语言。另外,如果你想让你的代码不能被某人读取,你也可以这样做。
|
||||
|
||||
这些是我选择的一些最好的程序员网站。如果你有经常访问的我没有提及的网站,请在下面的评论区让我知道。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/best-websites-programmers
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/12/best-websites-for-programmers.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo-550x110.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support-550x152.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support.png
|
||||
[6]:http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website-550x178.png
|
||||
[7]:http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website.png
|
||||
[8]:http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums-550x118.png
|
||||
[9]:http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums.png
|
||||
@ -1,106 +0,0 @@
|
||||
如何在 Linux 系统中结束结束进程或是中止程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
进程出错的时候,您可能会想要中止或是中断这个进程。本文,我们将在命令行和图形界面中探索进程或是应用程序的中断,这里我们使用 [gedit][1] 作为样例程序。
|
||||
|
||||
### 使用命令行、终端字符
|
||||
|
||||
#### Ctrl + C
|
||||
|
||||
在命令行中调用 `gedit` (如果您没有使用 `gedit &` 命令)程序发生错误时,shell 会话被阻塞,将不会释放出相应的错误提示,此下,`Ctrl + C` (Ctrl 和 C 的组合键) 会很管用。`gedit` 会被中断,由于 `Ctrl + C` 给 `gedit` 发送了 `SIGINT` 信号,之前的所有工作都将丢失(除非文件已经被保存)。`SIGINT` 是一个会默认执行进程中断的终止信号,它将指示 shell 终止 `gedit` 的运行,并返回到主函数的循环中,此时,您将得到提示语。
|
||||
|
||||
```
|
||||
$ gedit
|
||||
^C
|
||||
```
|
||||
|
||||
#### Ctrl + Z
|
||||
|
||||
它被称为挂起字符,能够为进程发送 `SIGTSTP` 信号。它也是一个中止信号,但是默认行为不是杀死进程,而是挂起进程。
|
||||
|
||||
下面的命令将会停止(杀死/中断) `gedit` 的运行,并返回 shell 提示。
|
||||
```
|
||||
$ gedit
|
||||
^Z
|
||||
[1]+ Stopped gedit
|
||||
$
|
||||
```
|
||||
|
||||
一旦进程被挂起(以 `gedit` 为例),将不能在 `gedit` 中做任何事情。而在后台,该进程任然是一个作业,可以使用 `jsbs` 命令验证。
|
||||
```
|
||||
$ jobs
|
||||
[1]+ Stopped gedit
|
||||
```
|
||||
|
||||
`jobs` 允许您在单个 shell 会话中控制多个进程。您可以在前台或是后台终止,恢复或是移动作业。
|
||||
|
||||
让我们在后台恢复 `gedit`,释放提示并运行其它命令吧。您可以根据作业 ID(注意,`jobs` 命令显示出来的 `[1]` 就是作业 ID)使用 `bg` 命令恢复进程。
|
||||
```
|
||||
$ bg 1
|
||||
[1]+ gedit &
|
||||
```
|
||||
|
||||
这和直接使用 `gedit &` 启动程序效果差不多:
|
||||
```
|
||||
$ gedit &
|
||||
```
|
||||
|
||||
### 使用 kill
|
||||
|
||||
`kill` 命令提供信号的精确控制,允许您通过进程 ID 或是 PID,根据特定的信号名或是信号数字为进程发送信号。
|
||||
|
||||
`kill` 命令能够根据作业 ID 控制进程,这一点是我喜欢的。让我们使用 `gedit &` 命令在后台开启 `gedit` 服务。假设通过 `jobs` 命令我得到了一个 `gedit` 的作业 ID,让我们为 `gedit` 发送 `SIGINT` 信号吧:
|
||||
```
|
||||
$ kill -s SIGINT %1
|
||||
```
|
||||
|
||||
作业 ID 需要使用 `%` 前缀,不然 `kill` 会将其视作 PID。
|
||||
|
||||
不明确指定的信号,`kill` 仍然可以工作。此时,默认会发送能中断进程的 `SIGTERM` 信号。执行 `kill -l` 查看信号名列表,使用 `man kill` 命令阅读手册。
|
||||
|
||||
### 使用 killall
|
||||
|
||||
如果您不想使用特定的工作 ID 或者 PID,`killall` 允许您使用特定的进程名。中断 `gedit` 最简单的 `killall` 使用方式是:
|
||||
```
|
||||
$ killall gedit
|
||||
```
|
||||
|
||||
它将终止所有名为 `gedit` 的进程。和 `kill` 想死,默认发送的信号时 `SIGTERM`。
|
||||
This will kill all the processes with the name `gedit`. Like `kill`, the default signal is `SIGTERM`. 使用 `-I` 选项忽略大小写。
|
||||
```
|
||||
$ gedit &
|
||||
[1] 14852
|
||||
|
||||
$ killall -I GEDIT
|
||||
[1]+ Terminated gedit
|
||||
```
|
||||
|
||||
查看手册学习更多 `killall` 命令选项(如 `-u`)。
|
||||
|
||||
### 使用 xkill
|
||||
|
||||
您是否遇见过播放器崩溃,比如 [VLC][2] 灰屏或挂起?现在,获得程序 PID 之后,您就可以使用 `xkill` 命令终止应用程序。
|
||||
|
||||
![Using xkill][3]
|
||||
|
||||
`xkill` 允许您使用鼠标关闭窗口。仅需在终端执行 `xkill` 命令,它将会改变鼠标光标为一个 **X** 或是一个骷髅图标。点击您想关闭的进程窗口上的 **X**。小心使用 `xkill`,如手册描述的一致,它很危险。我已经提醒过您了!
|
||||
|
||||
参阅手册,了解上述命令更多信息。您还可以接续探索 `pkill` 和 `pgrep` 命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/how-kill-process-stop-program-linux
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://wiki.gnome.org/Apps/Gedit
|
||||
[2]:https://www.videolan.org/vlc/index.html
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/xkill_gedit.png?itok=TBvMw0TN (Using xkill)
|
||||
@ -0,0 +1,134 @@
|
||||
使用 Stratis 从命令行管理 Linux 存储
|
||||
======
|
||||
|
||||

|
||||
|
||||
正如本系列的[第一部分][1]和[第二部分][2]中所讨论的,Stratis 是一个具有与 [ZFS][3] 和 [Btrfs] [4] 相似功能的卷管理文件系统。在本文中,我们将介绍如何在命令行上使用 Stratis。
|
||||
|
||||
### 安装 Stratis
|
||||
|
||||
对于非开发人员,现在尝试 Stratis 最简单的方法是在 [Fedora 28][5] 中。
|
||||
|
||||
你可以用以下命令安装 Stratis 守护进程和 Stratis 命令行工具:
|
||||
```
|
||||
# dnf install stratis-cli stratisd
|
||||
|
||||
```
|
||||
|
||||
### 创建一个池
|
||||
|
||||
Stratis 有三个概念:blockdevs、池和文件系统。 Blockdevs 是组成池的块设备,例如磁盘或磁盘分区。一旦创建池,就可以从中创建文件系统。
|
||||
|
||||
假设你的系统上有一个名为 `vdg` 的块设备,它目前没有被使用或挂载,你可以在它上面创建一个 Stratis 池:
|
||||
```
|
||||
# stratis pool create mypool /dev/vdg
|
||||
|
||||
```
|
||||
|
||||
这假设 `vdg` 是完全清零并且是空的。如果它没有被使用,但有旧数据,则可能需要使用 `pool create` 的 ` - force` 选项。如果正在使用,请勿将它用于 Stratis。
|
||||
|
||||
如果你想从多个块设备创建一个池,只需在 `pool create` 命令行中列出它们。你也可以稍后使用 `blockdev add-data` 命令添加更多的 blockdevs。请注意,Stratis 要求 blockdevs 的大小至少为 1 GiB。
|
||||
|
||||
### 创建文件系统
|
||||
|
||||
在你创建了一个名为 `mypool` 的池后,你可以从它创建文件系统:
|
||||
```
|
||||
# stratis fs create mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
从 `mypool` 池创建一个名为 `myfs1` 的文件系统后,可以使用 Stratis 在 /dev/stratis 中创建的条目来挂载并使用它:
|
||||
```
|
||||
# mkdir myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
文件系统现在已被挂载在 `myfs1` 上并准备可以使用。
|
||||
|
||||
### 快照
|
||||
|
||||
除了创建空文件系统之外,你还可以创建一个文件系统作为现有文件系统的快照:
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1 myfs1-experiment
|
||||
|
||||
```
|
||||
|
||||
这样做后,你可以挂载新的 `myfs1-experiment`,它将初始包含与 `myfs1` 相同的文件内容,但它可能随着文件系统的修改而改变。无论你对 `myfs1-experiment` 所做的任何更改都不会反映到 `myfs1` 中,除非你卸载了 `myfs1` 并将其销毁:
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
然后进行快照以重新创建并重新挂载它:
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1-experiment myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
### 获取信息
|
||||
|
||||
Stratis 可以列出系统中的池:
|
||||
```
|
||||
# stratis pool list
|
||||
|
||||
```
|
||||
|
||||
随着文件系统写入更多数据,你将看到 “Total Physical Used” 值的增加。当这个值接近 “Total Physical Size” 时要小心。我们仍在努力处理这个问题。
|
||||
|
||||
列出池中的文件系统:
|
||||
```
|
||||
# stratis fs list mypool
|
||||
|
||||
```
|
||||
|
||||
列出组成池的 blockdevs:
|
||||
```
|
||||
# stratis blockdev list mypool
|
||||
|
||||
```
|
||||
|
||||
目前只提供这些最少的信息,但它们将在未来提供更多信息。
|
||||
|
||||
#### 摧毁池
|
||||
|
||||
当你了解了 Stratis 可以做什么后,要摧毁池,首先确保从它创建的所有文件系统都被卸载并销毁,然后使用 `pool destroy` 命令:
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# umount myfs1-experiment (if you created it)
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1-experiment
|
||||
|
||||
# stratis pool destroy mypool
|
||||
|
||||
```
|
||||
|
||||
`stratis pool list` 现在应该显示没有池。
|
||||
|
||||
就是这些!有关更多信息,请参阅手册页:“man stratis”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/stratis-storage-linux-command-line
|
||||
|
||||
作者:[Andy Grover][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/agrover
|
||||
[1]:https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux
|
||||
[2]:https://opensource.com/article/18/4/stratis-lessons-learned
|
||||
[3]:https://en.wikipedia.org/wiki/ZFS
|
||||
[4]:https://en.wikipedia.org/wiki/Btrfs
|
||||
[5]:https://fedoraproject.org/wiki/Releases/28/Schedule
|
||||
Loading…
Reference in New Issue
Block a user