mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
Translated by qhwdw
This commit is contained in:
parent
cc68f1d0b2
commit
33f7f351c3
@ -1,105 +0,0 @@
|
||||
#Translating by qhwdw [Journey to the Stack, Part I][1]
|
||||
|
||||
Earlier we've explored the [anatomy of a program in memory][2], the landscape of how our programs run in a computer. Now we turn to the call stack, the work horse in most programming languages and virtual machines. Along the way we'll meet fantastic creatures like closures, recursion, and buffer overflows. But the first step is a precise picture of how the stack operates.
|
||||
|
||||
The stack is so important because it keeps track of the functions running in a program, and functions are in turn the building blocks of software. In fact, the internal operation of programs is normally very simple. It consists mostly of functions pushing data onto and popping data off the stack as they call each other, while allocating memory on the heap for data that must survive across function calls. This is true for both low-level C software and VM-based languages like JavaScript and C#. A solid grasp of this reality is invaluable for debugging, performance tuning and generally knowing what the hell is going on.
|
||||
|
||||
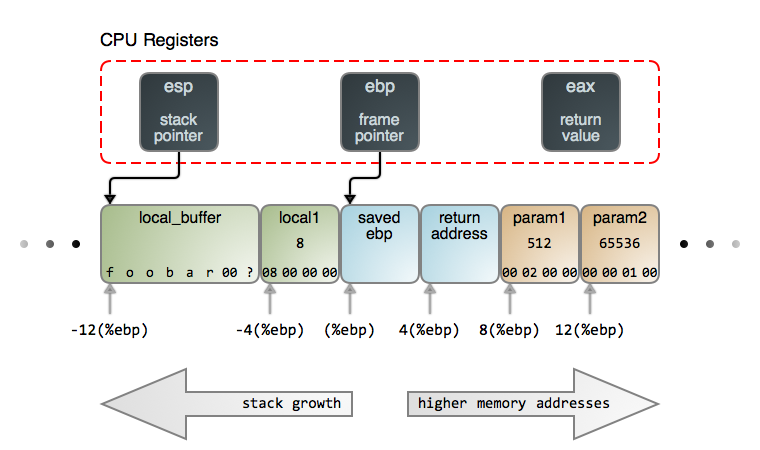
When a function is called, a stack frame is created to support the function's execution. The stack frame contains the function's local variables and the arguments passed to the function by its caller. The frame also contains housekeeping information that allows the called function (the callee) to return to the caller safely. The exact contents and layout of the stack vary by processor architecture and function call convention. In this post we look at Intel x86 stacks using C-style function calls (cdecl). Here's a single stack frame sitting live on top of the stack:
|
||||
|
||||
|
||||
|
||||
Right away, three CPU registers burst into the scene. The stack pointer, esp, points to the top of the stack. The top is always occupied by the last item that was pushed onto the stack but has not yet been popped off, just as in a real-world stack of plates or $100 bills.
|
||||
|
||||
The address stored in esp constantly changes as stack items are pushed and popped, such that it always points to the last item. Many CPU instructions automatically update esp as a side effect, and it's impractical to use the stack without this register.
|
||||
|
||||
In the Intel architecture, as in most, the stack grows towards lower memory addresses. So the "top" is the lowest memory address in the stack containing live data: local_buffer in this case. Notice there's nothing vague about the arrow from esp to local_buffer. This arrow means business: it points specifically to the first byte occupied by local_buffer because that is the exact address stored in esp.
|
||||
|
||||
The second register tracking the stack is ebp, the base pointer or frame pointer. It points to a fixed location within the stack frame of the function currently running and provides a stable reference point (base) for access to arguments and local variables. ebp changes only when a function call begins or ends. Thus we can easily address each item in the stack as an offset from ebp, as shown in the diagram.
|
||||
|
||||
Unlike esp, ebp is mostly maintained by program code with little CPU interference. Sometimes there are performance benefits in ditching ebp altogether, which can be done via [compiler flags][3]. The Linux kernel is one example where this is done.
|
||||
|
||||
Finally, the eax register is used by convention to transfer return values back to the caller for most C data types.
|
||||
|
||||
Now let's inspect the data in our stack frame. These diagram shows precise byte-for-byte contents as you'd see in a debugger, with memory growing left-to-right, top-to-bottom. Here it is:
|
||||
|
||||

|
||||
|
||||
The local variable local_buffer is a byte array containing a null-terminated ascii string, a staple of C programs. The string was likely read from somewhere, for example keyboard input or a file, and it is 7 bytes long. Since local_buffer can hold 8 bytes, there's 1 free byte left. The content of this byte is unknown because in the stack's infinite dance of pushes and pops, you never know what memory holds unless you write to it. Since the C compiler does not initialize the memory for a stack frame, contents are undetermined
|
||||
|
||||
* and somewhat random - until written to. This has driven some into madness.
|
||||
|
||||
Moving on, local1 is a 4-byte integer and you can see the contents of each byte. It looks like a big number, with all those zeros following the 8, but here your intuition leads you astray.
|
||||
|
||||
Intel processors are little endian machines, meaning that numbers in memory start with the little end first. So the least significant byte of a multi-byte number is in the lowest memory address. Since that is normally shown leftmost, this departs from our usual representation of numbers. It helps to know that this endian talk is borrowed from Gulliver's Travels: just as folks in Lilliput eat their eggs starting from the little end, Intel processors eat their numbers starting from the little byte.
|
||||
|
||||
So local1 in fact holds the number 8, as in the legs of an octopus. param1, however, has a value of 2 in the second byte position, so its mathematical value is 2 * 256 = 512 (we multiply by 256 because each place value ranges from 0 to 255). Meanwhile, param2 is carrying weight at 1 * 256 * 256 = 65536.
|
||||
|
||||
The housekeeping data in this stack frame consists of two crucial pieces: the address of the previous stack frame (saved ebp) and the address of the instruction to be executed upon the function's exit (the return address). Together, they make it possible for the function to return sanely and for the program to keep running along.
|
||||
|
||||
Now let's see the birth of a stack frame to build a clear mental picture of how this all works together. Stack growth is puzzling at first because it happens in the opposite direction you'd expect. For example, to allocate 8 bytes on the stack one subtracts 8 from esp, and subtraction is an odd way to grow something.
|
||||
|
||||
Let's take a simple C program:
|
||||
|
||||
```
|
||||
Simple Add Program - add.c
|
||||
|
||||
int add(int a, int b)
|
||||
{
|
||||
int result = a + b;
|
||||
return result;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer;
|
||||
answer = add(40, 2);
|
||||
}
|
||||
```
|
||||
|
||||
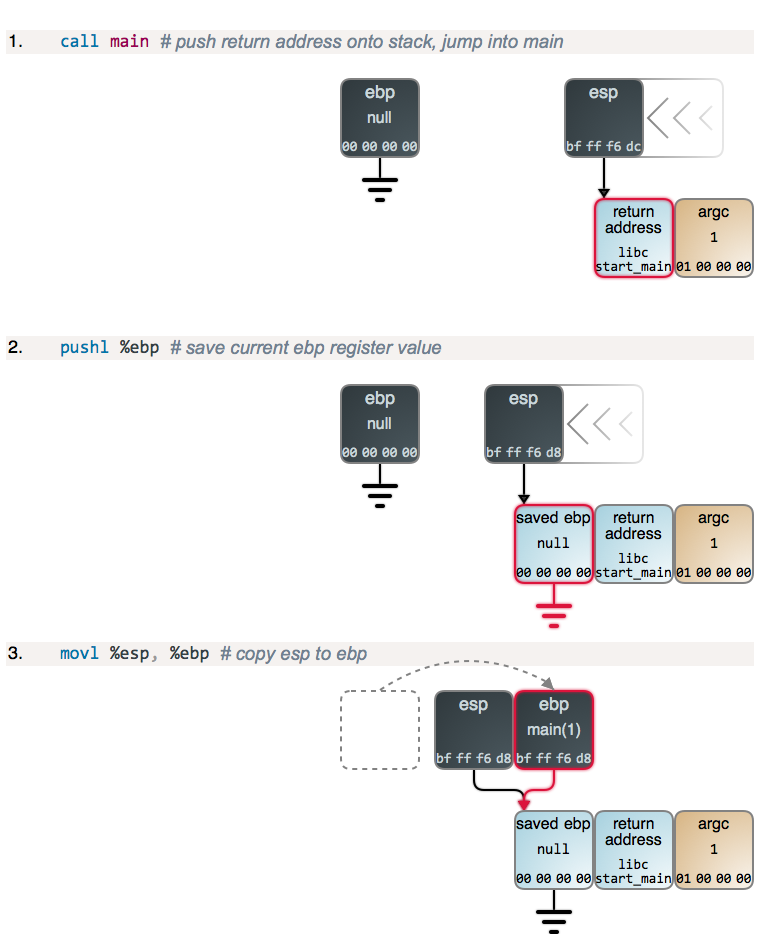
Suppose we run this in Linux without command-line parameters. When you run a C program, the first code to actually execute is in the C runtime library, which then calls our main function. The diagrams below show step-by-step what happens as the program runs. Each diagram links to GDB output showing the state of memory and registers. You may also see the [GDB commands][4] used and the whole [GDB output][5]. Here we go:
|
||||
|
||||
|
||||
|
||||
Steps 2 and 3, along with 4 below, are the function prologue, which is common to nearly all functions: the current value of ebp is saved to the top of the stack, and then esp is copied to ebp, establishing a new frame. main's prologue is like any other, but with the peculiarity that ebp is zeroed out when the program starts.
|
||||
|
||||
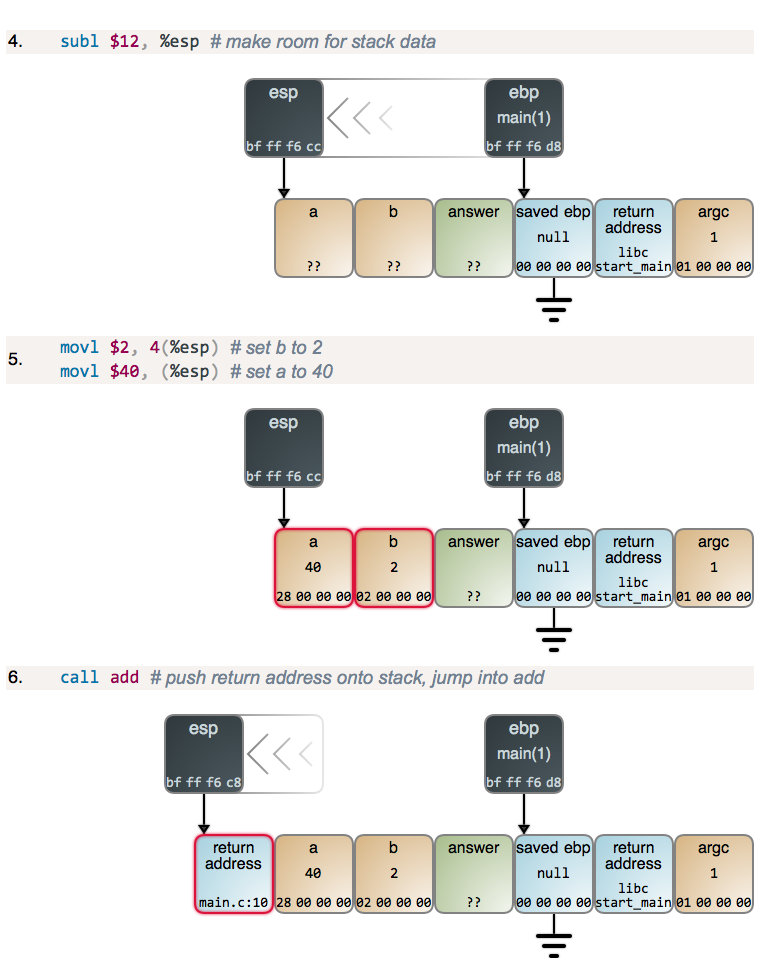
If you were to inspect the stack below argc (to the right) you'd find more data, including pointers to the program name and command-line parameters (the traditional C argv), plus pointers to Unix environment variables and their actual contents. But that's not important here, so the ball keeps rolling towards the add() call:
|
||||
|
||||
|
||||
|
||||
After main subtracts 12 from esp to get the stack space it needs, it sets the values for a and b. Values in memory are shown in hex and little-endian format, as you'd see in a debugger. Once parameter values are set, main calls add and it starts running:
|
||||
|
||||
|
||||
|
||||
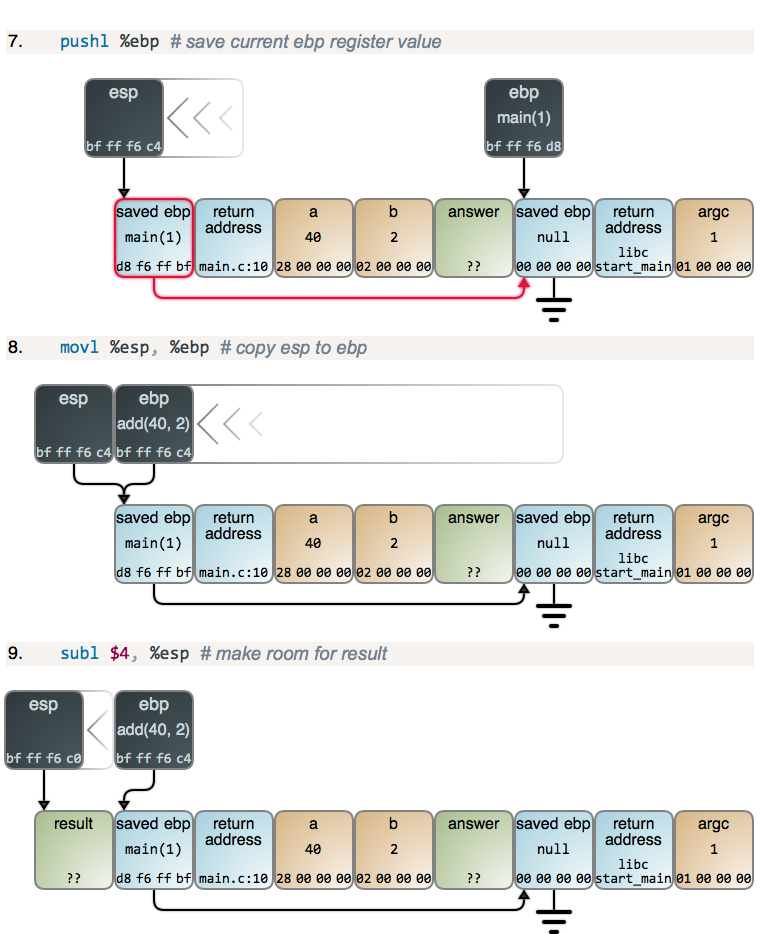
Now there's some excitement! We get another prologue, but this time you can see clearly how the stack frames form a linked list, starting at ebp and going down the stack. This is how debuggers and Exception objects in higher-level languages get their stack traces. You can also see the much more typical catching up of ebp to esp when a new frame is born. And again, we subtract from esp to get more stack space.
|
||||
|
||||
There's also the slightly weird reversal of bytes when the ebp register value is copied to memory. What's happening here is that registers don't really have endianness: there are no "growing addresses" inside a register as there are for memory. Thus by convention debuggers show register values in the most natural format to humans: most significant to least significant digits. So the results of the copy in a little-endian machine appear reversed in the usual left-to-right notation for memory. I want the diagrams to provide an accurate picture of what you find in the trenches, so there you have it.
|
||||
|
||||
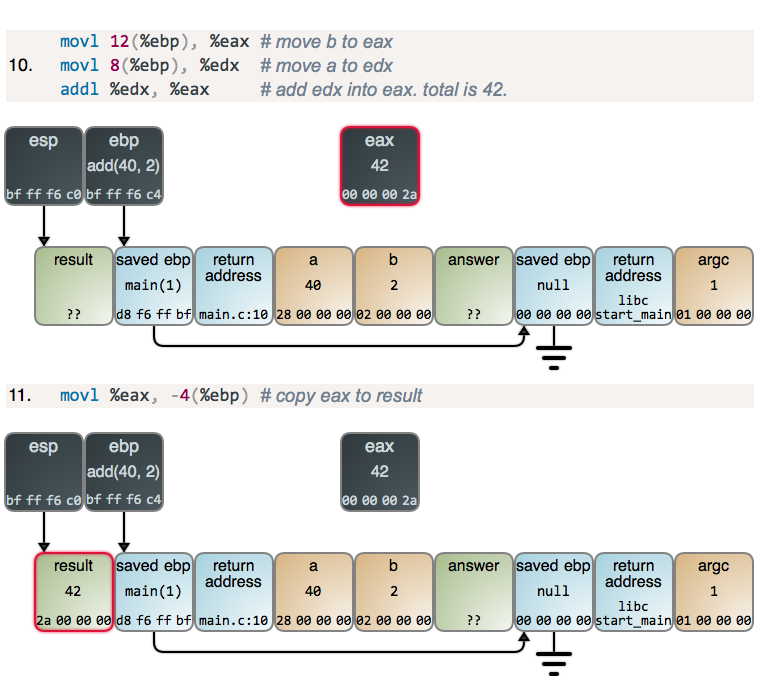
With the hard part behind us, we add:
|
||||
|
||||
|
||||
|
||||
There are guest register appearances to help out with the addition, but otherwise no alarms and no surprises. add did its job, and at this point the stack action would go in reverse, but we'll save that for next time.
|
||||
|
||||
Anybody who's read this far deserves a souvenir, so I've made a large diagram showing [all the steps combined][6] in a fit of nerd pride.
|
||||
|
||||
It looks tame once it's all laid out. Those little boxes help a lot. In fact, little boxes are the chief tool of computer science. I hope the pictures and register movements provide an intuitive mental picture that integrates stack growth and memory contents. Up close, our software doesn't look too far from a simple Turing machine.
|
||||
|
||||
This concludes the first part of our stack tour. There's some more byte spelunking ahead, and then it's on to see higher level programming concepts built on this foundation. See you next week.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[3]:http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
|
||||
[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt
|
||||
[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt
|
||||
[6]:https://manybutfinite.com/img/stack/callSequence.png
|
||||
103
translated/tech/20140510 Journey to the Stack Part I.md
Normal file
103
translated/tech/20140510 Journey to the Stack Part I.md
Normal file
@ -0,0 +1,103 @@
|
||||
#[探秘“栈”之旅(I)][1]
|
||||
|
||||
早些时候,我们讲解了 [“剖析内存中的程序之秘”][2],我们欣赏了在一台电脑中是如何运行我们的程序的。今天,我们去探索栈的调用,它在大多数编程语言和虚拟机中都默默地存在。在此过程中,我们将接触到一些平时很难见到的东西,像闭包(closures)、递归、以及缓冲溢出等等。但是,我们首先要作的事情是,描绘出栈是如何运作的。
|
||||
|
||||
栈非常重要,因为它持有着在一个程序中运行的函数,而函数又是一个软件的重要组成部分。事实上,程序的内部操作都是非常简单的。它大部分是由函数向栈中推入数据或者从栈中弹出数据的相互调用组成的,虽然为数据分配内存是在堆上,但是,在跨函数的调用中数据必须要保存下来,不论是低级(low-leverl)的 C 软件还是像 JavaScript 和 C# 这样的基于虚拟机的语言,它们都是这样的。而对这些行为的深刻理解,对排错、性能调优以及大概了解究竟发生了什么是非常重要的。
|
||||
|
||||
当一个函数被调用时,将会创建一个栈帧(stack frame)去支持函数的运行。这个栈帧包含函数的本地变量和调用者传递给它的参数。这个栈帧也包含了允许被调用的函数安全返回给调用者的内部事务信息。栈帧的精确内容和结构因处理器架构和函数调用规则而不同。在本文中我们以 Intel x86 架构和使用 C 风格的函数调用(cdecl)的栈为例。下图是一个处于栈顶部的一个单个栈帧:
|
||||
|
||||

|
||||
|
||||
在图上的场景中,有三个 CPU 寄存器进入栈。栈指针 `esp`(译者注:扩展栈指针寄存器) 指向到栈的顶部。栈的顶部总是被最后一个推入到栈且还没有弹出的东西所占据,就像现实世界中堆在一起的一叠板子或者面值 $100 的钞票。
|
||||
|
||||
保存在 `esp` 中的地址始终在变化着,因为栈中的东西不停被推入和弹出,而它总是指向栈中的最后一个推入的东西。许多 CPU 指令的一个副作用就是自动更新 `esp`,离开寄存器而使用栈是行不通的。
|
||||
|
||||
在 Intel 的架构中,绝大多数情况下,栈的增长是向着低位内存地址的方向。因此,这个“顶部” 在包含数据(在这种情况下,包含的数据是 `local_buffer`)的栈中是处于低位的内存地址。注意,关于从 `esp` 到 `local_buffer` 的箭头,这里并没有模糊的地方。这个箭头代表着事务:它专门指向到由 `local_buffer` 所拥有的第一个字节,因为,那是一个保存在 `esp` 中的精确地址。
|
||||
|
||||
第二个寄存器跟踪的栈是 `ebp`(译者注:扩展基址指针寄存器),它包含一个基指针或者称为帧指针。它指向到一个当前运行的函数的栈帧内的固定的位置,并且它为参数和本地变量的访问提供一个稳定的参考点(基址)。仅当开始或者结束调用一个函数时,`ebp` 的内容才会发生变化。因此,我们可以很容易地处理每个在栈中的从 `ebp` 开始偏移后的一个东西。如下图所示。
|
||||
|
||||
不像 `esp`, `ebp` 大多数情况下是在程序代码中通过花费很少的 CPU 来进行维护的。有时候,完成抛弃 `ebp` 有一些性能优势,可以通过 [编译标志][3] 来做到这一点。Linux 内核中有一个实现的示例。
|
||||
|
||||
最后,`eax`(译者注:扩展的 32 位通用数据寄存器)寄存器是被调用规则所使用的寄存器,对于大多数 C 数据类型来说,它的作用是转换一个返回值给调用者。
|
||||
|
||||
现在,我们来看一下在我们的栈帧中的数据。下图清晰地按字节展示了字节的内容,就像你在一个调试器中所看到的内容一样,内存是从左到右、从底部到顶部增长的,如下图所示:
|
||||
|
||||

|
||||
|
||||
本地变量 `local_buffer` 是一个字节数组,它包含一个空终止(null-terminated)的 ascii 字符串,这是一个 C 程序中的基本元素。这个字符串可以从任意位置读取,例如,从键盘输入或者来自一个文件,它只有 7 个字节的长度。因为,`local_buffer` 只能保存 8 字节,在它的左侧保留了 1 个未使用的字节。这个字节的内容是未知的,因为栈的推入和弹出是极其活跃的,除了你写入的之外,你从不知道内存中保存了什么。因为 C 编译器并不为栈帧初始化内存,所以它的内容是未知的并且是随机的 - 除非是你自己写入。这使得一些人对此很困惑。
|
||||
|
||||
再往上走,`local1` 是一个 4 字节的整数,并且你可以看到每个字节的内容。它似乎是一个很大的数字,所有的零都在 8 后面,在这里可能会让你误入歧途。
|
||||
|
||||
Intel 处理器是按从小到大的机制来处理的,这表示在内存中的数字也是首先从小的位置开始的。因此,在一个多字节数字中,最小的标志字节在内存中处于低端地址。因为一般情况下是从左边开始显示的,这背离了我们一般意义上对数字的认识。我们讨论的这种从小到大的机制,使我想起《Gulliver 游记》:就像 Lilliput 吃鸡蛋是从小头开始的一样,Intel 处理器处理它们的数字也是从字节的小端开始的。
|
||||
|
||||
因此,`local1` 事实上只保存了一个数字 8,就像一个章鱼的腿。然而,`param1` 在第二个字节的位置有一个值 2,因此,它的数学上的值是 2 * 256 = 512(我们与 256 相乘是因为,每个位置值的范围都是从 0 到 255)。同时,`param2` 承载的数量是 1 * 256 * 256 = 65536。
|
||||
|
||||
这个栈帧的内部数据是由两个重要的部分组成:前一个栈帧的地址和函数的出口(返回地址)上运行的指令的地址。它们一起确保了函数能够正常返回,从而使程序可以继续正常运行。
|
||||
|
||||
现在,我们来看一下栈帧是如何产生的,以及去建立一个它们如何共同工作的内部蓝图。在刚开始的时候,栈的增长是非常令人困惑的,因为它发生的一切都不是你所期望的东西。例如,在栈上从 `esp` 减去 8,去分配一个 8 字节,而减法是以一种奇怪的方式去开始的。
|
||||
|
||||
我们来看一个简单的 C 程序:
|
||||
|
||||
```
|
||||
Simple Add Program - add.c
|
||||
|
||||
int add(int a, int b)
|
||||
{
|
||||
int result = a + b;
|
||||
return result;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer;
|
||||
answer = add(40, 2);
|
||||
}
|
||||
```
|
||||
|
||||
假设我们在 Linux 中不使用命令行参数去运行它。当你运行一个 C 程序时,去真实运行的第一个代码是 C 运行时库,由它来调用我们的 `main` 函数。下图展示了程序运行时每一步都发生了什么。每个图链接的 GDB 输出展示了内存的状态和寄存器。你也可以看到所使用的 [GDB 命令][4],以及整个 [GDB 输出][5]。如下:
|
||||
|
||||

|
||||
|
||||
第 2 步和第 3 步,以及下面的第 4 步,都只是函数的开端,几乎所有的函数都是这样的:`ebp` 的当前值保存着栈的顶部,然后,将 `esp` 的内容拷贝到 `ebp`,维护一个新帧。`main` 的开端和任何一个其它函数都是一样,但是,不同之处在于,当程序启动时 `ebp` 被清零。
|
||||
|
||||
如果你去检查栈下面的整形变量(argc),你将找到更多的数据,包括指向到程序名和命令行参数(传统的 C 参数数组)、Unix 环境变量以及它们真实的内容的指针。但是,在这里这些并不是重点,因此,继续向前调用 add():
|
||||
|
||||

|
||||
|
||||
在 `main` 从 `esp` 减去 12 之后得到它所需的栈空间,它为 a 和 b 设置值。在内存中值展示为十六进制,并且是从小到大的格式。与你从调试器中看到的一样。一旦设置了参数值,`main` 将调用 `add` ,并且它开始运行:
|
||||
|
||||

|
||||
|
||||
现在,有一点小激动!我们进入了另一个开端,在这时你可以明确看到栈帧是如何从 `ebp` 的一个链表开始进入到栈的。这就是在高级语言中调试器和异常对象如何对它们的栈进行跟踪的。当一个新帧产生时,你也可以看到更多这种从 `ebp` 到 `esp` 的典型的捕获。我们再次从 `esp` 中做减法得到更多的栈空间。
|
||||
|
||||
当 `ebp` 寄存器的值拷贝到内存时,这里也有一个稍微有些怪异的地方。在这里发生的奇怪事情是,寄存器并没有真的按字节顺序拷贝:因为对于内存,没有像寄存器那样的“增长的地址”。因此,通过调试器的规则以最自然的格式给人展示了寄存器的值:从最重要的到最不重要的数字。因此,这个在从小到大的机制中拷贝的结果,与内存中常用的从左到右的标记法正好相反。我想用图去展示你将会看到的东西,因此有了下面的图。
|
||||
|
||||
在比较难懂的部分,我们增加了注释:
|
||||
|
||||

|
||||
|
||||
这是一个临时寄存器,用于帮你做加法,因此没有什么警报或者惊喜。对于加法这样的作业,栈的动作正好相反,我们留到下次再讲。
|
||||
|
||||
对于任何读到这篇文章的人都应该有一个小礼物,因此,我做了一个大的图表展示了 [组合到一起的所有步骤][6]。
|
||||
|
||||
一旦把它们全部布置好了,看上起似乎很乏味。这些小方框给我们提供了很多帮助。事实上,在计算机科学中,这些小方框是主要的展示工具。我希望这些图片和寄存器的移动能够提供一种更直观的构想图,将栈的增长和内存的内容整合到一起。从软件的底层运作来看,我们的软件与一个简单的图灵机器差不多。
|
||||
|
||||
这就是我们栈探秘的第一部分,再讲一些内容之后,我们将看到构建在这个基础上的高级编程的概念。下周见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[3]:http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
|
||||
[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt
|
||||
[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt
|
||||
[6]:https://manybutfinite.com/img/stack/callSequence.png
|
||||
Loading…
Reference in New Issue
Block a user