mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
339b46756e
71
README.md
71
README.md
@ -38,7 +38,7 @@ LCTT 的组成
|
||||
* 2013/09/16 公开发布了翻译组成立消息后,又有新的成员申请加入了。并从此建立见习成员制度。
|
||||
* 2013/09/24 鉴于大家使用 GitHub 的水平不一,容易导致主仓库的一些错误,因此换成了常规的 fork+PR 的模式来进行翻译流程。
|
||||
* 2013/10/11 根据对 LCTT 的贡献,划分了 Core Translators 组,最先的加入成员是 vito-L 和 tinyeyeser。
|
||||
* 2013/10/12 取消对 LINUX.CN 注册用户的依赖,在 QQ 群内、文章内都采用 GitHub 的注册 ID。
|
||||
* 2013/10/12 取消对 LINUX.CN 注册用户的关联,在 QQ 群内、文章内都采用 GitHub 的注册 ID。
|
||||
* 2013/10/18 正式启动 man 翻译计划。
|
||||
* 2013/11/10 举行第一次北京线下聚会。
|
||||
* 2014/01/02 增加了 Core Translators 成员: geekpi。
|
||||
@ -52,7 +52,10 @@ LCTT 的组成
|
||||
* 2015/04/19 发起 LFS-BOOK-7.7-systemd 项目。
|
||||
* 2015/06/09 提升 ictlyh 和 dongfengweixiao 为 Core Translators 成员。
|
||||
* 2015/11/10 提升 strugglingyouth、FSSlc、Vic020、alim0x 为 Core Translators 成员。
|
||||
* 2016/02/18 由于选题 DeadFire 重病,任命 oska874 接手选题工作。
|
||||
* 2016/02/29 选题 DeadFire 病逝。
|
||||
* 2016/05/09 提升 PurlingNayuki 为校对。
|
||||
* 2016/09/10 LCTT 三周年。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
@ -61,25 +64,26 @@ LCTT 的组成
|
||||
- Leader @wxy,
|
||||
- Source @oska874,
|
||||
- Proofreader @PurlingNayuki,
|
||||
- Proofreader @carolinewuyan,
|
||||
- CORE @geekpi,
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
- CORE @carolinewuyan,
|
||||
- CORE @strugglingyouth,
|
||||
- CORE @FSSlc
|
||||
- CORE @zpl1025,
|
||||
- CORE @runningwater,
|
||||
- CORE @bazz2,
|
||||
- CORE @Vic020,
|
||||
- CORE @dongfengweixiao,
|
||||
- CORE @alim0x,
|
||||
- CORE @tinyeyeser,
|
||||
- CORE @Locez,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir222,
|
||||
- Senior @tinyeyeser,
|
||||
- Senior @vito-L,
|
||||
- Senior @jasminepeng,
|
||||
- Senior @willqian,
|
||||
- Senior @vizv,
|
||||
- Senior @dongfengweixiao,
|
||||
- ZTinoZ,
|
||||
- martin2011qi,
|
||||
- theo-l,
|
||||
@ -87,94 +91,81 @@ LCTT 的组成
|
||||
- wi-cuckoo,
|
||||
- disylee,
|
||||
- haimingfg,
|
||||
- KayGuoWhu,
|
||||
- wwy-hust,
|
||||
- felixonmars,
|
||||
- KayGuoWhu,
|
||||
- mr-ping,
|
||||
- su-kaiyao,
|
||||
- GHLandy,
|
||||
- ivo-wang,
|
||||
- cvsher,
|
||||
- StdioA,
|
||||
- wyangsun,
|
||||
- ivo-wang,
|
||||
- GHLandy,
|
||||
- cvsher,
|
||||
- DongShuaike,
|
||||
- flsf,
|
||||
- SPccman,
|
||||
- Stevearzh
|
||||
- mr-ping,
|
||||
- Linchenguang,
|
||||
- Linux-pdz,
|
||||
- 2q1w2007,
|
||||
- H-mudcup,
|
||||
- cposture,
|
||||
- MikeCoder,
|
||||
- NearTan,
|
||||
- goreliu,
|
||||
- xiqingongzi,
|
||||
- goreliu,
|
||||
- NearTan,
|
||||
- TxmszLou,
|
||||
- ZhouJ-sh,
|
||||
- wangjiezhe,
|
||||
- icybreaker,
|
||||
- vim-kakali,
|
||||
- shipsw,
|
||||
- Moelf,
|
||||
- name1e5s,
|
||||
- johnhoow,
|
||||
- soooogreen,
|
||||
- kokialoves,
|
||||
- linuhap,
|
||||
- GitFuture,
|
||||
- ChrisLeeGit,
|
||||
- blueabysm,
|
||||
- boredivan,
|
||||
- name1e5s,
|
||||
- StdioA,
|
||||
- yechunxiao19,
|
||||
- l3b2w1,
|
||||
- XLCYun,
|
||||
- KevinSJ,
|
||||
- zky001,
|
||||
- l3b2w1,
|
||||
- tenght,
|
||||
- coloka,
|
||||
- luoyutiantang,
|
||||
- sonofelice,
|
||||
- jiajia9linuxer,
|
||||
- scusjs,
|
||||
- tnuoccalanosrep,
|
||||
- woodboow,
|
||||
- 1w2b3l,
|
||||
- JonathanKang,
|
||||
- bestony,
|
||||
- crowner,
|
||||
- dingdongnigetou,
|
||||
- mtunique,
|
||||
- CNprober,
|
||||
- Rekii008,
|
||||
- hyaocuk,
|
||||
- szrlee,
|
||||
- KnightJoker,
|
||||
- Xuanwo,
|
||||
- nd0104,
|
||||
- Moelf,
|
||||
- xiaoyu33,
|
||||
- guodongxiaren,
|
||||
- ynmlml,
|
||||
- vim-kakali,
|
||||
- Flowsnow,
|
||||
- ggaaooppeenngg,
|
||||
- Ricky-Gong,
|
||||
- zky001,
|
||||
- lfzark,
|
||||
- 213edu,
|
||||
- bestony,
|
||||
- mudongliang,
|
||||
- Tanete,
|
||||
- lfzark,
|
||||
- liuaiping,
|
||||
- Timeszoro,
|
||||
- rogetfan,
|
||||
- JeffDing,
|
||||
- Yuking-net,
|
||||
|
||||
|
||||
(按增加行数排名前百)
|
||||
|
||||
LFS 项目活跃成员有:
|
||||
|
||||
- @ictlyh
|
||||
- @dongfengweixiao
|
||||
- @wxy
|
||||
- @H-mudcup
|
||||
- @zpl1025
|
||||
- @KevinSJ
|
||||
- @Yuking-net
|
||||
|
||||
(更新于2016/06/20)
|
||||
(按增加行数排名前百,更新于2016/09/10)
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
42
lctt2016.md
Normal file
42
lctt2016.md
Normal file
@ -0,0 +1,42 @@
|
||||
LCTT 2016:LCTT 成立三周年了!
|
||||
===========================
|
||||
|
||||
不知不觉,LCTT 已经成立三年了,对于我这样已经迈过四张的人来说,愈发的感觉时间过得真快。
|
||||
|
||||
这三年来,我们 LCTT 经历了很多事情,有些事情想起来仍恍如昨日。
|
||||
|
||||
三年前的这一天,我的一个偶发的想法促使我在 Linux 中国的 QQ 群里面发了一则消息,具体的消息内容已经不可考了,大意是鉴于英文 man 手册的中文翻译太差,想组织一些人来重新翻译。不料发出去之后很快赢得一些有热情、有理想的小伙伴们的响应。于是我匆匆建了一个群,拉了一些人进来,甚至当时连翻译组的名称都没有确定。LCTT (Linux.Cn Translation Team)这个名称都是后来逐步定下来的。
|
||||
|
||||
关于 LCTT 的早期发展情况,可以参考 LCTT 2014 年周年[总结](http://linux.cn/article-3784-1.html)。
|
||||
|
||||
虽然说“翻译 man 手册”这个最初建群的目标因为种种原因搁浅而一直未能重启,但是,这三年来,我们组织了 [213 位志愿者](https://github.com/LCTT/TranslateProject/graphs/contributors)翻译了 2155 篇文章,接受了 [4263 个 PR](https://github.com/LCTT/TranslateProject/pulls?q=is%3Apr+is%3Aclosed),得到了 476 个星。
|
||||
|
||||
这三年来,我们经历了 man 项目的流产、 LFS 手册的翻译发布、选题 DeadFire 的离去。得益于 Linux 中国的网站和微博,乃至微信的兴起后的传播,志愿者们的译文传播很广,切实的为国内的开源社区做出了贡献(当然,与此同时,Linux 中国社区也随之更加壮大)。
|
||||
|
||||
这些年间,LCTT 来了很多人,也有人慢慢淡出,这里面涌现了不少做出了卓越贡献的人,比如:
|
||||
|
||||
- geekpi,作为整个 LCTT 项目中翻译量最大贡献者,却鲜少在群内说话,偶尔露面,被戏称为“鸡排兄”。
|
||||
- GOLinux,紧追“鸡排兄”的第二位强人,嗯,群内大部分人的昵称都是他起的,包括楼上。
|
||||
- tinyeyeser,“小眼儿”以翻译风趣幽默著称,是 LCTT 早期初创成员之一。
|
||||
- Vito-L,早期成员,LCTT 的多数 Wiki 出自于其手。
|
||||
- DeadFire,创始成员,从最开始到其离世,一直负责 LCTT 的所有选题工作。
|
||||
- oska874,在接过选题工作的重任后,全面主持 LCTT 的工作。
|
||||
- carolinewuyan,承担了相当多的校对工作。
|
||||
- alim0x,独立完成了 Android 编年史系列的翻译(多达 26 篇,现在还没发布完)等等。
|
||||
|
||||
其它还有 ictlyh、strugglingyouth、FSSlc、zpl1025、runningwater、bazz2、Vic020、dongfengweixiao、jasminepeng、willqian、vizv、ZTinoZ、martin2011qi、felixonmars、su-kaiyao、GHLandy、flsf、H-mudcup、StdioA、crowner、vim-kakali 等等,以及还有很多这里没有提到名字的人,都对 LCTT 做出不可磨灭的贡献。
|
||||
|
||||
具体的贡献排行榜,可以看[这里](https://github.com/LCTT/TranslateProject/graphs/contributors)。
|
||||
|
||||
每年写总结时,我都需要和 gource 以及 ffmpeg 搏斗半天,今年,我又用 gource 重新制作了一份 LCTT 的 GitHub 版本仓库的变迁视频,以飨众人。
|
||||
|
||||
本来想写很多,或许 LCTT 和 Linux 中国已经成了我的生活的一部分,竟然不知道该写点什么了,那就此搁笔罢。
|
||||
|
||||
另外,为 LCTT 的诸位兄弟姐妹们献上我及管理团队的祝福,也欢迎更多的志愿者加入 LCTT ,传送门在此:
|
||||
|
||||
- 项目网站:https://lctt.github.io/ ,请先访问此处了解情况。
|
||||
- “Linux中国”开源社区:https://linux.cn/ ,所有翻译的文章都在这里以及它的同名微博、微信发布。
|
||||
|
||||
LCTT 组长 wxy
|
||||
|
||||
2016/9/10
|
||||
@ -1,21 +1,15 @@
|
||||
|
||||
|
||||
【flankershen翻译中】
|
||||
|
||||
|
||||
|
||||
How to Set Nginx as Reverse Proxy on Centos7 CPanel
|
||||
如何在 CentOS 7 用 cPanel 配置 Nginx 反向代理
|
||||
================================================================================
|
||||
|
||||
Nginx is one of the fastest and most powerful web-server. It is known for its high performance and low resource utilization. It can be installed as both a standalone and a Reverse Proxy Web-server. In this article, I'm discussing about the installation of Nginx as a reverse proxy along with Apache on a CPanel server with latest CentOS 7 installed.
|
||||
Nginx 是最快和最强大的 Web 服务器之一,以其高性能和低资源占用率而闻名。它既可以被安装为一个独立的 Web 服务器,也可以安装成反向代理 Web 服务器。在这篇文章,我将讨论在安装了 cPanel 管理系统的 Centos 7 服务器上安装 Nginx 作为 Apache 的反向代理服务器。
|
||||
|
||||
Nginx as a reverse proxy will work as a frontend webserver serving static contents along with Apache serving the dynamic files in backend. This setup will boost up the overall server performance.
|
||||
Nginx 作为前端服务器用反向代理为静态文件提供服务,Apache 作为后端为动态文件提供服务。这个设置将整体提高服务器的性能。
|
||||
|
||||
Let's walk through the installation steps for Nginx as reverse proxy in CentOS7 x86_64 bit server with cPanel 11.52 installed.
|
||||
让我们过一遍在已经安装好 cPanel 11.52 的 CentOS 7 x86_64 服务器上配置 Nginx 作为反向代理的安装过程。
|
||||
|
||||
First of all, we need to install the EPEL repo to start-up with the process.
|
||||
首先,我们需要安装 EPEL 库来启动这个进程
|
||||
|
||||
### Step 1: Install the EPEL repo. ###
|
||||
### 第一步: 安装 EPEL 库###
|
||||
|
||||
root@server1 [/usr]# yum -y install epel-release
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
@ -31,13 +25,13 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Package Arch Version Repository Size
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Installing:
|
||||
epel-release noarch 7-5 extras 14 k
|
||||
|
||||
### Step 2: After installing the repo, we can start with the installation of the nDeploy RPM repo for CentOS to install our required nDeploy Webstack and Nginx plugin. ###
|
||||
### 第二步: 可以安装 nDeploy 的 CentOS RPM 库来安装我们所需的 nDeploy Web 类软件和 Nginx 插件 ###
|
||||
|
||||
root@server1 [/usr]# yum -y install http://rpm.piserve.com/nDeploy-release-centos-1.0-1.noarch.rpm
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
@ -51,13 +45,13 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Package Arch Version Repository Size
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Installing:
|
||||
nDeploy-release-centos noarch 1.0-1 /nDeploy-release-centos-1.0-1.noarch 110
|
||||
|
||||
### Step 3: Install the nDeploy and Nginx nDeploy plugins. ###
|
||||
### 第三步:安装 nDeploy 和 Nginx nDeploy 插件 ###
|
||||
|
||||
root@server1 [/usr]# yum --enablerepo=ndeploy install nginx-nDeploy nDeploy
|
||||
Loaded plugins: fastestmirror, tsflags, universal-hooks
|
||||
@ -70,9 +64,9 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Package Arch Version Repository Size
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Installing:
|
||||
nDeploy noarch 2.0-11.el7 ndeploy 80 k
|
||||
nginx-nDeploy x86_64 1.8.0-34.el7 ndeploy 36 M
|
||||
@ -84,12 +78,12 @@ First of all, we need to install the EPEL repo to start-up with the process.
|
||||
python-lxml x86_64 3.2.1-4.el7 base 758 k
|
||||
|
||||
Transaction Summary
|
||||
===============================================================================================================================================
|
||||
========================================================================================
|
||||
Install 2 Packages (+5 Dependent packages)
|
||||
|
||||
With these steps, we've completed with the installation of Nginx plugin in our server. Now we need to configure Nginx as reverse proxy and create the virtualhost for the existing cPanel user accounts. For that we can run the following script.
|
||||
通过以上这些步骤,我们完成了在我们的服务器上 Nginx 插件的安装。现在我们可以配置 Nginx 作为反向代理和为已有的 cPanel 用户账户创建虚拟主机,为此我们可以运行如下脚本。
|
||||
|
||||
### Step 4: To enable Nginx as a front end Web Server and create the default configuration files. ###
|
||||
### 第四步:启动 Nginx 作为默认的前端 Web 服务器,并创建默认的配置文件###
|
||||
|
||||
root@server1 [/usr]# /opt/nDeploy/scripts/cpanel-nDeploy-setup.sh enable
|
||||
Modifying apache http and https port in cpanel
|
||||
@ -101,9 +95,9 @@ With these steps, we've completed with the installation of Nginx plugin in our s
|
||||
ConfGen:: saheetha
|
||||
ConfGen:: satest
|
||||
|
||||
As you can see these script will modify the Apache port from 80 to another port to make Nginx run as a front end web server and create the virtual host configuration files for the existing cPanel accounts. Once it is done, confirm the status of both Apache and Nginx.
|
||||
你可以看到这个脚本将修改 Apache 的端口从 80 到另一个端口来让 Nginx 作为前端 Web 服务器,并为现有的 cPanel 用户创建虚拟主机配置文件。一旦完成,确认 Apache 和 Nginx 的状态。
|
||||
|
||||
### Apache Status: ###
|
||||
#### Apache 状态:####
|
||||
|
||||
root@server1 [/var/run/httpd]# systemctl status httpd
|
||||
● httpd.service - Apache Web Server
|
||||
@ -118,7 +112,7 @@ As you can see these script will modify the Apache port from 80 to another port
|
||||
Jan 18 06:34:23 server1.centos7-test.com apachectl[25606]: httpd (pid 24760) already running
|
||||
Jan 18 06:34:23 server1.centos7-test.com systemd[1]: Started Apache Web Server.
|
||||
|
||||
### Nginx Status: ###
|
||||
#### Nginx 状态:####
|
||||
|
||||
root@server1 [~]# systemctl status nginx
|
||||
● nginx.service - nginx-nDeploy - high performance web server
|
||||
@ -137,7 +131,7 @@ As you can see these script will modify the Apache port from 80 to another port
|
||||
Jan 17 17:18:29 server1.centos7-test.com nginx[3804]: nginx: configuration file /etc/nginx/nginx.conf test is successful
|
||||
Jan 17 17:18:29 server1.centos7-test.com systemd[1]: Started nginx-nDeploy - high performance web server.
|
||||
|
||||
Nginx act as a frontend webserver running on port 80 and Apache configuration is modified to listen on http port 9999 and https port 4430. Please see their status below:
|
||||
Nginx 作为前端服务器运行在 80 端口,Apache 配置被更改为监听 http 端口 9999 和 https 端口 4430。请看他们的情况:
|
||||
|
||||
root@server1 [/usr/local/src]# netstat -plan | grep httpd
|
||||
tcp 0 0 0.0.0.0:4430 0.0.0.0:* LISTEN 17270/httpd
|
||||
@ -151,13 +145,13 @@ Nginx act as a frontend webserver running on port 80 and Apache configuration is
|
||||
tcp 0 0 127.0.0.1:80 0.0.0.0:* LISTEN 17802/nginx: master
|
||||
tcp 0 0 45.79.183.73:80 0.0.0.0:* LISTEN 17802/nginx: master
|
||||
|
||||
The virtualhost entries created for the existing users as located in the folder "**/etc/nginx/sites-enabled**". This file path is included in the Nginx main configuration file.
|
||||
为已有用户创建的虚拟主机的配置文件在 "**/etc/nginx/sites-enabled**"。 这个文件路径包含了 Nginx 主要配置文件。
|
||||
|
||||
root@server1 [/etc/nginx/sites-enabled]# ll | grep .conf
|
||||
-rw-r--r-- 1 root root 311 Jan 17 09:02 saheetha.com.conf
|
||||
-rw-r--r-- 1 root root 336 Jan 17 09:02 saheethastest.com.conf
|
||||
|
||||
### Sample Vhost for a domain: ###
|
||||
#### 一个域名的示例虚拟主机:###
|
||||
|
||||
server {
|
||||
|
||||
@ -173,7 +167,7 @@ The virtualhost entries created for the existing users as located in the folder
|
||||
|
||||
}
|
||||
|
||||
We can confirm the working of the web server status by calling a website in the browser. Please see the web server information on my server after the installation.
|
||||
我们可以启动浏览器查看网站来确定 Web 服务器的工作状态。安装后,请阅读服务器上的 web 服务信息。
|
||||
|
||||
root@server1 [/home]# ip a | grep -i eth0
|
||||
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
|
||||
@ -183,24 +177,24 @@ We can confirm the working of the web server status by calling a website in the
|
||||
|
||||

|
||||
|
||||
Nginx will create the virtual host automatically for any newly created accounts in cPanel. With these simple steps we can configure Nginx as reverse proxy on a CentOS 7/CPanel server.
|
||||
Nginx 将会为任何最新在 cPanel 中创建的账户创建虚拟主机。通过这些简单的的步骤,我们能够在一台 CentOS 7 / cPanel 的服务器上配置 Nginx 作为反向代理。
|
||||
|
||||
### Advantages of Nginx as Reverse Proxy: ###
|
||||
### Nginx 作为反向代理的优势###
|
||||
|
||||
1. Easy to install and configure
|
||||
2. Performance and efficiency
|
||||
3. Prevent DDOS attacks
|
||||
4. Allows .htaccess PHP rewrite rules
|
||||
1. 便于安装和配置。
|
||||
2. 效率高、性能好。
|
||||
3. 防止 Ddos 攻击。
|
||||
4. 支持使用 .htaccess 作为 PHP 的重写规则。
|
||||
|
||||
I hope this article is useful for you guys. Thank you for referring to this. I would appreciate your valuable comments and suggestions on this for further improvements.
|
||||
我希望这篇文章对你们有用。感谢你看它。我非常高兴收到你的宝贵意见和建议,并进一步改善。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/set-nginx-reverse-proxy-centos-7-cpanel/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
一位跨平台开发者的自白
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
[Andreia Gaita][1] 在 OSCON 开源大会上发表了一个题为[跨平台开发者的自白][2]的演讲。她长期从事于开源工作,并且为 [Mono][3] 工程(LCTT 译注:一个致力于开创 .NET 在 Linux 上使用的开源工程)做着贡献,主要以 C#/C++ 开发。Andreia 任职于 GitHub,她的工作是专注构建 Visual Studio 的 GitHub 扩展管理器。
|
||||
|
||||
我在她发表演讲前就迫不及待的想要问她一些关于跨平台开发的事,问问她作为一名跨平台开发者在这 16 年之中学习到了什么。
|
||||
|
||||

|
||||
|
||||
**在你开发跨平台代码中,你使用过的最简单的和最难的代码语言是什么?**
|
||||
|
||||
我很少讨论某种语言的好坏,更多是讨论是那些语言有哪些库和工具。语言的编译器、解释器以及构建系统决定了用它们做跨平台开发的难易程度(或者它们是否可能做跨平台开发),可用的 UI 库和对本地系统的访问能力决定了与该操作系统集成的紧密程度。按照我的观点,我认为 C# 最适合完成跨平台开发工作。这种语言自身包括了允许快速的本地调用和精确的内存映射的功能,如果你希望你的代码能够与系统和本地函数库进行交互就需要这些功能。而当我需要非常特殊的系统功能时,我就会切换到 C 或者 C++。
|
||||
|
||||
**你使用的跨平台开发工具或者抽象层有哪些?**
|
||||
|
||||
我的大部分跨平台工作都是为其它需要开发跨平台应用的人开发工具、库和绑定(binding),一般是用 MONO/C# 和 C/C++。在抽象的层面我用的不多,更多是在 glib 库和友元(friends)方面。大多数时候,我用 Mono 去完成各种跨平台应用的,包括 UI,或者偶然在游戏开发中用到 Unity3D 的部分。我经常使用 Electron(LCTT 译注:Atom 编辑器的兄弟项目,可以用 Electron 开发桌面应用)。
|
||||
|
||||
**你接触过哪些构建系统?它们之间的区别是由于语言还是平台的不同?**
|
||||
|
||||
我试着选择适合我使用的语言的构建系统。那样,就会很少遇到让我头疼的问题(希望如此)。它需要支持平台和体系结构间的选择、构建输出结果位置可以智能些(多个并行构建),以及易配置性等。大多数时候,我的项目会结合使用 C/C++ 和 C#,我要从同一源代码同时构建不同的配置环境(调试、发布、Windows、OSX、Linux、Android、iOS 等等),这通常需要为每个构建的输出结果选择带有不同参数的不同编译器。构建系统可以帮我做到这一切而不用让我(太)费心。我时常尝试着用不同的构建系统,看看有些什么新的变化,但是最终,我还是回到了使用 makefile 的情况,并结合使用 shell 和批处理脚本或 Perl 脚本来完成工作(因为如果我希望用户来构建我的软件,我还是最好选择一种到处都可以用的命令行脚本语言)。
|
||||
|
||||
**你怎样平衡在这种使用统一的用户界面下提供原生的外观和体验的需求呢?**
|
||||
|
||||
跨平台的用户界面的实现很困难。在过去几年中我已经使用了一些跨平台 GUI,并且我认为这些事情上并没有最优解。基本上有两种选择。你可以选择一个跨平台工具去做一个并不是完全适合你所有支持的平台的 UI,但是代码库比较小,维护成本比较低。或者你可以选择去开发针对平台的 UI,那样看起来更原生,集成的也更好,但是需要更大的代码库和更高的维护成本。这种决定完全取决于 APP 的类型、它有多少功能、你有多少资源,以及你要把它运行在多少平台上?
|
||||
|
||||
最后,我认为用户比较接受这种“一个 UI 打通关”了,就比如 Electron 框架。我有个 Chromium+C+C# 的框架侧项目,有一天我希望可以用 C# 构建 Electron 型的 app,这样的话我就可以做到两全其美了。
|
||||
|
||||
**构建/打包系统的依赖性对你有影响吗 ?**
|
||||
|
||||
我依赖的使用方面很保守,我被崩溃的 ABI(LCTT 译注:应用程序二进制接口)、冲突的符号、以及丢失的包等问题困扰了太多次。我决定我要针对的操作系统版本,并选择最低的公有部分来使问题最小化。通常这就意味着有五种不同的 Xcode 和 OSX 框架库,要在同样的机器上相应安装五种不同的 Visual Studio 版本,多种 clang(LCTT 译注:C语言、C++、Object-C、C++ 语言的轻量级编译器)和 gcc 版本,一系列的运行着各种发行版的虚拟机。如果我不能确定我要使用的操作系统的包的状态,我有时就会静态连接库,有时会子模块化依赖以确保它们一直可用。大多时候,我会避免这些很棘手的问题,除非我非常需要使用他们。
|
||||
|
||||
**你使用持续集成(CI)、代码审查以及相关的工具吗?**
|
||||
|
||||
基本每天都用。这是保持高效的唯一方式。我在一个项目中做的第一件事情是配置跨平台构建脚本,保证每件事尽可能自动化完成。当你面向多平台开发的时候,持续集成是至关重要的。没有人能在一个机器上构建各种平台的不同组合,并且一旦你的构建过程没有包含所有的平台,你就不会注意到你搞砸的事情。在一个共享式的多平台代码库中,不同的人拥有不同的平台和功能,所以保证质量的唯一的方法是跨团队代码审查结合持续集成和其他分析工具。这不同于其他的软件项目,如果不使用相关的工具就会面临失败。
|
||||
|
||||
**你依赖于自动构建测试,或者倾向于在每个平台上构建并且进行本地测试吗?**
|
||||
|
||||
对于不包括 UI 的工具和库,我通常使用自动构建测试。如果有 UI,两种方法我都会用到——针对已有的 GUI 工具的可靠的、可脚本化的 UI 自动化少到几乎没有,所以我要么我去针对我要跨我所支持的平台创建 UI 自动化工具,要么手动进行测试。如果一个项目使用了定制的 UI 库(比如说一个类似 Unity3D 的 OpenGL UI),开发可编程的自动化工具并自动化大多数工作就相当容易。不过,没有什么东西会像人一样双击就测试出问题。
|
||||
|
||||
**如果你要做跨平台开发,你喜欢用跨编辑器的构建系统,比如在 Windows 上使用 Visual Studio,在 Linux 上使用 Qt Creator,在 Mac 上使用 XCode 吗?还是你更趋向于使用 Eclipse 这样的可以在所有平台上使用的单一平台?**
|
||||
|
||||
我喜欢使用跨编辑器的构建系统。我更喜欢在不同的IDE上保存项目文件(这样可以使增加 IDE 变得更容易),通过使用构建脚本让 IDE 在它们支持的平台上去构建。对于一个开发者来说编辑器是最重要的工具,学习它们是需要花费时间和精力的,而它们是不可相互替代的。我有我自己喜欢的编辑器和工具,每个人也可以使用他们最喜爱的工具。
|
||||
|
||||
**在跨平台开发的时候,你更喜欢使用什么样的编辑器、开发环境和 IDE 呢?**
|
||||
|
||||
跨平台开发者被限制在只能选择可以在多数平台上工作的所共有的不多选择之一。我爱用 Visual Studio,但是我不能依赖它完成除 Windows 平台之外的工作(你可能不想让 Windows 成为你的主要的交叉编译平台),所以我不会使用它作为我的主要 IDE。即使可以,跨平台开发者的核心技能也是尽可能的了解和使用大量的平台。这就意味着必须很熟悉它们——使用该平台上的编辑器和库,了解这种操作系统及其适用场景、运行方式以及它的局限性等。做这些事情就需要头脑清醒(我的捷径是加强记忆),我必须依赖跨平台的编辑器。所以我使用 Emacs 和 Sublime。
|
||||
|
||||
**你之前和现在最喜欢的跨平台项目是什么?**
|
||||
|
||||
我一直很喜欢 Mono,并且得心应手,其它的项目大部分都是以某种方式围绕着它进行的。Gluezilla 是我在多年前开发的一个 Mozilla 绑定(binding),可以把 C# 开发的应用嵌入到 Web 浏览器页面中,并且看起来很有特色。我开发过一个 Winform 应用,它是在 linux 上开发的,它可以在 Windows 上运行在一个 Mozilla 浏览器页面里嵌入的 GTK 视图中。CppSharp 项目(以前叫做 Cxxi,更早时叫做 CppInterop)是一个我开始为 C++ 库生成 C# 绑定(binding)的项目,这样就可以在 C# 中调用、创建实例、子类化 C++ 类。这样,它在运行的时候就能够检测到所使用的平台,以及用来创建本地运行库的是什么编译器,并为它生成正确的 C# 绑定(binding)。这多么有趣啊。
|
||||
|
||||
**你怎样看跨平台开发的未来趋势呢?**
|
||||
|
||||
我们构建本地应用程序的方式已经改变了,我感觉在各种桌面操作系统的明显差异在慢慢变得模糊;所以构建跨平台的应用程序将会更加容易,而且对系统的集成也不需要完全本地化。不好的是,这可能意味着应用程序易用性更糟,并且在发挥操作系统特性方面所能做的更少。库、工具以及运行环境的跨平台开发是一种我们知道怎样做的更好,但是跨平台应用程序的开发仍然需要我们的努力。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/oscon-interview-andreia-gaita
|
||||
|
||||
作者:[Marcus D. Hanwell][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhanwell
|
||||
[1]: https://twitter.com/sh4na
|
||||
[2]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/48702
|
||||
[3]: http://www.mono-project.com/
|
||||
|
||||
85
published/20160506 Setup honeypot in Kali Linux.md
Normal file
85
published/20160506 Setup honeypot in Kali Linux.md
Normal file
@ -0,0 +1,85 @@
|
||||
在 Kali Linux 环境下设置蜜罐
|
||||
=========================
|
||||
|
||||
Pentbox 是一个包含了许多可以使渗透测试工作变得简单流程化的工具的安全套件。它是用 Ruby 编写并且面向 GNU / Linux,同时也支持 Windows、MacOS 和其它任何安装有 Ruby 的系统。在这篇短文中我们将讲解如何在 Kali Linux 环境下设置蜜罐。如果你还不知道什么是蜜罐(honeypot),“蜜罐是一种计算机安全机制,其设置用来发现、转移、或者以某种方式,抵消对信息系统的非授权尝试。"
|
||||
|
||||
### 下载 Pentbox:
|
||||
|
||||
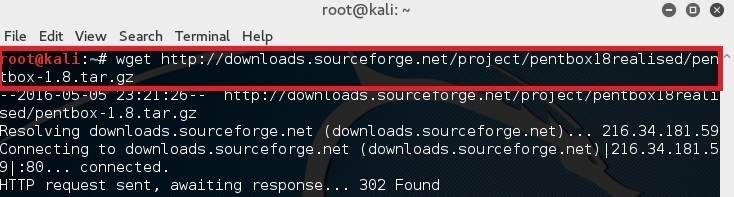
在你的终端中简单的键入下面的命令来下载 pentbox-1.8。
|
||||
|
||||
```
|
||||
root@kali:~# wget http://downloads.sourceforge.net/project/pentbox18realised/pentbox-1.8.tar.gz
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 解压 pentbox 文件
|
||||
|
||||
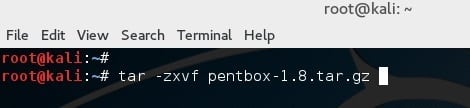
使用如下命令解压文件:
|
||||
|
||||
```
|
||||
root@kali:~# tar -zxvf pentbox-1.8.tar.gz
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 运行 pentbox 的 ruby 脚本
|
||||
|
||||
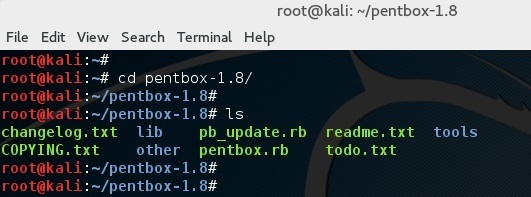
改变目录到 pentbox 文件夹:
|
||||
|
||||
```
|
||||
root@kali:~# cd pentbox-1.8/
|
||||
```
|
||||
|
||||
|
||||
|
||||
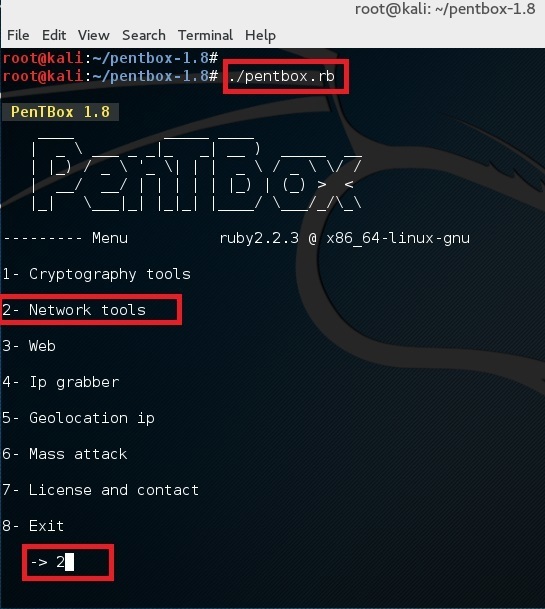
使用下面的命令来运行 pentbox:
|
||||
|
||||
```
|
||||
root@kali:~# ./pentbox.rb
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 设置一个蜜罐
|
||||
|
||||
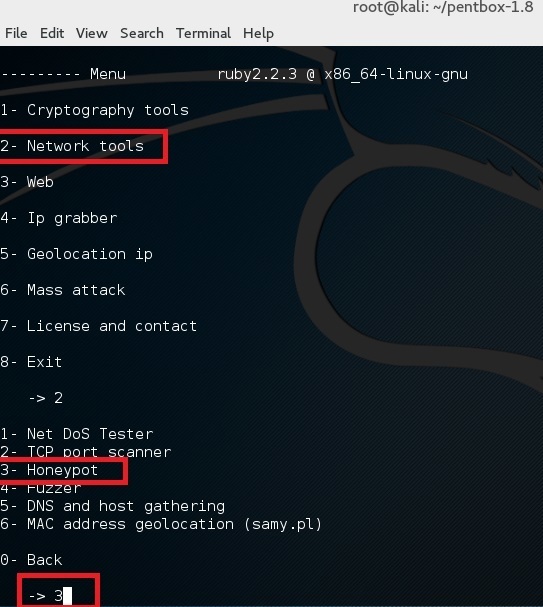
使用选项 2 (Network Tools) 然后是其中的选项 3 (Honeypot)。
|
||||
|
||||
|
||||
|
||||
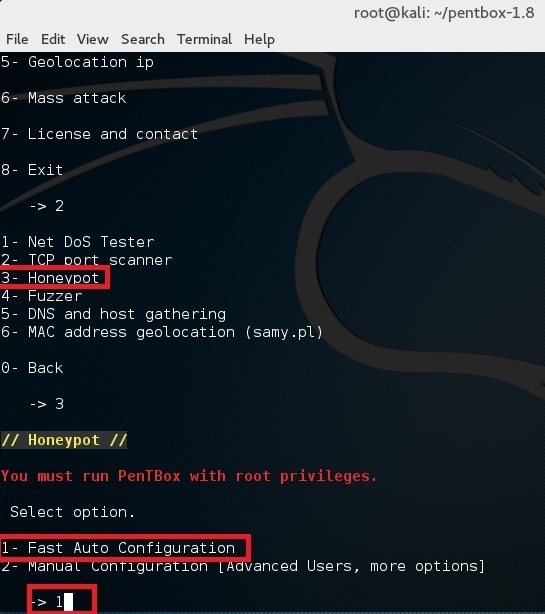
完成让我们执行首次测试,选择其中的选项 1 (Fast Auto Configuration)
|
||||
|
||||
|
||||
|
||||
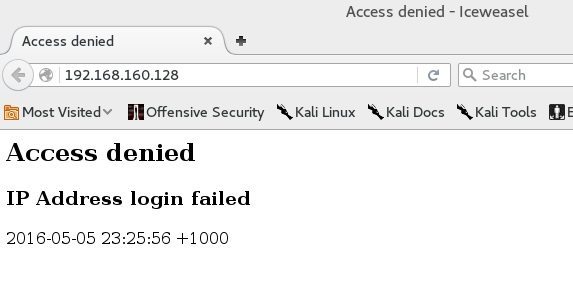
这样就在 80 端口上开启了一个蜜罐。打开浏览器并且打开链接 http://192.168.160.128 (这里的 192.168.160.128 是你自己的 IP 地址。)你应该会看到一个 Access denied 的报错。
|
||||
|
||||
|
||||
|
||||
|
||||
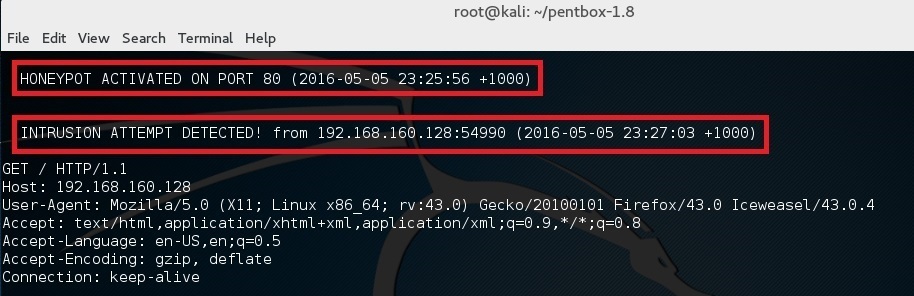
并且在你的终端应该会看到 “HONEYPOT ACTIVATED ON PORT 80” 和跟着的 “INTRUSION ATTEMPT DETECTED”。
|
||||
|
||||
|
||||
|
||||
现在,如果你在同一步选择了选项 2 (Manual Configuration), 你应该看见更多的其它选项:
|
||||
|
||||
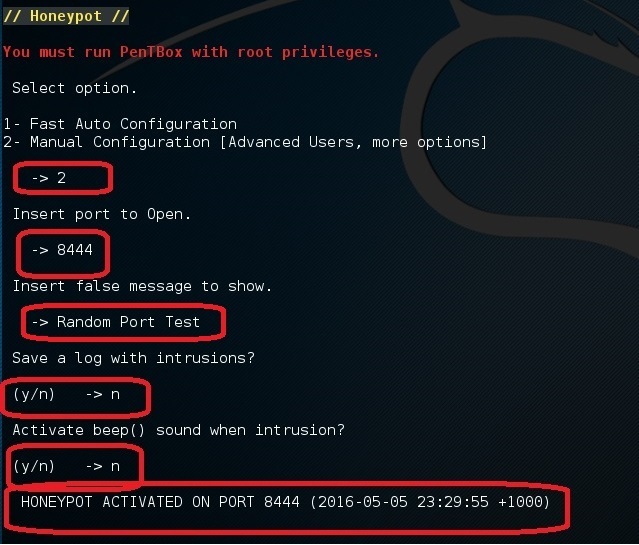
|
||||
|
||||
执行相同的步骤但是这次选择 22 端口 (SSH 端口)。接着在你家里的路由器上做一个端口转发,将外部的 22 端口转发到这台机器的 22 端口上。或者,把这个蜜罐设置在你的云端服务器的一个 VPS 上。
|
||||
|
||||
你将会被有如此多的机器在持续不断地扫描着 SSH 端口而震惊。 你知道你接着应该干什么么? 你应该黑回它们去!桀桀桀!
|
||||
|
||||
如果视频是你的菜的话,这里有一个设置蜜罐的视频:
|
||||
|
||||
<https://youtu.be/NufOMiktplA>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.blackmoreops.com/2016/05/06/setup-honeypot-in-kali-linux/
|
||||
|
||||
作者:[blackmoreops.com][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: blackmoreops.com
|
||||
89
published/20160509 Android vs. iPhone Pros and Cons.md
Normal file
89
published/20160509 Android vs. iPhone Pros and Cons.md
Normal file
@ -0,0 +1,89 @@
|
||||
对比 Android 和 iPhone 的优缺点
|
||||
===================================
|
||||
|
||||
>当我们比较 Android 与 iPhone 的时候,很显然 Android 具有一定的优势,而 iPhone 则在一些关键方面更好。但是,究竟哪个比较好呢?
|
||||
|
||||
对 Android 与 iPhone 比较是个个人的问题。
|
||||
|
||||
就好比我来说,我两个都用。我深知这两个平台的优缺点。所以,我决定分享我关于这两个移动平台的观点。另外,然后谈谈我对新的 Ubuntu 移动平台的印象和它的优势。
|
||||
|
||||
### iPhone 的优点
|
||||
|
||||
虽然这些天我是个十足的 Android 用户,但我必须承认 iPhone 在某些方面做的是不错。首先,苹果公司在他们的设备更新方面有更好的成绩。这对于运行着 iOS 的旧设备来说尤其是这样。反观 Android ,如果不是谷歌亲生的 Nexus,它最好也不过是一个更高端的运营商支持的手机,你将发现它们的更新少的可怜或者根本没有。
|
||||
|
||||
其中 iPhone 做得很好的另一个领域是应用程序的可用性。展开来说,iPhone 应用程序几乎总是有一个简洁的外观。这并不是说 Android 应用程序就是丑陋的,而是,它们可能只是没有像 iOS 上一样的保持不变的操控习惯和一以贯之的用户体验。两个典型的例子, [Dark Sky][1] (天气)和 [Facebook Paper][2] 很好表现了 iOS 独有的布局。
|
||||
|
||||
再有就是备份过程。 Android 可以备份,默认情况下是备份到谷歌。但是对应用数据起不了太大作用。对比 iPhone ,iCloud 基本上可以对你的 iOS 设备进行了完整备份。
|
||||
|
||||
### iPhone 令我失望的地方
|
||||
|
||||
对 iPhone 来说,最无可争辩的问题是它的硬件限制要比软件限制更大,换句话来说,就是存储容量问题。
|
||||
|
||||
你看,对于大多数 Android 手机,我可以买一个容量较小的手机,然后以后可以添加 SD 卡。这意味着两件事:第一,我可以使用 SD 卡来存储大量的媒体文件。其次,我甚至可以用 SD 卡来存储“一些”我的应用程序。而苹果完全不能这么做。
|
||||
|
||||
另一个 iPhone 让我失望的地方是它提供的选择很少。备份您的设备?希望你喜欢 iTunes 或 iCloud 吧。但对一些像我一样用 Linux 的人,那就意味着,我唯一的选择便是使用 iCloud。
|
||||
|
||||
要公平的说,如果你愿意越狱,你的 iPhone 还有一些其他解决方案的,但这并不是这篇文章所讲的。 Android 的 解锁 root 也一样。本文章针对的是两个平台的原生设置。
|
||||
|
||||
最后,让我们不要忘记这件看起来很小的事—— [iTunes 会删掉用户的音乐][3],因为它认为和苹果音乐的内容重复了……或者因为一些其它的类似规定。这不是 iPhone 特有的情况?我不同意,因为那些音乐最终就是在 iPhone 上没有了。我能十分肯定地这么说,是因为不管在哪里我都不会说这种谎话。
|
||||
|
||||

|
||||
|
||||
*Android 和 iPhone 的对决取决于什么功能对你来说最重要。*
|
||||
|
||||
### Android 的优点
|
||||
|
||||
Android 给我最大的好处就是 iPhone 所提供不了的:选择。这包括对应用程序、设备以及手机是整体如何工作的选择。
|
||||
|
||||
我爱桌面小工具!对于 iPhone 用户来说,它们也许看上去很蠢。但我可以告诉你,它们可以让我不用打开应用程序就可以看到所需的数据,而无需额外的麻烦。另一个类似的功能,我喜欢安装定制的桌面界面,而不是我的手机默认的那个!
|
||||
|
||||
最后,我可以通过像 [Airdroid][4] 和 [Tasker][5] 这样的工具给我的智能手机添加计算机级的完整功能。AirDroid 可以让我把我的 Android 手机当成带有一个文件管理和通信功能的计算机——这可以让我可以轻而易举的使用鼠标和键盘。Tasker 更厉害,我可以用它让我手机根据环境变得可联系或不可联系,当我设置好了之后,当我到会议室之后我的手机就会自己进入会议模式,甚至变成省电模式。我还可以设置它当我到达特定的目的地时自动启动某个应用程序。
|
||||
|
||||
### Android 让我失望的地方
|
||||
|
||||
Android 备份选项仅限于特定的用户数据,而不是手机的完整克隆。如果不解锁 root,要么你只能听之任之,要么你必须用 Android SDK 来解决。期望普通用户会解锁 root 或运行 SDK 来完成备份(我的意思是一切都备份)显然是一个笑话。
|
||||
|
||||
是的,谷歌的备份服务会备份谷歌应用程序的数据、以及其他相关的自定义设置。但它是远不及我们所看到的苹果服务一样完整。为了完成类似于苹果那样的功能,我发现你就要么必须解锁 root ,要么将其连接到一个在 PC 机上使用一些不知道是什么的软件来干这个。
|
||||
|
||||
不过,公平的说,我知道使用 Nexus 的人能从该设备特有的[完整备份服务][6]中得到帮助。对不起,但是谷歌的默认备份方案是不行的。对于通过在 PC 上使用 adb (Android Debug Bridge) 来备份也是一样的——不会总是如预期般的恢复。
|
||||
|
||||
等吧,它会变好的。经过了很多失败的失望和挫折之后,我发现有一个应用程序,看起来它“可能”提供了一点点微小的希望,它叫 Helium 。它不像我发现的其他应用程序那样拥有误导性的和令人沮丧的局限性,[Helium][7] 最初看起来像是谷歌应该一直提供的备份应用程序——注意,只是“看起来像”。可悲的是,它绊了我一跤。第一次运行时,我不仅需要将它连接到我的计算机上,甚至使用他们提供的 Linux 脚本都不工作。在删除他们的脚本后,我弄了一个很好的老式 adb 来备份到我的 Linux PC 上。你可能要知道的是:你需要在开发工具里打开一箩筐东西,而且如果你运行 Twilight 应用的话还要关闭它。当 adb 的备份选项在我的手机上不起作用时,我花了一点时间把这个搞好了。
|
||||
|
||||
最后,Android 为非 root 用户也提供了可以轻松备份一些如联系人、短信等简单东西的选择。但是,要深度手机备份的话,以我经验还是通过有线连接和 adb。
|
||||
|
||||
### Ubuntu 能拯救我们吗?
|
||||
|
||||
在手机领域,通过对这两大玩家之间的优劣比较,我们很期望从 Ubuntu 看到更好的表现。但是,迄今为止,它的表现相当低迷。
|
||||
|
||||
我喜欢开发人员基于这个操作系统正在做的那些努力,我当然想在 iPhone 和 Android 手机之外有第三种选择。但是不幸的是,它在手机和平板上并不受欢迎,而且由于硬件的低端以及在 YouTube 上的糟糕的演示,有很多不好的传闻。
|
||||
|
||||
公平来说,我在以前也用过 iPhone 和 Android 的低端机,所以这不是对 Ubuntu 的挖苦。但是它要表现出准备与 iPhone 和 Android 相竞争的功能生态时,那就另说了,这还不是我现在特别感兴趣的东西。在以后的日子里,也许吧,我会觉得 Ubuntu 手机可以满足我的需要了。
|
||||
|
||||
###Android 与 iPhone 之争:为什么 Android 将终究赢得胜利
|
||||
|
||||
忽视 Android 那些痛苦的缺点,它起码给我了选择。它并没有把我限制在只有两种备份数据的方式上。是的,一些 Android 的限制事实上是由于它的关注点在于让我选择如何处理我的数据。但是,我可以选择我自己的设备,想加内存就加内存。Android 可以我让做很多很酷的东西,而 iPhone 根本就没有能力这些事情。
|
||||
|
||||
从根本上来说, Android 给非 root 用户提供了访问手机功能的更大自由。无论是好是坏,这是人们想要的一种自由。现在你们其中有很多 iPhone 的粉丝应该感谢像 [libimobiledevice][8] 这样项目带来的影响。看看苹果阻止 Linux 用户所做的事情……然后问问你自己:作为一个 Linux 用户这真的值得吗?
|
||||
|
||||
发表下评论吧,分享你对 iPhone 、Android 或 Ubuntu 的看法。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/mobile-wireless/android-vs.-iphone-pros-and-cons.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[jovov](https://github.com/jovov)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]: http://darkskyapp.com/
|
||||
[2]: https://www.facebook.com/paper/
|
||||
[3]: https://blog.vellumatlanta.com/2016/05/04/apple-stole-my-music-no-seriously/
|
||||
[4]: https://www.airdroid.com/
|
||||
[5]: http://tasker.dinglisch.net/
|
||||
[6]: https://support.google.com/nexus/answer/2819582?hl=en
|
||||
[7]: https://play.google.com/store/apps/details?id=com.koushikdutta.backup&hl=en
|
||||
[8]: http://www.libimobiledevice.org/
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
Linux 将成为 21 世纪汽车的主要操作系统
|
||||
===============================================================
|
||||
|
||||
> 汽车可不单单是由引擎和华丽外壳组成的,汽车里还有许许多多的计算部件,而 Linux 就在它们里面跑着。
|
||||
|
||||
Linux 不只运行在你的服务器和手机(安卓)上。它还运行在你的车里。当然了,没人会因为某个车载系统而去买辆车。但是 Linux 已经为像丰田、日产、捷豹路虎这些大型汽车制造商提供了信息娱乐系统、平视显示以及其联网汽车(connected car)的 4G 与 Wi-Fi 系统,而且 [Linux 即将登陆福特汽车][1]、马自达、三菱、斯巴鲁。
|
||||
|
||||

|
||||
|
||||
*如今,所有的 Linux 和开源汽车软件的成果都已经在 Linux 基金会的 Automotive Grade Linux (AGL)项目下统一标准化了。*
|
||||
|
||||
传统软件公司也进入了移动物联网领域。 Movimento、甲骨文、高通、Texas Instruments、UIEvolution 和 VeriSilicon 都已经[加入 Automotive Grade Linux(AGL)项目][2]。 [AGL][3] 是一个相互协作的开源项目,志在于为联网汽车打造一个基于 Linux 的通用软件栈。
|
||||
|
||||
“随着联网汽车技术和信息娱乐系统需求的快速增长,AGL 过去几年中得到了极大的发展,” Linux 基金会汽车总经理 Dan Cauchy 如是说。
|
||||
|
||||
Cauchy 又补充道,“我们的会员基础不单单只是迅速壮大,而且通过横跨不同的业界实现了多元化,从半导体和车载软件到 IoT 和连接云服务。这是一个明显的迹象,即联网汽车的革命已经间接影响到许多行业纵向市场。”
|
||||
|
||||
这些公司在 AGL 发布了新的 AGL Unified Code Base (UCB) 之后加入了 AGL 项目。这个新的 Linux 发行版基于 AGL 和另外两个汽车开源项目: [Tizen][4] 和 [GENIVI Alliance][5] 。 UCB 是第二代 Linux 汽车系统。它从底层开始开发,一直到特定的汽车应用软件。它能处理导航、通信、安全、安保和信息娱乐系统。
|
||||
|
||||
“汽车行业需要一个标准的开源系统和框架来让汽车制造商和供应商能够快速地将类似智能手机的功能带入到汽车中来。” Cauchy 说。“这个新的发行版将 AGL、Tizen、GENIVI 项目和相关开源代码中的精华部分整合进 AGL Unified Code Base (UCB)中,使得汽车制造商能够利用一个通用平台进行快速创新。 在汽车中采用基于 Linux 的系统来实现所有功能时, AGL 的 UCB 发行版将扮演一个重大的角色。”
|
||||
|
||||
他说得对。自从 2016 年 1 月发布以来,已有四个汽车公司和十个新的软件厂商加入了 AGL。Esso,如今的 Exxon, 曾让 “把老虎装入油箱” 这条广告语出了名。我怀疑 “把企鹅装到引擎盖下” 这样的广告语是否也会变得家喻户晓,但是它却道出了事实。 Linux 正在慢慢成为 21 世纪汽车的主要操作系统。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/the-linux-in-your-car-movement-gains-momentum/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: https://www.automotivelinux.org/news/announcement/2016/01/ford-mazda-mitsubishi-motors-and-subaru-join-linux-foundation-and
|
||||
[2]: https://www.automotivelinux.org/news/announcement/2016/05/oracle-qualcomm-innovation-center-texas-instruments-and-others-support
|
||||
[3]: https://www.automotivelinux.org/
|
||||
[4]: https://www.tizen.org/
|
||||
[5]: http://www.genivi.org/
|
||||
@ -0,0 +1,74 @@
|
||||
使用 Python 和 Asyncio 编写在线多人游戏(一)
|
||||
===================================================================
|
||||
|
||||
你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个[能工作的例子][1]来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
|
||||
|
||||
- [游戏入口在此,点此体验][2]。
|
||||
|
||||
###1、简介
|
||||
|
||||
在技术和文化领域,大规模多人在线游戏(MMO)毋庸置疑是我们当今世界的潮流之一。很长时间以来,为一个 MMO 游戏写一个服务器这件事总是会涉及到大量的预算与复杂的底层编程技术,不过在最近这几年,事情迅速发生了变化。基于动态语言的现代框架允许在中档的硬件上面处理大量并发的用户连接。同时,HTML5 和 WebSockets 标准使得创建基于实时图形的游戏的直接运行至浏览器上的客户端成为可能,而不需要任何的扩展。
|
||||
|
||||
对于创建可扩展的非堵塞性的服务器来说,Python 可能不是最受欢迎的工具,尤其是和在这个领域里最受欢迎的 Node.js 相比而言。但是最近版本的 Python 正在改变这种现状。[asyncio][3] 的引入和一个特别的 [async/await][4] 语法使得异步代码看起来像常规的阻塞代码一样,这使得 Python 成为了一个值得信赖的异步编程语言,所以我将尝试利用这些新特点来创建一个多人在线游戏。
|
||||
|
||||
###2、异步
|
||||
|
||||
一个游戏服务器应该可以接受尽可能多的用户并发连接,并实时处理这些连接。一个典型的解决方案是创建线程,然而在这种情况下并不能解决这个问题。运行上千的线程需要 CPU 在它们之间不停的切换(这叫做上下文切换),这将导致开销非常大,效率很低下。更糟糕的是使用进程来实现,因为,不但如此,它们还会占用大量的内存。在 Python 中,甚至还有一个问题,Python 的解释器(CPython)并不是针对多线程设计的,相反它主要针对于单线程应用实现最大的性能。这就是为什么它使用 GIL(global interpreter lock),这是一个不允许同时运行多线程 Python 代码的架构,以防止同一个共享对象出现使用不可控。正常情况下,在当前线程正在等待的时候,解释器会转换到另一个线程,通常是等待一个 I/O 的响应(举例说,比如等待 Web 服务器的响应)。这就允许在你的应用中实现非阻塞 I/O 操作,因为每一个操作仅仅阻塞一个线程而不是阻塞整个服务器。然而,这也使得通常的多线程方案变得几近无用,因为它不允许你并发执行 Python 代码,即使是在多核心的 CPU 上也是这样。而与此同时,在一个单一线程中拥有非阻塞 I/O 是完全有可能的,因而消除了经常切换上下文的需要。
|
||||
|
||||
实际上,你可以用纯 Python 代码来实现一个单线程的非阻塞 I/O。你所需要的只是标准的 [select][5] 模块,这个模块可以让你写一个事件循环来等待未阻塞的 socket 的 I/O。然而,这个方法需要你在一个地方定义所有 app 的逻辑,用不了多久,你的 app 就会变成非常复杂的状态机。有一些框架可以简化这个任务,比较流行的是 [tornade][6] 和 [twisted][7]。它们被用来使用回调方法实现复杂的协议(这和 Node.js 比较相似)。这种框架运行在它自己的事件循环中,按照定义的事件调用你的回调函数。并且,这或许是一些情况的解决方案,但是它仍然需要使用回调的方式编程,这使你的代码变得碎片化。与写同步代码并且并发地执行多个副本相比,这就像我们在普通的线程上做的一样。在单个线程上这为什么是不可能的呢?
|
||||
|
||||
这就是为什么出现微线程(microthread)概念的原因。这个想法是为了在一个线程上并发执行任务。当你在一个任务中调用阻塞的方法时,有一个叫做“manager” (或者“scheduler”)的东西在执行事件循环。当有一些事件准备处理的时候,一个 manager 会转移执行权给一个任务,并等着它执行完毕。任务将一直执行,直到它遇到一个阻塞调用,然后它就会将执行权返还给 manager。
|
||||
|
||||
> 微线程也称为轻量级线程(lightweight threads)或绿色线程(green threads)(来自于 Java 中的一个术语)。在伪线程中并发执行的任务叫做 tasklets、greenlets 或者协程(coroutines)。
|
||||
|
||||
Python 中的微线程最早的实现之一是 [Stackless Python][8]。它之所以这么知名是因为它被用在了一个叫 [EVE online][9] 的非常有名的在线游戏中。这个 MMO 游戏自称说在一个持久的“宇宙”中,有上千个玩家在做不同的活动,这些都是实时发生的。Stackless 是一个独立的 Python 解释器,它代替了标准的函数栈调用,并且直接控制程序运行流程来减少上下文切换的开销。尽管这非常有效,这个解决方案不如在标准解释器中使用“软”库更流行,像 [eventlet][10] 和 [gevent][11] 的软件包配备了修补过的标准 I/O 库,I/O 函数会将执行权传递到内部事件循环。这使得将正常的阻塞代码转变成非阻塞的代码变得简单。这种方法的一个缺点是从代码上看这并不分明,它的调用是非阻塞的。新版本的 Python 引入了本地协程作为生成器的高级形式。在 Python 的 3.4 版本之后,引入了 asyncio 库,这个库依赖于本地协程来提供单线程并发。但是仅仅到了 Python 3.5 ,协程就变成了 Python 语言的一部分,使用新的关键字 async 和 await 来描述。这是一个简单的例子,演示了使用 asyncio 来运行并发任务。
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
我们启动了两个任务,一个睡眠 1 秒钟,另一个睡眠 2 秒钟,输出如下:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
正如你所看到的,协程不会阻塞彼此——第二个任务在第一个结束之前启动。这发生的原因是 asyncio.sleep 是协程,它会返回执行权给调度器,直到时间到了。
|
||||
|
||||
在下一节中,我们将会使用基于协程的任务来创建一个游戏循环。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
@ -1,37 +1,37 @@
|
||||
用Python实现Python解释器
|
||||
用 Python 实现 Python 解释器
|
||||
===
|
||||
|
||||
_Allison是Dropbox的工程师,在那里她维护着世界上最大的由Python客户组成的网络。在Dropbox之前,她是Recurse Center的导师, 曾在纽约写作。在北美的PyCon做过关于Python内部机制的演讲,并且她喜欢奇怪的bugs。她的博客地址是[akaptur.com](http://akaptur.com)._
|
||||
_Allison 是 Dropbox 的工程师,在那里她维护着这个世界上最大的 Python 客户端网络之一。在去 Dropbox 之前,她是 Recurse Center 的协调人, 是这个位于纽约的程序员深造机构的作者。她在北美的 PyCon 做过关于 Python 内部机制的演讲,并且她喜欢研究奇怪的 bug。她的博客地址是 [akaptur.com](http://akaptur.com)。_
|
||||
|
||||
## Introduction
|
||||
### 介绍
|
||||
|
||||
Byterun是一个用Python实现的Python解释器。随着我在Byterun上的工作,我惊讶并很高兴地的发现,这个Python解释器的基础结构可以满足500行的限制。在这一章我们会搞清楚这个解释器的结构,给你足够的知识探索下去。我们的目标不是向你展示解释器的每个细节---像编程和计算机科学其他有趣的领域一样,你可能会投入几年的时间去搞清楚这个主题。
|
||||
Byterun 是一个用 Python 实现的 Python 解释器。随着我对 Byterun 的开发,我惊喜地的发现,这个 Python 解释器的基础结构用 500 行代码就能实现。在这一章我们会搞清楚这个解释器的结构,给你足够探索下去的背景知识。我们的目标不是向你展示解释器的每个细节---像编程和计算机科学其他有趣的领域一样,你可能会投入几年的时间去深入了解这个主题。
|
||||
|
||||
Byterun是Ned Batchelder和我完成的,建立在Paul Swartz的工作之上。它的结构和主要的Python实现(CPython)差不多,所以理解Byterun会帮助你理解大多数解释器特别是CPython解释器。(如果你不知道你用的是什么Python,那么很可能它就是CPython)。尽管Byterun很小,但它能执行大多数简单的Python程序。
|
||||
Byterun 是 Ned Batchelder 和我完成的,建立在 Paul Swartz 的工作之上。它的结构和主要的 Python 实现(CPython)差不多,所以理解 Byterun 会帮助你理解大多数解释器,特别是 CPython 解释器。(如果你不知道你用的是什么 Python,那么很可能它就是 CPython)。尽管 Byterun 很小,但它能执行大多数简单的 Python 程序(这一章是基于 Python 3.5 及其之前版本生成的字节码的,在 Python 3.6 中生成的字节码有一些改变)。
|
||||
|
||||
### A Python Interpreter
|
||||
#### Python 解释器
|
||||
|
||||
在开始之前,让我们缩小一下“Pyhton解释器”的意思。在讨论Python的时候,“解释器”这个词可以用在很多不同的地方。有的时候解释器指的是REPL,当你在命令行下敲下`python`时所得到的交互式环境。有时候人们会相互替代的使用Python解释器和Python来说明执行Python代码的这一过程。在本章,“解释器”有一个更精确的意思:执行Python程序过程中的最后一步。
|
||||
在开始之前,让我们限定一下“Pyhton 解释器”的意思。在讨论 Python 的时候,“解释器”这个词可以用在很多不同的地方。有的时候解释器指的是 Python REPL,即当你在命令行下敲下 `python` 时所得到的交互式环境。有时候人们会或多或少的互换使用 “Python 解释器”和“Python”来说明从头到尾执行 Python 代码的这一过程。在本章中,“解释器”有一个更精确的意思:Python 程序的执行过程中的最后一步。
|
||||
|
||||
在解释器接手之前,Python会执行其他3个步骤:词法分析,语法解析和编译。这三步合起来把源代码转换成_code object_,它包含着解释器可以理解的指令。而解释器的工作就是解释code object中的指令。
|
||||
在解释器接手之前,Python 会执行其他 3 个步骤:词法分析,语法解析和编译。这三步合起来把源代码转换成代码对象(code object),它包含着解释器可以理解的指令。而解释器的工作就是解释代码对象中的指令。
|
||||
|
||||
你可能很奇怪执行Python代码会有编译这一步。Python通常被称为解释型语言,就像Ruby,Perl一样,它们和编译型语言相对,比如C,Rust。然而,这里的术语并不是它看起来的那样精确。大多数解释型语言包括Python,确实会有编译这一步。而Python被称为解释型的原因是相对于编译型语言,它在编译这一步的工作相对较少(解释器做相对多的工作)。在这章后面你会看到,Python的编译器比C语言编译器需要更少的关于程序行为的信息。
|
||||
你可能很奇怪执行 Python 代码会有编译这一步。Python 通常被称为解释型语言,就像 Ruby,Perl 一样,它们和像 C,Rust 这样的编译型语言相对。然而,这个术语并不是它看起来的那样精确。大多数解释型语言包括 Python 在内,确实会有编译这一步。而 Python 被称为解释型的原因是相对于编译型语言,它在编译这一步的工作相对较少(解释器做相对多的工作)。在这章后面你会看到,Python 的编译器比 C 语言编译器需要更少的关于程序行为的信息。
|
||||
|
||||
### A Python Python Interpreter
|
||||
#### Python 的 Python 解释器
|
||||
|
||||
Byterun是一个用Python写的Python解释器,这点可能让你感到奇怪,但没有比用C语言写C语言编译器更奇怪。(事实上,广泛使用的gcc编译器就是用C语言本身写的)你可以用几乎的任何语言写一个Python解释器。
|
||||
Byterun 是一个用 Python 写的 Python 解释器,这点可能让你感到奇怪,但没有比用 C 语言写 C 语言编译器更奇怪的了。(事实上,广泛使用的 gcc 编译器就是用 C 语言本身写的)你可以用几乎任何语言写一个 Python 解释器。
|
||||
|
||||
用Python写Python既有优点又有缺点。最大的缺点就是速度:用Byterun执行代码要比用CPython执行慢的多,CPython解释器是用C语言实现的并做了优化。然而Byterun是为了学习而设计的,所以速度对我们不重要。使用Python最大优点是我们可以*仅仅*实现解释器,而不用担心Python运行时的部分,特别是对象系统。比如当Byterun需要创建一个类时,它就会回退到“真正”的Python。另外一个优势是Byterun很容易理解,部分原因是它是用高级语言写的(Python!)(另外我们不会对解释器做优化 --- 再一次,清晰和简单比速度更重要)
|
||||
用 Python 写 Python 既有优点又有缺点。最大的缺点就是速度:用 Byterun 执行代码要比用 CPython 执行慢的多,CPython 解释器是用 C 语言实现的,并做了认真优化。然而 Byterun 是为了学习而设计的,所以速度对我们不重要。使用 Python 最大优势是我们可以*仅仅*实现解释器,而不用担心 Python 运行时部分,特别是对象系统。比如当 Byterun 需要创建一个类时,它就会回退到“真正”的 Python。另外一个优势是 Byterun 很容易理解,部分原因是它是用人们很容易理解的高级语言写的(Python !)(另外我们不会对解释器做优化 --- 再一次,清晰和简单比速度更重要)
|
||||
|
||||
## Building an Interpreter
|
||||
### 构建一个解释器
|
||||
|
||||
在我们考察Byterun代码之前,我们需要一些对解释器结构的高层次视角。Python解释器是如何工作的?
|
||||
在我们考察 Byterun 代码之前,我们需要从高层次对解释器结构有一些了解。Python 解释器是如何工作的?
|
||||
|
||||
Python解释器是一个_虚拟机_,模拟真实计算机的软件。我们这个虚拟机是栈机器,它用几个栈来完成操作(与之相对的是寄存器机器,它从特定的内存地址读写数据)。
|
||||
Python 解释器是一个虚拟机(virtual machine),是一个模拟真实计算机的软件。我们这个虚拟机是栈机器(stack machine),它用几个栈来完成操作(与之相对的是寄存器机器(register machine),它从特定的内存地址读写数据)。
|
||||
|
||||
Python解释器是一个_字节码解释器_:它的输入是一些命令集合称作_字节码_。当你写Python代码时,词法分析器,语法解析器和编译器生成code object让解释器去操作。每个code object都包含一个要被执行的指令集合 --- 它就是字节码 --- 另外还有一些解释器需要的信息。字节码是Python代码的一个_中间层表示_:它以一种解释器可以理解的方式来表示源代码。这和汇编语言作为C语言和机器语言的中间表示很类似。
|
||||
Python 解释器是一个字节码解释器(bytecode interpreter):它的输入是一些称作字节码(bytecode)的指令集。当你写 Python 代码时,词法分析器、语法解析器和编译器会生成代码对象(code object)让解释器去操作。每个代码对象都包含一个要被执行的指令集 —— 它就是字节码 —— 以及还有一些解释器需要的信息。字节码是 Python 代码的一个中间层表示( intermediate representation):它以一种解释器可以理解的方式来表示源代码。这和汇编语言作为 C 语言和机器语言的中间表示很类似。
|
||||
|
||||
### A Tiny Interpreter
|
||||
#### 微型解释器
|
||||
|
||||
为了让说明更具体,让我们从一个非常小的解释器开始。它只能计算两个数的和,只能理解三个指令。它执行的所有代码只是这三个指令的不同组合。下面就是这三个指令:
|
||||
|
||||
@ -39,7 +39,7 @@ Python解释器是一个_字节码解释器_:它的输入是一些命令集合
|
||||
- `ADD_TWO_VALUES`
|
||||
- `PRINT_ANSWER`
|
||||
|
||||
我们不关心词法,语法和编译,所以我们也不在乎这些指令是如何产生的。你可以想象,你写下`7 + 5`,然后一个编译器为你生成那三个指令的组合。如果你有一个合适的编译器,你甚至可以用Lisp的语法来写,只要它能生成相同的指令。
|
||||
我们不关心词法、语法和编译,所以我们也不在乎这些指令集是如何产生的。你可以想象,当你写下 `7 + 5`,然后一个编译器为你生成那三个指令的组合。如果你有一个合适的编译器,你甚至可以用 Lisp 的语法来写,只要它能生成相同的指令。
|
||||
|
||||
假设
|
||||
|
||||
@ -58,13 +58,13 @@ what_to_execute = {
|
||||
"numbers": [7, 5] }
|
||||
```
|
||||
|
||||
Python解释器是一个_栈机器_,所以它必须通过操作栈来完成这个加法。(\aosafigref{500l.interpreter.stackmachine}.)解释器先执行第一条指令,`LOAD_VALUE`,把第一个数压到栈中。接着它把第二个数也压到栈中。然后,第三条指令,`ADD_TWO_VALUES`,先把两个数从栈中弹出,加起来,再把结果压入栈中。最后一步,把结果弹出并输出。
|
||||
Python 解释器是一个栈机器(stack machine),所以它必须通过操作栈来完成这个加法(见下图)。解释器先执行第一条指令,`LOAD_VALUE`,把第一个数压到栈中。接着它把第二个数也压到栈中。然后,第三条指令,`ADD_TWO_VALUES`,先把两个数从栈中弹出,加起来,再把结果压入栈中。最后一步,把结果弹出并输出。
|
||||
|
||||
\aosafigure[240pt]{interpreter-images/interpreter-stack.png}{A stack machine}{500l.interpreter.stackmachine}
|
||||

|
||||
|
||||
`LOAD_VALUE`这条指令告诉解释器把一个数压入栈中,但指令本身并没有指明这个数是多少。指令需要一个额外的信息告诉解释器去哪里找到这个数。所以我们的指令集有两个部分:指令本身和一个常量列表。(在Python中,字节码就是我们称为的“指令”,而解释器执行的是_code object_。)
|
||||
`LOAD_VALUE`这条指令告诉解释器把一个数压入栈中,但指令本身并没有指明这个数是多少。指令需要一个额外的信息告诉解释器去哪里找到这个数。所以我们的指令集有两个部分:指令本身和一个常量列表。(在 Python 中,字节码就是我们所称的“指令”,而解释器“执行”的是代码对象。)
|
||||
|
||||
为什么不把数字直接嵌入指令之中?想象一下,如果我们加的不是数字,而是字符串。我们可不想把字符串这样的东西加到指令中,因为它可以有任意的长度。另外,我们这种设计也意味着我们只需要对象的一份拷贝,比如这个加法 `7 + 7`, 现在常量表 `"numbers"`只需包含一个`7`。
|
||||
为什么不把数字直接嵌入指令之中?想象一下,如果我们加的不是数字,而是字符串。我们可不想把字符串这样的东西加到指令中,因为它可以有任意的长度。另外,我们这种设计也意味着我们只需要对象的一份拷贝,比如这个加法 `7 + 7`, 现在常量表 `"numbers"`只需包含一个`[7]`。
|
||||
|
||||
你可能会想为什么会需要除了`ADD_TWO_VALUES`之外的指令。的确,对于我们两个数加法,这个例子是有点人为制作的意思。然而,这个指令却是建造更复杂程序的轮子。比如,就我们目前定义的三个指令,只要给出正确的指令组合,我们可以做三个数的加法,或者任意个数的加法。同时,栈提供了一个清晰的方法去跟踪解释器的状态,这为我们增长的复杂性提供了支持。
|
||||
|
||||
@ -89,7 +89,7 @@ class Interpreter:
|
||||
self.stack.append(total)
|
||||
```
|
||||
|
||||
这三个方法完成了解释器所理解的三条指令。但解释器还需要一样东西:一个能把所有东西结合在一起并执行的方法。这个方法就叫做`run_code`, 它把我们前面定义的字典结构`what-to-execute`作为参数,循环执行里面的每条指令,如何指令有参数,处理参数,然后调用解释器对象中相应的方法。
|
||||
这三个方法完成了解释器所理解的三条指令。但解释器还需要一样东西:一个能把所有东西结合在一起并执行的方法。这个方法就叫做 `run_code`,它把我们前面定义的字典结构 `what-to-execute` 作为参数,循环执行里面的每条指令,如果指令有参数就处理参数,然后调用解释器对象中相应的方法。
|
||||
|
||||
```python
|
||||
def run_code(self, what_to_execute):
|
||||
@ -106,20 +106,20 @@ class Interpreter:
|
||||
self.PRINT_ANSWER()
|
||||
```
|
||||
|
||||
为了测试,我们创建一个解释器对象,然后用前面定义的 7 + 5 的指令集来调用`run_code`。
|
||||
为了测试,我们创建一个解释器对象,然后用前面定义的 7 + 5 的指令集来调用 `run_code`。
|
||||
|
||||
```python
|
||||
interpreter = Interpreter()
|
||||
interpreter.run_code(what_to_execute)
|
||||
```
|
||||
|
||||
显然,它会输出12
|
||||
显然,它会输出12。
|
||||
|
||||
尽管我们的解释器功能受限,但这个加法过程几乎和真正的Python解释器是一样的。这里,我们还有几点要注意。
|
||||
尽管我们的解释器功能十分受限,但这个过程几乎和真正的 Python 解释器处理加法是一样的。这里,我们还有几点要注意。
|
||||
|
||||
首先,一些指令需要参数。在真正的Python bytecode中,大概有一半的指令有参数。像我们的例子一样,参数和指令打包在一起。注意_指令_的参数和传递给对应方法的参数是不同的。
|
||||
首先,一些指令需要参数。在真正的 Python 字节码当中,大概有一半的指令有参数。像我们的例子一样,参数和指令打包在一起。注意指令的参数和传递给对应方法的参数是不同的。
|
||||
|
||||
第二,指令`ADD_TWO_VALUES`不需要任何参数,它从解释器栈中弹出所需的值。这正是以栈为基础的解释器的特点。
|
||||
第二,指令`ADD_TWO_VALUES`不需要任何参数,它从解释器栈中弹出所需的值。这正是以基于栈的解释器的特点。
|
||||
|
||||
记得我们说过只要给出合适的指令集,不需要对解释器做任何改变,我们就能做多个数的加法。考虑下面的指令集,你觉得会发生什么?如果你有一个合适的编译器,什么代码才能编译出下面的指令集?
|
||||
|
||||
@ -134,11 +134,11 @@ class Interpreter:
|
||||
"numbers": [7, 5, 8] }
|
||||
```
|
||||
|
||||
从这点出发,我们开始看到这种结构的可扩展性:我们可以通过向解释器对象增加方法来描述更多的操作(只要有一个编译器能为我们生成组织良好的指令集)。
|
||||
从这点出发,我们开始看到这种结构的可扩展性:我们可以通过向解释器对象增加方法来描述更多的操作(只要有一个编译器能为我们生成组织良好的指令集就行)。
|
||||
|
||||
#### Variables
|
||||
##### 变量
|
||||
|
||||
接下来给我们的解释器增加变量的支持。我们需要一个保存变量值的指令,`STORE_NAME`;一个取变量值的指令`LOAD_NAME`;和一个变量到值的映射关系。目前,我们会忽略命名空间和作用域,所以我们可以把变量和值的映射直接存储在解释器对象中。最后,我们要保证`what_to_execute`除了一个常量列表,还要有个变量名字的列表。
|
||||
接下来给我们的解释器增加变量的支持。我们需要一个保存变量值的指令 `STORE_NAME`;一个取变量值的指令`LOAD_NAME`;和一个变量到值的映射关系。目前,我们会忽略命名空间和作用域,所以我们可以把变量和值的映射直接存储在解释器对象中。最后,我们要保证`what_to_execute`除了一个常量列表,还要有个变量名字的列表。
|
||||
|
||||
```python
|
||||
>>> def s():
|
||||
@ -159,9 +159,9 @@ class Interpreter:
|
||||
"names": ["a", "b"] }
|
||||
```
|
||||
|
||||
我们的新的的实现在下面。为了跟踪哪名字绑定到那个值,我们在`__init__`方法中增加一个`environment`字典。我们也增加了`STORE_NAME`和`LOAD_NAME`方法,它们获得变量名,然后从`environment`字典中设置或取出这个变量值。
|
||||
我们的新的实现在下面。为了跟踪哪个名字绑定到哪个值,我们在`__init__`方法中增加一个`environment`字典。我们也增加了`STORE_NAME`和`LOAD_NAME`方法,它们获得变量名,然后从`environment`字典中设置或取出这个变量值。
|
||||
|
||||
现在指令参数就有两个不同的意思,它可能是`numbers`列表的索引,也可能是`names`列表的索引。解释器通过检查所执行的指令就能知道是那种参数。而我们打破这种逻辑 ,把指令和它所用何种参数的映射关系放在另一个单独的方法中。
|
||||
现在指令的参数就有两个不同的意思,它可能是`numbers`列表的索引,也可能是`names`列表的索引。解释器通过检查所执行的指令就能知道是那种参数。而我们打破这种逻辑 ,把指令和它所用何种参数的映射关系放在另一个单独的方法中。
|
||||
|
||||
```python
|
||||
class Interpreter:
|
||||
@ -207,7 +207,7 @@ class Interpreter:
|
||||
self.LOAD_NAME(argument)
|
||||
```
|
||||
|
||||
仅仅五个指令,`run_code`这个方法已经开始变得冗长了。如果保持这种结构,那么每条指令都需要一个`if`分支。这里,我们要利用Python的动态方法查找。我们总会给一个称为`FOO`的指令定义一个名为`FOO`的方法,这样我们就可用Python的`getattr`函数在运行时动态查找方法,而不用这个大大的分支结构。`run_code`方法现在是这样:
|
||||
仅仅五个指令,`run_code`这个方法已经开始变得冗长了。如果保持这种结构,那么每条指令都需要一个`if`分支。这里,我们要利用 Python 的动态方法查找。我们总会给一个称为`FOO`的指令定义一个名为`FOO`的方法,这样我们就可用 Python 的`getattr`函数在运行时动态查找方法,而不用这个大大的分支结构。`run_code`方法现在是这样:
|
||||
|
||||
```python
|
||||
def execute(self, what_to_execute):
|
||||
@ -222,9 +222,9 @@ class Interpreter:
|
||||
bytecode_method(argument)
|
||||
```
|
||||
|
||||
## Real Python Bytecode
|
||||
### 真实的 Python 字节码
|
||||
|
||||
现在,放弃我们的小指令集,去看看真正的Python字节码。字节码的结构和我们的小解释器的指令集差不多,除了字节码用一个字节而不是一个名字来指示这条指令。为了理解它的结构,我们将考察一个函数的字节码。考虑下面这个例子:
|
||||
现在,放弃我们的小指令集,去看看真正的 Python 字节码。字节码的结构和我们的小解释器的指令集差不多,除了字节码用一个字节而不是一个名字来代表这条指令。为了理解它的结构,我们将考察一个函数的字节码。考虑下面这个例子:
|
||||
|
||||
```python
|
||||
>>> def cond():
|
||||
@ -236,7 +236,7 @@ class Interpreter:
|
||||
...
|
||||
```
|
||||
|
||||
Python在运行时会暴露一大批内部信息,并且我们可以通过REPL直接访问这些信息。对于函数对象`cond`,`cond.__code__`是与其关联的code object,而`cond.__code__.co_code`就是它的字节码。当你写Python代码时,你永远也不会想直接使用这些属性,但是这可以让我们做出各种恶作剧,同时也可以看看内部机制。
|
||||
Python 在运行时会暴露一大批内部信息,并且我们可以通过 REPL 直接访问这些信息。对于函数对象`cond`,`cond.__code__`是与其关联的代码对象,而`cond.__code__.co_code`就是它的字节码。当你写 Python 代码时,你永远也不会想直接使用这些属性,但是这可以让我们做出各种恶作剧,同时也可以看看内部机制。
|
||||
|
||||
```python
|
||||
>>> cond.__code__.co_code # the bytecode as raw bytes
|
||||
@ -247,9 +247,9 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
100, 4, 0, 83, 100, 0, 0, 83]
|
||||
```
|
||||
|
||||
当我们直接输出这个字节码,它看起来完全无法理解 --- 唯一我们了解的是它是一串字节。很幸运,我们有一个很强大的工具可以用:Python标准库中的`dis`模块。
|
||||
当我们直接输出这个字节码,它看起来完全无法理解 —— 唯一我们了解的是它是一串字节。很幸运,我们有一个很强大的工具可以用:Python 标准库中的`dis`模块。
|
||||
|
||||
`dis`是一个字节码反汇编器。反汇编器以为机器而写的底层代码作为输入,比如汇编代码和字节码,然后以人类可读的方式输出。当我们运行`dis.dis`, 它输出每个字节码的解释。
|
||||
`dis`是一个字节码反汇编器。反汇编器以为机器而写的底层代码作为输入,比如汇编代码和字节码,然后以人类可读的方式输出。当我们运行`dis.dis`,它输出每个字节码的解释。
|
||||
|
||||
```python
|
||||
>>> dis.dis(cond)
|
||||
@ -270,9 +270,9 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
29 RETURN_VALUE
|
||||
```
|
||||
|
||||
这些都是什么意思?让我们以第一条指令`LOAD_CONST`为例子。第一列的数字(`2`)表示对应源代码的行数。第二列的数字是字节码的索引,告诉我们指令`LOAD_CONST`在0位置。第三列是指令本身对应的人类可读的名字。如果第四列存在,它表示指令的参数。如果第5列存在,它是一个关于参数是什么的提示。
|
||||
这些都是什么意思?让我们以第一条指令`LOAD_CONST`为例子。第一列的数字(`2`)表示对应源代码的行数。第二列的数字是字节码的索引,告诉我们指令`LOAD_CONST`在位置 0 。第三列是指令本身对应的人类可读的名字。如果第四列存在,它表示指令的参数。如果第五列存在,它是一个关于参数是什么的提示。
|
||||
|
||||
考虑这个字节码的前几个字节:[100, 1, 0, 125, 0, 0]。这6个字节表示两条带参数的指令。我们可以使用`dis.opname`,一个字节到可读字符串的映射,来找到指令100和指令125代表是什么:
|
||||
考虑这个字节码的前几个字节:[100, 1, 0, 125, 0, 0]。这 6 个字节表示两条带参数的指令。我们可以使用`dis.opname`,一个字节到可读字符串的映射,来找到指令 100 和指令 125 代表的是什么:
|
||||
|
||||
```python
|
||||
>>> dis.opname[100]
|
||||
@ -281,11 +281,11 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
'STORE_FAST'
|
||||
```
|
||||
|
||||
第二和第三个字节 --- 1 ,0 ---是`LOAD_CONST`的参数,第五和第六个字节 --- 0,0 --- 是`STORE_FAST`的参数。就像我们前面的小例子,`LOAD_CONST`需要知道的到哪去找常量,`STORE_FAST`需要找到名字。(Python的`LOAD_CONST`和我们小例子中的`LOAD_VALUE`一样,`LOAD_FAST`和`LOAD_NAME`一样)。所以这六个字节代表第一行源代码`x = 3`.(为什么用两个字节表示指令的参数?如果Python使用一个字节,每个code object你只能有256个常量/名字,而用两个字节,就增加到了256的平方,65536个)。
|
||||
第二和第三个字节 —— 1 、0 ——是`LOAD_CONST`的参数,第五和第六个字节 —— 0、0 —— 是`STORE_FAST`的参数。就像我们前面的小例子,`LOAD_CONST`需要知道的到哪去找常量,`STORE_FAST`需要知道要存储的名字。(Python 的`LOAD_CONST`和我们小例子中的`LOAD_VALUE`一样,`LOAD_FAST`和`LOAD_NAME`一样)。所以这六个字节代表第一行源代码`x = 3` (为什么用两个字节表示指令的参数?如果 Python 使用一个字节,每个代码对象你只能有 256 个常量/名字,而用两个字节,就增加到了 256 的平方,65536个)。
|
||||
|
||||
### Conditionals and Loops
|
||||
#### 条件语句与循环语句
|
||||
|
||||
到目前为止,我们的解释器只能一条接着一条的执行指令。这有个问题,我们经常会想多次执行某个指令,或者在特定的条件下跳过它们。为了可以写循环和分支结构,解释器必须能够在指令中跳转。在某种程度上,Python在字节码中使用`GOTO`语句来处理循环和分支!让我们再看一个`cond`函数的反汇编结果:
|
||||
到目前为止,我们的解释器只能一条接着一条的执行指令。这有个问题,我们经常会想多次执行某个指令,或者在特定的条件下跳过它们。为了可以写循环和分支结构,解释器必须能够在指令中跳转。在某种程度上,Python 在字节码中使用`GOTO`语句来处理循环和分支!让我们再看一个`cond`函数的反汇编结果:
|
||||
|
||||
```python
|
||||
>>> dis.dis(cond)
|
||||
@ -306,11 +306,11 @@ b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x0
|
||||
29 RETURN_VALUE
|
||||
```
|
||||
|
||||
第三行的条件表达式`if x < 5`被编译成四条指令:`LOAD_FAST`, `LOAD_CONST`, `COMPARE_OP`和 `POP_JUMP_IF_FALSE`。`x < 5`对应加载`x`,加载5,比较这两个值。指令`POP_JUMP_IF_FALSE`完成`if`语句。这条指令把栈顶的值弹出,如果值为真,什么都不发生。如果值为假,解释器会跳转到另一条指令。
|
||||
第三行的条件表达式`if x < 5`被编译成四条指令:`LOAD_FAST`、 `LOAD_CONST`、 `COMPARE_OP`和 `POP_JUMP_IF_FALSE`。`x < 5`对应加载`x`、加载 5、比较这两个值。指令`POP_JUMP_IF_FALSE`完成这个`if`语句。这条指令把栈顶的值弹出,如果值为真,什么都不发生。如果值为假,解释器会跳转到另一条指令。
|
||||
|
||||
这条将被加载的指令称为跳转目标,它作为指令`POP_JUMP`的参数。这里,跳转目标是22,索引为22的指令是`LOAD_CONST`,对应源码的第6行。(`dis`用`>>`标记跳转目标。)如果`X < 5`为假,解释器会忽略第四行(`return yes`),直接跳转到第6行(`return "no"`)。因此解释器通过跳转指令选择性的执行指令。
|
||||
这条将被加载的指令称为跳转目标,它作为指令`POP_JUMP`的参数。这里,跳转目标是 22,索引为 22 的指令是`LOAD_CONST`,对应源码的第 6 行。(`dis`用`>>`标记跳转目标。)如果`X < 5`为假,解释器会忽略第四行(`return yes`),直接跳转到第6行(`return "no"`)。因此解释器通过跳转指令选择性的执行指令。
|
||||
|
||||
Python的循环也依赖于跳转。在下面的字节码中,`while x < 5`这一行产生了和`if x < 10`几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行`POP_JUMP_IF_FALSE`来控制下一条执行哪个指令。第四行的最后一条字节码`JUMP_ABSOLUT`(循环体结束的地方),让解释器返回到循环开始的第9条指令处。当 `x < 10`变为假,`POP_JUMP_IF_FALSE`会让解释器跳到循环的终止处,第34条指令。
|
||||
Python 的循环也依赖于跳转。在下面的字节码中,`while x < 5`这一行产生了和`if x < 10`几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行`POP_JUMP_IF_FALSE`来控制下一条执行哪个指令。第四行的最后一条字节码`JUMP_ABSOLUT`(循环体结束的地方),让解释器返回到循环开始的第 9 条指令处。当 `x < 10`变为假,`POP_JUMP_IF_FALSE`会让解释器跳到循环的终止处,第 34 条指令。
|
||||
|
||||
```python
|
||||
>>> def loop():
|
||||
@ -340,23 +340,23 @@ Python的循环也依赖于跳转。在下面的字节码中,`while x < 5`这
|
||||
38 RETURN_VALUE
|
||||
```
|
||||
|
||||
### Explore Bytecode
|
||||
#### 探索字节码
|
||||
|
||||
我希望你用`dis.dis`来试试你自己写的函数。一些有趣的问题值得探索:
|
||||
|
||||
- 对解释器而言for循环和while循环有什么不同?
|
||||
- 对解释器而言 for 循环和 while 循环有什么不同?
|
||||
- 能不能写出两个不同函数,却能产生相同的字节码?
|
||||
- `elif`是怎么工作的?列表推导呢?
|
||||
|
||||
## Frames
|
||||
### 帧
|
||||
|
||||
到目前为止,我们已经知道了Python虚拟机是一个栈机器。它能顺序执行指令,在指令间跳转,压入或弹出栈值。但是这和我们期望的解释器还有一定距离。在前面的那个例子中,最后一条指令是`RETURN_VALUE`,它和`return`语句相对应。但是它返回到哪里去呢?
|
||||
到目前为止,我们已经知道了 Python 虚拟机是一个栈机器。它能顺序执行指令,在指令间跳转,压入或弹出栈值。但是这和我们期望的解释器还有一定距离。在前面的那个例子中,最后一条指令是`RETURN_VALUE`,它和`return`语句相对应。但是它返回到哪里去呢?
|
||||
|
||||
为了回答这个问题,我们必须再增加一层复杂性:frame。一个frame是一些信息的集合和代码的执行上下文。frames在Python代码执行时动态的创建和销毁。每个frame对应函数的一次调用。--- 所以每个frame只有一个code object与之关联,而一个code object可以有多个frame。比如你有一个函数递归的调用自己10次,这会产生11个frame,每次调用对应一个,再加上启动模块对应的一个frame。总的来说,Python程序的每个作用域有一个frame,比如,模块,函数,类。
|
||||
为了回答这个问题,我们必须再增加一层复杂性:帧(frame)。一个帧是一些信息的集合和代码的执行上下文。帧在 Python 代码执行时动态地创建和销毁。每个帧对应函数的一次调用 —— 所以每个帧只有一个代码对象与之关联,而一个代码对象可以有多个帧。比如你有一个函数递归的调用自己 10 次,这会产生 11 个帧,每次调用对应一个,再加上启动模块对应的一个帧。总的来说,Python 程序的每个作用域都有一个帧,比如,模块、函数、类定义。
|
||||
|
||||
Frame存在于_调用栈_中,一个和我们之前讨论的完全不同的栈。(你最熟悉的栈就是调用栈,就是你经常看到的异常回溯,每个以"File 'program.py'"开始的回溯对应一个frame。)解释器在执行字节码时操作的栈,我们叫它_数据栈_。其实还有第三个栈,叫做_块栈_,用于特定的控制流块,比如循环和异常处理。调用栈中的每个frame都有它自己的数据栈和块栈。
|
||||
帧存在于调用栈(call stack)中,一个和我们之前讨论的完全不同的栈。(你最熟悉的栈就是调用栈,就是你经常看到的异常回溯,每个以"File 'program.py'"开始的回溯对应一个帧。)解释器在执行字节码时操作的栈,我们叫它数据栈(data stack)。其实还有第三个栈,叫做块栈(block stack),用于特定的控制流块,比如循环和异常处理。调用栈中的每个帧都有它自己的数据栈和块栈。
|
||||
|
||||
让我们用一个具体的例子来说明。假设Python解释器执行到标记为3的地方。解释器正在`foo`函数的调用中,它接着调用`bar`。下面是frame调用栈,块栈和数据栈的示意图。我们感兴趣的是解释器先从最底下的`foo()`开始,接着执行`foo`的函数体,然后到达`bar`。
|
||||
让我们用一个具体的例子来说明一下。假设 Python 解释器执行到下面标记为 3 的地方。解释器正处于`foo`函数的调用中,它接着调用`bar`。下面是帧调用栈、块栈和数据栈的示意图。我们感兴趣的是解释器先从最底下的`foo()`开始,接着执行`foo`的函数体,然后到达`bar`。
|
||||
|
||||
```python
|
||||
>>> def bar(y):
|
||||
@ -372,32 +372,30 @@ Frame存在于_调用栈_中,一个和我们之前讨论的完全不同的栈
|
||||
3
|
||||
```
|
||||
|
||||
\aosafigure[240pt]{interpreter-images/interpreter-callstack.png}{The call stack}{500l.interpreter.callstack}
|
||||
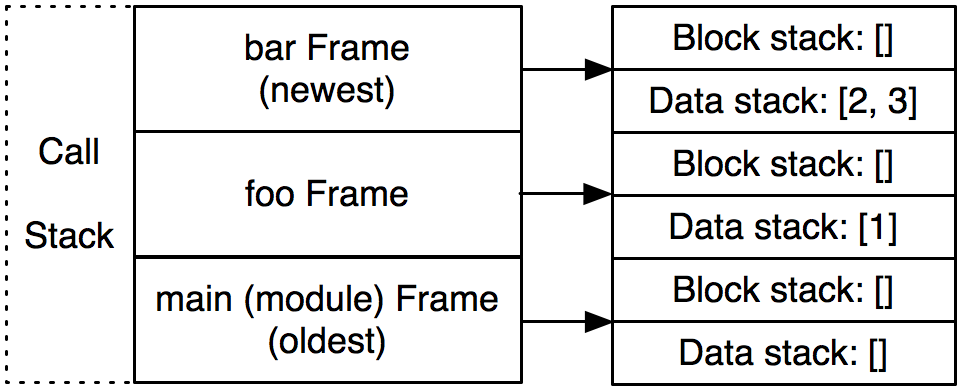
|
||||
|
||||
现在,解释器在`bar`函数的调用中。调用栈中有3个frame:一个对应于模块层,一个对应函数`foo`,别一个对应函数`bar`。(\aosafigref{500l.interpreter.callstack}.)一旦`bar`返回,与它对应的frame就会从调用栈中弹出并丢弃。
|
||||
现在,解释器处于`bar`函数的调用中。调用栈中有 3 个帧:一个对应于模块层,一个对应函数`foo`,另一个对应函数`bar`。(见上图)一旦`bar`返回,与它对应的帧就会从调用栈中弹出并丢弃。
|
||||
|
||||
字节码指令`RETURN_VALUE`告诉解释器在frame间传递一个值。首先,它把位于调用栈栈顶的frame中的数据栈的栈顶值弹出。然后把整个frame弹出丢弃。最后把这个值压到下一个frame的数据栈中。
|
||||
字节码指令`RETURN_VALUE`告诉解释器在帧之间传递一个值。首先,它把位于调用栈栈顶的帧中的数据栈的栈顶值弹出。然后把整个帧弹出丢弃。最后把这个值压到下一个帧的数据栈中。
|
||||
|
||||
当Ned Batchelder和我在写Byterun时,很长一段时间我们的实现中一直有个重大的错误。我们整个虚拟机中只有一个数据栈,而不是每个frame都有一个。我们写了很多测试代码,同时在Byterun和真正的Python上运行,希望得到一致结果。我们几乎通过了所有测试,只有一样东西不能通过,那就是生成器。最后,通过仔细的阅读CPython的源码,我们发现了错误所在[^thanks]。把数据栈移到每个frame就解决了这个问题。
|
||||
当 Ned Batchelder 和我在写 Byterun 时,很长一段时间我们的实现中一直有个重大的错误。我们整个虚拟机中只有一个数据栈,而不是每个帧都有一个。我们写了很多测试代码,同时在 Byterun 和真正的 Python 上运行,希望得到一致结果。我们几乎通过了所有测试,只有一样东西不能通过,那就是生成器(generators)。最后,通过仔细的阅读 CPython 的源码,我们发现了错误所在(感谢 Michael Arntzenius 对这个 bug 的洞悉)。把数据栈移到每个帧就解决了这个问题。
|
||||
|
||||
[^thanks]: 感谢 Michael Arntzenius 对这个bug的洞悉。
|
||||
回头在看看这个 bug,我惊讶的发现 Python 真的很少依赖于每个帧有一个数据栈这个特性。在 Python 中几乎所有的操作都会清空数据栈,所以所有的帧公用一个数据栈是没问题的。在上面的例子中,当`bar`执行完后,它的数据栈为空。即使`foo`公用这一个栈,它的值也不会受影响。然而,对应生成器,它的一个关键的特点是它能暂停一个帧的执行,返回到其他的帧,一段时间后它能返回到原来的帧,并以它离开时的相同状态继续执行。
|
||||
|
||||
回头在看看这个bug,我惊讶的发现Python真的很少依赖于每个frame有一个数据栈这个特性。在Python中几乎所有的操作都会清空数据栈,所以所有的frame公用一个数据栈是没问题的。在上面的例子中,当`bar`执行完后,它的数据栈为空。即使`foo`公用这一个栈,它的值也不会受影响。然而,对应生成器,一个关键的特点是它能暂停一个frame的执行,返回到其他的frame,一段时间后它能返回到原来的frame,并以它离开时的相同状态继续执行。
|
||||
### Byterun
|
||||
|
||||
## Byterun
|
||||
现在我们有足够的 Python 解释器的知识背景去考察 Byterun。
|
||||
|
||||
现在我们有足够的Python解释器的知识背景去考察Byterun。
|
||||
Byterun 中有四种对象。
|
||||
|
||||
Byterun中有四种对象。
|
||||
- `VirtualMachine`类,它管理高层结构,尤其是帧调用栈,并包含了指令到操作的映射。这是一个比前面`Inteprter`对象更复杂的版本。
|
||||
- `Frame`类,每个`Frame`类都有一个代码对象,并且管理着其他一些必要的状态位,尤其是全局和局部命名空间、指向调用它的整的指针和最后执行的字节码指令。
|
||||
- `Function`类,它被用来代替真正的 Python 函数。回想一下,调用函数时会创建一个新的帧。我们自己实现了`Function`,以便我们控制新的`Frame`的创建。
|
||||
- `Block`类,它只是包装了块的 3 个属性。(块的细节不是解释器的核心,我们不会花时间在它身上,把它列在这里,是因为 Byterun 需要它。)
|
||||
|
||||
- `VirtualMachine`类,它管理高层结构,frame调用栈,指令到操作的映射。这是一个比前面`Inteprter`对象更复杂的版本。
|
||||
- `Frame`类,每个`Frame`类都有一个code object,并且管理者其他一些必要的状态信息,全局和局部命名空间,指向调用它的frame的指针和最后执行的字节码指令。
|
||||
- `Function`类,它被用来代替真正的Python函数。回想一下,调用函数时会创建一个新的frame。我们自己实现`Function`,所以我们控制新frame的创建。
|
||||
- `Block`类,它只是包装了block的3个属性。(block的细节不是解释器的核心,我们不会花时间在它身上,把它列在这里,是因为Byterun需要它。)
|
||||
#### `VirtualMachine` 类
|
||||
|
||||
### The `VirtualMachine` Class
|
||||
|
||||
程序运行时只有一个`VirtualMachine`被创建,因为我们只有一个解释器。`VirtualMachine`保存调用栈,异常状态,在frame中传递的返回值。它的入口点是`run_code`方法,它以编译后的code object为参数,以创建一个frame为开始,然后运行这个frame。这个frame可能再创建出新的frame;调用栈随着程序的运行增长缩短。当第一个frame返回时,执行结束。
|
||||
每次程序运行时只会创建一个`VirtualMachine`实例,因为我们只有一个 Python 解释器。`VirtualMachine` 保存调用栈、异常状态、在帧之间传递的返回值。它的入口点是`run_code`方法,它以编译后的代码对象为参数,以创建一个帧为开始,然后运行这个帧。这个帧可能再创建出新的帧;调用栈随着程序的运行而增长和缩短。当第一个帧返回时,执行结束。
|
||||
|
||||
```python
|
||||
class VirtualMachineError(Exception):
|
||||
@ -418,9 +416,9 @@ class VirtualMachine(object):
|
||||
|
||||
```
|
||||
|
||||
### The `Frame` Class
|
||||
#### `Frame` 类
|
||||
|
||||
接下来,我们来写`Frame`对象。frame是一个属性的集合,它没有任何方法。前面提到过,这些属性包括由编译器生成的code object;局部,全局和内置命名空间;前一个frame的引用;一个数据栈;一个块栈;最后执行的指令指针。(对于内置命名空间我们需要多做一点工作,Python在不同模块中对这个命名空间有不同的处理;但这个细节对我们的虚拟机不重要。)
|
||||
接下来,我们来写`Frame`对象。帧是一个属性的集合,它没有任何方法。前面提到过,这些属性包括由编译器生成的代码对象;局部、全局和内置命名空间;前一个帧的引用;一个数据栈;一个块栈;最后执行的指令指针。(对于内置命名空间我们需要多做一点工作,Python 在不同模块中对这个命名空间有不同的处理;但这个细节对我们的虚拟机不重要。)
|
||||
|
||||
```python
|
||||
class Frame(object):
|
||||
@ -441,7 +439,7 @@ class Frame(object):
|
||||
self.block_stack = []
|
||||
```
|
||||
|
||||
接着,我们在虚拟机中增加对frame的操作。这有3个帮助函数:一个创建新的frame的方法,和压栈和出栈的方法。第四个函数,`run_frame`,完成执行frame的主要工作,待会我们再讨论这个方法。
|
||||
接着,我们在虚拟机中增加对帧的操作。这有 3 个帮助函数:一个创建新的帧的方法(它负责为新的帧找到名字空间),和压栈和出栈的方法。第四个函数,`run_frame`,完成执行帧的主要工作,待会我们再讨论这个方法。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -481,9 +479,9 @@ class VirtualMachine(object):
|
||||
# we'll come back to this shortly
|
||||
```
|
||||
|
||||
### The `Function` Class
|
||||
#### `Function` 类
|
||||
|
||||
`Function`的实现有点扭曲,但是大部分的细节对理解解释器不重要。重要的是当调用函数时 --- `__call__`方法被调用 --- 它创建一个新的`Frame`并运行它。
|
||||
`Function`的实现有点曲折,但是大部分的细节对理解解释器不重要。重要的是当调用函数时 —— 即调用 `__call__`方法 —— 它创建一个新的`Frame`并运行它。
|
||||
|
||||
```python
|
||||
class Function(object):
|
||||
@ -534,7 +532,7 @@ def make_cell(value):
|
||||
return fn.__closure__[0]
|
||||
```
|
||||
|
||||
接着,回到`VirtualMachine`对象,我们对数据栈的操作也增加一些帮助方法。字节码操作的栈总是在当前frame的数据栈。这些帮助函数让我们能实现`POP_TOP`,`LOAD_FAST`字节码,并且让其他操作栈的指令可读性更高。
|
||||
接着,回到`VirtualMachine`对象,我们对数据栈的操作也增加一些帮助方法。字节码操作的栈总是在当前帧的数据栈。这些帮助函数让我们的`POP_TOP`、`LOAD_FAST`以及其他操作栈的指令的实现可读性更高。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -562,11 +560,11 @@ class VirtualMachine(object):
|
||||
return []
|
||||
```
|
||||
|
||||
在我们运行frame之前,我们还需两个方法。
|
||||
在我们运行帧之前,我们还需两个方法。
|
||||
|
||||
第一个方法,`parse_byte_and_args`,以一个字节码为输入,先检查它是否有参数,如果有,就解析它的参数。这个方法同时也更新frame的`last_instruction`属性,它指向最后执行的指令。一条没有参数的指令只有一个字节长度,而有参数的字节有3个字节长。参数的意义依赖于指令是什么。比如,前面说过,指令`POP_JUMP_IF_FALSE`,它的参数指的是跳转目标。`BUILD_LIST`, 它的参数是列表的个数。`LOAD_CONST`,它的参数是常量的索引。
|
||||
第一个方法,`parse_byte_and_args` 以一个字节码为输入,先检查它是否有参数,如果有,就解析它的参数。这个方法同时也更新帧的`last_instruction`属性,它指向最后执行的指令。一条没有参数的指令只有一个字节长度,而有参数的字节有3个字节长。参数的意义依赖于指令是什么。比如,前面说过,指令`POP_JUMP_IF_FALSE`,它的参数指的是跳转目标。`BUILD_LIST`,它的参数是列表的个数。`LOAD_CONST`,它的参数是常量的索引。
|
||||
|
||||
一些指令用简单的数字作为参数。对于另一些,虚拟机需要一点努力去发现它含意。标准库中的`dis`模块中有一个备忘单,它解释什么参数有什么意思,这让我们的代码更加简洁。比如,列表`dis.hasname`告诉我们`LOAD_NAME`, `IMPORT_NAME`,`LOAD_GLOBAL`,以及另外的9个指令都有同样的意思:名字列表的索引。
|
||||
一些指令用简单的数字作为参数。对于另一些,虚拟机需要一点努力去发现它含意。标准库中的`dis`模块中有一个备忘单,它解释什么参数有什么意思,这让我们的代码更加简洁。比如,列表`dis.hasname`告诉我们`LOAD_NAME`、 `IMPORT_NAME`、`LOAD_GLOBAL`,以及另外的 9 个指令的参数都有同样的意义:对于这些指令,它们的参数代表了代码对象中的名字列表的索引。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -600,8 +598,7 @@ class VirtualMachine(object):
|
||||
return byte_name, argument
|
||||
```
|
||||
|
||||
下一个方法是`dispatch`,它查看给定的指令并执行相应的操作。在CPython中,这个分派函数用一个巨大的switch语句实现,有超过1500行的代码。幸运的是,我们用的是Python,我们的代码会简洁的多。我们会为每一个字节码名字定义一个方法,然后用`getattr`来查找。就像我们前面的小解释器一样,如果一条指令叫做`FOO_BAR`,那么它对应的方法就是`byte_FOO_BAR`。现在,我们先把这些方法当做一个黑盒子。每个指令方法都会返回`None`或者一个字符串`why`,有些情况下虚拟机需要这个额外`why`信息。这些指令方法的返回值,仅作为解释器状态的内部指示,千万不要和执行frame的返回值相混淆。
|
||||
|
||||
下一个方法是`dispatch`,它查找给定的指令并执行相应的操作。在 CPython 中,这个分派函数用一个巨大的 switch 语句实现,有超过 1500 行的代码。幸运的是,我们用的是 Python,我们的代码会简洁的多。我们会为每一个字节码名字定义一个方法,然后用`getattr`来查找。就像我们前面的小解释器一样,如果一条指令叫做`FOO_BAR`,那么它对应的方法就是`byte_FOO_BAR`。现在,我们先把这些方法当做一个黑盒子。每个指令方法都会返回`None`或者一个字符串`why`,有些情况下虚拟机需要这个额外`why`信息。这些指令方法的返回值,仅作为解释器状态的内部指示,千万不要和执行帧的返回值相混淆。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -662,13 +659,13 @@ class VirtualMachine(object):
|
||||
return self.return_value
|
||||
```
|
||||
|
||||
### The `Block` Class
|
||||
#### `Block` 类
|
||||
|
||||
在我们完成每个字节码方法前,我们简单的讨论一下块。一个块被用于某种控制流,特别是异常处理和循环。它负责保证当操作完成后数据栈处于正确的状态。比如,在一个循环中,一个特殊的迭代器会存在栈中,当循环完成时它从栈中弹出。解释器需要检查循环仍在继续还是已经停止。
|
||||
|
||||
为了跟踪这些额外的信息,解释器设置了一个标志来指示它的状态。我们用一个变量`why`实现这个标志,它可以是`None`或者是下面几个字符串这一,`"continue"`, `"break"`,`"excption"`,`return`。他们指示对块栈和数据栈进行什么操作。回到我们迭代器的例子,如果块栈的栈顶是一个`loop`块,`why`是`continue`,迭代器就因该保存在数据栈上,不是如果`why`是`break`,迭代器就会被弹出。
|
||||
为了跟踪这些额外的信息,解释器设置了一个标志来指示它的状态。我们用一个变量`why`实现这个标志,它可以是`None`或者是下面几个字符串之一:`"continue"`、`"break"`、`"excption"`、`return`。它们指示对块栈和数据栈进行什么操作。回到我们迭代器的例子,如果块栈的栈顶是一个`loop`块,`why`的代码是`continue`,迭代器就应该保存在数据栈上,而如果`why`是`break`,迭代器就会被弹出。
|
||||
|
||||
块操作的细节比较精细,我们不会花时间在这上面,但是有兴趣的读者值得仔细的看看。
|
||||
块操作的细节比这个还要繁琐,我们不会花时间在这上面,但是有兴趣的读者值得仔细的看看。
|
||||
|
||||
```python
|
||||
Block = collections.namedtuple("Block", "type, handler, stack_height")
|
||||
@ -737,9 +734,9 @@ class VirtualMachine(object):
|
||||
return why
|
||||
```
|
||||
|
||||
## The Instructions
|
||||
### 指令
|
||||
|
||||
剩下了的就是完成那些指令方法了:`byte_LOAD_FAST`,`byte_BINARY_MODULO`等等。而这些指令的实现并不是很有趣,这里我们只展示了一小部分,完整的实现在这儿https://github.com/nedbat/byterun。(足够执行我们前面所述的所有代码了。)
|
||||
剩下了的就是完成那些指令方法了:`byte_LOAD_FAST`、`byte_BINARY_MODULO`等等。而这些指令的实现并不是很有趣,这里我们只展示了一小部分,完整的实现[在 GitHub 上](https://github.com/nedbat/byterun)。(这里包括的指令足够执行我们前面所述的所有代码了。)
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
@ -926,11 +923,11 @@ class VirtualMachine(object):
|
||||
return "return"
|
||||
```
|
||||
|
||||
## Dynamic Typing: What the Compiler Doesn't Know
|
||||
### 动态类型:编译器不知道它是什么
|
||||
|
||||
你可能听过Python是一种动态语言 --- 是它是动态类型的。在我们建造解释器的过程中,已经透露出这样的信息。
|
||||
你可能听过 Python 是一种动态语言 —— 它是动态类型的。在我们建造解释器的过程中,已经透露出这样的信息。
|
||||
|
||||
动态的一个意思是很多工作在运行时完成。前面我们看到Python的编译器没有很多关于代码真正做什么的信息。举个例子,考虑下面这个简单的函数`mod`。它取两个参数,返回它们的模运算值。从它的字节码中,我们看到变量`a`和`b`首先被加载,然后字节码`BINAY_MODULO`完成这个模运算。
|
||||
动态的一个意思是很多工作是在运行时完成的。前面我们看到 Python 的编译器没有很多关于代码真正做什么的信息。举个例子,考虑下面这个简单的函数`mod`。它取两个参数,返回它们的模运算值。从它的字节码中,我们看到变量`a`和`b`首先被加载,然后字节码`BINAY_MODULO`完成这个模运算。
|
||||
|
||||
```python
|
||||
>>> def mod(a, b):
|
||||
@ -944,25 +941,25 @@ class VirtualMachine(object):
|
||||
4
|
||||
```
|
||||
|
||||
计算19 % 5得4,--- 一点也不奇怪。如果我们用不同类的参数呢?
|
||||
计算 19 % 5 得4,—— 一点也不奇怪。如果我们用不同类的参数呢?
|
||||
|
||||
```python
|
||||
>>> mod("by%sde", "teco")
|
||||
'bytecode'
|
||||
```
|
||||
|
||||
刚才发生了什么?你可能见过这样的语法,格式化字符串。
|
||||
刚才发生了什么?你可能在其它地方见过这样的语法,格式化字符串。
|
||||
|
||||
```
|
||||
>>> print("by%sde" % "teco")
|
||||
bytecode
|
||||
```
|
||||
|
||||
用符号`%`去格式化字符串会调用字节码`BUNARY_MODULO`.它取栈顶的两个值求模,不管这两个值是字符串,数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
|
||||
用符号`%`去格式化字符串会调用字节码`BUNARY_MODULO`。它取栈顶的两个值求模,不管这两个值是字符串、数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
|
||||
|
||||
Python的编译器关于字节码的功能知道的很少。而取决于解释器来决定`BINAYR_MODULO`应用于什么类型的对象并完成正确的操作。这就是为什么Python被描述为_动态类型_:直到运行前你不必知道这个函数参数的类型。相反,在一个静态类型语言中,程序员需要告诉编译器参数的类型是什么(或者编译器自己推断出参数的类型。)
|
||||
Python 的编译器关于字节码的功能知道的很少,而取决于解释器来决定`BINAYR_MODULO`应用于什么类型的对象并完成正确的操作。这就是为什么 Python 被描述为动态类型(dynamically typed):直到运行前你不必知道这个函数参数的类型。相反,在一个静态类型语言中,程序员需要告诉编译器参数的类型是什么(或者编译器自己推断出参数的类型。)
|
||||
|
||||
编译器的无知是优化Python的一个挑战 --- 只看字节码,而不真正运行它,你就不知道每条字节码在干什么!你可以定义一个类,实现`__mod__`方法,当你对这个类的实例使用`%`时,Python就会自动调用这个方法。所以,`BINARY_MODULO`其实可以运行任何代码。
|
||||
编译器的无知是优化 Python 的一个挑战 —— 只看字节码,而不真正运行它,你就不知道每条字节码在干什么!你可以定义一个类,实现`__mod__`方法,当你对这个类的实例使用`%`时,Python 就会自动调用这个方法。所以,`BINARY_MODULO`其实可以运行任何代码。
|
||||
|
||||
看看下面的代码,第一个`a % b`看起来没有用。
|
||||
|
||||
@ -972,25 +969,23 @@ def mod(a,b):
|
||||
return a %b
|
||||
```
|
||||
|
||||
不幸的是,对这段代码进行静态分析 --- 不运行它 --- 不能确定第一个`a % b`没有做任何事。用 `%`调用`__mod__`可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在Python中完成的事。很难优化一个你不知道它会做什么的函数。在Russell Power和Alex Rubinsteyn的优秀论文中写道,“我们可以用多快的速度解释Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个`INVOKE_ARBITRARY_METHOD`。”
|
||||
不幸的是,对这段代码进行静态分析 —— 不运行它 —— 不能确定第一个`a % b`没有做任何事。用 `%`调用`__mod__`可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在 Python 中完成的事。很难优化一个你不知道它会做什么的函数。在 Russell Power 和 Alex Rubinsteyn 的优秀论文中写道,“我们可以用多快的速度解释 Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个`INVOKE_ARBITRARY_METHOD`。”
|
||||
|
||||
## Conclusion
|
||||
### 总结
|
||||
|
||||
Byterun是一个比CPython容易理解的简洁的Python解释器。Byterun复制了CPython的主要结构:一个基于栈的指令集称为字节码,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建,销毁frame,并在frame间跳转。Byterun也有着和真正解释器一样的限制:因为Python使用动态类型,解释器必须在运行时决定指令的正确行为。
|
||||
Byterun 是一个比 CPython 容易理解的简洁的 Python 解释器。Byterun 复制了 CPython 的主要结构:一个基于栈的解释器对称之为字节码的指令集进行操作,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建、销毁帧,并在帧之间跳转。Byterun 也有着和真正解释器一样的限制:因为 Python 使用动态类型,解释器必须在运行时决定指令的正确行为。
|
||||
|
||||
我鼓励你去反汇编你的程序,然后用Byterun来运行。你很快会发现这个缩短版的Byterun所没有实现的指令。完整的实现在https://github.com/nedbat/byterun,或者仔细阅读真正的CPython解释器`ceval.c`,你也可以实现自己的解释器!
|
||||
我鼓励你去反汇编你的程序,然后用 Byterun 来运行。你很快会发现这个缩短版的 Byterun 所没有实现的指令。完整的实现在 https://github.com/nedbat/byterun ,或者你可以仔细阅读真正的 CPython 解释器`ceval.c`,你也可以实现自己的解释器!
|
||||
|
||||
## Acknowledgements
|
||||
### 致谢
|
||||
|
||||
Thanks to Ned Batchelder for originating this project and guiding my contributions, Michael Arntzenius for his help debugging the code and editing the prose, Leta Montopoli for her edits, and the entire Recurse Center community for their support and interest. Any errors are my own.
|
||||
感谢 Ned Batchelder 发起这个项目并引导我的贡献,感谢 Michael Arntzenius 帮助调试代码和这篇文章的修订,感谢 Leta Montopoli 的修订,以及感谢整个 Recurse Center 社区的支持和鼓励。所有的不足全是我自己没搞好。
|
||||
|
||||
--------------------------------------
|
||||
via:http://aosabook.org/en/500L/a-python-interpreter-written-in-python.html
|
||||
|
||||
作者: Allison Kaptur Allison
|
||||
via: http://aosabook.org/en/500L/a-python-interpreter-written-in-python.html
|
||||
|
||||
作者: Allison Kaptur
|
||||
译者:[qingyunha](https://github.com/qingyunha)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,236 @@
|
||||
使用 Python 和 Asyncio 编写在线多用人游戏(二)
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
> 你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个[能工作的例子][1]来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
|
||||
|
||||
介绍和理论部分参见“[第一部分 异步化][2]”。
|
||||
|
||||
- [游戏入口在此,点此体验][1]。
|
||||
|
||||
### 3、编写游戏循环主体
|
||||
|
||||
游戏循环是每一个游戏的核心。它持续地运行以读取玩家的输入、更新游戏的状态,并且在屏幕上渲染游戏结果。在在线游戏中,游戏循环分为客户端和服务端两部分,所以一般有两个循环通过网络通信。通常客户端的角色是获取玩家输入,比如按键或者鼠标移动,将数据传输给服务端,然后接收需要渲染的数据。服务端处理来自玩家的所有数据,更新游戏的状态,执行渲染下一帧的必要计算,然后将结果传回客户端,例如游戏中对象的新位置。如果没有可靠的理由,不混淆客户端和服务端的角色是一件很重要的事。如果你在客户端执行游戏逻辑的计算,很容易就会和其它客户端失去同步,其实你的游戏也可以通过简单地传递客户端的数据来创建。
|
||||
|
||||
> 游戏循环的一次迭代称为一个嘀嗒(tick)。嘀嗒是一个事件,表示当前游戏循环的迭代已经结束,下一帧(或者多帧)的数据已经就绪。
|
||||
|
||||
在后面的例子中,我们使用相同的客户端,它使用 WebSocket 从一个网页上连接到服务端。它执行一个简单的循环,将按键码发送给服务端,并显示来自服务端的所有信息。[客户端代码戳这里][4]。
|
||||
|
||||
### 例子 3.1:基本游戏循环
|
||||
|
||||
> [例子 3.1 源码][5]。
|
||||
|
||||
我们使用 [aiohttp][6] 库来创建游戏服务器。它可以通过 asyncio 创建网页服务器和客户端。这个库的一个优势是它同时支持普通 http 请求和 websocket。所以我们不用其他网页服务器来渲染游戏的 html 页面。
|
||||
|
||||
下面是启动服务器的方法:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
`web.run_app` 是创建服务主任务的快捷方法,通过它的 `run_forever()` 方法来执行 `asyncio` 事件循环。建议你查看这个方法的源码,弄清楚服务器到底是如何创建和结束的。
|
||||
|
||||
`app` 变量就是一个类似于字典的对象,它用于在所连接的客户端之间共享数据。我们使用它来存储连接的套接字的列表。随后会用这个列表来给所有连接的客户端发送消息。`asyncio.ensure_future()` 调用会启动主游戏循环的任务,每隔2 秒向客户端发送嘀嗒消息。这个任务会在同样的 asyncio 事件循环中和网页服务器并行执行。
|
||||
|
||||
有两个网页请求处理器:`handle` 是提供 html 页面的处理器;`wshandler` 是主要的 websocket 服务器任务,处理和客户端之间的交互。在事件循环中,每一个连接的客户端都会创建一个新的 `wshandler` 任务。这个任务会添加客户端的套接字到列表中,以便 `game_loop` 任务可以给所有的客户端发送消息。然后它将随同消息回显客户端的每个击键。
|
||||
|
||||
在启动的任务中,我们在 `asyncio` 的主事件循环中启动 worker 循环。任务之间的切换发生在它们之间任何一个使用 `await`语句来等待某个协程结束时。例如 `asyncio.sleep` 仅仅是将程序执行权交给调度器一段指定的时间;`ws.receive` 等待 websocket 的消息,此时调度器可能切换到其它任务。
|
||||
|
||||
在浏览器中打开主页,连接上服务器后,试试随便按下键。它们的键值会从服务端返回,每隔 2 秒这个数字会被游戏循环中发给所有客户端的嘀嗒消息所覆盖。
|
||||
|
||||
我们刚刚创建了一个处理客户端按键的服务器,主游戏循环在后台做一些处理,周期性地同时更新所有的客户端。
|
||||
|
||||
### 例子 3.2: 根据请求启动游戏
|
||||
|
||||
> [例子 3.2 的源码][7]
|
||||
|
||||
在前一个例子中,在服务器的生命周期内,游戏循环一直运行着。但是现实中,如果没有一个人连接服务器,空运行游戏循环通常是不合理的。而且,同一个服务器上可能有不同的“游戏房间”。在这种假设下,每一个玩家“创建”一个游戏会话(比如说,多人游戏中的一个比赛或者大型多人游戏中的副本),这样其他用户可以加入其中。当游戏会话开始时,游戏循环才开始执行。
|
||||
|
||||
在这个例子中,我们使用一个全局标记来检测游戏循环是否在执行。当第一个用户发起连接时,启动它。最开始,游戏循环没有执行,标记设置为 `False`。游戏循环是通过客户端的处理方法启动的。
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
当 `game_loop()` 运行时,这个标记设置为 `True`;当所有客户端都断开连接时,其又被设置为 `False`。
|
||||
|
||||
### 例子 3.3:管理任务
|
||||
|
||||
> [例子3.3源码][8]
|
||||
|
||||
这个例子用来解释如何和任务对象协同工作。我们把游戏循环的任务直接存储在游戏循环的全局字典中,代替标记的使用。在像这样的一个简单例子中并不一定是最优的,但是有时候你可能需要控制所有已经启动的任务。
|
||||
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
这里 `ensure_future()` 返回我们存放在全局字典中的任务对象,当所有用户都断开连接时,我们使用下面方式取消任务:
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
这个 `cancel()` 调用将通知调度器不要向这个协程传递执行权,而且将它的状态设置为已取消:`cancelled`,之后可以通过 `cancelled()` 方法来检查是否已取消。这里有一个值得一提的小注意点:当你持有一个任务对象的外部引用时,而这个任务执行中发生了异常,这个异常不会抛出。取而代之的是为这个任务设置一个异常状态,可以通过 `exception()` 方法来检查是否出现了异常。这种悄无声息地失败在调试时不是很有用。所以,你可能想用抛出所有异常来取代这种做法。你可以对所有未完成的任务显式地调用 `result()` 来实现。可以通过如下的回调来实现:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
如果我们打算在我们代码中取消这个任务,但是又不想产生 `CancelError` 异常,有一个检查 `cancelled` 状态的点:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
注意仅当你持有任务对象的引用时才需要这么做。在前一个例子,所有的异常都是没有额外的回调,直接抛出所有异常。
|
||||
|
||||
### 例子 3.4:等待多个事件
|
||||
|
||||
> [例子 3.4 源码][9]
|
||||
|
||||
在许多场景下,在客户端的处理方法中你需要等待多个事件的发生。除了来自客户端的消息,你可能需要等待不同类型事件的发生。比如,如果你的游戏时间有限制,那么你可能需要等一个来自定时器的信号。或者你需要使用管道来等待来自其它进程的消息。亦或者是使用分布式消息系统的网络中其它服务器的信息。
|
||||
|
||||
为了简单起见,这个例子是基于例子 3.1。但是这个例子中我们使用 `Condition` 对象来与已连接的客户端保持游戏循环的同步。我们不保存套接字的全局列表,因为只在该处理方法中使用套接字。当游戏循环停止迭代时,我们使用 `Condition.notify_all()` 方法来通知所有的客户端。这个方法允许在 `asyncio` 的事件循环中使用发布/订阅的模式。
|
||||
|
||||
为了等待这两个事件,首先我们使用 `ensure_future()` 来封装任务中这个可等待对象。
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
在我们调用 `Condition.wait()` 之前,我们需要在它后面获取一把锁。这就是我们为什么先调用 `tick.acquire()` 的原因。在调用 `tick.wait()` 之后,锁会被释放,这样其他的协程也可以使用它。但是当我们收到通知时,会重新获取锁,所以在收到通知后需要调用 `tick.release()` 来释放它。
|
||||
|
||||
我们使用 `asyncio.wait()` 协程来等待两个任务。
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
程序会阻塞,直到列表中的任意一个任务完成。然后它返回两个列表:执行完成的任务列表和仍然在执行的任务列表。如果任务执行完成了,其对应变量赋值为 `None`,所以在下一个迭代时,它可能会被再次创建。
|
||||
|
||||
### 例子 3.5: 结合多个线程
|
||||
|
||||
> [例子 3.5 源码][10]
|
||||
|
||||
在这个例子中,我们结合 `asyncio` 循环和线程,在一个单独的线程中执行主游戏循环。我之前提到过,由于 `GIL` 的存在,Python 代码的真正并行执行是不可能的。所以使用其它线程来执行复杂计算并不是一个好主意。然而,在使用 `asyncio` 时结合线程有原因的:当我们使用的其它库不支持 `asyncio` 时就需要。在主线程中调用这些库会阻塞循环的执行,所以异步使用他们的唯一方法是在不同的线程中使用他们。
|
||||
|
||||
我们使用 `asyncio` 循环的`run_in_executor()` 方法和 `ThreadPoolExecutor` 来执行游戏循环。注意 `game_loop()` 已经不再是一个协程了。它是一个由其它线程执行的函数。然而我们需要和主线程交互,在游戏事件到来时通知客户端。`asyncio` 本身不是线程安全的,它提供了可以在其它线程中执行你的代码的方法。普通函数有 `call_soon_threadsafe()`,协程有 `run_coroutine_threadsafe()`。我们在 `notify()` 协程中增加了通知客户端游戏的嘀嗒的代码,然后通过另外一个线程执行主事件循环。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
当你执行这个例子时,你会看到 “Notify thread id” 和 “Main thread id” 相等,因为 `notify()` 协程在主线程中执行。与此同时 `sleep(1)` 在另外一个线程中执行,因此它不会阻塞主事件循环。
|
||||
|
||||
### 例子 3.6:多进程和扩展
|
||||
|
||||
> [例子 3.6 源码][11]
|
||||
|
||||
单线程的服务器可能运行得很好,但是它只能使用一个 CPU 核。为了将服务扩展到多核,我们需要执行多个进程,每个进程执行各自的事件循环。这样我们需要在进程间交互信息或者共享游戏的数据。而且在一个游戏中经常需要进行复杂的计算,例如路径查找之类。这些任务有时候在一个游戏嘀嗒中没法快速完成。在协程中不推荐进行费时的计算,因为它会阻塞事件的处理。在这种情况下,将这个复杂任务交给其它并行执行的进程可能更合理。
|
||||
|
||||
最简单的使用多个核的方法是启动多个使用单核的服务器,就像之前的例子中一样,每个服务器占用不同的端口。你可以使用 `supervisord` 或者其它进程控制的系统。这个时候你需要一个像 `HAProxy` 这样的负载均衡器,使得连接的客户端分布在多个进程间。已经有一些可以连接 asyncio 和一些流行的消息及存储系统的适配系统。例如:
|
||||
|
||||
- [aiomcache][12] 用于 memcached 客户端
|
||||
- [aiozmq][13] 用于 zeroMQ
|
||||
- [aioredis][14] 用于 Redis 存储,支持发布/订阅
|
||||
|
||||
你可以在 github 或者 pypi 上找到其它的软件包,大部分以 `aio` 开头。
|
||||
|
||||
使用网络服务在存储持久状态和交换某些信息时可能比较有效。但是如果你需要进行进程间通信的实时处理,它的性能可能不足。此时,使用标准的 unix 管道可能更合适。`asyncio` 支持管道,在`aiohttp`仓库有个 [使用管道的服务器的非常底层的例子][15]。
|
||||
|
||||
在当前的例子中,我们使用 Python 的高层类库 [multiprocessing][16] 来在不同的核上启动复杂的计算,使用 `multiprocessing.Queue` 来进行进程间的消息交互。不幸的是,当前的 `multiprocessing` 实现与 `asyncio` 不兼容。所以每一个阻塞方法的调用都会阻塞事件循环。但是此时线程正好可以起到帮助作用,因为如果在不同线程里面执行 `multiprocessing` 的代码,它就不会阻塞主线程。所有我们需要做的就是把所有进程间的通信放到另外一个线程中去。这个例子会解释如何使用这个方法。和上面的多线程例子非常类似,但是我们从线程中创建的是一个新的进程。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
这里我们在另外一个进程中运行 `worker()` 函数。它包括一个执行复杂计算并把计算结果放到 `queue` 中的循环,这个 `queue` 是 `multiprocessing.Queue` 的实例。然后我们就可以在另外一个线程的主事件循环中获取结果并通知客户端,就和例子 3.5 一样。这个例子已经非常简化了,它没有合理的结束进程。而且在真实的游戏中,我们可能需要另外一个队列来将数据传递给 `worker`。
|
||||
|
||||
有一个项目叫 [aioprocessing][17],它封装了 `multiprocessing`,使得它可以和 `asyncio` 兼容。但是实际上它只是和上面例子使用了完全一样的方法:从线程中创建进程。它并没有给你带来任何方便,除了它使用了简单的接口隐藏了后面的这些技巧。希望在 Python 的下一个版本中,我们能有一个基于协程且支持 `asyncio` 的 `multiprocessing` 库。
|
||||
|
||||
> 注意!如果你从主线程或者主进程中创建了一个不同的线程或者子进程来运行另外一个 `asyncio` 事件循环,你需要显式地使用 `asyncio.new_event_loop()` 来创建循环,不然的话可能程序不会正常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://linux.cn/article-7767-1.html
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
@ -0,0 +1,134 @@
|
||||
使用 Python 和 Asyncio 来编写在线多人游戏(三)
|
||||
=================================================================
|
||||
|
||||

|
||||
|
||||
> 在这个系列中,我们基于多人游戏 [贪吃蛇][1] 来制作一个异步的 Python 程序。上一篇文章聚焦于[编写游戏循环][2]上,而本系列第 1 部分则涵盖了如何[异步化][3]。
|
||||
|
||||
- 代码戳[这里][4]
|
||||
|
||||
### 4、制作一个完整的游戏
|
||||
|
||||

|
||||
|
||||
#### 4.1 工程概览
|
||||
|
||||
在此部分,我们将回顾一个完整在线游戏的设计。这是一个经典的贪吃蛇游戏,增加了多玩家支持。你可以自己在 (<http://snakepit-game.com>) 亲自试玩。源码在 GitHub 的这个[仓库][5]。游戏包括下列文件:
|
||||
|
||||
- [server.py][6] - 处理主游戏循环和连接。
|
||||
- [game.py][7] - 主要的 `Game` 类。实现游戏的逻辑和游戏的大部分通信协议。
|
||||
- [player.py][8] - `Player` 类,包括每一个独立玩家的数据和蛇的展现。这个类负责获取玩家的输入并相应地移动蛇。
|
||||
- [datatypes.py][9] - 基本数据结构。
|
||||
- [settings.py][10] - 游戏设置,在注释中有相关的说明。
|
||||
- [index.html][11] - 客户端所有的 html 和 javascript代码都放在一个文件中。
|
||||
|
||||
#### 4.2 游戏循环内窥
|
||||
|
||||
多人的贪吃蛇游戏是个用于学习十分好的例子,因为它简单。所有的蛇在每个帧中移动到一个位置,而且帧以非常低的频率进行变化,这样就可以让你就观察到游戏引擎到底是如何工作的。因为速度慢,对于玩家的按键不会立马响应。按键先是记录下来,然后在一个游戏循环迭代的最后计算下一帧时使用。
|
||||
|
||||
> 现代的动作游戏帧频率更高,而且通常服务端和客户端的帧频率是不相等的。客户端的帧频率通常依赖于客户端的硬件性能,而服务端的帧频率则是固定的。一个客户端可能根据一个游戏“嘀嗒”的数据渲染多个帧。这样就可以创建平滑的动画,这个受限于客户端的性能。在这个例子中,服务端不仅传输物体的当前位置,也要传输它们的移动方向、速度和加速度。客户端的帧频率称之为 FPS(每秒帧数:frames per second),服务端的帧频率称之为 TPS(每秒滴答数:ticks per second)。在这个贪吃蛇游戏的例子中,二者的值是相等的,在客户端显示的一帧是在服务端的一个“嘀嗒”内计算出来的。
|
||||
|
||||
我们使用类似文本模式的游戏区域,事实上是 html 表格中的一个字符宽的小格。游戏中的所有对象都是通过表格中的不同颜色字符来表示。大部分时候,客户端将按键的码发送至服务端,然后每个“滴答”更新游戏区域。服务端一次更新包括需要更新字符的坐标和颜色。所以我们将所有游戏逻辑放置在服务端,只将需要渲染的数据发送给客户端。此外,我们通过替换通过网络发送的数据来减少游戏被破解的概率。
|
||||
|
||||
#### 4.3 它是如何运行的?
|
||||
|
||||
这个游戏中的服务端出于简化的目的,它和例子 3.2 类似。但是我们用一个所有服务端都可访问的 `Game` 对象来代替之前保存了所有已连接 websocket 的全局列表。一个 `Game` 实例包括一个表示连接到此游戏的玩家的 `Player` 对象的列表(在 `self._players` 属性里面),以及他们的个人数据和 websocket 对象。将所有游戏相关的数据存储在一个 `Game` 对象中,会方便我们增加多个游戏房间这个功能——如果我们要增加这个功能的话。这样,我们维护多个 `Game` 对象,每个游戏开始时创建一个。
|
||||
|
||||
客户端和服务端的所有交互都是通过编码成 json 的消息来完成。来自客户端的消息仅包含玩家所按下键码对应的编号。其它来自客户端消息使用如下格式:
|
||||
|
||||
```
|
||||
[command, arg1, arg2, ... argN ]
|
||||
```
|
||||
|
||||
来自服务端的消息以列表的形式发送,因为通常一次要发送多个消息 (大多数情况下是渲染的数据):
|
||||
|
||||
```
|
||||
[[command, arg1, arg2, ... argN ], ... ]
|
||||
```
|
||||
|
||||
在每次游戏循环迭代的最后会计算下一帧,并且将数据发送给所有的客户端。当然,每次不是发送完整的帧,而是发送两帧之间的变化列表。
|
||||
|
||||
注意玩家连接上服务端后不是立马加入游戏。连接开始时是观望者(spectator)模式,玩家可以观察其它玩家如何玩游戏。如果游戏已经开始或者上一个游戏会话已经在屏幕上显示 “game over” (游戏结束),用户此时可以按下 “Join”(参与),来加入一个已经存在的游戏,或者如果游戏没有运行(没有其它玩家)则创建一个新的游戏。后一种情况下,游戏区域在开始前会被先清空。
|
||||
|
||||
游戏区域存储在 `Game._field` 这个属性中,它是由嵌套列表组成的二维数组,用于内部存储游戏区域的状态。数组中的每一个元素表示区域中的一个小格,最终小格会被渲染成 html 表格的格子。它有一个 `Char` 的类型,是一个 `namedtuple` ,包括一个字符和颜色。在所有连接的客户端之间保证游戏区域的同步很重要,所以所有游戏区域的更新都必须依据发送到客户端的相应的信息。这是通过 `Game.apply_render()` 来实现的。它接受一个 `Draw` 对象的列表,其用于内部更新游戏区域和发送渲染消息给客户端。
|
||||
|
||||
> 我们使用 `namedtuple` 不仅因为它表示简单数据结构很方便,也因为用它生成 json 格式的消息时相对于 `dict` 更省空间。如果你在一个真实的游戏循环中需要发送复杂的数据结构,建议先将它们序列化成一个简单的、更短的格式,甚至打包成二进制格式(例如 bson,而不是 json),以减少网络传输。
|
||||
|
||||
`Player` 对象包括用 `deque` 对象表示的蛇。这种数据类型和 `list` 相似,但是在两端增加和删除元素时效率更高,用它来表示蛇很理想。它的主要方法是 `Player.render_move()`,它返回移动玩家的蛇至下一个位置的渲染数据。一般来说它在新的位置渲染蛇的头部,移除上一帧中表示蛇的尾巴的元素。如果蛇吃了一个数字变长了,在相应的多个帧中尾巴是不需要移动的。蛇的渲染数据在主类的 `Game.next_frame()` 中使用,该方法中实现所有的游戏逻辑。这个方法渲染所有蛇的移动,检查每一个蛇前面的障碍物,而且生成数字和“石头”。每一个“嘀嗒”,`game_loop()` 都会直接调用它来生成下一帧。
|
||||
|
||||
如果蛇头前面有障碍物,在 `Game.next_frame()` 中会调用 `Game.game_over()`。它后通知所有的客户端那个蛇死掉了 (会调用 `player.render_game_over()` 方法将其变成石头),然后更新表中的分数排行榜。`Player` 对象的 `alive` 标记被置为 `False`,当渲染下一帧时,这个玩家会被跳过,除非他重新加入游戏。当没有蛇存活时,游戏区域会显示 “game over” (游戏结束)。而且,主游戏循环会停止,设置 `game.running` 标记为 `False`。当某个玩家下次按下 “Join” (加入)时,游戏区域会被清空。
|
||||
|
||||
在渲染游戏的每个下一帧时也会产生数字和石头,它们是由随机值决定的。产生数字或者石头的概率可以在 `settings.py` 中修改成其它值。注意数字的产生是针对游戏区域每一个活的蛇的,所以蛇越多,产生的数字就越多,这样它们都有足够的食物来吃掉。
|
||||
|
||||
#### 4.4 网络协议
|
||||
|
||||
从客户端发送消息的列表:
|
||||
|
||||
命令 | 参数 |描述
|
||||
:-- |:-- |:--
|
||||
new_player | [name] |设置玩家的昵称
|
||||
join | |玩家加入游戏
|
||||
|
||||
|
||||
从服务端发送消息的列表:
|
||||
|
||||
命令 | 参数 |描述
|
||||
:-- |:-- |:--
|
||||
handshake |[id] |给一个玩家指定 ID
|
||||
world |[[(char, color), ...], ...] |初始化游戏区域(世界地图)
|
||||
reset_world | |清除实际地图,替换所有字符为空格
|
||||
render |[x, y, char, color] |在某个位置显示字符
|
||||
p_joined |[id, name, color, score] |新玩家加入游戏
|
||||
p_gameover |[id] |某个玩家游戏结束
|
||||
p_score |[id, score] |给某个玩家计分
|
||||
top_scores |[[name, score, color], ...] |更新排行榜
|
||||
|
||||
典型的消息交换顺序:
|
||||
|
||||
客户端 -> 服务端 |服务端 -> 客户端 |服务端 -> 所有客户端 |备注
|
||||
:-- |:-- |:-- |:--
|
||||
new_player | | |名字传递给服务端
|
||||
|handshake | |指定 ID
|
||||
|world | |初始化传递的世界地图
|
||||
|top_scores | |收到传递的排行榜
|
||||
join | | |玩家按下“Join”,游戏循环开始
|
||||
| |reset_world |命令客户端清除游戏区域
|
||||
| |render, render, ... |第一个游戏“滴答”,渲染第一帧
|
||||
(key code) | | |玩家按下一个键
|
||||
| |render, render, ... |渲染第二帧
|
||||
| |p_score |蛇吃掉了一个数字
|
||||
| |render, render, ... |渲染第三帧
|
||||
| | |... 重复若干帧 ...
|
||||
| |p_gameover |试着吃掉障碍物时蛇死掉了
|
||||
| |top_scores |更新排行榜(如果需要更新的话)
|
||||
|
||||
### 5. 总结
|
||||
|
||||
说实话,我十分享受 Python 最新的异步特性。新的语法做了改善,所以异步代码很容易阅读。可以明显看出哪些调用是非阻塞的,什么时候发生 greenthread 的切换。所以现在我可以宣称 Python 是异步编程的好工具。
|
||||
|
||||
SnakePit 在 7WebPages 团队中非常受欢迎。如果你在公司想休息一下,不要忘记给我们在 [Twitter][12] 或者 [Facebook][13] 留下反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://linux.cn/article-7784-1.html
|
||||
[3]: https://linux.cn/article-7767-1.html
|
||||
[4]: https://github.com/7WebPages/snakepit-game
|
||||
[5]: https://github.com/7WebPages/snakepit-game
|
||||
[6]: https://github.com/7WebPages/snakepit-game/blob/master/server.py
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/game.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/player.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/datatypes.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/settings.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/index.html
|
||||
[12]: https://twitter.com/7WebPages
|
||||
[13]: https://www.facebook.com/7WebPages/
|
||||
464
published/20160608 Simple Python Framework from Scratch.md
Normal file
464
published/20160608 Simple Python Framework from Scratch.md
Normal file
@ -0,0 +1,464 @@
|
||||
从零构建一个简单的 Python 框架
|
||||
===================================
|
||||
|
||||
为什么你想要自己构建一个 web 框架呢?我想,原因有以下几点:
|
||||
|
||||
- 你有一个新奇的想法,觉得将会取代其他的框架
|
||||
- 你想要获得一些名气
|
||||
- 你遇到的问题很独特,以至于现有的框架不太合适
|
||||
- 你对 web 框架是如何工作的很感兴趣,因为你想要成为一位更好的 web 开发者。
|
||||
|
||||
接下来的笔墨将着重于最后一点。这篇文章旨在通过对设计和实现过程一步一步的阐述告诉读者,我在完成一个小型的服务器和框架之后学到了什么。你可以在这个[代码仓库][1]中找到这个项目的完整代码。
|
||||
|
||||
我希望这篇文章可以鼓励更多的人来尝试,因为这确实很有趣。它让我知道了 web 应用是如何工作的,而且这比我想的要容易的多!
|
||||
|
||||
### 范围
|
||||
|
||||
框架可以处理请求-响应周期、身份认证、数据库访问、模板生成等部分工作。Web 开发者使用框架是因为,大多数的 web 应用拥有大量相同的功能,而对每个项目都重新实现同样的功能意义不大。
|
||||
|
||||
比较大的的框架如 Rails 和 Django 实现了高层次的抽象,或者说“自备电池”(“batteries-included”,这是 Python 的口号之一,意即所有功能都自足。)。而实现所有的这些功能可能要花费数千小时,因此在这个项目上,我们重点完成其中的一小部分。在开始写代码前,我先列举一下所需的功能以及限制。
|
||||
|
||||
功能:
|
||||
|
||||
- 处理 HTTP 的 GET 和 POST 请求。你可以在[这篇 wiki][2] 中对 HTTP 有个大致的了解。
|
||||
- 实现异步操作(我*喜欢* Python 3 的 asyncio 模块)。
|
||||
- 简单的路由逻辑以及参数撷取。
|
||||
- 像其他微型框架一样,提供一个简单的用户级 API 。
|
||||
- 支持身份认证,因为学会这个很酷啊(微笑)。
|
||||
|
||||
限制:
|
||||
|
||||
- 将只支持 HTTP 1.1 的一个小子集,不支持传输编码(transfer-encoding)、HTTP 认证(http-auth)、内容编码(content-encoding,如 gzip)以及[持久化连接][3]等功能。
|
||||
- 不支持对响应内容的 MIME 判断 - 用户需要手动指定。
|
||||
- 不支持 WSGI - 仅能处理简单的 TCP 连接。
|
||||
- 不支持数据库。
|
||||
|
||||
我觉得一个小的用例可以让上述内容更加具体,也可以用来演示这个框架的 API:
|
||||
|
||||
```
|
||||
from diy_framework import App, Router
|
||||
from diy_framework.http_utils import Response
|
||||
|
||||
|
||||
# GET simple route
|
||||
async def home(r):
|
||||
rsp = Response()
|
||||
rsp.set_header('Content-Type', 'text/html')
|
||||
rsp.body = '<html><body><b>test</b></body></html>'
|
||||
return rsp
|
||||
|
||||
|
||||
# GET route + params
|
||||
async def welcome(r, name):
|
||||
return "Welcome {}".format(name)
|
||||
|
||||
# POST route + body param
|
||||
async def parse_form(r):
|
||||
if r.method == 'GET':
|
||||
return 'form'
|
||||
else:
|
||||
name = r.body.get('name', '')[0]
|
||||
password = r.body.get('password', '')[0]
|
||||
|
||||
return "{0}:{1}".format(name, password)
|
||||
|
||||
# application = router + http server
|
||||
router = Router()
|
||||
router.add_routes({
|
||||
r'/welcome/{name}': welcome,
|
||||
r'/': home,
|
||||
r'/login': parse_form,})
|
||||
|
||||
app = App(router)
|
||||
app.start_server()
|
||||
```
|
||||
'
|
||||
用户需要定义一些能够返回字符串或 `Response` 对象的异步函数,然后将这些函数与表示路由的字符串配对,最后通过一个函数调用(`start_server`)开始处理请求。
|
||||
|
||||
完成设计之后,我将它抽象为几个我需要编码的部分:
|
||||
|
||||
- 接受 TCP 连接以及调度一个异步函数来处理这些连接的部分
|
||||
- 将原始文本解析成某种抽象容器的部分
|
||||
- 对于每个请求,用来决定调用哪个函数的部分
|
||||
- 将上述部分集中到一起,并为开发者提供一个简单接口的部分
|
||||
|
||||
我先编写一些测试,这些测试被用来描述每个部分的功能。几次重构后,整个设计被分成若干部分,每个部分之间是相对解耦的。这样就非常好,因为每个部分可以被独立地研究学习。以下是我上文列出的抽象的具体体现:
|
||||
|
||||
- 一个 HTTPServer 对象,需要一个 Router 对象和一个 http_parser 模块,并使用它们来初始化。
|
||||
- HTTPConnection 对象,每一个对象表示一个单独的客户端 HTTP 连接,并且处理其请求-响应周期:使用 http_parser 模块将收到的字节流解析为一个 Request 对象;使用一个 Router 实例寻找并调用正确的函数来生成一个响应;最后将这个响应发送回客户端。
|
||||
- 一对 Request 和 Response 对象为用户提供了一种友好的方式,来处理实质上是字节流的字符串。用户不需要知道正确的消息格式和分隔符是怎样的。
|
||||
- 一个包含“路由:函数”对应关系的 Router 对象。它提供一个添加配对的方法,可以根据 URL 路径查找到相应的函数。
|
||||
- 最后,一个 App 对象。它包含配置信息,并使用它们实例化一个 HTTPServer 实例。
|
||||
|
||||
让我们从 `HTTPConnection` 开始来讲解各个部分。
|
||||
|
||||
### 模拟异步连接
|
||||
|
||||
为了满足上述约束条件,每一个 HTTP 请求都是一个单独的 TCP 连接。这使得处理请求的速度变慢了,因为建立多个 TCP 连接需要相对高的花销(DNS 查询,TCP 三次握手,[慢启动][4]等等的花销),不过这样更加容易模拟。对于这一任务,我选择相对高级的 [asyncio-stream][5] 模块,它建立在 [asyncio 的传输和协议][6]的基础之上。我强烈推荐你读一读标准库中的相应代码,很有意思!
|
||||
|
||||
一个 `HTTPConnection` 的实例能够处理多个任务。首先,它使用 `asyncio.StreamReader` 对象以增量的方式从 TCP 连接中读取数据,并存储在缓存中。每一个读取操作完成后,它会尝试解析缓存中的数据,并生成一个 `Request` 对象。一旦收到了这个完整的请求,它就生成一个回复,并通过 `asyncio.StreamWriter` 对象发送回客户端。当然,它还有两个任务:超时连接以及错误处理。
|
||||
|
||||
你可以在[这里][7]浏览这个类的完整代码。我将分别介绍代码的每一部分。为了简单起见,我移除了代码文档。
|
||||
|
||||
```
|
||||
class HTTPConnection(object):
|
||||
def init(self, http_server, reader, writer):
|
||||
self.router = http_server.router
|
||||
self.http_parser = http_server.http_parser
|
||||
self.loop = http_server.loop
|
||||
|
||||
self._reader = reader
|
||||
self._writer = writer
|
||||
self._buffer = bytearray()
|
||||
self._conn_timeout = None
|
||||
self.request = Request()
|
||||
```
|
||||
|
||||
这个 `init` 方法没啥意思,它仅仅是收集了一些对象以供后面使用。它存储了一个 `router` 对象、一个 `http_parser` 对象以及 `loop` 对象,分别用来生成响应、解析请求以及在事件循环中调度任务。
|
||||
|
||||
然后,它存储了代表一个 TCP 连接的读写对,和一个充当原始字节缓冲区的空[字节数组][8]。`_conn_timeout` 存储了一个 [asyncio.Handle][9] 的实例,用来管理超时逻辑。最后,它还存储了 `Request` 对象的一个单一实例。
|
||||
|
||||
下面的代码是用来接受和发送数据的核心功能:
|
||||
|
||||
```
|
||||
async def handle_request(self):
|
||||
try:
|
||||
while not self.request.finished and not self._reader.at_eof():
|
||||
data = await self._reader.read(1024)
|
||||
if data:
|
||||
self._reset_conn_timeout()
|
||||
await self.process_data(data)
|
||||
if self.request.finished:
|
||||
await self.reply()
|
||||
elif self._reader.at_eof():
|
||||
raise BadRequestException()
|
||||
except (NotFoundException,
|
||||
BadRequestException) as e:
|
||||
self.error_reply(e.code, body=Response.reason_phrases[e.code])
|
||||
except Exception as e:
|
||||
self.error_reply(500, body=Response.reason_phrases[500])
|
||||
|
||||
self.close_connection()
|
||||
```
|
||||
|
||||
所有内容被包含在 `try-except` 代码块中,这样在解析请求或响应期间抛出的异常可以被捕获到,然后一个错误响应会发送回客户端。
|
||||
|
||||
在 `while` 循环中不断读取请求,直到解析器将 `self.request.finished` 设置为 True ,或者客户端关闭连接所触发的信号使得 `self._reader_at_eof()` 函数返回值为 True 为止。这段代码尝试在每次循环迭代中从 `StreamReader` 中读取数据,并通过调用 `self.process_data(data)` 函数以增量方式生成 `self.request`。每次循环读取数据时,连接超时计数器被重置。
|
||||
|
||||
这儿有个错误,你发现了吗?稍后我们会再讨论这个。需要注意的是,这个循环可能会耗尽 CPU 资源,因为如果没有读取到东西 `self._reader.read()` 函数将会返回一个空的字节对象 `b''`。这就意味着循环将会不断运行,却什么也不做。一个可能的解决方法是,用非阻塞的方式等待一小段时间:`await asyncio.sleep(0.1)`。我们暂且不对它做优化。
|
||||
|
||||
还记得上一段我提到的那个错误吗?只有从 `StreamReader` 读取数据时,`self._reset_conn_timeout()` 函数才会被调用。这就意味着,**直到第一个字节到达时**,`timeout` 才被初始化。如果有一个客户端建立了与服务器的连接却不发送任何数据,那就永远不会超时。这可能被用来消耗系统资源,从而导致拒绝服务式攻击(DoS)。修复方法就是在 `init` 函数中调用 `self._reset_conn_timeout()` 函数。
|
||||
|
||||
当请求接受完成或连接中断时,程序将运行到 `if-else` 代码块。这部分代码会判断解析器收到完整的数据后是否完成了解析。如果是,好,生成一个回复并发送回客户端。如果不是,那么请求信息可能有错误,抛出一个异常!最后,我们调用 `self.close_connection` 执行清理工作。
|
||||
|
||||
解析请求的部分在 `self.process_data` 方法中。这个方法非常简短,也易于测试:
|
||||
|
||||
```
|
||||
async def process_data(self, data):
|
||||
self._buffer.extend(data)
|
||||
|
||||
self._buffer = self.http_parser.parse_into(
|
||||
self.request, self._buffer)
|
||||
```
|
||||
|
||||
每一次调用都将数据累积到 `self._buffer` 中,然后试着用 `self.http_parser` 来解析已经收集的数据。这里需要指出的是,这段代码展示了一种称为[依赖注入(Dependency Injection)][10]的模式。如果你还记得 `init` 函数的话,应该知道我们传入了一个包含 `http_parser` 对象的 `http_server` 对象。在这个例子里,`http_parser` 对象是 `diy_framework` 包中的一个模块。不过它也可以是任何含有 `parse_into` 函数的类,这个 `parse_into` 函数接受一个 `Request` 对象以及字节数组作为参数。这很有用,原因有二:一是,这意味着这段代码更易扩展。如果有人想通过一个不同的解析器来使用 `HTTPConnection`,没问题,只需将它作为参数传入即可。二是,这使得测试更加容易,因为 `http_parser` 不是硬编码的,所以使用虚假数据或者 [mock][11] 对象来替代是很容易的。
|
||||
|
||||
下一段有趣的部分就是 `reply` 方法了:
|
||||
|
||||
```
|
||||
async def reply(self):
|
||||
request = self.request
|
||||
handler = self.router.get_handler(request.path)
|
||||
|
||||
response = await handler.handle(request)
|
||||
|
||||
if not isinstance(response, Response):
|
||||
response = Response(code=200, body=response)
|
||||
|
||||
self._writer.write(response.to_bytes())
|
||||
await self._writer.drain()
|
||||
```
|
||||
|
||||
这里,一个 `HTTPConnection` 的实例使用了 `HTTPServer` 中的 `router` 对象来得到一个生成响应的对象。一个路由可以是任何一个拥有 `get_handler` 方法的对象,这个方法接收一个字符串作为参数,返回一个可调用的对象或者抛出 `NotFoundException` 异常。而这个可调用的对象被用来处理请求以及生成响应。处理程序由框架的使用者编写,如上文所说的那样,应该返回字符串或者 `Response` 对象。`Response` 对象提供了一个友好的接口,因此这个简单的 if 语句保证了无论处理程序返回什么,代码最终都得到一个统一的 `Response` 对象。
|
||||
|
||||
接下来,被赋值给 `self._writer` 的 `StreamWriter` 实例被调用,将字节字符串发送回客户端。函数返回前,程序在 `await self._writer.drain()` 处等待,以确保所有的数据被发送给客户端。只要缓存中还有未发送的数据,`self._writer.close()` 方法就不会执行。
|
||||
|
||||
`HTTPConnection` 类还有两个更加有趣的部分:一个用于关闭连接的方法,以及一组用来处理超时机制的方法。首先,关闭一条连接由下面这个小函数完成:
|
||||
|
||||
```
|
||||
def close_connection(self):
|
||||
self._cancel_conn_timeout()
|
||||
self._writer.close()
|
||||
```
|
||||
|
||||
每当一条连接将被关闭时,这段代码首先取消超时,然后把连接从事件循环中清除。
|
||||
|
||||
超时机制由三个相关的函数组成:第一个函数在超时后给客户端发送错误消息并关闭连接;第二个函数用于取消当前的超时;第三个函数调度超时功能。前两个函数比较简单,我将详细解释第三个函数 `_reset_cpmm_timeout()` 。
|
||||
|
||||
```
|
||||
def _conn_timeout_close(self):
|
||||
self.error_reply(500, 'timeout')
|
||||
self.close_connection()
|
||||
|
||||
def _cancel_conn_timeout(self):
|
||||
if self._conn_timeout:
|
||||
self._conn_timeout.cancel()
|
||||
|
||||
def _reset_conn_timeout(self, timeout=TIMEOUT):
|
||||
self._cancel_conn_timeout()
|
||||
self._conn_timeout = self.loop.call_later(
|
||||
timeout, self._conn_timeout_close)
|
||||
```
|
||||
|
||||
每当 `_reset_conn_timeout` 函数被调用时,它会先取消之前所有赋值给 `self._conn_timeout` 的 `asyncio.Handle` 对象。然后,使用 [BaseEventLoop.call_later][12] 函数让 `_conn_timeout_close` 函数在超时数秒(`timeout`)后执行。如果你还记得 `handle_request` 函数的内容,就知道每当接收到数据时,这个函数就会被调用。这就取消了当前的超时并且重新安排 `_conn_timeout_close` 函数在超时数秒(`timeout`)后执行。只要接收到数据,这个循环就会不断地重置超时回调。如果在超时时间内没有接收到数据,最后函数 `_conn_timeout_close` 就会被调用。
|
||||
|
||||
### 创建连接
|
||||
|
||||
我们需要创建 `HTTPConnection` 对象,并且正确地使用它们。这一任务由 `HTTPServer` 类完成。`HTTPServer` 类是一个简单的容器,可以存储着一些配置信息(解析器,路由和事件循环实例),并使用这些配置来创建 `HTTPConnection` 实例:
|
||||
|
||||
```
|
||||
class HTTPServer(object):
|
||||
def init(self, router, http_parser, loop):
|
||||
self.router = router
|
||||
self.http_parser = http_parser
|
||||
self.loop = loop
|
||||
|
||||
async def handle_connection(self, reader, writer):
|
||||
connection = HTTPConnection(self, reader, writer)
|
||||
asyncio.ensure_future(connection.handle_request(), loop=self.loop)
|
||||
```
|
||||
|
||||
`HTTPServer` 的每一个实例能够监听一个端口。它有一个 `handle_connection` 的异步方法来创建 `HTTPConnection` 的实例,并安排它们在事件循环中运行。这个方法被传递给 [asyncio.start_server][13] 作为一个回调函数。也就是说,每当一个 TCP 连接初始化时(以 `StreamReader` 和 `StreamWriter` 为参数),它就会被调用。
|
||||
|
||||
```
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
```
|
||||
|
||||
这就是构成整个应用程序工作原理的核心:`asyncio.start_server` 接受 TCP 连接,然后在一个预配置的 `HTTPServer` 对象上调用一个方法。这个方法将处理一条 TCP 连接的所有逻辑:读取、解析、生成响应并发送回客户端、以及关闭连接。它的重点是 IO 逻辑、解析和生成响应。
|
||||
|
||||
讲解了核心的 IO 部分,让我们继续。
|
||||
|
||||
### 解析请求
|
||||
|
||||
这个微型框架的使用者被宠坏了,不愿意和字节打交道。它们想要一个更高层次的抽象 —— 一种更加简单的方法来处理请求。这个微型框架就包含了一个简单的 HTTP 解析器,能够将字节流转化为 Request 对象。
|
||||
|
||||
这些 Request 对象是像这样的容器:
|
||||
|
||||
```
|
||||
class Request(object):
|
||||
def init(self):
|
||||
self.method = None
|
||||
self.path = None
|
||||
self.query_params = {}
|
||||
self.path_params = {}
|
||||
self.headers = {}
|
||||
self.body = None
|
||||
self.body_raw = None
|
||||
self.finished = False
|
||||
```
|
||||
|
||||
它包含了所有需要的数据,可以用一种容易理解的方法从客户端接受数据。哦,不包括 cookie ,它对身份认证是非常重要的,我会将它留在第二部分。
|
||||
|
||||
每一个 HTTP 请求都包含了一些必需的内容,如请求路径和请求方法。它们也包含了一些可选的内容,如请求体、请求头,或是 URL 参数。随着 REST 的流行,除了 URL 参数,URL 本身会包含一些信息。比如,"/user/1/edit" 包含了用户的 id 。
|
||||
|
||||
一个请求的每个部分都必须被识别、解析,并正确地赋值给 Request 对象的对应属性。HTTP/1.1 是一个文本协议,事实上这简化了很多东西。(HTTP/2 是一个二进制协议,这又是另一种乐趣了)
|
||||
|
||||
解析器不需要跟踪状态,因此 `http_parser` 模块其实就是一组函数。调用函数需要用到 `Request` 对象,并将它连同一个包含原始请求信息的字节数组传递给 `parse_into` 函数。然后解析器会修改 `Request` 对象以及充当缓存的字节数组。字节数组的信息被逐渐地解析到 request 对象中。
|
||||
|
||||
`http_parser` 模块的核心功能就是下面这个 `parse_into` 函数:
|
||||
|
||||
```
|
||||
def parse_into(request, buffer):
|
||||
_buffer = buffer[:]
|
||||
if not request.method and can_parse_request_line(_buffer):
|
||||
(request.method, request.path,
|
||||
request.query_params) = parse_request_line(_buffer)
|
||||
remove_request_line(_buffer)
|
||||
|
||||
if not request.headers and can_parse_headers(_buffer):
|
||||
request.headers = parse_headers(_buffer)
|
||||
if not has_body(request.headers):
|
||||
request.finished = True
|
||||
|
||||
remove_intro(_buffer)
|
||||
|
||||
if not request.finished and can_parse_body(request.headers, _buffer):
|
||||
request.body_raw, request.body = parse_body(request.headers, _buffer)
|
||||
clear_buffer(_buffer)
|
||||
request.finished = True
|
||||
return _buffer
|
||||
```
|
||||
|
||||
从上面的代码中可以看到,我把解析的过程分为三个部分:解析请求行(这行像这样:GET /resource HTTP/1.1),解析请求头以及解析请求体。
|
||||
|
||||
请求行包含了 HTTP 请求方法以及 URL 地址。而 URL 地址则包含了更多的信息:路径、url 参数和开发者自定义的 url 参数。解析请求方法和 URL 还是很容易的 - 合适地分割字符串就好了。函数 `urlparse.parse` 可以用来解析 URL 参数。开发者自定义的 URL 参数可以通过正则表达式来解析。
|
||||
|
||||
接下来是 HTTP 头部。它们是一行行由键值对组成的简单文本。问题在于,可能有多个 HTTP 头有相同的名字,却有不同的值。一个值得关注的 HTTP 头部是 `Content-Length`,它描述了请求体的字节长度(不是整个请求,仅仅是请求体)。这对于决定是否解析请求体有很重要的作用。
|
||||
|
||||
最后,解析器根据 HTTP 方法和头部来决定是否解析请求体。
|
||||
|
||||
### 路由!
|
||||
|
||||
在某种意义上,路由就像是连接框架和用户的桥梁,用户用合适的方法创建 `Router` 对象并为其设置路径/函数对,然后将它赋值给 App 对象。而 App 对象依次调用 `get_handler` 函数生成相应的回调函数。简单来说,路由就负责两件事,一是存储路径/函数对,二是返回需要的路径/函数对
|
||||
|
||||
`Router` 类中有两个允许最终开发者添加路由的方法,分别是 `add_routes` 和 `add_route`。因为 `add_routes` 就是 `add_route` 函数的一层封装,我们将主要讲解 `add_route` 函数:
|
||||
|
||||
```
|
||||
def add_route(self, path, handler):
|
||||
compiled_route = self.class.build_route_regexp(path)
|
||||
if compiled_route not in self.routes:
|
||||
self.routes[compiled_route] = handler
|
||||
else:
|
||||
raise DuplicateRoute
|
||||
```
|
||||
|
||||
首先,这个函数使用 `Router.build_router_regexp` 的类方法,将一条路由规则(如 '/cars/{id}' 这样的字符串),“编译”到一个已编译的正则表达式对象。这些已编译的正则表达式用来匹配请求路径,以及解析开发者自定义的 URL 参数。如果已经存在一个相同的路由,程序就会抛出一个异常。最后,这个路由/处理程序对被添加到一个简单的字典`self.routes`中。
|
||||
|
||||
下面展示 Router 是如何“编译”路由的:
|
||||
|
||||
```
|
||||
@classmethod
|
||||
def build_route_regexp(cls, regexp_str):
|
||||
"""
|
||||
Turns a string into a compiled regular expression. Parses '{}' into
|
||||
named groups ie. '/path/{variable}' is turned into
|
||||
'/path/(?P<variable>[a-zA-Z0-9_-]+)'.
|
||||
|
||||
:param regexp_str: a string representing a URL path.
|
||||
:return: a compiled regular expression.
|
||||
"""
|
||||
def named_groups(matchobj):
|
||||
return '(?P<{0}>[a-zA-Z0-9_-]+)'.format(matchobj.group(1))
|
||||
|
||||
re_str = re.sub(r'{([a-zA-Z0-9_-]+)}', named_groups, regexp_str)
|
||||
re_str = ''.join(('^', re_str, '$',))
|
||||
return re.compile(re_str)
|
||||
```
|
||||
|
||||
这个方法使用正则表达式将所有出现的 `{variable}` 替换为 `(?P<variable>)`。然后在字符串头尾分别添加 `^` 和 `$` 标记,最后编译正则表达式对象。
|
||||
|
||||
完成了路由存储仅成功了一半,下面是如何得到路由对应的函数:
|
||||
|
||||
```
|
||||
def get_handler(self, path):
|
||||
logger.debug('Getting handler for: {0}'.format(path))
|
||||
for route, handler in self.routes.items():
|
||||
path_params = self.class.match_path(route, path)
|
||||
if path_params is not None:
|
||||
logger.debug('Got handler for: {0}'.format(path))
|
||||
wrapped_handler = HandlerWrapper(handler, path_params)
|
||||
return wrapped_handler
|
||||
|
||||
raise NotFoundException()
|
||||
```
|
||||
|
||||
一旦 `App` 对象获得一个 `Request` 对象,也就获得了 URL 的路径部分(如 /users/15/edit)。然后,我们需要匹配函数来生成一个响应或者 404 错误。`get_handler` 函数将路径作为参数,循环遍历路由,对每条路由调用 `Router.match_path` 类方法检查是否有已编译的正则对象与这个请求路径匹配。如果存在,我们就调用 `HandleWrapper` 来包装路由对应的函数。`path_params` 字典包含了路径变量(如 '/users/15/edit' 中的 '15'),若路由没有指定变量,字典就为空。最后,我们将包装好的函数返回给 `App` 对象。
|
||||
|
||||
如果遍历了所有的路由都找不到与路径匹配的,函数就会抛出 `NotFoundException` 异常。
|
||||
|
||||
这个 `Route.match` 类方法挺简单:
|
||||
|
||||
```
|
||||
def match_path(cls, route, path):
|
||||
match = route.match(path)
|
||||
try:
|
||||
return match.groupdict()
|
||||
except AttributeError:
|
||||
return None
|
||||
```
|
||||
|
||||
它使用正则对象的 [match 方法][14]来检查路由是否与路径匹配。若果不匹配,则返回 None 。
|
||||
|
||||
最后,我们有 `HandleWraapper` 类。它的唯一任务就是封装一个异步函数,存储 `path_params` 字典,并通过 `handle` 方法对外提供一个统一的接口。
|
||||
|
||||
```
|
||||
class HandlerWrapper(object):
|
||||
def init(self, handler, path_params):
|
||||
self.handler = handler
|
||||
self.path_params = path_params
|
||||
self.request = None
|
||||
|
||||
async def handle(self, request):
|
||||
return await self.handler(request, **self.path_params)
|
||||
```
|
||||
|
||||
### 组合到一起
|
||||
|
||||
框架的最后部分就是用 `App` 类把所有的部分联系起来。
|
||||
|
||||
`App` 类用于集中所有的配置细节。一个 `App` 对象通过其 `start_server` 方法,使用一些配置数据创建一个 `HTTPServer` 的实例,然后将它传递给 [asyncio.start_server 函数][15]。`asyncio.start_server` 函数会对每一个 TCP 连接调用 `HTTPServer` 对象的 `handle_connection` 方法。
|
||||
|
||||
```
|
||||
def start_server(self):
|
||||
if not self._server:
|
||||
self.loop = asyncio.get_event_loop()
|
||||
self._server = HTTPServer(self.router, self.http_parser, self.loop)
|
||||
self._connection_handler = asyncio.start_server(
|
||||
self._server.handle_connection,
|
||||
host=self.host,
|
||||
port=self.port,
|
||||
reuse_address=True,
|
||||
reuse_port=True,
|
||||
loop=self.loop)
|
||||
|
||||
logger.info('Starting server on {0}:{1}'.format(
|
||||
self.host, self.port))
|
||||
self.loop.run_until_complete(self._connection_handler)
|
||||
|
||||
try:
|
||||
self.loop.run_forever()
|
||||
except KeyboardInterrupt:
|
||||
logger.info('Got signal, killing server')
|
||||
except DiyFrameworkException as e:
|
||||
logger.error('Critical framework failure:')
|
||||
logger.error(e.traceback)
|
||||
finally:
|
||||
self.loop.close()
|
||||
else:
|
||||
logger.info('Server already started - {0}'.format(self))
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
如果你查看源码,就会发现所有的代码仅 320 余行(包括测试代码的话共 540 余行)。这么少的代码实现了这么多的功能,让我有点惊讶。这个框架没有提供模板、身份认证以及数据库访问等功能(这些内容也很有趣哦)。这也让我知道,像 Django 和 Tornado 这样的框架是如何工作的,而且我能够快速地调试它们了。
|
||||
|
||||
这也是我按照测试驱动开发完成的第一个项目,整个过程有趣而有意义。先编写测试用例迫使我思考设计和架构,而不仅仅是把代码放到一起,让它们可以运行。不要误解我的意思,有很多时候,后者的方式更好。不过如果你想给确保这些不怎么维护的代码在之后的几周甚至几个月依然工作,那么测试驱动开发正是你需要的。
|
||||
|
||||
我研究了下[整洁架构][16]以及依赖注入模式,这些充分体现在 `Router` 类是如何作为一个更高层次的抽象的(实体?)。`Router` 类是比较接近核心的,像 `http_parser` 和 `App` 的内容比较边缘化,因为它们只是完成了极小的字符串和字节流、或是中层 IO 的工作。测试驱动开发(TDD)迫使我独立思考每个小部分,这使我问自己这样的问题:方法调用的组合是否易于理解?类名是否准确地反映了我正在解决的问题?我的代码中是否很容易区分出不同的抽象层?
|
||||
|
||||
来吧,写个小框架,真的很有趣:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://mattscodecave.com/posts/simple-python-framework-from-scratch.html
|
||||
|
||||
作者:[Matt][a]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://mattscodecave.com/hire-me.html
|
||||
[1]: https://github.com/sirMackk/diy_framework
|
||||
[2]:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
|
||||
[3]: https://en.wikipedia.org/wiki/HTTP_persistent_connection
|
||||
[4]: https://en.wikipedia.org/wiki/TCP_congestion-avoidance_algorithm#Slow_start
|
||||
[5]: https://docs.python.org/3/library/asyncio-stream.html
|
||||
[6]: https://docs.python.org/3/library/asyncio-protocol.html
|
||||
[7]: https://github.com/sirMackk/diy_framework/blob/88968e6b30e59504251c0c7cd80abe88f51adb79/diy_framework/http_server.py#L46
|
||||
[8]: https://docs.python.org/3/library/functions.html#bytearray
|
||||
[9]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.Handle
|
||||
[10]: https://en.wikipedia.org/wiki/Dependency_injection
|
||||
[11]: https://docs.python.org/3/library/unittest.mock.html
|
||||
[12]: https://docs.python.org/3/library/asyncio-eventloop.html#asyncio.BaseEventLoop.call_later
|
||||
[13]: https://docs.python.org/3/library/asyncio-stream.html#asyncio.start_server
|
||||
[14]: https://docs.python.org/3/library/re.html#re.match
|
||||
[15]: https://docs.python.org/3/library/asyncio-stream.html?highlight=start_server#asyncio.start_server
|
||||
[16]: https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html
|
||||
@ -0,0 +1,141 @@
|
||||
科学音频处理(一):怎样使用 Octave 对音频文件进行读写操作
|
||||
================
|
||||
|
||||
Octave 是一个类似于 Linux 上的 Matlab 的软件,它拥有数量众多的函数和命令,支持声音采集、记录、回放以及音频信号的数字化处理,用于娱乐应用、研究、医学以及其它科学领域。在本教程中,我们会在 Ubuntu 上使用 Octave 的 4.0.0 版本读取音频文件,然后通过生成信号并且播放来模仿在各种情况下对音频信号的使用。
|
||||
|
||||
本教程中关注的不是安装和学习使用安装好的音频处理软件,而是从设计和音频工程的角度理解它是如何工作的。
|
||||
|
||||
### 环境准备
|
||||
|
||||
首先是安装 octave,在 Ubuntu 终端运行下面的命令添加 Octave PPA,然后安装 Octave 。
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:octave/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install octave
|
||||
```
|
||||
|
||||
### 步骤1:打开 Octave
|
||||
|
||||
在这一步中我们单击软件图标打开 Octave,可以通过单击下拉式按钮选择工作路径。
|
||||
|
||||
|
||||
|
||||
### 步骤2:音频信息
|
||||
|
||||
使用`audioinfo`命令查看要处理的音频文件的相关信息。
|
||||
|
||||
```
|
||||
>> info = audioinfo ('testing.ogg')
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
### 步骤3:读取音频文件
|
||||
|
||||
在本教程中我会使用 ogg 文件来读取这种文件的属性,比如采样、音频类型(stereo 和 mono)、信道数量等。必须声明的一点是教程中使用的所有的命令都是在 Octave 终端窗口中执行的。首先,我们必须要把这个 ogg 文件赋给一个变量。注意:**文件必须在 Octave 的工作路径中。**
|
||||
|
||||
```
|
||||
>> file='yourfile.ogg'
|
||||
```
|
||||
|
||||
```
|
||||
>> [M, fs] = audioread(file)
|
||||
```
|
||||
|
||||
这里的 M 是一个一列或两列的矩阵,取决于信道的数量,fs 是采样率。
|
||||
|
||||
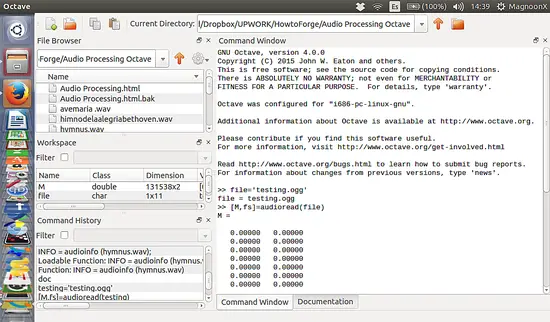
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
下面的操作都可以读取音频文件:
|
||||
|
||||
```
|
||||
>> [y, fs] = audioread (filename, samples)
|
||||
|
||||
>> [y, fs] = audioread (filename, datatype)
|
||||
|
||||
>> [y, fs] = audioread (filename, samples, datatype)
|
||||
```
|
||||
|
||||
samples 指定开始帧和结束帧,datatype 指定返回的数据类型。可以为所有变量设置值:
|
||||
|
||||
```
|
||||
>> samples = [1, fs)
|
||||
|
||||
>> [y, fs] = audioread (filename, samples)
|
||||
```
|
||||
|
||||
数据类型:
|
||||
|
||||
```
|
||||
>> [y,Fs] = audioread(filename,'native')
|
||||
```
|
||||
|
||||
如果值是“native”,那么它的数据类型就依数据在音频文件中的存储情况而定。
|
||||
|
||||
### 步骤4:音频文件的写操作
|
||||
|
||||
新建一个 ogg 文件:
|
||||
|
||||
我们会从一个余弦值创建一个 ogg 文件。采样率是每秒 44100 次,这个文件最少进行 10 秒的采样。余弦信号的频率是 440 Hz。
|
||||
|
||||
```
|
||||
>> filename='cosine.ogg';
|
||||
>> fs=44100;
|
||||
>> t=0:1/fs:10;
|
||||
>> w=2*pi*440*t;
|
||||
>> signal=cos(w);
|
||||
>> audiowrite(filename, signal, fs);
|
||||
```
|
||||
|
||||
这就在工作路径中创建了一个 'cosine.ogg' 文件,这个文件中包含余弦信号。
|
||||
|
||||
|
||||
|
||||
播放这个 'cosine.ogg' 文件就会产生一个 440Hz 的 音调,这个音调正好是乐理中的 'A' 调。如果需要查看保存在文件中的值就必须使用 'audioread' 函数读取文件。在后续的教程中,我们会看到怎样在两个信道中读取一个音频文件。
|
||||
|
||||
### 步骤5:播放音频文件
|
||||
|
||||
Octave 有一个默认的音频播放器,可以用这个音频播放器进行测试。使用下面的函数:
|
||||
|
||||
```
|
||||
>> [y,fs]=audioread('yourfile.ogg');
|
||||
>> player=audioplayer(y, fs, 8)
|
||||
|
||||
scalar structure containing the fields:
|
||||
|
||||
BitsPerSample = 8
|
||||
CurrentSample = 0
|
||||
DeviceID = -1
|
||||
NumberOfChannels = 1
|
||||
Running = off
|
||||
SampleRate = 44100
|
||||
TotalSamples = 236473
|
||||
Tag =
|
||||
Type = audioplayer
|
||||
UserData = [](0x0)
|
||||
>> play(player);
|
||||
```
|
||||
|
||||
|
||||
在这个教程的续篇,我们会进入音频处理的高级特性部分,可能会接触到一些科学和商业应用中的实例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-read-and-write-audio-files-with-octave-4-in-ubuntu/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/intent/follow?original_referer=https%3A%2F%2Fwww.howtoforge.com%2Ftutorial%2Fhow-to-read-and-write-audio-files-with-octave-4-in-ubuntu%2F&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=howtoforgecom&tw_p=followbutton
|
||||
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
5 个给 Linux 新手的最佳包管理器
|
||||
=====================================================
|
||||
|
||||
一个 Linux 新用户应该知道他或她的进步源自于对 Linux 发行版的使用,而 Linux 发行版有好几种,并以不同的方式管理软件包。
|
||||
|
||||
在 Linux 中,包管理器非常重要,知道如何使用多种包管理器可以让你像一个高手一样活得很舒适,从在仓库下载软件、安装软件,到更新软件、处理依赖和删除软件是非常重要的,这也是Linux 系统管理的一个重要部分。
|
||||
|
||||

|
||||
|
||||
*最好的Linux包管理器*
|
||||
|
||||
成为一个 Linux 高手的一个标志是了解主要的 Linux 发行版如何处理包,在这篇文章中,我们应该看一些你在 Linux 上能找到的最佳的包管理器,
|
||||
|
||||
在这里,我们的主要重点是关于一些最佳包管理器的相关信息,但不是如何使用它们,这些留给你亲自发现。但我会提供一些有意义的链接,使用指南或更多。
|
||||
|
||||
### 1. DPKG - Debian 包管理系统(Debian Package Management System)
|
||||
|
||||
Dpkg 是 Debian Linux 家族的基础包管理系统,它用于安装、删除、存储和提供`.deb`包的信息。
|
||||
|
||||
这是一个低层面的工具,并且有多个前端工具可以帮助用户从远程的仓库获取包,或处理复杂的包关系的工具,包括如下:
|
||||
|
||||
- 参考:[15 个用于基于 Debian 的发行版的 “dpkg” 命令实例][1]
|
||||
|
||||
#### APT (高级打包工具(Advanced Packaging Tool))
|
||||
|
||||
这个是一个 dpkg 包管理系统的前端工具,它是一个非常受欢迎的、自由而强大的,有用的命令行包管理器系统。
|
||||
|
||||
Debian 及其衍生版,例如 Ubuntu 和 Linux Mint 的用户应该非常熟悉这个包管理工具。
|
||||
|
||||
想要了解它是如何工作的,你可以去看看下面这些 HOW TO 指南:
|
||||
|
||||
- 参考:[15 个怎样在 Ubuntu/Debian 上使用新的 APT 工具的例子][2]
|
||||
- 参考:[25 个用于包管理的有用的 APT-GET 和 APT-CACHE 的基础命令][3]
|
||||
|
||||
#### Aptitude 包管理器
|
||||
|
||||
这个也是 Debian Linux 家族一个非常出名的命令行前端包管理工具,它工作方式类似 APT ,它们之间有很多可以比较的地方,不过,你应该两个都试试才知道哪个工作的更好。
|
||||
|
||||
它最初为 Debian 及其衍生版设计的,但是现在它的功能延伸到 RHEL 家族。你可以参考这个指南了解更多关于 APT 和 Aptitude。
|
||||
|
||||
- 参考:[APT 和 Aptitude 是什么?它们知道到底有什么不同?][4]
|
||||
|
||||
#### Synaptic 包管理器
|
||||
|
||||
Synaptic是一个基于GTK+的APT的可视化包管理器,对于一些不想使用命令行的用户,它非常好用。
|
||||
|
||||
### 2. RPM 红帽包管理器(Red Hat Package Manager)
|
||||
|
||||
这个是红帽创建的 Linux 基本标准(LSB)打包格式和基础包管理系统。基于这个底层系统,有多个前端包管理工具可供你使用,但我们应该只看那些最好的,那就是:
|
||||
|
||||
#### YUM (黄狗更新器,修改版(Yellowdog Updater, Modified))
|
||||
|
||||
这个是一个开源、流行的命令行包管理器,它是用户使用 RPM 的界面(之一)。你可以把它和 Debian Linux 系统中的 APT 进行对比,它和 APT 拥有相同的功能。你可以从这个 HOW TO 指南中的例子更加清晰的理解YUM:
|
||||
|
||||
- 参考:[20 个用于包管理的 YUM 命令][5]
|
||||
|
||||
#### DNF(优美的 Yum(Dandified Yum))
|
||||
|
||||
这个也是一个用于基于 RPM 的发行版的包管理器,Fedora 18 引入了它,它是下一代 YUM。
|
||||
|
||||
如果你用 Fedora 22 及更新版本,你肯定知道它是默认的包管理器。这里有一些链接,将为你提供更多关于 DNF 的信息和如何使用它。
|
||||
|
||||
- 参考:[DNF - 基于 RPM 的发行版的下一代通用包管理软件][6]
|
||||
- 参考: [27 个管理 Fedora 软件包的 ‘DNF’ 命令例子][7]
|
||||
|
||||
### 3. Pacman 包管理器 – Arch Linux
|
||||
|
||||
这个是一个流行的、强大而易用的包管理器,它用于 Arch Linux 和其他的一些小众发行版。它提供了一些其他包管理器提供的基本功能,包括安装、自动解决依赖关系、升级、卸载和降级软件。
|
||||
|
||||
但是最大的用处是,它为 Arch 用户创建了一个简单易用的包管理方式。你可以阅读 [Pacman 概览][8],它会解释上面提到的一些功能。
|
||||
|
||||
### 4. Zypper 包管理器 – openSUSE
|
||||
|
||||
这个是一个使用 libzypp 库制作的用于 OpenSUSE 系统上的命令行包管理器,它的常用功能包括访问仓库、安装包、解决依赖问题和其他功能。
|
||||
|
||||
更重要的是,它也可以支持存储库扩展功能,如模式、补丁和产品。新的 OpenSUSE 用户可以参考下面的链接来掌控它。
|
||||
|
||||
- 参考:[45 个让你精通 openSUSE 包管理的 Zypper 命令][9]
|
||||
|
||||
### 5. Portage 包管理器 – Gentoo
|
||||
|
||||
这个是 Gentoo 的包管理器,当下不怎么流行的一个发行版,但是这并不阻止它成为 Linux 下最好的软件包管理器之一。
|
||||
|
||||
Portage 项目的主要目标是创建一个简单、无故障的包管理系统,包含向后兼容、自动化等功能。
|
||||
|
||||
如果希望理解的更清晰,可以看下: [Portage 项目页][10]。
|
||||
|
||||
### 结束语
|
||||
|
||||
正如我在开始时提到的,这个指南的主要意图是给 Linux 用户提供一个最佳软件包管理器的列表,但知道如何使用它们可以通过其后提供的重要的链接,并实际去试试它们。
|
||||
|
||||
各个发行版的用户需要学习超出他们的发行版之外的一些东西,才能更好理解上述提到的这些不同的包管理器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-package-managers/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/admin/
|
||||
[1]: http://www.tecmint.com/dpkg-command-examples/
|
||||
[2]: http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]: http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[4]: http://www.tecmint.com/difference-between-apt-and-aptitude/
|
||||
[5]: http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]: http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[7]: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[8]: https://wiki.archlinux.org/index.php/Pacman
|
||||
[9]: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
[10]: https://wiki.gentoo.org/wiki/Project:Portage
|
||||
@ -0,0 +1,46 @@
|
||||
DAISY : 一种 Linux 上可用的服务于视力缺陷者的文本格式
|
||||
=================================================================
|
||||
|
||||
|
||||

|
||||
|
||||
*图片: 由Kate Ter Haar提供图片。 opensource.com 后期修饰。 CC BY-SA 2.0 *
|
||||
|
||||
如果你是盲人或像我一样有视力障碍,你可能经常需要各种软硬件才能做到视觉正常的人们视之为理所当然的事情。这其中之一就是阅读的印刷图书的专用格式:布莱叶盲文(Braille)(假设你知道怎样阅读它)或特殊的文本格式例如DAISY。
|
||||
|
||||
### DAISY 是什么?
|
||||
|
||||
DAISY 是数字化无障碍信息系统(Digital Accessible Information System)的缩写。 它是一种开放的标准,专用于帮助盲人阅读课本、杂志、报纸、小说,以及你想到的各种东西。 它由[ DAISY 联盟][1]创立于上世纪 90 年代中期,该联盟包括的组织们致力于制定出一套标准,可以让以这种方式标记的文本易于阅读、可以跳转、进行注释以及其它的文本操作,就像视觉正常的人能做的一样。
|
||||
|
||||
当前的 DAISY 3.0 版本发布于 2005 年中期,是一个完全重写了的标准。它创建的目的是更容易撰写遵守该规范的书籍。值得注意的是,DAISY 能够仅支持纯文本、或仅是录音(PCM wave 文件格式或者 MP3 格式)、或既有文本也有录音。特殊的软件能阅读这类书,并支持用户设置书签和目录导航,就像正常人阅读印刷书籍一样。
|
||||
|
||||
### DAISY 是怎样工作的呢?
|
||||
|
||||
DAISY,除开特殊的版本,它工作时有点像这样:你拥有自己的主向导文件(在 DAISY 2.02 中是 ncc.html),它包含书籍的元数据,比如作者姓名、版权信息、书籍页数等等。而在 DAISY 3.0 中这个文件是一个有效的 XML 文件,以及一个被强烈建议包含在每一本书中的 DTD(文档类型定义)文件。
|
||||
|
||||
在导航控制文件中,标记精确描述了各个位置——无论是文本导航中当前光标位置还是录音中的毫秒级定位,这让该软件可以跳到确切的位置,就像视力健康的人翻到某个章节一样。值得注意的是这种导航控制文件仅包含书中主要的、最大的书籍组成部分的位置。
|
||||
|
||||
更小的内容组成部分由 SMIL(同步多媒体集成语言(synchronized multimedia integration language))文件处理。导航的层次很大程度上取决于书籍的标记的怎么样。这样设想一下,如果印刷书籍没有章节标题,你就需要花很多的时间来确定自己阅读的位置。如果一本 DAISY 格式的书籍被标记的很差,你可能只能转到书本的开头或者目录。如果书籍被标记的太差了(或者完全没有标记),你的 DAISY 阅读软件很可能会直接忽略它。
|
||||
|
||||
### 为什么需要专门的软件?
|
||||
|
||||
你可能会问,如果 DAISY 仅仅是 HTML、XML、录音文件,为什么还需要使用专门的软件进行阅读和操作。单纯从技术上而言,你并不需要。专业化的软件大多数情况下是为了方便。这就像在 Linux 操作系统中,一个简单的 Web 浏览器可以被用来打开并阅读书籍。如果你在一本 DAISY 3 的书中点击 XML 文件,软件通常做的就是读取那些你赋予访问权限的书籍的名称,并建立一个列表让你点击选择要打开的书。如果书籍被标记的很差,它不会显示在这份清单中。
|
||||
|
||||
创建 DAISY 则完全是另一件事了,通常需要专门的软件,或需要拥有足够的专业知识来修改一个通用的软件以达到这样的目的。
|
||||
|
||||
### 结语
|
||||
|
||||
幸运的是,DAISY 是一个已确立的标准。虽然它在阅读方面表现的很棒,但是需要特殊软件来生产它使得视力缺陷者孤立于正常人眼中的世界,在那里人们可以以各种格式去阅读他们电子化书籍。这就是 DAISY 联盟在 EPUB 格式取得了 DAISY 成功的原因,它的第 3 版支持一种叫做“媒体覆盖”的规范,基本上来说是在 EPUB 电子书中可选增加声频或视频。由于 EPUB 和 DAISY 共享了很多 XML 标记,一些能够阅读 DAISY 的软件能够看到 EPUB 电子书但不能阅读它们。这也就意味着只要网站为我们换到这种开放格式的书籍,我们将会有更多可选的软件来阅读我们的书籍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/daisy-linux-compatible-text-format-visually-impaired
|
||||
|
||||
作者:[Kendell Clark][a]
|
||||
译者:[theArcticOcean](https://github.com/theArcticOcean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kendell-clark
|
||||
[1]: http://www.daisy.org
|
||||
@ -0,0 +1,110 @@
|
||||
Ubuntu 的 Snap、Red Hat 的 Flatpak 这种通吃所有发行版的打包方式真的有用吗?
|
||||
=================================================================================
|
||||
|
||||

|
||||
|
||||
**对新一代的打包格式开始渗透到 Linux 生态系统中的深入观察**
|
||||
|
||||
最近我们听到越来越多的有关于 Ubuntu 的 Snap 包和由 Red Hat 员工 Alexander Larsson 创造的 Flatpak (曾经叫做 xdg-app)的消息。
|
||||
|
||||
这两种下一代打包方法在本质上拥有相同的目标和特点:即不依赖于第三方系统功能库的独立包装。
|
||||
|
||||
这种 Linux 新技术方向似乎自然会让人脑海中浮现这样的问题:独立包的优点/缺点是什么?这是否让我们拥有更好的 Linux 系统?其背后的动机是什么?
|
||||
|
||||
为了回答这些问题,让我们先深入了解一下 Snap 和 Flatpak。
|
||||
|
||||
### 动机
|
||||
|
||||
根据 [Flatpak][1] 和 [Snap][2] 的声明,背后的主要动机是使同一版本的应用程序能够运行在多个 Linux 发行版。
|
||||
|
||||
> “从一开始它的主要目标是允许相同的应用程序运行在各种 Linux 发行版和操作系统上。” —— Flatpak
|
||||
|
||||
> “……‘snap’ 通用 Linux 包格式,使简单的二进制包能够完美的、安全的运行在任何 Linux 桌面、服务器、云和设备上。” —— Snap
|
||||
|
||||
说得更具体一点,站在 Snap 和 Flatpak (以下称之为 S&F)背后的人认为,Linux 平台存在碎片化的问题。
|
||||
|
||||
这个问题导致了开发者们需要做许多不必要的工作来使他的软件能够运行在各种不同的发行版上,这影响了整个平台的前进。
|
||||
|
||||
所以,作为 Linux 发行版(Ubuntu 和 Red Hat)的领导者,他们希望消除这个障碍,推动平台发展。
|
||||
|
||||
但是,是否是更多的个人收益刺激了 S&F 的开发?
|
||||
|
||||
#### 个人收益?
|
||||
|
||||
虽然没有任何官方声明,但是试想一下,如果能够创造这种可能会被大多数发行版(即便不是全部)所采用的打包方式,那么这个项目的领导者将可能成为一个能够决定 Linux 大船航向的重要人物。
|
||||
|
||||
### 优势
|
||||
|
||||
这种独立包的好处多多,并且取决于不同的因素。
|
||||
|
||||
这些因素基本上可以归为两类:
|
||||
|
||||
#### 用户角度
|
||||
|
||||
**+** 从 Liunx 用户的观点来看:Snap 和 Flatpak 带来了将任何软件包(软件或应用)安装在用户使用的任何发行版上的可能性。
|
||||
|
||||
例如你在使用一个不是很流行的发行版,由于开发工作的缺乏,它的软件仓库只有很稀少的包。现在,通过 S&F 你就可以显著的增加包的数量,这是一个多么美好的事情。
|
||||
|
||||
**+** 同样,对于使用流行的发行版的用户,即使该发行版的软件仓库上有很多的包,他也可以在不改变它现有的功能库的同时安装一个新的包。
|
||||
|
||||
比方说, 一个 Debian 的用户想要安装一个 “测试分支” 的包,但是他又不想将他的整个系统变成测试版(来让该包运行在更新的功能库上)。现在,他就可以简单的想安装哪个版本就安装哪个版本,而不需要考虑库的问题。
|
||||
|
||||
对于持后者观点的人,可能基本上都是使用源文件编译他们的包的人,然而,除非你使用类似 Gentoo 这样基于源代码的发行版,否则大多数用户将从头编译视为是一个恶心到吐的事情。
|
||||
|
||||
**+** 高级用户,或者称之为 “拥有安全意识的用户” 可能会觉得更容易接受这种类型的包,只要它们来自可靠来源,这种包倾向于提供另一层隔离,因为它们通常是与系统包想隔离的。
|
||||
|
||||
\* 不论是 Snap 还是 Flatpak 都在不断努力增强它们的安全性,通常他们都使用 “沙盒化” 来隔离,以防止它们可能携带病毒感染整个系统,就像微软 Windows 系统中的 .exe 程序一样。(关于微软和 S&F 后面还会谈到)
|
||||
|
||||
#### 开发者角度
|
||||
|
||||
与普通用户相比,对于开发者来说,开发 S&F 包的优点可能更加清楚。这一点已经在上一节有所提示。
|
||||
|
||||
尽管如此,这些优点有:
|
||||
|
||||
**+** S&F 通过统一开发的过程,将多发行版的开发变得简单了起来。对于需要将他的应用运行在多个发行版的开发者来说,这大大的减少了他们的工作量。
|
||||
|
||||
**++** 因此,开发者能够更容易的使他的应用运行在更多的发行版上。
|
||||
|
||||
**+** S&F 允许开发者私自发布他的包,不需要依靠发行版维护者在每一个/每一次发行版中发布他的包。
|
||||
|
||||
**++** 通过上述方法,开发者可以不依赖发行版而直接获取到用户安装和卸载其软件的统计数据。
|
||||
|
||||
**++** 同样是通过上述方法,开发者可以更好的直接与用户互动,而不需要通过中间媒介,比如发行版这种中间媒介。
|
||||
|
||||
### 缺点
|
||||
|
||||
**–** 膨胀。就是这么简单。Flatpak 和 Snap 并不是凭空变出来它的依赖关系。相反,它是通过将依赖关系预构建在其中来代替使用系统中的依赖关系。
|
||||
|
||||
就像谚语说的:“山不来就我,我就去就山”。
|
||||
|
||||
**–** 之前提到安全意识强的用户会喜欢 S&F 提供的额外的一层隔离,只要该应用来自一个受信任的来源。但是从另外一个角度看,对这方面了解较少的用户,可能会从一个不靠谱的地方弄来一个包含恶意软件的包从而导致危害。
|
||||
|
||||
上面提到的观点可以说是有很有意义的,虽说今天的流行方法,像 PPA、overlay 等也可能是来自不受信任的来源。
|
||||
|
||||
但是,S&F 包更加增加这个风险,因为恶意软件开发者只需要开发一个版本就可以感染各种发行版。相反,如果没有 S&F,恶意软件的开发者就需要创建不同的版本以适应不同的发行版。
|
||||
|
||||
### 原来微软一直是正确的吗?
|
||||
|
||||
考虑到上面提到的,很显然,在大多数情况下,使用 S&F 包的优点超过缺点。
|
||||
|
||||
至少对于二进制发行版的用户,或者重点不是轻量级的发行版的用户来说是这样的。
|
||||
|
||||
这促使我问出这个问题,可能微软一直是正确的吗?如果是的,那么当 S&F 变成 Linux 的标准后,你还会一如既往的使用 Linux 或者类 Unix 系统吗?
|
||||
|
||||
很显然,时间会是这个问题的最好答案。
|
||||
|
||||
不过,我认为,即使不完全正确,但是微软有些地方也是值得赞扬的,并且以我的观点来看,所有这些方式在 Linux 上都立马能用也确实是一个亮点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/ubuntus-snap-red-hats-flatpack-and-is-one-fits-all-linux-packages-useful/
|
||||
|
||||
作者:[Editorials][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com/category/editorials/
|
||||
[1]: http://flatpak.org/press/2016-06-21-flatpak-released.html
|
||||
[2]: https://insights.ubuntu.com/2016/06/14/universal-snap-packages-launch-on-multiple-linux-distros
|
||||
@ -0,0 +1,404 @@
|
||||
旅行时通过树莓派和 iPad Pro 备份图片
|
||||
===================================================================
|
||||
|
||||

|
||||
|
||||
*旅行中备份图片 - 组件*
|
||||
|
||||
### 介绍
|
||||
|
||||
我在很长的时间内一直在寻找一个旅行中备份图片的理想方法,把 SD 卡放进你的相机包会让你暴露在太多的风险之中:SD 卡可能丢失或者被盗,数据可能损坏或者在传输过程中失败。比较好的一个选择是复制到另外一个介质中,即使它也是个 SD 卡,并且将它放到一个比较安全的地方去,备份到远端也是一个可行的办法,但是如果去了一个没有网络的地方就不太可行了。
|
||||
|
||||
我理想的备份步骤需要下面的工具:
|
||||
|
||||
1. 用一台 iPad pro 而不是一台笔记本。我喜欢轻装旅行,我的大部分旅程都是商务相关的(而不是拍摄休闲的),我痛恨带着个人笔记本的时候还得带着商务本。而我的 iPad 却一直带着,这就是我为什么选择它的原因。
|
||||
2. 用尽可能少的硬件设备。
|
||||
3. 设备之间的连接需要很安全。我需要在旅馆和机场使用这套设备,所以设备之间的连接需要是封闭而加密的。
|
||||
4. 整个过程应该是可靠稳定的,我还用过其他的路由器/组合设备,但是[效果不太理想][1]。
|
||||
|
||||
### 设备
|
||||
|
||||
我配置了一套满足上面条件并且在未来可以扩充的设备,它包含下面这些部件的使用:
|
||||
|
||||
1. [9.7 英寸的 iPad Pro][2],这是本文写作时最强大、轻薄的 iOS 设备,苹果笔不是必需的,但是作为零件之一,当我在路上可以做一些编辑工作,所有的重活由树莓派做 ,其他设备只能通过 SSH 连接就行。
|
||||
2. 安装了 Raspbian 操作系统[树莓派 3][3](LCTT 译注:Raspbian 是基于 Debian 的树莓派操作系统)。
|
||||
3. 树莓派的 [Mini SD卡][4] 和 [盒子/外壳][5]。
|
||||
5. [128G 的优盘][6],对于我是够用了,你可以买个更大的。你也可以买个像[这样][7]的移动硬盘,但是树莓派没法通过 USB 给移动硬盘提供足够的电量,这意味你需要额外准备一个[供电的 USB hub][8] 以及电缆,这就破坏了我们让设备轻薄的初衷。
|
||||
6. [SD 读卡器][9]
|
||||
7. [另外的 SD 卡][10],我会使用几个 SD 卡,在用满之前就会立即换一个,这样就会让我在一次旅途当中的照片散布在不同的 SD 卡上。
|
||||
|
||||
下图展示了这些设备之间如何相互连接。
|
||||
|
||||

|
||||
|
||||
*旅行时照片的备份-流程图*
|
||||
|
||||
树莓派会作为一个安全的热点。它会创建一个自己的 WPA2 加密的 WIFI 网络,iPad Pro 会连入其中。虽然有很多在线教程教你如何创建 Ad Hoc 网络(计算机到计算机的单对单网络),还更简单一些,但是它的连接是不加密的,而且附件的设备很容易就能连接进去。因此我选择创建 WIFI 网络。
|
||||
|
||||
相机的 SD 卡通过 SD 读卡器插到树莓派 USB 端口之一,128G 的大容量优盘一直插在树莓派的另外一个 USB 端口上,我选择了一款[闪迪的][11],因为体积比较小。主要的思路就是通过 Python 脚本把 SD 卡的照片备份到优盘上,备份过程是增量备份,每次脚本运行时都只有变化的(比如新拍摄的照片)部分会添加到备份文件夹中,所以这个过程特别快。如果你有很多的照片或者拍摄了很多 RAW 格式的照片,在就是个巨大的优势。iPad 将用来运行 Python 脚本,而且用来浏览 SD 卡和优盘的文件。
|
||||
|
||||
作为额外的好处,如果给树莓派连上一根能上网的网线(比如通过以太网口),那么它就可以共享互联网连接给那些通过 WIFI 连入的设备。
|
||||
|
||||
### 1. 树莓派的设置
|
||||
|
||||
这部分需要你卷起袖子亲自动手了,我们要用到 Raspbian 的命令行模式,我会尽可能详细的介绍,方便大家进行下去。
|
||||
|
||||
#### 安装和配置 Raspbian
|
||||
|
||||
给树莓派连接鼠标、键盘和 LCD 显示器,将 SD 卡插到树莓派上,按照[树莓派官网][12]的步骤安装 Raspbian。
|
||||
|
||||
安装完后,打开 Raspbian 的终端,执行下面的命令:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
```
|
||||
|
||||
这将升级机器上所有的软件到最新,我将树莓派连接到本地网络,而且为了安全更改了默认的密码。
|
||||
|
||||
Raspbian 默认开启了 SSH,这样所有的设置可以在一个远程的设备上完成。我也设置了 RSA 验证,但这是可选的功能,可以在[这里][13]查看更多信息。
|
||||
|
||||
这是一个在 Mac 上在 [iTerm][14] 里建立 SSH 连接到树莓派上的截图[14]。(LCTT 译注:原文图丢失。)
|
||||
|
||||
#### 建立 WPA2 加密的 WIFI AP
|
||||
|
||||
安装过程基于[这篇文章][15],根据我的情况进行了调整。
|
||||
|
||||
**1. 安装软件包**
|
||||
|
||||
我们需要安装下面的软件包:
|
||||
|
||||
```
|
||||
sudo apt-get install hostapd
|
||||
sudo apt-get install dnsmasq
|
||||
```
|
||||
|
||||
hostapd 用来使用内置的 WiFi 来创建 AP,dnsmasp 是一个组合的 DHCP 和 DNS 服务其,很容易设置。
|
||||
|
||||
**2. 编辑 dhcpcd.conf**
|
||||
|
||||
通过以太网连接树莓派,树莓派上的网络接口配置由 `dhcpd` 控制,因此我们首先忽略这一点,将 `wlan0` 设置为一个静态的 IP。
|
||||
|
||||
用 `sudo nano /etc/dhcpcd.conf` 命令打开 dhcpcd 的配置文件,在最后一行添加上如下内容:
|
||||
|
||||
```
|
||||
denyinterfaces wlan0
|
||||
```
|
||||
|
||||
注意:它必须放在如果已经有的其它接口行**之上**。
|
||||
|
||||
**3. 编辑接口**
|
||||
|
||||
现在设置静态 IP,使用 `sudo nano /etc/network/interfaces` 打开接口配置文件,按照如下信息编辑`wlan0`部分:
|
||||
|
||||
```
|
||||
allow-hotplug wlan0
|
||||
iface wlan0 inet static
|
||||
address 192.168.1.1
|
||||
netmask 255.255.255.0
|
||||
network 192.168.1.0
|
||||
broadcast 192.168.1.255
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
同样,然后 `wlan1` 编辑如下:
|
||||
|
||||
```
|
||||
#allow-hotplug wlan1
|
||||
#iface wlan1 inet manual
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
重要: 使用 `sudo service dhcpcd restart` 命令重启 `dhcpd`服务,然后用 `sudo ifdown eth0; sudo ifup wlan0` 命令来重载`wlan0`的配置。
|
||||
|
||||
**4. 配置 Hostapd**
|
||||
|
||||
接下来,我们需要配置 hostapd,使用 `sudo nano /etc/hostapd/hostapd.conf` 命令创建一个新的配置文件,内容如下:
|
||||
|
||||
```
|
||||
interface=wlan0
|
||||
|
||||
# Use the nl80211 driver with the brcmfmac driver
|
||||
driver=nl80211
|
||||
|
||||
# This is the name of the network
|
||||
ssid=YOUR_NETWORK_NAME_HERE
|
||||
|
||||
# Use the 2.4GHz band
|
||||
hw_mode=g
|
||||
|
||||
# Use channel 6
|
||||
channel=6
|
||||
|
||||
# Enable 802.11n
|
||||
ieee80211n=1
|
||||
|
||||
# Enable QoS Support
|
||||
wmm_enabled=1
|
||||
|
||||
# Enable 40MHz channels with 20ns guard interval
|
||||
ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40]
|
||||
|
||||
# Accept all MAC addresses
|
||||
macaddr_acl=0
|
||||
|
||||
# Use WPA authentication
|
||||
auth_algs=1
|
||||
|
||||
# Require clients to know the network name
|
||||
ignore_broadcast_ssid=0
|
||||
|
||||
# Use WPA2
|
||||
wpa=2
|
||||
|
||||
# Use a pre-shared key
|
||||
wpa_key_mgmt=WPA-PSK
|
||||
|
||||
# The network passphrase
|
||||
wpa_passphrase=YOUR_NEW_WIFI_PASSWORD_HERE
|
||||
|
||||
# Use AES, instead of TKIP
|
||||
rsn_pairwise=CCMP
|
||||
```
|
||||
|
||||
配置完成后,我们需要告诉`dhcpcd` 在系统启动运行时到哪里寻找配置文件。 使用 `sudo nano /etc/default/hostapd` 命令打开默认配置文件,然后找到`#DAEMON_CONF=""` 替换成`DAEMON_CONF="/etc/hostapd/hostapd.conf"`。
|
||||
|
||||
**5. 配置 Dnsmasq**
|
||||
|
||||
自带的 dnsmasp 配置文件包含很多信息方便你使用它,但是我们不需要那么多选项,我建议把它移动到别的地方(而不要删除它),然后自己创建一个新文件:
|
||||
|
||||
```
|
||||
sudo mv /etc/dnsmasq.conf /etc/dnsmasq.conf.orig
|
||||
sudo nano /etc/dnsmasq.conf
|
||||
```
|
||||
|
||||
粘贴下面的信息到新文件中:
|
||||
|
||||
```
|
||||
interface=wlan0 # Use interface wlan0
|
||||
listen-address=192.168.1.1 # Explicitly specify the address to listen on
|
||||
bind-interfaces # Bind to the interface to make sure we aren't sending things elsewhere
|
||||
server=8.8.8.8 # Forward DNS requests to Google DNS
|
||||
domain-needed # Don't forward short names
|
||||
bogus-priv # Never forward addresses in the non-routed address spaces.
|
||||
dhcp-range=192.168.1.50,192.168.1.100,12h # Assign IP addresses in that range with a 12 hour lease time
|
||||
```
|
||||
|
||||
**6. 设置 IPv4 转发**
|
||||
|
||||
最后我们需要做的事就是配置包转发,用 `sudo nano /etc/sysctl.conf` 命令打开 `sysctl.conf` 文件,将包含 `net.ipv4.ip_forward=1`的那一行之前的#号删除,它将在下次重启时生效。
|
||||
|
||||
我们还需要给连接到树莓派的设备通过 WIFI 分享互联网连接,做一个 `wlan0`和 `eth0` 之间的 NAT。我们可以参照下面的脚本来实现。
|
||||
|
||||
```
|
||||
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
|
||||
sudo iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
sudo iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
|
||||
```
|
||||
|
||||
我命名这个脚本名为 `hotspot-boot.sh`,然后让它可以执行:
|
||||
|
||||
```
|
||||
sudo chmod 755 hotspot-boot.sh
|
||||
```
|
||||
|
||||
该脚本应该在树莓派启动的时候运行。有很多方法实现,下面是我实现的方式:
|
||||
|
||||
1. 把文件放到`/home/pi/scripts`目录下。
|
||||
2. 输入`sudo nano /etc/rc.local`命令编辑 `rc.local` 文件,将运行该脚本的命令放到 `exit 0`之前。(更多信息参照[这里][16])。
|
||||
|
||||
编辑后`rc.local`看起来像这样:
|
||||
|
||||
```
|
||||
#!/bin/sh -e
|
||||
#
|
||||
# rc.local
|
||||
#
|
||||
# This script is executed at the end of each multiuser runlevel.
|
||||
# Make sure that the script will "exit 0" on success or any other
|
||||
# value on error.
|
||||
#
|
||||
# In order to enable or disable this script just change the execution
|
||||
# bits.
|
||||
#
|
||||
# By default this script does nothing.
|
||||
|
||||
# Print the IP address
|
||||
_IP=$(hostname -I) || true
|
||||
if [ "$_IP" ]; then
|
||||
printf "My IP address is %s\n" "$_IP"
|
||||
fi
|
||||
|
||||
sudo /home/pi/scripts/hotspot-boot.sh &
|
||||
|
||||
exit 0
|
||||
|
||||
```
|
||||
|
||||
#### 安装 Samba 服务和 NTFS 兼容驱动
|
||||
|
||||
我们要安装下面几个软件来启用 samba 协议,使[文件浏览器][20]能够访问树莓派分享的文件夹,`ntfs-3g` 可以使我们能够访问移动硬盘中 ntfs 文件系统的文件。
|
||||
|
||||
```
|
||||
sudo apt-get install ntfs-3g
|
||||
sudo apt-get install samba samba-common-bin
|
||||
```
|
||||
|
||||
你可以参照[这些文档][17]来配置 Samba。
|
||||
|
||||
重要提示:参考的文档介绍的是挂载外置硬盘到树莓派上,我们不这样做,是因为在这篇文章写作的时候,树莓派在启动时的 auto-mounts 功能同时将 SD 卡和优盘挂载到`/media/pi/`上,该文章有一些多余的功能我们也不会采用。
|
||||
|
||||
### 2. Python 脚本
|
||||
|
||||
树莓派配置好后,我们需要开发脚本来实际拷贝和备份照片。注意,这个脚本只是提供了特定的自动化备份进程,如果你有基本的 Linux/树莓派命令行操作的技能,你可以 ssh 进树莓派,然后创建需要的文件夹,使用`cp`或`rsync`命令拷贝你自己的照片从一个设备到另外一个设备上。在脚本里我们用`rsync`命令,这个命令比较可靠而且支持增量备份。
|
||||
|
||||
这个过程依赖两个文件,脚本文件自身和`backup_photos.conf`这个配置文件,后者只有几行包含被挂载的目的驱动器(优盘)和应该挂载到哪个目录,它看起来是这样的:
|
||||
|
||||
```
|
||||
mount folder=/media/pi/
|
||||
destination folder=PDRIVE128GB
|
||||
```
|
||||
|
||||
重要提示:在这个符号`=`前后不要添加多余的空格,否则脚本会失效。
|
||||
|
||||
下面是这个 Python 脚本,我把它命名为`backup_photos.py`,把它放到了`/home/pi/scripts/`目录下,我在每行都做了注释可以方便的查看各行的功能。
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from sh import rsync
|
||||
|
||||
'''
|
||||
脚本将挂载到 /media/pi 的 SD 卡上的内容复制到目的磁盘的同名目录下,目的磁盘的名字在 .conf文件里定义好了。
|
||||
|
||||
|
||||
Argument: label/name of the mounted SD Card.
|
||||
'''
|
||||
|
||||
CONFIG_FILE = '/home/pi/scripts/backup_photos.conf'
|
||||
ORIGIN_DEV = sys.argv[1]
|
||||
|
||||
def create_folder(path):
|
||||
|
||||
print ('attempting to create destination folder: ',path)
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.mkdir(path)
|
||||
print ('Folder created.')
|
||||
except:
|
||||
print ('Folder could not be created. Stopping.')
|
||||
return
|
||||
else:
|
||||
print ('Folder already in path. Using that instead.')
|
||||
|
||||
|
||||
|
||||
confFile = open(CONFIG_FILE,'rU')
|
||||
#重要:: rU 选项将以统一换行模式打开文件,
|
||||
#所以 \n 和/或 \r 都被识别为一个新行。
|
||||
|
||||
confList = confFile.readlines()
|
||||
confFile.close()
|
||||
|
||||
|
||||
for line in confList:
|
||||
line = line.strip('\n')
|
||||
|
||||
try:
|
||||
name , value = line.split('=')
|
||||
|
||||
if name == 'mount folder':
|
||||
mountFolder = value
|
||||
elif name == 'destination folder':
|
||||
destDevice = value
|
||||
|
||||
|
||||
except ValueError:
|
||||
print ('Incorrect line format. Passing.')
|
||||
pass
|
||||
|
||||
|
||||
destFolder = mountFolder+destDevice+'/'+ORIGIN_DEV
|
||||
create_folder(destFolder)
|
||||
|
||||
print ('Copying files...')
|
||||
|
||||
# 取消这行备注将删除不在源处的文件
|
||||
# rsync("-av", "--delete", mountFolder+ORIGIN_DEV, destFolder)
|
||||
rsync("-av", mountFolder+ORIGIN_DEV+'/', destFolder)
|
||||
|
||||
print ('Done.')
|
||||
```
|
||||
|
||||
### 3. iPad Pro 的配置
|
||||
|
||||
因为重活都由树莓派干了,文件不通过 iPad Pro 传输,这比我[之前尝试的一种方案][18]有巨大的优势。我们在 iPad 上只需要安装上 [Prompt2][19] 来通过 SSH 连接树莓派就行了,这样你既可以运行 Python 脚本也可以手动复制文件了。
|
||||
|
||||

|
||||
|
||||
*iPad 用 Prompt2 通过 SSH 连接树莓派*
|
||||
|
||||
因为我们安装了 Samba,我们可以以更图形化的方式访问连接到树莓派的 USB 设备,你可以看视频,在不同的设备之间复制和移动文件,[文件浏览器][20]对于这种用途非常完美。
|
||||
|
||||
### 4. 将它们结合在一起
|
||||
|
||||
我们假设`SD32GB-03`是连接到树莓派 USB 端口之一的 SD 卡的卷标,`PDRIVE128GB`是那个优盘的卷标,也连接到设备上,并在上面指出的配置文件中定义好。如果我们想要备份 SD 卡上的图片,我们需要这么做:
|
||||
|
||||
1. 给树莓派加电打开,将驱动器自动挂载好。
|
||||
2. 连接树莓派配置好的 WIFI 网络。
|
||||
3. 用 [Prompt2][21] 这个 app 通过 SSH 连接到树莓派。
|
||||
4. 连接好后输入下面的命令:`python3 backup_photos.py SD32GB-03`
|
||||
|
||||
首次备份需要一些时间,这依赖于你的 SD 卡使用了多少容量。这意味着你需要一直保持树莓派和 iPad 设备连接不断,你可以在脚本运行之前通过 `nohup` 命令解决:
|
||||
|
||||
```
|
||||
nohup python3 backup_photos.py SD32GB-03 &
|
||||
```
|
||||
|
||||

|
||||
|
||||
*运行完成的脚本如图所示*
|
||||
|
||||
### 未来的定制
|
||||
|
||||
我在树莓派上安装了 vnc 服务,这样我可以通过其它计算机或在 iPad 上用 [Remoter App][23]连接树莓派的图形界面,我安装了 [BitTorrent Sync][24] 用来远端备份我的图片,当然需要先设置好。当我有了可以运行的解决方案之后,我会补充我的文章。
|
||||
|
||||
你可以在下面发表你的评论和问题,我会在此页下面回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
|
||||
作者:[Lenin][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
[1]: http://bit.ly/1MVVtZi
|
||||
[2]: http://www.amazon.com/dp/B01D3NZIMA/?tag=movinelect0e-20
|
||||
[3]: http://www.amazon.com/dp/B01CD5VC92/?tag=movinelect0e-20
|
||||
[4]: http://www.amazon.com/dp/B010Q57T02/?tag=movinelect0e-20
|
||||
[5]: http://www.amazon.com/dp/B01F1PSFY6/?tag=movinelect0e-20
|
||||
[6]: http://amzn.to/293kPqX
|
||||
[7]: http://amzn.to/290syFY
|
||||
[8]: http://amzn.to/290syFY
|
||||
[9]: http://amzn.to/290syFY
|
||||
[10]: http://amzn.to/290syFY
|
||||
[11]: http://amzn.to/293kPqX
|
||||
[12]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[13]: https://www.raspberrypi.org/documentation/remote-access/ssh/passwordless.md
|
||||
[14]: https://www.iterm2.com/
|
||||
[15]: https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
|
||||
[16]: https://www.raspberrypi.org/documentation/linux/usage/rc-local.md
|
||||
[17]: http://www.howtogeek.com/139433/how-to-turn-a-raspberry-pi-into-a-low-power-network-storage-device/
|
||||
[18]: http://bit.ly/1MVVtZi
|
||||
[19]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[20]: https://itunes.apple.com/us/app/filebrowser-access-files-on/id364738545?mt=8&uo=4&at=11lqkH
|
||||
[21]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[22]: https://en.m.wikipedia.org/wiki/Nohup
|
||||
[23]: https://itunes.apple.com/us/app/remoter-pro-vnc-ssh-rdp/id519768191?mt=8&uo=4&at=11lqkH
|
||||
[24]: https://getsync.com/
|
||||
@ -0,0 +1,257 @@
|
||||
Fabric - 通过 SSH 来自动化管理 Linux 任务和布署应用
|
||||
===========================
|
||||
|
||||
当要管理远程机器或者要布署应用时,虽然你有多种命令行工具可以选择,但是其中很多工具都缺少详细的使用文档。
|
||||
|
||||
在这篇教程中,我们将会一步一步地向你介绍如何使用 fabric 来帮助你更好得管理多台服务器。
|
||||
|
||||

|
||||
|
||||
*使用 Fabric 来自动化地管理 Linux 任务*
|
||||
|
||||
Fabric 是一个用 Python 编写的命令行工具库,它可以帮助系统管理员高效地执行某些任务,比如通过 SSH 到多台机器上执行某些命令,远程布署应用等。
|
||||
|
||||
在使用之前,如果你拥有使用 Python 的经验能帮你更好的使用 Fabric。当然,如果没有那也不影响使用 Fabric。
|
||||
|
||||
我们为什么要选择 Fabric:
|
||||
|
||||
- 简单
|
||||
- 完备的文档
|
||||
- 如果你会 Python,不用增加学习其他语言的成本
|
||||
- 易于安装使用
|
||||
- 使用便捷
|
||||
- 支持多台机器并行操作
|
||||
|
||||
### 在 Linux 上如何安装 Fabric
|
||||
|
||||
Fabric 有一个特点就是要远程操作的机器只需要支持标准的 OpenSSH 服务即可。只要保证在机器上安装并开启了这个服务就能使用 Fabric 来管理机器。
|
||||
|
||||
#### 依赖
|
||||
|
||||
- Python 2.5 或更新版本,以及对应的开发组件
|
||||
- Python-setuptools 和 pip(可选,但是非常推荐)gcc
|
||||
|
||||
我们推荐使用 pip 安装 Fabric,但是你也可以使用系统自带的包管理器如 `yum`, `dnf` 或 `apt-get` 来安装,包名一般是 `fabric` 或 `python-fabric`。
|
||||
|
||||
如果是基于 RHEL/CentOS 的发行版本的系统,你可以使用系统自带的 [EPEL 源][1] 来安装 fabric。
|
||||
|
||||
```
|
||||
# yum install fabric [适用于基于 RedHat 系统]
|
||||
# dnf install fabric [适用于 Fedora 22+ 版本]
|
||||
```
|
||||
|
||||
如果你是 Debian 或者其派生的系统如 Ubuntu 和 Mint 的用户,你可以使用 apt-get 来安装,如下所示:
|
||||
|
||||
```
|
||||
# apt-get install fabric
|
||||
```
|
||||
|
||||
如果你要安装开发版的 Fabric,你需要安装 pip 来安装 master 分支上最新版本。
|
||||
|
||||
```
|
||||
# yum install python-pip [适用于基于 RedHat 系统]
|
||||
# dnf install python-pip [适用于Fedora 22+ 版本]
|
||||
# apt-get install python-pip [适用于基于 Debian 系统]
|
||||
```
|
||||
|
||||
安装好 pip 后,你可以使用 pip 获取最新版本的 Fabric。
|
||||
|
||||
```
|
||||
# pip install fabric
|
||||
```
|
||||
|
||||
### 如何使用 Fabric 来自动化管理 Linux 任务
|
||||
|
||||
现在我们来开始使用 Fabric,在之前的安装的过程中,Fabric Python 脚本已经被放到我们的系统目录,当我们要运行 Fabric 时输入 `fab` 命令即可。
|
||||
|
||||
#### 在本地 Linux 机器上运行命令行
|
||||
|
||||
按照惯例,先用你喜欢的编辑器创建一个名为 fabfile.py 的 Python 脚本。你可以使用其他名字来命名脚本,但是就需要指定这个脚本的路径,如下所示:
|
||||
|
||||
```
|
||||
# fabric --fabfile /path/to/the/file.py
|
||||
```
|
||||
|
||||
Fabric 使用 `fabfile.py` 来执行任务,这个文件应该放在你执行 Fabric 命令的目录里面。
|
||||
|
||||
**例子 1**:创建入门的 `Hello World` 任务:
|
||||
|
||||
```
|
||||
# vi fabfile.py
|
||||
```
|
||||
|
||||
在文件内输入如下内容:
|
||||
|
||||
```
|
||||
def hello():
|
||||
print('Hello world, Tecmint community')
|
||||
```
|
||||
|
||||
保存文件并执行以下命令:
|
||||
|
||||
```
|
||||
# fab hello
|
||||
```
|
||||
|
||||
|
||||
|
||||
*Fabric 工具使用说明*
|
||||
|
||||
**例子 2**:新建一个名为 fabfile.py 的文件并打开:
|
||||
|
||||
粘贴以下代码至文件:
|
||||
|
||||
```
|
||||
#! /usr/bin/env python
|
||||
from fabric.api import local
|
||||
def uptime():
|
||||
local('uptime')
|
||||
```
|
||||
|
||||
保存文件并执行以下命令:
|
||||
|
||||
```
|
||||
# fab uptime
|
||||
```
|
||||
|
||||

|
||||
|
||||
*Fabric: 检查系统运行时间*
|
||||
|
||||
让我们看看这个例子,fabfile.py 文件在本机执行了 uptime 这个命令。
|
||||
|
||||
#### 在远程 Linux 机器上运行命令来执行自动化任务
|
||||
|
||||
Fabric API 使用了一个名为 `env` 的关联数组(Python 中的词典)作为配置目录,来储存 Fabric 要控制的机器的相关信息。
|
||||
|
||||
`env.hosts` 是一个用来存储你要执行 Fabric 任务的机器的列表,如果你的 IP 地址是 192.168.0.0,想要用 Fabric 来管理地址为 192.168.0.2 和 192.168.0.6 的机器,需要的配置如下所示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env
|
||||
env.hosts = [ '192.168.0.2', '192.168.0.6' ]
|
||||
```
|
||||
|
||||
上面这几行代码只是声明了你要执行 Fabric 任务的主机地址,但是实际上并没有执行任何任务,下面我们就来定义一些任务。Fabric 提供了一系列可以与远程服务器交互的方法。
|
||||
|
||||
Fabric 提供了众多的方法,这里列出几个经常会用到的:
|
||||
|
||||
- run - 可以在远程机器上运行的 shell 命令
|
||||
- local - 可以在本机上运行的 shell 命令
|
||||
- sudo - 使用 root 权限在远程机器上运行的 shell 命令
|
||||
- get - 从远程机器上下载一个或多个文件
|
||||
- put - 上传一个或多个文件到远程机器
|
||||
|
||||
**例子 3**:在多台机子上输出信息,新建新的 fabfile.py 文件如下所示
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def echo():
|
||||
run("echo -n 'Hello, you are tuned to Tecmint ' ")
|
||||
```
|
||||
|
||||
运行以下命令执行 Fabric 任务
|
||||
|
||||
```
|
||||
# fab echo
|
||||
```
|
||||
|
||||

|
||||
|
||||
*fabric: 自动在远程 Linux 机器上执行任务*
|
||||
|
||||
**例子 4**:你可以继续改进之前创建的执行 uptime 任务的 fabfile.py 文件,让它可以在多台服务器上运行 uptime 命令,也可以检查其磁盘使用情况,如下所示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def uptime():
|
||||
run('uptime')
|
||||
def disk_space():
|
||||
run('df -h')
|
||||
```
|
||||
|
||||
保存并执行以下命令
|
||||
|
||||
```
|
||||
# fab uptime
|
||||
# fab disk_space
|
||||
```
|
||||
|
||||
|
||||
|
||||
*Fabric:自动在多台服务器上执行任务*
|
||||
|
||||
#### 在远程服务器上自动化布署 LAMP
|
||||
|
||||
**例子 5**:我们来尝试一下在远程服务器上布署 LAMP(Linux, Apache, MySQL/MariaDB and PHP)
|
||||
|
||||
我们要写个函数在远程使用 root 权限安装 LAMP。
|
||||
|
||||
##### 在 RHEL/CentOS 或 Fedora 上
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def deploy_lamp():
|
||||
run ("yum install -y httpd mariadb-server php php-mysql")
|
||||
```
|
||||
|
||||
##### 在 Debian/Ubuntu 或 Linux Mint 上
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
from fabric.api import env, run
|
||||
env.hosts = ['192.168.0.2','192.168.0.6']
|
||||
def deploy_lamp():
|
||||
sudo("apt-get install -q apache2 mysql-server libapache2-mod-php5 php5-mysql")
|
||||
```
|
||||
|
||||
保存并执行以下命令:
|
||||
|
||||
```
|
||||
# fab deploy_lamp
|
||||
```
|
||||
|
||||
注:由于安装时会输出大量信息,这个例子我们就不提供屏幕 gif 图了
|
||||
|
||||
现在你可以使用 Fabric 和上文例子所示的功能来[自动化的管理 Linux 服务器上的任务][2]了。
|
||||
|
||||
#### 一些 Fabric 有用的选项
|
||||
|
||||
- 你可以运行 `fab -help` 输出帮助信息,里面列出了所有可以使用的命令行信息
|
||||
- `–fabfile=PATH` 选项可以让你定义除了名为 fabfile.py 之外的模块
|
||||
- 如果你想用指定的用户名登录远程主机,请使用 `-user=USER` 选项
|
||||
- 如果你需要密码进行验证或者 sudo 提权,请使用 `–password=PASSWORD` 选项
|
||||
- 如果需要输出某个命令的详细信息,请使用 `–display=命令名` 选项
|
||||
- 使用 `--list` 输出所有可用的任务
|
||||
- 使用 `--list-format=FORMAT` 选项能格式化 `-list` 选项输出的信息,可选的有 short、normal、 nested
|
||||
- `--config=PATH` 选项可以指定读取配置文件的地址
|
||||
- `-–colorize-errors` 能显示彩色的错误输出信息
|
||||
- `--version` 输出当前版本
|
||||
|
||||
### 总结
|
||||
|
||||
Fabric 是一个强大并且文档完备的工具,对于新手来说也能很快上手,阅读提供的文档能帮助你更好的了解它。如果你在安装和使用 Fabric 时发现什么问题可以在评论区留言,我们会及时回复。
|
||||
|
||||
参考:[Fabric 文档][3]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/automating-linux-system-administration-tasks/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://linux.cn/article-2324-1.html
|
||||
[2]: http://www.tecmint.com/use-ansible-playbooks-to-automate-complex-tasks-on-multiple-linux-servers/
|
||||
[3]: http://docs.fabfile.org/en/1.4.0/usage/env.html
|
||||
@ -0,0 +1,94 @@
|
||||
给学习 OpenStack 架构的新手入门指南
|
||||
===========================================================
|
||||
|
||||
OpenStack 欢迎新成员的到来,但是,对于这个发展趋近成熟并且快速迭代的开源社区而言,能够拥有一个新手指南并不是件坏事。在奥斯汀举办的 OpenStack 峰会上,[Paul Belanger][1] (来自红帽公司)、 [Elizabeth K. Joseph][2] (来自 HPE 公司)和 [Christopher Aedo][3] (来自 IBM 公司)就[针对新人的 OpenStack 架构][4]作了一场专门的讲演。在这次采访中,他们提供了一些建议和资源来帮助新人成为 OpenStack 贡献者中的一员。
|
||||
|
||||

|
||||
|
||||
**你的讲演介绍中说你将“深入架构核心,并解释你需要知道的关于让 OpenStack 工作起来的每一件事情”。这对于 40 分钟的讲演来说是一个艰巨的任务。那么,对于学习 OpenStack 架构的新手来说最需要知道那些事情呢?**
|
||||
|
||||
**Elizabeth K. Joseph (EKJ)**: 我们没有为 OpenStack 使用 GitHub 这种提交补丁的方式,这是因为这样做会对新手造成巨大的困扰,尽管由于历史原因我们还是在 GitHub 上维护了所有库的一个镜像。相反,我们使用了一种完全开源的评审形式,而且持续集成(CI)是由 OpenStack 架构团队维护的。与之有关的,自从我们使用了 CI 系统,每一个提交给 OpenStack 的改变都会在被合并之前进行测试。
|
||||
|
||||
**Paul Belanger (PB)**: 这个项目中的大多数都是富有激情的人,因此当你提交的补丁被某个人否定时不要感到沮丧。
|
||||
|
||||
**Christopher Aedo (CA)**:社区会帮助你取得成功,因此不要害怕提问或者寻求更多的那些能够促进你理解某些事物的引导者。
|
||||
|
||||
**在你的讲话中,对于一些你无法涉及到的方面,你会向新手推荐哪些在线资源来让他们更加容易入门?**
|
||||
|
||||
**PB**:当然是我们的 [OpenStack 项目架构文档][5]。我们已经花了足够大的努力来尽可能让这些文档能够随时保持最新状态。在 OpenStack 运行中使用的每个系统都作为一个项目,都制作了专门的页面来进行说明。甚至于连 OpenStack 云这种架构团队也会放到线上。
|
||||
|
||||
**EKJ**:我对于架构文档这件事上的观点和 Paul 是一致的,另外,我们十分乐意看到来自那些正在学习项目的人们提交上来的补丁。我们通常不会意识到我们忽略了文档中的某些内容,除非它们恰好被人问起。因此,阅读、学习,会帮助我们修补这些知识上的漏洞。你可以在 [OpenStack 架构邮件清单]提出你的问题,或者在我们位于 FreeNode 上的 #OpenStack-infra 的 IRC 专栏发起你的提问。
|
||||
|
||||
**CA**:我喜欢[这个详细的帖子][7],它是由 Ian Wienand 写的一篇关于构建镜像的文章。
|
||||
|
||||
**"gotchas" 会是 OpenStack 新的贡献者们所寻找的吗?**
|
||||
|
||||
**EKJ**:向项目作出贡献并不仅仅是提交新的代码和新的特性;OpenStack 社区高度重视代码评审。如果你想要别人查看你的补丁,那你最好先看看其他人是如何做的,然后参考他们的风格,最后一步步做到你也能够向其他人一样提交清晰且结构分明的代码补丁。你越是能让你的同伴了解你的工作并知道你正在做的评审,那他们也就越有可能及时评审你的代码。
|
||||
|
||||
**CA**:我看到过大量的新手在面对 [Gerrit][8] 时受挫,阅读开发者引导中的[开发者工作步骤][9],有可能的话多读几遍。如果你没有用过 Gerrit,那你最初对它的感觉可能是困惑和无力的。但是,如果你随后做了一些代码评审的工作,那么你就能轻松应对它。此外,我是 IRC 的忠实粉丝,它可能是一个获得帮助的好地方,但是,你最好保持一个长期在线的状态,这样,尽管你在某个时候没有出现,人们也可以回答你的问题。(阅读 [IRC,开源成功的秘诀][10])你不必总是在线,但是你最好能够轻松的在一个频道中回溯之前信息,以此来跟上最新的动态,这种能力非常重要。
|
||||
|
||||
**PB**:我同意 Elizabeth 和 Chris 的观点, Gerrit 是需要花点精力的,它将汇聚你的开发方面的努力。你不仅仅要提交代码给别人去评审,同时,你也要能够评审其他人的代码。看到 Gerrit 的界面,你可能一时会变的很困惑。我推荐新手去尝试 [Gertty][11],它是一个基于控制台的终端界面,用于 Gerrit 代码评审系统,而它恰好也是 OpenStack 架构所驱动的一个项目。
|
||||
|
||||
**你对于 OpenStack 新手如何通过网络与其他贡献者交流方面有什么好的建议?**
|
||||
|
||||
**PB**:对我来说,是通过 IRC 并在 Freenode 上参加 #OpenStack-infra 频道([IRC 日志][12])。这频道上面有很多对新手来说很有价值的资源。你可以看到 OpenStack 项目日复一日的运作情况,同时,一旦你知道了 OpenStack 项目的工作原理,你将更好的知道如何为 OpenStack 的未来发展作出贡献。
|
||||
|
||||
**CA**:我想要为 IRC 再次说明一点,在 IRC 上保持全天在线记录对我来说有非常重大的意义,因为我会时刻保持连接并随时接到提醒。这也是一种非常好的获得帮助的方式,特别是当你和某人卡在了项目中出现的某一个难题的时候,而在一个活跃的 IRC 频道中,总会有一些人很乐意为你解决问题。
|
||||
|
||||
**EKJ**:[OpenStack 开发邮件列表][13]对于能够时刻查看到你所致力于的 OpenStack 项目的最新情况是非常重要的。因此,我推荐一定要订阅它。邮件列表使用主题标签来区分项目,因此你可以设置你的邮件客户端来使用它来专注于你所关心的项目。除了在线资源之外,全世界范围内也成立了一些 OpenStack 小组,他们被用来为 OpenStack 的用户和贡献者提供服务。这些小组可能会定期要求 OpenStack 主要贡献者们举办座谈和活动。你可以在 MeetUp.com 上搜素你所在地域的贡献者活动聚会,或者在 [groups.openstack.org][14] 上查看你所在的地域是否存在 OpenStack 小组。最后,还有一个每六个月举办一次的 [OpenStack 峰会][15],这个峰会上会作一些关于架构的演说。当前状态下,这个峰会包含了用户会议和开发者会议,会议内容都是和 OpenStack 相关的东西,包括它的过去,现在和未来。
|
||||
|
||||
**OpenStack 需要在那些方面得到提升来让新手更加容易学会并掌握?**
|
||||
|
||||
**PB**: 我认为我们的 [account-setup][16] 环节对于新的贡献者已经做的比较容易了,特别是教他们如何提交他们的第一个补丁。真正参与到 OpenStack 开发者模式中是需要花费很大的努力的,相比贡献者来说已经显得非常多了;然而,一旦融入进去了,这个模式将会运转的十分高效和令人满意。
|
||||
|
||||
**CA**: 我们拥有一个由专业开发者组成的社区,而且我们的关注点都是发展 OpenStack 本身,同时,我们致力于让用户付出更小的代价去使用 OpenStack 云架构平台。我们需要发掘更多的应用开发者,并且鼓励更多的人去开发能在 OpenStack 云上完美运行的云应用程序,我们还鼓励他们在[社区 App 目录][17]上去贡献那些由他们开发的应用。我们可以通过不断提升我们的 API 标准和保证我们不同的库(比如 libcloud,phpopencloud 以及其他一些库)持续地为开发者提供可信赖的支持来实现这一目标。还有一点就是通过举办更多的 OpenStack 黑客比赛。所有的这些事情都可以降低新人的学习门槛,这样也能引导他们与这个社区之间的关系更加紧密。
|
||||
|
||||
**EKJ**: 我已经致力于开源软件很多年了。但是,对于大量的 OpenStack 开发者而言,这是一个他们自己所从事的第一个开源项目。我发现他们之前使用私有软件的背景并没有为他们塑造开源的观念、方法论,以及在开源项目中需要具备的合作技巧。我乐于看到我们能够让那些曾经一直在使用私有软件工作的人能够真正的明白他们在开源如软件社区所从事的事情的巨大价值。
|
||||
|
||||
**我想把 2016 年打造成开源俳句之年。请用俳句来向新手解释 OpenStack 一下。**
|
||||
|
||||
(LCTT 译注:俳句(Haiku)是一种日本古典短诗,以5-7-5音节为三句,校对者不揣浅陋,诌了几句歪诗,勿笑 :D,另外 OpenStack 本身音节太长,就捏造了一个中文译名“开栈”——明白就好。)
|
||||
|
||||
**PB**: 开栈在云上//倘钟情自由软件//先当造补丁(OpenStack runs clouds
|
||||
If you enjoy free software
|
||||
Submit your first patch)
|
||||
|
||||
**CA**:时光不必久//开栈将支配世界//协力早来到(In the near future
|
||||
OpenStack will rule the world
|
||||
Help make it happen!)
|
||||
|
||||
**EKJ**:开栈有自由//放在自家服务器//运行你的云(OpenStack is free
|
||||
Deploy on your own servers
|
||||
And run your own cloud!)
|
||||
|
||||
*Paul、Elizabeth 和 Christopher 在 4 月 25 号星期一上午 11:15 于奥斯汀举办的 OpenStack 峰会发表了[演说][18]。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/4/interview-openstack-infrastructure-beginners
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://rikkiendsley.com/
|
||||
[1]: https://twitter.com/pabelanger
|
||||
[2]: https://twitter.com/pleia2
|
||||
[3]: https://twitter.com/docaedo
|
||||
[4]: https://www.openstack.org/summit/austin-2016/summit-schedule/events/7337
|
||||
[5]: http://docs.openstack.org/infra/system-config/
|
||||
[6]: http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-infra
|
||||
[7]: https://www.technovelty.org/openstack/image-building-in-openstack-ci.html
|
||||
[8]: https://code.google.com/p/gerrit/
|
||||
[9]: http://docs.openstack.org/infra/manual/developers.html#development-workflow
|
||||
[10]: https://developer.ibm.com/opentech/2015/12/20/irc-the-secret-to-success-in-open-source/
|
||||
[11]: https://pypi.python.org/pypi/gertty
|
||||
[12]: http://eavesdrop.openstack.org/irclogs/%23openstack-infra/
|
||||
[13]: http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev
|
||||
[14]: https://groups.openstack.org/
|
||||
[15]: https://www.openstack.org/summit/
|
||||
[16]: http://docs.openstack.org/infra/manual/developers.html#account-setup
|
||||
[17]: https://apps.openstack.org/
|
||||
[18]: https://www.openstack.org/summit/austin-2016/summit-schedule/events/7337
|
||||
@ -1,16 +1,10 @@
|
||||
---
|
||||
date: 2016-07-09 14:42
|
||||
status: public
|
||||
title: 20160512 Bitmap in Linux Kernel
|
||||
---
|
||||
|
||||
Linux 内核里的数据结构
|
||||
Linux 内核里的数据结构——位数组
|
||||
================================================================================
|
||||
|
||||
Linux 内核中的位数组和位操作
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
除了不同的基于[链式](https://en.wikipedia.org/wiki/Linked_data_structure)和[树](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)的数据结构以外,Linux 内核也为[位数组](https://en.wikipedia.org/wiki/Bit_array)或`位图`提供了 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。位数组在 Linux 内核里被广泛使用,并且在以下的源代码文件中包含了与这样的结构搭配使用的通用 `API`:
|
||||
除了不同的基于[链式](https://en.wikipedia.org/wiki/Linked_data_structure)和[树](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)的数据结构以外,Linux 内核也为[位数组](https://en.wikipedia.org/wiki/Bit_array)(或称为位图(bitmap))提供了 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。位数组在 Linux 内核里被广泛使用,并且在以下的源代码文件中包含了与这样的结构搭配使用的通用 `API`:
|
||||
|
||||
* [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c)
|
||||
* [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h)
|
||||
@ -19,14 +13,14 @@ Linux 内核中的位数组和位操作
|
||||
|
||||
* [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)
|
||||
|
||||
头文件。正如我上面所写的,`位图`在 Linux 内核中被广泛地使用。例如,`位数组`常常用于保存一组在线/离线处理器,以便系统支持[热插拔](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)的 CPU(你可以在 [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html) 部分阅读更多相关知识 ),一个`位数组`可以在 Linux 内核初始化等期间保存一组已分配的中断处理。
|
||||
头文件。正如我上面所写的,`位图`在 Linux 内核中被广泛地使用。例如,`位数组`常常用于保存一组在线/离线处理器,以便系统支持[热插拔](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)的 CPU(你可以在 [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html) 部分阅读更多相关知识 ),一个位数组(bit array)可以在 Linux 内核初始化等期间保存一组已分配的[中断处理](https://en.wikipedia.org/wiki/Interrupt_request_%28PC_architecture%29)。
|
||||
|
||||
因此,本部分的主要目的是了解位数组是如何在 Linux 内核中实现的。让我们现在开始吧。
|
||||
因此,本部分的主要目的是了解位数组(bit array)是如何在 Linux 内核中实现的。让我们现在开始吧。
|
||||
|
||||
位数组声明
|
||||
================================================================================
|
||||
|
||||
在我们开始查看位图操作的 `API` 之前,我们必须知道如何在 Linux 内核中声明它。有两中通用的方法声明位数组。第一种简单的声明一个位数组的方法是,定义一个 unsigned long 的数组,例如:
|
||||
在我们开始查看`位图`操作的 `API` 之前,我们必须知道如何在 Linux 内核中声明它。有两种声明位数组的通用方法。第一种简单的声明一个位数组的方法是,定义一个 `unsigned long` 的数组,例如:
|
||||
|
||||
```C
|
||||
unsigned long my_bitmap[8]
|
||||
@ -44,7 +38,7 @@ unsigned long my_bitmap[8]
|
||||
* `name` - 位图名称;
|
||||
* `bits` - 位图中位数;
|
||||
|
||||
并且只是使用 `BITS_TO_LONGS(bits)` 元素展开 `unsigned long` 数组的定义。 `BITS_TO_LONGS` 宏将一个给定的位数转换为 `longs` 的个数,换言之,就是计算 `bits` 中有多少个 `8` 字节元素:
|
||||
并且只是使用 `BITS_TO_LONGS(bits)` 元素展开 `unsigned long` 数组的定义。 `BITS_TO_LONGS` 宏将一个给定的位数转换为 `long` 的个数,换言之,就是计算 `bits` 中有多少个 `8` 字节元素:
|
||||
|
||||
```C
|
||||
#define BITS_PER_BYTE 8
|
||||
@ -70,18 +64,18 @@ unsigned long my_bitmap[1];
|
||||
体系结构特定的位操作
|
||||
================================================================================
|
||||
|
||||
我们已经看了以上一对源文件和头文件,它们提供了位数组操作的 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。其中重要且广泛使用的位数组 API 是体系结构特定的且位于已提及的头文件中 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)。
|
||||
我们已经看了上面提及的一对源文件和头文件,它们提供了位数组操作的 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。其中重要且广泛使用的位数组 API 是体系结构特定的且位于已提及的头文件中 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)。
|
||||
|
||||
首先让我们查看两个最重要的函数:
|
||||
|
||||
* `set_bit`;
|
||||
* `clear_bit`.
|
||||
|
||||
我认为没有必要解释这些函数的作用。从它们的名字来看,这已经很清楚了。让我们直接查看它们的实现。如果你浏览 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,你将会注意到这些函数中的每一个都有[原子性](https://en.wikipedia.org/wiki/Linearizability)和非原子性两种变体。在我们开始深入这些函数的实现之前,首先,我们必须了解一些有关原子操作的知识。
|
||||
我认为没有必要解释这些函数的作用。从它们的名字来看,这已经很清楚了。让我们直接查看它们的实现。如果你浏览 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,你将会注意到这些函数中的每一个都有[原子性](https://en.wikipedia.org/wiki/Linearizability)和非原子性两种变体。在我们开始深入这些函数的实现之前,首先,我们必须了解一些有关原子(atomic)操作的知识。
|
||||
|
||||
简而言之,原子操作保证两个或以上的操作不会并发地执行同一数据。`x86` 体系结构提供了一系列原子指令,例如, [xchg](http://x86.renejeschke.de/html/file_module_x86_id_328.html)、[cmpxchg](http://x86.renejeschke.de/html/file_module_x86_id_41.html) 等指令。除了原子指令,一些非原子指令可以在 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令的帮助下具有原子性。目前已经对原子操作有了充分的理解,我们可以接着探讨 `set_bit` 和 `clear_bit` 函数的实现。
|
||||
简而言之,原子操作保证两个或以上的操作不会并发地执行同一数据。`x86` 体系结构提供了一系列原子指令,例如, [xchg](http://x86.renejeschke.de/html/file_module_x86_id_328.html)、[cmpxchg](http://x86.renejeschke.de/html/file_module_x86_id_41.html) 等指令。除了原子指令,一些非原子指令可以在 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令的帮助下具有原子性。现在你已经对原子操作有了足够的了解,我们可以接着探讨 `set_bit` 和 `clear_bit` 函数的实现。
|
||||
|
||||
我们先考虑函数的非原子性变体。非原子性的 `set_bit` 和 `clear_bit` 的名字以双下划线开始。正如我们所知道的,所有这些函数都定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并且第一个函数就是 `__set_bit`:
|
||||
我们先考虑函数的非原子性(non-atomic)变体。非原子性的 `set_bit` 和 `clear_bit` 的名字以双下划线开始。正如我们所知道的,所有这些函数都定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并且第一个函数就是 `__set_bit`:
|
||||
|
||||
```C
|
||||
static inline void __set_bit(long nr, volatile unsigned long *addr)
|
||||
@ -92,25 +86,25 @@ static inline void __set_bit(long nr, volatile unsigned long *addr)
|
||||
|
||||
正如我们所看到的,它使用了两个参数:
|
||||
|
||||
* `nr` - 位数组中的位号(从0开始,译者注)
|
||||
* `nr` - 位数组中的位号(LCTT 译注:从 0开始)
|
||||
* `addr` - 我们需要置位的位数组地址
|
||||
|
||||
注意,`addr` 参数使用 `volatile` 关键字定义,以告诉编译器给定地址指向的变量可能会被修改。 `__set_bit` 的实现相当简单。正如我们所看到的,它仅包含一行[内联汇编代码](https://en.wikipedia.org/wiki/Inline_assembler)。在我们的例子中,我们使用 [bts](http://x86.renejeschke.de/html/file_module_x86_id_25.html) 指令,从位数组中选出一个第一操作数(我们的例子中的 `nr`),存储选出的位的值到 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 标志寄存器并设置该位(即 `nr` 指定的位置为1,译者注)。
|
||||
注意,`addr` 参数使用 `volatile` 关键字定义,以告诉编译器给定地址指向的变量可能会被修改。 `__set_bit` 的实现相当简单。正如我们所看到的,它仅包含一行[内联汇编代码](https://en.wikipedia.org/wiki/Inline_assembler)。在我们的例子中,我们使用 [bts](http://x86.renejeschke.de/html/file_module_x86_id_25.html) 指令,从位数组中选出一个第一操作数(我们的例子中的 `nr`)所指定的位,存储选出的位的值到 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 标志寄存器并设置该位(LCTT 译注:即 `nr` 指定的位置为 1)。
|
||||
|
||||
注意,我们了解了 `nr` 的用法,但这里还有一个参数 `addr` 呢!你或许已经猜到秘密就在 `ADDR`。 `ADDR` 是一个定义在同一头文件的宏,它展开为一个包含给定地址和 `+m` 约束的字符串:
|
||||
注意,我们了解了 `nr` 的用法,但这里还有一个参数 `addr` 呢!你或许已经猜到秘密就在 `ADDR`。 `ADDR` 是一个定义在同一个头文件中的宏,它展开为一个包含给定地址和 `+m` 约束的字符串:
|
||||
|
||||
```C
|
||||
#define ADDR BITOP_ADDR(addr)
|
||||
#define BITOP_ADDR(x) "+m" (*(volatile long *) (x))
|
||||
```
|
||||
|
||||
除了 `+m` 之外,在 `__set_bit` 函数中我们可以看到其他约束。让我们查看并试图理解它们所表示的意义:
|
||||
除了 `+m` 之外,在 `__set_bit` 函数中我们可以看到其他约束。让我们查看并试着理解它们所表示的意义:
|
||||
|
||||
* `+m` - 表示内存操作数,这里的 `+` 表明给定的操作数为输入输出操作数;
|
||||
* `I` - 表示整型常量;
|
||||
* `+m` - 表示内存操作数,这里的 `+` 表明给定的操作数为输入输出操作数;
|
||||
* `I` - 表示整型常量;
|
||||
* `r` - 表示寄存器操作数
|
||||
|
||||
除了这些约束之外,我们也能看到 `memory` 关键字,其告诉编译器这段代码会修改内存中的变量。到此为止,现在我们看看相同的原子性变体函数。它看起来比非原子性变体更加复杂:
|
||||
除了这些约束之外,我们也能看到 `memory` 关键字,其告诉编译器这段代码会修改内存中的变量。到此为止,现在我们看看相同的原子性(atomic)变体函数。它看起来比非原子性(non-atomic)变体更加复杂:
|
||||
|
||||
```C
|
||||
static __always_inline void
|
||||
@ -128,7 +122,7 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
(BITOP_ADDR 的定义为:`#define BITOP_ADDR(x) "=m" (*(volatile long *) (x))`,ORB 为字节按位或,译者注)
|
||||
(LCTT 译注:BITOP_ADDR 的定义为:`#define BITOP_ADDR(x) "=m" (*(volatile long *) (x))`,ORB 为字节按位或。)
|
||||
|
||||
首先注意,这个函数使用了与 `__set_bit` 相同的参数集合,但额外地使用了 `__always_inline` 属性标记。 `__always_inline` 是一个定义于 [include/linux/compiler-gcc.h](https://github.com/torvalds/linux/blob/master/include/linux/compiler-gcc.h) 的宏,并且只是展开为 `always_inline` 属性:
|
||||
|
||||
@ -136,19 +130,19 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
#define __always_inline inline __attribute__((always_inline))
|
||||
```
|
||||
|
||||
其意味着这个函数总是内联的,以减少 Linux 内核映像的大小。现在我们试着了解 `set_bit` 函数的实现。首先我们在 `set_bit` 函数的开头检查给定的位数量。`IS_IMMEDIATE` 宏定义于相同[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h),并展开为 gcc 内置函数的调用:
|
||||
其意味着这个函数总是内联的,以减少 Linux 内核映像的大小。现在让我们试着了解下 `set_bit` 函数的实现。首先我们在 `set_bit` 函数的开头检查给定的位的数量。`IS_IMMEDIATE` 宏定义于相同的[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h),并展开为 [gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection) 内置函数的调用:
|
||||
|
||||
```C
|
||||
#define IS_IMMEDIATE(nr) (__builtin_constant_p(nr))
|
||||
```
|
||||
|
||||
如果给定的参数是编译期已知的常量,`__builtin_constant_p` 内置函数则返回 `1`,其他情况返回 `0`。假若给定的位数是编译期已知的常量,我们便无须使用效率低下的 `bts` 指令去设置位。我们可以只需在给定地址指向的字节和和掩码上执行 [按位或](https://en.wikipedia.org/wiki/Bitwise_operation#OR) 操作,其字节包含给定的位,而掩码为位号高位 `1`,其他位为 0。在其他情况下,如果给定的位号不是编译期已知常量,我们便做和 `__set_bit` 函数一样的事。`CONST_MASK_ADDR` 宏:
|
||||
如果给定的参数是编译期已知的常量,`__builtin_constant_p` 内置函数则返回 `1`,其他情况返回 `0`。假若给定的位数是编译期已知的常量,我们便无须使用效率低下的 `bts` 指令去设置位。我们可以只需在给定地址指向的字节上执行 [按位或](https://en.wikipedia.org/wiki/Bitwise_operation#OR) 操作,其字节包含给定的位,掩码位数表示高位为 `1`,其他位为 0 的掩码。在其他情况下,如果给定的位号不是编译期已知常量,我们便做和 `__set_bit` 函数一样的事。`CONST_MASK_ADDR` 宏:
|
||||
|
||||
```C
|
||||
#define CONST_MASK_ADDR(nr, addr) BITOP_ADDR((void *)(addr) + ((nr)>>3))
|
||||
```
|
||||
|
||||
展开为带有到包含给定位的字节偏移的给定地址,例如,我们拥有地址 `0x1000` 和 位号是 `0x9`。因为 `0x9` 是 `一个字节 + 一位`,所以我们的地址是 `addr + 1`:
|
||||
展开为带有到包含给定位的字节偏移的给定地址,例如,我们拥有地址 `0x1000` 和位号 `0x9`。因为 `0x9` 代表 `一个字节 + 一位`,所以我们的地址是 `addr + 1`:
|
||||
|
||||
```python
|
||||
>>> hex(0x1000 + (0x9 >> 3))
|
||||
@ -166,7 +160,7 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
'0b10'
|
||||
```
|
||||
|
||||
最后,我们应用 `按位或` 运算到这些变量上面,因此,假如我们的地址是 `0x4097` ,并且我们需要置位号为 `9` 的位 为 1:
|
||||
最后,我们应用 `按位或` 运算到这些变量上面,因此,假如我们的地址是 `0x4097` ,并且我们需要置位号为 `9` 的位为 1:
|
||||
|
||||
```python
|
||||
>>> bin(0x4097)
|
||||
@ -175,11 +169,11 @@ set_bit(long nr, volatile unsigned long *addr)
|
||||
'0b100010'
|
||||
```
|
||||
|
||||
`第 9 位` 将会被置位。(这里的 9 是从 0 开始计数的,比如0010,按照作者的意思,其中的 1 是第 1 位,译者注)
|
||||
`第 9 位` 将会被置位。(LCTT 译注:这里的 9 是从 0 开始计数的,比如0010,按照作者的意思,其中的 1 是第 1 位)
|
||||
|
||||
注意,所有这些操作使用 `LOCK_PREFIX` 标记,其展开为 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令,保证该操作的原子性。
|
||||
|
||||
正如我们所知,除了 `set_bit` 和 `__set_bit` 操作之外,Linux 内核还提供了两个功能相反的函数,在原子性和非原子性的上下文中清位。它们为 `clear_bit` 和 `__clear_bit`。这两个函数都定义于同一个[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 并且使用相同的参数集合。不仅参数相似,一般而言,这些函数与 `set_bit` 和 `__set_bit` 也非常相似。让我们查看非原子性 `__clear_bit` 的实现吧:
|
||||
正如我们所知,除了 `set_bit` 和 `__set_bit` 操作之外,Linux 内核还提供了两个功能相反的函数,在原子性和非原子性的上下文中清位。它们是 `clear_bit` 和 `__clear_bit`。这两个函数都定义于同一个[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 并且使用相同的参数集合。不仅参数相似,一般而言,这些函数与 `set_bit` 和 `__set_bit` 也非常相似。让我们查看非原子性 `__clear_bit` 的实现吧:
|
||||
|
||||
```C
|
||||
static inline void __clear_bit(long nr, volatile unsigned long *addr)
|
||||
@ -188,7 +182,7 @@ static inline void __clear_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
没错,正如我们所见,`__clear_bit` 使用相同的参数集合,并包含极其相似的内联汇编代码块。它仅仅使用 [btr](http://x86.renejeschke.de/html/file_module_x86_id_24.html) 指令替换 `bts`。正如我们从函数名所理解的一样,通过给定地址,它清除了给定的位。`btr` 指令表现得像 `bts`(原文这里为 btr,可能为笔误,修正为 bts,译者注)。该指令选出第一操作数指定的位,存储它的值到 `CF` 标志寄存器,并且清楚第二操作数指定的位数组中的对应位。
|
||||
没错,正如我们所见,`__clear_bit` 使用相同的参数集合,并包含极其相似的内联汇编代码块。它只是使用 [btr](http://x86.renejeschke.de/html/file_module_x86_id_24.html) 指令替换了 `bts`。正如我们从函数名所理解的一样,通过给定地址,它清除了给定的位。`btr` 指令表现得像 `bts`(LCTT 译注:原文这里为 btr,可能为笔误,修正为 bts)。该指令选出第一操作数所指定的位,存储它的值到 `CF` 标志寄存器,并且清除第二操作数指定的位数组中的对应位。
|
||||
|
||||
`__clear_bit` 的原子性变体为 `clear_bit`:
|
||||
|
||||
@ -208,11 +202,11 @@ clear_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
并且正如我们所看到的,它与 `set_bit` 非常相似,同时只包含了两处差异。第一处差异为 `clear_bit` 使用 `btr` 指令来清位,而 `set_bit` 使用 `bts` 指令来置位。第二处差异为 `clear_bit` 使用否定的位掩码和 `按位与` 在给定的字节上置位,而 `set_bit` 使用 `按位或` 指令。
|
||||
并且正如我们所看到的,它与 `set_bit` 非常相似,只有两处不同。第一处差异为 `clear_bit` 使用 `btr` 指令来清位,而 `set_bit` 使用 `bts` 指令来置位。第二处差异为 `clear_bit` 使用否定的位掩码和 `按位与` 在给定的字节上置位,而 `set_bit` 使用 `按位或` 指令。
|
||||
|
||||
到此为止,我们可以在任何位数组置位和清位了,并且能够转到位掩码上的其他操作。
|
||||
到此为止,我们可以在任意位数组置位和清位了,我们将看看位掩码上的其他操作。
|
||||
|
||||
在 Linux 内核位数组上最广泛使用的操作是设置和清除位,但是除了这两个操作外,位数组上其他操作也是非常有用的。Linux 内核里另一种广泛使用的操作是知晓位数组中一个给定的位是否被置位。我们能够通过 `test_bit` 宏的帮助实现这一功能。这个宏定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并展开为 `constant_test_bit` 或 `variable_test_bit` 的调用,这要取决于位号。
|
||||
在 Linux 内核中对位数组最广泛使用的操作是设置和清除位,但是除了这两个操作外,位数组上其他操作也是非常有用的。Linux 内核里另一种广泛使用的操作是知晓位数组中一个给定的位是否被置位。我们能够通过 `test_bit` 宏的帮助实现这一功能。这个宏定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并根据位号分别展开为 `constant_test_bit` 或 `variable_test_bit` 调用。
|
||||
|
||||
```C
|
||||
#define test_bit(nr, addr) \
|
||||
@ -221,7 +215,7 @@ clear_bit(long nr, volatile unsigned long *addr)
|
||||
: variable_test_bit((nr), (addr)))
|
||||
```
|
||||
|
||||
因此,如果 `nr` 是编译期已知常量,`test_bit` 将展开为 `constant_test_bit` 函数的调用,而其他情况则为 `variable_test_bit`。现在让我们看看这些函数的实现,我们从 `variable_test_bit` 开始看起:
|
||||
因此,如果 `nr` 是编译期已知常量,`test_bit` 将展开为 `constant_test_bit` 函数的调用,而其他情况则为 `variable_test_bit`。现在让我们看看这些函数的实现,让我们从 `variable_test_bit` 开始看起:
|
||||
|
||||
```C
|
||||
static inline int variable_test_bit(long nr, volatile const unsigned long *addr)
|
||||
@ -237,7 +231,7 @@ static inline int variable_test_bit(long nr, volatile const unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
`variable_test_bit` 函数调用了与 `set_bit` 及其他函数使用的相似的参数集合。我们也可以看到执行 [bt](http://x86.renejeschke.de/html/file_module_x86_id_22.html) 和 [sbb](http://x86.renejeschke.de/html/file_module_x86_id_286.html) 指令的内联汇编代码。`bt` 或 `bit test` 指令从第二操作数指定的位数组选出第一操作数指定的一个指定位,并且将该位的值存进标志寄存器的 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 位。第二个指令 `sbb` 从第二操作数中减去第一操作数,再减去 `CF` 的值。因此,这里将一个从给定位数组中的给定位号的值写进标志寄存器的 `CF` 位,并且执行 `sbb` 指令计算: `00000000 - CF`,并将结果写进 `oldbit` 变量。
|
||||
`variable_test_bit` 函数使用了与 `set_bit` 及其他函数使用的相似的参数集合。我们也可以看到执行 [bt](http://x86.renejeschke.de/html/file_module_x86_id_22.html) 和 [sbb](http://x86.renejeschke.de/html/file_module_x86_id_286.html) 指令的内联汇编代码。`bt` (或称 `bit test`)指令从第二操作数指定的位数组选出第一操作数指定的一个指定位,并且将该位的值存进标志寄存器的 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 位。第二个指令 `sbb` 从第二操作数中减去第一操作数,再减去 `CF` 的值。因此,这里将一个从给定位数组中的给定位号的值写进标志寄存器的 `CF` 位,并且执行 `sbb` 指令计算: `00000000 - CF`,并将结果写进 `oldbit` 变量。
|
||||
|
||||
`constant_test_bit` 函数做了和我们在 `set_bit` 所看到的一样的事:
|
||||
|
||||
@ -251,7 +245,7 @@ static __always_inline int constant_test_bit(long nr, const volatile unsigned lo
|
||||
|
||||
它生成了一个位号对应位为高位 `1`,而其他位为 `0` 的字节(正如我们在 `CONST_MASK` 所看到的),并将 [按位与](https://en.wikipedia.org/wiki/Bitwise_operation#AND) 应用于包含给定位号的字节。
|
||||
|
||||
下一广泛使用的位数组相关操作是改变一个位数组中的位。为此,Linux 内核提供了两个辅助函数:
|
||||
下一个被广泛使用的位数组相关操作是改变一个位数组中的位。为此,Linux 内核提供了两个辅助函数:
|
||||
|
||||
* `__change_bit`;
|
||||
* `change_bit`.
|
||||
@ -274,7 +268,7 @@ static inline void __change_bit(long nr, volatile unsigned long *addr)
|
||||
1
|
||||
```
|
||||
|
||||
`__change_bit` 的原子版本为 `change_bit` 函数:
|
||||
`__change_bit` 的原子版本为 `change_bit` 函数:
|
||||
|
||||
```C
|
||||
static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
@ -291,14 +285,14 @@ static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
}
|
||||
```
|
||||
|
||||
它和 `set_bit` 函数很相似,但也存在两点差异。第一处差异为 `xor` 操作而不是 `or`。第二处差异为 `btc`(原文为 `bts`,为作者笔误,译者注) 而不是 `bts`。
|
||||
它和 `set_bit` 函数很相似,但也存在两点不同。第一处差异为 `xor` 操作而不是 `or`。第二处差异为 `btc`( LCTT 译注:原文为 `bts`,为作者笔误) 而不是 `bts`。
|
||||
|
||||
目前,我们了解了最重要的体系特定的位数组操作,是时候看看一般的位图 API 了。
|
||||
|
||||
通用位操作
|
||||
================================================================================
|
||||
|
||||
除了 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 中体系特定的 API 外,Linux 内核提供了操作位数组的通用 API。正如我们本部分开头所了解的一样,我们可以在 [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件和* [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c) 源文件中找到它。但在查看这些源文件之前,我们先看看 [include/linux/bitops.h](https://github.com/torvalds/linux/blob/master/include/linux/bitops.h) 头文件,其提供了一系列有用的宏,让我们看看它们当中一部分。
|
||||
除了 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 中体系特定的 API 外,Linux 内核提供了操作位数组的通用 API。正如我们本部分开头所了解的一样,我们可以在 [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件和 [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c) 源文件中找到它。但在查看这些源文件之前,我们先看看 [include/linux/bitops.h](https://github.com/torvalds/linux/blob/master/include/linux/bitops.h) 头文件,其提供了一系列有用的宏,让我们看看它们当中一部分。
|
||||
|
||||
首先我们看看以下 4 个 宏:
|
||||
|
||||
@ -307,7 +301,7 @@ static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
* `for_each_clear_bit`
|
||||
* `for_each_clear_bit_from`
|
||||
|
||||
所有这些宏都提供了遍历位数组中某些位集合的迭代器。第一个红迭代那些被置位的位。第二个宏也是一样,但它是从某一确定位开始。最后两个宏做的一样,但是迭代那些被清位的位。让我们看看 `for_each_set_bit` 宏:
|
||||
所有这些宏都提供了遍历位数组中某些位集合的迭代器。第一个宏迭代那些被置位的位。第二个宏也是一样,但它是从某一个确定的位开始。最后两个宏做的一样,但是迭代那些被清位的位。让我们看看 `for_each_set_bit` 宏:
|
||||
|
||||
```C
|
||||
#define for_each_set_bit(bit, addr, size) \
|
||||
@ -316,7 +310,7 @@ static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
(bit) = find_next_bit((addr), (size), (bit) + 1))
|
||||
```
|
||||
|
||||
正如我们所看到的,它使用了三个参数,并展开为一个循环,该循环从作为 `find_first_bit` 函数返回结果的第一个置位开始到最后一个置位且小于给定大小为止。
|
||||
正如我们所看到的,它使用了三个参数,并展开为一个循环,该循环从作为 `find_first_bit` 函数返回结果的第一个置位开始,到小于给定大小的最后一个置位为止。
|
||||
|
||||
除了这四个宏, [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 也提供了 `64-bit` 或 `32-bit` 变量循环的 API 等等。
|
||||
|
||||
@ -339,7 +333,7 @@ static inline void bitmap_zero(unsigned long *dst, unsigned int nbits)
|
||||
}
|
||||
```
|
||||
|
||||
首先我们可以看到对 `nbits` 的检查。 `small_const_nbits` 是一个定义在同一[头文件](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 的宏:
|
||||
首先我们可以看到对 `nbits` 的检查。 `small_const_nbits` 是一个定义在同一个[头文件](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 的宏:
|
||||
|
||||
```C
|
||||
#define small_const_nbits(nbits) \
|
||||
@ -398,7 +392,7 @@ via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/bitmap.md
|
||||
|
||||
作者:[0xAX][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
66
published/201608/20160516 Scaling Collaboration in DevOps.md
Normal file
66
published/201608/20160516 Scaling Collaboration in DevOps.md
Normal file
@ -0,0 +1,66 @@
|
||||
DevOps 的弹性合作
|
||||
=================================
|
||||
|
||||

|
||||
|
||||
那些熟悉 DevOps 的人通常认为与其说 DevOps 是一种技术不如说是一种文化。在 DevOps 的有效实践上需要一些特定的工具和经验,但是 DevOps 成功的基础在于企业内如何做好[团队和个体协作][1],从而可以让事情更快、更高效而有效的完成。
|
||||
|
||||
大多数的 DevOps 平台和工具都是以可扩展性为设计理念的。DevOps 环境通常运行在云端,并且容易发生变化。对于DevOps 软件来说,支持实时伸缩以解决冲突和摩擦是重要的。这同样对于人的因素也是一样的,但弹性合作却是完全不同的。
|
||||
|
||||
跨企业协同是 DevOps 成功的关键。好的代码和开发最终需要形成产品才能给用户带来价值。公司所面临的挑战是如何做到无缝衔接和尽可能的提高速度及自动化水平,而不是牺牲质量或性能。企业如何才能流水线化代码的开发和部署,同时保持维护工作的明晰、可控和合规?
|
||||
|
||||
### 新兴趋势
|
||||
|
||||
首先,我先提供一些背景,分享一些 [451 Research][2] 在 DevOps 及其常规应用方面获取的数据。云、敏捷和Devops 的能力在今天是非常重要的,不管是理念还是现实。451 研究公司发现采用这些东西以及容器技术的企业在不断增多,包括在生产环境中的大量使用。
|
||||
|
||||
拥抱这些技术和方式有许多优点,比如提高灵活性和速度,降低成本,提高适应能力和可靠性,适应新的或新兴的应用。据 451 Research 称,团队也面临着一些障碍,包括缺乏熟悉其中所需的技能的人、这些新兴技术的不成熟、成本和安全问题等。
|
||||
|
||||
在 “[Voice of the Enterprise: SDI Q4 2015 survey][2]” 报告中,451 Research 发现超过一半的受访者(57.1%)考虑他们稍晚些再采用,甚至会最后才采用这些新技术。另一方面,近半受访者(48.3 %)认为自己是率先或早期的采用者。
|
||||
|
||||
这些普遍性的情绪也表现在对其他问题的调查中。当问起容器的执行情况时,50.3% 的人表示这根本不在他们的计划中。剩下 49.7% 的人则是在计划、试点或积极使用容器技术。近 2/3(65.1%)的人表示,他们用敏捷开发方式来开发应用,但是只有 39.6% 的人回应称他们正在积极拥抱 DevOps。然而,敏捷软件开发已经在行业内存在了多年,451 Research 注意到容器和 Devops 的采用率显著提升,这是一个新的趋势。
|
||||
|
||||
当被问及首要的三个 IT 痛点是什么,被提及最多的是成本或预算、人员不足和遗留软件问题。随着企业向云、DevOps、和容器等转型,这些问题都需要加以解决,以及如何规划技术和有效协作。
|
||||
|
||||
### 当前状况
|
||||
|
||||
软件行业正处于急剧变化之中,这很大程度是由 DevOps 所推动的,它使得软件开发变得越来越横跨整个业务高度集成。软件的开发变得不再闭门造车,而越来越体现协作和社交化的功能。
|
||||
|
||||
几年还是在小说和展板中的理念和方法迅速成熟,成为了今天推动价值的主流技术和框架。企业依靠如敏捷、精益、虚拟化、云计算、自动化和微服务等概念来简化开发,同时使工作更加有效和高效。
|
||||
|
||||
为了适应和发展,企业需要完成一系列的关键任务。当今面临的挑战是如何加快发展的同时降低成本。团队需要消除 IT 和其他业务之间存在的障碍,并在一个由技术驱动的竞争环境中提供更多有效的战略合作。
|
||||
|
||||
敏捷、云计算、DevOps 和容器在这个过程中起着重要的作用,而将它们连接在一起的是有效的合作。每一种技术和方法都提供了独特的优势,但真正的价值来自于团队作为一个整体能够进行规模协同,以及团队所使用的工具和平台。成功的 DevOps 的实现也需要开发和 IT 运营团队之外其他利益相关者的参与,包括安全、数据库、存储和业务队伍。
|
||||
|
||||
### 合作即平台
|
||||
|
||||
有一些在线的服务和平台,比如 Github 促进和增进了协作。这个在线平台的功能是一个在线代码库,但是所产生的价值远超乎存储代码。
|
||||
|
||||
这样一个[协作平台][4]之所以有助于开发人员和团队合作,是因为它提供了一个可以分享和讨论代码和流程的社区。管理者可以监视进度和跟踪将要发布的代码。开发人员在将实验性的想法放到实际的产品环境中之前,可以在一个安全的环境中进行实验,新的想法和实验可以有效地与适当的团队进行沟通。
|
||||
|
||||
更加敏捷的开发和 DevOps 的关键之一是允许开发人员测试一些东西并快速收集相关的反馈。目标是生产高质量的代码和功能,而不是浪费时间建立和管理基础设施或者安排更多的会议来讨论这个问题。比如 GitHub 平台,能够更有效的和可扩展的协作是因为当参与者想要进行代码审查时很方便。不需要尝试协调和安排代码审查会议,所以开发人员可以继续工作而不被打断,从而产生更大的生产力和工作满意度。
|
||||
|
||||
Sendachi 的 Steven Anderson 指出,Github 是一个协作平台,但它也是一个和你一起工作的工具。这样意味着它不仅可以帮助协作和持续集成,还影响了代码质量。
|
||||
|
||||
合作平台的好处之一是,大型团队的开发人员可以分解成更小的团队,可以更有效地专注于特定的组件。它还提供了诸如文件共享这样的代码之外的功能,模糊了技术和非技术的贡献,增加了协作和可见性。
|
||||
|
||||
### 合作是关键
|
||||
|
||||
合作的重要性不言而喻。合作是 DevOps 文化的关键,也是在当今世界能够进行敏捷开发并保持竞争优势的决定因素。执行或管理支持以及内部传道是很重要的。团队还需要拥抱文化的转变---迈向共同目标的跨职能部门的技能融合。
|
||||
|
||||
要建立起来这样的文化,有效的合作是至关重要的。一个合作平台是弹性合作的必要组件,因为简化了生产活动,并且减少了冗余和尝试,同时还产生了更高质量的结果。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://devops.com/2016/05/16/scaling-collaboration-devops/
|
||||
|
||||
作者:[TONY BRADLEY][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://devops.com/author/tonybsg/
|
||||
[1]: http://devops.com/2014/12/15/four-strategies-supporting-devops-collaboration/
|
||||
[2]: https://451research.com/
|
||||
[3]: https://451research.com/customer-insight-voice-of-the-enterprise-overview
|
||||
[4]: http://devops.com/events/analytics-of-collaboration-on-github/
|
||||
@ -1,38 +1,40 @@
|
||||
在 Linux 上用 SELinux 或 AppArmor 实现强制访问控制
|
||||
在 Linux 上用 SELinux 或 AppArmor 实现强制访问控制(MAC)
|
||||
===========================================================================
|
||||
|
||||
为了克服标准 用户-组-其他/读-写-执行 权限以及[访问控制列表][1]的限制以及加强安全机制,美国国家安全局(NSA)设计出一个灵活的强制访问控制(MAC)方法 SELinux(Security Enhanced Linux 的缩写),来限制其他事物,在仍然允许对这个模型后续修改的情况下,让进程尽可能以最小权限访问或在系统对象(如文件,文件夹,网络端口等)上执行其他操作。
|
||||
为了解决标准的“用户-组-其他/读-写-执行”权限以及[访问控制列表][1]的限制以及加强安全机制,美国国家安全局(NSA)设计出一个灵活的强制访问控制(Mandatory Access Control:MAC)方法 SELinux(Security Enhanced Linux 的缩写),来限制标准的权限之外的种种权限,在仍然允许对这个控制模型后续修改的情况下,让进程尽可能以最小权限访问或在系统对象(如文件,文件夹,网络端口等)上执行其他操作。
|
||||
|
||||

|
||||
>SELinux 和 AppArmor 加固 Linux 安全
|
||||
|
||||
另一个流行并且广泛使用的 MAC 是 AppArmor,相比于 SELinux 它提供额外的特性,包括一个学习模型,让系统“学习”一个特定应用的行为,通过配置文件设置限制实现安全的应用使用。
|
||||
*SELinux 和 AppArmor 加固 Linux 安全*
|
||||
|
||||
在 CentOS 7 中,SELinux 合并进了内核并且默认启用强制(Enforcing)模式(下一节会介绍这方面更多的内容),与使用 AppArmor 的 openSUSE 和 Ubuntu 完全不同。
|
||||
另一个流行并且被广泛使用的 MAC 是 AppArmor,相比于 SELinux 它提供更多的特性,包括一个学习模式,可以让系统“学习”一个特定应用的行为,以及通过配置文件设置限制实现安全的应用使用。
|
||||
|
||||
在这篇文章中我们会解释 SELinux 和 AppArmor 的本质以及如何在你选择的发行版上使用这两个工具之一并从中获益。
|
||||
在 CentOS 7 中,SELinux 合并进了内核并且默认启用强制(Enforcing)模式(下一节会介绍这方面更多的内容),与之不同的是,openSUSE 和 Ubuntu 使用的是 AppArmor 。
|
||||
|
||||
在这篇文章中我们会解释 SELinux 和 AppArmor 的本质,以及如何在你选择的发行版上使用这两个工具之一并从中获益。
|
||||
|
||||
### SELinux 介绍以及如何在 CentOS 7 中使用
|
||||
|
||||
Security Enhanced Linux 可以以两种不同模式运行:
|
||||
|
||||
- 强制(Enforcing):SELinux 基于 SELinux 策略规则拒绝访问,一个指导准则集合控制安全引擎。
|
||||
- 宽容(Permissive):SELinux 不拒绝访问,但如果在强制模式下会被拒绝的操作会被记录下来。
|
||||
- 强制(Enforcing):这种情况下,SELinux 基于 SELinux 策略规则拒绝访问,策略规则是一套控制安全引擎的规则。
|
||||
- 宽容(Permissive):这种情况下,SELinux 不拒绝访问,但如果在强制模式下会被拒绝的操作会被记录下来。
|
||||
|
||||
SELinux 也能被禁用。尽管这不是它的一个操作模式,不过也是一个选项。但学习如何使用这个工具强过只是忽略它。时刻牢记这一点!
|
||||
SELinux 也能被禁用。尽管这不是它的一个操作模式,不过也是一种选择。但学习如何使用这个工具强过只是忽略它。时刻牢记这一点!
|
||||
|
||||
使用 getenforce 命令来显示 SELinux 的当前模式。如果你想要更改模式,使用 setenforce 0(设置为宽容模式)或 setenforce 1(强制模式)。
|
||||
使用 `getenforce` 命令来显示 SELinux 的当前模式。如果你想要更改模式,使用 `setenforce 0`(设置为宽容模式)或 `setenforce 1`(强制模式)。
|
||||
|
||||
因为这些设置重启后就失效了,你需要编辑 /etc/selinux/ 的配置文件并设置 SELINUX 变量为 enforcing,permissive 或 disabled 来保存设置让其重启后也有效:
|
||||
因为这些设置重启后就失效了,你需要编辑 `/etc/selinux/config` 配置文件并设置 `SELINUX` 变量为 `enforcing`、`permissive` 或 `disabled` ,保存设置让其重启后也有效:
|
||||
|
||||
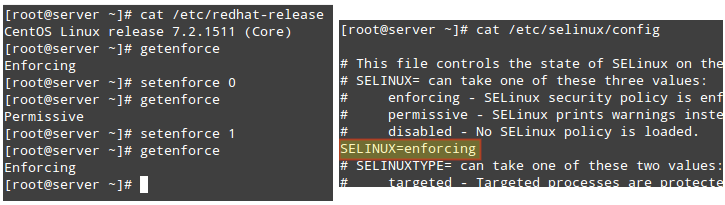
|
||||
>如何启用和禁用 SELinux 模式
|
||||
|
||||
还有一点要注意,如果 getenforce 返回 Disabled,你得编辑 /etc/selinux/ 配置为你想要的操作模式并重启。否则你无法利用 setenforce 设置(或切换)操作模式。
|
||||
*如何启用和禁用 SELinux 模式*
|
||||
|
||||
setenforce 的典型用法之一包括在 SELinux 模式之间切换(从强制到宽容或相反)来定位一个应用是否行为不端或没有像预期一样工作。如果它在你将 SELinux 设置为宽容模式正常工作,你就可以确定你遇到的是 SELinux 权限问题。
|
||||
还有一点要注意,如果 `getenforce` 返回 Disabled,你得编辑 `/etc/selinux/config` 配置文件为你想要的操作模式并重启。否则你无法利用 `setenforce` 设置(或切换)操作模式。
|
||||
|
||||
两种我们使用 SELinux 可能需要解决的典型案例:
|
||||
`setenforce` 的典型用法之一包括在 SELinux 模式之间切换(从强制到宽容或相反)来定位一个应用是否行为不端或没有像预期一样工作。如果它在你将 SELinux 设置为宽容模式正常工作,你就可以确定你遇到的是 SELinux 权限问题。
|
||||
|
||||
有两种我们使用 SELinux 可能需要解决的典型案例:
|
||||
|
||||
- 改变一个守护进程监听的默认端口。
|
||||
- 给一个虚拟主机设置 /var/www/html 以外的文档根路径值。
|
||||
@ -41,7 +43,7 @@ setenforce 的典型用法之一包括在 SELinux 模式之间切换(从强制
|
||||
|
||||
#### 例 1:更改 sshd 守护进程的默认端口
|
||||
|
||||
大部分系统管理员为了加强服务器安全首先要做的事情之一就是更改 SSH 守护进程监听的端口,主要是为了组织端口扫描和外部攻击。要达到这个目的,我们要更改 `/etc/ssh/sshd_config` 中的 Port 值为以下值(我们在这里使用端口 9999 为例):
|
||||
大部分系统管理员为了加强服务器安全首先要做的事情之一就是更改 SSH 守护进程监听的端口,主要是为了阻止端口扫描和外部攻击。要达到这个目的,我们要更改 `/etc/ssh/sshd_config` 中的 Port 值为以下值(我们在这里使用端口 9999 为例):
|
||||
|
||||
```
|
||||
Port 9999
|
||||
@ -55,18 +57,20 @@ Port 9999
|
||||
```
|
||||
|
||||
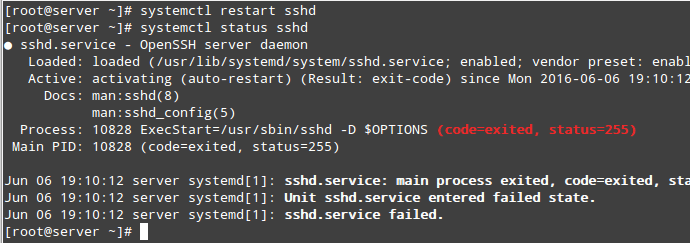
|
||||
>检查 SSH 服务状态
|
||||
|
||||
如果我们看看 /var/log/audit/audit.log,就会看到 sshd 被 SELinux 组织在端口 9999 上启动,因为他是 JBoss 管理服务的保留端口(SELinux 日志信息包含了词语“AVC”,所以应该很容易把它同其他信息区分开来):
|
||||
*检查 SSH 服务状态*
|
||||
|
||||
如果我们看看 `/var/log/audit/audit.log`,就会看到 sshd 被 SELinux 阻止在端口 9999 上启动,因为它是 JBoss 管理服务的保留端口(SELinux 日志信息包含了词语“AVC”,所以应该很容易把它同其他信息区分开来):
|
||||
|
||||
```
|
||||
# cat /var/log/audit/audit.log | grep AVC | tail -1
|
||||
```
|
||||
|
||||

|
||||
>检查 Linux 审计日志
|
||||
|
||||
在这种情况下大部分人可能会禁用 SELinux,但我们不这么做。我们会看到有个让 Selinux 和监听其他端口的 sshd 和谐共处的方法。首先确保你有 policycoreutils-python 这个包,执行:
|
||||
*检查 Linux 审计日志*
|
||||
|
||||
在这种情况下大部分人可能会禁用 SELinux,但我们不这么做。我们会看到有个让 SELinux 和监听其他端口的 sshd 和谐共处的方法。首先确保你有 `policycoreutils-python` 这个包,执行:
|
||||
|
||||
```
|
||||
# yum install policycoreutils-python
|
||||
@ -84,7 +88,7 @@ Port 9999
|
||||
# semanage port -m -t ssh_port_t -p tcp 9999
|
||||
```
|
||||
|
||||
在那之后,我们可以用第一个 semanage 命令检查端口是否正确分配了,或用 -lC 参数(list custom 的简称):
|
||||
这之后,我们就可以用前一个 `semanage` 命令检查端口是否正确分配了,即使用 `-lC` 参数(list custom 的简称):
|
||||
|
||||
```
|
||||
# semanage port -lC
|
||||
@ -92,19 +96,20 @@ Port 9999
|
||||
```
|
||||
|
||||
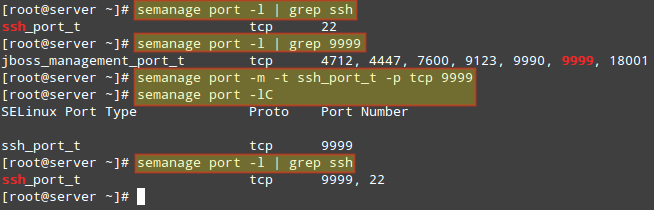
|
||||
>给 SSH 分配端口
|
||||
|
||||
*给 SSH 分配端口*
|
||||
|
||||
我们现在可以重启 SSH 服务并通过端口 9999 连接了。注意这个更改重启之后依然有效。
|
||||
|
||||
#### 例 2:给一个虚拟主机设置 /var/www/html 以外的文档根路径值
|
||||
#### 例 2:给一个虚拟主机设置 /var/www/html 以外的文档根路径(DocumentRoot)
|
||||
|
||||
如果你需要用除 /var/www/html 以外目录作为文档根目录[设置一个 Apache 虚拟主机][2](也就是说,比如 `/websrv/sites/gabriel/public_html`):
|
||||
如果你需要用除 `/var/www/html` 以外目录作为文档根目录(DocumentRoot)[设置一个 Apache 虚拟主机][2](也就是说,比如 `/websrv/sites/gabriel/public_html`):
|
||||
|
||||
```
|
||||
DocumentRoot “/websrv/sites/gabriel/public_html”
|
||||
```
|
||||
|
||||
Apache 会拒绝提供内容,因为 index.html 已经被标记为了 default_t SELinux 类型,Apache 无法访问它:
|
||||
Apache 会拒绝提供内容,因为 `index.html` 已经被标记为了 `default_t SELinux` 类型,Apache 无法访问它:
|
||||
|
||||
```
|
||||
# wget http://localhost/index.html
|
||||
@ -112,7 +117,8 @@ Apache 会拒绝提供内容,因为 index.html 已经被标记为了 default_t
|
||||
```
|
||||
|
||||

|
||||
>被标记为 default_t SELinux 类型
|
||||
|
||||
*被标记为 default_t SELinux 类型*
|
||||
|
||||
和之前的例子一样,你可以用以下命令验证这是不是 SELinux 相关的问题:
|
||||
|
||||
@ -121,9 +127,10 @@ Apache 会拒绝提供内容,因为 index.html 已经被标记为了 default_t
|
||||
```
|
||||
|
||||

|
||||
>检查日志确定是不是 SELinux 的问题
|
||||
|
||||
要将 /websrv/sites/gabriel/public_html 整个目录内容标记为 httpd_sys_content_t,执行:
|
||||
*检查日志确定是不是 SELinux 的问题*
|
||||
|
||||
要将 `/websrv/sites/gabriel/public_html` 整个目录内容标记为 `httpd_sys_content_t`,执行:
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/websrv/sites/gabriel/public_html(/.*)?"
|
||||
@ -144,20 +151,20 @@ Apache 会拒绝提供内容,因为 index.html 已经被标记为了 default_t
|
||||
```
|
||||
|
||||
|
||||
>访问 Apache 目录
|
||||
|
||||
要获取关于 SELinux 的更多信息,参阅 Fedora 22 [SELinux 以及 管理员指南][3]。
|
||||
*访问 Apache 目录*
|
||||
|
||||
要获取关于 SELinux 的更多信息,参阅 Fedora 22 中的 [SELinux 用户及管理员指南][3]。
|
||||
|
||||
### AppArmor 介绍以及如何在 OpenSUSE 和 Ubuntu 上使用它
|
||||
|
||||
AppArmor 的操作是基于纯文本文件的规则定义,该文件中含有允许权限和访问控制规则。安全配置文件用来限制应用程序如何与系统中的进程和文件进行交互。
|
||||
AppArmor 的操作是基于写在纯文本文件中的规则定义,该文件中含有允许权限和访问控制规则。安全配置文件用来限制应用程序如何与系统中的进程和文件进行交互。
|
||||
|
||||
系统初始就提供了一系列的配置文件,但其他的也可以由应用程序安装的时候设置或由系统管理员手动设置。
|
||||
系统初始就提供了一系列的配置文件,但其它的也可以由应用程序在安装的时候设置或由系统管理员手动设置。
|
||||
|
||||
像 SELinux 一样,AppArmor 以两种模式运行。在 enforce 模式下,应用被赋予它们运行所需要的最小权限,但在 complain 模式下 AppArmor 允许一个应用执行有限的操作并将操作造成的“抱怨”记录到日志里(/var/log/kern.log,/var/log/audit/audit.log,和其它在 /var/log/apparmor 中的日志)。
|
||||
像 SELinux 一样,AppArmor 以两种模式运行。在 enforce 模式下,应用被赋予它们运行所需要的最小权限,但在 complain 模式下 AppArmor 允许一个应用执行受限的操作并将操作造成的“抱怨”记录到日志里(`/var/log/kern.log`,`/var/log/audit/audit.log`,和其它放在 `/var/log/apparmor` 中的日志)。
|
||||
|
||||
日志中会显示配置文件在强制模式下运行时会产生错误的记录,它们中带有审计这个词。因此,你可以在 AppArmor 的 enforce 模式下运行之前,先在 complain 模式下尝试运行一个应用并调整它的行为。
|
||||
日志中会显示配置文件在强制模式下运行时会产生错误的记录,它们中带有 `audit` 这个词。因此,你可以在 AppArmor 的 enforce 模式下运行之前,先在 complain 模式下尝试运行一个应用并调整它的行为。
|
||||
|
||||
可以用这个命令显示 AppArmor 的当前状态:
|
||||
|
||||
@ -166,24 +173,26 @@ $ sudo apparmor_status
|
||||
```
|
||||
|
||||
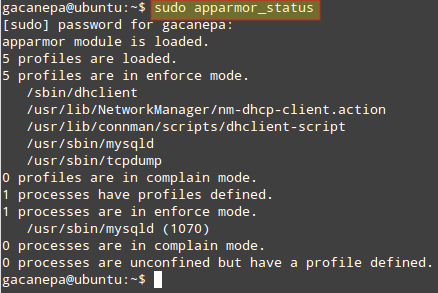
|
||||
>查看 AppArmor 的状态
|
||||
|
||||
上面的图片指明配置 /sbin/dhclient,/usr/sbin/,和 /usr/sbin/tcpdump 在 enforce 模式下(在 Ubuntu 下默认就是这样的)。
|
||||
*查看 AppArmor 的状态*
|
||||
|
||||
因为不是所有的应用都包含相关的 AppArmor 配置,apparmor-profiles 包提供了其它配置给没有提供限制的包。默认它们配置在 complain 模式下运行以便系统管理员能够测试并选择一个所需要的配置。
|
||||
上面的图片指明配置 `/sbin/dhclient`,`/usr/sbin/`,和 `/usr/sbin/tcpdump` 等处在 enforce 模式下(在 Ubuntu 下默认就是这样的)。
|
||||
|
||||
因为不是所有的应用都包含相关的 AppArmor 配置,apparmor-profiles 包给其它没有提供限制的包提供了配置。默认它们配置在 complain 模式下运行,以便系统管理员能够测试并选择一个所需要的配置。
|
||||
|
||||
我们将会利用 apparmor-profiles,因为写一份我们自己的配置已经超出了 LFCS [认证][4]的范围了。但是,由于配置都是纯文本文件,你可以查看并学习它们,为以后创建自己的配置做准备。
|
||||
|
||||
AppArmor 配置保存在 /etc/apparmor.d 中。让我们来看看这个文件夹在安装 apparmor-profiles 之前和之后有什么不同:
|
||||
AppArmor 配置保存在 `/etc/apparmor.d` 中。让我们来看看这个文件夹在安装 apparmor-profiles 之前和之后有什么不同:
|
||||
|
||||
```
|
||||
$ ls /etc/apparmor.d
|
||||
```
|
||||
|
||||

|
||||
>查看 AppArmor 文件夹内容
|
||||
|
||||
如果你再次执行 sudo apparmor_status,你会在 complain 模式看到更长的配置文件列表。你现在可以执行下列操作:
|
||||
*查看 AppArmor 文件夹内容*
|
||||
|
||||
如果你再次执行 `sudo apparmor_status`,你会在 complain 模式看到更长的配置文件列表。你现在可以执行下列操作。
|
||||
|
||||
将当前在 enforce 模式下的配置文件切换到 complain 模式:
|
||||
|
||||
@ -203,7 +212,7 @@ $ sudo aa-enforce /path/to/file
|
||||
$ sudo aa-complain /etc/apparmor.d/*
|
||||
```
|
||||
|
||||
会将 /etc/apparmor.d 中的所有配置文件设置为 complain 模式,反之
|
||||
会将 `/etc/apparmor.d` 中的所有配置文件设置为 complain 模式,反之
|
||||
|
||||
```
|
||||
$ sudo aa-enforce /etc/apparmor.d/*
|
||||
@ -211,28 +220,27 @@ $ sudo aa-enforce /etc/apparmor.d/*
|
||||
|
||||
会将所有配置文件设置为 enforce 模式。
|
||||
|
||||
要完全禁用一个配置,在 /etc/apparmor.d/disabled 目录中创建一个符号链接:
|
||||
要完全禁用一个配置,在 `/etc/apparmor.d/disabled` 目录中创建一个符号链接:
|
||||
|
||||
```
|
||||
$ sudo ln -s /etc/apparmor.d/profile.name /etc/apparmor.d/disable/
|
||||
```
|
||||
|
||||
要获取关于 AppArmor 的更多信息,参阅[官方 AppArmor wiki][5] 以及 [Ubuntu 提供的][6]文档。
|
||||
要获取关于 AppArmor 的更多信息,参阅[官方的 AppArmor wiki][5] 以及 [Ubuntu 提供的][6]文档。
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中我们学习了一些 SELinux 和 AppArmor 这两个著名强制访问控制系统的基本知识。什么时候使用两者中的一个或是另一个?为了避免提高难度,你可能需要考虑专注于你选择的发行版自带的那一个。不管怎样,它们会帮助你限制进程和系统资源的访问,以提高你服务器的安全性。
|
||||
在这篇文章中我们学习了一些 SELinux 和 AppArmor 这两个著名的强制访问控制系统的基本知识。什么时候使用两者中的一个或是另一个?为了避免提高难度,你可能需要考虑专注于你选择的发行版自带的那一个。不管怎样,它们会帮助你限制进程和系统资源的访问,以提高你服务器的安全性。
|
||||
|
||||
关于本文你有任何的问题,评论,或建议,欢迎在下方发表。不要犹豫,让我们知道你是否有疑问或评论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,110 @@
|
||||
Ubuntu Snap 软件包接管 Linux 桌面和 IoT 软件的发行
|
||||
===========================================================================
|
||||
|
||||
[Canonical][28] 和 [Ubuntu][29] 创始人 Mark Shuttleworth 在一次采访中说他不准备宣布 Ubuntu 的新 [ Snap 程序包格式][30]。但是就在几个月之后,很多 Linux 发行版的开发者和公司都宣布他们会把 Snap 作为通用 Linux 程序包格式。
|
||||
|
||||

|
||||
|
||||
*Linux 供应商,独立软件开发商和公司门全都采用 Ubuntu Snap 作为多种 Linux 系统的配置和更新程序包。*
|
||||
|
||||
为什么呢?因为 Snap 能使一个单一的二进制程序包可以完美、安全地运行在任何 Linux 台式机、服务器、云或物联网设备上。据 Canonical 的 Ubuntu 客户端产品和版本负责人 Olli Ries 说:
|
||||
|
||||
>[Snap 程序包的安全机制][1]让我们在更快的跨发行版的应用更新中打开了新的局面,因为 Snap 应用是与系统的其它部分想隔离的。用户可以安装一个 Snap 而不用担心是否会影响其他的应用程序和操作系统。
|
||||
|
||||
当然了,如 Linux 内核的早期开发者和 CoreOS 安全维护者 Matthew Garrett 指出的那样:如果你[将 Snap 用在不安全的程序中,比如 X11 窗口系统][2],实际上您并不会获得安全性。(LCTT 译注:X11 也叫做 X Window 系统,X Window 系统 ( X11 或 X )是一种位图显示的视窗系统 。它是在 Unix 和类 Unix 操作系统 ,以及 OpenVMS 上建立图形用户界面的标准工具包和协议,并可用于几乎所有已有的现代操作系统。)
|
||||
|
||||
Shuttleworth 同意 Garrett 的观点,但是他也说你可以控制 Snap 应用是如何与系统的其它部分如何交互的。比如,一个 web 浏览器可以包含在一个安全的 Snap 程序包中,这个 Snap 使用 Ubuntu 打包的 [openssl][3] TLS 和 SSL 库。除此之外,即使有些东西影响到了浏览器实例内部,也不能进入到底层的操作系统。
|
||||
|
||||
很多公司也这样认为。戴尔、三星、Mozilla、[krita][7](LCTT 译注:Krita 是一个位图形编辑软件,KOffice 套装的一部份。包含一个绘画程式和照片编辑器,Krita 是自由软件,并根据GNU通用公共许可证发布)、[Mycroft][8](LCTT 译注:Mycroft 是一个开源AI智能家居平台,配置 Raspberry Pi 2 和 Arduino 控制器),以及 [Horizon Computing][9](LCTT 译注:为客户提供优质的硬件架构为其运行云平台)都将使用 Snap。Arch Linux、Debain、Gentoo 和 OpenWrt 开发团队也已经拥抱了 Snap,也会把 Snap 加入到他们各自的发行版中。
|
||||
|
||||
Snap 包又叫做“Snaps”,现在已经可以原生的运行在 Arch、Debian、Fedora、Kubuntu、Lubuntu、Ubuntu GNOME、Ubuntu Kylin、Ubuntu MATE、Ubuntu Unity 和 Xubuntu 之上。 Snap 也在 CentOS、Elementary、Gentoo、Mint、OpenSUSE 和 Red Hat Enterprise Linux (RHEL) 上取得了验证,并且也很容易运行在其他 Linux 发行版上。
|
||||
|
||||
这些发行版正在使用 Snaps,Shuttleworth 声称:“Snaps 为每个 Linux 台式机、服务器、设备和云机器带来了很多应用程序,在让用户使用最好的应用的同时也给了用户选择发行版的自由。”
|
||||
|
||||
这些发行版共同代表了 Linux 桌面、服务器和云系统发行版的主流。为什么它们从现有的软件包管理系统换了过来呢? Arch Linux 的贡献者 Tim Jester-Pfadt 解释说,“Snaps 最棒的一点是它支持先锐和测试通道,这可以让用户选择使用预发布的开发者版本或跟着最新的稳定版本。”
|
||||
|
||||
除过这些 Linux 分支,独立软件开发商也将会因为 Snap 很好的简化了第三方 Linux 应用程序分发和安全维护问题而拥抱 Snap。例如,[文档基金会][14]也将会让流行的开源办公套件 [LibreOffice][15] 支持 Snap 程序包。
|
||||
|
||||
文档基金会的联合创始人 Thorsten Behrens 这样说:
|
||||
|
||||
> 我们的目标是尽可能的使 LibreOffice 能被大多数人更容易使用。Snap 使我们的用户能够在不同的桌面系统和发行版上更快捷、更容易、持续地获取最新的 LibreOffice 版本。更好的是,它也会帮助我们的发布工程师最终从周而复始的、自产的、陈旧的 Linux 开发解决方案中解放出来,很多东西都可以一同维护了。
|
||||
|
||||
Mozilla 的 Firefix 副总裁 Nick Nguyen 在该声明中提到:
|
||||
|
||||
> 我们力求为用户提供良好的使用体验,并且使火狐浏览器能够在更多平台、设备和操作系统上运行。随着引入 Snaps ,对火狐浏览器的持续优化成为可能,使它可以为 Linux 用户提供最新的特性。
|
||||
|
||||
[Krita 基金会][17] (基于 KDE 的图形程序)项目领导 Boudewijn Rempt 说:
|
||||
|
||||
> 在一个私有仓库中维护 DEB 包是复杂而耗时的。Snaps 更容易维护、打包和分发。把 Snap 放进软件商店也特别容易,这是我发布软件用过的最舒服的软件商店了。[Krita 3.0][18] 刚刚作为一个 snap 程序包发行,新版本出现时它会自动更新。
|
||||
|
||||
不仅 Linux 桌面系统程序为 Snap 而激动。物联网(IoT)和嵌入式开发者也以双手拥抱了 Snap。
|
||||
|
||||
由于 Snaps 彼此隔离,带来了数据安全性,它们还可以自动更新或回滚,这对于硬件设备是极好的。多个厂商都发布了运行着 snappy 的设备(LCTT 译注:Snap 基于 snappy进行构建),这带来了一种新的带有物联网应用商店的“智能新锐”设备。Snappy 设备能够自动接收系统更新,并且连同安装在设备上的应用程序也会得到更新。
|
||||
|
||||
据 Shuttleworth 说,戴尔公司是最早一批认识到 Snap 的巨大潜力的物联网供应商之一,也决定在他们的设备上使用 Snap 了。
|
||||
|
||||
戴尔公司的物联网战略和合作伙伴主管 Jason Shepherd 说:“我们认为,Snaps 能解决在单一物联网网关上部署和运行多个第三方应用程序所带来的安全风险和可管理性挑战。这种可信赖的通用的应用程序格式才是戴尔真正需要的,我们的物联网解决方案合作伙伴和商业客户都对构建一个可扩展的、IT 级的、充满活力的物联网应用生态系统有极大的兴趣。”
|
||||
|
||||
OpenWrt 的开发者 Matteo Croce 说:“这很简单, Snaps 可以在保持核心系统不变的情况下递送新的应用... Snaps 是为 OpenWrt AP 和路由器提供大量软件的最快方式。”
|
||||
|
||||
Shuttleworth 并不认为 Snaps 会取代已经存在的 Linux 程序包比如 [RPM][19] 和 [DEB][20]。相反,他认为它们将会相辅相成。Snaps 将会与现有软件包共存。每个发行版都有其自己提供和更新核心系统及其更新的机制。Snap 为桌面系统带来的是通用的应用程序,这些应用程序不会影响到操作系统的基础。
|
||||
|
||||
每个 Snap 都通过使用大量的内核隔离和安全机制而限制,以满足 Snap 应用的需求。谨慎的审核过程可以确保 Snap 仅仅得到其完成请求操作的权限。用户在安装 Snap 的时候也不必考虑复杂的安全问题。
|
||||
|
||||
Snap 本质上是一个自包容的 zip 文件,能够快速地在包内执行。流行的[优麒麟][21]团队的负责人 Jack Yu 称:“Snaps 比传统的 Linux 包更容易构建,允许我们独立于操作系统解决依赖性,所以我们很容易地跨发行版为所有用户提供最好、最新的中国 Linux 应用。”
|
||||
|
||||
由 Canonical 设计的 Snap 程序包格式由 [snapd][22] 所处理。它的开发工作放在 GitHub 上。将其移植到更多的 Linux 发行版已经被证明是很简单的,社区还在不断增长,吸引了大量具有 Linux 经验的贡献者。
|
||||
|
||||
Snap 程序包使用 snapcraft 工具来构建。项目官网是 [snapcraft.io][24],其上有构建 Snap 的指导和逐步指南,以及给项目开发者和使用者的文档。Snap 能够基于现有的发行版程序包构建,但通常使用源代码来构建,以获得优化和减小软件包大小。
|
||||
|
||||
如果你不是 Ubuntu 的忠实粉丝或者一个专业的 Linux 开发者,你可能还不知道 Snap。未来,在任何平台上需要用 Linux 完成工作的任何人都会知道这个软件。它会成为主流,尤其是在 Linux 应用程序的安装和更新机制方面。
|
||||
|
||||
### 相关内容:
|
||||
|
||||
- [Linux 专家 Matthew Garrett:Ubuntu 16.04 的新 Snap 程序包格式存在安全风险 ][25]
|
||||
- [Ubuntu Linux 16.04 ]
|
||||
- [Microsoft 和 Canonical 合作使 Ubuntu 可以在 Windows 10 上运行 ]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-snap-takes-charge-of-linux-desktop-and-iot-software-distribution/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[28]: http://www.canonical.com/
|
||||
[29]: http://www.ubuntu.com/
|
||||
[30]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[1]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[2]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[3]: https://www.openssl.org/
|
||||
[4]: http://www.dell.com/en-us/
|
||||
[5]: http://www.samsung.com/us/
|
||||
[6]: http://www.mozilla.com/
|
||||
[7]: https://krita.org/en/
|
||||
[8]: https://mycroft.ai/
|
||||
[9]: http://www.horizon-computing.com/
|
||||
[10]: https://www.archlinux.org/
|
||||
[11]: https://www.debian.org/
|
||||
[12]: https://www.gentoo.org/
|
||||
[13]: https://openwrt.org/
|
||||
[14]: https://www.documentfoundation.org/
|
||||
[15]: https://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[16]: https://www.mozilla.org/en-US/firefox/new/
|
||||
[17]: https://krita.org/en/about/krita-foundation/
|
||||
[18]: https://krita.org/en/item/krita-3-0-released/
|
||||
[19]: http://rpm5.org/
|
||||
[20]: https://www.debian.org/doc/manuals/debian-faq/ch-pkg_basics.en.html
|
||||
[21]: http://www.ubuntu.com/desktop/ubuntu-kylin
|
||||
[22]: https://launchpad.net/ubuntu/+source/snapd
|
||||
[23]: https://github.com/snapcore/snapd
|
||||
[24]: http://snapcraft.io/
|
||||
[25]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[26]: http://www.zdnet.com/article/ubuntu-linux-16-04-is-here/
|
||||
[27]: http://www.zdnet.com/article/microsoft-and-canonical-partner-to-bring-ubuntu-to-windows-10/
|
||||
|
||||
|
||||
@ -1,38 +1,32 @@
|
||||
Mock 在 Python 中的使用介绍
|
||||
Mock 在 Python 单元测试中的使用
|
||||
=====================================
|
||||
|
||||
本文讲述的是 Python 中 Mock 的使用
|
||||
本文讲述的是 Python 中 Mock 的使用。
|
||||
|
||||
**如何在避免测试你的耐心的情况下执行单元测试**
|
||||
|
||||
很多时候,我们编写的软件会直接与那些被标记为肮脏无比的服务交互。用外行人的话说:交互已设计好的服务对我们的应用程序很重要,但是这会给我们带来不希望的副作用,也就是那些在一个自动化测试运行的上下文中不希望的功能。
|
||||
|
||||
例如:我们正在写一个社交 app,并且想要测试一下 "发布到 Facebook" 的新功能,但是不想每次运行测试集的时候真的发布到 Facebook。
|
||||
### 如何执行单元测试而不用考验你的耐心
|
||||
|
||||
很多时候,我们编写的软件会直接与那些被标记为“垃圾”的服务交互。用外行人的话说:服务对我们的应用程序很重要,但是我们想要的是交互,而不是那些不想要的副作用,这里的“不想要”是在自动化测试运行的语境中说的。例如:我们正在写一个社交 app,并且想要测试一下 "发布到 Facebook" 的新功能,但是不想每次运行测试集的时候真的发布到 Facebook。
|
||||
|
||||
Python 的 `unittest` 库包含了一个名为 `unittest.mock` 或者可以称之为依赖的子包,简称为
|
||||
`mock` —— 其提供了极其强大和有用的方法,通过它们可以模拟和打桩来去除我们不希望的副作用。
|
||||
`mock` —— 其提供了极其强大和有用的方法,通过它们可以模拟(mock)并去除那些我们不希望的副作用。
|
||||
|
||||

|
||||
|
||||
>Source | <http://www.toptal.com/python/an-introduction-to-mocking-in-python>
|
||||
|
||||
> 注意:`mock` [最近收录][1]到了 Python 3.3 的标准库中;先前发布的版本必须通过 [PyPI][2] 下载 Mock 库。
|
||||
*注意:`mock` [最近被收录][1]到了 Python 3.3 的标准库中;先前发布的版本必须通过 [PyPI][2] 下载 Mock 库。*
|
||||
|
||||
### 恐惧系统调用
|
||||
|
||||
再举另一个例子,思考一个我们会在余文讨论的系统调用。不难发现,这些系统调用都是主要的模拟对象:无论你是正在写一个可以弹出 CD 驱动的脚本,还是一个用来删除 /tmp 下过期的缓存文件的 Web 服务,或者一个绑定到 TCP 端口的 socket 服务器,这些调用都是在你的单元测试上下文中不希望的副作用。
|
||||
再举另一个例子,我们在接下来的部分都会用到它,这是就是**系统调用**。不难发现,这些系统调用都是主要的模拟对象:无论你是正在写一个可以弹出 CD 驱动器的脚本,还是一个用来删除 /tmp 下过期的缓存文件的 Web 服务,或者一个绑定到 TCP 端口的 socket 服务器,这些调用都是在你的单元测试上下文中不希望产生的副作用。
|
||||
|
||||
> 作为一个开发者,你需要更关心你的库是否成功地调用了一个可以弹出 CD 的系统函数,而不是切身经历 CD 托盘每次在测试执行的时候都打开了。
|
||||
作为一个开发者,你需要更关心你的库是否成功地调用了一个可以弹出 CD 的系统函数(使用了正确的参数等等),而不是切身经历 CD 托盘每次在测试执行的时候都打开了。(或者更糟糕的是,弹出了很多次,在一个单元测试运行期间多个测试都引用了弹出代码!)
|
||||
|
||||
作为一个开发者,你需要更关心你的库是否成功地调用了一个可以弹出 CD 的系统函数(使用了正确的参数等等),而不是切身经历 CD 托盘每次在测试执行的时候都打开了。(或者更糟糕的是,很多次,在一个单元测试运行期间多个测试都引用了弹出代码!)
|
||||
同样,保持单元测试的效率和性能意味着需要让如此多的“缓慢代码”远离自动测试,比如文件系统和网络访问。
|
||||
|
||||
同样,保持单元测试的效率和性能意味着需要让如此多的 "缓慢代码" 远离自动测试,比如文件系统和网络访问。
|
||||
|
||||
对于首个例子,我们要从原始形式到使用 `mock` 重构一个标准 Python 测试用例。我们会演示如何使用 mock 写一个测试用例,使我们的测试更加智能、快速,并展示更多关于我们软件的工作原理。
|
||||
对于第一个例子来说,我们要从原始形式换成使用 `mock` 重构一个标准 Python 测试用例。我们会演示如何使用 mock 写一个测试用例,使我们的测试更加智能、快速,并展示更多关于我们软件的工作原理。
|
||||
|
||||
### 一个简单的删除函数
|
||||
|
||||
有时,我们都需要从文件系统中删除文件,因此,让我们在 Python 中写一个可以使我们的脚本更加轻易完成此功能的函数。
|
||||
我们都有过需要从文件系统中一遍又一遍的删除文件的时候,因此,让我们在 Python 中写一个可以使我们的脚本更加轻易完成此功能的函数。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
@ -73,9 +67,9 @@ class RmTestCase(unittest.TestCase):
|
||||
self.assertFalse(os.path.isfile(self.tmpfilepath), "Failed to remove the file.")
|
||||
```
|
||||
|
||||
我们的测试用例相当简单,但是在它每次运行的时候,它都会创建一个临时文件并且随后删除。此外,我们没有办法测试我们的 `rm` 方法是否正确地将我们的参数向下传递给 `os.remove` 调用。我们可以基于以上的测试认为它做到了,但还有很多需要改进的地方。
|
||||
我们的测试用例相当简单,但是在它每次运行的时候,它都会创建一个临时文件并且随后删除。此外,我们没有办法测试我们的 `rm` 方法是否正确地将我们的参数向下传递给 `os.remove` 调用。我们可以基于以上的测试*认为*它做到了,但还有很多需要改进的地方。
|
||||
|
||||
### 使用 Mock 重构
|
||||
#### 使用 Mock 重构
|
||||
|
||||
让我们使用 mock 重构我们的测试用例:
|
||||
|
||||
@ -99,24 +93,23 @@ class RmTestCase(unittest.TestCase):
|
||||
|
||||
使用这些重构,我们从根本上改变了测试用例的操作方式。现在,我们有一个可以用于验证其他功能的内部对象。
|
||||
|
||||
### 潜在陷阱
|
||||
##### 潜在陷阱
|
||||
|
||||
第一件需要注意的事情就是,我们使用了 `mock.patch` 方法装饰器,用于模拟位于 `mymodule.os` 的对象,并且将 mock 注入到我们的测试用例方法。那么只是模拟 `os` 本身,而不是 `mymodule.os` 下 `os` 的引用(注意 `@mock.patch('mymodule.os')` 便是模拟 `mymodule.os` 下的 `os`,译者注),会不会更有意义呢?
|
||||
第一件需要注意的事情就是,我们使用了 `mock.patch` 方法装饰器,用于模拟位于 `mymodule.os` 的对象,并且将 mock 注入到我们的测试用例方法。那么只是模拟 `os` 本身,而不是 `mymodule.os` 下 `os` 的引用(LCTT 译注:注意 `@mock.patch('mymodule.os')` 便是模拟 `mymodule.os` 下的 `os`),会不会更有意义呢?
|
||||
|
||||
当然,当涉及到导入和管理模块,Python 的用法非常灵活。在运行时,`mymodule` 模块拥有被导入到本模块局部作用域的 `os`。因此,如果我们模拟 `os`,我们是看不到 mock 在 `mymodule` 模块中的作用的。
|
||||
当然,当涉及到导入和管理模块,Python 的用法就像蛇一样灵活。在运行时,`mymodule` 模块有它自己的被导入到本模块局部作用域的 `os`。因此,如果我们模拟 `os`,我们是看不到 mock 在 `mymodule` 模块中的模仿作用的。
|
||||
|
||||
这句话需要深刻地记住:
|
||||
|
||||
> 模拟测试一个项目,只需要了解它用在哪里,而不是它从哪里来。
|
||||
> 模拟一个东西要看它用在何处,而不是来自哪里。
|
||||
|
||||
如果你需要为 `myproject.app.MyElaborateClass` 模拟 `tempfile` 模块,你可能需要将 mock 用于 `myproject.app.tempfile`,而其他模块保持自己的导入。
|
||||
|
||||
先将那个陷阱置身事外,让我们继续模拟。
|
||||
先将那个陷阱放一边,让我们继续模拟。
|
||||
|
||||
### 向 ‘rm’ 中加入验证
|
||||
|
||||
之前定义的 rm 方法相当的简单。在盲目地删除之前,我们倾向于验证一个路径是否存在,并验证其是否是一个文件。让我们重构 rm 使其变得更加智能:
|
||||
#### 向 ‘rm’ 中加入验证
|
||||
|
||||
之前定义的 rm 方法相当的简单。在盲目地删除之前,我们倾向于验证一个路径是否存在,并验证其是否是一个文件。让我们重构 rm 使其变得更加智能:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
@ -162,11 +155,11 @@ class RmTestCase(unittest.TestCase):
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
我们的测试用例完全改变了。现在我们可以在没有任何副作用下核实并验证方法的内部功能。
|
||||
我们的测试用例完全改变了。现在我们可以在没有任何副作用的情况下核实并验证方法的内部功能。
|
||||
|
||||
### 将文件删除作为服务
|
||||
#### 将文件删除作为服务
|
||||
|
||||
到目前为止,我们只是将 mock 应用在函数上,并没应用在需要传递参数的对象和实例的方法。我们现在开始涵盖对象的方法。
|
||||
到目前为止,我们只是将 mock 应用在函数上,并没应用在需要传递参数的对象和实例的方法上。我们现在开始涵盖对象的方法。
|
||||
|
||||
首先,我们将 `rm` 方法重构成一个服务类。实际上将这样一个简单的函数转换成一个对象,在本质上这不是一个合理的需求,但它能够帮助我们了解 `mock` 的关键概念。让我们开始重构:
|
||||
|
||||
@ -220,8 +213,7 @@ class RemovalServiceTestCase(unittest.TestCase):
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
很好,我们知道 `RemovalService` 会如期工作。接下来让我们创建另一个服务,将 `RemovalService` 声明为它的一个依赖:
|
||||
:
|
||||
很好,我们知道 `RemovalService` 会如预期般的工作。接下来让我们创建另一个服务,将 `RemovalService` 声明为它的一个依赖:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
@ -256,7 +248,7 @@ class UploadService(object):
|
||||
|
||||
因为这两种方法都是单元测试中非常重要的方法,所以我们将同时对这两种方法进行回顾。
|
||||
|
||||
### 方法 1:模拟实例的方法
|
||||
##### 方法 1:模拟实例的方法
|
||||
|
||||
`mock` 库有一个特殊的方法装饰器,可以模拟对象实例的方法和属性,即 `@mock.patch.object decorator` 装饰器:
|
||||
|
||||
@ -311,9 +303,9 @@ class UploadServiceTestCase(unittest.TestCase):
|
||||
removal_service.rm.assert_called_with("my uploaded file")
|
||||
```
|
||||
|
||||
非常棒!我们验证了 UploadService 成功调用了我们实例的 rm 方法。你是否注意到一些有趣的地方?这种修补机制(patching mechanism)实际上替换了我们测试用例中的所有 `RemovalService` 实例的 `rm` 方法。这意味着我们可以检查实例本身。如果你想要了解更多,可以试着在你模拟的代码下断点,以对这种修补机制的原理获得更好的认识。
|
||||
非常棒!我们验证了 `UploadService` 成功调用了我们实例的 `rm` 方法。你是否注意到一些有趣的地方?这种修补机制(patching mechanism)实际上替换了我们测试用例中的所有 `RemovalService` 实例的 `rm` 方法。这意味着我们可以检查实例本身。如果你想要了解更多,可以试着在你模拟的代码下断点,以对这种修补机制的原理获得更好的认识。
|
||||
|
||||
### 陷阱:装饰顺序
|
||||
##### 陷阱:装饰顺序
|
||||
|
||||
当我们在测试方法中使用多个装饰器,其顺序是很重要的,并且很容易混乱。基本上,当装饰器被映射到方法参数时,[装饰器的工作顺序是反向的][3]。思考这个例子:
|
||||
|
||||
@ -326,17 +318,17 @@ class UploadServiceTestCase(unittest.TestCase):
|
||||
pass
|
||||
```
|
||||
|
||||
注意到我们的参数和装饰器的顺序是反向匹配了吗?这多多少少是由 [Python 的工作方式][4] 导致的。这里是使用多个装饰器的情况下它们执行顺序的伪代码:
|
||||
注意到我们的参数和装饰器的顺序是反向匹配了吗?这部分是由 [Python 的工作方式][4]所导致的。这里是使用多个装饰器的情况下它们执行顺序的伪代码:
|
||||
|
||||
```
|
||||
patch_sys(patch_os(patch_os_path(test_something)))
|
||||
```
|
||||
|
||||
因为 sys 补丁位于最外层,所以它最晚执行,使得它成为实际测试方法参数的最后一个参数。请特别注意这一点,并且在运行你的测试用例时,使用调试器来保证正确的参数以正确的顺序注入。
|
||||
因为 `sys` 补丁位于最外层,所以它最晚执行,使得它成为实际测试方法参数的最后一个参数。请特别注意这一点,并且在运行你的测试用例时,使用调试器来保证正确的参数以正确的顺序注入。
|
||||
|
||||
### 方法 2:创建 Mock 实例
|
||||
##### 方法 2:创建 Mock 实例
|
||||
|
||||
我们可以使用构造函数为 UploadService 提供一个 Mock 实例,而不是模拟特定的实例方法。我更推荐方法 1,因为它更加精确,但在多数情况,方法 2 或许更加有效和必要。让我们再次重构测试用例:
|
||||
我们可以使用构造函数为 `UploadService` 提供一个 Mock 实例,而不是模拟特定的实例方法。我更推荐方法 1,因为它更加精确,但在多数情况,方法 2 或许更加有效和必要。让我们再次重构测试用例:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
@ -385,13 +377,13 @@ class UploadServiceTestCase(unittest.TestCase):
|
||||
mock_removal_service.rm.assert_called_with("my uploaded file")
|
||||
```
|
||||
|
||||
在这个例子中,我们甚至不需要补充任何功能,只需为 `RemovalService` 类创建一个 auto-spec,然后将实例注入到我们的 `UploadService` 以验证功能。
|
||||
在这个例子中,我们甚至不需要修补任何功能,只需为 `RemovalService` 类创建一个 auto-spec,然后将实例注入到我们的 `UploadService` 以验证功能。
|
||||
|
||||
`mock.create_autospec` 方法为类提供了一个同等功能实例。实际上来说,这意味着在使用返回的实例进行交互的时候,如果使用了非法的方式将会引发异常。更具体地说,如果一个方法被调用时的参数数目不正确,将引发一个异常。这对于重构来说是非常重要。当一个库发生变化的时候,中断测试正是所期望的。如果不使用 auto-spec,尽管底层的实现已经被破坏,我们的测试仍然会通过。
|
||||
|
||||
### 陷阱:mock.Mock 和 mock.MagicMock 类
|
||||
##### 陷阱:mock.Mock 和 mock.MagicMock 类
|
||||
|
||||
`mock` 库包含了两个重要的类 [mock.Mock](http://www.voidspace.org.uk/python/mock/mock.html) 和 [mock.MagicMock](http://www.voidspace.org.uk/python/mock/magicmock.html#magic-mock),大多数内部函数都是建立在这两个类之上的。当在选择使用 `mock.Mock` 实例,`mock.MagicMock` 实例或 auto-spec 的时候,通常倾向于选择使用 auto-spec,因为对于未来的变化,它更能保持测试的健全。这是因为 `mock.Mock` 和 `mock.MagicMock` 会无视底层的 API,接受所有的方法调用和属性赋值。比如下面这个用例:
|
||||
`mock` 库包含了两个重要的类 [mock.Mock](http://www.voidspace.org.uk/python/mock/mock.html) 和 [mock.MagicMock](http://www.voidspace.org.uk/python/mock/magicmock.html#magic-mock),大多数内部函数都是建立在这两个类之上的。当在选择使用 `mock.Mock` 实例、`mock.MagicMock` 实例还是 auto-spec 的时候,通常倾向于选择使用 auto-spec,因为对于未来的变化,它更能保持测试的健全。这是因为 `mock.Mock` 和 `mock.MagicMock` 会无视底层的 API,接受所有的方法调用和属性赋值。比如下面这个用例:
|
||||
|
||||
```
|
||||
class Target(object):
|
||||
@ -430,7 +422,7 @@ class Target(object):
|
||||
|
||||
### 现实例子:模拟 Facebook API 调用
|
||||
|
||||
为了完成,我们写一个更加适用的现实例子,一个在介绍中提及的功能:发布消息到 Facebook。我将写一个不错的包装类及其对应的测试用例。
|
||||
作为这篇文章的结束,我们写一个更加适用的现实例子,一个在介绍中提及的功能:发布消息到 Facebook。我将写一个不错的包装类及其对应的测试用例。
|
||||
|
||||
```
|
||||
import facebook
|
||||
@ -468,15 +460,15 @@ class SimpleFacebookTestCase(unittest.TestCase):
|
||||
|
||||
### Python Mock 总结
|
||||
|
||||
对 [单元测试][7] 来说,Python 的 `mock` 库可以说是一个游戏变革者,即使对于它的使用还有点困惑。我们已经演示了单元测试中常见的用例以开始使用 `mock`,并希望这篇文章能够帮助 [Python 开发者][8] 克服初期的障碍,写出优秀、经受过考验的代码。
|
||||
即使对它的使用还有点不太熟悉,对[单元测试][7]来说,Python 的 `mock` 库可以说是一个规则改变者。我们已经演示了常见的用例来了解了 `mock` 在单元测试中的使用,希望这篇文章能够帮助 [Python 开发者][8]克服初期的障碍,写出优秀、经受过考验的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://slviki.com/index.php/2016/06/18/introduction-to-mocking-in-python/
|
||||
via: https://www.toptal.com/python/an-introduction-to-mocking-in-python
|
||||
|
||||
作者:[Dasun Sucharith][a]
|
||||
作者:[NAFTULI TZVI KAY][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,279 @@
|
||||
使用 Docker Swarm 部署可扩展的 Python3 应用
|
||||
==============
|
||||
|
||||
[Ben Firshman][2] 最近在 [Dockercon][1] 做了一个关于使用 Docker 构建无服务应用的演讲,你可以在[这里查看详情][3](还有视频)。之后,我写了一篇关于如何使用 [AWS Lambda][5] 构建微服务系统的[文章][4]。
|
||||
|
||||
今天,我想展示给你的就是如何使用 [Docker Swarm][6] 部署一个简单的 Python Falcon REST 应用。这里我不会使用[dockerrun][7] 或者是其他无服务特性,你可能会惊讶,使用 Docker Swarm 部署(复制)一个 Python(Java、Go 都一样)应用是如此的简单。
|
||||
|
||||
注意:这展示的部分步骤是截取自 [Swarm Tutorial][8],我已经修改了部分内容,并且[增加了一个 Vagrant Helper 的仓库][9]来启动一个可以让 Docker Swarm 工作起来的本地测试环境。请确保你使用的是 1.12 或以上版本的 Docker Engine。我写这篇文章的时候,使用的是 1.12RC2 版本。注意的是,这只是一个测试版本,可能还会有修改。
|
||||
|
||||
你要做的第一件事,就是如果你想本地运行的话,你要保证 [Vagrant][10] 已经正确的安装和运行了。你也可以按如下步骤使用你最喜欢的云服务提供商部署 Docker Swarm 虚拟机系统。
|
||||
|
||||
我们将会使用这三台 VM:一个简单的 Docker Swarm 管理平台和两台 worker。
|
||||
|
||||
安全注意事项:Vagrantfile 代码中包含了部分位于 Docker 测试服务器上的 shell 脚本。这是一个潜在的安全问题,它会运行你不能控制的脚本,所以请确保你会在运行代码之前[审查过这部分的脚本][11]。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/chadlung/vagrant-docker-swarm
|
||||
$ cd vagrant-docker-swarm
|
||||
$ vagrant plugin install vagrant-vbguest
|
||||
$ vagrant up
|
||||
```
|
||||
|
||||
Vagrant up 命令需要一些时间才能完成。
|
||||
|
||||
SSH 登陆进入 manager1 虚拟机:
|
||||
|
||||
```
|
||||
$ vagrant ssh manager1
|
||||
```
|
||||
|
||||
在 manager1 的 ssh 终端会话中执行如下命令:
|
||||
|
||||
```
|
||||
$ sudo docker swarm init --listen-addr 192.168.99.100:2377
|
||||
```
|
||||
|
||||
现在还没有 worker 注册上来:
|
||||
|
||||
```
|
||||
$ sudo docker node ls
|
||||
```
|
||||
|
||||
让我们注册两个新的 worker,请打开两个新的终端会话(保持 manager1 会话继续运行):
|
||||
|
||||
```
|
||||
$ vagrant ssh worker1
|
||||
```
|
||||
|
||||
在 worker1 的 ssh 终端会话上执行如下命令:
|
||||
|
||||
```
|
||||
$ sudo docker swarm join 192.168.99.100:2377
|
||||
```
|
||||
|
||||
在 worker2 的 ssh 终端会话上重复这些命令。
|
||||
|
||||
在 manager1 终端上执行如下命令:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||

|
||||
|
||||
在 manager1 的终端里部署一个简单的服务。
|
||||
|
||||
```
|
||||
sudo docker service create --replicas 1 --name pinger alpine ping google.com
|
||||
```
|
||||
|
||||
这个命令将会部署一个服务,它会从 worker 之一 ping google.com。(或者 manager,manager 也可以运行服务,不过如果你只是想 worker 运行容器的话,[也可以禁用这一点][12])。可以使用如下命令,查看哪些节点正在执行服务:
|
||||
|
||||
```
|
||||
$ sudo docker service tasks pinger
|
||||
```
|
||||
|
||||
结果会和这个比较类似:
|
||||
|
||||

|
||||
|
||||
所以,我们知道了服务正跑在 worker1 上。我们可以回到 worker1 的会话里,然后进入正在运行的容器:
|
||||
|
||||
```
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以看到容器的 id 是: ae56769b9d4d,在我的例子中,我运行如下的代码:
|
||||
|
||||
```
|
||||
$ sudo docker attach ae56769b9d4d
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以按下 CTRL-C 来停止服务。
|
||||
|
||||
回到 manager1,然后移除这个 pinger 服务。
|
||||
|
||||
```
|
||||
$ sudo docker service rm pinger
|
||||
```
|
||||
|
||||
现在,我们将会部署可复制的 Python 应用。注意,为了保持文章的简洁,而且容易复制,所以部署的是一个简单的应用。
|
||||
|
||||
你需要做的第一件事就是将镜像放到 [Docker Hub][13]上,或者使用我[已经上传的一个][14]。这是一个简单的 Python 3 Falcon REST 应用。它有一个简单的入口: /hello 带一个 value 参数。
|
||||
|
||||
放在 [chadlung/hello-app][15] 上的 Python 代码看起来像这样:
|
||||
|
||||
```
|
||||
import json
|
||||
from wsgiref import simple_server
|
||||
|
||||
import falcon
|
||||
|
||||
|
||||
class HelloResource(object):
|
||||
def on_get(self, req, resp):
|
||||
try:
|
||||
value = req.get_param('value')
|
||||
|
||||
resp.content_type = 'application/json'
|
||||
resp.status = falcon.HTTP_200
|
||||
resp.body = json.dumps({'message': str(value)})
|
||||
except Exception as ex:
|
||||
resp.status = falcon.HTTP_500
|
||||
resp.body = str(ex)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
app = falcon.API()
|
||||
hello_resource = HelloResource()
|
||||
app.add_route('/hello', hello_resource)
|
||||
httpd = simple_server.make_server('0.0.0.0', 8080, app)
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
Dockerfile 很简单:
|
||||
|
||||
```
|
||||
FROM python:3.4.4
|
||||
|
||||
RUN pip install -U pip
|
||||
RUN pip install -U falcon
|
||||
|
||||
EXPOSE 8080
|
||||
|
||||
COPY . /hello-app
|
||||
WORKDIR /hello-app
|
||||
|
||||
CMD ["python", "app.py"]
|
||||
```
|
||||
|
||||
上面表示的意思很简单,如果你想,你可以在本地运行该进行来访问这个入口: <http://127.0.0.1:8080/hello?value=Fred>
|
||||
|
||||
这将返回如下结果:
|
||||
|
||||
```
|
||||
{"message": "Fred"}
|
||||
```
|
||||
|
||||
在 Docker Hub 上构建和部署这个 hello-app(修改成你自己的 Docker Hub 仓库或者[使用这个][15]):
|
||||
|
||||
```
|
||||
$ sudo docker build . -t chadlung/hello-app:2
|
||||
$ sudo docker push chadlung/hello-app:2
|
||||
```
|
||||
|
||||
现在,我们可以将应用部署到之前的 Docker Swarm 了。登录 manager1 的 ssh 终端会话,并且执行:
|
||||
|
||||
```
|
||||
$ sudo docker service create -p 8080:8080 --replicas 2 --name hello-app chadlung/hello-app:2
|
||||
$ sudo docker service inspect --pretty hello-app
|
||||
$ sudo docker service tasks hello-app
|
||||
```
|
||||
|
||||
现在,我们已经可以测试了。使用任何一个 Swarm 节点的 IP 来访问 /hello 入口。在本例中,我在 manager1 的终端里使用 curl 命令:
|
||||
|
||||
注意,Swarm 中的所有的 IP 都可以,不管这个服务是运行在一台还是更多的节点上。
|
||||
|
||||
```
|
||||
$ curl -v -X GET "http://192.168.99.100:8080/hello?value=Chad"
|
||||
$ curl -v -X GET "http://192.168.99.101:8080/hello?value=Test"
|
||||
$ curl -v -X GET "http://192.168.99.102:8080/hello?value=Docker"
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
* Hostname was NOT found in DNS cache
|
||||
* Trying 192.168.99.101...
|
||||
* Connected to 192.168.99.101 (192.168.99.101) port 8080 (#0)
|
||||
> GET /hello?value=Chad HTTP/1.1
|
||||
> User-Agent: curl/7.35.0
|
||||
> Host: 192.168.99.101:8080
|
||||
> Accept: */*
|
||||
>
|
||||
* HTTP 1.0, assume close after body
|
||||
< HTTP/1.0 200 OK
|
||||
< Date: Tue, 28 Jun 2016 23:52:55 GMT
|
||||
< Server: WSGIServer/0.2 CPython/3.4.4
|
||||
< content-type: application/json
|
||||
< content-length: 19
|
||||
<
|
||||
{"message": "Chad"}
|
||||
```
|
||||
|
||||
从浏览器中访问其他节点:
|
||||
|
||||

|
||||
|
||||
如果你想看运行的所有服务,你可以在 manager1 节点上运行如下代码:
|
||||
|
||||
```
|
||||
$ sudo docker service ls
|
||||
```
|
||||
|
||||
如果你想添加可视化控制平台,你可以安装 [Docker Swarm Visualizer][16](这对于展示非常方便)。在 manager1 的终端中执行如下代码:
|
||||
|
||||
```
|
||||
$ sudo docker run -it -d -p 5000:5000 -e HOST=192.168.99.100 -e PORT=5000 -v /var/run/docker.sock:/var/run/docker.sock manomarks/visualizer)
|
||||
```
|
||||
|
||||
打开你的浏览器,并且访问: <http://192.168.99.100:5000/>
|
||||
|
||||
结果如下(假设已经运行了两个 Docker Swarm 服务):
|
||||
|
||||

|
||||
|
||||
要停止运行 hello-app(已经在两个节点上运行了),可以在 manager1 上执行这个代码:
|
||||
|
||||
```
|
||||
$ sudo docker service rm hello-app
|
||||
```
|
||||
|
||||
如果想停止 Visualizer, 那么在 manager1 的终端中执行:
|
||||
|
||||
```
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
获得容器的 ID,这里是: f71fec0d3ce1,从 manager1 的终端会话中执行这个代码:
|
||||
|
||||
```
|
||||
$ sudo docker stop f71fec0d3ce1
|
||||
```
|
||||
|
||||
祝你成功使用 Docker Swarm。这篇文章主要是以 1.12 版本来进行描述的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.giantflyingsaucer.com/blog/?p=5923
|
||||
|
||||
作者:[Chad Lung][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.giantflyingsaucer.com/blog/?author=2
|
||||
[1]: http://dockercon.com/
|
||||
[2]: https://blog.docker.com/author/bfirshman/
|
||||
[3]: https://blog.docker.com/author/bfirshman/
|
||||
[4]: http://www.giantflyingsaucer.com/blog/?p=5730
|
||||
[5]: https://aws.amazon.com/lambda/
|
||||
[6]: https://docs.docker.com/swarm/
|
||||
[7]: https://github.com/bfirsh/dockerrun
|
||||
[8]: https://docs.docker.com/engine/swarm/swarm-tutorial/
|
||||
[9]: https://github.com/chadlung/vagrant-docker-swarm
|
||||
[10]: https://www.vagrantup.com/
|
||||
[11]: https://test.docker.com/
|
||||
[12]: https://docs.docker.com/engine/reference/commandline/swarm_init/
|
||||
[13]: https://hub.docker.com/
|
||||
[14]: https://hub.docker.com/r/chadlung/hello-app/
|
||||
[15]: https://hub.docker.com/r/chadlung/hello-app/
|
||||
[16]: https://github.com/ManoMarks/docker-swarm-visualizer
|
||||
@ -0,0 +1,79 @@
|
||||
如何在 nginx 中缓存静态文件
|
||||
===========================
|
||||
|
||||
这篇教程说明你应该怎样配置 nginx、设置 HTTP 头部过期时间,用 Cache-Control 中的 max-age 标记为静态文件(比如图片、 CSS 和 Javascript 文件)设置一个时间,这样用户的浏览器就会缓存这些文件。这样能节省带宽,并且在访问你的网站时会显得更快些(如果用户第二次访问你的网站,将会使用浏览器缓存中的静态文件)。
|
||||
|
||||
### 1、准备事项
|
||||
|
||||
我想你需要一个正常工作的 nginx 软件,就像这篇教程里展示的:[在 Ubuntu 16.04 LTS 上安装 Nginx,PHP 7 和 MySQL 5.7 (LEMP)](1)。
|
||||
|
||||
### 2 配置 nginx
|
||||
|
||||
可以参考 [expires](2) 指令手册来设置 HTTP 头部过期时间,这个标记可以放在 `http {}`、`server {}`、`location {}` 等语句块或者 `location {}` 语句块中的条件语句中。一般会在 `location` 语句块中用 `expires` 指令控制你的静态文件,就像下面一样:
|
||||
|
||||
```
|
||||
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
|
||||
expires 365d;
|
||||
}
|
||||
```
|
||||
|
||||
在上面的例子中,所有后缀名是 `.jpg`、 `.jpeg`、 `.png`、 `.gif`、 `.ico`、 `.css` 和 `.js` 的文件会在浏览器访问该文件之后的 365 天后过期。因此你要确保 `location {}` 语句块仅仅包含能被浏览器缓存的静态文件。
|
||||
|
||||
然后重启 nginx 进程:
|
||||
|
||||
```
|
||||
/etc/init.d/nginx reload
|
||||
```
|
||||
|
||||
你可以在 `expires` 指令中使用以下的时间设置:
|
||||
|
||||
- `off` 让 `Expires` 和 `Cache-Control` 头部不能被更改。
|
||||
- `epoch` 将 `Expires` 头部设置成 1970 年 1 月 1 日 00:00:01。
|
||||
- `max` 设置 `Expires` 头部为 2037 年 12 月 31 日 23:59:59,设置 `Cache-Control` 的最大存活时间为 10 年
|
||||
- 没有 `@` 前缀的时间意味着这是一个与浏览器访问时间有关的过期时间。可以指定一个负值的时间,就会把 Cache-Control 头部设置成 no-cache。例如:`expires 10d` 或者 `expires 14w3d`。
|
||||
- 有 `@` 前缀的时间指定在一天中的某个时间过期,格式是 Hh 或者 Hh:Mm,H 的范围是 0 到 24,M 的范围是 0 到 59,例如:`expires @15:34`。
|
||||
|
||||
你可以用以下的时间单位:
|
||||
|
||||
- `ms`: 毫秒
|
||||
- `s`: 秒
|
||||
- `m`: 分钟
|
||||
- `h`: 小时
|
||||
- `d`: 天
|
||||
- `w`: 星期
|
||||
- `M`: 月 (30 天)
|
||||
- `y`: 年 (365 天)
|
||||
|
||||
例如:`1h30m` 表示一小时三十分钟,`1y6m` 表示一年六个月。
|
||||
|
||||
注意,要是你用一个在将来很久才会过期的头部,当组件修改时你就要改变组件的文件名。因此给文件指定版本是一个不错的方法。例如,如果你有个 javascript.js 文件 并且你要修改它,你可以在修改的文件名字后面添加一个版本号。这样浏览器就要下载这个文件,如果你没有更改文件名,浏览器将从缓存里面加载(旧的)文件。
|
||||
|
||||
除了把基于浏览器访问时间设置 `Expires` 头部(比如 `expires 10d`)之外,也可以通过在时间前面的 `modified` 关键字,将 `Expires` 头部的基准设为文件修改的时间(请注意这仅仅对存储在硬盘的实际文件有效)。
|
||||
|
||||
```
|
||||
expires modified 10d;
|
||||
```
|
||||
|
||||
### 3 测试
|
||||
|
||||
要测试你的配置是否有效,可以用火狐浏览器的开发者工具中的网络分析功能,然后用火狐访问一个静态文件(比如一张图片)。在输出的头部信息里,应该能看到 `Expires` 头部和有 `max-age` 标记的 `Cache-Control` 头部(`max-age` 标记包含了一个以秒为单位的值,比如 31536000 就是指今后的一年)
|
||||
|
||||
|
||||
|
||||
### 4 链接
|
||||
|
||||
nginx 的 Http 头部模块(HttpHeadersModule): <http://wiki.nginx.org/HttpHeadersModule>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-cache-static-files-on-nginx/
|
||||
|
||||
作者:[Falko Timme][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/how-to-cache-static-files-on-nginx/
|
||||
[1]: https://linux.cn/article-7551-1.html
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_headers_module.html#expires
|
||||
43
published/201608/20160809 7 reasons to love Vim.md
Normal file
43
published/201608/20160809 7 reasons to love Vim.md
Normal file
@ -0,0 +1,43 @@
|
||||
爱 Vim 的七个理由
|
||||
====================
|
||||
|
||||

|
||||
|
||||
当我刚刚开始用 vi 文本编辑器的时候,我憎恨它!我认为这是有史以来设计上最痛苦和反人类的编辑器。但我还是决定我必须学会它,因为如果你使用的是 Unix,vi 无处不在并且是唯一一个保证你可以使用的编辑器。在 1998 年是如此,但是直到今天 vi 也仍然是可用的,现有的几乎每个发行版中,vi 基本上都是基础安装的一部分。
|
||||
|
||||
在我学会能使用任何功能前,我已经在 vi 上花费差不多 1 个月的时间,但是我仍然不喜欢它。不过那时我已经意识到有个强大的编辑器隐藏在这个古怪的外表后面。所以我坚持使用它,并且最终发现一旦你知道你在干什么,它就是一个快的令人难以置信的编辑器。
|
||||
|
||||
“vi” 这个名称是 “可视(visual)” 的缩写。在 vi 出现的时候,行编辑器是很普遍的,能一次性显示并编辑多个行是非同寻常的。Vim,来自“Vi IMproved”的缩写,最初由 Bram Moolenaar 发布于 1991 年,它成为了主要的仿 vi 软件,并且扩展了这个强大的编辑器已有的功能。Vim 强大的正则表达式和“:”命令行语法开始于行编辑和电传打字机时代。
|
||||
|
||||
Vim,有 40 年的历史了,有足够的时间发展出海量而复杂的技巧,即使是懂得最多的用户都不能完全掌握它。这里列出了一些爱 Vim 的理由:
|
||||
|
||||
1. 配色方案:你可能知道 Vim 有彩色语法高亮。但你知道可以下载数以百计的配色方案么?[在这找到些更好的][1]。
|
||||
2. 你再也不需要让你的手离开键盘或者去碰触鼠标。
|
||||
3. Vi 或者 Vim 存在任何地方,甚至在 [OpenWRT][2] 里面也有 vi(好吧,其实是在 [BusyBox][3]中,它挺好用的)。
|
||||
4. Vimscript:你可能会想重映射几个键,但是你知道 Vim 有自己的编程语言么?你可以重新定义你的编辑器的行为,或者创造特定语言的编辑器扩展。(最近我在定制 Vim 用于 Ansible 的行为。)学习这个语言最佳的切入点是看 Steve Losh 著名的书《[Learn Vimscript the Hard Way][4]》。
|
||||
5. Vim 有插件。使用 [vundle][5](我用的就是它)或者 [Pathogen][6] 来管理你的插件来提升 Vim 的功能。
|
||||
6. 插件可以将 git(或者你选择的 VCS)集成到 Vim 中。
|
||||
7. 有庞大而活跃的线上社区,如果你在线上提问关于 Vim 的问题,肯定会有人回答。
|
||||
|
||||
我一开始讨厌 vi 的可笑之处在于,这 5 年来不断的在尝试新的编辑器中碰壁,总是想找到“一些更好的”。我从来没有像讨厌 vi 一样讨厌过其它的编辑器,现在我已经使用它 17 年了,因为我想象不出一个更好的编辑器。额,或许有稍微好一点的:可以尝试下 Neovim -这是未来的主流。看起来 Bram Moolenaar 将会把 Neovim 的大部分融入到 Vim 第 8 版中,这意味着将会在现有的代码基础上减少 30%、更好的代码补全功能、真正的异步、内置终端、内置鼠标支持、完全兼容。
|
||||
|
||||
*在本文作者在多伦多的 [LinuxCon 演讲][7]中(LCTT 译注:LinuxCon 是 Linux 基金会举办的年度会议),他解释了一些在你可能错过的、过去四十年增加的杂乱的扩展和改进。这个内容不适合初学者,所以如果你不知道为什么“hjklia:wq”是很重要的,这就可能不是讲给你听的。它还会涉及一点关于 vi 的历史,因为知道一些历史能帮助我们理解我们的处境。关注他的演讲能让你知道如何使你最喜欢的编辑器更好更快。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/8/7-reasons-love-vim
|
||||
|
||||
作者:[Giles Orr][a]
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gilesorr
|
||||
[1]: http://www.gilesorr.com/blog/vim-colours.html
|
||||
[2]: https://www.openwrt.org/
|
||||
[3]: https://busybox.net/
|
||||
[4]: http://learnvimscriptthehardway.stevelosh.com/
|
||||
[5]: https://github.com/VundleVim/Vundle.vim
|
||||
[6]: https://github.com/tpope/vim-pathogen
|
||||
[7]: http://sched.co/7JWz
|
||||
@ -0,0 +1,59 @@
|
||||
浅谈 Linux 容器和镜像签名
|
||||
====================
|
||||
|
||||

|
||||
|
||||
从根本上说,几乎所有的主要软件,即使是开源软件,都是在基于镜像的容器技术出现之前设计的。这意味着把软件放到容器中相当于是一次平台移植。这也意味着一些程序可以很容易就迁移,[而一些就更困难][1]。
|
||||
|
||||
我大约在三年半前开展基于镜像的容器相关工作。到目前为止,我已经容器化了大量应用。我了解到什么是现实情况,什么是迷信。今天,我想简要介绍一下 Linux 容器是如何设计的,以及谈谈镜像签名。
|
||||
|
||||
### Linux 容器是如何设计的
|
||||
|
||||
对于基于镜像的 Linux 容器,让大多数人感到困惑的是,它把操作系统分割成两个部分:[内核空间与用户空间][2]。在传统操作系统中,内核运行在硬件上,你无法直接与其交互。用户空间才是你真正能交互的,这包括所有你可以通过文件浏览器或者运行`ls`命令能看到的文件、类库、程序。当你使用`ifconfig`命令调整 IP 地址时,你实际上正在借助用户空间的程序来使内核根据 TCP 协议栈改变。这点经常让没有研究过 [Linux/Unix 基础][3]的人大吃一惊。
|
||||
|
||||
过去,用户空间中的类库支持了与内核交互的程序(比如 ifconfig、sysctl、tuned-adm)以及如网络服务器和数据库之类的面向用户的程序。这些所有的东西都堆积在一个单一的文件系统结构中。用户可以在 /sbin 或者 /lib 文件夹中找到所有操作系统本身支持的程序和类库,或者可以在 /usr/sbin 或 /usr/lib 文件夹中找到所有面向用户的程序或类库(参阅[文件系统层次结构标准][4])。这个模型的问题在于操作系统程序和业务支持程序没有绝对的隔离。/usr/bin 中的程序可能依赖 /lib 中的类库。如果一个应用所有者需要改变一些东西,就很有可能破坏操作系统。相反地,如果负责安全更新的团队需要改变一个类库,就(常常)有可能破坏面向业务的应用。这真是一团糟。
|
||||
|
||||
借助基于镜像的容器,比如 Docker、LXD、RKT,应用程序所有者可以打包和调整所有放在 /sbin、/lib、/usr/bin 和 /usr/lib 中的依赖部分,而不用担心破坏底层操作系统。本质上讲,容器技术再次干净地将操作系统隔离为两部分:内核空间与用户空间。现在开发人员和运维人员可以分别独立地更新各自的东西。
|
||||
|
||||
然而还是有些令人困扰的地方。通常,每个应用所有者(或开发者)并不想负责更新这些应用依赖:像 openssl、glibc,或很底层的基础组件,比如,XML 解析器、JVM,再或者处理与性能相关的设置。过去,这些问题都委托给运维团队来处理。由于我们在容器中打包了很多依赖,对于很多组织来讲,对容器内的所有东西负责仍是个严峻的问题。
|
||||
|
||||
### 迁移现有应用到 Linux 容器
|
||||
|
||||
把应用放到容器中算得上是平台移植,我准备突出介绍究竟是什么让移植某些应用到容器当中这么困难。
|
||||
|
||||
(通过容器,)开发者现在对 /sbin 、/lib、 /usr/bin、 /usr/lib 中的内容有完全的控制权。但是,他们面临的挑战是,他们仍需要将数据和配置放到 /etc 或者 /var/lib 文件夹中。对于基于镜像的容器来说,这是一个糟糕的想法。我们真正需要的是代码、配置以及数据的隔离。我们希望开发者把代码放在容器当中,而数据和配置通过不同的环境(比如,开发、测试或生产环境)来获得。
|
||||
|
||||
这意味着我们(或者说平台)在实例化容器时,需要挂载 /etc 或 /var/lib 中的一些文件或文件夹。这会允许我们到处移动容器并仍能从环境中获得数据和配置。听起来很酷吧?这里有个问题,我们需要能够干净地隔离配置和数据。很多现代开源软件比如 Apache、MySQL、MongoDB、Nginx 默认就这么做了。[但很多自产的、历史遗留的、或专有程序并未默认这么设计][5]。对于很多组织来讲,这是主要的痛点。对于开发者来讲的最佳实践是,开始架构新的应用,移植遗留代码,以完成配置和数据的完全隔离。
|
||||
|
||||
### 镜像签名简介
|
||||
|
||||
信任机制是容器的重要议题。容器镜像签名允许用户添加数字指纹到镜像中。这个指纹随后可被加密算法测试验证。这使得容器镜像的用户可以验证其来源并信任。
|
||||
|
||||
容器社区经常使用“容器镜像”这个词组,但这个命名方法会让人相当困惑。Docker、LXD 和 RKT 推行获取远程文件来当作容器运行这样的概念。这些技术各自通过不同的方式处理容器镜像。LXD 用单独的一层来获取单独一个容器,而 Docker 和 RKT 使用基于开放容器镜像(OCI)格式,可由多层组成。糟糕的是,会出现不同团队和组织对容器镜像中的不同层负责的情况。容器镜像概念下隐含的是容器镜像格式的概念。拥有标准的镜像格式比如 OCI 会让容器生态系统围绕着镜像扫描、签名,和在不同云服务提供商间转移而繁荣发展。
|
||||
|
||||
现在谈到签名了。
|
||||
|
||||
容器存在一个问题,我们把一堆代码、二进制文件和类库放入其中。一旦我们打包了代码,我们就要把它和必要的文件服务器(注册服务器)共享。代码只要被共享,它基本上就是不具名的,缺少某种密文签名。更糟糕的是,容器镜像经常由不同人或团队控制的各个镜像层组成。每个团队都需要能够检查上一个团队的工作,增加他们自己的工作内容,并在上面添加他们自己的批准印记。然后他们需要继续把工作交给下个团队。
|
||||
|
||||
(由很多镜像组成的)容器镜像的最终用户需要检查监管链。他们需要验证每个往其中添加文件的团队的可信度。对于最终用户而言,对容器镜像中的每一层都有信心是极其重要的。
|
||||
|
||||
*作者 Scott McCarty 于 8 月 24 日在 ContainerCon 会议上作了题为 [Containers for Grownups: Migrating Traditional & Existing Applications][6] 的报告,更多内容请参阅报告[幻灯片][7]。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing
|
||||
|
||||
作者:[Scott McCarty][a]
|
||||
译者:[Tanete](https://github.com/Tanete)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/fatherlinux
|
||||
[1]: http://rhelblog.redhat.com/2016/04/21/architecting-containers-part-4-workload-characteristics-and-candidates-for-containerization/
|
||||
[2]: http://rhelblog.redhat.com/2015/07/29/architecting-containers-part-1-user-space-vs-kernel-space/
|
||||
[3]: http://rhelblog.redhat.com/tag/architecting-containers/
|
||||
[4]: https://linux.cn/article-6132-1.html
|
||||
[5]: http://rhelblog.redhat.com/2016/04/21/architecting-containers-part-4-workload-characteristics-and-candidates-for-containerization/
|
||||
[6]: https://lcccna2016.sched.org/event/7JUc/containers-for-grownups-migrating-traditional-existing-applications-scott-mccarty-red-hat
|
||||
[7]: http://schd.ws/hosted_files/lcccna2016/91/Containers%20for%20Grownups_%20Migrating%20Traditional%20%26%20Existing%20Applications.pdf
|
||||
36
published/20160803 The revenge of Linux.md
Normal file
36
published/20160803 The revenge of Linux.md
Normal file
@ -0,0 +1,36 @@
|
||||
Linux 的逆袭
|
||||
========================
|
||||
|
||||

|
||||
|
||||
Linux 系统在早期的时候被人们嘲笑,它什么也干不了。而现在,Linux 无处不在!
|
||||
|
||||
我当时还是个在巴西学习计算机工程的大三学生,并同时在一个全球审计和顾问公司兼职系统管理员。公司决定用 Oracle 数据库开发一些企业资源计划(ERP)软件。因此,我得以在 Digital UNIX OS (DEC Alpha) 进行训练,这个训练颠覆了我的三观。
|
||||
|
||||
UNIX 系统非常的强大,而且给予了我们对机器上包括存储系统、网络、应用和其他一切的绝对控制权。
|
||||
|
||||
我开始在 ksh 和 Bash 里编写大量的脚本让系统进行自动备份、文件传输、提取转换加载(ETL)操作、自动化 DBA 日常工作,还为各种不同的项目创建了许多服务。此外,调整数据库和操作系统的工作让我更好的理解了如何让服务器以最佳方式运行。在那时,我在自己的个人电脑上使用的是 Windows 95 系统,而我非常想要在我的个人电脑里放进一个 Digital UNIX,或者哪怕是 Solaris 或 HP-UX 也行,但是那些 UNIX 系统都得在特定的硬件才能上运行。我阅读了所有的系统文档,还找过其它的书籍以求获得更多的信息,也在我们的开发环境里对这些疯狂的想法进行了实验。
|
||||
|
||||
后来在大学里,我从我的同事那听说了 Linux。我那时非常激动的从还在用拨号方式连接的因特网上下载了它。在我的正宗的个人电脑里装上 UNIX 这类系统的这个想法真是太酷了!
|
||||
|
||||
Linux 不同于 UNIX 系统,它设计用来在各种常见个人电脑硬件上运行,在起初,让它开始工作确实有点困难,Linux 针对的用户群只有系统管理员和极客们。我为了让它能运行,甚至用 C 语言修改了驱动软件。我之前使用 UNIX 的经历让我在编译 Linux 内核,排错这些过程中非常的顺手。由于它不同于那些只适合特定硬件配置的封闭系统,所以让 Linux 跟各种意料之外的硬件配置一起工作真的是件非常具有挑战性的事。
|
||||
|
||||
我曾见过 Linux 在数据中心获得一席之地。一些具有冒险精神的系统管理员使用它来帮他们完成每天监视和管理基础设施的工作,随后,Linux 作为 DNS 和 DHCP 服务器、打印管理和文件服务器等赢得了更多的使用。企业曾对 Linux 有着很多顾虑(恐惧,不确定性,怀疑(FUD:fear, uncertainty and doubt))和诟病:谁是它的拥有者?由谁来支持它?有适用于它的应用吗?
|
||||
|
||||
但现在看来,Linux 在各个地方进行着逆袭!从开发者的个人电脑到大企业的服务器;我们能在智能手机、智能手表以及像树莓派这样的物联网(IoT)设备里找到它。甚至 Mac OS X 有些命令跟我们所熟悉的命令一样。微软在制造它自己的发行版,在 Azure 上运行,然后…… Windows 10 要装备 Bash。
|
||||
|
||||
有趣的是 IT 市场会不断地创造并迅速的用新技术替代,但是我们所掌握的 Digital UNIX、HP-UX 和 Solaris 这些旧系统的知识还依然有效并跟 Linux 息息相关,不论是为了工作还是玩。现在我们能完全的掌控我们的系统,并使它发挥最大的效用。此外,Linux 有个充满热情的社区。
|
||||
|
||||
我真的建议想在计算机方面发展的年轻人学习 Linux,不论你处于 IT 界里的哪个分支。如果你深入了解了一个普通的家用个人电脑是如何工作的,你就可以以基本相同的方式来面对任何机器。你可以通过 Linux 学习最基本的计算机知识,并通过它建立能在 IT 界任何地方都有用的能力!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/8/revenge-linux
|
||||
|
||||
作者:[Daniel Carvalho][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/danielscarvalho
|
||||
@ -0,0 +1,36 @@
|
||||
为什么计量 IT 的生产力如此具有挑战性?
|
||||
===========================
|
||||
|
||||

|
||||
|
||||
在某些行业里,人们可以根据一些测量标准判定一个人的生产力。比如,如果你是一个零件制造商,可以通过一个月你能够制造的零件数量来确定你的生产效率。如果你在客户服务中心工作,你解答了多少个客户来电,你的平均解答时间都会成为评判你的生产效率的依据。这些都是相当简单的案例,但即便你是一位医生,也可以通过你主刀的临床手术次数或者一个月你确诊的患者数量来确定你的生产效率。无论这些评判标准正确与否,但它们提供了一个通用的方法来评断一个人在给定时间内的执行能力。
|
||||
|
||||
然而在 IT 这方面,通过上述方法来衡量一个人的生产力是不可能的,因为 IT 有太多的变化性。比如,通过一个开发者编写的代码行数来衡量开发者所用的时间看起来很诱人。但是,编程的语言很大程度上能影响到根据这种方法得到的结论。因为一种编程语言的一行代码比用其他编程语言编写所花费的时间和难度可能会明显的多或少。
|
||||
|
||||
它总是这样不可捉摸吗?多年以前,你可能听说过或者经历过根据功能点来衡量 IT 工作人员的生产效率。这些措施是针对开发者们能够创建的关键特征来衡量开发者的生产效率的。但这种方法在今天也变得逐渐难以实施,开发者经常将可能已有的逻辑封装进内部,比如,按供应商来整合功能点。这使得仅仅是基于功能点的数目来估量生产效率难度加大。
|
||||
|
||||
这两个例子能够阐述为什么当我们 CIO 之间谈论 IT 生产效率的时候有时会引起争论。考虑以下这个假想中的谈话:
|
||||
|
||||
> IT leader:“天啊,我想这些开发者一定很厉害。”
|
||||
> HR:“真的假的,他们做了什么?”
|
||||
> IT leader:“他们做了个相当好的应用。”
|
||||
> HR:“好吧,那他们比那些做了 10 个应用的开发者更好吗”
|
||||
> IT leader:“这要看你怎么理解 ‘更好’。”
|
||||
|
||||
这个对话比较有代表性。当我们处于上述的这种交谈时,这里面有太多的主观因素导致我们很难回答这个问题。当我们用一种有意义的方法来测试 IT 的效率时,类似上述谈话的这种问题仅仅是冰山一角。这不仅仅使谈话更加困难-它还会使 CIO 们很难展示他们的团队在商业上的价值。
|
||||
|
||||
确实这不是一个新出现的问题。我已经花费差不多 30 年的时间来思考这个问题。我得出的结论是我们真的不应该在谈论 IT 的生产效率这件事上面相互烦扰-因为我们永远不可能有结论。
|
||||
|
||||
我认为我们需要在改变这种对话同时停止根据生产能力和成本来谈论 IT 的生产效率,将目光集中于衡量 IT 的整体商业价值上。重申一下,这个过程不会很容易。商业价值的实现是一件困难的事情。但如果 CIO 们能够和商业人员合作来解决这个问题,就可以将实际价值变的更加科学而非一种艺术形式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2016/8/why-measuring-it-productivity-so-challenging
|
||||
|
||||
作者:[Anil Cheriyan][a]
|
||||
译者:[LemonDemo](https://github.com/LemonDemo) [WangYueScream](https://github.com/WangYueScream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/anil-cheriyan
|
||||
@ -0,0 +1,58 @@
|
||||
我的 Android 开发者之路以及我在其中学到了什么
|
||||
=============================
|
||||
|
||||
大家都说所有的关系都需要经历两年、七年甚至十年的磨砺。我忘了是谁说的这句话,但肯定有人在几年前这么跟我说过。
|
||||
|
||||
下周是我来悉尼两周年,所以我想现在正是我写这篇文章的好时候。
|
||||
|
||||
去年五月份参加 I/O 年会的时候,我遇到了亚斯曼女士,她十分漂亮。她向我询问我是如何成长为一名安卓开发者的,当我说完我的经历时,她认为我应该写个博客记下来。所以亚斯曼,如你所愿,虽然迟了点,但好过没做。;)
|
||||
|
||||
### 故事的开始
|
||||
|
||||
如果有件事我可能希望你知道,那就是我发现自己有选择困难症。你最好的朋友是谁?你最喜欢的食物是什么?你应该给你的玩具熊猫命名吗?我连这些问题都不知道该怎么回答才好。所以你可以想象到,16 岁的、即将高中毕业的我对于专业选择根本就没有任何想法。那我最初申请的大学是?在交表给注册员前,我在她面前逐字掂量着写下这个打算申请的专业(商业经济学)。
|
||||
|
||||
可我最后去了另外一间学校,就读电子与通信工程。大一时我有一门计算机编程课程。但我很讨厌编程,十分地讨厌。关于编程的一切我都一无所知。我曾发誓再也不要写代码了。
|
||||
|
||||
我大学毕业后的第一份工作是在英特尔做产品工程师并在那呆了两年。我很迷茫,无所适从,整天长时间工作。这在我意料之中,身为成年人难道不该努力工作吗?可之后菲律宾的半导体行业开始呈现颓势,大批工厂纷纷倒闭,以前由我们维护一些产品被转移到其他分公司。我便决定去找另一份工作而不是等着被裁员,因为被裁员后我都不知道自己多久才能找到另一份工作。
|
||||
|
||||
### 现在呢?
|
||||
|
||||
我想留在城市里找到一份工作,但我不想呆在正在没落的半导体行业里了。但话说回来,我又不知道该做什么好。对了,我可是拿了毕业证书的工程师,所以从技术上来说我可以在电信运营商或电视台找到工作。可这种时候,如果想入职电信运营商,我应该在大学毕业之际就去他们那实习,这样更容易被录用。可惜我没有,所以我放弃了这个想法。虽然有很多软件开发人员的招聘信息,但我讨厌编程,所以我真的不知道怎么做才好。
|
||||
|
||||
接下来是我第一个幸运的机遇,我很幸运地遇到了信任我的上司,我也和她坦诚了我什么都不会。之后我不得不边工作边学习,一开始这个过程很漫长。无需多言,我在这份工作上学到了很多,也结识了很多很好的人,与我一起的是一群很厉害的同事(我们曾开发出安装在 SIM 卡上的 APP)。但更重要的是我开始踏上了软件开发的征途。
|
||||
|
||||
最后我做得更多是一些公司的琐事(十分无聊)直到项目完结。换句话说,我总在是在办公室里闲逛并坐等发薪。之后我发现这确实是在浪费时间,2009 年的时候,我不停地接触到关于谷歌的新系统 Android 的消息,并得知它的 SDK 已经公布!是时候尝试一波了。于是我安装了所有相关软件并着手 Android 开发。
|
||||
|
||||
### 事情变得有趣了
|
||||
|
||||
所以现在我能够构建一个在运行在仿真器的 Hello World 应用,在我看来意味着我有胜任安卓开发工作的能力。我加入了一个创业公司,并且再次坦诚我不知道该怎么做,我只是接触过一些;但如果你们愿意付薪水给我继续尝试,我们就可以成为朋友。然后我很幸运地遇到另一个机遇。
|
||||
|
||||
那时成为开发者是一件令人欣喜的事。StackOverflow 上的 Android 开发社区非常小,我们都在相互交流学习,说真的,我认为里面的所有人都很友好、很豪迈(注 1)!
|
||||
|
||||
我最后去了一家企业,这家企业的移动开发团队在马尼拉、悉尼、纽约都设有办公地点。而我是马尼拉办公地点的第一个安卓开发人员,但那时我很习惯,并没有在意。
|
||||
|
||||
在那里我认识了最后令我永远感激的引荐我参与 Domain 项目的人。Domain 项目不管在个人或职业上对我来说都意味深重。我和一支很有才华的团队一起共事,也从没见过一个公司能如此执着于一款产品。Domain 让我实现了参加 I/O 年会的梦。与他们共事后我懂得了很多之前没想到的可爱特性(注 2)。这是又一个幸运的机遇,我是说最大限度地利用它。
|
||||
|
||||
### 然后呢?
|
||||
|
||||
我想说的是,虽然这些年都在晃荡,但至少我很诚实,对吧?如上就是我所学到的全部东西。说一句「我不懂」没什么可怕的。有时候我们是该装懂,但更多时候我们需要坦诚地接受这样一个事实:我们还不懂。
|
||||
|
||||
别害怕尝试新事物,不管它让你感觉多害怕。我知道说比做简单。但总有一些东西能让你鼓起勇气动手去尝试的(注3)。Lundagin mo, baby!(LCTT 译注:一首歌名)
|
||||
|
||||
|
||||
注 1: 我翻阅着以前在 StackOverflow 提的问题,认真想想,如果现在我问他们这些,估计会收到很多「你是谁啊,傻瓜」的评论。我不知道是不是因为我老了,而且有些愤世妒俗。但关键是,我们有缘在同一个社区中,所以大家相互之间友善些,好吗?
|
||||
注 2: 这一点写在另一篇文章里了。
|
||||
注 3: 我还清晰地记得第一次申请 Android 开发职位的情形:我写完求职信后又通读了一遍,提交前鼠标在发送按钮上不断徘徊,深呼吸之后我趁改变主意之前把它发出去了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdominguez.com/2016/08/winging-it-how-i-got-to-be-android-dev.html
|
||||
|
||||
作者:[Zarah Dominguez][a]
|
||||
译者:[JianhuanZhuo](https://github.com/JianhuanZhuo)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/102371834744366149197
|
||||
@ -0,0 +1,102 @@
|
||||
LXDE、Xfce 及 MATE 桌面环境下的又一系统监视器应用:Multiload-ng
|
||||
======
|
||||
|
||||
[Multiload-ng][1] 是一个 GTK2 图形化系统监视器应用,可集成到 Xfce、LXDE 及 MATE 的桌面面板中, 它 fork 自原来的 GNOME Multiload 应用。它也可以运行在一个独立的窗口中。
|
||||
|
||||

|
||||
|
||||
Multiload-ng 的特点有:
|
||||
|
||||
- 支持以下资源的图形块: CPU,内存,网络,交换空间,平均负载,磁盘以及温度;
|
||||
- 高度可定制;
|
||||
- 支持配色方案;
|
||||
- 自动适应容器(面板或窗口)的改变;
|
||||
- 极低的 CPU 和内存占用;
|
||||
- 提供基本或详细的提示信息;
|
||||
- 可自定义双击触发的动作。
|
||||
|
||||
相比于原来的 Multiload 应用,Multiload-ng 含有一个额外的图形块(温度),以及更多独立的图形自定义选项,例如独立的边框颜色,支持配色方案,可根据自定义的动作对鼠标的点击做出反应,图形块的方向可以被设定为与面板的方向无关。
|
||||
|
||||
它也可以运行在一个独立的窗口中,而不需要面板:
|
||||
|
||||
|
||||
|
||||
另外,它的 GitHub page 上说还会带来更多的图形块支持。
|
||||
|
||||
下图展示的是在带有一个垂直面板的 Xubuntu 16.04 中,该应用分别处于水平和垂直方向的效果:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
这个应用的偏好设置窗口虽然不是非常好看,但是有计划去改进它:
|
||||
|
||||
|
||||
|
||||
Multiload-ng 当前使用的是 GTK2,所以它不能在构建自 GTK3 下的 Xfce 或 MATE 桌面环境(面板)下工作。
|
||||
|
||||
对于 Ubuntu 系统而言,只有 Ubuntu MATE 16.10 使用 GTK3。但是鉴于 MATE 的系统监视器应用也是 Multiload GNOME 的一个分支,所以它们大多数的功能相同(除了 Multiload-ng 提供的额外自定义选项和温度图形块)。
|
||||
|
||||
该应用的[愿望清单][2] 中提及到了计划支持 GTK3 的集成以及各种各样的改进,例如温度块资料的更多来源,能够显示十进制(KB、MB、GB……)或二进制(KiB、MiB、GiB……)单位等等。
|
||||
|
||||
### 安装 Multiload-ng
|
||||
|
||||
请注意因为依赖的关系, Multiload-ng 不能在 Lubuntu 14.04 上构建。
|
||||
|
||||
Multiload-ng 可在 WebUpd8 的主 PPA (针对 Ubuntu 14.04 - 16.04 / Linux Mint 17.x 和 18)中获取到。可以使用下面的命令来添加 PPA 并更新软件源:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
然后可以使用下面的命令来安装这个应用:
|
||||
|
||||
- 对于 LXDE (Lubuntu):
|
||||
|
||||
```
|
||||
sudo apt install lxpanel-multiload-ng-plugin
|
||||
```
|
||||
|
||||
- 对于 Xfce (Xubuntu,Linux Mint Xfce):
|
||||
|
||||
```
|
||||
sudo apt install xfce4-multiload-ng-plugin
|
||||
```
|
||||
|
||||
- 对于 MATE (Ubuntu MATE,Linux Mint MATE):
|
||||
|
||||
```
|
||||
sudo apt install mate-multiload-ng-applet
|
||||
```
|
||||
|
||||
- 独立安装 (不需要集成到面板):
|
||||
|
||||
```
|
||||
sudo apt install multiload-ng-standalone
|
||||
```
|
||||
|
||||
一旦安装完毕,便可以像其他应用那样添加到桌面面板中了。需要注意的是在 LXDE 中,Multiload-ng 不能马上出现在面板清单中,除非重新启动面板。你可以通过重启会话(登出后再登录)或者使用下面的命令来重启面板:
|
||||
|
||||
```
|
||||
lxpanelctl restart
|
||||
```
|
||||
|
||||
独立的 Multiload-ng 应用可以像其他正常应用那样从菜单中启动。
|
||||
|
||||
如果要下载源码或报告 bug 等,请看 Multiload-ng 的 [GitHub page][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/08/alternative-system-monitor-applet-for.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: https://github.com/udda/multiload-ng
|
||||
[2]: https://github.com/udda/multiload-ng/wiki/Wishlist
|
||||
[3]: https://github.com/udda/multiload-ng
|
||||
@ -0,0 +1,111 @@
|
||||
使用 HTTP/2 服务端推送技术加速 Node.js 应用
|
||||
=========================================================
|
||||
|
||||
四月份,我们宣布了对 [HTTP/2 服务端推送技术][3]的支持,我们是通过 HTTP 的 [Link 头部](https://www.w3.org/wiki/LinkHeader)来实现这项支持的。我的同事 John 曾经通过一个例子演示了[在 PHP 里支持服务端推送功能][4]是多么的简单。
|
||||
|
||||

|
||||
|
||||
我们想让现今使用 Node.js 构建的网站能够更加轻松的获得性能提升。为此,我们开发了 [netjet][1] 中间件,它可以解析应用生成的 HTML 并自动添加 Link 头部。当在一个示例的 Express 应用中使用这个中间件时,我们可以看到应用程序的输出多了如下 HTTP 头:
|
||||
|
||||
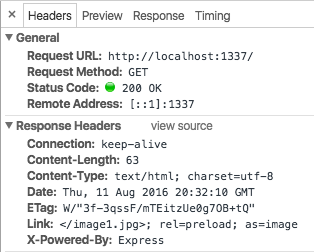
|
||||
|
||||
[本博客][5]是使用 [Ghost](https://ghost.org/)(LCTT 译注:一个博客发布平台)进行发布的,因此如果你的浏览器支持 HTTP/2,你已经在不知不觉中享受了服务端推送技术带来的好处了。接下来,我们将进行更详细的说明。
|
||||
|
||||
netjet 使用了带有定制插件的 [PostHTML](https://github.com/posthtml/posthtml) 来解析 HTML。目前,netjet 用它来查找图片、脚本和外部 CSS 样式表。你也可以用其它的技术来实现这个。
|
||||
|
||||
在响应过程中增加 HTML 解析器有个明显的缺点:这将增加页面加载的延时(到加载第一个字节所花的时间)。大多数情况下,所新增的延时被应用里的其他耗时掩盖掉了,比如数据库访问。为了解决这个问题,netjet 包含了一个可调节的 LRU 缓存,该缓存以 HTTP 的 ETag 头部作为索引,这使得 netjet 可以非常快的为已经解析过的页面插入 Link 头部。
|
||||
|
||||
不过,如果我们现在从头设计一款全新的应用,我们就应该考虑把页面内容和页面中的元数据分开存放,从而整体地减少 HTML 解析和其它可能增加的延时了。
|
||||
|
||||
任意的 Node.js HTML 框架,只要它支持类似 Express 这样的中间件,netjet 都是能够兼容的。只要把 netjet 像下面这样加到中间件加载链里就可以了。
|
||||
|
||||
```javascript
|
||||
var express = require('express');
|
||||
var netjet = require('netjet');
|
||||
var root = '/path/to/static/folder';
|
||||
|
||||
express()
|
||||
.use(netjet({
|
||||
cache: {
|
||||
max: 100
|
||||
}
|
||||
}))
|
||||
.use(express.static(root))
|
||||
.listen(1337);
|
||||
```
|
||||
|
||||
稍微加点代码,netjet 也可以摆脱 HTML 框架,独立工作:
|
||||
|
||||
```javascript
|
||||
var http = require('http');
|
||||
var netjet = require('netjet');
|
||||
|
||||
var port = 1337;
|
||||
var hostname = 'localhost';
|
||||
var preload = netjet({
|
||||
cache: {
|
||||
max: 100
|
||||
}
|
||||
});
|
||||
|
||||
var server = http.createServer(function (req, res) {
|
||||
preload(req, res, function () {
|
||||
res.statusCode = 200;
|
||||
res.setHeader('Content-Type', 'text/html');
|
||||
res.end('<!doctype html><h1>Hello World</h1>');
|
||||
});
|
||||
});
|
||||
|
||||
server.listen(port, hostname, function () {
|
||||
console.log('Server running at http://' + hostname + ':' + port+ '/');
|
||||
});
|
||||
```
|
||||
|
||||
[netjet 文档里][1]有更多选项的信息。
|
||||
|
||||
### 查看推送了什么数据
|
||||
|
||||
|
||||
|
||||
访问[本文][5]时,通过 Chrome 的开发者工具,我们可以轻松的验证网站是否正在使用服务器推送技术(LCTT 译注: Chrome 版本至少为 53)。在“Network”选项卡中,我们可以看到有些资源的“Initiator”这一列中包含了`Push`字样,这些资源就是服务器端推送的。
|
||||
|
||||
不过,目前 Firefox 的开发者工具还不能直观的展示被推送的资源。不过我们可以通过页面响应头部里的`cf-h2-pushed`头部看到一个列表,这个列表包含了本页面主动推送给浏览器的资源。
|
||||
|
||||
希望大家能够踊跃为 netjet 添砖加瓦,我也乐于看到有人正在使用 netjet。
|
||||
|
||||
### Ghost 和服务端推送技术
|
||||
|
||||
Ghost 真是包罗万象。在 Ghost 团队的帮助下,我把 netjet 也集成到里面了,而且作为测试版内容可以在 Ghost 的 0.8.0 版本中用上它。
|
||||
|
||||
如果你正在使用 Ghost,你可以通过修改 config.js、并在`production`配置块中增加 `preloadHeaders` 选项来启用服务端推送。
|
||||
|
||||
```javascript
|
||||
production: {
|
||||
url: 'https://my-ghost-blog.com',
|
||||
preloadHeaders: 100,
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
Ghost 已经为其用户整理了[一篇支持文档][2]。
|
||||
|
||||
### 总结
|
||||
|
||||
使用 netjet,你的 Node.js 应用也可以使用浏览器预加载技术。并且 [CloudFlare][5] 已经使用它在提供了 HTTP/2 服务端推送了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.cloudflare.com/accelerating-node-js-applications-with-http-2-server-push/
|
||||
|
||||
作者:[Terin Stock][a]
|
||||
译者:[echoma](https://github.com/echoma)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.cloudflare.com/author/terin-stock/
|
||||
[1]: https://www.npmjs.com/package/netjet
|
||||
[2]: http://support.ghost.org/preload-headers/
|
||||
[3]: https://www.cloudflare.com/http2/server-push/
|
||||
[4]: https://blog.cloudflare.com/using-http-2-server-push-with-php/
|
||||
[5]: https://blog.cloudflare.com/accelerating-node-js-applications-with-http-2-server-push/
|
||||
54
published/20160817 Build an integration for GitHub.md
Normal file
54
published/20160817 Build an integration for GitHub.md
Normal file
@ -0,0 +1,54 @@
|
||||
为 Github 创造集成件(Integration)
|
||||
=============
|
||||
|
||||

|
||||
|
||||
现在你可以从我们的 [集成件目录][1]里面找到更多工具。这个目录目前有超过 15 个分类 — 从 [API 管理][2] 到 [应用监控][3], Github 的集成件可以支持您的开发周期的每一个阶段。
|
||||
|
||||
我们邀请了具有不同层面的专长的开发人员,来创造有助于开发者更好的工作的集成件。如果你曾经为 Github 构建过一个很棒的集成件,我们希望来让更多人知道它! [Gitter][4]、[AppVeyor][5] 和 [ZenHub][6] 都做到了,你也可以!
|
||||
|
||||
### 我们在寻找什么?
|
||||
|
||||
良好的软件开发依赖于上乘的工具,开发人员如今有了更多的选择,无论是语言、框架、工作流程,还是包含了其他因素的环境。我们正在寻找能够创造更好的整体开发体验的开发工具。
|
||||
|
||||
#### 进入集成件目录清单的指南:
|
||||
|
||||
- 稳步增多( 你的 Github OAuth 接口当前可以支持超过 500 个用户 )
|
||||
- 查看我们的 [技术要求][7]
|
||||
- 遵从[服务条款][8] 和[隐私政策][9]
|
||||
- 专注于软件开发生命周期
|
||||
|
||||
### 有帮助的资源
|
||||
|
||||
如果想要被列在目录里,请按照[列出需求页][10]中概述的步骤。
|
||||
|
||||
你也应该阅读我们的[营销指南][11]和[已有目录清单][12]来更好的了解如何把它们全都放在一起。请把你的列表的内容记录在一个[私密 gist][13] 中(markdown 格式),并且通过邮件联系我们 <partnerships@github.com>。 如果你有任何问题,不要犹疑,请联系 <partnerships@github.com>。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2226-build-an-integration-for-github
|
||||
|
||||
作者:[chobberoni][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/chobberoni
|
||||
|
||||
[1]: https://github.com/integrations
|
||||
[2]: https://github.com/integrations/feature/api-management
|
||||
[3]: https://github.com/integrations/feature/monitoring
|
||||
[4]: https://github.com/integrations/feature/monitoring
|
||||
[5]: https://github.com/integrations/appveyor
|
||||
[6]: https://github.com/integrations/zenhub
|
||||
[7]: https://developer.github.com/integrations-directory/getting-listed/#technical-requirements
|
||||
[8]: https://help.github.com/articles/github-terms-of-service/
|
||||
[9]: https://help.github.com/articles/github-privacy-policy/
|
||||
[10]: https://developer.github.com/integrations-directory/getting-listed/
|
||||
[11]: https://developer.github.com/integrations-directory/marketing-guidelines/
|
||||
[12]: https://github.com/integrations
|
||||
[13]: https://gist.github.com/
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
Turtl:安全、开源的 Evernote 替代品
|
||||
=============================
|
||||
|
||||
Turtl 是一个安全、开源的 Evernote 替代品,在Linux、Windows、Mac 和 Android 等系统上都能使用。iOS版本仍在开发当中,Firefox 和 Chrome 也有扩展程序可以使用。
|
||||
|
||||
|
||||
|
||||
这个产品仍在测试阶段,它能够让你把你的笔记(便签编辑器支持 Markdown)、网站书签、密码、文档、图片等单独放在一个隐秘地方。
|
||||
|
||||
笔记可以按模块组织起来,支持嵌套,也可以和其他 Turtl 用户分享。
|
||||
|
||||
|
||||
|
||||
你可以给你的笔记打上标签。Turtl 通过创建时间、最后修改时间或者标签来找你的笔记。
|
||||
|
||||
这个是便签编辑器(文件便签):
|
||||
|
||||
|
||||
|
||||
那么安全性如何呢?Turtl 会在保存数据之前加密,使用的是一个加密密钥,而密码并不保存在服务器上。只有你和你想要分享的人能获取数据。你可以从[这里][1]获得更多关于 Turtl 安全和加密的信息。
|
||||
|
||||
更新(感谢 Dimitry!):根据[错误反馈][2],Turtl 有个严重的安全性问题。Turtl 允许创建多个相同用户名的账号,却只使用密码来区分它们。希望能马上修复这个问题。
|
||||
|
||||
Turtl 团队提供了一个托管服务来同步你的记录,它是完全免费的,”除非你的文件足够大,或者你需要更好的服务”,在我写这篇文章的时候这个高级服务还不能用。
|
||||
|
||||
并且你也不一定要用这个托管服务,因为就像其桌面应用和手机应用一样,这个自托管服务器也是一个自由、开源的软件,所以你可以自己搭建一个 [Turtl 服务器][3]。
|
||||
|
||||
Turtl 没有像 Evernote 那么多的功能,但它在它的[计划][4]中也有一些新的功能,比如:支持导入/导出文本和Evernote 格式的数据、原生支持 PDF 阅读器、界面锁定等。
|
||||
|
||||
不得不提醒的是,每次启动都要输入密码,虽然安全,但有时候实在是麻烦。
|
||||
|
||||
###下载 Turtl
|
||||
|
||||
[下载 Turtl 应用][5](二进制文件支持 Linux (32位/64位)、Windows 64 位、Mac 64位、Android,以及 Chrome 和Firefox 浏览器插件)
|
||||
|
||||
**更新**:Turtl 用了一个新的服务器,注销然后在登录框的下面选择高级设置,把 Turtl 服务器设置为 "https://api.turtlapp.com/v2"(没有引号)。
|
||||
|
||||
下载源代码(桌面应用、移动应用和服务器)、反馈问题等,参见 Turtl 的 [GitHub][6] 项目站点。
|
||||
|
||||
Arch Linux 用户可以通过 [AUR][7] 来安装 Turtl。
|
||||
|
||||
要在 Linux 上安装,把安装包解压后运行 install.sh,安装之前请确保 ~/.local/share/applications 目录存在,若不存在请自行创建:
|
||||
|
||||
```
|
||||
mkdir -p ~/.local/share/applications
|
||||
```
|
||||
|
||||
注意:如果使用 sudo 命令安装,那么只有 root 用户才能使用。所以,要么不用 sudo 命令安装,要么在安装完成后修改权限。你可以参考[AUR 软件包的设置][8]来了解如何修改权限。
|
||||
|
||||
使用如下命令把 Turtl 安装到 ~/turtl 文件夹下(假定你已经把安装包解压在你的家目录下了):
|
||||
|
||||
````
|
||||
~/turtl-*/install.sh ~/turtl
|
||||
```
|
||||
|
||||
可以使用 ~/.turtl 代替 ~/turtl 把 Turtl 安装到你的家目录的隐藏文件夹下。你也可以用些小技巧把它隐藏起来。
|
||||
|
||||
如果 Turtl 没有在你的 Unity Dash 上显示出来,请注销/登录以重启会话。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/08/turtl-secure-open-source-evernote.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[chisper](https://github.com/chisper)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: https://turtl.it/docs/security/
|
||||
[2]: https://github.com/turtl/api/issues/20
|
||||
[3]: https://turtl.it/docs/server/
|
||||
[4]: https://trello.com/b/yIQGkHia/turtl-product-dev
|
||||
[5]: https://turtl.it/download/
|
||||
[6]: https://github.com/turtl
|
||||
[7]: https://aur.archlinux.org/packages/turtl/
|
||||
[8]: https://aur.archlinux.org/cgit/aur.git/tree/PKGBUILD?h=turtl
|
||||
[9]: https://turtlapp.com/
|
||||
@ -0,0 +1,554 @@
|
||||
MySQL 中你应该使用什么数据类型表示时间?
|
||||
==========================================================
|
||||
|
||||

|
||||
|
||||
_当你需要保存日期时间数据时,一个问题来了:你应该使用 MySQL 中的什么类型?使用 MySQL 原生的 DATE 类型还是使用 INT 字段把日期和时间保存为一个纯数字呢?_
|
||||
|
||||
在这篇文章中,我将解释 MySQL 原生的方案,并给出一个最常用数据类型的对比表。我们也将对一些典型的查询做基准测试,然后得出在给定场景下应该使用什么数据类型的结论。
|
||||
|
||||
## 原生的 MySQL Datetime 数据类型
|
||||
|
||||
Datetime 数据表示一个时间点。这可以用作日志记录、物联网时间戳、日历事件数据,等等。MySQL 有两种原生的类型可以将这种信息保存在单个字段中:Datetime 和 Timestamp。MySQL 文档中是这么介绍这些数据类型的:
|
||||
|
||||
> DATETIME 类型用于保存同时包含日期和时间两部分的值。MySQL 以 'YYYY-MM-DD HH:MM:SS' 形式接收和显示 DATETIME 类型的值。
|
||||
|
||||
> TIMESTAMP 类型用于保存同时包含日期和时间两部分的值。
|
||||
|
||||
> DATETIME 或 TIMESTAMP 类型的值可以在尾部包含一个毫秒部分,精确度最高到微秒(6 位数)。
|
||||
|
||||
> TIMESTAMP 和 DATETIME 数据类型提供自动初始化和更新到当前的日期和时间的功能,只需在列的定义中设置 DEFAULT CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP。
|
||||
|
||||
作为一个例子:
|
||||
|
||||
```SQL
|
||||
CREATE TABLE `datetime_example` (
|
||||
`id` int(11) NOT NULL AUTO_INCREMENT,
|
||||
`measured_on` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `measured_on` (`measured_on`)
|
||||
) ENGINE=InnoDB;
|
||||
```
|
||||
|
||||
```SQL
|
||||
CREATE TABLE `timestamp_example` (
|
||||
`id` int(11) NOT NULL AUTO_INCREMENT,
|
||||
`measured_on` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `measured_on` (`measured_on`)
|
||||
) ENGINE=InnoDB;
|
||||
```
|
||||
|
||||
除了原生的日期时间表示方法,还有另一种常用的存储日期和时间信息的方法。即使用 INT 字段保存 Unix 时间(从1970 年 1 月 1 日协调世界时(UTC)建立所经过的秒数)。
|
||||
|
||||
MySQL 也提供了只保存时间信息中的一部分的方式,通过使用 Date、Year 或 Time 类型。由于这篇文章是关于保存准确时间点的最佳方式的,我们没有讨论这些不那么精确的局部类型。
|
||||
|
||||
## 使用 INT 类型保存 Unix 时间
|
||||
|
||||
使用一个简单的 INT 列保存 Unix 时间是最普通的方法。使用 INT,你可以确保你要保存的数字可以快速、可靠地插入到表中,就像这样:
|
||||
|
||||
```SQL
|
||||
INSERT INTO `vertabelo`.`sampletable`
|
||||
(
|
||||
`id`,
|
||||
`measured_on` ### INT 类型的列
|
||||
)
|
||||
VALUES
|
||||
(
|
||||
1,
|
||||
946684801
|
||||
### 至 01/01/2000 @ 12:00am (UTC) 的 UNIX 时间戳 http://unixtimestamp.com
|
||||
);
|
||||
```
|
||||
|
||||
这就是关于它的所有内容了。它仅仅是个简单的 INT 列,MySQL 的处理方式是这样的:在内部使用 4 个字节保存那些数据。所以如果你在这个列上使用 SELECT 你将会得到一个数字。如果你想把这个列用作日期进行比较,下面的查询并不能正确工作:
|
||||
|
||||
```SQL
|
||||
SELECT
|
||||
id, measured_on, FROM_UNIXTIME(measured_on)
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures
|
||||
WHERE
|
||||
measured_on > '2016-01-01' ### measured_on 会被作为字符串比较以进行查询
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
这是因为 MySQL 把 INT 视为数字,而非日期。为了进行日期比较,你必须要么获取( LCTT 译注:从 1970-01-01 00:00:00)到 2016-01-01 经过的秒数,要么使用 MySQL 的 FROM\_UNIXTIME() 函数把 INT 列转为 Date 类型。下面的查询展示了 FROM\_UNIXTIME() 函数的用法:
|
||||
|
||||
```SQL
|
||||
SELECT
|
||||
id, measured_on, FROM_UNIXTIME(measured_on)
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures
|
||||
WHERE
|
||||
FROM_UNIXTIME(measured_on) > '2016-01-01'
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
这会正确地获取到日期在 2016-01-01 之后的记录。你也可以直接比较数字和 2016-01-01 的 Unix 时间戳表示形式,即 1451606400。这样做意味着不用使用任何特殊的函数,因为你是在直接比较数字。查询如下:
|
||||
|
||||
```SQL
|
||||
SELECT
|
||||
id, measured_on, FROM_UNIXTIME(measured_on)
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures
|
||||
WHERE
|
||||
measured_on > 1451606400
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
假如这种方式不够高效甚至提前做这种转换是不可行的话,那该怎么办?例如,你想获取 2016 年所有星期三的记录。要做到这样而不使用任何 MySQL 日期函数,你就不得不查出 2016 年每个星期三的开始和结束时间的 Unix 时间戳。然后你不得不写很大的查询,至少要在 WHERE 中包含 104 个比较。(2016 年有 52 个星期三,你不得不考虑一天的开始(0:00 am)和结束(11:59:59 pm)...)
|
||||
|
||||
结果是你很可能最终会使用 FROM\_UNIXTIME() 转换函数。既然如此,为什么不试下真正的日期类型呢?
|
||||
|
||||
## 使用 Datetime 和 Timestamp
|
||||
|
||||
Datetime 和 Timestamp 几乎以同样的方式工作。两种都保存日期和时间信息,毫秒部分最高精确度都是 6 位数。同时,使用人类可读的日期形式如 "2016-01-01" (为了便于比较)都能工作。查询时两种类型都支持“宽松格式”。宽松的语法允许任何标点符号作为分隔符。例如,"YYYY-MM-DD HH:MM:SS" 和 "YY-MM-DD HH:MM:SS" 两种形式都可以。在宽松格式情况下以下任何一种形式都能工作:
|
||||
|
||||
```
|
||||
2012-12-31 11:30:45
|
||||
2012^12^31 11+30+45
|
||||
2012/12/31 11*30*45
|
||||
2012@12@31 11^30^45
|
||||
```
|
||||
|
||||
其它宽松格式也是允许的;你可以在 [MySQL 参考手册](https://dev.mysql.com/doc/refman/5.7/en/date-and-time-literals.html) 找到所有的格式。
|
||||
|
||||
默认情况下,Datetime 和 Timestamp 两种类型查询结果都以标准输出格式显示 —— 年-月-日 时:分:秒 (如 2016-01-01 23:59:59)。如果使用了毫秒部分,它们应该以小数值出现在秒后面 (如 2016-01-01 23:59:59.5)。
|
||||
|
||||
Timestamp 和 Datetime 的核心不同点主要在于 MySQL 在内部如何表示这些信息:两种都以二进制而非字符串形式存储,但在表示日期/时间部分时 Timestamp (4 字节) 比 Datetime (5 字节) 少使用 1 字节。当保存毫秒部分时两种都使用额外的空间 (1-3 字节)。如果你存储 150 万条记录,这种 1 字节的差异是微不足道的:
|
||||
|
||||
> 150 万条记录 * 每条记录 1 字节 / (1048576 字节/MB) = __1.43 MB__
|
||||
|
||||
Timestamp 节省的 1 字节是有代价的:你只能存储从 '1970-01-01 00:00:01.000000' 到 '2038-01-19 03:14:07.999999' 之间的时间。而 Datetime 允许你存储从 '1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999' 之间的任何时间。
|
||||
|
||||
另一个重要的差别 —— 很多 MySQL 开发者没意识到的 —— 是 MySQL 使用__服务器的时区__转换 Timestamp 值到它的 UTC 等价值再保存。当获取值是它会再次进行时区转换,所以你得回了你“原始的”日期/时间值。有可能,下面这些情况会发生。
|
||||
|
||||
理想情况下,如果你一直使用同一个时区,MySQL 会获取到和你存储的同样的值。以我的经验,如果你的数据库涉及时区变换,你可能会遇到问题。例如,服务器变化(比如,你把数据库从都柏林的一台服务器迁移到加利福尼亚的一台服务器上,或者你只是修改了一下服务器的时区)时可能会发生这种情况。不管哪种方式,如果你获取数据时的时区是不同的,数据就会受影响。
|
||||
|
||||
Datetime 列不会被数据库改变。无论时区怎样配置,每次都会保存和获取到同样的值。就我而言,我认为这是一个更可靠的选择。
|
||||
|
||||
> __MySQL 文档:__
|
||||
|
||||
> MySQL 把 TIMESTAMP 值从当前的时区转换到 UTC 再存储,获取时再从 UTC 转回当前的时区。(其它类型如 DATETIME 不会这样,它们会“原样”保存。) 默认情况下,每个连接的当前时区都是服务器的时区。时区可以基于连接设置。只要时区设置保持一致,你就能得到和保存的相同的值。如果你保存了一个 TIMESTAMP 值,然后改变了时区再获取这个值,获取到的值和你存储的是不同的。这是因为在写入和查询的会话上没有使用同一个时区。当前时区可以通过系统变量 [time_zone](https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_time_zone) 的值得到。更多信息,请查看 [MySQL Server Time Zone Support](https://dev.mysql.com/doc/refman/5.7/en/time-zone-support.html)。
|
||||
|
||||
## 对比总结
|
||||
|
||||
在深入探讨使用各数据类型的性能差异之前,让我们先看一个总结表格以给你更多了解。每种类型的弱点以红色显示。
|
||||
|
||||
特性 | Datetime | Timestamp | Int (保存 Unix 时间)
|
||||
:--|:--|:--|:--
|
||||
原生时间表示 | 是 | 是 | 否,所以大多数操作需要先使用转换函数,如 FROM_UNIXTIME()
|
||||
能保存毫秒 | 是,最高 6 位精度 | 是,最高 6 位精度 | **否**
|
||||
合法范围 | '1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999 | **'1970-01-01 00:00:01.000000' 到 '2038-01-19 03:14:07.999999'** | 若使用 unsigned, '1970-01-01 00:00:01.000000; 理论上最大到 '2106-2-07 06:28:15'
|
||||
自动初始化(MySQL 5.6.5+) | 是 | 是 | **否**
|
||||
宽松解释 ([MySQL docs](https://dev.mysql.com/doc/refman/5.7/en/date-and-time-literals.html)) | 是 | 是 | **否,必须使用正确的格式**
|
||||
值被转换到 UTC 存储 | 否 | **是** | 否
|
||||
可转换到其它类型 | 是,如果值在合法的 Timestamp 范围中 | 是,总是 | 是,如果值在合法的范围中并使用转换函数
|
||||
存储需求([MySQL 5.6.4+](https://dev.mysql.com/doc/refman/5.7/en/storage-requirements.html)) | **5 字节**(如果使用了毫秒部分,再加最多 3 字节) | 4 字节 (如果使用了毫秒部分,再加最多 3 字节) | 4 字节 (不允许毫秒部分)
|
||||
无需使用函数即可作为真实日期可读 | 是 | 是 | **否,你必须格式化输出**
|
||||
数据分区 | 是 | 是,使用 [UNIX_TIMESTAMP()](https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html#function_unix-timestamp);在 MySQL 5.7 中其它表达式是不允许包含 [TIMESTAMP](https://dev.mysql.com/doc/refman/5.7/en/datetime.html) 值的。同时,注意[分区裁剪时的这些考虑](https://dev.mysql.com/doc/refman/5.7/en/partitioning-pruning.html) | 是,使用 INT 上的任何合法操作
|
||||
|
||||
## 基准测试 INT、Timestamp 和 Datetime 的性能
|
||||
|
||||
为了比较这些类型的性能,我会使用我创建的一个天气预报网络的 150 万记录(准确说是 1,497,421)。这个网络每分钟都收集数据。为了让这些测试可复现,我已经删除了一些私有列,所以你可以使用这些数据运行你自己的测试。
|
||||
|
||||
基于我原始的表格,我创建了三个版本:
|
||||
|
||||
- `datetimemeasures` 表在 `measured_on` 列使用 Datetime 类型,表示天气预报记录的测量时间
|
||||
- `timestampmeasures` 表在 `measured_on` 列使用 Timestamp 类型
|
||||
- `inttimestampmeasures` 表在 `measured_on` 列使用 INT (unsigned) 类型
|
||||
|
||||
这三个表拥有完全相同的数据;唯一的差别就是 `measured_on` 字段的类型。所有表都在 `measured_on` 列上设置了一个索引。
|
||||
|
||||
|
||||
|
||||
### 基准测试工具
|
||||
|
||||
为了评估这些数据类型的性能,我使用了两种方法。一种基于 [Sysbench](https://github.com/akopytov/sysbench),它的官网是这么描述的:
|
||||
|
||||
_“... 一个模块化、跨平台和多线程的基准测试工具,用以评估那些对运行高负载数据库的系统非常重要的系统参数。”_
|
||||
|
||||
这个工具是 [MySQL 文档](https://dev.mysql.com/downloads/benchmarks.html)中推荐的。
|
||||
|
||||
如果你使用 Windows (就像我),你可以下载一个包含可执行文件和我使用的测试查询的 zip 文件。它们基于 [一种推荐的基准测试方法](https://dba.stackexchange.com/questions/39221/stress-test-mysql-with-queries-captured-with-general-log-in-mysql)。
|
||||
|
||||
为了执行一个给定的测试,你可以使用下面的命令(插入你自己的连接参数):
|
||||
|
||||
```bash
|
||||
sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=sysbench_test_file.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
这会正常工作,这里 `sysbench_test_file.lua` 是测试文件,并包含了各个测试中指向各个表的 SQL 查询。
|
||||
|
||||
为了进一步验证结果,我也运行了 [mysqlslap](https://dev.mysql.com/doc/refman/5.7/en/mysqlslap.html)。它的官网是这么描述的:
|
||||
|
||||
_“[mysqlslap](https://dev.mysql.com/doc/refman/5.7/en/mysqlslap.html) 是一个诊断程序,为模拟 MySQL 服务器的客户端负载并报告各个阶段的用时而设计。它工作起来就像是很多客户端在同时访问服务器。_
|
||||
|
||||
记得这些测试中最重要的不是所需的_绝对_时间。而是在不同数据类型上执行相同查询时的_相对_时间。这两个基准测试工具的测试时间不一定相同,因为不同工具的工作方式不同。重要的是数据类型的比较,随着我们深入到测试中,这将会变得清楚。
|
||||
|
||||
### 基准测试
|
||||
|
||||
我将使用三种可以评估几个性能方面的查询:
|
||||
|
||||
* 时间范围选择
|
||||
* 在 Datetime 和 Timestamp 数据类型上这允许我们直接比较而不需要使用任何特殊的日期函数。
|
||||
* 同时,我们可以评估在 INT 类型的列上使用日期函数相对于使用简单的数值比较的影响。为了做到这些我们需要把范围转换为 Unix 时间戳数值。
|
||||
* 日期函数选择
|
||||
* 与前个测试中比较操作针对一个简单的 DATE 值相反,这个测试使得我们可以评估使用日期函数作为 “WHERE” 子句的一部分的性能。
|
||||
* 我们还可以测试一个场景,即我们必须使用一个函数将 INT 列转换为一个合法的 DATE 类型然后执行查询。
|
||||
* count() 查询
|
||||
* 作为对前面测试的补充,这将评估在三种不同的表示类型上进行典型的统计查询的性能。
|
||||
|
||||
我们将在这些测试中覆盖一些常见的场景,并看到三种类型上的性能表现。
|
||||
|
||||
### 关于 SQL\_NO\_CACHE
|
||||
|
||||
当在查询中使用 SQL\_NO\_CACHE 时,服务器不使用查询缓存。它既不检查查询缓存以确认结果是不是已经在那儿了,也不会保存查询结果。因此,每个查询将反映真实的性能影响,就像每次查询都是第一次被调用。
|
||||
|
||||
### 测试 1:选择一个日期范围中的值
|
||||
|
||||
这个查询返回总计 1,497,421 行记录中的 75,706 行。
|
||||
|
||||
#### 查询 1 和 Datetime:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
measured_on
|
||||
FROM
|
||||
vertabelo.datetimemeasures m
|
||||
WHERE
|
||||
m.measured_on > '2016-01-01 00:00:00.0'
|
||||
AND m.measured_on < '2016-02-01 00:00:00.0';
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 152 | 296 |
|
||||
| 最大 | 1261 | 3203 |
|
||||
| 平均 | 362 | 809 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.datetimemeasures m WHERE m.measured_on > '2016-01-01 00:00:00.0' AND m.measured_on < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 查询 1 和 Timestamp:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
measured_on
|
||||
FROM
|
||||
vertabelo.timestampmeasures m
|
||||
WHERE
|
||||
m.measured_on > '2016-01-01 00:00:00.0'
|
||||
AND m.measured_on < '2016-02-01 00:00:00.0';
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 214 | 359 |
|
||||
| 最大 | 1389 | 3313 |
|
||||
| 平均 | 431 | 1004 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.timestampmeasures m WHERE m.measured_on > '2016-01-01 00:00:00.0' AND m.measured_on < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 查询 1 和 INT:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
measured_on
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures m
|
||||
WHERE
|
||||
FROM_UNIXTIME(m.measured_on) > '2016-01-01 00:00:00.0'
|
||||
AND FROM_UNIXTIME(m.measured_on) < '2016-02-01 00:00:00.0';
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 2472 | 7968 |
|
||||
| 最大 | 6554 | 10312 |
|
||||
| 平均 | 4107 | 8527 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE FROM_UNIXTIME(m.measured_on) > '2016-01-01 00:00:00.0' AND FROM_UNIXTIME(m.measured_on) < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 另一种 INT 上的查询 1:
|
||||
|
||||
由于这是个相当直接的范围搜索,而且查询中的日期可以轻易地转为简单的数值比较,我将它包含在了这个测试中。结果证明这是最快的方法 (你大概已经预料到了),因为它仅仅是比较数字而没有使用任何日期转换函数:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
measured_on
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures m
|
||||
WHERE
|
||||
m.measured_on > 1451617200
|
||||
AND m.measured_on < 1454295600;
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 88 | 171 |
|
||||
| 最大 | 275 | 2157 |
|
||||
| 平均 | 165 | 514 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=basic_int.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE m.measured_on > 1451617200 AND m.measured_on < 1454295600" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 测试 1 总结
|
||||
|
||||
| 平均响应时间 (ms) | Sysbench | 相对于 Datetime 的速度 | mysqlslap | 相对于 Datetime 的速度 |
|
||||
|-----------------|----------|----------------------|-----------|----------------------|
|
||||
| Datetime | 362 | - | 809 | - |
|
||||
| Timestamp | 431 | 慢 19% | 1004 | 慢 24% |
|
||||
| INT | 4107 | 慢 1134% | 8527 | 慢 1054% |
|
||||
| 另一种 INT 查询 | 165 | 快 55% | 514 | 快 36% |
|
||||
|
||||
两种基准测试工具都显示 Datetime 比 Timestamp 和 INT 更快。但 Datetime 没有我们在另一种 INT 查询中使用的简单数值比较快。
|
||||
|
||||
### 测试 2:选择星期一产生的记录
|
||||
|
||||
这个查询返回总计 1,497,421 行记录中的 221,850 行。
|
||||
|
||||
#### 查询 2 和 Datetime:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE measured_on
|
||||
FROM
|
||||
vertabelo.datetimemeasures m
|
||||
WHERE
|
||||
WEEKDAY(m.measured_on) = 0; # MONDAY
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 1874 | 4343 |
|
||||
| 最大 | 6168 | 7797 |
|
||||
| 平均 | 3127 | 6103 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime_1.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.datetimemeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 查询 2 和 Timestamp:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
measured_on
|
||||
FROM
|
||||
vertabelo.timestampmeasures m
|
||||
WHERE
|
||||
WEEKDAY(m.measured_on) = 0; # MONDAY
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 2688 | 5953 |
|
||||
| 最大 | 6666 | 13531 |
|
||||
| 平均 | 3653 | 8412 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp_1.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.timestampmeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 查询 2 和 INT:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
measured_on
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures m
|
||||
WHERE
|
||||
WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0; # MONDAY
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 2051 | 5844 |
|
||||
| 最大 | 7007 | 10469 |
|
||||
| 平均 | 3486 | 8088 |
|
||||
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int_1.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 测试 2 总结
|
||||
|
||||
| 平均响应时间 (ms) | Sysbench | 相对于 Datetime 的速度 | mysqlslap | 相对于 Datetime 的速度 |
|
||||
|-----------------|----------|----------------------|-----------|----------------------|
|
||||
| Datetime | 3127 | - | 6103 | - |
|
||||
| Timestamp | 3653 | 慢 17% | 8412 | 慢 38% |
|
||||
| INT | 3486 | 慢 11% | 8088 | 慢 32% |
|
||||
|
||||
再次,在两个基准测试工具中 Datetime 比 Timestamp 和 INT 快。但在这个测试中,INT 查询 —— 即使它使用了一个函数以转换日期 —— 比 Timestamp 查询更快得到结果。
|
||||
|
||||
### 测试 3:选择星期一产生的记录总数
|
||||
|
||||
这个查询返回一行,包含产生于星期一的所有记录的总数(从总共 1,497,421 行可用记录中)。
|
||||
|
||||
#### 查询 3 和 Datetime:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
COUNT(measured_on)
|
||||
FROM
|
||||
vertabelo.datetimemeasures m
|
||||
WHERE
|
||||
WEEKDAY(m.measured_on) = 0; # MONDAY
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 1720 | 4063 |
|
||||
| 最大 | 4594 | 7812 |
|
||||
| 平均 | 2797 | 5540 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime_1_count.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.datetimemeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 查询 3 和 Timestamp:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
COUNT(measured_on)
|
||||
FROM
|
||||
vertabelo.timestampmeasures m
|
||||
WHERE
|
||||
WEEKDAY(m.measured_on) = 0; # MONDAY
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 1907 | 4578 |
|
||||
| 最大 | 5437 | 10235 |
|
||||
| 平均 | 3408 | 7102 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp_1_count.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.timestampmeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 查询 3 和 INT:
|
||||
|
||||
```SQL
|
||||
SELECT SQL_NO_CACHE
|
||||
COUNT(measured_on)
|
||||
FROM
|
||||
vertabelo.inttimestampmeasures m
|
||||
WHERE
|
||||
WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0; # MONDAY
|
||||
```
|
||||
|
||||
#### 性能
|
||||
|
||||
| 响应时间 (ms) | Sysbench | mysqlslap |
|
||||
|-------------|----------|-----------|
|
||||
| 最小 | 2108 | 5609 |
|
||||
| 最大 | 4764 | 9735 |
|
||||
| 平均 | 3307 | 7416 |
|
||||
|
||||
```bash
|
||||
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int_1_count.lua --num-threads=8 --max-requests=100 run
|
||||
```
|
||||
|
||||
```bash
|
||||
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.inttimestampmeasures m WHERE WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
||||
```
|
||||
|
||||
#### 测试 3 总结
|
||||
|
||||
| 平均响应时间 (ms) | Sysbench | 相对于 Datetime 的速度 | mysqlslap | 相对于 Datetime 的速度 |
|
||||
|-----------------|----------|----------------------|-----------|----------------------|
|
||||
| Datetime | 2797 | - | 5540 | - |
|
||||
| Timestamp | 3408 | 慢 22% | 7102 | 慢 28% |
|
||||
| INT | 3307 | 慢 18% | 7416 | 慢 33% |
|
||||
|
||||
再一次,两个基准测试工具都显示 Datetime 比 Timestamp 和 INT 快。不能判断 INT 是否比 Timestamp 快,因为 mysqlslap 显示 INT 比 Timestamp 略快而 Sysbench 却相反。
|
||||
|
||||
_注意:_ 所有测试都是在一台 Windows 10 机器上本地运行的,这台机器拥有一个双核 i7 CPU,16GB 内存,运行 MariaDB v10.1.9,使用 innoDB 引擎。
|
||||
|
||||
## 结论
|
||||
|
||||
基于这些数据,我确信 Datetime 是大多数场景下的最佳选择。原因是:
|
||||
|
||||
* 更快(根据我们的三个基准测试)。
|
||||
* 无需任何转换即是人类可读的。
|
||||
* 不会因为时区变换产生问题。
|
||||
* 只比它的对手们多用 1 字节
|
||||
* 支持更大的日期范围(从 1000 年到 9999 年)
|
||||
|
||||
如果你只是存储 Unix 时间戳(并且在它的合法日期范围内),而且你真的不打算在它上面使用任何基于日期的查询,我觉得使用 INT 是可以的。我们已经看到,它执行简单数值比较查询时非常快,因为只是在处理简单的数字。
|
||||
|
||||
Timestamp 怎么样呢?如果 Datetime 相对于 Timestamp 的优势不适用于你特殊的场景,你最好使用时间戳。阅读这篇文章后,你对三种类型间的区别应该有了更好的理解,可以根据你的需要做出最佳的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.vertabelo.com/blog/technical-articles/what-datatype-should-you-use-to-represent-time-in-mysql-we-compare-datetime-timestamp-and-int
|
||||
|
||||
作者:[Francisco Claria][a]
|
||||
译者:[bianjp](https://github.com/bianjp)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.axones.com.ar/
|
||||
@ -0,0 +1,49 @@
|
||||
使用 Github Pages 发布你的项目文档
|
||||
=====
|
||||
|
||||
你可能比较熟悉[如何用 Github Pages 来分享你的工作][3],又或许你看过[一堂][4]教你建立你的第一个 Github Pages 网站的教程。近期 Github Pages 的改进使得[从不同的数据源来发布您的网站][5]更加的方便,其中的来源之一就是你的仓库的 /docs 目录。
|
||||
|
||||
文档的质量是一个软件项目健康发展的标志。对于开源项目来说,维护一个可靠而不出错的知识库、详细说明所有的细节是至关重要的。精心策划的文档可以让增加项目的亲切感,提供一步步的指导并促进各种方式的合作可以推动开源软件开发的协作进程。
|
||||
|
||||
在 Web 上托管你的文档是一个消耗时间的挑战,而且对于它的发布和维护也没有省事的办法,然而这是并非不可避免的。面对多种不同的发布工具,又是 FTP 服务器,又是数据库,文件以各种不同的方式存放在不同的位置下,而这些都需要你手动来调整。需要说明的是,传统的 Web 发布方式提供了无与伦比的灵活性和性能,但是在许多情况下,这是以牺牲简单易用为代价的。
|
||||
|
||||
当作为文档使用时,麻烦更少的方式显然更容易去维护。
|
||||
|
||||
[GitHub Pages][2] 可以以指定的方式为你的项目创建网站,这使得它天然地适合发布和维护文档。因为 Github Pages 支持 Jekyll,所以你可以使用纯文本或 Markdown 来书写你的文档,从而降低你维护的成本、减少维护时的障碍。Jekyll 还支持许多有用的工具比如变量、模板、以及自动代码高亮等等,它会给你更多的灵活性而不会增加复杂性,这些你在一些笨重的平台是见不到的。
|
||||
|
||||
最重要的是,在 Github 上使用 GitHub Pages 意味着你的文档和代码可以使用诸如 Issues 和 Pull Requests 来确保它得到应有的高水平维护,而且因为 GitHub Pages 允许您发布代码库主分支上的 /docs 目录,这样您就可以在同一分支同时维护你的代码库及其文档。
|
||||
|
||||
### 现在开始!
|
||||
|
||||
发布你的第一个文档页面只需要短短几分钟。
|
||||
|
||||
1. 在你的仓库的主分支里创建一个 /docs/index.md 文件。
|
||||
|
||||
2. 把你的内容以 Jekyll 格式添加进去,并提交你的修改。
|
||||
|
||||

|
||||
|
||||
3. 查看你的仓库的设置分支然后选择主分支 /docs 目录,将其设置为 GitHub Pages 的源 ,点击保存,你就搞定了。
|
||||
|
||||

|
||||
|
||||
GitHub Pages 将会从你的 /docs 目录中读取内容,转换 index.md 为 HTML。然后把它发布到你的 GitHub Pages 的 URL 上。
|
||||
|
||||
这样将会创建并输出一个最基础的 HTML ,而且你可以使用 Jekyll 的自定义模板、CSS 和其他特性。如果想要看所有的可能,你可以看看 [GitHub Pages Showcase][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2233-publish-your-project-documentation-with-github-pages
|
||||
|
||||
作者:[loranallensmith][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/loranallensmith
|
||||
[1]: https://github.com/showcases/github-pages-examples
|
||||
[2]: https://pages.github.com/
|
||||
[3]: https://www.youtube.com/watch?v=2MsN8gpT6jY
|
||||
[4]: https://www.youtube.com/watch?v=RaKX4A5EiQo
|
||||
[5]: https://help.github.com/articles/configuring-a-publishing-source-for-github-pages/
|
||||
@ -0,0 +1,48 @@
|
||||
百度运用 FPGA 方法大规模加速 SQL 查询
|
||||
===================================================================
|
||||
|
||||
尽管我们对百度今年工作焦点的关注集中在这个中国搜索巨头在深度学习方面的举措上,许多其他的关键的,尽管不那么前沿的应用表现出了大数据带来的挑战。
|
||||
|
||||
正如百度的欧阳剑在本周 Hot Chips 大会上谈论的,百度坐拥超过 1 EB 的数据,每天处理大约 100 PB 的数据,每天更新 100 亿的网页,每 24 小时更新处理超过 1 PB 的日志更新,这些数字和 Google 不分上下,正如人们所想象的。百度采用了类似 Google 的方法去大规模地解决潜在的瓶颈。
|
||||
|
||||
正如刚刚我们谈到的,Google 寻找一切可能的方法去打败摩尔定律,百度也在进行相同的探索,而令人激动的、使人着迷的机器学习工作是迷人的,业务的核心关键任务的加速同样也是,因为必须如此。欧阳提到,公司基于自身的数据提供高端服务的需求和 CPU 可以承载的能力之间的差距将会逐渐增大。
|
||||
|
||||
|
||||
|
||||
对于百度的百亿亿级问题,在所有数据的接受端是一系列用于数据分析的框架和平台,从该公司的海量知识图谱,多媒体工具,自然语言处理框架,推荐引擎,和点击流分析都是这样。简而言之,大数据的首要问题就是这样的:一系列各种应用和与之匹配的具有压倒性规模的数据。
|
||||
|
||||
当谈到加速百度的大数据分析,所面临的几个挑战,欧阳谈到抽象化运算核心去寻找一个普适的方法是困难的。“大数据应用的多样性和变化的计算类型使得这成为一个挑战,把所有这些整合成为一个分布式系统是困难的,因为有多变的平台和编程模型(MapReduce,Spark,streaming,user defined,等等)。将来还会有更多的数据类型和存储格式。”
|
||||
|
||||
尽管存在这些障碍,欧阳讲到他们团队找到了(它们之间的)共同线索。如他所指出的那样,那些把他们的许多数据密集型的任务相连系在一起的就是传统的 SQL。“我们的数据分析任务大约有 40% 是用 SQL 写的,而其他的用 SQL 重写也是可用做到的。” 更进一步,他讲道他们可以享受到现有的 SQL 系统的好处,并可以和已有的框架相匹配,比如 Hive,Spark SQL,和 Impala 。下一步要做的事情就是 SQL 查询加速,百度发现 FPGA 是最好的硬件。
|
||||
|
||||

|
||||
|
||||
这些主板,被称为处理单元( 下图中的 PE ),当执行 SQL 时会自动地处理关键的 SQL 功能。这里所说的都是来自演讲,我们不承担责任。确切的说,这里提到的 FPGA 有点神秘,或许是故意如此。如果百度在基准测试中得到了如下图中的提升,那这可是一个有竞争力的信息。后面我们还会继续介绍这里所描述的东西。简单来说,FPGA 运行在数据库中,当其收到 SQL 查询的时候,该团队设计的软件就会与之紧密结合起来。
|
||||
|
||||
|
||||
|
||||
欧阳提到了一件事,他们的加速器受限于 FPGA 的带宽,不然性能表现本可以更高,在下面的评价中,百度安装了 2 块12 核心,主频 2.0 GHz 的 intl E26230 CPU,运行在 128G 内存。SDA 具有 5 个处理单元,(上图中的 300MHz FPGA 主板)每个分别处理不同的核心功能(筛选(filter),排序(sort),聚合(aggregate),联合(join)和分组(group by))
|
||||
|
||||
为了实现 SQL 查询加速,百度针对 TPC-DS 的基准测试进行了研究,并且创建了称做处理单元(PE)的特殊引擎,用于在基准测试中加速 5 个关键功能,这包括筛选(filter),排序(sort),聚合(aggregate),联合(join)和分组(group by),(我们并没有把这些单词都像 SQL 那样大写)。SDA 设备使用卸载模型,具有多个不同种类的处理单元的加速卡在 FPGA 中组成逻辑,SQL 功能的类型和每张卡的数量由特定的工作量决定。由于这些查询在百度的系统中执行,用来查询的数据被以列格式推送到加速卡中(这会使得查询非常快速),而且通过一个统一的 SDA API 和驱动程序,SQL 查询工作被分发到正确的处理单元而且 SQL 操作实现了加速。
|
||||
|
||||
SDA 架构采用一种数据流模型,加速单元不支持的操作被退回到数据库系统然后在那里本地运行,比其他任何因素,百度开发的 SQL 加速卡的性能被 FPGA 卡的内存带宽所限制。加速卡跨整个集群机器工作,顺便提一下,但是数据和 SQL 操作如何分发到多个机器的准确原理没有被百度披露。
|
||||
|
||||
|
||||
|
||||
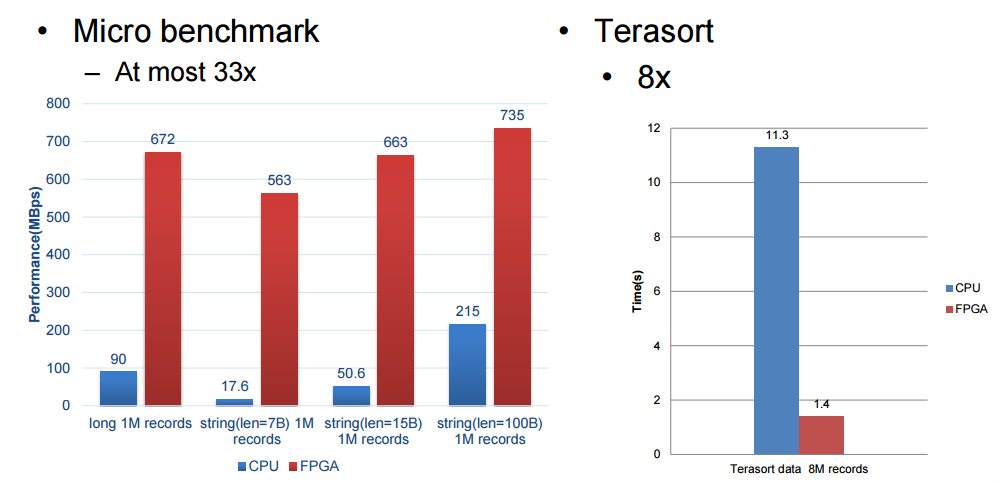
|
||||
|
||||
我们受限与百度所愿意披露的细节,但是这些基准测试结果是十分令人鼓舞的,尤其是 Terasort 方面,我们将在 Hot Chips 大会之后跟随百度的脚步去看看我们是否能得到关于这是如何连接到一起的和如何解决内存带宽瓶颈的细节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.nextplatform.com/2016/08/24/baidu-takes-fpga-approach-accelerating-big-sql/
|
||||
|
||||
作者:[Nicole Hemsoth][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.nextplatform.com/author/nicole/
|
||||
[1]: http://www.nextplatform.com/?s=baidu+deep+learning
|
||||
[2]: http://www.hotchips.org/wp-content/uploads/hc_archives/hc26/HC26-12-day2-epub/HC26.12-5-FPGAs-epub/HC26.12.545-Soft-Def-Acc-Ouyang-baidu-v3--baidu-v4.pdf
|
||||
@ -0,0 +1,53 @@
|
||||
Azure SQL 数据库已经支持 JSON
|
||||
===========
|
||||
|
||||
我们很高兴地宣布你现在可以在 Azure SQL 中查询及存储关系型数据或者 JSON 了、Azure SQL 数据库提供了读取 JSON 文本数据的简单的内置函数,将 JSON 文本转化成表,以及将表的数据转化成 JSON。
|
||||
|
||||

|
||||
|
||||
你可以使用 JSON 函数来从 JSON 文本中提取值([JSON_VALUE][4])、提取对象([JSON_QUERY][5]), 更新JSON 中的值([JSON_MODIFY][6]),并且验证 JSON 文本的正确性([ISJSON][7])。[OPENJSON][8] 函数让你可以将 JSON 文本转化成表结构。最后,JSON 功能函数可以让你很简单地从 SQL 查询中使用 [FOR JSON][9] 从句来获得 JSON 文本结果。
|
||||
|
||||
### 你可以用 JSON 做什么?
|
||||
|
||||
Azure SQL 数据库中的 JSON 可以让您构建并与现代 web、移动设备和 HTML5/单页应用、诸如 Azure DocumentDB 等包含 JSON 格式化数据的 NoSQL 存储等交换数据,分析来自不同系统和服务的日志和消息。现在你可以轻易地将 Azure SQL 数据库与任何使用使用 JSON 的服务集成。
|
||||
|
||||
#### 轻易地开放数据给现代框架和服务
|
||||
|
||||
你有没有在使用诸如 REST 或者 Azure App 使用 JSON 来交换数据的服务?你有使用诸如 AngularJS、ReactJS、D3 或者 JQuery 等使用 JSON 的组件或框架么?使用新的 JSON 功能函数,你可以轻易地格式化存储在 Azure SQL 数据库中的数据,并将它用在任何现代服务或者应用中。
|
||||
|
||||
#### 轻松采集 JSON 数据
|
||||
|
||||
你有在使用移动设备、传感器、如 Azure Stream Analytics 或者 Insight 这样产生 JSON 的服务、如 Azure DocumentDB 或者 MongoDB 这样存储 JSON 的系统么?你需要在 Azure SQL 数据中使用熟悉的 SQL 语句来查询并分析 JSON 数据么?现在你可以轻松采集 JSON 数据并存储到 Azure SQL 数据库中,并且可以使用任何 Azure SQL 数据库支持的语言或者工具来查询和分析加载的数据。
|
||||
|
||||
#### 简化你的数据模型
|
||||
|
||||
你需要同时存储及查询数据库中关系型及半结构化的数据么?你需简化像 NoSQL 平台下的数据模型么?现在你可以在一张表中同时存储结构化数据及非结构化数据了。在 Azure SQL 数据库中,你可以同时从关系型及 NoSQL 的世界中使用最好的方法来调整你的数据模型。Azure SQL 数据库让你可以使用 Transact-SQL 语言来查询关系及 JSON 数据。程序和工具将不会在从表中取出的值及 JSON 文本中提取的值看出差别。
|
||||
|
||||
### 下一步
|
||||
|
||||
要学习如何在你的应用中集成 JSON,查看我们的[开始学习][1]页面或者 [Channel 9的视频][2]。要了解不同的情景下如何集成 JSON,观看 Channel 9 的视频或者在这些 [JSON 分类文章][3]中查找你感兴趣的使用情景。
|
||||
|
||||
我们将持续增加新的 JSON 特性并让 JSON 支持的更好。请敬请关注。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://azure.microsoft.com/en-us/blog/json-support-is-generally-available-in-azure-sql-database/
|
||||
|
||||
作者:[Jovan Popovic][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://azure.microsoft.com/en-us/blog/author/jovanpop/
|
||||
[1]: https://azure.microsoft.com/en-us/documentation/articles/sql-database-json-features/
|
||||
[2]: https://channel9.msdn.com/Shows/Data-Exposed/SQL-Server-2016-and-JSON-Support
|
||||
[3]: http://blogs.msdn.com/b/sqlserverstorageengine/archive/tags/json/
|
||||
[4]: https://msdn.microsoft.com/en-us/library/dn921898.aspx
|
||||
[5]: https://msdn.microsoft.com/en-us/library/dn921884.aspx
|
||||
[6]: https://msdn.microsoft.com/en-us/library/dn921892.aspx
|
||||
[7]: https://msdn.microsoft.com/en-us/library/dn921896.aspx
|
||||
[8]: https://msdn.microsoft.com/en-us/library/dn921885.aspx
|
||||
[9]: https://msdn.microsoft.com/en-us/library/dn921882.aspx
|
||||
|
||||
76
published/20160828 4 Best Linux Boot Loaders.md
Normal file
76
published/20160828 4 Best Linux Boot Loaders.md
Normal file
@ -0,0 +1,76 @@
|
||||
4 个最好的 Linux 引导程序
|
||||
==================
|
||||
|
||||
当你打开你的机器,开机自检(POST)成功完成后,BIOS(基本输入输出系统)立即定位所配置的引导介质,并从 MBR(主引导记录)或 GUID(全局唯一标识符)分区表读取一些命令,这是引导介质的最前面 512 个字节内容。主引导记录(MBR)中包含两个重要的信息集合,第一个是引导程序,第二个是分区表。
|
||||
|
||||
### 什么是引导程序?
|
||||
|
||||
引导程序(Boot Loader)是存储在 MBR(主引导记录)或 GUID(全局唯一标识符)分区表中的一个小程序,用于帮助把操作系统装载到内存中。如果没有引导程序,那么你的操作系统将不能够装载到内存中。
|
||||
|
||||
有一些我们可以随同 Linux 安装到系统上的引导程序,在这篇文章里,我将简要地谈论几个最好的可以与 Linux 一同工作的 Linux 引导程序。
|
||||
|
||||
### 1. GNU GRUB
|
||||
|
||||
GNU GRUB 是一个非常受欢迎,也可能是用的最多的具有多重引导能力的 Linux 引导程序,它以原始的 Eirch Stefan Broleyn 发明的 GRUB(GRand Unified Bootlader)为基础。GNU GRUB 增强了原来的 GRUB,带来了一些改进、新的特性和漏洞修复。
|
||||
|
||||
重要的是,GRUB 2 现在已经取代了 GRUB。值得注意的是,GRUB 这个名字被重新命名为 GRUB Legacy,但没有活跃开发,不过,它可以用来引导老的系统,因为漏洞修复依然继续。
|
||||
|
||||
GRUB 具有下面一些显著的特性:
|
||||
|
||||
- 支持多重引导
|
||||
- 支持多种硬件结构和操作系统,比如 Linux 和 Windows
|
||||
- 提供一个类似 Bash 的交互式命令行界面,从而用户可以运行 GRUB 命令来和配置文件进行交互
|
||||
- 允许访问 GRUB 编辑器
|
||||
- 支持设置加密口令以确保安全
|
||||
- 支持从网络进行引导,以及一些次要的特性
|
||||
|
||||
访问主页: <https://www.gnu.org/software/grub/>
|
||||
|
||||
### 2. LILO(Linux 引导程序(LInux LOader))
|
||||
|
||||
LILO 是一个简单但强大且非常稳定的 Linux 引导程序。由于 GRUB 有很大改善和增加了许多强大的特性,越来越受欢迎,因此 LILO 在 Linux 用户中已经不是很流行了。
|
||||
|
||||
当 LILO 引导的时候,单词“LILO”会出现在屏幕上,并且每一个字母会在一个特定的事件发生前后出现。然而,从 2015 年 12 月开始,LILO 的开发停止了,它有许多特性比如下面列举的:
|
||||
|
||||
- 不提供交互式命令行界面
|
||||
- 支持一些错误代码
|
||||
- 不支持网络引导(LCTT 译注:其变体 ELILO 支持 TFTP/DHCP 引导)
|
||||
- 所有的文件存储在驱动的最开始 1024 个柱面上
|
||||
- 面临 BTFS、GTP、RAID 等的限制
|
||||
|
||||
访问主页: <http://lilo.alioth.debian.org/>
|
||||
|
||||
### 3. BURG - 新的引导程序
|
||||
|
||||
基于 GRUB,BURG 是一个相对来说比较新的引导程序(LCTT 译注:已于 2011 年停止了开发)。由于 BURG 起源于 GRUB, 所以它带有一些 GRUB 主要特性。尽管如此, BURG 也提供了一些出色的特性,比如一种新的对象格式可以支持包括 Linux、Windows、Mac OS、 FreeBSD 等多种平台。
|
||||
|
||||
另外,BURG 支持可高度配置的文本和图标模式的引导菜单,计划增加的“流”支持未来可以不同的输入/输出设备一同工作。
|
||||
|
||||
访问主页: <https://launchpad.net/burg>
|
||||
|
||||
### 4. Syslinux
|
||||
|
||||
Syslinux 是一种能从光盘驱动器、网络等进行引导的轻型引导程序。Syslinux 支持诸如 MS-DOS 上的 FAT、 Linux 上的 ext2、ext3、ext4 等文件系统。Syslinux 也支持未压缩的单一设备上的 Btrfs。
|
||||
|
||||
注意由于 Syslinux 仅能访问自己分区上的文件,因此不具备多重文件系统引导能力。
|
||||
|
||||
访问主页: <http://www.syslinux.org/wiki/index.php?title=The_Syslinux_Project>
|
||||
|
||||
### 结论
|
||||
|
||||
一个引导程序允许你在你的机器上管理多个操作系统,并在某个的时间选择其中一个使用。没有引导程序,你的机器就不能够装载内核以及操作系统的剩余部分。
|
||||
|
||||
我们是否遗漏了任何一流的 Linux 引导程序?如果有请让我们知道,请在下面的评论表中填入值得推荐的 Linux 系统引导程序。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-linux-boot-loaders/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/best-linux-boot-loaders/
|
||||
@ -0,0 +1,99 @@
|
||||
JavaScript 现状:方言篇
|
||||
===========
|
||||
|
||||
JavaScript 和其他编程语言有一个很大的不同,它不像单纯的一个语言,而像一个由众多方言组成大家族。
|
||||
|
||||
从 2009 年 CoffeeScript 出现开始,近几年出现了大量基于 JavaScript 语言,或者叫方言,例如 ES6、TypeScript、Elm 等等。它们都有自己的优势,且都可以被完美编译成标准 JavaScript。
|
||||
|
||||
所以,继上周的前端框架篇,今天带来 JavaScript 现状之方言篇,看一下大家对于 JavaScript 的方言是怎么选择的。
|
||||
|
||||
> 声明:下面的部分结论来自部分数据,这是在我想要展示完整数据时找到的最好的办法,这便于我分享我的一些想法。
|
||||
|
||||
> 注意:如果你还没有参与[这个调查][3],现在就来参加吧,可以花十分钟完成调查然后再回来看这篇文章。
|
||||
|
||||
### 认知度
|
||||
|
||||
首先,我想看一下参与问卷调查的人是否**知道**下面六种语言:
|
||||
|
||||
- 经典的 JavaScript: 97%
|
||||
- ES6: 98%
|
||||
- CoffeeScript: 99%
|
||||
- TypeScript: 98%
|
||||
- Elm: 66%
|
||||
- ClojureScript: 77%
|
||||
|
||||
你可能觉得 100% 的人都应该知道『经典的 JavaScript 』,我想是有人无法抵抗在一个 JavaScript 调查中投『我从来没有听说过 JavaScript 』这个选项的强大诱惑吧……
|
||||
|
||||
几乎所有人都知道 ES6、CoffeeScript 和 TypeScript 这三种语言,比较令我惊讶的是 TypeScript 竟然会稍微落后于 ES6 和 CoffeeScript。
|
||||
|
||||
另一方面,Elm 和 ClojureScript 得分就要低得多,当然这也有道理,因为它们跟自己的生态环境绑定的比较紧密,也很难在已有的 App 中进行使用。
|
||||
|
||||
### 兴趣度
|
||||
|
||||
接下来,让我们一起看一下,哪一种方言吸引新开发者的能力更强一些:
|
||||
|
||||
|
||||
|
||||
要注意,该表是统计该语言对从未使用过它们的用户的吸引度,因为只有很少人没有用过经典 JavaScript,所以『经典 JavaScript 』这一列的数值很低。
|
||||
|
||||
ES6的数值很有趣:已有很大比例的用户在使用 ES6 了,没有用过的人中的绝大部分(89%)也很想学习它。
|
||||
|
||||
TypeScript 和 Elm 的状态差不多:用过的人不多,但感兴趣的比例表现不错,分别是 53% 和 58%。
|
||||
|
||||
如果让我预测一下,那我觉得 TypeScript 和 Elm 都很难向普通的 JavaScript 开发者讲明自己的优势。毕竟如果开发者只懂 JavaScript 的话,你很难解释清楚静态类型的好处。
|
||||
|
||||
另外,只有很少开发者用过 CoffeeScript,而且很明显几乎没人想去学。我觉得我该写一本 12 卷厚的 CoffeeScript 百科全书了……
|
||||
|
||||
### 满意度
|
||||
|
||||
现在是最重要的问题的时间了:有多少开发者用过这些语言,有多少人还想继续使用这些方言呢?
|
||||
|
||||
|
||||
|
||||
虽然经典 JavaScript 拥有最多的用户量,但就满意度来说 ES6 才是大赢家,而且我想现在已经能安全的说,ES6 可以作为开发 JavaScript App 默认的语言。
|
||||
|
||||
TypeScript 和 Elm 有相似的高满意度,都在 85% 上下。然后,只有可怜的 17% 的开发者会考虑继续使用 CoffeeScript。
|
||||
|
||||
### 快乐度
|
||||
|
||||
最后一个问题,我问大家在用现在的方式写 JavaScript 时是否感到快乐:
|
||||
|
||||
|
||||
|
||||
这个问题的答案和上一个问题的满意度想匹配:平均分达到 3.96 分(1 - 5 分),大家在使用 JavaScript 时候确实是快乐的。
|
||||
|
||||
不过很难说高分是因为 JavaScript 最近的一些改进造成的呢,还是发现 JavaScript 可能(仅仅是可能)没有大家认为的那么讨厌。总之,JavaScript 令人满意。
|
||||
|
||||
### 总结
|
||||
|
||||
如果说上次的赢家是 React 和 Vue,那此次调查的冠军毫无争议是 ES6 了。 ES6 并带来没有开天辟地的变化,但整个社区都还是很认可当前 JavaScript 演进方向的。
|
||||
|
||||
我觉得一年之后我们再来一次这样的调查,结果会很有趣。同时也可以关注一下 TypeScript、Elm 还有ClojureScript 有没有继续进步。
|
||||
|
||||
个人认为,当前 JavaScript 大家庭百花齐放的现象还只是一个开始,或许几年之后 JavaScript 就会变得非常不同了。
|
||||
|
||||
### 结语 & 敬请期待
|
||||
|
||||
对于我这样的调查来说数据越多就意味着数据越准确!越多人参加这个调查,那就越能代表整个 JavaScript 社区。
|
||||
|
||||
所以,我十分希望你能帮忙分享这个调查问卷:
|
||||
|
||||
- [在 Twitter 上][1]
|
||||
- [在 Facebook 上][2]
|
||||
|
||||
另外,如果你想收到我下一个调查结果分析,前往 [调查问卷主页][3] 并留下自己的邮箱吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@sachagreif/the-state-of-javascript-javascript-flavors-1e02b0bfefb6
|
||||
|
||||
作者:[Sacha Greif][a]
|
||||
译者:[eriwoon](https://github.com/eriwoon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://medium.com/@sachagreif
|
||||
[1]: https://twitter.com/intent/tweet/?text=The%20State%20Of%20JavaScript%3A%20take%20a%20short%20survey%20about%20popular%20JavaScript%20technologies%20http%3A%2F%2Fstateofjs.com%20%23stateofjs
|
||||
[2]: https://facebook.com/sharer/sharer.php?u=http%3A%2F%2Fstateofjs.com
|
||||
[3]: http://stateofjs.com/
|
||||
@ -0,0 +1,77 @@
|
||||
QOwnNotes:一款记录笔记和待办事项的应用,集成 ownCloud 云服务
|
||||
===============
|
||||
|
||||
[QOwnNotes][1] 是一款自由而开源的笔记记录和待办事项的应用,可以运行在 Linux、Windows 和 mac 上。
|
||||
|
||||
这款程序将你的笔记保存为纯文本文件,它支持 Markdown 支持,并与 ownCloud 云服务紧密集成。
|
||||
|
||||
|
||||
|
||||
QOwnNotes 的亮点就是它集成了 ownCloud 云服务(当然是可选的)。在 ownCloud 上用这款 APP,你就可以在网路上记录和搜索你的笔记,也可以在移动设备上使用(比如一款像 CloudNotes 的软件[2])。
|
||||
|
||||
不久以后,用你的 ownCloud 账户连接上 QOwnNotes,你就可以从你 ownCloud 服务器上分享笔记和查看或恢复之前版本记录的笔记(或者丢到垃圾箱的笔记)。
|
||||
|
||||
同样,QOwnNotes 也可以与 ownCloud 任务或者 Tasks Plus 应用程序相集成。
|
||||
|
||||
如果你不熟悉 [ownCloud][3] 的话,这是一款替代 Dropbox、Google Drive 和其他类似商业性的网络服务的自由软件,它可以安装在你自己的服务器上。它有一个网络界面,提供了文件管理、日历、照片、音乐、文档浏览等等功能。开发者同样提供桌面同步客户端以及移动 APP。
|
||||
|
||||
因为笔记被保存为纯文本,它们可以在不同的设备之间通过云存储服务进行同步,比如 Dropbox,Google Drive 等等,但是在这些应用中不能完全替代 ownCloud 的作用。
|
||||
|
||||
我提到的上述特点,比如恢复之前的笔记,只能在 ownCloud 下可用(尽管 Dropbox 和其他类似的也提供恢复以前的文件的服务,但是你不能在 QOwnnotes 中直接访问到)。
|
||||
|
||||
鉴于 QOwnNotes 有这么多优点,它支持 Markdown 语言(内置了 Markdown 预览模式),可以标记笔记,对标记和笔记进行搜索,在笔记中加入超链接,也可以插入图片:
|
||||
|
||||
|
||||
|
||||
标记嵌套和笔记文件夹同样支持。
|
||||
|
||||
代办事项管理功能比较基本还可以做一些改进,它现在打开在一个单独的窗口里,它也不用和笔记一样的编辑器,也不允许添加图片或者使用 Markdown 语言。
|
||||
|
||||
|
||||
|
||||
它可以让你搜索你代办事项,设置事项优先级,添加提醒和显示完成的事项。此外,待办事项可以加入笔记中。
|
||||
|
||||
这款软件的界面是可定制的,允许你放大或缩小字体,切换窗格等等,也支持无干扰模式。
|
||||
|
||||

|
||||
|
||||
从程序的设置里,你可以开启黑夜模式(这里有个 bug,在 Ubuntu 16.04 里有些工具条图标消失了),改变状态条大小,字体和颜色方案(白天和黑夜):
|
||||
|
||||
|
||||
|
||||
其他的特点有支持加密(笔记只能在 QOwnNotes 中加密),自定义键盘快捷键,输出笔记为 pdf 或者 Markdown,自定义笔记自动保存间隔等等。
|
||||
|
||||
访问 [QOwnNotes][11] 主页查看完整的特性。
|
||||
|
||||
### 下载 QOwnNotes
|
||||
|
||||
如何安装,请查看安装页(支持 Debian、Ubuntu、Linux Mint、openSUSE、Fedora、Arch Linux、KaOS、Gentoo、Slackware、CentOS 以及 Mac OSX 和 Windows)。
|
||||
|
||||
QOwnNotes 的 [snap][5] 包也是可用的,在 Ubuntu 16.04 或更新版本中,你可以通过 Ubuntu 的软件管理器直接安装它。
|
||||
|
||||
为了集成 QOwnNotes 到 ownCloud,你需要有 [ownCloud 服务器][6],同样也需要 [Notes][7]、[QOwnNotesAPI][8]、[Tasks][9]、[Tasks Plus][10] 等 ownColud 应用。这些可以从 ownCloud 的 Web 界面上安装,不需要手动下载。
|
||||
|
||||
请注意 QOenNotesAPI 和 Notes ownCloud 应用是实验性的,你需要“启用实验程序”来发现并安装他们,可以从 ownCloud 的 Web 界面上进行设置,在 Apps 菜单下,在左下角点击设置按钮。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.webupd8.org/2016/09/qownnotes-is-note-taking-and-todo-list.html
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.webupd8.org/p/about.html
|
||||
[1]: http://www.qownnotes.org/
|
||||
[2]: http://peterandlinda.com/cloudnotes/
|
||||
[3]: https://owncloud.org/
|
||||
[4]: http://www.qownnotes.org/installation
|
||||
[5]: https://uappexplorer.com/app/qownnotes.pbek
|
||||
[6]: https://download.owncloud.org/download/repositories/stable/owncloud/
|
||||
[7]: https://github.com/owncloud/notes
|
||||
[8]: https://github.com/pbek/qownnotesapi
|
||||
[9]: https://apps.owncloud.com/content/show.php/Tasks?content=164356
|
||||
[10]: https://apps.owncloud.com/content/show.php/Tasks+Plus?content=170561
|
||||
[11]: http://www.qownnotes.org/
|
||||
@ -0,0 +1,63 @@
|
||||
Linus Torvalds 透露他编程最喜欢使用的笔记本
|
||||
=================
|
||||
|
||||
> 是戴尔 XPS 13 开发者版。下面就是原因。
|
||||
|
||||
我最近和一些 Linux 开发者讨论了对于严谨的程序员来说,最好的笔记本是什么样的问题。结果,我从这些程序员的观点中筛选出了多款笔记本电脑。那么依我之见赢家是谁呢?就是戴尔 XPS 13 开发者版。和我观点一样的大有人在。Linux的缔造者 Linus Torvalds 也认同这个观点。对于他来说,戴尔 XPS 13 开发者版大概是最好的笔记本电脑了。
|
||||
|
||||

|
||||
|
||||
Torvalds 的需求可能和你的不同。
|
||||
|
||||
在 Google+ 上,Torvalds 解释道,“第一:[我从来不把笔记本当成台式机的替代品][1],并且,我每年旅游不了几次。所以对于我来说,笔记本是一个相当专用的东西,并不是每日(甚至每周)都要使用,因此,主要的标准不是那种“差不多每天都使用”的标准,而是非常适合于旅游时使用。”
|
||||
|
||||
因此,对于 Torvalds 来说,“我最后比较关心的一点是它是相当的小和轻,因为在会议上我可能一整天都需要带着它。我同样需要一个好的屏幕,因为到目前为止,我主要是在桌子上使用它,我希望文字的显示小而且清晰。”
|
||||
|
||||
戴尔的显示器是由 Intel's Iris 540 GPU 支持的。在我的印象中,它表现的非常的不错。
|
||||
|
||||
Iris 驱动了 13.3 英寸的 3200×1800 的显示屏。每英寸有 280 像素,比我喜欢的 [2015 年的 Chromebook Pixel][2] 多了 40 个像素,比 [Retina 屏的 MacBook Pro][3] 还要多 60 个像素。
|
||||
|
||||
然而,要让上面说的硬件配置在 [Gnome][4] 桌面上玩好也不容易。正如 Torvalds 在另一篇文章解释的那样,它“[和我的桌面电脑有一样的分辨率][5],但是,显然因为笔记本的显示屏更小,Gnome 桌面似乎自己做了个艰难的决定,认为我需要 2 倍的自动缩放比例,这简直愚蠢到炸裂(例如窗口显示,图标等)。”
|
||||
|
||||
解决方案?你不用想着在用户界面里面找了。你需要在 shell下运行:`gsettings set org.gnome.desktop.interface scaling-factor 1`。
|
||||
|
||||
Torvalds 或许使用 Gnome 桌面,但是他不是很喜欢 Gnome 3.x 系列。这一点上我跟他没有不同意见。这就是为什么我使用 [Cinnamon][7] 来代替。
|
||||
|
||||
他还希望“一个相当强大的 CPU,因为当我旅游的时候,我依旧需要编译 Linux 内核很多次。我并不会像在家那样每次 pull request 都进行一次完整的“make allmodconfig”编译,但是我希望可以比我以前的笔记本多编译几次,实际上,这(也包括屏幕)应该是我想升级的主要原因。”
|
||||
|
||||
Linus 没有描述他的 XPS 13 的细节,但是我测评过的那台是一个高端机型。它带有双核 2.2GHz 的第 6 代英特尔的酷睿 i7-6550U Skylake 处理器,16GBs DDR3 内存,以及一块半 TB (500GB)的 PCIe 固态硬盘(SSD)。我可以肯定,Torvalds 的系统至少是精良装备。”
|
||||
|
||||
一些你或许会关注的特征没有在 Torvalds 的清单中:
|
||||
|
||||
> “我不会关心的是触摸屏,因为我的手指相对于我所看到的文字是又大又笨拙(我也无法处理污渍:也许我的手指特别油腻,但是我真的不想碰那些屏幕)。
|
||||
|
||||
> 我并不十分关心那些“一整天的电池寿命”,因为坦率的讲,我不记得上次没有接入电源时什么时候了。我可能着急忙慌而忘记插电,但它不是一个天大的问题。现在电池的寿命“超过两小时”,我只是不那么在乎了。”
|
||||
|
||||
戴尔声称,XPS 13,搭配 56 瓦小时的 4 芯电池,拥有 12 小时的电池寿命。以我的使用经验它已经很好的用过了 10 个小时。我从没有尝试过把电量完全耗完是什么状态。
|
||||
|
||||
Torvalds 也没有遇到 Intel 的 Wi-Fi 设备问题。非开发者版使用 Broadcom 的芯片设备,已经被 Windows 和 Linux 用户发现了一些问题。戴尔的技术支持对于我来解决这些问题非常有帮助。
|
||||
|
||||
一些用户在使用 XPS 13 触摸板的时候,遇到了问题。Torvalds 和我都几乎没有什么困扰。Torvalds 写到,“XPS13 触摸板对于我来说运行的非常好。这可能只是个人喜好,但它操作起来比较流畅,响应比较快。”
|
||||
|
||||
不过,尽管 Torvalds 喜欢 XPS 13,他同时也钟情于最新版的联想 X1 Carbon、惠普 Spectre 13 x360,和去年的联想 Yoga 900。至于我?我喜欢 XPS 13 开发者版。至于价钱,我以前测评过的型号是 $1949.99,可能刷你的信用卡就够了。
|
||||
|
||||
因此,如果你希望像世界上顶级的程序员之一一样开发的话,Dell XPS 13 开发者版对得起它的价格。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linus-torvalds-reveals-his-favorite-programming-laptop/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: https://plus.google.com/+LinusTorvalds/posts/VZj8vxXdtfe
|
||||
[2]: http://www.zdnet.com/article/the-best-chromebook-ever-the-chromebook-pixel-2015/
|
||||
[3]: http://www.zdnet.com/product/apple-15-inch-macbook-pro-with-retina-display-mid-2015/
|
||||
[4]: https://www.gnome.org/
|
||||
[5]: https://plus.google.com/+LinusTorvalds/posts/d7nfnWSXjfD
|
||||
[6]: http://www.zdnet.com/article/linus-torvalds-finds-gnome-3-4-to-be-a-total-user-experience-design-failure/
|
||||
[7]: http://www.zdnet.com/article/how-to-customise-your-linux-desktop-cinnamon/
|
||||
@ -0,0 +1,140 @@
|
||||
Googler:现在可以 Linux 终端下进行 Google 搜索了!
|
||||
============================================
|
||||
|
||||

|
||||
|
||||
一个小问题:你每天做什么事?当然了,好多事情,但是我可以指出一件事,你几乎每天(如果不是每天)都会用 Google 搜索,我说的对吗?(LCTT 译注:Google 是啥?/cry )
|
||||
|
||||
现在,如果你是一位 Linux 用户(我猜你也是),这里有另外一个问题:如果你甚至不用离开终端就可以进行 Google 搜索那岂不是相当棒?甚至不用打开一个浏览器窗口?
|
||||
|
||||
如果你是一位类 [*nix][7] 系统的狂热者而且也是喜欢终端界面的人,我知道你的答案是肯定的,而且我认为,接下来你也将喜欢上我今天将要介绍的这个漂亮的小工具。它被称做 Googler。
|
||||
|
||||
### Googler:在你 linux 终端下的 google
|
||||
|
||||
Googler 是一个简单的命令行工具,它用于直接在命令行窗口中进行 google 搜索,Googler 主要支持三种类型的 Google 搜索:
|
||||
|
||||
- Google 搜索:简单的 Google 搜索,和在 Google 主页搜索是等效的。
|
||||
- Google 新闻搜索:Google 新闻搜索,和在 Google News 中的搜索一样。
|
||||
- Google 站点搜索:Google 从一个特定的网站搜索结果。
|
||||
|
||||
Googler 用标题、链接和网页摘要来显示搜索结果。搜索出来的结果可以仅通过两个按键就可以在浏览器里面直接打开。
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 下安装 Googler
|
||||
|
||||
先让我们进行软件的安装。
|
||||
|
||||
首先确保你的 python 版本大于等于 3.3,可以用以下命令查看。
|
||||
|
||||
```
|
||||
python3 --version
|
||||
```
|
||||
|
||||
如果不是的话,就更新一下。Googler 要求 python 版本 3.3 及以上运行。
|
||||
|
||||
虽然 Googler 现在还不能在 Ununtu 的软件库中找到,我们可以很容易地从 GitHub 仓库中安装它。我们需要做的就是运行以下命令:
|
||||
|
||||
```
|
||||
cd /tmp
|
||||
git clone https://github.com/jarun/googler.git
|
||||
cd googler
|
||||
sudo make install
|
||||
cd auto-completion/bash/
|
||||
sudo cp googler-completion.bash /etc/bash_completion.d/
|
||||
```
|
||||
|
||||
这样 Googler 就带着命令自动完成特性安装完毕了。
|
||||
|
||||
### 特点 & 基本用法
|
||||
|
||||
如果我们快速浏览它所有的特点,我们会发现 Googler 实际上是一个十分强大的工具,它的一些主要特点就是:
|
||||
|
||||
#### 交互界面
|
||||
|
||||
在终端下运行以下命令:
|
||||
|
||||
```
|
||||
googler
|
||||
```
|
||||
|
||||
交互界面就会被打开,Googler 的开发者 [Arun Prakash Jana][1] 称之为全向提示符(omniprompt),你可以输入 `?` 去寻找可用的命令参数:
|
||||
|
||||

|
||||
|
||||
在提示符处,输入任何搜索词汇关键字去开始搜索,然后你可以输入`n`或者`p`导航到搜索结果的后一页和前一页。
|
||||
|
||||
要在浏览器窗口中打开搜索结果,直接输入搜索结果的编号,或者你可以输入 `o` 命令来打开这个搜索网页。
|
||||
|
||||
#### 新闻搜索
|
||||
|
||||
如果你想去搜索新闻,直接以`N`参数启动 Googler:
|
||||
|
||||
```
|
||||
googler -N
|
||||
```
|
||||
|
||||
随后的搜索将会从 Google News 抓取结果。
|
||||
|
||||
#### 站点搜索
|
||||
|
||||
如果你想从某个特定的站点进行搜索,以`w 域名`参数启动 Googler:
|
||||
|
||||
```
|
||||
googler -w itsfoss.com
|
||||
```
|
||||
|
||||
随后的搜索会只从这个博客中抓取结果!
|
||||
|
||||
#### 手册页
|
||||
|
||||
运行以下命令去查看 Googler 的带着各种用例的手册页:
|
||||
|
||||
```
|
||||
man googler
|
||||
```
|
||||
|
||||
#### 指定国家/地区的 Google 搜索引擎
|
||||
|
||||
```
|
||||
googler -c in "hello world"
|
||||
```
|
||||
|
||||
上面的示例命令将会开始从 Google 的印度域名搜索结果(in 代表印度)
|
||||
|
||||
还支持:
|
||||
|
||||
- 通过时间和语言偏好来过滤搜索结果
|
||||
- 支持 Google 查询关键字,例如:`site:example.com` 或者 `filetype:pdf` 等等
|
||||
- 支持 HTTPS 代理
|
||||
- Shell 命令自动补全
|
||||
- 禁用自动拼写纠正
|
||||
|
||||
这里还有更多特性。你可以用 Googler 去满足你的需要。
|
||||
|
||||
Googler 也可以和一些基于文本的浏览器整合在一起(例如:[elinks][2]、[links][3]、[lynx][4]、w3m 等),所以你甚至都不用离开终端去浏览网页。在 [Googler 的 GitHub 项目页][5]可以找到指导。
|
||||
|
||||
如果你想看一下 Googler 不同的特性的视频演示,方便的话你可以查看 GitHub 项目页附带的终端记录演示页: [jarun/googler v2.7 quick demo][6]。
|
||||
|
||||
### 对于 Googler 的看法?
|
||||
|
||||
尽管 googler 可能并不是对每个人都是必要和渴望的,对于一些不想打开浏览器进行 google 搜索或者就是想泡在终端窗口里面的人来说,这是一个很棒的工具。你认为呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/review-googler-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]: https://github.com/jarun
|
||||
[2]: http://elinks.or.cz/
|
||||
[3]: http://links.twibright.com/
|
||||
[4]: http://lynx.browser.org/
|
||||
[5]: https://github.com/jarun/googler#faq
|
||||
[6]: https://asciinema.org/a/85019
|
||||
[7]: https://en.wikipedia.org/wiki/Unix-like
|
||||
@ -0,0 +1,85 @@
|
||||
如何在 Ubuntu 16.04 和 Fedora 22-24 上安装最新的 XFCE 桌面?
|
||||
==========================
|
||||
|
||||
Xfce 是一款针对 Linux 系统的现代化[轻型开源桌面环境][1],它在其他的类 Unix 系统上,比如 Mac OS X、 Solaries、 *BSD 以及其它几种上也能工作得很好。它非常快并以简洁而优雅的用户界面展现了用户友好性。
|
||||
|
||||
在服务器上安装一个桌面环境有时还是有用的,因为某些应用程序可能需要一个桌面界面,以便高效而可靠的管理。 Xfce 的一个卓越的特性是其内存消耗等系统资源占用率很低,因此,如果服务器需要一个桌面环境的话它会是首选。
|
||||
|
||||
### XFCE 桌面的功能特性
|
||||
|
||||
另外,它的一些值得注意的组件和功能特性列在下面:
|
||||
|
||||
- Xfwm 窗口管理器
|
||||
- Thunar 文件管理器
|
||||
- 用户会话管理器:用来处理用户登录、电源管理之类
|
||||
- 桌面管理器:用来设置背景图片、桌面图标等等
|
||||
- 应用管理器
|
||||
- 它的高度可连接性以及一些其他次要功能特性
|
||||
|
||||
Xfce 的最新稳定发行版是 Xfce 4.12,它所有的功能特性和与旧版本的变化都列在了[这儿][2]。
|
||||
|
||||
#### 在 Ubuntu 16.04 上安装 Xfce 桌面
|
||||
|
||||
Linux 发行版,比如 Xubuntu、Manjaro、OpenSUSE、Fedora Xfce Spin、Zenwalk 以及许多其他发行版都提供它们自己的 Xfce 桌面安装包,但你也可以像下面这样安装最新的版本。
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install xfce4
|
||||
```
|
||||
|
||||
等待安装过程结束,然后退出当前会话,或者你也可以选择重启系统。在登录界面,选择 Xfce 桌面,然后登录,截图如下:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
#### 在 Fedora 22-24 上安装 Xfce 桌面
|
||||
|
||||
如果你已经有一个安装好的 Linux 发行版 Fedora,想在上面安装 xfce 桌面,那么你可以使用如下所示的 yum 或 dnf 命令。
|
||||
|
||||
```
|
||||
-------------------- 在 Fedora 22 上 --------------------
|
||||
# yum install @xfce
|
||||
-------------------- 在 Fedora 23-24 上 --------------------
|
||||
# dnf install @xfce-desktop-environment
|
||||
```
|
||||
|
||||
|
||||
安装 Xfce 以后,你可以从会话菜单选择 Xfce 登录或者重启系统。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
如果你不再想要 Xfce 桌面留在你的系统上,那么可以使用下面的命令来卸载它:
|
||||
|
||||
```
|
||||
-------------------- 在 Ubuntu 16.04 上 --------------------
|
||||
$ sudo apt purge xfce4
|
||||
$ sudo apt autoremove
|
||||
-------------------- 在 Fedora 22 上 --------------------
|
||||
# yum remove @xfce
|
||||
-------------------- 在 Fedora 23-24 上 --------------------
|
||||
# dnf remove @xfce-desktop-environment
|
||||
```
|
||||
|
||||
|
||||
在这个简单的入门指南中,我们讲解了如何安装最新版 Xfce 桌面的步骤,我相信这很容易掌握。如果一切进行良好,你可以享受一下使用 xfce —— 这个[ Linux 系统上最佳桌面环境][1]之一。
|
||||
|
||||
此外,如果你再次回来,你可以通过下面的反馈表单和我们始终保持联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-xfce-desktop-in-ubuntu-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: http://www.tecmint.com/best-linux-desktop-environments/
|
||||
[2]: https://www.xfce.org/about/news/?post=1425081600
|
||||
@ -1,43 +1,45 @@
|
||||
LFCS 系列第十三讲:如何配置并排除 GNU 引导加载程序(GRUB)故障
|
||||
=====================================================================================
|
||||
|
||||
由于 LFCS 考试需求的变动已于 2016 年 2 月 2 日生效,因此我们向 [LFCS 系列][1] 添加了一些必要的话题。为了准备认证考试,我们也强烈推荐你去看 [LFCE 系列][2]。
|
||||
由于 LFCS 考试需求的变动已于 2016 年 2 月 2 日生效,因此我们向 [LFCS 系列][1] 添加了一些必要的话题。为了准备认证考试,我们也强烈推荐你去看看 [LFCE 系列][2]。
|
||||
|
||||

|
||||
>LFCS 系列第十三讲:配置并排除 Grub 引导加载程序故障。
|
||||
|
||||
本文将会向你介绍 GRUB 的知识,并会说明你为什么需要一个引导加载程序,以及它是如何增强系统通用性的。
|
||||
*LFCS 系列第十三讲:配置并排除 Grub 引导加载程序故障。*
|
||||
|
||||
[Linux 引导过程][3] 是从你按下你的电脑电源键开始,直到你拥有一个全功能的系统为止,整个过程遵循着这样的高层次顺序:
|
||||
本文将会向你介绍 GRUB 的知识,并会说明你为什么需要一个引导加载程序,以及它是如何给系统增加功能的。
|
||||
|
||||
[Linux 引导过程][3] 是从你按下你的电脑电源键开始,直到你拥有一个全功能的系统为止,整个过程遵循着这样的主要步骤:
|
||||
|
||||
* 1. 一个叫做 **POST**(**上电自检**)的过程会对你的电脑硬件组件做全面的检查。
|
||||
* 2. 当 **POST** 完成后,它会把控制权转交给引导加载程序,接下来引导加载程序会将 Linux 内核(以及 **initramfs**)加载到内存中并执行。
|
||||
* 3. 内核首先检查并访问硬件,然后运行初始进程(主要以它的通用名 **init** 而为人熟知),接下来初始进程会启动一些服务,最后完成系统启动过程。
|
||||
* 3. 内核首先检查并访问硬件,然后运行初始化进程(主要以它的通用名 **init** 而为人熟知),接下来初始化进程会启动一些服务,最后完成系统启动过程。
|
||||
|
||||
在该系列的第七讲(“[SysVinit, Upstart, 和 Systemd][4]”)中,我们介绍了现代 Linux 发行版使用的一些服务管理系统和工具。在继续学习之前,你可能想要回顾一下那一讲的知识。
|
||||
在该系列的第七讲(“[SysVinit、Upstart 和 Systemd][4]”)中,我们介绍了现代 Linux 发行版使用的一些服务管理系统和工具。在继续学习之前,你可能想要回顾一下那一讲的知识。
|
||||
|
||||
### GRUB 引导装载程序介绍
|
||||
|
||||
在现代系统中,你会发现有两种主要的 **GRUB** 版本(一种是偶尔被成为 **GRUB Legacy** 的 **v1** 版本,另一种则是 **v2** 版本),虽说多数最新版本的发行版系统都默认使用了 **v2** 版本。如今,只有 **红帽企业版 Linux 6** 及其衍生系统仍在使用 **v1** 版本。
|
||||
在现代系统中,你会发现有两种主要的 **GRUB** 版本(一种是有时被称为 **GRUB Legacy** 的 **v1** 版本,另一种则是 **v2** 版本),虽说多数最新版本的发行版系统都默认使用了 **v2** 版本。如今,只有 **红帽企业版 Linux 6** 及其衍生系统仍在使用 **v1** 版本。
|
||||
|
||||
因此,在本指南中,我们将着重关注 **v2** 版本的功能。
|
||||
|
||||
不管 **GRUB** 的版本是什么,一个引导加载程序都允许用户:
|
||||
|
||||
* 1). 通过指定使用不同的内核来修改系统的表现方式;
|
||||
* 2). 从多个操作系统中选择一个启动;
|
||||
* 3). 添加或编辑配置节点来改变启动选项等。
|
||||
1. 通过指定使用不同的内核来修改系统的行为;
|
||||
2. 从多个操作系统中选择一个启动;
|
||||
3. 添加或编辑配置区块来改变启动选项等。
|
||||
|
||||
如今,**GNU** 项目负责维护 **GRUB**,并在它们的网站上提供了丰富的文档。当你在阅读这篇指南时,我们强烈建议你看下 [GNU 官方文档][6]。
|
||||
|
||||
当系统引导时,你会在主控制台看到如下的 **GRUB** 画面。最开始,你可以根据提示在多个内核版本中选择一个内核(默认情况下,系统将会使用最新的内核启动),并且可以进入 **GRUB** 命令行模式(使用 `c` 键),或者编辑启动项(按下 `e` 键)。
|
||||
|
||||

|
||||
> GRUB 启动画面
|
||||
|
||||
你会考虑使用一个旧版内核启动的原因之一是之前工作正常的某个硬件设备在一次升级后出现了“怪毛病(acting up)”(例如,你可以参考 AskUbuntu 论坛中的 [这条链接][7])。
|
||||
*GRUB 启动画面*
|
||||
|
||||
**GRUB v2** 的配置文件会在启动时从 `/boot/grub/grub.cfg` 或 `/boot/grub2/grub.cfg` 文件中读取,而 **GRUB v1** 使用的配置文件则来自 `/boot/grub/grub.conf` 或 `/boot/grub/menu.lst`。这些文件不能直接手动编辑,而是根据 `/etc/default/grub` 的内容和 `/etc/grub.d` 目录中的文件来修改的。
|
||||
你会考虑使用一个旧版内核启动的原因之一是之前工作正常的某个硬件设备在一次升级后出现了“怪毛病(acting up)”(例如,你可以参考 AskUbuntu 论坛中的[这条链接][7])。
|
||||
|
||||
在启动时会从 `/boot/grub/grub.cfg` 或 `/boot/grub2/grub.cfg` 文件中读取**GRUB v2** 的配置文件,而 **GRUB v1** 使用的配置文件则来自 `/boot/grub/grub.conf` 或 `/boot/grub/menu.lst`。这些文件**不应该**直接手动编辑,而应通过 `/etc/default/grub` 的内容和 `/etc/grub.d` 目录中的文件来更新。
|
||||
|
||||
在 **CentOS 7** 上,当系统最初完成安装后,会生成如下的配置文件:
|
||||
|
||||
@ -65,7 +67,7 @@ GRUB_DISABLE_RECOVERY="true"
|
||||
|
||||
使用上述命令,你会发现 `GRUB_TIMEOUT` 用于设置启动画面出现和系统自动开始启动(除非被用户中断)之间的时间。当该变量值为 `-1` 时,除非用户主动做出选择,否则不会开始启动。
|
||||
|
||||
当同一台机器上安装了多个操作系统或内核后,`GRUB_DEFAULT` 就需要用一个整数来指定 GRUB 启动画面默认选择启动的操作系统或内核条目。我们既可以通过上述启动画查看启动条目列表,也可以使用下面的命令:
|
||||
当同一台机器上安装了多个操作系统或内核后,`GRUB_DEFAULT` 就需要用一个整数来指定 GRUB 启动画面默认选择启动的操作系统或内核条目。我们既可以通过上述启动画面查看启动条目列表,也可以使用下面的命令:
|
||||
|
||||
### 在 CentOS 和 openSUSE 系统上
|
||||
|
||||
@ -86,18 +88,20 @@ GRUB_DEFAULT=3
|
||||
```
|
||||
|
||||

|
||||
> 使用旧版内核启动系统
|
||||
|
||||
最后一个需要特别关注的 GRUB 配置变量是 `GRUB_CMDLINE_LINUX`,它是用来给内核传递选项的。我们可以在 [内核变量文件][8] 和 [man 7 bootparam][9] 中找到能够通过 GRUB 传递给内核的选项的详细文档。
|
||||
*使用旧版内核启动系统*
|
||||
|
||||
最后一个需要特别关注的 GRUB 配置变量是 `GRUB_CMDLINE_LINUX`,它是用来给内核传递选项的。我们可以在 [内核变量文件][8] 和 [`man 7 bootparam`][9] 中找到能够通过 GRUB 传递给内核的选项的详细文档。
|
||||
|
||||
我的 **CentOS 7** 服务器上当前的选项是:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap crashkernel=auto vconsole.font=latarcyrheb-sun16 rd.lvm.lv=centos_centos7-2/root rhgb quiet"
|
||||
```
|
||||
为什么你希望修改默认的内核参数或者传递额外的选项呢?简单来说,在很多情况下,你需要告诉内核某些由内核自身无法判断的硬件参数,或者是覆盖一些内核会检测的值。
|
||||
|
||||
不久之前,就在我身上发生过这样的事情,当时我在自己已用了 10 年的老笔记本上尝试衍生自 **Slackware** 的 **Vector Linux**。完成安装后,内核并没有检测出我的显卡的正确配置,所以我不得不通过 GRUB 传递修改过的内核选项来让它工作。
|
||||
为什么你希望修改默认的内核参数或者传递额外的选项呢?简单来说,在很多情况下,你需要告诉内核某些由内核自身无法判断的硬件参数,或者是覆盖一些内核检测的值。
|
||||
|
||||
不久之前,就在我身上发生过这样的事情,当时我在自己已用了 10 年的老笔记本上尝试了衍生自 **Slackware** 的 **Vector Linux**。完成安装后,内核并没有检测出我的显卡的正确配置,所以我不得不通过 GRUB 传递修改过的内核选项来让它工作。
|
||||
|
||||
另外一个例子是当你需要将系统切换到单用户模式以执行维护工作时。为此,你可以直接在 `GRUB_CMDLINE_LINUX` 变量中直接追加 `single` 并重启即可:
|
||||
|
||||
@ -107,7 +111,7 @@ GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap cr
|
||||
|
||||
编辑完 `/etc/default/grub` 之后,你需要运行 `update-grub` (在 Ubuntu 上)或者 `grub2-mkconfig -o /boot/grub2/grub.cfg` (在 **CentOS** 和 **openSUSE** 上)命令来更新 `grub.cfg` 文件(否则,改动会在系统启动时丢失)。
|
||||
|
||||
这条命令会处理早先提到的一些启动配置文件来更新 `grub.cfg` 文件。这种方法可以确保改动持久化,而在启动时刻通过 GRUB 传递的选项仅在当前会话期间有效。
|
||||
这条命令会处理早先提到的那些启动配置文件来更新 `grub.cfg` 文件。这种方法可以确保改动持久化,而在启动时刻通过 GRUB 传递的选项仅在当前会话期间有效。
|
||||
|
||||
### 修复 Linux GRUB 问题
|
||||
|
||||
@ -116,13 +120,14 @@ GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap cr
|
||||
在启动画面中按下 `c` 键进入 GRUB 命令行模式(记住,你也可以按下 `e` 键编辑默认启动选项),并可以在 GRUB 提示中输入 `help` 命令获得可用命令:
|
||||
|
||||

|
||||
> 修复 Linux 的 Grub 配置问题
|
||||
|
||||
我们将会着重关注 **ls** 命令,它会列出已安装的设备和文件系统,并且我们将会看看它可以查找什么。在下面的图片中,我们可以看到有 4 块硬盘(`hd0` 到 `hd3`)。
|
||||
*修复 Linux 的 Grub 配置问题*
|
||||
|
||||
我们将会着重关注 **ls** 命令,它会列出已安装的设备和文件系统,并且我们将会看看它查找到的东西。在下面的图片中,我们可以看到有 4 块硬盘(`hd0` 到 `hd3`)。
|
||||
|
||||
貌似只有 `hd0` 已经分区了(msdos1 和 msdos2 可以证明,这里的 1 和 2 是分区号,msdos 则是分区方案)。
|
||||
|
||||
现在我们来看看能否在第一个分区 `hd0`(**msdos1**)上找到 GRUB。这种方法允许我们启动 Linux,并且使用高级工具修复配置文件或者如果有必要的话,干脆重新安装 GRUB:
|
||||
现在我们来看看能否在第一个分区 `hd0`(**msdos1**)上找到 GRUB。这种方法允许我们启动 Linux,并且使用高级工具修复配置文件,或者如果有必要的话,干脆重新安装 GRUB:
|
||||
|
||||
```
|
||||
# ls (hd0,msdos1)/
|
||||
@ -131,7 +136,8 @@ GRUB_CMDLINE_LINUX="vconsole.keymap=la-latin1 rd.lvm.lv=centos_centos7-2/swap cr
|
||||
从高亮区域可以发现,`grub2` 目录就在这个分区:
|
||||
|
||||

|
||||
> 查找 Grub 配置
|
||||
|
||||
*查找 Grub 配置*
|
||||
|
||||
一旦我们确信了 GRUB 位于 (**hd0, msdos1**),那就让我们告诉 GRUB 该去哪儿查找它的配置文件并指示它去尝试启动它的菜单:
|
||||
|
||||
@ -143,9 +149,10 @@ normal
|
||||
```
|
||||
|
||||

|
||||
> 查找并启动 Grub 菜单
|
||||
|
||||
然后,在 GRUB 菜单中,选择一个条目并按下 **Enter** 键以使用它启动。一旦系统成功启动后,你就可以运行 `grub2-install /dev/sdX` 命令修复问题了(将 `sdX` 改成你想要安装 GRUB 的设备)。然后启动信息将会更新,并且所有相关文件都会得到恢复。
|
||||
*查找并启动 Grub 菜单*
|
||||
|
||||
然后,在 GRUB 菜单中,选择一个条目并按下回车键以使用它启动。一旦系统成功启动后,你就可以运行 `grub2-install /dev/sdX` 命令修复问题了(将 `sdX` 改成你想要安装 GRUB 的设备)。然后启动信息将会更新,并且所有相关文件都会得到恢复。
|
||||
|
||||
```
|
||||
# grub2-install /dev/sdX
|
||||
@ -167,7 +174,7 @@ via: http://www.tecmint.com/configure-and-troubleshoot-grub-boot-loader-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -175,7 +182,7 @@ via: http://www.tecmint.com/configure-and-troubleshoot-grub-boot-loader-linux/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/linux-boot-process/
|
||||
[4]: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
[4]: https://linux.cn/article-7365-1.html
|
||||
[5]: http://www.tecmint.com/best-linux-log-monitoring-and-management-tools/
|
||||
[6]: http://www.gnu.org/software/grub/manual/
|
||||
[7]: http://askubuntu.com/questions/82140/how-can-i-boot-with-an-older-kernel-version
|
||||
@ -1,10 +1,11 @@
|
||||
LFCS 系列第十四讲: Linux 进程资源使用监控和基于每个用户的进程限制设置
|
||||
=============================================================================================
|
||||
LFCS 系列第十四讲: Linux 进程资源用量监控和按用户设置进程限制
|
||||
============================================================
|
||||
|
||||
由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求,我们在已经发表的 [LFCS 系列][1] 基础上增加了一些必要的主题。为了准备考试,同时也建议你看看 [LFCE 系列][2] 文章。
|
||||
|
||||

|
||||
>第十四讲: 监控 Linux 进程并为每个用户设置进程限制
|
||||
|
||||
*第十四讲: 监控 Linux 进程并为每个用户设置进程限制*
|
||||
|
||||
每个 Linux 系统管理员都应该知道如何验证硬件、资源和主要进程的完整性和可用性。另外,基于每个用户设置资源限制也是其中一项必备技能。
|
||||
|
||||
@ -26,13 +27,13 @@ LFCS 系列第十四讲: Linux 进程资源使用监控和基于每个用户
|
||||
|
||||
安装完 **mpstat** 之后,就可以使用它生成处理器统计信息的报告。
|
||||
|
||||
你可以使用下面的命令每隔 2 秒显示所有 CPU(用 `-P` ALL 表示) 的 CPU 利用率(`-u`),共显示 **3** 次。
|
||||
你可以使用下面的命令每隔 2 秒显示所有 CPU(用 `-P` ALL 表示)的 CPU 利用率(`-u`),共显示 **3** 次。
|
||||
|
||||
```
|
||||
# mpstat -P ALL -u 2 3
|
||||
```
|
||||
|
||||
### 事例输出
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
@ -72,7 +73,7 @@ Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00
|
||||
# mpstat -P 0 -u 2 3
|
||||
```
|
||||
|
||||
### 事例输出
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Linux 3.19.0-32-generic (tecmint.com) Wednesday 30 March 2016 _x86_64_ (4 CPU)
|
||||
@ -86,16 +87,16 @@ Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00
|
||||
|
||||
上面命令的输出包括这些列:
|
||||
|
||||
* `CPU`: 整数表示的处理器号或者 all 表示所有处理器的平局值。
|
||||
* `CPU`: 整数表示的处理器号或者 all 表示所有处理器的平均值。
|
||||
* `%usr`: 运行在用户级别的应用的 CPU 利用率百分数。
|
||||
* `%nice`: 和 `%usr` 相同,但有 nice 优先级。
|
||||
* `%sys`: 执行内核应用的 CPU 利用率百分比。这不包括用于处理中断或者硬件请求的时间。
|
||||
* `%iowait`: 指定(或所有) CPU 的空闲时间百分比,这表示当前 CPU 处于 I/O 操作密集的状态。更详细的解释(附带示例)可以查看[这里][4]。
|
||||
* `%iowait`: 指定(或所有)CPU 的空闲时间百分比,这表示当前 CPU 处于 I/O 操作密集的状态。更详细的解释(附带示例)可以查看[这里][4]。
|
||||
* `%irq`: 用于处理硬件中断的时间所占百分比。
|
||||
* `%soft`: 和 `%irq` 相同,但是软中断。
|
||||
* `%steal`: 当一个客户虚拟机在竞争 CPU 时,非自主等待(时间片窃取)所占时间的百分比。应该保持这个值尽可能小。如果这个值很大,意味着虚拟机正在或者将要停止运转。
|
||||
* `%soft`: 和 `%irq` 相同,但是是软中断。
|
||||
* `%steal`: 虚拟机非自主等待(时间片窃取)所占时间的百分比,即当虚拟机在竞争 CPU 时所从虚拟机管理程序那里“赢得”的时间。应该保持这个值尽可能小。如果这个值很大,意味着虚拟机正在或者将要停止运转。
|
||||
* `%guest`: 运行虚拟处理器所用的时间百分比。
|
||||
* `%idle`: CPU(s) 没有运行任何任务所占时间的百分比。如果你观察到这个值很小,意味着系统负载很重。在这种情况下,你需要查看详细的进程列表、以及下面将要讨论的内容来确定这是什么原因导致的。
|
||||
* `%idle`: CPU 没有运行任何任务所占时间的百分比。如果你观察到这个值很小,意味着系统负载很重。在这种情况下,你需要查看详细的进程列表、以及下面将要讨论的内容来确定这是什么原因导致的。
|
||||
|
||||
运行下面的命令使处理器处于极高负载,然后在另一个终端执行 mpstat 命令:
|
||||
|
||||
@ -109,7 +110,8 @@ Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00
|
||||
最后,和 “正常” 情况下 **mpstat** 的输出作比较:
|
||||
|
||||

|
||||
> Linux 处理器相关统计信息报告
|
||||
|
||||
*Linux 处理器相关统计信息报告*
|
||||
|
||||
正如你在上面图示中看到的,在前面两个例子中,根据 `%idle` 的值可以判断 **CPU 0** 负载很高。
|
||||
|
||||
@ -126,7 +128,8 @@ Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00
|
||||
上面的命令只会显示 `PID`、`PPID`、和进程相关的命令、 CPU 使用率以及 RAM 使用率,并按照 CPU 使用率降序排序。创建 .iso 文件的时候运行上面的命令,下面是输出的前面几行:
|
||||
|
||||

|
||||
>根据 CPU 使用率查找进程
|
||||
|
||||
*根据 CPU 使用率查找进程*
|
||||
|
||||
一旦我们找到了感兴趣的进程(例如 `PID=2822` 的进程),我们就可以进入 `/proc/PID`(本例中是 `/proc/2822`) 列出目录内容。
|
||||
|
||||
@ -134,10 +137,9 @@ Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00
|
||||
|
||||
#### 例如:
|
||||
|
||||
* `/proc/2822/io` 包括该进程的 IO 统计信息( IO 操作时的读写字符数)。
|
||||
* `/proc/2822/io` 包括该进程的 IO 统计信息(IO 操作时的读写字符数)。
|
||||
* `/proc/2822/attr/current` 显示了进程当前的 SELinux 安全属性。
|
||||
* `/proc/2822/attr/current` shows the current SELinux security attributes of the process.
|
||||
* `/proc/2822/cgroup` 如果启用了 CONFIG_CGROUPS 内核设置选项,这会显示该进程所属的控制组(简称 cgroups),你可以使用下面命令验证是否启用了 CONFIG_CGROUPS:
|
||||
* `/proc/2822/cgroup` 如果启用了 CONFIG_CGROUPS 内核设置选项,这会显示该进程所属的控制组(简称 cgroups),你可以使用下面命令验证是否启用了 CONFIG_CGROUPS:
|
||||
|
||||
```
|
||||
# cat /boot/config-$(uname -r) | grep -i cgroups
|
||||
@ -154,7 +156,8 @@ CONFIG_CGROUPS=y
|
||||
`/proc/2822/fd` 这个目录包含每个打开的描述进程的文件的符号链接。下面的截图显示了 tty1(第一个终端) 中创建 **.iso** 镜像进程的相关信息:
|
||||
|
||||

|
||||
>查找 Linux 进程信息
|
||||
|
||||
*查找 Linux 进程信息*
|
||||
|
||||
上面的截图显示 **stdin**(文件描述符 **0**)、**stdout**(文件描述符 **1**)、**stderr**(文件描述符 **2**) 相应地被映射到 **/dev/zero**、 **/root/test.iso** 和 **/dev/tty1**。
|
||||
|
||||
@ -170,14 +173,15 @@ CONFIG_CGROUPS=y
|
||||
* hard nproc 10
|
||||
```
|
||||
|
||||
第一个字段可以用来表示一个用户、组或者所有`(*)`, 第二个字段强制限制可以使用的进程数目(nproc) 为 **10**。退出并重新登录就可以使设置生效。
|
||||
第一个字段可以用来表示一个用户、组或者所有人`(*)`, 第二个字段强制限制可以使用的进程数目(nproc) 为 **10**。退出并重新登录就可以使设置生效。
|
||||
|
||||
然后,让我们来看看非 root 用户(合法用户或非法用户) 试图引起 shell fork bomb[WiKi][12] 时会发生什么。如果我们没有设置限制, shell fork bomb 会无限制地启动函数的两个实例,然后无限循环地复制任意一个实例。最终导致你的系统卡死。
|
||||
然后,让我们来看看非 root 用户(合法用户或非法用户) 试图引起 shell fork 炸弹 (参见 [WiKi][12]) 时会发生什么。如果我们没有设置限制, shell fork 炸弹会无限制地启动函数的两个实例,然后无限循环地复制任意一个实例。最终导致你的系统卡死。
|
||||
|
||||
但是,如果使用了上面的限制,fort bomb 就不会成功,但用户仍然会被锁在外面直到系统管理员杀死相关的进程。
|
||||
但是,如果使用了上面的限制,fort 炸弹就不会成功,但用户仍然会被锁在外面直到系统管理员杀死相关的进程。
|
||||
|
||||
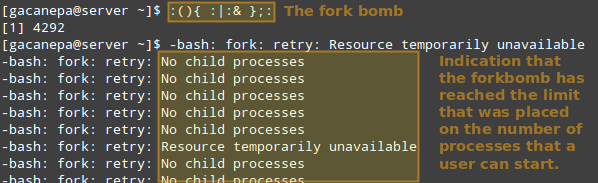
|
||||
>运行 Shell Fork Bomb
|
||||
|
||||
*运行 Shell Fork 炸弹*
|
||||
|
||||
**提示**: `limits.conf` 文件中可以查看其它 **ulimit** 可以更改的限制。
|
||||
|
||||
@ -185,7 +189,7 @@ CONFIG_CGROUPS=y
|
||||
|
||||
除了上面讨论的工具, 一个系统管理员还可能需要:
|
||||
|
||||
**a)** 通过使用 **renice** 调整执行优先级(系统资源使用)。这意味着内核会根据分配的优先级(众所周知的 “**niceness**”,它是一个范围从 `-20` 到 `19` 的整数)给进程分配更多或更少的系统资源。
|
||||
**a)** 通过使用 **renice** 调整执行优先级(系统资源的使用)。这意味着内核会根据分配的优先级(众所周知的 “**niceness**”,它是一个范围从 `-20` 到 `19` 的整数)给进程分配更多或更少的系统资源。
|
||||
|
||||
这个值越小,执行优先级越高。普通用户(而非 root)只能调高他们所有的进程的 niceness 值(意味着更低的优先级),而 root 用户可以调高或调低任何进程的 niceness 值。
|
||||
|
||||
@ -195,9 +199,9 @@ renice 命令的基本语法如下:
|
||||
# renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
|
||||
```
|
||||
|
||||
如果没有 new priority 后面的参数(为空),默认就是 PID。在这种情况下, **PID=identifier** 的进程的 niceness 值会被设置为 `<new priority>`。
|
||||
如果 new priority 后面的参数没有(为空),默认就是 PID。在这种情况下,**PID=identifier** 的进程的 niceness 值会被设置为 `<new priority>`。
|
||||
|
||||
**b)** 需要的时候中断一个进程的正常执行。这也就是通常所说的 [“杀死”进程][9]。实质上,这意味着给进程发送一个信号使它恰当地结束运行并以有序的方式释放任何占用的资源。
|
||||
**b)** 需要的时候中断一个进程的正常执行。这也就是通常所说的[“杀死”进程][9]。实质上,这意味着给进程发送一个信号使它恰当地结束运行并以有序的方式释放任何占用的资源。
|
||||
|
||||
按照下面的方式使用 **kill** 命令[杀死进程][10]:
|
||||
|
||||
@ -205,7 +209,7 @@ renice 命令的基本语法如下:
|
||||
# kill PID
|
||||
```
|
||||
|
||||
另外,你也可以使用 [pkill][11] 结束指定用户`(-u)`、指定组`(-G)` 甚至有共同 PPID`(-P)` 的所有进程。这些选项后面可以使用数字或者名称表示的标识符。
|
||||
另外,你也可以使用 [pkill][11] 结束指定用户`(-u)`、指定组`(-G)` 甚至有共同的父进程 ID `(-P)` 的所有进程。这些选项后面可以使用数字或者名称表示的标识符。
|
||||
|
||||
```
|
||||
# pkill [options] identifier
|
||||
@ -217,9 +221,7 @@ renice 命令的基本语法如下:
|
||||
# pkill -G 1000
|
||||
```
|
||||
|
||||
会杀死组 `GID=1000` 的所有进程。
|
||||
|
||||
而
|
||||
会杀死组 `GID=1000` 的所有进程。而
|
||||
|
||||
```
|
||||
# pkill -P 4993
|
||||
@ -236,7 +238,8 @@ renice 命令的基本语法如下:
|
||||
用下面的图片说明:
|
||||
|
||||

|
||||
>在 Linux 中查找用户运行的进程
|
||||
|
||||
*在 Linux 中查找用户运行的进程*
|
||||
|
||||
### 总结
|
||||
|
||||
@ -246,17 +249,13 @@ renice 命令的基本语法如下:
|
||||
|
||||
我们希望本篇中介绍的概念能对你有所帮助。如果你有任何疑问或者评论,可以使用下面的联系方式联系我们。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
via: http://www.tecmint.com/monitor-linux-processes-and-set-process-limits-per-user/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
559
published/LXD/Part 3 - LXD 2.0--Your first LXD container.md
Normal file
559
published/LXD/Part 3 - LXD 2.0--Your first LXD container.md
Normal file
@ -0,0 +1,559 @@
|
||||
LXD 2.0 系列( 三):你的第一个 LXD 容器
|
||||
==========================================
|
||||
|
||||
这是 [LXD 2.0 系列][0]的第三篇博客。
|
||||
|
||||
由于在管理 LXD 容器时涉及到大量的命令,所以这篇文章的篇幅是比较长的,如果你更喜欢使用同样的命令来快速的一步步实现整个过程,你可以[尝试我们的在线示例][1]!
|
||||
|
||||

|
||||
|
||||
### 创建并启动一个新的容器
|
||||
|
||||
正如我在先前的文章中提到的一样,LXD 命令行客户端预配置了几个镜像源。Ubuntu 的所有发行版和架构平台全都提供了官方镜像,但是对于其他的发行版也有大量的非官方镜像,那些镜像都是由社区制作并且被 LXC 上游贡献者所维护。
|
||||
|
||||
#### Ubuntu
|
||||
|
||||
如果你想要支持最为完善的 Ubuntu 版本,你可以按照下面的去做:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:
|
||||
```
|
||||
|
||||
注意,这里意味着会随着 Ubuntu LTS 的发布而变化。因此,如果用于脚本,你需要指明你具体安装的版本(参见下面)。
|
||||
|
||||
#### Ubuntu14.04 LTS
|
||||
|
||||
得到最新更新的、已经测试过的、稳定的 Ubuntu 14.04 LTS 镜像,你可以简单的执行:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04
|
||||
```
|
||||
|
||||
在该模式下,会指定一个随机的容器名。
|
||||
|
||||
如果你更喜欢指定一个你自己的名字,你可以这样做:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 c1
|
||||
```
|
||||
|
||||
如果你想要指定一个特定的体系架构(非主流平台),比如 32 位 Intel 镜像,你可以这样做:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04/i386 c2
|
||||
```
|
||||
|
||||
#### 当前的 Ubuntu 开发版本
|
||||
|
||||
上面使用的“ubuntu:”远程仓库只会给你提供官方的并经过测试的 Ubuntu 镜像。但是如果你想要未经测试过的日常构建版本,开发版可能对你来说是合适的,你需要使用“ubuntu-daily:”远程仓库。
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:devel c3
|
||||
```
|
||||
|
||||
在这个例子中,将会自动选中最新的 Ubuntu 开发版本。
|
||||
|
||||
你也可以更加精确,比如你可以使用代号名:
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:xenial c4
|
||||
```
|
||||
|
||||
#### 最新的Alpine Linux
|
||||
|
||||
Alpine 镜像可以在“Images:”远程仓库中找到,通过如下命令执行:
|
||||
|
||||
```
|
||||
lxc launch images:alpine/3.3/amd64 c5
|
||||
```
|
||||
|
||||
#### 其他
|
||||
|
||||
全部的 Ubuntu 镜像列表可以这样获得:
|
||||
|
||||
```
|
||||
lxc image list ubuntu:
|
||||
lxc image list ubuntu-daily:
|
||||
```
|
||||
|
||||
全部的非官方镜像:
|
||||
|
||||
```
|
||||
lxc image list images:
|
||||
```
|
||||
|
||||
某个给定的原程仓库的全部别名(易记名称)可以这样获得(比如对于“ubuntu:”远程仓库):
|
||||
|
||||
```
|
||||
lxc image alias list ubuntu:
|
||||
```
|
||||
|
||||
### 创建但不启动一个容器
|
||||
|
||||
如果你想创建一个容器或者一批容器,但是你不想马上启动它们,你可以使用`lxc init`替换掉`lxc launch`。所有的选项都是相同的,唯一的不同就是它并不会在你创建完成之后启动容器。
|
||||
|
||||
```
|
||||
lxc init ubuntu:
|
||||
```
|
||||
|
||||
### 关于你的容器的信息
|
||||
|
||||
#### 列出所有的容器
|
||||
|
||||
要列出你的所有容器,你可以这样这做:
|
||||
|
||||
```
|
||||
lxc list
|
||||
```
|
||||
|
||||
有大量的选项供你选择来改变被显示出来的列。在一个拥有大量容器的系统上,默认显示的列可能会有点慢(因为必须获取容器中的网络信息),你可以这样做来避免这种情况:
|
||||
|
||||
```
|
||||
lxc list --fast
|
||||
```
|
||||
|
||||
上面的命令显示了另外一套列的组合,这个组合在服务器端需要处理的信息更少。
|
||||
|
||||
你也可以基于名字或者属性来过滤掉一些东西:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list security.privileged=true
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| suse | RUNNING | 172.17.0.105 (eth0) | 2607:f2c0:f00f:2700:216:3eff:fef2:aff4 (eth0) | PERSISTENT | 0 |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
在这个例子中,只有那些特权容器(禁用了用户命名空间)才会被列出来。
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list --fast alpine
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| NAME | STATE | ARCHITECTURE | CREATED AT | PROFILES | TYPE |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine | RUNNING | x86_64 | 2016/03/20 02:11 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine-edge | RUNNING | x86_64 | 2016/03/20 02:19 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
```
|
||||
|
||||
在这个例子中,只有在名字中带有“alpine”的容器才会被列出来(也支持复杂的正则表达式)。
|
||||
|
||||
#### 获取容器的详细信息
|
||||
|
||||
由于 list 命令显然不能以一种友好的可读方式显示容器的所有信息,因此你可以使用如下方式来查询单个容器的信息:
|
||||
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc info zerotier
|
||||
Name: zerotier
|
||||
Architecture: x86_64
|
||||
Created: 2016/02/20 20:01 UTC
|
||||
Status: Running
|
||||
Type: persistent
|
||||
Profiles: default
|
||||
Pid: 31715
|
||||
Processes: 32
|
||||
Ips:
|
||||
eth0: inet 172.17.0.101
|
||||
eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
|
||||
eth0: inet6 fe80::216:3eff:feec:65a8
|
||||
lo: inet 127.0.0.1
|
||||
lo: inet6 ::1
|
||||
lxcbr0: inet 10.0.3.1
|
||||
lxcbr0: inet6 fe80::c0a4:ceff:fe52:4d51
|
||||
zt0: inet 29.17.181.59
|
||||
zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
|
||||
zt0: inet6 fe80::79:e7ff:fe0d:5123
|
||||
Snapshots:
|
||||
zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
|
||||
```
|
||||
|
||||
### 生命周期管理命令
|
||||
|
||||
这些命令对于任何容器或者虚拟机管理器或许都是最普通的命令,但是它们仍然需要讲到。
|
||||
|
||||
所有的这些命令在批量操作时都能接受多个容器名。
|
||||
|
||||
#### 启动
|
||||
|
||||
启动一个容器就向下面一样简单:
|
||||
|
||||
```
|
||||
lxc start <container>
|
||||
```
|
||||
|
||||
#### 停止
|
||||
|
||||
停止一个容器可以这样来完成:
|
||||
|
||||
```
|
||||
lxc stop <container>
|
||||
```
|
||||
|
||||
如果容器不合作(即没有对发出的 SIGPWR 信号产生回应),这时候,你可以使用下面的方式强制执行:
|
||||
|
||||
```
|
||||
lxc stop <container> --force
|
||||
```
|
||||
|
||||
#### 重启
|
||||
|
||||
通过下面的命令来重启一个容器:
|
||||
|
||||
```
|
||||
lxc restart <container>
|
||||
```
|
||||
|
||||
如果容器不合作(即没有对发出的 SIGINT 信号产生回应),你可以使用下面的方式强制执行:
|
||||
|
||||
```
|
||||
lxc restart <container> --force
|
||||
```
|
||||
|
||||
#### 暂停
|
||||
|
||||
你也可以“暂停”一个容器,在这种模式下,所有的容器任务将会被发送相同的 SIGSTOP 信号,这也意味着它们将仍然是可见的,并且仍然会占用内存,但是它们不会从调度程序中得到任何的 CPU 时间片。
|
||||
|
||||
如果你有一个很占用 CPU 的容器,而这个容器需要一点时间来启动,但是你却并不会经常用到它。这时候,你可以先启动它,然后将它暂停,并在你需要它的时候再启动它。
|
||||
|
||||
```
|
||||
lxc pause <container>
|
||||
```
|
||||
|
||||
#### 删除
|
||||
|
||||
最后,如果你不需要这个容器了,你可以用下面的命令删除它:
|
||||
|
||||
```
|
||||
lxc delete <container>
|
||||
```
|
||||
|
||||
注意,如果容器还处于运行状态时你将必须使用“-force”。
|
||||
|
||||
### 容器的配置
|
||||
|
||||
LXD 拥有大量的容器配置设定,包括资源限制,容器启动控制以及对各种设备是否允许访问的配置选项。完整的清单因为太长所以并没有在本文中列出,但是,你可以从[这里]获取它。
|
||||
|
||||
就设备而言,LXD 当前支持下面列出的这些设备类型:
|
||||
|
||||
- 磁盘
|
||||
既可以是一块物理磁盘,也可以只是一个被挂挂载到容器上的分区,还可以是一个来自主机的绑定挂载路径。
|
||||
- 网络接口卡
|
||||
一块网卡。它可以是一块桥接的虚拟网卡,或者是一块点对点设备,还可以是一块以太局域网设备或者一块已经被连接到容器的真实物理接口。
|
||||
- unix 块设备
|
||||
一个 UNIX 块设备,比如 /dev/sda
|
||||
- unix 字符设备
|
||||
一个 UNIX 字符设备,比如 /dev/kvm
|
||||
- none
|
||||
这种特殊类型被用来隐藏那种可以通过配置文件被继承的设备。
|
||||
|
||||
#### 配置 profile 文件
|
||||
|
||||
所有可用的配置文件列表可以这样获取:
|
||||
|
||||
```
|
||||
lxc profile list
|
||||
```
|
||||
|
||||
为了看到给定配置文件的内容,最简单的方式是这样做:
|
||||
|
||||
```
|
||||
lxc profile show <profile>
|
||||
```
|
||||
|
||||
你可能想要改变文件里面的内容,可以这样做:
|
||||
|
||||
```
|
||||
lxc profile edit <profile>
|
||||
```
|
||||
|
||||
你可以使用如下命令来改变应用到给定容器的配置文件列表:
|
||||
|
||||
```
|
||||
lxc profile apply <container> <profile1>,<profile2>,<profile3>,...
|
||||
```
|
||||
|
||||
#### 本地配置
|
||||
|
||||
有些配置是某个容器特定的,你并不想将它放到配置文件中,你可直接对容器设置它们:
|
||||
|
||||
```
|
||||
lxc config edit <container>
|
||||
```
|
||||
|
||||
上面的命令做的和“profile edit”命令是一样。
|
||||
|
||||
如果不想在文本编辑器中打开整个文件的内容,你也可以像这样修改单独的配置:
|
||||
|
||||
```
|
||||
lxc config set <container> <key> <value>
|
||||
```
|
||||
|
||||
或者添加设备,例如:
|
||||
|
||||
```
|
||||
lxc config device add my-container kvm unix-char path=/dev/kvm
|
||||
```
|
||||
|
||||
上面的命令将会为名为“my-container”的容器设置一个 /dev/kvm 项。
|
||||
|
||||
对一个配置文件使用`lxc profile set`和`lxc profile device add`命令也能实现上面的功能。
|
||||
|
||||
#### 读取配置
|
||||
|
||||
你可以使用如下命令来读取容器的本地配置:
|
||||
|
||||
```
|
||||
lxc config show <container>
|
||||
```
|
||||
|
||||
或者得到已经被展开了的配置(包含了所有的配置值):
|
||||
|
||||
```
|
||||
lxc config show --expanded <container>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc config show --expanded zerotier
|
||||
name: zerotier
|
||||
profiles:
|
||||
- default
|
||||
config:
|
||||
security.nesting: "true"
|
||||
user.a: b
|
||||
volatile.base_image: a49d26ce5808075f5175bf31f5cb90561f5023dcd408da8ac5e834096d46b2d8
|
||||
volatile.eth0.hwaddr: 00:16:3e:ec:65:a8
|
||||
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
|
||||
devices:
|
||||
eth0:
|
||||
name: eth0
|
||||
nictype: macvlan
|
||||
parent: eth0
|
||||
type: nic
|
||||
limits.ingress: 10Mbit
|
||||
limits.egress: 10Mbit
|
||||
root:
|
||||
path: /
|
||||
size: 30GB
|
||||
type: disk
|
||||
tun:
|
||||
path: /dev/net/tun
|
||||
type: unix-char
|
||||
ephemeral: false
|
||||
```
|
||||
|
||||
这样做可以很方便的检查有哪些配置属性被应用到了给定的容器。
|
||||
|
||||
#### 实时配置更新
|
||||
|
||||
注意,除非在文档中已经被明确指出,否则所有的配置值和设备项的设置都会对容器实时发生影响。这意味着在不重启正在运行的容器的情况下,你可以添加和移除某些设备或者修改安全配置文件。
|
||||
|
||||
### 获得一个 shell
|
||||
|
||||
LXD 允许你直接在容器中执行任务。最常用的做法是在容器中得到一个 shell 或者执行一些管理员任务。
|
||||
|
||||
和 SSH 相比,这样做的好处是你不需要容器是网络可达的,也不需要任何软件和特定的配置。
|
||||
|
||||
#### 执行环境
|
||||
|
||||
与 LXD 在容器内执行命令的方式相比,有一点是不同的,那就是 shell 并不是在容器中运行。这也意味着容器不知道使用的是什么样的 shell,以及设置了什么样的环境变量和你的家目录在哪里。
|
||||
|
||||
通过 LXD 来执行命令总是使用最小的路径环境变量设置,并且 HOME 环境变量必定为 /root,以容器的超级用户身份来执行(即 uid 为 0,gid 为 0)。
|
||||
|
||||
其他的环境变量可以通过命令行来设置,或者在“environment.<key>”配置中设置成永久环境变量。
|
||||
|
||||
#### 执行命令
|
||||
|
||||
在容器中获得一个 shell 可以简单的执行下列命令得到:
|
||||
|
||||
```
|
||||
lxc exec <container> bash
|
||||
```
|
||||
|
||||
当然,这样做的前提是容器内已经安装了 bash。
|
||||
|
||||
更复杂的命令要求使用分隔符来合理分隔参数。
|
||||
|
||||
```
|
||||
lxc exec <container> -- ls -lh /
|
||||
```
|
||||
|
||||
如果想要设置或者重写变量,你可以使用“-env”参数,例如:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier --env mykey=myvalue env | grep mykey
|
||||
mykey=myvalue
|
||||
```
|
||||
|
||||
### 管理文件
|
||||
|
||||
因为 LXD 可以直接访问容器的文件系统,因此,它可以直接读取和写入容器中的任意文件。当我们需要提取日志文件或者与容器传递文件时,这个特性是很有用的。
|
||||
|
||||
#### 从容器中取回一个文件
|
||||
|
||||
想要从容器中获得一个文件,简单的执行下列命令:
|
||||
|
||||
```
|
||||
lxc file pull <container>/<path> <dest>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts hosts
|
||||
```
|
||||
|
||||
或者将它读取到标准输出:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts -
|
||||
127.0.0.1 localhost
|
||||
|
||||
# The following lines are desirable for IPv6 capable hosts
|
||||
::1 ip6-localhost ip6-loopback
|
||||
fe00::0 ip6-localnet
|
||||
ff00::0 ip6-mcastprefix
|
||||
ff02::1 ip6-allnodes
|
||||
ff02::2 ip6-allrouters
|
||||
ff02::3 ip6-allhosts
|
||||
```
|
||||
|
||||
#### 向容器发送一个文件
|
||||
|
||||
发送以另一种简单的方式完成:
|
||||
|
||||
```
|
||||
lxc file push <source> <container>/<path>
|
||||
```
|
||||
|
||||
#### 直接编辑一个文件
|
||||
|
||||
编辑是一个方便的功能,其实就是简单的提取一个给定的路径,在你的默认文本编辑器中打开它,在你关闭编辑器时会自动将编辑的内容保存到容器。
|
||||
|
||||
```
|
||||
lxc file edit <container>/<path>
|
||||
```
|
||||
|
||||
### 快照管理
|
||||
|
||||
LXD 允许你对容器执行快照功能并恢复它。快照包括了容器在某一时刻的完整状态(如果`-stateful`被使用的话将会包括运行状态),这也意味着所有的容器配置,容器设备和容器文件系统也会被保存。
|
||||
|
||||
#### 创建一个快照
|
||||
|
||||
你可以使用下面的命令来执行快照功能:
|
||||
|
||||
```
|
||||
lxc snapshot <container>
|
||||
```
|
||||
|
||||
命令执行完成之后将会生成名为snapX(X 为一个自动增长的数)的记录。
|
||||
|
||||
除此之外,你还可以使用如下命令命名你的快照:
|
||||
|
||||
```
|
||||
lxc snapshot <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### 列出所有的快照
|
||||
|
||||
一个容器的所有快照的数量可以使用`lxc list`来得到,但是具体的快照列表只能执行`lxc info`命令才能看到。
|
||||
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
#### 恢复快照
|
||||
|
||||
为了恢复快照,你可以简单的执行下面的命令:
|
||||
|
||||
```
|
||||
lxc restore <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### 给快照重命名
|
||||
|
||||
可以使用如下命令来给快照重命名:
|
||||
|
||||
```
|
||||
lxc move <container>/<snapshot name> <container>/<new snapshot name>
|
||||
```
|
||||
|
||||
#### 从快照中创建一个新的容器
|
||||
|
||||
你可以使用快照来创建一个新的容器,而这个新的容器除了一些可变的信息将会被重置之外(例如 MAC 地址)其余所有信息都将和快照完全相同。
|
||||
|
||||
```
|
||||
lxc copy <source container>/<snapshot name> <destination container>
|
||||
```
|
||||
|
||||
#### 删除一个快照
|
||||
|
||||
最后,你可以执行下面的命令来删除一个快照:
|
||||
|
||||
```
|
||||
lxc delete <container>/<snapshot name>
|
||||
```
|
||||
|
||||
### 克隆并重命名
|
||||
|
||||
得到一个纯净的发行版镜像总是让人感到愉悦,但是,有时候你想要安装一系列的软件到你的容器中,这时,你需要配置它然后将它分支成多个其他的容器。
|
||||
|
||||
#### 复制一个容器
|
||||
|
||||
为了复制一个容器并有效的将它克隆到一个新的容器中,你可以执行下面的命令:
|
||||
|
||||
```
|
||||
lxc copy <source container> <destination container>
|
||||
```
|
||||
|
||||
目标容器在所有方面将会完全和源容器等同。除了新的容器没有任何源容器的快照以及一些可变值将会被重置之外(例如 MAC 地址)。
|
||||
|
||||
#### 移动一个快照
|
||||
|
||||
LXD 允许你复制容器并在主机之间移动它。但是,关于这一点将在后面的文章中介绍。
|
||||
|
||||
现在,“move”命令将会被用作给容器重命名。
|
||||
|
||||
```
|
||||
lxc move <old name> <new name>
|
||||
```
|
||||
|
||||
唯一的要求就是当容器应该被停止,容器内的任何事情都会被保存成它本来的样子,包括可变化的信息(类似 MAC 地址等)。
|
||||
|
||||
### 结论
|
||||
|
||||
这篇如此长的文章介绍了大多数你可能会在日常操作中使用到的命令。
|
||||
|
||||
很显然,这些如此之多的命令都会有不少选项,可以让你的命令更加有效率或者可以让你指定你的 LXD 容器的某个具体方面的参数。最好的学习这些命令的方式就是深入学习它们的帮助文档( --help)。
|
||||
|
||||
### 更多信息
|
||||
|
||||
- LXD 的主要网站是:<https://linuxcontainers.org/lxd>
|
||||
- Github 上的开发动态: <https://github.com/lxc/lxd>
|
||||
- 邮件列表支持:<https://lists.linuxcontainers.org>
|
||||
- IRC 支持: #lxcontainers on irc.freenode.net
|
||||
|
||||
如果你不想或者不能在你的机器上安装 LXD,你可以[试试在线版本][1]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://linuxcontainers.org/lxd/try-it
|
||||
[2]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
|
||||
@ -0,0 +1,87 @@
|
||||
Torvalds 2.0: Linus 之女谈计算机、大学、女权主义和提升技术界的多元化
|
||||
====================
|
||||
|
||||

|
||||
|
||||
*图片来源:照片来自 Becky Svartström, Opensource.com 修改*
|
||||
|
||||
Patricia Torvalds 暂时还不像她的父亲 Linus 一样闻名于 Linux 和开源领域。
|
||||
|
||||

|
||||
|
||||
在她 18 岁的时候,Patricia 已经是一个有多项技术成就、拥有开源行业经验的女权主义者,而且她已经把目标放在进入杜克大学普拉特工程学院的新学期上了。当时她以实习生的身份在位于美国奥勒冈州伯特兰市的 [Puppet 实验室][2]工作。但不久后,她就将前往北卡罗纳州的达拉莫,开始秋季学期的大学学习。
|
||||
|
||||
在这次独家采访中,Patricia 谈到了使她对计算机科学与工程学感兴趣的(剧透警告:不是因为她的父亲)原因,她所在高中学校在技术教学上所采取的“正确”方法,女权主义在她的生活中扮演的重要角色,以及对技术缺乏多元化的思考。
|
||||
|
||||

|
||||
|
||||
###是什么使你对学习计算机科学与工程学发生兴趣?###
|
||||
|
||||
我在技术方面的兴趣主要来自于高中时代。我曾一度想投身于生物学,这种想法一直维持到大约大学二年级的时候。大二结束以后,我在波特兰 [VA][11] 做网页设计实习生。与此同时,我参加了一个叫做“探索冒险家(Exploratory Ventures,XV)”的工程学课程,在我大二学年的后期,我们把一个水下机器人送入了太平洋。但是,转折点大概是在我大三学年的中期被授予“[NCWIT 的计算机之理想][6]”奖的地区冠军和全国亚军的时候出现的(LCTT 译注:NCWIT - National Center for Women & IT,女性与 IT 国家中心)。
|
||||
|
||||
这个奖项的获得让我感觉到确立了自己的兴趣。当然,我认为最重要的部分是我加入到一个由所有获奖者组成的 Facebook 群。女孩们获奖很难想象,因此我们彼此非常支持。由于在 XV 和 [VA][11] 的工作,我在获奖前就已经确实对计算机科学发生了兴趣,但是和这些女孩们的交谈更加坚定了这份兴趣,使之更加强烈。再后来,后期大三、大四年级的时候执教 XV 也使我体会到工程学和计算机科学的乐趣。
|
||||
|
||||
###你打算学习什么?你已经知道自己毕业后想干什么了吗?###
|
||||
|
||||
我希望要么主修机械,要么是电子和计算机工程学,以及计算机科学,并且辅修女性学。毕业以后,我希望在一个支持社会公益或者为其创造技术的公司工作,或者自己开公司。
|
||||
|
||||
###我的女儿在高中有一门 Visual Basic 的编程课。她是整个班上唯一的一个女生,并且以困扰和痛苦的经历结束了这门课程。你的经历是什么样的呢?###
|
||||
|
||||
我的高中在高年级的时候开设了计算机科学的课程,我也学习了 Visual Basic!这门课不是很糟糕,但我的确是 20 多个人的班级里仅有的三四个女生之一。其他的计算机课程似乎也有相似的性别比例差异。然而,我所在的高中极其小,并且老师对技术包容性非常支持,所以我并没有感到困扰。希望在未来的一些年里这些课程会变得更加多样化。
|
||||
|
||||
###你的学校做了哪些促进技术的举措?它们如何能够变得更好?###
|
||||
|
||||
我的高中学校给了我们长时间接触计算机的机会,老师们会突然在不相关的课程上安排技术相关的任务,有几次我们还为社会实践课程建了一个网站,我认为这很棒,因为它使我们每一个人都能接触到技术。机器人俱乐部也很活跃并且资金充足,但是非常小,不过我不是其中的成员。学校的技术/工程学项目中一个非常重要的组成部分是一门叫做”[探索冒险家(Exploratory Ventures)][8]“的由学生自己教的工程学课程,这是一门需要亲自动手的课程,并且每年换一个工程学或者计算机科学方面的难题。我和我的一个同学在这儿教了两年,在课程结束以后,有学生上来告诉我他们对从事工程学或者计算机科学发生了兴趣。
|
||||
|
||||
然而,我的高中没有特别的关注于让年轻女性加入到这些课程中来,并且在人种上也没有呈现多样化。计算机的课程和俱乐部大量的主要成员都是男性白人学生。这的确应该需要有所改善。
|
||||
|
||||
###在成长过程中,你如何在家运用技术?###
|
||||
|
||||
老实说,小的时候,我使用我的上机时间([我的父亲 Linus][9] 设置了一个跟踪装置,当我们上网一个小时就会断线)来玩[尼奥宠物][10]和或者相似的游戏。我想我本可以搞乱跟踪装置或者在不连接网络的情况下玩游戏,但我没有这样做。我有时候也会和我的父亲做一些小的科学项目,我还记得有一次我和他在电脑终端上打印出几千个“Hello world”。但是大多数时候,我都是和我的妹妹一起玩网络游戏,直到高中的时候才开始学习计算机。
|
||||
|
||||
###你在高中学校的女权俱乐部很活跃,从这份经历中你学到了什么?现在对你来说什么女权问题是最重要的?###
|
||||
|
||||
在高中二年级的后期,我和我的朋友一起建立了女权俱乐部。刚开始,我们受到了很多人对俱乐部的排斥,并且这从来就没有完全消失过。到我们毕业的时候,女权主义思想已经彻底成为了学校文化的一部分。我们在学校做的女权主义工作通常是在一些比较直接的方面,并集中于像着装要求这样一些问题。
|
||||
|
||||
就我个人来说,我更关注于新女性主义( intersectional feminism),这是一种致力于(消除)其它方面压迫(比如,种族歧视和阶级压迫等)的女权主义。Facebook 上的 [Gurrilla Feminism][4] 专页是新女性主义一个非常好的例子,并且我从中学到了很多。我目前管理着波特兰分会。
|
||||
|
||||
在技术多样性方面女权主义对我也非常重要,尽管作为一名和技术世界有很强联系的高年级白人女性,女权主义问题对我产生的影响相比其他人来说少得多,我所参与的新女性主义也是同样的。[《Model View Culture》][5]的出版非常鼓舞我,谢谢 Shanley Kane 所做的这一切。
|
||||
|
||||
###你会给想教他们的孩子学习编程的父母什么样的建议?###
|
||||
|
||||
老实说,从没有人推着我学习计算机科学或者工程学。正如我前面说的,在很长一段时间里,我想成为一名遗传学家。大二结束的那个夏天,我在 [VA][11] 做了一个夏天的网页设计实习生,这彻底改变了我之前的想法。所以我不知道我是否能够充分回答这个问题。
|
||||
|
||||
我的确认为真正的兴趣很重要。如果在我 12 岁的时候,我的父亲让我坐在一台电脑前,教我配置一台网站服务器,我认为我不会对计算机科学感兴趣。相反,我的父母给了我很多可以支配的自由时间让我去做自己想做的事情,绝大多数时候是我在为我的尼奥宠物游戏编写糟糕的 HTML 网站。比我小的妹妹们没有一个对工程学或计算机科学感兴趣,我的父母也不在乎。我感到很幸运的是我的父母给了我和我的妹妹们鼓励和资源去探索自己的兴趣。
|
||||
|
||||
仍然要讲的是,在我成长过程中我也常说未来职业生涯要“像我爹一样”,尽管那时我还不知道我父亲是干什么的,只知道他有一个很酷的工作。另外,中学的时候有一次我告诉我的父亲这件事,然后他没有发表什么看法只是告诉我高中的时候不要想这事。所以我猜想这从一定程度上鼓励了我。
|
||||
|
||||
###对于开源社区的领导者们,你有什么建议给他们来吸引和维持更加多元化的贡献者?###
|
||||
|
||||
我实际上在开源社区并不是特别积极和活跃,我更喜欢和其它女性讨论计算机。我是“[NCWIT 的计算机之理想][6]”成员之一,这是我对技术持久感到兴趣的一个重要方面,同样也包括 Facebook 的”[Ladies Storm Hackathons][7]” 群。
|
||||
|
||||
我认为对于吸引和留住那些天才而形形色色的贡献者,安全的空间很重要。我曾经看到过在一些开源社区有人发表关于女性歧视和种族主义的评论,当人们指出这一问题随后该人就被解职了。我认为要维持一个专业的社区必须就骚扰事件和不正当行为有一个高标准。当然,人们已经有而且还会有,关于在开源社区或其他任何社区能够表达什么意见的更多的观点。然而,如果社区领导人真的想吸引和留住形形色色的天才们,他们必须创造一个安全的空间并且以高标准要求社区成员们。
|
||||
|
||||
我也觉得一些社区领导者不明白多元化的价值。很容易觉得在技术上是唯才是举的,并且这个原因有一些是技术上不处于中心位置的人是他们不在意的,问题来自于发展的早期。他们争论如果一个人在自己的工作上做得很好,那么他的性别或者民族还有性取向这些情况都变得不重要了。这很容易反驳,但我不想看到为这些错误找的理由。我认为多元化的缺失是一个错误,我们应该为之负责并尽力去改善这件事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/life/15/8/patricia-torvalds-interview
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[LinuxBars](https://github.com/LinuxBars), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/rikki-endsley
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://puppetlabs.com/
|
||||
[3]:https://www.aspirations.org/
|
||||
[4]:https://www.facebook.com/guerrillafeminism
|
||||
[5]:https://modelviewculture.com/
|
||||
[6]:https://www.aspirations.org/
|
||||
[7]:https://www.facebook.com/groups/LadiesStormHackathons/
|
||||
[8]: http://exploratoryventures.com/
|
||||
[9]: https://plus.google.com/+LinusTorvalds/about
|
||||
[10]: http://www.neopets.com/
|
||||
[11]: http://www.va.gov/
|
||||
@ -0,0 +1,246 @@
|
||||
awk 系列:在 awk 中如何使用流程控制语句
|
||||
===========================================
|
||||
|
||||
当你回顾所有到目前为止我们已经覆盖的 awk 实例,从 awk 系列的开始,你会注意到各种实例的所有指令是顺序执行的,即一个接一个地执行。但在某些情况下,我们可能希望基于一些条件进行文本过滤操作,即流程控制语句允许的那些语句。
|
||||
|
||||

|
||||
|
||||
在 awk 编程中有各种各样的流程控制语句,其中包括:
|
||||
|
||||
- if-else 语句
|
||||
- for 语句
|
||||
- while 语句
|
||||
- do-while 语句
|
||||
- break 语句
|
||||
- continue 语句
|
||||
- next 语句
|
||||
- nextfile 语句
|
||||
- exit 语句
|
||||
|
||||
然而,对于本系列的这一部分,我们将阐述:`if-else`、`for`、`while` 和 `do while` 语句。请记住,我们已经在这个 [awk 系列的第 6 部分][1]介绍过如何使用 awk 的 `next` 语句。
|
||||
|
||||
### 1. if-else 语句
|
||||
|
||||
如你想的那样。if 语句的语法类似于 shell 中的 if 语句:
|
||||
|
||||
```
|
||||
if (条件 1) {
|
||||
动作 1
|
||||
}
|
||||
else {
|
||||
动作 2
|
||||
}
|
||||
```
|
||||
|
||||
在上述语法中,`条件 1` 和`条件 2` 是 awk 表达式,而`动作 1` 和`动作 2` 是当各自的条件得到满足时所执行的 awk 命令。
|
||||
|
||||
当`条件 1` 满足时,意味着它为真,那么`动作 1` 被执行并退出 `if 语句`,否则`动作 2` 被执行。
|
||||
|
||||
if 语句还能扩展为如下的 `if-else_if-else` 语句:
|
||||
|
||||
```
|
||||
if (条件 1){
|
||||
动作 1
|
||||
}
|
||||
else if (条件 2){
|
||||
动作 2
|
||||
}
|
||||
else{
|
||||
动作 3
|
||||
}
|
||||
```
|
||||
|
||||
对于上面的形式,如果`条件 1` 为真,那么`动作 1` 被执行并退出 `if 语句`,否则`条件 2` 被求值且如果值为真,那么`动作 2` 被执行并退出 `if 语句`。然而,当`条件 2` 为假时,那么`动作 3` 被执行并退出 `if 语句`。
|
||||
|
||||
这是在使用 if 语句的一个实例,我们有一个用户和他们年龄的列表,存储在文件 users.txt 中。
|
||||
|
||||
我们要打印一个清单,显示用户的名称和用户的年龄是否小于或超过 25 岁。
|
||||
|
||||
```
|
||||
aaronkilik@tecMint ~ $ cat users.txt
|
||||
Sarah L 35 F
|
||||
Aaron Kili 40 M
|
||||
John Doo 20 M
|
||||
Kili Seth 49 M
|
||||
```
|
||||
|
||||
我们可以写一个简短的 shell 脚本来执行上文中我们的工作,这是脚本的内容:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
awk ' {
|
||||
if ( $3 <= 25 ){
|
||||
print "User",$1,$2,"is less than 25 years old." ;
|
||||
}
|
||||
else {
|
||||
print "User",$1,$2,"is more than 25 years old" ;
|
||||
}
|
||||
}' ~/users.txt
|
||||
```
|
||||
|
||||
然后保存文件并退出,按如下方式使脚本可执行并运行它:
|
||||
|
||||
```
|
||||
$ chmod +x test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
|
||||
输出样例
|
||||
|
||||
```
|
||||
User Sarah L is more than 25 years old
|
||||
User Aaron Kili is more than 25 years old
|
||||
User John Doo is less than 25 years old.
|
||||
User Kili Seth is more than 25 years old
|
||||
```
|
||||
|
||||
### 2. for 语句
|
||||
|
||||
如果你想在一个循环中执行一些 awk 命令,那么 `for 语句`为你提供一个做这个的合适方式,格式如下:
|
||||
|
||||
```
|
||||
for ( 计数器的初始化 ; 测试条件 ; 计数器增加 ){
|
||||
动作
|
||||
}
|
||||
```
|
||||
|
||||
这里,该方法是通过一个计数器来控制循环执行来定义的,首先你需要初始化这个计数器,然后针对测试条件运行它,如果它为真,执行这些动作并最终增加这个计数器。当计数器不满足条件时,循环终止。
|
||||
|
||||
在我们想要打印数字 0 到 10 时,以下 awk 命令显示 for 语句是如何工作的:
|
||||
|
||||
```
|
||||
$ awk 'BEGIN{ for(counter=0;counter<=10;counter++){ print counter} }'
|
||||
```
|
||||
|
||||
输出样例
|
||||
|
||||
```
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
```
|
||||
|
||||
### 3. while 语句
|
||||
|
||||
while 语句的传统语法如下:
|
||||
|
||||
```
|
||||
while ( 条件 ) {
|
||||
动作
|
||||
}
|
||||
```
|
||||
|
||||
这个`条件`是一个 awk 表达式而`动作`是当条件为真时被执行的 awk 命令。
|
||||
|
||||
下面是一个说明使用 `while` 语句来打印数字 0 到 10 的脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
awk ' BEGIN{ counter=0;
|
||||
|
||||
while(counter<=10){
|
||||
print counter;
|
||||
counter+=1;
|
||||
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
保存文件并使脚本可执行,然后运行它:
|
||||
|
||||
```
|
||||
$ chmod +x test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
|
||||
输出样例
|
||||
|
||||
```
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
```
|
||||
|
||||
### 4. do while 语句
|
||||
|
||||
它是上文中 `while` 语句的一个变型,具有以下语法:
|
||||
|
||||
```
|
||||
do {
|
||||
动作
|
||||
}
|
||||
while (条件)
|
||||
```
|
||||
|
||||
这轻微的区别在于,在 `do while` 语句下,awk 的命令在求值条件之前执行。使用上文 `while` 语句的例子,我们可以通过按如下所述修改 test.sh 脚本中的 awk 命令来说明 `do while` 语句的用法:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
awk ' BEGIN{ counter=0;
|
||||
do{
|
||||
print counter;
|
||||
counter+=1;
|
||||
}
|
||||
while (counter<=10)
|
||||
}'
|
||||
```
|
||||
|
||||
修改脚本之后,保存文件并退出。按如下方式使脚本可执行并执行它:
|
||||
|
||||
```
|
||||
$ chmod +x test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
|
||||
输出样例
|
||||
|
||||
```
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
这不是关于 awk 的流程控制语句的一个全面的指南,正如我早先提到的,在 awk 里还有其他几个流程控制语句。
|
||||
|
||||
尽管如此,awk 系列的这一部分使应该你明白了一个明确的基于某些条件控制的 awk 命令是如何执行的基本概念。
|
||||
|
||||
你还可以了解其余更多的流程控制语句以获得更多关于该主题的理解。最后,在 awk 的系列下一节,我们将进入编写 awk 脚本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-flow-control-statements-with-awk-command/
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[robot527](https://github.com/robot527)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://linux.cn/article-7609-1.html
|
||||
@ -1,82 +0,0 @@
|
||||
Torvalds 2.0: Patricia Torvalds on computing, college, feminism, and increasing diversity in tech
|
||||
================================================================================
|
||||
|
||||

|
||||
Image by : Photo by Becky Svartström. Modified by Opensource.com. [CC BY-SA 4.0][1]
|
||||
|
||||
Patricia Torvalds isn't the Torvalds name that pops up in Linux and open source circles. Yet.
|
||||
|
||||

|
||||
|
||||
At 18, Patricia is a feminist with a growing list of tech achievements, open source industry experience, and her sights set on diving into her freshman year of college at Duke University's Pratt School of Engineering. She works for [Puppet Labs][2] in Portland, Oregon, as an intern, but soon she'll head to Durham, North Carolina, to start the fall semester of college.
|
||||
|
||||
In this exclusive interview, Patricia explains what got her interested in computer science and engineering (spoiler alert: it wasn't her father), what her high school did "right" with teaching tech, the important role feminism plays in her life, and her thoughts on the lack of diversity in technology.
|
||||
|
||||

|
||||
|
||||
### What made you interested in studying computer science and engineering? ###
|
||||
|
||||
My interest in tech really grew throughout high school. I wanted to go into biology for a while, until around my sophomore year. I had a web design internship at the Portland VA after my sophomore year. And I took an engineering class called Exploratory Ventures, which sent an ROV into the Pacific ocean late in my sophomore year, but the turning point was probably when I was named a regional winner and national runner up for the [NCWIT Aspirations in Computing][3] award halfway through my junior year.
|
||||
|
||||
The award made me feel validated in my interest, of course, but I think the most important part of it was getting to join a Facebook group for all the award winners. The girls who have won the award are absolutely incredible and so supportive of each other. I was definitely interested in computer science before I won the award, because of my work in XV and at the VA, but having these girls to talk to solidified my interest and has kept it really strong. Teaching XV—more on that later—my junior and senior year, also, made engineering and computer science really fun for me.
|
||||
|
||||
### What do you plan to study? And do you already know what you want to do after college? ###
|
||||
|
||||
I hope to major in either Mechanical or Electrical and Computer Engineering as well as Computer Science, and minor in Women's Studies. After college, I hope to work for a company that supports or creates technology for social good, or start my own company.
|
||||
|
||||
### My daughter had one high school programming class—Visual Basic. She was the only girl in her class, and she ended up getting harassed and having a miserable experience. What was your experience like? ###
|
||||
|
||||
My high school began offering computer science classes my senior year, and I took Visual Basic as well! The class wasn't bad, but I was definitely one of three or four girls in the class of 20 or so students. Other computing classes seemed to have similar gender breakdowns. However, my high school was extremely small and the teacher was supportive of inclusivity in tech, so there was no harassment that I noticed. Hopefully the classes become more diverse in future years.
|
||||
|
||||
### What did your schools do right technology-wise? And how could they have been better? ###
|
||||
|
||||
My high school gave us consistent access to computers, and teachers occasionally assigned technology-based assignments in unrelated classes—we had to create a website for a social studies class a few times—which I think is great because it exposes everyone to tech. The robotics club was also pretty active and well-funded, but fairly small; I was not a member. One very strong component of the school's technology/engineering program is actually a student-taught engineering class called Exploratory Ventures, which is a hands-on class that tackles a new engineering or computer science problem every year. I taught it for two years with a classmate of mine, and have had students come up to me and tell me they're interested in pursuing engineering or computer science as a result of the class.
|
||||
|
||||
However, my high school was not particularly focused on deliberately including young women in these programs, and it isn't very racially diverse. The computing-based classes and clubs were, by a vast majority, filled with white male students. This could definitely be improved on.
|
||||
|
||||
### Growing up, how did you use technology at home? ###
|
||||
|
||||
Honestly, when I was younger I used my computer time (my dad created a tracker, which logged us off after an hour of Internet use) to play Neopets or similar games. I guess I could have tried to mess with the tracker or played on the computer without Internet use, but I just didn't. I sometimes did little science projects with my dad, and I remember once printing "Hello world" in the terminal with him a thousand times, but mostly I just played online games with my sisters and didn't get my start in computing until high school.
|
||||
|
||||
### You were active in the Feminism Club at your high school. What did you learn from that experience? What feminist issues are most important to you now? ###
|
||||
|
||||
My friend and I co-founded Feminism Club at our high school late in our sophomore year. We did receive lots of resistance to the club at first, and while that never entirely went away, by the time we graduated feminist ideals were absolutely a part of the school's culture. The feminist work we did at my high school was generally on a more immediate scale and focused on issues like the dress code.
|
||||
|
||||
Personally, I'm very focused on intersectional feminism, which is feminism as it applies to other aspects of oppression like racism and classism. The Facebook page [Guerrilla Feminism][4] is a great example of an intersectional feminism and has done so much to educate me. I currently run the Portland branch.
|
||||
|
||||
Feminism is also important to me in terms of diversity in tech, although as an upper-class white woman with strong connections in the tech world, the problems here affect me much less than they do other people. The same goes for my involvement in intersectional feminism. Publications like [Model View Culture][5] are very inspiring to me, and I admire Shanley Kane so much for what she does.
|
||||
|
||||
### What advice would you give parents who want to teach their children how to program? ###
|
||||
|
||||
Honestly, nobody ever pushed me into computer science or engineering. Like I said, for a long time I wanted to be a geneticist. I got a summer internship doing web design for the VA the summer after my sophomore year and totally changed my mind. So I don't know if I can fully answer that question.
|
||||
|
||||
I do think genuine interest is important, though. If my dad had sat me down in front of the computer and told me to configure a webserver when I was 12, I don't think I'd be interested in computer science. Instead, my parents gave me a lot of free reign to do what I wanted, which was mostly coding terrible little HTML sites for my Neopets. Neither of my younger sisters are interested in engineering or computer science, and my parents don't care. I'm really lucky my parents have given me and my sisters the encouragement and resources to explore our interests.
|
||||
|
||||
Still, I grew up saying my future career would be "like my dad's"—even when I didn't know what he did. He has a pretty cool job. Also, one time when I was in middle school, I told him that and he got a little choked up and said I wouldn't think that in high school. So I guess that motivated me a bit.
|
||||
|
||||
### What suggestions do you have for leaders in open source communities to help them attract and maintain a more diverse mix of contributors? ###
|
||||
|
||||
I'm actually not active in particular open source communities. I feel much more comfortable discussing computing with other women; I'm a member of the [NCWIT Aspirations in Computing][6] network and it's been one of the most important aspects of my continued interest in technology, as well as the Facebook group [Ladies Storm Hackathons][7].
|
||||
|
||||
I think this applies well to attracting and maintaining a talented and diverse mix of contributors: Safe spaces are important. I have seen the misogynistic and racist comments made in some open source communities, and subsequent dismissals when people point out the issues. I think that in maintaining a professional community there have to be strong standards on what constitutes harassment or inappropriate conduct. Of course, people can—and will—have a variety of opinions on what they should be able to express in open source communities, or any community. However, if community leaders actually want to attract and maintain diverse talent, they need to create a safe space and hold community members to high standards.
|
||||
|
||||
I also think that some community leaders just don't value diversity. It's really easy to argue that tech is a meritocracy, and the reason there are so few marginalized people in tech is just that they aren't interested, and that the problem comes from earlier on in the pipeline. They argue that if someone is good enough at their job, their gender or race or sexual orientation doesn't matter. That's the easy argument. But I was raised not to make excuses for mistakes. And I think the lack of diversity is a mistake, and that we should be taking responsibility for it and actively trying to make it better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/life/15/8/patricia-torvalds-interview
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/rikki-endsley
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://puppetlabs.com/
|
||||
[3]:https://www.aspirations.org/
|
||||
[4]:https://www.facebook.com/guerrillafeminism
|
||||
[5]:https://modelviewculture.com/
|
||||
[6]:https://www.aspirations.org/
|
||||
[7]:https://www.facebook.com/groups/LadiesStormHackathons/
|
||||
@ -1,39 +0,0 @@
|
||||
KevinSJ Translating
|
||||
Linux will be the major operating system of 21st century cars
|
||||
===============================================================
|
||||
|
||||
>Cars are more than engines and good looking bodies. They're also complex computing devices so, of course, Linux runs inside them.
|
||||
|
||||
Linux doesn't just run your servers and, via Android, your phones. It also runs your cars. Of course, no one has ever bought a car for its operating system. But Linux is already powering the infotainment, heads-up display and connected car 4G and Wi-Fi systems for such major car manufacturers as Toyota, Nissan, and Jaguar Land Rover and [Linux is on its way to Ford][1], Mazda, Mitsubishi, and Subaru cars.
|
||||
|
||||

|
||||
>All the Linux and open-source car software efforts have now been unified under the Automotive Grade Linux project.
|
||||
|
||||
Software companies are also getting into this Internet of mobile things act. Movimento, Oracle, Qualcomm, Texas Instruments, UIEvolution and VeriSilicon have all [joined the Automotive Grade Linux (AGL)][2] project. The [AGL][3] is a collaborative open-source project devoted to creating a common, Linux-based software stack for the connected car.
|
||||
|
||||
AGL has seen tremendous growth over the past year as demand for connected car technology and infotainment are rapidly increasing," said Dan Cauchy, the Linux Foundation's General Manager of Automotive, in a statement.
|
||||
|
||||
Cauchy continued, "Our membership base is not only growing rapidly, but it is also diversifying across various business interests, from semiconductors and in-vehicle software to IoT and connected cloud services. This is a clear indication that the connected car revolution has broad implications across many industry verticals."
|
||||
|
||||
These companies have joined after AGL's recent announcement of a new AGL Unified Code Base (UCB). This new Linux distribution is based on AGL and two other car open-source projects: [Tizen][4] and the [GENIVI Alliance][5]. UCB is a second-generation car Linux. It was built from the ground up to address automotive specific applications. It handles navigation, communications, safety, security and infotainment functionality,
|
||||
|
||||
"The automotive industry needs a standard open operating system and framework to enable automakers and suppliers to quickly bring smartphone-like capabilities to the car," said Cauchy. "This new distribution integrates the best components from AGL, Tizen, GENIVI and related open-source code into a single AGL Unified Code Base, allowing car-makers to leverage a common platform for rapid innovation. The AGL UCB distribution will play a huge role in the adoption of Linux-based systems for all functions in the vehicle."
|
||||
|
||||
He's right. Since its release in January 2016, four car companies and ten new software businesses have joined AGL. Esso, now Exxon, made the advertising slogan, "Put a tiger in your tank!" famous. I doubt that "Put a penguin under your hood" will ever become well-known, but that's exactly what's happening. Linux is well on its way to becoming the major operating system of 21st century cars.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/the-linux-in-your-car-movement-gains-momentum/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: https://www.automotivelinux.org/news/announcement/2016/01/ford-mazda-mitsubishi-motors-and-subaru-join-linux-foundation-and
|
||||
[2]: https://www.automotivelinux.org/news/announcement/2016/05/oracle-qualcomm-innovation-center-texas-instruments-and-others-support
|
||||
[3]: https://www.automotivelinux.org/
|
||||
[4]: https://www.tizen.org/
|
||||
[5]: http://www.genivi.org/
|
||||
@ -1,118 +0,0 @@
|
||||
transalting by ynmlml
|
||||
5 Best Linux Package Managers for Linux Newbies
|
||||
=====================================================
|
||||
|
||||
|
||||
One thing a new Linux user will get to know as he/she progresses in using it is the existence of several Linux distributions and the different ways they manage packages.
|
||||
|
||||
Package management is very important in Linux, and knowing how to use multiple package managers can proof life saving for a power user, since downloading or installing software from repositories, plus updating, handling dependencies and uninstalling software is very vital and a critical section in Linux system Administration.
|
||||
|
||||

|
||||
>Best Linux Package Managers
|
||||
|
||||
Therefore to become a Linux power user, it is significant to understand how the major Linux distributions actually handle packages and in this article, we shall take a look at some of the best package managers you can find in Linux.
|
||||
|
||||
Here, our main focus is on relevant information about some of the best package managers, but not how to use them, that is left to you to discover more. But I will provide meaningful links that point out usage guides and many more.
|
||||
|
||||
### 1. DPKG – Debian Package Management System
|
||||
|
||||
Dpkg is a base package management system for the Debian Linux family, it is used to install, remove, store and provide information about `.deb` packages.
|
||||
|
||||
It is a low-level tool and there are front-end tools that help users to obtain packages from remote repositories and/or handle complex package relations and these include:
|
||||
|
||||
Don’t Miss: [15 Practical Examples of “dpkg commands” for Debian Based Distros][1]
|
||||
|
||||
#### APT (Advanced Packaging Tool)
|
||||
|
||||
It is a very popular, free, powerful and more so, useful command line package management system that is a front end for dpkg package management system.
|
||||
|
||||
Users of Debian or its derivatives such as Ubuntu and Linux Mint should be familiar with this package management tool.
|
||||
|
||||
To understand how it actually works, you can go over these how to guides:
|
||||
|
||||
Don’t Miss: [15 Examples of How to Use New Advanced Package Tool (APT) in Ubuntu/Debian][2]
|
||||
|
||||
Don’t Miss: [25 Useful Basic Commands of APT-GET and APT-CACHE for Package Management][3]
|
||||
|
||||
#### Aptitude Package Manager
|
||||
|
||||
This is also a popular command line front-end package management tool for Debian Linux family, it works similar to APT and there have been a lot of comparisons between the two, but above all, testing out both can make you understand which one actually works better.
|
||||
|
||||
It was initially built for Debian and its derivatives but now its functionality stretches to RHEL family as well. You can refer to this guide for more understanding of APT and Aptitude:
|
||||
|
||||
Don’t Miss: [What is APT and Aptitude? and What’s real Difference Between Them?][4]
|
||||
|
||||
#### Synaptic Package Manager
|
||||
|
||||
Synaptic is a GUI package management tool for APT based on GTK+ and it works fine for users who may not want to get their hands dirty on a command line. It implements the same features as apt-get command line tool.
|
||||
|
||||
### 2. RPM (Red Hat Package Manager)
|
||||
|
||||
This is the Linux Standard Base packing format and a base package management system created by RedHat. Being the underlying system, there several front-end package management tools that you can use with it and but we shall only look at the best and that is:
|
||||
|
||||
#### YUM (Yellowdog Updater, Modified)
|
||||
|
||||
It is an open source and popular command line package manager that works as a interface for users to RPM. You can compare it to APT under Debian Linux systems, it incorporates the common functionalities that APT has. You can get a clear understanding of YUM with examples from this how to guide:
|
||||
|
||||
Don’t Miss: [20 Linux YUM Commands for Package Management][5]
|
||||
|
||||
#### DNF – Dandified Yum
|
||||
|
||||
It is also a package manager for the RPM-based distributions, introduced in Fedora 18 and it is the next generation of version of YUM.
|
||||
|
||||
If you have been using Fedora 22 onwards, you must have realized that it is the default package manager. Here are some links that will provide you more information about DNF and how to use it:
|
||||
|
||||
Don’t Miss: [DNF – The Next Generation Package Management for RPM Based Distributions][6]
|
||||
|
||||
Don’t Miss: [27 ‘DNF’ Commands Examples to Manage Fedora Package Management][7]
|
||||
|
||||
### 3. Pacman Package Manager – Arch Linux
|
||||
|
||||
It is a popular and powerful yet simple package manager for Arch Linux and some little known Linux distributions, it provides some of the fundamental functionalities that other common package managers provide including installing, automatic dependency resolution, upgrading, uninstalling and also downgrading software.
|
||||
|
||||
But most effectively, it is built to be simple for easy package management by Arch users. You can read this [Pacman overview][8] which explains into details some of its functions mentioned above.
|
||||
|
||||
### 4. Zypper Package Manager – openSUSE
|
||||
|
||||
It is a command line package manager on OpenSUSE Linux and makes use of the libzypp library, its common functionalities include repository access, package installation, resolution of dependencies issues and many more.
|
||||
|
||||
Importantly, it can also handle repository extensions such as patterns, patches, and products. New OpenSUSE user can refer to this following guide to master it.
|
||||
|
||||
Don’t Miss: [45 Zypper Commands to Master OpenSUSE Package Management][9]
|
||||
|
||||
### 5. Portage Package Manager – Gentoo
|
||||
|
||||
It is a package manager for Gentoo, a less popular Linux distribution as of now, but this won’t limit it as one of the best package managers in Linux.
|
||||
|
||||
The main aim of the Portage project is to make a simple and trouble free package management system to include functionalities such as backwards compatibility, automation plus many more.
|
||||
|
||||
For better understanding, try reading [Portage project page][10].
|
||||
|
||||
### Concluding Remarks
|
||||
|
||||
As I already hinted at the beginning, the main purpose of this guide was to provide Linux users a list of the best package managers but knowing how to use them can be done by following the necessary links provided and trying to test them out.
|
||||
|
||||
Users of the different Linux distributions will have to learn more on their own to better understand the different package managers mentioned above.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-package-managers/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/admin/
|
||||
[1]: http://www.tecmint.com/dpkg-command-examples/
|
||||
[2]: http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]: http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[4]: http://www.tecmint.com/difference-between-apt-and-aptitude/
|
||||
[5]: http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]: http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[7]: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[8]: https://wiki.archlinux.org/index.php/Pacman
|
||||
[9]: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
[10]: https://wiki.gentoo.org/wiki/Project:Portage
|
||||
@ -1,110 +0,0 @@
|
||||
Ubuntu’s Snap, Red Hat’s Flatpak And Is ‘One Fits All’ Linux Packages Useful?
|
||||
=================================================================================
|
||||
|
||||

|
||||
|
||||
An in-depth look into the new generation of packages starting to permeate the Linux ecosystem.
|
||||
|
||||
|
||||
Lately we’ve been hearing more and more about Ubuntu’s Snap packages and Flatpak (formerly referred to as xdg-app) created by Red Hat’s employee Alexander Larsson.
|
||||
|
||||
These 2 types of next generation packages are in essence having the same goal and characteristics which are: being standalone packages that doesn’t rely on 3rd-party system libraries in order to function.
|
||||
|
||||
This new technology direction which Linux seems to be headed is automatically giving rise to questions such as, what are the advantages / disadvantages of standalone packages? does this lead us to a better Linux overall? what are the motives behind it?
|
||||
|
||||
To answer these questions and more, let us explore the things we know about Snap and Flatpak so far.
|
||||
|
||||
### The Motive
|
||||
|
||||
According to both [Flatpak][1] and [Snap][2] statements, the main motive behind them is to be able to bring one and the same version of application to run across multiple Linux distributions.
|
||||
|
||||
>“From the very start its primary goal has been to allow the same application to run across a myriad of Linux distributions and operating systems.” Flatpak
|
||||
|
||||
>“… ‘snap’ universal Linux package format, enabling a single binary package to work perfectly and securely on any Linux desktop, server, cloud or device.” Snap
|
||||
|
||||
To be more specific, the guys behind Snap and Flatpak (S&F) believe that there’s a barrier of fragmentation on the Linux platform.
|
||||
|
||||
A barrier which holds back the platform advancement by burdening developers with more, perhaps unnecessary, work to get their software run on the many distributions out there.
|
||||
|
||||
Therefore, as leading Linux distributions (Ubuntu & Red Hat), they wish to eliminate the barrier and strengthen the platform in general.
|
||||
|
||||
But what are the more personal gains which motivate the development of S&F?
|
||||
|
||||
#### Personal Gains?
|
||||
|
||||
Although not officially stated anywhere, it may be assumed that by leading the efforts of creating a unified package that could potentially be adopted by the vast majority of Linux distros (if not all of them), the captains of these projects could assume a key position in determining where the Linux ship sails.
|
||||
|
||||
### The Advantages
|
||||
|
||||
The benefits of standalone packages are diverse and can depend on different factors.
|
||||
|
||||
Basically however, these factors can be categorized under 2 distinct criteria:
|
||||
|
||||
#### User Perspective
|
||||
|
||||
+ From a Linux user point of view, Snap and Flatpak both bring the possibility of installing any package (software / app) on any distribution the user is using.
|
||||
|
||||
That is, for instance, if you’re using a not so popular distribution which has only a scarce supply of packages available in their repo, due to workforce limitations probably, you’ll now be able to easily and significantly increase the amount of packages available to you – which is a great thing.
|
||||
|
||||
+ Also, users of popular distributions that do have many packages available in their repos, will enjoy the ability of installing packages that might not have behaved with their current set of installed libraries.
|
||||
|
||||
For example, a Debian user who wants to install a package from ‘testing branch’ will not have to convert his entire system into ‘testing’ (in order for the package to run against newer libraries), rather, that user will simply be able to install only the package he wants from whichever branch he likes and on whatever branch he’s on.
|
||||
|
||||
The latter point, was already basically possible for users who were compiling their packages straight from source, however, unless using a source based distribution such as Gentoo, most users will see this as just an unworthily hassle.
|
||||
|
||||
+ The advanced user, or perhaps better put, the security aware user might feel more comfortable with this type of packages as long as they come from a reliable source as they tend to provide another layer of isolation since they are generally isolated from system packages.
|
||||
|
||||
* Both S&F are being developed with enhanced security in mind, which generally makes use of “sandboxing” i.e isolation in order to prevent cases where they carry a virus which can infect the entire system, similar to the way .exe files on MS Windows may. (More on MS and S&F later)
|
||||
|
||||
#### Developer Perspective
|
||||
|
||||
For developers, the advantages of developing S&F packages will probably be a lot clearer than they are to the average user, some of these were already hinted in a previous section of this post.
|
||||
|
||||
Nonetheless, here they are:
|
||||
|
||||
+ S&F will make it easier on devs who want to develop for more than one Linux distribution by unifying the process of development, therefore minimizing the amount of work a developer needs to do in order to get his app running on multiple distributions.
|
||||
|
||||
++ Developers could therefore gain easier access to a wider range of distributions.
|
||||
|
||||
+ S&F allow devs to privately distribute their packages without being dependent on distribution maintainers to stabilize their package for each and every distro.
|
||||
|
||||
++ Through the above, devs may gain access to direct statistics of user adoption / engagement for their software.
|
||||
|
||||
++ Also through the above, devs could get more directly involved with users, rather than having to do so through a middleman, in this case, the distribution.
|
||||
|
||||
### The Downsides
|
||||
|
||||
– Bloat. Simple as that. Flatpak and Snap aren’t just magic making dependencies evaporate into thin air. Rather, instead of relying on the target system to provide the required dependencies, S&F comes with the dependencies prebuilt into them.
|
||||
|
||||
As the saying goes “if the mountain won’t come to Muhammad, Muhammad must go to the mountain…”
|
||||
|
||||
– Just as the security-aware user might enjoy S&F packages extra layer of isolation, as long they come from a trusted source. The less knowledgeable user on the hand, might be prone to the other side of the coin hazard which is using a package from an unknown source which may contain malicious software.
|
||||
|
||||
The above point can be said to be valid even with today’s popular methods, as PPAs, overlays, etc might also be maintained by untrusted sources.
|
||||
|
||||
However, with S&F packages the risk increases since malicious software developers need to create only one version of their program in order to infect a large number of distributions, whereas, without it they’d needed to create multiple versions in order to adjust their malware to other distributions.
|
||||
|
||||
Was Microsoft Right All Along?
|
||||
|
||||
With all that’s mentioned above in mind, it’s pretty clear that for the most part, the advantages of using S&F packages outweighs the drawbacks.
|
||||
|
||||
At the least for users of binary-based distributions, or, non lightweight focused distros.
|
||||
|
||||
Which eventually lead me to asking the above question – could it be that Microsoft was right all along? if so and S&F becomes the Linux standard, would you still consider Linux a Unix-like variant?
|
||||
|
||||
Well apparently, the best one to answer those questions is probably time.
|
||||
|
||||
Nevertheless, I’d argue that even if not entirely right, MS certainly has a good point to their credit, and having all these methods available here on Linux out of the box is certainly a plus in my book.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/ubuntus-snap-red-hats-flatpack-and-is-one-fits-all-linux-packages-useful/
|
||||
|
||||
作者:[Editorials][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com/category/editorials/
|
||||
@ -1,90 +0,0 @@
|
||||
Linux Applications That Works On All Distributions – Are They Any Good?
|
||||
============================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
A revisit of Linux community’s latest ambitions – promoting decentralized applications in order to tackle distribution fragmentation.
|
||||
|
||||
Following last week’s article: [Ubuntu’s Snap, Red Hat’s Flatpak And Is ‘One Fits All’ Linux Packages Useful][1]?, a couple of new opinions rose to the surface which may contain crucial information about the usefulness of such apps.
|
||||
|
||||
### The Con Side
|
||||
|
||||
Commenting on the subject [here][2], a [Gentoo][3] user who goes by the name Till, gave rise to a few points which hasn’t been addressed to the fullest the last time we covered the issue.
|
||||
|
||||
While previously we settled on merely calling it bloat, Till here on the other hand, is dissecting that bloat further so to help us better understand both its components and its consequences.
|
||||
|
||||
Referring to such apps as “bundled applications” – for the way they work on all distributions is by containing dependencies together with the apps themselves, Till says:
|
||||
|
||||
>“bundles ship a lot of software that now needs to be maintained by the application developer. If library X has a security problem and needs an update, you rely on every single applications to ship correct updates in order to make your system save.”
|
||||
|
||||
Essentially, Till raises an important security point. However, it isn’t necessarily has to be tied to security alone, but can also be linked to other aspects such as system maintenance, atomic updates, etc…
|
||||
|
||||
Furthermore, if we take that notion one step further and assume that dependencies developers may cooperate, therefore releasing their software in correlation with the apps who use them (an utopic situation), we shall then get an overall slowdown of the entire platform development.
|
||||
|
||||
Another problem that arises from the same point made above is dependencies-transparency becomes obscure, that is, if you’d want to know which libraries are bundled with a certain app, you’ll have to rely on the developer to publish such data.
|
||||
|
||||
Or, as Till puts it: “Questions like, did package XY already include the updated library Z, will be your daily bread”.
|
||||
|
||||
For comparison, with the standard methods available on Linux nowadays (both binary and source distributions), you can easily notice which libraries are being updated upon a system update.
|
||||
|
||||
And you can also rest assure that all other apps on the system will use it, freeing you from the need to check each app individually.
|
||||
|
||||
Other cons that may be deduced from the term bloat include: bigger package size (each app is bundled with dependencies), higher memory usage (no more library sharing) and also –
|
||||
|
||||
One less filter mechanism to prevent malicious software – distributions package maintainers also serve as a filter between developers and users, helping to assure users get quality software.
|
||||
|
||||
With bundled apps this may no longer be the case.
|
||||
|
||||
As a finalizing general point, Till asserts that although useful in some cases, for the most part, bundled apps weakens the free software position in distributions (as proprietary vendors will now be able to deliver software without sharing it on public repositories).
|
||||
|
||||
And apart from that, it introduces many other issues. Many problems are simply moved towards the developers.
|
||||
|
||||
### The Pro Side
|
||||
|
||||
In contrast, another comment by a person named Sven tries to contradict common claims that basically go against the use of bundled applications, hence justifying and promoting the use of it.
|
||||
|
||||
“waste of space” – Sven claims that in today’s world we have many other things that wastes disk space, such as movies stored on hard drive, installed locals, etc…
|
||||
|
||||
Ultimately, these things are infinitely more wasteful than a mere “100 MB to run a program you use all day … Don’t be ridiculous.”
|
||||
|
||||
“waste of RAM” – the major points in favor are:
|
||||
|
||||
- Shared libraries waste significantly less RAM compared to application runtime data.
|
||||
- RAM is cheap today.
|
||||
|
||||
“security nightmare” – not every application you run is actually security-critical.
|
||||
|
||||
Also, many applications never even see any security updates, unless on a ‘rolling distro’.
|
||||
|
||||
In addition to Sven’s opinions, who try to stick to the pragmatic side, a few advantages were also pointed by Till who admits that bundled apps has their merits in certain cases:
|
||||
|
||||
- Proprietary vendors who want to keep their code out of the public repositories will be able to do so more easily.
|
||||
- Niche applications, which are not packaged by your distribution, will now be more readily available.
|
||||
- Testing on binary distributions which do not have beta packages will become easier.
|
||||
- Freeing users from solving dependencies problems.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Although shedding new light onto the matter, it seems that one conclusion still stands and accepted by all parties – bundled apps has their niche to fill in the Linux ecosystem.
|
||||
|
||||
Nevertheless, the role that niche should take, whether main or marginal one, appears to be a lot clearer now, at least from a theoretical point of view.
|
||||
|
||||
Users who are looking to make their system optimized as possible, should, in the majority of cases, avoid using bundled apps.
|
||||
|
||||
Whereas, users that are after ease-of-use, meaning – doing the least of work in order to maintain their systems, should and probably would feel very comfortable adopting the new method.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.iwillfolo.com/linux-applications-that-works-on-all-distributions-are-they-any-good/
|
||||
|
||||
作者:[Editorials][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.iwillfolo.com/category/editorials/
|
||||
[1]: http://www.iwillfolo.com/ubuntus-snap-red-hats-flatpack-and-is-one-fits-all-linux-packages-useful/
|
||||
[2]: http://www.proli.net/2016/06/25/gnulinux-bundled-application-ramblings/
|
||||
[3]: http://www.iwillfolo.com/5-reasons-use-gentoo-linux/
|
||||
@ -1,101 +0,0 @@
|
||||
Tips for managing your project's issue tracker
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
Issue-tracking systems are important for many open source projects, and there are many open source tools that provide this functionality but many projects opt to use GitHub's built-in issue tracker.
|
||||
|
||||
Its simple structure makes it easy for others to weigh in, but issues are really only as good as you make them.
|
||||
|
||||
Without a process, your repository can become unwieldy, overflowing with duplicate issues, vague feature requests, or confusing bug reports. Project maintainers can become burdened by the organizational load, and it can become difficult for new contributors to understand where priorities lie.
|
||||
|
||||
In this article, I'll discuss how to take your GitHub issues from good to great.
|
||||
|
||||
### The issue as user story
|
||||
|
||||
My team spoke with open source expert [Jono Bacon][1]—author of [The Art of Community][2], a strategy consultant, and former Director of Community at GitHub—who said that high-quality issues are at the core of helping a projects succeed. He says that while some see issues as merely a big list of problems you have to tend to, well-managed, triaged, and labeled issues can provide incredible insight into your code, your community, and where the problem spots are.
|
||||
|
||||
"At the point of submission of an issue, the user likely has little patience or interest in providing expansive detail. As such, you should make it as easy as possible to get the most useful information from them in the shortest time possible," Jono Bacon said.
|
||||
|
||||
A consistent structure can take a lot of burden off project maintainers, particularly for open source projects. We've found that encouraging a user story approach helps make clarity a constant. The common structure for a user story addresses the "who, what, and why" of a feature: As a [user type], I want to [task] so that [goal].
|
||||
|
||||
Here's what that looks like in practice:
|
||||
|
||||
>As a customer, I want to create an account so that I can make purchases.
|
||||
|
||||
We suggest sticking that user story in the issue's title. You can also set up [issue templates][3] to keep things consistent.
|
||||
|
||||
|
||||
> Issue templates bring consistency to feature requests.
|
||||
|
||||
The point is to make the issue well-defined for everyone involved: it identifies the audience (or user), the action (or task), and the outcome (or goal) as simply as possible. There's no need to obsess over this structure, though; as long as the what and why of a story are easy to spot, you're good.
|
||||
|
||||
### Qualities of a good issue
|
||||
|
||||
Not all issues are created equal—as any OSS contributor or maintainer can attest. A well-formed issue meets these qualities outlined in [The Agile Samurai][4].
|
||||
|
||||
Ask yourself if it is...
|
||||
|
||||
- something of value to customers
|
||||
- avoids jargon or mumbo jumbo; a non-expert should be able to understand it
|
||||
- "slices the cake," which means it goes end-to-end to deliver something of value
|
||||
- independent from other issues if possible; dependent issues reduce flexibility of scope
|
||||
- negotiable, meaning there are usually several ways to get to the stated goal
|
||||
- small and easily estimable in terms of time and resources required
|
||||
- measurable; you can test for results
|
||||
|
||||
### What about everything else? Working with constraints
|
||||
|
||||
If an issue is difficult to measure or doesn't seem feasible to complete within a short time period, you can still work with it. Some people call these "constraints."
|
||||
|
||||
For example, "the product needs to be fast" doesn't fit the story template, but it is non-negotiable. But how fast is fast? Vague requirements don't meet the criteria of a "good issue", but if you further define these concepts—for example, "the product needs to be fast" can be "each page needs to load within 0.5 seconds"—you can work with it more easily. Constraints can be seen as internal metrics of success, or a landmark to shoot for. Your team should test for them periodically.
|
||||
|
||||
### What's inside your issue?
|
||||
|
||||
In agile, user stories typically include acceptance criteria or requirements. In GitHub, I suggest using markdown checklists to outline any tasks that make up an issue. Issues should get more detail as they move up in priority.
|
||||
|
||||
Say you're creating an issue around a new homepage for a website. The sub-tasks for that task might look something like this.
|
||||
|
||||
|
||||
>Use markdown checklists to split a complicated issue into several parts.
|
||||
|
||||
If necessary, link to other issues to further define a task. (GitHub makes this really easy.)
|
||||
|
||||
Defining features as granularly as possible makes it easier to track progress, test for success, and ultimately ship valuable code more frequently.
|
||||
|
||||
Once you've gathered some data points in the form of issues, you can use APIs to glean deeper insight into the health of your project.
|
||||
|
||||
"The GitHub API can be hugely helpful here in identifying patterns and trends in your issues," Bacon said. "With some creative data science, you can identify problem spots in your code, active members of your community, and other useful insights."
|
||||
|
||||
Some issue management tools provide APIs that add additional context, like time estimates or historical progress.
|
||||
|
||||
### Getting others on board
|
||||
|
||||
Once your team decides on an issue structure, how do you get others to buy in? Think of your repo's ReadMe.md file as your project's "how-to." It should clearly define what your project does (ideally using searchable language) and explain how others can contribute (by submitting requests, bug reports, suggestions, or by contributing code itself.)
|
||||
|
||||
|
||||
>Edit your ReadMe file with clear instructions for new collaborators.
|
||||
|
||||
This is the perfect spot to share your GitHub issue guidelines. If you want feature requests to follow the user story format, share that here. If you use a tracking tool to organize your product backlog, share the badge so others can gain visibility.
|
||||
|
||||
"Issue templates, sensible labels, documentation for how to file issues, and ensuring your issues get triaged and responded to quickly are all important" for your open source project, Bacon said.
|
||||
|
||||
Remember: It's not about adding process for the process' sake. It's about setting up a structure that makes it easy for others to discover, understand, and feel confident contributing to your community.
|
||||
|
||||
"Focus your community growth efforts not just on growing the number of programmers, but also [on] people interested in helping issues be accurate, up to date, and a source of active conversation and productive problem solving," Bacon said.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/how-take-your-projects-github-issues-good-great
|
||||
|
||||
作者:[Matt Butler][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattzenhub
|
||||
[1]: http://www.jonobacon.org/
|
||||
[2]: http://www.artofcommunityonline.org/
|
||||
[3]: https://help.github.com/articles/creating-an-issue-template-for-your-repository/
|
||||
[4]: https://www.amazon.ca/Agile-Samurai-Masters-Deliver-Software/dp/1934356581
|
||||
@ -1,66 +0,0 @@
|
||||
I've been Linuxing since before you were born
|
||||
=====================
|
||||
|
||||

|
||||
|
||||
Once upon a time, there was no Linux. No, really! It did not exist. It was not like today, with Linux everywhere. There were multiple flavors of Unix, there was Apple, and there was Microsoft Windows.
|
||||
|
||||
When it comes to Windows, the more things change, the more they stay the same. Despite adding 20+ gigabytes of gosh-knows-what, Windows is mostly the same. (Except you can't drop to a DOS prompt to get actual work done.) Hey, who remembers Gorilla.bas, the exploding banana game that came in DOS? Fun times! The Internet never forgets, and you can play a Flash version on Kongregate.com.
|
||||
|
||||
Apple changed, evolving from a friendly system that encouraged hacking to a sleek, sealed box that you are not supposed to open, and that dictates what hardware interfaces you are allowed to use. 1998: no more floppy disk. 2012: no more optical drive. The 12-inch MacBook has only a single USB Type-C port that supplies power, Bluetooth, Wi-Fi, external storage, video output, and accessories. If you want to plug in more than one thing at a time and don't want to tote a herd of dongles and adapters around with you, too bad. Next up: The headphone jack. Yes, the one remaining non-proprietary standard hardware port in Apple-land is doomed.
|
||||
|
||||
There was a sizable gaggle of other operating systems such as Amiga, BeOS, OS/2, and dozens more that you can look up should you feel so inclined, which I encourage because looking things up is so easy now there is no excuse not to. Amiga, BeOS, and OS/2 were noteworthy for having advanced functionality such as 32-bit multitasking and advanced graphics handling. But marketing clout defeats higher quality, and so the less-capable Apple and Windows dominated the market while the others faded away.
|
||||
|
||||
Then came Linux, and the world changed.
|
||||
|
||||
### First PC
|
||||
|
||||
The first PC I ever used was an Apple IIc, somewheres around 1994, when Linux was three years old. A friend loaned it to me and it was all right, but too inflexible. Then I bought a used Tandy PC for something like $500, which was sad for the person who sold it because it cost a couple thousand dollars. Back then, computers depreciated very quickly. It was a monster: an Intel 386SX CPU, 4 megabytes RAM, a 107-megabyte hard drive, 14-inch color CRT monitor, running MS-DOS 5 and Windows 3.1.
|
||||
|
||||
I tore that poor thing apart multiple times and reinstalled Windows and DOS many times. Windows was marginally usable, so I did most of my work in DOS. I loved gory video games and played Doom, Duke Nukem, Quake, and Heretic. Ah, those glorious, jiggedy 8-bit graphics.
|
||||
|
||||
In those days the hardware was always behind the software, so I upgraded frequently. Now we have all the horsepower we need and then some. I haven't had to upgrade the hardware in any of my computers for several years.
|
||||
|
||||
### Computer bits
|
||||
|
||||
Back in those golden years, there were independent computer stores on every corner and you could hardly walk down the block without tripping over a local independent Internet service provider (ISP). ISPs were very different then. They were not horrid customer-hostile megacorporations like our good friends the American telcos and cable companies. They were nice, and offered all kinds of extra services like Bulletin Board Services (BBS), file downloads, and Multi-User Domains (MUDs), which were multi-player online games.
|
||||
|
||||
I spent a lot of time buying parts in the computer stores, and half the fun was shocking the store staff by being a woman. It is puzzling how this is so upsetting to some people. Now I'm an old fart of 58 and they're still not used to it. I hope that being a woman nerd will become acceptable by the time I die.
|
||||
|
||||
Those stores had racks of Computer Bits magazine. Check out this old issue of Computer Bits on the Internet Archive. Computer Bits was a local free paper with good articles and tons of ads. Unfortunately, the print ads did not appear in the online edition, so you can't see how they included a wealth of detailed information. You know how advertisers are so whiny, and complain about ad blockers, and have turned tech journalism into barely-disguised advertising? They need to learn some lessons from the past. Those ads were useful. People wanted to read them. I learned everything about computer hardware from reading the ads in Computer Bits and other computer magazines. Computer Shopper was an especially fabulous resource; it had several hundred pages of ads and high-quality articles.
|
||||
|
||||

|
||||
|
||||
The publisher of Computer Bits, Paul Harwood, launched my writing career. My first ever professional writing was for Computer Bits. Paul, if you're still around, thank you!
|
||||
|
||||
You can see something in the Internet Archives of Computer Bits that barely exists anymore, and that is the classified ads section. Classified ads generated significant income for print publications. Craigslist killed the classifieds, which killed newspapers and publications like Computer Bits.
|
||||
|
||||
One of my cherished memories is when the 12-year-old twit who ran my favorite computer store, who could never get over my blatant woman-ness and could never accept that I knew what I was doing, handed me a copy of Computer Bits as a good resource for beginners. I opened it to show him one of my Linux articles and said "Oh yes, I know." He turned colors I didn't think were physiologically possible and scuttled away. (No, my fine literalists, he was not really 12, but in his early 20s. Perhaps by now his emotional maturity has caught up a little.)
|
||||
|
||||
### Discovering Linux
|
||||
|
||||
I first learned about Linux in Computer Bits magazine, maybe around 1997 or so. My first Linuxes were Red Hat 5 and Mandrake Linux. Mandrake was glorious. It was the first easy-to-install Linux, and it bundled graphics and sound drivers so I could immediately play Tux Racer. Unlike most Linux nerds at the time I did not come from a Unix background, so I had a steep learning curve. But that was alright, because everything I learned was useful. In contrast to my Windows adventures, where most of what I learned was working around its awfulness, then giving up and dropping to a DOS shell.
|
||||
|
||||
Playing with computers was so much fun I drifted into freelance consulting, forcing Windows computers to more or less function, and helping IT staff in small shops migrate to Linux servers. Usually we did this on the sneak, because those were the days of Microsoft calling Linux a cancer, and implying that it was a communist conspiracy to sap and impurify all of our precious bodily fluids.
|
||||
|
||||
### Linux won
|
||||
|
||||
I continued consulting for a number of years, doing a little bit of everything: Repairing and upgrading hardware, pulling cable, system and network administration, and running mixed Apple/Windows/Linux networks. Apple and Windows were absolutely hellish to integrate into mixed networks as they deliberately tried to make it impossible. One of the coolest things about Linux and FOSS is there is always someone ready and able to defeat the barriers erected by proprietary vendors.
|
||||
|
||||
It is very different now. There are still proprietary barriers to interoperability, and there is still no Tier 1 desktop Linux OEM vendor. In my opinion this is because Microsoft and Apple have a hard lock on retail distribution. Maybe they're doing us a favor, because you get way better service and quality from wonderful independent Linux vendors like ZaReason and System76. They're Linux experts, and they don't treat us like unwelcome afterthoughts.
|
||||
|
||||
Aside from the retail desktop, Linux dominates all aspects of computing from embedded to supercomputing and distributed computing. Open source dominates software development. All of the significant new frontiers in software, such as containers, clusters, and artificial intelligence are all powered by open source software. When you measure the distance from my first little old 386SX PC til now, that is phenomenal progress.
|
||||
|
||||
It would not have happened without Linux and open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/my-linux-story-carla-schroder
|
||||
|
||||
作者:[Carla Schroder ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/carlaschroder
|
||||
@ -1,36 +0,0 @@
|
||||
The revenge of Linux
|
||||
========================
|
||||
|
||||

|
||||
|
||||
In the beginning of Linux they laughed at it and didn't think it could do anything. Now Linux is everywhere!
|
||||
|
||||
I was a junior at college studying Computer Engineering in Brazil, and working at the same time in a global auditing and consulting company as a sysadmin. The company decided to implement some enterprise resource planning (ERP) software with an Oracle database. I got training in Digital UNIX OS (DEC Alpha), and it blew my mind.
|
||||
|
||||
The UNIX system was very powerful and gave us absolute control of the machine: storage systems, networking, applications, and everything.
|
||||
|
||||
I started writing lots of scripts in ksh and Bash to automate backup, file transfer, extract, transform, load (ETL) operations, automate DBA routines, and created many other services that came up from different projects. Moreover, doing database and operating system tuning gave me a good understanding of how to get the best from a server. At that time, I used Windows 95 on my PC, and I would have loved to have Digital UNIX in my PC box, or even Solaris or HP-UX, but those UNIX systems were made to run on specific hardware. I read all the documentation that came with the systems, looked for additional books to get more information, and tested crazy ideas in our development environment.
|
||||
|
||||
Later in college, I heard about Linux from my colleagues. I downloaded it back in the time of dialup internet, and I was very excited. The idea of having my standard PC with a UNIX-like system was amazing!
|
||||
|
||||
As Linux is made to run in any general PC hardware, unlike UNIX systems, at the beginning it was really hard to get it working. Linux was just for sysadmins and geeks. I even made adjustments in drivers using C language to get it running. My previous experience with UNIX made me feel at home when I was compiling the Linux kernel, troubleshooting, and so on. It was very challenging for Linux to work with any unexpected hardware setups, as opposed to closed systems that fit just some specific hardware.
|
||||
|
||||
I have been seeing Linux get space in data centers. Some adventurous sysadmins start boxes to help in everyday tasks for monitoring and managing the infrastructure, and then Linux gets more space as DNS and DHCP servers, printer management, and file servers. There used to be lots of FUD (fear, uncertainty and doubt) and criticism about Linux for the enterprise: Who is the owner of it? Who supports it? Are there applications for it?
|
||||
|
||||
But nowadays it seems the revenge of Linux is everywhere! From developer's PCs to huge enterprise servers; we can find it in smart phones, watches, and in the Internet of Things (IoT) devices such as Raspberry Pi. Even Mac OS X has a kind of prompt with commands we are used to. Microsoft is making its own distribution, runs it at Azure, and then... Windows 10 is going to get Bash on it.
|
||||
|
||||
The interesting thing is that the IT market creates and quickly replaces new technologies, but the knowledge we got with old systems such as Digital UNIX, HP-UX, and Solaris is still useful and relevant with Linux, for business and just for fun. Now we can get absolute control of our systems, and use it at its maximum capabilities. Moreover Linux has an enthusiastic community!
|
||||
|
||||
I really recommend that youngsters looking for a career in computing learn Linux. It does not matter what your branch in IT is. If you learn deeply how a standard home PC works, you can get in front of any big box talking basically the same language. With Linux you learn fundamental computing, and build skills that work anywhere in IT.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/8/revenge-linux
|
||||
|
||||
作者:[Daniel Carvalho][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/danielscarvalho
|
||||
@ -1,3 +1,5 @@
|
||||
rusking 翻译中
|
||||
|
||||
What is open source
|
||||
===========================
|
||||
|
||||
|
||||
@ -1,39 +0,0 @@
|
||||
Why measuring IT productivity is so challenging
|
||||
===========================
|
||||
|
||||

|
||||
|
||||
In some professions, there are metrics that one can use to determine an individual’s productivity. If you’re a widget maker, for instance, you might be measured on how many widgets you can make in a month. If you work in a call center – how many calls did you answer, and what’s your average handle time? These are over-simplified examples, but even if you're a doctor, you may be measured on how many operations you perform, or how many patients you can see in a month. Whether or not these are the right metrics, they offer a general picture of how an individual performed within a set timeframe.
|
||||
|
||||
In the case of technology, however, it becomes almost impossible to measure a person’s productivity because there is so much variability. For example, it may be tempting to measure a developer's time by lines of code built. But, depending on the coding language, one line of code in one language versus another might be significantly more or less time consuming or difficult.
|
||||
|
||||
Has it always been this nuanced? Many years ago, you might have heard about or experienced IT measurement in terms of function points. These measurements were about the critical features that developers were able to create. But that, too, is becoming harder to do in today’s environment, where developers are often encapsulating logic that may already exist, such as integration of function points through a vendor. This makes it harder to measure productivity based simply on the number of function points built.
|
||||
|
||||
These two examples shed light on why CIOs sometimes struggle when we talk to our peers about IT productivity. Consider this hypothetical conversation:
|
||||
|
||||
>IT leader: “Wow, I think this developer is great.”
|
||||
>HR: “Really? What do they do?”
|
||||
>IT leader: “They built this excellent application.”
|
||||
>HR: “Well, are they better than the other developer who built ten applications?”
|
||||
>IT leader: “That depends on what you mean by 'better.'”
|
||||
|
||||
Typically, when in the midst of a conversation like the above, there is so much subjectivity involved that it's difficult to answer the question. This is just the tip of the iceberg when it comes to measuring IT performance in a meaningful way. And it doesn't just make conversations harder – it makes it harder for CIOs to showcase the value of their organization to the business.
|
||||
|
||||
This certainly isn't a new problem. I’ve been trying to figure this out for the last 30 years, and I’ve mostly come to the conclusion that we really shouldn’t bother with productivity – we'll never get there.
|
||||
|
||||
I believe we need to change the conversation and stop trying to speak in terms of throughput and cost and productivity but instead, focus on measuring the overall business value of IT. Again, it won't be easy. Business value realization is a hard thing to do. But if CIOs can partner with the business to figure that out, then attributing real value can become more of a science than an art form.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2016/8/why-measuring-it-productivity-so-challenging
|
||||
|
||||
作者:[Anil Cheriyan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/anil-cheriyan
|
||||
|
||||
@ -1,48 +0,0 @@
|
||||
hkurj translating
|
||||
|
||||
7 reasons to love Vim
|
||||
====================
|
||||
|
||||

|
||||
|
||||
When I started using the vi text editor, I hated it. I thought it was the most painful and counter-intuitive editor ever designed. But I'd decided I had to learn the thing, because if you're using Unix, vi was everywhere and was the only editor you were guaranteed to have access to. That was back in 1998, but it remains true today—vi is available, usually as part of the base install, on almost every Linux distribution in existence.
|
||||
|
||||
It took about a month before I could do anything with any proficiency in vi and I still didn't love it, but by then I'd realized that there was an insanely powerful editor hiding behind this bizarre facade. So I stuck with it, and eventually found out that once you know what you're doing, it's an incredibly fast editor.
|
||||
|
||||
The name "vi" is short for "visual." When vi originated, line editing was the norm and being able to display and edit multiple lines at once was unusual. Vim, a contraction of "Vi IMproved" and originally released by Bram Moolenaar in 1991, has become the dominant vi clone and continued to extend the capabilities of an already powerful editor. Vim's powerful regex and ":" command-line syntax started in the world of line editing and teletypes.
|
||||
|
||||
Vim, with its 40 years of history, has had time to develop a massive and complex bag of tricks that even the most knowledgeable users don't fully grasp. Here are a few reasons to love Vim:
|
||||
|
||||
1. Colour schemes: You probably know Vim has colour syntax highlighting. Did you know you can download literally hundreds of colour schemes? [Find some of the better ones here][1].
|
||||
2. You never need to take your hands off the keyboard or reach for the mouse.
|
||||
3. Vi or Vim is everywhere. Even [OpenWRT][2] has vi (okay, it's [BusyBox][3], but it works).
|
||||
4. Vimscript: You've probably remapped a few keys, but did you know that Vim has its own programming language? You can rewrite the behaviour of your editor, or create language-specific editor extensions. (Recently I've spent time customizing Vim's behaviour with Ansible.) The best entry point to the language is Steve Losh's brilliant [Learn Vimscript the Hard Way][4].
|
||||
5. Vim has plugins. Use [Vundle][5] (my choice) or [Pathogen][6] to manage your plugins to improve Vim's capabilities.
|
||||
6. Plugins to integrate git (or your VCS of choice) into Vim are available.
|
||||
7. The online community is huge and active, and if you ask your question about Vim online, it will be answered.
|
||||
|
||||
The irony of my original hatred of vi is that I'd been bouncing from editor to editor for five years, always looking for "something better." I never hated any editor as much as I hated vi, and now I've stuck with it for 17 years because I can no longer imagine a better editor. Well, maybe a little better: Go try Neovim—it's the future. It looks like Bram Moolenaar will be merging most of Neovim into Vim version 8, which will mean a 30% reduction in the code base, better tab completion, real async, built-in terminal, built-in mouse support, and complete compatibility.
|
||||
|
||||
In his [LinuxCon talk][7] in Toronto, Giles will explain some of the features you may have missed in the welter of extensions and improvements added in the past four decades. The class isn't for beginners, so if you don't know why "hjklia:wq" are important, this probably isn't the talk for you. He'll also cover a bit about the history of vi, because knowing some history helps to understand how we've ended up where we are now. Attend his talk to find out how to make your favourite editor better and faster.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/8/7-reasons-love-vim
|
||||
|
||||
作者:[Giles Orr][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gilesorr
|
||||
[1]: http://www.gilesorr.com/blog/vim-colours.html
|
||||
[2]: https://www.openwrt.org/
|
||||
[3]: https://busybox.net/
|
||||
[4]: http://learnvimscriptthehardway.stevelosh.com/
|
||||
[5]: https://github.com/VundleVim/Vundle.vim
|
||||
[6]: https://github.com/tpope/vim-pathogen
|
||||
[7]: http://sched.co/7JWz
|
||||
@ -0,0 +1,52 @@
|
||||
translating by Chao-zhi
|
||||
|
||||
Adobe's new CIO shares leadership advice for starting a new role
|
||||
====
|
||||
|
||||

|
||||
|
||||
I’m currently a few months into a new CIO role at a highly-admired, cloud-based technology company. One of my first tasks was to get to know the organization’s people, culture, and priorities.
|
||||
|
||||
As part of that goal, I am visiting all the major IT sites. While In India, less than two months into the job, I was asked directly: “What are you going to do? What is your plan?” My response, which will not surprise seasoned CIOs, was that I was still in discovery mode, and I was there to listen and learn.
|
||||
|
||||
I’ve never gone into an organization with a set blueprint for what I’ll do. I know some CIOs have a playbook for how they will operate. They’ll come in and blow the whole organization up and put their set plan in motion.
|
||||
|
||||
Yes, there may be situations where things are massively broken and not working, so that course of action makes sense. Once I’m inside a company, however, my strategy is to go through a discovery process. I don’t want to have any preconceived notions about the way things should be or what’s working versus what’s not.
|
||||
|
||||
Here are my guiding principles as a newly-appointed leader:
|
||||
|
||||
### Get to know your people
|
||||
|
||||
This means building relationships, and it includes your IT staff as well as your business users and your top salespeople. What are the top things on their lists? What do they want you to focus on? What’s working well? What’s not? How is the customer experience? Knowing how you can help everyone be more successful will help you shape the way you deliver services to them.
|
||||
|
||||
If your department is spread across several floors, as mine is, consider meet-and-greet lunches or mini-tech fairs so people can introduce themselves, discuss what they’re working on, and share stories about their family, if they feel comfortable doing that. If you have an open-door office policy, make sure they know that as well. If your staff spreads across countries or continents, get out there and visit as soon as you reasonably can.
|
||||
|
||||
### Get to know your products and company culture
|
||||
|
||||
One of the things that surprised me coming into to Adobe was how broad our product portfolio is. We have a platform of solutions and services across three clouds – Adobe Creative Cloud, Document Cloud and Marketing Cloud – and a vast portfolio of products within each. You’ll never know how much opportunity your new company presents until you get to know your products and learn how to support all of them. At Adobe we use many of our digital media and digital marketing solutions as Customer Zero, so we have first-hand experiences to share with our customers
|
||||
|
||||
### Get to know customers
|
||||
|
||||
Very early on, I started getting requests to meet with customers. Meeting with customers is a great way to jump-start your thinking into the future of the IT organization, which includes the different types of technologies, customers, and consumers we could have going forward.
|
||||
|
||||
### Plan for the future
|
||||
|
||||
As a new leader, I have a fresh perspective and can think about the future of the organization without getting distracted by challenges or obstacles.
|
||||
|
||||
What CIOs need to do is jump-start IT into its next generation. When I meet my staff, I’m asking them what we want to be three to five years out so we can start positioning ourselves for that future. That means discussing the initiatives and priorities.
|
||||
|
||||
After that, it makes sense to bring the leadership team together so you can work to co-create the next generation of the organization – its mission, vision, modes of alignment, and operating norms. If you start changing IT from the inside out, it will percolate into business and everything else you do.
|
||||
|
||||
Through this whole process, I’ve been very open with people that this is not going to be a top-down directive. I have ideas on priorities and what we need to focus on, but we have to be in lockstep, working as a team and figuring out what we want to do jointly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2016/9/adobes-new-cio-shares-leadership-advice-starting-new-role
|
||||
|
||||
作者:[Cynthia Stoddard][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://enterprisersproject.com/user/cynthia-stoddard
|
||||
@ -0,0 +1,54 @@
|
||||
Should Smartphones Do Away with the Headphone Jack? Here Are Our Thoughts
|
||||
====
|
||||
|
||||

|
||||
|
||||
Even though Apple removing the headphone jack from the iPhone 7 has been long-rumored, after the official announcement last week confirming the news, it has still become a hot topic.
|
||||
|
||||
For those not in the know on this latest news, Apple has removed the headphone jack from the phone, and the headphones will now plug into the lightning port. Those that want to still use their existing headphones may, as there is an adapter that ships with the phone along with the lightning headphones. They are also selling a new product: AirPods. These are wireless and are inserted into your ear. The biggest advantage is that by eliminating the jack they were able to make the phone dust and water-resistant.
|
||||
|
||||
Being it’s such a big story right now, we asked our writers, “What are your thoughts on Smartphones doing away with the headphone jack?”
|
||||
|
||||
### Our Opinion
|
||||
|
||||
Derrik believes that “Apple’s way of doing it is a play to push more expensive peripherals that do not comply to an open standard.” He also doesn’t want to have to charge something every five hours, meaning the AirPods. While he understands that the 3.5mm jack is aging, as an “audiophile” he would love a new, open standard, but “proprietary pushes” worry him about device freedom.
|
||||
|
||||

|
||||
|
||||
Damien doesn’t really even use the headphone jack these days as he has Bluetooth headphones. He hates that wire anyway, so feels “this is a good move.” Yet he also understands Derrik’s point about the wireless headphones running out of battery, leaving him with “nothing to fall back on.”
|
||||
|
||||
Trevor is very upfront in saying he thought it was “dumb” until he heard you couldn’t charge the phone and use the headphones at the same time and realized it was “dumb X 2.” He uses the headphones/headphone jack all the time in a work van without Bluetooth and listens to audio or podcasts. He uses the plug-in style as Bluetooth drains his battery.
|
||||
|
||||
Simon is not a big fan. He hasn’t seen much reasoning past it leaving more room within the device. He figures “it will then come down to whether or not consumers favor wireless headphones, an adapter, and water-resistance over not being locked into AirPods, lightning, or an adapter”. He fears it might be “too early to jump into removing ports” and likes a “one pair fits all” standard.
|
||||
|
||||
James believes that wireless technology is progressive, so he sees it as a good move “especially for Apple in terms of hardware sales.” He happens to use expensive headphones, so personally he’s “yet to be convinced,” noting his Xperia is waterproof and has a jack.
|
||||
|
||||
Jeffry points out that “almost every transition attempt in the tech world always starts with strong opposition from those who won’t benefit from the changes.” He remembers the flak Apple received when they removed the floppy disk drive and decided not to support Flash, and now both are industry standards. He believes everything is evolving for the better, removing the audio jack is “just the first step toward the future,” and Apple is just the one who is “brave enough to lead the way (and make a few bucks in doing so).”
|
||||
|
||||

|
||||
|
||||
Vamsi doesn’t mind the removal of the headphone jack as long as there is a “better solution applicable to all the users that use different headphones and other gadgets.” He doesn’t feel using headphones via a lightning port is a good solution as it renders nearly all other headphones obsolete. Regarding Bluetooth headphones, he just doesn’t want to deal with another gadget. Additionally, he doesn’t get the argument of it being good for water resistance since there are existing devices with headphone jacks that are water resistant.
|
||||
|
||||
Mahesh prefers a phone with a jack because many times he is charging his phone and listening to music simultaneously. He believes we’ll get to see how it affects the public in the next few months.
|
||||
|
||||
Derrik chimed back in to say that by “removing open standard ports and using a proprietary connection too.,” you can be technical and say there are adapters, but Thunderbolt is also closed, and Apple can stop selling those adapters at any time. He also notes that the AirPods won’t be Bluetooth.
|
||||
|
||||

|
||||
|
||||
As for me, I’m always up for two things: New technology and anything Apple. I’ve been using iPhones since a few weeks past the very first model being introduced, yet I haven’t updated since 2012 and the iPhone 5, so I was overdue. I’ll be among the first to get my hands on the iPhone 7. I hate that stupid white wire being in my face, so I just might be opting for AirPods at some point. I am very appreciative of the phone becoming water-resistant. As for charging vs. listening, the charge on new iPhones lasts so long that I don’t expect it to be much of a problem. Even my old iPhone 5 usually lasts about twenty hours on a good day and twelve hours on a bad day. So I don’t expect that to be a problem.
|
||||
|
||||
### Your Opinion
|
||||
|
||||
Our writers have given you a lot to think about. What are your thoughts on Smartphones doing away with the headphone jack? Will you miss it? Is it a deal breaker for you? Or do you relish the upgrade in technology? Will you be trying the iPhone 5 or the AirPods? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/should-smartphones-do-away-with-the-headphone-jack/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Laura Tucker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/lauratucker/
|
||||
@ -0,0 +1,57 @@
|
||||
What the rise of permissive open source licenses means
|
||||
====
|
||||
|
||||
Why restrictive licenses such as the GNU GPL are steadily falling out of favor.
|
||||
|
||||
"If you use any open source software, you have to make the rest of your software open source." That's what former Microsoft CEO Steve Ballmer said back in 2001, and while his statement was never true, it must have spread some FUD (fear, uncertainty and doubt) about free software. Probably that was the intention.
|
||||
|
||||
This FUD about open source software is mainly about open source licensing. There are many different licenses, some more restrictive (some people use the term "protective") than others. Restrictive licenses such as the GNU General Public License (GPL) use the concept of copyleft, which grants people the right to freely distribute copies and modified versions of a piece of software as long as the same rights are preserved in derivative works. The GPL (v3) is used by open source projects such as bash and GIMP. There's also the Affero GPL, which provides copyleft to software that is offered over a network (for example as a web service.)
|
||||
|
||||
What this means is that if you take code that is licensed in this way and you modify it by adding some of your own proprietary code, then in some circumstances the whole new body of code, including your code, becomes subject to the restrictive open source license. It was this type of license that Ballmer was probably referring to when he made his statement.
|
||||
|
||||
But permissive licenses are a different animal. The MIT License, for example, lets anyone take open source code and do what they want with it — including modifying and selling it — as long as they provide attribution and don't hold the developer liable. Another popular permissive open source license, the Apache License 2.0, also provides an express grant of patent rights from contributors to users. JQuery, the .NET Core and Rails are licensed using the MIT license, while the Apache 2.0 license is used by software including Android, Apache and Swift.
|
||||
|
||||
Ultimately both license types are intended to make software more useful. Restrictive licenses aim to foster the open source ideals of participation and sharing so everyone gets the maximum benefit from software. And permissive licenses aim to ensure that people can get the maximum benefit from software by allowing them to do what they want with it — even if that means they take the code, modify it and keep it for themselves or even sell the resulting work as proprietary software without contributing anything back.
|
||||
|
||||
Figures compiled by open source license management company Black Duck Software show that the restrictive GPL 2.0 was the most commonly used open source license last year with about 25 percent of the market. The permissive MIT and Apache 2.0 licenses were next with about 18 percent and 16 percent respectively, followed by the GPL 3.0 with about 10 percent. That's almost evenly split at 35 percent restrictive and 34 percent permissive.
|
||||
|
||||
But this snapshot misses the trend. Black Duck's data shows that in the six years from 2009 to 2015 the MIT license's share of the market has gone up 15.7 percent and Apache's share has gone up 12.4 percent. GPL v2 and v3's share during the same period has dropped by a staggering 21.4 percent. In other words there was a significant move away from restrictive licenses and towards permissive ones during that period.
|
||||
|
||||
And the trend is continuing. Black Duck's [latest figures][1] show that MIT is now at 26 percent, GPL v2 21 percent, Apache 2 16 percent, and GPL v3 9 percent. That's 30 percent restrictive, 42 percent permissive — a huge swing from last year’s 35 percent restrictive and 34 percent permissive. Separate [research][2] of the licenses used on GitHub appears to confirm this shift. It shows that MIT is overwhelmingly the most popular license with a 45 percent share, compared to GLP v2 with just 13 percent and Apache with 11 percent.
|
||||
|
||||

|
||||
|
||||
### Driving the trend
|
||||
|
||||
What’s behind this mass move from restrictive to permissive licenses? Do companies fear that if they let restrictive software into the house they will lose control of their proprietary software, as Ballmer warned? In fact, that may well be the case. Google, for example, has [banned Affero GPL software][3] from its operations.
|
||||
|
||||
Jim Farmer, chairman of [Instructional Media + Magic][4], a developer of open source technology for education, believes that many companies avoid restrictive licenses to avoid legal difficulties. "The problem is really about complexity. The more complexity in a license, the more chance there is that someone has a cause of action to bring you to court. Complexity makes litigation more likely," he says.
|
||||
|
||||
He adds that fear of restrictive licenses is being driven by lawyers, many of whom recommend that clients use software that is licensed with the MIT or Apache 2.0 licenses, and who specifically warn against the Affero license.
|
||||
|
||||
This has a knock-on effect with software developers, he says, because if companies avoid software with restrictive licenses then developers have more incentive to license their new software with permissive ones if they want it to get used.
|
||||
|
||||
But Greg Soper, CEO of SalesAgility, the company behind the open source SuiteCRM, believes that the move towards permissive licenses is also being driven by some developers. "Look at an application like Rocket.Chat. The developers could have licensed that with GPL 2.0 or Affero but they chose a permissive license," he says. "That gives the app the widest possible opportunity, because a proprietary vendor can take it and not harm their product or expose it to an open source license. So if a developer wants an application to be used inside a third-party application it makes sense to use a permissive license."
|
||||
|
||||
Soper points out that restrictive licenses are designed to help an open source project succeed by stopping developers from taking other people's code, working on it, and then not sharing the results back with the community. "The Affero license is critical to the health of our product because if people could make a fork that was better than ours and not give the code back that would kill our product," he says. "For Rocket.Chat it's different because if it used Affero then it would pollute companies' IP and so it wouldn't get used. Different licenses have different use cases."
|
||||
|
||||
Michael Meeks, an open source developer who has worked on Gnome, OpenOffice and now LibreOffice, agrees with Jim Farmer that many companies do choose to use software with permissive licenses for fear of legal action. "There are risks with copyleft licenses, but there are also huge benefits. Unfortunately people listen to lawyers, and lawyers talk about risk but they never tell you that something is safe."
|
||||
|
||||
Fifteen years after Ballmer made his inaccurate statement it seems that the FUD it generated it is still having an effect — even if the move from restrictive licenses to permissive ones is not quite the effect he intended.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3120235/open-source-tools/what-the-rise-of-permissive-open-source-licenses-means.html
|
||||
|
||||
作者:[Paul Rubens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cio.com/author/Paul-Rubens/
|
||||
[1]: https://www.blackducksoftware.com/top-open-source-licenses
|
||||
[2]: https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[3]: http://www.theregister.co.uk/2011/03/31/google_on_open_source_licenses/
|
||||
[4]: http://immagic.com/
|
||||
|
||||
@ -0,0 +1,837 @@
|
||||
Building a data science portfolio: Machine learning project
|
||||
===========================================================
|
||||
|
||||
>这是这个系列的第三次发布关于如何建立科学的投资数据. 如果你喜欢这个系列并且想继续关注, 你可以在订阅页面的底部找到链接[subscribe at the bottom of the page][1].
|
||||
|
||||
数据科学公司越来越关注投资组合问题. 这其中的一个原因是,投资组合是最好的判断人们生活技能的方法. 好消息是投资组合是完全在你的控制之下的. 只要你做些投资方面的工作,就可以做出很棒的投资组合.
|
||||
|
||||
高质量投资组合的第一步就是知道需要什么技能. 客户想要将这些初级技能应用到数据科学, 因此这些投资技能显示如下:
|
||||
|
||||
- 沟通能力
|
||||
- 协作能力
|
||||
- 技术能力
|
||||
- 数据推理能力
|
||||
- 主动性
|
||||
|
||||
任何好的投资组合都由多个能力组成,其中必然包含以上一到两点. 这里我们主要讲第三点如何做好科学的数据投资组合. 在这一节, 我们主要讲第二项以及如何创建一个端对端的机器学习项目. 在最后, 在最后我们将拥有一个项目它将显示你的能力和技术水平. [Here’s][2]如果你想看一下这里有一个完整的例子.
|
||||
|
||||
### 一个端到端的项目
|
||||
|
||||
作为一个数据科学家, 有时候你会拿到一个数据集并被问到是 [如何产生的][3]. 在这个时候, 交流是非常重要的, 走一遍流程. 用用Jupyter notebook, 看一看以前的例子,这对你非常有帮助. 在这里你能找到一些可以用的报告或者文档.
|
||||
|
||||
不管怎样, 有时候你会被要求创建一个具有操作价值的项目. 一个直接影响公司业务的项目, 不止一次的, 许多人用的项目. 这个任务可能像这样 “创建一个算法来预测波动率”或者 “创建一个模型来自动标签我们的文章”. 在这种情况下, 技术能力比说评书更重要. 你必须能够创建一个数据集, 并且理解它, 然后创建脚本处理该数据. 还有很重要的脚本要运行的很快, 占用系统资源很小. 它可能要运行很多次, 脚本的可使用性也很重要,并不仅仅是一个演示版. 可使用性是指整合操作流程, 因为他很有可能是面向用户的.
|
||||
|
||||
端对端项目的主要组成部分:
|
||||
|
||||
- 理解背景
|
||||
- 浏览数据并找出细微差别
|
||||
- 创建结构化项目, 那样比较容易整合操作流程
|
||||
- 运行速度快占用系统资源小的代码
|
||||
- 写好文档以便其他人用
|
||||
|
||||
为类有效的创建这种类型的项目, 我们可能需要处理多个文件. 强烈推荐使用 [Atom][4]或者[PyCharm][5] . 这些工具允许你在文件间跳转, 编辑不同类型的文件, 例如 markdown 文件, Python 文件, 和csv 文件. 结构化你的项目还利于版本控制 [Github][6] 也很有用.
|
||||
|
||||

|
||||
>Github上的这个项目.
|
||||
|
||||
在这一节中我们将使用 [Pandas][7] 和 [scikit-learn][8]扩展包 . 我们还将用到Pandas [DataFrames][9], 它使得python读取和处理表格数据更加方便.
|
||||
|
||||
### 找到好的数据集
|
||||
|
||||
找到一个好的端到端投资项目数据集很难. [The dataset][10]数据集需要足够大但是内存和性能限制了它. 它还需要实际有用的. 例如, 这个数据集, 它包含有美国院校的录取标准, 毕业率以及毕业以后的收入是个很好的数据集了. 不管怎样, 不管你如何想这个数据, 很显然它不适合创建端到端的项目. 比如, 你能告诉人们他们去了这些大学以后的未来收益, 但是却没有足够的细微差别. 你还能找出院校招生标准收入更高, 但是却没有告诉你如何实际操作.
|
||||
|
||||
这里还有内存和性能约束的问题比如你有几千兆的数据或者有一些细微差别需要你去预测或者运行什么样的算法数据集等.
|
||||
|
||||
一个好的数据集包括你可以动态的转换数组, 并且回答动态的问题. 一个很好的例子是股票价格数据集. 你可以预测明天的价格, 持续的添加数据在算法中. 它将有助于你预测利润. 这不是讲故事这是真实的.
|
||||
|
||||
一些找到数据集的好地方:
|
||||
|
||||
- [/r/datasets][11] – subreddit(Reddit是国外一个社交新闻站点,subreddit指该论坛下的各不同板块).
|
||||
- [Google Public Datasets][12] – 通过Google BigQuery发布的可用数据集.
|
||||
- [Awesome datasets][13] – Github上的数据集.
|
||||
|
||||
当你查看这些数据集, 想一下人们想要在这些数据集中得到什么答案, 哪怕这些问题只想过一次 (“放假是如何S&P 500关联的?”), 或者更进一步(“你能预测股市吗?”). 这里的关键是更进一步找出问题, 并且多次运行不同的数据相同的代码.
|
||||
|
||||
为了这个目标, 我们来看一下[Fannie Mae 贷款数据][14]. Fannie Mae 是一家政府赞助的企业抵押贷款公司它从其他银行购买按揭贷款. 然后捆绑这些贷款为抵押贷款来倒卖证券. 这使得贷款机构可以提供更多的抵押贷款, 在市场上创造更多的流动性. 这在理论上会导致更多的住房和更好的贷款条件. 从借款人的角度来说,他们大体上差不多, 话虽这样说.
|
||||
|
||||
Fannie Mae 发布了两种类型的数据 – 它获得的贷款, 随着时间的推移这些贷款是否被偿还.在理想的情况下, 有人向贷款人借钱, 然后还清贷款. 不管怎样, 有些人没还的起钱, 丧失了抵押品赎回权. Foreclosure 是说没钱还了被银行把房子给回收了. Fannie Mae 追踪谁没还钱, 并且需要收回房屋抵押权. 每个季度会发布此数据, 并滞后一年. 当前可用是2015年第一季度数据.
|
||||
|
||||
采集数据是由Fannie Mae发布的贷款数据, 它包含借款人的信息, 信用评分, 和他们的家庭贷款信息. 性能数据, 贷款回收后的每一个季度公布, 包含借贷人所支付款项信息和丧失抵押品赎回状态, 收回贷款的性能数据可能有十几行.一个很好的思路是这样的采集数据告诉你Fannie Mae所控制的贷款, 性能数据包含几个属性来更新贷款. 其中一个属性告诉我们每个季度的贷款赎回权.
|
||||
|
||||

|
||||
>一个没有及时还贷的房子就这样的被卖了.
|
||||
|
||||
### 选择一个角度
|
||||
|
||||
这里有几个方向我们可以去分析 Fannie Mae 数据集. 我们可以:
|
||||
|
||||
- 预测房屋的销售价格.
|
||||
- 预测借款人还款历史.
|
||||
- 在收购时为每一笔贷款打分.
|
||||
|
||||
最重要的事情是坚持单一的角度. 关注太多的事情很难做出效果. 选择一个有着足够细节的角度也很重要. 下面的理解就没有太多差别:
|
||||
|
||||
- 找出哪些银行将贷款出售给Fannie Mae.
|
||||
- 计算贷款人的信用评分趋势.
|
||||
- 搜索哪些类型的家庭没有偿还贷款的能力.
|
||||
- 搜索贷款金额和抵押品价格之间的关系
|
||||
|
||||
上面的想法非常有趣, 它会告诉我们很多有意思的事情, 但是不是一个很适合操作的项目。
|
||||
|
||||
在Fannie Mae数据集中, 我们将预测贷款是否能被偿还. 实际上, 我们将建立一个抵押贷款的分数来告诉 Fannie Mae买还是不买. 这将给我提供很好的基础.
|
||||
|
||||
------------
|
||||
|
||||
### 理解数据
|
||||
我们来简单看一下原始数据文件。下面是2012年1季度前几行的采集数据。
|
||||
```
|
||||
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
|
||||
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
|
||||
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
|
||||
```
|
||||
|
||||
下面是2012年1季度的前几行执行数据
|
||||
```
|
||||
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
|
||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
|
||||
```
|
||||
在开始编码之前,花些时间真正理解数据是值得的。这对于操作项目优为重要,因为我们没有交互式探索数据,将很难察觉到细微的差别除非我们在前期发现他们。在这种情况下,第一个步骤是阅读房利美站点的资料:
|
||||
- [概述][15]
|
||||
- [有用的术语表][16]
|
||||
- [问答][17]
|
||||
- [采集和执行文件中的列][18]
|
||||
- [采集数据文件样本][19]
|
||||
- [执行数据文件样本][20]
|
||||
|
||||
在看完这些文件后后,我们了解到一些能帮助我们的关键点:
|
||||
- 从2000年到现在,每季度都有一个采集和执行文件,因数据是滞后一年的,所以到目前为止最新数据是2015年的。
|
||||
- 这些文件是文本格式的,采用管道符号“|”进行分割。
|
||||
- 这些文件是没有表头的,但我们有文件列明各列的名称。
|
||||
- 所有一起,文件包含2200万个贷款的数据。
|
||||
由于执行文件包含过去几年获得的贷款的信息,在早些年获得的贷款将有更多的执行数据(即在2014获得的贷款没有多少历史执行数据)。
|
||||
这些小小的信息将会为我们节省很多时间,因为我们知道如何构造我们的项目和利用这些数据。
|
||||
|
||||
### 构造项目
|
||||
在我们开始下载和探索数据之前,先想一想将如何构造项目是很重要的。当建立端到端项目时,我们的主要目标是:
|
||||
- 创建一个可行解决方案
|
||||
- 有一个快速运行且占用最小资源的解决方案
|
||||
- 容易可扩展
|
||||
- 写容易理解的代码
|
||||
- 写尽量少的代码
|
||||
|
||||
为了实现这些目标,需要对我们的项目进行良好的构造。一个结构良好的项目遵循几个原则:
|
||||
- 分离数据文件和代码文件
|
||||
- 从原始数据中分离生成的数据。
|
||||
- 有一个README.md文件帮助人们安装和使用该项目。
|
||||
- 有一个requirements.txt文件列明项目运行所需的所有包。
|
||||
- 有一个单独的settings.py 文件列明其它文件中使用的所有的设置
|
||||
- 例如,如果从多个Python脚本读取相同的文件,把它们全部import设置和从一个集中的地方获得文件名是有用的。
|
||||
- 有一个.gitignore文件,防止大的或秘密文件被提交。
|
||||
- 分解任务中每一步可以单独执行的步骤到单独的文件中。
|
||||
- 例如,我们将有一个文件用于读取数据,一个用于创建特征,一个用于做出预测。
|
||||
- 保存中间结果,例如,一个脚本可输出下一个脚本可读取的文件。
|
||||
|
||||
- 这使我们无需重新计算就可以在数据处理流程中进行更改。
|
||||
|
||||
|
||||
我们的文件结构大体如下:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 创建初始文件
|
||||
首先,我们需要创建一个loan-prediction文件夹,在此文件夹下面,再创建一个data文件夹和一个processed文件夹。data文件夹存放原始数据,processed文件夹存放所有的中间计算结果。
|
||||
其次,创建.gitignore文件,.gitignore文件将保证某些文件被git忽略而不会被推送至github。关于这个文件的一个好的例子是由OSX在每一个文件夹都会创建的.DS_Store文件,.gitignore文件一个很好的起点就是在这了。我们还想忽略数据文件因为他们实在是太大了,同时房利美的条文禁止我们重新分发该数据文件,所以我们应该在我们的文件后面添加以下2行:
|
||||
```
|
||||
data
|
||||
processed
|
||||
```
|
||||
|
||||
这是该项目的一个关于.gitignore文件的例子。
|
||||
再次,我们需要创建README.md文件,它将帮助人们理解该项目。后缀.md表示这个文件采用markdown格式。Markdown使你能够写纯文本文件,同时还可以添加你想要的梦幻格式。这是关于markdown的导引。如果你上传一个叫README.md的文件至Github,Github会自动处理该markdown,同时展示给浏览该项目的人。
|
||||
至此,我们仅需在README.md文件中添加简单的描述:
|
||||
```
|
||||
Loan Prediction
|
||||
-----------------------
|
||||
|
||||
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
|
||||
```
|
||||
|
||||
现在,我们可以创建requirements.txt文件了。这会唯其它人可以很方便地安装我们的项目。我们还不知道我们将会具体用到哪些库,但是以下几个库是一个很好的开始:
|
||||
```
|
||||
pandas
|
||||
matplotlib
|
||||
scikit-learn
|
||||
numpy
|
||||
ipython
|
||||
scipy
|
||||
```
|
||||
|
||||
以上几个是在python数据分析任务中最常用到的库。可以认为我们将会用到大部分这些库。这里是【24】该项目requirements文件的一个例子。
|
||||
创建requirements.txt文件之后,你应该安装包了。我们将会使用python3.如果你没有安装python,你应该考虑使用 [Anaconda][25],一个python安装程序,同时安装了上面列出的所有包。
|
||||
最后,我们可以建立一个空白的settings.py文件,因为我们的项目还没有任何设置。
|
||||
|
||||
|
||||
----------------
|
||||
|
||||
### 获取数据
|
||||
|
||||
一旦我们拥有项目的基本架构,我们就可以去获得原始数据
|
||||
|
||||
Fannie Mae 对获取数据有一些限制,所有你需要去注册一个账户。在创建完账户之后,你可以找到下载页面[在这里][26],你可以按照你所需要的下载非常少量或者很多的借款数据文件。文件格式是zip,在解压后当然是非常大的。
|
||||
|
||||
为了达到我们这个博客文章的目的,我们将要下载从2012年1季度到2015
|
||||
年1季度的所有数据。接着我们需要解压所有的文件。解压过后,删掉原来的.zip格式的文件。最后,借款预测文件夹看起来应该像下面的一样:
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
在下载完数据后,你可以在shell命令行中使用head和tail命令去查看文件中的行数据,你看到任何的不需要的列数据了吗?在做这件事的同时查阅[列名称的pdf文件][27]可能是有用的事情。
|
||||
### 读入数据
|
||||
|
||||
有两个问题让我们的数据难以现在就使用:
|
||||
- 收购数据和业绩数据被分割在多个文件中
|
||||
- 每个文件都缺少标题
|
||||
|
||||
在我们开始使用数据之前,我们需要首先明白我们要在哪里去存一个收购数据的文件,同时到哪里去存储一个业绩数据的文件。每个文件仅仅需要包括我们关注的那些数据列,同时拥有正确的标题。这里有一个小问题是业绩数据非常大,因此我们需要尝试去修剪一些数据列。
|
||||
|
||||
第一步是向settings.py文件中增加一些变量,这个文件中同时也包括了我们原始数据的存放路径和处理出的数据存放路径。我们同时也将添加其他一些可能在接下来会用到的设置数据:
|
||||
```
|
||||
DATA_DIR = "data"
|
||||
PROCESSED_DIR = "processed"
|
||||
MINIMUM_TRACKING_QUARTERS = 4
|
||||
TARGET = "foreclosure_status"
|
||||
NON_PREDICTORS = [TARGET, "id"]
|
||||
CV_FOLDS = 3
|
||||
```
|
||||
|
||||
把路径设置在settings.py中将使它们放在一个集中的地方,同时使其修改更加的容易。当提到在多个文件中的相同的变量时,你想改变它的话,把他们放在一个地方比分散放在每一个文件时更加容易。[这里的][28]是一个这个工程的示例settings.py文件
|
||||
|
||||
第二步是创建一个文件名为assemble.py,它将所有的数据分为2个文件。当我们运行Python assemble.py,我们在处理数据文件的目录会获得2个数据文件。
|
||||
|
||||
接下来我们开始写assemble.py文件中的代码。首先我们需要为每个文件定义相应的标题,因此我们需要查看[列名称的pdf文件][29]同时创建在每一个收购数据和业绩数据的文件的列数据的列表:
|
||||
```
|
||||
HEADERS = {
|
||||
"Acquisition": [
|
||||
"id",
|
||||
"channel",
|
||||
"seller",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_term",
|
||||
"origination_date",
|
||||
"first_payment_date",
|
||||
"ltv",
|
||||
"cltv",
|
||||
"borrower_count",
|
||||
"dti",
|
||||
"borrower_credit_score",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"unit_count",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"zip",
|
||||
"insurance_percentage",
|
||||
"product_type",
|
||||
"co_borrower_credit_score"
|
||||
],
|
||||
"Performance": [
|
||||
"id",
|
||||
"reporting_period",
|
||||
"servicer_name",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_age",
|
||||
"months_to_maturity",
|
||||
"maturity_date",
|
||||
"msa",
|
||||
"delinquency_status",
|
||||
"modification_flag",
|
||||
"zero_balance_code",
|
||||
"zero_balance_date",
|
||||
"last_paid_installment_date",
|
||||
"foreclosure_date",
|
||||
"disposition_date",
|
||||
"foreclosure_costs",
|
||||
"property_repair_costs",
|
||||
"recovery_costs",
|
||||
"misc_costs",
|
||||
"tax_costs",
|
||||
"sale_proceeds",
|
||||
"credit_enhancement_proceeds",
|
||||
"repurchase_proceeds",
|
||||
"other_foreclosure_proceeds",
|
||||
"non_interest_bearing_balance",
|
||||
"principal_forgiveness_balance"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
接下来一步是定义我们想要保持的数据列。我们将需要保留收购数据中的所有列数据,丢弃列数据将会使我们节省下内存和硬盘空间,同时也会加速我们的代码。
|
||||
```
|
||||
SELECT = {
|
||||
"Acquisition": HEADERS["Acquisition"],
|
||||
"Performance": [
|
||||
"id",
|
||||
"foreclosure_date"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
下一步,我们将编写一个函数来连接数据集。下面的代码将:
|
||||
- 引用一些需要的库,包括设置。
|
||||
- 定义一个函数concatenate, 目的是:
|
||||
- 获取到所有数据目录中的文件名.
|
||||
- 在每个文件中循环.
|
||||
- 如果文件不是正确的格式 (不是以我们需要的格式作为开头), 我们将忽略它.
|
||||
- 把文件读入一个[数据帧][30] 伴随着正确的设置通过使用Pandas [读取csv][31]函数.
|
||||
- 在|处设置分隔符以便所有的字段能被正确读出.
|
||||
- 数据没有标题行,因此设置标题为None来进行标示.
|
||||
- 从HEADERS字典中设置正确的标题名称 – 这将会是我们数据帧中的数据列名称.
|
||||
- 通过SELECT来选择我们加入数据的数据帧中的列.
|
||||
- 把所有的数据帧共同连接在一起.
|
||||
- 把已经连接好的数据帧写回一个文件.
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def concatenate(prefix="Acquisition"):
|
||||
files = os.listdir(settings.DATA_DIR)
|
||||
full = []
|
||||
for f in files:
|
||||
if not f.startswith(prefix):
|
||||
continue
|
||||
|
||||
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
|
||||
data = data[SELECT[prefix]]
|
||||
full.append(data)
|
||||
|
||||
full = pd.concat(full, axis=0)
|
||||
|
||||
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
|
||||
```
|
||||
|
||||
我们可以通过调用上面的函数,通过传递的参数收购和业绩两次以将所有收购和业绩文件连接在一起。下面的代码将:
|
||||
- 仅仅在脚本被在命令行中通过python assemble.py被唤起而执行.
|
||||
- 将所有的数据连接在一起,并且产生2个文件:
|
||||
- `processed/Acquisition.txt`
|
||||
- `processed/Performance.txt`
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
concatenate("Acquisition")
|
||||
concatenate("Performance")
|
||||
```
|
||||
|
||||
我们现在拥有了一个漂亮的,划分过的assemble.py文件,它很容易执行,也容易被建立。通过像这样把问题分解为一块一块的,我们构建工程就会变的容易许多。不用一个可以做所有的凌乱的脚本,我们定义的数据将会在多个脚本间传递,同时使脚本间完全的0耦合。当你正在一个大的项目中工作,这样做是一个好的想法,因为这样可以更佳容易的修改其中的某一部分而不会引起其他项目中不关联部分产生超出预期的结果。
|
||||
|
||||
一旦我们完成assemble.py脚本文件, 我们可以运行python assemble.py命令. 你可以查看完整的assemble.py文件[在这里][32].
|
||||
|
||||
这将会在处理结果目录下产生2个文件:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
├── .gitignore
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
|
||||
--------------
|
||||
|
||||
|
||||
### 计算运用数据中的值
|
||||
|
||||
接下来我们会计算过程数据或运用数据中的值。我们要做的就是推测这些数据代表的贷款是否被收回。如果能够计算出来,我们只要看一下包含贷款的运用数据的参数 foreclosure_date 就可以了。如果这个参数的值是 None ,那么这些贷款肯定没有收回。为了避免我们的样例中存在少量的运用数据,我们会计算出运用数据中有贷款数据的行的行数。这样我们就能够从我们的训练数据中筛选出贷款数据,排除了一些运用数据。
|
||||
|
||||
下面是一种区分贷款数据和运用数据的方法:
|
||||
|
||||

|
||||
|
||||
|
||||
在上面的表格中,采集数据中的每一行数据都与运用数据中的多行数据有联系。在运用数据中,在收回贷款的时候 foreclosure_date 就会以季度的的形式显示出收回时间,而且它会在该行数据的最前面显示一个空格。一些贷款没有收回,所以与运用数据中的贷款数据有关的行都会在前面出现一个表示 foreclosure_date 的空格。
|
||||
|
||||
我们需要计算 foreclosure_status 的值,它的值是布尔类型,可以表示一个特殊的贷款数据 id 是否被收回过,还有一个参数 performance_count ,它记录了运用数据中每个贷款 id 出现的行数。
|
||||
|
||||
计算这些行数有多种不同的方法:
|
||||
|
||||
- 我们能够读取所有的运用数据,然后我们用 Pandas 的 groupby 方法在数据框中计算出与每个贷款 id 有关的行的行数,然后就可以查看贷款 id 的 foreclosure_date 值是否为 None 。
|
||||
- 这种方法的优点是从语法上来说容易执行。
|
||||
- 它的缺点需要读取所有的 129236094 行数据,这样就会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以读取所有的运用数据,然后使用采集到的数据框去计算每个贷款 id 出现的次数。
|
||||
- 这种方法的优点是容易理解。
|
||||
- 缺点是需要读取所有的 129236094 行数据。这样会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以在迭代访问运用数据中的每一行数据,而且会建立一个区分开的计数字典。
|
||||
- 这种方法的优点是数据不需要被加载到内存中,所以运行起来会很快且不需要占用内存。
|
||||
- 缺点是这样的话理解和执行上可能有点耗费时间,我们需要对每一行数据进行语法分析。
|
||||
|
||||
加载所有的数据会非常耗费内存,所以我们采用第三种方法。我们要做的就是迭代运用数据中的每一行数据,然后为每一个贷款 id 生成一个字典值。在这个字典中,我们会计算出贷款 id 在运用数据中出现的次数,而且如果 foreclosure_date 不是 Nnoe 。我们可以查看 foreclosure_status 和 performance_count 的值 。
|
||||
|
||||
我们会新建一个 annotate.py 文件,文件中的代码可以计算这些值。我们会使用下面的代码:
|
||||
|
||||
- 导入需要的库
|
||||
- 定义一个函数 count_performance_rows 。
|
||||
- 打开 processed/Performance.txt 文件。这不是在内存中读取文件而是打开了一个文件标识符,这个标识符可以用来以行为单位读取文件。
|
||||
- 迭代文件的每一行数据。
|
||||
- 使用分隔符(|)分开每行的不同数据。
|
||||
- 检查 loan_id 是否在计数字典中。
|
||||
- 如果不存在,进行一次计数。
|
||||
- loan_id 的 performance_count 参数自增 1 次,因为我们这次迭代也包含其中。
|
||||
- 如果日期是 None ,我们就会知道贷款被收回了,然后为foreclosure_status 设置合适的值。
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def count_performance_rows():
|
||||
counts = {}
|
||||
with open(os.path.join(settings.PROCESSED_DIR, "Performance.txt"), 'r') as f:
|
||||
for i, line in enumerate(f):
|
||||
if i == 0:
|
||||
# Skip header row
|
||||
continue
|
||||
loan_id, date = line.split("|")
|
||||
loan_id = int(loan_id)
|
||||
if loan_id not in counts:
|
||||
counts[loan_id] = {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
}
|
||||
counts[loan_id]["performance_count"] += 1
|
||||
if len(date.strip()) > 0:
|
||||
counts[loan_id]["foreclosure_status"] = True
|
||||
return counts
|
||||
```
|
||||
|
||||
### 获取值
|
||||
|
||||
只要我们创建了计数字典,我们就可以使用一个函数通过一个 loan_id 和一个 key 从字典中提取到需要的参数的值:
|
||||
|
||||
```
|
||||
def get_performance_summary_value(loan_id, key, counts):
|
||||
value = counts.get(loan_id, {
|
||||
"foreclosure_status": False,
|
||||
"performance_count": 0
|
||||
})
|
||||
return value[key]
|
||||
```
|
||||
|
||||
|
||||
上面的函数会从计数字典中返回合适的值,我们也能够为采集数据中的每一行赋一个 foreclosure_status 值和一个 performance_count 值。如果键不存在,字典的 [get][33] 方法会返回一个默认值,所以在字典中不存在键的时候我们就可以得到一个可知的默认值。
|
||||
|
||||
|
||||
|
||||
------------------
|
||||
|
||||
|
||||
### 注解数据
|
||||
|
||||
我们已经在annotate.py中添加了一些功能, 现在我们来看一看数据文件. 我们需要将采集到的数据转换到训练数据表来进行机器学习的训练. 这涉及到以下几件事情:
|
||||
|
||||
- 转换所以列数字.
|
||||
- 填充缺失值.
|
||||
- 分配 performance_count 和 foreclosure_status.
|
||||
- 移除出现次数很少的行(performance_count 计数低).
|
||||
|
||||
我们有几个列是文本类型的, 看起来对于机器学习算法来说并不是很有用. 然而, 他们实际上是分类变量, 其中有很多不同的类别代码, 例如R,S等等. 我们可以把这些类别标签转换为数值:
|
||||
|
||||

|
||||
|
||||
通过这种方法转换的列我们可以应用到机器学习算法中.
|
||||
|
||||
还有一些包含日期的列 (first_payment_date 和 origination_date). 我们可以将这些日期放到两个列中:
|
||||
|
||||

|
||||
在下面的代码中, 我们将转换采集到的数据. 我们将定义一个函数如下:
|
||||
|
||||
- 在采集到的数据中创建foreclosure_status列 .
|
||||
- 在采集到的数据中创建performance_count列.
|
||||
- 将下面的string列转换为integer列:
|
||||
- channel
|
||||
- seller
|
||||
- first_time_homebuyer
|
||||
- loan_purpose
|
||||
- property_type
|
||||
- occupancy_status
|
||||
- property_state
|
||||
- product_type
|
||||
- 转换first_payment_date 和 origination_date 为两列:
|
||||
- 通过斜杠分离列.
|
||||
- 将第一部分分离成月清单.
|
||||
- 将第二部分分离成年清单.
|
||||
- 删除这一列.
|
||||
- 最后, 我们得到 first_payment_month, first_payment_year, origination_month, and origination_year.
|
||||
- 所有缺失值填充为-1.
|
||||
|
||||
```
|
||||
def annotate(acquisition, counts):
|
||||
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
|
||||
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
|
||||
for column in [
|
||||
"channel",
|
||||
"seller",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"product_type"
|
||||
]:
|
||||
acquisition[column] = acquisition[column].astype('category').cat.codes
|
||||
|
||||
for start in ["first_payment", "origination"]:
|
||||
column = "{}_date".format(start)
|
||||
acquisition["{}_year".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(1))
|
||||
acquisition["{}_month".format(start)] = pd.to_numeric(acquisition[column].str.split('/').str.get(0))
|
||||
del acquisition[column]
|
||||
|
||||
acquisition = acquisition.fillna(-1)
|
||||
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
|
||||
return acquisition
|
||||
```
|
||||
|
||||
### 聚合到一起
|
||||
|
||||
我们差不多准备就绪了, 我们只需要再在annotate.py添加一点点代码. 在下面代码中, 我们将:
|
||||
|
||||
- 定义一个函数来读取采集的数据.
|
||||
- 定义一个函数来写入数据到/train.csv
|
||||
- 如果我们在命令行运行annotate.py来读取更新过的数据文件,它将做如下事情:
|
||||
- 读取采集到的数据.
|
||||
- 计算数据性能.
|
||||
- 注解数据.
|
||||
- 将注解数据写入到train.csv.
|
||||
|
||||
```
|
||||
def read():
|
||||
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
|
||||
return acquisition
|
||||
|
||||
def write(acquisition):
|
||||
acquisition.to_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"), index=False)
|
||||
|
||||
if __name__ == "__main__":
|
||||
acquisition = read()
|
||||
counts = count_performance_rows()
|
||||
acquisition = annotate(acquisition, counts)
|
||||
write(acquisition)
|
||||
```
|
||||
|
||||
修改完成以后为了确保annotate.py能够生成train.csv文件. 你可以在这里找到完整的 annotate.py file [here][34].
|
||||
|
||||
文件夹结果应该像这样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 找到标准
|
||||
|
||||
我们已经完成了训练数据表的生成, 现在我们需要最后一步, 生成预测. 我们需要找到错误的标准, 以及该如何评估我们的数据. 在这种情况下, 因为有很多的贷款没有收回, 所以根本不可能做到精确的计算.
|
||||
|
||||
我们需要读取数据, 并且计算foreclosure_status列, 我们将得到如下信息:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
import settings
|
||||
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
train["foreclosure_status"].value_counts()
|
||||
```
|
||||
|
||||
```
|
||||
False 4635982
|
||||
True 1585
|
||||
Name: foreclosure_status, dtype: int64
|
||||
```
|
||||
|
||||
因为只有一点点贷款收回, 通过百分比标签来建立的机器学习模型会把每行都设置为Fasle, 所以我们在这里要考虑每个样本的不平衡性,确保我们做出的预测是准确的. 我们不想要这么多假的false, 我们将预计贷款收回但是它并没有收回, 我们预计贷款不会回收但是却回收了. 通过以上两点, Fannie Mae的false太多了, 因此显示他们可能无法收回投资.
|
||||
|
||||
所以我们将定义一个百分比,就是模型预测没有收回但是实际上收回了, 这个数除以总的负债回收总数. 这个负债回收百分比模型实际上是“没有的”. 下面看这个图表:
|
||||
|
||||

|
||||
|
||||
通过上面的图表, 1个负债预计不会回收, 也确实没有回收. 如果我们将这个数除以总数, 2, 我们将得到false的概率为50%. 我们将使用这个标准, 因此我们可以评估一下模型的性能.
|
||||
|
||||
### 设置机器学习分类器
|
||||
|
||||
我们使用交叉验证预测. 通过交叉验证法, 我们将数据分为3组. 按照下面的方法来做:
|
||||
|
||||
- Train a model on groups 1 and 2, and use the model to make predictions for group 3.
|
||||
- Train a model on groups 1 and 3, and use the model to make predictions for group 2.
|
||||
- Train a model on groups 2 and 3, and use the model to make predictions for group 1.
|
||||
|
||||
将它们分割到不同的组 ,这意味着我们永远不会用相同的数据来为预测训练模型. 这样就避免了overfitting(过拟合). 如果我们overfit(过拟合), 我们将得到很低的false概率, 这使得我们难以改进算法或者应用到现实生活中.
|
||||
|
||||
[Scikit-learn][35] 有一个叫做 [cross_val_predict][36] 他可以帮助我们理解交叉算法.
|
||||
|
||||
我们还需要一种算法来帮我们预测. 我们还需要一个分类器 [binary classification][37](二元分类). 目标变量foreclosure_status 只有两个值, True 和 False.
|
||||
|
||||
我们用[logistic regression][38](回归算法), 因为它能很好的进行binary classification(二元分类), 并且运行很快, 占用内存很小. 我们来说一下它是如何工作的 – 取代许多树状结构, 更像随机森林, 进行转换, 更像一个向量机, 逻辑回归涉及更少的步骤和更少的矩阵.
|
||||
|
||||
我们可以使用[logistic regression classifier][39](逻辑回归分类器)算法 来实现scikit-learn. 我们唯一需要注意的是每个类的标准. 如果我们使用同样标准的类, 算法将会预测每行都为false, 因为它总是试图最小化误差.不管怎样, 我们关注有多少贷款能够回收而不是有多少不能回收. 因此, 我们通过 [LogisticRegression][40](逻辑回归)来平衡标准参数, 并计算回收贷款的标准. 这将使我们的算法不会认为每一行都为false.
|
||||
|
||||
|
||||
----------------------
|
||||
|
||||
### 做出预测
|
||||
|
||||
既然完成了前期准备,我们可以开始准备做出预测了。我将创建一个名为 predict.py 的新文件,它会使用我们在最后一步创建的 train.csv 文件。下面的代码:
|
||||
|
||||
- 导入所需的库
|
||||
- 创建一个名为 `cross_validate` 的函数:
|
||||
- 使用正确的关键词参数创建逻辑回归分类器(logistic regression classifier)
|
||||
- 创建移除了 `id` 和 `foreclosure_status` 属性的用于训练模型的列
|
||||
- 跨 `train` 数据帧使用交叉验证
|
||||
- 返回预测结果
|
||||
|
||||
```python
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
from sklearn import cross_validation
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
from sklearn import metrics
|
||||
|
||||
def cross_validate(train):
|
||||
clf = LogisticRegression(random_state=1, class_weight="balanced")
|
||||
|
||||
predictors = train.columns.tolist()
|
||||
predictors = [p for p in predictors if p not in settings.NON_PREDICTORS]
|
||||
|
||||
predictions = cross_validation.cross_val_predict(clf, train[predictors], train[settings.TARGET], cv=settings.CV_FOLDS)
|
||||
return predictions
|
||||
```
|
||||
|
||||
### 预测误差
|
||||
|
||||
现在,我们仅仅需要写一些函数来计算误差。下面的代码:
|
||||
|
||||
- 创建函数 `compute_error`:
|
||||
- 使用 scikit-learn 计算一个简单的精确分数(与实际 `foreclosure_status` 值匹配的预测百分比)
|
||||
- 创建函数 `compute_false_negatives`:
|
||||
- 为了方便,将目标和预测结果合并到一个数据帧
|
||||
- 查找漏报率
|
||||
- 找到原本应被预测模型取消但没有取消的贷款数目
|
||||
- 除以没被取消的贷款总数目
|
||||
|
||||
```python
|
||||
def compute_error(target, predictions):
|
||||
return metrics.accuracy_score(target, predictions)
|
||||
|
||||
def compute_false_negatives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 1) & (df["predictions"] == 0)].shape[0] / (df[(df["target"] == 1)].shape[0] + 1)
|
||||
|
||||
def compute_false_positives(target, predictions):
|
||||
df = pd.DataFrame({"target": target, "predictions": predictions})
|
||||
return df[(df["target"] == 0) & (df["predictions"] == 1)].shape[0] / (df[(df["target"] == 0)].shape[0] + 1)
|
||||
```
|
||||
|
||||
### 聚合到一起
|
||||
|
||||
现在,我们可以把函数都放在 `predict.py`。下面的代码:
|
||||
|
||||
- 读取数据集
|
||||
- 计算交叉验证预测
|
||||
- 计算上面的 3 个误差
|
||||
- 打印误差
|
||||
|
||||
```python
|
||||
def read():
|
||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||
return train
|
||||
|
||||
if __name__ == "__main__":
|
||||
train = read()
|
||||
predictions = cross_validate(train)
|
||||
error = compute_error(train[settings.TARGET], predictions)
|
||||
fn = compute_false_negatives(train[settings.TARGET], predictions)
|
||||
fp = compute_false_positives(train[settings.TARGET], predictions)
|
||||
print("Accuracy Score: {}".format(error))
|
||||
print("False Negatives: {}".format(fn))
|
||||
print("False Positives: {}".format(fp))
|
||||
```
|
||||
|
||||
一旦你添加完代码,你可以运行 `python predict.py` 来产生预测结果。运行结果向我们展示漏报率为 `.26`,这意味着我们没能预测 `26%` 的取消贷款。这是一个好的开始,但仍有很多改善的地方!
|
||||
|
||||
你可以在[这里][41]找到完整的 `predict.py` 文件
|
||||
|
||||
你的文件树现在看起来像下面这样:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
│ ├── train.csv
|
||||
├── .gitignore
|
||||
├── annotate.py
|
||||
├── assemble.py
|
||||
├── predict.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
### 撰写 README
|
||||
|
||||
既然我们完成了端到端的项目,那么我们可以撰写 README.md 文件了,这样其他人便可以知道我们做的事,以及如何复制它。一个项目典型的 README.md 应该包括这些部分:
|
||||
|
||||
- 一个高水准的项目概览,并介绍项目目的
|
||||
- 任何必需的数据和材料的下载地址
|
||||
- 安装命令
|
||||
- 如何安装要求依赖
|
||||
- 使用命令
|
||||
- 如何运行项目
|
||||
- 每一步之后会看到的结果
|
||||
- 如何为这个项目作贡献
|
||||
- 扩展项目的下一步计划
|
||||
|
||||
[这里][42] 是这个项目的一个 README.md 样例。
|
||||
|
||||
### 下一步
|
||||
|
||||
恭喜你完成了端到端的机器学习项目!你可以在[这里][43]找到一个完整的示例项目。一旦你完成了项目,把它上传到 [Github][44] 是一个不错的主意,这样其他人也可以看到你的文件夹的部分项目。
|
||||
|
||||
这里仍有一些留待探索数据的角度。总的来说,我们可以把它们分割为 3 类 - 扩展这个项目并使它更加精确,发现预测其他列并探索数据。这是其中一些想法:
|
||||
|
||||
- 在 `annotate.py` 中生成更多的特性
|
||||
- 切换 `predict.py` 中的算法
|
||||
- 尝试使用比我们发表在这里的更多的来自 `Fannie Mae` 的数据
|
||||
- 添加对未来数据进行预测的方法。如果我们添加更多数据,我们所写的代码仍然可以起作用,这样我们可以添加更多过去和未来的数据。
|
||||
- 尝试看看是否你能预测一个银行是否应该发放贷款(相对地,`Fannie Mae` 是否应该获得贷款)
|
||||
- 移除 train 中银行不知道发放贷款的时间的任何列
|
||||
- 当 Fannie Mae 购买贷款时,一些列是已知的,但不是之前
|
||||
- 做出预测
|
||||
- 探索是否你可以预测除了 foreclosure_status 的其他列
|
||||
- 你可以预测在销售时财产值多少?
|
||||
- 探索探索性能更新之间的细微差别
|
||||
- 你能否预测借款人会逾期还款多少次?
|
||||
- 你能否标出的典型贷款周期?
|
||||
- 标出一个州到州或邮政编码到邮政级水平的数据
|
||||
- 你看到一些有趣的模式了吗?
|
||||
|
||||
如果你建立了任何有趣的东西,请在评论中让我们知道!
|
||||
|
||||
如果你喜欢这个,你可能会喜欢阅读 ‘Build a Data Science Porfolio’ 系列的其他文章:
|
||||
|
||||
- [Storytelling with data][45].
|
||||
- [How to setup up a data science blog][46].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/
|
||||
|
||||
作者:[Vik Paruchuri][a]
|
||||
译者:[kokialoves](https://github.com/译者ID),[zky001](https://github.com/译者ID),[vim-kakali](https://github.com/译者ID),[cposture](https://github.com/译者ID),[ideas4u](https://github.com/译者ID)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.dataquest.io/blog
|
||||
[1]: https://www.dataquest.io/blog/data-science-portfolio-machine-learning/#email-signup
|
||||
[2]: https://github.com/dataquestio/loan-prediction
|
||||
[3]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[4]: https://atom.io/
|
||||
[5]: https://www.jetbrains.com/pycharm/
|
||||
[6]: https://github.com/
|
||||
[7]: http://pandas.pydata.org/
|
||||
[8]: http://scikit-learn.org/
|
||||
[9]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[10]: https://collegescorecard.ed.gov/data/
|
||||
[11]: https://reddit.com/r/datasets
|
||||
[12]: https://cloud.google.com/bigquery/public-data/#usa-names
|
||||
[13]: https://github.com/caesar0301/awesome-public-datasets
|
||||
[14]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[15]: http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html
|
||||
[16]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_glossary.pdf
|
||||
[17]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_faq.pdf
|
||||
[18]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[19]: https://loanperformancedata.fanniemae.com/lppub-docs/acquisition-sample-file.txt
|
||||
[20]: https://loanperformancedata.fanniemae.com/lppub-docs/performance-sample-file.txt
|
||||
[21]: https://github.com/dataquestio/loan-prediction/blob/master/.gitignore
|
||||
[22]: https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
|
||||
[23]: https://github.com/dataquestio/loan-prediction
|
||||
[24]: https://github.com/dataquestio/loan-prediction/blob/master/requirements.txt
|
||||
[25]: https://www.continuum.io/downloads
|
||||
[26]: https://loanperformancedata.fanniemae.com/lppub/index.html
|
||||
[27]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[28]: https://github.com/dataquestio/loan-prediction/blob/master/settings.py
|
||||
[29]: https://loanperformancedata.fanniemae.com/lppub-docs/lppub_file_layout.pdf
|
||||
[30]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html
|
||||
[31]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
|
||||
[32]: https://github.com/dataquestio/loan-prediction/blob/master/assemble.py
|
||||
[33]: https://docs.python.org/3/library/stdtypes.html#dict.get
|
||||
[34]: https://github.com/dataquestio/loan-prediction/blob/master/annotate.py
|
||||
[35]: http://scikit-learn.org/
|
||||
[36]: http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.cross_val_predict.html
|
||||
[37]: https://en.wikipedia.org/wiki/Binary_classification
|
||||
[38]: https://en.wikipedia.org/wiki/Logistic_regression
|
||||
[39]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[40]: http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
|
||||
[41]: https://github.com/dataquestio/loan-prediction/blob/master/predict.py
|
||||
[42]: https://github.com/dataquestio/loan-prediction/blob/master/README.md
|
||||
[43]: https://github.com/dataquestio/loan-prediction
|
||||
[44]: https://www.github.com/
|
||||
[45]: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
[46]: https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/
|
||||
@ -1,194 +0,0 @@
|
||||
### Acquiring the data
|
||||
|
||||
Once we have the skeleton of our project, we can get the raw data.
|
||||
|
||||
Fannie Mae has some restrictions around acquiring the data, so you’ll need to sign up for an account. You can find the download page [here][26]. After creating an account, you’ll be able to download as few or as many loan data files as you want. The files are in zip format, and are reasonably large after decompression.
|
||||
|
||||
For the purposes of this blog post, we’ll download everything from Q1 2012 to Q1 2015, inclusive. We’ll then need to unzip all of the files. After unzipping the files, remove the original .zip files. At the end, the loan-prediction folder should look something like this:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
├── .gitignore
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
|
||||
After downloading the data, you can use the head and tail shell commands to look at the lines in the files. Do you see any columns that aren’t needed? It might be useful to consult the [pdf of column names][27] while doing this.
|
||||
|
||||
### Reading in the data
|
||||
|
||||
There are two issues that make our data hard to work with right now:
|
||||
|
||||
- The acquisition and performance datasets are segmented across multiple files.
|
||||
- Each file is missing headers.
|
||||
|
||||
Before we can get started on working with the data, we’ll need to get to the point where we have one file for the acquisition data, and one file for the performance data. Each of the files will need to contain only the columns we care about, and have the proper headers. One wrinkle here is that the performance data is quite large, so we should try to trim some of the columns if we can.
|
||||
|
||||
The first step is to add some variables to settings.py, which will contain the paths to our raw data and our processed data. We’ll also add a few other settings that will be useful later on:
|
||||
|
||||
```
|
||||
DATA_DIR = "data"
|
||||
PROCESSED_DIR = "processed"
|
||||
MINIMUM_TRACKING_QUARTERS = 4
|
||||
TARGET = "foreclosure_status"
|
||||
NON_PREDICTORS = [TARGET, "id"]
|
||||
CV_FOLDS = 3
|
||||
```
|
||||
|
||||
Putting the paths in settings.py will put them in a centralized place and make them easy to change down the line. When referring to the same variables in multiple files, it’s easier to put them in a central place than edit them in every file when you want to change them. [Here’s][28] an example settings.py file for this project.
|
||||
|
||||
The second step is to create a file called assemble.py that will assemble all the pieces into 2 files. When we run python assemble.py, we’ll get 2 data files in the processed directory.
|
||||
|
||||
We’ll then start writing code in assemble.py. We’ll first need to define the headers for each file, so we’ll need to look at [pdf of column names][29] and create lists of the columns in each Acquisition and Performance file:
|
||||
|
||||
```
|
||||
HEADERS = {
|
||||
"Acquisition": [
|
||||
"id",
|
||||
"channel",
|
||||
"seller",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_term",
|
||||
"origination_date",
|
||||
"first_payment_date",
|
||||
"ltv",
|
||||
"cltv",
|
||||
"borrower_count",
|
||||
"dti",
|
||||
"borrower_credit_score",
|
||||
"first_time_homebuyer",
|
||||
"loan_purpose",
|
||||
"property_type",
|
||||
"unit_count",
|
||||
"occupancy_status",
|
||||
"property_state",
|
||||
"zip",
|
||||
"insurance_percentage",
|
||||
"product_type",
|
||||
"co_borrower_credit_score"
|
||||
],
|
||||
"Performance": [
|
||||
"id",
|
||||
"reporting_period",
|
||||
"servicer_name",
|
||||
"interest_rate",
|
||||
"balance",
|
||||
"loan_age",
|
||||
"months_to_maturity",
|
||||
"maturity_date",
|
||||
"msa",
|
||||
"delinquency_status",
|
||||
"modification_flag",
|
||||
"zero_balance_code",
|
||||
"zero_balance_date",
|
||||
"last_paid_installment_date",
|
||||
"foreclosure_date",
|
||||
"disposition_date",
|
||||
"foreclosure_costs",
|
||||
"property_repair_costs",
|
||||
"recovery_costs",
|
||||
"misc_costs",
|
||||
"tax_costs",
|
||||
"sale_proceeds",
|
||||
"credit_enhancement_proceeds",
|
||||
"repurchase_proceeds",
|
||||
"other_foreclosure_proceeds",
|
||||
"non_interest_bearing_balance",
|
||||
"principal_forgiveness_balance"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The next step is to define the columns we want to keep. Since all we’re measuring on an ongoing basis about the loan is whether or not it was ever foreclosed on, we can discard many of the columns in the performance data. We’ll need to keep all the columns in the acquisition data, though, because we want to maximize the information we have about when the loan was acquired (after all, we’re predicting if the loan will ever be foreclosed or not at the point it’s acquired). Discarding columns will enable us to save disk space and memory, while also speeding up our code.
|
||||
|
||||
```
|
||||
SELECT = {
|
||||
"Acquisition": HEADERS["Acquisition"],
|
||||
"Performance": [
|
||||
"id",
|
||||
"foreclosure_date"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Next, we’ll write a function to concatenate the data sets. The below code will:
|
||||
|
||||
- Import a few needed libraries, including settings.
|
||||
- Define a function concatenate, that:
|
||||
- Gets the names of all the files in the data directory.
|
||||
- Loops through each file.
|
||||
- If the file isn’t the right type (doesn’t start with the prefix we want), we ignore it.
|
||||
- Reads the file into a [DataFrame][30] with the right settings using the Pandas [read_csv][31] function.
|
||||
- Sets the separator to | so the fields are read in correctly.
|
||||
- The data has no header row, so sets header to None to indicate this.
|
||||
- Sets names to the right value from the HEADERS dictionary – these will be the column names of our DataFrame.
|
||||
- Picks only the columns from the DataFrame that we added in SELECT.
|
||||
- Concatenates all the DataFrames together.
|
||||
- Writes the concatenated DataFrame back to a file.
|
||||
|
||||
```
|
||||
import os
|
||||
import settings
|
||||
import pandas as pd
|
||||
|
||||
def concatenate(prefix="Acquisition"):
|
||||
files = os.listdir(settings.DATA_DIR)
|
||||
full = []
|
||||
for f in files:
|
||||
if not f.startswith(prefix):
|
||||
continue
|
||||
|
||||
data = pd.read_csv(os.path.join(settings.DATA_DIR, f), sep="|", header=None, names=HEADERS[prefix], index_col=False)
|
||||
data = data[SELECT[prefix]]
|
||||
full.append(data)
|
||||
|
||||
full = pd.concat(full, axis=0)
|
||||
|
||||
full.to_csv(os.path.join(settings.PROCESSED_DIR, "{}.txt".format(prefix)), sep="|", header=SELECT[prefix], index=False)
|
||||
```
|
||||
|
||||
We can call the above function twice with the arguments Acquisition and Performance to concatenate all the acquisition and performance files together. The below code will:
|
||||
|
||||
- Only execute if the script is called from the command line with python assemble.py.
|
||||
- Concatenate all the files, and result in two files:
|
||||
- `processed/Acquisition.txt`
|
||||
- `processed/Performance.txt`
|
||||
|
||||
```
|
||||
if __name__ == "__main__":
|
||||
concatenate("Acquisition")
|
||||
concatenate("Performance")
|
||||
```
|
||||
|
||||
We now have a nice, compartmentalized assemble.py that’s easy to execute, and easy to build off of. By decomposing the problem into pieces like this, we make it easy to build our project. Instead of one messy script that does everything, we define the data that will pass between the scripts, and make them completely separate from each other. When you’re working on larger projects, it’s a good idea to do this, because it makes it much easier to change individual pieces without having unexpected consequences on unrelated pieces of the project.
|
||||
|
||||
Once we finish the assemble.py script, we can run python assemble.py. You can find the complete assemble.py file [here][32].
|
||||
|
||||
This will result in two files in the processed directory:
|
||||
|
||||
```
|
||||
loan-prediction
|
||||
├── data
|
||||
│ ├── Acquisition_2012Q1.txt
|
||||
│ ├── Acquisition_2012Q2.txt
|
||||
│ ├── Performance_2012Q1.txt
|
||||
│ ├── Performance_2012Q2.txt
|
||||
│ └── ...
|
||||
├── processed
|
||||
│ ├── Acquisition.txt
|
||||
│ ├── Performance.txt
|
||||
├── .gitignore
|
||||
├── assemble.py
|
||||
├── README.md
|
||||
├── requirements.txt
|
||||
├── settings.py
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user