mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
321455a5dd
@ -1,40 +1,41 @@
|
||||
UKTools - 安装最新 Linux 内核的简便方法
|
||||
UKTools:安装最新 Linux 内核的简便方法
|
||||
======
|
||||
|
||||
Ubuntu 中有许多实用程序可以将 Linux 内核升级到最新的稳定版本。我们之前已经写过关于这些实用程序的文章,例如 Linux Kernel Utilities (LKU), Ubuntu Kernel Upgrade Utility (UKUU) 和 Ubunsys。
|
||||
Ubuntu 中有许多实用程序可以将 Linux 内核升级到最新的稳定版本。我们之前已经写过关于这些实用程序的文章,例如 Linux Kernel Utilities (LKU)、 Ubuntu Kernel Upgrade Utility (UKUU) 和 Ubunsys。
|
||||
|
||||
另外还有一些其它实用程序可供使用。我们计划在其它文章中包含这些,例如 `ubuntu-mainline-kernel.sh` 和从主线内核手动安装的方式。
|
||||
|
||||
另外还有一些其它实用程序可供使用。我们计划在其它文章中包含这些,例如 ubuntu-mainline-kernel.sh 和 manual method from mainline kernel.
|
||||
今天我们还会教你类似的使用工具 —— UKTools。你可以尝试使用这些实用程序中的任何一个来将 Linux 内核升级至最新版本。
|
||||
|
||||
今天我们还会教你类似的使用工具 -- UKTools。你可以尝试使用这些实用程序中的任何一个来将 Linux 内核升级至最新版本。
|
||||
|
||||
最新的内核版本附带了安全漏洞修复和一些改进,因此,最好保持最新的内核版本以获得可靠,安全和更好的硬件性能。
|
||||
最新的内核版本附带了安全漏洞修复和一些改进,因此,最好保持最新的内核版本以获得可靠、安全和更好的硬件性能。
|
||||
|
||||
有时候最新的内核版本可能会有一些漏洞,并且会导致系统崩溃,这是你的风险。我建议你不要在生产环境中安装它。
|
||||
|
||||
**建议阅读:**
|
||||
**(#)** [Linux 内核实用程序(LKU)- 在 Ubuntu/LinuxMint 中编译,安装和更新最新内核的一组 Shell 脚本][1]
|
||||
**(#)** [Ukuu - 在基于 Ubuntu 的系统中安装或升级 Linux 内核的简便方法][2]
|
||||
**(#)** [6 种检查系统上正在运行的 Linux 内核版本的方法][3]
|
||||
**建议阅读:**
|
||||
|
||||
- [Linux 内核实用程序(LKU)- 在 Ubuntu/LinuxMint 中编译,安装和更新最新内核的一组 Shell 脚本][1]
|
||||
- [Ukuu - 在基于 Ubuntu 的系统中安装或升级 Linux 内核的简便方法][2]
|
||||
- [6 种检查系统上正在运行的 Linux 内核版本的方法][3]
|
||||
|
||||
### 什么是 UKTools
|
||||
|
||||
[UKTools][4] 意思是 Ubuntu 内核工具,它包含两个 shell 脚本 `ukupgrade` 和 `ukpurge`。
|
||||
|
||||
ukupgrade 意思是 “Ubuntu Kernel Upgrade”,它允许用户将 Linux 内核升级到 Ubuntu/Mint 的最新稳定版本以及基于 [kernel.ubuntu.com][5] 的衍生版本。
|
||||
`ukupgrade` 意思是 “Ubuntu Kernel Upgrade”,它允许用户将 Linux 内核升级到 Ubuntu/Mint 的最新稳定版本以及基于 [kernel.ubuntu.com][5] 的衍生版本。
|
||||
|
||||
ukpurge 意思是 “Ubuntu Kernel Purge”,它允许用户在机器中删除旧的 Linux 内核镜像或头文件,用于 Ubuntu/Mint 和其衍生版本。它将只保留三个内核版本。
|
||||
`ukpurge` 意思是 “Ubuntu Kernel Purge”,它允许用户在机器中删除旧的 Linux 内核镜像或头文件,用于 Ubuntu/Mint 和其衍生版本。它将只保留三个内核版本。
|
||||
|
||||
此实用程序没有 GUI,但它看起来非常简单直接,因此,新手可以在没有任何问题的情况下进行升级。
|
||||
|
||||
我正在运行 Ubuntu 17.10,目前的内核版本如下:
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux ubuntu 4.13.0-39-generic #44-Ubuntu SMP Thu Apr 5 14:25:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
运行以下命令来获取系统上已安装内核的列表(Ubuntu 及其衍生产品)。目前我持有 `7` 个内核。
|
||||
|
||||
```
|
||||
$ dpkg --list | grep linux-image
|
||||
ii linux-image-4.13.0-16-generic 4.13.0-16.19 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
|
||||
@ -52,7 +53,6 @@ ii linux-image-extra-4.13.0-37-generic 4.13.0-37.42 amd64 Linux kernel extra mod
|
||||
ii linux-image-extra-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
|
||||
ii linux-image-extra-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
|
||||
ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
|
||||
|
||||
```
|
||||
|
||||
### 如何安装 UKTools
|
||||
@ -60,18 +60,19 @@ ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
|
||||
在 Ubuntu 及其衍生产品上,只需运行以下命令来安装 UKTools 即可。
|
||||
|
||||
在你的系统上运行以下命令来克隆 UKTools 仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/usbkey9/uktools
|
||||
|
||||
```
|
||||
|
||||
进入 uktools 目录:
|
||||
|
||||
```
|
||||
$ cd uktools
|
||||
|
||||
```
|
||||
|
||||
运行 Makefile 以生成必要的文件。此外,这将自动安装最新的可用内核。只需重新启动系统即可使用最新的内核。
|
||||
运行 `Makefile` 以生成必要的文件。此外,这将自动安装最新的可用内核。只需重新启动系统即可使用最新的内核。
|
||||
|
||||
```
|
||||
$ sudo make
|
||||
[sudo] password for daygeek:
|
||||
@ -188,30 +189,30 @@ done
|
||||
|
||||
Thanks for using this script! Hope it helped.
|
||||
Give it a star: https://github.com/MarauderXtreme/uktools
|
||||
|
||||
```
|
||||
|
||||
重新启动系统以激活最新的内核。
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
|
||||
```
|
||||
|
||||
一旦系统重新启动,重新检查内核版本。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux ubuntu 4.16.7-041607-generic #201805021131 SMP Wed May 2 15:34:55 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
此 make 命令会将下面的文件放到 `/usr/local/bin` 目录中。
|
||||
|
||||
```
|
||||
do-kernel-upgrade
|
||||
do-kernel-purge
|
||||
|
||||
```
|
||||
|
||||
要移除旧内核,运行以下命令:
|
||||
|
||||
```
|
||||
$ do-kernel-purge
|
||||
|
||||
@ -364,10 +365,10 @@ run-parts: executing /etc/kernel/postrm.d/initramfs-tools 4.13.0-37-generic /boo
|
||||
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
|
||||
|
||||
Thanks for using this script!!!
|
||||
|
||||
```
|
||||
|
||||
使用以下命令重新检查已安装内核的列表。它将只保留三个旧的内核。
|
||||
|
||||
```
|
||||
$ dpkg --list | grep linux-image
|
||||
ii linux-image-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
|
||||
@ -376,14 +377,13 @@ ii linux-image-extra-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel extra mod
|
||||
ii linux-image-extra-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
|
||||
ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
|
||||
ii linux-image-unsigned-4.16.7-041607-generic 4.16.7-041607.201805021131 amd64 Linux kernel image for version 4.16.7 on 64 bit x86 SMP
|
||||
|
||||
```
|
||||
|
||||
下次你可以调用 `do-kernel-upgrade` 实用程序来安装新的内核。如果有任何新内核可用,那么它将安装。如果没有,它将报告当前没有可用的内核更新。
|
||||
|
||||
```
|
||||
$ do-kernel-upgrade
|
||||
Kernel up to date. Finishing
|
||||
|
||||
```
|
||||
|
||||
再次运行 `do-kernel-purge` 命令以确认。如果发现超过三个内核,那么它将移除。如果不是,它将报告没有删除消息。
|
||||
@ -400,7 +400,6 @@ Linux Kernel 4.16.7-041607 Generic (linux-image-4.16.7-041607-generic)
|
||||
Nothing to remove!
|
||||
|
||||
Thanks for using this script!!!
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -411,7 +410,7 @@ via: https://www.2daygeek.com/uktools-easy-way-to-install-latest-stable-linux-ke
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,37 @@
|
||||
用在你终端的 4 款酷炫应用
|
||||
4 款酷炫的终端应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
许多 Linux 用户认为在终端中工作太复杂或无聊,并试图逃避它。但这里有个改善 - 四款终端下的很棒的开源程序。它们既有趣又易于使用,甚至可以在你需要在命令行中工作时照亮你的生活。
|
||||
许多 Linux 用户认为在终端中工作太复杂、无聊,并试图逃避它。但这里有个改善方法 —— 四款终端下很棒的开源程序。它们既有趣又易于使用,甚至可以在你需要在命令行中工作时照亮你的生活。
|
||||
|
||||
### No More Secrets
|
||||
|
||||
这是一个简单的命令行工具,可以重现 1992 年电影 [Sneakers][1] 中所见的著名数据解密效果。该项目让你编译 nms 命令,该命令与管道数据一起使用并以混乱字符的形式打印输出。开始后,你可以按任意键,并能在输出中看到很酷的好莱坞效果的现场“解密”。
|
||||
这是一个简单的命令行工具,可以重现 1992 年电影 [Sneakers][1] 中所见的著名数据解密效果。该项目让你编译个 `nms` 命令,该命令与管道数据一起使用并以混乱字符的形式打印输出。开始后,你可以按任意键,并能在输出中看到很酷的好莱坞效果的现场“解密”。
|
||||
|
||||
![][2]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
一个全新安装的 Fedora Workstation 系统已经包含了从源代码构建 No More Secrets 所需的一切。只需在终端中输入以下命令:
|
||||
|
||||
```
|
||||
git clone https://github.com/bartobri/no-more-secrets.git
|
||||
cd ./no-more-secrets
|
||||
make nms
|
||||
make sneakers ## Optional
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
对于那些记得原始电影的人来说,sneakers 命令是一个小小的彩蛋,但主要的英雄是 nms。使用管道将任何 Linux 命令重定向到 nms,如下所示:
|
||||
对于那些记得原来的电影的人来说,`sneakers` 命令是一个小小的彩蛋,但主要的英雄是 `nms`。使用管道将任何 Linux 命令重定向到 `nms`,如下所示:
|
||||
|
||||
```
|
||||
systemctl list-units --type=target | nms
|
||||
|
||||
```
|
||||
|
||||
当文本停止闪烁,按任意键“解密”它。上面的 systemctl 命令只是一个例子 - 你几乎可以用任何东西替换它!
|
||||
当文本停止闪烁,按任意键“解密”它。上面的 `systemctl` 命令只是一个例子 —— 你几乎可以用任何东西替换它!
|
||||
|
||||
### Lolcat
|
||||
### lolcat
|
||||
|
||||
这是一个用彩虹为终端输出着色的命令。没什么用,但是它看起来很棒!
|
||||
|
||||
@ -39,50 +39,50 @@ systemctl list-units --type=target | nms
|
||||
|
||||
#### 安装说明
|
||||
|
||||
Lolcat 是一个 Ruby 软件包,可从官方 Ruby Gems 托管中获得。所以,你首先需要 gem 客户端:
|
||||
`lolcat` 是一个 Ruby 软件包,可从官方 Ruby Gems 托管中获得。所以,你首先需要 gem 客户端:
|
||||
|
||||
```
|
||||
sudo dnf install -y rubygems
|
||||
|
||||
```
|
||||
|
||||
然后安装 Lolcat 本身:
|
||||
然后安装 `lolcat` 本身:
|
||||
|
||||
```
|
||||
gem install lolcat
|
||||
|
||||
```
|
||||
|
||||
再说一次,使用 lolcat 命令管道任何其他命令,并在 Fedora 终端中享受彩虹(和独角兽!)。
|
||||
再说一次,使用 `lolcat` 命令管道任何其他命令,并在 Fedora 终端中享受彩虹(和独角兽!)。
|
||||
|
||||
### Chafa
|
||||
### chafa
|
||||
|
||||
![][4]
|
||||
|
||||
Chafa 是一个[命令行图像转换器和查看器][5]。它可以帮助你在不离开终端的情况下欣赏图像。语法非常简单:
|
||||
`chafa` 是一个[命令行图像转换器和查看器][5]。它可以帮助你在不离开终端的情况下欣赏图像。语法非常简单:
|
||||
|
||||
```
|
||||
chafa /path/to/your/image
|
||||
|
||||
```
|
||||
|
||||
你可以将几乎任何类型的图像投射到 Chafa,包括 JPG、PNG、TIFF、BMP 或几乎任何 ImageMagick 支持的图像 - 这是 Chafa 用于解析输入文件的引擎。最酷的部分是 Chafa 还可以在你的终端内显示非常流畅的 GIF 动画!
|
||||
你可以将几乎任何类型的图像投射到 `chafa`,包括 JPG、PNG、TIFF、BMP 或几乎任何 ImageMagick 支持的图像 - 这是 `chafa` 用于解析输入文件的引擎。最酷的部分是 `chafa` 还可以在你的终端内显示非常流畅的 GIF 动画!
|
||||
|
||||
#### 安装说明
|
||||
|
||||
Chafa 还没有为 Fedora 打包,但从源代码构建它很容易。首先,获取必要的构建依赖项:
|
||||
`chafa` 还没有为 Fedora 打包,但从源代码构建它很容易。首先,获取必要的构建依赖项:
|
||||
|
||||
```
|
||||
sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
|
||||
|
||||
```
|
||||
|
||||
接下来,克隆代码或从项目的 Github 页面下载快照,然后 cd 到 Chafa 目录。在那之后就好了:
|
||||
接下来,克隆代码或从项目的 GitHub 页面下载快照,然后 cd 到 `chafa` 目录,这样就行了:
|
||||
|
||||
```
|
||||
git clone https://github.com/hpjansson/chafa
|
||||
./autogen.sh
|
||||
make
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
大的图像在第一次运行时可能需要一段时间处理,但 Chafa 会缓存你加载的所有内容。下一次运行几乎是瞬间完成的。
|
||||
大的图像在第一次运行时可能需要一段时间处理,但 `chafa` 会缓存你加载的所有内容。下一次运行几乎是瞬间完成的。
|
||||
|
||||
### Browsh
|
||||
|
||||
@ -93,12 +93,12 @@ Browsh 是完善的终端网页浏览器。它比 Lynx 更强大,当然更引
|
||||
#### 安装说明
|
||||
|
||||
该项目为各种 Linux 发行版提供了包,包括 Fedora。以这种方式安装:
|
||||
|
||||
```
|
||||
sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
|
||||
|
||||
```
|
||||
|
||||
之后,启动 browsh 命令并给它几秒钟加载。按 Ctrl+L 将焦点切换到地址栏并开始浏览 Web,就像以前一样使用!使用 Ctrl+Q 返回终端。
|
||||
之后,启动 `browsh` 命令并给它几秒钟加载。按 `Ctrl+L` 将焦点切换到地址栏并开始浏览 Web,就像以前一样使用!使用 `Ctrl+Q` 返回终端。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -108,7 +108,7 @@ via: https://fedoramagazine.org/4-cool-apps-for-your-terminal/
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,62 +0,0 @@
|
||||
translating by lujun9972
|
||||
How to Play Sound Through Two or More Output Devices in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Handling audio in Linux can be a pain. Pulseaudio has made it both better and worse. While some things work better than they did before, other things have become more complicated. Handling audio output is one of those things.
|
||||
|
||||
If you want to enable multiple audio outputs from your Linux PC, you can use a simple utility to enable your other sound devices on a virtual interface. It's a lot easier than it sounds.
|
||||
|
||||
In case you're wondering why you'd want to do this, a pretty common instance is playing video from your computer on a TV and using both the PC and TV speakers.
|
||||
|
||||
### Install Paprefs
|
||||
|
||||
The easiest way to enable audio playback from multiple sources is to use a simple graphical utility called "paprefs." It's short for PulseAudio Preferences.
|
||||
|
||||
It's available through the Ubuntu repositories, so just install it with Apt.
|
||||
```
|
||||
sudo apt install paprefs
|
||||
```
|
||||
|
||||
When the install finishes, you can just launch the program.
|
||||
|
||||
### Enable Dual Audio Playback
|
||||
|
||||
Even though the utility is graphical, it's still probably easier to launch it by typing `paprefs` in the command line as a regular user.
|
||||
|
||||
The window that opens has a few tabs with settings that you can tweak. The tab that you're looking for is the last one, "Simultaneous Output."
|
||||
|
||||
![Paprefs on Ubuntu][1]
|
||||
|
||||
There isn't a whole lot on the tab, just a checkbox to enable the setting.
|
||||
|
||||
Next, open up the regular sound preferences. It's in different places on different distributions. On Ubuntu it'll be under the GNOME system settings.
|
||||
|
||||
![Enable Simultaneous Audio][2]
|
||||
|
||||
Once you have your sound preferences open, select the "Output" tab. Select the "Simultaneous output" radio button. It's now your default output.
|
||||
|
||||
### Test It
|
||||
|
||||
To test it, you can use anything you like, but music always works. If you are using a video, like suggested earlier, you can certainly test it with that as well.
|
||||
|
||||
If everything is working well, you should hear audio out of all connected devices.
|
||||
|
||||
That's all there really is to do. This works best when there are multiple devices, like the HDMI port and the standard analog output. You can certainly try it with other configurations, too. You should also keep in mind that there will only be a single volume control, so adjust the physical output devices accordingly.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/play-sound-through-multiple-devices-linux/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-paprefs.jpg (Paprefs on Ubuntu)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-enable.jpg (Enable Simultaneous Audio)
|
||||
[3]:https://depositphotos.com/89314442/stock-photo-headphones-on-speakers.html
|
||||
@ -1,121 +0,0 @@
|
||||
|
||||
FSSlc is translating
|
||||
|
||||
netdev day 1: IPsec!
|
||||
============================================================
|
||||
|
||||
Hello! This year, like last year, I’m at the [netdev conference][3]. (here are my [notes from last year][4]).
|
||||
|
||||
Today at the conference I learned a lot about IPsec, so we’re going to talk about IPsec! There was an IPsec workshop given by Sowmini Varadhan and [Paul Wouters][5]. All of the mistakes in this post are 100% my fault though :).
|
||||
|
||||
### what’s IPsec?
|
||||
|
||||
IPsec is a protocol used to encrypt IP packets. Some VPNs are implemented with IPsec. One big thing I hadn’t really realized until today is that there isn’t just one protocol used for VPNs – I think VPN is just a general term meaning “your IP packets get encrypted and sent through another server” and VPNs can be implemented using a bunch of different protocols (OpenVPN, PPTP, SSTP, IPsec, etc) in a bunch of different ways.
|
||||
|
||||
Why is IPsec different from other VPN protocols? (like, why was there a tutorial about it at netdev and not the other protocols?) My understanding is that there are 2 things that make it different:
|
||||
|
||||
* It’s an IETF standard, documented in eg [RFC 6071][1] (did you know the IETF is the group that makes RFCs? I didn’t until today!)
|
||||
|
||||
* it’s implemented in the Linux kernel (so it makes sense that there was a netdev tutorial on it, since netdev is a Linux kernel networking conference :))
|
||||
|
||||
### How does IPsec work?
|
||||
|
||||
So let’s say your laptop is using IPsec to encrypt its packets and send them through another device. How does that work? There are 2 parts to IPsec: a userspace part, and a kernel part.
|
||||
|
||||
The userspace part of IPsec is responsible for key exchange, using a protocol called [IKE][6] (“internet key exchange”). Basically when you open a new VPN connection, you need to talk to the VPN server and negotiate a key to do encryption.
|
||||
|
||||
The kernel part of IPsec is responsible for the actual encryption of packets – once a key is generated using IKE, the userspace part of IPsec will tell the kernel which encryption key to use. Then the kernel will use that key to encrypt packets!
|
||||
|
||||
### Security Policy & Security Associations
|
||||
|
||||
The kernel part of IPSec has two databases: the security policy database(SPD) and the security association database (SAD).
|
||||
|
||||
The security policy database has IP ranges and rules for what to do to packets for that IP range (“do IPsec to it”, “drop the packet”, “let it through”). I find this a little confusing because I’m used to rules about what to do to packets in various IP ranges being in the route table (`sudo ip route list`), but apparently you can have IPsec rules too and they’re in a different place!
|
||||
|
||||
The security association database I think has the encryption keys to use for various IPs.
|
||||
|
||||
The way you inspect these databases is, extremely unintuitively, using a command called `ip xfrm`. What does xfrm mean? I don’t know!
|
||||
|
||||
```
|
||||
# security policy database
|
||||
$ sudo ip xfrm policy
|
||||
$ sudo ip x p
|
||||
|
||||
# security association database
|
||||
$ sudo ip xfrm state
|
||||
$ sudo ip x s
|
||||
|
||||
```
|
||||
|
||||
### Why is IPsec implemented in the Linux kernel and TLS isn’t?
|
||||
|
||||
For both TLS and IPsec, you need to do a key exchange when opening the connection (using Diffie-Hellman or something). For some reason that might be obvious but that I don’t understand yet (??) people don’t want to do key exchange in the kernel.
|
||||
|
||||
The reason IPsec is easier to implement in the kernel is that with IPsec, you need to negotiate key exchanges much less frequently (once for every IP address you want to open a VPN connection with), and IPsec sessions are much longer lived. So it’s easy for userspace to do a key exchange, get the key, and hand it off to the kernel which will then use that key for every IP packet.
|
||||
|
||||
With TLS, there are a couple of problems:
|
||||
|
||||
a. you’re constantly doing new key exchanges every time you open a new TLS connection, and TLS connections are shorter-lived b. there isn’t a natural protocol boundary where you need to start doing encryption – with IPsec, you just encrypt every IP packet in a given IP range, but with TLS you need to look at your TCP stream, recognize whether the TCP packet is a data packet or not, and decide to encrypt it
|
||||
|
||||
There’s actually a patch [implementing TLS in the Linux kernel][7] which lets userspace do key exchange and then pass the kernel the keys, so this obviously isn’t impossible, but it’s a much newer thing and I think it’s more complicated with TLS than with IPsec.
|
||||
|
||||
### What software do you use to do IPsec?
|
||||
|
||||
The ones I know about are Libreswan and Strongswan. Today’s tutorial focused on Libreswan.
|
||||
|
||||
Somewhat confusingly, even though Libreswan and Strongswan are different software packages, they both install a binary called `ipsec` for managing IPsec connections, and the two `ipsec` binaries are not the same program (even though they do have the same role).
|
||||
|
||||
Strongswan and Libreswan do what’s described in the “how does IPsec work” section above – they do key exchange with IKE and tell the kernel about keys to configure it to do encryption.
|
||||
|
||||
### IPsec isn’t only for VPNs!
|
||||
|
||||
At the beginning of this post I said “IPsec is a VPN protocol”, which is true, but you don’t have to use IPsec to implement VPNs! There are actually two ways to use IPsec:
|
||||
|
||||
1. “transport mode”, where the IP header is unchanged and only the contents of the IP packet are encrypted. This mode is a little more like using TLS – you talk to the server you’re communicating with directly (not through a VPN server or something), it’s just that the contents of the IP packet get encrypted
|
||||
|
||||
2. “tunnel mode”, where the IP header and its contents are all encrypted and encapsulated into another UDP packet. This is the mode that’s used for VPNs – you take your packet that you’re sending to secret_site.com, encrypt it, send it to your VPN server, and the VPN server passes it on for you.
|
||||
|
||||
### opportunistic IPsec
|
||||
|
||||
An interesting application of “transport mode” IPsec I learned about today (where you open an IPsec connection directly with the host you’re communicating with instead of some other intermediary server) is this thing called “opportunistic IPsec”. There’s an opportunistic IPsec server here:[http://oe.libreswan.org/][8].
|
||||
|
||||
I think the idea is that if you set up Libreswan and unbound up on your computer, then when you connect to [http://oe.libreswan.org][9], what happens is:
|
||||
|
||||
1. `unbound` makes a DNS query for the IPSECKEY record of oe.libreswan.org (`dig ipseckey oe.libreswan.org`) to get a public key to use for that domain. (this requires DNSSEC to be secure which when I learn about it will be a whole other blog post, but you can just run that DNS query with dig and it will work if you want to see the results)
|
||||
|
||||
2. `unbound` gives the public key to libreswan, which uses it to do a key exchange with the IKE server running on oe.libreswan.org
|
||||
|
||||
3. `libreswan` finishes the key exchange, gives the encryption key to the kernel, and tells the kernel to use that encryption key when talking to `oe.libreswan.org`
|
||||
|
||||
4. Your connection is now encrypted! Even though it’s a HTTP connection! so interesting!
|
||||
|
||||
### IPsec and TLS learn from each other
|
||||
|
||||
One interesting tidbit from the tutorial today was that the IPsec and TLS protocols have actually learned from each other over time – like they said IPsec’s IKE protocol had perfect forward secrecy before TLS, and IPsec has also learned some things from TLS. It’s neat to hear about how different internet protocols are learning & changing over time!
|
||||
|
||||
### IPsec is interesting!
|
||||
|
||||
I’ve spent quite a lot of time learning about TLS, which is obviously a super important networking protocol (let’s encrypt the internet! :D). But IPsec is an important internet encryption protocol too, and it has a different role from TLS! Apparently some mobile phone protocols (like 5G/LTE) use IPsec to encrypt their network traffic!
|
||||
|
||||
I’m happy I know a little more about it now! As usual several things in this post are probably wrong, but hopefully not too wrong :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://tools.ietf.org/html/rfc6071
|
||||
[2]:https://jvns.ca/categories/netdev
|
||||
[3]:https://www.netdevconf.org/0x12/
|
||||
[4]:https://jvns.ca/categories/netdev/
|
||||
[5]:https://nohats.ca/
|
||||
[6]:https://en.wikipedia.org/wiki/Internet_Key_Exchange
|
||||
[7]:https://blog.filippo.io/playing-with-kernel-tls-in-linux-4-13-and-go/
|
||||
[8]:http://oe.libreswan.org/
|
||||
[9]:http://oe.libreswan.org/
|
||||
@ -1,283 +0,0 @@
|
||||
FSSlc is translating
|
||||
|
||||
A sysadmin's guide to SELinux: 42 answers to the big questions
|
||||
============================================================
|
||||
|
||||
> Get answers to the big questions about life, the universe, and everything else about Security-Enhanced Linux.
|
||||
|
||||

|
||||
Image credits : [JanBaby][13], via Pixabay [CC0][14].
|
||||
|
||||
> "It is an important and popular fact that things are not always what they seem…"
|
||||
> ―Douglas Adams, _The Hitchhiker's Guide to the Galaxy_
|
||||
|
||||
Security. Hardening. Compliance. Policy. The Four Horsemen of the SysAdmin Apocalypse. In addition to our daily tasks—monitoring, backup, implementation, tuning, updating, and so forth—we are also in charge of securing our systems. Even those systems where the third-party provider tells us to disable the enhanced security. It seems like a job for _Mission Impossible_ 's [Ethan Hunt][15].
|
||||
|
||||
Faced with this dilemma, some sysadmins decide to [take the blue pill][16] because they think they will never know the answer to the big question of life, the universe, and everything else. And, as we all know, that answer is **[42][2]**.
|
||||
|
||||
In the spirit of _The Hitchhiker's Guide to the Galaxy_ , here are the 42 answers to the big questions about managing and using [SELinux][17] with your systems.
|
||||
|
||||
1. SELinux is a LABELING system, which means every process has a LABEL. Every file, directory, and system object has a LABEL. Policy rules control access between labeled processes and labeled objects. The kernel enforces these rules.
|
||||
|
||||
1. The two most important concepts are: _Labeling_ (files, process, ports, etc.) and _Type enforcement_ (which isolates processes from each other based on types).
|
||||
|
||||
1. The correct Label format is `user:role:type:level` ( _optional_ ).
|
||||
|
||||
1. The purpose of _Multi-Level Security (MLS) enforcement_ is to control processes ( _domains_ ) based on the security level of the data they will be using. For example, a secret process cannot read top-secret data.
|
||||
|
||||
1. _Multi-Category Security (MCS) enforcement_ protects similar processes from each other (like virtual machines, OpenShift gears, SELinux sandboxes, containers, etc.).
|
||||
|
||||
1. Kernel parameters for changing SELinux modes at boot:
|
||||
* `autorelabel=1` → forces the system to relabel
|
||||
|
||||
* `selinux=0` → kernel doesn't load any part of the SELinux infrastructure
|
||||
|
||||
* `enforcing=0` → boot in permissive mode
|
||||
|
||||
1. If you need to relabel the entire system:
|
||||
`# touch /.autorelabel
|
||||
#reboot`
|
||||
If the system labeling contains a large amount of errors, you might need to boot in permissive mode in order for the autorelabel to succeed.
|
||||
|
||||
1. To check if SELinux is enabled: `# getenforce`
|
||||
|
||||
1. To temporarily enable/disable SELinux: `# setenforce [1|0]`
|
||||
|
||||
1. SELinux status tool: `# sestatus`
|
||||
|
||||
1. Configuration file: `/etc/selinux/config`
|
||||
|
||||
1. How does SELinux work? Here's an example of labeling for an Apache Web Server:
|
||||
* Binary: `/usr/sbin/httpd`→`httpd_exec_t`
|
||||
|
||||
* Configuration directory: `/etc/httpd`→`httpd_config_t`
|
||||
|
||||
* Logfile directory: `/var/log/httpd` → `httpd_log_t`
|
||||
|
||||
* Content directory: `/var/www/html` → `httpd_sys_content_t`
|
||||
|
||||
* Startup script: `/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
|
||||
* Process: `/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
|
||||
* Ports: `80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
A process running in the `httpd_t` context can interact with an object with the `httpd_something_t` label.
|
||||
|
||||
1. Many commands accept the argument `-Z` to view, create, and modify context:
|
||||
* `ls -Z`
|
||||
|
||||
* `id -Z`
|
||||
|
||||
* `ps -Z`
|
||||
|
||||
* `netstat -Z`
|
||||
|
||||
* `cp -Z`
|
||||
|
||||
* `mkdir -Z`
|
||||
|
||||
Contexts are set when files are created based on their parent directory's context (with a few exceptions). RPMs can set contexts as part of installation.
|
||||
|
||||
1. There are four key causes of SELinux errors, which are further explained in items 15-21 below:
|
||||
* Labeling problems
|
||||
|
||||
* Something SELinux needs to know
|
||||
|
||||
* A bug in an SELinux policy/app
|
||||
|
||||
* Your information may be compromised
|
||||
|
||||
1. _Labeling problem:_ If your files in `/srv/myweb` are not labeled correctly, access might be denied. Here are some ways to fix this:
|
||||
* If you know the label:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
|
||||
* If you know the file with the equivalent labeling:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
|
||||
* Restore the context (for both cases):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
1. _Labeling problem:_ If you move a file instead of copying it, the file keeps its original context. To fix these issues:
|
||||
* Change the context command with the label:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
|
||||
* Change the context command with the reference label:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
|
||||
* Restore the context (for both cases): `# restorecon -vR /var/www/html/`
|
||||
|
||||
1. If _SELinux needs to know_ HTTPD listens on port 8585, tell SELinux:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
1. _SELinux needs to know_ booleans allow parts of SELinux policy to be changed at runtime without any knowledge of SELinux policy writing. For example, if you want httpd to send email, enter: `# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
1. _SELinux needs to know_ booleans are just off/on settings for SELinux:
|
||||
* To see all booleans: `# getsebool -a`
|
||||
|
||||
* To see the description of each one: `# semanage boolean -l`
|
||||
|
||||
* To set a boolean execute: `# setsebool [_boolean_] [1|0]`
|
||||
|
||||
* To configure it permanently, add `-P`. For example:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
1. SELinux policies/apps can have bugs, including:
|
||||
* Unusual code paths
|
||||
|
||||
* Configurations
|
||||
|
||||
* Redirection of `stdout`
|
||||
|
||||
* Leaked file descriptors
|
||||
|
||||
* Executable memory
|
||||
|
||||
* Badly built libraries
|
||||
Open a ticket (do not file a Bugzilla report; there are no SLAs with Bugzilla).
|
||||
|
||||
1. _Your information may be compromised_ if you have confined domains trying to:
|
||||
* Load kernel modules
|
||||
|
||||
* Turn off the enforcing mode of SELinux
|
||||
|
||||
* Write to `etc_t/shadow_t`
|
||||
|
||||
* Modify iptables rules
|
||||
|
||||
1. SELinux tools for the development of policy modules:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
Reboot or restart `auditd` after you install.
|
||||
|
||||
1. Use `journalctl` for listing all logs related to `setroubleshoot`:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
1. Use `journalctl` for listing all logs related to a particular SELinux label. For example:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
1. Use `setroubleshoot` log when an SELinux error occurs and suggest some possible solutions. For example, from `journalctl`:
|
||||
```
|
||||
Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
If you want to fix the label,
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
Then you can restorecon.
|
||||
Do
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
```
|
||||
|
||||
1. Logging: SELinux records information all over the place:
|
||||
* `/var/log/messages`
|
||||
|
||||
* `/var/log/audit/audit.log`
|
||||
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
1. Logging: Looking for SELinux errors in the audit log:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
1. To search for SELinux Access Vector Cache (AVC) messages for a particular service:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
1. The `audit2allow` utility gathers information from logs of denied operations and then generates SELinux policy-allow rules. For example:
|
||||
* To produce a human-readable description of why the access was denied: `# audit2allow -w -a`
|
||||
|
||||
* To view the type enforcement rule that allows the denied access: `# audit2allow -a`
|
||||
|
||||
* To create a custom module: `# audit2allow -a -M mypolicy`
|
||||
The `-M` option creates a type enforcement file (.te) with the name specified and compiles the rule into a policy package (.pp): `mypolicy.pp mypolicy.te`
|
||||
|
||||
* To install the custom module: `# semodule -i mypolicy.pp`
|
||||
|
||||
1. To configure a single process (domain) to run permissive: `# semanage permissive -a httpd_t`
|
||||
|
||||
1. If you no longer want a domain to be permissive: `# semanage permissive -d httpd_t`
|
||||
|
||||
1. To disable all permissive domains: `# semodule -d permissivedomains`
|
||||
|
||||
1. Enabling SELinux MLS policy: `# yum install selinux-policy-mls`
|
||||
In `/etc/selinux/config:`
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
Make sure SELinux is running in permissive mode: `# setenforce 0`
|
||||
Use the `fixfiles` script to ensure that files are relabeled upon the next reboot:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
1. Create a user with a specific MLS range: `# useradd -Z staff_u john`
|
||||
Using the `useradd` command, map the new user to an existing SELinux user (in this case, `staff_u`).
|
||||
|
||||
1. To view the mapping between SELinux and Linux users: `# semanage login -l`
|
||||
|
||||
1. Define a specific range for a user: `# semanage login --modify --range s2:c100 john`
|
||||
|
||||
1. To correct the label on the user's home directory (if needed): `# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
1. To list the current categories: `# chcat -L`
|
||||
|
||||
1. To modify the categories or to start creating your own, modify the file as follows:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
1. To run a command or script in a specific file, role, and user context:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` is the _file context_
|
||||
|
||||
* `-r` is the _role context_
|
||||
|
||||
* `-u` is the _user context_
|
||||
|
||||
1. Containers running with SELinux disabled:
|
||||
* With Podman: `# podman run --security-opt label=disable` …
|
||||
|
||||
* With Docker: `# docker run --security-opt label=disable` …
|
||||
|
||||
1. If you need to give a container full access to the system:
|
||||
* With Podman: `# podman run --privileged` …
|
||||
|
||||
* With Docker: `# docker run --privileged` …
|
||||
|
||||
And with this, you already know the answer. So please: **Don't panic, and turn on SELinux**.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
Alex Callejas - Alex Callejas is a Technical Account Manager of Red Hat in the LATAM region, based in Mexico City. With more than 10 years of experience as SysAdmin, he has strong expertise on Infrastructure Hardening. Enthusiast of the Open Source, supports the community sharing his knowledge in different events of public access and universities. Geek by nature, Linux by choice, Fedora of course.[More about me][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[ Alex Callejas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[1]:https://opensource.com/article/18/7/sysadmin-guide-selinux?rate=hR1QSlwcImXNksBPPrLOeP6ooSoOU7PZaR07aGFuYVo
|
||||
[2]:https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29
|
||||
[3]:https://fedorapeople.org/~dwalsh/SELinux/SELinux
|
||||
[4]:https://opensource.com/users/rhatdan
|
||||
[5]:https://opensource.com/business/13/11/selinux-policy-guide
|
||||
[6]:http://people.redhat.com/tcameron/Summit2018/selinux/SELinux_for_Mere_Mortals_Summit_2018.pdf
|
||||
[7]:http://twitter.com/thomasdcameron
|
||||
[8]:http://blog.linuxgrrl.com/2014/04/16/the-selinux-coloring-book/
|
||||
[9]:https://opensource.com/users/mairin
|
||||
[10]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/selinux_users_and_administrators_guide/index
|
||||
[11]:https://opensource.com/users/darkaxl
|
||||
[12]:https://opensource.com/user/219886/feed
|
||||
[13]:https://pixabay.com/en/security-secure-technology-safety-2168234/
|
||||
[14]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
|
||||
[15]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[16]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[17]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[18]:https://opensource.com/users/darkaxl
|
||||
[19]:https://opensource.com/users/darkaxl
|
||||
[20]:https://opensource.com/article/18/7/sysadmin-guide-selinux#comments
|
||||
[21]:https://opensource.com/tags/security
|
||||
[22]:https://opensource.com/tags/linux
|
||||
[23]:https://opensource.com/tags/sysadmin
|
||||
@ -1,124 +0,0 @@
|
||||
FSSlc is translating
|
||||
|
||||
|
||||
netdev day 2: moving away from "as fast as possible" in networking code
|
||||
============================================================
|
||||
|
||||
Hello! Today was day 2 of netdev. I only made it to the morning of the conference, but the morning was VERY EXCITING. The highlight of this morning was a keynote by [Van Jacobson][1] about the future of congestion control on the internet (!!!) called “Evolving from As Fast As Possible: Teaching NICs about time”
|
||||
|
||||
I’m going to try to summarize what I learned from this talk. I almost certainly have some things wrong, but let’s go!
|
||||
|
||||
This talk was about how the internet has changed since 1988, why we need new algorithms today, and how we can change Linux’s networking stack to implement those algorithms more easily.
|
||||
|
||||
### what’s congestion control?
|
||||
|
||||
Everyone on the internet is sending packets all at once, all the time. The links on the internet are of dramatically different speeds (some are WAY slower than others), and sometimes they get full! When a device on the internet receives packets at a rate faster than it can handle, it drops the packets.
|
||||
|
||||
The most naive you way you could imagine sending packets is:
|
||||
|
||||
1. Send all the packets you have to send all at once
|
||||
|
||||
2. If you discover any of those packets got dropped, resend the packet right away
|
||||
|
||||
It turns out that if you implemented TCP that way, the internet would collapse and grind to a halt. We know that it would collapse because it did kinda collapse, in 1986\. To fix this, folks invented congestion control algorithms – the original paper describing how they avoided collapsing the internet is [Congestion Avoidance and Control][2], by Van Jacobson from 1988\. (30 years ago!)
|
||||
|
||||
### How has the internet changed since 1988?
|
||||
|
||||
The main thing he said has changed about the internet is – it used to be that switches would always have faster network cards than servers on the internet. So the servers in the middle of the internet would be a lot faster than the clients, and it didn’t matter as much how fast clients sent packets.
|
||||
|
||||
Today apparently that’s not true! As we all know, computers today aren’t really faster than computers 5 years ago (we ran into some problems with the speed of light). So what happens (I think) is that the big switches in routers are not really that much faster than the NICs on servers in datacenters.
|
||||
|
||||
This is bad because it means that clients are much more easily able to saturate the links in the middle, which results in the internet getting slower. (and there’s [buffer bloat][3] which results in high latency)
|
||||
|
||||
So to improve performance on the internet and not saturate all the queues on every router, clients need to be a little better behaved and to send packets a bit more slowly.
|
||||
|
||||
### sending more packets more slowly results in better performance
|
||||
|
||||
Here’s an idea that was really surprising to me – sending packets more slowly often actually results in better performance (even if you are the only one doing it). Here’s why!
|
||||
|
||||
Suppose you’re trying to send 10MB of data, and there’s a link somewhere in the middle between you and the client you’re trying to talk to that is SLOW, like 1MB/s or something. Assuming that you can tell the speed of this slow link (more on that later), you have 2 choices:
|
||||
|
||||
1. Send the entire 10MB of data at once and see what happens
|
||||
|
||||
2. Slow it down so you send it at 1MB/s
|
||||
|
||||
Now – either way, you’re probably going to end up with some packet loss. So it seems like you might as well just send all the data at once if you’re going to end up with packet loss either way, right? No!! The key observation is that packet loss in the middle of your stream is much better than packet loss at the end of your stream. If a few packets in the middle are dropped, the client you’re sending to will realize, tell you, and you can just resend them. No big deal! But if packets at the END are dropped, the client has no way of knowing you sent those packets at all! So you basically need to time out at some point when you don’t get an ACK for those packets and resend it. And timeouts typically take a long time to happen!
|
||||
|
||||
So why is sending data more slowly better? Well, if you send data faster than the bottleneck for the link, what will happen is that all the packets will pile up in a queue somewhere, the queue will get full, and then the packets at the END of your stream will get dropped. And, like we just explained, the packets at the end of the stream are the worst packets to drop! So then you have all these timeouts, and sending your 10MB of data will take way longer than if you’d just sent your packets at the correct speed in the first place.
|
||||
|
||||
I thought this was really cool because it doesn’t require cooperation from anybody else on the internet – even if everybody else is sending all their packets really fast, it’s _still_ more advantageous for you to send your packets at the correct rate (the rate of the bottleneck in the middle)
|
||||
|
||||
### how to tell the right speed to send data at: BBR!
|
||||
|
||||
Earlier I said “assuming that you can tell the speed of the slow link between your client and server…“. How do you do that? Well, some folks from Google (where Jacobson works) came up with an algorithm for measuring the speed of bottlenecks! It’s called BBR. This post is already long enough, but for more about BBR, see [BBR: Congestion-based congestion control][4] and [the summary from the morning paper][5].
|
||||
|
||||
(as an aside, [https://blog.acolyer.org][6]’s daily “the morning paper” summaries are basically the only way I learn about / understand CS papers, it’s possibly the greatest blog on the internet)
|
||||
|
||||
### networking code is designed to run “as fast as possible”
|
||||
|
||||
So! Let’s say we believe we want to send data a little more slowly, at the speed of the bottleneck in our connection. This is all very well, but networking software isn’t really designed to send data at a controlled rate! This (as far as I understand it) is how most networking stuff is designed:
|
||||
|
||||
1. There’s a queue of packets coming in
|
||||
|
||||
2. It reads off the queue and sends the packets out as as fast as possible
|
||||
|
||||
3. That’s it
|
||||
|
||||
This is pretty inflexible! Like – suppose I have one really fast connection I’m sending packets on, and one really slow connection. If all I have is a queue to put packets on, I don’t get that much control over when the packets I’m sending actually get sent out. I can’t slow down the queue!
|
||||
|
||||
### a better way: give every packet an “earliest departure time”
|
||||
|
||||
His proposal was to modify the skb data structure in the Linux kernel (which is the data structure used to represent network packets) to have a TIMESTAMP on it representing the earliest time that packet should go out.
|
||||
|
||||
I don’t know a lot about the Linux network stack, but the interesting thing to me about this proposal is that it doesn’t sound like a huge change! It’s just an extra timestamp.
|
||||
|
||||
### replace queues with timing wheels!!!
|
||||
|
||||
Once we have all these packets with times on them, how do we get them sent out at the right time? TIMING WHEELS!
|
||||
|
||||
At Papers We Love a while back ([some good links in the meetup description][7]) there was a talk about timing wheels. Timing wheels are the algorithm the Linux process scheduler decides when to run processes.
|
||||
|
||||
He said that timing wheels actually perform better than queues for scheduling work – they both offer constant time operations, but the timing wheels constant is smaller because of some stuff to do with cache performance. I didn’t really follow the performance arguments.
|
||||
|
||||
One point he made about timing wheels is that you can easily implement a queue with a timing wheel (though not vice versa!) – if every time you add a new packet, you say that you want it to be sent RIGHT NOW at the earliest, then you effectively end up with a queue. So this timing wheel approach is backwards compatible, but it makes it much easier to implement more complex traffic shaping algorithms where you send out different packets at different rates.
|
||||
|
||||
### maybe we can fix the internet by improving Linux!
|
||||
|
||||
With any internet-scale problem, the tricky thing about making progress on it is that you need cooperation from SO MANY different parties to change how internet protocols are implemented. You have Linux machines, BSD machines, Windows machines, different kinds of phones, Juniper/Cisco routers, and lots of other devices!
|
||||
|
||||
But Linux is in kind of an interesting position in the networking landscape!
|
||||
|
||||
* Android phones run Linux
|
||||
|
||||
* Most consumer wifi routers run Linux
|
||||
|
||||
* Lots of servers run Linux
|
||||
|
||||
So in any given network connection, you’re actually relatively likely to have a Linux machine at both ends (a linux server, and either a Linux router or Android device).
|
||||
|
||||
So the point is that if you want to improve congestion on the internet in general, it would make a huge difference to just change the Linux networking stack. (and maybe the iOS networking stack too) Which is why there was a keynote at this Linux networking conference about it!
|
||||
|
||||
### the internet is still changing! Cool!
|
||||
|
||||
I usually think of TCP/IP as something that we figured out in the 80s, so it was really fascinating to hear that folks think that there are still serious issues with how we’re designing our networking protocols, and that there’s work to do to design them differently.
|
||||
|
||||
And of course it makes sense – the landscape of networking hardware and the relative speeds of everything and the kinds of things people are using the internet for (netflix!) is changing all the time, so it’s reasonable that at some point we need to start designing our algorithms differently for the internet of 2018 instead of the internet of 1998.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/12/netdev-day-2--moving-away-from--as-fast-as-possible/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://en.wikipedia.org/wiki/Van_Jacobson
|
||||
[2]:https://cs162.eecs.berkeley.edu/static/readings/jacobson-congestion.pdf
|
||||
[3]:https://apenwarr.ca/log/?m=201101#10
|
||||
[4]:https://queue.acm.org/detail.cfm?id=3022184
|
||||
[5]:https://blog.acolyer.org/2017/03/31/bbr-congestion-based-congestion-control/
|
||||
[6]:https://blog.acolyer.org/
|
||||
[7]:https://www.meetup.com/Papers-We-Love-Montreal/events/235100825/
|
||||
@ -1,73 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 open source media conversion tools for the Linux desktop
|
||||
======
|
||||
|
||||

|
||||
|
||||
Ah, so many file formats—especially audio and video ones—can make for fun times if you get a file with an extension you don't recognize, if your media player doesn't play a file in that format, or if you want to use an open format.
|
||||
|
||||
So, what can a Linux user do? Turn to one of the many open source media conversion tools for the Linux desktop, of course. Let's take a look at four of them.
|
||||
|
||||
### Gnac
|
||||
|
||||
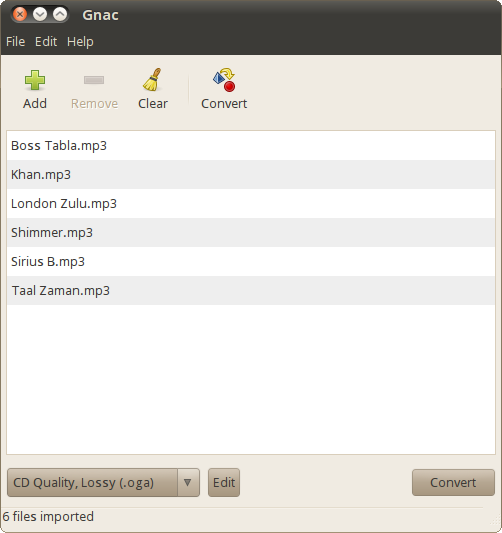
|
||||
|
||||
[Gnac][1] is one of my favorite audio converters and has been for years. It's easy to use, it's powerful, and it does one thing well—as any top-notch utility should.
|
||||
|
||||
How easy? You click a toolbar button to add one or more files to convert, choose a format to convert to, and then click **Convert**. The conversions are quick, and they're clean.
|
||||
|
||||
How powerful? Gnac can handle all the audio formats that the [GStreamer][2] multimedia framework supports. Out of the box, you can convert between Ogg, FLAC, AAC, MP3, WAV, and SPX. You can also change the conversion options for each format or add new ones.
|
||||
|
||||
### SoundConverter
|
||||
|
||||
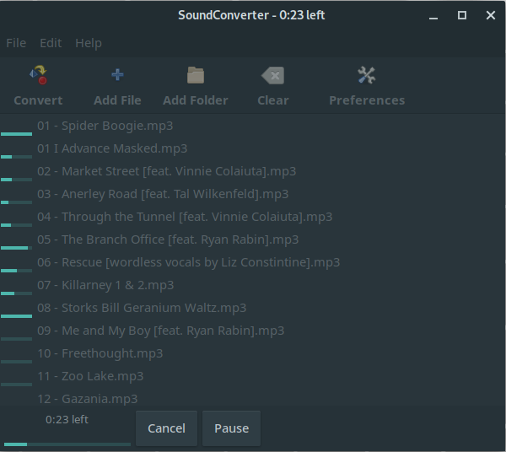
|
||||
|
||||
If simplicity with a few extra features is your thing, then give [SoundConverter][3] a look. As its name states, SoundConverter works its magic only on audio files. Like Gnac, it can read the formats that GStreamer supports, and it can spit out Ogg Vorbis, MP3, FLAC, WAV, AAC, and Opus files.
|
||||
|
||||
Load individual files or an entire folder by either clicking **Add File** or dragging and dropping it into the SoundConverter window. Click **Convert** , and the software powers through the conversion. It's fast, too—I've converted a folder containing a couple dozen files in about a minute.
|
||||
|
||||
SoundConverter has options for setting the quality of your converted files. You can change the way files are named (for example, include a track number or album name in the title) and create subfolders for the converted files.
|
||||
|
||||
### WinFF
|
||||
|
||||
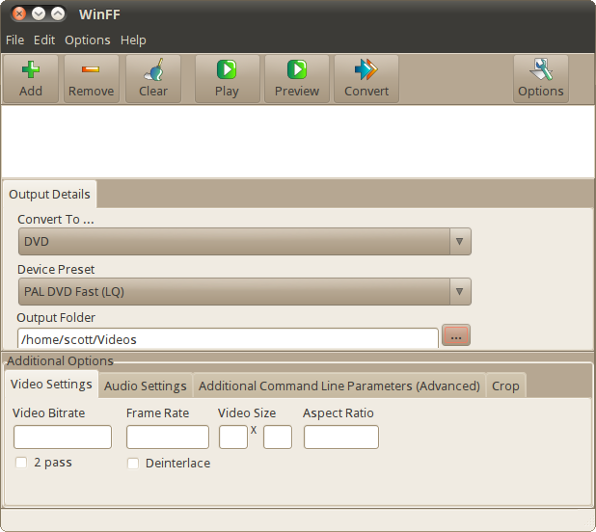
|
||||
|
||||
[WinFF][4], on its own, isn't a converter. It's a graphical frontend to FFmpeg, which [Tim Nugent looked at][5] for Opensource.com. While WinFF doesn't have all the flexibility of FFmpeg, it makes FFmpeg easier to use and gets the job done quickly and fairly easily.
|
||||
|
||||
Although it's not the prettiest application out there, WinFF doesn't need to be. It's more than usable. You can choose what formats to convert to from a dropdown list and select several presets. On top of that, you can specify options like bitrates and frame rates, the number of audio channels to use, and even the size at which to crop videos.
|
||||
|
||||
The conversions, especially video, take a bit of time, but the results are generally quite good. Once in a while, the conversion gets a bit mangled—but not often enough to be a concern. And, as I said earlier, using WinFF can save me a bit of time.
|
||||
|
||||
### Miro Video Converter
|
||||
|
||||
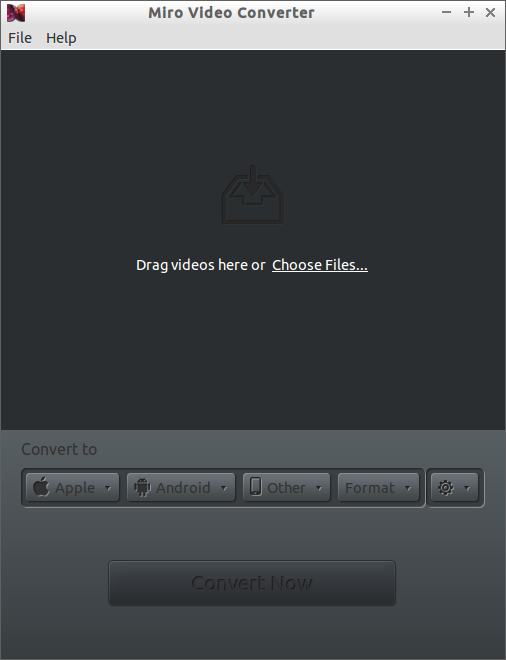
|
||||
|
||||
Not all video files are created equally. Some are in proprietary formats. Others look great on a monitor or TV screen but aren't optimized for a mobile device. That's where [Miro Video Converter][6] comes to the rescue.
|
||||
|
||||
Miro Video Converter has a heavy emphasis on mobile. It can convert video that you can play on Android phones, Apple devices, the PlayStation Portable, and the Kindle Fire. It will convert most common video formats to MP4, [WebM][7] , and [Ogg Theora][8] . You can find a full list of supported devices and formats [on Miro's website][6]
|
||||
|
||||
To use it, either drag and drop a file into the window or select the file that you want to convert. Then, click the Format menu to choose the format for the conversion. You can also click the Apple, Android, or Other menus to choose a device for which you want to convert the file. Miro Video Converter resizes the video for the device's screen resolution.
|
||||
|
||||
Do you have a favorite Linux media conversion application? Feel free to share it by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/media-conversion-tools-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://gnac.sourceforge.net
|
||||
[2]:http://www.gstreamer.net/
|
||||
[3]:http://soundconverter.org/
|
||||
[4]:https://www.biggmatt.com/winff/
|
||||
[5]:https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
|
||||
[6]:http://www.mirovideoconverter.com/
|
||||
[7]:https://en.wikipedia.org/wiki/WebM
|
||||
[8]:https://en.wikipedia.org/wiki/Ogg_theora
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
Getting started with Mu, a Python editor for beginners
|
||||
======
|
||||
|
||||
|
||||
101
sources/tech/20180803 UNIX curiosities.md
Normal file
101
sources/tech/20180803 UNIX curiosities.md
Normal file
@ -0,0 +1,101 @@
|
||||
UNIX curiosities
|
||||
======
|
||||
Recently I've been doing more UNIXy things in various tools I'm writing, and I hit two interesting issues. Neither of these are "bugs", but behaviors that I wasn't expecting.
|
||||
|
||||
### Thread-safe printf
|
||||
|
||||
I have a C application that reads some images from disk, does some processing, and writes output about these images to STDOUT. Pseudocode:
|
||||
```
|
||||
for(imagefilename in images)
|
||||
{
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The processing is independent for each image, so naturally I want to distribute this processing between various CPUs to speed things up. I usually use `fork()`, so I wrote this:
|
||||
```
|
||||
for(child in children)
|
||||
{
|
||||
pipe = create_pipe();
|
||||
worker(pipe);
|
||||
}
|
||||
|
||||
// main parent process
|
||||
for(imagefilename in images)
|
||||
{
|
||||
write(pipe[i_image % N_children], imagefilename)
|
||||
}
|
||||
|
||||
worker()
|
||||
{
|
||||
while(1)
|
||||
{
|
||||
imagefilename = read(pipe);
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This is the normal thing: I make pipes for IPC, and send the child workers image filenames through these pipes. Each worker _could_ write its results back to the main process via another set of pipes, but that's a pain, so here each worker writes to the shared STDOUT directly. This works OK, but as one would expect, the writes to STDOUT clash, so the results for the various images end up interspersed. That's bad. I didn't feel like setting up my own locks, but fortunately GNU libc provides facilities for that: [`flockfile()`][1]. I put those in, and … it didn't work! Why? Because whatever `flockfile()` does internally ends up restricted to a single subprocess because of `fork()`'s copy-on-write behavior. I.e. the extra safety provided by `fork()` (compared to threads) actually ends up breaking the locks.
|
||||
|
||||
I haven't tried using other locking mechanisms (like pthread mutexes for instance), but I can imagine they'll have similar problems. And I want to keep things simple, so sending the output back to the parent for output is out of the question: this creates more work for both me the programmer, and for the computer running the program.
|
||||
|
||||
The solution: use threads instead of forks. This has a nice side effect of making the pipes redundant. Final pseudocode:
|
||||
```
|
||||
for(children)
|
||||
{
|
||||
pthread_create(worker, child_index);
|
||||
}
|
||||
for(children)
|
||||
{
|
||||
pthread_join(child);
|
||||
}
|
||||
|
||||
worker(child_index)
|
||||
{
|
||||
for(i_image = child_index; i_image < N_images; i_image += N_children)
|
||||
{
|
||||
results = process(images[i_image]);
|
||||
flockfile(stdout);
|
||||
printf(results);
|
||||
funlockfile(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Much simpler, and actually works as desired. I guess sometimes threads are better.
|
||||
|
||||
### Passing a partly-read file to a child process
|
||||
|
||||
For various [vnlog][2] tools I needed to implement this sequence:
|
||||
|
||||
1. process opens a file with O_CLOEXEC turned off
|
||||
2. process reads a part of this file (up-to the end of the legend in the case of vnlog)
|
||||
3. process calls exec to invoke another program to process the rest of the already-opened file
|
||||
|
||||
The second program may require a file name on the commandline instead of an already-opened file descriptor because this second program may be calling open() by itself. If I pass it the filename, this new program will re-open the file, and then start reading the file from the beginning, not from the location where the original program left off. It is important for my application that this does not happen, so passing the filename to the second program does not work.
|
||||
|
||||
So I really need to pass the already-open file descriptor somehow. I'm using Linux (other OSs maybe behave differently here), so I can in theory do this by passing /dev/fd/N instead of the filename. But it turns out this does not work either. On Linux (again, maybe this is Linux-specific somehow) for normal files /dev/fd/N is a symlink to the original file. So this ends up doing exactly the same thing that passing the filename does.
|
||||
|
||||
But there's a workaround! If we're reading a pipe instead of a file, then there's nothing to symlink to, and /dev/fd/N ends up passing the original pipe down to the second process, and things then work correctly. And I can fake this by changing the open("filename") above to something like popen("cat filename"). Yuck! Is this really the best we can do? What does this look like on one of the BSDs, say?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://notes.secretsauce.net/notes/2018/08/03_unix-curiosities.html
|
||||
|
||||
作者:[Dima Kogan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://notes.secretsauce.net/
|
||||
[1]:https://www.gnu.org/software/libc/manual/html_node/Streams-and-Threads.html
|
||||
[2]:http://www.github.com/dkogan/vnlog
|
||||
159
sources/tech/20180804 Installing Android on VirtualBox.md
Normal file
159
sources/tech/20180804 Installing Android on VirtualBox.md
Normal file
@ -0,0 +1,159 @@
|
||||
Installing Android on VirtualBox
|
||||
======
|
||||
If you are developing mobile apps Android can be a bit of a hassle. While iOS comes with its niceties, provided you are using macOS, Android comes with just Android Studio which is designed to support more than a few Android version, including wearables.
|
||||
|
||||
Needless to say, all the binaries, SDKs, frameworks and debuggers are going to pollute your filesystem with lots and lots of files, logs and other miscellaneous objects. An efficient work around for this is installing Android on your VirtualBox which takes away one of the sluggiest aspect of Android development — The device emulator. You can use this VM to run your test application or just fiddle with Android’s internals. So without further ado let’s set on up!
|
||||
|
||||
### Getting Started
|
||||
|
||||
To get started we will need to have VirtualBox installed on our system, you can get a copy for Windows, macOS or any major distro of Linux [here][1]. Next you would need a copy of Android meant to run on x86 hardware, because that’s what VirtualBox is going to offer to a Virtual Machine an x86 or an x86_64 (a.k.a AMD64) platform to run.
|
||||
|
||||
While most Android devices run on ARM, we can take help of the project [Android on x86][2]. These fine folks have ported Android to run on x86 hardware (both real and virtual) and we can get a copy of the latest release candidate (Android 7.1) for our purposes. You may prefer using a more stable release but in that case Android 6.0 is about as latest as you can get, at the time of this writing.
|
||||
|
||||
#### Creating VM
|
||||
|
||||
Open VirtualBox and click on “New” (top-left corner) and in the Create Virtual Machine window select the type to be Linux and version Linux 2.6 / 3.x /4.x (64-bit) or (32-bit) depending upon whether the ISO you downloaded was x86_64 or x86 respectively.
|
||||
|
||||
RAM size could be anywhere from 2 GB to as much as your system resources can allow. Although if you want to emulate real world devices you should allocate upto 6GB for memory and 32GB for disk size which are typical in Android devices.
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
Upon creation, you might want to tweak a few additional settings, add in an additional processor core and improve display memory for starters. To do this, right-click on the VM and open up settings. In the Settings → System → Processor section you can allocate a few more cores if your desktop can pull it off.
|
||||
|
||||
![][5]
|
||||
|
||||
And in Settings → Display → Video Memory you can allocate a decent chunk of memory and enable 3D acceleration for a more responsive experience.
|
||||
|
||||
![][6]
|
||||
|
||||
Now we are ready to boot the VM.
|
||||
|
||||
#### Installing Android
|
||||
|
||||
Starting the VM for the first time, VirtualBox will insist you to supply it with a bootable media. Select the Android iso that you previously downloaded to boot the machine of with.
|
||||
|
||||
![][7]
|
||||
|
||||
Next, select the Installation option if you wish to install Android on the VM for a long term use, otherwise feel free to log into the live media and play around with the environment.
|
||||
|
||||
![][8]
|
||||
|
||||
Hit <Enter>.
|
||||
|
||||
##### Partitioning the Drive
|
||||
|
||||
Partitioning is done using a textual interface, which means we don’t get the niceties of a GUI and we will have to use the follow careful at what is being shown on the screen. For example, in the first screen when no partition has been created and just a raw (virtual) disk is detected you will see the following.
|
||||
|
||||
![][9]
|
||||
|
||||
The red lettered C and D indicates that if you hit the key C you can create or modify partitions and D will detect additional devices. You can press D and the live media will detect the disks attached, but that is optional since it did a check during the boot.
|
||||
|
||||
Let’s hit C and create partitions in the virtual disk. The offical page recommends against using GPT so we will not use that scheme. Select No using the arrow keys and hit <Enter>.
|
||||
|
||||
![][10]
|
||||
|
||||
And now you will be ushered into the fdisk utility.
|
||||
|
||||
![][11]
|
||||
|
||||
We will create just a single giant partition so as to keep things simple. Using arrow keys navigate to the New option and hit <Enter>. Select primary as the type of partition, and hit <Enter> to confirm
|
||||
|
||||
![][12]
|
||||
|
||||
The maximum size will already be selected for you, hit <Enter> to confirm that.
|
||||
|
||||
![][13]
|
||||
|
||||
This partition is where Android OS will reside, so of course we want it to be bootable. So select Bootable and hit enter (Boot will appear in the flags section in the table above) and then you can navigate to the Write section and hit <Enter> to write the changes to the partitioning table.
|
||||
|
||||
![][14]
|
||||
|
||||
Then you can Quit the partitioning utility and move on with the installation.
|
||||
|
||||
![][15]
|
||||
|
||||
##### Formatting with Ext4 and installing Android
|
||||
|
||||
A new partition will come in the Choose Partition menu where we were before we down the partitioning digression. Let’s select this partition and hit OK.
|
||||
|
||||
![][16]
|
||||
|
||||
Select ext4 as the de facto file system in the next menu. Confirm the changes in the next window by selecting **Yes** and the formatting will begin. When asked, say **Yes** to the GRUB boot loader installation. Similarly, say **Yes** to allowing read-write operations on the /system directory. Now the installation will begin.
|
||||
|
||||
Once it is installed, you can safely reboot the system when prompted to reboot. You may have to power down the machine before the next reboot happens, go to Settings → Storage and remove the android iso if it is still attached to the VM.
|
||||
|
||||
![][17]
|
||||
|
||||
Remove the media and save the changes, before starting up the VM.
|
||||
|
||||
##### Running Android
|
||||
|
||||
In the GRUB menu you will get options for running the OS in debug mode or the normal way. Let’s take a tour of Android in a VM using the default option, as shown below:
|
||||
|
||||
![][18]
|
||||
|
||||
And if everything works fine, you will see this:
|
||||
|
||||
![][19]
|
||||
|
||||
Now Android uses touch screen as an interface instead of a mouse, as far as its normal use is concerned. While the x86 port does come with a mouse point-and-click support you may have to use arrow keys a lot in the beginning.
|
||||
|
||||
![][20]
|
||||
|
||||
Navigate to let’s go, and hit enter, if you are using arrow keys and then select Setup as New.
|
||||
|
||||
![][21]
|
||||
|
||||
It will check for updates and device info, before asking you to sign in using a Google account. You can skip this if you want and move on to setting up Data and Time and give your username to the device after that.
|
||||
|
||||
A few other options would be presented, similar to the options you see when setting up a new Android device. Select appropriate options for privacy, updates, etc and of course Terms of Service, which we might have to Agree to.
|
||||
|
||||
![][22]
|
||||
|
||||
After this, it may ask you to add another email account or set up “On-body detection” since it is a VM, neither of the options are of much use to us and we can click on “All Set”
|
||||
|
||||
It would ask you to select Home App after that, which is upto you to decide, as it is a matter of Preference and you will finally be in a virtualized Android system.
|
||||
|
||||
![][23]
|
||||
|
||||
You may benefit greatly from a touch screen laptop if you desire to do some intensive testing on this VM, since that would emulate a real world use case much closely.
|
||||
|
||||
Hope you have found this tutorial useful in case, you have any other similar request for us to write about, please feel free to reach out to us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxhint.com/install_android_virtualbox/
|
||||
|
||||
作者:[Ranvir Singh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxhint.com/author/sranvir155/
|
||||
[1]:https://www.virtualbox.org/wiki/Downloads
|
||||
[2]:http://www.android-x86.org/
|
||||
[3]:https://linuxhint.com/wp-content/uploads/2018/08/a.png
|
||||
[4]:https://linuxhint.com/wp-content/uploads/2018/08/a1.png
|
||||
[5]:https://linuxhint.com/wp-content/uploads/2018/08/a2.png
|
||||
[6]:https://linuxhint.com/wp-content/uploads/2018/08/a3.png
|
||||
[7]:https://linuxhint.com/wp-content/uploads/2018/08/a4.png
|
||||
[8]:https://linuxhint.com/wp-content/uploads/2018/08/a5.png
|
||||
[9]:https://linuxhint.com/wp-content/uploads/2018/08/a6.png
|
||||
[10]:https://linuxhint.com/wp-content/uploads/2018/08/a7.png
|
||||
[11]:https://linuxhint.com/wp-content/uploads/2018/08/a8.png
|
||||
[12]:https://linuxhint.com/wp-content/uploads/2018/08/a9.png
|
||||
[13]:https://linuxhint.com/wp-content/uploads/2018/08/a10.png
|
||||
[14]:https://linuxhint.com/wp-content/uploads/2018/08/a11.png
|
||||
[15]:https://linuxhint.com/wp-content/uploads/2018/08/a12.png
|
||||
[16]:https://linuxhint.com/wp-content/uploads/2018/08/a13.png
|
||||
[17]:https://linuxhint.com/wp-content/uploads/2018/08/a14.png
|
||||
[18]:https://linuxhint.com/wp-content/uploads/2018/08/a16.png
|
||||
[19]:https://linuxhint.com/wp-content/uploads/2018/08/a17.png
|
||||
[20]:https://linuxhint.com/wp-content/uploads/2018/08/a18.png
|
||||
[21]:https://linuxhint.com/wp-content/uploads/2018/08/a19.png
|
||||
[22]:https://linuxhint.com/wp-content/uploads/2018/08/a20.png
|
||||
[23]:https://linuxhint.com/wp-content/uploads/2018/08/a21.png
|
||||
238
sources/tech/20180806 A gawk script to convert smart quotes.md
Normal file
238
sources/tech/20180806 A gawk script to convert smart quotes.md
Normal file
@ -0,0 +1,238 @@
|
||||
A gawk script to convert smart quotes
|
||||
======
|
||||
|
||||

|
||||
|
||||
I manage a personal website and edit the web pages by hand. Since I don't have many pages on my site, this works well for me, letting me "scratch the itch" of getting into the site's code.
|
||||
|
||||
When I updated my website's design recently, I decided to turn all the plain quotes into "smart quotes," or quotes that look like those used in print material: “” instead of "".
|
||||
|
||||
Editing all of the quotes by hand would take too long, so I decided to automate the process of converting the quotes in all of my HTML files. But doing so via a script or program requires some intelligence. The script needs to know when to convert a plain quote to a smart quote, and which quote to use.
|
||||
|
||||
You can use different methods to convert quotes. Greg Pittman wrote a [Python script][1] for fixing smart quotes in text. I wrote mine in GNU [awk][2] (gawk).
|
||||
|
||||
> Get our awk cheat sheet. [Free download][3].
|
||||
|
||||
To start, I wrote a simple gawk function to evaluate a single character. If that character is a quote, the function determines if it should output a plain quote or a smart quote. The function looks at the previous character; if the previous character is a space, the function outputs a left smart quote. Otherwise, the function outputs a right smart quote. The script does the same for single quotes.
|
||||
```
|
||||
function smartquote (char, prevchar) {
|
||||
|
||||
# print smart quotes depending on the previous character
|
||||
|
||||
# otherwise just print the character as-is
|
||||
|
||||
|
||||
|
||||
if (prevchar ~ /\s/) {
|
||||
|
||||
# prev char is a space
|
||||
|
||||
if (char == "'") {
|
||||
|
||||
printf("‘");
|
||||
|
||||
}
|
||||
|
||||
else if (char == "\"") {
|
||||
|
||||
printf("“");
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
printf("%c", char);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
# prev char is not a space
|
||||
|
||||
if (char == "'") {
|
||||
|
||||
printf("’");
|
||||
|
||||
}
|
||||
|
||||
else if (char == "\"") {
|
||||
|
||||
printf("”");
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
printf("%c", char);
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
With that function, the body of the gawk script processes the HTML input file character by character. The script prints all text verbatim when inside an HTML tag (for example, `<html lang="en">`. Outside any HTML tags, the script uses the `smartquote()` function to print text. The `smartquote()` function does the work of evaluating when to print plain quotes or smart quotes.
|
||||
```
|
||||
function smartquote (char, prevchar) {
|
||||
|
||||
...
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
BEGIN {htmltag = 0}
|
||||
|
||||
|
||||
|
||||
{
|
||||
|
||||
# for each line, scan one letter at a time:
|
||||
|
||||
|
||||
|
||||
linelen = length($0);
|
||||
|
||||
|
||||
|
||||
prev = "\n";
|
||||
|
||||
|
||||
|
||||
for (i = 1; i <= linelen; i++) {
|
||||
|
||||
char = substr($0, i, 1);
|
||||
|
||||
|
||||
|
||||
if (char == "<") {
|
||||
|
||||
htmltag = 1;
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
if (htmltag == 1) {
|
||||
|
||||
printf("%c", char);
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
smartquote(char, prev);
|
||||
|
||||
prev = char;
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
if (char == ">") {
|
||||
|
||||
htmltag = 0;
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
# add trailing newline at end of each line
|
||||
|
||||
printf ("\n");
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Here's an example:
|
||||
```
|
||||
gawk -f quotes.awk test.html > test2.html
|
||||
|
||||
```
|
||||
|
||||
Sample input:
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
|
||||
<html lang="en">
|
||||
|
||||
<head>
|
||||
|
||||
<title>Test page</title>
|
||||
|
||||
<link rel="stylesheet" type="text/css" href="/test.css" />
|
||||
|
||||
<meta charset="UTF-8">
|
||||
|
||||
<meta name="viewport" content="width=device-width" />
|
||||
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<h1><a href="/"><img src="logo.png" alt="Website logo" /></a></h1>
|
||||
|
||||
<p>"Hi there!"</p>
|
||||
|
||||
<p>It's and its.</p>
|
||||
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
|
||||
<html lang="en">
|
||||
|
||||
<head>
|
||||
|
||||
<title>Test page</title>
|
||||
|
||||
<link rel="stylesheet" type="text/css" href="/test.css" />
|
||||
|
||||
<meta charset="UTF-8">
|
||||
|
||||
<meta name="viewport" content="width=device-width" />
|
||||
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
<h1><a href="/"><img src="logo.png" alt="Website logo" /></a></h1>
|
||||
|
||||
<p>“Hi there!”</p>
|
||||
|
||||
<p>It’s and its.</p>
|
||||
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/gawk-script-convert-smart-quotes
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/article/17/3/python-scribus-smart-quotes
|
||||
[2]:/downloads/cheat-sheet-awk-features
|
||||
[3]:https://opensource.com/downloads/cheat-sheet-awk-features
|
||||
@ -0,0 +1,96 @@
|
||||
GPaste Is A Great Clipboard Manager For Gnome Shell
|
||||
======
|
||||
**[GPaste][1] is a clipboard management system that consists of a library, daemon, and interfaces for the command line and Gnome (using a native Gnome Shell extension).**
|
||||
|
||||
A clipboard manager allows keeping track of what you're copying and pasting, providing access to previously copied items. GPaste, with its native Gnome Shell extension, makes the perfect addition for those looking for a Gnome clipboard manager.
|
||||
|
||||
[![GPaste Gnome Shell extension Ubuntu 18.04][2]][3]
|
||||
GPaste Gnome Shell extension
|
||||
**Using GPaste in Gnome, you get a configurable, searchable clipboard history, available with a click on the top panel. GPaste remembers not only the text you copy, but also file paths and images** (the latter needs to be enabled from its settings as it's disabled by default).
|
||||
|
||||
What's more, GPaste can detect growing lines, meaning it can detect when a new text copy is an extension of another and replaces it if it's true, useful for keeping your clipboard clean.
|
||||
|
||||
From the extension menu you can pause GPaste from tracking the clipboard, and remove items from the clipboard history or the whole history. You'll also find a button that launches the GPaste user interface window.
|
||||
|
||||
**If you prefer to use the keyboard, you can use a key shortcut to open the GPaste history from the top bar** (`Ctrl + Alt + H`), **or open the full GPaste GUI** (`Ctrl + Alt + G`).
|
||||
|
||||
The tool also incorporates keyboard shortcuts to (can be changed):
|
||||
|
||||
* delete the active item from history: `Ctrl + Alt + V`
|
||||
|
||||
* **mark the active item as being a password (which obfuscates the clipboard entry in GPaste):** `Ctrl + Alt + S`
|
||||
|
||||
* sync the clipboard to the primary selection: `Ctrl + Alt + O`
|
||||
|
||||
* sync the primary selection to the clipboard: `Ctrl + Alt + P`
|
||||
|
||||
* upload the active item to a pastebin service: `Ctrl + Alt + U`
|
||||
|
||||
[![][4]][5]
|
||||
GPaste GUI
|
||||
|
||||
The GPaste interface window provides access to the clipboard history (with options to clear, edit or upload items), which can be searched, an option to pause GPaste from tracking the clipboard, restart the GPaste daemon, backup current clipboard history, as well as to its settings.
|
||||
|
||||
[![][6]][7]
|
||||
GPaste GUI
|
||||
|
||||
From the GPaste UI you can change settings like:
|
||||
|
||||
* Enable or disable the Gnome Shell extension
|
||||
* Sync the daemon state with the extension's one
|
||||
* Primary selection affects history
|
||||
* Synchronize clipboard with primary selection
|
||||
* Image support
|
||||
* Trim items
|
||||
* Detect growing lines
|
||||
* Save history
|
||||
* History settings like max history size, memory usage, max text item length, and more
|
||||
* Keyboard shortcuts
|
||||
|
||||
|
||||
|
||||
### Download GPaste
|
||||
|
||||
[Download GPaste](https://github.com/Keruspe/GPaste)
|
||||
|
||||
The Gpaste project page does not link to any GPaste binaries, and only source installation instructions. Users running Linux distributions other than Debian or Ubuntu (for which you'll find GPaste installation instructions below) can search their distro repositories for GPaste.
|
||||
|
||||
Do not confuse GPaste with the GPaste Integration extension posted on the Gnome Shell extension website. That is a Gnome Shell extension that uses GPaste daemon, which is no longer maintained. The native Gnome Shell extension built into GPaste is still maintained.
|
||||
|
||||
#### Install GPaste in Ubuntu (18.04, 16.04) or Debian (Jessie and newer)
|
||||
|
||||
**For Debian, GPaste is available for Jessie and newer, while for Ubuntu, GPaste is in the repositories for 16.04 and newer (so it's available in the Ubuntu 18.04 Bionic Beaver).**
|
||||
|
||||
**You can install GPaste (the daemon and the Gnome Shell extension) in Debian or Ubuntu using this command:**
|
||||
```
|
||||
sudo apt install gnome-shell-extensions-gpaste gpaste
|
||||
|
||||
```
|
||||
|
||||
After the installation completes, restart Gnome Shell by pressing `Alt + F2` and typing `r` , then pressing the `Enter` key. The GPaste Gnome Shell extension should now be enabled and its icon should show up on the top Gnome Shell panel. If it's not, use Gnome Tweaks (Gnome Tweak Tool) to enable the extension.
|
||||
|
||||
**The GPaste 3.28.0 package from[Debian][8] and [Ubuntu][9] has a bug that makes it crash if the image support option is enabled, so do not enable this feature for now.** This was marked as
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/Keruspe/GPaste
|
||||
[2]:https://2.bp.blogspot.com/-2ndArDBcrwY/W2gyhMc1kEI/AAAAAAAABS0/ZAe_onuGCacMblF733QGBX3XqyZd--WuACLcBGAs/s400/gpaste-gnome-shell-extension-ubuntu1804.png (Gpaste Gnome Shell)
|
||||
[3]:https://2.bp.blogspot.com/-2ndArDBcrwY/W2gyhMc1kEI/AAAAAAAABS0/ZAe_onuGCacMblF733QGBX3XqyZd--WuACLcBGAs/s1600/gpaste-gnome-shell-extension-ubuntu1804.png
|
||||
[4]:https://2.bp.blogspot.com/-7FBRsZJvYek/W2gyvzmeRxI/AAAAAAAABS4/LhokMFSn8_kZndrNB-BTP4W3e9IUuz9BgCLcBGAs/s640/gpaste-gui_1.png
|
||||
[5]:https://2.bp.blogspot.com/-7FBRsZJvYek/W2gyvzmeRxI/AAAAAAAABS4/LhokMFSn8_kZndrNB-BTP4W3e9IUuz9BgCLcBGAs/s1600/gpaste-gui_1.png
|
||||
[6]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s640/gpaste-gui_2.png
|
||||
[7]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s1600/gpaste-gui_2.png
|
||||
[8]:https://packages.debian.org/buster/gpaste
|
||||
[9]:https://launchpad.net/ubuntu/+source/gpaste
|
||||
[10]:https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html
|
||||
@ -0,0 +1,126 @@
|
||||
How ProPublica Illinois uses GNU Make to load 1.4GB of data every day
|
||||
======
|
||||
|
||||

|
||||
|
||||
I avoided using GNU Make in my data journalism work for a long time, partly because the documentation was so obtuse that I couldn’t see how Make, one of many extract-transform-load (ETL) processes, could help my day-to-day data reporting. But this year, to build [The Money Game][1], I needed to load 1.4GB of Illinois political contribution and spending data every day, and the ETL process was taking hours, so I gave Make another chance.
|
||||
|
||||
Now the same process takes less than 30 minutes.
|
||||
|
||||
Here’s how it all works, but if you want to skip directly to the code, [we’ve open-sourced it here][2].
|
||||
|
||||
Fundamentally, Make lets you say:
|
||||
|
||||
* File X depends on a transformation applied to file Y
|
||||
* If file X doesn’t exist, apply that transformation to file Y and make file X
|
||||
|
||||
|
||||
|
||||
This “start with file Y to get file X” pattern is a daily reality of data journalism, and using Make to load political contribution and spending data was a great use case. The data is fairly large, accessed via a slow FTP server, has a quirky format, has just enough integrity issues to keep things interesting, and needs to be compatible with a legacy codebase. To tackle it, I needed to start from the beginning.
|
||||
|
||||
### Overview
|
||||
|
||||
The financial disclosure data we’re using is from the Illinois State Board of Elections, but the [Illinois Sunshine project][3] had released open source code (no longer available) to handle the ETL process and fundraising calculations. Using their code, the ETL process took about two hours to run on robust hardware and over five hours on our servers, where it would sometimes fail for reasons I never quite understood. I needed it to work better and work faster.
|
||||
|
||||
The process looks like this:
|
||||
|
||||
* **Download** data files via FTP from Illinois State Board Of Elections.
|
||||
* **Clean** the data using Python to resolve integrity issues and create clean versions of the data files.
|
||||
* **Load** the clean data into PostgreSQL using its highly efficient but finicky “\copy” command.
|
||||
* **Transform** the data in the database to clean up column names and provide more immediately useful forms of the data using “raw” and “public” PostgreSQL schemas and materialized views (essentially persistently cached versions of standard SQL views).
|
||||
|
||||
|
||||
|
||||
The cleaning step must happen before any data is loaded into the database, so we can take advantage of PostgreSQL’s efficient import tools. If a single row has a string in a column where it’s expecting an integer, the whole operation fails.
|
||||
|
||||
GNU Make is well-suited to this task. Make’s model is built around describing the output files your ETL process should produce and the operations required to go from a set of original source files to a set of output files.
|
||||
|
||||
As with any ETL process, the goal is to preserve your original data, keep operations atomic and provide a simple and repeatable process that can be run over and over.
|
||||
|
||||
Let’s examine a few of the steps:
|
||||
|
||||
### Download and pre-import cleaning
|
||||
|
||||
Take a look at this snippet, which could be a standalone Makefile:
|
||||
```
|
||||
data/download/%.txt : aria2c -x5 -q -d data/download --ftp-user="$(ILCAMPAIGNCASH_FTP_USER)" --ftp-passwd="$(ILCAMPAIGNCASH_FTP_PASSWD)" ftp://ftp.elections.il.gov/CampDisclDataFiles/$*.txt data/processed/%.csv : data/download/%.txt python processors/clean_isboe_tsv.py $< $* > $@
|
||||
|
||||
```
|
||||
|
||||
This snippet first downloads a file via FTP and then uses Python to process it. For example, if “Expenditures.txt” is one of my source data files, I can run `make data/processed/Expenditures.csv` to download and process the expenditure data.
|
||||
|
||||
There are two things to note here.
|
||||
|
||||
The first is that we use [Aria2][4] to handle FTP duties. Earlier versions of the script used other FTP clients that were either slow as molasses or painful to use. After some trial and error, I found Aria2 did the job better than lftp (which is fast but fussy) or good old ftp (which is both slow and fussy). I also found some incantations that took download times from roughly an hour to less than 20 minutes.
|
||||
|
||||
Second, the cleaning step is crucial for this dataset. It uses a simple class-based Python validation scheme you can [see here][5]. The important thing to note is that while Python is pretty slow generally, Python 3 is fast enough for this. And as long as you are [only processing row-by-row][6] without any objects accumulating in memory or doing any extra disk writes, performance is fine, even on low-resource machines like the servers in ProPublica’s cluster, and there aren’t any unexpected quirks.
|
||||
|
||||
### Loading
|
||||
|
||||
Make is built around file inputs and outputs. But what happens if our data is both in files and database tables? Here are a few valuable tricks I learned for integrating database tables into Makefiles:
|
||||
|
||||
**One SQL file per table / transform** : Make loves both files and simple mappings, so I created individual files with the schema definitions for each table or any other atomic table-level operation. The table names match the SQL filenames, the SQL filenames match the source data filenames. You can see them [here][7].
|
||||
|
||||
**Use exit code magic to make tables look like files to Make** : Hannah Cushman and Forrest Gregg from DataMade [introduced me to this trick on Twitter][8]. Make can be fooled into treating tables like files if you prefix table level commands with commands that emit appropriate exit codes. If a table exists, emit a successful code. If it doesn’t, emit an error.
|
||||
|
||||
Beyond that, loading consists solely of the highly efficient PostgreSQL `\copy` command. While the `COPY` command is even more efficient, it doesn’t play nicely with Amazon RDS. Even if ProPublica moved to a different database provider, I’d continue to use `\copy` for portability unless eking out a little more performance was mission-critical.
|
||||
|
||||
There’s one last curveball: The loading step imports data to a PostgreSQL schema called `raw` so that we can cleanly transform the data further. Postgres schemas provide a useful way of segmenting data within a single database — instead of a single namespace with tables like `raw_contributions` and `clean_contributions`, you can keep things simple and clear with an almost folder-like structure of `raw.contributions` and `public.contributions`.
|
||||
|
||||
### Post-import transformations
|
||||
|
||||
The Illinois Sunshine code also renames columns and slightly reshapes the data for usability and performance reasons. Column aliasing is useful for end users and the intermediate tables are required for compatibility with the legacy code.
|
||||
|
||||
In this case, the loader imports into a schema called `raw` that is as close to the source data as humanly possible.
|
||||
|
||||
The data is then transformed by creating materialized views of the raw tables that rename columns and handle some light post-processing. This is enough for our purposes, but more elaborate transformations could be applied without sacrificing clarity or obscuring the source data. Here’s a snippet of one of these view definitions:
|
||||
```
|
||||
CREATE MATERIALIZED VIEW d2_reports AS SELECT id as id, committeeid as committee_id, fileddocid as filed_doc_id, begfundsavail as beginning_funds_avail, indivcontribi as individual_itemized_contrib, indivcontribni as individual_non_itemized_contrib, xferini as transfer_in_itemized, xferinni as transfer_in_non_itemized, # …. FROM raw.d2totals WITH DATA;
|
||||
```
|
||||
|
||||
These transformations are very simple, but simply using more readable column names is a big improvement for end-users.
|
||||
|
||||
As with table schema definitions, there is a file for each table that describes the transformed view. We use materialized views, which, again, are essentially persistently cached versions of standard SQL views, because storage is cheap and they are faster than traditional SQL views.
|
||||
|
||||
### A note about security
|
||||
|
||||
You’ll notice we use environment variables that are expanded inline when the commands are run. That’s useful for debugging and helps with portability. But it’s not a good idea if you think log files or terminal output could be compromised or people who shouldn’t know these secrets have access to logs or shared systems. For more security, you could use a system like the PostgreSQL `pgconf` file and remove the environment variable references.
|
||||
|
||||
### Makefiles for the win
|
||||
|
||||
My only prior experience with Make was in a computational math course 15 years ago, where it was a frustrating and poorly explained footnote. The combination of obtuse documentation, my bad experience in school and an already reliable framework kept me away. Plus, my shell scripts and Python Fabric/Invoke code were doing a fine job building reliable data processing pipelines based on the same principles for the smaller, quick turnaround projects I was doing.
|
||||
|
||||
But after trying Make for this project, I was more than impressed with the results. It’s concise and expressive. It enforces atomic operations, but rewards them with dead simple ways to handle partial builds, which is a big deal during development when you really don’t want to be repeating expensive operations to test individual components. Combined with PostgreSQL’s speedy import tools, schemas, and materialized views, I was able to load the data in a fraction of the time. And just as important, the performance of the new process is less sensitive to varying system resources.
|
||||
|
||||
If you’re itching to get started with Make, here are a few additional resources:
|
||||
|
||||
+ [Making Data, The Datamade Way][9], by Hannah Cushman. My original inspiration.
|
||||
+ [“Why Use Make”][10] by Mike Bostock.
|
||||
+ [“Practical Makefiles, by example”][11] by John Tsiombikas is a nice resource if you want to dig deeper, but Make’s documentation is intimidating.
|
||||
|
||||
|
||||
In the end, the best build/processing system is any system that never alters source data, clearly shows transformations, uses version control and can be easily run over and over. Grunt, Gulp, Rake, Make, Invoke … you have options. As long as you like what you use and use it religiously, your work will benefit.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/how-propublica-illinois-uses-gnu-make
|
||||
|
||||
作者:[David Eads][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eads
|
||||
[1]:https://www.propublica.org/article/illinois-governors-race-campaign-widget-update
|
||||
[2]:https://github.com/propublica/ilcampaigncash/
|
||||
[3]:https://illinoissunshine.org/
|
||||
[4]:https://aria2.github.io/
|
||||
[5]:https://github.com/propublica/ilcampaigncash/blob/master/processors/lib/models.py
|
||||
[6]:https://github.com/propublica/ilcampaigncash/blob/master/processors/clean_isboe_tsv.py#L13
|
||||
[7]:https://github.com/propublica/ilcampaigncash/tree/master/sql/tables
|
||||
[8]:https://twitter.com/eads/status/968970130427404293
|
||||
[9]: https://github.com/datamade/data-making-guidelines
|
||||
[10]: https://bost.ocks.org/mike/make/
|
||||
[11]: http://nuclear.mutantstargoat.com/articles/make/
|
||||
@ -0,0 +1,160 @@
|
||||
Installing and using Git and GitHub on Ubuntu Linux: A beginner's guide
|
||||
======
|
||||
|
||||
GitHub is a treasure trove of some of the world's best projects, built by the contributions of developers all across the globe. This simple, yet extremely powerful platform helps every individual interested in building or developing something big to contribute and get recognized in the open source community.
|
||||
|
||||
This tutorial is a quick setup guide for installing and using GitHub and how to perform its various functions of creating a repository locally, connecting this repo to the remote host that contains your project (where everyone can see), committing the changes and finally pushing all the content in the local system to GitHub.
|
||||
|
||||
Please note that this tutorial assumes that you have a basic knowledge of the terms used in Git such as push, pull requests, commit, repository, etc. It also requires you to register to GitHub [here][1] and make a note of your GitHub username. So let's begin:
|
||||
|
||||
### 1 Installing Git for Linux
|
||||
|
||||
Download and install Git for Linux:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
The above command is for Ubuntu and works on all Recent Ubuntu versions, tested from Ubuntu 16.04 to Ubuntu 18.04 LTS (Bionic Beaver) and it's likely to work the same way on future versions.
|
||||
|
||||
### 2 Configuring GitHub
|
||||
|
||||
Once the installation has successfully completed, the next thing to do is to set up the configuration details of the GitHub user. To do this use the following two commands by replacing "user_name" with your GitHub username and replacing "email_id" with your email-id you used to create your GitHub account.
|
||||
|
||||
```
|
||||
git config --global user.name "user_name"
|
||||
|
||||
git config --global user.email "email_id"
|
||||
```
|
||||
|
||||
The following image shows an example of my configuration with my "user_name" being "akshaypai" and my "email_id" being "[[email protected]][2]"
|
||||
|
||||
[![Git config][3]][4]
|
||||
|
||||
### 3 Creating a local repository
|
||||
|
||||
Create a folder on your system. This will serve as a local repository which will later be pushed onto the GitHub website. Use the following command:
|
||||
|
||||
```
|
||||
git init Mytest
|
||||
```
|
||||
|
||||
If the repository is created successfully, then you will get the following line:
|
||||
|
||||
Initialized empty Git repository in /home/akshay/Mytest/.git/
|
||||
|
||||
This line may vary depending on your system.
|
||||
|
||||
So here, Mytest is the folder that is created and "init" makes the folder a GitHub repository. Change the directory to this newly created folder:
|
||||
|
||||
```
|
||||
cd Mytest
|
||||
```
|
||||
|
||||
### 4 Creating a README file to describe the repository
|
||||
|
||||
Now create a README file and enter some text like "this is a git setup on Linux". The README file is generally used to describe what the repository contains or what the project is all about. Example:
|
||||
|
||||
```
|
||||
gedit README
|
||||
```
|
||||
|
||||
You can use any other text editors. I use gedit. The content of the README file will be:
|
||||
|
||||
This is a git repo
|
||||
|
||||
### 5 Adding repository files to an index
|
||||
|
||||
This is an important step. Here we add all the things that need to be pushed onto the website into an index. These things might be the text files or programs that you might add for the first time into the repository or it could be adding a file that already exists but with some changes (a newer version/updated version).
|
||||
|
||||
Here we already have the README file. So, let's create another file which contains a simple C program and call it sample.c. The contents of it will be:
|
||||
```
|
||||
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
printf("hello world");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So, now that we have 2 files
|
||||
|
||||
README and sample.c
|
||||
|
||||
add it to the index by using the following 2 commands:
|
||||
|
||||
```
|
||||
git add README
|
||||
|
||||
git add smaple.c
|
||||
```
|
||||
|
||||
Note that the "git add" command can be used to add any number of files and folders to the index. Here, when I say index, what I am referring to is a buffer like space that stores the files/folders that have to be added into the Git repository.
|
||||
|
||||
### 6 Committing changes made to the index
|
||||
|
||||
Once all the files are added, we can commit it. This means that we have finalized what additions and/or changes have to be made and they are now ready to be uploaded to our repository. Use the command :
|
||||
|
||||
```
|
||||
git commit -m "some_message"
|
||||
```
|
||||
|
||||
"some_message" in the above command can be any simple message like "my first commit" or "edit in readme", etc.
|
||||
|
||||
### 7 Creating a repository on GitHub
|
||||
|
||||
Create a repository on GitHub. Notice that the name of the repository should be the same as the repository's on the local system. In this case, it will be "Mytest". To do this login to your account on <https://github.com>. Then click on the "plus(+)" symbol at the top right corner of the page and select "create new repository". Fill the details as shown in the image below and click on "create repository" button.
|
||||
|
||||
[![Creating a repository on GitHub][5]][6]
|
||||
|
||||
Once this is created, we can push the contents of the local repository onto the GitHub repository in your profile. Connect to the repository on GitHub using the command:
|
||||
|
||||
Important Note: Make sure you replace 'user_name' and 'Mytest' in the path with your Github username and folder before running the command!
|
||||
|
||||
```
|
||||
git remote add origin <https://github.com/user\_name/Mytest.git>
|
||||
```
|
||||
|
||||
### 8 Pushing files in local repository to GitHub repository
|
||||
|
||||
The final step is to push the local repository contents into the remote host repository (GitHub), by using the command:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
Enter the login credentials [user_name and password].
|
||||
|
||||
The following image shows the procedure from step 5 to step 8
|
||||
|
||||
[![Pushing files in local repository to GitHub repository][7]][8]
|
||||
|
||||
So this adds all the contents of the 'Mytest' folder (my local repository) to GitHub. For subsequent projects or for creating repositories, you can start off with step 3 directly. Finally, if you log in to your GitHub account and click on your Mytest repository, you can see that the 2 files README and sample.c have been uploaded and are visible to all as shown in the following image.
|
||||
|
||||
[![Content uploaded to Github][9]][10]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
|
||||
|
||||
作者:[Akshay Pai][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://github.com/
|
||||
[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
|
||||
[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
|
||||
[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
|
||||
[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
|
||||
[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
|
||||
[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
|
||||
[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
|
||||
[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
|
||||
@ -0,0 +1,75 @@
|
||||
Learn Python programming the easy way with EduBlocks
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are you looking for a way to move your students (or yourself) from programming in [Scratch][1] to learning [Python][2], I recommend you look into [EduBlocks][3]. It brings a familiar drag-and-drop graphical user interface (GUI) to Python 3 programming.
|
||||
|
||||
One of the barriers when transitioning from Scratch to Python is the absence of the drag-and-drop GUI that has made Scratch the go-to application in K-12 schools. EduBlocks' drag-and-drop version of Python 3 changes that paradigm. It aims to "help teachers to introduce text-based programming languages, like Python, to children at an earlier age."
|
||||
|
||||
The hardware requirements for EduBlocks are quite modest—a Raspberry Pi and an internet connection—and should be available in many classrooms.
|
||||
|
||||
EduBlocks was developed by Joshua Lowe, a 14-year-old Python developer from the United Kingdom. I saw Joshua demonstrate his project at [PyCon 2018][4] in May 2018.
|
||||
|
||||
### Getting started
|
||||
|
||||
It's easy to install EduBlocks. The website provides clear installation instructions, and you can find detailed screenshots in the project's [GitHub][5] repository.
|
||||
|
||||
Install EduBlocks from the Raspberry Pi command line by issuing the following command:
|
||||
```
|
||||
curl -sSL get.edublocks.org | bash
|
||||
|
||||
```
|
||||
|
||||
### Programming EduBlocks
|
||||
|
||||
Once the installation is complete, launch EduBlocks from either the desktop shortcut or the Programming menu on the Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
Once you launch the application, you can start creating Python 3 code with EduBlocks' drag-and-drop interface. Its menus are clearly labeled. You can start with sample code by clicking the **Samples** menu button. You can also choose a different color scheme for your programming palette by clicking **Theme**. With the **Save** menu, you can save your code as you work, then **Download** your Python code. Click **Run** to execute and test your code.
|
||||
|
||||
You can see your code by clicking the **Blockly** button at the far right. It allows you to toggle between the "Blockly" interface and the normal Python code view (as you would see in any other Python editor).
|
||||
|
||||
|
||||
|
||||
EduBlocks comes with a range of code libraries, including [EduPython][6], [Minecraft][7], [Sonic Pi][8], [GPIO Zero][9], and [Sense Hat][10].
|
||||
|
||||
### Learning and support
|
||||
|
||||
The project maintains a [learning portal][11] with tutorials and other resources for easily [hacking][12] the version of Minecraft that comes with Raspberry Pi, programming the GPIOZero and Sonic Pi, and controlling LEDs with the Micro:bit code editor. Support for EduBlocks is available on Twitter [@edu_blocks][13] and [@all_about_code][14] and through [email][15].
|
||||
|
||||
For a deeper dive, you can access EduBlocks' source code on [GitHub][16]; the application is [licensed][17] under GNU Affero General Public License v3.0. EduBlocks' creators (project lead [Joshua Lowe][18] and fellow developers [Chris Dell][19] and [Les Pounder][20]) want it to be a community project and invite people to open issues, provide feedback, and submit pull requests to add features or fixes to the project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/edublocks
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://scratch.mit.edu/
|
||||
[2]:https://www.python.org/
|
||||
[3]:https://edublocks.org/
|
||||
[4]:https://us.pycon.org/2018/about/
|
||||
[5]:https://github.com/AllAboutCode/EduBlocks
|
||||
[6]:https://edupython.tuxfamily.org/
|
||||
[7]:https://minecraft.net/en-us/edition/pi/
|
||||
[8]:https://sonic-pi.net/
|
||||
[9]:https://gpiozero.readthedocs.io/en/stable/
|
||||
[10]:https://www.raspberrypi.org/products/sense-hat/
|
||||
[11]:https://edublocks.org/learn.html
|
||||
[12]:https://edublocks.org/resources/1.pdf
|
||||
[13]:https://twitter.com/edu_blocks?lang=en
|
||||
[14]:https://twitter.com/all_about_code
|
||||
[15]:mailto:support@edublocks.org
|
||||
[16]:https://github.com/allaboutcode/edublocks
|
||||
[17]:https://github.com/AllAboutCode/EduBlocks/blob/tarball-install/LICENSE
|
||||
[18]:https://github.com/JoshuaLowe1002
|
||||
[19]:https://twitter.com/cjdell?lang=en
|
||||
[20]:https://twitter.com/biglesp?lang=en
|
||||
220
sources/tech/20180806 Systemd Timers- Three Use Cases.md
Normal file
220
sources/tech/20180806 Systemd Timers- Three Use Cases.md
Normal file
@ -0,0 +1,220 @@
|
||||
Systemd Timers: Three Use Cases
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this systemd tutorial series, we have[ already talked about systemd timer units to some degree][1], but, before moving on to the sockets, let's look at three examples that illustrate how you can best leverage these units.
|
||||
|
||||
### Simple _cron_ -like behavior
|
||||
|
||||
This is something I have to do: collect [popcon data from Debian][2] every week, preferably at the same time so I can see how the downloads for certain applications evolve. This is the typical thing you can have a _cron_ job do, but a systemd timer can do it too:
|
||||
```
|
||||
# cron-like popcon.timer
|
||||
|
||||
[Unit]
|
||||
Description= Says when to download and process popcons
|
||||
|
||||
[Timer]
|
||||
OnCalendar= Thu *-*-* 05:32:07
|
||||
Unit= popcon.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The actual _popcon.service_ runs a regular _wget_ job, so nothing special. What is new in here is the `OnCalendar=` directive. This is what lets you set a service to run on a certain date at a certain time. In this case, `Thu` means " _run on Thursdays_ " and the `*-*-*` means " _the exact date, month and year don't matter_ ", which translates to " _run on Thursday, regardless of the date, month or year_ ".
|
||||
|
||||
Then you have the time you want to run the service. I chose at about 5:30 am CEST, which is when the server is not very busy.
|
||||
|
||||
If the server is down and misses the weekly deadline, you can also work an _anacron_ -like functionality into the same timer:
|
||||
```
|
||||
# popcon.timer with anacron-like functionality
|
||||
|
||||
[Unit]
|
||||
Description=Says when to download and process popcons
|
||||
|
||||
[Timer]
|
||||
Unit=popcon.service
|
||||
OnCalendar=Thu *-*-* 05:32:07
|
||||
Persistent=true
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
When you set the `Persistent=` directive to true, it tells systemd to run the service immediately after booting if the server was down when it was supposed to run. This means that if the machine was down, say for maintenance, in the early hours of Thursday, as soon as it is booted again, _popcon.service_ will be run immediately and then it will go back to the routine of running the service every Thursday at 5:32 am.
|
||||
|
||||
So far, so straightforward.
|
||||
|
||||
### Delayed execution
|
||||
|
||||
But let's kick thing up a notch and "improve" the [systemd-based surveillance system][3]. Remember that the system started taking pictures the moment you plugged in a camera. Suppose you don't want pictures of your face while you install the camera. You will want to delay the start up of the picture-taking service by a minute or two so you can plug in the camera and move out of frame.
|
||||
|
||||
To do this; first change the Udev rule so it points to a timer:
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
|
||||
```
|
||||
|
||||
The timer looks like this:
|
||||
```
|
||||
# picchanged.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs picchanged 1 minute after the camera is plugged in
|
||||
|
||||
[Timer]
|
||||
OnActiveSec= 1 m
|
||||
Unit= picchanged.path
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The Udev rule gets triggered when you plug the camera in and it calls the timer. The timer waits for one minute after it starts (`OnActiveSec= 1 m`) and then runs _picchanged.path_ , which [monitors to see if the master image changes][4]. The _picchanged.path_ is also in charge of pulling in the _webcam.service_ , the service that actually takes the picture.
|
||||
|
||||
### Start and stop Minetest server at a certain time every day
|
||||
|
||||
In the final example, let's say you have decided to delegate parenting to systemd. I mean, systemd seems to be already taking over most of your life anyway. Why not embrace the inevitable?
|
||||
|
||||
So you have your Minetest service set up for your kids. You also want to give some semblance of caring about their education and upbringing and have them do homework and chores. What you want to do is make sure Minetest is only available for a limited time (say from 5 pm to 7 pm) every evening.
|
||||
|
||||
This is different from " _starting a service at certain time_ " in that, writing a timer to start the service at 5 pm is easy...:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs the minetest.service at 5pm everyday
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17:00:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
... But writing a counterpart timer that shuts down a service at a certain time needs a bigger dose of lateral thinking.
|
||||
|
||||
Let's start with the obvious -- the timer:
|
||||
```
|
||||
# stopminetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Stops the minetest.service at 7 pm everyday
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 19:05:00
|
||||
Unit= stopminetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The tricky part is how to tell _stopminetest.service_ to actually, you know, stop the Minetest. There is no way to pass the PID of the Minetest server from _minetest.service_. and there are no obvious commands in systemd's unit vocabulary to stop or disable a running service.
|
||||
|
||||
The trick is to use systemd's `Conflicts=` directive. The `Conflicts=` directive is similar to systemd's `Wants=` directive, in that it does _exactly the opposite_. If you have `Wants=a.service` in a unit called _b.service_ , when it starts, _b.service_ will run _a.service_ if it is not running already. Likewise, if you have a line that reads `Conflicts= a.service` in your _b.service_ unit, as soon as _b.service_ starts, systemd will stop _a.service_.
|
||||
|
||||
This was created for when two services could clash when trying to take control of the same resource simultaneously, say when two services needed to access your printer at the same time. By putting a `Conflicts=` in your preferred service, you could make sure it would override the least important one.
|
||||
|
||||
You are going to use `Conflicts=` a bit differently, however. You will use `Conflicts=` to close down cleanly the _minetest.service_ :
|
||||
```
|
||||
# stopminetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Closes down the Minetest service
|
||||
Conflicts= minetest.service
|
||||
|
||||
[Service]
|
||||
Type= oneshot
|
||||
ExecStart= /bin/echo "Closing down minetest.service"
|
||||
|
||||
```
|
||||
|
||||
The _stopminetest.service_ doesn't do much at all. Indeed, it could do nothing at all, but just because it contins that `Conflicts=` line in there, when it is started, systemd will close down _minetest.service_.
|
||||
|
||||
There is one last wrinkle in your perfect Minetest set up: What happens if you are late home from work, it is past the time when the server should be up but playtime is not over? The `Persistent=` directive (see above) that runs a service if it has missed its start time is no good here, because if you switch the server on, say at 11 am, it would start Minetest and that is not what you want. What you really want is a way to make sure that systemd will only start Minetest between the hours of 5 and 7 in the evening:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs the minetest.service every minute between the hours of 5pm and 7pm
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17..19:*:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The line `OnCalendar= *-*-* 17..19:*:00` is interesting for two reasons: (1) `17..19` is not a point in time, but a period of time, in this case the period of time between the times of 17 and 19; and (2) the `*` in the minute field indicates that the service must be run every minute. Hence, you would read this as " _run the minetest.service every minute between 5 and 7 pm_ ".
|
||||
|
||||
There is still one catch, though: once the _minetest.service_ is up and running, you want _minetest.timer_ to stop trying to run it again and again. You can do that by including a `Conflicts=` directive into _minetest.service_ :
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Runs Minetest server
|
||||
Conflicts= minetest.timer
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User= <your user name>
|
||||
|
||||
ExecStart= /usr/bin/minetest --server
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.targe
|
||||
|
||||
```
|
||||
|
||||
The `Conflicts=` directive shown above makes sure _minetest.timer_ is stopped as soon as the _minetest.service_ is successfully started.
|
||||
|
||||
Now enable and start _minetest.timer_ :
|
||||
```
|
||||
systemctl enable minetest.timer
|
||||
systemctl start minetest.timer
|
||||
|
||||
```
|
||||
|
||||
And, if you boot the server at, say, 6 o'clock, _minetest.timer_ will start up and, as the time falls between 5 and 7, _minetest.timer_ will try and start _minetest.service_ every minute. But, as soon as _minetest.service_ is running, systemd will stop _minetest.timer_ because it "conflicts" with _minetest.service_ , thus avoiding the timer from trying to start the service over and over when it is already running.
|
||||
|
||||
It is a bit counterintuitive that you use the service to kill the timer that started it up in the first place, but it works.
|
||||
|
||||
### Conclusion
|
||||
|
||||
You probably think that there are better ways of doing all of the above. I have heard the term "overengineered" in regard to these articles, especially when using systemd timers instead of cron.
|
||||
|
||||
But, the purpose of this series of articles is not to provide the best solution to any particular problem. The aim is to show solutions that use systemd units as much as possible, even to a ridiculous length. The aim is to showcase plenty of examples of how the different types of units and the directives they contain can be leveraged. It is up to you, the reader, to find the real practical applications for all of this.
|
||||
|
||||
Be that as it may, there is still one more thing to go: next time, we'll be looking at _sockets_ and _targets_ , and then we'll be done with systemd units.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cases-0
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
[2]:https://popcon.debian.org/
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
312
sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
Normal file
312
sources/tech/20180806 Use Gstreamer and Python to rip CDs.md
Normal file
@ -0,0 +1,312 @@
|
||||
Use Gstreamer and Python to rip CDs
|
||||
======
|
||||
|
||||

|
||||
|
||||
In a previous article, you learned how to use the MusicBrainz service to provide tag information for your audio files, using a simple Python script. This article shows you how to also script an all-in-one solution to copy your CDs down to a music library folder in your choice of formats.
|
||||
|
||||
Unfortunately, the powers that be make it impossible for Fedora to carry the necessary bits to encode MP3 in official repos. So that part is left as an exercise for the reader. But if you use a cloud service such as Google Play to host your music, this script makes audio files you can upload easily.
|
||||
|
||||
The script will record your CD down to one of the following file formats:
|
||||
|
||||
* Uncompressed WAV, which you can further encode or play with.
|
||||
* Compressed but lossless FLAC. Lossless files preserve all the fidelity of the original audio.
|
||||
* Compressed, lossy Ogg Vorbis. Like MP3 and Apple’s AAC, Ogg Vorbis uses special algorithms and psychoacoustic properties to sound close to the original audio. However, Ogg Vorbis usually produces superior results to those other compressed formats at the same file sizes. You can[read more about it here][1] if you like technical details.
|
||||
|
||||
|
||||
|
||||
### The components
|
||||
|
||||
The first element of the script is a [GStreamer][2] pipeline. GStreamer is a full featured multimedia framework included in Fedora. It comes [installed by default in Workstation][3], too. GStreamer is used behind the scene by many multimedia apps in Fedora. It lets apps manipulate all kinds of video and audio files.
|
||||
|
||||
The second major component in this script is choosing, and using, a multimedia tagging library. In this case [the mutagen library][4] makes it easy to tag many kinds of multimedia files. The script in this article uses mutagen to tag Ogg Vorbis or FLAC files.
|
||||
|
||||
Finally, the script uses [Python’s argparse, part of the standard library][5], for some easy to use options and help text. The argparse library is useful for most Python scripts where you expect the user to provide parameters. This article won’t cover this part of the script in great detail.
|
||||
|
||||
### The script
|
||||
|
||||
You may recall [the previous article][6] that used MusicBrainz to fetch tag information. This script includes that code, with some tweaks to make it integrate better with the new functions. (You may find it easier to read this script if you copy and paste it into your favorite editor.)
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os, sys
|
||||
import subprocess
|
||||
from argparse import ArgumentParser
|
||||
import libdiscid
|
||||
import musicbrainzngs as mb
|
||||
import requests
|
||||
import json
|
||||
from getpass import getpass
|
||||
|
||||
parser = ArgumentParser()
|
||||
parser.add_argument('-f', '--flac', action='store_true', dest='flac',
|
||||
default=False, help='Rip to FLAC format')
|
||||
parser.add_argument('-w', '--wav', action='store_true', dest='wav',
|
||||
default=False, help='Rip to WAV format')
|
||||
parser.add_argument('-o', '--ogg', action='store_true', dest='ogg',
|
||||
default=False, help='Rip to Ogg Vorbis format')
|
||||
options = parser.parse_args()
|
||||
|
||||
# Set up output varieties
|
||||
if options.wav + options.ogg + options.flac > 1:
|
||||
raise parser.error("Only one of -f, -o, -w please")
|
||||
if options.wav:
|
||||
fmt = 'wav'
|
||||
encoding = 'wavenc'
|
||||
elif options.flac:
|
||||
fmt = 'flac'
|
||||
encoding = 'flacenc'
|
||||
from mutagen.flac import FLAC as audiofile
|
||||
elif options.ogg:
|
||||
fmt = 'oga'
|
||||
quality = 'quality=0.3'
|
||||
encoding = 'vorbisenc {} ! oggmux'.format(quality)
|
||||
from mutagen.oggvorbis import OggVorbis as audiofile
|
||||
|
||||
# Get MusicBrainz info
|
||||
this_disc = libdiscid.read(libdiscid.default_device())
|
||||
mb.set_useragent(app='get-contents', version='0.1')
|
||||
mb.auth(u=input('Musicbrainz username: '), p=getpass())
|
||||
|
||||
release = mb.get_releases_by_discid(this_disc.id, includes=['artists',
|
||||
'recordings'])
|
||||
if release.get('disc'):
|
||||
this_release=release['disc']['release-list'][0]
|
||||
|
||||
album = this_release['title']
|
||||
artist = this_release['artist-credit'][0]['artist']['name']
|
||||
year = this_release['date'].split('-')[0]
|
||||
|
||||
for medium in this_release['medium-list']:
|
||||
for disc in medium['disc-list']:
|
||||
if disc['id'] == this_disc.id:
|
||||
tracks = medium['track-list']
|
||||
break
|
||||
|
||||
# We assume here the disc was found. If you see this:
|
||||
# NameError: name 'tracks' is not defined
|
||||
# ...then the CD doesn't appear in MusicBrainz and can't be
|
||||
# tagged. Use your MusicBrainz account to create a release for
|
||||
# the CD and then try again.
|
||||
|
||||
# Get cover art to cover.jpg
|
||||
if this_release['cover-art-archive']['artwork'] == 'true':
|
||||
url = 'http://coverartarchive.org/release/' + this_release['id']
|
||||
art = json.loads(requests.get(url, allow_redirects=True).content)
|
||||
for image in art['images']:
|
||||
if image['front'] == True:
|
||||
cover = requests.get(image['image'], allow_redirects=True)
|
||||
fname = '{0} - {1}.jpg'.format(artist, album)
|
||||
print('Saved cover art as {}'.format(fname))
|
||||
f = open(fname, 'wb')
|
||||
f.write(cover.content)
|
||||
f.close()
|
||||
break
|
||||
|
||||
for trackn in range(len(tracks)):
|
||||
track = tracks[trackn]['recording']['title']
|
||||
|
||||
# Output file name based on MusicBrainz values
|
||||
outfname = '{:02} - {}.{}'.format(trackn+1, track, fmt).replace('/', '-')
|
||||
|
||||
print('Ripping track {}...'.format(outfname))
|
||||
cmd = 'gst-launch-1.0 cdiocddasrc track={} ! '.format(trackn+1) + \
|
||||
'audioconvert ! {} ! '.format(encoding) + \
|
||||
'filesink location="{}"'.format(outfname)
|
||||
msgs = subprocess.getoutput(cmd)
|
||||
|
||||
if not options.wav:
|
||||
audio = audiofile(outfname)
|
||||
print('Tagging track {}...'.format(outfname))
|
||||
audio['TITLE'] = track
|
||||
audio['TRACKNUMBER'] = str(trackn+1)
|
||||
audio['ARTIST'] = artist
|
||||
audio['ALBUM'] = album
|
||||
audio['DATE'] = year
|
||||
audio.save()
|
||||
|
||||
```
|
||||
|
||||
#### Determining output format
|
||||
|
||||
This part of the script lets the user decide how to format the output files:
|
||||
```
|
||||
parser = ArgumentParser()
|
||||
parser.add_argument('-f', '--flac', action='store_true', dest='flac',
|
||||
default=False, help='Rip to FLAC format')
|
||||
parser.add_argument('-w', '--wav', action='store_true', dest='wav',
|
||||
default=False, help='Rip to WAV format')
|
||||
parser.add_argument('-o', '--ogg', action='store_true', dest='ogg',
|
||||
default=False, help='Rip to Ogg Vorbis format')
|
||||
options = parser.parse_args()
|
||||
|
||||
# Set up output varieties
|
||||
if options.wav + options.ogg + options.flac > 1:
|
||||
raise parser.error("Only one of -f, -o, -w please")
|
||||
if options.wav:
|
||||
fmt = 'wav'
|
||||
encoding = 'wavenc'
|
||||
elif options.flac:
|
||||
fmt = 'flac'
|
||||
encoding = 'flacenc'
|
||||
from mutagen.flac import FLAC as audiofile
|
||||
elif options.ogg:
|
||||
fmt = 'oga'
|
||||
quality = 'quality=0.3'
|
||||
encoding = 'vorbisenc {} ! oggmux'.format(quality)
|
||||
from mutagen.oggvorbis import OggVorbis as audiofile
|
||||
|
||||
```
|
||||
|
||||
The parser, built from the argparse library, gives you a built in –help function:
|
||||
```
|
||||
$ ipod-cd --help
|
||||
usage: ipod-cd [-h] [-b BITRATE] [-w] [-o]
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-b BITRATE, --bitrate BITRATE
|
||||
Set a target bitrate
|
||||
-w, --wav Rip to WAV format
|
||||
-o, --ogg Rip to Ogg Vorbis format
|
||||
|
||||
```
|
||||
|
||||
The script allows the user to use -f, -w, or -o on the command line to choose a format. Since these are stored as True (a Python boolean value), they can also be treated as the integer value 1. If more than one is selected, the parser generates an error.
|
||||
|
||||
Otherwise, the script sets an appropriate encoding string to be used with GStreamer later in the script. Notice the Ogg Vorbis selection also includes a quality setting, which is then included in the encoding. Care to try your hand at an easy change? Try making a parser argument and additional formatting code so the user can select a quality value between -0.1 and 1.0.
|
||||
|
||||
Notice also that for each of the file formats that allows tagging (WAV does not), the script imports a different tagging class. This way the script can have simpler, less confusing tagging code later in the script. In this script, both Ogg Vorbis and FLAC are using classes from the mutagen library.
|
||||
|
||||
#### Getting CD info
|
||||
|
||||
The next section of the script attempts to load MusicBrainz info for the disc. You’ll find that audio files ripped with this script have data not included in the Python code here. This is because GStreamer is also capable of detecting CD-Text that’s included on some discs during the mastering and manufacturing process. Often, though, this data is in all capitals (like “TRACK TITLE”). MusicBrainz info is more compatible with modern apps and other platforms.
|
||||
|
||||
For more information on this section, [refer to the previous article here on the Magazine][6]. A few trivial changes appear here to make the script work better as a single process.
|
||||
|
||||
One item to note is this warning:
|
||||
```
|
||||
# We assume here the disc was found. If you see this:
|
||||
# NameError: name 'tracks' is not defined
|
||||
# ...then the CD doesn't appear in MusicBrainz and can't be
|
||||
# tagged. Use your MusicBrainz account to create a release for
|
||||
# the CD and then try again.
|
||||
|
||||
```
|
||||
|
||||
The script as shown doesn’t include a way to handle cases where CD information isn’t found. This is on purpose. If it happens, take a moment to help the community by [entering CD information on MusicBrainz][7], using your login account.
|
||||
|
||||
#### Ripping and labeling tracks
|
||||
|
||||
The next section of the script actually does the work. It’s a simple loop that iterates through the track list found via MusicBrainz.
|
||||
|
||||
First, the script sets the output filename for the individual track based on the format the user selected:
|
||||
```
|
||||
for trackn in range(len(tracks)):
|
||||
track = tracks[trackn]['recording']['title']
|
||||
|
||||
# Output file name based on MusicBrainz values
|
||||
outfname = '{:02} - {}.{}'.format(trackn+1, track, fmt)
|
||||
|
||||
```
|
||||
|
||||
Then, the script calls a CLI GStreamer utility to perform the ripping and encoding process. That process turns each CD track into an audio file in your current directory:
|
||||
```
|
||||
print('Ripping track {}...'.format(outfname))
|
||||
cmd = 'gst-launch-1.0 cdiocddasrc track={} ! '.format(trackn+1) + \
|
||||
'audioconvert ! {} ! '.format(encoding) + \
|
||||
'filesink location="{}"'.format(outfname)
|
||||
msgs = subprocess.getoutput(cmd)
|
||||
|
||||
```
|
||||
|
||||
The complete GStreamer pipeline would look like this at a command line:
|
||||
```
|
||||
gst-launch-1.0 cdiocddasrc track=1 ! audioconvert ! vorbisenc quality=0.3 ! oggmux ! filesink location="01 - Track Name.oga"
|
||||
|
||||
```
|
||||
|
||||
GStreamer has Python libraries to let you use the framework in interesting ways directly without using subprocess. To keep this article less complex, the script calls the command line utility from Python to do the multimedia work.
|
||||
|
||||
Finally, the script labels the output file if it’s not a WAV file. Both Ogg Vorbis and FLAC use similar methods in their mutagen classes. That means this code can remain very simple:
|
||||
```
|
||||
if not options.wav:
|
||||
audio = audiofile(outfname)
|
||||
print('Tagging track {}...'.format(outfname))
|
||||
audio['TITLE'] = track
|
||||
audio['TRACKNUMBER'] = str(trackn+1)
|
||||
audio['ARTIST'] = artist
|
||||
audio['ALBUM'] = album
|
||||
audio['DATE'] = year
|
||||
audio.save()
|
||||
|
||||
```
|
||||
|
||||
If you decide to write code for another file format, you need to import the correct class earlier, and then perform the tagging correctly. You don’t have to use the mutagen class. For instance, you might choose to use eyed3 for tagging MP3 files. In that case, the tagging code might look like this:
|
||||
```
|
||||
...
|
||||
# In the parser handling for MP3 format
|
||||
from eyed3 import load as audiofile
|
||||
...
|
||||
# In the handling for MP3 tags
|
||||
audio.tag.version = (2, 3, 0)
|
||||
audio.tag.artist = artist
|
||||
audio.tag.title = track
|
||||
audio.tag.album = album
|
||||
audio.tag.track_num = (trackn+1, len(tracks))
|
||||
audio.tag.save()
|
||||
|
||||
```
|
||||
|
||||
(Note the encoding function is up to you to provide.)
|
||||
|
||||
### Running the script
|
||||
|
||||
Here’s an example output of the script:
|
||||
```
|
||||
$ ipod-cd -o
|
||||
Ripping track 01 - Shout, Pt. 1.oga...
|
||||
Tagging track 01 - Shout, Pt. 1.oga...
|
||||
Ripping track 02 - Stars of New York.oga...
|
||||
Tagging track 02 - Stars of New York.oga...
|
||||
Ripping track 03 - Breezy.oga...
|
||||
Tagging track 03 - Breezy.oga...
|
||||
Ripping track 04 - Aeroplane.oga...
|
||||
Tagging track 04 - Aeroplane.oga...
|
||||
Ripping track 05 - Minor Is the Lonely Key.oga...
|
||||
Tagging track 05 - Minor Is the Lonely Key.oga...
|
||||
Ripping track 06 - You Can Come Round If You Want To.oga...
|
||||
Tagging track 06 - You Can Come Round If You Want To.oga...
|
||||
Ripping track 07 - I'm Gonna Haunt This Place.oga...
|
||||
Tagging track 07 - I'm Gonna Haunt This Place.oga...
|
||||
Ripping track 08 - Crash That Piano.oga...
|
||||
Tagging track 08 - Crash That Piano.oga...
|
||||
Ripping track 09 - Save Yourself.oga...
|
||||
Tagging track 09 - Save Yourself.oga...
|
||||
Ripping track 10 - Get on Home.oga...
|
||||
Tagging track 10 - Get on Home.oga...
|
||||
|
||||
```
|
||||
|
||||
Enjoy burning your old CDs into easily portable audio files!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-gstreamer-python-rip-cds/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://xiph.org/vorbis/
|
||||
[2]:https://gstreamer.freedesktop.org/
|
||||
[3]:https://getfedora.org/workstation
|
||||
[4]:https://mutagen.readthedocs.io/en/latest/
|
||||
[5]:https://docs.python.org/3/library/argparse.html
|
||||
[6]:https://fedoramagazine.org/use-musicbrainz-get-cd-information/
|
||||
[7]:https://musicbrainz.org/
|
||||
223
sources/tech/20180806 What is CI-CD.md
Normal file
223
sources/tech/20180806 What is CI-CD.md
Normal file
@ -0,0 +1,223 @@
|
||||
What is CI/CD?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Continuous integration (CI) and continuous delivery (CD) are extremely common terms used when talking about producing software. But what do they really mean? In this article, I'll explain the meaning and significance behind these and related terms, such as continuous testing and continuous deployment.
|
||||
|
||||
### Quick summary
|
||||
|
||||
An assembly line in a factory produces consumer goods from raw materials in a fast, automated, reproducible manner. Similarly, a software delivery pipeline produces releases from source code in a fast, automated, and reproducible manner. The overall design for how this is done is called "continuous delivery." The process that kicks off the assembly line is referred to as "continuous integration." The process that ensures quality is called "continuous testing" and the process that makes the end product available to users is called "continuous deployment." And the overall efficiency experts that make everything run smoothly and simply for everyone are known as "DevOps" practitioners.
|
||||
|
||||
### What does "continuous" mean?
|
||||
|
||||
Continuous is used to describe many different processes that follow the practices I describe here. It doesn't mean "always running." It does mean "always ready to run." In the context of creating software, it also includes several core concepts/best practices. These are:
|
||||
|
||||
* **Frequent releases:** The goal behind continuous practices is to enable delivery of quality software at frequent intervals. Frequency here is variable and can be defined by the team or company. For some products, once a quarter, month, week, or day may be frequent enough. For others, multiple times a day may be desired and doable. Continuous can also take on an "occasional, as-needed" aspect. The end goal is the same: Deliver software updates of high quality to end users in a repeatable, reliable process. Often this may be done with little to no interaction or even knowledge of the users (think device updates).
|
||||
|
||||
* **Automated processes:** A key part of enabling this frequency is having automated processes to handle nearly all aspects of software production. This includes building, testing, analysis, versioning, and, in some cases, deployment.
|
||||
|
||||
* **Repeatable:** If we are using automated processes that always have the same behavior given the same inputs, then processing should be repeatable. That is, if we go back and enter the same version of code as an input, we should get the same set of deliverables. This also assumes we have the same versions of external dependencies (i.e., other deliverables we don't create that our code uses). Ideally, this also means that the processes in our pipelines can be versioned and re-created (see the DevOps discussion later on).
|
||||
|
||||
* **Fast processing:** "Fast" is a relative term here, but regardless of the frequency of software updates/releases, continuous processes are expected to process changes from source code to deliverables in an efficient manner. Automation takes care of much of this, but automated processes may still be slow. For example, integrated testing across all aspects of a product that takes most of the day may be too slow for product updates that have a new candidate release multiple times per day.
|
||||
|
||||
|
||||
|
||||
|
||||
### What is a "continuous delivery pipeline"?
|
||||
|
||||
The different tasks and jobs that handle transforming source code into a releasable product are usually strung together into a software "pipeline" where successful completion of one automatic process kicks off the next process in the sequence. Such pipelines go by many different names, such as continuous delivery pipeline, deployment pipeline, and software development pipeline. An overall supervisor application manages the definition, running, monitoring, and reporting around the different pieces of the pipeline as they are executed.
|
||||
|
||||
### How does a continuous delivery pipeline work?
|
||||
|
||||
The actual implementation of a software delivery pipeline can vary widely. There are a large number and variety of applications that may be used in a pipeline for the various aspects of source tracking, building, testing, gathering metrics, managing versions, etc. But the overall workflow is generally the same. A single orchestration/workflow application manages the overall pipeline, and each of the processes runs as a separate job or is stage-managed by that application. Typically, the individual "jobs" are defined in a syntax and structure that the orchestration application understands and can manage as a workflow.
|
||||
|
||||
Jobs are created to do one or more functions (building, testing, deploying, etc.). Each job may use a different technology or multiple technologies. The key is that the jobs are automated, efficient, and repeatable. If a job is successful, the workflow manager application triggers the next job in the pipeline. If a job fails, the workflow manager alerts developers, testers, and others so they can correct the problem as quickly as possible. Because of the automation, errors can be found much more quickly than by running a set of manual processes. This quick identification of errors is called "fail fast" and can be just as valuable in getting to the pipeline's endpoint.
|
||||
|
||||
### What is meant by "fail fast"?
|
||||
|
||||
One of a pipeline's jobs is to quickly process changes. Another is to monitor the different tasks/jobs that create the release. Since code that doesn't compile or fails a test can hold up the pipeline, it's important for the users to be notified quickly of such situations. Fail fast refers to the idea that the pipeline processing finds problems as soon as possible and quickly notifies users so the problems can be corrected and code resubmitted for another run through the pipeline. Often, the pipeline process can look at the history to determine who made that change and notify the person and their team.
|
||||
|
||||
### Do all parts of a continuous delivery pipeline have to be automated?
|
||||
|
||||
Nearly all parts of the pipeline should be automated. For some parts, it may make sense to have a spot for human intervention/interaction. An example might be for user-acceptance testing (having end users try out the software and make sure it does what they want/expect). Another case might be deployment to production environments where groups want to have more human control. And, of course, human intervention is required if the code isn't correct and breaks.
|
||||
|
||||
With that background on the meaning of continuous, let's look at the different types of continuous processing and what each means in the context of a software pipeline.
|
||||
|
||||
### What is continuous integration?
|
||||
|
||||
Continuous integration (CI) is the process of automatically detecting, pulling, building, and (in most cases) doing unit testing as source code is changed for a product. CI is the activity that starts the pipeline (although certain pre-validations—often called "pre-flight checks"—are sometimes incorporated ahead of CI).
|
||||
|
||||
The goal of CI is to quickly make sure a new change from a developer is "good" and suitable for further use in the code base.
|
||||
|
||||
### How does continuous integration work?
|
||||
|
||||
The basic idea is having an automated process "watching" one or more source code repositories for changes. When a change is pushed to the repositories, the watching process detects the change, pulls down a copy, builds it, and runs any associated unit tests.
|
||||
|
||||
### How does continuous integration detect changes?
|
||||
|
||||
These days, the watching process is usually an application like [Jenkins][1] that also orchestrates all (or most) of the processes running in the pipeline and monitors for changes as one of its functions. The watching application can monitor for changes in several different ways. These include:
|
||||
|
||||
* **Polling:** The monitoring program repeatedly asks the source management system, "Do you have anything new in the repositories I'm interested in?" When the source management system has new changes, the monitoring program "wakes up" and does its work to pull the new code and build/test it.
|
||||
|
||||
* **Periodic:** The monitoring program is configured to periodically kick off a build regardless of whether there are changes or not. Ideally, if there are no changes, then nothing new is built, so this doesn't add much additional cost.
|
||||
|
||||
* **Push:** This is the inverse of the monitoring application checking with the source management system. In this case, the source management system is configured to "push out" a notification to the monitoring application when a change is committed into a repository. Most commonly, this can be done in the form of a "webhook"—a program that is "hooked" to run when new code is pushed and sends a notification over the internet to the monitoring program. For this to work, the monitoring program must have an open port that can receive the webhook information over the internet.
|
||||
|
||||
|
||||
|
||||
|
||||
### What are "pre-checks" (aka pre-flight checks)?
|
||||
|
||||
Additional validations may be done before code is introduced into the source repository and triggers continuous integration. These follow best practices such as test builds and code reviews. They are usually built into the development process before the code is introduced in the pipeline. But some pipelines may also include them as part of their monitored processes or workflows.
|
||||
|
||||
As an example, a tool called [Gerrit][2] allows for formal code reviews, validations, and test builds after a developer has pushed code but before it is allowed into the ([Git][3] remote) repository. Gerrit sits between the developer's workspace and the Git remote repository. It "catches" pushes from the developer and can do pass/fail validations to ensure they pass before being allowed to make it into the repository. This can include detecting the proposed change and kicking off a test build (a form of CI). It also allows for groups to do formal code reviews at that point. In this way, there is an extra measure of confidence that the change will not break anything when it is merged into the codebase.
|
||||
|
||||
### What are "unit tests"?
|
||||
|
||||
Unit tests (also known as "commit tests") are small, focused tests written by developers to ensure new code works in isolation. "In isolation" here means not depending on or making calls to other code that isn't directly accessible nor depending on external data sources or other modules. If such a dependency is required for the code to run, those resources can be represented by mocks. Mocks refer to using a code stub that looks like the resource and can return values but doesn't implement any functionality.
|
||||
|
||||
In most organizations, developers are responsible for creating unit tests to prove their code works. In fact, one model (known as test-driven development [TDD]) requires unit tests to be designed first as a basis for clearly identifying what the code should do. Because such code changes can be fast and numerous, they must also be fast to execute.
|
||||
|
||||
As they relate to the continuous integration workflow, a developer creates or updates the source in their local working environment and uses the unit tests to ensure the newly developed function or method works. Typically, these tests take the form of asserting that a given set of inputs to a function or method produces a given set of outputs. They generally test to ensure that error conditions are properly flagged and handled. Various unit-testing frameworks, such as [JUnit][4] for Java development, are available to assist.
|
||||
|
||||
### What is continuous testing?
|
||||
|
||||
Continuous testing refers to the practice of running automated tests of broadening scope as code goes through the CD pipeline. Unit testing is typically integrated with the build processes as part of the CI stage and focused on testing code in isolation from other code interacting with it.
|
||||
|
||||
Beyond that, there are various forms of testing that can/should occur. These can include:
|
||||
|
||||
* **Integration testing** validates that groups of components and services all work together.
|
||||
|
||||
* **Functional testing** validates the result of executing functions in the product are as expected.
|
||||
|
||||
* **Acceptance testing** measures some characteristic of the system against acceptable criteria. Examples include performance, scalability, stress, and capacity.
|
||||
|
||||
|
||||
|
||||
|
||||
All of these may not be present in the automated pipeline, and the lines between some of the different types can be blurred. But the goal of continuous testing in a delivery pipeline is always the same: to prove by successive levels of testing that the code is of a quality that it can be used in the release that's in progress. Building on the continuous principle of being fast, a secondary goal is to find problems quickly and alert the development team. This is usually referred to as fail fast.
|
||||
|
||||
### Besides testing, what other kinds of validations can be done against code in the pipeline?
|
||||
|
||||
In addition to the pass/fail aspects of tests, applications exist that can also tell us the number of source code lines that are exercised (covered) by our test cases. This is an example of a metric that can be computed across the source code. This metric is called code-coverage and can be measured by tools (such as [JaCoCo][5] for Java source).
|
||||
|
||||
Many other types of metrics exist, such as counting lines of code, measuring complexity, and comparing coding structures against known patterns. Tools such as [SonarQube][6] can examine source code and compute these metrics. Beyond that, users can set thresholds for what kind of ranges they are willing to accept as "passing" for these metrics. Then, processing in the pipeline can be set to check the computed values against the thresholds, and if the values aren't in the acceptable range, processing can be stopped. Applications such as SonarQube are highly configurable and can be tuned to check only for the things that a team is interested in.
|
||||
|
||||
### What is continuous delivery?
|
||||
|
||||
Continuous delivery (CD) generally refers to the overall chain of processes (pipeline) that automatically gets source code changes and runs them through build, test, packaging, and related operations to produce a deployable release, largely without any human intervention.
|
||||
|
||||
The goals of CD in producing software releases are automation, efficiency, reliability, reproducibility, and verification of quality (through continuous testing).
|
||||
|
||||
CD incorporates CI (automatically detecting source code changes, executing build processes for the changes, and running unit tests to validate), continuous testing (running various kinds of tests on the code to gain successive levels of confidence in the quality of the code), and (optionally) continuous deployment (making releases from the pipeline automatically available to users).
|
||||
|
||||
### How are multiple versions identified/tracked in pipelines?
|
||||
|
||||
Versioning is a key concept in working with CD and pipelines. Continuous implies the ability to frequently integrate new code and make updated releases available. But that doesn't imply that everyone always wants the "latest and greatest." This may be especially true for internal teams that want to develop or test against a known, stable release. So, it is important that the pipeline versions objects that it creates and can easily store and access those versioned objects.
|
||||
|
||||
The objects created in the pipeline processing from the source code can generally be called artifacts. Artifacts should have versions applied to them when they are built. The recommended strategy for assigning version numbers to artifacts is called semantic versioning. (This also applies to versions of dependent artifacts that are brought in from external sources.)
|
||||
|
||||
Semantic version numbers have three parts: major, minor, and patch. (For example, 1.4.3 reflects major version 1, minor version 4, and patch version 3.) The idea is that a change in one of these parts represents a level of update in the artifact. The major version is incremented only for incompatible API changes. The minor version is incremented when functionality is added in a backward-compatible manner. And the patch version is incremented when backward-compatible bug fixes are made. These are recommended guidelines, but teams are free to vary from this approach, as long as they do so in a consistent and well-understood manner across the organization. For example, a number that increases each time a build is done for a release may be put in the patch field.
|
||||
|
||||
### How are artifacts "promoted"?
|
||||
|
||||
Teams can assign a promotion "level" to artifacts to indicate suitability for testing, production, etc. There are various approaches. Applications such as Jenkins or [Artifactory][7] can be enabled to do promotion. Or a simple scheme can be to add a label to the end of the version string. For example, -snapshot can indicate the latest version (snapshot) of the code was used to build the artifact. Various promotion strategies or tools can be used to "promote" the artifact to other levels such as -milestone or -production as an indication of the artifact's stability and readiness for release.
|
||||
|
||||
### How are multiple versions of artifacts stored and accessed?
|
||||
|
||||
Versioned artifacts built from source can be stored via applications that manage "artifact repositories." Artifact repositories are like source management for built artifacts. The application (such as Artifactory or [Nexus][8]) can accept versioned artifacts, store and track them, and provide ways for them to be retrieved.
|
||||
|
||||
Pipeline users can specify the versions they want to use and have the pipeline pull in those versions.
|
||||
|
||||
### What is continuous deployment?
|
||||
|
||||
Continuous deployment (CD) refers to the idea of being able to automatically take a release of code that has come out of the CD pipeline and make it available for end users. Depending on the way the code is "installed" by users, that may mean automatically deploying something in a cloud, making an update available (such as for an app on a phone), updating a website, or simply updating the list of available releases.
|
||||
|
||||
An important point here is that just because continuous deployment can be done doesn't mean that every set of deliverables coming out of a pipeline is always deployed. It does mean that, via the pipeline, every set of deliverables is proven to be "deployable." This is accomplished in large part by the successive levels of continuous testing (see the section on Continuous Testing in this article).
|
||||
|
||||
Whether or not a release from a pipeline run is deployed may be gated by human decisions and various methods employed to "try out" a release before fully deploying it.
|
||||
|
||||
### What are some ways to test out deployments before fully deploying to all users?
|
||||
|
||||
Since having to rollback/undo a deployment to all users can be a costly situation (both technically and in the users' perception), numerous techniques have been developed to allow "trying out" deployments of new functionality and easily "undoing" them if issues are found. These include:
|
||||
|
||||
#### Blue/green testing/deployments
|
||||
|
||||
In this approach to deploying software, two identical hosting environments are maintained — a _blue_ one and a _green_ one. (The colors are not significant and only serves as identifers.) At any given point, one of these is the _production_ deployment and the other is the _candidate_ deployment.
|
||||
|
||||
In front of these instances is a router or other system that serves as the customer “gateway” to the product or application. By pointing the router to the desired blue or green instance, customer traffic can be directed to the desired deployment. In this way, swapping out which deployment instance is pointed to (blue or green) is quick, easy, and transparent to the user.
|
||||
|
||||
When a new release is ready for testing, it can be deployed to the non-production environment. After it’s been tested and approved, the router can be changed to point the incoming production traffic to it (so it becomes the new production site). Now the hosting environment that was production is available for the next candidate.
|
||||
|
||||
Likewise, if a problem is found with the latest deployment and the previous production instance is still deployed in the other environment, a simple change can point the customer traffic back to the previous production instance — effectively taking the instance with the problem “offline” and rolling back to the previous version. The new deployment with the problem can then be fixed in the other area.
|
||||
|
||||
#### Canary testing/deployment
|
||||
|
||||
In some cases, swapping out the entire deployment via a blue/green environment may not be workable or desired. Another approach is known as _canary_ testing/deployment. In this model, a portion of customer traffic is rerouted to new pieces of the product. For example, a new version of a search service in a product may be deployed alongside the current production version of the service. Then, 10% of search queries may be routed to the new version to test it out in a production environment.
|
||||
|
||||
If the new service handles the limited traffic with no problems, then more traffic may be routed to it over time. If no problems arise, then over time, the amount of traffic routed to the new service can be increased until 100% of the traffic is going to it. This effectively “retires” the previous version of the service and puts the new version into effect for all customers.
|
||||
|
||||
#### Feature toggles
|
||||
|
||||
For new functionality that may need to be easily backed out (in case a problem is found), developers can add a feature toggle. This is a software if-then switch in the code that only activates the code if a data value is set. This data value can be a globally accessible place that the deployed application checks to see whether it should execute the new code. If the data value is set, it executes the code; if not, it doesn't.
|
||||
|
||||
This gives developers a remote "kill switch" to turn off the new functionality if a problem is found after deployment to production.
|
||||
|
||||
#### Dark launch
|
||||
|
||||
In this practice, code is incrementally tested/deployed into production, but changes are not made visible to users (thus the "dark" name). For example, in the production release, some portion of web queries might be redirected to a service that queries a new data source. This information can be collected by development for analysis—without exposing any information about the interface, transaction, or results back to users.
|
||||
|
||||
The idea here is to get real information on how a candidate change would perform under a production load without impacting users or changing their experience. Over time, more load can be redirected until either a problem is found or the new functionality is deemed ready for all to use. Feature flags can be used actually to handle the mechanics of dark launches.
|
||||
|
||||
### What is DevOps?
|
||||
|
||||
[DevOps][9] is a set of ideas and recommended practices around how to make it easier for development and operational teams to work together on developing and releasing software. Historically, development teams created products but did not install/deploy them in a regular, repeatable way, as customers would do. That set of install/deploy tasks (as well as other support tasks) were left to the operations teams to sort out late in the cycle. This often resulted in a lot of confusion and problems, since the operations team was brought into the loop late in the cycle and had to make what they were given work in a short timeframe. As well, development teams were often left in a bad position—because they had not sufficiently tested the product's install/deploy functionality, they could be surprised by problems that emerged during that process.
|
||||
|
||||
This often led to a serious disconnect and lack of cooperation between development and operations teams. The DevOps ideals advocate ways of doing things that involve both development and operations staff from the start of the cycle through the end, such as CD.
|
||||
|
||||
### How does CD intersect with DevOps?
|
||||
|
||||
The CD pipeline is an implementation of several DevOps ideals. The later stages of a product, such as packaging and deployment, can always be done on each run of the pipeline rather than waiting for a specific point in the product development cycle. As well, both development and operations staff can clearly see when things work and when they don't, from development to deployment. For a cycle of a CD pipeline to be successful, it must pass through not only the processes associated with development but also the ones associated with operations.
|
||||
|
||||
Carried to the next level, DevOps suggests that even the infrastructure that implements the pipeline be treated like code. That is, it should be automatically provisioned, trackable, easy to change, and spawn a new run of the pipeline if it changes. This can be done by implementing the pipeline as code.
|
||||
|
||||
### What is "pipeline-as-code"?
|
||||
|
||||
Pipeline-as-code is a general term for creating pipeline jobs/tasks via programming code, just as developers work with source code for products. The goal is to have the pipeline implementation expressed as code so it can be stored with the code, reviewed, tracked over time, and easily spun up again if there is a problem and the pipeline must be stopped. Several tools allow this, including [Jenkins 2][1].
|
||||
|
||||
### How does DevOps impact infrastructure for producing software?
|
||||
|
||||
Traditionally, individual hardware systems used in pipelines were configured with software (operating systems, applications, development tools, etc.) one at a time. At the extreme, each system was a custom, hand-crafted setup. This meant that when a system had problems or needed to be updated, that was frequently a custom task as well. This kind of approach goes against the fundamental CD ideal of having an easily reproducible and trackable environment.
|
||||
|
||||
Over the years, applications have been developed to standardize provisioning (installing and configuring) systems. As well, virtual machines were developed as programs that emulate computers running on top of other computers. These VMs require a supervisory program to run them on the underlying host system. And they require their own operating system copy to run.
|
||||
|
||||
Next came containers. Containers, while similar in concept to VMs, work differently. Instead of requiring a separate program and a copy of an OS to run, they simply use some existing OS constructs to carve out isolated space in the operating system. Thus, they behave similarly to a VM to provide the isolation but don't require the overhead.
|
||||
|
||||
Because VMs and containers are created from stored definitions, they can be destroyed and re-created easily with no impact to the host systems where they are running. This allows a re-creatable system to run pipelines on. Also, for containers, we can track changes to the definition file they are built from—just as we would for source code.
|
||||
|
||||
Thus, if we run into a problem in a VM or container, it may be easier and quicker to just destroy and re-create it instead of trying to debug and make a fix to the existing one.
|
||||
|
||||
This also implies that any change to the code for the pipeline can trigger a new run of the pipeline (via CI) just as a change to code would. This is one of the core ideals of DevOps regarding infrastructure.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/what-cicd
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:https://jenkins.io
|
||||
[2]:https://www.gerritcodereview.com
|
||||
[3]:https://opensource.com/resources/what-is-git
|
||||
[4]:https://junit.org/junit5/
|
||||
[5]:https://www.eclemma.org/jacoco/
|
||||
[6]:https://www.sonarqube.org/
|
||||
[7]:https://jfrog.com/artifactory/
|
||||
[8]:https://www.sonatype.com/nexus-repository-sonatype
|
||||
[9]:https://opensource.com/resources/devops
|
||||
@ -0,0 +1,61 @@
|
||||
Linux 下如何通过两个或多个输出设备播放声音
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 上处理音频是一件很痛苦的事情。Pulseaudio 的出现则是利弊参半。虽然有些事情 Pluseaudio 能够做的更好,但有些事情则反而变得更复杂了。处理音频的输出就是这么一件事情。
|
||||
|
||||
如果你想要在 Linux PC 上启用多个音频输出,你只需要利用一个简单的工具就能在一个虚拟界面上启用另一个发音设备。这比看起来要简单的多。
|
||||
|
||||
你可能会好奇为什么要这么做,一个很常见的情况是用电脑在电视上播放视频,你可以同时使用电脑和电视上的扬声器。
|
||||
|
||||
### 安装 Paprefs
|
||||
|
||||
实现从多个来源启用音频播放的最简单的方法是是一款名为 "paprefs" 的简单图形化工具。它是 PulseAudio Preferences 的缩写。
|
||||
|
||||
该软件包含在 Ubuntu 仓库中,可以直接用 apt 来进行安装。
|
||||
```
|
||||
sudo apt install paprefs
|
||||
```
|
||||
|
||||
安装后就能狗启动这款程序了。
|
||||
|
||||
### 启动双音频播放
|
||||
|
||||
虽然这款工具是图形化的,但作为普通用户在命令行中输入 `paprefs` 来启动它恐怕还是要更容易一些。
|
||||
|
||||
打开的窗口中有一些标签页,这些标签页内有一些可以调整的设置项。我们这里选择最后那个标签页,"Simultaneous Output。"
|
||||
|
||||
![Paprefs on Ubuntu][1]
|
||||
|
||||
这个标签页中没有什么内容,只是一个复选框用来启用设置。
|
||||
|
||||
下一步,打开常规的声音首选项。这在不同的发行版中位于不同的位置。在 Ubuntu 上,它位于 GNOME 系统设置内。
|
||||
|
||||
![Enable Simultaneous Audio][2]
|
||||
|
||||
打开声音首选项后,选择 "output" 标签页。勾选 "Simultaneous output" 单选按钮。现在它就成了你的默认输出了。
|
||||
|
||||
### 测试一下
|
||||
|
||||
用什么东西进行测试随你喜欢,不过播放音乐总是可行的。如果你像前面建议的一样,用视频来进行测试也没问题。
|
||||
|
||||
一切顺利的话,你就能从所有连接的设备中听到有声音传出了。
|
||||
|
||||
这就是所有要做的事了。此功能最适用于有多个设备(如 HDMI 端口和标准模拟输出)时。你当然也可以试一下其他配置。你还需要注意,只有一个音量控制器存在,因此你需要根据实际情况调整物理输出设备。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/play-sound-through-multiple-devices-linux/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-paprefs.jpg (Paprefs on Ubuntu)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-enable.jpg (Enable Simultaneous Audio)
|
||||
[3]:https://depositphotos.com/89314442/stock-photo-headphones-on-speakers.html
|
||||
@ -1,32 +1,31 @@
|
||||
translating by lujun9972
|
||||
How to Read Outlook Emails by Python
|
||||
如何用 Python 读取 Outlook 中的电子邮件
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
when you start e-mail marketing , You need opt-in email address list. You have opt-in list. You are using email client software and If you can export your list from your email client, You will have good list.
|
||||
从事电子邮件营销,准入邮箱列表是必不可少的。你可能已经有了准入列表,同时还使用电子邮件客户端软件。如果你能从电子邮件客户端中导出准入列表,那这份列表想必是极好的。
|
||||
|
||||
Now I am trying to explain my codes to write all emails into test file from your outlook profile.
|
||||
我使用一些代码来将 outlook 配置中的所有邮件写入一个临时文件中,现在让我来尝试解释一下这些代码。
|
||||
|
||||
First you should import win32com.client, You need to install pywin32
|
||||
首先你需要倒入 win32com.client,为此你需要安装 pywin32
|
||||
```
|
||||
pip install pywin32
|
||||
|
||||
```
|
||||
|
||||
We should connect to Outlook by MAPI
|
||||
我们需要通过 MAPI 协议连接 Outlok
|
||||
```
|
||||
outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI")
|
||||
|
||||
```
|
||||
|
||||
Then we should get all accounts in your outlook profile.
|
||||
然后从 outlook 配置中获取所有的账户。
|
||||
```
|
||||
accounts= win32com.client.Dispatch("Outlook.Application").Session.Accounts;
|
||||
|
||||
```
|
||||
|
||||
Then You need to get emails from inbox folder that is named emailleri_al.
|
||||
在然后需要从名为 emaileri_al 的收件箱中获取邮件。
|
||||
```
|
||||
def emailleri_al(folder):
|
||||
messages = folder.Items
|
||||
@ -49,7 +48,7 @@ def emailleri_al(folder):
|
||||
pass
|
||||
```
|
||||
|
||||
You should go to all account and get inbox folder and get emails
|
||||
你需要进入所有账户的所有收件箱中获取电子邮件
|
||||
```
|
||||
for account in accounts:
|
||||
global inbox
|
||||
@ -78,7 +77,7 @@ for account in accounts:
|
||||
print("*************************************************", file=
|
||||
```
|
||||
|
||||
All Code is as the following
|
||||
下面是完整的代码
|
||||
```
|
||||
import win32com.client
|
||||
import win32com
|
||||
120
translated/tech/20180711 netdev-day-1--ipsec.md
Normal file
120
translated/tech/20180711 netdev-day-1--ipsec.md
Normal file
@ -0,0 +1,120 @@
|
||||
netdev 第一天:IPsec!
|
||||
============================================================
|
||||
|
||||
嗨!和去年一样,今年我又参加了 [netdev 会议][3]。([这里][14]是我上一年所做的笔记)。
|
||||
|
||||
在今天的会议中,我学到了很多有关 IPsec 的知识,所以下面我将介绍它们!其中 Sowmini Varadhan 和 [Paul Wouters][5] 做了一场关于 IPsec 的专题研讨会。本文中的错误 100% 都是我的错:)。
|
||||
|
||||
### 什么是 IPsec?
|
||||
|
||||
IPsec 是一个用来加密 IP 包的协议。某些 VPN 已经是通过使用 IPsec 来实现的。直到今天我才真正意识到 VPN 使用了不只一种协议,原来我以为 VPN 只是一个通用术语,指的是“你的数据包将被加密,然后通过另一台服务器去发送“。VPN 可以使用一系列不同的协议(OpenVPN、PPTP、SSTP、IPsec 等)以不同的方式来实现。
|
||||
|
||||
为什么 IPsec 和其他的 VPN 协议如此不同呢?(或者说,为什么在本次 netdev 会议中,将会给出 IPsec 的教学而不是其他的协议呢?)我的理解是有 2 点使得它如此不同:
|
||||
|
||||
* 它是一个 IETF 标准,例如可以在文档 [RFC 6071][1] 等中查到(你知道 IETF 是制定 RFC 标准的组织吗?我也是直到今天才知道的!)。
|
||||
|
||||
* 它在 Linux 内核中被实现了(所以这才是为什么本次 netdev 会议中有关于它的教学,因为 netdev 是一个跟 Linux 内核网络有关的会议 :))。
|
||||
|
||||
### IPsec 是如何工作的?
|
||||
|
||||
假如说你的笔记本正使用 IPsec 来加密数据包并通过另一台设备来发送它们,那这是怎么工作的呢?对于 IPsec 来说,它有 2 个部分:一个是用户空间部分,另一个是内核空间部分。
|
||||
|
||||
IPsec 的用户空间部分负责**密钥的交换**,使用名为 [IKE][6] ("internet key exchange",网络密钥传输)的协议。总的来说,当你打开一个 VPN 连接的时候,你需要与 VPN 服务器通信,并且和它协商使用一个密钥来进行加密。
|
||||
|
||||
IPsec 的内核部分负责数据包的实际加密工作——一旦使用 `IKE` 生成了一个密钥,IPsec 的用户空间部分便会告诉内核使用哪个密钥来进行加密。然后内核便会使用该密钥来加密数据包!
|
||||
|
||||
### 安全策略以及安全关联
|
||||
(译者注:security association 我翻译为安全关联, 参考自 https://zh.wikipedia.org/wiki/%E5%AE%89%E5%85%A8%E9%97%9C%E8%81%AF)
|
||||
|
||||
IPSec 的内核部分有两个数据库:**安全策略数据库**(SPD)和**安全关联数据库**(SAD)。
|
||||
|
||||
安全策略数据库包含 IP 范围和用于该范围的数据包需要执行的操作(对其执行 IPsec、丢弃数据包、让数据包通过)。对于这点我有点迷糊,因为针对不同 IP 范围的数据包所采取的规则已经在路由表(`sudo ip route list`)中使用过,但显然你也可以设定 IPsec 规则,但它们位于不同的地方!
|
||||
|
||||
而在我眼中,安全关联数据库存放有用于各种不同 IP 的加密密钥。
|
||||
|
||||
查看这些数据库的方式却是非常不直观的,需要使用一个名为 `ip xfrm` 的命令,至于 `xfrm` 是什么意思呢?我也不知道!
|
||||
(译者注:我在 https://www.allacronyms.com/XFMR/Transformer 上查到 xfmr 是 Transformer 的简写,又根据 man7 上 http://man7.org/linux/man-pages/man8/ip-xfrm.8.html 的简介, 我认为这个说法可信。)
|
||||
```
|
||||
# security policy database
|
||||
$ sudo ip xfrm policy
|
||||
$ sudo ip x p
|
||||
|
||||
# security association database
|
||||
$ sudo ip xfrm state
|
||||
$ sudo ip x s
|
||||
|
||||
```
|
||||
|
||||
### 为什么 IPsec 被实现在 Linux 内核中而 TLS 没有?
|
||||
|
||||
对于 TLS 和 IPsec 来说,当打开一个连接时,它们都需要做密钥交换(使用 Diffie-Hellman 或者其他算法)。基于某些可能很明显但我现在还没有理解(??)的原因,在内核中人们并不想做密钥的交换。
|
||||
|
||||
IPsec 更容易在内核实现的原因是使用 IPsec 你可以更少频率地协商密钥的交换(对于每个你想通过 VPN 来连接的 IP 只需要一次),并且 IPsec 会话存活得更长。所以对于用户空间来说,使用 IPsec 来做密钥交换、密钥的获取和将密钥传递给内核将更容易,内核得到密钥后将使用该密钥来处理每个 IP 数据包。
|
||||
|
||||
而对于 TLS 来说,则存在一些问题:
|
||||
|
||||
a. 当你每一打开一个 TLS 连接时,每次你都要做新的密钥交换,并且 TLS 连接存活时间较短。
|
||||
|
||||
b. 当你需要开始做加密时,使用 IPsec 没有一个自然的协议边界,你只需要加密给定 IP 范围内的每个 IP 包即可,但如果使用 TLS,你需要查看 TCP 流,辨别 TCP 包是否是一个数据包,然后决定是否加密它。
|
||||
|
||||
实际上存在一个补丁用于 [在 Linux 内核中实现 TLS][7],它让用户空间做密钥交换,然后传给内核密钥,所以很明显,使用 TLS 不是不可能的,但它是一个新事物,并且我认为相比使用 IPsec,使用 TLS 更加复杂。
|
||||
|
||||
### 使用什么软件来实现 IPsec 呢?
|
||||
|
||||
据我所知有 Libreswan 和 Strongswan 两个软件。今天的教程关注的是 libreswan。
|
||||
|
||||
有些让人迷糊的是,尽管 Libreswan 和 Strongswan 是不同的程序包,但它们都会安装一个名为 `ipsec` 的二进制文件来管理 IPsec 连接,并且这两个 `ipsec` 二进制文件并不是相同的程序(尽管它们担任同样的角色)。
|
||||
|
||||
在上面的“IPsec 如何工作”部分,我已经描述了 Strongswan 和 Libreswan 做了什么——使用 IKE 做密钥交换,并告诉内核有关如何使用密钥来做加密。
|
||||
|
||||
### VPN 不是只能使用 IPsec 来实现!
|
||||
|
||||
在本文的开头我说“IPsec 是一个 VPN 协议”,这是对的,但你并不必须使用 IPsec 来实现 VPN!实际上有两种方式来使用 IPsec:
|
||||
|
||||
1. “传输模式”,其中 IP 表头没有改变,只有 IP 数据包的内容被加密。这种模式有点类似于使用 TLS -- 你直接告诉服务器你正在通信(而不是通过一个 VPN 服务器或其他设备),只有 IP 包里的内容被加密。
|
||||
|
||||
2. ”隧道模式“,其中 IP 表头和它的内容都被加密了,并且被封装进另一个 UDP 包内。这个模式被 VPN 所使用 -- 你获取你正传送给一个秘密网站的包,然后加密它,并将它送给你的 VPN 服务器,然后 VPN 服务器再传送给你。
|
||||
|
||||
### opportunistic IPsec
|
||||
|
||||
今天我学到了 IPsec “传输模式”的一个有趣应用,它叫做 “opportunistic IPsec”(通过它,你可以通过开启一个 IPsec 连接来直接和你要通信的主机连接,而不是通过其他的中介服务器),现在已经有一个 opportunistic IPsec 服务器了,它位于 [http://oe.libreswan.org/][8]。
|
||||
|
||||
我认为当你在你的电脑上设定好 `libreswan` 和 unbound DNS 程序后,当你连接到 [http://oe.libreswan.org][8] 时,主要发生了如下的几件事:
|
||||
|
||||
1. `unbound` 做一次 DNS 查询来获取 `oe.libreswan.org` (`dig ipseckey oe.libreswan.org`) 的 IPSECKEY 记录,以便获取到公钥来用于该网站(这需要 DNSSEC 是安全的,并且当我获得足够多这方面的知识后,我将用另一篇文章来说明它。假如你想看到相关的结果,并且如果你只是使用 dig 命令来运行此次 DNS 查询的话,它也可以工作)。
|
||||
|
||||
2. `unbound` 将公钥传给 `libreswan` 程序,然后 `libreswan` 使用它来和运行在 `oe.libreswan.org` 网站上的 IKE 服务器做一次密钥交换。
|
||||
|
||||
3. `libreswan` 完成了密钥交换,将加密密钥传给内核并告诉内核当和 `oe.libreswan.org` 做通信时使用该密钥。
|
||||
|
||||
4. 你的连接现在被加密了!即便它是 HTTP 连接!有趣吧!
|
||||
|
||||
### IPsec 和 TLS 相互借鉴
|
||||
|
||||
在今天的教程中听到一个有趣的花絮是 IPsec 和 TLS 协议实际上总是从对方学习 -- 正如他们说在 TLS 出现前, IPsec 的 IKE 协议有着完美的正向加密,而 IPsec 也从 TLS 那里学了很多。很高兴能听到不同的网络协议之间是如何从对方那里学习并与时俱进的事实!
|
||||
|
||||
### IPsec 是有趣的!
|
||||
|
||||
我已经花了很长时间来学习 TLS,很明显它是一个超级重要的网络协议(让我们来加密网络吧!:D)。但 IPsec 也是一个很重要的网络加密协议,它与 TLS 有着不同的角色!很明显有些移动电话协议(例如 5G/LTE)使用 IPsec 来加密它们的网络流量!
|
||||
|
||||
现在我很高兴我知道更多关于 IPsec 的知识!和以前一样可能本文有些错误,但希望不会错的太多 :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://tools.ietf.org/html/rfc6071
|
||||
[2]:https://jvns.ca/categories/netdev
|
||||
[3]:https://www.netdevconf.org/0x12/
|
||||
[4]:https://jvns.ca/categories/netdev/
|
||||
[5]:https://nohats.ca/
|
||||
[6]:https://en.wikipedia.org/wiki/Internet_Key_Exchange
|
||||
[7]:https://blog.filippo.io/playing-with-kernel-tls-in-linux-4-13-and-go/
|
||||
[8]:http://oe.libreswan.org/
|
||||
@ -0,0 +1,269 @@
|
||||
系统管理员的 SELinux 指南: 42 个重大相关问题的答案
|
||||
============================================================
|
||||
|
||||
> 获取有关生活、宇宙和除了有关 SELinux 的重要问题的答案
|
||||
|
||||

|
||||
Image credits : [JanBaby][13], via Pixabay [CC0][14].
|
||||
|
||||
> ”一个重要并且受欢迎的事实是:事情并不总是它们该有的样子“
|
||||
> ―Douglas Adams,_银河系漫游指南_
|
||||
|
||||
安全、加固、规范化、策略是末世中系统管理员的四骑士。除了我们的日常任务--监控、备份、实现、调优、升级以及类似任务--我们还需要对我们系统的安全负责。即使这些系统是第三方提供商告诉我们该禁用增强安全性的系统。这就像 [Ethan Hunt][15] 面临的 _不可能的任务_。
|
||||
|
||||
面对这些困境,有些系统管理员决定 [拿绿色药丸][16],因为他们认为他们将不会知道诸如生活、宇宙和其他事情等重大问题的答案,并且众所周知的是,那个答案是 42.
|
||||
|
||||
受到_银河系漫游指南_启发,下面有 42 个有关在你系统中管理和使用 [SELinux][17] 这个重大问题的答案。
|
||||
|
||||
1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录和系统事物都有一个标签。策略规则控制着被标记的进程和被标记的事物之间的获取。内核强制执行这些规则。
|
||||
|
||||
1. 最重要的两个概念是: _标签_(文件、进程、端口等)和 _类型强制_(基于不同的类型隔离不同的进程)。
|
||||
|
||||
1. 正确的标签格式是 `user:role:type:level`(_可选_)。
|
||||
|
||||
1. _多层安全(MLS)强制_ 的目的是基于它们索要使用数据的安全级别来控制进程(_区域_)。例如一个秘密级别的进程不能读取绝密级别的数据。
|
||||
|
||||
1. _多目录安全(MCS)强制_ 相互保护相似的进程(例如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)。
|
||||
|
||||
1. 在启动时改变 SELinux 模式的内核参数有:
|
||||
* `autorelabel=1` → 强制系统重新标签
|
||||
|
||||
* `selinux=0` → 内核并不加载 SELinux 设施的任何部分
|
||||
|
||||
* `enforcing=0` → 以许可模式启动
|
||||
|
||||
1. 假如你需要重新标签整个系统:
|
||||
`# touch /.autorelabel
|
||||
#reboot`
|
||||
假如你的标签中包含大量错误,为了让 autorelabel 能够成功,你需要以许可模式启动
|
||||
|
||||
1. 检查 SELinux 是否启用:`# getenforce`
|
||||
|
||||
1. 临时启用或禁用 SELinux:`# setenforce [1|0]`
|
||||
|
||||
1. SELinux 状态工具:`# sestatus`
|
||||
|
||||
1. 配置文件:`/etc/selinux/config`
|
||||
|
||||
1. SELinux 是如何工作的呢?下面是一个标签一个 Apache Web 服务器的例子:
|
||||
* 二进制:`/usr/sbin/httpd`→`httpd_exec_t`
|
||||
|
||||
* 配置目录:`/etc/httpd`→`httpd_config_t`
|
||||
|
||||
* 日志文件目录:`/var/log/httpd` → `httpd_log_t`
|
||||
|
||||
* 内容目录:`/var/www/html` → `httpd_sys_content_t`
|
||||
|
||||
* 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
|
||||
|
||||
* 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
|
||||
|
||||
* 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`
|
||||
|
||||
一个运行在 `httpd_t` 安全上下文的端口可以和被标记为 `httpd_something_t` 标签的事物交互。
|
||||
|
||||
1. 许多命令接收 `-Z` 参数来查看、创建和修改安全上下文:
|
||||
* `ls -Z`
|
||||
|
||||
* `id -Z`
|
||||
|
||||
* `ps -Z`
|
||||
|
||||
* `netstat -Z`
|
||||
|
||||
* `cp -Z`
|
||||
|
||||
* `mkdir -Z`
|
||||
|
||||
当文件被创建时,它们的安全上下文会根据它们父目录的安全上下文来创建(可能有某些例外)。RPM 可以在安装过程中设定安全上下文。
|
||||
|
||||
1. 导致 SELinux 错误的四个关键的因素如下,它们将在 15-21 条深入解释:
|
||||
* 标签问题
|
||||
|
||||
* SELinux 需要知晓更多信息
|
||||
|
||||
* SELinux 策略或者应用有 bug
|
||||
|
||||
* 你的信息可能被损坏了
|
||||
|
||||
1. _标签问题:_ 假如你的位于 `/srv/myweb` 的文件没有被正确地标志,获取这些资源时可能会被拒绝。下面是一些解决方法:
|
||||
* 假如你知道标签:
|
||||
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
|
||||
|
||||
* 假如你知道和它有相同标签的文件:
|
||||
`# semanage fcontext -a -e /srv/myweb /var/www`
|
||||
|
||||
* 恢复安全上下文(针对上述两种情形):
|
||||
`# restorecon -vR /srv/myweb`
|
||||
|
||||
1. _标识问题:_ 假如你移动了一个文件而不是复制它,这个文件仍然保留原来的安全上下文。为了修复这些问题,你需要:
|
||||
* 使用标签来改变安全上下文:
|
||||
`# chcon -t httpd_system_content_t /var/www/html/index.html`
|
||||
|
||||
* 使用参考文件的标签来改变安全上下文:
|
||||
`# chcon --reference /var/www/html/ /var/www/html/index.html`
|
||||
|
||||
* 恢复安全上下文(针对上述两种情形): `# restorecon -vR /var/www/html/`
|
||||
|
||||
1. 假如_SELinux 需要知道_ HTTPD 在端口 8585 上监听,使用下面的命令告诉它:
|
||||
`# semanage port -a -t http_port_t -p tcp 8585`
|
||||
|
||||
1. _SELinux 需要知道_ 布尔值来允许在运行时改变 SELinux 的策略,而不需要知道任何关于 SELinux 策略读写的信息。例如,假如你想让 httpd 去发送邮件,键入:`# setsebool -P httpd_can_sendmail 1`
|
||||
|
||||
1. _SELinux 需要知道_ 布尔值来做 SELinux 的开关设定:
|
||||
* 查看所有的布尔值:`# getsebool -a`
|
||||
|
||||
* 查看每一个的描述:`# semanage boolean -l`
|
||||
|
||||
* 设定某个布尔值,执行:`# setsebool [_boolean_] [1|0]`
|
||||
|
||||
* 添加 `-P` 参数来作为永久设置,例如:
|
||||
`# setsebool httpd_enable_ftp_server 1 -P`
|
||||
|
||||
1. SELinux 策略或者应用有 bug,包括:
|
||||
* 不寻常的代码路径
|
||||
|
||||
* 配置
|
||||
|
||||
* `stdout` 的重定向
|
||||
|
||||
* 泄露的文件描述符
|
||||
|
||||
* 可执行内存
|
||||
|
||||
* 损坏的已构建的库
|
||||
打开一个工单(但别书写一个 Bugzilla 报告,使用 Bugzilla 没有对应的服务)。
|
||||
|
||||
1. _你的信息可能被损坏了_ 假如你被限制在某个区域,尝试这样做:
|
||||
* 加载内核模块
|
||||
|
||||
* 关闭 SELinux 的强制模式
|
||||
|
||||
* 向 `etc_t/shadow_t` 写入东西
|
||||
|
||||
* 修改 iptables 规则
|
||||
|
||||
1. 下面是安装针对策略模块的发展的 SELinux 工具:
|
||||
`# yum -y install setroubleshoot setroubleshoot-server`
|
||||
在你安装后重启或重启动 `auditd` 服务
|
||||
|
||||
1. 使用 `journalctl` 来监听所有跟 `setroubleshoot` 有关的日志:
|
||||
`# journalctl -t setroubleshoot --since=14:20`
|
||||
|
||||
1. 使用 `journalctl` 来监听所有跟某个特定 SELinux 标签相关的日志,例如:
|
||||
`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
|
||||
|
||||
1. 当 SELinux 错误发生时,使用`setroubleshoot` 的日志,并尝试找到某些可能的解决方法。例如,从 `journalctl`:
|
||||
```
|
||||
Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
|
||||
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
|
||||
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
|
||||
|
||||
***** Plugin restorecon (99.5 confidence) suggests ************************
|
||||
|
||||
If you want to fix the label,
|
||||
/var/www/html/index.html default label should be httpd_syscontent_t.
|
||||
Then you can restorecon.
|
||||
Do
|
||||
# /sbin/restorecon -v /var/www/html/index.html
|
||||
```
|
||||
|
||||
1. 带有 SELinux 记录的日志:
|
||||
* `/var/log/messages`
|
||||
|
||||
* `/var/log/audit/audit.log`
|
||||
|
||||
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
|
||||
|
||||
1. 在 audit 日志文件中查找有关 SELinux 的错误:
|
||||
`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
|
||||
|
||||
1. 针对某个特定的服务,搜寻 SELinux 的访问向量缓存(Access Vector Cache,,AVC)信息:
|
||||
`# ausearch -m avc -c httpd`
|
||||
|
||||
1. `audit2allow` 程序可以通过从日志中搜集有关被拒绝的操作,然后生成 SELinux 策略允许的规则,例如:
|
||||
* 生成一个为什么会被拒绝访问的对人友好的描述: `# audit2allow -w -a`
|
||||
|
||||
* 查看允许被拒绝的访问的类型强制规则: `# audit2allow -a`
|
||||
|
||||
* 创建一个自定义模块:`# audit2allow -a -M mypolicy`
|
||||
其中的 `-M` 选项将创建一个特定名称的类型强制文件(.te),(.te) 并且将规则编译进一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
|
||||
|
||||
* 安装自定义模块:`# semodule -i mypolicy.pp`
|
||||
|
||||
1. 为了配置一个单独的进程(区域)来更宽松地运行: `# semanage permissive -a httpd_t`
|
||||
|
||||
1. 假如你不在想某个区域是宽松的:`# semanage permissive -d httpd_t`
|
||||
|
||||
1. 禁用所有的宽松区域: `# semodule -d permissivedomains`
|
||||
|
||||
1. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`
|
||||
在 `/etc/selinux/config` 文件中配置:
|
||||
`SELINUX=permissive`
|
||||
`SELINUXTYPE=mls`
|
||||
确保 SELinux 正运行在宽松模式下:`# setenforce 0`
|
||||
使用 `fixfiles` 脚本来确保在下一次重启时文件将被重新标识:
|
||||
`# fixfiles -F onboot # reboot`
|
||||
|
||||
1. 创建一个带有特定 MLS 范围的用户:`# useradd -Z staff_u john`
|
||||
使用 `useradd` 命令来将新的用户映射到一个现存的 SELinux 用户(在这个例子中,用户为 `staff_u`)。
|
||||
|
||||
1. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
|
||||
|
||||
1. 为某个用户定义一个特别的范围:`# semanage login --modify --range s2:c100 john`
|
||||
|
||||
1. 更正用户家目录的标志(假如需要的话):`# chcon -R -l s2:c100 /home/john`
|
||||
|
||||
1. 列出当前的类别:`# chcat -L`
|
||||
|
||||
1. 更改类别或者创建你自己类别,修改如下的文件:
|
||||
`/etc/selinux/_<selinuxtype>_/setrans.conf`
|
||||
|
||||
1. 以某个特定的文件、角色和用户安全上下文来运行一个命令或者脚本:
|
||||
`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
|
||||
* `-t` 是 _文件安全上下文_
|
||||
|
||||
* `-r` 是 _角色安全上下文_
|
||||
|
||||
* `-u` 是 _用户安全上下文_
|
||||
|
||||
1. 禁用 SELinux 来运行容器:
|
||||
* 使用 Podman:`# podman run --security-opt label=disable` …
|
||||
|
||||
* 使用 Docker:`# docker run --security-opt label=disable` …
|
||||
|
||||
1. 假如你需要给一个容器对系统的完整访问权限:
|
||||
* 使用 Podman:`# podman run --privileged` …
|
||||
|
||||
* 使用 Docker:`# docker run --privileged` …
|
||||
|
||||
知道了上面的这些,你就已经知道答案了。所以请 **不要惊慌,打开 SELinux**。
|
||||
|
||||
### 作者简介
|
||||
|
||||
Alex Callejas - Alex Callejas 是位于墨西哥城的红帽公司拉丁美洲区的一名技术客服经理。作为一名系统管理员,他已有超过 10 年的经验。在基础设施强化方面具有很强的专业知识。对开源抱有热情,通过在不同的公共事件和大学中分享他的知识来支持社区。天生的极客,当然他一般选择使用 Fedora Linux 发行版。[这里][11]有更多关于我的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-selinux
|
||||
|
||||
作者:[Alex Callejas][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/darkaxl
|
||||
[11]:https://opensource.com/users/darkaxl
|
||||
[13]:https://pixabay.com/en/security-secure-technology-safety-2168234/
|
||||
[14]:https://creativecommons.org/publicdomain/zero/1.0/deed.en
|
||||
[15]:https://en.wikipedia.org/wiki/Ethan_Hunt
|
||||
[16]:https://en.wikipedia.org/wiki/Red_pill_and_blue_pill
|
||||
[17]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[18]:https://opensource.com/users/darkaxl
|
||||
[19]:https://opensource.com/users/darkaxl
|
||||
[20]:https://opensource.com/article/18/7/sysadmin-guide-selinux#comments
|
||||
[21]:https://opensource.com/tags/security
|
||||
[22]:https://opensource.com/tags/linux
|
||||
[23]:https://opensource.com/tags/sysadmin
|
||||
@ -0,0 +1,121 @@
|
||||
netdev 第二天:从网络代码中移除“尽可能快”这个目标
|
||||
============================================================
|
||||
|
||||
嗨!今天是 netdev 会议的第 2 天,我只参加了早上的会议,但它_非常有趣_。今早会议的主角是 [Van Jacobson][1] 给出的一场名为 “从尽可能快中变化:教网卡以时间”的演讲,它的主题是 关于网络中拥塞控制的未来!!!
|
||||
|
||||
下面我将尝试着对我从这次演讲中学到的东西做总结,我几乎肯定下面的内容有些错误,但不管怎样,让我们开始吧!
|
||||
|
||||
这次演讲是关于互联网是如何从 1988 开始改变的,为什么现在我们需要新的算法,以及我们可以怎样改变 Linux 的网络栈来更容易地实现这些算法。
|
||||
|
||||
### 什么是拥塞控制?
|
||||
|
||||
在网络上的任何成员总是无时无刻地发送信息包,而在互联网上的连接之间有着极其不同的速度(某些相比其他极其缓慢),而有时候它们将被塞满!当互联网的一个设备以超过它能处理的速率接收信息包时,它将丢弃某些信息包。
|
||||
|
||||
你所能想象的最天真的发送信息包方式是:
|
||||
|
||||
1. 将你必须发送的信息包一次性发送完。
|
||||
|
||||
2. 假如你发现其中有的信息包被丢弃了,就马上重新发送这些包。
|
||||
|
||||
结果表明假如你按照上面的思路来实现 TCP,互联网将会崩溃并停止运转。我们知道它会崩溃是因为在 1986 年确实发生了崩溃的现象。为了解决这个问题,专家发明了拥塞控制算法--描述如何避免互联网的崩溃的原始论文是 Van Jacobson 于 1988 年发表的 [拥塞避免与控制][2](30 年前!)。
|
||||
|
||||
### 从 1988 年后互联网发生了什么改变?
|
||||
|
||||
在演讲中,Van Jacobson 说互联网的这些已经发生了改变:在以前的互联网上,交换机可能总是拥有比服务器更快的网卡,所以位于互联网中间层的服务器也可能比客户端更快,并且这些改变并不能对客户端发送信息包的速率有多大影响。
|
||||
|
||||
很显然今天已经不是这样的了!众所周知,今天的计算机相比于 5 年前的计算机在速度上并没有多大的提升(我们遇到了某些有关光速的问题)。所以我想路由器上的大型交换机并不会在速度上大幅领先于数据中心里服务器上的网卡。
|
||||
|
||||
这听起来有些糟糕,因为这意味着在中间层的客户端更容易在连接中达到饱和,而这将导致互联网变慢(而且 [缓冲膨胀][3] 将带来更高的延迟)。
|
||||
|
||||
所以为了提高互联网的性能且不让每个路由上的任务队列都达到饱和,客户端需要表现得更好并且在发送信息包的时候慢一点。
|
||||
|
||||
### 以更慢的速率发送更多的信息包以达到更好的性能
|
||||
|
||||
下面的结论真的让我非常意外 -- 以更慢的速率发送信息包实际上可能会带来更好的性能(即便你是在整个传输过程中,这样做的唯一的人),下面是原因:
|
||||
|
||||
假设你打算发送 10MB 的数据,在你和你需要连接的客户端之间有一个中间层,并且它的传输速率_非常低_,例如 1MB/s。假设你可以辨别这个慢连接(或者更多的后续中间层)的速度,那么你有 2 个选择:
|
||||
|
||||
1. 一次性将这 10MB 的数据发送完,然后看看会发生什么。
|
||||
|
||||
2. 减慢速率使得你能够以 1MB/s 的速率传给它。
|
||||
|
||||
现在,无论你选择何种方式,你可能都会发生丢包的现象。所以这样看起来,你可能需要选择一次性发送所有的信息包这种方式,对吧?不!!实际上在你的数据流的中间环节丢包要比在你的数据流的最后丢包要好得多。假如在中间环节有些包被丢弃了,你需要送往的那个客户端可以察觉到这个事情,然后再告诉你,这样你就可以再次发送那些被丢弃的包,这样便没有多大的损失。但假如信息包在最末端被丢弃,那么客户端将完全没有办法知道你一次性发送了所有的信息包!所以基本上在某个时刻被丢弃的包没有让你收到 ACK 信号时,你需要启用超时机制,并且还得重新发送它们。而超时往往意味着需要花费很长时间!
|
||||
|
||||
所以为什么以更慢的速率发送数据会更好呢?假如你发送数据的速率快于连接中的瓶颈,这时所有的信息包将会在某个地方堆积成一个队列,这个队列将会被塞满,然后在你的数据流的最末端的信息包将会被丢弃。并且像我们刚才解释的那样,处于数据流最后面的信息包很有可能丢弃!所以相比于最初以合适的速率发送信息包,一次性发送它们将会触发超时机制,发送 10MB 的数据将会花费更长的时间。
|
||||
|
||||
我认为这非常酷,因为这个过程并不需要与互联网中的其他人合作 —— 即便其他的所有人都已非常快的速率传送他们的信息包,对你来说以合适的速率(中间层的瓶颈速率)传送你自己的信息包_仍然_更有优势。
|
||||
|
||||
### 如何辨别发送数据的合适速率:BBR!
|
||||
|
||||
在上面我说过:“假设你可以辨别出位于你的终端和服务器之间慢连接的速率。。。”,那么如何做到呢?来自 Google(Jacobson 工作的地方)的某些专家已经提出了一个算法来估计瓶颈的速率!它叫做 BBR,由于本次的分享已经很长了,所以这里不做具体介绍,但你可以参考 [BBR:基于拥塞的拥塞控制][4] 和 [来自晨读论文的总结][5] 这两处链接。
|
||||
|
||||
(另外,[https://blog.acolyer.org][6] 的每日“晨读论文”总结基本上是我学习和理解计算机科学论文的唯一方式,它有可能是整个互联网上最好的博客之一!)
|
||||
|
||||
### 网络代码被设计为运行得“尽可能快“
|
||||
|
||||
所以,假设我们相信我们想以一个更慢的速率(例如以我们连接中的瓶颈速率)来传输数据。这很好,但网络软件并不是被设计为以一个可控速率来传输数据的!下面是我所理解的大多数网络软件怎么做的:
|
||||
|
||||
1. 现在有一个队列的信息包来临;
|
||||
|
||||
2. 然后软件读取队列并尽可能快地发送信息包;
|
||||
|
||||
3. 就这样,没有了。
|
||||
|
||||
这个过程非常呆板——假设我以一个非常快的速率发送信息包,而另一端的连接却非常慢。假如我所拥有的就是一个放置所有信息包的队列,当我实际要发送数据时,我并没有办法来控制这个发送过程,所以我便不能减慢这个队列传输的速率。
|
||||
|
||||
### 一个更好的方式:给每个信息包一个”最早的出发时间“
|
||||
|
||||
BBR 协议将会修改 Linux 内核中 skb 的数据结构(这个数据结构被用来表达网络信息包),使得它有一个时间戳,这个时间戳代表着这个信息包应该被发送出去的最早时间。
|
||||
|
||||
对于 Linux 网络栈我不知道更多的详情了,但对于我来说,这个协议最有趣的地方是这个改动并不是一个非常大的改动!它只是添加了一个额外的时间戳而已。
|
||||
|
||||
### 用时间轮盘替换队列!!!
|
||||
|
||||
一旦我们将时间戳打到这些信息包上,我们怎样在合适的时间将它们发送出去呢?使用_时间轮盘_!
|
||||
|
||||
在前不久的”我们喜爱的论文“活动中(这是关于这次聚会的描述的[某些好的链接][7]),有一个演讲谈论了关于时间轮盘的话题。时间轮盘是一类用来指导 Linux 的进程调度器决定何时运行进程的算法。
|
||||
|
||||
Van Jacobson 说道:时间轮盘实际上比队列调度工作得更好——它们都提供常数时间的操作,但因为某些缓存机制,时间轮盘的常数要更小一些。我真的没有太明白这里他说的关于性能的解释。
|
||||
|
||||
他说道:关于时间轮盘的一个关键点是你可以很轻松地用时间轮盘实现一个队列(但反之不能!)——假如每次你增加一个新的信息包,在最开始你说我想让它_现在_就被发送走,很显然这样你就可以得到一个队列了。而这个时间轮盘方法是向后兼容的,它使得你可以更容易地实现某些更加复杂的对流量非常敏感的算法,例如让你针对不同的信息包以不同的速率去发送它们。
|
||||
|
||||
### 或许我们可以通过改善 Linux 来修复互联网!
|
||||
|
||||
对于任何影响到整个互联网规模的问题,最为棘手的问题是当你要做出改善时,例如改变互联网协议的实现,你需要面对各种不同的设备。你要面对 Linux 的机子,BSD 的机子, Windows 的机子,各种各样的手机,瞻博或者思科的路由器以及数量繁多的其他设备!
|
||||
|
||||
但是在网络环境中 Linux 处于某种有趣的位置上!
|
||||
|
||||
* Android 手机运行着 Linux
|
||||
|
||||
* 大多数的消费级 WiFi 路由器运行着 Linux
|
||||
|
||||
* 无数的服务器运行着 Linux
|
||||
|
||||
所以在任何给定的网络连接中,实际上很有可能在不同的终端有一台 Linux 机子(例如一个 Linux 服务器,或者一个 Linux 路由器,一台 Android 设备)。
|
||||
|
||||
所以重点是假如你想大幅改善互联网上的拥塞状况,只需要改变 Linux 网络栈就会大所不同(或许 iOS 网络栈也是类似的)。这也就是为什么在本次的 Linux 网络会议上有这样的一个演讲!
|
||||
|
||||
### 互联网仍在改变!酷!
|
||||
|
||||
通常我以为 TCP/IP 仍然是上世纪 80 年代的东西,所以当从这些专家口中听说这些我们正在设计的网路协议仍然有许多严重的问题时,真的是非常有趣,并且听说现在有不同的方式来设计它们。
|
||||
|
||||
当然也确实是这样——网络硬件以及和速度相关的任何设备,以及人们使用网络来干的各种事情(例如观看网飞 Netflix 的节目)等等,一直都在随着时间发生着改变,所以正因为这样,我们需要为 2018 年的互联网而不是为 1988 年的互联网设计我们不同的算法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/07/12/netdev-day-2--moving-away-from--as-fast-as-possible/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://en.wikipedia.org/wiki/Van_Jacobson
|
||||
[2]:https://cs162.eecs.berkeley.edu/static/readings/jacobson-congestion.pdf
|
||||
[3]:https://apenwarr.ca/log/?m=201101#10
|
||||
[4]:https://queue.acm.org/detail.cfm?id=3022184
|
||||
[5]:https://blog.acolyer.org/2017/03/31/bbr-congestion-based-congestion-control/
|
||||
[6]:https://blog.acolyer.org/
|
||||
[7]:https://www.meetup.com/Papers-We-Love-Montreal/events/235100825/
|
||||
@ -0,0 +1,71 @@
|
||||
Linux 桌面中 4 个开源媒体转换工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
啊,有这么多的文件格式,特别是音频和视频格式,如果你不认识这个文件扩展名或者你的播放器无法播放那个格式,或者你想使用一种开放格式,那会有点有趣。
|
||||
|
||||
那么,Linux 用户可以做些什么呢?当然是去使用 Linux 桌面的众多开源媒体转换工具之一。我们来看看其中的四个。
|
||||
|
||||
### Gnac
|
||||
|
||||

|
||||
|
||||
[Gnac][1] 是我最喜欢的音频转换器之一,已经存在很多年了。它易于使用,功能强大,并且它做得很好 - 任何一流的程序都应该如此。
|
||||
|
||||
有多简单?单击工具栏按钮添加一个或多个要转换的文件,选择要转换的格式,然后单击**转换**。转换很快,而且很干净。
|
||||
|
||||
有多强大?Gnac 可以处理 [GStreamer][2] 多媒体框架支持的所有音频格式。开箱即用,你可以在 Ogg、FLAC、AAC、MP3、WAV 和 SPX 之间进行转换。你还可以更改每种格式的转换选项或添加新格式。
|
||||
|
||||
### SoundConverter
|
||||
|
||||

|
||||
|
||||
如果在简单的同时你还要一些额外的功能,那么请看一下 [SoundConverter][3]。正如其名称所述,SoundConverter 仅对音频文件起作用。与 Gnac 一样,它可以读取 GStreamer 支持的格式,它可以输出 Ogg Vorbis、MP3、FLAC、WAV、AAC 和 Opus 文件。
|
||||
|
||||
通过单击**添加文件**或将其拖放到 SoundConverter 窗口中来加载单个文件或整个文件夹。单击**转换**,软件将完成转换。它也很快 - 我已经在大约一分钟内转换了一个包含几十个文件的文件夹。
|
||||
|
||||
SoundConverter 有设置转换文件质量的选项。你可以更改文件的命名方式(例如,在标题中包含曲目编号或专辑名称),并为转换后的文件创建子文件夹。
|
||||
|
||||
### WinFF
|
||||
|
||||

|
||||
|
||||
[WinFF][4] 本身并不是转换器。它是 FFmpeg 的图形化前端,[Tim Nugent][5] 在 Opensource.com 写了篇文章。虽然 WinFF 没有 FFmpeg 的所有灵活性,但它使 FFmpeg 更易于使用,并且可以快速,轻松地完成工作。
|
||||
|
||||
虽然它不是这里最漂亮的程序,WinFF 也并不需要。它不仅仅是可用的。你可以从下拉列表中选择要转换的格式,并选择多个预设。最重要的是,你可以指定比特率和帧速率,要使用的音频通道数量,甚至裁剪视频的大小等选项。
|
||||
|
||||
转换,特别是视频,需要一些时间,但结果通常非常好。有时,转换会有点受损 - 但往往不足以引起关注。而且,正如我之前所说,使用 WinFF 可以节省一些时间。
|
||||
|
||||
### Miro Video Converter
|
||||
|
||||

|
||||
|
||||
并非所有视频文件都是平等创建的。有些是专有格式。有的在显示器或电视屏幕上看起来很棒但是没有针对移动设备进行优化。这就是 [Miro Video Converter][6] 可以用的地方。
|
||||
|
||||
Miro Video Converter 非常重视移动设备。它可以转换在 Android 手机、Apple 设备、PlayStation Portable 和 Kindle Fire 上播放的视频。它会将最常见的视频格式转换为 MP4、[WebM][7] 和 [Ogg Theora][8]。你可以[在 Miro 的网站][6]上找到支持的设备和格式的完整列表
|
||||
|
||||
要使用它,可以将文件拖放到窗口中,也可以选择要转换的文件。然后,单击“格式”菜单以选择转换的格式。你还可以单击 Apple、Android 或其他菜单以选择要转换文件的设备。Miro Video Converter 会为设备屏幕分辨率调整视频大小。
|
||||
|
||||
你有最喜欢的 Linux 媒体转换程序吗?请留下评论,随意分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/media-conversion-tools-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:http://gnac.sourceforge.net
|
||||
[2]:http://www.gstreamer.net/
|
||||
[3]:http://soundconverter.org/
|
||||
[4]:https://www.biggmatt.com/winff/
|
||||
[5]:https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
|
||||
[6]:http://www.mirovideoconverter.com/
|
||||
[7]:https://en.wikipedia.org/wiki/WebM
|
||||
[8]:https://en.wikipedia.org/wiki/Ogg_theora
|
||||
Loading…
Reference in New Issue
Block a user