mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
31f53656cf
@ -0,0 +1,435 @@
|
||||
使用 sar 和 kSar 来发现 Linux 性能瓶颈
|
||||
======
|
||||
|
||||
`sar` 命令用用收集、报告、或者保存 UNIX / Linux 系统的活动信息。它保存选择的计数器到操作系统的 `/var/log/sa/sadd` 文件中。从收集的数据中,你可以得到许多关于你的服务器的信息:
|
||||
|
||||
1. CPU 使用率
|
||||
2. 内存页面和使用率
|
||||
3. 网络 I/O 和传输统计
|
||||
4. 进程创建活动
|
||||
5. 所有的块设备活动
|
||||
6. 每秒中断数等等
|
||||
|
||||
`sar` 命令的输出能够用于识别服务器瓶颈。但是,分析 `sar` 命令提供的信息可能比较困难,所以要使用 kSar 工具。kSar 工具可以将 `sar` 命令的输出绘制成基于时间周期的、易于理解的图表。
|
||||
|
||||
### sysstat 包
|
||||
|
||||
`sar`、`sa1`、和 `sa2` 命令都是 sysstat 包的一部分。它是 Linux 包含的性能监视工具集合。
|
||||
|
||||
1. `sar`:显示数据
|
||||
2. `sa1` 和 `sa2`:收集和保存数据用于以后分析。`sa2` shell 脚本在 `/var/log/sa` 目录中每日写入一个报告。`sa1` shell 脚本将每日的系统活动信息以二进制数据的形式写入到文件中。
|
||||
3. sadc —— 系统活动数据收集器。你可以通过修改 `sa1` 和 `sa2` 脚本去配置各种选项。它们位于以下的目录:
|
||||
* `/usr/lib64/sa/sa1` (64 位)或者 `/usr/lib/sa/sa1` (32 位) —— 它调用 `sadc` 去记录报告到 `/var/log/sa/sadX` 格式。
|
||||
* `/usr/lib64/sa/sa2` (64 位)或者 `/usr/lib/sa/sa2` (32 位) —— 它调用 `sar` 去记录报告到 `/var/log/sa/sarX` 格式。
|
||||
|
||||
#### 如何在我的系统上安装 sar?
|
||||
|
||||
在一个基于 CentOS/RHEL 的系统上,输入如下的 [yum 命令][1] 去安装 sysstat:
|
||||
|
||||
```
|
||||
# yum install sysstat
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
Loaded plugins: downloadonly, fastestmirror, priorities,
|
||||
: protectbase, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* addons: mirror.cs.vt.edu
|
||||
* base: mirror.ash.fastserv.com
|
||||
* epel: serverbeach1.fedoraproject.org
|
||||
* extras: mirror.cogentco.com
|
||||
* updates: centos.mirror.nac.net
|
||||
0 packages excluded due to repository protections
|
||||
Setting up Install Process
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
====================================================================
|
||||
Package Arch Version Repository Size
|
||||
====================================================================
|
||||
Installing:
|
||||
sysstat x86_64 7.0.2-3.el5 base 173 k
|
||||
|
||||
Transaction Summary
|
||||
====================================================================
|
||||
Install 1 Package(s)
|
||||
Update 0 Package(s)
|
||||
Remove 0 Package(s)
|
||||
|
||||
Total download size: 173 k
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
|
||||
Running rpm_check_debug
|
||||
Running Transaction Test
|
||||
Finished Transaction Test
|
||||
Transaction Test Succeeded
|
||||
Running Transaction
|
||||
Installing : sysstat 1/1
|
||||
|
||||
Installed:
|
||||
sysstat.x86_64 0:7.0.2-3.el5
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
#### 为 sysstat 配置文件
|
||||
|
||||
编辑 `/etc/sysconfig/sysstat` 文件去指定日志文件保存多少天(最长为一个月):
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/sysstat
|
||||
```
|
||||
|
||||
示例输出如下 :
|
||||
|
||||
```
|
||||
# keep log for 28 days
|
||||
# the default is 7
|
||||
HISTORY=28
|
||||
```
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
### 找到 sar 默认的 cron 作业
|
||||
|
||||
[默认的 cron 作业位于][2] `/etc/cron.d/sysstat`:
|
||||
|
||||
```
|
||||
# cat /etc/cron.d/sysstat
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
#### 告诉 sadc 去报告磁盘的统计数据
|
||||
|
||||
使用一个文本编辑器去编辑 `/etc/cron.d/sysstat` 文件,比如使用 `vim` 命令,输入如下:
|
||||
|
||||
```
|
||||
# vi /etc/cron.d/sysstat
|
||||
```
|
||||
|
||||
像下面的示例那样更新这个文件,以记录所有的硬盘统计数据(`-d` 选项强制记录每个块设备的统计数据,而 `-I` 选项强制记录所有系统中断的统计数据):
|
||||
|
||||
```
|
||||
# run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
|
||||
# generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
在 CentOS/RHEL 7.x 系统上你需要传递 `-S DISK` 选项去收集块设备的数据。传递 `-S XALL` 选项去采集如下所列的数据:
|
||||
|
||||
1. 磁盘
|
||||
2. 分区
|
||||
3. 系统中断
|
||||
4. SNMP
|
||||
5. IPv6
|
||||
|
||||
```
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
|
||||
# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
|
||||
# Generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
```
|
||||
|
||||
保存并关闭这个文件。
|
||||
|
||||
#### 打开 CentOS/RHEL 版本 5.x/6.x 的服务
|
||||
|
||||
输入如下命令:
|
||||
|
||||
```
|
||||
chkconfig sysstat on
|
||||
service sysstat start
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
Calling the system activity data collector (sadc):
|
||||
```
|
||||
|
||||
对于 CentOS/RHEL 7.x,运行如下的命令:
|
||||
|
||||
```
|
||||
# systemctl enable sysstat
|
||||
# systemctl start sysstat.service
|
||||
# systemctl status sysstat.service
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
● sysstat.service - Resets System Activity Logs
|
||||
Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
|
||||
Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
|
||||
Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
|
||||
Main PID: 28297 (code=exited, status=0/SUCCESS)
|
||||
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
|
||||
Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
|
||||
```
|
||||
|
||||
### 如何使用 sar?如何查看统计数据?
|
||||
|
||||
使用 `sar` 命令去显示操作系统中选定的累积活动计数器输出。在这个示例中,运行 `sar` 命令行,去实时获得 CPU 使用率的报告:
|
||||
|
||||
```
|
||||
# sar -u 3 10
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
|
||||
|
||||
09:49:47 PM CPU %user %nice %system %iowait %steal %idle
|
||||
09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
|
||||
09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
|
||||
09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
|
||||
09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
|
||||
09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
|
||||
09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
|
||||
09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
|
||||
09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
|
||||
09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
|
||||
09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
|
||||
Average: all 9.24 0.69 1.84 0.03 0.00 88.20
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* 3 表示间隔时间
|
||||
* 10 表示次数
|
||||
|
||||
查看进程创建的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -c 3 10
|
||||
```
|
||||
|
||||
查看 I/O 和传输率统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -b 3 10
|
||||
```
|
||||
|
||||
查看内存页面统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -B 3 10
|
||||
```
|
||||
|
||||
查看块设备统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -d 3 10
|
||||
```
|
||||
|
||||
查看所有中断的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -I XALL 3 10
|
||||
```
|
||||
|
||||
查看网络设备特定的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -n DEV 3 10
|
||||
# sar -n EDEV 3 10
|
||||
```
|
||||
|
||||
查看 CPU 特定的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -P ALL
|
||||
# Only 1st CPU stats
|
||||
# sar -P 1 3 10
|
||||
```
|
||||
|
||||
查看队列长度和平均负载的统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -q 3 10
|
||||
```
|
||||
|
||||
查看内存和交换空间的使用统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -r 3 10
|
||||
# sar -R 3 10
|
||||
```
|
||||
|
||||
查看 inode、文件、和其它内核表统计数据状态,输入:
|
||||
|
||||
```
|
||||
# sar -v 3 10
|
||||
```
|
||||
|
||||
查看系统切换活动统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -w 3 10
|
||||
```
|
||||
|
||||
查看交换统计数据,输入:
|
||||
|
||||
```
|
||||
# sar -W 3 10
|
||||
```
|
||||
|
||||
查看一个 PID 为 3256 的 Apache 进程,输入:
|
||||
|
||||
```
|
||||
# sar -x 3256 3 10
|
||||
```
|
||||
|
||||
### kSar 介绍
|
||||
|
||||
`sar` 和 `sadf` 提供了基于命令行界面的输出。这种输出可能会使新手用户/系统管理员感到无从下手。因此,你需要使用 kSar,它是一个图形化显示你的 `sar` 数据的 Java 应用程序。它也允许你以 PDF/JPG/PNG/CSV 格式导出数据。你可以用三种方式去加载数据:本地文件、运行本地命令、以及通过 SSH 远程运行的命令。kSar 可以处理下列操作系统的 `sar` 输出:
|
||||
|
||||
1. Solaris 8, 9 和 10
|
||||
2. Mac OS/X 10.4+
|
||||
3. Linux (Systat Version >= 5.0.5)
|
||||
4. AIX (4.3 & 5.3)
|
||||
5. HPUX 11.00+
|
||||
|
||||
#### 下载和安装 kSar
|
||||
|
||||
访问 [官方][3] 网站去获得最新版本的源代码。使用 [wget][4] 去下载源代码,输入:
|
||||
|
||||
```
|
||||
$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar
|
||||
```
|
||||
|
||||
#### 如何运行 kSar?
|
||||
|
||||
首先要确保你的机器上 [JAVA jdk][5] 已安装并能够正常工作。输入下列命令去启动 kSar:
|
||||
|
||||
```
|
||||
$ java -jar ksar-5.2.4-SNAPSHOT-all.jar
|
||||
```
|
||||
|
||||
![Fig.01: kSar welcome screen][6]
|
||||
|
||||
接下来你将看到 kSar 的主窗口,和有两个菜单的面板。
|
||||
|
||||
![Fig.02: kSar - the main window][7]
|
||||
|
||||
左侧有一个列表,是 kSar 根据数据已经解析出的可用图表的列表。右侧窗口将展示你选定的图表。
|
||||
|
||||
#### 如何使用 kSar 去生成 sar 图表?
|
||||
|
||||
首先,你需要从命名为 server1 的服务器上采集 `sar` 命令的统计数据。输入如下的命令:
|
||||
|
||||
```
|
||||
[ server1 ]# LC_ALL=C sar -A > /tmp/sar.data.txt
|
||||
```
|
||||
|
||||
接下来,使用 `scp` 命令从本地桌面拷贝到远程电脑上:
|
||||
|
||||
```
|
||||
[ desktop ]$ scp user@server1.nixcraft.com:/tmp/sar.data.txt /tmp/
|
||||
```
|
||||
|
||||
切换到 kSar 窗口,点击 “Data” > “Load data from text file” > 从 `/tmp/` 中选择 `sar.data.txt` > 点击 “Open” 按钮。
|
||||
|
||||
现在,图表类型树已经出现在左侧面板中并选定了一个图形:
|
||||
|
||||
![Fig.03: Processes for server1][8]
|
||||
|
||||
![Fig.03: Disk stats (blok device) stats for server1][9]
|
||||
|
||||
![Fig.05: Memory stats for server1][10]
|
||||
|
||||
##### 放大和缩小
|
||||
|
||||
通过移动你可以交互式缩放图像的一部分。在要缩放的图像的左上角点击并按下鼠标,移动到要缩放区域的右下角,可以选定要缩放的区域。返回到未缩放状态,点击并拖动鼠标到除了右下角外的任意位置,你也可以点击并选择 zoom 选项。
|
||||
|
||||
##### 了解 kSar 图像和 sar 数据
|
||||
|
||||
我强烈建议你去阅读 `sar` 和 `sadf` 命令的 man 页面:
|
||||
|
||||
```
|
||||
$ man sar
|
||||
$ man sadf
|
||||
```
|
||||
|
||||
### 案例学习:识别 Linux 服务器的 CPU 瓶颈
|
||||
|
||||
使用 `sar` 命令和 kSar 工具,可以得到内存、CPU、以及其它子系统的详细快照。例如,如果 CPU 使用率在一个很长的时间内持续高于 80%,有可能就是出现了一个 CPU 瓶颈。使用 `sar -x ALL` 你可以找到大量消耗 CPU 的进程。
|
||||
|
||||
[mpstat 命令][11] 的输出(sysstat 包的一部分)也会帮你去了解 CPU 的使用率。但你可以使用 kSar 很容易地去分析这些信息。
|
||||
|
||||
#### 找出 CPU 瓶颈后 …
|
||||
|
||||
对 CPU 执行如下的调整:
|
||||
|
||||
1. 确保没有不需要的进程在后台运行。关闭 [Linux 上所有不需要的服务][12]。
|
||||
2. 使用 [cron][13] 在一个非高峰时刻运行任务(比如,备份)。
|
||||
3. 使用 [top 和 ps 命令][14] 去找出所有非关键的后台作业/服务。使用 [renice 命令][15] 去调整低优先级作业。
|
||||
4. 使用 [taskset 命令去设置进程使用的 CPU ][16] (卸载所使用的 CPU),即,绑定进程到不同的 CPU 上。例如,在 2# CPU 上运行 MySQL 数据库,而在 3# CPU 上运行 Apache。
|
||||
5. 确保你的系统使用了最新的驱动程序和固件。
|
||||
6. 如有可能在系统上增加额外的 CPU。
|
||||
7. 为单线程应用程序使用更快的 CPU(比如,Lighttpd web 服务器应用程序)。
|
||||
8. 为多线程应用程序使用多个 CPU(比如,MySQL 数据库服务器应用程序)。
|
||||
9. 为一个 web 应用程序使用多个计算节点并设置一个 [负载均衡器][17]。
|
||||
|
||||
### isag —— 交互式系统活动记录器(替代工具)
|
||||
|
||||
`isag` 命令图形化显示了以前运行 `sar` 命令时存储在二进制文件中的系统活动数据。`isag` 命令引用 `sar` 并提取出它的数据来绘制图形。与 kSar 相比,`isag` 的选项比较少。
|
||||
|
||||
![Fig.06: isag CPU utilization graphs][18]
|
||||
|
||||
### 关于作者
|
||||
|
||||
本文作者是 nixCraft 的创始人和一位经验丰富的 Linux 操作系统/Unix shell 脚本培训师。他与包括 IT、教育、国防和空间研究、以及非营利组织等全球各行业客户一起合作。可以在 [Twitter][19]、[Facebook][20]、[Google+][21] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[3]:https://github.com/vlsi/ksar
|
||||
[4]:https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html
|
||||
[5]:https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2009/12/sar-welcome.png "kSar welcome screen"
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/12/screenshot-kSar-a-sar-grapher-01.png "kSar - the main window"
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/12/cpu-ksar.png "Linux kSar Processes for server1 "
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/12/disk-stats-ksar.png "Linux Disk I/O Stats Using kSar"
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/12/memory-ksar.png "Linux Memory paging and its utilization stats"
|
||||
[11]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
|
||||
[12]:https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/
|
||||
[13]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[14]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
|
||||
[15]:https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/
|
||||
[16]:https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/
|
||||
[17]:https://www.cyberciti.biz/tips/load-balancer-open-source-software.html
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2009/12/isag.cpu_.png "Fig.06: isag CPU utilization graphs"
|
||||
[19]:https://twitter.com/nixcraft
|
||||
[20]:https://facebook.com/nixcraft
|
||||
[21]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,26 +1,27 @@
|
||||
让我们做个简单的解释器(1)
|
||||
让我们做个简单的解释器(一)
|
||||
======
|
||||
|
||||
> “如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道它们是如何工作的。” --Steve Yegge
|
||||
|
||||
> **" If you don't know how compilers work, then you don't know how computers work. If you're not 100% sure whether you know how compilers work, then you don't know how they work."** -- Steve Yegge
|
||||
> **“如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道他们是如何工作的。”** --Steve Yegge
|
||||
就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道<ruby>编译器<rt>compiler</rt></ruby>和<ruby>解释器<rt>interpreter</rt></ruby>是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
|
||||
|
||||
就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道编译器和解释器是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
|
||||
所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。
|
||||
|
||||
所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。![][1]
|
||||
![][1]
|
||||
|
||||
或者如果你不知道但你非常想要了解它。 ![][2]
|
||||
或者如果你不知道但你非常想要了解它。
|
||||
|
||||
不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。![][3]。
|
||||
![][2]
|
||||
|
||||
不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。
|
||||
|
||||
![][3]
|
||||
|
||||
为什么要学习编译器和解释器?有三点理由。
|
||||
|
||||
1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对写软件非常有用,而不是仅仅局限于解释器或编译器。
|
||||
2. 你确实想要了解电脑是怎么工作的。一般解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解他们的原理,把事情做好。
|
||||
3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
|
||||
|
||||
|
||||
|
||||
1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对编写软件非常有用,而不是仅仅局限于解释器或编译器。
|
||||
2. 你确实想要了解电脑是怎么工作的。通常解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解它们的原理,把事情做好。
|
||||
3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
|
||||
|
||||
好,但什么是解释器和编译器?
|
||||
|
||||
@ -32,11 +33,12 @@
|
||||
|
||||
我希望你现在确信你很想学习构建一个编译器和解释器。你期望在这个教程里学习解释器的哪些知识呢?
|
||||
|
||||
你看这样如何。你和我一起做一个简单的解释器当作 [Pascal][5] 语言的子集。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb][6] 那样的源代码级别的调试器。
|
||||
你看这样如何。你和我一起为 [Pascal][5] 语言的一个大子集做一个简单的解释器。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb][6] 那样的源代码级别的调试器。
|
||||
|
||||
你或许会问,为什么是 Pascal?有一点,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错:)。
|
||||
你或许会问,为什么是 Pascal?一方面,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错 :))。
|
||||
|
||||
这有个 Pascal 中的阶乘函数示例,你将能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
|
||||
|
||||
这有个 Pascal 中的阶乘函数示例,你能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
|
||||
```
|
||||
program factorial;
|
||||
|
||||
@ -57,15 +59,14 @@ begin
|
||||
end.
|
||||
```
|
||||
|
||||
这个 Pascal 解释器的实现语言会用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
|
||||
|
||||
你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 **3+5**。这是你的计算器的源代码,不好意思,是解释器:
|
||||
这个 Pascal 解释器的实现语言会使用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
|
||||
|
||||
你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 `3+5`。下面是你的计算器的源代码——不好意思,是解释器:
|
||||
|
||||
```
|
||||
# 标记类型
|
||||
#
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
|
||||
|
||||
|
||||
@ -73,7 +74,7 @@ class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token 类型: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token 值: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', 或 None
|
||||
# token 值: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, '+', 或 None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
@ -187,7 +188,8 @@ if __name__ == '__main__':
|
||||
```
|
||||
|
||||
|
||||
把上面的代码保存到 calc1.py 文件,或者直接从 [GitHub][7] 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 raw_input 换成 input):
|
||||
把上面的代码保存到 `calc1.py` 文件,或者直接从 [GitHub][7] 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 `raw_input` 换成 `input`):
|
||||
|
||||
```
|
||||
$ python calc1.py
|
||||
calc> 3+4
|
||||
@ -205,31 +207,32 @@ calc>
|
||||
* 此时支持的唯一一个运算符是加法
|
||||
* 输入中不允许有任何的空格符号
|
||||
|
||||
|
||||
|
||||
要让计算器变得简单,这些限制非常必要。不用担心,你很快就会让它变得很复杂。
|
||||
|
||||
好,现在让我们深入它,看看解释器是怎么工作,它是怎么评估出算术表达式的。
|
||||
|
||||
当你在命令行中输入一个表达式 3+5,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 **token(标记)** 的容器里。**标记** 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
|
||||
当你在命令行中输入一个表达式 `3+5`,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 `token`(标记)的容器里。<ruby>标记<rt>token</rt></ruby> 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
|
||||
|
||||
把输入字符串分成标记的过程叫 **词法分析**。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做 **词法分析器**,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如 **扫描器** 或者 **标记器**。他们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
|
||||
把输入字符串分成标记的过程叫<ruby>词法分析<rt>lexical analysis</rt></ruby>。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做<ruby>词法分析器<rt>lexical analyzer</rt></ruby>,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如<ruby>扫描器<rt>scanner</rt></ruby>或者<ruby>标记器<rt>tokenizer</rt></ruby>。它们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
|
||||
|
||||
Interpreter 类中的 get_next_token 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。pos 开始时设为 0,指向 ‘3’.这个方法一开始检查字符是不是数字,如果是,就将 pos 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:
|
||||
`Interpreter` 类中的 `get_next_token` 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。`pos` 开始时设为 0,指向字符 ‘3’。这个方法一开始检查字符是不是数字,如果是,就将 `pos` 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:
|
||||
|
||||
![][8]
|
||||
|
||||
现在 pos 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 pos 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 pos 加一,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
|
||||
现在 `pos` 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 `pos` 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 `pos` 加 1,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
|
||||
|
||||
![][9]
|
||||
|
||||
pos 现在指向字符 ‘5’。当你再调用 get_next_token 方法时,该方法会检查这是不是个数字,就是这样,然后它把 pos 加一,返回一个新的 INTEGER 标记,该标记的值被设为 5:
|
||||
`pos` 现在指向字符 ‘5’。当你再调用 `get_next_token` 方法时,该方法会检查这是不是个数字,就是这样,然后它把 `pos` 加 1,返回一个新的 INTEGER 标记,该标记的值被设为整数 5:
|
||||
|
||||
![][10]
|
||||
|
||||
因为 pos 索引现在到了字符串 “3+5” 的末尾,你每次调用 get_next_token 方法时,它将会返回 EOF 标记:
|
||||
因为 `pos` 索引现在到了字符串 “3+5” 的末尾,你每次调用 `get_next_token` 方法时,它将会返回 EOF 标记:
|
||||
|
||||
![][11]
|
||||
|
||||
自己试一试,看看计算器里的词法分析器的运行:
|
||||
|
||||
```
|
||||
>>> from calc1 import Interpreter
|
||||
>>>
|
||||
@ -248,17 +251,16 @@ Token(EOF, None)
|
||||
>>>
|
||||
```
|
||||
|
||||
既然你的解释器能够从输入字符中获取标记流,解释器需要做点什么:它需要在词法分析器 get_next_token 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
|
||||
既然你的解释器能够从输入字符中获取标记流,解释器需要对它做点什么:它需要在词法分析器 `get_next_token` 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
|
||||
|
||||
负责找出并解释结构的方法就是 expr。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
|
||||
负责找出并解释结构的方法就是 `expr`。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
|
||||
|
||||
expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,eat 方法获取下一个标记,并将其赋给 current_token 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER PLUS INTEGER 标记序列不对应,eat 方法就抛出一个异常。
|
||||
`expr` 方法用了一个助手方法 `eat` 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,`eat` 方法会获取下一个标记,并将其赋给 `current_token` 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER -> PLUS -> INTEGER 标记序列不对应,`eat` 方法就抛出一个异常。
|
||||
|
||||
让我们回顾下解释器做了什么来对算术表达式进行评估的:
|
||||
|
||||
* 解释器接受输入字符串,就把它当作 “3+5”
|
||||
* 解释器调用 expr 方法,在词法分析器 get_next_token 返回的标记流中找出结构。这个结构就是 INTEGER PLUS INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加解释输入,因为此时对于解释器来说很清楚,他要做的就是把两个整数 3 和 5 进行相加。
|
||||
|
||||
* 解释器接受输入字符串,比如说 “3+5”
|
||||
* 解释器调用 `expr` 方法,在词法分析器 `get_next_token` 返回的标记流中找出结构。这个结构就是 INTEGER -> PLUS -> INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加来解释输入,因为此时对于解释器来说很清楚,它要做的就是把两个整数 3 和 5 进行相加。
|
||||
|
||||
恭喜。你刚刚学习了怎么构建自己的第一个解释器!
|
||||
|
||||
@ -268,42 +270,38 @@ expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与
|
||||
|
||||
看了这篇文章,你肯定觉得不够,是吗?好,准备好做这些练习:
|
||||
|
||||
1. 修改代码,允许输入多位数,比如 “12+3”
|
||||
2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如“12 + 3”
|
||||
3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
|
||||
|
||||
1. 修改代码,允许输入多位数,比如 “12+3”
|
||||
2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如 “12 + 3”
|
||||
3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
|
||||
|
||||
**检验你的理解**
|
||||
|
||||
1. 什么是解释器?
|
||||
2. 什么是编译器
|
||||
3. 解释器和编译器有什么差别?
|
||||
4. 什么是标记?
|
||||
5. 将输入分隔成若干个标记的过程叫什么?
|
||||
6. 解释器中进行词法分析的部分叫什么?
|
||||
7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
|
||||
|
||||
|
||||
1. 什么是解释器?
|
||||
2. 什么是编译器
|
||||
3. 解释器和编译器有什么差别?
|
||||
4. 什么是标记?
|
||||
5. 将输入分隔成若干个标记的过程叫什么?
|
||||
6. 解释器中进行词法分析的部分叫什么?
|
||||
7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
|
||||
|
||||
在结束本文前,我衷心希望你能留下学习解释器和编译器的承诺。并且现在就开始做。不要把它留到以后。不要拖延。如果你已经看完了本文,就开始吧。如果已经仔细看完了但是还没做什么练习 —— 现在就开始做吧。如果已经开始做练习了,那就把剩下的做完。你懂得。而且你知道吗?签下承诺书,今天就开始学习解释器和编译器!
|
||||
|
||||
> 本人, ______,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!
|
||||
|
||||
_本人, ______,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!_
|
||||
>
|
||||
|
||||
签字人:
|
||||
> 签字人:
|
||||
|
||||
日期:
|
||||
> 日期:
|
||||
|
||||
![][13]
|
||||
|
||||
签字,写上日期,把它放在你每天都能看到的地方,确保你能坚守承诺。谨记你的承诺:
|
||||
|
||||
> "Commitment is doing the thing you said you were going to do long after the mood you said it in has left you." -- Darren Hardy
|
||||
> “承诺就是,你说自己会去做的事,在你说完就一直陪着你的东西。” —— Darren Hardy
|
||||
|
||||
好,今天的就结束了。这个系列的下一篇文章里,你将会扩展自己的计算器,让它能够处理更复杂的算术表达式。敬请期待。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part1/
|
||||
@ -311,7 +309,7 @@ via: https://ruslanspivak.com/lsbasi-part1/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
@ -0,0 +1,189 @@
|
||||
Linux 跟踪器之选
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
> Linux 跟踪很神奇!
|
||||
|
||||
<ruby>跟踪器<rt>tracer</rt></ruby>是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
|
||||
|
||||
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
|
||||
|
||||
你喜欢使用哪一个呢?
|
||||
|
||||
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
|
||||
|
||||
### 对于大多数人
|
||||
|
||||
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
|
||||
|
||||
#### 1. 使用 perf_events 进行 CPU 剖析
|
||||
|
||||
可以使用 perf_events 进行 CPU <ruby>剖析<rt>profiling</rt></ruby>。它可以用一个 [火焰图][3] 来形象地表示。比如:
|
||||
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
```
|
||||
|
||||
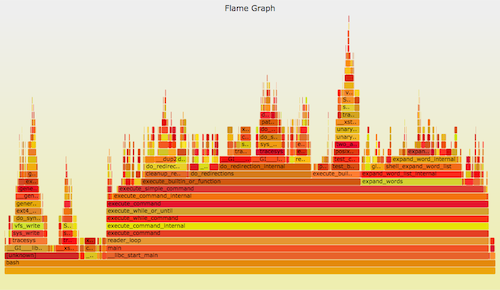
|
||||
|
||||
Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
|
||||
|
||||
`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是<ruby>采样<rt>sampling</rt></ruby>。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
|
||||
|
||||
#### 2. 知道它能干什么
|
||||
|
||||
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
|
||||
|
||||
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
|
||||
|
||||
#### 3. 需要一个前端工具
|
||||
|
||||
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
|
||||
|
||||
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
|
||||
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
```
|
||||
|
||||
在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
|
||||
|
||||
### 对于性能或者内核工程师
|
||||
|
||||
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
|
||||
|
||||
在这里我建议选择如下,要么:
|
||||
|
||||
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
|
||||
|
||||
B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
|
||||
|
||||
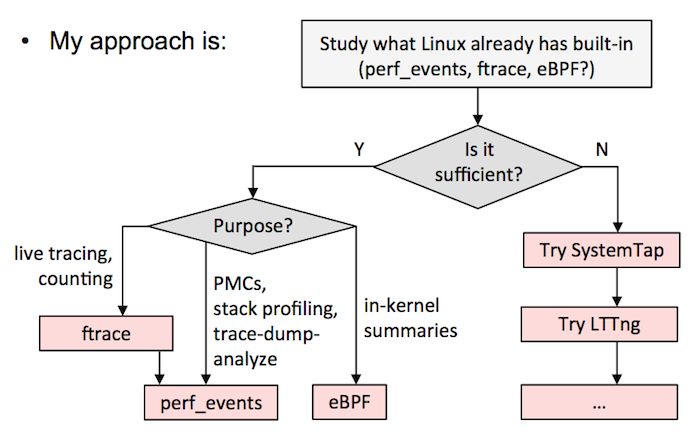
|
||||
|
||||
以下是我对各个跟踪器的评价:
|
||||
|
||||
#### 1. ftrace
|
||||
|
||||
我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;<ruby>函数流步进<rt>function-flow walking</rt></ruby>。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易<ruby>调校<rt>hackable</rt></ruby>,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是<ruby>可编程的<rt>programmable</rt></ruby>,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
|
||||
|
||||
#### 2. perf_events
|
||||
|
||||
[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用<ruby>调试信息<rt>debuginfo</rt></ruby>进行<ruby>行级跟踪<rt>line tracing</rt></ruby>。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
|
||||
|
||||
#### 3. eBPF
|
||||
|
||||
<ruby>扩展的伯克利包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>(eBPF)是一个<ruby>内核内<rt>in-kernel</rt></ruby>的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供<ruby>内核内编程<rt>in-kernel programming</rt></ruby>,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的<ruby>延迟热力图<rt>latency heat map</rt></ruby>。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
|
||||
|
||||
#### 4. SystemTap
|
||||
|
||||
[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
|
||||
|
||||
#### 5. LTTng
|
||||
|
||||
[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
|
||||
|
||||
#### 6. ktap
|
||||
|
||||
[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
|
||||
|
||||
#### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些<ruby>供应器<rt>provider</rt></ruby>可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
|
||||
|
||||
#### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
|
||||
|
||||
#### 9. sysdig
|
||||
|
||||
[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理<ruby>系统调用<rt>syscall</rt></ruby>事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
|
||||
|
||||
### 深入阅读
|
||||
|
||||
我自己的工作中使用到的跟踪器包括:
|
||||
|
||||
- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
|
||||
- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
|
||||
- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
|
||||
- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
|
||||
- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
|
||||
- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
|
||||
- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
|
||||
- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
|
||||
- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
|
||||
- **其它** : 关于 [strace][46],我写了一些告诫文章。
|
||||
|
||||
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
|
||||
|
||||
感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -0,0 +1,210 @@
|
||||
9 个提高系统运行速度的轻量级 Linux 应用
|
||||
======
|
||||
|
||||
**简介:** [加速 Ubuntu 系统][1]有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序][2],如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
|
||||
|
||||
![在 ubunt 使用轻量级应用程序替代方案][4]
|
||||
|
||||
### 9 个常用 Linux 应用程序的轻量级替代方案
|
||||
|
||||
你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
|
||||
|
||||
所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
|
||||
|
||||
由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
|
||||
|
||||
### 1. Midori: Web 浏览器
|
||||
|
||||
[Midori][8] 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
|
||||
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Midori
|
||||
|
||||
在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
|
||||
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita:电子邮件客户端
|
||||
|
||||
[Trojita][11] 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Trojita
|
||||
|
||||
Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi:包安装程序
|
||||
|
||||
有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
|
||||
|
||||
Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 GDebi
|
||||
|
||||
只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid:软件中心
|
||||
|
||||
如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid][15] 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid 支持应用程序的评分、评论和屏幕截图。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 App Grid
|
||||
|
||||
App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock:音乐播放器
|
||||
|
||||
[Yarock][17] 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
|
||||
|
||||
### 在基于 Ubuntu 的发行版上安装 Yarock
|
||||
|
||||
您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC:视频播放器
|
||||
|
||||
谁不需要视频播放器?谁还从未听说过 [VLC][19]?我想并不需要对它做任何介绍。
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 VLC
|
||||
|
||||
VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM:文件管理器
|
||||
|
||||
PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 PCManFM
|
||||
|
||||
在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
|
||||
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad:文本编辑器
|
||||
|
||||
在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Mousepad
|
||||
|
||||
想要安装 Mousepad ,可以使用以下指令:
|
||||
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office:办公软件
|
||||
|
||||
许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
|
||||
|
||||
**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
在 [Gnome Office][24] 下面还有一些其它应用程序。你可以在官方页面找到它们。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
|
||||
|
||||
要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
|
||||
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:http://trojita.flaska.net/img/2016-03-22-trojita-home.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,28 +1,21 @@
|
||||
|
||||
如何提供有帮助的回答
|
||||
=============================
|
||||
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧。他们都是非常实用的。
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧,它们都是非常实用的。
|
||||
|
||||
一开始 - 有时向你提问的人不尊重你的时间,这很糟糕。
|
||||
|
||||
理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
一开始 —— 有时向你提问的人不尊重你的时间,这很糟糕。理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题,而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
|
||||
下面是有助于回答问题的一些方法!
|
||||
|
||||
|
||||
### 如果他们提问不清楚,帮他们澄清
|
||||
### 如果他们的提问不清楚,帮他们澄清
|
||||
|
||||
通常初学者不会提出很清晰的问题,或者问一些对回答问题没有必要信息的问题。你可以尝试以下方法 澄清问题:
|
||||
|
||||
* ** 重述为一个更明确的问题 ** 来回复他们(”你是想问 X 吗?“)
|
||||
|
||||
* ** 向他们了解更具体的他们并没有提供的信息 ** (”你使用 IPv6 ?”)
|
||||
|
||||
* ** 问是什么导致了他们的问题 ** 例如,有时有些人会进入我的团队频道,询问我们的服务发现(service discovery )如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的 pull requests 吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自 [如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完 “如何提出有意义的问题”这篇文章后再来像我提问)
|
||||
* **重述为一个更明确的问题**来回复他们(“你是想问 X 吗?”)
|
||||
* **向他们了解更具体的他们并没有提供的信息** (“你使用 IPv6 ?”)
|
||||
* **问是什么导致了他们的问题**。例如,有时有些人会进入我的团队频道,询问我们的<ruby>服务发现<rt>service discovery</rt></ruby>如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的‘拉取请求’吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自[如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完《如何提出有意义的问题》这篇文章后再来向我提问)
|
||||
|
||||
### 弄清楚他们已经知道了什么
|
||||
|
||||
@ -30,66 +23,54 @@
|
||||
|
||||
Harold Treen 给了我一个很好的例子:
|
||||
|
||||
> 前几天,有人请我解释“ Redux-Sagas ”。与其深入解释不如说“ 他们就像 worker threads 监听行为(actions),让你更新 Redux store 。
|
||||
> 前几天,有人请我解释 “Redux-Sagas”。与其深入解释,不如说 “它们就像监听 action 的工人线程,并可以让你更新 Redux store。
|
||||
|
||||
> 我开始搞清楚他们对 Redux 、行为(actions)、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
> 我开始搞清楚他们对 Redux、action、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“ Redux 是什么?“),或者他们可能是专家但是恰巧遇到了微妙的极端情况(corner case)。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“Redux 是什么?”),或者他们可能是专家,但是恰巧遇到了微妙的<ruby>极端情况<rt>corner case</rt></ruby>。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
|
||||
这里有一个很实用的技巧来了解他们已经知道什么 - 比如可以尝试用“你对 X 了解多少?”而不是问“你知道 X 吗?”。
|
||||
|
||||
|
||||
### 给他们一个文档
|
||||
|
||||
“RTFM” (“去读那些他妈的手册”(Read The Fucking Manual))是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
“RTFM” (<ruby>“去读那些他妈的手册”<rt>Read The Fucking Manual</rt></ruby>)是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
|
||||
我认为明确你所给的文档的确能够解决问题是非常重要的,或者至少经过查阅后确认它对解决问题有帮助。否则,你可能将以下面这种情形结束对话(非常常见):
|
||||
|
||||
* Ali:我应该如何处理 X ?
|
||||
* Jada:\<文档链接>
|
||||
* Ali: 这个没有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
* Jada:<文档链接>
|
||||
|
||||
* Ali: 这个并有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有44000个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的:)
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有 44000 个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的 :)
|
||||
|
||||
### 告诉他们一个有用的搜索
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案:)
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索来找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案 :)
|
||||
|
||||
### 写新文档
|
||||
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有10个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有 10 个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
|
||||
1. 马上写新文档
|
||||
|
||||
2. 给他们我们刚刚写好的新文档
|
||||
|
||||
3. 公示
|
||||
|
||||
写文档有时往往比回答问题需要花很多时间,但这是值得的。写文档尤其重要,如果:
|
||||
|
||||
a. 这个问题被问了一遍又一遍
|
||||
|
||||
b. 随着时间的推移,这个答案不会变化太大(如果这个答案每一个星期或者一个月就会变化,文档就会过时并且令人受挫)
|
||||
|
||||
|
||||
### 解释你做了什么
|
||||
|
||||
对于一个话题,作为初学者来说,这样的交流会真让人沮丧:
|
||||
|
||||
* 新人:“嗨!你如何处理 X ?”
|
||||
|
||||
* 有经验的人:“我已经处理过了,而且它已经完美解决了”
|
||||
|
||||
* 新人:”...... 但是你做了什么?!“
|
||||
|
||||
如果问你问题的人想知道事情是如何进行的,这样是有帮助的:
|
||||
|
||||
* 让他们去完成任务而不是自己做
|
||||
|
||||
* 告诉他们你是如何得到你给他们的答案的。
|
||||
|
||||
这可能比你自己做的时间还要长,但对于被问的人来说这是一个学习机会,因为那样做使得他们将来能够更好地解决问题。
|
||||
@ -97,88 +78,74 @@ b. 随着时间的推移,这个答案不会变化太大(如果这个答案
|
||||
这样,你可以进行更好的交流,像这:
|
||||
|
||||
* 新人:“这个网站出现了错误,发生了什么?”
|
||||
|
||||
* 有经验的人:(2分钟后)”oh 这是因为发生了数据库故障转移“
|
||||
|
||||
* 新人: ”你是怎么知道的??!?!?“
|
||||
|
||||
* 有经验的人:“以下是我所做的!“:
|
||||
|
||||
* 有经验的人:(2分钟后)“oh 这是因为发生了数据库故障转移”
|
||||
* 新人: “你是怎么知道的??!?!?”
|
||||
* 有经验的人:“以下是我所做的!”:
|
||||
1. 通常这些错误是因为服务器 Y 被关闭了。我查看了一下 `$PLACE` 但它表明服务器 Y 开着。所以,并不是这个原因导致的。
|
||||
|
||||
2. 然后我查看 X 的仪表盘 ,仪表盘的这个部分显示这里发生了数据库故障转移。
|
||||
|
||||
3. 然后我在日志中找到了相应服务器,并且它显示连接数据库错误,看起来错误就是这里。
|
||||
|
||||
如果你正在解释你是如何调试一个问题,解释你是如何发现问题,以及如何找出问题的。尽管看起来你好像已经得到正确答案,但感觉更好的是能够帮助他们提高学习和诊断能力,并了解可用的资源。
|
||||
|
||||
|
||||
### 解决根本问题
|
||||
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只要再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
|
||||
* Jasminda:”你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。“
|
||||
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。“
|
||||
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
|
||||
* Jasminda:“你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。”
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。”
|
||||
|
||||
Jasminda 一点都没有回答 George 的问题!反而,她猜测 George 并不想处理 X ,并且她是猜对了。这是非常有用的!
|
||||
|
||||
如果你这样做可能会产生高高在上的感觉:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
|
||||
* Jasminda:“不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。”
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。”
|
||||
|
||||
* Jasminda:不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。
|
||||
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。
|
||||
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。”
|
||||
|
||||
|
||||
### 询问”那个回答可以解决您的问题吗?”
|
||||
### 询问“那个回答可以解决您的问题吗?”
|
||||
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:”这个回答解决了您的问题吗?您还有其他问题吗?“在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:“这个回答解决了您的问题吗?您还有其他问题吗?”在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
|
||||
我发现尤其是问“这个回答解决了您的问题吗”这个额外的步骤在写完文档后是非常有用的。通常,在写关于我熟悉的东西的文档时,我会忽略掉重要的东西而不会意识到它。
|
||||
|
||||
|
||||
### 结对编程和面对面交谈
|
||||
|
||||
我是远程工作的,所以我的很多对话都是基于文本的。我认为这是沟通的默认方式。
|
||||
|
||||
今天,我们生活在一个方便进行小视频会议和屏幕共享的世界!在工作时候,在任何时间我都可以点击一个按钮并快速加入与他人的视频对话或者屏幕共享的对话中!
|
||||
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视屏会话并在5分钟后,我们解决了他们问题。
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视频会话并在 5 分钟后,我们解决了他们问题。
|
||||
|
||||
我认为,特别是如果有人真的被困在该如何开始一项任务时,开启视频进行结对编程几分钟真的比电子邮件或者一些即时通信更有效。
|
||||
|
||||
|
||||
### 不要表现得过于惊讶
|
||||
|
||||
这是源自 Recurse Center 的一则法则:[不要故作惊讶][4]。这里有一个常见的情景:
|
||||
|
||||
* 某人1:“什么是 Linux 内核”
|
||||
* 某甲:“什么是 Linux 内核”
|
||||
* 某乙:“你竟然不知道什么是 Linux 内核?!!!!?!!!????”
|
||||
|
||||
* 某人2:“你竟然不知道什么是 Linux 内核(LINUX KERNEL)?!!!!?!!!????”
|
||||
某乙的表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某甲不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
|
||||
某人2表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某人1不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
我一直在假装不惊讶,即使我事实上确实有点惊讶那个人不知道这种东西。
|
||||
|
||||
我一直在假装不惊讶即使我事实上确实有点惊讶那个人不知道这种东西但它是令人敬畏的。
|
||||
|
||||
### 回答问题是令人敬畏的
|
||||
### 回答问题真的很棒
|
||||
|
||||
显然并不是所有方法都是合适的,但希望你能够发现这里有些是有帮助的!我发现花时间去回答问题并教导人们是其实是很有收获的。
|
||||
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder的阅读或评论。
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder 的阅读或评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/answer-questions-well/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,34 @@
|
||||
绕过 Linux/Unix 命令别名
|
||||
4 种绕过 Linux/Unix 命令别名的方法
|
||||
======
|
||||
|
||||
我在我的 Linux 系统上定义了如下 mount 别名:
|
||||
|
||||
```
|
||||
alias mount='mount | column -t'
|
||||
```
|
||||
但是我需要在挂载文件系统和其他用途时绕过 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
|
||||
|
||||
但是我需要在挂载文件系统和其他用途时绕过这个 bash 别名。我如何在 Linux、*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
|
||||
|
||||
你可以使用 `alias` 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
|
||||
|
||||
你可以使用 alias 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
|
||||
[![Bash Bypass Alias Linux BSD macOS Unix Command][1]][1]
|
||||
|
||||
## 4 种绕过 bash 别名的方法
|
||||
|
||||
### 4 种绕过 bash 别名的方法
|
||||
|
||||
尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名][2]:
|
||||
`alias mount='mount | column -t'`
|
||||
|
||||
```
|
||||
alias mount='mount | column -t'
|
||||
```
|
||||
|
||||
运行如下:
|
||||
`mount `
|
||||
|
||||
```
|
||||
mount
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
|
||||
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
|
||||
@ -30,45 +41,83 @@ binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_m
|
||||
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
|
||||
```
|
||||
|
||||
### 方法1 - 使用 \command
|
||||
#### 方法 1 - 使用 `\command`
|
||||
|
||||
输入以下命令暂时绕过名为 mount 的 bash 别名:
|
||||
`\mount`
|
||||
输入以下命令暂时绕过名为 `mount` 的 bash 别名:
|
||||
|
||||
### 方法2 - 使用 "command" 或 'command'
|
||||
```
|
||||
\mount
|
||||
```
|
||||
|
||||
#### 方法 2 - 使用 `"command"` 或 `'command'`
|
||||
|
||||
如下引用 `mount` 命令调用实际的 `/bin/mount`:
|
||||
|
||||
```
|
||||
"mount"
|
||||
```
|
||||
|
||||
如下引用 mount 命令调用实际的 /bin/mount:
|
||||
`"mount"`
|
||||
或者
|
||||
`'mount'`
|
||||
|
||||
### Method 3 - Use full command path
|
||||
```
|
||||
'mount'
|
||||
```
|
||||
|
||||
Use full binary path such as /bin/mount:
|
||||
`/bin/mount
|
||||
/bin/mount /dev/sda1 /mnt/sda`
|
||||
#### 方法 3 - 使用命令的完全路径
|
||||
|
||||
### 方法3 - 使用完整的命令路径
|
||||
使用完整的二进制路径,如 `/bin/mount`:
|
||||
|
||||
```
|
||||
/bin/mount
|
||||
/bin/mount /dev/sda1 /mnt/sda
|
||||
```
|
||||
|
||||
#### 方法 4 - 使用内部命令 `command`
|
||||
|
||||
语法是:
|
||||
`command cmd
|
||||
command cmd arg1 arg2`
|
||||
要覆盖 .bash_aliases 中设置的别名,例如 mount:
|
||||
`command mount
|
||||
command mount /dev/sdc /mnt/pendrive/`
|
||||
[”command“ 运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
|
||||
|
||||
## 关于 unalias 命令的说明
|
||||
```
|
||||
command cmd
|
||||
command cmd arg1 arg2
|
||||
```
|
||||
|
||||
要覆盖 `.bash_aliases` 中设置的别名,例如 `mount`:
|
||||
|
||||
```
|
||||
command mount
|
||||
command mount /dev/sdc /mnt/pendrive/
|
||||
```
|
||||
|
||||
[“command” 直接运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
|
||||
|
||||
### 关于 unalias 命令的说明
|
||||
|
||||
要从当前会话的已定义别名列表中移除别名,请使用 `unalias` 命令:
|
||||
|
||||
```
|
||||
unalias mount
|
||||
```
|
||||
|
||||
要从当前会话的已定义别名列表中移除别名,请使用 unalias 命令:
|
||||
`unalias mount`
|
||||
要从当前 bash 会话中删除所有别名定义:
|
||||
`unalias -a`
|
||||
确保你更新你的 ~/.bashrc 或 $HOME/.bash_aliases。如果要永久删除定义的别名,则必须删除定义的别名:
|
||||
`vi ~/.bashrc`
|
||||
|
||||
```
|
||||
unalias -a
|
||||
```
|
||||
|
||||
确保你更新你的 `~/.bashrc` 或 `$HOME/.bash_aliases`。如果要永久删除定义的别名,则必须删除定义的别名:
|
||||
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
或者
|
||||
`joe $HOME/.bash_aliases`
|
||||
|
||||
```
|
||||
joe $HOME/.bash_aliases
|
||||
```
|
||||
|
||||
想了解更多信息,参考[这里][4]的在线手册,或者输入下面的命令查看:
|
||||
|
||||
```
|
||||
man bash
|
||||
help command
|
||||
@ -76,14 +125,13 @@ help unalias
|
||||
help alias
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,45 +1,44 @@
|
||||
# 让 “rm” 命令将文件移动到“垃圾桶”,而不是完全删除它们
|
||||
给 “rm” 命令添加个“垃圾桶”
|
||||
============
|
||||
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf * `。当你使用 rm 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 `垃圾箱`。
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
|
||||
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误的删除文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
|
||||
我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
|
||||
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 rm 命令时,可以节省你的时间,但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 **GNOME 、KDE、Unity 或 LXDE** 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 **\$HOME/.local/share/Trash/files**,否则会在您的主目录中创建垃圾箱文件夹 **$HOME/Trash**。
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
|
||||
|
||||
`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
|
||||
|
||||
saferm.sh 脚本托管在 Github 中,可以从 repository 中克隆,也可以创建一个名为 saferm.sh 的文件并复制其上的代码。
|
||||
```
|
||||
$ git clone https://github.com/lagerspetz/linux-stuff
|
||||
$ sudo mv linux-stuff/scripts/saferm.sh /bin
|
||||
$ rm -Rf linux-stuff
|
||||
|
||||
```
|
||||
|
||||
在 `bashrc` 文件中设置别名,
|
||||
在 `.bashrc` 文件中设置别名,
|
||||
|
||||
```
|
||||
alias rm=saferm.sh
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效,
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
一切就绪,现在你可以执行 rm 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行显式的说明了 `Moving magi.txt to $HOME/.local/share/Trash/file`
|
||||
|
||||
```
|
||||
$ rm -rf magi.txt
|
||||
Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
|
||||
```
|
||||
|
||||
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
|
||||
@ -47,47 +46,16 @@ Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
```
|
||||
$ ls -lh /home/magi/.local/share/Trash/files
|
||||
Permissions Size User Date Modified Name
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
```
|
||||
|
||||
或者我们可以通过文件管理器界面中查看相同的内容。
|
||||
|
||||
![![][3]][4]
|
||||
|
||||
创建一个定时任务,每天清理一次“垃圾桶”,( LCTT 注:原文为每周一次,但根据下面的代码,应该是每天一次)
|
||||
(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
|
||||
|
||||
```
|
||||
$ 1 1 * * * trash-empty
|
||||
|
||||
```
|
||||
|
||||
`注意` 对于服务器环境,我们需要使用 rm 命令手动删除。
|
||||
|
||||
```
|
||||
$ rm -rf /root/Trash/
|
||||
/root/Trash/magi1.txt is on . Unsafe delete (y/n)? y
|
||||
Deleting /root/Trash/magi1.txt
|
||||
|
||||
```
|
||||
|
||||
对于桌面环境,trash-put 命令也可以做到这一点。
|
||||
|
||||
在 `bashrc` 文件中创建别名,
|
||||
|
||||
```
|
||||
alias rm=trash-put
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
要了解 saferm.sh 的其他选项,请查看帮助。
|
||||
要了解 `saferm.sh` 的其他选项,请查看帮助。
|
||||
|
||||
```
|
||||
$ saferm.sh -h
|
||||
@ -112,7 +80,7 @@ via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
我的 Linux 主目录中的隐藏文件是干什么用的?
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 系统中,你可能会在主目录中存储了大量文件和文件夹。但在这些文件之外,你知道你的主目录还附带了很多隐藏的文件和文件夹吗?如果你在主目录中运行 `ls -a`,你会发现一堆带有点前缀的隐藏文件和目录。这些隐藏的文件到底做了什么?
|
||||
|
||||
### 在主目录中隐藏的文件是干什么用的?
|
||||
|
||||
![hidden-files-liunux-2][1]
|
||||
|
||||
通常,主目录中的隐藏文件和目录包含该用户程序访问的设置或数据。它们不打算让用户编辑,只需要应用程序进行编辑。这就是为什么它们被隐藏在用户的正常视图之外。
|
||||
|
||||
通常,删除和修改自己主目录中的文件不会损坏操作系统。然而,依赖这些隐藏文件的应用程序可能不那么灵活。从主目录中删除隐藏文件时,通常会丢失与其关联的应用程序的设置。
|
||||
|
||||
依赖该隐藏文件的程序通常会重新创建它。 但是,你将从“开箱即用”设置开始,如全新用户一般。如果你在使用应用程序时遇到问题,那实际上可能是一个巨大的帮助。它可以让你删除可能造成麻烦的自定义设置。但如果你不这样做,这意味着你需要把所有的东西都设置成原来的样子。
|
||||
|
||||
### 主目录中某些隐藏文件的特定用途是什么?
|
||||
|
||||
![hidden-files-linux-3][2]
|
||||
|
||||
每个人在他们的主目录中都会有不同的隐藏文件。每个人都有一些。但是,无论应用程序如何,这些文件都有类似的用途。
|
||||
|
||||
#### 系统设置
|
||||
|
||||
系统设置包括桌面环境和 shell 的配置。
|
||||
|
||||
* shell 和命令行程序的**配置文件**:根据你使用的特定 shell 和类似命令的应用程序,特定的文件名称会变化。你会看到 `.bashrc`、`.vimrc` 和 `.zshrc`。这些文件包含你已经更改的有关 shell 的操作环境的任何设置,或者对 `vim` 等命令行实用工具的设置进行的调整。删除这些文件将使关联的应用程序返回到其默认状态。考虑到许多 Linux 用户多年来建立了一系列微妙的调整和设置,删除这个文件可能是一个非常头疼的问题。
|
||||
* **用户配置文件**:像上面的配置文件一样,这些文件(通常是 `.profile` 或 `.bash_profile`)保存 shell 的用户设置。该文件通常包含你的 `PATH` 环境变量。它还包含你设置的[别名][3]。用户也可以在 `.bashrc` 或其他位置放置别名。`PATH` 环境变量控制着 shell 寻找可执行命令的位置。通过添加或修改 `PATH`,可以更改 shell 的命令查找位置。别名更改了原有命令的名称。例如:一个别名可能将 `ls -l` 设置为 `ll`。这为经常使用的命令提供基于文本的快捷方式。如果删除 `.profile` 文件,通常可以在 `/etc/skel` 目录中找到默认版本。
|
||||
* **桌面环境设置**:这里保存你的桌面环境的任何定制。其中包括桌面背景、屏幕保护程序、快捷键、菜单栏和任务栏图标以及用户针对其桌面环境设置的其他任何内容。当你删除这个文件时,用户的环境会在下一次登录时恢复到新的用户环境。
|
||||
|
||||
#### 应用配置文件
|
||||
|
||||
你会在 Ubuntu 的 `.config` 文件夹中找到它们。 这些是针对特定应用程序的设置。 它们将包含喜好列表和设置等内容。
|
||||
|
||||
* **应用程序的配置文件**:这包括应用程序首选项菜单中的设置、工作区配置等。 你在这里找到的具体取决于应用程序。
|
||||
* **Web 浏览器数据**:这可能包括书签和浏览历史记录等内容。这些文件大部分是缓存。这是 Web 浏览器临时存储下载文件(如图片)的地方。删除这些内容可能会降低你首次访问某些媒体网站的速度。
|
||||
* **缓存**:如果用户应用程序缓存仅与该用户相关的数据(如 [Spotify 应用程序存储播放列表的缓存][4]),则主目录是存储该目录的默认地点。 这些缓存可能包含大量数据或仅包含几行代码:这取决于应用程序需要什么。 如果你删除这些文件,则应用程序会根据需要重新创建它们。
|
||||
* **日志**:一些用户应用程序也可能在这里存储日志。根据开发人员设置应用程序的方式,你可能会发现存储在你的主目录中的日志文件。然而,这不是一个常见的选择。
|
||||
|
||||
### 结论
|
||||
|
||||
在大多数情况下,你的 Linux 主目录中的隐藏文件用于存储用户设置。 这包括命令行程序以及基于 GUI 的应用程序的设置。删除它们将删除用户设置。 通常情况下,它不会导致程序被破坏。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/hidden-files-linux-home-directory/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-liunux-2.png (hidden-files-liunux-2)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-linux-3.png (hidden-files-linux-3)
|
||||
[3]:https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases
|
||||
[4]:https://www.maketecheasier.com/clear-spotify-cache/
|
||||
@ -12,17 +12,17 @@
|
||||
|
||||
### 使用 libuv 抽象出事件驱动循环
|
||||
|
||||
在 [第三节][11] 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中已有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
|
||||
在 [第三节][11] 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中也有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
|
||||
|
||||
虽然 libuv 为抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环在 `main` 函数中是很明确的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 epoll,等等。
|
||||
虽然 libuv 为了抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环是显式定义在 `main` 函数中的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 `epoll`,等等。
|
||||
|
||||

|
||||
|
||||
libuv 支持多路事件循环,并且,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,和创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
|
||||
libuv 支持多路事件循环,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,以及创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
|
||||
|
||||
### 使用 libuv 的并发服务器
|
||||
|
||||
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 select 和 epoll 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
|
||||
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 `select` 和 `epoll` 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
|
||||
|
||||
```
|
||||
int portnum = 9090;
|
||||
@ -47,9 +47,9 @@ if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0
|
||||
}
|
||||
```
|
||||
|
||||
除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得一个可工作于任何 libuv 支持的平台上的可移植接口。
|
||||
除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得了一个可工作于任何 libuv 支持的平台上的可移植接口。
|
||||
|
||||
这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想为一个更优雅的错误恢复。
|
||||
这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想一个更优雅的错误恢复。
|
||||
|
||||
现在,那个套接字已经绑定,是时候去监听它了。这里我们运行首个回调注册:
|
||||
|
||||
@ -73,7 +73,7 @@ uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
return uv_loop_close(uv_default_loop());
|
||||
```
|
||||
|
||||
注意,在运行事件循环之前,只有一个回调是通过 main 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
|
||||
注意,在运行事件循环之前,只有一个回调是通过 `main` 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
|
||||
|
||||
这是一个 `on_peer_connected`,它处理到服务器的新的客户端连接:
|
||||
|
||||
@ -132,8 +132,8 @@ void on_peer_connected(uv_stream_t* server_stream, int status) {
|
||||
|
||||
这些代码都有很好的注释,但是,这里有一些重要的 libuv 语法我想去强调一下:
|
||||
|
||||
* 传入自定义数据到回调中:因为 C 还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
|
||||
* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个它们注册的完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 main,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放。这些都是些需要实践的内容 [[1]][6]。
|
||||
* 传入自定义数据到回调中:因为 C 语言还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
|
||||
* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个与它们注册的地方完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 `main`,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放(`free()`)。这些都是些需要实践的内容 ^注1 。
|
||||
|
||||
这个服务器上对端的状态如下:
|
||||
|
||||
@ -146,7 +146,7 @@ typedef struct {
|
||||
} peer_state_t;
|
||||
```
|
||||
|
||||
它与第三部分中的状态非常类似;我们不再需要 sendptr,因为,在调用 "done writing" 回调之前,`uv_write` 将确保去发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
|
||||
它与第三部分中的状态非常类似;我们不再需要 `sendptr`,因为,在调用 “done writing” 回调之前,`uv_write` 将确保发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
|
||||
|
||||
```
|
||||
void on_wrote_init_ack(uv_write_t* req, int status) {
|
||||
@ -171,7 +171,7 @@ void on_wrote_init_ack(uv_write_t* req, int status) {
|
||||
}
|
||||
```
|
||||
|
||||
然后,我们确信知道了这个初始的 '*' 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个回调(`on_peer_read`)去被调用,不论什么时候,事件循环都在套接字上接收来自客户端的调用:
|
||||
然后,我们确信知道了这个初始的 `'*'` 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个将被事件循环调用的回调(`on_peer_read`),不论什么时候,事件循环都在套接字上接收来自客户端的调用:
|
||||
|
||||
```
|
||||
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
|
||||
@ -236,11 +236,11 @@ void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
|
||||
}
|
||||
```
|
||||
|
||||
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且一些行为被维护在服务器代码中:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
|
||||
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且类似的,一些特定的行为必须在服务器代码中维护:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
|
||||
|
||||
### 在事件驱动循环中的长周期运行的操作
|
||||
|
||||
单线程的事件驱动代码使它先天地对一些常见问题非常敏感:整个循环中的长周期运行的代码块。参见如下的程序:
|
||||
单线程的事件驱动代码使它先天就容易受到一些常见问题的影响:长周期运行的代码会阻塞整个循环。参见如下的程序:
|
||||
|
||||
```
|
||||
void on_timer(uv_timer_t* timer) {
|
||||
@ -280,23 +280,21 @@ on_timer [18850 ms]
|
||||
...
|
||||
```
|
||||
|
||||
`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 在这个时间帧中被调用。这个睡眠调用阻塞当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
|
||||
`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 会在这个时间帧中被调用。这个睡眠调用阻塞了当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
|
||||
|
||||
这个示例演示了在事件驱动的调用中为什么回调不能被阻塞是多少的重要。并且,同样适用于 Node.js 服务器、客户端侧的 Javascript、大多数的 GUI 编程框架、以及许多其它的异步编程模型。
|
||||
|
||||
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 APIs;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
|
||||
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 API;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
|
||||
|
||||
### “转换” 阻塞调用到异步调用的线程
|
||||
### “转换” 阻塞调用为异步调用的线程
|
||||
|
||||
一个线程池可以被用于去转换阻塞调用到异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。一个给定的阻塞函数 `do_work()`,这里介绍了它是怎么运行的:
|
||||
一个线程池可以用于转换阻塞调用为异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。以阻塞函数 `do_work()` 为例,这里介绍了它是怎么运行的:
|
||||
|
||||
1. 在一个回调中,用 `do_work()` 代表直接调用,我们将它打包进一个 “任务”,并且请求线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
|
||||
1. 不在一个回调中直接调用 `do_work()` ,而是将它打包进一个 “任务”,让线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
|
||||
2. 在这个时间点,我们的回调就可以返回了,而事件循环保持运行;在同一时间点,线程池中的有一个线程运行这个任务。
|
||||
3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且事件循环调用 `on_work_done()`。
|
||||
|
||||
2. 在这个时间点,我们的回调可以返回并且事件循环保持运行;在同一时间点,线程池中的一个线程运行这个任务。
|
||||
|
||||
3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且,通过事件循环调用 `on_work_done()`。
|
||||
|
||||
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的 timer/sleep 示例中展示的问题的:
|
||||
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的计时器/睡眠示例中展示的问题的:
|
||||
|
||||
```
|
||||
void on_after_work(uv_work_t* req, int status) {
|
||||
@ -327,7 +325,7 @@ int main(int argc, const char** argv) {
|
||||
}
|
||||
```
|
||||
|
||||
通过一个 work_req [[2]][14] 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 在这里是指发生的 “work”(阻塞中的/耗时的操作)。在这两个回调传递到 `uv_queue_work` 时,注意一个关键的区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 - 就好像是其它的回调一样。
|
||||
通过一个 `work_req` ^注2 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 是指 “work”(阻塞中的/耗时的操作)进行的地方。注意在这两个回调传递到 `uv_queue_work` 时的一个关键区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 —— 就好像是其它的回调一样。
|
||||
|
||||
让我们看一下这种方式的运行:
|
||||
|
||||
@ -347,25 +345,25 @@ on_timer [97578 ms]
|
||||
...
|
||||
```
|
||||
|
||||
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠(sleeping)现在运行在一个单独的线程中,并且不会阻塞事件循环。
|
||||
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠现在运行在一个单独的线程中,并且不会阻塞事件循环。
|
||||
|
||||
### 一个用于练习的素数测试服务器
|
||||
|
||||
因为通过睡眼去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 - 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] - 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
|
||||
因为通过睡眠去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 —— 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] —— 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
|
||||
|
||||
这个服务器使用了一个原生的素数测试算法,因此,对于大的素数可能花很长时间才返回一个回答。在我的机器中,对于 2305843009213693951,它花了 ~5 秒钟去计算,但是,你的方法可能不同。
|
||||
|
||||
练习 1:服务器有一个设置(通过一个名为 MODE 的环境变量)要么去在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
|
||||
练习 1:服务器有一个设置(通过一个名为 `MODE` 的环境变量)要么在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
|
||||
|
||||
练习 2;libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
|
||||
练习 2:libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
|
||||
|
||||
### 在非阻塞文件系统中使用工作队列
|
||||
|
||||
对于仅傻傻的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 APIs 中本身就大量使用了这种性能。通过这种方式,libuv 使用一个异步 API,在一个轻便的方式中,显示出它强大的文件系统的处理能力。
|
||||
对于只是呆板的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 API 中本身就大量使用了这种能力。通过这种方式,libuv 使用一个异步 API,以一个轻便的方式显示出它强大的文件系统的处理能力。
|
||||
|
||||
让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(以一个 `uv_fs_t` 句柄为代表)读取一个文件到一个缓冲中 [[3]][16],并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,甚至如果文件在一个类似 NFS 的系统上,并且,数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv APIs 是异步的。这是怎么工作的呢?
|
||||
让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(表示为一个 `uv_fs_t` 句柄)读取一个文件到一个缓冲中 ^注3,并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,即使是文件在一个类似 NFS 的系统上,而数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv API 是异步的。这是怎么工作的呢?
|
||||
|
||||
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个便携的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 src/unix/fs.c。
|
||||
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个可移植的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 `src/unix/fs.c`。
|
||||
|
||||
这是 `uv_fs_read` 的代码:
|
||||
|
||||
@ -400,9 +398,9 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
}
|
||||
```
|
||||
|
||||
第一次看可能觉得很困难,因为它延缓真实的工作到 INIT 和 POST 宏中,在 POST 中与一些本地变量一起设置。这样做可以避免了文件中的许多重复代码。
|
||||
第一次看可能觉得很困难,因为它延缓真实的工作到 `INIT` 和 `POST` 宏中,以及为 `POST` 设置了一些本地变量。这样做可以避免了文件中的许多重复代码。
|
||||
|
||||
这是 INIT 宏:
|
||||
这是 `INIT` 宏:
|
||||
|
||||
```
|
||||
#define INIT(subtype) \
|
||||
@ -421,9 +419,9 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
while (0)
|
||||
```
|
||||
|
||||
它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 invokes INIT(READ),它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
|
||||
它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 `INIT(READ)`,它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
|
||||
|
||||
这是 POST 宏:
|
||||
这是 `POST` 宏:
|
||||
|
||||
```
|
||||
#define POST \
|
||||
@ -440,31 +438,25 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
while (0)
|
||||
```
|
||||
|
||||
它做什么取决于回调是否为 NULL。在 libuv 文件系统 APIs 中,一个 NULL 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,POST 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个 non-NULL 回调,它提交 `uv__fs_work` 作为一个工作事项到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
|
||||
它做什么取决于回调是否为 `NULL`。在 libuv 文件系统 API 中,一个 `NULL` 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,`POST` 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个非 `NULL` 回调,它把 `uv__fs_work` 作为一个工作项提交到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
|
||||
|
||||
如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏去按需路由工作到真实的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX APIs 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
|
||||
如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏按照需求将工作分发到实际的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX API 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
|
||||
|
||||
在 Node.js 中,fs.readFile 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
|
||||
在 Node.js 中,`fs.readFile` 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[[1]][1] 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” - 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
|
||||
|
||||
|
||||
[[2]][2] 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
|
||||
|
||||
|
||||
[[3]][3] `uv_fs_read()` 提供了一个类似于 preadv Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
|
||||
|
||||
- 注1: 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” —— 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
|
||||
- 注2: 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
|
||||
- 注3: `uv_fs_read()` 提供了一个类似于 `preadv` Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,94 @@
|
||||
如何在 Linux 中配置 ssh 登录导语
|
||||
======
|
||||
|
||||
> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
|
||||
|
||||
![Login banners in Linux][1]
|
||||
|
||||
无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是<ruby>登录导语<rt>login banner</rt></ruby>。
|
||||
|
||||
![Login welcome messages in Linux][2]
|
||||
|
||||
在本文中,我们将引导你配置它们。
|
||||
|
||||
你可以配置两种类型的导语。
|
||||
|
||||
1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
|
||||
2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
|
||||
|
||||
### 如何在用户登录前连接系统时显示消息
|
||||
|
||||
当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
|
||||
|
||||
你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
|
||||
|
||||
```
|
||||
# cat /etc/login.warn
|
||||
!!!! Welcome to KernelTalks test server !!!!
|
||||
This server is meant for testing Linux commands and tools. If you are
|
||||
not associated with kerneltalks.com and not authorized please dis-connect
|
||||
immediately.
|
||||
```
|
||||
|
||||
现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
|
||||
|
||||
这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
|
||||
|
||||
保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
|
||||
|
||||
```
|
||||
root@kerneltalks # ps -ef | grep -i sshd
|
||||
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
|
||||
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
|
||||
|
||||
root@kerneltalks # kill -HUP 14255
|
||||
```
|
||||
|
||||
就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。
|
||||
|
||||
![Login banner in Linux][3]
|
||||
|
||||
你可以在用户输入密码登录系统之前看到此消息。
|
||||
|
||||
### 如何在用户登录后显示消息
|
||||
|
||||
消息用户在成功登录系统后看到的<ruby>当天消息<rt>Message Of The Day</rt></ruby>(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
|
||||
|
||||
```
|
||||
root@kerneltalks # cat /etc/motd
|
||||
W E L C O M E
|
||||
Welcome to the testing environment of kerneltalks.
|
||||
Feel free to use this system for testing your Linux
|
||||
skills. In case of any issues reach out to admin at
|
||||
info@kerneltalks.com. Thank you.
|
||||
|
||||
```
|
||||
|
||||
你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。
|
||||
|
||||
![motd in linux][4]
|
||||
|
||||
你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
|
||||
|
||||
你可以使用 [cowsay][5]、[banner][6]、[figlet][7]、[lolcat][8] 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
|
||||
[2]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
|
||||
[3]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
|
||||
[4]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
|
||||
[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
|
||||
[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
|
||||
[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
|
||||
[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
|
||||
@ -3,11 +3,11 @@
|
||||
|
||||
### 目标
|
||||
|
||||
学习在 Linux 上使用 "pass" 密码管理器来管理你的密码
|
||||
学习在 Linux 上使用 pass 密码管理器来管理你的密码
|
||||
|
||||
### 条件
|
||||
|
||||
* 需要 root 权限来安装需要的包
|
||||
* 需要 root 权限来安装需要的包
|
||||
|
||||
### 难度
|
||||
|
||||
@ -15,75 +15,81 @@
|
||||
|
||||
### 约定
|
||||
|
||||
* **#** - 执行指定命令需要 root 权限,可以是直接使用 root 用户来执行或者使用 `sudo` 命令来执行
|
||||
* **$** - 使用普通的非特权用户执行指定命令
|
||||
* `#` - 执行指定命令需要 root 权限,可以是直接使用 root 用户来执行或者使用 `sudo` 命令来执行
|
||||
* `$` - 使用普通的非特权用户执行指定命令
|
||||
|
||||
### 介绍
|
||||
|
||||
如果你有根据不同的意图设置不同密码的好习惯,你可能已经感受到需要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专利软件(如果你敢的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
|
||||
如果你有根据不同的意图设置不同密码的好习惯,你可能已经感受到需要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专有软件(如果你敢用的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
|
||||
|
||||
### First steps
|
||||
### 第一步
|
||||
|
||||
Pass 作为一个密码管理器,其实际上是一些你可能早已每天使用的、可信赖且实用的工具的一种封装,比如 `gpg` 和 `git` 。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless machines 上工作 (LCTT 注:根据 wikipedia 的说法,所谓 headless machines 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
|
||||
pass 作为一个密码管理器,其实际上是一些你可能早已每天使用的、可信赖且实用的工具的一种封装,比如 `gpg` 和 `git` 。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless 机器上工作(LCTT 译注:根据 wikipedia 的说法,所谓 headless 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
|
||||
|
||||
### 步骤 1 - 安装
|
||||
### 安装
|
||||
|
||||
Pass 在主流的 linux 发行版中都是可用的,你可以通过包管理器安装:
|
||||
pass 在主流的 Linux 发行版中都是可用的,你可以通过包管理器安装:
|
||||
|
||||
#### Fedora
|
||||
|
||||
```
|
||||
# dnf install pass
|
||||
```
|
||||
|
||||
#### RHEL and CentOS
|
||||
#### RHEL 和 CentOS
|
||||
|
||||
pass 不在官方仓库中,但你可以从 `epel` 中获取道它。要在 CentOS7 上启用后面这个源,只需要执行:
|
||||
|
||||
Pass 不在官方仓库中,但你可以从 `epel` 中获取道它。要在 CentOS7 上启用后面这个源,只需要执行:
|
||||
```
|
||||
# yum install epel-release
|
||||
```
|
||||
|
||||
然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从 EPEL 官方网站上下载它。
|
||||
然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从 EPEL 官方网站上下载它。
|
||||
|
||||
#### Debian 和 Ubuntu
|
||||
|
||||
#### Debian and Ubuntu
|
||||
```
|
||||
# apt-get install pass
|
||||
```
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
```
|
||||
# pacman -S pass
|
||||
```
|
||||
|
||||
### 初始化密码仓库
|
||||
|
||||
安装好 `pass` 后,就可以开始使用和配置它了。首先,由于 pass 依赖 `gpg` 来对我们的密码进行加密并以安全的方式进行存储,我们必须准备好一个 `gpg 密钥对`。
|
||||
安装好 `pass` 后,就可以开始使用和配置它了。首先,由于 `pass` 依赖于 `gpg` 来对我们的密码进行加密并以安全的方式进行存储,我们必须准备好一个 gpg 密钥对。
|
||||
|
||||
首先我们要初始化密码仓库:这就是一个用来存放 gpg 加密后的密码的目录。默认情况下它会在你的 `$HOME` 创建一个隐藏目录,不过你也可以通过使用 `PASSWORD_STORE_DIR` 这一环境变量来指定另一个路径。让我们运行:
|
||||
|
||||
首先我们要初始化 `密码仓库`:这就是一个用来存放 gpg 加密后的密码的目录。默认情况下它会在你的 `$HOME` 创建一个隐藏目录,不过你也可以通过使用 `PASSWORD_STORE_DIR` 这一环境变量来指定另一个路径。让我们运行:
|
||||
```
|
||||
$ pass init
|
||||
```
|
||||
|
||||
然后`密码仓库`目录就创建好了。现在,让我们来存储我们第一个密码:
|
||||
然后 `password-store` 目录就创建好了。现在,让我们来存储我们第一个密码:
|
||||
|
||||
```
|
||||
$ pass edit mysite
|
||||
```
|
||||
|
||||
这会打开默认文本编辑器,我么只需要输入密码就可以了。输入的内容会用 gpg 加密并存储为密码仓库目录中的 `mysite.gpg` 文件。
|
||||
|
||||
Pass 以目录树的形式存储加密后的文件,也就是说我们可以在逻辑上将多个文件放在子目录中以实现更好的组织形式,我们只需要在创建文件时指定存在哪个目录下就行了,像这样:
|
||||
`pass` 以目录树的形式存储加密后的文件,也就是说我们可以在逻辑上将多个文件放在子目录中以实现更好的组织形式,我们只需要在创建文件时指定存在哪个目录下就行了,像这样:
|
||||
|
||||
```
|
||||
$ pass edit foo/bar
|
||||
```
|
||||
|
||||
跟上面的命令一样,它也会让你输入密码,但是创建的文件是放在密码仓库目录下的 `foo` 子目录中的。要查看文件组织结构,只需要不带任何参数运行 `pass` 命令即可:
|
||||
```
|
||||
|
||||
```
|
||||
$ pass
|
||||
Password Store
|
||||
├── foo
|
||||
│ └── bar
|
||||
└── mysite
|
||||
|
||||
```
|
||||
|
||||
若想修改密码,只需要重复创建密码的操作就行了。
|
||||
@ -91,11 +97,13 @@ Password Store
|
||||
### 获取密码
|
||||
|
||||
有两种方法可以获取密码:第一种会显示密码到终端上,方法是运行:
|
||||
|
||||
```
|
||||
pass mysite
|
||||
```
|
||||
|
||||
然而更好的方法是使用 `-c` 选项让 pass 将密码直接拷贝到剪切板上:
|
||||
然而更好的方法是使用 `-c` 选项让 `pass` 将密码直接拷贝到剪切板上:
|
||||
|
||||
```
|
||||
pass -c mysite
|
||||
```
|
||||
@ -104,29 +112,32 @@ pass -c mysite
|
||||
|
||||
### 生成密码
|
||||
|
||||
Pass 也可以为我们自动生成(并自动存储)安全密码。假设我们想要生成一个由 15 个字符组成的密码:包含字母,数字和特殊符号,其命令如下:
|
||||
`pass` 也可以为我们自动生成(并自动存储)安全密码。假设我们想要生成一个由 15 个字符组成的密码:包含字母,数字和特殊符号,其命令如下:
|
||||
|
||||
```
|
||||
pass generate mysite 15
|
||||
```
|
||||
|
||||
若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 pass 把密码直接拷贝到剪切板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:
|
||||
若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 `pass` 把密码直接拷贝到剪切板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:
|
||||
|
||||
![qrcode][1]
|
||||
|
||||
从上面的截屏中尅看出,生成了一个二维码,不过由于 `mysite` 的密码已经存在了,pass 会提示我们确认是否要覆盖原密码。
|
||||
从上面的截屏中可看出,生成了一个二维码,不过由于运行该命令时 `mysite` 的密码已经存在了,`pass` 会提示我们确认是否要覆盖原密码。
|
||||
|
||||
Pass 使用 `/dev/urandom` 设备作为(伪)随机数据生成器来生成密码,同时它使用 `xclip` 工具来将密码拷贝到粘帖板中,同时使用 `qrencode` 来将密码以二维码的形式显示出来。在我看来,这种模块化的设计正是它最大的优势:它并不重复造轮子,而只是将常用的工具包装起来完成任务。
|
||||
`pass` 使用 `/dev/urandom` 设备作为(伪)随机数据生成器来生成密码,同时它使用 `xclip` 工具来将密码拷贝到粘帖板中,而使用 `qrencode` 来将密码以二维码的形式显示出来。在我看来,这种模块化的设计正是它最大的优势:它并不重复造轮子,而只是将常用的工具包装起来完成任务。
|
||||
|
||||
你也可以使用 `pass mv`,`pass cp`,和 `pass rm` 来重命名,拷贝和删除密码仓库中的文件。
|
||||
你也可以使用 `pass mv`、`pass cp` 和 `pass rm` 来重命名、拷贝和删除密码仓库中的文件。
|
||||
|
||||
### 将密码仓库变成 git 仓库
|
||||
|
||||
`pass` 另一个很棒的功能就是可以将密码仓库当成 git 仓库来用:通过版本管理系统能让我们管理密码更方便。
|
||||
|
||||
```
|
||||
pass git init
|
||||
```
|
||||
|
||||
这会创建 git 仓库,并自动提交所有已存在的文件。下一步就是指定跟踪的远程仓库了:
|
||||
|
||||
```
|
||||
pass git remote add <name> <url>
|
||||
```
|
||||
@ -135,7 +146,6 @@ pass git remote add <name> <url>
|
||||
|
||||
`pass` 有一个叫做 `qtpass` 的图形界面,而且也支持 Windows 和 MacOs。通过使用 `PassFF` 插件,它还能获取 firefox 中存储的密码。在它的项目网站上可以查看更多详细信息。试一下 `pass` 吧,你不会失望的!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-manager
|
||||
@ -147,4 +157,4 @@ via: https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
[1]:/https://linuxconfig.org/images/pass-manager-qrcode.png
|
||||
[1]:https://linuxconfig.org/images/pass-manager-qrcode.png
|
||||
@ -1,32 +1,31 @@
|
||||
在你下一次技术面试的时候要提的 3 个基本问题
|
||||
下一次技术面试时要问的 3 个重要问题
|
||||
======
|
||||
|
||||

|
||||
|
||||
面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Linux 基金会
|
||||
> 面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Dice 和 Linux 基金会的年度[开源工作报告][1]揭示了开源专业人士的前景以及未来一年的招聘活动。在今年的报告中,86% 的科技专业人士表示,了解开源推动了他们的职业生涯。然而,当在他们自己的组织内推进或在别处申请新职位的时候,有这些经历会发生什么呢?
|
||||
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你对我有什么问题吗?”时适当的回答更增添了压力。
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你有什么问题要问吗?”时,适当的回答更增添了压力。
|
||||
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司里雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
|
||||
多年来,我在面试中了解到提出好问题的重要性。这是一个了解你的潜在新雇主的机会,以及更好地了解他们是否与你的技能相匹配。
|
||||
|
||||
这里有三个重要的问题需要以及其重要的原因:
|
||||
这里有三个要问的重要问题,以及其重要的原因:
|
||||
|
||||
**1\. 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?**
|
||||
### 1、 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?
|
||||
|
||||
这个问题的答案会告诉正在面试的公司的很多信息。一般来说,只要它与你在该公司所从事的工作没有冲突,公司会希望技术专家为网站或项目做出贡献。在公司之外允许这种情况,也会在技术组织中培养出一种创业精神,并教授技术技能,否则在正常的日常工作中你可能无法获得这些技能。
|
||||
|
||||
**2\. 项目在这如何分优先级?**
|
||||
### 2、 项目如何区分优先级?
|
||||
|
||||
由于所有的公司都成为了科技公司,所以在创新的客户面对技术项目与改进平台本身之间往往存在着分歧。你会努力保持现有的平台最新么?或者致力于公众开发新产品?根据你的兴趣,答案可以决定公司是否适合你。
|
||||
|
||||
**3\. 谁主要决定新产品,开发者在决策过程中有多少投入?**
|
||||
### 3、 谁主要决定新产品,开发者在决策过程中有多少投入?
|
||||
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来没有困难,但有时会错过这步,意味着在新产品发布之前是协作环境或者混乱的过程。
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来不用多想,但有时会错过这步,意味着在新产品发布之前协作环境的不同或者混乱的过程。
|
||||
|
||||
面试可能会有压力,但是 58% 的公司告诉 Dice 和 Linux 基金会他们需要在未来几个月内聘用开源人才,所以记住高需求会让像你这样的专业人士成为雇员。以你想要的方向引导你的事业。
|
||||
|
||||
@ -38,7 +37,7 @@ via: https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-n
|
||||
|
||||
作者:[Brian Hostetter][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
并发服务器(五):Redis 案例研究
|
||||
======
|
||||
|
||||
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis][10]。
|
||||
|
||||

|
||||
|
||||
Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能、大并发的内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
|
||||
|
||||
我们来看看前四部分讨论的概念在真实世界中的应用程序。
|
||||
|
||||
本系列的所有文章有:
|
||||
|
||||
* [第一节 - 简介][3]
|
||||
* [第二节 - 线程][4]
|
||||
* [第三节 - 事件驱动][5]
|
||||
* [第四节 - libuv][6]
|
||||
* [第五节 - Redis 案例研究][7]
|
||||
|
||||
### 事件处理库
|
||||
|
||||
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用*一个单线程*来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
|
||||
|
||||
Redis 之所以如此牛逼是因为,它在给定的系统上使用了其可用的最快的事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae][11]。ae 使得编写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证 ^注1 了这一点。
|
||||
|
||||
在这里,我们的兴趣点主要是它对*文件事件*的支持 —— 当文件描述符(如网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环(参阅本系列的[第三节][5]和[第四节][6])和不应该感到意外的 `aeCreateFileEvent` 信号:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
它在 `fd` 上使用一个给定的事件循环,为新的文件事件注册一个回调(`proc`)函数。当使用的是 epoll 时,它将调用 `epoll_ctl` 在文件描述符上添加一个事件(可能是 `EPOLLIN`、`EPOLLOUT`、也或许两者都有,取决于 `mask` 参数)。ae 的 `aeProcessEvents` 功能是 “运行事件循环和发送回调函数”,它在底层调用了 `epoll_wait`。
|
||||
|
||||
### 处理客户端请求
|
||||
|
||||
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。`initServer` 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 `acceptTcpHandler` 来调用 `aeCreateFileEvent`。当新的连接可用时,这个回调函数被调用。它调用 `accept` ^注2 ,接下来是 `acceptCommonHandler`,它转而去调用 `createClient` 以初始化新客户端连接所需要的数据结构。
|
||||
|
||||
`createClient` 的工作是去监听来自客户端的入站数据。它将套接字设置为非阻塞模式(一个异步事件循环中的关键因素)并使用 `aeCreateFileEvent` 去注册另外一个文件事件回调函数以读取事件 —— `readQueryFromClient`。每当客户端发送数据,这个函数将被事件循环调用。
|
||||
|
||||
`readQueryFromClient` 就让我们期望的那样 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,所以这个函数必须能够处理 `EAGAIN`,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能被分割在回调函数的多个调用当中。
|
||||
|
||||
### 将数据发送回客户端
|
||||
|
||||
在前面的内容中,我说到了 `readQueryFromClient` 结束了发送给客户端的回复。这在逻辑上是正确的,因为 `readQueryFromClient` *准备*要发送回复,但它不真正去做实质的发送 —— 因为这里并不能保证客户端套接字已经准备好写入/发送数据。我们必须为此使用事件循环机制。
|
||||
|
||||
Redis 是这样做的,它注册一个 `beforeSleep` 函数,每次事件循环即将进入休眠时,调用它去等待套接字变得可以读取/写入。`beforeSleep` 做的其中一件事情就是调用 `handleClientsWithPendingWrites`。它的作用是通过调用 `writeToClient` 去尝试立即发送所有可用的回复;如果一些套接字不可用时,那么*当*套接字可用时,它将注册一个事件循环去调用 `sendReplyToClient`。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——直接发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
|
||||
|
||||
### 为什么 Redis 要实现它自己的事件库?
|
||||
|
||||
在 [第四节][14] 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章][15] 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行他理解的非常透彻的代码;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
|
||||
|
||||
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
|
||||
|
||||
这是我 [前些年在一篇文章中][16] 提到的软件项目依赖关系的另一个很好的示例:
|
||||
|
||||
> 依赖的优势与在软件项目上花费的工作量成反比。
|
||||
|
||||
在某种程度上,Antirez 在他的文章中也提到了这一点。他提到,提供大量附加价值(在我的文章中的“基础” 依赖)的依赖比像 libuv 这样的依赖更有意义(它的例子是 jemalloc 和 Lua),对于 Redis 特定需求,其功能的实现相当容易。
|
||||
|
||||
### Redis 中的多线程
|
||||
|
||||
[在 Redis 的绝大多数历史中][17],它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
|
||||
|
||||
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
|
||||
|
||||
1. “惰性” [内存释放][8]。
|
||||
2. 在后台线程中使用 fsync 调用写一个 [持久化日志][9]。
|
||||
3. 运行需要执行一个长周期运行的操作的用户定义模块。
|
||||
|
||||
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它运行预设数量的线程,每个 Redis 后台作业类型需要一个线程。
|
||||
|
||||
而对于第三个特性,[Redis 模块][18] 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 `src/modules/helloblock.c` 提供了这样的一个示例。
|
||||
|
||||
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节][19] 讨论的工作队列。
|
||||
|
||||
- 注1: Redis 的一个核心部分是:它是一个 _内存中_ 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。
|
||||
- 注2: 使用 `anetAccept`;`anet` 是 Redis 对 TCP 套接字代码的封装。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:https://linux.cn/article-8993-1.html
|
||||
[4]:https://linux.cn/article-9002-1.html
|
||||
[5]:https://linux.cn/article-9117-1.html
|
||||
[6]:https://linux.cn/article-9397-1.html
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:https://linux.cn/article-9397-1.html
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:https://linux.cn/article-9397-1.html
|
||||
115
published/20171214 6 open source home automation tools.md
Normal file
115
published/20171214 6 open source home automation tools.md
Normal file
@ -0,0 +1,115 @@
|
||||
6 个开源的家庭自动化工具
|
||||
======
|
||||
|
||||
> 用这些开源软件解决方案构建一个更智能的家庭。
|
||||
|
||||

|
||||
|
||||
[物联网][13] 不仅是一个时髦词,在现实中,自 2016 年我们发布了一篇关于家庭自动化工具的评论文章以来,它也在迅速占领着我们的生活。在 2017,[26.5% 的美国家庭][14] 已经使用了一些智能家居技术;预计五年内,这一数字还将翻倍。
|
||||
|
||||
随着这些数量持续增加的各种设备的使用,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 这是一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人访问它呢?
|
||||
|
||||
[对安全的担心][16] 是为什么开源对我们将来使用的互联设备至关重要的众多理由之一。由于源代码运行在他们自己的设备上,完全可以去搞明白控制你的家庭的程序,也就是说你可以查看它的代码,如果必要的话甚至可以去修改它。
|
||||
|
||||
虽然联网设备通常都包含它们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口 —— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
|
||||
这里有几个我比较喜欢的。
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] 是一个设计为全栈的家庭自动化平台,包含一个服务器应用程序、触摸屏界面、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
|
||||
Calaos 使用的是 [GPL][18] v3 的许可证,你可以在 [GitHub][19] 上查看它的源代码。
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成软件][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
|
||||
Domoticz 是用 C++ 写的,使用 [GPLv3][22] 许可证。它的 [源代码][23] 在 GitHub 上。
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
|
||||
Home Assistant 以 [MIT 许可证][25] 发布,它的源代码可以从 [GitHub][26] 上下载。
|
||||
|
||||
### MisterHouse
|
||||
|
||||
从 2016 年起,[MisterHouse][27] 取得了很多的进展,我们把它作为一个“可以考虑的另外选择”列在这个清单上。它使用 Perl 脚本去监视任何东西,它可以通过一台计算机来查询或者控制任何可以远程控制的东西。它可以响应语音命令,查询当前时间、天气、位置、以及其它事件,比如去打开灯、唤醒你、记下你喜欢的电视节目、通报呼入的来电、开门报警、记录你儿子上了多长时间的网、如果你女儿汽车超速它也可以告诉你等等。它可以运行在 Linux、macOS、以及 Windows 计算机上,它可以读/写很多的设备,包括安全系统、气象站、来电显示、路由器、机动车位置系统等等。
|
||||
|
||||
MisterHouse 使用 [GPLv2][28] 许可证,你可以在 [GitHub][29] 上查看它的源代码。
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中所熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
|
||||
你可以在 GitHub 上找到 OpenHAB 的 [源代码][31],它使用 [Eclipse 公共许可证][32]。
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
|
||||
OpenMotics 使用 [GPLv2][35] 许可证,它的源代码可以从 [GitHub][36] 上下载。
|
||||
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是他们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
|
||||
如果上面的解决方案并不能满足你的需求,下面还有一些潜在的替代者可以去考虑:
|
||||
|
||||
* [EventGhost][1] 是一个开源的([GPL v2][2])家庭影院自动化工具,它只能运行在 Microsoft Windows PC 上。它允许用户去控制多媒体电脑和连接的硬件,它通过触发宏指令的插件或者定制的 Python 脚本来使用。
|
||||
* [ioBroker][3] 是一个基于 JavaScript 的物联网平台,它能够控制灯、锁、空调、多媒体、网络摄像头等等。它可以运行在任何可以运行 Node.js 的硬件上,包括 Windows、Linux、以及 macOS,它使用 [MIT 许可证][4]。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hub,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [LinuxMCE][7] 标称它是你的多媒体与电子设备之间的“数字粘合剂”。它运行在 Linux(包括树莓派)上,它基于 Pluto 开源 [许可证][8] 发布,它可以用于家庭安全、电话(VoIP 和语音信箱)、A/V 设备、家庭自动化、以及玩视频游戏。
|
||||
* [OpenNetHome][9],和这一类中的其它解决方案一样,是一个控制灯、报警、应用程序等等的一个开源软件。它基于 Java 和 Apache Maven,可以运行在 Windows、macOS、以及 Linux —— 包括树莓派,它以 [GPLv3][10] 许可证发布。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户界面。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
|
||||
现在该轮到你了:你已经准备好家庭自动化系统了吗?或者正在研究去设计一个。你对家庭自动化的新手有什么建议,你会推荐什么样的系统?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://www.eventghost.net/
|
||||
[2]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[3]:http://iobroker.net/
|
||||
[4]:https://github.com/ioBroker/ioBroker#license
|
||||
[5]:https://www.jeedom.com/site/en/index.html
|
||||
[6]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[7]:http://www.linuxmce.com/
|
||||
[8]:http://wiki.linuxmce.org/index.php/License
|
||||
[9]:http://opennethome.org/
|
||||
[10]:https://github.com/NetHome/NetHomeServer/blob/master/LICENSE
|
||||
[11]:https://www.smarthomatic.org/
|
||||
[12]:https://github.com/breaker27/smarthomatic/blob/develop/GPL3.txt
|
||||
[13]:https://opensource.com/resources/internet-of-things
|
||||
[14]:https://www.statista.com/outlook/279/109/smart-home/united-states
|
||||
[15]:http://www.crn.com/slide-shows/internet-of-things/300089496/black-hat-2017-9-iot-security-threats-to-watch.htm
|
||||
[16]:https://opensource.com/business/15/5/why-open-source-means-stronger-security
|
||||
[17]:https://calaos.fr/en/
|
||||
[18]:https://github.com/calaos/calaos-os/blob/master/LICENSE
|
||||
[19]:https://github.com/calaos
|
||||
[20]:https://domoticz.com/
|
||||
[21]:https://www.domoticz.com/wiki/Integrations_and_Protocols
|
||||
[22]:https://github.com/domoticz/domoticz/blob/master/License.txt
|
||||
[23]:https://github.com/domoticz/domoticz
|
||||
[24]:https://home-assistant.io/
|
||||
[25]:https://github.com/home-assistant/home-assistant/blob/dev/LICENSE.md
|
||||
[26]:https://github.com/balloob/home-assistant
|
||||
[27]:http://misterhouse.sourceforge.net/
|
||||
[28]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[29]:https://github.com/hollie/misterhouse
|
||||
[30]:http://www.openhab.org/
|
||||
[31]:https://github.com/openhab/openhab
|
||||
[32]:https://github.com/openhab/openhab/blob/master/LICENSE.TXT
|
||||
[33]:https://www.openmotics.com/
|
||||
[34]:https://opensource.com/life/14/12/open-source-home-automation-system-opemmotics
|
||||
[35]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[36]:https://github.com/openmotics
|
||||
@ -1,47 +1,47 @@
|
||||
什么是 CGManager?[][1]
|
||||
什么是 CGManager?
|
||||
============================================================
|
||||
|
||||
CGManager 是一个核心的特权守护进程,通过一个简单的 D-Bus API 管理你所有的 cgroup。它被设计用来处理嵌套的 LXC 容器以及接受无特权的请求,包括解析用户名称空间的 UID/GID。
|
||||
|
||||
# 组件[][2]
|
||||
### 组件
|
||||
|
||||
### cgmanager[][3]
|
||||
#### cgmanager
|
||||
|
||||
这个守护进程在主机上运行,将 cgroupfs 挂载到一个独立的挂载名称空间(所以它不能从主机上看到),绑定 /sys/fs/cgroup/cgmanager/sock 用于传入的 D-Bus 查询,并通常处理主机上直接运行的所有客户端。
|
||||
这个守护进程在宿主机上运行,将 cgroupfs 挂载到一个独立的挂载名称空间(所以它不能从宿主机上看到),绑定 `/sys/fs/cgroup/cgmanager/sock` 用于传入的 D-Bus 查询,并通常处理宿主机上直接运行的所有客户端。
|
||||
|
||||
cgmanager 同时接受使用 D-Bus + SCM 凭证的身份验证请求,用于在命名空间之间转换 uid、gid 和 pid,或者使用简单的 “unauthenticated”(只是初始的 ucred)D-Bus 来查询来自主机级别的查询。
|
||||
cgmanager 既接受使用 D-Bus + SCM 凭证的身份验证请求,用于在命名空间之间转换 uid、gid 和 pid,也可以使用简单的 “unauthenticated”(只是初始的 ucred)D-Bus 来查询来自宿主机级别的查询。
|
||||
|
||||
### cgproxy[][4]
|
||||
#### cgproxy
|
||||
|
||||
你可能会在两种情况下看到这个守护进程运行。在主机上,如果你的内核小于 3.8(没有 pidns 连接支持)或在容器中(只有 cgproxy 运行)。
|
||||
你可能会在两种情况下看到这个守护进程运行。在宿主机上,如果你的内核老于 3.8(没有 pidns 连接支持)或处于容器中(只有 cgproxy 运行)。
|
||||
|
||||
cgproxy 本身并不做任何 cgroup 配置更改,而是如其名称所示,代理请求给主 cgmanager 进程。
|
||||
|
||||
这是必要的,所以一个进程可以直接使用 D-Bus(例如使用 dbus-send)与 /sys/fs/cgroup/cgmanager/sock 进行通信。
|
||||
这是必要的,所以一个进程可以直接使用 D-Bus(例如使用 dbus-send)与 `/sys/fs/cgroup/cgmanager/sock` 进行通信。
|
||||
|
||||
之后 cgproxy 将从该查询中得到 ucred,并对真正的 cgmanager 套接字进行经过身份验证的 SCM 查询,并通过 ucred 结构体传递参数,使它们能够正确地转换为 cgmanager 可以理解的主机命名空间 。
|
||||
之后 cgproxy 将从该查询中得到 ucred,并对真正的 cgmanager 套接字进行身份验证的 SCM 查询,并通过 ucred 结构体传递参数,使它们能够正确地转换为 cgmanager 可以理解的宿主机命名空间 。
|
||||
|
||||
### cgm[][5]
|
||||
#### cgm
|
||||
|
||||
一个简单的命令行工具,与 D-Bus 服务通信,并允许你从命令行执行所有常见的 cgroup 操作。
|
||||
|
||||
# 通信协议[][6]
|
||||
### 通信协议
|
||||
|
||||
如上所述,cgmanager 和 cgproxy 使用 D-Bus。建议外部客户端(所以不要是 cgproxy)使用标准的 D-Bus API,不要试图实现 SCM creds 协议,因为它是不必要的,并且容易出错。
|
||||
|
||||
相反,只要简单假设与 /sys/fs/cgroup/cgmanager/sock 的通信总是正确的。
|
||||
相反,只要简单假设与 `/sys/fs/cgroup/cgmanager/sock` 的通信总是正确的。
|
||||
|
||||
cgmanager API 仅在独立的 D-Bus 套接字上可用,cgmanager 本身不连接到系统总线,所以 cgmanager/cgproxy 不要求有运行中的 dbus 守护进程。
|
||||
|
||||
你可以在[这里][7]阅读更多关于 D-Bus API。
|
||||
|
||||
# Licensing[][8]
|
||||
### 许可证
|
||||
|
||||
CGManager 是免费软件,大部分代码是根据 GNU LGPLv2.1+ 许可条款发布的,一些二进制文件是在 GNU GPLv2 许可下发布的。
|
||||
|
||||
该项目的默认许可证是 GNU LGPLv2.1+
|
||||
|
||||
# Support[][9]
|
||||
### 支持
|
||||
|
||||
CGManager 的稳定版本支持依赖于 Linux 发行版以及它们自己承诺推出稳定修复和安全更新。
|
||||
|
||||
@ -51,9 +51,9 @@ CGManager 的稳定版本支持依赖于 Linux 发行版以及它们自己承诺
|
||||
|
||||
via: https://linuxcontainers.org/cgmanager/introduction/
|
||||
|
||||
作者:[Canonical Ltd. ][a]
|
||||
作者:[Canonical Ltd.][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
176
published/20180102 HTTP errors in WordPress.md
Normal file
176
published/20180102 HTTP errors in WordPress.md
Normal file
@ -0,0 +1,176 @@
|
||||
如何修复 WordPress 中的 HTTP 错误
|
||||
======
|
||||
|
||||
![http error wordpress][1]
|
||||
|
||||
我们会向你介绍,如何在 Linux VPS 上修复 WordPress 中的 HTTP 错误。 下面列出了 WordPress 用户遇到的最常见的 HTTP 错误,我们的建议侧重于如何发现错误原因以及解决方法。
|
||||
|
||||
|
||||
### 1、 修复在上传图像时出现的 HTTP 错误
|
||||
|
||||
如果你在基于 WordPress 的网页中上传图像时出现错误,这也许是因为服务器上 PHP 的配置,例如存储空间不足或者其他配置问题造成的。
|
||||
|
||||
用如下命令查找 php 配置文件:
|
||||
|
||||
```
|
||||
php -i | grep php.ini
|
||||
Configuration File (php.ini) Path => /etc
|
||||
Loaded Configuration File => /etc/php.ini
|
||||
```
|
||||
|
||||
根据输出结果,php 配置文件位于 `/etc` 文件夹下。编辑 `/etc/php.ini` 文件,找出下列行,并按照下面的例子修改其中相对应的值:
|
||||
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
|
||||
```
|
||||
upload_max_filesize = 64M
|
||||
post_max_size = 32M
|
||||
max_execution_time = 300
|
||||
max_input_time 300
|
||||
memory_limit = 128M
|
||||
```
|
||||
|
||||
当然,如果你不习惯使用 vi 文本编辑器,你可以选用自己喜欢的。
|
||||
|
||||
不要忘记重启你的网页服务器来让改动生效。
|
||||
|
||||
如果你安装的网页服务器是 Apache,你也可以使用 `.htaccess` 文件。首先,找到 `.htaccess` 文件。它位于 WordPress 安装路径的根文件夹下。如果没有找到 `.htaccess` 文件,需要自己手动创建一个,然后加入如下内容:
|
||||
|
||||
|
||||
```
|
||||
vi /www/html/path_to_wordpress/.htaccess
|
||||
```
|
||||
|
||||
```
|
||||
php_value upload_max_filesize 64M
|
||||
php_value post_max_size 32M
|
||||
php_value max_execution_time 180
|
||||
php_value max_input_time 180
|
||||
|
||||
# BEGIN WordPress
|
||||
<IfModule mod_rewrite.c>
|
||||
RewriteEngine On
|
||||
RewriteBase /
|
||||
RewriteRule ^index\.php$ - [L]
|
||||
RewriteCond %{REQUEST_FILENAME} !-f
|
||||
RewriteCond %{REQUEST_FILENAME} !-d
|
||||
RewriteRule . /index.php [L]
|
||||
</IfModule>
|
||||
# END WordPress
|
||||
```
|
||||
|
||||
如果你使用的网页服务器是 nginx,在 nginx 的 `server` 配置块中配置你的 WordPress 实例。详细配置和下面的例子相似:
|
||||
|
||||
```
|
||||
server {
|
||||
|
||||
listen 80;
|
||||
client_max_body_size 128m;
|
||||
client_body_timeout 300;
|
||||
|
||||
server_name your-domain.com www.your-domain.com;
|
||||
|
||||
root /var/www/html/wordpress;
|
||||
index index.php;
|
||||
|
||||
location = /favicon.ico {
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location = /robots.txt {
|
||||
allow all;
|
||||
log_not_found off;
|
||||
access_log off;
|
||||
}
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ /index.php?$args;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
include fastcgi_params;
|
||||
fastcgi_pass 127.0.0.1:9000;
|
||||
fastcgi_index index.php;
|
||||
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
|
||||
}
|
||||
|
||||
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
|
||||
expires max;
|
||||
log_not_found off;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
根据自己的 PHP 配置,你需要将 `fastcgi_pass 127.0.0.1:9000;` 用类似于 `fastcgi_pass unix:/var/run/php7-fpm.sock;` 替换掉(依照实际连接方式)
|
||||
|
||||
重启 nginx 服务来使改动生效。
|
||||
|
||||
### 2、 修复因为不恰当的文件权限而产生的 HTTP 错误
|
||||
|
||||
如果你在 WordPress 中出现一个意外错误,也许是因为不恰当的文件权限导致的,所以需要给 WordPress 文件和文件夹设置一个正确的权限:
|
||||
|
||||
```
|
||||
chown www-data:www-data -R /var/www/html/path_to_wordpress/
|
||||
```
|
||||
|
||||
将 `www-data` 替换成实际的网页服务器用户,将 `/var/www/html/path_to_wordpress` 换成 WordPress 的实际安装路径。
|
||||
|
||||
### 3、 修复因为内存不足而产生的 HTTP 错误
|
||||
|
||||
你可以通过在 `wp-config.php` 中添加如下内容来设置 PHP 的最大内存限制:
|
||||
|
||||
```
|
||||
define('WP_MEMORY_LIMIT', '128MB');
|
||||
```
|
||||
|
||||
### 4、 修复因为 php.ini 文件错误配置而产生的 HTTP 错误
|
||||
|
||||
编辑 PHP 配置主文件,然后找到 `cgi.fix_pathinfo` 这一行。 这一行内容默认情况下是被注释掉的,默认值为 `1`。取消这一行的注释(删掉这一行最前面的分号),然后将 `1` 改为 `0` 。同时需要修改 `date.timezone` 这一 PHP 设置,再次编辑 PHP 配置文件并将这一选项改成 `date.timezone = Asia/Shanghai` (或者将等号后内容改为你所在的时区)。
|
||||
|
||||
```
|
||||
vi /etc/php.ini
|
||||
```
|
||||
```
|
||||
cgi.fix_pathinfo=0
|
||||
date.timezone = Asia/Shanghai
|
||||
```
|
||||
|
||||
### 5、 修复因为 Apache mod_security 模块而产生的 HTTP 错误
|
||||
|
||||
如果你在使用 Apache mod_security 模块,这可能也会引起问题。试着禁用这一模块,确认是否因为在 `.htaccess` 文件中加入如下内容而引起了问题:
|
||||
|
||||
```
|
||||
<IfModule mod_security.c>
|
||||
SecFilterEngine Off
|
||||
SecFilterScanPOST Off
|
||||
</IfModule>
|
||||
```
|
||||
|
||||
### 6、 修复因为有问题的插件/主题而产生的 HTTP 错误
|
||||
|
||||
一些插件或主题也会导致 HTTP 错误以及其他问题。你可以首先禁用有问题的插件/主题,或暂时禁用所有 WordPress 插件。如果你有 phpMyAdmin,使用它来禁用所有插件:在其中找到 `wp_options` 数据表,在 `option_name` 这一列中找到 `active_plugins` 这一记录,然后将 `option_value` 改为 :`a:0:{}`。
|
||||
|
||||
或者用以下命令通过SSH重命名插件所在文件夹:
|
||||
|
||||
```
|
||||
mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
|
||||
```
|
||||
|
||||
通常情况下,HTTP 错误会被记录在网页服务器的日志文件中,所以寻找错误时一个很好的切入点就是查看服务器日志。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/http-error-wordpress/
|
||||
|
||||
作者:[rosehosting][a]
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/http-error-wordpress.jpg
|
||||
[2]:https://www.rosehosting.com/wordpress-hosting.html
|
||||
@ -1,83 +1,85 @@
|
||||
如何使用 syslog-ng 从远程 Linux 机器上收集日志
|
||||
======
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
Image: Jack Wallen
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
如果你的数据中心全是 Linux 服务器,而你就是系统管理员。那么你的其中一项工作内容就是查看服务器的日志文件。但是,如果你在大量的机器上去查看日志文件,那么意味着你需要挨个去登入到机器中来阅读日志文件。如果你管理的机器很多,仅这项工作就可以花费你一天的时间。
|
||||
|
||||
另外的选择是,你可以配置一台单独的 Linux 机器去收集这些日志。这将使你的每日工作更加高效。要实现这个目的,有很多的不同系统可供你选择,而 syslog-ng 就是其中之一。
|
||||
|
||||
使用 syslog-ng 的问题是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
syslog-ng 的不足是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 ,将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
现在我们来开始安装和配置。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
安装很简单。为了尽可能容易,我将从标准仓库安装。打开一个终端窗口,运行如下命令:
|
||||
|
||||
```
|
||||
sudo apt install syslog-ng
|
||||
```
|
||||
|
||||
在作为收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
你必须在收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
|
||||
## 配置收集器
|
||||
### 配置收集器
|
||||
|
||||
现在,我们开始日志收集器的配置。它的配置文件是 `/etc/syslog-ng/syslog-ng.conf`。syslog-ng 安装完成时就已经包含了一个配置文件。我们不使用这个默认的配置文件,可以使用 `mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK` 将这个自带的默认配置文件重命名。现在使用 `sudo nano /etc/syslog/syslog-ng.conf` 命令创建一个新的配置文件。在这个文件中添加如下的行:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
```
|
||||
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保你的网络上它可以被访问。
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保在你的网络上它可以被访问。
|
||||
|
||||
保存并关闭这个文件。上面的配置将转存期望的日志文件(由 `system()` 和 `internal()` 指出)到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
|
||||
保存和关闭这个文件。上面的配置将转存期望的日志文件(使用 system() and internal())到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
```
|
||||
sudo mkdir /var/log/syslog-ng
|
||||
sudo touch /var/log/syslog-ng/logs.txt
|
||||
```
|
||||
|
||||
使用如下的命令启动和启用 syslog-ng:
|
||||
|
||||
```
|
||||
sudo systemctl start syslog-ng
|
||||
sudo systemctl enable syslog-ng
|
||||
```
|
||||
|
||||
## 配置为客户端
|
||||
### 配置客户端
|
||||
|
||||
我们将在客户端上做同样的事情(移动默认配置文件并创建新配置文件)。拷贝下列文本到新的客户端配置文件中:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
source s_local { system(); internal(); };
|
||||
destination d_syslog_tcp {
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
log { source(s_local);destination(d_syslog_tcp); };
|
||||
```
|
||||
|
||||
@ -87,11 +89,9 @@ log { source(s_local);destination(d_syslog_tcp); };
|
||||
|
||||
## 查看日志文件
|
||||
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出 ( **Figure A** )。
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出(图 A)。
|
||||
|
||||
**Figure A**
|
||||
|
||||
![Figure A][3]
|
||||
![图 A][3]
|
||||
|
||||
恭喜你!syslog-ng 已经正常工作了。你现在可以登入到你的收集器上查看本地机器和远程客户端的日志了。如果你的数据中心有很多 Linux 服务器,在每台服务器上都安装上 syslog-ng 并配置它们作为客户端发送日志到收集器,这样你就不需要登入到每个机器去查看它们的日志了。
|
||||
|
||||
@ -101,7 +101,7 @@ via: https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-f
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,56 +1,56 @@
|
||||
如何在 Linux 上安装/更新 Intel 微码固件
|
||||
======
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行方式去安装或者更新 Intel/AMD CPU 的微码固件呢?
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行选项去安装或者更新 Intel/AMD CPU 的微码固件?
|
||||
|
||||
|
||||
微码只是由 Intel/AMD 提供的 CPU 固件而已。Linux 的内核可以在系统引导时不需要升级 BIOS 的情况下更新 CPU 的固件。处理器微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的升级微码可以去修复 bug 或者使用补丁来防范 bugs。这篇文章演示了如何使用包管理器去安装 AMD 或者 Intel 微码更新,或者由 lntel 提供的 Linux 上的处理器微码更新。
|
||||
|
||||
## 如何查看当前的微码状态
|
||||
<ruby>微码<rt>microcode</rt></ruby>就是由 Intel/AMD 提供的 CPU 固件。Linux 的内核可以在引导时更新 CPU 固件,而无需 BIOS 更新。处理器的微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的微码的更新可以去修复 bug 或者使用补丁来防范 bug。这篇文章演示了如何使用包管理器或由 lntel 提供的 Linux 处理器微码更新来安装 AMD 或 Intel 的微码更新。
|
||||
|
||||
### 如何查看当前的微码状态
|
||||
|
||||
以 root 用户运行下列命令:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下图这样的:
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下这样的:
|
||||
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 Linux 系统的 x86/amd64 架构的 CPU 上,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:**sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux 用户输入:**sudo yum install microcode_ctl**
|
||||
### 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 x86/amd64 架构的 CPU 上的 Linux 系统,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:`sudo apt install intel-microcode`
|
||||
3. CentOS/RHEL Linux 用户输入:`sudo yum install microcode_ctl`
|
||||
|
||||
对于流行的 Linux 发行版,这个包的名字一般如下 :
|
||||
|
||||
* microcode_ctl 和 linux-firmware —— CentOS/RHEL 微码更新包
|
||||
* intel-microcode —— Debian/Ubuntu 和 clones 发行版适用于 Intel CPU 的微码更新包
|
||||
* amd64-microcode —— Debian/Ubuntu 和 clones 发行版适用于 AMD CPU 的微码固件
|
||||
* linux-firmware —— 适用于 AMD CPU 的 Arch Linux 发行版微码固件(你不用做任何操作,它是默认安装的)
|
||||
* intel-ucode —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* microcode_ctl 和 ucode-intel —— Suse/OpenSUSE Linux 微码更新包
|
||||
* `microcode_ctl` 和 `linux-firmware` —— CentOS/RHEL 微码更新包
|
||||
* `intel-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 Intel CPU 的微码更新包
|
||||
* `amd64-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 AMD CPU 的微码固件
|
||||
* `linux-firmware` —— 适用于 AMD CPU 的 Arch Linux 发行版的微码固件(你不用做任何操作,它是默认安装的)
|
||||
* `intel-ucode` —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* `microcode_ctl` 、`linux-firmware` 和 `ucode-intel` —— Suse/OpenSUSE Linux 微码更新包
|
||||
|
||||
**警告 :在某些情况下,微码更新可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
|
||||
**警告 :在某些情况下,更新微码可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
### 示例
|
||||
#### 示例
|
||||
|
||||
在使用 Intel CPU 的 Debian/Ubuntu Linux 系统上,输入如下的 [apt 命令][2]/[apt-get 命令][3]:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
```
|
||||
$ sudo apt-get install intel-microcode
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -58,11 +58,15 @@
|
||||
|
||||
你 [必须重启服务器以激活微码][5] 更新:
|
||||
|
||||
`$ sudo reboot`
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后检查微码状态:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
```
|
||||
# dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -70,7 +74,6 @@
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 RHEL/CentOS 系统,使用 [yum 命令][6] 尝试去安装或者更新以下两个包:
|
||||
@ -81,13 +84,14 @@ $ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## 如何去更新/安装从 Intel 网站上下载的微码
|
||||
### 如何更新/安装从 Intel 网站上下载的微码
|
||||
|
||||
仅当你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
只有在你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护、更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
|
||||
### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
#### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 `~/Downloads/microcode-20180108.tgz` 的文件(不要忘了去验证它的检验和),它的用途是去防范 `meltdown/Spectre` bug。先使用 `tar` 命令去提取它:
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 ~/Downloads/microcode-20180108.tgz(不要忘了去验证它的检验和),它的用途是去防范 meltdown/Spectre bugs。先使用 tar 命令去提取它:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
@ -101,33 +105,44 @@ $ ls -l
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
检查一下,确保存在 /sys/devices/system/cpu/microcode/reload 目录:
|
||||
> 我只在 CentOS 7.x/RHEL、 7.x/Debian 9.x 和 Ubuntu 17.10 上测试了如下操作。如果你没有找到 `/sys/devices/system/cpu/microcode/reload` 文件的话,更老的发行版所带的更老的内核也许不能使用此方法。参见下面的讨论。请注意,在应用了固件更新之后,有一些客户遇到了系统重启现象。特别是对于[那些运行 Intel Broadwell 和 Haswell CPU][12] 的用于客户机和数据中心服务器上的系统。不要在 Intel Broadwell 和 Haswell CPU 上应用 20180108 版本。尽可能使用软件包管理器方式。
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
检查一下,确保存在 `/sys/devices/system/cpu/microcode/reload`:
|
||||
|
||||
你必须使用 [cp 命令][8] 拷贝 intel-ucode 目录下的所有文件到 /lib/firmware/intel-ucode/ 下面:
|
||||
```
|
||||
$ ls -l /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
你必须使用 [cp 命令][8] 拷贝 `intel-ucode` 目录下的所有文件到 `/lib/firmware/intel-ucode/` 下面:
|
||||
|
||||
你只需要将 intel-ucode 这个目录整个拷贝到 /lib/firmware/ 目录下即可。然后在重新加载接口中写入 1 去重新加载微码文件:
|
||||
```
|
||||
$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/
|
||||
```
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
你只需要将 `intel-ucode` 这个目录整个拷贝到 `/lib/firmware/` 目录下即可。然后在重新加载接口中写入 `1` 去重新加载微码文件:
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时通过内核来加载:
|
||||
```
|
||||
# echo 1 > /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时它能通过内核来加载:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后通过以下的命令验证微码是否已经更新:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
到此为止,就是更新处理器微码的全部步骤。如果一切顺利的话,你的 Intel CPU 的固件将已经是最新的版本了。
|
||||
|
||||
## 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人、一位经验丰富的系统管理员、Linux/Unix 操作系统 shell 脚本培训师。他与全球的包括 IT、教育、国防和空间研究、以及非盈利组织等各行业的客户一起工作。可以在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。
|
||||
|
||||
@ -137,7 +152,7 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -153,3 +168,4 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://newsroom.intel.com/news/intel-security-issue-update-addressing-reboot-issues/
|
||||
@ -0,0 +1,119 @@
|
||||
fold 命令入门示例教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
你有没有发现自己在某种情况下想要折叠或中断命令的输出,以适应特定的宽度?在运行虚拟机的时候,我遇到了几次这种的情况,特别是没有 GUI 的服务器。 以防万一,如果你想限制一个命令的输出为一个特定的宽度,现在看看这里! `fold` 命令在这里就能派的上用场了! `fold` 命令会以适合指定的宽度调整输入文件中的每一行,并将其打印到标准输出。
|
||||
|
||||
在这个简短的教程中,我们将看到 `fold` 命令的用法,带有实例。
|
||||
|
||||
### fold 命令示例教程
|
||||
|
||||
`fold` 命令是 GNU coreutils 包的一部分,所以我们不用为安装的事情烦恼。
|
||||
|
||||
`fold` 命令的典型语法:
|
||||
|
||||
```
|
||||
fold [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
请允许我向您展示一些示例,以便您更好地了解 `fold` 命令。 我有一个名为 `linux.txt` 文件,内容是随机的。
|
||||
|
||||
|
||||
![][2]
|
||||
|
||||
要将上述文件中的每一行换行为默认宽度,请运行:
|
||||
|
||||
```
|
||||
fold linux.txt
|
||||
```
|
||||
|
||||
每行 80 列是默认的宽度。 这里是上述命令的输出:
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的输出中看到的,`fold` 命令已经将输出限制为 80 个字符的宽度。
|
||||
|
||||
当然,我们可以指定您的首选宽度,例如 50,如下所示:
|
||||
|
||||
```
|
||||
fold -w50 linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][4]
|
||||
|
||||
我们也可以将输出写入一个新的文件,如下所示:
|
||||
|
||||
```
|
||||
fold -w50 linux.txt > linux1.txt
|
||||
```
|
||||
|
||||
以上命令将把 `linux.txt` 的行宽度改为 50 个字符,并将输出写入到名为 `linux1.txt` 的新文件中。
|
||||
|
||||
让我们检查一下新文件的内容:
|
||||
|
||||
```
|
||||
cat linux1.txt
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
你有没有注意到前面的命令的输出? 有些词在行之间被中断。 为了解决这个问题,我们可以使用 `-s` 标志来在空格处换行。
|
||||
|
||||
以下命令将给定文件中的每行调整为宽度 50,并在空格处换到新行:
|
||||
|
||||
```
|
||||
fold -w50 -s linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][6]
|
||||
|
||||
看清楚了吗? 现在,输出很清楚。 换到新行中的单词都是用空格隔开的,所在行单词的长度大于 50 的时候就会被调整到下一行。
|
||||
|
||||
在所有上面的例子中,我们用列来限制输出宽度。 但是,我们可以使用 `-b` 选项将输出的宽度强制为指定的字节数。 以下命令以 20 个字节中断输出。
|
||||
|
||||
```
|
||||
fold -b20 linux.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][7]
|
||||
|
||||
另请阅读:
|
||||
|
||||
- [Uniq 命令入门级示例教程][8]
|
||||
|
||||
有关更多详细信息,请参阅 man 手册页。
|
||||
|
||||
```
|
||||
man fold
|
||||
```
|
||||
|
||||
这些就是所有的内容了。 您现在知道如何使用 `fold` 命令以适应特定的宽度来限制命令的输出。 我希望这是有用的。 我们将每天发布更多有用的指南。 敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/fold-command-tutorial-examples-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-3-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-4.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-5-1.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-6-1.png
|
||||
[8]:https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/
|
||||
@ -1,35 +1,38 @@
|
||||
如何在 Linux 上使用 Vundle 管理 Vim 插件
|
||||
======
|
||||
|
||||
|
||||
|
||||
毋庸置疑,**Vim** 是一款强大的文本文件处理的通用工具,能够管理系统配置文件,编写代码。通过插件,vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 **~/.vim** 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
毋庸置疑,Vim 是一款强大的文本文件处理的通用工具,能够管理系统配置文件和编写代码。通过插件,Vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 `~/.vim` 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
|
||||
Vundle 为每一个你安装和存储的拓展配置文件创建各自独立的目录树。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已存在的插件、更新插件配置、搜索安装插件和清理不使用的插件。所有的操作都可以在单一按键的交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
Vundle 为每一个你安装的插件创建一个独立的目录树,并在相应的插件目录中存储附加的配置文件。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已有的插件、更新插件配置、搜索安装的插件和清理不使用的插件。所有的操作都可以在一键交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
|
||||
### Vundle 安装
|
||||
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 **vim**。如果没有,安装 vim,尽情 **git**(下载 vundle)去吧。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 Vim。如果没有,请安装 Vim 和 git(以下载 Vundle)。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
|
||||
```
|
||||
sudo apt-get install vim git
|
||||
```
|
||||
|
||||
**下载 Vundle**
|
||||
#### 下载 Vundle
|
||||
|
||||
复制 Vundle 的 GitHub 仓库地址:
|
||||
|
||||
```
|
||||
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
```
|
||||
|
||||
**配置 Vundle**
|
||||
#### 配置 Vundle
|
||||
|
||||
创建 **~/.vimrc** 文件,通知 vim 使用新的插件管理器。这个文件获得有安装、更新、配置和移除插件的权限。
|
||||
创建 `~/.vimrc` 文件,以通知 Vim 使用新的插件管理器。安装、更新、配置和移除插件需要这个文件。
|
||||
|
||||
```
|
||||
vim ~/.vimrc
|
||||
```
|
||||
|
||||
在此文件顶部,加入如下若干行内容:
|
||||
|
||||
```
|
||||
set nocompatible " be iMproved, required
|
||||
filetype off " required
|
||||
@ -76,35 +79,39 @@ filetype plugin indent on " required
|
||||
" Put your non-Plugin stuff after this line
|
||||
```
|
||||
|
||||
被标记的行中,是 Vundle 的请求项。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。一旦你安装过,键入 **:wq** 保存退出。
|
||||
被标记为 “required” 的行是 Vundle 的所需配置。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。完成后,键入 `:wq` 保存退出。
|
||||
|
||||
最后,打开 Vim:
|
||||
|
||||
最后,打开 vim
|
||||
```
|
||||
vim
|
||||
```
|
||||
|
||||
然后键入下列命令安装插件。
|
||||
然后键入下列命令安装插件:
|
||||
|
||||
```
|
||||
:PluginInstall
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
将会弹出一个新的分窗口,.vimrc 中陈列的项目都会自动安装。
|
||||
将会弹出一个新的分窗口,我们加在 `.vimrc` 文件中的所有插件都会自动安装。
|
||||
|
||||
[![][1]][3]
|
||||
![][3]
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口:
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口。
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
在终端上使用下面命令,规避使用 vim 安装插件
|
||||
你也可以在终端上使用下面命令安装插件,而不用打开 Vim:
|
||||
|
||||
```
|
||||
vim +PluginInstall +qall
|
||||
```
|
||||
|
||||
使用 [**fish shell**][4] 的朋友,添加下面这行到你的 **.vimrc** 文件中。
|
||||
使用 [fish shell][4] 的朋友,添加下面这行到你的 `.vimrc` 文件中。
|
||||
|
||||
```
|
||||
set shell=/bin/bash
|
||||
@ -112,123 +119,138 @@ set shell=/bin/bash
|
||||
|
||||
### 使用 Vundle 管理 Vim 插件
|
||||
|
||||
**添加新的插件**
|
||||
#### 添加新的插件
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件:
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件。
|
||||
```
|
||||
:PluginSearch
|
||||
```
|
||||
|
||||
命令之后添加 **"! "**,刷新 vimscripts 网站内容到本地。
|
||||
要从 vimscripts 网站刷新本地的列表,请在命令之后添加 `!`。
|
||||
|
||||
```
|
||||
:PluginSearch!
|
||||
```
|
||||
|
||||
一个陈列可用插件列表的新分窗口将会被弹出。
|
||||
会弹出一个列出可用插件列表的新分窗口:
|
||||
|
||||
[![][1]][5]
|
||||
![][5]
|
||||
|
||||
你还可以通过直接指定插件名的方式,缩小搜索范围。
|
||||
|
||||
```
|
||||
:PluginSearch vim
|
||||
```
|
||||
|
||||
这样将会列出包含关键词“vim”的插件。
|
||||
这样将会列出包含关键词 “vim” 的插件。
|
||||
|
||||
当然你也可以指定确切的插件名,比如:
|
||||
|
||||
```
|
||||
:PluginSearch vim-dasm
|
||||
```
|
||||
|
||||
移动焦点到正确的一行上,点击 **" i"** 来安装插件。现在,被选择的插件将会被安装。
|
||||
移动焦点到正确的一行上,按下 `i` 键来安装插件。现在,被选择的插件将会被安装。
|
||||
|
||||
[![][1]][6]
|
||||
![][6]
|
||||
|
||||
类似的,在你的系统中安装所有想要的插件。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
|
||||
在你的系统中,所有想要的的插件都以类似的方式安装。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
现在,插件已经安装完成。在 .vimrc 文件中添加安装好的插件名,让插件正确加载。
|
||||
现在,插件已经安装完成。为了让插件正确的自动加载,我们需要在 `.vimrc` 文件中添加安装好的插件名。
|
||||
|
||||
这样做:
|
||||
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
添加这一行:
|
||||
|
||||
```
|
||||
[...]
|
||||
Plugin 'vim-dasm'
|
||||
[...]
|
||||
```
|
||||
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 ESC,键入 **:wq** 保存退出。
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 `ESC`,键入 `:wq` 保存退出。
|
||||
|
||||
请注意,所有插件都必须在 `.vimrc` 文件中追加如下内容。
|
||||
|
||||
请注意,所有插件都必须在 .vimrc 文件中追加如下内容。
|
||||
```
|
||||
[...]
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
**列出已安装的插件**
|
||||
#### 列出已安装的插件
|
||||
|
||||
键入下面命令列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
[![][1]][7]
|
||||
![][7]
|
||||
|
||||
**更新插件**
|
||||
#### 更新插件
|
||||
|
||||
键入下列命令更新插件:
|
||||
|
||||
```
|
||||
:PluginUpdate
|
||||
```
|
||||
|
||||
键入下列命令重新安装所有插件
|
||||
键入下列命令重新安装所有插件:
|
||||
|
||||
```
|
||||
:PluginInstall!
|
||||
```
|
||||
|
||||
**卸载插件**
|
||||
#### 卸载插件
|
||||
|
||||
首先,列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
之后将焦点置于正确的一行上,敲 **" SHITF+d"** 组合键。
|
||||
之后将焦点置于正确的一行上,按下 `SHITF+d` 组合键。
|
||||
|
||||
[![][1]][8]
|
||||
![][8]
|
||||
|
||||
然后编辑你的 `.vimrc` 文件:
|
||||
|
||||
然后编辑你的 .vimrc 文件:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
再然后删除插件入口。最后,键入 **:wq** 保存退出。
|
||||
删除插件入口。最后,键入 `:wq` 保存退出。
|
||||
|
||||
或者,你可以通过移除插件所在 `.vimrc` 文件行,并且执行下列命令,卸载插件:
|
||||
|
||||
或者,你可以通过移除插件所在 .vimrc 文件行,并且执行下列命令,卸载插件:
|
||||
```
|
||||
:PluginClean
|
||||
```
|
||||
|
||||
这个命令将会移除所有不在你的 .vimrc 文件中但是存在于 bundle 目录中的插件。
|
||||
这个命令将会移除所有不在你的 `.vimrc` 文件中但是存在于 bundle 目录中的插件。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 Vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
```
|
||||
:h vundle
|
||||
```
|
||||
|
||||
**捎带看看:**
|
||||
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注 OSTechNix!
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
**来源:**
|
||||
### 资源
|
||||
|
||||
[Vundle GitHub 仓库][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -236,16 +258,17 @@ via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png
|
||||
[9]:https://github.com/VundleVim/Vundle.vim
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Linux 上安装 Spotify
|
||||
如何在 Linux 上使用 snap 安装 Spotify(声破天)
|
||||
======
|
||||
|
||||
如何在 Ubuntu Linux 桌面上安装 Spotify 来在线听音乐?
|
||||
如何在 Ubuntu Linux 桌面上安装 spotify 来在线听音乐?
|
||||
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅。可以创建播放列表。订阅用户可以免广告收听音乐。你会得到更好的音质。本教程**展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版**上的 snap 包管理器安装 Spotify。
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅,可以创建播放列表。订阅用户可以免广告收听音乐,你会得到更好的音质。本教程展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版上的 snap 包管理器安装 Spotify。
|
||||
|
||||
### 在 Linux 上安装 spotify
|
||||
|
||||
@ -11,33 +11,28 @@ Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以
|
||||
|
||||
1. 安装 snapd
|
||||
2. 打开 snapd
|
||||
3. 找到 Spotify snap:
|
||||
```
|
||||
snap find spotify
|
||||
```
|
||||
4. 安装 spotify:
|
||||
```
|
||||
do snap install spotify
|
||||
```
|
||||
5. 运行:
|
||||
```
|
||||
spotify &
|
||||
```
|
||||
3. 找到 Spotify snap:`snap find spotify`
|
||||
4. 安装 spotify:`sudo snap install spotify`
|
||||
5. 运行:`spotify &`
|
||||
|
||||
让我们详细看看所有的步骤和例子。
|
||||
|
||||
### 步骤 1 - 安装 Snapd
|
||||
### 步骤 1 - 安装 snapd
|
||||
|
||||
你需要安装 snapd 包。它是一个守护进程(服务),并能在 Linux 系统上启用 snap 包管理。
|
||||
|
||||
#### Debian/Ubuntu/Mint Linux 上的 Snapd
|
||||
#### Debian/Ubuntu/Mint Linux 上的 snapd
|
||||
|
||||
输入以下[ apt 命令][1]/ [apt-get 命令][2]:
|
||||
`$ sudo apt install snapd`
|
||||
输入以下 [apt 命令][1]/ [apt-get 命令][2]:
|
||||
|
||||
```
|
||||
$ sudo apt install snapd
|
||||
```
|
||||
|
||||
#### 在 Arch Linux 上安装 snapd
|
||||
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 yaourt 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 `yaourt` 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
|
||||
```
|
||||
$ sudo yaourt -S snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
@ -45,7 +40,8 @@ $ sudo systemctl enable --now snapd.socket
|
||||
|
||||
#### 在 Fedora 上获取 snapd
|
||||
|
||||
运行 snapd 命令
|
||||
运行 snapd 命令:
|
||||
|
||||
```
|
||||
sudo dnf install snapd
|
||||
sudo ln -s /var/lib/snapd/snap /snap
|
||||
@ -53,26 +49,67 @@ sudo ln -s /var/lib/snapd/snap /snap
|
||||
|
||||
#### OpenSUSE 安装 snapd
|
||||
|
||||
执行如下的 `zypper` 命令:
|
||||
|
||||
```
|
||||
### Tumbleweed verson ###
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Tumbleweed/ snappy
|
||||
### Leap version ##
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Leap_42.3/ snappy
|
||||
```
|
||||
|
||||
安装:
|
||||
|
||||
```
|
||||
$ sudo zypper install snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
```
|
||||
|
||||
### 步骤 2 - 在 Linux 上使用 snap 安装 spofity
|
||||
|
||||
执行 snap 命令:
|
||||
`$ snap find spotify`
|
||||
|
||||
```
|
||||
$ snap find spotify
|
||||
```
|
||||
|
||||
[![snap search for spotify app command][4]][4]
|
||||
|
||||
安装它:
|
||||
`$ sudo snap install spotify`
|
||||
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
```
|
||||
|
||||
[![How to install Spotify application on Linux using snap command][5]][5]
|
||||
|
||||
### 步骤 3 - 运行 spotify 并享受它(译注:原博客中就是这么直接跳到 step3 的)
|
||||
### 步骤 3 - 运行 spotify 并享受它
|
||||
|
||||
从 GUI 运行它,或者只需输入:
|
||||
`$ spotify`
|
||||
|
||||
```
|
||||
$ spotify
|
||||
```
|
||||
|
||||
在启动时自动登录你的帐户:
|
||||
|
||||
```
|
||||
$ spotify --username vivek@nixcraft.com
|
||||
$ spotify --username vivek@nixcraft.com --password 'myPasswordHere'
|
||||
```
|
||||
|
||||
在初始化时使用给定的 URI 启动 Spotify 客户端:
|
||||
`$ spotify--uri=<uri>`
|
||||
|
||||
```
|
||||
$ spotify --uri=<uri>
|
||||
```
|
||||
|
||||
以指定的网址启动:
|
||||
`$ spotify--url=<url>`
|
||||
|
||||
```
|
||||
$ spotify --url=<url>
|
||||
```
|
||||
|
||||
[![Spotify client app running on my Ubuntu Linux desktop][6]][6]
|
||||
|
||||
### 关于作者
|
||||
@ -85,7 +122,7 @@ via: https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
搭建私有云:OwnCloud
|
||||
======
|
||||
|
||||
所有人都在讨论云。尽管市面上有很多为我们提供云存储和其他云服务的主要服务商,但是我们还是可以为自己搭建一个私有云。
|
||||
|
||||
在本教程中,我们将讨论如何利用 OwnCloud 搭建私有云。OwnCloud 是一个可以安装在我们 Linux 设备上的 web 应用程序,能够存储和用我们的数据提供服务。OwnCloud 可以分享日历、联系人和书签,共享音/视频流等等。
|
||||
|
||||
本教程中,我们使用的是 CentOS 7 系统,但是本教程同样适用于其他 Linux 发行版中安装 OwnCloud。让我们开始安装 OwnCloud 并且做一些准备工作,
|
||||
|
||||
- 推荐阅读:[如何在 CentOS & RHEL 上使用 Apache 作为反向代理服务器][1]
|
||||
- 同时推荐:[实时 Linux 服务器监测和 GLANCES 监测工具][2]
|
||||
|
||||
### 预备
|
||||
|
||||
* 我们需要在机器上配置 LAMP。参照阅读我们的文章《[在 CentOS/RHEL 上配置 LAMP 服务器最简单的教程][3]》 & 《[在 Ubuntu 搭建 LAMP][4]》。
|
||||
* 我们需要在自己的设备里安装这些包,`php-mysql`、 `php-json`、 `php-xml`、 `php-mbstring`、 `php-zip`、 `php-gd`、 `curl、 `php-curl` 、`php-pdo`。使用包管理器安装它们。
|
||||
|
||||
```
|
||||
$ sudo yum install php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo
|
||||
```
|
||||
|
||||
### 安装
|
||||
|
||||
安装 OwnCloud,我们现在需要在服务器上下载 OwnCloud 安装包。使用下面的命令从官方网站下载最新的安装包(10.0.4-1):
|
||||
|
||||
```
|
||||
$ wget https://download.owncloud.org/community/owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
使用下面的命令解压:
|
||||
|
||||
```
|
||||
$ tar -xvf owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
现在,将所有解压后的文件移动至 `/var/www/html`:
|
||||
|
||||
```
|
||||
$ mv owncloud/* /var/www/html
|
||||
```
|
||||
|
||||
下一步,我们需要在 Apache 的配置文件 `httpd.conf` 上做些修改:
|
||||
|
||||
```
|
||||
$ sudo vim /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
更改下面的选项:
|
||||
|
||||
```
|
||||
AllowOverride All
|
||||
```
|
||||
|
||||
保存该文件,并修改 OwnCloud 文件夹的文件权限:
|
||||
|
||||
```
|
||||
$ sudo chown -R apache:apache /var/www/html/
|
||||
$ sudo chmod 777 /var/www/html/config/
|
||||
```
|
||||
|
||||
然后重启 Apache 服务器执行修改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
```
|
||||
|
||||
现在,我们需要在 MariaDB 上创建一个数据库,保存来自 OwnCloud 的数据。使用下面的命令创建数据库和数据库用户:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
MariaDB [(none)] > create database owncloud;
|
||||
MariaDB [(none)] > GRANT ALL ON owncloud.* TO ocuser@localhost IDENTIFIED BY 'owncloud';
|
||||
MariaDB [(none)] > flush privileges;
|
||||
MariaDB [(none)] > exit
|
||||
```
|
||||
|
||||
服务器配置部分完成后,现在我们可以在网页浏览器上访问 OwnCloud。打开浏览器,输入您的服务器 IP 地址,我这边的服务器是 10.20.30.100:
|
||||
|
||||
![安装 owncloud][7]
|
||||
|
||||
一旦 URL 加载完毕,我们将呈现上述页面。这里,我们将创建管理员用户同时提供数据库信息。当所有信息提供完毕,点击“Finish setup”。
|
||||
|
||||
我们将被重定向到登录页面,在这里,我们需要输入先前创建的凭据:
|
||||
|
||||
![安装 owncloud][9]
|
||||
|
||||
认证成功之后,我们将进入 OwnCloud 面板:
|
||||
|
||||
![安装 owncloud][11]
|
||||
|
||||
我们可以使用手机应用程序,同样也可以使用网页界面更新我们的数据。现在,我们已经有自己的私有云了,同时,关于如何安装 OwnCloud 创建私有云的教程也进入尾声。请在评论区留下自己的问题或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-personal-cloud-install-owncloud/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/apache-as-reverse-proxy-centos-rhel/
|
||||
[2]:http://linuxtechlab.com/linux-server-glances-monitoring-tool/
|
||||
[3]:http://linuxtechlab.com/easiest-guide-creating-lamp-server/
|
||||
[4]:http://linuxtechlab.com/install-lamp-stack-on-ubuntu/
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=400%2C647
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud1-compressor.jpg?resize=400%2C647
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=876%2C541
|
||||
[9]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud2-compressor1.jpg?resize=876%2C541
|
||||
[10]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=981%2C474
|
||||
[11]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud3-compressor1.jpg?resize=981%2C474
|
||||
62
published/20180129 How programmers learn to code.md
Normal file
62
published/20180129 How programmers learn to code.md
Normal file
@ -0,0 +1,62 @@
|
||||
程序员如何学习编码
|
||||
============================================================
|
||||
|
||||
[][8]
|
||||
|
||||
HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程序员询问了他们何时开始编码。
|
||||
|
||||
39,441 名专业人员和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。(LCTT 译注:日期恐有误)
|
||||
|
||||
### 程序员是如何学习的
|
||||
|
||||
报告称,就程序员如何学习编码而言,自学是所有年龄段开发者的常态。
|
||||
|
||||
“尽管 67% 的开发者拥有计算机科学学位,但大约 74% 的人表示他们至少一部分是自学的。”
|
||||
|
||||
开发者平均了解四种语言,但他们想学习更多语言。
|
||||
|
||||
对学习的渴望因人而异 —— 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
|
||||
|
||||
[][5]
|
||||
|
||||
### 程序员想要什么
|
||||
|
||||
HackerRank 还研究了开发者最想从雇主那里得到什么。
|
||||
|
||||
平均而言,良好的工作与生活平衡,紧随其后的是专业成长与学习,是最理想的要求。
|
||||
|
||||
按地区划分的数据显示,美国人比亚洲和欧洲的开发者更渴望工作与生活的平衡。
|
||||
|
||||
学生倾向于将成长和学习列在工作与生活的平衡之上,而专业人员对薪酬的排名比学生高得多。
|
||||
|
||||
在小公司工作的人倾向于降低工作与生活的平衡,但仍处于前三名。
|
||||
|
||||
年龄也制造了不同,25 岁以上的开发者将工作与生活的平衡评为最重要的,而 18 岁至 24 岁的人们则认为其重要性较低。
|
||||
|
||||
HackerRank 说:“在某些方面,我们发现了一个小矛盾。开发人员需要工作与生活的平衡,但他们也渴望学习“。
|
||||
|
||||
它建议,专注于做你喜欢的事情,而不是试图学习一切,这可以帮助实现更好的工作与生活的平衡。
|
||||
|
||||
[][6]
|
||||
|
||||
[][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html
|
||||
|
||||
作者:[Staff Writer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://mybroadband.co.za/news/author/staff-writer
|
||||
[1]:https://mybroadband.co.za/news/author/staff-writer
|
||||
[2]:https://twitter.com/intent/tweet/?text=How+programmers+learn+to+code%20https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html&via=mybroadband
|
||||
[3]:mailto:?subject=How%20programmers%20learn%20to%20code&body=HackerRank%20recently%20published%20the%20results%20of%20its%202018%20Developer%20Skills%20Report.%0A%0Ahttps%3A%2F%2Fmybroadband.co.za%2Fnews%2Fsmartphones%2F246583-how-programmers-learn-to-code.html
|
||||
[4]:https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html#disqus_thread
|
||||
[5]:https://mybroadband.co.za/news/wp-content/uploads/2018/01/HackerRank-2018-how-did-you-learn-to-code.jpg
|
||||
[6]:https://mybroadband.co.za/news/wp-content/uploads/2018/01/HackerRank-2018-what-do-developers-want-most.jpg
|
||||
[7]:https://mybroadband.co.za/news/wp-content/uploads/2018/01/HackerRank-2018-how-to-improve-work-life-balance.jpg
|
||||
[8]:https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html
|
||||
@ -1,223 +1,272 @@
|
||||
Translated by shipsw
|
||||
20 个 OpenSSH 最佳安全实践
|
||||
======
|
||||
|
||||
20 个 OpenSSH 安全实践
|
||||
======
|
||||
![OpenSSH 安全提示][1]
|
||||
|
||||
OpenSSH 是 SSH 协议的一个实现。一般被 scp 或 sftp 用在远程登录、备份、远程文件传输等功能上。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,他主要用在使用公匙加密的服务器验证上。不时出现关于 OpenSSH 零日漏洞的[谣言][2]。本文描述**如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性**。
|
||||
OpenSSH 是 SSH 协议的一个实现。一般通过 `scp` 或 `sftp` 用于远程登录、备份、远程文件传输等功能。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,它最大的优势是使用公匙加密来进行服务器验证。时不时会出现关于 OpenSSH 零日漏洞的[传言][2]。本文将描述如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性。
|
||||
|
||||
|
||||
#### OpenSSH 默认设置
|
||||
### OpenSSH 默认设置
|
||||
|
||||
* TCP 端口 - 22
|
||||
* OpenSSH 服务配置文件 - sshd_config (位于 /etc/ssh/)
|
||||
* TCP 端口 - 22
|
||||
* OpenSSH 服务配置文件 - `sshd_config` (位于 `/etc/ssh/`)
|
||||
|
||||
### 1、 基于公匙的登录
|
||||
|
||||
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 `ssh-keygen` 命令在本地电脑上创建密匙对:
|
||||
|
||||
#### 1. 基于公匙的登录
|
||||
|
||||
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 ssh-keygen 命令在本地电脑上创建密匙对:
|
||||
|
||||
低于 1024 位的 DSA 和 RSA 加密是很弱的,请不要使用。RSA 密匙主要是在考虑 ssh 客户端兼容性的时候代替 ECDSA 密匙使用的。
|
||||
> 1024 位或低于它的 DSA 和 RSA 加密是很弱的,请不要使用。当考虑 ssh 客户端向后兼容性的时候,请使用 RSA密匙代替 ECDSA 密匙。所有的 ssh 密钥要么使用 ED25519 ,要么使用 RSA,不要使用其它类型。
|
||||
|
||||
```
|
||||
$ ssh-keygen -t key_type -b bits -C "comment"
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
|
||||
或
|
||||
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
|
||||
```
|
||||
下一步,使用 ssh-copy-id 命令安装公匙:
|
||||
|
||||
下一步,使用 `ssh-copy-id` 命令安装公匙:
|
||||
|
||||
```
|
||||
$ ssh-copy-id -i /path/to/public-key-file user@host
|
||||
或
|
||||
$ ssh-copy-id user@remote-server-ip-or-dns-name
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-copy-id vivek@rhel7-aws-server
|
||||
```
|
||||
提示输入用户名和密码的时候,使用你自己的 ssh 公匙:
|
||||
`$ ssh vivek@rhel7-aws-server`
|
||||
[![OpenSSH 服务安全最佳实践][3]][3]
|
||||
|
||||
提示输入用户名和密码的时候,确认基于 ssh 公匙的登录是否工作:
|
||||
|
||||
```
|
||||
$ ssh vivek@rhel7-aws-server
|
||||
```
|
||||
|
||||
[![OpenSSH 服务安全最佳实践][3]][3]
|
||||
|
||||
更多有关 ssh 公匙的信息,参照以下文章:
|
||||
|
||||
* [为备份脚本设置无密码安全登录][48]
|
||||
|
||||
* [sshpass: 使用脚本密码登录SSH服务器][49]
|
||||
|
||||
* [如何为一个 Linux/类Unix 系统设置 SSH 登录密匙][50]
|
||||
|
||||
* [如何使用 Ansible 工具上传 ssh 登录授权公匙][51]
|
||||
* [为备份脚本设置无密码安全登录][48]
|
||||
* [sshpass:使用脚本密码登录 SSH 服务器][49]
|
||||
* [如何为一个 Linux/类 Unix 系统设置 SSH 登录密匙][50]
|
||||
* [如何使用 Ansible 工具上传 ssh 登录授权公匙][51]
|
||||
|
||||
|
||||
#### 2. 禁用 root 用户登录
|
||||
### 2、 禁用 root 用户登录
|
||||
|
||||
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 sudo 命令以 root 身份登录。
|
||||
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 `sudo` 命令以 root 身份登录。
|
||||
|
||||
##### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
#### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中][4]:
|
||||
`$ sudo adduser vivek sudo`
|
||||
使用 [id 命令][5] 验证用户组。
|
||||
`$ id vivek`
|
||||
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中][4]:
|
||||
|
||||
##### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
```
|
||||
$ sudo adduser vivek sudo
|
||||
```
|
||||
|
||||
使用 [id 命令][5] 验证用户组。
|
||||
|
||||
```
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
#### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 `usermod` 命令将用户 vivek 添加到 wheel 组中:
|
||||
|
||||
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 uermod 命令将用户 vivek 添加到 wheel 组中:
|
||||
```
|
||||
$ sudo usermod -aG wheel vivek
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
##### 测试 sudo 权限并禁用 ssh root 登录
|
||||
#### 测试 sudo 权限并禁用 ssh root 登录
|
||||
|
||||
测试并确保用户 vivek 可以以 root 身份登录执行以下命令:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
$ sudo /etc/init.d/sshd status
|
||||
$ sudo systemctl status httpd
|
||||
```
|
||||
添加以下内容到 sshd_config 文件中来禁用 root 登录。
|
||||
|
||||
添加以下内容到 `sshd_config` 文件中来禁用 root 登录:
|
||||
|
||||
```
|
||||
PermitRootLogin no
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
```
|
||||
|
||||
更多信息参见“[如何通过禁用 Linux 的 ssh 密码登录来增强系统安全][6]” 。
|
||||
|
||||
#### 3. 禁用密码登录
|
||||
### 3、 禁用密码登录
|
||||
|
||||
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 `sshd_config` 文件中:
|
||||
|
||||
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 sshd_config 文件中:
|
||||
```
|
||||
AuthenticationMethods publickey
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
CentOS 6.x/RHEL 6.x 系统中老版本的 SSHD 用户可以使用以下设置:
|
||||
|
||||
CentOS 6.x/RHEL 6.x 系统中老版本的 sshd 用户可以使用以下设置:
|
||||
|
||||
```
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
#### 4. 限制用户的 ssh 权限
|
||||
### 4、 限制用户的 ssh 访问
|
||||
|
||||
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。然而,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情)等的脚本语言。通过添加以下内容到 `sshd_config` 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
|
||||
|
||||
```
|
||||
AllowUsers vivek jerry
|
||||
```
|
||||
|
||||
当然,你也可以添加以下内容到 `sshd_config` 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
|
||||
|
||||
```
|
||||
DenyUsers root saroj anjali foo
|
||||
```
|
||||
|
||||
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。所以,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情) 等的脚本语言。通过添加以下内容到 sshd_config 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
|
||||
`AllowUsers vivek jerry`
|
||||
当然,你也可以添加以下内容到 sshd_config 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
|
||||
`DenyUsers root saroj anjali foo`
|
||||
你也可以通过[配置 Linux PAM][7] 来禁用或允许用户通过 sshd 登录。也可以允许或禁止一个[用户组列表][8]通过 ssh 登录系统。
|
||||
|
||||
#### 5. 禁用空密码
|
||||
### 5、 禁用空密码
|
||||
|
||||
你需要明确禁止空密码账户远程登录系统,更新 sshd_config 文件的以下内容:
|
||||
`PermitEmptyPasswords no`
|
||||
你需要明确禁止空密码账户远程登录系统,更新 `sshd_config` 文件的以下内容:
|
||||
|
||||
#### 6. 为 ssh 用户或者密匙使用强密码
|
||||
```
|
||||
PermitEmptyPasswords no
|
||||
```
|
||||
|
||||
### 6、 为 ssh 用户或者密匙使用强密码
|
||||
|
||||
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开[字典密码][9]并使用[约翰的开膛手工具][10]来检测弱密码。以下是一个随机密码生成器(放到你的 `~/.bashrc` 下):
|
||||
|
||||
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开字典密码并使用[约翰的开膛手工具][10]来检测弱密码。以下是一个随机密码生成器(放到你的 ~/.bashrc 下):
|
||||
```
|
||||
genpasswd() {
|
||||
local l=$1
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
}
|
||||
```
|
||||
|
||||
运行:
|
||||
`genpasswd 16`
|
||||
输出:
|
||||
运行:
|
||||
|
||||
```
|
||||
genpasswd 16
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
uw8CnDVMwC6vOKgW
|
||||
```
|
||||
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码][52]
|
||||
|
||||
* [Linux / UNIX: 生成密码][53]
|
||||
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码][52]
|
||||
* [Linux / UNIX: 生成密码][53]
|
||||
* [Linux 随机密码生成命令][54]
|
||||
|
||||
* [Linux 随机密码生成命令][54]
|
||||
### 7、 为 SSH 的 22端口配置防火墙
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
你需要更新 `iptables`/`ufw`/`firewall-cmd` 或 pf 防火墙配置来为 ssh 的 TCP 端口 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
|
||||
|
||||
#### 7. 为 SSH 端口 # 22 配置防火墙
|
||||
#### Netfilter(Iptables) 配置
|
||||
|
||||
你需要更新 iptables/ufw/firewall-cmd 或 pf firewall 来为 ssh TCP 端口 # 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
|
||||
更新 [/etc/sysconfig/iptables (Redhat 和其派生系统特有文件) ][11] 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接,输入:
|
||||
|
||||
##### Netfilter (Iptables) 配置
|
||||
|
||||
更新 [/etc/sysconfig/iptables (Redhat和其派生系统特有文件) ][11] 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接, 输入:
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
如果同时使用 IPv6 的话,可以编辑/etc/sysconfig/ip6tables(Redhat 和其派生系统特有文件),输入:
|
||||
如果同时使用 IPv6 的话,可以编辑 `/etc/sysconfig/ip6tables` (Redhat 和其派生系统特有文件),输入:
|
||||
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
将 ipv6network::/ipv6mask 替换为实际的 IPv6 网段。
|
||||
将 `ipv6network::/ipv6mask` 替换为实际的 IPv6 网段。
|
||||
|
||||
##### Debian/Ubuntu Linux 下的 UFW
|
||||
#### Debian/Ubuntu Linux 下的 UFW
|
||||
|
||||
[UFW 是 uncomplicated firewall 的首字母缩写,主要用来管理 Linux 防火墙][12],目的是提供一种用户友好的界面。输入[以下命令使得系统进允许网段 202.54.1.5/29 接入端口 22][13]:
|
||||
`$ sudo ufw allow from 202.54.1.5/29 to any port 22`
|
||||
更多信息请参见 "[Linux: 菜鸟管理员的 25 个 Iptables Netfilter 命令][14]"。
|
||||
[UFW 是 Uncomplicated FireWall 的首字母缩写,主要用来管理 Linux 防火墙][12],目的是提供一种用户友好的界面。输入[以下命令使得系统仅允许网段 202.54.1.5/29 接入端口 22][13]:
|
||||
|
||||
##### *BSD PF 防火墙配置
|
||||
```
|
||||
$ sudo ufw allow from 202.54.1.5/29 to any port 22
|
||||
```
|
||||
|
||||
更多信息请参见 “[Linux:菜鸟管理员的 25 个 Iptables Netfilter 命令][14]”。
|
||||
|
||||
#### *BSD PF 防火墙配置
|
||||
|
||||
如果使用 PF 防火墙 [/etc/pf.conf][15] 配置如下:
|
||||
|
||||
```
|
||||
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
|
||||
```
|
||||
|
||||
#### 8. 修改 SSH 端口和绑定 IP
|
||||
### 8、 修改 SSH 端口和绑定 IP
|
||||
|
||||
ssh 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 `sshd_config` 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
|
||||
|
||||
SSH 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 sshd_config 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
|
||||
```
|
||||
Port 300
|
||||
ListenAddress 192.168.1.5
|
||||
ListenAddress 202.54.1.5
|
||||
```
|
||||
|
||||
端口 300 监听地址 192.168.1.5 监听地址 202.54.1.5
|
||||
|
||||
当需要接受动态广域网地址的连接时,使用主动脚本是个不错的选择,比如 fail2ban 或 denyhosts。
|
||||
|
||||
#### 9. 使用 TCP wrappers (可选的)
|
||||
### 9、 使用 TCP wrappers (可选的)
|
||||
|
||||
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 `/etc/hosts.allow` 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
|
||||
|
||||
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 /etc/hosts.allow 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
|
||||
```
|
||||
sshd : 192.168.1.2 172.16.23.12
|
||||
```
|
||||
|
||||
在 Linux/Mac OS X 和类 UNIX 系统中参见 [TCP wrappers 设置和使用的常见问题][16]。
|
||||
|
||||
#### 10. 阻止 SSH 破解或暴力攻击
|
||||
### 10、 阻止 SSH 破解或暴力攻击
|
||||
|
||||
暴力破解是一种在单一或者分布式网络中使用大量组合(用户名和密码的组合)来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
|
||||
暴力破解是一种在单一或者分布式网络中使用大量(用户名和密码的)组合来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
|
||||
|
||||
* [DenyHosts][17] 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始IP的方式来应对暴力攻击。
|
||||
* RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts][18]。
|
||||
* [Fail2ban][19] 是另一个类似的用来预防针对 SSH 攻击的工具。
|
||||
* [sshguard][20] 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
|
||||
* [security/sshblock][21] 阻止滥用 SSH 尝试登录。
|
||||
* [IPQ BDB filter][22] 可以看做是 fail2ban 的一个简化版。
|
||||
* [DenyHosts][17] 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始 IP 的方式来应对暴力攻击。
|
||||
* RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts][18]。
|
||||
* [Fail2ban][19] 是另一个类似的用来预防针对 SSH 攻击的工具。
|
||||
* [sshguard][20] 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
|
||||
* [security/sshblock][21] 阻止滥用 SSH 尝试登录。
|
||||
* [IPQ BDB filter][22] 可以看做是 fail2ban 的一个简化版。
|
||||
|
||||
### 11、 限制 TCP 端口 22 的传入速率(可选的)
|
||||
|
||||
netfilter 和 pf 都提供速率限制选项可以对端口 22 的传入速率进行简单的限制。
|
||||
|
||||
#### 11. 限制 TCP 端口 # 22 的传入速率 (可选的)
|
||||
|
||||
netfilter 和 pf 都提供速率限制选项可以对端口 # 22 的传入速率进行简单的限制。
|
||||
|
||||
##### Iptables 示例
|
||||
#### Iptables 示例
|
||||
|
||||
以下脚本将会阻止 60 秒内尝试登录 5 次以上的客户端的连入。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
inet_if=eth1
|
||||
ssh_port=22
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
```
|
||||
|
||||
在你的 iptables 脚本中调用以上脚本。其他配置选项:
|
||||
|
||||
```
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
# another one line example
|
||||
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
|
||||
@ -225,9 +274,10 @@ $IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLI
|
||||
|
||||
其他细节参见 iptables 用户手册。
|
||||
|
||||
##### *BSD PF 示例
|
||||
#### *BSD PF 示例
|
||||
|
||||
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒内的连接不超过 15 个。如果客户端触发此规则,则将其加入 abusive_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的连接。
|
||||
|
||||
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒范围的连接不超过 15 个。如果客户端触发此规则则将其加入 abusive_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的状态。
|
||||
```
|
||||
sshd_server_ip = "202.54.1.5"
|
||||
table <abusive_ips> persist
|
||||
@ -235,9 +285,10 @@ block in quick from <abusive_ips>
|
||||
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
|
||||
```
|
||||
|
||||
#### 12. 使用端口敲门 (可选的)
|
||||
### 12、 使用端口敲门(可选的)
|
||||
|
||||
[端口敲门][23]是通过在一组预先指定的封闭端口上生成连接尝试,以便从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
|
||||
|
||||
[端口敲门][23]是通过在一组预先指定的封闭端口上生成连接尝试来从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
|
||||
```
|
||||
$IPT -N stage1
|
||||
$IPT -A stage1 -m recent --remove --name knock
|
||||
@ -257,24 +308,31 @@ $IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j
|
||||
$IPT -A INPUT -p tcp --syn -j door
|
||||
```
|
||||
|
||||
更多信息请参见:
|
||||
|
||||
更多信息请参见:
|
||||
[Debian / Ubuntu: 使用 Knockd and Iptables 设置端口敲门][55]
|
||||
|
||||
#### 13. 配置空闲超时注销时长
|
||||
### 13、 配置空闲超时注销时长
|
||||
|
||||
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 `sshd_config` 并确保配置以下值:
|
||||
|
||||
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 sshd_config 并确保配置以下值:
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户][24]。
|
||||
|
||||
#### 14. 为 ssh 用户启用警示标语
|
||||
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户][24]。
|
||||
|
||||
### 14、 为 ssh 用户启用警示标语
|
||||
|
||||
更新 `sshd_config` 文件如下行来设置用户的警示标语:
|
||||
|
||||
```
|
||||
Banner /etc/issue
|
||||
```
|
||||
|
||||
`/etc/issue 示例文件:
|
||||
|
||||
更新 sshd_config 文件如下来设置用户的警示标语
|
||||
`Banner /etc/issue`
|
||||
/etc/issue 示例文件:
|
||||
```
|
||||
----------------------------------------------------------------------------------------------
|
||||
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
|
||||
@ -297,45 +355,61 @@ or monitoring of the content of privileged communications, or work product, rela
|
||||
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
|
||||
product are private and confidential. See User Agreement for details.
|
||||
----------------------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
以上是一个标准的示例,更多的用户协议和法律细节请咨询你的律师团队。
|
||||
|
||||
#### 15. 禁用 .rhosts 文件 (核实)
|
||||
### 15、 禁用 .rhosts 文件(需核实)
|
||||
|
||||
禁止读取用户的 `~/.rhosts` 和 `~/.shosts` 文件。更新 `sshd_config` 文件中的以下内容:
|
||||
|
||||
```
|
||||
IgnoreRhosts yes
|
||||
```
|
||||
|
||||
禁止读取用户的 ~/.rhosts 和 ~/.shosts 文件。更新 sshd_config 文件中的以下内容:
|
||||
`IgnoreRhosts yes`
|
||||
SSH 可以模拟过时的 rsh 命令,所以应该禁用不安全的 RSH 连接。
|
||||
|
||||
#### 16. 禁用 host-based 授权 (核实)
|
||||
### 16、 禁用基于主机的授权(需核实)
|
||||
|
||||
禁用 host-based 授权,更新 sshd_config 文件的以下选项:
|
||||
`HostbasedAuthentication no`
|
||||
禁用基于主机的授权,更新 `sshd_config` 文件的以下选项:
|
||||
|
||||
#### 17. 为 OpenSSH 和 操作系统打补丁
|
||||
```
|
||||
HostbasedAuthentication no
|
||||
```
|
||||
|
||||
### 17、 为 OpenSSH 和操作系统打补丁
|
||||
|
||||
推荐你使用类似 [yum][25]、[apt-get][26] 和 [freebsd-update][27] 等工具保持系统安装了最新的安全补丁。
|
||||
|
||||
#### 18. Chroot OpenSSH (将用户锁定在主目录)
|
||||
### 18、 Chroot OpenSSH (将用户锁定在主目录)
|
||||
|
||||
默认设置下用户可以浏览诸如 /etc/、/bin 等目录。可以使用 chroot 或者其他专有工具如 [rssh][28] 来保护ssh连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 ChrootDirectory 指令将用户锁定在其主目录,参见[这篇博文][29]。
|
||||
默认设置下用户可以浏览诸如 `/etc`、`/bin` 等目录。可以使用 chroot 或者其他专有工具如 [rssh][28] 来保护 ssh 连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 `ChrootDirectory` 指令将用户锁定在其主目录,参见[这篇博文][29]。
|
||||
|
||||
#### 19. 禁用客户端的 OpenSSH 服务
|
||||
### 19. 禁用客户端的 OpenSSH 服务
|
||||
|
||||
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 ssh 远程登录和文件传输功能的话,可以禁用 sshd 服务。CentOS / RHEL 用户可以使用 [yum 命令][30] 禁用或删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo yum erase openssh-server
|
||||
```
|
||||
|
||||
Debian / Ubuntu 用户可以使用 [apt 命令][31]/[apt-get 命令][32] 删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo apt-get remove openssh-server
|
||||
```
|
||||
|
||||
有可能需要更新 iptables 脚本来移除 ssh 的例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 `/etc/sysconfig/iptables` 和 `/etc/sysconfig/ip6tables`。最后[重启 iptables][33] 服务:
|
||||
|
||||
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 SSH 远程登录和文件传输功能的话,可以禁用 SSHD 服务。CentOS / RHEL 用户可以使用 [yum 命令][30] 禁用或删除openssh-server:
|
||||
`$ sudo yum erase openssh-server`
|
||||
Debian / Ubuntu 用户可以使用 [apt 命令][31]/[apt-get 命令][32] 删除 openssh-server:
|
||||
`$ sudo apt-get remove openssh-server`
|
||||
有可能需要更新 iptables 脚本来移除 ssh 例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 /etc/sysconfig/iptables 和 /etc/sysconfig/ip6tables。最后[重启 iptables][33] 服务:
|
||||
```
|
||||
# service iptables restart
|
||||
# service ip6tables restart
|
||||
```
|
||||
|
||||
#### 20. 来自 Mozilla 的额外提示
|
||||
### 20. 来自 Mozilla 的额外提示
|
||||
|
||||
如果使用 6.7+ 版本的 OpenSSH,可以尝试下[以下设置][34]:
|
||||
|
||||
如果使用 6.7+ 版本的 OpenSSH,可以尝试下以下设置:
|
||||
```
|
||||
#################[ WARNING ]########################
|
||||
# Do not use any setting blindly. Read sshd_config #
|
||||
@ -361,10 +435,11 @@ MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@op
|
||||
LogLevel VERBOSE
|
||||
|
||||
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
```
|
||||
|
||||
使用以下命令获取 OpenSSH 支持的加密方法:
|
||||
|
||||
```
|
||||
$ ssh -Q cipher
|
||||
$ ssh -Q cipher-auth
|
||||
@ -372,15 +447,25 @@ $ ssh -Q mac
|
||||
$ ssh -Q kex
|
||||
$ ssh -Q key
|
||||
```
|
||||
[![OpenSSH安全教程查询密码和算法选择][35]][35]
|
||||
|
||||
#### 如何测试 sshd_config 文件并重启/重新加载 SSH 服务?
|
||||
[![OpenSSH安全教程查询密码和算法选择][35]][35]
|
||||
|
||||
### 如何测试 sshd_config 文件并重启/重新加载 SSH 服务?
|
||||
|
||||
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
|
||||
|
||||
```
|
||||
$ sudo sshd -t
|
||||
```
|
||||
|
||||
扩展测试模式:
|
||||
|
||||
```
|
||||
$ sudo sshd -T
|
||||
```
|
||||
|
||||
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
|
||||
`$ sudo sshd -t`
|
||||
扩展测试模式:
|
||||
`$ sudo sshd -T`
|
||||
最后,根据系统的的版本[重启 Linux 或类 Unix 系统中的 sshd 服务][37]:
|
||||
|
||||
```
|
||||
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
|
||||
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
|
||||
@ -388,25 +473,21 @@ $ doas /etc/rc.d/sshd restart ## OpenBSD##
|
||||
$ sudo service sshd restart ## FreeBSD##
|
||||
```
|
||||
|
||||
#### 其他建议
|
||||
### 其他建议
|
||||
|
||||
1. [使用 2FA 加强 SSH 的安全性][40] - 可以使用[OATH Toolkit][41] 或 [DuoSecurity][42] 启用多重身份验证。
|
||||
2. [基于密匙链的身份验证][43] - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
|
||||
1. [使用 2FA 加强 SSH 的安全性][40] - 可以使用 [OATH Toolkit][41] 或 [DuoSecurity][42] 启用多重身份验证。
|
||||
2. [基于密匙链的身份验证][43] - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
|
||||
|
||||
### 更多信息:
|
||||
|
||||
* [OpenSSH 官方][44] 项目。
|
||||
* 用户手册: sshd(8)、ssh(1)、ssh-add(1)、ssh-agent(1)。
|
||||
|
||||
#### 更多信息:
|
||||
如果知道这里没用提及的方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
|
||||
|
||||
* [OpenSSH 官方][44] 项目.
|
||||
* 用户手册: sshd(8),ssh(1),ssh-add(1),ssh-agent(1)
|
||||
### 关于作者
|
||||
|
||||
|
||||
|
||||
如果你发现一个方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
|
||||
|
||||
#### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][45]、[Facebook][46]、[Google+][47] 上关注他。
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][45]、[Facebook][46]、[Google+][47] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -414,7 +495,7 @@ via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -467,7 +548,7 @@ via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[48]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[49]:https://www.cyberciti.biz/faq/noninteractive-shell-script-ssh-password-provider/
|
||||
[49]:https://linux.cn/article-8086-1.html
|
||||
[50]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[51]:https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/
|
||||
[52]:https://www.cyberciti.biz/faq/generating-random-password/
|
||||
@ -0,0 +1,124 @@
|
||||
在 Linux 上安装必应桌面墙纸更换器
|
||||
======
|
||||
|
||||
你是否厌倦了 Linux 桌面背景,想要设置好看的壁纸,但是不知道在哪里可以找到?别担心,我们在这里会帮助你。
|
||||
|
||||
我们都知道必应搜索引擎,但是由于一些原因很少有人使用它,每个人都喜欢必应网站的背景壁纸,它是非常漂亮和惊人的高分辨率图像。
|
||||
|
||||
如果你想使用这些图片作为你的桌面壁纸,你可以手动下载它,但是很难去每天下载一个新的图片,然后把它设置为壁纸。这就是自动壁纸改变的地方。
|
||||
|
||||
[必应桌面墙纸更换器][1]会自动下载并将桌面壁纸更改为当天的必应照片。所有的壁纸都储存在 `/home/[user]/Pictures/BingWallpapers/`。
|
||||
|
||||
### 方法 1: 使用 Utkarsh Gupta Shell 脚本
|
||||
|
||||
这个小型 Python 脚本会自动下载并将桌面壁纸更改为当天的必应照片。该脚本在机器启动时自动运行,并工作于 GNU/Linux 上的 Gnome 或 Cinnamon 环境。它不需要手动工作,安装程序会为你做所有事情。
|
||||
|
||||
从 2.0+ 版本开始,该脚本的安装程序就可以像普通的 Linux 二进制命令一样工作,它会为某些任务请求 sudo 权限。
|
||||
|
||||
只需克隆仓库并切换到项目目录,然后运行 shell 脚本即可安装必应桌面墙纸更换器。
|
||||
|
||||
```
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
```
|
||||
|
||||
运行 `installer.sh` 使用 `--install` 选项来安装必应桌面墙纸更换器。它会下载并设置必应照片为你的 Linux 桌面。
|
||||
|
||||
```
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: ******
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? :Press Enter
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : y
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : y
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
要卸载该脚本:
|
||||
|
||||
```
|
||||
$ ./installer.sh --uninstall
|
||||
```
|
||||
|
||||
使用帮助页面了解更多关于此脚本的选项。
|
||||
|
||||
```
|
||||
$ ./installer.sh --help
|
||||
```
|
||||
|
||||
### 方法 2: 使用 GNOME Shell 扩展
|
||||
|
||||
这个轻量级 [GNOME shell 扩展][4],可将你的壁纸每天更改为微软必应的壁纸。它还会显示一个包含图像标题和解释的通知。
|
||||
|
||||
该扩展大部分基于 Elinvention 的 NASA APOD 扩展,受到了 Utkarsh Gupta 的 Bing Desktop WallpaperChanger 启发。
|
||||
|
||||
#### 特点
|
||||
|
||||
- 获取当天的必应壁纸并设置为锁屏和桌面墙纸(这两者都是用户可选的)
|
||||
- 可强制选择某个特定区域(即地区)
|
||||
- 为多个显示器自动选择最高分辨率(和最合适的墙纸)
|
||||
- 可以选择在 1 到 7 天之后清理墙纸目录(删除最旧的)
|
||||
- 只有当它们被更新时,才会尝试下载壁纸
|
||||
- 不会持续进行更新 - 每天只进行一次,启动时也要进行一次(更新是在必应更新时进行的)
|
||||
|
||||
#### 如何安装
|
||||
|
||||
访问 [extenisons.gnome.org][5] 网站并将切换按钮拖到 “ON”,然后点击 “Install” 按钮安装必应壁纸 GNOME 扩展。(LCTT 译注:页面上并没有发现 ON 按钮,但是有 Download 按钮)
|
||||
|
||||
![][6]
|
||||
|
||||
安装必应壁纸 GNOME 扩展后,它会自动下载并为你的 Linux 桌面设置当天的必应照片,并显示关于壁纸的通知。
|
||||
|
||||
![][7]
|
||||
|
||||
托盘指示器将帮助你执行少量操作,也可以打开设置。
|
||||
|
||||
![][8]
|
||||
|
||||
根据你的要求自定义设置。
|
||||
|
||||
![][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user