mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
31b47f2b3f
@ -0,0 +1,146 @@
|
||||
如何使用 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
======
|
||||
|
||||
`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行][1] 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新][2]系统补丁或更新呢?
|
||||
|
||||
首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
|
||||
|
||||
### CentOS/RHEL 6.x/7.x 上安装 yum cron
|
||||
|
||||
输入以下 [yum 命令][3]:
|
||||
|
||||
```
|
||||
$ sudo yum install yum-cron
|
||||
```
|
||||
|
||||

|
||||
|
||||
使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
|
||||
在 CentOS/RHEL 6.x 系统中,运行:
|
||||
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||
|
||||

|
||||
|
||||
`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
|
||||
|
||||
### 配置 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
|
||||
使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/yum/yum-cron.conf
|
||||
```
|
||||
|
||||
确保更新可用时自动更新:
|
||||
|
||||
```
|
||||
apply_updates = yes
|
||||
```
|
||||
|
||||
可以设置通知 email 的发件地址。注意: localhost` 将会被 `system_name` 的值代替。
|
||||
|
||||
```
|
||||
email_from = root@localhost
|
||||
```
|
||||
|
||||
列出发送到的 email 地址。
|
||||
|
||||
```
|
||||
email_to = your-it-support@some-domain-name
|
||||
```
|
||||
|
||||
发送 email 信息的主机名。
|
||||
|
||||
```
|
||||
email_host = localhost
|
||||
```
|
||||
|
||||
[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
|
||||
|
||||
```
|
||||
exclude=kernel*
|
||||
```
|
||||
|
||||
RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
|
||||
|
||||
```
|
||||
YUM_PARAMETER=kernel*
|
||||
```
|
||||
|
||||
[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令][7] 查看):
|
||||
|
||||
```
|
||||
$ cat /etc/cron.daily/0yum-daily.cron
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
|
||||
|
||||
```
|
||||
$ man yum-cron
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ [4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
@ -0,0 +1,189 @@
|
||||
Linux 跟踪器之选
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
> Linux 跟踪很神奇!
|
||||
|
||||
<ruby>跟踪器<rt>tracer</rt></ruby>是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
|
||||
|
||||
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
|
||||
|
||||
你喜欢使用哪一个呢?
|
||||
|
||||
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
|
||||
|
||||
### 对于大多数人
|
||||
|
||||
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
|
||||
|
||||
#### 1. 使用 perf_events 进行 CPU 剖析
|
||||
|
||||
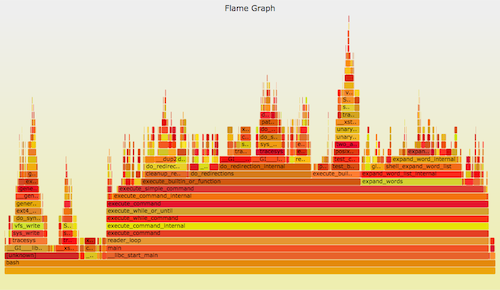
可以使用 perf_events 进行 CPU <ruby>剖析<rt>profiling</rt></ruby>。它可以用一个 [火焰图][3] 来形象地表示。比如:
|
||||
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
```
|
||||
|
||||
|
||||
|
||||
Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
|
||||
|
||||
`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是<ruby>采样<rt>sampling</rt></ruby>。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
|
||||
|
||||
#### 2. 知道它能干什么
|
||||
|
||||
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
|
||||
|
||||
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
|
||||
|
||||
#### 3. 需要一个前端工具
|
||||
|
||||
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
|
||||
|
||||
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
|
||||
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
```
|
||||
|
||||
在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
|
||||
|
||||
### 对于性能或者内核工程师
|
||||
|
||||
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
|
||||
|
||||
在这里我建议选择如下,要么:
|
||||
|
||||
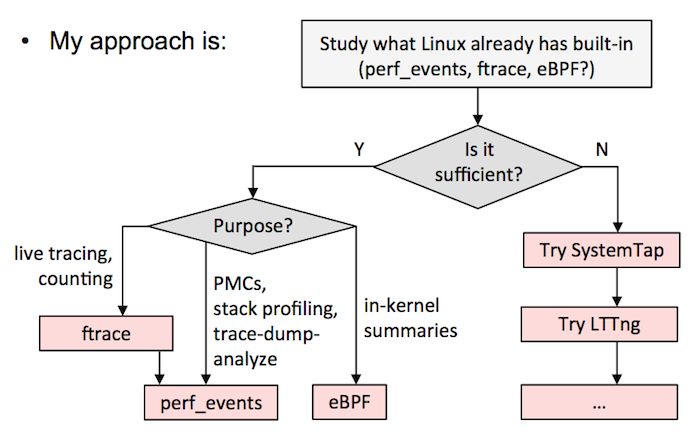
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
|
||||
|
||||
B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
|
||||
|
||||
|
||||
|
||||
以下是我对各个跟踪器的评价:
|
||||
|
||||
#### 1. ftrace
|
||||
|
||||
我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;<ruby>函数流步进<rt>function-flow walking</rt></ruby>。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易<ruby>调校<rt>hackable</rt></ruby>,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是<ruby>可编程的<rt>programmable</rt></ruby>,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
|
||||
|
||||
#### 2. perf_events
|
||||
|
||||
[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用<ruby>调试信息<rt>debuginfo</rt></ruby>进行<ruby>行级跟踪<rt>line tracing</rt></ruby>。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
|
||||
|
||||
#### 3. eBPF
|
||||
|
||||
<ruby>扩展的伯克利包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>(eBPF)是一个<ruby>内核内<rt>in-kernel</rt></ruby>的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供<ruby>内核内编程<rt>in-kernel programming</rt></ruby>,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的<ruby>延迟热力图<rt>latency heat map</rt></ruby>。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
|
||||
|
||||
#### 4. SystemTap
|
||||
|
||||
[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
|
||||
|
||||
#### 5. LTTng
|
||||
|
||||
[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
|
||||
|
||||
#### 6. ktap
|
||||
|
||||
[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
|
||||
|
||||
#### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些<ruby>供应器<rt>provider</rt></ruby>可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
|
||||
|
||||
#### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
|
||||
|
||||
#### 9. sysdig
|
||||
|
||||
[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理<ruby>系统调用<rt>syscall</rt></ruby>事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
|
||||
|
||||
### 深入阅读
|
||||
|
||||
我自己的工作中使用到的跟踪器包括:
|
||||
|
||||
- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
|
||||
- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
|
||||
- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
|
||||
- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
|
||||
- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
|
||||
- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
|
||||
- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
|
||||
- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
|
||||
- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
|
||||
- **其它** : 关于 [strace][46],我写了一些告诫文章。
|
||||
|
||||
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
|
||||
|
||||
感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -0,0 +1,210 @@
|
||||
9 个提高系统运行速度的轻量级 Linux 应用
|
||||
======
|
||||
|
||||
**简介:** [加速 Ubuntu 系统][1]有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序][2],如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
|
||||
|
||||
![在 ubunt 使用轻量级应用程序替代方案][4]
|
||||
|
||||
### 9 个常用 Linux 应用程序的轻量级替代方案
|
||||
|
||||
你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
|
||||
|
||||
所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
|
||||
|
||||
由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
|
||||
|
||||
### 1. Midori: Web 浏览器
|
||||
|
||||
[Midori][8] 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
|
||||
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Midori
|
||||
|
||||
在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
|
||||
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita:电子邮件客户端
|
||||
|
||||
[Trojita][11] 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Trojita
|
||||
|
||||
Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi:包安装程序
|
||||
|
||||
有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
|
||||
|
||||
Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 GDebi
|
||||
|
||||
只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid:软件中心
|
||||
|
||||
如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid][15] 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid 支持应用程序的评分、评论和屏幕截图。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 App Grid
|
||||
|
||||
App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock:音乐播放器
|
||||
|
||||
[Yarock][17] 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
|
||||
|
||||
### 在基于 Ubuntu 的发行版上安装 Yarock
|
||||
|
||||
您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC:视频播放器
|
||||
|
||||
谁不需要视频播放器?谁还从未听说过 [VLC][19]?我想并不需要对它做任何介绍。
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 VLC
|
||||
|
||||
VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM:文件管理器
|
||||
|
||||
PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 PCManFM
|
||||
|
||||
在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
|
||||
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad:文本编辑器
|
||||
|
||||
在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Mousepad
|
||||
|
||||
想要安装 Mousepad ,可以使用以下指令:
|
||||
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office:办公软件
|
||||
|
||||
许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
|
||||
|
||||
**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
在 [Gnome Office][24] 下面还有一些其它应用程序。你可以在官方页面找到它们。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
|
||||
|
||||
要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
|
||||
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:http://trojita.flaska.net/img/2016-03-22-trojita-home.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,18 +1,20 @@
|
||||
使用一个命令重置 Linux 桌面到默认设置
|
||||
使用一个命令重置 Linux 桌面为默认设置
|
||||
======
|
||||
|
||||

|
||||
|
||||
前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
前段时间,我们分享了一篇关于 [Resetter][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
|
||||
### 将 Linux 桌面重置为默认设置
|
||||
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
|
||||
|
||||
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
|
||||
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
@ -29,12 +31,13 @@ dconf reset -f /
|
||||
|
||||
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
|
||||
|
||||
有关 “dconf” 命令的更多详细信息,请参阅手册页。
|
||||
有关 `dconf` 命令的更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
|
||||
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
|
||||
|
||||
@ -48,12 +51,12 @@ via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-comma
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[1]:https://linux.cn/article-9217-1.html
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png
|
||||
@ -0,0 +1,137 @@
|
||||
如何使用 GNU Stow 来管理从源代码安装的程序和点文件
|
||||
=====
|
||||
|
||||
### 目的
|
||||
|
||||
使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:<ruby>点文件<rt>dotfile</rt></ruby>,即以 `.` 开头的文件,在 *nix 下默认为隐藏文件,常用于存储程序的配置信息。)
|
||||
|
||||
### 要求
|
||||
|
||||
* root 权限
|
||||
|
||||
### 难度
|
||||
|
||||
简单
|
||||
|
||||
### 约定
|
||||
|
||||
* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
|
||||
* `$` - 给定的命令将作为普通的非特权用户来执行
|
||||
|
||||
### 介绍
|
||||
|
||||
有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的<ruby>符号链接工厂<rt>symlinks factory</rt></ruby>程序,它可以帮助我们保持文件的整洁,易于维护。
|
||||
|
||||
### 获得 stow
|
||||
|
||||
你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
|
||||
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
在 Ubuntu/Debian 中,安装 `stow` 需要执行:
|
||||
|
||||
```
|
||||
# apt install stow
|
||||
```
|
||||
|
||||
在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
|
||||
|
||||
一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
|
||||
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
最后,安装软件包:
|
||||
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
|
||||
|
||||
此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
|
||||
|
||||
### stow 是如何工作的?
|
||||
|
||||
`stow` 背后主要的概念在程序手册中有很好的解释:
|
||||
|
||||
> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
|
||||
|
||||
为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
|
||||
|
||||
#### stow 文件目录
|
||||
|
||||
stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
|
||||
|
||||
#### stow 软件包
|
||||
|
||||
如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
|
||||
|
||||
#### stow 目标目录
|
||||
|
||||
stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
|
||||
|
||||
### 一个实际的例子
|
||||
|
||||
我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
|
||||
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
|
||||
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
然后我们构建该程序并安装它:
|
||||
|
||||
```
|
||||
$ make
|
||||
# make install
|
||||
```
|
||||
|
||||
`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
|
||||
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
|
||||
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
|
||||
|
||||
stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
|
||||
|
||||
就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,129 @@
|
||||
Linux 容器安全的 10 个层面
|
||||
======
|
||||
|
||||
> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
|
||||
|
||||

|
||||
|
||||
容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。
|
||||
|
||||

|
||||
|
||||
企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
|
||||
|
||||
对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
|
||||
|
||||
请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
|
||||
|
||||
### 1. 容器宿主机操作系统和多租户环境
|
||||
|
||||
由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
|
||||
|
||||
容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux][1])、[cgroups][2] 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),这五种 Linux 的安全特性可以用于保护容器的安全。
|
||||
|
||||
### 2. 容器内容(使用可信来源)
|
||||
|
||||
在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
|
||||
|
||||
### 3. 容器注册(安全访问容器镜像)
|
||||
|
||||
你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
|
||||
|
||||
### 4. 安全性与构建过程
|
||||
|
||||
在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
|
||||
|
||||
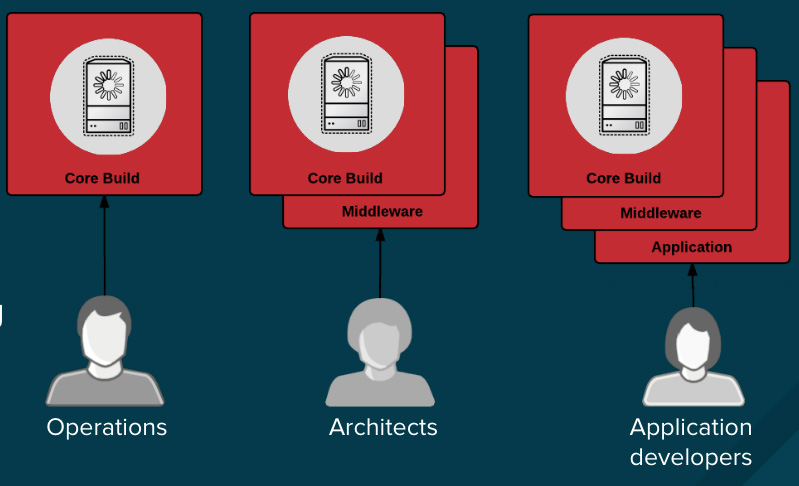
不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
|
||||
|
||||
* 运营团队管理基础镜像
|
||||
* 架构师管理中间件、运行时、数据库,以及其它解决方案
|
||||
* 开发者专注于应用程序层面,并且只写代码
|
||||
|
||||
|
||||
|
||||
最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
|
||||
|
||||
### 5. 控制好在同一个集群内部署应用
|
||||
|
||||
如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
|
||||
|
||||
我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
|
||||
|
||||
一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
|
||||
|
||||
### 6. 容器编配:保护容器平台安全
|
||||
|
||||
当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:
|
||||
|
||||
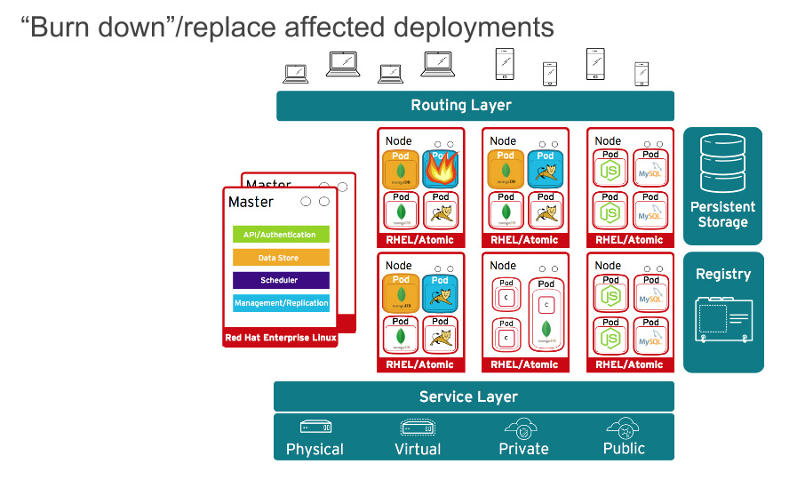
|
||||
|
||||
在大规模的容器部署时,你应该考虑:
|
||||
|
||||
* 哪个容器应该被部署在哪个宿主机上?
|
||||
* 那个宿主机应该有什么样的性能?
|
||||
* 哪个容器需要访问其它容器?它们之间如何发现彼此?
|
||||
* 你如何控制和管理对共享资源的访问,像网络和存储?
|
||||
* 如何监视容器健康状况?
|
||||
* 如何去自动扩展性能以满足应用程序的需要?
|
||||
* 如何在满足安全需求的同时启用开发者的自助服务?
|
||||
|
||||
考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
|
||||
|
||||
### 7. 网络隔离
|
||||
|
||||
在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
|
||||
|
||||
使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
|
||||
|
||||
### 8. 存储
|
||||
|
||||
容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
|
||||
|
||||
一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
|
||||
|
||||
### 9. API 管理、终端安全、以及单点登录(SSO)
|
||||
|
||||
保护你的应用安全,包括管理应用、以及 API 的认证和授权。
|
||||
|
||||
Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
|
||||
|
||||
API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
|
||||
|
||||
这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
|
||||
|
||||
### 10. 在一个联合集群中的角色和访问管理
|
||||
|
||||
在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
|
||||
|
||||
当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
|
||||
|
||||
### 选择一个容器平台
|
||||
|
||||
当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
|
||||
|
||||
想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
|
||||
|
||||
### 关于作者
|
||||
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -1,45 +1,44 @@
|
||||
# 让 “rm” 命令将文件移动到“垃圾桶”,而不是完全删除它们
|
||||
给 “rm” 命令添加个“垃圾桶”
|
||||
============
|
||||
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf * `。当你使用 rm 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 `垃圾箱`。
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
|
||||
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误的删除文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
|
||||
我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
|
||||
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 rm 命令时,可以节省你的时间,但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 **GNOME 、KDE、Unity 或 LXDE** 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 **\$HOME/.local/share/Trash/files**,否则会在您的主目录中创建垃圾箱文件夹 **$HOME/Trash**。
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
|
||||
|
||||
`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
|
||||
|
||||
saferm.sh 脚本托管在 Github 中,可以从 repository 中克隆,也可以创建一个名为 saferm.sh 的文件并复制其上的代码。
|
||||
```
|
||||
$ git clone https://github.com/lagerspetz/linux-stuff
|
||||
$ sudo mv linux-stuff/scripts/saferm.sh /bin
|
||||
$ rm -Rf linux-stuff
|
||||
|
||||
```
|
||||
|
||||
在 `bashrc` 文件中设置别名,
|
||||
在 `.bashrc` 文件中设置别名,
|
||||
|
||||
```
|
||||
alias rm=saferm.sh
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效,
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
一切就绪,现在你可以执行 rm 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行显式的说明了 `Moving magi.txt to $HOME/.local/share/Trash/file`
|
||||
|
||||
```
|
||||
$ rm -rf magi.txt
|
||||
Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
|
||||
```
|
||||
|
||||
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
|
||||
@ -47,47 +46,16 @@ Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
```
|
||||
$ ls -lh /home/magi/.local/share/Trash/files
|
||||
Permissions Size User Date Modified Name
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
```
|
||||
|
||||
或者我们可以通过文件管理器界面中查看相同的内容。
|
||||
|
||||
![![][3]][4]
|
||||
|
||||
创建一个定时任务,每天清理一次“垃圾桶”,( LCTT 注:原文为每周一次,但根据下面的代码,应该是每天一次)
|
||||
(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
|
||||
|
||||
```
|
||||
$ 1 1 * * * trash-empty
|
||||
|
||||
```
|
||||
|
||||
`注意` 对于服务器环境,我们需要使用 rm 命令手动删除。
|
||||
|
||||
```
|
||||
$ rm -rf /root/Trash/
|
||||
/root/Trash/magi1.txt is on . Unsafe delete (y/n)? y
|
||||
Deleting /root/Trash/magi1.txt
|
||||
|
||||
```
|
||||
|
||||
对于桌面环境,trash-put 命令也可以做到这一点。
|
||||
|
||||
在 `bashrc` 文件中创建别名,
|
||||
|
||||
```
|
||||
alias rm=trash-put
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
要了解 saferm.sh 的其他选项,请查看帮助。
|
||||
要了解 `saferm.sh` 的其他选项,请查看帮助。
|
||||
|
||||
```
|
||||
$ saferm.sh -h
|
||||
@ -112,7 +80,7 @@ via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
140
published/20171102 What is huge pages in Linux.md
Normal file
140
published/20171102 What is huge pages in Linux.md
Normal file
@ -0,0 +1,140 @@
|
||||
Linux 中的“大内存页”(hugepage)是个什么?
|
||||
======
|
||||
|
||||
> 学习 Linux 中的<ruby>大内存页<rt>hugepage</rt></ruby>。理解什么是“大内存页”,如何进行配置,如何查看当前状态以及如何禁用它。
|
||||
|
||||
![Huge Pages in Linux][1]
|
||||
|
||||
本文中我们会详细介绍<ruby>大内存页<rt>huge page</rt></ruby>,让你能够回答:Linux 中的“大内存页”是什么?在 RHEL6、RHEL7、Ubuntu 等 Linux 中,如何启用/禁用“大内存页”?如何查看“大内存页”的当前值?
|
||||
|
||||
首先让我们从“大内存页”的基础知识开始讲起。
|
||||
|
||||
### Linux 中的“大内存页”是个什么玩意?
|
||||
|
||||
“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
|
||||
|
||||
在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
|
||||
|
||||
### 为什么使用“大内存页”?
|
||||
|
||||
在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
|
||||
|
||||
使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
|
||||
|
||||
简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
|
||||
|
||||
### 如何配置“大内存页”?
|
||||
|
||||
运行下面命令来查看当前“大内存页”的详细内容。
|
||||
|
||||
```
|
||||
root@kerneltalks # grep Huge /proc/meminfo
|
||||
AnonHugePages: 0 kB
|
||||
HugePages_Total: 0
|
||||
HugePages_Free: 0
|
||||
HugePages_Rsvd: 0
|
||||
HugePages_Surp: 0
|
||||
Hugepagesize: 2048 kB
|
||||
```
|
||||
|
||||
从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`),并且系统中目前有 `0` 个“大内存页”(`HugePages_Total`)。这里“大内存页”的大小可以从 `2MB` 增加到 `1GB`。
|
||||
|
||||
运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#
|
||||
# hugepages_settings.sh
|
||||
#
|
||||
# Linux bash script to compute values for the
|
||||
# recommended HugePages/HugeTLB configuration
|
||||
#
|
||||
# Note: This script does calculation for all shared memory
|
||||
# segments available when the script is run, no matter it
|
||||
# is an Oracle RDBMS shared memory segment or not.
|
||||
# Check for the kernel version
|
||||
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
|
||||
# Find out the HugePage size
|
||||
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
|
||||
# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
|
||||
NUM_PG=1
|
||||
# Cumulative number of pages required to handle the running shared memory segments
|
||||
for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
|
||||
do
|
||||
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
|
||||
if [ $MIN_PG -gt 0 ]; then
|
||||
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
|
||||
fi
|
||||
done
|
||||
# Finish with results
|
||||
case $KERN in
|
||||
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
|
||||
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
|
||||
'2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
|
||||
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
|
||||
esac
|
||||
# End
|
||||
```
|
||||
|
||||
将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
|
||||
|
||||
```
|
||||
root@kerneltalks # sh /tmp/hugepages_settings.sh
|
||||
Recommended setting: vm.nr_hugepages = 124
|
||||
```
|
||||
|
||||
你的输出类似如上结果,只是数字会有一些出入。
|
||||
|
||||
这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
|
||||
|
||||
### 配置内核中的“大内存页”
|
||||
|
||||
本文最后一部分内容是配置上面提到的 [内核参数 ][2] ,然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
|
||||
|
||||
```
|
||||
vm.nr_hugepages=126
|
||||
```
|
||||
|
||||
注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
|
||||
|
||||
现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
|
||||
|
||||
你需要编辑 `/etc/security/limits.conf` 中的如下配置:
|
||||
|
||||
```
|
||||
soft memlock 258048
|
||||
hard memlock 258048
|
||||
```
|
||||
|
||||
某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
|
||||
|
||||
这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
|
||||
|
||||
### 如何禁用“大内存页”?
|
||||
|
||||
“大内存页”默认是开启的。使用下面命令来查看“大内存页”的当前状态。
|
||||
|
||||
```
|
||||
root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
|
||||
[always] madvise never
|
||||
```
|
||||
|
||||
输出中的 `[always]` 标志说明系统启用了“大内存页”。
|
||||
|
||||
若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
|
||||
|
||||
若想禁用“大内存页”,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
|
||||
[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
|
||||
@ -0,0 +1,94 @@
|
||||
如何在 Linux 中配置 ssh 登录导语
|
||||
======
|
||||
|
||||
> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
|
||||
|
||||
![Login banners in Linux][1]
|
||||
|
||||
无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是<ruby>登录导语<rt>login banner</rt></ruby>。
|
||||
|
||||
![Login welcome messages in Linux][2]
|
||||
|
||||
在本文中,我们将引导你配置它们。
|
||||
|
||||
你可以配置两种类型的导语。
|
||||
|
||||
1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
|
||||
2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
|
||||
|
||||
### 如何在用户登录前连接系统时显示消息
|
||||
|
||||
当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
|
||||
|
||||
你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
|
||||
|
||||
```
|
||||
# cat /etc/login.warn
|
||||
!!!! Welcome to KernelTalks test server !!!!
|
||||
This server is meant for testing Linux commands and tools. If you are
|
||||
not associated with kerneltalks.com and not authorized please dis-connect
|
||||
immediately.
|
||||
```
|
||||
|
||||
现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
|
||||
|
||||
这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
|
||||
|
||||
保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
|
||||
|
||||
```
|
||||
root@kerneltalks # ps -ef | grep -i sshd
|
||||
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
|
||||
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
|
||||
|
||||
root@kerneltalks # kill -HUP 14255
|
||||
```
|
||||
|
||||
就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。
|
||||
|
||||
![Login banner in Linux][3]
|
||||
|
||||
你可以在用户输入密码登录系统之前看到此消息。
|
||||
|
||||
### 如何在用户登录后显示消息
|
||||
|
||||
消息用户在成功登录系统后看到的<ruby>当天消息<rt>Message Of The Day</rt></ruby>(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
|
||||
|
||||
```
|
||||
root@kerneltalks # cat /etc/motd
|
||||
W E L C O M E
|
||||
Welcome to the testing environment of kerneltalks.
|
||||
Feel free to use this system for testing your Linux
|
||||
skills. In case of any issues reach out to admin at
|
||||
info@kerneltalks.com. Thank you.
|
||||
|
||||
```
|
||||
|
||||
你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。
|
||||
|
||||
![motd in linux][4]
|
||||
|
||||
你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
|
||||
|
||||
你可以使用 [cowsay][5]、[banner][6]、[figlet][7]、[lolcat][8] 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
|
||||
[2]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
|
||||
[3]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
|
||||
[4]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
|
||||
[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
|
||||
[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
|
||||
[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
|
||||
[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
|
||||
@ -0,0 +1,46 @@
|
||||
如何使用看板(kanban)创建更好的文档
|
||||
======
|
||||
> 通过卡片分类和看板来给用户提供他们想要的信息。
|
||||
|
||||

|
||||
|
||||
如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么再出色的内容也没有用。
|
||||
|
||||
卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在计划在网站或文档中的部分分类标注一些索引卡,并要求用户按照查找信息的方式对卡片进行分类。一个变体是让人们编写自己的菜单标题或内容元素。
|
||||
|
||||
我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当尝试从多个位置的人员获得反馈时,这会更具挑战性。
|
||||
|
||||
我发现[<ruby>看板<rt>kanban</rt></ruby>][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡片进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
|
||||
|
||||
我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品][2]。
|
||||
|
||||
### 怎么运行的
|
||||
|
||||
我最成功的看板体验是在写 [Gluster][3] 文档的时候 —— 这是一个自由开源的可扩展的网络存储文件系统。我需要携带大量随着时间而增长的文档,并将其分成若干类别以创建导航系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
|
||||
|
||||
首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为这些卡片应该组织到的地方,然后给我一个他们认为是理想状态的截图。
|
||||
|
||||
处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
|
||||
|
||||
### 使用数据
|
||||
|
||||
在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
|
||||
|
||||
将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写的培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
|
||||
|
||||
我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/kanban-boards-card-sorting
|
||||
|
||||
作者:[Heidi Waterhouse][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hwaterhouse
|
||||
[1]:https://en.wikipedia.org/wiki/Kanban
|
||||
[2]:https://opensource.com/alternatives/trello
|
||||
[3]:https://www.gluster.org/
|
||||
@ -0,0 +1,78 @@
|
||||
使用 Showterm 录制和分享终端会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
|
||||
|
||||
Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
|
||||
|
||||
**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
|
||||
|
||||
### 在 Linux 中安装 Showterm
|
||||
|
||||
Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
|
||||
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
如果你没有在 Linux 上安装 Ruby,可以这样:
|
||||
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
如果你只是想运行程序而不是安装:
|
||||
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
|
||||
### 录制终端会话
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
|
||||
|
||||
Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
|
||||
在查看录制内容时,还可以通过在 URL 中添加 `#slow`、`#fast` 或 `#stop` 来控制视频的计时。`#slow` 让视频以正常速度播放、`#fast` 是速度加倍、`#stop`,如名称所示,停止播放视频。
|
||||
|
||||
Showterm 终端录制视频可以通过 iframe 轻松嵌入到网页中。这可以通过将 iframe 源添加到 showterm 视频地址来实现,如下所示。
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
作为开源工具,Showterm 允许进一步定制。例如,要运行你自己的 Showterm 服务器,你需要运行以下命令:
|
||||
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此 [GitHub 页面][1]获得。
|
||||
|
||||
### 结论
|
||||
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 —— 只有几千字节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/brunoedoh/
|
||||
[1]:https://github.com/ConradIrwin/showterm
|
||||
[2]:https://www.maketecheasier.com/record-terminal-session-as-video/ (2 Simple Applications That Record Your Terminal Session as Video [Linux])
|
||||
[3]:https://www.maketecheasier.com/record-terminal-session-in-ubuntu/ (How to Record Terminal Session in Ubuntu)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-interface.png (showterm terminal)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-site.png (showtermio)
|
||||
@ -1,32 +1,31 @@
|
||||
在你下一次技术面试的时候要提的 3 个基本问题
|
||||
下一次技术面试时要问的 3 个重要问题
|
||||
======
|
||||
|
||||

|
||||
|
||||
面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Linux 基金会
|
||||
> 面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Dice 和 Linux 基金会的年度[开源工作报告][1]揭示了开源专业人士的前景以及未来一年的招聘活动。在今年的报告中,86% 的科技专业人士表示,了解开源推动了他们的职业生涯。然而,当在他们自己的组织内推进或在别处申请新职位的时候,有这些经历会发生什么呢?
|
||||
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你对我有什么问题吗?”时适当的回答更增添了压力。
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你有什么问题要问吗?”时,适当的回答更增添了压力。
|
||||
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司里雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
|
||||
多年来,我在面试中了解到提出好问题的重要性。这是一个了解你的潜在新雇主的机会,以及更好地了解他们是否与你的技能相匹配。
|
||||
|
||||
这里有三个重要的问题需要以及其重要的原因:
|
||||
这里有三个要问的重要问题,以及其重要的原因:
|
||||
|
||||
**1\. 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?**
|
||||
### 1、 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?
|
||||
|
||||
这个问题的答案会告诉正在面试的公司的很多信息。一般来说,只要它与你在该公司所从事的工作没有冲突,公司会希望技术专家为网站或项目做出贡献。在公司之外允许这种情况,也会在技术组织中培养出一种创业精神,并教授技术技能,否则在正常的日常工作中你可能无法获得这些技能。
|
||||
|
||||
**2\. 项目在这如何分优先级?**
|
||||
### 2、 项目如何区分优先级?
|
||||
|
||||
由于所有的公司都成为了科技公司,所以在创新的客户面对技术项目与改进平台本身之间往往存在着分歧。你会努力保持现有的平台最新么?或者致力于公众开发新产品?根据你的兴趣,答案可以决定公司是否适合你。
|
||||
|
||||
**3\. 谁主要决定新产品,开发者在决策过程中有多少投入?**
|
||||
### 3、 谁主要决定新产品,开发者在决策过程中有多少投入?
|
||||
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来没有困难,但有时会错过这步,意味着在新产品发布之前是协作环境或者混乱的过程。
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来不用多想,但有时会错过这步,意味着在新产品发布之前协作环境的不同或者混乱的过程。
|
||||
|
||||
面试可能会有压力,但是 58% 的公司告诉 Dice 和 Linux 基金会他们需要在未来几个月内聘用开源人才,所以记住高需求会让像你这样的专业人士成为雇员。以你想要的方向引导你的事业。
|
||||
|
||||
@ -38,7 +37,7 @@ via: https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-n
|
||||
|
||||
作者:[Brian Hostetter][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
并发服务器(五):Redis 案例研究
|
||||
======
|
||||
|
||||
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis][10]。
|
||||
|
||||

|
||||
|
||||
Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能、大并发的内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
|
||||
|
||||
我们来看看前四部分讨论的概念在真实世界中的应用程序。
|
||||
|
||||
本系列的所有文章有:
|
||||
|
||||
* [第一节 - 简介][3]
|
||||
* [第二节 - 线程][4]
|
||||
* [第三节 - 事件驱动][5]
|
||||
* [第四节 - libuv][6]
|
||||
* [第五节 - Redis 案例研究][7]
|
||||
|
||||
### 事件处理库
|
||||
|
||||
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用*一个单线程*来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
|
||||
|
||||
Redis 之所以如此牛逼是因为,它在给定的系统上使用了其可用的最快的事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae][11]。ae 使得编写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证 ^注1 了这一点。
|
||||
|
||||
在这里,我们的兴趣点主要是它对*文件事件*的支持 —— 当文件描述符(如网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环(参阅本系列的[第三节][5]和[第四节][6])和不应该感到意外的 `aeCreateFileEvent` 信号:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
它在 `fd` 上使用一个给定的事件循环,为新的文件事件注册一个回调(`proc`)函数。当使用的是 epoll 时,它将调用 `epoll_ctl` 在文件描述符上添加一个事件(可能是 `EPOLLIN`、`EPOLLOUT`、也或许两者都有,取决于 `mask` 参数)。ae 的 `aeProcessEvents` 功能是 “运行事件循环和发送回调函数”,它在底层调用了 `epoll_wait`。
|
||||
|
||||
### 处理客户端请求
|
||||
|
||||
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。`initServer` 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 `acceptTcpHandler` 来调用 `aeCreateFileEvent`。当新的连接可用时,这个回调函数被调用。它调用 `accept` ^注2 ,接下来是 `acceptCommonHandler`,它转而去调用 `createClient` 以初始化新客户端连接所需要的数据结构。
|
||||
|
||||
`createClient` 的工作是去监听来自客户端的入站数据。它将套接字设置为非阻塞模式(一个异步事件循环中的关键因素)并使用 `aeCreateFileEvent` 去注册另外一个文件事件回调函数以读取事件 —— `readQueryFromClient`。每当客户端发送数据,这个函数将被事件循环调用。
|
||||
|
||||
`readQueryFromClient` 就让我们期望的那样 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,所以这个函数必须能够处理 `EAGAIN`,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能被分割在回调函数的多个调用当中。
|
||||
|
||||
### 将数据发送回客户端
|
||||
|
||||
在前面的内容中,我说到了 `readQueryFromClient` 结束了发送给客户端的回复。这在逻辑上是正确的,因为 `readQueryFromClient` *准备*要发送回复,但它不真正去做实质的发送 —— 因为这里并不能保证客户端套接字已经准备好写入/发送数据。我们必须为此使用事件循环机制。
|
||||
|
||||
Redis 是这样做的,它注册一个 `beforeSleep` 函数,每次事件循环即将进入休眠时,调用它去等待套接字变得可以读取/写入。`beforeSleep` 做的其中一件事情就是调用 `handleClientsWithPendingWrites`。它的作用是通过调用 `writeToClient` 去尝试立即发送所有可用的回复;如果一些套接字不可用时,那么*当*套接字可用时,它将注册一个事件循环去调用 `sendReplyToClient`。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——直接发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
|
||||
|
||||
### 为什么 Redis 要实现它自己的事件库?
|
||||
|
||||
在 [第四节][14] 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章][15] 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行他理解的非常透彻的代码;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
|
||||
|
||||
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
|
||||
|
||||
这是我 [前些年在一篇文章中][16] 提到的软件项目依赖关系的另一个很好的示例:
|
||||
|
||||
> 依赖的优势与在软件项目上花费的工作量成反比。
|
||||
|
||||
在某种程度上,Antirez 在他的文章中也提到了这一点。他提到,提供大量附加价值(在我的文章中的“基础” 依赖)的依赖比像 libuv 这样的依赖更有意义(它的例子是 jemalloc 和 Lua),对于 Redis 特定需求,其功能的实现相当容易。
|
||||
|
||||
### Redis 中的多线程
|
||||
|
||||
[在 Redis 的绝大多数历史中][17],它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
|
||||
|
||||
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
|
||||
|
||||
1. “惰性” [内存释放][8]。
|
||||
2. 在后台线程中使用 fsync 调用写一个 [持久化日志][9]。
|
||||
3. 运行需要执行一个长周期运行的操作的用户定义模块。
|
||||
|
||||
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它运行预设数量的线程,每个 Redis 后台作业类型需要一个线程。
|
||||
|
||||
而对于第三个特性,[Redis 模块][18] 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 `src/modules/helloblock.c` 提供了这样的一个示例。
|
||||
|
||||
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节][19] 讨论的工作队列。
|
||||
|
||||
- 注1: Redis 的一个核心部分是:它是一个 _内存中_ 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。
|
||||
- 注2: 使用 `anetAccept`;`anet` 是 Redis 对 TCP 套接字代码的封装。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:https://linux.cn/article-8993-1.html
|
||||
[4]:https://linux.cn/article-9002-1.html
|
||||
[5]:https://linux.cn/article-9117-1.html
|
||||
[6]:https://linux.cn/article-9397-1.html
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:https://linux.cn/article-9397-1.html
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:https://linux.cn/article-9397-1.html
|
||||
@ -0,0 +1,198 @@
|
||||
使用 pelican 和 Github pages 来搭建博客
|
||||
===============================
|
||||
|
||||
今天我将谈一下[我这个博客][a]是如何搭建的。在我们开始之前,我希望你熟悉使用 Github 并且可以搭建一个 Python 虚拟环境来进行开发。如果你不能做到这些,我推荐你去学习一下 [Django Girls 教程][2],它包含以上和更多的内容。
|
||||
|
||||
这是一篇帮助你发布由 Github 托管的个人博客的教程。为此,你需要一个正常的 Github 用户账户 (而不是一个工程账户)。
|
||||
|
||||
你要做的第一件事是创建一个放置代码的 Github 仓库。如果你想要你的博客仅仅指向你的用户名 (比如 rsip22.github.io) 而不是一个子文件夹 (比如 rsip22.github.io/blog),你必须创建一个带有全名的仓库。
|
||||
|
||||
![][3]
|
||||
|
||||
*Github 截图,打开了创建新仓库的菜单,正在以 'rsip22.github.io' 名字创建一个新的仓库*
|
||||
|
||||
我推荐你使用 `README`、用于 Python 的 `.gitignore` 和 [一个自由软件许可证][4] 初始化你的仓库。如果你使用自由软件许可证,你仍然拥有这些代码,但是你使得其他人能从中受益,允许他们学习和复用它,并且更重要的是允许他们享有这些代码。
|
||||
|
||||
既然仓库已经创建好了,那我们就克隆到本机中将用来保存代码的文件夹下:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/YOUR_USERNAME/YOUR_USERNAME.github.io.git
|
||||
```
|
||||
|
||||
并且切换到新的目录:
|
||||
|
||||
```
|
||||
$ cd YOUR_USERNAME.github.io
|
||||
```
|
||||
|
||||
因为 Github Pages 偏好运行的方式是从 master 分支提供文件,你必须将你的源代码放到新的分支,防止 Pelican 产生的静态文件输出到 master 分支。为此,你必须创建一个名为 source 的分支。
|
||||
|
||||
```
|
||||
$ git checkout -b source
|
||||
```
|
||||
|
||||
用你的系统所安装的 Pyhton 3 创建该虚拟环境(virtualenv)。
|
||||
|
||||
在 GNU/Linux 系统中,命令可能如下:
|
||||
|
||||
```
|
||||
$ python3 -m venv venv
|
||||
```
|
||||
|
||||
或者像这样:
|
||||
|
||||
```
|
||||
$ virtualenv --python=python3.5 venv
|
||||
```
|
||||
|
||||
并且激活它:
|
||||
|
||||
```
|
||||
$ source venv/bin/activate
|
||||
```
|
||||
|
||||
在虚拟环境里,你需要安装 pelican 和它的依赖包。你也应该安装 ghp-import (来帮助我们发布到 Github 上)和 Markdown (为了使用 markdown 语法来写文章)。运行如下命令:
|
||||
|
||||
```
|
||||
(venv)$ pip install pelican markdown ghp-import
|
||||
```
|
||||
|
||||
一旦完成,你就可以使用 `pelican-quickstart` 开始创建你的博客了:
|
||||
|
||||
```
|
||||
(venv)$ pelican-quickstart
|
||||
```
|
||||
|
||||
这将会提示我们一系列的问题。在回答它们之前,请看一下如下我的答案:
|
||||
|
||||
```
|
||||
> Where do you want to create your new web site? [.] ./
|
||||
> What will be the title of this web site? Renata's blog
|
||||
> Who will be the author of this web site? Renata
|
||||
> What will be the default language of this web site? [pt] en
|
||||
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
|
||||
> Do you want to enable article pagination? (Y/n) y
|
||||
> How many articles per page do you want? [10] 10
|
||||
> What is your time zone? [Europe/Paris] America/Sao_Paulo
|
||||
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) Y **# PAY ATTENTION TO THIS!**
|
||||
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) n
|
||||
> Do you want to upload your website using FTP? (y/N) n
|
||||
> Do you want to upload your website using SSH? (y/N) n
|
||||
> Do you want to upload your website using Dropbox? (y/N) n
|
||||
> Do you want to upload your website using S3? (y/N) n
|
||||
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
|
||||
> Do you want to upload your website using GitHub Pages? (y/N) y
|
||||
> Is this your personal page (username.github.io)? (y/N) y
|
||||
Done. Your new project is available at /home/username/YOUR_USERNAME.github.io
|
||||
```
|
||||
|
||||
关于时区,应该指定为 TZ 时区(这里是全部列表: [tz 数据库时区列表][5])。
|
||||
|
||||
现在,继续往下走并开始创建你的第一篇博文!你可能想在你喜爱的代码编辑器里打开工程目录并且找到里面的 `content` 文件夹。然后创建一个新文件,它可以被命名为 `my-first-post.md` (别担心,这只是为了测试,以后你可以改变它)。在文章内容之前,应该以元数据开始,这些元数据标识标题、日期、目录及更多,像下面这样:
|
||||
|
||||
```
|
||||
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||
Title: My first post
|
||||
Date: 2017-11-26 10:01
|
||||
Modified: 2017-11-27 12:30
|
||||
Category: misc
|
||||
Tags: first, misc
|
||||
Slug: My-first-post
|
||||
Authors: Your name
|
||||
Summary: What does your post talk about? Write here.
|
||||
|
||||
This is the *first post* from my Pelican blog. **YAY!**
|
||||
```
|
||||
|
||||
让我们看看它长什么样?
|
||||
|
||||
进入终端,产生静态文件并且启动服务器。要这么做,使用下面命令:
|
||||
|
||||
```
|
||||
(venv)$ make html && make serve
|
||||
```
|
||||
|
||||
当这条命令正在运行,你应该可以在你喜爱的 web 浏览器地址栏中键入 `localhost:8000` 来访问它。
|
||||
|
||||
![][6]
|
||||
|
||||
*博客主页的截图。它有一个带有 Renata's blog 标题的头部,第一篇博文在左边,文章的信息在右边,链接和社交在底部*
|
||||
|
||||
相当简洁,对吧?
|
||||
|
||||
现在,如果你想在文章中放一张图片,该怎么做呢?好,首先你在放置文章的内容目录里创建一个目录。为了引用简单,我们将这个目录命名为 `image`。现在你必须让 Pelican 使用它。找到 `pelicanconf.py` 文件,这个文件是你配置系统的地方,并且添加一个包含你的图片目录的变量:
|
||||
|
||||
```
|
||||
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||
STATIC_PATHS = ['images']
|
||||
```
|
||||
|
||||
保存它。打开文章并且以如下方式添加图片:
|
||||
|
||||
```
|
||||
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||

|
||||
```
|
||||
|
||||
你可以在终端中随时按下 `CTRL+C` 来中断服务器。但是你应该再次启动它并检查图片是否正确。你能记住怎么样做吗?
|
||||
|
||||
```
|
||||
(venv)$ make html && make serve
|
||||
```
|
||||
|
||||
在你代码完工之前的最后一步:你应该确保任何人都可以使用 ATOM 或 RSS 流来读你的文章。找到 `pelicanconf.py` 文件,这个文件是你配置系统的地方,并且编辑关于 RSS 流产生的部分:
|
||||
|
||||
```
|
||||
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||
FEED_ALL_ATOM = 'feeds/all.atom.xml'
|
||||
FEED_ALL_RSS = 'feeds/all.rss.xml'
|
||||
AUTHOR_FEED_RSS = 'feeds/%s.rss.xml'
|
||||
RSS_FEED_SUMMARY_ONLY = False
|
||||
```
|
||||
|
||||
保存所有,这样你才可以将代码上传到 Github 上。你可以通过添加所有文件,使用一个信息(“first commit”)来提交它,并且使用 `git push`。你将会被问起你的 Github 登录名和密码。
|
||||
|
||||
```
|
||||
$ git add -A && git commit -a -m 'first commit' && git push --all
|
||||
```
|
||||
|
||||
还有...记住在最开始的时候,我给你说的怎样防止 Pelican 产生的静态文件输出 master 分支吗。现在对你来说是时候产生它们了:
|
||||
|
||||
```
|
||||
$ make github
|
||||
```
|
||||
|
||||
你将会被再次问及 Github 登录名和密码。好了!你的新博客应该创建在 `https://YOUR_USERNAME.github.io`。
|
||||
|
||||
如果你在过程中任何一步遇到一个错误,请重新读一下这篇手册,尝试并看看你是否能发现错误发生的部分,因为这是调试的第一步。有时甚至一些简单的东西比如一个错字或者 Python 中错误的缩进都可以给我们带来麻烦。说出来并向网上或你的社区求助。
|
||||
|
||||
对于如何使用 Markdown 来写文章,你可以读一下 [Daring Fireball Markdown 指南][7]。
|
||||
|
||||
为了获取其它主题,我建议你访问 [Pelican 主题][8]。
|
||||
|
||||
这篇文章改编自 [Adrien Leger 的使用一个 Bottstrap3 主题来搭建由 Github 托管的 Pelican 博客][9]。
|
||||
|
||||
-----------------------------------------------------------
|
||||
|
||||
via: https://rsip22.github.io/blog/create-a-blog-with-pelican-and-github-pages.html
|
||||
|
||||
作者:[rsip22][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rsip22.github.io
|
||||
[1]:https://rsip22.github.io/blog/category/blog.html
|
||||
[2]:https://tutorial.djangogirls.org
|
||||
[3]:https://rsip22.github.io/blog/img/create_github_repository.png
|
||||
[4]:https://www.gnu.org/licenses/license-list.html
|
||||
[5]:https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
|
||||
[6]:https://rsip22.github.io/blog/img/blog_screenshot.png
|
||||
[7]:https://daringfireball.net/projects/markdown/syntax
|
||||
[8]:http://www.pelicanthemes.com/
|
||||
[9]:https://a-slide.github.io/blog/github-pelican
|
||||
@ -1,35 +1,37 @@
|
||||
6 个开源的家庭自动化工具
|
||||
======
|
||||
|
||||
> 用这些开源软件解决方案构建一个更智能的家庭。
|
||||
|
||||

|
||||
|
||||
[物联网][13] 不仅是一个时髦词,在现实中,自 2016 年我们发布了一篇关于家庭自动化工具的评论文章以来,它也在迅速占领着我们的生活。在 2017,[26.5% 的美国家庭][14] 已经使用了一些智能家居技术;预计五年内,这一数字还将翻倍。
|
||||
|
||||
使用数量持续增加的各种设备,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
随着这些数量持续增加的各种设备的使用,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人能够访问它呢?
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 这是一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人访问它呢?
|
||||
|
||||
[对安全的担心][16] 是为什么开源对我们将来使用的互联设备至关重要的众多理由之一。由于源代码运行在他们自己的设备上,完全可以去搞明白控制你的家庭的程序,也就是说你可以查看它的代码,如果必要的话甚至可以去修改它。
|
||||
|
||||
虽然联网设备通常都包含他们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口—— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
虽然联网设备通常都包含它们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口 —— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
|
||||
这里有几个我比较喜欢的。
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] 是一个设计为全栈家庭自动化的平台,包含一个服务器应用程序、触摸屏接口、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
[Calaos][17] 是一个设计为全栈的家庭自动化平台,包含一个服务器应用程序、触摸屏界面、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
|
||||
Calaos 使用的是 [GPL][18] v3 的许可证,你可以在 [GitHub][19] 上查看它的源代码。
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成软件][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
|
||||
Domoticz 是用 C++ 写的,使用 [GPLv3][22] 许可证。它的 [源代码][23] 在 GitHub 上。
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络附加存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源的和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
|
||||
Home Assistant 以 [MIT 许可证][25] 发布,它的源代码可以从 [GitHub][26] 上下载。
|
||||
|
||||
@ -41,26 +43,26 @@ MisterHouse 使用 [GPLv2][28] 许可证,你可以在 [GitHub][29] 上查看
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中大家熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中所熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
|
||||
你可以在 GitHub 上找到 OpenHAB 的 [源代码][31],它使用 [Eclipse 公共许可证][32]。
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便的改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
|
||||
OpenMotics 使用 [GPLv2][35] 许可证,它的源代码可以从 [GitHub][36] 上下载。
|
||||
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是它们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是他们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
|
||||
如果上面的解决方案并不能满足你的需求,下面还有一些潜在的替代者可以去考虑:
|
||||
|
||||
* [EventGhost][1] 是一个开源的([GPL v2][2])家庭影院自动化工具,它只能运行在 Microsoft Windows PC 上。它允许用户去控制多媒体电脑和连接的硬件,它通过触发宏指令的插件或者定制的 Python 脚本来使用。
|
||||
* [ioBroker][3] 是一个基于 JavaScript 的物联网平台,它能够控制灯、锁、空调、多媒体、网络摄像头等等。它可以运行在任何可以运行 Node.js 的硬件上,包括 Windows、Linux、以及 macOS,它使用 [MIT 许可证][4]。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hubs,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hub,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [LinuxMCE][7] 标称它是你的多媒体与电子设备之间的“数字粘合剂”。它运行在 Linux(包括树莓派)上,它基于 Pluto 开源 [许可证][8] 发布,它可以用于家庭安全、电话(VoIP 和语音信箱)、A/V 设备、家庭自动化、以及玩视频游戏。
|
||||
* [OpenNetHome][9],和这一类中的其它解决方案一样,是一个控制灯、报警、应用程序等等的一个开源软件。它基于 Java 和 Apache Maven,可以运行在 Windows、macOS、以及 Linux —— 包括树莓派,它以 [GPLv3][10] 许可证发布。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户接口。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户界面。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
|
||||
现在该轮到你了:你已经准备好家庭自动化系统了吗?或者正在研究去设计一个。你对家庭自动化的新手有什么建议,你会推荐什么样的系统?
|
||||
|
||||
@ -70,7 +72,7 @@ via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
@ -0,0 +1,110 @@
|
||||
在 Linux 中自动配置 IPv6 地址
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 [KVM 中测试 IPv6 网络:第 1 部分][1] 一文中,我们学习了关于<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)的相关内容。在本文中,我们将学习如何为 ULA 自动配置 IP 地址。
|
||||
|
||||
### 何时使用唯一本地地址
|
||||
|
||||
<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)使用 `fd00::/8` 地址块,它类似于我们常用的 IPv4 的私有地址:`10.0.0.0/8`、`172.16.0.0/12`、以及 `192.168.0.0/16`。但它们并不能直接替换。IPv4 的私有地址分类和网络地址转换(NAT)功能是为了缓解 IPv4 地址短缺的问题,这是个明智的解决方案,它延缓了本该被替换的 IPv4 的生命周期。IPv6 也支持 NAT,但是我想不出使用它的理由。IPv6 的地址数量远远大于 IPv4;它是不一样的,因此需要做不一样的事情。
|
||||
|
||||
那么,ULA 存在的意义是什么呢?尤其是在我们已经有了<ruby>本地链路地址<rt>link-local addresses</rt></ruby>(`fe80::/10`)时,到底需不需要我们去配置它们呢?它们之间(LCTT 译注:指的是唯一本地地址和本地链路地址)有两个重要的区别。一是,本地链路地址是不可路由的,因此,你不能跨子网使用它。二是,ULA 是你自己管理的;你可以自己选择它用于子网的地址范围,并且它们是可路由的。
|
||||
|
||||
使用 ULA 的另一个好处是,如果你只是在局域网中“混日子”的话,你不需要为它们分配全局单播 IPv6 地址。当然了,如果你的 ISP 已经为你分配了 IPv6 的<ruby>全局单播地址<rt>global unicast addresses</rt></ruby>,就不需要使用 ULA 了。你也可以在同一个网络中混合使用全局单播地址和 ULA,但是,我想不出这样使用的一个好理由,并且要一定确保你不使用网络地址转换(NAT)以使 ULA 可公共访问。在我看来,这是很愚蠢的行为。
|
||||
|
||||
ULA 是仅为私有网络使用的,并且应该阻止其流出你的网络,不允许进入因特网。这很简单,在你的边界设备上只要阻止整个 `fd00::/8` 范围的 IPv6 地址即可实现。
|
||||
|
||||
### 地址自动配置
|
||||
|
||||
ULA 不像本地链路地址那样自动配置的,但是使用 radvd 设置自动配置是非常容易的,radva 是路由器公告守护程序。在你开始之前,运行 `ifconfig` 或者 `ip addr show` 去查看你现有的 IP 地址。
|
||||
|
||||
在生产系统上使用时,你应该将 radvd 安装在一台单独的路由器上,如果只是测试使用,你可以将它安装在你的网络中的任意 Linux PC 上。在我的小型 KVM 测试实验室中,我使用 `apt-get install radvd` 命令把它安装在 Ubuntu 上。安装完成之后,我先不启动它,因为它还没有配置文件:
|
||||
|
||||
```
|
||||
$ sudo systemctl status radvd
|
||||
● radvd.service - LSB: Router Advertising Daemon
|
||||
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
|
||||
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
|
||||
Docs: man:systemd-sysv-generator(8)
|
||||
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
|
||||
```
|
||||
|
||||
这些所有的消息有点让人困惑,实际上 radvd 并没有运行,你可以使用经典命令 `ps | grep radvd` 来验证这一点。因此,我们现在需要去创建 `/etc/radvd.conf` 文件。拷贝这个示例,将第一行的网络接口名替换成你自己的接口名字:
|
||||
|
||||
```
|
||||
interface ens7 {
|
||||
AdvSendAdvert on;
|
||||
MinRtrAdvInterval 3;
|
||||
MaxRtrAdvInterval 10;
|
||||
prefix fd7d:844d:3e17:f3ae::/64
|
||||
{
|
||||
AdvOnLink on;
|
||||
AdvAutonomous on;
|
||||
};
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
前缀(`prefix`)定义了你的网络地址,它是地址的前 64 位。前两个字符必须是 `fd`,前缀接下来的剩余部分你自己定义它,最后的 64 位留空,因为 radvd 将去分配最后的 64 位。前缀后面的 16 位用来定义子网,剩余的地址定义为主机地址。你的子网必须总是 `/64`。RFC 4193 要求地址必须随机生成;查看 [在 KVM 中测试 IPv6 Networking:第 1 部分][1] 学习创建和管理 ULAs 的更多知识。
|
||||
|
||||
### IPv6 转发
|
||||
|
||||
IPv6 转发必须要启用。下面的命令去启用它,重启后生效:
|
||||
|
||||
```
|
||||
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
|
||||
```
|
||||
|
||||
取消注释或者添加如下的行到 `/etc/sysctl.conf` 文件中,以使它永久生效:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.forwarding = 1
|
||||
```
|
||||
|
||||
启动 radvd 守护程序:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop radvd
|
||||
$ sudo systemctl start radvd
|
||||
```
|
||||
|
||||
这个示例在我的 Ubuntu 测试系统中遇到了一个怪事;radvd 总是停止,我查看它的状态却没有任何问题,做任何改变之后都需要重新启动 radvd。
|
||||
|
||||
启动成功后没有任何输出,并且失败也是如此,因此,需要运行 `sudo systemctl status radvd` 去查看它的运行状态。如果有错误,`systemctl` 会告诉你。一般常见的错误都是 `/etc/radvd.conf` 中的语法错误。
|
||||
|
||||
在 Twitter 上抱怨了上述问题之后,我学到了一件很酷的技巧:当你运行 ` journalctl -xe --no-pager` 去调试 `systemctl` 错误时,你的输出会被换行,然后,你就可以看到错误信息。
|
||||
|
||||
现在检查你的主机,查看它们自动分配的新地址:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
|
||||
[...]
|
||||
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
|
||||
[...]
|
||||
```
|
||||
|
||||
本文到此为止,下周继续学习如何为 ULA 管理 DNS,这样你就可以使用一个合适的主机名来代替这些长长的 IPv6 地址。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的 [“Linux 入门”][2] 免费课程学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,44 +1,47 @@
|
||||
什么是容器?为什么我们关注它?
|
||||
======
|
||||
|
||||

|
||||
|
||||
什么是容器?你需要它们吗?为什么?在这篇文章中,我们会回答这些基本问题。
|
||||
|
||||
但是,为了回答这些问题,我们要提出更多的问题。当你开始考虑怎么用容器适配你的工作时,你需要弄清楚:你在哪开发应用?你在哪测试它?你在哪使用它?
|
||||
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件,扩展包,开发工具,和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产。问题是这三种环境不一定都是一样的;他们没有同样的工具,框架,和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件、扩展包、开发工具和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产环境。问题是这三种环境不一定都是一样的;它们没有同样的工具、框架和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的,独立的,可执行的包,包括了执行它所需要的所有东西:代码,运行环境,系统工具,系统库,设置。”
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。”
|
||||
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发者,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发人员,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
|
||||
### 容器对开发者的好处
|
||||
### 容器对开发人员的好处
|
||||
|
||||
现在开发者或执行者不再需要关注他们要使用什么平台来运行应用。开发者不会再说:“这在我的系统上运行得好好的。”
|
||||
现在开发人员或运维人员不再需要关注他们要使用什么平台来运行应用。开发人员不会再说:“这在我的系统上运行得好好的。”
|
||||
|
||||
容器的另一个重大优势时它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
容器的另一个重大优势是它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
|
||||
这不是虚拟机( VM )所提供的吗?是的,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
这不是虚拟机( VM )所提供的吗?既是,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
|
||||
### 容器对应用生态的好处
|
||||
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经允许公司大规模地运用容器,不管是用于编排,监控,记录,或者生命周期管理。
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经可以让公司大规模地运用容器,不管是用于编排、监控、记录或者生命周期管理。
|
||||
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器空间中不会有任何碎片。
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器领域中不会有任何不一致。
|
||||
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux,Windows,Azure,AWS,Google 计算引擎,Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux、Windows、Azure、AWS、Google 计算引擎、Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
|
||||
### 容器对 CIO 的好处
|
||||
|
||||
容器在开发者中因为以上的原因而变得十分流行,同时他们也给CIO提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
容器在开发人员中因为以上的原因而变得十分流行,同时他们也给 CIO 提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是独立于平台的,有时需要经过几年的努力才能看到生产效果。由于这个生命周期,开发者会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是依赖于平台的,有时几年也不能到达产品阶段。由于这个生命周期,开发人员会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
|
||||
这个过程影响了公司内部的创新文化。当人们几个月甚至几年都不能看到他们的创意被实现时,他们就不再有动力了。
|
||||
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发,测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发、测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
|
||||
### 结论
|
||||
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本属于,然后我们会解释如何开始构建容器。
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本术语,然后我们会解释如何开始构建容器。
|
||||
|
||||
通过 Linux 基金会和 edX 提供的免费的 ["Introduction to Linux" ][4] 课程学习更多 Linux 知识。
|
||||
|
||||
@ -46,9 +49,9 @@
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
|
||||
作者:[wapnil Bhartiya][a]
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
Tlog:录制/播放终端 IO 和会话的工具
|
||||
======
|
||||
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现一个集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 ElasticSearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,它们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 `tlog-rec`、tlog-rec-session` 和 `tlog-play`。
|
||||
|
||||
* `tlog-rec` 工具一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `tlog-rec-session` 工具用于录制整个终端会话的 I/O,包括录制的用户。
|
||||
* `tlog-play` 工具用于回放录制。
|
||||
|
||||
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
|
||||
|
||||
### 安装
|
||||
|
||||
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
|
||||
|
||||
```
|
||||
# yum update
|
||||
```
|
||||
|
||||
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
|
||||
|
||||
```
|
||||
# yum install wget gcc
|
||||
# yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
完成这些安装后,我们可以下载该工具的[源码包][1]并根据需要将其解压到服务器上:
|
||||
|
||||
```
|
||||
# wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
# tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
现在,你可以使用我们通常的配置和编译方法开始构建此工具。
|
||||
|
||||
```
|
||||
# ./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
# make install
|
||||
# ldconfig
|
||||
```
|
||||
|
||||
最后,你需要运行 `ldconfig`。它对命令行中指定目录、`/etc/ld.so.conf` 文件,以及信任的目录( `/lib` 和 `/usr/lib`)中最近的共享库创建必要的链接和缓存。
|
||||
|
||||
### Tlog 工作流程图
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换器(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并在 PTY 中启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
|
||||
### 用法
|
||||
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它,以测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
|
||||
#### 录制到文件中
|
||||
|
||||
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
|
||||
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令会将我们的终端会话录制到名为 `tlog.log` 的文件中,并将其保存在命令中指定的路径中。
|
||||
|
||||
#### 从文件中回放
|
||||
|
||||
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
|
||||
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令从指定的路径读取先前录制的文件 `tlog.log`。
|
||||
|
||||
### 总结
|
||||
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切,并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
|
||||
**关于 Saheetha Shameer (作者)**
|
||||
|
||||
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -0,0 +1,180 @@
|
||||
Ansible:像系统管理员一样思考的自动化框架
|
||||
======
|
||||
|
||||
这些年来,我已经写了许多关于 DevOps 工具的文章,也培训了这方面的人员。尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触 Ansible,我才觉得这才是系统管理员喜欢的东西。
|
||||
|
||||
喜欢的一部分原因是 Ansible 与客户端计算机通信的方式,是通过 SSH 的。作为系统管理员,你们都非常熟悉通过 SSH 连接到计算机,所以从单词“去”的角度来看,相对于其它选择,你更容易理解 Ansible。
|
||||
|
||||
考虑到这一点,我打算写一些文章,探讨如何使用 Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。这并不是学习曲线陡峭。事实上,问题是在开始使用 Ansible 之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible 没有在客户端计算机上安装任何软件),那么您将如何启动?
|
||||
|
||||
### 踏出第一步
|
||||
|
||||
起初 Ansible 对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible 并不关心你如何设置 SSH 系统。它会利用你现有的任何配置。需要考虑以下几件事情:
|
||||
|
||||
1. Ansible 需要通过 SSH 连接到客户端计算机。
|
||||
2. 连接后,Ansible 需要提升权限才能配置系统,安装软件包等等。
|
||||
|
||||
不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。当您在远程计算机上安装代理并使用 Chef 或 Puppet 处理特权升级问题时,似乎感觉就没那么可怕了。 Ansible 并非不安全,而是安全的决定权在你手中。
|
||||
|
||||
接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像 Vagrant 这样的系统,因为尽管 Vagrant 在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
|
||||
|
||||
### 一些 SSH 场景
|
||||
|
||||
#### 1)在 Ansible 配置中,root 用户以密码进入远程计算机。
|
||||
|
||||
拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以 root 身份进行 SSH 登录。默认的配置之所以如此,坦率地说,是因为允许 root 用户远程连接是一个不好的主意。 其次,将 root 密码放在 Ansible 机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可以的,但这是应该避免的。 请记住,Ansible 允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
|
||||
|
||||
#### 2)使用存储在 Ansible 配置中的密码,以普通用户的身份进入远程计算机。
|
||||
|
||||
这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用 SSH,因此 Ansible 应该能够使用用户凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少它不是 root 密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得 sudo 访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
|
||||
|
||||
#### 3)使用具有空密码的密钥对进行身份验证,以普通用户身份进入远程计算机。
|
||||
|
||||
这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
|
||||
|
||||
#### 4)使用通过密码保护的密钥对进行身份验证,以普通用户的身份通过 SSH 连接到远程计算机。
|
||||
|
||||
这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行 Ansible,这可能是理想的设置。 当你运行命令时,Ansible 会提示你输入私钥的密码,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
|
||||
|
||||
#### 5)使用密码保护密钥对进行 SSH 连接,但是使用 ssh-agent “解锁”私钥。
|
||||
|
||||
这并不能完美地解决无人值守、自动化的 Ansible 命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent 程序一次验证密码,然后使用该验证进行后续连接。当我使用 Ansible 时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
|
||||
|
||||
在配置 SSH 环境时还要记住一些其他注意事项。 也许你可以限制 Ansible 用户(通常是你的本地用户),以便它只能从一个特定的 IP 地址登录。 也许您的 Ansible 服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许 Ansible 服务器本身没有安装 SSH 服务器,所以根本没法访问。 同样,Ansible 的优势之一是它使用 SSH 协议进行通信,而且这是一个你用了多年的协议,你已经把你的系统调整到最适合你的环境了。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
|
||||
|
||||
### 权限提升
|
||||
|
||||
一旦您的 Ansible 服务器通过 SSH 连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项 1,那么你已经是 root 了,这是一个有争议的问题。 但是由于没有人选择选项 1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible 支持各种权限提升的系统,但在 Linux 中,最常用的选项是 `sudo` 和 `su`。 和 SSH 一样,有几种情况需要考虑,虽然肯定还有其他选择。
|
||||
|
||||
#### 1)使用 su 提升权限。
|
||||
|
||||
对于 RedHat/CentOS 用户来说,可能默认是使用 `su` 来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了 root 密码,要想获得特殊访问权限,您需要输入该密码。使用 `su` 的问题在于,虽说它可以给了您完全访问远程系统,而您确实也可以完全访问远程系统。 (是的,这是讽刺。)另外,`su` 程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是 root 密码,因此将其存储在配置文件中听起来像、也确实是一个可怕的想法。
|
||||
|
||||
#### 2)使用 sudo 提升权限。
|
||||
|
||||
这就是 Debian/Ubuntu 系统的配置方式。 正常用户组中的用户可以使用 `sudo` 命令并使用 root 权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用 `su` 的一个进步,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入 `sudo` 和 `su -` 都将允许用户成为 root 用户,就像拥有 root 密码一样。)
|
||||
|
||||
#### 3) 使用 sudo 提升权限,并在 sudoers 文件中配置 NOPASSWD。
|
||||
|
||||
再次,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的 root 权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的 SSH 密钥对时,我可以让 Ansible 命令更轻松的自动化。 再次提示,虽然这很方便,但这不是一个非常安全的想法。
|
||||
|
||||
#### 4)使用 sudo 提升权限,并在特定的可执行文件上配置 NOPASSWD。
|
||||
|
||||
这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用 Ansible 做什么,那么你可以为远程用户使用的那些应用程序提供 NOPASSWD 权限。 这可能会让人有些困惑,因为 Ansible 使用 Python 来处理很多事情,但是经过足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
|
||||
|
||||
### 计划实施
|
||||
|
||||
一旦你决定如何处理 Ansible 认证和权限提升,就需要设置它。 在熟悉 Ansible 之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从头开始自动化要好。
|
||||
|
||||
我已经写过关于 SSH 密钥对的文章,网上有无数的设置类的文章。 来自 Ansible 服务器的简短版本看起来像这样:
|
||||
|
||||
```
|
||||
# ssh-keygen
|
||||
# ssh-copy-id -i .ssh/id_dsa.pub remoteuser@remote.computer.ip
|
||||
# ssh remoteuser@remote.computer.ip
|
||||
```
|
||||
|
||||
如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
|
||||
|
||||
为了在 `sudo` 中设置权限提升,您需要编辑 `sudoers` 文件。 你不应该直接编辑文件,而是使用:
|
||||
|
||||
```
|
||||
# sudo visudo
|
||||
```
|
||||
|
||||
这将打开 `sudoers` 文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
|
||||
|
||||
一旦配置完成,您应该在使用 Ansible 之前进行手动测试。 尝试 SSH 到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的方式可以连接,就可以安装 Ansible 了。
|
||||
|
||||
### 安装 Ansible
|
||||
|
||||
由于 Ansible 程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu 系统的软件包安装有点不同,但都不是很困难。
|
||||
|
||||
在 Red Hat/CentOS 中,首先启用 EPEL 库:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo yum install ansible
|
||||
```
|
||||
|
||||
在 Ubuntu 中,首先启用 Ansible PPA:
|
||||
|
||||
```
|
||||
sudo apt-add-repository spa:ansible/ansible
|
||||
(press ENTER to access the key and add the repo)
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install ansible
|
||||
```
|
||||
|
||||
### Ansible 主机文件配置
|
||||
|
||||
Ansible 系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
|
||||
|
||||
```
|
||||
# file /etc/ansible/hosts
|
||||
|
||||
[webservers]
|
||||
blogserver ansible_host=192.168.1.5
|
||||
wikiserver ansible_host=192.168.1.10
|
||||
|
||||
[dbservers]
|
||||
mysql_1 ansible_host=192.168.1.22
|
||||
pgsql_1 ansible_host=192.168.1.23
|
||||
```
|
||||
|
||||
方括号内的部分是指定的组。 单个主机可以列在多个组中,而 Ansible 可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在 `ansible_host` 语句之后添加多个声明。 一些有用的选项是:
|
||||
|
||||
```
|
||||
ansible_ssh_pass
|
||||
ansible_become
|
||||
ansible_become_method
|
||||
ansible_become_user
|
||||
ansible_become_pass
|
||||
```
|
||||
|
||||
### Ansible <ruby>保险库<rt>Vault</rt></ruby>
|
||||
|
||||
(LCTT 译注:Vault 作为 ansible 的一项新功能可将例如密码、密钥等敏感数据文件进行加密,而非明文存放)
|
||||
|
||||
我也应该注意到,尽管安装程序比较复杂,而且这不是在您首次进入 Ansible 世界时可能会做的事情,但该程序确实提供了一种加密保险库中的密码的方法。 一旦您熟悉 Ansible,并且希望将其投入生产,将这些密码存储在加密的 Ansible 保险库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
|
||||
|
||||
### 系统测试
|
||||
|
||||
最后,你应该测试你的系统,以确保客户端可以正常连接。 `ping` 测试将确保 Ansible 计算机可以 `ping` 每个主机:
|
||||
|
||||
```
|
||||
ansible -m ping all
|
||||
```
|
||||
|
||||
运行后,如果 `ping` 成功,您应该看到每个定义的主机显示 `ping` 的消息:`pong`。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
|
||||
|
||||
```
|
||||
ansible -m shell -a 'uptime' webservers
|
||||
```
|
||||
|
||||
您应该可以看到 webservers 组中每个主机的运行时间命令的结果。
|
||||
|
||||
在后续文章中,我计划开始深入 Ansible 管理远程计算机的功能。 我将介绍各种模块,以及如何使用 ad-hoc 模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例 Ansible 命令中获得预期的结果,请花些时间确保身份验证可以工作。 如果遇到困难,请查阅 [Ansible 文档][1]获取更多帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/shawn-powers
|
||||
[1]:http://docs.ansible.com
|
||||
@ -1,83 +1,85 @@
|
||||
如何使用 syslog-ng 从远程 Linux 机器上收集日志
|
||||
======
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
Image: Jack Wallen
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
如果你的数据中心全是 Linux 服务器,而你就是系统管理员。那么你的其中一项工作内容就是查看服务器的日志文件。但是,如果你在大量的机器上去查看日志文件,那么意味着你需要挨个去登入到机器中来阅读日志文件。如果你管理的机器很多,仅这项工作就可以花费你一天的时间。
|
||||
|
||||
另外的选择是,你可以配置一台单独的 Linux 机器去收集这些日志。这将使你的每日工作更加高效。要实现这个目的,有很多的不同系统可供你选择,而 syslog-ng 就是其中之一。
|
||||
|
||||
使用 syslog-ng 的问题是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
syslog-ng 的不足是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 ,将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
现在我们来开始安装和配置。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
安装很简单。为了尽可能容易,我将从标准仓库安装。打开一个终端窗口,运行如下命令:
|
||||
|
||||
```
|
||||
sudo apt install syslog-ng
|
||||
```
|
||||
|
||||
在作为收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
你必须在收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
|
||||
## 配置收集器
|
||||
### 配置收集器
|
||||
|
||||
现在,我们开始日志收集器的配置。它的配置文件是 `/etc/syslog-ng/syslog-ng.conf`。syslog-ng 安装完成时就已经包含了一个配置文件。我们不使用这个默认的配置文件,可以使用 `mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK` 将这个自带的默认配置文件重命名。现在使用 `sudo nano /etc/syslog/syslog-ng.conf` 命令创建一个新的配置文件。在这个文件中添加如下的行:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
```
|
||||
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保你的网络上它可以被访问。
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保在你的网络上它可以被访问。
|
||||
|
||||
保存并关闭这个文件。上面的配置将转存期望的日志文件(由 `system()` 和 `internal()` 指出)到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
|
||||
保存和关闭这个文件。上面的配置将转存期望的日志文件(使用 system() and internal())到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
```
|
||||
sudo mkdir /var/log/syslog-ng
|
||||
sudo touch /var/log/syslog-ng/logs.txt
|
||||
```
|
||||
|
||||
使用如下的命令启动和启用 syslog-ng:
|
||||
|
||||
```
|
||||
sudo systemctl start syslog-ng
|
||||
sudo systemctl enable syslog-ng
|
||||
```
|
||||
|
||||
## 配置为客户端
|
||||
### 配置客户端
|
||||
|
||||
我们将在客户端上做同样的事情(移动默认配置文件并创建新配置文件)。拷贝下列文本到新的客户端配置文件中:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
source s_local { system(); internal(); };
|
||||
destination d_syslog_tcp {
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
log { source(s_local);destination(d_syslog_tcp); };
|
||||
```
|
||||
|
||||
@ -87,11 +89,9 @@ log { source(s_local);destination(d_syslog_tcp); };
|
||||
|
||||
## 查看日志文件
|
||||
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出 ( **Figure A** )。
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出(图 A)。
|
||||
|
||||
**Figure A**
|
||||
|
||||
![Figure A][3]
|
||||
![图 A][3]
|
||||
|
||||
恭喜你!syslog-ng 已经正常工作了。你现在可以登入到你的收集器上查看本地机器和远程客户端的日志了。如果你的数据中心有很多 Linux 服务器,在每台服务器上都安装上 syslog-ng 并配置它们作为客户端发送日志到收集器,这样你就不需要登入到每个机器去查看它们的日志了。
|
||||
|
||||
@ -101,7 +101,7 @@ via: https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-f
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
Linux 下最好的图片截取和视频截录工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 Stack Overflow 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送截图。在 GNOME 中有一些这种类型的程序和 shell 拓展工具。这里介绍的是 Linux 最好的屏幕截图工具,可以供你截取图片或截录视频。
|
||||
|
||||
### 1. Shutter
|
||||
|
||||
[][2]
|
||||
|
||||
[Shutter][3] 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。它也有一个扩展菜单,展示在 GNOME 顶部面板,使得用户进入软件变得更人性化,非常方便使用。
|
||||
|
||||
你可以截取选区、窗口、桌面、当前光标下的窗口、区域、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务商。它同样允许用户在保存截图之前编辑器图片;同时提供了一些可自由添加或移除的插件。
|
||||
|
||||
终端内键入下列命令安装此工具:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:shutter/ppa
|
||||
sudo apt-get update && sudo apt-get install shutter
|
||||
```
|
||||
|
||||
### 2. Vokoscreen
|
||||
|
||||
[][4]
|
||||
|
||||
[Vokoscreen][5] 是一款允许你记录和叙述屏幕活动的一款软件。它易于使用,有一个简洁的界面和顶部面板的菜单,方便用户录制视频。
|
||||
|
||||
你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个选区。自定义记录可以让你轻松得到所需的保存类型,你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,用于你写作教程吸引学习者。记录完成后,你还可以在该应用程序中回放视频记录,这样就不必到处去找你记录的内容。
|
||||
|
||||
[][6]
|
||||
|
||||
你可以从你的发行版仓库安装 Vocoscreen,或者你也可以在 [pkgs.org][7] 选择下载你需要的版本。
|
||||
|
||||
```
|
||||
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
|
||||
```
|
||||
|
||||
### 3. OBS
|
||||
|
||||
[][8]
|
||||
|
||||
[OBS][9] 可以用来录制自己的屏幕亦可用来录制互联网上的流媒体。它允许你看到自己所录制的内容或你叙述的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件进行视频编辑。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
|
||||
|
||||
sudo apt-get update && sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
如果 FFmpeg 安装完成,在终端中键入如下安装 OBS:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:obsproject/obs-studio
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install obs-studio
|
||||
```
|
||||
|
||||
### 4. Green Recorder
|
||||
|
||||
[][10]
|
||||
|
||||
[Green recorder][11] 是一款界面简单的程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是屏幕上的选区,以便于只在自己的记录中保留需要的内容;你还可以自定义最终保存的视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束后的命令运行选项,这样,就可以在视频录制结束后立即运行。
|
||||
|
||||
在终端中键入如下命令来安装 green recorder:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossproject/ppa
|
||||
|
||||
sudo apt update && sudo apt install green-recorder
|
||||
```
|
||||
|
||||
### 5. Kazam
|
||||
|
||||
[][12]
|
||||
|
||||
[Kazam][13] 在几乎所有使用截图工具的 Linux 用户中都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制,也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口安排的非常好,和其它软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
|
||||
|
||||
终端中键入如下命令来安装 Kazam:
|
||||
|
||||
```
|
||||
sudo apt-get install kazam
|
||||
```
|
||||
|
||||
如果没有找到该 PPA,你需要使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kazam-team/stable-series
|
||||
|
||||
sudo apt-get update && sudo apt-get install kazam
|
||||
```
|
||||
|
||||
### 6. GNOME 扩展截屏工具
|
||||
|
||||
[][1]
|
||||
|
||||
GNOME 的一个扩展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它的话。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在调整工具中禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索 “_Screenshot Tool_”,在你的 GNOME 中安装它。
|
||||
|
||||
你需要安装 gnome 扩展的 chrome 扩展组件和 GNOME 调整工具才能使用这个工具。
|
||||
|
||||
[][14]
|
||||
|
||||
当你碰到一个问题,不知道怎么处理,想要在 [Linux 社区][15] 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
|
||||
[3]:http://shutter-project.org/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
|
||||
[5]:https://github.com/vkohaupt/vokoscreen
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
|
||||
[7]:https://pkgs.org/download/vokoscreen
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
|
||||
[9]:https://obsproject.com/
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
|
||||
[11]:https://github.com/foss-project/green-recorder
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
|
||||
[13]:https://launchpad.net/kazam
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
|
||||
@ -1,56 +1,56 @@
|
||||
如何在 Linux 上安装/更新 Intel 微码固件
|
||||
======
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行方式去安装或者更新 Intel/AMD CPU 的微码固件呢?
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行选项去安装或者更新 Intel/AMD CPU 的微码固件?
|
||||
|
||||
|
||||
微码只是由 Intel/AMD 提供的 CPU 固件而已。Linux 的内核可以在系统引导时不需要升级 BIOS 的情况下更新 CPU 的固件。处理器微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的升级微码可以去修复 bug 或者使用补丁来防范 bugs。这篇文章演示了如何使用包管理器去安装 AMD 或者 Intel 微码更新,或者由 lntel 提供的 Linux 上的处理器微码更新。
|
||||
|
||||
## 如何查看当前的微码状态
|
||||
<ruby>微码<rt>microcode</rt></ruby>就是由 Intel/AMD 提供的 CPU 固件。Linux 的内核可以在引导时更新 CPU 固件,而无需 BIOS 更新。处理器的微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的微码的更新可以去修复 bug 或者使用补丁来防范 bug。这篇文章演示了如何使用包管理器或由 lntel 提供的 Linux 处理器微码更新来安装 AMD 或 Intel 的微码更新。
|
||||
|
||||
### 如何查看当前的微码状态
|
||||
|
||||
以 root 用户运行下列命令:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下图这样的:
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下这样的:
|
||||
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 Linux 系统的 x86/amd64 架构的 CPU 上,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:**sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux 用户输入:**sudo yum install microcode_ctl**
|
||||
### 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 x86/amd64 架构的 CPU 上的 Linux 系统,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:`sudo apt install intel-microcode`
|
||||
3. CentOS/RHEL Linux 用户输入:`sudo yum install microcode_ctl`
|
||||
|
||||
对于流行的 Linux 发行版,这个包的名字一般如下 :
|
||||
|
||||
* microcode_ctl 和 linux-firmware —— CentOS/RHEL 微码更新包
|
||||
* intel-microcode —— Debian/Ubuntu 和 clones 发行版适用于 Intel CPU 的微码更新包
|
||||
* amd64-microcode —— Debian/Ubuntu 和 clones 发行版适用于 AMD CPU 的微码固件
|
||||
* linux-firmware —— 适用于 AMD CPU 的 Arch Linux 发行版微码固件(你不用做任何操作,它是默认安装的)
|
||||
* intel-ucode —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* microcode_ctl 和 ucode-intel —— Suse/OpenSUSE Linux 微码更新包
|
||||
* `microcode_ctl` 和 `linux-firmware` —— CentOS/RHEL 微码更新包
|
||||
* `intel-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 Intel CPU 的微码更新包
|
||||
* `amd64-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 AMD CPU 的微码固件
|
||||
* `linux-firmware` —— 适用于 AMD CPU 的 Arch Linux 发行版的微码固件(你不用做任何操作,它是默认安装的)
|
||||
* `intel-ucode` —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* `microcode_ctl` 、`linux-firmware` 和 `ucode-intel` —— Suse/OpenSUSE Linux 微码更新包
|
||||
|
||||
**警告 :在某些情况下,微码更新可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
|
||||
**警告 :在某些情况下,更新微码可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
### 示例
|
||||
#### 示例
|
||||
|
||||
在使用 Intel CPU 的 Debian/Ubuntu Linux 系统上,输入如下的 [apt 命令][2]/[apt-get 命令][3]:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
```
|
||||
$ sudo apt-get install intel-microcode
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -58,11 +58,15 @@
|
||||
|
||||
你 [必须重启服务器以激活微码][5] 更新:
|
||||
|
||||
`$ sudo reboot`
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后检查微码状态:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
```
|
||||
# dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -70,7 +74,6 @@
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 RHEL/CentOS 系统,使用 [yum 命令][6] 尝试去安装或者更新以下两个包:
|
||||
@ -81,13 +84,14 @@ $ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## 如何去更新/安装从 Intel 网站上下载的微码
|
||||
### 如何更新/安装从 Intel 网站上下载的微码
|
||||
|
||||
仅当你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
只有在你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护、更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
|
||||
### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
#### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 `~/Downloads/microcode-20180108.tgz` 的文件(不要忘了去验证它的检验和),它的用途是去防范 `meltdown/Spectre` bug。先使用 `tar` 命令去提取它:
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 ~/Downloads/microcode-20180108.tgz(不要忘了去验证它的检验和),它的用途是去防范 meltdown/Spectre bugs。先使用 tar 命令去提取它:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
@ -101,33 +105,44 @@ $ ls -l
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
检查一下,确保存在 /sys/devices/system/cpu/microcode/reload 目录:
|
||||
> 我只在 CentOS 7.x/RHEL、 7.x/Debian 9.x 和 Ubuntu 17.10 上测试了如下操作。如果你没有找到 `/sys/devices/system/cpu/microcode/reload` 文件的话,更老的发行版所带的更老的内核也许不能使用此方法。参见下面的讨论。请注意,在应用了固件更新之后,有一些客户遇到了系统重启现象。特别是对于[那些运行 Intel Broadwell 和 Haswell CPU][12] 的用于客户机和数据中心服务器上的系统。不要在 Intel Broadwell 和 Haswell CPU 上应用 20180108 版本。尽可能使用软件包管理器方式。
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
检查一下,确保存在 `/sys/devices/system/cpu/microcode/reload`:
|
||||
|
||||
你必须使用 [cp 命令][8] 拷贝 intel-ucode 目录下的所有文件到 /lib/firmware/intel-ucode/ 下面:
|
||||
```
|
||||
$ ls -l /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
你必须使用 [cp 命令][8] 拷贝 `intel-ucode` 目录下的所有文件到 `/lib/firmware/intel-ucode/` 下面:
|
||||
|
||||
你只需要将 intel-ucode 这个目录整个拷贝到 /lib/firmware/ 目录下即可。然后在重新加载接口中写入 1 去重新加载微码文件:
|
||||
```
|
||||
$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/
|
||||
```
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
你只需要将 `intel-ucode` 这个目录整个拷贝到 `/lib/firmware/` 目录下即可。然后在重新加载接口中写入 `1` 去重新加载微码文件:
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时通过内核来加载:
|
||||
```
|
||||
# echo 1 > /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时它能通过内核来加载:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后通过以下的命令验证微码是否已经更新:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
到此为止,就是更新处理器微码的全部步骤。如果一切顺利的话,你的 Intel CPU 的固件将已经是最新的版本了。
|
||||
|
||||
## 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人、一位经验丰富的系统管理员、Linux/Unix 操作系统 shell 脚本培训师。他与全球的包括 IT、教育、国防和空间研究、以及非盈利组织等各行业的客户一起工作。可以在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。
|
||||
|
||||
@ -137,7 +152,7 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -153,3 +168,4 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://newsroom.intel.com/news/intel-security-issue-update-addressing-reboot-issues/
|
||||
@ -1,21 +1,21 @@
|
||||
Partclone - 多功能的分区和克隆免费软件
|
||||
Partclone:多功能的分区和克隆的自由软件
|
||||
======
|
||||
|
||||
|
||||
|
||||
**[Partclone][1]** 是由 **Clonezilla** 开发者开发的免费开源的用于创建和克隆分区镜像的软件。实际上,**Partclone** 是基于 **Clonezilla** 的工具之一。
|
||||
[Partclone][1] 是由 Clonezilla 的开发者们开发的用于创建和克隆分区镜像的自由开源软件。实际上,Partclone 是 Clonezilla 所基于的工具之一。
|
||||
|
||||
它为用户提供了备份与恢复占用的分区块工具,并与多个文件系统的高度兼容,这要归功于它能够使用像 **e2fslibs** 这样的现有库来读取和写入分区,例如 **ext2**。
|
||||
它为用户提供了备份与恢复已用分区的工具,并与多个文件系统高度兼容,这要归功于它能够使用像 e2fslibs 这样的现有库来读取和写入分区,例如 ext2。
|
||||
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs +、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs+、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
|
||||
它还有许多的程序,包括 **partclone.ext2**ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
它还有许多的程序,包括 partclone.ext2(ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
|
||||
### Partclone中的功能
|
||||
|
||||
* **免费软件:** **Partclone**免费供所有人下载和使用。
|
||||
* **开源:** **Partclone**是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* **跨平台**:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 免费软件: Partclone 免费供所有人下载和使用。
|
||||
* 开源: Partclone 是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* 跨平台:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 一个在线的[文档页面][3],你可以从中查看帮助文档并跟踪其 GitHub 问题。
|
||||
* 为初学者和专业人士提供的在线[用户手册][4]。
|
||||
* 支持救援。
|
||||
@ -25,55 +25,53 @@ Partclone - 多功能的分区和克隆免费软件
|
||||
* 支持 raw 克隆。
|
||||
* 显示传输速率和持续时间。
|
||||
* 支持管道。
|
||||
* 支持 crc32。
|
||||
* 支持 crc32 校验。
|
||||
* 支持 ESX vmware server 的 vmfs 和 FreeBSD 的文件系统 ufs。
|
||||
|
||||
Partclone 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
|
||||
**Partclone** 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
[下载 Linux 中的 Partclone][6]
|
||||
- [下载 Linux 中的 Partclone][6]
|
||||
|
||||
### 如何安装和使用 Partclone
|
||||
|
||||
在 Linux 上安装 Partclone。
|
||||
|
||||
```
|
||||
$ sudo apt install partclone [On Debian/Ubuntu]
|
||||
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
```
|
||||
|
||||
克隆分区为镜像。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
|
||||
|
||||
```
|
||||
|
||||
将镜像恢复到分区。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
分区到分区克隆。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
|
||||
|
||||
```
|
||||
|
||||
显示镜像信息。
|
||||
|
||||
```
|
||||
# partclone.info -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
检查镜像。
|
||||
|
||||
```
|
||||
# partclone.chkimg -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
你是 **Partclone** 的用户吗?我最近在 [**Deepin Clone**][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
你是 Partclone 的用户吗?我最近在 [Deepin Clone][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
|
||||
请在下面的评论区与我们分享你的想法和建议。
|
||||
|
||||
@ -81,13 +79,13 @@ $ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts;Peter Beck;Martins Divine Okoi][a]
|
||||
作者:[Martins D. Okoi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://partclone.org/
|
||||
[2]:https://github.com/Thomas-Tsai/partclone
|
||||
[3]:https://partclone.org/help/
|
||||
224
published/20180116 Analyzing the Linux boot process.md
Normal file
224
published/20180116 Analyzing the Linux boot process.md
Normal file
@ -0,0 +1,224 @@
|
||||
Linux 启动过程分析
|
||||
======
|
||||
|
||||
> 理解运转良好的系统对于处理不可避免的故障是最好的准备。
|
||||
|
||||

|
||||
|
||||
*图片由企鹅和靴子“赞助”,由 Opensource.com 修改。CC BY-SA 4.0。*
|
||||
|
||||
关于开源软件最古老的笑话是:“代码是<ruby>自具文档化的<rt>self-documenting</rt></ruby>”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个功能正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
|
||||
|
||||
从某些方面看,启动过程非常简单。内核在单核上以单线程和同步状态启动,似乎可以理解。但内核本身是如何启动的呢?[initrd(initial ramdisk)][1] 和<ruby>引导程序<rt>bootloader</rt></ruby>具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
|
||||
|
||||
请继续阅读寻找答案。在 GitHub 上也提供了 [介绍演示和练习的代码][2]。
|
||||
|
||||
### 启动的开始:OFF 状态
|
||||
|
||||
#### <ruby>局域网唤醒<rt>Wake-on-LAN</rt></ruby>
|
||||
|
||||
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用了局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
|
||||
|
||||
```
|
||||
# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
其中 `<interface name>` 是网络接口的名字,比如 `eth0`。(`ethtool` 可以在同名的 Linux 软件包中找到。)如果输出中的 `Wake-on` 显示 `g`,则远程主机可以通过发送 [<ruby>魔法数据包<rt>MagicPacket</rt></ruby>][3] 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
|
||||
|
||||
```
|
||||
# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 [<ruby>底板管理控制器<rt>Baseboard Management Controller</rt></ruby>][4](BMC)。
|
||||
|
||||
#### 英特尔管理引擎、平台控制器单元和 Minix
|
||||
|
||||
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,它开启了如 KVM 远程控制和英特尔功能许可服务等 [功能][5]。根据 [Intel 自己的检测工具][7],[IME 存在尚未修补的漏洞][6]。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 [me_cleaner 项目][8],它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
|
||||
|
||||
IME 固件和<ruby>系统管理模式<rt>System Management Mode</rt></ruby>(SMM)软件是 [基于 Minix 操作系统][9] 的,并运行在单独的<ruby>平台控制器单元<rt>Platform Controller Hub</rt></ruby>上(LCTT 译注:即南桥芯片),而不是主 CPU 上。然后,SMM 启动位于主处理器上的<ruby>通用可扩展固件接口<rt>Universal Extensible Firmware Interface</rt></ruby>(UEFI)软件,相关内容 [已被提及多次][10]。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 [<ruby>非扩展性缩减版固件<rt>Non-Extensible Reduced Firmware</rt></ruby>][11](NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 [禁用了 IME][12] 的笔记本电脑,另外 [带有 ARM 64 位处理器笔记本电脑][13] 还是值得期待的。
|
||||
|
||||
#### 引导程序
|
||||
|
||||
除了启动那些问题不断的间谍软件外,早期引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供通用操作系统(如 Linux)所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 闪存和 NAND 闪存。引导程序还与 [<ruby>可信平台模块<rt>Trusted Platform Module</rt></ruby>][14](TPM)等硬件安全设备进行交互,在启动最开始建立信任链。
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
*在构建主机上的沙盒中运行 U-boot 引导程序。*
|
||||
|
||||
包括树莓派、任天堂设备、汽车主板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 [U-Boot][17]。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续集成(CI)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
|
||||
|
||||
```
|
||||
# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
# make ARCH=sandbox defconfig
|
||||
# make; ./u-boot
|
||||
=> printenv
|
||||
=> help
|
||||
```
|
||||
|
||||
在 x86_64 上运行 U-Boot,可以测试一些棘手的功能,如 [模拟存储设备][2] 的重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 `Ctrl + C` 恢复一个“变砖”的沙盒。
|
||||
|
||||
### 启动内核
|
||||
|
||||
#### 配置引导内核
|
||||
|
||||
引导程序完成任务后将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 `file /boot/vmlinuz` 可以看到它是一个 “bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— [extract-vmlinux][18]:
|
||||
|
||||
```
|
||||
# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
# file vmlinux
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
内核是一个 [<ruby>可执行与可链接格式<rt> Executable and Linking Format</rt></ruby>][19](ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 `binutils` 包中的命令,如 `readelf` 来检查它。比较一下输出,例如:
|
||||
|
||||
```
|
||||
# readelf -S /bin/date
|
||||
# readelf -S vmlinux
|
||||
```
|
||||
|
||||
这两个二进制文件中的段内容大致相同。
|
||||
|
||||
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 `main()` 函数中?并不确切。
|
||||
|
||||
在 `main()` 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 `stdio`、`stdout` 和 `stderr` 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用 “glibc”)中获取这些资源。参照以下输出:
|
||||
|
||||
```
|
||||
# file /bin/date
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 `#!` 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 `_start()` 函数来用所需资源 [配置一个二进制文件][20],这个函数可以从 glibc 源代码包中找到,可以 [用 GDB 查看][21]。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
|
||||
|
||||
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个<ruby>未剥离的<rt>unstripped</rt></ruby> vmlinux,例如 `apt-get install linux-image-amd64-dbg`,或者从源代码编译和安装你自己的内核,可以参照 [Debian Kernel Handbook][22] 中的指令。`gdb vmlinux` 后加 `info files` 可显示 ELF 段 `init.text`。在 `init.text` 中用 `l *(address)` 列出程序执行的开头,其中 `address` 是 `init.text` 的十六进制开头。用 GDB 可以看到 x86_64 内核从内核文件 [arch/x86/kernel/head_64.S][23] 开始启动,在这个文件中我们找到了汇编函数 `start_cpu0()`,以及一段明确的代码显示在调用 `x86_64 start_kernel()` 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 [arch/arm/kernel/head.S][24]。`start_kernel()` 不针对特定的体系结构,所以这个函数驻留在内核的 [init/main.c][25] 中。`start_kernel()` 可以说是 Linux 真正的 `main()` 函数。
|
||||
|
||||
### 从 start_kernel() 到 PID 1
|
||||
|
||||
#### 内核的硬件清单:设备树和 ACPI 表
|
||||
|
||||
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法:[<ruby>设备树<rt>device-tree</rt></ruby>][26] 和 [高级配置和电源接口(ACPI)表][27]。内核通过读取这些文件了解每次启动时需要运行的硬件。
|
||||
|
||||
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 `vmlinux` 一样位于 `/boot` 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 `/boot/*.dtb` 匹配的文件执行 `binutils` 包中的 `strings` 命令即可,这里 `dtb` 是指<ruby>设备树二进制文件<rt>device-tree binary</rt></ruby>。显然,只需编辑构成它的类 JSON 的文件并重新运行随内核源代码提供的特殊 `dtc` 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 [设备树覆盖][28] 的功能,内核在启动后可以动态加载热插拔的附加设备。
|
||||
|
||||
x86 系列和许多企业级的 ARM64 设备使用 [ACPI][27] 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 `/sys/firmware/acpi/tables` 虚拟文件系统中。读取 ACPI 表的简单方法是使用 `acpica-tools` 包中的 `acpidump` 命令。例如:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
*联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。*
|
||||
|
||||
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 `acpi_listen` 命令(在 `apcid` 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 [覆盖 ACPI 表][31] 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 [安装 coreboot][32],这是开源固件的替代品。
|
||||
|
||||
#### 从 start_kernel() 到用户空间
|
||||
|
||||
[init/main.c][25] 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 `dmesg | head`,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 `timekeeping_init()` 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,`dmesg` 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 `rest_init()` 中,该函数在终止时由 `start_kernel()` 调用。
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
*早期的内核启动流程。*
|
||||
|
||||
函数 `rest_init()` 产生了一个新进程以运行 `kernel_init()`,并调用了 `do_initcalls()`。用户可以通过将 `initcall_debug` 附加到内核命令行来监控 `initcalls`,这样每运行一次 `initcall` 函数就会产生 一个 `dmesg` 条目。`initcalls` 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。`initcalls` 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。`rest_init()` 也会在引导处理器上产生第二个线程,它首先运行 `cpu_idle()`,然后等待调度器分配工作。
|
||||
|
||||
`kernel_init()` 也可以 [设置对称多处理(SMP)结构][35]。在较新的内核中,如果 `dmesg` 的输出中出现 “Bringing up secondary CPUs...” 等字样,系统便使用了 SMP。SMP 通过“热插拔” CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个<ruby>核<rt>core</rt></ruby>离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 [BCC 工具][36] 称为 `offcputime.py`。
|
||||
|
||||
请注意,`init/main.c` 中的代码在 `smp_init()` 运行时几乎已执行完毕:引导处理器已经完成了大部分一次性初始化操作,其它核无需重复。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 `ps -o psr` 命令可以查看服务每个 CPU 上的线程的 softirqs 和 workqueues。
|
||||
|
||||
```
|
||||
# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
PID PSR COMMAND
|
||||
7 0 ksoftirqd/0
|
||||
16 1 ksoftirqd/1
|
||||
22 2 ksoftirqd/2
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
# ps -o pid,psr,comm $(pgrep kworker)
|
||||
PID PSR COMMAND
|
||||
4 0 kworker/0:0H
|
||||
18 1 kworker/1:0H
|
||||
24 2 kworker/2:0H
|
||||
30 3 kworker/3:0H
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
其中,PSR 字段代表“<ruby>处理器<rt>processor</rt></ruby>”。每个核还必须拥有自己的定时器和 `cpuhp` 热插拔处理程序。
|
||||
|
||||
那么用户空间是如何启动的呢?在最后,`kernel_init()` 寻找可以代表它执行 `init` 进程的 `initrd`。如果没有找到,内核直接执行 `init` 本身。那么为什么需要 `initrd` 呢?
|
||||
|
||||
#### 早期的用户空间:谁规定要用 initrd?
|
||||
|
||||
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 `initrd` 的路径。`initrd` 通常位于 `/boot` 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 `initramfs-tools-core` 软件包中的 `lsinitramfs` 工具可以列出 `initrd` 的内容。发行版的 `initrd` 方案包含了最小化的 `/bin`、`/sbin` 和 `/etc` 目录以及内核模块,还有 `/scripts` 中的一些文件。所有这些看起来都很熟悉,因为 `initrd` 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 `/bin` 和 `/sbin` 目录下的所有可执行文件几乎都是指向 [BusyBox 二进制文件][38] 的符号链接,由此导致 `/bin` 和 `/sbin` 目录比 glibc 的小 10 倍。
|
||||
|
||||
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 `init`,为什么还要创建一个 `initrd` 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 `/lib/modules` 的内核模块,当然还有 `initrd` 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 `initrd` 中。`initrd` 基本上包含了任何挂载根文件系统所必需的非内核代码。`initrd` 也是用户存放 [自定义ACPI][38] 表代码的地方。
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
*救援模式的 shell 和自定义的 `initrd` 还是很有意思的。*
|
||||
|
||||
`initrd` 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 `initrd` 中,并从内存中运行测试,而不是从被测对象中运行。
|
||||
|
||||
最后,当 `init` 开始运行时,系统就启动啦!由于第二个处理器现在在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,`ps -o pid,psr,comm -p 1` 很容易显示用户空间的 `init` 进程已不在引导处理器上运行了。
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 引导过程听起来或许令人生畏,即使是简单嵌入式设备上的软件数量也是如此。但换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
|
||||
|
||||
要了解更多信息,请参阅 Alison Chaiken 的演讲——[Linux: The first second][41],已于 1 月 22 日至 26 日在悉尼举行。参见 [linux.conf.au][42]。
|
||||
|
||||
感谢 [Akkana Peck][43] 的提议和指正。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&amp;amp;amp;amp;amp;index=65&amp;amp;amp;amp;amp;list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&amp;amp;amp;amp;amp;languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png "Running the U-boot bootloader"
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png "ACPI tables on Lenovo laptops"
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png "Summary of early kernel boot process."
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png "Rescue shell and a custom <code>initrd</code>."
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
@ -1,4 +1,4 @@
|
||||
SPARTA —— 用于网络渗透测试的 GUI 工具套件
|
||||
SPARTA:用于网络渗透测试的 GUI 工具套件
|
||||
======
|
||||
|
||||

|
||||
@ -7,12 +7,11 @@ SPARTA 是使用 Python 开发的 GUI 应用程序,它是 Kali Linux 内置的
|
||||
|
||||
SPARTA GUI 工具套件最擅长的事情是扫描和发现目标端口和运行的服务。
|
||||
|
||||
因此,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
此外,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
延伸阅读:[网络渗透检查清单][1]
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
请从 GitHub 上克隆最新版本的 SPARTA:
|
||||
|
||||
@ -21,64 +20,58 @@ git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
|
||||
或者,从 [这里][2] 下载最新版本的 Zip 文件。
|
||||
|
||||
```
|
||||
cd /usr/share/
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
将 "sparta" 文件放到 /usr/bin/ 目录下并赋于可运行权限。
|
||||
|
||||
将 `sparta` 文件放到 `/usr/bin/` 目录下并赋于可运行权限。
|
||||
|
||||
在任意终端中输入 'sparta' 来启动应用程序。
|
||||
|
||||
### 网络渗透测试的范围
|
||||
|
||||
## 网络渗透测试的范围:
|
||||
|
||||
* 添加一个目标主机或者目标主机的列表到范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
* 选择菜单条 - File > Add host(s) to scope
|
||||
|
||||
添加一个目标主机或者目标主机的列表到测试范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
|
||||
选择菜单条 - “File” -> “Add host(s) to scope”
|
||||
|
||||
[![Network Penetration Testing][3]][4]
|
||||
|
||||
[![Network Penetration Testing][5]][6]
|
||||
|
||||
* 上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
* 扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
|
||||
|
||||
## 打开 Ports & Services:
|
||||
|
||||
* Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
### 打开的端口及服务
|
||||
|
||||
Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
|
||||
[![Network Penetration Testing][7]][8]
|
||||
|
||||
* 上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
|
||||
|
||||
## 在开放端口上实施暴力攻击:
|
||||
|
||||
* 我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
### 在开放端口上实施暴力攻击
|
||||
|
||||
我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
|
||||
[![Network Penetration Testing][9]][10]
|
||||
|
||||
* 右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
* 浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
|
||||
浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
[![Network Penetration Testing][11]][12]
|
||||
|
||||
* 点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
* 在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
* 密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
* 强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登陆尝试之后将锁定帐户)
|
||||
* 将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
|
||||
在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
|
||||
密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
|
||||
强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登录尝试之后将锁定帐户)。
|
||||
|
||||
将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
|
||||
SPARTA 对渗透测试的扫描和枚举阶段来说是一个非常省时的 GUI 工具套件。SPARTA 可以扫描和暴力破解各种协议。它有许多的功能!祝你测试顺利!
|
||||
|
||||
@ -88,7 +81,7 @@ via: https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/
|
||||
|
||||
作者:[Balaganesh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,35 +1,38 @@
|
||||
如何在 Linux 上使用 Vundle 管理 Vim 插件
|
||||
======
|
||||
|
||||
|
||||
|
||||
毋庸置疑,**Vim** 是一款强大的文本文件处理的通用工具,能够管理系统配置文件,编写代码。通过插件,vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 **~/.vim** 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
毋庸置疑,Vim 是一款强大的文本文件处理的通用工具,能够管理系统配置文件和编写代码。通过插件,Vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 `~/.vim` 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
|
||||
Vundle 为每一个你安装和存储的拓展配置文件创建各自独立的目录树。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已存在的插件、更新插件配置、搜索安装插件和清理不使用的插件。所有的操作都可以在单一按键的交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
Vundle 为每一个你安装的插件创建一个独立的目录树,并在相应的插件目录中存储附加的配置文件。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已有的插件、更新插件配置、搜索安装的插件和清理不使用的插件。所有的操作都可以在一键交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
|
||||
### Vundle 安装
|
||||
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 **vim**。如果没有,安装 vim,尽情 **git**(下载 vundle)去吧。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 Vim。如果没有,请安装 Vim 和 git(以下载 Vundle)。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
|
||||
```
|
||||
sudo apt-get install vim git
|
||||
```
|
||||
|
||||
**下载 Vundle**
|
||||
#### 下载 Vundle
|
||||
|
||||
复制 Vundle 的 GitHub 仓库地址:
|
||||
|
||||
```
|
||||
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
```
|
||||
|
||||
**配置 Vundle**
|
||||
#### 配置 Vundle
|
||||
|
||||
创建 **~/.vimrc** 文件,通知 vim 使用新的插件管理器。这个文件获得有安装、更新、配置和移除插件的权限。
|
||||
创建 `~/.vimrc` 文件,以通知 Vim 使用新的插件管理器。安装、更新、配置和移除插件需要这个文件。
|
||||
|
||||
```
|
||||
vim ~/.vimrc
|
||||
```
|
||||
|
||||
在此文件顶部,加入如下若干行内容:
|
||||
|
||||
```
|
||||
set nocompatible " be iMproved, required
|
||||
filetype off " required
|
||||
@ -76,35 +79,39 @@ filetype plugin indent on " required
|
||||
" Put your non-Plugin stuff after this line
|
||||
```
|
||||
|
||||
被标记的行中,是 Vundle 的请求项。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。一旦你安装过,键入 **:wq** 保存退出。
|
||||
被标记为 “required” 的行是 Vundle 的所需配置。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。完成后,键入 `:wq` 保存退出。
|
||||
|
||||
最后,打开 Vim:
|
||||
|
||||
最后,打开 vim
|
||||
```
|
||||
vim
|
||||
```
|
||||
|
||||
然后键入下列命令安装插件。
|
||||
然后键入下列命令安装插件:
|
||||
|
||||
```
|
||||
:PluginInstall
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
将会弹出一个新的分窗口,.vimrc 中陈列的项目都会自动安装。
|
||||
将会弹出一个新的分窗口,我们加在 `.vimrc` 文件中的所有插件都会自动安装。
|
||||
|
||||
[![][1]][3]
|
||||
![][3]
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口:
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口。
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
在终端上使用下面命令,规避使用 vim 安装插件
|
||||
你也可以在终端上使用下面命令安装插件,而不用打开 Vim:
|
||||
|
||||
```
|
||||
vim +PluginInstall +qall
|
||||
```
|
||||
|
||||
使用 [**fish shell**][4] 的朋友,添加下面这行到你的 **.vimrc** 文件中。
|
||||
使用 [fish shell][4] 的朋友,添加下面这行到你的 `.vimrc` 文件中。
|
||||
|
||||
```
|
||||
set shell=/bin/bash
|
||||
@ -112,123 +119,138 @@ set shell=/bin/bash
|
||||
|
||||
### 使用 Vundle 管理 Vim 插件
|
||||
|
||||
**添加新的插件**
|
||||
#### 添加新的插件
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件:
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件。
|
||||
```
|
||||
:PluginSearch
|
||||
```
|
||||
|
||||
命令之后添加 **"! "**,刷新 vimscripts 网站内容到本地。
|
||||
要从 vimscripts 网站刷新本地的列表,请在命令之后添加 `!`。
|
||||
|
||||
```
|
||||
:PluginSearch!
|
||||
```
|
||||
|
||||
一个陈列可用插件列表的新分窗口将会被弹出。
|
||||
会弹出一个列出可用插件列表的新分窗口:
|
||||
|
||||
[![][1]][5]
|
||||
![][5]
|
||||
|
||||
你还可以通过直接指定插件名的方式,缩小搜索范围。
|
||||
|
||||
```
|
||||
:PluginSearch vim
|
||||
```
|
||||
|
||||
这样将会列出包含关键词“vim”的插件。
|
||||
这样将会列出包含关键词 “vim” 的插件。
|
||||
|
||||
当然你也可以指定确切的插件名,比如:
|
||||
|
||||
```
|
||||
:PluginSearch vim-dasm
|
||||
```
|
||||
|
||||
移动焦点到正确的一行上,点击 **" i"** 来安装插件。现在,被选择的插件将会被安装。
|
||||
移动焦点到正确的一行上,按下 `i` 键来安装插件。现在,被选择的插件将会被安装。
|
||||
|
||||
[![][1]][6]
|
||||
![][6]
|
||||
|
||||
类似的,在你的系统中安装所有想要的插件。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
|
||||
在你的系统中,所有想要的的插件都以类似的方式安装。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
现在,插件已经安装完成。在 .vimrc 文件中添加安装好的插件名,让插件正确加载。
|
||||
现在,插件已经安装完成。为了让插件正确的自动加载,我们需要在 `.vimrc` 文件中添加安装好的插件名。
|
||||
|
||||
这样做:
|
||||
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
添加这一行:
|
||||
|
||||
```
|
||||
[...]
|
||||
Plugin 'vim-dasm'
|
||||
[...]
|
||||
```
|
||||
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 ESC,键入 **:wq** 保存退出。
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 `ESC`,键入 `:wq` 保存退出。
|
||||
|
||||
请注意,所有插件都必须在 `.vimrc` 文件中追加如下内容。
|
||||
|
||||
请注意,所有插件都必须在 .vimrc 文件中追加如下内容。
|
||||
```
|
||||
[...]
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
**列出已安装的插件**
|
||||
#### 列出已安装的插件
|
||||
|
||||
键入下面命令列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
[![][1]][7]
|
||||
![][7]
|
||||
|
||||
**更新插件**
|
||||
#### 更新插件
|
||||
|
||||
键入下列命令更新插件:
|
||||
|
||||
```
|
||||
:PluginUpdate
|
||||
```
|
||||
|
||||
键入下列命令重新安装所有插件
|
||||
键入下列命令重新安装所有插件:
|
||||
|
||||
```
|
||||
:PluginInstall!
|
||||
```
|
||||
|
||||
**卸载插件**
|
||||
#### 卸载插件
|
||||
|
||||
首先,列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
之后将焦点置于正确的一行上,敲 **" SHITF+d"** 组合键。
|
||||
之后将焦点置于正确的一行上,按下 `SHITF+d` 组合键。
|
||||
|
||||
[![][1]][8]
|
||||
![][8]
|
||||
|
||||
然后编辑你的 `.vimrc` 文件:
|
||||
|
||||
然后编辑你的 .vimrc 文件:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
再然后删除插件入口。最后,键入 **:wq** 保存退出。
|
||||
删除插件入口。最后,键入 `:wq` 保存退出。
|
||||
|
||||
或者,你可以通过移除插件所在 `.vimrc` 文件行,并且执行下列命令,卸载插件:
|
||||
|
||||
或者,你可以通过移除插件所在 .vimrc 文件行,并且执行下列命令,卸载插件:
|
||||
```
|
||||
:PluginClean
|
||||
```
|
||||
|
||||
这个命令将会移除所有不在你的 .vimrc 文件中但是存在于 bundle 目录中的插件。
|
||||
这个命令将会移除所有不在你的 `.vimrc` 文件中但是存在于 bundle 目录中的插件。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 Vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
```
|
||||
:h vundle
|
||||
```
|
||||
|
||||
**捎带看看:**
|
||||
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注 OSTechNix!
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
**来源:**
|
||||
### 资源
|
||||
|
||||
[Vundle GitHub 仓库][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -236,16 +258,17 @@ via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png
|
||||
[9]:https://github.com/VundleVim/Vundle.vim
|
||||
@ -1,28 +1,28 @@
|
||||
为初学者介绍的 Linux tee 命令(6 个例子)
|
||||
======
|
||||
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 **tee** 的命令可以帮助你。
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 `tee` 的命令可以帮助你。
|
||||
|
||||
本教程中,我们将基于 tee 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
本教程中,我们将基于 `tee` 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
|
||||
### Linux tee 命令
|
||||
|
||||
tee 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
`tee` 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
|
||||
```
|
||||
tee [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
这里是帮助文档的说明:
|
||||
```
|
||||
从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
```
|
||||
|
||||
> 从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
|
||||
|
||||
让 Q&A(问&答)风格的实例给我们带来更多灵感,深入了解这个命令。
|
||||
|
||||
### Q1. 如何在 Linux 上使用这个命令?
|
||||
### Q1、 如何在 Linux 上使用这个命令?
|
||||
|
||||
假设因为某些原因,你正在使用 ping 命令。
|
||||
假设因为某些原因,你正在使用 `ping` 命令。
|
||||
|
||||
```
|
||||
ping google.com
|
||||
@ -30,29 +30,29 @@ ping google.com
|
||||
|
||||
[![如何在 Linux 上使用 tee 命令][1]][2]
|
||||
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,tee 命令就有其用武之地了。
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,`tee` 命令就有其用武之地了。
|
||||
|
||||
```
|
||||
ping google.com | tee output.txt
|
||||
```
|
||||
|
||||
下面的截图展示了这个输出内容不仅被写入 ‘output.txt’ 文件,也被显示在标准输出中。
|
||||
下面的截图展示了这个输出内容不仅被写入 `output.txt` 文件,也被显示在标准输出中。
|
||||
|
||||
[![tee command 输出][3]][4]
|
||||
|
||||
如此应当明确了 tee 的基础用法。
|
||||
如此应当明白了 `tee` 的基础用法。
|
||||
|
||||
### Q2. 如何确保 tee 命令追加信息到文件中?
|
||||
### Q2、 如何确保 tee 命令追加信息到文件中?
|
||||
|
||||
默认情况下,在同一个文件下再次使用 tee 命令会覆盖之前的信息。如果你想的话,可以通过 -a 命令选项改变默认设置。
|
||||
默认情况下,在同一个文件下再次使用 `tee` 命令会覆盖之前的信息。如果你想的话,可以通过 `-a` 命令选项改变默认设置。
|
||||
|
||||
```
|
||||
[command] | tee -a [file]
|
||||
```
|
||||
|
||||
基本上,-a 选项强制 tee 命令追加信息到文件。
|
||||
基本上,`-a` 选项强制 `tee` 命令追加信息到文件。
|
||||
|
||||
### Q3. 如何让 tee 写入多个文件?
|
||||
### Q3、 如何让 tee 写入多个文件?
|
||||
|
||||
这非常之简单。你仅仅只需要写明文件名即可。
|
||||
|
||||
@ -70,7 +70,7 @@ ping google.com | tee output1.txt output2.txt output3.txt
|
||||
|
||||
### Q4. 如何让 tee 命令的输出内容直接作为另一个命令的输入内容?
|
||||
|
||||
使用 tee 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入‘output.txt’文件中,还会通过 wc 命令让你知道输入到 output.txt 中的文件数目。
|
||||
使用 `tee` 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入 `output.txt` 文件中,还会通过 `wc` 命令让你知道输入到 `output.txt` 中的文件数目。
|
||||
|
||||
```
|
||||
ls file* | tee output.txt | wc -l
|
||||
@ -80,11 +80,11 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q5. 如何使用 tee 命令提升文件写入权限?
|
||||
|
||||
假如你使用 [Vim editor][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 sudo 权限保存修改。
|
||||
假如你使用 [Vim 编辑器][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 `sudo` 权限保存修改。
|
||||
|
||||
[![如何使用 tee 命令提升文件写入权限][10]][11]
|
||||
|
||||
如此情况下,你可以使用 tee 命令来提高权限。
|
||||
如此情况下,你可以(在 Vim 内)使用 `tee` 命令来提高权限。
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
@ -94,17 +94,17 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q6. 如何让 tee 命令忽视中断?
|
||||
|
||||
-i 命令行选项使 tee 命令忽视通常由 crl+c 组合键发起的中断信号(`SIGINT`)。
|
||||
`-i` 命令行选项使 `tee` 命令忽视通常由 `ctrl+c` 组合键发起的中断信号(`SIGINT`)。
|
||||
|
||||
```
|
||||
[command] | tee -i [file]
|
||||
```
|
||||
|
||||
当你想要使用 crl+c 中断命令的同时,让 tee 命令优雅的退出,这个选项尤为实用。
|
||||
当你想要使用 `ctrl+c` 中断该命令,同时让 `tee` 命令优雅的退出,这个选项尤为实用。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你可能已经认同 tee 是一个非常实用的命令。基于 tee 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
现在你可能已经认同 `tee` 是一个非常实用的命令。基于 `tee` 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -113,7 +113,7 @@ via: https://www.howtoforge.com/linux-tee-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
5 个在视觉上最轻松的黑暗主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
人们在电脑上选择黑暗主题有几个原因。有些人觉得对于眼睛轻松,而另一些人因为他们的医学条件选择黑色。特别地,程序员喜欢黑暗的主题,因为可以减少眼睛的眩光。
|
||||
|
||||
如果你是一位 Linux 用户和黑暗主题爱好者,那么你很幸运。这里有五个最好的 Linux 黑暗主题。去看一下!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
顾名思义,这个主题受 OS X 的启发,它是基于 Arc 的平面主题。该主题支持 GTK 3 和 GTK 2 桌面环境,因此 Gnome、Cinnamon、Unity、Manjaro、Mate 和 XFCE 用户可以安装和使用该主题。[OSX-Arc-Shadow][2] 是 OSX-Arc 主题集合的一部分。该集合还包括其他几个主题(黑暗和明亮)。你可以下载整个系列并使用黑色主题。
|
||||
|
||||
基于 Debian 和 Ubuntu 的发行版用户可以选择使用此[页面][3]中找到的 .deb 文件来安装稳定版本。压缩的源文件也位于同一页面上。Arch Linux 用户,请查看此 [AUR 链接][4]。最后,要手动安装主题,请将 zip 解压到 `~/.themes` ,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
该主题发布不久。与 OSX-Arc-Shadow 相比它有更黑的外观和红色选择框。对于那些希望电脑屏幕上有更强对比度和更少眩光的人尤其有吸引力。因此,它可以减少在夜间使用或在光线较暗的地方使用时的注意力分散。它支持 GTK 3 和 GTK2。
|
||||
|
||||
前往 [gnome-looks][6],在“文件”菜单下下载主题。安装过程很简单:将主题解压到 `~/.themes` 中,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux 是另一个基于 Materia 主题的简单的黑暗主题。它有一个中性的深色调,并不过分花哨。选择框之间的对比度也很小,并且没有 Kiss-Kool-Red 中红色的锐利。这个主题的确是为减轻眼睛疲劳而做的。
|
||||
|
||||
[下载压缩文件][8]并将其解压缩到你的 `~/.themes` 中。然后,你可以将其设置为你的主题。你可以查看[它的 GitHub 页面][9]了解最新的增加内容。
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
![Deepin Dark][10]
|
||||
|
||||
Deepin Dark 是一个完全黑暗的主题。对于那些喜欢更黑暗的人来说,这个主题绝对是值得考虑的。此外,它还可以减少电脑屏幕的眩光量。另外,它支持 Unity。[在这里下载 Deepin Dark][11]。
|
||||
|
||||
### 5. Ambiance DS BlueSB12
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 是一个简单的黑暗主题,它使得重要细节突出。它有助于专注,不花哨。它与 Deepin Dark 非常相似。特别是对于 Ubuntu 用户,它与 Ubuntu 17.04 兼容。你可以从[这里][13]下载并尝试。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你长时间使用电脑,黑暗主题是减轻眼睛疲劳的好方法。即使你不这样做,黑暗主题也可以在其他方面帮助你,例如提高专注。让我们知道你最喜欢哪一个。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/12/osx-arc-shadow.png (OSX-Arc-Shadow Theme)
|
||||
[2]:https://github.com/LinxGem33/OSX-Arc-Shadow/
|
||||
[3]:https://github.com/LinxGem33/OSX-Arc-Shadow/releases
|
||||
[4]:https://aur.archlinux.org/packages/osx-arc-shadow/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/Kiss-Kool-Red.png (Kiss-Kool-Red version 2 )
|
||||
[6]:https://www.gnome-look.org/p/1207964/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/12/equilux.png (Equilux)
|
||||
[8]:https://www.gnome-look.org/p/1182169/
|
||||
[9]:https://github.com/ddnexus/equilux-theme
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/deepin-dark.png (Deepin Dark )
|
||||
[11]:https://www.gnome-look.org/p/1190867/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/ambience.png (Ambiance DS BlueSB12 )
|
||||
[13]:https://www.gnome-look.org/p/1013664/
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Linux 上安装 Spotify
|
||||
如何在 Linux 上使用 snap 安装 Spotify(声破天)
|
||||
======
|
||||
|
||||
如何在 Ubuntu Linux 桌面上安装 Spotify 来在线听音乐?
|
||||
如何在 Ubuntu Linux 桌面上安装 spotify 来在线听音乐?
|
||||
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅。可以创建播放列表。订阅用户可以免广告收听音乐。你会得到更好的音质。本教程**展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版**上的 snap 包管理器安装 Spotify。
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅,可以创建播放列表。订阅用户可以免广告收听音乐,你会得到更好的音质。本教程展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版上的 snap 包管理器安装 Spotify。
|
||||
|
||||
### 在 Linux 上安装 spotify
|
||||
|
||||
@ -11,33 +11,28 @@ Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以
|
||||
|
||||
1. 安装 snapd
|
||||
2. 打开 snapd
|
||||
3. 找到 Spotify snap:
|
||||
```
|
||||
snap find spotify
|
||||
```
|
||||
4. 安装 spotify:
|
||||
```
|
||||
do snap install spotify
|
||||
```
|
||||
5. 运行:
|
||||
```
|
||||
spotify &
|
||||
```
|
||||
3. 找到 Spotify snap:`snap find spotify`
|
||||
4. 安装 spotify:`sudo snap install spotify`
|
||||
5. 运行:`spotify &`
|
||||
|
||||
让我们详细看看所有的步骤和例子。
|
||||
|
||||
### 步骤 1 - 安装 Snapd
|
||||
### 步骤 1 - 安装 snapd
|
||||
|
||||
你需要安装 snapd 包。它是一个守护进程(服务),并能在 Linux 系统上启用 snap 包管理。
|
||||
|
||||
#### Debian/Ubuntu/Mint Linux 上的 Snapd
|
||||
#### Debian/Ubuntu/Mint Linux 上的 snapd
|
||||
|
||||
输入以下[ apt 命令][1]/ [apt-get 命令][2]:
|
||||
`$ sudo apt install snapd`
|
||||
输入以下 [apt 命令][1]/ [apt-get 命令][2]:
|
||||
|
||||
```
|
||||
$ sudo apt install snapd
|
||||
```
|
||||
|
||||
#### 在 Arch Linux 上安装 snapd
|
||||
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 yaourt 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 `yaourt` 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
|
||||
```
|
||||
$ sudo yaourt -S snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
@ -45,7 +40,8 @@ $ sudo systemctl enable --now snapd.socket
|
||||
|
||||
#### 在 Fedora 上获取 snapd
|
||||
|
||||
运行 snapd 命令
|
||||
运行 snapd 命令:
|
||||
|
||||
```
|
||||
sudo dnf install snapd
|
||||
sudo ln -s /var/lib/snapd/snap /snap
|
||||
@ -53,26 +49,67 @@ sudo ln -s /var/lib/snapd/snap /snap
|
||||
|
||||
#### OpenSUSE 安装 snapd
|
||||
|
||||
执行如下的 `zypper` 命令:
|
||||
|
||||
```
|
||||
### Tumbleweed verson ###
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Tumbleweed/ snappy
|
||||
### Leap version ##
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Leap_42.3/ snappy
|
||||
```
|
||||
|
||||
安装:
|
||||
|
||||
```
|
||||
$ sudo zypper install snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
```
|
||||
|
||||
### 步骤 2 - 在 Linux 上使用 snap 安装 spofity
|
||||
|
||||
执行 snap 命令:
|
||||
`$ snap find spotify`
|
||||
|
||||
```
|
||||
$ snap find spotify
|
||||
```
|
||||
|
||||
[![snap search for spotify app command][4]][4]
|
||||
|
||||
安装它:
|
||||
`$ sudo snap install spotify`
|
||||
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
```
|
||||
|
||||
[![How to install Spotify application on Linux using snap command][5]][5]
|
||||
|
||||
### 步骤 3 - 运行 spotify 并享受它(译注:原博客中就是这么直接跳到 step3 的)
|
||||
### 步骤 3 - 运行 spotify 并享受它
|
||||
|
||||
从 GUI 运行它,或者只需输入:
|
||||
`$ spotify`
|
||||
|
||||
```
|
||||
$ spotify
|
||||
```
|
||||
|
||||
在启动时自动登录你的帐户:
|
||||
|
||||
```
|
||||
$ spotify --username vivek@nixcraft.com
|
||||
$ spotify --username vivek@nixcraft.com --password 'myPasswordHere'
|
||||
```
|
||||
|
||||
在初始化时使用给定的 URI 启动 Spotify 客户端:
|
||||
`$ spotify--uri=<uri>`
|
||||
|
||||
```
|
||||
$ spotify --uri=<uri>
|
||||
```
|
||||
|
||||
以指定的网址启动:
|
||||
`$ spotify--url=<url>`
|
||||
|
||||
```
|
||||
$ spotify --url=<url>
|
||||
```
|
||||
|
||||
[![Spotify client app running on my Ubuntu Linux desktop][6]][6]
|
||||
|
||||
### 关于作者
|
||||
@ -85,7 +122,7 @@ via: https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
构建你自己的 RSS 提示系统——让杂志文章一篇也不会错过
|
||||
用 Python 构建你自己的 RSS 提示系统
|
||||
======
|
||||
|
||||

|
||||
@ -7,9 +7,9 @@
|
||||
|
||||
### Fedora 和 Python —— 入门知识
|
||||
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [**sqlite3**][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是在标准库中没有的特定的问题,也有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [**feedparser**][3] 去解析 RSS 源。
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [sqlite3][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是这样的一个特定问题,在标准库中没有包含,而有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [feedparser][3] 去解析 RSS 源。
|
||||
|
||||
因为 **feedparser** 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 **feedparser**:
|
||||
因为 feedparser 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 feedparser:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
@ -18,11 +18,12 @@ $ sudo dnf install python3-feedparser
|
||||
|
||||
### 存储源数据
|
||||
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的**标题**和**发布日期**。
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的标题和发布日期。
|
||||
|
||||
因此,我们来使用 Python **sqlite3** 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(**feedparse**,**smtplib**,和 **email**)。
|
||||
因此,我们来使用 Python sqlite3 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(feedparse,smtplib,和 email)。
|
||||
|
||||
#### 创建数据库
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
@ -34,14 +35,14 @@ import feedparser
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
这几行代码创建一个新的保存在一个名为 'magazine_rss.sqlite' 文件中的 sqlite 数据库,然后在数据库创建一个名为 'magazine' 的新表。这个表有两个列 —— 'title' 和 'date' —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
这几行代码创建一个名为 `magazine_rss.sqlite` 文件的新 sqlite 数据库,然后在数据库创建一个名为 `magazine` 的新表。这个表有两个列 —— `title` 和 `date` —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
|
||||
#### 检查数据库中的旧文章
|
||||
|
||||
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
|
||||
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
@ -60,13 +61,14 @@ def article_is_not_db(article_title, article_date):
|
||||
return False
|
||||
```
|
||||
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 SELECT 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(title 和 date)。然后,我们使用查询的 WHERE 条件 `article_title` and `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 `SELECT` 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(`title` 和 `date`)。然后,我们使用查询的 `WHERE` 条件 `article_title` 和 `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
|
||||
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
|
||||
|
||||
#### 在数据库中添加新文章
|
||||
|
||||
现在我们可以写一些代码去添加新文章到数据库中。
|
||||
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
@ -78,13 +80,14 @@ def add_article_to_db(article_title, article_date):
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 'magazine' 表的 article_title 和 article_date 列中。然后提交它到数据库中永久保存。
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 `magazine` 表的 `article_title` 和 `article_date` 列中。然后提交它到数据库中永久保存。
|
||||
|
||||
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
|
||||
|
||||
### 发送电子邮件提示
|
||||
|
||||
我们来使用 Python 标准库模块 **smtplib** 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 **email** 模块去格式化我们的电子邮件信息。
|
||||
我们使用 Python 标准库模块 smtplib 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 email 模块去格式化我们的电子邮件信息。
|
||||
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
@ -113,6 +116,7 @@ def send_notification(article_title, article_url):
|
||||
### 读取 Fedora Magazine 的 RSS 源
|
||||
|
||||
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
|
||||
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
@ -127,25 +131,26 @@ if __name__ == '__main__':
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
在这里我们将使用 **feedparser.parse** 功能。这个功能返回一个用字典表示的 RSS 源,对于 **feedparser** 的完整描述可以参考它的 [文档][5]。
|
||||
在这里我们将使用 `feedparser.parse` 功能。这个功能返回一个用字典表示的 RSS 源,对于 feedparser 的完整描述可以参考它的 [文档][5]。
|
||||
|
||||
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
|
||||
|
||||
当运行我们的脚本时,最后的 if 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
当运行我们的脚本时,最后的 `if` 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
|
||||
### 运行我们的脚本
|
||||
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 **cron** 实用程序去每小时自动运行一次我们的脚本。**cron** 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 cron 实用程序去每小时自动运行一次我们的脚本。cron 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
**为了使该教程保持简单**,我们使用了 cron.hourly 目录每小时运行一次我们的脚本,如果你想学习关于 **cron** 的更多知识以及如何配置 **crontab**,请阅读 **cron** 的 wikipedia [页面][6]。
|
||||
为了使该教程保持简单,我们使用了 `cron.hourly` 目录每小时运行一次我们的脚本,如果你想学习关于 cron 的更多知识以及如何配置 crontab,请阅读 cron 的 wikipedia [页面][6]。
|
||||
|
||||
### 总结
|
||||
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,**使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事**。
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事。
|
||||
|
||||
这个脚本在 [GitHub][7] 上可以找到。
|
||||
|
||||
@ -155,7 +160,7 @@ via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notificat
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
147
published/20180125 Keep Accurate Time on Linux with NTP.md
Normal file
147
published/20180125 Keep Accurate Time on Linux with NTP.md
Normal file
@ -0,0 +1,147 @@
|
||||
在 Linux 上使用 NTP 保持精确的时间
|
||||
======
|
||||
|
||||

|
||||
|
||||
如何保持正确的时间,如何使用 NTP 和 systemd 让你的计算机在不滥用时间服务器的前提下保持同步。
|
||||
|
||||
### 它的时间是多少?
|
||||
|
||||
让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
|
||||
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
|
||||
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
|
||||
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
|
||||
```
|
||||
|
||||
有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。请查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
|
||||
|
||||
### 检查当前设置
|
||||
|
||||
NTP —— 网络时间协议,它是保持计算机正确时间的老式方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖地 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
|
||||
|
||||
在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
|
||||
|
||||
你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(<ruby>世界标准时间<rt>Coordinated Universal Time</rt></ruby>)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
|
||||
|
||||
```
|
||||
$ sudo hwclock --debug
|
||||
hwclock from util-linux 2.27.1
|
||||
Using the /dev interface to the clock.
|
||||
Hardware clock is on UTC time
|
||||
Assuming hardware clock is kept in UTC time.
|
||||
Waiting for clock tick...
|
||||
...got clock tick
|
||||
Time read from Hardware Clock: 2018/01/22 22:14:31
|
||||
Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
|
||||
Time since last adjustment is 1516659271 seconds
|
||||
Calculated Hardware Clock drift is 0.000000 seconds
|
||||
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
|
||||
```
|
||||
|
||||
`Hardware clock is on UTC time` 表明了你的计算机的 RTC 是使用 UTC 时间的,虽然它把该时间转换为你的本地时间。如果它被设置为本地时间,它将显示 `Hardware clock is on local time`。
|
||||
|
||||
你应该有一个 `/etc/adjtime` 文件。如果没有的话,使用如下命令同步你的 RTC 为系统时间,
|
||||
|
||||
```
|
||||
$ sudo hwclock -w
|
||||
```
|
||||
|
||||
这个命令将生成该文件,内容看起来类似如下:
|
||||
|
||||
```
|
||||
$ cat /etc/adjtime
|
||||
0.000000 1516661953 0.000000
|
||||
1516661953
|
||||
UTC
|
||||
```
|
||||
|
||||
新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Mon 2018-01-22 14:17:51 PST
|
||||
Universal time: Mon 2018-01-22 22:17:51 UTC
|
||||
RTC time: Mon 2018-01-22 22:17:51
|
||||
Time zone: America/Los_Angeles (PST, -0800)
|
||||
Network time on: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
`RTC in local TZ: no` 表明它使用 UTC 时间。那么怎么改成使用本地时间?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你也可使用 `timedatectl`:
|
||||
|
||||
```
|
||||
$ timedatectl set-local-rtc 0
|
||||
```
|
||||
|
||||
或者编辑 `/etc/adjtime`,将 `UTC` 替换为 `LOCAL`。
|
||||
|
||||
### systemd-timesyncd 客户端
|
||||
|
||||
现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
|
||||
|
||||
systemd 提供了 `systemd-timesyncd.service` 客户端,它可以查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的(时间)服务器。大多数 Linux 发行版都提供了一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
|
||||
|
||||
```
|
||||
[Time]
|
||||
#NTP=
|
||||
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
|
||||
```
|
||||
|
||||
你可以输入你希望使用的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 `FallbackNTP` 行上的配置项。
|
||||
|
||||
如果你不想使用 systemd 呢?那么,你将需要 NTP 就行。
|
||||
|
||||
### 配置 NTP 服务器和客户端
|
||||
|
||||
配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 上的 NTP 都来自 `ntp` 包,它们大多都提供 `/etc/ntp.conf` 文件去配置时间服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4 - 5 个服务器,每个服务器用单独的一行:
|
||||
|
||||
```
|
||||
driftfile /var/ntp.drift
|
||||
logfile /var/log/ntp.log
|
||||
server 0.europe.pool.ntp.org
|
||||
server 1.europe.pool.ntp.org
|
||||
server 2.europe.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
```
|
||||
|
||||
`driftfile` 告诉 `ntpd` 它需要保存用于启动时使用时间服务器快速同步你的系统时钟的信息。而日志也将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
|
||||
|
||||
现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================
|
||||
+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
|
||||
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
|
||||
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
|
||||
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
|
||||
```
|
||||
|
||||
我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
|
||||
|
||||
现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
|
||||
|
||||
NTP 服务器会受到攻击,而且需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][3] 来学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
|
||||
[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,426 @@
|
||||
如何在 CentOS 7 / RHEL 7 终端服务器上安装 KVM
|
||||
======
|
||||
|
||||
如何在 CnetOS 7 或 RHEL 7(Red Hat 企业版 Linux)服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CentOS 7 上设置 KVM 并使用云镜像 / cloud-init 来安装客户虚拟机?
|
||||
|
||||
基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 可以将你的服务器变成虚拟机管理器。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用命令行在物理服务器上安装和管理虚拟机(VM)。请确保在服务器的 BIOS 中启用了**虚拟化技术(VT)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
|
||||
|
||||
```
|
||||
$ lscpu | grep Virtualization
|
||||
Virtualization: VT-x
|
||||
```
|
||||
|
||||
按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作。
|
||||
|
||||
### 步骤 1: 安装 kvm
|
||||
|
||||
输入以下 [yum 命令][2]:
|
||||
|
||||
```
|
||||
# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install
|
||||
```
|
||||
|
||||
[![How to install KVM on CentOS 7 RHEL 7 Headless Server][3]][3]
|
||||
|
||||
启动 libvirtd 服务:
|
||||
|
||||
```
|
||||
# systemctl enable libvirtd
|
||||
# systemctl start libvirtd
|
||||
```
|
||||
|
||||
### 步骤 2: 确认 kvm 安装
|
||||
|
||||
使用 `lsmod` 命令和 [grep命令][4] 确认加载了 KVM 模块:
|
||||
|
||||
```
|
||||
# lsmod | grep -i kvm
|
||||
```
|
||||
|
||||
### 步骤 3: 配置桥接网络
|
||||
|
||||
默认情况下,由 libvirtd 配置基于 dhcpd 的网桥。你可以使用以下命令验证:
|
||||
|
||||
```
|
||||
# brctl show
|
||||
# virsh net-list
|
||||
```
|
||||
|
||||
[![KVM default networking][5]][5]
|
||||
|
||||
所有虚拟机(客户机)只能对同一台服务器上的其它虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
|
||||
|
||||
```
|
||||
# virsh net-dumpxml default
|
||||
```
|
||||
|
||||
如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-enp3s0
|
||||
```
|
||||
|
||||
添加一行:
|
||||
|
||||
```
|
||||
BRIDGE=br0
|
||||
```
|
||||
|
||||
[使用 vi 保存并关闭文件][6]。编辑 `/etc/sysconfig/network-scripts/ifcfg-br0`:
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-br0
|
||||
```
|
||||
|
||||
添加以下内容:
|
||||
|
||||
```
|
||||
DEVICE="br0"
|
||||
# I am getting ip from DHCP server #
|
||||
BOOTPROTO="dhcp"
|
||||
IPV6INIT="yes"
|
||||
IPV6_AUTOCONF="yes"
|
||||
ONBOOT="yes"
|
||||
TYPE="Bridge"
|
||||
DELAY="0"
|
||||
```
|
||||
|
||||
重新启动网络服务(警告:ssh 命令将断开连接,最好重新启动该设备):
|
||||
|
||||
```
|
||||
# systemctl restart NetworkManager
|
||||
```
|
||||
|
||||
用 `brctl` 命令验证它:
|
||||
|
||||
```
|
||||
# brctl show
|
||||
```
|
||||
|
||||
### 步骤 4: 创建你的第一个虚拟机
|
||||
|
||||
我将会创建一个 CentOS 7.x 虚拟机。首先,使用 `wget` 命令获取 CentOS 7.x 最新的 ISO 镜像:
|
||||
|
||||
```
|
||||
# cd /var/lib/libvirt/boot/
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
|
||||
```
|
||||
|
||||
验证 ISO 镜像:
|
||||
|
||||
```
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
|
||||
# sha256sum -c sha256sum.txt
|
||||
```
|
||||
|
||||
#### 创建 CentOS 7.x 虚拟机
|
||||
|
||||
在这个例子中,我创建了 2GB RAM,2 个 CPU 核心,1 个网卡和 40 GB 磁盘空间的 CentOS 7.x 虚拟机,输入:
|
||||
|
||||
```
|
||||
# virt-install \
|
||||
--virt-type=kvm \
|
||||
--name centos7 \
|
||||
--ram 2048 \
|
||||
--vcpus=1 \
|
||||
--os-variant=centos7.0 \
|
||||
--cdrom=/var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-1708.iso \
|
||||
--network=bridge=br0,model=virtio \
|
||||
--graphics vnc \
|
||||
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
|
||||
```
|
||||
|
||||
从另一个终端通过 `ssh` 配置 vnc 登录,输入:
|
||||
|
||||
```
|
||||
# virsh dumpxml centos7 | grep v nc
|
||||
<graphics type='vnc' port='5901' autoport='yes' listen='127.0.0.1'>
|
||||
```
|
||||
|
||||
请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务器。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转发命令:
|
||||
|
||||
```
|
||||
$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901
|
||||
```
|
||||
|
||||
一旦你建立了 ssh 隧道,你可以将你的 VNC 客户端指向你自己的 127.0.0.1 (localhost) 地址和端口 5901,如下所示:
|
||||
|
||||
[![][7]][7]
|
||||
|
||||
你应该看到 CentOS Linux 7 客户虚拟机安装屏幕如下:
|
||||
|
||||
[![][8]][8]
|
||||
|
||||
现在只需按照屏幕说明进行操作并安装CentOS 7。一旦安装完成后,请继续并单击重启按钮。 远程服务器关闭了我们的 VNC 客户端的连接。 你可以通过 KVM 客户端重新连接,以配置服务器的其余部分,包括基于 SSH 的会话或防火墙。
|
||||
|
||||
### 使用云镜像
|
||||
|
||||
以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 可以试试云镜像。你可以根据需要修改预先构建的云镜像。例如,使用 [Cloud-init][9] 添加用户、ssh 密钥、设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(LCTT 译注: vCPU 即电脑中的虚拟处理器)
|
||||
|
||||
#### 获取 CentOS 7 云镜像
|
||||
|
||||
```
|
||||
# cd /var/lib/libvirt/boot
|
||||
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
|
||||
```
|
||||
|
||||
#### 创建所需的目录
|
||||
|
||||
```
|
||||
# D=/var/lib/libvirt/images
|
||||
# VM=centos7-vm1 ## vm name ##
|
||||
# mkdir -vp $D/$VM
|
||||
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
|
||||
```
|
||||
|
||||
#### 创建元数据文件
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi meta-data
|
||||
```
|
||||
|
||||
添加以下内容:
|
||||
|
||||
```
|
||||
instance-id: centos7-vm1
|
||||
local-hostname: centos7-vm1
|
||||
```
|
||||
|
||||
#### 创建用户数据文件
|
||||
|
||||
我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh 密钥:
|
||||
|
||||
```
|
||||
# ssh-keygen -t ed25519 -C "VM Login ssh key"
|
||||
```
|
||||
|
||||
[![ssh-keygen command][10]][11]
|
||||
|
||||
请参阅 “[如何在 Linux/Unix 系统上设置 SSH 密钥][12]” 来获取更多信息。编辑用户数据如下:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi user-data
|
||||
```
|
||||
|
||||
添加如下(根据你的设置替换 `hostname`、`users`、`ssh-authorized-keys`):
|
||||
|
||||
```
|
||||
#cloud-config
|
||||
|
||||
# Hostname management
|
||||
preserve_hostname: False
|
||||
hostname: centos7-vm1
|
||||
fqdn: centos7-vm1.nixcraft.com
|
||||
|
||||
# Users
|
||||
users:
|
||||
- default
|
||||
- name: vivek
|
||||
groups: ['wheel']
|
||||
shell: /bin/bash
|
||||
sudo: ALL=(ALL) NOPASSWD:ALL
|
||||
ssh-authorized-keys:
|
||||
- ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIMP3MOF2ot8MOdNXCpHem0e2Wemg4nNmL2Tio4Ik1JY VM Login ssh key
|
||||
|
||||
# Configure where output will go
|
||||
output:
|
||||
all: ">> /var/log/cloud-init.log"
|
||||
|
||||
# configure interaction with ssh server
|
||||
ssh_genkeytypes: ['ed25519', 'rsa']
|
||||
|
||||
# Install my public ssh key to the first user-defined user configured
|
||||
# in cloud.cfg in the template (which is centos for CentOS cloud images)
|
||||
ssh_authorized_keys:
|
||||
- ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIMP3MOF2ot8MOdNXCpHem0e2Wemg4nNmL2Tio4Ik1JY VM Login ssh key
|
||||
|
||||
# set timezone for VM
|
||||
timezone: Asia/Kolkata
|
||||
|
||||
# Remove cloud-init
|
||||
runcmd:
|
||||
- systemctl stop network && systemctl start network
|
||||
- yum -y remove cloud-init
|
||||
```
|
||||
|
||||
#### 复制云镜像
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
|
||||
```
|
||||
|
||||
#### 创建 20GB 磁盘映像
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# export LIBGUESTFS_BACKEND=direct
|
||||
# qemu-img create -f qcow2 -o preallocation=metadata $VM.new.image 20G
|
||||
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
|
||||
```
|
||||
[![Set VM image disk size][13]][13]
|
||||
|
||||
用压缩后的镜像覆盖它:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# mv $VM.new.image $VM.qcow2
|
||||
```
|
||||
|
||||
#### 创建一个 cloud-init ISO
|
||||
|
||||
```
|
||||
# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data
|
||||
```
|
||||
|
||||
[![Creating a cloud-init ISO][14]][14]
|
||||
|
||||
#### 创建一个池
|
||||
|
||||
```
|
||||
# virsh pool-create-as --name $VM --type dir --target $D/$VM
|
||||
Pool centos7-vm1 created
|
||||
```
|
||||
|
||||
#### 安装 CentOS 7 虚拟机
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# virt-install --import --name $VM \
|
||||
--memory 1024 --vcpus 1 --cpu host \
|
||||
--disk $VM.qcow2,format=qcow2,bus=virtio \
|
||||
--disk $VM-cidata.iso,device=cdrom \
|
||||
--network bridge=virbr0,model=virtio \
|
||||
--os-type=linux \
|
||||
--os-variant=centos7.0 \
|
||||
--graphics spice \
|
||||
--noautoconsole
|
||||
```
|
||||
|
||||
删除不需要的文件:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# virsh change-media $VM hda --eject --config
|
||||
# rm meta-data user-data centos7-vm1-cidata.iso
|
||||
```
|
||||
|
||||
#### 查找虚拟机的 IP 地址
|
||||
|
||||
```
|
||||
# virsh net-dhcp-leases default
|
||||
```
|
||||
|
||||
[![CentOS7-VM1- Created][15]][15]
|
||||
|
||||
#### 登录到你的虚拟机
|
||||
|
||||
使用 ssh 命令:
|
||||
|
||||
```
|
||||
# ssh vivek@192.168.122.85
|
||||
```
|
||||
|
||||
[![Sample VM session][16]][16]
|
||||
|
||||
### 有用的命令
|
||||
|
||||
让我们看看管理虚拟机的一些有用的命令。
|
||||
|
||||
#### 列出所有虚拟机
|
||||
|
||||
```
|
||||
# virsh list --all
|
||||
```
|
||||
|
||||
#### 获取虚拟机信息
|
||||
|
||||
```
|
||||
# virsh dominfo vmName
|
||||
# virsh dominfo centos7-vm1
|
||||
```
|
||||
|
||||
#### 停止/关闭虚拟机
|
||||
|
||||
```
|
||||
# virsh shutdown centos7-vm1
|
||||
```
|
||||
|
||||
#### 开启虚拟机
|
||||
|
||||
```
|
||||
# virsh start centos7-vm1
|
||||
```
|
||||
|
||||
#### 将虚拟机标记为在引导时自动启动
|
||||
|
||||
```
|
||||
# virsh autostart centos7-vm1
|
||||
```
|
||||
|
||||
#### 重新启动(软安全重启)虚拟机
|
||||
|
||||
```
|
||||
# virsh reboot centos7-vm1
|
||||
```
|
||||
|
||||
重置(硬重置/不安全)虚拟机
|
||||
|
||||
```
|
||||
# virsh reset centos7-vm1
|
||||
```
|
||||
|
||||
#### 删除虚拟机
|
||||
|
||||
```
|
||||
# virsh shutdown centos7-vm1
|
||||
# virsh undefine centos7-vm1
|
||||
# virsh pool-destroy centos7-vm1
|
||||
# D=/var/lib/libvirt/images
|
||||
# VM=centos7-vm1
|
||||
# rm -ri $D/$VM
|
||||
```
|
||||
|
||||
查看 virsh 命令类型的完整列表:
|
||||
|
||||
```
|
||||
# virsh help | less
|
||||
# virsh help | grep reboot
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,也是经验丰富的系统管理员和 Linux 操作系统/ Unix shell 脚本的培训师。 他曾与全球客户以及 IT,教育,国防和空间研究以及非营利部门等多个行业合作。 在 [Twitter][17],[Facebook][18],[Google +][19] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/linux-xen-vmware-kvm-intel-vt-amd-v-support/
|
||||
[2]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-KVM-on-CentOS-7-RHEL-7-Headless-Server.jpg
|
||||
[4]:https://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/ (See Linux/Unix grep command examples for more info)
|
||||
[5]:https://www.cyberciti.biz/media/new/faq/2018/01/KVM-default-networking.jpg
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/media/new/faq/2016/01/vnc-client.jpg
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2016/01/centos7-guest-vnc.jpg
|
||||
[9]:https://cloudinit.readthedocs.io/en/latest/index.html
|
||||
[10]:https://www.cyberciti.biz/media/new/faq/2018/01/ssh-keygen-pub-key.jpg
|
||||
[11]:https://www.cyberciti.biz/faq/linux-unix-generating-ssh-keys/
|
||||
[12]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[13]:https://www.cyberciti.biz/media/new/faq/2018/01/Set-VM-image-disk-size.jpg
|
||||
[14]:https://www.cyberciti.biz/media/new/faq/2018/01/Creating-a-cloud-init-ISO.jpg
|
||||
[15]:https://www.cyberciti.biz/media/new/faq/2018/01/CentOS7-VM1-Created.jpg
|
||||
[16]:https://www.cyberciti.biz/media/new/faq/2018/01/Sample-VM-session.jpg
|
||||
[17]:https://twitter.com/nixcraft
|
||||
[18]:https://facebook.com/nixcraft
|
||||
[19]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,113 @@
|
||||
搭建私有云:OwnCloud
|
||||
======
|
||||
|
||||
所有人都在讨论云。尽管市面上有很多为我们提供云存储和其他云服务的主要服务商,但是我们还是可以为自己搭建一个私有云。
|
||||
|
||||
在本教程中,我们将讨论如何利用 OwnCloud 搭建私有云。OwnCloud 是一个可以安装在我们 Linux 设备上的 web 应用程序,能够存储和用我们的数据提供服务。OwnCloud 可以分享日历、联系人和书签,共享音/视频流等等。
|
||||
|
||||
本教程中,我们使用的是 CentOS 7 系统,但是本教程同样适用于其他 Linux 发行版中安装 OwnCloud。让我们开始安装 OwnCloud 并且做一些准备工作,
|
||||
|
||||
- 推荐阅读:[如何在 CentOS & RHEL 上使用 Apache 作为反向代理服务器][1]
|
||||
- 同时推荐:[实时 Linux 服务器监测和 GLANCES 监测工具][2]
|
||||
|
||||
### 预备
|
||||
|
||||
* 我们需要在机器上配置 LAMP。参照阅读我们的文章《[在 CentOS/RHEL 上配置 LAMP 服务器最简单的教程][3]》 & 《[在 Ubuntu 搭建 LAMP][4]》。
|
||||
* 我们需要在自己的设备里安装这些包,`php-mysql`、 `php-json`、 `php-xml`、 `php-mbstring`、 `php-zip`、 `php-gd`、 `curl、 `php-curl` 、`php-pdo`。使用包管理器安装它们。
|
||||
|
||||
```
|
||||
$ sudo yum install php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo
|
||||
```
|
||||
|
||||
### 安装
|
||||
|
||||
安装 OwnCloud,我们现在需要在服务器上下载 OwnCloud 安装包。使用下面的命令从官方网站下载最新的安装包(10.0.4-1):
|
||||
|
||||
```
|
||||
$ wget https://download.owncloud.org/community/owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
使用下面的命令解压:
|
||||
|
||||
```
|
||||
$ tar -xvf owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
现在,将所有解压后的文件移动至 `/var/www/html`:
|
||||
|
||||
```
|
||||
$ mv owncloud/* /var/www/html
|
||||
```
|
||||
|
||||
下一步,我们需要在 Apache 的配置文件 `httpd.conf` 上做些修改:
|
||||
|
||||
```
|
||||
$ sudo vim /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
更改下面的选项:
|
||||
|
||||
```
|
||||
AllowOverride All
|
||||
```
|
||||
|
||||
保存该文件,并修改 OwnCloud 文件夹的文件权限:
|
||||
|
||||
```
|
||||
$ sudo chown -R apache:apache /var/www/html/
|
||||
$ sudo chmod 777 /var/www/html/config/
|
||||
```
|
||||
|
||||
然后重启 Apache 服务器执行修改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
```
|
||||
|
||||
现在,我们需要在 MariaDB 上创建一个数据库,保存来自 OwnCloud 的数据。使用下面的命令创建数据库和数据库用户:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
MariaDB [(none)] > create database owncloud;
|
||||
MariaDB [(none)] > GRANT ALL ON owncloud.* TO ocuser@localhost IDENTIFIED BY 'owncloud';
|
||||
MariaDB [(none)] > flush privileges;
|
||||
MariaDB [(none)] > exit
|
||||
```
|
||||
|
||||
服务器配置部分完成后,现在我们可以在网页浏览器上访问 OwnCloud。打开浏览器,输入您的服务器 IP 地址,我这边的服务器是 10.20.30.100:
|
||||
|
||||
![安装 owncloud][7]
|
||||
|
||||
一旦 URL 加载完毕,我们将呈现上述页面。这里,我们将创建管理员用户同时提供数据库信息。当所有信息提供完毕,点击“Finish setup”。
|
||||
|
||||
我们将被重定向到登录页面,在这里,我们需要输入先前创建的凭据:
|
||||
|
||||
![安装 owncloud][9]
|
||||
|
||||
认证成功之后,我们将进入 OwnCloud 面板:
|
||||
|
||||
![安装 owncloud][11]
|
||||
|
||||
我们可以使用手机应用程序,同样也可以使用网页界面更新我们的数据。现在,我们已经有自己的私有云了,同时,关于如何安装 OwnCloud 创建私有云的教程也进入尾声。请在评论区留下自己的问题或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-personal-cloud-install-owncloud/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/apache-as-reverse-proxy-centos-rhel/
|
||||
[2]:http://linuxtechlab.com/linux-server-glances-monitoring-tool/
|
||||
[3]:http://linuxtechlab.com/easiest-guide-creating-lamp-server/
|
||||
[4]:http://linuxtechlab.com/install-lamp-stack-on-ubuntu/
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=400%2C647
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud1-compressor.jpg?resize=400%2C647
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=876%2C541
|
||||
[9]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud2-compressor1.jpg?resize=876%2C541
|
||||
[10]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=981%2C474
|
||||
[11]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud3-compressor1.jpg?resize=981%2C474
|
||||
@ -3,10 +3,9 @@
|
||||
|
||||
[][8]
|
||||
|
||||
|
||||
HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程序员询问了他们何时开始编码。
|
||||
|
||||
39,441 名专业和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。
|
||||
39,441 名专业人员和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。(LCTT 译注:日期恐有误)
|
||||
|
||||
### 程序员是如何学习的
|
||||
|
||||
@ -16,7 +15,7 @@ HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程
|
||||
|
||||
开发者平均了解四种语言,但他们想学习更多语言。
|
||||
|
||||
对学习的渴望因人而异 - 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
|
||||
对学习的渴望因人而异 —— 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
|
||||
|
||||
[][5]
|
||||
|
||||
@ -46,9 +45,9 @@ HackerRank 说:“在某些方面,我们发现了一个小矛盾。开发人
|
||||
|
||||
via: https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html
|
||||
|
||||
作者:[Staff Writer ][a]
|
||||
作者:[Staff Writer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,85 +1,85 @@
|
||||
du 及 df 命令的使用(附带示例)
|
||||
======
|
||||
在本文中,我将讨论 du 和 df 命令。du 和 df 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
|
||||
|
||||
**(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
|
||||
在本文中,我将讨论 `du` 和 `df` 命令。`du` 和 `df` 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
|
||||
|
||||
**(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
|
||||
- **(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
|
||||
- **(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
|
||||
|
||||
### du 命令
|
||||
|
||||
du(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。du 命令在与各种选项一起使用时能以多种格式提供结果。
|
||||
`du`(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。`du` 命令在与各种选项一起使用时能以多种格式提供结果。
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
**1- 得到一个目录下所有子目录的磁盘使用概况**
|
||||
#### 1、 得到一个目录下所有子目录的磁盘使用概况
|
||||
|
||||
```
|
||||
$ du /home
|
||||
$ du /home
|
||||
```
|
||||
|
||||
![du command][4]
|
||||
|
||||
该命令的输出将显示 /home 中的所有文件和目录以及显示块大小。
|
||||
该命令的输出将显示 `/home` 中的所有文件和目录以及显示块大小。
|
||||
|
||||
**2- 以人类可读格式也就是 kb、mb 等显示文件/目录大小**
|
||||
#### 2、 以人类可读格式也就是 kb、mb 等显示文件/目录大小
|
||||
|
||||
```
|
||||
$ du -h /home
|
||||
$ du -h /home
|
||||
```
|
||||
|
||||
![du command][6]
|
||||
|
||||
**3- 目录的总磁盘大小**
|
||||
#### 3、 目录的总磁盘大小
|
||||
|
||||
```
|
||||
$ du -s /home
|
||||
$ du -s /home
|
||||
```
|
||||
|
||||
![du command][8]
|
||||
|
||||
它是 /home 目录的总大小
|
||||
它是 `/home` 目录的总大小
|
||||
|
||||
### df 命令
|
||||
|
||||
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。
|
||||
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。(LCTT 译注:`df` 可能应该是 disk free 的简称。)
|
||||
|
||||
下面是一些例子。
|
||||
|
||||
**1- 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。**
|
||||
#### 1、 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。
|
||||
|
||||
```
|
||||
$ df
|
||||
$ df
|
||||
```
|
||||
|
||||
|
||||
![df command][10]
|
||||
|
||||
**2- 人类可读格式的信息**
|
||||
#### 2、 人类可读格式的信息
|
||||
|
||||
```
|
||||
$ df -h
|
||||
$ df -h
|
||||
```
|
||||
|
||||
![df command][12]
|
||||
|
||||
上面的命令以人类可读格式显示信息。
|
||||
|
||||
**3- 显示特定分区的信息**
|
||||
#### 3、 显示特定分区的信息
|
||||
|
||||
```
|
||||
$ df -hT /etc
|
||||
$ df -hT /etc
|
||||
```
|
||||
|
||||
![df command][14]
|
||||
|
||||
-hT 加上目标目录将以可读格式显示 /etc 的信息。
|
||||
`-hT` 加上目标目录将以可读格式显示 `/etc` 的信息。
|
||||
|
||||
虽然 du 和 df 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
|
||||
虽然 `du` 和 `df` 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
|
||||
|
||||
另外,[**在这**][15]阅读我的其他帖子,在那里我分享了一些其他重要和经常使用的 Linux 命令。
|
||||
|
||||
如往常一样,你的评论和疑问是受欢迎的,因此在下面留下你的评论和疑问,我会回复你。
|
||||
如往常一样,欢迎你留下评论和疑问,因此在下面留下你的评论和疑问,我会回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -87,7 +87,7 @@ via: http://linuxtechlab.com/du-df-commands-examples/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
136
published/20180131 10 things I love about Vue.md
Normal file
136
published/20180131 10 things I love about Vue.md
Normal file
@ -0,0 +1,136 @@
|
||||
我喜欢 Vue 的 10 个方面
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
我喜欢 Vue。当我在 2016 年第一次接触它时,也许那时我已经对 JavaScript 框架感到疲劳了,因为我已经具有Backbone、Angular、React 等框架的经验,没有太多的热情去尝试一个新的框架。直到我在 Hacker News 上读到一份评论,其描述 Vue 是类似于“新 jQuery” 的 JavaScript 框架,从而激发了我的好奇心。在那之前,我已经相当满意 React 这个框架,它是一个很好的框架,建立于可靠的设计原则之上,围绕着视图模板、虚拟 DOM 和状态响应等技术。而 Vue 也提供了这些重要的内容。
|
||||
|
||||
在这篇文章中,我旨在解释为什么 Vue 适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家使用 Vue 开发现代 JavaScript 应用一些灵感。
|
||||
|
||||
### 1、 极少的模板语法
|
||||
|
||||
Vue 默认提供的视图模板语法是极小的、简洁的和可扩展的。像其他 Vue 部分一样,可以很简单的使用类似 JSX 一样语法,而不使用标准的模板语法(甚至有官方文档说明了如何做),但是我觉得没必要这么做。JSX 有好的方面,也有一些有依据的批评,如混淆了 JavaScript 和 HTML,使得很容易导致在模板中出现复杂的代码,而本来应该分开写在不同的地方的。
|
||||
|
||||
Vue 没有使用标准的 HTML 来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
|
||||
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
我也喜欢 Vue 提供的简短绑定语法,`:` 用于在模板中绑定数据变量,`@` 用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
|
||||
|
||||
### 2、 单文件组件
|
||||
|
||||
大多数人使用 Vue,都使用“单文件组件”。本质上就是一个 .vue 文件对应一个组件,其中包含三部分(CSS、HTML和JavaScript)。
|
||||
|
||||
这种技术结合是对的。它让人很容易在一个单独的地方了解每个组件,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中 JavaScript、CSS 和 HTML 代码占了很多行,那么就到了进一步模块化的时刻了。
|
||||
|
||||
在使用 Vue 组件中的 `<style>` 标签时,我们可以添加 `scoped` 属性。这会让整个样式完全的封装到当前组件,意思是在组件中如果我们写了 `.name` 的 css 选择器,它不会把样式应用到其他组件中。我非常喜欢这种方式来应用样式而不是像其他主要框架流行在 JS 中编写 CSS 的方式。
|
||||
|
||||
关于单文件组件另一个好处是 .vue 文件实际上是一个有效的 HTML 5 文件。`<template>`、 `<script>`、 `<style>` 都是 w3c 官方规范的标签。这就表示很多如 linters (LCTT 译注:一种代码检查工具插件)这样我们用于开发过程中的工具能够开箱即用或者添加一些适配后使用。
|
||||
|
||||
### 3、 Vue “新的 jQuery”
|
||||
|
||||
事实上,这两个库不相似而且用于做不同的事。让我提供给你一个很精辟的类比(我实际上非常喜欢描述 Vue 和 jQuery 之间的关系):披头士乐队和齐柏林飞船乐队(LCTT 译注:两个都是英国著名的乐队)。披头士乐队不需要介绍,他们是 20 世纪 60 年代最大的和最有影响力的乐队。但很难说披头士乐队是 20 世纪 70 年代最大的乐队,因为有时这个荣耀属于是齐柏林飞船乐队。你可以说两个乐队之间有着微妙的音乐联系或者说他们的音乐是明显不同的,但两者一些先前的艺术和影响力是不可否认的。也许 21 世纪初 JavaScript 的世界就像 20 世纪 70 年代的音乐世界一样,随着 Vue 获得更多关注使用,只会吸引更多粉丝。
|
||||
|
||||
一些使 jQuery 牛逼的哲学理念在 Vue 中也有呈现:非常容易的学习曲线但却具有基于现代 web 标准构建牛逼 web 应用所有你需要的功能。Vue 的核心本质上就是在 JavaScript 对象上包装了一层。
|
||||
|
||||
### 4、 极易扩展
|
||||
|
||||
正如前述,Vue 默认使用标准的 HTML、JS 和 CSS 构建组件,但可以很容易插入其他技术。如果我们想使用pug(LCTT译注:一款功能丰富的模板引擎,专门为 Node.js 平台开发)替换 HTML 或者使用 Typescript(LCTT译注:一种由微软开发的编程语言,是 JavaScript 的一个超集)替换 js 或者 Sass (LCTT 译注:一种 CSS 扩展语言)替换 CSS,只需要安装相关的 node 模块和在我们的单文件组件中添加一个属性到相关的标签即可。你甚至可以在一个项目中混合搭配使用 —— 如一些组件使用 HTML 其他使用 pug ——然而我不太确定这么做是最好的做法。
|
||||
|
||||
### 5、 虚拟 DOM
|
||||
|
||||
虚拟 DOM 是很好的技术,被用于现如今很多框架。其意味着这些框架能够做到根据我们状态的改变来高效的完成 DOM 更新,减少重新渲染,从而优化我们应用的性能。现如今每个框架都有虚拟 DOM 技术,所以虽然它不是什么独特的东西,但它仍然很出色。
|
||||
|
||||
### 6、 Vuex 很棒
|
||||
|
||||
对于大多数应用,管理状态成为一个棘手的问题,单独使用一个视图库不能解决这个问题。Vue 使用 Vuex 库来解决这个问题。Vuex 很容易构建而且和 Vue 集成的很好。熟悉 redux(另一个管理状态的库)的人学习 Vuex 会觉得轻车熟路,但是我发现 Vue 和 Vuex 集成起来更加简洁。最新 JavaScript 草案中(LCTT 译注:应该是指 ES7)提供了对象展开运算符(LCTT 译注:符号为 `...`),允许我们在状态或函数中进行合并,以操纵从 Vuex 到需要它的 Vue 组件中的状态。
|
||||
|
||||
### 7、 Vue 的命令行界面(CLI)
|
||||
|
||||
Vue 提供的命令行界面非常不错,很容易用 Vue 搭建一个基于 Webpack(LCTT 译注:一个前端资源加载/打包工具)的项目。单文件组件支持、babel(LCTT 译注:js 语法转换器)、linting(LCTT译注:代码检查工具)、测试工具支持,以及合理的项目结构,都可以在终端中一行命令创建。
|
||||
|
||||
然而有一个命令,我在 CLI 中没有找到,那就是 `vue build`。
|
||||
|
||||
> 如:
|
||||
> ```
|
||||
echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o
|
||||
```
|
||||
|
||||
`vue build` 命令构建和运行组件并在浏览器中测试看起来非常简单。很不幸这个命令后来在 Vue 中删除了,现在推荐使用 Poi。Poi 本质上是在 Webpack 工具上封装了一层,但我不认我它像推特上说的那样简单。
|
||||
|
||||
### 8、 重新渲染优化
|
||||
|
||||
使用 Vue,你不必手动声明 DOM 的哪部分应该被重新渲染。我从来都不喜欢操纵 React 组件的渲染,像在`shouldComponentUpdate` 方法中停止整个 DOM 树重新渲染这种。Vue 在这方面非常巧妙。
|
||||
|
||||
### 9、 容易获得帮助
|
||||
|
||||
Vue 已经达到了使用这个框架来构建各种各样的应用的一种群聚效应。开发文档非常完善。如果你需要进一步的帮助,有多种渠道可用,每个渠道都有很多活跃开发者:stackoverflow、discord、twitter 等。相对于其他用户量少的框架,这就应该给你更多的信心来使用Vue构建应用。
|
||||
|
||||
### 10、 多机构维护
|
||||
|
||||
我认为,一个开源库,在发展方向方面的投票权利没有被单一机构操纵过多,是一个好事。就如同 React 的许可证问题(现已解决),Vue 就不可能涉及到。
|
||||
|
||||
总之,作为你接下来要开发的任何 JavaScript 项目,我认为 Vue 都是一个极好的选择。Vue 可用的生态圈比我博客中涉及到的其他库都要大。如果想要更全面的产品,你可以关注 Nuxt.js。如果你需要一些可重复使用的样式组件你可以关注类似 Vuetify 的库。
|
||||
|
||||
Vue 是 2017 年增长最快的库之一,我预测在 2018 年增长速度不会放缓。
|
||||
|
||||
如果你有空闲的 30 分钟,为什么不尝试下 Vue,看它可以给你提供什么呢?
|
||||
|
||||
P.S. — 这篇文档很好的展示了 Vue 和其他框架的比较:[https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
File diff suppressed because it is too large
Load Diff
50
published/20180131 An old DOS BBS in a Docker container.md
Normal file
50
published/20180131 An old DOS BBS in a Docker container.md
Normal file
@ -0,0 +1,50 @@
|
||||
Docker 容器中的老式 DOS BBS
|
||||
======
|
||||
|
||||
不久前,我写了一篇[我的 Debian Docker 基本映像][1]。我决定进一步扩展这个概念:在 Docker 中运行 DOS 程序。
|
||||
|
||||
但首先,来看一张截图:
|
||||
|
||||
![][2]
|
||||
|
||||
事实证明这是可能的,但很难。我使用了所有三种主要的 DOS 模拟器(dosbox、qemu 和 dosemu)。我让它们都能在 Docker 容器中运行,但有很多有趣的问题需要解决。
|
||||
|
||||
都要做的事是在 DOS 环境下提供一个伪造的调制解调器。它需要作为 TCP 端口暴露在容器外部。有很多方法可以做到 —— 我使用的是 tcpser。dosbox 有一个 TCP 调制解调器接口,但事实证明,这样做太问题太多了。
|
||||
|
||||
挑战来自你希望能够一次接受多个传入 telnet(或 TCP)连接。DOS 不是一个多任务操作系统,所以当时有很多黑客式的方法。一种是有多台物理机,每个有一根传入电话线。或者它们可能会在 [DESQview][3]、OS/2 甚至 Windows 3.1 等多任务层下运行多个伪 DOS 实例。
|
||||
|
||||
(注意:我刚刚了解到 [DESQview/X][4],它将 DESQview 与 X11R5 集成在一起,并[取代了 Windows 3 驱动程序][5]来把 Windows 作为 X 应用程序运行。)
|
||||
|
||||
出于各种原因,我不想尝试在 Docker 中运行其中任何一个系统。这让我模拟了原来的多物理节点设置。从理论上讲,非常简单 —— 运行一组 DOS 实例,每个实例最多使用 1MB 的模拟 RAM,这就行了。但是这里面临挑战。
|
||||
|
||||
在多物理节点设置中,你需要某种文件共享,因为你的节点需要访问共享的消息和文件存储。在老式的 DOS 时代,有很多笨重的方法可以做到这一点 —— [Netware][6]、[LAN manager][7],甚至一些 PC NFS 客户端。我没有访问 Netware。我尝试了 DOS 中的 Microsoft LM 客户端,与在 Docker 容器内运行的 Samba 服务器交互。这样可以使用,但 LM 客户端即使有各种高内存技巧还是占用了很多内存,BBS 软件也无法运行。我无法在多个 dosbox 实例中挂载底层文件系统,因为 dosbox 缓存不兼容。
|
||||
|
||||
这就是为什么我使用 dosemu 的原因。除了有比 dosbox 更完整的模拟器之外,它还有一种共享主机文件系统的方式。
|
||||
|
||||
所以,所有这一切都在此:[jgoerzen/docker-bbs-renegade][8]。
|
||||
|
||||
我还为其他想做类似事情的人准备了构建块:[docker-dos-bbs][9] 和底层 [docker-dosemu][10]。
|
||||
|
||||
意外的收获是,我也试图了在 Joyent 的 Triton(基于 Solaris 的 SmartOS)下运行它。让我感到高兴的印象是,几乎可以在这下面工作。是的,在 Solaris 机器上的一个基于 Linux 的 DOS 模拟器的容器中运行 Renegade DOS BBS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
@ -0,0 +1,119 @@
|
||||
如何在使用 Vim 时访问/查看 Python 帮助
|
||||
======
|
||||
|
||||
我是一名新的 Vim 编辑器用户。我用它编写 Python 代码。有没有办法在 vim 中查看 Python 文档而无需访问互联网?假设我的光标在 Python 的 `print` 关键字下,然后按下 F1,我想查看关键字 `print` 的帮助。如何在 vim 中显示 python `help()` ?如何在不离开 vim 的情况下调用 `pydoc3`/`pydoc` 寻求帮助?
|
||||
|
||||
`pydoc` 或 `pydoc3` 命令可以根据 Python 关键字、主题、函数、模块或包的名称显示文本文档,或在模块内或包中的模块对类或函数的引用。你可以从 Vim 中调用 `pydoc`。让我们看看如何在 Vim 编辑器中使用 `pydoc` 访问 Python 文档。
|
||||
|
||||
### 使用 pydoc 访问 python 帮助
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
pydoc keyword
|
||||
pydoc3 keyword
|
||||
pydoc len
|
||||
pydoc print
|
||||
```
|
||||
|
||||
编辑你的 `~/.vimrc`:
|
||||
|
||||
```
|
||||
$ vim ~/.vimrc
|
||||
```
|
||||
|
||||
为 `pydoc3` 添加以下配置(python v3.x 文档)。在正常模式下创建 `H` 键的映射:
|
||||
|
||||
```
|
||||
nnoremap <buffer> H :<C-u>execute "!pydoc3 " . expand("<cword>")<CR>
|
||||
```
|
||||
|
||||
保存并关闭文件。打开 Vim 编辑器:
|
||||
|
||||
```
|
||||
$ vim file.py
|
||||
```
|
||||
|
||||
写一些代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
x=5
|
||||
y=10
|
||||
z=x+y
|
||||
print(z)
|
||||
print("Hello world")
|
||||
```
|
||||
|
||||
将光标置于 Python 关键字 `print` 的下方,然后按下 `Shift`,然后按 `H`。你将看到下面的输出:
|
||||
|
||||
[![Access Python Help Within Vim][1]][1]
|
||||
|
||||
*按 H 查看 Python 关键字 print 的帮助*
|
||||
|
||||
### 如何在使用 Vim 时查看 python 帮助
|
||||
|
||||
[jedi-vim][2] 是一个绑定自动补全库 Jed 的 Vim 插件。它可以做很多事情,包括当你按下 `Shift` 后跟 `K` (即按大写 `K`) 就显示关键字的帮助。
|
||||
|
||||
#### 如何在 Linux 或类 Unix 系统上安装 jedi-vim
|
||||
|
||||
使用 [pathogen][3]、[vim-plug][4] 或 [Vundle][5] 安装 jedi-vim。我使用的是 vim-plug。在 `~/.vimrc` 中添加以下行:
|
||||
|
||||
```
|
||||
Plug 'davidhalter/jedi-vim'
|
||||
```
|
||||
|
||||
保存并关闭文件。启动 Vim 并输入:
|
||||
|
||||
```
|
||||
PlugInstall
|
||||
```
|
||||
|
||||
在 Arch Linux 上,你还可以使用 `pacman` 命令从官方仓库中的 vim-jedi 安装 jedi-vim:
|
||||
|
||||
```
|
||||
$ sudo pacman -S vim-jedi
|
||||
```
|
||||
|
||||
它也可以在 Debian(比如 8)和 Ubuntu( 比如 14.04)上使用 [apt-get command][6]/[apt-get command][7] 安装 vim-python-jedi:
|
||||
|
||||
```
|
||||
$ sudo apt install vim-python-jedi
|
||||
```
|
||||
|
||||
在 Fedora Linux 上,它可以用 `dnf` 安装 vim-jedi:
|
||||
|
||||
```
|
||||
$ sudo dnf install vim-jedi
|
||||
```
|
||||
|
||||
Jedi 默认是自动初始化的。所以你不需要进一步的配置。要查看 Documentation/Pydoc,请按 `K`。它将弹出帮助窗口:
|
||||
|
||||
[![How to view python help when using vim][8]][8]
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,也是经验丰富的系统管理员和 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-access-view-python-help-when-using-vim/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Access-Python-Help-Within-Vim.gif
|
||||
[2]:https://github.com/davidhalter/jedi-vim
|
||||
[3]:https://github.com/tpope/vim-pathogen
|
||||
[4]:https://www.cyberciti.biz/programming/vim-plug-a-beautiful-and-minimalist-vim-plugin-manager-for-unix-and-linux-users/
|
||||
[5]:https://github.com/gmarik/vundle
|
||||
[6]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-view-Python-Documentation-using-pydoc-within-vim-on-Linux-Unix.jpg
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,18 +1,18 @@
|
||||
如何检查你的 Linux PC 是否存在 Meltdown 或者 Spectre 漏洞
|
||||
如何检查你的 Linux 系统是否存在 Meltdown 或者 Spectre 漏洞
|
||||
======
|
||||
|
||||

|
||||
|
||||
Meltdown 和 Specter 漏洞的最恐怖的现实之一是它们涉及非常广泛。几乎每台现代计算机都会受到一些影响。真正的问题是_你_是否受到了影响?每个系统都处于不同的脆弱状态,具体取决于已经或者还没有打补丁的软件。
|
||||
|
||||
由于 Meltdown 和 Spectre 都是相当新的,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
由于 Meltdown 和 Spectre 都是相当新的漏洞,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
|
||||
### 简单测试
|
||||
|
||||
顶级的 Linux 内核开发人员之一提供了一种简单的方式来检查系统在 Meltdown 和 Specter 漏洞方面的状态。它是简单的,也是最简洁的,但它不适用于每个系统。有些发行版不支持它。即使如此,也值得一试。
|
||||
|
||||
```
|
||||
grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
|
||||
```
|
||||
|
||||
![Kernel Vulnerability Check][1]
|
||||
@ -24,24 +24,24 @@ grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
如果上面的方法不适合你,或者你希望看到更详细的系统报告,一位开发人员已创建了一个 shell 脚本,它将检查你的系统来查看系统收到什么漏洞影响,还有做了什么来减轻 Meltdown 和 Spectre 的影响。
|
||||
|
||||
要得到脚本,请确保你的系统上安装了 Git,然后将脚本仓库克隆到一个你不介意运行它的目录中。
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
git clone https://github.com/speed47/spectre-meltdown-checker.git
|
||||
|
||||
```
|
||||
|
||||
这不是一个大型仓库,所以它应该只需要几秒钟就克隆完成。完成后,输入新创建的目录并运行提供的脚本。
|
||||
|
||||
```
|
||||
cd spectre-meltdown-checker
|
||||
./spectre-meltdown-checker.sh
|
||||
|
||||
```
|
||||
|
||||
你会在中断看到很多输出。别担心,它不是太难查看。首先,脚本检查你的硬件,然后运行三个漏洞:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
你会在终端看到很多输出。别担心,它不是太难理解。首先,脚本检查你的硬件,然后运行三个漏洞检查:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
|
||||
![Meltdown Spectre Check Script Ubuntu][2]
|
||||
|
||||
每个部分为你提供潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
每个部分为你提供了潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
|
||||
### 这意味着什么
|
||||
|
||||
@ -53,7 +53,7 @@ via: https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,102 @@
|
||||
如何在 Linux 上运行你自己的公共时间服务器
|
||||
======
|
||||
|
||||

|
||||
|
||||
最重要的公共服务之一就是<ruby>报时<rt>timekeeping</rt></ruby>,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。这里学习一下如何运行你自己的时间服务器,为基础公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间][1] 去学习如何设置一台局域网时间服务器)
|
||||
|
||||
### 著名的时间服务器滥用事件
|
||||
|
||||
就像现实生活中任何一件事情一样,即便是像时间服务器这样的公益项目,也会遭受不称职的或者恶意的滥用。
|
||||
|
||||
消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,NetGear 在它们的路由器中硬编码了威斯康星大学的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次威斯康星大学的 NTP 服务器。Netgear 给威斯康星大学捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
|
||||
|
||||
对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的目标受害者的源地址向时间服务器发送请求,称为反射攻击;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的源地址受到轰炸。放大攻击是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
|
||||
|
||||
那么,如何保护提供公益服务的公共 NTP 服务器呢?从使用 NTP 4.2.7p26 或者更新的版本开始,它们可以帮助你的 Linux 发行版不会发生前面所说的这种问题,因为它们都是在 2010 年以后发布的。这个发行版都默认禁用了最常见的滥用攻击。目前,[最新版本是 4.2.8p10][2],它发布于 2017 年。
|
||||
|
||||
你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞宣称来自你的网络的数据包进入你的网络,以及拦截发送到伪造返回地址的出站数据包。入站过滤器可以帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info][3] 了解更多信息。
|
||||
|
||||
### 层级为 0、1、2 的时间服务器
|
||||
|
||||
NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与世界标准时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。<ruby>层次<rt>Stratum</rt></ruby> 0 包含主报时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
|
||||
|
||||
过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池][4],它使用轮询的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不用使用这些池地址。
|
||||
|
||||
### 公共 NTP 服务器配置
|
||||
|
||||
运行一台公共 NTP 服务器只有两步:设置你的服务器,然后申请加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道这意味着什么。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
|
||||
|
||||
你需要一个静态的公共 IP 地址,一个至少 512Kb/s 带宽的、可靠的、持久的因特网连接。NTP 使用的是 UDP 的 123 端口。它对机器本身要求并不高,很多管理员在其它的面向公共的服务器(比如,Web 服务器)上顺带架设了 NTP 服务。
|
||||
|
||||
配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则][5] 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers][6] 中选择 4 到 7 个层级 2 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
|
||||
|
||||
以下的 `/etc/ntp.conf` 配置示例文件,包括了 IPv4 和 IPv6,以及基本的安全防护:
|
||||
|
||||
```
|
||||
# stratum 2 server list
|
||||
server servername_1 iburst
|
||||
server servername_2 iburst
|
||||
server servername_3 iburst
|
||||
server servername_4 iburst
|
||||
server servername_5 iburst
|
||||
|
||||
# access restrictions
|
||||
restrict -4 default kod noquery nomodify notrap nopeer limited
|
||||
restrict -6 default kod noquery nomodify notrap nopeer limited
|
||||
|
||||
# Allow ntpq and ntpdc queries only from localhost
|
||||
restrict 127.0.0.1
|
||||
restrict ::1
|
||||
```
|
||||
|
||||
启动你的 NTP 服务器,让它运行几分钟,然后测试它对远程服务器的查询:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
=================================================================
|
||||
+tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
|
||||
+PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
|
||||
*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
|
||||
+time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
|
||||
|
||||
```
|
||||
|
||||
目前表现很好。现在从另一台 PC 上使用你的 NTP 服务器名字进行测试。以下的示例是一个正确的输出。如果有不正确的地方,你将看到一些错误信息。
|
||||
|
||||
```
|
||||
$ ntpdate -q yourservername
|
||||
server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
|
||||
server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
|
||||
server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
|
||||
server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
|
||||
26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
|
||||
```
|
||||
|
||||
一旦你的服务器运行的很好,你就可以向 [manage.ntppool.org][7] 申请加入池中。
|
||||
|
||||
查看官方的手册 [分布式网络时间服务器(NTP)][8] 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][9] 学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://linux.cn/article-9462-1.html
|
||||
[2]:http://www.ntp.org/downloads.html
|
||||
[3]:http://www.bcp38.info/index.php/Main_Page
|
||||
[4]:http://www.pool.ntp.org/en/use.html
|
||||
[5]:http://support.ntp.org/bin/view/Servers/RulesOfEngagement
|
||||
[6]:http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo
|
||||
[7]:https://manage.ntppool.org/manage
|
||||
[8]:https://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,114 +1,94 @@
|
||||
如何使用 Seahorse 管理 PGP 和 SSH 密钥
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。[Creative Commons Zero][6]
|
||||
|
||||
安全无异于内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是当你可以采用几种方法和技术去确保你的桌面或者服务器系统的安全时,你为什么还要停止使用差不多已经接受的平台呢?
|
||||
> 学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。
|
||||
|
||||
其中一项技术涉及到密钥 —在 PGP 和 SSH 中,PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
|
||||
安全即内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是为什么要止步于仅仅采用该平台,你还可以采用多种方法和技术去确保你的桌面或者服务器系统的安全。
|
||||
|
||||
当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于摆脱命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平因此,使用 GUI!
|
||||
其中一项技术涉及到密钥 —— 用在 PGP 和 SSH 中。PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
|
||||
|
||||
当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于脱离命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平,因此,使用 GUI 吧!
|
||||
|
||||
在本文中,我将带你探索如何使用 [Seahorse][14] GUI 工具来管理 PGP 和 SSH 密钥。Seahorse 有非常强大的功能,它可以:
|
||||
|
||||
* 加密/解密/签名文件和文本。
|
||||
|
||||
* 管理你的密钥和密钥对。
|
||||
|
||||
* 同步你的密钥和密钥对到远程密钥服务器。
|
||||
|
||||
* 签名和发布密钥。
|
||||
|
||||
* 缓存你的密码。
|
||||
|
||||
* 备份密钥和密钥对。
|
||||
|
||||
* 在任何一个 GDK 支持的格式中添加一个图像作为一个 OpenPGP photo ID。
|
||||
|
||||
* 创建、配置、和缓存 SSH 密钥。
|
||||
|
||||
对于那些不了解 Seahorse 的人来说,它是一个在 GNOME 密钥对中管理加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面上。并且由于 Seahorse 是在标准仓库中创建的,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。因此,你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
|
||||
对于那些不了解 Seahorse 的人来说,它是一个管理 GNOME 钥匙环中的加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面环境上。并且由于 Seahorse 可以在标准的仓库中找到,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
|
||||
|
||||
我们开始去使用它吧。
|
||||
|
||||
### PGP 密钥
|
||||
|
||||
我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(使用一些工具,像 [Thunderbird][15] 的 [Enigmail][16] 或者使用 [Evolution][17] 内置的加密功能)。一个 PGP 密钥也可以用于加密文件。任何人使用你的公钥都可以解密你的电子邮件和文件。没有 PGP 密钥是做不到的。
|
||||
我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(通过一些工具,像 [Thunderbird][15] 的 [Enigmail][16] 或者使用 [Evolution][17] 内置的加密功能)。PGP 密钥也可以用于加密文件。任何人都可以使用你的公钥加密电子邮件和文件发给你(LCTT 译注:原文此处“加密”误作“解密”)。没有 PGP 密钥是做不到的。
|
||||
|
||||
使用 Seahorse 创建一个新的 PGP 密钥对是非常简单的。以下是操作步骤:
|
||||
|
||||
1. 打开 Seahorse 应用程序
|
||||
|
||||
2. 在主面板的左上角点击 + 按钮
|
||||
|
||||
3. 选择 PGP Key(如图 1 )
|
||||
|
||||
4. 点击 Continue
|
||||
|
||||
2. 在主面板的左上角点击 “+” 按钮
|
||||
3. 选择 “<ruby>PGP 密钥<rt>PGP Key</rt></ruby>”(如图 1 )
|
||||
4. 点击 “<ruby>继续<rt>Continue</rt></ruby>”
|
||||
5. 当提示时,输入完整的名字和电子邮件地址
|
||||
|
||||
6. 点击 Create
|
||||
|
||||
6. 点击 “<ruby>创建<rt>Create</rt></ruby>”
|
||||
|
||||

|
||||
图 1:使用 Seahorse 创建一个 PGP 密钥。[Used with permission][1]
|
||||
|
||||
在创建你的 PGP 密钥期间,你可以点击 Advanced key options 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。
|
||||
*图 1:使用 Seahorse 创建一个 PGP 密钥。*
|
||||
|
||||
在创建你的 PGP 密钥期间,你可以点击 “<ruby>高级密钥选项<rt>Advanced key options</rt></ruby>” 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。
|
||||
|
||||

|
||||
图 2:PGP 密钥高级选项[Used with permission][2]
|
||||
|
||||
*图 2:PGP 密钥高级选项*
|
||||
|
||||
增加注释部分可以很方便帮你记住密钥的用途(或者其它的信息)。
|
||||
要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 Names 和 Signatures 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 Sign 按钮然后(在结果窗口中)标识 how carefully you’ve checked this key 和 how others will see the signature(如图 3)。
|
||||
|
||||
要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 “<ruby>名字<rt>Names</rt></ruby>” 和 “<ruby>签名<rt>Signatures</rt></ruby>” 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 “<ruby>签名<rt>Sign</rt></ruby>” 按钮然后(在结果窗口中)指出 “<ruby>你是如何仔细的检查这个密钥的?<rt>how carefully you’ve checked this key?</rt></ruby>” 和 “<ruby>其他人将如何看到该签名<rt>how others will see the signature</rt></ruby>”(如图 3)。
|
||||
|
||||

|
||||
图 3:签名一个密钥表示信任级别。[Used with permission][3]
|
||||
|
||||
当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项工作并且完全信任这个重要的密钥。
|
||||
*图 3:签名一个密钥表示信任级别。*
|
||||
|
||||
谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 .asc 为后缀)。你的系统上有其他人的公钥,意味着你可以解密从他们那里发送给你的电子邮件和文件。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug][18]。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 olivia.asc,你想去导入到 Seahorse 中使用它,你将只能运行命令 gpg2 --import olivia.asc。那个密钥将出现在 GnuPG 密钥列表中。你可以打开密钥,点击 I trust signatures 按钮,然后在问题 how carefully you’ve checked the key 中,点击 Sign this key 按钮去标示。
|
||||
当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项签名工作并且完全信任这个重要的密钥。
|
||||
|
||||
谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 `.asc` 为后缀)。你的系统上有其他人的公钥,意味着你可以加密发送给他们的电子邮件和文件(LCTT 译注:原文将“加密”误作“解密”)。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug][18]。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 `olivia.asc`,你想去导入到 Seahorse 中使用它,你将只能运行命令 `gpg2 --import olivia.asc`。那个密钥将出现在 GnuPG 密钥列表中。你可以打开该密钥,点击 “<ruby>我信任签名<rt>I trust signatures</rt></ruby>” 按钮,然后在问题 “<ruby>你是如何仔细地检查该密钥的?<rt>how carefully you’ve checked the key</rt></ruby>” 中,点击 “<ruby>签名这个密钥<rt>Sign this key</rt></ruby>” 按钮去签名。
|
||||
|
||||
### SSH 密钥
|
||||
|
||||
现在我们来谈谈我认为 Seahorse 中最重要的一个方面 — SSH 密钥。Seahorse 不仅可以很容易地生成一个 SSH 密钥,而且它也可以很容易地将生成的密钥发送到服务器上,因此,你可以享受到 SSH 密钥验证的好处。下面是如何生成一个新的密钥以及如何导出它到一个远程服务器上。
|
||||
|
||||
1. 打开 Seahorse 应用程序
|
||||
|
||||
2. 点击 + 按钮
|
||||
|
||||
3. 选择 Secure Shell Key
|
||||
|
||||
4. 点击 Continue
|
||||
|
||||
2. 点击 “+” 按钮
|
||||
3. 选择 “Secure Shell Key”
|
||||
4. 点击 “Continue”
|
||||
5. 提供一个密钥描述信息
|
||||
|
||||
6. 点击 Set Up 去创建密钥
|
||||
|
||||
6. 点击 “Set Up” 去创建密钥
|
||||
7. 输入密钥的验证密钥
|
||||
|
||||
8. 点击 OK
|
||||
|
||||
9. 输入远程服务器地址和服务器上的登陆名(如图 4)
|
||||
|
||||
9. 输入远程服务器地址和服务器上的登录名(如图 4)
|
||||
10. 输入远程用户的密码
|
||||
|
||||
11. 点击 OK
|
||||
|
||||
|
||||

|
||||
图 4:上传一个 SSH 密钥到远程服务器。[Used with permission][4]
|
||||
|
||||
新密钥将上传到远程服务器上以准备好使用它。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
|
||||
*图 4:上传一个 SSH 密钥到远程服务器。*
|
||||
|
||||
需要注意的是,在创建一个 SSH 密钥期间,你可以点击 Advanced key options 去展开它,配置加密类型和密钥长度(如图 5)。
|
||||
新密钥将上传到远程服务器上以备使用。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
|
||||
|
||||
需要注意的是,在创建一个 SSH 密钥期间,你可以点击 “<ruby>高级密钥选项<rt>Advanced key options</rt></ruby>”去展开它,配置加密类型和密钥长度(如图 5)。
|
||||
|
||||

|
||||
图 5:高级 SSH 密钥选项。[Used with permission][5]
|
||||
|
||||
*图 5:高级 SSH 密钥选项。*
|
||||
|
||||
### Linux 新手必备
|
||||
|
||||
@ -120,9 +100,9 @@
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-manage-pgp-and-ssh-keys-seahorse
|
||||
|
||||
作者:[JACK WALLEN ][a]
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxt](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,21 @@
|
||||
如何检查你的计算机使用的是 UEFI 还是 BIOS
|
||||
======
|
||||
**简介:一个快速的教程,来告诉你的系统使用的是现代 UEFI 或者传统 BIOS。同时提供 Windows 和 Linux 的说明。**
|
||||
|
||||
当你尝试[双启动 Linux 和 Windows ][1]时,你需要知道系统上是否有 UEFI 或 BIOS 启动模式。它可以帮助你决定安装 Linux 的分区。
|
||||
**简介:这是一个快速的教程,来告诉你的系统使用的是现代 UEFI 或者传统 BIOS。同时提供 Windows 和 Linux 的说明。**
|
||||
|
||||
当你尝试[双启动 Linux 和 Windows][1] 时,你需要知道系统上是否有 UEFI 或 BIOS 启动模式。它可以帮助你决定安装 Linux 的分区。
|
||||
|
||||
我不打算在这里讨论[什么是 BIOS][2]。不过,我想通过 BIOS 告诉你一些 [UEFI][3] 的优点。
|
||||
|
||||
UEFI 或者说统一可扩展固件接口旨在克服 BIO S的某些限制。它增加了使用大于 2TB 磁盘的能力,并具有独立于 CPU 的体系结构和驱动程序。采用模块化设计,即使没有安装操作系统,也可以支持远程诊断和修复,以及灵活的无操作系统环境(包括网络功能)。
|
||||
UEFI 即(<ruby>统一可扩展固件接口<rt>Unified Extensible Firmware Interface</rt></ruby>)旨在克服 BIOS 的某些限制。它增加了使用大于 2TB 磁盘的能力,并具有独立于 CPU 的体系结构和驱动程序。采用模块化设计,即使没有安装操作系统,也可以支持远程诊断和修复,以及灵活的无操作系统环境(包括网络功能)。
|
||||
|
||||
### UEFI 优于 BIOS 的点
|
||||
### UEFI 优于 BIOS 的地方
|
||||
|
||||
* UEFI在初始化硬件时速度更快。
|
||||
* UEFI 在初始化硬件时速度更快。
|
||||
* 提供安全启动,这意味着你在加载操作系统之前加载的所有内容都必须签名。这为你的系统提供了额外的保护层。
|
||||
* BIOS 不支持超过 2TB 的分区。
|
||||
* 最重要的是,如果你是双引导,那么建议始终在相同的引导模式下安装两个操作系统。
|
||||
|
||||
|
||||
|
||||
![How to check if system has UEFI or BIOS][4]
|
||||
|
||||
如果试图查看你的系统运行的是 UEFI 还是 BIOS,这并不难。首先让我从 Windows 开始,然后看看如何在 Linux 系统上查看用的是 UEFI 还是 BIOS。
|
||||
@ -27,39 +26,39 @@ UEFI 或者说统一可扩展固件接口旨在克服 BIO S的某些限制。它
|
||||
|
||||
![][5]
|
||||
|
||||
**另一个方法**:如果你使用 Windows 10,可以打开文件资源管理器并进入到 C:\Windows\Panther 来查看你使用的是 UEFI 还是 BIOS。打开文件 setupact.log 并搜索下面的字符串。
|
||||
**另一个方法**:如果你使用 Windows 10,可以打开文件资源管理器并进入到 `C:\Windows\Panther` 来查看你使用的是 UEFI 还是 BIOS。打开文件 setupact.log 并搜索下面的字符串。
|
||||
|
||||
```
|
||||
Detected boot environment
|
||||
|
||||
```
|
||||
|
||||
我建议在 notepad++ 中打开这个文件,因为这是一个很大的文件和记事本可能挂起(至少它对我来说是 6GB )。
|
||||
我建议在 notepad++ 中打开这个文件,因为这是一个很大的文件,记事本很可能挂起(至少它对我来说是 6GB !)。
|
||||
|
||||
你会看到几行有用的信息。
|
||||
|
||||
```
|
||||
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect:FirmwareType 1.
|
||||
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect: Detected boot environment: BIOS
|
||||
|
||||
```
|
||||
|
||||
### 在 Linux 中检查使用的是 UEFI 还是 BIOS
|
||||
|
||||
最简单地找出使用的是 UEFI 还是 BIOS 的方法是查找 /sys/firmware/efi 文件夹。如果使用的 BIOS 那么文件夹不存在。
|
||||
最简单地找出使用的是 UEFI 还是 BIOS 的方法是查找 `/sys/firmware/efi` 文件夹。如果使用的 BIOS 那么该文件夹不存在。
|
||||
|
||||
![Find if system uses UEFI or BIOS on Ubuntu Linux][6]
|
||||
|
||||
**另一种方法**:安装名为 efibootmgr 的软件包。
|
||||
|
||||
在基于 Debian 和 Ubuntu 的发行版中,你可以使用以下命令安装 efibootmgr 包:
|
||||
|
||||
```
|
||||
sudo apt install efibootmgr
|
||||
|
||||
```
|
||||
|
||||
完成后,输入以下命令:
|
||||
|
||||
```
|
||||
sudo efibootmgr
|
||||
|
||||
```
|
||||
|
||||
如果你的系统支持 UEFI,它会输出不同的变量。如果没有,你将看到一条消息指出 EFI 变量不支持。
|
||||
@ -76,7 +75,7 @@ via: https://itsfoss.com/check-uefi-or-bios/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
LKRG:用于运行时完整性检查的可加载内核模块
|
||||
======
|
||||
![LKRG logo][1]
|
||||
|
||||
开源社区的人们正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 Linux 内核运行时防护(Linux Kernel Runtime Guard,简称:LKRG),它是一个在 Linux 内核执行运行时完整性检查的可加载内核模块(LKM)。
|
||||
|
||||
它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
|
||||
|
||||
LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
|
||||
|
||||
### 这个项目开发始于 2011 年,首个版本已经发布
|
||||
|
||||
因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,将会部署一个完整的漏洞利用缓减系统。
|
||||
|
||||
LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了一个“重新开发"阶段。
|
||||
|
||||
LKRG 的首个公开版本是 LKRG v0.0,它现在可以从 [这个页面][2] 下载使用。[这里][3] 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面][4]。
|
||||
|
||||
虽然 LKRG 仍然是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
|
||||
|
||||
### LKRG 是一个内核模块而不是一个补丁。
|
||||
|
||||
一个类似的项目是<ruby>附加内核监视器<rt>Additional Kernel Observer</rt></ruby>(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模块而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
|
||||
|
||||
而以内核模块的方式提供,可以在每个系统上更容易部署 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
|
||||
|
||||
LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
|
||||
|
||||
### 它并非是一个完美的解决方案
|
||||
|
||||
LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 “设计为**可旁通**的”,并且仅仅提供了“多元化安全” 的**一个**方面。
|
||||
|
||||
> 虽然 LKRG 可以防御许多已有的 Linux 内核漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
|
||||
|
||||
LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
|
||||
|
||||
### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
|
||||
|
||||
Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
|
||||
|
||||
经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
|
||||
|
||||
测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的“可旁通”的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
|
||||
|
||||
> 在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 “旁通”,并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/
|
||||
|
||||
作者:[Catalin Cimpanu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||
[1]:https://www.bleepstatic.com/content/posts/2018/02/04/LKRG-logo.png
|
||||
[2]:http://www.openwall.com/lkrg/
|
||||
[3]:http://openwall.info/wiki/p_lkrg/Main
|
||||
[4]:https://www.patreon.com/p_lkrg
|
||||
@ -1,113 +1,113 @@
|
||||
Python 中的 Hello World 和字符串操作
|
||||
初识 Python:Hello World 和字符串操作
|
||||
======
|
||||
|
||||
|
||||
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 github 上找到。
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 GitHub 上找到。
|
||||
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的[视频][3]。
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的视频。
|
||||
|
||||
[Python 的 Hello World 和字符串操作视频][2]
|
||||
- [Python 的 Hello World 和字符串操作视频][2]
|
||||
|
||||
#### ** 开始 (先决条件)
|
||||
### 开始 (先决条件)
|
||||
|
||||
在你的操作系统上安装 Anaconda(Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
首先在你的操作系统上安装 Anaconda (Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
|
||||
在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Mac 上安装 Anaconda: [链接][6]
|
||||
- 在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
在 Mac 上安装 Anaconda: [链接][6]
|
||||
|
||||
在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
#### 打开一个 Jupyter Notebook
|
||||
### 打开一个 Jupyter Notebook
|
||||
|
||||
打开你的终端(Mac)或命令行,并输入以下内容([请参考视频中的 1:16 处][8])来打开 Jupyter Notebook:
|
||||
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### 打印语句/Hello World
|
||||
### 打印语句/Hello World
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 `shift + 回车`来执行代码。
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 **shift + 回车**来执行代码。
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
打印输出 “Hello World!”
|
||||

|
||||
|
||||
#### 字符串和字符串操作
|
||||
*打印输出 “Hello World!”*
|
||||
|
||||
### 字符串和字符串操作
|
||||
|
||||
字符串是 Python 类的一种特殊类型。作为对象,在类中,你可以使用 `.methodName()` 来调用字符串对象的方法。字符串类在 Python 中默认是可用的,所以你不需要 `import` 语句来使用字符串对象接口。
|
||||
|
||||
字符串是 python 类的一种特殊类型。作为对象,在类中,你可以使用 .methodName() 来调用字符串对象的方法。字符串类在 python 中默认是可用的,所以你不需要 import 语句来使用字符串对象接口。
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
输出打印变量 firstVariable
|
||||
|
||||
|
||||
*输出打印变量 firstVariable*
|
||||
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 .lower()、.upper() 和 title() 方法输出
|
||||

|
||||
|
||||
*使用 .lower()、.upper() 和 title() 方法输出*
|
||||
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 split 方法输出(此例中以空格分隔)
|
||||
|
||||
|
||||
*使用 split 方法输出(此例中以空格分隔)*
|
||||
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
字符串连接
|
||||
|
||||
|
||||
#### 查询方法的功能
|
||||
*字符串连接*
|
||||
|
||||
### 查询方法的功能
|
||||
|
||||
对于新程序员,他们经常问你如何知道每种方法的功能。Python 提供了两种方法来实现。
|
||||
|
||||
1.(在不在 Jupyter Notebook 中都可用)使用 **help** 查询每个方法的功能。
|
||||
1、(在不在 Jupyter Notebook 中都可用)使用 `help` 查询每个方法的功能。
|
||||
|
||||
|
||||
|
||||
*查询每个方法的功能*
|
||||
|
||||
![][9]
|
||||
查询每个方法的功能
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
在 Jupyter 中查找每个方法的功能
|
||||
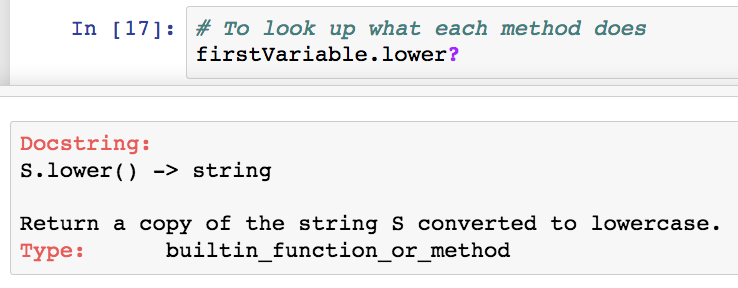
|
||||
|
||||
#### 结束语
|
||||
*在 Jupyter 中查找每个方法的功能*
|
||||
|
||||
如果你对本文或在[ YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [github][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
### 结束语
|
||||
|
||||
如果你对本文或在 [YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [GitHub][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -115,7 +115,7 @@ via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulati
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,93 @@
|
||||
Zsync:一个仅下载文件新的部分的传输工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
就算是网费每天变得越来越便宜,你也不应该重复下载相同的东西来浪费你的流量。一个很好的例子就是下载 Ubuntu 或任何 Linux 镜像的开发版本。如你所知,Ubuntu 开发人员每隔几个月就会发布一次日常构建、alpha、beta 版 ISO 镜像以供测试。在过去,一旦发布我就会下载这些镜像,并审查每个版本。现在不用了!感谢 Zsync 文件传输程序。现在可以仅下载 ISO 镜像新的部分。这将为你节省大量时间和 Internet 带宽。不仅时间和带宽,它将为你节省服务端和客户端的资源。
|
||||
|
||||
Zsync 使用与 Rsync 相同的算法,如果你会得到一份已有文件旧版本,它只下载该文件新的部分。 Rsync 主要用于在计算机之间同步数据,而 Zsync 则用于分发数据。简单地说,可以使用 Zsync 将中心的一个文件分发给数千个下载者。它在 Artistic License V2 许可证下发布,完全免费且开源。
|
||||
|
||||
### 安装 Zsync
|
||||
|
||||
Zsync 在大多数 Linux 发行版的默认仓库中有。
|
||||
|
||||
在 Arch Linux 及其衍生版上,使用命令安装它:
|
||||
```
|
||||
$ sudo pacman -S zsync
|
||||
```
|
||||
|
||||
在 Fedora 上,启用 Zsync 仓库:
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable ngompa/zsync
|
||||
```
|
||||
|
||||
并使用命令安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install zsync
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install zsync
|
||||
```
|
||||
|
||||
对于其他发行版,你可以从 [Zsync 下载页面][1]下载二进制打包文件,并手动编译安装它,如下所示。
|
||||
|
||||
```
|
||||
$ wget http://zsync.moria.org.uk/download/zsync-0.6.2.tar.bz2
|
||||
$ tar xjf zsync-0.6.2.tar.bz2
|
||||
$ cd zsync-0.6.2/
|
||||
$ configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
请注意,只有当人们提供 zsync 下载方式时,zsync 才有用。目前,Debian、Ubuntu(所有版本)的 ISO 镜像都有 .zsync 下载链接。例如,请访问以下链接。
|
||||
|
||||
你可能注意到,Ubuntu 18.04 LTS 每日构建版有直接的 ISO 和 .zsync 文件。如果你下载 .ISO 文件,则必须在 ISO 更新时下载完整的 ISO 文件。但是,如果你下载的是 .zsync 文件,那么 Zsync 以后仅会下载新的更改。你不需要每次都下载整个 ISO 映像。
|
||||
|
||||
.zsync 文件包含 zsync 程序所需的元数据。该文件包含 rsync 算法的预先计算的校验和。它在服务器上生成一次,然后由任意数量的下载器使用。要使用 Zsync 客户端程序下载 .zsync 文件,你只需执行以下操作:
|
||||
|
||||
```
|
||||
$ zsync <.zsync-file-URL>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ zsync http://cdimage.ubuntu.com/ubuntu/daily-live/current/bionic-desktop-amd64.iso.zsync
|
||||
```
|
||||
|
||||
如果你的系统中已有以前的镜像文件,那么 Zsync 将计算远程服务器中旧文件和新文件之间的差异,并仅下载新的部分。你将在终端看见计算过程一系列的点或星星。
|
||||
|
||||
如果你下载的文件的旧版本存在于当前工作目录,那么 Zsync 将只下载新的部分。下载完成后,你将看到两个镜像,一个你刚下载的镜像和以 .iso.zs-old 为扩展名的旧镜像。
|
||||
|
||||
如果没有找到相关的本地数据,Zsync 会下载整个文件。
|
||||
|
||||
|
||||
|
||||
你可以随时按 `CTRL-C` 取消下载过程。
|
||||
|
||||
试想一下,如果你直接下载 .ISO 文件或使用 torrent,每当你下载新镜像时,你将损失约 1.4GB 流量。因此,Zsync 不会下载整个 Alpha、beta 和日常构建映像,而只是在你的系统上下载了 ISO 文件的新部分,并在系统中有一个旧版本的拷贝。
|
||||
|
||||
今天就到这里。希望对你有帮助。我将很快另外写一篇有用的指南。在此之前,请保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/zsync-file-transfer-utility-download-new-parts-file/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://zsync.moria.org.uk/downloads
|
||||
@ -7,13 +7,13 @@ Linux 新用户?来试试这 8 款重要的软件
|
||||
|
||||
下面这些应用程序大多不是 Linux 独有的。如果有过使用 Windows/Mac 的经验,您很可能会熟悉其中一些软件。根据兴趣和需求,下面的程序可能不全符合您的要求,但是在我看来,清单里大多数甚至全部的软件,对于新用户开启 Linux 之旅都是有帮助的。
|
||||
|
||||
**相关链接** : [每一个 Linux 用户都应该使用的 11 个便携软件][1]
|
||||
**相关链接** : [每一个 Linux 用户都应该使用的 11 个可移植软件][1]
|
||||
|
||||
### 1. Chromium 网页浏览器
|
||||
|
||||
![linux-apps-01-chromium][2]
|
||||
|
||||
很难有一个不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
|
||||
几乎不会不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
|
||||
|
||||
### 2. LibreOffice
|
||||
|
||||
@ -21,13 +21,13 @@ Linux 新用户?来试试这 8 款重要的软件
|
||||
|
||||
[LibreOffice][6] 是一个开源办公套件,其包括文字处理(Writer)、电子表格(Calc)、演示(Impress)、数据库(Base)、公式编辑器(Math)、矢量图和流程图(Draw)应用程序。它与 Microsoft Office 文档兼容,如果其基本功能不能满足需求,您可以使用 [LibreOffice 拓展][7]。
|
||||
|
||||
LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
|
||||
LibreOffice 显然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
|
||||
|
||||
### 3. GIMP(GNU Image Manipulation Program、GUN 图像处理程序)
|
||||
### 3. GIMP(<ruby>GUN 图像处理程序<rt>GNU Image Manipulation Program</rt></ruby>)
|
||||
|
||||
![linux-apps-03-gimp][8]
|
||||
|
||||
[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
|
||||
[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 Web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
|
||||
|
||||
### 4. VLC 媒体播放器
|
||||
|
||||
@ -39,15 +39,15 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
|
||||
|
||||
![linux-apps-05-jitsi][12]
|
||||
|
||||
[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),桌面流和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
|
||||
[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),<ruby>桌面流<rt>desktop streaming</rt></ruby>和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
|
||||
|
||||
### 6. Synaptic
|
||||
|
||||
![linux-apps-06-synaptic][14]
|
||||
|
||||
[Synaptic][15] 是一款基于 Debian 的系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
|
||||
[Synaptic][15] 是一款基于 Debian 系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
|
||||
|
||||
**相关链接** : [10 款您没听说过的充当生产力的 Linux 应用程序][17]
|
||||
**相关链接** : [10 款您没听说过的 Linux 生产力应用程序][17]
|
||||
|
||||
### 7. VirtualBox
|
||||
|
||||
@ -59,9 +59,9 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
|
||||
|
||||
![linux-apps-08-aisleriot][20]
|
||||
|
||||
对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十中纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,这些只是预告片 - 它是会上瘾的,您可能会花很长时间沉迷于此!
|
||||
对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌游戏包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十种纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,作为预警 - 它是会上瘾的,您可能会花很长时间沉迷于此!
|
||||
|
||||
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不和您的胃口,您可以轻松地删除它们。
|
||||
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不合您的胃口,您可以轻松地删除它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -69,7 +69,7 @@ via: https://www.maketecheasier.com/essential-linux-apps/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -8,23 +8,23 @@
|
||||
### 在 Linux 中纠正拼写错误的 Bash 命令
|
||||
|
||||
你有没有运行过类似于下面的错误输入命令?
|
||||
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
你注意到了吗?上面的命令中有一个错误。我在 “uname” 命令缺少了字母 “a”。
|
||||
你注意到了吗?上面的命令中有一个错误。我在 `uname` 命令缺少了字母 `a`。
|
||||
|
||||
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
|
||||
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令,并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
|
||||
|
||||
要轻松更正上述拼写错误的命令,只需运行:
|
||||
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
这会将 “uname” 命令中将 “nm” 替换为 “nam”。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。
|
||||
这会将 `uname` 命令中将 `nm` 替换为 `nam`。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
@ -32,49 +32,49 @@ $ ^nm^nam^
|
||||
|
||||
**额外提示:**
|
||||
|
||||
你有没有想过在使用 “cd” 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
|
||||
你有没有想过在使用 `cd` 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
|
||||
|
||||
这个技巧只能纠正使用 “cd” 命令时的拼写错误。
|
||||
这个技巧只能纠正使用 `cd` 命令时的拼写错误。
|
||||
|
||||
比如说,你想使用命令切换到 `Downloads` 目录:
|
||||
|
||||
比如说,你想使用命令切换到 “Downloads” 目录:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
哎呀!没有名称为 “Donloads” 的文件或目录。是的,正确的名称是 “Downloads”。上面的命令中缺少 “w”。
|
||||
哎呀!没有名称为 `Donloads` 的文件或目录。是的,正确的名称是 `Downloads`。上面的命令中缺少 `w`。
|
||||
|
||||
要解决此问题并在使用 `cd` 命令时自动更正错误,请编辑你的 `.bashrc` 文件:
|
||||
|
||||
要解决此问题并在使用 cd 命令时自动更正错误,请编辑你的 **.bashrc** 文件:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
最后添加以下行。
|
||||
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
输入 **:wq** 保存并退出文件。
|
||||
输入 `:wq` 保存并退出文件。
|
||||
|
||||
最后,运行以下命令更新更改。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
现在,如果在使用 cd 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。
|
||||
现在,如果在使用 `cd` 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的命令中看到的那样,我故意输错(“Donloads” 而不是 “Downloads”),但 Bash 自动检测到正确的目录名并 cd 进入它。
|
||||
正如你在上面的命令中看到的那样,我故意输错(`Donloads` 而不是 `Downloads`),但 Bash 自动检测到正确的目录名并 `cd` 进入它。
|
||||
|
||||
[**Fish**][4] 和**Zsh** shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
|
||||
[Fish][4] 和 Zsh shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
|
||||
|
||||
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 “cd donloads” 而不是 “cd Donloads”,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
|
||||
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 `cd donloads` 而不是 `cd Donloads`,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -83,7 +83,7 @@ via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,11 +3,12 @@ Dnsmasq 进阶技巧
|
||||
|
||||

|
||||
|
||||
许多人熟知和热爱 Dnsmasq,并在他们的本地域名服务上使用它。今天我们将介绍进阶配置文件管理、如何测试你的配置、一些基础的安全知识、DNS 泛域名、快速 DNS 配置,以及其他一些技巧与窍门。下个星期我们将继续详细讲解如何配置 DNS 和 DHCP。
|
||||
许多人熟知并热爱 Dnsmasq,并在他们的本地域名服务上使用它。今天我们将介绍进阶配置文件管理、如何测试你的配置、一些基础的安全知识、DNS 泛域名、快速 DNS 配置,以及其他一些技巧与窍门。下个星期我们将继续详细讲解如何配置 DNS 和 DHCP。
|
||||
|
||||
### 测试配置
|
||||
|
||||
当你测试新的配置的时候,你应该从命令行运行 Dnsmasq,而不是使用守护进程。下面的例子演示了如何不用守护进程运行它,同时显示指令的输出并保留运行日志:
|
||||
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries
|
||||
dnsmasq: started, version 2.75 cachesize 150
|
||||
@ -17,112 +18,111 @@ dnsmasq: compile time options: IPv6 GNU-getopt
|
||||
dnsmasq: reading /etc/resolv.conf
|
||||
dnsmasq: using nameserver 192.168.0.1#53
|
||||
dnsmasq: read /etc/hosts - 9 addresses
|
||||
|
||||
```
|
||||
|
||||
在这个小例子中你能看到许多有用的信息,包括版本、编译参数、系统域名服务文件、以及它的监听地址。可以使用 Ctrl+C 停止进程。在默认情况下,Dnsmasq 没有自己的日志文件,所以日志会被记录到 `/var/log` 目录下的多个地方。你可以使用经典的 `grep` 来找到 Dnsmasq 的日志文件。下面这条指令会递归式地搜索 `/var/log`、在每个匹配的文件名之后显示匹配的行数,并忽略 `/var/log/dist-upgrade` 里的内容:
|
||||
在这个小例子中你能看到许多有用的信息,包括版本、编译参数、系统名字服务文件,以及它的监听地址。可以使用 `Ctrl+C` 停止进程。在默认情况下,Dnsmasq 没有自己的日志文件,所以日志会被记录到 `/var/log` 目录下的多个地方。你可以使用经典的 `grep` 来找到 Dnsmasq 的日志文件。下面这条指令会递归式地搜索 `/var/log`,在每个匹配的文件名之后显示匹配的行号,并忽略 `/var/log/dist-upgrade` 里的内容:
|
||||
|
||||
```
|
||||
# grep -ir --exclude-dir=dist-upgrade dnsmasq /var/log/
|
||||
|
||||
```
|
||||
|
||||
使用 `grep --exclude-dir=` 时有一个有趣的小陷阱需要注意:不要使用完整路径,而应该只写目录名称。
|
||||
|
||||
你可以使用如下的命令行参数来让 Dnsmasq 使用你指定的文件作为它专属的日志文件:
|
||||
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries --log-facility=/var/log/dnsmasq.log
|
||||
|
||||
```
|
||||
|
||||
或者在你的 Dnsmasq 配置文件中加上 `log-facility=/var/log/dnsmasq.log`。
|
||||
|
||||
### 配置文件
|
||||
|
||||
Dnsmasq 的配置文件位于 `/etc/dnsmasq.conf`。你的 Linux 发行版也可能会使用 `/etc/default/dnsmasq`、`/etc/dnsmasq.d/`,或者 `/etc/dnsmasq.d-available/`(不,我们不能统一标准,因为这违反了 Linux 七嘴八舌秘密议会的旨意)。你有很多自由来随意安置你的配置文件。
|
||||
Dnsmasq 的配置文件位于 `/etc/dnsmasq.conf`。你的 Linux 发行版也可能会使用 `/etc/default/dnsmasq`、`/etc/dnsmasq.d/`,或者 `/etc/dnsmasq.d-available/`(不,我们不能统一标准,因为这违反了 <ruby>Linux 七嘴八舌秘密议会<rt>Linux Cat Herd Ruling Cabal</rt></ruby>的旨意)。你有很多自由来随意安置你的配置文件。
|
||||
|
||||
`/etc/dnsmasq.conf` 是德高望重的老大。Dnsmasq 在启动时会最先读取它。`/etc/dnsmasq.conf` 可以使用 `conf-file=` 选项来调用其他的配置文件,例如 `conf-file=/etc/dnsmasqextrastuff.conf`,或使用 `conf-dir=` 选项来调用目录下的所有文件,例如 `conf-dir=/etc/dnsmasq.d`。
|
||||
|
||||
每当你对配置文件进行了修改,你都必须重启 Dnsmasq。
|
||||
|
||||
你可以根据扩展名来包含或忽略配置文件。星号表示包含,不加星号表示忽略:
|
||||
```
|
||||
conf-dir=/etc/dnsmasq.d/,*.conf, *.foo
|
||||
conf-dir=/etc/dnsmasq.d,.old, .bak, .tmp
|
||||
你也可以根据扩展名来包含或忽略配置文件。星号表示包含,不加星号表示排除:
|
||||
|
||||
```
|
||||
conf-dir=/etc/dnsmasq.d/, *.conf, *.foo
|
||||
conf-dir=/etc/dnsmasq.d, .old, .bak, .tmp
|
||||
```
|
||||
|
||||
你可以用 `--addn-hosts=` 选项来把你的主机配置分布在多个文件中。
|
||||
|
||||
Dnsmasq 包含了一个语法检查器:
|
||||
|
||||
```
|
||||
$ dnsmasq --test
|
||||
dnsmasq: syntax check OK.
|
||||
|
||||
```
|
||||
|
||||
### 实用配置
|
||||
|
||||
永远加入这几行:
|
||||
|
||||
```
|
||||
domain-needed
|
||||
bogus-priv
|
||||
|
||||
```
|
||||
|
||||
它们可以避免含有格式出错的域名或私人 IP 地址的数据包离开你的网络。
|
||||
它们可以避免含有格式出错的域名或私有 IP 地址的数据包离开你的网络。
|
||||
|
||||
让你的名字服务只使用 Dnsmasq,而不去使用 `/etc/resolv.conf` 或任何其他的名字服务文件:
|
||||
|
||||
让你的域名服务只使用 Dnsmasq,而不去使用 `/etc/resolv.conf` 或任何其他的域名服务文件:
|
||||
```
|
||||
no-resolv
|
||||
|
||||
```
|
||||
|
||||
使用其他的域名服务器。第一个例子是只对于某一个域名使用不同的域名服务器。第二个和第三个例子是 OpenDNS 公用服务器:
|
||||
|
||||
```
|
||||
server=/fooxample.com/192.168.0.1
|
||||
server=208.67.222.222
|
||||
server=208.67.220.220
|
||||
|
||||
```
|
||||
|
||||
你也可以将某些域名限制为只能本地解析,但不影响其他域名。这些被限制的域名只能从 `/etc/hosts` 或 DHCP 解析:
|
||||
|
||||
```
|
||||
local=/mehxample.com/
|
||||
local=/fooxample.com/
|
||||
|
||||
```
|
||||
|
||||
限制 Dnsmasq 监听的网络接口:
|
||||
|
||||
```
|
||||
interface=eth0
|
||||
interface=wlan1
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 在默认设置下会读取并使用 `/etc/hosts`。这是一个又快又好的配置大量域名的方法,并且 `/etc/hosts` 只需要和 Dnsmasq 在同一台电脑上。你还可以让这个过程再快一些,可以在 `/etc/hosts` 文件中只写主机名,然后用 Dnsmasq 来添加域名。`/etc/hosts` 看上去是这样的:
|
||||
|
||||
```
|
||||
127.0.0.1 localhost
|
||||
192.168.0.1 host2
|
||||
192.168.0.2 host3
|
||||
192.168.0.3 host4
|
||||
|
||||
```
|
||||
|
||||
然后把这几行写入 `dnsmasq.conf`(当然,要换成你自己的域名):
|
||||
然后把下面这几行写入 `dnsmasq.conf`(当然,要换成你自己的域名):
|
||||
|
||||
```
|
||||
expand-hosts
|
||||
domain=mehxample.com
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 会自动把这些主机名扩展为完整的域名,比如 host2 会变为 host2.mehxample.com。
|
||||
Dnsmasq 会自动把这些主机名扩展为完整的域名,比如 `host2` 会变为 `host2.mehxample.com`。
|
||||
|
||||
### DNS 泛域名
|
||||
|
||||
一般来说,使用 DNS 泛域名不是一个好习惯,因为它们太容易被误用了。但它们有时会很有用,比如在你的局域网的严密保护之下的时候。一个例子是使用 DNS 泛域名会让 Kubernetes 集群变得容易管理许多,除非你喜欢给你成百上千的应用写 DNS 记录。假设你的 Kubernetes 域名是 mehxample.com,那么下面这行配置可以让 Dnsmasq 解析所有对 mehxample.com 的请求:
|
||||
|
||||
```
|
||||
address=/mehxample.com/192.168.0.5
|
||||
|
||||
```
|
||||
|
||||
这里使用的地址是你的集群的公网 IP 地址。这会响应对 mehxample.com 的所有主机名和子域名的请求,除非请求的目标地址已经在 DHCP 或者 `/etc/hosts` 中配置过。
|
||||
@ -131,21 +131,18 @@ address=/mehxample.com/192.168.0.5
|
||||
|
||||
### 更多参考
|
||||
|
||||
* [使用 Dnsmasq 进行 DNS 欺骗][1]
|
||||
|
||||
* [使用 Dnsmasq 进行 DNS 伪装][1]
|
||||
* [使用 Dnsmasq 配置简单的局域网域名服务][2]
|
||||
|
||||
* [Dnsmasq][3]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/advanced-dnsmasq-tips-and-tricks
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,42 @@
|
||||
没有 chrome-gnome-shell 的 Gnome
|
||||
去掉了 chrome-gnome-shell 的 Gnome
|
||||
======
|
||||
|
||||
新的笔记本有触摸屏,它可以折叠成平板电脑,我听说 gnome-shell 将是桌面环境的一个很好的选择,我设法调整它足以按照现有的习惯重用。
|
||||
新的笔记本有触摸屏,它可以折叠成平板电脑,我听说 gnome-shell 将是桌面环境的一个很好的选择,我设法调整它以按照现有的习惯使用。
|
||||
|
||||
然而,我有一个很大的问题,它怎么会鼓励人们从互联网上下载随机扩展,并将它们作为整个桌面环境的一部分运行。 一个更大的问题是,[gnome-core][1] 对 [chrome-gnome-shell] [2] 有强制依赖,插件不用 root 用户编辑 `/etc` 下的文件则无法禁用,这会给网站暴露我的桌面环境。
|
||||
然而,我发现一个很大的问题,它怎么会鼓励人们从互联网上下载随机扩展,并将它们作为整个桌面环境的一部分运行呢? 一个更大的问题是,[gnome-core][1] 对 [chrome-gnome-shell] [2] 有强制依赖,这个插件如果不用 root 用户编辑 `/etc` 下的文件则无法禁用,这会给将我的桌面环境暴露给网站。
|
||||
|
||||
访问[这个网站][3],它会知道你已经安装了哪些扩展,并且能够安装更多。我不信任它,我不需要那样,我不想那样。我为此感到震惊。
|
||||
|
||||
[我想出了一个临时解决方法][4]。
|
||||
[我想出了一个临时解决方法][4]。(LCTT 译注:作者做了一个空的依赖包来满足依赖,而不会做任何可能危害你的隐私和安全的操作。)
|
||||
|
||||
人们会在 firefox 中如何做呢?
|
||||
|
||||
### 描述
|
||||
|
||||
chrome-gnome-shell 是 gnome-core 的一个强制依赖项,它安装了一个可能不需要的浏览器插件,并强制它使用系统范围的 chrome 策略。
|
||||
chrome-gnome-shell 是 gnome-core 的一个强制依赖项,它安装了一个你可能不需要的浏览器插件,并强制它使用系统级的 chrome 策略。
|
||||
|
||||
我认为使用 chrome-gnome-shell 会不必要地增加系统的攻击面,我作为主要用户,它会获取下载和执行随机未经审查代码的可疑特权。
|
||||
|
||||
这个包满足了 chrome-gnome-shell 的依赖,但不会安装任何东西。
|
||||
(我做的)这个包满足了 chrome-gnome-shell 的依赖,但不会安装任何东西。
|
||||
|
||||
请注意,在安装此包之后,如果先前安装了 chrome-gnome-shell,则需要清除 chrome-gnome-shell,以使其在 /etc/chromium 中删除 chromium 策略文件
|
||||
请注意,在安装此包之后,如果先前安装了 chrome-gnome-shell,则需要清除 chrome-gnome-shell,以使其在 `/etc/chromium` 中删除 chromium 策略文件。
|
||||
|
||||
### 说明
|
||||
|
||||
```
|
||||
apt install equivs
|
||||
equivs-build contain-gnome-shell
|
||||
sudo dpkg -i contain-gnome-shell_1.0_all.deb
|
||||
sudo dpkg --purge chrome-gnome-shell
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.enricozini.org/blog/2018/debian/gnome-without-chrome-gnome-shell/
|
||||
|
||||
作者:[Enrico Zini][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
117
published/20180213 Getting started with the RStudio IDE.md
Normal file
117
published/20180213 Getting started with the RStudio IDE.md
Normal file
@ -0,0 +1,117 @@
|
||||
RStudio IDE 入门
|
||||
======
|
||||
|
||||
> 用于统计技术的 R 项目是分析数据的有力方式,而 RStudio IDE 则可使这一切更加容易。
|
||||
|
||||

|
||||
|
||||
从我记事起,我就一直喜欢摆弄数字。作为 20 世纪 70 年代后期的大学生,我上过统计学的课程,学习了如何检查和分析数据以揭示其意义。
|
||||
|
||||
那时候,我有一部科学计算器,它让统计计算变得比以往更容易。在 90 年代早期,作为一名从事 <ruby>t 检验<rt>t-test</rt></ruby>、相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入到 IBM 主机的文本文件来进行计算。这个主机远超我的手持计算器,但是一个小的空格错误就会导致整个过程无效,而且这个过程仍然有点乏味。
|
||||
|
||||
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表,并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但这条路每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
|
||||
|
||||
### 快速回到现在
|
||||
|
||||
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件感兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
|
||||
|
||||
起初,这只是一个偶发的一个想法。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R 项目][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
|
||||
|
||||
### 安装 R
|
||||
|
||||
根据你的操作系统和发行版情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN)网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
|
||||
|
||||
我在使用 Ubuntu,按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
|
||||
|
||||
```
|
||||
deb https://<my.favorite.cran.mirror>/bin/linux/ubuntu artful/
|
||||
```
|
||||
|
||||
接着我在终端运行下面命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install r-base
|
||||
```
|
||||
|
||||
根据 CRAN 说明,“需要从源码编译 R 的用户[如包的维护者,或者任何通过 `install.packages()` 安装包的用户]也应该安装 `r-base-dev` 的包。”
|
||||
|
||||
### 使用 R 和 RStudio
|
||||
|
||||
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “R 语言入门”,并且我也在 [Code School][11] 找到了适用于 R 新手的免费课程。两门课程都帮助我学习了 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch 出版社][14] 上购买了 [R 之书][13]。
|
||||
|
||||
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 语言的开源 IDE,易于在 [Debian、Ubuntu、 Fedora 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
|
||||
|
||||
根据 RStudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
|
||||
|
||||

|
||||
|
||||
R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo()` 从控制台访问。`demo(plotmath)` 和 `demo(perspective)` 选项为 R 强大的功能提供了很好的例证。我尝试过一些简单的 [vectors][17] 并在 R 控制台的命令行中绘制,如下所示。
|
||||
|
||||

|
||||
|
||||
你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];有一个这样的数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。RStudio 可以接受各种格式的数据,包括 CSV、Excel、SPSS 和 SAS。
|
||||
|
||||
|
||||
|
||||
数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值、最大值、四分之一位数、四分之三位数、中位数以及平均数。
|
||||
|
||||

|
||||
|
||||
我从摘要统计信息中知道航空乘客样本的均值为 280.3。在命令行中输入 `sd(AirPassengers)` 会得到标准偏差,在 RStudio 控制台中可以看到:
|
||||
|
||||

|
||||
|
||||
接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这会以图形的方式显示此数据集;RStudio 可以将数据导出为 PNG、PDF、JPEG、TIFF、SVG、EPS 或 BMP。
|
||||
|
||||
|
||||
|
||||
除了生成统计数据和图形数据外,R 还记录了我所有的历史操作。这使得我能够返回先前的操作,并且我可以保存此历史记录以供将来参考。
|
||||
|
||||

|
||||
|
||||
在 RStudio 的脚本编辑器中,我可以编写我发出的所有命令的脚本,然后保存该脚本以便在我的数据更改后能再次运行,或者想重新访问它。
|
||||
|
||||

|
||||
|
||||
### 获得帮助
|
||||
|
||||
在 R 提示符下输入 `help()` 可以很容易找到帮助信息。输入你正在寻找的信息的特定主题可以找到具体的帮助信息,例如 `help(sd)` 可以获得有关标准差的帮助。通过在提示符处输入 `contributors()` 可以获得有关 R 项目贡献者的信息。您可以通过在提示符处输入 `citation()` 来了解如何引用 R。通过在提示符出输入 `license()` 可以很容易地获得 R 的许可证信息。
|
||||
|
||||
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R 项目官网][20]。
|
||||
|
||||
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 快捷表(可作为 PDF 下载),[RStudio][21]的在线学习、RStudio 文档、支持和 [许可证信息][22]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-started-RStudio-IDE
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Analysis_of_variance
|
||||
[2]:https://www.michael-j-gallagher.com/high-performance-computing
|
||||
[3]:https://www.r-project.org/
|
||||
[4]:https://cran.r-project.org/index.html
|
||||
[5]:https://cran.r-project.org/
|
||||
[6]:https://cran.r-project.org/bin/linux/
|
||||
[7]:https://cran.r-project.org/bin/linux/redhat/README
|
||||
[8]:https://cran.r-project.org/bin/macosx/
|
||||
[9]:https://cran.r-project.org/bin/windows/
|
||||
[10]:https://www.datacamp.com/onboarding/learn?from=home&technology=r
|
||||
[11]:http://tryr.codeschool.com/levels/1/challenges/1
|
||||
[12]:https://www.udemy.com/r-programming
|
||||
[13]:https://nostarch.com/bookofr
|
||||
[14]:https://opensource.com/article/17/10/no-starch
|
||||
[15]:https://www.rstudio.com/
|
||||
[16]:https://www.rstudio.com/products/rstudio/download/
|
||||
[17]:http://www.r-tutor.com/r-introduction/vector
|
||||
[18]:https://vincentarelbundock.github.io/Rdatasets/datasets.html
|
||||
[19]:https://fred.stlouisfed.org/
|
||||
[20]:https://www.r-project.org/Licenses/
|
||||
[21]:https://www.rstudio.com/online-learning/#R
|
||||
[22]:https://support.rstudio.com/hc/en-us/articles/217801078-What-license-is-RStudio-available-under-
|
||||
@ -0,0 +1,95 @@
|
||||
简单介绍 ldd 命令
|
||||
=========================================
|
||||
|
||||
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 `ldd` ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
|
||||
|
||||
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
|
||||
### Linux ldd 命令
|
||||
|
||||
正如开头已经提到的,`ldd` 命令打印共享对象依赖关系。以下是该命令的语法:
|
||||
|
||||
```
|
||||
ldd [option]... file...
|
||||
```
|
||||
|
||||
下面是该工具的手册页对它作出的解释:
|
||||
|
||||
> ldd 会输出命令行指定的每个程序或共享对象所需的共享对象(共享库)。
|
||||
|
||||
以下使用问答的方式让您更好地了解ldd的工作原理。
|
||||
|
||||
### 问题一、 如何使用 ldd 命令?
|
||||
|
||||
`ldd` 的基本用法非常简单,只需运行 `ldd` 命令以及可执行文件或共享对象的文件名称作为输入。
|
||||
|
||||
```
|
||||
ldd [object-name]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
ldd test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
所以你可以看到所有的共享库依赖已经在输出中产生了。
|
||||
|
||||
### Q2、 如何使 ldd 在输出中生成详细的信息?
|
||||
|
||||
如果您想要 `ldd` 生成详细信息,包括符号版本控制数据,则可以使用 `-v` 命令行选项。例如,该命令
|
||||
|
||||
```
|
||||
ldd -v test
|
||||
```
|
||||
|
||||
当使用 `-v` 命令行选项时,在输出中产生以下内容:
|
||||
|
||||
[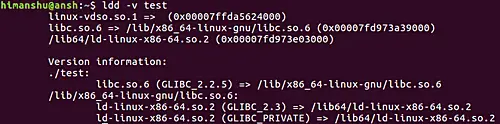](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3、 如何使 ldd 产生未使用的直接依赖关系?
|
||||
|
||||
对于这个信息,使用 `-u` 命令行选项。这是一个例子:
|
||||
|
||||
```
|
||||
ldd -u test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4、 如何让 ldd 执行重定位?
|
||||
|
||||
您可以在这里使用几个命令行选项:`-d` 和 `-r`。 前者告诉 `ldd` 执行数据重定位,后者则使 `ldd` 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
|
||||
|
||||
```
|
||||
ldd -d
|
||||
ldd -r
|
||||
```
|
||||
|
||||
### Q5、 如何获得关于ldd的帮助?
|
||||
|
||||
`--help` 命令行选项使 `ldd` 为该工具生成有用的用法相关信息。
|
||||
|
||||
```
|
||||
ldd --help
|
||||
```
|
||||
|
||||
[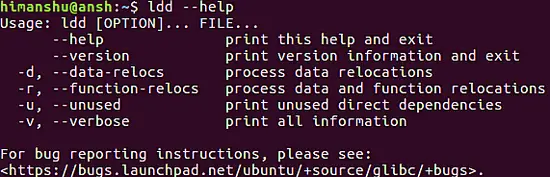](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### 总结
|
||||
|
||||
`ldd` 不像 `cd`、`rm` 和 `mkdir` 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 `ldd` 的[手册页](https://linux.die.net/man/1/ldd)。
|
||||
|
||||
---------
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/)
|
||||
选题: [lujun9972](https://github.com/lujun9972)
|
||||
译者: [MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
149
published/20180217 The List Of Useful Bash Keyboard Shortcuts.md
Normal file
149
published/20180217 The List Of Useful Bash Keyboard Shortcuts.md
Normal file
@ -0,0 +1,149 @@
|
||||
有用的 Bash 快捷键清单
|
||||
======
|
||||

|
||||
|
||||
现如今,我在终端上花的时间更多,尝试在命令行完成比在图形界面更多的工作。随着时间推移,我学了许多 BASH 的技巧。这是一份每个 Linux 用户都应该知道的 BASH 快捷键,这样在终端做事就会快很多。我不会说这是一份完全的 BASH 快捷键清单,但是这足够让你的 BASH shell 操作比以前更快了。学习更快地使用 BASH 不仅节省了更多时间,也让你因为学到了有用的知识而感到自豪。那么,让我们开始吧。
|
||||
|
||||
### ALT 快捷键
|
||||
|
||||
1. `ALT+A` – 光标移动到行首。
|
||||
2. `ALT+B` – 光标移动到所在单词词首。
|
||||
3. `ALT+C` – 终止正在运行的命令/进程。与 `CTRL+C` 相同。
|
||||
4. `ALT+D` – 关闭空的终端(也就是它会关闭没有输入的终端)。也删除光标后的全部字符。
|
||||
5. `ALT+F` – 移动到光标所在单词词末。
|
||||
6. `ALT+T` – 交换最后两个单词。
|
||||
7. `ALT+U` – 将单词内光标后的字母转为大写。
|
||||
8. `ALT+L` – 将单词内光标后的字母转为小写。
|
||||
9. `ALT+R` – 撤销对从历史记录中带来的命令的修改。
|
||||
|
||||
正如你在上面输出所见,我使用反向搜索拉取了一个指令,并更改了那个指令的最后一个字母,并使用 `ALT+R` 撤销了更改。
|
||||
10. `ALT+.` (注意末尾的点号) – 使用上一条命令的最后一个单词。
|
||||
|
||||
如果你想要对多个命令进行相同的操作的话,你可以使用这个快捷键来获取前几个指令的最后一个单词。例如,我需要使用 `ls -r` 命令输出以文件名逆序排列的目录内容。同时,我也想使用 `uname -r` 命令来查看我的内核版本。在这两个命令中,相同的单词是 `-r` 。这就是需要 `ALT+.` 的地方。快捷键很顺手。首先运行 `ls -r` 来按文件名逆序输出,然后在其他命令,比如 `uname` 中使用最后一个单词 `-r` 。
|
||||
|
||||
### CTRL 快捷键
|
||||
|
||||
1. `CTRL+A` – 快速移动到行首。
|
||||
|
||||
我们假设你输入了像下面这样的命令。当你在第 N 行时,你发现在行首字符有一个输入错误
|
||||
|
||||
```
|
||||
$ gind . -mtime -1 -type
|
||||
```
|
||||
|
||||
注意到了吗?上面的命令中我输入了 `gind` 而不是 `find` 。你可以通过一直按着左箭头键定位到第一个字母然后用 `g` 替换 `f` 。或者,仅通过 `CTRL+A` 或 `HOME` 键来立刻定位到行首,并替换拼错的单词。这将节省你几秒钟的时间。
|
||||
|
||||
2. `CTRL+B` – 光标向前移动一个字符。
|
||||
|
||||
这个快捷键可以使光标向前移动一个字符,即光标前的一个字符。或者,你可以使用左箭头键来向前移动一个字符。
|
||||
|
||||
3. `CTRL+C` – 停止当前运行的命令。
|
||||
|
||||
如果一个命令运行时间过久,或者你误运行了,你可以通过使用 `CTRL+C` 来强制停止或退出。
|
||||
|
||||
4. `CTRL+D` – 删除光标后的一个字符。
|
||||
|
||||
如果你的系统退格键无法工作的话,你可以使用 `CTRL+D` 来删除光标后的一个字符。这个快捷键也可以让你退出当前会话,和 exit 类似。
|
||||
|
||||
5. `CTRL+E` – 移动到行末。
|
||||
|
||||
当你修正了行首拼写错误的单词,按下 `CTRL+E` 来快速移动到行末。或者,你也可以使用你键盘上的 `END` 键。
|
||||
|
||||
6. `CTRL+F` – 光标向后移动一个字符。
|
||||
|
||||
如果你想将光标向后移动一个字符的话,按 `CTRL+F` 来替代右箭头键。
|
||||
|
||||
7. `CTRL+G` – 退出历史搜索模式,不运行命令。
|
||||
|
||||
正如你在上面的截图看到的,我进行了反向搜索,但是我执行命令,并退出了历史搜索模式。
|
||||
|
||||
8. `CTRL+H` – 删除光标签的一个字符,和退格键相同。
|
||||
|
||||
9. `CTRL+J` – 和 ENTER/RETURN 键相同。
|
||||
|
||||
回车键不工作?没问题! `CTRL+J` 或 `CTRL+M` 可以用来替换回车键。
|
||||
|
||||
10. `CTRL+K` – 删除光标后的所有字符。
|
||||
|
||||
你不必一直按着删除键来删除光标后的字符。只要按 `CTRL+K` 就能删除光标后的所有字符。
|
||||
|
||||
11. `CTRL+L` – 清空屏幕并重新显示当前行。
|
||||
|
||||
别输入 `clear` 来清空屏幕了。只需按 `CTRL+M` 即可清空并重新显示当前行。
|
||||
|
||||
12. `CTRL+M` – 和 `CTRL+J` 或 RETURN键相同。
|
||||
|
||||
13. `CTRL+N` – 在命令历史中显示下一行。
|
||||
|
||||
你也可以使用下箭头键。
|
||||
|
||||
14. `CTRL+O` – 运行你使用反向搜索时发现的命令,即 CTRL+R。
|
||||
|
||||
15. `CTRL+P` – 显示命令历史的上一条命令。
|
||||
|
||||
你也可以使用上箭头键。
|
||||
|
||||
16. `CTRL+R` – 向后搜索历史记录(反向搜索)。
|
||||
|
||||
17. `CTRL+S` – 向前搜索历史记录。
|
||||
|
||||
18. `CTRL+T` – 交换最后两个字符。
|
||||
|
||||
这是我最喜欢的一个快捷键。假设你输入了 `sl` 而不是 `ls` 。没问题!这个快捷键会像下面这张截图一样交换字符。
|
||||
|
||||
![][2]
|
||||
|
||||
19. `CTRL+U` – 删除光标前的所有字符(从光标后的点删除到行首)。
|
||||
|
||||
这个快捷键立刻删除前面的所有字符。
|
||||
|
||||
20. `CTRL+V` – 逐字显示输入的下一个字符。
|
||||
|
||||
21. `CTRL+W` – 删除光标前的一个单词。
|
||||
|
||||
不要和 CTRL+U 弄混了。CTRL+W 不会删除光标前的所有东西,而是只删除一个单词。
|
||||
|
||||
![][3]
|
||||
|
||||
22. `CTRL+X` – 列出当前单词可能的文件名补全。
|
||||
|
||||
23. `CTRL+XX` – 移动到行首位置(再移动回来)。
|
||||
|
||||
24. `CTRL+Y` – 恢复你上一个删除或剪切的条目。
|
||||
|
||||
记得吗,我们在第 21 个命令用 `CTRL+W` 删除了单词“-al”。你可以使用 `CTRL+Y` 立刻恢复。
|
||||
|
||||
![][4]
|
||||
|
||||
看见了吧?我没有输入“-al”。取而代之,我按了 `CTRL+Y` 来恢复它。
|
||||
|
||||
25. `CTRL+Z` – 停止当前的命令。
|
||||
|
||||
你也许很了解这个快捷键。它终止了当前运行的命令。你可以在前台使用 `fg` 或在后台使用 `bg` 来恢复它。
|
||||
|
||||
26. `CTRL+[` – 和 `ESC` 键等同。
|
||||
|
||||
### 杂项
|
||||
|
||||
1. `!!` – 重复上一个命令。
|
||||
|
||||
2. `ESC+t` – 交换最后两个单词。
|
||||
|
||||
这就是我所能想到的了。将来我遇到 Bash 快捷键时我会持续添加的。如果你觉得文章有错的话,请在下方的评论区留言。我会尽快更新。
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[heart4lor](https://github.com/heart4lor)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLT-1.gif
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLW-1.gif
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLY-1.gif
|
||||
69
published/20180219 How Linux became my job.md
Normal file
69
published/20180219 How Linux became my job.md
Normal file
@ -0,0 +1,69 @@
|
||||
Linux 如何成为我的工作
|
||||
======
|
||||
|
||||
> IBM 工程师 Phil Estes 分享了他的 Linux 爱好如何使他成为了一位开源领袖、贡献者和维护者。
|
||||
|
||||

|
||||
|
||||
从很早很早以前起,我就一直使用开源软件。那个时候,没有所谓的社交媒体。没有火狐,没有谷歌浏览器(甚至连谷歌也没有),没有亚马逊,甚至几乎没有互联网。事实上,那个时候最热门的是最新的 Linux 2.0 内核。当时的技术挑战是什么?嗯,是 Linux 发行版本中旧的 [a.out][2] 格式被 [ELF 格式][1]代替,导致升级一些 [Linux][3] 的安装可能有些棘手。
|
||||
|
||||
我如何将我自己对这个初出茅庐的年轻操作系统的兴趣转变为开源事业是一个有趣的故事。
|
||||
|
||||
### Linux 为乐趣为生,而非利益
|
||||
|
||||
1994 年我大学毕业时,计算机实验室是 UNIX 系统的小型网络;如果你幸运的话,它们会连接到这个叫做互联网的新东西上。我知道这难以置信!(那时,)“Web”(就是所知道的那个)大多是手写的 HTML,`cgi-bin` 目录是启用动态 Web 交互的一个新平台。我们许多人对这些新技术感到兴奋,我们还自学了 shell 脚本、[Perl][4]、HTML,以及所有我们在父母的 Windows 3.1 PC 上从没有见过的简短的 UNIX 命令。
|
||||
|
||||
毕业后,我加入 IBM,工作在一个不能访问 UNIX 系统的 PC 操作系统上,不久,我的大学切断了我通往工程实验室的远程通道。我该如何继续通过 [Pine][6] 使用 `vi` 和 `ls` 读我的电子邮件的呢?我一直听说开源 Linux,但我还没有时间去研究它。
|
||||
|
||||
1996 年,我在德克萨斯大学奥斯丁分校开始读硕士学位。我知道这将涉及编程和写论文,不知道还有什么,但我不想使用专有的编辑器,编译器或者文字处理器。我想要的是我的 UNIX 体验!
|
||||
|
||||
所以我拿了一个旧电脑,找到了一个 Linux 发行版本 Slackware 3.0,在我的 IBM 办公室下载了一张又一张的软盘。可以说我在第一次安装 Linux 后就没有回过头了。在最初的那些日子里,我学习了很多关于 Makefile 和 `make` 系统、构建软件、补丁还有源码控制的知识。虽然我开始使用 Linux 只是为了兴趣和个人知识,但它最终改变了我的职业生涯。
|
||||
|
||||
虽然我是一个愉快的 Linux 用户,但我认为开源开发仍然是其他人的工作;我觉得在线邮件列表都是神秘的 [UNIX][7] 极客的。我很感激像 Linux HOWTO 这样的项目,它们在我尝试添加软件包、升级 Linux 版本,或者安装新硬件和新 PC 的设备驱动程序撞得鼻青脸肿时帮助了我。但是要处理源代码并进行修改或提交到上游……那是别人的事,不是我。
|
||||
|
||||
### Linux 如何成为我的工作
|
||||
|
||||
1999 年,我终于有理由把我对 Linux 的个人兴趣与我在 IBM 的日常工作结合起来了。我接了一个研究项目,将 IBM 的 Java 虚拟机(JVM)移植到 Linux 上。为了确保我们在法律上是安全的,IBM 购买了一个塑封的盒装的 Red Hat Linux 6.1 副本来完成这项工作。在 IBM 东京研究实验室工作时,为了编写我们的 JVM 即时编译器(JIT),参考了 AIX JVM 源代码和 Windows 及 OS/2 的 JVM 源代码,我们在几周内就有了一个可以工作在 Linux 上的 JVM,击败了 SUN 公司官方宣告花了几个月才把 Java 移植到 Linux。既然我在 Linux 平台上做得了开发,我就更喜欢它了。
|
||||
|
||||
到 2000 年,IBM 使用 Linux 的频率迅速增加。由于 [Dan Frye][8] 的远见和坚持,IBM 在 Linux 上下了“[一亿美元的赌注][9]”,在 1999 年创建了 Linux 技术中心(LTC)。在 LTC 里面有内核开发者、开源贡献者、IBM 硬件设备的驱动程序编写者,以及各种各样的针对 Linux 的开源工作。比起留在与 LTC 联系不大的部门,我更想要成为这个令人兴奋的 IBM 新天地的一份子。
|
||||
|
||||
从 2003 年到 2013 年我深度参与了 IBM 的 Linux 战略和 Linux 发行版(在 IBM 内部)的使用,最终组成了一个团队成为大约 60 个产品的信息交换所,Linux 的使用涉及了 IBM 每个部门。我参与了收购,期望每个设备、管理系统和虚拟机或者基于物理设备的中间件都能运行 Linux。我开始熟悉 Linux 发行版的构建,包括打包、选择上游来源、开发发行版维护的补丁集、做定制,并通过我们的发行版合作伙伴提供支持。
|
||||
|
||||
由于我们的下游供应商,我很少提交补丁到上游,但我通过配合 [Ulrich Drepper][10] (将一个小补丁提交到 glibc)和改变[时区数据库][11]的工作贡献了自己的力量(Arthur David Olson 在 NIH 的 FTP 站点维护它的时候接受了这个改变)。但我仍然没有把开源项目的正式贡献者的工作来当做我的工作的一部分。是该改变这种情况的时候了。
|
||||
|
||||
在 2013 年末,我加入了 IBM 在开源社区的云组织,并正在寻找一个上游社区参与进来。我会在 Cloud Foundry 工作,还是会加入 IBM 为 OpenStack 贡献的大组中呢?都不是,因为在 2014 年 Docker 席卷了全球,IBM 要我们几个参与到这个热门的新技术。我在接下来的几个月里,经历了许多的第一次:使用 GitHub,比起只是 `git clone` [学习了关于 Git 的更多知识][12],做过 Pull Request 的审查,用 Go 语言写代码,等等。在接下来的一年中,我在 Docker 引擎项目上成为一个维护者,为 Dockr 创造下一版的镜像规范(支持多个架构),并在一个关于容器技术的会议上出席和讲话。
|
||||
|
||||
### 如今的我
|
||||
|
||||
一晃几年过去,我已经成为了包括 CNCF 的 [containerd][13] 项目在内的开源项目的维护者。我还创建了项目(如 [manifest-tool][14] 和 [bucketbench][15])。我也通过 OCI 参与了开源治理,我现在是技术监督委员会的成员;而在Moby 项目,我是技术指导委员会的成员。我乐于在世界各地的会议、沙龙、IBM 内部发表关于开源的演讲。
|
||||
|
||||
开源现在是我在 IBM 职业生涯的一部分。我与工程师、开发人员和行业领袖的联系可能比我在 IBM 内认识的人的联系还要多。虽然开源与专有开发团队和供应商合作伙伴有许多相同的挑战,但据我的经验,开源与全球各地的人们的关系和联系远远超过困难。随着不同的意见、观点和经验的不断优化,可以对软件和涉及的在其中的人产生一种不断学习和改进的文化。
|
||||
|
||||
这个旅程 —— 从我第一次使用 Linux 到今天成为一个领袖、贡献者,和现在云原生开源世界的维护者 —— 我获得了极大的收获。我期待着与全球各地的人们长久的进行开源协作和互动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[ranchong](https://github.com/ranchong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://linux.cn/article-9319-1.html
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -0,0 +1,113 @@
|
||||
使用 Zim 在你的 Linux 桌面上创建一个维基
|
||||
======
|
||||
|
||||
> 用强大而小巧的 Zim 在桌面上像维基一样管理信息。
|
||||
|
||||
|
||||
|
||||
不可否认<ruby>维基<rt>wiki</rt></ruby>的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了几个维基,要么是为了我自己的工作,要么就是为了我接到的各种合同和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版维基][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,有许多可以用在 Linux 中的桌面版维基。
|
||||
|
||||
让我们来看看更好的桌面版的 维基 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
安装好了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是<ruby>笔记本<rt>notebook</rt></ruby>,它们就像某个单一主题的维基页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 `Notes` 来表示文件夹的名称和指定文件夹为 `~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||
|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 “OK” 。你得到的本质上是你的维基页面的容器。
|
||||
|
||||
|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 “File > New Page”。
|
||||
|
||||
|
||||
|
||||
输入该页面的名称,然后单击 “OK”。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||
|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记、一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 圆点和编号清单
|
||||
* 核对清单
|
||||
|
||||
你可以添加图片和附加文件到你的维基页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的维基语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用维基标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(`*`)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [驼峰命名法][7] 来命名这些页面。假设我有个叫做 “Course Notes” 的笔记本。我可以通过输入 “AnalysisCourse” 来重命名为我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 “AnalysisCourse” 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 “Insert link” 按钮。 在 “Link to” 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 “Link”。
|
||||
|
||||
|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的维基页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息 —— 比如,在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种。而不是复制和粘贴(和丢失格式):
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
为此,点击你想要导出的维基页面。然后,选择 “File > Export”。决定是要导出整个笔记本还是一个页面,然后点击 “Forward”。
|
||||
|
||||
|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如,如果你想把你的维基页面变成 HTML 演示幻灯片,你可以在 “Template” 中选择 “SlideShow s5”。 如果你想知道,这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||
|
||||
|
||||
点击 “Forward”,如果你在导出一个笔记本,你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||
|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版维基,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -0,0 +1,99 @@
|
||||
解读 ip 命令展示的网络连接信息
|
||||
======
|
||||
|
||||

|
||||
|
||||
`ip` 命令可以告诉你很多网络连接配置和状态的信息,但是所有这些词和数字意味着什么? 让我们深入了解一下,看看所有显示的值都试图告诉你什么。
|
||||
|
||||
当您使用 `ip a`(或 `ip addr`)命令获取系统上所有网络接口的信息时,您将看到如下所示的内容:
|
||||
|
||||
```
|
||||
$ ip a
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 00:1e:4f:c8:43:fc brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.0.24/24 brd 192.168.0.255 scope global dynamic enp0s25
|
||||
valid_lft 57295sec preferred_lft 57295sec
|
||||
inet6 fe80::2c8e:1de0:a862:14fd/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
这个系统上的两个接口 - 环回(`lo`)和网络(`enp0s25`)——显示了很多统计数据。 `lo` 接口显然是<ruby>环回地址<rt>loolback</rt></ruby>。 我们可以在列表中看到环回 IPv4 地址(`127.0.0.1`)和环回 IPv6(`::1`)。 而普通的网络接口更有趣。
|
||||
|
||||
### 为什么是 enp0s25 而不是 eth0
|
||||
|
||||
如果你想知道为什么它在这个系统上被称为 `enp0s25`,而不是可能更熟悉的 `eth0`,那我们可以稍微解释一下。
|
||||
|
||||
新的命名方案被称为“<ruby>可预测的网络接口<rt>Predictable Network Interface</rt></ruby>”。 它已经在基于systemd 的 Linux 系统上使用了一段时间了。 接口名称取决于硬件的物理位置。 `en` 仅仅就是 “ethernet” 的意思,就像 “eth” 用于对应 `eth0`,一样。 `p` 是以太网卡的总线编号,`s` 是插槽编号。 所以 `enp0s25` 告诉我们很多我们正在使用的硬件的信息。
|
||||
|
||||
`<BROADCAST,MULTICAST,UP,LOWER_UP>` 这个配置串告诉我们:
|
||||
|
||||
```
|
||||
BROADCAST 该接口支持广播
|
||||
MULTICAST 该接口支持多播
|
||||
UP 网络接口已启用
|
||||
LOWER_UP 网络电缆已插入,设备已连接至网络
|
||||
```
|
||||
|
||||
列出的其他值也告诉了我们很多关于接口的知识,但我们需要知道 `brd` 和 `qlen` 这些词代表什么意思。 所以,这里显示的是上面展示的 `ip` 信息的其余部分的翻译。
|
||||
|
||||
```
|
||||
mtu 1500 最大传输单位(数据包大小)为1,500字节
|
||||
qdisc pfifo_fast 用于数据包排队
|
||||
state UP 网络接口已启用
|
||||
group default 接口组
|
||||
qlen 1000 传输队列长度
|
||||
link/ether 00:1e:4f:c8:43:fc 接口的 MAC(硬件)地址
|
||||
brd ff:ff:ff:ff:ff:ff 广播地址
|
||||
inet 192.168.0.24/24 IPv4 地址
|
||||
brd 192.168.0.255 广播地址
|
||||
scope global 全局有效
|
||||
dynamic enp0s25 地址是动态分配的
|
||||
valid_lft 80866sec IPv4 地址的有效使用期限
|
||||
preferred_lft 80866sec IPv4 地址的首选生存期
|
||||
inet6 fe80::2c8e:1de0:a862:14fd/64 IPv6 地址
|
||||
scope link 仅在此设备上有效
|
||||
valid_lft forever IPv6 地址的有效使用期限
|
||||
preferred_lft forever IPv6 地址的首选生存期
|
||||
```
|
||||
|
||||
您可能已经注意到,`ifconfig` 命令提供的一些信息未包含在 `ip a` 命令的输出中 —— 例如传输数据包的统计信息。 如果您想查看发送和接收的数据包数量以及冲突数量的列表,可以使用以下 `ip` 命令:
|
||||
|
||||
```
|
||||
$ ip -s link show enp0s25
|
||||
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
|
||||
link/ether 00:1e:4f:c8:43:fc brd ff:ff:ff:ff:ff:ff
|
||||
RX: bytes packets errors dropped overrun mcast
|
||||
224258568 418718 0 0 0 84376
|
||||
TX: bytes packets errors dropped carrier collsns
|
||||
6131373 78152 0 0 0 0
|
||||
```
|
||||
|
||||
另一个 `ip` 命令提供有关系统路由表的信息。
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.0.1 dev enp0s25 proto static metric 100
|
||||
169.254.0.0/16 dev enp0s25 scope link metric 1000
|
||||
192.168.0.0/24 dev enp0s25 proto kernel scope link src 192.168.0.24 metric 100
|
||||
```
|
||||
|
||||
`ip` 命令是非常通用的。 您可以从 `ip` 命令及其来自[Red Hat][1]的选项获得有用的备忘单。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3262045/linux/checking-your-network-connections-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://access.redhat.com/sites/default/files/attachments/rh_ip_command_cheatsheet_1214_jcs_print.pdf
|
||||
@ -1,112 +0,0 @@
|
||||
Evolutional Steps of Computer Systems
|
||||
======
|
||||
Throughout the history of the modern computer, there were several evolutional steps related to the way we interact with the system. I tend to categorize those steps as following:
|
||||
|
||||
1. Numeric Systems
|
||||
2. Application-Specific Systems
|
||||
3. Application-Centric Systems
|
||||
4. Information-Centric Systems
|
||||
5. Application-Less Systems
|
||||
|
||||
|
||||
|
||||
Following sections describe how I see those categories.
|
||||
|
||||
### Numeric Systems
|
||||
|
||||
[Early computers][1] were designed with numbers in mind. They could add, subtract, multiply, divide. Some of them were able to perform more complex mathematical operations such as differentiate or integrate.
|
||||
|
||||
If you map characters to numbers, they were able to «compute» [strings][2] as well but this is somewhat «creative use of numbers» instead of meaningful processing arbitrary information.
|
||||
|
||||
### Application-Specific Systems
|
||||
|
||||
For higher-level problems, pure numeric systems are not sufficient. Application-specific systems were developed to do one single task. They were very similar to numeric systems. However, with sufficiently complex number calculations, systems were able to accomplish very well-defined higher level tasks such as calculations related to scheduling problems or other optimization problems.
|
||||
|
||||
Systems of this category were built for one single purpose, one distinct problem they solved.
|
||||
|
||||
### Application-Centric Systems
|
||||
|
||||
Systems that are application-centric are the first real general purpose systems. Their main usage style is still mostly application-specific but with multiple applications working either time-sliced (one app after another) or in multi-tasking mode (multiple apps at the same time).
|
||||
|
||||
Early personal computers [from the 70s][3] of the previous century were the first application-centric systems that became popular for a wide group of people.
|
||||
|
||||
Yet modern operating systems - Windows, macOS, most GNU/Linux desktop environments - still follow the same principles.
|
||||
|
||||
Of course, there are sub-categories as well:
|
||||
|
||||
1. Strict Application-Centric Systems
|
||||
2. Loose Application-Centric Systems
|
||||
|
||||
|
||||
|
||||
Strict application-centric systems such as [Windows 3.1][4] (Program Manager and File Manager) or even the initial version of [Windows 95][5] had no pre-defined folder hierarchy. The user did start text processing software like [WinWord][6] and saved the files in the program folder of WinWord. When working with a spreadsheet program, its files were saved in the application folder of the spreadsheet tool. And so on. Users did not create their own hierarchy of folders mostly because of convenience, laziness, or because they did not saw any necessity. The number of files per user were sill within dozens up to a few hundreds.
|
||||
|
||||
For accessing information, the user typically opened an application and within the application, the files containing the generated data were retrieved using file/open.
|
||||
|
||||
It was [Windows 95][5] SP2 that introduced «[My Documents][7]» for the Windows platform. With this file hierarchy template, application designers began switching to «My Documents» as a default file save/open location instead of using the software product installation path. This made the users embrace this pattern and start to maintain folder hierarchies on their own.
|
||||
|
||||
This resulted in loose application-centric systems: typical file retrieval is done via a file manager. When a file is opened, the associated application is started by the operating system. It is a small or subtle but very important usage shift. Application-centric systems are still the dominant usage pattern for personal computers.
|
||||
|
||||
Nevertheless, this pattern comes with many disadvantages. For example in order to prevent data retrieval problems, there is the need to maintain a strict hierarchy of folders that contain all related files of a given project. Unfortunately, nature does not fit well in strict hierarchy of folders. Further more, [this does not scale well][8]. Desktop search engines and advanced data organizing tools like [tagstore][9] are able to smooth the edged a bit. As studies show, only a minority of users are using such advanced retrieval tools. Most users still navigate through the file system without using any alternative or supplemental retrieval techniques.
|
||||
|
||||
### Information-Centric Systems
|
||||
|
||||
One possible way of dealing with the issue that a certain topic needs to have a folder that holds all related files is to switch from an application-centric system to an information-centric systems.
|
||||
|
||||
Instead of opening a spreadsheet application to work with the project budget, opening a word processor application to write the project report, and opening another tool to work with image files, an information-centric system combines all the information on the project in one place, in one application.
|
||||
|
||||
The calculations for the previous month is right beneath notes from a client meeting which is right beneath a photography of the whiteboard notes which is right beneath some todo tasks. Without any application or file border in between.
|
||||
|
||||
Early attempts to create such an environment were IBM [OS/2][10], Microsoft [OLE][11] or [NeXT][12]. None of them were a major success for a variety of reasons. A very interesting information-centric environment is [Acme][13] from [Plan 9][14]. It combines [a wide variety of applications][15] within one application but it never reached a notable distribution even with its ports to Windows or GNU/Linux.
|
||||
|
||||
Modern approaches for an information-centric system are advanced [personal wikis][16] like [TheBrain][17] or [Microsoft OneNote][18].
|
||||
|
||||
My personal tool of choice is the [GNU/Emacs][19] platform with its [Org-mode][19] extension. I hardly leave Org-mode when I work with my computer. For accessing external data sources, I created [Memacs][20] which brings me a broad variety of data into Org-mode. I love to do spreadsheet calculations right beneath scheduled tasks, in-line images, internal and external links, and so forth. It is truly an information-centric system where the user doesn't have to deal with application borders or strictly hierarchical file-system folders. Multi-classifications is possible using simple or advanced tagging. All kinds of views can be derived with a single command. One of those views is my calendar, the agenda. Another derived view is the list of borrowed things. And so on. There are no limits for Org-mode users. If you can think of it, it is most likely possible within Org-mode.
|
||||
|
||||
Is this the end of the evolution? Certainly not.
|
||||
|
||||
### Application-Less Systems
|
||||
|
||||
I can think of a class of systems which I refer to as application-less systems. As the next logical step, there is no need to have single-domain applications even when they are as capable as Org-mode. The computer offers a nice to use interface to information and features, not files and applications. Even a classical operating system is not accessible.
|
||||
|
||||
Application-less systems might as well be combined with [artificial intelligence][21]. Think of it as some kind of [HAL 9000][22] from [A Space Odyssey][23]. Or [LCARS][24] from Star Trek.
|
||||
|
||||
It is hard to believe that there is a transition between our application-based, vendor-based software culture and application-less systems. Maybe the open source movement with its slow but constant development will be able to form a truly application-less environment where all kinds of organizations and people are contributing to.
|
||||
|
||||
Information and features to retrieve and manipulate information, this is all it takes. This is all we need. Everything else is just limiting distraction.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -1,51 +0,0 @@
|
||||
An old DOS BBS in a Docker container
|
||||
======
|
||||
Awhile back, I wrote about [my Debian Docker base images][1]. I decided to extend this concept a bit further: to running DOS applications in Docker.
|
||||
|
||||
But first, a screenshot:
|
||||
|
||||
![][2]
|
||||
|
||||
It turns out this is possible, but difficult. I went through all three major DOS emulators available (dosbox, qemu, and dosemu). I got them all running inside the Docker container, but had a number of, er, fun issues to resolve.
|
||||
|
||||
The general thing one has to do here is present a fake modem to the DOS environment. This needs to be exposed outside the container as a TCP port. That much is possible in various ways -- I wound up using tcpser. dosbox had a TCP modem interface, but it turned out to be too buggy for this purpose.
|
||||
|
||||
The challenge comes in where you want to be able to accept more than one incoming telnet (or TCP) connection at a time. DOS was not a multitasking operating system, so there were any number of hackish solutions back then. One might have had multiple physical computers, one for each incoming phone line. Or they might have run multiple pseudo-DOS instances under a multitasking layer like [DESQview][3], OS/2, or even Windows 3.1.
|
||||
|
||||
(Side note: I just learned of [DESQview/X][4], which integrated DESQview with X11R5 and [replaced the Windows 3 drivers][5] to allow running Windows as an X application).
|
||||
|
||||
For various reasons, I didn't want to try running one of those systems inside Docker. That left me with emulating the original multiple physical node setup. In theory, pretty easy -- spin up a bunch of DOS boxes, each using at most 1MB of emulated RAM, and go to town. But here came the challenge.
|
||||
|
||||
In a multiple-physical-node setup, you need some sort of file sharing, because your nodes have to access the shared message and file store. There were a myriad of clunky ways to do this in the old DOS days - [Netware][6], [LAN manager][7], even some PC NFS clients. I didn't have access to Netware. I tried the Microsoft LM client in DOS, talking to a Samba server running inside the Docker container. This I got working, but the LM client used so much RAM that, even with various high memory tricks, BBS software wasn't going to run. I couldn't just mount an underlying filesystem in multiple dosbox instances either, because dosbox did caching that wasn't going to be compatible.
|
||||
|
||||
This is why I wound up using dosemu. Besides being a more complete emulator than dosbox, it had a way of sharing the host's filesystems that was going to work.
|
||||
|
||||
So, all of this wound up with this: [jgoerzen/docker-bbs-renegade][8].
|
||||
|
||||
I also prepared building blocks for others that want to do something similar: [docker-dos-bbs][9] and the lower-level [docker-dosemu][10].
|
||||
|
||||
As a side bonus, I also attempted running this under Joyent's Triton (SmartOS, Solaris-based). I was pleasantly impressed that I got it all almost working there. So yes, a Renegade DOS BBS running under a Linux-based DOS emulator in a container on a Solaris machine.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
@ -1,104 +0,0 @@
|
||||
[fuzheng1998 tranlating]
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
### Christine Peterson 最终发布了对于二十年前那决定命运一天的陈述。
|
||||
|
||||

|
||||
图片来自: opensource.com
|
||||
|
||||
In a few days, on February 3, the 20th anniversary of the introduction of the term "[开源软件][6]" is upon us. As open source software grows in popularity and powers some of the most robust and important innovations of our time, we reflect on its rise to prominence.
|
||||
|
||||
I am the originator of the term "open source software" and came up with it while executive director at Foresight Institute. Not a software developer like the rest, I thank Linux programmer Todd Anderson for supporting the term and proposing it to the group.
|
||||
|
||||
This is my account of how I came up with it, how it was proposed, and the subsequent reactions. Of course, there are a number of accounts of the coining of the term, for example by Eric Raymond and Richard Stallman, yet this is mine, written on January 2, 2006.
|
||||
|
||||
直到今天,它才公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
The introduction of the term "open source software" was a deliberate effort to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that—to newcomers—its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
|
||||
|
||||
This term had long been used in an "intelligence" (i.e., spying) context, but to my knowledge, use of the term with respect to software prior to 1998 has not been confirmed. The account below describes how the term [open source software][7] caught on and became the name of both an industry and a movement.
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
In late 1997, weekly meetings were being held at Foresight Institute to discuss computer security. Foresight is a nonprofit think tank focused on nanotechnology and artificial intelligence, and software security is regarded as central to the reliability and security of both. We had identified free software as a promising approach to improving software security and reliability and were looking for ways to promote it. Interest in free software was starting to grow outside the programming community, and it was increasingly clear that an opportunity was coming to change the world. However, just how to do this was unclear, and we were groping for strategies.
|
||||
|
||||
At these meetings, we discussed the need for a new term due to the confusion factor. The argument was as follows: those new to the term "free software" assume it is referring to the price. Oldtimers must then launch into an explanation, usually given as follows: "We mean free as in freedom, not free as in beer." At this point, a discussion on software has turned into one about the price of an alcoholic beverage. The problem was not that explaining the meaning is impossible—the problem was that the name for an important idea should not be so confusing to newcomers. A clearer term was needed. No political issues were raised regarding the free software term; the issue was its lack of clarity to those new to the concept.
|
||||
|
||||
### 网景发布
|
||||
|
||||
On February 2, 1998, Eric Raymond arrived on a visit to work with Netscape on the plan to release the browser code under a free-software-style license. We held a meeting that night at Foresight's office in Los Altos to strategize and refine our message. In addition to Eric and me, active participants included Brian Behlendorf, Michael Tiemann, Todd Anderson, Mark S. Miller, and Ka-Ping Yee. But at that meeting, the field was still described as free software or, by Brian, "source code available" software.
|
||||
|
||||
While in town, Eric used Foresight as a base of operations. At one point during his visit, he was called to the phone to talk with a couple of Netscape legal and/or marketing staff. When he was finished, I asked to be put on the phone with them—one man and one woman, perhaps Mitchell Baker—so I could bring up the need for a new term. They agreed in principle immediately, but no specific term was agreed upon.
|
||||
|
||||
Between meetings that week, I was still focused on the need for a better name and came up with the term "open source software." While not ideal, it struck me as good enough. I ran it by at least four others: Eric Drexler, Mark Miller, and Todd Anderson liked it, while a friend in marketing and public relations felt the term "open" had been overused and abused and believed we could do better. He was right in theory; however, I didn't have a better idea, so I thought I would try to go ahead and introduce it. In hindsight, I should have simply proposed it to Eric Raymond, but I didn't know him well at the time, so I took an indirect strategy instead.
|
||||
|
||||
Todd had agreed strongly about the need for a new term and offered to assist in getting the term introduced. This was helpful because, as a non-programmer, my influence within the free software community was weak. My work in nanotechnology education at Foresight was a plus, but not enough for me to be taken very seriously on free software questions. As a Linux programmer, Todd would be listened to more closely.
|
||||
|
||||
### 关键的会议
|
||||
|
||||
Later that week, on February 5, 1998, a group was assembled at VA Research to brainstorm on strategy. Attending—in addition to Eric Raymond, Todd, and me—were Larry Augustin, Sam Ockman, and attending by phone, Jon "maddog" Hall.
|
||||
|
||||
The primary topic was promotion strategy, especially which companies to approach. I said little, but was looking for an opportunity to introduce the proposed term. I felt that it wouldn't work for me to just blurt out, "All you technical people should start using my new term." Most of those attending didn't know me, and for all I knew, they might not even agree that a new term was greatly needed, or even somewhat desirable.
|
||||
|
||||
Fortunately, Todd was on the ball. Instead of making an assertion that the community should use this specific new term, he did something less directive—a smart thing to do with this community of strong-willed individuals. He simply used the term in a sentence on another topic—just dropped it into the conversation to see what happened. I went on alert, hoping for a response, but there was none at first. The discussion continued on the original topic. It seemed only he and I had noticed the usage.
|
||||
|
||||
Not so—memetic evolution was in action. A few minutes later, one of the others used the term, evidently without noticing, still discussing a topic other than terminology. Todd and I looked at each other out of the corners of our eyes to check: yes, we had both noticed what happened. I was excited—it might work! But I kept quiet: I still had low status in this group. Probably some were wondering why Eric had invited me at all.
|
||||
|
||||
Toward the end of the meeting, the [question of terminology][8] was brought up explicitly, probably by Todd or Eric. Maddog mentioned "freely distributable" as an earlier term, and "cooperatively developed" as a newer term. Eric listed "free software," "open source," and "sourceware" as the main options. Todd advocated the "open source" model, and Eric endorsed this. I didn't say much, letting Todd and Eric pull the (loose, informal) consensus together around the open source name. It was clear that to most of those at the meeting, the name change was not the most important thing discussed there; a relatively minor issue. Only about 10% of my notes from this meeting are on the terminology question.
|
||||
|
||||
But I was elated. These were some key leaders in the community, and they liked the new name, or at least didn't object. This was a very good sign. There was probably not much more I could do to help; Eric Raymond was far better positioned to spread the new meme, and he did. Bruce Perens signed on to the effort immediately, helping set up [Opensource.org][9] and playing a key role in spreading the new term.
|
||||
|
||||
For the name to succeed, it was necessary, or at least highly desirable, that Tim O'Reilly agree and actively use it in his many projects on behalf of the community. Also helpful would be use of the term in the upcoming official release of the Netscape Navigator code. By late February, both O'Reilly & Associates and Netscape had started to use the term.
|
||||
|
||||
### 名字的诞生
|
||||
|
||||
After this, there was a period during which the term was promoted by Eric Raymond to the media, by Tim O'Reilly to business, and by both to the programming community. It seemed to spread very quickly.
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key leaders in the field. Announced in advance as the first "[Freeware Summit][10]," by April 14 it was referred to as the first "[Open Source Summit][11]."
|
||||
|
||||
These months were extremely exciting for open source. Every week, it seemed, a new company announced plans to participate. Reading Slashdot became a necessity, even for those like me who were only peripherally involved. I strongly believe that the new term was helpful in enabling this rapid spread into business, which then enabled wider use by the public.
|
||||
|
||||
A quick Google search indicates that "open source" appears more often than "free software," but there still is substantial use of the free software term, which remains useful and should be included when communicating with audiences who prefer it.
|
||||
|
||||
### A happy twinge
|
||||
|
||||
When an [early account][12] of the terminology change written by Eric Raymond was posted on the Open Source Initiative website, I was listed as being at the VA brainstorming meeting, but not as the originator of the term. This was my own fault; I had neglected to tell Eric the details. My impulse was to let it pass and stay in the background, but Todd felt otherwise. He suggested to me that one day I would be glad to be known as the person who coined the name "open source software." He explained the situation to Eric, who promptly updated his site.
|
||||
|
||||
Coming up with a phrase is a small contribution, but I admit to being grateful to those who remember to credit me with it. Every time I hear it, which is very often now, it gives me a little happy twinge.
|
||||
|
||||
The big credit for persuading the community goes to Eric Raymond and Tim O'Reilly, who made it happen. Thanks to them for crediting me, and to Todd Anderson for his role throughout. The above is not a complete account of open source history; apologies to the many key players whose names do not appear. Those seeking a more complete account should refer to the links in this article and elsewhere on the net.
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Christine Peterson - Christine Peterson writes, lectures, and briefs the media on coming powerful technologies, especially nanotechnology, artificial intelligence, and longevity. She is Cofounder and Past President of Foresight Institute, the leading nanotech public interest group. Foresight educates the public, technical community, and policymakers on coming powerful technologies and how to guide their long-term impact. She serves on the Advisory Board of the [Machine Intelligence... ][2][more about Christine Peterson][3][More about me][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[ Christine Peterson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -1,3 +1,5 @@
|
||||
fuzheng1998 translating
|
||||
|
||||
Why Linux is better than Windows or macOS for security
|
||||
======
|
||||
|
||||
|
||||
98
sources/talk/20180214 11 awesome vi tips and tricks.md
Normal file
98
sources/talk/20180214 11 awesome vi tips and tricks.md
Normal file
@ -0,0 +1,98 @@
|
||||
11 awesome vi tips and tricks
|
||||
======
|
||||
|
||||

|
||||
|
||||
The [vi editor][1] is one of the most popular text editors on Unix and Unix-like systems, such as Linux. Whether you're new to vi or just looking for a refresher, these 11 tips will enhance how you use it.
|
||||
|
||||
### Editing
|
||||
|
||||
Editing a long script can be tedious, especially when you need to edit a line so far down that it would take hours to scroll to it. Here's a faster way.
|
||||
|
||||
1. The command `:set number` numbers each line down the left side.
|
||||
|
||||

|
||||
|
||||
You can directly reach line number 26 by opening the file and entering this command on the CLI: `vi +26 sample.txt`. To edit line 26 (for example), the command `:26` will take you directly to it.
|
||||
|
||||

|
||||
|
||||
### Fast navigation
|
||||
|
||||
2. `i` changes your mode from "command" to "insert" and starts inserting text at the current cursor position.
|
||||
3. `a` does the same, except it starts just after the current cursor position.
|
||||
4. `o` starts the cursor position from the line below the current cursor position.
|
||||
|
||||
|
||||
|
||||
### Delete
|
||||
|
||||
If you notice an error or typo, being able to make a quick fix is important. Good thing vi has it all figured out.
|
||||
|
||||
Understanding vi's delete function so you don't accidentally press a key and permanently remove a line, paragraph, or more, is critical.
|
||||
|
||||
5. `x` deletes the character under the cursor.
|
||||
6. `dd` deletes the current line. (Yes, the whole line!)
|
||||
|
||||
|
||||
|
||||
Here's the scary part: `30dd` would delete 30 lines starting with the current line! Proceed with caution when using this command.
|
||||
|
||||
### Search
|
||||
|
||||
You can search for keywords from the "command" mode rather than manually navigating and looking for a specific word in a plethora of text.
|
||||
|
||||
7. `:/<keyword>` searches for the word mentioned in the `< >` space and takes your cursor to the first match.
|
||||
8. To navigate to the next instance of that word, type `n`, and keep pressing it until you get to the match you're looking for.
|
||||
|
||||
|
||||
|
||||
For example, in the image below I searched for `ssh`, and vi highlighted the beginning of the first result.
|
||||
|
||||

|
||||
|
||||
After I pressed `n`, vi highlighted the next instance.
|
||||
|
||||

|
||||
|
||||
### Save and exit
|
||||
|
||||
Developers (and others) will probably find this next command useful.
|
||||
|
||||
9. `:x` saves your work and exits vi.
|
||||
|
||||

|
||||
|
||||
10. If you think every nanosecond is worth saving, here's a faster way to shift to terminal mode in vi. Instead of pressing `Shift+:` on the keyboard, you can press `Shift+q` (or Q, in caps) to access [Ex mode][2], but this doesn't really make any difference if you just want to save and quit by typing `x` (as shown above).
|
||||
|
||||
|
||||
|
||||
### Substitution
|
||||
|
||||
Here is a neat trick if you want to substitute every occurrence of one word with another. For example, if you want to substitute "desktop" with "laptop" in a large file, it would be monotonous and waste time to search for each occurrence of "desktop," delete it, and type "laptop."
|
||||
|
||||
11. The command `:%s/desktop/laptop/g` would replace each occurrence of "desktop" with "laptop" throughout the file; it works just like the Linux `sed` command.
|
||||
|
||||
|
||||
|
||||
In this example, I replaced "root" with "user":
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
These tricks should help anyone get started using vi. Are there other neat tips I missed? Share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/top-11-vi-tips-and-tricks
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes#Ex-mode
|
||||
@ -1,69 +0,0 @@
|
||||
How Linux became my job translation by ranchong
|
||||
======
|
||||
|
||||

|
||||
|
||||
I've been using open source since what seems like prehistoric times. Back then, there was nothing called social media. There was no Firefox, no Google Chrome (not even a Google), no Amazon, barely an internet. In fact, the hot topic of the day was the new Linux 2.0 kernel. The big technical challenges in those days? Well, the [ELF format][1] was replacing the old [a.out][2] format in binary [Linux][3] distributions, and the upgrade could be tricky on some installs of Linux.
|
||||
|
||||
How I transformed a personal interest in this fledgling young operating system to a [career][4] in open source is an interesting story.
|
||||
|
||||
### Linux for fun, not profit
|
||||
|
||||
I graduated from college in 1994 when computer labs were small networks of UNIX systems; if you were lucky they connected to this new thing called the internet. Hard to believe, I know! The "web" (as we knew it) was mostly handwritten HTML, and the `cgi-bin` directory was a new playground for enabling dynamic web interactions. Many of us were excited about these new technologies, and we taught ourselves shell scripting, [Perl][5], HTML, and all the terse UNIX commands that we had never seen on our parents' Windows 3.1 PCs.
|
||||
|
||||
`vi` and `ls` and reading my email via
|
||||
|
||||
After graduation, I joined IBM, working on a PC operating system with no access to UNIX systems, and soon my university cut off my remote access to the engineering lab. How was I going to keep usingandand reading my email via [Pine][6] ? I kept hearing about open source Linux, but I hadn't had time to look into it.
|
||||
|
||||
In 1996, I was about to begin a master's degree program at the University of Texas at Austin. I knew it would involve programming and writing papers, and who knows what else, and I didn't want to use proprietary editors or compilers or word processors. I wanted my UNIX experience!
|
||||
|
||||
So I took an old PC, found a Linux distribution—Slackware 3.0—and downloaded it, diskette after diskette, in my IBM office. Let's just say I've never looked back after that first install of Linux. In those early days, I learned a lot about makefiles and the `make` system, about building software, and about patches and source code control. Even though I started working with Linux for fun and personal knowledge, it ended up transforming my career.
|
||||
|
||||
While I was a happy Linux user, I thought open source development was still other people's work; I imagined an online mailing list of mystical [UNIX][7] geeks. I appreciated things like the Linux HOWTO project for helping with the bumps and bruises I acquired trying to add packages, upgrade my Linux distribution, or install device drivers for new hardware or a new PC. But working with source code and making modifications or submitting them upstream … that was for other people, not me.
|
||||
|
||||
### How Linux became my job
|
||||
|
||||
In 1999, I finally had a reason to combine my personal interest in Linux with my day job at IBM. I took on a skunkworks project to port the IBM Java Virtual Machine (JVM) to Linux. To ensure we were legally safe, IBM purchased a shrink-wrapped, boxed copy of Red Hat Linux 6.1 to do this work. Working with the IBM Tokyo Research lab, which wrote our JVM just-in-time (JIT) compiler, and both the AIX JVM source code and the Windows & OS/2 JVM source code reference, we had a working JVM on Linux within a few weeks, beating the announcement of Sun's official Java on Linux port by several months. Now that I had done development on the Linux platform, I was sold on it.
|
||||
|
||||
By 2000, IBM's use of Linux was growing rapidly. Due to the vision and persistence of [Dan Frye][8], IBM made a "[billion dollar bet][9]" on Linux, creating the Linux Technology Center (LTC) in 1999. Inside the LTC were kernel developers, open source contributors, device driver authors for IBM hardware, and all manner of Linux-focused open source work. Instead of remaining tangentially connected to the LTC, I wanted to be part of this exciting new area at IBM.
|
||||
|
||||
From 2003 to 2013 I was deeply involved in IBM's Linux strategy and use of Linux distributions, culminating with having a team that became the clearinghouse for about 60 different product uses of Linux across every division of IBM. I was involved in acquisitions where it was an expectation that every appliance, management system, and virtual or physical appliance-based middleware ran Linux. I became well-versed in the construction of Linux distributions, including packaging, selecting upstream sources, developing distro-maintained patch sets, doing customizations, and offering support through our distro partners.
|
||||
|
||||
Due to our downstream providers, I rarely got to submit patches upstream, but I got to contribute by interacting with [Ulrich Drepper][10] (including getting a small patch into glibc) and working on changes to the [timezone database][11], which Arthur David Olson accepted while he was maintaining it on the NIH FTP site. But I still hadn't worked as a regular contributor on an open source project as part of my work. It was time for that to change.
|
||||
|
||||
In late 2013, I joined IBM's cloud organization in the open source group and was looking for an upstream community in which to get involved. Would it be our work on Cloud Foundry, or would I join IBM's large group of contributors to OpenStack? It was neither, because in 2014 Docker took the world by storm, and IBM asked a few of us to get involved with this hot new technology. I experienced many firsts in the next few months: using GitHub, [learning a lot more about Git][12] than just `git clone`, having pull requests reviewed, writing in Go, and more. Over the next year, I became a maintainer in the Docker engine project, working with Docker on creating the next version of the image specification (to support multiple architectures), and attending and speaking at conferences about container technology.
|
||||
|
||||
### Where I am today
|
||||
|
||||
Fast forward a few years, and I've become a maintainer of open source projects, including the Cloud Native Computing Foundation (CNCF) [containerd][13] project. I've also created projects (such as [manifest-tool][14] and [bucketbench][15]). I've gotten involved in open source governance via the Open Containers Initiative (OCI), where I'm now a member of the Technical Oversight Board, and the Moby Project, where I'm a member of the Technical Steering Committee. And I've had the pleasure of speaking about open source at conferences around the world, to meetup groups, and internally at IBM.
|
||||
|
||||
Open source is now part of the fiber of my career at IBM. The connections I've made to engineers, developers, and leaders across the industry may rival the number of people I know and work with inside IBM. While open source has many of the same challenges as proprietary development teams and vendor partnerships have, in my experience the relationships and connections with people around the globe in open source far outweigh the difficulties. The sharpening that occurs with differing opinions, perspectives, and experiences can generate a culture of learning and improvement for both the software and the people involved.
|
||||
|
||||
This journey—from my first use of Linux to becoming a leader, contributor, and maintainer in today's cloud-native open source world—has been extremely rewarding. I'm looking forward to many more years of open source collaboration and interactions with people around the globe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
42
sources/talk/20180221 3 warning flags of DevOps metrics.md
Normal file
42
sources/talk/20180221 3 warning flags of DevOps metrics.md
Normal file
@ -0,0 +1,42 @@
|
||||
3 warning flags of DevOps metrics
|
||||
======
|
||||

|
||||
|
||||
Metrics. Measurements. Data. Monitoring. Alerting. These are all big topics for DevOps and for cloud-native infrastructure and application development more broadly. In fact, acm Queue, a magazine published by the Association of Computing Machinery, recently devoted an [entire issue][1] to the topic.
|
||||
|
||||
I've argued before that we conflate a lot of things under the "metrics" term, from key performance indicators to critical failure alerts to data that may be vaguely useful someday for something or other. But that's a topic for another day. What I want to discuss here is how metrics affect behavior.
|
||||
|
||||
In 2008, Daniel Ariely published [Predictably Irrational][2] , one of a number of books written around that time that introduced behavioral psychology and behavioral economics to the general public. One memorable quote from that book is the following: "Human beings adjust behavior based on the metrics they're held against. Anything you measure will impel a person to optimize his score on that metric. What you measure is what you'll get. Period."
|
||||
|
||||
This shouldn't be surprising. It's a finding that's been repeatedly confirmed by research. It should also be familiar to just about anyone with business experience. It's certainly not news to anyone in sales management, for example. Base sales reps' (or their managers'!) bonuses solely on revenue, and they'll discount whatever it takes to maximize revenue even if it puts margin in the toilet. Conversely, want the sales force to push a new product line—which will probably take extra effort—but skip the [spiffs][3]? Probably not happening.
|
||||
|
||||
And lest you think I'm unfairly picking on sales, this behavior is pervasive, all the way up to the CEO, as Ariely describes in [a 2010 Harvard Business Review article][4]. "CEOs care about stock value because that's how we measure them. If we want to change what they care about, we should change what we measure," writes Ariely.
|
||||
|
||||
Think developers and operations folks are immune from such behaviors? Think again. Let's consider some problematic measurements. They're not all bad or wrong but, if you rely too much on them, warning flags should go up.
|
||||
|
||||
### Three warning signs for DevOps metrics
|
||||
|
||||
First, there are the quantity metrics. Lines of code or bugs fixed are perhaps self-evidently absurd. But there are also the deployments per week or per month that are so widely quoted to illustrate DevOps velocity relative to more traditional development and deployment practices. Speed is good. It's one of the reasons you're probably doing DevOps—but don't reward people on it excessively relative to quality and other measures.
|
||||
|
||||
Second, it's obvious that you want to reward individuals who do their work quickly and well. Yes. But. Whether it's your local pro sports team or some project team you've been on, you can probably name someone who was really a talent, but was just so toxic and such a distraction for everyone else that they were a net negative for the team. Moral: Don't provide incentives that solely encourage individual behaviors. You may also want to put in place programs, such as peer rewards, that explicitly value collaboration. [As Red Hat's Jen Krieger told me][5] in a podcast last year: "Having those automated pots of awards, or some sort of system that's tracked for that, can only help teams feel a little more cooperative with one another as in, 'Hey, we're all working together to get something done.'"
|
||||
|
||||
The third red flag area is incentives that don't actually incent because neither the individual nor the team has a meaningful ability to influence the outcome. It's often a good thing when DevOps metrics connect to business goals and outcomes. For example, customer ticket volume relates to perceived shortcomings in applications and infrastructure. And it's also a reasonable proxy for overall customer satisfaction, which certainly should be of interest to the executive suite. The best reward systems to drive DevOps behaviors should be tied to specific individual and team actions as opposed to just company success generally.
|
||||
|
||||
You've probably noticed a common theme. That theme is balance. Velocity is good but so is quality. Individual achievement is good but not when it damages the effectiveness of the team. The overall success of the business is certainly important, but the best reward systems also tie back to actions and behaviors within development and operations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/three-warning-flags-devops-metrics
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://queue.acm.org/issuedetail.cfm?issue=3178368
|
||||
[2]:https://en.wikipedia.org/wiki/Predictably_Irrational
|
||||
[3]:https://en.wikipedia.org/wiki/Spiff
|
||||
[4]:https://hbr.org/2010/06/column-you-are-what-you-measure
|
||||
[5]:http://bitmason.blogspot.com/2015/09/podcast-making-devops-succeed-with-red.html
|
||||
48
sources/talk/20180301 How to hire the right DevOps talent.md
Normal file
48
sources/talk/20180301 How to hire the right DevOps talent.md
Normal file
@ -0,0 +1,48 @@
|
||||
How to hire the right DevOps talent
|
||||
======
|
||||
|
||||

|
||||
|
||||
DevOps culture is quickly gaining ground, and demand for top-notch DevOps talent is greater than ever at companies all over the world. With the [annual base salary for a junior DevOps engineer][1] now topping $100,000, IT professionals are hurrying to [make the transition into DevOps.][2]
|
||||
|
||||
But how do you choose the right candidate to fill your DevOps role?
|
||||
|
||||
### Overview
|
||||
|
||||
Most teams are looking for candidates with a background in operations and infrastructure, software engineering, or development. This is in conjunction with skills that relate to configuration management, continuous integration, and deployment (CI/CD), as well as cloud infrastructure. Knowledge of container orchestration is also in high demand.
|
||||
|
||||
In a perfect world, the two backgrounds would meet somewhere in the middle to form Dev and Ops, but in most cases, candidates lean toward one side or the other. Yet they must possess the skills necessary to understand the needs of their counterparts to work effectively as a team to achieve continuous delivery and deployment. Since every company is different, there is no single right or wrong since so much depends on a company’s tech stack and infrastructure, as well as the goals and the skills of other team members. So how do you focus your search?
|
||||
|
||||
### Decide on the background
|
||||
|
||||
Begin by assessing the strength of your current team. Do you have rock-star software engineers but lack infrastructure knowledge? Focus on closing the skill gaps. Just because you have the budget to hire a DevOps engineer doesn’t mean you should spend weeks, or even months, trying to find the best software engineer who also happens to use Kubernetes and Docker because they are currently the trend. Instead, look for someone who will provide the most value in your environment, and see how things go from there.
|
||||
|
||||
### There is no “Ctrl + F” solution
|
||||
|
||||
Instead of concentrating on specific tools, concentrate on a candidate's understanding of DevOps and CI/CD-related processes. You'll be better off with someone who understands methodologies over tools. It is more important to ensure that candidates comprehend the concept of CI/CD than to ask if they prefer Jenkins, Bamboo, or TeamCity. Don’t get too caught up in the exact toolchain—rather, focus on problem-solving skills and the ability to increase efficiency, save time, and automate manual processes. You don't want to miss out on the right candidate just because the word “Puppet” was not on their resume.
|
||||
|
||||
### Check your ego
|
||||
|
||||
As mentioned above, DevOps is a rapidly growing field, and DevOps engineers are in hot demand. That means candidates have great buying power. You may have an amazing company or product, but hiring top talent is no longer as simple as putting up a “Help Wanted” sign and waiting for top-quality applicants to rush in. I'm not suggesting that maintaining a reputation a great place to work is unimportant, but in today's environment, you need to make an effort to sell your position. Flaws or glitches in the hiring process, such as abruptly canceling interviews or not offering feedback after interviews, can lead to negative reviews spreading across the industry. Remember, it takes just a couple of minutes to leave a negative review on Glassdoor.
|
||||
|
||||
### Contractor or permanent employee?
|
||||
|
||||
Most recruiters and hiring managers immediately start searching for a full-time employee, even though they may have other options. If you’re looking to design, build, and implement a new DevOps environment, why not hire a senior person who has done this in the past? Consider hiring a senior contractor, along with a junior full-time hire. That way, you can tap the knowledge and experience of the contractor by having them work with the junior employee. Contractors can be expensive, but they bring invaluable knowledge—especially if the work can be done within a short timeframe.
|
||||
|
||||
### Cultivate from within
|
||||
|
||||
With so many companies competing for talent, it is difficult to find the right DevOps engineer. Not only will you need to pay top dollar to hire this person, but you must also consider that the search can take several months. However, since few companies are lucky enough to find the ideal DevOps engineer, consider searching for a candidate internally. You might be surprised at the talent you can cultivate from within your own organization.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-hire-right-des-talentvop
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://www.glassdoor.com/Salaries/junior-devops-engineer-salary-SRCH_KO0,22.htm
|
||||
[2]:https://squadex.com/insights/system-administrator-making-leap-devops/
|
||||
@ -0,0 +1,53 @@
|
||||
Beyond metrics: How to operate as team on today's open source project
|
||||
======
|
||||
|
||||

|
||||
|
||||
How do we traditionally think about community health and vibrancy?
|
||||
|
||||
We might quickly zero in on metrics related primarily to code contributions: How many companies are contributing? How many individuals? How many lines of code? Collectively, these speak to both the level of development activity and the breadth of the contributor base. The former speaks to whether the project continues to be enhanced and expanded; the latter to whether it has attracted a diverse group of developers or is controlled primarily by a single organization.
|
||||
|
||||
The [Linux Kernel Development Report][1] tracks these kinds of statistics and, unsurprisingly, it appears extremely healthy on all counts.
|
||||
|
||||
However, while development cadence and code contributions are still clearly important, other aspects of the open source communities are also coming to the forefront. This is in part because, increasingly, open source is about more than a development model. It’s also about making it easier for users and other interested parties to interact in ways that go beyond being passive recipients of code. Of course, there have long been user groups. But open source streamlines the involvement of users, just as it does software development.
|
||||
|
||||
This was the topic of my discussion with Diane Mueller, the director of community development for OpenShift.
|
||||
|
||||
When OpenShift became a container platform based in part on Kubernetes in version 3, Mueller saw a need to broaden the community beyond the core code contributors. In part, this was because OpenShift was increasingly touching a broad range of open source projects and organizations such those associated with the [Open Container Initiative (OCI)][2] and the [Cloud Native Computing Foundation (CNCF)][3]. In addition to users, cloud service providers who were offering managed services also wanted ways to get involved in the project.
|
||||
|
||||
“What we tried to do was open up our minds about what the community constituted,” Mueller explained, adding, “We called it the [Commons][4] because Red Hat's near Boston, and I'm from that area. Boston Common is a shared resource, the grass where you bring your cows to graze, and you have your farmer's hipster market or whatever it is today that they do on Boston Common.”
|
||||
|
||||
This new model, she said, was really “a new ecosystem that incorporated all of those different parties and different perspectives. We used a lot of virtual tools, a lot of new tools like Slack. We stepped up beyond the mailing list. We do weekly briefings. We went very virtual because, one, I don't scale. The Evangelist and Dev Advocate team didn't scale. We need to be able to get all that word out there, all this new information out there, so we went very virtual. We worked with a lot of people to create online learning stuff, a lot of really good tooling, and we had a lot of community help and support in doing that.”
|
||||
|
||||
![diane mueller open shift][6]
|
||||
|
||||
Diane Mueller, director of community development at Open Shift, discusses the role of strong user communities in open source software development. (Credit: Gordon Haff, CC BY-SA 4.0)
|
||||
|
||||
However, one interesting aspect of the Commons model is that it isn’t just virtual. We see the same pattern elsewhere in many successful open source communities, such as the Linux kernel. Lots of day-to-day activities happen on mailings lists, IRC, and other collaboration tools. But this doesn’t eliminate the benefits of face-to-face time that allows for both richer and informal discussions and exchanges.
|
||||
|
||||
This interview with Mueller took place in London the day after the [OpenShift Commons Gathering][7]. Gatherings are full-day events, held a number of times a year, which are typically attended by a few hundred people. Much of the focus is on users and user stories. In fact, Mueller notes, “Here in London, one of the Commons members, Secnix, was really the major reason we actually hosted the gathering here. Justin Cook did an amazing job organizing the venue and helping us pull this whole thing together in less than 50 days. A lot of the community gatherings and things are driven by the Commons members.”
|
||||
|
||||
Mueller wants to focus on users more and more. “The OpenShift Commons gathering at [Red Hat] Summit will be almost entirely case studies,” she noted. “Users talking about what's in their stack. What lessons did they learn? What are the best practices? Sharing those ideas that they've done just like we did here in London.”
|
||||
|
||||
Although the Commons model grew out of some specific OpenShift needs at the time it was created, Mueller believes it’s an approach that can be applied more broadly. “I think if you abstract what we've done, you can apply it to any existing open source community,” she said. “The foundations still, in some ways, play a nice role in giving you some structure around governance, and helping incubate stuff, and helping create standards. I really love what OCI is doing to create standards around containers. There's still a role for that in some ways. I think the lesson that we can learn from the experience and we can apply to other projects is to open up the community so that it includes feedback mechanisms and gives the podium away.”
|
||||
|
||||
The evolution of the community model though approaches like the OpenShift Commons mirror the healthy evolution of open source more broadly. Certainly, some users have been involved in the development of open source software for a long time. What’s striking today is how widespread and pervasive direct user participation has become. Sure, open source remains central to much of modern software development. But it’s also becoming increasingly central to how users learn from each other and work together with their partners and developers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-communities-are-evolving
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://www.linuxfoundation.org/2017-linux-kernel-report-landing-page/
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://commons.openshift.org/
|
||||
[5]:/file/388586
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/39369010275_7df2c3c260_z.jpg?itok=gIhnBl6F (diane mueller open shift)
|
||||
[7]:https://www.meetup.com/London-OpenShift-User-Group/events/246498196/
|
||||
75
sources/talk/20180303 4 meetup ideas- Make your data open.md
Normal file
75
sources/talk/20180303 4 meetup ideas- Make your data open.md
Normal file
@ -0,0 +1,75 @@
|
||||
4 meetup ideas: Make your data open
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Open Data Day][1] (ODD) is an annual, worldwide celebration of open data and an opportunity to show the importance of open data in improving our communities.
|
||||
|
||||
Not many individuals and organizations know about the meaningfulness of open data or why they might want to liberate their data from the restrictions of copyright, patents, and more. They also don't know how to make their data open—that is, publicly available for anyone to use, share, or republish with modifications.
|
||||
|
||||
This year ODD falls on Saturday, March 3, and there are [events planned][2] in every continent except Antarctica. While it might be too late to organize an event for this year, it's never too early to plan for next year. Also, since open data is important every day of the year, there's no reason to wait until ODD 2019 to host an event in your community.
|
||||
|
||||
There are many ways to build local awareness of open data. Here are four ideas to help plan an excellent open data event any time of year.
|
||||
|
||||
### 1. Organize an entry-level event
|
||||
|
||||
You can host an educational event at a local library, college, or another public venue about how open data can be used and why it matters for all of us. If possible, invite a [local speaker][3] or have someone present remotely. You could also have a roundtable discussion with several knowledgeable people in your community.
|
||||
|
||||
Consider offering resources such as the [Open Data Handbook][4], which not only provides a guide to the philosophy and rationale behind adopting open data, but also offers case studies, use cases, how-to guides, and other material to support making data open.
|
||||
|
||||
### 2. Organize an advanced-level event
|
||||
|
||||
For a deeper experience, organize a hands-on training event for open data newbies. Ideas for good topics include [training teachers on open science][5], [creating audiovisual expressions from open data][6], and using [open government data][7] in meaningful ways.
|
||||
|
||||
The options are endless. To choose a topic, think about what is locally relevant, identify issues that open data might be able to address, and find people who can do the training.
|
||||
|
||||
### 3. Organize a hackathon
|
||||
|
||||
Open data hackathons can be a great way to bring open data advocates, developers, and enthusiasts together under one roof. Hackathons are more than just training sessions, though; the idea is to build prototypes or solve real-life challenges that are tied to open data. In a hackathon, people in various groups can contribute to the entire assembly line in multiple ways, such as identifying issues by working collaboratively through [Etherpad][8] or creating focus groups.
|
||||
|
||||
Once the hackathon is over, make sure to upload all the useful data that is produced to the internet with an open license.
|
||||
|
||||
### 4. Release or relicense data as open
|
||||
|
||||
Open data is about making meaningful data publicly available under open licenses while protecting any data that might put people's private information at risk. (Learn [how to protect private data][9].) Try to find existing, interesting, and useful data that is privately owned by individuals or organizations and negotiate with them to relicense or release the data online under any of the [recommended open data licenses][10]. The widely popular [Creative Commons licenses][11] (particularly the CC0 license and the 4.0 licenses) are quite compatible with relicensing public data. (See this FAQ from Creative Commons for more information on [openly licensing data][12].)
|
||||
|
||||
Open data can be published on multiple platforms—your website, [GitHub][13], [GitLab][14], [DataHub.io][15], or anywhere else that supports open standards.
|
||||
|
||||
### Tips for event success
|
||||
|
||||
No matter what type of event you decide to do, here are some general planning tips to improve your chances of success.
|
||||
|
||||
* Find a venue that's accessible to the people you want to reach, such as a library, a school, or a community center.
|
||||
* Create a curriculum that will engage the participants.
|
||||
* Invite your target audience—make sure to distribute information through social media, community events calendars, Meetup, and the like.
|
||||
|
||||
|
||||
|
||||
Have you attended or hosted a successful open data event? If so, please share your ideas in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/celebrate-open-data-day
|
||||
|
||||
作者:[Subhashish Panigraphi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psubhashish
|
||||
[1]:http://www.opendataday.org/
|
||||
[2]:http://opendataday.org/#map
|
||||
[3]:https://openspeakers.org/
|
||||
[4]:http://opendatahandbook.org/
|
||||
[5]:https://docs.google.com/forms/d/1BRsyzlbn8KEMP8OkvjyttGgIKuTSgETZW9NHRtCbT1s/viewform?edit_requested=true
|
||||
[6]:http://dattack.lv/en/
|
||||
[7]:https://www.eventbrite.co.nz/e/open-data-open-potential-event-friday-2-march-2018-tickets-42733708673
|
||||
[8]:http://etherpad.org/
|
||||
[9]:https://ssd.eff.org/en/module/keeping-your-data-safe
|
||||
[10]:https://opendatacommons.org/licenses/
|
||||
[11]:https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[12]:https://wiki.creativecommons.org/wiki/Data#Frequently_asked_questions_about_data_and_CC_licenses
|
||||
[13]:https://github.com/MartinBriza/MediaWriter
|
||||
[14]:https://about.gitlab.com/
|
||||
[15]:https://datahub.io/
|
||||
@ -0,0 +1,130 @@
|
||||
What’s next in IT automation: 6 trends to watch
|
||||
======
|
||||
|
||||

|
||||
|
||||
We’ve recently covered the [factors fueling IT automation][1], the [current trends][2] to watch as adoption grows, and [helpful tips][3] for those organizations just beginning to automate certain processes.
|
||||
|
||||
Oh, and we also shared expert advice on [how to make the case for automation][4] in your company, as well as [keys for long-term success][5].
|
||||
|
||||
Now, there’s just one question: What’s next? We asked a range of experts to share a peek into the not-so-distant future of [automation][6]. Here are six trends they advise IT leaders to monitor closely.
|
||||
|
||||
### 1. Machine learning matures
|
||||
|
||||
For all of the buzz around [machine learning][7] (and the overlapping phrase “self-learning systems”), it’s still very early days for most organizations in terms of actual implementations. Expect that to change, and for machine learning to play a significant role in the next waves of IT automation.
|
||||
|
||||
Mehul Amin, director of engineering for [Advanced Systems Concepts, Inc.][8], points to machine learning as one of the next key growth areas for IT automation.
|
||||
|
||||
“With the data that is developed, automation software can make decisions that otherwise might be the responsibility of the developer,” Amin says. “For example, the developer builds what needs to be executed, but identifying the best system to execute the processes might be [done] by software using analytics from within the system.”
|
||||
|
||||
That extends elsewhere in this same hypothetical system; Amin notes that machine learning can enable automated systems to provision additional resources when necessary to meet timelines or SLAs, as well as retire those resources when they’re no longer needed, and other possibilities.
|
||||
|
||||
Amin is certainly not alone.
|
||||
|
||||
“IT automation is moving towards self-learning,” says Kiran Chitturi, CTO architect at [Sungard Availability Services][9]. “Systems will be able to test and monitor themselves, enhancing business processes and software delivery.”
|
||||
|
||||
Chitturi points to automated testing as an example; test scripts are already in widespread adoption, but soon those automated testing processes may be more likely to learn as they go, developing, for example, wider recognition of how new code or code changes will impact production environments.
|
||||
|
||||
### 2. Artificial intelligence spawns automation opportunities
|
||||
|
||||
The same principles above hold true for the related (but separate) field of [artificial intelligence][10]. Depending on your definition of AI, it seems likely that machine learning will have the more significant IT impact in the near term (and we’re likely to see a lot of overlapping definitions and understandings of the two fields). Assume that emerging AI technologies will spawn new automation opportunities, too.
|
||||
|
||||
“The integration of artificial intelligence (AI) and machine learning capabilities is widely perceived as critical for business success in the coming years,” says Patrick Hubbard, head geek at [SolarWinds][11].
|
||||
|
||||
### 3. That doesn’t mean people are obsolete
|
||||
|
||||
Let’s try to calm those among us who are now hyperventilating into a paper bag: The first two trends don’t necessarily mean we’re all going to be out of a job.
|
||||
|
||||
It is likely to mean changes to various roles – and the creation of [new roles][12] altogether.
|
||||
|
||||
But in the foreseeable future, at least, you don’t need to practice bowing to your robot overlords.
|
||||
|
||||
“A machine can only consider the environment variables that it is given – it can’t choose to include new variables, only a human can do this today,” Hubbard explains. “However, for IT professionals this will necessitate the cultivation of AI- and automation-era skills such as programming, coding, a basic understanding of the algorithms that govern AI and machine learning functionality, and a strong security posture in the face of more sophisticated cyberattacks.”
|
||||
|
||||
Hubbard shares the example of new tools or capabilities such as AI-enabled security software or machine-learning applications that remotely spot maintenance needs in an oil pipeline. Both might improve efficiency and effectiveness; neither automatically replaces the people necessary for information security or pipeline maintenance.
|
||||
|
||||
“Many new functionalities still require human oversight,” Hubbard says. “In order for a machine to determine if something ‘predictive’ could become ‘prescriptive,’ for example, human management is needed.”
|
||||
|
||||
The same principle holds true even if you set machine learning and AI aside for a moment and look at IT automation more generally, especially in the software development lifecycle.
|
||||
|
||||
Matthew Oswalt, lead architect for automation at [Juniper Networks][13], points out that the fundamental reason IT automation is growing is that it is creating immediate value by reducing the amount of manual effort required to operate infrastructure.
|
||||
|
||||
Rather than responding to an infrastructure issue at 3 a.m. themselves, operations engineers can use event-driven automation to define their workflows ahead of time, as code.
|
||||
|
||||
“It also sets the stage for treating their operations workflows as code rather than easily outdated documentation or tribal knowledge,” Oswalt explains. “Operations staff are still required to play an active role in how [automation] tooling responds to events. The next phase of adopting automation is to put in place a system that is able to recognize interesting events that take place across the IT spectrum and respond in an autonomous fashion. Rather than responding to an infrastructure issue at 3 a.m. themselves, operations engineers can use event-driven automation to define their workflows ahead of time, as code. They can rely on this system to respond in the same way they would, at any time.”
|
||||
|
||||
### 4. Automation anxiety will decrease
|
||||
|
||||
Hubbard of SolarWinds notes that the term “automation” itself tends to spawn a lot of uncertainty and concern, not just in IT but across professional disciplines, and he says that concern is legitimate. But some of the attendant fears may be overblown, and even perpetuated by the tech industry itself. Reality might actually be the calming force on this front: When the actual implementation and practice of automation helps people realize #3 on this list, then we’ll see #4 occur.
|
||||
|
||||
“This year we’ll likely see a decrease in automation anxiety and more organizations begin to embrace AI and machine learning as a way to augment their existing human resources,” Hubbard says. “Automation has historically created room for more jobs by lowering the cost and time required to accomplish smaller tasks and refocusing the workforce on things that cannot be automated and require human labor. The same will be true of AI and machine learning.”
|
||||
|
||||
Automation will also decrease some anxiety around the topic most likely to increase an IT leader’s blood pressure: Security. As Matt Smith, chief architect, [Red Hat][14], recently [noted][15], automation will increasingly help IT groups reduce the security risks associated with maintenance tasks.
|
||||
|
||||
His advice: “Start by documenting and automating the interactions between IT assets during maintenance activities. By relying on automation, not only will you eliminate tasks that historically required much manual effort and surgical skill, you will also be reducing the risks of human error and demonstrating what’s possible when your IT organization embraces change and new methods of work. Ultimately, this will reduce resistance to promptly applying security patches. And it could also help keep your business out of the headlines during the next major security event.”
|
||||
|
||||
**[ Read the full article: [12 bad enterprise security habits to break][16]. ] **
|
||||
|
||||
### 5. Continued evolution of scripting and automation tools
|
||||
|
||||
Many organizations see the first steps toward increasing automation – usually in the form of scripting or automation tools (sometimes referred to as configuration management tools) – as "early days" work.
|
||||
|
||||
But views of those tools are evolving as the use of various automation technologies grows.
|
||||
|
||||
“There are many processes in the data center environment that are repetitive and subject to human error, and technologies such as [Ansible][17] help to ameliorate those issues,” says Mark Abolafia, chief operating officer at [DataVision][18]. “With Ansible, one can write a specific playbook for a set of actions and input different variables such as addresses, etc., to automate long chains of process that were previously subject to human touch and longer lead times.”
|
||||
|
||||
**[ Want to learn more about this aspect of Ansible? Read the related article:[Tips for success when getting started with Ansible][19]. ]**
|
||||
|
||||
Another factor: The tools themselves will continue to become more advanced.
|
||||
|
||||
“With advanced IT automation tools, developers will be able to build and automate workflows in less time, reducing error-prone coding,” says Amin of ASCI. “These tools include pre-built, pre-tested drag-and-drop integrations, API jobs, the rich use of variables, reference functionality, and object revision history.”
|
||||
|
||||
### 6. Automation opens new metrics opportunities
|
||||
|
||||
As we’ve said previously in this space, automation isn’t IT snake oil. It won’t fix busted processes or otherwise serve as some catch-all elixir for what ails your organization. That’s true on an ongoing basis, too: Automation doesn’t eliminate the need to measure performance.
|
||||
|
||||
**[ See our related article[DevOps metrics: Are you measuring what matters?][20] ]**
|
||||
|
||||
In fact, automation should open up new opportunities here.
|
||||
|
||||
“As more and more development activities – source control, DevOps pipelines, work item tracking – move to the API-driven platforms – the opportunity and temptation to stitch these pieces of raw data together to paint the picture of your organization's efficiency increases,” says Josh Collins, VP of architecture at [Janeiro Digital][21].
|
||||
|
||||
Collins thinks of this as a possible new “development organization metrics-in-a-box.” But don’t mistake that to mean machines and algorithms can suddenly measure everything IT does.
|
||||
|
||||
“Whether measuring individual resources or the team in aggregate, these metrics can be powerful – but should be balanced with a heavy dose of context,” Collins says. “Use this data for high-level trends and to affirm qualitative observations – not to clinically grade your team.”
|
||||
|
||||
**Want more wisdom like this, IT leaders?[Sign up for our weekly email newsletter][22].**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
|
||||
[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
|
||||
[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
|
||||
[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
|
||||
[6]:https://enterprisersproject.com/tags/automation
|
||||
[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
|
||||
[8]:https://www.advsyscon.com/en-us/
|
||||
[9]:https://www.sungardas.com/en/
|
||||
[10]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[11]:https://www.solarwinds.com/
|
||||
[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
|
||||
[13]:https://www.juniper.net/
|
||||
[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
|
||||
[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://opensource.com/tags/ansible
|
||||
[18]:https://datavision.com/
|
||||
[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
|
||||
[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
|
||||
[21]:https://www.janeirodigital.com/
|
||||
[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -0,0 +1,59 @@
|
||||
Try, learn, modify: The new IT leader's code
|
||||
======
|
||||
|
||||

|
||||
|
||||
Just about every day, new technological developments threaten to destabilize even the most intricate and best-laid business plans. Organizations often find themselves scrambling to adapt to new conditions, and that's created a shift in how they plan for the future.
|
||||
|
||||
According to a 2017 [study][1] by CompTIA, only 34% of companies are currently developing IT architecture plans that extend beyond 12 months. One reason for that shift away from a longer-term plan is that business contexts are changing so quickly that planning any further into the future is nearly impossible. "If your company is trying to set a plan that will last five to 10 years down the road," [CIO.com writes][1], "forget it."
|
||||
|
||||
I've heard similar statements from countless customers and partners around the world. Technological innovations are occurring at an unprecedented pace.
|
||||
|
||||
The result is that long-term planning is dead. We need to be thinking differently about the way we run our organizations if we're going to succeed in this new world.
|
||||
|
||||
### How planning died
|
||||
|
||||
As I wrote in The Open Organization, traditionally-run organizations are optimized for industrial economies. They embrace hierarchical structures and rigidly prescribed processes as they work to achieve positional competitive advantage. To be successful, they have to define the strategic positions they want to achieve. Then they have to formulate and dictate plans for getting there, and execute on those plans in the most efficient ways possible—by coordinating activities and driving compliance.
|
||||
|
||||
Management's role is to optimize this process: plan, prescribe, execute. It consists of saying: Let's think of a competitively advantaged position; let's configure our organization to ultimately get there; and then let's drive execution by making sure all aspects of the organization comply. It's what I'll call "mechanical management," and it's a brilliant solution for a different time.
|
||||
|
||||
In today's volatile and uncertain world, our ability to predict and define strategic positions is diminishing—because the pace of change, the rate of introduction of new variables, is accelerating. Classic, long-term, strategic planning and execution isn't as effective as it used to be.
|
||||
|
||||
If long-term planning has become so difficult, then prescribing necessary behaviors is even more challenging. And measuring compliance against a plan is next to impossible.
|
||||
|
||||
All this dramatically affects the way people work. Unlike workers in the traditionally-run organizations of the past—who prided themselves on being able to act repetitively, with little variation and comfortable certainty—today's workers operate in contexts of abundant ambiguity. Their work requires greater creativity, intuition, and critical judgment—there is a greater demand to deviate from yesterday's "normal" and adjust to today's new conditions.
|
||||
|
||||
In today's volatile and uncertain world, our ability to predict and define strategic positions is diminishing—because the pace of change, the rate of introduction of new variables, is accelerating.
|
||||
|
||||
Working in this new way has become more critical to value creation. Our management systems must focus on building structures, systems, and processes that help create engaged, motivated workers—people who are enabled to innovate and act with speed and agility.
|
||||
|
||||
We need to come up with a different solution for optimizing organizations for a very different economic era, one that works from the bottom up rather than the top down. We need to replace that old three-step formula for success—plan, prescribe, execute—with one much better suited to today's tumultuous climate: try, learn, modify.
|
||||
|
||||
### Try, learn, modify
|
||||
|
||||
Because conditions can change so rapidly and with so little warning—and because the steps we need to take next are no longer planned in advance—we need to cultivate environments that encourage creative trial and error, not unyielding allegiance to a five-year schedule. Here are just a few implications of beginning to work this way:
|
||||
|
||||
* **Shorter planning cycles (try).** Rather than agonize over long-term strategic directions, managers need to be thinking of short-term experiments they can try quickly. They should be seeking ways to help their teams take calculated risks and leverage the data at their disposal to make best guesses about the most beneficial paths forward. They can do this by lowering overhead and giving teams the freedom to try new approaches quickly.
|
||||
* **Higher tolerance for failure (learn).** Greater frequency of experimentation means greater opportunity for failure. Creative and resilient organizations have a[significantly higher tolerance for failure][2] than traditional organizations do. Managers should treat failures as learning opportunities—moments to gather feedback on the tests their teams are running.
|
||||
* **More adaptable structures (modify).** An ability to easily modify organizational structures and strategic directions—and the willingness to do it when conditions necessitate—is the key to ensuring that organizations can evolve in line with rapidly changing environmental conditions. Managers can't be wedded to any idea any longer than that idea proves itself to be useful for accomplishing a short-term goal.
|
||||
|
||||
|
||||
|
||||
If long-term planning is dead, then long live shorter-term experimentation. Try, learn, and modify—that's the best path forward during uncertain times.
|
||||
|
||||
[Subscribe to our weekly newsletter][3] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/try-learn-modify
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://www.cio.com/article/3246027/enterprise-architecture/the-death-of-long-term-it-planning.html?upd=1515780110970
|
||||
[2]:https://opensource.com/open-organization/16/12/building-culture-innovation-your-organization
|
||||
[3]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,134 @@
|
||||
20 questions DevOps job candidates should be prepared to answer
|
||||
======
|
||||
|
||||

|
||||
Hiring the wrong person is [expensive][1]. Recruiting, hiring, and onboarding a new employee can cost a company as much as $240,000, according to Jörgen Sundberg, CEO of Link Humans. When you make the wrong hire:
|
||||
|
||||
* You lose what they know.
|
||||
* You lose who they know.
|
||||
* Your team could go into the [storming][2] phase of group development.
|
||||
* Your company risks disorganization.
|
||||
|
||||
|
||||
|
||||
When you lose an employee, you lose a piece of the fabric of the company. It's also worth mentioning the pain on the other end. The person hired into the wrong job may experience stress, feelings of overall dissatisfaction, and even health issues.
|
||||
|
||||
On the other hand, when you get it right, your new hire will:
|
||||
|
||||
* Enhance the existing culture, making your organization an even a better place to work. Studies show that a positive work culture helps [drive long-term financial performance][3] and that if you work in a happy environment, you’re more likely to do better in life.
|
||||
* Love working with your organization. When people love what they do, they tend to do it well.
|
||||
|
||||
|
||||
|
||||
Hiring to fit or enhance your existing culture is essential in DevOps and agile teams. That means hiring someone who can encourage effective collaboration so that individual contributors from varying backgrounds, and teams with different goals and working styles, can work together productively. Your new hire should help teams collaborate to maximize their value while also increasing employee satisfaction and balancing conflicting organizational goals. He or she should be able to choose tools and workflows wisely to complement your organization. Culture is everything.
|
||||
|
||||
As a follow-up to our November 2017 post, [20 questions DevOps hiring managers should be prepared to answer][4], this article will focus on how to hire for the best mutual fit.
|
||||
|
||||
### Why hiring goes wrong
|
||||
|
||||
The typical hiring strategy many companies use today is based on a talent surplus:
|
||||
|
||||
* Post on job boards.
|
||||
* Focus on candidates with the skills they need.
|
||||
* Find as many candidates as possible.
|
||||
* Interview to weed out the weak.
|
||||
* Conduct formal interviews to do more weeding.
|
||||
* Assess, vote, and select.
|
||||
* Close on compensation.
|
||||
|
||||

|
||||
|
||||
Job boards were invented during the Great Depression when millions of people were out of work and there was a talent surplus. There is no talent surplus in today's job market, yet we’re still using a hiring strategy that's based on one.
|
||||
|
||||

|
||||
|
||||
### Hire for mutual fit: Use culture and emotions
|
||||
|
||||
The idea behind the talent surplus hiring strategy is to design jobs and then slot people into them.
|
||||
|
||||
Instead, do the opposite: Find talented people who will positively add to your business culture, then find the best fit for them in a job they’ll love. To do this, you must be open to creating jobs around their passions.
|
||||
|
||||
**Who is looking for a job?** According to a 2016 survey of more than 50,000 U.S. developers, [85.7% of respondents][5] were either not interested in new opportunities or were not actively looking for them. And of those who were looking, a whopping [28.3% of job discoveries][5] came from referrals by friends. If you’re searching only for people who are looking for jobs, you’re missing out on top talent.
|
||||
|
||||
**Use your team to find and vet potential recruits**. For example, if Diane is a developer on your team, chances are she has [been coding for years][6] and has met fellow developers along the way who also love what they do. Wouldn’t you think her chances of vetting potential recruits for skills, knowledge, and intelligence would be higher than having someone from HR find and vet potential recruits? And before asking Diane to share her knowledge of fellow recruits, inform her of the upcoming mission, explain your desire to hire a diverse team of passionate explorers, and describe some of the areas where help will be needed in the future.
|
||||
|
||||
**What do employees want?** A comprehensive study comparing the wants and needs of Millennials, GenX’ers, and Baby Boomers shows that within two percentage points, we all [want the same things][7]:
|
||||
|
||||
1. To make a positive impact on the organization
|
||||
2. To help solve social and/or environmental challenges
|
||||
3. To work with a diverse group of people
|
||||
|
||||
|
||||
|
||||
### The interview challenge
|
||||
|
||||
The interview should be a two-way conversation for finding a mutual fit between the person hiring and the person interviewing. Focus your interview on CQ ([Cultural Quotient][7]) and EQ ([Emotional Quotient][8]): Will this person reinforce and add to your culture and love working with you? Can you help make them successful at their job?
|
||||
|
||||
**For the hiring manager:** Every interview is an opportunity to learn how your organization could become more irresistible to prospective team members, and every positive interview can be your best opportunity to finding talent, even if you don’t hire that person. Everyone remembers being interviewed if it is a positive experience. Even if they don’t get hired, they will talk about the experience with their friends, and you may get a referral as a result. There is a big upside to this: If you’re not attracting this talent, you have the opportunity to learn the reason and fix it.
|
||||
|
||||
**For the interviewee** : Each interview experience is an opportunity to unlock your passions.
|
||||
|
||||
### 20 questions to help you unlock the passions of potential hires
|
||||
|
||||
1. What are you passionate about?
|
||||
|
||||
2. What makes you think, "I can't wait to get to work this morning!”
|
||||
|
||||
3. What is the most fun you’ve ever had?
|
||||
|
||||
4. What is your favorite example of a problem you’ve solved, and how did you solve it?
|
||||
|
||||
5. How do you feel about paired learning?
|
||||
|
||||
6. What’s at the top of your mind when you arrive at, and leave, the office?
|
||||
|
||||
7. If you could have changed one thing in your previous/current job, what would it be?
|
||||
|
||||
8. What are you excited to learn while working here?
|
||||
|
||||
9. What do you aspire to in life, and how are you pursuing it?
|
||||
|
||||
10. What do you want, or feel you need, to learn to achieve these aspirations?
|
||||
|
||||
11. What values do you hold?
|
||||
|
||||
12. How do you live those values?
|
||||
|
||||
13. What does balance mean in your life?
|
||||
|
||||
14. What work interactions are you are most proud of? Why?
|
||||
|
||||
15. What type of environment do you like to create?
|
||||
|
||||
16. How do you like to be treated?
|
||||
|
||||
17. What do you trust vs. verify?
|
||||
|
||||
18. Tell me about a recent learning you had when working on a project.
|
||||
|
||||
19. What else should we know about you?
|
||||
|
||||
20. If you were hiring me, what questions would you ask me?
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/questions-devops-employees-should-answer
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:https://www.shrm.org/resourcesandtools/hr-topics/employee-relations/pages/cost-of-bad-hires.aspx
|
||||
[2]:https://en.wikipedia.org/wiki/Tuckman%27s_stages_of_group_development
|
||||
[3]:http://www.forbes.com/sites/johnkotter/2011/02/10/does-corporate-culture-drive-financial-performance/
|
||||
[4]:https://opensource.com/article/17/11/inclusive-workforce-takes-work
|
||||
[5]:https://insights.stackoverflow.com/survey/2016#work-job-discovery
|
||||
[6]:https://research.hackerrank.com/developer-skills/2018/
|
||||
[7]:http://www-935.ibm.com/services/us/gbs/thoughtleadership/millennialworkplace/
|
||||
[8]:https://en.wikipedia.org/wiki/Emotional_intelligence
|
||||
95
sources/talk/20180308 What is open source programming.md
Normal file
95
sources/talk/20180308 What is open source programming.md
Normal file
@ -0,0 +1,95 @@
|
||||
What is open source programming?
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the simplest level, open source programming is merely writing code that other people can freely use and modify. But you've heard the old chestnut about playing Go, right? "So simple it only takes a minute to learn the rules, but so complex it requires a lifetime to master." Writing open source code is a pretty similar experience. It's easy to chuck a few lines of code up on GitHub, Bitbucket, SourceForge, or your own blog or site. But doing it right requires some personal investment, effort, and forethought.
|
||||
|
||||

|
||||
|
||||
### What open source programming isn't
|
||||
|
||||
Let's be clear up front about something: Just being on GitHub in a public repo does not make your code open source. Copyright in nearly all countries attaches automatically when a work is fixed in a medium, without need for any action by the author. For any code that has not been licensed by the author, it is only the author who can exercise the rights associated with copyright ownership. Unlicensed code—no matter how publicly accessible—is a ticking time bomb for anyone who is unwise enough to use it.
|
||||
|
||||
A well-meaning author may think, "well, it's obvious this is free to use," and have no plans ever to sue anyone, but that doesn't mean the code is safe to use. No matter what you think someone will do, that author has the right to sue anyone who uses, modifies, or embeds that code anywhere else without an expressly granted license.
|
||||
|
||||
Clearly, you shouldn't put your own code out in public without a license and expect others to use or contribute to it. I would also recommend you avoid using (or even looking at) such code yourself. If you create a highly similar function or routine to a piece of unlicensed work you inspected at some point in the past, you could open yourself or your employer to infringement lawsuits.
|
||||
|
||||
Let's say that Jill Schmill writes AwesomeLib and puts it on GitHub without a license. Even if Jill never sues anybody, she might eventually sell all the rights to AwesomeLib to EvilCorp, who will. (Think of it as a lurking vulnerability, just waiting to be exploited.)
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
### Choosing the right license
|
||||
|
||||
OK, you've decided you want to write a new program, and you want people to have open source rights to use it. The next step is figuring out which [license][1] best fits your needs. You can get started with the GitHub-curated [choosealicense.com][2], which is just what it says on the tin. The site is laid out a bit like a simple quiz, and most people should be one or two clicks at most from finding the right license for their project.
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the [Apache License][3] or the [GPLv3][4] , it's easy for people to understand what their rights are and what your rights are without needing a team of lawyers to look for pitfalls and problems. The further you stray from the beaten path, though, the more problems you open yourself and others up to.
|
||||
|
||||
Most importantly, do not write your own license! Making up your own license is an unnecessary source of confusion for everyone. Don't do it. If you absolutely must have your own special terms that you can't find in any existing license, write them as an addendum to an otherwise well-understood license... and keep the main license and your addendum clearly separated so everyone involved knows which parts they've got to be extra careful about.
|
||||
|
||||
I know some people stubborn up and say, "I don't care about licenses and don't want to think about them; it's public domain." The problem with that is that "public domain" isn't a universally understood term in a legal sense. It means different things from one country to the next, with different rights and terms attached. In some countries, you can't even place your own works in the public domain, because the government reserves control over that. Luckily, the [Unlicense][5] has you covered. The Unlicense uses as few words as possible to clearly describe what "just make it public domain!" means in a clear and universally enforceable way.
|
||||
|
||||
### How to apply the license
|
||||
|
||||
Once you've chosen a license, you need to clearly and unambiguously apply it. If you're publishing somewhere like GitHub or GitLab or BitBucket, you'll have what amounts to a folder structure for your project's files. In the root folder of your project, you should have a plaintext file called LICENSE.txt that contains the text of the license you selected.
|
||||
|
||||
Putting LICENSE.txt in the root folder of your project isn't quite the last step—you also need a comment block declaring the license at the header of each significant file in your project. This is one of those times where it comes in handy to be using a well-established license. A comment that says: `# this work (c)2018 myname, licensed GPLv3—see https://www.gnu.org/licenses/gpl-3.0.en.html` is much, much stronger and more useful than a comment block that merely makes a cryptic reference to a completely custom license.
|
||||
|
||||
If you're self-publishing your code on your own site, you'll want to follow basically the same process. Have a LICENSE.txt, put the full copy of your license in it, and link to your license in an abbreviated comment block at the head of each significant file.
|
||||
|
||||
### Open source code is different
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen. As a 40-something sysadmin, I've written a lot of code. Most of it has been effectively proprietary—I started out writing code for myself to make my own jobs easier and scratch my own and/or my company's itches. The goal of such code is simple: All it has to do is work, in the exact way and under the exact circumstance its creator planned. As long as the thing you expected to happen when you invoked the program happens more frequently than not, it's a success.
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen.
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Your open source code also has to avoid unduly embarrassing you. That means that after you struggle and struggle to get a balky function or sub to finally produce the output you expected, you don't just sigh and move on to the next thing—you clean it up, because you don't want the rest of the world seeing your obvious house of cards. It means that you stop littering your code with variables like `$variable` and `$lol` and replace them with meaningful names like `$iterationcounter` or `$modelname`. And it means commenting things professionally (even if they're obvious to you in the heat of the moment) since you expect other people to be able to follow your code later.
|
||||
|
||||
This can be a little painful and frustrating at first—it's work you're not accustomed to doing. It makes you a better programmer, though, and it makes your code better as well. Just as important: Even if you're the only contributor your project ever has, it saves you work in the long run. Trust me, a year from now when you have to revisit your app, you're going to be very glad that `$modelname`, which gets parsed by several stunningly opaque regular expressions before getting socked into some other array somewhere, isn't named `$lol` anymore.
|
||||
|
||||
### You're not writing just for yourself
|
||||
|
||||
The true heart of open source isn't the code at all: it's the community. Projects with a strong community survive longer and are adopted much more heavily than those that don't. With that in mind, it's a good idea not only to embrace but actively plan for the community you hope to build around your project.
|
||||
|
||||
Batman might spend hundreds of hours in seclusion furiously building a project in secrecy, but you don't have to. Take to Twitter, Reddit, or mailing lists relevant to your project's scope, and announce that you're thinking of creating a new project. Talk about your design goals and how you plan to achieve them. Request input, listen to similar (but maybe not identical) use cases, and build that information into your process as you write code. You don't have to accept every suggestion or request—but if you know about them ahead of time, you can avoid pitfalls that require arduous major overhauls later.
|
||||
|
||||
This process doesn't end with the initial announcement. If you want your project to be adopted and used by other people, you need to develop it that way too. This isn't a barrier to entry; it's just a pattern to use. So don't just hunker down privately on your own machine with a text editor—start a real, publicly accessible project at one of the big foundries, and treat it as though the community was already there and watching.
|
||||
|
||||
### Ways to build a real public project
|
||||
|
||||
You can open accounts for open source projects at GitHub, GitLab, or BitBucket for free. Once you've opened your account and created a repository for your project, use it—create a README, assign a LICENSE, and push code incrementally as you develop it. This will build the habits you'll need to work with a real team later as you get accustomed to writing your code in measurable, documented commits with clear goals. The further you go, the more likely you'll start generating interest—usually in the form of end users first.
|
||||
|
||||
The users will start opening tickets, which will both delight and annoy you. You should take those tickets seriously and treat their owners courteously. Some of them will be based on tremendous misunderstandings of what your project is and what is or isn't within its scope—treat those courteously and professionally, also. In some cases, you'll guide those users into the fold of what you're doing. In others, however haltingly, they'll guide you into realizing the larger—or slightly differently centered—scope you probably should have planned for in the first place.
|
||||
|
||||
If you do a good job with the users, eventually fellow developers will show up and take an interest. This will also both delight and annoy you. At first, you'll probably just get trivial bugfixes. Eventually, you'll start to get pull requests that would either hardcode really, really niche special use-cases into your project (which would be a nightmare to maintain) or significantly alter the scope or even the focus of your project. You'll need to learn how to recognize which contributions are which and decide which ones you want to embrace and which you should politely reject.
|
||||
|
||||
### Why bother with all of this?
|
||||
|
||||
If all of this sounds like a lot of work, there's a good reason: it is. But it's rewarding work that you can cash in on in plenty of ways. Open source work sharpens your skills in ways you never realized were dull—from writing cleaner, more maintainable code to learning how to communicate well and work as a team. It's also the best possible resume builder for a working or aspiring professional developer; potential employers can hit your repository and see what you're capable of, and developers you've worked with on community projects may want to bring you in on paying gigs.
|
||||
|
||||
Ultimately, working on open source projects—yours or others'—means personal growth, because you're working on something larger than yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/tags/licensing
|
||||
[2]:https://choosealicense.com/
|
||||
[3]:https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]:https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]:https://choosealicense.com/licenses/unlicense/
|
||||
@ -0,0 +1,89 @@
|
||||
How to apply systems thinking in DevOps
|
||||
======
|
||||
|
||||

|
||||
For most organizations, adopting DevOps requires a mindset shift. Unless you understand the core of [DevOps][1], you might think it's hype or just another buzzword—or worse, you might believe you have already adopted DevOps because you are using the right tools.
|
||||
|
||||
Let’s dig deeper into what DevOps means, and explore how to apply systems thinking in your organization.
|
||||
|
||||
### What is systems thinking?
|
||||
|
||||
Systems thinking is a holistic approach to problem-solving. It's the opposite of analytical thinking, which separates a problem from the "bigger picture" to better understand it. Instead, systems thinking studies all the elements of a problem, along with the interactions between these elements.
|
||||
|
||||
Most people are not used to thinking this way. Since childhood, most of us were taught math, science, and every other subject separately, by different teachers. This approach to learning follows us throughout our lives, from school to university to the workplace. When we first join an organization, we typically work in only one department.
|
||||
|
||||
Unfortunately, the world is not that simple. Complexity, unpredictability, and sometimes chaos are unavoidable and require a broader way of thinking. Systems thinking helps us understand the systems we are part of, which in turn enables us to manage them rather than be controlled by them.
|
||||
|
||||
According to systems thinking, everything is a system: your body, your family, your neighborhood, your city, your company, and even the communities you belong to. These systems evolve organically; they are alive and fluid. The better you understand a system's behavior, the better you can manage and leverage it. You become their change agent and are accountable for them.
|
||||
|
||||
### Systems thinking and DevOps
|
||||
|
||||
All systems include properties that DevOps addresses through its practices and tools. Awareness of these properties helps us properly adapt to DevOps. Let's look at the properties of a system and how DevOps relates to each one.
|
||||
|
||||
### How systems work
|
||||
|
||||
The figure below represents a system. To reach a goal, the system requires input, which is processed and generates output. Feedback is essential for moving the system toward the goal. Without a purpose, the system dies.
|
||||
|
||||

|
||||
|
||||
If an organization is a system, its departments are subsystems. The flow of work moves through each department, starting with identifying a market need (the first input on the left) and moving toward releasing a solution that meets that need (the last output on the right). The output that each department generates serves as required input for the next department in the chain.
|
||||
|
||||
The more specialized teams an organization has, the more handoffs happen between departments. The process of generating value to clients is more likely to create bottlenecks and thus it takes longer to deliver value. Also, when work is passed between teams, the gap between the goal and what has been done widens.
|
||||
|
||||
DevOps aims to optimize the flow of work throughout the organization to deliver value to clients faster—in other words, DevOps reduces time to market. This is done in part by maximizing automation, but mainly by targeting the organization's goals. This empowers prioritization and reduces duplicated work and other inefficiencies that happen during the delivery process.
|
||||
|
||||
### System deterioration
|
||||
|
||||
All systems are affected by entropy. Nothing can prevent system degradation; that's irreversible. The tendency to decline shows the failure nature of systems. Moreover, systems are subject to threats of all types, and failure is a matter of time.
|
||||
|
||||
To mitigate entropy, systems require constant maintenance and improvements. The effects of entropy can be delayed only when new actions are taken or input is changed.
|
||||
|
||||
This pattern of deterioration and its opposite force, survival, can be observed in living organisms, social relationships, and other systems as well as in organizations. In fact, if an organization is not evolving, entropy is guaranteed to be increasing.
|
||||
|
||||
DevOps attempts to break the entropy process within an organization by fostering continuous learning and improvement. With DevOps, the organization becomes fault-tolerant because it recognizes the inevitability of failure. DevOps enables a blameless culture that offers the opportunity to learn from failure. The [postmortem][2] is an example of a DevOps practice used by organizations that embrace inherent failure.
|
||||
|
||||
The idea of intentionally embracing failure may sound counterintuitive, but that's exactly what happens in techniques like [Chaos Monkey][3]: Failure is intentionally introduced to improve availability and reliability in the system. DevOps suggests that putting some pressure into the system in a controlled way is not a bad thing. Like a muscle that gets stronger with exercise, the system benefits from the challenge.
|
||||
|
||||
### System complexity
|
||||
|
||||
The figure below shows how complex the systems can be. In most cases, one effect can have multiple causes, and one cause can generate multiple effects. The more elements and interactions a system has, the more complex the system.
|
||||
|
||||

|
||||
|
||||
In this scenario, we can't immediately identify the reason for a particular event. Likewise, we can't predict with 100% certainty what will happen if a specific action is taken. We are constantly making assumptions and dealing with hypotheses.
|
||||
|
||||
System complexity can be explained using the scientific method. In a recent study, for example, mice that were fed excess salt showed suppressed cerebral blood flow. This same experiment would have had different results if, say, the mice were fed sugar and salt. One variable can radically change results in complex systems.
|
||||
|
||||
DevOps handles complexity by encouraging experimentation—for example, using the scientific method—and reducing feedback cycles. Smaller changes inserted into the system can be tested and validated more quickly. With a "[fail-fast][4]" approach, organizations can pivot quickly and achieve resiliency. Reacting rapidly to changes makes organizations more adaptable.
|
||||
|
||||
DevOps also aims to minimize guesswork and maximize understanding by making the process of delivering value more tangible. By measuring processes, revealing flaws and advantages, and monitoring as much as possible, DevOps helps organizations discover the changes they need to make.
|
||||
|
||||
### System limitations
|
||||
|
||||
All systems have constraints that limit their performance; a system's overall capacity is delimited by its restrictions. Most of us have learned from experience that systems operating too long at full capacity can crash, and most systems work better when they function with some slack. Ignoring limitations puts systems at risk. For example, when we are under too much stress for a long time, we get sick. Similarly, overused vehicle engines can be damaged.
|
||||
|
||||
This principle also applies to organizations. Unfortunately, organizations can't put everything into a system at once. Although this limitation may sometimes lead to frustration, the quality of work usually improves when input is reduced.
|
||||
|
||||
Consider what happened when the speed limit on the main roads in São Paulo, Brazil was reduced from 90 km/h to 70 km/h. Studies showed that the number of accidents decreased by 38.5% and the average speed increased by 8.7%. In other words, the entire road system improved and more vehicles arrived safely at their destinations.
|
||||
|
||||
For organizations, DevOps suggests global rather than local improvements. It doesn't matter if some improvement is put after a constraint because there's no effect on the system at all. One constraint that DevOps addresses, for instance, is dependency on specialized teams. DevOps brings to organizations a more collaborative culture, knowledge sharing, and cross-functional teams.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Before adopting DevOps, understand what is involved and how you want to apply it to your organization. Systems thinking will help you accomplish that while also opening your mind to new possibilities. DevOps may be seen as a popular trend today, but in 10 or 20 years, it will be status quo.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-apply-systems-thinking-devops
|
||||
|
||||
作者:[Gustavo Muniz do Carmo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gustavomcarmo
|
||||
[1]:https://opensource.com/tags/devops
|
||||
[2]:https://landing.google.com/sre/book/chapters/postmortem-culture.html
|
||||
[3]:https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
|
||||
[4]:https://en.wikipedia.org/wiki/Fail-fast
|
||||
@ -0,0 +1,63 @@
|
||||
Pi Day: 12 fun facts and ways to celebrate
|
||||
======
|
||||
|
||||

|
||||
Today, tech teams around the world will celebrate a number. March 14 (written 3/14 in the United States) is known as Pi Day, a holiday that people ring in with pie eating contests, pizza parties, and math puns. If the most important number in mathematics wasn’t enough of a reason to reach for a slice of pie, March 14 also happens to be Albert Einstein’s birthday, the release anniversary of Linux kernel 1.0.0, and the day Eli Whitney patented the cotton gin.
|
||||
|
||||
In honor of this special day, we’ve rounded up a dozen fun facts and interesting pi-related projects. Master you team’s Pi Day trivia, or borrow an idea or two for a team-building exercise. Do a project with a budding technologist. And let us know in the comments if you are doing anything unique to celebrate everyone’s favorite never-ending number.
|
||||
|
||||
### Pi Day celebrations:
|
||||
|
||||
* Today is the 30th anniversary of Pi Day. The first was held in 1988 in San Francisco at the Exploratorium by physicist Larry Shaw. “On [the first Pi Day][1], staff brought in fruit pies and a tea urn for the celebration. At 1:59 – the pi numbers that follow 3.14 – Shaw led a circular parade around the museum with his boombox blaring the digits of pi to the music of ‘Pomp and Circumstance.’” It wasn’t until 21 years later, March 2009, that Pi Day became an official national holiday in the U.S.
|
||||
* Although it started in San Francisco, one of the biggest Pi Day celebrations can be found in Princeton. The town holds a [number of events][2] over the course of five days, including an Einstein look-alike contest, a pie-throwing event, and a pi recitation competition. Some of the activities even offer a cash prize of $314.15 for the winner.
|
||||
* MIT Sloan School of Management (on Twitter as [@MITSloan][3]) is celebrating Pi Day with fun facts about pi – and pie. Follow along with the Twitter hashtag #PiVersusPie
|
||||
|
||||
|
||||
|
||||
### Pi-related projects and activities:
|
||||
|
||||
* If you want to keep your math skills sharpened, NASA Jet Propulsion Lab has posted a [new set of math problems][4] that illustrate how pi can be used to unlock the mysteries of space. This marks the fifth year of NASA’s Pi Day Challenge, geared toward students.
|
||||
* There's no better way to get into the spirit of Pi Day than to take on a [Raspberry Pi][5] project. Whether you are looking for a project to do with your kids or with your team, there’s no shortage of ideas out there. Since its launch in 2012, millions of the basic computer boards have been sold. In fact, it’s the [third best-selling general purpose computer][6] of all time. Here are a few Raspberry Pi projects and activities that caught our eye:
|
||||
* Grab an AIY (AI-Yourself) kit from Google. You can create a [voice-controlled digital assistant][7] or an [image-recognition device][8].
|
||||
* [Run Kubernetes][9] on a Raspberry Pi.
|
||||
* Save Princess Peach by building a [retro gaming system][10].
|
||||
* Host a [Raspberry Jam][11] with your team. The Raspberry Pi Foundation has released a [Guidebook][12] to make hosting easy. According to the website, Raspberry Jams provide, “a support network for people of all ages in digital making. All around the world, like-minded people meet up to discuss and share their latest projects, give workshops, and chat about all things Pi.”
|
||||
|
||||
|
||||
|
||||
### Other fun Pi facts:
|
||||
|
||||
* The current [world record holder][13] for reciting pi is Suresh Kumar Sharma, who in October 2015 recited 70,030 digits. It took him 17 hours and 14 minutes to do so. However, the [unofficial record][14] goes to Akira Haraguchi, who claims he can recite up to 111,700 digits.
|
||||
* And, there’s more to remember than ever before. In November 2016, R&D scientist Peter Trueb calculated 22,459,157,718,361 digits of pi – [9 trillion more digits][15] than the previous world record set in 2013. According to New Scientist, “The final file containing the 22 trillion digits of pi is nearly 9 terabytes in size. If printed out, it would fill a library of several million books containing a thousand pages each."
|
||||
|
||||
|
||||
|
||||
Happy Pi Day!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
|
||||
|
||||
作者:[Carla Rudder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/crudder
|
||||
[1]:https://www.exploratorium.edu/pi/pi-day-history
|
||||
[2]:https://princetontourcompany.com/activities/pi-day/
|
||||
[3]:https://twitter.com/MITSloan
|
||||
[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
|
||||
[5]:https://opensource.com/resources/raspberry-pi
|
||||
[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
|
||||
[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
|
||||
[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
|
||||
[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
[10]:https://opensource.com/article/18/1/retro-gaming
|
||||
[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
|
||||
[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
|
||||
[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
|
||||
[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
|
||||
[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
|
||||
@ -0,0 +1,111 @@
|
||||
6 ways a thriving community will help your project succeed
|
||||
======
|
||||
|
||||

|
||||
NethServer is an open source product that my company, [Nethesis][1], launched just a few years ago. [The product][2] wouldn't be [what it is today][3] without the vibrant community that surrounds and supports it.
|
||||
|
||||
In my previous article, I [discussed what organizations should expect to give][4] if they want to experience the benefits of thriving communities. In this article, I'll describe what organizations should expect to receive in return for their investments in the passionate people that make up their communities.
|
||||
|
||||
Let's review six benefits.
|
||||
|
||||
### 1\. Innovation
|
||||
|
||||
"Open innovation" occurs when a company sharing information also listens to the feedback and suggestions from outside the company. As a company, we don't just look at the crowd for ideas. We innovate in, with, and through communities.
|
||||
|
||||
You may know that "[the best way to have a good idea is to have a lot of ideas][5]." You can't always expect to have the right idea on your own, so having different point of views on your product is essential. How many truly disruptive ideas can a small company (like Nethesis) create? We're all young, caucasian, and European—while in our community, we can pick up a set of inspirations from a variety of people, with different genders, backgrounds, skills, and ethnicities.
|
||||
|
||||
So the ability to invite the entire world to continuously improve the product is now no longer a dream; it's happening before our eyes. Your community could be the idea factory for innovation. With the community, you can really leverage the power of the collective.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
### 2\. Research
|
||||
|
||||
A community can be your strongest source of valuable product research.
|
||||
|
||||
First, it can help you avoid "ivory tower development." [As Stack Exchange co-founder Jeff Atwood has said][6], creating an environment where developers have no idea who the users are is dangerous. Isolated developers, who have worked for years in their high towers, often encounter bad results because they don't have any clue about how users actually use their software. Developing in an Ivory tower keeps you away from your users and can only lead to bad decisions. A community brings developers back to reality and helps them stay grounded. Gone are the days of developers working in isolation with limited resources. In this day and age, thanks to the advent of open source communities research department is opening up to the entire world.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
Second, a community can be an obvious source of product feedback—always necessary as you're researching potential paths forward. If someone gives you feedback, it means that person cares about you. It's a big gift. The community is a good place to acquire such invaluable feedback. Receiving early feedback is super important, because it reduces the cost of developing something that doesn't work in your target market. You can safely fail early, fail fast, and fail often.
|
||||
|
||||
And third, communities help you generate comparisons with other projects. You can't know all the features, pros, and cons of your competitors' offerings. [The community, however, can.][7] Ask your community.
|
||||
|
||||
### 3\. Perspective
|
||||
|
||||
Communities enable companies to look at themselves and their products [from the outside][8], letting them catch strengths and weaknesses, and mostly realize who their products' audiences really are.
|
||||
|
||||
Let me offer an example. When we launched the NethServer, we chose a catchy tagline for it. We were all convinced the following sentence was perfect:
|
||||
|
||||
> [NethServer][9] is an operating system for Linux enthusiasts, designed for small offices and medium enterprises.
|
||||
|
||||
Two years have passed since then. And we've learned that sentence was an epic fail.
|
||||
|
||||
We failed to realize who our audience was. Now we know: NethServer is not just for Linux enthusiasts; actually, Windows users are the majority. It's not just for small offices and medium enterprises; actually, several home users install NethServer for personal use. Our community helps us to fully understand our product and look at it from our users' eyes.
|
||||
|
||||
### 4\. Development
|
||||
|
||||
In open source communities especially, communities can be a welcome source of product development.
|
||||
|
||||
They can, first of all, provide testing and bug reporting. In fact, if I ask my developers about the most important community benefit, they'd answer "testing and bug reporting." Definitely. But because your code is freely available to the whole world, practically anyone with a good working knowledge of it (even hobbyists and other companies) has the opportunity to play with it, tweak it, and constantly improve it (even develop additional modules, as in our case). People can do more than just report bugs; they can fix those bugs, too, if they have the time and knowledge.
|
||||
|
||||
But the community doesn't just create code. It can also generate resources like [how-to guides,][10] FAQs, support documents, and case studies. How much would it cost to fully translate your product in seven different languages? At NethServer, we got that for free—thanks to our community members.
|
||||
|
||||
### 5\. Marketing
|
||||
|
||||
Communities can help your company go global. Our small Italian company, for example, wasn't prepared for a global market. The community got us prepared. For example, we needed to study and improve our English so we could read and write correctly or speak in public without looking foolish for an audience. The community gently forced us to organize [our first NethServer Conference][11], too—only in English.
|
||||
|
||||
A strong community can also help your organization attain the holy grail of marketers everywhere: word of mouth marketing (or what Seth Godin calls "[tribal marketing][12]").
|
||||
|
||||
Communities ensure that your company's messaging travels not only from company to tribe but also "sideways," from tribe member to potential tribe member. The community will become your street team, spreading word of your organization and its projects to anyone who will listen.
|
||||
|
||||
In addition, communities help organizations satisfy one of the most fundamental members needs: the desire to belong, to be involved in something bigger than themselves, and to change the world together.
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
### 6\. Loyalty
|
||||
|
||||
Attracting new users costs a business five times as much as keeping an existing one. So loyalty can have a huge impact on your bottom line. Quite simply, community helps us build brand loyalty. It's much more difficult to leave a group of people you're connected to than a faceless product or company. In a community, you're building connections with people, which is way more powerful than features or money (trust me!).
|
||||
|
||||
### Conclusion
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
And I wouldn't be honest with you if I didn't admit that the approach has some drawbacks. Doing everything in the open means moderating, evaluating, and processing of all the data you're receiving. Supporting your members and leading the discussions definitely takes time and resources. But, if you look at what a community enables, you'll see that all this is totally worth the effort.
|
||||
|
||||
As my friend and mentor [David Spinks keeps saying over and over again][13], "Companies fail their communities when when they treat community as a tactic instead of making it a core part of their business philosophy." And [as I've said][4]: Communities aren't simply extensions of your marketing teams; "community" isn't an efficient short-term strategy. When community is a core part of your business philosophy, it can do so much more than give you short-term returns.
|
||||
|
||||
At Nethesis we experience that every single day. As a small company, we could never have achieved the results we have without our community. Never.
|
||||
|
||||
Community can completely set your business apart from every other company in the field. It can redefine markets. It can inspire millions of people, give them a sense of belonging, and make them feel an incredible bond with your company.
|
||||
|
||||
And it can make you a whole lot of money.
|
||||
|
||||
Community-driven companies will always win. Remember that.
|
||||
|
||||
[Subscribe to our weekly newsletter][14] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/why-build-community-3
|
||||
|
||||
作者:[Alessio Fattorini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alefattorini
|
||||
[1]:http://www.nethesis.it/
|
||||
[2]:https://www.nethserver.org/
|
||||
[3]:https://distrowatch.com/table.php?distribution=nethserver
|
||||
[4]:https://opensource.com/open-organization/18/2/why-build-community-2
|
||||
[5]:https://www.goodreads.com/author/quotes/52938.Linus_Pauling
|
||||
[6]:https://blog.codinghorror.com/ivory-tower-development/
|
||||
[7]:https://community.nethserver.org/tags/comparison
|
||||
[8]:https://community.nethserver.org/t/improve-our-communication/2569
|
||||
[9]:http://www.nethserver.org/
|
||||
[10]:https://community.nethserver.org/c/howto
|
||||
[11]:https://community.nethserver.org/t/nethserver-conference-in-italy-sept-29-30-2017/6404
|
||||
[12]:https://www.ted.com/talks/seth_godin_on_the_tribes_we_lead
|
||||
[13]:http://cmxhub.com/article/community-business-philosophy-tactic/
|
||||
[14]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,40 @@
|
||||
Lessons Learned from Growing an Open Source Project Too Fast
|
||||
======
|
||||
![open source project][1]
|
||||
|
||||
Are you managing an open source project or considering launching one? If so, it may come as a surprise that one of the challenges you can face is rapid growth. Matt Butcher, Principal Software Development Engineer at Microsoft, addressed this issue in a presentation at Open Source Summit North America. His talk covered everything from teamwork to the importance of knowing your goals and sticking to them.
|
||||
|
||||
Butcher is no stranger to managing open source projects. As [Microsoft invests more deeply into open source][2], Butcher has been involved with many projects, including toolkits for Kubernetes and QueryPath, the jQuery-like library for PHP.
|
||||
|
||||
Butcher described a case study involving Kubernetes Helm, a package system for Kubernetes. Helm arose from a company team-building hackathon, with an original team of three people giving birth to it. Within 18 months, the project had hundreds of contributors and thousands of active users.
|
||||
|
||||
### Teamwork
|
||||
|
||||
“We were stretched to our limits as we learned to grow,” Butcher said. “When you’re trying to set up your team of core maintainers and they’re all trying to work together, you want to spend some actual time trying to optimize for a process that lets you be cooperative. You have to adjust some expectations regarding how you treat each other. When you’re working as a group of open source collaborators, the relationship is not employer/employee necessarily. It’s a collaborative effort.”
|
||||
|
||||
In addition to focusing on the right kinds of teamwork, Butcher and his collaborators learned that managing governance and standards is an ongoing challenge. “You want people to understand who makes decisions, how they make decisions and why they make the decisions that they make,” he said. “When we were a small project, there might have been two paragraphs in one of our documents on standards, but as a project grows and you get growing pains, these documented things gain a life of their own. They get their very own repositories, and they just keep getting bigger along with the project.”
|
||||
|
||||
Should all discussion surrounding a open source project go on in public, bathed in the hot lights of community scrutiny? Not necessarily, Butcher noted. “A minor thing can get blown into catastrophic proportions in a short time because of misunderstandings and because something that should have been done in private ended up being public,” he said. “Sometimes we actually make architectural recommendations as a closed group. The reason we do this is that we don’t want to miscue the community. The people who are your core maintainers are core maintainers because they’re experts, right? These are the people that have been selected from the community because they understand the project. They understand what people are trying to do with it. They understand the frustrations and concerns of users.”
|
||||
|
||||
### Acknowledge Contributions
|
||||
|
||||
Butcher added that it is essential to acknowledge people’s contributions to keep the environment surrounding a fast-growing project from becoming toxic. “We actually have an internal rule in our core maintainers guide that says, ‘Make sure that at least one comment that you leave on a code review, if you’re asking for changes, is a positive one,” he said. “It sounds really juvenile, right? But it serves a specific purpose. It lets somebody know, ‘I acknowledge that you just made a gift of your time and your resources.”
|
||||
|
||||
Want more tips on successfully launching and managing open source projects? Stay tuned for more insight from Matt Butcher’s talk, in which he provides specific project management issues faced by Kubernetes Helm.
|
||||
|
||||
For more information, be sure to check out [The Linux Foundation’s growing list of Open Source Guides for the Enterprise][3], covering topics such as starting an open source project, improving your open source impact, and participating in open source communities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/lessons-learned-from-growing-an-open-source-project-too-fast/
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sdean/
|
||||
[1]:https://www.linuxfoundation.org/wp-content/uploads/2018/03/huskies-2279627_1920.jpg
|
||||
[2]:https://thenewstack.io/microsoft-shifting-emphasis-open-source/
|
||||
[3]:https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
@ -0,0 +1,119 @@
|
||||
How to avoid humiliating newcomers: A guide for advanced developers
|
||||
======
|
||||
|
||||

|
||||
Every year in New York City, a few thousand young men come to town, dress up like Santa Claus, and do a pub crawl. One year during this SantaCon event, I was walking on the sidewalk and minding my own business, when I saw an extraordinary scene. There was a man dressed up in a red hat and red jacket, and he was talking to a homeless man who was sitting in a wheelchair. The homeless man asked Santa Claus, "Can you spare some change?" Santa dug into his pocket and brought out a $5 bill. He hesitated, then gave it to the homeless man. The homeless man put the bill in his pocket.
|
||||
|
||||
In an instant, something went wrong. Santa yelled at the homeless man, "I gave you $5. I wanted to give you one dollar, but five is the smallest I had, so you oughtta be grateful. This is your lucky day, man. You should at least say thank you!"
|
||||
|
||||
This was a terrible scene to witness. First, the power difference was terrible: Santa was an able-bodied white man with money and a home, and the other man was black, homeless, and using a wheelchair. It was also terrible because Santa Claus was dressed like the very symbol of generosity! And he was behaving like Santa until, in an instant, something went wrong and he became cruel.
|
||||
|
||||
This is not merely a story about Drunk Santa, however; this is a story about technology communities. We, too, try to be generous when we answer new programmers' questions, and every day our generosity turns to rage. Why?
|
||||
|
||||
### My cruelty
|
||||
|
||||
I'm reminded of my own bad behavior in the past. I was hanging out on my company's Slack when a new colleague asked a question.
|
||||
|
||||
> **New Colleague:** Hey, does anyone know how to do such-and-such with MongoDB?
|
||||
> **Jesse:** That's going to be implemented in the next release.
|
||||
> **New Colleague:** What's the ticket number for that feature?
|
||||
> **Jesse:** I memorize all ticket numbers. It's #12345.
|
||||
> **New Colleague:** Are you sure? I can't find ticket 12345.
|
||||
|
||||
He had missed my sarcasm, and his mistake embarrassed him in front of his peers. I laughed to myself, and then I felt terrible. As one of the most senior programmers at MongoDB, I should not have been setting this example. And yet, such behavior is commonplace among programmers everywhere: We get sarcastic with newcomers, and we humiliate them.
|
||||
|
||||
### Why does it matter?
|
||||
|
||||
Perhaps you are not here to make friends; you are here to write code. If the code works, does it matter if we are nice to each other or not?
|
||||
|
||||
A few months ago on the Stack Overflow blog, David Robinson showed that [Python has been growing dramatically][1], and it is now the top language that people view questions about on Stack Overflow. Even in the most pessimistic forecast, it will far outgrow the other languages this year.
|
||||
|
||||
![Projections for programming language popularity][2]
|
||||
|
||||
If you are a Python expert, then the line surging up and to the right is good news for you. It does not represent competition, but confirmation. As more new programmers learn Python, our expertise becomes ever more valuable, and we will see that reflected in our salaries, our job opportunities, and our job security.
|
||||
|
||||
But there is a danger. There are soon to be more new Python programmers than ever before. To sustain this growth, we must welcome them, and we are not always a welcoming bunch.
|
||||
|
||||
### The trouble with Stack Overflow
|
||||
|
||||
I searched Stack Overflow for rude answers to beginners' questions, and they were not hard to find.
|
||||
|
||||
![An abusive answer on StackOverflow][3]
|
||||
|
||||
The message is plain: If you are asking a question this stupid, you are doomed. Get out.
|
||||
|
||||
I immediately found another example of bad behavior:
|
||||
|
||||
![Another abusive answer on Stack Overflow][4]
|
||||
|
||||
Who has never been confused by Unicode in Python? Yet the message is clear: You do not belong here. Get out.
|
||||
|
||||
Do you remember how it felt when you needed help and someone insulted you? It feels terrible. And it decimates the community. Some of our best experts leave every day because they see us treating each other this way. Maybe they still program Python, but they are no longer participating in conversations online. This cruelty drives away newcomers, too, particularly members of groups underrepresented in tech who might not be confident they belong. People who could have become the great Python programmers of the next generation, but if they ask a question and somebody is cruel to them, they leave.
|
||||
|
||||
This is not in our interest. It hurts our community, and it makes our skills less valuable because we drive people out. So, why do we act against our own interests?
|
||||
|
||||
### Why generosity turns to rage
|
||||
|
||||
There are a few scenarios that really push my buttons. One is when I act generously but don't get the acknowledgment I expect. (I am not the only person with this resentment: This is probably why Drunk Santa snapped when he gave a $5 bill to a homeless man and did not receive any thanks.)
|
||||
|
||||
Another is when answering requires more effort than I expect. An example is when my colleague asked a question on Slack and followed-up with, "What's the ticket number?" I had judged how long it would take to help him, and when he asked for more help, I lost my temper.
|
||||
|
||||
These scenarios boil down to one problem: I have expectations for how things are going to go, and when those expectations are violated, I get angry.
|
||||
|
||||
I've been studying Buddhism for years, so my understanding of this topic is based in Buddhism. I like to think that the Buddha discussed the problem of expectations in his first tech talk when, in his mid-30s, he experienced a breakthrough after years of meditation and convened a small conference to discuss his findings. He had not rented a venue, so he sat under a tree. The attendees were a handful of meditators the Buddha had met during his wanderings in northern India. The Buddha explained that he had discovered four truths:
|
||||
|
||||
* First, that to be alive is to be dissatisfied—to want things to be better than they are now.
|
||||
* Second, this dissatisfaction is caused by wants; specifically, by our expectation that if we acquire what we want and eliminate what we do not want, it will make us happy for a long time. This expectation is unrealistic: If I get a promotion or if I delete 10 emails, it is temporarily satisfying, but it does not make me happy over the long-term. We are dissatisfied because every material thing quickly disappoints us.
|
||||
* The third truth is that we can be liberated from this dissatisfaction by accepting our lives as they are.
|
||||
* The fourth truth is that the way to transform ourselves is to understand our minds and to live a generous and ethical life.
|
||||
|
||||
|
||||
|
||||
I still get angry at people on the internet. It happened to me recently, when someone posted a comment on [a video I published about Python co-routines][5]. It had taken me months of research and preparation to create this video, and then a newcomer commented, "I want to master python what should I do."
|
||||
|
||||
![Comment on YouTube][6]
|
||||
|
||||
This infuriated me. My first impulse was to be sarcastic, "For starters, maybe you could spell Python with a capital P and end a question with a question mark." Fortunately, I recognized my anger before I acted on it, and closed the tab instead. Sometimes liberation is just a Command+W away.
|
||||
|
||||
### What to do about it
|
||||
|
||||
If you joined a community with the intent to be helpful but on occasion find yourself flying into a rage, I have a method to prevent this. For me, it is the step when I ask myself, "Am I angry?" Knowing is most of the battle. Online, however, we can lose track of our emotions. It is well-established that one reason we are cruel on the internet is because, without seeing or hearing the other person, our natural empathy is not activated. But the other problem with the internet is that, when we use computers, we lose awareness of our bodies. I can be angry and type a sarcastic message without even knowing I am angry. I do not feel my heart pound and my neck grow tense. So, the most important step is to ask myself, "How do I feel?"
|
||||
|
||||
If I am too angry to answer, I can usually walk away. As [Thumper learned in Bambi][7], "If you can't say something nice, don't say nothing at all."
|
||||
|
||||
### The reward
|
||||
|
||||
Helping a newcomer is its own reward, whether you receive thanks or not. But it does not hurt to treat yourself to a glass of whiskey or a chocolate, or just a sigh of satisfaction after your good deed.
|
||||
|
||||
But besides our personal rewards, the payoff for the Python community is immense. We keep the line surging up and to the right. Python continues growing, and that makes our own skills more valuable. We welcome new members, people who might not be sure they belong with us, by reassuring them that there is no such thing as a stupid question. We use Python to create an inclusive and diverse community around writing code. And besides, it simply feels good to be part of a community where people treat each other with respect. It is the kind of community that I want to be a member of.
|
||||
|
||||
### The three-breath vow
|
||||
|
||||
There is one idea I hope you remember from this article: To control our behavior online, we must occasionally pause and notice our feelings. I invite you, if you so choose, to repeat the following vow out loud:
|
||||
|
||||
> I vow
|
||||
> to take three breaths
|
||||
> before I answer a question online.
|
||||
|
||||
This article is based on a talk, [Why Generosity Turns To Rage, and What To Do About It][8], that Jesse gave at PyTennessee in February. For more insight for Python developers, attend [PyCon 2018][9], May 9-17 in Cleveland, Ohio.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/avoid-humiliating-newcomers
|
||||
|
||||
作者:[A. Jesse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/emptysquare
|
||||
[1]:https://stackoverflow.blog/2017/09/06/incredible-growth-python/
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/projections.png?itok=5QTeJ4oe (Projections for programming language popularity)
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-1.jpg?itok=BIWW10Rl (An abusive answer on StackOverflow)
|
||||
[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-2.jpg?itok=0L-n7T-k (Another abusive answer on Stack Overflow)
|
||||
[5]:https://www.youtube.com/watch?v=7sCu4gEjH5I
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/i-want-to-master-python.png?itok=Y-2u1XwA (Comment on YouTube)
|
||||
[7]:https://www.youtube.com/watch?v=nGt9jAkWie4
|
||||
[8]:https://www.pytennessee.org/schedule/presentation/175/
|
||||
[9]:https://us.pycon.org/2018/
|
||||
@ -0,0 +1,59 @@
|
||||
6 common questions about agile development practices for teams
|
||||
======
|
||||
|
||||

|
||||
"Any questions?"
|
||||
|
||||
You’ve probably heard a speaker ask this question at the end of their presentation. This is the most important part of the presentation—after all, you didn't attend just to hear a lecture but to participate in a conversation and a community.
|
||||
|
||||
Recently I had the opportunity to hear my fellow Red Hatters present a session called "[Agile in Practice][1]" to a group of technical students at a local university. During the session, software engineer Tomas Tomecek and agile practitioners Fernando Colleone and Pavel Najman collaborated to explain the foundations of agile methodology and showcase best practices for day-to-day activities.
|
||||
|
||||
### 1\. What is the perfect team size?
|
||||
|
||||
Knowing that students attended this session to learn what agile practice is and how to apply it to projects, I wondered how the students' questions would compare to those I hear every day as an agile practitioner at Red Hat. It turns out that the students asked the same questions as my colleagues. These questions drive straight into the core of agile in practice.
|
||||
|
||||
Students wanted to know the size of a small team versus a large team. This issue is relevant to anyone who has ever teamed up to work on a project. Based on Tomas's experience as a tech leader, 12 people working on a project would be considered a large team. In the real world, team size is not often directly correlated to productivity. In some cases, a smaller team located in a single location or time zone might be more productive than a larger team that's spread around the world. Ultimately, the presenters suggested that the ideal team size is probably five people (which aligns with scrum 7, +-2).
|
||||
|
||||
### 2\. What operational challenges do teams face?
|
||||
|
||||
The presenters compared projects supported by local teams (teams with all members in one office or within close proximity to each other) with distributed teams (teams located in different time zones). Engineers prefer local teams when the project requires close cooperation among team members because delays caused by time differences can destroy the "flow" of writing software. At the same time, distributed teams can bring together skill sets that may not be available locally and are great for certain development use cases. Also, there are various best practices to improve cooperation in distributed teams.
|
||||
|
||||
### 3\. How much time is needed to groom the backlog?
|
||||
|
||||
Because this was an introductory talk targeting students who were new to agile, the speakers focused on [Scrum][2] and [Kanban][3] as ways to make agile specific for them. They used the Scrum framework to illustrate a method of writing software and Kanban for a communication and work planning system. On the question of time needed to groom a project's backlog, the speakers explained that there is no fixed rule. Rather, practice makes perfect: During the early stages of development, when a project is new—and especially if some members of the team are new to agile—grooming can consume several hours per week. Over time and with practice, it becomes more efficient.
|
||||
|
||||
### 4\. Is a product owner necessary? What is their role?
|
||||
|
||||
Product owners help facilitate scaling; however, what matters is not the job title, but that you have someone on your team who represents the customer's voice and goals. In many teams, especially those that are part of a larger group of engineering teams working on a single output, a lead engineer can serve as the product owner.
|
||||
|
||||
### 5\. What agile tools do you suggest using? Is specific software necessary to implement Scrum or Kanban in practice?
|
||||
|
||||
Although using proprietary software such as Jira or Trello can be helpful, especially when working with large numbers of contributors working on big enterprise projects, they are not required. Scrum and Kanban can be done with tools as simple as paper cards. The key is to have a clear source of information and strong communication across the entire team. That said, two excellent open source kanban tools are [Taiga][4] and [Wekan][5]. For more information, see [5 open source alternatives to Trello][6] and [Top 7 open source project management tools for agile teams][7].
|
||||
|
||||
### 6\. How can students use agile techniques for school projects?
|
||||
|
||||
The presenters encouraged students to use kanban to visualize and outline tasks to be completed before the end of the project. The key is to create a common board so the entire team can see the status of the project. By using kanban or a similar high-visibility strategy, students won’t get to the end of the project and discover that any particular team member has not been keeping up.
|
||||
|
||||
Scrum practices such as sprints and daily standups are also excellent ways to ensure that everyone is making progress and that the various parts of the project will work together at the end. Regular check-ins and information-sharing are also essential. To learn more about Scrum, see [What is scrum?][8].
|
||||
|
||||
Remember that Kanban and Scrum are just two of many tools and frameworks that make up agile. They may not be the best approach for every situation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/agile-mindset
|
||||
|
||||
作者:[Dominika Bula][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dominika
|
||||
[1]:http://zijemeit.cz/sessions/agile-in-practice/
|
||||
[2]:https://www.scrum.org/resources/what-is-scrum
|
||||
[3]:https://en.wikipedia.org/wiki/Kanban
|
||||
[4]:https://taiga.io/
|
||||
[5]:https://wekan.github.io/
|
||||
[6]:https://opensource.com/alternatives/trello
|
||||
[7]:https://opensource.com/article/18/2/agile-project-management-tools
|
||||
[8]:https://opensource.com/resources/scrum
|
||||
@ -0,0 +1,70 @@
|
||||
Can we build a social network that serves users rather than advertisers?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, open source software is far-reaching and has played a key role driving innovation in our digital economy. The world is undergoing radical change at a rapid pace. People in all parts of the world need a purpose-built, neutral, and transparent online platform to meet the challenges of our time.
|
||||
|
||||
And open principles might just be the way to get us there. What would happen if we married digital innovation with social innovation using open-focused thinking?
|
||||
|
||||
This question is at the heart of our work at [Human Connection][1], a forward-thinking, Germany-based knowledge and action network with a mission to create a truly social network that serves the world. We're guided by the notion that human beings are inherently generous and sympathetic, and that they thrive on benevolent actions. But we haven't seen a social network that has fully supported our natural tendency towards helpfulness and cooperation to promote the common good. Human Connection aspires to be the platform that allows everyone to become an active changemaker.
|
||||
|
||||
In order to achieve the dream of a solution-oriented platform that enables people to take action around social causes by engaging with charities, community groups, and social change activists, Human Connection embraces open values as a vehicle for social innovation.
|
||||
|
||||
Here's how.
|
||||
|
||||
### Transparency first
|
||||
|
||||
Transparency is one of Human Connection's guiding principles. Human Connection invites programmers around the world to jointly work on the platform's source code (JavaScript, Vue, nuxt) by [making their source code available on Github][2] and support the idea of a truly social network by contributing to the code or programming additional functions.
|
||||
|
||||
But our commitment to transparency extends beyond our development practices. In fact—when it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better—making the source code available is just one step towards being transparent.
|
||||
|
||||
To facilitate open dialogue, the Human Connection team holds [regular public meetings online][3]. Here we answer questions, encourage suggestions, and respond to potential concerns. Our Meet The Team events are also recorded and made available to the public afterwards. By being fully transparent with our process, our source code, and our finances, we can protect ourselves against critics or other potential backlashes.
|
||||
|
||||
The commitment to transparency also means that all user contributions that shared publicly on Human Connection will be released under a Creative Commons license and can eventually be downloaded as a data pack. By making crowd knowledge available, especially in a decentralized way, we create the opportunity for social pluralism.
|
||||
|
||||
Guiding all of our organizational decisions is one question: "Does it serve the people and the greater good?" And we use the [UN Charter][4] and the Universal Declaration of Human Rights as a foundation for our value system. As we'll grow bigger, especially with our upcoming open beta launch, it's important for us to stay accountable to that mission. I'm even open to the idea of inviting the Chaos Computer Club or other hacker clubs to verify the integrity of our code and our actions by randomly checking into our platform.
|
||||
|
||||
When it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better, making the source code available is just one step towards being transparent.
|
||||
|
||||
### A collaborative community
|
||||
|
||||
A [collaborative, community-centered approach][5] to programming the Human Connection platform is the foundation for an idea that extends beyond the practical applications of a social network. Our team is driven by finding an answer to the question: "What makes a social network truly social?"
|
||||
|
||||
A network that abandons the idea of a profit-driven algorithm serving advertisers instead of end-users can only thrive by turning to the process of peer production and collaboration. Organizations like [Code Alliance][6] and [Code for America][7], for example, have demonstrated how technology can be created in an open source environment to benefit humanity and disrupt the status quo. Community-driven projects like the map-based reporting platform [FixMyStreet][8] or the [Tasking Manager][9] built for the Humanitarian OpenStreetMap initiative have embraced crowdsourcing as a way to move their mission forward.
|
||||
|
||||
Our approach to building Human Connection has been collaborative from the start. To gather initial data on the necessary functions and the purpose of a truly social network, we collaborated with the National Institute for Oriental Languages and Civilizations (INALCO) at the University Sorbonne in Paris and the Stuttgart Media University in Germany. Research findings from both projects were incorporated into the early development of Human Connection. Thanks to that research, [users will have a whole new set of functions available][10] that put them in control of what content they see and how they engage with others. As early supporters are [invited to the network's alpha version][10], they can experience the first available noteworthy functions. Here are just a few:
|
||||
|
||||
* Linking information to action was one key theme emerging from our research sessions. Current social networks leave users in the information stage. Student groups at both universities saw a need for an action-oriented component that serves our human instinct of working together to solve problems. So we built a ["Can Do" function][11] into our platform. It's one of the ways individuals can take action after reading about a certain topic. "Can Do's" are user-suggested activities in the "Take Action" area that everyone can implement.
|
||||
* The "Versus" function is another defining result. Where traditional social networks are limited to a comment function, our student groups saw the need for a more structured and useful way to engage in discussions and arguments. A "Versus" is a counter-argument to a public post that is displayed separately and provides an opportunity to highlight different opinions around an issue.
|
||||
* Today's social networks don't provide a lot of options to filter content. Research has shown that a filtering option by emotions can help us navigate the social space in accordance with our daily mood and potentially protect our emotional wellbeing by not displaying sad or upsetting posts on a day where we want to see uplifting content only.
|
||||
|
||||
|
||||
|
||||
Human Connection invites changemakers to collaborate on the development of a network with the potential to mobilize individuals and groups around the world to turn negative news into "Can Do's"—and participate in social innovation projects in conjunction with charities and non-profit organizations.
|
||||
|
||||
[Subscribe to our weekly newsletter][12] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dhack
|
||||
[1]:https://human-connection.org/en/
|
||||
[2]:https://github.com/human-connection/
|
||||
[3]:https://youtu.be/tPcYRQcepYE
|
||||
[4]:http://www.un.org/en/charter-united-nations/index.html
|
||||
[5]:https://youtu.be/BQHBno-efRI
|
||||
[6]:http://codealliance.org/
|
||||
[7]:https://www.codeforamerica.org/
|
||||
[8]:http://fixmystreet.org/
|
||||
[9]:https://tasks.hotosm.org/
|
||||
[10]:https://youtu.be/AwSx06DK2oU
|
||||
[11]:https://youtu.be/g2gYLNx686I
|
||||
[12]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,66 @@
|
||||
8 tips for better agile retrospective meetings
|
||||
======
|
||||
|
||||

|
||||
I’ve often thought that retrospectives should be called prospectives, as that term concerns the future rather than focusing on the past. The retro itself is truly future-looking: It’s the space where we can ask the question, “With what we know now, what’s the next experiment we need to try for improving our lives, and the lives of our customers?”
|
||||
|
||||
### What’s a retro supposed to look like?
|
||||
|
||||
There are two significant loops in product development: One produces the desired potentially shippable nugget. The other is where we examine how we’re working—not only to avoid doing what didn’t work so well, but also to determine how we can amplify the stuff we do well—and devise an experiment to pull into the next production loop to improve how our team is delighting our customers. This is the loop on the right side of this diagram:
|
||||
|
||||
|
||||
![Retrospective 1][2]
|
||||
|
||||
### When retros implode
|
||||
|
||||
While attending various teams' iteration retrospective meetings, I saw a common thread of malcontent associated with a relentless focus on continuous improvement.
|
||||
|
||||
One of the engineers put it bluntly: “[Our] continuous improvement feels like we are constantly failing.”
|
||||
|
||||
The teams talked about what worked, restated the stuff that didn’t work (perhaps already feeling like they were constantly failing), nodded to one another, and gave long sighs. Then one of the engineers (already late for another meeting) finally summed up the meeting: “Ok, let’s try not to submit all of the code on the last day of the sprint.” There was no opportunity to amplify the good, as the good was not discussed.
|
||||
|
||||
In effect, here’s what the retrospective felt like:
|
||||
|
||||

|
||||
|
||||
The anti-pattern is where retrospectives become dreaded sessions where we look back at the last iteration, make two columns—what worked and what didn’t work—and quickly come to some solution for the next iteration. There is no [scientific method][3] involved. There is no data gathering and research, no hypothesis, and very little deep thought. The result? You don’t get an experiment or a potential improvement to pull into the next iteration.
|
||||
|
||||
### 8 tips for better retrospectives
|
||||
|
||||
1. Amplify the good! Instead of focusing on what didn’t work well, why not begin the retro by having everyone mention one positive item first?
|
||||
2. Don’t jump to a solution. Thinking about a problem deeply instead of trying to solve it right away might be a better option.
|
||||
3. If the retrospective doesn’t make you feel excited about an experiment, maybe you shouldn’t try it in the next iteration.
|
||||
4. If you’re not analyzing how to improve, ([5 Whys][4], [force-field analysis][5], [impact mapping][6], or [fish-boning][7]), you might be jumping to solutions too quickly.
|
||||
5. Vary your methods. If every time you do a retrospective you ask, “What worked, what didn’t work?” and then vote on the top item from either column, your team will quickly get bored. [Retromat][8] is a great free retrospective tool to help vary your methods.
|
||||
6. End each retrospective by asking for feedback on the retro itself. This might seem a bit meta, but it works: Continually improving the retrospective is recursively improving as a team.
|
||||
7. Remove the impediments. Ask how you are enabling the team's search for improvement, and be prepared to act on any feedback.
|
||||
8. There are no "iteration police." Take breaks as needed. Deriving hypotheses from analysis and coming up with experiments involves creativity, and it can be taxing. Every once in a while, go out as a team and enjoy a nice retrospective lunch.
|
||||
|
||||
|
||||
|
||||
This article was inspired by [Retrospective anti-pattern: continuous improvement should not feel like constantly failing][9], posted at [Podojo.com][10].
|
||||
|
||||
**[See our related story,[How to build a business case for DevOps transformation][11].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/tips-better-agile-retrospective-meetings
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:/file/389021
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/retro_1.jpg?itok=bggmHN1Q (Retrospective 1)
|
||||
[3]:https://en.wikipedia.org/wiki/Scientific_method
|
||||
[4]:https://en.wikipedia.org/wiki/5_Whys
|
||||
[5]:https://en.wikipedia.org/wiki/Force-field_analysis
|
||||
[6]:https://opensource.com/open-organization/17/6/experiment-impact-mapping
|
||||
[7]:https://en.wikipedia.org/wiki/Ishikawa_diagram
|
||||
[8]:https://plans-for-retrospectives.com/en/?id=28
|
||||
[9]:http://www.podojo.com/retrospective-anti-pattern-continuous-improvement-should-not-feel-like-constantly-failing/
|
||||
[10]:http://www.podojo.com/
|
||||
[11]:https://opensource.com/article/18/2/how-build-business-case-devops-transformation
|
||||
@ -1,143 +0,0 @@
|
||||
translating by shipsw
|
||||
|
||||
How to use yum-cron to automatically update RHEL/CentOS Linux
|
||||
======
|
||||
The yum command line tool is used to install and update software packages under RHEL / CentOS Linux server. I know how to apply updates using [yum update command line][1], but I would like to use cron to update packages where appropriate manually. How do I configure yum to install software patches/updates [automatically with cron][2]?
|
||||
|
||||
You need to install yum-cron package. It provides files needed to run yum updates as a cron job. Install this package if you want auto yum updates nightly via cron.
|
||||
|
||||
### How to install yum cron on a CentOS/RHEL 6.x/7.x
|
||||
|
||||
Type the following [yum command][3] on:
|
||||
`$ sudo yum install yum-cron`
|
||||

|
||||
|
||||
Turn on service using systemctl command on **CentOS/RHEL 7.x** :
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
If you are using **CentOS/RHEL 6.x** , run:
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||

|
||||
|
||||
yum-cron is an alternate interface to yum. Very convenient way to call yum from cron. It provides methods to keep repository metadata up to date, and to check for, download, and apply updates. Rather than accepting many different command line arguments, the different functions of yum-cron can be accessed through config files.
|
||||
|
||||
### How to configure yum-cron to automatically update RHEL/CentOS Linux
|
||||
|
||||
You need to edit /etc/yum/yum-cron.conf and /etc/yum/yum-cron-hourly.conf files using a text editor such as vi command:
|
||||
`$ sudo vi /etc/yum/yum-cron.conf`
|
||||
Make sure updates should be applied when they are available
|
||||
`apply_updates = yes`
|
||||
You can set the address to send email messages from. Please note that ‘localhost’ will be replaced with the value of system_name.
|
||||
`email_from = root@localhost`
|
||||
List of addresses to send messages to.
|
||||
`email_to = your-it-support@some-domain-name`
|
||||
Name of the host to connect to to send email messages.
|
||||
`email_host = localhost`
|
||||
If you [do not want to update kernel package add the following on CentOS/RHEL 7.x][4]:
|
||||
`exclude=kernel*`
|
||||
For RHEL/CentOS 6.x add [the following to exclude kernel package from updating][5]:
|
||||
`YUM_PARAMETER=kernel*`
|
||||
[Save and close the file in vi/vim][6]. You also need to update /etc/yum/yum-cron-hourly.conf file if you want to apply update hourly. Otherwise /etc/yum/yum-cron.conf will run on daily using the following cron job (us [cat command][7]:
|
||||
`$ cat /etc/cron.daily/0yum-daily.cron`
|
||||
Sample outputs:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
That is all. Now your system will update automatically everyday using yum-cron. See man page of yum-cron for more details:
|
||||
`$ man yum-cron`
|
||||
|
||||
### Method 2 – Use shell scripts
|
||||
|
||||
**Warning** : The following method is outdated. Do not use it on RHEL/CentOS 6.x/7.x. I kept it below for historical reasons only when I used it on CentOS/RHEL version 4.x/5.x.
|
||||
|
||||
Let us see how to configure CentOS/RHEL for yum automatic update retrieval and installation of security packages. You can use yum-updatesd service provided with CentOS / RHEL servers. However, this service provides a few overheads. You can create daily or weekly updates with the following shell script. Create
|
||||
|
||||
* **/etc/cron.daily/yumupdate.sh** to apply updates one a day.
|
||||
* **/etc/cron.weekly/yumupdate.sh** to apply updates once a week.
|
||||
|
||||
|
||||
|
||||
#### Sample shell script to update system
|
||||
|
||||
A shell script that instructs yum to update any packages it finds via [cron][8]:
|
||||
```
|
||||
#!/bin/bash
|
||||
YUM=/usr/bin/yum
|
||||
$YUM -y -R 120 -d 0 -e 0 update yum
|
||||
$YUM -y -R 10 -e 0 -d 0 update
|
||||
```
|
||||
|
||||
(Code listing -01: /etc/cron.daily/yumupdate.sh)
|
||||
|
||||
Where,
|
||||
|
||||
1. First command will update yum itself and next will apply system updates.
|
||||
2. **-R 120** : Sets the maximum amount of time yum will wait before performing a command
|
||||
3. **-e 0** : Sets the error level to 0 (range 0 – 10). 0 means print only critical errors about which you must be told.
|
||||
4. -d 0 : Sets the debugging level to 0 – turns up or down the amount of things that are printed. (range: 0 – 10).
|
||||
5. **-y** : Assume yes; assume that the answer to any question which would be asked is yes.
|
||||
|
||||
|
||||
|
||||
Make sure you setup executable permission:
|
||||
`# chmod +x /etc/cron.daily/yumupdate.sh`
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
Posted by:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][12]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
104
sources/tech/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
104
sources/tech/20140107 Caffeinated 6.828- Exercise- Shell.md
Normal file
@ -0,0 +1,104 @@
|
||||
Caffeinated 6.828: Exercise: Shell
|
||||
======
|
||||
|
||||
This assignment will make you more familiar with the Unix system call interface and the shell by implementing several features in a small shell. You can do this assignment on any operating system that supports the Unix API (a Linux Athena machine, your laptop with Linux or Mac OS, etc.). Please submit your shell to the the [submission web site][1] at any time before the first lecture.
|
||||
|
||||
While you shouldn't be shy about emailing the [staff mailing list][2] if you get stuck or don't understand something in this exercise, we do expect you to be able to handle this level of C programming on your own for the rest of the class. If you're not very familiar with C, consider this a quick check to see how familiar you are. Again, do feel encouraged to ask us for help if you have any questions.
|
||||
|
||||
Download the [skeleton][3] of the xv6 shell, and look it over. The skeleton shell contains two main parts: parsing shell commands and implementing them. The parser recognizes only simple shell commands such as the following:
|
||||
```
|
||||
ls > y
|
||||
cat < y | sort | uniq | wc > y1
|
||||
cat y1
|
||||
rm y1
|
||||
ls | sort | uniq | wc
|
||||
rm y
|
||||
|
||||
```
|
||||
|
||||
Cut and paste these commands into a file `t.sh`
|
||||
|
||||
You can compile the skeleton shell as follows:
|
||||
```
|
||||
$ gcc sh.c
|
||||
|
||||
```
|
||||
|
||||
which produces a file named `a.out`, which you can run:
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
|
||||
```
|
||||
|
||||
This execution will panic because you have not implemented several features. In the rest of this assignment you will implement those features.
|
||||
|
||||
### Executing simple commands
|
||||
|
||||
Implement simple commands, such as:
|
||||
```
|
||||
$ ls
|
||||
|
||||
```
|
||||
|
||||
The parser already builds an `execcmd` for you, so the only code you have to write is for the ' ' case in `runcmd`. To test that you can run "ls". You might find it useful to look at the manual page for `exec`; type `man 3 exec`.
|
||||
|
||||
You do not have to implement quoting (i.e., treating the text between double-quotes as a single argument).
|
||||
|
||||
### I/O redirection
|
||||
|
||||
Implement I/O redirection commands so that you can run:
|
||||
```
|
||||
echo "6.828 is cool" > x.txt
|
||||
cat < x.txt
|
||||
|
||||
```
|
||||
|
||||
The parser already recognizes '>' and '<', and builds a `redircmd` for you, so your job is just filling out the missing code in `runcmd` for those symbols. Make sure your implementation runs correctly with the above test input. You might find the man pages for `open` (`man 2 open`) and `close` useful.
|
||||
|
||||
Note that this shell will not process quotes in the same way that `bash`, `tcsh`, `zsh` or other UNIX shells will, and your sample file `x.txt` is expected to contain the quotes.
|
||||
|
||||
### Implement pipes
|
||||
|
||||
Implement pipes so that you can run command pipelines such as:
|
||||
```
|
||||
$ ls | sort | uniq | wc
|
||||
|
||||
```
|
||||
|
||||
The parser already recognizes "|", and builds a `pipecmd` for you, so the only code you must write is for the '|' case in `runcmd`. Test that you can run the above pipeline. You might find the man pages for `pipe`, `fork`, `close`, and `dup` useful.
|
||||
|
||||
Now you should be able the following command correctly:
|
||||
```
|
||||
$ ./a.out < t.sh
|
||||
|
||||
```
|
||||
|
||||
Don't forget to submit your solution to the [submission web site][1], with or without challenge solutions.
|
||||
|
||||
### Challenge exercises
|
||||
|
||||
If you'd like to experiment more, you can add any feature of your choice to your shell. You might try one of the following suggestions:
|
||||
|
||||
* Implement lists of commands, separated by `;`
|
||||
* Implement subshells by implementing `(` and `)`
|
||||
* Implement running commands in the background by supporting `&` and `wait`
|
||||
* Implement quoting of arguments
|
||||
|
||||
|
||||
|
||||
All of these require making changing to the parser and the `runcmd` function.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/shell/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:https://exokernel.scripts.mit.edu/submit/
|
||||
[2]:mailto:sipb-iap-6.828@mit.edu
|
||||
[3]:https://sipb.mit.edu/iap/6.828/files/sh.c
|
||||
624
sources/tech/20140110 Caffeinated 6.828- Lab 1- Booting a PC.md
Normal file
624
sources/tech/20140110 Caffeinated 6.828- Lab 1- Booting a PC.md
Normal file
@ -0,0 +1,624 @@
|
||||
Caffeinated 6.828: Lab 1: Booting a PC
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our 6.828 kernel, which resides in the `boot` directory of the `lab` tree. Finally, the third part delves into the initial template for our 6.828 kernel itself, named JOS, which resides in the `kernel` directory.
|
||||
|
||||
#### Software Setup
|
||||
|
||||
The files you will need for this and subsequent lab assignments in this course are distributed using the [Git][1] version control system. To learn more about Git, take a look at the [Git user's manual][2], or, if you are already familiar with other version control systems, you may find this [CS-oriented overview of Git][3] useful.
|
||||
|
||||
The URL for the course Git repository is `https://exokernel.scripts.mit.edu/joslab.git`. To install the files in your Athena account, you need to clone the course repository, by running the commands below. You can log into a public Athena host with `ssh -X athena.dialup.mit.edu`.
|
||||
```
|
||||
athena% mkdir ~/6.828
|
||||
athena% cd ~/6.828
|
||||
athena% add git
|
||||
athena% git clone https://exokernel.scripts.mit.edu/joslab.git lab
|
||||
Cloning into lab...
|
||||
athena% cd lab
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
Git allows you to keep track of the changes you make to the code. For example, if you are finished with one of the exercises, and want to checkpoint your progress, you can commit your changes by running:
|
||||
```
|
||||
athena% git commit -am 'my solution for lab1 exercise 9'
|
||||
Created commit 60d2135: my solution for lab1 exercise 9
|
||||
1 files changed, 1 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
You can keep track of your changes by using the `git diff` command. Running `git diff` will display the changes to your code since your last commit, and `git diff origin/lab1` will display the changes relative to the initial code supplied for this lab. Here, `origin/lab1` is the name of the git branch with the initial code you downloaded from our server for this assignment.
|
||||
|
||||
We have set up the appropriate compilers and simulators for you on Athena. To use them, run `add exokernel`. You must run this command every time you log in (or add it to your `~/.environment` file). If you get obscure errors while compiling or running `qemu`, double check that you added the course locker.
|
||||
|
||||
If you are working on a non-Athena machine, you'll need to install `qemu` and possibly `gcc` following the directions on the [tools page][4]. We've made several useful debugging changes to `qemu` and some of the later labs depend on these patches, so you must build your own. If your machine uses a native ELF toolchain (such as Linux and most BSD's, but notably not OS X), you can simply install `gcc` from your package manager. Otherwise, follow the directions on the tools page.
|
||||
|
||||
#### Hand-In Procedure
|
||||
|
||||
We use different Git repositories for you to hand in your lab. The hand-in repositories reside behind an SSH server. You will get your own hand-in repository, which is inaccessible by any other students. To authenticate yourself with the SSH server, you should have an RSA key pair, and let the server know your public key.
|
||||
|
||||
The lab code comes with a script that helps you to set up access to your hand-in repository. Before running the script, you must have an account at our [submission web interface][5]. On the login page, type in your Athena user name and click on "Mail me my password". You will receive your `6.828` password in your mailbox shortly. Note that every time you click the button, the system will assign you a new random password.
|
||||
|
||||
Now that you have your `6.828` password, in the `lab` directory, set up the hand-in repository by running:
|
||||
```
|
||||
athena% make handin-prep
|
||||
Using public key from ~/.ssh/id_rsa:
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
|
||||
Continue? [Y/n] Y
|
||||
|
||||
Login to 6.828 submission website.
|
||||
If you do not have an account yet, sign up at https://exokernel.scripts.mit.edu/submit/
|
||||
before continuing.
|
||||
Username: <your Athena username>
|
||||
Password: <your 6.828 password>
|
||||
Your public key has been successfully updated.
|
||||
Setting up hand-in Git repository...
|
||||
Adding remote repository ssh://josgit@exokernel.mit.edu/joslab.git as 'handin'.
|
||||
Done! Use 'make handin' to submit your lab code.
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
The script may also ask you to generate a new key pair if you did not have one:
|
||||
```
|
||||
athena% make handin-prep
|
||||
SSH key file ~/.ssh/id_rsa does not exists, generate one? [Y/n] Y
|
||||
Generating public/private rsa key pair.
|
||||
Your identification has been saved in ~/.ssh/id_rsa.
|
||||
Your public key has been saved in ~/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx
|
||||
The keyʼs randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
| ........ |
|
||||
| ........ |
|
||||
+-----------------+
|
||||
Using public key from ~/.ssh/id_rsa:
|
||||
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
|
||||
Continue? [Y/n] Y
|
||||
.....
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
When you are ready to hand in your lab, first commit your changes with git commit, and then type make handin in the `lab` directory. The latter will run git push handin HEAD, which pushes the current branch to the same name on the remote `handin` repository.
|
||||
```
|
||||
athena% git commit -am "ready to submit my lab"
|
||||
[lab1 c2e3c8b] ready to submit my lab
|
||||
2 files changed, 18 insertions(+), 2 deletions(-)
|
||||
|
||||
athena% make handin
|
||||
Handin to remote repository using 'git push handin HEAD' ...
|
||||
Counting objects: 59, done.
|
||||
Delta compression using up to 4 threads.
|
||||
Compressing objects: 100% (55/55), done.
|
||||
Writing objects: 100% (59/59), 49.75 KiB, done.
|
||||
Total 59 (delta 3), reused 0 (delta 0)
|
||||
To ssh://josgit@am.csail.mit.edu/joslab.git
|
||||
* [new branch] HEAD -> lab1
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
If you have made changes to your hand-in repository, an email receipt will be sent to you to confirm the submission. You can run make handin (or git push handin) as many times as you want. The late hours of your submission for a specific lab is based on the latest hand-in (push) time of the corresponding branch.
|
||||
|
||||
In the case that make handin does not work properly, try fixing the problem with Git commands. Or you can run make tarball. This will make a tar file for you, which you can then upload via our [web interface][5]. `make handin` provides more specific directions.
|
||||
|
||||
For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
|
||||
|
||||
We will be grading your solutions with a grading program. You can run make grade to test your solutions with the grading program.
|
||||
|
||||
### Part 1: PC Bootstrap
|
||||
|
||||
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
|
||||
|
||||
#### Getting Started with x86 assembly
|
||||
|
||||
If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The [PC Assembly Language Book][6] is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
|
||||
|
||||
Warning: Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called Intel syntax while GNU uses the AT&T syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in [Brennan's Guide to Inline Assembly][7].
|
||||
|
||||
> **Exercise 1**
|
||||
>
|
||||
> Familiarize yourself with the assembly language materials available on [the 6.828 reference page][8]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
|
||||
|
||||
We do recommend reading the section "The Syntax" in [Brennan's Guide to Inline Assembly][7]. It gives a good (and quite brief) description of the AT&T assembly syntax we'll be using with the GNU assembler in JOS.
|
||||
|
||||
Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on [the 6.828 reference page][8] in two flavors: an HTML edition of the old [80386 Programmer's Reference Manual][9], which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in 6.828; and the full, latest and greatest [IA-32 Intel Architecture Software Developer's Manuals][10] from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (and often friendlier) set of manuals is [available from AMD][11]. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
|
||||
|
||||
#### Simulating the x86
|
||||
|
||||
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
|
||||
|
||||
In 6.828 we will use the [QEMU Emulator][12], a modern and relatively fast emulator. While QEMU's built-in monitor provides only limited debugging support, QEMU can act as a remote debugging target for the [GNU debugger][13] (GDB), which we'll use in this lab to step through the early boot process.
|
||||
|
||||
To get started, extract the Lab 1 files into your own directory on Athena as described above in "Software Setup", then type make (or gmake on BSD systems) in the `lab` directory to build the minimal 6.828 boot loader and kernel you will start with. (It's a little generous to call the code we're running here a "kernel," but we'll flesh it out throughout the semester.)
|
||||
```
|
||||
athena% cd lab
|
||||
athena% make
|
||||
+ as kern/entry.S
|
||||
+ cc kern/init.c
|
||||
+ cc kern/console.c
|
||||
+ cc kern/monitor.c
|
||||
+ cc kern/printf.c
|
||||
+ cc lib/printfmt.c
|
||||
+ cc lib/readline.c
|
||||
+ cc lib/string.c
|
||||
+ ld obj/kern/kernel
|
||||
+ as boot/boot.S
|
||||
+ cc -Os boot/main.c
|
||||
+ ld boot/boot
|
||||
boot block is 414 bytes (max 510)
|
||||
+ mk obj/kern/kernel.img
|
||||
|
||||
```
|
||||
|
||||
(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
|
||||
|
||||
Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (`obj/boot/boot`) and our kernel (`obj/kernel`).
|
||||
```
|
||||
athena% make qemu
|
||||
|
||||
```
|
||||
|
||||
This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
|
||||
```
|
||||
Booting from Hard Disk...
|
||||
6828 decimal is XXX octal!
|
||||
entering test_backtrace 5
|
||||
entering test_backtrace 4
|
||||
entering test_backtrace 3
|
||||
entering test_backtrace 2
|
||||
entering test_backtrace 1
|
||||
entering test_backtrace 0
|
||||
leaving test_backtrace 0
|
||||
leaving test_backtrace 1
|
||||
leaving test_backtrace 2
|
||||
leaving test_backtrace 3
|
||||
leaving test_backtrace 4
|
||||
leaving test_backtrace 5
|
||||
Welcome to the JOS kernel monitor!
|
||||
Type 'help' for a list of commands.
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Everything after '`Booting from Hard Disk...`' was printed by our skeletal JOS kernel; the `K>` is the prompt printed by the small monitor, or interactive control program, that we've included in the kernel. These lines printed by the kernel will also appear in the regular shell window from which you ran QEMU. This is because for testing and lab grading purposes we have set up the JOS kernel to write its console output not only to the virtual VGA display (as seen in the QEMU window), but also to the simulated PC's virtual serial port, which QEMU in turn outputs to its own standard output. Likewise, the JOS kernel will take input from both the keyboard and the serial port, so you can give it commands in either the VGA display window or the terminal running QEMU. Alternatively, you can use the serial console without the virtual VGA by running make qemu-nox. This may be convenient if you are SSH'd into an Athena dialup.
|
||||
|
||||
There are only two commands you can give to the kernel monitor, `help` and `kerninfo`.
|
||||
```
|
||||
K> help
|
||||
help - display this list of commands
|
||||
kerninfo - display information about the kernel
|
||||
K> kerninfo
|
||||
Special kernel symbols:
|
||||
entry f010000c (virt) 0010000c (phys)
|
||||
etext f0101a75 (virt) 00101a75 (phys)
|
||||
edata f0112300 (virt) 00112300 (phys)
|
||||
end f0112960 (virt) 00112960 (phys)
|
||||
Kernel executable memory footprint: 75KB
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
The `help` command is obvious, and we will shortly discuss the meaning of what the `kerninfo` command prints. Although simple, it's important to note that this kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of `obj/kern/kernel.img` onto the first few sectors of a real hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying `kernel.img` onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
|
||||
|
||||
#### The PC's Physical Address Space
|
||||
|
||||
We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
|
||||
```
|
||||
+------------------+ <- 0xFFFFFFFF (4GB)
|
||||
| 32-bit |
|
||||
| memory mapped |
|
||||
| devices |
|
||||
| |
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
| |
|
||||
| Unused |
|
||||
| |
|
||||
+------------------+ <- depends on amount of RAM
|
||||
| |
|
||||
| |
|
||||
| Extended Memory |
|
||||
| |
|
||||
| |
|
||||
+------------------+ <- 0x00100000 (1MB)
|
||||
| BIOS ROM |
|
||||
+------------------+ <- 0x000F0000 (960KB)
|
||||
| 16-bit devices, |
|
||||
| expansion ROMs |
|
||||
+------------------+ <- 0x000C0000 (768KB)
|
||||
| VGA Display |
|
||||
+------------------+ <- 0x000A0000 (640KB)
|
||||
| |
|
||||
| Low Memory |
|
||||
| |
|
||||
+------------------+ <- 0x00000000
|
||||
|
||||
```
|
||||
|
||||
The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at `0x00000000` but end at `0x000FFFFF` instead of `0xFFFFFFFF`. The 640KB area marked "Low Memory" was the only random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
|
||||
|
||||
The 384KB area from `0x000A0000` through `0x000FFFFF` was reserved by the hardware for special uses such as video display buffers and firmware held in non-volatile memory. The most important part of this reserved area is the Basic Input/Output System (BIOS), which occupies the 64KB region from `0x000F0000` through `0x000FFFFF`. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
|
||||
|
||||
When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from `0x000A0000` to `0x00100000`, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices.
|
||||
|
||||
Recent x86 processors can support more than 4GB of physical RAM, so RAM can extend further above `0xFFFFFFFF`. In this case the BIOS must arrange to leave a second hole in the system's RAM at the top of the 32-bit addressable region, to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will use only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
|
||||
|
||||
#### The ROM BIOS
|
||||
|
||||
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
|
||||
|
||||
Open two terminal windows. In one, enter `make qemu-gdb` (or `make qemu-nox-gdb`). This starts up QEMU, but QEMU stops just before the processor executes the first instruction and waits for a debugging connection from GDB. In the second terminal, from the same directory you ran `make`, run `make gdb`. You should see something like this,
|
||||
```
|
||||
athena% make gdb
|
||||
GNU gdb (GDB) 6.8-debian
|
||||
Copyright (C) 2008 Free Software Foundation, Inc.
|
||||
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
|
||||
and "show warranty" for details.
|
||||
This GDB was configured as "i486-linux-gnu".
|
||||
+ target remote localhost:1234
|
||||
The target architecture is assumed to be i8086
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
0x0000fff0 in ?? ()
|
||||
+ symbol-file obj/kern/kernel
|
||||
(gdb)
|
||||
|
||||
```
|
||||
|
||||
The `make gdb` target runs a script called `.gdbrc`, which sets up GDB to debug the 16-bit code used during early boot and directs it to attach to the listening QEMU.
|
||||
|
||||
The following line:
|
||||
```
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
|
||||
```
|
||||
|
||||
is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
|
||||
|
||||
* The IBM PC starts executing at physical address `0x000ffff0`, which is at the very top of the 64KB area reserved for the ROM BIOS.
|
||||
* The PC starts executing with `CS = 0xf000` and `IP = 0xfff0`.
|
||||
* The first instruction to be executed is a `jmp` instruction, which jumps to the segmented address `CS = 0xf000` and `IP = 0xe05b`.
|
||||
|
||||
|
||||
|
||||
Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range `0x000f0000-0x000fffff`, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart - which is crucial because on power-up there is no other software anywhere in the machine's RAM that the processor could execute. The QEMU emulator comes with its own BIOS, which it places at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor enters real mode and sets CS to `0xf000` and the IP to `0xfff0`, so that execution begins at that (CS:IP) segment address. How does the segmented address 0xf000:fff0 turn into a physical address?
|
||||
|
||||
To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: physical address = 16 * segment + offset. So, when the PC sets CS to `0xf000` and IP to `0xfff0`, the physical address referenced is:
|
||||
```
|
||||
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
|
||||
= 0xf0000 + 0xfff0 # easy--just append a 0.
|
||||
= 0xffff0
|
||||
|
||||
```
|
||||
|
||||
`0xffff0` is 16 bytes before the end of the BIOS (`0x100000`). Therefore we shouldn't be surprised that the first thing that the BIOS does is `jmp` backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
|
||||
|
||||
> **Exercise 2**
|
||||
>
|
||||
> Use GDB's `si` (Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at [Phil Storrs I/O Ports Description][14], as well as other materials on the [6.828 reference materials page][8]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
|
||||
|
||||
When the BIOS runs, it sets up an interrupt descriptor table and initializes various devices such as the VGA display. This is where the "`Starting SeaBIOS`" message you see in the QEMU window comes from.
|
||||
|
||||
After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the boot loader from the disk and transfers control to it.
|
||||
|
||||
### Part 2: The Boot Loader
|
||||
|
||||
Floppy and hard disks for PCs are divided into 512 byte regions called sectors. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the boot sector, since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through `0x7dff`, and then uses a `jmp` instruction to set the CS:IP to `0000:7c00`, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
|
||||
|
||||
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the ["El Torito" Bootable CD-ROM Format Specification][15].
|
||||
|
||||
For 6.828, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, `boot/boot.S`, and one C source file, `boot/main.c` Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
|
||||
|
||||
1. First, the boot loader switches the processor from real mode to 32-bit protected mode, because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of [PC Assembly Language][6], and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of 16.
|
||||
2. Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here mean, check out the "IDE hard drive controller" section on [the 6.828 reference page][8]. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
|
||||
|
||||
|
||||
|
||||
After you understand the boot loader source code, look at the file `obj/boot/boot.asm`. This file is a disassembly of the boot loader that our GNUmakefile creates after compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in GDB. Likewise, `obj/kern/kernel.asm` contains a disassembly of the JOS kernel, which can often be useful for debugging.
|
||||
|
||||
You can set address breakpoints in GDB with the `b` command. For example, `b *0x7c00` sets a breakpoint at address `0x7C00`. Once at a breakpoint, you can continue execution using the `c` and `si` commands: `c` causes QEMU to continue execution until the next breakpoint (or until you press Ctrl-C in GDB), and `si N` steps through the instructions `N` at a time.
|
||||
|
||||
To examine instructions in memory (besides the immediate next one to be executed, which GDB prints automatically), you use the `x/i` command. This command has the syntax `x/Ni ADDR`, where `N` is the number of consecutive instructions to disassemble and `ADDR` is the memory address at which to start disassembling.
|
||||
|
||||
> **Exercise 3**
|
||||
>
|
||||
> Take a look at the [lab tools guide][16], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
|
||||
|
||||
Set a breakpoint at address 0x7c00, which is where the boot sector will be loaded. Continue execution until that breakpoint. Trace through the code in `boot/boot.S`, using the source code and the disassembly file `obj/boot/boot.asm` to keep track of where you are. Also use the `x/i` command in GDB to disassemble sequences of instructions in the boot loader, and compare the original boot loader source code with both the disassembly in `obj/boot/boot.asm` and GDB.
|
||||
|
||||
Trace into `bootmain()` in `boot/main.c`, and then into `readsect()`. Identify the exact assembly instructions that correspond to each of the statements in `readsect()`. Trace through the rest of `readsect()` and back out into `bootmain()`, and identify the begin and end of the `for` loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
* At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
|
||||
* What is the last instruction of the boot loader executed, and what is the first instruction of the kernel it just loaded?
|
||||
* Where is the first instruction of the kernel?
|
||||
* How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
|
||||
|
||||
|
||||
|
||||
#### Loading the Kernel
|
||||
|
||||
We will now look in further detail at the C language portion of the boot loader, in `boot/main.c`. But before doing so, this is a good time to stop and review some of the basics of C programming.
|
||||
|
||||
> **Exercise 4**
|
||||
>
|
||||
> Download the code for [pointers.c][17], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in lines 1 and 6 come from, how all the values in lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.
|
||||
>
|
||||
> If you're not familiar with pointers, The C Programming Language by Brian Kernighan and Dennis Ritchie (known as 'K&R') is a good reference. Students can purchase this book (here is an [Amazon Link][18]) or find one of [MIT's 7 copies][19]. 3 copies are also available for perusal in the [SIPB Office][20].
|
||||
>
|
||||
> [A tutorial by Ted Jensen][21] that cites K&R heavily is available in the course readings.
|
||||
>
|
||||
> Warning: Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
|
||||
|
||||
To make sense out of `boot/main.c` you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('`.c`') file into an object ('`.o`') file containing assembly language instructions encoded in the binary format expected by the hardware. The linker then combines all of the compiled object files into a single binary image such as `obj/kern/kernel`, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
|
||||
|
||||
Full information about this format is available in [the ELF specification][22] on [our reference page][8], but you will not need to delve very deeply into the details of this format in this class. Although as a whole the format is quite powerful and complex, most of the complex parts are for supporting dynamic loading of shared libraries, which we will not do in this class.
|
||||
|
||||
For purposes of 6.828, you can consider an ELF executable to be a header with loading information, followed by several program sections, each of which is a contiguous chunk of code or data intended to be loaded into memory at a specified address. The boot loader does not modify the code or data; it loads it into memory and starts executing it.
|
||||
|
||||
An ELF binary starts with a fixed-length ELF header, followed by a variable-length program header listing each of the program sections to be loaded. The C definitions for these ELF headers are in `inc/elf.h`. The program sections we're interested in are:
|
||||
|
||||
* `.text`: The program's executable instructions.
|
||||
* `.rodata`: Read-only data, such as ASCII string constants produced by the C compiler. (We will not bother setting up the hardware to prohibit writing, however.)
|
||||
* `.data`: The data section holds the program's initialized data, such as global variables declared with initializers like `int x = 5;`.
|
||||
|
||||
|
||||
|
||||
When the linker computes the memory layout of a program, it reserves space for uninitialized global variables, such as `int x;`, in a section called `.bss` that immediately follows `.data` in memory. C requires that "uninitialized" global variables start with a value of zero. Thus there is no need to store contents for `.bss` in the ELF binary; instead, the linker records just the address and size of the `.bss` section. The loader or the program itself must arrange to zero the `.bss` section.
|
||||
|
||||
Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -h obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You can substitute `objdump` for `i386-jos-elf-objdump` if your computer uses an ELF toolchain by default like most modern Linuxen and BSDs.
|
||||
|
||||
You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
|
||||
|
||||
Take particular note of the "VMA" (or link address) and the "LMA" (or load address) of the `.text` section. The load address of a section is the memory address at which that section should be loaded into memory. In the ELF object, this is stored in the `ph->p_pa` field (in this case, it really is a physical address, though the ELF specification is vague on the actual meaning of this field).
|
||||
|
||||
The link address of a section is the memory address from which the section expects to execute. The linker encodes the link address in the binary in various ways, such as when the code needs the address of a global variable, with the result that a binary usually won't work if it is executing from an address that it is not linked for. (It is possible to generate position-independent code that does not contain any such absolute addresses. This is used extensively by modern shared libraries, but it has performance and complexity costs, so we won't be using it in 6.828.)
|
||||
|
||||
Typically, the link and load addresses are the same. For example, look at the `.text` section of the boot loader:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -h obj/boot/boot.out
|
||||
|
||||
```
|
||||
|
||||
The BIOS loads the boot sector into memory starting at address 0x7c00, so this is the boot sector's load address. This is also where the boot sector executes from, so this is also its link address. We set the link address by passing `-Ttext 0x7C00` to the linker in `boot/Makefrag`, so the linker will produce the correct memory addresses in the generated code.
|
||||
|
||||
> **Exercise 5**
|
||||
>
|
||||
> Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in `boot/Makefrag` to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
|
||||
|
||||
Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
|
||||
|
||||
Besides the section information, there is one more field in the ELF header that is important to us, named `e_entry`. This field holds the link address of the entry point in the program: the memory address in the program's text section at which the program should begin executing. You can see the entry point:
|
||||
```
|
||||
athena% i386-jos-elf-objdump -f obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You should now be able to understand the minimal ELF loader in `boot/main.c`. It reads each section of the kernel from disk into memory at the section's load address and then jumps to the kernel's entry point.
|
||||
|
||||
> **Exercise 6**
|
||||
>
|
||||
> We can examine memory using GDB's x command. The [GDB manual][23] has full details, but for now, it is enough to know that the command `x/Nx ADDR` prints `N` words of memory at `ADDR`. (Note that both `x`s in the command are lowercase.) Warning: The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
|
||||
|
||||
Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at `0x00100000` at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.)
|
||||
|
||||
### Part 3: The Kernel
|
||||
|
||||
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
|
||||
|
||||
#### Using virtual memory to work around position dependence
|
||||
|
||||
When you inspected the boot loader's link and load addresses above, they matched perfectly, but there was a (rather large) disparity between the kernel's link address (as printed by objdump) and its load address. Go back and check both and make sure you can see what we're talking about. (Linking the kernel is more complicated than the boot loader, so the link and load addresses are at the top of `kern/kernel.ld`.)
|
||||
|
||||
Operating system kernels often like to be linked and run at very high virtual address, such as `0xf0100000`, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab.
|
||||
|
||||
Many machines don't have any physical memory at address `0xf0100000`, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address `0xf0100000` (the link address at which the kernel code expects to run) to physical address `0x00100000` (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address `0x00100000` works), but this is likely to be true of any PC built after about 1990.
|
||||
|
||||
In fact, in the next lab, we will map the entire bottom 256MB of the PC's physical address space, from physical addresses `0x00000000` through `0x0fffffff`, to virtual addresses `0xf0000000` through `0xffffffff` respectively. You should now see why JOS can only use the first 256MB of physical memory.
|
||||
|
||||
For now, we'll just map the first 4MB of physical memory, which will be enough to get us up and running. We do this using the hand-written, statically-initialized page directory and page table in `kern/entrypgdir.c`. For now, you don't have to understand the details of how this works, just the effect that it accomplishes. Up until `kern/entry.S` sets the `CR0_PG` flag, memory references are treated as physical addresses (strictly speaking, they're linear addresses, but boot/boot.S set up an identity mapping from linear addresses to physical addresses and we're never going to change that). Once `CR0_PG` is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. `entry_pgdir` translates virtual addresses in the range `0xf0000000` through `0xf0400000` to physical addresses `0x00000000` through `0x00400000`, as well as virtual addresses `0x00000000` through `0x00400000` to physical addresses `0x00000000` through `0x00400000`. Any virtual address that is not in one of these two ranges will cause a hardware exception which, since we haven't set up interrupt handling yet, will cause QEMU to dump the machine state and exit (or endlessly reboot if you aren't using the 6.828-patched version of QEMU).
|
||||
|
||||
> **Exercise 7**
|
||||
>
|
||||
> Use QEMU and GDB to trace into the JOS kernel and stop at the `movl %eax, %cr0`. Examine memory at `0x00100000` and at `0xf0100000`. Now, single step over that instruction using the `stepi` GDB command. Again, examine memory at `0x00100000` and at `0xf0100000`. Make sure you understand what just happened.
|
||||
|
||||
What is the first instruction after the new mapping is established that would fail to work properly if the mapping weren't in place? Comment out the `movl %eax, %cr0` in `kern/entry.S`, trace into it, and see if you were right.
|
||||
|
||||
#### Formatted Printing to the Console
|
||||
|
||||
Most people take functions like `printf()` for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, we have to implement all I/O ourselves.
|
||||
|
||||
Read through `kern/printf.c`, `lib/printfmt.c`, and `kern/console.c`, and make sure you understand their relationship. It will become clear in later labs why `printfmt.c` is located in the separate `lib` directory.
|
||||
|
||||
> **Exercise 8**
|
||||
>
|
||||
> We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
|
||||
>
|
||||
> Be able to answer the following questions:
|
||||
>
|
||||
> 1. Explain the interface between `printf.c` and `console.c`. Specifically, what function does `console.c` export? How is this function used by `printf.c`?
|
||||
>
|
||||
> 2. Explain the following from `console.c`:
|
||||
[code] > if (crt_pos >= CRT_SIZE) {
|
||||
> int i;
|
||||
> memcpy(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
|
||||
> for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
|
||||
> crt_buf[i] = 0x0700 | ' ';
|
||||
> crt_pos -= CRT_COLS;
|
||||
> }
|
||||
>
|
||||
```
|
||||
>
|
||||
> 3. For the following questions you might wish to consult the notes for Lecture 1. These notes cover GCC's calling convention on the x86.
|
||||
>
|
||||
> Trace the execution of the following code step-by-step:
|
||||
[code] > int x = 1, y = 3, z = 4;
|
||||
> cprintf("x %d, y %x, z %d\n", x, y, z);
|
||||
>
|
||||
```
|
||||
>
|
||||
> 1. In the call to `cprintf()`, to what does `fmt` point? To what does `ap` point?
|
||||
> 2. List (in order of execution) each call to `cons_putc`, `va_arg`, and `vcprintf`. For `cons_putc`, list its argument as well. For `va_arg`, list what `ap` points to before and after the call. For `vcprintf` list the values of its two arguments.
|
||||
> 4. Run the following code.
|
||||
[code] > unsigned int i = 0x00646c72;
|
||||
> cprintf("H%x Wo%s", 57616, &i);
|
||||
>
|
||||
```
|
||||
>
|
||||
> What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise. [Here's an ASCII table][24] that maps bytes to characters.
|
||||
>
|
||||
> The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set `i` to in order to yield the same output? Would you need to change `57616` to a different value?
|
||||
>
|
||||
> [Here's a description of little- and big-endian][25] and [a more whimsical description][26].
|
||||
>
|
||||
> 5. In the following code, what is going to be printed after `y=`? (note: the answer is not a specific value.) Why does this happen?
|
||||
[code] > cprintf("x=%d y=%d", 3);
|
||||
>
|
||||
```
|
||||
>
|
||||
> 6. Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change `cprintf` or its interface so that it would still be possible to pass it a variable number of arguments?
|
||||
>
|
||||
>
|
||||
|
||||
|
||||
#### The Stack
|
||||
|
||||
In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a backtrace of the stack: a list of the saved Instruction Pointer (IP) values from the nested `call` instructions that led to the current point of execution.
|
||||
|
||||
> **Exercise 9**
|
||||
>
|
||||
> Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
|
||||
|
||||
The x86 stack pointer (`esp` register) points to the lowest location on the stack that is currently in use. Everything below that location in the region reserved for the stack is free. Pushing a value onto the stack involves decreasing the stack pointer and then writing the value to the place the stack pointer points to. Popping a value from the stack involves reading the value the stack pointer points to and then increasing the stack pointer. In 32-bit mode, the stack can only hold 32-bit values, and esp is always divisible by four. Various x86 instructions, such as `call`, are "hard-wired" to use the stack pointer register.
|
||||
|
||||
The `ebp` (base pointer) register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's prologue code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current `esp` value into `ebp` for the duration of the function. If all the functions in a program obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved `ebp` pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an `assert` failure or `panic` because bad arguments were passed to it, but you aren't sure who passed the bad arguments. A stack backtrace lets you find the offending function.
|
||||
|
||||
> **Exercise 10**
|
||||
>
|
||||
> To become familiar with the C calling conventions on the x86, find the address of the `test_backtrace` function in `obj/kern/kernel.asm`, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of `test_backtrace` push on the stack, and what are those words?
|
||||
|
||||
The above exercise should give you the information you need to implement a stack backtrace function, which you should call `mon_backtrace()`. A prototype for this function is already waiting for you in `kern/monitor.c`. You can do it entirely in C, but you may find the `read_ebp()` function in `inc/x86.h` useful. You'll also have to hook this new function into the kernel monitor's command list so that it can be invoked interactively by the user.
|
||||
|
||||
The backtrace function should display a listing of function call frames in the following format:
|
||||
```
|
||||
Stack backtrace:
|
||||
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
|
||||
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first line printed reflects the currently executing function, namely `mon_backtrace` itself, the second line reflects the function that called `mon_backtrace`, the third line reflects the function that called that one, and so on. You should print all the outstanding stack frames. By studying `kern/entry.S` you'll find that there is an easy way to tell when to stop.
|
||||
|
||||
Within each line, the `ebp` value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed `eip` value is the function's return instruction pointer: the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the `call` instruction (why?). Finally, the five hex values listed after `args` are the first five arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than five arguments, of course, then not all five of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
|
||||
|
||||
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
|
||||
|
||||
* If `int *p = (int*)100`, then `(int)p + 1` and `(int)(p + 1)` are different numbers: the first is `101` but the second is `104`. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
|
||||
* `p[i]` is defined to be the same as `*(p+i)`, referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
|
||||
* `&p[i]` is the same as `(p+i)`, yielding the address of the i'th object in the memory pointed to by p.
|
||||
|
||||
|
||||
|
||||
Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
|
||||
|
||||
> **Exercise 11**
|
||||
>
|
||||
> Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. After you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
|
||||
|
||||
At this point, your backtrace function should give you the addresses of the function callers on the stack that lead to `mon_backtrace()` being executed. However, in practice you often want to know the function names corresponding to those addresses. For instance, you may want to know which functions could contain a bug that's causing your kernel to crash.
|
||||
|
||||
To help you implement this functionality, we have provided the function `debuginfo_eip()`, which looks up `eip` in the symbol table and returns the debugging information for that address. This function is defined in `kern/kdebug.c`.
|
||||
|
||||
> **Exercise 12**
|
||||
>
|
||||
> Modify your stack backtrace function to display, for each `eip`, the function name, source file name, and line number corresponding to that `eip`.
|
||||
|
||||
In `debuginfo_eip`, where do `__STAB_*` come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
|
||||
|
||||
* look in the file `kern/kernel.ld` for `__STAB_*`
|
||||
* run i386-jos-elf-objdump -h obj/kern/kernel
|
||||
* run i386-jos-elf-objdump -G obj/kern/kernel
|
||||
* run i386-jos-elf-gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
|
||||
* see if the bootloader loads the symbol table in memory as part of loading the kernel binary
|
||||
|
||||
|
||||
|
||||
Complete the implementation of `debuginfo_eip` by inserting the call to `stab_binsearch` to find the line number for an address.
|
||||
|
||||
Add a `backtrace` command to the kernel monitor, and extend your implementation of `mon_backtrace` to call `debuginfo_eip` and print a line for each stack frame of the form:
|
||||
```
|
||||
K> backtrace
|
||||
Stack backtrace:
|
||||
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
|
||||
kern/monitor.c:143: monitor+106
|
||||
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
|
||||
kern/init.c:49: i386_init+59
|
||||
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
|
||||
kern/entry.S:70: <unknown>+0
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Each line gives the file name and line within that file of the stack frame's `eip`, followed by the name of the function and the offset of the `eip` from the first instruction of the function (e.g., `monitor+106` means the return `eip` is 106 bytes past the beginning of `monitor`).
|
||||
|
||||
Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
|
||||
|
||||
Tip: printf format strings provide an easy, albeit obscure, way to print non-null-terminated strings like those in STABS tables. `printf("%.*s", length, string)` prints at most `length` characters of `string`. Take a look at the printf man page to find out why this works.
|
||||
|
||||
You may find that some functions are missing from the backtrace. For example, you will probably see a call to `monitor()` but not to `runcmd()`. This is because the compiler in-lines some function calls. Other optimizations may cause you to see unexpected line numbers. If you get rid of the `-O2` from `GNUMakefile`, the backtraces may make more sense (but your kernel will run more slowly).
|
||||
|
||||
**This completes the lab.** In the `lab` directory, commit your changes with `git commit` and type `make handin` to submit your code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/lab1/
|
||||
|
||||
作者:[mit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sipb.mit.edu
|
||||
[1]:http://www.git-scm.com/
|
||||
[2]:http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
|
||||
[3]:http://eagain.net/articles/git-for-computer-scientists/
|
||||
[4]:https://sipb.mit.edu/iap/6.828/tools
|
||||
[5]:https://exokernel.scripts.mit.edu/submit/
|
||||
[6]:https://sipb.mit.edu/iap/6.828/readings/pcasm-book.pdf
|
||||
[7]:http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html
|
||||
[8]:https://sipb.mit.edu/iap/6.828/reference
|
||||
[9]:https://sipb.mit.edu/iap/6.828/readings/i386/toc.htm
|
||||
[10]:http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
|
||||
[11]:http://developer.amd.com/documentation/guides/Pages/default.aspx#manuals
|
||||
[12]:http://www.qemu.org/
|
||||
[13]:http://www.gnu.org/software/gdb/
|
||||
[14]:http://web.archive.org/web/20040404164813/members.iweb.net.au/%7Epstorr/pcbook/book2/book2.htm
|
||||
[15]:https://sipb.mit.edu/iap/6.828/readings/boot-cdrom.pdf
|
||||
[16]:https://sipb.mit.edu/iap/6.828/labguide
|
||||
[17]:https://sipb.mit.edu/iap/6.828/files/pointers.c
|
||||
[18]:http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&s=books
|
||||
[19]:http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&doc_library=MIT01&doc_number=000355242&year=&volume=&sub_library=
|
||||
[20]:http://sipb.mit.edu/
|
||||
[21]:https://sipb.mit.edu/iap/6.828/readings/pointers.pdf
|
||||
[22]:https://sipb.mit.edu/iap/6.828/readings/elf.pdf
|
||||
[23]:http://sourceware.org/gdb/current/onlinedocs/gdb_9.html#SEC63
|
||||
[24]:http://web.cs.mun.ca/%7Emichael/c/ascii-table.html
|
||||
[25]:http://www.webopedia.com/TERM/b/big_endian.html
|
||||
[26]:http://www.networksorcery.com/enp/ien/ien137.txt
|
||||
@ -1,94 +0,0 @@
|
||||
How To Safely Generate A Random Number — Quarrelsome
|
||||
======
|
||||
### Use urandom
|
||||
|
||||
Use [urandom][1]. Use [urandom][2]. Use [urandom][3]. Use [urandom][4]. Use [urandom][5]. Use [urandom][6].
|
||||
|
||||
### But what about for crypto keys?
|
||||
|
||||
Still [urandom][6].
|
||||
|
||||
### Why not {SecureRandom, OpenSSL, havaged, &c}?
|
||||
|
||||
These are userspace CSPRNGs. You want to use the kernel’s CSPRNG, because:
|
||||
|
||||
* The kernel has access to raw device entropy.
|
||||
|
||||
* It can promise not to share the same state between applications.
|
||||
|
||||
* A good kernel CSPRNG, like FreeBSD’s, can also promise not to feed you random data before it’s seeded.
|
||||
|
||||
|
||||
|
||||
|
||||
Study the last ten years of randomness failures and you’ll read a litany of userspace randomness failures. [Debian’s OpenSSH debacle][7]? Userspace random. Android Bitcoin wallets [repeating ECDSA k’s][8]? Userspace random. Gambling sites with predictable shuffles? Userspace random.
|
||||
|
||||
Userspace OpenSSL also seeds itself from “from uninitialized memory, magical fairy dust and unicorn horns” generators almost always depend on the kernel’s generator anyways. Even if they don’t, the security of your whole system sure does. **A userspace CSPRNG doesn’t add defense-in-depth; instead, it creates two single points of failure.**
|
||||
|
||||
### Doesn’t the man page say to use /dev/random?
|
||||
|
||||
You But, more on this later. Stay your pitchforks. should ignore the man page. Don’t use /dev/random. The distinction between /dev/random and /dev/urandom is a Unix design wart. The man page doesn’t want to admit that, so it invents a security concern that doesn’t really exist. Consider the cryptographic advice in random(4) an urban legend and get on with your life.
|
||||
|
||||
### But what if I need real random values, not psuedorandom values?
|
||||
|
||||
Both urandom and /dev/random provide the same kind of randomness. Contrary to popular belief, /dev/random doesn’t provide “true random” data. For cryptography, you don’t usually want “true random”.
|
||||
|
||||
Both urandom and /dev/random are based on a simple idea. Their design is closely related to that of a stream cipher: a small secret is stretched into an indefinite stream of unpredictable values. Here the secrets are “entropy”, and the stream is “output”.
|
||||
|
||||
Only on Linux are /dev/random and urandom still meaningfully different. The Linux kernel CSPRNG rekeys itself regularly (by collecting more entropy). But /dev/random also tries to keep track of how much entropy remains in its kernel pool, and will occasionally go on strike if it decides not enough remains. This design is as silly as I’ve made it sound; it’s akin to AES-CTR blocking based on how much “key” is left in the “keystream”.
|
||||
|
||||
If you use /dev/random instead of urandom, your program will unpredictably (or, if you’re an attacker, very predictably) hang when Linux gets confused about how its own RNG works. Using /dev/random will make your programs less stable, but it won’t make them any more cryptographically safe.
|
||||
|
||||
### There’s a catch here, isn’t there?
|
||||
|
||||
No, but there’s a Linux kernel bug you might want to know about, even though it doesn’t change which RNG you should use.
|
||||
|
||||
On Linux, if your software runs immediately at boot, and/or the OS has just been installed, your code might be in a race with the RNG. That’s bad, because if you win the race, there could be a window of time where you get predictable outputs from urandom. This is a bug in Linux, and you need to know about it if you’re building platform-level code for a Linux embedded device.
|
||||
|
||||
This is indeed a problem with urandom (and not /dev/random) on Linux. It’s also a [bug in the Linux kernel][9]. But it’s also easily fixed in userland: at boot, seed urandom explicitly. Most Linux distributions have done this for a long time. But don’t switch to a different CSPRNG.
|
||||
|
||||
### What about on other operating systems?
|
||||
|
||||
FreeBSD and OS X do away with the distinction between urandom and /dev/random; the two devices behave identically. Unfortunately, the man page does a poor job of explaining why this is, and perpetuates the myth that Linux urandom is scary.
|
||||
|
||||
FreeBSD’s kernel crypto RNG doesn’t block regardless of whether you use /dev/random or urandom. Unless it hasn’t been seeded, in which case both block. This behavior, unlike Linux’s, makes sense. Linux should adopt it. But if you’re an app developer, this makes little difference to you: Linux, FreeBSD, iOS, whatever: use urandom.
|
||||
|
||||
### tl;dr
|
||||
|
||||
Use urandom.
|
||||
|
||||
### Epilog
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> Right now, SecureRandom.random_bytes tries to detect an OpenSSL to use before it tries to detect /dev/urandom. I think it should be the other way around. In both cases, you just need random bytes to unpack, so SecureRandom could skip the middleman (and second point of failure) and just talk to /dev/urandom directly if it’s available.
|
||||
|
||||
Resolution:
|
||||
|
||||
> /dev/urandom is not suitable to be used to generate directly session keys and other application level random data which is generated frequently.
|
||||
>
|
||||
> [the] random(4) [man page] on GNU/Linux [says]…
|
||||
|
||||
Thanks to Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci for reading drafts of this. Fair warning: Matthew only mostly agrees with me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas;Erin;Matasano][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -1,220 +0,0 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb work?
|
||||
============================================================
|
||||
|
||||
Hello! Today I was working a bit on my [ruby stacktrace project][1] and I realized that now I know a couple of things about how gdb works internally.
|
||||
|
||||
Lately I’ve been using gdb to look at Ruby programs, so we’re going to be running gdb on a Ruby program. This really means the Ruby interpreter. First, we’re going to print out the address of a global variable: `ruby_current_thread`:
|
||||
|
||||
### getting a global variable
|
||||
|
||||
Here’s how to get the address of the global `ruby_current_thread`:
|
||||
|
||||
```
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
There are a few places a variable can live: on the heap, the stack, or in your program’s text. Global variables are part of your program! You can think of them as being allocated at compile time, kind of. It turns out we can figure out the address of a global variable pretty easily! Let’s see how `gdb` came up with `0x5598a9a8f7f0`.
|
||||
|
||||
We can find the approximate region this variable lives in by looking at a cool file in `/proc` called `/proc/$pid/maps`.
|
||||
|
||||
```
|
||||
$ sudo cat /proc/2983/maps | grep bin/ruby
|
||||
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
|
||||
```
|
||||
|
||||
So! There’s this starting address `5598a9605000` That’s _like_ `0x5598a9a8f7f0`, but different. How different? Well, here’s what I get when I subtract them:
|
||||
|
||||
```
|
||||
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
|
||||
$4 = 0x48a7f0
|
||||
|
||||
```
|
||||
|
||||
“What’s that number?”, you might ask? WELL. Let’s look at the **symbol table**for our program with `nm`.
|
||||
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
What’s that we see? Could it be `0x48a7f0`? Yes it is! So!! If we want to find the address of a global variable in our program, all we need to do is look up the name of the variable in the symbol table, and then add that to the start of the range in `/proc/whatever/maps`, and we’re done!
|
||||
|
||||
So now we know how gdb does that. But gdb does so much more!! Let’s skip ahead to…
|
||||
|
||||
### dereferencing pointers
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
The next thing we’re going to do is **dereference** that `ruby_current_thread`pointer. We want to see what’s in that address! To do that, gdb will run a bunch of system calls like this:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
You remember this address `0x5598a9a8f7f0`? gdb is asking “hey, what’s in that address exactly”? `2983` is the PID of the process we’re running gdb on. It’s using the `ptrace` system call which is how gdb does everything.
|
||||
|
||||
Awesome! So we can dereference memory and figure out what bytes are at what memory addresses. Some useful gdb commands to know here are `x/40w variable` and `x/40b variable` which will display 40 words / bytes at a given address, respectively.
|
||||
|
||||
### describing structs
|
||||
|
||||
The memory at an address looks like this. A bunch of bytes!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
|
||||
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
That’s useful, but not that useful! If you are a human like me and want to know what it MEANS, you need more. Like this:
|
||||
|
||||
```
|
||||
(gdb) p *(ruby_current_thread)
|
||||
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
|
||||
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
GOODNESS. That is a lot more useful. How does gdb know that there are all these cool fields like `stack_size`? Enter DWARF. DWARF is a way to store extra debugging data about your program, so that debuggers like gdb can do their job better! It’s generally stored as part of a binary. If I run `dwarfdump` on my Ruby binary, I get some output like this:
|
||||
|
||||
(I’ve redacted it heavily to make it easier to understand)
|
||||
|
||||
```
|
||||
DW_AT_name "rb_thread_struct"
|
||||
DW_AT_byte_size 0x000003e8
|
||||
DW_TAG_member
|
||||
DW_AT_name "self"
|
||||
DW_AT_type <0x00000579>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 0
|
||||
DW_TAG_member
|
||||
DW_AT_name "vm"
|
||||
DW_AT_type <0x0000270c>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 8
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack"
|
||||
DW_AT_type <0x000006b3>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 16
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack_size"
|
||||
DW_AT_type <0x00000031>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 24
|
||||
DW_TAG_member
|
||||
DW_AT_name "cfp"
|
||||
DW_AT_type <0x00002712>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 32
|
||||
DW_TAG_member
|
||||
DW_AT_name "safe_level"
|
||||
DW_AT_type <0x00000066>
|
||||
|
||||
```
|
||||
|
||||
So. The name of the type of `ruby_current_thread` is `rb_thread_struct`. It has size `0x3e8` (or 1000 bytes), and it has a bunch of member items. `stack_size` is one of them, at an offset of 24, and it has type 31\. What’s 31? No worries! We can look that up in the DWARF info too!
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
DW_AT_name "size_t"
|
||||
DW_AT_type <0x0000003c>
|
||||
< 1><0x0000003c> DW_TAG_base_type
|
||||
DW_AT_byte_size 0x00000008
|
||||
DW_AT_encoding DW_ATE_unsigned
|
||||
DW_AT_name "long unsigned int"
|
||||
|
||||
```
|
||||
|
||||
So! `stack_size` has type `size_t`, which means `long unsigned int`, and is 8 bytes. That means that we can read the stack size!
|
||||
|
||||
How that would break down, once we have the DWARF debugging data, is:
|
||||
|
||||
1. Read the region of memory that `ruby_current_thread` is pointing to
|
||||
|
||||
2. Add 24 bytes to get to `stack_size`
|
||||
|
||||
3. Read 8 bytes (in little-endian format, since we’re on x86)
|
||||
|
||||
4. Get the answer!
|
||||
|
||||
Which in this case is 131072 or 128 kb.
|
||||
|
||||
To me, this makes it a lot more obvious what debugging info is **for** – if we didn’t have all this extra metadata about what all these variables meant, we would have no idea what the bytes at address `0x5598ab3235b0` meant.
|
||||
|
||||
This is also why you can install debug info for a program separately from your program – gdb doesn’t care where it gets the extra debug info from.
|
||||
|
||||
### DWARF is confusing
|
||||
|
||||
I’ve been reading a bunch of DWARF info recently. Right now I’m using libdwarf which hasn’t been the best experience – the API is confusing, you initialize everything in a weird way, and it’s really slow (it takes 0.3 seconds to read all the debugging data out of my Ruby program which seems ridiculous). I’ve been told that libdw from elfutils is better.
|
||||
|
||||
Also, I casually remarked that you can look at `DW_AT_data_member_location` to get the offset of a struct member! But I looked up on Stack Overflow how to actually do that and I got [this answer][2]. Basically you start with a check like:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
and then it keeps GOING. Why are there 8 million different `DW_FORM_data` things I need to check for? What is happening? I have no idea.
|
||||
|
||||
Anyway my impression is that DWARF is a large and complicated standard (and possibly the libraries people use to generate DWARF are subtly incompatible?), but it’s what we have, so that’s what we work with!
|
||||
|
||||
I think it’s really cool that I can write code that reads DWARF and my code actually mostly works. Except when it crashes. I’m working on that.
|
||||
|
||||
### unwinding stacktraces
|
||||
|
||||
In an earlier version of this post, I said that gdb unwinds stacktraces using libunwind. It turns out that this isn’t true at all!
|
||||
|
||||
Someone who’s worked on gdb a lot emailed me to say that they actually spent a ton of time figuring out how to unwind stacktraces so that they can do a better job than libunwind does. This means that if you get stopped in the middle of a weird program with less debug info than you might hope for that’s done something strange with its stack, gdb will try to figure out where you are anyway. Thanks <3
|
||||
|
||||
### other things gdb does
|
||||
|
||||
The few things I’ve described here (reading memory, understanding DWARF to show you structs) aren’t everything gdb does – just looking through Brendan Gregg’s [gdb example from yesterday][3], we see that gdb also knows how to
|
||||
|
||||
* disassemble assembly
|
||||
|
||||
* show you the contents of your registers
|
||||
|
||||
and in terms of manipulating your program, it can
|
||||
|
||||
* set breakpoints and step through a program
|
||||
|
||||
* modify memory (!! danger !!)
|
||||
|
||||
Knowing more about how gdb works makes me feel a lot more confident when using it! I used to get really confused because gdb kind of acts like a C REPL sometimes – you type `ruby_current_thread->cfp->iseq`, and it feels like writing C code! But you’re not really writing C at all, and it was easy for me to run into limitations in gdb and not understand why.
|
||||
|
||||
Knowing that it’s using DWARF to figure out the contents of the structs gives me a better mental model and have more correct expectations! Awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/
|
||||
[2]:https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info
|
||||
[3]:http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
|
||||
@ -1,215 +0,0 @@
|
||||
translating by imquanquan
|
||||
|
||||
9 Lightweight Linux Applications to Speed Up Your System
|
||||
======
|
||||
**Brief:** One of the many ways to [speed up Ubuntu][1] system is to use lightweight alternatives of the popular applications. We have already seen [must have Linux application][2] earlier. we'll see the lightweight alternative applications for Ubuntu and other Linux distributions.
|
||||
|
||||
![Use these Lightweight alternative applications in Ubuntu Linux][4]
|
||||
|
||||
## 9 Lightweight alternatives of popular Linux applications
|
||||
|
||||
Is your Linux system slow? Are the applications taking a long time to open? The best option you have is to use a [light Linux distro][5]. But it's not always possible to reinstall an operating system, is it?
|
||||
|
||||
So if you want to stick to your present Linux distribution, but want improved performance, you should use lightweight alternatives of the applications you are using. Here, I'm going to put together a small list of lightweight alternatives to various Linux applications.
|
||||
|
||||
Since I am using Ubuntu, I have provided installation instructions for Ubuntu-based Linux distributions. But these applications will work on almost all other Linux distribution. You just have to find a way to install these lightweight Linux software in your distro.
|
||||
|
||||
### 1. Midori: Web Browser
|
||||
|
||||
Midori is one of the most lightweight web browsers that have reasonable compatibility with the modern web. It is open source and uses the same rendering engine that Google Chrome was initially built on -- WebKit. It is super fast and minimal yet highly customizable.
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
It has plenty of extensions and options to tinker with. So if you are a power user, it's a great choice for you too. If you face any problems browsing round the web, check the [Frequently Asked Question][7] section of their website -- it contains the common problems you might face along with their solution.
|
||||
|
||||
[Midori][8]
|
||||
|
||||
#### Installing Midori on Ubuntu based distributions
|
||||
|
||||
Midori is available on Ubuntu via the official repository. Just run the following commands for installing it:
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita: email client
|
||||
|
||||
Trojita is an open source robust IMAP e-mail client. It is fast and resource efficient. I can certainly call it one of the [best email clients for Linux][9]. If you can live with only IMAP support on your e-mail client, you might not want to look any further.
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita uses various techniques -- on-demand e-mail loading, offline caching, bandwidth-saving mode etc. -- for achieving its impressive performance.
|
||||
|
||||
[Trojita][11]
|
||||
|
||||
#### Installing Trojita on Ubuntu based distributions
|
||||
|
||||
Trojita currently doesn't have an official PPA for Ubuntu. But that shouldn't be a problem. You can install it quite easily using the following commands:
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi: Package Installer
|
||||
|
||||
Sometimes you need to quickly install DEB packages. Ubuntu Software Center is a resource-heavy application and using it just for installing .deb files is not wise.
|
||||
|
||||
Gdebi is certainly a nifty tool for the same purpose, just with a minimal graphical interface.
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi is totally lightweight and does its job flawlessly. You should even [make Gdebi the default installer for DEB files][13].
|
||||
|
||||
#### Installing GDebi on Ubuntu based distributions
|
||||
|
||||
You can install GDebi on Ubuntu with this simple one-liner:
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid: Software Center
|
||||
|
||||
If you use software center frequently for searching, installing and managing applications on Ubuntu, App Grid is a must have application. It is the most visually appealing and yet fast alternative to the default Ubuntu Software Center.
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid supports ratings, reviews and screenshots for applications.
|
||||
|
||||
[App Grid][15]
|
||||
|
||||
#### Installing App Grid on Ubuntu based distributions
|
||||
|
||||
App Grid has its official PPA for Ubuntu. Use the following commands for installing App Grid:
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock: Music Player
|
||||
|
||||
Yarock is an elegant music player with a modern and minimal user interface. It is lightweight in design and yet it has a comprehensive list of advanced features.
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
The main features of Yarock include multiple music collections, rating, smart playlist, multiple back-end option, desktop notification, scrobbling, context fetching etc.
|
||||
|
||||
[Yarock][17]
|
||||
|
||||
#### Installing Yarock on Ubuntu based distributions
|
||||
|
||||
You will have to install Yarock on Ubuntu via PPA using the following commands:
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC: Video Player
|
||||
|
||||
Who doesn't need a video player? And who has never heard about VLC? It doesn't really need any introduction.
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC is all you need to play various media files on Ubuntu and it is quite lightweight too. It works flawlessly on even on very old PCs.
|
||||
|
||||
[VLC][19]
|
||||
|
||||
#### Installing VLC on Ubuntu based distributions
|
||||
|
||||
VLC has official PPA for Ubuntu. Enter the following commands for installing it:
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM: File Manager
|
||||
|
||||
PCManFM is the standard file manager from LXDE. As with the other applications from LXDE, this one too is lightweight. If you are looking for a lighter alternative for your file manager, try this one.
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
Although coming from LXDE, PCManFM works with other desktop environments just as well.
|
||||
|
||||
#### Installing PCManFM on Ubuntu based distributions
|
||||
|
||||
Installing PCManFM on Ubuntu will just take one simple command:
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad: Text Editor
|
||||
|
||||
Nothing can beat command-line text editors like - nano, vim etc. in terms of being lightweight. But if you want a graphical interface, here you go -- Mousepad is a minimal text editor. It's extremely lightweight and blazing fast. It comes with a simple customizable user interface with multiple themes.
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad supports syntax highlighting. So, you can also use it as a basic code editor.
|
||||
|
||||
#### Installing Mousepad on Ubuntu based distributions
|
||||
|
||||
For installing Mousepad use the following command:
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office: Office Suite
|
||||
|
||||
Many of us need to use office applications quite often. Generally, most of the office applications are bulky in size and resource hungry. Gnome Office is quite lightweight in that respect. Gnome Office is technically not a complete office suite. It's composed of different standalone applications and among them, **AbiWord** & **Gnumeric** stands out.
|
||||
|
||||
**AbiWord** is the word processor. It is lightweight and a lot faster than other alternatives. But that came to be at a cost -- you might miss some features like macros, grammar checking etc. It's not perfect but it works.
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** is the spreadsheet editor. Just like AbiWord, Gnumeric is also very fast and it provides accurate calculations. If you are looking for a simple and lightweight spreadsheet editor, Gnumeric has got you covered.
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
There are some other applications listed under Gnome Office. You can find them in the official page.
|
||||
|
||||
[Gnome Office][24]
|
||||
|
||||
#### Installing AbiWord & Gnumeric on Ubuntu based distributions
|
||||
|
||||
For installing AbiWord & Gnumeric, simply enter the following command in your terminal:
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
That's all for today. Would you like to add some other **lightweight Linux applications** to this list? Do let us know!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Trojit%C3%A1-800x608.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,142 +0,0 @@
|
||||
How to use GNU Stow to manage programs installed from source and dotfiles
|
||||
======
|
||||
|
||||
### Objective
|
||||
|
||||
Easily manage programs installed from source and dotfiles using GNU stow
|
||||
|
||||
### Requirements
|
||||
|
||||
* Root permissions
|
||||
|
||||
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** \- requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** \- given command to be executed as a regular non-privileged user
|
||||
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
Sometimes we have to install programs from source: maybe they are not available through standard channels, or maybe we want a specific version of a software. GNU stow is a very nice `symlinks factory` program which helps us a lot by keeping files organized in a very clean and easy to maintain way.
|
||||
|
||||
### Obtaining stow
|
||||
|
||||
Your distribution repositories is very likely to contain `stow`, for example in Fedora, all you have to do to install it is:
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
or on Ubuntu/Debian you can install stow by executing:
|
||||
```
|
||||
|
||||
# apt install stow
|
||||
|
||||
```
|
||||
|
||||
In some distributions, stow it's not available in standard repositories, but it can be easily obtained by adding some extra software sources (for example epel in the case of Rhel and CentOS7) or, as a last resort, by compiling it from source: it requires very little dependencies.
|
||||
|
||||
### Compiling stow from source
|
||||
|
||||
The latest available stow version is the `2.2.2`: the tarball is available for download here: `https://ftp.gnu.org/gnu/stow/`.
|
||||
|
||||
Once you have downloaded the sources, you must extract the tarball. Navigate to the directory where you downloaded the package and simply run:
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
After the sources have been extracted, navigate inside the stow-2.2.2 directory, and to compile the program simply run:
|
||||
```
|
||||
|
||||
$ ./configure
|
||||
$ make
|
||||
|
||||
```
|
||||
|
||||
Finally, to install the package:
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
By default the package will be installed in the `/usr/local/` directory, but we can change this, specifying the directory via the `--prefix` option of the configure script, or by adding `prefix="/your/dir"` when running the `make install` command.
|
||||
|
||||
At this point, if all worked as expected we should have `stow` installed on our system
|
||||
|
||||
### How does stow work?
|
||||
|
||||
The main concept behind stow it's very well explained in the program manual:
|
||||
```
|
||||
|
||||
The approach used by Stow is to install each package into its own tree,
|
||||
then use symbolic links to make it appear as though the files are
|
||||
installed in the common tree.
|
||||
|
||||
```
|
||||
|
||||
To better understand the working of the package, let's analyze its key concepts:
|
||||
|
||||
#### The stow directory
|
||||
|
||||
The stow directory is the root directory which contains all the `stow packages`, each with their own private subtree. The typical stow directory is `/usr/local/stow`: inside it, each subdirectory represents a `package`
|
||||
|
||||
#### Stow packages
|
||||
|
||||
As said above, the stow directory contains "packages", each in its own separate subdirectory, usually named after the program itself. A package is nothing more than a list of files and directories related to a specific software, managed as an entity.
|
||||
|
||||
#### The stow target directory
|
||||
|
||||
The stow target directory is very a simple concept to explain. It is the directory in which the package files must appear to be installed. By default the stow target directory is considered to be the one above the directory in which stow is invoked from. This behaviour can be easily changed by using the `-t` option (short for --target), which allows us to specify an alternative directory.
|
||||
|
||||
### A practical example
|
||||
|
||||
I believe a well done example is worth 1000 words, so let's show how stow works. Suppose we want to compile and install `libx264`. Lets clone the git repository containing its sources:
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
Few seconds after running the command, the "x264" directory will be created, and it will contain the sources, ready to be compiled. We now navigate inside it and run the `configure` script, specifying the /usr/local/stow/libx264 directory as `--prefix`:
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
Then we build the program and install it:
|
||||
```
|
||||
|
||||
$ make
|
||||
# make install
|
||||
|
||||
```
|
||||
|
||||
The directory x264 should have been created inside of the stow directory: it contains all the stuff that would have been normally installed in the system directly. Now, all we have to do, is to invoke stow. We must run the command either from inside the stow directory, by using the `-d` option to specify manually the path to the stow directory (default is the current directory), or by specifying the target with `-t` as said before. We should also provide the name of the package to be stowed as an argument. In this case we run the program from the stow directory, so all we need to type is:
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
All the files and directories contained in the libx264 package have now been symlinked in the parent directory (/usr/local) of the one from which stow has been invoked, so that, for example, libx264 binaries contained in `/usr/local/stow/x264/bin` are now symlinked in `/usr/local/bin`, files contained in `/usr/local/stow/x264/etc` are now symlinked in `/usr/local/etc` and so on. This way it will appear to the system that the files were installed normally, and we can easily keep track of each program we compile and install. To revert the action, we just use the `-D` option:
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
It is done! The symlinks don't exist anymore: we just "uninstalled" a stow package, keeping our system in a clean and consistent state. At this point it should be clear why stow it's also used to manage dotfiles. A common practice is to have all user-specific configuration files inside a git repository, to manage them easily and have them available everywhere, and then using stow to place them where appropriate, in the user home directory.
|
||||
|
||||
Stow will also prevent you from overriding files by mistake: it will refuse to create symbolic links if the destination file already exists and doesn't point to a package into the stow directory. This situation is called a conflict in stow terminology.
|
||||
|
||||
That's it! For a complete list of options, please consult the stow manpage and don't forget to tell us your opinions about it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -1,3 +1,5 @@
|
||||
[translating for laujinseoi]
|
||||
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
702
sources/tech/20171024 Learn Blockchains by Building One.md
Normal file
702
sources/tech/20171024 Learn Blockchains by Building One.md
Normal file
@ -0,0 +1,702 @@
|
||||
Learn Blockchains by Building One
|
||||
======
|
||||
|
||||

|
||||
You’re here because, like me, you’re psyched about the rise of Cryptocurrencies. And you want to know how Blockchains work—the fundamental technology behind them.
|
||||
|
||||
But understanding Blockchains isn’t easy—or at least wasn’t for me. I trudged through dense videos, followed porous tutorials, and dealt with the amplified frustration of too few examples.
|
||||
|
||||
I like learning by doing. It forces me to deal with the subject matter at a code level, which gets it sticking. If you do the same, at the end of this guide you’ll have a functioning Blockchain with a solid grasp of how they work.
|
||||
|
||||
### Before you get started…
|
||||
|
||||
Remember that a blockchain is an _immutable, sequential_ chain of records called Blocks. They can contain transactions, files or any data you like, really. But the important thing is that they’re _chained_ together using _hashes_ .
|
||||
|
||||
If you aren’t sure what a hash is, [here’s an explanation][1].
|
||||
|
||||
**_Who is this guide aimed at?_** You should be comfy reading and writing some basic Python, as well as have some understanding of how HTTP requests work, since we’ll be talking to our Blockchain over HTTP.
|
||||
|
||||
**_What do I need?_** Make sure that [Python 3.6][2]+ (along with `pip`) is installed. You’ll also need to install Flask and the wonderful Requests library:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
Oh, you’ll also need an HTTP Client, like [Postman][3] or cURL. But anything will do.
|
||||
|
||||
**_Where’s the final code?_** The source code is [available here][4].
|
||||
|
||||
* * *
|
||||
|
||||
### Step 1: Building a Blockchain
|
||||
|
||||
Open up your favourite text editor or IDE, personally I ❤️ [PyCharm][5]. Create a new file, called `blockchain.py`. We’ll only use a single file, but if you get lost, you can always refer to the [source code][6].
|
||||
|
||||
#### Representing a Blockchain
|
||||
|
||||
We’ll create a `Blockchain` class whose constructor creates an initial empty list (to store our blockchain), and another to store transactions. Here’s the blueprint for our class:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
def __init__(self):
|
||||
self.chain = []
|
||||
self.current_transactions = []
|
||||
|
||||
def new_block(self):
|
||||
# Creates a new Block and adds it to the chain
|
||||
pass
|
||||
|
||||
def new_transaction(self):
|
||||
# Adds a new transaction to the list of transactions
|
||||
pass
|
||||
|
||||
@staticmethod
|
||||
def hash(block):
|
||||
# Hashes a Block
|
||||
pass
|
||||
|
||||
@property
|
||||
def last_block(self):
|
||||
# Returns the last Block in the chain
|
||||
pass
|
||||
```
|
||||
|
||||
|
||||
Our Blockchain class is responsible for managing the chain. It will store transactions and have some helper methods for adding new blocks to the chain. Let’s start fleshing out some methods.
|
||||
|
||||
#### What does a Block look like?
|
||||
|
||||
Each Block has an index, a timestamp (in Unix time), a list of transactions, a proof (more on that later), and the hash of the previous Block.
|
||||
|
||||
Here’s an example of what a single Block looks like:
|
||||
|
||||
```
|
||||
block = {
|
||||
'index': 1,
|
||||
'timestamp': 1506057125.900785,
|
||||
'transactions': [
|
||||
{
|
||||
'sender': "8527147fe1f5426f9dd545de4b27ee00",
|
||||
'recipient': "a77f5cdfa2934df3954a5c7c7da5df1f",
|
||||
'amount': 5,
|
||||
}
|
||||
],
|
||||
'proof': 324984774000,
|
||||
'previous_hash': "2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824"
|
||||
}
|
||||
```
|
||||
|
||||
At this point, the idea of a chain should be apparent—each new block contains within itself, the hash of the previous Block. This is crucial because it’s what gives blockchains immutability: If an attacker corrupted an earlier Block in the chain then all subsequent blocks will contain incorrect hashes.
|
||||
|
||||
Does this make sense? If it doesn’t, take some time to let it sink in—it’s the core idea behind blockchains.
|
||||
|
||||
#### Adding Transactions to a Block
|
||||
|
||||
We’ll need a way of adding transactions to a Block. Our new_transaction() method is responsible for this, and it’s pretty straight-forward:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
...
|
||||
|
||||
def new_transaction(self, sender, recipient, amount):
|
||||
"""
|
||||
Creates a new transaction to go into the next mined Block
|
||||
:param sender: <str> Address of the Sender
|
||||
:param recipient: <str> Address of the Recipient
|
||||
:param amount: <int> Amount
|
||||
:return: <int> The index of the Block that will hold this transaction
|
||||
"""
|
||||
|
||||
self.current_transactions.append({
|
||||
'sender': sender,
|
||||
'recipient': recipient,
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
After new_transaction() adds a transaction to the list, it returns the index of the block which the transaction will be added to—the next one to be mined. This will be useful later on, to the user submitting the transaction.
|
||||
|
||||
#### Creating new Blocks
|
||||
|
||||
When our Blockchain is instantiated we’ll need to seed it with a genesis block—a block with no predecessors. We’ll also need to add a “proof” to our genesis block which is the result of mining (or proof of work). We’ll talk more about mining later.
|
||||
|
||||
In addition to creating the genesis block in our constructor, we’ll also flesh out the methods for new_block(), new_transaction() and hash():
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
from time import time
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
def __init__(self):
|
||||
self.current_transactions = []
|
||||
self.chain = []
|
||||
|
||||
# Create the genesis block
|
||||
self.new_block(previous_hash=1, proof=100)
|
||||
|
||||
def new_block(self, proof, previous_hash=None):
|
||||
"""
|
||||
Create a new Block in the Blockchain
|
||||
:param proof: <int> The proof given by the Proof of Work algorithm
|
||||
:param previous_hash: (Optional) <str> Hash of previous Block
|
||||
:return: <dict> New Block
|
||||
"""
|
||||
|
||||
block = {
|
||||
'index': len(self.chain) + 1,
|
||||
'timestamp': time(),
|
||||
'transactions': self.current_transactions,
|
||||
'proof': proof,
|
||||
'previous_hash': previous_hash or self.hash(self.chain[-1]),
|
||||
}
|
||||
|
||||
# Reset the current list of transactions
|
||||
self.current_transactions = []
|
||||
|
||||
self.chain.append(block)
|
||||
return block
|
||||
|
||||
def new_transaction(self, sender, recipient, amount):
|
||||
"""
|
||||
Creates a new transaction to go into the next mined Block
|
||||
:param sender: <str> Address of the Sender
|
||||
:param recipient: <str> Address of the Recipient
|
||||
:param amount: <int> Amount
|
||||
:return: <int> The index of the Block that will hold this transaction
|
||||
"""
|
||||
self.current_transactions.append({
|
||||
'sender': sender,
|
||||
'recipient': recipient,
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
|
||||
@property
|
||||
def last_block(self):
|
||||
return self.chain[-1]
|
||||
|
||||
@staticmethod
|
||||
def hash(block):
|
||||
"""
|
||||
Creates a SHA-256 hash of a Block
|
||||
:param block: <dict> Block
|
||||
:return: <str>
|
||||
"""
|
||||
|
||||
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
|
||||
block_string = json.dumps(block, sort_keys=True).encode()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
The above should be straight-forward—I’ve added some comments and docstrings to help keep it clear. We’re almost done with representing our blockchain. But at this point, you must be wondering how new blocks are created, forged or mined.
|
||||
|
||||
#### Understanding Proof of Work
|
||||
|
||||
A Proof of Work algorithm (PoW) is how new Blocks are created or mined on the blockchain. The goal of PoW is to discover a number which solves a problem. The number must be difficult to find but easy to verify—computationally speaking—by anyone on the network. This is the core idea behind Proof of Work.
|
||||
|
||||
We’ll look at a very simple example to help this sink in.
|
||||
|
||||
Let’s decide that the hash of some integer x multiplied by another y must end in 0\. So, hash(x * y) = ac23dc...0\. And for this simplified example, let’s fix x = 5\. Implementing this in Python:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
|
||||
x = 5
|
||||
y = 0 # We don't know what y should be yet...
|
||||
|
||||
while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
y += 1
|
||||
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
The solution here is y = 21\. Since, the produced hash ends in 0:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
The network is able to easily verify their solution.
|
||||
|
||||
#### Implementing basic Proof of Work
|
||||
|
||||
Let’s implement a similar algorithm for our blockchain. Our rule will be similar to the example above:
|
||||
|
||||
> Find a number p that when hashed with the previous block’s solution a hash with 4 leading 0s is produced.
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
...
|
||||
|
||||
def proof_of_work(self, last_proof):
|
||||
"""
|
||||
Simple Proof of Work Algorithm:
|
||||
- Find a number p' such that hash(pp') contains leading 4 zeroes, where p is the previous p'
|
||||
- p is the previous proof, and p' is the new proof
|
||||
:param last_proof: <int>
|
||||
:return: <int>
|
||||
"""
|
||||
|
||||
proof = 0
|
||||
while self.valid_proof(last_proof, proof) is False:
|
||||
proof += 1
|
||||
|
||||
return proof
|
||||
|
||||
@staticmethod
|
||||
def valid_proof(last_proof, proof):
|
||||
"""
|
||||
Validates the Proof: Does hash(last_proof, proof) contain 4 leading zeroes?
|
||||
:param last_proof: <int> Previous Proof
|
||||
:param proof: <int> Current Proof
|
||||
:return: <bool> True if correct, False if not.
|
||||
"""
|
||||
|
||||
guess = f'{last_proof}{proof}'.encode()
|
||||
guess_hash = hashlib.sha256(guess).hexdigest()
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
To adjust the difficulty of the algorithm, we could modify the number of leading zeroes. But 4 is sufficient. You’ll find out that the addition of a single leading zero makes a mammoth difference to the time required to find a solution.
|
||||
|
||||
Our class is almost complete and we’re ready to begin interacting with it using HTTP requests.
|
||||
|
||||
* * *
|
||||
|
||||
### Step 2: Our Blockchain as an API
|
||||
|
||||
We’re going to use the Python Flask Framework. It’s a micro-framework and it makes it easy to map endpoints to Python functions. This allows us talk to our blockchain over the web using HTTP requests.
|
||||
|
||||
We’ll create three methods:
|
||||
|
||||
* `/transactions/new` to create a new transaction to a block
|
||||
|
||||
* `/mine` to tell our server to mine a new block.
|
||||
|
||||
* `/chain` to return the full Blockchain.
|
||||
|
||||
#### Setting up Flask
|
||||
|
||||
Our “server” will form a single node in our blockchain network. Let’s create some boilerplate code:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
from textwrap import dedent
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
from flask import Flask
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
...
|
||||
|
||||
|
||||
# Instantiate our Node
|
||||
app = Flask(__name__)
|
||||
|
||||
# Generate a globally unique address for this node
|
||||
node_identifier = str(uuid4()).replace('-', '')
|
||||
|
||||
# Instantiate the Blockchain
|
||||
blockchain = Blockchain()
|
||||
|
||||
|
||||
@app.route('/mine', methods=['GET'])
|
||||
def mine():
|
||||
return "We'll mine a new Block"
|
||||
|
||||
@app.route('/transactions/new', methods=['POST'])
|
||||
def new_transaction():
|
||||
return "We'll add a new transaction"
|
||||
|
||||
@app.route('/chain', methods=['GET'])
|
||||
def full_chain():
|
||||
response = {
|
||||
'chain': blockchain.chain,
|
||||
'length': len(blockchain.chain),
|
||||
}
|
||||
return jsonify(response), 200
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
A brief explanation of what we’ve added above:
|
||||
|
||||
* Line 15: Instantiates our Node. Read more about Flask [here][7].
|
||||
|
||||
* Line 18: Create a random name for our node.
|
||||
|
||||
* Line 21: Instantiate our Blockchain class.
|
||||
|
||||
* Line 24–26: Create the /mine endpoint, which is a GET request.
|
||||
|
||||
* Line 28–30: Create the /transactions/new endpoint, which is a POST request, since we’ll be sending data to it.
|
||||
|
||||
* Line 32–38: Create the /chain endpoint, which returns the full Blockchain.
|
||||
|
||||
* Line 40–41: Runs the server on port 5000.
|
||||
|
||||
#### The Transactions Endpoint
|
||||
|
||||
This is what the request for a transaction will look like. It’s what the user sends to the server:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
```
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
from textwrap import dedent
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
from flask import Flask, jsonify, request
|
||||
|
||||
...
|
||||
|
||||
@app.route('/transactions/new', methods=['POST'])
|
||||
def new_transaction():
|
||||
values = request.get_json()
|
||||
|
||||
# Check that the required fields are in the POST'ed data
|
||||
required = ['sender', 'recipient', 'amount']
|
||||
if not all(k in values for k in required):
|
||||
return 'Missing values', 400
|
||||
|
||||
# Create a new Transaction
|
||||
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
|
||||
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
```
|
||||
A method for creating Transactions
|
||||
|
||||
#### The Mining Endpoint
|
||||
|
||||
Our mining endpoint is where the magic happens, and it’s easy. It has to do three things:
|
||||
|
||||
1. Calculate the Proof of Work
|
||||
|
||||
2. Reward the miner (us) by adding a transaction granting us 1 coin
|
||||
|
||||
3. Forge the new Block by adding it to the chain
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
|
||||
from time import time
|
||||
from uuid import uuid4
|
||||
|
||||
from flask import Flask, jsonify, request
|
||||
|
||||
...
|
||||
|
||||
@app.route('/mine', methods=['GET'])
|
||||
def mine():
|
||||
# We run the proof of work algorithm to get the next proof...
|
||||
last_block = blockchain.last_block
|
||||
last_proof = last_block['proof']
|
||||
proof = blockchain.proof_of_work(last_proof)
|
||||
|
||||
# We must receive a reward for finding the proof.
|
||||
# The sender is "0" to signify that this node has mined a new coin.
|
||||
blockchain.new_transaction(
|
||||
sender="0",
|
||||
recipient=node_identifier,
|
||||
amount=1,
|
||||
)
|
||||
|
||||
# Forge the new Block by adding it to the chain
|
||||
previous_hash = blockchain.hash(last_block)
|
||||
block = blockchain.new_block(proof, previous_hash)
|
||||
|
||||
response = {
|
||||
'message': "New Block Forged",
|
||||
'index': block['index'],
|
||||
'transactions': block['transactions'],
|
||||
'proof': block['proof'],
|
||||
'previous_hash': block['previous_hash'],
|
||||
}
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
Note that the recipient of the mined block is the address of our node. And most of what we’ve done here is just interact with the methods on our Blockchain class. At this point, we’re done, and can start interacting with our blockchain.
|
||||
|
||||
### Step 3: Interacting with our Blockchain
|
||||
|
||||
You can use plain old cURL or Postman to interact with our API over a network.
|
||||
|
||||
Fire up the server:
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
```
|
||||
|
||||
Let’s try mining a block by making a GET request to http://localhost:5000/mine:
|
||||
|
||||
|
||||
Using Postman to make a GET request
|
||||
|
||||
Let’s create a new transaction by making a POST request tohttp://localhost:5000/transactions/new with a body containing our transaction structure:
|
||||
|
||||
|
||||
Using Postman to make a POST request
|
||||
|
||||
If you aren’t using Postman, then you can make the equivalent request using cURL:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
I restarted my server, and mined two blocks, to give 3 in total. Let’s inspect the full chain by requesting http://localhost:5000/chain:
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
{
|
||||
"index": 1,
|
||||
"previous_hash": 1,
|
||||
"proof": 100,
|
||||
"timestamp": 1506280650.770839,
|
||||
"transactions": []
|
||||
},
|
||||
{
|
||||
"index": 2,
|
||||
"previous_hash": "c099bc...bfb7",
|
||||
"proof": 35293,
|
||||
"timestamp": 1506280664.717925,
|
||||
"transactions": [
|
||||
{
|
||||
"amount": 1,
|
||||
"recipient": "8bbcb347e0634905b0cac7955bae152b",
|
||||
"sender": "0"
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"index": 3,
|
||||
"previous_hash": "eff91a...10f2",
|
||||
"proof": 35089,
|
||||
"timestamp": 1506280666.1086972,
|
||||
"transactions": [
|
||||
{
|
||||
"amount": 1,
|
||||
"recipient": "8bbcb347e0634905b0cac7955bae152b",
|
||||
"sender": "0"
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"length": 3
|
||||
```
|
||||
### Step 4: Consensus
|
||||
|
||||
This is very cool. We’ve got a basic Blockchain that accepts transactions and allows us to mine new Blocks. But the whole point of Blockchains is that they should be decentralized. And if they’re decentralized, how on earth do we ensure that they all reflect the same chain? This is called the problem of Consensus, and we’ll have to implement a Consensus Algorithm if we want more than one node in our network.
|
||||
|
||||
#### Registering new Nodes
|
||||
|
||||
Before we can implement a Consensus Algorithm, we need a way to let a node know about neighbouring nodes on the network. Each node on our network should keep a registry of other nodes on the network. Thus, we’ll need some more endpoints:
|
||||
|
||||
1. /nodes/register to accept a list of new nodes in the form of URLs.
|
||||
|
||||
2. /nodes/resolve to implement our Consensus Algorithm, which resolves any conflicts—to ensure a node has the correct chain.
|
||||
|
||||
We’ll need to modify our Blockchain’s constructor and provide a method for registering nodes:
|
||||
|
||||
```
|
||||
...
|
||||
from urllib.parse import urlparse
|
||||
...
|
||||
|
||||
|
||||
class Blockchain(object):
|
||||
def __init__(self):
|
||||
...
|
||||
self.nodes = set()
|
||||
...
|
||||
|
||||
def register_node(self, address):
|
||||
"""
|
||||
Add a new node to the list of nodes
|
||||
:param address: <str> Address of node. Eg. 'http://192.168.0.5:5000'
|
||||
:return: None
|
||||
"""
|
||||
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
A method for adding neighbouring nodes to our Network
|
||||
|
||||
Note that we’ve used a set() to hold the list of nodes. This is a cheap way of ensuring that the addition of new nodes is idempotent—meaning that no matter how many times we add a specific node, it appears exactly once.
|
||||
|
||||
#### Implementing the Consensus Algorithm
|
||||
|
||||
As mentioned, a conflict is when one node has a different chain to another node. To resolve this, we’ll make the rule that the longest valid chain is authoritative. In other words, the longest chain on the network is the de-facto one. Using this algorithm, we reach Consensus amongst the nodes in our network.
|
||||
|
||||
```
|
||||
...
|
||||
import requests
|
||||
|
||||
|
||||
class Blockchain(object)
|
||||
...
|
||||
|
||||
def valid_chain(self, chain):
|
||||
"""
|
||||
Determine if a given blockchain is valid
|
||||
:param chain: <list> A blockchain
|
||||
:return: <bool> True if valid, False if not
|
||||
"""
|
||||
|
||||
last_block = chain[0]
|
||||
current_index = 1
|
||||
|
||||
while current_index < len(chain):
|
||||
block = chain[current_index]
|
||||
print(f'{last_block}')
|
||||
print(f'{block}')
|
||||
print("\n-----------\n")
|
||||
# Check that the hash of the block is correct
|
||||
if block['previous_hash'] != self.hash(last_block):
|
||||
return False
|
||||
|
||||
# Check that the Proof of Work is correct
|
||||
if not self.valid_proof(last_block['proof'], block['proof']):
|
||||
return False
|
||||
|
||||
last_block = block
|
||||
current_index += 1
|
||||
|
||||
return True
|
||||
|
||||
def resolve_conflicts(self):
|
||||
"""
|
||||
This is our Consensus Algorithm, it resolves conflicts
|
||||
by replacing our chain with the longest one in the network.
|
||||
:return: <bool> True if our chain was replaced, False if not
|
||||
"""
|
||||
|
||||
neighbours = self.nodes
|
||||
new_chain = None
|
||||
|
||||
# We're only looking for chains longer than ours
|
||||
max_length = len(self.chain)
|
||||
|
||||
# Grab and verify the chains from all the nodes in our network
|
||||
for node in neighbours:
|
||||
response = requests.get(f'http://{node}/chain')
|
||||
|
||||
if response.status_code == 200:
|
||||
length = response.json()['length']
|
||||
chain = response.json()['chain']
|
||||
|
||||
# Check if the length is longer and the chain is valid
|
||||
if length > max_length and self.valid_chain(chain):
|
||||
max_length = length
|
||||
new_chain = chain
|
||||
|
||||
# Replace our chain if we discovered a new, valid chain longer than ours
|
||||
if new_chain:
|
||||
self.chain = new_chain
|
||||
return True
|
||||
|
||||
return False
|
||||
```
|
||||
|
||||
The first method valid_chain() is responsible for checking if a chain is valid by looping through each block and verifying both the hash and the proof.
|
||||
|
||||
resolve_conflicts() is a method which loops through all our neighbouring nodes, downloads their chains and verifies them using the above method. If a valid chain is found, whose length is greater than ours, we replace ours.
|
||||
|
||||
Let’s register the two endpoints to our API, one for adding neighbouring nodes and the another for resolving conflicts:
|
||||
|
||||
```
|
||||
@app.route('/nodes/register', methods=['POST'])
|
||||
def register_nodes():
|
||||
values = request.get_json()
|
||||
|
||||
nodes = values.get('nodes')
|
||||
if nodes is None:
|
||||
return "Error: Please supply a valid list of nodes", 400
|
||||
|
||||
for node in nodes:
|
||||
blockchain.register_node(node)
|
||||
|
||||
response = {
|
||||
'message': 'New nodes have been added',
|
||||
'total_nodes': list(blockchain.nodes),
|
||||
}
|
||||
return jsonify(response), 201
|
||||
|
||||
|
||||
@app.route('/nodes/resolve', methods=['GET'])
|
||||
def consensus():
|
||||
replaced = blockchain.resolve_conflicts()
|
||||
|
||||
if replaced:
|
||||
response = {
|
||||
'message': 'Our chain was replaced',
|
||||
'new_chain': blockchain.chain
|
||||
}
|
||||
else:
|
||||
response = {
|
||||
'message': 'Our chain is authoritative',
|
||||
'chain': blockchain.chain
|
||||
}
|
||||
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
At this point you can grab a different machine if you like, and spin up different nodes on your network. Or spin up processes using different ports on the same machine. I spun up another node on my machine, on a different port, and registered it with my current node. Thus, I have two nodes: [http://localhost:5000][9] and http://localhost:5001.
|
||||
|
||||
|
||||
Registering a new Node
|
||||
|
||||
I then mined some new Blocks on node 2, to ensure the chain was longer. Afterward, I called GET /nodes/resolve on node 1, where the chain was replaced by the Consensus Algorithm:
|
||||
|
||||
|
||||
Consensus Algorithm at Work
|
||||
|
||||
And that’s a wrap... Go get some friends together to help test out your Blockchain.
|
||||
|
||||
* * *
|
||||
|
||||
I hope that this has inspired you to create something new. I’m ecstatic about Cryptocurrencies because I believe that Blockchains will rapidly change the way we think about economies, governments and record-keeping.
|
||||
|
||||
**Update:** I’m planning on following up with a Part 2, where we’ll extend our Blockchain to have a Transaction Validation Mechanism as well as discuss some ways in which you can productionize your Blockchain.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@vanflymen?source=post_header_lockup
|
||||
[1]:https://learncryptography.com/hash-functions/what-are-hash-functions
|
||||
[2]:https://www.python.org/downloads/
|
||||
[3]:https://www.getpostman.com
|
||||
[4]:https://github.com/dvf/blockchain
|
||||
[5]:https://www.jetbrains.com/pycharm/
|
||||
[6]:https://github.com/dvf/blockchain
|
||||
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
|
||||
[8]:http://localhost:5000/transactions/new
|
||||
[9]:http://localhost:5000
|
||||
@ -1,200 +0,0 @@
|
||||
How to Use GNOME Shell Extensions [Complete Guide]
|
||||
======
|
||||
**Brief: This is a detailed guide showing you how to install GNOME Shell Extensions manually or easily via a browser. **
|
||||
|
||||
While discussing [how to install themes in Ubuntu 17.10][1], I briefly mentioned GNOME Shell Extension. It was used to enable user themes. Today, we'll have a detailed look at GNOME Shell Extensions in Ubuntu 17.10.
|
||||
|
||||
I may use the term GNOME Extensions instead of GNOME Shell Extensions but both have the same meaning here.
|
||||
|
||||
What are GNOME Shell Extensions? How to install GNOME Shell Extensions? And how to manage and remove GNOME Shell Extensions? I'll explain all these questions, one by one.
|
||||
|
||||
Before that, if you prefer video, I have demonstrated all these on [It's FOSS YouTube channel][2]. I highly recommend that you subscribe to it for more Linux videos.
|
||||
|
||||
## What is a GNOME Shell Extension?
|
||||
|
||||
A [GNOME Shell Extension][3] is basically a tiny piece of code that enhances the capability of GNOME desktop.
|
||||
|
||||
Think of it as an add-on in your browser. For example, you can install an add-on in your browser to disable ads. This add-on is developed by a third-party developer. Though your web browser doesn't provide it by default, installing this add-on enhances the capability of your web browser.
|
||||
|
||||
Similarly, GNOME Shell Extensions are like those third-party add-ons and plugins that you can install on top of GNOME. These extensions are created to perform specific tasks such as display weather condition, internet speed etc. Mostly, you can access them in the top panel.
|
||||
|
||||
![GNOME Shell Extension in action][5]
|
||||
|
||||
There are also GNOME Extensions that are not visible on the top panel. But they still tweak GNOME's behavior. For example, middle mouse button can be used to close an application with one such extension.
|
||||
|
||||
## Installing GNOME Shell Extensions
|
||||
|
||||
Now that you know what are GNOME Shell Extensions, let's see how to install them. There are three ways you can use GNOME Extensions:
|
||||
|
||||
* Use a minimal set of extensions from Ubuntu (or your Linux distribution)
|
||||
* Find and install extensions in your web browser
|
||||
* Download and manually install extensions
|
||||
|
||||
|
||||
|
||||
Before you learn how to use GNOME Shell Extensions, you should install GNOME Tweak Tool. You can find it in the Software Center. Alternatively, you can use this command:
|
||||
```
|
||||
sudo apt install gnome-tweak-tool
|
||||
```
|
||||
|
||||
At times, you would also need to know the version of GNOME Shell you are using. This helps in determining whether an extension is compatible with your system or not. You can use the command below to find it:
|
||||
```
|
||||
gnome-shell --version
|
||||
```
|
||||
|
||||
### 1\. Use gnome-shell-extensions package [easiest and safest way]
|
||||
|
||||
Ubuntu (and several other Linux distributions such as Fedora) provide a package with a minimal set of GNOME extensions. You don't have to worry about the compatibility here as it is tested by your Linux distribution.
|
||||
|
||||
If you want a no-brainer, just get this package and you'll have 8-10 GNOME extensions installed.
|
||||
```
|
||||
sudo apt install gnome-shell-extensions
|
||||
```
|
||||
|
||||
You'll have to reboot your system (or maybe just restart GNOME Shell, I don't remember it at this point). After that, start GNOME Tweaks and you'll find a few extensions installed. You can just toggle the button to start using an installed extension.
|
||||
|
||||
![Change GNOME Shell theme in Ubuntu 17.1][6]
|
||||
|
||||
### 2. Install GNOME Shell extensions from a web browser
|
||||
|
||||
GNOME project has an entire website dedicated to extensions. That's not it. You can find, install, and manage your extensions on this website itself. No need even for GNOME Tweaks tool.
|
||||
|
||||
[GNOME Shell Extensions Website][3]
|
||||
|
||||
But in order to install extensions a web browser, you need two things: a browser add-on and a native host connector in your system.
|
||||
|
||||
#### Step 1: Install browser add-on
|
||||
|
||||
When you visit the GNOME Shell Extensions website, you'll see a message like this:
|
||||
|
||||
> "To control GNOME Shell extensions using this site you must install GNOME Shell integration that consists of two parts: browser extension and native host messaging application."
|
||||
|
||||
![Installing GNOME Shell Extensions][7]
|
||||
|
||||
You can simply click on the suggested add-on link by your web browser. You can install them from the link below as well:
|
||||
|
||||
#### Step 2: Install native connector
|
||||
|
||||
Just installing browser add-on won't help you. You'll still see an error like:
|
||||
|
||||
> "Although GNOME Shell integration extension is running, native host connector is not detected. Refer documentation for instructions about installing connector"
|
||||
|
||||
![How to install GNOME Shell Extensions][8]
|
||||
|
||||
This is because you haven't installed the host connector yet. To do that, use this command:
|
||||
```
|
||||
sudo apt install chrome-gnome-shell
|
||||
```
|
||||
|
||||
Don't worry about the 'chrome' prefix in the package name. It has nothing to do with Chrome. You don't have to install a separate package for Firefox or Opera here.
|
||||
|
||||
#### Step 3: Installing GNOME Shell Extensions in web browser
|
||||
|
||||
Once you have completed these two requirements, you are all set to roll. Now when you go to GNOME Shell Extension, you won't see any error message.
|
||||
|
||||
![GNOME Shell Extension][9]
|
||||
|
||||
A good thing to do would be to sort the extensions by your GNOME Shell version. It is not mandatory though. What happens here is that a developer creates an extension for the present GNOME version. In one year, there will be two more GNOME releases. But the developer didn't have time to test or update his/her extension.
|
||||
|
||||
As a result, you wouldn't know if that extension is compatible with your system or not. It's possible that the extension works fine even in the newer GNOME Shell version despite that the extension is years old. It is also possible that the extension doesn't work in the newer GNOME Shell.
|
||||
|
||||
You can search for an extension as well. Let's say you want to install a weather extension. Just search for it and go for one of the search results.
|
||||
|
||||
When you visit the extension page, you'll see a toggle button.
|
||||
|
||||
![Installing GNOME Shell Extension ][10]
|
||||
|
||||
Click on it and you'll be prompted if you want to install this extension:
|
||||
|
||||
![Install GNOME Shell Extensions via web browser][11]
|
||||
|
||||
Obviously, go for Install here. Once it's installed, you'll see that the toggle button is now on and there is a setting option available next to it. You can configure the extension using the setting option. You can also disable the extension from here.
|
||||
|
||||
![Configuring installed GNOME Shell Extensions][12]
|
||||
|
||||
You can also configure the settings of an extension that you installed via the web browser in GNOME Tweaks tool:
|
||||
|
||||
![GNOME Tweaks to handle GNOME Shell Extensions][13]
|
||||
|
||||
You can see all your installed extensions on the website under [installed extensions section][14]. You can also delete the extensions that you installed via web browser here
|
||||
|
||||
![Manage your installed GNOME Shell Extensions][15]
|
||||
|
||||
One major advantage of using the GNOME Extensions website is that you can see if there is an update available for an extension. You won't get it in GNOME Tweaks or system update.
|
||||
|
||||
### 3. Install GNOME Shell Extensions manually
|
||||
|
||||
It's not that you have to be always online to install GNOME Shell extensions. You can download the files and install it later, without needing internet.
|
||||
|
||||
Go to GNOME Extensions website and download the extension with the latest version.
|
||||
|
||||
![Download GNOME Shell Extension][16]
|
||||
|
||||
Extract the downloaded file. Copy the folder to **~/.local/share/gnome-shell/extensions** directory. Go to your Home directory and press Crl+H to show hidden folders. Locate .local folder here and from there, you can find your path till extensions directory.
|
||||
|
||||
Once you have the files copied in the correct directory, go inside it and open metadata.json file. Look for the value of uuid.
|
||||
|
||||
Make sure that the name of the extension's folder is same as the value of uuid in the metadata.json file. If not, rename the directory to the value of this uuid.
|
||||
|
||||
![Manually install GNOME Shell extension][17]
|
||||
|
||||
Almost there! Now restart GNOME Shell. Press Alt+F2 and enter r to restart GNOME Shell.
|
||||
|
||||
![Restart GNOME Shell][18]
|
||||
|
||||
Restart GNOME Tweaks tool as well. You should see the manually installed GNOME extension in the Tweak tool now. You can configure or enable the newly installed extension here.
|
||||
|
||||
And that's all you need to know about installing GNOME Shell Extensions.
|
||||
|
||||
## Remove GNOME Shell Extensions
|
||||
|
||||
It is totally understandable that you might want to remove an installed GNOME Shell Extension.
|
||||
|
||||
If you installed it via a web browser, you can go to the [installed extensions section on GNOME website][14] and remove it from there (as shown in an earlier picture).
|
||||
|
||||
If you installed it manually, you can remove it by deleting the extension files from ~/.local/share/gnome-shell/extensions directory.
|
||||
|
||||
## Bonus Tip: Get notified of GNOME Shell Extensions updates
|
||||
|
||||
By now you have realized that there is no way to know if an update is available for a GNOME Shell extension except for visiting the GNOME extension website.
|
||||
|
||||
Luckily for you, there is a GNOME Shell Extension that notifies you if there is an update available for an installed extension. You can get it from the link below:
|
||||
|
||||
[Extension Update Notifier][19]
|
||||
|
||||
### How do you manage GNOME Shell Extensions?
|
||||
|
||||
I find it rather weird that you cannot update the extensions via the system updates. It's as if GNOME Shell extensions are not even part of the system.
|
||||
|
||||
If you are looking for some recommendation, read this article about [best GNOME extensions][20]. At the same time, share your experience with GNOME Shell extensions. Do you often use them? If yes, which ones are your favorite?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gnome-shell-extensions/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[2]:https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[3]:https://extensions.gnome.org/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-weather.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/enableuser-themes-extension-gnome.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-1.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-2.jpeg
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-3.jpeg
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-4.jpeg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-5.jpeg
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-6.jpeg
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-7-800x572.jpeg
|
||||
[14]:https://extensions.gnome.org/local/
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-8.jpeg
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-9-800x456.jpeg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-10-800x450.jpg
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/restart-gnome-shell-800x299.jpeg
|
||||
[19]:https://extensions.gnome.org/extension/1166/extension-update-notifier/
|
||||
[20]:https://itsfoss.com/best-gnome-extensions/
|
||||
@ -1,97 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora)
|
||||
======
|
||||
Learn how to create login banners in Linux to display different warning or information messages to user who is about to log in or after he logs in.
|
||||
|
||||
![Login banners in Linux][1]
|
||||
|
||||
Whenever you login to some production systems of firm, you get to see some login messages, warnings or info about server you are about to login or already logged in like below. Those are the login banners.
|
||||
|
||||
![Login welcome messages in Linux][2]
|
||||
|
||||
In this article we will walk you through how to configure them.
|
||||
|
||||
There are two types of banners you can configure.
|
||||
|
||||
1. Banner message to display before user log in (configure in file of your choice eg. `/etc/login.warn`)
|
||||
2. Banner message to display after user successfully logged in (configure in `/etc/motd`)
|
||||
|
||||
|
||||
|
||||
### How to display message when user connects to system before login
|
||||
|
||||
This message will be displayed to user when he connects to server and before he logged in. Means when he enter the username, this message will be displayed before password prompt.
|
||||
|
||||
You can use any filename and enter your message within. Here we used `/etc/login.warn` file and put our messages inside.
|
||||
|
||||
```
|
||||
# cat /etc/login.warn
|
||||
!!!! Welcome to KernelTalks test server !!!!
|
||||
This server is meant for testing Linux commands and tools. If you are
|
||||
not associated with kerneltalks.com and not authorized please dis-connect
|
||||
immediately.
|
||||
```
|
||||
|
||||
Now, you need to supply this file and path to `sshd` daemon so that it can fetch this banner for each user login request. For that open `/etc/sshd/sshd_config` file and search for line `#Banner none`
|
||||
|
||||
Here you have to edit file and write your filename and remove hash mark. It should look like : `Banner /etc/login.warn`
|
||||
|
||||
Save file and restart `sshd` daemon. To avoid disconnecting existing connected users, use HUP signal to restart sshd.
|
||||
|
||||
```
|
||||
oot@kerneltalks # ps -ef |grep -i sshd
|
||||
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
|
||||
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
|
||||
|
||||
root@kerneltalks # kill -HUP 14255
|
||||
```
|
||||
|
||||
Thats it! Open new session and try login. You will be greeted with the message you configured in above steps .
|
||||
|
||||
![Login banner in Linux][3]
|
||||
|
||||
You can see message is displayed before user enter his password and log in to system.
|
||||
|
||||
### How to display message after user logs in
|
||||
|
||||
Message user sees after he logs into system successfully is **M** essage **O** f **T** he **D** ay & is controlled by `/etc/motd` file. Edit this file and enter message you want to greet user with once he successfully logged in.
|
||||
|
||||
```
|
||||
root@kerneltalks # cat /etc/motd
|
||||
W E L C O M E
|
||||
Welcome to the testing environment of kerneltalks.
|
||||
Feel free to use this system for testing your Linux
|
||||
skills. In case of any issues reach out to admin at
|
||||
info@kerneltalks.com. Thank you.
|
||||
|
||||
```
|
||||
|
||||
You dont need to restart `sshd` daemon to take this change effect. As soon as you save the file, its content will be read and displayed by sshd daemon from very next login request it serves.
|
||||
|
||||
![motd in linux][4]
|
||||
|
||||
You can see in above screenshot : Yellow box is MOTD controlled by `/etc/motd` and green box is what we saw earlier login banner.
|
||||
|
||||
You can use tools like [cowsay][5], [banner][6], [figlet][7], [lolcat ][8]to create fancy, eye-catching messages to display at login. This method works on almost all Linux distros like RedHat, CentOs, Ubuntu, Fedora etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://c3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
|
||||
[2]:https://c3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
|
||||
[3]:https://c1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
|
||||
[4]:https://c3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
|
||||
[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
|
||||
[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
|
||||
[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
|
||||
[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
|
||||
@ -1,129 +0,0 @@
|
||||
My Adventure Migrating Back To Windows
|
||||
======
|
||||
I have had linux as my primary OS for about a decade now, and primarily use Ubuntu. But with the latest release I have decided to migrate back to an OS I generally dislike, Windows 10.
|
||||
|
||||
![Ubuntu On Windows][1]
|
||||
I have always been a fan of Linux, with my two favorite distributions being debian and ubuntu. Now as a server OS, linus is perfect and unquestionable, but there has always been problems of varing degree on the desktop.
|
||||
|
||||
The most recent set of problems I had made me realise that I dont need to use linux as my desktop os to still be a fan so based on my experience fresh installing Ubutnu 17.10 I have decided to move back to windows.
|
||||
|
||||
### What Caused Me to Switch Back?
|
||||
|
||||
The problem was, when 17.10 came out I did a fresh install like usual but faced some really strange an new issues.
|
||||
|
||||
* Dell D3100 Dock no longer worked (Including the Work Arounds)
|
||||
* Ubuntu kept Freezing (Randomly)
|
||||
* Double Clicking Icons on the desktop did nothing
|
||||
* Using the HUD to search for programs such as "tweaks" would try installing MATE versions.
|
||||
* The GUI felt worse than standard GNOME
|
||||
|
||||
|
||||
|
||||
Now I did considor going back to using 16.04 or to another distro. But I feel Unity 7 was the most polished desktop environment, and the only other which is as polished and stable is windows 10.
|
||||
|
||||
In addition to the above, there were also the inherent set backs from using Linux over Windows. Such as;
|
||||
|
||||
* Most Propriatry Commerical Software is unavailable, E.G Maya, PhotoShop, Microsoft Office (In most cases the alternatives are not on par)
|
||||
* Most Games are not ported to Linux, including games from major studios like EA, Rockstar Ect.
|
||||
* Drivers for most hardware is a second thought for the manufacturers when it comes to linux.
|
||||
|
||||
|
||||
|
||||
Before deciding upon windows I did look at other distributions and operatong systems.
|
||||
|
||||
While doing so I looked more at the "Microsoft Loves Linux" compaign and came across WSL. Their new developer focused angle was interesting to me, so I gave it a try.
|
||||
|
||||
### What I am Looking For in Windows
|
||||
|
||||
I use computers mainly for programming, and I use virtual machines, git , ssh and rely heavily on bash for most of what I do. I also occasionally game, watch netflix and some light office work.
|
||||
|
||||
In short I am looking to keep my current workflow in Ubuntu and transplant it onto Windows. I also want to take advantage of Windows strong points.
|
||||
|
||||
* All PC Games Written For Windows
|
||||
* Native Support for Most Programs
|
||||
* Microsoft Office
|
||||
|
||||
|
||||
|
||||
Now there are caveats with using windows, but I intend to maintain it correctly so I am not worried about the usual windows nasties such as viruses and malware.
|
||||
|
||||
### Windows Subsystem For Linux (Bash on Ubuntu on Windows)
|
||||
|
||||
Microsoft has worked closely with Canonical to bring Ubuntu to Windows. After quickly setting up and launching the program, you have a very familiar bash interface.
|
||||
|
||||
Now I have been looking into the limitations of this, but the only real limitation I hit at the time of writing this article is that it is abstracted away from the hardware. For instance lsblk won't show what partitions you have, because Ubuntu is not being given that information.
|
||||
|
||||
But besides accessing low level tools, I found the experience to be quite familiar and nice.
|
||||
|
||||
I utilised this within my workflow for the following.
|
||||
|
||||
* Generating SSH Keypair
|
||||
* Using Git with Github to manage my repositories
|
||||
* SSH into several servers, including passwordless
|
||||
* Running MySQL for Local Databases
|
||||
* Monitoring System Resources
|
||||
* Using VIM for Config Files
|
||||
* Running Bash Scripts
|
||||
* Running Local Web Server
|
||||
* Running PHP, NodeJS
|
||||
|
||||
|
||||
|
||||
It has proven so far to be quite the formidable tool, and besides being in the Window 10 UI, my workflow feels almost identical to when I was on Ubuntu itself. Although most of my workload can be handled in WSL, i still intend on having virtual machines on had for mote indepth work which may be beyond the scope of wsl.
|
||||
|
||||
### No WINE for me
|
||||
|
||||
Another major upside I am experiencing is compatibility.Now I rarely used WINE to enable me to use windows software. But on occasion it was needed, and usually was not very good.
|
||||
|
||||
#### HeidiSQL
|
||||
|
||||
One of the first Programs I installed was HeidiSQL, one of my favourite DB Clients. It does work under wine, but it felt horrid so I ditched it for MySQL Workbench. Having it back in pride of place in windows is like having a trusty old friend back.
|
||||
|
||||
#### Gaming / Steam
|
||||
|
||||
What is a Windows PC without a little gaming. I installed steam from its website and was greated with all my linux catalogue, plus my windows catalogue which was 5 times bigger and including AAA titles like GTA V. Something I could only dream about in Ubuntu.
|
||||
|
||||
Now I had so much hope for SteamOS and still do, but I don't think it will ever make a dent in the gaming market anywhere in the near future. So if you want to game on a pc, you really do need windows.
|
||||
|
||||
Something else noted, the driver support was better for ny nvidia graphics card which made some linux native games like TF2 run slightly better.
|
||||
|
||||
**Windows will always be superior in gaming, so this was not much of a surprise**
|
||||
|
||||
### Running From a USB HDD and WHY
|
||||
|
||||
I run linux on my main sss drives, but have in the past run from usb keys and usb hard drives. I got used to this durability of linux which allowed me to try out multiple versiobs long term without loosing my main os. Now the last time i tried installing windows to a usb connected hdd it just did not work and was impossoble, so when I did a clone of my Windows HDD as a backup, I was surprised when I could boot from it over USB.
|
||||
|
||||
This has become a handy option for me as I plan to migrate my work laptop back to windows, but did not want to be risky and just throw it on there.
|
||||
|
||||
So for the past few days I have ran it from the USB, and apart from a few buggy messages, I have had no real downside from running it over USB.
|
||||
|
||||
The notable issues doing this is:
|
||||
|
||||
* Slower Boot Speed
|
||||
* Annoying Don't Unplug Your USB message
|
||||
* Not been able to get it to Activate
|
||||
|
||||
|
||||
|
||||
**I might do an article just on Windows on a USB Drive so we can go into more detail.**
|
||||
|
||||
### So what is the verdict?
|
||||
|
||||
I have been using windows 10 for about two weeks now, and have not noticed any negative effect to my work flow. All the tools I need are on hand and the OS is generally behaving, although there have been some minor hiccups along the way.
|
||||
|
||||
## Will I stay with windows
|
||||
|
||||
Although it's early days, I think I will be sticking with windows the the forseable future.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:https://winaero.com/blog/wp-content/uploads/2016/07/Ubutntu-on-Windows-10-logo-banner.jpg
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by rockouc
|
||||
|
||||
Why pair writing helps improve documentation
|
||||
======
|
||||

|
||||
|
||||
@ -1,43 +0,0 @@
|
||||
How to create better documentation with a kanban board
|
||||
======
|
||||

|
||||
If you're working on documentation, a website, or other user-facing content, it's helpful to know what users expect to find--both the information they want and how the information is organized and structured. After all, great content isn't very useful if people can't find what they're looking for.
|
||||
|
||||
Card sorting is a simple and effective way to gather input from users about what they expect from menu interfaces and pages. The simplest implementation is to label a stack of index cards with the sections you plan to include in your website or documentation and ask users to sort the cards in the way they would look for the information. Variations include letting people write their own menu headers or content elements.
|
||||
|
||||
The goal is to learn what your users expect and where they expect to find it, rather than having to figure out your menu and layout on your own. This is relatively straightforward when you have users in the same physical location, but it's more challenging when you are trying to get feedback from people in many locations.
|
||||
|
||||
I've found [kanban][1] boards are a great tool for these situations. They allow people to easily drag virtual cards around to categorize and rank them, and they are multi-purpose, unlike dedicated card-sorting software.
|
||||
|
||||
I often use Trello for card sorting, but there are several [open source alternatives][2] that you might want to try.
|
||||
|
||||
### How it works
|
||||
|
||||
My most successful kanban experiment was when I was working on documentation for [Gluster][3], a free and open source scalable network-attached storage filesystem. I needed to take a large pile of documentation that had grown over time and break it into categories to create a navigation system. BEcause I didn't have the technical knowledge necessary to sort it, I turned to the Gluster team and developer community for guidance.
|
||||
|
||||
First, I created a shared Kanban board. I gave the columns general names that would enable sorting and created cards for all the topics I planned to cover in the documentation. I flagged some cards with different colors to indicate either a topic was missing and needed to be created, or it was present and needed to be removed. Then I put all the cards into an "unsorted" column and asked people to drag them where they thought the cards should be organized and send me a screen capture of what they thought was the ideal state.
|
||||
|
||||
Dealing with all the screen captures was the trickiest part. I wish there was a merge or consensus feature that would've helped me aggregate everyone's data, rather than having to examine a bunch of screen captures. Fortunately, after the first person sorted the cards, people more or less agreed on the structure and made only minor modifications. When opinions differed on a topic's placement, I set up flash meetings where people could explain their thinking and we could hash out the disagreements.
|
||||
|
||||
### Using the data
|
||||
|
||||
From here, it was easy to convert the information I captured into menus and refine it. If users thought items should become submenus, they usually told me in comments or when we talked on the phone. Perceptions of menu organization vary depending upon people's job tasks, so you never have complete agreement, but testing with users means you won't have as many blind spots about what people use and where they will look for it.
|
||||
|
||||
Pairing card sorting with analytics gives you even more insight on what people are looking for. Once, when I ran analytics on some training documentation I was working on, I was surprised that to learn that the most searched page was about title capitalization. So I surfaced that page at the top-menu level, even though my "logical" setting put it far down in a sub-menu.
|
||||
|
||||
I've found kanban card-sorting a great way to help me create content that users want to see and put it where they expect to find it. Have you found another great way to organize your content for users' benefit? Or another interesting use for kanban boards? If so, please share your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/kanban-boards-card-sorting
|
||||
|
||||
作者:[Heidi Waterhouse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hwaterhouse
|
||||
[1]:https://en.wikipedia.org/wiki/Kanban
|
||||
[2]:https://opensource.com/alternatives/trello
|
||||
[3]:https://www.gluster.org/
|
||||
@ -1,76 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Record and Share Terminal Session with Showterm
|
||||
======
|
||||
|
||||

|
||||
|
||||
You can easily record your terminal sessions with virtually all screen recording programs. However, you are very likely to end up with an oversized video file. There are several terminal recorders available in Linux, each with its own strengths and weakness. Showterm is a tool that makes it pretty easy to record terminal sessions, upload them, share, and embed them in any web page. On the plus side, you don't end up with any huge file to deal with.
|
||||
|
||||
Showterm is open source, and the project can be found on this [GitHub page][1].
|
||||
|
||||
**Related** : [2 Simple Applications That Record Your Terminal Session as Video [Linux]][2]
|
||||
|
||||
### Installing Showterm for Linux
|
||||
|
||||
Showterm requires that you have Ruby installed on your computer. Here's how to go about installing the program.
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
If you don't have Ruby installed on your Linux system:
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
If you just want to run the application without installation:
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
You can type `showterm --help` for the help screen. If a help page doesn't appear, showterm is probably not installed. Now that you have Showterm installed (or are running the standalone version), let us dive into using the tool to record.
|
||||
|
||||
**Related** : [How to Record Terminal Session in Ubuntu][3]
|
||||
|
||||
### Recording Terminal Session
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
Recording a terminal session is pretty simple. From the command line run `showterm`. This should start the terminal recording in the background. All commands entered in the command line from hereon are recorded by Showterm. Once you are done recording, press Ctrl + D or type `exit` in the command line to stop your recording.
|
||||
|
||||
Showterm should upload your video and output a link to the video that looks like http://showterm.io/<long alpha-numeric characters>. It is rather unfortunate that terminal sessions are uploaded right away without any prompting. Don't panic! You can delete any uploaded recording by entering `showterm --delete <recording URL>`. Before uploading your recordings, you'll have the chance to change the timing by adding the `-e` option to the showterm command. If by any chance a recording fails to upload, you can use `showterm --retry <script> <times>` to force a retry.
|
||||
|
||||
When viewing your recordings, the timing of the video can also be controlled by appending "#slow," "#fast," or "#stop" to the URL. Slow makes the video run at normal speed; fast doubles the speed; and stop, as the name suggests, stops the video.
|
||||
|
||||
Showterm terminal recordings can easily be embedded in web pages via iframes. This can be achieved by adding the iframe source to the showterm video URL as shown below.
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
As an open source tool, Showterm allows for further customization. For instance, to run your own Showterm server, you need to run the command:
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
|
||||
so your client can communicate with it. Additional features can be added with little programming knowledge. The Showterm server project is available from this [GitHub page][1].
|
||||
|
||||
### Conclusion
|
||||
|
||||
In case you are thinking of sharing some command line tutorials with a colleague, be sure to remember Showterm. Showterm is text-based; hence, it will yield a relatively small-sized video compared to other screen recorders. The tool itself is pretty small in size - only a few kilobytes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/brunoedoh/
|
||||
[1]:https://github.com/ConradIrwin/showterm
|
||||
[2]:https://www.maketecheasier.com/record-terminal-session-as-video/ (2 Simple Applications That Record Your Terminal Session as Video [Linux])
|
||||
[3]:https://www.maketecheasier.com/record-terminal-session-in-ubuntu/ (How to Record Terminal Session in Ubuntu)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-interface.png (showterm terminal)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-site.png (showtermio)
|
||||
@ -1,83 +0,0 @@
|
||||
translating by yizhuoyan
|
||||
|
||||
5 Tips to Improve Technical Writing for an International Audience
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Writing in English for an international audience takes work; here are some handy tips to remember.[Creative Commons Zero][2]
|
||||
|
||||
Writing in English for an international audience does not necessarily put native English speakers in a better position. On the contrary, they tend to forget that the document's language might not be the first language of the audience. Let's have a look at the following simple sentence as an example: “Encrypt the password using the 'foo bar' command.”
|
||||
|
||||
Grammatically, the sentence is correct. Given that "-ing" forms (gerunds) are frequently used in the English language, most native speakers would probably not hesitate to phrase a sentence like this. However, on closer inspection, the sentence is ambiguous: The word “using” may refer either to the object (“the password”) or to the verb (“encrypt”). Thus, the sentence can be interpreted in two different ways:
|
||||
|
||||
* Encrypt the password that uses the 'foo bar' command.
|
||||
|
||||
* Encrypt the password by using the 'foo bar' command.
|
||||
|
||||
As long as you have previous knowledge about the topic (password encryption or the 'foo bar' command), you can resolve this ambiguity and correctly decide that the second reading is the intended meaning of this sentence. But what if you lack in-depth knowledge of the topic? What if you are not an expert but a translator with only general knowledge of the subject? Or, what if you are a non-native speaker of English who is unfamiliar with advanced grammatical forms?
|
||||
|
||||
### Know Your Audience
|
||||
|
||||
Even native English speakers may need some training to write clear and straightforward technical documentation. Raising awareness of usability and potential problems is the first step. This article, based on my talk at[ Open Source Summit EU][5], offers several useful techniques. Most of them are useful not only for technical documentation but also for everyday written communication, such as writing email or reports.
|
||||
|
||||
**1. Change perspective. **Step into your audience's shoes. Step one is to know your intended audience. If you are a developer writing for end users, view the product from their perspective. The [persona technique][6] can help to focus on the target audience and to provide the right level of detail for your readers.
|
||||
|
||||
**2\. Follow the KISS principle. **Keep it short and simple. The principle can be applied to several levels, like grammar, sentences, or words. Here are some examples:
|
||||
|
||||
_Words: _ Uncommon and long words slow down reading and might be obstacles for non-native speakers. Use simpler alternatives:
|
||||
|
||||
“utilize” → “use”
|
||||
|
||||
“indicate” → “show”, “tell”, “say”
|
||||
|
||||
“prerequisite” → “requirement”
|
||||
|
||||
_Grammar: _ Use the simplest tense that is appropriate. For example, use present tense when mentioning the result of an action: "Click _OK_ . The _Printer Options_ dialog appears.”
|
||||
|
||||
_Sentences: _ As a rule of thumb, present one idea in one sentence. However, restricting sentence length to a certain amount of words is not useful in my opinion. Short sentences are not automatically easy to understand (especially if they are a cluster of nouns). Sometimes, trimming down sentences to a certain word count can introduce ambiquities, which can, in turn, make sentences even more difficult to understand.
|
||||
|
||||
**3\. Beware of ambiguities. **As authors, we often do not notice ambiguity in a sentence. Having your texts reviewed by others can help identify such problems. If that's not an option, try to look at each sentence from different perspectives: Does the sentence also work for readers without in-depth knowledge of the topic? Does it work for readers with limited language skills? Is the grammatical relationship between all sentence parts clear? If the sentence does not meet these requirements, rephrase it to resolve the ambiguity.
|
||||
|
||||
**4\. Be consistent. **This applies to choice of words, spelling, and punctuation as well as phrases and structure. For lists, use parallel grammatical construction. For example:
|
||||
|
||||
Why white space is important:
|
||||
|
||||
* It focuses attention.
|
||||
|
||||
* It visually separates sections.
|
||||
|
||||
* It splits content into chunks.
|
||||
|
||||
**5\. Remove redundant content.** Keep only information that is relevant for your target audience. On a sentence level, avoid fillers (basically, easily) and unnecessary modifications:
|
||||
|
||||
"already existing" → "existing"
|
||||
|
||||
"completely new" → "new"
|
||||
|
||||
As you might have guessed by now, writing is rewriting. Good writing requires effort and practice. But even if you write only occasionally, you can significantly improve your texts by focusing on the target audience and by using basic writing techniques. The better the readability of a text, the easier it is to process, even for an audience with varying language skills. When it comes to localization especially, good quality of the source text is important: Garbage in, garbage out. If the original text has deficiencies, it will take longer to translate the text, resulting in higher costs. In the worst case, the flaws will be multiplied during translation and need to be corrected in various languages.
|
||||
|
||||
|
||||

|
||||
|
||||
Tanja Roth, Technical Documentation Specialist at SUSE Linux GmbH[Used with permission][1]
|
||||
|
||||
_Driven by an interest in both language and technology, Tanja has been working as a technical writer in mechanical engineering, medical technology, and IT for many years. She joined SUSE in 2005 and contributes to a wide range of product and project documentation, including High Availability and Cloud topics._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/event/open-source-summit-eu/2017/12/technical-writing-international-audience?sf175396579=1
|
||||
|
||||
作者:[TANJA ROTH ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/tanja-roth
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/tanja-rothjpg
|
||||
[4]:https://www.linux.com/files/images/typewriter-8019211920jpg
|
||||
[5]:https://osseu17.sched.com/event/ByIW
|
||||
[6]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
@ -1,59 +0,0 @@
|
||||
What DevOps teams really need from a CIO
|
||||
======
|
||||
IT leaders can learn from plenty of material exploring [DevOps][1] and the challenging cultural shift required for [making the DevOps transition][2]. But are you in tune with the short and long term challenges that a DevOps team faces - and what they really need from a CIO?
|
||||
|
||||
In my conversations with DevOps team members, some of what I heard might surprise you. DevOps pros (whether part of an internal or external team) want to put the following things at the top of your CIO radar screen.
|
||||
|
||||
### 1. Communication
|
||||
|
||||
First and foremost, DevOps pros need peer-level communication. An experienced DevOps team is extremely knowledgeable on current DevOps trends, successes, and failures in the industry and is interested in sharing this information. DevOps concepts are difficult to convey, so be open to a new working relationship in which there are regular (don't worry, not weekly) conversations about the current state of your IT, how the pieces in the environment communicate, and your overall IT estate.
|
||||
|
||||
**[ Want even more wisdom from CIOs on leading DevOps? See our comprehensive resource,[DevOps: The IT Leader's Guide][3]. ]**
|
||||
|
||||
Conversely, be prepared to share current business needs and goals with the DevOps team. Business objectives no longer exist in isolation from IT: They are now an integral component of what drives your IT advancements, and your IT determines how effectively you can execute on your business needs and goals.
|
||||
|
||||
Focus on participating rather than leading. You are still the ultimate arbiter when it comes to decisions, but understand that these decisions are best made collaboratively in order to empower and motivate your DevOps team.
|
||||
|
||||
### 2. Reduction of technical debt
|
||||
|
||||
Second, strive to better understand technical debt and how DevOps efforts are going to reduce it. Your DevOps team is working hard on this front. In this case, technical debt refers to the manpower and infrastructure resources that are usurped daily by maintaining and adding new features on top of a monolithic, non-sustainable environment (read Rube Goldberg).
|
||||
|
||||
Common CIO questions include:
|
||||
|
||||
* Why do we need to do things in a new way?
|
||||
* Why are we spending time and money on this?
|
||||
* If there's no new functionality, just existing pieces being broken out with automation, then where is the gain?
|
||||
|
||||
|
||||
|
||||
The "if it ain't broke don't fix it" thinking is understandable. But if the car is driving fine while everyone on the road accelerates past you, your environment IS broken. Precious resources continue to be sucked into propping up or augmenting an environmental kluge.
|
||||
|
||||
Addressing every issue in isolation results in a compromised choice from the start that is worsened with each successive patch - layer upon layer added to a foundation that wasn't built to support it. In actuality, this approach is similar to plugging a continuously failing dike. Sooner or later you run out of fingers and the whole thing buckles under the added pressures, drowning your resources.
|
||||
|
||||
The solution: automation. The result of automation is scalability - less effort per person to maintain and grow your IT environment. If adding manpower is the only way to grow your business, then scalability is a pipe dream.
|
||||
|
||||
Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution. Simple, right? Yes, but you must be prepared for delayed gratification. An upfront investment of time and effort for architectural and structural changes is required in order to reap the back-end financial benefits of automation with improved productivity and efficiency. Embracing these challenges as an IT leader is crucial in order for your DevOps team to successfully execute.
|
||||
|
||||
### 3. Trust
|
||||
|
||||
Lastly, trust your DevOps team and make sure they know it. DevOps experts understand that this is a tough request, but they must have your unquestionable support and your willingness to actively participate. It will often be a "learn as you go" experience for you as the DevOps team successively refines your IT environment, while they themselves adapt to ever-changing technology.
|
||||
|
||||
Listen, listen, listen to them and trust them. DevOps changes are valuable and well worth the time and money through increased efficiency, productivity, and business responsiveness. Trusting your DevOps team gives them the freedom to make the most effective IT improvements.
|
||||
|
||||
The new CIO bottom line: To maximize your DevOps team's potential, leave your leadership comfort zone and embrace a "CIOps" transition. Continuously work on finding common ground with the DevOps team throughout the DevOps transition, to help your organization achieve long-term IT success.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
|
||||
作者:[John Allessio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/john-allessio
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
@ -1,120 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Concurrent Servers: Part 5 - Redis case study
|
||||
======
|
||||
This is part 5 in a series of posts on writing concurrent network servers. After discussing techniques for constructing concurrent servers in parts 1-4, this time we're going to do a case study of an existing production-quality server - [Redis][10].
|
||||
|
||||

|
||||
|
||||
Redis is a fascinating project and I've been following it with interest for a while now. One of the things I admire most about Redis is the clarity of its C source code. It also happens to be a great example of a high-performance concurrent in-memory database server, so the opportunity to use it as a case study for this series was too good to ignore.
|
||||
|
||||
Let's see how the ideas discussed in parts 1-4 apply to a real-world application.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][3]
|
||||
|
||||
* [Part 2 - Threads][4]
|
||||
|
||||
* [Part 3 - Event-driven][5]
|
||||
|
||||
* [Part 4 - libuv][6]
|
||||
|
||||
* [Part 5 - Redis case study][7]
|
||||
|
||||
### Event-handling library
|
||||
|
||||
One of Redis's main claims to fame around the time of its original release in 2009 was its speed - the sheer number of concurrent client connections the server could handle. It was especially notable that Redis did this all in a single thread, without any complex locking and synchronization schemes on the data stored in memory.
|
||||
|
||||
This feat was achieved by Redis's own implementation of an event-driven library which is wrapping the fastest event loop available on a system (epoll for Linux, kqueue for BSD and so on). This library is called [ae][11]. ae makes it possible to write a fast server as long as none of the internals are blocking, which Redis goes to great lengths to guarantee [[1]][12].
|
||||
|
||||
What mainly interests us here is ae's support of file events - registering callbacks to be invoked when file descriptors (like network sockets) have something interesting pending. Like libuv, ae supports multiple event loops and - having read parts 3 and 4 in this series - the signature of aeCreateFileEvent shouldn't be surprising:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
It registers a callback (proc) for new file events on fd, with the given event loop. When using epoll, it will call epoll_ctl to add an event on the file descriptor (either EPOLLIN, EPOLLOUT or both, depending on the mask parameter). ae's aeProcessEvents is the "run the event loop and dispatch callbacks" function, and it calls epoll_wait under the hood.
|
||||
|
||||
### Handling client requests
|
||||
|
||||
Let's trace through the Redis server code to see how ae is used to register callbacks for client events. initServer starts it by registering a callback for read events on the socket(s) being listened to, by calling aeCreateFileEvent with the callback acceptTcpHandler. This callback is invoked when new client connections are available. It calls accept [[2]][13] and then acceptCommonHandler, which in turn calls createClient to initialize the data structures required to track a new client connection.
|
||||
|
||||
createClient's job is to start listening for data coming in from the client. It sets the socket to non-blocking mode (a key ingredient in an asynchronous event loop) and registers another file event callback with aeCreateFileEvent - for read events - readQueryFromClient. This function will be invoked by the event loop every time the client sends some data.
|
||||
|
||||
readQueryFromClient does just what we'd expect - parses the client's command and acts on it by querying and/or manipulating data and sending a reply back. Since the client socket is non-blocking, this function has to be able to handle EAGAIN, as well as partial data; data read from the client is accumulated in a client-specific buffer, and the full query may be split across multiple invocations of the callback.
|
||||
|
||||
### Sending data back to clients
|
||||
|
||||
In the previous paragraph I said that readQueryFromClient ends up sending replies back to clients. This is logically true, because readQueryFromClient prepares the reply to be sent, but it doesn't actually do the physical sending - since there's no guarantee the client socket is ready for writing/sending data. We have to use the event loop machinery for that.
|
||||
|
||||
The way Redis does this is by registering a beforeSleep function to be called every time the event loop is about to go sleeping waiting for sockets to become available for reading/writing. One of the things beforeSleep does is call handleClientsWithPendingWrites. This function tries to send all available replies immediately by calling writeToClient; if some of the sockets are unavailable, it registers an event-loop callback to invoke sendReplyToClient when the socket is ready. This can be seen as a kind of optimization - if the socket is immediately ready for sending (which often is the case for TCP sockets), there's no need to register the event - just send the data. Since sockets are non-blocking, this never actually blocks the loop.
|
||||
|
||||
### Why does Redis roll its own event library?
|
||||
|
||||
In [part 4][14] we've discussed building asynchronous concurrent servers using libuv. It's interesting to ponder the fact that Redis doesn't use libuv, or any similar event library, and instead implements its own - ae, including wrappers for epoll, kqueue and select. In fact, antirez (Redis's creator) answered precisely this question [in a blog post in 2011][15]. The gist of his answer: ae is ~770 lines of code he intimately understands; libuv is huge, without providing additional functionality Redis needs.
|
||||
|
||||
Today, ae has grown to ~1300 lines, which is still trivial compared to libuv's 26K (this is without Windows, test, samples, docs). libuv is a far more general library, which makes it more complex and more difficult to adapt to the particular needs of another project; ae, on the other hand, was designed for Redis, co-evolved with Redis and contains only what Redis needs.
|
||||
|
||||
This is another great example of the dependencies in software projects formula I mentioned [in a post earlier this year][16]:
|
||||
|
||||
> The benefit of dependencies is inversely proportional to the amount of effort spent on a software project.
|
||||
|
||||
antirez referred to this, to some extent, in his post. He mentioned that dependencies that provide a lot of added value ("foundational" dependencies in my post) make more sense (jemalloc and Lua are his examples) than dependencies like libuv, whose functionality is fairly easy to implement for the particular needs of Redis.
|
||||
|
||||
### Multi-threading in Redis
|
||||
|
||||
[For the vast majority of its history][17], Redis has been a purely single-threaded affair. Some people find this surprising, but it makes total sense with a bit of thought. Redis is inherently network-bound - as long as the database size is reasonable, for any given client request, much more time is spent waiting on the network than inside Redis's data structures.
|
||||
|
||||
These days, however, things are not quite that simple. There are several new capabilities in Redis that use threads:
|
||||
|
||||
1. "Lazy" [freeing of memory][8].
|
||||
|
||||
2. Writing a [persistence journal][9] with fsync calls in a background thread.
|
||||
|
||||
3. Running user-defined modules that need to perform a long-running operation.
|
||||
|
||||
For the first two features, Redis uses its own simple bio library (the acronym stands for "Background I/O"). The library is hard-coded for Redis's needs and can't be used outside it - it runs a pre-set number of threads, one per background job type Redis needs.
|
||||
|
||||
For the third feature, [Redis modules][18] could define new Redis commands, and thus are held to the same standards as regular Redis commands, including not blocking the main thread. If a custom Redis command defined in a module wants to perform a long-running operation, it has to spin up a thread to run it in the background. src/modules/helloblock.c in the Redis tree provides an example.
|
||||
|
||||
With these features, Redis combines an event loop with threading to get both speed in the common case and flexibility in the general case, similarly to the work queue discussion in [part 4][19] of this series.
|
||||
|
||||
|
||||
| [[1]][1] | A core aspect of Redis is its being an _in-memory_ database; therefore, queries should never take too long to execute. There are all kinds of complications, however. In case of partitioning, a server may end up routing the request to another instance; in this case async I/O is used to avoid blocking other clients. |
|
||||
|
||||
|
||||
| [[2]][2] | Through anetAccept; anet is Redis's wrapper for TCP socket code. |
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[4]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[5]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[6]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
@ -1,58 +0,0 @@
|
||||
Will DevOps steal my job?
|
||||
======
|
||||
|
||||
>Are you worried automation will replace people in the workplace? You may be right, but here's why that's not a bad thing.
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
It's a common fear: Will DevOps be the end of my job? After all, DevOps means developers doing operations, right? DevOps is automation. What if I automate myself out of a job? Do continuous delivery and containers mean operations staff are obsolete? DevOps is all about coding: infrastructure-as-code and testing-as-code and this-or-that-as-code. What if I don't have the skill set to be a part of this?
|
||||
|
||||
[DevOps][1] is a looming change, disruptive in the field, with seemingly fanatical followers talking about changing the world with the [Three Ways][2]--the three underpinnings of DevOps--and the tearing down of walls. It can all be overwhelming. So what's it going to be--is DevOps going to steal my job?
|
||||
|
||||
### The first fear: I'm not needed
|
||||
|
||||
As developers managing the entire lifecycle of an application, it's all too easy to get caught up in the idea of DevOps. Containers are probably a big contributing factor to this line of thought. When containers exploded onto the scene, they were touted as a way for developers to build, test, and deploy their code all-in-one. What role does DevOps leave for the operations team, or testing, or QA?
|
||||
|
||||
This stems from a misunderstanding of the principles of DevOps. The first principle of DevOps, or the First Way, is _Systems Thinking_ , or placing emphasis on a holistic approach to managing and understanding the whole lifecycle of an application or service. This does not mean that the developers of the application learn and manage the whole process. Rather, it is the collaboration of talented and skilled individuals to ensure success as a whole. To make developers solely responsible for the process is practically the extreme opposite of this tenant--essentially the enshrining of a single silo with the importance of the entire lifecycle.
|
||||
|
||||
There is a place for specialization in DevOps. Just as the classically educated software engineer with knowledge of linear regression and binary search is wasted writing Ansible playbooks and Docker files, the highly skilled sysadmin with the knowledge of how to secure a system and optimize database performance is wasted writing CSS and designing user flows. The most effective group to write, test, and maintain an application is a cross-discipline, functional team of people with diverse skill sets and backgrounds.
|
||||
|
||||
### The second fear: My job will be automated
|
||||
|
||||
Accurate or not, DevOps can sometimes be seen as a synonym for automation. What work is left for operations staff and testing teams when automated builds, testing, deployment, monitoring, and notifications are a huge part of the application lifecycle? This focus on automation can be partially related to the Second Way: _Amplify Feedback Loops_. This second tenant of DevOps deals with prioritizing quick feedback between teams in the opposite direction an application takes to deployment --from monitoring and maintaining to deployment, testing, development, etc., and the emphasis to make the feedback important and actionable. While the Second Way is not specifically related to automation, many of the automation tools teams use within their deployment pipelines facilitate quick notification and quick action, or course-correction based on feedback in support of this tenant. Traditionally done by humans, it is easy to understand why a focus on automation might lead to anxiety about the future of one's job.
|
||||
|
||||
Automation is just a tool, not a replacement for people. Smart people trapped doing the same things over and over, pushing the big red George Jetson button are a wasted, untapped wealth of intelligence and creativity. Automation of the drudgery of daily work means more time to spend solving real problems and coming up with creative solutions. Humans are needed to figure out the "how and why;" computers can handle the "copy and paste."
|
||||
|
||||
There will be no end of repetitive, predictable things to automate, and automation frees teams to focus on higher-order tasks in their field. Monitoring teams, no longer spending all their time configuring alerts or managing trending configuration, can start to focus on predicting alarms, correlating statistics, and creating proactive solutions. Systems administrators, freed of scheduled patching or server configuration, can spend time focusing on fleet management, performance, and scaling. Unlike the striking images of factory floors and assembly lines totally devoid of humans, automated tasks in the DevOps world mean humans can focus on creative, rewarding tasks instead of mind-numbing drudgery.
|
||||
|
||||
### The third fear: I do not have the skillset for this
|
||||
|
||||
"How am I going to keep up with this? I don't know how to automate. Everything is code now--do I have to be a developer and write code for a living to work in DevOps?" The third fear is ultimately a fear of self-confidence. As the culture changes, yes, teams will be asked to change along with it, and some may fear they lack the skills to perform what their jobs will become.
|
||||
|
||||
Most folks, however, are probably already closer than they think. What is the Dockerfile, or configuration management like Puppet or Ansible, but environment as code? System administrators already write shell scripts and Python programs to handle repetitive tasks for them. It's hardly a stretch to learn a little more and begin using some of the tools already at their disposal to solve more problems--orchestration, deployment, maintenance-as-code--especially when freed from the drudgery of manual tasks to focus on growth.
|
||||
|
||||
The answer to this fear lies in the third tenant of DevOps, the Third Way: _A Culture of Continual Experimentation and Learning_. The ability to try and fail and learn from mistakes without blame is a major factor in creating ever-more creative solutions. The Third Way is empowered by the first two ways --allowing for for quick detection of and repair of problems, and just as the developer is free to try and learn, other teams are as well. Operations teams that have never used configuration management or written programs to automate infrastructure provisioning are free to try and learn. Testing and QA teams are free to implement new testing pipelines and automate approval and release processes. In a culture that embraces learning and growing, everyone has the freedom to acquire the skills they need to succeed at and enjoy their job.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Any disruptive practice or change in an industry can create fear or uncertainty, and DevOps is no exception. A concern for one's job is a reasonable response to the hundreds of articles and presentations enumerating the countless practices and technologies seemingly dedicated to empowering developers to take responsibility for every aspect of the industry.
|
||||
|
||||
In truth, however, DevOps is "[a cross-disciplinary community of practice dedicated to the study of building, evolving, and operating rapidly changing resilient systems at scale][3]." DevOps means the end of silos, but not specialization. It is the delegation of drudgery to automated systems, freeing you to do what people do best: think and imagine. And if you're motivated to learn and grow, there will be no end of opportunities to solve new and challenging problems.
|
||||
|
||||
Will DevOps take away your job? Yes, but it will give you a better one.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/will-devops-steal-my-job
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://opensource.com/resources/devops
|
||||
[2]:http://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[3]:https://theagileadmin.com/what-is-devops/
|
||||
@ -1,191 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Find (Top-10) Largest Files In Linux
|
||||
======
|
||||
When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
|
||||
|
||||
You have to spend huge amount of time to get the largest files in the system using the above commands, that to you have to navigate to each and every directory to achieve this.
|
||||
|
||||
It's making you to face trouble and this is not the right way to do it.
|
||||
|
||||
If so, what would be the suggested way to get top 10 largest files in Linux?
|
||||
|
||||
I have spend a lot of time with google but i didn't found this. Everywhere i could see an article which list the top 10 files in the current directory. So, i want to make this article useful for people whoever looking to get the top 10 largest files in the system.
|
||||
|
||||
In this tutorial, we are going to teach you how to find top 10 largest files in Linux system using below four methods.
|
||||
|
||||
### Method-1 :
|
||||
|
||||
There is no specific command available in Linux to do this, hence we are using more than one command (all together) to get this done.
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-print0`** : Print the full file name on the standard output, followed by a null character
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`xargs`** : It 's a command, which build and execute command lines from standard input.
|
||||
**`-0`** : Input items are terminated by a null character instead of by whitespace
|
||||
**`du -h`** : It 's a command to calculate disk usage with human readable format
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
**`-h`** : Print the output with human readable format
|
||||
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`n -10`** : Print the first 10 files.
|
||||
|
||||
### Method-2 :
|
||||
|
||||
This is an another way to find or check top 10 largest files in Linux system. Here also, we are putting few commands together to achieve this.
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-exec`** : This variant of the -exec action runs the specified command on the selected files
|
||||
**`du`** : It 's a command to estimate file space usage.
|
||||
|
||||
**`-S`** : Do not include size of subdirectories
|
||||
**`-h`** : Print sizes in human readable format
|
||||
**`{}`** : Summarize disk usage of each FILE, recursively for directories.
|
||||
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
|
||||
**`-h`** : Compare human readable numbers
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`n -10`** : Print the first 10 files.
|
||||
|
||||
### Method-3 :
|
||||
|
||||
It 's an another method to find or search top 10 largest files in Linux system.
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-print0`** : Print the full file name on the standard output, followed by a null character
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`xargs`** : It 's a command, which build and execute command lines from standard input.
|
||||
**`-0`** : Input items are terminated by a null character instead of by whitespace
|
||||
**`du`** : It 's a command to estimate file space usage.
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-n`** : Compare according to string numerical value
|
||||
**`tail -10`** : It 's a command, output the last part of files (last 10 files)
|
||||
|
||||
**`cut`** : It 's a command, remove sections from each line of files
|
||||
**`-f2`** : Select only these fields value.
|
||||
**`-I{}`** : Replace occurrences of replace-str in the initial-arguments with names read from standard input.
|
||||
|
||||
**`-s`** : Display only a total for each argument
|
||||
**`-h`** : Print sizes in human readable format
|
||||
**`{}`** : Summarize disk usage of each FILE, recursively for directories.
|
||||
|
||||
### Method-4 :
|
||||
|
||||
It 's an another method to find or search top 10 largest files in Linux system.
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-ls`** : List current file in ls -dils format on standard output.
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-k`** : start a key at POS1
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
|
||||
**`-n`** : Compare according to string numerical value
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`-10`** : Print the first 10 files.
|
||||
|
||||
**`column`** : It 's a command, formats its input into multiple columns.
|
||||
**`-t`** : Determine the number of columns the input contains and create a table.
|
||||
**`awk`** : It 's a command, Pattern scanning and processing language
|
||||
**`'{print $7,$11}'`** : Print only mentioned column.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -1,3 +1,5 @@
|
||||
lontow translating
|
||||
|
||||
5 ways open source can strengthen your job search
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
transalting by wyxplus
|
||||
4 Tools for Network Snooping on Linux
|
||||
======
|
||||
Computer networking data has to be exposed, because packets can't travel blindfolded, so join us as we use `whois`, `dig`, `nmcli`, and `nmap` to snoop networks.
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user