mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
316c488323
@ -1,42 +0,0 @@
|
||||
Adobe Pulls Linux PDF Reader Downloads From Website
|
||||
================================================================================
|
||||

|
||||
|
||||
Other PDF solutions are available on Linux
|
||||
|
||||
**Things are about to get tricky for anyone needing to use Adobe’s own PDF reader application on Linux, as the company has pulled the software from download.**
|
||||
|
||||
As flagged by a [Reddit user][1] who visited the Adobe site to grab the app, Linux builds are no longer listed alongside other ‘[supported’ operating][2] systems.
|
||||
|
||||
It’s not know when, much less why, the Linux build was removed but reports first began to surface online in August.
|
||||
|
||||
Not that this is too surprising. The official Linux version had not been updated since May 2013, and even then continued to lag behind on version 9.5.x while Windows and Mac builds sped on to v11.x.
|
||||
|
||||
### Who Cares, Right? Well… ###
|
||||
|
||||
Is this a great loss? You might think not. After all, Adobe Reader is an app with a tarnished reputation. Slow, resource intensive and bloated. Native PDF reading apps like Evince and Okular provide first-class experience without the overhead.
|
||||
|
||||
Snark aside, the decision will impact some. Some government websites still provide official documents and applications that can only be completed or submitted using the official Adobe app.
|
||||
|
||||
Adobe is no stranger to giving penguins the brush off. The company [stopped releasing official builds of][3] Flash for Linux in 2012 (leaving it to Google to tend to), [and excluded Tux-loving users from its cross-platform application runtime “Air” the year before][4].
|
||||
|
||||
All is not lost. While the links are no longer offered through the website the Debian installer remains accessible from the Adobe FTP server. Plan on using the old release? You do so at your own risk and without support from Adobe. Also note that these builds are likely contain unfixed vulnerabilities.
|
||||
|
||||
- [Download Adobe Reader 9.5.5 for Ubuntu][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/adobe-reader-linux-download-pulled-website
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://www.reddit.com/r/linux/comments/2hsgq6/linux_version_of_adobe_reader_no_longer/
|
||||
[2]:http://get.adobe.com/reader/otherversions/
|
||||
[3]:http://www.omgubuntu.co.uk/2012/02/adobe-adandons-flash-on-linux
|
||||
[4]:http://www.omgubuntu.co.uk/2011/06/adobe-air-for-linux-axed
|
||||
[5]:ftp://ftp.adobe.com/pub/adobe/reader/unix/9.x/9.5.5/enu/AdbeRdr9.5.5-1_i386linux_enu.deb
|
||||
@ -1,3 +1,4 @@
|
||||
诗诗来翻译!disylee
|
||||
How to configure a network printer and scanner on Ubuntu desktop
|
||||
================================================================================
|
||||
In a [previous article][1](注:这篇文章在2014年8月12号的原文里做过,不知道翻译了没有,如果翻译发布了,发布此文章的时候可改成翻译后的链接), we discussed how to install several kinds of printers (and also a network scanner) in a Linux server. Today we will deal with the other end of the line: how to access the network printer/scanner devices from a desktop client.
|
||||
|
||||
@ -1,123 +0,0 @@
|
||||
[bazz2 bazz2 bazz2]
|
||||
20 Postfix Interview Questions & Answers
|
||||
================================================================================
|
||||
### Q:1 What is postfix and default port used for postfix ? ###
|
||||
|
||||
Ans: Postfix is a open source MTA (Mail Transfer agent) which is used to route & deliver emails. Postfix is the alternate of widely used Sendmail MTA. Default port for postfix is 25.
|
||||
|
||||
### Q:2 What is the difference between Postfix & Sendmail ? ###
|
||||
|
||||
Ans: Postfix uses a modular approach and is composed of multiple independent executables. Sendmail has a more monolithic design utilizing a single always running daemon.
|
||||
|
||||
### Q:3 What is MTA and it’s role in mailing system ? ###
|
||||
|
||||
Ans: MTA Stands for Mail Transfer Agent.MTA receives and delivers email. Determines message routing and possible address rewriting. Locally delivered messages are handed off to an MDA for final delivery. Examples Qmail, Postfix, Sendmail
|
||||
|
||||
### Q:4 What is MDA ? ###
|
||||
|
||||
Ans: MDA stands for Mail Delivery Agent. MDA is a Program that handles final delivery of messages for a system's local recipients. MDAs can often filter or categorize messages upon delivery. An MDA might also determine that a message must be forwarded to another email address. Example Procmail
|
||||
|
||||
### Q:5 What is MUA ? ###
|
||||
|
||||
Ans: MUA stands for Mail User Agent. MUA is aEmail client software used to compose, send, and retrieve email messages. Sends messages through an MTA. Retrieves messages from a mail store either directly or through a POP/ IMAP server. Examples Outlook, Thunderbird, Evolution.
|
||||
|
||||
### Q:6 What is the use of postmaster account in Mailserver ? ###
|
||||
|
||||
Ans: An email administrator is commonly referred to as a postmaster. An individual with postmaster responsibilities makes sure that the mail system is working correctly, makes configuration changes, and adds/removes email accounts, among other things. You must have a postmaster alias at all domains for which you handle email that directs messages to the correct person or persons .
|
||||
|
||||
### Q:7 What are the important daemons in postfix ? ###
|
||||
|
||||
Ans : Below are the lists of impportant daemons in postfix mail server :
|
||||
|
||||
- **master** :The master daemon is the brain of the Postfix mail system. It spawns all other daemons.
|
||||
- **smtpd**: The smtpd daemon (server) handles incoming connections.
|
||||
- **smtp** :The smtp client handles outgoing connections.
|
||||
- **qmgr** :The qmgr-Daemon is the heart of the Postfix mail system. It processes and controls all messages in the mail queues.
|
||||
- **local** : The local program is Postfix’ own local delivery agent. It stores messages in mailboxes.
|
||||
|
||||
### Q:8 What are the configuration files of postfix server ? ###
|
||||
|
||||
Ans: There are two main Configuration files of postfix :
|
||||
|
||||
- **/etc/postfix/main.cf** : This file holds global configuration options. They will be applied to all instances of a daemon, unless they are overridden in master.cf
|
||||
- **/etc/postfix/master.cf** : This file defines runtime environment for daemons attached to services. Runtime behavior defined in main.cf may be overridden by setting service specific options.
|
||||
|
||||
### Q:9 How to restart the postfix service & make it enable across reboot ? ###
|
||||
|
||||
Ans: Use this command to restart service “ Service postfix restart” and to make the service persist across the reboot, use the command “ chkconfig postfix on”
|
||||
|
||||
### Q:10 How to check the mail's queue in postfix ? ###
|
||||
|
||||
Ans: Postfix maintains two queues, the pending mails queue, and the deferred mail queue,the deferred mail queue has the mail that has soft-fail and should be retried (Temporary failure), Postfix retries the deferred queue on set intervals (configurable, and by default 5 minutes)
|
||||
|
||||
To display the list of queued mails :
|
||||
|
||||
# postqueue -p
|
||||
|
||||
To Save the output of above command :
|
||||
|
||||
# postqueue -p > /mnt/queue-backup.txt
|
||||
|
||||
Tell Postfix to process the Queue now
|
||||
|
||||
# postqueue -f
|
||||
|
||||
### Q:11 How to delete mails from the queue in postfix ? ###
|
||||
|
||||
Ans: Use below command to delete all queued mails
|
||||
|
||||
# postsuper -d ALL
|
||||
|
||||
To delete only deferred mails from queue , use below command
|
||||
|
||||
# postsuper -d ALL deferred
|
||||
|
||||
### Q:12 How to check postfix configuration from the command line ? ###
|
||||
|
||||
Ans: Using the command 'postconf -n' we can see current configuration of postfix excluding the lines which are commented.
|
||||
|
||||
### Q:13 Which command is used to see live mail logs in postfix ? ###
|
||||
|
||||
Ans: Use the command 'tail -f /var/log/maillog' or 'tailf /var/log/maillog'
|
||||
|
||||
### Q:14 How to send a test mail from command line ? ###
|
||||
|
||||
Ans: Use the below command to send a test mail from postfix itself :
|
||||
|
||||
# echo "Test mail from postfix" | mail -s "Plz ignore" info@something.com
|
||||
|
||||
### Q:15 What is an Open mail relay ? ###
|
||||
|
||||
Ans: An open mail relay is an SMTP server configured in such a way that it allows anyone on the Internet to send e-mail through it, not just mail destined to or originating from known users.This used to be the default configuration in many mail servers; indeed, it was the way the Internet was initially set up, but open mail relays have become unpopular because of their exploitation by spammers and worms.
|
||||
|
||||
### Q:16 What is relay host in postfix ? ###
|
||||
|
||||
Ans: Relay host is the smtp address , if mentioned in postfix config file , then all the incoming mails be relayed through smtp server.
|
||||
|
||||
### Q:17 What is Greylisting ? ###
|
||||
|
||||
Ans: Greylisting is a method of defending e-mail users against spam. A mail transfer agent (MTA) using greylisting will "temporarily reject" any email from a sender it does not recognize. If the mail is legitimate the originating server will, after a delay, try again and, if sufficient time has elapsed, the email will be accepted.
|
||||
|
||||
### Q:18 What is the importance of SPF records in mail servers ? ###
|
||||
|
||||
Ans: SPF (Sender Policy Framework) is a system to help domain owners specify the servers which are supposed to send mail from their domain. The aim is that other mail systems can then check to make sure the server sending email from that domain is authorized to do so – reducing the chance of email 'spoofing', phishing schemes and spam!
|
||||
|
||||
### Q:19 What is the use of Domain Keys(DKIM) in mail servers ? ###
|
||||
|
||||
Ans: DomainKeys is an e-mail authentication system designed to verify the DNS domain of an e-mail sender and the message integrity. The DomainKeys specification has adopted aspects of Identified Internet Mail to create an enhanced protocol called DomainKeys Identified Mail (DKIM).
|
||||
|
||||
### Q:20 What is the role of Anti-Spam SMTP Proxy (ASSP) in mail server ? ###
|
||||
|
||||
Ans: ASSP is a gateway server which is install in front of your MTA and implements auto-whitelists, self learning Bayesian, Greylisting, DNSBL, DNSWL, URIBL, SPF, SRS, Backscatter, Virus scanning, attachment blocking, Senderbase and multiple other filter methods
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/postfix-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,171 @@
|
||||
How to debug a C/C++ program with GDB command-line debugger
|
||||
================================================================================
|
||||
What is the worst part of coding without a debugger? Compiling on your knees praying that nothing will crash? Running the executable with a blood offering? Or just having to write printf("test") at every line hoping to find where the problem is coming from? As you probably know, there are not many advantages to coding without a debugger. But the good side is that debugging on Linux is easy. While most people use the debugger included in their favorite IDE, Linux is famous for its powerful command line C/C++ debugger: GDB. However, like most command line utilities, GDB requires a bit of training to master fully. In this tutorial, I will give you a quick rundown of GDB debugger.
|
||||
|
||||
### Installation of GDB ###
|
||||
|
||||
GDB is available in most distributions' repositories.
|
||||
|
||||
For Debian or Ubuntu:
|
||||
|
||||
$ sudo apt-get install gdb
|
||||
|
||||
For Arch Linux:
|
||||
|
||||
$ sudo pacman -S gdb
|
||||
|
||||
For Fedora, CentOS or RHEL:
|
||||
|
||||
$ sudo yum install gdb
|
||||
|
||||
If you cannot find it anywhere else, it is always possible to download it from the [official page][1].
|
||||
|
||||
### Code Sample ###
|
||||
|
||||
When you are learning GDB, it is always better to have a piece of code to try things. Here is a quick sample that I coded to show the best features of GDB. Feel free to copy paste it to try the examples. That's the best way to learn.
|
||||
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
|
||||
int main(int argc, char **argv)
|
||||
{
|
||||
int i;
|
||||
int a=0, b=0, c=0;
|
||||
double d;
|
||||
for (i=0; i<100; i++)
|
||||
{
|
||||
a++;
|
||||
if (i>97)
|
||||
d = i / 2.0;
|
||||
b++;
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
|
||||
### Usage of GDB ###
|
||||
|
||||
First and foremost, you will need to compile your program with the flag "-g" (for debug) to run it via GDB. From there the syntax to start debugging is:
|
||||
|
||||
$ gdb -tui [executable's name]
|
||||
|
||||
The "-tui” option will show your code in a nice interactive terminal window (so-called "text user interface") that you can navigate in with the arrow keys, while typing in the GDB shell below.
|
||||
|
||||
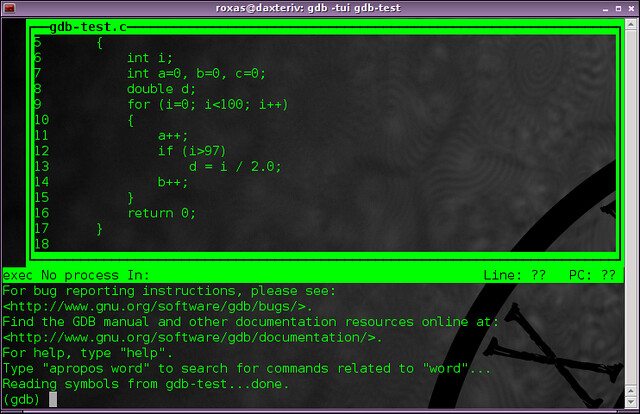
|
||||
|
||||
We can now start playing around placing breakpoints anywhere in the source code with debugger. Here you have the options to set a breakpoint at a line number of the current source file:
|
||||
|
||||
break [line number]
|
||||
|
||||
or at a line number of a specific source file:
|
||||
|
||||
break [file name]:[line number]
|
||||
|
||||
or at a particular function:
|
||||
|
||||
break [function name]
|
||||
|
||||
And even better, you can set conditional breakpoints:
|
||||
|
||||
break [line number] if [condition]
|
||||
|
||||
For example, in our code sample, I can set:
|
||||
|
||||
break 11 if i > 97
|
||||
|
||||
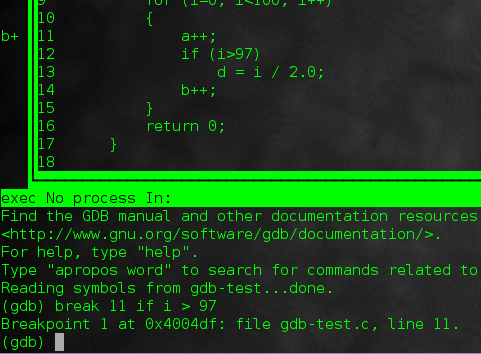
|
||||
|
||||
which will have an effect of stopping me at "a++;" after 97 iterations of the for loop. As you have guessed, this is very handy when you do not want to step through the loop 97 times on your own.
|
||||
|
||||
Last but not least, you can place a "watchpoint" which will pause the program if a variable is modified:
|
||||
|
||||
watch [variable]
|
||||
|
||||
Here, I can set one like:
|
||||
|
||||
watch d
|
||||
|
||||
which will stop the program as soon as variable d is set to a new value (i.e. when i > 97 is true).
|
||||
|
||||
Once our breakpoints are set, we can run the program with the "run" command, or simply:
|
||||
|
||||
r [command line arguments if your program takes some]
|
||||
|
||||
as most words can be abbreviated in just a letter with gdb.
|
||||
|
||||
And without surprises, we are stopped at line 11. From there, we can do interesting things. The command:
|
||||
|
||||
bt
|
||||
|
||||
for backtrack will tell us how we got to that point.
|
||||
|
||||

|
||||
|
||||
info locals
|
||||
|
||||
will display all the local variables and their current values (as you can see I didn't set my d variable to anything so its value is currently garbage).
|
||||
|
||||
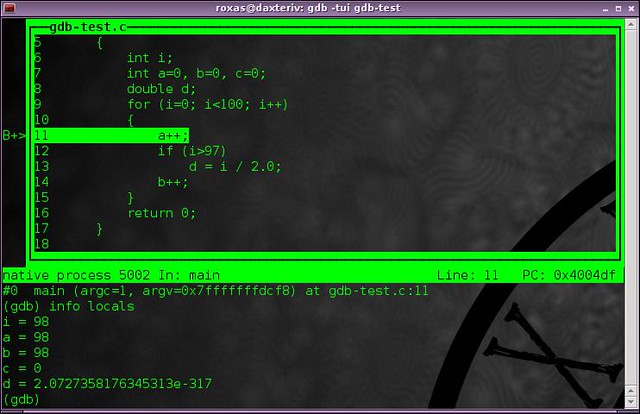
|
||||
|
||||
Of course:
|
||||
|
||||
p [variable]
|
||||
|
||||
will show the value of a particular variable. But even better:
|
||||
|
||||
ptype [variable]
|
||||
|
||||
shows the type of a local variable. So here we can confirm that d is double type.
|
||||
|
||||
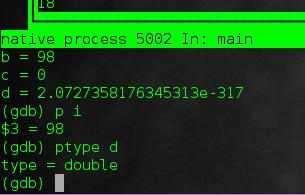
|
||||
|
||||
And since we are playing with fire, might as well do it all the way:
|
||||
|
||||
set var [variable] = [new value]
|
||||
|
||||
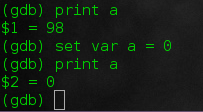
will override the value of the variable. Be careful though as you can't create a new variable or change its type. But here we can do:
|
||||
|
||||
set var a = 0
|
||||
|
||||
|
||||
|
||||
And just like any good debugger, we can "step" with:
|
||||
|
||||
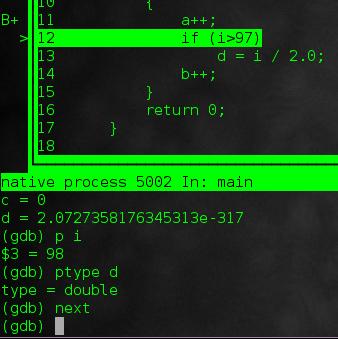
step
|
||||
|
||||
to run the next line and potentially step into a function. Or just:
|
||||
|
||||
next
|
||||
|
||||
to just go straight to the line below, ignoring any function call.
|
||||
|
||||
|
||||
|
||||
And to finish testing, you can delete a breakpoint with:
|
||||
|
||||
delete [line number]
|
||||
|
||||
Keep running the program from the current breakpoint with:
|
||||
|
||||
continue
|
||||
|
||||
and exit GDB with:
|
||||
|
||||
quit
|
||||
|
||||
To conclude, with GDB, no more praying to compile, no more blood offerings to run, no more printf("test"). Of course this post is not exhaustive and GDB's capabilities run beyond this, so I really encourage you to learn more about it on your own (or in a future post maybe?). What I am the most interested now is to integrate GDB nicely in Vim. In the meantime, here is a very [big memo][2] of all the GDB commands for future reference.
|
||||
|
||||
What do you think of GDB? Would you consider its advantages over a graphical debugger or an IDE's? And what about integrating into Vim? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/gdb-command-line-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:https://www.gnu.org/software/gdb/
|
||||
[2]:http://users.ece.utexas.edu/~adnan/gdb-refcard.pdf
|
||||
@ -0,0 +1,86 @@
|
||||
How to convert image, audio and video formats on Ubuntu
|
||||
================================================================================
|
||||
If you need to work with a variety of image, audio and video files encoded in all sorts of different formats, you are probably using more than one tools to convert among all those heterogeneous media formats. If there is a versatile all-in-one media conversion tool that is capable of dealing with all different image/audio/video formats, that will be awesome.
|
||||
|
||||
[Format Junkie][1] is one such all-in-one media conversion tool with an extremely user-friendly GUI. Better yet, it is free software! With Format Junkie, you can convert image, audio, video and archive files of pretty much all the popular formats simply with a few mouse clicks.
|
||||
|
||||
### Install Format Junkie on Ubuntu 12.04, 12.10 and 13.04 ###
|
||||
|
||||
Format Junkie is available for installation via Ubuntu PPA format-junkie-team. This PPA supports Ubuntu 12.04, 12.10 and 13.04. To install Format Junkie on one of those Ubuntu releases, simply run the following.
|
||||
|
||||
$ sudo add-apt-repository ppa:format-junkie-team/release
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### Install Format Junkie on Ubuntu 13.10 ###
|
||||
|
||||
If you are running Ubuntu 13.10 (Saucy Salamander), you can download and install .deb package for Ubuntu 13.04 as follows. Since the .deb package for Format Junkie requires quite a few dependent packages, install it using [gdebi deb installer][2].
|
||||
|
||||
On 32-bit Ubuntu 13.10:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
On 64-bit Ubuntu 13.10:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### Install Format Junkie on Ubuntu 14.04 or Later ###
|
||||
|
||||
The currently available official Format Junkie .deb file requires libavcodec-extra-53 which has become obsolete starting from Ubuntu 14.04. Thus if you want to install Format Junkie on Ubuntu 14.04 or later, you can use the following third-party PPA repositories instead.
|
||||
|
||||
$ sudo add-apt-repository ppa:jon-severinsson/ffmpeg
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
|
||||
### How to Use Format Junkie ###
|
||||
|
||||
To start Format Junkie after installation, simply run:
|
||||
|
||||
$ formatjunkie
|
||||
|
||||
#### Convert audio, video, image and archive formats with Format Junkie ####
|
||||
|
||||
The user interface of Format Junkie is pretty simple and intuitive, as shown below. To choose among audio, video, image and iso media, click on one of four tabs at the top. You can add as many files as you want for batch conversion. After you add files, and select output format, simply click on "Start Converting" button to convert.
|
||||
|
||||

|
||||
|
||||
Format Junkie supports conversion among the following media formats:
|
||||
|
||||
- **Audio**: mp3, wav, ogg, wma, flac, m4r, aac, m4a, mp2.
|
||||
- **Video**: avi, ogv, vob, mp4, 3gp, wmv, mkv, mpg, mov, flv, webm.
|
||||
- **Image**: jpg, png, ico, bmp, svg, tif, pcx, pdf, tga, pnm.
|
||||
- **Archive**: iso, cso.
|
||||
|
||||
#### Subtitle encoding with Format Junkie ####
|
||||
|
||||
Besides media conversion, Format Junkie also provides GUI for subtitle encoding. Actual subtitle encoding is done by MEncoder. In order to do subtitle encoding via Format Junkie interface, first you need to install MEencoder.
|
||||
|
||||
$ sudo apt-get install mencoder
|
||||
|
||||
Then click on "Advanced" tab on Format Junkie. Choose AVI/subtitle files to use for encoding, as shown below.
|
||||
|
||||

|
||||
|
||||
Overall, Format Junkie is an extremely easy-to-use and versatile media conversion tool. One drawback, though, is that it does not allow any sort of customization during conversion (e.g., bitrate, fps, sampling frequency, image quality, size). So this tool is recommended for newbies who are looking for an easy-to-use simple media conversion tool.
|
||||
|
||||
Enjoyed this post? I will appreciate your like/share buttons on Facebook, Twitter and Google+.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://launchpad.net/format-junkie
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -0,0 +1,139 @@
|
||||
How to set up RAID 10 for high performance and fault tolerant disk I/O on Linux
|
||||
================================================================================
|
||||
A RAID 10 (aka RAID 1+0 or stripe of mirrors) array provides high performance and fault-tolerant disk I/O operations by combining features of RAID 0 (where read/write operations are performed in parallel across multiple drives) and RAID 1 (where data is written identically to two or more drives).
|
||||
|
||||
In this tutorial, I'll show you how to set up a software RAID 10 array using five identical 8 GiB disks. While the minimum number of disks for setting up a RAID 10 array is four (e.g., a striped set of two mirrors), we will add an extra spare drive should one of the main drives become faulty. We will also share some tools that you can later use to analyze the performance of your RAID array.
|
||||
|
||||
Please note that going through all the pros and cons of RAID 10 and other partitioning schemes (with different-sized drives and filesystems) is beyond the scope of this post.
|
||||
|
||||
### How Does a Raid 10 Array Work? ###
|
||||
|
||||
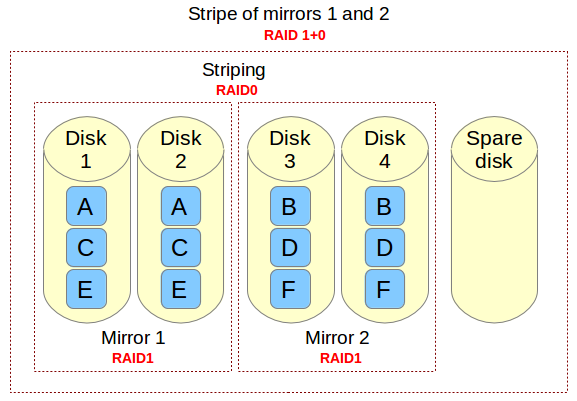
If you need to implement a storage solution that supports I/O-intensive operations (such as database, email, and web servers), RAID 10 is the way to go. Let me show you why. Let's refer to the below image.
|
||||
|
||||
|
||||
|
||||
Imagine a file that is composed of blocks A, B, C, D, E, and F in the above diagram. Each RAID 1 mirror set (e.g., Mirror 1 or 2) replicates blocks on each of its two devices. Because of this configuration, write performance is reduced because every block has to be written twice, once for each disk, whereas read performance remains unchanged compared to reading from single disks. The bright side is that this setup provides redundancy in that unless more than one of the disks in each mirror fail, normal disk I/O operations can be maintained.
|
||||
|
||||
The RAID 0 stripe works by dividing data into blocks and writing block A to Mirror 1, block B to Mirror 2 (and so on) simultaneously, thereby improving the overall read and write performance. On the other hand, none of the mirrors contains the entire information for any piece of data committed to the main set. This means that if one of the mirrors fail, the entire RAID 0 component (and therefore the RAID 10 set) is rendered inoperable, with unrecoverable loss of data.
|
||||
|
||||
### Setting up a RAID 10 Array ###
|
||||
|
||||
There are two possible setups for a RAID 10 array: complex (built in one step) or nested (built by creating two or more RAID 1 arrays, and then using them as component devices in a RAID 0). In this tutorial, we will cover the creation of a complex RAID 10 array due to the fact that it allows us to create an array using either an even or odd number of disks, and can be managed as a single RAID device, as opposed to the nested setup (which only permits an even number of drives, and must be managed as a nested device, dealing with RAID 1 and RAID 0 separately).
|
||||
|
||||
It is assumed that you have mdadm installed, and the daemon running on your system. Refer to [this tutorial][1] for details. It is also assumed that a primary partition sd[bcdef]1 has been created on each disk. Thus, the output of:
|
||||
|
||||
ls -l /dev | grep sd[bcdef]
|
||||
|
||||
should be like:
|
||||
|
||||

|
||||
|
||||
Let's go ahead and create a RAID 10 array with the following command:
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]1 --spare-devices=1 /dev/sdf1
|
||||
|
||||

|
||||
|
||||
When the array has been created (it should not take more than a few minutes), the output of:
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||
should look like:
|
||||
|
||||

|
||||
|
||||
A couple of things to note before we proceed further.
|
||||
|
||||
1. **Used Dev Space** indicates the capacity of each member device used by the array.
|
||||
|
||||
2. **Array Size** is the total size of the array. For a RAID 10 array, this is equal to (N*C)/M, where N: number of active devices, C: capacity of active devices, M: number of devices in each mirror. So in this case, (N*C)/M equals to (4*8GiB)/2 = 16GiB.
|
||||
|
||||
3. **Layout** refers to the fine details of data layout. The possible layout values are as follows.
|
||||
|
||||
----------
|
||||
|
||||
- **n** (default option): means near copies. Multiple copies of one data block are at similar offsets in different devices. This layout yields similar read and write performance than that of a RAID 0 array.
|
||||
|
||||

|
||||
|
||||
- **o** indicates offset copies. Rather than the chunks being duplicated within a stripe, whole stripes are duplicated, but are rotated by one device so duplicate blocks are on different devices. Thus subsequent copies of a block are in the next drive, one chunk further down. To use this layout for your RAID 10 array, add --layout=o2 to the command that is used to create the array.
|
||||
|
||||

|
||||
|
||||
- **f** represents far copies (multiple copies with very different offsets). This layout provides better read performance but worse write performance. Thus, it is the best option for systems that will need to support far more reads than writes. To use this layout for your RAID 10 array, add --layout=f2 to the command that is used to create the array.
|
||||
|
||||

|
||||
|
||||
The number that follows the **n**, **f**, and **o** in the --layout option indicates the number of replicas of each data block that are required. The default value is 2, but it can be 2 to the number of devices in the array. By providing an adequate number of replicas, you can minimize I/O impact on individual drives.
|
||||
|
||||
4. **Chunk Size**, as per the [Linux RAID wiki][2], is the smallest unit of data that can be written to the devices. The optimal chunk size depends on the rate of I/O operations and the size of the files involved. For large writes, you may see lower overhead by having fairly large chunks, whereas arrays that are primarily holding small files may benefit more from a smaller chunk size. To specify a certain chunk size for your RAID 10 array, add **--chunk=desired_chunk_size** to the command that is used to create the array.
|
||||
|
||||
Unfortunately, there is no one-size-fits-all formula to improve performance. Here are a few guidelines to consider.
|
||||
|
||||
- Filesystem: overall, [XFS][3] is said to be the best, while EXT4 remains a good choice.
|
||||
- Optimal layout: far layout improves read performance, but worsens write performance.
|
||||
- Number of replicas: more replicas minimize I/O impact, but increase costs as more disks will be needed.
|
||||
- Hardware: SSDs are more likely to show increased performance (under the same context) than traditional (spinning) disks.
|
||||
|
||||
### RAID Performance Tests using DD ###
|
||||
|
||||
The following benchmarking tests can be used to check on the performance of our RAID 10 array (/dev/md0).
|
||||
|
||||
#### 1. Write operation ####
|
||||
|
||||
A single file of 256MB is written to the device:
|
||||
|
||||
# dd if=/dev/zero of=/dev/md0 bs=256M count=1 oflag=dsync
|
||||
|
||||
512 bytes are written 1000 times:
|
||||
|
||||
# dd if=/dev/zero of=/dev/md0 bs=512 count=1000 oflag=dsync
|
||||
|
||||
With dsync flag, dd bypasses filesystem cache, and performs synchronized write to a RAID array. This option is used to eliminate caching effect during RAID performance tests.
|
||||
|
||||
#### 2. Read operation ####
|
||||
|
||||
256KiB*15000 (3.9 GB) are copied from the array to /dev/null:
|
||||
|
||||
# dd if=/dev/md0 of=/dev/null bs=256K count=15000
|
||||
|
||||
### RAID Performance Tests Using Iozone ###
|
||||
|
||||
[Iozone][4] is a filesystem benchmark tool that allows us to measure a variety of disk I/O operations, including random read/write, sequential read/write, and re-read/re-write. It can export the results to a Microsoft Excel or LibreOffice Calc file.
|
||||
|
||||
#### Installing Iozone on CentOS/RHEL 7 ####
|
||||
|
||||
Enable [Repoforge][5]. Then:
|
||||
|
||||
# yum install iozone
|
||||
|
||||
#### Installing Iozone on Debian 7 ####
|
||||
|
||||
# aptitude install iozone3
|
||||
|
||||
The iozone command below will perform all tests in the RAID-10 array:
|
||||
|
||||
# iozone -Ra /dev/md0 -b /tmp/md0.xls
|
||||
|
||||
- **-R**: generates an Excel-compatible report to standard out.
|
||||
- **-a**: runs iozone in a full automatic mode with all tests and possible record/file sizes. Record sizes: 4k-16M and file sizes: 64k-512M.
|
||||
- **-b /tmp/md0.xls**: stores test results in a specified file.
|
||||
|
||||
Hope this helps. Feel free to add your thoughts or add tips to consider on how to improve performance of RAID 10.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-raid10-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[2]:https://raid.wiki.kernel.org/
|
||||
[3]:http://ask.xmodulo.com/create-mount-xfs-file-system-linux.html
|
||||
[4]:http://www.iozone.org/
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
251
sources/tech/20141009 Linux Terminal--An lsof Primer.md
Normal file
251
sources/tech/20141009 Linux Terminal--An lsof Primer.md
Normal file
@ -0,0 +1,251 @@
|
||||
Linux Terminal: An lsof Primer
|
||||
================================================================================
|
||||

|
||||
|
||||
Article by Daniel Miessler first posted on his [blog][1]
|
||||
|
||||
**lsof** is the sysadmin/[security][2] über-tool. I use it most for getting [network][3] connection related information from a system, but that’s just the beginning for this powerful and too-little-known application. The tool is aptly called lsof because it “**lists openfiles**“. And remember, in UNIX just about everything (including a network socket) is a file.
|
||||
|
||||
Interestingly, lsof is also the Linux/Unix command with the most switches. It has so many it has to use both minuses andpluses.
|
||||
|
||||
usage: [-?abhlnNoOPRstUvV] [+|-c c] [+|-d s] [+D D] [+|-f[cgG]]
|
||||
[-F [f]] [-g [s]] [-i [i]] [+|-L [l]] [+|-M] [-o [o]]
|
||||
[-p s] [+|-r [t]] [-S [t]] [-T [t]] [-u s] [+|-w] [-x [fl]] [--] [names]
|
||||
|
||||
As you can see, lsof has a truly staggering number of options. You can use it to get information about devices on your system, what a given user is touching at any given point, or even what files or network connectivity a process is using.
|
||||
|
||||
For me, lsof replaces both netstat and ps entirely. It has everything I get from those tools and much, much more. So let’s look at some of its primary capabilities:
|
||||
|
||||
### Key Options ###
|
||||
|
||||
It’s important to understand a few key things about how lsofworks. Most importantly, when you’re passing options to it, the default behavior is to OR the results. So if you are pulling a list of ports with -i and also a process list with -p you’re by default going to get both results.
|
||||
|
||||
Here are a few others like that to keep in mind:
|
||||
|
||||
- **default** : without options, lsof lists all open files for active processes
|
||||
- **grouping** : it’s possible to group options, e.g. -abC, but you have to watch for which options take parameters
|
||||
- **-a** : AND the results (instead of OR)
|
||||
- **-l** : show the userID instead of the username in the output
|
||||
- **-h** : get help
|
||||
- **-t** : get process IDs only
|
||||
- **-U** : get the UNIX socket address
|
||||
- **-F** : the output is ready for another command, which can be formatted in various ways, e.g. -F pcfn (for process id, command name, file descriptor, and file name, with a null terminator)
|
||||
|
||||
#### Getting Information About the Network ####
|
||||
|
||||
As I said, one of my main usecases for lsof is getting information about how my system is interacting with the network. Here are some staples for getting this info:
|
||||
|
||||
### Show all connections with -i ###
|
||||
|
||||
Some like to use netstat to get network connections, but I much prefer using lsof for this. The display shows things in a format that’s intuitive to me, and I like knowing that from there I can simply change my syntax and get more information using the same command.
|
||||
|
||||
# lsof -i
|
||||
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
|
||||
dhcpcd 6061 root 4u IPv4 4510 UDP *:bootpc
|
||||
sshd 7703 root 3u IPv6 6499 TCP *:ssh (LISTEN)
|
||||
sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
|
||||
|
||||
### Get only IPv6 traffic with -i 6 ###
|
||||
|
||||
# lsof -i 6
|
||||
|
||||
### Show only TCP connections (works the same for UDP) ###
|
||||
|
||||
You can also show only TCP or UDP connections by providing the protocol right after the -i.
|
||||
|
||||
# lsof -iTCP
|
||||
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
|
||||
sshd 7703 root 3u IPv6 6499 TCP *:ssh (LISTEN)
|
||||
sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
|
||||
|
||||
### Show networking related to a given port using -i :port ###
|
||||
|
||||
Or you can search by port instead, which is great for figuring out what’s preventing another app from binding to a given port.
|
||||
|
||||
# lsof -i :22
|
||||
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
|
||||
sshd 7703 root 3u IPv6 6499 TCP *:ssh (LISTEN)
|
||||
sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
|
||||
|
||||
### Show connections to a specific host using @host ###
|
||||
|
||||
This is quite useful when you’re looking into whether you have open connections with a given host on the network or on the internet.
|
||||
|
||||
# lsof -i@172.16.12.5
|
||||
|
||||
sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->172.16.12.5:49901 (ESTABLISHED)
|
||||
|
||||
### Show connections based on the host and the port using@host:port ###
|
||||
|
||||
You can also combine the display of host and port.
|
||||
|
||||
# lsof -i@172.16.12.5:22
|
||||
|
||||
sshd 7892 root 3u IPv6 6757 TCP 10.10.1.5:ssh->192.168.1.5:49901 (ESTABLISHED)
|
||||
|
||||
### Find listening ports ###
|
||||
|
||||
Find ports that are awaiting connections.
|
||||
|
||||
# lsof -i -sTCP:LISTEN
|
||||
|
||||
You can also do this by grepping for “LISTEN” as well.
|
||||
|
||||
# lsof -i | grep -i LISTEN
|
||||
|
||||
iTunes 400 daniel 16u IPv4 0x4575228 0t0 TCP *:daap (LISTEN)
|
||||
|
||||
### Find established connections ###
|
||||
|
||||
You can also show any connections that are already pinned up.
|
||||
|
||||
# lsof -i -sTCP:ESTABLISHED
|
||||
|
||||
You can also do this just by searching for “ESTABLISHED” in the output via grep.
|
||||
|
||||
# lsof -i | grep -i ESTABLISHED
|
||||
|
||||
firefox-b 169 daniel 49u IPv4 0t0 TCP 1.2.3.3:1863->1.2.3.4:http (ESTABLISHED)
|
||||
|
||||
#### User Information ####
|
||||
|
||||
You can also get information on various users and what they’re doing on the system, including their activity on the network, their interactions with files, etc.
|
||||
|
||||
### Show what a given user has open using -u ###
|
||||
|
||||
# lsof -u daniel
|
||||
|
||||
-- snipped --
|
||||
Dock 155 daniel txt REG 14,2 2798436 823208 /usr/lib/libicucore.A.dylib
|
||||
Dock 155 daniel txt REG 14,2 1580212 823126 /usr/lib/libobjc.A.dylib
|
||||
Dock 155 daniel txt REG 14,2 2934184 823498 /usr/lib/libstdc++.6.0.4.dylib
|
||||
Dock 155 daniel txt REG 14,2 132008 823505 /usr/lib/libgcc_s.1.dylib
|
||||
Dock 155 daniel txt REG 14,2 212160 823214 /usr/lib/libauto.dylib
|
||||
-- snipped --
|
||||
|
||||
### Show what all users are doing except a certain user using-u ^user ###
|
||||
|
||||
# lsof -u ^daniel
|
||||
|
||||
-- snipped --
|
||||
Dock 155 jim txt REG 14,2 2798436 823208 /usr/lib/libicucore.A.dylib
|
||||
Dock 155 jim txt REG 14,2 1580212 823126 /usr/lib/libobjc.A.dylib
|
||||
Dock 155 jim txt REG 14,2 2934184 823498 /usr/lib/libstdc++.6.0.4.dylib
|
||||
Dock 155 jim txt REG 14,2 132008 823505 /usr/lib/libgcc_s.1.dylib
|
||||
Dock 155 jim txt REG 14,2 212160 823214 /usr/lib/libauto.dylib
|
||||
-- snipped --
|
||||
|
||||
### Kill everything a given user is doing ###
|
||||
|
||||
It’s nice to be able to nuke everything being run by a given user.
|
||||
|
||||
# kill -9 `lsof -t -u daniel`
|
||||
|
||||
#### Commands and Processes ####
|
||||
|
||||
It’s often useful to be able to see what a given program or process is up to, and with lsof you can do this by name or by process ID. Here are a few options:
|
||||
|
||||
### See what files and network connections a named command is using with -c ###
|
||||
|
||||
# lsof -c syslog-ng
|
||||
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
|
||||
syslog-ng 7547 root cwd DIR 3,3 4096 2 /
|
||||
syslog-ng 7547 root rtd DIR 3,3 4096 2 /
|
||||
syslog-ng 7547 root txt REG 3,3 113524 1064970 /usr/sbin/syslog-ng
|
||||
-- snipped --
|
||||
|
||||
### See what a given process ID has open using -p ###
|
||||
|
||||
# lsof -p 10075
|
||||
|
||||
-- snipped --
|
||||
sshd 10068 root mem REG 3,3 34808 850407 /lib/libnss_files-2.4.so
|
||||
sshd 10068 root mem REG 3,3 34924 850409 /lib/libnss_nis-2.4.so
|
||||
sshd 10068 root mem REG 3,3 26596 850405 /lib/libnss_compat-2.4.so
|
||||
sshd 10068 root mem REG 3,3 200152 509940 /usr/lib/libssl.so.0.9.7
|
||||
sshd 10068 root mem REG 3,3 46216 510014 /usr/lib/liblber-2.3
|
||||
sshd 10068 root mem REG 3,3 59868 850413 /lib/libresolv-2.4.so
|
||||
sshd 10068 root mem REG 3,3 1197180 850396 /lib/libc-2.4.so
|
||||
sshd 10068 root mem REG 3,3 22168 850398 /lib/libcrypt-2.4.so
|
||||
sshd 10068 root mem REG 3,3 72784 850404 /lib/libnsl-2.4.so
|
||||
sshd 10068 root mem REG 3,3 70632 850417 /lib/libz.so.1.2.3
|
||||
sshd 10068 root mem REG 3,3 9992 850416 /lib/libutil-2.4.so
|
||||
-- snipped --
|
||||
|
||||
### The -t option returns just a PID ###
|
||||
|
||||
# lsof -t -c Mail
|
||||
|
||||
350
|
||||
|
||||
#### Files and Directories ####
|
||||
|
||||
By looking at a given file or directory you can see what all on the system is interacting with it–including users, processes, etc.
|
||||
|
||||
#### Show everything interacting with a given directory ####
|
||||
|
||||
# lsof /var/log/messages/
|
||||
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
|
||||
syslog-ng 7547 root 4w REG 3,3 217309 834024 /var/log/messages
|
||||
|
||||
### Show everything interacting with a given file ###
|
||||
|
||||
# lsof /home/daniel/firewall_whitelist.txt
|
||||
|
||||
#### Advanced Usage ####
|
||||
|
||||
Similar to [tcpdump][4], the power really shows itself when you start combining queries.
|
||||
|
||||
### Show me everything daniel is doing connected to 1.1.1.1 ###
|
||||
|
||||
# lsof -u daniel -i @1.1.1.1
|
||||
|
||||
bkdr 1893 daniel 3u IPv6 3456 TCP 10.10.1.10:1234->1.1.1.1:31337 (ESTABLISHED)
|
||||
|
||||
### Using the -t and -c options together to HUP processes ###
|
||||
|
||||
# kill -HUP `lsof -t -c sshd`
|
||||
|
||||
### lsof +L1 shows you all open files that have a link count less than 1 ###
|
||||
|
||||
This is often (but not always) indicative of an attacker trying to hide file content by unlinking it.
|
||||
|
||||
# lsof +L1
|
||||
|
||||
(hopefully nothing)
|
||||
|
||||
### Show open connections with a port range ###
|
||||
|
||||
# lsof -i @fw.google.com:2150=2180
|
||||
|
||||
#### Conclusion ####
|
||||
|
||||
This primer just scratches the surface of lsof‘s functionality. For a full reference, run man lsof or check out [the online version][5]. I hope this has been useful to you, and as always,[comments and corrections are welcomed][6].
|
||||
|
||||
### Resources ###
|
||||
|
||||
- The lsof man page:[http://www.netadmintools.com/html/lsof.man.html][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxaria.com/howto/linux-terminal-an-lsof-primer
|
||||
|
||||
作者:[Daniel Miessler][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/101727609700016666852/posts?rel=author
|
||||
[1]:http://danielmiessler.com/study/lsof/
|
||||
[2]:http://linuxaria.com/tag/security
|
||||
[3]:http://linuxaria.com/tag/network
|
||||
[4]:http://danielmiessler.com/study/tcpdump/
|
||||
[5]:http://www.netadmintools.com/html/lsof.man.html
|
||||
[6]:http://danielmiessler.com/connect/
|
||||
[7]:http://www.netadmintools.com/html/lsof.man.html
|
||||
@ -0,0 +1,127 @@
|
||||
Linux/UNIX wget command with practical examples
|
||||
================================================================================
|
||||
wget is a Linux/UNIX command line **file downloader**.Wget is a free utility for non-interactive download of files from the Web. It supports **HTTP**, **HTTPS**, and **FTP** protocols, as well as retrieval through HTTP proxies.Wget is non-interactive, meaning that it can work in the background, while the user is not logged on.
|
||||
|
||||
In this post we will discuss different examples of wget command.
|
||||
|
||||
### Example:1 Download Single File ###
|
||||
|
||||
# wget http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
|
||||
This command will download the CentOS 7 ISO file in the user’s current working directtory.
|
||||
|
||||
### Example:2 Resume Partial Downloaded File ###
|
||||
|
||||
There are some scenarios where we start downloading a large file but in the middle Internet got disconnected , so using the option ‘**-c**’ in wget command we can resume our download from where it got disconnected.
|
||||
|
||||
# wget -c http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
|
||||

|
||||
|
||||
### Example:3 Download Files in the background ###
|
||||
|
||||
We can download the file in the background using the option ‘-b’ in wget command.
|
||||
|
||||
linuxtechi@localhost:~$ wget -b http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/
|
||||
CentOS-7.0-1406-x86_64-DVD.iso
|
||||
Continuing in background, pid 4505.
|
||||
Output will be written to ‘wget-log’.
|
||||
|
||||
As we can see above that downloading progress is capture in ‘wget-log’ file in user’s current directory.
|
||||
|
||||
linuxtechi@localhost:~$ tail -f wget-log
|
||||
2300K ………. ………. ………. ………. ………. 0% 48.1K 18h5m
|
||||
2350K ………. ………. ………. ………. ………. 0% 53.7K 18h9m
|
||||
2400K ………. ………. ………. ………. ………. 0% 52.1K 18h13m
|
||||
2450K ………. ………. ………. ………. ………. 0% 58.3K 18h14m
|
||||
2500K ………. ………. ………. ………. ………. 0% 63.6K 18h14m
|
||||
2550K ………. ………. ………. ………. ………. 0% 63.4K 18h13m
|
||||
2600K ………. ………. ………. ………. ………. 0% 72.8K 18h10m
|
||||
2650K ………. ………. ………. ………. ………. 0% 59.8K 18h11m
|
||||
2700K ………. ………. ………. ………. ………. 0% 52.8K 18h14m
|
||||
2750K ………. ………. ………. ………. ………. 0% 58.4K 18h15m
|
||||
2800K ………. ………. ………. ………. ………. 0% 58.2K 18h16m
|
||||
2850K ………. ………. ………. ………. ………. 0% 52.2K 18h20m
|
||||
|
||||
### Example:4 Limiting Download Speed . ###
|
||||
|
||||
By default wget command try to use full bandwidth , but there may be case that you are using shared internet , so if you try to download huge file using wget , this may slow down Internet of other users. This situation can be avoided if you limit the download speed using ‘–limit-rate‘ option.
|
||||
|
||||
#wget --limit-rate=100k http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
|
||||
In the above example,the download speed is limited to 100k.
|
||||
|
||||
### Example:5 Download Multiple Files using ‘-i’ option ###
|
||||
|
||||
If you want to download multiple files using wget command , then first create a text file and add all URLs in the text file.
|
||||
|
||||
# cat download-list.txt
|
||||
url1
|
||||
url2
|
||||
url3
|
||||
url4
|
||||
|
||||
Now issue issue below Command :
|
||||
|
||||
# wget -i download-list.txt
|
||||
|
||||
### Example:6 Increase Retry Attempts. ###
|
||||
|
||||
We can increase the retry attempts using ‘–tries‘ option in wget. By default wget command retries 20 times to make the download successful.
|
||||
|
||||
This option becomes very useful when you have internet connection problem and you are downloading a large file , then there is a chance of failures in the download.
|
||||
|
||||
# wget --tries=75 http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
|
||||
### Example:7 Redirect wget Logs to a log File using -o ###
|
||||
|
||||
We can redirect the wget command logs to a log file using ‘-o‘ option.
|
||||
|
||||
#wget -o download.log http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
|
||||
Download.log file will be created in the user’s current directory.
|
||||
|
||||
### Example:8 Download Full website for local viewing. ###
|
||||
|
||||
# wget --mirror -p --convert-links -P ./<Local-Folder> website-url
|
||||
|
||||
Whereas
|
||||
|
||||
- **–mirror** : turn on options suitable for mirroring.
|
||||
- **-p** : download all files that are necessary to properly display a given HTML page.
|
||||
- **–convert-links** : after the download, convert the links in document for local viewing.
|
||||
- -**P ./Local-Folder** : save all the files and directories to the specified directory.
|
||||
|
||||
### Example:9 Reject file types while downloading. ###
|
||||
|
||||
When you are planning to download full website , then we can force wget command not to download images using ‘–reject’ option .
|
||||
|
||||
# wget --reject=png Website-To-Be-Downloaded
|
||||
|
||||
### Example:10 Setting Download Quota using wget -Q ###
|
||||
|
||||
We can force wget command to quit downloading when download size exceeds certain size using ‘-Q’ option
|
||||
|
||||
# wget -Q10m -i download-list.txt
|
||||
|
||||
Note that quota will never affect downloading a single file. So if you specify wget -Q10m ftp://wuarchive.wustl.edu/ls-lR.gz, all of the ls-lR.gz will be downloaded. The same goes even when several URLs are specified on the command-line. However, quota is respected when retrieving either recursively, or from an input file. Thus you may safely type ‘wget -Q10m -i download-list.txt’ download will be aborted when the quota is exceeded.
|
||||
|
||||
### Example:11 Downloading file from password protected site. ###
|
||||
|
||||
# wget --ftp-user=<user-name> --ftp-password=<password> Download-URL
|
||||
|
||||
Another way to specify username and password is in the URL itself.
|
||||
|
||||
Either method reveals your password to anyone who bothers to run “ps”. To prevent the passwords from being seen, store them in .wgetrc or .netrc, and make sure to protect those files from other users with “chmod”. If the passwords are really important, do not leave them lying in those files either edit the files and delete them after Wget has started the download.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/wget-command-practical-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,42 @@
|
||||
Adobe从网站上撤下了Linux PDF Reader的下载链接。
|
||||
================================================================================
|
||||

|
||||
|
||||
Linux上的其他PDF解决方案
|
||||
|
||||
**由于该公司从网站上撤下了软件的下载链接,因此这对于任何需要在Linux上使用Adobe这家公司的PDF阅读器的人而言这事变得棘手了。**
|
||||
|
||||
由一位访问Adobe抓取app的[Reddit 用户][1]标记的,Linux版本不再与其他[支持的操作系统][2]列在一起了。
|
||||
|
||||
不知道什么时候,更不知道为什么,Linux版本被删除了,但报告在八月份才开始浮出水面。
|
||||
|
||||
这也并没有太惊讶。官方的Linux版本在2013年5月才更新,而且当时还在滞后的版本9.5.x上,而Windows和Mac版已经在v11.x。
|
||||
|
||||
### 谁在意呢?是吗 ###
|
||||
|
||||
这是一个巨大的损失么?你可能并不会这么想。毕竟Adobe Reader是一款名声不好的app。速度慢,资源密集型而且臃肿。原生的PDF阅读app像Evince和Okular提供了一流的体验而没有上面的那些缺点。
|
||||
|
||||
除开Snark,这一决定将会影响一些事。一些政府网站只能使用官方Abode应用才能完成或者提交提供的官方文档和程序。
|
||||
|
||||
Adobe把企鹅给刷了并不陌生。公司在2012年[停止Linux上flash版本的更新][3](把它留给Google去做)。[并且先前将喜爱Tux的用户从它们的跨平台运行时“Air”中排除了][4]。
|
||||
|
||||
并没有失去一切。虽然网在不再提供链接了,然而在Adobe FTP服务器上仍有Debian的安装程序。计划使用老的版本?自己承担风险且没有来自Adobe的支持。同样注意这些版本可能还有没有修复的漏洞。
|
||||
|
||||
- [下载Ubuntu版本的 Adobe Reader 9.5.5][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/adobe-reader-linux-download-pulled-website
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://www.reddit.com/r/linux/comments/2hsgq6/linux_version_of_adobe_reader_no_longer/
|
||||
[2]:http://get.adobe.com/reader/otherversions/
|
||||
[3]:http://www.omgubuntu.co.uk/2012/02/adobe-adandons-flash-on-linux
|
||||
[4]:http://www.omgubuntu.co.uk/2011/06/adobe-air-for-linux-axed
|
||||
[5]:ftp://ftp.adobe.com/pub/adobe/reader/unix/9.x/9.5.5/enu/AdbeRdr9.5.5-1_i386linux_enu.deb
|
||||
@ -0,0 +1,122 @@
|
||||
Postfix的20个问答题
|
||||
================================================================================
|
||||
### 问题1:什么是 Postfix,它的默认端口是多少? ###
|
||||
|
||||
答:Postfix 是一个开源的 MTA(邮件传送代理,英文名:Mail Transfer Agent),用于转发 email。相信很多人知道 Sendmail,而 Postfix 是它的替代品。默认端口是25。
|
||||
|
||||
### 问题2:Postfix 和 Sendmail 有什么区别? ###
|
||||
|
||||
答:Postfix 使用模块化设计,由多个独立的可执行程序组成;而 Sendmail 被设计成有一个强大的后台进程提供所有服务。
|
||||
|
||||
### 问题3:什么是 MTA,它在邮件系统中扮演什么角色? ###
|
||||
|
||||
答:MTA 是 Mail Transfer Agent 的缩写。MTA 负责接收和发送邮件、确定发送路径和地址重写(LCTT:address rewriting,就是完善发送地址,比如将“username”这个地址重写为“username@example.com”)。本地转发就是将邮件发送给 MDA。Qmail、Postix、Sendmail 都是 MTA。
|
||||
|
||||
### 问题4:什么是 MDA? ###
|
||||
|
||||
答:MDA 是 Mail Delivery Agent 的缩写。MDA 这个程序用于从 MTA 获取邮件并传送至本地接受者的邮箱。MDA 通常可以过滤邮件或为邮件分类。一个 MDA 也能决定一封邮件是否需要转发到另一个邮箱地址。Procmail 就是一个 MDA。
|
||||
|
||||
### 问题5:什么是 MUA? ###
|
||||
|
||||
答:MUA 是 Mail User Agent 的缩写。MUA 是一个邮件客户端软件,可以用来写邮件、发送邮件、接收邮件。发送邮件时使用的是 MTA;接收邮件时可以从邮件存储区直接收取,也可以通过 POP/IMAP 服务器间接收取。Outlook、Thunkerbird、Evolution 都是 MUA。
|
||||
|
||||
### 问题6:Mailserver 里 postmaster 的作用是什么? ###
|
||||
|
||||
答:邮件管理者一般就是 postmaster。一个 postmaster 的责任就是保证邮件系统正常工作、更新系统配置、添加/删除邮箱帐号,以及其他。每个域中必须存在一个 postmaster 的别名(LCTT:postmaster 别名的作用就是能让你的邮件系统以外的用户往邮件系统里面的用户发邮件,当然也能接收来自系统内部用户发送出来的邮件),用于将邮件发往正确的用户。
|
||||
|
||||
### 问题7:Postfix 都有些什么重要的进程? ###
|
||||
|
||||
答:以下是 Postfix 邮件系统里最重要的后台进程列表:
|
||||
|
||||
- **master**:这条进程是 Postfix 邮件系统的大脑,它产生所有其他进程。
|
||||
- **smtpd**:作为服务器端程序处理所有外部连进来的请求。
|
||||
- **smtp**:作为客户端程序处理所有对外发起连接的请求。
|
||||
- **qmgr**:它是 Postfix 邮件系统的心脏,处理和控制邮件列表里面的所有消息。
|
||||
- **local**:这是 Postfix 自有的本地传送代理,就是它负责把邮件保存到邮箱里。
|
||||
|
||||
### 问题8:Postfix 服务器的配置什么是什么? ###
|
||||
|
||||
答:有两个主要配置文件:
|
||||
|
||||
- **/etc/postfix/main.cf**:这个文件保存全局配置信息,所有进程都会用到,除非这些配置在 master.cf 文件中被重新设置了。
|
||||
- **/etc/postfix/master.cf**:这个文件保存了额外的进程运行时环境参数,在 main.cf 文件中定义的配置可能会被本文件的配置覆盖掉。
|
||||
|
||||
### 问题9:如何将 Postfix 重启以及设为开机启动? ###
|
||||
|
||||
答:使用这个命令重启:`service postfix restart`;使用这个命令设为开机启动:`chkconfig postfix on`
|
||||
|
||||
### 问题10:怎么查看 Postfix 的邮件列表? ###
|
||||
|
||||
答:Postfix 维护两个列表:未决邮件队列(pending mails queue)和等待邮件队列(deferred mail queue)。等待队列包含了暂时发送失败、需要重新发送的邮件,Postfix 会定期重发(默认5分钟,可自定义设置)。(LCTT:其实 Postfix 维护5个队列:输入队列,邮件进入 Postfix 系统的第一站;活动队列,qmgr 将输入队列的邮件移到活动队列;等待队列,保存暂时不能发送出去的邮件;故障队列,保存受损或无法解读的邮件;保留队列,将邮件无限期留在 Postfix 队列系统中。)
|
||||
|
||||
列出邮件队列里面所有邮件:
|
||||
|
||||
# postqueue -p
|
||||
|
||||
保存邮件队列名单:
|
||||
|
||||
# postqueue -p > /mnt/queue-backup.txt
|
||||
|
||||
让 Postfix 马上处理队列:
|
||||
|
||||
# postqueue -f
|
||||
|
||||
### 问题11:如何删除邮件队列里面的邮件? ###
|
||||
|
||||
答:以下命令删除所有邮件:
|
||||
|
||||
# postsuper -d ALL
|
||||
|
||||
以下命令只删除等待队列中的邮件:
|
||||
|
||||
# postsuper -d ALL deferred
|
||||
|
||||
### 问题12:如何通过命令来检查 Postfix 配置信息? ###
|
||||
|
||||
答:使用`postconf -n`命令可以查看,它会过滤掉配置文件里面被注释掉的配置信息。
|
||||
|
||||
### 问题13:实时查看邮件日志要用什么命令? ###
|
||||
|
||||
答:`tail -f /var/log/maillog` 或 `tailf /var/log/maillog`
|
||||
|
||||
### 问题14:如何通过命令行发送测试邮件? ###
|
||||
|
||||
答:参考下面的命令:
|
||||
|
||||
# echo "Test mail from postfix" | mail -s "Plz ignore" info@something.com
|
||||
|
||||
### 问题15:什么是“开放邮件转发”? ###
|
||||
|
||||
答:开放邮件转发是 SMTP 服务器的一项设定,允许因特网上其他用户能通过该服务器转发邮件,而不是直接发送到某个帐号。过去,这项功能在许多邮件服务器中都是默认开启的,但是现在已经不再流行了,因为邮件转发会导致大量垃圾邮件和病毒邮件在网络上肆虐。
|
||||
|
||||
### 问题16:什么是 Postfix 上的邮件转发主机? ###
|
||||
|
||||
答:转发主机是 SMTP 的地址,如果在配置文件中有配置,那么所有输入邮件都将被 SMTP 服务器转发。
|
||||
|
||||
### 问题17:什么是灰名单? ###
|
||||
|
||||
答:灰名单(LCTT:介于白名单和黑名单之间)用于拦截垃圾邮件。一个 MTA 使用灰名单时就会“暂时拒绝”未被识别的发送者发来的所有邮件。如果邮件是正当合理的,发起者会在一段时间后重新发送,然后这份邮件就能被接收。(LCTT:灰名单基于这样一个事实,就是大多数的垃圾邮件服务器和僵尸网络的邮件只发送一次,而会忽略要求它们在一定的时间间隔后再次发送的请求。)
|
||||
|
||||
### 问题18:邮件系统中 SPF 记录有什么重要作用? ###
|
||||
|
||||
答:SPF 是 Sender Policy Framework 的缩写,用于帮助域的拥有者确认发送方是否来自他们的域,目的是其他邮件系统能够保证发送方在发送邮件时是否经过授权 —— 这种方法可以减小遇到邮件地址欺骗、网络钓鱼和垃圾邮件的风险。
|
||||
|
||||
### 问题19:邮件系统中 DKIM 有什么用处? ###
|
||||
|
||||
答:域名密匙是一套电子邮件身份认证系统,用于验证邮件发送方的 DNS 域和邮件的完整性。域名密匙规范采用互联网电子邮件认证技术,建立了一套加强版协议:域名密匙识别邮件(就是 DKIM)。
|
||||
|
||||
### 问题20:邮件系统中 ASSP 的规则是什么? ###
|
||||
|
||||
答:ASSP(Anti-Spam SMTP Proxy,反垃圾代理) 是一个网关服务器,安装在你的 MTA 前面,通过自建白名单、自动学习贝叶斯算法、灰名单、DNS 黑名单(DNSBL)、DNS 白名单(DNSWL)、URI黑名单(URIBL)、SPF、SRS、Backscatter、病毒扫描功能、附件阻拦功能、基于发送方等多种方法来反垃圾邮件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/postfix-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
Loading…
Reference in New Issue
Block a user