mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
304802f9a9
@ -1,13 +1,15 @@
|
||||
调试器到底怎样工作
|
||||
======
|
||||
|
||||
> 你也许用过调速器检查过你的代码,但你知道它们是如何做到的吗?
|
||||
|
||||

|
||||
|
||||
供图:opensource.com
|
||||
|
||||
调试器是那些大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器...使用 [Rust][2]!
|
||||
调试器是大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的那些软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器……使用 [Rust][2]!
|
||||
|
||||
在本文中,术语调试器/跟踪器可以互换。 “被跟踪者”是指正在被跟踪者跟踪的进程。
|
||||
在本文中,术语<ruby>调试器<rt>debugger</rt></ruby>和<ruby>跟踪器<rt>tracer</rt></ruby>可以互换。 “<ruby>被跟踪者<rt>Tracee</rt></ruby>”是指正在被跟踪器跟踪的进程。
|
||||
|
||||
### ptrace 系统调用
|
||||
|
||||
@ -17,59 +19,46 @@
|
||||
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
|
||||
```
|
||||
|
||||
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是......我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
|
||||
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是……我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
|
||||
|
||||
现在被跟踪者可以被调试器追踪,重要的变化发生了:
|
||||
|
||||
* 每当一个信号被传送到被调试者时,它就会停止,并且一个可以被 `wait` 系列系统调用捕获的等待事件被传送给跟踪器。
|
||||
* 每当一个信号被传送到被跟踪者时,它就会停止,并且一个可以被 `wait` 系列的系统调用捕获的等待事件被传送给跟踪器。
|
||||
* 每个 `execve` 系统调用都会导致 `SIGTRAP` 被传递给被跟踪者。(与之前的项目相结合,这意味着被跟踪者在一个 `execve` 完全发生之前停止。)
|
||||
|
||||
这意味着,一旦我们发出 `PTRACE_TRACEME` 请求并调用 `execve` 系统调用来实际在被跟踪者(进程上下文)中启动程序时,被跟踪者将立即停止,因为 `execve` 会传递一个 `SIGTRAP`,并且会被跟踪器中的等待事件捕获。我们如何继续?正如人们所期望的那样,`ptrace` 有大量的请求可以用来告诉被跟踪者可以继续:
|
||||
|
||||
|
||||
* `PTRACE_CONT`:这是最简单的。 被跟踪者运行,直到它接收到一个信号,此时等待事件被传递给跟踪器。这是最常见的实现真实世界调试器的“继续直至断点”和“永远继续”选项的方式。断点将在下面介绍。
|
||||
* `PTRACE_SYSCALL`:与 `PTRACE_CONT` 非常相似,但在进入系统调用之前以及在系统调用返回到用户空间之前停止。它可以与其他请求(我们将在本文后面介绍)结合使用来监视和修改系统调用的参数或返回值。系统调用追踪程序 `strace` 很大程度上使用这个请求来获知进程发起了哪些系统调用。
|
||||
* `PTRACE_SINGLESTEP`:这个很好理解。如果您之前使用过调试器(你会知道),此请求会执行下一条指令,然后立即停止。
|
||||
|
||||
|
||||
|
||||
我们可以通过各种各样的请求停止进程,但我们如何获得被调试者的状态?进程的状态大多是通过其寄存器捕获的,所以当然 `ptrace` 有一个请求来获得(或修改)寄存器:
|
||||
|
||||
* `PTRACE_GETREGS`:这个请求将给出被跟踪者刚刚被停止时的寄存器的状态。
|
||||
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值并使用 `PTRACE_SETREGS` 将寄存器设为新值。
|
||||
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值,并使用 `PTRACE_SETREGS` 将寄存器设为新值。
|
||||
* `PTRACE_PEEKUSER` 和 `PTRACE_POKEUSER`:这些允许从被跟踪者的 `USER` 区读取信息,这里保存了寄存器和其他有用的信息。 这可以用来修改单一寄存器,而避免使用更重的 `PTRACE_{GET,SET}REGS` 请求。
|
||||
|
||||
|
||||
|
||||
在调试器仅仅修改寄存器是不够的。调试器有时需要读取一部分内存,甚至对其进行修改。GDB 可以使用 `print` 得到一个内存位置或变量的值。`ptrace` 通过下面的方法实现这个功能:
|
||||
|
||||
* `PTRACE_PEEKTEXT` 和 `PTRACE_POKETEXT`:这些允许读取和写入被跟踪者地址空间中的一个字。当然,使用这个功能时被跟踪者要被暂停。
|
||||
|
||||
|
||||
|
||||
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑x86。
|
||||
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑 x86。
|
||||
|
||||
### 体系结构的支持
|
||||
|
||||
`ptrace` 很酷,但它是如何工作? 在前面的部分中,我们已经看到 `ptrace` 跟信号有很大关系:`SIGTRAP` 可以在单步跟踪、`execve` 之前以及系统调用前后被传送。信号可以通过一些方式产生,但我们将研究两个具体的例子,以展示信号可以被调试器用来在给定的位置停止程序(有效地创建一个断点!):
|
||||
|
||||
|
||||
* **未定义的指令**:当一个进程尝试执行一个未定义的指令,CPU 将产生一个异常。此异常通过 CPU 中断处理,内核中相应的中断处理程序被调用。这将导致一个 `SIGILL` 信号被发送给进程。 这依次导致进程被停止,跟踪器通过一个等待事件被通知,然后它可以决定后面做什么。在 x86 上,指令 `ud2` 被确保始终是未定义的。
|
||||
|
||||
* **调试中断**:前面的方法的问题是,`ud2` 指令需要占用两个字节的机器码。存在一条特殊的单字节指令能够触发一个中断,它是 `int $3`,机器码是 `0xCC`。 当该中断发出时,内核向进程发送一个 `SIGTRAP`,如前所述,跟踪器被通知。
|
||||
|
||||
|
||||
|
||||
这很好,但如何做我们胁迫的被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
|
||||
这很好,但如何我们才能胁迫被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
|
||||
|
||||
好吧,我们已经讲过了断点,那观察点呢? 当一个特定的内存位置被读或写,调试器如何停止程序? 当然你不可能为了能够读或写内存而去把每一个指令都覆盖为 `int $3`。有一组调试寄存器为了更有效的满足这个目的而被设计出来:
|
||||
|
||||
|
||||
* `DR0` 到 `DR3`:这些寄存器中的每个都包含一个地址(内存位置),调试器因为某种原因希望被跟踪者在那些地址那里停止。 其原因以掩码方式被设定在 `DR7` 寄存器中。
|
||||
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7`过时的别名。
|
||||
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7` 过时的别名。
|
||||
* `DR6`:调试状态。包含有关 `DR0` 到 `DR3` 中的哪个寄存器导致调试异常被引发的信息。这被 Linux 用来计算与 `SIGTRAP` 信号一起传递给被跟踪者的信息。
|
||||
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释DR0至DR3中指定的地址。位掩码控制监视点的尺寸(监视1,2,4或8个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
|
||||
|
||||
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释 `DR0` 至 `DR3` 中指定的地址。位掩码控制监视点的尺寸(监视1、2、4 或 8 个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
|
||||
|
||||
由于调试寄存器是进程的 `USER` 区域的一部分,调试器可以使用 `PTRACE_POKEUSER` 将值写入调试寄存器。调试寄存器只与特定进程相关,因此在进程抢占并重新获得 CPU 控制权之前,调试寄存器会被恢复。
|
||||
|
||||
@ -88,7 +77,7 @@ via: https://opensource.com/article/18/1/how-debuggers-really-work
|
||||
|
||||
作者:[Levente Kurusa][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,15 @@
|
||||
我们能否建立一个服务于用户而非广告商的社交网络?
|
||||
=====
|
||||
|
||||
> 找出 Human Connection 是如何将透明度和社区放在首位的。
|
||||
|
||||

|
||||
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的,中立的,透明的在线平台来迎接我们这个时代的挑战。
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
|
||||
|
||||
开放的原则可能会成为让我们到达那里的方法(to 校正者:这句上下文没有理解)。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们自然倾向,于乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
|
||||
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
|
||||
|
||||
@ -15,31 +17,28 @@
|
||||
|
||||
### 首先是透明
|
||||
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript, Vue, nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些对让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team (to 校正者:这里如果可以,请翻译得稍微优雅,我想不出来一个词)活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
|
||||
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
|
||||
|
||||
一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章(UN Charter)][4]和“世界人权宣言(Universal Declaration of Human Rights)”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (译者注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用<ruby>[联合国宪章][4]<rt>UN Charter</rt></ruby>和“<ruby>世界人权宣言<rt>Universal Declaration of Human Rights</rt></ruby>”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
|
||||
### 一个合作的社会
|
||||
|
||||
以一种[以社区为中心的协作方法][5]来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
|
||||
|
||||
一个抛弃了以利润为导向的算法,为广告商而不是最终用户服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并破坏(to 校正:这里译为改变较好)现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学(University Sorbonne)的国家东方语言与文明研究所(National Institute for Oriental Languages and Civilizations (INALCO) )和德国斯图加特媒体大学(Stuttgart Media University )合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动(Take Action)”领域,每个人都可以实现。
|
||||
|
||||
* “Versus” 功能是另一个定义结果的方式(to 校正者:这句话稍微注意一下)。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎<ruby>索邦大学<rt>University Sorbonne</rt></ruby>的<ruby>国家东方语言与文明研究所<rt>National Institute for Oriental Languages and Civilizations</rt></ruby>(INALCO)和德国<ruby>斯图加特媒体大学<rt>Stuttgart Media University</rt></ruby>合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“<ruby>采取行动<rt>Take Action</rt></ruby>”领域,每个人都可以实现。
|
||||
* “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
|
||||
|
||||
|
||||
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
|
||||
|
||||
[订阅我们的每周时事通讯][12]以了解有关开放组织的更多信息。
|
||||
@ -51,7 +50,7 @@ via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,60 @@
|
||||
macOS 和 Linux 的内核有什么区别
|
||||
======
|
||||
|
||||
有些人可能会认为 macOS 和 Linux 内核之间存在相似之处,因为它们可以处理类似的命令和类似的软件。有些人甚至认为苹果公司的 macOS 是基于 Linux 的。事实上是,两个内核有着截然不同的历史和特征。今天,我们来看看 macOS 和 Linux 的内核之间的区别。
|
||||
|
||||
![macOS vs Linux][1]
|
||||
|
||||
### macOS 内核的历史
|
||||
|
||||
我们将从 macOS 内核的历史开始。1985 年,由于与首席执行官 John Sculley 和董事会不和,<ruby>史蒂夫·乔布斯<rt>Steve Jobs</rt></ruby>离开了苹果公司。然后,他成立了一家名为 [NeXT][2] 的新电脑公司。乔布斯希望将一款(带有新操作系统的)新计算机快速推向市场。为了节省时间,NeXT 团队使用了卡耐基梅隆大学的 [Mach 内核][3] 和部分 BSD 代码库来创建 [NeXTSTEP 操作系统][4]。
|
||||
|
||||
NeXT 从来没有取得过财务上的成功,部分归因于乔布斯花钱的习惯,就像他还在苹果公司一样。与此同时,苹果公司曾多次试图更新其操作系统,甚至与 IBM 合作,但从未成功。1997年,苹果公司以 4.29 亿美元收购了 NeXT。作为交易的一部分,史蒂夫·乔布斯回到了苹果公司,同时 NeXTSTEP 成为了 macOS 和 iOS 的基础。
|
||||
|
||||
### Linux 内核的历史
|
||||
|
||||
与 macOS 内核不同,Linux 的创建并非源于商业尝试。相反,它是由[芬兰计算机科学专业学生<ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>于 1991 年创建的][5]。最初,内核是按照林纳斯自己的计算机的规格编写的,因为他想利用其新的 80386 处理器(的特性)。林纳斯[于 1991 年 8 月在 Usenet 上][6]发布了他的新内核代码。很快,他就收到了来自世界各地的代码和功能建议。次年,Orest Zborowski 将 X Window 系统移植到 Linux,使其能够支持图形用户界面。
|
||||
|
||||
在过去的 27 年中,Linux 已经慢慢成长并增加了不少功能。这不再是一个学生的小型项目。现在它运行在[世界上][7]大多数的[计算设备][8]和[超级计算机][9]上。不错!
|
||||
|
||||
### macOS 内核的特性
|
||||
|
||||
macOS 内核被官方称为 XNU。这个[首字母缩写词][10]代表“XNU is Not Unix”。根据 [苹果公司的 Github 页面][10],XNU 是“将卡耐基梅隆大学开发的 Mach 内核和 FreeBSD 组件整合而成的混合内核,加上用于编写驱动程序的 C++ API”。代码的 BSD 子系统部分[“在微内核系统中通常实现为用户空间的服务”][11]。Mach 部分负责底层工作,例如多任务、内存保护、虚拟内存管理、内核调试支持和控制台 I/O。
|
||||
|
||||
### Linux 内核的特性
|
||||
|
||||
虽然 macOS 内核结合了微内核([Mach][12])和宏内核([BSD][13])的特性,但 Linux 只是一个宏内核。[宏内核][14]负责管理 CPU、内存、进程间通信、设备驱动程序、文件系统和系统服务调用( LCTT 译注:原文为 system server calls,但结合 Linux 内核的构成,译者认为这里翻译成系统服务调用更合适,即 system service calls)。
|
||||
|
||||
### 用一句话总结 Linux 和 Mac 的区别
|
||||
|
||||
macOS 内核(XNU)比 Linux 历史更悠久,并且基于两个更古老一些的代码库的结合;另一方面,Linux 新一些,是从头开始编写的,并且在更多设备上使用。
|
||||
|
||||
如果您发现这篇文章很有趣,请花一点时间在社交媒体,黑客新闻或 [Reddit][15] 上分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mac-linux-difference/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
|
||||
[2]:https://en.wikipedia.org/wiki/NeXT
|
||||
[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
|
||||
[4]:https://en.wikipedia.org/wiki/NeXTSTEP
|
||||
[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
|
||||
[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
|
||||
[8]:https://www.linuxinsider.com/story/31855.html
|
||||
[9]:https://itsfoss.com/linux-supercomputers-2017/
|
||||
[10]:https://github.com/apple/darwin-xnu
|
||||
[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
|
||||
[12]:https://en.wikipedia.org/wiki/Mach_(kernel
|
||||
[13]:https://en.wikipedia.org/wiki/FreeBSD
|
||||
[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
|
||||
[15]:http://reddit.com/r/linuxusersgroup
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Give Your Linux Desktop a Stunning Makeover With Xenlism Themes
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,124 +0,0 @@
|
||||
**Translating by distant1219**
|
||||
|
||||
5 open source alternatives to Dropbox
|
||||
======
|
||||
|
||||

|
||||
|
||||
Dropbox is the 800-pound gorilla of filesharing applications. Even though it's a massively popular tool, you may choose to use an alternative.
|
||||
|
||||
Maybe that's because you're dedicated to the [open source way][1] for all the good reasons, including security and freedom, or possibly you've been spooked by data breaches. Or perhaps the pricing plan doesn't work out in your favor for the amount of storage you actually need.
|
||||
|
||||
Fortunately, there are a variety of open source filesharing applications out there that give you more storage, security, and control over your data at a far lower price than Dropbox charges. How much lower? Try free, if you're a bit tech savvy and have a Linux server to use.
|
||||
|
||||
Here are five of the best open source alternatives to Dropbox, plus a few others that you might want to consider.
|
||||
|
||||
### ownCloud
|
||||
|
||||
|
||||
|
||||
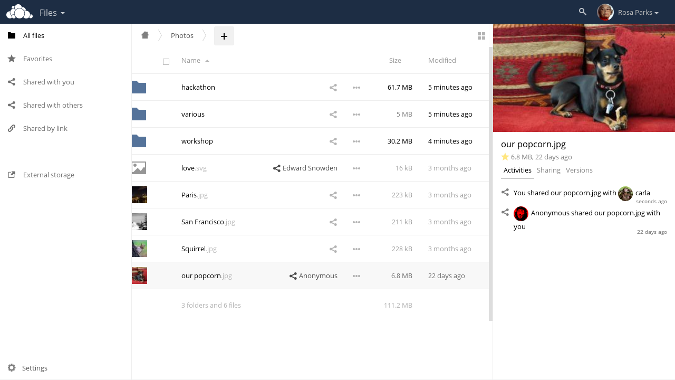
[ownCloud][2], launched in 2010, is the oldest application on this list, but don't let that fool you: It's still very popular (with over 1.5 million users, according to the company) and actively maintained by a community of 1,100 contributors, with updates released regularly.
|
||||
|
||||
Its primary features—file and folding sharing, document collaboration—are similar to Dropbox's. Its primary difference (aside from its [open source license][3]) is that your files are hosted on your private Linux server or cloud, giving users complete control over your data. (Self-hosting is a common thread among the apps on this list.)
|
||||
|
||||
With ownCloud, you can sync and access files through clients for Linux, MacOS, or Windows computers or mobile apps for Android and iOS devices, and provide password-protected links to others for collaboration or file upload/download. Data transfers are secured by end-to-end encryption (E2EE) and SSL encryption. You can also expand its functionality with a wide variety of third-party apps available in its [marketplace][4], and there is also a paid, commercially licensed enterprise edition.
|
||||
|
||||
ownCloud offers comprehensive [documentation][5], including an installation guide and manuals for users, admins, and developers, and you can access its [source code][6] in its GitHub repository.
|
||||
|
||||
### NextCloud
|
||||
|
||||
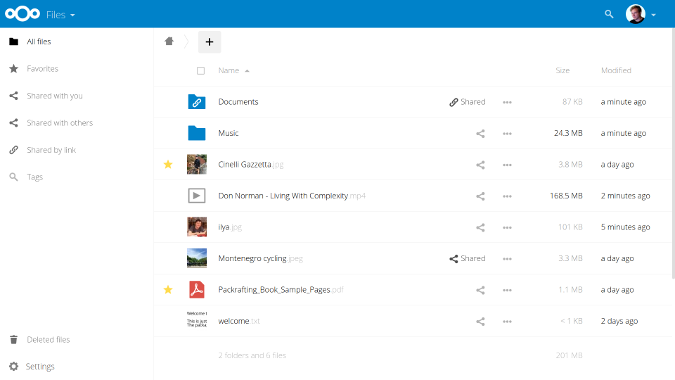
|
||||
|
||||
[NextCloud][7] spun out of ownCloud in 2016 and shares much of the same functionality. Nextcloud [touts][8] its high security and regulatory compliance as a distinguishing feature. It has HIPAA (healthcare) and GDPR (privacy) compliance features and offers extensive data-policy enforcement, encryption, user management, and auditing capabilities. It also encrypts data during transfer and at rest and integrates with mobile device management and authentication mechanisms (including LDAP/AD, single-sign-on, two-factor authentication, etc.).
|
||||
|
||||
Like the other solutions on this list, NextCloud is self-hosted, but if you don't want to roll your own NextCloud server on Linux, the company partners with several [providers][9] for setup and hosting and sells servers, appliances, and support. A [marketplace][10] offers numerous apps to extend its features.
|
||||
|
||||
NextCloud's [documentation][11] page offers thorough information for users, admins, and developers as well as links to its forums, IRC channel, and social media pages for community-based support. If you'd like to contribute, access its source code, report a bug, check out its (AGPLv3) license, or just learn more, visit the project's [GitHub repository][12].
|
||||
|
||||
### Seafile
|
||||
|
||||
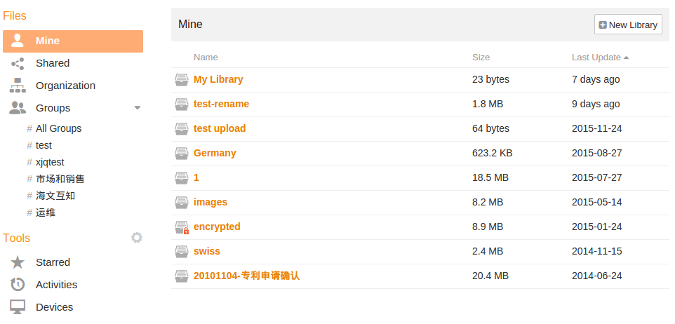
|
||||
|
||||
[Seafile][13] may not have the bells and whistles (or app ecosystem) of ownCloud or Nextcloud, but it gets the job done. Essentially, it acts as a virtual drive on your Linux server to extend your desktop storage and allow you to share files selectively with password protection and various levels of permission (i.e., read-only or read/write).
|
||||
|
||||
Its collaboration features include per-folder access control, password-protected download links, and Git-like version control and retention. Files are secured with two-factor authentication, file encryption, and AD/LDAP integration, and they're accessible from Windows, MacOS, Linux, iOS, or Android devices.
|
||||
|
||||
For more information, visit Seafile's [GitHub repository][14], [server manual][15], [wiki][16], and [forums][17]. Note that Seafile's community edition is licensed under [GPLv2][18], but its professional edition is not open source.
|
||||
|
||||
### OnionShare
|
||||
|
||||
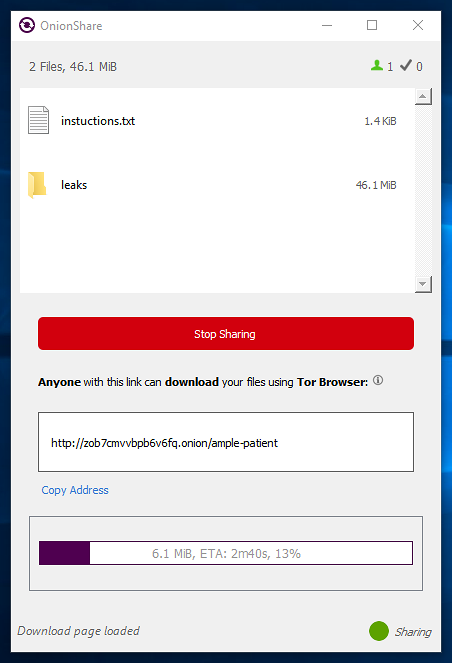
|
||||
|
||||
[OnionShare][19] is a cool app that does one thing: It allows you to share individual files or folders securely and, if you want, anonymously. There's no server to set up or maintain—all you need to do is [download and install][20] the app on MacOS, Windows, or Linux. Files are always hosted on your own computer; when you share a file, OnionShare creates a web server, makes it accessible as a Tor Onion service, and generates an unguessable .onion URL that allows the recipient to access the file via [Tor browser][21].
|
||||
|
||||
You can set limits on your fileshare, such as limiting the number of times it can be downloaded or using an auto-stop timer, which sets a strict expiration date/time after which the file is inaccessible (even if it hasn't been accessed yet).
|
||||
|
||||
OnionShare is licensed under [GPLv3][22]; for more information, check out its GitHub [repository][22], which also includes [documentation][23] that covers the features in this easy-to-use filesharing application.
|
||||
|
||||
### Pydio Cells
|
||||
|
||||
|
||||
|
||||
[Pydio Cells][24], which achieved stability in May 2018, is a complete overhaul of the Pydio filesharing application's core server code. Due to limitations with Pydio's PHP-based backend, the developers decided to rewrite the backend in the Go server language with a microservices architecture. (The frontend is still based on PHP.)
|
||||
|
||||
Pydio Cells includes the usual filesharing and version control features, as well as in-app messaging, mobile apps (Android and iOS), and a social network-style approach to collaboration. Security includes OpenID Connect-based authentication, encryption at rest, security policies, and more. Advanced features are included in the enterprise distribution, but there's plenty of power for most small and midsize businesses and home users in the community (or "Home") version.
|
||||
|
||||
You can [download][25] Pydio Cells for Linux and MacOS. For more information, check out the [documentation FAQ][26], [source code][27] repository, and [AGPLv3 license][28].
|
||||
|
||||
### Others to consider
|
||||
|
||||
If these choices don't meet your needs, you may want to consider these open source filesharing-type applications.
|
||||
|
||||
* If your main goal is to sync files between devices, rather than to share files, check out [Syncthing][29]).
|
||||
* If you're a Git fan and don't need a mobile app, you might appreciate [SparkleShare][30].
|
||||
* If you primarily want a place to aggregate all your personal data, take a look at [Cozy][31].
|
||||
* And, if you're looking for a lightweight or dedicated filesharing tool, peruse [Scott Nesbitt's review][32] of some lesser-known options.
|
||||
|
||||
|
||||
|
||||
What is your favorite open source filesharing application? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/dropbox
|
||||
|
||||
作者:[OPensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/open-source-way
|
||||
[2]:https://owncloud.org/
|
||||
[3]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[4]:https://marketplace.owncloud.com/
|
||||
[5]:https://doc.owncloud.com/
|
||||
[6]:https://github.com/owncloud
|
||||
[7]:https://nextcloud.com/
|
||||
[8]:https://nextcloud.com/secure/
|
||||
[9]:https://nextcloud.com/providers/
|
||||
[10]:https://apps.nextcloud.com/
|
||||
[11]:https://nextcloud.com/support/
|
||||
[12]:https://github.com/nextcloud
|
||||
[13]:https://www.seafile.com/en/home/
|
||||
[14]:https://github.com/haiwen/seafile
|
||||
[15]:https://manual.seafile.com/
|
||||
[16]:https://seacloud.cc/group/3/wiki/
|
||||
[17]:https://forum.seafile.com/
|
||||
[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
|
||||
[19]:https://onionshare.org/
|
||||
[20]:https://onionshare.org/#downloads
|
||||
[21]:https://www.torproject.org/
|
||||
[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
|
||||
[23]:https://github.com/micahflee/onionshare/wiki
|
||||
[24]:https://pydio.com/en
|
||||
[25]:https://pydio.com/download/
|
||||
[26]:https://pydio.com/en/docs/faq
|
||||
[27]:https://github.com/pydio/cells
|
||||
[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
|
||||
[29]:https://syncthing.net/
|
||||
[30]:http://www.sparkleshare.org/
|
||||
[31]:https://cozy.io/en/
|
||||
[32]:https://opensource.com/article/17/3/file-sharing-tools
|
||||
@ -1,294 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Intercepting and Emulating Linux System Calls with Ptrace « null program
|
||||
======
|
||||
|
||||
The `ptrace(2)` (“process trace”) system call is usually associated with debugging. It’s the primary mechanism through which native debuggers monitor debuggees on unix-like systems. It’s also the usual approach for implementing [strace][1] — system call trace. With Ptrace, tracers can pause tracees, [inspect and set registers and memory][2], monitor system calls, or even intercept system calls.
|
||||
|
||||
By intercept, I mean that the tracer can mutate system call arguments, mutate the system call return value, or even block certain system calls. Reading between the lines, this means a tracer can fully service system calls itself. This is particularly interesting because it also means **a tracer can emulate an entire foreign operating system**. This is done without any special help from the kernel beyond Ptrace.
|
||||
|
||||
The catch is that a process can only have one tracer attached at a time, so it’s not possible emulate a foreign operating system while also debugging that process with, say, GDB. The other issue is that emulated systems calls will have higher overhead.
|
||||
|
||||
For this article I’m going to focus on [Linux’s Ptrace][3] on x86-64, and I’ll be taking advantage of a few Linux-specific extensions. For the article I’ll also be omitting error checks, but the full source code listings will have them.
|
||||
|
||||
You can find runnable code for the examples in this article here:
|
||||
|
||||
**<https://github.com/skeeto/ptrace-examples>**
|
||||
|
||||
### strace
|
||||
|
||||
Before getting into the really interesting stuff, let’s start by reviewing a bare bones implementation of strace. It’s [no DTrace][4], but strace is still incredibly useful.
|
||||
|
||||
Ptrace has never been standardized. Its interface is similar across different operating systems, especially in its core functionality, but it’s still subtly different from system to system. The `ptrace(2)` prototype generally looks something like this, though the specific types may be different.
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
|
||||
```
|
||||
|
||||
The `pid` is the tracee’s process ID. While a tracee can have only one tracer attached at a time, a tracer can be attached to many tracees.
|
||||
|
||||
The `request` field selects a specific Ptrace function, just like the `ioctl(2)` interface. For strace, only two are needed:
|
||||
|
||||
* `PTRACE_TRACEME`: This process is to be traced by its parent.
|
||||
* `PTRACE_SYSCALL`: Continue, but stop at the next system call entrance or exit.
|
||||
* `PTRACE_GETREGS`: Get a copy of the tracee’s registers.
|
||||
|
||||
|
||||
|
||||
The other two fields, `addr` and `data`, serve as generic arguments for the selected Ptrace function. One or both are often ignored, in which case I pass zero.
|
||||
|
||||
The strace interface is essentially a prefix to another command.
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
|
||||
```
|
||||
|
||||
My minimal strace doesn’t have any options, so the first thing to do — assuming it has at least one argument — is `fork(2)` and `exec(2)` the tracee process on the tail of `argv`. But before loading the target program, the new process will inform the kernel that it’s going to be traced by its parent. The tracee will be paused by this Ptrace system call.
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The parent waits for the child’s `PTRACE_TRACEME` using `wait(2)`. When `wait(2)` returns, the child will be paused.
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
Before allowing the child to continue, we tell the operating system that the tracee should be terminated along with its parent. A real strace implementation may want to set other options, such as `PTRACE_O_TRACEFORK`.
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
|
||||
```
|
||||
|
||||
All that’s left is a simple, endless loop that catches on system calls one at a time. The body of the loop has four steps:
|
||||
|
||||
1. Wait for the process to enter the next system call.
|
||||
2. Print a representation of the system call.
|
||||
3. Allow the system call to execute and wait for the return.
|
||||
4. Print the system call return value.
|
||||
|
||||
|
||||
|
||||
The `PTRACE_SYSCALL` request is used in both waiting for the next system call to begin, and waiting for that system call to exit. As before, a `wait(2)` is needed to wait for the tracee to enter the desired state.
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
When `wait(2)` returns, the registers for the thread that made the system call are filled with the system call number and its arguments. However, the operating system has not yet serviced this system call. This detail will be important later.
|
||||
|
||||
The next step is to gather the system call information. This is where it gets architecture specific. On x86-64, [the system call number is passed in `rax`][5], and the arguments (up to 6) are passed in `rdi`, `rsi`, `rdx`, `r10`, `r8`, and `r9`. Reading the registers is another Ptrace call, though there’s no need to `wait(2)` since the tracee isn’t changing state.
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
|
||||
```
|
||||
|
||||
There’s one caveat. For [internal kernel purposes][6], the system call number is stored in `orig_rax` rather than `rax`. All the other system call arguments are straightforward.
|
||||
|
||||
Next it’s another `PTRACE_SYSCALL` and `wait(2)`, then another `PTRACE_GETREGS` to fetch the result. The result is stored in `rax`.
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
|
||||
```
|
||||
|
||||
The output from this simple program is very crude. There is no symbolic name for the system call and every argument is printed numerically, even if it’s a pointer to a buffer. A more complete strace would know which arguments are pointers and use `process_vm_readv(2)` to read those buffers from the tracee in order to print them appropriately.
|
||||
|
||||
However, this does lay the groundwork for system call interception.
|
||||
|
||||
### System call interception
|
||||
|
||||
Suppose we want to use Ptrace to implement something like OpenBSD’s [`pledge(2)`][7], in which [a process pledges to use only a restricted set of system calls][8]. The idea is that many programs typically have an initialization phase where they need lots of system access (opening files, binding sockets, etc.). After initialization they enter a main loop in which they processing input and only a small set of system calls are needed.
|
||||
|
||||
Before entering this main loop, a process can limit itself to the few operations that it needs. If [the program has a flaw][9] allowing it to be exploited by bad input, the pledge significantly limits what the exploit can accomplish.
|
||||
|
||||
Using the same strace model, rather than print out all system calls, we could either block certain system calls or simply terminate the tracee when it misbehaves. Termination is easy: just call `exit(2)` in the tracer. Since it’s configured to also terminate the tracee. Blocking the system call and allowing the child to continue is a little trickier.
|
||||
|
||||
The tricky part is that **there’s no way to abort a system call once it’s started**. When tracer returns from `wait(2)` on the entrance to the system call, the only way to stop a system call from happening is to terminate the tracee.
|
||||
|
||||
However, not only can we mess with the system call arguments, we can change the system call number itself, converting it to a system call that doesn’t exist. On return we can report a “friendly” `EPERM` error in `errno` [via the normal in-band signaling][10].
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This simple example only checks against a whitelist or blacklist of system calls. And there’s no nuance, such as allowing files to be opened (`open(2)`) read-only but not as writable, allowing anonymous memory maps but not non-anonymous mappings, etc. There’s also no way to the tracee to dynamically drop privileges.
|
||||
|
||||
How could the tracee communicate to the tracer? Use an artificial system call!
|
||||
|
||||
### Creating an artificial system call
|
||||
|
||||
For my new pledge-like system call — which I call `xpledge()` to distinguish it from the real thing — I picked system call number 10000, a nice high number that’s unlikely to ever be used for a real system call.
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
|
||||
```
|
||||
|
||||
Just for demonstration purposes, I put together a minuscule interface that’s not good for much in practice. It has little in common with OpenBSD’s `pledge(2)`, which uses a [string interface][11]. Actually designing robust and secure sets of privileges is really complicated, as the `pledge(2)` manpage shows. Here’s the entire interface and implementation of the system call for the tracee:
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
|
||||
```
|
||||
|
||||
If it passes zero for the argument, only a few basic system calls are allowed, including those used to allocate memory (e.g. `brk(2)`). The `PLEDGE_RDWR` bit allows [various][12] read and write system calls (`read(2)`, `readv(2)`, `pread(2)`, `preadv(2)`, etc.). The `PLEDGE_OPEN` bit allows `open(2)`.
|
||||
|
||||
To prevent privileges from being escalated back, `pledge()` blocks itself — though this also prevents dropping more privileges later down the line.
|
||||
|
||||
In the xpledge tracer, I just need to check for this system call:
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The operating system will return `ENOSYS` (Function not implemented) since this isn’t a real system call. So on the way out I overwrite this with a success (0).
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I wrote a little test program that opens `/dev/urandom`, makes a read, tries to pledge, then tries to open `/dev/urandom` a second time, then confirms it can read from the original `/dev/urandom` file descriptor. Running without a pledge tracer, the output looks like this:
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
|
||||
```
|
||||
|
||||
Making an invalid system call doesn’t crash an application. It just fails, which is a rather convenient fallback. When run under the tracer, it looks like this:
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
|
||||
```
|
||||
|
||||
The pledge succeeds but the second `fopen(3)` does not since the tracer blocked it with `EPERM`.
|
||||
|
||||
This concept could be taken much further, to, say, change file paths or return fake results. A tracer could effectively chroot its tracee, prepending some chroot path to the root of any path passed through a system call. It could even lie to the process about what user it is, claiming that it’s running as root. In fact, this is exactly how the [Fakeroot NG][13] program works.
|
||||
|
||||
### Foreign system emulation
|
||||
|
||||
Suppose you don’t just want to intercept some system calls, but all system calls. You’ve got [a binary intended to run on another operating system][14], so none of the system calls it makes will ever work.
|
||||
|
||||
You could manage all this using only what I’ve described so far. The tracer would always replace the system call number with a dummy, allow it to fail, then service the system call itself. But that’s really inefficient. That’s essentially three context switches for each system call: one to stop on the entrance, one to make the always-failing system call, and one to stop on the exit.
|
||||
|
||||
The Linux version of PTrace has had a more efficient operation for this technique since 2005: `PTRACE_SYSEMU`. PTrace stops only once per a system call, and it’s up to the tracer to service that system call before allowing the tracee to continue.
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To run binaries for the same architecture from any system with a stable (enough) system call ABI, you just need this `PTRACE_SYSEMU` tracer, a loader (to take the place of `exec(2)`), and whatever system libraries the binary needs (or only run static binaries).
|
||||
|
||||
In fact, this sounds like a fun weekend project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nullprogram.com
|
||||
[1]:https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]:http://nullprogram.com/blog/2016/09/03/
|
||||
[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]:http://nullprogram.com/blog/2018/01/17/
|
||||
[5]:http://nullprogram.com/blog/2015/05/15/
|
||||
[6]:https://stackoverflow.com/a/6469069
|
||||
[7]:https://man.openbsd.org/pledge.2
|
||||
[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]:http://nullprogram.com/blog/2017/07/19/
|
||||
[10]:http://nullprogram.com/blog/2016/09/23/
|
||||
[11]:https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]:http://nullprogram.com/blog/2017/03/01/
|
||||
[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]:http://nullprogram.com/blog/2017/11/30/
|
||||
@ -1,125 +0,0 @@
|
||||
translating-----geekpi
|
||||
|
||||
How To Upgrade Everything Using A Single Command In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
As we all know already, keeping our Linux system up-to-date involves invoking more than one package manager. Say for instance, in Ubuntu you can’t upgrade everything using “sudo apt update && sudo apt upgrade” command. This command will only upgrade the applications which are installed using APT package manager. There are chances that you might have installed some other applications using **cargo** , [**pip**][1], **npm** , **snap** , **flatpak** or [**Linuxbrew**][2] package managers. You need to use the respective package manager in order to keep them all updated. Not anymore! Say hello to **“topgrade”** , an utility to upgrade all the things in your system in one go.
|
||||
|
||||
You need not to run every package manager to update the packages. The topgrade tool resolves this problem by detecting the installed packages, tools, plugins and run their appropriate package manager to update everything in your Linux box with a single command. It is free, open source and written using **rust programming language**. It supports GNU/Linux and Mac OS X.
|
||||
|
||||
### Upgrade Everything Using A Single Command In Linux
|
||||
|
||||
The topgrade is available in AUR. So, you can install it using [**Yay**][3] helper program in any Arch-based systems.
|
||||
```
|
||||
$ yay -S topgrade
|
||||
|
||||
```
|
||||
|
||||
On other Linux distributions, you can install topgrade utility using **cargo** package manager. To install cargo package manager, refer the following link.
|
||||
|
||||
And, then run the following command to install topgrade.
|
||||
```
|
||||
$ cargo install topgrade
|
||||
|
||||
```
|
||||
|
||||
Once installed, run the topgrade to upgrade all the things in your Linux system.
|
||||
```
|
||||
$ topgrade
|
||||
|
||||
```
|
||||
|
||||
Once topgrade is invoked, it will perform the following tasks one by one. You will be asked to enter root/sudo user password wherever necessary.
|
||||
|
||||
1 Run your system’s package manager:
|
||||
|
||||
* Arch: Run **yay** or fall back to [**pacman**][4]
|
||||
* CentOS/RHEL: Run `yum upgrade`
|
||||
* Fedora – Run `dnf upgrade`
|
||||
* Debian/Ubuntu: Run `apt update && apt dist-upgrade`
|
||||
* Linux/macOS: Run `brew update && brew upgrade`
|
||||
|
||||
|
||||
|
||||
2\. Check if the following paths are tracked by Git. If so, pull them:
|
||||
|
||||
* ~/.emacs.d (Should work whether you use **Spacemacs** or a custom configuration)
|
||||
* ~/.zshrc
|
||||
* ~/.oh-my-zsh
|
||||
* ~/.tmux
|
||||
* ~/.config/fish/config.fish
|
||||
* Custom defined paths
|
||||
|
||||
|
||||
|
||||
3\. Unix: Run **zplug** update
|
||||
|
||||
4\. Unix: Upgrade **tmux** plugins with **TPM**
|
||||
|
||||
5\. Run **Cargo install-update**
|
||||
|
||||
6\. Upgrade **Emacs** packages
|
||||
|
||||
7\. Upgrade Vim packages. Works with the following plugin frameworks:
|
||||
|
||||
* NeoBundle
|
||||
* [**Vundle**][5]
|
||||
* Plug
|
||||
|
||||
|
||||
|
||||
8\. Upgrade [**NPM**][6] globally installed packages
|
||||
|
||||
9\. Upgrade **Atom** packages
|
||||
|
||||
10\. Update [**Flatpak**][7] packages
|
||||
|
||||
11\. Update [**snap**][8] packages
|
||||
|
||||
12\. **Linux:** Run **fwupdmgr** to show firmware upgrade. (View only. No upgrades will actually be performed)
|
||||
|
||||
13\. Run custom defined commands.
|
||||
|
||||
Finally, topgrade utility will run **needrestart** to restart all services. In Mac OS X, it will upgrade App Store applications.
|
||||
|
||||
Sample output from my Ubuntu 18.04 LTS test box:
|
||||
|
||||
![][10]
|
||||
|
||||
The good thing is if one task is failed, it will automatically run the next task and complete all other subsequent tasks. Finally, it will display the summary with details such as how many tasks did it run, how many succeeded and how many failed etc.
|
||||
|
||||
![][11]
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
Personally, I liked this idea of creating an utility like topgrade and upgrade everything installed with various package managers with a single command. I hope you find it useful too. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
|
||||
@ -1,59 +0,0 @@
|
||||
tranWhat is the Difference Between the macOS and Linux Kernels
|
||||
======
|
||||
Some people might think that there are similarities between the macOS and the Linux kernel because they can handle similar commands and similar software. Some people even think that Apple’s macOS is based on Linux. The truth is that both kernels have very different histories and features. Today, we will take a look at the difference between macOS and Linux kernels.
|
||||
|
||||
![macOS vs Linux][1]
|
||||
|
||||
### History of macOS Kernel
|
||||
|
||||
We will start with the history of the macOS kernel. In 1985, Steve Jobs left Apple due to a falling out with CEO John Sculley and the Apple board of directors. He then founded a new computer company named [NeXT][2]. Jobs wanted to get a new computer (with a new operating system) to market quickly. To save time, the NeXT team used the [Mach kernel][3] from Carnegie Mellon and parts of the BSD code base to created the [NeXTSTEP operating system][4].
|
||||
|
||||
NeXT never became a financial success, due in part to Jobs’ habit of spending money like he was still at Apple. Meanwhile, Apple had tried unsuccessfully on several occasions to update their operating system, even going so far as to partner with IBM. In 1997, Apple purchased NeXT for $429 million. As part of the deal, Steve Jobs returned to Apple and NeXTSTEP became the foundation of macOS and iOS.
|
||||
|
||||
### History of Linux Kernel
|
||||
|
||||
Unlike the macOS kernel, Linux was not created as part of a commercial endeavor. Instead, it was [created in 1991 by Finnish computer science student Linus Torvalds][5]. Originally, the kernel was written to the specifications of Linus’ computer because he wanted to take advantage of its new 80386 processor. Linus posted the code for his new kernel to [the Usenet in August of 1991][6]. Soon, he was receiving code and feature suggestions from all over the world. The following year Orest Zborowski ported the X Window System to Linux, giving it the ability to support a graphical user interface.
|
||||
|
||||
Over the last 27 years, Linux has slowly grown and gained features. It’s no longer a student’s small-time project. Now it runs most of the [world’s][7] [computing devices][8] and the [world’s supercomputers][9]. Not too shabby.
|
||||
|
||||
### Features of the macOS Kernel
|
||||
|
||||
The macOS kernel is officially known as XNU. The [acronym][10] stands for “XNU is Not Unix.” According to [Apple’s Github page][10], XNU is “a hybrid kernel combining the Mach kernel developed at Carnegie Mellon University with components from FreeBSD and C++ API for writing drivers”. The BSD subsystem part of the code is [“typically implemented as user-space servers in microkernel systems”][11]. The Mach part is responsible for low-level work, such as multitasking, protected memory, virtual memory management, kernel debugging support, and console I/O.
|
||||
|
||||
### Features of Linux Kernel
|
||||
|
||||
While the macOS kernel combines the feature of a microkernel ([Mach][12])) and a monolithic kernel ([BSD][13]), Linux is solely a monolithic kernel. A [monolithic kernel][14] is responsible for managing the CPU, memory, inter-process communication, device drivers, file system, and system server calls.
|
||||
|
||||
### Difference between Mac and Linux kernel in one line
|
||||
|
||||
The macOS kernel (XNU) has been around longer than Linux and was based on a combination of two even older code bases. On the other hand, Linux is newer, written from scratch, and is used on many more devices.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mac-linux-difference/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
|
||||
[2]:https://en.wikipedia.org/wiki/NeXT
|
||||
[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
|
||||
[4]:https://en.wikipedia.org/wiki/NeXTSTEP
|
||||
[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
|
||||
[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
|
||||
[8]:https://www.linuxinsider.com/story/31855.html
|
||||
[9]:https://itsfoss.com/linux-supercomputers-2017/
|
||||
[10]:https://github.com/apple/darwin-xnu
|
||||
[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
|
||||
[12]:https://en.wikipedia.org/wiki/Mach_(kernel
|
||||
[13]:https://en.wikipedia.org/wiki/FreeBSD
|
||||
[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
|
||||
[15]:http://reddit.com/r/linuxusersgroup
|
||||
@ -1,98 +0,0 @@
|
||||
Translating by SunWave...
|
||||
|
||||
How to use dd in Linux without destroying your disk
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article is excerpted from chapter 4 of [Linux in Action][1], published by Manning.
|
||||
|
||||
Whether you're trying to rescue data from a dying storage drive, backing up archives to remote storage, or making a perfect copy of an active partition somewhere else, you'll need to know how to safely and reliably copy drives and filesystems. Fortunately, `dd` is a simple and powerful image-copying tool that's been around, well, pretty much forever. And in all that time, nothing's come along that does the job better.
|
||||
|
||||
### Making perfect copies of drives and partitions
|
||||
|
||||
`dd` if you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, use `tar` or even `scp` to replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
|
||||
|
||||
There's all kinds of stuff you can do withif you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, useor evento replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
|
||||
|
||||
Using `dd`, on the other hand, can make perfect byte-for-byte images of, well, just about anything digital. But before you start flinging partitions from one end of the earth to the other, I should mention that there's some truth to that old Unix admin joke: "dd stands for disk destroyer." If you type even one wrong character in a `dd` command, you can instantly and permanently wipe out an entire drive of valuable data. And yes, spelling counts.
|
||||
|
||||
**Remember:** Before pressing that Enter key to invoke `dd`, pause and think very carefully!
|
||||
|
||||
### Basic dd operations
|
||||
|
||||
Now that you've been suitably warned, we'll start with something straightforward. Suppose you want to create an exact image of an entire disk of data that's been designated as `/dev/``sda`. You've plugged in an empty drive (ideally having the same capacity as your `/dev/``sda` system). The syntax is simple: `if=` defines the source drive and `of=` defines the file or location where you want your data saved:
|
||||
```
|
||||
# dd if=/dev/sda of=/dev/sdb
|
||||
|
||||
```
|
||||
|
||||
The next example will create an .img archive of the `/dev/``sda` drive and save it to the home directory of your user account:
|
||||
```
|
||||
# dd if=/dev/sda of=/home/username/sdadisk.img
|
||||
|
||||
```
|
||||
|
||||
Those commands created images of entire drives. You could also focus on a single partition from a drive. The next example does that and also uses `bs` to set the number of bytes to copy at a single time (4,096, in this case). Playing with the `bs` value can have an impact on the overall speed of a `dd` operation, although the ideal setting will depend on your hardware profile and other considerations.
|
||||
```
|
||||
# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
|
||||
|
||||
```
|
||||
|
||||
Restoring is simple: Effectively, you reverse the values of `if` and `of`. In this case, `if=` takes the image you want to restore, and `of=` takes the target drive to which you want to write the image:
|
||||
```
|
||||
# dd if=sdadisk.img of=/dev/sdb
|
||||
|
||||
```
|
||||
|
||||
You can also perform both the create and copy operations in one command. This example, for instance, will create a compressed image of a remote drive using SSH and save the resulting archive to your local machine:
|
||||
```
|
||||
# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
|
||||
|
||||
```
|
||||
|
||||
You should always test your archives to confirm they're working. If it's a boot drive you've created, stick it into a computer and see if it launches as expected. If it's a normal data partition, mount it to make sure the files both exist and are appropriately accessible.
|
||||
|
||||
### Wiping disks with dd
|
||||
|
||||
Years ago, I had a friend who was responsible for security at his government's overseas embassies. He once told me that each embassy under his watch was provided with an official government-issue hammer. Why? In case the facility was ever at risk of being overrun by unfriendlies, the hammer was to be used to destroy all their hard drives.
|
||||
|
||||
What's that? Why not just delete the data? You're kidding, right? Everyone knows that deleting files containing sensitive data from storage devices doesn't actually remove the data. Given enough time and motivation, nearly anything can be retrieved from virtually any digital media, with the possible exception of the ones that have been well and properly hammered.
|
||||
|
||||
You can, however, use `dd` to make it a whole lot more difficult for the bad guys to get at your old data. This command will spend some time writing millions and millions of zeros over every nook and cranny of the `/dev/sda1` partition:
|
||||
```
|
||||
# dd if=/dev/zero of=/dev/sda1
|
||||
|
||||
```
|
||||
|
||||
But it gets better. Using `/dev/``urandom` file as your source, you can write over a disk with random characters:
|
||||
```
|
||||
# dd if=/dev/urandom of=/dev/sda1
|
||||
|
||||
```
|
||||
|
||||
### Monitoring dd operations
|
||||
|
||||
Since disk or partition archiving can take a very long time, you might want to add a progress monitor to your command. Install Pipe Viewer (`sudo apt install pv` on Ubuntu) and insert it into `dd`. With `pv`, that last command might look something like this:
|
||||
```
|
||||
# dd if=/dev/urandom | pv | dd of=/dev/sda1
|
||||
|
||||
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
|
||||
|
||||
```
|
||||
|
||||
Putting off backups and disk management? With dd, you aren't left with too many excuses. It's really not difficult, but be careful. Good luck!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-use-dd-linux
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Boost your typing with emoji in Fedora 28 Workstation
|
||||
======
|
||||
|
||||
|
||||
@ -1,88 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Getting started with Perlbrew
|
||||
======
|
||||
|
||||

|
||||
|
||||
What's better than having Perl installed on your system? Having multiple Perls installed on your system! With [Perlbrew][1] you can do just that. But why—apart from surrounding yourself in Perl—would you want to do that?
|
||||
|
||||
The short answer is that different versions of Perl are… different. Application A may depend on behavior deprecated in a newer release, while Application B needs new features that weren't available last year. If you have multiple versions of Perl installed, each script can use the version that best suits it. This also comes in handy if you're a developer—you can test your application against multiple versions of Perl so that, no matter what your users are running, you know it works.
|
||||
|
||||
### Install Perlbrew
|
||||
|
||||
The other benefit is that Perlbrew installs to the user's home directory. That means each user can manage their Perl versions (and the associated CPAN packages) without having to involve the system administrators. Self-service means quicker installation for the users and gives sysadmins more time to work on the hard problems.
|
||||
|
||||
The first step is to install Perlbrew on your system. Many Linux distributions have it in the package repo already, so you're just a `dnf install perlbrew` (or whatever is the appropriate command for your distribution) away. You can also install the `App::perlbrew` module from CPAN with `cpan App::perlbrew`. Or you can download and run the installation script at [install.perlbrew.pl][2].
|
||||
|
||||
To begin using Perlbrew, run `perlbrew init`.
|
||||
|
||||
### Install a new Perl version
|
||||
|
||||
Let's say you want to try the latest development release (5.27.11 as of this writing). First, you need to install the package:
|
||||
```
|
||||
perlbrew install 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### Switch Perl version
|
||||
|
||||
Now that you have a new version installed, you can use it for just that shell:
|
||||
```
|
||||
perlbrew use 5.27.11
|
||||
|
||||
```
|
||||
|
||||
Or you can make it the default Perl version for your account (assuming you set up your profile as instructed by the output of `perlbrew init`):
|
||||
```
|
||||
perlbrew switch 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### Run a single script
|
||||
|
||||
You can run a single command against a specific version of Perl, too:
|
||||
```
|
||||
perlberew exec 5.27.11 myscript.pl
|
||||
|
||||
```
|
||||
|
||||
Or you can run a command against all your installed versions. This is particularly handy if you want to run tests against a variety of versions. In this case, specify Perl as the version:
|
||||
```
|
||||
.plperlbrew exec perl myscriptpl
|
||||
|
||||
```
|
||||
|
||||
### Install CPAN modules
|
||||
|
||||
If you want to install CPAN modules, the `cpanm` package is an easy-to-use interface that works well with Perlbrew. Install it with:
|
||||
```
|
||||
perlbrew install-cpamn
|
||||
|
||||
```
|
||||
|
||||
You can then install CPAN modules with the `cpanm` command:
|
||||
```
|
||||
cpanm CGI::simple
|
||||
|
||||
```
|
||||
|
||||
### But wait, there's more!
|
||||
|
||||
This article covers basic Perlbrew usage. There are many more features and options available. Look at the output of `perlbrew help` as a starting point, or check out the [App::perlbrew documentation][3]. What other features do you love in Perlbrew? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/perlbrew
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://perlbrew.pl/
|
||||
[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
|
||||
[3]:https://metacpan.org/pod/App::perlbrew
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Auk7F7
|
||||
|
||||
Install Microsoft Windows Fonts In Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||
|
||||
@ -1,242 +1,186 @@
|
||||
[谁是 Python 的目标受众?][40]
|
||||
谁是 Python 的目标受众?
|
||||
============================================================
|
||||
|
||||
Python 是为谁设计的?
|
||||
|
||||
* [Python 使用情况的参考][8]
|
||||
|
||||
* [CPython 主要服务于哪些受众?][9]
|
||||
|
||||
* [这些相关问题的原因是什么?][10]
|
||||
|
||||
* [适合进入 PyPI 规划的方面有哪些?][11]
|
||||
|
||||
* [当增加它到标准库中时,为什么一些 APIs 会被改变?][12]
|
||||
|
||||
* [为什么一些 API 是以临时(provisional)的形式被增加的?][13]
|
||||
|
||||
* [为什么只有一些标准库 APIs 被升级?][14]
|
||||
|
||||
* [当增加它到标准库中时,为什么一些 API 会被改变?][12]
|
||||
* [为什么一些 API 是以<ruby>临时<rt>provisional</rt></ruby>的形式被增加的?][13]
|
||||
* [为什么只有一些标准库 API 被升级?][14]
|
||||
* [标准库任何部分都有独立的版本吗?][15]
|
||||
|
||||
* [这些注意事项为什么很重要?][16]
|
||||
|
||||
几年前, 我在 python-dev 邮件列表中、活跃的 CPython 核心开发人员、以及决定参与该过程的人员中[强调][38]说,“CPython 的动作太快了也太慢了”,作为这种冲突的一个主要原因是,它们不能有效地使用他们的个人时间和精力。
|
||||
几年前, 我在 python-dev 邮件列表里面、活跃的 CPython 核心开发人员、以及决定参与该过程的人员中[强调][38]说,“CPython 的动作太快了也太慢了”,作为这种冲突的一个主要原因是,他们不能有效地使用他们的个人时间和精力。
|
||||
|
||||
我一直在考虑这种情况,在参与的这几年,我也花费了一些时间去思考这一点,在我写那篇文章的时候,我还在波音防务澳大利亚公司(Boeing Defence Australia)工作。下个月,我将离开波音进入红帽亚太(Red Hat Asia-Pacific),并且开始在大企业的[开源供应链管理][39]上获得重分发者(redistributor)级别的观点。
|
||||
我一直在考虑这种情况,在参与的这几年,我也花费了一些时间去思考这一点,在我写那篇文章的时候,我还在<ruby>波音防务澳大利亚公司<rt>Boeing Defence Australia</rt></ruby>工作。下个月,我将离开波音进入<ruby>红帽亚太<rt>Red Hat Asia-Pacific</rt></ruby>,并且开始在大企业的[开源供应链管理][39]上形成<ruby>再分发者<rt>redistributor</rt></ruby>层面的观点。
|
||||
|
||||
### [Python 使用情况的参考][17]
|
||||
### Python 使用情况的参考
|
||||
|
||||
我将分解 CPython 的使用情况如下,它虽然有些过于简化(注意,这些分类并不是很清晰,他们仅关注影响新软件特性和版本的部署不同因素):
|
||||
我尝试将 CPython 的使用情况分解如下,它虽然有些过于简化(注意,这些分类并不是很清晰,他们仅关注影响新软件特性和版本的部署不同因素):
|
||||
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不_ 写或维护软件产品。例如:
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不会去_ 写或维护软件产品。例如:
|
||||
* 澳大利亚的 [数字课程][1]
|
||||
|
||||
* Lorena A. Barba 的 [AeroPython][2]
|
||||
|
||||
* 个人的自动化爱好者的项目:主要的是软件,经常是只有软件,而且用户通常是写它的人。例如:
|
||||
* my Digital Blasphemy [image download notebook][3]
|
||||
|
||||
* Paul Fenwick's (Inter)National [Rick Astley Hotline][4]
|
||||
|
||||
* 组织(organisational)过程的自动化:主要是软件,经常是只有软件,用户是为了利益而编写它的组织。例如:
|
||||
* CPython 的 [核发工作流工具][5]
|
||||
|
||||
* Linux 发行版的开发、构建&发行工具
|
||||
|
||||
* “一劳永逸(Set-and-forget)” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中软件几乎不会升级,但是,在底层平台可能会升级。例如:
|
||||
* Paul Fenwick 的 (Inter)National [Rick Astley Hotline][4]
|
||||
* <ruby>组织<rt>organisational</rt></ruby>过程的自动化:主要是软件,经常是只有软件,用户是为了利益而编写它的组织。例如:
|
||||
* CPython 的 [核心开发工作流工具][5]
|
||||
* Linux 发行版的开发、构建 & 发行工具
|
||||
* “<ruby>一劳永逸<rt>Set-and-forget</rt></ruby>” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中该软件几乎不会升级,但是,在底层平台可能会升级。例如:
|
||||
* 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这是让人非常不安的)
|
||||
|
||||
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
|
||||
|
||||
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规更新来说要昂贵很多)
|
||||
|
||||
* 没有自动升级功能的嵌入式软件系统
|
||||
|
||||
* 持续升级的基础设施:具有健壮的持续工程化模型的软件,对于依赖和平台升级被认为是例行的,而不去关心其它的代码改变。例如:
|
||||
* Facebook 的 Python 服务基础设施
|
||||
|
||||
* 滚动发布的 Linux 分发版
|
||||
|
||||
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions等等)
|
||||
|
||||
* 间歇性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* [VFX 平台][6]
|
||||
|
||||
* 长周期支持的 Linux 分发版
|
||||
|
||||
* CPython 和 Python 标准库
|
||||
|
||||
* 基础设施管理 & 业务流程工具(比如 OpenStack、 Ansible)
|
||||
|
||||
* 硬件控制系统
|
||||
|
||||
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
|
||||
* 临时(Ad hoc)自动脚本
|
||||
|
||||
* <ruby>临时<rt>Ad hoc</rt></ruby>自动脚本
|
||||
* 被确定为 “终止” 的单用户游戏(你玩它们一次后,甚至都忘了去卸载它,或许在一个新的设备上都不打算再去安装它)
|
||||
|
||||
* 短暂的或非持久状态的单用户游戏(如果你卸载并重安装它们,你的游戏体验也不会有什么大的变化)
|
||||
|
||||
* 特定事件的应用程序(这些应用程序与特定的物理事件捆绑,一旦事件结束,这些应用程序就不再有用了)
|
||||
|
||||
* 定期使用的应用程序:部署后定期升级的软件。例如:
|
||||
* 业务管理软件
|
||||
|
||||
* 个人 & 专业的生产力应用程序(比如,Blender)
|
||||
|
||||
* 开发工具 & 服务(比如,Mercurial、 Buildbot、 Roundup)
|
||||
|
||||
* 多用户游戏,和其它明显的处于持续状态的还没有被定义为 “终止” 的游戏
|
||||
|
||||
* 有自动升级功能的嵌入式软件系统
|
||||
|
||||
* 共享的抽象层:软件组件的设计使它能够在特定的问题域有效地工作,即使你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 大多数的运行时库和归入这一类的框架(比如,Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
|
||||
|
||||
* 也适合归入这里的许多测试和类型引用工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
|
||||
* 其它应用程序的插件(比如,Blender plugins、OpenStack hardware adapters)
|
||||
|
||||
* 本身就代表了 “Python 世界” 的基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
|
||||
|
||||
### [CPython 主要服务于哪些受众?][18]
|
||||
### CPython 主要服务于哪些受众?
|
||||
|
||||
最终,CPython 和标准库的主要受众是哪些,不论什么原因,一个更多的有限的标准库和从 PyPI 安装的显式声明的第三方库的组合,提供的服务是不够的。
|
||||
最终,CPython 和标准库的主要受众是哪些,不论什么原因,比较有限的标准库和从 PyPI 安装的显式声明的第三方库的组合,所提供的服务是不够的。
|
||||
|
||||
为了更一步简化上面回顾的不同用法和部署模式,为了尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些环境中将 Python 作为一种_脚本语言_使用的,另外一种是将它用作一个_应用程序开发语言_,最终发布的是一种产品而不是他们的脚本。
|
||||
为了更进一步简化上面回顾的不同用法和部署模式,尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些环境中将 Python 作为一种_脚本语言_使用的;另外一种是将它用作一个_应用程序开发语言_,最终发布的是一种产品而不是他们的脚本。
|
||||
|
||||
当把 Python 作为一种脚本语言来使用时,它们典型的开发者特性包括:
|
||||
|
||||
* 主要的处理单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 目录和元数据文件
|
||||
|
||||
* 没有任何形式的单独的构建步骤 - 是_作为_一个脚本分发的,类似于分发一个单独的 shell 脚本的方法。
|
||||
|
||||
* 没有任何形式的单独的构建步骤 —— 是_作为_一个脚本分发的,类似于分发一个单独的 shell 脚本的方法
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境
|
||||
|
||||
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
|
||||
|
||||
* 没有单独的测试套件,使用 "通过你给定的输入,这个脚本是否给出了你期望的结果?" 这种方式来进行测试
|
||||
|
||||
* 如果在执行前需要测试,它将以 “dry run” 和 “预览” 模式来向用户展示软件_将_怎样运行
|
||||
|
||||
* 没有单独的测试套件,使用“通过你给定的输入,这个脚本是否给出了你期望的结果?” 这种方式来进行测试
|
||||
* 如果在执行前需要测试,它将以 “试运行” 和 “预览” 模式来向用户展示软件_将_怎样运行
|
||||
* 如果可以完全使用静态代码分析工具,它是通过集成进用户的软件开发环境的,而不是为个别的脚本单独设置的。
|
||||
|
||||
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
|
||||
|
||||
* 主要的工作单元是由 Python 的目录和元数据文件组成的,而不是单个 Python 文件
|
||||
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,即使是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档
|
||||
|
||||
* 是否有独立的安装步骤去预处理将要使用的应用程序,取决于应用程序是如何打包的,和支持的目标环境
|
||||
|
||||
* 外部的依赖直接在项目目录中的一个元数据文件中表示(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),或作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
|
||||
|
||||
* 存在一个独立的测试套件,或者作为一个 Python API 的一个测试单元、功能接口的集成测试、或者是两者的一个结合
|
||||
|
||||
* 静态分析工具的使用是在项目级配置的,作为测试管理的一部分,而不是依赖
|
||||
|
||||
作为以上分类的一个结果,CPython 和标准库最终提供的主要用途是,在合适的 CPython 特性发布后3 - 5年,为教育和临时(ad hoc)的 Python 脚本环境的呈现的功能,定义重新分发的独立基准。
|
||||
作为以上分类的一个结果,CPython 和标准库最终提供的主要用途是,在合适的 CPython 特性发布后 3 - 5 年,为教育和<ruby>临时<rt>ad hoc</rt></ruby>的 Python 脚本环境呈现的功能,定义重新分发的独立基准。
|
||||
|
||||
对于临时(ad hoc)脚本使用的情况,这个 3-5 年的延迟是由于新版本重分发给用户的延迟组成的,以及那些重分发版的用户花在修改他们的标准操作环境上的时间。
|
||||
对于<ruby>临时<rt>ad hoc</rt></ruby>脚本使用的情况,这个 3 - 5 年的延迟是由于新版本重分发给用户的延迟造成的,以及那些再分发版的用户花在修改他们的标准操作环境上的时间。
|
||||
|
||||
在教育环境中的情况,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
|
||||
|
||||
### [这些相关问题的原因是什么?][19]
|
||||
### 这些相关问题的原因是什么?
|
||||
|
||||
这篇文章很大程序上是受 Twitter 上 [我的评论][20] 的讨论鼓舞的,定义在 [PEP 411][21] 中引用临时(Provisional)的 API 的情形,作为一个开源项目发行的例子,一个真实的被邀请用户,作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
这篇文章很大程序上是受 Twitter 上对 [我的这个评论][20] 的讨论鼓舞的,它援引了定义在 [PEP 411][21] 中<ruby>临时<rt>Provisional</rt></ruby> API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
|
||||
这些回复包括一些在更高级别的库中支持的临时(Provisional) API 的一些相关的沮丧的表述,这些库没有临时(Provisional)状态的传递,以及因此而被限制为只有最新版本的临时(Provisional) API 支持这些相关特性,而不是任何的早期迭代版本。
|
||||
这些回复包括一些在更高级别的库中支持的临时 API 的困难程度的一些沮丧表述,这些库没有临时状态的传递,以及因此而被限制为只有临时 API 的最新版本支持这些相关特性,而没有任何的早期迭代版本。
|
||||
|
||||
我的 [主要反应][22] 是去建议,开源提供者应该努力加强他们需要的有限支持,以加强他们的维护工作的可持续性。这意味着,如果支持老版本的临时(Provisional) API 是非常痛苦的,然后,只有项目开发人员自己需要时,或者,有人为此支付费用时,他们才会去提供支持。这类似于我的观点,志愿者提供的项目是否应该免费支持老的商业的长周期支持的 Python 发行版,这对他们来说是非常麻烦的事,我[不认他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的习以为常的惯性,而不是真正的需求(真正的需求,它应该去支付费用来解决问题)
|
||||
我的 [主要反应][22] 是去建议,开源提供者应该努力加强他们需要的有限支持,以加强他们的维护工作的可持续性。这意味着,如果支持老版本的临时 API 是非常痛苦的,然后,只有项目开发人员自己需要时,或者,有人为此支付费用时,他们才会去提供支持。这类似于我的观点,志愿者提供的项目是否应该免费支持老的商业的长周期支持的 Python 版本,这对他们来说是非常麻烦的事,我[不认他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的、习以为常的惯性,而不是真正的需求(真正的需求,它应该去支付费用来解决问题)
|
||||
|
||||
然而,我的[第二个反应][24]是,去认识到这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中 2011 的一篇年的文章中,以及在 Python 3 问答的回答中 [在这里][25]、[这里][26]、和[这里][27],和在去年的 [Python 包生态系统][28]上的一篇文章中的一小部分),我从来没有真实尝试直接去解释过它对标准库设计过程中的影响。
|
||||
|
||||
如果没有这些背景,设计过程中的一些方面,如临时(Provisional) API 的介绍,或者是受到不同的启发(inspired-by-not-the-same-as)的介绍,看起来似乎是很荒谬的,因为它们似乎是在试图标准化 API,而实际上并没有对 API 进行标准化。
|
||||
如果没有这些背景,设计过程中的一些方面,如临时 API 的介绍,或者是<ruby>受到不同的启发<rt>inspired-by-not-the-same-as</rt></ruby>的介绍,看起来似乎是很荒谬的,因为它们似乎是在试图标准化 API,而实际上并没有对 API 进行标准化。
|
||||
|
||||
### [适合进入 PyPI 规划的方面有哪些?][29]
|
||||
### 适合进入 PyPI 规划的方面有哪些?
|
||||
|
||||
提交给 python-ideas 或 python-dev 的_任何_建议的第一个门槛就是,清楚地回答这个问题,“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,但通过他们得到了几个共同的主题:
|
||||
|
||||
* 大多数新手可能经常是从互联网上去 “复制粘贴” 错误的建议,而不是去下载一个合适的第三方库。(比如,这就是为什么存在 `secrets` 库的原因:使得很少的人去使用 `random` 模块,因为安全敏感的原因,这是用于游戏和统计模拟的)
|
||||
提交给 python-ideas 或 python-dev 的_任何_建议的第一个门槛就是,清楚地回答这个问题,“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,但有几个常见的方面可以考虑:
|
||||
|
||||
* 大多数新手可能经常是从互联网上去 “复制粘贴” 错误的指导,而不是去下载一个合适的第三方库。(比如,这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,因为安全敏感的原因,这是用于游戏和统计模拟的)
|
||||
* 这个模块是用于提供一个实现的参考,并去允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
|
||||
|
||||
* 这个模块是用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
|
||||
|
||||
* 这个模块是被设计去支持语言之外的一些语法(比如,`contextlib`、`asyncio` 和 `typing` 模块,就是这种情况)
|
||||
|
||||
* 这个模块只是普通的临时(ad hoc)脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
|
||||
|
||||
* 这个模块只是普通的临时的脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
|
||||
* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你不会用它来做全部的统计分析)
|
||||
|
||||
通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足够转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的 Python 开发人员的经验有所改提升?”
|
||||
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的介绍也明确地告诉分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的介绍也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
|
||||
### [当增加它到标准库中时,为什么一些 APIs 会被改变?][30]
|
||||
### 当增加它到标准库中时,为什么一些 API 会被改变?
|
||||
|
||||
现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上增加进行的是重新设计和重新实现的 API,只是它参照了现有 API 的用户体验,但是,根据另外的设计参考,删除或修改了一些细节,和附属于语言参考实现部分的权限。
|
||||
|
||||
例如,不像广受欢迎的第三方库的前身 `path.py`,`pathlib` 并_不_规定字符串子类,而是独立的类型。作为解决文件互操作性问题的结果,是定义了文件系统路径协议,它允许与文件系统路径一起使用的接口,去使用更大范围的对象。
|
||||
例如,不像第三方库的广受欢迎的前身 `path.py`,`pathlib` 并_没有_定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许与文件系统路径一起使用的接口,去使用更大范围的对象。
|
||||
|
||||
为 `ipaddress` 模块设计的 API 是为教学 IP 地址概念,从定义的地址和网络中,为显式的单独主机接口调整的(IP 地址关联到特定的 IP 网络),为了提供一个最佳的教学工具,而最原始的 “ipaddr” 模块中,使用网络术语的方式不那么严谨。
|
||||
为 `ipaddress` 模块设计的 API 将地址和网络的定义,调整为显式的单独主机接口定义(IP 地址关联到特定的 IP 网络),是为教学 IP 地址概念而提供的一个最佳的教学工具,而最原始的 `ipaddr` 模块中,使用网络术语的方式不那么严格。
|
||||
|
||||
在其它情况下,标准库被构建为多种现有方法的一个综合,而且,还有可能依赖于定义现有库的 API 时不存在的特性。应用于 `asyncio` 和 `typing` 模块的所有的这些考虑,虽然后来考虑适用于 `dataclasses` 的 API 被认为是 PEP 557 (它可以被总结为 “像属性一样,但是使用变量注释作为字段声明”)。
|
||||
在其它情况下,标准库被构建为多种现有方法的一个综合,而且,还有可能依赖于定义现有库的 API 时所不存在的特性。对于 `asyncio` 和 `typing` 模块就有这些考虑因素,虽然后来对 `dataclasses` API 的考虑因素被放到了 PEP 557 (它可以被总结为 “像属性一样,但是使用变量注释作为字段声明”)。
|
||||
|
||||
这类改变的工作原理是,这类库不会消失,而且,它们的维护者经常并不关心与标准库相关的限制(特别是,相对缓慢的发行节奏)。在这种情况下,对于标准库版本的文档来说,使用 “See Also” 链接指向原始模块是很常见的,特别是,如果第三方版本提供了标准库模块中忽略的其他特性和灵活性时。
|
||||
|
||||
### [为什么一些 API 是以临时(provisional)的形式被增加的?][31]
|
||||
### 为什么一些 API 是以临时的形式被增加的?
|
||||
|
||||
虽然 CPython 确实设置了 API 的弃用策略,但我们通常不希望在没有令人信服的理由的情况下去使用它(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
虽然 CPython 确实设置了 API 的弃用策略,但我们通常不希望在没有令人信服的理由的情况下去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
|
||||
然而,当增加一个受已有的第三方启发去设计的而不是去拷贝的新的 API 时,在设计实践中,有些设计实践可能会出现问题,这比平常的风险要高。
|
||||
然而,当增加一个受已有的第三方启发去设计的而不是去拷贝的新 API 时,在设计实践中,有些设计实践可能会出现问题,这比平常的风险要高。
|
||||
|
||||
当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时(provisional),表示保守的终端用户可以希望避免完全依赖他们,并且,共享抽象层的开发者可能希望考虑,对他们准备支持的临时(provisional) API 的版本实施比平时更严格的限制。
|
||||
当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时(`provisional`),表示保守的终端用户要避免完全依赖它们,并且,共享抽象层的开发者可能希望考虑,对他们准备支持的临时 API 的版本实施比平时更严格的限制。
|
||||
|
||||
### [为什么只有一些标准库 APIs 被升级?][32]
|
||||
### 为什么只有一些标准库 API 被升级?
|
||||
|
||||
这里简短的回答升级的主要 APIs 有哪些?:
|
||||
这里简短的回答得到升级的主要 API 有哪些?:
|
||||
|
||||
* 不适合外部因素驱动的补充更新
|
||||
|
||||
* 无论是临时(ad hoc)脚本使用情况,还是为促进将来的多个第三方解决方案之间的互操作性,都有明显好外的
|
||||
|
||||
* 无论是临时脚本使用情况,还是为促进将来的多个第三方解决方案之间的互操作性,都有明显好处的
|
||||
* 对这方面感兴趣的人提交了一个可接受的建议
|
||||
|
||||
如果一个用于应用程序开发的模块存在一个非常明显的限制(limitations),比如,`datetime`,如果重分发版通过替代一个现成的第三方模块有所改善,比如,`requests`,或者,如果标准库的发布节奏与需要的有问题的包之间有真正的冲突,比如,`certifi`,那么,计划对标准库版本进行改变的因素将显著减少。
|
||||
如果一个用于应用程序开发的模块存在一个非常明显的限制,比如,`datetime`,如果重分发版通过替代一个现成的第三方模块有所改善,比如,`requests`,或者,如果标准库的发布节奏与所需要的包之间真的存在冲突,比如,`certifi`,那么,计划对标准库版本进行改变的因素将显著减少。
|
||||
|
||||
从本质上说,这和关于 PyPI 上面的问题是相反的:因为,PyPI 分发机制对增强应用程序开发人员经验来说,通常_是_足够好的,这样的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为缺省提供的一部分。
|
||||
从本质上说,这和关于 PyPI 上面的问题是相反的:因为,PyPI 分发机制对增强应用程序开发人员的体验来说,通常_是_足够好的,这样的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为缺省提供的一部分。
|
||||
|
||||
当改变后的能力(capabilities)假设在 3-5 年内缺省出现时被认为是有价值的,才会将这些改变进入到 CPython 和标准库中。
|
||||
当改变后的能力假设在 3-5 年内缺省出现时被认为是有价值的,才会将这些改变进入到 CPython 和标准库中。
|
||||
|
||||
### [标准库任何部分都有独立的版本吗?][33]
|
||||
### 标准库任何部分都有独立的版本吗?
|
||||
|
||||
是的,它就像是 `ensurepip` 使用的捆绑模式( CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
|
||||
是的,它就像是 `ensurepip` 使用的捆绑模式(CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
|
||||
|
||||
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
|
||||
|
||||
这种处理方式的其它可能的候选对象是 Tcl/Tk graphics 捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成安装可选项。
|
||||
这种处理方式的其它可能的候选者是 Tcl/Tk 图形捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成可选安装项。
|
||||
|
||||
### [这些注意事项为什么很重要?][34]
|
||||
### 这些注意事项为什么很重要?
|
||||
|
||||
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
从最本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
|
||||
写一些临时(ad hoc)脚本和为学生设计一些教学习题的人,通常不会认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师、等等。
|
||||
写一些临时脚本和为学生设计一些教学习题的人,通常不会认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师等等。
|
||||
|
||||
当所有我们的担心是,语言是开发人员的经验时,那么,我们可以简单假设人们知道一些什么,他们使用的工具,所遵循的开发流程,以及构建和部署他们软件的方法。
|
||||
当我们所有的担心是,语言是开发人员的经验时,那么,我们可以简单假设人们知道一些什么,他们使用的工具,所遵循的开发流程,以及构建和部署他们软件的方法。
|
||||
|
||||
当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在一个项目中去平衡两种需求,就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
|
||||
|
||||
这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是指出添加到 Python 标准库中的看上去很荒谬的特性的最合理的反应(reaction),它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此,它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是指出添加到 Python 标准库中的看上去很荒谬的特性的最合理的反应,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此,它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan ][a]
|
||||
作者:[Nick Coghlan][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
可代替Dropbox的5个开源软件
|
||||
=====
|
||||

|
||||
|
||||
Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
|
||||
|
||||
出于所有的好的原因, 包括安全和自由,这使你决定用[开源方式][1]。或许你已经被数据泄露吓坏了。或者定价计划不能满足你实际需要的存储量。
|
||||
|
||||
幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
|
||||
|
||||
这里有5个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
|
||||
|
||||
### ownCloud
|
||||
|
||||

|
||||
|
||||
[ownCloud][2]发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据公司统计,有超过 150 万用户),并且由 1100 个参与者的社区积极维护, 定期发布更新。
|
||||
|
||||
它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议][3])是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
|
||||
|
||||
使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它[marketplace][4]中的各种各样的第三方应用来扩展它的功能。当然,他也提供付费的,商业许可的企业版本。
|
||||
|
||||
ownCloud 提供了详尽的[文档][5],包括安装指南和这对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码][6]。
|
||||
|
||||
### NextCloud
|
||||
|
||||

|
||||
|
||||
[NextCloud][7]在2016年从 ownCloud 脱离出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵守作为它们的一个独特的[推崇的卖点][8]。它具有 HIPAA (healthcare) 和 GDPR (隐私) 法规遵守功能, 并提供广泛的数据政策执行、加密、用户管理和审核功能。它还在传输和暂停期间对数据进行加密, 并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
|
||||
像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,公司与几个[提供商][9]伙伴合作,提供安装和托管, 并销售服务器、设备和服务支持。
|
||||
在[marketplace][10]中提供了大量的apps来扩展它的功能。
|
||||
|
||||
NextCloud 的[文档][11]为用户、管理员和开发者提供了详细的信息,并且向它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码,报告一个错误,查看它的 AGPLv3 许可,或者通过它的[GitHub 项目主页][12]了解更多。
|
||||
### Seafile
|
||||
|
||||

|
||||
与ownCloud或NextCloud相比,[Seafile][13]或许没有花里胡哨的卖点(或者 app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器, 以扩展你的桌面存储, 并允许你有选择地使用密码保护和各种级别的权限 (即只读或读写) 共享文件。
|
||||
|
||||
它的协作的功能包括文件夹权限控制,密码保护的下载链接和像Git一样的版本控制和保留。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护, 并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
|
||||
|
||||
更多详细信息, 请访问 Seafile 的[GitHub仓库][14]、[服务手册][15]、[wiki][16]和[论坛][17]。请注意, Seafile 的社区版在[GPLv2][18]下获得许可, 但其专业版不是开源的。
|
||||
### OnionShare
|
||||
|
||||

|
||||
|
||||
[OnionShare][19]是一个很酷的应用: 如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装][20] 无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时, OnionShare创建一个 web 服务器, 使其可作为 Tor 洋葱服务访问, 并生成一个不可猜测的 .onion URL, 这个URL允许收件人通过[ Tor 浏览器][21]获取文件。
|
||||
|
||||
你可以设置文件共享的限制, 例如限制可以下载的次数或使用自动停止计时器, 这会设置一个严格的过期日期/时间,超过这个期限便不可访问 (即使尚未访问该文件)。
|
||||
|
||||
OnionShare 在 [GPLv3][22] 之下被许可; 有关详细信息, 请查阅其 [GitHub 仓库][22], 其中还包括[文档][23], 介绍了这个易用文件共享软件的特点。
|
||||
|
||||
### Pydio Cells
|
||||
|
||||

|
||||
|
||||
[Pydio Cells][24]在2018年5月推出了稳定版, 是对 Pydio 共享应用程序的核心服务器代码的全面检修。由于 Pydio 的基于 PHP 的后端的限制, 开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
|
||||
|
||||
Pydio Cells 包括通常的共享和版本控制功能, 以及应用程序中的消息接受、移动应用程序 (Android 和 iOS), 以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能, 但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
|
||||
|
||||
您可以 在Linux 和 MacOS[下载][25] Pydio Cells。有关详细信息, 请查阅 [文档常见问题][26]、[源码库][27] 和 [AGPLv3 许可证][28]
|
||||
|
||||
### 其他
|
||||
如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
|
||||
* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing][29]。
|
||||
* 如果你是一个Git的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare][30]。
|
||||
* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy][31]。
|
||||
* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review][32]——一个罕为人知的工具。
|
||||
|
||||
|
||||
哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/dropbox
|
||||
|
||||
作者:[OPensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/open-source-way
|
||||
[2]:https://owncloud.org/
|
||||
[3]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[4]:https://marketplace.owncloud.com/
|
||||
[5]:https://doc.owncloud.com/
|
||||
[6]:https://github.com/owncloud
|
||||
[7]:https://nextcloud.com/
|
||||
[8]:https://nextcloud.com/secure/
|
||||
[9]:https://nextcloud.com/providers/
|
||||
[10]:https://apps.nextcloud.com/
|
||||
[11]:https://nextcloud.com/support/
|
||||
[12]:https://github.com/nextcloud
|
||||
[13]:https://www.seafile.com/en/home/
|
||||
[14]:https://github.com/haiwen/seafile
|
||||
[15]:https://manual.seafile.com/
|
||||
[16]:https://seacloud.cc/group/3/wiki/
|
||||
[17]:https://forum.seafile.com/
|
||||
[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
|
||||
[19]:https://onionshare.org/
|
||||
[20]:https://onionshare.org/#downloads
|
||||
[21]:https://www.torproject.org/
|
||||
[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
|
||||
[23]:https://github.com/micahflee/onionshare/wiki
|
||||
[24]:https://pydio.com/en
|
||||
[25]:https://pydio.com/download/
|
||||
[26]:https://pydio.com/en/docs/faq
|
||||
[27]:https://github.com/pydio/cells
|
||||
[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
|
||||
[29]:https://syncthing.net/
|
||||
[30]:http://www.sparkleshare.org/
|
||||
[31]:https://cozy.io/en/
|
||||
[32]:https://opensource.com/article/17/3/file-sharing-tools
|
||||
@ -0,0 +1,293 @@
|
||||
使用 Ptrace 去监听和仿真 Linux 系统调用 « null program
|
||||
======
|
||||
|
||||
`ptrace(2)`(”进程跟踪“)系统调用通常都与调试有关。它是类 Unix 系统上通过原生调试器监测调试进程的主要机制。它也是实现 [strace][1](系统调用跟踪)的常见方法。使用 Ptrace,跟踪器可以暂停跟踪过程,[检查和设置寄存器和内存][2],监视系统调用,甚至可以监听系统调用。
|
||||
|
||||
通过监听功能,意味着跟踪器可以修改系统调用参数,修改系统调用的返回值,甚至监听某些系统调用。言外之意就是,一个跟踪器可以完全服务于系统调用本身。这是件非常有趣的事,因为这意味着**一个跟踪器可以仿真一个完整的外部操作系统**,而这些都是在没有得到内核任何帮助的情况下由 Ptrace 实现的。
|
||||
|
||||
问题是,在同一时间一个进程只能被一个跟踪器附着,因此在那个进程的调试期间,不可能再使用诸如 GDB 这样的工具去仿真一个外部操作系统。另外的问题是,仿真系统调用的开销非常高。
|
||||
|
||||
在本文中,我们将专注于 x86-64 [Linux 的 Ptrace][3],并将使用一些 Linux 专用的扩展。同时,在本文中,我们将忽略掉一些错误检查,但是完整的源代码仍然会包含这些错误检查。
|
||||
|
||||
本文中的可直接运行的示例代码在这里:
|
||||
|
||||
**<https://github.com/skeeto/ptrace-examples>**
|
||||
|
||||
### strace
|
||||
|
||||
在进入到最有趣的部分之前,我们先从回顾 strace 的基本实现来开始。它不是 [DTrace][4],但 strace 仍然非常有用。
|
||||
|
||||
Ptrace 还没有被标准化。它的界面在不同的操作系统上非常类似,尤其是在核心功能方面,但是在不同的系统之间仍然存在细微的差别。`ptrace(2)` 的样子看起来应该像下面这样,但特定的类型可能有些差别。
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
|
||||
```
|
||||
|
||||
`pid` 是跟踪的进程 ID。虽然**同一个时间**只有一个跟踪器可以附着到进程上,但是一个跟踪器可以附着跟踪多个进程。
|
||||
|
||||
`request` 字段选择一个具体的 Ptrace 函数,比如 `ioctl(2)` 接口。对于 strace,只需要两个:
|
||||
|
||||
* `PTRACE_TRACEME`:这个进程被它的父进程跟踪。
|
||||
* `PTRACE_SYSCALL`:继续跟踪,但是在下一下系统调用入口或出口时停止。
|
||||
* `PTRACE_GETREGS`:取得被跟踪进程的寄存器内容副本。
|
||||
|
||||
|
||||
|
||||
另外两个字段,`addr` 和 `data`,作为所选的 Ptrace 函数的一般参数。一般情况下,可以忽略一个或全部忽略,在那种情况下,传递零个参数。
|
||||
|
||||
strace 接口实质上是另一个命令的前缀。
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
|
||||
```
|
||||
|
||||
最小化的 strace 不需要任何选项,因此需要做的第一件事情是 — 假设它至少有一个参数 — 在 `argv` 尾部的 `fork(2)` 和 `exec(2)` 被跟踪进程。但是在加载目标程序之前,新的进程将告知内核,目标程序将被它的父进程继续跟踪。被跟踪进程将被这个 Ptrace 系统调用暂停。
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
父进程使用 `wait(2)` 等待子进程的 `PTRACE_TRACEME`,当 `wait(2)` 返回后,子进程将被暂停。
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
在允许子进程继续运行之前,我们告诉操作系统,被跟踪进程被它的父进程的跟踪应该被终止。一个真实的 strace 实现可能会设置其它的选择,比如: `PTRACE_O_TRACEFORK`。
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
|
||||
```
|
||||
|
||||
剩余部分就是一个简单的、无休止的循环了,每循环一次捕获一个系统调用。循环体总共有四步:
|
||||
|
||||
1. 等待进程进入下一个系统调用。
|
||||
2. 输出一个系统调用的描述。
|
||||
3. 允许系统调用去运行和等待返回。
|
||||
4. 输出系统调用返回值。
|
||||
|
||||
|
||||
|
||||
`PTRACE_SYSCALL` 要求用于等待下一个系统调用时开始,和等待那个系统调用去退出。和前面一样,需要一个 `wait(2)` 去等待跟踪进入期望的状态。
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
当 `wait(2)` 返回时,线程寄存器中写入了被系统调用所产生的系统调用号和它的参数。尽管如此,操作系统将不再为这个系统调用提供服务。线程寄存器中的详细内容对后续操作很重要。
|
||||
|
||||
接下来的一步是采集系统调用信息。这是得到特定系统架构的地方。在 x86-64 上,[系统调用号是在 `rax` 中传递的][5],而参数(最多 6 个)是在 `rdi`、`rsi`、`rdx`、`r10`、`r8`、和 `r9` 中传递的。另外的 Ptrace 调用将读取这些寄存器,不过这里再也不需要 `wait(2)` 了,因为跟踪状态再也不会发生变化了。
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
|
||||
```
|
||||
|
||||
这里有一个敬告。由于 [内核的内部用途][6],系统调用号是保存在 `orig_rax` 中而不是 `rax` 中。而所有的其它系统调用参数都是非常简单明了的。
|
||||
|
||||
接下来是它的另一个 `PTRACE_SYSCALL` 和 `wait(2)`,然后是另一个 `PTRACE_GETREGS` 去获取结果。结果保存在 `rax` 中。
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
|
||||
```
|
||||
|
||||
这个简单程序的输出也是非常粗糙的。这里的系统调用都没有符号名,并且所有的参数都是以数字形式输出,甚至是一个指向缓冲区的指针。更完整的 strace 输出将能知道哪个参数是指针,以及 `process_vm_readv(2)` 为了从跟踪中正确输出内容而读取了哪些缓冲区。
|
||||
|
||||
然后,这些仅仅是系统调用监听的基础工作。
|
||||
|
||||
### 系统调用监听
|
||||
|
||||
假设我们想使用 Ptrace 去实现如 OpenBSD 的 [`pledge(2)`][7] 这样的功能,它是 [一个进程承诺只使用一套受限的系统调用][8]。初步想法是,许多程序一般都有一个初始化阶段,这个阶段它们都需要进行许多的系统访问(比如,打开文件、绑定套接字、等等)。初始化完成以后,它们进行一个主循环,在主循环中它们处理输入,并且仅使用所需的、很少的一套系统调用。
|
||||
|
||||
在进入主循环之前,可以限制一个进程只能运行它自己所需要的几个操作。如果 [程序有 Bug][9],允许通过恶意的输入去利用这个 Bug,这个承诺可以有效地限制漏洞利用的实现。
|
||||
|
||||
使用与 strace 相同的模型,但不是输出所有的系统调用,我们既能够拦截某些系统调用,也可以在它的行为异常时简单地终止被跟踪进程。终止它很容易:只需要在跟踪器中调用 `exit(2)`。因此,它也可以被设置为去终止被跟踪进程。拦截系统调用和允许子进程继续运行都只是些雕虫小技而已。
|
||||
|
||||
最棘手的部分是**当系统调用启动后没有办法去中断它**。进入系统调用之后,当跟踪器从 `wait(2)` 中返回,停止一个系统调用的仅有方式是,发生被跟踪进程终止的情况。
|
||||
|
||||
然而,我们不仅可以“搞乱”系统调用的参数,也可以改变系统调用号本身,将它修改为一个不存在的系统调用。返回时,在 `errno` 中 [通过正常的内部信号][10],我们就可以报告一个“友好的”错误信息。
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个简单的示例只是检查了系统调用是否违反白名单或黑名单。而它们在这里并没有差别,比如,允许文件以只读而不是读写方式打开(`open(2)`),允许匿名内存映射但不允许非匿名映射等等。但是这里仍然没有办法去动态撤销被跟踪进程的权限。
|
||||
|
||||
跟踪器与被跟踪进程如何沟通?使用人为的系统调用!
|
||||
|
||||
### 创建一个人为的系统调用
|
||||
|
||||
对于我的这个类似于 pledge 的系统调用 — 我可以通过调用 `xpledge()` 将它与真实的系统调用区分开 — 我设置 10000 作为它的系统调用号,这是一个非常大的数字,真实的系统调用中从来不会用到它。
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
|
||||
```
|
||||
|
||||
为演示需要,我同时构建了一个非常小的界面,这在实践中并不是个好主意。它与 OpenBSD 的 `pledge(2)` 稍有一些相似之处,它使用了一个 [字符串界面][11]。事实上,设计一个健壮且安全的权限集是非常复杂的,正如在 `pledge(2)` 的手册页面上所显示的那样。下面是对被跟踪进程的完整界面和系统调用的实现:
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
|
||||
```
|
||||
|
||||
如果给它传递零个参数,仅允许一些基本的系统调用,包括那些用于去分配内存的系统调用(比如 `brk(2)`)。 `PLEDGE_RDWR` 位允许 [各种][12] 读和写的系统调用(`read(2)`、`readv(2)`、`pread(2)`、`preadv(2)` 等等)。`PLEDGE_OPEN` 位允许 `open(2)`。
|
||||
|
||||
为防止发生提升权限的行为,`pledge()` 会拦截它自己 — 但这样也防止了权限撤销,以后再细说这方面内容。
|
||||
|
||||
在 xpledge 跟踪器中,我需要去检查这个系统调用:
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
操作系统将返回 `ENOSYS`(因为函数还没有实现),因此它不是一个真实的系统调用。为此在退出时我用一个 `success (0)` 去覆写它。
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我写了一小段测试程序去打开 `/dev/urandom`,做一个读操作,尝试去承诺后,我第二次打开 `/dev/urandom`,然后确认它能够读取原始的 `/dev/urandom` 文件描述符。在没有承诺跟踪器的情况下运行,输出如下:
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
|
||||
```
|
||||
|
||||
做一个无效的系统调用并不会让应用程序崩溃。它只是失败,这是一个很方便的返回方式。当它在跟踪器下运行时,它的输出如下:
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
|
||||
```
|
||||
|
||||
这个承诺很成功,第二次的 `fopen(3)` 并没有实现,因为跟踪器用一个 `EPERM` 拦截了它。
|
||||
|
||||
可以将这种思路进一步发扬光大,比如,改变文件路径或返回一个假的结果。一个跟踪器可以很高效地 chroot 它的被跟踪进程,通过一个系统调用将任意路径传递给 root 从而实现 chroot 路径。它甚至可以对用户进行欺骗,告诉用户它以 root 运行。事实上,这些就是 [Fakeroot NG][13] 程序所做的事情。
|
||||
|
||||
### 仿真外部系统
|
||||
|
||||
假设你不满足于仅监听一些系统调用,而是想监听全部系统调用。你收到 [一个打算在其它操作系统上运行的二进制程序][14],因为没有系统调用,这个二进制程序将无法正常运行。
|
||||
|
||||
使用我在前面所描述的这些内容你就可以管理这一切。跟踪器可以使用一个假冒的东西去代替系统调用号,允许它去失败,以及为系统调用本身提供服务。但那样做的效率很低。其实质上是对每个系统调用做了三个上下文切换:一个是在入口上停止,一个是让系统调用总是以失败告终,还有一个是在系统调用退出时停止。
|
||||
|
||||
从 2005 年以后,对于这个技术,PTrace 的 Linux 版本有更高效的操作:`PTRACE_SYSEMU`。PTrace 仅在每个系统调用发出时停止一次,在允许被跟踪进程继续运行之前,由跟踪器为系统调用提供服务。
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
从任何使用(足够)稳定的系统调用 ABI(译注:应用程序二进制接口),在相同架构的机器上运行一个二进制程序时,你只需要 `PTRACE_SYSEMU` 跟踪器,一个加载器(用于代替 `exec(2)`),和这个二进制程序所需要(或仅运行静态的二进制程序)的任何系统库即可。
|
||||
|
||||
事实上,这听起来有点像一个有趣的周末项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nullprogram.com
|
||||
[1]:https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]:http://nullprogram.com/blog/2016/09/03/
|
||||
[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]:http://nullprogram.com/blog/2018/01/17/
|
||||
[5]:http://nullprogram.com/blog/2015/05/15/
|
||||
[6]:https://stackoverflow.com/a/6469069
|
||||
[7]:https://man.openbsd.org/pledge.2
|
||||
[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]:http://nullprogram.com/blog/2017/07/19/
|
||||
[10]:http://nullprogram.com/blog/2016/09/23/
|
||||
[11]:https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]:http://nullprogram.com/blog/2017/03/01/
|
||||
[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]:http://nullprogram.com/blog/2017/11/30/
|
||||
@ -0,0 +1,122 @@
|
||||
如何在 Linux 中使用一个命令升级所有软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
众所周知,让我们的 Linux 系统保持最新状态涉及调用多个包管理器。比如说,在 Ubuntu 中,你无法使用 “sudo apt update 和 sudo apt upgrade” 命令升级所有软件。此命令仅升级使用 APT 包管理器安装的应用程序。你有可能使用 **cargo**、[**pip**][1]、**npm**、**snap** 、**flatpak** 或 [**Linuxbrew**][2] 包管理器安装了其他软件。你需要使用相应的包管理器才能使它们全部更新。再也不用这样了!跟 **“topgrade”** 打个招呼,这是一个可以一次性升级系统中所有软件的工具。
|
||||
|
||||
你无需运行每个包管理器来更新包。topgrade 工具通过检测已安装的软件包、工具、插件并运行相应的软件包管理器并使用一个命令更新 Linux 中的所有软件来解决这个问题。它是免费的、开源的,使用 **rust 语言**编写。它支持 GNU/Linux 和 Mac OS X.
|
||||
|
||||
### 在 Linux 中使用一个命令升级所有软件
|
||||
|
||||
topgrade 存在于 AUR 中。因此,你可以在任何基于 Arch 的系统中使用 [**Yay**][3 ] 助手程序安装它。
|
||||
```
|
||||
$ yay -S topgrade
|
||||
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,你可以使用 **cargo** 包管理器安装 topgrade。要安装 cargo 包管理器,请参阅以下链接。
|
||||
|
||||
然后,运行以下命令来安装 topgrade。
|
||||
```
|
||||
$ cargo install topgrade
|
||||
|
||||
```
|
||||
|
||||
安装完成后,运行 topgrade 以升级 Linux 系统中的所有软件。
|
||||
```
|
||||
$ topgrade
|
||||
|
||||
```
|
||||
|
||||
一旦调用了 topgrade,它将逐个执行以下任务。如有必要,系统会要求输入 root/sudo 用户密码。
|
||||
|
||||
1\. 运行系统的包管理器:
|
||||
|
||||
* Arch:运行 **yay** 或者回退到 [**pacman**][4]
|
||||
* CentOS/RHEL:运行 `yum upgrade`
|
||||
* Fedora :运行 `dnf upgrade`
|
||||
* Debian/Ubuntu:运行 `apt update 和 apt dist-upgrade`
|
||||
* Linux/macOS:运行 `brew update 和 brew upgrade`
|
||||
|
||||
|
||||
|
||||
2\. 检查 Git 是否跟踪了以下路径。如果有,则拉取它们:
|
||||
|
||||
* ~/.emacs.d (无论你使用 **Spacemacs** 还是自定义配置都应该可用)
|
||||
* ~/.zshrc
|
||||
* ~/.oh-my-zsh
|
||||
* ~/.tmux
|
||||
* ~/.config/fish/config.fish
|
||||
* 自定义路径
|
||||
|
||||
|
||||
|
||||
3\. Unix:运行 **zplug** 更新
|
||||
|
||||
4\. Unix:使用 **TPM** 升级 **tmux** 插件
|
||||
|
||||
5\. 运行 **Cargo install-update**
|
||||
|
||||
6\. 升级 **Emacs** 包
|
||||
|
||||
7\. 升级 Vim 包。对以下插件框架均可用:
|
||||
|
||||
* NeoBundle
|
||||
* [**Vundle**][5]
|
||||
* Plug
|
||||
|
||||
|
||||
|
||||
8\. 升级 [**NPM**][6]全局安装的包
|
||||
|
||||
9\. 升级 **Atom** 包
|
||||
|
||||
10\. 升级 [**Flatpak**][7] 包
|
||||
|
||||
11\. 升级 [**snap**][8] 包
|
||||
|
||||
12\. ** Linux:**运行 **fwupdmgr**显示固件升级。 (仅查看。实际不会执行升级)
|
||||
|
||||
13\. 运行自定义命令。
|
||||
|
||||
最后,topgrade 将运行 **needrestart** 以重新启动所有服务。在 Mac OS X 中,它会升级 App Store 程序。
|
||||
|
||||
我的 Ubuntu 18.04 LTS 测试环境的示例输出:
|
||||
|
||||
![][10]
|
||||
|
||||
好处是如果一个任务失败,它将自动运行下一个任务并完成所有其他后续任务。最后,它将显示摘要,其中包含运行的任务数量,成功的数量和失败的数量等详细信息。
|
||||
|
||||
![][11]
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
就个人而言,我喜欢创建一个像 topgrade 程序的想法,并使用一个命令升级使用各种包管理器安装的所有软件。我希望你也觉得它有用。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
|
||||
@ -0,0 +1,80 @@
|
||||
## 如何在linux系统中使用dd命令而不会损毁你的磁盘
|
||||
|
||||

|
||||
|
||||
这篇文章节选自 Manning 出版社出版的图书[Linux in Action](https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource)的第4章.
|
||||
|
||||
你是否正在从一个即将损坏的存储驱动器挽救数据,把本地文件进行远程备份,或者把一个活动分区的数据完整的复制到别处,那么你需要懂得如何安全而可靠的复制驱动器和文件系统数据.幸运的是,dd 是一个可以使用的简单而又功能强大的镜像复制命令,从现在到未来很长的时间内,也许直到永远都不会出现比 dd 更好的工具了。
|
||||
|
||||
### 完整的复制驱动器和分区中的数据
|
||||
|
||||
仔细研究后,你会发现你可以使用 dd 做各种任务,但是它最重要的功能是处理磁盘分区。当然,你可以使用 tar 命令或者 scp 命令从一台计算机复制整个文件系统的文件, 然后把这些文件原样粘贴在另一台刚刚安装好 linux 操作系统的计算机中。但是,因为文件系统的文件不是映像文件,所以在复制文件的过程中需要计算机操作系统的运行作为基础。
|
||||
|
||||
另一方面,使用 dd 可以对任何数字信息完美的进行逐个字节的镜像。但是不论何时何地,当你要对分区进行操作时,我要告诉你早期的Unix管理员曾开过这样的玩笑: " dd 象征着磁盘毁灭者"。 在使用 dd 命令的时候,如果你输入了哪怕是一个字母,也可能立即永久性的擦除掉整个磁盘驱动器里的所有重要的数据。因此,一定要注意命令的拼写格式规范。
|
||||
|
||||
**记住:** 在按下 Enter 键执行 dd 命令之前,暂时停下来仔细的认真思考一下。
|
||||
|
||||
### dd 命令的基本操作
|
||||
|
||||
现在你已经得到了适当的提醒,我们将从简单的事情开始。假设你要对代号为 /dev/sda 的整个磁盘数据创建精确的映像,你已经插入了一张空的磁盘驱动器 (理想情况下具有与代号为 /dev/sda 的磁盘驱动器相同的容量)。语法很简单: if = 定义源驱动器 `of =` 定义你要将数据保存到的文件或位置:
|
||||
```
|
||||
# dd if=/dev/sda of=/dev/sdb
|
||||
```
|
||||
接下来的例子将要对 /dev/sda 驱动器创建一个 .img 的映像文件,然后把该文件保存的你的用户帐号家目录:
|
||||
```
|
||||
# dd if=/dev/sda of=/home/username/sdadisk.img
|
||||
```
|
||||
上面的命令针对整个驱动器创建映像文件,你也可以针对驱动器上的单个分区进行操作。 下面的例子针对驱动器的单个分区进行操作,同时使用了一个 bs 参数用于设置单次拷贝的字节数量 (此例中是 4096)。设定 bs 参数值可能会影响 dd 命令的整体操作速度,但理想的设置取决于你的硬件配置和其它考虑。
|
||||
```
|
||||
# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
|
||||
```
|
||||
数据的恢复非常简单:通过颠倒 if 和 of 参数可以有效的完成任务。在此例中,if = 使用你要恢复的映像,of = 使用你想要写入映像的目标驱动器:
|
||||
```
|
||||
# dd if=sdadisk.img of=/dev/sdb
|
||||
```
|
||||
你也可以在一条命令中同时完成创建和拷贝任务。下面的例子中将从支持 SSH 的远程驱动器创建一个压缩的映像文件并把该文件保存到你的本地计算机中:
|
||||
```
|
||||
# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
|
||||
```
|
||||
你应该经常测试你的档案,确保它们可正常使用。如果它是你创建的启动驱动器,将它粘贴到计算机中,看看它是否能够按预期启动。如果它是普通分区的数据,挂载该分区,确保文件都存在而且可以正常的访问。
|
||||
|
||||
### 使用 dd 擦除磁盘数据
|
||||
|
||||
多年以前,我的一个负责政府海外大使馆安全的朋友曾经告诉我,在他当时在任的时候, 政府会给每一个大使馆提供一个官方版的锤子。为什么呢? 一旦大使馆设施可能被不友善的人员侵占,就会使用这个锤子毁坏所有的硬盘.
|
||||
|
||||
为什么要那样做?为什么不仅仅删除数据?你在开玩笑,对吧?所有人都知道从存储设备中删除包含敏感信息的文件实际上并没有真正移除这些数据。除非使用锤子彻底的毁坏这些存储介质,否则,只要有足够的时间和动机, 几乎所有的内容都可以从几乎任何数字存储介质重新获取。
|
||||
|
||||
但是,你可以使用 dd 命令让坏人非常难以获得你的旧数据。这个命令需要花费一些时间在 `/dev/sda1` 分区的每个扇区写入数百万个 zero:
|
||||
```
|
||||
# dd if=/dev/zero of=/dev/sda1
|
||||
|
||||
```
|
||||
|
||||
还有更好的方法。通过使用 /dev/urandom 作为源文件,你可以在磁盘上写入随机字符:
|
||||
```
|
||||
# dd if=/dev/urandom of=/dev/sda1
|
||||
|
||||
```
|
||||
|
||||
### 监控 dd 的操作
|
||||
|
||||
由于磁盘或磁盘分区的存档可能需要很长的时间,因此你可能需要在命令中添加进度查看器。安装 Pipe Viewer(在Ubuntu系统上安装命令为 sudo apt install pv),然后把 pv 命令和 dd 命令结合在一起。使用 pv,最终的命令是这样的:
|
||||
```
|
||||
# dd if=/dev/urandom | pv | dd of=/dev/sda1
|
||||
|
||||
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
|
||||
```
|
||||
想要推迟备份和磁盘管理工作?有了 dd 工具,你不会有太多的借口。它真的非常简单,但是要小心。祝你好运!
|
||||
|
||||
----------------
|
||||
|
||||
编译自:https://opensource.com/article/18/7/how-use-dd-linux
|
||||
|
||||
作者:[David Clinton](https://opensource.com/users/remyd)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
86
translated/tech/20180710 Getting started with Perlbrew.md
Normal file
86
translated/tech/20180710 Getting started with Perlbrew.md
Normal file
@ -0,0 +1,86 @@
|
||||
开始使用 Perlbrew
|
||||
======
|
||||
|
||||

|
||||
|
||||
什么比在系统上安装 Perl 更好?在系统中安装多个版本的 Perl。使用 [Perlbrew][1] 你可以做到这一点。但是为什么,除了让你包围在 Perl 下之外,你想要那样做吗?
|
||||
|
||||
简短的回答是不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它是否工作。
|
||||
|
||||
### 安装 Perlbrew
|
||||
|
||||
另一个好处是 Perlbrew 安装到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
|
||||
|
||||
第一步是在你的系统上安装 Perlbrew。许多 Linux 发行版已经在包仓库中拥有它,因此你只需要 `dnf install perlbrew`(或者适用于你的发行版的命令)。你还可以使用 `cpan App::perlbrew` 从 CPAN 安装 `App::perlbrew` 模块。或者你可以在 [install.perlbrew.pl][2] 下载并运行安装脚本。
|
||||
|
||||
要开始使用 Perlbrew,请运行 `perlbrew init`。
|
||||
|
||||
### 安装新的 Perl 版本
|
||||
|
||||
假设你想尝试最新的开发版本(撰写本文时为 5.27.11)。首先,你需要安装包:
|
||||
```
|
||||
perlbrew install 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### 切换 Perl 版本
|
||||
|
||||
现在你已经安装了新版本,你可以将它用于该 shell:
|
||||
```
|
||||
perlbrew use 5.27.11
|
||||
|
||||
```
|
||||
|
||||
或者你可以将其设置为你帐户的默认 Perl 版本(假设你按照 `perlbrew init` 的输出设置了你的配置文件):
|
||||
```
|
||||
perlbrew switch 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### 运行单个脚本
|
||||
|
||||
你也可以用特定版本的 Perl 运行单个命令:
|
||||
```
|
||||
perlberew exec 5.27.11 myscript.pl
|
||||
|
||||
```
|
||||
|
||||
或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请将 Perl 指定版本:
|
||||
```
|
||||
.plperlbrew exec perl myscriptpl
|
||||
|
||||
```
|
||||
|
||||
### 安装 CPAN 模块
|
||||
|
||||
如果你想安装 CPAN 模块,`cpanm` 包是一个易于使用的界面,可以很好地与 Perlbrew 一起使用。用下面命令安装它:
|
||||
```
|
||||
perlbrew install-cpamn
|
||||
|
||||
```
|
||||
|
||||
然后,你可以使用 `cpanm` 命令安装 CPAN 模块:
|
||||
```
|
||||
cpanm CGI::simple
|
||||
|
||||
```
|
||||
|
||||
### 但是等下,还有更多!
|
||||
|
||||
本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[ App::perlbrew 文档][3]。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/perlbrew
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://perlbrew.pl/
|
||||
[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
|
||||
[3]:https://metacpan.org/pod/App::perlbrew
|
||||
Loading…
Reference in New Issue
Block a user