mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
303bea3dfb
published
20140210 Three steps to learning GDB.md20160808 Top 10 Command Line Games For Linux.md20170319 ftrace trace your kernel functions.md20170524 Working with Vi-Vim Editor - Advanced concepts.md20170607 Why Car Companies Are Hiring Computer Security Experts.md20171002 Connect To Wifi From The Linux Command Line.md20171004 How To Create A Video From PDF Files In Linux.md20171005 python-hwinfo - Display Summary Of Hardware Information In Linux.md20171008 The most important Firefox command line options.md20171016 Fixing vim in Debian - There and back again.md20171207 How To Find Files Based On their Permissions.md20180104 4 artificial intelligence trends to watch.md
sources
talk
20160605 Manjaro Gaming- Gaming on Linux Meets Manjaro-s Awesomeness.md20170523 Best Websites to Download Linux Games.md20170915 Deep learning wars- Facebook-backed PyTorch vs Google-s TensorFlow.md20180104 4 artificial intelligence trends to watch.md20180107 7 leadership rules for the DevOps age.md20180110 8 simple ways to promote team communication.md20180122 How to price cryptocurrencies.md20180123 Moving to Linux from dated Windows machines.md20180124 Containers, the GPL, and copyleft- No reason for concern.md20180124 Security Chaos Engineering- A new paradigm for cybersecurity.md
tech
20070129 How To Debug a Bash Shell Script Under Linux or UNIX.md20090627 30 Linux System Monitoring Tools Every SysAdmin Should Know.md20130319 Linux - Unix Bash Shell List All Builtin Commands.md20140523 Tail Calls Optimization and ES6.md20160810 How does gdb work.md20170216 25 Free Books To Learn Linux For Free.md20170508 Ansible Tutorial- Intorduction to simple Ansible commands.md20170920 Easy APT Repository - Iain R. Learmonth.md20171016 5 SSH alias examples in Linux.md20171027 Easy guide to secure VNC server with TLS encryption.md20171113 The big break in computer languages.md20171127 Protecting Your Website From Application Layer DOS Attacks With mod.md20171218 Internet Chemotherapy.md20171219 How to generate webpages using CGI scripts.md20180104 How does gdb call functions.md20180117 How To Manage Vim Plugins Using Vundle On Linux.md20180117 Linux tee Command Explained for Beginners (6 Examples).md20180120 The World Map In Your Terminal.md20180121 Shell Scripting a Bunco Game.md20180122 A Simple Command-line Snippet Manager.md20180123 Never miss a Magazine-s article, build your own RSS notification system.md20180123 What Is bashrc and Why Should You Edit It.md20180124 4 cool new projects to try in COPR for January.md20180124 8 ways to generate random password in Linux.md20180124 Containers the GPL and copyleft No reason for concern.md20180125 A step-by-step guide to Git.md20180125 Keep Accurate Time on Linux with NTP.md20180125 Linux whereis Command Explained for Beginners (5 Examples).md
translated/tech
20070129 How To Debug a Bash Shell Script Under Linux or UNIX.md20140210 Three steps to learning GDB.md20140410 Recursion- dream within a dream.md20140523 Tail Calls Optimization and ES6.md20141027 Closures Objects and the Fauna of the Heap.md20170216 25 Free Books To Learn Linux For Free.md20170920 Easy APT Repository - Iain R. Learmonth.md20171002 Bash Bypass Alias Linux-Unix Command.md20171008 The most important Firefox command line options.md20171027 Easy guide to secure VNC server with TLS encryption.md20171113 The big break in computer languages.md20171127 Protecting Your Website From Application Layer DOS Attacks With mod.md20171207 How To Find Files Based On their Permissions.md20180123 Linux mkdir Command Explained for Beginners (with examples).md
113
published/20140210 Three steps to learning GDB.md
Normal file
113
published/20140210 Three steps to learning GDB.md
Normal file
@ -0,0 +1,113 @@
|
||||
三步上手 GDB
|
||||
===============
|
||||
|
||||
调试 C 程序,曾让我很困扰。然而当我之前在写我的[操作系统][2]时,我有很多的 Bug 需要调试。我很幸运的使用上了 qemu 模拟器,它允许我将调试器附加到我的操作系统。这个调试器就是 `gdb`。
|
||||
|
||||
我得解释一下,你可以使用 `gdb` 先做一些小事情,因为我发现初学它的时候真的很混乱。我们接下来会在一个小程序中,设置断点,查看内存。.
|
||||
|
||||
### 1、 设断点
|
||||
|
||||
如果你曾经使用过调试器,那你可能已经会设置断点了。
|
||||
|
||||
下面是一个我们要调试的程序(虽然没有任何 Bug):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
```
|
||||
|
||||
另存为 `hello.c`. 我们可以使用 `dbg` 调试它,像这样:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
以上是带调试信息编译 `hello.c`(为了 `gdb` 可以更好工作),并且它会给我们醒目的提示符,就像这样:
|
||||
|
||||
```
|
||||
(gdb)
|
||||
```
|
||||
|
||||
我们可以使用 `break` 命令设置断点,然后使用 `run` 开始调试程序。
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
|
||||
程序暂停在了 `do_thing` 开始的地方。
|
||||
|
||||
我们可以通过 `where` 查看我们所在的调用栈。
|
||||
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2、 阅读汇编代码
|
||||
|
||||
使用 `disassemble` 命令,我们可以看到这个函数的汇编代码。棒级了,这是 x86 汇编代码。虽然我不是很懂它,但是 `callq` 这一行是 `printf` 函数调用。
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
你也可以使用 `disassemble` 的缩写 `disas`。
|
||||
|
||||
### 3、 查看内存
|
||||
|
||||
当调试我的内核时,我使用 `gdb` 的主要原因是,以确保内存布局是如我所想的那样。检查内存的命令是 `examine`,或者使用缩写 `x`。我们将使用`x`。
|
||||
|
||||
通过阅读上面的汇编代码,似乎 `0x40060c` 可能是我们所要打印的字符串地址。我们来试一下。
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
的确是这样。`x/s` 中 `/s` 部分,意思是“把它作为字符串展示”。我也可以“展示 10 个字符”,像这样:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
你可以看到前四个字符是 `H`、`i`、`!` 和 `\0`,并且它们之后的是一些不相关的东西。
|
||||
|
||||
我知道 `gdb` 很多其他的东西,但是我仍然不是很了解它,其中 `x` 和 `break` 让我获得很多。你还可以阅读 [do umentation for examining memory][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:https://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
@ -1,178 +1,196 @@
|
||||
Linux 命令行游戏 Top 10
|
||||
十大 Linux 命令行游戏
|
||||
======
|
||||
概要: 本文列举了 **Linux 中最好的命令行游戏**。
|
||||
|
||||
Linux 从来都不是游戏的首选操作系统。尽管近日来 [Linux 的游戏][1] 提供了很多。你可以在 [下载 Linux 游戏][2] 得到许多资源。
|
||||
概要: 本文列举了 Linux 中最好的命令行游戏。
|
||||
|
||||
这有专门的 [游戏版 Linux][3]。它确实存在。但是今天,我们并不是要欣赏游戏版 Linux。
|
||||
Linux 从来都不是游戏的首选操作系统,尽管近日来 [Linux 的游戏][1]提供了很多,你也可以从许多资源[下载到 Linux 游戏][2]。
|
||||
|
||||
也有专门的 [游戏版 Linux][3]。没错,确实有。但是今天,我们并不是要欣赏游戏版 Linux。
|
||||
|
||||
Linux 有一个超过 Windows 的优势。它拥有一个强大的 Linux 终端。在 Linux 终端上,你可以做很多事情,包括玩 **命令行游戏**。
|
||||
|
||||
当然,毕竟是 Linux 终端的核心爱好者、拥护者。终端游戏轻便,快速,有地狱般的魔力。而这最有意思的事情是,你可以在 Linux 终端上重温大量经典游戏。
|
||||
|
||||
[推荐阅读:Linux 上游戏,你所需要了解的全部][20]
|
||||
当然,我们都是 Linux 终端的骨灰粉。终端游戏轻便、快速、有地狱般的魔力。而这最有意思的事情是,你可以在 Linux 终端上重温大量经典游戏。
|
||||
|
||||
### 最好的 Linux 终端游戏
|
||||
|
||||
来揭秘这张榜单,找出 Linux 终端最好的游戏。
|
||||
|
||||
### 1. Bastet
|
||||
#### 1. Bastet
|
||||
|
||||
谁还没花上几个小时玩 [俄罗斯方块][4] ?简单而且容易上瘾。 Bastet 就是 Linux 版的俄罗斯方块。
|
||||
谁还没花上几个小时玩[俄罗斯方块][4]?它简单而且容易上瘾。 Bastet 就是 Linux 版的俄罗斯方块。
|
||||
|
||||
![Linux 终端游戏 Bastet][5]
|
||||
|
||||
使用下面的命令获取 Bastet:
|
||||
使用下面的命令获取 Bastet:
|
||||
|
||||
```
|
||||
sudo apt install bastet
|
||||
```
|
||||
|
||||
运行下列命令,在终端上开始这个游戏:
|
||||
运行下列命令,在终端上开始这个游戏:
|
||||
|
||||
```
|
||||
bastet
|
||||
```
|
||||
|
||||
使用空格键旋转方块,方向键控制方块移动
|
||||
使用空格键旋转方块,方向键控制方块移动。
|
||||
|
||||
### 2. Ninvaders
|
||||
#### 2. Ninvaders
|
||||
|
||||
Space Invaders(太空侵略者)。我任记得这个游戏里,和我弟弟(哥哥)在高分之路上扭打。这是最好的街机游戏之一。
|
||||
Space Invaders(太空侵略者)。我仍记得这个游戏里,和我兄弟为了最高分而比拼。这是最好的街机游戏之一。
|
||||
|
||||
![Linux 终端游戏 nInvaders][6]
|
||||
|
||||
复制粘贴这段代码安装 Ninvaders。
|
||||
|
||||
```
|
||||
sudo apt-get install ninvaders
|
||||
```
|
||||
|
||||
使用下面的命令开始游戏:
|
||||
使用下面的命令开始游戏:
|
||||
|
||||
```
|
||||
ninvaders
|
||||
```
|
||||
|
||||
方向键移动太空飞船。空格键设计外星人。
|
||||
方向键移动太空飞船。空格键射击外星人。
|
||||
|
||||
[推荐阅读:2016 你可以开始的 Linux 游戏 Top 10][21]
|
||||
|
||||
### 3. Pacman4console
|
||||
#### 3. Pacman4console
|
||||
|
||||
是的,这个就是街机之王。Pacman4console 是最受欢迎的街机游戏 Pacman(吃豆豆)终端版。
|
||||
是的,这个就是街机之王。Pacman4console 是最受欢迎的街机游戏 Pacman(吃豆人)的终端版。
|
||||
|
||||
![Linux 命令行吃豆豆游戏 Pacman4console][7]
|
||||
|
||||
使用以下命令获取 pacman4console:
|
||||
|
||||
```
|
||||
sudo apt-get install pacman4console
|
||||
```
|
||||
|
||||
打开终端,建议使用最大的终端界面(29x32)。键入以下命令启动游戏:
|
||||
打开终端,建议使用最大的终端界面。键入以下命令启动游戏:
|
||||
|
||||
```
|
||||
pacman4console
|
||||
```
|
||||
|
||||
使用方向键控制移动。
|
||||
|
||||
### 4. nSnake
|
||||
#### 4. nSnake
|
||||
|
||||
记得在老式诺基亚手机里玩的贪吃蛇游戏吗?
|
||||
|
||||
这个游戏让我保持对手机着迷很长时间。我曾经设计过各种姿态去获得更长的蛇身。
|
||||
这个游戏让我在很长时间内着迷于手机。我曾经设计过各种姿态去获得更长的蛇身。
|
||||
|
||||
![nsnake : Linux 终端上的贪吃蛇游戏][8]
|
||||
|
||||
我们拥有 [Linux 终端上的贪吃蛇游戏][9] 得感谢 [nSnake][9]。使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install nsnake
|
||||
```
|
||||
|
||||
键入下面的命令开始游戏:
|
||||
|
||||
```
|
||||
nsnake
|
||||
```
|
||||
|
||||
使用方向键控制蛇身,获取豆豆。
|
||||
使用方向键控制蛇身并喂它。
|
||||
|
||||
### 5. Greed
|
||||
#### 5. Greed
|
||||
|
||||
Greed 有点像精简调加速和肾上腺素的 Tron(类似贪吃蛇的进化版)。
|
||||
Greed 有点像 Tron(类似贪吃蛇的进化版),但是减少了速度,也没那么刺激。
|
||||
|
||||
你当前的位置由‘@’表示。你被数字包围了,你可以在四个方向任意移动。你选择的移动方向上标识的数字,就是你能移动的步数。走过的路不能再走,如果你无路可走,游戏结束。
|
||||
你当前的位置由闪烁的 ‘@’ 表示。你被数字所环绕,你可以在四个方向任意移动。
|
||||
|
||||
听起来,似乎我让它变得更复杂了。
|
||||
你选择的移动方向上标识的数字,就是你能移动的步数。你将重复这个步骤。走过的路不能再走,如果你无路可走,游戏结束。
|
||||
|
||||
似乎我让它听起来变得更复杂了。
|
||||
|
||||
![Greed : 命令行上的 Tron][10]
|
||||
|
||||
通过下列命令获取 Greed:
|
||||
|
||||
```
|
||||
sudo apt-get install greed
|
||||
```
|
||||
|
||||
通过下列命令启动游戏,使用方向键控制游戏。
|
||||
|
||||
```
|
||||
greed
|
||||
```
|
||||
|
||||
### 6. Air Traffic Controller
|
||||
#### 6. Air Traffic Controller
|
||||
|
||||
还有什么比做飞行员更有意思的?空中交通管制员。在你的终端中,你可以模拟一个空中要塞。说实话,在终端里管理空中交通蛮有意思的。
|
||||
还有什么比做飞行员更有意思的?那就是空中交通管制员。在你的终端中,你可以模拟一个空中交通系统。说实话,在终端里管理空中交通蛮有意思的。
|
||||
|
||||
![Linux 空中交通管理员][11]
|
||||
|
||||
使用下列命令安装游戏:
|
||||
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
atc
|
||||
```
|
||||
|
||||
ATC 不是孩子玩的游戏。建议查看官方文档。
|
||||
|
||||
### 7. Backgammon(双陆棋)
|
||||
#### 7. Backgammon(双陆棋)
|
||||
|
||||
无论之前你有没有玩过 [双陆棋][12],你都应该看看这个。 它的说明书和控制手册都非常友好。如果你喜欢,可以挑战你的电脑或者你的朋友。
|
||||
|
||||
![Linux 终端上的双陆棋][13]
|
||||
|
||||
使用下列命令安装双陆棋:
|
||||
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
backgammon
|
||||
```
|
||||
|
||||
当你需要提示游戏规则时,回复 ‘y’。
|
||||
当你提示游戏规则时,回复 ‘y’ 即可。
|
||||
|
||||
### 8. Moon Buggy
|
||||
#### 8. Moon Buggy
|
||||
|
||||
跳跃。疯狂。欢乐时光不必多言。
|
||||
跳跃、开火。欢乐时光不必多言。
|
||||
|
||||
![Moon buggy][14]
|
||||
|
||||
使用下列命令安装游戏:
|
||||
|
||||
```
|
||||
sudo apt-get install moon-buggy
|
||||
```
|
||||
|
||||
使用下列命令启动游戏:
|
||||
|
||||
```
|
||||
moon-buggy
|
||||
```
|
||||
|
||||
空格跳跃,‘a’或者‘l’射击。尽情享受吧。
|
||||
空格跳跃,‘a’ 或者 ‘l’射击。尽情享受吧。
|
||||
|
||||
### 9. 2048
|
||||
#### 9. 2048
|
||||
|
||||
2048 可以活跃你的大脑。[2048][15] 是一个策咯游戏,很容易上瘾。以获取 2048 分为目标。
|
||||
|
||||
![Linux 终端上的 2048][16]
|
||||
|
||||
复制粘贴下面的命令安装游戏:
|
||||
|
||||
```
|
||||
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
|
||||
|
||||
@ -180,28 +198,28 @@ gcc -o 2048 2048.c
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
./2048
|
||||
```
|
||||
|
||||
### 10. Tron
|
||||
#### 10. Tron
|
||||
|
||||
没有动作类游戏,这张榜单怎么可能结束?
|
||||
|
||||
![Linux 终端游戏 Tron][17]
|
||||
|
||||
是的,Linux 终端可以实现这种精力充沛的游戏 Tron。为接下来迅捷的反应做准备吧。无需被下载和安装困扰。一个命令即可启动游戏,你只需要一个网络连接
|
||||
是的,Linux 终端可以实现这种精力充沛的游戏 Tron。为接下来迅捷的反应做准备吧。无需被下载和安装困扰。一个命令即可启动游戏,你只需要一个网络连接:
|
||||
|
||||
```
|
||||
ssh sshtron.zachlatta.com
|
||||
```
|
||||
|
||||
如果由别的在线游戏者,你可以多人游戏。了解更多:[Linux 终端游戏 Tron][18].
|
||||
如果有别的在线游戏者,你可以多人游戏。了解更多:[Linux 终端游戏 Tron][18]。
|
||||
|
||||
### 你看上了哪一款?
|
||||
|
||||
朋友,Linux 终端游戏 Top 10,都分享给你了。我猜你现在正准备键入 ctrl+alt+T(终端快捷键) 了。榜单中,那个是你最喜欢的游戏?或者为终端提供其他的有趣的事物?尽情分享吧!
|
||||
|
||||
在 [Abhishek Prakash][19] 回复。
|
||||
伙计,十大 Linux 终端游戏都分享给你了。我猜你现在正准备键入 `ctrl+alt+T`(终端快捷键) 了。榜单中那个是你最喜欢的游戏?或者你有其它的终端游戏么?尽情分享吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -209,12 +227,12 @@ via: https://itsfoss.com/best-command-line-games-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[CYLeft](https://github.com/CYleft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/linux-gaming-guide/
|
||||
[1]:https://linux.cn/article-7316-1.html
|
||||
[2]:https://itsfoss.com/download-linux-games/
|
||||
[3]:https://itsfoss.com/manjaro-gaming-linux/
|
||||
[4]:https://en.wikipedia.org/wiki/Tetris
|
||||
@ -3,43 +3,42 @@ ftrace:跟踪你的内核函数!
|
||||
|
||||
大家好!今天我们将去讨论一个调试工具:ftrace,之前我的博客上还没有讨论过它。还有什么能比一个新的调试工具更让人激动呢?
|
||||
|
||||
这个非常棒的 ftrace 并不是个新的工具!它大约在 Linux 的 2.6 内核版本中就有了,时间大约是在 2008 年。[这里是我用谷歌能找到的一些文档][10]。因此,如果你是一个调试系统的“老手”,可能早就已经使用它了!
|
||||
这个非常棒的 ftrace 并不是个新的工具!它大约在 Linux 的 2.6 内核版本中就有了,时间大约是在 2008 年。[这一篇是我用谷歌能找到的最早的文档][10]。因此,如果你是一个调试系统的“老手”,可能早就已经使用它了!
|
||||
|
||||
我知道,ftrace 已经存在了大约 2.5 年了,但是还没有真正的去学习它。假设我明天要召开一个专题研究会,那么,关于 ftrace 应该讨论些什么?因此,今天是时间去讨论一下它了!
|
||||
我知道,ftrace 已经存在了大约 2.5 年了(LCTT 译注:距本文初次写作时),但是还没有真正的去学习它。假设我明天要召开一个专题研究会,那么,关于 ftrace 应该讨论些什么?因此,今天是时间去讨论一下它了!
|
||||
|
||||
### 什么是 ftrace?
|
||||
|
||||
ftrace 是一个 Linux 内核特性,它可以让你去跟踪 Linux 内核的函数调用。为什么要这么做呢?好吧,假设你调试一个奇怪的问题,而你已经得到了你的内核版本中这个问题在源代码中的开始的位置,而你想知道这里到底发生了什么?
|
||||
|
||||
每次在调试的时候,我并不会经常去读内核源代码,但是,极个别的情况下会去读它!例如,本周在工作中,我有一个程序在内核中卡死了。查看到底是调用了什么函数、哪些系统涉及其中,能够帮我更好的理解在内核中发生了什么!(在我的那个案例中,它是虚拟内存系统)
|
||||
每次在调试的时候,我并不会经常去读内核源代码,但是,极个别的情况下会去读它!例如,本周在工作中,我有一个程序在内核中卡死了。查看到底是调用了什么函数,能够帮我更好的理解在内核中发生了什么,哪些系统涉及其中!(在我的那个案例中,它是虚拟内存系统)。
|
||||
|
||||
我认为 ftrace 是一个十分好用的工具(它肯定没有 strace 那样广泛被使用,使用难度也低于它),但是它还是值得你去学习。因此,让我们开始吧!
|
||||
我认为 ftrace 是一个十分好用的工具(它肯定没有 `strace` 那样使用广泛,也比它难以使用),但是它还是值得你去学习。因此,让我们开始吧!
|
||||
|
||||
### 使用 ftrace 的第一步
|
||||
|
||||
不像 strace 和 perf,ftrace 并不是真正的 **程序** – 你不能只运行 `ftrace my_cool_function`。那样太容易了!
|
||||
不像 `strace` 和 `perf`,ftrace 并不是真正的 **程序** – 你不能只运行 `ftrace my_cool_function`。那样太容易了!
|
||||
|
||||
如果你去读 [使用 Ftrace 调试内核][11],它会告诉你从 `cd /sys/kernel/debug/tracing` 开始,然后做很多文件系统的操作。
|
||||
如果你去读 [使用 ftrace 调试内核][11],它会告诉你从 `cd /sys/kernel/debug/tracing` 开始,然后做很多文件系统的操作。
|
||||
|
||||
对于我来说,这种办法太麻烦 – 使用 ftrace 的一个简单例子应该像这样:
|
||||
对于我来说,这种办法太麻烦——一个使用 ftrace 的简单例子像是这样:
|
||||
|
||||
```
|
||||
cd /sys/kernel/debug/tracing
|
||||
echo function > current_tracer
|
||||
echo do_page_fault > set_ftrace_filter
|
||||
cat trace
|
||||
|
||||
```
|
||||
|
||||
这个文件系统到跟踪系统的接口(“给这些神奇的文件赋值,然后该发生的事情就会发生”)理论上看起来似乎可用,但是它不是我的首选方式。
|
||||
这个文件系统是跟踪系统的接口(“给这些神奇的文件赋值,然后该发生的事情就会发生”)理论上看起来似乎可用,但是它不是我的首选方式。
|
||||
|
||||
幸运的是,ftrace 团队也考虑到这个并不友好的用户界面,因此,它有了一个更易于使用的界面,它就是 **trace-cmd**!!!trace-cmd 是一个带命令行参数的普通程序。我们后面将使用它!我在 LWN 上找到了一个 trace-cmd 的使用介绍:[trace-cmd: Ftrace 的一个前端][12]。
|
||||
幸运的是,ftrace 团队也考虑到这个并不友好的用户界面,因此,它有了一个更易于使用的界面,它就是 `trace-cmd`!!!`trace-cmd` 是一个带命令行参数的普通程序。我们后面将使用它!我在 LWN 上找到了一个 `trace-cmd` 的使用介绍:[trace-cmd: Ftrace 的一个前端][12]。
|
||||
|
||||
### 开始使用 trace-cmd:让 trace 仅跟踪一个函数
|
||||
### 开始使用 trace-cmd:让我们仅跟踪一个函数
|
||||
|
||||
首先,我需要去使用 `sudo apt-get install trace-cmd` 安装 `trace-cmd`,这一步很容易。
|
||||
|
||||
对于第一个 ftrace 的演示,我决定去了解我的内核如何去处理一个页面故障。当 Linux 分配内存时,它经常偷懒,(“你并不是 _真的_ 计划去使用内存,对吗?”)。这意味着,当一个应用程序尝试去对分配给它的内存进行写入时,就会发生一个页面故障,而这个时候,内核才会真正的为应用程序去分配物理内存。
|
||||
对于第一个 ftrace 的演示,我决定去了解我的内核如何去处理一个页面故障。当 Linux 分配内存时,它经常偷懒,(“你并不是_真的_计划去使用内存,对吗?”)。这意味着,当一个应用程序尝试去对分配给它的内存进行写入时,就会发生一个页面故障,而这个时候,内核才会真正的为应用程序去分配物理内存。
|
||||
|
||||
我们开始使用 `trace-cmd` 并让它跟踪 `do_page_fault` 函数!
|
||||
|
||||
@ -47,7 +46,6 @@ cat trace
|
||||
$ sudo trace-cmd record -p function -l do_page_fault
|
||||
plugin 'function'
|
||||
Hit Ctrl^C to stop recording
|
||||
|
||||
```
|
||||
|
||||
我将它运行了几秒钟,然后按下了 `Ctrl+C`。 让我大吃一惊的是,它竟然产生了一个 2.5MB 大小的名为 `trace.dat` 的跟踪文件。我们来看一下这个文件的内容!
|
||||
@ -68,7 +66,7 @@ $ sudo trace-cmd report
|
||||
|
||||
```
|
||||
|
||||
看起来很整洁 – 它展示了进程名(chrome)、进程 ID (15144)、CPU(000)、以及它跟踪的函数。
|
||||
看起来很整洁 – 它展示了进程名(chrome)、进程 ID(15144)、CPU ID(000),以及它跟踪的函数。
|
||||
|
||||
通过察看整个文件,(`sudo trace-cmd report | grep chrome`)可以看到,我们跟踪了大约 1.5 秒,在这 1.5 秒的时间段内,Chrome 发生了大约 500 个页面故障。真是太酷了!这就是我们做的第一个 ftrace!
|
||||
|
||||
@ -81,14 +79,13 @@ $ sudo trace-cmd report
|
||||
```
|
||||
sudo trace-cmd record --help # I read the help!
|
||||
sudo trace-cmd record -p function -P 25314 # record for PID 25314
|
||||
|
||||
```
|
||||
|
||||
`sudo trace-cmd report` 输出了 18,000 行。如果你对这些感兴趣,你可以看 [这里是所有的 18,000 行的输出][13]。
|
||||
|
||||
18,000 行太多了,因此,在这里仅摘录其中几行。
|
||||
|
||||
当系统调用 `clock_gettime` 运行时,都发生了什么。
|
||||
当系统调用 `clock_gettime` 运行的时候,都发生了什么:
|
||||
|
||||
```
|
||||
compat_SyS_clock_gettime
|
||||
@ -99,7 +96,6 @@ sudo trace-cmd record -p function -P 25314 # record for PID 25314
|
||||
__getnstimeofday64
|
||||
arch_counter_read
|
||||
__compat_put_timespec
|
||||
|
||||
```
|
||||
|
||||
这是与进程调试相关的一些东西:
|
||||
@ -128,10 +124,9 @@ sudo trace-cmd record -p function -P 25314 # record for PID 25314
|
||||
|
||||
```
|
||||
sudo trace-cmd record -p function_graph -P 25314
|
||||
|
||||
```
|
||||
|
||||
同样,这里只是一个片断(这次来自 futex 代码)
|
||||
同样,这里只是一个片断(这次来自 futex 代码):
|
||||
|
||||
```
|
||||
| futex_wake() {
|
||||
@ -149,7 +144,6 @@ sudo trace-cmd record -p function_graph -P 25314
|
||||
5.250 us | }
|
||||
0.583 us | put_page();
|
||||
+ 24.208 us | }
|
||||
|
||||
```
|
||||
|
||||
我们看到在这个示例中,在 `futex_wake` 后面调用了 `get_futex_key`。这是在源代码中真实发生的事情吗?我们可以检查一下!![这里是在 Linux 4.4 中 futex_wake 的定义][15] (我的内核版本是 4.4)。
|
||||
@ -170,7 +164,6 @@ futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
|
||||
return -EINVAL;
|
||||
|
||||
ret = get_futex_key(uaddr, flags & FLAGS_SHARED, &key, VERIFY_READ);
|
||||
|
||||
```
|
||||
|
||||
如你所见,在 `futex_wake` 中的第一个函数调用真的是 `get_futex_key`! 太棒了!相比阅读内核代码,阅读函数跟踪肯定是更容易的找到结果的办法,并且让人高兴的是,还能看到所有的函数用了多长时间。
|
||||
@ -183,7 +176,7 @@ futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
|
||||
|
||||
现在,我们已经知道了怎么去跟踪内核中的函数,真是太酷了!
|
||||
|
||||
还有一类我们可以跟踪的东西!有些事件与我们的函数调用并不相符。例如,你可能想去知道当一个程序被调度进入或者离开 CPU 时,都发生了什么事件!你可能想通过“盯着”函数调用计算出来,但是,我告诉你,不可行!
|
||||
还有一类我们可以跟踪的东西!有些事件与我们的函数调用并不相符。例如,你可能想知道当一个程序被调度进入或者离开 CPU 时,都发生了什么事件!你可能想通过“盯着”函数调用计算出来,但是,我告诉你,不可行!
|
||||
|
||||
由于函数也为你提供了几种事件,因此,你可以看到当重要的事件发生时,都发生了什么事情。你可以使用 `sudo cat /sys/kernel/debug/tracing/available_events` 来查看这些事件的一个列表。
|
||||
|
||||
@ -193,7 +186,6 @@ futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
|
||||
sudo cat /sys/kernel/debug/tracing/available_events
|
||||
sudo trace-cmd record -e sched:sched_switch
|
||||
sudo trace-cmd report
|
||||
|
||||
```
|
||||
|
||||
输出如下:
|
||||
@ -207,23 +199,23 @@ sudo trace-cmd report
|
||||
|
||||
```
|
||||
|
||||
现在,可以很清楚地看到这些切换,从 PID 24817 -> 15144 -> kernel -> 24817 -> 1561 -> 15114\。(所有的这些事件都发生在同一个 CPU 上)
|
||||
现在,可以很清楚地看到这些切换,从 PID 24817 -> 15144 -> kernel -> 24817 -> 1561 -> 15114。(所有的这些事件都发生在同一个 CPU 上)。
|
||||
|
||||
### ftrace 是如何工作的?
|
||||
|
||||
ftrace 是一个动态跟踪系统。当启动 ftracing 去跟踪内核函数时,**函数的代码会被改变**。因此 – 我们假设去跟踪 `do_page_fault` 函数。内核将在那个函数的汇编代码中插入一些额外的指令,以便每次该函数被调用时去提示跟踪系统。内核之所以能够添加额外的指令的原因是,Linux 将额外的几个 NOP 指令编译进每个函数中,因此,当需要的时候,这里有添加跟踪代码的地方。
|
||||
ftrace 是一个动态跟踪系统。当我们开始 ftrace 内核函数时,**函数的代码会被改变**。让我们假设去跟踪 `do_page_fault` 函数。内核将在那个函数的汇编代码中插入一些额外的指令,以便每次该函数被调用时去提示跟踪系统。内核之所以能够添加额外的指令的原因是,Linux 将额外的几个 NOP 指令编译进每个函数中,因此,当需要的时候,这里有添加跟踪代码的地方。
|
||||
|
||||
这是一个十分复杂的问题,因为,当不需要使用 ftrace 去跟踪我的内核时,它根本就不影响性能。而当我需要跟踪时,跟踪的函数越多,产生的开销就越大。
|
||||
|
||||
(或许有些是不对的,但是,我认为的 ftrace 就是这样工作的)
|
||||
|
||||
### 更容易地使用 ftrace:brendan gregg 的工具 & kernelshark
|
||||
### 更容易地使用 ftrace:brendan gregg 的工具及 kernelshark
|
||||
|
||||
正如我们在文件中所讨论的,你需要去考虑很多的关于单个的内核函数/事件直接使用 ftrace 都做了些什么。能够做到这一点很酷!但是也需要做大量的工作!
|
||||
|
||||
Brendan Gregg (我们的 linux 调试工具“大神”)有个工具仓库,它使用 ftrace 去提供关于像 I/O 延迟这样的各种事情的信息。这是它在 GitHub 上全部的 [perf-tools][16] 仓库。
|
||||
Brendan Gregg (我们的 Linux 调试工具“大神”)有个工具仓库,它使用 ftrace 去提供关于像 I/O 延迟这样的各种事情的信息。这是它在 GitHub 上全部的 [perf-tools][16] 仓库。
|
||||
|
||||
这里有一个权衡(tradeoff),那就是这些工具易于使用,但是被限制仅用于 Brendan Gregg 认可的事情。决定将它做成一个工具,那需要做很多的事情!:)
|
||||
这里有一个权衡,那就是这些工具易于使用,但是你被限制仅能用于 Brendan Gregg 认可并做到工具里面的方面。它包括了很多方面!:)
|
||||
|
||||
另一个工具是将 ftrace 的输出可视化,做的比较好的是 [kernelshark][17]。我还没有用过它,但是看起来似乎很有用。你可以使用 `sudo apt-get install kernelshark` 来安装它。
|
||||
|
||||
@ -236,30 +228,22 @@ Brendan Gregg (我们的 linux 调试工具“大神”)有个工具仓库
|
||||
最后,这里是我找到的一些 ftrace 方面的文章。它们大部分在 LWN (Linux 新闻周刊)上,它是 Linux 的一个极好的资源(你可以购买一个 [订阅][18]!)
|
||||
|
||||
* [使用 Ftrace 调试内核 - part 1][1] (Dec 2009, Steven Rostedt)
|
||||
|
||||
* [使用 Ftrace 调试内核 - part 2][2] (Dec 2009, Steven Rostedt)
|
||||
|
||||
* [Linux 函数跟踪器的秘密][3] (Jan 2010, Steven Rostedt)
|
||||
|
||||
* [trace-cmd:Ftrace 的一个前端][4] (Oct 2010, Steven Rostedt)
|
||||
|
||||
* [使用 KernelShark 去分析实时调试器][5] (2011, Steven Rostedt)
|
||||
|
||||
* [Ftrace: 神秘的开关][6] (2014, Brendan Gregg)
|
||||
|
||||
* 内核文档:(它十分有用) [Documentation/ftrace.txt][7]
|
||||
|
||||
* 你能跟踪的事件的文档 [Documentation/events.txt][8]
|
||||
|
||||
* linux 内核开发上的一些 ftrace 设计文档 (不是有用,而是有趣!) [Documentation/ftrace-design.txt][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/03/19/getting-started-with-ftrace/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
使用 Vi/Vim 编辑器:高级概念
|
||||
======
|
||||
|
||||
早些时候我们已经讨论了一些关于 VI/VIM 编辑器的基础知识,但是 VI 和 VIM 都是非常强大的编辑器,还有很多其他的功能可以和编辑器一起使用。在本教程中,我们将学习 VI/VIM 编辑器的一些高级用法。
|
||||
|
||||
(**推荐阅读**:[使用 VI 编辑器:基础知识] [1])
|
||||
|
||||
## 使用 VI/VIM 编辑器打开多个文件
|
||||
### 使用 VI/VIM 编辑器打开多个文件
|
||||
|
||||
要打开多个文件,命令将与打开单个文件相同。我们只要添加第二个文件的名称。
|
||||
|
||||
@ -12,59 +13,65 @@
|
||||
$ vi file1 file2 file 3
|
||||
```
|
||||
|
||||
要浏览到下一个文件,我们可以使用
|
||||
要浏览到下一个文件,我们可以(在 vim 命令模式中)使用:
|
||||
|
||||
```
|
||||
$ :n
|
||||
:n
|
||||
```
|
||||
|
||||
或者我们也可以使用
|
||||
|
||||
```
|
||||
$ :e filename
|
||||
:e filename
|
||||
```
|
||||
|
||||
## 在编辑器中运行外部命令
|
||||
### 在编辑器中运行外部命令
|
||||
|
||||
我们可以在 vi 编辑器内部运行外部的 Linux/Unix 命令,也就是说不需要退出编辑器。要在编辑器中运行命令,如果在插入模式下,先返回到命令模式,我们使用 BANG 也就是 “!” 接着是需要使用的命令。运行命令的语法是:
|
||||
我们可以在 vi 编辑器内部运行外部的 Linux/Unix 命令,也就是说不需要退出编辑器。要在编辑器中运行命令,如果在插入模式下,先返回到命令模式,我们使用 BANG 也就是 `!` 接着是需要使用的命令。运行命令的语法是:
|
||||
|
||||
```
|
||||
$ :! command
|
||||
:! command
|
||||
```
|
||||
|
||||
这是一个例子
|
||||
这是一个例子:
|
||||
|
||||
```
|
||||
$ :! df -H
|
||||
:! df -H
|
||||
```
|
||||
|
||||
## 根据模板搜索
|
||||
### 根据模板搜索
|
||||
|
||||
要在文本文件中搜索一个单词或模板,我们在命令模式下使用以下两个命令:
|
||||
|
||||
* 命令 “/” 代表正向搜索模板
|
||||
|
||||
* 命令 “?” 代表正向搜索模板
|
||||
|
||||
* 命令 `/` 代表正向搜索模板
|
||||
* 命令 `?` 代表正向搜索模板
|
||||
|
||||
这两个命令都用于相同的目的,唯一不同的是它们搜索的方向。一个例子是:
|
||||
|
||||
`$ :/ search pattern` (如果在文件的开头)
|
||||
|
||||
`$ :? search pattern` (如果在文件末尾)
|
||||
|
||||
## 搜索并替换一个模板
|
||||
|
||||
我们可能需要搜索和替换我们的文本中的单词或模板。我们不是从整个文本中找到单词的出现的地方并替换它,我们可以在命令模式中使用命令来自动替换单词。使用搜索和替换的语法是:
|
||||
如果在文件的开头向前搜索,
|
||||
|
||||
```
|
||||
$ :s/pattern_to_be_found/New_pattern/g
|
||||
:/ search pattern
|
||||
```
|
||||
|
||||
如果在文件末尾向后搜索,
|
||||
|
||||
```
|
||||
:? search pattern
|
||||
```
|
||||
|
||||
### 搜索并替换一个模式
|
||||
|
||||
我们可能需要搜索和替换我们的文本中的单词或模式。我们不是从整个文本中找到单词的出现的地方并替换它,我们可以在命令模式中使用命令来自动替换单词。使用搜索和替换的语法是:
|
||||
|
||||
```
|
||||
:s/pattern_to_be_found/New_pattern/g
|
||||
```
|
||||
|
||||
假设我们想要将单词 “alpha” 用单词 “beta” 代替,命令就是这样:
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/g
|
||||
:s/alpha/beta/g
|
||||
```
|
||||
|
||||
如果我们只想替换第一个出现的 “alpha”,那么命令就是:
|
||||
@ -73,31 +80,35 @@ $ :s/alpha/beta/g
|
||||
$ :s/alpha/beta/
|
||||
```
|
||||
|
||||
## 使用 set 命令
|
||||
### 使用 set 命令
|
||||
|
||||
我们也可以使用 set 命令自定义 vi/vim 编辑器的行为和外观。下面是一些可以使用 set 命令修改 vi/vim 编辑器行为的选项列表:
|
||||
|
||||
`$ :set ic ` 在搜索时忽略大小写
|
||||
```
|
||||
:set ic ' 在搜索时忽略大小写
|
||||
|
||||
`$ :set smartcase ` 搜索强制区分大小写
|
||||
:set smartcase ' 搜索强制区分大小写
|
||||
|
||||
`$ :set nu` 在每行开始显示行号
|
||||
:set nu ' 在每行开始显示行号
|
||||
|
||||
`$ :set hlsearch ` 高亮显示匹配的单词
|
||||
:set hlsearch ' 高亮显示匹配的单词
|
||||
|
||||
`$ : set ro ` 将文件类型更改为只读
|
||||
:set ro ' 将文件类型更改为只读
|
||||
|
||||
`$ : set term ` 打印终端类型
|
||||
:set term ' 打印终端类型
|
||||
|
||||
`$ : set ai ` 设置自动缩进
|
||||
:set ai ' 设置自动缩进
|
||||
|
||||
`$ :set noai ` 取消自动缩进
|
||||
:set noai ' 取消自动缩进
|
||||
```
|
||||
|
||||
其他一些修改 vi 编辑器的命令是:
|
||||
|
||||
`$ :colorscheme ` 用来改变编辑器的配色方案 。(仅适用于 VIM 编辑器)
|
||||
```
|
||||
:colorscheme ' 用来改变编辑器的配色方案 。(仅适用于 VIM 编辑器)
|
||||
|
||||
`$ :syntax on ` 为 .xml、.html 等文件打开颜色方案。(仅适用于VIM编辑器)
|
||||
:syntax on ' 为 .xml、.html 等文件打开颜色方案。(仅适用于VIM编辑器)
|
||||
```
|
||||
|
||||
这篇结束了本系列教程,请在下面的评论栏中提出你的疑问/问题或建议。
|
||||
|
||||
@ -108,7 +119,7 @@ via: http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,29 @@
|
||||
为什么车企纷纷招聘计算机安全专家
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉的进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。纽约时报 CreditChristie Hemm Klok 拍摄
|
||||
|
||||
大约在七年前,伊朗的数位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉汽车进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。(纽约时报 CreditChristie Hemm Klok 拍摄)
|
||||
|
||||
大约在七年前,伊朗的几位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
|
||||
安全专家们警告人们,再过 7 年,凶手们不再需要摩托车或磁性炸弹。他们所需要的只是一台笔记本电脑和发送给无人驾驶汽车的一段代码——让汽车坠桥、被货车撞扁或者在高速公路上突然抛锚。
|
||||
|
||||
汽车制造商眼中的无人驾驶汽车。在黑客眼中只是一台可以达到时速 100 公里的计算机。
|
||||
|
||||
网络安全公司CloudFlare的首席安全研究员马克·罗杰斯(Marc Rogers)说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
网络安全公司 CloudFlare 的首席安全研究员<ruby>马克·罗杰斯<rt>Marc Rogers</rt></ruby>说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
|
||||
两年前,两名“白帽”黑客——寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的破坏者(Cracker)——成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
两年前,两名“白帽”黑客(寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的<ruby>破坏者<rt>Cracker</rt></ruby>)成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
|
||||
黑客 Chris Valasek 和 Charlie Miller(现在是 Uber 和滴滴的安全研究人员)发现了一条 [由 Jeep 娱乐系统通向仪表板的电路][10]。他们利用这条线路控制了车辆转向、刹车和变速——他们在高速公路上撞击假人所需的一切。
|
||||
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有人的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有谁的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商菲亚特克莱斯勒(Fiat Chrysler)付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商<ruby>菲亚特克莱斯勒<rt>Fiat Chrysler</rt></ruby>付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
|
||||
毫无疑问,后来通用汽车首席执行官玛丽·巴拉(Mary Barra)把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
毫无疑问,后来通用汽车首席执行官<ruby>玛丽·巴拉<rt>Mary Barra</rt></ruby>把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
|
||||
优步 、[特斯拉][11]、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
优步 、特斯拉、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
|
||||
去年,特斯拉挖走了苹果 iOS 操作系统的安全经理 Aaron Sigel。优步挖走了 Facebook 的白帽黑客 Chris Gates。Miller 先生在发现 Jeep 的漏洞后就职于优步,然后被滴滴挖走。计算机安全领域已经有数十名优秀的工程师加入无人驾驶汽车项目研究的行列。
|
||||
|
||||
@ -31,19 +31,19 @@ Miller 先生说,他离开了优步的一部分原因是滴滴给了他更自
|
||||
|
||||
Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的威胁似乎更加严肃,但我仍然希望有更大的透明度。”
|
||||
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司们提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
|
||||
在 Miller 和 Valasek 发现 Jeep 漏洞的一年后,他们又向人们演示了所有其他可能危害乘客安全的方式,包括劫持车辆的速度控制系统,猛打方向盘或在高速行驶下拉动手刹——这一切都是由汽车外的电脑操作的。(在测试中使用的汽车最后掉进路边的沟渠,他们只能寻求当地拖车公司的帮助)
|
||||
|
||||
虽然他们必须在 Jeep 车上才能做到这一切,但这也证明了入侵的可能性。
|
||||
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的安全研究人员第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的[安全研究人员][12]第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
|
||||
2015年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官凯文·马哈菲(Kevin Mahaffey)找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
2015 年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官<ruby>凯文·马哈菲<rt>Kevin Mahaffey</rt></ruby>找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复安全漏洞,这使得黑客的远程入侵也变的可能。
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器达12 米远。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复那些可能被黑的安全漏洞。
|
||||
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员。但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员,但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
|
||||
黑客入侵汽车的动机是无穷的。在得知 Rogers 先生和 Mahaffey 先生对特斯拉 Model S 的研究之后,一位中国 app 开发者和他们联系、询问他们是否愿意分享或者出售他们发现的漏洞。(这位 app 开发者正在寻找后门,试图在特斯拉的仪表盘上偷偷安装 app)
|
||||
|
||||
@ -51,25 +51,25 @@ Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的
|
||||
|
||||
但随着越来越多的无人驾驶和半自动驾驶的汽车驶入公路,它们将成为更有价值的目标。安全专家警告道:无人驾驶汽车面临着更复杂、更多面的入侵风险,每一辆新无人驾驶汽车的加入,都使这个系统变得更复杂,而复杂性不可避免地带来脆弱性。
|
||||
|
||||
20年前,平均每辆汽车有100万行代码,通用汽车公司的2010雪佛兰Volt有大约1000万行代码——比一架F-35战斗机的代码还要多。
|
||||
20 年前,平均每辆汽车有 100 万行代码,通用汽车公司的 2010 [雪佛兰 Volt][13] 有大约 1000 万行代码——比一架 [F-35 战斗机][14]的代码还要多。
|
||||
|
||||
如今, 平均每辆汽车至少有1亿行代码。无人驾驶汽车公司预计不久以后它们将有2亿行代码。当你停下来考虑:平均每1000行代码有15到50个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
如今, 平均每辆汽车至少有 1 亿行代码。无人驾驶汽车公司预计不久以后它们将有 2 亿行代码。当你停下来考虑:平均每 1000 行代码有 15 到 50 个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
|
||||
“计算机最大的安全威胁仅仅是数据被删除,但无人驾驶汽车一旦出现安全事故,失去的却是乘客的生命。”一家致力于解决汽车安全问题的以色列初创公司 Karamba Security 的联合创始人 David Barzilai 说。
|
||||
|
||||
安全专家说道:要想真正保障无人驾驶汽车的安全,汽车制造商必须想办法避免所有可能产生的漏洞——即使漏洞不可避免。其中最大的挑战,是汽车制造商和软件开发商们之间的缺乏合作经验。
|
||||
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。“
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。”
|
||||
|
||||
Mahaffey 先生说:”在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家“
|
||||
Mahaffey 先生说:“在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
作者:[NICOLE PERLROTH][a]
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -28,22 +28,20 @@ wpa_supplicant 可以作为命令行工具来用。使用一个简单的配置
|
||||
wpa_supplicant 中有一个工具叫做 `wpa_cli`,它提供了一个命令行接口来管理你的 WiFi 连接。事实上你可以用它来设置任何东西,但是设置一个配置文件看起来要更容易一些。
|
||||
|
||||
使用 root 权限运行 `wpa_cli`,然后扫描网络。
|
||||
```
|
||||
|
||||
```
|
||||
# wpa_cli
|
||||
> scan
|
||||
|
||||
```
|
||||
|
||||
扫描过程要花上一点时间,并且会显示所在区域的那些网络。记住你想要连接的那个网络。然后输入 `quit` 退出。
|
||||
|
||||
### 生成配置块并且加密你的密码
|
||||
|
||||
还有更方便的工具可以用来设置配置文件。它接受网络名称和密码作为参数,然后生成一个包含该网路配置块(其中的密码被加密处理了)的配置文件。
|
||||
还有更方便的工具可以用来设置配置文件。它接受网络名称和密码作为参数,然后生成一个包含该网路配置块(其中的密码被加密处理了)的配置文件。
|
||||
|
||||
```
|
||||
|
||||
# wpa_passphrase networkname password > /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
|
||||
```
|
||||
|
||||
### 裁剪你的配置
|
||||
@ -51,9 +49,9 @@ wpa_supplicant 中有一个工具叫做 `wpa_cli`,它提供了一个命令行
|
||||
现在你已经有了一个配置文件了,这个配置文件就是 `/etc/wpa_supplicant/wpa_supplicant.conf`。其中的内容并不多,只有一个网络块,其中有网络名称和密码,不过你可以在此基础上对它进行修改。
|
||||
|
||||
用喜欢的编辑器打开该文件,首先删掉说明密码的那行注释。然后,将下面行加到配置最上方。
|
||||
|
||||
```
|
||||
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
|
||||
|
||||
```
|
||||
|
||||
这一行只是让 `wheel` 组中的用户可以管理 wpa_supplicant。这会方便很多。
|
||||
@ -61,29 +59,29 @@ ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
|
||||
其他的内容则添加到网络块中。
|
||||
|
||||
如果你要连接到一个隐藏网络,你可以添加下面行来通知 wpa_supplicant 先扫描该网络。
|
||||
|
||||
```
|
||||
scan_ssid=1
|
||||
|
||||
```
|
||||
|
||||
下一步,设置协议以及密钥管理方面的配置。下面这些是 WPA2 相关的配置。
|
||||
|
||||
```
|
||||
proto=RSN
|
||||
key_mgmt=WPA-PSK
|
||||
|
||||
```
|
||||
|
||||
group 和 pairwise 配置告诉 wpa_supplicant 你是否使用了 CCMP,TKIP,或者两者都用到了。为了安全考虑,你应该只用 CCMP。
|
||||
`group` 和 `pairwise` 配置告诉 wpa_supplicant 你是否使用了 CCMP、TKIP,或者两者都用到了。为了安全考虑,你应该只用 CCMP。
|
||||
|
||||
```
|
||||
group=CCMP
|
||||
pairwise=CCMP
|
||||
|
||||
```
|
||||
|
||||
最后,设置网络优先级。越高的值越会优先连接。
|
||||
|
||||
```
|
||||
priority=10
|
||||
|
||||
```
|
||||
|
||||
![Complete WPA_Supplicant Settings][1]
|
||||
@ -94,14 +92,13 @@ priority=10
|
||||
|
||||
当然,该方法并不是用于即时配置无线网络的最好方法,但对于定期连接的网络来说,这种方法非常有效。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/connect-to-wifi-from-the-linux-command-line
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,70 +1,79 @@
|
||||
如何在 Linux 中从 PDF 创建视频
|
||||
======
|
||||
|
||||

|
||||
|
||||
我在我的平板电脑中收集了大量的 PDF 文件,其中主要是 Linux 教程。有时候我懒得在平板电脑上看。我认为如果我能够从 PDF 创建视频,并在大屏幕设备(如电视机或计算机)中观看会更好。虽然我对 [**FFMpeg**][1] 有一些经验,但我不知道如何使用它来创建视频。经过一番 Google 搜索,我想出了一个很好的解决方案。对于那些想从一组 PDF 文件制作视频文件的人,请继续阅读。这并不困难。
|
||||
我在我的平板电脑中收集了大量的 PDF 文件,其中主要是 Linux 教程。有时候我懒得在平板电脑上看。我认为如果我能够从 PDF 创建视频,并在大屏幕设备(如电视机或计算机)中观看会更好。虽然我对 [FFMpeg][1] 有一些经验,但我不知道如何使用它来创建视频。经过一番 Google 搜索,我想出了一个很好的解决方案。对于那些想从一组 PDF 文件制作视频文件的人,请继续阅读。这并不困难。
|
||||
|
||||
### 在 Linux 中从 PDF 创建视频
|
||||
|
||||
为此,你需要在系统中安装 **“FFMpeg”** 和 **“ImageMagick”** 。
|
||||
为此,你需要在系统中安装 “FFMpeg” 和 “ImageMagick”。
|
||||
|
||||
要安装 FFMpeg,请参考以下链接。
|
||||
|
||||
- [在 Linux 上安装 FFMpeg][2]
|
||||
|
||||
Imagemagick 可在大多数 Linux 发行版的官方仓库中找到。
|
||||
|
||||
在 **Arch Linux** 以及 **Antergos** 、**Manjaro Linux** 等衍生产品上,运行以下命令进行安装。
|
||||
在 Arch Linux 以及 Antergos、Manjaro Linux 等衍生产品上,运行以下命令进行安装。
|
||||
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
**Debian、Ubuntu、Linux Mint:**
|
||||
Debian、Ubuntu、Linux Mint:
|
||||
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
**Fedora:**
|
||||
Fedora:
|
||||
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
**RHEL、CentOS、Scientific Linux:**
|
||||
RHEL、CentOS、Scientific Linux:
|
||||
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
**SUSE、 openSUSE:**
|
||||
SUSE、 openSUSE:
|
||||
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
在安装 ffmpeg 和 imagemagick 之后,将你的 PDF 文件转换成图像格式,如 PNG 或 JPG,如下所示。
|
||||
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
这里,**-density 400** 指定输出图像的水平分辨率。
|
||||
这里,`-density 400` 指定输出图像的水平分辨率。
|
||||
|
||||
上面的命令会将指定 PDF 的所有页面转换为 PNG 格式。PDF 中的每个页面都将被转换成 PNG 文件,并保存在当前目录中,文件名为: **picture-1.png**、 **picture-2.png** 等。根据选择的 PDF 的页数,这将需要一些时间。
|
||||
上面的命令会将指定 PDF 的所有页面转换为 PNG 格式。PDF 中的每个页面都将被转换成 PNG 文件,并保存在当前目录中,文件名为: `picture-1.png`、 `picture-2.png` 等。根据选择的 PDF 的页数,这将需要一些时间。
|
||||
|
||||
将 PDF 中的所有页面转换为 PNG 格式后,运行以下命令以从 PNG 创建视频文件。
|
||||
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* **-r 1/10** :每张图像显示 10 秒。
|
||||
* **-i picture-%01d.png** :读取以 **“picture-”** 开头,接着是一位数字(%01d),最后以 **.png** 结尾的所有图片。如果图片名称带有2位数字(也就是 picture-10.png、picture11.png 等),在上面的命令中使用(%02d)。
|
||||
* **-c:v libx264**:输出的视频编码器(即 h264)。
|
||||
* **-r 30** :输出视频的帧率
|
||||
* **-pix_fmt yuv420p**:输出的视频分辨率
|
||||
* **video.mp4**:以 .mp4 格式输出视频文件。
|
||||
|
||||
|
||||
* `-r 1/10` :每张图像显示 10 秒。
|
||||
* `-i picture-%01d.png` :读取以 `picture-` 开头,接着是一位数字(`%01d`),最后以 `.png` 结尾的所有图片。如果图片名称带有 2 位数字(也就是 `picture-10.png`、`picture11.png` 等),在上面的命令中使用(`%02d`)。
|
||||
* `-c:v libx264`:输出的视频编码器(即 h264)。
|
||||
* `-r 30` :输出视频的帧率
|
||||
* `-pix_fmt yuv420p`:输出的视频分辨率
|
||||
* `video.mp4`:以 .mp4 格式输出视频文件。
|
||||
|
||||
好了,视频文件完成了!你可以在任何支持 .mp4 格式的设备上播放它。接下来,我需要找到一种方法来为我的视频插入一个很酷的音乐。我希望这也不难。
|
||||
|
||||
如果你想要更高的分辨率,你不必重新开始。只要将输出的视频文件转换为你选择的任何其他更高/更低的分辨率,比如说 720p,如下所示。
|
||||
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
@ -73,17 +82,16 @@ ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
|
||||
就是这些了。希望你觉得这个有帮助。还会有更好的东西。敬请关注!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
[2]:https://www.ostechnix.com/install-ffmpeg-linux/
|
||||
@ -1,80 +1,81 @@
|
||||
# python-hwinfo:使用Linux系统工具展示硬件信息概况
|
||||
python-hwinfo:使用 Linux 系统工具展示硬件信息概况
|
||||
==========
|
||||
|
||||
---
|
||||
到目前为止,获取Linux系统硬件信息和配置已经被大部分工具所涵盖,不过也有许多命令可用于相同目的。
|
||||
到目前为止,我们已经介绍了大部分获取 Linux 系统硬件信息和配置的工具,不过也有许多命令可用于相同目的。
|
||||
|
||||
而且,一些工具会显示所有硬件组成的详细信息,重置后,只显示特定设备的信息。
|
||||
而且,一些工具会显示所有硬件组件的详细信息,或只显示特定设备的信息。
|
||||
|
||||
在这个系列中, 今天我们讨论一下关于[python-hwinfo][1], 它是一个展示硬件信息概况和整洁配置的工具之一。
|
||||
在这个系列中, 今天我们讨论一下关于 [python-hwinfo][1], 它是一个展示硬件信息概况的工具之一,并且其配置简洁。
|
||||
|
||||
### 什么是python-hwinfo
|
||||
### 什么是 python-hwinfo
|
||||
|
||||
这是一个通过解析系统工具(例如lspci和dmidecode)的输出,来检查硬件和设备的Python库。
|
||||
这是一个通过解析系统工具(例如 `lspci` 和 `dmidecode`)的输出,来检查硬件和设备的 Python 库。
|
||||
|
||||
它提供了一个简单的命令行工具,可以用来检查本地,远程和捕获到的主机。用sudo运行命令以获得最大的信息。
|
||||
它提供了一个简单的命令行工具,可以用来检查本地、远程的主机和记录的信息。用 `sudo` 运行该命令以获得最大的信息。
|
||||
|
||||
另外,你可以提供服务器IP或者主机名,用户名和密码,在远程的服务器上执行它。当然你也可以使用这个工具查看其它工具捕获的输出(例如demidecode输出的'dmidecode.out',/proc/cpuinfo输出的'cpuinfo',lspci -nnm输出的'lspci-nnm.out')。
|
||||
另外,你可以提供服务器 IP 或者主机名、用户名和密码,在远程的服务器上执行它。当然你也可以使用这个工具查看其它工具捕获的输出(例如 `demidecode` 输出的 `dmidecode.out`,`/proc/cpuinfo` 输出的 `cpuinfo`,`lspci -nnm` 输出的 `lspci-nnm.out`)。
|
||||
|
||||
**建议阅读 :**
|
||||
**(#)** [inxi - A Great Tool to Check Hardware Information on Linux][2]
|
||||
**(#)** [Dmidecode - Easy Way To Get Linux System Hardware Information][3]
|
||||
**(#)** [LSHW (Hardware Lister) - A Nifty Tool To Get A Hardware Information On Linux][4]
|
||||
**(#)** [hwinfo (Hardware Info) - A Nifty Tool To Detect System Hardware Information On Linux][5]
|
||||
**(#)** [How To Use lspci, lsscsi, lsusb, And lsblk To Get Linux System Devices Information][6]
|
||||
建议阅读:
|
||||
|
||||
### Linux上如何安装python-hwinfo
|
||||
- [Inxi:一个功能强大的获取 Linux 系统信息的命令行工具][2]
|
||||
- [Dmidecode:获取 Linux 系统硬件信息的简易方式][3]
|
||||
- [LSHW (Hardware Lister): 一个在 Linux 上获取硬件信息的漂亮工具][4]
|
||||
- [hwinfo (Hardware Info):一个在 Linux 上检测系统硬件信息的漂亮工具][5]
|
||||
- [如何使用 lspci、lsscsi、lsusb 和 lsblk 获取 Linux 系统设备信息][6]
|
||||
|
||||
在绝大多数Linux发行版,都可以通过pip包安装。为了安装python-hwinfo, 确保你的系统已经有python和python-pip包作为先决条件。
|
||||
### Linux 上如何安装 python-hwinfo
|
||||
|
||||
pip是Python附带的一个包管理工具,在Linux上安装Python包的推荐工具之一。
|
||||
在绝大多数 Linux 发行版,都可以通过 pip 包安装。为了安装 python-hwinfo, 确保你的系统已经有 Python 和python-pip 包作为先决条件。
|
||||
|
||||
`pip` 是 Python 附带的一个包管理工具,在 Linux 上安装 Python 包的推荐工具之一。
|
||||
|
||||
在 Debian/Ubuntu 平台,使用 [APT-GET 命令][7] 或者 [APT 命令][8] 安装 `pip`。
|
||||
|
||||
在**`Debian/Ubuntu`**平台,使用[APT-GET 命令][7] 或者 [APT 命令][8] 安装pip。
|
||||
```
|
||||
$ sudo apt install python-pip
|
||||
|
||||
```
|
||||
|
||||
在**`RHEL/CentOS`**平台,使用[YUM 命令][9]安装pip。
|
||||
在 RHEL/CentOS 平台,使用 [YUM 命令][9]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip python-devel
|
||||
|
||||
```
|
||||
|
||||
在**`Fedora`**平台,使用[DNF 命令][10]安装pip。
|
||||
在 Fedora 平台,使用 [DNF 命令][10]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip
|
||||
|
||||
```
|
||||
|
||||
在**`Arch Linux`**平台,使用[Pacman 命令][11]安装pip。
|
||||
在 Arch Linux 平台,使用 [Pacman 命令][11]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip
|
||||
|
||||
```
|
||||
|
||||
在**`openSUSE`**平台,使用[Zypper 命令][12]安装pip。
|
||||
在 openSUSE 平台,使用 [Zypper 命令][12]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo zypper python-pip
|
||||
|
||||
```
|
||||
|
||||
最后,执行下面的pip命令安装python-hwinfo。
|
||||
最后,执行下面的 `pip` 命令安装 python-hwinfo。
|
||||
|
||||
```
|
||||
$ sudo pip install python-hwinfo
|
||||
|
||||
```
|
||||
|
||||
### 怎么使用python-hwinfo在本地机器
|
||||
### 怎么在本地机器使用 python-hwinfo
|
||||
|
||||
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
|
||||
|
||||
它的输出分为了五类。
|
||||
它的输出分为了五类:
|
||||
|
||||
* **`Bios Info:`** bios供应商名称,系统产品名称, 系统序列号,系统唯一标识符,系统制造商,bios发布日期和bios版本。
|
||||
* **`CPU Info:`** 处理器编号,供应商ID,cpu系列代号,型号,制作更新版本,型号名称,cpu主频。
|
||||
* **`Ethernet Controller Info:`** 供应商名称,供应商ID,设备名称,设备ID,子供应商名称,子供应商ID,子设备名称,子设备ID。
|
||||
* **`Storage Controller Info:`** 供应商名称,供应商ID,设备名称,设备ID,子供应商名称,子供应商ID,子设备名称,子设备ID。
|
||||
* **`GPU Info:`** 供应商名称,供应商ID,设备名称,设备ID,子供应商名称,子供应商ID,子设备名称,子设备ID。
|
||||
* Bios Info(BIOS 信息): BIOS 供应商名称、系统产品名称、系统序列号、系统唯一标识符、系统制造商、BIOS 发布日期和BIOS 版本。
|
||||
* CPU Info(CPU 信息):处理器编号、供应商 ID,CPU 系列代号、型号、步进编号、型号名称、CPU 主频。
|
||||
* Ethernet Controller Info(网卡信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID,子设备名称、子设备 ID。
|
||||
* Storage Controller Info(存储设备信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称,子供应商 ID、子设备名称、子设备 ID。
|
||||
* GPU Info(GPU 信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID、子设备名称、子设备 ID。
|
||||
|
||||
|
||||
```
|
||||
@ -136,20 +137,20 @@ GPU Info:
|
||||
|
||||
```
|
||||
|
||||
### 怎么使用python-hwinfo在远处机器上
|
||||
### 怎么在远处机器上使用 python-hwinfo
|
||||
|
||||
执行下面的命令检查远程机器现有的硬件,需要远程机器 IP,用户名和密码:
|
||||
|
||||
执行下面的命令检查远程机器现有的硬件,需要远程机器IP,用户名和密码
|
||||
```
|
||||
$ hwinfo -m x.x.x.x -u root -p password
|
||||
|
||||
```
|
||||
|
||||
### 如何使用python-hwinfo读取捕获的输出
|
||||
### 如何使用 python-hwinfo 读取记录的输出
|
||||
|
||||
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
|
||||
|
||||
```
|
||||
$ hwinfo -f [Path to file]
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -158,13 +159,13 @@ via: https://www.2daygeek.com/python-hwinfo-check-display-system-hardware-config
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/rdobson/python-hwinfo
|
||||
[2]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[2]:https://linux.cn/article-8424-1.html
|
||||
[3]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[4]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[5]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
@ -0,0 +1,55 @@
|
||||
最重要的 Firefox 命令行选项
|
||||
======
|
||||
|
||||
Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
|
||||
|
||||
你可能已经接触过一些了,比如 `-P "配置文件名"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
|
||||
|
||||
本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
|
||||
|
||||
你可以在 Firefox 开发者网站上看到[完整][1] 的命令行选项列表。需要注意的是,很多命令行选项对其它基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
|
||||
|
||||
### 重要的 Firefox 命令行选项
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
#### 配置文件相关选项
|
||||
|
||||
- `-CreateProfile 配置文件名` -- 创建新的用户配置信息,但并不立即使用它。
|
||||
- `-CreateProfile "配置文件名 存放配置文件的目录"` -- 跟上面一样,只是指定了存放配置文件的目录。
|
||||
- `-ProfileManager`,或 `-P` -- 打开内置的配置文件管理器。
|
||||
- `-P "配置文件名"` -- 使用指定的配置文件启动 Firefox。若指定的配置文件不存在则会打开配置文件管理器。只有在没有其他 Firefox 实例运行时才有用。
|
||||
- `-no-remote` -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个配置文件。
|
||||
|
||||
#### 浏览器相关选项
|
||||
|
||||
- `-headless` -- 以无头模式(LCTT 译注:无显示界面)启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
|
||||
- `-new-tab URL` -- 在 Firefox 的新标签页中加载指定 URL。
|
||||
- `-new-window URL` -- 在 Firefox 的新窗口中加载指定 URL。
|
||||
- `-private` -- 以隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
|
||||
- `-private-window` -- 打开一个隐私窗口。
|
||||
- `-private-window URL` -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
|
||||
- `-search 单词` -- 使用 FIrefox 默认的搜索引擎进行搜索。
|
||||
- - `url URL` -- 在新的标签页或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
|
||||
|
||||
#### 其他选项
|
||||
|
||||
- `-safe-mode` -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
|
||||
- `-devtools` -- 启动 Firefox,同时加载并打开开发者工具。
|
||||
- `-inspector URL` -- 使用 DOM Inspector 查看指定的 URL
|
||||
- `-jsconsole` -- 启动 Firefox,同时打开浏览器终端。
|
||||
- `-tray` -- 启动 Firefox,但保持最小化。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
[2]:https://cdn.ghacks.net/wp-content/uploads/2017/10/firefox-command-line.png
|
||||
@ -1,18 +1,20 @@
|
||||
在 Debian 中修复 vim - 去而复得
|
||||
修复 Debian 中的 vim 奇怪行为
|
||||
======
|
||||
I was wondering for quite some time why on my server vim behaves so stupid with respect to the mouse: Jumping around, copy and paste wasn't possible the usual way. All this despite having
|
||||
我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了
|
||||
|
||||
我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了。
|
||||
|
||||
```
|
||||
set mouse=
|
||||
set mouse=
|
||||
```
|
||||
|
||||
最后我终于知道为什么了,多谢 bug [#864074][1] 并且修复了它。
|
||||
|
||||
![][2]
|
||||
|
||||
原因是,当没有 `~/.vimrc` 的时候,vim在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
|
||||
原因是,当没有 `~/.vimrc` 的时候,vim 在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
|
||||
|
||||
在 `/etc/vim/vimrc` 中有一个注释(虽然我没有看到)解释了这一点:
|
||||
|
||||
```
|
||||
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
|
||||
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
|
||||
@ -22,12 +24,12 @@ I was wondering for quite some time why on my server vim behaves so stupid with
|
||||
" let g:skip_defaults_vim = 1
|
||||
```
|
||||
|
||||
|
||||
我同意这是在正常安装 vim 后设置 vim 的好方法,但 Debian 包可以做得更好。在错误报告中清楚地说明了这个问题:如果没有 `~/.vimrc`,`/etc/vim/vimrc.local` 中的设置被覆盖。
|
||||
|
||||
这在Debian中是违反直觉的 - 而且我也不知道其他包中是否采用类似的方法。
|
||||
|
||||
由于 `defaults.vim` 中的设置非常合理,所以我希望使用它,但只修改了一些我不同意的项目,比如鼠标。最后,我在 `/etc/vim/vimrc.local` 中做了以下操作:
|
||||
|
||||
```
|
||||
if filereadable("/usr/share/vim/vim80/defaults.vim")
|
||||
source /usr/share/vim/vim80/defaults.vim
|
||||
@ -40,7 +42,6 @@ set mouse=
|
||||
" other override settings go here
|
||||
```
|
||||
|
||||
|
||||
可能有更好的方式来获得一个不依赖于 vim 版本的通用加载语句, 但现在我对此很满意。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -49,7 +50,7 @@ via: https://www.preining.info/blog/2017/10/fixing-vim-in-debian/
|
||||
|
||||
作者:[Norbert Preining][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,188 @@
|
||||
如何根据文件权限查找文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 中查找文件并不是什么大问题。市面上也有很多可靠的自由开源的可视化查找工具。但对我而言,查找文件,用命令行的方式会更快更简单。我们已经知道 [如何根据访问和修改文件的时间寻找或整理文件][1]。今天,在基于 Unix 的操作系统中,我们将见识如何通过权限查找文件。
|
||||
|
||||
本段教程中,我将创建三个文件名为 `file1`,`file2` 和 `file3` 分别赋予 `777`,`766` 和 `655` 文件权限,并分别置于名为 `ostechnix` 的文件夹中。
|
||||
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
install -b -m 777 /dev/null file1
|
||||
install -b -m 766 /dev/null file2
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
现在,让我们通过权限来查找一下文件。
|
||||
|
||||
### 根据权限查找文件
|
||||
|
||||
根据权限查找文件最具代表性的语法:
|
||||
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
mode 可以是代表权限的八进制数字(777、666 …)也可以是权限符号(u=x,a=r+x)。
|
||||
|
||||
在深入之前,我们就以下三点详细说明 mode 参数。
|
||||
|
||||
1. 如果我们不指定任何参数前缀,它将会寻找**具体**权限的文件。
|
||||
2. 如果我们使用 `-` 参数前缀, 寻找到的文件至少拥有 mode 所述的权限,而不是具体的权限(大于或等于此权限的文件都会被查找出来)。
|
||||
3. 如果我们使用 `/` 参数前缀,那么所有者、组或者其他人任意一个应当享有此文件的权限。
|
||||
|
||||
为了让你更好的理解,让我举些例子。
|
||||
|
||||
首先,我们将要看到基于数字权限查找文件。
|
||||
|
||||
### 基于数字(八进制)权限查找文件
|
||||
|
||||
让我们运行下列命令:
|
||||
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
这条命令将会查找到当前目录权限为**确切为 777** 权限的文件。
|
||||
|
||||
![1][4]
|
||||
|
||||
如你看见的屏幕输出,file1 是唯一一个拥有**确切为 777 权限**的文件。
|
||||
|
||||
现在,让我们使用 `-` 参数前缀,看看会发生什么。
|
||||
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
如你所见,命令行上显示两个文件。我们给 file2 设置了 766 权限,但是命令行显示两个文件,什么鬼?因为,我们设置了 `-` 参数前缀。它意味着这条命令将在所有文件中查找文件所有者的“读/写/执行”权限,文件用户组的“读/写”权限和其他用户的“读/写”权限。本例中,file1 和 file2 都符合要求。换句话说,文件并不一样要求时确切的 766 权限。它将会显示任何属于(高于)此权限的文件 。
|
||||
|
||||
然后,让我们使用 `/` 参数前置,看看会发生什么。
|
||||
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
上述命令将会查找某些人(要么是所有者、用户组,要么是其他人)拥有写权限的文件。这里有另外一个例子:
|
||||
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
这条命令会查找所有者或用户组中拥有写权限的文件。这意味着匹配所有者和用户组任一可写的文件,而其他人的权限随意。
|
||||
|
||||
如果你使用 `-` 前缀运行相同的命令,你只会看到所有者和用户组都拥有写权限的文件。
|
||||
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
下面的截图会告诉你这两个参数前缀的不同。
|
||||
|
||||
![][7]
|
||||
|
||||
如我之前说过的一样,我们也可以使用符号表示文件权限。
|
||||
|
||||
请阅读:
|
||||
|
||||
- [如何在 Linux 中找到最大和最小的目录和文件][10]
|
||||
- [如何在 Linux 的目录树中找到最老的文件][11]
|
||||
- [如何在 Linux 中找到超过或小于某个大小的文件][12]
|
||||
|
||||
### 基于符号的文件权限查找文件
|
||||
|
||||
在下面的例子中,我们使用例如 `u`(所有者)、`g`(用户组) 和 `o`(其他) 的符号表示法。我们也可以使用字母 `a` 代表上述三种类型。我们可以通过特指的 `r` (读)、 `w` (写)、 `x` (执行)分别代表它们的权限。
|
||||
|
||||
例如,寻找用户组中拥有 `写` 权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
上面的例子中,file1 和 file2 都拥有 `写` 权限。请注意,你可以等效使用 `=` 或 `+` 两种符号标识。例如,下列两行相同效果的代码。
|
||||
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
查找文件所有者中拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
查找所有用户中拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
查找所有者和用户组中同时拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
上述命令等效与 `find -perm -220`。
|
||||
|
||||
查找所有者或用户组中拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
上述命令等效于 `find -perm /220`。
|
||||
|
||||
更多详情,参照 man 手册。
|
||||
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
了解更多简化案例或其他 Linux 命令,查看[man 手册][9]。
|
||||
|
||||
然后,这就是所有的内容。希望这个教程有用。更多干货,敬请关注。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7/
|
||||
[3]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png
|
||||
[4]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png
|
||||
[5]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png
|
||||
|
||||
[6]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png
|
||||
[7]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png
|
||||
[8]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png
|
||||
[9]:https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
[10]:https://www.ostechnix.com/how-to-find-largest-and-smallest-directories-and-files-in-linux/
|
||||
[11]:https://www.ostechnix.com/find-oldest-file-directory-tree-linux/
|
||||
[12]:https://www.ostechnix.com/find-files-bigger-smaller-x-size-linux/
|
||||
@ -0,0 +1,71 @@
|
||||
2018 年 4 个需要关注的人工智能趋势
|
||||
======
|
||||
|
||||
> 今年人工智能决策将变得更加透明?
|
||||
|
||||

|
||||
|
||||
|
||||
无论你的 IT 业务现在使用了多少[人工智能][1],预计你将会在 2018 年使用更多。即便你从来没有涉猎过 AI 项目,这也可能是将谈论转变为行动的一年,[德勤][2]董事总经理 David Schatsky 说。他说:“与 AI 开展合作的公司数量正在上升。”
|
||||
|
||||
看看他对未来一年的AI预测:
|
||||
|
||||
### 1、预期更多的企业 AI 试点项目
|
||||
|
||||
如今我们经常使用的许多现成的应用程序和平台都将 AI 结合在一起。 Schatsky 说:“除此之外,越来越多的公司正在试验机器学习或自然语言处理来解决特定的问题,或者帮助理解他们的数据,或者使内部流程自动化,或者改进他们自己的产品和服务。
|
||||
|
||||
“除此之外,公司与人工智能的合作强度将会上升。”他说,“早期采纳它的公司已经有五个或略少的项目正在进行中,但是我们认为这个数字会上升到十个或有更多正在进行的计划。” 他说,这个预测的一个原因是人工智能技术正在变得越来越好,也越来越容易使用。
|
||||
|
||||
### 2、人工智能将缓解数据科学人才紧缺的现状
|
||||
|
||||
人才是数据科学中的一个大问题,大多数大公司都在努力聘用他们所需要的数据科学家。 Schatsky 说,AI 可以承担一些负担。他说:“数据科学的实践,逐渐成为由创业公司和大型成熟的技术供应商提供的自动化的工具。”他解释说,大量的数据科学工作是重复的、乏味的,自动化的时机已经成熟。 “数据科学家不会消亡,但他们将会获得更高的生产力,所以一家只能做一些数据科学项目而没有自动化的公司将能够使用自动化来做更多的事情,虽然它不能雇用更多的数据科学家”。
|
||||
|
||||
### 3、合成数据模型将缓解瓶颈
|
||||
|
||||
Schatsky 指出,在你训练机器学习模型之前,你必须得到数据来训练它。 这并不容易,他说:“这通常是一个商业瓶颈,而不是生产瓶颈。 在某些情况下,由于有关健康记录和财务信息的规定,你无法获取数据。”
|
||||
|
||||
他说,合成数据模型可以采集一小部分数据,并用它来生成可能需要的较大集合。 “如果你以前需要 10000 个数据点来训练一个模型,但是只能得到 2000 个,那么现在就可以产生缺少的 8000 个数据点,然后继续训练你的模型。”
|
||||
|
||||
### 4、人工智能决策将变得更加透明
|
||||
|
||||
AI 的业务问题之一就是它经常作为一个黑匣子来操作。也就是说,一旦你训练了一个模型,它就会吐出你不能解释的答案。 Schatsky 说:“机器学习可以自动发现人类无法看到的数据模式,因为数据太多或太复杂。 “发现了这些模式后,它可以预测未见的新数据。”
|
||||
|
||||
问题是,有时你确实需要知道 AI 发现或预测背后的原因。 “以医学图像为例子来说,模型说根据你给我的数据,这个图像中有 90% 的可能性是肿瘤。 “Schatsky 说,“你说,‘你为什么这么认为?’ 模型说:‘我不知道,这是数据给的建议。’”
|
||||
|
||||
Schatsky 说,如果你遵循这些数据,你将不得不对患者进行探查手术。 当你无法解释为什么时,这是一个艰难的请求。 “但在很多情况下,即使模型产生了非常准确的结果,如果不能解释为什么,也没有人愿意相信它。”
|
||||
|
||||
还有一些情况是由于规定,你确实不能使用你无法解释的数据。 Schatsky 说:“如果一家银行拒绝贷款申请,就需要能够解释为什么。 这是一个法规,至少在美国是这样。传统上来说,人类分销商会打个电话做回访。一个机器学习模式可能会更准确,但如果不能解释它的答案,就不能使用。”
|
||||
|
||||
大多数算法不是为了解释他们的推理而设计的。 他说:“所以研究人员正在找到聪明的方法来让 AI 泄漏秘密,并解释哪些变量使得这个病人更可能患有肿瘤。 一旦他们这样做,人们可以发现答案,看看为什么会有这样的结论。”
|
||||
|
||||
他说,这意味着人工智能的发现和决定可以用在许多今天不可能的领域。 “这将使这些模型更加值得信赖,在商业世界中更具可用性。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/4-ai-trends-watch
|
||||
|
||||
作者:[Minda Zetlin][a]
|
||||
译者:[Wuod3n](https://github.com/Wuod3n)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/minda-zetlin
|
||||
[1]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[2]:https://www2.deloitte.com/us/en.html
|
||||
[3]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros?sc_cid=70160000000h0aXAAQ
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
Manjaro Gaming: Gaming on Linux Meets Manjaro’s Awesomeness
|
||||
======
|
||||
[![Meet Manjaro Gaming, a Linux distro designed for gamers with the power of Manjaro][1]][1]
|
||||
|
||||
[Gaming on Linux][2]? Yes, that's very much possible and we have a dedicated new Linux distribution aiming for gamers.
|
||||
|
||||
Manjaro Gaming is a Linux distro designed for gamers with the power of Manjaro. Those who have used Manjaro Linux before, know exactly why it is a such a good news for gamers.
|
||||
|
||||
[Manjaro][3] is a Linux distro based on one of the most popular distro - [Arch Linux][4]. Arch Linux is widely known for its bleeding-edge nature offering a lightweight, powerful, extensively customizable and up-to-date experience. And while all those are absolutely great, the main drawback is that Arch Linux embraces the DIY (do it yourself) approach where users need to possess a certain level of technical expertise to get along with it.
|
||||
|
||||
Manjaro strips that requirement and makes Arch accessible to newcomers, and at the same time provides all the advanced and powerful features of Arch for the experienced users as well. In short, Manjaro is an user-friendly Linux distro that works straight out of the box.
|
||||
|
||||
The reasons why Manjaro makes a great and extremely suitable distro for gaming are:
|
||||
|
||||
* Manjaro automatically detects computer's hardware (e.g. Graphics cards)
|
||||
* Automatically installs the necessary drivers and software (e.g. Graphics drivers)
|
||||
* Various codecs for media files playback comes pre-installed with it
|
||||
* Has dedicated repositories that deliver fully tested and stable packages
|
||||
|
||||
|
||||
|
||||
Manjaro Gaming is packed with all of Manjaro's awesomeness with the addition of various tweaks and software packages dedicated to make gaming on Linux smooth and enjoyable.
|
||||
|
||||
![Inside Manjaro Gaming][5]
|
||||
|
||||
#### Tweaks
|
||||
|
||||
Some of the tweaks made on Manjaro Gaming are:
|
||||
|
||||
* Manjaro Gaming uses highly customizable XFCE desktop environment with an overall dark theme.
|
||||
* Sleep mode is disabled for preventing computers from sleeping while playing games with GamePad or watching long cutscenes.
|
||||
|
||||
|
||||
|
||||
#### Softwares
|
||||
|
||||
Maintaining Manjaro's tradition of working straight out of the box, Manjaro Gaming comes bundled with various Open Source software to provide often needed functionalities for gamers. Some of the software included are:
|
||||
|
||||
* [**KdenLIVE**][6]: Videos editing software for editing gaming videos
|
||||
* [**Mumble**][7]: Voice chatting software for gamers
|
||||
* [**OBS Studio**][8]: Software for video recording and live streaming games videos on [Twitch][9]
|
||||
* **[OpenShot][10]** : Powerful video editor for Linux
|
||||
* [**PlayOnLinux**][11]: For running Windows games on Linux with [Wine][12] backend
|
||||
* [**Shutter**][13]: Feature-rich screenshot tool
|
||||
|
||||
|
||||
|
||||
#### Emulators
|
||||
|
||||
Manjaro Gaming comes with a long list of gaming emulators:
|
||||
|
||||
* **[DeSmuME][14]** : Nintendo DS emulator
|
||||
* **[Dolphin Emulator][15]** : GameCube and Wii emulator
|
||||
* [**DOSBox**][16]: DOS Games emulator
|
||||
* **[FCEUX][17]** : Nintendo Entertainment System (NES), Famicom, and Famicom Disk System (FDS) emulator
|
||||
* **Gens/GS** : Sega Mega Drive emulator
|
||||
* **[PCSXR][18]** : PlayStation Emulator
|
||||
* [**PCSX2**][19]: Playstation 2 emulator
|
||||
* [**PPSSPP**][20]: PSP emulator
|
||||
* **[Stella][21]** : Atari 2600 VCS emulator
|
||||
* [**VBA-M**][22]: Gameboy and GameboyAdvance emulator
|
||||
* [**Yabause**][23]: Sega Saturn Emulator
|
||||
* **[ZSNES][24]** : Super Nintendo emulator
|
||||
|
||||
|
||||
|
||||
#### Others
|
||||
|
||||
There are some terminal add-ons - Color, ILoveCandy and Screenfetch. [Conky Manager][25] with Retro Conky theme is also included.
|
||||
|
||||
**Point to be noted: Not all the features mentioned are included in the current release of Manjaro Gaming (which is 16.03). Some of them are scheduled to be included in the next release - Manjaro Gaming 16.06.**
|
||||
|
||||
### Downloads
|
||||
|
||||
Manjaro Gaming 16.06 is going to be the first proper release of Manjaro Gaming. But if you are interested enough to try it now, Manjaro Gaming 16.03 is available for downloading on the Sourceforge [project page][26]. Go there and grab the ISO.
|
||||
|
||||
How do you feel about this new Gaming Linux distro? Are you thinking of giving it a try? Let us know!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/manjaro-gaming-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming.jpg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://manjaro.github.io/
|
||||
[4]:https://www.archlinux.org/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming-Inside-1024x576.png
|
||||
[6]:https://kdenlive.org/
|
||||
[7]:https://www.mumble.info
|
||||
[8]:https://obsproject.com/
|
||||
[9]:https://www.twitch.tv/
|
||||
[10]:http://www.openshot.org/
|
||||
[11]:https://www.playonlinux.com
|
||||
[12]:https://www.winehq.org/
|
||||
[13]:http://shutter-project.org/
|
||||
[14]:http://desmume.org/
|
||||
[15]:https://dolphin-emu.org
|
||||
[16]:https://www.dosbox.com/
|
||||
[17]:http://www.fceux.com/
|
||||
[18]:https://pcsxr.codeplex.com
|
||||
[19]:http://pcsx2.net/
|
||||
[20]:http://www.ppsspp.org/
|
||||
[21]:http://stella.sourceforge.net/
|
||||
[22]:http://vba-m.com/
|
||||
[23]:https://yabause.org/
|
||||
[24]:http://www.zsnes.com/
|
||||
[25]:https://itsfoss.com/conky-gui-ubuntu-1304/
|
||||
[26]:https://sourceforge.net/projects/mgame/
|
||||
141
sources/talk/20170523 Best Websites to Download Linux Games.md
Normal file
141
sources/talk/20170523 Best Websites to Download Linux Games.md
Normal file
@ -0,0 +1,141 @@
|
||||
申请翻译 WangYueScream
|
||||
================================
|
||||
Best Websites to Download Linux Games
|
||||
======
|
||||
Brief: New to Linux gaming and wondering where to **download Linux games** from? We list the best resources from where you can **download free Linux games** as well as buy premium Linux games.
|
||||
|
||||
Linux and Games? Once upon a time, it was hard to imagine these two going together. Then time passed and a lot of things happened. Fast-forward to the present, there are thousands and thousands of games available for Linux and more are being developed by both big game companies and independent developers.
|
||||
|
||||
[Gaming on Linux][1] is real now and today we are going to see where you can find games for Linux platform and hunt down the games that you like.
|
||||
|
||||
### Where to download Linux games?
|
||||
|
||||
![Websites to download Linux games][2]
|
||||
|
||||
First and foremost, look into your Linux distribution's software center (if it has one). You should find plenty of games there already.
|
||||
|
||||
But that doesn't mean you should restrict yourself to the software center. Let me list you some websites to download Linux games.
|
||||
|
||||
#### 1. Steam
|
||||
|
||||
If you are a seasoned gamer, you have heard about Steam. Yes, if you don't know it already, Steam is available for Linux. Steam recommends Ubuntu but it should run on other major distributions too. And if you are really psyched up about Steam, there is even a dedicated operating system for playing Steam games - [SteamOS][3]. We covered it last year in the [Best Linux Gaming Distribution][4] article.
|
||||
|
||||
![Steam Store][5]
|
||||
|
||||
Steam has the largest games store for Linux. While writing this article, it has exactly 3487 games on Linux platform and that's really huge. You can find games from wide range of genre. As for [Digital Rights Management][6], most of the Steam games have some kind of DRM.
|
||||
|
||||
For using Steam either you will have to install the [Steam client][7] on your Linux distribution or use SteamOS. One of the advantages of Steam is that, after your initial setup, for most of the games you wouldn't need to worry about dependencies and complex installation process. Steam client will do the heavy tasks for you.
|
||||
|
||||
[Steam Store][8]
|
||||
|
||||
#### 2. GOG
|
||||
|
||||
If you are solely interested in DRM-free games, GOG has a pretty large collection of it. At this moment, GOG has 1978 DRM-free games in their library. GOG is kind of famous for its vast collection of DRM-free games.
|
||||
|
||||
![GOG Store][9]
|
||||
|
||||
Officially, GOG games support Ubuntu LTS versions and Linux Mint. So, Ubuntu and its derivatives will have no problem installing them. Installing them on other distributions might need some extra works, such as - installing correct dependencies.
|
||||
|
||||
You will not need any extra clients for downloading games from GOG. All the purchased games will be available in your accounts section. You can download them directly with your favorite download manager.
|
||||
|
||||
[GOG Store][10]
|
||||
|
||||
#### 3. Humble Store
|
||||
|
||||
The Humble Store is another place where you can find various games for Linux. There are both DRM-free and non-DRM-free games available on Humble Store. The non-DRM-free games are generally from the Steam. Currently there are about 1826 games for Linux in the Humble Store.
|
||||
|
||||
![The Humble Store][11]
|
||||
|
||||
Humble Store is famous for another reason though. They have a program called [**Humble Indie Bundle**][12] where they offer a bunch of games together with a compelling discount for a limited time period. Another thing about Humble is that when you make a purchase, 10% of the revenue from your purchase goes to charities.
|
||||
|
||||
Humble doesn't have any extra clients for downloading their games.
|
||||
|
||||
[The Humble Store][13]
|
||||
|
||||
#### 4. itch.io
|
||||
|
||||
itch.io is an open marketplace for independent digital creators with a focus on independent video games. itch.io has some of the most interesting and unique games that you can find. Most games available on itch.io are DRM-free.
|
||||
|
||||
![itch.io Store][14]
|
||||
|
||||
Right now, itch.io has 9514 games available in their store for Linux platform.
|
||||
|
||||
itch.io has their own [client][15] for effortlessly downloading, installing, updating and playing their games.
|
||||
|
||||
[itch.io Store][16]
|
||||
|
||||
#### 5. LGDB
|
||||
|
||||
LGDB is an abbreviation for Linux Game Database. Though technically not a game store, it has a large collection of games for Linux along with various information about them. Every game is documented with links of where you can find them.
|
||||
|
||||
![Linux Game Database][17]
|
||||
|
||||
As of now, there are 2046 games entries in the database. They also have very long lists for [Emulators][18], [Tools][19] and [Game Engines][20].
|
||||
|
||||
[LGDB][21]
|
||||
|
||||
[Annoying Experiences Every Linux Gamer Never Wanted!][27]
|
||||
|
||||
#### 6. Game Jolt
|
||||
|
||||
Game Jolt has a very impressive collection with about 5000 indie games for Linux under their belt.
|
||||
|
||||
![GameJolt Store][22]
|
||||
|
||||
Game Jolt has an (pre-release) [client][23] for downloading, installing, updating and playing games with ease.
|
||||
|
||||
[Game Jolt Store][24]
|
||||
|
||||
### Others
|
||||
|
||||
There are many other stores that sells Linux Games. Also there are many places you can find free games too. Here are a couple of them:
|
||||
|
||||
* [**Bundle Stars**][25]: Bundle Stars currently has 814 Linux games and 31 games bundles.
|
||||
* [**GamersGate**][26]: GamersGate has 595 Linux games as for now. There are both DRM-free and non-DRM-free games.
|
||||
|
||||
|
||||
|
||||
#### App Stores, Software Center & Repositories
|
||||
|
||||
Linux distribution has their own application stores or repositories. Though not many, but there you can find various games too.
|
||||
|
||||
That's all for today. Did you know there are this many games available for Linux? How do you feel about this? Do you use some other websites to download Linux games? Do share your favorites with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/download-linux-games/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/linux-gaming-guide/
|
||||
[2]:https://itsfoss.com/wp-content/uploads/2017/05/download-linux-games-800x450.jpg
|
||||
[3]:http://store.steampowered.com/steamos/
|
||||
[4]:https://itsfoss.com/linux-gaming-distributions/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2017/05/Steam-Store-800x382.jpg
|
||||
[6]:https://www.wikiwand.com/en/Digital_rights_management
|
||||
[7]:http://store.steampowered.com/about/
|
||||
[8]:http://store.steampowered.com/linux
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2017/05/GOG-Store-800x366.jpg
|
||||
[10]:https://www.gog.com/games?system=lin_mint,lin_ubuntu
|
||||
[11]:https://itsfoss.com/wp-content/uploads/2017/05/The-Humble-Store-800x393.jpg
|
||||
[12]:https://www.humblebundle.com/?partner=itsfoss
|
||||
[13]:https://www.humblebundle.com/store?partner=itsfoss
|
||||
[14]:https://itsfoss.com/wp-content/uploads/2017/05/itch.io-Store-800x485.jpg
|
||||
[15]:https://itch.io/app
|
||||
[16]:https://itch.io/games/platform-linux
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2017/05/LGDB-800x304.jpg
|
||||
[18]:https://lgdb.org/emulators
|
||||
[19]:https://lgdb.org/tools
|
||||
[20]:https://lgdb.org/engines
|
||||
[21]:https://lgdb.org/games
|
||||
[22]:https://itsfoss.com/wp-content/uploads/2017/05/GameJolt-Store-800x357.jpg
|
||||
[23]:http://gamejolt.com/client
|
||||
[24]:http://gamejolt.com/games/best?os=linux
|
||||
[25]:https://www.bundlestars.com/en/games?page=1&platforms=Linux
|
||||
[26]:https://www.gamersgate.com/games?state=available
|
||||
[27]:https://itsfoss.com/linux-gaming-problems/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by Wuod3n
|
||||
Deep learning wars: Facebook-backed PyTorch vs Google's TensorFlow
|
||||
======
|
||||
The rapid rise of tools and techniques in Artificial Intelligence and Machine learning of late has been astounding. Deep Learning, or "Machine learning on steroids" as some say, is one area where data scientists and machine learning experts are spoilt for choice in terms of the libraries and frameworks available. A lot of these frameworks are Python-based, as Python is a more general-purpose and a relatively easier language to work with. [Theano][1], [Keras][2] [TensorFlow][3] are a few of the popular deep learning libraries built on Python, developed with an aim to make the life of machine learning experts easier.
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
4 artificial intelligence trends to watch
|
||||
======
|
||||
|
||||

|
||||
|
||||
However much your IT operation is using [artificial intelligence][1] today, expect to be doing more with it in 2018. Even if you have never dabbled in AI projects, this may be the year talk turns into action, says David Schatsky, managing director at [Deloitte][2]. "The number of companies doing something with AI is on track to rise," he says.
|
||||
|
||||
Check out his AI predictions for the coming year:
|
||||
|
||||
### 1. Expect more enterprise AI pilot projects
|
||||
|
||||
Many of today's off-the-shelf applications and platforms that companies already routinely use incorporate AI. "But besides that, a growing number of companies are experimenting with machine learning or natural language processing to solve particular problems or help understand their data, or automate internal processes, or improve their own products and services," Schatsky says.
|
||||
|
||||
**[ What IT jobs will be hot in the AI age? See our related article, [8 emerging AI jobs for IT pros][3]. ]**
|
||||
|
||||
"Beyond that, the intensity with which companies are working with AI will rise," he says. "Companies that are early adopters already mostly have five or fewer projects underway, but we think that number will rise to having 10 or more pilots underway." One reason for this prediction, he says, is that AI technologies are getting better and easier to use.
|
||||
|
||||
### 2. AI will help with data science talent crunch
|
||||
|
||||
Talent is a huge problem in data science, where most large companies are struggling to hire the data scientists they need. AI can take up some of the load, Schatsky says. "The practice of data science is increasingly automatable with tools offered both by startups and large, established technology vendors," he says. A lot of data science work is repetitive and tedious, and ripe for automation, he explains. "Data scientists aren't going away, but they're going to get much more productive. So a company that can only do a few data science projects without automation will be able to do much more with automation, even if it can't hire any more data scientists."
|
||||
|
||||
### 3. Synthetic data models will ease bottlenecks
|
||||
|
||||
Before you can train a machine learning model, you have to get the data to train it on, Schatsky notes. That's not always easy. "That's often a business bottleneck, not a production bottleneck," he says. In some cases you can't get the data because of regulations governing things like health records and financial information.
|
||||
|
||||
Synthetic data models can take a smaller set of data and use it to generate the larger set that may be needed, he says. "If you used to need 10,000 data points to train a model but could only get 2,000, you can now generate the missing 8,000 and go ahead and train your model."
|
||||
|
||||
### 4. AI decision-making will become more transparent
|
||||
|
||||
One of the business problems with AI is that it often operates as a black box. That is, once you train a model, it will spit out answers that you can't necessarily explain. "Machine learning can automatically discover patterns in data that a human can't see because it's too much data or too complex," Schatsky says. "Having discovered these patterns, it can make predictions about new data it hasn't seen."
|
||||
|
||||
The problem is that sometimes you really do need to know the reasons behind an AI finding or prediction. "You feed in a medical image and the model says, based on the data you've given me, there's a 90 percent chance that there's a tumor in this image," Schatsky says. "You say, 'Why do you think so?' and the model says, 'I don't know, that's what the data would suggest.'"
|
||||
|
||||
If you follow that data, you're going to have to do exploratory surgery on a patient, Schatsky says. That's a tough call to make when you can't explain why. "There are a lot of situations where even though the model produces very accurate results, if it can't explain how it got there, nobody wants to trust it."
|
||||
|
||||
There are also situations where because of regulations, you literally can't use data that you can't explain. "If a bank declines a loan application, it needs to be able to explain why," Schatsky says. "That's a regulation, at least in the U.S. Traditionally, a human underwriter makes that call. A machine learning model could be more accurate, but if it can't explain its answer, it can't be used."
|
||||
|
||||
Most algorithms were not designed to explain their reasoning. "So researchers are finding clever ways to get AI to spill its secrets and explain what variables make it more likely that this patient has a tumor," he says. "Once they do that, a human can look at the answers and see why it came to that conclusion."
|
||||
|
||||
That means AI findings and decisions can be used in many areas where they can't be today, he says. "That will make these models more trustworthy and more usable in the business world."
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/4-ai-trends-watch
|
||||
|
||||
作者:[Minda Zetlin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/minda-zetlin
|
||||
[1]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[2]:https://www2.deloitte.com/us/en.html
|
||||
[3]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros?sc_cid=70160000000h0aXAAQ
|
||||
124
sources/talk/20180107 7 leadership rules for the DevOps age.md
Normal file
124
sources/talk/20180107 7 leadership rules for the DevOps age.md
Normal file
@ -0,0 +1,124 @@
|
||||
7 leadership rules for the DevOps age
|
||||
======
|
||||
|
||||

|
||||
|
||||
If [DevOps][1] is ultimately more about culture than any particular technology or platform, then remember this: There isn't a finish line. It's about continuous change and improvement - and the C-suite doesn't get a pass.
|
||||
|
||||
Rather, leaders need to [revise some of their traditional approaches][2] if they expect DevOps to help drive the outcomes they seek. Let's consider seven ideas for more effective IT leadership in the DevOps era.
|
||||
|
||||
### 1. Say "yes" to failure
|
||||
|
||||
The word "failure" has long had very specific connotations in IT, and they're almost universally bad: server failure, backup failure, hard drive failure - you get the picture.
|
||||
|
||||
A healthy DevOps culture, however, depends upon redefining failure - IT leaders should rewrite their thesaurus to make the word synonymous with "opportunity."
|
||||
|
||||
"Prior to DevOps, we had a culture of punishing failure," says Robert Reeves, CTO and co-founder of [Datical][3]. "The only learning we had was to avoid mistakes. The number one way to avoid mistakes in IT is to not change anything: Don't accelerate the release schedule, don't move to the cloud, don't do anything differently!"
|
||||
|
||||
That's a playbook for a bygone era and, as Reeves puts plainly, it doesn't work. In fact, that kind of stasis is actual failure.
|
||||
|
||||
"Companies that release slowly and avoid the cloud are paralyzed by fear - and they will fail," Reeves says. "IT leaders must embrace failure as an opportunity. Humans not only learn from their mistakes, they learn from others' mistakes. A culture of openness and ['psychological safety'][4] fosters learning and improvement."
|
||||
|
||||
**[ Related article: [Why agile leaders must move beyond talking about "failure."][5] ]**
|
||||
|
||||
### 2. Live, eat, and breathe DevOps in the C-suite
|
||||
|
||||
While DevOps culture can certainly grow organically in all directions, companies that are shifting from monolithic, siloed IT practices - and likely encountering headwinds en route - need total buy-in from executive leadership. Without it, you're sending mixed messages and likely emboldening those who'd rather push a _but this is the way we 've always done things_ agenda. [Culture change is hard][6]; people need to see leadership fully invested in that change for it to actually happen.
|
||||
|
||||
"Top management must fully support DevOps in order for it to be successful in delivering the benefits," says Derek Choy, CIO at [Rainforest QA][7].
|
||||
|
||||
Becoming a DevOps shop. Choy notes, touches pretty much everything in the organization, from technical teams to tools to processes to roles and responsibilities.
|
||||
|
||||
"Without unified sponsorship from top management, DevOps implementation will not be successful," Choy says. "Therefore, it is important to have leaders aligned at the top level before transitioning to DevOps."
|
||||
|
||||
### 3. Don 't just declare "DevOps" - define it
|
||||
|
||||
Even in IT organizations that have welcomed DevOps with open arms, it's possible that's not everyone's on the same page.
|
||||
|
||||
**[Read our related article,**[ **3 areas where DevOps and CIOs must get on the same page**][8] **.]**
|
||||
|
||||
One fundamental reason for such disconnects: People might be operating with different definitions for what the term even means.
|
||||
|
||||
"DevOps can mean different things to different people," Choy says. "It is important for C-level [and] VP-level execs to define the goals of DevOps, clearly stating the expected outcome, understand how this outcome can benefit the business and be able to measure and report on success along the way."
|
||||
|
||||
Indeed, beyond the baseline definition and vision, DevOps requires ongoing and frequent communication, not just in the trenches but throughout the organization. IT leaders must make that a priority.
|
||||
|
||||
"Inevitably, there will be hiccups, there will be failures and disruptions to the business," Choy says. "Leaders need to clearly communicate the journey to the rest of the company and what they can expect as part of the process."
|
||||
|
||||
### 4.DevOps is as much about business as technology
|
||||
|
||||
IT leaders running successful DevOps shops have embraced its culture and practices as a business strategy as much as an approach to building and operating software. DevOps culture is a great enabler of IT's shift from support arm to strategic business unit.
|
||||
|
||||
"IT leaders must shift their thinking and approach from being cost/service centers to driving business outcomes, and a DevOps culture helps speed up those outcomes via automation and stronger collaboration," says Mike Kail, CTO and co-founder at [CYBRIC][9].
|
||||
|
||||
Indeed, this is a strong current that runs through much of these new "rules" for leading in the age of DevOps.
|
||||
|
||||
"Promoting innovation and encouraging team members to take smart risks is a key part of a DevOps culture and IT leaders need to clearly communicate that on a continuous basis," Kail says.
|
||||
|
||||
"An effective IT leader will need to be more engaged with the business than ever before," says Evan Callendar, director, performance services at [West Monroe Partners][10]. "Gone are the days of yearly or quarterly reviews - you need to welcome the [practice of] [bi-weekly backlog grooming][11]. The ability to think strategically at the year level, but interact at the sprint level, will be rewarded when business expectations are met."
|
||||
|
||||
### 5. Change anything that hampers DevOps goals
|
||||
|
||||
|
||||
While DevOps veterans generally agree that DevOps is much more a matter of culture than technology, success does depend on enabling that culture with the right processes and tools. Declaring your department a DevOps shop while resisting the necessary changes to processes or technologies is like buying a Ferrari but keeping the engine from your 20-year-old junker that billows smoke each time you turn the key.
|
||||
|
||||
Exhibit A: [Automation][12]. It's critical parallel strategy for DevOps success.
|
||||
|
||||
"IT leadership has to put an emphasis on automation," Callendar says. "This will be an upfront investment, but without it, DevOps simply will engulf itself with inefficiency and lack of delivery."
|
||||
|
||||
Automation is a fundamental, but change doesn't stop there.
|
||||
|
||||
"Leaders need to push for automation, monitoring, and a continuous delivery process. This usually means changes to many existing practices, processes, team structures, [and] roles," Choy says. "Leaders need to be willing to change anything that'll hinder the team's ability to fully automate the process."
|
||||
|
||||
### 6. Rethink team structure and performance metrics
|
||||
|
||||
While we're on the subject of change...if that org chart collecting dust on your desktop is the same one you've been plugging names into for the better part of a decade (or more), it's time for an overhaul.
|
||||
|
||||
"IT executives need to take a completely different approach to organizational structure in this new era of DevOps culture," Kail says. "Remove strict team boundaries, which tend to hamper collaboration, and allow for the teams to be self-organizing and agile."
|
||||
|
||||
Kail says this kind of rethinking can and should extend to other areas in the DevOps age, too, including how you measure individual and team success, and even how you interact with people.
|
||||
|
||||
"Measure initiatives in terms of business outcomes and overall positive impact," Kail advises. "Finally, and something that I believe to be the most important aspect of management: Be empathetic."
|
||||
|
||||
Beware easily collected measurements that are not truly DevOps metrics, writes [Red Hat ][13]technology evangelist Gordon Haff. "DevOps metrics should be tied to business outcomes in some manner," he notes. "You probably don't really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is. In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor." See his full article, [DevOps metrics: Are you measuring what matters?][14]
|
||||
|
||||
### 7. Chuck conventional wisdom out the window
|
||||
|
||||
If the DevOps age requires new ways of thinking about IT leadership, it follows that some of the old ways need to be retired. But which ones?
|
||||
|
||||
"To be honest, all of them," Kail says. "Get rid of the 'because that's the way we've always done things' mindset. The transition to a culture of DevOps is a complete paradigm shift, not a few subtle changes to the old days of Waterfall and Change Advisory Boards."
|
||||
|
||||
Indeed, IT leaders recognize that real transformation requires more than minor touch-ups to old approaches. Often, it requires a total reboot of a previous process or strategy.
|
||||
|
||||
Callendar of West Monroe Partners shares a parting example of legacy leadership thinking that hampers DevOps: Failing to embrace hybrid IT models and modern infrastructure approaches such as containers and microservices.
|
||||
|
||||
"One of the big rules I see going out the window is architecture consolidation, or the idea that long-term maintenance is cheaper if done within a homogenous environment," Callendar says.
|
||||
|
||||
**Want more wisdom like this, IT leaders? [Sign up for our weekly email newsletter][15].**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,6 +1,6 @@
|
||||
8 simple ways to promote team communication
|
||||
======
|
||||
|
||||
translating
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
73
sources/talk/20180122 How to price cryptocurrencies.md
Normal file
73
sources/talk/20180122 How to price cryptocurrencies.md
Normal file
@ -0,0 +1,73 @@
|
||||
How to price cryptocurrencies
|
||||
======
|
||||
|
||||

|
||||
|
||||
Predicting cryptocurrency prices is a fool's game, yet this fool is about to try. The drivers of a single cryptocurrency's value are currently too varied and vague to make assessments based on any one point. News is trending up on Bitcoin? Maybe there's a hack or an API failure that is driving it down at the same time. Ethereum looking sluggish? Who knows: Maybe someone will build a new smarter DAO tomorrow that will draw in the big spenders.
|
||||
|
||||
So how do you invest? Or, more correctly, on which currency should you bet?
|
||||
|
||||
The key to understanding what to buy or sell and when to hold is to use the tools associated with assessing the value of open-source projects. This has been said again and again, but to understand the current crypto boom you have to go back to the quiet rise of Linux.
|
||||
|
||||
Linux appeared on most radars during the dot-com bubble. At that time, if you wanted to set up a web server, you had to physically ship a Windows server or Sun Sparc Station to a server farm where it would do the hard work of delivering Pets.com HTML. At the same time, Linux, like a freight train running on a parallel path to Microsoft and Sun, would consistently allow developers to build one-off projects very quickly and easily using an OS and toolset that were improving daily. In comparison, then, the massive hardware and software expenditures associated with the status quo solution providers were deeply inefficient, and very quickly all of the tech giants that made their money on software now made their money on services or, like Sun, folded.
|
||||
|
||||
From the acorn of Linux an open-source forest bloomed. But there was one clear problem: You couldn't make money from open source. You could consult and you could sell products that used open-source components, but early builders built primarily for the betterment of humanity and not the betterment of their bank accounts.
|
||||
|
||||
Cryptocurrencies have followed the Linux model almost exactly, but cryptocurrencies have cash value. Therefore, when you're working on a crypto project you're not doing it for the common good or for the joy of writing free software. You're writing it with the expectation of a big payout. This, therefore, clouds the value judgements of many programmers. The same folks that brought you Python, PHP, Django and Node.js are back… and now they're programming money.
|
||||
|
||||
### Check the codebase
|
||||
|
||||
This year will be the year of great reckoning in the token sale and cryptocurrency space. While many companies have been able to get away with poor or unusable codebases, I doubt developers will let future companies get away with so much smoke and mirrors. It's safe to say we can [expect posts like this one detailing Storj's anemic codebase to become the norm][1] and, more importantly, that these commentaries will sink many so-called ICOs. Though massive, the money trough that is flowing from ICO to ICO is finite and at some point there will be greater scrutiny paid to incomplete work.
|
||||
|
||||
What does this mean? It means to understand cryptocurrency you have to treat it like a startup. Does it have a good team? Does it have a good product? Does the product work? Would someone want to use it? It's far too early to assess the value of cryptocurrency as a whole, but if we assume that tokens or coins will become the way computers pay each other in the future, this lets us hand wave away a lot of doubt. After all, not many people knew in 2000 that Apache was going to beat nearly every other web server in a crowded market or that Ubuntu instances would be so common that you'd spin them up and destroy them in an instant.
|
||||
|
||||
The key to understanding cryptocurrency pricing is to ignore the froth, hype and FUD and instead focus on true utility. Do you think that some day your phone will pay another phone for, say, an in-game perk? Do you expect the credit card system to fold in the face of an Internet of Value? Do you expect that one day you'll move through life splashing out small bits of value in order to make yourself more comfortable? Then by all means, buy and hold or speculate on things that you think will make your life better. If you don't expect the Internet of Value to improve your life the way the TCP/IP internet did (or you do not understand enough to hold an opinion), then you're probably not cut out for this. NASDAQ is always open, at least during banker's hours.
|
||||
|
||||
Still will us? Good, here are my predictions.
|
||||
|
||||
### The rundown
|
||||
|
||||
Here is my assessment of what you should look at when considering an "investment" in cryptocurrencies. There are a number of caveats we must address before we begin:
|
||||
|
||||
* Crypto is not a monetary investment in a real currency, but an investment in a pie-in-the-sky technofuture. That's right: When you buy crypto you're basically assuming that we'll all be on the deck of the Starship Enterprise exchanging them like Galactic Credits one day. This is the only inevitable future for crypto bulls. While you can force crypto into various economic models and hope for the best, the entire platform is techno-utopianist and assumes all sorts of exciting and unlikely things will come to pass in the next few years. If you have spare cash lying around and you like Star Wars, then you're golden. If you bought bitcoin on a credit card because your cousin told you to, then you're probably going to have a bad time.
|
||||
* Don't trust anyone. There is no guarantee and, in addition to offering the disclaimer that this is not investment advice and that this is in no way an endorsement of any particular cryptocurrency or even the concept in general, we must understand that everything I write here could be wrong. In fact, everything ever written about crypto could be wrong, and anyone who is trying to sell you a token with exciting upside is almost certainly wrong. In short, everyone is wrong and everyone is out to get you, so be very, very careful.
|
||||
* You might as well hold. If you bought when BTC was $18,000 you'd best just hold on. Right now you're in Pascal's Wager territory. Yes, maybe you're angry at crypto for screwing you, but maybe you were just stupid and you got in too high and now you might as well keep believing because nothing is certain, or you can admit that you were a bit overeager and now you're being punished for it but that there is some sort of bitcoin god out there watching over you. Ultimately you need to take a deep breath, agree that all of this is pretty freaking weird, and hold on.
|
||||
|
||||
|
||||
|
||||
Now on with the assessments.
|
||||
|
||||
**Bitcoin** - Expect a rise over the next year that will surpass the current low. Also expect [bumps as the SEC and other federal agencies][2] around the world begin regulating the buying and selling of cryptocurrencies in very real ways. Now that banks are in on the joke they're going to want to reduce risk. Therefore, the bitcoin will become digital gold, a staid, boring and volatility proof safe haven for speculators. Although all but unusable as a real currency, it's good enough for what we need it to do and we also can expect quantum computing hardware to change the face of the oldest and most familiar cryptocurrency.
|
||||
|
||||
**Ethereum** - Ethereum could sustain another few thousand dollars on its price as long as Vitalik Buterin, the creator, doesn't throw too much cold water on it. Like a remorseful Victor Frankenstein, Buterin tends to make amazing things and then denigrate them online, a sort of self-flagellation that is actually quite useful in a space full of froth and outright lies. Ethereum is the closest we've come to a useful cryptocurrency, but it is still the Raspberry Pi of distributed computing -- it's a useful and clever hack that makes it easy to experiment but no one has quite replaced the old systems with new distributed data stores or applications. In short, it's a really exciting technology, but nobody knows what to do with it.
|
||||
|
||||
![][3]
|
||||
|
||||
Where will the price go? It will hover around $1,000 and possibly go as high as $1,500 this year, but this is a principled tech project and not a store of value.
|
||||
|
||||
**Altcoins** - One of the signs of a bubble is when average people make statements like "I couldn't afford a Bitcoin so I bought a Litecoin." This is exactly what I've heard multiple times from multiple people and it's akin to saying "I couldn't buy hamburger so I bought a pound of sawdust instead. I think the kids will eat it, right?" Play at your own risk. Altcoins are a very useful low-risk play for many, and if you create an algorithm -- say to sell when the asset hits a certain level -- then you could make a nice profit. Further, most altcoins will not disappear overnight. I would honestly recommend playing with Ethereum instead of altcoins, but if you're dead set on it, then by all means, enjoy.
|
||||
|
||||
**Tokens** - This is where cryptocurrency gets interesting. Tokens require research, education and a deep understanding of technology to truly assess. Many of the tokens I've seen are true crapshoots and are used primarily as pump and dump vehicles. I won't name names, but the rule of thumb is that if you're buying a token on an open market then you've probably already missed out. The value of the token sale as of January 2018 is to allow crypto whales to turn a few cent per token investment into a 100X return. While many founders talk about the magic of their product and the power of their team, token sales are quite simply vehicles to turn 4 cents into 20 cents into a dollar. Multiply that by millions of tokens and you see the draw.
|
||||
|
||||
The answer is simple: find a few projects you like and lurk in their message boards. Assess if the team is competent and figure out how to get in very, very early. Also expect your money to disappear into a rat hole in a few months or years. There are no sure things, and tokens are far too bleeding-edge a technology to assess sanely.
|
||||
|
||||
You are reading this post because you are looking to maintain confirmation bias in a confusing space. That's fine. I've spoken to enough crypto-heads to know that nobody knows anything right now and that collusion and dirty dealings are the rule of the day. Therefore, it's up to folks like us to slowly buy surely begin to understand just what's going on and, perhaps, profit from it. At the very least we'll all get a new Linux of Value when we're all done.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2018/01/22/how-to-price-cryptocurrencies/
|
||||
|
||||
作者:[John Biggs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/john-biggs/
|
||||
[1]:https://shitcoin.com/storj-not-a-dropbox-killer-1a9f27983d70
|
||||
[2]:http://www.businessinsider.com/bitcoin-price-cryptocurrency-warning-from-sec-cftc-2018-1
|
||||
[3]:https://tctechcrunch2011.files.wordpress.com/2018/01/vitalik-twitter-1312.png?w=525&h=615
|
||||
[4]:https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/cash?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,50 @@
|
||||
Moving to Linux from dated Windows machines
|
||||
======
|
||||
|
||||

|
||||
|
||||
Every day, while working in the marketing department at ONLYOFFICE, I see Linux users discussing our office productivity software on the internet. Our products are popular among Linux users, which made me curious about using Linux as an everyday work tool. My old Windows XP-powered computer was an obstacle to performance, so I started reading about Linux systems (particularly Ubuntu) and decided to try it out as an experiment. Two of my colleagues joined me.
|
||||
|
||||
### Why Linux?
|
||||
|
||||
We needed to make a change, first, because our old systems were not enough in terms of performance: we experienced regular crashes, an overload every time more than two apps were active, a 50% chance of freezing when a machine was shut down, and so forth. This was rather distracting to our work, which meant we were considerably less efficient than we could be.
|
||||
|
||||
Upgrading to newer versions of Windows was an option, too, but that is an additional expense, plus our software competes against Microsoft's office suite. So that was an ideological question, too.
|
||||
|
||||
Second, as I mentioned earlier, ONLYOFFICE products are rather popular within the Linux community. By reading about Linux users' experience with our software, we became interested in joining them.
|
||||
|
||||
A week after we asked to change to Linux, we got our shiny new computer cases with [Kubuntu][1] inside. We chose version 16.04, which features KDE Plasma 5.5 and many KDE apps including Dolphin, as well as LibreOffice 5.1 and Firefox 45.
|
||||
|
||||
### What we like about Linux
|
||||
|
||||
Linux's biggest advantage, I believe, is its speed; for instance, it takes just seconds from pushing the machine's On button to starting your work. Everything seemed amazingly rapid from the very beginning: the overall responsiveness, the graphics, and even system updates.
|
||||
|
||||
One other thing that surprised me compared to Windows is that Linux allows you to configure nearly everything, including the entire look of your desktop. In Settings, I found how to change the color and shape of bars, buttons, and fonts; relocate any desktop element; and build a composition of widgets, even including comics and Color Picker. I believe I've barely scratched the surface of the available options and have yet to explore most of the customization opportunities that this system is well known for.
|
||||
|
||||
Linux distributions are generally a very safe environment. People rarely use antivirus apps in Linux, simply because there are so few viruses written for it. You save system speed, time, and, sure enough, money.
|
||||
|
||||
In general, Linux has refreshed our everyday work lives, surprising us with a number of new options and opportunities. Even in the short time we've been using it, we'd characterize it as:
|
||||
|
||||
* Fast and smooth to operate
|
||||
* Highly customizable
|
||||
* Relatively newcomer-friendly
|
||||
* Challenging with basic components, however very rewarding in return
|
||||
* Safe and secure
|
||||
* An exciting experience for everyone who seeks to refresh their workplace
|
||||
|
||||
|
||||
|
||||
Have you switched from Windows or MacOS to Kubuntu or another Linux variant? Or are you considering making the change? Please share your reasons for wanting to adopt Linux, as well as your impressions of going open source, in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/move-to-linux-old-windows
|
||||
|
||||
作者:[Michael Korotaev][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/michaelk
|
||||
[1]:https://kubuntu.org/
|
||||
@ -0,0 +1,44 @@
|
||||
Containers, the GPL, and copyleft: No reason for concern
|
||||
======
|
||||
|
||||

|
||||
|
||||
Though open source is thoroughly mainstream, new software technologies and old technologies that get newly popularized sometimes inspire hand-wringing about open source licenses. Most often the concern is about the GNU General Public License (GPL), and specifically the scope of its copyleft requirement, which is often described (somewhat misleadingly) as the GPL's derivative work issue.
|
||||
|
||||
One imperfect way of framing the question is whether GPL-licensed code, when combined in some sense with proprietary code, forms a single modified work such that the proprietary code could be interpreted as being subject to the terms of the GPL. While we haven't yet seen much of that concern directed to Linux containers, we expect more questions to be raised as adoption of containers continues to grow. But it's fairly straightforward to show that containers do _not_ raise new or concerning GPL scope issues.
|
||||
|
||||
Statutes and case law provide little help in interpreting a license like the GPL. On the other hand, many of us give significant weight to the interpretive views of the Free Software Foundation (FSF), the drafter and steward of the GPL, even in the typical case where the FSF is not a copyright holder of the software at issue. In addition to being the author of the license text, the FSF has been engaged for many years in providing commentary and guidance on its licenses to the community. Its views have special credibility and influence based on its public interest mission and leadership in free software policy.
|
||||
|
||||
The FSF's existing guidance on GPL interpretation has relevance for understanding the effects of including GPL and non-GPL code in containers. The FSF has placed emphasis on the process boundary when considering copyleft scope, and on the mechanism and semantics of the communication between multiple software components to determine whether they are closely integrated enough to be considered a single program for GPL purposes. For example, the [GNU Licenses FAQ][1] takes the view that pipes, sockets, and command-line arguments are mechanisms that are normally suggestive of separateness (in the absence of sufficiently "intimate" communications).
|
||||
|
||||
Consider the case of a container in which both GPL code and proprietary code might coexist and execute. A container is, in essence, an isolated userspace stack. In the [OCI container image format][2], code is packaged as a set of filesystem changeset layers, with the base layer normally being a stripped-down conventional Linux distribution without a kernel. As with the userspace of non-containerized Linux distributions, these base layers invariably contain many GPL-licensed packages (both GPLv2 and GPLv3), as well as packages under licenses considered GPL-incompatible, and commonly function as a runtime for proprietary as well as open source applications. The ["mere aggregation" clause][3] in GPLv2 (as well as its counterpart GPLv3 provision on ["aggregates"][4]) shows that this type of combination is generally acceptable, is specifically contemplated under the GPL, and has no effect on the licensing of the two programs, assuming incompatibly licensed components are separate and independent.
|
||||
|
||||
Of course, in a given situation, the relationship between two components may not be "mere aggregation," but the same is true of software running in non-containerized userspace on a Linux system. There is nothing in the technical makeup of containers or container images that suggests a need to apply a special form of copyleft scope analysis.
|
||||
|
||||
It follows that when looking at the relationship between code running in a container and code running outside a container, the "separate and independent" criterion is almost certainly met. The code will run as separate processes, and the whole technical point of using containers is isolation from other software running on the system.
|
||||
|
||||
Now consider the case where two components, one GPL-licensed and one proprietary, are running in separate but potentially interacting containers, perhaps as part of an application designed with a [microservices][5] architecture. In the absence of very unusual facts, we should not expect to see copyleft scope extending across multiple containers. Separate containers involve separate processes. Communication between containers by way of network interfaces is analogous to such mechanisms as pipes and sockets, and a multi-container microservices scenario would seem to preclude what the FSF calls "[intimate][6]" communication by definition. The composition of an application using multiple containers may not be dispositive of the GPL scope issue, but it makes the technical boundaries between the components more apparent and provides a strong basis for arguing separateness. Here, too, there is no technical feature of containers that suggests application of a different and stricter approach to copyleft scope analysis.
|
||||
|
||||
A company that is overly concerned with the potential effects of distributing GPL-licensed code might attempt to prohibit its developers from adding any such code to a container image that it plans to distribute. Insofar as the aim is to avoid distributing code under the GPL, this is a dubious strategy. As noted above, the base layers of conventional container images will contain multiple GPL-licensed components. If the company pushes a container image to a registry, there is normally no way it can guarantee that this will not include the base layer, even if it is widely shared.
|
||||
|
||||
On the other hand, the company might decide to embrace containerization as a means of limiting copyleft scope issues by isolating GPL and proprietary code--though one would hope that technical benefits would drive the decision, rather than legal concerns likely based on unfounded anxiety about the GPL. While in a non-containerized setting the relationship between two interacting software components will often be mere aggregation, the evidence of separateness that containers provide may be comforting to those who worry about GPL scope.
|
||||
|
||||
Open source license compliance obligations may arise when sharing container images. But there's nothing technically different or unique about containers that changes the nature of these obligations or makes them harder to satisfy. With respect to copyleft scope, containerization should, if anything, ease the concerns of the extra-cautious.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/containers-gpl-and-copyleft
|
||||
|
||||
作者:[Richard Fontana][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/fontana
|
||||
[1]:https://www.gnu.org/licenses/gpl-faq.en.html#MereAggregation
|
||||
[2]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[3]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#section2
|
||||
[4]:https://www.gnu.org/licenses/gpl.html#section5
|
||||
[5]:https://www.redhat.com/en/topics/microservices
|
||||
[6]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPlugins
|
||||
@ -0,0 +1,87 @@
|
||||
Security Chaos Engineering: A new paradigm for cybersecurity
|
||||
======
|
||||

|
||||
|
||||
Security is always changing and failure always exists.
|
||||
|
||||
This toxic scenario requires a fresh perspective on how we think about operational security. We must understand that we are often the primary cause of our own security flaws. The industry typically looks at cybersecurity and failure in isolation or as separate matters. We believe that our lack of insight and operational intelligence into our own security control failures is one of the most common causes of security incidents and, subsequently, data breaches.
|
||||
|
||||
> Fall seven times, stand up eight." --Japanese proverb
|
||||
|
||||
The simple fact is that "to err is human," and humans derive their success as a direct result of the failures they encounter. Their rate of failure, how they fail, and their ability to understand that they failed in the first place are important building blocks to success. Our ability to learn through failure is inherent in the systems we build, the way we operate them, and the security we use to protect them. Yet there has been a lack of focus when it comes to how we approach preventative security measures, and the spotlight has trended toward the evolving attack landscape and the need to buy or build new solutions.
|
||||
|
||||
### Security spending is continually rising and so are security incidents
|
||||
|
||||
We spend billions on new information security technologies, however, we rarely take a proactive look at whether those security investments perform as expected. This has resulted in a continual increase in security spending on new solutions to keep up with the evolving attacks.
|
||||
|
||||
Despite spending more on security, data breaches are continuously getting bigger and more frequent across all industries. We have marched so fast down this path of the "get-ahead-of-the-attacker" strategy that we haven't considered that we may be a primary cause of our own demise. How is it that we are building more and more security measures, but the problem seems to be getting worse? Furthermore, many of the notable data breaches over the past year were not the result of an advanced nation-state or spy-vs.-spy malicious advanced persistent threats (APTs); rather the principal causes of those events were incomplete implementation, misconfiguration, design flaws, and lack of oversight.
|
||||
|
||||
The 2017 Ponemon Cost of a Data Breach Study breaks down the [root causes of data breaches][1] into three areas: malicious or criminal attacks, human factors or errors, and system glitches, including both IT and business-process failure. Of the three categories, malicious or criminal attacks comprises the largest distribution (47%), followed by human error (28%), and system glitches (25%). Cybersecurity vendors have historically focused on malicious root causes of data breaches, as it is the largest sole cause, but together human error and system glitches total 53%, a larger share of the overall problem.
|
||||
|
||||
What is not often understood, whether due to lack of insight, reporting, or analysis, is that malicious or criminal attacks are often successful due to human error and system glitches. Both human error and system glitches are, at their root, primary markers of the existence of failure. Whether it's IT system failures, failures in process, or failures resulting from humans, it begs the question: "Should we be focusing on finding a method to identify, understand, and address our failures?" After all, it can be an arduous task to predict the next malicious attack, which often requires investment of time to sift threat intelligence, dig through forensic data, or churn threat feeds full of unknown factors and undetermined motives. Failure instrumentation, identification, and remediation are mostly comprised of things that we know, have the ability to test, and can measure.
|
||||
|
||||
Failures we can analyze consist not only of IT, business, and general human factors but also the way we design, build, implement, configure, operate, observe, and manage security controls. People are the ones designing, building, monitoring, and managing the security controls we put in place to defend against malicious attackers. How often do we proactively instrument what we designed, built, and are operationally managing to determine if the controls are failing? Most organizations do not discover that their security controls were failing until a security incident results from that failure. The worst time to find out your security investment failed is during a security incident at 3 a.m.
|
||||
|
||||
> Security incidents are not detective measures and hope is not a strategy when it comes to operating effective security controls.
|
||||
|
||||
We hypothesize that a large portion of data breaches are caused not by sophisticated nation-state actors or hacktivists, but rather simple things rooted in human error and system glitches. Failure in security controls can arise from poor control placement, technical misconfiguration, gaps in coverage, inadequate testing practices, human error, and numerous other things.
|
||||
|
||||
### The journey into Security Chaos Testing
|
||||
|
||||
Our venture into this new territory of Security Chaos Testing has shifted our thinking about the root cause of many of our notable security incidents and data breaches.
|
||||
|
||||
We were brought together by [Bruce Wong][2], who now works at Stitch Fix with Charles, one of the authors of this article. Prior to Stitch Fix, Bruce was a founder of the Chaos Engineering and System Reliability Engineering (SRE) practices at Netflix, the company commonly credited with establishing the field. Bruce learned about this article's other author, Aaron, through the open source [ChaoSlingr][3] Security Chaos Testing tool project, on which Aaron was a contributor. Aaron was interested in Bruce's perspective on the idea of applying Chaos Engineering to cybersecurity, which led Bruce to connect us to share what we had been working on. As security practitioners, we were both intrigued by the idea of Chaos Engineering and had each begun thinking about how this new method of instrumentation might have a role in cybersecurity.
|
||||
|
||||
Within a short timeframe, we began finishing each other's thoughts around testing and validating security capabilities, which we collectively call "Security Chaos Engineering." We directly challenged many of the concepts we had come to depend on in our careers, such as compensating security controls, defense-in-depth, and how to design preventative security. Quickly we realized that we needed to challenge the status quo "set-it-and-forget-it" model and instead execute on continuous instrumentation and validation of security capabilities.
|
||||
|
||||
Businesses often don't fully understand whether their security capabilities and controls are operating as expected until they are not. We had both struggled throughout our careers to provide measurements on security controls that go beyond simple uptime metrics. Our journey has shown us there is a need for a more pragmatic approach that emphasizes proactive instrumentation and experimentation over blind faith.
|
||||
|
||||
### Defining new terms
|
||||
|
||||
In the security industry, we have a habit of not explaining terms and assuming we are speaking the same language. To correct that, here are a few key terms in this new approach:
|
||||
|
||||
* **(Security) Chaos Experiments** are foundationally rooted in the scientific method, in that they seek not to validate what is already known to be true or already known to be false, rather they are focused on deriving new insights about the current state.
|
||||
* **Security Chaos Engineering** is the discipline of instrumentation, identification, and remediation of failure within security controls through proactive experimentation to build confidence in the system's ability to defend against malicious conditions in production.
|
||||
|
||||
|
||||
|
||||
### Security and distributed systems
|
||||
|
||||
Consider the evolving nature of modern application design where systems are becoming more and more distributed, ephemeral, and immutable in how they operate. In this shifting paradigm, it is becoming difficult to comprehend the operational state and health of our systems' security. Moreover, how are we ensuring that it remains effective and vigilant as the surrounding environment is changing its parameters, components, and methodologies?
|
||||
|
||||
What does it mean to be effective in terms of security controls? After all, a single security capability could easily be implemented in a wide variety of diverse scenarios in which failure may arise from many possible sources. For example, a standard firewall technology may be implemented, placed, managed, and configured differently depending on complexities in the business, web, and data logic.
|
||||
|
||||
It is imperative that we not operate our business products and services on the assumption that something works. We must constantly, consistently, and proactively instrument our security controls to ensure they cut the mustard when it matters. This is why Security Chaos Testing is so important. What Security Chaos Engineering does is it provides a methodology for the experimentation of the security of distributed systems in order to build confidence in the ability to withstand malicious conditions.
|
||||
|
||||
In Security Chaos Engineering:
|
||||
|
||||
* Security capabilities must be end-to-end instrumented.
|
||||
* Security must be continuously instrumented to build confidence in the system's ability to withstand malicious conditions.
|
||||
* Readiness of a system's security defenses must be proactively assessed to ensure they are battle-ready and operating as intended.
|
||||
* The security capability toolchain must be instrumented from end to end to drive new insights into not only the effectiveness of the functionality within the toolchain but also to discover where added value and improvement can be injected.
|
||||
* Practiced instrumentation seeks to identify, detect, and remediate failures in security controls.
|
||||
* The focus is on vulnerability and failure identification, not failure management.
|
||||
* The operational effectiveness of incident management is sharpened.
|
||||
|
||||
|
||||
|
||||
As Henry Ford said, "Failure is only the opportunity to begin again, this time more intelligently." Security Chaos Engineering and Security Chaos Testing give us that opportunity.
|
||||
|
||||
Would you like to learn more? Join the discussion by following [@aaronrinehart][4] and [@charles_nwatu][5] on Twitter.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/new-paradigm-cybersecurity
|
||||
|
||||
作者:[Aaron Rinehart][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaronrinehart
|
||||
[1]:https://www.ibm.com/security/data-breach
|
||||
[2]:https://twitter.com/bruce_m_wong?lang=en
|
||||
[3]:https://github.com/Optum/ChaoSlingr
|
||||
[4]:https://twitter.com/aaronrinehart
|
||||
[5]:https://twitter.com/charles_nwatu
|
||||
@ -1,249 +0,0 @@
|
||||
How To Debug a Bash Shell Script Under Linux or UNIX
|
||||
======
|
||||
From my mailbag:
|
||||
**I wrote a small hello world script. How can I Debug a bash shell scripts running on a Linux or Unix like systems?**
|
||||
It is the most common question asked by new sysadmins or Linux/UNIX user. Shell scripting debugging can be a tedious job (read as not easy). There are various ways to debug a shell script.
|
||||
|
||||
You need to pass the -x or -v argument to bash shell to walk through each line in the script.
|
||||
|
||||
[![How to debug a bash shell script on Linux or Unix][1]][1]
|
||||
|
||||
Let us see how to debug a bash script running on Linux and Unix using various methods.
|
||||
|
||||
### -x option to debug a bash shell script
|
||||
|
||||
Run a shell script with -x option.
|
||||
```
|
||||
$ bash -x script-name
|
||||
$ bash -x domains.sh
|
||||
```
|
||||
|
||||
### Use of set builtin command
|
||||
|
||||
Bash shell offers debugging options which can be turn on or off using the [set command][2]:
|
||||
|
||||
* **set -x** : Display commands and their arguments as they are executed.
|
||||
* **set -v** : Display shell input lines as they are read.
|
||||
|
||||
|
||||
|
||||
You can use above two command in shell script itself:
|
||||
```
|
||||
#!/bin/bash
|
||||
clear
|
||||
|
||||
# turn on debug mode
|
||||
set -x
|
||||
for f in *
|
||||
do
|
||||
file $f
|
||||
done
|
||||
# turn OFF debug mode
|
||||
set +x
|
||||
ls
|
||||
# more commands
|
||||
```
|
||||
|
||||
You can replace the [standard Shebang][3] line:
|
||||
`#!/bin/bash`
|
||||
with the following (for debugging) code:
|
||||
`#!/bin/bash -xv`
|
||||
|
||||
### Use of intelligent DEBUG function
|
||||
|
||||
First, add a special variable called _DEBUG. Set _DEBUG to 'on' when you need to debug a script:
|
||||
`_DEBUG="on"`
|
||||
|
||||
Put the following function at the beginning of the script:
|
||||
```
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
```
|
||||
|
||||
function DEBUG() { [ "$_DEBUG" == "on" ] && $@ }
|
||||
|
||||
Now wherever you need debugging simply use the DEBUG function as follows:
|
||||
`DEBUG echo "File is $filename"`
|
||||
OR
|
||||
```
|
||||
DEBUG set -x
|
||||
Cmd1
|
||||
Cmd2
|
||||
DEBUG set +x
|
||||
```
|
||||
|
||||
When done with debugging (and before moving your script to production) set _DEBUG to 'off'. No need to delete debug lines.
|
||||
`_DEBUG="off" # set to anything but not to 'on'`
|
||||
|
||||
Sample script:
|
||||
```
|
||||
#!/bin/bash
|
||||
_DEBUG="on"
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
|
||||
DEBUG echo 'Reading files'
|
||||
for i in *
|
||||
do
|
||||
grep 'something' $i > /dev/null
|
||||
[ $? -eq 0 ] && echo "Found in $i file"
|
||||
done
|
||||
DEBUG set -x
|
||||
a=2
|
||||
b=3
|
||||
c=$(( $a + $b ))
|
||||
DEBUG set +x
|
||||
echo "$a + $b = $c"
|
||||
```
|
||||
|
||||
Save and close the file. Run the script as follows:
|
||||
`$ ./script.sh`
|
||||
Output:
|
||||
```
|
||||
Reading files
|
||||
Found in xyz.txt file
|
||||
+ a=2
|
||||
+ b=3
|
||||
+ c=5
|
||||
+ DEBUG set +x
|
||||
+ '[' on == on ']'
|
||||
+ set +x
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
Now set DEBUG to off (you need to edit the file):
|
||||
`_DEBUG="off"`
|
||||
Run script:
|
||||
`$ ./script.sh`
|
||||
Output:
|
||||
```
|
||||
Found in xyz.txt file
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
Above is a simple but quite effective technique. You can also try to use DEBUG as an alias instead of function.
|
||||
|
||||
### Debugging Common Bash Shell Scripting Errors
|
||||
|
||||
Bash or sh or ksh gives various error messages on screen and in many case the error message may not provide detailed information.
|
||||
|
||||
#### Skipping to apply execute permission on the file
|
||||
|
||||
When you [write your first hello world bash shell script][4], you might end up getting an error that read as follows:
|
||||
`bash: ./hello.sh: Permission denied`
|
||||
Set permission using chmod command:
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
$ bash hello.sh
|
||||
```
|
||||
|
||||
#### End of file unexpected Error
|
||||
|
||||
If you are getting an End of file unexpected error message, open your script file and and make sure it has both opening and closing quotes. In this example, the echo statement has an opening quote but no closing quote:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
...
|
||||
....
|
||||
|
||||
|
||||
echo 'Error: File not found
|
||||
^^^^^^^
|
||||
missing quote
|
||||
```
|
||||
|
||||
Also make sure you check for missing parentheses and braces ({}):
|
||||
```
|
||||
#!/bin/bash
|
||||
.....
|
||||
[ ! -d $DIRNAME ] && { echo "Error: Chroot dir not found"; exit 1;
|
||||
^^^^^^^^^^^^^
|
||||
missing brace }
|
||||
...
|
||||
```
|
||||
|
||||
#### Missing Keywords Such As fi, esac, ;;, etc.
|
||||
|
||||
If you missed ending keyword such as fi or ;; you will get an error such as as "xxx unexpected". So make sure all nested if and case statements ends with proper keywords. See bash man page for syntax requirements. In this example, fi is missing:
|
||||
```
|
||||
#!/bin/bash
|
||||
echo "Starting..."
|
||||
....
|
||||
if [ $1 -eq 10 ]
|
||||
then
|
||||
if [ $2 -eq 100 ]
|
||||
then
|
||||
echo "Do something"
|
||||
fi
|
||||
|
||||
for f in $files
|
||||
do
|
||||
echo $f
|
||||
done
|
||||
|
||||
# note fi is missing
|
||||
```
|
||||
|
||||
#### Moving or editing shell script on Windows or Unix boxes
|
||||
|
||||
Do not create the script on Linux/Unix and move to Windows. Another problem is editing the bash shell script on Windows 10 and move/upload to Unix server. It will result in an error like command not found due to the carriage return (DOS CR-LF). You [can convert DOS newlines CR-LF to Unix/Linux format using][5] the following syntax:
|
||||
`dos2unix my-script.sh`
|
||||
|
||||
### Tip 1 - Send Debug Message To stderr
|
||||
|
||||
[Standard error][6] is the default error output device, which is used to write all system error messages. So it is a good idea to send messages to the default error device:
|
||||
```
|
||||
# Write error to stdout
|
||||
echo "Error: $1 file not found"
|
||||
#
|
||||
# Write error to stderr (note 1>&2 at the end of echo command)
|
||||
#
|
||||
echo "Error: $1 file not found" 1>&2
|
||||
```
|
||||
|
||||
### Tip 2 - Turn On Syntax Highlighting when using vim text editor
|
||||
|
||||
Most modern text editors allows you to set syntax highlighting option. This is useful to detect syntax and prevent common errors such as opening or closing quote. You can see bash script in different colors. This feature eases writing in a shell script structures and syntax errors are visually distinct. Highlighting does not affect the meaning of the text itself; it's made only for you. In this example, vim syntax highlighting is used for my bash script:
|
||||
[![How To Debug a Bash Shell Script Under Linux or UNIX Using Vim Syntax Highlighting Feature][7]][7]
|
||||
|
||||
### Tip 3 - Use shellcheck to lint script
|
||||
|
||||
[ShellCheck is a static analysis tool for shell scripts][8]. One can use it to finds bugs in your shell scripts. It is written in Haskell. You can find warnings and suggestions for bash/sh shell scripts with this tool. Let us see how to install and use ShellCheck on a Linux or Unix-like system to enhance your shell scripts, avoid errors and productivity.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
Posted by:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/debugging-shell-script.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/wp-content/uploads/2007/01/How-to-debug-a-bash-shell-script-on-Linux-or-Unix.jpg
|
||||
[2]:https://bash.cyberciti.biz/guide/Set_command
|
||||
[3]:https://bash.cyberciti.biz/guide/Shebang
|
||||
[4]:https://www.cyberciti.biz/faq/hello-world-bash-shell-script/
|
||||
[5]:https://www.cyberciti.biz/faq/howto-unix-linux-convert-dos-newlines-cr-lf-unix-text-format/
|
||||
[6]:https://bash.cyberciti.biz/guide/Standard_error
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2007/01/bash-vim-debug-syntax-highlighting.png
|
||||
[8]:https://www.cyberciti.biz/programming/improve-your-bashsh-shell-script-with-shellcheck-lint-script-analysis-tool/
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
30 Linux System Monitoring Tools Every SysAdmin Should Know
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,170 @@
|
||||
Linux / Unix Bash Shell List All Builtin Commands
|
||||
======
|
||||
|
||||
Builtin commands contained within the bash shell itself. How do I list all built-in bash commands on Linux / Apple OS X / *BSD / Unix like operating systems without reading large size bash man page?
|
||||
|
||||
A shell builtin is nothing but command or a function, called from a shell, that is executed directly in the shell itself. The bash shell executes the command directly, without invoking another program. You can view information for Bash built-ins with help command. There are different types of built-in commands.
|
||||
|
||||
|
||||
### built-in command types
|
||||
|
||||
1. Bourne Shell Builtins: Builtin commands inherited from the Bourne Shell.
|
||||
2. Bash Builtins: Table of builtins specific to Bash.
|
||||
3. Modifying Shell Behavior: Builtins to modify shell attributes and optional behavior.
|
||||
4. Special Builtins: Builtin commands classified specially by POSIX.
|
||||
|
||||
|
||||
|
||||
### How to see all bash builtins
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
$ help
|
||||
$ help | less
|
||||
$ help | grep read
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
GNU bash, version 4.1.5(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or hist>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif C>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs >
|
||||
: kill [-s sigspec | -n signum | -sigs>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-n count] [-O origin] [-s c>
|
||||
bind [-lpvsPVS] [-m keymap] [-f filen> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...)> read [-ers] [-a array] [-d delim] [->
|
||||
cd [-L|-P] [dir] readarray [-n count] [-O origin] [-s>
|
||||
command [-pVv] command [arg ...] readonly [-af] [name[=value] ...] or>
|
||||
compgen [-abcdefgjksuv] [-o option] > return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DE] > select NAME [in WORDS ... ;] do COMM>
|
||||
compopt [-o|+o option] [-DE] [name ..> set [--abefhkmnptuvxBCHP] [-o option>
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFilrtux] [-p] [name[=val> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ...] test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [na> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [argume> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or ex> typeset [-aAfFilrtux] [-p] name[=val>
|
||||
false ulimit [-SHacdefilmnpqrstuvx] [limit>
|
||||
fc [-e ename] [-lnr] [first] [last] o> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMAND> unset [-f] [-v] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMAN> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name > variables - Names and meanings of so>
|
||||
getopts optstring name [arg] wait [id]
|
||||
hash [-lr] [-p pathname] [-dt] [name > while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
### Viewing information for Bash built-ins
|
||||
|
||||
To get detailed info run:
|
||||
```
|
||||
help command
|
||||
help read
|
||||
```
|
||||
To just get a list of all built-ins with a short description, execute:
|
||||
|
||||
`$ help -d`
|
||||
|
||||
### Find syntax and other options for builtins
|
||||
|
||||
Use the following syntax ' to find out more about the builtins commands:
|
||||
```
|
||||
help name
|
||||
help cd
|
||||
help fg
|
||||
help for
|
||||
help read
|
||||
help :
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
:: :
|
||||
Null command.
|
||||
|
||||
No effect; the command does nothing.
|
||||
|
||||
Exit Status:
|
||||
Always succeeds
|
||||
```
|
||||
|
||||
### Find out if a command is internal (builtin) or external
|
||||
|
||||
Use the type command or command command:
|
||||
```
|
||||
type -a command-name-here
|
||||
type -a cd
|
||||
type -a uname
|
||||
type -a :
|
||||
type -a ls
|
||||
```
|
||||
|
||||
|
||||
OR
|
||||
```
|
||||
type -a cd uname : ls uname
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
cd is a shell builtin
|
||||
uname is /bin/uname
|
||||
: is a shell builtin
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /bin/ls
|
||||
l is a function
|
||||
l ()
|
||||
{
|
||||
ls --color=auto
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
command -V ls
|
||||
command -V cd
|
||||
command -V foo
|
||||
```
|
||||
|
||||
[![View list bash built-ins command info on Linux or Unix][1]][1]
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][2], [Facebook][3], [Google+][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-bash-shell-list-all-builtin-commands/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2013/03/View-list-bash-built-ins-command-info-on-Linux-or-Unix.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
173
sources/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
173
sources/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
@ -0,0 +1,173 @@
|
||||
#Translating by qhwdw [Tail Calls, Optimization, and ES6][1]
|
||||
|
||||
|
||||
In this penultimate post about the stack, we take a quick look at tail calls, compiler optimizations, and the proper tail calls landing in the newest version of JavaScript.
|
||||
|
||||
A tail call happens when a function F makes a function call as its final action. At that point F will do absolutely no more work: it passes the ball to whatever function is being called and vanishes from the game. This is notable because it opens up the possibility of tail call optimization: instead of [creating a new stack frame][6] for the function call, we can simply reuse F's stack frame, thereby saving stack space and avoiding the work involved in setting up a new frame. Here are some examples in C and their results compiled with [mild optimization][7]:
|
||||
|
||||
Simple Tail Calls[download][2]
|
||||
|
||||
```
|
||||
int add5(int a)
|
||||
{
|
||||
return a + 5;
|
||||
}
|
||||
|
||||
int add10(int a)
|
||||
{
|
||||
int b = add5(a); // not tail
|
||||
return add5(b); // tail
|
||||
}
|
||||
|
||||
int add5AndTriple(int a){
|
||||
int b = add5(a); // not tail
|
||||
return 3 * add5(a); // not tail, doing work after the call
|
||||
}
|
||||
|
||||
int finicky(int a){
|
||||
if (a > 10){
|
||||
return add5AndTriple(a); // tail
|
||||
}
|
||||
|
||||
if (a > 5){
|
||||
int b = add5(a); // not tail
|
||||
return finicky(b); // tail
|
||||
}
|
||||
|
||||
return add10(a); // tail
|
||||
}
|
||||
```
|
||||
|
||||
You can normally spot tail call optimization (hereafter, TCO) in compiler output by seeing a [jump][8] instruction where a [call][9] would have been expected. At runtime TCO leads to a reduced call stack.
|
||||
|
||||
A common misconception is that tail calls are necessarily [recursive][10]. That's not the case: a tail call may be recursive, such as in finicky() above, but it need not be. As long as caller F is completely done at the call site, we've got ourselves a tail call. Whether it can be optimized is a different question whose answer depends on your programming environment.
|
||||
|
||||
"Yes, it can, always!" is the best answer we can hope for, which is famously the case for Scheme, as discussed in [SICP][11] (by the way, if when you program you don't feel like "a Sorcerer conjuring the spirits of the computer with your spells," I urge you to read that book). It's also the case for [Lua][12]. And most importantly, it is the case for the next version of JavaScript, ES6, whose spec does a good job defining [tail position][13] and clarifying the few conditions required for optimization, such as [strict mode][14]. When a language guarantees TCO, it supports proper tail calls.
|
||||
|
||||
Now some of us can't kick that C habit, heart bleed and all, and the answer there is a more complicated "sometimes" that takes us into compiler optimization territory. We've seen the [simple examples][15] above; now let's resurrect our factorial from [last post][16]:
|
||||
|
||||
Recursive Factorial[download][3]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
So, is line 11 a tail call? It's not, because of the multiplication by n afterwards. But if you're not used to optimizations, gcc's [result][17] with [O2 optimization][18] might shock you: not only it transforms factorial into a [recursion-free loop][19], but the factorial(5) call is eliminated entirely and replaced by a [compile-time constant][20] of 120 (5! == 120). This is why debugging optimized code can be hard sometimes. On the plus side, if you call this function it will use a single stack frame regardless of n's initial value. Compiler algorithms are pretty fun, and if you're interested I suggest you check out [Building an Optimizing Compiler][21] and [ACDI][22].
|
||||
|
||||
However, what happened here was not tail call optimization, since there was no tail call to begin with. gcc outsmarted us by analyzing what the function does and optimizing away the needless recursion. The task was made easier by the simple, deterministic nature of the operations being done. By adding a dash of chaos (e.g., getpid()) we can throw gcc off:
|
||||
|
||||
Recursive PID Factorial[download][4]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int pidFactorial(int n)
|
||||
{
|
||||
if (1 == n) {
|
||||
return getpid(); // tail
|
||||
}
|
||||
|
||||
return n * pidFactorial(n-1) * getpid(); // not tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = pidFactorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
Optimize that, unix fairies! So now we have a regular [recursive call][23] and this function allocates O(n) stack frames to do its work. Heroically, gcc still does [TCO for getpid][24] in the recursion base case. If we now wished to make this function tail recursive, we'd need a slight change:
|
||||
|
||||
tailPidFactorial.c[download][5]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int tailPidFactorial(int n, int acc)
|
||||
{
|
||||
if (1 == n) {
|
||||
return acc * getpid(); // not tail
|
||||
}
|
||||
|
||||
acc = (acc * getpid() * n);
|
||||
return tailPidFactorial(n-1, acc); // tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = tailPidFactorial(5, 1);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
The accumulation of the result is now [a loop][25] and we've achieved true TCO. But before you go out partying, what can we say about the general case in C? Sadly, while good C compilers do TCO in a number of cases, there are many situations where they cannot do it. For example, as we saw in our [function epilogues][26], the caller is responsible for cleaning up the stack after a function call using the standard C calling convention. So if function F takes two arguments, it can only make TCO calls to functions taking two or fewer arguments. This is one among many restrictions. Mark Probst wrote an excellent thesis discussing [Proper Tail Recursion in C][27] where he discusses these issues along with C stack behavior. He also does [insanely cool juggling][28].
|
||||
|
||||
"Sometimes" is a rocky foundation for any relationship, so you can't rely on TCO in C. It's a discrete optimization that may or may not take place, rather than a language feature like proper tail calls, though in practice the compiler will optimize the vast majority of cases. But if you must have it, say for transpiling Scheme into C, you will [suffer][29].
|
||||
|
||||
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It's like Christmas for JS programmers.
|
||||
|
||||
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/tail.c
|
||||
[3]:https://manybutfinite.com/code/x86-stack/factorial.c
|
||||
[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
|
||||
[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
|
||||
[6]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
|
||||
[10]:https://manybutfinite.com/post/recursion/
|
||||
[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
|
||||
[12]:http://www.lua.org/pil/6.3.html
|
||||
[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
|
||||
[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
|
||||
[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
|
||||
[16]:https://manybutfinite.com/post/recursion/
|
||||
[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
|
||||
[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
|
||||
[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
|
||||
[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
|
||||
[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
|
||||
[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
|
||||
[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
|
||||
[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
|
||||
[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
|
||||
[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
|
||||
[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
|
||||
[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb work?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,297 +0,0 @@
|
||||
Translating by yyyfor
|
||||
|
||||
25 Free Books To Learn Linux For Free
|
||||
======
|
||||
Brief: In this article, I'll share with you the best resource to **learn Linux for free**. This is a collection of websites, online video courses and free eBooks.
|
||||
|
||||
**How to learn Linux?**
|
||||
|
||||
This is perhaps the most commonly asked question in our Facebook group for Linux users.
|
||||
|
||||
The answer to this simple looking question 'how to learn Linux' is not at all simple.
|
||||
|
||||
Problem is that different people have different meanings of learning Linux.
|
||||
|
||||
* If someone has never used Linux, be it command line or desktop version, that person might be just wondering to know more about it.
|
||||
* If someone uses Windows as the desktop but have to use Linux command line at work, that person might be interested in learning Linux commands.
|
||||
* If someone has been using Linux for sometimes and is aware of the basics but he/she might want to go to the next level.
|
||||
* If someone is just interested in getting your way around a specific Linux distribution.
|
||||
* If someone is trying to improve or learn Bash scripting which is almost synonymous with Linux command line.
|
||||
* If someone is willing to make a career as a Linux SysAdmin or trying to improve his/her sysadmin skills.
|
||||
|
||||
|
||||
|
||||
You see, the answer to "how do I learn Linux" depends on what kind of Linux knowledge you are seeking. And for this purpose, I have collected a bunch of resources that you could use for learning Linux.
|
||||
|
||||
These free resources include eBooks, video courses, websites etc. And these are divided into sub-categories so that you can easily find what you are looking for when you seek to learn Linux.
|
||||
|
||||
Again, there is no **best way to learn Linux**. It totally up to you how you go about learning Linux, by online web portals, downloaded eBooks, video courses or something else.
|
||||
|
||||
Let's see how you can learn Linux.
|
||||
|
||||
**Disclaimer** : All the books listed here are legal to download. The sources mentioned here are the official sources, as per my knowledge. However, if you find it otherwise, please let me know so that I can take appropriate action.
|
||||
|
||||
![Best Free eBooks to learn Linux for Free][1]
|
||||
|
||||
## 1. Free materials to learn Linux for absolute beginners
|
||||
|
||||
So perhaps you have just heard of Linux from your friends or from a discussion online. You are intrigued about the hype around Linux and you are overwhelmed by the vast information available on the internet but just cannot figure out exactly where to look for to know more about Linux.
|
||||
|
||||
Worry not. Most of us, if not all, have been to your stage.
|
||||
|
||||
### Introduction to Linux by Linux Foundation [Video Course]
|
||||
|
||||
If you have no idea about what is Linux and you want to get started with it, I suggest you to go ahead with the free video course provided by the [Linux Foundation][2] on [edX][3]. Consider it an official course by the organization that 'maintains' Linux. And yes, it is endorsed by [Linus Torvalds][4], the father of Linux himself.
|
||||
|
||||
[Introduction To Linux][5]
|
||||
|
||||
### Linux Journey [Online Portal]
|
||||
|
||||
Not official and perhaps not very popular. But this little website is the perfect place for a no non-sense Linux learning for beginners.
|
||||
|
||||
The website is designed beautifully and is well organized based on the topics. It also has interactive quizzes that you can take after reading a section or chapter. My advice, bookmark this website:
|
||||
|
||||
[Linux Journey][6]
|
||||
|
||||
### Learn Linux in 5 Days [eBook]
|
||||
|
||||
This brilliant eBook is available for free exclusively to It's FOSS readers all thanks to [Linux Training Academy][7].
|
||||
|
||||
Written for absolute beginners in mind, this free Linux eBook gives you a quick overview of Linux, common Linux commands and other things that you need to learn to get started with Linux.
|
||||
|
||||
You can download the book from the page below:
|
||||
|
||||
[Learn Linux In 5 Days][8]
|
||||
|
||||
### The Ultimate Linux Newbie Guide [eBook]
|
||||
|
||||
This is a free to download eBook for Linux beginners. The eBook starts with explaining what is Linux and then go on to provide more practical usage of Linux as a desktop.
|
||||
|
||||
You can download the latest version of this eBook from the link below:
|
||||
|
||||
[The Ultimate Linux Newbie Guide][9]
|
||||
|
||||
## 2. Free Linux eBooks for Beginners to Advanced
|
||||
|
||||
This section lists out those Linux eBooks that are 'complete' in nature.
|
||||
|
||||
What I mean is that these are like academic textbooks that focus on each and every aspects of Linux, well most of it. You can read those as an absolute beginner or you can read those for deeper understanding as an intermediate Linux user. You can also use them for reference even if you are at expert level.
|
||||
|
||||
### Introduction to Linux [eBook]
|
||||
|
||||
Introduction to Linux is a free eBook from [The Linux Documentation Project][10] and it is one of the most popular free Linux books out there. Though I think some parts of this book needs to be updated, it is still a very good book to teach you about Linux, its file system, command line, networking and other related stuff.
|
||||
|
||||
[Introduction To Linux][11]
|
||||
|
||||
### Linux Fundamentals [eBook]
|
||||
|
||||
This free eBook by Paul Cobbaut teaches you about Linux history, installation and focuses on the basic Linux commands you should know. You can get the book from the link below:
|
||||
|
||||
[Linux Fundamentals][12]
|
||||
|
||||
### Advanced Linux Programming [eBook]
|
||||
|
||||
As the name suggests, this is for advanced users who are or want to develop software for Linux. It deals with sophisticated features such as multiprocessing, multi-threading, interprocess communication, and interaction with hardware devices.
|
||||
|
||||
Following the book will help you develop a faster, reliable and secure program that uses the full capability of a GNU/Linux system.
|
||||
|
||||
[Advanced Linux Programming][13]
|
||||
|
||||
### Linux From Scratch [eBook]
|
||||
|
||||
If you think you know enough about Linux and you are a pro, then why not create your own Linux distribution? Linux From Scratch (LFS) is a project that provides you with step-by-step instructions for building your own custom Linux system, entirely from source code.
|
||||
|
||||
Call it DIY Linux but this is a great way to put your Linux expertise to the next level.
|
||||
|
||||
There are various sub-parts of this project, you can check it out on its website and download the books from there.
|
||||
|
||||
[Linux From Scratch][14]
|
||||
|
||||
## 3. Free eBooks to learn Linux command line and Shell scripting
|
||||
|
||||
The real power of Linux lies in the command line and if you want to conquer Linux, you must learn Linux command line and Shell scripting.
|
||||
|
||||
In fact, if you have to work on Linux terminal on your job, having a good knowledge of Linux command line will actually help you in your tasks and perhaps help you in advancing your career as well (as you'll be more efficient).
|
||||
|
||||
In this section, we'll see various Linux commands free eBooks.
|
||||
|
||||
### GNU/Linux Command−Line Tools Summary [eBook]
|
||||
|
||||
This eBook from The Linux Documentation Project is a good place to begin with Linux command line and get acquainted with Shell scripting.
|
||||
|
||||
[GNU/Linux Command−Line Tools Summary][15]
|
||||
|
||||
### Bash Reference Manual from GNU [eBook]
|
||||
|
||||
This is a free eBook to download from [GNU][16]. As the name suggests, it deals with Bash Shell (if I can call that). This book has over 175 pages and it covers a number of topics around Linux command line in Bash.
|
||||
|
||||
You can get it from the link below:
|
||||
|
||||
[Bash Reference Manual][17]
|
||||
|
||||
### The Linux Command Line [eBook]
|
||||
|
||||
This 500+ pages of free eBook by William Shotts is the MUST HAVE for anyone who is serious about learning Linux command line.
|
||||
|
||||
Even if you think you know things about Linux, you'll be amazed at how much this book still teaches you.
|
||||
|
||||
It covers things from beginners to advanced level. I bet that you'll be a hell lot of better Linux user after reading this book. Download it and keep it with you always.
|
||||
|
||||
[The Linux Command Line][18]
|
||||
|
||||
### Bash Guide for Beginners [eBook]
|
||||
|
||||
If you just want to get started with Bash scripting, this could be a good companion for you. The Linux Documentation Project is behind this eBook again and it's the same author who wrote Introduction to Linux eBook (discussed earlier in this article).
|
||||
|
||||
[Bash Guide for Beginners][19]
|
||||
|
||||
### Advanced Bash-Scripting Guide [eBook]
|
||||
|
||||
If you think you already know basics of Bash scripting and you want to take your skills to the next level, this is what you need. This book has over 900+ pages of various advanced commands and their examples.
|
||||
|
||||
[Advanced Bash-Scripting Guide][20]
|
||||
|
||||
### The AWK Programming Language [eBook]
|
||||
|
||||
Not the prettiest book here but if you really need to go deeper with your scripts, this old-yet-gold book could be helpful.
|
||||
|
||||
[The AWK Programming Language][21]
|
||||
|
||||
### Linux 101 Hacks [eBook]
|
||||
|
||||
This 270 pages eBook from The Geek Stuff teaches you the essentials of Linux command lines with easy to follow practical examples. You can get the book from the link below:
|
||||
|
||||
[Linux 101 Hacks][22]
|
||||
|
||||
## 4. Distribution specific free learning material
|
||||
|
||||
This section deals with material that are dedicated to a certain Linux distribution. What we saw so far was the Linux in general, more focused on file systems, commands and other core stuff.
|
||||
|
||||
These books, on the other hand, can be termed as manual or getting started guide for various Linux distributions. So if you are using a certain Linux distribution or planning to use it, you can refer to these resources. And yes, these books are more desktop Linux focused.
|
||||
|
||||
I would also like to add that most Linux distributions have their own wiki or documentation section which are often pretty vast. You can always refer to them when you are online.
|
||||
|
||||
### Ubuntu Manual
|
||||
|
||||
Needless to say that this eBook is for Ubuntu users. It's an independent project that provides Ubuntu manual in the form of free eBook. It is updated for each version of Ubuntu.
|
||||
|
||||
The book is rightly called manual because it is basically a composition of step by step instruction and aimed at absolute beginners to Ubuntu. So, you get to know Unity desktop, how to go around it and find applications etc.
|
||||
|
||||
It's a must have if you never used Ubuntu Unity because it helps you to figure out how to use Ubuntu for your daily usage.
|
||||
|
||||
[Ubuntu Manual][23]
|
||||
|
||||
### For Linux Mint: Just Tell Me Damnit! [eBook]
|
||||
|
||||
A very basic eBook that focuses on Linux Mint. It shows you how to install Linux Mint in a virtual machine, how to find software, install updates and customize the Linux Mint desktop.
|
||||
|
||||
You can download the eBook from the link below:
|
||||
|
||||
[Just Tell Me Damnit!][24]
|
||||
|
||||
### Solus Linux Manual [eBook]
|
||||
|
||||
Caution! This used to be the official manual from Solus Linux but I cannot find its mentioned on Solus Project's website anymore. I don't know if it's outdated or not. But in any case, a little something about Solu Linux won't really hurt, will it?
|
||||
|
||||
[Solus Linux User Guide][25]
|
||||
|
||||
## 5. Free eBooks for SysAdmin
|
||||
|
||||
This section is dedicated to the SysAdmins, the superheroes for developers. I have listed a few free eBooks here for SysAdmin which will surely help anyone who is already a SysAdmin or aspirs to be one. I must add that you should also focus on essential Linux command lines as it will make your job easier.
|
||||
|
||||
### The Debian Administration's Handbook [eBook]
|
||||
|
||||
If you use Debian Linux for your servers, this is your bible. Book starts with Debian history, installation, package management etc and then moves on to cover topics like [LAMP][26], virtual machines, storage management and other core sysadmin stuff.
|
||||
|
||||
[The Debian Administration's Handbook][27]
|
||||
|
||||
### Advanced Linux System Administration [eBook]
|
||||
|
||||
This is an ideal book if you are preparing for [LPI certification][28]. The book deals straightway to the topics essential for sysadmins. So knowledge of Linux command line is a prerequisite in this case.
|
||||
|
||||
[Advanced Linux System Administration][29]
|
||||
|
||||
### Linux System Administration [eBook]
|
||||
|
||||
Another free eBook by Paul Cobbaut. The 370 pages long eBook covers networking, disk management, user management, kernel management, library management etc.
|
||||
|
||||
[Linux System Administration][30]
|
||||
|
||||
### Linux Servers [eBook]
|
||||
|
||||
One more eBook from Paul Cobbaut of [linux-training.be][31]. This book covers web servers, mysql, DHCP, DNS, Samba and other file servers.
|
||||
|
||||
[Linux Servers][32]
|
||||
|
||||
### Linux Networking [eBook]
|
||||
|
||||
Networking is the bread and butter of a SysAdmin, and this book by Paul Cobbaut (again) is a good reference material.
|
||||
|
||||
[Linux Networking][33]
|
||||
|
||||
### Linux Storage [eBook]
|
||||
|
||||
This book by Paul Cobbaut (yes, him again) explains disk management on Linux in detail and introduces a lot of other storage-related technologies.
|
||||
|
||||
[Linux Storage][34]
|
||||
|
||||
### Linux Security [eBook]
|
||||
|
||||
This is the last eBook by Paul Cobbaut in our list here. Security is one of the most important part of a sysadmin's job. This book focuses on file permissions, acls, SELinux, users and passwords etc.
|
||||
|
||||
[Linux Security][35]
|
||||
|
||||
## Your favorite Linux learning material?
|
||||
|
||||
I know that this is a good collection of free Linux eBooks. But this could always be made better.
|
||||
|
||||
If you have some other resources that could be helpful in learning Linux, do share with us. Please note to share only the legal downloads so that I can update this article with your suggestion(s) without any problem.
|
||||
|
||||
I hope you find this article helpful in learning Linux. Your feedback is welcome :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/learn-linux-for-free/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/02/free-ebooks-linux-800x450.png
|
||||
[2]:https://www.linuxfoundation.org/
|
||||
[3]:https://www.edx.org
|
||||
[4]:https://www.youtube.com/watch?v=eE-ovSOQK0Y
|
||||
[5]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0
|
||||
[6]:https://linuxjourney.com/
|
||||
[7]:https://www.linuxtrainingacademy.com/
|
||||
[8]:https://courses.linuxtrainingacademy.com/itsfoss-ll5d/
|
||||
[9]:https://linuxnewbieguide.org/ulngebook/
|
||||
[10]:http://www.tldp.org/index.html
|
||||
[11]:http://tldp.org/LDP/intro-linux/intro-linux.pdf
|
||||
[12]:http://linux-training.be/linuxfun.pdf
|
||||
[13]:http://advancedlinuxprogramming.com/alp-folder/advanced-linux-programming.pdf
|
||||
[14]:http://www.linuxfromscratch.org/
|
||||
[15]:http://tldp.org/LDP/GNU-Linux-Tools-Summary/GNU-Linux-Tools-Summary.pdf
|
||||
[16]:https://www.gnu.org/home.en.html
|
||||
[17]:https://www.gnu.org/software/bash/manual/bash.pdf
|
||||
[18]:http://linuxcommand.org/tlcl.php
|
||||
[19]:http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
|
||||
[20]:http://www.tldp.org/LDP/abs/abs-guide.pdf
|
||||
[21]:https://ia802309.us.archive.org/25/items/pdfy-MgN0H1joIoDVoIC7/The_AWK_Programming_Language.pdf
|
||||
[22]:http://www.thegeekstuff.com/linux-101-hacks-ebook/
|
||||
[23]:https://ubuntu-manual.org/
|
||||
[24]:http://downtoearthlinux.com/resources/just-tell-me-damnit/
|
||||
[25]:https://drive.google.com/file/d/0B5Ymf8oYXx-PWTVJR0pmM3daZUE/view
|
||||
[26]:https://en.wikipedia.org/wiki/LAMP_(software_bundle)
|
||||
[27]:https://debian-handbook.info/about-the-book/
|
||||
[28]:https://www.lpi.org/our-certifications/getting-started
|
||||
[29]:http://www.nongnu.org/lpi-manuals/manual/pdf/GNU-FDL-OO-LPI-201-0.1.pdf
|
||||
[30]:http://linux-training.be/linuxsys.pdf
|
||||
[31]:http://linux-training.be/
|
||||
[32]:http://linux-training.be/linuxsrv.pdf
|
||||
[33]:http://linux-training.be/linuxnet.pdf
|
||||
[34]:http://linux-training.be/linuxsto.pdf
|
||||
[35]:http://linux-training.be/linuxsec.pdf
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Ansible Tutorial: Intorduction to simple Ansible commands
|
||||
======
|
||||
In our earlier Ansible tutorial, we discussed [**the installation & configuration of Ansible**][1]. Now in this ansible tutorial, we will learn some basic examples of ansible commands that we will use to manage our infrastructure. So let us start by looking at the syntax of a complete ansible command,
|
||||
|
||||
@ -1,85 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Easy APT Repository · Iain R. Learmonth
|
||||
======
|
||||
|
||||
The [PATHspider][5] software I maintain as part of my work depends on some features in [cURL][6] and in [PycURL][7] that have [only][8] [just][9] been mereged or are still [awaiting][10] merge. I need to build a docker container that includes these as Debian packages, so I need to quickly build an APT repository.
|
||||
|
||||
A Debian repository can essentially be seen as a static website and the contents are GPG signed so it doesn't necessarily need to be hosted somewhere trusted (unless availability is critical for your application). I host my blog with [Netlify][11], a static website host, and I figured they would be perfect for this use case. They also [support open source projects][12].
|
||||
|
||||
There is a CLI tool for netlify which you can install with:
|
||||
```
|
||||
sudo apt install npm
|
||||
sudo npm install -g netlify-cli
|
||||
|
||||
```
|
||||
|
||||
The basic steps for setting up a repository are:
|
||||
```
|
||||
mkdir repository
|
||||
cp /path/to/*.deb repository/
|
||||
|
||||
|
||||
cd
|
||||
|
||||
repository
|
||||
apt-ftparchive packages . > Packages
|
||||
apt-ftparchive release . > Release
|
||||
gpg --clearsign -o InRelease Release
|
||||
netlify deploy
|
||||
|
||||
```
|
||||
|
||||
Once you've followed these steps, and created a new site on Netlify, you'll be able to manage this site also through the web interface. A few things you might want to do are set up a custom domain name for your repository, or enable HTTPS with Let's Encrypt. (Make sure you have `apt-transport-https` if you're going to enable HTTPS though.)
|
||||
|
||||
To add this repository to your apt sources:
|
||||
```
|
||||
gpg --export -a YOURKEYID | sudo apt-key add -
|
||||
|
||||
|
||||
echo
|
||||
|
||||
|
||||
|
||||
"deb https://SUBDOMAIN.netlify.com/ /"
|
||||
|
||||
| sudo tee -a /etc/apt/sources.list
|
||||
sudo apt update
|
||||
|
||||
```
|
||||
|
||||
You'll now find that those packages are installable. Beware of [APT pinning][13] as you may find that the newer versions on your repository are not actually the preferred versions according to your policy.
|
||||
|
||||
**Update** : If you're wanting a solution that would be more suitable for regular use, take a look at [repropro][14]. If you're wanting to have end-users add your apt repository as a third-party repository to their system, please take a look at [this page on the Debian wiki][15] which contains advice on how to instruct users to use your repository.
|
||||
|
||||
**Update 2** : Another commenter has pointed out [aptly][16], which offers a greater feature set and removes some of the restrictions imposed by repropro. I've never use aptly myself so can't comment on specifics, but from the website it looks like it might be a nicely polished tool.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iain.learmonth.me/blog/2017/2017w383/
|
||||
|
||||
作者:[Iain R. Learmonth][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iain.learmonth.me
|
||||
[1]:https://iain.learmonth.me/tags/netlify/
|
||||
[2]:https://iain.learmonth.me/tags/debian/
|
||||
[3]:https://iain.learmonth.me/tags/apt/
|
||||
[4]:https://iain.learmonth.me/tags/foss/
|
||||
[5]:https://pathspider.net
|
||||
[6]:http://curl.haxx.se/
|
||||
[7]:http://pycurl.io/
|
||||
[8]:https://github.com/pycurl/pycurl/pull/456
|
||||
[9]:https://github.com/pycurl/pycurl/pull/458
|
||||
[10]:https://github.com/curl/curl/pull/1847
|
||||
[11]:http://netlify.com/
|
||||
[12]:https://www.netlify.com/open-source/
|
||||
[13]:https://wiki.debian.org/AptPreferences
|
||||
[14]:https://mirrorer.alioth.debian.org/
|
||||
[15]:https://wiki.debian.org/DebianRepository/UseThirdParty
|
||||
[16]:https://www.aptly.info/
|
||||
@ -1,3 +1,4 @@
|
||||
ch-cn translating
|
||||
5 SSH alias examples in Linux
|
||||
======
|
||||
[![][1]][1]
|
||||
|
||||
@ -1,137 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Easy guide to secure VNC server with TLS encryption
|
||||
======
|
||||
In this tutorial, we will learn to install VNC server & secure VNC server sessions with TLS encryption.
|
||||
This method has been tested on CentOS 6 & 7 but should work on other versions/OS as well (RHEL, Scientific Linux etc).
|
||||
|
||||
**(Recommended Read:[Ultimate guide for Securing SSH sessions][1] )**
|
||||
|
||||
### Installing VNC server
|
||||
|
||||
Before we install VNC server on our machines, make sure we are have a working GUI. If GUI is not installed on our machine, we can install it by executing the following command,
|
||||
|
||||
```
|
||||
yum groupinstall "GNOME Desktop"
|
||||
```
|
||||
|
||||
Now we will tigervnc as our VNC server, to install it run,
|
||||
|
||||
```
|
||||
# yum install tigervnc-server
|
||||
```
|
||||
|
||||
Once VNC server has been installed, we will create a new user to access the server,
|
||||
|
||||
```
|
||||
# useradd vncuser
|
||||
```
|
||||
|
||||
& assign it a password for accessing VNC by using following command,
|
||||
|
||||
```
|
||||
# vncpasswd vncuser
|
||||
```
|
||||
|
||||
Now we have a little change in configuration on CentOS 6 & 7, we will first address the CentOS 6 configuration,
|
||||
|
||||
#### CentOS 6
|
||||
|
||||
Now we need to edit VNC configuration file,
|
||||
|
||||
```
|
||||
**# vim /etc/sysconfig/vncservers**
|
||||
```
|
||||
|
||||
& add the following lines,
|
||||
|
||||
```
|
||||
[ …]
|
||||
VNCSERVERS= "1:vncuser"
|
||||
VNCSERVERARGS[1]= "-geometry 1024×768″
|
||||
```
|
||||
|
||||
Save the file & exit. Next restart the vnc service to implement the changes,
|
||||
|
||||
```
|
||||
# service vncserver restart
|
||||
```
|
||||
|
||||
& enable it at boot,
|
||||
|
||||
```
|
||||
# chkconfig vncserver on
|
||||
```
|
||||
|
||||
#### CentOS 7
|
||||
|
||||
On CentOS 7, /etc/sysconfig/vncservers file has been changed to /lib/systemd/system/vncserver@.service. We will use this configuration file as reference, so create a copy of the file,
|
||||
|
||||
```
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
```
|
||||
|
||||
Next we will edit the file to include our created user,
|
||||
|
||||
```
|
||||
# vim /etc/systemd/system/vncserver@:1.service
|
||||
```
|
||||
|
||||
& edit the user on the following 2 lines,
|
||||
|
||||
```
|
||||
ExecStart=/sbin/runuser -l vncuser -c "/usr/bin/vncserver %i"
|
||||
PIDFile=/home/vncuser/.vnc/%H%i.pid
|
||||
```
|
||||
|
||||
Save file & exit. Next restart the service & enable it at boot,
|
||||
|
||||
```
|
||||
systemctl restart[[email protected]][2]:1.service
|
||||
systemctl enable[[email protected]][2]:1.service
|
||||
```
|
||||
|
||||
We now have our VNC server ready & can connect to it from a client machine using the IP address of VNC server. But we before we do that, we will secure our connections with TLS encryption.
|
||||
|
||||
### Securing the VNC session
|
||||
|
||||
To secure VNC server session, we will first configure the encryption method to secure VNC server sessions. We will be using TLS encryption but can also use SSL encryption. Execute the following command to start using TLS encrytption on VNC server,
|
||||
|
||||
```
|
||||
# vncserver -SecurityTypes=VeNCrypt,TLSVnc
|
||||
```
|
||||
|
||||
You will asked to enter a password to access VNC (if using any other user, than the above mentioned user)
|
||||
|
||||
![secure vnc server][4]
|
||||
|
||||
We can now access the server using the VNC viewer from the client machine, use the following command to start vnc viewer with secure connection,
|
||||
|
||||
**# vncviewer -SecurityTypes=VeNCrypt,TLSVnc 192.168.1.45:1**
|
||||
|
||||
here, 192.168.1.45 is the IP address of the VNC server.
|
||||
|
||||
![secure vnc server][6]
|
||||
|
||||
Enter the password & we can than access the server remotely & that too with TLS encryption.
|
||||
|
||||
This completes our tutorial, feel free to send your suggestions or queries using the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/secure-vnc-server-tls-encryption/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
[2]:/cdn-cgi/l/email-protection
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=642%2C241
|
||||
[4]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-1.png?resize=642%2C241
|
||||
[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=665%2C419
|
||||
[6]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-2.png?resize=665%2C419
|
||||
@ -1,93 +0,0 @@
|
||||
Translated by name1e5s
|
||||
|
||||
The big break in computer languages
|
||||
============================================================
|
||||
|
||||
|
||||
My last post ([The long goodbye to C][3]) elicited a comment from a C++ expert I was friends with long ago, recommending C++ as the language to replace C. Which ain’t gonna happen; if that were a viable future, Go and Rust would never have been conceived.
|
||||
|
||||
But my readers deserve more than a bald assertion. So here, for the record, is the story of why I don’t touch C++ any more. This is a launch point for a disquisition on the economics of computer-language design, why some truly unfortunate choices got made and baked into our infrastructure, and how we’re probably going to fix them.
|
||||
|
||||
Along the way I will draw aside the veil from a rather basic mistake that people trying to see into the future of programming languages (including me) have been making since the 1980s. Only very recently do we have the field evidence to notice where we went wrong.
|
||||
|
||||
I think I first picked up C++ because I needed GNU eqn to be able to output MathXML, and eqn was written in C++. That project succeeded. Then I was a senior dev on Battle For Wesnoth for a number of years in the 2000s and got comfortable with the language.
|
||||
|
||||
Then came the day we discovered that a person we incautiously gave commit privileges to had fucked up the games’s AI core. It became apparent that I was the only dev on the team not too frightened of that code to go in. And I fixed it all right – took me two weeks of struggle. After which I swore a mighty oath never to go near C++ again.
|
||||
|
||||
My problem with the language, starkly revealed by that adventure, is that it piles complexity on complexity upon chrome upon gingerbread in an attempt to address problems that cannot actually be solved because the foundational abstractions are leaky. It’s all very well to say “well, don’t do that” about things like bare pointers, and for small-scale single-developer projects (like my eqn upgrade) it is realistic to expect the discipline can be enforced.
|
||||
|
||||
Not so on projects with larger scale or multiple devs at varying skill levels (the case I normally deal with). With probability asymptotically approaching one over time and increasing LOC, someone is inadvertently going to poke through one of the leaks. At which point you have a bug which, because of over-layers of gnarly complexity such as STL, is much more difficult to characterize and fix than the equivalent defect in C. My Battle For Wesnoth experience rubbed my nose in this problem pretty hard.
|
||||
|
||||
What works for a Steve Heller (my old friend and C++ advocate) doesn’t scale up when I’m dealing with multiple non-Steve-Hellers and might end up having to clean up their mess. So I just don’t go there any more. Not worth the aggravation. C is flawed, but it does have one immensely valuable property that C++ didn’t keep – if you can mentally model the hardware it’s running on, you can easily see all the way down. If C++ had actually eliminated C’s flaws (that it, been type-safe and memory-safe) giving away that transparency might be a trade worth making. As it is, nope.
|
||||
|
||||
One way we can tell that C++ is not sufficient is to imagine an alternate world in which it is. In that world, older C projects would routinely up-migrate to C++. Major OS kernels would be written in C++, and existing kernel implementations like Linux would be upgrading to it. In the real world, this ain’t happening. Not only has C++ failed to present enough of a value proposition to keep language designers uninterested in imagining languages like D, Go, and Rust, it has failed to displace its own ancestor. There’s no path forward from C++ without breaching its core assumptions; thus, the abstraction leaks won’t go away.
|
||||
|
||||
Since I’ve mentioned D, I suppose this is also the point at which I should explain why I don’t see it as a serious contender to replace C. Yes, it was spun up eight years before Rust and nine years before Go – props to Walter Bright for having the vision. But in 2001 the example of Perl and Python had already been set – the window when a proprietary language could compete seriously with open source was already closing. The wrestling match between the official D library/runtime and Tango hurt it, too. It has never recovered from those mistakes.
|
||||
|
||||
So now there’s Go (I’d say “…and Rust”, but for reasons I’ve discussed before I think it will be years before Rust is fully competitive). It _is_ type-safe and memory-safe (well, almost; you can partway escape using interfaces, but it’s not normal to have to go to the unsafe places). One of my regulars, Mark Atwood, has correctly pointed out that Go is a language made of grumpy-old-man rage, specifically rage by _one of the designers of C_ (Ken Thompson) at the bloated mess that C++ became.
|
||||
|
||||
I can relate to Ken’s grumpiness; I’ve been muttering for decades that C++ attacked the wrong problem. There were two directions a successor language to C might have gone. One was to do what C++ did – accept C’s leaky abstractions, bare pointers and all, for backward compatibility, than try to build a state-of-the-art language on top of them. The other would have been to attack C’s problems at their root – _fix_ the leaky abstractions. That would break backward compatibility, but it would foreclose the class of problems that dominate C/C++ defects.
|
||||
|
||||
The first serious attempt at the second path was Java in 1995\. It wasn’t a bad try, but the choice to build it over a j-code interpreter mode it unsuitable for systems programming. That left a huge hole in the options for systems programming that wouldn’t be properly addressed for another 15 years, until Rust and Go. In particular, it’s why software like my GPSD and NTPsec projects is still predominantly written in C in 2017 despite C’s manifest problems.
|
||||
|
||||
This is in many ways a bad situation. It was hard to really see this because of the lack of viable alternatives, but C/C++ has not scaled well. Most of us take for granted the escalating rate of defects and security compromises in infrastructure software without really thinking about how much of that is due to really fundamental language problems like buffer-overrun vulnerabilities.
|
||||
|
||||
So, why did it take so long to address that? It was 37 years from C (1972) to Go (2009); Rust only launched a year sooner. I think the underlying reasons are economic.
|
||||
|
||||
Ever since the very earliest computer languages it’s been understood that every language design embodies an assertion about the relative value of programmer time vs. machine resources. At one end of that spectrum you have languages like assembler and (later) C that are designed to extract maximum performance at the cost of also pessimizing developer time and costs; at the other, languages like Lisp and (later) Python that try to automate away as much housekeeping detail as possible, at the cost of pessimizing machine performance.
|
||||
|
||||
In broadest terms, the most important discriminator between the ends of this spectrum is the presence or absence of automatic memory management. This corresponds exactly to the empirical observation that memory-management bugs are by far the most common class of defects in machine-centric languages that require programmers to manage that resource by hand.
|
||||
|
||||
A language becomes economically viable where and when its relative-value assertion matches the actual cost drivers of some particular area of software development. Language designers respond to the conditions around them by inventing languages that are a better fit for present or near-future conditions than the languages they have available to use.
|
||||
|
||||
Over time, there’s been a gradual shift from languages that require manual memory management to languages with automatic memory management and garbage collection (GC). This shift corresponds to the Moore’s Law effect of decreasing hardware costs making programmer time relatively more expensive. But there are at least two other relevant dimensions.
|
||||
|
||||
One is distance from the bare metal. Inefficiency low in the software stack (kernels and service code) ripples multiplicatively up the stack. This, we see machine-centric languages down low and programmer-centric languages higher up, most often in user-facing software that only has to respond at human speed (time scale 0.1 sec).
|
||||
|
||||
Another is project scale. Every language also has an expected rate of induced defects per thousand lines of code due to programmers tripping over leaks and flaws in its abstractions. This rate runs higher in machine-centric languages, much lower in programmer-centric ones with GC. As project scale goes up, therefore, languages with GC become more and more important as a strategy against unacceptable defect rates.
|
||||
|
||||
When we view language deployments along these three dimensions, the observed pattern today – C down below, an increasing gallimaufry of languages with GC above – almost makes sense. Almost. But there is something else going on. C is stickier than it ought to be, and used way further up the stack than actually makes sense.
|
||||
|
||||
Why do I say this? Consider the classic Unix command-line utilities. These are generally pretty small programs that would run acceptably fast implemented in a scripting language with a full POSIX binding. Re-coded that way they would be vastly easier to debug, maintain and extend.
|
||||
|
||||
Why are these still in C (or, in unusual exceptions like eqn, in C++)? Transition costs. It’s difficult to translate even small, simple programs between languages and verify that you have faithfully preserved all non-error behaviors. More generally, any area of applications or systems programming can stay stuck to a language well after the tradeoff that language embodies is actually obsolete.
|
||||
|
||||
Here’s where I get to the big mistake I and other prognosticators made. We thought falling machine-resource costs – increasing the relative cost of programmer-hours – would be enough by themselves to displace C (and non-GC languages generally). In this we were not entirely or even mostly wrong – the rise of scripting languages, Java, and things like Node.js since the early 1990s was pretty obviously driven that way.
|
||||
|
||||
Not so the new wave of contending systems-programming languages, though. Rust and Go are both explicitly responses to _increasing project scale_ . Where scripting languages got started as an effective way to write small programs and gradually scaled up, Rust and Go were positioned from the start as ways to reduce defect rates in _really large_ projects. Like, Google’s search service and Facebook’s real-time-chat multiplexer.
|
||||
|
||||
I think this is the answer to the “why not sooner” question. Rust and Go aren’t actually late at all, they’re relatively prompt responses to a cost driver that was underweighted until recently.
|
||||
|
||||
OK, so much for theory. What predictions does this one generate? What does it tell us about what comes after C?
|
||||
|
||||
Here’s the big one. The largest trend driving development towards GC languages haven’t reversed, and there’s no reason to expect it will. Therefore: eventually we _will_ have GC techniques with low enough latency overhead to be usable in kernels and low-level firmware, and those will ship in language implementations. Those are the languages that will truly end C’s long reign.
|
||||
|
||||
There are broad hints in the working papers from the Go development group that they’re headed in this direction – references to academic work on concurrent garbage collectors that never have stop-the-world pauses. If Go itself doesn’t pick up this option, other language designers will. But I think they will – the business case for Google to push them there is obvious (can you say “Android development”?).
|
||||
|
||||
Well before we get to GC that good, I’m putting my bet on Go to replace C anywhere that the GC it has now is affordable – which means not just applications but most systems work outside of kernels and embedded. The reason is simple: there is no path out of C’s defect rates with lower transition costs.
|
||||
|
||||
I’ve been experimenting with moving C code to Go over the last week, and I’m noticing two things. One is that it’s easy to do – C’s idioms map over pretty well. The other is that the resulting code is much simpler. One would expect that, with GC in the language and maps as a first-class data type, but I’m seeing larger reductions in code volume than initially expected – about 2:1, similar to what I see when moving C code to Python.
|
||||
|
||||
Sorry, Rustaceans – you’ve got a plausible future in kernels and deep firmware, but too many strikes against you to beat Go over most of C’s range. No GC, plus Rust is a harder transition from C because of the borrow checker, plus the standardized part of the API is still seriously incomplete (where’s my select(2), again?).
|
||||
|
||||
The only consolation you get, if it is one, is that the C++ fans are screwed worse than you are. At least Rust has a real prospect of dramatically lowering downstream defect rates relative to C anywhere it’s not crowded out by Go; C++ doesn’t have that.
|
||||
|
||||
This entry was posted in [Software][4] by [Eric Raymond][5]. Bookmark the [permalink][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7724
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7724
|
||||
[3]:http://esr.ibiblio.org/?p=7711
|
||||
[4]:http://esr.ibiblio.org/?cat=13
|
||||
[5]:http://esr.ibiblio.org/?author=2
|
||||
[6]:http://esr.ibiblio.org/?p=7724
|
||||
@ -1,223 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Protecting Your Website From Application Layer DOS Attacks With mod
|
||||
======
|
||||
There exist many ways of maliciously taking a website offline. The more complicated methods involve technical knowledge of databases and programming. A far simpler method is known as a "Denial Of Service", or "DOS" attack. This attack derives its name from its goal which is to deny your regular clients or site visitors normal website service.
|
||||
|
||||
There are, generally speaking, two forms of DOS attack;
|
||||
|
||||
1. Layer 3,4 or Network-Layer attacks.
|
||||
2. Layer 7 or Application-Layer attacks.
|
||||
|
||||
|
||||
|
||||
The first type of DOS attack, network-layer, is when a huge quantity of junk traffic is directed at the web server. When the quantity of junk traffic exceeds the capacity of the network infrastructure the website is taken offline.
|
||||
|
||||
The second type of DOS attack, application-layer, is where instead of junk traffic legitimate looking page requests are made. When the number of page requests exceeds the capacity of the web server to serve pages legitimate visitors will not be able to use the site.
|
||||
|
||||
This guide will look at mitigating application-layer attacks. This is because mitigating networking-layer attacks requires huge quantities of available bandwidth and the co-operation of upstream providers. This is usually not something that can be protected against through configuration of the web server.
|
||||
|
||||
An application-layer attack, at least a modest one, can be protected against through the configuration of a normal web server. Protecting against this form of attack is important because [Cloudflare][1] have [recently reported][2] that the number of network-layer attacks is diminishing while the number of application-layer attacks is increasing.
|
||||
|
||||
This guide will explain using the Apache2 module [mod_evasive][3] by [zdziarski][4].
|
||||
|
||||
In addition, mod_evasive will stop an attacker trying to guess a username/password combination by attempting hundreds of combinations i.e. a brute force attack.
|
||||
|
||||
Mod_evasive works by keeping a record of the number of requests arriving from each IP address. When this number exceeds one of the several thresholds that IP is served an error page. Error pages require far fewer resources than a site page keeping the site online for legitimate visitors.
|
||||
|
||||
### Installing mod_evasive on Ubuntu 16.04
|
||||
|
||||
Mod_evasive is contained in the default Ubuntu 16.04 repositories with the package name "libapache2-mod-evasive". A simple `apt-get` will get it installed:
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libapache2-mod-evasive
|
||||
|
||||
```
|
||||
|
||||
We now need to configure mod_evasive.
|
||||
|
||||
It's configuration file is located at `/etc/apache2/mods-available/evasive.conf`. By default, all the modules settings are commented after installation. Therefore, the module won't interfere with site traffic until the configuration file has been edited.
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
#DOSHashTableSize 3097
|
||||
#DOSPageCount 2
|
||||
#DOSSiteCount 50
|
||||
#DOSPageInterval 1
|
||||
#DOSSiteInterval 1
|
||||
#DOSBlockingPeriod 10
|
||||
|
||||
#DOSEmailNotify you@yourdomain.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
#DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
The first block of directives mean as follows:
|
||||
|
||||
* **DOSHashTableSize** - The current list of accessing IP's and their request count.
|
||||
* **DOSPageCount** - The threshold number of page requests per DOSPageInterval.
|
||||
* **DOSPageInterval** - The amount of time in which mod_evasive counts up the page requests.
|
||||
* **DOSSiteCount** - The same as the DOSPageCount but counts requests from the same IP for any page on the site.
|
||||
* **DOSSiteInterval** - The amount of time that mod_evasive counts up the site requests.
|
||||
* **DOSBlockingPeriod** - The amount of time in seconds that an IP is blocked for.
|
||||
|
||||
|
||||
|
||||
If the default configuration shown above is used then an IP will be blocked if it:
|
||||
|
||||
* Requests a single page more than twice a second.
|
||||
* Requests more than 50 pages different pages per second.
|
||||
|
||||
|
||||
|
||||
If an IP exceeds these thresholds it is blocked for 10 seconds.
|
||||
|
||||
This may not seem like a lot, however, mod_evasive will continue monitoring the page requests even for blocked IP's and reset their block period. As long as an IP is attempting to DOS the site it will remain blocked.
|
||||
|
||||
The remaining directives are:
|
||||
|
||||
* **DOSEmailNotify** - An email address to receive notification of DOS attacks and IP's being blocked.
|
||||
* **DOSSystemCommand** - A command to run in the event of a DOS.
|
||||
* **DOSLogDir** - The directory where mod_evasive keeps some temporary files.
|
||||
|
||||
|
||||
|
||||
### Configuring mod_evasive
|
||||
|
||||
The default configuration is a good place to start as it should not block any legitimate users. The configuration file with all directives (apart from DOSSystemCommand) uncommented looks like the following:
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
|
||||
DOSEmailNotify JohnW@example.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
The log directory must be created and given the same owner as the apache process. Here it is created at `/var/log/mod_evasive` and given the owner and group of the Apache web server on Ubuntu `www-data`:
|
||||
```
|
||||
mkdir /var/log/mod_evasive
|
||||
chown www-data:www-data /var/log/mod_evasive
|
||||
|
||||
```
|
||||
|
||||
After editing Apache's configuration, especially on a live website, it is always a good idea to check the syntax of the edits before restarting or reloading. This is because a syntax error will stop Apache from re-starting and taking your site offline.
|
||||
|
||||
Apache comes packaged with a helper command that has a configuration syntax checker. Simply run the following command to check your edits:
|
||||
```
|
||||
apachectl configtest
|
||||
|
||||
```
|
||||
|
||||
If your configuration is correct you will get the response:
|
||||
```
|
||||
Syntax OK
|
||||
|
||||
```
|
||||
|
||||
However, if there is a problem you will be told where it occurred and what it was, e.g.:
|
||||
```
|
||||
AH00526: Syntax error on line 6 of /etc/apache2/mods-enabled/evasive.conf:
|
||||
DOSSiteInterval takes one argument, Set site interval
|
||||
Action 'configtest' failed.
|
||||
The Apache error log may have more information.
|
||||
|
||||
```
|
||||
|
||||
If your configuration passes the configtest then the module can be safely enabled and Apache reloaded:
|
||||
```
|
||||
a2enmod evasive
|
||||
systemctl reload apache2.service
|
||||
|
||||
```
|
||||
|
||||
Mod_evasive is now configured and running.
|
||||
|
||||
### Testing
|
||||
|
||||
In order to test mod_evasive, we simply need to make enough web requests to the server that we exceed the threshold and record the response codes from Apache.
|
||||
|
||||
A normal, successful page request will receive the response:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
```
|
||||
|
||||
However, one that has been denied by mod_evasive will return the following:
|
||||
```
|
||||
HTTP/1.1 403 Forbidden
|
||||
|
||||
```
|
||||
|
||||
The following script will make HTTP requests to `127.0.0.1:80`, that is localhost on port 80, as rapidly as possible and print out the response code of every request.
|
||||
|
||||
All you need to do is to copy the following bash script into a file e.g. `mod_evasive_test.sh`:
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
for i in {1..50}; do
|
||||
curl -s -I 127.0.0.1 | head -n 1
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
The parts of this script mean as follows:
|
||||
|
||||
* curl - This is a command to make web requests.
|
||||
* -s - Hide the progress meter.
|
||||
* -I - Only display the response header information.
|
||||
* head - Print the first part of a file.
|
||||
* -n 1 - Only display the first line.
|
||||
|
||||
|
||||
|
||||
Then make it executable:
|
||||
```
|
||||
chmod 755 mod_evasive_test.sh
|
||||
|
||||
```
|
||||
|
||||
When the script is run **before** mod_evasive is enabled you will see 50 lines of `HTTP/1.1 200 OK` returned.
|
||||
|
||||
However, after mod_evasive is enabled you will see the following:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first two requests were allowed, but then once a third in the same second was made mod_evasive denied any further requests. You will also receive an email letting you know that a DOS attempt was detected to the address you set with the `DOSEmailNotify` option.
|
||||
|
||||
Mod_evasive is now protecting your site!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/mod_proxy/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net/about/
|
||||
[1]:https://www.cloudflare.com
|
||||
[2]:https://blog.cloudflare.com/the-new-ddos-landscape/
|
||||
[3]:https://github.com/jzdziarski/mod_evasive
|
||||
[4]:https://www.zdziarski.com/blog/
|
||||
@ -1,3 +1,4 @@
|
||||
(yixunx translating)
|
||||
Internet Chemotherapy
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ucasFL
|
||||
|
||||
How to generate webpages using CGI scripts
|
||||
======
|
||||
Back in the stone age of the Internet when I first created my first business website, life was good.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb call functions?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translated by cyleft
|
||||
|
||||
How To Manage Vim Plugins Using Vundle On Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translated by cyleft
|
||||
|
||||
Linux tee Command Explained for Beginners (6 Examples)
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
The World Map In Your Terminal
|
||||
======
|
||||
I just stumbled upon an interesting utility. The World map in the Terminal! Yes, It is so cool. Say hello to **MapSCII** , a Braille and ASCII world map renderer for your xterm-compatible terminals. It supports GNU/Linux, Mac OS, and Windows. I thought it is a just another project hosted on GitHub. But I was wrong! It is really impressive what they did there. We can use our mouse pointer to drag and zoom in and out a location anywhere in the world map. The other notable features are;
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wenwensnow
|
||||
Shell Scripting a Bunco Game
|
||||
======
|
||||
I haven't dug into any game programming for a while, so I thought it was high time to do something in that realm. At first, I thought "Halo as a shell script?", but then I came to my senses. Instead, let's look at a simple dice game called Bunco. You may not have heard of it, but I bet your Mom has—it's a quite popular game for groups of gals at a local pub or tavern.
|
||||
|
||||
319
sources/tech/20180122 A Simple Command-line Snippet Manager.md
Normal file
319
sources/tech/20180122 A Simple Command-line Snippet Manager.md
Normal file
@ -0,0 +1,319 @@
|
||||
A Simple Command-line Snippet Manager
|
||||
======
|
||||
|
||||

|
||||
|
||||
We can't remember all the commands, right? Yes. Except the frequently used commands, it is nearly impossible to remember some long commands that we rarely use. That's why we need to some external tools to help us to find the commands when we need them. In the past, we have reviewed two useful utilities named [**" Bashpast"**][1] and [**" Keep"**][2]. Using Bashpast, we can easily bookmark the Linux commands for easier repeated invocation. And, the Keep utility can be used to keep the some important and lengthy commands in your Terminal, so you can use them on demand. Today, we are going to see yet another tool in the series to help you remembering commands. Say hello to **" Pet"**, a simple command-line snippet manager written in **Go** language.
|
||||
|
||||
Using Pet, you can;
|
||||
|
||||
* Register/add your important, long and complex command snippets.
|
||||
* Search the saved command snippets interactively.
|
||||
* Run snippets directly without having to type over and over.
|
||||
* Edit the saved command snippets easily.
|
||||
* Sync the snippets via Gist.
|
||||
* Use variables in snippets.
|
||||
* And more yet to come.
|
||||
|
||||
|
||||
|
||||
#### Installing Pet CLI Snippet Manager
|
||||
|
||||
Since it is written in Go language, make sure you have installed Go in your system.
|
||||
|
||||
After Go language, grab the latest binaries from [**the releases page**][3].
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
For 32 bit:
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
Extract the downloaded archive:
|
||||
```
|
||||
unzip pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
32 bit:
|
||||
```
|
||||
unzip pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
Copy the pet binary file to your PATH (i.e **/usr/local/bin** or the like).
|
||||
```
|
||||
sudo cp pet /usr/local/bin/
|
||||
```
|
||||
|
||||
Finally, make it executable:
|
||||
```
|
||||
sudo chmod +x /usr/local/bin/pet
|
||||
```
|
||||
|
||||
If you're using Arch based systems, then you can install it from AUR using any AUR helper tools.
|
||||
|
||||
Using [**Pacaur**][4]:
|
||||
```
|
||||
pacaur -S pet-git
|
||||
```
|
||||
|
||||
Using [**Packer**][5]:
|
||||
```
|
||||
packer -S pet-git
|
||||
```
|
||||
|
||||
Using [**Yaourt**][6]:
|
||||
```
|
||||
yaourt -S pet-git
|
||||
```
|
||||
|
||||
Using [**Yay** :][7]
|
||||
```
|
||||
yay -S pet-git
|
||||
```
|
||||
|
||||
Also, you need to install **[fzf][8]** or [**peco**][9] tools to enable interactive search. Refer the official GitHub links to know how to install these tools.
|
||||
|
||||
#### Usage
|
||||
|
||||
Run 'pet' without any arguments to view the list of available commands and general options.
|
||||
```
|
||||
$ pet
|
||||
pet - Simple command-line snippet manager.
|
||||
|
||||
Usage:
|
||||
pet [command]
|
||||
|
||||
Available Commands:
|
||||
configure Edit config file
|
||||
edit Edit snippet file
|
||||
exec Run the selected commands
|
||||
help Help about any command
|
||||
list Show all snippets
|
||||
new Create a new snippet
|
||||
search Search snippets
|
||||
sync Sync snippets
|
||||
version Print the version number
|
||||
|
||||
Flags:
|
||||
--config string config file (default is $HOME/.config/pet/config.toml)
|
||||
--debug debug mode
|
||||
-h, --help help for pet
|
||||
|
||||
Use "pet [command] --help" for more information about a command.
|
||||
```
|
||||
|
||||
To view the help section of a specific command, run:
|
||||
```
|
||||
$ pet [command] --help
|
||||
```
|
||||
|
||||
**Configure Pet**
|
||||
|
||||
It just works fine with default values. However, you can change the default directory to save snippets, choose the selector (fzf or peco) to use, the default text editor to edit snippets, add GIST id details etc.
|
||||
|
||||
To configure Pet, run:
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
This command will open the default configuration in the default text editor (for example **vim** in my case). Change/edit the values as per your requirements.
|
||||
```
|
||||
[General]
|
||||
snippetfile = "/home/sk/.config/pet/snippet.toml"
|
||||
editor = "vim"
|
||||
column = 40
|
||||
selectcmd = "fzf"
|
||||
|
||||
[Gist]
|
||||
file_name = "pet-snippet.toml"
|
||||
access_token = ""
|
||||
gist_id = ""
|
||||
public = false
|
||||
~
|
||||
```
|
||||
|
||||
**Creating Snippets**
|
||||
|
||||
To create a new snippet, run:
|
||||
```
|
||||
$ pet new
|
||||
```
|
||||
|
||||
Add the command and the description and hit ENTER to save it.
|
||||
```
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'
|
||||
Description> Remove numbers from output.
|
||||
```
|
||||
|
||||
[![][10]][11]
|
||||
|
||||
This is a simple command to remove all numbers from the echo command output. You can easily remember it. But, if you rarely use it, you may forgot it completely after few days. Of course we can search the history using "CTRL+r", but "Pet" is much easier. Also, Pet can help you to add any number of entries.
|
||||
|
||||
Another cool feature is we can easily add the previous command. To do so, add the following lines in your **.bashrc** or **.zshrc** file.
|
||||
```
|
||||
function prev() {
|
||||
PREV=$(fc -lrn | head -n 1)
|
||||
sh -c "pet new `printf %q "$PREV"`"
|
||||
}
|
||||
```
|
||||
|
||||
Do the following command to take effect the saved changes.
|
||||
```
|
||||
source .bashrc
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
source .zshrc
|
||||
```
|
||||
|
||||
Now, run any command, for example:
|
||||
```
|
||||
$ cat Documents/ostechnix.txt | tr '|' '\n' | sort | tr '\n' '|' | sed "s/.$/\\n/g"
|
||||
```
|
||||
|
||||
To add the above command, you don't have to use "pet new" command. just do:
|
||||
```
|
||||
$ prev
|
||||
```
|
||||
|
||||
Add the description to the command snippet and hit ENTER to save.
|
||||
|
||||
[![][10]][12]
|
||||
|
||||
**List snippets**
|
||||
|
||||
To view the saved snippets, run:
|
||||
```
|
||||
$ pet list
|
||||
```
|
||||
|
||||
[![][10]][13]
|
||||
|
||||
**Edit Snippets**
|
||||
|
||||
If you want to edit the description or the command of a snippet, run:
|
||||
```
|
||||
$ pet edit
|
||||
```
|
||||
|
||||
This will open all saved snippets in your default text editor. You can edit or change the snippets as you wish.
|
||||
```
|
||||
[[snippets]]
|
||||
description = "Remove numbers from output."
|
||||
command = "echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'"
|
||||
output = ""
|
||||
|
||||
[[snippets]]
|
||||
description = "Alphabetically sort one line of text"
|
||||
command = "\t prev"
|
||||
output = ""
|
||||
```
|
||||
|
||||
**Use Tags in snippets**
|
||||
|
||||
To use tags to a snippet, use **-t** flag like below.
|
||||
```
|
||||
$ pet new -t
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9
|
||||
Description> Remove numbers from output.
|
||||
Tag> tr command examples
|
||||
|
||||
```
|
||||
|
||||
**Execute Snippets**
|
||||
|
||||
To execute a saved snippet, run:
|
||||
```
|
||||
$ pet exec
|
||||
```
|
||||
|
||||
Choose the snippet you want to run from the list and hit ENTER to run it.
|
||||
|
||||
[![][10]][14]
|
||||
|
||||
Remember you need to install fzf or peco to use this feature.
|
||||
|
||||
**Search Snippets**
|
||||
|
||||
If you have plenty of saved snippets, you can easily search them using a string or key word like below.
|
||||
```
|
||||
$ pet search
|
||||
```
|
||||
|
||||
Enter the search term or keyword to narrow down the search results.
|
||||
|
||||
[![][10]][15]
|
||||
|
||||
**Sync Snippets**
|
||||
|
||||
First, you need to obtain the access token. Go to this link <https://github.com/settings/tokens/new> and create access token (only need "gist" scope).
|
||||
|
||||
Configure Pet using command:
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
Set that token to **access_token** in **[Gist]** field.
|
||||
|
||||
After setting, you can upload snippets to Gist like below.
|
||||
```
|
||||
$ pet sync -u
|
||||
Gist ID: 2dfeeeg5f17e1170bf0c5612fb31a869
|
||||
Upload success
|
||||
|
||||
```
|
||||
|
||||
You can also download snippets on another PC. To do so, edit configuration file and set **Gist ID** to **gist_id** in **[Gist]**.
|
||||
|
||||
Then, download the snippets using command:
|
||||
```
|
||||
$ pet sync
|
||||
Download success
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section:
|
||||
```
|
||||
pet -h
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
pet [command] -h
|
||||
```
|
||||
|
||||
And, that's all. Hope this helps. As you can see, Pet usage is fairly simple and easy to use! If you're having hard time remembering lengthy commands, Pet utility can definitely be useful.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pet-simple-command-line-snippet-manager/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
|
||||
[2]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
[3]:https://github.com/knqyf263/pet/releases
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://github.com/junegunn/fzf
|
||||
[9]:https://github.com/peco/peco
|
||||
[10]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-1.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-2.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-3.png ()
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-4.png ()
|
||||
[15]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-5.png ()
|
||||
@ -0,0 +1,170 @@
|
||||
Never miss a Magazine's article, build your own RSS notification system
|
||||
======
|
||||
|
||||

|
||||
|
||||
Python is a great programming language to quickly build applications that make our life easier. In this article we will learn how to use Python to build a RSS notification system, the goal being to have fun learning Python using Fedora. If you are looking for a complete RSS notifier application, there are a few already packaged in Fedora.
|
||||
|
||||
### Fedora and Python - getting started
|
||||
|
||||
Python 3.6 is available by default in Fedora, that includes Python's extensive standard library. The standard library provides a collection of modules which make some tasks simpler for us. For example, in our case we will use the [**sqlite3**][1] module to create, add and read data from a database. In the case where a particular problem we are trying to solve is not covered by the standard library, the chance is that someone has already developed a module for everyone to use. The best place to search for such modules is the Python Package Index known as [PyPI][2]. In our example we are going to use the [**feedparser**][3] to parse an RSS feed.
|
||||
|
||||
Since **feedparser** is not in the standard library, we have to install it in our system. Luckily for us there is an rpm package in Fedora, so the installation of **feedparser** is as simple as:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
|
||||
We now have everything we need to start coding our application.
|
||||
|
||||
### Storing the feed data
|
||||
|
||||
We need to store data from the articles that have already been published so that we send a notification only for new articles. The data we want to store will give us a unique way to identify an article. Therefore we will store the **title** and the **publication date** of the article.
|
||||
|
||||
So let's create our database using python **sqlite3** module and a simple SQL query. We are also adding the modules we are going to use later ( **feedparser** , **smtplib** and **email** ).
|
||||
|
||||
#### Creating the Database
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
import smtplib
|
||||
from email.mime.text import MIMEText
|
||||
|
||||
import feedparser
|
||||
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
These few lines of code create a new sqlite database stored in a file called 'magazine_rss.sqlite', and then create a new table within the database called 'magazine'. This table has two columns - 'title' and 'date' - that can store data of the type TEXT, which means that the value of each column will be a text string.
|
||||
|
||||
#### Checking the Database for old articles
|
||||
|
||||
Since we only want to add new articles to our database we need a function that will check if the article we get from the RSS feed is already in our database or not. We will use it to decide if we should send an email notification (new article) or not (old article). Ok let's code this function.
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
is in the database.
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
Return:
|
||||
True if the article is not in the database
|
||||
False if the article is already present in the database
|
||||
"""
|
||||
db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date))
|
||||
if not db.fetchall():
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
```
|
||||
|
||||
The main part of this function is the SQL query we execute to search through the database. We are using a SELECT instruction to define which column of our magazine table we will run the query on. We are using the 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh symbol to select all columns ( title and date). Then we ask to select only the rows of the table WHERE the article_title and article_date string are equal to the value of the title and date column.
|
||||
|
||||
To finish, we have a simple logic that will return True if the query did not return any results and False if the query found an article in database matching our title, date pair.
|
||||
|
||||
#### Adding a new article to the Database
|
||||
|
||||
Now we can code the function to add a new article to the database.
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
"""
|
||||
db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date))
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
This function is straight forward, we are using a SQL query to INSERT a new row INTO the magazine table with the VALUES of the article_title and article_date. Then we commit the change to make it persistent.
|
||||
|
||||
That's all we need from the database's point of view, let's look at the notification system and how we can use python to send emails.
|
||||
|
||||
### Sending an email notification
|
||||
|
||||
Let's create a function to send an email using the python standard library module **smtplib.** We are also using the **email** module from the standard library to format our email message.
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_url (str): The url to access the article
|
||||
"""
|
||||
|
||||
smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
|
||||
smtp_server.ehlo()
|
||||
smtp_server.starttls()
|
||||
smtp_server.login('your_email@gmail.com', '123your_password')
|
||||
msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}')
|
||||
msg['Subject'] = 'New Fedora Magazine Article Available'
|
||||
msg['From'] = 'your_email@gmail.com'
|
||||
msg['To'] = 'destination_email@gmail.com'
|
||||
smtp_server.send_message(msg)
|
||||
smtp_server.quit()
|
||||
```
|
||||
|
||||
In this example I am using the Google mail smtp server to send an email, but this will work with any email services that provides you with a SMTP server. Most of this function is boilerplate needed to configure the access to the smtp server. You will need to update the code with your email address and credentials.
|
||||
|
||||
If you are using 2 Factor Authentication with your gmail account you can setup a password app that will give you a unique password to use for this application. Check out this help [page][4].
|
||||
|
||||
### Reading Fedora Magazine RSS feed
|
||||
|
||||
We now have functions to store an article in the database and send an email notification, let's create a function that parses the Fedora Magazine RSS feed and extract the articles' data.
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
feed = feedparser.parse('https://fedoramagazine.org/feed/')
|
||||
for article in feed['entries']:
|
||||
if article_is_not_db(article['title'], article['published']):
|
||||
send_notification(article['title'], article['link'])
|
||||
add_article_to_db(article['title'], article['published'])
|
||||
|
||||
if __name__ == '__main__':
|
||||
read_article_feed()
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
Here we are making use of the **feedparser.parse** function. The function returns a dictionary representation of the RSS feed, for the full reference of the representation you can consult **feedparser** 's [documentation][5].
|
||||
|
||||
The RSS feed parser will return the last 10 articles as entries and then we extract the following information: the title, the link and the date the article was published. As a result, we can now use the functions we have previously defined to check if the article is not in the database, then send a notification email and finally, add the article to our database.
|
||||
|
||||
The last if statement is used to execute our read_article_feed function and then close the database connection when we execute our script.
|
||||
|
||||
### Running our script
|
||||
|
||||
Finally, to run our script we need to give the correct permission to the file. Next, we make use of the **cron** utility to automatically execute our script every hour (1 minute past the hour). **cron** is a job scheduler that we can use to run a task at a fixed time.
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
To keep this tutorial simple, we are using the cron.hourly directory to execute the script every hours, I you wish to learn more about **cron** and how to configure the **crontab,** please read **cron 's** wikipedia [page][6].
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this tutorial we have learned how to use Python to create a simple sqlite database, parse an RSS feed and send emails. I hope that this showed you how you can easily build your own application using Python and Fedora.
|
||||
|
||||
The script is available on github [here][7].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://docs.python.org/3/library/sqlite3.html
|
||||
[2]:https://pypi.python.org/pypi
|
||||
[3]:https://pypi.python.org/pypi/feedparser/5.2.1
|
||||
[4]:https://support.google.com/accounts/answer/185833?hl=en
|
||||
[5]:https://pythonhosted.org/feedparser/reference.html
|
||||
[6]:https://en.wikipedia.org/wiki/Cron
|
||||
[7]:https://github.com/cverna/rss_feed_notifier
|
||||
@ -0,0 +1,108 @@
|
||||
What Is bashrc and Why Should You Edit It
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are a number of hidden files tucked away in your home directory. If you run macOS or a popular Linux distribution, you'll see a file named ".bashrc" up near the top of your hidden files. What is bashrc, and why is editing bashrc useful?
|
||||
|
||||
![finder-find-bashrc][1]
|
||||
|
||||
If you run a Unix-based or Unix-like operating system, you likely have bash installed as your default terminal. While many [different shells][2] exist, bash is both the most common and, likely, the most popular. If you don't know what that means, bash interprets your typed input in the Terminal program and runs commands based on your input. It allows for some degree of customization using scripting, which is where bashrc comes in.
|
||||
|
||||
In order to load your preferences, bash runs the contents of the bashrc file at each launch. This shell script is found in each user's home directory. It's used to save and load your terminal preferences and environmental variables.
|
||||
|
||||
Terminal preferences can contain a number of different things. Most commonly, the bashrc file contains aliases that the user always wants available. Aliases allow the user to refer to commands by shorter or alternative names, and can be a huge time-saver for those that work in a terminal regularly.
|
||||
|
||||
![terminal-edit-bashrc-1][3]
|
||||
|
||||
You can edit bashrc in any terminal text editor. We will use `nano` in the following examples.
|
||||
|
||||
To edit bashrc using `nano`, invoke the following command in Terminal:
|
||||
```
|
||||
nano ~/.bashrc
|
||||
```
|
||||
|
||||
If you've never edited your bashrc file before, you might find that it's empty. That's fine! If not, you can feel free to put your additions on any line.
|
||||
|
||||
Any changes you make to bashrc will be applied next time you launch terminal. If you want to apply them immediately, run the command below:
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
You can add to bashrc where ever you like, but feel free to use command (proceeded by `#`) to organize your code.
|
||||
|
||||
Edits in bashrc have to follow [bash's scripting format][4]. If you don't know how to script with bash, there are a number of resources you can use online. This guide represents a fairly [comprehensive introduction][5] into the aspects of bashrc that we couldn't mention here.
|
||||
|
||||
**Related** : [How to Run Bash Script as Root During Startup on Linux][6]
|
||||
|
||||
There's a couple of useful tricks you can do to make your terminal experience more efficient and user-friendly.
|
||||
|
||||
### Why should I edit bashrc?
|
||||
|
||||
#### Bash Prompt
|
||||
|
||||
The bash prompt allows you to style up your terminal and have it to show prompts when you run a command. A customized bash prompt can indeed make your work on the terminal more productive and efficient.
|
||||
|
||||
Check out some of the [useful][7] and [interesting][8] bash prompts you can add to your bashrc.
|
||||
|
||||
#### Aliases
|
||||
|
||||
![terminal-edit-bashrc-3][9]
|
||||
|
||||
Aliases can also allow you to access a favored form of a command with a shorthand code. Let's take the command `ls` as an example. By default, `ls` displays the contents of your directory. That's useful, but it's often more useful to know more about the directory, or know the hidden contents of the directory. As such, a common alias is `ll`, which is set to run `ls -lha` or something similar. That will display the most details about files, revealing hidden files and showing file sizes in "human readable" units instead of blocks.
|
||||
|
||||
You'll need to format your aliases like so:
|
||||
```
|
||||
alias ll = "ls -lha"
|
||||
```
|
||||
|
||||
Type the text you want to replace on the left, and the command on the right between quotes. You can use to this to create shorter versions of command, guard against common typos, or force a command to always run with your favored flags. You can also circumvent annoying or easy-to-forget syntax with your own preferred shorthand. Here are some of the [commonly used aliases][10] you can add to your bashrc.
|
||||
|
||||
#### Functions
|
||||
|
||||
![terminal-edit-bashrc-2][11]
|
||||
|
||||
In addition to shorthand command names, you can combine multiple commands into a single operation using bash functions. They can get pretty complicated, but they generally follow this syntax:
|
||||
```
|
||||
function_name () {
|
||||
command_1
|
||||
command_2
|
||||
}
|
||||
```
|
||||
|
||||
The command below combines `mkdir` and `cd`. Typing `md folder_name` creates a directory named "folder_name" in your working directory and navigates into it immediately.
|
||||
```
|
||||
md () {
|
||||
mkdir -p $1
|
||||
cd $1
|
||||
}
|
||||
```
|
||||
|
||||
The `$1` you see in the function represents the first argument, which is the text you type immediately after the function name.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Unlike some terminal customization tricks, messing with bashrc is fairly straight-forward and low risk. If you mess anything up, you can always delete the bashrc file completely and start over again. Try it out now and you will be amazed at your improved productivity.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/what-is-bashrc/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2018/01/finder-find-bashrc.png (finder-find-bashrc)
|
||||
[2]:https://www.maketecheasier.com/alternative-linux-shells/
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/01/terminal-edit-bashrc-1.png (terminal-edit-bashrc-1)
|
||||
[4]:http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO.html
|
||||
[5]:https://www.digitalocean.com/community/tutorials/an-introduction-to-useful-bash-aliases-and-functions
|
||||
[6]:https://www.maketecheasier.com/run-bash-script-as-root-during-startup-linux/ (How to Run Bash Script as Root During Startup on Linux)
|
||||
[7]:https://www.maketecheasier.com/8-useful-and-interesting-bash-prompts/
|
||||
[8]:https://www.maketecheasier.com/more-useful-and-interesting-bash-prompts/
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2018/01/terminal-edit-bashrc-3.png (terminal-edit-bashrc-3)
|
||||
[10]:https://www.maketecheasier.com/install-software-in-various-linux-distros/#aliases
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/01/terminal-edit-bashrc-2.png (terminal-edit-bashrc-2)
|
||||
@ -0,0 +1,85 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for January
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR is a [collection][1] of personal repositories for software that isn't carried in Fedora. Some software doesn't conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn't supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here's a set of new and interesting projects in COPR.
|
||||
|
||||
### Elisa
|
||||
|
||||
[Elisa][2] is a minimal music player. It lets you browse music by albums, artists or tracks. It automatically detects all playable music in your ~/Music directory, thus it requires no set up at all - neither does it offer any. Currently, Elisa focuses on being a simple music player, so it offers no tools for managing your music collection.
|
||||
|
||||
![][3]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Elisa for Fedora 26, 27 and Rawhide. To install Elisa, use these commands:
|
||||
```
|
||||
sudo dnf copr enable eclipseo/elisa
|
||||
sudo dnf install elisa
|
||||
```
|
||||
|
||||
### Bing Wallpapers
|
||||
|
||||
[Bing Wallpapers][4] is a simple program that downloads Bing's wallpaper of the day and sets it as a desktop wallpaper or a lock screen image. The program can rotate over pictures in its directory in set intervals as well as delete old pictures after a set amount of time.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Bing Wallpapers for Fedora 25, 26, 27 and Rawhide. To install Bing Wallpapers, use these commands:
|
||||
```
|
||||
sudo dnf copr enable julekgwa/Bingwallpapers
|
||||
sudo dnf install bingwallpapers
|
||||
```
|
||||
|
||||
### Polybar
|
||||
|
||||
[Polybar][5] is a tool for creating status bars. It has a lot of customization options as well as built-in functionality to display information about commonly used services, such as systray icons, window title, workspace and desktop panel for [bspwm][6], [i3][7], and more. You can also configure your own modules for your status bar. See [Polybar's wiki][8] for more information about usage and configuration.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Polybar for Fedora 27. To install Polybar, use these commands:
|
||||
```
|
||||
sudo dnf copr enable tomwishaupt/polybar
|
||||
sudo dnf install polybar
|
||||
```
|
||||
|
||||
### Netdata
|
||||
|
||||
[Netdata][9] is a distributed monitoring system. It can run on all your systems including PCs, servers, containers and IoT devices, from which it collects metrics in real time. All the information then can be accessed using netdata's web dashboard. Additionally, Netdata provides pre-configured alarms and notifications for detecting performance issue, as well as templates for creating your own alarms.
|
||||
|
||||
![][10]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides netdata for EPEL 7, Fedora 27 and Rawhide. To install netdata, use these commands:
|
||||
```
|
||||
sudo dnf copr enable recteurlp/netdata
|
||||
sudo dnf install netdata
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:https://community.kde.org/Elisa
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/01/elisa.png
|
||||
[4]:http://bingwallpapers.lekgoara.com/
|
||||
[5]:https://github.com/jaagr/polybar
|
||||
[6]:https://github.com/baskerville/bspwm
|
||||
[7]:https://i3wm.org/
|
||||
[8]:https://github.com/jaagr/polybar/wiki
|
||||
[9]:http://my-netdata.io/
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/01/netdata.png
|
||||
@ -0,0 +1,272 @@
|
||||
8 ways to generate random password in Linux
|
||||
======
|
||||
Learn 8 different ways to generate random password in Linux using Linux native commands or third party utilities.
|
||||
|
||||
![][1]
|
||||
|
||||
In this article, we will walk you through various different ways to generate random password in Linux terminal. Few of them are using native Linux commands and others are using third party tools or utilities which can easily be installed on Linux machine. Here we are looking at native commands like `openssl`, [dd][2], `md5sum`, `tr`, `urandom` and third party tools like mkpasswd, randpw, pwgen, spw, gpg, xkcdpass, diceware, revelation, keepaasx, passwordmaker.
|
||||
|
||||
These are actually ways to get some random alphanumeric string which can be utilized as password. Random passwords can be used for new users so that there will be uniqueness no matter how large your user base is. Without any further delay lets jump into those 15 different ways to generate random password in Linux.
|
||||
|
||||
##### Generate password using mkpasswd utility
|
||||
|
||||
`mkpasswd` comes with install of `expect` package on RHEL based systems. On Debian based systems `mkpasswd` comes with package `whois`. Trying to install `mkpasswd` package will results in error -
|
||||
|
||||
No package mkpasswd available. on RHEL system and E: Unable to locate package mkpasswd in Debian based.
|
||||
|
||||
So install their parent packages as mentioned above and you are good to go.
|
||||
|
||||
Run `mkpasswd` to get passwords
|
||||
|
||||
```
|
||||
root@kerneltalks# mkpasswd << on RHEL
|
||||
zt*hGW65c
|
||||
|
||||
root@kerneltalks# mkpas
|
||||
```
|
||||
|
||||
Command behaves differently on different systems so work accordingly. There are many switches which can be used to control length etc parameters. You can explore them from man pages.
|
||||
|
||||
##### Generate password using openssl
|
||||
|
||||
Openssl comes in build with almost all the Linux distributions. We can use its random function to get alphanumeric string generated which can be used as password.
|
||||
|
||||
```
|
||||
root@kerneltalks # openssl rand -base64 10
|
||||
nU9LlHO5nsuUvw==
|
||||
```
|
||||
|
||||
Here, we are using `base64` encoding with random function and last digit for argument to `base64` encoding.
|
||||
|
||||
##### Generate password using urandom
|
||||
|
||||
Device file `/dev/urandom` is another source of getting random characters. We are using `tr` function and trimming output to get random string to use as password.
|
||||
|
||||
```
|
||||
root@kerneltalks # strings /dev/urandom |tr -dc A-Za-z0-9 | head -c20; echo
|
||||
UiXtr0NAOSIkqtjK4c0X
|
||||
```
|
||||
|
||||
##### dd command to generate password
|
||||
|
||||
We can even use /dev/urandom device along with [dd command ][2]to get string of random characters.
|
||||
|
||||
```
|
||||
oot@kerneltalks# dd if=/dev/urandom bs=1 count=15|base64 -w 0
|
||||
15+0 records in
|
||||
15+0 records out
|
||||
15 bytes (15 B) copied, 5.5484e-05 s, 270 kB/s
|
||||
QMsbe2XbrqAc2NmXp8D0
|
||||
```
|
||||
|
||||
We need to pass output through `base64` encoding to make it human readable. You can play with count value to get desired length. For much cleaner output, redirect std2 to `/dev/null`. Clean command will be -
|
||||
|
||||
```
|
||||
oot@kerneltalks # dd if=/dev/urandom bs=1 count=15 2>/dev/null|base64 -w 0
|
||||
F8c3a4joS+a3BdPN9C++
|
||||
```
|
||||
|
||||
##### Using md5sum to generate password
|
||||
|
||||
Another way to get array of random characters which can be used as password is to calculate MD5 checksum! s you know checksum value is indeed looks like random characters grouped together we can use it as password. Make sure you use source as something variable so that you get different checksum every time you run command. For example `date` ! [date command][3] always yields changing output.
|
||||
|
||||
```
|
||||
root@kerneltalks # date |md5sum
|
||||
4d8ce5c42073c7e9ca4aeffd3d157102 -
|
||||
```
|
||||
|
||||
Here we passed `date` command output to `md5sum` and get the checksum hash! You can use [cut command][4] to get desired length of output.
|
||||
|
||||
##### Generate password using pwgen
|
||||
|
||||
`pwgen` package comes with [repositories like EPEL][5]. `pwgen` is more focused on generating passwords which are pronounceable but not a dictionary word or not in plain English. You may not find it in standard distribution repo. Install the package and run `pwgen` command. Boom !
|
||||
|
||||
```
|
||||
root@kerneltalks # pwgen
|
||||
thu8Iox7 ahDeeQu8 Eexoh0ai oD8oozie ooPaeD9t meeNeiW2 Eip6ieph Ooh1tiet
|
||||
cootad7O Gohci0vo wah9Thoh Ohh3Ziur Ao1thoma ojoo6aeW Oochai4v ialaiLo5
|
||||
aic2OaDa iexieQu8 Aesoh4Ie Eixou9ph ShiKoh0i uThohth7 taaN3fuu Iege0aeZ
|
||||
cah3zaiW Eephei0m AhTh8guo xah1Shoo uh8Iengo aifeev4E zoo4ohHa fieDei6c
|
||||
aorieP7k ahna9AKe uveeX7Hi Ohji5pho AigheV7u Akee9fae aeWeiW4a tiex8Oht
|
||||
```
|
||||
You will be presented with list of passwords at your terminal! What else you want? Ok. You still want to explore, `pwgen` comes with many custom options which can be referred for man page.
|
||||
|
||||
##### Generate password using gpg tool
|
||||
|
||||
GPG is a OpenPGP encryption and signing tool. Mostly gpg tool comes pre-installed (at least it is on my RHEL7). But if not you can look for `gpg` or `gpg2` package and [install][6] it.
|
||||
|
||||
Use below command to generate password from gpg tool.
|
||||
|
||||
```
|
||||
root@kerneltalks # gpg --gen-random --armor 1 12
|
||||
mL8i+PKZ3IuN6a7a
|
||||
```
|
||||
|
||||
Here we are passing generate random byte sequence switch (`--gen-random`) of quality 1 (first argument) with count of 12 (second argument). Switch `--armor` ensures output is `base64` encoded.
|
||||
|
||||
##### Generate password using xkcdpass
|
||||
|
||||
Famous geek humor website [xkcd][7], published a very interesting post about memorable but still complex passwords. You can view it [here][8]. So `xkcdpass` tool took inspiration from this post and did its work! Its a python package and available on python's official website [here][9]
|
||||
|
||||
All installation and usage instructions are mentioned on that page. Here is install steps and outputs from my test RHEL server for your reference.
|
||||
|
||||
```
|
||||
root@kerneltalks # wget https://pypi.python.org/packages/b4/d7/3253bd2964390e034cf0bba227db96d94de361454530dc056d8c1c096abc/xkcdpass-1.14.3.tar.gz#md5=5f15d52f1d36207b07391f7a25c7965f
|
||||
--2018-01-23 19:09:17-- https://pypi.python.org/packages/b4/d7/3253bd2964390e034cf0bba227db96d94de361454530dc056d8c1c096abc/xkcdpass-1.14.3.tar.gz
|
||||
Resolving pypi.python.org (pypi.python.org)... 151.101.32.223, 2a04:4e42:8::223
|
||||
Connecting to pypi.python.org (pypi.python.org)|151.101.32.223|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 871848 (851K) [binary/octet-stream]
|
||||
Saving to: ‘xkcdpass-1.14.3.tar.gz’
|
||||
|
||||
100%[==============================================================================================================================>] 871,848 --.-K/s in 0.01s
|
||||
|
||||
2018-01-23 19:09:17 (63.9 MB/s) - ‘xkcdpass-1.14.3.tar.gz’ saved [871848/871848]
|
||||
|
||||
|
||||
root@kerneltalks # tar -xvf xkcdpass-1.14.3.tar.gz
|
||||
xkcdpass-1.14.3/
|
||||
xkcdpass-1.14.3/examples/
|
||||
xkcdpass-1.14.3/examples/example_import.py
|
||||
xkcdpass-1.14.3/examples/example_json.py
|
||||
xkcdpass-1.14.3/examples/example_postprocess.py
|
||||
xkcdpass-1.14.3/LICENSE.BSD
|
||||
xkcdpass-1.14.3/MANIFEST.in
|
||||
xkcdpass-1.14.3/PKG-INFO
|
||||
xkcdpass-1.14.3/README.rst
|
||||
xkcdpass-1.14.3/setup.cfg
|
||||
xkcdpass-1.14.3/setup.py
|
||||
xkcdpass-1.14.3/tests/
|
||||
xkcdpass-1.14.3/tests/test_list.txt
|
||||
xkcdpass-1.14.3/tests/test_xkcdpass.py
|
||||
xkcdpass-1.14.3/tests/__init__.py
|
||||
xkcdpass-1.14.3/xkcdpass/
|
||||
xkcdpass-1.14.3/xkcdpass/static/
|
||||
xkcdpass-1.14.3/xkcdpass/static/eff-long
|
||||
xkcdpass-1.14.3/xkcdpass/static/eff-short
|
||||
xkcdpass-1.14.3/xkcdpass/static/eff-special
|
||||
xkcdpass-1.14.3/xkcdpass/static/fin-kotus
|
||||
xkcdpass-1.14.3/xkcdpass/static/ita-wiki
|
||||
xkcdpass-1.14.3/xkcdpass/static/legacy
|
||||
xkcdpass-1.14.3/xkcdpass/static/spa-mich
|
||||
xkcdpass-1.14.3/xkcdpass/xkcd_password.py
|
||||
xkcdpass-1.14.3/xkcdpass/__init__.py
|
||||
xkcdpass-1.14.3/xkcdpass.1
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/dependency_links.txt
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/entry_points.txt
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/not-zip-safe
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/PKG-INFO
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/SOURCES.txt
|
||||
xkcdpass-1.14.3/xkcdpass.egg-info/top_level.txt
|
||||
|
||||
|
||||
root@kerneltalks # cd xkcdpass-1.14.3
|
||||
|
||||
root@kerneltalks # python setup.py install
|
||||
running install
|
||||
running bdist_egg
|
||||
running egg_info
|
||||
writing xkcdpass.egg-info/PKG-INFO
|
||||
writing top-level names to xkcdpass.egg-info/top_level.txt
|
||||
writing dependency_links to xkcdpass.egg-info/dependency_links.txt
|
||||
writing entry points to xkcdpass.egg-info/entry_points.txt
|
||||
reading manifest file 'xkcdpass.egg-info/SOURCES.txt'
|
||||
reading manifest template 'MANIFEST.in'
|
||||
writing manifest file 'xkcdpass.egg-info/SOURCES.txt'
|
||||
installing library code to build/bdist.linux-x86_64/egg
|
||||
running install_lib
|
||||
running build_py
|
||||
creating build
|
||||
creating build/lib
|
||||
creating build/lib/xkcdpass
|
||||
copying xkcdpass/xkcd_password.py -> build/lib/xkcdpass
|
||||
copying xkcdpass/__init__.py -> build/lib/xkcdpass
|
||||
creating build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/eff-long -> build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/eff-short -> build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/eff-special -> build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/fin-kotus -> build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/ita-wiki -> build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/legacy -> build/lib/xkcdpass/static
|
||||
copying xkcdpass/static/spa-mich -> build/lib/xkcdpass/static
|
||||
creating build/bdist.linux-x86_64
|
||||
creating build/bdist.linux-x86_64/egg
|
||||
creating build/bdist.linux-x86_64/egg/xkcdpass
|
||||
copying build/lib/xkcdpass/xkcd_password.py -> build/bdist.linux-x86_64/egg/xkcdpass
|
||||
copying build/lib/xkcdpass/__init__.py -> build/bdist.linux-x86_64/egg/xkcdpass
|
||||
creating build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/eff-long -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/eff-short -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/eff-special -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/fin-kotus -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/ita-wiki -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/legacy -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
copying build/lib/xkcdpass/static/spa-mich -> build/bdist.linux-x86_64/egg/xkcdpass/static
|
||||
byte-compiling build/bdist.linux-x86_64/egg/xkcdpass/xkcd_password.py to xkcd_password.pyc
|
||||
byte-compiling build/bdist.linux-x86_64/egg/xkcdpass/__init__.py to __init__.pyc
|
||||
creating build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
copying xkcdpass.egg-info/PKG-INFO -> build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
copying xkcdpass.egg-info/SOURCES.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
copying xkcdpass.egg-info/dependency_links.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
copying xkcdpass.egg-info/entry_points.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
copying xkcdpass.egg-info/not-zip-safe -> build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
copying xkcdpass.egg-info/top_level.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
|
||||
creating dist
|
||||
creating 'dist/xkcdpass-1.14.3-py2.7.egg' and adding 'build/bdist.linux-x86_64/egg' to it
|
||||
removing 'build/bdist.linux-x86_64/egg' (and everything under it)
|
||||
Processing xkcdpass-1.14.3-py2.7.egg
|
||||
creating /usr/lib/python2.7/site-packages/xkcdpass-1.14.3-py2.7.egg
|
||||
Extracting xkcdpass-1.14.3-py2.7.egg to /usr/lib/python2.7/site-packages
|
||||
Adding xkcdpass 1.14.3 to easy-install.pth file
|
||||
Installing xkcdpass script to /usr/bin
|
||||
|
||||
Installed /usr/lib/python2.7/site-packages/xkcdpass-1.14.3-py2.7.egg
|
||||
Processing dependencies for xkcdpass==1.14.3
|
||||
Finished processing dependencies for xkcdpass==1.14.3
|
||||
```
|
||||
|
||||
Now running xkcdpass command will give you random set of dictionary words like below -
|
||||
|
||||
```
|
||||
root@kerneltalks # xkcdpass
|
||||
broadside unpadded osmosis statistic cosmetics lugged
|
||||
```
|
||||
|
||||
You can use these words as input to other commands like `md5sum` to get random password (like below) or you can even use Nth letter of each words to form your password!
|
||||
|
||||
```
|
||||
oot@kerneltalks # xkcdpass |md5sum
|
||||
45f2ec9b3ca980c7afbd100268c74819 -
|
||||
|
||||
root@kerneltalks # xkcdpass |md5sum
|
||||
ad79546e8350744845c001d8836f2ff2 -
|
||||
```
|
||||
Or even you can use all those words together as such a long password which is easy to remember for a user and very hard to crack using computer program.
|
||||
|
||||
There are tools like [Diceware][10], [KeePassX][11], [Revelation][12], [PasswordMaker][13] for Linux which can be considered for making strong random passwords.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/8-ways-to-generate-random-password-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a1.kerneltalks.com/wp-content/uploads/2018/01/different-ways-to-generate-password-in-linux.png
|
||||
[2]:https://kerneltalks.com/commands/learn-dd-command-with-examples/
|
||||
[3]:https://kerneltalks.com/commands/date-time-management-using-timedatectl-command/
|
||||
[4]:https://kerneltalks.com/linux/cut-command-examples/
|
||||
[5]:https://kerneltalks.com/package/how-to-install-epel-repository/
|
||||
[6]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[7]:https://xkcd.com/
|
||||
[8]:https://xkcd.com/936/
|
||||
[9]:https://pypi.python.org/pypi/xkcdpass/
|
||||
[10]:http://world.std.com/~reinhold/diceware.html
|
||||
[11]:https://www.keepassx.org/
|
||||
[12]:https://packages.debian.org/sid/gnome/revelation
|
||||
[13]:https://passwordmaker.org/
|
||||
@ -0,0 +1,61 @@
|
||||
Containers, the GPL, and copyleft: No reason for concern
|
||||
============================================================
|
||||
|
||||
### Wondering how open source licensing affects Linux containers? Here's what you need to know.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Though open source is thoroughly mainstream, new software technologies and old technologies that get newly popularized sometimes inspire hand-wringing about open source licenses. Most often the concern is about the GNU General Public License (GPL), and specifically the scope of its copyleft requirement, which is often described (somewhat misleadingly) as the GPL’s derivative work issue.
|
||||
|
||||
One imperfect way of framing the question is whether GPL-licensed code, when combined in some sense with proprietary code, forms a single modified work such that the proprietary code could be interpreted as being subject to the terms of the GPL. While we haven’t yet seen much of that concern directed to Linux containers, we expect more questions to be raised as adoption of containers continues to grow. But it’s fairly straightforward to show that containers do _not_ raise new or concerning GPL scope issues.
|
||||
|
||||
Statutes and case law provide little help in interpreting a license like the GPL. On the other hand, many of us give significant weight to the interpretive views of the Free Software Foundation (FSF), the drafter and steward of the GPL, even in the typical case where the FSF is not a copyright holder of the software at issue. In addition to being the author of the license text, the FSF has been engaged for many years in providing commentary and guidance on its licenses to the community. Its views have special credibility and influence based on its public interest mission and leadership in free software policy.
|
||||
|
||||
The FSF’s existing guidance on GPL interpretation has relevance for understanding the effects of including GPL and non-GPL code in containers. The FSF has placed emphasis on the process boundary when considering copyleft scope, and on the mechanism and semantics of the communication between multiple software components to determine whether they are closely integrated enough to be considered a single program for GPL purposes. For example, the [GNU Licenses FAQ][4] takes the view that pipes, sockets, and command-line arguments are mechanisms that are normally suggestive of separateness (in the absence of sufficiently "intimate" communications).
|
||||
|
||||
Consider the case of a container in which both GPL code and proprietary code might coexist and execute. A container is, in essence, an isolated userspace stack. In the [OCI container image format][5], code is packaged as a set of filesystem changeset layers, with the base layer normally being a stripped-down conventional Linux distribution without a kernel. As with the userspace of non-containerized Linux distributions, these base layers invariably contain many GPL-licensed packages (both GPLv2 and GPLv3), as well as packages under licenses considered GPL-incompatible, and commonly function as a runtime for proprietary as well as open source applications. The ["mere aggregation" clause][6] in GPLv2 (as well as its counterpart GPLv3 provision on ["aggregates"][7]) shows that this type of combination is generally acceptable, is specifically contemplated under the GPL, and has no effect on the licensing of the two programs, assuming incompatibly licensed components are separate and independent.
|
||||
|
||||
Of course, in a given situation, the relationship between two components may not be "mere aggregation," but the same is true of software running in non-containerized userspace on a Linux system. There is nothing in the technical makeup of containers or container images that suggests a need to apply a special form of copyleft scope analysis.
|
||||
|
||||
It follows that when looking at the relationship between code running in a container and code running outside a container, the "separate and independent" criterion is almost certainly met. The code will run as separate processes, and the whole technical point of using containers is isolation from other software running on the system.
|
||||
|
||||
Now consider the case where two components, one GPL-licensed and one proprietary, are running in separate but potentially interacting containers, perhaps as part of an application designed with a [microservices][8] architecture. In the absence of very unusual facts, we should not expect to see copyleft scope extending across multiple containers. Separate containers involve separate processes. Communication between containers by way of network interfaces is analogous to such mechanisms as pipes and sockets, and a multi-container microservices scenario would seem to preclude what the FSF calls "[intimate][9]" communication by definition. The composition of an application using multiple containers may not be dispositive of the GPL scope issue, but it makes the technical boundaries between the components more apparent and provides a strong basis for arguing separateness. Here, too, there is no technical feature of containers that suggests application of a different and stricter approach to copyleft scope analysis.
|
||||
|
||||
A company that is overly concerned with the potential effects of distributing GPL-licensed code might attempt to prohibit its developers from adding any such code to a container image that it plans to distribute. Insofar as the aim is to avoid distributing code under the GPL, this is a dubious strategy. As noted above, the base layers of conventional container images will contain multiple GPL-licensed components. If the company pushes a container image to a registry, there is normally no way it can guarantee that this will not include the base layer, even if it is widely shared.
|
||||
|
||||
On the other hand, the company might decide to embrace containerization as a means of limiting copyleft scope issues by isolating GPL and proprietary code—though one would hope that technical benefits would drive the decision, rather than legal concerns likely based on unfounded anxiety about the GPL. While in a non-containerized setting the relationship between two interacting software components will often be mere aggregation, the evidence of separateness that containers provide may be comforting to those who worry about GPL scope.
|
||||
|
||||
Open source license compliance obligations may arise when sharing container images. But there’s nothing technically different or unique about containers that changes the nature of these obligations or makes them harder to satisfy. With respect to copyleft scope, containerization should, if anything, ease the concerns of the extra-cautious.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][10] Richard Fontana - Richard is Senior Commercial Counsel on the Products and Technologies team in Red Hat's legal department. Most of his work focuses on open source-related legal issues.[More about me][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/containers-gpl-and-copyleft
|
||||
|
||||
作者:[Richard Fontana ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/fontana
|
||||
[1]:https://opensource.com/article/18/1/containers-gpl-and-copyleft?rate=qTlANxnuA2tf0hcGE6Po06RGUzcbB-cBxbU3dCuCt9w
|
||||
[2]:https://opensource.com/users/fontana
|
||||
[3]:https://opensource.com/user/10544/feed
|
||||
[4]:https://www.gnu.org/licenses/gpl-faq.en.html#MereAggregation
|
||||
[5]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[6]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#section2
|
||||
[7]:https://www.gnu.org/licenses/gpl.html#section5
|
||||
[8]:https://www.redhat.com/en/topics/microservices
|
||||
[9]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPlugins
|
||||
[10]:https://opensource.com/users/fontana
|
||||
[11]:https://opensource.com/users/fontana
|
||||
[12]:https://opensource.com/users/fontana
|
||||
[13]:https://opensource.com/tags/licensing
|
||||
[14]:https://opensource.com/tags/containers
|
||||
130
sources/tech/20180125 A step-by-step guide to Git.md
Normal file
130
sources/tech/20180125 A step-by-step guide to Git.md
Normal file
@ -0,0 +1,130 @@
|
||||
A step-by-step guide to Git
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you've never used [Git][1], you may be nervous about it. There's nothing to worry about--just follow along with this step-by-step getting-started guide, and you will soon have a new Git repository hosted on [GitHub][2].
|
||||
|
||||
Before we dive in, let's clear up a common misconception: Git isn't the same thing as GitHub. Git is a version-control system (i.e., a piece of software) that helps you keep track of your computer programs and files and the changes that are made to them over time. It also allows you to collaborate with your peers on a program, code, or file. GitHub and similar services (including GitLab and BitBucket) are websites that host a Git server program to hold your code.
|
||||
|
||||
### Step 1: Create a GitHub account
|
||||
|
||||
The easiest way to get started is to create an account on [GitHub.com][3] (it's free).
|
||||
|
||||
|
||||
|
||||
Pick a username (e.g., octocat123), enter your email address and a password, and click **Sign up for GitHub**. Once you are in, it will look something like this:
|
||||
|
||||
|
||||
|
||||
### Step 2: Create a new repository
|
||||
|
||||
A repository is like a place or a container where something is stored; in this case we're creating a Git repository to store code. To create a new repository, select **New Repository** from the `+` sign dropdown menu (you can see I've selected it in the upper-right corner in the image above).
|
||||
|
||||
|
||||
|
||||
Enter a name for your repository (e.g, "Demo") and click **Create Repository**. Don't worry about changing any other options on this page.
|
||||
|
||||
Congratulations! You have set up your first repo on GitHub.com.
|
||||
|
||||
### Step 3: Create a file
|
||||
|
||||
Once your repo is created, it will look like this:
|
||||
|
||||
|
||||
|
||||
Don't panic, it's simpler than it looks. Stay with me. Look at the section that starts "...or create a new repository on the command line," and ignore the rest for now.
|
||||
|
||||
Open the Terminal program on your computer.
|
||||
|
||||
|
||||
|
||||
Type `git` and hit **Enter**. If it says command `bash: git: command not found`, then [install Git][4] with the command for your Linux operating system or distribution. Check the installation by typing `git` and hitting **Enter** ; if it's installed, you should see a bunch of information about how you can use the command.
|
||||
|
||||
In the terminal, type:
|
||||
```
|
||||
mkdir Demo
|
||||
```
|
||||
|
||||
This command will create a directory (or folder) named Demo.
|
||||
|
||||
Change your terminal to the Demo directory with the command:
|
||||
```
|
||||
cd Demo
|
||||
```
|
||||
|
||||
Then enter:
|
||||
```
|
||||
echo "#Demo" >> README.md
|
||||
```
|
||||
|
||||
This creates a file named `README.md` and writes `#Demo` in it. To check that the file was created successfully, enter:
|
||||
```
|
||||
cat README.md
|
||||
```
|
||||
|
||||
This will show you what is inside the `README.md` file, if the file was created correctly. Your terminal will look like this:
|
||||
|
||||
|
||||
|
||||
To tell your computer that Demo is a directory managed by the Git program, enter:
|
||||
```
|
||||
git init
|
||||
```
|
||||
|
||||
Then, to tell the Git program you care about this file and want to track any changes from this point forward, enter:
|
||||
```
|
||||
git add README.md
|
||||
```
|
||||
|
||||
### Step 4: Make a commit
|
||||
|
||||
So far you've created a file and told Git about it, and now it's time to create a commit. Commit can be thought of as a milestone. Every time you accomplish some work, you can write a Git commit to store that version of your file, so you can go back later and see what it looked like at that point in time. Whenever you make a change to your file, you create a new version of that file, different from the previous one.
|
||||
|
||||
To make a commit, enter:
|
||||
```
|
||||
git commit -m "first commit"
|
||||
```
|
||||
|
||||
That's it! You just created a Git commit and included a message that says first commit. You must always write a message in commit; it not only helps you identify a commit, but it also enables you to understand what you did with the file at that point. So tomorrow, if you add a new piece of code in your file, you can write a commit message that says, Added new code, and when you come back in a month to look at your commit history or Git log (the list of commits), you will know what you changed in the files.
|
||||
|
||||
### Step 5: Connect your GitHub repo with your computer
|
||||
|
||||
Now, it's time to connect your computer to GitHub with the command:
|
||||
```
|
||||
git remote add origin https://github.com/<your_username>/Demo.git
|
||||
```
|
||||
|
||||
Let's look at this command step by step. We are telling Git to add a `remote` called `origin` with the address `https://github.com/<your_username>/Demo.git` (i.e., the URL of your Git repo on GitHub.com). This allows you to interact with your Git repository on GitHub.com by typing `origin` instead of the full URL and Git will know where to send your code. Why `origin`? Well, you can name it anything else if you'd like.
|
||||
|
||||
Now we have connected our local copy of the Demo repository to its remote counterpart on GitHub.com. Your terminal looks like this:
|
||||
|
||||
|
||||
|
||||
Now that we have added the remote, we can push our code (i.e., upload our `README.md` file) to GitHub.com.
|
||||
|
||||
Once you are done, your terminal will look like this:
|
||||
|
||||
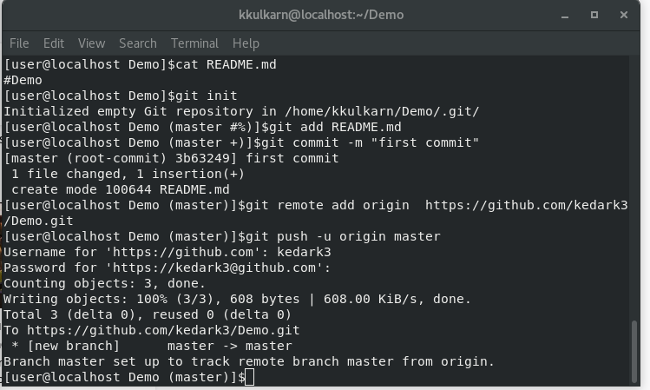
|
||||
|
||||
And if you go to `https://github.com/<your_username>/Demo` you will see something like this:
|
||||
|
||||
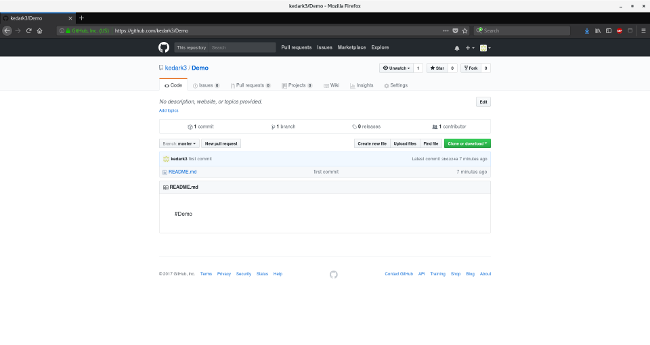
|
||||
|
||||
That's it! You have created your first GitHub repo, connected it to your computer, and pushed (or uploaded) a file from your computer to your repository called Demo on GitHub.com. Next time, I will write about Git cloning (downloading your code from GitHub to your computer), adding new files, modifying existing files, and pushing (uploading) files to GitHub.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/step-step-guide-git
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/resources/what-is-git
|
||||
[2]:https://opensource.com/life/15/11/short-introduction-github
|
||||
[3]:https://github.com/
|
||||
[4]:https://www.linuxbabe.com/linux-server/install-git-verion-control-on-linux-debianubuntufedoraarchlinux#crt-2
|
||||
146
sources/tech/20180125 Keep Accurate Time on Linux with NTP.md
Normal file
146
sources/tech/20180125 Keep Accurate Time on Linux with NTP.md
Normal file
@ -0,0 +1,146 @@
|
||||
Keep Accurate Time on Linux with NTP
|
||||
======
|
||||
|
||||

|
||||
|
||||
How to keep the correct time and keep your computers synchronized without abusing time servers, using NTP and systemd.
|
||||
|
||||
### What Time is It?
|
||||
|
||||
Linux is funky when it comes to telling the time. You might think that the `time` tells the time, but it doesn't because it is a timer that measures how long a process runs. To get the time, you run the `date` command, and to view more than one date, you use `cal`. Timestamps on files are also a source of confusion as they are typically displayed in two different ways, depending on your distro defaults. This example is from Ubuntu 16.04 LTS:
|
||||
```
|
||||
$ ls -l
|
||||
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
|
||||
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
|
||||
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
|
||||
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
|
||||
|
||||
```
|
||||
|
||||
Some display the year, some display the time, which makes ordering your files rather a mess. The GNU default is files dated within the last six months display the time instead of the year. I suppose there is a reason for this. If your Linux does this, try `ls -l --time-style=long-iso` to display the timestamps all the same way, sorted alphabetically. See [How to Change the Linux Date and Time: Simple Commands][1] to learn all manner of fascinating ways to manage the time on Linux.
|
||||
|
||||
### Check Current Settings
|
||||
|
||||
NTP, the network time protocol, is the old-fashioned way of keeping correct time on computers. `ntpd`, the NTP daemon, periodically queries a public time server and adjusts your system time as needed. It's a simple lightweight protocol that is easy to set up for basic use. Systemd has barged into NTP territory with the `systemd-timesyncd.service`, which acts as a client to `ntpd`.
|
||||
|
||||
Before messing with NTP, let's take a minute to check that current time settings are correct.
|
||||
|
||||
There are (at least) two timekeepers on your system: system time, which is managed by the Linux kernel, and the hardware clock on your motherboard, which is also called the real-time clock (RTC). When you enter your system BIOS, you see the hardware clock time and you can change its settings. When you install a new Linux, and in some graphical time managers, you are asked if you want your RTC set to the UTC (Coordinated Universal Time) zone. It should be set to UTC, because all time zone and daylight savings time calculations are based on UTC. Use the `hwclock` command to check:
|
||||
```
|
||||
$ sudo hwclock --debug
|
||||
hwclock from util-linux 2.27.1
|
||||
Using the /dev interface to the clock.
|
||||
Hardware clock is on UTC time
|
||||
Assuming hardware clock is kept in UTC time.
|
||||
Waiting for clock tick...
|
||||
...got clock tick
|
||||
Time read from Hardware Clock: 2018/01/22 22:14:31
|
||||
Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
|
||||
Time since last adjustment is 1516659271 seconds
|
||||
Calculated Hardware Clock drift is 0.000000 seconds
|
||||
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
|
||||
|
||||
```
|
||||
|
||||
"Hardware clock is kept in UTC time" confirms that your RTC is on UTC, even though it translates the time to your local time. If it were set to local time it would report "Hardware clock is kept in local time."
|
||||
|
||||
You should have a `/etc/adjtime` file. If you don't, sync your RTC to system time:
|
||||
```
|
||||
$ sudo hwclock -w
|
||||
|
||||
```
|
||||
|
||||
This should generate the file, and the contents should look like this example:
|
||||
```
|
||||
$ cat /etc/adjtime
|
||||
0.000000 1516661953 0.000000
|
||||
1516661953
|
||||
UTC
|
||||
|
||||
```
|
||||
|
||||
The new-fangled systemd way is to run `timedatectl`, which does not need root permissions:
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Mon 2018-01-22 14:17:51 PST
|
||||
Universal time: Mon 2018-01-22 22:17:51 UTC
|
||||
RTC time: Mon 2018-01-22 22:17:51
|
||||
Time zone: America/Los_Angeles (PST, -0800)
|
||||
Network time on: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
|
||||
```
|
||||
|
||||
"RTC in local TZ: no" confirms that it is on UTC time. What if it is on local time? There are, as always, multiple ways to change it. The easy way is with a nice graphical configuration tool, like YaST in openSUSE. You can use `timedatectl`:
|
||||
```
|
||||
$ timedatectl set-local-rtc 0
|
||||
```
|
||||
|
||||
Or edit `/etc/adjtime`, replacing UTC with LOCAL.
|
||||
|
||||
### systemd-timesyncd Client
|
||||
|
||||
Now I'm tired, and we've just gotten to the good part. Who knew timekeeping was so complex? We haven't even scratched the surface; read `man 8 hwclock` to get an idea of how time is kept on computers.
|
||||
|
||||
Systemd provides the `systemd-timesyncd.service` client, which queries remote time servers and adjusts your system time. Configure your servers in `/etc/systemd/timesyncd.conf`. Most Linux distributions provide a default configuration that points to time servers that they maintain, like Fedora:
|
||||
```
|
||||
[Time]
|
||||
#NTP=
|
||||
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
|
||||
|
||||
```
|
||||
|
||||
You may enter any other servers you desire, such as your own local NTP server, on the `NTP=` line in a space-delimited list. (Remember to uncomment this line.) Anything you put on the `NTP=` line overrides the fallback.
|
||||
|
||||
What if you are not using systemd? Then you need only NTP.
|
||||
|
||||
### Setting up NTP Server and Client
|
||||
|
||||
It is a good practice to set up your own LAN NTP server, so that you are not pummeling public NTP servers from all of your computers. On most Linuxes NTP comes in the `ntp` package, and most of them provide `/etc/ntp.conf` to configure the service. Consult [NTP Pool Time Servers][2] to find the NTP server pool that is appropriate for your region. Then enter 4-5 servers in your `/etc/ntp.conf` file, with each server on its own line:
|
||||
```
|
||||
driftfile /var/ntp.drift
|
||||
logfile /var/log/ntp.log
|
||||
server 0.europe.pool.ntp.org
|
||||
server 1.europe.pool.ntp.org
|
||||
server 2.europe.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
```
|
||||
|
||||
The `driftfile` tells `ntpd` where to store the information it needs to quickly synchronize your system clock with the time servers at startup, and your logs should have their own home instead of getting dumped into the syslog. Use your Linux distribution defaults for these files if it provides them.
|
||||
|
||||
Now start the daemon; on most Linuxes this is `sudo systemctl start ntpd`. Let it run for a few minutes, then check its status:
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================
|
||||
+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
|
||||
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
|
||||
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
|
||||
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
|
||||
|
||||
```
|
||||
|
||||
I have no idea what any of that means, other than your daemon is talking to the remote time servers, and that is what you want. To permanently enable it, run `sudo systemctl enable ntpd`. If your Linux doesn't use systemd then it is your homework to figure out how to run `ntpd`.
|
||||
|
||||
Now you can set up `systemd-timesyncd` on your other LAN hosts to use your local NTP server, or install NTP on them and enter your local server in their `/etc/ntp.conf` files.
|
||||
|
||||
NTP servers take a beating, and demand continually increases. You can help by running your own public NTP server. Come back next week to learn how.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
|
||||
[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,108 @@
|
||||
Linux whereis Command Explained for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line, we just need to quickly find out the location of the binary file for a command. Yes, the [find][1] command is an option in this case, but it's a bit time consuming and will likely produce some non-desired results as well. There's a specific command that's designed for this purpose: **whereis**.
|
||||
|
||||
In this article, we will discuss the basics of this command using some easy to understand examples. But before we do that, it's worth mentioning that all examples in this tutorial have been tested on Ubuntu 16.04LTS.
|
||||
|
||||
### Linux whereis command
|
||||
|
||||
The whereis command lets users locate binary, source, and manual page files for a command. Following is its syntax:
|
||||
|
||||
```
|
||||
whereis [options] [-BMS directory... -f] name...
|
||||
```
|
||||
|
||||
And here's how the tool's man page explains it:
|
||||
```
|
||||
whereis locates the binary, source and manual files for the specified command names. The supplied
|
||||
names are first stripped of leading pathname components and any (single) trailing extension of the
|
||||
form .ext (for example: .c) Prefixes of s. resulting from use of source code control are also dealt
|
||||
with. whereis then attempts to locate the desired program in the standard Linux places, and in the
|
||||
places specified by $PATH and $MANPATH.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a good idea on how the whereis command works.
|
||||
|
||||
### Q1. How to find location of binary file using whereis?
|
||||
|
||||
Suppose you want to find the location for, let's say, the whereis command itself. Then here's how you can do that:
|
||||
|
||||
```
|
||||
whereis whereis
|
||||
```
|
||||
|
||||
[![How to find location of binary file using whereis][2]][3]
|
||||
|
||||
Note that the first path in the output is what you are looking for. The whereis command also produces paths for manual pages and source code (if available, which isn't in this case). So the second path you see in the output above is the path to the whereis manual file(s).
|
||||
|
||||
### Q2. How to specifically search for binaries, manuals, or source code?
|
||||
|
||||
If you want to search specifically for, say binary, then you can use the **-b** command line option. For example:
|
||||
|
||||
```
|
||||
whereis -b cp
|
||||
```
|
||||
|
||||
[![How to specifically search for binaries, manuals, or source code][4]][5]
|
||||
|
||||
Similarly, the **-m** and **-s** options are used in case you want to find manuals and sources.
|
||||
|
||||
### Q3. How to limit whereis search as per requirement?
|
||||
|
||||
By default whereis tries to find files from hard-coded paths, which are defined with glob patterns. However, if you want, you can limit the search using specific command line options. For example, if you want whereis to only search for binary files in /usr/bin, then you can do this using the **-B** command line option.
|
||||
|
||||
```
|
||||
whereis -B /usr/bin/ -f cp
|
||||
```
|
||||
|
||||
**Note** : Since you can pass multiple paths this way, the **-f** command line option terminates the directory list and signals the start of file names.
|
||||
|
||||
Similarly, if you want to limit manual or source searches, you can use the **-M** and **-S** command line options.
|
||||
|
||||
### Q4. How to see paths that whereis uses for search?
|
||||
|
||||
There's an option for this as well. Just run the command with **-l**.
|
||||
|
||||
```
|
||||
whereis -l
|
||||
```
|
||||
|
||||
Here is the list (partial) it produced for us:
|
||||
|
||||
[![How to see paths that whereis uses for search][6]][7]
|
||||
|
||||
### Q5. How to find command names with unusual entries?
|
||||
|
||||
For whereis, a command becomes unusual if it does not have just one entry of each explicitly requested type. For example, commands with no documentation available, or those with documentation in multiple places are considered unusual. The **-u** command line option, when used, makes whereis show the command names that have unusual entries.
|
||||
|
||||
For example, the following command should display files in the current directory which have no documentation file, or more than one.
|
||||
|
||||
```
|
||||
whereis -m -u *
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
Agreed, whereis is not the kind of command line tool that you'll require very frequently. But when the situation arises, it definitely makes your life easy. We've covered some of the important command line options the tool offers, so do practice them. For more info, head to its [man page][8].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-whereis-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-find-command/
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/whereis-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/whereis-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/whereis-b-option.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/whereis-b-option.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/whereis-l.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/big/whereis-l.png
|
||||
[8]:https://linux.die.net/man/1/whereis
|
||||
@ -0,0 +1,246 @@
|
||||
如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本
|
||||
======
|
||||
来自我的邮箱:
|
||||
**我写了一个你好世界的小脚本。我如何能调试运行在 Linux 或者类 UNIX 的系统上的 bash shell 脚本呢?**
|
||||
这是 Linux / Unix 系统管理员或新用户最常问的问题。shell 脚本调试可能是一项繁琐的工作(不容易阅读)。调试 shell 脚本有多种方法。
|
||||
|
||||
您需要传递 -X 或 -V 参数,以在 bash shell 中浏览每行代码。
|
||||
|
||||
[![如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本][1]][1]
|
||||
|
||||
让我们看看如何使用各种方法调试 Linux 和 UNIX 上运行的脚本。
|
||||
|
||||
```
|
||||
### -x 选项来调试脚本
|
||||
|
||||
用 -x 选项来运行脚本
|
||||
```
|
||||
$ bash -x script-name
|
||||
$ bash -x domains.sh
|
||||
```
|
||||
|
||||
### 使用 set 内置命令
|
||||
|
||||
bash shell 提供调试选项,可以打开或关闭使用 [set 命令][2]:
|
||||
|
||||
* **set -x** : 显示命令及其执行时的参数。
|
||||
* **set -v** : 显示 shell 输入行作为它们读取的
|
||||
|
||||
可以在shell脚本本身中使用上面的两个命令:
|
||||
```
|
||||
#!/bin/bash
|
||||
clear
|
||||
|
||||
# turn on debug mode
|
||||
set -x
|
||||
for f in *
|
||||
do
|
||||
file $f
|
||||
done
|
||||
# turn OFF debug mode
|
||||
set +x
|
||||
ls
|
||||
# more commands
|
||||
```
|
||||
|
||||
你可以代替 [标准 Shebang][3] 行:
|
||||
`#!/bin/bash`
|
||||
用一下代码(用于调试):
|
||||
`#!/bin/bash -xv`
|
||||
|
||||
### 使用智能调试功能
|
||||
|
||||
首先添加一个叫做 _DEBUG 的特殊变量。当你需要调试脚本的时候,设置 _DEBUG 为 'on':
|
||||
`_DEBUG="on"`
|
||||
|
||||
|
||||
在脚本的开头放置以下函数:
|
||||
```
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
```
|
||||
|
||||
function DEBUG() { [ "$_DEBUG" == "on" ] && $@ }
|
||||
|
||||
现在,只要你需要调试,只需使用 DEBUG 函数如下:
|
||||
`DEBUG echo "File is $filename"`
|
||||
或者
|
||||
```
|
||||
DEBUG set -x
|
||||
Cmd1
|
||||
Cmd2
|
||||
DEBUG set +x
|
||||
```
|
||||
|
||||
当调试完(在移动你的脚本到生产环境之前)设置 _DEBUG 为 'off'。不需要删除调试行。
|
||||
`_DEBUG="off" # 设置为非 'on' 的任何字符`
|
||||
|
||||
|
||||
示例脚本:
|
||||
```
|
||||
#!/bin/bash
|
||||
_DEBUG="on"
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
|
||||
DEBUG echo 'Reading files'
|
||||
for i in *
|
||||
do
|
||||
grep 'something' $i > /dev/null
|
||||
[ $? -eq 0 ] && echo "Found in $i file"
|
||||
done
|
||||
DEBUG set -x
|
||||
a=2
|
||||
b=3
|
||||
c=$(( $a + $b ))
|
||||
DEBUG set +x
|
||||
echo "$a + $b = $c"
|
||||
```
|
||||
|
||||
保存并关闭文件。运行脚本如下:
|
||||
`$ ./script.sh`
|
||||
输出:
|
||||
```
|
||||
Reading files
|
||||
Found in xyz.txt file
|
||||
+ a=2
|
||||
+ b=3
|
||||
+ c=5
|
||||
+ DEBUG set +x
|
||||
+ '[' on == on ']'
|
||||
+ set +x
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
现在设置 DEBUG 为关闭(你需要编辑文件):
|
||||
`_DEBUG="off"`
|
||||
运行脚本:
|
||||
`$ ./script.sh`
|
||||
输出:
|
||||
```
|
||||
Found in xyz.txt file
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
以上是一个简单但非常有效的技术。还可以尝试使用 DEBUG 作为别名替代函数。
|
||||
|
||||
### 调试 Bash Shell 的常见错误
|
||||
|
||||
Bash 或者 sh 或者 ksh 在屏幕上给出各种错误信息,在很多情况下,错误信息可能不提供详细的信息。
|
||||
|
||||
#### 跳过在文件上应用执行权限
|
||||
When you [write your first hello world bash shell script][4], you might end up getting an error that read as follows:
|
||||
当你 [编写你的第一个 hello world 脚本][4],您可能会得到一个错误,如下所示:
|
||||
`bash: ./hello.sh: Permission denied`
|
||||
设置权限使用 chmod 命令:
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
$ bash hello.sh
|
||||
```
|
||||
|
||||
#### 文件结束时发生意外的错误
|
||||
|
||||
如果您收到文件结束意外错误消息,请打开脚本文件,并确保它有打开和关闭引号。在这个例子中,echo 语句有一个开头引号,但没有结束引号:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
...
|
||||
....
|
||||
|
||||
|
||||
echo 'Error: File not found
|
||||
^^^^^^^
|
||||
missing quote
|
||||
```
|
||||
|
||||
还要确保你检查缺少的括号和大括号 ({}):
|
||||
```
|
||||
#!/bin/bash
|
||||
.....
|
||||
[ ! -d $DIRNAME ] && { echo "Error: Chroot dir not found"; exit 1;
|
||||
^^^^^^^^^^^^^
|
||||
missing brace }
|
||||
...
|
||||
```
|
||||
|
||||
#### 丢失像 fi,esac,;; 等关键字。
|
||||
如果你缺少了结尾的关键字,如 fi 或 ;; 你会得到一个错误,如 “XXX 意外”。因此,确保所有嵌套的 if 和 case 语句以适当的关键字结束。有关语法要求的页面。在本例中,缺少 fi:
|
||||
```
|
||||
#!/bin/bash
|
||||
echo "Starting..."
|
||||
....
|
||||
if [ $1 -eq 10 ]
|
||||
then
|
||||
if [ $2 -eq 100 ]
|
||||
then
|
||||
echo "Do something"
|
||||
fi
|
||||
|
||||
for f in $files
|
||||
do
|
||||
echo $f
|
||||
done
|
||||
|
||||
# 注意 fi 已经丢失
|
||||
```
|
||||
|
||||
#### 在 Windows 或 UNIX 框中移动或编辑 shell 脚本
|
||||
|
||||
不要在 Linux 上创建脚本并移动到 Windows。另一个问题是编辑 Windows 10上的 shell 脚本并将其移动到 UNIX 服务器上。这将导致一个错误的命令没有发现由于回车返回(DOS CR-LF)。你可以 [将 DOS 换行转换为 CR-LF 的Unix/Linux 格式][5] 使用下列命令:
|
||||
`dos2unix my-script.sh`
|
||||
|
||||
### 提示1 - 发送调试信息输出到标准错误
|
||||
[标准错误] 是默认错误输出设备,用于写所有系统错误信息。因此,将消息发送到默认的错误设备是个好主意:
|
||||
```
|
||||
# 写错误到标准输出
|
||||
echo "Error: $1 file not found"
|
||||
#
|
||||
# 写错误到标准错误(注意 1>&2 在 echo 命令末尾)
|
||||
#
|
||||
echo "Error: $1 file not found" 1>&2
|
||||
```
|
||||
|
||||
### 提示2 - 在使用 vim 文本编辑器时,打开语法高亮。
|
||||
大多数现代文本编辑器允许设置语法高亮选项。这对于检测语法和防止常见错误如打开或关闭引号非常有用。你可以在不同的颜色中看到。这个特性简化了 shell 脚本结构中的编写,语法错误在视觉上截然不同。强调不影响文本本身的意义,它只为你编写。在这个例子中,我的脚本使用了 vim 语法高亮:
|
||||
[!如何调试 Bash Shell 脚本,在 Linux 或者 UNIX 使用 Vim 语法高亮特性][7]][7]
|
||||
|
||||
### 提示3 - 使用 shellcheck 检查脚本
|
||||
[shellcheck 是一个用于静态分析 shell 脚本的工具][8]。可以使用它来查找 shell 脚本中的错误。这是用 Haskell 编写的。您可以使用这个工具找到警告和建议。让我们看看如何在 Linux 或 类UNIX 系统上安装和使用 shellcheck 来改善你的 shell 脚本,避免错误和高效。
|
||||
|
||||
### 关于作者
|
||||
发表者:
|
||||
|
||||
作者是 nixCraft 创造者,一个经验丰富的系统管理员和一个练习 Linux 操作系统/ UNIX shell 脚本的教练。他曾与全球客户和各种行业,包括 IT,教育,国防和空间研究,以及非营利部门。跟随他 [推特][9],[脸谱网][10],[谷歌+ ][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/debugging-shell-script.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/wp-content/uploads/2007/01/How-to-debug-a-bash-shell-script-on-Linux-or-Unix.jpg
|
||||
[2]:https://bash.cyberciti.biz/guide/Set_command
|
||||
[3]:https://bash.cyberciti.biz/guide/Shebang
|
||||
[4]:https://www.cyberciti.biz/faq/hello-world-bash-shell-script/
|
||||
[5]:https://www.cyberciti.biz/faq/howto-unix-linux-convert-dos-newlines-cr-lf-unix-text-format/
|
||||
[6]:https://bash.cyberciti.biz/guide/Standard_error
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2007/01/bash-vim-debug-syntax-highlighting.png
|
||||
[8]:https://www.cyberciti.biz/programming/improve-your-bashsh-shell-script-with-shellcheck-lint-script-analysis-tool/
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
|
||||
|
||||
@ -1,108 +0,0 @@
|
||||
# 三步上手GDB
|
||||
|
||||
调试C程序,曾让我很困扰。然而当我之前在写我的[操作系统][2]时,我有很多的BUG需要调试。我很幸运的使用上了qemu模拟器,它允许我将调试器附加到我的操作系统。这个调试器就是`gdb`。
|
||||
|
||||
我得解释一下,你可以使用`gdb`先做一些小事情,因为我发现初学它的时候真的很混乱。我们接下来会在一个小程序中,设置断点,查看内存。.
|
||||
|
||||
### 1. 设断点
|
||||
|
||||
如果你曾经使用过调试器,那你可能已经会设置断点了。
|
||||
|
||||
下面是一个我们要调试的程序(虽然没有任何Bug):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
另存为 `hello.c`. 我们可以使用dbg调试它,像这样:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
以上是带调试信息编译 `hello.c`(为了gdb可以更好工作),并且它会给我们醒目的提示符,就像这样:
|
||||
`(gdb)`
|
||||
|
||||
我们可以使用`break`命令设置断点,然后使用`run`开始调试程序。
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
程序暂停在了`do_thing`开始的地方。
|
||||
|
||||
我们可以通过`where`查看我们所在的调用栈。
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2. 阅读汇编代码
|
||||
|
||||
使用`disassemble`命令,我们可以看到这个函数的汇编代码。棒级了。这是x86汇编代码。虽然我不是很懂它,但是`callq`这一行是`printf`函数调用。
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
你也可以使用`disassemble`的缩写`disas`。`
|
||||
|
||||
### 3. 查看内存
|
||||
|
||||
当调试我的内核时,我使用`gdb`的主要原因是,以确保内存布局是如我所想的那样。检查内存的命令是`examine`,或者使用缩写`x`。我们将使用`x`。
|
||||
|
||||
通过阅读上面的汇编代码,似乎`0x40060c`可能是我们所要打印的字符串地址。我们来试一下。
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
的确是这样。`x/s`中`/s`部分,意思是“把它作为字符串展示”。我也可以“展示10个字符”,像这样:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
你可以看到前四个字符是'H','i','!',和'\0',并且它们之后的是一些不相关的东西。
|
||||
|
||||
我知道gdb很多其他的东西,但是我任然不是很了解它,其中`x`和`break`让我获得很多。你还可以阅读 [do umentation for examining memory][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:http://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
122
translated/tech/20140410 Recursion- dream within a dream.md
Normal file
122
translated/tech/20140410 Recursion- dream within a dream.md
Normal file
@ -0,0 +1,122 @@
|
||||
#[递归:梦中梦][1]
|
||||
递归是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压以及让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”这就是人们不愿意使用递归的原因。这是很糟糕的,因为在算法中,递归是最强大的。
|
||||
|
||||
我们来看一下这个经典的递归阶乘:
|
||||
|
||||
递归阶乘 - factorial.c
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
函数的目的是调用它自己,这在一开始是让人很难理解的。为了解具体的内容,当调用 `factorial(5)` 并且达到 `n == 1` 时,[在栈上][3] 究竟发生了什么?
|
||||
|
||||
|
||||
|
||||
每次调用 `factorial` 都生成一个新的 [栈帧][4]。这些栈帧的创建和 [销毁][5] 是递归慢于迭代的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
|
||||
|
||||
而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧取 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 最多可以被运行 ~512,000 次。这是一个 [巨大无比的结果][6],它相当于 8,971,833 比特,因此,栈空间根本就不是什么问题:一个极小的整数 - 甚至是一个 64 位的整数 - 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
|
||||
|
||||
过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法总结为将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是,你只是把它用作一种另外的数据结构。我希望示意图可以让你明白这一点。
|
||||
|
||||
当你看到栈调用作为一种数据结构使用,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
|
||||
|
||||
但是,螺丝钉太多了,我们只能挑一个。有一个经典的面试题,在迷宫里有一只老鼠,你必须帮助这只老鼠找到一个奶酪。假设老鼠能够在迷宫中向左或者向右转弯。你该怎么去建模来解决这个问题?
|
||||
|
||||
就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再返回来右转。这是一个老鼠行走的 [迷宫示例][7]:
|
||||
|
||||
|
||||
|
||||
每到边缘(线)都让老鼠左转或者右转来到达一个新的位置。如果向哪边转都被拦住,说明相关的边缘不存在。现在,我们来讨论一下!这个过程无论你是调用栈还是其它数据结构,它都离不开一个递归的过程。而使用调用栈是非常容易的:
|
||||
|
||||
递归迷宫求解 [下载][2]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include "maze.h"
|
||||
|
||||
int explore(maze_t *node)
|
||||
{
|
||||
int found = 0;
|
||||
|
||||
if (node == NULL)
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
if (node->hasCheese){
|
||||
return 1;// found cheese
|
||||
}
|
||||
|
||||
found = explore(node->left) || explore(node->right);
|
||||
return found;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int found = explore(&maze);
|
||||
}
|
||||
```
|
||||
当我们在 `maze.c:13` 中找到奶酪时,栈的情况如下图所示。你也可以在 [GDB 输出][8] 中看到更详细的数据,它是使用 [命令][9] 采集的数据。
|
||||
|
||||
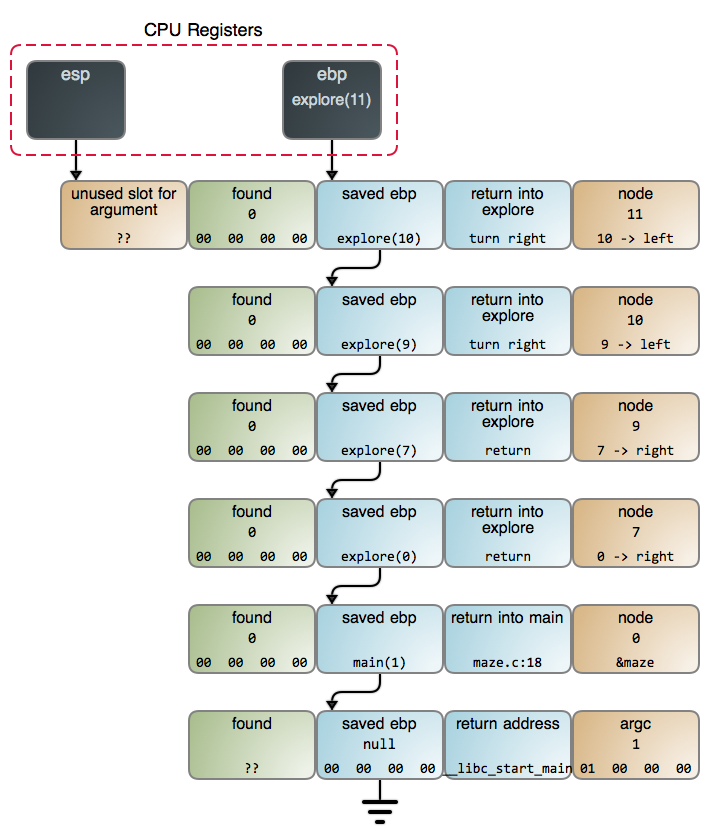
|
||||
|
||||
它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,递归是一种使用较多的算法,而不是被排除在外的。当进行搜索时、当进行遍历树和其它数据结构时、当进行解析时、当需要排序时:它的用途无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它在计算的结构中。
|
||||
|
||||
Steven Skienna 的优秀著作 [算法设计指南][10] 的精彩之处在于,他通过“战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个较好的做法是,去读 McCarthy 的 [LISP 上的原创论文][11]。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
|
||||
|
||||
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 “RRLL” 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录奶酪的状态。你仍然是去实现一个递归的过程,但是需要你实现一个自己的数据结构。
|
||||
|
||||
那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
|
||||
|
||||
正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:哑阶乘(dumb factorial)和可怕的无记忆的 O(2n) [Fibonacci 递归][12]。它们并不是栈递归算法的正确代表。
|
||||
|
||||
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存][13] 中是热点,并且是由专门的指令来操作它。同时,使用你自己定义的堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的][14] ,并且一般 CPU 不会是性能瓶颈所在。要注意牺牲简单性与保持性能的关系。[测量][15]。
|
||||
|
||||
下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/recursion/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/recursion/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/maze.c
|
||||
[3]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-gdb-output.txt
|
||||
[4]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[5]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[6]:https://gist.github.com/gduarte/9944878
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze.h
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-output.txt
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-commands.txt
|
||||
[10]:http://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693/
|
||||
[11]:https://github.com/papers-we-love/papers-we-love/blob/master/comp_sci_fundamentals_and_history/recursive-functions-of-symbolic-expressions-and-their-computation-by-machine-parti.pdf
|
||||
[12]:http://stackoverflow.com/questions/360748/computational-complexity-of-fibonacci-sequence
|
||||
[13]:https://manybutfinite.com/post/intel-cpu-caches/
|
||||
[14]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
|
||||
[15]:https://manybutfinite.com/post/performance-is-a-science
|
||||
173
translated/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
173
translated/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
@ -0,0 +1,173 @@
|
||||
#[尾调用,优化,和 ES6][1]
|
||||
|
||||
|
||||
在探秘“栈”的倒数第二篇文章中,我们提到了**尾调用**、编译优化、以及新发布的 JavaScript 上*特有的*尾调用。
|
||||
|
||||
当一个函数 F 调用另一个函数作为它的结束动作时,就发生了一个**尾调用**。在那个时间点,函数 F 绝对不会有多余的工作:函数 F 将“球”传给被它调用的任意函数之后,它自己就“消失”了。这就是关键点,因为它打开了尾调用优化的“可能之门”:我们可以简单地重用函数 F 的栈帧,而不是为函数调用 [创建一个新的栈帧][6],因此节省了栈空间并且避免了新建一个栈帧所需要的工作量。下面是一个用 C 写的简单示例,然后使用 [mild 优化][7] 来编译它的结果:
|
||||
|
||||
简单的尾调用 [下载][2]
|
||||
|
||||
```
|
||||
int add5(int a)
|
||||
{
|
||||
return a + 5;
|
||||
}
|
||||
|
||||
int add10(int a)
|
||||
{
|
||||
int b = add5(a); // not tail
|
||||
return add5(b); // tail
|
||||
}
|
||||
|
||||
int add5AndTriple(int a){
|
||||
int b = add5(a); // not tail
|
||||
return 3 * add5(a); // not tail, doing work after the call
|
||||
}
|
||||
|
||||
int finicky(int a){
|
||||
if (a > 10){
|
||||
return add5AndTriple(a); // tail
|
||||
}
|
||||
|
||||
if (a > 5){
|
||||
int b = add5(a); // not tail
|
||||
return finicky(b); // tail
|
||||
}
|
||||
|
||||
return add10(a); // tail
|
||||
}
|
||||
```
|
||||
|
||||
在编译器的输出中,在预期会有一个 [调用][9] 的地方,你可以看到一个 [跳转][8] 指令,一般情况下你可以发现尾调用优化(以下简称 TCO)。在运行时中,TCO 将会引起调用栈的减少。
|
||||
|
||||
一个通常认为的错误观念是,尾调用必须要 [递归][10]。实际上并不是这样的:一个尾调用可以被递归,比如在上面的 `finicky()` 中,但是,并不是必须要使用递归的。在调用点只要函数 F 完成它的调用,我们将得到一个单独的尾调用。是否能够进行优化这是一个另外的问题,它取决于你的编程环境。
|
||||
|
||||
“是的,它总是可以!”,这是我们所希望的最佳答案,它是在这个结构下这个案例最好的结果,就像是,在 [SICP][11](顺便说一声,如果你的程序不像“一个魔法师使用你的咒语召唤你的电脑精灵”那般有效,建议你读一下那本书)上所讨论的那样。它是 [Lua][12] 的案例。而更重要的是,它是下一个版本的 JavaScript —— ES6 的案例,这个规范定义了[尾的位置][13],并且明确了优化所需要的几个条件,比如,[严格模式][14]。当一个编程语言保证可用 TCO 时,它将支持特有的尾调用。
|
||||
|
||||
现在,我们中的一些人不能抛开那些 C 的习惯,心脏出血,等等,而答案是一个更复杂的“有时候(sometimes)”,它将我们带进了编译优化的领域。我们看一下上面的那个 [简单示例][15];把我们 [上篇文章][16] 的阶乘程序重新拿出来:
|
||||
|
||||
递归阶乘 [下载][3]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
像第 11 行那样的,是尾调用吗?答案是:“不是”,因为它被后面的 n 相乘了。但是,如果你不去优化它,GCC 使用 [O2 优化][18] 的 [结果][17] 会让你震惊:它不仅将阶乘转换为一个 [无递归循环][19],而且 `factorial(5)` 调用被消除了,以一个 120 (5! == 120) 的 [编译时常数][20]来替换。这就是调试优化代码有时会很难的原因。好的方面是,如果你调用这个函数,它将使用一个单个的栈帧,而不会去考虑 n 的初始值。编译算法是非常有趣的,如果你对它感兴趣,我建议你去阅读 [构建一个优化编译器][21] 和 [ACDI][22]。
|
||||
|
||||
但是,这里**没有**做尾调用优化时到底发生了什么?通过分析函数的功能和无需优化的递归发现,GCC 比我们更聪明,因为一开始就没有使用尾调用。由于过于简单以及很确定的操作,这个任务变得很简单。我们给它增加一些可以引起混乱的东西(比如,getpid()),我们给 GCC 增加难度:
|
||||
|
||||
递归 PID 阶乘 [下载][4]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int pidFactorial(int n)
|
||||
{
|
||||
if (1 == n) {
|
||||
return getpid(); // tail
|
||||
}
|
||||
|
||||
return n * pidFactorial(n-1) * getpid(); // not tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = pidFactorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
优化它,unix 精灵!现在,我们有了一个常规的 [递归调用][23] 并且这个函数分配 O(n) 栈帧来完成工作。GCC 在递归的基础上仍然 [为 getpid 使用了 TCO][24]。如果我们现在希望让这个函数尾调用递归,我需要稍微变一下:
|
||||
|
||||
tailPidFactorial.c [下载][5]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int tailPidFactorial(int n, int acc)
|
||||
{
|
||||
if (1 == n) {
|
||||
return acc * getpid(); // not tail
|
||||
}
|
||||
|
||||
acc = (acc * getpid() * n);
|
||||
return tailPidFactorial(n-1, acc); // tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = tailPidFactorial(5, 1);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
现在,结果的累加是 [一个循环][25],并且我们获得了真实的 TCO。但是,在你庆祝之前,我们能说一下关于在 C 中的一般案例吗?不幸的是,虽然优秀的 C 编译器在大多数情况下都可以实现 TCO,但是,在一些情况下它们仍然做不到。例如,正如我们在 [函数开端][26] 中所看到的那样,函数调用者在使用一个标准的 C 调用规则调用一个函数之后,它要负责去清理栈。因此,如果函数 F 带了两个参数,它只能使 TCO 调用的函数使用两个或者更少的参数。这是 TCO 的众多限制之一。Mark Probst 写了一篇非常好的论文,他们讨论了 [在 C 中正确使用尾递归][27],在这篇论文中他们讨论了这些属于 C 栈行为的问题。他也演示一些 [疯狂的、很酷的欺骗方法][28]。
|
||||
|
||||
“有时候” 对于任何一种关系来说都是不坚定的,因此,在 C 中你不能依赖 TCO。它是一个在某些地方可以或者某些地方不可以的离散型优化,而不是像特有的尾调用一样的编程语言的特性,在实践中,可以使用编译器来优化绝大部分的案例。但是,如果你想必须要实现 TCO,比如将架构编译转换进 C,你将会 [很痛苦][29]。
|
||||
|
||||
因为 JavaScript 现在是非常流行的转换对象,特有的尾调用在那里尤其重要。因此,从 kudos 到 ES6 的同时,还提供了许多其它的重大改进。它就像 JS 程序员的圣诞节一样。
|
||||
|
||||
这就是尾调用和编译优化的简短结论。感谢你的阅读,下次再见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/tail.c
|
||||
[3]:https://manybutfinite.com/code/x86-stack/factorial.c
|
||||
[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
|
||||
[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
|
||||
[6]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
|
||||
[10]:https://manybutfinite.com/post/recursion/
|
||||
[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
|
||||
[12]:http://www.lua.org/pil/6.3.html
|
||||
[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
|
||||
[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
|
||||
[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
|
||||
[16]:https://manybutfinite.com/post/recursion/
|
||||
[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
|
||||
[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
|
||||
[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
|
||||
[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
|
||||
[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
|
||||
[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
|
||||
[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
|
||||
[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
|
||||
[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
|
||||
[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
|
||||
[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
|
||||
[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
|
||||
@ -0,0 +1,234 @@
|
||||
#[闭包,对象,以及堆“族”][1]
|
||||
|
||||
|
||||
在上篇文章中我们提到了闭包、对象、以及栈外的其它东西。我们学习的大部分内容都是与特定编程语言无关的元素,但是,我主要还是专注于 JavaScript,以及一些 C。让我们以一个简单的 C 程序开始,它的功能是读取一首歌曲和乐队名字,然后将它们输出给用户:
|
||||
|
||||
stackFolly.c [下载][2]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
char *read()
|
||||
{
|
||||
char data[64];
|
||||
fgets(data, 64, stdin);
|
||||
return data;
|
||||
}
|
||||
|
||||
int main(int argc, char *argv[])
|
||||
{
|
||||
char *song, *band;
|
||||
|
||||
puts("Enter song, then band:");
|
||||
song = read();
|
||||
band = read();
|
||||
|
||||
printf("\n%sby %s", song, band);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
如果你运行这个程序,你会得到什么?(=> 表示程序输出):
|
||||
|
||||
```
|
||||
./stackFolly
|
||||
=> Enter song, then band:
|
||||
The Past is a Grotesque Animal
|
||||
of Montreal
|
||||
|
||||
=> ?ǿontreal
|
||||
=> by ?ǿontreal
|
||||
```
|
||||
|
||||
(曾经的 C 新手说)发生了错误?
|
||||
|
||||
事实证明,函数的栈变量的内容仅在栈帧活动期间才是可用的,也就是说,仅在函数返回之前。在上面的返回中,被栈帧使用的内存 [被认为是可用的][3],并且在下一个函数调用中可以被覆写。
|
||||
|
||||
下面的图展示了这种情况下究竟发生了什么。这个图现在有一个镜像映射,因此,你可以点击一个数据片断去看一下相关的 GDB 输出(GDB 命令在 [这里][4])。只要 `read()` 读取了歌曲的名字,栈将是这个样子:
|
||||
|
||||
|
||||
|
||||
在这个时候,这个 `song` 变量立即指向到歌曲的名字。不幸的是,存储字符串的内存位置准备被下次调用的任意函数的栈帧重用。在这种情况下,`read()` 再次被调用,而且使用的是同一个位置的栈帧,因此,结果变成下图的样子:
|
||||
|
||||
|
||||
|
||||
乐队名字被读入到相同的内存位置,并且覆盖了前面存储的歌曲名字。`band` 和 `song` 最终都准确指向到相同点。最后,我们甚至都不能得到 “of Montreal”(译者注:一个欧美乐队的名字) 的正确输出。你能猜到是为什么吗?
|
||||
|
||||
因此,即使栈很有用,但也有很重要的限制。它不能被一个函数用于去存储比该函数的运行周期还要长的数据。你必须将它交给 [堆][5],然后与热点缓存、明确的瞬时操作、以及频繁计算的偏移等内容道别。有利的一面是,它是[工作][6] 的:
|
||||
|
||||
|
||||
|
||||
这个代价是你必须记得去`free()` 内存,或者由一个垃圾回收机制花费一些性能来随机回收,垃圾回收将去找到未使用的堆对象,然后去回收它们。那就是栈和堆之间在本质上的权衡:性能 vs. 灵活性。
|
||||
|
||||
大多数编程语言的虚拟机都有一个中间层用来做一个 C 程序员该做的一些事情。栈被用于**值类型**,比如,整数、浮点数、以及布尔型。这些都按特定值(像上面的 `argc` )的字节顺序被直接保存在本地变量和对象字段中。相比之下,堆被用于**引用类型**,比如,字符串和 [对象][7]。 变量和字段包含一个引用到这个对象的内存地址,像上面的 `song` 和 `band`。
|
||||
|
||||
参考这个 JavaScript 函数:
|
||||
|
||||
```
|
||||
function fn()
|
||||
{
|
||||
var a = 10;
|
||||
var b = { name: 'foo', n: 10 };
|
||||
}
|
||||
```
|
||||
它可能的结果如下:
|
||||
|
||||
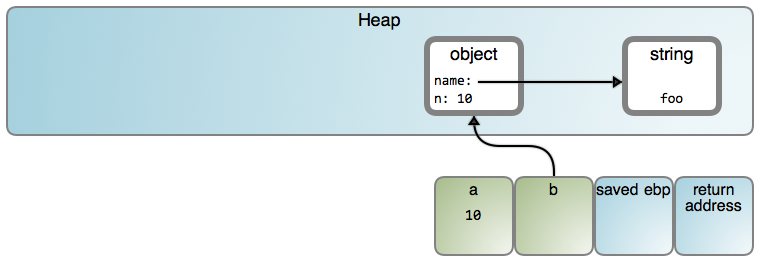
|
||||
|
||||
我之所以说“可能”的原因是,特定的行为高度依赖于实现。这篇文章使用的许多图形是以一个 V8 为中心的方法,这些图形都链接到相关的源代码。在 V8 中,仅 [小整数][8] 是 [以值的方式保存][9]。因此,从现在开始,我将在对象中直接以字符串去展示,以避免引起混乱,但是,请记住,正如上图所示的那样,它们在堆中是分开保存的。
|
||||
|
||||
现在,我们来看一下闭包,它其实很简单,但是由于我们将它宣传的过于夸张,以致于有点神化了。先看一个简单的 JS 函数:
|
||||
|
||||
```
|
||||
function add(a, b)
|
||||
{
|
||||
var c = a + b;
|
||||
return c;
|
||||
}
|
||||
```
|
||||
|
||||
这个函数定义了一个词法域(lexical scope),它是一个快乐的小王国,在这里它的名字 a,b,c 是有明确意义的。它有两个参数和由函数声明的一个本地变量。程序也可以在别的地方使用相同的名字,但是在 `add` 内部它们所引用的内容是明确的。尽管词法域是一个很好的术语,它符合我们直观上的理解:毕竟,我们从字面意义上看,我们可以像词法分析器一样,把它看作在源代码中的一个文本块。
|
||||
|
||||
在看到栈帧的操作之后,很容易想像出这个名称的具体实现。在 `add` 内部,这些名字引用到函数的每个运行实例中私有的栈的位置。这种情况在一个虚拟机中经常发生。
|
||||
|
||||
现在,我们来嵌套两个词法域:
|
||||
|
||||
```
|
||||
function makeGreeter()
|
||||
{
|
||||
return function hi(name){
|
||||
console.log('hi, ' + name);
|
||||
}
|
||||
}
|
||||
|
||||
var hi = makeGreeter();
|
||||
hi('dear reader'); // prints "hi, dear reader"
|
||||
```
|
||||
|
||||
那样更有趣。函数 `hi` 在函数 `makeGreeter` 运行的时候被构建在它内部。它有它自己的词法域,`name` 在这个地方是一个栈上的参数,但是,它似乎也可以访问父级的词法域,它可以那样做。我们来看一下那样做的好处:
|
||||
|
||||
```
|
||||
function makeGreeter(greeting)
|
||||
{
|
||||
return function greet(name){
|
||||
console.log(greeting + ', ' + name);
|
||||
}
|
||||
}
|
||||
|
||||
var heya = makeGreeter('HEYA');
|
||||
heya('dear reader'); // prints "HEYA, dear reader"
|
||||
```
|
||||
|
||||
虽然有点不习惯,但是很酷。即便这样违背了我们的直觉:`greeting` 确实看起来像一个栈变量,这种类型应该在 `makeGreeter()` 返回后消失。可是因为 `greet()` 一直保持工作,出现了一些奇怪的事情。进入闭包:
|
||||
|
||||
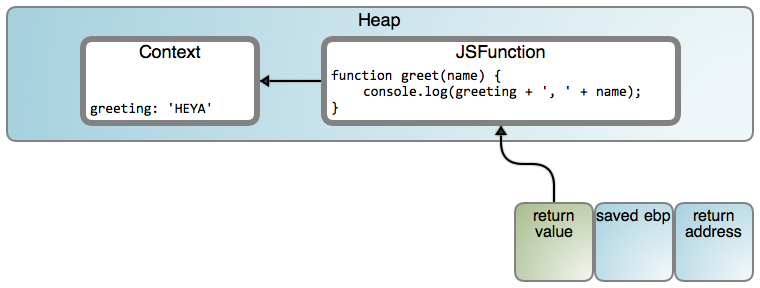
|
||||
|
||||
虚拟机分配一个对象去保存被里面的 `greet()` 使用的父级变量。它就好像是 `makeGreeter` 的词法作用域在那个时刻被关闭了,一旦需要时被具体化到一个堆对象(在这个案例中,是指返回的函数的生命周期)。因此叫做闭包,当你这样去想它的时候,它的名字就有意义了。如果使用(或者捕获)了更多的父级变量,对象内容将有更多的属性,每个捕获的变量有一个。当然,发送到 `greet()` 的代码知道从对象内容中去读取问候语,而不是从栈上。
|
||||
|
||||
这是完整的示例:
|
||||
|
||||
```
|
||||
function makeGreeter(greetings)
|
||||
{
|
||||
var count = 0;
|
||||
var greeter = {};
|
||||
|
||||
for (var i = 0; i < greetings.length; i++) {
|
||||
var greeting = greetings[i];
|
||||
|
||||
greeter[greeting] = function(name){
|
||||
count++;
|
||||
console.log(greeting + ', ' + name);
|
||||
}
|
||||
}
|
||||
|
||||
greeter.count = function(){return count;}
|
||||
|
||||
return greeter;
|
||||
}
|
||||
|
||||
var greeter = makeGreeter(["hi", "hello","howdy"])
|
||||
greeter.hi('poppet');//prints "howdy, poppet"
|
||||
greeter.hello('darling');// prints "howdy, darling"
|
||||
greeter.count(); // returns 2
|
||||
```
|
||||
|
||||
是的,`count()` 在工作,但是我们的 `greeter` 是在 `howdy` 中的栈上。你能告诉我为什么吗?我们使用 `count` 是一条线索:尽管词法域进入一个堆对象中被关闭,但是变量(或者对象属性)带的值仍然可能被改变。下图是我们拥有的内容:
|
||||
|
||||
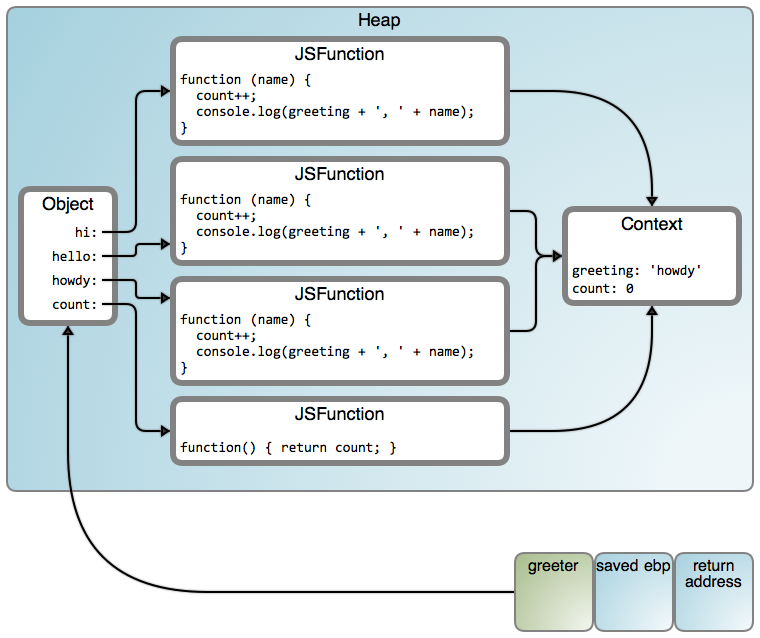
|
||||
|
||||
|
||||
|
||||
这是一个被所有函数共享的公共内容。那就是为什么 `count` 工作的原因。但是,`greeting` 也是被共享的,并且它被设置为迭代结束后的最后一个值,在这个案例中是“howdy”。这是一个很常见的一般错误,避免它的简单方法是,引用一个函数调用,以闭包变量作为一个参数。在 CoffeeScript 中, [do][10] 命令提供了一个实现这种目的的简单方式。下面是对我们的 `greeter` 的一个简单的解决方案:
|
||||
|
||||
```
|
||||
function makeGreeter(greetings)
|
||||
{
|
||||
var count = 0;
|
||||
var greeter = {};
|
||||
|
||||
greetings.forEach(function(greeting){
|
||||
greeter[greeting] = function(name){
|
||||
count++;
|
||||
console.log(greeting + ', ' + name);
|
||||
}
|
||||
});
|
||||
|
||||
greeter.count = function(){return count;}
|
||||
|
||||
return greeter;
|
||||
}
|
||||
|
||||
var greeter = makeGreeter(["hi", "hello", "howdy"])
|
||||
greeter.hi('poppet'); // prints "hi, poppet"
|
||||
greeter.hello('darling'); // prints "hello, darling"
|
||||
greeter.count(); // returns 2
|
||||
```
|
||||
|
||||
它现在是工作的,并且结果将变成下图所示:
|
||||
|
||||
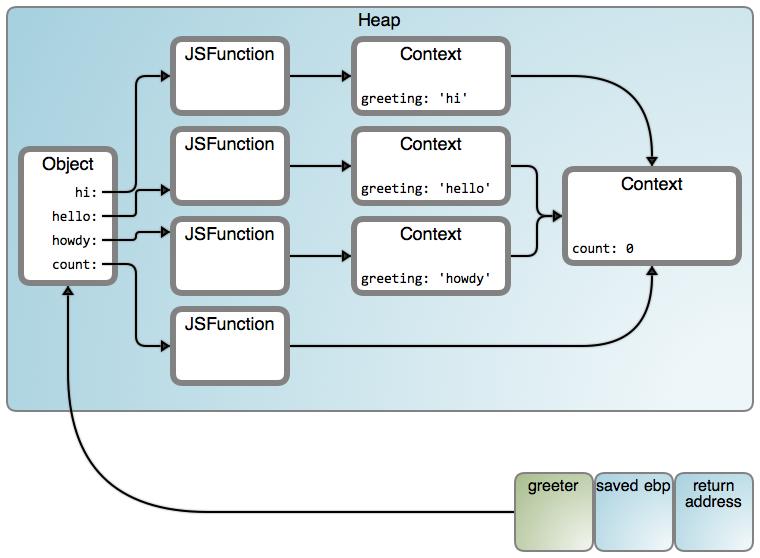
|
||||
|
||||
这里有许多箭头!在这里我们感兴趣的特性是:在我们的代码中,我们闭包了两个嵌套的词法内容,并且完全可以确保我们得到了两个链接到堆上的对象内容。你可以嵌套并且闭包任何词法内容、“俄罗斯套娃”类型、并且最终从本质上说你使用的是所有那些对象内容的一个链表。
|
||||
|
||||
当然,就像受信鸽携带信息启发实现了 TCP 一样,去实现这些编程语言的特性也有很多种方法。例如,ES6 规范定义了 [词法环境][11] 作为 [环境记录][12]( 大致相当于在一个块内的本地标识)的组成部分,加上一个链接到外部环境的记录,这样就允许我们看到的嵌套。逻辑规则是由规范(一个希望)所确定的,但是其实现取决于将它们变成比特和字节的转换。
|
||||
|
||||
你也可以检查具体案例中由 V8 产生的汇编代码。[Vyacheslav Egorov][13] 有一篇很好的文章,它在细节中使用 V8 的 [闭包内部构件][14] 解释了这一过程。我刚开始学习 V8,因此,欢迎指教。如果你熟悉 C#,检查闭包产生的中间代码将会很受启发 - 你将看到显式定义的 V8 内容和实例化的模拟。
|
||||
|
||||
闭包是个强大的“家伙”。它在被一组函数共享期间,提供了一个简单的方式去隐藏来自调用者的信息。我喜欢它们真正地隐藏你的数据:不像对象字段,调用者并不能访问或者甚至是看到闭包变量。保持接口清晰而安全。
|
||||
|
||||
但是,它们并不是“银弹”(译者注:意指极为有效的解决方案,或者寄予厚望的新技术)。有时候一个对象的拥护者和一个闭包的狂热者会无休止地争论它们的优点。就像大多数的技术讨论一样,他们通常更关注的是自尊而不是真正的权衡。不管怎样,Anton van Straaten 的这篇 [史诗级的公案][15] 解决了这个问题:
|
||||
|
||||
> 德高望重的老师 Qc Na 和它的学生 Anton 一起散步。Anton 希望将老师引入到一个讨论中,Anton 说:“老师,我听说对象是一个非常好的东西,是这样的吗?Qc Na 同情地看了一眼,责备它的学生说:“可怜的孩子 - 对象不过是穷人的闭包。” Anton 待它的老师走了之后,回到他的房间,专心学习闭包。他认真地阅读了完整的 “Lambda:The Ultimate…" 系列文章和它的相关资料,并使用一个基于闭包的对象系统实现了一个小的架构解释器。他学到了很多的东西,并期待告诉老师他的进步。在又一次和 Qc Na 散步时,Anton 尝试给老师留下一个好的印象,说“老师,我仔细研究了这个问题,并且,现在理解了对象真的是穷人的闭包。”Qc Na 用它的手杖打了一下 Anton 说:“你什么时候才能明白?闭包是穷人的对象。”在那个时候,Anton 顿悟了。Anton van Straaten 说:“原来架构这么酷啊?”
|
||||
|
||||
探秘“栈”系列文章到此结束了。后面我将计划去写一些其它的编程语言实现的主题,像对象绑定和虚表。但是,内核调用是很强大的,因此,明天将发布一篇操作系统的文章。我邀请你 [订阅][16] 并 [关注我][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/closures-objects-heap/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/closures-objects-heap/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/stackFolly.c
|
||||
[3]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-commands.txt
|
||||
[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap.c
|
||||
[6]:https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap-gdb-output.txt#L47
|
||||
[7]:https://code.google.com/p/v8/source/browse/trunk/src/objects.h#37
|
||||
[8]:https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1264
|
||||
[9]:https://code.google.com/p/v8/source/browse/trunk/src/objects.h#148
|
||||
[10]:http://coffeescript.org/#loops
|
||||
[11]:http://people.mozilla.org/~jorendorff/es6-draft.html#sec-lexical-environments
|
||||
[12]:http://people.mozilla.org/~jorendorff/es6-draft.html#sec-environment-records
|
||||
[13]:http://mrale.ph
|
||||
[14]:http://mrale.ph/blog/2012/09/23/grokking-v8-closures-for-fun.html
|
||||
[15]:http://people.csail.mit.edu/gregs/ll1-discuss-archive-html/msg03277.html
|
||||
[16]:https://manybutfinite.com/feed.xml
|
||||
[17]:http://twitter.com/manybutfinite
|
||||
@ -0,0 +1,292 @@
|
||||
25本免费学习linux的书
|
||||
======
|
||||
简介: 在这篇文章中,我将与你分享**免费学习Linux**的最佳资源。这是一个网站,在线视频课程和免费电子书的集合。
|
||||
|
||||
**如何学习linux?**
|
||||
|
||||
这可能是 Facebook Linux 用户群组中最常见的问题。
|
||||
|
||||
'如何学习linux'这个看起来简单的问题的答案并不简单。
|
||||
|
||||
问题在于不同的人对于学习 linux 有不同的意义。
|
||||
* 比如有人从来没有使用过 Linux,无论是命令行还是桌面版本,那个人可能只是想知道更多关于它的信息。
|
||||
* 比如有人使用 Windows 作为桌面,但必须在工作中使用 Linux 命令行,那个人可能对学习 Linux 命令感兴趣。
|
||||
* 比如有人已经使用过一段时间的 Linux,而且懂得一些基础,但他/她可能想要更上一层楼。
|
||||
* 比如有人只是对 Linux 特定的发行版本感兴趣。
|
||||
* 比如有人想要改进或学习几乎与 Linux 命令行差不多的Bash脚本。
|
||||
* 比如有人想要从事一个 Linux 系统管理员的职业,或者想提高他/她的系统管理技能。
|
||||
|
||||
你看,'我如何学习Linux'的答案取决于你追求什么样的 linux 知识。为此,我收集了大量能用来学习Linux的资源
|
||||
|
||||
这些免费的资源包括电子书,视频课程,网站等。这些资源分成几个子类别,以便当你试图学习 Linux 时可以很容易地找到你想要的东西。
|
||||
|
||||
再者,这里没有**最好的方式来学习Linux**。这完全取决于你如何去学习 Linux,通过在线门户网站,下载电子书,视频课程或者其他。
|
||||
|
||||
让我们看看你能如何学习 Linux。
|
||||
|
||||
**免责声明** : 这里列举的所有书都可以合法的下载。 据我所知,这里提到的资源都是官方的资源。但是,如果你发现它不是,请让我知道以便我可以采取适当的措施。
|
||||
|
||||
![Best Free eBooks to learn Linux for Free][1]
|
||||
|
||||
## 1. 对于完全新手的免费资料
|
||||
|
||||
也许你刚刚从朋友那里或者从网上的讨论中听到了 Linux。关于 Linux 的炒作让你对Linux很感兴趣,你被互联网上的大量信息所淹没,不知道在哪里寻找更多的关于Linux的知识。
|
||||
|
||||
不用担心, 我们中的大多数, 即使不是全部, 已经来到你的身边
|
||||
|
||||
### Linux基金会关于Linux的介绍 [Video Course]
|
||||
|
||||
如果你对于什么是Linux和如何开始学习Linux完全没有概念的话,我建议你从学习Linux基金会[Linux Foundation][2]在[edX][3]提供的免费的视频课程开始。
|
||||
把它当做一个'维护'Linux组织的官方的课程。是的,它是由Linux之父[Linus Torvalds][4]赞同的
|
||||
|
||||
[Introduction To Linux][5]
|
||||
|
||||
### Linux 旅程 [Online Portal]
|
||||
|
||||
不是官方的,也许不是很受欢迎。但是这个小网站对于初学者来说是一个Linux学习的完美场所。
|
||||
|
||||
该网站设计精美,并根据主题组织得很好。它给你提供了能够在阅读完一个片段或章节后的进行的互动式测验。我的建议,收藏这个网站:
|
||||
[Linux Journey][6]
|
||||
|
||||
### 5天学习Linux [eBook]
|
||||
|
||||
这本出色的书对于它专门的 FOSS 读者 来说完全的免费,这完全得感谢[Linux Training Academy][7]。
|
||||
|
||||
为了完全的新手而写,这本免费的 Linux 电子书给你一个关于 Linux的概述,常用的 Linux指令和你开始学习 Linux 所需要的其他东西
|
||||
|
||||
你能够从下面的网页下载书:
|
||||
|
||||
[Learn Linux In 5 Days][8]
|
||||
|
||||
### 终极的Linux新手指南 [eBook]
|
||||
|
||||
这是一本Linux初学者可以免费下载的电子书。电子书从解释什么是 Linux 开始,然后继续提供了更多Linux作为桌面的实际的使用。
|
||||
|
||||
您可以从下面的链接下载最新版本的电子书:
|
||||
|
||||
[The Ultimate Linux Newbie Guide][9]
|
||||
|
||||
## 2. 初学者进阶的免费书籍
|
||||
|
||||
本节列出了那些已经"完成"的 Linux 电子书。
|
||||
|
||||
我的意思是,这些之中的大部分就像是专注于 Linux 的每个方面的学术教科书。你可以作为一个绝对的新手阅读这些书或者你可以作为一个中级的 Linux 用户来深入学习。即使你已经是专家级,你也可以把它们作为参考
|
||||
|
||||
### Introduction to Linux [eBook]
|
||||
|
||||
Linux 简介是[The Linux Documentation Project][10]的免费电子书,而且它是最热门的 Linux 免费电子书之一。即使我认为其中的部分段落需要更新,它仍然是一本非常好的电子书来教你 Linux,Linux 的文件系统,命令行,网络和其他相关的东西。
|
||||
|
||||
[Introduction To Linux][11]
|
||||
|
||||
### Linux 基础 [eBook]
|
||||
|
||||
这本由 Paul Cobbaut 编写的免费的电子书教你关于 Linux 的历史,安装和你需要知道的基本的 Linux 命令。你能够从下列链接上得到这本书:
|
||||
|
||||
[Linux Fundamentals][12]
|
||||
|
||||
### 高级的 Linux 编程[eBook]
|
||||
|
||||
顾名思义,这是一本对于想要或者正在开发 Linux 软件的高级用户的书。它解决了负责的功能比如多进程,多线程,进程间通信以及和硬件设备的交互。
|
||||
|
||||
跟着这本书学习会帮你开发一个更快速,更可靠,更安全的使用 GNU/Linux 系统全部功能的项目
|
||||
|
||||
[Advanced Linux Programming][13]
|
||||
|
||||
### Linux From Scratch(就是一种从网上直接下载源码,从头编译LINUX的安装方式) [eBook]
|
||||
|
||||
如果你认为自己对Linux有足够的了解,并且你是一个专业人士,那么为什么不创建自己的Linux版本呢? Linux From Scratch(LFS)是一个完全基于源代码,为你构建你自定义的 Linux 系统提供手把手的指导。
|
||||
|
||||
把它叫做 DIY Linux 但是它是一个把你的 Linux 专业知识提高到新的高度的方法。
|
||||
|
||||
这里有许多的关于这个项目的子项目,你能够在这个网站上查看和下载。
|
||||
|
||||
[Linux From Scratch][14]
|
||||
|
||||
## 3.免费的电子书来学习 Linux 命令和 Shell脚本
|
||||
|
||||
Linux 的真正强大在于命令行,如果你想要征服 Linux,你必须学习命令行和shell
|
||||
|
||||
事实上,如果你必须在你的工作中使用Linux终端,那么熟悉Linux命令行实际上会帮助你完成任务,也有可能帮助你提高你的职业生涯(因为你会更有效率)。
|
||||
|
||||
在本节中,我们将看到各种Linux命令的免费电子书。
|
||||
|
||||
### GNU/Linux Command−Line Tools Summary [eBook]
|
||||
|
||||
这本Linux文档项目中的电子书是接触Linux命令行并开始熟悉Shell脚本的好地方
|
||||
|
||||
[GNU/Linux Command−Line Tools Summary][15]
|
||||
|
||||
### 来自 GNU 的 Bash 参考指南[eBook]
|
||||
|
||||
这是一本从[GNU][16]下载的免费电子书。 就像名字暗示的那样, 它涉及 Bash Shell (如果我能这么叫的话). 这本书有超过175页而且它包括了许多在 Bash里和 Linux有关的主题。
|
||||
|
||||
你能够从下面的链接中获取:
|
||||
|
||||
[Bash Reference Manual][17]
|
||||
|
||||
### Linux 命令行 [eBook]
|
||||
|
||||
这本500多页的由William Shotts编写的免费电子书,对于那些认真学习Linux命令行的人来说,是一本必须拥有的书。
|
||||
|
||||
即使你认为你知道关于Linux的东西,你还是会惊讶于这本书能教你很多东西。
|
||||
|
||||
它涵盖了从初学者到高级的东西。我敢打赌读完这本书之后你会成为一个更好的Linux用户。请下载这本书并且随时携带它。
|
||||
|
||||
[The Linux Command Line][18]
|
||||
|
||||
### Bash 入门指南 [eBook]
|
||||
|
||||
如果你是想从 Bash 脚本开始,这可能对于你来说是一个很好的助手。 Linux 文档项目又是这本电子书的基础,它是编写 Linux 介绍的电子书的作者(本文前面讨论过)。
|
||||
|
||||
[Bash Guide for Beginners][19]
|
||||
|
||||
### 高级的 Bash 脚本指南[eBook]
|
||||
|
||||
如果你认为你已经知道了基本的Bash脚本的知识,并且你想把你的技能提高到一个新的水平,这本书就是你所需要的。这本书有超过900页的各种高级命令和举例。
|
||||
|
||||
[Advanced Bash-Scripting Guide][20]
|
||||
|
||||
### AWK 编程语言 [eBook]
|
||||
|
||||
这不是最漂亮的书,但是如果你真的想要通过脚本研究的更深,这本旧的但是依然发光的书会很有帮助。
|
||||
|
||||
[The AWK Programming Language][21]
|
||||
|
||||
### Linux 101 黑客 [eBook]
|
||||
|
||||
这本来自 "The Geek Stuf" 的书通过易于跟踪学习的例子教你基本的 Linux 命令行。你能够从下列的链接获取:
|
||||
|
||||
[Linux 101 Hacks][22]
|
||||
|
||||
## 4. 特定版本的免费学习资料
|
||||
|
||||
这个章节专注于特定 Linux 版本的材料。到目前为止,我们看到的都是常规的 Linux,更多的关注文件系统,命令和其他的核心内容。
|
||||
|
||||
这些书,在另一方面,可以被认为是用户手册或者开始学习各种各样的 Linux 版本的指南。所以如果你正在使用一个特定的 Linux 版本或者你准备使用它,你可以参考这些资源。是的,这些书更加关注 Linux 桌面。
|
||||
|
||||
我还想补充的是大部分的 Linux 版本有它们自己的大量的 wiki 或者文档。你能够从网上随时找到它们。
|
||||
|
||||
### Ubuntu 用户指南
|
||||
|
||||
不用说这本书是针对 Ubuntu 用户的。这是一个独立的项目在免费的电子书中提供 Ubuntun 的用户指南。它对于每个版本的 Ubuntu 都有更新。
|
||||
|
||||
这本书被叫做用户指南因为它是由一步步的指导组成而且受众目标是对于 Ubuntu 绝对的新手。所以,你会去了解 Unity 桌面,怎样慢慢走近而且查找应用等等。
|
||||
|
||||
如果你从来没有使用过 Ubuntu Unity 那么这是一本你必须拥有的书因为它帮助你理解怎样在日常中使用 Ubuntu。
|
||||
|
||||
[Ubuntu Manual][23]
|
||||
|
||||
### 对于 Linux Mint: 只要告诉我 Damnit! [eBook]
|
||||
|
||||
一本非常基本的关于 Linux Mint 的电子书。它告诉你怎么样在虚拟机中安装 Linux Mint,怎么样去查找软件,安装更新和自定义 Linux Mint 桌面。
|
||||
|
||||
你能够在下面的链接下载电子书:
|
||||
|
||||
[Just Tell Me Damnit!][24]
|
||||
|
||||
### Solus Linux 用户指南 [eBook]
|
||||
|
||||
注意!这本书过去是 Solus Linux 的官方用户指南但是我找不到 Solux 项目的网站上在哪里有提到它。我不知道它是不是已经过时了。尽管如此,学习一点Solu Linux 并不是受到伤害,不是吗?
|
||||
|
||||
[Solus Linux User Guide][25]
|
||||
|
||||
## 5. 对于系统管理者的免费电子书
|
||||
|
||||
这个章节主要关注与系统管理者,开发者的超级英雄。我已经列了一部分会真正帮助那些已经是系统管理者或者想要成为系统管理者的免费的电子书。我必须补充你必须要关注基本的 Linux 命令行因为它会使你的工作更加简单
|
||||
|
||||
### The Debian 管理者的手册 [eBook]
|
||||
|
||||
如果你使用 Debian Linux 作为你的服务器,这本书就是你的圣经。这本书从 Debian 的历史,安装,包管理等等开始,接着覆盖一些主题,比如说[LAMP][26],虚拟机,存储管理和其他核心系统管理。
|
||||
|
||||
[The Debian Administration's Handbook][27]
|
||||
|
||||
### 高级的 Linux 系统管理者[eBook]
|
||||
|
||||
如果在准备[LPI certification][28],那么这本书是一本理想的书。这本书的涉及系统管理员必要的主题。所以了解 Linux 命令行在这个条件下是一个前置条件。
|
||||
|
||||
[Advanced Linux System Administration][29]
|
||||
|
||||
### Linux 系统管理者 [eBook]
|
||||
|
||||
Paul Cobbaut 编写的另一本免费的电子书。370页长的的书包括了网络,磁盘管理,用户管理,内核管理,库管理等等。
|
||||
|
||||
[Linux System Administration][30]
|
||||
|
||||
### Linux 服务器 [eBook]
|
||||
|
||||
又一本 Paul Cobbaut 编写的[linux-training.be][31]. 这本书包括了网页服务器,mysql,DHCP,DNS,Samba和其他文件服务器。
|
||||
|
||||
[Linux Servers][32]
|
||||
|
||||
### Linux 网络 [eBook]
|
||||
|
||||
网络是系统管理者的面包和黄油,这本由 Paul Cobbaut 编写的书是一本好的参考资料。
|
||||
|
||||
[Linux Networking][33]
|
||||
|
||||
### Linux 存储 [eBook]
|
||||
|
||||
这本由 Paul Cobbaut(对,还是他) 编写的书解释了 Linux 的详细的磁盘管理而且介绍了许多其他的和存储相关的技术
|
||||
|
||||
[Linux Storage][34]
|
||||
|
||||
### Linux 安全 [eBook]
|
||||
|
||||
这是最后一本在这个书单里由 Paul Cobbaut 编写的书。 安全是系统管理员最重要的工作之一。这本书关注文件权限,acls,SELinux,用户和密码等等。
|
||||
|
||||
[Linux Security][35]
|
||||
|
||||
## 你最喜爱的 Linux 资料?
|
||||
|
||||
我知道这是一个免费 Linux 电子书的集合。但是它可以做的更好。
|
||||
|
||||
如果你有其他的在学习 Linux 有更大帮助的资料,请务必和我们共享。请注意只共享合法的下载资料以便我可以根据你的建议更新这篇文章而不会有任何问题。
|
||||
|
||||
我希望你觉得这篇文章在学习 Linux 时有帮助,欢迎你的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/learn-linux-for-free/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[yyyfor](https://github.com/yyyfor)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/02/free-ebooks-linux-800x450.png
|
||||
[2]:https://www.linuxfoundation.org/
|
||||
[3]:https://www.edx.org
|
||||
[4]:https://www.youtube.com/watch?v=eE-ovSOQK0Y
|
||||
[5]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0
|
||||
[6]:https://linuxjourney.com/
|
||||
[7]:https://www.linuxtrainingacademy.com/
|
||||
[8]:https://courses.linuxtrainingacademy.com/itsfoss-ll5d/
|
||||
[9]:https://linuxnewbieguide.org/ulngebook/
|
||||
[10]:http://www.tldp.org/index.html
|
||||
[11]:http://tldp.org/LDP/intro-linux/intro-linux.pdf
|
||||
[12]:http://linux-training.be/linuxfun.pdf
|
||||
[13]:http://advancedlinuxprogramming.com/alp-folder/advanced-linux-programming.pdf
|
||||
[14]:http://www.linuxfromscratch.org/
|
||||
[15]:http://tldp.org/LDP/GNU-Linux-Tools-Summary/GNU-Linux-Tools-Summary.pdf
|
||||
[16]:https://www.gnu.org/home.en.html
|
||||
[17]:https://www.gnu.org/software/bash/manual/bash.pdf
|
||||
[18]:http://linuxcommand.org/tlcl.php
|
||||
[19]:http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
|
||||
[20]:http://www.tldp.org/LDP/abs/abs-guide.pdf
|
||||
[21]:https://ia802309.us.archive.org/25/items/pdfy-MgN0H1joIoDVoIC7/The_AWK_Programming_Language.pdf
|
||||
[22]:http://www.thegeekstuff.com/linux-101-hacks-ebook/
|
||||
[23]:https://ubuntu-manual.org/
|
||||
[24]:http://downtoearthlinux.com/resources/just-tell-me-damnit/
|
||||
[25]:https://drive.google.com/file/d/0B5Ymf8oYXx-PWTVJR0pmM3daZUE/view
|
||||
[26]:https://en.wikipedia.org/wiki/LAMP_(software_bundle)
|
||||
[27]:https://debian-handbook.info/about-the-book/
|
||||
[28]:https://www.lpi.org/our-certifications/getting-started
|
||||
[29]:http://www.nongnu.org/lpi-manuals/manual/pdf/GNU-FDL-OO-LPI-201-0.1.pdf
|
||||
[30]:http://linux-training.be/linuxsys.pdf
|
||||
[31]:http://linux-training.be/
|
||||
[32]:http://linux-training.be/linuxsrv.pdf
|
||||
[33]:http://linux-training.be/linuxnet.pdf
|
||||
[34]:http://linux-training.be/linuxsto.pdf
|
||||
[35]:http://linux-training.be/linuxsec.pdf
|
||||
@ -0,0 +1,83 @@
|
||||
简化 APT 仓库
|
||||
======
|
||||
|
||||
作为我工作的一部分,我所维护的 [PATHspider][5] 依赖于 [cURL][6] 和 [PycURL][7]中的一些[刚刚][8][被][9]合并或仍在[等待][10]被合并的功能。我需要构建一个包含这些 Debian 包的 Docker 容器,所以我需要快速构建一个 APT 仓库。
|
||||
|
||||
Debian 仓库本质上可以看作是一个静态的网站,而且内容是经过 GPG 签名的,所以它不一定需要托管在某个可信任的地方(除非可用性对你的程序来说是至关重要的)。我在 [Netlify][11] 上托管我的博客,一个静态的网站主机,在这种情况下,我认为用它很完美。他们也[支持开源项目][12]。
|
||||
|
||||
你可以用下面的命令安装 netlify 的 CLI 工具:
|
||||
```
|
||||
sudo apt install npm
|
||||
sudo npm install -g netlify-cli
|
||||
|
||||
```
|
||||
|
||||
设置仓库的基本步骤是:
|
||||
```
|
||||
mkdir repository
|
||||
cp /path/to/*.deb repository/
|
||||
|
||||
|
||||
cd
|
||||
|
||||
repository
|
||||
apt-ftparchive packages . > Packages
|
||||
apt-ftparchive release . > Release
|
||||
gpg --clearsign -o InRelease Release
|
||||
netlify deploy
|
||||
|
||||
```
|
||||
|
||||
当你完成这些步骤后这些步骤,并在 Netlify 上创建了一个新的网站,你也可以通过网页来管理这个网站。你可能想要做的一些事情是为你的仓库设置自定义域名,或者使用 Let's Encrypt 启用 HTTPS。(如果你打算启用 HTTPS,请确保命令中有 “apt-transport-https”。)
|
||||
|
||||
要将这个仓库添加到你的 apt 源:
|
||||
```
|
||||
gpg --export -a YOURKEYID | sudo apt-key add -
|
||||
|
||||
|
||||
echo
|
||||
|
||||
|
||||
|
||||
"deb https://SUBDOMAIN.netlify.com/ /"
|
||||
|
||||
| sudo tee -a /etc/apt/sources.list
|
||||
sudo apt update
|
||||
|
||||
```
|
||||
|
||||
你会发现这些软件包是可以安装的。注意下[ APT pinnng][13],因为你可能会发现,根据你的策略,仓库上的较新版本实际上并不是首选版本。
|
||||
|
||||
**更新**:如果你想要一个更适合平时使用的解决方案,请参考 [repropro][14]。如果你想让最终用户将你的 apt 仓库作为第三方仓库添加到他们的系统中,请查看[ Debian wiki 上的这个页面][15],其中包含关于如何指导用户使用你的仓库。
|
||||
|
||||
**更新 2**:有一位评论者指出用 [aptly][16],它提供了更多的功能,并消除了 repropro 的一些限制。我从来没有用过 aptly,所以不能评论具体细节,但从网站看来,这是一个很好的工具。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iain.learmonth.me/blog/2017/2017w383/
|
||||
|
||||
作者:[Iain R. Learmonth][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iain.learmonth.me
|
||||
[1]:https://iain.learmonth.me/tags/netlify/
|
||||
[2]:https://iain.learmonth.me/tags/debian/
|
||||
[3]:https://iain.learmonth.me/tags/apt/
|
||||
[4]:https://iain.learmonth.me/tags/foss/
|
||||
[5]:https://pathspider.net
|
||||
[6]:http://curl.haxx.se/
|
||||
[7]:http://pycurl.io/
|
||||
[8]:https://github.com/pycurl/pycurl/pull/456
|
||||
[9]:https://github.com/pycurl/pycurl/pull/458
|
||||
[10]:https://github.com/curl/curl/pull/1847
|
||||
[11]:http://netlify.com/
|
||||
[12]:https://www.netlify.com/open-source/
|
||||
[13]:https://wiki.debian.org/AptPreferences
|
||||
[14]:https://mirrorer.alioth.debian.org/
|
||||
[15]:https://wiki.debian.org/DebianRepository/UseThirdParty
|
||||
[16]:https://www.aptly.info/
|
||||
@ -1,26 +1,23 @@
|
||||
translating---geekpi
|
||||
|
||||
Bash Bypass Alias Linux/Unix Command
|
||||
绕过 Linux/Unix 命令别名
|
||||
======
|
||||
I defined mount bash shell alias as follows on my Linux system:
|
||||
我在我的 Linux 系统上定义了如下 mount 别名:
|
||||
```
|
||||
alias mount='mount | column -t'
|
||||
```
|
||||
However, I need to bash bypass alias for mounting the file system and another usage. How can I disable or bypass my bash shell aliases temporarily on a Linux, *BSD, macOS or Unix-like system?
|
||||
但是我需要在挂载文件系统和其他用途时绕过 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
|
||||
|
||||
|
||||
|
||||
You can define or display bash shell aliases with alias command. Once bash shell aliases created, they take precedence over external or internal commands. This page shows how to bypass bash aliases temporarily so that you can run actual internal or external command.
|
||||
你可以使用 alias 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
|
||||
[![Bash Bypass Alias Linux BSD macOS Unix Command][1]][1]
|
||||
|
||||
## Four ways to bash bypass alias
|
||||
## 4 种绕过 bash 别名的方法
|
||||
|
||||
|
||||
Try any one of the following ways to run a command that is shadowed by a bash shell alias. Let us [define an alias as follows][2]:
|
||||
尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名][2]:
|
||||
`alias mount='mount | column -t'`
|
||||
Run it as follows:
|
||||
运行如下:
|
||||
`mount `
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
```
|
||||
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
|
||||
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
|
||||
@ -33,16 +30,16 @@ binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_m
|
||||
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
|
||||
```
|
||||
|
||||
### Method 1 - Use \command
|
||||
### 方法1 - 使用 \command
|
||||
|
||||
Type the following command to temporarily bypass a bash alias called mount:
|
||||
输入以下命令暂时绕过名为 mount 的 bash 别名:
|
||||
`\mount`
|
||||
|
||||
### Method 2 - Use "command" or 'command'
|
||||
### 方法2 - 使用 "command" 或 'command'
|
||||
|
||||
Quote the mount command as follows to call actual /bin/mount:
|
||||
如下引用 mount 命令调用实际的 /bin/mount:
|
||||
`"mount"`
|
||||
OR
|
||||
或者
|
||||
`'mount'`
|
||||
|
||||
### Method 3 - Use full command path
|
||||
@ -51,27 +48,27 @@ Use full binary path such as /bin/mount:
|
||||
`/bin/mount
|
||||
/bin/mount /dev/sda1 /mnt/sda`
|
||||
|
||||
### Method 4 - Use internal command
|
||||
### 方法3 - 使用完整的命令路径
|
||||
|
||||
The syntax is:
|
||||
语法是:
|
||||
`command cmd
|
||||
command cmd arg1 arg2`
|
||||
To override alias set in .bash_aliases such as mount:
|
||||
要覆盖 .bash_aliases 中设置的别名,例如 mount:
|
||||
`command mount
|
||||
command mount /dev/sdc /mnt/pendrive/`
|
||||
[The 'command' run a simple command or display][3] information about commands. It runs COMMAND with ARGS suppressing shell function lookup or aliases, or display information about the given COMMANDs.
|
||||
[”command“ 运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
|
||||
|
||||
## A note about unalias command
|
||||
## 关于 unalias 命令的说明
|
||||
|
||||
To remove each alias from the list of defined aliases from the current session use unalias command:
|
||||
要从当前会话的已定义别名列表中移除别名,请使用 unalias 命令:
|
||||
`unalias mount`
|
||||
To remove all alias definitions from the current bash session:
|
||||
要从当前 bash 会话中删除所有别名定义:
|
||||
`unalias -a`
|
||||
Make sure you update your ~/.bashrc or $HOME/.bash_aliases file. You must remove defined aliases if you want to remove them permanently:
|
||||
确保你更新你的 ~/.bashrc 或 $HOME/.bash_aliases。如果要永久删除定义的别名,则必须删除定义的别名:
|
||||
`vi ~/.bashrc`
|
||||
OR
|
||||
或者
|
||||
`joe $HOME/.bash_aliases`
|
||||
For more information see bash command man page online [here][4] or read it by typing the following command:
|
||||
想了解更多信息,参考[这里][4]的在线手册,或者输入下面的命令查看:
|
||||
```
|
||||
man bash
|
||||
help command
|
||||
@ -85,7 +82,7 @@ help alias
|
||||
via: https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,58 +0,0 @@
|
||||
最重要的 Firefox 命令行选项
|
||||
======
|
||||
Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
|
||||
|
||||
你可能已经接触过一些了,比如 `-P "profile name"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
|
||||
|
||||
本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
|
||||
|
||||
你可以在 Firefox 开发者网站上看到[完整 ][1] 的命令行选项。需要注意的是,很多命令行选项对其他基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
|
||||
|
||||
### 重要的 Firefox 命令行选项
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
#### Profile 相关选项
|
||||
|
||||
+ **-CreateProfile profile 名称** -- 创建新的用户配置信息,但并不立即使用它。
|
||||
+ **-CreateProfile "profile 名 存放 profile 的目录"** -- 跟上面一样,只是指定了存放 profile 的目录。
|
||||
+ **-ProfileManager**,或 **-P** -- 打开内置的 profile 管理器。
|
||||
+ - **P "profile 名"** -- 使用 n 指定的 profile 启动 Firefox。若指定的 profile 不存在则会打开 profile 管理器。只有在没有其他 Firefox 实例运行时才有用。
|
||||
+ **-no-remote** -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个 profile。
|
||||
|
||||
#### 浏览器相关选项
|
||||
|
||||
+ **-headless** -- 以无头模式启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
|
||||
+ **-new-tab URL** -- 在 Firefox 的新标签页中加载指定 URL。
|
||||
+ **-new-window URL** -- 在 Firefox 的新窗口中加载指定 URL。
|
||||
+ **-private** -- 以私隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
|
||||
+ **-private-window** -- 打开一个隐私窗口
|
||||
+ **-private-window URL** -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
|
||||
+ **-search 单词** -- 使用 FIrefox 默认的搜索引擎进行搜索。
|
||||
+ - **url URL** -- 在新的标签也或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
|
||||
|
||||
|
||||
|
||||
#### 其他 options
|
||||
|
||||
+ **-safe-mode** -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
|
||||
+ **-devtools** -- 启动 Firefox,同时加载并打开 Developer Tools。
|
||||
+ **-inspector URL** -- 使用 DOM Inspector 查看指定的 URL
|
||||
+ **-jsconsole** -- 启动 Firefox,同时打开 Browser Console。
|
||||
+ **-tray** -- 启动 Firefox,但保持最小化。
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
@ -0,0 +1,135 @@
|
||||
使用 TLS 加密保护 VNC 服务器的简单指南
|
||||
======
|
||||
在本教程中,我们将学习使用 TLS 加密安装 VNC 服务器并保护 VNC 会话。
|
||||
此方法已经在 CentOS 6&7 上测试过了,但是也可以在其他的版本/操作系统上运行(RHEL、Scientific Linux 等)。
|
||||
|
||||
**(推荐阅读:[保护 SSH 会话终极指南][1])**
|
||||
|
||||
### 安装 VNC 服务器
|
||||
|
||||
在机器上安装 VNC 服务器之前,请确保我们有一个可用的 GUI。如果机器上还没有安装 GUI,我们可以通过执行以下命令来安装:
|
||||
|
||||
```
|
||||
yum groupinstall "GNOME Desktop"
|
||||
```
|
||||
|
||||
现在我们将 tigervnc 作为我们的 VNC 服务器,运行下面的命令运行:
|
||||
|
||||
```
|
||||
# yum install tigervnc-server
|
||||
```
|
||||
|
||||
安装完成后,我们将创建一个新的用户访问服务器:
|
||||
|
||||
```
|
||||
# useradd vncuser
|
||||
```
|
||||
|
||||
并使用以下命令为其分配访问 VNC 的密码:
|
||||
|
||||
```
|
||||
# vncpasswd vncuser
|
||||
```
|
||||
|
||||
我们在 CentOS 6&7 上配置会有一点改变,我们首先看 CentOS 6 的配置。
|
||||
|
||||
#### CentOS 6
|
||||
|
||||
现在我们需要编辑 VNC 配置文件:
|
||||
|
||||
```
|
||||
**# vim /etc/sysconfig/vncservers**
|
||||
```
|
||||
|
||||
并添加下面这几行:
|
||||
|
||||
```
|
||||
[ …]
|
||||
VNCSERVERS= "1:vncuser"
|
||||
VNCSERVERARGS[1]= "-geometry 1024×768″
|
||||
```
|
||||
|
||||
保存文件并退出。接下来重启 vnc 服务使改动生效:
|
||||
|
||||
```
|
||||
# service vncserver restart
|
||||
```
|
||||
|
||||
并在启动时启用它:
|
||||
|
||||
```
|
||||
# chkconfig vncserver on
|
||||
```
|
||||
|
||||
#### CentOS 7
|
||||
|
||||
在 CentOS 7 上,/etc/sysconfig/vncservers 已经改为 /lib/systemd/system/vncserver@.service。我们将使用这个配置文件作为参考,所以创建一个文件的副本,
|
||||
|
||||
```
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
```
|
||||
|
||||
接下来,我们将编辑文件以包含我们创建的用户:
|
||||
|
||||
```
|
||||
# vim /etc/systemd/system/vncserver@:1.service
|
||||
```
|
||||
|
||||
编辑下面 2 行中的用户:
|
||||
|
||||
```
|
||||
ExecStart=/sbin/runuser -l vncuser -c "/usr/bin/vncserver %i"
|
||||
PIDFile=/home/vncuser/.vnc/%H%i.pid
|
||||
```
|
||||
|
||||
保存文件并退出。接下来重启服务并在启动时启用它:
|
||||
|
||||
```
|
||||
systemctl restart[[email protected]][2]:1.service
|
||||
systemctl enable[[email protected]][2]:1.service
|
||||
```
|
||||
|
||||
现在我们已经设置好了 VNC 服务器,并且可以使用 VNC 服务器的 IP 地址从客户机连接到它。但是,在此之前,我们将使用 TLS 加密保护我们的连接。
|
||||
|
||||
### 保护 VNC 会话
|
||||
|
||||
要保护 VNC 会话,我们将首先配置加密方法。我们将使用 TLS 加密,但也可以使用 SSL 加密。执行以下命令在 VNC 服务器上使用 TLS 加密:
|
||||
|
||||
```
|
||||
# vncserver -SecurityTypes=VeNCrypt,TLSVnc
|
||||
```
|
||||
|
||||
你将被要求输入密码来访问 VNC(如果使用其他用户,而不是上述用户)。
|
||||
|
||||
![secure vnc server][4]
|
||||
|
||||
现在,我们可以使用客户机上的 VNC 浏览器访问服务器,使用以下命令以安全连接启动 vnc 浏览器:
|
||||
|
||||
**# vncviewer -SecurityTypes=VeNCrypt,TLSVnc 192.168.1.45:1**
|
||||
|
||||
这里,192.168.1.45 是 VNC 服务器的 IP 地址。
|
||||
|
||||
![secure vnc server][6]
|
||||
|
||||
输入密码,我们可以远程访问服务器,并且也是 TLS 加密的。
|
||||
|
||||
这篇教程就完了,欢迎随时使用下面的评论栏提交你的建议或疑问。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/secure-vnc-server-tls-encryption/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
[2]:/cdn-cgi/l/email-protection
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=642%2C241
|
||||
[4]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-1.png?resize=642%2C241
|
||||
[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=665%2C419
|
||||
[6]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-2.png?resize=665%2C419
|
||||
@ -0,0 +1,91 @@
|
||||
计算机语言的巨变
|
||||
====================================================
|
||||
|
||||
|
||||
我的上一篇博文([与 C 的长久别离][3])引来了我的老朋友,一位 C++ 专家的评论。在评论里,他推荐把 C++ 作为 C 的替代品。这是不可能发生的,如果 C ++ 代替 C 是趋势的话,那么 Go 和 Rust 也就不会出现了。
|
||||
|
||||
但是我不能只给我的读者一个空洞的看法。所以,在这篇文章中,我来讲述一下为什么我不再碰 C++ 的故事。这是关于计算机语言设计经济学专题文章的起始点。这篇文章会讨论为什么一些真心不好的决策会被做出来,然后进入语言的基础设计之中,以及我们该如何修正这些问题。
|
||||
|
||||
在这篇文章中,我会一点一点的指出人们(当然也包括我)自从 20 世纪 80 年代以来就存在的关于未来的编程语言的预见失误。直到最近我们才找到了证明我们错了的证据。
|
||||
|
||||
我第一次学习 C++ 是因为我需要使用 GNU eqn 输出 MathXML,而 eqn 是使用 C++ 写的。那个项目不错。在那之后,21世纪初,我在韦诺之战那边当了多年的高级开发工程师,并且与 C++ 相处甚欢。
|
||||
|
||||
在那之后啊,有一天我们发现一个不小心被我们授予特权的人已经把游戏的 AI 核心搞崩掉了。显然,在团队中只有我是不那么害怕查看代码的。最终,我把一切都恢复正常了 —— 我折腾了整整两周。再那之后,我就发誓我再也不靠近 C++ 了。
|
||||
|
||||
在那次经历过后,我发现这个语言的问题就是它在尝试使得本来就复杂的东西更加复杂,来属兔补上因为基础概念的缺失造成的漏洞。对于裸指针,他说“别这样做”,这没有问题。对于小规模的个人项目(比如我的魔改版 eqn),遵守这些规定没有问题。
|
||||
|
||||
但是对于大型项目,或者开发者水平不同的多人项目(这是我经常要处理的情况)就不能这样。随着时间的推移以及代码行数的增加,有的人就会捅篓子。当别人指出有 BUG 时,因为诸如 STL 之类的东西给你增加了一层复杂度,你处理这种问题所需要的精力就比处理同等规模的 C 语言的问题就要难上很多。我在韦诺之战时,我就知道了,处理这种问题真的相当棘手。
|
||||
|
||||
我给 Stell Heller(我的老朋友 ,C++ 的支持者)写代码时不会发生的问题在我与非 Heller 们合作时就被放大了,我和他们合作的结局可能就是我得给他们擦屁股。所以我就不用 C++ ,我觉得不值得为了其花时间。 C 是有缺陷的,但是 C 有 C++ 没有的优点 —— 如果你能在脑内模拟出硬件,那么你就能很简单的看出程序是怎么运行的。如果 C++ 真的能解决 C 的问题(也就是说,C++ 是类型安全以及内存安全的),那么失去其透明性也是值得的。但是,C++ 并没有这样。
|
||||
|
||||
我们判断 C++ 做的还不够的方法之一是想象一个 C++ 已经搞得不错的世界。在那个世界里,老旧的 C 语言项目会被迁移到 C++ 上来。主流的操作系统内核会是 C++ 写就,而现存的内核实现,比如 Linux 会渐渐升级成那样。在现实世界,这些都没有发生。C++ 不仅没有打消语言设计者设想像 D,Go 以及 Rust 那样的新语言的想法,他甚至都没有取代他的前辈。不改变 C++ 的核心思想,他就没有未来,也因此,C++ 的抽象泄露也不会消失。
|
||||
|
||||
既然我刚刚提到了 D 语言,那我就说说为什么我不把 D 视为一个够格的 C 语言竞争者的原因吧.尽管他比 Rust 早出现了八年 -- 和 Rust 相比是九年 -- Walter Bright 早在那时就有了构建那样一个语言的想法.但是在 2001 年,以 Python 和 Perl 为首的语言的出现已经确定了,专有语言能和开源语言抗衡的时代已经过去.官方 D 语言库/运行时和 Tangle 的无谓纷争也打击了其发展.它从未修正这些错误。
|
||||
|
||||
然后就是 Go 语言(我本来想说“以及 Rust”。但是如前文所述,我认为 Rust 还需要几年时间才能有竞争力)。它 _的确是_ 类型安全以及内存安全的(好吧,是在大多数时候是这样,但是如果你要使用接口的话就不是如此了,但是自找麻烦可不是正常人的做法)。我的一位好友,Mark Atwood,曾指出过 Go 语言是脾气暴躁的老头子因为愤怒创造出的语言,主要是 _C 语言的作者之一_(Ken Thompson) 因为 C++ 的混乱臃肿造成的愤怒,我深以为然。
|
||||
|
||||
我能理解 Ken 恼火的原因。这几十年来我就一直认为 C++ 搞错了需要解决的问题。C 语言的后继者有两条路可走。其一就是 C++ 那样,接受 C 的抽象泄漏,裸指针等等,以保证兼容性。然后以此为基础,构建一个最先进的语言。还有一条道路,就是从根源上解决问题 —— _修正_ C语言的抽象泄露。这一来就会破环其兼容性,但是也会杜绝 C/C++ 现有的问题。
|
||||
|
||||
对于第二条道路,第一次严谨的尝试就是 1995 年出现的 Java。Java 搞得不错,但是在语言解释器上构建这门语言使其不适合系统编程。这就在系统编程那留下一个巨大的漏洞,在 Go 以及 Rust 出现之前的 15 年里,都没有语言来填补这个空白。这也就是我的GPSD和NTPsec等软件在2017年仍然主要用C写成的原因,尽管C的问题也很多。
|
||||
|
||||
程序员的现状很差。尽管由于缺少足够多样化的选择,我们很难认识到 C/C++ 做的不够好的地方。我们都认为在软件里面出现缺陷以及基于安全方面考虑的妥协是理所当然的,而不是想想这其中多少是真的由于语言的设计问题导致的,就像缓存区溢出漏洞一样。
|
||||
|
||||
所以,为什么我们花了这么长时间才开始解决这个问题?从 C(1972) 面世到 Go(2009) 出现,这其中隔了 37 年;Rust也是在其仅仅一年之前出现。我想根本原因还是经济。
|
||||
|
||||
从最早的计算机语言开始,人们就已经知道,每种语言的设计都体现了程序员时间与机器资源的相对价值。在机器这端,就是汇编语言,以及之后的 C 语言,这些语言以牺牲开发人员的时间为代价来提高性能。 另一方面,像 Lisp 和(之后的)Python 这样的语言则试图自动处理尽可能多的细节,但这是以牺牲机器性能为代价的。
|
||||
|
||||
广义地说,这两端的语言的最重要的区别就是有没有自动内存管理。这与经验一致,内存管理缺陷是以机器为中心的语言中最常见的一类缺陷,程序员需要手动管理资源。
|
||||
|
||||
当一个语言对于程序员和机器的价值的理念与软件开发的某些领域的理念一致时,这个语言就是在经济上可行的。语言设计者通过设计一个适合处理现在或者不远的将来出现的情况的语言,而不是使用现有的语言来解决他们遇到的问题。
|
||||
|
||||
今年来,时兴的编程语言已经渐渐从需要手动管理内存的语言变为带有自动内存管理以及垃圾回收(GC)机制的语言。这种变化对应了摩尔定律导致的计算机硬件成本的降低,使得程序员的时间与之前相比更加的宝贵。但是,除了程序员的时间以及机器效率的变化之外,至少还有两个维度与这种变化相关。
|
||||
|
||||
其一就是距离底层硬件的距离。底层软件(内核与服务代码)的低效率会被成倍地扩大。因此我们可以发现,以机器为中心的语言像底层推进而以程序员为中心的语言向着高级发展。因为大多数情况下面向用户的语言仅仅需要以人类的反应速度(0.1秒)做出回应即可。
|
||||
|
||||
另一个维度就是项目的规模。由于程序员抽象出的问题的漏洞以及自身的疏忽,任何语言都会有预期的每千行代码的出错率。这个比率在以机器为中心的语言上很高,而在程序员为中心的带有 GC 的语言里就大大降低。随着项目规模的增大,带有 GC 语言作为一个防止出错率不堪入目的策略就显得愈发重要起来。
|
||||
|
||||
当我们使用这三种维度来看当今的编程语言的形势 —— C 语言在底层,蓬勃发展的带有 GC 的语言在上层,我们会发现这基本上很合理。但是还有一些看似不合理的是 —— C 语言的应用不合理地广泛。
|
||||
|
||||
我为什么这么说?想想那些经典的 Unix 命令行工具吧。这些通常都是可以使用带有完整的POSIX绑定的脚本语言写出的小程序。那样重新编码的程序调试维护拓展起来都会更加简单。
|
||||
|
||||
但是为什么还是使用 C (或者某些像 eqn 的项目,使用 C++)?因为有转型成本。就算是把相当小相当简单的语言使用新的语言重写并且确认你已经忠实地保留了所有非错误行为都是相当困难的。笼统地说,在任何一个领域的应用编程或者系统编程在语言的权衡过去之后,都可以使用一种哪怕是过时的语言。
|
||||
|
||||
这就是我和其他预测者犯的大错。 我们认为,降低机器资源成本(增加程序员时间的相对成本)本身就足以取代C语言(以及没有 GC 的语言)。 在这个过程中,我们有一部分或者甚至一大部分都是错误的 - 自20世纪90年代初以来,脚本语言,Java 以及像 Node.js 这样的东西的兴起显然都是这样兴起的的。
|
||||
|
||||
但是,竞争系统编程语言的新浪潮并非如此。 Rust和Go都明确地回应了_增加项目规模_ 这一需求。 脚本语言是先是作为编写小程序的有效途径,并逐渐扩大规模,而Rust和Go从一开始就定位为减少_大型项目_中的缺陷率。 比如 Google 的搜索服务和 Facebook 的实时聊天多服务。
|
||||
|
||||
我认为这就是对 "为什么不再早点儿" 这个问题的回答。Rust 和 Go 实际上并不算晚,他们相对迅速地回应了一个直到最近才被发现低估的成本问题。
|
||||
|
||||
好,说了这么多理论上的问题。按照这些理论我们能预言什么?它高偶素我们在 C 之后会出现什么?
|
||||
|
||||
推动 GC 语言发展的趋势还没有扭转,也不要期待其扭转。这是大势所趋。因此:最终我们将拥有具有足够低延迟的 GC 技术,可用于内核和底层固件,这些技术将以语言实现方式被提供。 这些才是真正结束C长期统治的语言应有的特性。
|
||||
|
||||
我们能从 Go 语言开发团队的工作文件中发现端倪,他们正朝着这个方向前进 - 参考关于并发GC 的学术研究,从来没有停止研究。 如果 Go 语言自己没有选择这么做,其他的语言设计师也会这样。 但我认为他们会这么做 - 谷歌推动他们的项目的能力是显而易见的(我们从 “Android 的发展”就能看出来)。
|
||||
|
||||
在我们拥有那么理想的 GC 之前,我把能替换 C 语言的赌注押在 Go 语言上。因为其 GC 的开销是可以接受的 —— 也就是说不只是应用,甚至是大部分内核外的服务都可以使用。原因很简单: C 的出错率无药可医,转化成本还很高。
|
||||
|
||||
上周我尝试将 C 语言项目转化到 Go 语言上,我发现了两件事。其一就是这话很简单, C 的语言和 Go 对应的很好。还有就是写出的代码相当简单。因为 GC 的存在以及把集合视为首要的我数据结构,人人都要注意到这一点。但是我意识到我写的代码比我期望的多了不少,比例约为 2:1 —— 和 C 转 Python 类似。
|
||||
|
||||
抱歉呐,Rust 粉们。你们在内核以及底层固件上有着美好的未来。但是你们在别的领域被 Go 压的很惨。没有 GC ,再加上难以从 C 语言转化过来,还有就是有一部分 API 还是不够完善。(我的 select(2) 又哪去了啊?)。
|
||||
|
||||
对你们来说,唯一的安慰就是,C++ 粉比你们更糟糕 —— 如果这算是安慰的话。至少 Rust 还可以在 Go 顾及不到的 C 领域内大展宏图。C++ 可不能。
|
||||
|
||||
本文由 [Eric Raymond][5] 发布在 [Software][4] 栏。[收藏链接][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7724
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7724
|
||||
[3]:http://esr.ibiblio.org/?p=7711
|
||||
[4]:http://esr.ibiblio.org/?cat=13
|
||||
[5]:http://esr.ibiblio.org/?author=2
|
||||
[6]:http://esr.ibiblio.org/?p=7724
|
||||
@ -0,0 +1,216 @@
|
||||
用 mod 保护您的网站免受应用层 DOS 攻击
|
||||
======
|
||||
|
||||
有多种恶意攻击网站的方法,比较复杂的方法要涉及数据库和编程方面的技术知识。一个更简单的方法被称为“拒绝服务”或“DOS”攻击。这个攻击方法的名字来源于它的意图:使普通客户或网站访问者的正常服务请求被拒绝。
|
||||
|
||||
一般来说,有两种形式的 DOS 攻击:
|
||||
|
||||
1. OSI 模型的三、四层,即网络层攻击
|
||||
2. OSI 模型的七层,即应用层攻击
|
||||
|
||||
第一种类型的 DOS 攻击——网络层,发生于当大量的垃圾流量流向网页服务器时。当垃圾流量超过网络的处理能力时,网站就会宕机。
|
||||
|
||||
第二种类型的 DOS 攻击是在应用层,是利用合法的服务请求,而不是垃圾流量。当页面请求数量超过网页服务器能承受的容量时,即使是合法访问者也将无法使用该网站。
|
||||
|
||||
本文将着眼于缓解应用层攻击,因为减轻网络层攻击需要大量的可用带宽和上游提供商的合作,这通常不是通过配置网络服务器就可以做到的。
|
||||
|
||||
通过配置普通的网页服务器,可以保护网页免受应用层攻击,至少是适度的防护。防止这种形式的攻击是非常重要的,因为 [Cloudflare][1] 最近 [报道][2] 了网络层攻击的数量正在减少,而应用层攻击的数量则在增加。
|
||||
|
||||
本文将根据 [zdziarski 的博客][4] 来解释如何使用 Apache2 的模块 [mod_evasive][3]。
|
||||
|
||||
另外,mod_evasive 会阻止攻击者试图通过尝试数百个组合来猜测用户名和密码,即暴力攻击。
|
||||
|
||||
Mod_evasive 会记录来自每个 IP 地址的请求的数量。当这个数字超过相应 IP 地址的几个阈值之一时,会出现一个错误页面。错误页面所需的资源要比一个能够响应合法访问的在线网站少得多。
|
||||
|
||||
### 在 Ubuntu 16.04 上安装 mod_evasive
|
||||
|
||||
Ubuntu 16.04 默认的软件库中包含了 mod_evasive,名称为“libapache2-mod-evasive”。您可以使用 `apt-get` 来完成安装:
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libapache2-mod-evasive
|
||||
|
||||
```
|
||||
|
||||
现在我们需要配置 mod_evasive。
|
||||
|
||||
它的配置文件位于 `/etc/apache2/mods-available/evasive.conf`。默认情况下,所有模块的设置在安装后都会被注释掉。因此,在修改配置文件之前,模块不会干扰到网站流量。
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
#DOSHashTableSize 3097
|
||||
#DOSPageCount 2
|
||||
#DOSSiteCount 50
|
||||
#DOSPageInterval 1
|
||||
#DOSSiteInterval 1
|
||||
#DOSBlockingPeriod 10
|
||||
|
||||
#DOSEmailNotify you@yourdomain.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
#DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
第一部分的参数的含义如下:
|
||||
|
||||
* **DOSHashTableSize** - 正在访问网站的 IP 地址列表及其请求数。
|
||||
* **DOSPageCount** - 在一定的时间间隔内,每个的页面的请求次数。时间间隔由 DOSPageInterval 定义。
|
||||
* **DOSPageInterval** - mod_evasive 统计页面请求次数的时间间隔。
|
||||
* **DOSSiteCount** - 与 DOSPageCount 相同,但统计的是网站内任何页面的来自相同 IP 地址的请求数量。
|
||||
* **DOSSiteInterval** - mod_evasive 统计网站请求次数的时间间隔。
|
||||
* **DOSBlockingPeriod** - 某个 IP 地址被加入黑名单的时长(以秒为单位)。
|
||||
|
||||
|
||||
如果使用上面显示的默认配置,则在如下情况下,一个 IP 地址会被加入黑名单:
|
||||
|
||||
* 每秒请求同一页面超过两次。
|
||||
* 每秒请求 50 个以上不同页面。
|
||||
|
||||
|
||||
如果某个 IP 地址超过了这些阈值,则被加入黑名单 10 秒钟。
|
||||
|
||||
这看起来可能不算久,但是,mod_evasive 将一直监视页面请求,包括在黑名单中的 IP 地址,并重置其加入黑名单的起始时间。只要一个 IP 地址一直尝试使用 DOS 攻击该网站,它将始终在黑名单中。
|
||||
|
||||
其余的参数是:
|
||||
|
||||
* **DOSEmailNotify** - 用于接收 DOS 攻击信息和 IP 地址黑名单的电子邮件地址。
|
||||
* **DOSSystemCommand** - 检测到 DOS 攻击时运行的命令。
|
||||
* **DOSLogDir** - 用于存放 mod_evasive 的临时文件的目录。
|
||||
|
||||
|
||||
### 配置 mod_evasive
|
||||
|
||||
默认的配置是一个很好的开始,因为它的黑名单里不该有任何合法的用户。取消配置文件中的所有参数(DOSSystemCommand 除外)的注释,如下所示:
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
|
||||
DOSEmailNotify JohnW@example.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
必须要创建日志目录并且要赋予其与 apache 进程相同的所有者。这里创建的目录是 `/var/log/mod_evasive` ,并且在 Ubuntu 上将该目录的所有者和组设置为 `www-data` ,与 Apache 服务器相同:
|
||||
```
|
||||
mkdir /var/log/mod_evasive
|
||||
chown www-data:www-data /var/log/mod_evasive
|
||||
|
||||
```
|
||||
|
||||
在编辑了 Apache 的配置之后,特别是在正在运行的网站上,在重新启动或重新加载之前,最好检查一下语法,因为语法错误将影响 Apache 的启动从而使网站宕机。
|
||||
|
||||
Apache 包含一个辅助命令,是一个配置语法检查器。只需运行以下命令来检查您的语法:
|
||||
```
|
||||
apachectl configtest
|
||||
|
||||
```
|
||||
|
||||
如果您的配置是正确的,会得到如下结果:
|
||||
```
|
||||
Syntax OK
|
||||
|
||||
```
|
||||
|
||||
但是,如果出现问题,您会被告知在哪部分发生了什么错误,例如:
|
||||
```
|
||||
AH00526: Syntax error on line 6 of /etc/apache2/mods-enabled/evasive.conf:
|
||||
DOSSiteInterval takes one argument, Set site interval
|
||||
Action 'configtest' failed.
|
||||
The Apache error log may have more information.
|
||||
|
||||
```
|
||||
|
||||
如果您的配置通过了 configtest 的测试,那么这个模块可以安全地被启用并且 Apache 可以重新加载:
|
||||
```
|
||||
a2enmod evasive
|
||||
systemctl reload apache2.service
|
||||
|
||||
```
|
||||
|
||||
Mod_evasive 现在已配置好并正在运行了。
|
||||
|
||||
### 测试
|
||||
|
||||
为了测试 mod_evasive,我们只需要向服务器提出足够的网页访问请求,以使其超出阈值,并记录来自 Apache 的响应代码。
|
||||
|
||||
一个正常并成功的页面请求将收到如下响应:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
```
|
||||
|
||||
但是,被 mod_evasive 拒绝的将返回以下内容:
|
||||
```
|
||||
HTTP/1.1 403 Forbidden
|
||||
|
||||
```
|
||||
|
||||
以下脚本会尽可能迅速地向本地主机(127.0.0.1,localhost)的 80 端口发送 HTTP 请求,并打印出每个请求的响应代码。
|
||||
|
||||
你所要做的就是把下面的 bash 脚本复制到一个文件中,例如 `mod_evasive_test.sh`:
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
for i in {1..50}; do
|
||||
curl -s -I 127.0.0.1 | head -n 1
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
这个脚本的部分含义如下:
|
||||
|
||||
* curl - 这是一个发出网络请求的命令。
|
||||
* -s - 隐藏进度表。
|
||||
* -I - 仅显示响应头部信息。
|
||||
* head - 打印文件的第一部分。
|
||||
* -n 1 - 只显示第一行。
|
||||
|
||||
然后赋予其执行权限:
|
||||
```
|
||||
chmod 755 mod_evasive_test.sh
|
||||
|
||||
```
|
||||
|
||||
在启用 mod_evasive **之前**,脚本运行时,将会看到 50 行“HTTP / 1.1 200 OK”的返回值。
|
||||
|
||||
但是,启用 mod_evasive 后,您将看到以下内容:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
前两个请求被允许,但是在同一秒内第三个请求发出时,mod_evasive 拒绝了任何进一步的请求。您还将收到一封电子邮件(邮件地址在选项 `DOSEmailNotify` 中设置),通知您有 DOS 攻击被检测到。
|
||||
|
||||
Mod_evasive 现在已经在保护您的网站啦!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/mod_proxy/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net/about/
|
||||
[1]:https://www.cloudflare.com
|
||||
[2]:https://blog.cloudflare.com/the-new-ddos-landscape/
|
||||
[3]:https://github.com/jzdziarski/mod_evasive
|
||||
[4]:https://www.zdziarski.com/blog/
|
||||
@ -1,170 +0,0 @@
|
||||
根据权限查找文件
|
||||
======
|
||||
|
||||
在 Linux 中查找文件并不是什么大问题。市面上也有很多可靠的免费开源可视化的查询工具。但对我而言,查询文件,用命令行的方式会更快更简单。我们已经知道 [ 如何根据访问、修改文件时间寻找或整理文件 ][1]。今天,在基于 Unix 的操作系统中,我们将见识如何通过权限查询文件。
|
||||
|
||||
本段教程中,我将创建三个文件名为 **file1**,**file2** 和 **file3** 分别赋予 **777**,**766** 和 **655** 文件权限,并分别置于名为 **ostechnix** 的文件夹中。
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
```
|
||||
```
|
||||
install -b -m 777 /dev/null file1
|
||||
```
|
||||
```
|
||||
install -b -m 766 /dev/null file2
|
||||
```
|
||||
```
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
现在,让我们通过权限来查询一下文件。
|
||||
|
||||
### 根据权限查询文件
|
||||
|
||||
根据权限查询文件最具代表性的语法:
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
MODE 可以是代表权限的八进制数字(777,666…)也可以是权限符号(u=x,a=r+x)。
|
||||
|
||||
在深入之前,我们就以下三点详细说明 MODE 参数。
|
||||
|
||||
1. 如果我们不指定任何参数前缀,它将会寻找 **具体** 权限的文件。
|
||||
2. 如果我们使用 **“-”** 参数前缀, 寻找到的文件至少拥有 mode 所述的权限,而不是具体的权限(大于或等于此权限的文件都会被查找出来)。
|
||||
3. 如果我们使用 **“/”** 参数前缀,那么所有者、组或者其他人任意一个应当享有此文件的权限。
|
||||
|
||||
为了让你更好的理解,让我举些例子。
|
||||
|
||||
首先,我们将要看到基于数字权限查询文件。
|
||||
|
||||
### 基于数字(八进制)权限查询文件
|
||||
|
||||
让我们运行下列命令:
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
这条命令将会查询到当前目录权限为 **确切为 777** 权限的文件。
|
||||
|
||||
![1][4]
|
||||
|
||||
当你看见屏幕输出行时,file1 是唯一一个拥有 **确切为 777 权限** 的文件。
|
||||
|
||||
现在,让我们使用 “-” 参数前缀,看看会发生什么。
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
如你所见,命令行上显示两个文件。我们给 file2 设置了 766 权限,但是命令行显示两个文件,什么鬼?因为,我们设置了 “-” 参数前缀。它意味着这条命令将在所有文件中查询文件所有者的 读/写/执行 权限,文件用户组的 读/写权限和其他用户的 读/写 全西安。本例中,file1 和 file2 都符合要求。换句话说,文件并不一样要求时确切的 766 权限。它将会显示任何属于(高于)此权限的文件 。
|
||||
|
||||
然后,让我们使用 “/” 参数前置,看看会发生什么。
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
上述命令将会查询所有者、用户组或其他拥有写权限的文件。这里有另外一个例子
|
||||
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
这条命令会查询所有者或用户组中拥有写权限的文件。这意味着 **所有者和用户组** 中匹配 **不全拥有写权限**。
|
||||
|
||||
如果你使用 “-” 前缀运行相同的命令,你只会看到所有者和用户组都拥有写权限的文件。
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
下面的截图会告诉你这两个参数前缀的不同。
|
||||
|
||||
![][7]
|
||||
|
||||
如我之前说过的一样,我们可以使用符号表示文件权限。
|
||||
|
||||
请阅读:
|
||||
|
||||
### 基于符号的文件权限查询文件
|
||||
|
||||
在下面的例子中,我们使用例如 **u**(所有者),**g**(用户组) 和 **o**(其他) 的符号表示法。我们也可以使用字母 **a** 代表上述三种类型。我们可以通过特指的 **r** (读), **w** (写), **x** (执行) 分别代表它们的权限。
|
||||
|
||||
例如,寻找用户组中拥有 **写** 权限的文件,执行:
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
上面的例子中,file1 和 file2 都拥有 **写** 权限。请注意,你可以等效使用 “=”或“+”两种符号标识。例如,下列两行相同效果的代码。
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
查询文件所有者中拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
查询所有用户中拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
查询 **所有者** 和 **用户组** 中同时拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
上述命令等效与“find -perm -220”。
|
||||
|
||||
查询 **所有者** 或 **用户组** 中拥有写权限的文件,执行:
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
或者,
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
上述命令等效于 “find -perm /220”。
|
||||
更多详情,参照 man 手册。
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
了解更多简化案例或其他 Linux 命令,查看[**man 手册**][9]。
|
||||
|
||||
然后,这就是所有的内容。希望这个教程有用。更多干货,敬请关注。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7/
|
||||
[3]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png
|
||||
[4]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png
|
||||
[5]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png
|
||||
|
||||
[6]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png
|
||||
[7]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png
|
||||
[8]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png
|
||||
[9]:https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
@ -0,0 +1,95 @@
|
||||
Linux mkdir 命令的初学者教程
|
||||
======
|
||||
|
||||
当你使用命令行的时候,无论什么时候,你都位于一个目录中,它告诉了命令行当前所位于的完整目录。在 Linux 中,你可以使用 `rm` 命令删除目录,但是首先,你需要使用 `mkdir` 命令来创建目录。在这篇教程中,我将使用一些易于理解的例子来讲解这个工具的基本用法。
|
||||
|
||||
在开始之前,值得一提的是,这篇教程中的所有例子都已经在 Ubuntu 16.04 LTS 中测试过。
|
||||
|
||||
### Linux `mkdir` 命令
|
||||
|
||||
正如上面所提到的,用户可以使用 `mkdir` 命令来创建目录。它的语法如下:
|
||||
|
||||
```
|
||||
mkdir [OPTION]... DIRECTORY...
|
||||
```
|
||||
|
||||
下面的内容是 man 手册对这个工具的描述:
|
||||
```
|
||||
Create the DIRECTORY(ies), if they do not already exist.
|
||||
```
|
||||
|
||||
下面这些问答式的例子将能够帮助你更好的理解 `mkdir` 这个命令是如何工作的。
|
||||
|
||||
### Q1. 如何使用 `mkdir` 命令创建目录?
|
||||
|
||||
创建目录非常简单,你唯一需要做的就是把你想创建的目录的名字跟在 `mkdir` 命令的后面作为参数。
|
||||
|
||||
```
|
||||
mkdir [dir-name]
|
||||
```
|
||||
|
||||
下面是一个简单例子:
|
||||
|
||||
```
|
||||
mkdir test-dir
|
||||
```
|
||||
|
||||
### Q2. 如何确保当父目录不存在的时候,同时创建父目录?
|
||||
|
||||
有时候,我们需要使用一条 `mkdir` 命令来创建一个完整的目录结构,这时候,你只需要使用 `-p` 这个命令行选项即可。
|
||||
|
||||
比如,你想创建目录 `dir1/dir2/dir3`,但是,该目录的父目录都不存在,这时候,你可以像下面这样做:
|
||||
|
||||
```
|
||||
mkdir -p dir1/dir2/dir3
|
||||
```
|
||||
|
||||
[![How to make sure parent directories \(if non-existent\) are created][1]][2]
|
||||
|
||||
### Q3. 如何在创建目录时自定义权限?
|
||||
|
||||
默认情况下,`mkdir` 命令创建目录时会把权限设置为 `rwx, rwx, r-x` 。
|
||||
|
||||
[![How to set permissions for directory being created][3]][4]
|
||||
|
||||
但是,如果你想自定义权限,那么你可以使用 `-m` 这一命令行选项。
|
||||
|
||||
[![mkdir -m command option][5]][6]
|
||||
|
||||
### Q4. 如何使 `mkdir` 命令显示操作细节?
|
||||
|
||||
如果你希望 `mkdir` 命令显示它所执行的操作的完整细节,那么你可以使用 `-v` 这一命令行选项。
|
||||
|
||||
```
|
||||
mkdir -v [dir]
|
||||
```
|
||||
|
||||
下面是一个例子:
|
||||
|
||||
[![How to make mkdir emit details of operation][7]][8]
|
||||
|
||||
### 结论
|
||||
|
||||
你已经看到,`mkdir` 是一个非常简单,易于理解和使用的命令。学习这一命令不会遇到任何屏障。在这篇教程中,我们讨论到了它的绝大部分命令行选项。记得练习这些命令,并在日复一日的工作中使用这些命令。如果你想了解关于这一命令的更过内容,请查看它的 [man][9] 手册。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-mkdir-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/mkdir-p.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-p.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/mkdir-def-perm.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-def-perm.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/mkdir-custom-perm.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-custom-perm.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/mkdir-verbose.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-verbose.png
|
||||
[9]:https://linux.die.net/man/1/mkdir
|
||||
Loading…
Reference in New Issue
Block a user