mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
commit
2ff10bf121
75
published/20141127 Keeping (financial) score with Ledger .md
Normal file
75
published/20141127 Keeping (financial) score with Ledger .md
Normal file
@ -0,0 +1,75 @@
|
||||
使用 Ledger 记录(财务)情况
|
||||
======
|
||||
|
||||
自 2005 年搬到加拿大以来,我使用 [Ledger CLI][1] 来跟踪我的财务状况。我喜欢纯文本的方式,它支持虚拟信封意味着我可以同时将我的银行帐户余额和我的虚拟分配到不同的目录下。以下是我们如何使用这些虚拟信封分别管理我们的财务状况。
|
||||
|
||||
每个月,我都有一个条目将我生活开支分配到不同的目录中,包括家庭开支的分配。W- 不要求太多, 所以我要谨慎地处理这两者之间的差别和我自己的生活费用。我们处理它的方式是我支付固定金额,这是贷记我支付的杂货。由于我们的杂货总额通常低于我预算的家庭开支,因此任何差异都会留在标签上。我过去常常给他写支票,但最近我只是支付偶尔额外的大笔费用。
|
||||
|
||||
这是个示例信封分配:
|
||||
|
||||
```
|
||||
2014.10.01 * Budget
|
||||
[Envelopes:Living]
|
||||
[Envelopes:Household] $500
|
||||
;; More lines go here
|
||||
```
|
||||
|
||||
这是设置的信封规则之一。它鼓励我正确地分类支出。所有支出都从我的 “Play” 信封中取出。
|
||||
|
||||
```
|
||||
= /^Expenses/
|
||||
(Envelopes:Play) -1.0
|
||||
```
|
||||
|
||||
这个为家庭支出报销 “Play” 信封,将金额从 “Household” 信封转移到 “Play” 信封。
|
||||
|
||||
```
|
||||
= /^Expenses:House$/
|
||||
(Envelopes:Play) 1.0
|
||||
(Envelopes:Household) -1.0
|
||||
```
|
||||
|
||||
我有一套定期的支出来模拟我的预算中的家庭开支。例如,这是 10 月份的。
|
||||
|
||||
```
|
||||
2014.10.1 * House
|
||||
Expenses:House
|
||||
Assets:Household $-500
|
||||
```
|
||||
|
||||
这是杂货交易的形式:
|
||||
|
||||
```
|
||||
2014.09.28 * No Frills
|
||||
Assets:Household:Groceries $70.45
|
||||
Liabilities:MBNA:September $-70.45
|
||||
|
||||
```
|
||||
|
||||
接着 `ledger bal Assets:Household` 就会告诉我是否欠他钱(负余额)。如果我支付大笔费用(例如:机票、通管道),那么正常家庭开支预算会逐渐减少余额。
|
||||
|
||||
我从 W- 那找到了一个为我的信用卡交易添加一个月标签的技巧,他还使用 Ledger 跟踪他的交易。它允许我再次检查条目的余额,看看前一个条目是否已被正确清除。
|
||||
|
||||
这个资产分类使用有点奇怪,但它在精神上对我有用。
|
||||
|
||||
使用 Ledger 以这种方式跟踪它可以让我跟踪我们的杂货费用以及我实际支付费用和我预算费用之间的差额。如果我最终支出超出预期,我可以从更多可自由支配的信封中移动虚拟货币,因此我的预算始终保持平衡。
|
||||
|
||||
Ledger 是一个强大的工具。相当极客,但也许更多的工作流描述可能会帮助那些正在搞清楚它的人!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
|
||||
作者:[Sacha Chua][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://sachachua.com
|
||||
[1]:http://www.ledger-cli.org/
|
||||
[2]:http://sachachua.com/blog/category/finance/
|
||||
[3]:http://sachachua.com/blog/tag/ledger/
|
||||
[4]:http://pages.sachachua.com/sharing/blog.html?url=http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
[5]:http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/#comments
|
||||
@ -51,7 +51,7 @@
|
||||
|
||||
对于基于 Debian 的发行版,包括 Debian、Ubuntu、Linux Mint、Elementary OS 等,它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为<ruby>新立得<rt>Synaptic</rt></ruby>,它也可以安装在 Ubuntu 上。
|
||||
|
||||
你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比 <ruby>新立得<rt>synaptic</rt></ruy>更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
|
||||
你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比新立得更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
|
||||
|
||||
### 命令行工具
|
||||
|
||||
|
||||
@ -0,0 +1,178 @@
|
||||
在 Linux 上如何得到一个段错误的核心转储
|
||||
============================================================
|
||||
|
||||
本周工作中,我花了整整一周的时间来尝试调试一个段错误。我以前从来没有这样做过,我花了很长时间才弄清楚其中涉及的一些基本事情(获得核心转储、找到导致段错误的行号)。于是便有了这篇博客来解释如何做那些事情!
|
||||
|
||||
在看完这篇博客后,你应该知道如何从“哦,我的程序出现段错误,但我不知道正在发生什么”到“我知道它出现段错误时的堆栈、行号了! “。
|
||||
|
||||
### 什么是段错误?
|
||||
|
||||
“<ruby>段错误<rt>segmentation fault</rt></ruby>”是指你的程序尝试访问不允许访问的内存地址的情况。这可能是由于:
|
||||
|
||||
* 试图解引用空指针(你不被允许访问内存地址 `0`);
|
||||
* 试图解引用其他一些不在你内存(LCTT 译注:指不在合法的内存地址区间内)中的指针;
|
||||
* 一个已被破坏并且指向错误的地方的 <ruby>C++ 虚表指针<rt>C++ vtable pointer</rt></ruby>,这导致程序尝试执行没有执行权限的内存中的指令;
|
||||
* 其他一些我不明白的事情,比如我认为访问未对齐的内存地址也可能会导致段错误(LCTT 译注:在要求自然边界对齐的体系结构,如 MIPS、ARM 中更容易因非对齐访问产生段错误)。
|
||||
|
||||
这个“C++ 虚表指针”是我的程序发生段错误的情况。我可能会在未来的博客中解释这个,因为我最初并不知道任何关于 C++ 的知识,并且这种虚表查找导致程序段错误的情况也是我所不了解的。
|
||||
|
||||
但是!这篇博客后不是关于 C++ 问题的。让我们谈论的基本的东西,比如,我们如何得到一个核心转储?
|
||||
|
||||
### 步骤1:运行 valgrind
|
||||
|
||||
我发现找出为什么我的程序出现段错误的最简单的方式是使用 `valgrind`:我运行
|
||||
|
||||
```
|
||||
valgrind -v your-program
|
||||
```
|
||||
|
||||
这给了我一个故障时的堆栈调用序列。 简洁!
|
||||
|
||||
但我想也希望做一个更深入调查,并找出些 `valgrind` 没告诉我的信息! 所以我想获得一个核心转储并探索它。
|
||||
|
||||
### 如何获得一个核心转储
|
||||
|
||||
<ruby>核心转储<rt>core dump</rt></ruby>是您的程序内存的一个副本,并且当您试图调试您的有问题的程序哪里出错的时候它非常有用。
|
||||
|
||||
当您的程序出现段错误,Linux 的内核有时会把一个核心转储写到磁盘。 当我最初试图获得一个核心转储时,我很长一段时间非常沮丧,因为 - Linux 没有生成核心转储!我的核心转储在哪里?
|
||||
|
||||
这就是我最终做的事情:
|
||||
|
||||
1. 在启动我的程序之前运行 `ulimit -c unlimited`
|
||||
2. 运行 `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
|
||||
### ulimit:设置核心转储的最大尺寸
|
||||
|
||||
`ulimit -c` 设置核心转储的最大尺寸。 它往往设置为 0,这意味着内核根本不会写核心转储。 它以千字节为单位。 `ulimit` 是按每个进程分别设置的 —— 你可以通过运行 `cat /proc/PID/limit` 看到一个进程的各种资源限制。
|
||||
|
||||
例如这些是我的系统上一个随便一个 Firefox 进程的资源限制:
|
||||
|
||||
```
|
||||
$ cat /proc/6309/limits
|
||||
Limit Soft Limit Hard Limit Units
|
||||
Max cpu time unlimited unlimited seconds
|
||||
Max file size unlimited unlimited bytes
|
||||
Max data size unlimited unlimited bytes
|
||||
Max stack size 8388608 unlimited bytes
|
||||
Max core file size 0 unlimited bytes
|
||||
Max resident set unlimited unlimited bytes
|
||||
Max processes 30571 30571 processes
|
||||
Max open files 1024 1048576 files
|
||||
Max locked memory 65536 65536 bytes
|
||||
Max address space unlimited unlimited bytes
|
||||
Max file locks unlimited unlimited locks
|
||||
Max pending signals 30571 30571 signals
|
||||
Max msgqueue size 819200 819200 bytes
|
||||
Max nice priority 0 0
|
||||
Max realtime priority 0 0
|
||||
Max realtime timeout unlimited unlimited us
|
||||
```
|
||||
|
||||
内核在决定写入多大的核心转储文件时使用<ruby>软限制<rt>soft limit</rt></ruby>(在这种情况下,`max core file size = 0`)。 您可以使用 shell 内置命令 `ulimit`(`ulimit -c unlimited`) 将软限制增加到<ruby>硬限制<rt>hard limit</rt></ruby>。
|
||||
|
||||
### kernel.core_pattern:核心转储保存在哪里
|
||||
|
||||
`kernel.core_pattern` 是一个内核参数,或者叫 “sysctl 设置”,它控制 Linux 内核将核心转储文件写到磁盘的哪里。
|
||||
|
||||
内核参数是一种设定您的系统全局设置的方法。您可以通过运行 `sysctl -a` 得到一个包含每个内核参数的列表,或使用 `sysctl kernel.core_pattern` 来专门查看 `kernel.core_pattern` 设置。
|
||||
|
||||
所以 `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t` 将核心转储保存到目录 `/tmp` 下,并以 `core` 加上一系列能够标识(出故障的)进程的参数构成的后缀为文件名。
|
||||
|
||||
如果你想知道这些形如 `%e`、`%p` 的参数都表示什么,请参考 [man core][1]。
|
||||
|
||||
有一点很重要,`kernel.core_pattern` 是一个全局设置 —— 修改它的时候最好小心一点,因为有可能其它系统功能依赖于把它被设置为一个特定的方式(才能正常工作)。
|
||||
|
||||
### kernel.core_pattern 和 Ubuntu
|
||||
|
||||
默认情况下在 ubuntu 系统中,`kernel.core_pattern` 被设置为下面的值:
|
||||
|
||||
```
|
||||
$ sysctl kernel.core_pattern
|
||||
kernel.core_pattern = |/usr/share/apport/apport %p %s %c %d %P
|
||||
```
|
||||
|
||||
这引起了我的迷惑(这 apport 是干什么的,它对我的核心转储做了什么?)。以下关于这个我了解到的:
|
||||
|
||||
* Ubuntu 使用一种叫做 apport 的系统来报告 apt 包有关的崩溃信息。
|
||||
* 设定 `kernel.core_pattern=|/usr/share/apport/apport %p %s %c %d %P` 意味着核心转储将被通过管道送给 `apport` 程序。
|
||||
* apport 的日志保存在文件 `/var/log/apport.log` 中。
|
||||
* apport 默认会忽略来自不属于 Ubuntu 软件包一部分的二进制文件的崩溃信息
|
||||
|
||||
我最终只是跳过了 apport,并把 `kernel.core_pattern` 重新设置为 `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`,因为我在一台开发机上,我不在乎 apport 是否工作,我也不想尝试让 apport 把我的核心转储留在磁盘上。
|
||||
|
||||
### 现在你有了核心转储,接下来干什么?
|
||||
|
||||
好的,现在我们了解了 `ulimit` 和 `kernel.core_pattern` ,并且实际上在磁盘的 `/tmp` 目录中有了一个核心转储文件。太好了!接下来干什么?我们仍然不知道该程序为什么会出现段错误!
|
||||
|
||||
下一步将使用 `gdb` 打开核心转储文件并获取堆栈调用序列。
|
||||
|
||||
### 从 gdb 中得到堆栈调用序列
|
||||
|
||||
你可以像这样用 `gdb` 打开一个核心转储文件:
|
||||
|
||||
```
|
||||
$ gdb -c my_core_file
|
||||
```
|
||||
|
||||
接下来,我们想知道程序崩溃时的堆栈是什么样的。在 `gdb` 提示符下运行 `bt` 会给你一个<ruby>调用序列<rt>backtrace</rt></ruby>。在我的例子里,`gdb` 没有为二进制文件加载符号信息,所以这些函数名就像 “??????”。幸运的是,(我们通过)加载符号修复了它。
|
||||
|
||||
下面是如何加载调试符号。
|
||||
|
||||
```
|
||||
symbol-file /path/to/my/binary
|
||||
sharedlibrary
|
||||
```
|
||||
|
||||
这从二进制文件及其引用的任何共享库中加载符号。一旦我这样做了,当我执行 `bt` 时,gdb 给了我一个带有行号的漂亮的堆栈跟踪!
|
||||
|
||||
如果你想它能工作,二进制文件应该以带有调试符号信息的方式被编译。在试图找出程序崩溃的原因时,堆栈跟踪中的行号非常有帮助。:)
|
||||
|
||||
### 查看每个线程的堆栈
|
||||
|
||||
通过以下方式在 `gdb` 中获取每个线程的调用栈!
|
||||
|
||||
```
|
||||
thread apply all bt full
|
||||
```
|
||||
|
||||
### gdb + 核心转储 = 惊喜
|
||||
|
||||
|
||||
如果你有一个带调试符号的核心转储以及 `gdb`,那太棒了!您可以上下查看调用堆栈(LCTT 译注:指跳进调用序列不同的函数中以便于查看局部变量),打印变量,并查看内存来得知发生了什么。这是最好的。
|
||||
|
||||
如果您仍然正在基于 gdb 向导来工作上,只打印出栈跟踪与bt也可以。 :)
|
||||
|
||||
### ASAN
|
||||
|
||||
另一种搞清楚您的段错误的方法是使用 AddressSanitizer 选项编译程序(“ASAN”,即 `$CC -fsanitize=address`)然后运行它。 本文中我不准备讨论那个,因为本文已经相当长了,并且在我的例子中打开 ASAN 后段错误消失了,可能是因为 ASAN 使用了一个不同的内存分配器(系统内存分配器,而不是 tcmalloc)。
|
||||
|
||||
在未来如果我能让 ASAN 工作,我可能会多写点有关它的东西。(LCTT 译注:这里指使用 ASAN 也能复现段错误)
|
||||
|
||||
### 从一个核心转储得到一个堆栈跟踪真的很亲切!
|
||||
|
||||
这个博客听起来很多,当我做这些的时候很困惑,但说真的,从一个段错误的程序中获得一个堆栈调用序列不需要那么多步骤:
|
||||
|
||||
1. 试试用 `valgrind`
|
||||
|
||||
如果那没用,或者你想要拿到一个核心转储来调查:
|
||||
|
||||
1. 确保二进制文件编译时带有调试符号信息;
|
||||
2. 正确的设置 `ulimit` 和 `kernel.core_pattern`;
|
||||
3. 运行程序;
|
||||
4. 一旦你用 `gdb` 调试核心转储了,加载符号并运行 `bt`;
|
||||
5. 尝试找出发生了什么!
|
||||
|
||||
我可以使用 `gdb` 弄清楚有个 C++ 的虚表条目指向一些被破坏的内存,这有点帮助,并且使我感觉好像更懂了 C++ 一点。也许有一天我们会更多地讨论如何使用 `gdb` 来查找问题!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/04/28/debugging-a-segfault-on-linux/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about/
|
||||
[1]:http://man7.org/linux/man-pages/man5/core.5.html
|
||||
359
published/20180429 Passwordless Auth- Client.md
Normal file
359
published/20180429 Passwordless Auth- Client.md
Normal file
@ -0,0 +1,359 @@
|
||||
无密码验证:客户端
|
||||
======
|
||||
|
||||
我们继续 [无密码验证][1] 的文章。上一篇文章中,我们用 Go 写了一个 HTTP 服务,用这个服务来做无密码验证 API。今天,我们为它再写一个 JavaScript 客户端。
|
||||
|
||||
我们将使用 [这里的][2] 这个单页面应用程序(SPA)来展示使用的技术。如果你还没有读过它,请先读它。
|
||||
|
||||
记住流程:
|
||||
|
||||
- 用户输入其 email。
|
||||
- 用户收到一个带有魔法链接的邮件。
|
||||
- 用户点击该链接、
|
||||
- 用户验证成功。
|
||||
|
||||
对于根 URL(`/`),我们将根据验证的状态分别使用两个不同的页面:一个是带有访问表单的页面,或者是已验证通过的用户的欢迎页面。另一个页面是验证回调的重定向页面。
|
||||
|
||||
### 伺服
|
||||
|
||||
我们将使用相同的 Go 服务器来为客户端提供服务,因此,在我们前面的 `main.go` 中添加一些路由:
|
||||
|
||||
```
|
||||
router.Handle("GET", "/...", http.FileServer(SPAFileSystem{http.Dir("static")}))
|
||||
```
|
||||
|
||||
```
|
||||
type SPAFileSystem struct {
|
||||
fs http.FileSystem
|
||||
}
|
||||
|
||||
func (spa SPAFileSystem) Open(name string) (http.File, error) {
|
||||
f, err := spa.fs.Open(name)
|
||||
if err != nil {
|
||||
return spa.fs.Open("index.html")
|
||||
}
|
||||
return f, nil
|
||||
}
|
||||
```
|
||||
|
||||
这个伺服文件放在 `static` 下,配合 `static/index.html` 作为回调。
|
||||
|
||||
你可以使用你自己的服务器,但是你得在服务器上启用 [CORS][3]。
|
||||
|
||||
### HTML
|
||||
|
||||
我们来看一下那个 `static/index.html` 文件。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Passwordless Demo</title>
|
||||
<link rel="shortcut icon" href="data:,">
|
||||
<script src="/js/main.js" type="module"></script>
|
||||
</head>
|
||||
<body></body>
|
||||
</html>
|
||||
```
|
||||
|
||||
单页面应用程序的所有渲染由 JavaScript 来完成,因此,我们使用了一个空的 body 部分和一个 `main.js` 文件。
|
||||
|
||||
我们将使用 [上篇文章][2] 中的 Router。
|
||||
|
||||
### 渲染
|
||||
|
||||
现在,我们使用下面的内容来创建一个 `static/js/main.js` 文件:
|
||||
|
||||
```
|
||||
import Router from 'https://unpkg.com/@nicolasparada/router'
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
const router = new Router()
|
||||
|
||||
router.handle('/', guard(view('home')))
|
||||
router.handle('/callback', view('callback'))
|
||||
router.handle(/^\//, view('not-found'))
|
||||
|
||||
router.install(async resultPromise => {
|
||||
document.body.innerHTML = ''
|
||||
document.body.appendChild(await resultPromise)
|
||||
})
|
||||
|
||||
function view(name) {
|
||||
return (...args) => import(`/js/pages/${name}-page.js`)
|
||||
.then(m => m.default(...args))
|
||||
}
|
||||
|
||||
function guard(fn1, fn2 = view('welcome')) {
|
||||
return (...args) => isAuthenticated()
|
||||
? fn1(...args)
|
||||
: fn2(...args)
|
||||
}
|
||||
```
|
||||
|
||||
与上篇文章不同的是,我们实现了一个 `isAuthenticated()` 函数和一个 `guard()` 函数,使用它去渲染两种验证状态的页面。因此,当用户访问 `/` 时,它将根据用户是否通过了验证来展示主页或者是欢迎页面。
|
||||
|
||||
### 验证
|
||||
|
||||
现在,我们来编写 `isAuthenticated()` 函数。使用下面的内容来创建一个 `static/js/auth.js` 文件:
|
||||
|
||||
```
|
||||
export function getAuthUser() {
|
||||
const authUserItem = localStorage.getItem('auth_user')
|
||||
const expiresAtItem = localStorage.getItem('expires_at')
|
||||
|
||||
if (authUserItem !== null && expiresAtItem !== null) {
|
||||
const expiresAt = new Date(expiresAtItem)
|
||||
|
||||
if (!isNaN(expiresAt.valueOf()) && expiresAt > new Date()) {
|
||||
try {
|
||||
return JSON.parse(authUserItem)
|
||||
} catch (_) { }
|
||||
}
|
||||
}
|
||||
|
||||
return null
|
||||
}
|
||||
|
||||
export function isAuthenticated() {
|
||||
return localStorage.getItem('jwt') !== null && getAuthUser() !== null
|
||||
}
|
||||
```
|
||||
|
||||
当有人登入时,我们将保存 JSON 格式的 web 令牌、它的过期日期,以及在 `localStorage` 上的当前已验证用户。这个模块就是这个用处。
|
||||
|
||||
* `getAuthUser()` 用于从 `localStorage` 获取已认证的用户,以确认 JSON 格式的 Web 令牌没有过期。
|
||||
* `isAuthenticated()` 在前面的函数中用于去检查它是否没有返回 `null`。
|
||||
|
||||
### 获取
|
||||
|
||||
在继续这个页面之前,我将写一些与服务器 API 一起使用的 HTTP 工具。
|
||||
|
||||
我们使用以下的内容去创建一个 `static/js/http.js` 文件:
|
||||
|
||||
```
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
function get(url, headers) {
|
||||
return fetch(url, {
|
||||
headers: Object.assign(getAuthHeader(), headers),
|
||||
}).then(handleResponse)
|
||||
}
|
||||
|
||||
function post(url, body, headers) {
|
||||
return fetch(url, {
|
||||
method: 'POST',
|
||||
headers: Object.assign(getAuthHeader(), { 'content-type': 'application/json' }, headers),
|
||||
body: JSON.stringify(body),
|
||||
}).then(handleResponse)
|
||||
}
|
||||
|
||||
function getAuthHeader() {
|
||||
return isAuthenticated()
|
||||
? { authorization: `Bearer ${localStorage.getItem('jwt')}` }
|
||||
: {}
|
||||
}
|
||||
|
||||
export async function handleResponse(res) {
|
||||
const body = await res.clone().json().catch(() => res.text())
|
||||
const response = {
|
||||
statusCode: res.status,
|
||||
statusText: res.statusText,
|
||||
headers: res.headers,
|
||||
body,
|
||||
}
|
||||
if (!res.ok) {
|
||||
const message = typeof body === 'object' && body !== null && 'message' in body
|
||||
? body.message
|
||||
: typeof body === 'string' && body !== ''
|
||||
? body
|
||||
: res.statusText
|
||||
const err = new Error(message)
|
||||
throw Object.assign(err, response)
|
||||
}
|
||||
return response
|
||||
}
|
||||
|
||||
export default {
|
||||
get,
|
||||
post,
|
||||
}
|
||||
```
|
||||
|
||||
这个模块导出了 `get()` 和 `post()` 函数。它们是 `fetch` API 的封装。当用户是已验证的,这二个函数注入一个 `Authorization: Bearer <token_here>` 头到请求中;这样服务器就能对我们进行身份验证。
|
||||
|
||||
### 欢迎页
|
||||
|
||||
我们现在来到欢迎页面。用如下的内容创建一个 `static/js/pages/welcome-page.js` 文件:
|
||||
|
||||
```
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Passwordless Demo</h1>
|
||||
<h2>Access</h2>
|
||||
<form id="access-form">
|
||||
<input type="email" placeholder="Email" autofocus required>
|
||||
<button type="submit">Send Magic Link</button>
|
||||
</form>
|
||||
`
|
||||
|
||||
export default function welcomePage() {
|
||||
const page = template.content.cloneNode(true)
|
||||
|
||||
page.getElementById('access-form')
|
||||
.addEventListener('submit', onAccessFormSubmit)
|
||||
|
||||
return page
|
||||
}
|
||||
```
|
||||
|
||||
这个页面使用一个 `HTMLTemplateElement` 作为视图。这只是一个输入用户 email 的简单表单。
|
||||
|
||||
为了避免干扰,我将跳过错误处理部分,只是将它们输出到控制台上。
|
||||
|
||||
现在,我们来写 `onAccessFormSubmit()` 函数。
|
||||
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
function onAccessFormSubmit(ev) {
|
||||
ev.preventDefault()
|
||||
|
||||
const form = ev.currentTarget
|
||||
const input = form.querySelector('input')
|
||||
const email = input.value
|
||||
|
||||
sendMagicLink(email).catch(err => {
|
||||
console.error(err)
|
||||
if (err.statusCode === 404 && wantToCreateAccount()) {
|
||||
runCreateUserProgram(email)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
function sendMagicLink(email) {
|
||||
return http.post('/api/passwordless/start', {
|
||||
email,
|
||||
redirectUri: location.origin + '/callback',
|
||||
}).then(() => {
|
||||
alert('Magic link sent. Go check your email inbox.')
|
||||
})
|
||||
}
|
||||
|
||||
function wantToCreateAccount() {
|
||||
return prompt('No user found. Do you want to create an account?')
|
||||
}
|
||||
```
|
||||
|
||||
它对 `/api/passwordless/start` 发起了 POST 请求,请求体中包含 `email` 和 `redirectUri`。在本例中它返回 `404 Not Found` 状态码时,我们将创建一个用户。
|
||||
|
||||
```
|
||||
function runCreateUserProgram(email) {
|
||||
const username = prompt("Enter username")
|
||||
if (username === null) return
|
||||
|
||||
http.post('/api/users', { email, username })
|
||||
.then(res => res.body)
|
||||
.then(user => sendMagicLink(user.email))
|
||||
.catch(console.error)
|
||||
}
|
||||
```
|
||||
|
||||
这个用户创建程序,首先询问用户名,然后使用 email 和用户名做一个 `POST` 请求到 `/api/users`。成功之后,给创建的用户发送一个魔法链接。
|
||||
|
||||
### 回调页
|
||||
|
||||
这是访问表单的全部功能,现在我们来做回调页面。使用如下的内容来创建一个 `static/js/pages/callback-page.js` 文件:
|
||||
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Authenticating you</h1>
|
||||
`
|
||||
|
||||
export default function callbackPage() {
|
||||
const page = template.content.cloneNode(true)
|
||||
|
||||
const hash = location.hash.substr(1)
|
||||
const fragment = new URLSearchParams(hash)
|
||||
for (const [k, v] of fragment.entries()) {
|
||||
fragment.set(decodeURIComponent(k), decodeURIComponent(v))
|
||||
}
|
||||
const jwt = fragment.get('jwt')
|
||||
const expiresAt = fragment.get('expires_at')
|
||||
|
||||
http.get('/api/auth_user', { authorization: `Bearer ${jwt}` })
|
||||
.then(res => res.body)
|
||||
.then(authUser => {
|
||||
localStorage.setItem('jwt', jwt)
|
||||
localStorage.setItem('auth_user', JSON.stringify(authUser))
|
||||
localStorage.setItem('expires_at', expiresAt)
|
||||
|
||||
location.replace('/')
|
||||
})
|
||||
.catch(console.error)
|
||||
|
||||
return page
|
||||
}
|
||||
```
|
||||
|
||||
请记住……当点击魔法链接时,我们会来到 `/api/passwordless/verify_redirect`,它将把我们重定向到重定向 URI,我们将放在哈希中的 JWT 和过期日期传递给 `/callback`。
|
||||
|
||||
回调页面解码 URL 中的哈希,提取这些参数去做一个 `GET` 请求到 `/api/auth_user`,用 JWT 保存所有数据到 `localStorage` 中。最后,重定向到主页面。
|
||||
|
||||
### 主页
|
||||
|
||||
创建如下内容的 `static/pages/home-page.js` 文件:
|
||||
|
||||
```
|
||||
import { getAuthUser } from '../auth.js'
|
||||
|
||||
export default function homePage() {
|
||||
const authUser = getAuthUser()
|
||||
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Passwordless Demo</h1>
|
||||
<p>Welcome back, ${authUser.username} 👋</p>
|
||||
<button id="logout-button">Logout</button>
|
||||
`
|
||||
|
||||
const page = template.content
|
||||
|
||||
page.getElementById('logout-button')
|
||||
.addEventListener('click', logout)
|
||||
|
||||
return page
|
||||
}
|
||||
|
||||
function logout() {
|
||||
localStorage.clear()
|
||||
location.reload()
|
||||
}
|
||||
```
|
||||
|
||||
这个页面用于欢迎已验证用户,同时也有一个登出按钮。`logout()` 函数的功能只是清理掉 `localStorage` 并重载这个页面。
|
||||
|
||||
这就是全部内容了。我猜你在此之前已经看过这个 [demo][4] 了。当然,这些源代码也在同一个 [仓库][5] 中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/passwordless-auth-client/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://nicolasparada.netlify.com/
|
||||
[1]:https://linux.cn/article-9748-1.html
|
||||
[2]:https://linux.cn/article-9815-1.html
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
|
||||
[4]:https://go-passwordless-demo.herokuapp.com/
|
||||
[5]:https://github.com/nicolasparada/go-passwordless-demo
|
||||
@ -1,12 +1,16 @@
|
||||
在 Linux 命令行中自定义文本颜色
|
||||
======
|
||||
|
||||

|
||||
如果你在 Linux 命令行上花费了大量的时间(如果没有,那么你可能不会读这篇文章),你无疑注意到了 ls 以多种不同的颜色显示文件。你可能也注意到了一些区别 -- 目录是一种颜色,可执行文件是另一种颜色等等。
|
||||
> 在 Linux 命令行当中使用不同颜色以期提供一种根据文件类型来识别文件的简单方式。你可以修改这些颜色,但是在做之前应该对你做的事情有充分的理由。
|
||||
|
||||

|
||||
|
||||
如果你在 Linux 命令行上花费了大量的时间(如果没有,那么你可能不会读这篇文章),你无疑注意到了 `ls` 以多种不同的颜色显示文件。你可能也注意到了一些区别 —— 目录是一种颜色,可执行文件是另一种颜色等等。
|
||||
|
||||
这一切是如何发生的呢?以及,你可以选择哪些选项来改变颜色分配可能就不是很多人都知道的。
|
||||
|
||||
一种方法是运行 `dircolors` 命令得到一大堆展示了如何指定这些颜色的数据。它会显示以下这些东西:
|
||||
|
||||
这一切是如何发生的呢?而且,你可以选择哪些选项来改变颜色分配可能不是那么明显。
|
||||
|
||||
获取大量数据显示如何分配这些颜色的一种方法是运行 **dircolors** 命令。它会显示以下这些东西:
|
||||
```
|
||||
$ dircolors
|
||||
LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do
|
||||
@ -35,10 +39,10 @@ mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:
|
||||
36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;
|
||||
36:*.spx=00;36:*.xspf=00;36:';
|
||||
export LS_COLORS
|
||||
|
||||
```
|
||||
|
||||
如果你擅长解析文件,那么你可能会注意到这个列表有一个模式。加上冒号,你会看到这样的东西:
|
||||
如果你擅长解析文件,那么你可能会注意到这个列表有一种<ruby>模式<rt>patten</rt></ruby>。用冒号分隔开,你会看到这样的东西:
|
||||
|
||||
```
|
||||
$ dircolors | tr ":" "\n" | head -10
|
||||
LS_COLORS='rs=0
|
||||
@ -51,34 +55,34 @@ do=01;35
|
||||
bd=40;33;01
|
||||
cd=40;33;01
|
||||
or=40;31;01
|
||||
|
||||
```
|
||||
|
||||
好的,我们在这里有一个模式 -- 一系列定义,有一到三个数字组件。让我们来看看其中的一个定义。
|
||||
OK,这里有一个模式 —— 一系列定义,有一到三个数字组件。我们来看看其中的一个定义。
|
||||
|
||||
```
|
||||
pi=40;33
|
||||
|
||||
```
|
||||
|
||||
有些人可能会问的第一个问题是“ pi 是什么?”我们在这里处理颜色和文件类型,所以这显然不是以 3.14 开头的有趣数字。当然不是,这个“ pi ” 代表“ pipe (管道)” -- Linux 系统上的一种特殊类型的文件,它可以将数据从一个程序发送到另一个程序。所以,让我们建立一个。
|
||||
有些人可能会问的第一个问题是“pi 是什么?”在这里,我们研究的是颜色和文件类型,所以这显然不是以 3.14 开头的那个有趣的数字。当然不是,这个 “pi” 代表 “pipe(管道)” —— Linux 系统上的一种特殊类型的文件,它可以将数据从一个程序传递给另一个程序。所以,让我们建立一个管道。
|
||||
|
||||
```
|
||||
$ mknod /tmp/mypipe p
|
||||
$ ls -l /tmp/mypipe
|
||||
prw-rw-r-- 1 shs shs 0 May 1 14:00 /tmp/mypipe
|
||||
|
||||
```
|
||||
|
||||
当我们在终端窗口中查看我们的管道和其他几个文件时,颜色差异非常明显。
|
||||
|
||||
![font colors][1] Sandra Henry-Stocker
|
||||
![font colors][1]
|
||||
|
||||
在 pi 的定义中(如上所示),“40” 是文件显示在带有黑色背景的终端(或 PuTTY)窗口中,31 使字体颜色变红。管道是特殊的文件,这种特殊的处理使它们在目录列表中突出显示。
|
||||
在 `pi` 的定义中(如上所示),“40” 使文件在终端(或 PuTTY)窗口中使用黑色背景显示,31 使字体颜色变红。管道是特殊的文件,这种特殊的处理使它们在目录列表中突出显示。
|
||||
|
||||
**bd** 和 **cd** 定义是相同的 - 40;33;01 并且有一个额外的设置。设置会导致块(bd)和字符(cd)设备以黑色背景,橙色字体和另一种效果显示 -- 字符将以粗体显示。
|
||||
`bd` 和 `cd` 定义是相同的 —— `40;33;01`,它有一个额外的设置。这个设置会导致 <ruby>块设备<rt>block device</rt></ruby>(bd)和 <ruby>字符设备<rt>character device</rt></ruby>(cd)以黑色背景,橙色字体和另一种效果显示 —— 字符将以粗体显示。
|
||||
|
||||
以下列表显示由<ruby>文件类型<rt>file type</rt></ruby>所指定的颜色和字体分配:
|
||||
|
||||
以下列表显示由 **file type** 创建的颜色和字体分配:
|
||||
```
|
||||
setting file type
|
||||
setting file type
|
||||
======= =========
|
||||
rs=0 reset to no color
|
||||
di=01;34 directory
|
||||
@ -98,10 +102,10 @@ tw=30;42 directory with sticky bit and world writable
|
||||
ow=34;42 directory that is world writable
|
||||
st=37;44 directory with sticky bit
|
||||
ex=01;93 executable
|
||||
|
||||
```
|
||||
|
||||
你可能已经注意到,在我们的 **dircolors** 命令输出中,我们的大多数定义都以星号开头(例如,*.wav=00;36)。这些按**文件扩展名**而不是文件类型定义显示属性。这有一个示例:
|
||||
你可能已经注意到,在 `dircolors` 命令输出中,我们的大多数定义都以星号开头(例如,`*.wav=00;36`)。这些按<ruby>文件扩展名<rt>file extension</rt></ruby>而不是文件类型定义显示属性。这有一个示例:
|
||||
|
||||
```
|
||||
$ dircolors | tr ":" "\n" | tail -10
|
||||
*.mpc=00;36
|
||||
@ -114,49 +118,48 @@ $ dircolors | tr ":" "\n" | tail -10
|
||||
*.xspf=00;36
|
||||
';
|
||||
export LS_COLORS
|
||||
|
||||
```
|
||||
|
||||
这些设置(上面列表中的所有 00:36)将使这些文件名以青色显示。可用颜色如下所示。
|
||||
这些设置(上面列表中所有的 `00;36`)将使这些文件名以青色显示。可用的颜色如下所示。
|
||||
|
||||
![all colors][2] Sandra Henry-Stocker
|
||||
![all colors][2]
|
||||
|
||||
### 如何改变设置
|
||||
|
||||
所描述的颜色和字体变化要求你使用 ls 的别名来打开颜色功能。这通常是 Linux 系统上的默认设置,看起来是这样的:
|
||||
你要使用 `ls` 的别名来打开颜色显示功能。这通常是 Linux 系统上的默认设置,看起来是这样的:
|
||||
|
||||
```
|
||||
alias ls='ls --color=auto'
|
||||
|
||||
```
|
||||
|
||||
如果要关闭字体颜色,可以运行 **unalias ls** 命令,然后文件列表将仅以默认字体颜色显示。
|
||||
如果要关闭字体颜色,可以运行 `unalias ls` 命令,然后文件列表将仅以默认字体颜色显示。
|
||||
|
||||
你可以通过修改 `$LS_COLORS` 设置和导出修改后的设置来更改文本颜色。
|
||||
|
||||
你可以通过修改 $LS_COLORS 设置和导出修改后的设置来更改文本颜色。
|
||||
```
|
||||
$ export LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;...
|
||||
|
||||
```
|
||||
|
||||
注意:上面的命令被截断了。
|
||||
注意:上面的命令由于太长被截断了。
|
||||
|
||||
如果希望修改后的文本颜色是永久性的,则需要将修改后的 LS_COLORS 定义添加到一个启动文件中,例如 .bashrc。
|
||||
如果希望文本颜色的修改是永久性的,则需要将修改后的 `$LS_COLORS` 定义添加到一个启动文件中,例如 `.bashrc`。
|
||||
|
||||
### 更多关于命令行文本
|
||||
|
||||
你可以在 NetworkWorld 的 [2016 年 11 月][3]的帖子中找到有关文本颜色的其他信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: https://www.networkworld.com/article/3269587/linux/customizing-your-text-colors-on-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven ](https://github.com/MjSeven )
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://images.idgesg.net/images/article/2018/05/font-colors-100756483-large.jpg
|
||||
[2]:https://images.techhive.com/images/article/2016/11/all-colors-100691990-large.jpg
|
||||
[3]:https://www.networkworld.com/article/3138909/linux/coloring-your-world-with-ls-colors.html
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://images.idgesg.net/images/article/2018/05/font-colors-100756483-large.jpg
|
||||
[2]: https://images.techhive.com/images/article/2016/11/all-colors-100691990-large.jpg
|
||||
[3]: https://www.networkworld.com/article/3138909/linux/coloring-your-world-with-ls-colors.html
|
||||
71
published/20180606 6 Open Source AI Tools to Know.md
Normal file
71
published/20180606 6 Open Source AI Tools to Know.md
Normal file
@ -0,0 +1,71 @@
|
||||
你应该了解的 6 个开源 AI 工具
|
||||
======
|
||||
|
||||
> 让我们来看看几个任何人都能用的自由开源的 AI 工具。
|
||||
|
||||

|
||||
|
||||
在开源领域,不管你的想法是多少的新颖独到,先去看一下别人是否已经做成了这个概念,总是一个很明智的做法。对于有兴趣借助不断成长的<ruby>人工智能<rt>Artificial Intelligence</rt></ruby>(AI)的力量的组织和个人来说,许多优秀的工具不仅是自由开源的,而且在很多的情况下,它们都已经过测试和久经考验的。
|
||||
|
||||
在领先的公司和非盈利组织中,AI 的优先级都非常高,并且这些公司和组织都开源了很有价值的工具。下面的举例是任何人都可以使用的自由开源的 AI 工具。
|
||||
|
||||
### Acumos
|
||||
|
||||
[Acumos AI][1] 是一个平台和开源框架,使用它可以很容易地去构建、共享和分发 AI 应用。它规范了运行一个“开箱即用的”通用 AI 环境所需要的<ruby>基础设施栈<rt>infrastructure stack</rt></ruby>和组件。这使得数据科学家和模型训练者可以专注于它们的核心竞争力,而不用在无止境的定制、建模,以及训练一个 AI 实现上浪费时间。
|
||||
|
||||
Acumos 是 [LF 深度学习基金会][2] 的一部分,它是 Linux 基金会中的一个组织,它支持在人工智能、<ruby>机器学习<rt>machine learning</rt><ruby>、以及<ruby>深度学习<rt>deep learning</rt></ruby>方面的开源创新。它的目标是让这些重大的新技术可用于开发者和数据科学家,包括那些在深度学习和 AI 上经验有限的人。LF 深度学习基金会 [最近批准了一个项目生命周期和贡献流程][3],并且它现在正接受项目贡献的建议。
|
||||
|
||||
### Facebook 的框架
|
||||
|
||||
Facebook [开源了][4] 其中心机器学习系统,它设计用于做一些大规模的人工智能任务,以及一系列其它的 AI 技术。这个工具是经过他们公司验证使用的平台的一部分。Facebook 也开源了一个叫 [Caffe2][5] 的深度学习和人工智能的框架。
|
||||
|
||||
### CaffeOnSpark
|
||||
|
||||
**说到 Caffe**。 Yahoo 也在开源许可证下发布了它自己的关键的 AI 软件。[CaffeOnSpark 工具][6] 是基于深度学习的,它是人工智能的一个分支,在帮助机器识别人类语言,或者照片、视频的内容方面非常有用。同样地,IBM 的机器学习程序 [SystemML][7] 可以通过 Apache 软件基金会自由地共享和修改。
|
||||
|
||||
### Google 的工具
|
||||
|
||||
Google 花费了几年的时间开发了它自己的 [TensorFlow][8] 软件框架,用于去支持它的 AI 软件和其它预测和分析程序。TensorFlow 是你可能都已经在使用的一些 Google 工具背后的引擎,包括 Google Photos 和在 Google app 中使用的语言识别。
|
||||
|
||||
Google 开源了两个 [AIY 套件][9],它可以让个人很容易地使用人工智能,它们专注于计算机视觉和语音助理。这两个套件将用到的所有组件封装到一个盒子中。该套件目前在美国的 Target 中有售,并且它是基于开源的树莓派平台的 —— 有越来越多的证据表明,在开源和 AI 交集中将发生非常多的事情。
|
||||
|
||||
### H2O.ai
|
||||
|
||||
我 [以前介绍过][10] H2O.ai,它在机器学习和人工智能领域中占有一席之地,因为它的主要工具是自由开源的。你可以获取主要的 H2O 平台和 Sparkling Water,它与 Apache Spark 一起工作,只需要去 [下载][11] 它们即可。这些工具遵循 Apache 2.0 许可证,它是一个非常灵活的开源许可证,你甚至可以在 Amazon Web 服务(AWS)和其它的集群上运行它们,而这仅需要几百美元而已。
|
||||
|
||||
### Microsoft 入局
|
||||
|
||||
“我们的目标是让 AI 大众化,让每个人和组织获得更大的成就,“ Microsoft CEO 萨提亚·纳德拉 [说][12]。因此,微软持续迭代它的 [Microsoft Cognitive Toolkit][13](CNTK)。它是一个能够与 TensorFlow 和 Caffe 去竞争的一个开源软件框架。Cognitive Toolkit 可以工作在 64 位的 Windows 和 Linux 平台上。
|
||||
|
||||
Cognitive Toolkit 团队的报告称,“Cognitive Toolkit 通过允许用户去创建、训练,以及评估他们自己的神经网络,以使企业级的、生产系统级的 AI 成为可能,这些神经网络可能跨多个 GPU 以及多个机器在大量的数据集中高效伸缩。”
|
||||
|
||||
---
|
||||
|
||||
从来自 Linux 基金会的新电子书中学习更多的有关 AI 知识。Ibrahim Haddad 的 [开源 AI:项目、洞察和趋势][14] 调查了 16 个流行的开源 AI 项目—— 深入研究了他们的历史、代码库、以及 GitHub 的贡献。 [现在可以免费下载这个电子书][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.acumos.org/
|
||||
[2]:https://www.linuxfoundation.org/projects/deep-learning/
|
||||
[3]:https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/
|
||||
[4]:https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
|
||||
[5]:https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
|
||||
[6]:http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
|
||||
[7]:https://systemml.apache.org/
|
||||
[8]:https://www.tensorflow.org/
|
||||
[9]:https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control
|
||||
[10]:https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark
|
||||
[11]:http://www.h2o.ai/download
|
||||
[12]:https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/
|
||||
[13]:https://www.microsoft.com/en-us/cognitive-toolkit/
|
||||
[14]:https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/
|
||||
@ -1,14 +1,18 @@
|
||||
Buildah 入门
|
||||
======
|
||||
|
||||
> Buildah 提供一种灵活、可脚本编程的方式,来使用你熟悉的工具创建精简、高效的容器镜像。
|
||||
|
||||

|
||||
|
||||
[Buildah][1] 是一个命令行工具,可以方便、快捷的构建与[<ruby>开放容器标准<rt>Open Container Initiative, OCI</rt></ruby>][2]兼容的容器镜像,意味着构建的镜像也与 Docker 和 Kubernetes 兼容。该工具可作为 Docker 守护进程 `docker build` 命令(即使用传统的 Dockerfile 构建镜像)的一种<ruby>简单<rt>drop-in</rt></ruby>替换,而且更加灵活,允许构建镜像时使用你擅长的工具。Buildah 可以轻松与脚本集成并生成<ruby>流水线<rt>pipelines</rt></ruby>,最好之处在于构建镜像不再需要运行容器守护进程(LCTT 译注:这里主要是指 Docker 守护进程)。
|
||||
[Buildah][1] 是一个命令行工具,可以方便、快捷的构建与<ruby>[开放容器标准][2]<rt>Open Container Initiative</rt></ruby>(OCI)兼容的容器镜像,这意味着其构建的镜像与 Docker 和 Kubernetes 兼容。该工具可作为 Docker 守护进程 `docker build` 命令(即使用传统的 Dockerfile 构建镜像)的一种<ruby>简单<rt>drop-in</rt></ruby>替换,而且更加灵活,允许构建镜像时使用你擅长的工具。Buildah 可以轻松与脚本集成并生成<ruby>流水线<rt>pipeline</rt></ruby>,最好之处在于构建镜像不再需要运行容器守护进程(LCTT 译注:这里主要是指 Docker 守护进程)。
|
||||
|
||||
### docker build 的简单替换
|
||||
|
||||
目前你可能使用 Dockerfile 和 `docker build` 命令构建镜像,那么你可以马上使用 Buildah 进行替代。Buildah 的 `build-using-dockerfile` 或 `bud` 子命令与 `docker build` 基本等价,因此可以轻松的与已有脚本结合或构建流水线。
|
||||
目前你可能使用 Dockerfile 和 `docker build` 命令构建镜像,那么你可以马上使用 Buildah 进行替代。Buildah 的 `build-using-dockerfile` (或 `bud`)子命令与 `docker build` 基本等价,因此可以轻松的与已有脚本结合或构建流水线。
|
||||
|
||||
类似我的上一篇关于 Buildah 的[文章][3],我也将以使用源码安装 “GNU Hello” 为例进行说明,对应的 Dockerfile 文件如下:
|
||||
|
||||
类似我的上一篇关于 Buildah 的[文章][3],我也将以使用源码安装 "GNU Hello" 为例进行说明,对应的 Dockerfile 文件如下:
|
||||
```
|
||||
FROM fedora:28
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
@ -27,10 +31,10 @@ RUN make
|
||||
RUN make install
|
||||
RUN hello -v
|
||||
ENTRYPOINT "/usr/local/bin/hello"
|
||||
|
||||
```
|
||||
|
||||
使用 Buildah 从 Dockerfile 构建镜像也很简单,使用 `buildah bud -t hello .` 替换 `docker build -t hello .` 即可:
|
||||
|
||||
```
|
||||
[chris@krang] $ sudo buildah bud -t hello .
|
||||
STEP 1: FROM fedora:28
|
||||
@ -45,19 +49,19 @@ STEP 2: LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
STEP 3: RUN dnf install -y tar gzip gcc make && dnf clean all
|
||||
|
||||
<考虑篇幅,略去后续输出>
|
||||
|
||||
```
|
||||
|
||||
镜像构建完毕后,可以使用 `buildah images` 命令查看这个新镜像:
|
||||
|
||||
```
|
||||
[chris@krang] $ sudo buildah images
|
||||
IMAGE ID IMAGE NAME CREATED AT SIZE
|
||||
30190780b56e docker.io/library/fedora:28 Mar 7, 2018 16:53 247 MB
|
||||
6d54bef73e63 docker.io/library/hello:latest May 3, 2018 15:24 391.8 MB
|
||||
|
||||
```
|
||||
|
||||
新镜像的标签为 `hello:latest`,我们可以将其推送至远程镜像仓库,可以使用 [CRI-O][4] 或其它 Kubernetes CRI 兼容的运行时运行该镜像,也可以推送到远程仓库。如果你要测试对 Docker build 命令的替代性,你可以将镜像拷贝至 docker 守护进程的本地镜像存储中,这样 Docker 也可以使用该镜像。使用 `buildah push` 可以很容易的完成推送操作:
|
||||
新镜像的标签为 `hello:latest`,我们可以将其推送至远程镜像仓库,可以使用 [CRI-O][4] 或其它 Kubernetes CRI 兼容的运行时来运行该镜像,也可以推送到远程仓库。如果你要测试对 Docker build 命令的替代性,你可以将镜像拷贝至 docker 守护进程的本地镜像存储中,这样 Docker 也可以使用该镜像。使用 `buildah push` 可以很容易的完成推送操作:
|
||||
|
||||
```
|
||||
[chris@krang] $ sudo buildah push hello:latest docker-daemon:hello:latest
|
||||
Getting image source signatures
|
||||
@ -76,12 +80,11 @@ docker.io/hello latest 6d54bef73e63 2 minutes ago 398 MB
|
||||
|
||||
[chris@krang] $ sudo docker run -t hello:latest
|
||||
Hello, world!
|
||||
|
||||
```
|
||||
|
||||
### 若干差异
|
||||
|
||||
与 Docker build 不同,Buildah 不会自动的将 Dockerfile 中的每条指令产生的变更提到到新的<ruby>分层<rt>layer</rt></ruby>中,只是简单的每次从头到尾执行构建。类似于<ruby>自动化<rt>automation</rt></ruby>和<ruby>流水线构建<rt>build pipelines</rt></ruby>,这种<ruby>无缓存构建<rt>non-cached</rt></ruby>方式的好处是可以提高构建速度,在指令较多时尤为明显。从<ruby>自动部署<rt>automated deployment</rt></ruby>或<ruby>持续交付<rt>continuous delivery</rt></ruby>的视角来看,使用这种方式可以快速的将新变更落实到生产环境中。
|
||||
与 Docker build 不同,Buildah 不会自动的将 Dockerfile 中的每条指令产生的变更提到新的<ruby>分层<rt>layer</rt></ruby>中,只是简单的每次从头到尾执行构建。类似于<ruby>自动化<rt>automation</rt></ruby>和<ruby>流水线构建<rt>build pipeline</rt></ruby>,这种<ruby>无缓存构建<rt>non-cached</rt></ruby>方式的好处是可以提高构建速度,在指令较多时尤为明显。从<ruby>自动部署<rt>automated deployment</rt></ruby>或<ruby>持续交付<rt>continuous delivery</rt></ruby>的视角来看,使用这种方式可以快速的将新变更落实到生产环境中。
|
||||
|
||||
但从实际角度出发,缓存机制的缺乏对镜像开发不利,毕竟缓存层可以避免一遍遍的执行构建,从而显著的节省时间。自动分层只在 `build-using-dockerfile` 命令中生效。但我们在下面会看到,Buildah 原生命令允许我们选择将变更提交到硬盘的时间,提高了开发的灵活性。
|
||||
|
||||
@ -89,7 +92,8 @@ Hello, world!
|
||||
|
||||
Buildah _真正_ 有趣之处在于它的原生命令,你可以在容器构建过程中使用这些命令进行交互。相比与使用 `build-using-dockerfile/bud` 命令执行每次构建,Buildah 提供命令让你可以与构建过程中的临时容器进行交互。(Docker 也使用临时或<ruby> _中间_ <rt>intermediate</rt></ruby>容器,但你无法在镜像构建过程中与其交互。)
|
||||
|
||||
还是使用 "GNU Hello" 为例,考虑使用如下 Buildah 命令构建的镜像:
|
||||
还是使用 “GNU Hello” 为例,考虑使用如下 Buildah 命令构建的镜像:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
@ -123,18 +127,18 @@ buildah config --entrypoint /usr/local/bin/hello $container
|
||||
|
||||
# Finally saves the running container to an image
|
||||
buildah commit --format docker $container hello:latest
|
||||
|
||||
```
|
||||
|
||||
我们可以一眼看出这是一个 Bash 脚本而不是 Dockerfile。基于 Buildah 的原生命令,可以轻易的使用任何脚本语言或你擅长的自动化工具编写脚本。形式可以是 makefile、Python 脚本或其它你擅长的类型。
|
||||
|
||||
这个脚本做了哪些工作呢?首先,Buildah 命令 `container=$(buildah from fedora:28)` 基于 fedora:28 镜像创建了一个正在运行的容器,将容器名(buildah from 命令的返回值)保存到变量中,便于后续使用。后续所有命令都是有 $container 变量指明需要操作的容器。这些命令的功能大多可以从名称看出:`buildah copy` 将文件拷贝至容器,`buildah run` 会在容器中执行命令。可以很容易的将上述命令与 Dockerfile 中的指令对应起来。
|
||||
这个脚本做了哪些工作呢?首先,Buildah 命令 `container=$(buildah from fedora:28)` 基于 fedora:28 镜像创建了一个正在运行的容器,将容器名(`buildah from` 命令的返回值)保存到变量中,便于后续使用。后续所有命令都是有 `$container` 变量指明需要操作的容器。这些命令的功能大多可以从名称看出:`buildah copy` 将文件拷贝至容器,`buildah run` 会在容器中执行命令。可以很容易的将上述命令与 Dockerfile 中的指令对应起来。
|
||||
|
||||
最后一条命令 `buildah commit` 将容器提交到硬盘上的镜像中。当不使用 Dockerfile 而是使用 Buildah 命令构建镜像时,你可以使用 `commit` 命令决定何时保存变更。在上例中,所有的变更是一起提交的;但也可以增加中间提交,让你可以选择作为起点的<ruby>缓存点<rt>cache points</rt></ruby>。(例如,执行完 `dnf install` 命令后将变更缓存到硬盘是特别有意义的,一方面因为该操作耗时较长,另一方面每次执行的结果也确实相同。)
|
||||
最后一条命令 `buildah commit` 将容器提交到硬盘上的镜像中。当不使用 Dockerfile 而是使用 Buildah 命令构建镜像时,你可以使用 `commit` 命令决定何时保存变更。在上例中,所有的变更是一起提交的;但也可以增加中间提交,让你可以选择作为起点的<ruby>缓存点<rt>cache point</rt></ruby>。(例如,执行完 `dnf install` 命令后将变更缓存到硬盘是特别有意义的,一方面因为该操作耗时较长,另一方面每次执行的结果也确实相同。)
|
||||
|
||||
### 挂载点,安装目录以及 chroot
|
||||
|
||||
另一个可以大大增加构建镜像灵活性的 Buildah 命令是 `buildah mount`,可以将容器的根目录挂载到你主机的一个挂载点上。例如:
|
||||
|
||||
```
|
||||
[chris@krang] $ container=$(sudo buildah from fedora:28)
|
||||
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
|
||||
@ -145,9 +149,10 @@ Fedora release 28 (Twenty Eight)
|
||||
[chris@krang] $ ls ${mountpoint}
|
||||
bin dev home lib64 media opt root sbin sys usr
|
||||
boot etc lib lost+found mnt proc run srv tmp var
|
||||
|
||||
```
|
||||
这太棒了,你可以通过挂载点交互对容器镜像进行修改。这允许你使用主机上的工具进行构建和安装软件,不用将这些构建工具打包到容器镜像本身中。例如,在我们上面的 Bash 脚本中,我们需要安装 tar、Gzip、GCC 和 make,在容器内编译 "GNU Hello"。如果使用挂载点,我仍使用同样的工具进行构建,但下载的压缩包和 tar、Gzip 等 RPM 包都在主机而不是容器和生成的镜像内:
|
||||
|
||||
这太棒了,你可以通过与挂载点交互对容器镜像进行修改。这允许你使用主机上的工具进行构建和安装软件,不用将这些构建工具打包到容器镜像本身中。例如,在我们上面的 Bash 脚本中,我们需要安装 tar、Gzip、GCC 和 make,在容器内编译 “GNU Hello”。如果使用挂载点,我仍使用同样的工具进行构建,但下载的压缩包和 tar、Gzip 等 RPM 包都在主机而不是容器和生成的镜像内:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
@ -174,7 +179,6 @@ chroot $mountpoint bash -c "/usr/local/bin/hello -v"
|
||||
buildah config --entrypoint "/usr/local/bin/hello" $container
|
||||
buildah commit --format docker $container hello
|
||||
buildah unmount $container
|
||||
|
||||
```
|
||||
|
||||
在上述脚本中,需要提到如下几点:
|
||||
@ -185,22 +189,22 @@ buildah unmount $container
|
||||
4. 这里的 `chroot` 命令用于将挂载点本身当作根路径并测试 "hello" 是否正常工作;类似于前面例子中用到的 `buildah run` 命令。
|
||||
|
||||
|
||||
这个脚本更加短小,使用大多数 Linux 爱好者都很熟悉的工具,最后生成的镜像也更小(没有压缩包,没有额外的软件包等)。你甚至可以使用主机系统上的包管理器为容器安装软件。例如,(出于某种原因)你希望安装 GNU Hello 的同时在容器中安装 [NGINX][5]:
|
||||
这个脚本更加短小,使用大多数 Linux 爱好者都很熟悉的工具,最后生成的镜像也更小(没有 tar 包,没有额外的软件包等)。你甚至可以使用主机系统上的包管理器为容器安装软件。例如,(出于某种原因)你希望安装 GNU Hello 的同时在容器中安装 [NGINX][5]:
|
||||
|
||||
```
|
||||
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
|
||||
[chris@krang] $ sudo dnf install nginx --installroot $mountpoint
|
||||
[chris@krang] $ sudo chroot $mountpoint nginx -v
|
||||
nginx version: nginx/1.12.1
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,DNF 使用 `--installroot` 参数将 NGINX 安装到容器中,可以通过 chroot 进行校验。
|
||||
|
||||
### 快来试试吧!
|
||||
|
||||
Buildah 是一种轻量级、灵活的容器镜像构建方法,不需要在主机上运行完整的 Docker 守护进程。除了提供基于 Dockerfiles 构建容器的开箱即用支持,Buildah 还可以很容易的与脚本或你喜欢的构建工具相结合,特别是可以使用主机上已有的工具构建容器镜像。Buildah 生成的容器体积更小,更便于网络传输,占用更小的存储空间,而且潜在的受攻击面更小。快来试试吧!
|
||||
Buildah 是一种轻量级、灵活的容器镜像构建方法,不需要在主机上运行完整的 Docker 守护进程。除了提供基于 Dockerfile 构建容器的开箱即用支持,Buildah 还可以很容易的与脚本或你喜欢的构建工具相结合,特别是可以使用主机上已有的工具构建容器镜像。Buildah 生成的容器体积更小,更便于网络传输,占用更小的存储空间,而且潜在的受攻击面更小。快来试试吧!
|
||||
|
||||
**[阅读相关的故事,[使用 Buildah 创建小体积容器][6]]**
|
||||
**[阅读相关的故事,[使用 Buildah 创建小体积的容器][6]]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -208,8 +212,8 @@ via: https://opensource.com/article/18/6/getting-started-buildah
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -219,4 +223,4 @@ via: https://opensource.com/article/18/6/getting-started-buildah
|
||||
[3]:http://chris.collins.is/2017/08/17/buildah-a-new-way-to-build-container-images/
|
||||
[4]:http://cri-o.io/
|
||||
[5]:https://www.nginx.com/
|
||||
[6]:https://opensource.com/article/18/5/containers-buildah
|
||||
[6]:https://linux.cn/article-9719-1.html
|
||||
@ -1,15 +1,17 @@
|
||||
Mesos 和 Kubernetes:不是竞争者
|
||||
======
|
||||
|
||||
> 人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。Ben Hindman 在这里解释了 Mesos 是如何对另外一种技术进行补充的。
|
||||
|
||||

|
||||
|
||||
Mesos 的起源可以追溯到 2009 年,当时,Ben Hindman 还是加州大学伯克利分校研究并行编程的博士生。他们在 128 核的芯片上做大规模的并行计算,并尝试去解决多个问题,比如怎么让软件和库在这些芯片上运行更高效。他与同学们讨论能否借鉴并行处理和多线程的思想,并将它们应用到集群管理上。
|
||||
Mesos 的起源可以追溯到 2009 年,当时,Ben Hindman 还是加州大学伯克利分校研究并行编程的博士生。他们在 128 核的芯片上做大规模的并行计算,以尝试去解决多个问题,比如怎么让软件和库在这些芯片上运行更高效。他与同学们讨论能否借鉴并行处理和多线程的思想,并将它们应用到集群管理上。
|
||||
|
||||
Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热门,并且 Hadoop 是其中一个热门技术。“我们发现,人们在集群上运行像 Hadoop 这样的程序与运行多线程应用和并行应用很相似。Hindman 说。
|
||||
Hindman 说 “最初,我们专注于大数据” 。那时,大数据非常热门,而 Hadoop 就是其中的一个热门技术。“我们发现,人们在集群上运行像 Hadoop 这样的程序与运行多线程应用及并行应用很相似。”Hindman 说。
|
||||
|
||||
但是,它们的效率并不高,因此,他们开始去思考,如何通过集群管理和资源管理让它们运行的更好。”我们查看了那个时间很多的不同技术“ Hindman 回忆道。
|
||||
但是,它们的效率并不高,因此,他们开始去思考,如何通过集群管理和资源管理让它们运行的更好。“我们查看了那个时期很多的各种技术” Hindman 回忆道。
|
||||
|
||||
然而,Hindman 和他的同事们,决定去采用一种全新的方法。”我们决定去对资源管理创建一个低级的抽象,然后在此之上运行调度服务和做其它的事情。“ Hindman 说,“基本上,这就是 Mesos 的本质 —— 将资源管理部分从调度部分中分离出来。”
|
||||
然后,Hindman 和他的同事们决定去采用一种全新的方法。“我们决定对资源管理创建一个低级的抽象,然后在此之上运行调度服务和做其它的事情。” Hindman 说,“基本上,这就是 Mesos 的本质 —— 将资源管理部分从调度部分中分离出来。”
|
||||
|
||||
他成功了,并且 Mesos 从那时开始强大了起来。
|
||||
|
||||
@ -17,21 +19,21 @@ Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热
|
||||
|
||||
这个项目发起于 2009 年。在 2010 年时,团队决定将这个项目捐献给 Apache 软件基金会(ASF)。它在 Apache 孵化,并于 2013 年成为顶级项目(TLP)。
|
||||
|
||||
为什么 Mesos 社区选择 Apache 软件基金会有很多的原因,比如,Apache 许可证,以及他们已经拥有了一个充满活力的此类项目的许多其它社区。
|
||||
为什么 Mesos 社区选择 Apache 软件基金会有很多的原因,比如,Apache 许可证,以及基金会已经拥有了一个充满活力的其它此类项目的社区。
|
||||
|
||||
与影响力也有关系。许多在 Mesos 上工作的人,也参与了 Apache,并且许多人也致力于像 Hadoop 这样的项目。同时,来自 Mesos 社区的许多人也致力于其它大数据项目,比如 Spark。这种交叉工作使得这三个项目 —— Hadoop、Mesos、以及 Spark —— 成为 ASF 的项目。
|
||||
与影响力也有关系。许多在 Mesos 上工作的人也参与了 Apache,并且许多人也致力于像 Hadoop 这样的项目。同时,来自 Mesos 社区的许多人也致力于其它大数据项目,比如 Spark。这种交叉工作使得这三个项目 —— Hadoop、Mesos,以及 Spark —— 成为 ASF 的项目。
|
||||
|
||||
与商业也有关系。许多公司对 Mesos 很感兴趣,并且开发者希望它能由一个中立的机构来维护它,而不是让它成为一个私有项目。
|
||||
|
||||
### 谁在用 Mesos?
|
||||
|
||||
更好的问题应该是,谁不在用 Mesos?从 Apple 到 Netflix 每个都在用 Mesos。但是,Mesos 也面临任何技术在早期所面对的挑战。”最初,我要说服人们,这是一个很有趣的新技术。它叫做“容器”,因为它不需要使用虚拟机“ Hindman 说。
|
||||
更好的问题应该是,谁不在用 Mesos?从 Apple 到 Netflix 每个都在用 Mesos。但是,Mesos 也面临任何技术在早期所面对的挑战。“最初,我要说服人们,这是一个很有趣的新技术。它叫做‘容器’,因为它不需要使用虚拟机” Hindman 说。
|
||||
|
||||
从那以后,这个行业发生了许多变化,现在,只要与别人聊到基础设施,必然是从”容器“开始的 —— 感谢 Docker 所做出的工作。今天再也不需要说服工作了,而在 Mesos 出现的早期,前面提到的像 Apple、Netflix、以及 PayPal 这样的公司。他们已经知道了容器化替代虚拟机给他们带来的技术优势。”这些公司在容器化成为一种现象之前,已经明白了容器化的价值所在“, Hindman 说。
|
||||
从那以后,这个行业发生了许多变化,现在,只要与别人聊到基础设施,必然是从”容器“开始的 —— 感谢 Docker 所做出的工作。今天再也不需要做说服工作了,而在 Mesos 出现的早期,前面提到的像 Apple、Netflix,以及 PayPal 这样的公司。他们已经知道了容器替代虚拟机给他们带来的技术优势。“这些公司在容器成为一种现象之前,已经明白了容器的价值所在”, Hindman 说。
|
||||
|
||||
可以在这些公司中看到,他们有大量的容器而不是虚拟机。他们所做的全部工作只是去管理和运行这些容器,并且他们欣然接受了 Mesos。在 Mesos 早期就使用它的公司有 Apple、Netflix、PayPal、Yelp、OpenTable、和 Groupon。
|
||||
可以在这些公司中看到,他们有大量的容器而不是虚拟机。他们所做的全部工作只是去管理和运行这些容器,并且他们欣然接受了 Mesos。在 Mesos 早期就使用它的公司有 Apple、Netflix、PayPal、Yelp、OpenTable 和 Groupon。
|
||||
|
||||
“大多数组织使用 Mesos 来运行任意需要的服务” Hindman 说,“但也有些公司用它做一些非常有趣的事情,比如,数据处理、数据流、分析负载和应用程序。“
|
||||
“大多数组织使用 Mesos 来运行各种服务” Hindman 说,“但也有些公司用它做一些非常有趣的事情,比如,数据处理、数据流、分析任务和应用程序。“
|
||||
|
||||
这些公司采用 Mesos 的其中一个原因是,资源管理层之间有一个明晰的界线。当公司运营容器的时候,Mesos 为他们提供了很好的灵活性。
|
||||
|
||||
@ -43,11 +45,11 @@ Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热
|
||||
|
||||
人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。大多数的技术在一些领域总是重叠的,并且它们可以是互补的。“我不喜欢将所有的这些东西都看做是竞争者。我认为它们中的一些与另一个在工作中是互补的,” Hindman 说。
|
||||
|
||||
“事实上,名字 Mesos 表示它处于 ‘中间’;它是一种中间的 OS,” Hindman 说,“我们有一个容器调度器的概念,它能够运行在像 Mesos 这样的东西之上。当 Kubernetes 刚出现的时候,我们实际上在 Mesos 的生态系统中接受它的,并将它看做是运行在 Mesos 之上、DC/OS 之中的另一种方式的容器。”
|
||||
“事实上,名字 Mesos 表示它处于 ‘中间’;它是一种中间的操作系统”, Hindman 说,“我们有一个容器调度器的概念,它能够运行在像 Mesos 这样的东西之上。当 Kubernetes 刚出现的时候,我们实际上在 Mesos 的生态系统中接受了它,并将它看做是在 Mesos 上的 DC/OS 中运行容器的另一种方式。”
|
||||
|
||||
Mesos 也复活了一个名为 [Marathon][1](一个用于 Mesos 和 DC/OS 的容器编排器)的项目,它在 Mesos 生态系统中是做的最好的容器编排器。但是,Marathon 确实无法与 Kubernetes 相比较。“Kubernetes 比 Marathon 做的更多,因此,你不能将它们简单地相互交换,” Hindman 说,“与此同时,我们在 Mesos 中做了许多 Kubernetes 中没有的东西。因此,这些技术之间是互补的。”
|
||||
Mesos 也复活了一个名为 [Marathon][1](一个用于 Mesos 和 DC/OS 的容器编排器)的项目,它成为了 Mesos 生态系统中最重要的成员。但是,Marathon 确实无法与 Kubernetes 相比较。“Kubernetes 比 Marathon 做的更多,因此,你不能将它们简单地相互交换,” Hindman 说,“与此同时,我们在 Mesos 中做了许多 Kubernetes 中没有的东西。因此,这些技术之间是互补的。”
|
||||
|
||||
不要将这些技术视为相互之间是敌对的关系,它们应该被看做是对行业有益的技术。它们不是技术上的重复;它们是多样化的。据 Hindman 说,“对于开源领域的终端用户来说,这可能会让他们很困惑,因为他们很难去知道哪个技术适用于哪种负载,但这是被称为开源的这种东西最令人讨厌的本质所在。“
|
||||
不要将这些技术视为相互之间是敌对的关系,它们应该被看做是对行业有益的技术。它们不是技术上的重复;它们是多样化的。据 Hindman 说,“对于开源领域的终端用户来说,这可能会让他们很困惑,因为他们很难去知道哪个技术适用于哪种任务,但这是这个被称之为开源的本质所在。“
|
||||
|
||||
这只是意味着有更多的选择,并且每个都是赢家。
|
||||
|
||||
@ -58,7 +60,7 @@ via: https://www.linux.com/blog/2018/6/mesos-and-kubernetes-its-not-competition
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,33 +1,35 @@
|
||||
使用 Open edX 托管课程入门
|
||||
使用 Open edX 托管课程
|
||||
======
|
||||
|
||||
> Open edX 为各种规模和类型的组织提供了一个强大而多功能的开源课程管理的解决方案。要不要了解一下。
|
||||
|
||||

|
||||
|
||||
[Open edX 平台][2] 是一个免费和开源的课程管理系统,它是 [全世界][3] 都在使用的大规模网络公开课(MOOCs)以及小型课程和培训模块的托管平台。在 Open edX 的 [第七个主要发行版][1] 中,到现在为止,它已经提供了超过 8,000 个原创课程和 5000 万个课程注册数。你可以使用你自己的本地设备或者任何行业领先的云基础设施服务提供商来安装这个平台,但是,随着项目的[服务提供商][4]名单越来越长,来自它们中的软件即服务(SaaS)的可用模型也越来越多了。
|
||||
[Open edX 平台][2] 是一个自由开源的课程管理系统,它是 [全世界][3] 都在使用的大规模网络公开课(MOOC)以及小型课程和培训模块的托管平台。在 Open edX 的 [第七个主要发行版][1] 中,到现在为止,它已经提供了超过 8,000 个原创课程和 5000 万个课程注册数。你可以使用你自己的本地设备或者任何行业领先的云基础设施服务提供商来安装这个平台,而且,随着项目的[服务提供商][4]名单越来越长,来自它们中的软件即服务(SaaS)的可用模型也越来越多了。
|
||||
|
||||
Open edX 平台被来自世界各地的顶尖教育机构、私人公司、公共机构、非政府组织、非营利机构、以及教育技术初创企业广泛地使用,并且项目服务提供商的全球社区持续让越来越小的组织可以访问这个平台。如果你打算向广大的读者设计和提供教育内容,你应该考虑去使用 Open edX 平台。
|
||||
Open edX 平台被来自世界各地的顶尖教育机构、私人公司、公共机构、非政府组织、非营利机构,以及教育技术初创企业广泛地使用,并且该项目的服务提供商全球社区不断地让甚至更小的组织也可以访问这个平台。如果你打算向广大的读者设计和提供教育内容,你应该考虑去使用 Open edX 平台。
|
||||
|
||||
### 安装
|
||||
|
||||
安装这个软件有多种方式,这可能是不一个不受欢迎的惊喜,至少刚开始是这样。但是不管你是以何种方式 [安装 Open edX][5],最终你都得到的是有相同功能的应用程序。默认安装包含一个为在线学习者提供的、全功能的学习管理系统(LMS),和一个全功能的课程管理工作室(CMS),CMS 可以让你的讲师团队用它来编写原创课程内容。你可以把 CMS 当做是课程内容设计和管理的 “[Wordpress][6]”,把 LMS 当做是课程销售、分发、和消费的 “[Magento][7]”。
|
||||
安装这个软件有多种方式,这可能有点让你难以选择,至少刚开始是这样。但是不管你是以何种方式 [安装 Open edX][5],最终你都得到的是有相同功能的应用程序。默认安装包含一个为在线学习者提供的、全功能的学习管理系统(LMS),和一个全功能的课程管理工作室(CMS),CMS 可以让你的讲师团队用它来编写原创课程内容。你可以把 CMS 当做是课程内容设计和管理的 “[Wordpress][6]”,把 LMS 当做是课程销售、分发、和消费的 “[Magento][7]”。
|
||||
|
||||
Open edX 是设备无关的和完全响应式的应用软件,并且不用花费很多的努力就可发布一个原生的 iOS 和 Android apps,它可以无缝地集成到你的实例后端。Open edX 平台的代码库、原生移动应用、以及安装脚本都发布在 [GitHub][8] 上。
|
||||
Open edX 是设备无关的、完全响应式的应用软件,并且不用花费很多的努力就可发布一个原生的 iOS 和 Android 应用,它可以无缝地集成到你的实例后端。Open edX 平台的代码库、原生移动应用、以及安装脚本都发布在 [GitHub][8] 上。
|
||||
|
||||
#### 有何期望
|
||||
|
||||
Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型组织的、性能很好的、产品级的代码。来自数百个机构的数千名程序员定期为 edX 仓库做贡献,并且这个平台是一个名副其实的,研究如何去构建和管理一个复杂的企业级应用的好案例。因此,尽管你可能会遇到大量的类似如何将平台迁移到生产环境中的问题,但是你不应该对 Open edX 平台代码库本身的质量和健状性担忧。
|
||||
Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型的组织的、性能很好的、产品级的代码。来自数百个机构的数千名程序员经常为 edX 仓库做贡献,并且这个平台是一个名副其实的、研究如何去构建和管理一个复杂的企业级应用的好案例。因此,尽管你可能会遇到大量的类似“如何将平台迁移到生产环境中”的问题,但是你无需对 Open edX 平台代码库本身的质量和健状性担忧。
|
||||
|
||||
通过少量的培训,你的讲师就可以去设计很好的在线课程。但是请记住,Open edX 是通过它的 [XBlock][10] 组件架构可扩展的,因此,通过他们和你的努力,你的讲师将有可能将好的课程变成精品课程。
|
||||
通过少量的培训,你的讲师就可以去设计不错的在线课程。但是请记住,Open edX 是通过它的 [XBlock][10] 组件架构进行扩展的,因此,通过他们和你的努力,你的讲师将有可能将不错的课程变成精品课程。
|
||||
|
||||
这个平台在单服务器环境下也运行的很好,并且它是高度模块化的,几乎可以进行无限地水平扩展。它也是主题化的和本地化的,平台的功能和外观可以根据你的需要进行几乎无限制地调整。平台在你的设备上可以按需安装并可靠地运行。
|
||||
|
||||
#### 一些封装要求
|
||||
#### 需要一些封装
|
||||
|
||||
请记住,有大量的 edX 软件模块是不包含在默认安装中的,并且这些模块提供的经常都是组织所需要的功能。比如,分析模块、电商模块、以及课程的通知/公告模块都是不包含在默认安装中的,并且这些单独的模块都是值得安装的。另外,在数据备份/恢复和系统管理方面要完全依赖你自己去处理。幸运的是,有关这方面的内容,社区有越来越多的文档和如何去做的文章。你可以通过 Google 和 Bing 去搜索,以帮助你在生产环境中安装它们。
|
||||
请记住,有大量的 edX 软件模块是不包含在默认安装中的,并且这些模块提供的经常都是各种组织所需要的功能。比如,分析模块、电商模块,以及课程的通知/公告模块都是不包含在默认安装中的,并且这些单独的模块都是值得安装的。另外,在数据备份/恢复和系统管理方面要完全依赖你自己去处理。幸运的是,有关这方面的内容,社区有越来越多的文档和如何去做的文章。你可以通过 Google 和 Bing 去搜索,以帮助你在生产环境中安装它们。
|
||||
|
||||
虽然有很多文档良好的程序,但是根据你的技能水平,配置 [oAuth][11] 和 [SSL/TLS][12],以及使用平台的 [REST API][13] 可能对你是一个挑战。另外,一些组织要求将 MySQL 和/或 MongoDB 数据库在中心化环境中管理,如果你正好是这种情况,你还需要将这些服务从默认平台安装中分离出来。edX 设计团队已经尽可能地为你做了简化,但是由于它是一个非常重大的更改,因此可能需要一些时间去实现。
|
||||
|
||||
如果你面临资源和/或技术上的困难 —— 不要气馁,Open edX 社区 SaaS 提供商,像 [appsembler][14] 和 [eduNEXT][15],提供了引人入胜的替代方案去进行 DIY 安装,尤其是如果你只适应窗口方式操作。
|
||||
如果你面临资源和/或技术上的困难 —— 不要气馁,Open edX 社区 SaaS 提供商,像 [appsembler][14] 和 [eduNEXT][15],提供了引人入胜的替代方案去进行 DIY 安装,尤其是如果你只想简单购买就行。
|
||||
|
||||
### 技术栈
|
||||
|
||||
@ -35,7 +37,7 @@ Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型组织的、性
|
||||
|
||||
![edx-architecture.png][24]
|
||||
|
||||
Open edX 技术栈(CC BY,来自 edX)
|
||||
*Open edX 技术栈(CC BY,来自 edX)*
|
||||
|
||||
将这些组件安装并配置好本身就是一件非常不容易的事情,但是以这样的一种方式将所有的组件去打包,并适合于任意规模和复杂性的组织,并且能够按他们的需要进行任意调整搭配而无需在代码上做重大改动,看起来似乎是不可能的事情 —— 它就是这种情况,直到你看到主要的平台配置参数安排和命名是多少的巧妙和直观。请注意,平台的组织结构有一个学习曲线,但是,你所学习的一切都是值的去学习的,不仅是对这个项目,对一般意义上的大型 IT 项目都是如此。
|
||||
|
||||
@ -43,7 +45,7 @@ Open edX 技术栈(CC BY,来自 edX)
|
||||
|
||||
### 采用
|
||||
|
||||
edX 项目能够迅速得到世界范围内的采纳,很大程度上取决于软件的运行情况。这一点也不奇怪,这个项目成功地吸引了大量才华卓越的人参与其中,他们作为程序员、项目顾问、翻译者、技术作者、以及博客作者参与了项目的贡献。一年一次的 [Open edX 会议][27]、[官方的 edX Google Group][28]、以及 [Open edX 服务提供商名单][4] 是了解这个多样化的、不断成长的生态系统的非常好的起点。我作为相对而言的新人,我发现参与和直接从事这个项目的各个方面是非常容易的。
|
||||
edX 项目能够迅速得到世界范围内的采纳,很大程度上取决于该软件的运行情况。这一点也不奇怪,这个项目成功地吸引了大量才华卓越的人参与其中,他们作为程序员、项目顾问、翻译者、技术作者、以及博客作者参与了项目的贡献。一年一次的 [Open edX 会议][27]、[官方的 edX Google Group][28]、以及 [Open edX 服务提供商名单][4] 是了解这个多样化的、不断成长的生态系统的非常好的起点。我作为相对而言的新人,我发现参与和直接从事这个项目的各个方面是非常容易的。
|
||||
|
||||
祝你学习之旅一切顺利,并且当你构思你的项目时,你可以随时联系我。
|
||||
|
||||
@ -54,7 +56,7 @@ via: https://opensource.com/article/18/6/getting-started-open-edx
|
||||
作者:[Lawrence Mc Daniel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,19 +2,17 @@ TrueOS 不再想要成为“桌面 BSD”了
|
||||
============================================================
|
||||
|
||||
|
||||
[TrueOS][9] 很快会有一些非常重大的变化。今天,我们将了解桌面 BSD 将会发生什么。
|
||||
[TrueOS][9] 很快会有一些非常重大的变化。今天,我们将了解桌面 BSD 领域将会发生什么。
|
||||
|
||||
### 通告
|
||||
|
||||

|
||||
|
||||
[TrueOS][10] 背后的团队[宣布][11],他们将改变项目的重点。到目前为止,TrueOS 使用开箱即用的图形用户界面来轻松安装 BSD。然而,它现在将成为“一个先进的操作系统,保留你所知道和喜欢 ZFS([OpenZFS][12])和 [FreeBSD][13]的所有稳定性,并添加额外的功能来创造一个全新的、创新的操作系统。我们的目标是创建一个中心操作系统,该系统具有模块化、功能性,非常适合自己动手和高级用户。“
|
||||
[TrueOS][10] 背后的团队[宣布][11],他们将改变项目的重点。到目前为止,TrueOS 使用开箱即用的图形用户界面来轻松安装 BSD。然而,它现在将成为“一个先进的操作系统,保留你所知道和喜欢的 ZFS([OpenZFS][12])和 [FreeBSD][13]的所有稳定性,并添加额外的功能来创造一个全新的、创新的操作系统。我们的目标是创建一个核心操作系统,该系统具有模块化、实用性,非常适合自己动手和高级用户。“
|
||||
|
||||
从本质上讲,TrueOs 将成为 FreeBSD 的下游分支。他们将更新的软件集成到系统中,例如 [OpenRC][14] 和 [LibreSSL][15]。他们希望坚持 6 个月的发布周期。
|
||||
从本质上讲,TrueOs 将成为 FreeBSD 的下游分支。他们将集成更新一些的软件到系统中,例如 [OpenRC][14] 和 [LibreSSL][15]。他们希望能坚持 6 个月的发布周期。
|
||||
|
||||
目标是使 TrueOS 成为可以作为其他项目构建的基础。缺少图形部分以使其更加发行无关。
|
||||
|
||||
[建议阅读有关 MidnightBSD 创始人兼首席开发人员 Lucas Holt 的访谈][16]
|
||||
其目标是使 TrueOS 成为可以作为其他项目构建的基础。缺少图形部分以使其更加地与发行版无关。
|
||||
|
||||
### 桌面用户如何?
|
||||
|
||||
@ -22,15 +20,13 @@ TrueOS 不再想要成为“桌面 BSD”了
|
||||
|
||||
如果你目前拥有 TrueOS,则无需担心迁移。TrueOS 团队表示,“对于那些希望迁移到其他基于 FreeBSD 的发行版,如 Project Trident 或 [GhostBSD][19] 的人而言将会有迁移方式。”
|
||||
|
||||
[建议阅读有关 FreeDOS 创始人及开发领导 Lucas Holt 的访谈][16]
|
||||
|
||||
### 想法
|
||||
|
||||
当我第一次阅读公告时,坦率地说有点担心。改变名字可能是一个坏主意。客户将习惯使用一个名称,但如果产品名称发生变化,他们可能很容易失去对项目的跟踪。TrueOS 经历过名称更改。该项目于 2006 年启动时,它被命名为 PC-BSD,但在 2016 年,名称更改为 TrueOS。它让我想起了[ArchMerge 和 Arcolinux 传奇][21]。
|
||||
当我第一次阅读该公告时,坦率地说有点担心。改变名字可能是一个坏主意。客户将习惯使用一个名称,但如果产品名称发生变化,他们可能很容易失去对项目的跟踪。TrueOS 经历过名称更改。该项目于 2006 年启动时,它被命名为 PC-BSD,但在 2016 年,名称更改为 TrueOS。它让我想起了[ArchMerge 和 Arcolinux 传奇][21]。
|
||||
|
||||
话虽这么说,我认为这对 BSD 的桌面用户来说是一件好事。我听见 PC-BSD 和 TrueOS 的一个常见批评是它不是很精致。剥离项目的两个部分将有助于提高相关开发人员的关注度。TrueOS 团队将能够为缓慢进展的 FreeBSD 添加更新的功能,Project Trident 团队将能够改善用户的桌面体验。
|
||||
话虽这么说,我认为这对 BSD 的桌面用户来说是一件好事。我常听见对 PC-BSD 和 TrueOS 的一个批评是它不是很精致。剥离项目的两个部分将有助于提高相关开发人员的关注度。TrueOS 团队将能够为缓慢进展的 FreeBSD 添加更新的功能,Project Trident 团队将能够改善用户的桌面体验。
|
||||
|
||||
我希望两个团队都好。请记住,当有人在开源上工作时,即使是我们不会使用的工作时,我们也都会受益。
|
||||
我希望两个团队都好。请记住,当有人为开源而努力时,即使是我们不会使用的部分,我们也都会受益。
|
||||
|
||||
你对 TrueOS 和 Project Trident 的未来有何看法?请在下面的评论中告诉我们。
|
||||
|
||||
@ -45,9 +41,9 @@ TrueOS 不再想要成为“桌面 BSD”了
|
||||
|
||||
via: https://itsfoss.com/trueos-plan-change/
|
||||
|
||||
作者:[John Paul Wohlscheid ][a]
|
||||
作者:[John Paul Wohlscheid][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,77 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Keeping (financial) score with Ledger –
|
||||
======
|
||||
I’ve used [Ledger CLI][1] to keep track of my finances since 2005, when I moved to Canada. I like the plain-text approach, and its support for virtual envelopes means that I can reconcile both my bank account balances and my virtual allocations to different categories. Here’s how we use those virtual envelopes to manage our finances separately.
|
||||
|
||||
Every month, I have an entry that moves things from my buffer of living expenses to various categories, including an allocation for household expenses. W- doesn’t ask for a lot, so I take care to be frugal with the difference between that and the cost of, say, living on my own. The way we handle it is that I cover a fixed amount, and this is credited by whatever I pay for groceries. Since our grocery total is usually less than the amount I budget for household expenses, any difference just stays on the tab. I used to write him cheques to even it out, but lately I just pay for the occasional additional large expense.
|
||||
|
||||
Here’s a sample envelope allocation:
|
||||
```
|
||||
2014.10.01 * Budget
|
||||
[Envelopes:Living]
|
||||
[Envelopes:Household] $500
|
||||
;; More lines go here
|
||||
|
||||
```
|
||||
|
||||
Here’s one of the envelope rules set up. This one encourages me to classify expenses properly. All expenses are taken out of my “Play” envelope.
|
||||
```
|
||||
= /^Expenses/
|
||||
(Envelopes:Play) -1.0
|
||||
|
||||
```
|
||||
|
||||
This one reimburses the “Play” envelope for household expenses, moving the amount from the “Household” envelope into the “Play” one.
|
||||
```
|
||||
= /^Expenses:House$/
|
||||
(Envelopes:Play) 1.0
|
||||
(Envelopes:Household) -1.0
|
||||
|
||||
```
|
||||
|
||||
I have a regular set of expenses that simulate the household expenses coming out of my budget. For example, here’s the one for October.
|
||||
```
|
||||
2014.10.1 * House
|
||||
Expenses:House
|
||||
Assets:Household $-500
|
||||
|
||||
```
|
||||
|
||||
And this is what a grocery transaction looks like:
|
||||
```
|
||||
2014.09.28 * No Frills
|
||||
Assets:Household:Groceries $70.45
|
||||
Liabilities:MBNA:September $-70.45
|
||||
|
||||
```
|
||||
|
||||
Then `ledger bal Assets:Household` will tell me if I owe him money (negative balance) or not. If I pay for something large (ex: plane tickets, plumbing), the regular household expense budget gradually reduces that balance.
|
||||
|
||||
I picked up the trick of adding a month label to my credit card transactions from W-, who also uses Ledger to track his transactions. It lets me doublecheck the balance of a statement and see if the previous statement has been properly cleared.
|
||||
|
||||
It’s a bit of a weird use of the assets category, but it works out for me mentally.
|
||||
|
||||
Using Ledger to track it in this way lets me keep track of our grocery expenses and the difference between what I’ve actually paid and what I’ve budgeted for. If I end up spending more than I expected, I can move virtual money from more discretionary envelopes, so my budget always stays balanced.
|
||||
|
||||
Ledger’s a powerful tool. Pretty geeky, but maybe more descriptions of workflow might help people who are figuring things out!
|
||||
|
||||
More posts about: [finance][2] Tags: [ledger][3] | [See in index][4] // **[5 Comments »][5]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
|
||||
作者:[Sacha Chua][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://sachachua.com
|
||||
[1]:http://www.ledger-cli.org/
|
||||
[2]:http://sachachua.com/blog/category/finance/
|
||||
[3]:http://sachachua.com/blog/tag/ledger/
|
||||
[4]:http://pages.sachachua.com/sharing/blog.html?url=http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
[5]:http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/#comments
|
||||
@ -0,0 +1,200 @@
|
||||
iWant – The Decentralized Peer To Peer File Sharing Commandline Application
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while ago, we have written a guide about two file sharing utilities named [**transfer.sh**][1], a free web service that allows you to share files over Internet easily and quickly, and [**PSiTransfer**][2], a simple open source self-hosted file sharing solution. Today, we will see yet another file sharing utility called **“iWant”**. It is a free and open source CLI-based decentralized peer to peer file sharing application.
|
||||
|
||||
What’s makes it different from other file sharing applications? You might wonder. Here are some prominent features of iWant.
|
||||
|
||||
* It’s commandline application. You don’t need any memory consuming GUI utilities. You need only the Terminal.
|
||||
* It is decentralized. That means your data will not be stored in any central location. So, there is no central point of failure.
|
||||
* iWant allows you to pause the download and you can resume it later when you want. You don’t need to download it from beginning, it just resumes the downloads from where you left off.
|
||||
* Any changes made in the files in the shared directory (such as deletion, addition, modification) will be reflected instantly in the network.
|
||||
* Just like torrents, iWant downloads the files from multiple peers. If any seeder left the group or failed to respond, it will continue the download from another seeder.
|
||||
* It is cross-platform, so, you can use it in GNU/Linux, MS Windows, and Mac OS X.
|
||||
|
||||
|
||||
|
||||
### iWant – A CLI-based Decentralized Peer To Peer File Sharing Solution
|
||||
|
||||
#### Install iWant
|
||||
|
||||
iWant can be easily installed using PIP package manager. Make sure you have pip installed in your Linux distribution. if it is not installed yet, refer the following guide.
|
||||
|
||||
[How To Manage Python Packages Using Pip](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
After installing PIP, make sure you have installed the the following dependencies:
|
||||
|
||||
* libffi-dev
|
||||
* libssl-dev
|
||||
|
||||
|
||||
|
||||
Say for example, on Ubuntu, you can install these dependencies using command:
|
||||
```
|
||||
$ sudo apt-get install libffi-dev libssl-dev
|
||||
|
||||
```
|
||||
|
||||
Once all dependencies installed, install iWant using the following command:
|
||||
```
|
||||
$ sudo pip install iwant
|
||||
|
||||
```
|
||||
|
||||
We have now iWant in our system. Let us go ahead and see how to use it to transfer files over network.
|
||||
|
||||
#### Usage
|
||||
|
||||
First, start iWant server using command:
|
||||
```
|
||||
$ iwanto start
|
||||
|
||||
```
|
||||
|
||||
At the first time, iWant will ask the Shared and Download folder’s location. Enter the actual location of both folders. Then, choose which interface you want to use:
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
Shared/Download folder details looks empty..
|
||||
Note: Shared and Download folder cannot be the same
|
||||
SHARED FOLDER(absolute path):/home/sk/myshare
|
||||
DOWNLOAD FOLDER(absolute path):/home/sk/mydownloads
|
||||
Network interface available
|
||||
1. lo => 127.0.0.1
|
||||
2. enp0s3 => 192.168.43.2
|
||||
Enter index of the interface:2
|
||||
now scanning /home/sk/myshare
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
Updating Leader 56f6d5e8-654e-11e7-93c8-08002712f8c1
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
connecting to 192.168.43.2:1235 for hashdump
|
||||
|
||||
```
|
||||
|
||||
If you see an output something like above, you can start using iWant right away.
|
||||
|
||||
Similarly, start iWant service on all systems in the network, assign valid Shared and Downloads folder’s location, and select the network interface card.
|
||||
|
||||
The iWant service will keep running in the current Terminal window until you press **CTRL+C** to quit it. You need to open a new tab or new Terminal window to use iWant.
|
||||
|
||||
iWant usage is very simple. It has few commands as listed below.
|
||||
|
||||
* **iwanto start** – Starts iWant server.
|
||||
* **iwanto search <name>** – Search for files.
|
||||
* **iwanto download <hash>** – Download a file.
|
||||
* **iwanto share <path>** – Change the Shared folder’s location.
|
||||
* **iwanto download to <destination>** – Change the Download folder’s location.
|
||||
* **iwanto view config** – View Shared and Download folders.
|
||||
* **iwanto –version** – Displays the iWant version.
|
||||
* **iwanto -h** – Displays the help section.
|
||||
|
||||
|
||||
|
||||
Allow me to show you some examples.
|
||||
|
||||
**Search files**
|
||||
|
||||
To search for a file, run:
|
||||
```
|
||||
$ iwanto search <filename>
|
||||
|
||||
```
|
||||
|
||||
Please note that you don’t need to specify the accurate name.
|
||||
|
||||
Example:
|
||||
```
|
||||
$ iwanto search command
|
||||
|
||||
```
|
||||
|
||||
The above command will search for any files that contains the string “command”.
|
||||
|
||||
Sample output from my Ubuntu system:
|
||||
```
|
||||
Filename Size Checksum
|
||||
------------------------------------------- ------- --------------------------------
|
||||
/home/sk/myshare/THE LINUX COMMAND LINE.pdf 3.85757 efded6cc6f34a3d107c67c2300459911
|
||||
|
||||
```
|
||||
|
||||
**Download files**
|
||||
|
||||
You can download the files from any system on your network. To download a file, just mention the hash (checksum) of the file as shown below. You can get hash value of a share using “iwanto search” command.
|
||||
```
|
||||
$ iwanto download efded6cc6f34a3d107c67c2300459911
|
||||
|
||||
```
|
||||
|
||||
The file will be saved in your Download location (/home/sk/mydownloads/ in my case).
|
||||
```
|
||||
Filename: /home/sk/mydownloads/THE LINUX COMMAND LINE.pdf
|
||||
Size: 3.857569 MB
|
||||
|
||||
```
|
||||
|
||||
**View configuration**
|
||||
|
||||
To view the configuration i.e the Shared and Download folders, run:
|
||||
```
|
||||
$ iwanto view config
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Shared folder:/home/sk/myshare
|
||||
Download folder:/home/sk/mydownloads
|
||||
|
||||
```
|
||||
|
||||
**Change Shared and Download folder’s location**
|
||||
|
||||
You can change the Shared folder and Download folder location to some other path like below.
|
||||
```
|
||||
$ iwanto share /home/sk/ostechnix
|
||||
|
||||
```
|
||||
|
||||
Now, the Shared location has been changed to /home/sk/ostechnix location.
|
||||
|
||||
Also, you can change the Downloads location using command:
|
||||
```
|
||||
$ iwanto download to /home/sk/Downloads
|
||||
|
||||
```
|
||||
|
||||
To view the changes made, run the config command:
|
||||
```
|
||||
$ iwanto view config
|
||||
|
||||
```
|
||||
|
||||
**Stop iWant**
|
||||
|
||||
Once you done with iWant, you can quit it by pressing **CTRL+C**.
|
||||
|
||||
If it is not working by any chance, it might be due to Firewall or your router doesn’t support multicast. You can view all logs in** ~/.iwant/.iwant.log** file. For more details, refer the project’s GitHub page provided at the end.
|
||||
|
||||
And, that’s all. Hope this tool helps. I will be here again with another interesting guide. Till then, stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-commandline-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/
|
||||
[2]:https://www.ostechnix.com/psitransfer-simple-open-source-self-hosted-file-sharing-solution/
|
||||
@ -1,195 +0,0 @@
|
||||
translating by stenphenxs
|
||||
How to get a core dump for a segfault on Linux
|
||||
============================================================
|
||||
|
||||
This week at work I spent all week trying to debug a segfault. I’d never done this before, and some of the basic things involved (get a core dump! find the line number that segfaulted!) took me a long time to figure out. So here’s a blog post explaining how to do those things!
|
||||
|
||||
At the end of this blog post, you should know how to go from “oh no my program is segfaulting and I have no idea what is happening” to “well I know what its stack / line number was when it segfaulted at at least!“.
|
||||
|
||||
### what’s a segfault?
|
||||
|
||||
A “segmentation fault” is when your program tries to access memory that it’s not allowed to access, or tries to . This can be caused by:
|
||||
|
||||
* trying to dereference a null pointer (you’re not allowed to access the memory address `0`)
|
||||
|
||||
* trying to dereference some other pointer that isn’t in your memory
|
||||
|
||||
* a C++ vtable pointer that got corrupted and is pointing to the wrong place, which causes the program to try to execute some memory that isn’t executable
|
||||
|
||||
* some other things that I don’t understand, like I think misaligned memory accesses can also segfault
|
||||
|
||||
This “C++ vtable pointer” thing is what was happening to my segfaulting program. I might explain that in a future blog post because I didn’t know any C++ at the beginning of this week and this vtable lookup thing was a new way for a program to segfault that I didn’t know about.
|
||||
|
||||
But! This blog post isn’t about C++ bugs. Let’s talk about the basics, like, how do we even get a core dump?
|
||||
|
||||
### step 1: run valgrind
|
||||
|
||||
I found the easiest way to figure out why my program is segfaulting was to use valgrind: I ran
|
||||
|
||||
```
|
||||
valgrind -v your-program
|
||||
|
||||
```
|
||||
|
||||
and this gave me a stack trace of what happened. Neat!
|
||||
|
||||
But I wanted also wanted to do a more in-depth investigation and find out more than just what valgrind was telling me! So I wanted to get a core dump and explore it.
|
||||
|
||||
### How to get a core dump
|
||||
|
||||
A core dump is a copy of your program’s memory, and it’s useful when you’re trying to debug what went wrong with your problematic program.
|
||||
|
||||
When your program segfaults, the Linux kernel will sometimes write a core dump to disk. When I originally tried to get a core dump, I was pretty frustrated for a long time because – Linux wasn’t writing a core dump!! Where was my core dump????
|
||||
|
||||
Here’s what I ended up doing:
|
||||
|
||||
1. Run `ulimit -c unlimited` before starting my program
|
||||
|
||||
2. Run `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
|
||||
### ulimit: set the max size of a core dump
|
||||
|
||||
`ulimit -c` sets the maximum size of a core dump. It’s often set to 0, which means that the kernel won’t write core dumps at all. It’s in kilobytes. ulimits are per process – you can see a process’s limits by running `cat /proc/PID/limit`
|
||||
|
||||
For example these are the limits for a random Firefox process on my system:
|
||||
|
||||
```
|
||||
$ cat /proc/6309/limits
|
||||
Limit Soft Limit Hard Limit Units
|
||||
Max cpu time unlimited unlimited seconds
|
||||
Max file size unlimited unlimited bytes
|
||||
Max data size unlimited unlimited bytes
|
||||
Max stack size 8388608 unlimited bytes
|
||||
Max core file size 0 unlimited bytes
|
||||
Max resident set unlimited unlimited bytes
|
||||
Max processes 30571 30571 processes
|
||||
Max open files 1024 1048576 files
|
||||
Max locked memory 65536 65536 bytes
|
||||
Max address space unlimited unlimited bytes
|
||||
Max file locks unlimited unlimited locks
|
||||
Max pending signals 30571 30571 signals
|
||||
Max msgqueue size 819200 819200 bytes
|
||||
Max nice priority 0 0
|
||||
Max realtime priority 0 0
|
||||
Max realtime timeout unlimited unlimited us
|
||||
|
||||
```
|
||||
|
||||
The kernel uses the soft limit (in this case, “max core file size = 0”) when deciding how big of a core file to write. You can increase the soft limit up to the hard limit using the `ulimit` shell builtin (`ulimit -c unlimited`!)
|
||||
|
||||
### kernel.core_pattern: where core dumps are written
|
||||
|
||||
`kernel.core_pattern` is a kernel parameter or a “sysctl setting” that controls where the Linux kernel writes core dumps to disk.
|
||||
|
||||
Kernel parameters are a way to set global settings on your system. You can get a list of every kernel parameter by running `sysctl -a`, or use `sysctl kernel.core_pattern` to look at the `kernel.core_pattern` setting specifically.
|
||||
|
||||
So `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t` will write core dumps to `/tmp/core-<a bunch of stuff identifying the process>`
|
||||
|
||||
If you want to know more about what these `%e`, `%p` parameters read, see [man core][1].
|
||||
|
||||
It’s important to know that `kernel.core_pattern` is a global settings – it’s good to be a little careful about changing it because it’s possible that other systems depend on it being set a certain way.
|
||||
|
||||
### kernel.core_pattern & Ubuntu
|
||||
|
||||
By default on Ubuntu systems, this is what `kernel.core_pattern` is set to
|
||||
|
||||
```
|
||||
$ sysctl kernel.core_pattern
|
||||
kernel.core_pattern = |/usr/share/apport/apport %p %s %c %d %P
|
||||
|
||||
```
|
||||
|
||||
This caused me a lot of confusion (what is this apport thing and what is it doing with my core dumps??) so here’s what I learned about this:
|
||||
|
||||
* Ubuntu uses a system called “apport” to report crashes in apt packages
|
||||
|
||||
* Setting `kernel.core_pattern=|/usr/share/apport/apport %p %s %c %d %P`means that core dumps will be piped to `apport`
|
||||
|
||||
* apport has logs in /var/log/apport.log
|
||||
|
||||
* apport by default will ignore crashes from binaries that aren’t part of an Ubuntu packages
|
||||
|
||||
I ended up just overriding this Apport business and setting `kernel.core_pattern` to `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t` because I was on a dev machine, I didn’t care whether Apport was working on not, and I didn’t feel like trying to convince Apport to give me my core dumps.
|
||||
|
||||
### So you have a core dump. Now what?
|
||||
|
||||
Okay, now we know about ulimits and `kernel.core_pattern` and you have actually have a core dump file on disk in `/tmp`. Amazing! Now what??? We still don’t know why the program segfaulted!
|
||||
|
||||
The next step is to open the core file with `gdb` and get a backtrace.
|
||||
|
||||
### Getting a backtrace from gdb
|
||||
|
||||
You can open a core file with gdb like this:
|
||||
|
||||
```
|
||||
$ gdb -c my_core_file
|
||||
|
||||
```
|
||||
|
||||
Next, we want to know what the stack was when the program crashed. Running `bt` at the gdb prompt will give you a backtrace. In my case gdb hadn’t loaded symbols for the binary, so it was just like `??????`. Luckily, loading symbols fixed it.
|
||||
|
||||
Here’s how to load debugging symbols.
|
||||
|
||||
```
|
||||
symbol-file /path/to/my/binary
|
||||
sharedlibrary
|
||||
|
||||
```
|
||||
|
||||
This loads symbols from the binary and from any shared libraries the binary uses. Once I did that, gdb gave me a beautiful stack trace with line numbers when I ran `bt`!!!
|
||||
|
||||
If you want this to work, the binary should be compiled with debugging symbols. Having line numbers in your stack traces is extremely helpful when trying to figure out why a program crashed :)
|
||||
|
||||
### look at the stack for every thread
|
||||
|
||||
Here’s how to get the stack for every thread in gdb!
|
||||
|
||||
```
|
||||
thread apply all bt full
|
||||
|
||||
```
|
||||
|
||||
### gdb + core dumps = amazing
|
||||
|
||||
If you have a core dump & debugging symbols and gdb, you are in an amazing situation!! You can go up and down the call stack, print out variables, and poke around in memory to see what happened. It’s the best.
|
||||
|
||||
If you are still working on being a gdb wizard, you can also just print out the stack trace with `bt` and that’s okay :)
|
||||
|
||||
### ASAN
|
||||
|
||||
Another path to figuring out your segfault is to do one compile the program with AddressSanitizer (“ASAN”) (`$CC -fsanitize=address`) and run it. I’m not going to discuss that in this post because this is already pretty long and anyway in my case the segfault disappeared with ASAN turned on for some reason, possibly because the ASAN build used a different memory allocator (system malloc instead of tcmalloc).
|
||||
|
||||
I might write about ASAN more in the future if I ever get it to work :)
|
||||
|
||||
### getting a stack trace from a core dump is pretty approachable!
|
||||
|
||||
This blog post sounds like a lot and I was pretty confused when I was doing it but really there aren’t all that many steps to getting a stack trace out of a segfaulting program:
|
||||
|
||||
1. try valgrind
|
||||
|
||||
if that doesn’t work, or if you want to have a core dump to investigate:
|
||||
|
||||
1. make sure the binary is compiled with debugging symbols
|
||||
|
||||
2. set `ulimit` and `kernel.core_pattern` correctly
|
||||
|
||||
3. run the program
|
||||
|
||||
4. open your core dump with `gdb`, load the symbols, and run `bt`
|
||||
|
||||
5. try to figure out what happened!!
|
||||
|
||||
I was able using gdb to figure out that there was a C++ vtable entry that is pointing to some corrupt memory, which was somewhat helpful and helped me feel like I understood C++ a bit better. Maybe we’ll talk more about how to use gdb to figure things out another day!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/04/28/debugging-a-segfault-on-linux/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about/
|
||||
[1]:http://man7.org/linux/man-pages/man5/core.5.html
|
||||
@ -1,270 +0,0 @@
|
||||
BriFuture is translating
|
||||
|
||||
You don't know Bash: An introduction to Bash arrays
|
||||
======
|
||||
|
||||

|
||||
|
||||
Although software engineers regularly use the command line for many aspects of development, arrays are likely one of the more obscure features of the command line (although not as obscure as the regex operator `=~`). But obscurity and questionable syntax aside, [Bash][1] arrays can be very powerful.
|
||||
|
||||
### Wait, but why?
|
||||
|
||||
Writing about Bash is challenging because it's remarkably easy for an article to devolve into a manual that focuses on syntax oddities. Rest assured, however, the intent of this article is to avoid having you RTFM.
|
||||
|
||||
#### A real (actually useful) example
|
||||
|
||||
To that end, let's consider a real-world scenario and how Bash can help: You are leading a new effort at your company to evaluate and optimize the runtime of your internal data pipeline. As a first step, you want to do a parameter sweep to evaluate how well the pipeline makes use of threads. For the sake of simplicity, we'll treat the pipeline as a compiled C++ black box where the only parameter we can tweak is the number of threads reserved for data processing: `./pipeline --threads 4`.
|
||||
|
||||
### The basics
|
||||
|
||||
`--threads` parameter that we want to test:
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
```
|
||||
|
||||
The first thing we'll do is define an array containing the values of theparameter that we want to test:
|
||||
|
||||
In this example, all the elements are numbers, but it need not be the case—arrays in Bash can contain both numbers and strings, e.g., `myArray=(1 2 "three" 4 "five")` is a valid expression. And just as with any other Bash variable, make sure to leave no spaces around the equal sign. Otherwise, Bash will treat the variable name as a program to execute, and the `=` as its first parameter!
|
||||
|
||||
Now that we've initialized the array, let's retrieve a few of its elements. You'll notice that simply doing `echo $allThreads` will output only the first element.
|
||||
|
||||
To understand why that is, let's take a step back and revisit how we usually output variables in Bash. Consider the following scenario:
|
||||
```
|
||||
type="article"
|
||||
|
||||
echo "Found 42 $type"
|
||||
|
||||
```
|
||||
|
||||
Say the variable `$type` is given to us as a singular noun and we want to add an `s` at the end of our sentence. We can't simply add an `s` to `$type` since that would turn it into a different variable, `$types`. And although we could utilize code contortions such as `echo "Found 42 "$type"s"`, the best way to solve this problem is to use curly braces: `echo "Found 42 ${type}s"`, which allows us to tell Bash where the name of a variable starts and ends (interestingly, this is the same syntax used in JavaScript/ES6 to inject variables and expressions in [template literals][2]).
|
||||
|
||||
So as it turns out, although Bash variables don't generally require curly brackets, they are required for arrays. In turn, this allows us to specify the index to access, e.g., `echo ${allThreads[1]}` returns the second element of the array. Not including brackets, e.g.,`echo $allThreads[1]`, leads Bash to treat `[1]` as a string and output it as such.
|
||||
|
||||
Yes, Bash arrays have odd syntax, but at least they are zero-indexed, unlike some other languages (I'm looking at you, `R`).
|
||||
|
||||
### Looping through arrays
|
||||
|
||||
Although in the examples above we used integer indices in our arrays, let's consider two occasions when that won't be the case: First, if we wanted the `$i`-th element of the array, where `$i` is a variable containing the index of interest, we can retrieve that element using: `echo ${allThreads[$i]}`. Second, to output all the elements of an array, we replace the numeric index with the `@` symbol (you can think of `@` as standing for `all`): `echo ${allThreads[@]}`.
|
||||
|
||||
#### Looping through array elements
|
||||
|
||||
With that in mind, let's loop through `$allThreads` and launch the pipeline for each value of `--threads`:
|
||||
```
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
./pipeline --threads $t
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### Looping through array indices
|
||||
|
||||
Next, let's consider a slightly different approach. Rather than looping over array elements, we can loop over array indices:
|
||||
```
|
||||
for i in ${!allThreads[@]}; do
|
||||
|
||||
./pipeline --threads ${allThreads[$i]}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
Let's break that down: As we saw above, `${allThreads[@]}` represents all the elements in our array. Adding an exclamation mark to make it `${!allThreads[@]}` will return the list of all array indices (in our case 0 to 7). In other words, the `for` loop is looping through all indices `$i` and reading the `$i`-th element from `$allThreads` to set the value of the `--threads` parameter.
|
||||
|
||||
This is much harsher on the eyes, so you may be wondering why I bother introducing it in the first place. That's because there are times where you need to know both the index and the value within a loop, e.g., if you want to ignore the first element of an array, using indices saves you from creating an additional variable that you then increment inside the loop.
|
||||
|
||||
### Populating arrays
|
||||
|
||||
So far, we've been able to launch the pipeline for each `--threads` of interest. Now, let's assume the output to our pipeline is the runtime in seconds. We would like to capture that output at each iteration and save it in another array so we can do various manipulations with it at the end.
|
||||
|
||||
#### Some useful syntax
|
||||
|
||||
But before diving into the code, we need to introduce some more syntax. First, we need to be able to retrieve the output of a Bash command. To do so, use the following syntax: `output=$( ./my_script.sh )`, which will store the output of our commands into the variable `$output`.
|
||||
|
||||
The second bit of syntax we need is how to append the value we just retrieved to an array. The syntax to do that will look familiar:
|
||||
```
|
||||
myArray+=( "newElement1" "newElement2" )
|
||||
|
||||
```
|
||||
|
||||
#### The parameter sweep
|
||||
|
||||
Putting everything together, here is our script for launching our parameter sweep:
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
allRuntimes=()
|
||||
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
runtime=$(./pipeline --threads $t)
|
||||
|
||||
allRuntimes+=( $runtime )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
And voilà!
|
||||
|
||||
### What else you got?
|
||||
|
||||
In this article, we covered the scenario of using arrays for parameter sweeps. But I promise there are more reasons to use Bash arrays—here are two more examples.
|
||||
|
||||
#### Log alerting
|
||||
|
||||
In this scenario, your app is divided into modules, each with its own log file. We can write a cron job script to email the right person when there are signs of trouble in certain modules:``
|
||||
```
|
||||
# List of logs and who should be notified of issues
|
||||
|
||||
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
|
||||
|
||||
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
|
||||
|
||||
|
||||
|
||||
# Look for signs of trouble in each log
|
||||
|
||||
for i in ${!logPaths[@]};
|
||||
|
||||
do
|
||||
|
||||
log=${logPaths[$i]}
|
||||
|
||||
stakeholder=${logEmails[$i]}
|
||||
|
||||
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
|
||||
|
||||
|
||||
|
||||
# Warn stakeholders if recently saw > 5 errors
|
||||
|
||||
if [[ "$numErrors" -gt 5 ]];
|
||||
|
||||
then
|
||||
|
||||
emailRecipient="$stakeholder"
|
||||
|
||||
emailSubject="WARNING: ${log} showing unusual levels of errors"
|
||||
|
||||
emailBody="${numErrors} errors found in log ${log}"
|
||||
|
||||
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
|
||||
|
||||
fi
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### API queries
|
||||
|
||||
Say you want to generate some analytics about which users comment the most on your Medium posts. Since we don't have direct database access, SQL is out of the question, but we can use APIs!
|
||||
|
||||
To avoid getting into a long discussion about API authentication and tokens, we'll instead use [JSONPlaceholder][3], a public-facing API testing service, as our endpoint. Once we query each post and retrieve the emails of everyone who commented, we can append those emails to our results array:
|
||||
```
|
||||
endpoint="https://jsonplaceholder.typicode.com/comments"
|
||||
|
||||
allEmails=()
|
||||
|
||||
|
||||
|
||||
# Query first 10 posts
|
||||
|
||||
for postId in {1..10};
|
||||
|
||||
do
|
||||
|
||||
# Make API call to fetch emails of this posts's commenters
|
||||
|
||||
response=$(curl "${endpoint}?postId=${postId}")
|
||||
|
||||
|
||||
|
||||
# Use jq to parse the JSON response into an array
|
||||
|
||||
allEmails+=( $( jq '.[].email' <<< "$response" ) )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
Note here that I'm using the [`jq` tool][4] to parse JSON from the command line. The syntax of `jq` is beyond the scope of this article, but I highly recommend you look into it.
|
||||
|
||||
As you might imagine, there are countless other scenarios in which using Bash arrays can help, and I hope the examples outlined in this article have given you some food for thought. If you have other examples to share from your own work, please leave a comment below.
|
||||
|
||||
### But wait, there's more!
|
||||
|
||||
Since we covered quite a bit of array syntax in this article, here's a summary of what we covered, along with some more advanced tricks we did not cover:
|
||||
|
||||
Syntax Result `arr=()` Create an empty array `arr=(1 2 3)` Initialize array `${arr[2]}` Retrieve third element `${arr[@]}` Retrieve all elements `${!arr[@]}` Retrieve array indices `${#arr[@]}` Calculate array size `arr[0]=3` Overwrite 1st element `arr+=(4)` Append value(s) `str=$(ls)` Save `ls` output as a string `arr=( $(ls) )` Save `ls` output as an array of files `${arr[@]:s:n}` Retrieve elements at indices `n` to `s+n`
|
||||
|
||||
### One last thought
|
||||
|
||||
As we've discovered, Bash arrays sure have strange syntax, but I hope this article convinced you that they are extremely powerful. Once you get the hang of the syntax, you'll find yourself using Bash arrays quite often.
|
||||
|
||||
#### Bash or Python?
|
||||
|
||||
Which begs the question: When should you use Bash arrays instead of other scripting languages such as Python?
|
||||
|
||||
To me, it all boils down to dependencies—if you can solve the problem at hand using only calls to command-line tools, you might as well use Bash. But for times when your script is part of a larger Python project, you might as well use Python.
|
||||
|
||||
For example, we could have turned to Python to implement the parameter sweep, but we would have ended up just writing a wrapper around Bash:
|
||||
```
|
||||
import subprocess
|
||||
|
||||
|
||||
|
||||
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
|
||||
|
||||
all_runtimes = []
|
||||
|
||||
|
||||
|
||||
# Launch pipeline on each number of threads
|
||||
|
||||
for t in all_threads:
|
||||
|
||||
cmd = './pipeline --threads {}'.format(t)
|
||||
|
||||
|
||||
|
||||
# Use the subprocess module to fetch the return output
|
||||
|
||||
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
|
||||
|
||||
output = p.communicate()[0]
|
||||
|
||||
all_runtimes.append(output)
|
||||
|
||||
```
|
||||
|
||||
Since there's no getting around the command line in this example, using Bash directly is preferable.
|
||||
|
||||
#### Time for a shameless plug
|
||||
|
||||
If you enjoyed this article, there's more where that came from! [Register here to attend OSCON][5], where I'll be presenting the live-coding workshop [You Don't Know Bash][6] on July 17, 2018. No slides, no clickers—just you and me typing away at the command line, exploring the wondrous world of Bash.
|
||||
|
||||
This article originally appeared on [Medium][7] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
|
||||
|
||||
作者:[Robert Aboukhalil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/robertaboukhalil
|
||||
[1]:https://opensource.com/article/17/7/bash-prompt-tips-and-tricks
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals
|
||||
[3]:https://github.com/typicode/jsonplaceholder
|
||||
[4]:https://stedolan.github.io/jq/
|
||||
[5]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[6]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67166
|
||||
[7]:https://medium.com/@robaboukhalil/the-weird-wondrous-world-of-bash-arrays-a86e5adf2c69
|
||||
@ -1,82 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for June 2018
|
||||
======
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
[Ghostwriter][2] is a text editor for [Markdown][3] format with a minimal interface. It provides a preview of the document in HTML and syntax highlighting for Markdown. It offers the option to highlight only the paragraph or sentence currently being written. In addition, Ghostwriter can export documents to several formats, including PDF and HTML. Finally, it has the so-called “Hemingway” mode, in which erasing is disabled, forcing the user to write now and edit later.![][4]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Ghostwriter for Fedora 26, 27, 28, and Rawhide, and EPEL 7. To install Ghostwriter, use these commands:
|
||||
```
|
||||
sudo dnf copr enable scx/ghostwriter
|
||||
sudo dnf install ghostwriter
|
||||
|
||||
```
|
||||
|
||||
### Lector
|
||||
|
||||
[Lector][5] is a simple ebook reader application. Lector supports most common ebook formats, such as EPUB, MOBI, and AZW, as well as comic book archives CBZ and CBR. It’s easy to setup — just specify the directory containing your ebooks. You can browse books in Lector’s library using either a table or book covers. Among Lector’s features are bookmarks, user-defined tags, and a built-in dictionary.![][6]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Lector for Fedora 26, 27, 28, and Rawhide. To install Lector, use these commands:
|
||||
```
|
||||
sudo dnf copr enable bugzy/lector
|
||||
sudo dnf install lector
|
||||
|
||||
```
|
||||
|
||||
### Ranger
|
||||
|
||||
Ranerger is a text-based file manager with Vim key bindings. It displays the directory structure in three columns. The left one shows the parent directory, the middle the contents of the current directory, and the right a preview of the selected file or directory. In the case of text files, Ranger shows actual contents of the file as a preview.![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Ranger for Fedora 27, 28, and Rawhide. To install Ranger, use these commands:
|
||||
```
|
||||
sudo dnf copr enable fszymanski/ranger
|
||||
sudo dnf install ranger
|
||||
|
||||
```
|
||||
|
||||
### PrestoPalette
|
||||
|
||||
PrestoPeralette is a tool that helps create balanced color palettes. A nice feature of PrestoPalette is the ability to use lighting to affect both lightness and saturation of the palette. You can export created palettes either as PNG or JSON.
|
||||
![][8]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides PrestoPalette for Fedora 26, 27, 28, and Rawhide, and EPEL 7. To install PrestoPalette, use these commands:
|
||||
```
|
||||
sudo dnf copr enable dagostinelli/prestopalette
|
||||
sudo dnf install prestopalette
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-june-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://wereturtle.github.io/ghostwriter/
|
||||
[3]:https://daringfireball.net/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/05/ghostwriter.png
|
||||
[5]:https://github.com/BasioMeusPuga/Lector
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/lector.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/ranger.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/prestopalette.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Check Which Groups A User Belongs To On Linux
|
||||
======
|
||||
Adding a user into existing group is one of the regular activity for Linux admin. This is daily activity for some of the administrator who’s working one big environments.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating-----geekpi
|
||||
|
||||
How To Upgrade Everything Using A Single Command In Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
What is the Difference Between the macOS and Linux Kernels
|
||||
======
|
||||
Some people might think that there are similarities between the macOS and the Linux kernel because they can handle similar commands and similar software. Some people even think that Apple’s macOS is based on Linux. The truth is that both kernels have very different histories and features. Today, we will take a look at the difference between macOS and Linux kernels.
|
||||
|
||||
![macOS vs Linux][1]
|
||||
|
||||
### History of macOS Kernel
|
||||
|
||||
We will start with the history of the macOS kernel. In 1985, Steve Jobs left Apple due to a falling out with CEO John Sculley and the Apple board of directors. He then founded a new computer company named [NeXT][2]. Jobs wanted to get a new computer (with a new operating system) to market quickly. To save time, the NeXT team used the [Mach kernel][3] from Carnegie Mellon and parts of the BSD code base to created the [NeXTSTEP operating system][4].
|
||||
|
||||
NeXT never became a financial success, due in part to Jobs’ habit of spending money like he was still at Apple. Meanwhile, Apple had tried unsuccessfully on several occasions to update their operating system, even going so far as to partner with IBM. In 1997, Apple purchased NeXT for $429 million. As part of the deal, Steve Jobs returned to Apple and NeXTSTEP became the foundation of macOS and iOS.
|
||||
|
||||
### History of Linux Kernel
|
||||
|
||||
Unlike the macOS kernel, Linux was not created as part of a commercial endeavor. Instead, it was [created in 1991 by Finnish computer science student Linus Torvalds][5]. Originally, the kernel was written to the specifications of Linus’ computer because he wanted to take advantage of its new 80386 processor. Linus posted the code for his new kernel to [the Usenet in August of 1991][6]. Soon, he was receiving code and feature suggestions from all over the world. The following year Orest Zborowski ported the X Window System to Linux, giving it the ability to support a graphical user interface.
|
||||
|
||||
Over the last 27 years, Linux has slowly grown and gained features. It’s no longer a student’s small-time project. Now it runs most of the [world’s][7] [computing devices][8] and the [world’s supercomputers][9]. Not too shabby.
|
||||
|
||||
### Features of the macOS Kernel
|
||||
|
||||
The macOS kernel is officially known as XNU. The [acronym][10] stands for “XNU is Not Unix.” According to [Apple’s Github page][10], XNU is “a hybrid kernel combining the Mach kernel developed at Carnegie Mellon University with components from FreeBSD and C++ API for writing drivers”. The BSD subsystem part of the code is [“typically implemented as user-space servers in microkernel systems”][11]. The Mach part is responsible for low-level work, such as multitasking, protected memory, virtual memory management, kernel debugging support, and console I/O.
|
||||
|
||||
### Features of Linux Kernel
|
||||
|
||||
While the macOS kernel combines the feature of a microkernel ([Mach][12])) and a monolithic kernel ([BSD][13]), Linux is solely a monolithic kernel. A [monolithic kernel][14] is responsible for managing the CPU, memory, inter-process communication, device drivers, file system, and system server calls.
|
||||
|
||||
### Difference between Mac and Linux kernel in one line
|
||||
|
||||
The macOS kernel (XNU) has been around longer than Linux and was based on a combination of two even older code bases. On the other hand, Linux is newer, written from scratch, and is used on many more devices.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mac-linux-difference/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
|
||||
[2]:https://en.wikipedia.org/wiki/NeXT
|
||||
[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
|
||||
[4]:https://en.wikipedia.org/wiki/NeXTSTEP
|
||||
[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
|
||||
[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
|
||||
[8]:https://www.linuxinsider.com/story/31855.html
|
||||
[9]:https://itsfoss.com/linux-supercomputers-2017/
|
||||
[10]:https://github.com/apple/darwin-xnu
|
||||
[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
|
||||
[12]:https://en.wikipedia.org/wiki/Mach_(kernel
|
||||
[13]:https://en.wikipedia.org/wiki/FreeBSD
|
||||
[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
|
||||
[15]:http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,54 @@
|
||||
5 Firefox extensions to protect your privacy
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the wake of the Cambridge Analytica story, I took a hard look at how far I had let Facebook penetrate my online presence. As I'm generally concerned about single points of failure (or compromise), I am not one to use social logins. I use a password manager and create unique logins for every site (and you should, too).
|
||||
|
||||
What I was most perturbed about was the pervasive intrusion Facebook was having on my digital life. I uninstalled the Facebook mobile app almost immediately after diving into the Cambridge Analytica story. I also [disconnected all apps, games, and websites][1] from Facebook. Yes, this will change your experience on Facebook, but it will also protect your privacy. As a veteran with friends spread out across the globe, maintaining the social connectivity of Facebook is important to me.
|
||||
|
||||
I went about the task of scrutinizing other services as well. I checked Google, Twitter, GitHub, and more for any unused connected applications. But I know that's not enough. I need my browser to be proactive in preventing behavior that violates my privacy. I began the task of figuring out how best to do that. Sure, I can lock down a browser, but I need to make the sites and tools I use work while trying to keep them from leaking data.
|
||||
|
||||
Following are five tools that will protect your privacy while using your browser. The first three extensions are available for Firefox and Chrome, while the latter two are only available for Firefox.
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
[Privacy Badger][2] has been my go-to extension for quite some time. Do other content or ad blockers do a better job? Maybe. The problem with a lot of content blockers is that they are "pay for play." Meaning they have "partners" that get whitelisted for a fee. That is the antithesis of why content blockers exist. Privacy Badger is made by the Electronic Frontier Foundation (EFF), a nonprofit entity with a donation-based business model. Privacy Badger promises to learn from your browsing habits and requires minimal tuning. For example, I have only had to whitelist a handful of sites. Privacy Badger also allows granular controls of exactly which trackers are enabled on what sites. It's my #1, must-install extension, no matter the browser.
|
||||
|
||||
### DuckDuckGo Privacy Essentials
|
||||
|
||||
The search engine DuckDuckGo has typically been privacy-conscious. [DuckDuckGo Privacy Essentials][3] works across major mobile devices and browsers. It's unique in the sense that it grades sites based on the settings you give them. For example, Facebook gets a D, even with Privacy Protection enabled. Meanwhile, [chrisshort.net][4] gets a B with Privacy Protection enabled and a C with it disabled. If you're not keen on EFF or Privacy Badger for whatever reason, I would recommend DuckDuckGo Privacy Essentials (choose one, not both, as they essentially do the same thing).
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
[HTTPS Everywhere][5] is another extension from the EFF. According to HTTPS Everywhere, "Many sites on the web offer some limited support for encryption over HTTPS, but make it difficult to use. For instance, they may default to unencrypted HTTP or fill encrypted pages with links that go back to the unencrypted site. The HTTPS Everywhere extension fixes these problems by using clever technology to rewrite requests to these sites to HTTPS." While a lot of sites and browsers are getting better about implementing HTTPS, there are a lot of sites that still need help. HTTPS Everywhere will try its best to make sure your traffic is encrypted.
|
||||
|
||||
### NoScript Security Suite
|
||||
|
||||
[NoScript Security Suite][6] is not for the faint of heart. While the Firefox-only extension "allows JavaScript, Java, Flash, and other plugins to be executed only by trusted websites of your choice," it doesn't do a great job at figuring out what your choices are. But, make no mistake, a surefire way to prevent leaking data is not executing code that could leak it. NoScript enables that via its "whitelist-based preemptive script blocking." This means you will need to build the whitelist as you go for sites not already on it. Note that NoScript is only available for Firefox.
|
||||
|
||||
### Facebook Container
|
||||
|
||||
[Facebook Container][7] makes Firefox the only browser where I will use Facebook. "Facebook Container works by isolating your Facebook identity into a separate container that makes it harder for Facebook to track your visits to other websites with third-party cookies." This means Facebook cannot snoop on activity happening elsewhere in your browser. Suddenly those creepy ads will stop appearing so frequently (assuming you uninstalled the Facebook app from your mobile devices). Using Facebook in an isolated space will prevent any additional collection of data. Remember, you've given Facebook data already, and Facebook Container can't prevent that data from being shared.
|
||||
|
||||
These are my go-to extensions for browser privacy. What are yours? Please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/firefox-extensions-protect-privacy
|
||||
|
||||
作者:[Chris Short][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.facebook.com/help/211829542181913
|
||||
[2]:https://www.eff.org/privacybadger
|
||||
[3]:https://duckduckgo.com/app
|
||||
[4]:https://chrisshort.net
|
||||
[5]:https://www.eff.org/https-everywhere
|
||||
[6]:https://noscript.net/
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
|
||||
@ -0,0 +1,200 @@
|
||||
A sysadmin's guide to network management
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you're a sysadmin, your daily tasks include managing servers and the data center's network. The following Linux utilities and commands—from basic to advanced—will help make network management easier.
|
||||
|
||||
In several of these commands, you'll see `<fqdn>`, which stands for "fully qualified domain name." When you see this, substitute your website URL or your server (e.g., `server-name.company.com`), as the case may be.
|
||||
|
||||
### Ping
|
||||
|
||||
As the name suggests, `ping` is used to check the end-to-end connectivity from your system to the one you are trying to connect to. It uses [ICMP][1] echo packets that travel back to your system when a ping is successful. It's also a good first step to check system/network connectivity. You can use the `ping` command with IPv4 and IPv6 addresses. (Read my article "[How to find your IP address in Linux][2]" to learn more about IP addresses.)
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* IPv4: `ping <ip address>/<fqdn>`
|
||||
* IPv6: `ping6 <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
You can also use `ping` to resolve names of websites to their corresponding IP address, as shown below:
|
||||
|
||||
|
||||
|
||||
### Traceroute
|
||||
|
||||
`ping` checks end-to-end connectivity, the `traceroute` utility tells you all the router IPs on the path you travel to reach the end system, website, or server. `traceroute` is usually is the second step after `ping` for network connection debugging.
|
||||
|
||||
This is a nice utility for tracing the full network path from your system to another. Wherechecks end-to-end connectivity, theutility tells you all the router IPs on the path you travel to reach the end system, website, or server.is usually is the second step afterfor network connection debugging.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `traceroute <ip address>/<fqdn>`
|
||||
|
||||
|
||||
|
||||
### Telnet
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `telnet <ip address>/<fqdn>` is used to [telnet][3] into any server.
|
||||
|
||||
|
||||
|
||||
### Netstat
|
||||
|
||||
The network statistics (`netstat`) utility is used to troubleshoot network-connection problems and to check interface/port statistics, routing tables, protocol stats, etc. It's any sysadmin's must-have tool.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `netstat -l` shows the list of all the ports that are in listening mode.
|
||||
* `netstat -a` shows all ports; to specify only TCP, use `-at` (for UDP use `-au`).
|
||||
* `netstat -r` provides a routing table.
|
||||
|
||||
|
||||
|
||||
* `netstat -s` provides a summary of statistics for each protocol.
|
||||
|
||||
|
||||
|
||||
* `netstat -i` displays transmission/receive (TX/RX) packet statistics for each interface.
|
||||
|
||||
|
||||
|
||||
### Nmcli
|
||||
|
||||
`nmcli` is a good utility for managing network connections, configurations, etc. It can be used to control Network Manager and modify any device's network configuration details.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `nmcli device` lists all devices on the system.
|
||||
|
||||
* `nmcli device show <interface>` shows network-related details of the specified interface.
|
||||
|
||||
* `nmcli connection` checks a device's connection.
|
||||
|
||||
* `nmcli connection down <interface>` shuts down the specified interface.
|
||||
|
||||
* `nmcli connection up <interface>` starts the specified interface.
|
||||
|
||||
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` adds a virtual LAN (VLAN) interface with the specified VLAN number, IP address, and gateway to a particular interface.
|
||||
|
||||
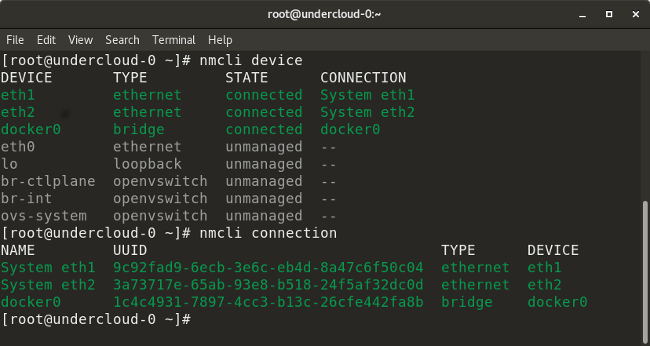
|
||||
|
||||
|
||||
### Routing
|
||||
|
||||
There are many commands you can use to check and configure routing. Here are some useful ones:
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `ip route` shows all the current routes configured for the respective interfaces.
|
||||
|
||||
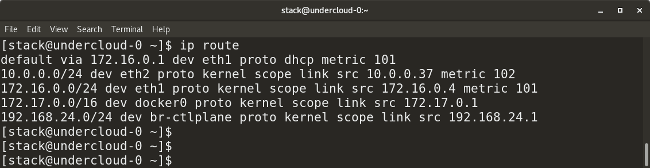
|
||||
|
||||
* `route add default gw <gateway-ip>` adds a default gateway to the routing table.
|
||||
* `route add -net <network ip/cidr> gw <gateway ip> <interface>` adds a new network route to the routing table. There are many other routing parameters, such as adding a default route, default gateway, etc.
|
||||
* `route del -net <network ip/cidr>` deletes a particular route entry from the routing table.
|
||||
|
||||
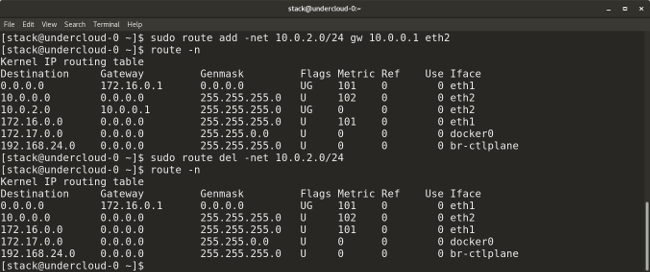
|
||||
|
||||
* `ip neighbor` shows the current neighbor table and can be used to add, change, or delete new neighbors.
|
||||
|
||||
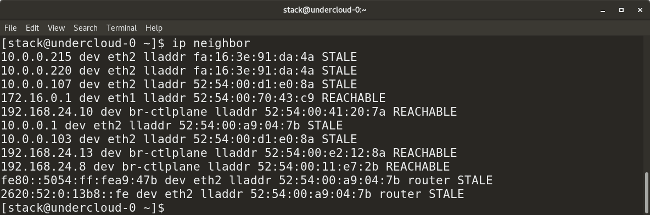
|
||||
|
||||
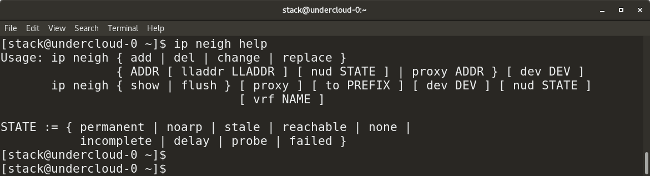
|
||||
|
||||
* `arp` (which stands for address resolution protocol) is similar to `ip neighbor`. `arp` maps a system's IP address to its corresponding MAC (media access control) address.
|
||||
|
||||
|
||||
|
||||
### Tcpdump and Wireshark
|
||||
|
||||
Linux provides many packet-capturing tools like `tcpdump`, `wireshark`, `tshark`, etc. They are used to capture network traffic in packets that are transmitted/received and hence are very useful for a sysadmin to debug any packet losses or related issues. For command-line enthusiasts, `tcpdump` is a great tool, and for GUI users, `wireshark` is a great utility to capture and analyze packets. `tcpdump` is a built-in Linux utility to capture network traffic. It can be used to capture/show traffic on specific ports, protocols, etc.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `tcpdump -i <interface-name>` shows live packets from the specified interface. Packets can be saved in a file by adding the `-w` flag and the name of the output file to the command, for example: `tcpdump -w <output-file.> -i <interface-name>`.
|
||||
|
||||
|
||||
|
||||
* `tcpdump -i <interface> src <source-ip>` captures packets from a particular source IP.
|
||||
* `tcpdump -i <interface> dst <destination-ip>` captures packets from a particular destination IP.
|
||||
* `tcpdump -i <interface> port <port-number>` captures traffic for a specific port number like 53, 80, 8080, etc.
|
||||
* `tcpdump -i <interface> <protocol>` captures traffic for a particular protocol, like TCP, UDP, etc.
|
||||
|
||||
|
||||
|
||||
### Iptables
|
||||
|
||||
`iptables` is a firewall-like packet-filtering utility that can allow or block certain traffic. The scope of this utility is very wide; here are some of its most common uses.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `iptables -L` lists all existing `iptables` rules.
|
||||
* `iptables -F` deletes all existing rules.
|
||||
|
||||
|
||||
|
||||
The following commands allow traffic from the specified port number to the specified interface:
|
||||
|
||||
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
The following commands allow loopback access to the system:
|
||||
|
||||
* `iptables -A INPUT -i lo -j ACCEPT`
|
||||
* `iptables -A OUTPUT -o lo -j ACCEPT`
|
||||
|
||||
|
||||
|
||||
### Nslookup
|
||||
|
||||
The `nslookup` tool is used to obtain IP address mapping of a website or domain. It can also be used to obtain information on your DNS server, such as all DNS records on a website (see the example below). A similar tool to `nslookup` is the `dig` (Domain Information Groper) utility.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `nslookup <website-name.com>` shows the IP address of your DNS server in the Server field, and, below that, gives the IP address of the website you are trying to reach.
|
||||
* `nslookup -type=any <website-name.com>` shows all the available records for the specified website/domain.
|
||||
|
||||
|
||||
|
||||
### Network/interface debugging
|
||||
|
||||
Here is a summary of the necessary commands and files used to troubleshoot interface connectivity or related network issues.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
* `ss` is a utility for dumping socket statistics.
|
||||
* `nmap <ip-address>`, which stands for Network Mapper, scans network ports, discovers hosts, detects MAC addresses, and much more.
|
||||
* `ip addr/ifconfig -a` provides IP addresses and related info on all the interfaces of a system.
|
||||
* `ssh -vvv user@<ip/domain>` enables you to SSH to another server with the specified IP/domain and username. The `-vvv` flag provides "triple-verbose" details of the processes going on while SSH'ing to the server.
|
||||
* `ethtool -S <interface>` checks the statistics for a particular interface.
|
||||
* `ifup <interface>` starts up the specified interface.
|
||||
* `ifdown <interface>` shuts down the specified interface.
|
||||
* `systemctl restart network` restarts a network service for the system.
|
||||
* `/etc/sysconfig/network-scripts/<interface-name>` is an interface configuration file used to set IP, network, gateway, etc. for the specified interface. DHCP mode can be set here.
|
||||
* `/etc/hosts` this file contains custom host/domain to IP mappings.
|
||||
* `/etc/resolv.conf` specifies the DNS nameserver IP of the system.
|
||||
* `/etc/ntp.conf` specifies the NTP server domain.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/sysadmin-guide-networking-commands
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[2]:https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[3]:https://en.wikipedia.org/wiki/Telnet
|
||||
@ -0,0 +1,101 @@
|
||||
Anbox: How To Install Google Play Store And Enable ARM (libhoudini) Support, The Easy Way
|
||||
======
|
||||
**[Anbox][1], or Android in a Box, is a free and open source tool that allows running Android applications on Linux.** It works by running the Android runtime environment in an LXC container, recreating the directory structure of Android as a mountable loop image, while using the native Linux kernel to execute applications.
|
||||
|
||||
Its key features are security, performance, integration and convergence (scales across different form factors), according to its website.
|
||||
|
||||
**Using Anbox, each Android application or game is launched in a separate window, just like system applications** , and they behave more or less like regular windows, showing up in the launcher, can be tiled, etc.
|
||||
|
||||
By default, Anbox doesn't ship with the Google Play Store or support for ARM applications. To install applications you must download each app APK and install it manually using adb. Also, installing ARM applications or games doesn't work by default with Anbox - trying to install ARM apps results in the following error being displayed:
|
||||
```
|
||||
Failed to install PACKAGE.NAME.apk: Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
|
||||
|
||||
```
|
||||
|
||||
You can set up both Google Play Store and support for ARM applications (through libhoudini) manually for Android in a Box, but it's a quite complicated process. **To make it easier to install Google Play Store and Google Play Services on Anbox, and get it to support ARM applications and games (using libhoudini), the folks at[geeks-r-us.de][2] (linked article is in German) have created a [script][3] that automates these tasks.**
|
||||
|
||||
Before using this, I'd like to make it clear that not all Android applications and games work in Anbox, even after integrating libhoudini for ARM support. Some Android applications and games may not show up in the Google Play Store at all, while others may be available for installation but will not work. Also, some features may not be available in some applications.
|
||||
|
||||
### Install Google Play Store and enable ARM applications / games support on Anbox (Android in a Box)
|
||||
|
||||
These instructions will obviously not work if Anbox is not already installed on your Linux desktop. If you haven't already, install Anbox by following the installation instructions found
|
||||
|
||||
`anbox.appmgr`
|
||||
|
||||
at least once after installing Anbox and before using this script, to avoid running into issues.
|
||||
|
||||
1\. Install the required dependencies (`wget` , `lzip` , `unzip` and `squashfs-tools`).
|
||||
|
||||
In Debian, Ubuntu or Linux Mint, use this command to install the required dependencies:
|
||||
```
|
||||
sudo apt install wget lzip unzip squashfs-tools
|
||||
|
||||
```
|
||||
|
||||
2\. Download and run the script that automatically downloads and installs Google Play Store (and Google Play Services) and libhoudini (for ARM apps / games support) on your Android in a Box installation.
|
||||
|
||||
**Warning: never run a script you didn't write without knowing what it does. Before running this script, check out its [code][4]. **
|
||||
|
||||
To download the script, make it executable and run it on your Linux desktop, use these commands in a terminal:
|
||||
```
|
||||
wget https://raw.githubusercontent.com/geeks-r-us/anbox-playstore-installer/master/install-playstore.sh
|
||||
chmod +x install-playstore.sh
|
||||
sudo ./install-playstore.sh
|
||||
|
||||
```
|
||||
|
||||
3\. To get Google Play Store to work in Anbox, you need to enable all the permissions for both Google Play Store and Google Play Services
|
||||
|
||||
To do this, run Anbox:
|
||||
```
|
||||
anbox.appmgr
|
||||
|
||||
```
|
||||
|
||||
Then go to `Settings > Apps > Google Play Services > Permissions` and enable all available permissions. Do the same for Google Play Store!
|
||||
|
||||
You should now be able to login using a Google account into Google Play Store.
|
||||
|
||||
Without enabling all permissions for Google Play Store and Google Play Services, you may encounter an issue when trying to login to your Google account, with the following error message: " _Couldn't sign in. There was a problem communicating with Google servers. Try again later_ ", as you can see in this screenshot:
|
||||
|
||||
After logging in, you can disable some of the Google Play Store / Google Play Services permissions.
|
||||
|
||||
**If you're encountering some connectivity issues when logging in to your Google account on Anbox,** make sure the `anbox-bride.sh` is running:
|
||||
|
||||
* to start it:
|
||||
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh start
|
||||
|
||||
```
|
||||
|
||||
* to restart it:
|
||||
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh restart
|
||||
|
||||
```
|
||||
|
||||
You may also need to install the dnsmasq package if you continue to have connectivity issues with Anbox, according to
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://anbox.io/
|
||||
[2]:https://geeks-r-us.de/2017/08/26/android-apps-auf-dem-linux-desktop/
|
||||
[3]:https://github.com/geeks-r-us/anbox-playstore-installer/
|
||||
[4]:https://github.com/geeks-r-us/anbox-playstore-installer/blob/master/install-playstore.sh
|
||||
[5]:https://docs.anbox.io/userguide/install.html
|
||||
[6]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
@ -0,0 +1,68 @@
|
||||
Boost your typing with emoji in Fedora 28 Workstation
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora 28 Workstation ships with a feature that allows you to quickly search, select and input emoji using your keyboard. Emoji, cute ideograms that are part of Unicode, are used fairly widely in messaging and especially on mobile devices. You may have heard the idiom “A picture is worth a thousand words.” This is exactly what emoji provide: simple images for you to use in communication. Each release of Unicode adds more, with over 200 new ones added in past releases of Unicode. This article shows you how to make them easy to use in your Fedora system.
|
||||
|
||||
It’s great to see emoji numbers growing. But at the same time it brings the challenge of how to input them in a computing device. Many people already use these symbols for input in mobile devices or social networking sites.
|
||||
|
||||
[**Editors’ note: **This article is an update to a previously published piece on this topic.]
|
||||
|
||||
### Enabling Emoji input on Fedora 28 Workstation
|
||||
|
||||
The new emoji input method ships by default in Fedora 28 Workstation. To use it, you must enable it using the Region and Language settings dialog. Open the Region and Language dialog from the main Fedora Workstation settings, or search for it in the Overview.
|
||||
|
||||
[![Region & Language settings tool][1]][2]
|
||||
|
||||
Choose the + control to add an input source. The following dialog appears:
|
||||
|
||||
[![Adding an input source][3]][4]
|
||||
|
||||
Choose the final option (three dots) to expand the selections fully. Then, find Other at the bottom of the list and select it:
|
||||
|
||||
[![Selecting other input sources][5]][6]
|
||||
|
||||
In the next dialog, find the Typing booster choice and select it:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
This advanced input method is powered behind the scenes by iBus. The advanced input methods are identifiable in the list by the cogs icon on the right of the list.
|
||||
|
||||
The Input Method drop-down automatically appears in the GNOME Shell top bar. Ensure your default method — in this example, English (US) — is selected as the current method, and you’ll be ready to input.
|
||||
|
||||
[![Input method dropdown in Shell top bar][9]][10]
|
||||
|
||||
## Using the new Emoji input method
|
||||
|
||||
Now the Emoji input method is enabled, search for emoji by pressing the keyboard shortcut **Ctrl+Shift+E**. A pop-over dialog appears where you can type a search term, such as smile, to find matching symbols.
|
||||
|
||||
[![Searching for smile emoji][11]][12]
|
||||
|
||||
Use the arrow keys to navigate the list. Then, hit **Enter** to make your selection, and the glyph will be placed as input.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
|
||||
@ -0,0 +1,225 @@
|
||||
How To Configure SSH Key-based Authentication In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
### What is SSH Key-based authentication?
|
||||
|
||||
As we all know, **Secure Shell** , shortly **SSH** , is the cryptographic network protocol that allows you to securely communicate/access a remote system over unsecured network, for example Internet. Whenever you send a data over an unsecured network using SSH, the data will be automatically encrypted in the source system, and decrypted in the destination side. SSH provides four authentication methods namely **password-based authentication** , **key-based authentication** , **Host-based authentication** , and **Keyboard authentication**. The most commonly used authentication methods are password-based and key-based authentication.
|
||||
|
||||
In password-based authentication, all you need is the password of the remote system’s user. If you know the password of remote user, you can access the respective system using **“ssh[[email protected]][1]”**. On the other hand, in key-based authentication, you need to generate SSH key pairs and upload the SSH public key to the remote system in order to communicate it via SSH. Each SSH key pair consists of a private key and public key. The private key should be kept within the client system, and the public key should uploaded to the remote systems. You shouldn’t disclose the private key to anyone. Hope you got the basic idea about SSH and its authentication methods.
|
||||
|
||||
In this tutorial, we will be discussing how to configure SSH key-based authentication in Linux.
|
||||
|
||||
### Configure SSH Key-based Authentication In Linux
|
||||
|
||||
For the purpose of this guide, I will be using Arch Linux system as local system and Ubuntu 18.04 LTS as remote system.
|
||||
|
||||
Local system details:
|
||||
|
||||
* **OS** : Arch Linux Desktop
|
||||
* **IP address** : 192.168.225.37 /24
|
||||
|
||||
|
||||
|
||||
Remote system details:
|
||||
|
||||
* **OS** : Ubuntu 18.04 LTS Server
|
||||
* **IP address** : 192.168.225.22/24
|
||||
|
||||
|
||||
|
||||
### Local system configuration
|
||||
|
||||
Like I said already, in SSH key-based authentication method, the public key should be uploaded to the remote system that you want to access via SSH. The public keys will usually be stored in a file called **~/.ssh/authorized_keys** in the remote SSH systems.
|
||||
|
||||
**Important note:** Do not generate key pairs as **root** , as only root would be able to use those keys. Create key pairs as normal user.
|
||||
|
||||
Now, let us create the SSH key pair in the local system. To do so, run the following command in your client system.
|
||||
```
|
||||
$ ssh-keygen
|
||||
|
||||
```
|
||||
|
||||
The above command will create 2048 bit RSA key pair. Enter the passphrase twice. More importantly, Remember your passphrase. You’ll need it later.
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/home/sk/.ssh/id_rsa):
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /home/sk/.ssh/id_rsa.
|
||||
Your public key has been saved in /home/sk/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
SHA256:wYOgvdkBgMFydTMCUI3qZaUxvjs+p2287Tn4uaZ5KyE [email protected]
|
||||
The key's randomart image is:
|
||||
+---[RSA 2048]----+
|
||||
|+=+*= + |
|
||||
|o.o=.* = |
|
||||
|.oo * o + |
|
||||
|. = + . o |
|
||||
|. o + . S |
|
||||
| . E . |
|
||||
| + o |
|
||||
| +.*o+o |
|
||||
| .o*=OO+ |
|
||||
+----[SHA256]-----+
|
||||
|
||||
```
|
||||
|
||||
In case you have already created the key pair, you will see the following message. Just type “y” to create overwrite the existing key .
|
||||
```
|
||||
/home/username/.ssh/id_rsa already exists.
|
||||
Overwrite (y/n)?
|
||||
|
||||
```
|
||||
|
||||
Please note that **passphrase is optional**. If you give one, you’ll be asked to enter the password every time when you try to SSH a remote system unless you are using any SSH agent to store the password. If you don’t want passphrase(not safe though), simply press ENTER key twice when you’ll be asked to enter the passphrase. However, we recommend you to use passphrase. Using a password-less ssh key is generally not a good idea from a security point of view. They should be limited to very specific cases such as services having to access a remote system without the user intervention (e.g. remote backups with rsync, …).
|
||||
|
||||
If you already have a ssh key without a passphrase in private file **~/.ssh/id_rsa** and wanted to update key with passphrase, use the following command:
|
||||
```
|
||||
$ ssh-keygen -p -f ~/.ssh/id_rsa
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Enter new passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved with the new passphrase.
|
||||
|
||||
```
|
||||
|
||||
Now, we have created the key pair in the local system. Now, copy the SSH public key to your remote SSH server using command:
|
||||
|
||||
Here, I will be copying the local (Arch Linux) system’s public key to the remote system (Ubuntu 18.04 LTS in my case). Technically speaking, the above command will copy the contents of local system’s **~/.ssh/id_rsa.pub key** into remote system’s **~/.ssh/authorized_keys** file. Clear? Good.
|
||||
|
||||
Type **yes** to continue connecting to your remote SSH server. And, then Enter the root user’s password of the remote system.
|
||||
```
|
||||
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
|
||||
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
|
||||
[email protected]2.168.225.22's password:
|
||||
|
||||
Number of key(s) added: 1
|
||||
|
||||
Now try logging into the machine, with: "ssh '[email protected]'"
|
||||
and check to make sure that only the key(s) you wanted were added.
|
||||
|
||||
```
|
||||
|
||||
If you have already copied the key, but want to update the key with new passphrase, use **-f** option to overwrite the existing key like below.
|
||||
|
||||
We have now successfully added the local system’s SSH public key to the remote system. Now, let us disable the password-based authentication completely in the remote system. Because, we have configured key-based authentication, so we don’t need password-base authentication anymore.
|
||||
|
||||
### Disable SSH Password-based authentication in remote system
|
||||
|
||||
You need to perform the following commands as root or sudo user.
|
||||
|
||||
To disable password-based authentication, go to your remote system’s console and edit **/etc/ssh/sshd_config** configuration file using any editor:
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
|
||||
```
|
||||
|
||||
Find the following line. Uncomment it and set it’s value as **no**.
|
||||
```
|
||||
PasswordAuthentication no
|
||||
|
||||
```
|
||||
|
||||
Restart ssh service to take effect the changes.
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
|
||||
```
|
||||
|
||||
### Access Remote system from local system
|
||||
|
||||
Go to your local system and SSH into your remote server using command:
|
||||
|
||||
Enter the passphrase.
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Enter passphrase for key '/home/sk/.ssh/id_rsa':
|
||||
Last login: Mon Jul 9 09:59:51 2018 from 192.168.225.37
|
||||
[email protected]:~$
|
||||
|
||||
```
|
||||
|
||||
Now, you’ll be able to SSH into your remote system. As you noticed, we have logged-in to the remote system’s account using passphrase which we created earlier using **ssh-keygen** command, not using the actual account’s password.
|
||||
|
||||
If you try to ssh from another client system, you will get this error message. Say for example, I am tried to SSH into my Ubuntu system from my CentOS using command:
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
The authenticity of host '192.168.225.22 (192.168.225.22)' can't be established.
|
||||
ECDSA key fingerprint is 67:fc:69:b7:d4:4d:fd:6e:38:44:a8:2f:08:ed:f4:21.
|
||||
Are you sure you want to continue connecting (yes/no)? yes
|
||||
Warning: Permanently added '192.168.225.22' (ECDSA) to the list of known hosts.
|
||||
Permission denied (publickey).
|
||||
|
||||
```
|
||||
|
||||
As you see in the above output, I can’t SSH into my remote Ubuntu 18.04 systems from any other systems, except the CentOS system.
|
||||
|
||||
### Adding more Client system’s keys to SSH server
|
||||
|
||||
This is very important. Like I said already, you can’t access the remote system via SSH, except the one you configured (In our case, it’s Ubuntu). I want to give permissions to more clients to access the remote SSH server. What should I do? Simple. You need to generate the SSH key pair in all your client systems and copy the ssh public key manually to the remote server that you want to access via SSH.
|
||||
|
||||
To create SSH key pair on your client system’s, run:
|
||||
```
|
||||
$ ssh-keygen
|
||||
|
||||
```
|
||||
|
||||
Enter the passphrase twice. Now, the ssh key pair is generated. You need to copy the public ssh key (not private key) to your remote server manually.
|
||||
|
||||
Display the pub key using command:
|
||||
```
|
||||
$ cat ~/.ssh/id_rsa.pub
|
||||
|
||||
```
|
||||
|
||||
You should an output something like below.
|
||||
|
||||
Copy the entire contents (via USB drive or any medium) and go to your remote server’s console. Create a directory called **ssh** in the home directory as shown below. You need to execute the following commands as root user.
|
||||
```
|
||||
$ mkdir -p ~/.ssh
|
||||
|
||||
```
|
||||
|
||||
Now, append the your client system’s pub key which you generated in the previous step in a file called
|
||||
```
|
||||
echo {Your_public_key_contents_here} >> ~/.ssh/authorized_keys
|
||||
|
||||
```
|
||||
|
||||
Restart ssh service on the remote system. Now, you’ll be able to SSH to your server from the new client.
|
||||
|
||||
If manually adding ssh pubkey seems difficult, enable password-based authentication temporarily in the remote system and copy the key using “ssh-copy-id” command from your local system and finally disable the password-based authentication.
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
And, that’s all for now. SSH Key-based authentication provides an extra layer protection from brute-force attacks. As you can see, configuring key-based authentication is not that difficult either. It is one of the recommended method to keep your Linux servers safe and secure.
|
||||
|
||||
I will be here soon with another useful article. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/cdn-cgi/l/email-protection
|
||||
@ -0,0 +1,43 @@
|
||||
Malware Found On The Arch User Repository (AUR)
|
||||
======
|
||||
|
||||
On July 7, an AUR package was modified with some malicious code, reminding [Arch Linux][1] users (and Linux users in general) that all user-generated packages should be checked (when possible) before installation.
|
||||
|
||||
[AUR][3] , or the Arch (Linux) User Repository contains package descriptions, also known as PKGBUILDs, which make compiling packages from source easier. While these packages are very useful, they should never be treated as safe, and users should always check their contents before using them, when possible. After all, the AUR webpage states in bold that "AUR packages are user produced content. Any use of the provided files is at your own risk."
|
||||
|
||||
The [discovery][4] of an AUR package containing malicious code proves this. [acroread][5] was modified on July 7 (it appears it was previously "orphaned", meaning it had no maintainer) by an user named "xeactor" to include a `curl` command that downloaded a script from a pastebin. The script then downloaded another script and installed a systemd unit to run that script periodically.
|
||||
|
||||
**It appears [two other][2] AUR packages were modified in the same way. All the offending packages were removed and the user account (which was registered in the same day those packages were updated) that was used to upload them was suspended.**
|
||||
|
||||
The malicious code didn't do anything truly harmful - it only tried to upload some system information, like the machine ID, the output of `uname -a` (which includes the kernel version, architecture, etc.), CPU information, pacman information, and the output of `systemctl list-units` (which lists systemd units information) to pastebin.com. I'm saying "tried" because no system information was actually uploaded due to an error in the second script (the upload function is called "upload", but the script tried to call it using a different name, "uploader").
|
||||
|
||||
Also, the person adding these malicious scripts to AUR left the personal Pastebin API key in the script in cleartext, proving once again that they don't know exactly what they are doing.
|
||||
|
||||
The purpose for trying to upload this information to Pastebin is not clear, especially since much more sensitive data could have been uploaded, like GPG / SSH keys.
|
||||
|
||||
**Update:** Reddit user u/xanaxdroid_ [mentions][6] that the same user named "xeactor" also had some cryptocurrency mining packages posted, so he speculates that "xeactor" was probably planning on adding some hidden cryptocurrency mining software to AUR (this was also the case with some Ubuntu Snap packages [two months ago][7]). That's why "xeactor" was probably trying to obtain various system information. All the packages uploaded by this AUR user have been removed so I cannot check this.
|
||||
|
||||
**Another update:**
|
||||
|
||||
What exactly should you check in user-generated packages such as those found in AUR? This varies and I can't tell you exactly but you can start by looking for anything that tries to download something using `curl` , `wget` and other similar tools, and see what exactly they are attempting to download. Also check the server from which the package source is downloaded from and make sure it's the official source. Unfortunately this is not an exact 'science'. For Launchpad PPAs for example, things get more complicated as you must know how Debian packaging works, and the source can be altered directly as it's hosted in the PPA and uploaded by the user. It gets even more complicated with Snap packages, because you cannot check such packages before installation (as far as I know). In these latter cases, and as a generic solution, I guess you should only install user-generated packages if you trust the uploader / packager.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -0,0 +1,74 @@
|
||||
15 open source applications for MacOS
|
||||
======
|
||||
|
||||

|
||||
|
||||
I use open source tools whenever and wherever I can. I returned to college a while ago to earn a master's degree in educational leadership. Even though I switched from my favorite Linux laptop to a MacBook Pro (since I wasn't sure Linux would be accepted on campus), I decided I would keep using my favorite tools, even on MacOS, as much as I could.
|
||||
|
||||
Fortunately, it was easy, and no professor ever questioned what software I used. Even so, I couldn't keep a secret.
|
||||
|
||||
I knew some of my classmates would eventually assume leadership positions in school districts, so I shared information about the open source applications described below with many of my MacOS or Windows-using classmates. After all, open source software is really about freedom and goodwill. I also wanted them to know that it would be easy to provide their students with world-class applications at little cost. Most of them were surprised and amazed because, as we all know, open source software doesn't have a marketing team except users like you and me.
|
||||
|
||||
### My MacOS learning curve
|
||||
|
||||
Through this process, I learned some of the nuances of MacOS. While most of the open source tools worked as I was used to, others required different installation methods. Tools like [yum][1], [DNF][2], and [APT][3] do not exist in the MacOS world—and I really missed them.
|
||||
|
||||
Some MacOS applications required dependencies and installations that were more difficult than what I was accustomed to with Linux. Nonetheless, I persisted. In the process, I learned how I could keep the best software on my new platform. Even much of MacOS's core is [open source][4].
|
||||
|
||||
Also, my Linux background made it easy to get comfortable with the MacOS command line. I still use it to create and copy files, add users, and use other [utilities][5]like cat, tac, more, less, and tail.
|
||||
|
||||
### 15 great open source applications for MacOS
|
||||
|
||||
* The college required that I submit most of my work electronically in DOCX format, and I did that easily, first with [OpenOffice][6] and later using [LibreOffice][7] to produce my papers.
|
||||
* When I needed to produce graphics for presentations, I used my favorite graphics applications, [GIMP][8] and [Inkscape][9].
|
||||
* My favorite podcast creation tool is [Audacity][10]. It's much simpler to use than the proprietary application that ships with the Mac. I use it to record interviews and create soundtracks for video presentations.
|
||||
* I discovered early on that I could use the [VideoLan][11] (VLC) media player on MacOS.
|
||||
* MacOS's built-in proprietary video creation tool is a good product, but you can easily install and use [OpenShot][12], which is a great content creation tool.
|
||||
* When I need to analyze networks for my clients, I use the easy-to-install [Nmap][13] (Network Mapper) and [Wireshark][14] tools on my Mac.
|
||||
* I use [VirtualBox][15] for MacOS to demonstrate Raspbian, Fedora, Ubuntu, and other Linux distributions, as well as Moodle, WordPress, Drupal, and Koha when I provide training for librarians and other educators.
|
||||
* I make boot drives on my MacBook using [Etcher.io][16]. I just download the ISO file and burn it on a USB stick drive.
|
||||
* I think [Firefox][17] is easier and more secure to use than the proprietary browser that comes with the MacBook Pro, and it allows me to synchronize my bookmarks across operating systems.
|
||||
* When it comes to eBook readers, [Calibre][18] cannot be beaten. It is easy to download and install, and you can even configure it for a [classroom eBook server][19] with a few clicks.
|
||||
* Recently I have been teaching Python to middle school students, I have found it is easy to download and install Python 3 and the IDLE3 editor from [Python.org][20]. I have also enjoyed learning about data science and sharing that with students. Whether you're interested in Python or R, I recommend you download and [install][21] the [Anaconda distribution][22]. It contains the great iPython editor, RStudio, Jupyter Notebooks, and JupyterLab, along with some other applications.
|
||||
* [HandBrake][23] is a great way to turn your old home video DVDs into MP4s, which you can share on YouTube, Vimeo, or your own [Kodi][24] server on MacOS.
|
||||
|
||||
|
||||
|
||||
Now it's your turn: What open source software are you using on MacOS (or Windows)? Share your favorites in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/open-source-tools-macos
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Yum_(software)
|
||||
[2]:https://en.wikipedia.org/wiki/DNF_(software)
|
||||
[3]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[4]:https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html
|
||||
[5]:https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[6]:https://www.openoffice.org/
|
||||
[7]:https://www.libreoffice.org/
|
||||
[8]:https://www.gimp.org/
|
||||
[9]:https://inkscape.org/en/
|
||||
[10]:https://www.audacityteam.org/
|
||||
[11]:https://www.videolan.org/index.html
|
||||
[12]:https://www.openshot.org/
|
||||
[13]:https://nmap.org/
|
||||
[14]:https://www.wireshark.org/
|
||||
[15]:https://www.virtualbox.org/
|
||||
[16]:https://etcher.io/
|
||||
[17]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[18]:https://calibre-ebook.com/
|
||||
[19]:https://opensource.com/article/17/6/raspberrypi-ebook-server
|
||||
[20]:https://www.python.org/downloads/release/python-370/
|
||||
[21]:https://opensource.com/article/18/4/getting-started-anaconda-python
|
||||
[22]:https://www.anaconda.com/download/#macos
|
||||
[23]:https://handbrake.fr/
|
||||
[24]:https://kodi.tv/download
|
||||
@ -0,0 +1,92 @@
|
||||
6 open source cryptocurrency wallets
|
||||
======
|
||||
|
||||

|
||||
|
||||
Without crypto wallets, cryptocurrencies like Bitcoin and Ethereum would just be another pie-in-the-sky idea. These wallets are essential for keeping, sending, and receiving cryptocurrencies.
|
||||
|
||||
The revolutionary growth of [cryptocurrencies][1] is attributed to the idea of decentralization, where a central authority is absent from the network and everyone has a level playing field. Open source technology is at the heart of cryptocurrencies and [blockchain][2] networks. It has enabled the vibrant, nascent industry to reap the benefits of decentralization—such as immutability, transparency, and security.
|
||||
|
||||
If you're looking for a free and open source cryptocurrency wallet, read on to start exploring whether any of the following options meet your needs.
|
||||
|
||||
### 1\. Copay
|
||||
|
||||
[Copay][3] is an open source Bitcoin crypto wallet that promises convenient storage. The software is released under the [MIT License][4].
|
||||
|
||||
The Copay server is also open source. Therefore, developers and Bitcoin enthusiasts can assume complete control of their activities by deploying their own applications on the server.
|
||||
|
||||
The Copay wallet empowers you to take the security of your Bitcoin in your own hands, instead of trusting unreliable third parties. It allows you to use multiple signatories for approving transactions and supports the storage of multiple, separate wallets within the same app.
|
||||
|
||||
Copay is available for a range of platforms, such as Android, Windows, MacOS, Linux, and iOS.
|
||||
|
||||
### 2\. MyEtherWallet
|
||||
|
||||
As the name implies, [MyEtherWallet][5] (abbreviated MEW) is a wallet for Ethereum transactions. It is open source (under the [MIT License][6]) and is completely online, accessible through a web browser.
|
||||
|
||||
The wallet has a simple client-side interface, which allows you to participate in the Ethereum blockchain confidently and securely.
|
||||
|
||||
### 3\. mSIGNA
|
||||
|
||||
[mSIGNA][7] is a powerful desktop application for completing transactions on the Bitcoin network. It is released under the [MIT License][8] and is available for MacOS, Windows, and Linux.
|
||||
|
||||
The blockchain wallet provides you with complete control over your Bitcoin stash. Some of its features include user-friendliness, versatility, decentralized offline key generation capabilities, encrypted data backups, and multi-device synchronization.
|
||||
|
||||
### 4\. Armory
|
||||
|
||||
[Armory][9] is an open source wallet (released under the [GNU AGPLv3][10]) for producing and keeping Bitcoin private keys on your computer. It enhances security by providing users with cold storage and multi-signature support capabilities.
|
||||
|
||||
With Armory, you can set up a wallet on a computer that is completely offline; you'll use the watch-only feature for observing your Bitcoin details on the internet, which improves security. The wallet also allows you to create multiple addresses and use them to complete different transactions.
|
||||
|
||||
Armory is available for MacOS, Windows, and several flavors of Linux (including Raspberry Pi).
|
||||
|
||||
### 5\. Electrum
|
||||
|
||||
[Electrum][11] is a Bitcoin wallet that navigates the thin line between beginner user-friendliness and expert functionality. The open source wallet is released under the [MIT License][12].
|
||||
|
||||
Electrum encrypts your private keys locally, supports cold storage, and provides multi-signature capabilities with minimal resource usage on your machine.
|
||||
|
||||
It is available for a wide range of operating systems and devices, including Windows, MacOS, Android, iOS, and Linux, and hardware wallets such as [Trezor][13].
|
||||
|
||||
### 6\. Etherwall
|
||||
|
||||
[Etherwall][14] is the first wallet for storing and sending Ethereum on the desktop. The open source wallet is released under the [GPLv3 License][15].
|
||||
|
||||
Etherwall is intuitive and fast. What's more, to enhance the security of your private keys, you can operate it on a full node or a thin node. Running it as a full-node client will enable you to download the whole Ethereum blockchain on your local machine.
|
||||
|
||||
Etherwall is available for MacOS, Linux, and Windows, and it also supports the Trezor hardware wallet.
|
||||
|
||||
### Words to the wise
|
||||
|
||||
Open source and free crypto wallets are playing a vital role in making cryptocurrencies easily available to more people.
|
||||
|
||||
Before using any digital currency software wallet, make sure to do your due diligence to protect your security, and always remember to comply with best practices for safeguarding your finances.
|
||||
|
||||
If your favorite open source cryptocurrency wallet is not on this list, please share what you know in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/crypto-wallets
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drmjg
|
||||
[1]:https://www.liveedu.tv/guides/cryptocurrency/
|
||||
[2]:https://opensource.com/tags/blockchain
|
||||
[3]:https://copay.io/
|
||||
[4]:https://github.com/bitpay/copay/blob/master/LICENSE
|
||||
[5]:https://www.myetherwallet.com/
|
||||
[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
|
||||
[7]:https://ciphrex.com/
|
||||
[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
|
||||
[9]:https://www.bitcoinarmory.com/
|
||||
[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
|
||||
[11]:https://electrum.org/#home
|
||||
[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
|
||||
[13]:https://trezor.io/
|
||||
[14]:https://www.etherwall.com/
|
||||
[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
|
||||
@ -0,0 +1,117 @@
|
||||
Display Weather Forecast In Your Terminal With Wttr.in
|
||||
======
|
||||
**[wttr.in][1] is a feature-packed weather forecast service that supports displaying the weather from the command line**. It can automatically detect your location (based on your IP address), supports specifying the location or searching for a geographical location (like a site in a city, a mountain and so on), and much more. Oh, and **you don't have to install it - all you need to use it is cURL or Wget** (see below).
|
||||
|
||||
wttr.in features include:
|
||||
|
||||
* **displays the current weather as well as a 3-day weather forecast, split into morning, noon, evening and night** (includes temperature range, wind speed and direction, viewing distance, precipitation amount and probability)
|
||||
|
||||
* **can display Moon phases**
|
||||
|
||||
* **automatic location detection based on your IP address**
|
||||
|
||||
* **allows specifying a location using the city name, 3-letter airport code, area code, GPS coordinates, IP address, or domain name**. You can also specify a geographical location like a lake, mountain, landmark, and so on)
|
||||
|
||||
* **supports multilingual location names** (the query string must be specified in Unicode)
|
||||
|
||||
* **supports specifying the language** in which the weather forecast should be displayed in (it supports more than 50 languages)
|
||||
|
||||
* **it uses USCS units for queries from the USA and the metric system for the rest of the world** , but you can change this by appending `?u` for USCS, and `?m` for the metric system (SI)
|
||||
|
||||
* **3 output formats: ANSI for the terminal, HTML for the browser, and PNG**.
|
||||
|
||||
|
||||
|
||||
|
||||
Like I mentioned in the beginning of the article, to use wttr.in, all you need is cURL or Wget, but you can also
|
||||
|
||||
**Before using wttr.in, make sure cURL is installed.** In Debian, Ubuntu or Linux Mint (and other Debian or Ubuntu-based Linux distributions), install cURL using this command:
|
||||
```
|
||||
sudo apt install curl
|
||||
|
||||
```
|
||||
|
||||
### wttr.in command line examples
|
||||
|
||||
Get the weather for your location (wttr.in tries to guess your location based on your IP address):
|
||||
```
|
||||
curl wttr.in
|
||||
|
||||
```
|
||||
|
||||
Force cURL to resolve names to IPv4 addresses (in case you're having issues with IPv6 and wttr.in) by adding `-4` after `curl` :
|
||||
```
|
||||
curl -4 wttr.in
|
||||
|
||||
```
|
||||
|
||||
**Wget also works** (instead of cURL) if you want to retrieve the current weather and forecast as a png, or if you use it like this:
|
||||
```
|
||||
wget -O- -q wttr.in
|
||||
|
||||
```
|
||||
|
||||
You can replace `curl` with `wget -O- -q` in all the commands below if you prefer Wget over cURL.
|
||||
|
||||
Specify the location:
|
||||
```
|
||||
curl wttr.in/Dublin
|
||||
|
||||
```
|
||||
|
||||
Display weather information for a landmark (the Eiffel Tower in this example):
|
||||
```
|
||||
curl wttr.in/~Eiffel+Tower
|
||||
|
||||
```
|
||||
|
||||
Get the weather information for an IP address' location (the IP below belongs to GitHub):
|
||||
```
|
||||
curl wttr.in/@192.30.253.113
|
||||
|
||||
```
|
||||
|
||||
Retrieve the weather using USCS units:
|
||||
```
|
||||
curl wttr.in/Paris?u
|
||||
|
||||
```
|
||||
|
||||
Force wttr.in to use the metric system (SI) if you're in the USA:
|
||||
```
|
||||
curl wttr.in/New+York?m
|
||||
|
||||
```
|
||||
|
||||
Use Wget to download the current weather and 3-day forecast as a PNG image:
|
||||
```
|
||||
wget wttr.in/Istanbul.png
|
||||
|
||||
```
|
||||
|
||||
You can specify the PNG
|
||||
|
||||
**For many other examples, check out the wttr.in[project page][2] or type this in a terminal:**
|
||||
```
|
||||
curl wttr.in/:help
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://wttr.in/
|
||||
[2]:https://github.com/chubin/wttr.in
|
||||
[3]:https://github.com/chubin/wttr.in#installation
|
||||
[4]:https://github.com/schachmat/wego
|
||||
[5]:https://github.com/chubin/wttr.in#supported-formats
|
||||
86
sources/tech/20180710 Getting started with Perlbrew.md
Normal file
86
sources/tech/20180710 Getting started with Perlbrew.md
Normal file
@ -0,0 +1,86 @@
|
||||
Getting started with Perlbrew
|
||||
======
|
||||
|
||||

|
||||
|
||||
What's better than having Perl installed on your system? Having multiple Perls installed on your system! With [Perlbrew][1] you can do just that. But why—apart from surrounding yourself in Perl—would you want to do that?
|
||||
|
||||
The short answer is that different versions of Perl are… different. Application A may depend on behavior deprecated in a newer release, while Application B needs new features that weren't available last year. If you have multiple versions of Perl installed, each script can use the version that best suits it. This also comes in handy if you're a developer—you can test your application against multiple versions of Perl so that, no matter what your users are running, you know it works.
|
||||
|
||||
### Install Perlbrew
|
||||
|
||||
The other benefit is that Perlbrew installs to the user's home directory. That means each user can manage their Perl versions (and the associated CPAN packages) without having to involve the system administrators. Self-service means quicker installation for the users and gives sysadmins more time to work on the hard problems.
|
||||
|
||||
The first step is to install Perlbrew on your system. Many Linux distributions have it in the package repo already, so you're just a `dnf install perlbrew` (or whatever is the appropriate command for your distribution) away. You can also install the `App::perlbrew` module from CPAN with `cpan App::perlbrew`. Or you can download and run the installation script at [install.perlbrew.pl][2].
|
||||
|
||||
To begin using Perlbrew, run `perlbrew init`.
|
||||
|
||||
### Install a new Perl version
|
||||
|
||||
Let's say you want to try the latest development release (5.27.11 as of this writing). First, you need to install the package:
|
||||
```
|
||||
perlbrew install 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### Switch Perl version
|
||||
|
||||
Now that you have a new version installed, you can use it for just that shell:
|
||||
```
|
||||
perlbrew use 5.27.11
|
||||
|
||||
```
|
||||
|
||||
Or you can make it the default Perl version for your account (assuming you set up your profile as instructed by the output of `perlbrew init`):
|
||||
```
|
||||
perlbrew switch 5.27.11
|
||||
|
||||
```
|
||||
|
||||
### Run a single script
|
||||
|
||||
You can run a single command against a specific version of Perl, too:
|
||||
```
|
||||
perlberew exec 5.27.11 myscript.pl
|
||||
|
||||
```
|
||||
|
||||
Or you can run a command against all your installed versions. This is particularly handy if you want to run tests against a variety of versions. In this case, specify Perl as the version:
|
||||
```
|
||||
.plperlbrew exec perl myscriptpl
|
||||
|
||||
```
|
||||
|
||||
### Install CPAN modules
|
||||
|
||||
If you want to install CPAN modules, the `cpanm` package is an easy-to-use interface that works well with Perlbrew. Install it with:
|
||||
```
|
||||
perlbrew install-cpamn
|
||||
|
||||
```
|
||||
|
||||
You can then install CPAN modules with the `cpanm` command:
|
||||
```
|
||||
cpanm CGI::simple
|
||||
|
||||
```
|
||||
|
||||
### But wait, there's more!
|
||||
|
||||
This article covers basic Perlbrew usage. There are many more features and options available. Look at the output of `perlbrew help` as a starting point, or check out the [App::perlbrew documentation][3]. What other features do you love in Perlbrew? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/perlbrew
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://perlbrew.pl/
|
||||
[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
|
||||
[3]:https://metacpan.org/pod/App::perlbrew
|
||||
@ -0,0 +1,72 @@
|
||||
The aftermath of the Gentoo GitHub hack
|
||||
======
|
||||
|
||||

|
||||
|
||||
### Gentoo GitHub hack: What happened?
|
||||
|
||||
Late last month (June 28), the Gentoo GitHub repository was attacked after someone gained control of an admin account. All access to the repositories was soon removed from Gentoo developers. Repository and page content were altered. But within 10 minutes of the attacker gaining access, someone noticed something was going on, 7 minutes later a report was sent, and within 70 minutes the attack was over. Legitimate Gentoo developers were shut out for 5 days while the dust settled and repairs and analysis were completed.
|
||||
|
||||
The attackers also attempted to add "rm -rf" commands to some repositories to cause user data to be recursively removed. As it turns out, this code was unlikely to be run because of technical precautions that were in place, but this wouldn't have been obvious to the attacker.
|
||||
|
||||
One of the things that constrained how big a disaster this break in might have turned out to be was that the attack was "loud." The removal of developers resulted in them being emailed, and developers quickly discovered they'd been shut out. A stealthier attack might have led to a significant delay in anyone responding to the problem and a significantly bigger problem.
|
||||
|
||||
A detailed timeline showing the details of what happened is available at the [Gentoo Linux site][1].
|
||||
|
||||
### How the Gentoo GitHub attack happened
|
||||
|
||||
Much of the focus in the aftermath of this very significant attack has been on how the attacker was able to gain admin access and what might have been done differently to keep the site safe. The most obvious take-home was that the admin's password was guessed because it too closely related to one that had been captured on another system. This might be like your using "Spring2018" on one system and "Summer2018" on another.
|
||||
|
||||
Another problem was that it was unclear how end users might have been able to tell whether or not they had a clean copy of the code, and there was no confirmation as to whether the malicious commits (accessible for a while) would execute.
|
||||
|
||||
### Lessons learned from the hack
|
||||
|
||||
The lessons learned should come as no surprise. We should all be careful not to use the same password on multiple systems and not to use passwords that relate to each other so strongly that knowing one in a set suggests another.
|
||||
|
||||
We also have to admit that two-factor authentication would have prevented this break-in. While something of a burden on users (i.e., they may have to carry a token generator or confirm their login through some secondary service), it very strongly limits who can get access to an account.
|
||||
|
||||
Of course the lessons learned should also not overlook what this incident showed us was going right. The fact that the break-in was noticed so quickly and that communications lines were functional meant the break-in could be quickly addressed. The breach was also made public, the repository was only a secondary copy of the main Gentoo source code, and changes in the main repository were signed and could be verified.
|
||||
|
||||
#### The best news
|
||||
|
||||
The really good news is that it appears that no one was affected by the break in other than the fact that developers were locked out for a while. The hackers weren't able to penetrate Gentoo's master repository (the default location for automatic updates). They also weren't able to get their hands on Gentoo's digital signing key. This means that default updates would have rejected their files as fakes.
|
||||
|
||||
The harm that could have been made to Gentoo's reputation was avoided by the precautions in place and their professional handling of the incident. What could have cost them a lot ended up as a confirmation of what they're doing right and added to their determination to make some changes to strengthen their security. They faced up to some cyberbullies and came out stronger and more confident.
|
||||
|
||||
### Fixing the potholes
|
||||
|
||||
Gentoo is already addressing the weaknesses that contributed to the break-in. They are making frequent backups of their GitHub Organization (i.e., their content), starting to use two-factor authentication by default, working on an incident response plan with a focus on sharing information about a security incident with their users, and tightening procedures around credential revocation. They are also reducing the number of users with elevated privileges, auditing logins, and publishing password policies that mandate the use of password managers.
|
||||
|
||||
### Gentoo and GitHub
|
||||
|
||||
For readers unfamiliar with Gentoo, it's important to understand that Gentoo is different than most Linux distributions. Users download and then compile the source to build the OS they will then be using. It's as close to the Linux mantra of “know how to do it yourself” as you can get.
|
||||
|
||||
Git is a code management system not unlike CVS, and GitHub provides repositories for the code.
|
||||
|
||||
### Gentoo strengths
|
||||
|
||||
Gentoo users tend to be more knowledgeable about the low-level aspects of the OS (e.g., kernel configuration and hardware support) than most Linux users — probably due to their interest in working with the source code. The OS is also highly scalable and flexible with a "build what you need" focus. The name derives from that of the "Gentoo penguin" — a penguin breed that lives on many sub-Antarctic islands. More information and downloads are available at [www.gentoo.org][2].
|
||||
|
||||
### More on the Gentoo GitHub break-in
|
||||
|
||||
More information on the break in is available on [Naked Security][3] and (as noted above) the [Gentoo site][1].
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3287973/linux/the-aftermath-of-the-gentoo-github-hack.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://wiki.gentoo.org/wiki/Project:Infrastructure/Incident_Reports/2018-06-28_Github
|
||||
[2]:https://www.gentoo.org/
|
||||
[3]:https://nakedsecurity.sophos.com/2018/06/29/linux-distro-hacked-on-github-all-code-considered-compromised/
|
||||
[4]:https://www.facebook.com/NetworkWorld/
|
||||
[5]:https://www.linkedin.com/company/network-world
|
||||
@ -1,338 +0,0 @@
|
||||
无密码验证:客户端
|
||||
======
|
||||
我们继续 [无密码验证][1] 的文章。上一篇文章中,我们用 Go 写了一个 HTTP 服务,用这个服务来做无密码验证 API。今天,我们为它再写一个 JavaScript 客户端。
|
||||
|
||||
我们将使用 [这里的][2] 这个单页面应用程序(SPA)来展示使用的技术。如果你还没有读过它,请先读它。
|
||||
|
||||
我们将根据验证的状态分别使用两个不同的根 URL(`/`):一个是访问状态的页面或者是欢迎已验证用户的页面。另一个页面是验证失败后重定向到验证页面。
|
||||
|
||||
### Serving
|
||||
|
||||
我们将使用相同的 Go 服务器来为客户端提供服务,因此,在我们前面的 `main.go` 中添加一些路由:
|
||||
```
|
||||
router.Handle("GET", "/js/", http.FileServer(http.Dir("static")))
|
||||
router.HandleFunc("GET", "/...", serveFile("static/index.html"))
|
||||
|
||||
```
|
||||
|
||||
这个伺服文件在 `static/js` 下,而 `static/index.html` 文件是为所有的访问提供服务的。
|
||||
|
||||
你可以使用你自己的服务器,但是你得在服务器上启用 [CORS][3]。
|
||||
|
||||
### HTML
|
||||
|
||||
我们来看一下那个 `static/index.html` 文件。
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Passwordless Demo</title>
|
||||
<link rel="shortcut icon" href="data:,">
|
||||
<script src="/js/main.js" type="module"></script>
|
||||
</head>
|
||||
<body></body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
单页面应用程序剩余的渲染由 JavaScript 来完成,因此,我们使用了一个空的 body 部分和一个 `main.js` 文件。
|
||||
|
||||
我们将使用 [上篇文章][2] 中的 Router。
|
||||
|
||||
### Rendering
|
||||
|
||||
现在,我们使用下面的内容来创建一个 `static/js/main.js` 文件:
|
||||
```
|
||||
import Router from 'https://unpkg.com/@nicolasparada/router'
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
const router = new Router()
|
||||
|
||||
router.handle('/', guard(view('home')))
|
||||
router.handle('/callback', view('callback'))
|
||||
router.handle(/^\//, view('not-found'))
|
||||
|
||||
router.install(async resultPromise => {
|
||||
document.body.innerHTML = ''
|
||||
document.body.appendChild(await resultPromise)
|
||||
})
|
||||
|
||||
function view(name) {
|
||||
return (...args) => import(`/js/pages/${name}-page.js`)
|
||||
.then(m => m.default(...args))
|
||||
}
|
||||
|
||||
function guard(fn1, fn2 = view('welcome')) {
|
||||
return (...args) => isAuthenticated()
|
||||
? fn1(...args)
|
||||
: fn2(...args)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
与上篇文章不同的是,我们实现了一个 `isAuthenticated()` 函数和一个 `guard()` 函数,使用它去渲染两种验证状态的页面。因此,当用户访问 `/` 时,它将根据用户是否通过了验证来展示 home 页面或者是欢迎页面。
|
||||
|
||||
### Auth
|
||||
|
||||
现在,我们来编写 `isAuthenticated()` 函数。使用下面的内容来创建一个 `static/js/auth.js` 文件:
|
||||
```
|
||||
export function getAuthUser() {
|
||||
const authUserItem = localStorage.getItem('auth_user')
|
||||
const expiresAtItem = localStorage.getItem('expires_at')
|
||||
|
||||
if (authUserItem !== null && expiresAtItem !== null) {
|
||||
const expiresAt = new Date(expiresAtItem)
|
||||
|
||||
if (!isNaN(expiresAt.valueOf()) && expiresAt > new Date()) {
|
||||
try {
|
||||
return JSON.parse(authUserItem)
|
||||
} catch (_) { }
|
||||
}
|
||||
}
|
||||
|
||||
return null
|
||||
}
|
||||
|
||||
export function isAuthenticated() {
|
||||
return localStorage.getItem('jwt') !== null && getAuthUser() !== null
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
当有人登入时,我们将保存 JSON 格式的 web 令牌、过期日期、以及在 `localStorage` 上的当前已验证用户。这个模块就是这个用处。
|
||||
|
||||
* `getAuthUser()` 用于从 `localStorage` 获取已认证的用户,以确认 JSON 格式的 Web 令牌没有过期。
|
||||
* `isAuthenticated()` 在前面的函数中用于去检查它是否返回了 `null`。
|
||||
|
||||
|
||||
|
||||
### Fetch
|
||||
|
||||
在继续这个页面之前,我将写一些与服务器 API 一起使用的 HTTP 工具。
|
||||
|
||||
我们使用以下的内容去创建一个 `static/js/http.js` 文件:
|
||||
```
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
function get(url, headers) {
|
||||
return fetch(url, {
|
||||
headers: Object.assign(getAuthHeader(), headers),
|
||||
}).then(handleResponse)
|
||||
}
|
||||
|
||||
function post(url, body, headers) {
|
||||
return fetch(url, {
|
||||
method: 'POST',
|
||||
headers: Object.assign(getAuthHeader(), { 'content-type': 'application/json' }, headers),
|
||||
body: JSON.stringify(body),
|
||||
}).then(handleResponse)
|
||||
}
|
||||
|
||||
function getAuthHeader() {
|
||||
return isAuthenticated()
|
||||
? { authorization: `Bearer ${localStorage.getItem('jwt')}` }
|
||||
: {}
|
||||
}
|
||||
|
||||
export async function handleResponse(res) {
|
||||
const body = await res.clone().json().catch(() => res.text())
|
||||
const response = {
|
||||
url: res.url,
|
||||
statusCode: res.status,
|
||||
statusText: res.statusText,
|
||||
headers: res.headers,
|
||||
body,
|
||||
}
|
||||
if (!res.ok) throw Object.assign(
|
||||
new Error(body.message || body || res.statusText),
|
||||
response
|
||||
)
|
||||
return response
|
||||
}
|
||||
|
||||
export default {
|
||||
get,
|
||||
post,
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个模块导出了 `get()` 和 `post()` 函数。它们是 `fetch` API 的封装。当用户是已验证的,这二个函数注入一个 `Authorization: Bearer <token_here>` 头到请求中;这样服务器就能对我们进行身份验证。
|
||||
|
||||
### Welcome Page
|
||||
|
||||
我们现在来到欢迎页面。用如下的内容创建一个 `static/js/pages/welcome-page.js` 文件:
|
||||
```
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Passwordless Demo</h1>
|
||||
<h2>Access</h2>
|
||||
<form id="access-form">
|
||||
<input type="email" placeholder="Email" autofocus required>
|
||||
<button type="submit">Send Magic Link</button>
|
||||
</form>
|
||||
`
|
||||
|
||||
export default function welcomePage() {
|
||||
const page = template.content.cloneNode(true)
|
||||
|
||||
page.getElementById('access-form')
|
||||
.addEventListener('submit', onAccessFormSubmit)
|
||||
|
||||
return page
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
正如你所见,这个页面使用一个 `HTMLTemplateElement`。这是一个只输入用户 email 的简单表格。
|
||||
|
||||
为了不让代码太乏味,我将跳过错误处理部分,只是将它们输出到控制台上。
|
||||
|
||||
现在,我们来写 `onAccessFormSubmit()` 函数。
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
function onAccessFormSubmit(ev) {
|
||||
ev.preventDefault()
|
||||
|
||||
const form = ev.currentTarget
|
||||
const input = form.querySelector('input')
|
||||
const email = input.value
|
||||
|
||||
sendMagicLink(email).catch(err => {
|
||||
console.error(err)
|
||||
if (err.statusCode === 404 && wantToCreateAccount()) {
|
||||
runCreateUserProgram(email)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
function sendMagicLink(email) {
|
||||
return http.post('/api/passwordless/start', {
|
||||
email,
|
||||
redirectUri: location.origin + '/callback',
|
||||
}).then(() => {
|
||||
alert('Magic link sent. Go check your email inbox.')
|
||||
})
|
||||
}
|
||||
|
||||
function wantToCreateAccount() {
|
||||
return prompt('No user found. Do you want to create an account?')
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
它使用 email 做了一个 `POST` 请求到 `/api/passwordless/start`,然后在 body 中做了 URI 转向。在本例中使用 `404 Not Found` 状态码返回,我们将创建一个用户。
|
||||
```
|
||||
function runCreateUserProgram(email) {
|
||||
const username = prompt("Enter username")
|
||||
if (username === null) return
|
||||
|
||||
http.post('/api/users', { email, username })
|
||||
.then(res => res.body)
|
||||
.then(user => sendMagicLink(user.email))
|
||||
.catch(console.error)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个用户创建程序,首先询问用户名,然后使用 email 和用户名,在 body 中做一个 `POST` 请求到 `/api/users`。成功之后,给创建的用户发送一个魔法链接。
|
||||
|
||||
### Callback Page
|
||||
|
||||
这就是访问表格的所有功能,现在我们来做回调页面。使用如下的内容来创建一个 `static/js/pages/callback-page.js` 文件:
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Authenticating you 👀</h1>
|
||||
`
|
||||
|
||||
export default function callbackPage() {
|
||||
const page = template.content.cloneNode(true)
|
||||
|
||||
const hash = location.hash.substr(1)
|
||||
const fragment = new URLSearchParams(hash)
|
||||
for (const [k, v] of fragment.entries()) {
|
||||
fragment.set(decodeURIComponent(k), decodeURIComponent(v))
|
||||
}
|
||||
const jwt = fragment.get('jwt')
|
||||
const expiresAt = fragment.get('expires_at')
|
||||
|
||||
http.get('/api/auth_user', { authorization: `Bearer ${jwt}` })
|
||||
.then(res => res.body)
|
||||
.then(authUser => {
|
||||
localStorage.setItem('jwt', jwt)
|
||||
localStorage.setItem('auth_user', JSON.stringify(authUser))
|
||||
localStorage.setItem('expires_at', expiresAt)
|
||||
|
||||
location.replace('/')
|
||||
})
|
||||
.catch(console.error)
|
||||
|
||||
return page
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
请记住 … 当点击魔法链接时,我们来到 `/api/passwordless/verify_redirect`,我们通过 (`/callback`)在 URL 的哈希中传递 JWT 和过期日期,将我们转向到重定向 URI。
|
||||
|
||||
回调页面解码 URL 中的哈希,提取这些参数去做一个 `GET` 请求到 `/api/auth_user`,用 JWT 保存所有数据到 `localStorage` 中。最后,重定向到主页面。
|
||||
|
||||
### Home Page
|
||||
|
||||
创建如下内容的 `static/pages/home-page.js` 文件:
|
||||
```
|
||||
import { getAuthUser } from '../auth.js'
|
||||
|
||||
export default function homePage() {
|
||||
const authUser = getAuthUser()
|
||||
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Passwordless Demo</h1>
|
||||
<p>Welcome back, ${authUser.username} 👋</p>
|
||||
<button id="logout-button">Logout</button>
|
||||
`
|
||||
|
||||
const page = template.content
|
||||
|
||||
page.getElementById('logout-button')
|
||||
.addEventListener('click', logout)
|
||||
|
||||
return page
|
||||
}
|
||||
|
||||
function logout() {
|
||||
localStorage.clear()
|
||||
location.reload()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个页面欢迎已验证用户,同时也有一个登出按钮。`logout()` 函数的功能只是清理掉 `localStorage` 并重载这个页面。
|
||||
|
||||
这就是全部内容了。我敢说你在此之前已经看过这个 [demo][4] 了。当然,这些源代码也在同一个 [仓库][5] 中。
|
||||
|
||||
👋👋👋
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/passwordless-auth-client/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://nicolasparada.netlify.com/
|
||||
[1]:https://nicolasparada.netlify.com/posts/passwordless-auth-server/
|
||||
[2]:https://nicolasparada.netlify.com/posts/javascript-client-router/
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
|
||||
[4]:https://go-passwordless-demo.herokuapp.com/
|
||||
[5]:https://github.com/nicolasparada/go-passwordless-demo
|
||||
@ -0,0 +1,291 @@
|
||||
你不知道的 Bash:关于 Bash 数组的介绍
|
||||
======
|
||||
|
||||

|
||||
|
||||
尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然没有正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash][1] 数组其实是非常有用的。
|
||||
|
||||
### 稍等,这是为什么?
|
||||
|
||||
写 Bash 相关的东西很难,但如果是写一篇像手册那样注重怪异语法的文章,就会非常简单。不过请放心,这篇文章的目的就是让你不用去读该死的使用手册。
|
||||
|
||||
#### 真实(通常是有用的)示例
|
||||
|
||||
为了这个目的,想象一下真实世界的场景以及 Bash 是怎么帮忙的:你正在公司里面主导一个新工作,评估并优化内部数据管线的运行时间。首先,你要做个参数扫描分析来评估管线使用线程的状况。简单起见,我们把这个管道当作一个编译好的 C++ 黑盒子,这里面我们能够调整的唯一的参数是用于处理数据的线程数量:`./pipeline --threads 4`。
|
||||
|
||||
### 基础
|
||||
|
||||
我们将要测试的 `--threads` 参数:
|
||||
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
```
|
||||
|
||||
我们首先要做的事是定义一个数组,用来容纳我们想要测试的参数:
|
||||
|
||||
本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的 数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
|
||||
|
||||
现在我们初始化了数组,让我们解析它其中的一些元素。仅仅输入 `echo $allThreads` ,你能发现,它只会输出第一个元素。
|
||||
|
||||
要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出 变量。考虑以下场景:
|
||||
|
||||
```
|
||||
type="article"
|
||||
|
||||
echo "Found 42 $type"
|
||||
|
||||
```
|
||||
|
||||
假如我们得到的变量 `$type` 是一个单词,我们想要添加在句子结尾一个 `s`。我们无法直接把 `s` 加到 `$type` 里面,因为这会把它变成另一个变量,`$types`。尽管我们可以利用像 `echo "Found 42 "$type"s"` 这样的代码形变,但解决这个问题的最好方法是用一个花括号:`echo "Found 42 ${type}s"`,这让我们能够告诉 Bash 变量名的起止位置(有趣的是,JavaScript/ES6 在 [template literals][2] 中注入变量和表达式的语法和这里是一样的)
|
||||
|
||||
事实上,尽管 Bash 变量一般不用花括号,但在数组中需要用到花括号。这反而允许我们指定要访问的索引,例如 `echo ${allThreads[1]}` 返回的是数组中的第二个元素。如果不写花括号,比如 `echo $allThreads[1]`,会导致 Bash 把 `[1]` 当作字符串然后输出。
|
||||
|
||||
是的,Bash 数组的语法很怪,但是至少他们是从 0 开始索引的,不像有些语言(说的就是你,`R` 语言)。
|
||||
|
||||
### 遍历数组
|
||||
|
||||
上面的例子中我们直接用整数作为数组的索引,我们现在考虑两种其他情况:第一,如果想要数组中的第 `$i` 个元素,这里 `$i` 是一个代表索引的变量,我们可以这样 `echo ${allThreads[$i]}` 解析这个元素。第二,要输出一个数组的所有元素,我们把数字索引换成 `@` 符号(你可以把 `@` 当作表示 `all` 的符号):`echo ${allThreads[@]}`。
|
||||
|
||||
#### 遍历数组元素
|
||||
|
||||
记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动 pipeline:
|
||||
|
||||
```
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
./pipeline --threads $t
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### 遍历数组索引
|
||||
|
||||
接下来,考虑一个稍稍不同的方法。不是遍历所有的数组元素,我们可以遍历所有的索引:
|
||||
|
||||
```
|
||||
for i in ${!allThreads[@]}; do
|
||||
|
||||
./pipeline --threads ${allThreads[$i]}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
一步一步看:如之前所见,`${allThreads[@]}` 表示数组中的所有元素。前面加了个感叹号,变成 `${!allThreads[@]}`,这会返回数组索引列表(这里是 0 到 7)。换句话说。`for` 循环就遍历所有的索引 `$i` 并从 `$allThreads` 中读取第 `$i` 个元素,当作 `--threads` 选项的参数。
|
||||
|
||||
这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引避免创建要在循环中累加的额外变量。
|
||||
|
||||
### 填充数组
|
||||
|
||||
到目前为止,我们已经能够用给定的 `--threads` 选项启动 pipeline 了。现在假设按秒计时的运行时间输出到 pipeline。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
|
||||
|
||||
#### 一些有用的语法
|
||||
|
||||
在深入代码前,我们要多介绍一些语法。首先,我们要能解析 Bash 命令的输出。用这个语法可以做到:`output=$( ./my_script.sh )`,这会把命令的输出存储到变量 `$output` 中。
|
||||
|
||||
我们需要的第二个语法是如何把我们刚刚解析的值添加到数组中。完成这个任务的语法看起来很熟悉:
|
||||
|
||||
```
|
||||
myArray+=( "newElement1" "newElement2" )
|
||||
|
||||
```
|
||||
|
||||
#### 参数扫描
|
||||
|
||||
万事具备,执行参数扫描的脚步如下:
|
||||
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
allRuntimes=()
|
||||
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
runtime=$(./pipeline --threads $t)
|
||||
|
||||
allRuntimes+=( $runtime )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
就是这个了!
|
||||
|
||||
### 还有什么能做的?
|
||||
|
||||
这篇文章中,我们讲过使用数组进行参数扫描的场景。我担保有很多理由要使用 Bash 数组,这里就有两个例子:
|
||||
|
||||
#### 日志警告
|
||||
|
||||
本场景中,把应用分成几个模块,每一个都有它自己的日志文件。我们可以编写一个 cron 任务脚本,当某个模块中出现问题标志时向特定的人发送邮件:
|
||||
|
||||
```
|
||||
# 日志列表,发生问题时应该通知的人
|
||||
|
||||
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
|
||||
|
||||
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
|
||||
|
||||
|
||||
|
||||
# 在每个日志中查找问题标志
|
||||
|
||||
for i in ${!logPaths[@]};
|
||||
|
||||
do
|
||||
|
||||
log=${logPaths[$i]}
|
||||
|
||||
stakeholder=${logEmails[$i]}
|
||||
|
||||
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
|
||||
|
||||
|
||||
|
||||
# 如果近期发现超过 5 个错误,就警告负责人
|
||||
|
||||
if [[ "$numErrors" -gt 5 ]];
|
||||
|
||||
then
|
||||
|
||||
emailRecipient="$stakeholder"
|
||||
|
||||
emailSubject="WARNING: ${log} showing unusual levels of errors"
|
||||
|
||||
emailBody="${numErrors} errors found in log ${log}"
|
||||
|
||||
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
|
||||
|
||||
fi
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### API 查询
|
||||
|
||||
如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,毫无疑问要用 SQL,但我们可以用 APIs!
|
||||
|
||||
为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder][3] 作为我们的目的,这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
|
||||
|
||||
```
|
||||
endpoint="https://jsonplaceholder.typicode.com/comments"
|
||||
|
||||
allEmails=()
|
||||
|
||||
|
||||
|
||||
# 查询前 10 个帖子
|
||||
|
||||
for postId in {1..10};
|
||||
|
||||
do
|
||||
|
||||
# 执行 API 调用,获取该帖子评论者的邮箱
|
||||
|
||||
response=$(curl "${endpoint}?postId=${postId}")
|
||||
|
||||
|
||||
|
||||
# 使用 jq 把 JSON 响应解析成数组
|
||||
|
||||
allEmails+=( $( jq '.[].email' <<< "$response" ) )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
注意这里我是用 [`jq` 工具][4] 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
|
||||
|
||||
你可能已经想到,使用 Bash 数组在数不胜数的场景中很有帮助,我希望这篇文章中的示例可以给你思维的启发。如果你从自己的工作中找到其它的例子想要分享出来,请在帖子下方评论。
|
||||
|
||||
### 请等等,还有很多东西!
|
||||
|
||||
由于我们在本文讲了很多数组语法,这里是关于我们讲到内容的总结,包含一些还没讲到的高级技巧:
|
||||
|
||||
| 语法 | 效果 |
|
||||
|:--|:--|
|
||||
| `arr=()` | 创建一个空数组 |
|
||||
| `arr=(1 2 3)` | 初始化数组 |
|
||||
| `${arr[2]}` | 解析第三个元素 |
|
||||
| `${arr[@]}` | 解析所有元素 |
|
||||
| `${!arr[@]}` | 解析数组索引 |
|
||||
| `${#arr[@]}` | 计算数组长度 |
|
||||
| `arr[0]=3` | 重写第 1 个元素 |
|
||||
| `arr+=(4)` | 添加值 |
|
||||
| `str=$(ls)` | 把 `ls` 输出保存到字符串 |
|
||||
| `arr=( $(ls) )` | 把 `ls` 输出的文件保存到数组里 |
|
||||
| `${arr[@]:s:n}` | 解析索引在 `n` 到 `s+n` 之间的元素|
|
||||
|
||||
>译者注: `${arr[@]:s:n}` 应该是解析索引在 `s` 到 `s+n-1` 之间的元素
|
||||
|
||||
### 最后一点思考
|
||||
|
||||
正如我们所见,Bash 数组的语法很奇怪,但我希望这篇文章让你相信它们很有用。只要你理解了这些语法,你会发现以后会经常使用 Bash 数组。
|
||||
|
||||
#### Bash 还是 Python?
|
||||
|
||||
问题来了:什么时候该用 Bash 数组而不是其他的脚本语法,比如 Python?
|
||||
|
||||
对我而言,完全取决于需求——如果你可以只需要调用命令行工具就能立马解决问题,你也可以用 Bash。但有些时候,当你的脚本属于一个更大的 Python 项目时,你也可以用 Python。
|
||||
|
||||
比如,我们可以用 Python 来实现参数扫描,但我们只用编写一个 Bash 的包装:
|
||||
|
||||
```
|
||||
import subprocess
|
||||
|
||||
|
||||
|
||||
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
|
||||
|
||||
all_runtimes = []
|
||||
|
||||
|
||||
|
||||
# 用不同的线程数字启动 pipeline
|
||||
|
||||
for t in all_threads:
|
||||
|
||||
cmd = './pipeline --threads {}'.format(t)
|
||||
|
||||
|
||||
|
||||
# 使用子线程模块获得返回的输出
|
||||
|
||||
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
|
||||
|
||||
output = p.communicate()[0]
|
||||
|
||||
all_runtimes.append(output)
|
||||
|
||||
```
|
||||
|
||||
由于本例中没法避免使用命令行,所以可以优先使用 Bash。
|
||||
|
||||
#### 羞耻的宣传时间
|
||||
|
||||
如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON][5],2018 年 7 月 17 号我会在这做一个主题为 [你不知道的 Bash][6] 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
|
||||
|
||||
本文章由 [Medium] 首发,再发布时已获得授权。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
|
||||
|
||||
作者:[Robert Aboukhalil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/robertaboukhalil
|
||||
[1]:https://opensource.com/article/17/7/bash-prompt-tips-and-tricks
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals
|
||||
[3]:https://github.com/typicode/jsonplaceholder
|
||||
[4]:https://stedolan.github.io/jq/
|
||||
[5]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[6]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67166
|
||||
[7]:https://medium.com/@robaboukhalil/the-weird-wondrous-world-of-bash-arrays-a86e5adf2c69
|
||||
@ -0,0 +1,80 @@
|
||||
2018 年 6 月 COPR 中值得尝试的 4 个很酷的新项目
|
||||
======
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中携带。某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。Fedora 基础设施不支持 COPR 中的软件或没有项目签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
[Ghostwriter][2] 是 [Markdown][3] 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中擦除被禁用,迫使用户现在编写并稍后编辑。![][4]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 Ghostwriter。要安装 Ghostwriter,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable scx/ghostwriter
|
||||
sudo dnf install ghostwriter
|
||||
|
||||
```
|
||||
|
||||
### Lector
|
||||
|
||||
[Lector][5] 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 - 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。![][6]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 26、27、28 和 Rawhide 提供Lector。要安装 Lector,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable bugzy/lector
|
||||
sudo dnf install lector
|
||||
|
||||
```
|
||||
|
||||
### Ranger
|
||||
|
||||
Ranerger 是一个基于文本的文件管理器,它带有 Vim 键绑定。它以三列显示目录结构。左边显示父目录,中间显示当前目录的内容,右边显示所选文件或目录的预览。对于文本文件,Ranger 将文件的实际内容作为预览。![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28 和 Rawhide 提供 Ranger。要安装 Ranger,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable fszymanski/ranger
|
||||
sudo dnf install ranger
|
||||
|
||||
```
|
||||
|
||||
### PrestoPalette
|
||||
|
||||
PrestoPeralette 是一款帮助创建平衡调色板的工具。PrestoPalette 的一个很好的功能是能够使用光照来影响调色板的亮度和饱和度。你可以将创建的调色板导出为 PNG 或 JSON。
|
||||
![][8]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 PrestoPalette。要安装 PrestoPalette,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable dagostinelli/prestopalette
|
||||
sudo dnf install prestopalette
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-june-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://wereturtle.github.io/ghostwriter/
|
||||
[3]:https://daringfireball.net/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/05/ghostwriter.png
|
||||
[5]:https://github.com/BasioMeusPuga/Lector
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/lector.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/ranger.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/prestopalette.png
|
||||
@ -1,55 +0,0 @@
|
||||
应该知道的 6 个开源 AI 工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
在开源领域,不管你的想法是多少的新颖独到,先去看一下别人是否已经做成了这个概念,总是一个很明智的做法。对于有兴趣借助不断成长的人工智能(AI)的力量的组织和个人来说,许多非常好的工具不仅是免费和开源的,而且在很多的情况下,它们都已经过测试和久经考验的。
|
||||
|
||||
在领先的公司和非盈利组织中,AI 的优先级都非常高,并且这些公司和组织都开源了很有价值的工具。下面的样本是任何人都可以使用的免费的、开源的 AI 工具。
|
||||
|
||||
**Acumos.** [Acumos AI][1] 是一个平台和开源框架,使用它可以很容易地去构建、共享和分发 AI 应用。它规范了需要的基础设施栈和组件,使其可以在一个“开箱即用的”通用 AI 环境中运行。这使得数据科学家和模型训练者可以专注于它们的核心竞争力,而不用在无止境的定制、建模、以及训练一个 AI 实现上浪费时间。
|
||||
|
||||
Acumos 是 [LF 深度学习基金会][2] 的一部分,它是 Linux 基金会中的一个组织,它支持在人工智能、机器学习、以及深度学习方面的开源创新。它的目标是让这些重大的新技术可用于开发者和数据科学家,包括那些在深度学习和 AI 上经验有限的人。LF 深度学习基金会 [最近批准了一个项目生命周期和贡献流程][3],并且它现在正接受项目贡献的建议。
|
||||
|
||||
**Facebook 的框架.** Facebook 它自己 [有开源的][4] 中央机器学习系统,它设计用于做一些大规模的人工智能任务,以及一系列其它的 AI 技术。这个工具是经过他们公司验证的平台的一部分。Facebook 也开源了一个叫 [Caffe2][5] 的深度学习和人工智能的框架。
|
||||
|
||||
**说到 Caffe.** Yahoo 也在开源许可证下发布了它自己的关键的 AI 软件。[CaffeOnSpark 工具][6] 是基于深度学习的,它是人工智能的一个分支,在帮助机器识别人类语言、或者照片、视频的内容方面非常有用。同样地,IBM 的机器学习程序 [SystemML][7] 可以通过 Apache 软件基金会免费共享和修改。
|
||||
|
||||
**Google 的工具.** Google 花费了几年的时间开发了它自己的 [TensorFlow][8] 软件框架,用于去支持它的 AI 软件和其它预测和分析程序。TensorFlow 是你可能都已经在使用的一些 Google 工具背后的引擎,包括 Google Photos 和在 Google app 中使用的语言识别。
|
||||
|
||||
Google 开源了两个 [AIY kits][9],它可以让个人很容易地使用人工智能,它们专注于计算机视觉和语音助理。这两个工具包将用到的所有组件封装到一个盒子中。这个工具包目前在美国的 Target 中有售,并且它是基于开源的树莓派平台的 —— 有越来越多的证据表明,在开源和 AI 交集中将发生非常多的事情。
|
||||
|
||||
**H2O.ai.** **** 我 [以前介绍过][10] H2O.ai,它在机器学习和人工智能领域中占有一席之地,因为它的主要工具是免费和开源的。你可以获取主要的 H2O 平台和 Sparkling Water,它与 Apache Spark 一起工作,只需要去 [下载][11] 它们即可。这些工具遵循 Apache 2.0 许可证,它是一个非常灵活的开源许可证,你甚至可以在 Amazon Web 服务(AWS)和其它的集群上运行它们,而这仅需要几百美元而已。
|
||||
|
||||
**Microsoft Onboard.** “我们的目标是让 AI 大众化,让每个人和组织获得更大的成就,“ Microsoft CEO Satya Nadella [说][12]。因此,微软持续迭代它的 [Microsoft Cognitive Toolkit][13]。它是一个能够与 TensorFlow 和 Caffe 去竞争的一个开源软件框架。Cognitive 工具套件可以工作在 64 位的 Windows 和 Linux 平台上。
|
||||
|
||||
Cognitive 工具套件团队的报告称,“Cognitive 工具套件通过允许用户去创建、训练、以及评估他们自己的神经网络,以使企业级的、生产系统级的 AI 成为可能,这些神经网络可能跨多个 GPU 以及多个机器在大量的数据集中高效伸缩。”
|
||||
|
||||
从来自 Linux 基金会的新电子书中学习更多的有关 AI 知识。Ibrahim Haddad 的 [开源 AI:项目、洞察、和趋势][14] 调查了 16 个流行的开源 AI 项目—— 深入研究了他们的历史、代码库、以及 GitHub 的贡献。 [现在可以免费下载这个电子书][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.acumos.org/
|
||||
[2]:https://www.linuxfoundation.org/projects/deep-learning/
|
||||
[3]:https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/
|
||||
[4]:https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
|
||||
[5]:https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
|
||||
[6]:http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
|
||||
[7]:https://systemml.apache.org/
|
||||
[8]:https://www.tensorflow.org/
|
||||
[9]:https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control
|
||||
[10]:https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark
|
||||
[11]:http://www.h2o.ai/download
|
||||
[12]:https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/
|
||||
[13]:https://www.microsoft.com/en-us/cognitive-toolkit/
|
||||
[14]:https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/
|
||||
Loading…
Reference in New Issue
Block a user