mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
2c8e98b3f8
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Org mode without Emacs)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-org-mode)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Org mode without Emacs
|
||||
======
|
||||
No, you don't need Emacs to use Org, the 16th in our series on open source tools that will make you more productive in 2019.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the 16th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Org (without Emacs)
|
||||
|
||||
[Org mode][1] (or just Org) is not in the least bit new, but there are still many people who have never used it. They would love to try it out to get a feel for how Org can help them be productive. But the biggest barrier is that Org is associated with Emacs, and many people think one requires the other. Not so! Org can be used with a variety of other tools and editors once you understand the basics.
|
||||
|
||||
|
||||
|
||||
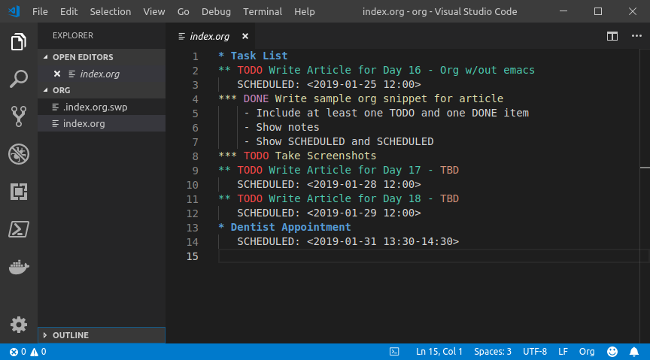
Org, at its very heart, is a structured text file. It has headers, subheaders, and keywords that allow other tools to parse files into agendas and to-do lists. Org files can be edited with any flat-text editor (e.g., [Vim][2], [Atom][3], or [Visual Studio Code][4]), and many have plugins that help create and manage Org files.
|
||||
|
||||
A basic Org file looks something like this:
|
||||
|
||||
```
|
||||
* Task List
|
||||
** TODO Write Article for Day 16 - Org w/out emacs
|
||||
DEADLINE: <2019-01-25 12:00>
|
||||
*** DONE Write sample org snippet for article
|
||||
- Include at least one TODO and one DONE item
|
||||
- Show notes
|
||||
- Show SCHEDULED and DEADLINE
|
||||
*** TODO Take Screenshots
|
||||
** Dentist Appointment
|
||||
SCHEDULED: <2019-01-31 13:30-14:30>
|
||||
```
|
||||
|
||||
Org uses an outline format that uses ***** as bullets to indicate an item's level. Any item that begins with the word TODO (yes, in all caps) is just that—a to-do item. The work DONE indicates it is completed. SCHEDULED and DEADLINE indicate dates and times relevant to the item. If there's no time in either field, the item is considered an all-day event.
|
||||
|
||||
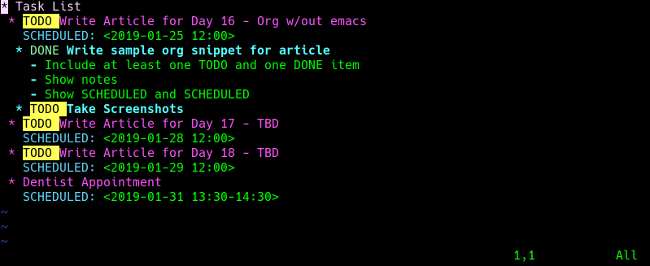
With the right plugins, your favorite text editor becomes a powerhouse of productivity and organization. For example, the [vim-orgmode][5] plugin's features include functions to create Org files, syntax highlighting, and key commands to generate agendas and comprehensive to-do lists across files.
|
||||
|
||||
|
||||
|
||||
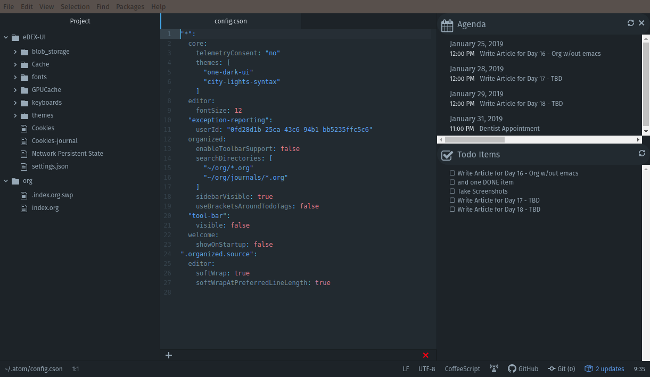
The Atom [Organized][6] plugin adds a sidebar on the right side of the screen that shows the agenda and to-do items in Org files. It can read from multiple files by default with a path set up in the configuration options. The Todo sidebar allows you to click on a to-do item to mark it done, then automatically updates the source Org file.
|
||||
|
||||
|
||||
|
||||
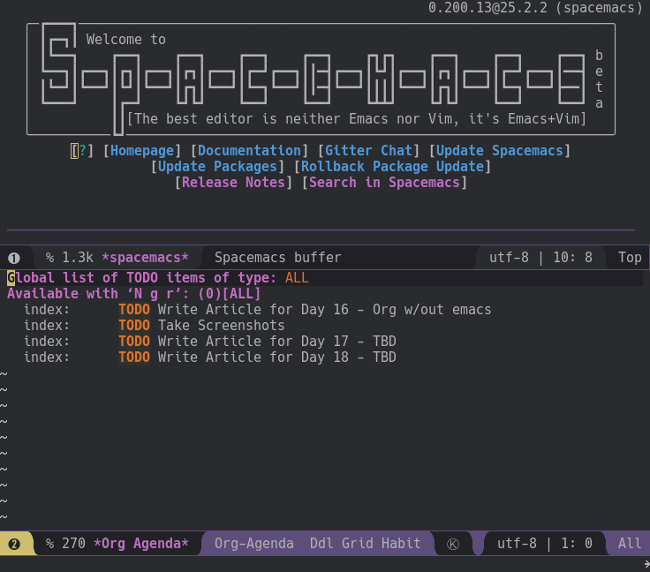
There are also a whole host of tools that "speak Org" to help keep you productive. With libraries in Python, Perl, PHP, NodeJS, and more, you can develop your own scripts and tools. And, of course, there is also [Emacs][7], which has Org support within the core distribution.
|
||||
|
||||
|
||||
|
||||
Org mode is one of the best tools for keeping on track with what needs to be done and when. And, contrary to myth, it doesn't need Emacs, just a text editor.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://orgmode.org/
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://atom.io/
|
||||
[4]: https://code.visualstudio.com/
|
||||
[5]: https://github.com/jceb/vim-orgmode
|
||||
[6]: https://atom.io/packages/organized
|
||||
[7]: https://www.gnu.org/software/emacs/
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Tips and tricks for using CUPS for printing with Linux)
|
||||
[#]: via: (https://opensource.com/article/19/1/cups-printing-linux)
|
||||
[#]: author: (Antoine Thomas https://opensource.com/users/ttoine)
|
||||
|
||||
Tips and tricks for using CUPS for printing with Linux
|
||||
======
|
||||
One of Apple's most important contributions to GNU/Linux was adopting CUPS in Mac OS X.
|
||||

|
||||
|
||||
Did you ever try to configure a printer on a GNU/Linux desktop distribution at the end of the '90s? Or even before?
|
||||
|
||||
To make a long story short: That was fine if you worked at a large organization with an IT team to handle it and dedicated hardware or a printing server. There were many different standards and protocols to handle printers. And only a few big vendors (usually Unix vendors) provided specific support and drivers for their entire range of products.
|
||||
|
||||
However, if open source enthusiasts wanted a home printer that would work with their favorite distribution, that was another story. They probably spent a fair amount of time on forums, newsgroups, or IRC (remember those ancestors of social networks and chats?) asking about printers with easy-to-install Linux drivers.
|
||||
|
||||
In 1999, the first version of [CUPS][1] (the Common Unix Printing System) was released by Easy Software Products. Most of the most popular distributions at the time adopted CUPS as their default printing system. That was a huge success: one standard could handle many printers and protocols.
|
||||
|
||||
But if the printer vendor didn't provide a CUPS driver, it was still tricky or impossible to make it work. Some smart people might do reverse engineering. And a few printers, with native support of PostScript and Internet Printing Protocol (IPP), worked "out of the box."
|
||||
|
||||
### Then came Apple
|
||||
|
||||
In the early 2000s, Apple was struggling to build a new printing system for its new Mac OS X. In March 2002, it decided to save time by adopting CUPS for its flagship operating system.
|
||||
|
||||
No printer vendor could ignore Apple computers' market share, so a lot of new printer drivers for Mac OS X's CUPS became available, spanning most vendors and product ranges, including corporate, graphic arts, consumer, and photo printing.
|
||||
|
||||
CUPS became so important for Apple that it bought the software from Easy Software Products in 2007; since then Apple has continued to maintain it and manage its intellectual property.
|
||||
|
||||
### But what does that have to do with GNU/Linux?
|
||||
|
||||
At the time Apple integrated CUPS in Mac OS X, it was already used by default in many distros and available for most others. But few dedicated drivers were available, meaning they were not packaged or listed as "for GNU/Linux."
|
||||
|
||||
However, once CUPS drivers were available for Mac OS X, a simple hack became popular with GNU/Linux enthusiasts: download the Mac driver, extract the PPD files, and test them with your printer. I used this hack many times with my Epson printers.
|
||||
|
||||
That's the CUPS magic: If a driver exists, it usually works with all operating systems that use CUPS for printing, as long as they use a supported protocol (like IPP).
|
||||
|
||||
That's how printer drivers began to be available for GNU/Linux.
|
||||
|
||||
### Nowadays
|
||||
|
||||
Afterward, printer vendors realized it was quite easy to provide drivers for GNU/Linux since they already developed them for Mac. It's now easy to find a GNU/Linux driver for a printer, even a newer one. Some distributions include packages with a lot of drivers, and most vendors provide dedicated drivers—sometimes via a package, other times with PPD files in an archive.
|
||||
|
||||
Advanced control applications are available too, some official, some not, which make it possible (for example) to look at ink levels or clean printing heads.
|
||||
|
||||
In some cases, installing a printer on GNU/Linux is even easier than on other operating systems, particularly with distributions using [zero-configuration networking][2] (e.g., Bonjour, Avahi) to auto-discover and share network printers.
|
||||
|
||||
### Tips and tricks
|
||||
|
||||
* **Install a PDF printer:** Installing a PDF printer on GNU/Linux is very easy. Just look for the **cups-pdf** package in your favorite distribution and install it. If the package doesn't automatically create the PDF printer, you can add one using your system preferences to print in PDF from any application.
|
||||
|
||||
* **Access the CUPS web interface:** If your usual interface for managing printers doesn't work or you don't like it, open a web browser and go to <http://localhost:631/admin>. You can manage all the printers installed on your computer, adjust their settings, and even add new ones—all from this web interface. Note that this might be available on other computers on your network; if so, replace "localhost" with the relevant hostname or IP address.
|
||||
|
||||
* **Check ink level:** If you have an Epson, Canon, HP, or Sony printer, you can see its ink level with a simple application. Look for the "ink" package in your distribution repositories.
|
||||
|
||||
* **Contribute to CUPS:** Like many open source project, CUPS is maintained on GitHub. Check the [CUPS website][1] and [GitHub issues][3] to find out how you can contribute to improving it.
|
||||
|
||||
|
||||
|
||||
|
||||
### CUPS license
|
||||
|
||||
Originally, CUPS was released under GPLv2. I'm not sure why; maybe to make it easier to distribute with GNU/Linux. Or maybe it was just what most open source projects did at the time.
|
||||
|
||||
Apple decided to [change the license][4] in November 2017 to the Apache 2.0 license. Many observers commented that it was consistent with Apple's strategy to move the IP of its open source projects to more business-compliant licenses.
|
||||
|
||||
While this change could create issues with shipping CUPS with GNU/Linux, it is still available in most distributions.
|
||||
|
||||
### Happy 20th birthday, CUPS!
|
||||
|
||||
CUPS was released in 1999, so, let's celebrate and thank all the people involved in this successful open source project, from the original authors to the driver developers to its current maintainers.
|
||||
|
||||
The next time you print with your favorite GNU/Linux operating system, remind yourself to say "thank you" to Apple.
|
||||
|
||||
The company isn't well known for its contributions to open source. But if you look carefully (at, for example, [Apple's Open Source Releases][5] and [Open Source Development][6] pages), you'll see how many open source components are in Apple's operating systems and applications.
|
||||
|
||||
You'll also discover other important open source projects Apple kicked off. For example, it forked KHTML, the KDE browser, to create [WebKit][7] for the Safari Browser. Wait, THE WebKit? Yes, Apple initiated WebKit. But that is another story...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/cups-printing-linux
|
||||
|
||||
作者:[Antoine Thomas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ttoine
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cups.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Zero-configuration_networking#Major_implementations
|
||||
[3]: https://github.com/apple/cups/issues
|
||||
[4]: https://www.cups.org/blog/2017-11-07-cups-license-change.html
|
||||
[5]: https://opensource.apple.com/
|
||||
[6]: https://developer.apple.com/opensource/
|
||||
[7]: https://webkit.org/
|
||||
@ -1,4 +1,3 @@
|
||||
Ryze-Borgia is translating
|
||||
A day in the life of a log message
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with HomeBank, an open source personal finance app)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tools-homebank)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with HomeBank, an open source personal finance app
|
||||
======
|
||||
Keep track of where your money is going with HomeBank, the eighth in our series on open source tools that will make you more productive in 2019.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the eighth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### HomeBank
|
||||
|
||||
Managing my finances can be really stressful. I don't look at my bank balance every day and sometimes have trouble keeping track of where my money is going. I often spend more time managing my finances than I need to, digging into accounts and payment histories to figure out where my money went. Knowing my finances are OK helps keep me calm and allows me to focus on other things.
|
||||
|
||||
|
||||
|
||||
[HomeBank][1] is a personal finance desktop application that helps decrease this type of stress by making it fairly easy to keep track of your finances. It has some nice reports to help you figure out where you're spending your money, allows you to set up rules for importing transactions, and supports most modern formats.
|
||||
|
||||
HomeBank is available on most distributions by default, so installation is very easy. When you start it up for the first time, it will walk you through setup and allow you to create an account. From there, you can either import one of the supported file formats or start entering transactions. The transaction register itself is just that—a list of transactions. [Unlike some other apps][2], you don't have to learn [double-entry bookkeeping][3] to use HomeBank.
|
||||
|
||||
|
||||
|
||||
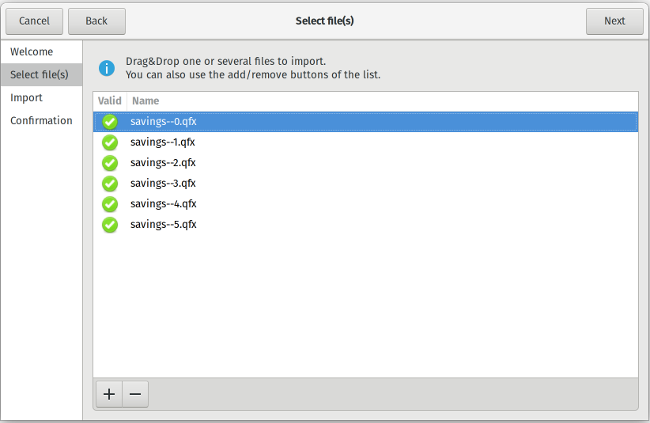
Importing files from your bank is handled with another step-by-step wizard, with options to create a new account or populate an existing one. Importing into a new account saves a little time since you don't have to pre-create all the accounts before starting the import. You can also import multiple files into an account at once, so you don't need to repeat the same steps for every file in every account.
|
||||
|
||||
|
||||
|
||||
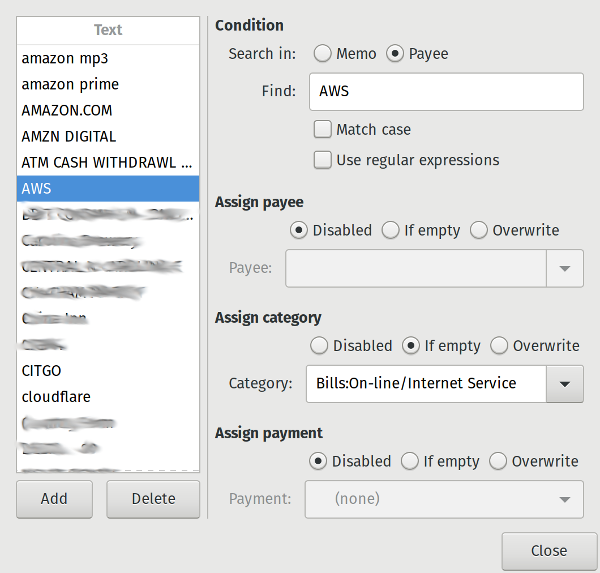
The one pain point I've had with importing and managing accounts is category assignment. Categories are what allow you to break down your spending and see what you are spending money on, in general terms. HomeBank, unlike commercial services (and some commercial programs), requires you to manually set up all the assignments. But this is generally a one-time thing, and then the categories can be auto-applied as transactions are added/imported. There is also a button to analyze the account and auto-apply things that already exist, which speeds up categorizing a large import (like I did the first time). HomeBank comes with a large number of categories you can start with, and you can add your own as well.
|
||||
|
||||
HomeBank also has budgeting features, allowing you to plan for the months ahead.
|
||||
|
||||
|
||||
|
||||
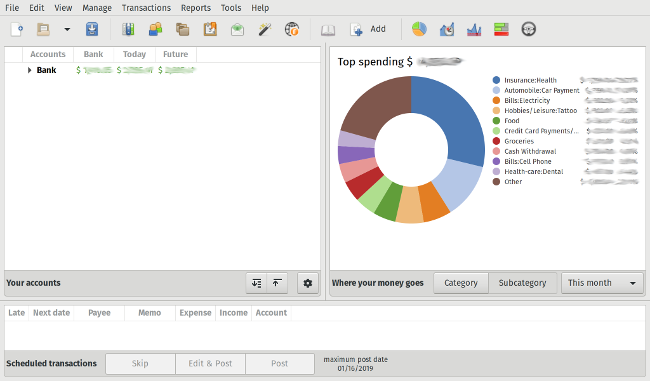
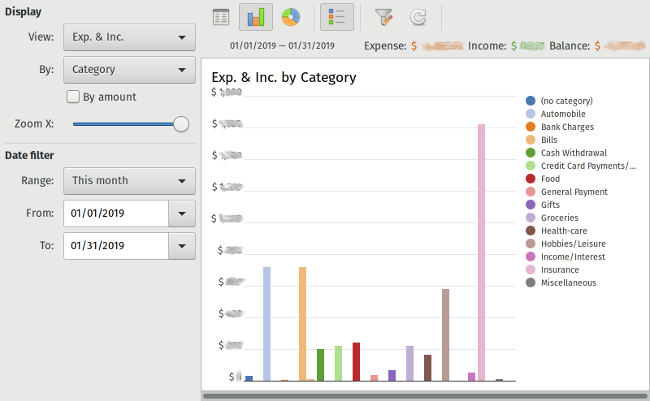
The big win, for me, is HomeBank's reports feature. Not only is there a chart on the main screen showing where you are spending your money, but there are a whole host of other reports you can look at. If you use the budget feature, there is a report that tracks your spending against your budget. You can also view those reports as pie and bar charts. There is also a trend report and a balance report, so you can look back and see changes or patterns over time.
|
||||
|
||||
Overall, HomeBank is a very friendly, useful application to help you keep your finances in order. It is simple to use and really helpful if keeping track of your money is a major stress point in your life.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tools-homebank
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://homebank.free.fr/en/index.php
|
||||
[2]: https://www.gnucash.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with LogicalDOC, an open source document management system)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-logicaldoc)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Get started with LogicalDOC, an open source document management system
|
||||
======
|
||||
Keep better track of document versions with LogicalDOC, the 12th in our series on open source tools that will make you more productive in 2019.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the 12th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### LogicalDOC
|
||||
|
||||
Part of being productive is being able to find what you need when you need it. We've all seen directories full of similar files with similar names, a result of renaming them every time a document changes to keep track of all the versions. For example, my wife is a writer, and she often saves document revisions with new names before she sends them to reviewers.
|
||||
|
||||

|
||||
|
||||
A coder's natural solution to this problem—Git or another version control tool—won't work for document creators because the systems used for code often don't play nice with the formats used by commercial text editors. And before someone says, "just change formats," [that isn't an option for everyone][1]. Also, many version control tools are not very friendly for the less technically inclined. In large organizations, there are tools to solve this problem, but they also require the resources of a large organization to run, manage, and support them.
|
||||
|
||||
|
||||
|
||||
[LogicalDOC CE][2] is an open source document management system built to solve this problem. It allows users to check in, check out, version, search, and lock document files and keeps a history of versions, similar to the version control tools used by coders.
|
||||
|
||||
LogicalDOC can be [installed][3] on Linux, MacOS, and Windows using a Java-based installer. During installation, you'll be prompted for details on the database where its data will be stored and have an option for a local-only file store. You'll get the URL and a default username and password to access the server as well as an option to save a script to automate future installations.
|
||||
|
||||
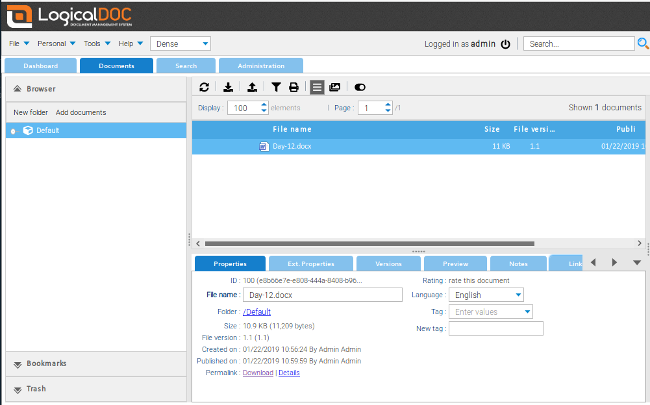
After you log in, LogicalDOC's default screen lists the documents you have tagged, checked out, and any recent notes on them. Switching to the Documents tab will show the files you have access to. You can upload documents by selecting a file through the interface or using drag and drop. If you upload a ZIP file, LogicalDOC will expand it and add its individual files to the repository.
|
||||
|
||||
|
||||
|
||||
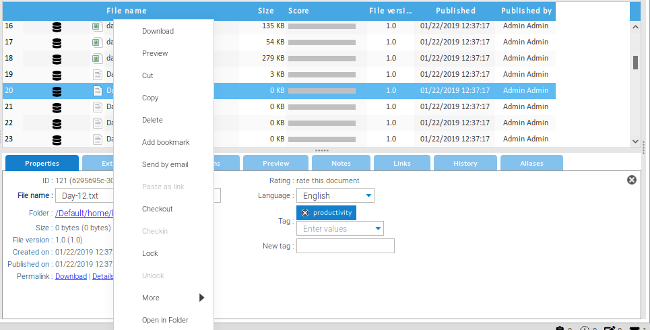
Right-clicking on a file will bring up a menu of options to check out files, lock files against changes, and do a whole host of other things. Checking out a file downloads it to your local machine where it can be edited. A checked-out file cannot be modified by anyone else until it's checked back in. When the file is checked back in (using the same menu), the user can add tags to the version and is required to comment on what was done to it.
|
||||
|
||||
|
||||
|
||||
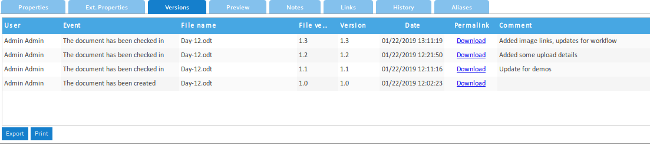
Going back and looking at earlier versions is as easy as downloading them from the Versions page. There are also import and export options for some third-party services, with [Dropbox][4] support built-in.
|
||||
|
||||
Document management is not just for big companies that can afford expensive solutions. LogicalDOC helps you keep track of the documents you're using with a revision history and a safe repository for documents that are otherwise difficult to manage.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-logicaldoc
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.antipope.org/charlie/blog-static/2013/10/why-microsoft-word-must-die.html
|
||||
[2]: https://www.logicaldoc.com/download-logicaldoc-community
|
||||
[3]: https://docs.logicaldoc.com/en/installation
|
||||
[4]: https://dropbox.com
|
||||
@ -1,154 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding Angle Brackets in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Understanding Angle Brackets in Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Bash][1] provides many important built-in commands, like `ls`, `cd`, and `mv`, as well as regular tools such as `grep`, `awk,` and `sed`. But, it is equally important to know the punctuation marks -- [the glue in the shape of dots][2], commas, brackets. and quotes -- that allow you to transform and push data from one place to another. Take angle brackets (`< >`), for example.
|
||||
|
||||
### Pushing Around
|
||||
|
||||
If you are familiar with other programming and scripting languages, you may have used `<` and `>` as logical operators to check in a condition whether one value is larger or smaller than another. If you have ever written HTML, you have used angle brackets to enclose tags.
|
||||
|
||||
In shell scripting, you can also use brackets to push data from place to place, for example, to a file:
|
||||
|
||||
```
|
||||
ls > dir_content.txt
|
||||
```
|
||||
|
||||
In this example, instead of showing the contents of the directory on the command line, `>` tells the shell to copy it into a file called _dir_content.txt_. If _dir_content.txt_ doesn't exist, Bash will create it for you, but if _dir_content.txt_ already exists and is not empty, you will overwrite whatever it contained, so be careful!
|
||||
|
||||
You can avoid overwriting existing content by tacking the new stuff onto the end of the old stuff. For that you use `>>` (instead of `>`):
|
||||
|
||||
```
|
||||
ls $HOME > dir_content.txt; wc -l dir_content.txt >> dir_content.txt
|
||||
```
|
||||
|
||||
This line stores the list of contents of your home directory into _dir_content.txt_. You then count the number of lines in _dir_content.txt_ (which gives you the number of items in the directory) with [`wc -l`][3] and you tack that value onto the end of the file.
|
||||
|
||||
After running the command line on my machine, this is what my _dir_content.txt_ file looks like:
|
||||
|
||||
```
|
||||
Applications
|
||||
bin
|
||||
cloud
|
||||
Desktop
|
||||
Documents
|
||||
Downloads
|
||||
Games
|
||||
ISOs
|
||||
lib
|
||||
logs
|
||||
Music
|
||||
OpenSCAD
|
||||
Pictures
|
||||
Public
|
||||
Templates
|
||||
test_dir
|
||||
Videos
|
||||
17 dir_content.txt
|
||||
```
|
||||
|
||||
The mnemonic here is to look at `>` and `>>` as arrows. In fact, the arrows can point the other way, too. Say you have a file called _CBActors_ containing some names of actors and the number of films by the Coen brothers they have been in. Something like this:
|
||||
|
||||
```
|
||||
John Goodman 5
|
||||
John Turturro 3
|
||||
George Clooney 2
|
||||
Frances McDormand 6
|
||||
Steve Buscemi 5
|
||||
Jon Polito 4
|
||||
Tony Shalhoub 3
|
||||
James Gandolfini 1
|
||||
```
|
||||
|
||||
Something like
|
||||
|
||||
```
|
||||
sort < CBActors # Do this
|
||||
Frances McDormand 6 # And you get this
|
||||
George Clooney 2
|
||||
James Gandolfini 1
|
||||
John Goodman 5
|
||||
John Turturro 3
|
||||
Jon Polito 4
|
||||
Steve Buscemi 5
|
||||
Tony Shalhoub 3
|
||||
```
|
||||
|
||||
Will [sort][4] the list alphabetically. But then again, you don't need `<` here since `sort` already expects a file anyway, so `sort CBActors` will work just as well.
|
||||
|
||||
However, if you need to see who is the Coens' favorite actor, you can check with :
|
||||
|
||||
```
|
||||
while read name surname films; do echo $films $name $surname > filmsfirst.txt; done < CBActors
|
||||
```
|
||||
|
||||
Or, to make that a bit more readable:
|
||||
|
||||
```
|
||||
while read name surname films;\
|
||||
do
|
||||
echo $films $name $surname >> filmsfirst;\
|
||||
done < CBActors
|
||||
```
|
||||
|
||||
Let's break this down, shall we?
|
||||
|
||||
* the [`while ...; do ... done`][5] structure is a loop. The instructions between `do` and `done` are repeatedly executed while a condition is met, in this case...
|
||||
* ... the [`read`][6] instruction has lines to read. `read` reads from the standard input and will continue reading until there is nothing more to read...
|
||||
* ... And as standard input is fed in via `<` and comes from _CBActors_ , that means the `while` loop will loop until the last line of _CBActors_ is piped into the loop.
|
||||
* Getting back to `read` for a sec, the tool is clever enough to see that there are three distinct fields separated by spaces on each line of the file. That allows you to put the first field from each line in the `name` variable, the second in `surname` and the third in `films`. This comes in handy later, on the line that says `echo $films $name $surname >> filmsfirst;\`, allowing you to reorder the fields and push them into a file called _filmsfirst_.
|
||||
|
||||
|
||||
|
||||
At the end of all that, you have a file called _filmsfirst_ that looks like this:
|
||||
|
||||
```
|
||||
5 John Goodman
|
||||
3 John Turturro
|
||||
2 George Clooney
|
||||
6 Frances McDormand
|
||||
5 Steve Buscemi
|
||||
4 Jon Polito
|
||||
3 Tony Shalhoub
|
||||
1 James Gandolfini
|
||||
```
|
||||
|
||||
which you can now use with `sort`:
|
||||
|
||||
```
|
||||
sort -r filmsfirst
|
||||
```
|
||||
|
||||
to see who is the Coens' favorite actor. Yes, it is Frances McDormand. (The [`-r`][4] option reverses the sort, so McDormand ends up on top).
|
||||
|
||||
We'll look at more angles on this topic next time!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/2019/1/bash-shell-utility-reaches-50-milestone
|
||||
[2]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
|
||||
[3]: https://linux.die.net/man/1/wc
|
||||
[4]: https://linux.die.net/man/1/sort
|
||||
[5]: http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO-7.html
|
||||
[6]: https://linux.die.net/man/2/read
|
||||
143
sources/tech/20190124 What does DevOps mean to you.md
Normal file
143
sources/tech/20190124 What does DevOps mean to you.md
Normal file
@ -0,0 +1,143 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What does DevOps mean to you?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-does-devops-mean-you)
|
||||
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||
|
||||
What does DevOps mean to you?
|
||||
======
|
||||
6 experts break down DevOps and the practices and philosophies key to making it work.
|
||||
|
||||

|
||||
|
||||
It's said if you ask 10 people about DevOps, you will get 12 answers. This is a result of the diversity in opinions and expectations around DevOps—not to mention the disparity in its practices.
|
||||
|
||||
To decipher the paradoxes around DevOps, we went to the people who know it the best—its top practitioners around the industry. These are people who have been around the horn, who know the ins and outs of technology, and who have practiced DevOps for years. Their viewpoints should encourage, stimulate, and provoke your thoughts around DevOps.
|
||||
|
||||
### What does DevOps mean to you?
|
||||
|
||||
Let's start with the fundamentals. We're not looking for textbook answers, rather we want to know what the experts say.
|
||||
|
||||
In short, the experts say DevOps is about principles, practices, and tools.
|
||||
|
||||
[Ann Marie Fred][1], DevOps lead for IBM Digital Business Group's Commerce Platform, says, "to me, DevOps is a set of principles and practices designed to make teams more effective in designing, developing, delivering, and operating software."
|
||||
|
||||
According to [Daniel Oh][2], senior DevOps evangelist at Red Hat, "in general, DevOps is compelling for enterprises to evolve current IT-based processes and tools related to app development, IT operations, and security protocol."
|
||||
|
||||
[Brent Reed][3], founder of Tactec Strategic Solutions, talks about continuous improvement for the stakeholders. "DevOps means to me a way of working that includes a mindset that allows for continuous improvement for operational performance, maturing to organizational performance, resulting in delighted stakeholders."
|
||||
|
||||
Many of the experts also emphasize culture. Ann Marie says, "it's also about continuous improvement and learning. It's about people and culture as much as it is about tools and technology."
|
||||
|
||||
To [Dan Barker][4], chief architect and DevOps leader at the National Association of Insurance Commissioners (NAIC), "DevOps is primarily about culture. … It has brought several independent areas together like lean, [just culture][5], and continuous learning. And I see culture as being the most critical and the hardest to execute on."
|
||||
|
||||
[Chris Baynham-Hughes][6], head of DevOps at Atos, says, "[DevOps] practice is adopted through the evolution of culture, process, and tooling within an organization. The key focus is culture change, and the key tenants of DevOps culture are collaboration, experimentation, fast-feedback, and continuous improvement."
|
||||
|
||||
[Geoff Purdy][7], cloud architect, talks about agility and feedback "shortening and amplifying feedback loops. We want teams to get feedback in minutes rather than weeks."
|
||||
|
||||
But in the end, Daniel nails it by explaining how open source and open culture allow him to achieve his goals "in easy and quick ways. In DevOps initiatives, the most important thing for me should be open culture rather than useful tools, multiple solutions."
|
||||
|
||||
### What DevOps practices have you found effective?
|
||||
|
||||
"Picking one, automated provisioning has been hugely effective for my team. "
|
||||
|
||||
The most effective practices cited by the experts are pervasive yet disparate.
|
||||
|
||||
According to Ann Marie, "some of the most powerful [practices] are agile project management; breaking down silos between cross-functional, autonomous squads; fully automated continuous delivery; green/blue deploys for zero downtime; developers setting up their own monitoring and alerting; blameless post-mortems; automating security and compliance."
|
||||
|
||||
Chris says, "particular breakthroughs have been empathetic collaboration; continuous improvement; open leadership; reducing distance to the business; shifting from vertical silos to horizontal, cross-functional product teams; work visualization; impact mapping; Mobius loop; shortening of feedback loops; automation (from environments to CI/CD)."
|
||||
|
||||
Brent supports "evolving a learning culture that includes TDD [test-driven development] and BDD [behavior-driven development] capturing of a story and automating the sequences of events that move from design, build, and test through implementation and production with continuous integration and delivery pipelines. A fail-first approach to testing, the ability to automate integration and delivery processes and include fast feedback throughout the lifecycle."
|
||||
|
||||
Geoff highlights automated provisioning. "Picking one, automated provisioning has been hugely effective for my team. More specifically, automated provisioning from a versioned Infrastructure-as-Code codebase."
|
||||
|
||||
Dan uses fun. "We do a lot of different things to create a DevOps culture. We hold 'lunch and learns' with free food to encourage everyone to come and learn together; we buy books and study in groups."
|
||||
|
||||
### How do you motivate your team to achieve DevOps goals?
|
||||
|
||||
```
|
||||
"Celebrate wins and visualize the progress made."
|
||||
```
|
||||
|
||||
Daniel emphasizes "automation that matters. In order to minimize objection from multiple teams in a DevOps initiative, you should encourage your team to increase the automation capability of development, testing, and IT operations along with new processes and procedures. For example, a Linux container is the key tool to achieve the automation capability of DevOps."
|
||||
|
||||
Geoff agrees, saying, "automate the toil. Are there tasks you hate doing? Great. Engineer them out of existence if possible. Otherwise, automate them. It keeps the job from becoming boring and routine because the job constantly evolves."
|
||||
|
||||
Dan, Ann Marie, and Brent stress team motivation.
|
||||
|
||||
Dan says, "at the NAIC, we have a great awards system for encouraging specific behaviors. We have multiple tiers of awards, and two of them can be given to anyone by anyone. We also give awards to teams after they complete something significant, but we often award individual contributors."
|
||||
|
||||
According to Ann Marie, "the biggest motivator for teams in my area is seeing the success of others. We have a weekly playback for each other, and part of that is sharing what we've learned from trying out new tools or practices. When teams are enthusiastic about something they're doing and willing to help others get started, more teams will quickly get on board."
|
||||
|
||||
Brent agrees. "Getting everyone educated and on the same baseline of knowledge is essential ... assessing what helps the team achieve [and] what it needs to deliver with the product owner and users is the first place I like to start."
|
||||
|
||||
Chris recommends a two-pronged approach. "Run small, weekly goals that are achievable and agreed by the team as being important and [where] they can see progress outside of the feature work they are doing. Celebrate wins and visualize the progress made."
|
||||
|
||||
### How do DevOps and agile work together?
|
||||
|
||||
```
|
||||
"DevOps != Agile, second Agile != Scrum."
|
||||
```
|
||||
|
||||
This is an important question because both DevOps and agile are cornerstones of modern software development.
|
||||
|
||||
DevOps is a process of software development focusing on communication and collaboration to facilitate rapid application and product deployment, whereas agile is a development methodology involving continuous development, continuous iteration, and continuous testing to achieve predictable and quality deliverables.
|
||||
|
||||
So, how do they relate? Let's ask the experts.
|
||||
|
||||
In Brent's view, "DevOps != Agile, second Agile != Scrum. … Agile tools and ways of working—that support DevOps strategies and goals—are how they mesh together."
|
||||
|
||||
Chris says, "agile is a fundamental component of DevOps for me. Sure, we could talk about how we adopt DevOps culture in a non-agile environment, but ultimately, improving agility in the way software is engineered is a key indicator as to the maturity of DevOps adoption within the organization."
|
||||
|
||||
Dan relates DevOps to the larger [Agile Manifesto][8]. "I never talk about agile without referencing the Agile Manifesto in order to set the baseline. There are many implementations that don't focus on the Manifesto. When you read the Manifesto, they've really described DevOps from a development perspective. Therefore, it is very easy to fit agile into a DevOps culture, as agile is focused on communication, collaboration, flexibility to change, and getting to production quickly."
|
||||
|
||||
Geoff sees "DevOps as one of many implementations of agile. Agile is essentially a set of principles, while DevOps is a culture, process, and toolchain that embodies those principles."
|
||||
|
||||
Ann Marie keeps it succinct, saying "agile is a prerequisite for DevOps. DevOps makes agile more effective."
|
||||
|
||||
### Has DevOps benefited from open source?
|
||||
|
||||
```
|
||||
"Open source done well requires a DevOps culture."
|
||||
```
|
||||
|
||||
This question receives a fervent "yes" from all participants followed by an explanation of the benefits they've seen.
|
||||
|
||||
Ann Marie says, "we get to stand on the shoulders of giants and build upon what's already available. The open source model of maintaining software, with pull requests and code reviews, also works very well for DevOps teams."
|
||||
|
||||
Chris agrees that DevOps has "undoubtedly" benefited from open source. "From the engineering and tooling side (e.g., Ansible), to the process and people side, through the sharing of stories within the industry and the open leadership community."
|
||||
|
||||
A benefit Geoff cites is "grassroots adoption. Nobody had to sign purchase requisitions for free (as in beer) software. Teams found tooling that met their needs, were free (as in freedom) to modify, [then] built on top of it, and contributed enhancements back to the larger community. Rinse, repeat."
|
||||
|
||||
Open source has shown DevOps "better ways you can adopt new changes and overcome challenges, just like open source software developers are doing it," says Daniel.
|
||||
|
||||
Brent concurs. "DevOps has benefited in many ways from open source. One way is the ability to use the tools to understand how they can help accelerate DevOps goals and strategies. Educating the development and operations folks on crucial things like automation, virtualization and containerization, auto-scaling, and many of the qualities that are difficult to achieve without introducing technology enablers that make DevOps easier."
|
||||
|
||||
Dan notes the two-way, symbiotic relationship between DevOps and open source. "Open source done well requires a DevOps culture. Most open source projects have very open communication structures with very little obscurity. This has actually been a great learning opportunity for DevOps practitioners around what they might bring into their own organizations. Also, being able to use tools from a community that is similar to that of your own organization only encourages your own culture growth. I like to use GitLab as an example of this symbiotic relationship. When I bring [GitLab] into a company, we get a great tool, but what I'm really buying is their unique culture. That brings substantial value through our interactions with them and our ability to contribute back. Their tool also has a lot to offer for a DevOps organization, but their culture has inspired awe in the companies where I've introduced it."
|
||||
|
||||
Now that our DevOps experts have weighed in, please share your thoughts on what DevOps means—as well as the other questions we posed—in the comments.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-does-devops-mean-you
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gammay
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twitter.com/DukeAMO
|
||||
[2]: https://twitter.com/danieloh30?lang=en
|
||||
[3]: https://twitter.com/brentareed
|
||||
[4]: https://twitter.com/barkerd427
|
||||
[5]: https://psnet.ahrq.gov/resources/resource/1582
|
||||
[6]: https://twitter.com/onlychrisbh?lang=en
|
||||
[7]: https://twitter.com/geoff_purdy
|
||||
[8]: https://agilemanifesto.org/
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 simple and useful GNOME Shell extensions)
|
||||
[#]: via: (https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
|
||||
|
||||
3 simple and useful GNOME Shell extensions
|
||||
======
|
||||
|
||||

|
||||
|
||||
The default desktop of Fedora Workstation — GNOME Shell — is known and loved by many users for its minimal, clutter-free user interface. It is also known for the ability to add to the stock interface using extensions. In this article, we cover 3 simple, and useful extensions for GNOME Shell. These three extensions provide a simple extra behaviour to your desktop; simple tasks that you might do every day.
|
||||
|
||||
|
||||
### Installing Extensions
|
||||
|
||||
The quickest and easiest way to install GNOME Shell extensions is with the Software Application. Check out the previous post here on the Magazine for more details:
|
||||
|
||||

|
||||
|
||||
### Removable Drive Menu
|
||||
|
||||
![][1]
|
||||
Removable Drive Menu extension on Fedora 29
|
||||
|
||||
First up is the [Removable Drive Menu][2] extension. It is a simple tool that adds a small widget in the system tray if you have a removable drive inserted into your computer. This allows you easy access to open Files for your removable drive, or quickly and easily eject the drive for safe removal of the device.
|
||||
|
||||
![][3]
|
||||
Removable Drive Menu in the Software application
|
||||
|
||||
### Extensions Extension.
|
||||
|
||||
![][4]
|
||||
|
||||
The [Extensions][5] extension is super useful if you are always installing and trying out new extensions. It provides a list of all the installed extensions, allowing you to enable or disable them. Additionally, if an extension has settings, it allows quick access to the settings dialog for each one.
|
||||
|
||||
![][6]
|
||||
the Extensions extension in the Software application
|
||||
|
||||
### Frippery Move Clock
|
||||
|
||||
![][7]
|
||||
|
||||
Finally, there is the simplest extension in the list. [Frippery Move Clock][8], simply moves the position of the clock from the center of the top bar to the right, next to the status area.
|
||||
|
||||
![][9]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-simple-and-useful-gnome-shell-extensions/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/01/removable-disk-1024x459.jpg
|
||||
[2]: https://extensions.gnome.org/extension/7/removable-drive-menu/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/01/removable-software-1024x723.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/extensions-extension-1024x459.jpg
|
||||
[5]: https://extensions.gnome.org/extension/1036/extensions/
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/01/extensions-software-1024x723.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/01/move_clock-1024x189.jpg
|
||||
[8]: https://extensions.gnome.org/extension/2/move-clock/
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-28-21-53-18-1024x723.png
|
||||
146
sources/tech/20190128 Top Hex Editors for Linux.md
Normal file
146
sources/tech/20190128 Top Hex Editors for Linux.md
Normal file
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top Hex Editors for Linux)
|
||||
[#]: via: (https://itsfoss.com/hex-editors-linux)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Top Hex Editors for Linux
|
||||
======
|
||||
|
||||
Hex editor lets you view/edit the binary data of a file – which is in the form of “hexadecimal” values and hence the name “Hex” editor. Let’s be frank, not everyone needs it. Only a specific group of users who have to deal with the binary data use it.
|
||||
|
||||
If you have no idea, what it is, let me give you an example. Suppose, you have the configuration files of a game, you can open them using a hex editor and change certain values to have more ammo/score and so on. To know more about Hex editors, you should start with the [Wikipedia page][1].
|
||||
|
||||
In case you already know what’s it used for – let us take a look at the best Hex editors available for Linux.
|
||||
|
||||
### 5 Best Hex Editors Available
|
||||
|
||||
![Best Hex Editors for Linux][2]
|
||||
|
||||
**Note:** The hex editors mentioned are in no particular order of ranking.
|
||||
|
||||
#### 1\. Bless Hex Editor
|
||||
|
||||
![bless hex editor][3]
|
||||
|
||||
**Key Features** :
|
||||
|
||||
* Raw disk editing
|
||||
* Multilevel undo/redo operations.
|
||||
* Multiple tabs
|
||||
* Conversion table
|
||||
* Plugin support to extend the functionality
|
||||
|
||||
|
||||
|
||||
Bless is one of the most popular Hex editor available for Linux. You can find it listed in your AppCenter or Software Center. If that is not the case, you can check out their [GitHub page][4] for the build and the instructions associated.
|
||||
|
||||
It can easily handle editing big files without slowing down – so it’s a fast hex editor.
|
||||
|
||||
#### 2\. GNOME Hex Editor
|
||||
|
||||
![gnome hex editor][5]
|
||||
|
||||
**Key Features:**
|
||||
|
||||
* View/Edit in either Hex/Ascii
|
||||
|
||||
* Edit large files
|
||||
|
||||
*
|
||||
|
||||
|
||||
Yet another amazing Hex editor – specifically tailored for GNOME. Well, I personally use Elementary OS, so I find it listed in the App Center. You should find it in the Software Center as well. If not, refer to the [GitHub page][6] for the source.
|
||||
|
||||
You can use this editor to view/edit in either hex or ASCII. The user interface is quite simple – as you can see in the image above.
|
||||
|
||||
#### 3\. Okteta
|
||||
|
||||
![okteta][7]
|
||||
|
||||
**Key Features:**
|
||||
|
||||
* Customizable data views
|
||||
* Multiple tabs
|
||||
* Character encodings: All 8-bit encodings as supplied by Qt, EBCDIC
|
||||
* Decoding table listing common simple data types.
|
||||
|
||||
|
||||
|
||||
Okteta is a simple hex editor with not so fancy features. Although it can handle most of the tasks. There’s a separate module of it which you can use to embed this in other programs to view/edit files.
|
||||
|
||||
Similar to all the above-mentioned editors, you can find this listed on your AppCenter and Software center as well.
|
||||
|
||||
#### 4\. wxHexEditor
|
||||
|
||||
![wxhexeditor][8]
|
||||
|
||||
**Key Features:**
|
||||
|
||||
* Easily handle big files
|
||||
* Has x86 disassembly support
|
||||
* **** Sector Indication **** on Disk devices
|
||||
* Supports customizable hex panel formatting and colors.
|
||||
|
||||
|
||||
|
||||
This is something interesting. It is primarily a Hex editor but you can also use it as a low level disk editor. For example, if you have a problem with your HDD, you can use this editor to edit the the sectors in raw hex and fix it.
|
||||
|
||||
You can find it listed on your App Center and Software Center. If not, [Sourceforge][9] is the way to go.
|
||||
|
||||
#### 5\. Hexedit (Command Line)
|
||||
|
||||
![hexedit][10]
|
||||
|
||||
**Key Features** :
|
||||
|
||||
* Works via terminal
|
||||
* It’s fast and simple
|
||||
|
||||
|
||||
|
||||
If you want something to work on your terminal, you can go ahead and install Hexedit via the console. It’s my favorite Linux hex editor in command line.
|
||||
|
||||
When you launch it, you will have to specify the location of the file, and it’ll then open it for you.
|
||||
|
||||
To install it, just type in:
|
||||
|
||||
```
|
||||
sudo apt install hexedit
|
||||
```
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Hex editors could come in handy to experiment and learn. If you are someone experienced, you should opt for the one with more feature – with a GUI. Although, it all comes down to personal preferences.
|
||||
|
||||
What do you think about the usefulness of Hex editors? Which one do you use? Did we miss listing your favorite? Let us know in the comments!
|
||||
|
||||
![][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/hex-editors-linux
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Hex_editor
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors-800x450.jpeg?resize=800%2C450&ssl=1
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/bless-hex-editor.jpg?ssl=1
|
||||
[4]: https://github.com/bwrsandman/Bless
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/ghex-hex-editor.jpg?ssl=1
|
||||
[6]: https://github.com/GNOME/ghex
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/okteta-hex-editor-800x466.jpg?resize=800%2C466&ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/wxhexeditor.jpg?ssl=1
|
||||
[9]: https://sourceforge.net/projects/wxhexeditor/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/hexedit-console.jpg?resize=800%2C566&ssl=1
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,524 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (fdisk – Easy Way To Manage Disk Partitions In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
fdisk – Easy Way To Manage Disk Partitions In Linux
|
||||
======
|
||||
|
||||
Hard disks can be divided into one or more logical disks called partitions.
|
||||
|
||||
This division is described in the partition table (MBR or GPT) found in sector 0 of the disk.
|
||||
|
||||
Linux needs at least one partition, namely for its root file system and we can’t install Linux OS without partitions.
|
||||
|
||||
Once created, a partition must be formatted with an appropriate file system before files can be written to it.
|
||||
|
||||
To do so, we need some utility to perform this in Linux.
|
||||
|
||||
There are many utilities are available for that in Linux. We had written about **[Parted Command][1]** in the past and today we are going to discuss about fdisk.
|
||||
|
||||
fdisk command is one of the the best tool to manage disk partitions in Linux.
|
||||
|
||||
It supports maximum `2 TB`, and everyone prefer to go with fdisk.
|
||||
|
||||
This tool is used by vast of Linux admin because we don’t use more than 2TB now a days due to LVM and SAN. It’s used in most of the infra structure around the world.
|
||||
|
||||
Still if you want to create a large partitions, like more than 2TB then you have to go either **Parted Command** or **cfdisk Command**.
|
||||
|
||||
Disk partition and file system creations is one of the routine task for Linux admin.
|
||||
|
||||
If you are working on vast environment then you have to perform this task multiple times in a day.
|
||||
|
||||
### How Linux Kernel Understand Hard Disks?
|
||||
|
||||
As a human we can easily understand things but computer needs the proper naming conversion to understand each and everything.
|
||||
|
||||
In Linux, devices are located on `/dev` partition and Kernel understand the hard disk in the following format.
|
||||
|
||||
* **`/dev/hdX[a-z]:`** IDE Disk is named hdX in Linux
|
||||
* **`/dev/sdX[a-z]:`** SCSI Disk is named sdX in Linux
|
||||
* **`/dev/xdX[a-z]:`** XT Disk is named sdX in Linux
|
||||
* **`/dev/vdX[a-z]:`** Virtual Hard Disk is named vdX in Linux
|
||||
* **`/dev/fdN:`** Floppy Drive is named fdN in Linux
|
||||
* **`/dev/scdN or /dev/srN:`** CD-ROM is named /dev/scdN or /dev/srN in Linux
|
||||
|
||||
|
||||
|
||||
### What Is fdisk Command?
|
||||
|
||||
fdisk stands for fixed disk or format disk is a cli utility that allow users to perform following actions on disks. It allows us to view, create, resize, delete, move and copy the partitions.
|
||||
|
||||
It understands MBR, Sun, SGI and BSD partition tables and it doesn’t understand GUID Partition Table (GPT) and it is not designed for large partitions.
|
||||
|
||||
fdisk allows us to create a maximum of four primary partitions per disk. One of these may be an extended partition and it holds multiple logical partitions.
|
||||
|
||||
1-4 is reserved for four primary partitions and Logical partitions start numbering from 5.
|
||||
![][3]
|
||||
|
||||
### How To Install fdisk On Linux
|
||||
|
||||
You don’t need to install fdisk in Linux system because it has installed by default as part of core utility.
|
||||
|
||||
### How To List Available Disks Using fdisk Command
|
||||
|
||||
First we have to know what are the disks were added in the system before performing any action. To list all available disks on your system run the following command.
|
||||
|
||||
It lists possible information about the disks such as disk name, how many partitions are created in it, Disk Size, Disklabel type, Disk Identifier, Partition ID and Partition Type.
|
||||
|
||||
```
|
||||
$ sudo fdisk -l
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
```
|
||||
|
||||
### How To List A Specific Disk Partitions Using fdisk Command
|
||||
|
||||
If you would like to see a specific disk and it’s partitions, use the following format.
|
||||
|
||||
```
|
||||
$ sudo fdisk -l /dev/sda
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
|
||||
```
|
||||
|
||||
### How To List Available Actions For fdisk Command
|
||||
|
||||
When you hit `m` in the fdisk command that will show you available actions for fdisk command.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Device does not contain a recognized partition table.
|
||||
Created a new DOS disklabel with disk identifier 0xe944b373.
|
||||
|
||||
Command (m for help): m
|
||||
|
||||
Help:
|
||||
|
||||
DOS (MBR)
|
||||
a toggle a bootable flag
|
||||
b edit nested BSD disklabel
|
||||
c toggle the dos compatibility flag
|
||||
|
||||
Generic
|
||||
d delete a partition
|
||||
F list free unpartitioned space
|
||||
l list known partition types
|
||||
n add a new partition
|
||||
p print the partition table
|
||||
t change a partition type
|
||||
v verify the partition table
|
||||
i print information about a partition
|
||||
|
||||
Misc
|
||||
m print this menu
|
||||
u change display/entry units
|
||||
x extra functionality (experts only)
|
||||
|
||||
Script
|
||||
I load disk layout from sfdisk script file
|
||||
O dump disk layout to sfdisk script file
|
||||
|
||||
Save & Exit
|
||||
w write table to disk and exit
|
||||
q quit without saving changes
|
||||
|
||||
Create a new label
|
||||
g create a new empty GPT partition table
|
||||
G create a new empty SGI (IRIX) partition table
|
||||
o create a new empty DOS partition table
|
||||
s create a new empty Sun partition table
|
||||
```
|
||||
|
||||
### How To List Partitions Types Using fdisk Command
|
||||
|
||||
When you hit `l` in the fdisk command that will show you an available partitions type for fdisk command.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Device does not contain a recognized partition table.
|
||||
Created a new DOS disklabel with disk identifier 0x9ffd00db.
|
||||
|
||||
Command (m for help): l
|
||||
|
||||
0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
|
||||
1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT-
|
||||
2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT-
|
||||
3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT-
|
||||
4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx
|
||||
5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data
|
||||
6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / .
|
||||
7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility
|
||||
8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt
|
||||
9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access
|
||||
a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O
|
||||
b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor
|
||||
c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment
|
||||
e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs
|
||||
f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT
|
||||
10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/
|
||||
11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b
|
||||
12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor
|
||||
14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor
|
||||
16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary
|
||||
17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS
|
||||
18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE
|
||||
1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto
|
||||
1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep
|
||||
1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT
|
||||
```
|
||||
|
||||
### How To Create A Disk Partition Using fdisk Command
|
||||
|
||||
If you would like to create a new partition use the following steps. In my case, i'm going to create 4 partitions (3 Primary and 1 Extended) on `/dev/sdc` disk. To the same for other partitions too.
|
||||
|
||||
As this takes value from partition table so, hit `Enter` for first sector. Enter the size which you want to set for the partition (We can add a partition size using KB,MB,G and TB) for last sector.
|
||||
|
||||
For example, if you would like to add 1GB partition then the last sector value should be `+1G`. Once you have created 3 partitions, it will automatically change the partition type to extended as a default. If you still want to create a fourth primary partitions then hit `p` instead of default value `e`.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
Partition type
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default p): Enter
|
||||
|
||||
Using default response p.
|
||||
Partition number (1-4, default 1): Enter
|
||||
First sector (2048-20971519, default 2048): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-20971519, default 20971519): +1G
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 1 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To Create A Extended Disk Partition Using fdisk Command
|
||||
|
||||
Make a note, you have to use remaining all space when you create a extended partition because again you can able to create multiple logical partition in that.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
Partition type
|
||||
p primary (3 primary, 0 extended, 1 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default e): Enter
|
||||
|
||||
Using default response e.
|
||||
Selected partition 4
|
||||
First sector (6293504-20971519, default 6293504): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (6293504-20971519, default 20971519): Enter
|
||||
|
||||
Created a new partition 4 of type 'Extended' and of size 7 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To View Unpartitioned Disk Space Using fdisk Command
|
||||
|
||||
As described in the above section, we have totally created 4 partitions (3 Primary and 1 Extended). Extended partition disk space will show unpartitioned until you create a logical partitions in that.
|
||||
|
||||
Use the following command to view the unpartitioned space for a disk. As per the below output we have `7GB` unpartitioned disk.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): F
|
||||
Unpartitioned space /dev/sdc: 7 GiB, 7515144192 bytes, 14678016 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
Start End Sectors Size
|
||||
6293504 20971519 14678016 7G
|
||||
|
||||
Command (m for help): q
|
||||
```
|
||||
|
||||
### How To Create A Logical Partition Using fdisk Command
|
||||
|
||||
Follow the same above procedure to create a logical partition once you have created the extended partition.
|
||||
Here, i have created `1GB` of logical partition called `/dev/sdc5`, you can double confirm this by checking the partition table value.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Command (m for help): n
|
||||
All primary partitions are in use.
|
||||
Adding logical partition 5
|
||||
First sector (6295552-20971519, default 6295552): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (6295552-20971519, default 20971519): +1G
|
||||
|
||||
Created a new partition 5 of type 'Linux' and of size 1 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To Delete A Partition Using fdisk Command
|
||||
|
||||
If the partition is no more used in the system than we can remove it by using the below steps.
|
||||
|
||||
Make sure you have to enter the correct partition number to delete it. In this case, i'm going to remove `/dev/sdc2` partition.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): d
|
||||
Partition number (1-5, default 5): 2
|
||||
|
||||
Partition 2 has been deleted.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To Format A Partition Or Create A FileSystem On The Partition
|
||||
|
||||
In computing, a file system or filesystem controls how data is stored and retrieved through inode tables.
|
||||
|
||||
Without a file system, the system can't find where the information is stored on the partition. Filesystem can be created in three ways. Here, i'm going to create a filesystem on `/dev/sdc1` partition.
|
||||
|
||||
```
|
||||
$ sudo mkfs.ext4 /dev/sdc1
|
||||
or
|
||||
$ sudo mkfs -t ext4 /dev/sdc1
|
||||
or
|
||||
$ sudo mke2fs /dev/sdc1
|
||||
|
||||
mke2fs 1.43.5 (04-Aug-2017)
|
||||
Creating filesystem with 262144 4k blocks and 65536 inodes
|
||||
Filesystem UUID: c0a99b51-2b61-4f6a-b960-eb60915faab0
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (8192 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
When you creating a filesystem on tha partition that will create the following important things on it.
|
||||
|
||||
* **`Filesystem UUID:`** UUID stands for Universally Unique Identifier, UUIDs are used to identify block devices in Linux. It's 128 bit long numbers represented by 32 hexadecimal digits.
|
||||
* **`Superblock:`** Superblock stores metadata of the file system. If the superblock of a file system is corrupted, then the filesystem cannot be mounted and thus files cannot be accessed.
|
||||
* **`Inode:`** An inode is a data structure on a filesystem on a Unix-like operating system that stores all the information about a file except its name and its actual data.
|
||||
* **`Journal:`** A journaling filesystem is a filesystem that maintains a special file called a journal that is used to repair any inconsistencies that occur as the result of an improper shutdown of a computer.
|
||||
|
||||
|
||||
|
||||
### How To Mount A Partition In Linux
|
||||
|
||||
Once you have created the partition and filesystem then we need to mount the partition to use.
|
||||
|
||||
To do so, we need to create a mountpoint to mount the partition. Use mkdir command to create a mountpoint.
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /mnt/2g-new
|
||||
```
|
||||
|
||||
For temporary mount, use the following command. You will be lose this mountpoint after rebooting your system.
|
||||
|
||||
```
|
||||
$ sudo mount /dev/sdc1 /mnt/2g-new
|
||||
```
|
||||
|
||||
For permanent mount, add the partition details in the fstab file. It can be done in two ways either adding device name or UUID value.
|
||||
|
||||
Permanent mount using Device Name:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
|
||||
/dev/sdc1 /mnt/2g-new ext4 defaults 0 0
|
||||
```
|
||||
|
||||
Permanent mount using UUID Value. To get a UUID of the partition use blkid command.
|
||||
|
||||
```
|
||||
$ sudo blkid
|
||||
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
|
||||
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
|
||||
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
|
||||
/dev/sdc5: PARTUUID="8cc8f9e5-05"
|
||||
|
||||
# vi /etc/fstab
|
||||
|
||||
UUID=d17e3c31-e2c9-4f11-809c-94a549bc43b7 /mnt/2g-new ext4 defaults 0 0
|
||||
```
|
||||
|
||||
The same has been verified using df Command.
|
||||
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 969M 0 969M 0% /dev
|
||||
tmpfs 200M 7.0M 193M 4% /run
|
||||
/dev/sda1 20G 16G 3.0G 85% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 28K 200M 1% /run/user/121
|
||||
tmpfs 200M 25M 176M 13% /run/user/1000
|
||||
/dev/sdc1 1008M 1.3M 956M 1% /mnt/2g-new
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2019/01/linux-fdisk-command-to-manage-disk-partitions-1a.png
|
||||
@ -0,0 +1,159 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 Methods To Identify Disk Partition/FileSystem UUID On Linux)
|
||||
[#]: via: (https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
7 Methods To Identify Disk Partition/FileSystem UUID On Linux
|
||||
======
|
||||
|
||||
As a Linux administrator you should aware of that how do you check partition UUID or filesystem UUID.
|
||||
|
||||
Because most of the Linux systems are mount the partitions with UUID. The same has been verified in the `/etc/fstab` file.
|
||||
|
||||
There are many utilities are available to check UUID. In this article we will show you how to check UUID in many ways and you can choose the one which is suitable for you.
|
||||
|
||||
### What Is UUID?
|
||||
|
||||
UUID stands for Universally Unique Identifier which helps Linux system to identify a hard drives partition instead of block device file.
|
||||
|
||||
libuuid is part of the util-linux-ng package since kernel version 2.15.1 and it’s installed by default in Linux system.
|
||||
|
||||
The UUIDs generated by this library can be reasonably expected to be unique within a system, and unique across all systems.
|
||||
|
||||
It’s a 128 bit number used to identify information in computer systems. UUIDs were originally used in the Apollo Network Computing System (NCS) and later UUIDs are standardized by the Open Software Foundation (OSF) as part of the Distributed Computing Environment (DCE).
|
||||
|
||||
UUIDs are represented as 32 hexadecimal (base 16) digits, displayed in five groups separated by hyphens, in the form 8-4-4-4-12 for a total of 36 characters (32 alphanumeric characters and four hyphens).
|
||||
|
||||
For example: d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
|
||||
Sample of my /etc/fstab file.
|
||||
|
||||
```
|
||||
# cat /etc/fstab
|
||||
|
||||
# /etc/fstab: static file system information.
|
||||
#
|
||||
# Use 'blkid' to print the universally unique identifier for a device; this may
|
||||
# be used with UUID= as a more robust way to name devices that works even if
|
||||
# disks are added and removed. See fstab(5).
|
||||
#
|
||||
#
|
||||
UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f / ext4 defaults,noatime 0 1
|
||||
UUID=a2092b92-af29-4760-8e68-7a201922573b swap swap defaults,noatime 0 2
|
||||
```
|
||||
|
||||
We can check this using the following seven commands.
|
||||
|
||||
* **`blkid Command:`** locate/print block device attributes.
|
||||
* **`lsblk Command:`** lsblk lists information about all available or the specified block devices.
|
||||
* **`hwinfo Command:`** hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system.
|
||||
* **`udevadm Command:`** udev management tool.
|
||||
* **`tune2fs Command:`** adjust tunable filesystem parameters on ext2/ext3/ext4 filesystems.
|
||||
* **`dumpe2fs Command:`** dump ext2/ext3/ext4 filesystem information.
|
||||
* **`Using by-uuid Path:`** The directory contains UUID and real block device files, UUIDs were symlink with real block device files.
|
||||
|
||||
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing blkid Command?
|
||||
|
||||
blkid is a command-line utility to locate/print block device attributes. It uses libblkid library to get disk partition UUID in Linux system.
|
||||
|
||||
```
|
||||
# blkid
|
||||
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
|
||||
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
|
||||
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
|
||||
/dev/sdc5: PARTUUID="8cc8f9e5-05"
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing lsblk Command?
|
||||
|
||||
lsblk lists information about all available or the specified block devices. The lsblk command reads the sysfs filesystem and udev db to gather information.
|
||||
|
||||
If the udev db is not available or lsblk is compiled without udev support than it tries to read LABELs, UUIDs and filesystem types from the block device. In this case root permissions are necessary. The command prints all block devices (except RAM disks) in a tree-like format by default.
|
||||
|
||||
```
|
||||
# lsblk -o name,mountpoint,size,uuid
|
||||
NAME MOUNTPOINT SIZE UUID
|
||||
sda 30G
|
||||
└─sda1 / 20G d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
sdb 10G
|
||||
sdc 10G
|
||||
├─sdc1 1G d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
├─sdc3 1G ca307aa4-0866-49b1-8184-004025789e63
|
||||
├─sdc4 1K
|
||||
└─sdc5 1G
|
||||
sdd 10G
|
||||
sde 10G
|
||||
sr0 1024M
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing by-uuid path?
|
||||
|
||||
The directory contains UUID and real block device files, UUIDs were symlink with real block device files.
|
||||
|
||||
```
|
||||
# ls -lh /dev/disk/by-uuid/
|
||||
total 0
|
||||
lrwxrwxrwx 1 root root 10 Jan 29 08:34 ca307aa4-0866-49b1-8184-004025789e63 -> ../../sdc3
|
||||
lrwxrwxrwx 1 root root 10 Jan 29 08:34 d17e3c31-e2c9-4f11-809c-94a549bc43b7 -> ../../sdc1
|
||||
lrwxrwxrwx 1 root root 10 Jan 29 08:34 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> ../../sda1
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing hwinfo Command?
|
||||
|
||||
**[hwinfo][1]** stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
|
||||
|
||||
```
|
||||
# hwinfo --block | grep by-uuid | awk '{print $3,$7}'
|
||||
/dev/sdc1, /dev/disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
/dev/sdc3, /dev/disk/by-uuid/ca307aa4-0866-49b1-8184-004025789e63
|
||||
/dev/sda1, /dev/disk/by-uuid/d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing udevadm Command?
|
||||
|
||||
udevadm expects a command and command specific options. It controls the runtime behavior of systemd-udevd, requests kernel events, manages the event queue, and provides simple debugging mechanisms.
|
||||
|
||||
```
|
||||
udevadm info -q all -n /dev/sdc1 | grep -i by-uuid | head -1
|
||||
S: disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing tune2fs Command?
|
||||
|
||||
tune2fs allows the system administrator to adjust various tunable filesystem parameters on Linux ext2, ext3, or ext4 filesystems. The current values of these options can be displayed by using the -l option.
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/sdc1 | grep UUID
|
||||
Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
### How To Check Disk Partition/FileSystem UUID In Linux Uusing dumpe2fs Command?
|
||||
|
||||
dumpe2fs prints the super block and blocks group information for the filesystem present on device.
|
||||
|
||||
```
|
||||
# dumpe2fs /dev/sdc1 | grep UUID
|
||||
dumpe2fs 1.43.5 (04-Aug-2017)
|
||||
Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
@ -0,0 +1,309 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Configure System-wide Proxy Settings Easily And Quickly)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-configure-system-wide-proxy-settings-easily-and-quickly/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Configure System-wide Proxy Settings Easily And Quickly
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, we will be discussing a simple, yet useful command line utility named **“ProxyMan”**. As the name says, it helps you to apply and manage proxy settings on our system easily and quickly. Using ProxyMan, we can set or unset proxy settings automatically at multiple points, without having to configure them manually one by one. It also allows you to save the settings for later use. In a nutshell, ProxyMan simplifies the task of configuring system-wide proxy settings with a single command. It is free, open source utility written in **Bash** and standard POSIX tools, no dependency required. ProxyMan can be helpful if you’re behind a proxy server and you want to apply the proxy settings system-wide in one go.
|
||||
|
||||
### Installing ProxyMan
|
||||
|
||||
Download the latest ProxyMan version from the [**releases page**][1]. It is available as zip and tar file. I am going to download zip file.
|
||||
|
||||
```
|
||||
$ wget https://github.com/himanshub16/ProxyMan/archive/v3.1.1.zip
|
||||
```
|
||||
|
||||
Extract the downloaded zip file:
|
||||
|
||||
```
|
||||
$ unzip v3.1.1.zip
|
||||
```
|
||||
|
||||
The above command will extract the contents in a folder named “ **ProxyMan-3.1.1** ” in your current working directory. Cd to that folder and install ProxyMan as shown below:
|
||||
|
||||
```
|
||||
$ cd ProxyMan-3.1.1/
|
||||
|
||||
$ ./install
|
||||
```
|
||||
|
||||
If you see **“Installed successfully”** message as output, congratulations! ProxyMan has been installed.
|
||||
|
||||
Let us go ahead and see how to configure proxy settings.
|
||||
|
||||
### Configure System-wide Proxy Settings
|
||||
|
||||
ProxyMan usage is pretty simple and straight forward. Like I already said, It allows us to set/unset proxy settings, list current proxy settings, list available configs, save settings in a profile and load profile later. Proxyman currently manages proxy settings for **GNOME gsettings** , **bash** , **apt** , **dnf** , **git** , **npm** and **Dropbox**.
|
||||
|
||||
**Set proxy settings**
|
||||
|
||||
To set proxy settings system-wide, simply run:
|
||||
|
||||
```
|
||||
$ proxyman set
|
||||
```
|
||||
|
||||
You will asked to answer a series of simple questions such as,
|
||||
|
||||
1. HTTP Proxy host IP address,
|
||||
2. HTTP port,
|
||||
3. Use username/password authentication,
|
||||
4. Use same settings for HTTPS and FTP,
|
||||
5. Save profile for later use,
|
||||
6. Finally, choose the list of targets to apply the proxy settings. You can choose all at once or separate multiple choices with space.
|
||||
|
||||
|
||||
|
||||
Sample output for the above command:
|
||||
|
||||
```
|
||||
Enter details to set proxy
|
||||
HTTP Proxy Host 192.168.225.22
|
||||
HTTP Proxy Port 8080
|
||||
Use auth - userid/password (y/n)? n
|
||||
Use same for HTTPS and FTP (y/n)? y
|
||||
No Proxy (default localhost,127.0.0.1,192.168.1.1,::1,*.local)
|
||||
Save profile for later use (y/n)? y
|
||||
Enter profile name : proxy1
|
||||
Saved to /home/sk/.config/proxyman/proxy1.
|
||||
|
||||
Select targets to modify
|
||||
| 1 | All of them ... Don't bother me
|
||||
| 2 | Terminal / bash / zsh (current user)
|
||||
| 3 | /etc/environment
|
||||
| 4 | apt/dnf (Package manager)
|
||||
| 5 | Desktop settings (GNOME/Ubuntu)
|
||||
| 6 | npm & yarn
|
||||
| 7 | Dropbox
|
||||
| 8 | Git
|
||||
| 9 | Docker
|
||||
|
||||
Separate multiple choices with space
|
||||
? 1
|
||||
Setting proxy...
|
||||
To activate in current terminal window
|
||||
run source ~/.bashrc
|
||||
[sudo] password for sk:
|
||||
Done
|
||||
```
|
||||
|
||||
**List proxy settings**
|
||||
|
||||
To view the current proxy settings, run:
|
||||
|
||||
```
|
||||
$ proxyman list
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Hmm... listing it all
|
||||
|
||||
Shell proxy settings : /home/sk/.bashrc
|
||||
export http_proxy="http://192.168.225.22:8080/"
|
||||
export ftp_proxy="ftp://192.168.225.22:8080/"
|
||||
export rsync_proxy="rsync://192.168.225.22:8080/"
|
||||
export no_proxy="localhost,127.0.0.1,192.168.1.1,::1,*.local"
|
||||
export HTTP_PROXY="http://192.168.225.22:8080/"
|
||||
export FTP_PROXY="ftp://192.168.225.22:8080/"
|
||||
export RSYNC_PROXY="rsync://192.168.225.22:8080/"
|
||||
export NO_PROXY="localhost,127.0.0.1,192.168.1.1,::1,*.local"
|
||||
export https_proxy="/"
|
||||
export HTTPS_PROXY="/"
|
||||
|
||||
git proxy settings :
|
||||
http http://192.168.225.22:8080/
|
||||
https https://192.168.225.22:8080/
|
||||
|
||||
APT proxy settings :
|
||||
3
|
||||
Done
|
||||
```
|
||||
|
||||
**Unset proxy settings**
|
||||
|
||||
To unset proxy settings, the command would be:
|
||||
|
||||
```
|
||||
$ proxyman unset
|
||||
```
|
||||
|
||||
You can unset proxy settings for all targets at once by entering number **1** or enter any given number to unset proxy settings for the respective target.
|
||||
|
||||
```
|
||||
Select targets to modify
|
||||
| 1 | All of them ... Don't bother me
|
||||
| 2 | Terminal / bash / zsh (current user)
|
||||
| 3 | /etc/environment
|
||||
| 4 | apt/dnf (Package manager)
|
||||
| 5 | Desktop settings (GNOME/Ubuntu)
|
||||
| 6 | npm & yarn
|
||||
| 7 | Dropbox
|
||||
| 8 | Git
|
||||
| 9 | Docker
|
||||
|
||||
Separate multiple choices with space
|
||||
? 1
|
||||
Unset all proxy settings
|
||||
To activate in current terminal window
|
||||
run source ~/.bashrc
|
||||
Done
|
||||
```
|
||||
|
||||
To apply the changes, simply run:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
On ZSH, use this command instead:
|
||||
|
||||
```
|
||||
$ source ~/.zshrc
|
||||
```
|
||||
|
||||
To verify if the proxy settings have been removed, simply run “proxyman list” command:
|
||||
|
||||
```
|
||||
$ proxyman list
|
||||
Hmm... listing it all
|
||||
|
||||
Shell proxy settings : /home/sk/.bashrc
|
||||
None
|
||||
|
||||
git proxy settings :
|
||||
http
|
||||
https
|
||||
|
||||
APT proxy settings :
|
||||
None
|
||||
Done
|
||||
```
|
||||
|
||||
As you can see, there is no proxy settings for all targets.
|
||||
|
||||
**View list of configs (profiles)**
|
||||
|
||||
Remember we saved proxy settings as a profile in the “Set proxy settings” section? You can view the list of available profiles with command:
|
||||
|
||||
```
|
||||
$ proxyman configs
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Here are available configs!
|
||||
proxy1
|
||||
Done
|
||||
```
|
||||
|
||||
As you can see, we have only one profile i.e **proxy1**.
|
||||
|
||||
**Load profiles**
|
||||
|
||||
The profiles will be available until you delete them permanently, so you can load a profile (E.g proxy1) at any time using command:
|
||||
|
||||
```
|
||||
$ proxyman load proxy1
|
||||
```
|
||||
|
||||
This command will list the proxy settings for proxy1 profile. You can apply these settings to all or multiple targets by entering the respective number with space-separated.
|
||||
|
||||
```
|
||||
Loading profile : proxy1
|
||||
HTTP > 192.168.225.22 8080
|
||||
HTTPS > 192.168.225.22 8080
|
||||
FTP > 192.168.225.22 8080
|
||||
no_proxy > localhost,127.0.0.1,192.168.1.1,::1,*.local
|
||||
Use auth > n
|
||||
Use same > y
|
||||
Config >
|
||||
Targets >
|
||||
Select targets to modify
|
||||
| 1 | All of them ... Don't bother me
|
||||
| 2 | Terminal / bash / zsh (current user)
|
||||
| 3 | /etc/environment
|
||||
| 4 | apt/dnf (Package manager)
|
||||
| 5 | Desktop settings (GNOME/Ubuntu)
|
||||
| 6 | npm & yarn
|
||||
| 7 | Dropbox
|
||||
| 8 | Git
|
||||
| 9 | Docker
|
||||
|
||||
Separate multiple choices with space
|
||||
? 1
|
||||
Setting proxy...
|
||||
To activate in current terminal window
|
||||
run source ~/.bashrc
|
||||
Done
|
||||
```
|
||||
|
||||
Finally, activate the changes using command:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
For ZSH:
|
||||
|
||||
```
|
||||
$ source ~/.zshrc
|
||||
```
|
||||
|
||||
**Deleting profiles**
|
||||
|
||||
To delete a profile, run:
|
||||
|
||||
```
|
||||
$ proxyman delete proxy1
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```
|
||||
Deleting profile : proxy1
|
||||
Done
|
||||
```
|
||||
|
||||
To display help, run:
|
||||
|
||||
```
|
||||
$ proxyman help
|
||||
```
|
||||
|
||||
|
||||
### Conclusion
|
||||
|
||||
Before I came to know about Proxyman, I used to apply proxy settings manually at multiple places, for example package manager, web browser etc. Not anymore! ProxyMan did this job automatically in couple seconds.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-configure-system-wide-proxy-settings-easily-and-quickly/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/himanshub16/ProxyMan/releases/
|
||||
@ -7,18 +7,18 @@
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-cal)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Plan your own holiday calendar at the Linux command line
|
||||
在 Linux 命令行中规划你的假期日历
|
||||
======
|
||||
Link commands together to build a colorful calendar, and then whisk it away in a snowstorm.
|
||||
将命令链接在一起,构建一个彩色日历,然后在暴风雪中将其拂去。
|
||||

|
||||
|
||||
Welcome to today's installment of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself, what’s a command-line toy. Even I'm not quite sure, but generally, it could be a game or any simple diversion that helps you have fun at the terminal.
|
||||
欢迎阅读今天推出的 Linux 命令行玩具降临日历。如果这是你第一次访问本系列,你可能会问:什么是命令行玩具。即使我不太确定,但一般来说,它可以是一个游戏或任何简单的娱乐,可以帮助你在终端玩得开心。
|
||||
|
||||
It's quite possible that some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
很可能你们中的一些人之前已经看过我们日历上的各种选择,但我们希望给每个人至少一件新东西。
|
||||
|
||||
We've somehow made it to the seventh day of our series without creating an actual calendar to celebrate with, so let's use a command-line tool to do that today: **cal**. By itself, **cal** is perhaps not the most amazing of tools, but we can use a few other utilities to spice it up a bit.
|
||||
我们在没有创建实际日历的情况下完成了本系列的第 7 天,所以今天让我们使用命令行工具来做到这一点:**cal**。就其本身而言,**cal** 可能不是最令人惊奇的工具,但我们可以使用其它一些实用程序来为它增添一些趣味。
|
||||
|
||||
Chances are, **cal** is installed on your system already. To use it in this instance, just type **cal**.
|
||||
很可能,你的系统上已经安装了 **cal**。要使用它,只需要输入 **cal** 即可。
|
||||
|
||||
```
|
||||
$ cal
|
||||
@ -32,9 +32,10 @@ Su Mo Tu We Th Fr Sa
|
||||
30 31
|
||||
```
|
||||
|
||||
We aren't going to go into advanced usage in this article, so if you want to learn more about **cal** , go check out Opensource.com Community Moderator Don Watkin's excellent [overview of the date and cal commands][1].
|
||||
我们不打算在本文中深入介绍高级用法,因此如果你想了解有关 **cal** 的更多信息,查看 Opensouce.com 社区版主 Don Watkin 的优秀文章 [date 和 cal 命令概述][1]。
|
||||
|
||||
现在,让我们用一个漂亮的盒子来为它增添趣味,就像我们在上一篇 Linux 玩具文章中介绍的那样。我将使用钻石块,用一点内边距来对齐。
|
||||
|
||||
Now, let's spice it up with a pretty box, as we covered in our previous Linux toy article. I'll use the diamonds box, and use a little bit of padding to get it nicely aligned.
|
||||
|
||||
```
|
||||
$ cal | boxes -d diamonds -p a1l4t2
|
||||
@ -60,7 +61,7 @@ $ cal | boxes -d diamonds -p a1l4t2
|
||||
\/ \/ \/
|
||||
```
|
||||
|
||||
That looks nice, but for good measure, let's put the whole thing in a second box, just for fun. We'll use the scoll design this time.
|
||||
看起来很不错,但是为了好的测量,让我们把整个东西放到另一个盒子里,为了好玩,这次我们将使用滚动设计。
|
||||
|
||||
```
|
||||
cal | boxes -d diamonds -p a1t2l3 | boxes -a c -d scroll
|
||||
@ -92,25 +93,25 @@ cal | boxes -d diamonds -p a1t2l3 | boxes -a c -d scroll
|
||||
~~~ ~~~
|
||||
```
|
||||
|
||||
Perfect. Now, here's where things get a little crazy. I like our design, but, I'd like to go all out. So I'm going to colorize it. But here in the Raleigh, NC office where Opensource.com's staff are based, there's a good chance for snow this weekend. So let's enjoy our colorized advent calendar, and then wipe it out with snow.
|
||||
完美。现在,事情变得有点疯狂了。我喜欢我们的设计,但我想全力以赴,所以我要给它上色。但是 Opensource.com 员工所在的北卡罗来版纳州罗利办公室,本周末很有可能下雪。所以,让我们享受彩色降临日历,然后用雪擦掉它。
|
||||
|
||||
For the snow, I'm grabbing a nifty [snippet][2] of Bash and Gawk goodness I found over on CLIMagic. If you're not familiar with CLIMagic, go check out their [website][3] and follow them on [Twitter][4]. You'll be glad you did.
|
||||
关于雪,我抓取了一些 Bash 和 Gawk 的漂亮[代码片段][2],幸亏我发现了 CLIMagic。如果你不熟悉 CLIMagic,去查看他们的[网站][3],在 [Twitter][4] 上关注他们。你会满意的。
|
||||
|
||||
So here we go. Let's clear the screen, throw up our boxy calendar, colorize it, wait a few seconds, then snowstorm it away. All here at the terminal, in one line.
|
||||
我们开始吧。让我们清除屏幕,扔掉四四方方的日历,给它上色,等几秒钟,然后用暴风雪把它吹走。这些在终端可以用一行命令完成。
|
||||
|
||||
```
|
||||
$ clear;cal|boxes -d diamonds -p a1t2l3|boxes -a c -d scroll|lolcat;sleep 3;while :;do echo $LINES $COLUMNS $(($RANDOM%$COLUMNS)) $(printf "\u2744\n");sleep 0.1;done|gawk '{a[$3]=0;for(x in a) {o=a[x];a[x]=a[x]+1;printf "\033[%s;%sH ",o,x;printf "\033[%s;%sH%s \033[0;0H",a[x],x,$4;}}'
|
||||
```
|
||||
|
||||
And there we go.
|
||||
大功告成。
|
||||
|
||||

|
||||
|
||||
For this to work on your system, you'll need all of the referenced utilities (boxes, lolcat, cal, gawk, etc.), and you'll need to use a terminal emulator that supports Unicode.
|
||||
要使它在你的系统上工作,你需要所有它引用的实用程序(box, lolcat, gawk 等),还需要使用支持 Unicode 的终端仿真器。
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。请在评论区留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
|
||||
|
||||
Check out yesterday's toy, [Take a break at the Linux command line with Nyan Cat][5], and check back tomorrow for another!
|
||||
看看昨天的玩具:[使用 Nyan Cat 在 Linux 命令行休息][5]。记得明天再来!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -118,7 +119,7 @@ via: https://opensource.com/article/18/12/linux-toy-cal
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,61 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with HomeBank, an open source personal finance app)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tools-homebank)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 HomeBank,一个开源个人财务应用
|
||||
======
|
||||
使用 HomeBank 跟踪你的资金流向,这是我们开源工具系列中的第八个工具,它将在 2019 年提高你的工作效率。
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
|
||||
|
||||
这是我挑选出的 19 个新的(或者对你而言新的)开源项目来帮助你在 2019 年更有效率。
|
||||
|
||||
### HomeBank
|
||||
|
||||
管理我的财务可能会很有压力。我不会每天查看我的银行余额,有时也很难跟踪我的钱流向哪里。我经常会花更多的时间来管理我的财务,挖掘账户和付款历史并找出我的钱去了哪里。了解我的财务状况可以帮助我保持冷静,并让我专注于其他事情。
|
||||
|
||||

|
||||
|
||||
[HomeBank][1] 是一款个人财务桌面应用,帮助你轻松跟踪你的财务状况,来帮助减少此类压力。它有很好的报告可以帮助你找出你花钱的地方,允许你设置导入交易的规则,并支持大多数现代格式。
|
||||
|
||||
HomeBank 默认可在大多数发行版上可用,因此安装它非常简单。当你第一次启动它时,它将引导你完成设置并让你创建一个帐户。之后,你可以导入任意一种支持的文件格式或开始输入交易。交易簿本身就是一个交易列表。 [与其他一些应用不同][2],你不必学习[复式簿记][3]来使用 HomeBank。
|
||||
|
||||

|
||||
|
||||
从银行导入文件将使用另一个分步向导进行处理,该向导提供了创建新帐户或填充现有帐户的选项。导入新帐户可节省一点时间,因为你无需在开始导入之前预先创建所有帐户。你还可以一次将多个文件导入帐户,因此不需要对每个帐户中的每个文件重复相同的步骤。
|
||||
|
||||

|
||||
|
||||
我在导入和管理帐户时遇到的一个痛点是指定类别。一般而言,类别可以让你分解你的支出,看看你花钱的方式。HomeBank 与一些商业服务(以及一些商业程序)不同,它要求你手动设置所有类别。但这通常是一次性的事情,它可以在添加/导入交易时自动添加类别。还有一个按钮来分析帐户并跳过已存在的内容,这样可以加快对大量导入的分类(就像我第一次做的那样)。HomeBank 提供了大量可用的类别,你也可以添加自己的类别。
|
||||
|
||||
HomeBank 还有预算功能,允许你计划未来几个月的开销。
|
||||
|
||||

|
||||
|
||||
对我来说,最棒的功能是 HomeBank 的报告。主页面上不仅有一个图表显示你花钱的地方,而且还有许多其他报告可供你查看。如果你使用预算功能,还会有一份报告会根据预算跟踪你的支出情况。你还可以以饼图和条形图的方式查看报告。它还有趋势报告和余额报告,因此你可以回顾并查看一段时间内的变化或模式。
|
||||
|
||||
总的来说,HomeBank 是一个非常友好,有用的程序,可以帮助你保持良好的财务。如果跟踪你的钱是你生活中的一件麻烦事,它使用起来很简单并且非常有用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tools-homebank
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://homebank.free.fr/en/index.php
|
||||
[2]: https://www.gnucash.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system
|
||||
151
translated/tech/20190124 Understanding Angle Brackets in Bash.md
Normal file
151
translated/tech/20190124 Understanding Angle Brackets in Bash.md
Normal file
@ -0,0 +1,151 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding Angle Brackets in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
理解 Bash 中的尖括号
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Bash][1] 内置了很多诸如 `ls`、`cd`、`mv` 这样的重要的命令,也有很多诸如 `grep`、`awk`、`sed` 这些有用的工具。但除此之外,其实 [Bash][1] 中还有很多可以[起到胶水作用][2]的标点符号,例如点号(`.`)、逗号(`,`)、括号(`<>`)、引号(`"`)之类。下面我们就来看一下可以用来进行数据转换和转移的尖括号()。
|
||||
|
||||
### 转移数据
|
||||
|
||||
如果你对其它编程语言有所了解,你会知道尖括号 `<` 和 `>` 一般是作为逻辑运算符,用来比较两个值之间的大小关系。如果你还编写 HTML,尖括号作为各种标签的一部分,就更不会让你感到陌生了。
|
||||
|
||||
在 shell 脚本语言中,尖括号可以将数据从一个地方转移到另一个地方。例如可以这样把数据存放到一个文件当中:
|
||||
|
||||
```
|
||||
ls > dir_content.txt
|
||||
```
|
||||
|
||||
在上面的例子中,`>` 符号让 shell 将 `ls` 命令的输出结果写入到 `dir_content.txt` 里,而不是直接显示在命令行中。需要注意的是,如果 `dir_content.txt` 这个文件不存在,Bash 会为你创建出来;但是如果 `dir_content.txt` 是一个已有得非空文件,它的内容就会被覆盖掉。所以执行类似的操作之前务必谨慎。
|
||||
|
||||
你也可以不使用 `>` 而使用 `>>`,这样就可以把新的数据追加到文件的末端而不会覆盖掉文件中已有的数据了。例如:
|
||||
|
||||
```
|
||||
ls $HOME > dir_content.txt; wc -l dir_content.txt >> dir_content.txt
|
||||
```
|
||||
|
||||
在这串命令里,首先将 home 目录的内容写入到 `dir_content.txt` 文件中,然后使用 `wc -l` 计算出 `dir_content.txt` 文件的行数(也就是 home 目录中的文件数)并追加到 `dir_content.txt` 的末尾。
|
||||
|
||||
在我的机器上执行上述命令之后,`dir_content.txt` 的内容会是以下这样:
|
||||
|
||||
```
|
||||
Applications
|
||||
bin
|
||||
cloud
|
||||
Desktop
|
||||
Documents
|
||||
Downloads
|
||||
Games
|
||||
ISOs
|
||||
lib
|
||||
logs
|
||||
Music
|
||||
OpenSCAD
|
||||
Pictures
|
||||
Public
|
||||
Templates
|
||||
test_dir
|
||||
Videos
|
||||
17 dir_content.txt
|
||||
```
|
||||
|
||||
你可以将 `>` 和 `>>` 作为箭头来理解。当然,这个箭头的指向也可以反过来。例如,Coen brothers 的一些演员以及他们出演电影的次数保存在 `CBActors` 文件中,就像这样:
|
||||
|
||||
```
|
||||
John Goodman 5
|
||||
John Turturro 3
|
||||
George Clooney 2
|
||||
Frances McDormand 6
|
||||
Steve Buscemi 5
|
||||
Jon Polito 4
|
||||
Tony Shalhoub 3
|
||||
James Gandolfini 1
|
||||
```
|
||||
|
||||
你可以执行这样的命令:
|
||||
|
||||
```
|
||||
sort < CBActors
|
||||
Frances McDormand 6 # 你会得到这样的输出
|
||||
George Clooney 2
|
||||
James Gandolfini 1
|
||||
John Goodman 5
|
||||
John Turturro 3
|
||||
Jon Polito 4
|
||||
Steve Buscemi 5
|
||||
Tony Shalhoub 3
|
||||
```
|
||||
|
||||
就可以使用 [`sort`][4] 命令将这个列表按照字母顺序输出。但是,`sort` 命令本来就可以接受传入一个文件,因此在这里使用 `<` 会略显多余,直接执行 `sort CBActors` 就可以得到期望的结果。
|
||||
|
||||
如果你想知道 Coens 最喜欢的演员是谁,你可以这样操作。首先:
|
||||
|
||||
```
|
||||
while read name surname films; do echo $films $name $surname > filmsfirst.txt; done < CBActors
|
||||
```
|
||||
|
||||
上面这串命令写在多行中可能会比较易读:
|
||||
|
||||
```
|
||||
while read name surname films;\
|
||||
do
|
||||
echo $films $name $surname >> filmsfirst;\
|
||||
done < CBActors
|
||||
```
|
||||
|
||||
下面来分析一下这些命令做了什么:
|
||||
|
||||
* [`while ...; do ... done`][5] 是一个循环结构。当 `while` 后面的条件成立时,`do` 和 `done` 之间的部分会一直重复执行;
|
||||
* [`read`][6] 语句会按行读入内容。`read` 会从标准输入中持续读入,直到没有内容可读入;
|
||||
* `CBActors` 文件的内容会通过 `<` 从标准输入中读入,因此 `while` 循环会将 `CBActors` 文件逐行完整读入;
|
||||
* `read` 命令可以按照空格将每一行内容划分为三个字段,然后分别将这三个字段赋值给 `name`、`surname` 和 `films` 三个变量,这样就可以很方便地通过 `echo $films $name $surname >> filmsfirst;\` 来重新排列几个字段的放置顺序并存放到 `filmfirst` 文件里面了。
|
||||
|
||||
执行完以后,查看 `filmsfirst` 文件,内容会是这样的:
|
||||
|
||||
```
|
||||
5 John Goodman
|
||||
3 John Turturro
|
||||
2 George Clooney
|
||||
6 Frances McDormand
|
||||
5 Steve Buscemi
|
||||
4 Jon Polito
|
||||
3 Tony Shalhoub
|
||||
1 James Gandolfini
|
||||
```
|
||||
|
||||
这时候再使用 `sort` 命令:
|
||||
|
||||
```
|
||||
sort -r filmsfirst
|
||||
```
|
||||
|
||||
就可以看到 Coens 最喜欢的演员是 Frances McDormand 了。(`-r` 参数表示降序排列,因此 McDormand 会排在最前面)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/2019/1/bash-shell-utility-reaches-50-milestone
|
||||
[2]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
|
||||
[3]: https://linux.die.net/man/1/wc
|
||||
[4]: https://linux.die.net/man/1/sort
|
||||
[5]: http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO-7.html
|
||||
[6]: https://linux.die.net/man/2/read
|
||||
|
||||
Loading…
Reference in New Issue
Block a user