mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
2c77ea2e94
82
published/20190114 You (probably) don-t need Kubernetes.md
Normal file
82
published/20190114 You (probably) don-t need Kubernetes.md
Normal file
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10469-1.html)
|
||||
[#]: subject: (You (probably) don't need Kubernetes)
|
||||
[#]: via: (https://arp242.net/weblog/dont-need-k8s.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
你(多半)不需要 Kubernetes
|
||||
======
|
||||
|
||||
这也许是一个不太受欢迎的观点,但大多数主流公司最好不要再使用 k8s 了。
|
||||
|
||||
你知道那个古老的“以程序员技能写 Hello world ”笑话吗?—— 从一个新手程序员的 `printf("hello, world\n")` 语句开始,最后结束于高级软件架构工程师令人费解的 Java OOP 模式设计。使用 k8s 就有点像这样。
|
||||
|
||||
* 新手系统管理员:
|
||||
|
||||
`./binary`
|
||||
* 有经验的系统管理员:
|
||||
|
||||
在 EC2 上的 `./binary`
|
||||
* DevOp:
|
||||
|
||||
在 EC2 上自部署的 CI 管道运行 `./binary`
|
||||
* 高级云编排工程师:
|
||||
|
||||
在 EC2 上通过 k8s 编排的自部署 CI 管道运行 `./binary`
|
||||
|
||||
`¯\\_(ツ)_/¯`
|
||||
|
||||
这不意味着 Kubernetes 或者任何这样的东西本身都是*坏的*,就像 Java 或者 OOP 设计本身并不是坏的一样,但是,在很多情况下,它们被严重地误用,就像在一个 hello world 的程序中可怕地误用 Java 面向对象设计模式一样。对大多数公司而言,系统运维从根本上来说并不十分复杂,此时在这上面应用 k8s 起效甚微。
|
||||
|
||||
复杂性本质上来说创造了工作,我十分怀疑使用 k8s 对大多数使用者来说是省时的这一说法。这就好像花一天时间来写一个脚本,用来自动完成一些你一个月进行一次,每次只花 10 分钟完成的工作。这不是一个好的时间投资(特别是你可能会在未来由于扩展或调试这个脚本而进一步投入的更多时间)。
|
||||
|
||||
你的部署大概应该*需要*自动化 – 以免你 [最终像 Knightmare][1] 那样 —— 但 k8s 通常可以被一个简单的 shell 脚本所替代。
|
||||
|
||||
在我们公司,系统运维团队用了很多时间来设置 k8s 。他们还不得不用了很大一部分时间来更新到新一点的版本(1.6 ➙ 1.8)。结果是如果没有真正深入理解 k8s ,有些东西就没人会真的明白,甚至连深入理解 k8s 这一点也很难(那些 YAML 文件,哦呦!)
|
||||
|
||||
在我能自己调试和修复部署问题之前 —— 现在这更难了,我理解基本概念,但在真正调试实际问题的时候,它们并不是那么有用。我不经常用 k8s 足以证明这点。
|
||||
|
||||
---
|
||||
|
||||
k8s 真的很难这点并不是什么新看法,这也是为什么现在会有这么多 “k8s 简单用”的解决方案。在 k8s 上再添一层来“让它更简单”的方法让我觉得,呃,不明智。复杂性并没有消失,你只是把它藏起来了。
|
||||
|
||||
以前我说过很多次:在确定一样东西是否“简单”时,我最关心的不是写东西的时候有多简单,而是当失败的时候调试起来有多容易。包装 k8s 并不会让调试更加简单,恰恰相反,它让事情更加困难了。
|
||||
|
||||
---
|
||||
|
||||
Blaise Pascal 有一句名言:
|
||||
|
||||
> 几乎所有的痛苦都来自于我们不善于在房间里独处。
|
||||
|
||||
k8s —— 略微拓展一下,Docker —— 似乎就是这样的例子。许多人似乎迷失在当下的兴奋中,觉得 “k8s 就是这么回事!”,就像有些人迷失在 Java OOP 刚出来时的兴奋中一样,所以一切都必须从“旧”方法转为“新”方法,即使“旧”方法依然可行。
|
||||
|
||||
有时候 IT 产业挺蠢的。
|
||||
|
||||
或者用 [一条推特][2] 来总结:
|
||||
|
||||
> - 2014 - 我们必须采用 #微服务 来解决独石应用的所有问题
|
||||
> - 2016 - 我们必须采用 #docker 来解决微服务的所有问题
|
||||
> - 2018 - 我们必须采用 #kubernetes 来解决 docker 的所有问题
|
||||
|
||||
你可以通过 [martin@arp242.net][3] 给我发邮件或者 [创建 GitHub issue][4] 来给我反馈或提出问题等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/dont-need-k8s.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://dougseven.com/2014/04/17/knightmare-a-devops-cautionary-tale/
|
||||
[2]: https://twitter.com/sahrizv/status/1018184792611827712
|
||||
[3]: mailto:martin@arp242.net
|
||||
[4]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -68,7 +68,7 @@ via: https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html
|
||||
|
||||
作者:[Josh Stella][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,494 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 10 Input01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 10 Input01
|
||||
======
|
||||
|
||||
Welcome to the Input lesson series. In this series, you will learn how to receive inputs to the Raspberry Pi using the keyboard. We will start with just revealing the input, and then move to a more traditional text prompt.
|
||||
|
||||
This first input lesson teaches some theory about drivers and linking, as well as about keyboards and ends up displaying text on the screen.
|
||||
|
||||
### 1 Getting Started
|
||||
|
||||
It is expected that you have completed the OK series, and it would be helpful to have completed the Screen series. Many of the files from that series will be called, without comment. If you do not have these files, or prefer to use a correct implementation, download the template for this lesson from the [Downloads][1] page. If you're using your own implementation, please remove everything after your call to SetGraphicsAddress.
|
||||
|
||||
### 2 USB
|
||||
|
||||
```
|
||||
The USB standard was designed to make simple hardware in exchange for complex software.
|
||||
```
|
||||
|
||||
As you are no doubt aware, the Raspberry Pi model B has two USB ports, commonly used for connecting a mouse and keyboard. This was a very good design decision, USB is a very generic connector, and many different kinds of device use it. It's simple to build new devices for, simple to write device drivers for, and is highly extensible thanks to USB hubs. Could it get any better? Well, no, in fact for an Operating Systems developer this is our worst nightmare. The USB standard is huge. I really mean it this time, it is over 700 pages, before you've even thought about connecting a device.
|
||||
|
||||
I spoke to a number of other hobbyist Operating Systems developers about this and they all say one thing: don't bother. "It will take too long to implement", "You won't be able to write a tutorial on it" and "It will be of little benefit". In many ways they are right, I'm not able to write a tutorial on the USB standard, as it would take weeks. I also can't teach how to write device drivers for all the different devices, so it is useless on its own. However, I can do the next best thing: Get a working USB driver, get a keyboard driver, and then teach how to use these in an Operating System. I set out searching for a free driver that would run in an operating system that doesn't even know what a file is yet, but I couldn't find one. They were all too high level. So, I attempted to write one. Everybody was right, this took weeks to do. However, I'm pleased to say I did get one that works with no external help from the Operating System, and can talk to a mouse and keyboard. It is by no means complete, efficient, or correct, but it does work. It has been written in C and the full source code can be found on the downloads page for those interested.
|
||||
|
||||
So, this tutorial won't be a lesson on the USB standard (at all). Instead we'll look at how to work with other people's code.
|
||||
|
||||
### 3 Linking
|
||||
|
||||
```
|
||||
Linking allows us to make reusable code 'libraries' that anyone can use in their program.
|
||||
```
|
||||
|
||||
Since we're about to incorporate external code into the Operating System, we need to talk about linking. Linking is a process which is applied to programs or Operating System to link in functions. What this means is that when a program is made, we don't necessarily code every function (almost certainly not in fact). Linking is what we do to make our program link to functions in other people's code. This has actually been going on all along in our Operating Systems, as the linker links together all of the different files, each of which is compiled separately.
|
||||
|
||||
```
|
||||
Programs often just call libraries, which call other libraries and so on until eventually they call an Operating System library which we would write.
|
||||
```
|
||||
|
||||
There are two types of linking: static and dynamic. Static linking is like what goes on when we make our Operating Systems. The linker finds all the addresses of the functions, and writes them into the code, before the program is finished. Dynamic linking is linking that occurs after the program is 'complete'. When it is loaded, the dynamic linker goes through the program and links any functions which are not in the program to libraries in the Operating System. This is one of the jobs our Operating System should eventually be capable of, but for now everything will be statically linked.
|
||||
|
||||
The USB driver I have written is suitable for static linking. This means I give you the compiled code for each of my files, and then the linker finds functions in your code which are not defined in your code, and links them to functions in my code. On the [Downloads][1] page for this lesson is a makefile and my USB driver, which you will need to continue. Download them and replace the makefile in your code with this one, and also put the driver in the same folder as that makefile.
|
||||
|
||||
### 4 Keyboards
|
||||
|
||||
In order to get input into our Operating System, we need to understand at some level how keyboards actually work. Keyboards have two types of keys: Normal and Modifier keys. The normal keys are the letters, numbers, function keys, etc. They constitute almost every key on the keyboard. The modifiers are up to 8 special keys. These are left shift, right shift, left control, right control, left alt, right alt, left GUI and right GUI. The keyboard can detect any combination of the modifier keys being held, as well as up to 6 normal keys. Every time a key changes (i.e. is pushed or released), it reports this to the computer. Typically, keyboards also have three LEDs for Caps Lock, Num Lock and Scroll Lock, which are controlled by the computer, not the keyboard itself. Keyboards may have many more lights such as power, mute, etc.
|
||||
|
||||
In order to help standardise USB keyboards, a table of values was produced, such that every keyboard key ever is given a unique number, as well as every conceivable LED. The table below lists the first 126 of values.
|
||||
|
||||
Table 4.1 USB Keyboard Keys
|
||||
| Number | Description | Number | Description | Number | Description | Number | Description | |
|
||||
| ------ | ---------------- | ------- | ---------------------- | -------- | -------------- | --------------- | -------------------- | |
|
||||
| 4 | a and A | 5 | b and B | 6 | c and C | 7 | d and D | |
|
||||
| 8 | e and E | 9 | f and F | 10 | g and G | 11 | h and H | |
|
||||
| 12 | i and I | 13 | j and J | 14 | k and K | 15 | l and L | |
|
||||
| 16 | m and M | 17 | n and N | 18 | o and O | 19 | p and P | |
|
||||
| 20 | q and Q | 21 | r and R | 22 | s and S | 23 | t and T | |
|
||||
| 24 | u and U | 25 | v and V | 26 | w and W | 27 | x and X | |
|
||||
| 28 | y and Y | 29 | z and Z | 30 | 1 and ! | 31 | 2 and @ | |
|
||||
| 32 | 3 and # | 33 | 4 and $ | 34 | 5 and % | 35 | 6 and ^ | |
|
||||
| 36 | 7 and & | 37 | 8 and * | 38 | 9 and ( | 39 | 0 and ) | |
|
||||
| 40 | Return (Enter) | 41 | Escape | 42 | Delete (Backspace) | 43 | Tab | |
|
||||
| 44 | Spacebar | 45 | - and _ | 46 | = and + | 47 | [ and { | |
|
||||
| 48 | ] and } | 49 | \ and | | 50 | # and ~ | 51 | ; and : |
|
||||
| 52 | ' and " | 53 | ` and ~ | 54 | , and < | 55 | . and > | |
|
||||
| 56 | / and ? | 57 | Caps Lock | 58 | F1 | 59 | F2 | |
|
||||
| 60 | F3 | 61 | F4 | 62 | F5 | 63 | F6 | |
|
||||
| 64 | F7 | 65 | F8 | 66 | F9 | 67 | F10 | |
|
||||
| 68 | F11 | 69 | F12 | 70 | Print Screen | 71 | Scroll Lock | |
|
||||
| 72 | Pause | 73 | Insert | 74 | Home | 75 | Page Up | |
|
||||
| 76 | Delete forward | 77 | End | 78 | Page Down | 79 | Right Arrow | |
|
||||
| 80 | Left Arrow | 81 | Down Arrow | 82 | Up Arrow | 83 | Num Lock | |
|
||||
| 84 | Keypad / | 85 | Keypad * | 86 | Keypad - | 87 | Keypad + | |
|
||||
| 88 | Keypad Enter | 89 | Keypad 1 and End | 90 | Keypad 2 and Down Arrow | 91 | Keypad 3 and Page Down | |
|
||||
| 92 | Keypad 4 and Left Arrow | 93 | Keypad 5 | 94 | Keypad 6 and Right Arrow | 95 | Keypad 7 and Home | |
|
||||
| 96 | Keypad 8 and Up Arrow | 97 | Keypad 9 and Page Up | 98 | Keypad 0 and Insert | 99 | Keypad . and Delete | |
|
||||
| 100 | \ and | | 101 | Application | 102 | Power | 103 | Keypad = |
|
||||
| 104 | F13 | 105 | F14 | 106 | F15 | 107 | F16 | |
|
||||
| 108 | F17 | 109 | F18 | 110 | F19 | 111 | F20 | |
|
||||
| 112 | F21 | 113 | F22 | 114 | F23 | 115 | F24 | |
|
||||
| 116 | Execute | 117 | Help | 118 | Menu | 119 | Select | |
|
||||
| 120 | Stop | 121 | Again | 122 | Undo | 123 | Cut | |
|
||||
| 124 | Copy | 125 | Paste | 126 | Find | 127 | Mute | |
|
||||
| 128 | Volume Up | 129 | Volume Down | | | | | |
|
||||
|
||||
The full list can be found in section 10, page 53 of [HID Usage Tables 1.12][2].
|
||||
|
||||
### 5 The Nut Behind the Wheel
|
||||
|
||||
```
|
||||
These summaries and the code they describe form an API - Application Product Interface.
|
||||
```
|
||||
|
||||
Normally, when you work with someone else's code, they provide a summary of their methods, what they do and roughly how they work, as well as how they can go wrong. Here is a table of the relevant instructions required to use my USB driver.
|
||||
|
||||
Table 5.1 Keyboard related functions in CSUD
|
||||
| Function | Arguments | Returns | Description |
|
||||
| ----------------------- | ----------------------- | ----------------------- | ----------------------- |
|
||||
| UsbInitialise | None | r0 is result code | This method is the all-in-one method that loads the USB driver, enumerates all devices and attempts to communicate with them. This method generally takes about a second to execute, though with a few USB hubs plugged in this can be significantly longer. After this method is completed methods in the keyboard driver become available, regardless of whether or not a keyboard is indeed inserted. Result code explained below. |
|
||||
| UsbCheckForChange | None | None | Essentially provides the same effect as UsbInitialise, but does not provide the same one time initialisation. This method checks every port on every connected hub recursively, and adds new devices if they have been added. This should be very quick if there are no changes, but can take up to a few seconds if a hub with many devices is attached. |
|
||||
| KeyboardCount | None | r0 is count | Returns the number of keyboards currently connected and detected. UsbCheckForChange may update this. Up to 4 keyboards are supported by default. Up to this many keyboards may be accessed through this driver. |
|
||||
| KeyboardGetAddress | r0 is index | r0 is address | Retrieves the address of a given keyboard. All other functions take a keyboard address in order to know which keyboard to access. Thus, to communicate with a keyboard, first check the count, then retrieve the address, then use other methods. Note, the order of keyboards that this method returns may change after calls to UsbCheckForChange. |
|
||||
| KeyboardPoll | r0 is address | r0 is result code | Reads in the current key state from the keyboard. This operates via polling the device directly, contrary to the best practice. This means that if this method is not called frequently enough, a key press could be missed. All reading methods simply return the value as of the last poll. |
|
||||
| KeyboardGetModifiers | r0 is address | r0 is modifier state | Retrieves the status of the modifier keys as of the last poll. These are the shift, alt control and GUI keys on both sides. This is returned as a bit field, such that a 1 in the bit 0 means left control is held, bit 1 means left shift, bit 2 means left alt, bit 3 means left GUI and bits 4 to 7 mean the right versions of those previous. If there is a problem r0 contains 0. |
|
||||
| KeyboardGetKeyDownCount | r0 is address | r0 is count | Retrieves the number of keys currently held down on the keyboard. This excludes modifier keys. Normally, this cannot go above 6. If there is an error this method returns 0. |
|
||||
| KeyboardGetKeyDown | r0 is address, r1 is key number | r0 is scan code | Retrieves the scan code (see Table 4.1) of a particular held down key. Normally, to work out which keys are down, call KeyboardGetKeyDownCount and then call KeyboardGetKeyDown up to that many times with increasing values of r1 to determine which keys are down. Returns 0 if there is a problem. It is safe (but not recommended) to call this method without calling KeyboardGetKeyDownCount and interpret 0s as keys not held. Note, the order or scan codes can change randomly (some keyboards sort numerically, some sort temporally, no guarantees are made). |
|
||||
| KeyboardGetKeyIsDown | r0 is address, r1 is scan code | r0 is status | Alternative to KeyboardGetKeyDown, checks if a particular scan code is among the held down keys. Returns 0 if not, or a non-zero value if so. Faster when detecting particular scan codes (e.g. looking for ctrl+c). On error, returns 0. |
|
||||
| KeyboardGetLedSupport | r0 is address | r0 is LEDs | Checks which LEDs a particular keyboard supports. Bit 0 being 1 represents Number Lock, bit 1 represents Caps Lock, bit 2 represents Scroll Lock, bit 3 represents Compose, bit 4 represents Kana, bit 5 represents Power, bit 6 represents Mute and bit 7 represents Compose. As per the USB standard, none of these LEDs update automatically (e.g. Caps Lock must be set manually when the Caps Lock scan code is detected). |
|
||||
| KeyboardSetLeds | r0 is address, r1 is LEDs | r0 is result code | Attempts to turn on/off the specified LEDs on the keyboard. See below for result code values. See KeyboardGetLedSupport for LEDs' values. |
|
||||
|
||||
```
|
||||
Result codes are an easy way to handle errors, but often more elegant solutions exist in higher level code.
|
||||
```
|
||||
|
||||
Several methods return 'result codes'. These are commonplace in C code, and are just numbers which represent what happened in a method call. By convention, 0 always indicates success. The following result codes are used by this driver.
|
||||
|
||||
Table 5.2 - CSUD Result Codes
|
||||
| Code | Description |
|
||||
| ---- | ----------------------------------------------------------------------- |
|
||||
| 0 | Method completed successfully. |
|
||||
| -2 | Argument: A method was called with an invalid argument. |
|
||||
| -4 | Device: The device did not respond correctly to the request. |
|
||||
| -5 | Incompatible: The driver is not compatible with this request or device. |
|
||||
| -6 | Compiler: The driver was compiled incorrectly, and is broken. |
|
||||
| -7 | Memory: The driver ran out of memory. |
|
||||
| -8 | Timeout: The device did not respond in the expected time. |
|
||||
| -9 | Disconnect: The device requested has disconnected, and cannot be used. |
|
||||
|
||||
The general usage of the driver is as follows:
|
||||
|
||||
1. Call UsbInitialise
|
||||
2. Call UsbCheckForChange
|
||||
3. Call KeyboardCount
|
||||
4. If this is 0, go to 2.
|
||||
5. For each keyboard you support:
|
||||
1. Call KeyboardGetAddress
|
||||
2. Call KeybordGetKeyDownCount
|
||||
3. For each key down:
|
||||
1. Check whether or not it has just been pushed
|
||||
2. Store that the key is down
|
||||
4. For each key stored:
|
||||
1. Check whether or not key is released
|
||||
2. Remove key if released
|
||||
6. Perform actions based on keys pushed/released
|
||||
7. Go to 2.
|
||||
|
||||
|
||||
|
||||
Ultimately, you may do whatever you wish to with the keyboard, and these methods should allow you to access all of its functionality. Over the next 2 lessons, we shall look at completing the input side of a text terminal, similarly to most command line computers, and interpreting the commands. In order to do this, we're going to need to have keyboard inputs in a more useful form. You may notice that my driver is (deliberately) unhelpful, because it doesn't have methods to deduce whether or not a key has just been pushed down or released, it only has methods about what is currently held down. This means we'll need to write such methods ourselves.
|
||||
|
||||
### 6 Updates Available
|
||||
|
||||
Repeatedly checking for updates is called 'polling'. This is in contrast to interrupt driven IO, where the device sends a signal when data is ready.
|
||||
|
||||
First of all, let's implement a method KeyboardUpdate which detects the first keyboard and uses its poll method to get the current input, as well as saving the last inputs for comparison. We can then use this data with other methods to translate scan codes to keys. The method should do precisely the following:
|
||||
|
||||
1. Retrieve a stored keyboard address (initially 0).
|
||||
2. If this is not 0, go to 9.
|
||||
3. Call UsbCheckForChange to detect new keyboards.
|
||||
4. Call KeyboardCount to detect how many keyboards are present.
|
||||
5. If this is 0 store the address as 0 and return; we can't do anything with no keyboard.
|
||||
6. Call KeyboardGetAddress with parameter 0 to get the first keyboard's address.
|
||||
7. Store this address.
|
||||
8. If this is 0, return; there is some problem.
|
||||
9. Call KeyboardGetKeyDown 6 times to get each key currently down and store them
|
||||
10. Call KeyboardPoll
|
||||
11. If the result is non-zero go to 3. There is some problem (such as disconnected keyboard).
|
||||
|
||||
|
||||
|
||||
To store the values mentioned above, we will need the following values in the .data section.
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 2
|
||||
KeyboardAddress:
|
||||
.int 0
|
||||
KeyboardOldDown:
|
||||
.rept 6
|
||||
.hword 0
|
||||
.endr
|
||||
```
|
||||
|
||||
```
|
||||
.hword num inserts the half word constant num into the file directly.
|
||||
```
|
||||
|
||||
```
|
||||
.rept num [commands] .endr copies the commands commands to the output num times.
|
||||
```
|
||||
|
||||
Try to implement the method yourself. My implementation for this is as follows:
|
||||
|
||||
1.
|
||||
```
|
||||
.section .text
|
||||
.globl KeyboardUpdate
|
||||
KeyboardUpdate:
|
||||
push {r4,r5,lr}
|
||||
|
||||
kbd .req r4
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr kbd,[r0]
|
||||
```
|
||||
We load in the keyboard address.
|
||||
2.
|
||||
```
|
||||
teq kbd,#0
|
||||
bne haveKeyboard$
|
||||
```
|
||||
If the address is non-zero, we have a keyboard. Calling UsbCheckForChanges is slow, and so if everything works we avoid it.
|
||||
3.
|
||||
```
|
||||
getKeyboard$:
|
||||
bl UsbCheckForChange
|
||||
```
|
||||
If we don't have a keyboard, we have to check for new devices.
|
||||
4.
|
||||
```
|
||||
bl KeyboardCount
|
||||
```
|
||||
Now we see if a new keyboard has been added.
|
||||
5.
|
||||
```
|
||||
teq r0,#0
|
||||
ldreq r1,=KeyboardAddress
|
||||
streq r0,[r1]
|
||||
beq return$
|
||||
```
|
||||
There are no keyboards, so we have no keyboard address.
|
||||
6.
|
||||
```
|
||||
mov r0,#0
|
||||
bl KeyboardGetAddress
|
||||
```
|
||||
Let's just get the address of the first keyboard. You may want to allow more.
|
||||
7.
|
||||
```
|
||||
ldr r1,=KeyboardAddress
|
||||
str r0,[r1]
|
||||
```
|
||||
Store the keyboard's address.
|
||||
8.
|
||||
```
|
||||
teq r0,#0
|
||||
beq return$
|
||||
mov kbd,r0
|
||||
```
|
||||
If we have no address, there is nothing more to do.
|
||||
9.
|
||||
```
|
||||
saveKeys$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
|
||||
ldr r1,=KeyboardOldDown
|
||||
add r1,r5,lsl #1
|
||||
strh r0,[r1]
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt saveKeys$
|
||||
```
|
||||
Loop through all the keys, storing them in KeyboardOldDown. If we ask for too many, this returns 0 which is fine.
|
||||
|
||||
10.
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardPoll
|
||||
```
|
||||
Now we get the new keys.
|
||||
|
||||
11.
|
||||
```
|
||||
teq r0,#0
|
||||
bne getKeyboard$
|
||||
|
||||
return$:
|
||||
pop {r4,r5,pc}
|
||||
.unreq kbd
|
||||
```
|
||||
Finally we check if KeyboardPoll worked. If not, we probably disconnected.
|
||||
|
||||
|
||||
With our new KeyboardUpdate method, checking for inputs becomes as simple as calling this method at regular intervals, and it will even check for disconnections etc. This is a useful method to have, as our actual key processing may differ based on the situation, and so being able to get the current input in its raw form with one method call is generally applicable. The next method we ideally want is KeyboardGetChar, a method that simply returns the next key pressed as an ASCII character, or returns 0 if no key has just been pressed. This could be extended to support typing a key multiple times if it is held for a certain duration, and to support the 'lock' keys as well as modifiers.
|
||||
|
||||
To make this method it is useful if we have a method KeyWasDown, which simply returns 0 if a given scan code is not in the KeyboardOldDown values, and returns a non-zero value otherwise. Have a go at implementing this yourself. As always, a solution can be found on the downloads page.
|
||||
|
||||
### 7 Look Up Tables
|
||||
|
||||
```
|
||||
In many areas of programming, the larger the program, the faster it is. Look up tables are large, but are very fast. Some problems can be solved by a mixture of look up tables and normal functions.
|
||||
```
|
||||
|
||||
The KeyboardGetChar method could be quite complex if we write it poorly. There are 100s of scan codes, each with different effects depending on the presence or absence of the shift key or other modifiers. Not all of the keys can be translated to a character. For some characters, multiple keys can produce the same character. A useful trick in situations with such vast arrays of possibilities is look up tables. A look up table, much like in the physical sense, is a table of values and their results. For some limited functions, the simplest way to deduce the answer is just to precompute every answer, and just return the correct one by retrieving it. In this case, we could build up a sequence of values in memory such that the nth value into the sequence is the ASCII character code for the scan code n. This means our method would simply have to detect if a key was pressed, and then retrieve its value from the table. Further, we could have a separate table for the values when shift is held, so that the shift key simply changes which table we're working with.
|
||||
|
||||
After the .section .data command, copy the following tables:
|
||||
|
||||
```
|
||||
.align 3
|
||||
KeysNormal:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'a', 'b', 'c', 'd'
|
||||
.byte 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l'
|
||||
.byte 'm', 'n', 'o', 'p', 'q', 'r', 's', 't'
|
||||
.byte 'u', 'v', 'w', 'x', 'y', 'z', '1', '2'
|
||||
.byte '3', '4', '5', '6', '7', '8', '9', '0'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '-', '=', '['
|
||||
.byte ']', '\\\', '#', ';', '\'', '`', ',', '.'
|
||||
.byte '/', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '\\\', 0x0, 0x0, '='
|
||||
|
||||
.align 3
|
||||
KeysShift:
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 'A', 'B', 'C', 'D'
|
||||
.byte 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L'
|
||||
.byte 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T'
|
||||
.byte 'U', 'V', 'W', 'X', 'Y', 'Z', '!', '"'
|
||||
.byte '£', '$', '%', '^', '&', '*', '(', ')'
|
||||
.byte '\n', 0x0, '\b', '\t', ' ', '_', '+', '{'
|
||||
.byte '}', '|', '~', ':', '@', '¬', '<', '>'
|
||||
.byte '?', 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
|
||||
.byte 0x0, 0x0, 0x0, 0x0, '/', '*', '-', '+'
|
||||
.byte '\n', '1', '2', '3', '4', '5', '6', '7'
|
||||
.byte '8', '9', '0', '.', '|', 0x0, 0x0, '='
|
||||
```
|
||||
|
||||
```
|
||||
.byte num inserts the byte constant num into the file directly.
|
||||
```
|
||||
|
||||
```
|
||||
Most assemblers and compilers recognise escape sequences; character sequences such as \t which insert special characters instead.
|
||||
```
|
||||
|
||||
These tables map directly the first 104 scan codes onto the ASCII characters as a table of bytes. We also have a separate table describing the effects of the shift key on those scan codes. I've used the ASCII null character (0) for all keys without direct mappings in ASCII (such as the function keys). Backspace is mapped to the ASCII backspace character (8 denoted \b), enter is mapped to the ASCII new line character (10 denoted \n) and tab is mapped to the ASCII horizontal tab character (9 denoted \t).
|
||||
|
||||
The KeyboardGetChar method will need to do the following:
|
||||
|
||||
1. Check if KeyboardAddress is 0. If so, return 0.
|
||||
2. Call KeyboardGetKeyDown up to 6 times. Each time:
|
||||
1. If key is 0, exit loop.
|
||||
2. Call KeyWasDown. If it was, go to the next key.
|
||||
3. If the scan code is more than 103, go to the next key.
|
||||
4. Call KeyboardGetModifiers
|
||||
5. If shift is held, load the address of KeysShift. Otherwise load KeysNormal.
|
||||
6. Read the ASCII value from the table.
|
||||
7. If it is 0, go to the next key otherwise return this ASCII code and exit.
|
||||
3. Return 0.
|
||||
|
||||
|
||||
|
||||
Try to implement this yourself. My implementation is presented below:
|
||||
|
||||
1.
|
||||
```
|
||||
.globl KeyboardGetChar
|
||||
KeyboardGetChar:
|
||||
ldr r0,=KeyboardAddress
|
||||
ldr r1,[r0]
|
||||
teq r1,#0
|
||||
moveq r0,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
Simple check to see if we have a keyboard.
|
||||
|
||||
2.
|
||||
```
|
||||
push {r4,r5,r6,lr}
|
||||
kbd .req r4
|
||||
key .req r6
|
||||
mov r4,r1
|
||||
mov r5,#0
|
||||
keyLoop$:
|
||||
mov r0,kbd
|
||||
mov r1,r5
|
||||
bl KeyboardGetKeyDown
|
||||
```
|
||||
r5 will hold the index of the key, r4 holds the keyboard address.
|
||||
|
||||
1.
|
||||
```
|
||||
teq r0,#0
|
||||
beq keyLoopBreak$
|
||||
```
|
||||
If a scan code is 0, it either means there is an error, or there are no more keys.
|
||||
|
||||
2.
|
||||
```
|
||||
mov key,r0
|
||||
bl KeyWasDown
|
||||
teq r0,#0
|
||||
bne keyLoopContinue$
|
||||
```
|
||||
If a key was already down it is uninteresting, we only want ot know about key presses.
|
||||
|
||||
3.
|
||||
```
|
||||
cmp key,#104
|
||||
bge keyLoopContinue$
|
||||
```
|
||||
If a key has a scan code higher than 104, it will be outside our table, and so is not relevant.
|
||||
|
||||
4.
|
||||
```
|
||||
mov r0,kbd
|
||||
bl KeyboardGetModifiers
|
||||
```
|
||||
We need to know about the modifier keys in order to deduce the character.
|
||||
|
||||
5.
|
||||
```
|
||||
tst r0,#0b00100010
|
||||
ldreq r0,=KeysNormal
|
||||
ldrne r0,=KeysShift
|
||||
```
|
||||
We detect both a left and right shift key as changing the characters to their shift variants. Remember, a tst instruction computes the logical AND and then compares it to zero, so it will be equal to 0 if and only if both of the shift bits are zero.
|
||||
|
||||
6.
|
||||
```
|
||||
ldrb r0,[r0,key]
|
||||
```
|
||||
Now we can load in the key from the look up table.
|
||||
|
||||
7.
|
||||
```
|
||||
teq r0,#0
|
||||
bne keyboardGetCharReturn$
|
||||
keyLoopContinue$:
|
||||
add r5,#1
|
||||
cmp r5,#6
|
||||
blt keyLoop$
|
||||
```
|
||||
If the look up code contains a zero, we must continue. To continue, we increment the index, and check if we've reached 6.
|
||||
|
||||
3.
|
||||
```
|
||||
keyLoopBreak$:
|
||||
mov r0,#0
|
||||
keyboardGetCharReturn$:
|
||||
pop {r4,r5,r6,pc}
|
||||
.unreq kbd
|
||||
.unreq key
|
||||
```
|
||||
We return our key here, if we reach keyLoopBreak$, then we know there is no key held, so return 0.
|
||||
|
||||
|
||||
|
||||
|
||||
### 8 Notepad OS
|
||||
|
||||
Now we have our KeyboardGetChar method, we can make an operating system that just types what the user writes to the screen. For simplicity we'll ignore all the unusual keys. In 'main.s' delete all code after bl SetGraphicsAddress. Call UsbInitialise, set r4 and r5 to 0, then loop forever over the following commands:
|
||||
|
||||
1. Call KeyboardUpdate
|
||||
2. Call KeyboardGetChar
|
||||
3. If it is 0, got to 1
|
||||
4. Copy r4 and r5 to r1 and r2 then call DrawCharacter
|
||||
5. Add r0 to r4
|
||||
6. If r4 is 1024, add r1 to r5 and set r4 to 0
|
||||
7. If r5 is 768 set r5 to 0
|
||||
8. Go to 1
|
||||
|
||||
|
||||
|
||||
Now compile this and test it on the Pi. You should almost immediately be able to start typing text to the screen when the Pi starts. If not, please see our troubleshooting page.
|
||||
|
||||
When it works, congratulations, you've achieved an interface with the computer. You should now begin to realise that you've almost got a primitive operating system together. You can now interface with the computer, issuing it commands, and receive feedback on screen. In the next tutorial, [Input02][3] we will look at producing a full text terminal, in which the user types commands, and the computer executes them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/hut1_12v2.pdf
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
|
||||
@ -0,0 +1,911 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 11 Input02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 11 Input02
|
||||
======
|
||||
|
||||
The Input02 lesson builds on Input01, by building a simple command line interface where the user can type commands and the computer interprets and displays them. It is assumed you have the code for the [Lesson 11: Input01][1] operating system as a basis.
|
||||
|
||||
### 1 Terminal 1
|
||||
|
||||
```
|
||||
In the early days of computing, there would usually be one large computer in a building, and many 'terminals' which sent commands to it. The computer would take it in turns to execute different incoming commands.
|
||||
```
|
||||
|
||||
Almost every operating system starts life out as a text terminal. This is typically a black screen with white writing, where you type commands for the computer to execute on the keyboard, and it explains how you've mistyped them, or very occasionally, does what you want. This approach has two main advantages: it provides a simple, robust control mechanism for the computer using only a keyboard and monitor, and it is done by almost every operating system, so is widely understood by system administrators.
|
||||
|
||||
Let's analyse what we want to do precisely:
|
||||
|
||||
1. Computer turns on, displays some sort of welcome message
|
||||
2. Computer indicates its ready for input
|
||||
3. User types a command, with parameters, on the keyboard
|
||||
4. User presses return or enter to commit the command
|
||||
5. Computer interprets command and performs actions if command is acceptable
|
||||
6. Computer displays messages to indicate if command was successful, and also what happened
|
||||
7. Loop back to 2
|
||||
|
||||
|
||||
|
||||
One defining feature of such terminals is that they are unified for both input and output. The same screen is used to enter inputs as is used to print outputs. This means it is useful to build an abstraction of a character based display. In a character based display, the smallest unit is a character, not a pixel. The screen is divided into a fixed number of characters which have varying colours. We can build this on top of our existing screen code, by storing the characters and their colours, and then using the DrawCharacter method to push them to the screen. Once we have a character based display, drawing text becomes a matter of drawing a line of characters.
|
||||
|
||||
In a new file called terminal.s copy the following code:
|
||||
```
|
||||
.section .data
|
||||
.align 4
|
||||
terminalStart:
|
||||
.int terminalBuffer
|
||||
terminalStop:
|
||||
.int terminalBuffer
|
||||
terminalView:
|
||||
.int terminalBuffer
|
||||
terminalColour:
|
||||
.byte 0xf
|
||||
.align 8
|
||||
terminalBuffer:
|
||||
.rept 128*128
|
||||
.byte 0x7f
|
||||
.byte 0x0
|
||||
.endr
|
||||
terminalScreen:
|
||||
.rept 1024/8 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 768/16
|
||||
.byte 0x7f
|
||||
.byte 0x0
|
||||
.endr
|
||||
```
|
||||
This sets up the data we need for the text terminal. We have two main storages: terminalBuffer and terminalScreen. terminalBuffer is storage for all of the text we have displayed. It stores up to 128 lines of text (each containing 128 characters). Each character consists of an ASCII character code and a colour, all of which are initially set to 0x7f (ASCII delete) and 0 (black on a black background). terminalScreen stores the characters that are currently displayed on the screen. It is 128 by 48 characters, similarly initialised. You may think that we only need this terminalScreen, not the terminalBuffer, but storing the buffer has 2 main advantages:
|
||||
|
||||
1. We can easily see which characters are different, so we only have to draw those.
|
||||
2. We can 'scroll' back through the terminal's history because it is stored (to a limit).
|
||||
|
||||
|
||||
|
||||
You should always try to design systems that do the minimum amount of work, as they run much faster for things which don't often change.
|
||||
|
||||
The differing trick is really common on low power Operating Systems. Drawing the screen is a slow operation, and so we only want to draw thing that we absolutely have to. In this system, we can freely alter the terminalBuffer, and then call a method which copies the bits that change to the screen. This means we don't have to draw each character as we go along, which may save time in the long run on very long sections of text that span many lines.
|
||||
|
||||
The other values in the .data section are as follows:
|
||||
|
||||
* terminalStart
|
||||
The first character which has been written in terminalBuffer.
|
||||
* terminalStop
|
||||
The last character which has been written in terminalBuffer.
|
||||
* terminalView
|
||||
The first character on the screen at present. We can use this to scroll the screen.
|
||||
* temrinalColour
|
||||
The colour to draw new characters with.
|
||||
|
||||
|
||||
|
||||
```
|
||||
Circular buffers are an example of an **data structure**. These are just ideas we have for organising data, that we sometimes implement in software.
|
||||
```
|
||||
|
||||
![Diagram showing hellow world being inserted into a circular buffer of size 5.][2]
|
||||
The reason why terminalStart needs to be stored is because termainlBuffer should be a circular buffer. This means that when the buffer is completely full, the end 'wraps' round to the start, and so the character after the very last one is the first one. Thus, we need to advance terminalStart so we know that we've done this. When wokring with the buffer this can easily be implemented by checking if the index goes beyond the end of the buffer, and setting it back to the beginning if it does. Circular buffers are a common and clever way of storing a lot of data, where only the most recent data is important. It allows us to keep writing indefinitely, while always being sure there is a certain amount of recent data available. They're often used in signal processing or compression algorithms. In this case, it allows us to store a 128 line history of the terminal, without any penalties for writing over 128 lines. If we didn't have this, we would have to copy 127 lines back a line very time we went beyond the 128th line, wasting valuable time.
|
||||
|
||||
I've mentioned the terminalColour here a few times. You can implement this however you, wish, however there is something of a standard on text terminals to have only 16 colours for foreground, and 16 colours for background (meaning there are 162 = 256 combinations). The colours on a CGA terminal are defined as follows:
|
||||
|
||||
Table 1.1 - CGA Colour Codes
|
||||
| Number | Colour (R, G, B) |
|
||||
| ------ | ------------------------|
|
||||
| 0 | Black (0, 0, 0) |
|
||||
| 1 | Blue (0, 0, ⅔) |
|
||||
| 2 | Green (0, ⅔, 0) |
|
||||
| 3 | Cyan (0, ⅔, ⅔) |
|
||||
| 4 | Red (⅔, 0, 0) |
|
||||
| 5 | Magenta (⅔, 0, ⅔) |
|
||||
| 6 | Brown (⅔, ⅓, 0) |
|
||||
| 7 | Light Grey (⅔, ⅔, ⅔) |
|
||||
| 8 | Grey (⅓, ⅓, ⅓) |
|
||||
| 9 | Light Blue (⅓, ⅓, 1) |
|
||||
| 10 | Light Green (⅓, 1, ⅓) |
|
||||
| 11 | Light Cyan (⅓, 1, 1) |
|
||||
| 12 | Light Red (1, ⅓, ⅓) |
|
||||
| 13 | Light Magenta (1, ⅓, 1) |
|
||||
| 14 | Yellow (1, 1, ⅓) |
|
||||
| 15 | White (1, 1, 1) |
|
||||
|
||||
```
|
||||
Brown was used as the alternative (dark yellow) was unappealing and not useful.
|
||||
```
|
||||
|
||||
We store the colour of each character by storing the fore colour in the low nibble of the colour byte, and the background colour in the high nibble. Apart from brown, all of these colours follow a pattern such that in binary, the top bit represents adding ⅓ to each component, and the other bits represent adding ⅔ to individual components. This makes it easy to convert to RGB colour values.
|
||||
|
||||
We need a method, TerminalColour, to read these 4 bit colour codes, and then call SetForeColour with the 16 bit equivalent. Try to implement this on your own. If you get stuck, or have not completed the Screen series, my implementation is given below:
|
||||
|
||||
```
|
||||
.section .text
|
||||
TerminalColour:
|
||||
teq r0,#6
|
||||
ldreq r0,=0x02B5
|
||||
beq SetForeColour
|
||||
|
||||
tst r0,#0b1000
|
||||
ldrne r1,=0x52AA
|
||||
moveq r1,#0
|
||||
tst r0,#0b0100
|
||||
addne r1,#0x15
|
||||
tst r0,#0b0010
|
||||
addne r1,#0x540
|
||||
tst r0,#0b0001
|
||||
addne r1,#0xA800
|
||||
mov r0,r1
|
||||
b SetForeColour
|
||||
```
|
||||
### 2 Showing the Text
|
||||
|
||||
The first method we really need for our terminal is TerminalDisplay, one that copies the current data from terminalBuffer to terminalScreen and the actual screen. As mentioned, this method should do a minimal amount of work, because we need to be able to call it often. It should compare the text in terminalBuffer with that in terminalDisplay, and copy it across if they're different. Remember, terminalBuffer is a circular buffer running, in this case, from terminalView to terminalStop or 128*48 characters, whichever comes sooner. If we hit terminalStop, we'll assume all characters after that point are 7f16 (ASCII delete), and have colour 0 (black on a black background).
|
||||
|
||||
Let's look at what we have to do:
|
||||
|
||||
1. Load in terminalView, terminalStop and the address of terminalDisplay.
|
||||
2. For each row:
|
||||
1. For each column:
|
||||
1. If view is not equal to stop, load the current character and colour from view
|
||||
2. Otherwise load the character as 0x7f and the colour as 0
|
||||
3. Load the current character from terminalDisplay
|
||||
4. If the character and colour are equal, go to 10
|
||||
5. Store the character and colour to terminalDisplay
|
||||
6. Call TerminalColour with the background colour in r0
|
||||
7. Call DrawCharacter with r0 = 0x7f (ASCII delete, a block), r1 = x, r2 = y
|
||||
8. Call TerminalColour with the foreground colour in r0
|
||||
9. Call DrawCharacter with r0 = character, r1 = x, r2 = y
|
||||
10. Increment the position in terminalDisplay by 2
|
||||
11. If view and stop are not equal, increment the view position by 2
|
||||
12. If the view position is at the end of textBuffer, set it to the start
|
||||
13. Increment the x co-ordinate by 8
|
||||
2. Increment the y co-ordinate by 16
|
||||
|
||||
|
||||
|
||||
Try to implement this yourself. If you get stuck, my solution is given below:
|
||||
|
||||
1.
|
||||
```
|
||||
.globl TerminalDisplay
|
||||
TerminalDisplay:
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
|
||||
x .req r4
|
||||
y .req r5
|
||||
char .req r6
|
||||
col .req r7
|
||||
screen .req r8
|
||||
taddr .req r9
|
||||
view .req r10
|
||||
stop .req r11
|
||||
|
||||
ldr taddr,=terminalStart
|
||||
ldr view,[taddr,#terminalView - terminalStart]
|
||||
ldr stop,[taddr,#terminalStop - terminalStart]
|
||||
add taddr,#terminalBuffer - terminalStart
|
||||
add taddr,#128*128*2
|
||||
mov screen,taddr
|
||||
```
|
||||
|
||||
I go a little wild with variables here. I'm using taddr to store the location of the end of the textBuffer for ease.
|
||||
|
||||
2.
|
||||
```
|
||||
mov y,#0
|
||||
yLoop$:
|
||||
```
|
||||
Start off the y loop.
|
||||
|
||||
1.
|
||||
```
|
||||
mov x,#0
|
||||
xLoop$:
|
||||
```
|
||||
Start off the x loop.
|
||||
|
||||
1.
|
||||
```
|
||||
teq view,stop
|
||||
ldrneh char,[view]
|
||||
```
|
||||
I load both the character and the colour into char simultaneously for ease.
|
||||
|
||||
2.
|
||||
```
|
||||
moveq char,#0x7f
|
||||
```
|
||||
This line complements the one above by acting as though a black delete character was read.
|
||||
|
||||
3.
|
||||
```
|
||||
ldrh col,[screen]
|
||||
```
|
||||
For simplicity I load both the character and colour into col simultaneously.
|
||||
|
||||
4.
|
||||
```
|
||||
teq col,char
|
||||
beq xLoopContinue$
|
||||
```
|
||||
Now we can check if anything has changed with a teq.
|
||||
|
||||
5.
|
||||
```
|
||||
strh char,[screen]
|
||||
```
|
||||
We can also easily save the current value.
|
||||
|
||||
6.
|
||||
```
|
||||
lsr col,char,#8
|
||||
and char,#0x7f
|
||||
lsr r0,col,#4
|
||||
bl TerminalColour
|
||||
```
|
||||
I split up char into the colour in col and the character in char with a bitshift and an and, then use a bitshift to get the background colour to call TerminalColour.
|
||||
|
||||
7.
|
||||
```
|
||||
mov r0,#0x7f
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
```
|
||||
Write out a delete character which is a coloured block.
|
||||
|
||||
8.
|
||||
```
|
||||
and r0,col,#0xf
|
||||
bl TerminalColour
|
||||
```
|
||||
Use an and to get the low nibble of col then call TerminalColour.
|
||||
|
||||
9.
|
||||
```
|
||||
mov r0,char
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
```
|
||||
Write out the character we're supposed to write.
|
||||
|
||||
10.
|
||||
```
|
||||
xLoopContinue$:
|
||||
add screen,#2
|
||||
```
|
||||
Increment the screen pointer.
|
||||
|
||||
11.
|
||||
```
|
||||
teq view,stop
|
||||
addne view,#2
|
||||
```
|
||||
Increment the view pointer if necessary.
|
||||
|
||||
12.
|
||||
```
|
||||
teq view,taddr
|
||||
subeq view,#128*128*2
|
||||
```
|
||||
It's easy to check for view going past the end of the buffer because the end of the buffer's address is stored in taddr.
|
||||
|
||||
13.
|
||||
```
|
||||
add x,#8
|
||||
teq x,#1024
|
||||
bne xLoop$
|
||||
```
|
||||
We increment x and then loop back if there are more characters to go.
|
||||
|
||||
2.
|
||||
```
|
||||
add y,#16
|
||||
teq y,#768
|
||||
bne yLoop$
|
||||
```
|
||||
We increment y and then loop back if there are more characters to go.
|
||||
|
||||
```
|
||||
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq char
|
||||
.unreq col
|
||||
.unreq screen
|
||||
.unreq taddr
|
||||
.unreq view
|
||||
.unreq stop
|
||||
```
|
||||
Don't forget to clean up at the end!
|
||||
|
||||
|
||||
### 3 Printing Lines
|
||||
|
||||
Now we have our TerminalDisplay method, which will automatically display the contents of terminalBuffer to terminalScreen, so theoretically we can draw text. However, we don't actually have any drawing routines that work on a character based display. A quick method that will come in handy first of all is TerminalClear, which completely clears the terminal. This can actually very easily be achieved with no loops. Try to deduce why the following method suffices:
|
||||
|
||||
```
|
||||
.globl TerminalClear
|
||||
TerminalClear:
|
||||
ldr r0,=terminalStart
|
||||
add r1,r0,#terminalBuffer-terminalStart
|
||||
str r1,[r0]
|
||||
str r1,[r0,#terminalStop-terminalStart]
|
||||
str r1,[r0,#terminalView-terminalStart]
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
Now we need to make a basic method for character based displays; the Print function. This takes in a string address in r0, and a length in r1, and simply writes it to the current location at the screen. There are a few special characters to be wary of, as well as special behaviour to ensure that terminalView is kept up to date. Let's analyse what it has to do:
|
||||
|
||||
1. Check if string length is 0, if so return
|
||||
2. Load in terminalStop and terminalView
|
||||
3. Deduce the x-coordinate of terminalStop
|
||||
4. For each character:
|
||||
1. Check if the character is a new line
|
||||
2. If so, increment bufferStop to the end of the line storing a black on black delete character.
|
||||
3. Otherwise, copy the character in the current terminalColour
|
||||
4. Check if we're at the end of a line
|
||||
5. If so, check if the number of characters between terminalView and terminalStop is more than one screen
|
||||
6. If so, increment terminalView by one line
|
||||
7. Check if terminalView is at the end of the buffer, replace it with the start if so
|
||||
8. Check if terminalStop is at the end of the buffer, replace it with the start if so
|
||||
9. Check if terminalStop equals terminalStart, increment terminalStart by one line if so
|
||||
10. Check if terminalStart is at the end of the buffer, replace it with the start if so
|
||||
5. Store back terminalStop and terminalView.
|
||||
|
||||
|
||||
|
||||
See if you can implement this yourself. My solution is provided below:
|
||||
|
||||
1.
|
||||
```
|
||||
.globl Print
|
||||
Print:
|
||||
teq r1,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
This quick check at the beginning makes a call to Print with a string of length 0 almost instant.
|
||||
|
||||
2.
|
||||
```
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
|
||||
bufferStart .req r4
|
||||
taddr .req r5
|
||||
x .req r6
|
||||
string .req r7
|
||||
length .req r8
|
||||
char .req r9
|
||||
bufferStop .req r10
|
||||
view .req r11
|
||||
|
||||
mov string,r0
|
||||
mov length,r1
|
||||
|
||||
ldr taddr,=terminalStart
|
||||
ldr bufferStop,[taddr,#terminalStop-terminalStart]
|
||||
ldr view,[taddr,#terminalView-terminalStart]
|
||||
ldr bufferStart,[taddr]
|
||||
add taddr,#terminalBuffer-terminalStart
|
||||
add taddr,#128*128*2
|
||||
```
|
||||
I do a lot of setup here. bufferStart contains terminalStart, bufferStop contains terminalStop, view contains terminalView, taddr is the address of the end of terminalBuffer.
|
||||
|
||||
3.
|
||||
```
|
||||
and x,bufferStop,#0xfe
|
||||
lsr x,#1
|
||||
```
|
||||
As per usual, a sneaky alignment trick makes everything easier. Because of the aligment of terminalBuffer, the x-coordinate of any character address is simply the last 8 bits divided by 2.
|
||||
|
||||
4.
|
||||
1.
|
||||
```
|
||||
charLoop$:
|
||||
ldrb char,[string]
|
||||
and char,#0x7f
|
||||
teq char,#'\n'
|
||||
bne charNormal$
|
||||
```
|
||||
We need to check for new lines.
|
||||
|
||||
2.
|
||||
```
|
||||
mov r0,#0x7f
|
||||
clearLine$:
|
||||
strh r0,[bufferStop]
|
||||
add bufferStop,#2
|
||||
add x,#1
|
||||
teq x,#128 blt clearLine$
|
||||
|
||||
b charLoopContinue$
|
||||
```
|
||||
Loop until the end of the line, writing out 0x7f; a delete character in black on a black background.
|
||||
|
||||
3.
|
||||
```
|
||||
charNormal$:
|
||||
strb char,[bufferStop]
|
||||
ldr r0,=terminalColour
|
||||
ldrb r0,[r0]
|
||||
strb r0,[bufferStop,#1]
|
||||
add bufferStop,#2
|
||||
add x,#1
|
||||
```
|
||||
Store the current character in the string and the terminalColour to the end of the terminalBuffer and then increment it and x.
|
||||
|
||||
4.
|
||||
```
|
||||
charLoopContinue$:
|
||||
cmp x,#128
|
||||
blt noScroll$
|
||||
```
|
||||
Check if x is at the end of a line; 128.
|
||||
|
||||
5.
|
||||
```
|
||||
mov x,#0
|
||||
subs r0,bufferStop,view
|
||||
addlt r0,#128*128*2
|
||||
cmp r0,#128*(768/16)*2
|
||||
```
|
||||
Set x back to 0 and check if we're currently showing more than one screen. Remember, we're using a circular buffer, so if the difference between bufferStop and view is negative, we're actually wrapping around the buffer.
|
||||
|
||||
6.
|
||||
```
|
||||
addge view,#128*2
|
||||
```
|
||||
Add one lines worth of bytes to the view address.
|
||||
|
||||
7.
|
||||
```
|
||||
teq view,taddr
|
||||
subeq view,taddr,#128*128*2
|
||||
```
|
||||
If the view address is at the end of the buffer we subtract the buffer length from it to move it back to the start. I set taddr to the address of the end of the buffer at the beginning.
|
||||
|
||||
8.
|
||||
```
|
||||
noScroll$:
|
||||
teq bufferStop,taddr
|
||||
subeq bufferStop,taddr,#128*128*2
|
||||
```
|
||||
If the stop address is at the end of the buffer we subtract the buffer length from it to move it back to the start. I set taddr to the address of the end of the buffer at the beginning.
|
||||
|
||||
9.
|
||||
```
|
||||
teq bufferStop,bufferStart
|
||||
addeq bufferStart,#128*2
|
||||
```
|
||||
Check if bufferStop equals bufferStart. If so, add one line to bufferStart.
|
||||
|
||||
10.
|
||||
```
|
||||
teq bufferStart,taddr
|
||||
subeq bufferStart,taddr,#128*128*2
|
||||
```
|
||||
If the start address is at the end of the buffer we subtract the buffer length from it to move it back to the start. I set taddr to the address of the end of the buffer at the beginning.
|
||||
|
||||
```
|
||||
subs length,#1
|
||||
add string,#1
|
||||
bgt charLoop$
|
||||
```
|
||||
Loop until the string is done.
|
||||
|
||||
5.
|
||||
```
|
||||
charLoopBreak$:
|
||||
sub taddr,#128*128*2
|
||||
sub taddr,#terminalBuffer-terminalStart
|
||||
str bufferStop,[taddr,#terminalStop-terminalStart]
|
||||
str view,[taddr,#terminalView-terminalStart]
|
||||
str bufferStart,[taddr]
|
||||
|
||||
pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
|
||||
.unreq bufferStart
|
||||
.unreq taddr
|
||||
.unreq x
|
||||
.unreq string
|
||||
.unreq length
|
||||
.unreq char
|
||||
.unreq bufferStop
|
||||
.unreq view
|
||||
```
|
||||
Store back the variables and return.
|
||||
|
||||
|
||||
This method allows us to print arbitrary text to the screen. Throughout, I've been using the colour variable, but no where have we actually set it. Normally, terminals use special combinations of characters to change the colour. For example ASCII Escape (1b16) followed by a number 0 to f in hexadecimal could set the foreground colour to that CGA colour number. You can try implementing this yourself; my version is in the further examples section on the download page.
|
||||
|
||||
### 4 Standard Input
|
||||
|
||||
```
|
||||
By convention, in many programming languages, every program has access to stdin and stdout, which are an input and and output stream linked to the terminal. This is still true on graphical programs, though many don't use it.
|
||||
```
|
||||
|
||||
Now we have an output terminal that in theory can print out text and display it. That is only half the story however, we want input. We want to implement a method, ReadLine, which stores the next line of text a user types to a location given in r0, up to a maximum length given in r1, and returns the length of the string read in r0. The tricky thing is, the user annoyingly wants to see what they're typing as they type it, they want to use backspace to delete mistakes and they want to use return to submit commands. They probably even want a flashing underscore character to indicate the computer would like input! These perfectly reasonable requests make this method a real challenge. One way to achieve all of this is to store the text they type in memory somewhere along with its length, and then after every character, move the terminalStop address back to where it started when ReadLine was called and calling Print. This means we only have to be able to manipulate a string in memory, and then make use of our Print function.
|
||||
|
||||
Lets have a look at what ReadLine will do:
|
||||
|
||||
1. If the maximum length is 0, return 0
|
||||
2. Retrieve the current values of terminalStop and terminalView
|
||||
3. If the maximum length is bigger than half the buffer size, set it to half the buffer size
|
||||
4. Subtract one from maximum length to ensure it can store our flashing underscore or a null terminator
|
||||
5. Write an underscore to the string
|
||||
6. Write the stored terminalView and terminalStop addresses back to the memory
|
||||
7. Call Print on the current string
|
||||
8. Call TerminalDisplay
|
||||
9. Call KeyboardUpdate
|
||||
10. Call KeyboardGetChar
|
||||
11. If it is a new line character go to 16
|
||||
12. If it is a backspace character, subtract 1 from the length of the string (if it is > 0)
|
||||
13. If it is an ordinary character, write it to the string (if the length < maximum length)
|
||||
14. If the string ends in an underscore, write a space, otherwise write an underscore
|
||||
15. Go to 6
|
||||
16. Write a new line character to the end of the string
|
||||
17. Call Print and TerminalDisplay
|
||||
18. Replace the new line with a null terminator
|
||||
19. Return the length of the string
|
||||
|
||||
|
||||
|
||||
Convince yourself that this will work, and then try to implement it yourself. My implementation is given below:
|
||||
|
||||
1.
|
||||
```
|
||||
.globl ReadLine
|
||||
ReadLine:
|
||||
teq r1,#0
|
||||
moveq r0,#0
|
||||
moveq pc,lr
|
||||
```
|
||||
Quick special handling for the zero case, which is otherwise difficult.
|
||||
|
||||
2.
|
||||
```
|
||||
string .req r4
|
||||
maxLength .req r5
|
||||
input .req r6
|
||||
taddr .req r7
|
||||
length .req r8
|
||||
view .req r9
|
||||
|
||||
push {r4,r5,r6,r7,r8,r9,lr}
|
||||
|
||||
mov string,r0
|
||||
mov maxLength,r1
|
||||
ldr taddr,=terminalStart
|
||||
ldr input,[taddr,#terminalStop-terminalStart]
|
||||
ldr view,[taddr,#terminalView-terminalStart]
|
||||
mov length,#0
|
||||
```
|
||||
As per the general theme, I do a lot of initialisations early. input contains the value of terminalStop and view contains terminalView. Length starts at 0.
|
||||
|
||||
3.
|
||||
```
|
||||
cmp maxLength,#128*64
|
||||
movhi maxLength,#128*64
|
||||
```
|
||||
We have to check for unusually large reads, as we can't process them beyond the size of the terminalBuffer (I suppose we CAN, but it would be very buggy, as terminalStart could move past the stored terminalStop).
|
||||
|
||||
4.
|
||||
```
|
||||
sub maxLength,#1
|
||||
```
|
||||
Since the user wants a flashing cursor, and we ideally want to put a null terminator on this string, we need 1 spare character.
|
||||
|
||||
5.
|
||||
```
|
||||
mov r0,#'_'
|
||||
strb r0,[string,length]
|
||||
```
|
||||
Write out the underscore to let the user know they can input.
|
||||
|
||||
6.
|
||||
```
|
||||
readLoop$:
|
||||
str input,[taddr,#terminalStop-terminalStart]
|
||||
str view,[taddr,#terminalView-terminalStart]
|
||||
```
|
||||
Save the stored terminalStop and terminalView. This is important to reset the terminal after each call to Print, which changes these variables. Strictly speaking it can change terminalStart too, but this is irreversible.
|
||||
|
||||
7.
|
||||
```
|
||||
mov r0,string
|
||||
mov r1,length
|
||||
add r1,#1
|
||||
bl Print
|
||||
```
|
||||
Write the current input. We add 1 to the length for the underscore.
|
||||
|
||||
8.
|
||||
```
|
||||
bl TerminalDisplay
|
||||
```
|
||||
Copy the new text to the screen.
|
||||
|
||||
9.
|
||||
```
|
||||
bl KeyboardUpdate
|
||||
```
|
||||
Fetch the latest keyboard input.
|
||||
|
||||
10.
|
||||
```
|
||||
bl KeyboardGetChar
|
||||
```
|
||||
Retrieve the key pressed.
|
||||
|
||||
11.
|
||||
```
|
||||
teq r0,#'\n'
|
||||
beq readLoopBreak$
|
||||
teq r0,#0
|
||||
beq cursor$
|
||||
teq r0,#'\b'
|
||||
bne standard$
|
||||
```
|
||||
|
||||
Break out of the loop if we have an enter key. Also skip these conditions if we have a null terminator and process a backspace if we have one.
|
||||
|
||||
12.
|
||||
```
|
||||
delete$:
|
||||
cmp length,#0
|
||||
subgt length,#1
|
||||
b cursor$
|
||||
```
|
||||
Remove one from the length to delete a character.
|
||||
|
||||
13.
|
||||
```
|
||||
standard$:
|
||||
cmp length,maxLength
|
||||
bge cursor$
|
||||
strb r0,[string,length]
|
||||
add length,#1
|
||||
```
|
||||
Write out an ordinary character where possible.
|
||||
|
||||
14.
|
||||
```
|
||||
cursor$:
|
||||
ldrb r0,[string,length]
|
||||
teq r0,#'_'
|
||||
moveq r0,#' '
|
||||
movne r0,#'_'
|
||||
strb r0,[string,length]
|
||||
```
|
||||
Load in the last character, and change it to an underscore if it isn't one, and a space if it is.
|
||||
|
||||
15.
|
||||
```
|
||||
b readLoop$
|
||||
readLoopBreak$:
|
||||
```
|
||||
Loop until the user presses enter.
|
||||
|
||||
16.
|
||||
```
|
||||
mov r0,#'\n'
|
||||
strb r0,[string,length]
|
||||
```
|
||||
Store a new line at the end of the string.
|
||||
|
||||
17.
|
||||
```
|
||||
str input,[taddr,#terminalStop-terminalStart]
|
||||
str view,[taddr,#terminalView-terminalStart]
|
||||
mov r0,string
|
||||
mov r1,length
|
||||
add r1,#1
|
||||
bl Print
|
||||
bl TerminalDisplay
|
||||
```
|
||||
Reset the terminalView and terminalStop and then Print and TerminalDisplay the final input.
|
||||
|
||||
18.
|
||||
```
|
||||
mov r0,#0
|
||||
strb r0,[string,length]
|
||||
```
|
||||
Write out the null terminator.
|
||||
|
||||
19.
|
||||
```
|
||||
mov r0,length
|
||||
pop {r4,r5,r6,r7,r8,r9,pc}
|
||||
.unreq string
|
||||
.unreq maxLength
|
||||
.unreq input
|
||||
.unreq taddr
|
||||
.unreq length
|
||||
.unreq view
|
||||
```
|
||||
Return the length.
|
||||
|
||||
|
||||
|
||||
|
||||
### 5 The Terminal: Rise of the Machine
|
||||
|
||||
So, now we can theoretically interact with the user on the terminal. The most obvious thing to do is to put this to the test! In 'main.s' delete everything after bl UsbInitialise and copy in the following code:
|
||||
|
||||
```
|
||||
reset$:
|
||||
mov sp,#0x8000
|
||||
bl TerminalClear
|
||||
|
||||
ldr r0,=welcome
|
||||
mov r1,#welcomeEnd-welcome
|
||||
bl Print
|
||||
|
||||
loop$:
|
||||
ldr r0,=prompt
|
||||
mov r1,#promptEnd-prompt
|
||||
bl Print
|
||||
|
||||
ldr r0,=command
|
||||
mov r1,#commandEnd-command
|
||||
bl ReadLine
|
||||
|
||||
teq r0,#0
|
||||
beq loopContinue$
|
||||
|
||||
mov r4,r0
|
||||
|
||||
ldr r5,=command
|
||||
ldr r6,=commandTable
|
||||
|
||||
ldr r7,[r6,#0]
|
||||
ldr r9,[r6,#4]
|
||||
commandLoop$:
|
||||
ldr r8,[r6,#8]
|
||||
sub r1,r8,r7
|
||||
|
||||
cmp r1,r4
|
||||
bgt commandLoopContinue$
|
||||
|
||||
mov r0,#0
|
||||
commandName$:
|
||||
ldrb r2,[r5,r0]
|
||||
ldrb r3,[r7,r0]
|
||||
teq r2,r3
|
||||
bne commandLoopContinue$
|
||||
add r0,#1
|
||||
teq r0,r1
|
||||
bne commandName$
|
||||
|
||||
ldrb r2,[r5,r0]
|
||||
teq r2,#0
|
||||
teqne r2,#' '
|
||||
bne commandLoopContinue$
|
||||
|
||||
mov r0,r5
|
||||
mov r1,r4
|
||||
mov lr,pc
|
||||
mov pc,r9
|
||||
b loopContinue$
|
||||
|
||||
commandLoopContinue$:
|
||||
add r6,#8
|
||||
mov r7,r8
|
||||
ldr r9,[r6,#4]
|
||||
teq r9,#0
|
||||
bne commandLoop$
|
||||
|
||||
ldr r0,=commandUnknown
|
||||
mov r1,#commandUnknownEnd-commandUnknown
|
||||
ldr r2,=formatBuffer
|
||||
ldr r3,=command
|
||||
bl FormatString
|
||||
|
||||
mov r1,r0
|
||||
ldr r0,=formatBuffer
|
||||
bl Print
|
||||
|
||||
loopContinue$:
|
||||
bl TerminalDisplay
|
||||
b loop$
|
||||
|
||||
echo:
|
||||
cmp r1,#5
|
||||
movle pc,lr
|
||||
|
||||
add r0,#5
|
||||
sub r1,#5
|
||||
b Print
|
||||
|
||||
ok:
|
||||
teq r1,#5
|
||||
beq okOn$
|
||||
teq r1,#6
|
||||
beq okOff$
|
||||
mov pc,lr
|
||||
|
||||
okOn$:
|
||||
ldrb r2,[r0,#3]
|
||||
teq r2,#'o'
|
||||
ldreqb r2,[r0,#4]
|
||||
teqeq r2,#'n'
|
||||
movne pc,lr
|
||||
mov r1,#0
|
||||
b okAct$
|
||||
|
||||
okOff$:
|
||||
ldrb r2,[r0,#3]
|
||||
teq r2,#'o'
|
||||
ldreqb r2,[r0,#4]
|
||||
teqeq r2,#'f'
|
||||
ldreqb r2,[r0,#5]
|
||||
teqeq r2,#'f'
|
||||
movne pc,lr
|
||||
mov r1,#1
|
||||
|
||||
okAct$:
|
||||
|
||||
mov r0,#16
|
||||
b SetGpio
|
||||
|
||||
.section .data
|
||||
.align 2
|
||||
welcome: .ascii "Welcome to Alex's OS - Everyone's favourite OS"
|
||||
welcomeEnd:
|
||||
.align 2
|
||||
prompt: .ascii "\n> "
|
||||
promptEnd:
|
||||
.align 2
|
||||
command:
|
||||
.rept 128
|
||||
.byte 0
|
||||
.endr
|
||||
commandEnd:
|
||||
.byte 0
|
||||
.align 2
|
||||
commandUnknown: .ascii "Command `%s' was not recognised.\n"
|
||||
commandUnknownEnd:
|
||||
.align 2
|
||||
formatBuffer:
|
||||
.rept 256
|
||||
.byte 0
|
||||
.endr
|
||||
formatEnd:
|
||||
|
||||
.align 2
|
||||
commandStringEcho: .ascii "echo"
|
||||
commandStringReset: .ascii "reset"
|
||||
commandStringOk: .ascii "ok"
|
||||
commandStringCls: .ascii "cls"
|
||||
commandStringEnd:
|
||||
|
||||
.align 2
|
||||
commandTable:
|
||||
.int commandStringEcho, echo
|
||||
.int commandStringReset, reset$
|
||||
.int commandStringOk, ok
|
||||
.int commandStringCls, TerminalClear
|
||||
.int commandStringEnd, 0
|
||||
```
|
||||
This code brings everything together into a simple command line operating system. The commands available are echo, reset, ok and cls. echo copies any text after it back to the terminal, reset resets the operating system if things go wrong, ok has two functions: ok on turns the OK LED on, and ok off turns the OK LED off, and cls clears the terminal using TerminalClear.
|
||||
|
||||
Have a go with this code on the Raspberry Pi. If it doesn't work, please see our troubleshooting page.
|
||||
|
||||
When it works, congratulations you've completed a basic terminal Operating System, and have completed the input series. Unfortunately, this is as far as these tutorials go at the moment, but I hope to make more in the future. Please send feedback to awc32@cam.ac.uk.
|
||||
|
||||
You're now in position to start building some simple terminal Operating Systems. My code above builds up a table of available commands in commandTable. Each entry in the table is an int for the address of the string, and an int for the address of the code to run. The last entry has to be commandStringEnd, 0. Try implementing some of your own commands, using our existing functions, or making new ones. The parameters for the functions to run are r0 is the address of the command the user typed, and r1 is the length. You can use this to pass inputs to your commands. Maybe you could make a calculator program, perhaps a drawing program or a chess program. Whatever ideas you've got, give them a go!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/circular_buffer.png
|
||||
@ -0,0 +1,503 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 6 Screen01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 6 Screen01
|
||||
======
|
||||
|
||||
Welcome to the Screen lesson series. In this series, you will learn how to control the screen using the Raspberry Pi in assembly code, starting at just displaying random data, then moving up to displaying a fixed image, displaying text and then formatting numbers into text. It is assumed that you have already completed the OK series, and so things covered in this series will not be repeated here.
|
||||
|
||||
This first screen lesson teaches some basic theory about graphics, and then applies it to display a gradient pattern to the screen or TV.
|
||||
|
||||
### 1 Getting Started
|
||||
|
||||
It is expected that you have completed the OK series, and so functions in the 'gpio.s' file and 'systemTimer.s' file from that series will be called. If you do not have these files, or prefer to use a correct implementation, download the solution to OK05.s. The 'main.s' file from here will also be useful, up to and including mov sp,#0x8000. Please delete anything after that line.
|
||||
|
||||
### 2 Computer Graphics
|
||||
|
||||
There are a few systems for representing colours as numbers. Here we focus on RGB systems, but HSL is another common system used.
|
||||
|
||||
As you're hopefully beginning to appreciate, at a fundamental level, computers are very stupid. They have a limited number of instructions, almost exclusively to do with maths, and yet somehow they are capable of doing many things. The thing we currently wish to understand is how a computer could possibly put an image on the screen. How would we translate this problem into binary? The answer is relatively straightforward; we devise some system of numbering each colour, and then we store one number for every pixel on the screen. A pixel is a small dot on your screen. If you move very close, you will probably be able to make out individual pixels on your screen, and be able to see that everything image is just made out of these pixels in combination.
|
||||
|
||||
As the computer age advanced, people wanted more and more complicated graphics, and so the concept of a graphics card was invented. The graphics card is a secondary processor on your computer which only exists to draw images to the screen. It has the job of turning the pixel value information into light intensity levels to be transmitted to the screen. On modern computers, graphics cards can also do a lot more than that, such as drawing 3D graphics. In this tutorial however, we will just concentrate on the first use of graphics cards; getting pixel colours from memory out to the screen.
|
||||
|
||||
One issue that is raised immediately by all this is the system we use for numbering colours. There are several choices, each producing outputs of different quality. I will outline a few here for completeness.
|
||||
|
||||
Although some images here have few colours they use a technique called spatial dithering. This allows them to still show a good representation of the image, with very few colours. Many early Operating Systems used this technique.
|
||||
|
||||
| Name | Unique Colours | Description | Examples |
|
||||
| ----------- | --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------- |
|
||||
| Monochrome | 2 | Use 1 bit to store each pixel, with a 1 being white, and a 0 being black. | ![Monochrome image of a bird][1] |
|
||||
| Greyscale | 256 | Use 1 byte to store each pixel, with 255 representing white, 0 representing black, and all values in between representing a linear combination of the two. | ![Geryscale image of a bird][2] |
|
||||
| 8 Colour | 8 | Use 3 bits to store each pixel, the first bit representing the presence of a red channel, the second representing a green channel and the third a blue channel. | ![8 colour image of a bird][3] |
|
||||
| Low Colour | 256 | Use 8 bits to store each pixel, the first 3 bit representing the intensity of the red channel, the next 3 bits representing the intensity of the green channel and the final 2 bits representing the intensity of the blue channel. | ![Low colour image of a bird][4] |
|
||||
| High Colour | 65,536 | Use 16 bits to store each pixel, the first 5 bit representing the intensity of the red channel, the next 6 bits representing the intensity of the green channel and the final 5 bits representing the intensity of the blue channel. | ![High colour image of a bird][5] |
|
||||
| True Colour | 16,777,216 | Use 24 bits to store each pixel, the first 8 bits representing the intensity of the red channel, the second 8 representing the green channel and the final 8 bits the blue channel. | ![True colour image of a bird][6] |
|
||||
| RGBA32 | 16,777,216 with 256 transparency levels | Use 32 bits to store each pixel, the first 8 bits representing the intensity of the red channel, the second 8 representing the green channel, the third 8 bits the blue channel, and the final 8 bits a transparency channel. The transparency channel is only considered when drawing one image on top of another and is stored such that a value of 0 indicates the image behind's colour, a value of 255 represents this image's colour, and all values between represent a mix. | |
|
||||
|
||||
|
||||
In this tutorial we shall use High Colour initially. As you can see form the image, it is produces clear, good quality images, but it doesn't take up as much space as True Colour. That said, for quite a small display of 800x600 pixels, it would still take just under 1 megabyte of space. It also has the advantage that the size is a multiple of a power of 2, which greatly reduces the complexity of getting information compared with True Colour.
|
||||
|
||||
```
|
||||
Storing the frame buffer places a heavy memory burden on a computer. For this reason, early computers often cheated, by, for example, storing a screens worth of text, and just drawing each letter to the screen every time it is refreshed separately.
|
||||
```
|
||||
|
||||
The Raspberry Pi has a very special and rather odd relationship with it's graphics processor. On the Raspberry Pi, the graphics processor actually runs first, and is responsible for starting up the main processor. This is very unusual. Ultimately it doesn't make too much difference, but in many interactions, it often feels like the processor is secondary, and the graphics processor is the most important. The two communicate on the Raspberry Pi by what is called the 'mailbox'. Each can deposit mail for the other, which will be collected at some future point and then dealt with. We shall use the mailbox to ask the graphics processor for an address. The address will be a location to which we can write the pixel colour information for the screen, called a frame buffer, and the graphics card will regularly check this location, and update the pixels on the screen appropriately.
|
||||
|
||||
### 3 Programming the Postman
|
||||
|
||||
```
|
||||
Message passing is quite a common way for components to communicate. Some Operating Systems use virtual message passing to allow programs to communicate.
|
||||
```
|
||||
|
||||
The first thing we are going to need to program is a 'postman'. This is just two methods: MailboxRead, reading one message from the mailbox channel in r0. and MailboxWrite, writing the value in the top 28 bits of r0 to the mailbox channel in r1. The Raspberry Pi has 7 mailbox channels for communication with the graphics processor, only the first of which is useful to us, as it is for negotiating the frame buffer.
|
||||
|
||||
The following table and diagrams describe the operation of the mailbox.
|
||||
|
||||
Table 3.1 Mailbox Addresses
|
||||
| Address | Size / Bytes | Name | Description | Read / Write |
|
||||
| 2000B880 | 4 | Read | Receiving mail. | R |
|
||||
| 2000B890 | 4 | Poll | Receive without retrieving. | R |
|
||||
| 2000B894 | 4 | Sender | Sender information. | R |
|
||||
| 2000B898 | 4 | Status | Information. | R |
|
||||
| 2000B89C | 4 | Configuration | Settings. | RW |
|
||||
| 2000B8A0 | 4 | Write | Sending mail. | W |
|
||||
|
||||
In order to send a message to a particular mailbox:
|
||||
|
||||
1. The sender waits until the Status field has a 0 in the top bit.
|
||||
2. The sender writes to Write such that the lowest 4 bits are the mailbox to write to, and the upper 28 bits are the message to write.
|
||||
|
||||
|
||||
|
||||
In order to read a message:
|
||||
|
||||
1. The receiver waits until the Status field has a 0 in the 30th bit.
|
||||
2. The receiver reads from Read.
|
||||
3. The receiver confirms the message is for the correct mailbox, and tries again if not.
|
||||
|
||||
|
||||
|
||||
If you're feeling particularly confident, you now have enough information to write the two methods we need. If not, read on.
|
||||
|
||||
As always the first method I recommend you implement is one to get the address of the mailbox region.
|
||||
|
||||
```
|
||||
.globl GetMailboxBase
|
||||
GetMailboxBase:
|
||||
ldr r0,=0x2000B880
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
The sending procedure is least complicated, so we shall implement this first. As your methods become more and more complicated, you will need to start planning them in advance. A good way to do this might be to write out a simple list of the steps that need to be done, in a fair amount of detail, like below.
|
||||
|
||||
1. Our input will be what to write (r0), and what mailbox to write it to (r1). We must validate this is by checking it is a real mailbox, and that the low 4 bits of the value are 0. Never forget to validate inputs.
|
||||
2. Use GetMailboxBase to retrieve the address.
|
||||
3. Read from the Status field.
|
||||
4. Check the top bit is 0. If not, go back to 3.
|
||||
5. Combine the value to write and the channel.
|
||||
6. Write to the Write.
|
||||
|
||||
|
||||
|
||||
Let's handle each of these in order.
|
||||
|
||||
1.
|
||||
```
|
||||
.globl MailboxWrite
|
||||
MailboxWrite:
|
||||
tst r0,#0b1111
|
||||
movne pc,lr
|
||||
cmp r1,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
```
|
||||
tst reg,#val computes and reg,#val and compares the result with 0.
|
||||
```
|
||||
|
||||
This achieves our validation on r0 and r1. tst is a function that compares two numbers by computing the logical and operation of the numbers, and then comparing the result with 0. In this case it checks that the lowest 4 bits of the input in r0 are all 0.
|
||||
|
||||
2.
|
||||
```
|
||||
channel .req r1
|
||||
value .req r2
|
||||
mov value,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
This code ensures we will not overwrite our value, or link register and calls GetMailboxBase.
|
||||
|
||||
3.
|
||||
```
|
||||
wait1$:
|
||||
status .req r3
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
This code loads in the current status.
|
||||
|
||||
4.
|
||||
```
|
||||
tst status,#0x80000000
|
||||
.unreq status
|
||||
bne wait1$
|
||||
```
|
||||
|
||||
This code checks that the top bit of the status field is 0, and loops back to 3. if it is not.
|
||||
|
||||
5.
|
||||
```
|
||||
add value,channel
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
This code combines the channel and value together.
|
||||
|
||||
6.
|
||||
```
|
||||
str value,[mailbox,#0x20]
|
||||
.unreq value
|
||||
.unreq mailbox
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
This code stores the result to the write field.
|
||||
|
||||
|
||||
|
||||
|
||||
The code for MailboxRead is quite similar.
|
||||
|
||||
1. Our input will be what mailbox to read from (r0). We must validate this is by checking it is a real mailbox. Never forget to validate inputs.
|
||||
2. Use GetMailboxBase to retrieve the address.
|
||||
3. Read from the Status field.
|
||||
4. Check the 30th bit is 0. If not, go back to 3.
|
||||
5. Read from the Read field.
|
||||
6. Check the mailbox is the one we want, if not go back to 3.
|
||||
7. Return the result.
|
||||
|
||||
|
||||
|
||||
Let's handle each of these in order.
|
||||
|
||||
1.
|
||||
```
|
||||
.globl MailboxRead
|
||||
MailboxRead:
|
||||
cmp r0,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
This achieves our validation on r0.
|
||||
|
||||
2.
|
||||
```
|
||||
channel .req r1
|
||||
mov channel,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
This code ensures we will not overwrite our value, or link register and calls GetMailboxBase.
|
||||
|
||||
3.
|
||||
```
|
||||
rightmail$:
|
||||
wait2$:
|
||||
status .req r2
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
This code loads in the current status.
|
||||
|
||||
4.
|
||||
```
|
||||
tst status,#0x40000000
|
||||
.unreq status
|
||||
bne wait2$
|
||||
```
|
||||
|
||||
This code checks that the 30th bit of the status field is 0, and loops back to 3. if it is not.
|
||||
|
||||
5.
|
||||
```
|
||||
mail .req r2
|
||||
ldr mail,[mailbox,#0]
|
||||
```
|
||||
|
||||
This code reads the next item from the mailbox.
|
||||
|
||||
6.
|
||||
```
|
||||
inchan .req r3
|
||||
and inchan,mail,#0b1111
|
||||
teq inchan,channel
|
||||
.unreq inchan
|
||||
bne rightmail$
|
||||
.unreq mailbox
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
This code checks that the channel of the mail we just read is the one we were supplied. If not it loops back to 3.
|
||||
|
||||
7.
|
||||
```
|
||||
and r0,mail,#0xfffffff0
|
||||
.unreq mail
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
This code moves the answer (the top 28 bits of mail) to r0.
|
||||
|
||||
|
||||
|
||||
|
||||
### 4 My Dearest Graphics Processor
|
||||
|
||||
Through our new postman, we now have the ability to send a message to the graphics card. What should we send though? This was certainly a difficult question for me to find the answer to, as it isn't in any online manual that I have found. Nevertheless, by looking at the GNU/Linux for the Raspberry Pi, we are able to work out what we needed to send.
|
||||
|
||||
```
|
||||
Since the RAM is shared between the graphics processor and the processor on the Pi, we can just send where to find our message. This is called DMA, many complicated devices use this to speed up access times.
|
||||
```
|
||||
|
||||
The message is very simple. We describe the framebuffer we would like, and the graphics card either agrees to our request, in which case it sends us back a 0, and fills in a small questionnaire we make, or it sends back a non-zero number, in which case we know it is unhappy. Unfortunately, I have no idea what any of the other numbers it can send back are, nor what they mean, but only when it sends a zero it is happy. Fortunately it always seems to send a zero for sensible inputs, so we don't need to worry too much.
|
||||
|
||||
For simplicity we shall design our request in advance, and store it in the .data section. In a file called 'framebuffer.s' place the following code:
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 4
|
||||
.globl FrameBufferInfo
|
||||
FrameBufferInfo:
|
||||
.int 1024 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #0 Physical Width */
|
||||
.int 768 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #4 Physical Height */
|
||||
.int 1024 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #8 Virtual Width */
|
||||
.int 768 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #12 Virtual Height */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #16 GPU - Pitch */
|
||||
.int 16 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #20 Bit Depth */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #24 X */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #28 Y */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #32 GPU - Pointer */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #36 GPU - Size */
|
||||
```
|
||||
|
||||
This is the format of our messages to the graphics processor. The first two words describe the physical width and height. The second pair is the virtual width and height. The framebuffer's width and height are the virtual width and height, and the GPU scales the framebuffer as need to fit the physical screen. The next word is one of the ones the GPU will fill in if it grants our request. It will be the number of bytes on each row of the frame buffer, in this case 2 × 1024 = 2048. The next word is how many bits to allocate to each pixel. Using a value of 16 means that the graphics processor uses High Colour mode described above. A value of 24 would use True Colour, and 32 would use RGBA32. The next two words are x and y offsets, which mean the number of pixels to skip in the top left corner of the screen when copying the framebuffer to the screen. Finally, the last two words are filled in by the graphics processor, the first of which is the actual pointer to the frame buffer, and the second is the size of the frame buffer in bytes.
|
||||
|
||||
```
|
||||
When working with devices using DMA, alignment constraints become very important. The GPU expects the message to be 16 byte aligned.
|
||||
```
|
||||
|
||||
I was very careful to include a .align 4 here. As discussed before, this ensures the lowest 4 bits of the address of the next line are 0. Thus, we know for sure that FrameBufferInfo will be placed at an address we can send to the graphics processor, as our mailbox only sends values with the low 4 bits all 0.
|
||||
|
||||
So, now that we have our message, we can write code to send it. The communication will go as follows:
|
||||
|
||||
1. Write the address of FrameBufferInfo + 0x40000000 to mailbox 1.
|
||||
2. Read the result from mailbox 1. If it is not zero, we didn't ask for a proper frame buffer.
|
||||
3. Copy our images to the pointer, and they will appear on screen!
|
||||
|
||||
|
||||
|
||||
I've said something that I've not mentioned before in step 1. We have to add 0x40000000 to the address of FrameBufferInfo before sending it. This is actually a special signal to the GPU of how it should write to the structure. If we just send the address, the GPU will write its response, but will not make sure we can see it by flushing its cache. The cache is a piece of memory where a processor stores values its working on before sending them to the RAM. By adding 0x40000000, we tell the GPU not to use its cache for these writes, which ensures we will be able to see the change.
|
||||
|
||||
Since there is quite a lot going on there, it would be best to implement this as a function, rather than just putting the code into main.s. We shall write a function InitialiseFrameBuffer which does all this negotiation and returns the pointer to the frame buffer info data above, once it has a pointer in it. For ease, we should also make it so that the width, height and bit depth of the frame buffer are inputs to this method, so that it is easy to change in main.s without having to get into the details of the negotiation.
|
||||
|
||||
Once again, let's write down in detail the steps we will have to take. If you're feeling confident, try writing the function straight away.
|
||||
|
||||
1. Validate our inputs.
|
||||
2. Write the inputs into the frame buffer.
|
||||
3. Send the address of the frame buffer + 0x40000000 to the mailbox.
|
||||
4. Receive the reply from the mailbox.
|
||||
5. If the reply is not 0, the method has failed. We should return 0 to indicate failure.
|
||||
6. Return a pointer to the frame buffer info.
|
||||
|
||||
|
||||
|
||||
Now we're getting into much bigger methods than before. Below is one implementation of the above.
|
||||
|
||||
1.
|
||||
```
|
||||
.section .text
|
||||
.globl InitialiseFrameBuffer
|
||||
InitialiseFrameBuffer:
|
||||
width .req r0
|
||||
height .req r1
|
||||
bitDepth .req r2
|
||||
cmp width,#4096
|
||||
cmpls height,#4096
|
||||
cmpls bitDepth,#32
|
||||
result .req r0
|
||||
movhi result,#0
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
This code checks that the width and height are less than or equal to 4096, and that the bit depth is less than or equal to 32. This is once again using a trick with conditional execution. Convince yourself that this works.
|
||||
|
||||
2.
|
||||
```
|
||||
fbInfoAddr .req r3
|
||||
push {lr}
|
||||
ldr fbInfoAddr,=FrameBufferInfo
|
||||
str width,[fbInfoAddr,#0]
|
||||
str height,[fbInfoAddr,#4]
|
||||
str width,[fbInfoAddr,#8]
|
||||
str height,[fbInfoAddr,#12]
|
||||
str bitDepth,[fbInfoAddr,#20]
|
||||
.unreq width
|
||||
.unreq height
|
||||
.unreq bitDepth
|
||||
```
|
||||
|
||||
This code simply writes into our frame buffer structure defined above. I also take the opportunity to push the link register onto the stack.
|
||||
|
||||
3.
|
||||
```
|
||||
mov r0,fbInfoAddr
|
||||
add r0,#0x40000000
|
||||
mov r1,#1
|
||||
bl MailboxWrite
|
||||
```
|
||||
|
||||
The inputs to the MailboxWrite method are the value to write in r0, and the channel to write to in r1.
|
||||
|
||||
4.
|
||||
```
|
||||
mov r0,#1
|
||||
bl MailboxRead
|
||||
```
|
||||
|
||||
The inputs to the MailboxRead method is the channel to write to in r0, and the output is the value read.
|
||||
|
||||
5.
|
||||
```
|
||||
teq result,#0
|
||||
movne result,#0
|
||||
popne {pc}
|
||||
```
|
||||
|
||||
This code checks if the result of the MailboxRead method is 0, and returns 0 if not.
|
||||
|
||||
6.
|
||||
```
|
||||
mov result,fbInfoAddr
|
||||
pop {pc}
|
||||
.unreq result
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
This code finishes off and returns the frame buffer info address.
|
||||
|
||||
|
||||
|
||||
|
||||
### 5 A Pixel Within a Row Within a Frame
|
||||
|
||||
So, we've now created our methods to communicate with the graphics processor. It should now be capable of giving us the pointer to a frame buffer we can draw graphics to. Let's draw something now.
|
||||
|
||||
In this first example, we'll just draw consecutive colours to the screen. It won't look pretty, but at least it will be working. How we will do this is by setting each pixel in the framebuffer to a consecutive number, and continually doing so.
|
||||
|
||||
Copy the following code to 'main.s' after mov sp,#0x8000
|
||||
|
||||
```
|
||||
mov r0,#1024
|
||||
mov r1,#768
|
||||
mov r2,#16
|
||||
bl InitialiseFrameBuffer
|
||||
```
|
||||
|
||||
This code simply uses our InitialiseFrameBuffer method to create a frame buffer with width 1024, height 768, and bit depth 16. You can try different values in here if you wish, as long as you are consistent throughout the code. Since it's possible that this method can return 0 if the graphics processor did not give us a frame buffer, we had better check for this, and turn the OK LED on if it happens.
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
bne noError$
|
||||
|
||||
mov r0,#16
|
||||
mov r1,#1
|
||||
bl SetGpioFunction
|
||||
mov r0,#16
|
||||
mov r1,#0
|
||||
bl SetGpio
|
||||
|
||||
error$:
|
||||
b error$
|
||||
|
||||
noError$:
|
||||
fbInfoAddr .req r4
|
||||
mov fbInfoAddr,r0
|
||||
```
|
||||
|
||||
Now that we have the frame buffer info address, we need to get the frame buffer pointer from it, and start drawing to the screen. We will do this using two loops, one going down the rows, and one going along the columns. On the Raspberry Pi, indeed in most applications, pictures are stored left to right then top to bottom, so we have to do the loops in the order I have said.
|
||||
|
||||
|
||||
```
|
||||
render$:
|
||||
|
||||
fbAddr .req r3
|
||||
ldr fbAddr,[fbInfoAddr,#32]
|
||||
|
||||
colour .req r0
|
||||
y .req r1
|
||||
mov y,#768
|
||||
drawRow$:
|
||||
|
||||
x .req r2
|
||||
mov x,#1024
|
||||
drawPixel$:
|
||||
|
||||
strh colour,[fbAddr]
|
||||
add fbAddr,#2
|
||||
sub x,#1
|
||||
teq x,#0
|
||||
bne drawPixel$
|
||||
|
||||
sub y,#1
|
||||
add colour,#1
|
||||
teq y,#0
|
||||
bne drawRow$
|
||||
|
||||
b render$
|
||||
|
||||
.unreq fbAddr
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
```
|
||||
strh reg,[dest] stores the low half word number in reg at the address given by dest.
|
||||
```
|
||||
|
||||
This is quite a large chunk of code, and has a loop within a loop within a loop. To help get your head around the looping, I've indented the code which is looped, depending on which loop it is in. This is quite common in most high level programming languages, and the assembler simply ignores the tabs. We see here that I load in the frame buffer address from the frame buffer information structure, and then loop over every row, then every pixel on the row. At each pixel, I use an strh (store half word) command to store the current colour, then increment the address we're writing to. After drawing each row, we increment the colour that we are drawing. After drawing the full screen, we branch back to the beginning.
|
||||
|
||||
### 6 Seeing the Light
|
||||
|
||||
Now you're ready to test this code on the Raspberry Pi. You should see a changing gradient pattern. Be careful: until the first message is sent to the mailbox, the Raspberry Pi displays a still gradient pattern between the four corners. If it doesn't work, please see our troubleshooting page.
|
||||
|
||||
If it does work, congratulations! You can now control the screen! Feel free to alter this code to draw whatever pattern you like. You can do some very nice gradient patterns, and can compute the value of each pixel directly, since y contains a y-coordinate for the pixel, and x contains an x-coordinate. In the next lesson, [Lesson 7: Screen 02][7], we will look at one of the most common drawing tasks, lines.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour1bImage.png
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8gImage.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour3bImage.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8bImage.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour16bImage.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour24bImage.png
|
||||
[7]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
@ -0,0 +1,449 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 7 Screen02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 7 Screen02
|
||||
======
|
||||
|
||||
The Screen02 lesson builds on Screen01, by teaching how to draw lines and also a small feature on generating pseudo random numbers. It is assumed you have the code for the [Lesson 6: Screen01][1] operating system as a basis.
|
||||
|
||||
### 1 Dots
|
||||
|
||||
Now that we've got the screen working, it is only natural to start waiting to create sensible images. It would be very nice indeed if we were able to actually draw something. One of the most basic components in all drawings is a line. If we were able to draw a line between any two points on the screen, we could start creating more complicated drawings just using combinations of these lines.
|
||||
|
||||
```
|
||||
To allow complex drawing, some systems use a colouring function rather than just one colour to draw things. Each pixel calls the colouring function to determine what colour to draw there.
|
||||
```
|
||||
|
||||
We will attempt to implement this in assembly code, but first we could really use some other functions to help. We need a function I will call SetPixel that changes the colour of a particular pixel, supplied as inputs in r0 and r1. It will be helpful for future if we write code that could draw to any memory, not just the screen, so first of all, we need some system to control where we are actually going to draw to. I think that the best way to do this would be to have a piece of memory which stores where we are going to draw to. What we should end up with is a stored address which normally points to the frame buffer structure from last time. We will use this at all times in our drawing method. That way, if we want to draw to a different image in another part of our operating system, we could make this value the address of a different structure, and use the exact same code. For simplicity we will use another piece of data to control the colour of our drawings.
|
||||
|
||||
Copy the following code to a new file called 'drawing.s'.
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 1
|
||||
foreColour:
|
||||
.hword 0xFFFF
|
||||
|
||||
.align 2
|
||||
graphicsAddress:
|
||||
.int 0
|
||||
|
||||
.section .text
|
||||
.globl SetForeColour
|
||||
SetForeColour:
|
||||
cmp r0,#0x10000
|
||||
movhs pc,lr
|
||||
ldr r1,=foreColour
|
||||
strh r0,[r1]
|
||||
mov pc,lr
|
||||
|
||||
.globl SetGraphicsAddress
|
||||
SetGraphicsAddress:
|
||||
ldr r1,=graphicsAddress
|
||||
str r0,[r1]
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
This is just the pair of functions that I described above, along with their data. We will use them in 'main.s' before drawing anything to control where and what we are drawing.
|
||||
|
||||
```
|
||||
Building generic methods like SetPixel which we can build other methods on top of is a useful idea. We have to make sure the method is fast though, since we will use it a lot.
|
||||
```
|
||||
|
||||
Our next task is to implement a SetPixel method. This needs to take two parameters, the x and y co-ordinate of a pixel, and it should use the graphicsAddress and foreColour we have just defined to control exactly what and where it is drawing. If you think you can implement this immediately, do, if not I shall outline the steps to be taken, and then give an example implementation.
|
||||
|
||||
1. Load in the graphicsAddress.
|
||||
2. Check that the x and y co-ordinates of the pixel are less than the width and height.
|
||||
3. Compute the address of the pixel to write. (hint: frameBufferAddress + (x + y core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated width) * pixel size)
|
||||
4. Load in the foreColour.
|
||||
5. Store it at the address.
|
||||
|
||||
|
||||
|
||||
An implementation of the above follows.
|
||||
|
||||
1.
|
||||
```
|
||||
.globl DrawPixel
|
||||
DrawPixel:
|
||||
px .req r0
|
||||
py .req r1
|
||||
addr .req r2
|
||||
ldr addr,=graphicsAddress
|
||||
ldr addr,[addr]
|
||||
```
|
||||
|
||||
2.
|
||||
```
|
||||
height .req r3
|
||||
ldr height,[addr,#4]
|
||||
sub height,#1
|
||||
cmp py,height
|
||||
movhi pc,lr
|
||||
.unreq height
|
||||
|
||||
width .req r3
|
||||
ldr width,[addr,#0]
|
||||
sub width,#1
|
||||
cmp px,width
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
Remember that the width and height are stored at offsets of 0 and 4 into the frame buffer description respectively. You can refer back to 'frameBuffer.s' if necessary.
|
||||
|
||||
3.
|
||||
```
|
||||
ldr addr,[addr,#32]
|
||||
add width,#1
|
||||
mla px,py,width,px
|
||||
.unreq width
|
||||
.unreq py
|
||||
add addr, px,lsl #1
|
||||
.unreq px
|
||||
```
|
||||
|
||||
```
|
||||
mla dst,reg1,reg2,reg3 multiplies the values from reg1 and reg2, adds the value from reg3 and places the least significant 32 bits of the result in dst.
|
||||
```
|
||||
|
||||
Admittedly, this code is specific to high colour frame buffers, as I use a bit shift directly to compute this address. You may wish to code a version of this function without the specific requirement to use high colour frame buffers, remembering to update the SetForeColour code. It may be significantly more complicated to implement.
|
||||
|
||||
4.
|
||||
```
|
||||
fore .req r3
|
||||
ldr fore,=foreColour
|
||||
ldrh fore,[fore]
|
||||
```
|
||||
|
||||
As above, this is high colour specific.
|
||||
|
||||
5.
|
||||
```
|
||||
strh fore,[addr]
|
||||
.unreq fore
|
||||
.unreq addr
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
As above, this is high colour specific.
|
||||
|
||||
|
||||
|
||||
|
||||
### 2 Lines
|
||||
|
||||
The trouble is, line drawing isn't quite as simple as you may expect. By now you must realise that when making operating system, we have to do almost everything ourselves, and line drawing is no exception. I suggest for a few minutes you have a think about how you would draw a line between any two points.
|
||||
|
||||
```
|
||||
When programming normally, we tend to be lazy with things like division. Operating Systems must be incredibly efficient, and so we must focus on doing things as best as possible.
|
||||
```
|
||||
|
||||
I expect the central idea of most strategies will involve computing the gradient of the line, and stepping along it. This sounds perfectly reasonable, but is actually a terrible idea. The problem with it is it involves division, which is something that we know can't easily be done in assembly, and also keeping track of decimal numbers, which is again difficult. There is, in fact, an algorithm called Bresenham's Algorithm, which is perfect for assembly code because it only involves addition, subtraction and bit shifts.
|
||||
```
|
||||
Let's start off by defining a reasonably straightforward line drawing algorithm as follows:
|
||||
|
||||
if x1 > x0 then
|
||||
|
||||
set deltax to x1 - x0
|
||||
set stepx to +1
|
||||
|
||||
otherwise
|
||||
|
||||
set deltax to x0 - x1
|
||||
set stepx to -1
|
||||
|
||||
end if
|
||||
|
||||
if y1 > y0 then
|
||||
|
||||
set deltay to y1 - y0
|
||||
set stepy to +1
|
||||
|
||||
otherwise
|
||||
|
||||
set deltay to y0 - y1
|
||||
set stepy to -1
|
||||
|
||||
end if
|
||||
|
||||
if deltax > deltay then
|
||||
|
||||
set error to 0
|
||||
until x0 = x1 + stepx
|
||||
|
||||
setPixel(x0, y0)
|
||||
set error to error + deltax ÷ deltay
|
||||
if error ≥ 0.5 then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error - 1
|
||||
|
||||
end if
|
||||
set x0 to x0 + stepx
|
||||
|
||||
repeat
|
||||
|
||||
otherwise
|
||||
|
||||
end if
|
||||
|
||||
This algorithm is a representation of the sort of thing you may have imagined. The variable error keeps track of how far away from the actual line we are. Every step we take along the x axis increases this error, and every time we move down the y axis, the error decreases by 1 unit again. The error is measured as a distance along the y axis.
|
||||
|
||||
While this algorithm works, it suffers a major problem in that we clearly have to use decimal numbers to store error, and also we have to do a division. An immediate optimisation would therefore be to change the units of error. There is no need to store it in any particular units, as long as we scale every use of it by the same amount. Therefore, we could rewrite the algorithm simply by multiplying all equations involving error by deltay, and simplifying the result. Just showing the main loop:
|
||||
|
||||
set error to 0 × deltay
|
||||
until x0 = x1 + stepx
|
||||
|
||||
setPixel(x0, y0)
|
||||
set error to error + deltax ÷ deltay × deltay
|
||||
if error ≥ 0.5 × deltay then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error - 1 × deltay
|
||||
|
||||
end if
|
||||
set x0 to x0 + stepx
|
||||
|
||||
repeat
|
||||
|
||||
Which simplifies to:
|
||||
|
||||
set error to 0
|
||||
until x0 = x1 + stepx
|
||||
|
||||
setPixel(x0, y0)
|
||||
set error to error + deltax
|
||||
if error × 2 ≥ deltay then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error - deltay
|
||||
|
||||
end if
|
||||
set x0 to x0 + stepx
|
||||
|
||||
repeat
|
||||
|
||||
Suddenly we have a much better algorithm. We see now that we've eliminated the need for division altogether. Better still, the only multiplication is by 2, which we know is just a bit shift left by 1! This is now very close to Bresenham's Algorithm, but one further optimisation can be made. At the moment, we have an if statement which leads to two very similar blocks of code, one for lines with larger x differences, and one for lines with larger y differences. It is worth checking if the code could be converted to a single statement for both types of line.
|
||||
|
||||
The difficulty arises somewhat in that in the first case, error is to do with y, and in the second case error is to do with x. The solution is to track the error in both variables simultaneously, using negative error to represent an error in x, and positive error in y.
|
||||
|
||||
set error to deltax - deltay
|
||||
until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
|
||||
setPixel(x0, y0)
|
||||
if error × 2 > -deltay then
|
||||
|
||||
set x0 to x0 + stepx
|
||||
set error to error - deltay
|
||||
|
||||
end if
|
||||
if error × 2 < deltax then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error + deltax
|
||||
|
||||
end if
|
||||
|
||||
repeat
|
||||
|
||||
It may take some time to convince yourself that this actually works. At each step, we consider if it would be correct to move in x or y. We do this by checking if the magnitude of the error would be lower if we moved in the x or y co-ordinates, and then moving if so.
|
||||
```
|
||||
|
||||
```
|
||||
Bresenham's Line Algorithm was developed in 1962 by Jack Elton Bresenham, 24 at the time, whilst studying for a PhD.
|
||||
```
|
||||
|
||||
Bresenham's Algorithm for drawing a line can be described by the following pseudo code. Pseudo code is just text which looks like computer instructions, but is actually intended for programmers to understand algorithms, rather than being machine readable.
|
||||
|
||||
```
|
||||
/* We wish to draw a line from (x0,y0) to (x1,y1), using only a function setPixel(x,y) which draws a dot in the pixel given by (x,y). */
|
||||
if x1 > x0 then
|
||||
set deltax to x1 - x0
|
||||
set stepx to +1
|
||||
otherwise
|
||||
set deltax to x0 - x1
|
||||
set stepx to -1
|
||||
end if
|
||||
|
||||
set error to deltax - deltay
|
||||
until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
setPixel(x0, y0)
|
||||
if error × 2 ≥ -deltay then
|
||||
set x0 to x0 + stepx
|
||||
set error to error - deltay
|
||||
end if
|
||||
if error × 2 ≤ deltax then
|
||||
set y0 to y0 + stepy
|
||||
set error to error + deltax
|
||||
end if
|
||||
repeat
|
||||
```
|
||||
|
||||
Rather than numbered lists as I have used so far, this representation of an algorithm is far more common. See if you can implement this yourself. For reference, I have provided my implementation below.
|
||||
|
||||
```
|
||||
.globl DrawLine
|
||||
DrawLine:
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
|
||||
x0 .req r9
|
||||
x1 .req r10
|
||||
y0 .req r11
|
||||
y1 .req r12
|
||||
|
||||
mov x0,r0
|
||||
mov x1,r2
|
||||
mov y0,r1
|
||||
mov y1,r3
|
||||
|
||||
dx .req r4
|
||||
dyn .req r5 /* Note that we only ever use -deltay, so I store its negative for speed. (hence dyn) */
|
||||
sx .req r6
|
||||
sy .req r7
|
||||
err .req r8
|
||||
|
||||
cmp x0,x1
|
||||
subgt dx,x0,x1
|
||||
movgt sx,#-1
|
||||
suble dx,x1,x0
|
||||
movle sx,#1
|
||||
|
||||
cmp y0,y1
|
||||
subgt dyn,y1,y0
|
||||
movgt sy,#-1
|
||||
suble dyn,y0,y1
|
||||
movle sy,#1
|
||||
|
||||
add err,dx,dyn
|
||||
add x1,sx
|
||||
add y1,sy
|
||||
|
||||
pixelLoop$:
|
||||
|
||||
teq x0,x1
|
||||
teqne y0,y1
|
||||
popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
|
||||
|
||||
mov r0,x0
|
||||
mov r1,y0
|
||||
bl DrawPixel
|
||||
|
||||
cmp dyn, err,lsl #1
|
||||
addle err,dyn
|
||||
addle x0,sx
|
||||
|
||||
cmp dx, err,lsl #1
|
||||
addge err,dx
|
||||
addge y0,sy
|
||||
|
||||
b pixelLoop$
|
||||
|
||||
.unreq x0
|
||||
.unreq x1
|
||||
.unreq y0
|
||||
.unreq y1
|
||||
.unreq dx
|
||||
.unreq dyn
|
||||
.unreq sx
|
||||
.unreq sy
|
||||
.unreq err
|
||||
```
|
||||
|
||||
### 3 Randomness
|
||||
|
||||
So, now we can draw lines. Although we could use this to draw pictures and whatnot (feel free to do so!), I thought I would take the opportunity to introduce the idea of computer randomness. What we will do is select a pair of random co-ordinates, and then draw a line from the last pair to that point in steadily incrementing colours. I do this purely because it looks quite pretty.
|
||||
|
||||
```
|
||||
Hardware random number generators are occasionally used in security, where the predictability sequence of random numbers may affect the security of some encryption.
|
||||
```
|
||||
|
||||
So, now it comes down to it, how do we be random? Unfortunately for us there isn't some device which generates random numbers (such devices are very rare). So somehow using only the operations we've learned so far we need to invent 'random numbers'. It shouldn't take you long to realise this is impossible. The operations always have well defined results, executing the same sequence of instructions with the same registers yields the same answer. What we instead do is deduce a sequence that is pseudo random. This means numbers that, to the outside observer, look random, but in fact were completely determined. So, we need a formula to generate random numbers. One might be tempted to just spam mathematical operators out for example: 4x2! / 64, but in actuality this generally produces low quality random numbers. In this case for example, if x were 0, the answer would be 0. Stupid though it sounds, we need a very careful choice of equation to produce high quality random numbers.
|
||||
|
||||
```
|
||||
This sort of discussion often begs the question what do we mean by a random number? We generally mean statistical randomness: A sequence of numbers that has no obvious patterns or properties that could be used to generalise it.
|
||||
```
|
||||
|
||||
The method I'm going to teach you is called the quadratic congruence generator. This is a good choice because it can be implemented in 5 instructions, and yet generates a seemingly random order of the numbers from 0 to 232-1.
|
||||
|
||||
The reason why the generator can create such long sequence with so few instructions is unfortunately a little beyond the scope of this course, but I encourage the interested to research it. It all centralises on the following quadratic formula, where xn is the nth random number generated.
|
||||
|
||||
x_(n+1) = ax_(n)^2 + bx_(n) + c mod 2^32
|
||||
|
||||
Subject to the following constraints:
|
||||
|
||||
1. a is even
|
||||
|
||||
2. b = a + 1 mod 4
|
||||
|
||||
3. c is odd
|
||||
|
||||
|
||||
|
||||
|
||||
If you've not seen mod before, it means the remainder of a division by the number after it. For example b = a + 1 mod 4 means that b is the remainder of dividing a + 1 by 4, so if a were 12 say, b would be 1 as a + 1 is 13, and 13 divided by 4 is 3 remainder 1.
|
||||
|
||||
Copy the following code into a file called 'random.s'.
|
||||
|
||||
```
|
||||
.globl Random
|
||||
Random:
|
||||
xnm .req r0
|
||||
a .req r1
|
||||
|
||||
mov a,#0xef00
|
||||
mul a,xnm
|
||||
mul a,xnm
|
||||
add a,xnm
|
||||
.unreq xnm
|
||||
add r0,a,#73
|
||||
|
||||
.unreq a
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
This is an implementation of the random function, with an input of the last value generated in r0, and an output of the next number. In my case, I've used a = EF0016, b = 1, c = 73. This choice was arbitrary but meets the requirements above. Feel free to use any numbers you wish instead, as long as they obey the rules.
|
||||
|
||||
### 4 Pi-casso
|
||||
|
||||
OK, now we have all the functions we're going to need, let's try it out. Alter main to do the following, after getting the frame buffer info address:
|
||||
|
||||
1. Call SetGraphicsAddress with r0 containing the frame buffer info address.
|
||||
2. Set four registers to 0. One will be the last random number, one will be the colour, one will be the last x co-ordinate and one will be the last y co-ordinate.
|
||||
3. Call random to generate the next x-coordinate, using the last random number as the input.
|
||||
4. Call random again to generate the next y-coordinate, using the x-coordinate you generated as an input.
|
||||
5. Update the last random number to contain the y-coordinate.
|
||||
6. Call SetForeColour with the colour, then increment the colour. If it goes above FFFF16, make sure it goes back to 0.
|
||||
7. The x and y coordinates we have generated are between 0 and FFFFFFFF16. Convert them to a number between 0 and 102310 by using a logical shift right of 22.
|
||||
8. Check the y coordinate is on the screen. Valid y coordinates are between 0 and 76710. If not, go back to 3.
|
||||
9. Draw a line from the last x and y coordinates to the current x and y coordinates.
|
||||
10. Update the last x and y coordinates to contain the current ones.
|
||||
11. Go back to 3.
|
||||
|
||||
|
||||
|
||||
As always, a solution for this can be found on the downloads page.
|
||||
|
||||
Once you've finished, test it on the Raspberry Pi. You should see a very fast sequence of random lines being drawn on the screen, in steadily incrementing colours. This should never stop. If it doesn't work, please see our troubleshooting page.
|
||||
|
||||
When you have it working, congratulations! We've now learned about meaningful graphics, and also about random numbers. I encourage you to play with line drawing, as it can be used to render almost anything you want. You may also want to explore more complicated shapes. Most can be made out of lines, but is this necessarily the best strategy? If you like the line program, try experimenting with the SetPixel function. What happens if instead of just setting the value of the pixel, you increase it by a small amount? What other patterns can you make? In the next lesson, [Lesson 8: Screen 03][2], we will look at the invaluable skill of drawing text.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
@ -0,0 +1,485 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 8 Screen03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 8 Screen03
|
||||
======
|
||||
|
||||
The Screen03 lesson builds on Screen02, by teaching how to draw text, and also a small feature on the command line arguments of the operating system. It is assumed you have the code for the [Lesson 7: Screen02][1] operating system as a basis.
|
||||
|
||||
### 1 String Theory
|
||||
|
||||
So, our task for this operating system is to draw text. We have several problems to address, the most pressing of which is probably about storing text. Unbelievably text has been one of the biggest flaws on computers to date. What should have been a straightforward type of data has brought down operating systems, crippled otherwise wonderful encryption, and caused many problems for users of different alphabets. Nevertheless, it is an incredibly important type of data, as it is an excellent link between the computer and the user. Text can be sufficiently structured that the operating system understands it, as well as sufficiently readable that humans can use it.
|
||||
|
||||
```
|
||||
Variable data types such as text require much more complex handling.
|
||||
```
|
||||
|
||||
So how exactly is text stored? Simply enough, we have some system by which we give each letter a unique number, and then store a sequence of such numbers. Sounds easy. The problem is that the number of numbers is not fixed. Some pieces of text are longer than others. With storing ordinary numbers, we have some fixed limit, e.g. 32 bits, and then we can't go beyond that, we write methods that use numbers of that length, etc. In terms of text, or strings as we often call it, we want to write functions that work on variable length strings, otherwise we would need a lot of functions! This is not a problem for numbers normally, as there are only a few common number formats (byte, word, half, double).
|
||||
|
||||
```
|
||||
Buffer overrun attacks have plagued computers for years. Recently, the Wii, Xbox and Playstation 2 all suffered buffer overrun attacks, as well as large systems like Microsoft's Web and Database servers.
|
||||
```
|
||||
|
||||
So, how do we determine how long the string is? I think the obvious answer is just to store how long the string is, and then to store the characters that make it up. This is called length prefixing, as the length comes before the string. Unfortunately, the pioneers of computer science did not agree. They felt it made more sense to have a special character called the null terminator (denoted \0) which represents when a string ends. This does indeed simplify many string algorithms, as you just keep working until the null terminator. Unfortunately this is the source of many security issues. What if a malicious user gives you a very long string? What if you didn't have enough space to store it. You might run a string copying function that copies until the null terminator, but because the string is so long, it overwrites your program. This may sound far fetched, but nevertheless, such buffer overrun attacks are incredibly common. Length prefixing mitigates this problem as it is easy to deduce the size of the buffer required to store the string. As an operating system developer, I leave it to you to decide how best to store text.
|
||||
|
||||
The next thing we need to establish is how best to map characters to numbers. Fortunately, this is reasonably well standardised, so you have two major choices, Unicode and ASCII. Unicode maps almost every single useful symbol that can be written to a number, in exchange for having a lot more numbers, and a more complicated encoding system. ASCII uses one byte per character, and so only stores the Latin alphabet, numbers, a few symbols and a few special characters. Thus, ASCII is very easy to implement, compared to Unicode, in which not every character takes the same space, making string algorithms tricky. Normally operating systems use ASCII for strings which will not be displayed to end users (but perhaps to developers or experts), and Unicode for displaying messages to users, as Unicode can support things like Japanese characters, and so could be localised.
|
||||
|
||||
Fortunately for us, this decision is irrelevant at the moment, as the first 128 characters of both are exactly the same, and are encoded exactly the same.
|
||||
|
||||
Table 1.1 ASCII/Unicode symbols 0-127
|
||||
|
||||
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|
||||
|----| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ----|
|
||||
| 00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI | |
|
||||
| 10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | |
|
||||
| 20 | ! | " | # | $ | % | & | . | ( | ) | * | + | , | - | . | / | | |
|
||||
| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
|
||||
| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
|
||||
| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | |
|
||||
| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
|
||||
| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
|
||||
|
||||
The table shows the first 128 symbols. The hexadecimal representation of the number for a symbol is the row value added to the column value, for example A is 4116. What you may find surprising is the first two rows, and the very last value. These 33 special characters are not printed at all. In fact, these days, many are ignored. They exist because ASCII was originally intended as a system for transmitting data over computer networks, and so a lot more information than just the symbols had to be sent. The key special symbols that you should learn are NUL, the null terminator character I mentioned before, HT, horizontal tab is what we normally refer to as a tab and LF, the line feed character is used to make a new line. You may wish to research and use the other characters for special meanings in your operating system.
|
||||
|
||||
### 2 Characters
|
||||
|
||||
So, now that we know a bit about strings, we can start to think about how they're displayed. The fundamental thing we need to do in order to be able to display a string is to be able to display a character. Our first task will be making a DrawCharacter function which takes in a character to draw and a location, and then draws the character.
|
||||
|
||||
```
|
||||
The true type font format used in many Operating Systems is so powerful, it has its own assembly language built in to ensure letters look correct at any resolution.
|
||||
```
|
||||
|
||||
Naturally, this leads to a discussion about fonts. We already know there are many ways to display any given letter in accordance with font choice. So how does a font work? In the very early days of computer science, a font was just a series of little pictures of all the letters, called a bitmap font, and all the draw character method would do is copy one of the pictures to the screen. The trouble with this is when people want to resize the text. Sometimes we need big letters, and sometimes small. Although we could keep drawing new pictures for every font at every size with every character, this would get tedious. Thus, vector fonts were invented. in vector fonts, rather than containing an image of the font, the font file contains a description of how to draw it, e.g. an 'o' could be circle with radius half that of the maximum letter height. Modern operating systems use such fonts almost exclusively, as they are perfect at any resolution.
|
||||
|
||||
Unfortunately, much though I would love to include an implementation of one of the vector font formats, it would take up the remainder of this website. Thus, we will implement a bitmap font, though if you wish to make a decent graphical operating system, a vector font would be useful.
|
||||
```
|
||||
00000000
|
||||
00000000
|
||||
00000000
|
||||
00010000
|
||||
00101000
|
||||
00101000
|
||||
00101000
|
||||
01000100
|
||||
01000100
|
||||
01111100
|
||||
11000110
|
||||
10000010
|
||||
00000000
|
||||
00000000
|
||||
00000000
|
||||
00000000
|
||||
```
|
||||
|
||||
On the downloads page, I have included several '.bin' files in the font section. These are just raw binary data files for a few fonts. For this tutorial, pick your favourite from the monospace, monochrome, 8x16 section. Download it and store it in the 'source' directory as 'font.bin'. These files are just monochrome images of each of the letters in turn, with each letter being exactly 8 by 16 pixels. Thus, each takes 16 bytes, the first byte being the top row, the second the next, etc.
|
||||
|
||||
The diagram shows the 'A' character in the monospace, monochrome, 8x16 font Bitstream Vera Sans Mono. In the file, we would find this starting at the 4116 × 1016 = 41016th byte as the following sequence in hexadecimal:
|
||||
|
||||
00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
|
||||
|
||||
We're going to use a monospace font here, because in a monospace font every character is the same size. Unfortunately, yet another complication with most fonts is that the character's widths vary, leading to more complex display code. I've included a few other fonts on the downloads page, as well as an explanation of the format I've stored them all in.
|
||||
|
||||
So let's get down to business. Copy the following to 'drawing.s' after the .int 0 of graphicsAddress.
|
||||
|
||||
```
|
||||
.align 4
|
||||
font:
|
||||
.incbin "font.bin"
|
||||
```
|
||||
|
||||
```
|
||||
.incbin "file" inserts the binary data from the file file.
|
||||
```
|
||||
|
||||
This code copies the font data from the file to the address labelled font. We've used an .align 4 here to ensure each character starts on a multiple of 16 bytes, which can be used for a speed trick later.
|
||||
|
||||
Now we want to write the draw character method. I'll give the pseudo code for this, so you can try to implement it yourself if you want to. Conventionally >> means logical shift right.
|
||||
|
||||
```
|
||||
function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
if character > 127 then exit
|
||||
set charAddress to font + character × 16
|
||||
for row = 0 to 15
|
||||
set bits to readByte(charAddress + row)
|
||||
for bit = 0 to 7
|
||||
if test(bits >> bit, 0x1)
|
||||
then setPixel(x + bit, y + row)
|
||||
next
|
||||
next
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
|
||||
```
|
||||
If implemented directly, this is deliberately not very efficient. With things like drawing characters, efficiency is a top priority, as we will do it a lot. Let's explore some improvements that bring this closer to optimal assembly code. Firstly, we have a × 16, which by now you should spot is the same as a logical shift left by 4 places. Next we have a variable row, which is only ever added to charAddress and to y. Thus, we can eliminate it by increasing these variables instead. The only issue now is how to tell when we've finished. This is where the .align 4 comes in handy. We know that charAddress will start with the low nibble containing 0. This means we can see how far into the character data we are by checking that low nibble.
|
||||
|
||||
Though we can eliminate the need for bits, we must introduce a new variable to do so, so it is best left in. The only other improvement that can be made is to remove the nested bits >> bit.
|
||||
|
||||
```
|
||||
function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
if character > 127 then exit
|
||||
set charAddress to font + character << 4
|
||||
loop
|
||||
set bits to readByte(charAddress)
|
||||
set bit to 8
|
||||
loop
|
||||
set bits to bits << 1
|
||||
set bit to bit - 1
|
||||
if test(bits, 0x100)
|
||||
then setPixel(x + bit, y)
|
||||
until bit = 0
|
||||
set y to y + 1
|
||||
set chadAddress to chadAddress + 1
|
||||
until charAddress AND 0b1111 = 0
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
```
|
||||
|
||||
Now we've got code that is much closer to assembly code, and is near optimal. Below is the assembly code version of the above.
|
||||
|
||||
```
|
||||
.globl DrawCharacter
|
||||
DrawCharacter:
|
||||
cmp r0,#127
|
||||
movhi r0,#0
|
||||
movhi r1,#0
|
||||
movhi pc,lr
|
||||
|
||||
push {r4,r5,r6,r7,r8,lr}
|
||||
x .req r4
|
||||
y .req r5
|
||||
charAddr .req r6
|
||||
mov x,r1
|
||||
mov y,r2
|
||||
ldr charAddr,=font
|
||||
add charAddr, r0,lsl #4
|
||||
|
||||
lineLoop$:
|
||||
|
||||
bits .req r7
|
||||
bit .req r8
|
||||
ldrb bits,[charAddr]
|
||||
mov bit,#8
|
||||
|
||||
charPixelLoop$:
|
||||
|
||||
subs bit,#1
|
||||
blt charPixelLoopEnd$
|
||||
lsl bits,#1
|
||||
tst bits,#0x100
|
||||
beq charPixelLoop$
|
||||
|
||||
add r0,x,bit
|
||||
mov r1,y
|
||||
bl DrawPixel
|
||||
|
||||
teq bit,#0
|
||||
bne charPixelLoop$
|
||||
|
||||
charPixelLoopEnd$:
|
||||
.unreq bit
|
||||
.unreq bits
|
||||
add y,#1
|
||||
add charAddr,#1
|
||||
tst charAddr,#0b1111
|
||||
bne lineLoop$
|
||||
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq charAddr
|
||||
|
||||
width .req r0
|
||||
height .req r1
|
||||
mov width,#8
|
||||
mov height,#16
|
||||
|
||||
pop {r4,r5,r6,r7,r8,pc}
|
||||
.unreq width
|
||||
.unreq height
|
||||
```
|
||||
|
||||
### 3 Strings
|
||||
|
||||
Now that we can draw characters, we can draw text. We need to make a method that, for a given string, draws each character in turn, at incrementing positions. To be nice, we shall also implement new lines and tabs. It's decision time as far as null terminators are concerned, and if you want to make your operating system use them, feel free by changing the code below. To avoid the issue, I will have the length of the string passed as an argument to the DrawString function, along with the address of the string, and the x and y coordinates.
|
||||
|
||||
```
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
set x0 to x
|
||||
for pos = 0 to length - 1
|
||||
set char to loadByte(string + pos)
|
||||
set (cwidth, cheight) to DrawCharacter(char, x, y)
|
||||
if char = '\n' then
|
||||
set x to x0
|
||||
set y to y + cheight
|
||||
otherwise if char = '\t' then
|
||||
set x1 to x
|
||||
until x1 > x0
|
||||
set x1 to x1 + 5 × cwidth
|
||||
loop
|
||||
set x to x1
|
||||
otherwise
|
||||
set x to x + cwidth
|
||||
end if
|
||||
next
|
||||
end function
|
||||
```
|
||||
|
||||
Once again, this function isn't that close to assembly code. Feel free to try to implement it either directly or by simplifying it. I will give the simplification and then the assembly code below.
|
||||
|
||||
Clearly the person who wrote this function wasn't being very efficient (me in case you were wondering). Once again we have a pos variable that just increments and is added to something else, which is completely unnecessary. We can remove it, and instead simultaneously decrement length until it is 0, saving the need for one register. The rest of the function is probably fine, except for that annoying multiplication by five. A key thing to do here would be to move the multiplication outside the loop; multiplication is slow even with bit shifts, and since we're always adding the same constant multiplied by 5, there is no need to recompute this. It can in fact be implemented in one operation using the argument shifting in assembly code, so I shall rephrase it like that.
|
||||
|
||||
```
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
set x0 to x
|
||||
until length = 0
|
||||
set length to length - 1
|
||||
set char to loadByte(string)
|
||||
set (cwidth, cheight) to DrawCharacter(char, x, y)
|
||||
if char = '\n' then
|
||||
set x to x0
|
||||
set y to y + cheight
|
||||
otherwise if char = '\t' then
|
||||
set x1 to x
|
||||
set cwidth to cwidth + cwidth << 2
|
||||
until x1 > x0
|
||||
set x1 to x1 + cwidth
|
||||
loop
|
||||
set x to x1
|
||||
otherwise
|
||||
set x to x + cwidth
|
||||
end if
|
||||
set string to string + 1
|
||||
loop
|
||||
end function
|
||||
```
|
||||
|
||||
In assembly code:
|
||||
|
||||
```
|
||||
.globl DrawString
|
||||
DrawString:
|
||||
x .req r4
|
||||
y .req r5
|
||||
x0 .req r6
|
||||
string .req r7
|
||||
length .req r8
|
||||
char .req r9
|
||||
push {r4,r5,r6,r7,r8,r9,lr}
|
||||
|
||||
mov string,r0
|
||||
mov x,r2
|
||||
mov x0,x
|
||||
mov y,r3
|
||||
mov length,r1
|
||||
|
||||
stringLoop$:
|
||||
subs length,#1
|
||||
blt stringLoopEnd$
|
||||
|
||||
ldrb char,[string]
|
||||
add string,#1
|
||||
|
||||
mov r0,char
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
cwidth .req r0
|
||||
cheight .req r1
|
||||
|
||||
teq char,#'\n'
|
||||
moveq x,x0
|
||||
addeq y,cheight
|
||||
beq stringLoop$
|
||||
|
||||
teq char,#'\t'
|
||||
addne x,cwidth
|
||||
bne stringLoop$
|
||||
|
||||
add cwidth, cwidth,lsl #2
|
||||
x1 .req r1
|
||||
mov x1,x0
|
||||
|
||||
stringLoopTab$:
|
||||
add x1,cwidth
|
||||
cmp x,x1
|
||||
bge stringLoopTab$
|
||||
mov x,x1
|
||||
.unreq x1
|
||||
b stringLoop$
|
||||
stringLoopEnd$:
|
||||
.unreq cwidth
|
||||
.unreq cheight
|
||||
|
||||
pop {r4,r5,r6,r7,r8,r9,pc}
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq x0
|
||||
.unreq string
|
||||
.unreq length
|
||||
```
|
||||
|
||||
```
|
||||
subs reg,#val subtracts val from the register reg and compares the result with 0.
|
||||
```
|
||||
|
||||
This code makes clever use of a new operation, subs which subtracts one number from another, stores the result and then compares it with 0. In truth, all comparisons are implemented as a subtraction and then comparison with 0, but the result is normally discarded. This means that this operation is as fast as cmp.
|
||||
|
||||
### 4 Your Wish is My Command Line
|
||||
|
||||
Now that we can print strings, the challenge is to find an interesting one to draw. Normally in tutorials such as this, people just draw "Hello World!", but after all we've done so far, I feel that is a little patronising (feel free to do so if it helps). Instead we're going to draw our command line.
|
||||
|
||||
A convention has been made for computers running ARM. When they boot, it is important they are given certain information about what they have available to them. Most all processors have some way of ascertaining this information, and on ARM this is by data left at the address 10016. The format of the data is as follows:
|
||||
|
||||
1. The data is broken down into a series of 'tags'.
|
||||
2. There are nine types of tag: 'core', 'mem', 'videotext', 'ramdisk', 'initrd2', 'serial' 'revision', 'videolfb', 'cmdline'.
|
||||
3. Each can only appear once, but all but the 'core' tag don't have to appear.
|
||||
4. The tags are placed from 0x100 in order one after the other.
|
||||
5. The end of the list of tags always contains 2 words which are 0.
|
||||
6. Every tag's size in bytes is a multiple of 4.
|
||||
7. Each tag starts with the size of the tag in words in the tag, including this number.
|
||||
8. This is followed by a half word containing the tag's number. These are numbered from 1 in the order above ('core' is 1, 'cmdline' is 9).
|
||||
9. This is followed by a half word containing 544116.
|
||||
10. After this comes the data of the tag, which varies depending on the tag. The size of the data in words + 2 is always the same as the length mentioned above.
|
||||
11. A 'core' tag is either 2 or 5 words in length. If it is 2, there is no data, if it is 5, it has 3 words.
|
||||
12. A 'mem' tag is always 4 words in length. The data is the first address in a block of memory, and the length of that block.
|
||||
13. A 'cmdline' tag contains a null terminated string which is the parameters of the kernel.
|
||||
|
||||
|
||||
```
|
||||
Almost all Operating Systems support the notion of programs having a 'command line'. The idea is to provide a common mechanism for choosing the desired behaviour of the program.
|
||||
```
|
||||
|
||||
On the current version of the Raspberry Pi, only the 'core', 'mem' and 'cmdline' tags are present. You may find these useful later, and a more complete reference for these is on our Raspberry Pi reference page. The one we're interested in at the moment is the 'cmdline' tag, because it contains a string. We're going to write some code to search for the command line tag, and, if found, to print it out with each item on a new line. The command line is just a list of things that either the graphics processor or the user thought it might be nice for the Operating System to know. On the Raspberry Pi, this includes the MAC Address, serial number and screen resolution. The string itself is just a list of expressions such as 'key.subkey=value' separated by spaces.
|
||||
|
||||
Let's start by finding the 'cmdline' tag. In a new file called 'tags.s' copy the following code.
|
||||
|
||||
```
|
||||
.section .data
|
||||
tag_core: .int 0
|
||||
tag_mem: .int 0
|
||||
tag_videotext: .int 0
|
||||
tag_ramdisk: .int 0
|
||||
tag_initrd2: .int 0
|
||||
tag_serial: .int 0
|
||||
tag_revision: .int 0
|
||||
tag_videolfb: .int 0
|
||||
tag_cmdline: .int 0
|
||||
```
|
||||
|
||||
Looking through the list of tags will be a slow operation, as it involves a lot of memory access. Therefore, we only want to have to do it once. This code creates some data which will store the memory address of the first tag of each of the types. Then, to find a tag the following pseudo code will suffice.
|
||||
|
||||
```
|
||||
function FindTag(r0 is tag)
|
||||
if tag > 9 or tag = 0 then return 0
|
||||
set tagAddr to loadWord(tag_core + (tag - 1) × 4)
|
||||
if not tagAddr = 0 then return tagAddr
|
||||
if readWord(tag_core) = 0 then return 0
|
||||
set tagAddr to 0x100
|
||||
loop forever
|
||||
set tagIndex to readHalfWord(tagAddr + 4)
|
||||
if tagIndex = 0 then return FindTag(tag)
|
||||
if readWord(tag_core+(tagIndex-1)×4) = 0
|
||||
then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
|
||||
set tagAddr to tagAddr + loadWord(tagAddr) × 4
|
||||
end loop
|
||||
end function
|
||||
```
|
||||
This code is already quite well optimised and close to assembly. It is optimistic in that the first thing it tries is loading the tag directly, as all but the first time this should be the case. If that fails, it checks if the core tag has an address. Since there must always be a core tag, the only reason that it would not have an address is if it doesn't exist. If it does have an address, the tag we were looking for didn't. If it doesn't we need to find the addresses of all the tags. It does this by reading the number of the tag. If it is zero, that must mean we are at the end of the list. This means we've now filled in all the tags in our directory. Therefore if we run our function again, it will now be able to produce an answer. If the tag number is not zero, we check to see if this tag type already has an address. If not, we store the address of this tag in our directory. We then add the length of this tag in bytes to the tag address to find the next tag.
|
||||
|
||||
Have a go at implementing this code in assembly. You will need to simplify it. If you get stuck, my answer is below. Don't forget the .section .text!
|
||||
|
||||
```
|
||||
.section .text
|
||||
.globl FindTag
|
||||
FindTag:
|
||||
tag .req r0
|
||||
tagList .req r1
|
||||
tagAddr .req r2
|
||||
|
||||
sub tag,#1
|
||||
cmp tag,#8
|
||||
movhi tag,#0
|
||||
movhi pc,lr
|
||||
|
||||
ldr tagList,=tag_core
|
||||
tagReturn$:
|
||||
add tagAddr,tagList, tag,lsl #2
|
||||
ldr tagAddr,[tagAddr]
|
||||
|
||||
teq tagAddr,#0
|
||||
movne r0,tagAddr
|
||||
movne pc,lr
|
||||
|
||||
ldr tagAddr,[tagList]
|
||||
teq tagAddr,#0
|
||||
movne r0,#0
|
||||
movne pc,lr
|
||||
|
||||
mov tagAddr,#0x100
|
||||
push {r4}
|
||||
tagIndex .req r3
|
||||
oldAddr .req r4
|
||||
tagLoop$:
|
||||
ldrh tagIndex,[tagAddr,#4]
|
||||
subs tagIndex,#1
|
||||
poplt {r4}
|
||||
blt tagReturn$
|
||||
|
||||
add tagIndex,tagList, tagIndex,lsl #2
|
||||
ldr oldAddr,[tagIndex]
|
||||
teq oldAddr,#0
|
||||
.unreq oldAddr
|
||||
streq tagAddr,[tagIndex]
|
||||
|
||||
ldr tagIndex,[tagAddr]
|
||||
add tagAddr, tagIndex,lsl #2
|
||||
b tagLoop$
|
||||
|
||||
.unreq tag
|
||||
.unreq tagList
|
||||
.unreq tagAddr
|
||||
.unreq tagIndex
|
||||
```
|
||||
|
||||
### 5 Hello World
|
||||
|
||||
Now that we have everything we need, we can draw our first string. In 'main.s' delete everything after bl SetGraphicsAddress, and replace it with the following:
|
||||
|
||||
```
|
||||
mov r0,#9
|
||||
bl FindTag
|
||||
ldr r1,[r0]
|
||||
lsl r1,#2
|
||||
sub r1,#8
|
||||
add r0,#8
|
||||
mov r2,#0
|
||||
mov r3,#0
|
||||
bl DrawString
|
||||
loop$:
|
||||
b loop$
|
||||
```
|
||||
|
||||
This code simply uses our FindTag method to find the 9th tag (cmdline) and then calculates its length and passes the command and the length to the DrawString method, and tells it to draw the string at 0,0. Now test this on the Raspberry Pi. You should see a line of text on the screen. If not please see our troubleshooting page.
|
||||
|
||||
Once it works, congratulations you've now got the ability to draw text. But there is still room for improvement. What if we wanted to write out a number, or a section of the memory or manipulate our command line? In [Lesson 9: Screen04][2], we will look at manipulating text and displaying useful numbers and information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
|
||||
@ -0,0 +1,540 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 9 Screen04)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 9 Screen04
|
||||
======
|
||||
|
||||
The Screen04 lesson builds on Screen03, by teaching how to manipulate text. It is assumed you have the code for the [Lesson 8: Screen03][1] operating system as a basis.
|
||||
|
||||
### 1 String Manipulation
|
||||
|
||||
```
|
||||
Variadic functions look much less intuitive in assembly code. Nevertheless, they are useful and powerful concepts.
|
||||
```
|
||||
|
||||
Being able to draw text is lovely, but unfortunately at the moment you can only draw strings which are already prepared. This is fine for displaying something like the command line, but ideally we would like to be able to display and text we so desire. As per usual, if we put the effort in and make an excellent function that does all the string manipulation we could ever want, we get much easier code later on in return. Once such complicated function in C programming is sprintf. This function generates a string based on a description given as another string and additional arguments. What is interesting about this function is that it is variadic. This means that it takes a variable number of parameters. The number of parameters depends on the exact format string, and so cannot be determined in advance.
|
||||
|
||||
The full function has many options, and I list a few here. I've highlighted the ones which we will implement in this tutorial, though you can try to implement more.
|
||||
|
||||
The function works by reading the format string, and then interpreting it using the table below. Once an argument is used, it is not considered again. The return value of the function is the number of characters written. If the method fails, a negative number is returned.
|
||||
|
||||
Table 1.1 sprintf formatting rules
|
||||
| Sequence | Meaning |
|
||||
| ---------------------- | ---------------------- |
|
||||
| Any character except % | Copies the character to the output. |
|
||||
| %% | Writes a % character to the output. |
|
||||
| %c | Writes the next argument as a character. |
|
||||
| %d or %i | Writes the next argument as a base 10 signed integer. |
|
||||
| %e | Writes the next argument in scientific notation using eN to mean ×10N. |
|
||||
| %E | Writes the next argument in scientific notation using EN to mean ×10N. |
|
||||
| %f | Writes the next argument as a decimal IEEE 754 floating point number. |
|
||||
| %g | Same as the shorter of %e and %f. |
|
||||
| %G | Same as the shorter of %E and %f. |
|
||||
| %o | Writes the next argument as a base 8 unsigned integer. |
|
||||
| %s | Writes the next argument as if it were a pointer to a null terminated string. |
|
||||
| %u | Writes the next argument as a base 10 unsigned integer. |
|
||||
| %x | Writes the next argument as a base 16 unsigned integer, with lowercase a,b,c,d,e and f. |
|
||||
| %X | Writes the next argument as a base 16 unsigned integer, with uppercase A,B,C,D,E and F. |
|
||||
| %p | Writes the next argument as a pointer address. |
|
||||
| %n | Writes nothing. Copies instead the number of characters written so far to the location addressed by the next argument. |
|
||||
|
||||
Further to the above, many additional tweaks exist to the sequences, such as specifying minimum length, signs, etc. More information can be found at [sprintf - C++ Reference][2].
|
||||
|
||||
Here are a few examples of calls to the method and their results to illustrate its use.
|
||||
|
||||
Table 1.2 sprintf example calls
|
||||
| Format String | Arguments | Result |
|
||||
| "%d" | 13 | "13" |
|
||||
| "+%d degrees" | 12 | "+12 degrees" |
|
||||
| "+%x degrees" | 24 | "+1c degrees" |
|
||||
| "'%c' = 0%o" | 65, 65 | "'A' = 0101" |
|
||||
| "%d * %d%% = %d" | 200, 40, 80 | "200 * 40% = 80" |
|
||||
| "+%d degrees" | -5 | "+-5 degrees" |
|
||||
| "+%u degrees" | -5 | "+4294967291 degrees" |
|
||||
|
||||
Hopefully you can already begin to see the usefulness of the function. It does take a fair amount of work to program, but our reward is a very general function we can use for all sorts of purposes.
|
||||
|
||||
### 2 Division
|
||||
|
||||
```
|
||||
Division is the slowest and most complicated of the basic mathematical operators. It is not implemented directly in ARM assembly code because it takes so long to deduce the answer, and so isn't a 'simple' operation.
|
||||
```
|
||||
|
||||
While this function does look very powerful, it also looks very complicated. The easiest way to deal with its many cases is probably to write functions to deal with some common tasks it has. What would be useful would be a function to generate the string for a signed and an unsigned number in any base. So, how can we go about doing that? Try to devise an algorithm quickly before reading on.
|
||||
|
||||
The easiest way is probably the exact way I mentioned in [Lesson 1: OK01][3], which is the division remainder method. The idea is the following:
|
||||
|
||||
1. Divide the current value by the base you're working in.
|
||||
2. Store the remainder.
|
||||
3. If the new value is not 0, go to 1.
|
||||
4. Reverse the order of the remainders. This is the answer.
|
||||
|
||||
|
||||
|
||||
For example:
|
||||
|
||||
Table 2.1 Example base 2
|
||||
conversion
|
||||
| Value | New Value | Remainder |
|
||||
| ----- | --------- | --------- |
|
||||
| 137 | 68 | 1 |
|
||||
| 68 | 34 | 0 |
|
||||
| 34 | 17 | 0 |
|
||||
| 17 | 8 | 1 |
|
||||
| 8 | 4 | 0 |
|
||||
| 4 | 2 | 0 |
|
||||
| 2 | 1 | 0 |
|
||||
| 1 | 0 | 1 |
|
||||
|
||||
So the answer is 100010012
|
||||
|
||||
The unfortunate part about this procedure is that it unavoidably uses division. Therefore, we must first contemplate division in binary.
|
||||
|
||||
For a refresher on long division expand the box below.
|
||||
|
||||
```
|
||||
Let's suppose we wish to divide 4135 by 17.
|
||||
|
||||
0243 r 4
|
||||
17)4135
|
||||
0 0 × 17 = 0000
|
||||
4135 4135 - 0 = 4135
|
||||
34 200 × 17 = 3400
|
||||
735 4135 - 3400 = 735
|
||||
68 40 × 17 = 680
|
||||
55 735 - 680 = 55
|
||||
51 3 × 17 = 51
|
||||
4 55 - 51 = 4
|
||||
Answer: 243 remainder 4
|
||||
|
||||
First of all we would look at the top digit of the dividend. We see that the smallest multiple of the divisor which is less or equal to it is 0. We output a 0 to the result.
|
||||
|
||||
Next we look at the second to top digit of the dividend and all higher digits. We see the smallest multiple of the divisor which is less than or equal is 34. We output a 2 and subtract 3400.
|
||||
|
||||
Next we look at the third digit of the dividend and all higher digits. The smallest multiple of the divisor that is less than or equal to this is 68. We output 4 and subtract 680.
|
||||
|
||||
Finally we look at all remaining digits. We see that the lowest multiple of the divisor that is less than the remaining digits is 51. We output a 3, subtract 51. The result of the subtraction is our remainder.
|
||||
```
|
||||
|
||||
To implement division in assembly code, we will implement binary long division. We do this because the numbers are stored in binary, which gives us easy access to the all important bit shift operations, and because division in binary is simpler than in any higher base due to the much lower number of cases.
|
||||
|
||||
```
|
||||
1011 r 1
|
||||
1010)1101111
|
||||
1010
|
||||
11111
|
||||
1010
|
||||
1011
|
||||
1010
|
||||
1
|
||||
This example shows how binary long division works. You simply shift the divisor as far right as possible without exceeding the dividend, output a 1 according to the poisition and subtract the number. Whatever remains is the remainder. In this case we show 11011112 ÷ 10102 = 10112 remainder 12. In decimal, 111 ÷ 10 = 11 remainder 1.
|
||||
```
|
||||
|
||||
|
||||
Try to implement long division yourself now. You should write a function, DivideU32 which divides r0 by r1, returning the result in r0, and the remainder in r1. Below, we will go through a very efficient implementation.
|
||||
|
||||
```
|
||||
function DivideU32(r0 is dividend, r1 is divisor)
|
||||
set shift to 31
|
||||
set result to 0
|
||||
while shift ≥ 0
|
||||
if dividend ≥ (divisor << shift) then
|
||||
set dividend to dividend - (divisor << shift)
|
||||
set result to result + 1
|
||||
end if
|
||||
set result to result << 1
|
||||
set shift to shift - 1
|
||||
loop
|
||||
return (result, dividend)
|
||||
end function
|
||||
```
|
||||
|
||||
This code does achieve what we need, but would not work as assembly code. Our problem comes from the fact that our registers only hold 32 bits, and so the result of divisor << shift may not fit in a register (we call this overflow). This is a real problem. Did your solution have overflow?
|
||||
|
||||
Fortunately, an instruction exists called clz or count leading zeros, which counts the number of zeros in the binary representation of a number starting at the top bit. Conveniently, this is exactly the number of times we can shift the register left before overflow occurs. Another optimisation you may spot is that we compute divisor << shift twice each loop. We could improve upon this by shifting the divisor at the beginning, then shifting it down at the end of each loop to avoid any need to shift it elsewhere.
|
||||
|
||||
Let's have a look at the assembly code to make further improvements.
|
||||
|
||||
```
|
||||
.globl DivideU32
|
||||
DivideU32:
|
||||
result .req r0
|
||||
remainder .req r1
|
||||
shift .req r2
|
||||
current .req r3
|
||||
|
||||
clz shift,r1
|
||||
lsl current,r1,shift
|
||||
mov remainder,r0
|
||||
mov result,#0
|
||||
|
||||
divideU32Loop$:
|
||||
cmp shift,#0
|
||||
blt divideU32Return$
|
||||
cmp remainder,current
|
||||
|
||||
addge result,result,#1
|
||||
subge remainder,current
|
||||
sub shift,#1
|
||||
lsr current,#1
|
||||
lsl result,#1
|
||||
b divideU32Loop$
|
||||
divideU32Return$:
|
||||
.unreq current
|
||||
mov pc,lr
|
||||
|
||||
.unreq result
|
||||
.unreq remainder
|
||||
.unreq shift
|
||||
```
|
||||
|
||||
```
|
||||
clz dest,src stores the number of zeros from the top to the first one of register dest to register src
|
||||
```
|
||||
|
||||
You may, quite rightly, think that this looks quite efficient. It is pretty good, but division is a very expensive operation, and one we may wish to do quite often, so it would be good if we could improve the speed in any way. When looking to optimise code with a loop in it, it is always important to consider how many times the loop must run. In this case, the loop will run a maximum of 31 times for an input of 1. Without making special cases, this could often be improved easily. For example when dividing 1 by 1, no shift is required, yet we shift the divisor to each of the positions above it. This could be improved by simply using the new clz command on the dividend and subtracting this from the shift. In the case of 1 ÷ 1, this means shift would be set to 0, rightly indicating no shift is required. If this causes the shift to be negative, the divisor is bigger than the dividend and so we know the result is 0 remainder the dividend. Another quick check we could make is if the current value is ever 0, then we have a perfect division and can stop looping.
|
||||
|
||||
```
|
||||
.globl DivideU32
|
||||
DivideU32:
|
||||
result .req r0
|
||||
remainder .req r1
|
||||
shift .req r2
|
||||
current .req r3
|
||||
|
||||
clz shift,r1
|
||||
clz r3,r0
|
||||
subs shift,r3
|
||||
lsl current,r1,shift
|
||||
mov remainder,r0
|
||||
mov result,#0
|
||||
blt divideU32Return$
|
||||
|
||||
divideU32Loop$:
|
||||
cmp remainder,current
|
||||
blt divideU32LoopContinue$
|
||||
|
||||
add result,result,#1
|
||||
subs remainder,current
|
||||
lsleq result,shift
|
||||
beq divideU32Return$
|
||||
divideU32LoopContinue$:
|
||||
subs shift,#1
|
||||
lsrge current,#1
|
||||
lslge result,#1
|
||||
bge divideU32Loop$
|
||||
|
||||
divideU32Return$:
|
||||
.unreq current
|
||||
mov pc,lr
|
||||
|
||||
.unreq result
|
||||
.unreq remainder
|
||||
.unreq shift
|
||||
```
|
||||
|
||||
Copy the code above to a file called 'maths.s'.
|
||||
|
||||
### 3 Number Strings
|
||||
|
||||
Now that we can do division, let's have another look at implementing number to string conversion. The following is pseudo code to convert numbers from registers into strings in up to base 36. By convention, a % b means the remainder of dividing a by b.
|
||||
|
||||
```
|
||||
function SignedString(r0 is value, r1 is dest, r2 is base)
|
||||
if value ≥ 0
|
||||
then return UnsignedString(value, dest, base)
|
||||
otherwise
|
||||
if dest > 0 then
|
||||
setByte(dest, '-')
|
||||
set dest to dest + 1
|
||||
end if
|
||||
return UnsignedString(-value, dest, base) + 1
|
||||
end if
|
||||
end function
|
||||
|
||||
function UnsignedString(r0 is value, r1 is dest, r2 is base)
|
||||
set length to 0
|
||||
do
|
||||
|
||||
set (value, rem) to DivideU32(value, base)
|
||||
if rem > 10
|
||||
then set rem to rem + '0'
|
||||
otherwise set rem to rem - 10 + 'a'
|
||||
if dest > 0
|
||||
then setByte(dest + length, rem)
|
||||
set length to length + 1
|
||||
|
||||
while value > 0
|
||||
if dest > 0
|
||||
then ReverseString(dest, length)
|
||||
return length
|
||||
end function
|
||||
|
||||
function ReverseString(r0 is string, r1 is length)
|
||||
set end to string + length - 1
|
||||
while end > start
|
||||
set temp1 to readByte(start)
|
||||
set temp2 to readByte(end)
|
||||
setByte(start, temp2)
|
||||
setByte(end, temp1)
|
||||
set start to start + 1
|
||||
set end to end - 1
|
||||
end while
|
||||
end function
|
||||
```
|
||||
|
||||
In a file called 'text.s' implement the above. Remember that if you get stuck, a full solution can be found on the downloads page.
|
||||
|
||||
### 4 Format Strings
|
||||
|
||||
Let's get back to our string formatting method. Since we're programming our own operating system, we can add or change formatting rules as we please. We may find it useful to add a %b operation that outputs a number in binary, and if you're not using null terminated strings, you may wish to alter the behaviour of %s to take the length of the string from another argument, or from a length prefix if you wish. I will use a null terminator in the example below.
|
||||
|
||||
One of the main obstacles to implementing this function is that the number of arguments varies. According to the ABI, additional arguments are pushed onto the stack before calling the method in reverse order. So, for example, if we wish to call our method with 8 parameters; 1,2,3,4,5,6,7 and 8, we would do the following:
|
||||
|
||||
1. Set r0 = 5, r1 = 6, r2 = 7, r3 = 8
|
||||
2. Push {r0,r1,r2,r3}
|
||||
3. Set r0 = 1, r1 = 2, r2 = 3, r3 = 4
|
||||
4. Call the function
|
||||
5. Add sp,#4*4
|
||||
|
||||
|
||||
|
||||
Now we must decide what arguments our function actually needs. In my case, I used the format string address in r0, the length of the format string in r1, the destination string address in r2, followed by the list of arguments required, starting in r3 and continuing on the stack as above. If you wish to use a null terminated format string, the parameter in r1 can be removed. If you wish to have a maximum buffer length, you could store this in r3. As an additional modification, I think it is useful to alter the function so that if the destination string address is 0, no string is outputted, but an accurate length is still returned, so that the length of a formatted string can be accurately determined.
|
||||
|
||||
If you wish to attempt the implementation on your own, try it now. If not, I will first construct the pseudo code for the method, then give the assembly code implementation.
|
||||
|
||||
```
|
||||
function StringFormat(r0 is format, r1 is formatLength, r2 is dest, ...)
|
||||
set index to 0
|
||||
set length to 0
|
||||
while index < formatLength
|
||||
if readByte(format + index) = '%' then
|
||||
set index to index + 1
|
||||
if readByte(format + index) = '%' then
|
||||
if dest > 0
|
||||
then setByte(dest + length, '%')
|
||||
set length to length + 1
|
||||
otherwise if readByte(format + index) = 'c' then
|
||||
if dest > 0
|
||||
then setByte(dest + length, nextArg)
|
||||
set length to length + 1
|
||||
otherwise if readByte(format + index) = 'd' or 'i' then
|
||||
set length to length + SignedString(nextArg, dest, 10)
|
||||
otherwise if readByte(format + index) = 'o' then
|
||||
set length to length + UnsignedString(nextArg, dest, 8)
|
||||
otherwise if readByte(format + index) = 'u' then
|
||||
set length to length + UnsignedString(nextArg, dest, 10)
|
||||
otherwise if readByte(format + index) = 'b' then
|
||||
set length to length + UnsignedString(nextArg, dest, 2)
|
||||
otherwise if readByte(format + index) = 'x' then
|
||||
set length to length + UnsignedString(nextArg, dest, 16)
|
||||
otherwise if readByte(format + index) = 's' then
|
||||
set str to nextArg
|
||||
while getByte(str) != '\0'
|
||||
if dest > 0
|
||||
then setByte(dest + length, getByte(str))
|
||||
set length to length + 1
|
||||
set str to str + 1
|
||||
loop
|
||||
otherwise if readByte(format + index) = 'n' then
|
||||
setWord(nextArg, length)
|
||||
end if
|
||||
otherwise
|
||||
if dest > 0
|
||||
then setByte(dest + length, readByte(format + index))
|
||||
set length to length + 1
|
||||
end if
|
||||
set index to index + 1
|
||||
loop
|
||||
return length
|
||||
end function
|
||||
```
|
||||
|
||||
Although this function is massive, it is quite straightforward. Most of the code goes into checking all the various conditions, the code for each one is simple. Further, all the various unsigned integer cases are the same but for the base, and so can be summarised in assembly. This is given below.
|
||||
|
||||
```
|
||||
.globl FormatString
|
||||
FormatString:
|
||||
format .req r4
|
||||
formatLength .req r5
|
||||
dest .req r6
|
||||
nextArg .req r7
|
||||
argList .req r8
|
||||
length .req r9
|
||||
|
||||
push {r4,r5,r6,r7,r8,r9,lr}
|
||||
mov format,r0
|
||||
mov formatLength,r1
|
||||
mov dest,r2
|
||||
mov nextArg,r3
|
||||
add argList,sp,#7*4
|
||||
mov length,#0
|
||||
|
||||
formatLoop$:
|
||||
subs formatLength,#1
|
||||
movlt r0,length
|
||||
poplt {r4,r5,r6,r7,r8,r9,pc}
|
||||
|
||||
ldrb r0,[format]
|
||||
add format,#1
|
||||
teq r0,#'%'
|
||||
beq formatArg$
|
||||
|
||||
formatChar$:
|
||||
teq dest,#0
|
||||
strneb r0,[dest]
|
||||
addne dest,#1
|
||||
add length,#1
|
||||
b formatLoop$
|
||||
|
||||
formatArg$:
|
||||
subs formatLength,#1
|
||||
movlt r0,length
|
||||
poplt {r4,r5,r6,r7,r8,r9,pc}
|
||||
|
||||
ldrb r0,[format]
|
||||
add format,#1
|
||||
teq r0,#'%'
|
||||
beq formatChar$
|
||||
|
||||
teq r0,#'c'
|
||||
moveq r0,nextArg
|
||||
ldreq nextArg,[argList]
|
||||
addeq argList,#4
|
||||
beq formatChar$
|
||||
|
||||
teq r0,#'s'
|
||||
beq formatString$
|
||||
|
||||
teq r0,#'d'
|
||||
beq formatSigned$
|
||||
|
||||
teq r0,#'u'
|
||||
teqne r0,#'x'
|
||||
teqne r0,#'b'
|
||||
teqne r0,#'o'
|
||||
beq formatUnsigned$
|
||||
|
||||
b formatLoop$
|
||||
|
||||
formatString$:
|
||||
ldrb r0,[nextArg]
|
||||
teq r0,#0x0
|
||||
ldreq nextArg,[argList]
|
||||
addeq argList,#4
|
||||
beq formatLoop$
|
||||
add length,#1
|
||||
teq dest,#0
|
||||
strneb r0,[dest]
|
||||
addne dest,#1
|
||||
add nextArg,#1
|
||||
b formatString$
|
||||
|
||||
formatSigned$:
|
||||
mov r0,nextArg
|
||||
ldr nextArg,[argList]
|
||||
add argList,#4
|
||||
mov r1,dest
|
||||
mov r2,#10
|
||||
bl SignedString
|
||||
teq dest,#0
|
||||
addne dest,r0
|
||||
add length,r0
|
||||
b formatLoop$
|
||||
|
||||
formatUnsigned$:
|
||||
teq r0,#'u'
|
||||
moveq r2,#10
|
||||
teq r0,#'x'
|
||||
moveq r2,#16
|
||||
teq r0,#'b'
|
||||
moveq r2,#2
|
||||
teq r0,#'o'
|
||||
moveq r2,#8
|
||||
|
||||
mov r0,nextArg
|
||||
ldr nextArg,[argList]
|
||||
add argList,#4
|
||||
mov r1,dest
|
||||
bl UnsignedString
|
||||
teq dest,#0
|
||||
addne dest,r0
|
||||
add length,r0
|
||||
b formatLoop$
|
||||
```
|
||||
|
||||
### 5 Convert OS
|
||||
|
||||
Feel free to try using this method however you wish. As an example, here is the code to generate a conversion chart from base 10 to binary to hexadecimal to octal and to ASCII.
|
||||
|
||||
Delete all code after bl SetGraphicsAddress in 'main.s' and replace it with the following:
|
||||
|
||||
```
|
||||
mov r4,#0
|
||||
loop$:
|
||||
ldr r0,=format
|
||||
mov r1,#formatEnd-format
|
||||
ldr r2,=formatEnd
|
||||
lsr r3,r4,#4
|
||||
push {r3}
|
||||
push {r3}
|
||||
push {r3}
|
||||
push {r3}
|
||||
bl FormatString
|
||||
add sp,#16
|
||||
|
||||
mov r1,r0
|
||||
ldr r0,=formatEnd
|
||||
mov r2,#0
|
||||
mov r3,r4
|
||||
|
||||
cmp r3,#768-16
|
||||
subhi r3,#768
|
||||
addhi r2,#256
|
||||
cmp r3,#768-16
|
||||
subhi r3,#768
|
||||
addhi r2,#256
|
||||
cmp r3,#768-16
|
||||
subhi r3,#768
|
||||
addhi r2,#256
|
||||
|
||||
bl DrawString
|
||||
|
||||
add r4,#16
|
||||
b loop$
|
||||
|
||||
.section .data
|
||||
format:
|
||||
.ascii "%d=0b%b=0x%x=0%o='%c'"
|
||||
formatEnd:
|
||||
```
|
||||
|
||||
Can you work out what will happen before testing? Particularly what happens for r3 ≥ 128? Try it on the Raspberry Pi to see if you're right. If it doesn't work, please see our troubleshooting page.
|
||||
|
||||
When it does work, congratulations, you've completed the Screen04 tutorial, and reached the end of the screen series! We've learned about pixels and frame buffers, and how these apply to the Raspberry Pi. We've learned how to draw simple lines, and also how to draw characters, as well as the invaluable skill of formatting numbers into text. We now have all that you would need to make graphical output on an Operating System. Can you make some more drawing methods? What about 3D graphics? Can you implement a 24bit frame buffer? What about reading the size of the framebuffer in from the command line?
|
||||
|
||||
The next series is the [Input][4] series, which teaches how to use the keyboard and mouse to really get towards a traditional console computer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
[2]: http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
tmux – A Powerful Terminal Multiplexer For Heavy Command-Line Linux User
|
||||
======
|
||||
tmux stands for terminal multiplexer, it allows users to create/enable multiple terminals (vertical & horizontal) in single window, this can be accessed and controlled easily from single window when you are working with different issues.
|
||||
|
||||
@ -1,128 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( Auk7F7)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux)
|
||||
[#]: via: (https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
[#]: url: ( )
|
||||
|
||||
|
||||
Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux
|
||||
======
|
||||
|
||||
We have to make the system up-to date to minimize the downtime and issues.
|
||||
|
||||
It’s one of the routine task for Linux administrator to patch the system once in a month or 60 days once or 90 days at maximum.
|
||||
|
||||
It would be sufficient schedule and we can’t do it this less than a month as it’s involve multiple activities and environments.
|
||||
|
||||
Basically infrastructure comes with Test, Development, QA a.k.a Staging & Prod environments.
|
||||
|
||||
Initially we will deploy the patches in the Test environment and corresponding team will be monitoring the system a week then they will give a status report like good or bad.
|
||||
|
||||
If it’s success then we will move forward to other environments. If everything is good then finally we will patch production servers.
|
||||
|
||||
Many of the organization has prepare to patch entire system. i mean full system update. It is a general patching schedule for a typical infrastructure.
|
||||
|
||||
In some of the infrastructure they may have only production environment so, we should not prepare for the full system update instead we can go with security patch to make the system more stable and secure.
|
||||
|
||||
Since Arch Linux and its derivatives distributions are fall under rolling release can be considered to be always up-to-date, as it uses the latest versions of software packages from the upstream.
|
||||
|
||||
In some cases if you want to update security patch alone then you have to use arch-audit tool to identify and fix the security patches.
|
||||
|
||||
### What is a Vulnerability?
|
||||
|
||||
A vulnerability is a security weakness in a software program or hardware components (firmware). It’s a flaw that can leave it open to attack.
|
||||
|
||||
To mitigate this we need to patch accordingly like for application/hardware it could be a code changes or config changes or parameter changes.
|
||||
|
||||
### What is Arch-Audit Tool?
|
||||
|
||||
[Arch-audit][1] is a tool like pkg-audit for Arch Linux system. It Uses data collected by the awesome Arch Security Team. It wont scan and find the vulnerable packages on your system like **yum –security check-update & yum updateinfo list available** and it will simply parse the <https://security.archlinux.org/> page and display the results in terminal. So, it would show the accurate data.
|
||||
|
||||
The Arch Security Team is a group of volunteers whose goal is to track security issues with Arch Linux packages. All issues are tracked on the Arch Linux security tracker.
|
||||
|
||||
The team was formerly known as the Arch CVE Monitoring Team. The mission of the Arch Security Team is to contribute to the improvement of the security of Arch Linux.
|
||||
|
||||
### How to Install arch-audit tool in Arch Linux
|
||||
|
||||
The arch-audit tool is available in community repository so you can use the Pacman Package Manager to install it.
|
||||
|
||||
```
|
||||
$ sudo pacman -S arch-audit
|
||||
```
|
||||
|
||||
Run the `arch-audit` tool to find the open vulnerable packages on Arch based distributions.
|
||||
|
||||
```
|
||||
$ arch-audit
|
||||
Package cairo is affected by CVE-2017-7475. Low risk!
|
||||
Package exiv2 is affected by CVE-2017-11592, CVE-2017-11591, CVE-2017-11553, CVE-2017-17725, CVE-2017-17724, CVE-2017-17723, CVE-2017-17722. Medium risk!
|
||||
Package libtiff is affected by CVE-2018-18661, CVE-2018-18557, CVE-2017-9935, CVE-2017-11613. High risk!. Update to 4.0.10-1!
|
||||
Package openssl is affected by CVE-2018-0735, CVE-2018-0734. Low risk!
|
||||
Package openssl-1.0 is affected by CVE-2018-5407, CVE-2018-0734. Low risk!
|
||||
Package patch is affected by CVE-2018-6952, CVE-2018-1000156. High risk!. Update to 2.7.6-7!
|
||||
Package pcre is affected by CVE-2017-11164. Low risk!
|
||||
Package systemd is affected by CVE-2018-6954, CVE-2018-15688, CVE-2018-15687, CVE-2018-15686. Critical risk!. Update to 239.300-1!
|
||||
Package unzip is affected by CVE-2018-1000035. Medium risk!
|
||||
Package webkit2gtk is affected by CVE-2018-4372. Critical risk!. Update to 2.22.4-1!
|
||||
```
|
||||
|
||||
The above result shows the vulnerability risk status as well such as Low, Medium and Critical.
|
||||
|
||||
To Show only vulnerable package names and their versions.
|
||||
|
||||
```
|
||||
$ arch-audit -q
|
||||
cairo
|
||||
exiv2
|
||||
libtiff>=4.0.10-1
|
||||
openssl
|
||||
openssl-1.0
|
||||
patch>=2.7.6-7
|
||||
pcre
|
||||
systemd>=239.300-1
|
||||
unzip
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
To show only packages that have already been fixed.
|
||||
|
||||
```
|
||||
$ arch-audit --upgradable --quiet
|
||||
libtiff>=4.0.10-1
|
||||
patch>=2.7.6-7
|
||||
systemd>=239.300-1
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
To cross check the above results, i’m going to test one of the package which is listed above in <https://www.archlinux.org/packages/> to confirm whether the vulnerability is still open or fixed it. Yes, it’s fixed and published the updated package in repository on yesterday.
|
||||
![][3]
|
||||
|
||||
To print only package names and associated CVEs alone.
|
||||
|
||||
```
|
||||
$ arch-audit -uf "%n|%c"
|
||||
libtiff|CVE-2018-18661,CVE-2018-18557,CVE-2017-9935,CVE-2017-11613
|
||||
patch|CVE-2018-6952,CVE-2018-1000156
|
||||
systemd|CVE-2018-6954,CVE-2018-15688,CVE-2018-15687,CVE-2018-15686
|
||||
webkit2gtk|CVE-2018-4372
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/ilpianista/arch-audit
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2018/11/A-Tool-To-Check-Vulnerable-Packages-In-Arch-Linux.png
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Joplin, a note-taking app)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-joplin)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Joplin, a note-taking app
|
||||
======
|
||||
Learn how open source tools can help you be more productive in 2019. First up, Joplin.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the first of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Joplin
|
||||
|
||||
In the realm of productivity tools, note-taking apps are VERY handy. Yes, you can use the open source [NixNote][1] to access [Evernote][2] notes, but it's still linked to the Evernote servers and still relies on a third party for security. And while you CAN export your Evernote notes from NixNote, the only format options are NixNote XML or PDF files.
|
||||
|
||||
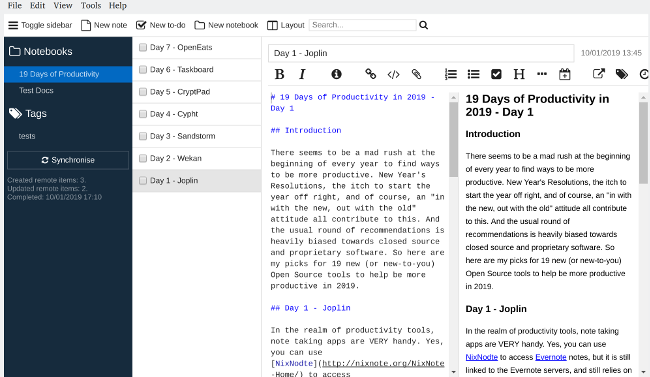
|
||||
|
||||
Enter [Joplin][3]. Joplin is a NodeJS application that runs and stores notes locally, allows you to encrypt your notes and supports multiple sync methods. Joplin can run as a console or graphical application on Windows, Mac, and Linux. Joplin also has mobile apps for Android and iOS, meaning you can take your notes with you without a major hassle. Joplin even allows you to format notes with Markdown, HTML, or plain text.
|
||||
|
||||
|
||||
|
||||
One really nice thing about Joplin is it supports two kinds of notes: plain notes and to-do notes. Plain notes are what you expect—documents containing text. To-do notes, on the other hand, have a checkbox in the notes list that allows you to mark them "done." And since the to-do note is still a note, you can include lists, documentation, and additional to-do items in a to-do note.
|
||||
|
||||
When using the GUI, you can toggle editor views between plain text, WYSIWYG, and a split screen showing both the source text and the rendered view. You can also specify an external editor in the GUI, making it easy to update notes with Vim, Emacs, or any other editor capable of handling text documents.
|
||||
|
||||
![Joplin console version][5]
|
||||
|
||||
Joplin in the console.
|
||||
|
||||
The console interface is absolutely fantastic. While it lacks a WYSIWYG editor, it defaults to the text editor for your login. It also has a powerful command mode that allows you to do almost everything you can do in the GUI version. And it renders Markdown correctly in the viewer.
|
||||
|
||||
You can group notes in notebooks and tag notes for easy grouping across your notebooks. And it even has built-in search, so you can find things if you forget where you put them.
|
||||
|
||||
Overall, Joplin is a first-class note-taking app ([and a great alternative to Evernote][6]) that will help you be organized and more productive over the next year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-joplin
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://nixnote.org/NixNote-Home/
|
||||
[2]: https://evernote.com/
|
||||
[3]: https://joplin.cozic.net/
|
||||
[4]: https://opensource.com/article/19/1/file/419776
|
||||
[5]: https://opensource.com/sites/default/files/uploads/joplin-2_0.png (Joplin console version)
|
||||
[6]: https://opensource.com/article/17/12/joplin-open-source-evernote-alternative
|
||||
@ -1,76 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (You (probably) don't need Kubernetes)
|
||||
[#]: via: (https://arp242.net/weblog/dont-need-k8s.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
你(大概)不需要 Kubernetes
|
||||
======
|
||||
|
||||
这也许是一个不太受欢迎的观点,但大多数主流公司最好不要再使用 k8s 了。
|
||||
|
||||
你知道那个古老的“根据程序员技能写 Hello world ”笑话吗?它从一个新手程序员的 printf("hello, world\n") 语句开始,最后结束于高级软件架构工程师令人费解的 Java OOP 模式设计。使用 k8s 就有点像这样。
|
||||
|
||||
* 新手 SysOp:
|
||||
`./binary`
|
||||
* 有经验的 SysOp:
|
||||
在 EC2 上的 `./binary`
|
||||
* DevOp:
|
||||
在 EC2 上自部署的 CI 管道运行 `./binary`
|
||||
* 高级云编排工程师:
|
||||
在 EC2 上通过 k8s 编排的自部署 CI 管道运行 `./binary`
|
||||
|
||||
|
||||
|
||||
¯\\_(ツ)_/¯
|
||||
|
||||
这不意味着 Kubernetes 或者任何这样的东西本身都是坏的,就像 Java 或者 OOP 设计本身并不是坏的一样,但是,在很多情况下,它们被严重地误用,就像在一个 hello world 的程序中可怕地误用 Java 面向对象设计模式一样。对大多数公司而言,系统运维从根本上来说并不十分复杂,此时在这上面应用 k8s 起效甚微。
|
||||
|
||||
复杂性本质上来说创造了工作,我十分怀疑使用 k8s 对大多数使用者来说是省时的这一说法。这就好像花一天时间来写一个脚本,用来自动完成一些你一个月一次,每次只花 10 分钟完成的工作。这不是一个好的时间投资(特别是你可能会在未来由于扩展或调试这个脚本来进一步投入更多的时间)。
|
||||
|
||||
你的部署大概应该需要自动化 – 以免你 [最终像 Knightmare][1] 那样 – 但 k8s 通常可以被一个简单的 shell 脚本所替代。
|
||||
|
||||
在我们公司,sysops 团队用了很多时间来设置 k8s 。他们还不得不用了很大一部分时间来更新到新一点的版本(1.6 – 1.8)。结果是如果没有真正深入理解 k8s ,没人会真正明白一些东西,甚至连深入理解 k8s 这一点也很难(那些 YAML 文件,哦呦!)
|
||||
|
||||
在我能自己调试和修复问题之前——现在这更难了,我理解基本概念,但在真正调试实际问题的时候,它们并不是那么有用。我不经常用 k8s 足以证明这点。
|
||||
|
||||
k8s 真的很难这点并不是什么新看法,这也是为什么现在会有这么多“ k8s 简单学”的解决方案。在 k8s 上再添一层来“让它更简单”的方法让我觉得,呃,不明智。复杂性并没有消失,你只是把它藏起来了。
|
||||
|
||||
以前我说过很多次:在确定一样东西是否“简单”时,我最关心的不是写东西的时候有多简单,而是当失败的时候调试起来有多容易。包装 k8s 并不会让调试更加简单,恰恰相反,它让事情更加困难了。
|
||||
|
||||
Blaise Pascal 有一句名言:
|
||||
|
||||
> 几乎所有的痛苦都来自于我们不善于在房间里独处。
|
||||
|
||||
k8s —— 略微拓展一下,Docker ——似乎就是这样的例子。许多人似乎迷失在当下的兴奋中,觉得“ k8s 就是这么回事!”,就像有些人迷失在 Java OOP 刚出来时的兴奋中一样,所以一切都必须从“旧”方法转为“新”方法,即使“旧”方法依然可行。
|
||||
|
||||
有时候 IT 产业挺蠢的。
|
||||
|
||||
或者用 [一条推特][2] 来总结:
|
||||
|
||||
> 2014 - 我们必须采用 #微服务 来解决 monolith 的所有问题
|
||||
> 2016 - 我们必须采用 #docker 来解决微服务的所有问题
|
||||
> 2018 - 我们必须采用 #kubernetes 来解决 docker 的所有问题
|
||||
|
||||
你可以通过 [martin@arp242.net][3] 给我发邮件或者 [创建 GitHub issue][4] 来给我反馈或提出问题等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/dont-need-k8s.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://dougseven.com/2014/04/17/knightmare-a-devops-cautionary-tale/
|
||||
[2]: https://twitter.com/sahrizv/status/1018184792611827712
|
||||
[3]: mailto:martin@arp242.net
|
||||
[4]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -0,0 +1,128 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: subject: "Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux"
|
||||
[#]: via: "https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/"
|
||||
[#]: author: "Prakash Subramanian https://www.2daygeek.com/author/prakash/"
|
||||
[#]: url: " "
|
||||
|
||||
Arch-Audit : 一款在 Arch Linux 上检查易受攻击包的工具
|
||||
======
|
||||
|
||||
我们必须经常更新我们的系统以减少宕机时间和问题。
|
||||
|
||||
每月给系统打一次补丁,60天一次或者最多90天一次,这是 Linux 管理员的例行任务之一。
|
||||
|
||||
这将是忙碌的工作计划,我们不能在不到一个月内做到这一点,因为它涉及到多种活动和环境。
|
||||
|
||||
基本上,基础架构与测试、开发、 QA (即分段和产品开发环境)一起提供。
|
||||
|
||||
最初,我们会在测试环境中部署补丁,相应的团队将监视系统一周,然后他们将给出一份比如好的或坏的状态报告。
|
||||
|
||||
如果它是成功的话,我们将会在其他环境中继续测试,若正常运行,那么最后我们会给生产服务器打上补丁。
|
||||
|
||||
许多组织已经准备好给整个系统打上补丁。我的意思是全部系统的更新,这是一种对于基础设施的常规修补计划。
|
||||
|
||||
在一些基础结构中,他们可能只有生产环境,因此,我们不应该为完整的系统更新做好准备,而是可以使用安全修补程序来使系统更加稳定和安全。
|
||||
|
||||
由于 Arch Linux 及其衍发行版本属于滚动更新版本,因此可以认为他们始终是最新的,因为它使用上游软件包的最新版本。
|
||||
|
||||
在某些情况下,如果要单独更新安全修补程序 ,则必须使用 arch-audit 工具来标识和修复安全修补程序。
|
||||
|
||||
### 漏洞是什么?
|
||||
|
||||
漏洞是软件程序或硬件组件(固件)中的安全漏洞。这是一个可以让它容易受到攻击的缺陷。
|
||||
|
||||
为了缓解这种情况,我们需要相应地修补,就像应用程序/硬件一样,它可能是代码更改或配置更改或参数更改。
|
||||
|
||||
### Arch-Audit 工具是什么?
|
||||
|
||||
[Arch-audit][1] 是一个类似于 Arch Linux 的 pkg-audit 工具。它使用了令人称赞的 Arch 安全小组收集的数据。他不会扫描并发现系统中易受攻击的包,如 **yum –security check-update & yum updateinfo list available**,它只需解析 <https://security.archlinux.org/> 页面并在终端中显示结果,因此,它将显示准确的数据。
|
||||
|
||||
Arch 安全小组是一群以跟踪 Arch Linux 软件包的安全问题为目的的志愿者。所有问题都在 Arch 安全追踪者的监视下。.
|
||||
|
||||
该小组以前被称为 Arch CVE 监测小组,Arch 安全小组的使命是为提高 Arch Linux 的安全性做出贡献。
|
||||
|
||||
### 如何在 Arch Linux 上安装 Arch-Audit 工具
|
||||
|
||||
arch-audit 工具已经存在社区源中,所以你可以使用 Pacman 包管理器来安装它。
|
||||
|
||||
```
|
||||
$ sudo pacman -S arch-audit
|
||||
```
|
||||
|
||||
运行 `arch-audit` 工具以查找在基于 Arch 的发行版本上的开放且易受攻击的包。
|
||||
|
||||
```
|
||||
$ arch-audit
|
||||
Package cairo is affected by CVE-2017-7475. Low risk!
|
||||
Package exiv2 is affected by CVE-2017-11592, CVE-2017-11591, CVE-2017-11553, CVE-2017-17725, CVE-2017-17724, CVE-2017-17723, CVE-2017-17722. Medium risk!
|
||||
Package libtiff is affected by CVE-2018-18661, CVE-2018-18557, CVE-2017-9935, CVE-2017-11613. High risk!. Update to 4.0.10-1!
|
||||
Package openssl is affected by CVE-2018-0735, CVE-2018-0734. Low risk!
|
||||
Package openssl-1.0 is affected by CVE-2018-5407, CVE-2018-0734. Low risk!
|
||||
Package patch is affected by CVE-2018-6952, CVE-2018-1000156. High risk!. Update to 2.7.6-7!
|
||||
Package pcre is affected by CVE-2017-11164. Low risk!
|
||||
Package systemd is affected by CVE-2018-6954, CVE-2018-15688, CVE-2018-15687, CVE-2018-15686. Critical risk!. Update to 239.300-1!
|
||||
Package unzip is affected by CVE-2018-1000035. Medium risk!
|
||||
Package webkit2gtk is affected by CVE-2018-4372. Critical risk!. Update to 2.22.4-1!
|
||||
```
|
||||
|
||||
上述结果显示了系统的脆弱性风险状况,比如:低、中和严重三种情况。
|
||||
|
||||
若要仅显示易受攻击的包及其版本,请执行以下操作。
|
||||
|
||||
```
|
||||
$ arch-audit -q
|
||||
cairo
|
||||
exiv2
|
||||
libtiff>=4.0.10-1
|
||||
openssl
|
||||
openssl-1.0
|
||||
patch>=2.7.6-7
|
||||
pcre
|
||||
systemd>=239.300-1
|
||||
unzip
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
仅显示已修复的包。
|
||||
|
||||
```
|
||||
$ arch-audit --upgradable --quiet
|
||||
libtiff>=4.0.10-1
|
||||
patch>=2.7.6-7
|
||||
systemd>=239.300-1
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
为了交叉检查上述结果,我将测试在 <https://www.archlinux.org/packages/> 列出的一个包以确认漏洞是否仍处于开放状态或已修复。是的,它已经被修复了,并于昨天在社区源中发布了更新后的包。
|
||||
|
||||
![][3]
|
||||
|
||||
仅打印包名称和其相关的 CVE。
|
||||
|
||||
```
|
||||
$ arch-audit -uf "%n|%c"
|
||||
libtiff|CVE-2018-18661,CVE-2018-18557,CVE-2017-9935,CVE-2017-11613
|
||||
patch|CVE-2018-6952,CVE-2018-1000156
|
||||
systemd|CVE-2018-6954,CVE-2018-15688,CVE-2018-15687,CVE-2018-15686
|
||||
webkit2gtk|CVE-2018-4372
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/ilpianista/arch-audit
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2018/11/A-Tool-To-Check-Vulnerable-Packages-In-Arch-Linux.png
|
||||
@ -0,0 +1,61 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Joplin, a note-taking app)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-joplin)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用一款笔记应用 Joplin
|
||||
======
|
||||
了解开源工具如何帮助你在 2019 年提高工作效率。先从 Joplin 开始。
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件。这不一定要这样。
|
||||
|
||||
这是我挑选出的 19 个新的(或者对你而言新的)开源项目来帮助你在 2019 年更有效率。
|
||||
|
||||
### Joplin
|
||||
|
||||
在生产力工具领域,笔记应用非常方便。是的,你可以使用开源 [NixNote][1] 访问 [Evernote][2 ] 笔记,但它仍然与 Evernote 服务器相关联,并且仍然依赖于第三方的安全性。虽然你可以从 NixNote 导出 Evernote 笔记,但可选格式只有 NixNote XML 或 PDF。
|
||||
|
||||

|
||||
|
||||
看看 [Joplin][3]。Joplin 是一个 NodeJS 应用,它在本地运行和存储笔记,它允许你加密笔记并支持多种同步方法。Joplin 可在 Windows、Mac 和 Linux 上作为控制台或图形应用运行。Joplin 还有适用于 Android 和 iOS 的移动应用,这意味着你可以随身携带笔记而不会有任何麻烦。Joplin 甚至允许你使用 Markdown、HTML 或纯文本格式笔记。
|
||||
|
||||

|
||||
|
||||
关于 Joplin 很棒的一件事是它支持两种类型笔记:普通笔记和待办事项笔记。普通笔记是你所想的包含文本的文档。另一个,待办事项笔记在笔记列表中有一个复选框,允许你将其标记为“已完成”。由于待办事项仍然是一个笔记,因此你可以在待办事项中添加列表、文档和其他待办事项。
|
||||
|
||||
当使用 GUI 时,你可以在纯文本、WYSIWYG 和同时显示源文本和渲染视图的分屏之间切换编辑器视图。你还可以在 GUI 中指定外部编辑器,以便使用 Vim、Emacs 或任何其他能够处理文本文档的编辑器轻松更新笔记。
|
||||
|
||||
![Joplin console version][5]
|
||||
|
||||
控制台中的 Joplin
|
||||
|
||||
控制台界面非常棒。虽然它缺少 WYSIWYG 编辑器,但默认登录使用文本编辑器。它还有强大的命令模式,它允许执行在 GUI 版本中几乎所有的操作。并且能够在视图中正确渲染 Markdown。
|
||||
|
||||
你可以将笔记本中的笔记分组,还能为笔记打上标记,以便于在笔记本中进行分组。它甚至还有内置的搜索功能,因此如果你忘了笔记在哪,你可以通过它找到它们。
|
||||
|
||||
总的来说,Joplin 是一款一流的笔记应用([还是 Evernote 的一个很好的替代品][6]),它能帮助你在明年组织化并提高工作效率。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-joplin
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://nixnote.org/NixNote-Home/
|
||||
[2]: https://evernote.com/
|
||||
[3]: https://joplin.cozic.net/
|
||||
[4]: https://opensource.com/article/19/1/file/419776
|
||||
[5]: https://opensource.com/sites/default/files/uploads/joplin-2_0.png (Joplin console version)
|
||||
[6]: https://opensource.com/article/17/12/joplin-open-source-evernote-alternative
|
||||
Loading…
Reference in New Issue
Block a user