mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
2c65d919dd
@ -1,18 +1,20 @@
|
||||
使用一个命令重置 Linux 桌面到默认设置
|
||||
使用一个命令重置 Linux 桌面为默认设置
|
||||
======
|
||||
|
||||

|
||||
|
||||
前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
前段时间,我们分享了一篇关于 [Resetter][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
|
||||
### 将 Linux 桌面重置为默认设置
|
||||
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
|
||||
|
||||
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
|
||||
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
@ -29,12 +31,13 @@ dconf reset -f /
|
||||
|
||||
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
|
||||
|
||||
有关 “dconf” 命令的更多详细信息,请参阅手册页。
|
||||
有关 `dconf` 命令的更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
|
||||
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
|
||||
|
||||
@ -48,12 +51,12 @@ via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-comma
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[1]:https://linux.cn/article-9217-1.html
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png
|
||||
@ -1,95 +0,0 @@
|
||||
translating by kimii
|
||||
How To Safely Generate A Random Number — Quarrelsome
|
||||
======
|
||||
### Use urandom
|
||||
|
||||
Use [urandom][1]. Use [urandom][2]. Use [urandom][3]. Use [urandom][4]. Use [urandom][5]. Use [urandom][6].
|
||||
|
||||
### But what about for crypto keys?
|
||||
|
||||
Still [urandom][6].
|
||||
|
||||
### Why not {SecureRandom, OpenSSL, havaged, &c}?
|
||||
|
||||
These are userspace CSPRNGs. You want to use the kernel’s CSPRNG, because:
|
||||
|
||||
* The kernel has access to raw device entropy.
|
||||
|
||||
* It can promise not to share the same state between applications.
|
||||
|
||||
* A good kernel CSPRNG, like FreeBSD’s, can also promise not to feed you random data before it’s seeded.
|
||||
|
||||
|
||||
|
||||
|
||||
Study the last ten years of randomness failures and you’ll read a litany of userspace randomness failures. [Debian’s OpenSSH debacle][7]? Userspace random. Android Bitcoin wallets [repeating ECDSA k’s][8]? Userspace random. Gambling sites with predictable shuffles? Userspace random.
|
||||
|
||||
Userspace OpenSSL also seeds itself from “from uninitialized memory, magical fairy dust and unicorn horns” generators almost always depend on the kernel’s generator anyways. Even if they don’t, the security of your whole system sure does. **A userspace CSPRNG doesn’t add defense-in-depth; instead, it creates two single points of failure.**
|
||||
|
||||
### Doesn’t the man page say to use /dev/random?
|
||||
|
||||
You But, more on this later. Stay your pitchforks. should ignore the man page. Don’t use /dev/random. The distinction between /dev/random and /dev/urandom is a Unix design wart. The man page doesn’t want to admit that, so it invents a security concern that doesn’t really exist. Consider the cryptographic advice in random(4) an urban legend and get on with your life.
|
||||
|
||||
### But what if I need real random values, not psuedorandom values?
|
||||
|
||||
Both urandom and /dev/random provide the same kind of randomness. Contrary to popular belief, /dev/random doesn’t provide “true random” data. For cryptography, you don’t usually want “true random”.
|
||||
|
||||
Both urandom and /dev/random are based on a simple idea. Their design is closely related to that of a stream cipher: a small secret is stretched into an indefinite stream of unpredictable values. Here the secrets are “entropy”, and the stream is “output”.
|
||||
|
||||
Only on Linux are /dev/random and urandom still meaningfully different. The Linux kernel CSPRNG rekeys itself regularly (by collecting more entropy). But /dev/random also tries to keep track of how much entropy remains in its kernel pool, and will occasionally go on strike if it decides not enough remains. This design is as silly as I’ve made it sound; it’s akin to AES-CTR blocking based on how much “key” is left in the “keystream”.
|
||||
|
||||
If you use /dev/random instead of urandom, your program will unpredictably (or, if you’re an attacker, very predictably) hang when Linux gets confused about how its own RNG works. Using /dev/random will make your programs less stable, but it won’t make them any more cryptographically safe.
|
||||
|
||||
### There’s a catch here, isn’t there?
|
||||
|
||||
No, but there’s a Linux kernel bug you might want to know about, even though it doesn’t change which RNG you should use.
|
||||
|
||||
On Linux, if your software runs immediately at boot, and/or the OS has just been installed, your code might be in a race with the RNG. That’s bad, because if you win the race, there could be a window of time where you get predictable outputs from urandom. This is a bug in Linux, and you need to know about it if you’re building platform-level code for a Linux embedded device.
|
||||
|
||||
This is indeed a problem with urandom (and not /dev/random) on Linux. It’s also a [bug in the Linux kernel][9]. But it’s also easily fixed in userland: at boot, seed urandom explicitly. Most Linux distributions have done this for a long time. But don’t switch to a different CSPRNG.
|
||||
|
||||
### What about on other operating systems?
|
||||
|
||||
FreeBSD and OS X do away with the distinction between urandom and /dev/random; the two devices behave identically. Unfortunately, the man page does a poor job of explaining why this is, and perpetuates the myth that Linux urandom is scary.
|
||||
|
||||
FreeBSD’s kernel crypto RNG doesn’t block regardless of whether you use /dev/random or urandom. Unless it hasn’t been seeded, in which case both block. This behavior, unlike Linux’s, makes sense. Linux should adopt it. But if you’re an app developer, this makes little difference to you: Linux, FreeBSD, iOS, whatever: use urandom.
|
||||
|
||||
### tl;dr
|
||||
|
||||
Use urandom.
|
||||
|
||||
### Epilog
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> Right now, SecureRandom.random_bytes tries to detect an OpenSSL to use before it tries to detect /dev/urandom. I think it should be the other way around. In both cases, you just need random bytes to unpack, so SecureRandom could skip the middleman (and second point of failure) and just talk to /dev/urandom directly if it’s available.
|
||||
|
||||
Resolution:
|
||||
|
||||
> /dev/urandom is not suitable to be used to generate directly session keys and other application level random data which is generated frequently.
|
||||
>
|
||||
> [the] random(4) [man page] on GNU/Linux [says]…
|
||||
|
||||
Thanks to Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci for reading drafts of this. Fair warning: Matthew only mostly agrees with me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas;Erin;Matasano][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -1,83 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Testing IPv6 Networking in KVM: Part 1
|
||||
======
|
||||
|
||||

|
||||
|
||||
Nothing beats hands-on playing with IPv6 addresses to get the hang of how they work, and setting up a little test lab in KVM is as easy as falling over — and more fun. In this two-part series, we will learn about IPv6 private addressing and configuring test networks in KVM.
|
||||
|
||||
### QEMU/KVM/Virtual Machine Manager
|
||||
|
||||
Let's start with understanding what KVM is. Here I use KVM as a convenient shorthand for the combination of QEMU, KVM, and the Virtual Machine Manager that is typically bundled together in Linux distributions. The simplified explanation is that QEMU emulates hardware, and KVM is a kernel module that creates the guest state on your CPU and manages access to memory and the CPU. Virtual Machine Manager is a lovely graphical overlay to all of this virtualization and hypervisor goodness.
|
||||
|
||||
But you're not stuck with pointy-clicky, no, for there are also fab command-line tools to use — such as virsh and virt-install.
|
||||
|
||||
If you're not experienced with KVM, you might want to start with [Creating Virtual Machines in KVM: Part 1][1] and [Creating Virtual Machines in KVM: Part 2 - Networking][2].
|
||||
|
||||
### IPv6 Unique Local Addresses
|
||||
|
||||
Configuring IPv6 networking in KVM is just like configuring IPv4 networks. The main difference is those weird long addresses. [Last time][3], we talked about the different types of IPv6 addresses. There is one more IPv6 unicast address class, and that is unique local addresses, fc00::/7 (see [RFC 4193][4]). This is analogous to the private address classes in IPv4, 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16.
|
||||
|
||||
This diagram illustrates the structure of the unique local address space. 48 bits define the prefix and global ID, 16 bits are for subnets, and the remaining 64 bits are the interface ID:
|
||||
```
|
||||
| 7 bits |1| 40 bits | 16 bits | 64 bits |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
| Prefix |L| Global ID | Subnet ID | Interface ID |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
|
||||
```
|
||||
|
||||
Here is another way to look at it, which is might be more helpful for understanding how to manipulate these addresses:
|
||||
```
|
||||
| Prefix | Global ID | Subnet ID | Interface ID |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
|
||||
```
|
||||
|
||||
fc00::/7 is divided into two /8 blocks, fc00::/8 and fd00::/8. fc00::/8 is reserved for future use. So, unique local addresses always start with fd, and the rest is up to you. The L bit, which is the eighth bit, is always set to 1, which makes fd00::/8. Setting it to zero makes fc00::/8. You can see this with subnetcalc:
|
||||
```
|
||||
$ subnetcalc fd00::/8 -n
|
||||
Address = fd00::
|
||||
fd00 = 11111101 00000000
|
||||
|
||||
$ subnetcalc fc00::/8 -n
|
||||
Address = fc00::
|
||||
fc00 = 11111100 00000000
|
||||
|
||||
```
|
||||
|
||||
RFC 4193 requires that addresses be randomly generated. You can invent addresses any way you choose, as long as they start with fd, because the IPv6 cops aren't going to invade your home and give you a hard time. Still, it is a best practice to follow what RFCs say. The addresses must not be assigned sequentially or with well-known numbers. RFC 4193 includes an algorithm for building a pseudo-random address generator, or you can find any number of generators online.
|
||||
|
||||
Unique local addresses are not centrally managed like global unicast addresses (assigned to you by your Internet service provider), but even so the probability of address collisions is very low. This is a nice benefit when you need to merge some local networks or want to route between discrete private networks.
|
||||
|
||||
You can mix unique local addresses and global unicast addresses on the same subnets. Unique local addresses are routable and require no extra router tweaks. However, you should configure your border routers and firewalls to not allow them to leave your network except between private networks at different locations.
|
||||
|
||||
RFC 4193 advises against mingling AAAA and PTR records with your global unicast address records, because there is no guarantee that they will be unique, even though the odds of duplicates are low. Just like we do with IPv4 addresses, keep your private local name services and public name services separate. The tried-and-true combination of Dnsmasq for local name services and BIND for public name services works just as well for IPv6 as it does for IPv4.
|
||||
|
||||
### Pseudo-Random Address Generator
|
||||
|
||||
One example of an online address generator is [Local IPv6 Address Generator][5]. You can find many cool online tools like this. You can use it to create a new address for you, or use it with your existing global ID and play with creating subnets.
|
||||
|
||||
Come back next week to learn how to plug all of this IPv6 goodness into KVM and do live testing.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][6]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2017/10/calculating-ipv6-subnets-linux
|
||||
[4]:https://tools.ietf.org/html/rfc4193
|
||||
[5]:https://www.ultratools.com/tools/rangeGenerator
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,60 +0,0 @@
|
||||
Translating by qhwdw
|
||||
What DevOps teams really need from a CIO
|
||||
======
|
||||
IT leaders can learn from plenty of material exploring [DevOps][1] and the challenging cultural shift required for [making the DevOps transition][2]. But are you in tune with the short and long term challenges that a DevOps team faces - and what they really need from a CIO?
|
||||
|
||||
In my conversations with DevOps team members, some of what I heard might surprise you. DevOps pros (whether part of an internal or external team) want to put the following things at the top of your CIO radar screen.
|
||||
|
||||
### 1. Communication
|
||||
|
||||
First and foremost, DevOps pros need peer-level communication. An experienced DevOps team is extremely knowledgeable on current DevOps trends, successes, and failures in the industry and is interested in sharing this information. DevOps concepts are difficult to convey, so be open to a new working relationship in which there are regular (don't worry, not weekly) conversations about the current state of your IT, how the pieces in the environment communicate, and your overall IT estate.
|
||||
|
||||
**[ Want even more wisdom from CIOs on leading DevOps? See our comprehensive resource,[DevOps: The IT Leader's Guide][3]. ]**
|
||||
|
||||
Conversely, be prepared to share current business needs and goals with the DevOps team. Business objectives no longer exist in isolation from IT: They are now an integral component of what drives your IT advancements, and your IT determines how effectively you can execute on your business needs and goals.
|
||||
|
||||
Focus on participating rather than leading. You are still the ultimate arbiter when it comes to decisions, but understand that these decisions are best made collaboratively in order to empower and motivate your DevOps team.
|
||||
|
||||
### 2. Reduction of technical debt
|
||||
|
||||
Second, strive to better understand technical debt and how DevOps efforts are going to reduce it. Your DevOps team is working hard on this front. In this case, technical debt refers to the manpower and infrastructure resources that are usurped daily by maintaining and adding new features on top of a monolithic, non-sustainable environment (read Rube Goldberg).
|
||||
|
||||
Common CIO questions include:
|
||||
|
||||
* Why do we need to do things in a new way?
|
||||
* Why are we spending time and money on this?
|
||||
* If there's no new functionality, just existing pieces being broken out with automation, then where is the gain?
|
||||
|
||||
|
||||
|
||||
The "if it ain't broke don't fix it" thinking is understandable. But if the car is driving fine while everyone on the road accelerates past you, your environment IS broken. Precious resources continue to be sucked into propping up or augmenting an environmental kluge.
|
||||
|
||||
Addressing every issue in isolation results in a compromised choice from the start that is worsened with each successive patch - layer upon layer added to a foundation that wasn't built to support it. In actuality, this approach is similar to plugging a continuously failing dike. Sooner or later you run out of fingers and the whole thing buckles under the added pressures, drowning your resources.
|
||||
|
||||
The solution: automation. The result of automation is scalability - less effort per person to maintain and grow your IT environment. If adding manpower is the only way to grow your business, then scalability is a pipe dream.
|
||||
|
||||
Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution. Simple, right? Yes, but you must be prepared for delayed gratification. An upfront investment of time and effort for architectural and structural changes is required in order to reap the back-end financial benefits of automation with improved productivity and efficiency. Embracing these challenges as an IT leader is crucial in order for your DevOps team to successfully execute.
|
||||
|
||||
### 3. Trust
|
||||
|
||||
Lastly, trust your DevOps team and make sure they know it. DevOps experts understand that this is a tough request, but they must have your unquestionable support and your willingness to actively participate. It will often be a "learn as you go" experience for you as the DevOps team successively refines your IT environment, while they themselves adapt to ever-changing technology.
|
||||
|
||||
Listen, listen, listen to them and trust them. DevOps changes are valuable and well worth the time and money through increased efficiency, productivity, and business responsiveness. Trusting your DevOps team gives them the freedom to make the most effective IT improvements.
|
||||
|
||||
The new CIO bottom line: To maximize your DevOps team's potential, leave your leadership comfort zone and embrace a "CIOps" transition. Continuously work on finding common ground with the DevOps team throughout the DevOps transition, to help your organization achieve long-term IT success.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
|
||||
作者:[John Allessio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/john-allessio
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
@ -1,191 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Find (Top-10) Largest Files In Linux
|
||||
======
|
||||
When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
|
||||
|
||||
You have to spend huge amount of time to get the largest files in the system using the above commands, that to you have to navigate to each and every directory to achieve this.
|
||||
|
||||
It's making you to face trouble and this is not the right way to do it.
|
||||
|
||||
If so, what would be the suggested way to get top 10 largest files in Linux?
|
||||
|
||||
I have spend a lot of time with google but i didn't found this. Everywhere i could see an article which list the top 10 files in the current directory. So, i want to make this article useful for people whoever looking to get the top 10 largest files in the system.
|
||||
|
||||
In this tutorial, we are going to teach you how to find top 10 largest files in Linux system using below four methods.
|
||||
|
||||
### Method-1 :
|
||||
|
||||
There is no specific command available in Linux to do this, hence we are using more than one command (all together) to get this done.
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-print0`** : Print the full file name on the standard output, followed by a null character
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`xargs`** : It 's a command, which build and execute command lines from standard input.
|
||||
**`-0`** : Input items are terminated by a null character instead of by whitespace
|
||||
**`du -h`** : It 's a command to calculate disk usage with human readable format
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
**`-h`** : Print the output with human readable format
|
||||
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`n -10`** : Print the first 10 files.
|
||||
|
||||
### Method-2 :
|
||||
|
||||
This is an another way to find or check top 10 largest files in Linux system. Here also, we are putting few commands together to achieve this.
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-exec`** : This variant of the -exec action runs the specified command on the selected files
|
||||
**`du`** : It 's a command to estimate file space usage.
|
||||
|
||||
**`-S`** : Do not include size of subdirectories
|
||||
**`-h`** : Print sizes in human readable format
|
||||
**`{}`** : Summarize disk usage of each FILE, recursively for directories.
|
||||
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
|
||||
**`-h`** : Compare human readable numbers
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`n -10`** : Print the first 10 files.
|
||||
|
||||
### Method-3 :
|
||||
|
||||
It 's an another method to find or search top 10 largest files in Linux system.
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-print0`** : Print the full file name on the standard output, followed by a null character
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`xargs`** : It 's a command, which build and execute command lines from standard input.
|
||||
**`-0`** : Input items are terminated by a null character instead of by whitespace
|
||||
**`du`** : It 's a command to estimate file space usage.
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-n`** : Compare according to string numerical value
|
||||
**`tail -10`** : It 's a command, output the last part of files (last 10 files)
|
||||
|
||||
**`cut`** : It 's a command, remove sections from each line of files
|
||||
**`-f2`** : Select only these fields value.
|
||||
**`-I{}`** : Replace occurrences of replace-str in the initial-arguments with names read from standard input.
|
||||
|
||||
**`-s`** : Display only a total for each argument
|
||||
**`-h`** : Print sizes in human readable format
|
||||
**`{}`** : Summarize disk usage of each FILE, recursively for directories.
|
||||
|
||||
### Method-4 :
|
||||
|
||||
It 's an another method to find or search top 10 largest files in Linux system.
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**Details :**
|
||||
**`find`** : It 's a command, Search for files in a directory hierarchy.
|
||||
**`/`** : Check in the whole system (starting from / directory)
|
||||
**`-type`** : File is of type
|
||||
|
||||
**`f`** : Regular file
|
||||
**`-ls`** : List current file in ls -dils format on standard output.
|
||||
**`|`** : Control operator that send the output of one program to another program for further processing.
|
||||
|
||||
**`sort`** : It 's a command, Sort lines of text files
|
||||
**`-k`** : start a key at POS1
|
||||
**`-r`** : Reverse the result of comparisons
|
||||
|
||||
**`-n`** : Compare according to string numerical value
|
||||
**`head`** : It 's a command, Output the first part of files
|
||||
**`-10`** : Print the first 10 files.
|
||||
|
||||
**`column`** : It 's a command, formats its input into multiple columns.
|
||||
**`-t`** : Determine the number of columns the input contains and create a table.
|
||||
**`awk`** : It 's a command, Pattern scanning and processing language
|
||||
**`'{print $7,$11}'`** : Print only mentioned column.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -1,266 +0,0 @@
|
||||
translating by amwps290
|
||||
How to format academic papers on Linux with groff -me
|
||||
======
|
||||
|
||||
|
||||
|
||||
I was an undergraduate student when I discovered Linux in 1993. I was so excited to have the power of a Unix system right in my dorm room, but despite its many capabilities, Linux lacked applications. Word processors like LibreOffice and OpenOffice were years away. If you wanted to use a word processor, you likely booted your system into MS-DOS and used WordPerfect, the shareware GalaxyWrite, or a similar program.
|
||||
|
||||
`nroff` and `troff`. They are different interfaces to the same system: `nroff` generates plaintext output, suitable for screens or line printers, and `troff` generates very pretty output, usually for printing on a laser printer.
|
||||
|
||||
That was my method, since I needed to write papers for my classes, but I preferred staying in Linux. I knew from our "big Unix" campus computer lab that Unix systems provided a set of text-formatting programs calledand. They are different interfaces to the same system:generates plaintext output, suitable for screens or line printers, andgenerates very pretty output, usually for printing on a laser printer.
|
||||
|
||||
On Linux, `nroff` and `troff` are combined as GNU troff, more commonly known as [groff][1]. I was happy to see a version of groff included in my early Linux distribution, so I set out to learn how to use it to write class papers. The first macro set I learned was the `-me` macro package, a straightforward, easy to learn macro set.
|
||||
|
||||
The first thing to know about `groff` is that it processes and formats text according to a set of macros. A macro is usually a two-character command, set on a line by itself, with a leading dot. A macro might carry one or more options. When `groff` encounters one of these macros while processing a document, it will automatically format the text appropriately.
|
||||
|
||||
Below, I'll share the basics of using `groff -me` to write simple documents like class papers. I won't go deep into the details, like how to create nested lists, keeps and displays, tables, and figures.
|
||||
|
||||
### Paragraphs
|
||||
|
||||
Let's start with an easy example you see in almost every type of document: paragraphs. Paragraphs can be formatted with the first line either indented or not (i.e., flush against the left margin). Many printed documents, including academic papers, magazines, journals, and books, use a combination of the two types, with the first (leading) paragraph in a document or chapter flush left and all other (regular) paragraphs indented. In `groff -me`, you can use both paragraph types: leading paragraphs (`.lp`) and regular paragraphs (`.pp`).
|
||||
```
|
||||
.lp
|
||||
|
||||
This is the first paragraph.
|
||||
|
||||
.pp
|
||||
|
||||
This is a standard paragraph.
|
||||
|
||||
```
|
||||
|
||||
### Text formatting
|
||||
|
||||
The macro to format text in bold is `.b` and to format in italics is `.i`. If you put `.b` or `.i` on a line by itself, then all text that comes after it will be in bold or italics. But it's more likely you just want to put one or a few words in bold or italics. To make one word bold or italics, put that word on the same line as `.b` or `.i`, as an option. To format multiple words in **bold** or italics, enclose your text in quotes.
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text."
|
||||
|
||||
```
|
||||
|
||||
In the above example, the period at the end of **bold text** will also be in bold type. In most cases, that's not what you want. It's more correct to only have the words **bold text** in bold, but not the trailing period. To get the effect you want, you can add a second argument to `.b` or `.i` to indicate any text that should trail the bolded or italicized text, but in normal type. For example, you might do this to ensure that the trailing period doesn't show up in bold type.
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text" .
|
||||
|
||||
```
|
||||
|
||||
### Lists
|
||||
|
||||
With `groff -me`, you can create two types of lists: bullet lists (`.bu`) and numbered lists (`.np`).
|
||||
```
|
||||
.pp
|
||||
|
||||
Bullet lists are easy to make:
|
||||
|
||||
.bu
|
||||
|
||||
Apple
|
||||
|
||||
.bu
|
||||
|
||||
Banana
|
||||
|
||||
.bu
|
||||
|
||||
Pineapple
|
||||
|
||||
.pp
|
||||
|
||||
Numbered lists are as easy as:
|
||||
|
||||
.np
|
||||
|
||||
One
|
||||
|
||||
.np
|
||||
|
||||
Two
|
||||
|
||||
.np
|
||||
|
||||
Three
|
||||
|
||||
.pp
|
||||
|
||||
Note that numbered lists will reset at the next pp or lp.
|
||||
|
||||
```
|
||||
|
||||
### Subheads
|
||||
|
||||
If you're writing a long paper, you might want to divide your content into sections. With `groff -me`, you can create numbered headings (`.sh`) and unnumbered headings (`.uh`). In either, enclose the section title in quotes as an argument. For numbered headings, you also need to provide the heading level: `1` will give a first-level heading (e.g., 1.). Similarly, `2` and `3` will give second and third level headings, such as 2.1 or 3.1.1.
|
||||
```
|
||||
.uh Introduction
|
||||
|
||||
.pp
|
||||
|
||||
Provide one or two paragraphs to describe the work
|
||||
|
||||
and why it is important.
|
||||
|
||||
.sh 1 "Method and Tools"
|
||||
|
||||
.pp
|
||||
|
||||
Provide a few paragraphs to describe how you
|
||||
|
||||
did the research, including what equipment you used
|
||||
|
||||
```
|
||||
|
||||
### Smart quotes and block quotes
|
||||
|
||||
It's standard in any academic paper to cite other people's work as evidence. If you're citing a brief quote to highlight a key message, you can just type quotes around your text. But groff won't automatically convert your quotes into the "smart" or "curly" quotes used by modern word processing systems. To create them in `groff -me`, insert an inline macro to create the left quote (`\*(lq`) and right quote mark (`\*(rq`).
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase \*(lqopen source.\*(rq
|
||||
|
||||
```
|
||||
|
||||
There's also a shortcut in `groff -me` to create these quotes (`.q`) that I find easier to use.
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase
|
||||
|
||||
.q "open source."
|
||||
|
||||
```
|
||||
|
||||
If you're citing a longer quote that spans several lines, you'll want to use a block quote. To do this, insert the blockquote macro (`.(q`) at the beginning and end of the quote.
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### Footnotes
|
||||
|
||||
To insert a footnote, include the footnote macro (`.(f`) before and after the footnote text, and use an inline macro (`\**`) to add the footnote mark. The footnote mark should appear both in the text and in the footnote itself.
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:\**
|
||||
|
||||
.(f
|
||||
|
||||
\**Christine Peterson.
|
||||
|
||||
.q "How I coined the term open source."
|
||||
|
||||
.i "OpenSource.com."
|
||||
|
||||
1 Feb 2018.
|
||||
|
||||
.)f
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### Cover page
|
||||
|
||||
Most class papers require a cover page containing the paper's title, your name, and the date. Creating a cover page in `groff -me` requires some assembly. I find the easiest way is to use centered blocks of text and add extra lines between the title, name, and date. (I prefer to use two blank lines between each.) At the top of your paper, start with the title page (`.tp`) macro, insert five blank lines (`.sp 5` ), then add the centered text (`.(c`), and extra blank lines (`.sp 2`).
|
||||
```
|
||||
.tp
|
||||
|
||||
.sp 5
|
||||
|
||||
.(c
|
||||
|
||||
.b "Writing Class Papers with groff -me"
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
Jim Hall
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
February XX, 2018
|
||||
|
||||
.)c
|
||||
|
||||
.bp
|
||||
|
||||
```
|
||||
|
||||
The last macro (`.bp`) tells groff to add a page break after the title page.
|
||||
|
||||
### Learning more
|
||||
|
||||
Those are the essentials of writing professional-looking a paper in `groff -me` with leading and indented paragraphs, bold and italics text, bullet and numbered lists, numbered and unnumbered section headings, block quotes, and footnotes.
|
||||
|
||||
I've included a sample groff file to demonstrate all of this formatting. Save the `lorem-ipsum.me` file to your system and run it through groff. The `-Tps` option sets the output type to PostScript so you can send the document to a printer or convert it to a PDF file using the `ps2pdf` program.
|
||||
```
|
||||
groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
|
||||
|
||||
ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
|
||||
|
||||
```
|
||||
|
||||
If you'd like to use more advanced functions in `groff -me`, refer to Eric Allman's "Writing Papers with Groff using `−me`," which you should find on your system as `meintro.me` in groff's `doc` directory. It's a great reference document that explains other ways to format papers using the `groff -me` macros.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://www.gnu.org/software/groff/
|
||||
@ -1,88 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to set up a print server on a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
|
||||
I like to work on small projects at home, so this year I picked up a [Raspberry Pi 3 Model B][1], a great model for home hobbyists like me. With built-in wireless on the Raspberry Pi 3 Model B, I can connect the Pi to my home network without a cable. This makes it really easy to put the Raspberry Pi to use right where it is needed.
|
||||
|
||||
At our house, my wife and I both have laptops, but we have just one printer: a slightly used HP Color LaserJet. Because our printer doesn't have a wireless card and can't connect to wireless networks, we usually leave the LaserJet connected to my laptop, since I do most of the printing. While that arrangement works most of the time, sometimes my wife would like to print something without having to go through me.
|
||||
|
||||
### Basic setup
|
||||
|
||||
I realized we really needed a solution to connect the printer to the wireless network so both of us could print to it whenever we wanted. I could buy a wireless print server to connect the USB printer to the wireless network, but I decided instead to use my Raspberry Pi to build a print server to make the LaserJet available to anyone in our house.
|
||||
|
||||
Setting up the Raspberry Pi is fairly straightforward. I downloaded the [Raspbian][2] image and wrote that to my microSD card. Then, I booted the Raspberry Pi with an HDMI display, a USB keyboard, and a USB mouse. With that, I was ready to go!
|
||||
|
||||
The Raspbian system automatically boots into a graphical desktop environment where I performed most of the basic setup: setting the keyboard language, connecting to my wireless network, setting the password for the regular user account (`pi`), and setting the password for the system administrator account (`root`).
|
||||
|
||||
I don't plan to use the Raspberry Pi as a desktop system. I only want to use it remotely from my regular Linux computer. So, I also used Raspbian's graphical administration tool to set the Raspberry Pi to boot into console mode, but not to automatically login as the `pi` user.
|
||||
|
||||
Once I rebooted the Raspberry Pi, I needed to make a few other system tweaks so I could use the Pi as a "server" on my network. I set the Dynamic Host Configuration Protocol (DHCP) client to use a static IP address; by default, the DHCP client might pick any available network address, which would make it tricky to know how to connect to the Raspberry Pi over the network. My home network uses a private class A network, so my router's IP address is `10.0.0.1` and all my IP addresses are `10.0.0.x`. In my case, IP addresses in the lower range are safe, so I set up a static IP address on the wireless network at `10.0.0.11` by adding these lines to the `/etc/dhcpcd.conf` file:
|
||||
```
|
||||
interface wlan0
|
||||
|
||||
static ip_address=10.0.0.11/24
|
||||
|
||||
static routers=10.0.0.1
|
||||
|
||||
static domain_name_servers=8.8.8.8 8.8.4.4
|
||||
|
||||
```
|
||||
|
||||
Before I rebooted again, I made sure that the secure shell daemon (SSHD) was running (you can set what services start at boot-up in Preferences). This allowed me to use a secure shell (SSH) client from my regular Linux system to connect to the Raspberry Pi over the network.
|
||||
|
||||
### Print setup
|
||||
|
||||
Now that my Raspberry Pi was on the network, I did the rest of the setup remotely, using SSH, from my regular Linux desktop machine. Make sure your printer is connected to the Raspberry Pi before taking the following steps.
|
||||
|
||||
Setting up printing is fairly easy. The modern print server is called CUPS, which stands for the Common Unix Printing System. Any recent Unix system should be able to print through a CUPS print server. To set up CUPS on Raspberry Pi, you just need to enter a few commands to install the CUPS software, allow printing by other systems, and restart the print server with the new configuration:
|
||||
```
|
||||
$ sudo apt-get install cups
|
||||
|
||||
$ sudo cupsctl --remote-any
|
||||
|
||||
$ sudo /etc/init.d/cups restart
|
||||
|
||||
```
|
||||
|
||||
Setting up a printer in CUPS is also straightforward and can be done through a web browser. CUPS listens on port 631, so just use your favorite web browser and surf to:
|
||||
```
|
||||
https://10.0.0.11:631/
|
||||
|
||||
```
|
||||
|
||||
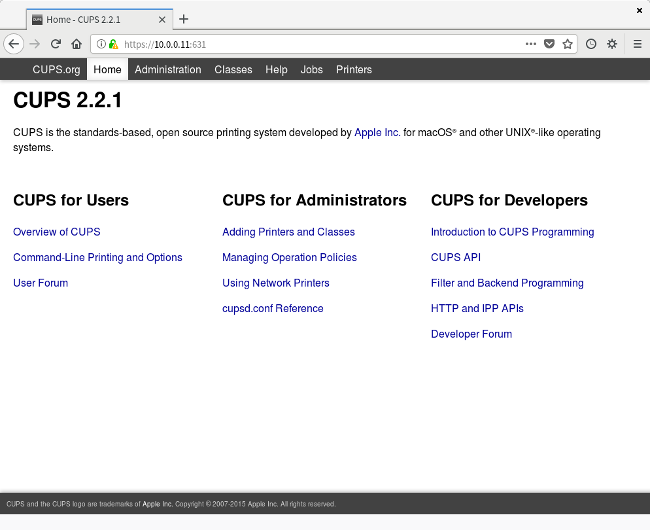
Your web browser may complain that it doesn't recognize the web server's https certificate; just accept it, and login as the system administrator. You should see the standard CUPS panel:
|
||||
|
||||
|
||||
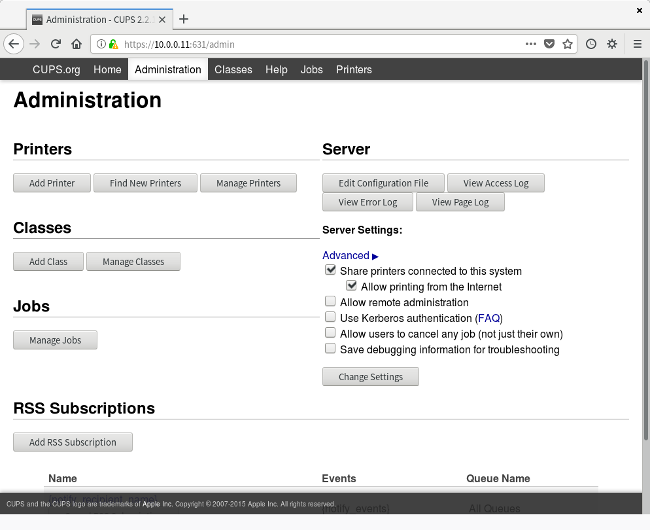
From there, navigate to the Administration tab, and select Add Printer.
|
||||
|
||||
|
||||
|
||||
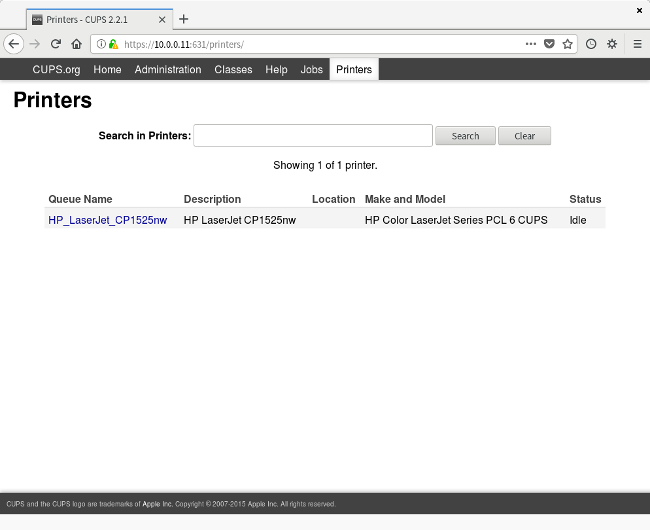
If your printer is already connected via USB, you should be able to easily select the printer's make and model. Don't forget to tick the Share This Printer box so others can use it, too. And now your printer should be set up in CUPS:
|
||||
|
||||
|
||||
|
||||
### Client setup
|
||||
|
||||
Setting up a network printer from the Linux desktop should be quite simple. My desktop is GNOME, and you can add the network printer right from the GNOME Settings application. Just navigate to Devices and Printers and unlock the panel. Click on the Add button to add the printer.
|
||||
|
||||
On my system, GNOME Settings automatically discovered the network printer and added it. If that doesn't happen for you, you may need to add the IP address for your Raspberry Pi to manually add the printer.
|
||||
|
||||
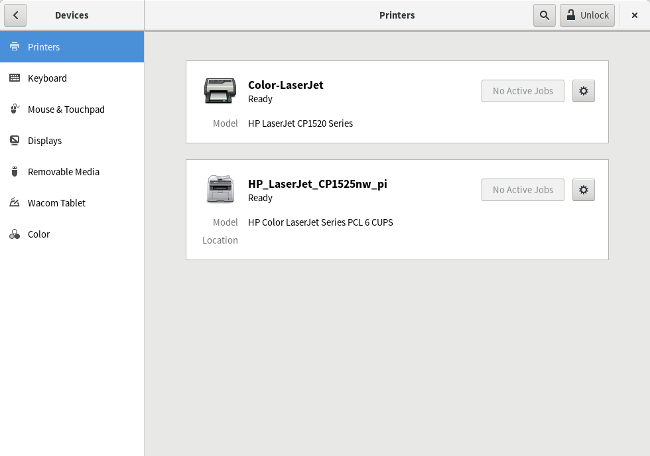
|
||||
|
||||
And that's it! We are now able to print to the Color LaserJet over the wireless network from wherever we are in the house. I no longer need to be physically connected to the printer, and everyone in the family can print on their own.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/print-server-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[2]:https://www.raspberrypi.org/downloads/
|
||||
@ -0,0 +1,94 @@
|
||||
如何安全地生成随机数 - 争论
|
||||
======
|
||||
### 使用 urandom
|
||||
|
||||
使用 urandom。使用 urandom。使用 urandom。使用 urandom。使用 urandom。使用 urandom。
|
||||
|
||||
### 但对于密码学密钥呢?
|
||||
|
||||
仍然使用 urandom[6]。
|
||||
|
||||
### 为什么不是 SecureRandom, OpenSSL, havaged 或者 c 语言实现呢?
|
||||
|
||||
这些是用户空间的 CSPRNG(伪随机数生成器)。你应该想用内核的 CSPRNG,因为:
|
||||
|
||||
* 内核可以访问原始设备熵。
|
||||
|
||||
* 它保证不在应用程序之间共享相同的状态。
|
||||
|
||||
* 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证在提供种子之前不给你随机数据。
|
||||
|
||||
|
||||
|
||||
|
||||
研究过去十年中的随机失败案例,你会看到一连串的用户空间随机失败。[Debian 的 OpenSSH 崩溃][7]?用户空间随机。安卓的比特币钱包[重复 ECDSA k's][8]?用户空间随机。可预测洗牌的赌博网站?用户空间随机。
|
||||
|
||||
用户空间生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
|
||||
|
||||
### 手册页不是说使用/dev/random嘛?
|
||||
|
||||
这个稍后详述,保留你的想法。你应该忽略掉手册页。不要使用 /dev/random。/dev/random 和 /dev/urandom 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全问题。把 random(4) 上的密码学上的建议当作传奇,继续你的生活。
|
||||
|
||||
### 但是如果我需要的是真随机值,而非伪随机值呢?
|
||||
|
||||
Urandom 和 /dev/random 提供的是同一类型的随机。与流行的观念相反,/dev/random 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
|
||||
|
||||
Urandom 和 /dev/random 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
|
||||
|
||||
只在 Linux 上 /dev/random 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 /dev/random 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
|
||||
|
||||
如果你使用 /dev/random 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 /dev/random 会使你的程序不太稳定,但在密码学角度上它也不会让程序更加安全。
|
||||
|
||||
### 这里有个缺陷,不是吗?
|
||||
|
||||
不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
|
||||
|
||||
在 Linux 上,如果你的软件在引导时立即运行,并且/或者刚刚安装了操作系统,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了比赛,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
|
||||
|
||||
在 Linux 上,这确实是 urandom(而不是 /dev/random)的问题。这也是[Linux 内核中的错误][9]。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但不要切换到不同的 CSPRNG。
|
||||
|
||||
### 在其它操作系统上呢?
|
||||
|
||||
FreeBSD 和 OS X 消除了 urandom 和 /dev/random 之间的区别; 这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
|
||||
|
||||
无论你使用 /dev/random 还是 urandom,FreeBSD 的内核加密 RNG 都不会阻塞。 除非它没有被提供种子,在这种情况下,这两者都会阻塞。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux,FreeBSD,iOS,无论什么:使用 urandom 吧。
|
||||
|
||||
### 太长了,懒得看
|
||||
|
||||
直接使用 urandom 吧。
|
||||
|
||||
### 结语
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> 现在,在尝试检测 /dev/urandom 之前,SecureRandom.random_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 /dev/urandom 进行交互。
|
||||
|
||||
总结:
|
||||
|
||||
> /dev/urandom 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据
|
||||
>
|
||||
> GNU/Linux 上的 random(4) 手册所述......
|
||||
|
||||
感谢 Matthew Green, Nate Lawson, Sean Devlin, Coda Hale, and Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas;Erin;Matasano][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -0,0 +1,82 @@
|
||||
在 KVM 中测试 IPv6 网络(第 1 部分)
|
||||
======
|
||||
|
||||

|
||||
|
||||
要理解 IPv6 地址是如何工作的,没有比亲自动手去实践更好的方法了,在 KVM 中配置一个小的测试实验室非常容易 —— 也很有趣。这个系列的文章共有两个部分,我们将学习关于 IPv6 私有地址的知识,以及如何在 KVM 中配置测试网络。
|
||||
|
||||
### QEMU/KVM/虚拟机管理器
|
||||
|
||||
我们先来了解什么是 KVM。在这里,我将使用 KVM 来表示 QEMU、KVM、以及虚拟机管理器的一个组合,虚拟机管理器在 Linux 发行版中一般内置了。简单解释就是,QEMU 模拟硬件,而 KVM 是一个内核模块,它在你的 CPU 上创建一个 “访客领地”,并去管理它们对内存和 CPU 的访问。虚拟机管理器是一个涵盖虚拟化和管理程序的图形工具。
|
||||
|
||||
但是你不能被图形界面下 “点击” 操作的方式 "缠住" ,因为,它们也有命令行工具可以使用 —— 比如 virsh 和 virt-install。
|
||||
|
||||
如果你在使用 KVM 方面没有什么经验,你可以从 [在 KVM 中创建虚拟机:第 1 部分][1] 和 [在 KVM 中创建虚拟机:第 2 部分 - 网络][2] 开始学起。
|
||||
|
||||
### IPv6 唯一本地地址
|
||||
|
||||
在 KVM 中配置 IPv6 网络与配置 IPv4 网络很类似。它们的主要不同在于这些怪异的长地址。[上一次][3],我们讨论了 IPv6 地址的不同类型。其中有一个 IPv6 单播地址类,fc00::/7(详细情况请查阅 [RFC 4193][4]),它类似于 IPv4 中的私有地址 —— 10.0.0.0/8、172.16.0.0/12、和 192.168.0.0/16。
|
||||
|
||||
下图解释了这个唯一本地地址空间的结构。前 48 位定义了前缀和全局 ID,随后的 16 位是子网,剩余的 64 位是接口 ID:
|
||||
```
|
||||
| 7 bits |1| 40 bits | 16 bits | 64 bits |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
| Prefix |L| Global ID | Subnet ID | Interface ID |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
|
||||
```
|
||||
|
||||
下面是另外一种表示方法,它可能更有助于你理解这些地址是如何管理的:
|
||||
```
|
||||
| Prefix | Global ID | Subnet ID | Interface ID |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
|
||||
```
|
||||
|
||||
fc00::/7 共分成两个 /8 地址块,fc00::/8 和 fd00::/8。fc00::/8 是为以后使用保留的。因此,唯一本地地址通常都是以 fd 开头的,而剩余部分是由你使用的。L 位,也就是第八位,它总是设置为 1,这样它可以表示为 fd00::/8。设置为 0 时,它就表示为 fc00::/8。你可以使用 `subnetcalc` 来看到这些东西:
|
||||
```
|
||||
$ subnetcalc fd00::/8 -n
|
||||
Address = fd00::
|
||||
fd00 = 11111101 00000000
|
||||
|
||||
$ subnetcalc fc00::/8 -n
|
||||
Address = fc00::
|
||||
fc00 = 11111100 00000000
|
||||
|
||||
```
|
||||
|
||||
RFC 4193 要求地址必须随机产生。你可以用你选择的任何方法来造出个地址,只要它们以 `fd` 打头就可以,因为 IPv6 范围非常大,它不会因为地址耗尽而无法使用。当然,最佳实践还是按 RFCs 的要求来做。地址不能按顺序分配或者使用众所周知的数字。RFC 4193 包含一个构建伪随机地址生成器的算法,或者你可以在线找到任何生成器产生的数字。
|
||||
|
||||
唯一本地地址不像全局单播地址(它由你的因特网服务提供商分配)那样进行中心化管理,即使如此,发生地址冲突的可能性也是非常低的。当你需要去合并一些本地网络或者想去在不相关的私有网络之间路由时,这是一个非常好的优势。
|
||||
|
||||
在同一个子网中,你可以混用唯一本地地址和全局单播地址。唯一本地地址是可路由的,并且它并不会因此要求对路由器做任何调整。但是,你应该在你的边界路由器和防火墙上配置为不允许它们离开你的网络,除非是在不同位置的两个私有网络之间。
|
||||
|
||||
RFC4193 建议,不要混用全局单播地址的 AAAA 和 PTR 记录,因为虽然它们重复的机率非常低,但是并不能保证它们就是独一无二的。就像我们使用的 IPv4 地址一样,要保持你本地的私有名称服务和公共名称服务的独立。将本地名称服务使用的 Dnsmasq 和公共名称服务使用的 BIND 组合起来,是一个在 IPv4 网络上经过实战检验的可靠组合,这个组合也同样适用于 IPv6 网络。
|
||||
|
||||
### 伪随机地址生成器
|
||||
|
||||
在线地址生成器的一个示例是 [本地 IPv6 地址生成器][5]。你可以在线找到许多这样很酷的工具。你可以使用它来为你创建一个新地址,或者使用它在你的现有全局 ID 下为你创建子网。
|
||||
|
||||
下周我们将讲解如何在 KVM 中配置这些 IPv6 的地址,并现场测试它们。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费在线课程 ["Linux 入门" ][6] 学习更多的 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2017/10/calculating-ipv6-subnets-linux
|
||||
[4]:https://tools.ietf.org/html/rfc4193
|
||||
[5]:https://www.ultratools.com/tools/rangeGenerator
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,58 @@
|
||||
CIO 真正需要 DevOps 团队做什么?
|
||||
======
|
||||
IT 领导者可以从大量的 [DevOps][1] 材料和 [向 DevOps 转变][2] 所要求的文化挑战中学习。但是,你在一个 DevOps 团队面对长期或短期挑战的调整中 —— 一个 CIO 真正需要他们做的是什么呢?
|
||||
|
||||
在我与 DevOps 团队成员的谈话中,我听到的其中一些内容让你感到非常的意外。DevOps 专家(无论是内部团队的还是外部团队的)都希望将下列的事情放在你的 CIO 优先关注的级别。
|
||||
|
||||
### 1. 沟通
|
||||
|
||||
第一个也是最重要的一个,DevOps 专家需要面对面的沟通。一个经验丰富的 DevOps 团队是非常了解当前 DevOps 的趋势,以及成功、和失败的经验,并且他们非常乐意去分享这些信息。表达 DevOps 的概念是很困难的,因此,要在这种新的工作关系中保持开放,定期(不用担心,不用每周)讨论有关你的 IT 的当前状态,如何评价你的沟通环境,以及你的整体的 IT 产业。
|
||||
|
||||
**[想从领导 DevOps 的 CIO 们处学习更多的知识吗?查看我们的综合资源,[DevOps: IT 领导者指南][3]。 ]**
|
||||
|
||||
相反,你应该准备好与 DevOps 团队去共享当前的业务需求和目标。业务不再是独立于 IT 的东西:它们现在是驱动 IT 发展的重要因素,并且 IT 决定了你的业务需求和目标运行的效果如何。
|
||||
|
||||
注重参与而不是领导。在需要做决策的时候,你仍然是最终的决策者,但是,理解这些决策的最好方式是协作,这样,你的 DevOps 团队将有更多的自主权,并因此受到更多激励。
|
||||
|
||||
### 2. 降低技术债务
|
||||
|
||||
第二,力争更好地理解技术债务,并在 DevOps 中努力降低它。你的 DevOps 团队面对的工作都非常难。在这种情况下,技术债务是指在一个庞大的、不可持续的环境(查看 Rube Goldberg)之中,通过维护和增加新功能而占用的人力资源和基础设备资源。
|
||||
|
||||
常见的 CIO 问题包括:
|
||||
|
||||
* 为什么我们要用一种新方法去做这件事情?
|
||||
* 为什么我们要在它上面花费时间和金钱?
|
||||
* 如果这里没有新功能,只是现有组件实现了自动化,那么我们的收益是什么?
|
||||
|
||||
|
||||
|
||||
"如果没有坏,就不要去修理它“ ,这样的事情是可以理解的。但是,如果你正在路上好好的开车,而每个人都加速超过你,这时候,你的环境就被破坏了。持续投入宝贵的资源去支撑或扩张拼凑起来的环境。
|
||||
|
||||
选择妥协,并且一个接一个的打补丁,以这种方式去处理每个独立的问题,结果将从一开始就变得很糟糕 —— 在一个不能支撑建筑物的地基上,一层摞一层地往上堆。事实上,这种方法就像不断地在电脑中插入坏磁盘一样。迟早有一天,面对出现的问题,你将会毫无办法。在外面持续增加的压力下,整个事情将变得一团糟,完全吞噬掉你的资源。
|
||||
|
||||
这种情况下,解决方案就是:自动化。使用自动化的结果是良好的可伸缩性 —— 每个维护人员在 IT 环境的维护和增长方面花费更少的努力。如果增加人力资源是实现业务增长的唯一办法,那么,可伸缩性就是白日做梦。
|
||||
|
||||
自动化降低了你的人力资源需求,并且对持续进行的 IT 提供了更灵活的需求。很简单,对吗?是的,但是你必须为迟到的满意做好心理准备。为了在提高生产力和效率的基础上获得后端经济效益,需要预先投入时间和精力对架构和结构进行变更。为了你的 DevOps 团队能够成功,接受这些挑战,对 IT 领导者来说是非常重要的。
|
||||
|
||||
### 3. 信任
|
||||
|
||||
最后,相信你的 DevOps 团队并且一定要理解他们。DevOps 专家也知道这个要求很难,但是他们必须有你的强大支持和你参与实践的意愿。因为 DevOps 团队持续改进你的 IT 环境,他们自身也在不断地适应这些变化的技术,而这些变化通常正是 “你要去学习的经验”。
|
||||
|
||||
倾听,倾听,倾听他们,并且相信他们。DevOps 的改变是非常有价值的,而且也是值的去投入时间和金钱的。它可以提高效率、生产力、和业务响应能力。信任你的 DevOps 团队,并且给予他们更多的自由,实现更高效率的 IT 改进。
|
||||
|
||||
新 CIO 的底线是:将你的 DevOps 团队的潜力最大化,离开你的领导 “舒适区”,拥抱一个 “CIOps" 的转变。通过 DevOps 转变,持续地与你的 DevOps 团队共同成长,以帮助你的组织获得长期的 IT 成功。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
|
||||
作者:[John Allessio][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/john-allessio
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
@ -0,0 +1,241 @@
|
||||
如何查找 Linux 中最大的 10 个文件
|
||||
======
|
||||
|
||||
|
||||
当系统的磁盘空间不足时,您可能更愿意使用 `df`、`du` 或 `ncdu` 命令进行检查,但这些命令只会显示当前目录的文件,并不会显示整个系统范围的文件。
|
||||
|
||||
您得花费大量的时间才能用上述命令获取系统中最大的文件,因为要进入到每个目录重复运行上述命令。
|
||||
|
||||
这个方法比较麻烦,也并不恰当。
|
||||
|
||||
如果是这样,那么该如何在 Linux 中找到最大的 10 个文件呢?
|
||||
|
||||
我在谷歌上搜索了很久,却没发现类似的文章,我反而看到了很多关于列出当前目录中最大的 10 个文件的文章。所以,我希望这篇文章对那些有类似需求的人有所帮助。
|
||||
|
||||
本教程中,我们将教您如何使用以下四种方法在 Linux 系统中查找最大的前 10 个文件。
|
||||
|
||||
### 方法 1:
|
||||
|
||||
在 Linux 中没有特定的命令可以直接执行此操作,因此我们需要将多个命令结合使用。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-print0`**:输出完整的文件名,其后跟一个空字符
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`xargs`**:将标准输入转换成命令行参数的命令
|
||||
|
||||
**`-0`**:以空字符(null)而不是空白字符(whitespace)(LCTT 译者注:即空格、制表符和换行)来分割记录
|
||||
|
||||
**`du -h`**:以可读格式计算磁盘空间使用情况的命令
|
||||
|
||||
**`sort`**:对文本文件进行排序的命令
|
||||
|
||||
**`-r`**:反转结果
|
||||
|
||||
**`-h`**:用可读格式打印输出
|
||||
|
||||
**`head`**:输出文件开头部分的命令
|
||||
|
||||
**`n -10`**:打印前 10 个文件
|
||||
|
||||
### 方法 2:
|
||||
|
||||
这是查找 Linux 系统中最大的前 10 个文件的另一种方法。我们依然使用多个命令共同完成这个任务。
|
||||
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-exec`**:在所选文件上运行指定命令
|
||||
|
||||
**`du`**:计算文件占用的磁盘空间的命令
|
||||
|
||||
**`-S`**:不包含子目录的大小
|
||||
|
||||
**`-h`**:以可读格式打印
|
||||
|
||||
**`{}`**:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`sort`**:对文本文件进行按行排序的命令
|
||||
|
||||
**`-r`**:反转结果
|
||||
|
||||
**`-h`**:用可读格式打印输出
|
||||
|
||||
**`head`**:输出文件开头部分的命令
|
||||
|
||||
**`n -10`**:打印前 10 个文件
|
||||
|
||||
### 方法 3:
|
||||
|
||||
这里介绍另一种方法,在 Linux 系统中搜索最大的前 10 个文件。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-print0`**:输出完整的文件名,其后跟一个空字符
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`xargs`**:将标准输入转换成命令行参数的命令
|
||||
|
||||
**`-0`**:以空字符(null)而不是空白字符(whitespace)来分割记录
|
||||
|
||||
**`du`**:计算文件占用的磁盘空间的命令
|
||||
|
||||
**`sort`**:对文本文件进行按行排序的命令
|
||||
|
||||
**`-n`**:根据数字大小进行比较
|
||||
|
||||
**`tail -10`**:输出文件结尾部分的命令(最后 10 个文件)
|
||||
|
||||
**`cut`**:从每行删除特定部分的命令
|
||||
|
||||
**`-f2`**:只选择特定字段值
|
||||
|
||||
**`-I{}`**:将初始参数中出现的每个替换字符串都替换为从标准输入读取的名称
|
||||
|
||||
**`-s`**:仅显示每个参数的总和
|
||||
|
||||
**`-h`**:用可读格式打印输出
|
||||
|
||||
**`{}`**:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
|
||||
### 方法 4:
|
||||
|
||||
还有一种在 Linux 系统中查找最大的前 10 个文件的方法。
|
||||
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
|
||||
```
|
||||
|
||||
**详解:**
|
||||
|
||||
**`find`**:在目录结构中搜索文件的命令
|
||||
|
||||
**`/`**:在整个系统(从根目录开始)中查找
|
||||
|
||||
**`-type`**:指定文件类型
|
||||
|
||||
**`f`**:普通文件
|
||||
|
||||
**`-ls`**:在标准输出中以 `ls -dils` 的格式列出当前文件
|
||||
|
||||
**`|`**:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
|
||||
**`sort`**:对文本文件进行按行排序的命令
|
||||
|
||||
**`-k`**:按指定列进行排序
|
||||
|
||||
**`-r`**:反转结果
|
||||
|
||||
**`-n`**:根据数字大小进行比较
|
||||
|
||||
**`head`**:输出文件开头部分的命令
|
||||
|
||||
**`-10`**:打印前 10 个文件
|
||||
|
||||
**`column`**:将其输入格式化为多列的命令
|
||||
|
||||
**`-t`**:确定输入包含的列数并创建一个表
|
||||
|
||||
**`awk`**:样式扫描和处理语言
|
||||
|
||||
**`'{print $7,$11}'`**:只打印指定的列
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -0,0 +1,277 @@
|
||||
# 在 Linux 上使用 groff -me 格式化你的学术论文
|
||||
|
||||

|
||||
|
||||
当我在 1993 年发现 Linux 时,我还是一名本科生。我很兴奋在我的宿舍里拥有 Unix 系统的强大功能,但是尽管它有很多功能,Linux 却缺乏应用程序。像 LibreOffice 和 OpenOffice 这样的文字处理程序还需要几年的时间。如果你想使用文字处理器,你可能会将你的系统引导到 MS-DOS 中,并使用 WordPerfect、shareware GalaxyWrite 或类似的程序。
|
||||
|
||||
`nroff` 和 `troff ` 。它们是同一系统的不同接口:`nroff` 生成纯文本输出,适用于屏幕或行式打印机,而 `troff` 产生非常优美的输出,通常用于在激光打印机上打印。
|
||||
|
||||
这就是我的方法,因为我需要为我的课程写论文,但我更喜欢呆在 Linux 中。我从我们的 “大 Unix ” 校园计算机实验室得知,Unix 系统提供了一组文本格式化的程序。它们是同一系统的不同接口:生成纯文本的输出,适合于屏幕或行打印机,或者生成非常优美的输出,通常用于在激光打印机上打印。
|
||||
|
||||
在 Linux 上,`nroff` 和 `troff` 被合并为 GNU troff,通常被称为 [groff][1]。 我很高兴看到早期的 Linux 发行版中包含了某个版本的 groff,因此我着手学习如何使用它来编写课程论文。 我学到的第一个宏集是 `-me` 宏包,一个简单易学的宏集。
|
||||
|
||||
关于 `groff` ,首先要了解的是它根据一组宏处理和格式化文本。一个宏通常是一个两个字符的命令,它自己设置在一行上,并带有一个引导点。宏可能包含一个或多个选项。当 groff 在处理文档时遇到这些宏中的一个时,它会自动对文本进行格式化。
|
||||
|
||||
下面,我将分享使用 `groff -me` 编写课程论文等简单文档的基础知识。 我不会深入细节进行讨论,比如如何创建嵌套列表,保存和显示,以及使用表格和数字。
|
||||
|
||||
### 段落
|
||||
|
||||
让我们从一个简单的例子开始,在几乎所有类型的文档中都可以看到:段落。段落可以格式化第一行的缩进或不缩进(即,与左边齐平)。 包括学术论文,杂志,期刊和书籍在内的许多印刷文档都使用了这两种类型的组合,其中文档或章节中的第一个(主要)段落与左侧的所有段落以及所有其他(常规)段落缩进。 在 `groff -me`中,您可以使用两种段落类型:前导段落(`.lp`)和常规段落(`.pp`)。
|
||||
|
||||
```
|
||||
.lp
|
||||
|
||||
This is the first paragraph.
|
||||
|
||||
.pp
|
||||
|
||||
This is a standard paragraph.
|
||||
|
||||
```
|
||||
|
||||
### 文本格式
|
||||
|
||||
用粗体格式化文本的宏是 `.b`,斜体格式是 `.i` 。 如果您将 `.b` 或 `.i` 放在一行上,则后面的所有文本将以粗体或斜体显示。 但更有可能你只是想用粗体或斜体来表示一个或几个词。 要将一个词加粗或斜体,将该单词放在与 `.b` 或 `.i` 相同的行上作为选项。 要用**粗体**或斜体格式化多个单词,请将文字用引号引起来。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text."
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,粗体文本结尾的句点也是粗体。 在大多数情况下,这不是你想要的。 只要文字是粗体字,而不是后面的句点也是粗体字。 要获得您想要的效果,您可以向 `.b` 或 `.i` 添加第二个参数,以指示要以粗体或斜体显示的文本,但是正常类型的文本。 您可以这样做,以确保尾随句点不会以粗体显示。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text" .
|
||||
|
||||
```
|
||||
|
||||
### 列表
|
||||
|
||||
使用 `groff -me`,您可以创建两种类型的列表:无序列表(`.bu`)和有序列表(`.np`)。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Bullet lists are easy to make:
|
||||
|
||||
.bu
|
||||
|
||||
Apple
|
||||
|
||||
.bu
|
||||
|
||||
Banana
|
||||
|
||||
.bu
|
||||
|
||||
Pineapple
|
||||
|
||||
.pp
|
||||
|
||||
Numbered lists are as easy as:
|
||||
|
||||
.np
|
||||
|
||||
One
|
||||
|
||||
.np
|
||||
|
||||
Two
|
||||
|
||||
.np
|
||||
|
||||
Three
|
||||
|
||||
.pp
|
||||
|
||||
Note that numbered lists will reset at the next pp or lp.
|
||||
|
||||
```
|
||||
|
||||
### 副标题
|
||||
|
||||
如果你正在写一篇长论文,你可能想把你的内容分成几部分。使用 `groff -me`,您可以创建编号的标题 (`.sh`) 和未编号的标题 (`.uh`)。在这两种方法中,将节标题作为参数括起来。对于编号的标题,您还需要提供标题级别 `:1` 将给出一个一级标题(例如,1)。同样,`2` 和 `3` 将给出第二和第三级标题,如 2.1 或 3.1.1。
|
||||
|
||||
```
|
||||
.uh Introduction
|
||||
|
||||
.pp
|
||||
|
||||
Provide one or two paragraphs to describe the work
|
||||
|
||||
and why it is important.
|
||||
|
||||
.sh 1 "Method and Tools"
|
||||
|
||||
.pp
|
||||
|
||||
Provide a few paragraphs to describe how you
|
||||
|
||||
did the research, including what equipment you used
|
||||
|
||||
```
|
||||
|
||||
### 智能引号和块引号
|
||||
|
||||
在任何学术论文中,引用他人的工作作为证据都是正常的。如果你引用一个简短的引用来突出一个关键信息,你可以在你的文本周围键入引号。但是 groff 不会自动将你的引用转换成现代文字处理系统所使用的“智能”或“卷曲”引用。要在 `groff -me` 中创建它们,插入一个内联宏来创建左引号(`\*(lq`)和右引号(`\*(rq`)。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase \*(lqopen source.\*(rq
|
||||
|
||||
```
|
||||
|
||||
`groff -me` 中还有一个快捷方式来创建这些引号(`.q`),我发现它更易于使用。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase
|
||||
|
||||
.q "open source."
|
||||
|
||||
```
|
||||
|
||||
如果引用的是跨越几行的较长的引用,则需要使用一个块引用。为此,在引用的开头和结尾插入块引用宏(
|
||||
|
||||
`.(q`)。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### 脚注
|
||||
|
||||
要插入脚注,请在脚注文本前后添加脚注宏(`.(f`),并使用内联宏(`\ **`)添加脚注标记。脚注标记应出现在文本中和脚注中。
|
||||
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:\**
|
||||
|
||||
.(f
|
||||
|
||||
\**Christine Peterson.
|
||||
|
||||
.q "How I coined the term open source."
|
||||
|
||||
.i "OpenSource.com."
|
||||
|
||||
1 Feb 2018.
|
||||
|
||||
.)f
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### 封面
|
||||
|
||||
大多数课程论文都需要一个包含论文标题,姓名和日期的封面。 在 `groff -me` 中创建封面需要一些组件。 我发现最简单的方法是使用居中的文本块并在标题,名称和日期之间添加额外的行。 (我倾向于在每一行之间使用两个空行)。在文章顶部,从标题页(`.tp`)宏开始,插入五个空白行(`.sp 5`),然后添加居中文本(`.(c`) 和额外的空白行(`.sp 2`)。
|
||||
|
||||
```
|
||||
.tp
|
||||
|
||||
.sp 5
|
||||
|
||||
.(c
|
||||
|
||||
.b "Writing Class Papers with groff -me"
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
Jim Hall
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
February XX, 2018
|
||||
|
||||
.)c
|
||||
|
||||
.bp
|
||||
|
||||
```
|
||||
|
||||
最后一个宏(`.bp`)告诉 groff 在标题页后添加一个分页符。
|
||||
|
||||
### 更多内容
|
||||
|
||||
这些是用 `groff-me` 写一份专业的论文非常基础的东西,包括前导和缩进段落,粗体和斜体,有序和无需列表,编号和不编号的章节标题,块引用以及脚注。
|
||||
|
||||
我已经包含一个示例 groff 文件来演示所有这些格式。 将 `lorem-ipsum.me` 文件保存到您的系统并通过 groff 运行。 `-Tps` 选项将输出类型设置为 `PostScript` ,以便您可以将文档发送到打印机或使用 `ps2pdf` 程序将其转换为 PDF 文件。
|
||||
|
||||
```
|
||||
groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
|
||||
|
||||
ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
|
||||
|
||||
```
|
||||
|
||||
如果你想使用 groff-me 的更多高级功能,请参阅 Eric Allman 所著的 “使用 `Groff-me` 来写论文”,你可以在你系统的 groff 的 `doc` 目录下找到一个名叫 `meintro.me` 的文件。这份文档非常完美的说明了如何使用 `groff-me` 宏来格式化你的论文。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://www.gnu.org/software/groff/
|
||||
@ -0,0 +1,87 @@
|
||||
如何将树莓派配置为打印服务器
|
||||
======
|
||||
|
||||

|
||||
|
||||
我喜欢在家做一些小项目,因此,今年我选择使用一个 [树莓派 3 Model B][1],这是一个像我这样的业余爱好者非常适合的东西。使用树莓派 3 Model B 的无线功能,我可以不使用线缆将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种它所需要的地方。
|
||||
|
||||
在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,一般情况下,使用我的笔记本电脑时,我并不连接打印机,因为,我做的大多数工作并不需要打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
|
||||
|
||||
### 基本设置
|
||||
|
||||
我觉得我们需要一个将打印机连接到无线网络的解决方案,以便于我们都能够随时随地打印。我本想买一个无线打印服务器将我的 USB 打印机连接到家里的无线网络上。后来,我决定使用我的树莓派,将它设置为打印服务器,这样就可以让家里的每个人都可以随时来打印。
|
||||
|
||||
设置树莓派是非常简单的事。我下载了 [Raspbian][2] 镜像,并将它写入到我的 microSD 卡中。然后,使用它引导连接了一个 HDMI 显示器、一个 USB 键盘和一个 USB 鼠标的树莓派。之后,我们开始对它进行设置!
|
||||
|
||||
这个树莓派系统自动引导到一个图形桌面,然后我做了一些基本设置:设置键盘语言、连接无线网络、设置普通用户帐户(`pi`)的密码、设置管理员用户(`root`)的密码。
|
||||
|
||||
我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,而且不以 `pi` 用户自动登入。
|
||||
|
||||
重新启动树莓派之后,我需要做一些其它的系统方面的小调整,以便于我在家用网络中使用树莓派做为 “服务器”。我设置它的 DHCP 客户端为使用静态 IP 地址;默认情况下,DHCP 客户端可能任选一个可用的网络地址,这样我会不知道应该用哪个地址连接到树莓派。我的家用网络使用一个私有的 A 类地址,因此,我的路由器的 IP 地址是 `10.0.0.1`,并且我的全部可用地 IP 地址是 `10.0.0.x`。在我的案例中,低位的 IP 地址是安全的,因此,我通过在 `/etc/dhcpcd.conf` 中添加如下的行,设置它的无线网络使用 `10.0.0.11` 这个静态地址。
|
||||
```
|
||||
interface wlan0
|
||||
|
||||
static ip_address=10.0.0.11/24
|
||||
|
||||
static routers=10.0.0.1
|
||||
|
||||
static domain_name_servers=8.8.8.8 8.8.4.4
|
||||
|
||||
```
|
||||
|
||||
在我再次重启之前,我需要去确认安全 shell 守护程序(SSHD)已经正常运行(你可以在 “偏好” 中设置哪些服务在引导时启动它)。这样我就可以使用 SSH 从普通的 Linux 系统上基于网络连接到树莓派中。
|
||||
|
||||
### 打印设置
|
||||
|
||||
现在,我的树莓派已经在网络上正常工作了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
|
||||
|
||||
设置打印机很容易。现在的打印服务器都称为 CUPS,它是标准的通用 Unix 打印系统。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
|
||||
```
|
||||
$ sudo apt-get install cups
|
||||
|
||||
$ sudo cupsctl --remote-any
|
||||
|
||||
$ sudo /etc/init.d/cups restart
|
||||
|
||||
```
|
||||
|
||||
在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你可以在浏览器中收藏这个地址:
|
||||
```
|
||||
https://10.0.0.11:631/
|
||||
|
||||
```
|
||||
|
||||
你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 ”接受它“,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:
|
||||

|
||||
|
||||
这时候,导航到管理标签,选择 “Add Printer"。
|
||||
|
||||

|
||||
|
||||
如果打印机已经通过 USB 连接,你只需要简单地选择这个打印机和型号。不要忘记去勾选共享这个打印机的选择框,因为其它人也要使用它。现在,你的打印机已经在 CUPS 中设置好了。
|
||||
|
||||

|
||||
|
||||
### 客户端设置
|
||||
|
||||
从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的设置应用程序中添加网络打印机。只需要导航到设备和打印机,然后解锁这个面板。点击 “Add" 按钮去添加打印机。
|
||||
|
||||
在我的系统中,GNOME 设置为 ”自动发现网络打印机并添加它“。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。
|
||||
|
||||

|
||||
|
||||
设置到此为止!我们现在已经可以通过家中的无线网络来使用这台打印机了。我不再需要物理连接到这台打印机了,家里的任何人都可以使用它了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/print-server-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[2]:https://www.raspberrypi.org/downloads/
|
||||
Loading…
Reference in New Issue
Block a user