mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
2b8eb8c2e2
@ -1,8 +1,7 @@
|
||||
IPv6:IPv4犯的罪,为什么要我来弥补
|
||||
IPv6:IPv4犯的错,为什么要我来弥补
|
||||
================================================================================
|
||||
(LCTT:标题党了一把,哈哈哈好过瘾,求不拍砖)
|
||||
|
||||
在过去的十年间,IPv6 本来应该得到很大的发展,但事实上这种好事并没有降临。由此导致了一个结果,那就是大部分人都不了解 IPv6 的一些知识:它是什么,怎么使用,以及,为什么它会存在?(LCTT:这是要回答蒙田的“我是谁”哲学思考题吗?)
|
||||
在过去的十年间,IPv6 本来应该得到很大的发展,但事实上这种好事并没有降临。由此导致了一个结果,那就是大部分人都不了解 IPv6 的一些知识:它是什么,怎么使用,以及,为什么它会存在?
|
||||
|
||||

|
||||
|
||||
@ -12,15 +11,15 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
自从1981年发布了 RFC 791 标准以来我们就一直在使用 **IPv4**。在那个时候,电脑又大又贵还不多见,而 IPv4 号称能提供**40亿条 IP 地址**,在当时看来,这个数字好大好大。不幸的是,这么多的 IP 地址并没有被充分利用起来,地址与地址之间存在间隙。举个例子,一家公司可能有**254(2^8-2)**条地址,但只使用其中的25条,剩下的229条被空占着,以备将来之需。于是这些空闲着的地址不能服务于真正需要它们的用户,原因就是网络路由规则的限制。最终的结果是在1981年看起来那个好大好大的数字,在2014年看起来变得好小好小。
|
||||
|
||||
互联网工程任务组(**IETF**)在90年代指出了这个问题,并提供了两套解决方案:无类型域间选路(**CIDR**)以及私有地址。在 CIDR 出现之前,你只能选择三种网络地址长度:**24 位** (共可用16,777,214个地址), **20位** (共可用1,048,574个地址)以及**16位** (共可用65,534个地址)。CIDR 出现之后,你可以将一个网络再划分成多个子网。
|
||||
互联网工程任务组(**IETF**)在90年代初指出了这个问题,并提供了两套解决方案:无类型域间选路(**CIDR**)以及私有IP地址。在 CIDR 出现之前,你只能选择三种网络地址长度:**24 位** (共16,777,214个可用地址), **20位** (共1,048,574个可用地址)以及**16位** (共65,534个可用地址)。CIDR 出现之后,你可以将一个网络再划分成多个子网。
|
||||
|
||||
举个例子,如果你需要**5个 IP 地址**,你的 ISP 会为你提供一个子网,里面的主机地址长度为3位,也就是说你最多能得到**6个地址**(LCTT:抛开子网的网络号,3位主机地址长度可以表示0~7共8个地址,但第0个和第7个有特殊用途,不能被用户使用,所以你最多能得到6个地址)。这种方法让 ISP 能尽最大效率分配 IP 地址。“私有地址”这套解决方案的效果是,你可以自己创建一个网络,里面的主机可以访问外网的主机,但外网的主机很难访问到你创建的那个网络上的主机,因为你的网络是私有的、别人不可见的。你可以创建一个非常大的网络,因为你可以使用16,777,214个主机地址,并且你可以将这个网络分割成更小的子网,方便自己管理。
|
||||
|
||||
也许你现在正在使用私有地址。看看你自己的 IP 地址,如果这个地址在这些范围内:**10.0.0.0 – 10.255.255.255**、**172.16.0.0 – 172.31.255.255**或**192.168.0.0 – 192.168.255.255**,就说明你在使用私有地址。这两套方案有效地将“IP 地址用尽”这个灾难延迟了好长时间,但这毕竟只是权宜之计,现在我们正面临最终的审判。
|
||||
|
||||
**IPv4** 还有另外一个问题,那就是这个协议的消息头长度可变。如果数据通过软件来路由,这个问题还好说。但现在路由器功能都是由硬件提供的,处理变长消息头对硬件来说是一件困难的事情。一个大的路由器需要处理来自世界各地的大量数据包,这个时候路由器的负载是非常大的。所以很明显,我们需要固定消息头的长度。
|
||||
**IPv4** 还有另外一个问题,那就是这个协议的消息头长度可变。如果数据的路由通过软件来实现,这个问题还好说。但现在路由器功能都是由硬件提供的,处理变长消息头对硬件来说是一件困难的事情。一个大的路由器需要处理来自世界各地的大量数据包,这个时候路由器的负载是非常大的。所以很明显,我们需要固定消息头的长度。
|
||||
|
||||
还有一个问题,在分配 IP 地址的时候,美国人发了因特网(LCTT:这个万恶的资本主义国家占用了大量 IP 地址)。其他国家只得到了 IP 地址的碎片。我们需要重新定制一个架构,让连续的 IP 地址能在地理位置上集中分布,这样一来路由表可以做的更小(LCTT:想想吧,网速肯定更快)。
|
||||
在分配 IP 地址的同时,还有一个问题,因特网是美国人发明的(LCTT:这个万恶的资本主义国家占用了大量 IP 地址)。其他国家只得到了 IP 地址的碎片。我们需要重新定制一个架构,让连续的 IP 地址能在地理位置上集中分布,这样一来路由表可以做的更小(LCTT:想想吧,网速肯定更快)。
|
||||
|
||||
还有一个问题,这个问题你听起来可能还不大相信,就是 IPv4 配置起来比较困难,而且还不好改变。你可能不会碰到这个问题,因为你的路由器为你做了这些事情,不用你去操心。但是你的 ISP 对此一直是很头疼的。
|
||||
|
||||
@ -28,10 +27,10 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
### IPv6 和它的优点 ###
|
||||
|
||||
**IETF** 在1995年12月公布了下一代 IP 地址标准,名字叫 IPv6,为什么不是 IPv5?因为某个错误原因,“版本5”这个编号被其他项目用去了。IPv6 的优点如下:
|
||||
**IETF** 在1995年12月公布了下一代 IP 地址标准,名字叫 IPv6,为什么不是 IPv5?→_→ 因为某个错误原因,“版本5”这个编号被其他项目用去了。IPv6 的优点如下:
|
||||
|
||||
- 128位地址长度(共有3.402823669×10³⁸个地址)
|
||||
- 这个架构下的地址在逻辑上聚合
|
||||
- 其架构下的地址在逻辑上聚合
|
||||
- 消息头长度固定
|
||||
- 支持自动配置和修改你的网络。
|
||||
|
||||
@ -43,7 +42,7 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
#### 聚合 ####
|
||||
|
||||
有这么多的地址,这个地址可以被稀稀拉拉地分配给主机,从而更高效地路由数据包。算一笔帐啊,你的 ISP 拿到一个**80位**地址长度的网络空间,其中16位是 ISP 的子网地址,剩下64位分给你作为主机地址。这样一来,你的 ISP 可以分配65,534个子网。
|
||||
有这么多的地址,这些地址可以被稀稀拉拉地分配给主机,从而更高效地路由数据包。算一笔帐啊,你的 ISP 拿到一个**80位**地址长度的网络空间,其中16位是 ISP 的子网地址,剩下64位分给你作为主机地址。这样一来,你的 ISP 可以分配65,534个子网。
|
||||
|
||||
然而,这些地址分配不是一成不变地,如果 ISP 想拥有更多的小子网,完全可以做到(当然,土豪 ISP 可能会要求再来一个80位网络空间)。最高的48位地址是相互独立地,也就是说 ISP 与 ISP 之间虽然可能分到相同地80位网络空间,但是这两个空间是相互隔离的,好处就是一个网络空间里面的地址会聚合在一起。
|
||||
|
||||
@ -51,25 +50,25 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
**IPv4** 消息头长度可变,但 **IPv6** 消息头长度被固定为40字节。IPv4 会由于额外的参数导致消息头变长,IPv6 中,如果有额外参数,这些信息会被放到一个紧挨着消息头的地方,不会被路由器处理,当消息到达目的地时,这些额外参数会被软件提取出来。
|
||||
|
||||
IPv6 消息头有一个部分叫“flow”,是一个20位伪随机数,用于简化路由器对数据包地路由过程。如果一个数据包存在“flow”,路由器就可以根据这个值作为索引查找路由表,不必慢吞吞地遍历整张路由表来查询路由路径。这个优点使 **IPv6** 更容易被路由。
|
||||
IPv6 消息头有一个部分叫“flow”,是一个20位伪随机数,用于简化路由器对数据包的路由过程。如果一个数据包存在“flow”,路由器就可以根据这个值作为索引查找路由表,不必慢吞吞地遍历整张路由表来查询路由路径。这个优点使 **IPv6** 更容易被路由。
|
||||
|
||||
#### 自动配置 ####
|
||||
|
||||
**IPv6** 中,当主机开机时,会检查本地网络,看看有没有其他主机使用了自己的 IP 地址。如果地址没有被使用,就接着查询本地的 IPv6 路由器,找到后就向它请求一个 IPv6 地址。然后这台主机就可以连上互联网了 —— 它有自己的 IP 地址,和自己的默认路由器。
|
||||
|
||||
如果这台默认路由器当机,主机就会接着找其他路由器,作为备用路由器。这个功能在 IPv4 协议里实现起来非常困难。同样地,假如路由器想改变自己的地址,自己改掉就好了。主机会自动搜索路由器,并自动更新路由器地址。路由器会同时保存新老地址,直到所有主机都把自己地路由器地址更新成新地址。
|
||||
如果这台默认路由器宕机,主机就会接着找其他路由器,作为备用路由器。这个功能在 IPv4 协议里实现起来非常困难。同样地,假如路由器想改变自己的地址,自己改掉就好了。主机会自动搜索路由器,并自动更新路由器地址。路由器会同时保存新老地址,直到所有主机都把自己地路由器地址更新成新地址。
|
||||
|
||||
IPv6 自动配置还不是一个完整地解决方案。想要有效地使用互联网,一台主机还需要另外的东西:域名服务器、时间同步服务器、或者还需要一台文件服务器。于是 **dhcp6** 出现了,提供与 dhcp 一样的服务,唯一的区别是 dhcp6 的机器可以在可路由的状态下启动,一个 dhcp 进程可以为大量网络提供服务。
|
||||
|
||||
#### 唯一的大问题 ####
|
||||
|
||||
如果 IPv6 真的比 IPv4 好那么多,为什么它还没有被广泛使用起来(Google 在**2014年5月份**估计 IPv6 的市场占有率为**4%**)?一个最基本的原因是“先有鸡还是先有蛋”问题,用户需要让自己的服务器能为尽可能多的客户提供服务,这就意味着他们必须部署一个 **IPv4** 地址。
|
||||
如果 IPv6 真的比 IPv4 好那么多,为什么它还没有被广泛使用起来(Google 在**2014年5月份**估计 IPv6 的市场占有率为**4%**)?一个最基本的原因是“先有鸡还是先有蛋”。服务商想让自己的服务器为尽可能多的客户提供服务,这就意味着他们必须部署一个 **IPv4** 地址。
|
||||
|
||||
当然,他们可以同时使用 IPv4 和 IPv6 两套地址,但很少有客户会用到 IPv6,并且你还需要对你的软件做一些小修改来适应 IPv6。另外比较头疼的一点是,很多家庭的路由器压根不支持 IPv6。还有就是 ISP 也不愿意支持 IPv6,我问过我的 ISP 这个问题,得到的回答是:只有客户明确指出要部署这个时,他们才会用 IPv6。然后我问了现在有多少人有这个需求,答案是:包括我在内,共有1个。
|
||||
|
||||
与这种现实状况呈明显对比的是,所有主流操作系统:Windows、OS X、Linux 都默认支持 IPv6 好多年了。这些操作系统甚至提供软件让 IPv6 的数据包披上 IPv4 的皮来骗过那些会丢弃 IPv6 数据包的主机,从而达到传输数据的目的(LCTT:呃,这是高科技偷渡?)。
|
||||
与这种现实状况呈明显对比的是,所有主流操作系统:Windows、OS X、Linux 都默认支持 IPv6 好多年了。这些操作系统甚至提供软件让 IPv6 的数据包披上 IPv4 的皮来骗过那些会丢弃 IPv6 数据包的主机,从而达到传输数据的目的。
|
||||
|
||||
#### 总结 ####
|
||||
### 总结 ###
|
||||
|
||||
IPv4 已经为我们服务了好长时间。但是它的缺陷会在不远的将来遭遇不可克服的困难。IPv6 通过改变地址分配规则、简化数据包路由过程、简化首次加入网络时的配置过程等策略,可以完美解决这个问题。
|
||||
|
||||
@ -81,7 +80,7 @@ via: http://www.tecmint.com/ipv4-and-ipv6-comparison/
|
||||
|
||||
作者:[Jeff Silverman][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -95,7 +95,7 @@ via: http://xmodulo.com/configure-peer-to-peer-vpn-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,324 @@
|
||||
使用 Quagga 将你的 CentOS 系统变成一个 BGP 路由器
|
||||
================================================================================
|
||||
|
||||
在[之前的教程中][1],我对如何简单地使用Quagga把CentOS系统变成一个不折不扣地OSPF路由器做了一些介绍。Quagga是一个开源路由软件套件。在这个教程中,我将会重点讲讲**如何把一个Linux系统变成一个BGP路由器,还是使用Quagga**,演示如何建立BGP与其它BGP路由器对等。
|
||||
|
||||
在我们进入细节之前,一些BGP的背景知识还是必要的。边界网关协议(即BGP)是互联网的域间路由协议的实际标准。在BGP术语中,全球互联网是由成千上万相关联的自治系统(AS)组成,其中每一个AS代表每一个特定运营商提供的一个网络管理域([据说][2],美国前总统乔治.布什都有自己的 AS 编号)。
|
||||
|
||||
为了使其网络在全球范围内路由可达,每一个AS需要知道如何在英特网中到达其它的AS。这时候就需要BGP出来扮演这个角色了。BGP是一个AS去与相邻的AS交换路由信息的语言。这些路由信息通常被称为BGP线路或者BGP前缀。包括AS号(ASN;全球唯一号码)以及相关的IP地址块。一旦所有的BGP线路被当地的BGP路由表学习和记录,每一个AS将会知道如何到达互联网的任何公网IP。
|
||||
|
||||
在不同域(AS)之间路由的能力是BGP被称为外部网关协议(EGP)或者域间协议的主要原因。就如一些路由协议,例如OSPF、IS-IS、RIP和EIGRP都是内部网关协议(IGPs)或者域内路由协议,用于处理一个域内的路由.
|
||||
|
||||
### 测试方案 ###
|
||||
|
||||
在这个教程中,让我们来使用以下拓扑。
|
||||
|
||||

|
||||
|
||||
我们假设运营商A想要建立一个BGP来与运营商B对等交换路由。它们的AS号和IP地址空间的细节如下所示:
|
||||
|
||||
- **运营商 A**: ASN (100), IP地址空间 (100.100.0.0/22), 分配给BGP路由器eth1网卡的IP地址(100.100.1.1)
|
||||
|
||||
- **运营商 B**: ASN (200), IP地址空间 (200.200.0.0/22), 分配给BGP路由器eth1网卡的IP地址(200.200.1.1)
|
||||
|
||||
路由器A和路由器B使用100.100.0.0/30子网来连接到对方。从理论上来说,任何子网从运营商那里都是可达的、可互连的。在真实场景中,建议使用掩码为30位的公网IP地址空间来实现运营商A和运营商B之间的连通。
|
||||
|
||||
### 在 CentOS中安装Quagga ###
|
||||
|
||||
如果Quagga还没安装好,我们可以使用yum来安装Quagga。
|
||||
|
||||
# yum install quagga
|
||||
|
||||
如果你正在使用的是CentOS7系统,你需要应用一下策略来设置SELinux。否则,SElinux将会阻止Zebra守护进程写入它的配置目录。如果你正在使用的是CentOS6,你可以跳过这一步。
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
Quagga软件套件包含几个守护进程,这些进程可以协同工作。关于BGP路由,我们将把重点放在建立以下2个守护进程。
|
||||
|
||||
- **Zebra**:一个核心守护进程用于内核接口和静态路由.
|
||||
- **BGPd**:一个BGP守护进程.
|
||||
|
||||
### 配置日志记录 ###
|
||||
|
||||
在Quagga被安装后,下一步就是配置Zebra来管理BGP路由器的网络接口。我们通过创建一个Zebra配置文件和启用日志记录来开始第一步。
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
在CentOS7系统中:
|
||||
|
||||
# systemctl start zebra
|
||||
# systemctl enable zebra
|
||||
|
||||
Quagga提供了一个叫做vtysh特有的命令行工具,你可以输入与路由器厂商(例如Cisco和Juniper)兼容和支持的命令。我们将使用vtysh shell来配置BGP路由在教程的其余部分。
|
||||
|
||||
启动vtysh shell 命令,输入:
|
||||
|
||||
# vtysh
|
||||
|
||||
提示将被改成该主机名,这表明你是在vtysh shell中。
|
||||
|
||||
Router-A#
|
||||
|
||||
现在我们将使用以下命令来为Zebra配置日志文件:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# log file /var/log/quagga/quagga.log
|
||||
Router-A(config)# exit
|
||||
|
||||
永久保存Zebra配置:
|
||||
|
||||
Router-A# write
|
||||
|
||||
在路由器B操作同样的步骤。
|
||||
|
||||
### 配置对等的IP地址 ###
|
||||
|
||||
下一步,我们将在可用的接口上配置对等的IP地址。
|
||||
|
||||
Router-A# show interface #显示接口信息
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
配置eth0接口的参数:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 100.100.0.1/30
|
||||
site-A-RTR(config-if)# description "to Router-B"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
|
||||
继续配置eth1接口的参数:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 100.100.1.1/24
|
||||
site-A-RTR(config-if)# description "test ip from provider A network"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
现在确认配置:
|
||||
|
||||
Router-A# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
Description: "to Router-B"
|
||||
inet 100.100.0.1/30 broadcast 100.100.0.3
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
Description: "test ip from provider A network"
|
||||
inet 100.100.1.1/24 broadcast 100.100.1.255
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show interface description #显示接口描述
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown "to Router-B"
|
||||
eth1 up unknown "test ip from provider A network"
|
||||
|
||||
|
||||
如果一切看起来正常,别忘记保存配置。
|
||||
|
||||
Router-A# write
|
||||
|
||||
同样地,在路由器B重复一次配置。
|
||||
|
||||
在我们继续下一步之前,确认下彼此的IP是可以ping通的。
|
||||
|
||||
Router-A# ping 100.100.0.2
|
||||
|
||||
----------
|
||||
|
||||
PING 100.100.0.2 (100.100.0.2) 56(84) bytes of data.
|
||||
64 bytes from 100.100.0.2: icmp_seq=1 ttl=64 time=0.616 ms
|
||||
|
||||
下一步,我们将继续配置BGP对等和前缀设置。
|
||||
|
||||
### 配置BGP对等 ###
|
||||
|
||||
Quagga守护进程负责BGP的服务叫bgpd。首先我们来准备它的配置文件。
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service bgpd start
|
||||
# chkconfig bgpd on
|
||||
|
||||
在CentOS7中:
|
||||
|
||||
# systemctl start bgpd
|
||||
# systemctl enable bgpd
|
||||
|
||||
现在,让我们来进入Quagga 的shell。
|
||||
|
||||
# vtysh
|
||||
|
||||
第一步,我们要确认当前没有已经配置的BGP会话。在一些版本,我们可能会发现一个AS号为7675的BGP会话。由于我们不需要这个会话,所以把它移除。
|
||||
|
||||
Router-A# show running-config
|
||||
|
||||
----------
|
||||
|
||||
... ... ...
|
||||
router bgp 7675
|
||||
bgp router-id 200.200.1.1
|
||||
... ... ...
|
||||
|
||||
我们将移除一些预先配置好的BGP会话,并建立我们所需的会话取而代之。
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# no router bgp 7675
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# no auto-summary
|
||||
Router-A(config)# no synchronizaiton
|
||||
Router-A(config-router)# neighbor 100.100.0.2 remote-as 200
|
||||
Router-A(config-router)# neighbor 100.100.0.2 description "provider B"
|
||||
Router-A(config-router)# exit
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
路由器B将用同样的方式来进行配置,以下配置提供作为参考。
|
||||
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# no router bgp 7675
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# no auto-summary
|
||||
Router-B(config)# no synchronizaiton
|
||||
Router-B(config-router)# neighbor 100.100.0.1 remote-as 100
|
||||
Router-B(config-router)# neighbor 100.100.0.1 description "provider A"
|
||||
Router-B(config-router)# exit
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
|
||||
当相关的路由器都被配置好,两台路由器之间的对等将被建立。现在让我们通过运行下面的命令来确认:
|
||||
|
||||
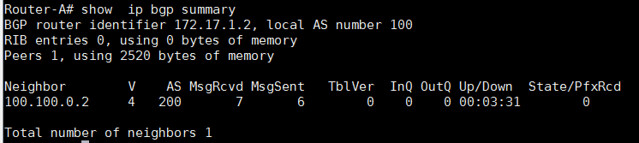
Router-A# show ip bgp summary
|
||||
|
||||
|
||||
|
||||
|
||||
从输出中,我们可以看到"State/PfxRcd"部分。如果对等关闭,输出将会显示"Idle"或者"Active'。请记住,单词'Active'这个词在路由器中总是不好的意思。它意味着路由器正在积极地寻找邻居、前缀或者路由。当对等是up状态,"State/PfxRcd"下的输出状态将会从特殊邻居接收到前缀号。
|
||||
|
||||
在这个例子的输出中,BGP对等只是在AS100和AS200之间呈up状态。因此没有前缀被更改,所以最右边列的数值是0。
|
||||
|
||||
### 配置前缀通告 ###
|
||||
|
||||
正如一开始提到,AS 100将以100.100.0.0/22作为通告,在我们的例子中AS 200将同样以200.200.0.0/22作为通告。这些前缀需要被添加到BGP配置如下。
|
||||
|
||||
在路由器-A中:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# network 100.100.0.0/22
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
在路由器-B中:
|
||||
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# network 200.200.0.0/22
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
在这一点上,两个路由器会根据需要开始通告前缀。
|
||||
|
||||
### 测试前缀通告 ###
|
||||
|
||||
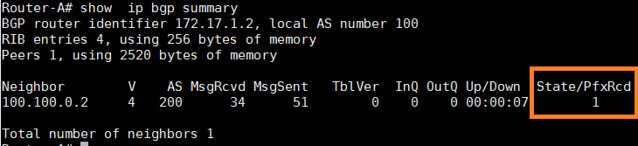
首先,让我们来确认前缀的数量是否被改变了。
|
||||
|
||||
Router-A# show ip bgp summary
|
||||
|
||||
|
||||
|
||||
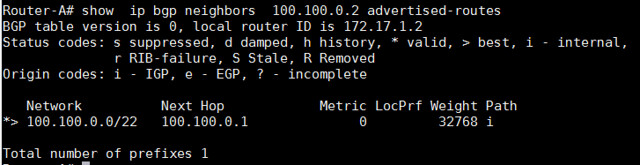
为了查看所接收的更多前缀细节,我们可以使用以下命令,这个命令用于显示邻居100.100.0.2所接收到的前缀总数。
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 advertised-routes
|
||||
|
||||
|
||||
|
||||
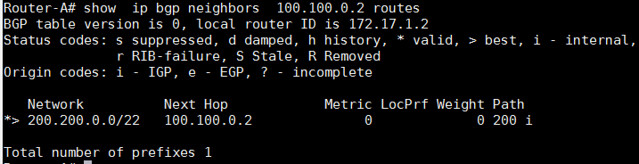
查看哪一个前缀是我们从邻居接收到的:
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 routes
|
||||
|
||||
|
||||
|
||||
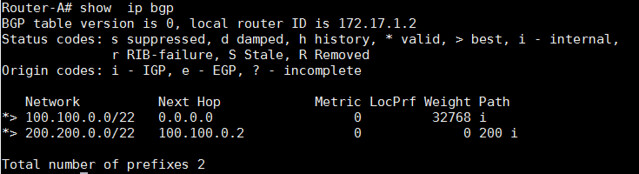
我们也可以查看所有的BGP路由器:
|
||||
|
||||
Router-A# show ip bgp
|
||||
|
||||
|
||||
|
||||
|
||||
以上的命令都可以被用于检查哪个路由器通过BGP在路由器表中被学习到。
|
||||
|
||||
Router-A# show ip route
|
||||
|
||||
----------
|
||||
|
||||
代码: K - 内核路由, C - 已链接 , S - 静态 , R - 路由信息协议 , O - 开放式最短路径优先协议,
|
||||
|
||||
I - 中间系统到中间系统的路由选择协议, B - 边界网关协议, > - 选择路由, * - FIB 路由
|
||||
|
||||
C>* 100.100.0.0/30 is directly connected, eth0
|
||||
C>* 100.100.1.0/24 is directly connected, eth1
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:06:45
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show ip route bgp
|
||||
|
||||
----------
|
||||
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:08:13
|
||||
|
||||
|
||||
BGP学习到的路由也将会在Linux路由表中出现。
|
||||
|
||||
[root@Router-A~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
100.100.0.0/30 dev eth0 proto kernel scope link src 100.100.0.1
|
||||
100.100.1.0/24 dev eth1 proto kernel scope link src 100.100.1.1
|
||||
200.200.0.0/22 via 100.100.0.2 dev eth0 proto zebra
|
||||
|
||||
|
||||
最后,我们将使用ping命令来测试连通。结果将成功ping通。
|
||||
|
||||
[root@Router-A~]# ping 200.200.1.1 -c 2
|
||||
|
||||
|
||||
总而言之,本教程将重点放在如何在CentOS系统中运行一个基本的BGP路由器。这个教程让你开始学习BGP的配置,一些更高级的设置例如设置过滤器、BGP属性调整、本地优先级和预先路径准备等,我将会在后续的教程中覆盖这些主题。
|
||||
|
||||
希望这篇教程能给大家一些帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://linux.cn/article-4232-1.html
|
||||
[2]:http://weibo.com/3181671860/BngyXxEUF
|
||||
@ -1,76 +0,0 @@
|
||||
翻译中 by小眼儿
|
||||
|
||||
Yes, This Trojan Infects Linux. No, It’s Not The Tuxpocalypse
|
||||
================================================================================
|
||||

|
||||
|
||||
Is something watching you?
|
||||
|
||||
Grab a crate of canned food, start digging a deep underground bunker and prepare to settle into a world that will never be the same again: [a powerful trojan has been uncovered on Linux][1].
|
||||
|
||||
Yes, the hitherto impregnable fortress of computing nirvana has been compromised in a way that has left security experts a touch perturbed.
|
||||
|
||||
Unplug your PC, disinfect your keyboard and buy a cat (no more YouTube ). The Tuxpocalypse is upon us. We’ve reached the end of days.
|
||||
|
||||
Right? RIGHT? Nah, not quite.
|
||||
|
||||
### A Terrifying Anomalous Thing! ###
|
||||
|
||||
Let me set off by saying that **I am not underplaying the severity of this threat (known by the nickname ‘Turla’)** nor, for the avoidance of doubt, am I suggesting that we as Linux users shouldn’t be concerned by the implications.
|
||||
|
||||
The discovery of a silent trojan infecting Linux systems is terrifying. The fact it was tasked with sucking up and sending off all sorts of sensitive information is horrific. And to learn it’s been doing this for at least four years and doesn’t require root privileges? My seat is wet. I’m sorry.
|
||||
|
||||
But — and along with hyphens and typos, there’s always a ‘but’ on this site — the panic currently sweeping desktop Linux fans, Mexican wave style, is a little out of context.
|
||||
|
||||
Vulnerability may be a new feeling for some of us, yet let’s keep it in check: Linux remains an inherently secure operating system for desktop users. One clever workaround does not negate that and shouldn’t send you scurrying offline.
|
||||
|
||||
### State Sponsored, Targeting Governments ###
|
||||
|
||||

|
||||
|
||||
Is a penguin snake a ‘Penguake’ or a ‘Snaguin’?
|
||||
|
||||
‘Turla’ is a complex APT (Advanced Persistent Threat) that has (thus far) targeted government, embassy and pharmaceutical companies’ systems for around four years using a method based on [14 year old code, no less][2].
|
||||
|
||||
On Windows, where the superhero security researchers at Symantec and Kaspersky Lab first sighted the slimy snake, Turla and components of it were found to have **infected hundreds (100s) of PCs across 45 countries**, many through unpatched zero-day exploits.
|
||||
|
||||
*Nice one Microsoft.*
|
||||
|
||||
Further diligence by Kaspersky Lab has now uncovered that parts of the same trojan have also been active on Linux for some time.
|
||||
|
||||
The Trojan doesn’t require elevated privileges and can “intercept incoming packets and run incoming commands on the system”, but it’s not yet clear how deep its tentacles reach or how many Linux systems are infected, nor is the full extent of its capabilities known.
|
||||
|
||||
“Turla” (and its children) are presumed to be nation-state sponsored due to its choice of targets. US and UK readers shouldn’t assume it’s “*them*“, either. Our own governments are just as happy to play in the mud, too.
|
||||
|
||||
#### Perspective and Responsibility ####
|
||||
|
||||
As terrible a breach as this discovery is emotionally, technically and ethically it remains far, far, far away from being an indication that we’re entering a new “free for all” era of viruses and malware aimed at the desktop.
|
||||
|
||||
**Turla is not a user-focused “i wantZ ur CredIt carD” virus** bundled inside a faux software download. It’s a complex, finessed and adaptable threat with specific targets in mind (ergo grander ambitions than collecting a bunch of fruity tube dot com passwords, sorry ego!).
|
||||
|
||||
Kaspersky Lab explains:
|
||||
|
||||
> “The Linux Turla module is a C/C++ executable statically linked against multiple libraries, greatly increasing its file size. It was stripped of symbol information, more likely intended to increase analysis effort than to decrease file size. Its functionality includes hidden network communications, arbitrary remote command execution, and remote management. Much of its code is based on public sources.”
|
||||
|
||||
Regardless of impact or infection rate its precedes will still raise big, big questions that clever, clever people will now spend time addressing, analysing and (importantly) solving.
|
||||
|
||||
IANACSE (I am not a computer security expert) but IAFOA (I am a fan of acronyms), and AFAICT (as far as I can tell) this news should be viewed as as a cautionary PSA or FYI than the kind of OMGGTFO that some sites are painting it as.
|
||||
|
||||
Until more details are known none of us should panic. Let’s continue to practice safe computing. Avoid downloading/running scripts, apps, or binaries from untrusted sites or PPAs, and don’t venture into dodgy dark parts of the web.
|
||||
|
||||
If you remain super concerned you can check out the [Kaspersky blog][1] for details on how to check that you’re not infected.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/12/government-spying-turla-linux-trojan-found
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[2]:https://twitter.com/joernchen/status/542060412188262400
|
||||
[3]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
@ -1,48 +0,0 @@
|
||||
[Translating by Stevarzh]
|
||||
How to Download Music from Grooveshark with a Linux OS
|
||||
================================================================================
|
||||
> The solution is actually much simpler than you think
|
||||
|
||||

|
||||
|
||||
**Grooveshark is a great online platform for people who want to listen to music, and there are a number of ways to download music from there. Groovesquid is just one of the applications that let users get music from Grooveshark, and it's multiplatform.**
|
||||
|
||||
If there is a service that streams something online, then there is a way to download the stuff that you are just watching or listening. As it turns out, it's not that difficult and there are a ton of solutions, no matter the platform. For example, there are dozens of YouTube downloaders and it stands to reason that it's not all that difficult to get stuff from Grooveshark either.
|
||||
|
||||
Now, there is the problem of legality. Like many other applications out there, Groovesquid is not actually illegal. It's the user's fault if they do something illegal with an application. The same reasoning can be applied to apps like utorrent or Bittorrent. As long as you don't touch copyrighted material, there are no problems in using Groovesquid.
|
||||
|
||||
### Groovesquid is fast and efficient ###
|
||||
|
||||
The only problem that you could find with Groovesquid is the fact that it's based on Java and that's never a good sign. This is a good way to ensure that an application runs on all the platforms, but it's an issue when it comes to the interface. It's not great, but it doesn't really matter all that much for users, especially since the app is doing a great job.
|
||||
|
||||
There is one caveat though. Groovesquid is a free application, but in order to remain free, it has to display an ad on the right side of the menu. This shouldn't be a problem for most people, but it's a good idea to mention that right from the start.
|
||||
|
||||
From a usability point of view, the application is pretty straightforward. Users can download a single song by entering the link in the top field, but the purpose of that field can be changed by accessing the small drop-down menu to its left. From there, it's possible to change to Song, Popular, Albums, Playlist, and Artist. Some of the options provide access to things like the most popular song on Grooveshark and other options allow you to download an entire playlist, for example.
|
||||
|
||||
You can download Groovesquid 0.7.0
|
||||
|
||||
- [jar][1] File size: 3.8 MB
|
||||
- [tar.gz][2] File size: 549 KB
|
||||
|
||||
You will get a Jar file and all you have to do is to make it executable and let Java do the rest.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/How-to-Download-Music-from-Grooveshark-with-a-Linux-OS-468268.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://github.com/groovesquid/groovesquid/releases/download/v0.7.0/Groovesquid.jar
|
||||
[2]:https://github.com/groovesquid/groovesquid/archive/v0.7.0.tar.gz
|
||||
@ -0,0 +1,59 @@
|
||||
This App Can Write a Single ISO to 20 USB Drives Simultaneously
|
||||
================================================================================
|
||||
**If I were to ask you to burn a single Linux ISO to 17 USB thumb drives how would you go about doing it?**
|
||||
|
||||
Code savvy folks would write a little bash script to automate the process, and a large number would use a GUI tool like the USB Startup Disk Creator to burn the ISO to each drive in turn, one by one. But the rest of us would fast conclude that neither method is ideal.
|
||||
|
||||
### Problem > Solution ###
|
||||
|
||||
|
||||
|
||||
GNOME MultiWriter in action
|
||||
|
||||
Richard Hughes, a GNOME developer, faced a similar dilemma. He wanted to create a number of USB drives pre-loaded with an OS, but wanted a tool simple enough for someone like his dad to use.
|
||||
|
||||
His response was to create a **brand new app** that combines both approaches into one easy to use tool.
|
||||
|
||||
It’s called “[GNOME MultiWriter][1]” and lets you write a single ISO or IMG to multiple USB drives at the same time.
|
||||
|
||||
It nixes the need to customize or create a command line script and relinquishes the need to waste an afternoon performing an identical set of actions on repeat.
|
||||
|
||||
All you need is this app, an ISO, some thumb-drives and lots of empty USB ports.
|
||||
|
||||
### Use Cases and Installing ###
|
||||
|
||||

|
||||
|
||||
The app can be installed on Ubuntu
|
||||
|
||||
The app has a pretty defined usage scenario, that being situations where USB sticks pre-loaded with an OS or live image are being distributed.
|
||||
|
||||
That being said, it should work just as well for anyone wanting to create a solitary bootable USB stick, too — and since I’ve never once successfully created a bootable image from Ubuntu’s built-in disk creator utility, working alternatives are welcome news to me!
|
||||
|
||||
Hughes, the developer, says it **supports up to 20 USB drives**, each being between 1GB and 32GB in size.
|
||||
|
||||
The drawback (for now) is that GNOME MultiWriter is not a finished, stable product. It works, but at this early blush there are no pre-built binaries to install or a PPA to add to your overstocked software sources.
|
||||
|
||||
If you know your way around the usual configure/make process you can get it up and running in no time. On Ubuntu 14.10 you may also need to install the following packages first:
|
||||
|
||||
sudo apt-get install gnome-common yelp-tools libcanberra-gtk3-dev libudisks2-dev gobject-introspection
|
||||
|
||||
If you get it up and running, give it a whirl and let us know what you think!
|
||||
|
||||
Bugs and pull requests can be longed on the GitHub page for the project, which is where you’ll also found tarball downloads for manual installation.
|
||||
|
||||
- [GNOME MultiWriter on Github][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/gnome-multiwriter-iso-usb-utility
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/hughsie/gnome-multi-writer/
|
||||
[2]:https://github.com/hughsie/gnome-multi-writer/
|
||||
@ -0,0 +1,47 @@
|
||||
2015: Open Source Has Won, But It Isn't Finished
|
||||
================================================================================
|
||||
> After the wins of 2014, what's next?
|
||||
|
||||
At the beginning of a new year, it's traditional to look back over the last 12 months. But as far as this column is concerned, it's easy to summarise what happened then: open source has won. Let's take it from the top:
|
||||
|
||||
**Supercomputers**. Linux is so dominant on the Top 500 Supercomputers lists it is almost embarrassing. The [November 2014 figures][1] show that 485 of the top 500 systems were running some form of Linux; Windows runs on just one. Things are even more impressive if you look at the numbers of cores involved. Here, Linux is to be found on 22,851,693 of them, while Windows is on just 30,720; what that means is that not only does Linux dominate, it is particularly strong on the bigger systems.
|
||||
|
||||
**Cloud computing**. The Linux Foundation produced an interesting [report][2] last year, which looked at the use of Linux in the cloud by large companies. It found that 75% of them use Linux as their primary platform there, against just 23% that use Windows. It's hard to translate that into market share, since the mix between cloud and non-cloud needs to be factored in; however, given the current popularity of cloud computing, it's safe to say that the use of Linux is high and increasing. Indeed, the same survey found Linux deployments in the cloud have increased from 65% to 79%, while those for Windows have fallen from 45% to 36%. Of course, some may not regard the Linux Foundation as totaly disinterested here, but even allowing for that, and for statistical uncertainties, it's pretty clear which direction things are moving in.
|
||||
|
||||
**Web servers**. Open source has dominated this sector for nearly 20 years - an astonishing record. However, more recently there's been some interesting movement in market share: at one point, Microsoft's IIS managed to overtake Apache in terms of the total number of Web servers. But as Netcraft explains in its most recent [analysis][3], there's more than meets the eye here:
|
||||
|
||||
> This is the second month in a row where there has been a large drop in the total number of websites, giving this month the lowest count since January. As was the case in November, the loss has been concentrated at just a small number of hosting companies, with the ten largest drops accounting for over 52 million hostnames. The active sites and web facing computers metrics were not affected by the loss, with the sites involved being mostly advertising linkfarms, having very little unique content. The majority of these sites were running on Microsoft IIS, causing it to overtake Apache in the July 2014 survey. However the recent losses have resulted in its market share dropping to 29.8%, leaving it now over 10 percentage points behind Apache.
|
||||
|
||||
As that indicates, Microsoft's "surge" was more apparent than real, and largely based on linkfarms with little useful content. Indeed, Netcraft's figures for active sites paints a very different picture: Apache has 50.57% market share, with nginx second on 14.73%; Microsoft IIS limps in with a rather feeble 11.72%. This means that open source has around 65% of the active Web server market - not quite at the supercomputer level, but pretty good.
|
||||
|
||||
**Mobile systems**. Here, the march of open source as the foundation of Android continues. Latest figures show that Android accounted for [83.6%][4] of smartphone shipments in the third quarter of 2014, up from 81.4% in the same quarter the previous year. Apple achieved 12.3%, down from 13.4%. As far as tablets are concerned, Android is following a similar trajectory: for the second quarter of 2014, Android notched up around [75% of global tablet sales][5], while Apple was on 25%.
|
||||
|
||||
**Embedded systems**. Although it's much harder to quantify the market share of Linux in the important embedded system market, but figures from one 2013 study indicated that around [half of planned embedded systems][6] would use it.
|
||||
|
||||
**Internet of Things**. In many ways this is simply another incarnation of embedded systems, with the difference that they are designed to be online, all the time. It's too early to talk of market share, but as I've [discussed][7] recently, AllSeen's open source framework is coming on apace. What's striking by their absence are any credible closed-source rivals; it therefore seems highly likely that the Internet of Things will see supercomputer-like levels of open source adoption.
|
||||
|
||||
Of course, this level of success always begs the question: where do we go from here? Given that open source is approaching saturation levels of success in many sectors, surely the only way is down? In answer to that question, I recommend a thought-provoking essay from 2013 written by Christopher Kelty for the Journal of Peer Production, with the intriguing title of "[There is no free software.][8]" Here's how it begins:
|
||||
|
||||
> Free software does not exist. This is sad for me, since I wrote a whole book about it. But it was also a point I tried to make in my book. Free software—and its doppelganger open source—is constantly becoming. Its existence is not one of stability, permanence, or persistence through time, and this is part of its power.
|
||||
|
||||
In other words, whatever amazing free software 2014 has already brought us, we can be sure that 2015 will be full of yet more of it, as it continues its never-ending evolution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -1,3 +1,5 @@
|
||||
翻译中 by小眼儿
|
||||
|
||||
Docker Image Insecurity
|
||||
================================================================================
|
||||
Recently while downloading an “official” container image with Docker I saw this line:
|
||||
@ -129,4 +131,4 @@ via: https://titanous.com/posts/docker-insecurity
|
||||
[24]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9356
|
||||
[25]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9357
|
||||
[26]:https://groups.google.com/d/topic/docker-user/nFAz-B-n4Bw/discussion
|
||||
[27]:https://docs.google.com/document/d/1JfWNzfwptsMgSx82QyWH_Aj0DRKyZKxYQ1aursxNorg/edit?pli=1
|
||||
[27]:https://docs.google.com/document/d/1JfWNzfwptsMgSx82QyWH_Aj0DRKyZKxYQ1aursxNorg/edit?pli=1
|
||||
|
||||
@ -1,47 +0,0 @@
|
||||
How To Install Winusb In Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
[WinUSB][1] is a simple and useful tool that lets you create USB stick Windows installer from the Windows ISO image or DVD. It comprises of both GUI and command line tool and you can decide to choose which to use based on your preference.
|
||||
|
||||
In this quick post we shall see **how to install WinUSB in Ubuntu 14.04, 14.10 and Linux Mint 17**.
|
||||
|
||||
### Install WinUSB in Ubuntu 14.04 and Ubuntu 14.10 ###
|
||||
|
||||
Until Ubuntu 13.10, WinUSB was developed actively and it was available for installation via its official PPA. This PPA has not been updated for Ubuntu 14.04 Trusty Tahr and 14.10 but the binaries are still there and works fine in newer version of Ubuntu and Linux Mint. Based on [whether your Ubuntu system is 32 bit or 64 bit][2], use the command below to download the binaries:
|
||||
|
||||
Open a terminal and use the following command for 32 bit system:
|
||||
|
||||
wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_i386.deb
|
||||
|
||||
For 64 bit systems, use the command below:
|
||||
|
||||
wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_amd64.deb
|
||||
|
||||
Once you have downloaded the correct binaries, you can install WinUSB using the command below:
|
||||
|
||||
sudo dpkg -i winusb*
|
||||
|
||||
Don’t worry if you see error when you try to install WinUSB. Fix the dependency errors with this command:
|
||||
|
||||
sudo apt-get -f install
|
||||
|
||||
Afterwards, you can search for WinUSB in Unity Dash and use it to create a live USB of Windows in Ubuntu 14.04.
|
||||
|
||||

|
||||
|
||||
I hope this quick post helped you to **install WinUSB in Ubuntu 14.04, 14.10 and Linux Mint 17**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-winusb-in-ubuntu-14-04/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.congelli.eu/prog_info_winusb.html
|
||||
[2]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
@ -0,0 +1,62 @@
|
||||
How To Install New Fonts In Ubuntu 14.04 and 14.10
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu does come with a bunch of fonts installed by default in it. But at times you might not be satisfied with the available lots of fonts. So, what you can do is to **install additional fonts in Ubuntu 14.04**, 14.10 or any other Linux system such as Linux Mint.
|
||||
|
||||
### Step 1: Get fonts ###
|
||||
|
||||
First and foremost, download your choice of fonts. Now you might be thinking from where can you get new fonts. Don’t worry, a simple Google search will provide you with several websites that have new fonts available for free. You can start with [fonts at Lost Type][1]. [Fonts Squirrel][2] is also a good place to download fonts.
|
||||
|
||||
### Step 2: Install new fonts in Ubuntu ###
|
||||
|
||||
The downloaded fonts might be in a zipped file. Extract it. Most of the fonts are either in [TTF][3] (TrueType Fonts) or in [OTF][4] (OpenType Fonts) format. Whichever it may be, just double click on the font file. It will open it in Font Viewer. In here, you can see the option to install the font in top right corner:
|
||||
|
||||

|
||||
|
||||
You won’t really see anything being installed as you see when installing a software. Couple of seconds later, you’ll see the status has been changed to Installed. No prizes for guessing that the font has been now installed.
|
||||
|
||||

|
||||
|
||||
Once installed, you can see the newly installed fonts in any application that uses fonts such as GIMP, Pinta etc.
|
||||
|
||||
### Step 2: Install several fonts at once in Linux ###
|
||||
|
||||
No, it is not typo. This is still step 2 but just an alternative. The method we saw above to install fonts in Ubuntu is just fine. But there is a little issue with it. What happens when you have like 20 new fonts to install. Installing all these fonts, one by one, by double clicking on them is cumbersome and inconvenient. Don’t you think the same?
|
||||
|
||||
To install several fonts at once in Ubuntu, all you need to do is to create .fonts directory, if it doesn’t exist already, in your Home directory. And extract or copy paste all those TTF or OTF files in this directory.
|
||||
|
||||
Go to your Home directory in File manager. Press Ctrl+H to [show hidden files in Ubuntu][5]. Right click to make a new folder and name it .fonts. That dot at the beginning is important. In Linux, if you put dot ahead of the file name, it hides the file from normal view.
|
||||
|
||||
#### Alternative: ####
|
||||
|
||||
Alternatively, you can install Font Manager application and manage fonts in GUI. To install Font Manager in Ubuntu, open a terminal and use the command below:
|
||||
|
||||
sudo apt-get install font-manager
|
||||
|
||||
Open the Font Manager from Unity Dash. You can see installed fonts and option to install new fonts, remove existing fonts etc here.
|
||||
|
||||

|
||||
|
||||
To remove Font Manager, use the command below:
|
||||
|
||||
sudo apt-get remove font-manager
|
||||
|
||||
I hope this quick helped you to install fonts in Ubuntu and other Linux systems. Do let me know if you have questions or suggestions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-fonts-ubuntu-1404-1410/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://www.losttype.com/browse/
|
||||
[2]:http://www.fontsquirrel.com/
|
||||
[3]:http://en.wikipedia.org/wiki/TrueType
|
||||
[4]:http://en.wikipedia.org/wiki/OpenType
|
||||
[5]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
@ -0,0 +1,76 @@
|
||||
How to deduplicate files on Linux with dupeGuru
|
||||
================================================================================
|
||||
Recently, I was given the task to clean up my father's files and folders. What made it difficult was the abnormal amount of duplicate files with incorrect names. By keeping a backup on an external drive, simultaneously editing multiple versions of the same file, or even changing the directory structure, the same file can get copied many times, change names, change locations, and just clog disk space. Hunting down every single one of them can become a problem of gigantic proportions. Hopefully, there exists nice little software that can save your precious hours by finding and removing duplicate files on your system: [dupeGuru][1]. Written in Python, this file deduplication software switched to a GPLv3 license a few hours ago. So time to apply your new year's resolutions and clean up your stuff!
|
||||
|
||||
### Installation of dupeGuru ###
|
||||
|
||||
On Ubuntu, you can add the Hardcoded Software PPA:
|
||||
|
||||
$ sudo apt-add-repository ppa:hsoft/ppa
|
||||
$ sudo apt-get update
|
||||
|
||||
And then install with:
|
||||
|
||||
$ sudo apt-get install dupeguru-se
|
||||
|
||||
On Arch Linux, the package is present in the [AUR][2].
|
||||
|
||||
If you prefer compiling it yourself, the sources are on [GitHub][3].
|
||||
|
||||
### Basic Usage of dupeGuru ###
|
||||
|
||||
DupeGuru is conceived to be fast and safe. Which means that the program is not going to run berserk on your system. It has a very low risk of deleting stuff that you did not intend to delete. However, as we are still talking about file deletion, it is always a good idea to stay vigilant and cautious: a good backup is always necessary.
|
||||
|
||||
Once you took your precautions, you can launch dupeGuru via the command:
|
||||
|
||||
$ dupeguru_se
|
||||
|
||||
You should be greeted by the folder selection screen, where you can add folders to scan for deduplication.
|
||||
|
||||

|
||||
|
||||
Once you selected your directories and launched the scan, dupeGuru will show its results by grouping duplicate files together in a list.
|
||||
|
||||

|
||||
|
||||
Note that by default dupeGuru matches files based on their content, and not their name. To be sure that you do not accidentally delete something important, the match column shows you the accuracy of the matching algorithm. From there, you can select the duplicate files that you want to take action on, and click on "Actions" button to see available actions.
|
||||
|
||||

|
||||
|
||||
The choice of actions is quite extensive. In short, you can delete the duplicates, move them to another location, ignore them, open them, rename them, or even invoke a custom command on them. If you choose to delete a duplicate, you might get as pleasantly surprised as I was by available deletion options.
|
||||
|
||||

|
||||
|
||||
You can not only send the duplicate files to the trash or delete them permanently, but you can also choose to leave a link to the original file (either using a symlink or a hardlink). In oher words, the duplicates will be erased, and a link to the original will be left instead, saving a lot of disk space. This can be particularly useful if you imported those files into a workspace, or have dependencies based on them.
|
||||
|
||||
Another fancy option: you can export the results to a HTML or CSV file. Not really sure why you would do that, but I suppose that it can be useful if you prefer keeping track of duplicates rather than use any of dupeGuru's actions on them.
|
||||
|
||||
Finally, last but not least, the preferences menu will make all your dream about duplicate busting come true.
|
||||
|
||||

|
||||
|
||||
There you can select the criterion for the scan, either content based or name based, and a threshold for duplicates to control the number of results. It is also possible to define the custom command that you can select in the actions. Among the myriad of other little options, it is good to notice that by default, dupeGuru ignores files less than 10KB.
|
||||
|
||||
For more information, I suggest that you go check out the [official website][4], which is filled with documention, support forums, and other goodies.
|
||||
|
||||
To conclude, dupeGuru is my go-to software whenever I have to prepare a backup or to free some space. I find it powerful enough for advanced users, and yet intuitive to use for newcomers. Cherry on the cake: dupeGuru is cross platform, which means that you can also use it for your Mac or Windows PC. If you have specific needs, and want to clean up music or image files, there exists two variations: [dupeguru-me][5] and [dupeguru-pe][6], which respectively find duplicate audio tracks and pictures. The main difference from the regular version is that it compares beyond file formats and takes into account specific media meta-data like quality and bit-rate.
|
||||
|
||||
What do you think of dupeGuru? Would you consider using it? Or do you have any alternative deduplication software to suggest? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/dupeguru-deduplicate-files-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://www.hardcoded.net/dupeguru/
|
||||
[2]:https://aur.archlinux.org/packages/dupeguru-se/
|
||||
[3]:https://github.com/hsoft/dupeguru
|
||||
[4]:http://www.hardcoded.net/dupeguru/
|
||||
[5]:http://www.hardcoded.net/dupeguru_me/
|
||||
[6]:http://www.hardcoded.net/dupeguru_pe/
|
||||
@ -0,0 +1,339 @@
|
||||
Managing Linux server configs with the SaltStack
|
||||
================================================================================
|
||||

|
||||
|
||||
I came across Salt while searching for an alternative to [Puppet][1]. I like puppet, but I am falling in love with Salt :). This maybe a personal opinion but I found Salt easier to configure and get started with as compared to Puppet. Another reason I like Salt is that it let’s you manage your server configurations from the command line, for example:
|
||||
|
||||
To update all your servers with Salt, just run
|
||||
|
||||
salt ‘*’ pkg.upgrade
|
||||
|
||||
**Installing the SaltStack on Linux.**
|
||||
|
||||
Salt is available in the EPEL repo if you are installing it on CentOS 6/7, Pi and Ubuntu linux users can add the Salt Repository from [here][2]. Since Salt is python based you can also use ‘pip’ to install it but you have take care of dependencies like yum-utils and other packages yourself.
|
||||
|
||||
Salt follows the Server-Client model, The Server is known as the master whereas clients are called minions.
|
||||
|
||||
**Installation and Configuration of a Salt Master**
|
||||
|
||||
[root@salt-master~]# yum install salt-master
|
||||
|
||||
Salt configurations files are stored in /etc/salt and /srv/salt. Salt is good to go out of the box, but I would recommend you configure a bit more verbose logging to help your troubleshoot.
|
||||
|
||||
[root@salt-master ~]# vim /etc/salt/master
|
||||
#Default is warning change to the following
|
||||
log_level: debug
|
||||
log_level_logfile: debug
|
||||
|
||||
[root@salt-master ~]# systemctl start salt-master
|
||||
|
||||
**Installation and Configuration of a Salt minion**
|
||||
|
||||
[root@salt-minion~]#yum install salt-minion
|
||||
|
||||
#Add the hostname of your Salt Master
|
||||
[root@salt-minion~]#vim /etc/salt/minion
|
||||
master: salt-master.com
|
||||
#start the minion
|
||||
[root@salt-minion~] systemctl start salt-minion
|
||||
|
||||
On Startup, a minion will generate a cryptographic key and an id. It will then connect to the Salt Master and identify itself. The Salt Master must accept the minion’s key before allowing the minion to download a configuration.
|
||||
|
||||
**Listing and Accepting keys on the Salt Master**
|
||||
|
||||
#List all keys
|
||||
[root@salt-master~] salt-key -L
|
||||
Accepted Keys:
|
||||
Unaccepted Keys:
|
||||
minion.com
|
||||
Rejected Keys:
|
||||
|
||||
#Accept key with id ‘minion.com’
|
||||
[root@salt-master~]salt-key -a minion.com
|
||||
|
||||
[root@salt-master~] salt-key -L
|
||||
Accepted Keys:
|
||||
minion.com
|
||||
Unaccepted Keys:
|
||||
Rejected Keys:
|
||||
|
||||
Once you have accepted a minions keys, you can get information on it immediately using the ‘salt’ command.
|
||||
|
||||
**Salt command line examples**
|
||||
|
||||
#Check if a minion is up and running
|
||||
[root@salt-master~] salt 'minion.com' test.ping
|
||||
minion.com:
|
||||
True
|
||||
# run shell commands on the minion
|
||||
[root@salt-master~]# salt 'minion.com' cmd.run 'ls -l'
|
||||
minion.com:
|
||||
total 2988
|
||||
-rw-r--r--. 1 root root 1024 Jul 31 08:24 1g.img
|
||||
-rw-------. 1 root root 940 Jul 14 15:04 anaconda-ks.cfg
|
||||
-rw-r--r--. 1 root root 1024 Aug 14 17:21 test
|
||||
#install/update a software on all your servers
|
||||
[root@salt-master ~]# salt '*' pkg.install git
|
||||
|
||||
The salt command needs a few components to send information. One of these components is the minion id and another is the function to be called on the minion.
|
||||
In the first example I used the ‘ping’ function of the ‘test’ module to check if the system is up. This function does not perform an actual ping, it just return’s ‘true’ if the minion responds.
|
||||
‘cmd.run’ is used to execute remote commands and ‘pkg’ module contains functions for package management. The full list of builin modules is at the end of this post.
|
||||
|
||||
**Grains example**
|
||||
|
||||
Salt uses an interface called **Grains** to get system information. You can use grains to run commands on systems with particular properties.
|
||||
|
||||
[root@vps4544 ~]# salt -G 'os:Centos' test.ping
|
||||
minion:
|
||||
True
|
||||
|
||||
More grain examples are available at http://docs.saltstack.com/en/latest/topics/targeting/grains.html
|
||||
|
||||
**Package Management via the State File System.**
|
||||
|
||||
In order to automate software configurations you will need to use the state system and create a state file. These files use the YAML format and python dictionaries, lists, strings and numbers for data structure. Reading up on them will help you understand the configurations better.
|
||||
|
||||
**VIM state file example**
|
||||
|
||||
[root@salt-master~]# vim /srv/salt/vim.sls
|
||||
vim-enhanced:
|
||||
pkg.installed
|
||||
/etc/vimrc:
|
||||
file.managed:
|
||||
- source: salt://vimrc
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 644
|
||||
|
||||
|
||||
The first and third line in this file are called state id. They must contain the exact name or path of the package or file to be managed. After the state ids are state and function declaration. ‘pkg’ and file are state declarations whereas ‘installed’ and ‘managed’ are function declarations. Functions accept arguments, user,group,mode and source are all arguments to the function ‘managed’.
|
||||
|
||||
To apply this configuration to a minion move your ‘vimrc’ file to ‘/srv/salt’ and run.
|
||||
|
||||
[root@salt-master~]# salt 'minion.com' state.sls vim
|
||||
minion.com:
|
||||
----------
|
||||
ID: vim-enhanced
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: The following packages were installed/updated: vim-enhanced.
|
||||
Started: 09:36:23.438571
|
||||
Duration: 94045.954 ms
|
||||
Changes:
|
||||
----------
|
||||
vim-enhanced:
|
||||
----------
|
||||
new:
|
||||
7.4.160-1.el7
|
||||
old:
|
||||
|
||||
|
||||
Summary
|
||||
------------
|
||||
Succeeded: 1 (changed=1)
|
||||
Failed: 0
|
||||
------------
|
||||
Total states run: 1
|
||||
|
||||
You can also add dependencies to your configurations.
|
||||
|
||||
[root@salt-master~]# vim /srv/salt/ssh.sls
|
||||
openssh-server:
|
||||
pkg.installed
|
||||
|
||||
|
||||
/etc/ssh/sshd_config:
|
||||
file.managed:
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 600
|
||||
- source: salt://ssh/sshd_config
|
||||
|
||||
sshd:
|
||||
service.running:
|
||||
- require:
|
||||
- pkg: openssh-server
|
||||
|
||||
The ‘require’ statement here is a requisite declaration, it creates a dependency between the ‘service’ and ‘pkg’ states. This declaration will first check if the package is installed and then run the service.
|
||||
|
||||
However, I prefer using the ‘watch’ statement as it also checks for file modifications and restarts the service.
|
||||
|
||||
[root@salt-master~]# vim /srv/salt/ssh.sls
|
||||
openssh-server:
|
||||
pkg.installed
|
||||
|
||||
|
||||
/etc/ssh/sshd_config:
|
||||
file.managed:
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 600
|
||||
- source: salt://sshd_config
|
||||
|
||||
sshd:
|
||||
service.running:
|
||||
- watch:
|
||||
- pkg: openssh-server
|
||||
- file: /etc/ssh/sshd_config
|
||||
|
||||
[root@vps4544 ssh]# salt 'minion.com' state.sls ssh
|
||||
seven.leog.in:
|
||||
Changes:
|
||||
----------
|
||||
ID: openssh-server
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: Package openssh-server is already installed.
|
||||
Started: 13:01:55.824367
|
||||
Duration: 1.156 ms
|
||||
Changes:
|
||||
----------
|
||||
ID: /etc/ssh/sshd_config
|
||||
Function: file.managed
|
||||
Result: True
|
||||
Comment: File /etc/ssh/sshd_config updated
|
||||
Started: 13:01:55.825731
|
||||
Duration: 334.539 ms
|
||||
Changes:
|
||||
----------
|
||||
diff:
|
||||
---
|
||||
+++
|
||||
@@ -14,7 +14,7 @@
|
||||
# SELinux about this change.
|
||||
# semanage port -a -t ssh_port_t -p tcp #PORTNUMBER
|
||||
#
|
||||
-Port 22
|
||||
+Port 422
|
||||
#AddressFamily any
|
||||
#ListenAddress 0.0.0.0
|
||||
#ListenAddress ::
|
||||
|
||||
----------
|
||||
ID: sshd
|
||||
Function: service.running
|
||||
Result: True
|
||||
Comment: Service restarted
|
||||
Started: 13:01:56.473121
|
||||
Duration: 407.214 ms
|
||||
Changes:
|
||||
----------
|
||||
sshd:
|
||||
True
|
||||
|
||||
Summary
|
||||
------------
|
||||
Succeeded: 4 (changed=2)
|
||||
Failed: 0
|
||||
------------
|
||||
Total states run: 4
|
||||
|
||||
Maintaining all config files in single directory can make scaling a complex task, hence you can create sub-directories and add your configuration in them with a init.sls file
|
||||
|
||||
[root@salt-master~]# mkdir /srv/salt/ssh
|
||||
[root@salt-master~]# vim /srv/salt/ssh/init.sls
|
||||
openssh-server:
|
||||
pkg.installed
|
||||
|
||||
|
||||
/etc/ssh/sshd_config:
|
||||
file.managed:
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 600
|
||||
- source: salt://ssh/sshd_config
|
||||
|
||||
sshd:
|
||||
service.running:
|
||||
- watch:
|
||||
- pkg: openssh-server
|
||||
- file: /etc/ssh/sshd_config
|
||||
|
||||
[root@vps4544 ssh]# cp /etc/ssh/sshd_config /srv/salt/ssh/
|
||||
[root@vps4544 ssh]# salt 'minion.com' state.sls ssh
|
||||
|
||||
**Top File and Environments.**
|
||||
|
||||
A Top file (top.sls) is where you define your environments. A top file allows you to map minions to packages. The default environment is ‘base’. You need to define which packages will be installed on which server under the base environment.
|
||||
|
||||
If there are multiple environments and more than one definitions for a particular minion is used then by default the base environment will supersede the others.
|
||||
|
||||
To define an environment you need to add it to the ‘file_roots’ directive in the master configuration file.
|
||||
|
||||
[root@salt-master ~]# vim /etc/salt/master
|
||||
file_roots:
|
||||
base:
|
||||
- /srv/salt
|
||||
dev:
|
||||
- /srv/salt/dev
|
||||
|
||||
Now add a top.sls file in /srv/salt
|
||||
|
||||
[root@salt-master ~]# vim /srv/salt/top.sls
|
||||
base:
|
||||
'*':
|
||||
- vim
|
||||
'minion.com':
|
||||
- ssh
|
||||
|
||||
Apply the top file configuration with
|
||||
|
||||
[root@salt-master~]# salt '*' state.highstate
|
||||
minion.com:
|
||||
----------
|
||||
ID: vim-enhanced
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: Package vim-enhanced is already installed.
|
||||
Started: 13:10:55
|
||||
Duration: 1678.779 ms
|
||||
Changes:
|
||||
----------
|
||||
ID: openssh-server
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: Package openssh-server is already installed.
|
||||
Started: 13:10:55.
|
||||
Duration: 2.156 ms
|
||||
|
||||
The minion will download the top file and search for it’s configuration. It will also apply the configuration for all minions.
|
||||
|
||||
This is just a brief introduction to Salt, for in depth understanding you can go through the links below and if you are already using Salt and have any recommendations do let me know.
|
||||
|
||||
Update: [Foreman][3] has support for salt via [plugins][4].
|
||||
|
||||
Read
|
||||
|
||||
- http://docs.saltstack.com/en/latest/ref/states/top.html#how-top-files-are-compiled
|
||||
- http://docs.saltstack.com/en/latest/topics/tutorials/states_pt1.html
|
||||
- http://docs.saltstack.com/en/latest/ref/states/highstate.html#state-declaration
|
||||
|
||||
Grains
|
||||
|
||||
- http://docs.saltstack.com/en/latest/topics/targeting/grains.html
|
||||
|
||||
List of Salt Modules
|
||||
|
||||
Good comparison of Salt and puppet
|
||||
|
||||
- https://mywushublog.com/2013/03/configuration-management-with-salt-stack/
|
||||
|
||||
Full list of builtin execution modules
|
||||
|
||||
- http://docs.saltstack.com/en/latest/ref/modules/all/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://techarena51.com/index.php/getting-started-with-saltstack/
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://techarena51.com/
|
||||
[1]:http://techarena51.com/index.php/a-simple-way-to-install-and-configure-a-puppet-server-on-linux/
|
||||
[2]:http://docs.saltstack.com/en/latest/topics/installation/index.html
|
||||
[3]:http://techarena51.com/index.php/using-foreman-opensource-frontend-puppet/
|
||||
[4]:https://github.com/theforeman/foreman_salt/wiki
|
||||
@ -0,0 +1,76 @@
|
||||
没错,Linux是感染了木马!但,这并非企鹅的末日。
|
||||
================================================================================
|
||||

|
||||
|
||||
译注:原文标题中Tuxpocalypse是作者造的词,由Tux和apocalypse组合而来。Tux是Linux的LOGO中那只企鹅的名字,apocalypse意为末世、大灾变,这里翻译成企鹅的末日。
|
||||
|
||||
你被监视了吗?
|
||||
|
||||
带上一箱罐头,挖一个深坑碉堡,准备进入一个完全不同的新世界吧:[一个强大的木马已经在Linux中被发现][1]。
|
||||
|
||||
没错,迄今为止最牢不可破的计算机世外桃源已经被攻破了,安全专家们都已成惊弓之鸟。
|
||||
|
||||
关掉电脑,拔掉键盘,然后再买只猫(忘掉YouTube吧)。企鹅末日已经降临,我们的日子不多了。
|
||||
|
||||
我去?这是真的吗?依我看,不一定吧~
|
||||
|
||||
### 一次可怕的异常事件! ###
|
||||
|
||||
先声明,**我并没有刻意轻视此次威胁(人们给这个木马起名为‘Turla’)的严重性**,为了避免质疑,我要强调的是,作为Linux用户,我们不应该为此次事件过分担心。
|
||||
|
||||
此次发现的木马能够在人们毫无察觉的情况下感染Linux系统,这是非常可怕的。事实上,它的主要工作是搜寻并向外发送各种类型的敏感信息,这一点同样令人感到恐惧。据了解,它已经存在至少4年时间,而且无需root权限就能完成这些工作。呃,这是要把人吓尿的节奏吗?
|
||||
|
||||
But - 但是 - 新闻稿里常常这个时候该出现‘but’了 - 要说恐慌正在横扫桌面Linux的粉丝,那就有点断章取义、甚至不着边际了。
|
||||
|
||||
对我们中的有些人来说,计算机安全隐患的确是一种新鲜事物,然而我们应该对其审慎对待:对桌面用户来说,Linux仍然是一个天生安全的操作系统。一次瑕疵不应该否定它的一切,我们没有必要慌忙地割断网线。
|
||||
|
||||
### 国家资助,目标政府 ###
|
||||
|
||||

|
||||
|
||||
企鹅和蛇的组合该叫‘企蛇’还是‘蛇鹅’?
|
||||
|
||||
‘Turla’木马是一个复杂、高级的持续威胁,四年多来,它以政府、大使馆以及制药公司的系统为目标,其使用的攻击方式所基于的代码[至少在14年前][2]就已存在了。
|
||||
|
||||
在Windows系统中,安全研究领域来自赛门铁克和卡巴斯基实验室的超级英雄们首先发现了这条黏黏的蛇,他们发现Turla及其组件已经**感染了45个国家的数百台个人电脑**,其中许多都是通过未打补丁的0day漏洞感染的。
|
||||
|
||||
*微软,干得漂亮。*
|
||||
|
||||
经过卡巴斯基实验室的进一步努力,他们发现,同样的木马出现在了Linux上。
|
||||
|
||||
这款木马无需高权限就可以“拦截传入的数据包,在系统中执行传入的命令”,但是它的触角到底有多深,有多少Linux系统被感染,它的完整功能都有哪些,这些目前都暂时还不明朗。
|
||||
|
||||
根据它选定的目标,我们推断“Turla”(及其变种)是由某些民族的国家资助的。美国和英国的读者不要想当然以为这些国家就是“那些国家”。不要忘了我们自己的政府也很乐于趟这摊浑水。
|
||||
|
||||
#### 观点 与 责任 ####
|
||||
|
||||
这次的发现从情感上、技术上、伦理上,都是一次严重的失利,但它远没有达到说我们已经进入一个病毒和恶意软件针对桌面自由肆虐的时代。
|
||||
|
||||
**Turla 并不是那种用户关注的“我想要你的信用卡”病毒**,那些病毒往往绑定在一个伪造的软件下载链接中。Turla是一种复杂的、经过巧妙处理的、具有高度适应性的威胁,它时刻都具有着特定的目标(因此它绝不仅仅满足于搜集一些卖萌少女的网站账户密码,sorry 绿茶婊们!)。
|
||||
|
||||
卡巴斯基实验室是这样介绍的:
|
||||
|
||||
> “Linux上的Turla模块是一个链接多个静态库的C/C++可执行文件,这大大增加了它的文件体积。但它并没有着重减小自身的文件体积,而是剥离了自身的符号信息,这样就增加了对它逆向分析的难度。它的功能主要包括隐藏网络通信、远程执行任意命令以及远程管理等等。它的大部分代码都基于公开源码。”
|
||||
|
||||
不管它的影响和感染率如何,它的技术优势都将不断给那些号称聪明的专家们留下一个又一个问题,就让他们花费大把时间去追踪、分析、解决这些问题吧。
|
||||
|
||||
我不是一个计算机安全专家,但我是一个理智的网络脑残粉,要我说,这次事件应该被看做是一个通(jing)报(gao),而并非有些网站所标榜的洪(shi)水(jie)猛(mo)兽(ri)。
|
||||
|
||||
在更多细节披露之前,我们都不必恐慌。只需继续计算机领域的安全实践,避免从不信任的网站或PPA源下载运行脚本、app或二进制文件,更不要冒险进入web网络的黑暗领域。
|
||||
|
||||
如果你仍然十分担心,你可以前往[卡巴斯基的博客][1]查看更多细节,以确定自己是否感染。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/12/government-spying-turla-linux-trojan-found
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[Mr小眼儿](http://blog.csdn.net/tinyeyeser)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[2]:https://twitter.com/joernchen/status/542060412188262400
|
||||
[3]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
@ -0,0 +1,47 @@
|
||||
如何使用 Linux 从 Grooveshark 下载音乐
|
||||
================================================================================
|
||||
> 解决办法通常没有那么难
|
||||
|
||||

|
||||
|
||||
**Grooveshark 对于喜欢音乐的人来说是一个不错的在线平台,同时有多种从上面下载音乐的方法。Groovesquid 是众多允许用户从 Grooveshark 上下载音乐的应用之一,并且是支持多平台的。**
|
||||
|
||||
只要有在线流媒体服务,就一定有方法从获取你之前看过或听过的视频及音乐。即使下载接口关闭了,也不是什么大不了的事,因为还有很多种解决方法,无论你用的什么操作系统。比如,网络上就有许多种 YouTube 下载器,同样的道理,从 Grooveshark 上下载音乐也并非难事。
|
||||
|
||||
现在,得考虑合法性的问题。与许多其他应用一样,Groovesquid 并非是完全不合法的。如果有用户使用应用去做一些非法的事情,那责任应归咎于用户。同样的道理也适用于 utorrent 或者 Bittorrent。只要你不触及版权问题,那你就可以无所顾忌的使用 Groovesquid 了。
|
||||
|
||||
### 快捷高效的 Groovesquid ###
|
||||
|
||||
你能够找到的 Groovesquid 的唯一缺点是,它是基于 Java 而编写的,这从来都不是一个好的兆头。虽然为了确保应用的可移植性这样做确实是一个好方法,但这样做的结果导致了其糟糕的界面。确实是非常糟糕的的界面,不过这一点并不会影响到用户的使用体验,特别是这款应用所完成的工作时如此的有用。
|
||||
|
||||
有一点需要注意的地方。Groovesquid 是一款免费的应用,但为了将免费保持下去,它会在菜单栏的右侧显示一则广告。这对大多数人来说都应该不是问题,不过最好在打开应用后注意下菜单栏右侧。
|
||||
|
||||
从易用性的角度来看,这款应用非常简洁。用户可以通过在顶部地址栏里输入链接直接下载单曲,地址栏的位置可以通过其左侧的下拉菜单进行修改。在下拉菜单中,也可以修改为歌曲名称、流行度、专辑名称、播放列表以及艺术家。有些选项向你提供了诸如查看 Grooveshark 上最流行的音乐,或者下载整个播放列表等。
|
||||
|
||||
你可以下载 Groovesquid 0.7.0
|
||||
|
||||
- [jar][1] 文件大小:3.8 MB
|
||||
- [tar.gz][2] 文件大小:549 KB
|
||||
|
||||
下载完 Jar 文件后,你所需要做的是将其权限修改为可执行,然后让 Java 来完成剩下的工作。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/How-to-Download-Music-from-Grooveshark-with-a-Linux-OS-468268.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://github.com/groovesquid/groovesquid/releases/download/v0.7.0/Groovesquid.jar
|
||||
[2]:https://github.com/groovesquid/groovesquid/archive/v0.7.0.tar.gz
|
||||
@ -1,61 +1,61 @@
|
||||
伴随苹果手表的揭幕,Ubuntu智能手表会成为下一个吗?
|
||||
伴随Apple Watch的揭幕,下一个智能手表会是Ubuntu吗?
|
||||
===
|
||||
|
||||
**今天,苹果借助‘苹果手表’的发布,证实了其进军穿戴式计算设备市场的长期传言**
|
||||
**苹果借助‘Apple Watch’的发布,证实了其进军穿戴式电子设备市场的长期传言**
|
||||
|
||||

|
||||
|
||||
Ubuntu智能手表 - 好的主意?
|
||||
Ubuntu智能手表 - 好主意?
|
||||
|
||||
拥有一系列稳定功能,硬件解决方案和应用合作伙伴关系的支持,手腕穿戴设备被许多公司预示为“人与技术关系的新篇章”。
|
||||
拥有一系列稳定功能、硬件解决方案和应用合作伙伴关系的支持,手腕穿戴设备被许多公司预示为“人与技术关系的新篇章”。
|
||||
|
||||
它的到来,以及用户兴趣的提升,有可能意味着Ubuntu需要遵循一个为智能手表定制的Ubuntu版本。
|
||||
它的到来,以及用户兴趣的提升,有可能意味着Ubuntu需要跟进一个为智能手表定制的Ubuntu版本。
|
||||
|
||||
### 大的方面还是成功的 ###
|
||||
|
||||
苹果在正确时间加入了快速发展的智能手表部门。约束手腕穿戴电脑功能的界限并不是一成不变。失败的设计,不良的用户界面以及主流用户使用穿戴技术功能的弱参数化,这些都见证了硬件种类保持着高效的影响力 - 一个准许Cupertino把时间花费在苹果手表上的因素。
|
||||
苹果在正确的时间加入了快速发展的智能手表行列。手腕穿戴设备功能的界限并不是一成不变。失败的设计、简陋的用户界面以及主流用户使用穿戴技术功能的弱定制化,这些都见证了硬件类产品仍然很脆弱 - 这一因素使得Cupertino把时间花费在Apple Watch上。
|
||||
|
||||
> ‘分析师说:超过2200万的智能手表将在今年销售’
|
||||
|
||||
去年全球范围内可穿戴设备的销售数量(包括健身追踪器)仅仅1000万。今年,分析师希望设备数量的改变可以超过2200万 - 不包括苹果手表,因为其直到2015年初才开始零售。
|
||||
去年全球范围内可穿戴设备的销售数量(包括健身追踪器)仅仅1000万。今年,分析师希望设备的销量可以超过2200万 - 不包括苹果手表,因为其直到2015年初才开始零售。
|
||||
|
||||
很容易就可以看出增长的来源。今年九月初柏林举办的IFA 2014展览会,展示了一系列来自主要制造商们的可穿戴设备,包括索尼和华硕。大多数搭载着Google最新发布的安卓穿戴系统。
|
||||
其实,我们很容易就可以看出增长的来源。今年九月初柏林举办的IFA 2014展览会,展示了一系列来自主要制造商们的可穿戴设备,包括索尼和华硕。大多数搭载着Google最新发布的安卓穿戴平台。
|
||||
|
||||
一个更加成熟的表现:安卓穿戴设备打破了与形式因素保持一致的新奇争论,进而呈现出一致并令人折服的用户方案。和新的苹果手表一样,它紧密地连接在一个现存的智能手机生态系统上。
|
||||
更成熟的一个表现是:安卓穿戴设备打破了与形式因素保持一致的新奇争论,进而呈现出一致且令人信服的用户方案。和新的苹果手表一样,它紧密地连接在一个现存的智能手机生态系统上。
|
||||
|
||||
可能它只是一个使用案例,Ubuntu手腕穿戴系统是否能匹配它还不清楚。
|
||||
但Ubuntu手腕穿戴系统是否能与之匹配,成为一个实用案例,目前还不清楚。
|
||||
|
||||
#### 目前还没有Ubuntu智能手表的计划 ####
|
||||
|
||||
Ubuntu操作系统的通用性,结合以为多装置设备和趋势性未来定制的严格版本,已经产生了典型目标智能电视,平板电脑和智能手机。Mir,公司的本土显示服务器,被用来运转所有尺寸屏幕上的接口(虽然不是公认1.5"的)
|
||||
Ubuntu操作系统的通用性将多种设备的严格标准与统一的未来目标联合在一起,Canonical已经将目标指向了智能电视,平板电脑和智能手机。公司自家的显示服务Mir,甚至被用来为所有尺寸的屏幕提供驱动接口(虽然不是公认1.5"的)。
|
||||
|
||||
今年年初,Canonical社区负责人Jono Bacon被询问是否有制作Ubuntu智能手表的打算。Bacon提供了他对这个问题的看法:“增加另一个形式因素到[Ubuntu触摸设备]路线只会减缓其余的东西”。
|
||||
今年年初,Canonical社区负责人Jono Bacon被问到是否有制作Ubuntu智能手表的打算。Bacon提供了他对这个问题的看法:“为[Ubuntu触摸设备]路线增加额外的形式因素只会减缓现有的进度”。
|
||||
|
||||
在Ubuntu电话发布两周年之际,我们还是挺赞同他的想法的。
|
||||
在Ubuntu手机发布两周年之际,我们还是挺赞同他的想法的。
|
||||
|
||||
滴答,滴答,对冲你的赌注点(实在不懂什么意思...)
|
||||
###除了A面还有B面!###
|
||||
|
||||
但是并不是没有希望的。在一个[几个月之后的电话采访][1]中,Ubuntu创始人Mark Shuttleworth提及到可穿戴技术和智能电视,平板电脑,智能手机一样,都在公司计划当中。
|
||||
但是并不是没有希望的。在[几个月之后的一次电话采访][1]中,Ubuntu创始人Mark Shuttleworth提到,可穿戴技术和智能电视、平板电脑、智能手机一样,都在公司计划当中。
|
||||
|
||||
> “Ubuntu因其在电话中的完美设计变得独一无二,但是它同时也被设计成满足其余生态系统的样子,比如从穿戴设备到PC机。”
|
||||
> “Ubuntu因其在电话中的完美设计变得独一无二,但同时它的设计也能够满足其他生态系统,从穿戴设备到PC机。”
|
||||
|
||||
然而这还没得到具体的证实,它更像一个指针,在这个方向是给我们提供一个乐观的指引。
|
||||
然而这还没得到具体的证实,它更像一个指针,在某个方向给我们提供一个乐观的指引。
|
||||
|
||||
### 不可能 — 这就是原因所在 ###
|
||||
#### 不大可能 — 但这就是原因所在 ####
|
||||
|
||||
Canonical并不反对利用牢固的专利进军市场。事实上,它的重要性犹如公司的DHA — 犹如服务器上的RHEL,桌面上的Windows,智能手机上的安卓...
|
||||
Canonical并不反对利用牢固的专利进军市场。事实上,它恰恰是公司DNA基因的一部分 — 犹如服务器端的RHEL,桌面端的Windows,智能手机上的安卓...
|
||||
|
||||
设备上的Ubuntu系统被制作成可以在更小的屏幕上扩展和适应性运行。甚至很有可能在和手表一样小的屏幕上运行。当普通的代码基础已经在手机,平板电脑,桌面和TV上准备就绪,我想如果我们没有看到来自社区这一方向上的努力,我会感到奇怪。
|
||||
设备上的Ubuntu系统被制作成可以在更小的屏幕上扩展和适配运行,甚至在小如手表一样的屏幕上。当普通的代码基础已经在手机、平板电脑、桌面和TV上准备就绪,在同样的方向上,如果看不到社区的努力是十分令人吃惊的。
|
||||
|
||||
但是我之所以不认为它会从规范社区发生,至少目前还没有,是今年早些时候Jono Bacon个人思想的共鸣:时间和努力。
|
||||
但是我之所以不认为它会从Canonical发生,至少目前还没有,是基于今年早些时候Jono Bacon的个人思想得出的结论:时间和努力。
|
||||
|
||||
Tim Cook在他的主题演讲中说道:“*我们并没有追随iPhone,也没有缩水用户界面,将其强硬捆绑在你的手腕上。*”这是一个很明显的陈述。为如此小的屏幕设计UI和UX模型;通过交互原则工作;对硬件和输入模式的恭维,都不是一件容易的事。
|
||||
Tim Cook在他的主题演讲中说道:“*我们并没有追随iPhone,也没有缩水用户界面,将其强硬捆绑在你的手腕上。*”这是一个很明显的陈述。为如此小的屏幕设计UI和UX模型、通过交互原则工作、对硬件和输入模式的推崇,这些都不是容易的事。
|
||||
|
||||
可穿戴技术仍然是一个新兴的市场。在这个阶段,Canonical将会浪费发展,设计以及进行中的业务。在一些更为紧迫的地区,任何利益的重要性将要超过损失。
|
||||
可穿戴技术仍然是一个新兴的市场。在这个阶段,Canonical可能会在探寻的过程中浪费一些发展、设计和商业上的机会。如果在一些更为紧迫的领域落后了,造成的后果远比眼前利益的损失更严重。
|
||||
|
||||
玩一局更久的游戏,等待直到看出那些努力在何地成功和失败,这是一条更难的路线。但是更适合Ubuntu的就是今天。在新产品出现之前,让Canonical把力量用在现存的产品上是更好的选择(这是一些已经来迟的理论)
|
||||
打一场持久战,耐心等待,看哪些努力成功哪些会失败,这是一条更难的路线,但是却更适合Ubuntu,就如同今天它做的一样。在新产品出现之前,Canonical把力量用在现存的产品上是更好的选择(这是一些已经来迟的理论)
|
||||
|
||||
想更进一步了解什么是Ubuntu智能手表,点击下面的[视频][2]。它展示了一个互动的主体性皮肤Tizen(它已经支持Samsung Galaxy Gear智能手表)。
|
||||
想更进一步了解什么是Ubuntu智能手表,点击下面的[视频][2],里面展示了一个交互的Unity主题皮肤Tizen(它已经支持Samsung Galaxy Gear智能手表)。
|
||||
|
||||
---
|
||||
|
||||
@ -63,7 +63,7 @@ via: http://www.omgubuntu.co.uk/2014/09/ubuntu-smartwatch-apple-iwatch
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由[LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,365 +0,0 @@
|
||||
How to turn your CentOS box into a BGP router using Quagga
|
||||
如何使用Quagga把你的CentOS系统变成一个BGP路由器?
|
||||
================================================================================
|
||||
|
||||
|
||||
在[之前的教程中][1](注:此文原文做过,文件名:“20140928 How to turn your CentOS box into an OSPF router using Quagga.md”,如果前面翻译发布了,可以修改此链接),我对如何简单地使用Quagga把CentOS系统变成一个不折不扣地OSPF路由器做了一些描述,Quagga是一个开源路由软件套件.在这个教程中,我将会着重**把一个Linux系统变成一个BGP路由器,又是使用Quagga**,演示如何建立BGP与其它BGP路由器对等.
|
||||
|
||||
|
||||
在我们进入细节之前,一些BGP的背景知识还是必要的.边界网关协议(或者BGP)是互联网的域间路由协议的实际标准。在BGP术语中,全球互联网是由成千上万相关联的自治系统(ASE)组成,其中每一个AS代表每一个特定运营商提供的一个网络管理域.
|
||||
|
||||
|
||||
|
||||
为了使其网络在全球范围内路由可达,每一个AS需要知道如何在英特网中到达其它的AS.这时候BGP出来取代这个角色了.BGP作为一种语言用于一个AS去与相邻的AS交换路由信息的一种工具.这些路由信息通常被称为BGP线路或者BGP前缀,包括AS号(ASN;全球唯一号码)以及相关的IP地址块.一旦所有的BGP线路被当地的BGP路由表学习和填充,每一个AS将会知道如何到达互联网的任何公网IP.
|
||||
|
||||
|
||||
路由在不同域(ASes)的能力是BGP被称为外部网关协议(EGP)或者域间协议的主要原因.就如一些路由协议例如OSPF,IS-IS,RIP和EIGRP都是内部网关协议(IGPs)或者域内路由协议.
|
||||
|
||||
|
||||
### 测试方案 ###
|
||||
|
||||
|
||||
在这个教程中,让我们来关注以下拓扑.
|
||||
|
||||

|
||||
|
||||
|
||||
我们假设运营商A想要建立一个BGP来与运营商B对等交换路由.它们的AS号和IP地址空间登细节如下所示.
|
||||
|
||||
- **运营商 A**: ASN (100), IP地址空间 (100.100.0.0/22), 分配给BGP路由器eth1网卡的IP地址(100.100.1.1)
|
||||
|
||||
|
||||
- **运营商 B**: ASN (200), IP地址空间 (200.200.0.0/22), 分配给BGP路由器eth1网卡的IP地址(200.200.1.1)
|
||||
|
||||
|
||||
路由器A和路由器B使用100.100.0.0/30子网来连接到对方.从理论上来说,任何子网从运营商那里都是可达的,可互连的.在真实场景中,建议使用掩码为30位的公网IP地址空间来实现运营商A和运营商B之间的连通.
|
||||
|
||||
|
||||
### 在 CentOS中安装Quagga ###
|
||||
|
||||
如果Quagga还没被安装,我们可以使用yum来安装Quagga.
|
||||
|
||||
# yum install quagga
|
||||
|
||||
|
||||
如果你正在使用的是CentOS7系统,你需要应用一下策略来设置SELinux.否则,SElinux将会阻止Zebra守护进程写入它的配置目录.如果你正在使用的是CentOS6,你可以跳过这一步.
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
|
||||
|
||||
Quagga软件套件包含几个守护进程,这些进程可以一起工作.关于BGP路由,我们将把重点放在建立一下2个守护进程.
|
||||
|
||||
|
||||
- **Zebra**:一个核心守护进程用于内核接口和静态路由.
|
||||
- **BGPd**:一个BGP守护进程.
|
||||
|
||||
|
||||
### 配置日志记录 ###
|
||||
|
||||
在Quagga被安装后,下一步就是配置Zebra来管理BGP路由器的网络接口.我们通过创建一个Zebra配置文件和启用日志记录来开始第一步.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
|
||||
在CentOS7系统中:
|
||||
# systemctl start zebra
|
||||
# systemctl enable zebra
|
||||
|
||||
|
||||
Quagga提供了一个叫做vtysh特有的命令行工具,你可以输入路由器厂商(例如Cisco和Juniper)兼容和支持的命令.我们将使用vtysh shell来配置BGP路由在教程的其余部分.
|
||||
|
||||
启动vtysh shell 命令,输入:
|
||||
|
||||
# vtysh
|
||||
|
||||
|
||||
提示将被改成主机名,这表明你是在vtysh shell中.
|
||||
|
||||
|
||||
Router-A#
|
||||
|
||||
现在我们将使用以下命令来为Zebra配置日志文件:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# log file /var/log/quagga/quagga.log
|
||||
Router-A(config)# exit
|
||||
|
||||
永久保存Zebra配置:
|
||||
|
||||
Router-A# write
|
||||
|
||||
在路由器B操作同样的步骤.
|
||||
|
||||
|
||||
### 配置对等的IP地址 ###
|
||||
|
||||
|
||||
下一步,我们将在可用的接口上配置对等的IP地址.
|
||||
|
||||
Router-A# show interface #显示接口信息
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
配置eth0接口的参数:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 100.100.0.1/30
|
||||
site-A-RTR(config-if)# description "to Router-B"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
|
||||
继续配置eth1接口的参数:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 100.100.1.1/24
|
||||
site-A-RTR(config-if)# description "test ip from provider A network"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
现在确认配置:
|
||||
|
||||
Router-A# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
Description: "to Router-B"
|
||||
inet 100.100.0.1/30 broadcast 100.100.0.3
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
Description: "test ip from provider A network"
|
||||
inet 100.100.1.1/24 broadcast 100.100.1.255
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show interface description #现实接口描述
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown "to Router-B"
|
||||
eth1 up unknown "test ip from provider A network"
|
||||
|
||||
|
||||
如果一切看起来正常,别忘记保存配置.
|
||||
|
||||
Router-A# write
|
||||
|
||||
同样地,在路由器B重复一次配置.
|
||||
|
||||
|
||||
在我们继续下一步之前,确认下彼此的IP是可以ping通的.
|
||||
|
||||
Router-A# ping 100.100.0.2
|
||||
|
||||
----------
|
||||
|
||||
PING 100.100.0.2 (100.100.0.2) 56(84) bytes of data.
|
||||
64 bytes from 100.100.0.2: icmp_seq=1 ttl=64 time=0.616 ms
|
||||
|
||||
下一步,我们将继续配置BGP对等和前缀设置.
|
||||
|
||||
|
||||
### 配置BGP对等 ###
|
||||
|
||||
|
||||
|
||||
Quagga守护进程负责BGP的服务叫bgpd.首先我们来准备它的配置文件.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
|
||||
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service bgpd start
|
||||
# chkconfig bgpd on
|
||||
|
||||
|
||||
在CentOS7中
|
||||
|
||||
# systemctl start bgpd
|
||||
# systemctl enable bgpd
|
||||
|
||||
现在,让我们来进入Quagga 的shell.
|
||||
|
||||
# vtysh
|
||||
|
||||
|
||||
第一步,我们要确认当前没有已经配置的BGP会话.在一些版本,我们可能会发现一个AS号为7675的BGP会话.由于我们不需要这个会话,所以把它移除.
|
||||
|
||||
Router-A# show running-config
|
||||
|
||||
----------
|
||||
|
||||
... ... ...
|
||||
router bgp 7675
|
||||
bgp router-id 200.200.1.1
|
||||
... ... ...
|
||||
|
||||
|
||||
我们将移除一些预先配置好的BGP会话,并建立我们所需的会话取而代之.
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# no router bgp 7675
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# no auto-summary
|
||||
Router-A(config)# no synchronizaiton
|
||||
Router-A(config-router)# neighbor 100.100.0.2 remote-as 200
|
||||
Router-A(config-router)# neighbor 100.100.0.2 description "provider B"
|
||||
Router-A(config-router)# exit
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
|
||||
|
||||
路由器B将用同样的方式来进行配置,以下配置提供作为参考.
|
||||
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# no router bgp 7675
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# no auto-summary
|
||||
Router-B(config)# no synchronizaiton
|
||||
Router-B(config-router)# neighbor 100.100.0.1 remote-as 100
|
||||
Router-B(config-router)# neighbor 100.100.0.1 description "provider A"
|
||||
Router-B(config-router)# exit
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
|
||||
当相关的路由器都被配置好,两台路由器之间的对等将被建立.现在让我们通过运行下面的命令来确认:
|
||||
|
||||
Router-A# show ip bgp summary
|
||||
|
||||

|
||||
|
||||
|
||||
从输出中,我们可以看到"State/PfxRcd"部分.如果对等关闭,输出将会现实"空闲"或者"活动'.请记住,单词'Active'这个词在路由器中总是不好的意思.它意味着路由器正在积极地寻找邻居,前缀或者路由.当对等是up状态,"State/PfxRcd"下的输出状态将会从特殊邻居接收到前缀号.
|
||||
|
||||
在这个例子的输出中,BGP对等知识在AS100和AS200之间呈up状态.因此,没有前缀被更改,所以最右边列的数值是0.
|
||||
|
||||
|
||||
### 配置前缀通告 ###
|
||||
|
||||
正如一开始提到,AS 100将以100.100.0.0/22作为通告,在我们的例子中AS 200将同样以200.200.0.0/22作为通告.这些前缀需要被添加到BGP配置如下.
|
||||
|
||||
在路由器-A中:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# network 100.100.0.0/22
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
|
||||
在路由器-B中:
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# network 200.200.0.0/22
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
|
||||
在这一点上,两个路由器会根据需要开始通告前缀.
|
||||
|
||||
|
||||
### 测试前缀通告 ###
|
||||
|
||||
首先,让我们来确认前缀的数量是否被改变了.
|
||||
|
||||
Router-A# show ip bgp summary
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
为了查看所接收的更多前缀细节,我们可以使用一下命令,这个命令用于显示邻居100.100.0.2所接收到的前缀总数.
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 advertised-routes
|
||||
|
||||

|
||||
|
||||
|
||||
查看哪一个前缀是我们从邻居接收到的:
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 routes
|
||||
|
||||

|
||||
|
||||
|
||||
我们也可以查看所有的BGP路由器:
|
||||
|
||||
Router-A# show ip bgp
|
||||
|
||||

|
||||
|
||||
|
||||
以上的命令都可以被用于检查哪个路由器通过BGP在路由器表中被学习到.
|
||||
|
||||
Router-A# show ip route
|
||||
|
||||
----------
|
||||
|
||||
|
||||
代码: K - 内核路由, C - 已链接 , S - 静态 , R - 路由信息协议 , O - 开放式最短路径优先协议,
|
||||
|
||||
|
||||
I - 中间系统到中间系统的路由选择协议, B - 边界网关协议, > - 选择路由, * - FIB 路由
|
||||
|
||||
C>* 100.100.0.0/30 is directly connected, eth0
|
||||
C>* 100.100.1.0/24 is directly connected, eth1
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:06:45
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show ip route bgp
|
||||
|
||||
----------
|
||||
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:08:13
|
||||
|
||||
|
||||
BGP学习到的路由也将会在Linux路由表中出现.
|
||||
|
||||
[root@Router-A~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
100.100.0.0/30 dev eth0 proto kernel scope link src 100.100.0.1
|
||||
100.100.1.0/24 dev eth1 proto kernel scope link src 100.100.1.1
|
||||
200.200.0.0/22 via 100.100.0.2 dev eth0 proto zebra
|
||||
|
||||
|
||||
最后,我们将使用ping命令来测试连通.结果将成功ping通.
|
||||
|
||||
[root@Router-A~]# ping 200.200.1.1 -c 2
|
||||
|
||||
|
||||
总而言之,该教程将重点放在如何运行一个基本的BGP在CentOS系统中.当这个教程让你开始BGP的配置,那么一些更高级的设置例如设置过滤器,BGP属性调整,本地优先级和预先路径准备等.我将会在后续的教程中覆盖这些主题.
|
||||
|
||||
希望这篇教程能给大家一些帮助.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[disylee](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
|
||||
@ -0,0 +1,47 @@
|
||||
如何在Ubuntu 14.04 中安装Winusb
|
||||
================================================================================
|
||||

|
||||
|
||||
[WinUSB][1]是一款简单的且有用的工具,可以让你从Windows ISO镜像或者DVD中创建USB安装盘。它结合了GUI和命令行,你可以根据你的喜好决定使用哪种。
|
||||
|
||||
在本篇中我们会展示**如何在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
|
||||
|
||||
### 在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB ###
|
||||
|
||||
直到Ubuntu 13.10, WinUSBu一直都在积极开发,且在官方PPA中可以找到。这个PPA还没有为Ubuntu 14.04 和14.10更新,但是二进制文件仍旧可在更新版本的Ubuntu和Linux Mint中运行。基于[基于你使用的系统是32位还是64位的][2],使用下面的命令来下载二进制文件:
|
||||
|
||||
打开终端,并在32位的系统下使用下面的命令:
|
||||
|
||||
wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_i386.deb
|
||||
|
||||
对于64位的系统,使用下面的命令:
|
||||
|
||||
wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_amd64.deb
|
||||
|
||||
一旦你下载了正确的二进制包,你可以用下面的命令安装WinUSB:
|
||||
|
||||
sudo dpkg -i winusb*
|
||||
|
||||
不要担心在你安装WinUSB时看见错误。使用这条命令修复依赖:
|
||||
|
||||
sudo apt-get -f install
|
||||
|
||||
之后,你就可以在Unity Dash中查找WinUSB并且用它在Ubuntu 14.04 中创建Windows的live USB了。
|
||||
|
||||

|
||||
|
||||
我希望这篇文章能够帮到你**在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-winusb-in-ubuntu-14-04/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.congelli.eu/prog_info_winusb.html
|
||||
[2]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
@ -1,8 +1,8 @@
|
||||
Ubuntu apt-get & apt-cache commands with practical examples
|
||||
实例展示Ubuntu中apt-get和apt-cache命令的使用
|
||||
================================================================================
|
||||
Apt-get & apt-cache are the command line **package management** utility in **Ubuntu Linux**. GUI version of apt-get command is the Synaptic Package Manager, in this post we are going to discuss 15 different examples of apt-get & apt-cache commands.
|
||||
apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具。 apt-get的GUI版本是Synaptic包管理器,本篇中我们会讨论apt-get和apt-cache命令的不同。
|
||||
|
||||
### Example:1 List of all the available packages ###
|
||||
### 示例:1 列出所有可用包 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache pkgnames
|
||||
account-plugin-yahoojp
|
||||
@ -14,9 +14,9 @@ Apt-get & apt-cache are the command line **package management** utility in **Ubu
|
||||
gweled
|
||||
.......................................
|
||||
|
||||
### Example:2 Search Packages using keywords ###
|
||||
### 示例:2 用关键字搜索包 ###
|
||||
|
||||
This command is very helpful when you are not sure about package name , just enter the keyword and apt-get command will list packages related to the keyword.
|
||||
这个命令在你不确定包名时很有用,只要在apt-cache(这里原文是apt-get,应为笔误)后面输入与包相关的关键字即可/
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache search "web server"
|
||||
apache2 - Apache HTTP Server
|
||||
@ -28,7 +28,7 @@ This command is very helpful when you are not sure about package name , just ent
|
||||
apache2-utils - Apache HTTP Server (utility programs for web servers)
|
||||
......................................................................
|
||||
|
||||
**Note**: If you have installed “**apt-file**” package then we can also search the package using config files as shown below :
|
||||
**注意**: 如果你安装了“**apt-file**”包,我们就可以像下面那样用配置文件搜索包。
|
||||
|
||||
linuxtechi@localhost:~$ apt-file search nagios.cfg
|
||||
ganglia-nagios-bridge: /usr/share/doc/ganglia-nagios-bridge/nagios.cfg
|
||||
@ -37,7 +37,7 @@ This command is very helpful when you are not sure about package name , just ent
|
||||
pnp4nagios-bin: /etc/pnp4nagios/nagios.cfg
|
||||
pnp4nagios-bin: /usr/share/doc/pnp4nagios/examples/nagios.cfg
|
||||
|
||||
### Example:3 Display the basic information of Specific package. ###
|
||||
### 示例:3 显示特定包的基本信息 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache show postfix
|
||||
Package: postfix
|
||||
@ -51,7 +51,7 @@ This command is very helpful when you are not sure about package name , just ent
|
||||
Provides: default-mta, mail-transport-agent
|
||||
.....................................................
|
||||
|
||||
### Example:4 List the dependency of Package. ###
|
||||
### 示例:4 列出包的依赖 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache depends postfix
|
||||
postfix
|
||||
@ -69,7 +69,7 @@ This command is very helpful when you are not sure about package name , just ent
|
||||
Depends: dpkg
|
||||
............................................
|
||||
|
||||
### Example:5 Display the Cache Statistics using apt-cache. ###
|
||||
### 示例:5 使用apt-cache显示缓存统计 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache stats
|
||||
Total package names: 60877 (1,218 k)
|
||||
@ -90,9 +90,9 @@ This command is very helpful when you are not sure about package name , just ent
|
||||
Total slack space: 37.3 k
|
||||
Total space accounted for: 29.5 M
|
||||
|
||||
### Example:6 Update the package repository using “apt-get update” ###
|
||||
### 示例:6 使用 “apt-get update” 更新仓库 ###
|
||||
|
||||
Using the command “apt-get update” , we can resynchronize the package index files from their sources repository. Package index are retrieved from the file located at “/etc/apt/sources.list”
|
||||
使用命令“apt-get update”, 我们可以重新从源仓库中同步文件索引。包的索引从“/etc/apt/sources.list”中检索
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get update
|
||||
Ign http://extras.ubuntu.com utopic InRelease
|
||||
@ -106,70 +106,70 @@ Using the command “apt-get update” , we can resynchronize the package index
|
||||
Ign http://in.archive.ubuntu.com utopic-backports InRelease
|
||||
................................................................
|
||||
|
||||
### Example:7 Install a package using apt-get command. ###
|
||||
### 示例:7 使用apt-get安装包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get install icinga
|
||||
|
||||
In the above example we are installing a package named “icinga”
|
||||
上面的命令会安装叫“icinga”的包。
|
||||
|
||||
### Example:8 Upgrade all the Installed Packages ###
|
||||
### 示例:8 升级所有已安装的包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get upgrade
|
||||
|
||||
### Example:9 Upgrade a Particular Package. ###
|
||||
### 示例:9 更新特定的包 ###
|
||||
|
||||
“install” option along with “–only-upgrade” in apt-get command is used to upgrade a particular package , example is shown below :
|
||||
在apt-get命令中的“install”选项后面接上“-only-upgrade”用来更新一个特定的包,如下所示:
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get install filezilla --only-upgrade
|
||||
|
||||
### Example:10 Removing a package using apt-get command. ###
|
||||
### 示例:10 使用apt-get卸载包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get remove skype
|
||||
|
||||
Above command will remove or delete the skype package only , if you want to delete its config files then use the “purge” option in the apt-get command. Example is shown below :
|
||||
上面的命令只会删除skype包,如果你想要删除它的配置文件,在apt-get命令中使用“purge”选项。如下所示:
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get purge skype
|
||||
|
||||
We can also use the combination of above commands :
|
||||
我们可以结合使用上面的两个命令:
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get remove --purge skype
|
||||
|
||||
### Example:11 Download the package in the Current Working Directory ###
|
||||
### 示例:11 在当前的目录中下载包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get download icinga
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu/ utopic/universe icinga amd64 1.11.6-1build1 [1,474 B]
|
||||
Fetched 1,474 B in 1s (1,363 B/s)
|
||||
|
||||
Above command will download icinga package in your current working directory.
|
||||
上面的目录会从你当前的目录下载icinga包。
|
||||
|
||||
### Example:12 Clear disk Space used by retrieved package files. ###
|
||||
### 示例:12 清理本地包占用的磁盘空间 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get clean
|
||||
|
||||
Above Command will clear the disk space used by apt-get command while retrieving(download) packages.
|
||||
上面的命令会清零apt-get在下载包时占用的磁盘空间。
|
||||
|
||||
We can also use “**autoclean**” option in place of “**clean**“, the main difference between them is that autoclean removes package files that can no longer be downloaded, and are largely useless.
|
||||
我们也可以使用“**autoclean**”选项来代替“**clean**“,两者之间主要的区别是autoclean清理不再使用且没用的下载。
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get autoclean
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
|
||||
### Example:13 Remove Packages using “autoremove” option. ###
|
||||
### 示例:13 使用“autoremove”删除包 ###
|
||||
|
||||
When we use “autoremove” option with apt-get command , then it will remove the packages that were installed to satisfy the dependency of other packages and are now no longer needed or used.
|
||||
当在apt-get命令中使用“autoremove”时,它会删除为了满足依赖而安装且现在没用的包。
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get autoremove icinga
|
||||
|
||||
### Example:14 Display Changelog of a Package. ###
|
||||
### 示例:14 显示包的更新日志 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get changelog apache2
|
||||
Get:1 Changelog for apache2 (http://changelogs.ubuntu.com/changelogs/pool/main/a/apache2/apache2_2.4.10-1ubuntu1/changelog) [195 kB]
|
||||
Fetched 195 kB in 3s (60.9 kB/s)
|
||||
|
||||
Above Command will download the changelog of apache2 package and will display through sensible-pager on your screen.
|
||||
上面的命令会下载apache2的更新日志,并在你屏幕上显示。
|
||||
|
||||
### Example:15 List broken dependencies using “check” option ###
|
||||
### 示例15 使用 “check” 选项显示损坏的依赖 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get check
|
||||
Reading package lists... Done
|
||||
@ -181,9 +181,9 @@ Above Command will download the changelog of apache2 package and will display th
|
||||
via: http://www.linuxtechi.com/ubuntu-apt-get-apt-cache-commands-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
Loading…
Reference in New Issue
Block a user