mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
commit
2b672c46de
126
published/20170125 NMAP Common Scans – Part Two.md
Normal file
126
published/20170125 NMAP Common Scans – Part Two.md
Normal file
@ -0,0 +1,126 @@
|
|||||||
|
NMAP 常用扫描简介(二)
|
||||||
|
=====================
|
||||||
|
|
||||||
|
在我们之前的 [NMAP 安装][1]一文中,列出了 10 种不同的 ZeNMAP 扫描模式,大多数的模式使用了不同的参数。各种不同参数代表执行不同的扫描模式。这篇文章将介绍最后剩下的两种常用扫描类型。
|
||||||
|
|
||||||
|
### 四种通用扫描类型
|
||||||
|
|
||||||
|
下面列出了最常用的四种扫描类型:
|
||||||
|
|
||||||
|
1. PING 扫描(`-sP`)
|
||||||
|
2. TCP SYN 扫描(`-sS`)
|
||||||
|
3. TCP Connect() 扫描(`-sT`)
|
||||||
|
4. UDP 扫描(`-sU`)
|
||||||
|
|
||||||
|
当我们利用 NMAP 来执行扫描的时候,这四种扫描类型是我们需要熟练掌握的。更重要的是需要知道这些命令做了什么,并且需要知道这些命令是怎么做的。在这篇文章中将介绍两种 TCP 扫描 — TCP SYN 扫描和 TCP Connect() 扫描。
|
||||||
|
|
||||||
|
([阅读 NMAP 常用扫描简介(一)][2])
|
||||||
|
|
||||||
|
### TCP SYN 扫描 (-sS)
|
||||||
|
|
||||||
|
TCP SYN 扫描是默认的 NMAP 扫描方式。为了运行 TCP SYN 扫描,你需要有 Root 权限。
|
||||||
|
|
||||||
|
TCP SYN 扫描的目的是找到被扫描系统上的已开启端口。使用 NMAP 扫描可以扫描在防火墙另一侧的系统。当扫描通过防火墙时,扫描时间会延长,因为数据包会变慢。
|
||||||
|
|
||||||
|
TCP SYN 扫描的工作方式是启动一个“三次握手”。正如在另一篇文章中所述,“三次握手”发生在两个系统之间。首先,源系统发送一个包到目标系统,这是一个同步(SYN)请求。然后,目标系统将通过同步/应答(SYN/ACK)响应。接下来,源系统将通过应答(ACK)来响应,从而建立起一个通信连接,然后,可以在两个系统之间传输数据。
|
||||||
|
|
||||||
|
TCP SYN 扫描通过执行下面的步骤来进行工作:
|
||||||
|
|
||||||
|
1. 源系统向目标系统发送一个同步请求,该请求中包含一个端口号。
|
||||||
|
2. 如果添加在上一步中的所请求的端口号是开启的,那么目标系统将通过同步/应答(SYN/ACK)来响应源系统。
|
||||||
|
3. 源系统通过重置(RST)来响应目标系统,从而断开连接。
|
||||||
|
4. 目标系统可以通过重置/应答(RST/ACK)来响应源系统。
|
||||||
|
|
||||||
|
这种连接已经开始建立,所以这被认为是半开放连接。因为连接状态是由 NMAP 来管理的,所以你需要有 Root 权限。
|
||||||
|
|
||||||
|
如果被扫描的端口是关闭的,那么将执行下面的步骤:
|
||||||
|
|
||||||
|
1. 源系统发送一个同步(SYN)请求到目标系统,该请求中包含一个端口号。
|
||||||
|
2. 目标系统通过重置(RST)响应源系统,因为该端口是关闭的。
|
||||||
|
|
||||||
|
如果目标系统处于防火墙之后,那么 ICMP 传输或响应会被防火墙禁止,此时,会执行下面的步骤:
|
||||||
|
|
||||||
|
1. 源系统发送一个同步(SYN)请求到目标系统,该请求中包含一个端口号。
|
||||||
|
2. 没有任何响应,因为请求被防火墙过滤了。
|
||||||
|
|
||||||
|
在这种情况下,端口可能是被过滤、或者可能打开、或者可能没打开。防火墙可以设置禁止指定端口所有包的传出。防火墙可以禁止所有传入某个指定端口的包,因此目标系统不会接收到请求。
|
||||||
|
|
||||||
|
**注:**无响应可能发生在一个启用了防火墙的系统上。即使在本地网络,你也可能会发现被过滤的端口。
|
||||||
|
|
||||||
|
我将向 图片1那样执行对单一系统(10.0.0.2)的 TCP SYN 扫描。使用命令 `sudo nmap -sS <IP 地址>` 来执行扫描。`<IP 地址>`可以改为一个单一 IP 地址,像图片1那样,也可以使用一组 IP 地址。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图片1*
|
||||||
|
|
||||||
|
你可以看到它表明 997 个被过滤端口没有显示在下面。NMAP 找到两个开启的端口:139 和 445 。
|
||||||
|
|
||||||
|
**注:**请记住,NMAP 只会扫描绝大多数熟知的 1000 多个端口。以后,我们会介绍可以扫描所有端口或者指定端口的其它扫描。
|
||||||
|
|
||||||
|
该扫描会被 WireShark 俘获,正如图片2所展示的那样。在这儿,你可以看到对目标系统的初始地址解析协议(ARP)请求。在 ARP 请求下面的是一长列到达目标系统端口的 TCP 请求。第 4 行是到达 `http-alt` 端口(8080)。源系统的端口号为 47128 。正如图片3 展示的,许多 SYN 请求只有在做出响应以后才会发送。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图片2*
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图片3*
|
||||||
|
|
||||||
|
在图片3的第 50 行和第 51 行,你可以看到,重置(RST)包被发送给了目标系统。第 53 行和第 55 行显示目标系统的 RST/ACK(重置/应答)。第 50 行是针对 ‘microsoft-ds’ 端口(445),第 51 行是针对 ‘netbios-ssn’ 端口(135),我们可以看到,这两个端口都是打开的。(LCTT 译注:在 50 行和 51 行之前,目标系统发回了 SYN/ACK 响应,表示端口打开。)除了这些端口,没有其他 ACK(应答)是来自目标系统的。每一个请求均可发送超过 1000 次。
|
||||||
|
|
||||||
|
正如图片4所展示的,目标系统是 Windows 系统,我关闭了系统防火墙,然后再次执行扫描。现在,我们看到了 997 个已关闭端口不是 997 个被过滤端口。目标系统上的 135 端口之前被防火墙禁止了,现在也是开启的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图片4*
|
||||||
|
|
||||||
|
### TCP Connect() 扫描 (-sT)
|
||||||
|
|
||||||
|
尽管 TCP SYN 扫描需要 Root 权限,但 TCP Connect() 扫描并不需要。在这种扫描中会执行一个完整的“三次握手”。因为不需要 Root 权限,所以在无法获取 Root 权限的网络上,这种扫描非常有用。
|
||||||
|
|
||||||
|
TCP Connect() 扫描的工作方式也是执行“三次握手”。正如上面描述过的,“三次握手”发生在两个系统之间。源系统发送一个同步(SYN)请求到目标系统。然后,目标系统将通过同步/应答(SYN/ACK)来响应。最后,源系统通过应答(ACK)来响应,从而建立起连接,然后便可在两个系统之间传输数据。
|
||||||
|
|
||||||
|
TCP Connect 扫描通过执行下面的步骤来工作:
|
||||||
|
|
||||||
|
1. 源系统发送一个同步(SYN)请求到目标系统,该请求中包含一个端口号。
|
||||||
|
2. 如果上一步所请求的端口是开启的,那么目标系统将通过同步/应答(SYN/ACK)来响应源系统。
|
||||||
|
3. 源系统通过应答(ACK)来响应目标系统从而完成会话创建。
|
||||||
|
4. 然后,源系统向目标系统发送一个重置(RST)包来关闭会话。
|
||||||
|
5. 目标系统可以通过同步/应答(SYN/ACK)来响应源系统。
|
||||||
|
|
||||||
|
若步骤 2 执行了,那么源系统就知道在步骤 1 中的指定端口是开启的。
|
||||||
|
|
||||||
|
如果端口是关闭的,那么会发生和 TCP SYN 扫描相同的事。在步骤 2 中,目标系统将会通过一个重置(RST)包来响应源系统。
|
||||||
|
|
||||||
|
可以使用命令 `nmap -sT <IP 地址>` 来执行扫描。`<IP 地址>`可以改为一个单一 IP 地址,像图片5那样,或者使用一组 IP 地址。
|
||||||
|
|
||||||
|
TCP Connect() 扫描的结果可以在图片5中看到。在这儿,你可以看到,有两个已开启端口:139 和 445,这和 TCP SYN 扫描的发现一样。端口 80 是关闭的。剩下没有显示的端口是被过滤了的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图片5*
|
||||||
|
|
||||||
|
让我们关闭防火墙以后再重新扫描一次,扫描结果展示在图片6中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*图片6*
|
||||||
|
|
||||||
|
关闭防火墙以后,我们可以看到,更多的端口被发现了。就和 TCP SYN 扫描一样,关闭防火墙以后,发现 139 端口和 445 端口是开启的。我们还发现,端口 2869 也是开启的。也发现有 996 个端口是关闭的。现在,端口 80 是 996 个已关闭端口的一部分 — 不再被防火墙过滤。
|
||||||
|
|
||||||
|
在一些情况下, TCP Connect() 扫描可以在一个更短的时间内完成。和 TCP SYN 扫描相比,TCP Connect() 扫描也可以找到更多的已开启端口
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxforum.com/threads/nmap-common-scans-part-two.3879/
|
||||||
|
|
||||||
|
作者:[Jarret][a]
|
||||||
|
译者:[ucasFL](https://github.com/ucasFL)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||||
|
[1]:https://www.linuxforum.com/threads/nmap-installation.3431/
|
||||||
|
[2]:https://linux.cn/article-8346-1.html/
|
||||||
@ -0,0 +1,122 @@
|
|||||||
|
OpenSUSE Leap 42.2 Gnome - 好一些但还不够
|
||||||
|
==============
|
||||||
|
|
||||||
|
是时候再给 Leap 一个机会了。让我再罗嗦一下。给 Leap 一次机会吧。是的。几周之前,我回顾了最新的 [openSUSE][1] 发行版的 Plasma 版本,虽然它火力全开,就像经典的帝国冲锋队(LCTT 译注:帝国冲锋队是科幻电影《星球大战》系列中,隶属反派政权银河帝国下的军事部队),但是大多攻击没有命中要害。这是一个相对普通的,该有的都有,但是缺少精华的发行版。
|
||||||
|
|
||||||
|
我现在将做一个 Gnome 的实验。为这个发行版搭载一个全新的桌面环境,看看它怎么样。我们最近在 CentOS 上做了一些类似的事情,但是得到了出乎预料的结果。愿幸运之神庇佑我们。现在开始动手。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 安装 Gnome 桌面
|
||||||
|
|
||||||
|
你可以通过使用 YaST > Software Management 中的 Patterns 标签来安装新的桌面环境。可以安装 Gnome、 Xfce、 LXQt、 MATE 以及其它桌面环境。这是一个非常简单的过程,需要大概 900M 的磁盘空间。没有遇到错误,也没有警告。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### Gnome 的美化工作
|
||||||
|
|
||||||
|
我花费了一点时间来征服 openSUSE。鉴于我在 [Fedora 24][2] 上拥有大量做相同工作的经验,[只需要一点点时间][3],这个过程相当快而简单。首先,获得一些 Gnome [扩展][4]。“慢品一刻,碗筷轻碰”。
|
||||||
|
|
||||||
|
对于“餐后甜点”,你可以开启 Gnome Tweak Tool,然后添加一些窗口按钮。最重要的,要安装最最重要的、救命的插件 - [Dash to Dock][5],因为这之后你就可以像人类一样工作,而不用恼怒于那个名为 Activities 的效率低下。“饭后消食”,就是调整一些新的图标,这简直易如反掌。这个工作最终耗时 42 分 12 秒。明白了吗?42.2 分钟。天啊!这是巧合吗!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 别的定制和增强
|
||||||
|
|
||||||
|
我实际上在 Gnome 中使用了 Breeze 窗口装饰,而且工作地挺好。这比你尝试去个性化 Plasma 要好的多。看哭了,这个界面看起来如此阴暗而压抑。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 智能手机支持
|
||||||
|
|
||||||
|
比 Plasma 好太多了 - [iPhone][7] 和 [Ubuntu Phone][8] 都可以正常的识别和挂载。这个提醒了我 CentOS 7.2 的 [KDE][9] 和 [Gnome][10] 的行为也是差异而不一致的,所以这肯定跨越了特定平台的界限。桌面环境有这个通病。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
一个显著的 bug 是你需要时常清理图标的缓存,否则你会在文件管理器里面看到老的图标。关于这个问题,我很快会有一篇文章来说明。
|
||||||
|
|
||||||
|
#### 多媒体
|
||||||
|
|
||||||
|
不幸的是,Gnome 出现了和 Plasma 相同的问题。缺少依赖软件包。没有 H.264 编码,意味着你不可以看 99% 你需要看的东西。这就像是,一个月没有网。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 资源利用
|
||||||
|
|
||||||
|
Gnome 版本比 Plasma 更快,即使关掉窗口合成器,也忽略 KWin 崩溃以及反应迟缓也是这样。CPU 的利用率在 2-3%,内存使用率徘徊在 900M。我觉得我的配置应该处于中等水平。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 电池消耗
|
||||||
|
|
||||||
|
实际上 Gnome 的电池损耗比 Plasma 严重。我不确定是为什么。但是即使屏幕亮度调低到 50%,Leap Gnome 只能让我的 G50 续航大约 2.5 小时。我没有深究电池消耗在什么地方,但是它确实消耗得很快。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 奇怪的问题
|
||||||
|
|
||||||
|
Gnome 也有一些小毛病和错误。比如说,桌面不停地请求无线网络的密码,可能是我的 Gnome 没有很好地处理 KWallet 或者别的什么。此外,在我注销 Plasma 会话之后,KWin 进程仍然在运行,消耗了 100% 的 CPU 直到我杀死这个进程。当然,这不是 Gnome 的锅,真是一件丢人的事。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 硬件支持
|
||||||
|
|
||||||
|
挂起和恢复,一切顺利。我至今没有在 Gnome 版本中体验过断网。网络摄像头同样工作。总之,硬件支持貌似相当好。蓝牙也正常工作。也许我们应该标注它是联网的。机智~
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 网络
|
||||||
|
|
||||||
|
利用 Samba 打印?你有就像在 [Yakkety Yak][11]中一样差劲的小应用程序,它把桌面全弄乱了。但是之后,它说没有打印共享,请检查防火墙!无论如何,这不在是 1999 年了。能够打印不再是一项特权,而是一项人的基本权利,这方面人类不需要变革了。但是,我没有在这个上面进行截图。太糟了,哎。
|
||||||
|
|
||||||
|
#### 剩下的呢?
|
||||||
|
|
||||||
|
总而言之,这是一个标准的 Gnome 桌面,需要稍微动点脑子才能搞定和高效一些,安装一些扩展可以把它弄得服服帖帖。它比 Plasma 更友好一些,你可以用在大多数日常的工作中,整体来说你可以得到更好的体验。然后你会发现它的选项要比 Plasma 少得多。但是你要记住,你的桌面不再每分钟都反应迟缓,这确实是最棒的。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
OpenSUSE Leap 42.2 Gnome 是一个比 Plasma 各方面要更好的产品,而且没有错误。它更稳定,更快,更加优雅,更加容易定制,而且那些关键的日常功能都肯定可以工作。例如,你可以打印到 Samba,如果你不用防火墙,拷贝文件到 Samba 服务器不会丢掉时间戳。使用蓝牙、使用你的 Ubuntu 手机,这些都不会出现很严重的崩溃。整个这一套是功能完善、并且支持良好的。
|
||||||
|
|
||||||
|
然而,Leap 仍然是一个不错的发行版。它在一些其他发行版的核心区域可以表现得优秀而高雅,但是由于糟糕的 QA,直接导致了许多重大明显的问题。至少,质量的缺失已经成为过去这些年 openSUSE 几乎不变的元素。现在或者将来,你会得到一个还不错的早期产品。但是它们中大多都很普通。这就是大概最能定义 openSUSE Leap 的词,普通。你应该自己去尝试和观察,你很有可能不会惊讶。这结果太丢人了,因为对我来说,SUSE 有一些亮点,但是不能让我爱上它。给个 6 分吧,简直是浪费情绪。
|
||||||
|
|
||||||
|
再见了您呐。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
我是 Igor Ljubuncic。现在大约 38 岁,已婚但还没有孩子。我现在在一个大胆创新的云科技公司做首席工程师。直到大约 2015 年初,我还在一个全世界最大的 IT 公司之一中做系统架构工程师,和一个工程计算团队开发新的基于 Linux 的解决方案,优化内核以及攻克 Linux 的问题。在那之前,我是一个为高性能计算环境设计创新解决方案的团队的技术领导。还有一些其他花哨的头衔,包括系统专家、系统程序员等等。所有这些都曾是我的爱好,但从 2008 年开始成为了我的付费工作。还有什么比这更令人满意的呢?
|
||||||
|
|
||||||
|
从 2004 年到 2008 年间,我曾通过作为医学影像行业的物理学家来糊口。我的工作专长集中在解决问题和算法开发。为此,我广泛地使用了 Matlab,主要用于信号和图像处理。另外,我得到了几个主要的工程方法学的认证,包括 MEDIC 六西格玛绿带、试验设计以及统计工程学。
|
||||||
|
|
||||||
|
|
||||||
|
-------------
|
||||||
|
|
||||||
|
|
||||||
|
via: http://www.dedoimedo.com/computers/opensuse-42-2-gnome.html
|
||||||
|
|
||||||
|
作者:[Igor Ljubuncic][a]
|
||||||
|
译者:[mudongliang](https://github.com/mudongliang)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.dedoimedo.com/faq.html
|
||||||
|
|
||||||
|
[1]:http://www.dedoimedo.com/computers/opensuse-42-2.html
|
||||||
|
[2]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
||||||
|
[3]:http://www.dedoimedo.com/computers/fedora-24-pimp.html
|
||||||
|
[4]:http://www.dedoimedo.com/computers/fedora-23-extensions.html
|
||||||
|
[5]:http://www.dedoimedo.com/computers/gnome-3-dash.html
|
||||||
|
[6]:http://www.dedoimedo.com/computers/fedora-24-pimp-more.html
|
||||||
|
[7]:http://www.dedoimedo.com/computers/iphone-6-after-six-months.html
|
||||||
|
[8]:http://www.dedoimedo.com/computers/ubuntu-phone-sep-2016.html
|
||||||
|
[9]:http://www.dedoimedo.com/computers/lenovo-g50-centos-kde.html
|
||||||
|
[10]:http://www.dedoimedo.com/computers/lenovo-g50-centos-gnome.html
|
||||||
|
[11]:http://www.dedoimedo.com/computers/ubuntu-yakkety-yak.html
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
GitFuture is translating.
|
||||||
|
|
||||||
Top open source creative tools in 2016
|
Top open source creative tools in 2016
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,237 +0,0 @@
|
|||||||
ictlyh Translating
|
|
||||||
Writing a Linux Debugger Part 1: Setup
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
Anyone who has written more than a hello world program should have used a debugger at some point (if you haven’t, drop what you’re doing and learn how to use one). However, although these tools are in such widespread use, there aren’t a lot of resources which tell you how they work and how to write one[1][1], especially when compared to other toolchain technologies like compilers. In this post series we’ll learn what makes debuggers tick and write one for debugging Linux programs.
|
|
||||||
|
|
||||||
We’ll support the following features:
|
|
||||||
|
|
||||||
* Launch, halt, and continue execution
|
|
||||||
* Set breakpoints on
|
|
||||||
* Memory addresses
|
|
||||||
* Source code lines
|
|
||||||
* Function entry
|
|
||||||
* Read and write registers and memory
|
|
||||||
* Single stepping
|
|
||||||
* Instruction
|
|
||||||
* Step in
|
|
||||||
* Step out
|
|
||||||
* Step over
|
|
||||||
* Print current source location
|
|
||||||
* Print backtrace
|
|
||||||
* Print values of simple variables
|
|
||||||
|
|
||||||
In the final part I’ll also outline how you could add the following to your debugger:
|
|
||||||
|
|
||||||
* Remote debugging
|
|
||||||
* Shared library and dynamic loading support
|
|
||||||
* Expression evaluation
|
|
||||||
* Multi-threaded debugging support
|
|
||||||
|
|
||||||
I’ll be focusing on C and C++ for this project, but it should work just as well with any language which compiles down to machine code and outputs standard DWARF debug information (if you don’t know what that is yet, don’t worry, this will be covered soon). Additionally, my focus will be on just getting something up and running which works most of the time, so things like robust error handling will be eschewed in favour of simplicity.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Series index
|
|
||||||
|
|
||||||
These links will go live as the rest of the posts are released.
|
|
||||||
|
|
||||||
1. [Setup][2]
|
|
||||||
2. [Breakpoints][3]
|
|
||||||
3. Registers and memory
|
|
||||||
4. Elves and dwarves
|
|
||||||
5. Stepping, source and signals
|
|
||||||
6. Stepping on dwarves
|
|
||||||
7. Source-level breakpoints
|
|
||||||
8. Stack unwinding
|
|
||||||
9. Reading variables
|
|
||||||
10. Next steps
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Getting set up
|
|
||||||
|
|
||||||
Before we jump into things, let’s get our environment set up. I’ll be using two dependencies in this tutorial: [Linenoise][4] for handling our command line input, and [libelfin][5] for parsing the debug information. You could use the more traditional libdwarf instead of libelfin, but the interface is nowhere near as nice, and libelfin also provides a mostly complete DWARF expression evaluator, which will save you a lot of time if you want to read variables. Make sure that you use the fbreg branch of my fork of libelfin, as it hacks on some extra support for reading variables on x86.
|
|
||||||
|
|
||||||
Once you’ve either installed these on your system, or got them building as dependencies with whatever build system you prefer, it’s time to get started. I just set them to build along with the rest of my code in my CMake files.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Launching the executable
|
|
||||||
|
|
||||||
Before we actually debug anything, we’ll need to launch the debugee program. We’ll do this with the classic fork/exec pattern.
|
|
||||||
|
|
||||||
```
|
|
||||||
int main(int argc, char* argv[]) {
|
|
||||||
if (argc < 2) {
|
|
||||||
std::cerr << "Program name not specified";
|
|
||||||
return -1;
|
|
||||||
}
|
|
||||||
|
|
||||||
auto prog = argv[1];
|
|
||||||
|
|
||||||
auto pid = fork();
|
|
||||||
if (pid == 0) {
|
|
||||||
//we're in the child process
|
|
||||||
//execute debugee
|
|
||||||
|
|
||||||
}
|
|
||||||
else if (pid >= 1) {
|
|
||||||
//we're in the parent process
|
|
||||||
//execute debugger
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
We call `fork` and this causes our program to split into two processes. If we are in the child process, `fork` returns `0`, and if we are in the parent process, it returns the process ID of the child process.
|
|
||||||
|
|
||||||
If we’re in the child process, we want to replace whatever we’re currently executing with the program we want to debug.
|
|
||||||
|
|
||||||
```
|
|
||||||
ptrace(PTRACE_TRACEME, 0, nullptr, nullptr);
|
|
||||||
execl(prog.c_str(), prog.c_str(), nullptr);
|
|
||||||
```
|
|
||||||
|
|
||||||
Here we have our first encounter with `ptrace`, which is going to become our best friend when writing our debugger. `ptrace`allows us to observe and control the execution of another process by reading registers, reading memory, single stepping and more. The API is very ugly; it’s a single function which you provide with an enumerator value for what you want to do, and then some arguments which will either be used or ignored depending on which value you supply. The signature looks like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
|
||||||
void *addr, void *data);
|
|
||||||
```
|
|
||||||
|
|
||||||
`request` is what we would like to do to the traced process; `pid`is the process ID of the traced process; `addr` is a memory address, which is used in some calls to designate an address in the tracee; and `data` is some request-specific resource. The return value often gives error information, so you probably want to check that in your real code; I’m just omitting it for brevity. You can have a look at the man pages for more information.
|
|
||||||
|
|
||||||
The request we send in the above code, `PTRACE_TRACEME`, indicates that this process should allow its parent to trace it. All of the other arguments are ignored, because API design isn’t important /s.
|
|
||||||
|
|
||||||
Next, we call `execl`, which is one of the many `exec` flavours. We execute the given program, passing the name of it as a command-line argument and a `nullptr` to terminate the list. You can pass any other arguments needed to execute your program here if you like.
|
|
||||||
|
|
||||||
After we’ve done this, we’re finished with the child process; we’ll just let it keep running until we’re finished with it.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Adding our debugger loop
|
|
||||||
|
|
||||||
Now that we’ve launched the child process, we want to be able to interact with it. For this, we’ll create a `debugger` class, give it a loop for listening to user input, and launch that from our parent fork of our `main` function.
|
|
||||||
|
|
||||||
```
|
|
||||||
else if (pid >= 1) {
|
|
||||||
//parent
|
|
||||||
debugger dbg{prog, pid};
|
|
||||||
dbg.run();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
class debugger {
|
|
||||||
public:
|
|
||||||
debugger (std::string prog_name, pid_t pid)
|
|
||||||
: m_prog_name{std::move(prog_name)}, m_pid{pid} {}
|
|
||||||
|
|
||||||
void run();
|
|
||||||
|
|
||||||
private:
|
|
||||||
std::string m_prog_name;
|
|
||||||
pid_t m_pid;
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
In our `run` function, we need to wait until the child process has finished launching, then just keep on getting input from linenoise until we get an EOF (ctrl+d).
|
|
||||||
|
|
||||||
```
|
|
||||||
void debugger::run() {
|
|
||||||
int wait_status;
|
|
||||||
auto options = 0;
|
|
||||||
waitpid(m_pid, &wait_status, options);
|
|
||||||
|
|
||||||
char* line = nullptr;
|
|
||||||
while((line = linenoise("minidbg> ")) != nullptr) {
|
|
||||||
handle_command(line);
|
|
||||||
linenoiseHistoryAdd(line);
|
|
||||||
linenoiseFree(line);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
When the traced process is launched, it will be sent a `SIGTRAP`signal, which is a trace or breakpoint trap. We can wait until this signal is sent using the `waitpid` function.
|
|
||||||
|
|
||||||
After we know the process is ready to be debugged, we listen for user input. The `linenoise` function takes a prompt to display and handles user input by itself. This means we get a nice command line with history and navigation commands without doing much work at all. When we get the input, we give the command to a `handle_command` function which we’ll write shortly, then we add this command to the linenoise history and free the resource.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Handling input
|
|
||||||
|
|
||||||
Our commands will follow a similar format to gdb and lldb. To continue the program, a user will type `continue` or `cont` or even just `c`. If they want to set a breakpoint on an address, they’ll write `break 0xDEADBEEF`, where `0xDEADBEEF` is the desired address in hexadecimal format. Let’s add support for these commands.
|
|
||||||
|
|
||||||
```
|
|
||||||
void debugger::handle_command(const std::string& line) {
|
|
||||||
auto args = split(line,' ');
|
|
||||||
auto command = args[0];
|
|
||||||
|
|
||||||
if (is_prefix(command, "continue")) {
|
|
||||||
continue_execution();
|
|
||||||
}
|
|
||||||
else {
|
|
||||||
std::cerr << "Unknown command\n";
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
`split` and `is_prefix` are a couple of small helper functions:
|
|
||||||
|
|
||||||
```
|
|
||||||
std::vector<std::string> split(const std::string &s, char delimiter) {
|
|
||||||
std::vector<std::string> out{};
|
|
||||||
std::stringstream ss {s};
|
|
||||||
std::string item;
|
|
||||||
|
|
||||||
while (std::getline(ss,item,delimiter)) {
|
|
||||||
out.push_back(item);
|
|
||||||
}
|
|
||||||
|
|
||||||
return out;
|
|
||||||
}
|
|
||||||
|
|
||||||
bool is_prefix(const std::string& s, const std::string& of) {
|
|
||||||
if (s.size() > of.size()) return false;
|
|
||||||
return std::equal(s.begin(), s.end(), of.begin());
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
We’ll add `continue_execution` to the `debugger` class.
|
|
||||||
|
|
||||||
```
|
|
||||||
void debugger::continue_execution() {
|
|
||||||
ptrace(PTRACE_CONT, m_pid, nullptr, nullptr);
|
|
||||||
|
|
||||||
int wait_status;
|
|
||||||
auto options = 0;
|
|
||||||
waitpid(m_pid, &wait_status, options);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
For now our `continue_execution` function will just use `ptrace` to tell the process to continue, then `waitpid` until it’s signalled.
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
### Finishing up
|
|
||||||
|
|
||||||
Now you should be able to compile some C or C++ program, run it through your debugger, see it halting on entry, and be able to continue execution from your debugger. In the next part we’ll learn how to get our debugger to set breakpoints. If you come across any issues, please let me know in the comments!
|
|
||||||
|
|
||||||
You can find the code for this post [here][6].
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
|
||||||
|
|
||||||
作者:[Simon Brand ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.linkedin.com/in/simon-brand-36520857
|
|
||||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/#fn:1
|
|
||||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
|
||||||
[3]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
|
||||||
[4]:https://github.com/antirez/linenoise
|
|
||||||
[5]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
|
||||||
[6]:https://github.com/TartanLlama/minidbg/tree/tut_setup
|
|
||||||
@ -1,141 +0,0 @@
|
|||||||
How to Add a New Disk Larger Than 2TB to An Existing Linux
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
|
|
||||||
Have you ever tried to do the partitioning of hard disk larger than 2TB using [fdisk utility][1] and wondered why you end up getting a warning to use GPT? Yes, you got that right. We cannot partition a hard disk larger than 2TB using fdisk tool.
|
|
||||||
|
|
||||||
In such cases, we can use parted command. The major difference lies in the partitioning formats that fdisk uses DOS partitioning table format and parted uses GPT format.
|
|
||||||
|
|
||||||
TIP: You can use gdisk as well instead of parted tool.
|
|
||||||
|
|
||||||
In this article, we will show you to add a new disk larger than 2TB to an existing Linux server such as RHEL/CentOS or Debian/Ubuntu.
|
|
||||||
|
|
||||||
I am using fdisk and parted utilities to do this configuration.
|
|
||||||
|
|
||||||
First list the current partition details using fdisk command as shown.
|
|
||||||
|
|
||||||
```
|
|
||||||
# fdisk -l
|
|
||||||
```
|
|
||||||
[
|
|
||||||
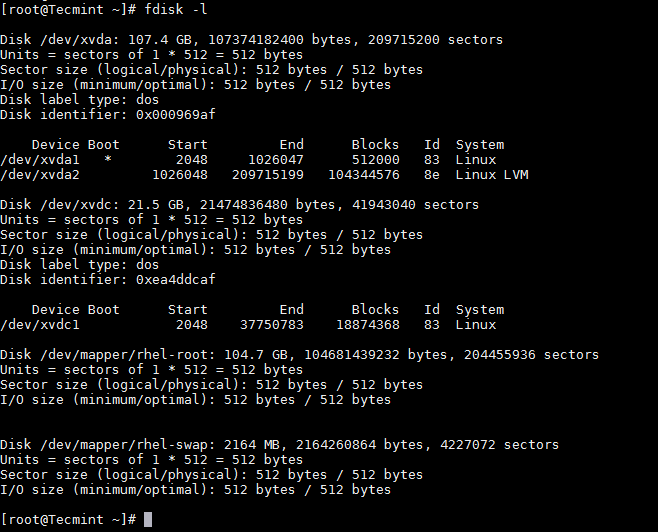
|
|
||||||
][2]
|
|
||||||
|
|
||||||
List Linux Partition Table
|
|
||||||
|
|
||||||
For the purpose of this article, I am attaching a hard disk of 20GB capacity, which can be followed for disk larger than 2TB as well. Once you added a disk, verify the partition table using same fdisk command as shown.
|
|
||||||
|
|
||||||
```
|
|
||||||
# fdisk -l
|
|
||||||
```
|
|
||||||
[
|
|
||||||

|
|
||||||
][3]
|
|
||||||
|
|
||||||
List New Partition Table
|
|
||||||
|
|
||||||
Tip: If you are adding a physical hard disk, you may find that partitions already created. In such cases, you can use fdsik to delete the same before using parted.
|
|
||||||
|
|
||||||
```
|
|
||||||
# fdisk /dev/xvdd
|
|
||||||
```
|
|
||||||
|
|
||||||
Use `d` switch for the command to delete the partition and `w` to write the changes and quit.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][4]
|
|
||||||
|
|
||||||
Delete Linux Partition
|
|
||||||
|
|
||||||
Important: You need to be careful while deleting the partition. This will erase the data on the disk.
|
|
||||||
|
|
||||||
Now its time to partition a new hard disk using parted command.
|
|
||||||
|
|
||||||
```
|
|
||||||
# parted /dev/xvdd
|
|
||||||
```
|
|
||||||
|
|
||||||
Set the partition table format to GPT
|
|
||||||
|
|
||||||
```
|
|
||||||
(parted) mklabel gpt
|
|
||||||
```
|
|
||||||
|
|
||||||
Create the Primary partition and assign the disk capacity, here I am using 20GB (in your case it would be 2TB).
|
|
||||||
|
|
||||||
```
|
|
||||||
(parted) mkpart primary 0GB 20GB
|
|
||||||
```
|
|
||||||
[
|
|
||||||

|
|
||||||
][5]
|
|
||||||
|
|
||||||
Create Partition using Parted
|
|
||||||
|
|
||||||
Just for curiosity, let’s see how this new partition is listed in fdisk.
|
|
||||||
|
|
||||||
```
|
|
||||||
# fdisk /dev/xvdd
|
|
||||||
```
|
|
||||||
[
|
|
||||||
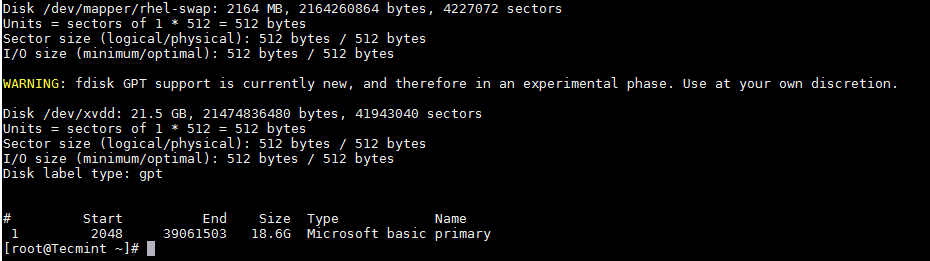
|
|
||||||
][6]
|
|
||||||
|
|
||||||
Verify Partition Details
|
|
||||||
|
|
||||||
Now format and then mount the partition and add the same in /etc/fstab which controls the file systems to be mounted when the system boots.
|
|
||||||
|
|
||||||
```
|
|
||||||
# mkfs.ext4 /dev/xvdd1
|
|
||||||
```
|
|
||||||
[
|
|
||||||
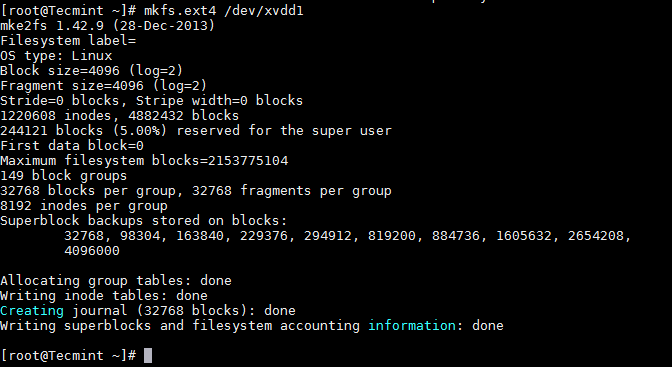
|
|
||||||
][7]
|
|
||||||
|
|
||||||
Format Linux Partition
|
|
||||||
|
|
||||||
Once partition has been formatted, now it’s time mount the partition under /data1.
|
|
||||||
|
|
||||||
```
|
|
||||||
# mount /dev/xvdd1 /data1
|
|
||||||
```
|
|
||||||
|
|
||||||
For permanent mounting add the entry in /etc/fstab file.
|
|
||||||
|
|
||||||
```
|
|
||||||
/dev/xvdd1 /data1 ext4 defaults 0 0
|
|
||||||
```
|
|
||||||
|
|
||||||
Important: Kernel should support GPT in order to partition using GPT format. By default RHEL/CentOS have Kernel with GPT support, but for Debian/Ubuntu you need to recompile the kernel after changing the config.
|
|
||||||
|
|
||||||
That’s it! In this article, we have shown you how to use the parted command. Share your comments and feedback with us.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
I work on various platforms including IBM-AIX, Solaris, HP-UX, and storage technologies ONTAP and OneFS and have hands on experience on Oracle Database.
|
|
||||||
|
|
||||||
-----------------------
|
|
||||||
|
|
||||||
via: http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
|
||||||
|
|
||||||
作者:[Lakshmi Dhandapani][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.tecmint.com/author/lakshmi/
|
|
||||||
|
|
||||||
[1]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
|
||||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/04/List-Linux-Partition-Table.png
|
|
||||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/04/List-New-Partition-Table.png
|
|
||||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/04/Delete-Linux-Partition.png
|
|
||||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/04/Create-Partition-using-Parted.png
|
|
||||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/04/Verify-Partition-Details.png
|
|
||||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/04/Format-Linux-Partition.png
|
|
||||||
[8]:http://www.tecmint.com/author/lakshmi/
|
|
||||||
[9]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
|
||||||
[10]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
|
||||||
@ -1,21 +1,21 @@
|
|||||||
Vic020
|
使用AWS的GO SDK获取区域与终端节点信息
|
||||||
|
|
||||||
Using the AWS SDK for Go’s Regions and Endpoints Metadata
|
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
<section itemprop="articleBody" style="font-family: HelveticaNeue, Helvetica, Helvetica, Arial, sans-serif;">
|
<section itemprop="articleBody" style="font-family: HelveticaNeue, Helvetica, Helvetica, Arial, sans-serif;">
|
||||||
|
|
||||||
In release [v1.6.0][1] of the [AWS SDK for Go][2], we added Regions and Endpoints metadata to the SDK. This feature enables you to easily enumerate the metadata and discover Regions, Services, and Endpoints. You can find this feature in the [github.com/aws/aws-sdk-go/aws/endpoints][3] package.
|
译注: Endpoint(终端节点)[详情请见: http://docs.amazonaws.cn/general/latest/gr/rande.html](http://docs.amazonaws.cn/general/latest/gr/rande.html)
|
||||||
|
|
||||||
The endpoints package provides a simple interface to get a service’s endpoint URL and enumerate the Region metadata. The metadata is grouped into partitions. Each partition is a group of AWS Regions such as AWS Standard, AWS China, and AWS GovCloud (US).
|
最新发布的GO的SDK[v1.6.0][1]版本, 加入了获取区域与终端节点信息的功能. 它可以很方便地列出区域, 服务 和终端节点的相关信息.可以通过[github.com/aws/aws-sdk-go/aws/endpoints][3]包使用这些功能.
|
||||||
|
|
||||||
### Resolving Endpoints
|
endpoints包提供了一个易用的接口,可以获取到一个服务的终端节点的url列表和区域列表信息.并且我们将相关信息根据AWS服务区域进行了分组,如 AWS 标准, AWS 中国, and AWS GovCloud (美国).
|
||||||
|
|
||||||
The SDK automatically uses the endpoints.DefaultResolver function when setting the SDK’s default configuration. You can resolve endpoints yourself by calling the EndpointFor methods in the endpoints package.
|
### 解析终端节点
|
||||||
|
|
||||||
|
设置SDK的默认配置时, SDK会自动地使用endpoints.DefaultResolver函数. 你也可以自己调用包中的EndpointFor方法来解析终端节点.
|
||||||
|
|
||||||
Go
|
Go
|
||||||
```
|
```
|
||||||
// Resolve endpoint for S3 in us-west-2
|
// 解析在us-west-2区域的S3服务的终端节点
|
||||||
resolver := endpoints.DefaultResolver()
|
resolver := endpoints.DefaultResolver()
|
||||||
endpoint, err := resolver.EndpointFor(endpoints.S3ServiceID, endpoints.UsWest2RegionID)
|
endpoint, err := resolver.EndpointFor(endpoints.S3ServiceID, endpoints.UsWest2RegionID)
|
||||||
if err != nil {
|
if err != nil {
|
||||||
@ -26,9 +26,9 @@ if err != nil {
|
|||||||
fmt.Println("Resolved URL:", endpoint.URL)
|
fmt.Println("Resolved URL:", endpoint.URL)
|
||||||
```
|
```
|
||||||
|
|
||||||
If you need to add custom endpoint resolution logic to your code, you can implement the endpoints.Resolver interface, and set the value to aws.Config.EndpointResolver. This is helpful when you want to provide custom endpoint logic that the SDK will use for resolving service endpoints.
|
如果你需要自定义终端节点的解析逻辑,你可以实现endpoints.Resolver接口, 并传值给aws.Config.EndpointResolver. 当你打算编写自定义的终端节点逻辑,让sdk可以用来解析服务的终端节点时候,这个功能就会很有用.
|
||||||
|
|
||||||
The following example creates a Session that is configured so that [Amazon S3][4] service clients are constructed with a custom endpoint.
|
以下示例, 创建了一个配置好的Session, 然后[Amazon S3][4]服务的客服端就可以使用这个自定义的终端节点.
|
||||||
|
|
||||||
Go
|
Go
|
||||||
```
|
```
|
||||||
@ -50,13 +50,13 @@ sess := session.Must(session.NewSessionWithOptions(session.Options{
|
|||||||
}))
|
}))
|
||||||
```
|
```
|
||||||
|
|
||||||
### Partitions
|
### 分区
|
||||||
|
|
||||||
The return value of the endpoints.DefaultResolver function can be cast to the endpoints.EnumPartitions interface. This will give you access to the slice of partitions that the SDK will use, and can help you enumerate over partition information for each partition.
|
endpoints.DefaultResolver函数的返回值可以被endpoints.EnumPartitions接口使用.这样就可以获取SDK使用的分区片段,也可以列出每个分区的分区信息。
|
||||||
|
|
||||||
Go
|
Go
|
||||||
```
|
```
|
||||||
// Iterate through all partitions printing each partition's ID.
|
// 迭代所有分区表打印每个分区的ID
|
||||||
resolver := endpoints.DefaultResolver()
|
resolver := endpoints.DefaultResolver()
|
||||||
partitions := resolver.(endpoints.EnumPartitions).Partitions()
|
partitions := resolver.(endpoints.EnumPartitions).Partitions()
|
||||||
|
|
||||||
@ -65,7 +65,7 @@ for _, p := range partitions {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
In addition to the list of partitions, the endpoints package also includes a getter function for each partition group. These utility functions enable you to enumerate a specific partition without having to cast and enumerate over all the default resolver’s partitions.
|
除了分区表之外, endpoints包也提供了每个分区组的getter函数. 这些工具函数可以方便列出指定分区,而不用执行默认解析器列出所有的分区.
|
||||||
|
|
||||||
Go
|
Go
|
||||||
```
|
```
|
||||||
@ -78,9 +78,9 @@ for id, _ := range region.Services() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Once you have a Region or Service value, you can call ResolveEndpoint on it. This provides a filtered view of the Partition when resolving endpoints.
|
当你获取区域和服务值后, 可以调用ResolveEndpoint. 这样解析端点时,就可以提供分区的过滤视图.
|
||||||
|
|
||||||
Check out the AWS SDK for Go repo for [more examples][5]. Let us know in the comments what you think of the endpoints package.
|
获取更多AWS SDK for GO信息, 请关注[开源库][5]. 若你有更好的看法,请留言评论.
|
||||||
|
|
||||||
</section>
|
</section>
|
||||||
|
|
||||||
@ -89,7 +89,7 @@ Check out the AWS SDK for Go repo for [more examples][5]. Let us know in the co
|
|||||||
via: https://aws.amazon.com/cn/blogs/developer/using-the-aws-sdk-for-gos-regions-and-endpoints-metadata
|
via: https://aws.amazon.com/cn/blogs/developer/using-the-aws-sdk-for-gos-regions-and-endpoints-metadata
|
||||||
|
|
||||||
作者:[ Jason Del Ponte][a]
|
作者:[ Jason Del Ponte][a]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[Vic020](http://vicyu.com)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
@ -1,128 +0,0 @@
|
|||||||
NMAP 常用扫描简介(二)
|
|
||||||
=====================
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
在我们之前的 [NMAP 安装][1]一文中,列出了 10 种不同的 ZeNMAP 扫描模式,大多数的模式使用了不同的参数。各种不同参数代表执行不同的扫描模式。这篇文章将介绍最后剩下的两种常用扫描类型。
|
|
||||||
|
|
||||||
**四种通用扫描类型**
|
|
||||||
|
|
||||||
下面列出了最常用的四种扫描类型:
|
|
||||||
|
|
||||||
1. PING 扫描(-sP)
|
|
||||||
2. TCP SYN 扫描(-sS)
|
|
||||||
3. TCP Connect() 扫描(-sT)
|
|
||||||
4. UDP 扫描(-sU)
|
|
||||||
|
|
||||||
当我们利用 NMAP 来执行扫描的时候,这四种扫描类型是我们需要熟练掌握的。更重要的是需要知道这些命令做了什么,并且需要知道这些命令是怎么做的。在这篇文章中将介绍两种 TCP 扫描 — TCP SYN 扫描和 TCP Connect() 扫描。
|
|
||||||
|
|
||||||
([阅读 NMAP 常用扫描简介(一)][2])
|
|
||||||
|
|
||||||
**TCP SYN 扫描 (-sS)**
|
|
||||||
|
|
||||||
TCP SYN 扫描是默认的 NMAP 扫描。为了运行 TCP SYN 扫描,你需要有 Root 权限。
|
|
||||||
|
|
||||||
TCP SYN 扫描的目的是找到被扫描系统上的已开启端口。使用 NMAP 扫描可以扫描在防火墙另一侧的系统。当扫描通过防火墙时,扫描时间会延长,因为数据包会变慢。
|
|
||||||
|
|
||||||
TCP SYN 扫描的工作方式是启动一个“三次握手”。正如在另一篇文章中所述,“三次握手”发生在两个系统之间。首先,源系统发送一个包到目标系统,这是一个同步(Sync)请求。然后,目标系统将通过同步/应答(SYN/ACK)响应。接下来,源系统将通过应答(ACK)来响应,从而建立起一个通信连接,然后,可以在两个系统之间传输数据。
|
|
||||||
|
|
||||||
TCP SYN 扫描通过执行下面的步骤来进行工作:
|
|
||||||
|
|
||||||
1. 源系统向目标系统发送一个同步请求,同时,一个端口号会被添加到请求中。
|
|
||||||
2. 如果添加在上一步中的请求中的端口号是开启的,那么目标系统将通过同步/应答(SYN/ACK)来响应源系统。
|
|
||||||
3. 源系统通过重置(RST)来响应目标系统,从而断开连接。
|
|
||||||
4. 目标系统可以通过重置/应答(SYN/ACK)来响应源系统。
|
|
||||||
|
|
||||||
连接已经建立,所以这被认为是半开放连接。因为连接状态是由 NMAP 管理的,所以你需要有 Root 权限。
|
|
||||||
|
|
||||||
如果被扫描的端口是关闭的,那么将执行下面的步骤:
|
|
||||||
|
|
||||||
1. 源系统发送一个同步(SYN)请求到目标系统,同时一个端口号被添加到请求中。
|
|
||||||
2. 目标系统通过重置(RST)响应源系统,因为该端口是关闭的。
|
|
||||||
|
|
||||||
如果目标系统被防火墙监控,那么 ICMP 传输或响应将会防火墙禁止,此时,会执行下面的步骤:
|
|
||||||
|
|
||||||
1. 源系统发送一个同步请求到目标系统,同时一个端口号被添加到请求中。
|
|
||||||
2. 没有任何响应,因为请求被防火墙过滤了。
|
|
||||||
|
|
||||||
在这种情况下,端口可能是被过滤、或者可能打开、或者可能没打开。防火墙可以设置禁止指定端口所有包的传出。防火墙可以禁止所有传入某个指定端口的包,因此目标系统不会接收到请求。
|
|
||||||
|
|
||||||
**注:**无响应可能发生在一个启用了防火墙的系统上。即使在本地网络,你也可能会发现被过滤端口
|
|
||||||
|
|
||||||
我将向图片1那样执行对单一系统(10.0.0.2)的扫描和执行 TCP SYN 扫描。使用命令 `sudo nmap -sS <IP 地址>` 来执行扫描。`<IP 地址>`可以改为一个单一 IP 地址,像图片1那样,也可以使用一组 IP 地址。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**图片1**
|
|
||||||
|
|
||||||
你可以看到,状态为 997 的被过滤端口没有显示。NMAP 找到两个开启的端口:139 和 445 。
|
|
||||||
|
|
||||||
**注:**请记住,NMAP 只会扫描绝大多数熟知的 1000 多个端口。以后,我们会介绍可以扫描所有端口或者指定端口的其他扫描。
|
|
||||||
|
|
||||||
扫描会被 WireShark 俘获,正如图片2所展示的那样。在这儿,你可以看到目标系统的初始地址解析协议(ARP)请求。在 ARP 请求下面的是一长列到达目标系统端口的 TCP 请求。第 4 行是到达 `http-alt` 端口(8080)。源系统的端口号为 47128 。正如图片3展示的,许多 SYN 请求只有在做出响应以后才会发送。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**图片2**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**图片3**
|
|
||||||
|
|
||||||
在图片3的第 50 行和第 51 行,你可以看到,重置(RST)包被发送给了源系统。第 53 行和第 55 行显示 RST/ACK(重置/应答)。第 50 行是针对 ‘microsoft-ds’ 端口(445),第 51 行是针对 ‘netbios-ssn’ 端口(135),我们可以看到,这两个端口都是打开的。除了这些端口,没有其他 ACK(应答)是来自目标系统的。每一个请求均可发送超过 1000 次。
|
|
||||||
|
|
||||||
正如图片4所展示的,目标系统是 Windows 系统,我关闭了系统防火墙,然后再次执行扫描。现在,我们看到 997 端口不是被过滤端口,而是已关闭端口。目标系统上的 135 端口之前被防火墙禁止了,现在也是开启的。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**图片4**
|
|
||||||
|
|
||||||
**TCP Connect() 扫描 (-sT)**
|
|
||||||
|
|
||||||
尽管 TCP SYN 扫描需要 Root 权限,但 TCP Connect() 扫描并不需要。一个完整的“三次握手”会在这次扫描中执行。因为不需要 Root 权限,所以在无法获取 Root 权限的网络上,这种扫描非常有用。
|
|
||||||
|
|
||||||
TCP Connect 扫描的工作方式也是执行“三次握手”。正如上面描述过的,“三次握手”发生在两个系统之间。源系统发送一个同步(Sync)请求到目标系统。然后,目标系统将通过同步/应答(SYN/ACK)来响应。最后,源系统通过应答(ACK)来响应,从而建立起连接,然后便可在两个系统之间传输数据。
|
|
||||||
|
|
||||||
TCP Connect 扫描通过执行下面的步骤来工作:
|
|
||||||
|
|
||||||
1. 源系统发送一个同步(SYN)请求到目标系统,同时一个端口号被添加到请求中。
|
|
||||||
2. 如果上一步添加到请求中的端口是开启的,那么目标系统将通过同步/应答(SYN/ACK)来响应源系统。
|
|
||||||
3. 源系统通过应答(ACK)来响应目标系统从而结束会话。
|
|
||||||
4. 然后,源系统向目标系统发送一个重置(RST)包来关闭会话。
|
|
||||||
5. 目标系统可以通过同步/应答(SYN/ACK)来响应源系统。
|
|
||||||
|
|
||||||
若步骤 2 执行了,那么源系统就知道在步骤 1 中的指定端口是开启的。
|
|
||||||
|
|
||||||
如果端口是关闭的,那么会发生和 TCP SYN 扫描相同的事。在步骤 2 中,目标系统将会通过一个重置(RST)包来响应源系统。
|
|
||||||
|
|
||||||
可以使用命令 `nmap -sT <IP 地址>` 来执行扫描。`<IP 地址>`可以改为一个单一 IP 地址,像图片5那样,或者使用一组 IP 地址。
|
|
||||||
|
|
||||||
TCP Connect 扫描的结果可以在图片5中看到。在这儿,你可以看到,有两个已开启端口:139 和 445,这和 TCP SYN 扫描的发现一样。端口 80 是关闭的。剩下没有显示的端口是被过滤了的。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**图片5**
|
|
||||||
|
|
||||||
让我们关闭防火墙以后再重新扫描一次,扫描结果展示在图片6中。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**图片6**
|
|
||||||
|
|
||||||
关闭防火墙以后,我们可以看到,更多的端口被发现了。就和 TCP SYN 扫描一样,关闭防火墙以后,发现 139 端口和 445 端口是开启的。我们还发现,端口 2869 也是开启的。也发现端口 996 是关闭的。现在,端口 80 是 996 已关闭端口的一部分 — 不再被防火墙过滤。
|
|
||||||
|
|
||||||
在一些情况下, TCP Connect 扫描可以在一个更短的时间内完成。和 TCP SYN 扫描相比,TCP Connect 扫描也可以找到更多的已开启端口
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.linuxforum.com/threads/nmap-common-scans-part-two.3879/
|
|
||||||
|
|
||||||
作者:[Jarret ][a]
|
|
||||||
译者:[ucasFL](https://github.com/ucasFL)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
|
||||||
[1]:https://www.linuxforum.com/threads/nmap-installation.3431/
|
|
||||||
[2]:https://linux.cn/article-8346-1.html/
|
|
||||||
@ -1,128 +0,0 @@
|
|||||||
# OpenSUSE Leap 42.2 Gnome - 好些了但是还不是那么好
|
|
||||||
|
|
||||||
更新: 2017 年二月六号
|
|
||||||
|
|
||||||
是时候再给 Leap 一个机会了。让我再罗嗦一下。给 Leap 一次机会吧。是的。几周之前,我回顾了最新的 [openSUSE][1] 发行版的 Plasma 版本,虽然它火力全开,就像经典的帝国冲锋队(注:帝国冲锋队是科幻电影《星球大战》系列中,隶属反派政权银河帝国下的军事部队),但是多部分攻击没有命中要害。这是一个相对普通的,传递一切,但是缺少精华的发行版。
|
|
||||||
|
|
||||||
我现在将做一个 Gnome 的实验。为这个发行版搭载一个全新的桌面环境,同时观察它的表现。我们最近在 CentOS 上做了一些类似的事情,但是得到了相当惊讶的结果。我们可能受幸运之神祝福。现在开始动手。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 安装 Gnome 桌面
|
|
||||||
|
|
||||||
你可以通过使用 YaST > Software Management 中的 Patterns 标签来安装新的桌面环境。特别的,你可以安装 Gnome, Xfce, LXQt, MATE 以及其他桌面环境。一个非常简单的过程需要大概 900M 的磁盘空间。没有错误,没有警告。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Gnome 的美化工作
|
|
||||||
|
|
||||||
我花费了较短时间来征服 openSUSE。鉴于我拥有大量的在 [Fedora 24][2] 上做相同工作,如[拉皮条(原文:pimping)][3],的经验,所以这个过程是相当快和简单的。首先,获得一些 Gnome [扩展][4]。静待 20 分钟,搅拌并服务于粘土碗(原文:Stir and serve in clay bowls)。
|
|
||||||
|
|
||||||
对于餐后甜点,开启 Gnome Tweak Tool ,然后添加一些窗口按钮。最重要的,安装最最重要的,救命的插件 - [Dash to Dock][5]。因为之后你终于可以想人类一样工作,而没有使人恼火的的低效率活动。消化,调整一些新的图标。这个工作最终耗时 42 分 12 秒。明白了吗?42.2 分钟。天啊。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 别的定制和增强
|
|
||||||
|
|
||||||
我实际上在 Gnome 中使用 Breeze 窗口装饰,而且工作地挺好。这比你尝试去个性化 Plasma 要好的多。看了一眼后流泪了,因为这个界面看起来太可怕了。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 智能手机支持
|
|
||||||
|
|
||||||
比 Plasma 好太多了 - [iPhone][7] 和 [Ubuntu Phone][8] 都可以正常的识别和挂载。这个提醒了所有 CentOS 7.2 的 [KDE][9] 和 [Gnome][10] 行为的差异和不一致。所以这个肯定跨越了特殊平台的界限。桌面环境有这个通病。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
一个显著的 bug 是你需要时常清理图标的缓存,否则你会在文件管理器里面看到老的图标。关于这个问题,我很快会有一整个文章来说明。
|
|
||||||
|
|
||||||
### 多媒体
|
|
||||||
|
|
||||||
不幸的是,Gnome 出现了和 Plasma 相同的问题。缺少依赖。没有 H.264 编码,意味着你不可以看99%你需要的东西。这就像是,一个月没有网。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 资源利用
|
|
||||||
|
|
||||||
Gnome 版本比 Plasma 更快,即使合成器(原文:Compositor)关掉,可以忽略 KWin 崩溃以及反应迟缓。CPU 的利用率在 2-3%,内存使用率徘徊在 900M。我觉得应该处于中游。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 电池消耗
|
|
||||||
|
|
||||||
实际上 Gnome 的电池损耗比 Plasma 严重。不确定为什么。但是即使屏幕亮度调到 50%,Leap Gnome 只能给我的 G50 续航大约 2.5 小时。我没有深究电池消耗在什么地方,但是它却确实消耗很快。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 奇怪的问题
|
|
||||||
|
|
||||||
Gnome 也有一些小毛病和错误。比如说,桌面不停地请求无线网络的密码,可能是我的 Gnome 没有很好地处理 KWallet 或者别的什么。同时,在我注销 Plasma 会话之后,KWi仍然在运行,消耗了100% 的 CPU 直到我杀死这个进行。真是一件丢人的事。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 硬件支持
|
|
||||||
|
|
||||||
暂停并恢复,一切顺利。我至今没有在 Gnome 版本中体验断网。webcam 同样工作。总之,硬件支持貌似相当好。蓝牙也正常工作。哇!可能是我们在网络下标注它。(原文:To wit)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 网络
|
|
||||||
|
|
||||||
利用 Samba 打印?你有相同的,差劲的小应用程序,就像在 [Yakkety Yak][11],它把视野全弄乱了。但是之后,它说没有打印共享,请检查防火墙。无论如何,这部在是 1999 年了。能够打印不再是一项特权,而是一个基本人的权利。人类在这上面已经举行变革。但是,我没有在这个上面进行截图。太糟了。
|
|
||||||
|
|
||||||
### 剩下的呢?
|
|
||||||
|
|
||||||
总而言之,这是一个标准的 Gnome 桌面,带有它的一点点智力上的挑战的方式去计算和人类工程学,也可以通过扩展的严密使用来驯服。它比 Plasma 更友好一些,你可以在大多数日常的工作中,得到更好的结果。之后,你就会被选项的缺少困住,但是这些选项在 Plasma 中压倒性地多。但是你要记住,你的桌面不再每分钟都反应迟缓,这确实是个奖励。
|
|
||||||
|
|
||||||
### 结论
|
|
||||||
|
|
||||||
OpenSUSE Leap 42.2 Gnome 是一个比 Plasma 部分更好的产品,而且没有错误。它更稳定,更快,更加优雅,更加容易定制,而且那些关键的日常功能都确定工作。例如,如果你倾向于不用防火墙,你可以打印到 Samba,在不失去时间戳的情况下拷贝文件到 Samba 服务器,使用蓝牙,使用你的 Ubuntu 手机,而且这些都不会出现很严重结果的崩溃。整个栈是非常有特色,并且更好地被支持。
|
|
||||||
|
|
||||||
然而,Leap 仍然是一个合理的发行版。它在一些其他发行版处理地优秀和高雅的核心地域挣扎,而且比较差的 QA,直接导致了许多大而显著的问题。至少,质量的缺失已经成为过去这些年 openSUSE 几乎不变的元素。现在或者将来,你会得到一个相当好的幼体。但是它们中大多很普通。这就是大概最能定义 openSUSE Leap 的词,普通。你应该自己去尝试和观察。你很有可能不会惊讶。这个羞愧的事情,因为对我来说,SUSE 有一个充满乐趣的地方,并且现在它倔强地拒绝重新点燃爱火。
|
|
||||||
|
|
||||||
干杯。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
我是 Igor Ljubuncic。现在大约 38 岁,已婚但还没有孩子。我现在在一个大胆创新的云科技公司做首席工程师。直到大约 2015 年初,我还在一个全世界最大的 IT 公司之一中做系统架构工程师,和一个工程计算团队开发新的基于 Linux 的解决方案,优化内核以及攻克 Linux 的问题。在那之前,我是一个为高性能计算环境设计创新解决方案的团队的技术领导。还有一些其他花哨的头衔,包括系统专家、系统程序员等等。所有这些都曾是我的爱好,但从 2008 年开始成为了我的有偿的工作。还有什么比这更令人满意的呢?
|
|
||||||
|
|
||||||
从 2004 年到 2008 年间,我曾通过作为医学影像行业的物理学家来糊口。我的工作专长集中在解决问题和算法开发。为此,我广泛地使用了Matlab,主要用于信号和图像处理。另外,我得到了几个主要的工程方法学的认证,包括 MEDIC 六西格玛绿带、试验设计以及统计工程学。
|
|
||||||
|
|
||||||
我也写过书,包括《Linux 上的高幻想和技术工作》和《相互包容》。
|
|
||||||
|
|
||||||
请参阅我的完整开源项目,出版物和专利列表,只需向下滚动。
|
|
||||||
|
|
||||||
有关我的奖项、提名和 IT 相关认证的完整列表,请进行跳转。
|
|
||||||
|
|
||||||
-------------
|
|
||||||
|
|
||||||
|
|
||||||
via: http://www.dedoimedo.com/computers/opensuse-42-2-gnome.html
|
|
||||||
|
|
||||||
作者:[Igor Ljubuncic][a]
|
|
||||||
译者:[mudongliang](https://github.com/mudongliang)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.dedoimedo.com/faq.html
|
|
||||||
|
|
||||||
[1]:http://www.dedoimedo.com/computers/opensuse-42-2.html
|
|
||||||
[2]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
|
||||||
[3]:http://www.dedoimedo.com/computers/fedora-24-pimp.html
|
|
||||||
[4]:http://www.dedoimedo.com/computers/fedora-23-extensions.html
|
|
||||||
[5]:http://www.dedoimedo.com/computers/gnome-3-dash.html
|
|
||||||
[6]:http://www.dedoimedo.com/computers/fedora-24-pimp-more.html
|
|
||||||
[7]:http://www.dedoimedo.com/computers/iphone-6-after-six-months.html
|
|
||||||
[8]:http://www.dedoimedo.com/computers/ubuntu-phone-sep-2016.html
|
|
||||||
[9]:http://www.dedoimedo.com/computers/lenovo-g50-centos-kde.html
|
|
||||||
[10]:http://www.dedoimedo.com/computers/lenovo-g50-centos-gnome.html
|
|
||||||
[11]:http://www.dedoimedo.com/computers/ubuntu-yakkety-yak.html
|
|
||||||
@ -0,0 +1,236 @@
|
|||||||
|
开发 Linux 调试器第一部分:起步
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
任何写过 hello world 程序的人都应该使用过调试器(如果你还没有,那就停下手头的工作先学习一下吧)。但是,尽管这些工具已经得到了广泛的使用,却并没有太多的资源告诉你它们的工作原理以及如何开发[1][1],尤其是和其它类似编译器等工具链技术相比的时候。
|
||||||
|
|
||||||
|
我们将会支持以下功能:
|
||||||
|
|
||||||
|
* 启动、暂停、继续执行
|
||||||
|
* 在不同地方设置断点
|
||||||
|
* 内存地址
|
||||||
|
* 源代码行
|
||||||
|
* 函数入口
|
||||||
|
* 读写寄存器和内存
|
||||||
|
* 单步执行
|
||||||
|
* 指令
|
||||||
|
* 进入函数
|
||||||
|
* 跳出函数
|
||||||
|
* 跳过函数
|
||||||
|
* 打印当前代码地址
|
||||||
|
* 打印函数调用栈
|
||||||
|
* 打印简单变量的值
|
||||||
|
|
||||||
|
在最后一部分,我还会大概介绍如何给你的调试器添加下面的功能:
|
||||||
|
|
||||||
|
* 远程调试
|
||||||
|
* 共享库和动态库支持
|
||||||
|
* 表达式计算
|
||||||
|
* 多线程调试支持
|
||||||
|
|
||||||
|
在本项目中我会将重点放在 C 和 C++,但对于那些将源码编译为机器码并输出标准 DWARE 调试信息的语言也应该能起作用(如果你还不知道这些东西是什么,别担心,马上就会介绍到啦)。另外,我只关注如何将程序运行起来并在大部分情况下能正常工作,为了简便,会避开类似健壮错误处理方面的东西。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 系列文章索引
|
||||||
|
|
||||||
|
随着后面文章的发布,这些链接会逐渐生效。
|
||||||
|
|
||||||
|
1. [启动][2]
|
||||||
|
2. [断点][3]
|
||||||
|
3. 寄存器和内存
|
||||||
|
4. Elves 和 dwarves
|
||||||
|
5. 逐步、源码和信号
|
||||||
|
6. Stepping on dwarves
|
||||||
|
7. 源码层断点
|
||||||
|
8. 调用栈
|
||||||
|
9. 读取变量
|
||||||
|
10. 下一步
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 准备环境
|
||||||
|
|
||||||
|
在我们正式开始之前,我们首先要设置环境。在这篇文章中我会依赖两个工具:[Linenoise][4] 用于处理命令行输入,[libelfin][5] 用于解析调试信息。你也可以使用更传统的 libdwarf 而不是 libelin,但是界面没有那么友好,另外 libelfin 还提供大部分完整的 DWARF 表达式求值程序,当你想读取变量的值时这能帮你节省很多时间。确认你使用的是我 libelfin 仓库中的 fbreg 分支,因为它提供 x86 上读取变量的额外支持。
|
||||||
|
|
||||||
|
一旦你在系统上安装或者使用你喜欢的编译系统编译好了这些依赖工具,就可以开始啦。我在 CMake 文件中把它们设置为和我其余的代码一起编译。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 启动可执行程序
|
||||||
|
|
||||||
|
在真正调试任何程序之前,我们需要启动被调试的程序。我们会使用经典的 fork/exec 模式。
|
||||||
|
|
||||||
|
```
|
||||||
|
int main(int argc, char* argv[]) {
|
||||||
|
if (argc < 2) {
|
||||||
|
std::cerr << "Program name not specified";
|
||||||
|
return -1;
|
||||||
|
}
|
||||||
|
|
||||||
|
auto prog = argv[1];
|
||||||
|
|
||||||
|
auto pid = fork();
|
||||||
|
if (pid == 0) {
|
||||||
|
//we're in the child process
|
||||||
|
//execute debugee
|
||||||
|
|
||||||
|
}
|
||||||
|
else if (pid >= 1) {
|
||||||
|
//we're in the parent process
|
||||||
|
//execute debugger
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我们调用 `fort` 把我们的程序分成两个进程。如果我们是在子进程,`fork` 返回 0,如果我们是在父进程,它会返回子进程的进程ID。
|
||||||
|
|
||||||
|
如果我们是在子进程,我们要用希望调试的程序替换正在执行的程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
ptrace(PTRACE_TRACEME, 0, nullptr, nullptr);
|
||||||
|
execl(prog.c_str(), prog.c_str(), nullptr);
|
||||||
|
```
|
||||||
|
|
||||||
|
这里我们第一次遇到了 `ptrace`,它会在我们编写调试器的时候经常遇到。`ptrace` 通过读取寄存器、内存、逐步调试等让我们观察和控制另一个进程的执行。API 非常简单;你需要给这个简单函数提供一个枚举值用于你想要进行的操作,然后是一些取决于你提供的值可能会被使用也可能会被忽略的参数。函数签名看起来类似:
|
||||||
|
|
||||||
|
```
|
||||||
|
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||||
|
void *addr, void *data);
|
||||||
|
```
|
||||||
|
|
||||||
|
`request` 是我们想对被跟踪进程进行的操作;`pid` 是被跟踪进程的进程 ID;`addr` 是一个内存地址,用于在一些调用中指定被跟踪程序的地址;`data` 是和 `request` 相应的资源。返回值通常是一些错误信息,因此在你实际的代码中你也许应该检查返回值;为了简洁我这里就省略了。你可以查看 man 手册获取更多(关于 ptrace)的信息。
|
||||||
|
|
||||||
|
上面代码中我们发送的请求 `PTRACE_TRACEME` 表示这个进程应该允许父进程跟踪它。所有其它参数都会被忽略,因为 API 设计并不是很重要
|
||||||
|
|
||||||
|
下一步,我们会调用 `execl`,这是很多类似的 `exec` 函数之一。我们执行指定的程序,通过命令行参数传递它的名称,然后用一个 `nullptr` 终止列表。如果你愿意,你还可以传递其它执行你的程序所需的参数。
|
||||||
|
|
||||||
|
在完成这些后,我们就会结束子进程的执行;在我们结束它之前它会一直执行。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 添加调试循环
|
||||||
|
|
||||||
|
现在我们已经启动了子进程,我们想要能够和它进行交互。为此,我们会创建一个 `debugger` 类,循环监听用户输入,然后在我们父进程的 `main` 函数中启动它。
|
||||||
|
|
||||||
|
```
|
||||||
|
else if (pid >= 1) {
|
||||||
|
//parent
|
||||||
|
debugger dbg{prog, pid};
|
||||||
|
dbg.run();
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
class debugger {
|
||||||
|
public:
|
||||||
|
debugger (std::string prog_name, pid_t pid)
|
||||||
|
: m_prog_name{std::move(prog_name)}, m_pid{pid} {}
|
||||||
|
|
||||||
|
void run();
|
||||||
|
|
||||||
|
private:
|
||||||
|
std::string m_prog_name;
|
||||||
|
pid_t m_pid;
|
||||||
|
};
|
||||||
|
```
|
||||||
|
|
||||||
|
在 `run` 函数中,我们需要等待,直到子进程完成启动,然后一直从 linenoise 获取输入直到收到 EOF(ctrl+d)。
|
||||||
|
|
||||||
|
```
|
||||||
|
void debugger::run() {
|
||||||
|
int wait_status;
|
||||||
|
auto options = 0;
|
||||||
|
waitpid(m_pid, &wait_status, options);
|
||||||
|
|
||||||
|
char* line = nullptr;
|
||||||
|
while((line = linenoise("minidbg> ")) != nullptr) {
|
||||||
|
handle_command(line);
|
||||||
|
linenoiseHistoryAdd(line);
|
||||||
|
linenoiseFree(line);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
当被跟踪的进程启动时,会发送一个 `SIGTRAP` 信号给它,这是一个跟踪或者断点中断。我们可以使用 `waitpid` 函数等待直到这个信号被发送。
|
||||||
|
|
||||||
|
当我们知道进程可以被调试之后,我们监听用户输入。`linenoise` 函数它自己会用一个窗口显示和处理用户输入。这意味着我们不需要做太多的工作就会有一个有历史记录和导航命令的命令行。当我们获取到输入时,我们把命令发给我们写的小程序 `handle_command`,然后我们把这个命令添加到 linenoise 历史并释放资源。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 处理输入
|
||||||
|
|
||||||
|
我们的命令和 gdb 以及 lldb 有类似的格式。要继续执行程序,用户需要输入 `continue` 或 `cont` 甚至只需 `c`。如果他们想在一个地址中设置断点,他们会输入 `break 0xDEADBEEF`,其中 `0xDEADBEEF` 就是所需地址的 16 进制格式。让我们来增加对这些命令的支持吧。
|
||||||
|
|
||||||
|
```
|
||||||
|
void debugger::handle_command(const std::string& line) {
|
||||||
|
auto args = split(line,' ');
|
||||||
|
auto command = args[0];
|
||||||
|
|
||||||
|
if (is_prefix(command, "continue")) {
|
||||||
|
continue_execution();
|
||||||
|
}
|
||||||
|
else {
|
||||||
|
std::cerr << "Unknown command\n";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
`split` 和 `is_prefix` 是一对有用的小程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
std::vector<std::string> split(const std::string &s, char delimiter) {
|
||||||
|
std::vector<std::string> out{};
|
||||||
|
std::stringstream ss {s};
|
||||||
|
std::string item;
|
||||||
|
|
||||||
|
while (std::getline(ss,item,delimiter)) {
|
||||||
|
out.push_back(item);
|
||||||
|
}
|
||||||
|
|
||||||
|
return out;
|
||||||
|
}
|
||||||
|
|
||||||
|
bool is_prefix(const std::string& s, const std::string& of) {
|
||||||
|
if (s.size() > of.size()) return false;
|
||||||
|
return std::equal(s.begin(), s.end(), of.begin());
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
我们会把 `continue_execution` 函数添加到 `debuger` 类。
|
||||||
|
|
||||||
|
```
|
||||||
|
void debugger::continue_execution() {
|
||||||
|
ptrace(PTRACE_CONT, m_pid, nullptr, nullptr);
|
||||||
|
|
||||||
|
int wait_status;
|
||||||
|
auto options = 0;
|
||||||
|
waitpid(m_pid, &wait_status, options);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我们的 `continue_execution` 函数会用 `ptrace` 告诉进程继续执行,然后用 `waitpid` 等待直到收到信号。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 完成
|
||||||
|
|
||||||
|
现在你应该编译一些 C 或者 C++ 程序,然后用你的调试器运行它们,看它是否能在函数入口暂停、从调试器中继续执行。在下一篇文章中,我们会学习如何让我们的调试器设置断点。如果你遇到了任何问题,在下面的评论框中告诉我吧!
|
||||||
|
|
||||||
|
你可以在[这里][6]找到该项目的代码。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||||
|
|
||||||
|
作者:[Simon Brand ][a]
|
||||||
|
译者:[ictlyh](https://github.com/ictlyh)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linkedin.com/in/simon-brand-36520857
|
||||||
|
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/#fn:1
|
||||||
|
[2]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||||
|
[3]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||||
|
[4]:https://github.com/antirez/linenoise
|
||||||
|
[5]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||||
|
[6]:https://github.com/TartanLlama/minidbg/tree/tut_setup
|
||||||
@ -0,0 +1,141 @@
|
|||||||
|
如何在 Linux 中添加一块大于 2TB 的新磁盘
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
你有没有试过使用 [fdisk][1] 对大于 2TB 的硬盘进行分区,并且想知道为什么会得到需要使用 GPT 的警告? 是的,你看到的没错。我们无法使用 fdisk 对大于 2TB 的硬盘进行分区。
|
||||||
|
|
||||||
|
在这种情况下,我们可以使用 parted 命令。它的主要区别在于 fdisk 使用 DOS 分区表格式而 parted 使用 GPT 格式。
|
||||||
|
|
||||||
|
提示:你可以使用 gdisk 来代替 parted。
|
||||||
|
|
||||||
|
在本文中,我们将介绍如何将大于 2TB 的新磁盘添加到现有的 Linux 服务器中(如 RHEL/CentOS 或 Debian/Ubuntu)中。
|
||||||
|
|
||||||
|
我使用的是 fdisk 和 parted 来进行此配置。
|
||||||
|
|
||||||
|
首先使用 fdisk 命令列出当前的分区详细信息,如图所示。
|
||||||
|
|
||||||
|
```
|
||||||
|
# fdisk -l
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][2]
|
||||||
|
|
||||||
|
列出 Linux 分区表
|
||||||
|
|
||||||
|
为了本文的目的,我加了一块 20GB 的磁盘,这也可以是大于 2TB 的磁盘。在你加完磁盘后,使用相同的 fdisk 命令验证分区表。
|
||||||
|
|
||||||
|
```
|
||||||
|
# fdisk -l
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][3]
|
||||||
|
|
||||||
|
列出新的分区表
|
||||||
|
|
||||||
|
提示:如果你添加了一块物理磁盘,你可能会发现分区已经创建了。此种情况下,你可以在使用 parted 之前使用 fdisk 删除它。
|
||||||
|
|
||||||
|
```
|
||||||
|
# fdisk /dev/xvdd
|
||||||
|
```
|
||||||
|
|
||||||
|
在命令中使用 `d` 开关删除分区,使用 `w` 保存更改并退出。
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
删除 Linux 分区
|
||||||
|
|
||||||
|
重要:在删除分区时你需要小心点。这会擦除磁盘上的数据。
|
||||||
|
|
||||||
|
现在是使用 parted 命令分区新的磁盘了。
|
||||||
|
|
||||||
|
```
|
||||||
|
# parted /dev/xvdd
|
||||||
|
```
|
||||||
|
|
||||||
|
将分区表格式化成 GPT
|
||||||
|
|
||||||
|
```
|
||||||
|
(parted) mklabel gpt
|
||||||
|
```
|
||||||
|
|
||||||
|
创建主分区并分配磁盘容量,这里我使用 20GB (在你这里可能是 2TB)。
|
||||||
|
|
||||||
|
```
|
||||||
|
(parted) mkpart primary 0GB 20GB
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][5]
|
||||||
|
|
||||||
|
使用 parted 创建分区
|
||||||
|
|
||||||
|
出于好奇,让我们用 fdisk 看看新的分区。
|
||||||
|
|
||||||
|
```
|
||||||
|
# fdisk /dev/xvdd
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][6]
|
||||||
|
|
||||||
|
验证分区细节
|
||||||
|
|
||||||
|
现在格式化并挂载分区,并在 /etc/fstab 添加相同的信息,它控制在系统启动时挂载文件系统。
|
||||||
|
|
||||||
|
```
|
||||||
|
# mkfs.ext4 /dev/xvdd1
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][7]
|
||||||
|
|
||||||
|
格式化 Linux 分区
|
||||||
|
|
||||||
|
一旦分区格式化之后,是时候在 /data1 下挂载分区了。
|
||||||
|
|
||||||
|
```
|
||||||
|
# mount /dev/xvdd1 /data1
|
||||||
|
```
|
||||||
|
|
||||||
|
要永久挂载,在 /etc/fstab 添加条目。
|
||||||
|
|
||||||
|
```
|
||||||
|
/dev/xvdd1 /data1 ext4 defaults 0 0
|
||||||
|
```
|
||||||
|
|
||||||
|
重要:要使用 GPT 分区格式需要内核支持。默认上 RHEL/CentOS 的内核已经支持 GPT,但是对于 Debian/Ubuntu,你需要在修改配置之后重新编译内核。
|
||||||
|
|
||||||
|
就是这样了!在本文中,我们向你展示了如何使用 parted 命令。与我们分享你的评论和反馈。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
我在包括 IBM-AIX、Solaris、HP-UX 以及 ONTAP 和 OneFS 存储技术的不同平台上工作,并掌握 Oracle 数据库。
|
||||||
|
|
||||||
|
-----------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||||
|
|
||||||
|
作者:[Lakshmi Dhandapani][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/lakshmi/
|
||||||
|
|
||||||
|
[1]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||||
|
[2]:http://www.tecmint.com/wp-content/uploads/2017/04/List-Linux-Partition-Table.png
|
||||||
|
[3]:http://www.tecmint.com/wp-content/uploads/2017/04/List-New-Partition-Table.png
|
||||||
|
[4]:http://www.tecmint.com/wp-content/uploads/2017/04/Delete-Linux-Partition.png
|
||||||
|
[5]:http://www.tecmint.com/wp-content/uploads/2017/04/Create-Partition-using-Parted.png
|
||||||
|
[6]:http://www.tecmint.com/wp-content/uploads/2017/04/Verify-Partition-Details.png
|
||||||
|
[7]:http://www.tecmint.com/wp-content/uploads/2017/04/Format-Linux-Partition.png
|
||||||
|
[8]:http://www.tecmint.com/author/lakshmi/
|
||||||
|
[9]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[10]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
Loading…
Reference in New Issue
Block a user