mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
2b3c5f18c3
@ -1,6 +1,7 @@
|
||||
如何在双系统引导下替换 Linux 发行版
|
||||
======
|
||||
在双系统引导的状态下,你可以将已安装的 Linux 发行版替换为另一个发行版,同时还可以保留原本的个人数据。
|
||||
|
||||
> 在双系统引导的状态下,你可以将已安装的 Linux 发行版替换为另一个发行版,同时还可以保留原本的个人数据。
|
||||
|
||||
![How to Replace One Linux Distribution With Another From Dual Boot][1]
|
||||
|
||||
@ -26,11 +27,9 @@
|
||||
* 需要安装的 Linux 发行版的 USB live 版
|
||||
* 在外部磁盘备份 Windows 和 Linux 中的重要文件(并非必要,但建议备份一下)
|
||||
|
||||
|
||||
|
||||
#### 在替换 Linux 发行版时要记住保留你的 home 目录
|
||||
|
||||
如果想让个人文件在安装新 Linux 系统的过程中不受影响,原有的 Linux 系统必须具有单独的 root 目录和 home 目录。你可能会发现我的[双系统引导教程][8]在安装过程中不选择“与 Windows 一起安装”选项,而选择“其它”选项,然后手动创建 root 和 home 分区。所以,手动创建单独的 home 分区也算是一个磨刀不误砍柴工的操作。因为如果要在不丢失文件的情况下,将现有的 Linux 发行版替换为另一个发行版,需要将 home 目录存放在一个单独的分区上。
|
||||
如果想让个人文件在安装新 Linux 系统的过程中不受影响,原有的 Linux 系统必须具有单独的 root 目录和 home 目录。你可能会发现我的[双系统引导教程][8]在安装过程中不选择“与 Windows 共存”选项,而选择“其它”选项,然后手动创建 root 和 home 分区。所以,手动创建单独的 home 分区也算是一个磨刀不误砍柴工的操作。因为如果要在不丢失文件的情况下,将现有的 Linux 发行版替换为另一个发行版,需要将 home 目录存放在一个单独的分区上。
|
||||
|
||||
不过,你必须记住现有 Linux 系统的用户名和密码才能使用与新系统中相同的 home 目录。
|
||||
|
||||
@ -51,69 +50,80 @@
|
||||
在安装过程中,进入“安装类型”界面时,选择“其它”选项。
|
||||
|
||||
![Replacing one Linux with another from dual boot][10]
|
||||
(在这里选择“其它”选项)
|
||||
|
||||
*在这里选择“其它”选项*
|
||||
|
||||
#### 步骤 3:准备分区操作
|
||||
|
||||
下图是分区界面。你会看到使用 Ext4 文件系统类型来安装 Linux。
|
||||
|
||||
![Identifying Linux partition in dual boot][11]
|
||||
(确定 Linux 的安装位置)
|
||||
|
||||
*确定 Linux 的安装位置*
|
||||
|
||||
在上图中,标记为 Linux Mint 19 的 Ext4 分区是 root 分区,大小为 82691 MB 的第二个 Ext4 分区是 home 分区。在这里我这里没有使用[交换空间][12]。
|
||||
|
||||
如果你只有一个 Ext4 分区,就意味着你的 home 目录与 root 目录位于同一分区。在这种情况下,你就无法保留 home 目录中的文件了,这个时候我建议将重要文件复制到外部磁盘,否则这些文件将不会保留。
|
||||
|
||||
然后是删除 root 分区。选择 root 分区,然后点击 - 号,这个操作释放了一些磁盘空间。
|
||||
然后是删除 root 分区。选择 root 分区,然后点击 `-` 号,这个操作释放了一些磁盘空间。
|
||||
|
||||
![Delete root partition of your existing Linux install][13]
|
||||
(删除 root 分区)
|
||||
|
||||
磁盘空间释放出来后,点击 + 号。
|
||||
*删除 root 分区*
|
||||
|
||||
磁盘空间释放出来后,点击 `+` 号。
|
||||
|
||||
![Create root partition for the new Linux][14]
|
||||
(创建新的 root 分区)
|
||||
|
||||
*创建新的 root 分区*
|
||||
|
||||
现在已经在可用空间中创建一个新分区。如果你之前的 Linux 系统中只有一个 root 分区,就应该在这里创建 root 分区和 home 分区。如果需要,还可以创建交换分区。
|
||||
|
||||
如果你之前已经有 root 分区和 home 分区,那么只需要从已删除的 root 分区创建 root 分区就可以了。
|
||||
|
||||
![Create root partition for the new Linux][15]
|
||||
(创建 root 分区)
|
||||
|
||||
你可能有疑问,为什么要经过“删除”和“添加”两个过程,而不使用“更改”选项。这是因为以前使用“更改”选项好像没有效果,所以我更喜欢用 - 和 +。这是迷信吗?也许是吧。
|
||||
*创建 root 分区*
|
||||
|
||||
你可能有疑问,为什么要经过“删除”和“添加”两个过程,而不使用“更改”选项。这是因为以前使用“更改”选项好像没有效果,所以我更喜欢用 `-` 和 `+`。这是迷信吗?也许是吧。
|
||||
|
||||
这里有一个重要的步骤,对新创建的 root 分区进行格式化。在没有更改分区大小的情况下,默认是不会对分区进行格式化的。如果分区没有被格式化,之后可能会出现问题。
|
||||
|
||||
![][16]
|
||||
(格式化 root 分区很重要)
|
||||
|
||||
*格式化 root 分区很重要*
|
||||
|
||||
如果你在新的 Linux 系统上已经划分了单独的 home 分区,选中它并点击更改。
|
||||
|
||||
![Recreate home partition][17]
|
||||
(修改已有的 home 分区)
|
||||
|
||||
*修改已有的 home 分区*
|
||||
|
||||
然后指定将其作为 home 分区挂载即可。
|
||||
|
||||
![Specify the home mount point][18]
|
||||
(指定 home 分区的挂载点)
|
||||
|
||||
*指定 home 分区的挂载点*
|
||||
|
||||
如果你还有交换分区,可以重复与 home 分区相同的步骤,唯一不同的是要指定将空间用作交换空间。
|
||||
|
||||
现在的状态应该是有一个 root 分区(将被格式化)和一个 home 分区(如果需要,还可以使用交换分区)。点击“立即安装”可以开始安装。
|
||||
|
||||
![Verify partitions while replacing one Linux with another][19]
|
||||
(检查分区情况)
|
||||
|
||||
*检查分区情况*
|
||||
|
||||
接下来的几个界面就很熟悉了,要重点注意的是创建用户和密码的步骤。如果你之前有一个单独的 home 分区,并且还想使用相同的 home 目录,那你必须使用和之前相同的用户名和密码,至于设备名称则可以任意指定。
|
||||
|
||||
![To keep the home partition intact, use the previous user and password][20]
|
||||
(要保持 home 分区不变,请使用之前的用户名和密码)
|
||||
|
||||
*要保持 home 分区不变,请使用之前的用户名和密码*
|
||||
|
||||
接下来只要静待安装完成,不需执行任何操作。
|
||||
|
||||
![Wait for installation to finish][21]
|
||||
(等待安装完成)
|
||||
|
||||
*等待安装完成*
|
||||
|
||||
安装完成后重新启动系统,你就能使用新的 Linux 发行版。
|
||||
|
||||
@ -126,7 +136,7 @@ via: https://itsfoss.com/replace-linux-from-dual-boot/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,33 @@
|
||||
介绍 Fedora上的 Swift
|
||||
介绍 Fedora 上的 Swift
|
||||
======
|
||||
|
||||

|
||||
|
||||
Swift 是一种使用现代方法构建安全性、性能和软件设计模式的通用编程语言。它旨在成为各种编程项目的最佳语言,从系统编程到桌面应用程序,以及扩展到云服务。阅读更多关于它的内容以及如何在 Fedora 中尝试它。
|
||||
Swift 是一种使用现代方法构建安全性、性能和软件设计模式的通用编程语言。它旨在成为各种编程项目的最佳语言,从系统编程到桌面应用程序,以及扩展到云服务。继续阅读了解它以及如何在 Fedora 中尝试它。
|
||||
|
||||
### 安全、快速、富有表现力
|
||||
|
||||
与许多现代编程语言一样,Swift 被设计为比基于 C 的语言更安全。例如,变量总是在可以使用之前初始化。检查数组和整数是否溢出。内存自动管理。
|
||||
与许多现代编程语言一样,Swift 被设计为比基于 C 的语言更安全。例如,变量总是在使用之前初始化。检查数组和整数是否溢出。内存自动管理。
|
||||
|
||||
Swift 将意图放在语法中。要声明变量,请使用 var 关键字。要声明常量,请使用 let。
|
||||
Swift 将意图放在语法中。要声明变量,请使用 `var` 关键字。要声明常量,请使用 `let`。
|
||||
|
||||
Swift 还保证对象永远不会是 nil。实际上,尝试使用已知为 nil 的对象将导致编译时错误。当使用 nil 值时,它支持一种称为 **optional** 的机制。optional 可能包含 nil,但使用 **?** 运算符可以安全地解包。
|
||||
Swift 还保证对象永远不会是 `nil`。实际上,尝试使用已知为 `nil` 的对象将导致编译时错误。当使用 `nil` 值时,它支持一种称为 **optional** 的机制。optional 可能包含 `nil`,但使用 `?` 运算符可以安全地解包。
|
||||
|
||||
一些额外的功能包括:
|
||||
|
||||
* 与函数指针统一的闭包
|
||||
* 元组和多个返回值
|
||||
* 泛型
|
||||
* 对范围或集合进行快速而简洁的迭代
|
||||
* 支持方法、扩展和协议的结构体
|
||||
* 函数式编程模式,例如 map 和 filter
|
||||
* 内置强大的错误处理
|
||||
* 拥有 do、guard、defer 和 repeat 关键字的高级控制流
|
||||
更多的功能包括:
|
||||
|
||||
* 与函数指针统一的闭包
|
||||
* 元组和多个返回值
|
||||
* 泛型
|
||||
* 对范围或集合进行快速而简洁的迭代
|
||||
* 支持方法、扩展和协议的结构体
|
||||
* 函数式编程模式,例如 `map` 和 `filter`
|
||||
* 内置强大的错误处理
|
||||
* 拥有 `do`、`guard`、`defer` 和 `repeat` 关键字的高级控制流
|
||||
|
||||
|
||||
### 尝试 Swift
|
||||
|
||||
Swift 在 Fedora 28 中可用,包名为 **swift-lang**。安装完成后,运行 swift 并启动 REPL 控制台。
|
||||
Swift 在 Fedora 28 中可用,包名为 **swift-lang**。安装完成后,运行 `swift` 并启动 REPL 控制台。
|
||||
|
||||
```
|
||||
$ swift
|
||||
@ -44,10 +43,9 @@ greeting = "Hello universe!"
|
||||
|
||||
|
||||
3>
|
||||
|
||||
```
|
||||
|
||||
Swift 有一个不断发展的社区,特别底,有一个[工作组][1]致力于使其成为一种高效且有力的服务器端编程语言。请访问[主页][2]了解更多参与方式。
|
||||
Swift 有一个不断发展的社区,特别的,有一个[工作组][1]致力于使其成为一种高效且有力的服务器端编程语言。请访问其[主页][2]了解更多参与方式。
|
||||
|
||||
图片由 [Uillian Vargas][3] 发布在 [Unsplash][4] 上。
|
||||
|
||||
@ -59,7 +57,7 @@ via: https://fedoramagazine.org/introducing-swift-fedora/
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,103 @@
|
||||
命令行小技巧:读取文件的不同方式
|
||||
======
|
||||
|
||||

|
||||
|
||||
作为图形操作系统,Fedora 的使用是令人愉快的。你可以轻松地点击完成任何任务。但你可能已经看到了,在底层还有一个强大的命令行。想要在 shell 下体验,只需要在 Fedora 系统中打开你的终端应用。这篇文章是向你展示常见的命令行使用方法的系列文章之一。
|
||||
|
||||
在这部分,你将学习如何以不同的方式读取文件,如果你在系统中打开一个终端完成一些工作,你就有可能需要读取一两个文件。
|
||||
|
||||
### 一应俱全的大餐
|
||||
|
||||
对命令行终端的用户来说, `cat` 命令众所周知。 当你 `cat` 一个文件,你很容易的把整个文件内容展示在你的屏幕上。而真正发生在底层的是文件一次读取一行,然后一行一行写入屏幕。
|
||||
|
||||
假设你有一个文件,叫做 `myfile`, 这个文件每行只有一个单词。为了简单起见,每行的单词就是这行的行号,就像这样:
|
||||
|
||||
```
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
```
|
||||
|
||||
所以如果你 `cat` 这个文件,你就会看到如下输出:
|
||||
|
||||
```
|
||||
$ cat myfile
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
```
|
||||
|
||||
并没有太惊喜,不是吗? 但是有个有趣的转折,只要使用 `tac` 命令,你可以从后往前 `cat` 这个文件。(请注意, Fedora 对这种有争议的幽默不承担任何责任!)
|
||||
|
||||
```
|
||||
$ tac myfile
|
||||
five
|
||||
four
|
||||
three
|
||||
two
|
||||
one
|
||||
```
|
||||
|
||||
`cat` 命令允许你以不同的方式装饰输出,比如,你可以输出行号:
|
||||
|
||||
```
|
||||
$ cat -n myfile
|
||||
1 one
|
||||
2 two
|
||||
3 three
|
||||
4 four
|
||||
5 five
|
||||
```
|
||||
|
||||
还有其他选项可以显示特殊字符和其他功能。要了解更多, 请运行 `man cat` 命令, 看完之后,按 `q` 即可退出回到 shell。
|
||||
|
||||
### 挑选你的食物
|
||||
|
||||
通常,文件太长会无法全部显示在屏幕上,您可能希望能够像文档一样查看它。 这种情况下,可以试试 `less` 命令:
|
||||
|
||||
```
|
||||
$ less myfile
|
||||
```
|
||||
|
||||
你可以用方向键,也可以用 `PgUp`/`PgDn` 来查看文件, 按 `q` 就可以退回到 shell。
|
||||
|
||||
实际上,还有一个 `more` 命令,其基于老式的 UNIX 系统命令。如果在退回 shell 后仍想看到该文件的内容,则可能需要使用它。而 `less` 命令则让你回到你离开 shell 之前的样子,并且清除屏幕上你看到的所有的文件内容。
|
||||
|
||||
### 一点披萨或甜点
|
||||
|
||||
有时,你所需的输出只是文件的开头。 比如,有一个非常长的文件,当你使用 `cat` 命令时,会显示这个文件所有内容,前几行的内容很容易滚动过去,导致你看不到。`head` 命令会帮你获取文件的前几行:
|
||||
|
||||
```
|
||||
$ head -n 2 myfile
|
||||
one
|
||||
two
|
||||
```
|
||||
同样,你会用 `tail` 命令来查看文件的末尾几行:
|
||||
|
||||
```
|
||||
$ tail -n 3 myfile
|
||||
three
|
||||
four
|
||||
five
|
||||
```
|
||||
|
||||
当然,这些只是在这个领域的几个简单的命令。但它们可以让你在阅读文件时容易入手。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-reading-files-different-ways/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,46 +0,0 @@
|
||||
translating by ypingcn
|
||||
|
||||
Creator of the World Wide Web is Creating a New Decentralized Web
|
||||
======
|
||||
**Creator of the world wide web, Tim Berners-Lee has unveiled his plans to create a new decentralized web where the data will be controlled by the users.**
|
||||
|
||||
[Tim Berners-Lee][1] is known for creating the world wide web, i.e., the internet you know today. More than two decades later, Tim is working to free the internet from the clutches of corporate giants and give the power back to the people via a decentralized web.
|
||||
|
||||
Berners-Lee was unhappy with the way ‘powerful forces’ of the internet handle data of the users for their own agenda. So he [started working on his own open source project][2] Solid “to restore the power and agency of individuals on the web.”
|
||||
|
||||
> Solid changes the current model where users have to hand over personal data to digital giants in exchange for perceived value. As we’ve all discovered, this hasn’t been in our best interests. Solid is how we evolve the web in order to restore balance — by giving every one of us complete control over data, personal or not, in a revolutionary way.
|
||||
|
||||
![Tim Berners-Lee is creating a decentralized web with open source project Solid][3]
|
||||
|
||||
Basically, [Solid][4] is a platform built using the existing web where you create own ‘pods’ (personal data store). You decide where this pod will be hosted, who will access which data element and how the data will be shared through this pod.
|
||||
|
||||
Berners-Lee believes that Solid “will empower individuals, developers and businesses with entirely new ways to conceive, build and find innovative, trusted and beneficial applications and services.”
|
||||
|
||||
Developers need to integrate Solid into their apps and sites. Solid is still in the early stages so there are no apps for now but the project website claims that “the first wave of Solid apps are being created now.”
|
||||
|
||||
Berners-Lee has created a startup called [Inrupt][5] and has taken a sabbatical from MIT to work full-time on Solid and to take it “from the vision of a few to the reality of many.”
|
||||
|
||||
If you are interested in Solid, [learn how to create apps][6] or [contribute to the project][7] in your own way. Of course, it will take a lot of effort to build and drive the broad adoption of Solid so every bit of contribution will count to the success of a decentralized web.
|
||||
|
||||
Do you think a [decentralized web][8] will be a reality? What do you think of decentralized web in general and project Solid in particular?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/solid-decentralized-web/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[2]: https://medium.com/@timberners_lee/one-small-step-for-the-web-87f92217d085
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/tim-berners-lee-solid-project.jpeg
|
||||
[4]: https://solid.inrupt.com/
|
||||
[5]: https://www.inrupt.com/
|
||||
[6]: https://solid.inrupt.com/docs/getting-started
|
||||
[7]: https://solid.inrupt.com/community
|
||||
[8]: https://tech.co/decentralized-internet-guide-2018-02
|
||||
@ -1,61 +0,0 @@
|
||||
translating by belitex
|
||||
|
||||
A sysadmin's guide to containers
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "containers" is heavily overused. Also, depending on the context, it can mean different things to different people.
|
||||
|
||||
Traditional Linux containers are really just ordinary processes on a Linux system. These groups of processes are isolated from other groups of processes using resource constraints (control groups [cgroups]), Linux security constraints (Unix permissions, capabilities, SELinux, AppArmor, seccomp, etc.), and namespaces (PID, network, mount, etc.).
|
||||
|
||||
If you boot a modern Linux system and took a look at any process with `cat /proc/PID/cgroup`, you see that the process is in a cgroup. If you look at `/proc/PID/status`, you see capabilities. If you look at `/proc/self/attr/current`, you see SELinux labels. If you look at `/proc/PID/ns`, you see the list of namespaces the process is in. So, if you define a container as a process with resource constraints, Linux security constraints, and namespaces, by definition every process on a Linux system is in a container. This is why we often say [Linux is containers, containers are Linux][1]. **Container runtimes** are tools that modify these resource constraints, security, and namespaces and launch the container.
|
||||
|
||||
Docker introduced the concept of a **container image** , which is a standard TAR file that combines:
|
||||
|
||||
* **Rootfs (container root filesystem):** A directory on the system that looks like the standard root (`/`) of the operating system. For example, a directory with `/usr`, `/var`, `/home`, etc.
|
||||
* **JSON file (container configuration):** Specifies how to run the rootfs; for example, what **command** or **entrypoint** to run in the rootfs when the container starts; **environment variables** to set for the container; the container's **working directory** ; and a few other settings.
|
||||
|
||||
|
||||
|
||||
Docker "`tar`'s up" the rootfs and the JSON file to create the **base image**. This enables you to install additional content on the rootfs, create a new JSON file, and `tar` the difference between the original image and the new image with the updated JSON file. This creates a **layered image**.
|
||||
|
||||
The definition of a container image was eventually standardized by the [Open Container Initiative (OCI)][2] standards body as the [OCI Image Specification][3].
|
||||
|
||||
Tools used to create container images are called **container image builders**. Sometimes container engines perform this task, but several standalone tools are available that can build container images.
|
||||
|
||||
Docker took these container images ( **tarballs** ) and moved them to a web service from which they could be pulled, developed a protocol to pull them, and called the web service a **container registry**.
|
||||
|
||||
**Container engines** are programs that can pull container images from container registries and reassemble them onto **container storage**. Container engines also launch **container runtimes** (see below).
|
||||
|
||||
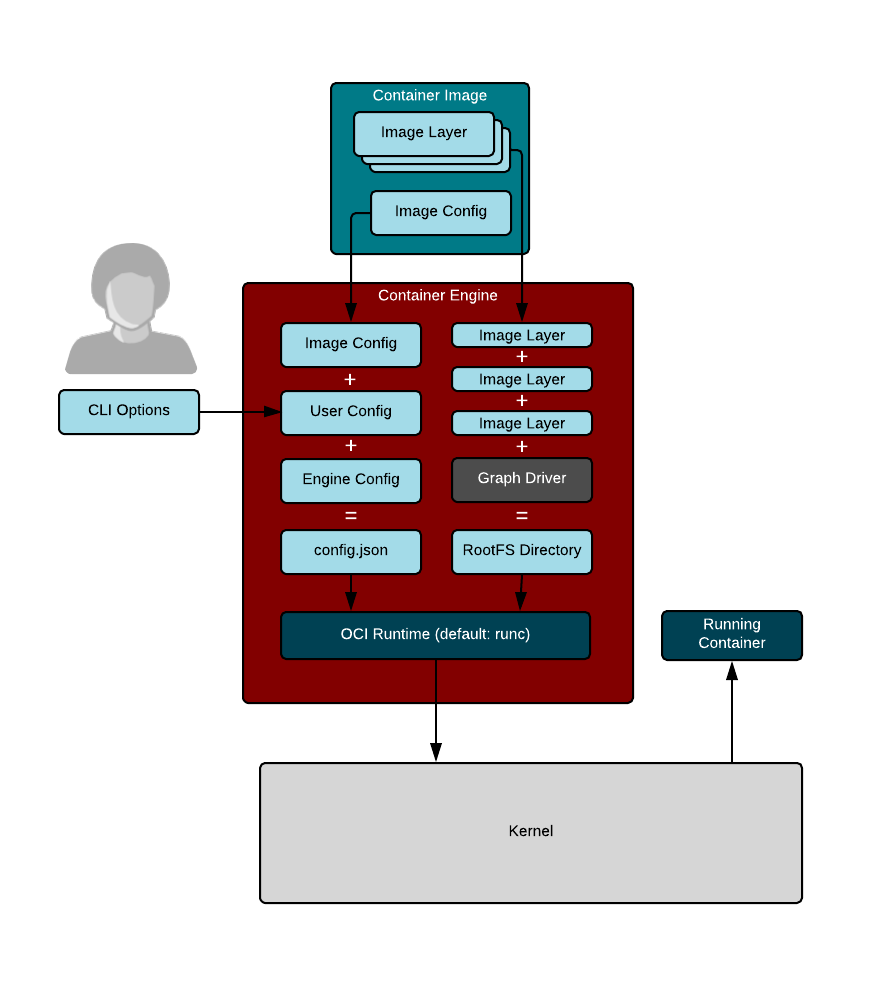
|
||||
|
||||
Container storage is usually a **copy-on-write** (COW) layered filesystem. When you pull down a container image from a container registry, you first need to untar the rootfs and place it on disk. If you have multiple layers that make up your image, each layer is downloaded and stored on a different layer on the COW filesystem. The COW filesystem allows each layer to be stored separately, which maximizes sharing for layered images. Container engines often support multiple types of container storage, including `overlay`, `devicemapper`, `btrfs`, `aufs`, and `zfs`.
|
||||
|
||||
|
||||
After the container engine downloads the container image to container storage, it needs to create aThe runtime configuration combines input from the caller/user along with the content of the container image specification. For example, the caller might want to specify modifications to a running container's security, add additional environment variables, or mount volumes to the container.
|
||||
|
||||
The layout of the container runtime configuration and the exploded rootfs have also been standardized by the OCI standards body as the [OCI Runtime Specification][4].
|
||||
|
||||
Finally, the container engine launches a **container runtime** that reads the container runtime specification; modifies the Linux cgroups, Linux security constraints, and namespaces; and launches the container command to create the container's **PID 1**. At this point, the container engine can relay `stdin`/`stdout` back to the caller and control the container (e.g., stop, start, attach).
|
||||
|
||||
Note that many new container runtimes are being introduced to use different parts of Linux to isolate containers. People can now run containers using KVM separation (think mini virtual machines) or they can use other hypervisor strategies (like intercepting all system calls from processes in containers). Since we have a standard runtime specification, these tools can all be launched by the same container engines. Even Windows can use the OCI Runtime Specification for launching Windows containers.
|
||||
|
||||
At a much higher level are **container orchestrators.** Container orchestrators are tools used to coordinate the execution of containers on multiple different nodes. Container orchestrators talk to container engines to manage containers. Orchestrators tell the container engines to start containers and wire their networks together. Orchestrators can monitor the containers and launch additional containers as the load increases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://www.redhat.com/en/blog/containers-are-linux
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[4]:https://github.com/opencontainers/runtime-spec
|
||||
@ -1,263 +0,0 @@
|
||||
[translating by jrg, 20181014]
|
||||
|
||||
16 iptables tips and tricks for sysadmins
|
||||
======
|
||||
Iptables provides powerful capabilities to control traffic coming in and out of your system.
|
||||
|
||||

|
||||
|
||||
Modern Linux kernels come with a packet-filtering framework named [Netfilter][1]. Netfilter enables you to allow, drop, and modify traffic coming in and going out of a system. The **iptables** userspace command-line tool builds upon this functionality to provide a powerful firewall, which you can configure by adding rules to form a firewall policy. [iptables][2] can be very daunting with its rich set of capabilities and baroque command syntax. Let's explore some of them and develop a set of iptables tips and tricks for many situations a system administrator might encounter.
|
||||
|
||||
### Avoid locking yourself out
|
||||
|
||||
Scenario: You are going to make changes to the iptables policy rules on your company's primary server. You want to avoid locking yourself—and potentially everybody else—out. (This costs time and money and causes your phone to ring off the wall.)
|
||||
|
||||
#### Tip #1: Take a backup of your iptables configuration before you start working on it.
|
||||
|
||||
Back up your configuration with the command:
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works
|
||||
|
||||
```
|
||||
#### Tip #2: Even better, include a timestamp in the filename.
|
||||
|
||||
Add the timestamp with the command:
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works-`date +%F`
|
||||
|
||||
```
|
||||
|
||||
You get a file with a name like:
|
||||
|
||||
```
|
||||
/root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
If you do something that prevents your system from working, you can quickly restore it:
|
||||
|
||||
```
|
||||
/sbin/iptables-restore < /root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
#### Tip #3: Every time you create a backup copy of the iptables policy, create a link to the file with 'latest' in the name.
|
||||
|
||||
```
|
||||
ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
|
||||
|
||||
```
|
||||
|
||||
#### Tip #4: Put specific rules at the top of the policy and generic rules at the bottom.
|
||||
|
||||
Avoid generic rules like this at the top of the policy rules:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 -j DROP
|
||||
|
||||
```
|
||||
|
||||
The more criteria you specify in the rule, the less chance you will have of locking yourself out. Instead of the very generic rule above, use something like this:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
|
||||
|
||||
```
|
||||
|
||||
This rule appends ( **-A** ) to the **INPUT** chain a rule that will **DROP** any packets originating from the CIDR block **10.0.0.0/8** on TCP ( **-p tcp** ) port 22 ( **\--dport 22** ) destined for IP address 192.168.100.101 ( **-d 192.168.100.101** ).
|
||||
|
||||
There are plenty of ways you can be more specific. For example, using **-i eth0** will limit the processing to a single NIC in your server. This way, the filtering actions will not apply the rule to **eth1**.
|
||||
|
||||
#### Tip #5: Whitelist your IP address at the top of your policy rules.
|
||||
|
||||
This is a very effective method of not locking yourself out. Everybody else, not so much.
|
||||
|
||||
```
|
||||
iptables -I INPUT -s <your IP> -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
You need to put this as the first rule for it to work properly. Remember, **-I** inserts it as the first rule; **-A** appends it to the end of the list.
|
||||
|
||||
#### Tip #6: Know and understand all the rules in your current policy.
|
||||
|
||||
Not making a mistake in the first place is half the battle. If you understand the inner workings behind your iptables policy, it will make your life easier. Draw a flowchart if you must. Also remember: What the policy does and what it is supposed to do can be two different things.
|
||||
|
||||
### Set up a workstation firewall policy
|
||||
|
||||
Scenario: You want to set up a workstation with a restrictive firewall policy.
|
||||
|
||||
#### Tip #1: Set the default policy as DROP.
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
*filter
|
||||
:INPUT DROP [0:0]
|
||||
:FORWARD DROP [0:0]
|
||||
:OUTPUT DROP [0:0]
|
||||
```
|
||||
|
||||
#### Tip #2: Allow users the minimum amount of services needed to get their work done.
|
||||
|
||||
The iptables rules need to allow the workstation to get an IP address, netmask, and other important information via DHCP ( **-p udp --dport 67:68 --sport 67:68** ). For remote management, the rules need to allow inbound SSH ( **\--dport 22** ), outbound mail ( **\--dport 25** ), DNS ( **\--dport 53** ), outbound ping ( **-p icmp** ), Network Time Protocol ( **\--dport 123 --sport 123** ), and outbound HTTP ( **\--dport 80** ) and HTTPS ( **\--dport 443** ).
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
*filter
|
||||
:INPUT DROP [0:0]
|
||||
:FORWARD DROP [0:0]
|
||||
:OUTPUT DROP [0:0]
|
||||
|
||||
# Accept any related or established connections
|
||||
-I INPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
-I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
# Allow all traffic on the loopback interface
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A OUTPUT -o lo -j ACCEPT
|
||||
|
||||
# Allow outbound DHCP request
|
||||
-A OUTPUT –o eth0 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
|
||||
|
||||
# Allow inbound SSH
|
||||
-A INPUT -i eth0 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT
|
||||
|
||||
# Allow outbound email
|
||||
-A OUTPUT -i eth0 -p tcp -m tcp --dport 25 -m state --state NEW -j ACCEPT
|
||||
|
||||
# Outbound DNS lookups
|
||||
-A OUTPUT -o eth0 -p udp -m udp --dport 53 -j ACCEPT
|
||||
|
||||
# Outbound PING requests
|
||||
-A OUTPUT –o eth0 -p icmp -j ACCEPT
|
||||
|
||||
# Outbound Network Time Protocol (NTP) requests
|
||||
-A OUTPUT –o eth0 -p udp --dport 123 --sport 123 -j ACCEPT
|
||||
|
||||
# Outbound HTTP
|
||||
-A OUTPUT -o eth0 -p tcp -m tcp --dport 80 -m state --state NEW -j ACCEPT
|
||||
-A OUTPUT -o eth0 -p tcp -m tcp --dport 443 -m state --state NEW -j ACCEPT
|
||||
|
||||
COMMIT
|
||||
```
|
||||
|
||||
### Restrict an IP address range
|
||||
|
||||
Scenario: The CEO of your company thinks the employees are spending too much time on Facebook and not getting any work done. The CEO tells the CIO to do something about the employees wasting time on Facebook. The CIO tells the CISO to do something about employees wasting time on Facebook. Eventually, you are told the employees are wasting too much time on Facebook, and you have to do something about it. You decide to block all access to Facebook. First, find out Facebook's IP address by using the **host** and **whois** commands.
|
||||
|
||||
```
|
||||
host -t a www.facebook.com
|
||||
www.facebook.com is an alias for star.c10r.facebook.com.
|
||||
star.c10r.facebook.com has address 31.13.65.17
|
||||
whois 31.13.65.17 | grep inetnum
|
||||
inetnum: 31.13.64.0 - 31.13.127.255
|
||||
```
|
||||
|
||||
Then convert that range to CIDR notation by using the [CIDR to IPv4 Conversion][3] page. You get **31.13.64.0/18**. To prevent outgoing access to [www.facebook.com][4], enter:
|
||||
|
||||
```
|
||||
iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
|
||||
```
|
||||
|
||||
### Regulate by time
|
||||
|
||||
Scenario: The backlash from the company's employees over denying access to Facebook access causes the CEO to relent a little (that and his administrative assistant's reminding him that she keeps HIS Facebook page up-to-date). The CEO decides to allow access to Facebook.com only at lunchtime (12PM to 1PM). Assuming the default policy is DROP, use iptables' time features to open up access.
|
||||
|
||||
```
|
||||
iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 --timestart 12:00 –timestop 13:00 –d
|
||||
31.13.64.0/18 -j ACCEPT
|
||||
```
|
||||
|
||||
This command sets the policy to allow ( **-j ACCEPT** ) http and https ( **-m multiport --dport http,https** ) between noon ( **\--timestart 12:00** ) and 13PM ( **\--timestop 13:00** ) to Facebook.com ( **–d[31.13.64.0/18][5]** ).
|
||||
|
||||
### Regulate by time—Take 2
|
||||
|
||||
Scenario: During planned downtime for system maintenance, you need to deny all TCP and UDP traffic between the hours of 2AM and 3AM so maintenance tasks won't be disrupted by incoming traffic. This will take two iptables rules:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
```
|
||||
|
||||
With these rules, TCP and UDP traffic ( **-p tcp and -p udp** ) are denied ( **-j DROP** ) between the hours of 2AM ( **\--timestart 02:00** ) and 3AM ( **\--timestop 03:00** ) on input ( **-A INPUT** ).
|
||||
|
||||
### Limit connections with iptables
|
||||
|
||||
Scenario: Your internet-connected web servers are under attack by bad actors from around the world attempting to DoS (Denial of Service) them. To mitigate these attacks, you restrict the number of connections a single IP address can have to your web server:
|
||||
|
||||
```
|
||||
iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
|
||||
```
|
||||
|
||||
Let's look at what this rule does. If a host makes more than 20 ( **-–connlimit-above 20** ) new connections ( **–p tcp –syn** ) in a minute to the web servers ( **-–dport http,https** ), reject the new connection ( **–j REJECT** ) and tell the connecting host you are rejecting the connection ( **-–reject-with-tcp-reset** ).
|
||||
|
||||
### Monitor iptables rules
|
||||
|
||||
Scenario: Since iptables operates on a "first match wins" basis as packets traverse the rules in a chain, frequently matched rules should be near the top of the policy and less frequently matched rules should be near the bottom. How do you know which rules are traversed the most or the least so they can be ordered nearer the top or the bottom?
|
||||
|
||||
#### Tip #1: See how many times each rule has been hit.
|
||||
|
||||
Use this command:
|
||||
|
||||
```
|
||||
iptables -L -v -n –line-numbers
|
||||
```
|
||||
|
||||
The command will list all the rules in the chain ( **-L** ). Since no chain was specified, all the chains will be listed with verbose output ( **-v** ) showing packet and byte counters in numeric format ( **-n** ) with line numbers at the beginning of each rule corresponding to that rule's position in the chain.
|
||||
|
||||
Using the packet and bytes counts, you can order the most frequently traversed rules to the top and the least frequently traversed rules towards the bottom.
|
||||
|
||||
#### Tip #2: Remove unnecessary rules.
|
||||
|
||||
Which rules aren't getting any matches at all? These would be good candidates for removal from the policy. You can find that out with this command:
|
||||
|
||||
```
|
||||
iptables -nvL | grep -v "0 0"
|
||||
```
|
||||
|
||||
Note: that's not a tab between the zeros; there are five spaces between the zeros.
|
||||
|
||||
#### Tip #3: Monitor what's going on.
|
||||
|
||||
You would like to monitor what's going on with iptables in real time, like with **top**. Use this command to monitor the activity of iptables activity dynamically and show only the rules that are actively being traversed:
|
||||
|
||||
```
|
||||
watch --interval=5 'iptables -nvL | grep -v "0 0"'
|
||||
```
|
||||
|
||||
**watch** runs **'iptables -nvL | grep -v "0 0"'** every five seconds and displays the first screen of its output. This allows you to watch the packet and byte counts change over time.
|
||||
|
||||
### Report on iptables
|
||||
|
||||
Scenario: Your manager thinks this iptables firewall stuff is just great, but a daily activity report would be even better. Sometimes it's more important to write a report than to do the work.
|
||||
|
||||
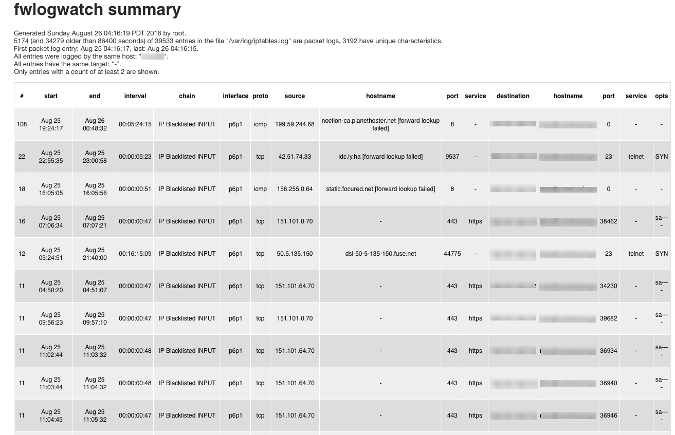
Use the packet filter/firewall/IDS log analyzer [FWLogwatch][6] to create reports based on the iptables firewall logs. FWLogwatch supports many log formats and offers many analysis options. It generates daily and monthly summaries of the log files, allowing the security administrator to free up substantial time, maintain better control over network security, and reduce unnoticed attacks.
|
||||
|
||||
Here is sample output from FWLogwatch:
|
||||
|
||||
|
||||
|
||||
### More than just ACCEPT and DROP
|
||||
|
||||
We've covered many facets of iptables, all the way from making sure you don't lock yourself out when working with iptables to monitoring iptables to visualizing the activity of an iptables firewall. These will get you started down the path to realizing even more iptables tips and tricks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/iptables-tips-and-tricks
|
||||
|
||||
作者:[Gary Smith][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greptile
|
||||
[1]: https://en.wikipedia.org/wiki/Netfilter
|
||||
[2]: https://en.wikipedia.org/wiki/Iptables
|
||||
[3]: http://www.ipaddressguide.com/cidr
|
||||
[4]: http://www.facebook.com
|
||||
[5]: http://31.13.64.0/18
|
||||
[6]: http://fwlogwatch.inside-security.de/
|
||||
@ -0,0 +1,45 @@
|
||||
万维网的创建者正在创建一个新的分布式网络
|
||||
======
|
||||
|
||||
**万维网的创建者 Tim Berners-Lee 公布了他计划创建一个新的分布式网络,网络中的数据将由用户控制**
|
||||
|
||||
[Tim Berners-Lee] [1]以创建万维网而闻名,万维网就是你现在所知的互联网。二十多年之后,Tim 致力于将互联网从企业巨头的掌控中解放出来,并通过分布式网络将权力交回给人们。
|
||||
|
||||
Berners-Lee 对互联网“强权”们处理用户数据的方式感到不满。所以他[开始致力于他自己的开源项目][2] Solid “来将在网络上的权力归还给人们”
|
||||
|
||||
> Solid 改变了当前用户必须将个人数据交给数字巨头以换取可感知价值的模型。正如我们都已发现的那样,这不符合我们的最佳利益。Solid 是我们如何驱动网络进化以恢复平衡——以一种革命性的方式,让我们每个人完全地控制数据,无论数据是否是个人数据。
|
||||
|
||||
![Tim Berners-Lee is creating a decentralized web with open source project Solid][3]
|
||||
|
||||
基本上,[Solid][4]是一个使用现有网络构建的平台,在这里你可以创建自己的 “pods” (个人数据存储)。你决定这个 “pods” 将被托管在哪里,谁将访问哪些数据元素以及数据将如何通过这个 pod 分享。
|
||||
|
||||
Berners-Lee 相信 Solid "将以一种全新的方式,授权个人、开发者和企业来构思、构建和寻找创新、可信和有益的应用和服务。"
|
||||
|
||||
开发人员需要将 Solid 集成进他们的应用程序和网站中。 Solid 仍在早期阶段,所以目前没有相关的应用程序。但是项目网站宣称“第一批 Solid 应用程序正在开发当中”。
|
||||
|
||||
Berners-Lee 已经创立一家名为[Inrupt][5] 的初创公司,并已从麻省理工学院休假来全职工作在 Solid,来将其”从少部分人的愿景带到多数人的现实“。
|
||||
|
||||
如果你对 Solid 感兴趣,[学习如何开发应用程序][6]或者以自己的方式[给项目做贡献][7]。当然,建立和推动 Solid 的广泛采用将需要大量的努力,所以每一点的贡献都将有助于分布式网络的成功。
|
||||
|
||||
你认为[分布式网络][8]会成为现实吗?你是如何看待分布式网络,特别是 Solid 项目的?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/solid-decentralized-web/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[2]: https://medium.com/@timberners_lee/one-small-step-for-the-web-87f92217d085
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/tim-berners-lee-solid-project.jpeg
|
||||
[4]: https://solid.inrupt.com/
|
||||
[5]: https://www.inrupt.com/
|
||||
[6]: https://solid.inrupt.com/docs/getting-started
|
||||
[7]: https://solid.inrupt.com/community
|
||||
[8]: https://tech.co/decentralized-internet-guide-2018-02
|
||||
56
translated/tech/20180827 A sysadmin-s guide to containers.md
Normal file
56
translated/tech/20180827 A sysadmin-s guide to containers.md
Normal file
@ -0,0 +1,56 @@
|
||||
写给系统管理员的容器手册
|
||||
======
|
||||
|
||||

|
||||
|
||||
现在人们严重地过度使用“容器”这个术语。另外,对不同的人来说,它可能会有不同的含义,这取决于上下文。
|
||||
|
||||
传统的 Linux 容器只是系统上普通的进程组成的进程组。进程组之间是相互隔离的,实现方法包括:资源限制(控制组 [cgoups])、Linux 安全限制(文件权限,基于 Capability 的安全模块,SELinux,AppArmor,seccomp 等)还有名字空间(进程 ID,网络,挂载等)。
|
||||
|
||||
如果你启动一台现代 Linux 操作系统,使用 `cat /proc/PID/cgroup` 命令就可以看到该进程是属于一个控制组的。还可以从 `/proc/PID/status` 文件中查看进程的 Capability 信息,从 `/proc/self/attr/current` 文件中查看进程的 SELinux 标签信息,从 `/proc/PID/ns` 目录下的文件查看进程所属的名字空间。因此,如果把容器定义为带有资源限制、Linux 安全限制和名字空间的进程,那么按照这个定义,Linux 操作系统上的每一个进程都在容器里。因此我们常说 [Linux 就是容器,容器就是 Linux][1]。而**容器运行时**是这样一种工具,它调整上述资源限制、安全限制和名字空间,并启动容器。
|
||||
|
||||
Docker 引入了**容器镜像**的概念,镜像是一个普通的 TAR 包文件,包含了:
|
||||
|
||||
* **Rootfs(容器的根文件系统):**一个目录,看起来像是操作系统的普通根目录(/),例如,一个包含 `/usr`, `/var`, `/home` 等的目录。
|
||||
* **JSON 文件(容器的配置):**定义了如何运行 rootfs;例如,当容器启动的时候要在 rootfs 里运行什么 **command** 或者 **entrypoint**,给容器定义什么样的**环境变量**,容器的**工作目录**是哪个,以及其他一些设置。
|
||||
|
||||
Docker 把 rootfs 和 JSON 配置文件打包成**基础镜像**。你可以在这个基础之上,给 rootfs 安装更多东西,创建新的 JSON 配置文件,然后把相对于原始镜像的不同内容打包到新的镜像。这种方法创建出来的是**分层的镜像**。
|
||||
|
||||
[Open Container Initiative(开放容器计划 OCI)][2] 标准组织最终把容器镜像的格式标准化了,也就是 [OCI Image Specification(OCI 镜像规范)][3]。
|
||||
|
||||
用来创建容器镜像的工具被称为**容器镜像构建器**。有时候容器引擎做这件事情,不过可以用一些独立的工具来构建容器镜像。
|
||||
|
||||
Docker 把这些容器镜像(**tar 包**)托管到 web 服务中,并开发了一种协议来支持从 web 拉取镜像,这个 web 服务就叫**容器仓库**。
|
||||
|
||||
**容器引擎**是能从镜像仓库拉取镜像并装载到**容器存储**上的程序。容器引擎还能启动**容器运行时**(见下图)。
|
||||
|
||||

|
||||
|
||||
容器存储一般是**写入时复制**(COW)的分层文件系统。从容器仓库拉取一个镜像时,其中的 rootfs 首先被解压到磁盘。如果这个镜像是多层的,那么每一层都会被下载到 COW 文件系统的不同分层。 COW 文件系统保证了镜像的每一层独立存储,这最大化了多个分层镜像之间的文件共享程度。容器引擎通常支持多种容器存储类型,包括 `overlay`、`devicemapper`、`btrfs`、`aufs` 和 `zfs`。
|
||||
|
||||
容器引擎将容器镜像下载到容器存储中之后,需要创建一份**容器运行时配置**,这份配置是用户/调用者的输入和镜像配置的合并。例如,容器的调用者可能会调整安全设置,添加额外的环境变量或者挂载一些卷到容器中。
|
||||
|
||||
容器运行时配置的格式,和解压出来的 rootfs 也都被开放容器计划 OCI 标准组织做了标准化,称为 [OCI 运行时规范][4]。
|
||||
|
||||
最终,容器引擎启动了一个**容器运行时**来读取运行时配置,修改 Linux 控制组、安全限制和名字空间,并执行容器命令来创建容器的 **PID 1**。至此,容器引擎已经可以把容器的标准输入/标准输出转给调用方,并控制容器了(例如,stop,start,attach)。
|
||||
|
||||
值得一提的是,现在出现了很多新的容器运行时,它们使用 Linux 的不同特性来隔离容器。可以使用 KVM 技术来隔离容器(想想迷你虚拟机),或者使用其他虚拟机监视器策略(例如拦截所有从容器内的进程发起的系统调用)。既然我们有了标准的运行时规范,这些工具都能被相同的容器引擎来启动。即使在 Windows 系统下,也可以使用 OCI 运行时规范来启动 Windows 容器。
|
||||
|
||||
容器编排器是一个更高层次的概念。它是在多个不同的节点上协调容器执行的工具。容器编排工具通过和容器引擎的通信来管理容器。编排器控制容器引擎做容器的启动和容器间的网络连接,它能够监控容器,在负载变高的时候进行容器扩容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://www.redhat.com/en/blog/containers-are-linux
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[4]:https://github.com/opencontainers/runtime-spec
|
||||
@ -0,0 +1,262 @@
|
||||
系统管理员需知的 16 个 iptables 使用技巧
|
||||
=======
|
||||
|
||||
iptables 是一款控制系统进出流量的强大配置工具。
|
||||
|
||||

|
||||
|
||||
现代 Linux 内核带有一个叫 [Netfilter][1] 的数据包过滤框架。Netfilter 提供了允许、禁止以及修改等操作来控制进出系统的流量数据包。基于 Netfilter 框架的用户层命令行工具 **iptables** 提供了强大的防火墙配置功能,允许你添加规则来构建防火墙策略。[iptables][2] 丰富复杂的功能以及其巴洛克式命令语法可能让人难以驾驭。我们就来探讨一下其中的一些功能,提供一些系统管理员解决某些问题需要的使用技巧。
|
||||
|
||||
### 避免封锁自己
|
||||
|
||||
应用场景:假设你将对公司服务器上的防火墙规则进行修改,需要避免封锁你自己以及其他同事的情况(这将会带来一定时间和金钱的损失,也许一旦发生马上就有部门打电话找你了)
|
||||
|
||||
#### 技巧 #1: 开始之前先备份一下 iptables 配置文件。
|
||||
|
||||
用如下命令备份配置文件:
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works
|
||||
|
||||
```
|
||||
#### 技巧 #2: 更妥当的做法,给文件加上时间戳。
|
||||
|
||||
用如下命令加时间戳:
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works-`date +%F`
|
||||
|
||||
```
|
||||
|
||||
然后你就可以生成如下名字的文件:
|
||||
|
||||
```
|
||||
/root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
这样万一使得系统不工作了,你也可以很快的利用备份文件恢复原状:
|
||||
|
||||
```
|
||||
/sbin/iptables-restore < /root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
#### 技巧 #3: 每次创建 iptables 配置文件副本时,都创建一个指向 `latest` 的文件的链接。
|
||||
|
||||
```
|
||||
ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
|
||||
|
||||
```
|
||||
|
||||
#### 技巧 #4: 将特定规则放在策略顶部,底部放置通用规则。
|
||||
|
||||
避免在策略顶部使用如下的一些通用规则:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 -j DROP
|
||||
|
||||
```
|
||||
|
||||
你在规则中指定的条件越多,封锁自己的可能性就越小。不要使用上面暗中通用规则,而是使用如下的规则:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
|
||||
|
||||
```
|
||||
|
||||
此规则表示在 **INPUT** 链尾追加一条新规则,将源地址为 **10.0.0.0/8**、 目的地址是 **192.168.100.101**、目的端口号是 **22** (**\--dport 22** ) 的 **tcp**(**-p tcp** )数据包通通丢弃掉。
|
||||
|
||||
还有很多方法可以设置更具体的规则。例如,使用 **-i eth0** 将会限制这条规则作用于 **eth0** 网卡,对 **eth1** 网卡则不生效。
|
||||
|
||||
#### 技巧 #5: 在策略规则顶部将你的 IP 列入白名单。
|
||||
|
||||
这是一个有效地避免封锁自己的设置:
|
||||
|
||||
```
|
||||
iptables -I INPUT -s <your IP> -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
你需要将该规则添加到策略首位置。**-I** 表示则策略首部插入规则,**-A** 表示在策略尾部追加规则。
|
||||
|
||||
#### 技巧 #6: 理解现有策略中的所有规则。
|
||||
|
||||
不犯错就已经成功了一半。如果你了解 iptables 策略背后的工作原理,使用起来更为得心应手。如果有必要,可以绘制流程图来理清数据包的走向。还要记住:策略的预期效果和实际效果可能完全是两回事。
|
||||
|
||||
### 设置防火墙策略
|
||||
|
||||
应用场景:你希望给工作站配置具有限制性策略的防火墙。
|
||||
|
||||
#### 技巧 #1: 设置默认规则为丢弃
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
*filter
|
||||
:INPUT DROP [0:0]
|
||||
:FORWARD DROP [0:0]
|
||||
:OUTPUT DROP [0:0]
|
||||
```
|
||||
|
||||
#### 技巧 #2: 将用户完成工作所需的最少量服务设置为允许
|
||||
|
||||
该策略需要允许工作站能通过 DHCP (**-p udp --dport 67:68 -sport 67:68**)来获取 IP 地址、子网掩码以及其他一些信息。对于远程操作,需要允许 SSH 服务(**-dport 22**),邮件服务(**--dport 25**),DNS服务(**--dport 53**),ping 功能(**-p icmp**),NTP 服务(**--dport 123 --sport 123**)以及HTTP 服务(**-dport 80**)和 HTTPS 服务(**--dport 443**)。
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
*filter
|
||||
:INPUT DROP [0:0]
|
||||
:FORWARD DROP [0:0]
|
||||
:OUTPUT DROP [0:0]
|
||||
|
||||
# Accept any related or established connections
|
||||
-I INPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
-I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
# Allow all traffic on the loopback interface
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A OUTPUT -o lo -j ACCEPT
|
||||
|
||||
# Allow outbound DHCP request
|
||||
-A OUTPUT –o eth0 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
|
||||
|
||||
# Allow inbound SSH
|
||||
-A INPUT -i eth0 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT
|
||||
|
||||
# Allow outbound email
|
||||
-A OUTPUT -i eth0 -p tcp -m tcp --dport 25 -m state --state NEW -j ACCEPT
|
||||
|
||||
# Outbound DNS lookups
|
||||
-A OUTPUT -o eth0 -p udp -m udp --dport 53 -j ACCEPT
|
||||
|
||||
# Outbound PING requests
|
||||
-A OUTPUT –o eth0 -p icmp -j ACCEPT
|
||||
|
||||
# Outbound Network Time Protocol (NTP) requests
|
||||
-A OUTPUT –o eth0 -p udp --dport 123 --sport 123 -j ACCEPT
|
||||
|
||||
# Outbound HTTP
|
||||
-A OUTPUT -o eth0 -p tcp -m tcp --dport 80 -m state --state NEW -j ACCEPT
|
||||
-A OUTPUT -o eth0 -p tcp -m tcp --dport 443 -m state --state NEW -j ACCEPT
|
||||
|
||||
COMMIT
|
||||
```
|
||||
|
||||
### 限制 IP 地址范围
|
||||
|
||||
应用场景:贵公司的 CEO 认为员工在 Facebook 上花费过多的时间,需要采取一些限制措施。CEO 命令下达给 CIO,CIO 命令CISO,最终任务由你来执行。你决定阻止一切到 Facebook 的访问连接。首先你使用 `host` 或者 `whois` 命令来获取 Facebook 的 IP 地址。
|
||||
|
||||
```
|
||||
host -t a www.facebook.com
|
||||
www.facebook.com is an alias for star.c10r.facebook.com.
|
||||
star.c10r.facebook.com has address 31.13.65.17
|
||||
whois 31.13.65.17 | grep inetnum
|
||||
inetnum: 31.13.64.0 - 31.13.127.255
|
||||
```
|
||||
然后使用 [CIDR to IPv4转换][3] 页面来将其转换为 CIDR 表示法。然后你得到 **31.13.64.0/18** 的地址。输入以下命令来阻止对 Facebook 的访问:
|
||||
|
||||
```
|
||||
iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
|
||||
```
|
||||
|
||||
### 按时间规定做限制-场景1
|
||||
|
||||
应用场景:公司员工强烈反对限制一切对 Facebook 的访问,这导致了 CEO 放宽了要求(考虑到员工的反对以及他的助理提醒说她将 HIS Facebook 页面保持在最新状态)。然后 CEO 决定允许在午餐时间访问 Facebook(中午12点到下午1点之间)。假设默认规则是丢弃,使用 iptables 的时间功能便可以实现。
|
||||
|
||||
```
|
||||
iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 –timestop 13:00 –d 31.13.64.0/18 -j ACCEPT
|
||||
```
|
||||
|
||||
该命令中指定在中午12点(**\--timestart 12:00**)到下午1点(**\--timestop 13:00**)之间允许(**-j ACCEPT**)到 Facebook.com (**-d [31.13.64.0/18][5]**)的 http 以及 https (**-m multiport --dport http,https**)的访问。
|
||||
|
||||
### 按时间规定做限制-场景2
|
||||
|
||||
应用场景
|
||||
Scenario: 在计划系统维护期间,你需要设置凌晨2点到3点之间拒绝所有的 TCP 和 UDP 访问,这样维护任务就不会受到干扰。使用两个 iptables 规则可实现:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
```
|
||||
|
||||
该规则禁止(**-j DROP**)在凌晨2点(**\--timestart 02:00**)到凌晨3点(**\--timestop 03:00**)之间的 TCP 和 UDP (**-p tcp and -p udp**)的数据进入(**-A INPUT**)访问。
|
||||
|
||||
### 限制连接数量
|
||||
|
||||
应用场景:你的 web 服务器有可能受到来自世界各地的 DoS 攻击,为了避免这些攻击,你可以限制单个 IP 地址到你的 web 服务器创建连接的数量:
|
||||
|
||||
```
|
||||
iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
|
||||
```
|
||||
|
||||
分析一下上面的命令。如果单个主机在一分钟之内新建立(**-p tcp -syn**)超过20个(**-connlimit-above 20**)到你的 web 服务器(**--dport http,https**)的连接,服务器将拒绝(**-j REJECT**)建立新的连接,然后通知该主机新建连接被拒绝(**--reject-with-tcp-reset**)。
|
||||
|
||||
### 监控 iptables 规则
|
||||
|
||||
应用场景:由于数据包会遍历链中的规则,iptables遵循 ”首次匹配获胜“ 的原则,因此经常匹配的规则应该靠近策略的顶部,而不太频繁匹配的规则应该接近底部。 你怎么知道哪些规则使用最多或最少,可以在顶部或底部附近监控?
|
||||
|
||||
#### 技巧 #1: 查看规则被访问了多少次
|
||||
|
||||
使用命令:
|
||||
|
||||
```
|
||||
iptables -L -v -n –line-numbers
|
||||
```
|
||||
|
||||
用 **-L** 选项列出链中的所有规则。因为没有指定具体哪条链,所有链规则都会被输出,使用 **-v** 选项显示详细信息,**-n** 选项则显示数字格式的数据包和字节计数器,每个规则开头的数值表示该规则在链中的位置。
|
||||
|
||||
根据数据包和字节计数的结果,你可以将访问频率最高的规则放到顶部,将访问频率最低的规则放到底部。
|
||||
|
||||
#### 技巧 #2: 删除不必要的规则
|
||||
|
||||
哪条规则从来没有被访问过?这些可以被清除掉。用如下命令查看:
|
||||
|
||||
```
|
||||
iptables -nvL | grep -v "0 0"
|
||||
```
|
||||
|
||||
注意:两个数字0之间不是 Tab 键,而是 5 个空格。
|
||||
|
||||
#### 技巧 #3: 监控正在发生什么
|
||||
|
||||
可能你也想像使用 **top** 命令一样来实时监控 iptables 的情况。使用如下命令来动态监视 iptables 中的活动,并仅显示正在遍历的规则:
|
||||
|
||||
```
|
||||
watch --interval=5 'iptables -nvL | grep -v "0 0"'
|
||||
```
|
||||
|
||||
**watch** 命令通过参数 **iptables -nvL | grep -v “0 0“** 每隔 5s 输出 iptables 的动态。这条命令允许你查看数据包和字节计数的变化。
|
||||
|
||||
### 输出日志
|
||||
|
||||
应用场景:经理觉得你这个防火墙员工的工作质量杠杠的,但如果能有网络流量活动日志最好了。有时候这比写一份有关工作的报告更有效。
|
||||
|
||||
使用工具 [FWLogwatch][6] 基于 iptables 防火墙记录来生成日志报告。FWLogwatch 工具支持很多形式的报告并且也提供了很多分析功能。它生成的日志以及月报告使得管理员可以节省大量时间并且还更好地管理网络,甚至减少未被注意的潜在攻击。
|
||||
|
||||
这里是一个 FWLogwatch 生成的报告示例:
|
||||
|
||||

|
||||
|
||||
### 不要满足于允许和丢弃规则
|
||||
|
||||
本文中已经涵盖了 iptables 的很多方面,从避免封锁自己、iptables 配置防火墙以及监控 iptables 中的活动等等方面介绍了 iptables。你可以从这里开始探索 iptables 甚至获取更多的使用技巧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/iptables-tips-and-tricks
|
||||
|
||||
作者:[Gary Smith][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greptile
|
||||
[1]: https://en.wikipedia.org/wiki/Netfilter
|
||||
[2]: https://en.wikipedia.org/wiki/Iptables
|
||||
[3]: http://www.ipaddressguide.com/cidr
|
||||
[4]: http://www.facebook.com
|
||||
[5]: http://31.13.64.0/18
|
||||
[6]: http://fwlogwatch.inside-security.de/
|
||||
|
||||
@ -1,44 +1,43 @@
|
||||
[translation by jrg]
|
||||
|
||||
An introduction to using tcpdump at the Linux command line
|
||||
Linux 命令行中使用 tcpdump 抓包
|
||||
======
|
||||
|
||||
This flexible, powerful command-line tool helps ease the pain of troubleshooting network issues.
|
||||
Tcpdump 是一款灵活、功能强大的抓包工具,能有效地帮助排查网络故障问题。
|
||||
|
||||

|
||||
|
||||
In my experience as a sysadmin, I have often found network connectivity issues challenging to troubleshoot. For those situations, tcpdump is a great ally.
|
||||
根据我作为管理员的经验,在网络连接中经常遇到十分难以排查的故障问题。对于这类情况,tcpdump 便能派上用场。
|
||||
|
||||
Tcpdump is a command line utility that allows you to capture and analyze network traffic going through your system. It is often used to help troubleshoot network issues, as well as a security tool.
|
||||
Tcpdump 是一个命令行实用工具,允许你抓取和分析经过系统的流量数据包。它通常被用作于网络故障分析工具以及安全工具。
|
||||
|
||||
A powerful and versatile tool that includes many options and filters, tcpdump can be used in a variety of cases. Since it's a command line tool, it is ideal to run in remote servers or devices for which a GUI is not available, to collect data that can be analyzed later. It can also be launched in the background or as a scheduled job using tools like cron.
|
||||
Tcpdump 是一款强大的工具,支持多种选项和过滤规则,适用场景十分广泛。由于它是命令行工具,因此适用于在远程服务器或者没有图形界面的设备中收集数据包以便于事后分析。它可以在后台启动,也可以用 cron 等定时工具创建定时任务启用它。
|
||||
|
||||
In this article, we'll look at some of tcpdump's most common features.
|
||||
本文中,我们将讨论 tcpdump 最常用的一些功能。
|
||||
|
||||
### 1\. Installation on Linux
|
||||
### 1\. 在 Linux 中安装 tcpdump
|
||||
|
||||
Tcpdump is included with several Linux distributions, so chances are, you already have it installed. Check if tcpdump is installed on your system with the following command:
|
||||
Tcpdump 支持多种 Linux 发行版,所以你的系统中很有可能已经安装了它。用下面的命令检查一下是否已经安装了 tcpdump:
|
||||
|
||||
```
|
||||
$ which tcpdump
|
||||
/usr/sbin/tcpdump
|
||||
```
|
||||
|
||||
If tcpdump is not installed, you can install it but using your distribution's package manager. For example, on CentOS or Red Hat Enterprise Linux, like this:
|
||||
如果还没有安装 tcpdump,你可以用软件包管理器安装它。
|
||||
例如,在 CentOS 或者 Red Hat Enterprise 系统中,用如下命令安装 tcpdump:
|
||||
|
||||
```
|
||||
$ sudo yum install -y tcpdump
|
||||
```
|
||||
|
||||
Tcpdump requires `libpcap`, which is a library for network packet capture. If it's not installed, it will be automatically added as a dependency.
|
||||
Tcpdump 依赖于 `libpcap`,该库文件用于捕获网络数据包。如果该库文件也没有安装,系统会根据依赖关系自动安装它。
|
||||
|
||||
You're ready to start capturing some packets.
|
||||
现在你可以开始抓包了。
|
||||
|
||||
### 2\. Capturing packets with tcpdump
|
||||
### 2\. 用 tcpdump 抓包
|
||||
|
||||
To capture packets for troubleshooting or analysis, tcpdump requires elevated permissions, so in the following examples most commands are prefixed with `sudo`.
|
||||
使用 tcpdump 抓包,需要管理员权限,因此下面的示例中绝大多数命令都是以 `sudo` 开头。
|
||||
|
||||
To begin, use the command `tcpdump -D` to see which interfaces are available for capture:
|
||||
首先,先用 `tcpdump -D` 命令列出可以抓包的网络接口:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -D
|
||||
@ -49,9 +48,9 @@ $ sudo tcpdump -D
|
||||
5.lo [Loopback]
|
||||
```
|
||||
|
||||
In the example above, you can see all the interfaces available in my machine. The special interface `any` allows capturing in any active interface.
|
||||
如上所示,可以看到我的机器中所有可以抓包的网络接口。其中特殊接口 `any` 可用于抓取所有活动的网络接口的数据包。
|
||||
|
||||
Let's use it to start capturing some packets. Capture all packets in any interface by running this command:
|
||||
我们就用如下命令先对 `any` 接口进行抓包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any
|
||||
@ -81,7 +80,7 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
$
|
||||
```
|
||||
|
||||
Tcpdump continues to capture packets until it receives an interrupt signal. You can interrupt capturing by pressing `Ctrl+C`. As you can see in this example, `tcpdump` captured more than 9,000 packets. In this case, since I am connected to this server using `ssh`, tcpdump captured all these packages. To limit the number of packets captured and stop `tcpdump`, use the `-c` option:
|
||||
Tcpdump 会持续抓包直到收到中断信号。你可以按 `Ctrl+C` 来停止抓包。正如上面示例所示,`tcpdump` 抓取了超过 9000 个数据包。在这个示例中,由于我是通过 `ssh` 连接到服务器,所以 tcpdump 也捕获了所有这类数据包。`-c` 选项可以用于限制 tcpdump 抓包的数量:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c 5
|
||||
@ -98,9 +97,9 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
$
|
||||
```
|
||||
|
||||
In this case, `tcpdump` stopped capturing automatically after capturing five packets. This is useful in different scenarios—for instance, if you're troubleshooting connectivity and capturing a few initial packages is enough. This is even more useful when we apply filters to capture specific packets (shown below).
|
||||
如上所示,`tcpdump` 在抓取 5 个数据包后自动停止了抓包。这在有些场景中十分有用——比如你只需要抓取少量的数据包用于分析。当我们需要使用过滤规则抓取特定的数据包(如下所示)时,`-c` 的作用就十分突出了。
|
||||
|
||||
By default, tcpdump resolves IP addresses and ports into names, as shown in the previous example. When troubleshooting network issues, it is often easier to use the IP addresses and port numbers; disable name resolution by using the option `-n` and port resolution with `-nn`:
|
||||
在上面示例中,tcpdump 默认是将 IP 地址和端口号解析为对应的接口名以及服务协议名称。而通常在网络故障排查中,使用 IP 地址和端口号更便于分析问题;用 `-n` 选项显示 IP 地址,`-nn` 选项显示端口号:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn
|
||||
@ -116,57 +115,57 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
As shown above, the capture output now displays the IP addresses and port numbers. This also prevents tcpdump from issuing DNS lookups, which helps to lower network traffic while troubleshooting network issues.
|
||||
如上所示,抓取的数据包中显示 IP 地址和端口号。这样还可以阻止 tcpdump 发出 DNS 查找,有助于在网络故障排查中减少数据流量。
|
||||
|
||||
Now that you're able to capture network packets, let's explore what this output means.
|
||||
现在你已经会抓包了,让我们来分析一下这些抓包输出的含义吧。
|
||||
|
||||
### 3\. Understanding the output format
|
||||
### 3\. 理解抓取的报文
|
||||
|
||||
Tcpdump is capable of capturing and decoding many different protocols, such as TCP, UDP, ICMP, and many more. While we can't cover all of them here, to help you get started, let's explore the TCP packet. You can find more details about the different protocol formats in tcpdump's [manual pages][1]. A typical TCP packet captured by tcpdump looks like this:
|
||||
Tcpdump 能够抓取并解码多种协议类型的数据报文,如 TCP,UDP,ICMP 等等。虽然这里我们不可能介绍所有的数据报文类型,但可以分析下 TCP 类型的数据报文,来帮助你入门。更多有关 tcpdump 的详细介绍可以参考其 [帮助手册][1]。Tcpdump 抓取的 TCP 报文看起来如下:
|
||||
|
||||
```
|
||||
08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372
|
||||
```
|
||||
|
||||
The fields may vary depending on the type of packet being sent, but this is the general format.
|
||||
具体的字段根据不同的报文类型会有不同,但上面这个例子是一般的格式形式。
|
||||
|
||||
The first field, `08:41:13.729687,` represents the timestamp of the received packet as per the local clock.
|
||||
第一个字段 `08:41:13.729687` 是该数据报文被抓取的系统本地时间戳。
|
||||
|
||||
Next, `IP` represents the network layer protocol—in this case, `IPv4`. For `IPv6` packets, the value is `IP6`.
|
||||
然后,`IP` 是网络层协议类型,这里是 `IPv4`,如果是 `IPv6` 协议,该字段值是 `IP6`。
|
||||
|
||||
The next field, `192.168.64.28.22`, is the source IP address and port. This is followed by the destination IP address and port, represented by `192.168.64.1.41916`.
|
||||
`192.168.64.28.22` 是源 ip 地址和端口号,紧跟其后的是目的 ip 地址和其端口号,这里是 `192.168.64.1.41916`。
|
||||
|
||||
After the source and destination, you can find the TCP Flags `Flags [P.]`. Typical values for this field include:
|
||||
在源 IP 和目的 IP 之后,可以看到是 TCP 报文标记段 `Flags [P.]`。该字段通常取值如下:
|
||||
|
||||
| Value | Flag Type | Description |
|
||||
|-------| --------- | ----------------- |
|
||||
| ----- | --------- | ----------------- |
|
||||
| S | SYN | Connection Start |
|
||||
| F | FIN | Connection Finish |
|
||||
| P | PUSH | Data push |
|
||||
| R | RST | Connection reset |
|
||||
| . | ACK | Acknowledgment |
|
||||
|
||||
This field can also be a combination of these values, such as `[S.]` for a `SYN-ACK` packet.
|
||||
该字段也可以是这些值的组合,例如 `[S.]` 代表 `SYN-ACK` 数据包。
|
||||
|
||||
Next is the sequence number of the data contained in the packet. For the first packet captured, this is an absolute number. Subsequent packets use a relative number to make it easier to follow. In this example, the sequence is `seq 196:568,` which means this packet contains bytes 196 to 568 of this flow.
|
||||
接下来是该数据包中数据的序列号。对于抓取的第一个数据包,该字段值是一个绝对数字,后续包使用相对数值,以便更容易查询跟踪。例如此处 `seq 196:568` 代表该数据包包含该数据流的第 196 到 568 字节。
|
||||
|
||||
This is followed by the Ack Number: `ack 1`. In this case, it is 1 since this is the side sending data. For the side receiving data, this field represents the next expected byte (data) on this flow. For example, the Ack number for the next packet in this flow would be 568.
|
||||
接下来是 ack 值:`ack 1`。该数据包是数据发送方,ack 值为1。在数据接收方,该字段代表数据流上的下一个预期字节数据,例如,该数据流中下一个数据包的 ack 值应该是 568。
|
||||
|
||||
The next field is the window size `win 309`, which represents the number of bytes available in the receiving buffer, followed by TCP options such as the MSS (Maximum Segment Size) or Window Scale. For details about TCP protocol options, consult [Transmission Control Protocol (TCP) Parameters][2].
|
||||
接下来字段是接收窗口大小 `win 309`,它表示接收缓冲区中可用的字节数,后跟 TCP 选项如 MSS(最大段大小)或者窗口比例值。更详尽的 TCP 协议内容请参考 [Transmission Control Protocol(TCP) Parameters][2]。
|
||||
|
||||
Finally, we have the packet length, `length 372`, which represents the length, in bytes, of the payload data. The length is the difference between the last and first bytes in the sequence number.
|
||||
最后,`length 372`代表数据包有效载荷字节长度。这个长度和 seq 序列号中字节数值长度是不一样的。
|
||||
|
||||
Now let's learn how to filter packages to narrow down results and make it easier to troubleshoot specific issues.
|
||||
现在让我们学习如何过滤数据报文以便更容易的分析定位问题。
|
||||
|
||||
### 4\. Filtering packets
|
||||
### 4\. 过滤数据包
|
||||
|
||||
As mentioned above, tcpdump can capture too many packages, some of which are not even related to the issue you're troubleshooting. For example, if you're troubleshooting a connectivity issue with a web server you're not interested in the SSH traffic, so removing the SSH packets from the output makes it easier to work on the real issue.
|
||||
正如上面所提,tcpdump 可以抓取很多种类型的数据报文,其中很多可能和我们需要查找的问题并没有关系。举个例子,假设你正在定位一个与 web 服务器连接的网络问题,就不必关系 SSH 数据报文,因此在抓包结果中过滤掉 SSH 报文可能更便于你分析问题。
|
||||
|
||||
One of tcpdump's most powerful features is its ability to filter the captured packets using a variety of parameters, such as source and destination IP addresses, ports, protocols, etc. Let's look at some of the most common ones.
|
||||
Tcpdump 有很多参数选项可以设置数据包过滤规则,例如根据源 IP 以及目的 IP 地址,端口号,协议等等规则来过滤数据包。下面就介绍一些最常用的过滤方法。
|
||||
|
||||
#### Protocol
|
||||
#### 协议
|
||||
|
||||
To filter packets based on protocol, specifying the protocol in the command line. For example, capture ICMP packets only by using this command:
|
||||
在命令中指定协议便可以按照协议类型来筛选数据包。比方说用如下命令只要抓取 ICMP 报文:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 icmp
|
||||
@ -174,7 +173,7 @@ tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
```
|
||||
|
||||
In a different terminal, try to ping another machine:
|
||||
然后再打开一个终端,去 ping 另一台机器:
|
||||
|
||||
```
|
||||
$ ping opensource.com
|
||||
@ -182,7 +181,7 @@ PING opensource.com (54.204.39.132) 56(84) bytes of data.
|
||||
64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
|
||||
```
|
||||
|
||||
Back in the tcpdump capture, notice that tcpdump captures and displays only the ICMP-related packets. In this case, tcpdump is not displaying name resolution packets that were generated when resolving the name `opensource.com`:
|
||||
回到运行 tcpdump 命令的终端中,可以看到它筛选出了 ICMP 报文。这里 tcpdump 并没有显示有关 `opensource.com`的域名解析数据包:
|
||||
|
||||
```
|
||||
09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
|
||||
@ -195,9 +194,9 @@ Back in the tcpdump capture, notice that tcpdump captures and displays only the
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
#### Host
|
||||
#### 主机
|
||||
|
||||
Limit capture to only packets related to a specific host by using the `host` filter:
|
||||
用 `host` 参数只抓取和特定主机相关的数据包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn host 54.204.39.132
|
||||
@ -212,12 +211,11 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
如上所示,只抓取和显示与 `54.204.39.132` 有关的数据包。
|
||||
|
||||
In this example, tcpdump captures and displays only packets to and from host `54.204.39.132`.
|
||||
#### 端口号
|
||||
|
||||
#### Port
|
||||
|
||||
To filter packets based on the desired service or port, use the `port` filter. For example, capture packets related to a web (HTTP) service by using this command:
|
||||
Tcpdump 可以根据服务类型或者端口号来筛选数据包。例如,抓取和 HTTP 服务相关的数据包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn port 80
|
||||
@ -233,9 +231,9 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
#### Source IP/hostname
|
||||
#### IP 地址/主机名
|
||||
|
||||
You can also filter packets based on the source or destination IP Address or hostname. For example, to capture packets from host `192.168.122.98`:
|
||||
同样,你也可以根据源 IP 地址或者目的 IP 地址或者主机名来筛选数据包。例如抓取源 IP 地址为 `192.168.122.98` 的数据包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98
|
||||
@ -251,9 +249,9 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
Notice that tcpdumps captured packets with source IP address `192.168.122.98` for multiple services such as name resolution (port 53) and HTTP (port 80). The response packets are not displayed since their source IP is different.
|
||||
注意此处示例中抓取了来自源 IP 地址 `192.168.122.98` 的 53 端口以及 80 端口的数据包,它们的应答包没有显示出来因为那些包的源 IP 地址已经变了。
|
||||
|
||||
Conversely, you can use the `dst` filter to filter by destination IP/hostname:
|
||||
相对的,使用 `dst` 就是按目的 IP/主机名来筛选数据包。
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn dst 192.168.122.98
|
||||
@ -269,9 +267,9 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
#### Complex expressions
|
||||
#### 多条件筛选
|
||||
|
||||
You can also combine filters by using the logical operators `and` and `or` to create more complex expressions. For example, to filter packets from source IP address `192.168.122.98` and service HTTP only, use this command:
|
||||
当然,可以使用多条件组合来筛选数据包,使用 `and` 以及 `or` 逻辑操作符来创建过滤规则。例如,筛选来自源 IP 地址 `192.168.122.98` 的 HTTP 数据包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98 and port 80
|
||||
@ -287,7 +285,7 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
You can create more complex expressions by grouping filter with parentheses. In this case, enclose the entire filter expression with quotation marks to prevent the shell from confusing them with shell expressions:
|
||||
你也可以使用括号来创建更为复杂的过滤规则,但在 shell 中请用引号包含你的过滤规则以防止被识别为 shell 表达式:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn "port 80 and (src 192.168.122.98 or src 54.204.39.132)"
|
||||
@ -303,13 +301,13 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
In this example, we're filtering packets for HTTP service only (port 80) and source IP addresses `192.168.122.98` or `54.204.39.132`. This is a quick way of examining both sides of the same flow.
|
||||
该例子中我们只抓取了来自源 IP 为 `192.168.122.98` 或者 `54.204.39.132` 的 HTTP (端口号80)的数据包。使用该方法就很容易抓取到数据流中交互双方的数据包了。
|
||||
|
||||
### 5\. Checking packet content
|
||||
### 5\. 检查数据包内容
|
||||
|
||||
In the previous examples, we're checking only the packets' headers for information such as source, destinations, ports, etc. Sometimes this is all we need to troubleshoot network connectivity issues. Sometimes, however, we need to inspect the content of the packet to ensure that the message we're sending contains what we need or that we received the expected response. To see the packet content, tcpdump provides two additional flags: `-X` to print content in hex, and ASCII or `-A` to print the content in ASCII.
|
||||
在以上的示例中,我们只按数据包头部的信息来建立规则筛选数据包,例如源地址、目的地址、端口号等等。有时我们需要分析网络连接问题,可能需要分析数据包中的内容来判断什么内容需要被发送、什么内容需要被接收等。Tcpdump 提供了两个选项可以查看数据包内容,`-X` 以十六进制打印出数据报文内容,`-A` 打印数据报文的 ASCII 值。
|
||||
|
||||
For example, inspect the HTTP content of a web request like this:
|
||||
例如,HTTP request 报文内容如下:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c10 -nn -A port 80
|
||||
@ -379,13 +377,13 @@ E..4..@.@.....zb6.'....P....o..............
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
This is helpful for troubleshooting issues with API calls, assuming the calls are using plain HTTP. For encrypted connections, this output is less useful.
|
||||
这对定位一些普通 HTTP 调用 API 接口的问题很有用。当然如果是加密报文,这个输出也就没多大用了。
|
||||
|
||||
### 6\. Saving captures to a file
|
||||
### 6\. 保存抓包数据
|
||||
|
||||
Another useful feature provided by tcpdump is the ability to save the capture to a file so you can analyze the results later. This allows you to capture packets in batch mode overnight, for example, and verify the results in the morning. It also helps when there are too many packets to analyze since real-time capture can occur too fast.
|
||||
Tcpdump 提供了保存抓包数据的功能以便后续分析数据包。例如,你可以夜里让它在那里抓包,然后早上起来再去分析它。同样当有很多数据包时,显示过快也不利于分析,将数据包保存下来,更有利于分析问题。
|
||||
|
||||
To save packets to a file instead of displaying them on screen, use the option `-w`:
|
||||
使用 `-w` 选项来保存数据包而不是在屏幕上显示出抓取的数据包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c10 -nn -w webserver.pcap port 80
|
||||
@ -396,11 +394,11 @@ tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 2621
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
This command saves the output in a file named `webserver.pcap`. The `.pcap` extension stands for "packet capture" and is the convention for this file format.
|
||||
该命令将抓取的数据包保存到文件 `webserver.pcap`。后缀名 `pcap` 表示文件是抓取的数据包格式。
|
||||
|
||||
As shown in this example, nothing gets displayed on-screen, and the capture finishes after capturing 10 packets, as per the option `-c10`. If you want some feedback to ensure packets are being captured, use the option `-v`.
|
||||
正如示例中所示,保存数据包到文件中时屏幕上就没有任何有关数据报文的输出,其中 `-c10` 表示抓取到 10 个数据包后就停止抓包。如果想有一些反馈来提示确实抓取到了数据包,可以使用 `-v` 选项。
|
||||
|
||||
Tcpdump creates a file in binary format so you cannot simply open it with a text editor. To read the contents of the file, execute tcpdump with the `-r` option:
|
||||
Tcpdump 将数据包保存在二进制文件中,所以不能简单的用文本编辑器去打开它。使用 `-r` 选项参数来阅读该文件中的报文内容:
|
||||
|
||||
```
|
||||
$ tcpdump -nn -r webserver.pcap
|
||||
@ -418,9 +416,9 @@ reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
|
||||
$
|
||||
```
|
||||
|
||||
Since you're no longer capturing the packets directly from the network interface, `sudo` is not required to read the file.
|
||||
这里不需要管理员权限 `sudo` 了,因为此刻并不是在网络接口处抓包。
|
||||
|
||||
You can also use any of the filters we've discussed to filter the content from the file, just as you would with real-time data. For example, inspect the packets in the capture file from source IP address `54.204.39.132` by executing this command:
|
||||
你还可以使用我们讨论过的任何过滤规则来过滤文件中的内容,就像使用实时数据一样。 例如,通过执行以下命令从源 IP 地址`54.204.39.132` 检查文件中的数据包:
|
||||
|
||||
```
|
||||
$ tcpdump -nn -r webserver.pcap src 54.204.39.132
|
||||
@ -431,13 +429,13 @@ reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
|
||||
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
|
||||
```
|
||||
|
||||
### What's next?
|
||||
### 下一步做什么?
|
||||
|
||||
These basic features of tcpdump will help you get started with this powerful and versatile tool. To learn more, consult the [tcpdump website][3] and [man pages][4].
|
||||
以上的基本功能已经可以帮助你使用强大的 tcpdump 抓包工具了。更多的内容请参考 [tcpdump网页][3] 以及它的 [帮助文件][4]。
|
||||
|
||||
The tcpdump command line interface provides great flexibility for capturing and analyzing network traffic. If you need a graphical tool to understand more complex flows, look at [Wireshark][5].
|
||||
Tcpdump 命令行工具为分析网络流量数据包提供了强大的灵活性。如果需要使用图形工具来抓包请参考 [Wireshark][5]。
|
||||
|
||||
One benefit of Wireshark is that it can read `.pcap` files captured by tcpdump. You can use tcpdump to capture packets in a remote machine that does not have a GUI and analyze the result file with Wireshark, but that is a topic for another day.
|
||||
Wireshark 还可以用来读取 tcpdump 保存的 `pcap` 文件。你可以使用 tcpdump 命令行在没有 GUI 界面的远程机器上抓包然后在 Wireshark 中分析数据包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -445,7 +443,7 @@ via: https://opensource.com/article/18/10/introduction-tcpdump
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -457,3 +455,4 @@ via: https://opensource.com/article/18/10/introduction-tcpdump
|
||||
[3]: http://www.tcpdump.org/#
|
||||
[4]: http://www.tcpdump.org/manpages/tcpdump.1.html
|
||||
[5]: https://www.wireshark.org/
|
||||
|
||||
@ -1,116 +0,0 @@
|
||||
命令行快速提示: 读取文件的不同方式
|
||||
======
|
||||
|
||||

|
||||
|
||||
作为图形操作系统,Fedora 的使用是令人愉快的。你可以轻松地点按,完成任何任务。 但你可能已经看到了,在引擎盖下还有一个强大的命令行。 想要在 shell 下使用,只需要在 Fedora 系统中打开你的命令行应用程序。 这篇文章是向你展示命令行使用方法的系列之一。
|
||||
|
||||
在这部分,你将学习如何以不同的方式读取文件,如果你在系统中打开一个命令行,你就有可能需要读取一个或两个文件。
|
||||
|
||||
### 一应俱全的大餐
|
||||
|
||||
对命令行终端的用户来说, **cat** 命令众所周知。 当你 **cat** 一个文件,你很容易的把整个文件内容展示在你的屏幕上。而真正发生在引擎盖下的是文件一次读取一行, 然后一行一行写入屏幕。
|
||||
|
||||
假设你有一个文件,叫做 myfile, 这个文件每行只有一个单词。为了简单起见,每行的单词就是这行的行号,就像这样:
|
||||
|
||||
```
|
||||
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
所以如果你 **cat** 这个文件,你就会看到如下输出:
|
||||
|
||||
```
|
||||
|
||||
$ cat myfile
|
||||
one
|
||||
two
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
并没有太惊喜,不是吗? 但是有个有趣的转折,只要使用 **tac** 命令,你可以从后往前 **cat** 这个文件。(请注意, Fedora 对这种有争议的幽默不承担任何责任!)
|
||||
```
|
||||
|
||||
$ tac myfile
|
||||
five
|
||||
four
|
||||
three
|
||||
two
|
||||
one
|
||||
|
||||
```
|
||||
|
||||
**cat** 命令允许你以不同的方式装饰输出,比如,你可以输出行号:
|
||||
|
||||
```
|
||||
|
||||
$ cat -n myfile
|
||||
1 one
|
||||
2 two
|
||||
3 three
|
||||
4 four
|
||||
5 five
|
||||
|
||||
```
|
||||
|
||||
还有其他选项将显示特殊字符和其他功能。 要了解更多, 请运行 **man cat** 命令, 看完之后, 按 **q** 即可退出回到 shell。
|
||||
|
||||
### 挑选你的食物
|
||||
|
||||
通常, 文件太长, 无法全部显示在屏幕上, 您可能希望能够像文档一样查看它。 这种情况下,可以试试 **less** 命令:
|
||||
|
||||
```
|
||||
|
||||
$ less myfile
|
||||
|
||||
```
|
||||
|
||||
你可以用方向键,也可以用 **PgUp/PgDn** 来查看文件, 按 **q** 就可以退回到 shell。
|
||||
|
||||
实际上,还有一个 **more** 命令,它是基于在旧的 UNIX 系统命令的。如果在退回 shell 后仍想看到该文件, 则可能需要使用它。**less** 命令使你回到你离开 shell 之前的样子,并且清除屏幕上你看到的所有的文件内容。
|
||||
|
||||
### 一点披萨或甜点
|
||||
|
||||
有时, 你所需的输出只是文件的开头。 比如,有一个非常长的文件,当你使用 **cat** 命令时,会显示这个文件所有内容,前几行的内容很容易滚动过去,导致你看不到。**head** 命令会帮你获取文件的前几行:
|
||||
|
||||
```
|
||||
|
||||
$ head -n 2 myfile
|
||||
one
|
||||
two
|
||||
|
||||
```
|
||||
同样,你会用 **tail** 命令来查看文件的末尾几行:
|
||||
|
||||
```
|
||||
|
||||
$ tail -n 3 myfile
|
||||
three
|
||||
four
|
||||
five
|
||||
|
||||
```
|
||||
|
||||
当然, 这些只是在这个领域的几个简单的命令。但当涉及到阅读文件时,你就能容易地开始。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-reading-files-different-ways/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
Loading…
Reference in New Issue
Block a user