mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
2b2a13ecbd
@ -0,0 +1,212 @@
|
||||
3 个在 Linux 中永久并安全删除文件和目录的方法
|
||||
============================================================
|
||||
|
||||
在大多数情况下,我们习惯于使用 `Delete` 键、垃圾箱或 `rm` 命令[从我们的计算机中删除文件][1],但这不是永久安全地从硬盘中(或任何存储介质)删除文件的方法。
|
||||
|
||||
该文件只是对用户隐藏,它驻留在硬盘上的某个地方。它有可能被数据窃贼、执法取证或其它方式来恢复。
|
||||
|
||||
假设文件包含密级或机密内容,例如安全系统的用户名和密码,具有必要知识和技能的攻击者可以轻松地[恢复删除文件的副本][2]并访问这些用户凭证(你可以猜测到这种情况的后果)。
|
||||
|
||||
在本文中,我们将解释一些命令行工具,用于永久并安全地删除 Linux 中的文件。
|
||||
|
||||
### 1、 shred – 覆盖文件来隐藏内容
|
||||
|
||||
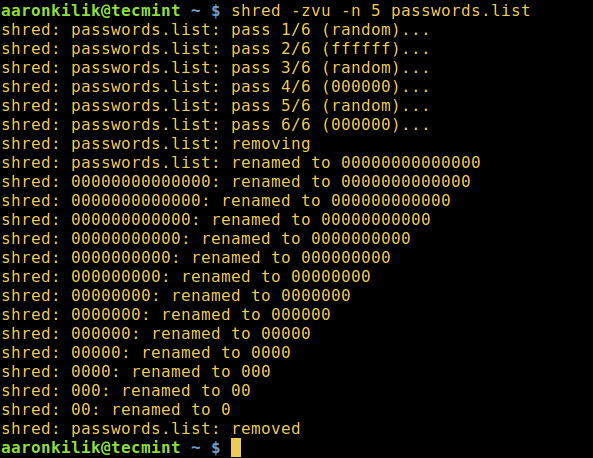
`shred` 会覆盖文件来隐藏它的内容,并且也可以选择删除它。
|
||||
|
||||
```
|
||||
$ shred -zvu -n 5 passwords.list
|
||||
```
|
||||
|
||||
在下面的命令中,选项有:
|
||||
|
||||
1. `-z` - 用零覆盖以隐藏碎片
|
||||
2. `-v` - 显示操作进度
|
||||
3. `-u` - 在覆盖后截断并删除文件
|
||||
4. `-n` - 指定覆盖文件内容的次数(默认值为3)
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
*shred - 覆盖文件来隐藏它的内容*
|
||||
|
||||
你可以在 `shred` 的帮助页中找到更多的用法选项和信息:
|
||||
|
||||
```
|
||||
$ man shred
|
||||
```
|
||||
|
||||
### 2、 wipe – 在 Linux 中安全删除文件
|
||||
|
||||
`wipe` 命令可以安全地擦除磁盘中的文件,从而不可能[恢复删除的文件或目录内容][4]。
|
||||
|
||||
首先,你需要安装 `wipe` 工具,运行以下适当的命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get install wipe [Debian 及其衍生版]
|
||||
$ sudo yum install wipe [基于 RedHat 的系统]
|
||||
```
|
||||
|
||||
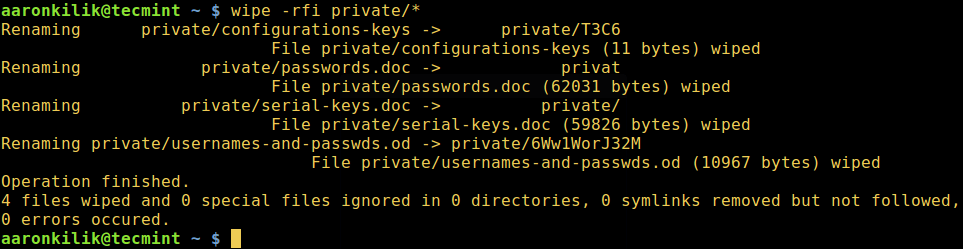
下面的命令会销毁 private 目录下的所有文件。
|
||||
|
||||
```
|
||||
$ wipe -rfi private/*
|
||||
```
|
||||
|
||||
当使用下面的标志时:
|
||||
|
||||
1. `-r` - 告诉 `wipe` 递归地擦除子目录
|
||||
2. `-f` - 启用强制删除并禁用确认查询
|
||||
3. `-i` - 显示擦除进度
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
*wipe – 在 Linux 中安全擦除文件*
|
||||
|
||||
注意:`wipe` 仅可以在磁性存储上可以可靠地工作,因此对固态磁盘(内存)请使用其他方法。
|
||||
|
||||
阅读 `wipe` 手册以获取其他使用选项和说明:
|
||||
|
||||
```
|
||||
$ man wipe
|
||||
```
|
||||
|
||||
### 3、 Linux 中的安全删除工具集
|
||||
|
||||
secure-delete 是一个安全文件删除工具的集合,它包含用于安全删除文件的 `srm`(secure_deletion)工具。
|
||||
|
||||
首先,你需要使用以下相关命令安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install secure-delete [On Debian and its derivatives]
|
||||
$ sudo yum install secure-delete [On RedHat based systems]
|
||||
```
|
||||
|
||||
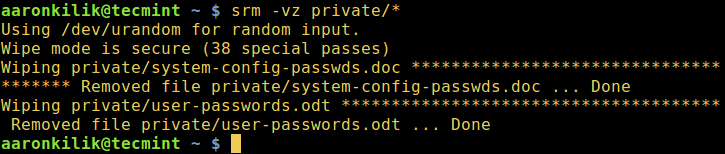
安装完成后,你可以使用 `srm` 工具在 Linux 中安全地删除文件和目录。
|
||||
|
||||
```
|
||||
$ srm -vz private/*
|
||||
```
|
||||
|
||||
下面是使用的选项:
|
||||
|
||||
1. `-v` – 启用 verbose 模式
|
||||
2. `-z` – 用0而不是随机数据来擦除最后的写入
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
*srm – 在 Linux 中安全删除文件*
|
||||
|
||||
阅读 srm 手册来获取更多的使用选项和信息:
|
||||
|
||||
```
|
||||
$ man srm
|
||||
```
|
||||
|
||||
### 4、 sfill -安全免费的磁盘 / inode 空间擦除器
|
||||
|
||||
`sfill` 是 secure-deletetion 工具包的一部分,是一个安全免费的磁盘和 inode 空间擦除器,它以安全的方法删除可用磁盘空间中的文件。 `sfill` 会[检查指定分区上的可用空间][7],并使用来自 `/dev/urandom` 的随机数据填充它。
|
||||
|
||||
以下命令将在我的根分区上执行 `sfill`,使用 `-v' 选项启用 verbose 模式:
|
||||
|
||||
```
|
||||
$ sudo sfill -v /home/aaronkilik/tmp/
|
||||
```
|
||||
|
||||
假设你创建了一个单独的分区 `/home` 来存储正常的系统用户主目录,你可以在该分区上指定一个目录,以便在其上应用 `sfill`:
|
||||
|
||||
```
|
||||
$ sudo sfill -v /home/username
|
||||
```
|
||||
|
||||
你可以在 sfill 的手册上看到一些限制,你也可以看到额外的使用标志和命令:
|
||||
|
||||
```
|
||||
$ man sfill
|
||||
```
|
||||
|
||||
注意:secure-deletetion 工具包中的另外两个工具(`sswap` 和 `sdmem`)与本指南的范围不直接相关,但是,为了将来的使用和传播知识的目的,我们会在下面介绍它们。
|
||||
|
||||
### 5、 sswap – 安全 swap 擦除器
|
||||
|
||||
它是一个安全的分区擦除器,`sswap` 以安全的方式删除 swap 分区上存在的数据。
|
||||
|
||||
警告:请记住在使用 `sswap` 之前卸载 swap 分区! 否则你的系统可能会崩溃!
|
||||
|
||||
要找到交换分区(并检查分页和交换设备/文件是否已经使用,请使用 `swapon` 命令),接下来,使用 `swapoff` 命令禁用分页和交换设备/文件(使 swap 分区不可用)。
|
||||
|
||||
然后在(关闭的) swap 分区上运行 `sswap` 命令:
|
||||
|
||||
```
|
||||
$ cat /proc/swaps
|
||||
$ swapon
|
||||
$ sudo swapoff /dev/sda6
|
||||
$ sudo sswap /dev/sda6 #this command may take some time to complete with 38 default passes
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*sswap – 安全 swap 擦除器*
|
||||
|
||||
阅读 `sswap` 的手册来获取更多的选项和信息:
|
||||
|
||||
```
|
||||
$ man sswap
|
||||
```
|
||||
|
||||
### 6、 sdmem – 安全内存擦除器
|
||||
|
||||
`sdmem` 是一个安全的内存擦除器,其设计目的是以安全的方式删除存储器(RAM)中的数据。
|
||||
|
||||
它最初命名为 [smem][9],但是因为在 Debain 系统上存在另一个包 [smem - 报告每个进程和每个用户的内存消耗][10],开发人员决定将它重命名为 `sdmem`。
|
||||
|
||||
```
|
||||
$ sudo sdmem -f -v
|
||||
```
|
||||
|
||||
关于更多的使用信息,阅读 `sdmen` 的手册:
|
||||
|
||||
```
|
||||
$ man sdmem
|
||||
```
|
||||
|
||||
**推荐阅读:** [在 Linux 系统下使用 PhotoRec & TestDisk 工具来恢复文件][11]。
|
||||
|
||||
就是这样了!在本文中,我们查看了一系列可以永久安全地删除 Linux 中的文件的工具。像往常一样,通过下面的评论栏发表你对本篇文章的想法或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Aaron Kili 是一个 Linux 系统及 F.O.S.S 爱好者,即将成为一名系统管理员及 Web 开发人员,他现在是 TecMint 网站的内容创建者,他喜欢使用电脑来工作,并且他坚信分享知识是一种美德。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:https://linux.cn/article-7954-1.html
|
||||
[2]:https://linux.cn/article-8122-1.html
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/shred-command-example.png
|
||||
[4]:https://linux.cn/article-7974-1.html
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/01/Wipe-Securely-Erase-Files.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/01/srm-securely-delete-Files-in-Linux.png
|
||||
[7]:https://linux.cn/article-8024-1.html
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/01/sswap-Secure-Swap-Wiper.png
|
||||
[9]:https://linux.cn/article-7681-1.html
|
||||
[10]:https://linux.cn/article-7681-1.html
|
||||
[11]:https://linux.cn/article-8122-1.html
|
||||
@ -0,0 +1,101 @@
|
||||
4 个 Linux 下最好的命令行下载管理器/加速器
|
||||
============================================================
|
||||
|
||||
我们经常由于不同需求使用下载管理器从互联网下载文件,它给我和其他人提供了很多帮助。我们都想要一个超级快速的下载管理器来完成下载尽可能多的任务,以便我们可以节省时间来进一步地工作。有很多可以加速下载的下载管理器和加速器可用(图形化界面和命令行界面)。
|
||||
|
||||
所有的下载工具做着同样的任务,但它们的处理方式和功能是不同的,比如,单线程和多线程、交互和非交互。 在这里,我们将列出 4 个最好的我们日常工作使用的命令行下载加速器。
|
||||
|
||||
#### #1 Aria2
|
||||
|
||||
[Aria2][1] 是一个用于 Linux、Windows 和 Mac OSX 的轻量级、多协议和多源的命令行下载管理器/实用程序。它支持 HTTP/HTTPS、FTP、SFTP、BitTorrent 和 Metalink。aria2 可以通过内置的 JSON-RPC 和 XML-RPC 接口操作。
|
||||
|
||||
它支持多线程,可以使用多个源或协议下载文件,确实可以加速并尽可能多的完成下载。
|
||||
|
||||
它非常轻量级,不需要太多的内存和 CPU。我们可以使用它作为 BitTorrent 客户端,因为它有所有你想要的 BitTorrent 客户端的功能。
|
||||
|
||||
#### Aria2 功能
|
||||
|
||||
* 支持 HTTP/HTTPS GET 方式
|
||||
* 支持 HTTP 代理
|
||||
* 支持 HTTP BASIC 认证
|
||||
* 支持 HTTP 代理认证
|
||||
* 支持 FTP (主动、被动模式)
|
||||
* 通过 HTTP 代理的 FTP(GET 命令或隧道)
|
||||
* 分段下载
|
||||
* 支持 Cookie
|
||||
* 它可以作为守护进程运行。
|
||||
* 支持 BitTorrent 协议和 fast 扩展。
|
||||
* 在含有多个文件的 torrent 中的选择性下载
|
||||
* 支持 Metalink 版本 3.0 (HTTP/FTP/BitTorrent)。
|
||||
* 限制下载/上传速度
|
||||
|
||||
有关 Aria2 的进一步用法,请参阅以下文章:[如何在 Linux 中安装和使用 Aria2][2]。
|
||||
|
||||
#### #2 Axel
|
||||
|
||||
[Axel][3] 是一个轻量级下载程序,它如其他加速器那样做着同样的事情。它可以为一个文件打开多个连接,每个连接下载单独的文件片段以更快地完成下载。
|
||||
|
||||
Axel 支持 HTTP、HTTPS、FTP 和 FTPS 协议。它也可以使用多个镜像站点来下载单个文件。 所以,Axel 可以为下载加速高达 40%(大约,我个人认为)。 它非常轻量级,因为没有依赖,而且使用非常少的 CPU 和内存。
|
||||
|
||||
Axel 使用一个单线程将所有数据直接下载到目标文件。
|
||||
|
||||
注意:没有可以在单条命令中下载两个文件的选项。
|
||||
|
||||
有关 Axel 的更多使用,请参阅以下文章:[如何在 Linux 中安装和使用 Axel][4]。
|
||||
|
||||
#### #3 Wget
|
||||
|
||||
[wget][5](以前称为 Geturl)是一个免费的、开源的命令行下载程序,它使用 HTTP、HTTPS 和 FTP 这些最广泛使用的 Internet 协议来获取文件。它是一个非交互式命令行工具,其名字是意思是从万维网中获取文件。
|
||||
|
||||
相比其它工具,wget 将下载处理得相当好,即使它不支持多线程以及包括后台工作、递归下载、多个文件下载、恢复下载、非交互式下载和大文件下载在内的功能。
|
||||
|
||||
默认情况下,所有的 Linux 发行版都包含 wget,所以我们可以从官方仓库轻松安装,也可以安装到 windows 和 Mac 操作系统。
|
||||
|
||||
wget 可在慢速或不稳定的网络连接下保持健壮性,如果由于网络问题下载失败,它将继续重试,直到整个文件下载完成。如果服务器支持重新获取,它将指示服务器从中断的地方继续下载。
|
||||
|
||||
#### wget 功能
|
||||
|
||||
* 可以使用 REST 和 RANGE 恢复中止的下载
|
||||
* 可以使用文件名通配符和递归来对目录进行镜像同步
|
||||
* 基于 NLS 消息文件,提供许多不同语言支持
|
||||
* 可选将下载的文档中的绝对链接转换为相对链接,以便下载的文档可以在本地链接到彼此
|
||||
* 可在大多数类 UNIX 操作系统以及 Microsoft Windows 上运行
|
||||
* 支持 HTTP 代理
|
||||
* 支持 HTTP cookie
|
||||
* 支持持久 HTTP 连接
|
||||
* 无人值守/后台操作
|
||||
* 使用本地文件时间戳来确定是否需要在镜像时重新下载文档
|
||||
|
||||
有关 wget 的进一步用法,请参阅以下文章:[如何在 Linux 中安装和使用 wget][6]。
|
||||
|
||||
#### #4 Curl
|
||||
|
||||
[curl][7] 类似于 wget,但是不支持多线程,但令人惊讶的是,与 wget 相比,它的下载速度更快。
|
||||
|
||||
curl 是一个向服务器上传或下载的数据传输工具,支持的协议有 DICT、FILE、FTP、FTPS、GOPHER、HTTP、HTTPS、IMAP、IMAPS、LDAP、LDAPS、POP3、POP3S、RTMP、RTSP、SCP、SFTP、SMTP、SMTPS、TELNET 和 TFT 等。
|
||||
|
||||
该命令无需用户交互即可工作。此外,curl 支持代理、用户身份验证、FTP 上传、HTTP POST、SSL 连接、Cookie、恢复文件传输、Metalink 等。curl 由 libcurl 为所有相关传输功能提供支持。
|
||||
|
||||
如果指定的 URL 没有 `protocol://` 前缀,curl 将尝试猜测你可能需要什么协议。例如,以 “ftp.” 开头的主机名 curl 将假定你要使用 FTP。如果没有找到特定的协议,那么默认为 HTTP。
|
||||
|
||||
参考下面的文章来进一步使用 curl:[如何在 Linux 中安装和使用 curl] [8]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/best-4-command-line-download-managers-accelerators-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:https://aria2.github.io/
|
||||
[2]:https://linux.cn/article-7982-1.html
|
||||
[3]:https://axel.alioth.debian.org/
|
||||
[4]:http://www.2daygeek.com/axel-command-line-downloader-accelerator-for-linux/
|
||||
[5]:https://www.gnu.org/software/wget/
|
||||
[6]:https://linux.cn/article-4129-1.html
|
||||
[7]:https://curl.haxx.se/
|
||||
[8]:http://www.2daygeek.com/curl-command-line-download-manager/
|
||||
@ -1,13 +1,13 @@
|
||||
使用 Axel 命令行下载器/加速器加速你的下载
|
||||
使用 Axel 命令行下载器/加速器加速下载
|
||||
============================================================
|
||||
|
||||
[Axel][7] 是一个轻量级下载程序,它和其他加速器一样,为一个文件打开多个连接,每个连接下载单独的文件片段以更快地完成下载。
|
||||
[Axel][7] 是一个轻量级下载程序,它和其他加速器一样,对同一个文件建立多个连接,每个连接下载单独的文件片段以更快地完成下载。
|
||||
|
||||
Axel 支持 HTTP、HTTPS、FTP和 FTPS 协议。它也可以使用多个镜像下载单个文件。所以,Axel 可以加速下载高达 40%(大约,我个人认为)。它非常轻量级,因为它没有依赖并且使用非常少的 CPU 和 RAM。
|
||||
Axel 支持 HTTP、HTTPS、FTP 和 FTPS 协议。它也可以使用多个镜像站点下载单个文件,所以,Axel 可以加速下载高达 40%(大约,我个人认为)。它非常轻量级,因为它没有依赖并且使用非常少的 CPU 和内存。
|
||||
|
||||
Axel 使用一个单线程将所有数据直接下载到目标文件。
|
||||
Axel 一步到位地将所有数据直接下载到目标文件(LCTT 译注:而不是像其它的下载软件那样下载成多个文件块,然后拼接)。
|
||||
|
||||
**注意**:没有选项可以在单条命令中下载两个文件。
|
||||
**注意**:不支持在单条命令中下载两个文件。
|
||||
|
||||
你还可以尝试其他命令行下载管理器/加速器。
|
||||
|
||||
@ -76,7 +76,7 @@ Downloaded 21.6 megabytes in 3 seconds. (5755.94 KB/s)
|
||||
|
||||
#### 2) 用不同的名称保存文件
|
||||
|
||||
要使用其他名称来保存文件,启动下载时可以添加 -o(小写)选项和文件名。这里我们使用文件名 **owncloud.tar.bz2** 来保存文件。
|
||||
要使用其他名称来保存文件,启动下载时可以添加 `-o`(小写字母)选项和文件名。这里我们使用文件名 `owncloud.tar.bz2` 来保存文件。
|
||||
|
||||
```
|
||||
# axel -o cloud.tar.bz2 https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -114,7 +114,7 @@ Downloaded 21.6 megabytes in 3 seconds. (6001.05 KB/s)
|
||||
|
||||
#### 3) 限制下载速度
|
||||
|
||||
默认 axel 以字节/秒为单位设置下载文件的最大速度。当我们的网络连接速度较慢时,可以使用此选项。只需添加 `-s` 选项,后面跟字节值。这里我们要限速 `512 KB/s` 下载一个文件。
|
||||
默认情况下 axel 以字节/秒为单位设置下载文件的最大速度。当我们的网络连接速度较慢时,可以使用此选项。只需添加 `-s` 选项,后面跟字节值。这里我们要限速 `512 KB/s` 下载一个文件。
|
||||
|
||||
```
|
||||
# axel -s 512000 https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -150,7 +150,7 @@ Downloaded 21.6 megabytes in 44 seconds. (494.54 KB/s)
|
||||
|
||||
#### 4) 限制连接数
|
||||
|
||||
axel 默认建立 4 个连接以从不同的镜像获取文件。此外,我们可以通过使用 `-n` 选项添加更多的连接,后跟连接数 `10` 来提高下载速度。我们为了更安全新添加了八个连接,但不幸的是,它花了更多时间来下载文件。
|
||||
axel 默认建立 4 个连接以从不同的镜像获取文件。此外,我们可以通过使用 `-n` 选项添加更多的连接,后跟连接数 `10` 来提高下载速度。保险起见,我们添加了十个连接,但不幸的是,它花了更多时间来下载文件。
|
||||
|
||||
```
|
||||
# axel -n 10 https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -267,7 +267,7 @@ Downloaded 3415.4 kilobytes in 1 second. (2264.93 KB/s)
|
||||
|
||||
#### 7) 替换进度条
|
||||
|
||||
如果你不喜欢默认的进度条,你可以使用 **-a** 选项来替换进度条。
|
||||
如果你不喜欢默认的进度条,你可以使用 `-a` 选项来替换进度条。
|
||||
|
||||
```
|
||||
# axel -a https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -281,7 +281,7 @@ Starting download
|
||||
Downloaded 14.3 megabytes in 2 seconds. (5916.11 KB/s)
|
||||
```
|
||||
|
||||
我们已经了中断上面的下载,以便在下载文件时能清楚地显示替代进度条状态。一旦文件成功下载后,你可以看到相同的输出,如下所示。
|
||||
我们中断了上面的下载,以便在下载文件时能清楚地显示替代进度条状态。一旦文件成功下载后,你可以看到相同的输出,如下所示。
|
||||
|
||||
```
|
||||
# axel -a https://download.owncloud.org/community/owncloud-9.0.0.tar.bz2
|
||||
@ -297,7 +297,7 @@ Connection 0 finished ]
|
||||
Downloaded 21.6 megabytes in 4 seconds. (5062.32 KB/s)
|
||||
```
|
||||
|
||||
#### 8) 阅读更多关于 axel
|
||||
#### 8) 了解关于 axel 的更多信息
|
||||
|
||||
如果你想要了解更多关于 axel 的选项,只需要进入它的手册。
|
||||
|
||||
@ -313,7 +313,7 @@ Downloaded 21.6 megabytes in 4 seconds. (5062.32 KB/s)
|
||||
|
||||
via: http://www.2daygeek.com/axel-command-line-downloader-accelerator-for-linux/
|
||||
|
||||
作者:[ MAGESH MARUTHAMUTHU][a]
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -323,7 +323,7 @@ via: http://www.2daygeek.com/axel-command-line-downloader-accelerator-for-linux/
|
||||
[1]:http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
[2]:http://www.2daygeek.com/wget-command-line-download-utility-tool/
|
||||
[3]:http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
[4]:http://www.2daygeek.com/best-4-command-line-download-managers-accelerators-for-linux/
|
||||
[5]:http://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[4]:https://linux.cn/article-8124-1.html
|
||||
[5]:https://linux.cn/article-2324-1.html
|
||||
[6]:http://www.2daygeek.com/author/magesh/
|
||||
[7]:https://axel.alioth.debian.org/
|
||||
@ -1,11 +1,11 @@
|
||||
让 sudo 在你输入错误的密码时冒犯你
|
||||
让 sudo 在你输入错误的密码时“嘲讽”你
|
||||
============================================================
|
||||
|
||||
sudoers 是 Linux 中的默认 sudo 安全策略插件,但是经验丰富的系统管理员可以自定义安全策略以及输入输出日志记录的插件。它由 `/etc/sudoers` 这个文件驱动,或者也可在 LDAP 中。
|
||||
**sudoers** 是 Linux 中的默认 sudo 安全策略插件,但是经验丰富的系统管理员可以自定义安全策略以及输入输出日志记录的插件。它由 `/etc/sudoers` 这个文件驱动,或者也可在 LDAP 中。
|
||||
|
||||
你可以在上面的文件中定义 sudoers insults 或其他选项。它在 defaults 部分下设置。请阅读通过我们的上一篇文章[在Linux中设置 `sudo` 时 10 个有用的 sudoers 配置][1]。
|
||||
你可以在上面的文件中定义 **sudoers** <ruby>嘲讽<rt>insults</rt></ruby> 或其他选项。它在 `defaults` 部分下设置。请阅读我们的上一篇文章[在 Linux 中设置 `sudo` 时 10 个有用的 sudoers 配置][1]。
|
||||
|
||||
在本文中,我们将解释一个 sudoers 配置参数,以允许个人或系统管理员设置[sudo 命令][2]来冒犯输入错误密码的系统用户。
|
||||
在本文中,我们将解释一个 sudoers 配置参数,以允许个人或系统管理员设置 [sudo 命令][2],当系统用户输入错误密码时“嘲讽”他们。
|
||||
|
||||
首先打开文件 `/etc/sudoers`,如下所示:
|
||||
|
||||
@ -13,25 +13,25 @@ sudoers 是 Linux 中的默认 sudo 安全策略插件,但是经验丰富的
|
||||
$ sudo visudo
|
||||
```
|
||||
|
||||
进入 defaults 部分,并添加下面的行:
|
||||
进入 `defaults` 部分,并添加下面的行:
|
||||
|
||||
```
|
||||
Defaults insults
|
||||
```
|
||||
|
||||
下面是我系统中 /etc/sudoers 默认展示的 defaults 部分。
|
||||
下面是我系统中 `/etc/sudoers` 默认展示的 `defaults` 部分。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
设置 sudo insults 参数
|
||||
*设置 sudo insults 参数*
|
||||
|
||||
从上面的截图中,你可以看到还有许多其他默认值定义,例如,当每次用户输入错误的密码、设置安全路径、配置自定义 sudo 日志文件等时发送邮件到 root。
|
||||
从上面的截图中,你可以看到 `defaults` 中还有许多其他默认值定义,例如,每次用户输入错误的密码时发送邮件到 root、设置安全路径、配置自定义 sudo 日志文件等。
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
使用 sudo 运行命令并输入错误的密码,然后观察 insults 选项是如何工作的:
|
||||
运行 `sudo` 命令并输入错误的密码,然后观察 insults 选项是如何工作的:
|
||||
|
||||
```
|
||||
$ sudo visudo
|
||||
@ -40,11 +40,11 @@ $ sudo visudo
|
||||

|
||||
][4]
|
||||
|
||||
实践 sudo insult
|
||||
*实践 sudo insult*
|
||||
|
||||
注意:当配置 insults 参数时,它会禁用 `badpass_message` 参数,该参数会在命令行中输出特定的消息(默认消息为 “sorry, try again”),以防用户输入错误的密码。
|
||||
**注意**:当配置 insults 参数时,它会禁用 `badpass_message` 参数,该参数在用户输入错误的密码时,会在命令行中输出特定的消息(默认消息为 “**sorry, try again**”)。
|
||||
|
||||
要修改消息,请将 `badpass_message` 参数添加到 /etc/sudoers 文件中,如下所示。
|
||||
要修改该消息,请将 `badpass_message` 参数添加到 `/etc/sudoers` 文件中,如下所示。
|
||||
|
||||
```
|
||||
Defaults badpass_message="Password is wrong, please try again" #try to set a message of your own
|
||||
@ -53,9 +53,9 @@ Defaults badpass_message="Password is wrong, please try again" #try to set a m
|
||||

|
||||
][5]
|
||||
|
||||
设置 sudo 错误密码消息
|
||||
*设置 sudo 错误密码消息*
|
||||
|
||||
保存并关闭文件,然后调用 sudo 查看它是如何工作的,你设置的 badpass_message 消息会在每次你或任何系统用户输入错误的密码的时候打印出来。
|
||||
保存并关闭文件,然后调用 `sudo` 查看它是如何工作的,你设置的 `badpass_message` 消息会在每次你或任何系统用户输入错误的密码的时候打印出来。
|
||||
|
||||
```
|
||||
$ sudo visudo
|
||||
@ -64,9 +64,9 @@ $ sudo visudo
|
||||

|
||||
][6]
|
||||
|
||||
sudo 错误密码消息
|
||||
*sudo 密码错误消息*
|
||||
|
||||
就是这样了,在本文中,我们回顾了如何在用户输入错误的密码时将 sudo 设置为打印 insults。请通过下面的评论栏分享你的想法。
|
||||
就是这样了,在本文中,我们回顾了如何在用户输入错误的密码时将 `sudo` 设置为显示嘲讽。请通过下面的评论栏分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -83,7 +83,7 @@ via: http://www.tecmint.com/sudo-insult-when-enter-wrong-password/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,49 +1,49 @@
|
||||
了解基础的 Linux I/O (输入/输出) 重定向原理
|
||||
Linux I/O 重定向基础
|
||||
============================================================
|
||||
|
||||
Linux 管理的一个最重要并且[有趣的话题][4]是 I/O 重定向。此功能在命令行中使你能够将命令的输入以及/或者输出输入或者输出到文件中,或使用管道将多个命令连接在一起以形成所谓的“命令管道”。
|
||||
Linux 管理的一个最重要并且[有趣的话题][4]是 I/O 重定向。此功能在命令行中使你能够将命令的输入输出取自或送到文件中,或者可以使用管道将多个命令连接在一起以形成所谓的“**命令管道**”。
|
||||
|
||||
我们运行的所有命令基本上产生两种输出:
|
||||
|
||||
1.命令结果 - 程序设计产生的数据
|
||||
2.程序状态和错误消息,用来通知用户程序的执行细节。
|
||||
- 命令结果 - 程序产生的数据,以及
|
||||
- 程序状态和错误消息,用来通知用户程序的执行细节。
|
||||
|
||||
在 Linux 和其他类 Unix 系统中,有三个默认文件,这些文件也由 shell 使用文件描述符号标识:
|
||||
在 Linux 和其他类 Unix 系统中,有三个默认文件(名称如下),这些文件也由 shell 使用文件描述符号标识:
|
||||
|
||||
1. stdin 或 0 - 它连接到键盘,大多数程序从此文件读取输入。
|
||||
2. stdout 或 1 - 它连接到屏幕,并且所有程序将其结果发送到此文件
|
||||
3. stderr 或 2 - 程序将状态/错误消息发送到此文件,该文件也发送到屏幕上。
|
||||
- stdin 或 0 - 它连接键盘,大多数程序从此文件读取输入。
|
||||
- stdout 或 1 - 它连接屏幕,并且所有程序将其结果发送到此文件
|
||||
- stderr 或 2 - 程序将状态/错误消息发送到此文件,它也连接到屏幕上。
|
||||
|
||||
因此,I/O 重定向允许你更改命令的输入源以及将输出和错误消息发送到其他地方。这可以通过 `“<”` 和 `“>”` 重定向操作符来实现。
|
||||
因此,I/O 重定向允许你更改命令的输入源以及将输出和错误消息发送到其他地方。这可以通过 `<` 和 `>` 重定向操作符来实现。
|
||||
|
||||
### 如何在 Linux 中重定向标准输出到文件中
|
||||
|
||||
如下面的示例所示,你可以重定向标准输出,这里,我们要存储[ top 命令][5]的输出以供以后检查:
|
||||
如下面的示例所示,你可以重定向标准输出,这里,我们要存储 [top 命令][5]的输出以供以后检查:
|
||||
|
||||
```
|
||||
$ top -bn 5 >top.log
|
||||
```
|
||||
|
||||
有这些标志:
|
||||
其中标志的含义:
|
||||
|
||||
1. `-b` - 让 top 以批处理模式运行,以便你可以将其输出重定向到一个文件或另一个命令。
|
||||
2. `-n` - 指定命令终止前的迭代次数。
|
||||
- `-b` - 让 `top` 以批处理模式运行,以便你可以将其输出重定向到一个文件或另一个命令。
|
||||
- `-n` - 指定命令终止前的迭代次数。
|
||||
|
||||
你可以使用[ cat 命令][6]来查看 `top.log` 文件的内容:
|
||||
你可以使用 [cat 命令][6]来查看 `top.log` 文件的内容:
|
||||
|
||||
```
|
||||
$ cat top.log
|
||||
```
|
||||
|
||||
要附加命令的输出,请使用 `“>>”` 操作符。
|
||||
要将命令输出**附加**在文件后面,请使用 `>>` 操作符。
|
||||
|
||||
例如,在 top.log 文件中,特别是在脚本(或命令行)中追加上面的[ top 命令][7]的输出,请输入下面的那行:
|
||||
例如,要将 [top 命令][7]的输出追加在上面的 `top.log` 文件中,特别是在脚本(或命令行)中,请输入下面的那行:
|
||||
|
||||
```
|
||||
$ top -bn 5 >>top.log
|
||||
```
|
||||
|
||||
注意: 使用文件描述符数字,上面的重定向命令等同于:
|
||||
**注意**: 也可以使用文件描述符数字,上面的重定向命令等同于:
|
||||
|
||||
```
|
||||
$ top -bn 5 1>top.log
|
||||
@ -53,7 +53,7 @@ $ top -bn 5 1>top.log
|
||||
|
||||
要重定向命令的标准错误,你需要明确指定文件描述符 `2`,以便让 shell 了解你正在尝试做什么。
|
||||
|
||||
例如,下面的[ ls 命令][8]将在没有 root 权限的普通系统用户执行时产生错误:
|
||||
例如,下面的 [ls 命令][8]将在没有 root 权限的普通系统用户执行时产生错误:
|
||||
|
||||
```
|
||||
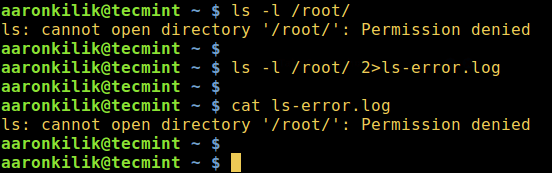
$ ls -l /root/
|
||||
@ -65,37 +65,39 @@ $ ls -l /root/
|
||||
$ ls -l /root/ 2>ls-error.log
|
||||
$ cat ls-error.log
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
重定向标准到文件中
|
||||
*重定向标准错误到文件中*
|
||||
|
||||
为了附加到标准错误,使用下面的命令:
|
||||
为了将标准错误附加在文件后,使用下面的命令:
|
||||
|
||||
```
|
||||
$ ls -l /root/ 2>>ls-error.log
|
||||
```
|
||||
|
||||
### 如何重定向标准输出/错误到一个文件中
|
||||
### 如何重定向标准输出及标准错误到一个文件中
|
||||
|
||||
还可以将命令的所有输出(标准输出和标准错误)捕获到单个文件中。这可以用两种可能的方式通过指定文件描述符来完成:
|
||||
还可以将命令的所有输出(包括标准输出和标准错误)捕获到单个文件中。这可以用两种可能的方式,通过指定文件描述符来完成:
|
||||
|
||||
1. 第一种是相对较旧的方法,其工作方式如下:
|
||||
1、 第一种是相对较旧的方法,其工作方式如下:
|
||||
|
||||
```
|
||||
$ ls -l /root/ >ls-error.log 2>&1
|
||||
```
|
||||
|
||||
上面的命令意思是 shell 首先将[ ls 命令][10]的输出发送到文件 ls-error.log(使用 `> ls-error.log`),然后将所有错误消息写入文件描述符 2(标准输出),它已被重定向到文件 ls-error.log(使用`2>&1`)中。这表示标准错误也被发送到与标准输出相同的文件中。
|
||||
上面的命令意思是 shell 首先将 [ls 命令][10]的输出发送到文件 `ls-error.log`(使用 `>ls-error.log`),然后将所有写到文件描述符 `2`(标准错误)的错误消息重定向到文件 `ls-error.log`(使用`2>&1`)中。(LCTT 译注:此处原文有误,径改。)这表示标准错误也被发送到与标准输出相同的文件中。
|
||||
|
||||
2. 第二种直接的方法是:
|
||||
|
||||
2、 第二种并且更直接的方法是:
|
||||
|
||||
```
|
||||
$ ls -l /root/ &>ls-error.log
|
||||
```
|
||||
|
||||
你也可以这样将标准输出和标准错误附加到单个文件中:
|
||||
你也可以这样将标准输出和标准错误附加到单个文件后:
|
||||
|
||||
```
|
||||
$ ls -l /root/ &>>ls-error.log
|
||||
@ -103,9 +105,9 @@ $ ls -l /root/ &>>ls-error.log
|
||||
|
||||
### 如何将标准输入重定向到文件中
|
||||
|
||||
大多数(如果不是全部)命令从标准输入获得其输入,并且默认标准输入连接到键盘。
|
||||
大多数(如果不是全部)命令从标准输入获得其输入,并且标准输入默认连接到键盘。
|
||||
|
||||
要从键盘以外的文件重定向标准输入,请使用 `“<”` 操作符,如下所示:
|
||||
要从键盘以外的文件重定向标准输入,请使用 `<` 操作符,如下所示:
|
||||
|
||||
```
|
||||
$ cat <domains.list
|
||||
@ -115,11 +117,11 @@ $ cat <domains.list
|
||||

|
||||
][11]
|
||||
|
||||
重定向文件到标准输入中
|
||||
*重定向文件到标准输入中*
|
||||
|
||||
### 如何重定向标准输入/输出到文件中
|
||||
|
||||
你可以如下在[ sort 命令中][12] 同时执行标准输入、标准输出重定向:
|
||||
你可以如下在 [sort 命令中][12] 同时执行标准输入、标准输出的重定向:
|
||||
|
||||
```
|
||||
$ sort <domains.list >sort.output
|
||||
@ -127,9 +129,10 @@ $ sort <domains.list >sort.output
|
||||
|
||||
### 如何使用管道进行 I/O 重定向
|
||||
|
||||
要将一个命令的输出重定向为另一个命令的输入,你可以使用管道,这是用于构建具有复杂操作命令的有力方法。
|
||||
要将一个命令的输出重定向为另一个命令的输入,你可以使用管道,这是用于构建复杂操作命令的有力方法。
|
||||
|
||||
例如,以下命令将[列出前五个最近修改的文件][13]。
|
||||
|
||||
例如,以下命令将[列出最近修改的前五个文件][13]。
|
||||
|
||||
```
|
||||
$ ls -lt | head -n 5
|
||||
@ -137,38 +140,39 @@ $ ls -lt | head -n 5
|
||||
|
||||
选项的意思是:
|
||||
|
||||
1. `-l` - 启用长列表格式
|
||||
2. `-t` - [最新修改的文件][1]首先显示
|
||||
3. `-n` - 指定要显示的标题行数
|
||||
- `-l` - 启用长列表格式
|
||||
- `-t` - [最新修改的文件][1]首先显示
|
||||
- `-n` - 指定要显示的标题行数
|
||||
|
||||
### 构建管道的重要命令
|
||||
|
||||
在这里,我们将简要回顾一下构建命令管道的两个重要命令,它们是:
|
||||
|
||||
xargs 用于从标准输入构建和执行命令行。下面是使用 xargs 的管道示例,此命令用于[将文件复制到 Linux 中的多个目录][14]:
|
||||
`xargs` 用于从标准输入构建和执行命令行。下面是使用 `xargs` 的管道示例,此命令用于[将文件复制到 Linux 中的多个目录][14]:
|
||||
|
||||
```
|
||||
$ echo /home/aaronkilik/test/ /home/aaronkilik/tmp | xargs -n 1 cp -v /home/aaronkilik/bin/sys_info.sh
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
复制文件到多个目录
|
||||
*复制文件到多个目录*
|
||||
|
||||
添加选项:
|
||||
选项含义:
|
||||
|
||||
1. -n 1` - 让 xargs 对每个命令行最多使用一个参数,并发送到[cp命令][2]
|
||||
2. `cp` - 复制文件
|
||||
3. `-v` - [显示 copy 命令的进度][3]。
|
||||
- `-n 1` - 让 `xargs` 对每个命令行最多使用一个参数,并发送到 [cp命令][2]
|
||||
- `cp` - 复制文件
|
||||
- `-v` - [显示 `cp` 命令的进度][3]。
|
||||
|
||||
有关更多的使用选项和信息,请阅读 xargs 手册页:
|
||||
有关更多的使用选项和信息,请阅读 `xargs` 手册页:
|
||||
|
||||
```
|
||||
$ man xargs
|
||||
```
|
||||
|
||||
tee 命令从标准输入读取,并写入到标准输出和文件中。我们可以演示 tee 如何工作:
|
||||
`tee` 命令从标准输入读取,并写入到标准输出和文件中。我们可以演示 `tee` 如何工作:
|
||||
|
||||
```
|
||||
$ echo "Testing how tee command works" | tee file1
|
||||
@ -177,9 +181,9 @@ $ echo "Testing how tee command works" | tee file1
|
||||

|
||||
][16]
|
||||
|
||||
tee 命令示例
|
||||
*tee 命令示例*
|
||||
|
||||
[文件或文本过滤器][17]通常与管道一起用于[有效地操作 Linux 文件][18],用强大的方式来处理信息,例如命令的重组输出(这对于[生成有用的 Linux 报告][19]是必不可少的)、修改文件中的文本和其他的[ Linux 系统管理任务][20]。
|
||||
[文件或文本过滤器][17]通常与管道一起用于[有效地操作 Linux 文件][18],来以强大的方式来处理信息,例如命令的重组输出(这对于[生成有用的 Linux 报告][19]是必不可少的)、修改文件中的文本和其他的 [Linux 系统管理任务][20]。
|
||||
|
||||
要了解有关 Linux 过滤器和管道的更多信息,请阅读这篇文章[查找前十个访问 Apache 服务器的 IP 地址][21],这里展示了使用过滤器和管道的一个例子。
|
||||
|
||||
@ -195,13 +199,11 @@ Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin、web 开
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
via: http://www.tecmint.com/linux-io-input-output-redirection-operators/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,146 +0,0 @@
|
||||
2017 is the year that front-end developers should go back and master the basics
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
In our fast-paced ecosystem, we tend to spend our time trying out the latest inventions, then arguing about them on the internet.
|
||||
|
||||
I’m not saying we shouldn’t do that. But we should probably slow down a bit and take a look at the things that don’t change all that much. Not only will this improve the quality of our work and the value we deliver — it will actually help us learn these new tools faster.
|
||||
|
||||
This post is a mix of my experience and my wishes for the New Year. And I want to hear your suggestions in the comments just as much as I want to share my own.
|
||||
|
||||
### Learn how to write readable code
|
||||
|
||||
Most of our work lies not in writing new code, but maintaining existing code. That means you end up reading code much more often then writing it, so you need to optimize your code for _the next programmer_, not for the interpreter.
|
||||
|
||||
I recommend reading these three amazing books — in this order, from shortest to longest:
|
||||
|
||||
* [The Art of Readable Code][1] by Dustin Boswell
|
||||
* [Clean Code: A Handbook of Agile Software Craftsmanship][2] by Robert C. Martin
|
||||
* [Code Complete: A Practical Handbook of Software Construction][3] by Steve McConnell
|
||||
|
||||

|
||||
|
||||
### Learn JavaScript deeper
|
||||
|
||||
When every week we have a new JavaScript framework that’s better than any older framework, it’s easy to spend most of your time learning frameworks rather than the language itself. If you’re using a framework but don’t understand how it works, _stop and start learning the language until you understand how the tools you use work_.
|
||||
|
||||
* A great start is [Kyle][4] Simpson’s book series [You Don’t Know JavaScript][5], which you can read online for free.
|
||||
* [Eric Elliott][6] has a huge list of [JavaScript topics to learn in 2017][7].
|
||||
* [Henrique Alves][8] has a list of [things you should know before using React][9](actually any framework).
|
||||
* [JavaScript Developers: Watch Your Language][10] by Mike Pennisi — understand TC-39 process for new ECMAScript features.
|
||||
|
||||
### Learn functional programming
|
||||
|
||||
For years we wanted classes in JavaScript. Now we finally have them but don’t want to use them anymore. Functions are all we want! We even write HTML using functions (JSX).
|
||||
|
||||
* [Functional-Light JavaScript][11] by Kyle Simpson.
|
||||
* Professor Frisby’s [Mostly adequate guide to functional programming ebook][12] and [his free course][13].
|
||||
|
||||

|
||||
|
||||
### Learn design basics
|
||||
|
||||
As front-end developers, we’re closer to users than anybody else on the team — maybe even closer than designers. And if designers have to verify every pixel you put on screen, you’re doing something wrong.
|
||||
|
||||
* Design for Hackers: [a book][14] and [a free course][15] by [David Kadavy][16].
|
||||
* [Design for Non-Designers][17] talk by [Tracy Osborn][18].
|
||||
* [Design of Web Applications][19] by [Nathan Barry][20].
|
||||
* [On Web Typography][21] by [Jason Santa Maria][22].
|
||||
* [The Inmates Are Running the Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity][23] by Alan Cooper.
|
||||
* A few articles on animation in UI: [How to Use Animation to Improve UX][24], [Transitional Interfaces][25].
|
||||
|
||||
### Learn how to work with humans
|
||||
|
||||
Some of us come to programming because we prefer to interact with computers more than with humans. Unfortunately, that’s not how it works.
|
||||
|
||||
We rarely work in isolation: we have to talk to other developers, designers, managers — and sometimes even users. That’s hard. But it’s important if you want to really understand what you’re doing and why, because that’s where the value in what we do lies.
|
||||
|
||||
* [Soft Skills: The software developer’s life manual][26] by [John Sonmez][27].
|
||||
* [The Clean Coder: A Code of Conduct for Professional Programmers][28] by Robert C. Martin.
|
||||
* [Start with No: The Negotiating Tools that the Pros Don’t Want You to Know][29] by Jim Camp.
|
||||
|
||||

|
||||
|
||||
### Learn how to write for humans
|
||||
|
||||
A big portion of communication with our colleagues and other people are textual: task descriptions and comments, code comments, Git commits, chat messages, emails, tweets, blog posts, etc.
|
||||
|
||||
Imagine how much time people spend reading and understanding all that. If you can reduce this time by writing more clearly and concisely, the world will be a better place to work.
|
||||
|
||||
* [On Writing Well: The Classic Guide to Writing Nonfiction][30] by William Zinsser.
|
||||
* [The Elements of Style][31] by William Strunk and E. B. White.
|
||||
* [Orwell’s rules on writing][32].
|
||||
* In Russian: awesome [Glavred course][33].
|
||||
|
||||
### Learn the old computer science wisdom
|
||||
|
||||
Front-end development isn’t just animated dropdown menus any more. It’s more complicated than ever before. Part of that notorious “JavaScript fatigue” stems from the increased complexity of the tasks we have to solve.
|
||||
|
||||
This, however, means that it’s time to learn from all wisdom that non-front-end developers have built up over the decades. And this is where I want to hear your recommendations the most.
|
||||
|
||||
Here are a couple resources I personally would recommend on this:
|
||||
|
||||
* [Learn To Think Like A Computer Scientist][34] course at Coursera.
|
||||
* [The five programming books that meant most to me][35] by [DHH][36]
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
What would you recommend? What are you going to learn in 2017?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Web developer, passionate photographer and owner of crazy dogs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.com/what-to-learn-in-2017-if-youre-a-frontend-developer-b6cfef46effd#.ss9xbwrew
|
||||
|
||||
作者:[Artem Sapegin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.com/@sapegin
|
||||
[1]:https://www.amazon.com/gp/product/0596802293/
|
||||
[2]:https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882/
|
||||
[3]:https://www.amazon.com/Code-Complete-Practical-Handbook-Construction/dp/0735619670/
|
||||
[4]:https://medium.com/u/5dccb9bb4625
|
||||
[5]:https://github.com/getify/You-Dont-Know-JS
|
||||
[6]:https://medium.com/u/c359511de780
|
||||
[7]:https://medium.com/javascript-scene/top-javascript-frameworks-topics-to-learn-in-2017-700a397b711#.zhnbn4rvg
|
||||
[8]:https://medium.com/u/b6c3841651ac
|
||||
[9]:http://alves.im/blog/before-dive-into-react.html
|
||||
[10]:https://bocoup.com/weblog/javascript-developers-watch-your-language
|
||||
[11]:https://github.com/getify/Functional-Light-JS
|
||||
[12]:https://github.com/MostlyAdequate/mostly-adequate-guide
|
||||
[13]:https://egghead.io/courses/professor-frisby-introduces-composable-functional-javascript
|
||||
[14]:https://www.amazon.com/Design-Hackers-Reverse-Engineering-Beauty-ebook/dp/B005J578EW
|
||||
[15]:http://designforhackers.com/
|
||||
[16]:https://medium.com/u/5377a93ef640
|
||||
[17]:https://youtu.be/ZbrzdMaumNk
|
||||
[18]:https://medium.com/u/e611097a5bd4
|
||||
[19]:http://nathanbarry.com/webapps/
|
||||
[20]:https://medium.com/u/ac3090433602
|
||||
[21]:https://abookapart.com/products/on-web-typography
|
||||
[22]:https://medium.com/u/8eddcb9e4ac4
|
||||
[23]:https://www.amazon.com/Inmates-Are-Running-Asylum-Products-ebook/dp/B000OZ0N62/
|
||||
[24]:http://babich.biz/how-to-use-animation-to-improve-ux/
|
||||
[25]:https://medium.com/@pasql/transitional-interfaces-926eb80d64e3#.igcwawszz
|
||||
[26]:https://www.amazon.com/Soft-Skills-software-developers-manual/dp/1617292397/
|
||||
[27]:https://medium.com/u/56e8cba02b
|
||||
[28]:https://www.amazon.com/Clean-Coder-Conduct-Professional-Programmers/dp/0137081073/
|
||||
[29]:https://www.amazon.com/Start-No-Negotiating-Tools-that-ebook/dp/B003EY7JEE/
|
||||
[30]:https://www.amazon.com/gp/product/0060891548/
|
||||
[31]:https://www.amazon.com/Elements-Style-4th-William-Strunk/dp/0205313426/
|
||||
[32]:http://www.economist.com/blogs/prospero/2013/07/george-orwell-writing
|
||||
[33]:http://maximilyahov.ru/glvrd-pro/
|
||||
[34]:https://www.coursera.org/specializations/algorithms
|
||||
[35]:https://signalvnoise.com/posts/3375-the-five-programming-books-that-meant-most-to-me
|
||||
[36]:https://medium.com/u/54bcbf647830
|
||||
@ -1,105 +0,0 @@
|
||||
# rusking translating
|
||||
|
||||
What engineers and marketers can learn from each other
|
||||
============================================================
|
||||
|
||||
### Marketers think engineering is all math; engineers think marketing is all fluff. They're both wrong.
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
After many years of practicing marketing in the B2B tech world, I think I've heard just about every misconception that engineers seem to have about marketers. Here are some of the more common:
|
||||
|
||||
* "Marketing is a waste of money that we should be putting into actual product development."
|
||||
* "Those marketers just throw stuff against the wall and hope it sticks. Where's the discipline?"
|
||||
* "Does anyone actually read this stuff?"
|
||||
* "The best thing a marketer can tell me is how to unsubscribe, unfollow, and unfriend."
|
||||
|
||||
And here's my personal favorite:
|
||||
|
||||
_"Marketing is all fluff."_
|
||||
|
||||
That last one is simply incorrect—but more than that, It's actually a major impediment to innovation in our organizations today.
|
||||
|
||||
Let me explain why.
|
||||
|
||||
### Seeing my own reflection
|
||||
|
||||
I think these comments from engineers bother me so much because I see a bit of my former self in them.
|
||||
|
||||
You see, I was once as geeky as they come—and was proud of it. I hold a Bachelor's in electrical engineering from Rensselaer Polytechnic Institute, and began my professional career as an officer in the US Air Force during Desert Storm. There, I was in charge of developing and deploying a near real-time intelligence system that correlated several sources of data to create a picture of the battlefield.
|
||||
|
||||
After I left the Air Force, I planned to pursue a doctorate from MIT. But my Colonel convinced me to take a look at their business school. "Are you really going to be in a lab?" he asked me. "Are you going to teach at a university? Jackie, you are gifted at orchestrating complex activities. I think you really need to look at MIT Sloan."
|
||||
|
||||
So I took his advice, believing I could still enroll in a few tech courses at MIT. Taking a marketing course, however, would certainly have been a step too far—a total waste of time. I continued to bring my analytical skills to bear on any problem put in front of me.
|
||||
|
||||
Soon after, I became a management consultant at The Boston Consulting Group. Throughout my six years there, I consistently heard the same feedback: "Jackie, you're not visionary enough. You're not thinking outside the box. You assume your analysis is going to point you to the answer."
|
||||
|
||||
And of course, I agreed with them—because that's the way the world works, isn't it? What I realize now (and wish I'd discovered out far earlier) is that by taking this approach I was missing something pivotal: the open mind, the art, the emotion—the human and creative elements.
|
||||
|
||||
All this became much more apparent when I joined Delta Air Lines soon after September 11, 2001, and was asked to help lead consumer marketing. Marketing _definitely_ wasn't my thing, but I was willing to help however they needed me to.
|
||||
|
||||
But suddenly, my rulebook for achieving familiar results was turned upside down. Thousands of people (both inside and outside the airline) were involved in this problem. Emotions were running high. I was facing problems that required different kinds of solutions, answers I couldn't reach simply by crunching numbers.
|
||||
|
||||
That's when I learned—and quickly, because we had much work to do if we were going to pull Delta back up to where it deserved to be—that marketing can be as much a strategic, problem-oriented and user-centered function as engineering is, even if these two camps don't immediately recognize it.
|
||||
|
||||
### Two cultures
|
||||
|
||||
That "great divide" between engineering and marketing is deep indeed—so entrenched that it resembles what C.P. Snow once called[ the "two cultures" problem][1]. Scientifically minded engineers and artistically minded marketers tend to speak different languages, and they're acculturated to believe they value divergent things.
|
||||
|
||||
But the fact is that they're more similar than they might think.[ A recent study][2] from the University of Washington (co-sponsored by Microsoft, Google, and the National Science Foundation) identified "what makes a great software engineer," and (not surprisingly) the list of characteristics sounds like it could apply to great marketers, too. For example, the authors list traits like:
|
||||
|
||||
* Passion
|
||||
* Open-mindedness
|
||||
* Curiosity
|
||||
* Cultivation of craft
|
||||
* Ability to handle complexity
|
||||
|
||||
And these are just a few! Of course, not every characteristic on the list applies to marketers—but the Venn diagram connecting these "two cultures" is tighter than I believe most of us think. _Both_ are striving to solve complex user and/or customer challenges. They just take a different approach to doing it.
|
||||
|
||||
Reading this list got me thinking: _What if these two personalities understood each other just a little bit more? Would there be power in that?_
|
||||
|
||||
You bet. I've seen it firsthand at Red Hat, where I'm surrounded by people I'd have quickly dismissed as "crazy creatives" during my early days. And I'd be willing to bet that a marketer has (at one time or another) looked at an engineer and thought, "Look at this data nerd. Can't see the forest beyond the trees."
|
||||
|
||||
I now understand the power of having both perspectives in the same room. And in reality, engineers and marketers are _both_ working at the _intersection of customers, creativity, and analytics_. And if they could just learn to recognize the ways their personalities compliment each other, we could see tremendously positive results—results far more surprising and innovative than we'd see if we kept them isolated from one another.
|
||||
|
||||
### Listening to the crazies (and the nerds)
|
||||
|
||||
Case in point: _The Open Organization_.
|
||||
|
||||
In my role at Red Hat I spent much of my day thinking about how to extend and amplify our brand—but never in a million years would I have thought to do it by asking our CEO to write a book. That idea came from a cross-functional team of those "crazy creatives," a group of people I rely on to help me imagine new and innovative solutions to branding challenges.
|
||||
|
||||
When I heard the idea, I recognized it right away as a quintessentially Red Hat approach to our work: something that would be valuable to a community of practitioners, and something that helps spread the message of openness just a little farther. By prioritizing these two goals above all others, we'd reinforce Red Hat's position as a positive force in the open source world, a trusted expert ready to help customers navigate the turbulence of[ digital disruption][3].
|
||||
|
||||
Here's the clincher: _That's exactly the same spirit guiding Red Hat engineers tackling problems of code._ The group of Red Hatters urging me to help make _The Open Organization_ a reality demonstrated one of the very same motivations as the programmers that make up our internal and external communities: a desire to share.
|
||||
|
||||
In the end, bringing _The Open Organization_ to life required help from across the spectrum of skills—both the intensely analytic and the beautifully artistic. Everyone pitched in. The project only cemented my belief that engineers and marketers are more alike than different.
|
||||
|
||||
But it also reinforced something else: The realization that openness shows no bias, no preference for a culture of engineering or a culture of marketing. The idea of a more open world can inspire them both equally, and the passion it ignites ripples across the artificial boundaries we draw around our groups.
|
||||
|
||||
That hardly sounds like fluff to me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Jackie Yeaney - Chief Marketing Officer at Ellucian
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/1/engineers-marketers-can-learn
|
||||
|
||||
作者:[Jackie Yeaney][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jackie-yeaney
|
||||
[1]:https://en.wikipedia.org/wiki/The_Two_Cultures#Implications_and_influence
|
||||
[2]:https://faculty.washington.edu/ajko/papers/Li2015GreatEngineers.pdf
|
||||
[3]:https://opensource.com/open-organization/16/7/future-belongs-open-leaders
|
||||
@ -1,131 +0,0 @@
|
||||
|
||||
translating by ypingcn
|
||||
|
||||
How to choose your first programming language
|
||||
============================================================[
|
||||
|
||||
][1]
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
The reasons for learning to program are as a varied as the people who want to learn. You might have a program you want to make, or maybe you just want to jump in. So, before choosing your first programming language, ask yourself: Where do you want that program to run? What do you want that program to do?
|
||||
|
||||
Your reasons for learning to code should inform your choice of a first language.
|
||||
|
||||
_In this article, I use "code," "program," and "develop" interchangeably as verbs, while "code," "program," "application," and "app" interchangeably as nouns. This is to reflect language usage you may hear._
|
||||
|
||||
### Know your device
|
||||
|
||||
Where your programs will run is a defining factor in your choice of language.
|
||||
|
||||
Desktop applications are the traditional software programs that run on a desktop or laptop computer. For these you'll be writing code that only runs on a single computer at a time. Mobile applications, known as apps, run on portable communications devices using iOS, Android, or other operating systems. Web applications are websites that function like applications.
|
||||
|
||||
Web development is often broken into two subcategories, based on the web's client-server architecture:
|
||||
|
||||
* Front-end programming, which is writing code that runs in the web browser itself. This is the part that faces the user, or the "front end" of the program. It's sometimes called "client-side" programming, because the web browser is the client half of the web's client-server architecture. The web browser runs on your local computer or device.
|
||||
|
||||
* Back-end programming, which is also known as "server-side" programming, the code written runs on a server, which is a computer you don't have physical access to.
|
||||
|
||||
### What to create
|
||||
|
||||
Programming is a broad discipline and can be used in a variety of fields. Common examples include:
|
||||
|
||||
* data science,
|
||||
* web development,
|
||||
* game development, and
|
||||
* work automation of various types.
|
||||
|
||||
Now that we've looked at why and where you want to program, let's look at two great languages for beginners.
|
||||
|
||||
### Python
|
||||
|
||||
[Python][2] is one of the most popular languages for first-time programmers, and that is not by accident. Python is a general-purpose language. This means it can be used for a wide range of programming tasks. There's almost _nothing_ you can't do with Python. This lets a wide range of beginners make practical use of the language. Additionally, Python has two key design features that make it great for new programmers: a clear, English-like [syntax][3] and an emphasis on code [readability][4].
|
||||
|
||||
A language's syntax is essentially what you type to make the language perform. This can include words, special characters (like `;`, `$`, `%`, or `{}`), white space, or any combination. Python uses English for as much of this as possible, unlike other languages, which often use punctuation or special characters. As a result, Python reads much more like a natural, human language. This helps new programmers focus on solving problems, and they spend less time struggling with the specifics of the language itself.
|
||||
|
||||
Combined with that clear syntax is a focus on readability. When writing code, you'll create logical "blocks" of code, sections of code that work together for some related purpose. In many languages, those blocks are marked (or delimited) by special characters. They may be enclosed in `{}` or some other character. The combination of block-delimiting characters and your ability to write your code in almost any fashion can decrease readability. Let's look at an example.
|
||||
|
||||
Here's a small function, called "fun," which takes a number, `x` as its input. If `x`equals **0**, it runs another function called `no_fun` (which does something that's no fun). That function takes no input. Otherwise, it runs the function `big_fun`, using the same input, `x`.
|
||||
|
||||
This function defined in the ["C" language][5] could be written like this:
|
||||
|
||||
```
|
||||
void fun(int x)
|
||||
{
|
||||
if (x == 0) {
|
||||
no_fun();
|
||||
} else {
|
||||
big_fun(x);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
or, like this:
|
||||
|
||||
```
|
||||
void fun(int x) { if (x == 0) {no_fun(); } else {big_fun(x); }}
|
||||
```
|
||||
|
||||
Both are functionally equivalent and both will run. The `{}` and `;` tell us where different parts of the block are; however, one is _clearly_ more readable to a human. Contrast that with the same function in Python:
|
||||
|
||||
```
|
||||
def fun(x):
|
||||
if x == 0:
|
||||
no_fun()
|
||||
else:
|
||||
big_fun(x)
|
||||
```
|
||||
|
||||
In this case, there's only one option. If the code isn't structured this way, it won't work, so if you have code that works, you have code that's readable. Also, notice the difference in syntax. Other than `def`, the words in the Python code are English and would be clear to a broad audience. In the C language example `void` and `int` are less intuitive.
|
||||
|
||||
Python also has an excellent ecosystem. This means two things. First, you have a large, active community of people using the language you can turn to when you need help and guidance. Second, it has a large number of preexisiting libraries, which are chunks of code that perform special functions. These range from advanced mathematical processing to graphics to computer vision to almost anything you can imagine.
|
||||
|
||||
Python has two drawbacks to it being your first language. The first is that it can sometimes be tricky to install, especially on computers running Windows. (If you have a Mac or a Linux computer, Python is already installed.) Although this issue isn't insurmountable, and the situation is improving all the time, it can be a deterrent for some people. The second drawback is for people who specifically want to build websites. While there are projects written in Python (like [Django][6] and [Flask][7]) that let you build websites, there aren't many options for writing Python that will run in a web browser. It is primarily a back-end or server-side language.
|
||||
|
||||
### JavaScript
|
||||
|
||||
If you know your primary reason for learning to program is to build websites, [JavaScript][8] may be the best choice for you. JavaScript is _the_ language of the web. Besides being the default language of the web, JavaScript has a few advantages as a beginner language.
|
||||
|
||||
First, there's nothing to install. You can open any text editor (like Notepad on Windows, but not a word processor like Microsoft Word) and start typing JavaScript. The code will run in your web browser. Most modern web browsers have a JavaScript engine built in, so your code will run on almost any computer and a lot of mobile devices. The fact that you can run your code immediately in a web browser provides a _very_ fast feedback loop, which is good for new coders. You can try something and see the results very quickly.
|
||||
|
||||
While JavaScript started life as a front-end language, an environment called [Node.js][9] lets you write code that runs in a web browser or on a server. Now JavaScript can be used as a front-end or back-end language. This has led to an increase in its popularity. JavaScript also has a huge number of packages that provide added functionality to the core language, allowing it to be used as a general-purpose language, and not just as the language of web development. Like Python, JavaScript has a vibrant, active ecosystem.
|
||||
|
||||
Despite these strengths, JavaScript is not without its drawbacks for new programmers. The [syntax of JavaScript][10] is not as clear or English-like as Python. It's much more like the C example above. It also doesn't have readability as a key design principle.
|
||||
|
||||
### Making a choice
|
||||
|
||||
It's hard to go wrong with either Python or JavaScript as your first language. The key factor is what you intend to do. Why are you learning to code? Your answer should influence your decision most heavily. If you're looking to make contributions to open source, you will find a _huge_ number of projects written in both languages. In addition, many projects that aren't primarily written in JavaScript still make use of it for their front-end component. As you're making a choice, don't forget about your local community. Do you have friends or co-workers who use either of these languages? For a new coder, having live support is very important.
|
||||
|
||||
Good luck and happy coding.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Kojo Idrissa - I'm a new software developer (1 year) who changed careers from accounting and university teaching. I've been a fan of Open Source software since around the time the term was coined, but I didn't have a NEED to do much coding in my prior careers. Tech-wise, I focus on Python, automated testing, and learning Django. I hope to learn more JavaScript soon. Topic-wise, I like to focus on helping new people get started with programing or getting involved in contributing to Open Source projects. I also focus on inclusive culture in tech environments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/choosing-your-first-programming-language
|
||||
|
||||
作者:[Kojo Idrissa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/transitionkojo
|
||||
[1]:https://opensource.com/article/17/1/choosing-your-first-programming-language?rate=fWoYXudAZ59IkAKZ8n5lQpsa4bErlSzDEo512Al6Onk
|
||||
[2]:https://www.python.org/about/
|
||||
[3]:https://en.wikipedia.org/wiki/Python_syntax_and_semantics
|
||||
[4]:https://en.wikipedia.org/wiki/Python_syntax_and_semantics#Indentation
|
||||
[5]:https://en.wikipedia.org/wiki/C_(programming_language
|
||||
[6]:https://www.djangoproject.com/
|
||||
[7]:http://flask.pocoo.org/
|
||||
[8]:https://en.wikipedia.org/wiki/JavaScript
|
||||
[9]:https://nodejs.org/en/
|
||||
[10]:https://en.wikipedia.org/wiki/JavaScript_syntax#Basics
|
||||
@ -0,0 +1,75 @@
|
||||
Can academic faculty members teach with Wikipedia?
|
||||
============================================================
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
Since 2010, 29,000 students have completed the Wiki Ed program. They have added 25 million words to Wikipedia, or the equivalent of 85,000 printed pages of content. This is 66% of the total words in the last print edition of Encyclopedia Britannica. When Wiki Ed students are most active, they are contributing 10% of all the content being added to underdeveloped, academic content areas on Wikipedia.
|
||||
|
||||
Eager to learn more I contacted LiAnna Davis, director of Programs for Wiki Ed, who enthusiastically agreed to answer my questions.
|
||||
|
||||
Bonus: [Wiki Education Foundation (Wiki Ed)][1]'s platform is built on free software; find it at [WikiEdu Dashboard GitHub][2].
|
||||
|
||||
**How did Wiki Ed get started? Tell us a little bit about your background and how you got involved.**
|
||||
|
||||
In 2010, the [Wikimedia Foundation][3] (WMF, the nonprofit that runs Wikipedia) noticed a trend that university faculty who were also Wikipedia editors (Wikipedians) were successfully incorporating Wikipedia editing assignments into their classes. WMF created a pilot program to answer the question: Can non-Wikipedian faculty members teach with Wikipedia if they have enough support for the Wikipedia editing portion of the course?
|
||||
|
||||
I was part of the team hired in 2010 to work on the pilot and the answer we provided was a resounding "Yes." In 2013, the WMF spun off the American and Canadian versions of the program into a new nonprofit organization, the Wiki Education Foundation (Wiki Ed); I moved from WMF to Wiki Ed. Since we became our own organization, we've been able to focus on the program and grow its impact from 75 classes each year when the program was with WMF to 275 classes this term.
|
||||
|
||||
**People automatically assume that college students are savvy in all things tech related, especially the Internet, but your website says, "University undergraduates may be tech-savvy, but that doesn't always mean they're digitally literate." Can you explain that?**
|
||||
|
||||
Just because someone can figure out how to use their iPhone doesn't mean they can tell whether something they read online is trustworthy or not. As a [Stanford study][4] ("Evaluating Information: The Cornerstone of Civic Online Reasoning November 22, 2016.") recently showed, students aren't very media literate. However, when students are writing Wikipedia articles, they have to be. They need to follow Wikipedia's [Reliable Source][5] guideline, which says information on Wikipedia must be cited to a source that goes through some sort of fact checking, is independent, etc. For many students, such sourcing is the first time they've had to do more than just Google their topic and cite the first source they see. They need to understand which sources are reliable and which aren't, and they become more digitally literate consumers of information.
|
||||
|
||||
**What do you say to those who make the statement: "Wikipedia isn't a reliable source."**
|
||||
|
||||
Wikipedia is an encyclopedia, which is by definition a tertiary source. By the time students reach undergrad, they should be consulting primary and secondary sources, not tertiary sources, so no, students shouldn't be citing Wikipedia. But it's a great place to start your research, to give yourself a broad overview of a subject, and discover links to sources at the bottom of the article that you can consult. As we like to say, "Don't cite it! Write it!"
|
||||
|
||||
>It puts students into the position of producers of knowledge, not just consumers of knowledge...
|
||||
|
||||
**How can a professor's involvement in Wiki Ed change a student's learning experience higher education?**
|
||||
|
||||
By teaching with Wikipedia, instructors provide students with valuable media literacy, critical thinking, online communications, and writing skills that they need to succeed, whether they continue in academia or enter the workforce upon graduation. It puts students into the position of producers of knowledge, not just consumers of knowledge, and gives them a meaningful assignment that actually makes a difference in the world, not just a rote academic exercise that gets thrown away at the end of a term.
|
||||
|
||||
We're actively onboarding new classes for the spring term. Interested faculty should visit [the Wikipedia Education Foundation's Teach page][6] to get started.
|
||||
|
||||
**What staff development is needed for a teacher to participate? How much training is necessary for students?**
|
||||
|
||||
When you sign up on [the Wikipedia Education Foundation's Teach page][7], Wiki Ed provides an online orientation for new faculty on the basics of how to teach with Wikipedia. We also have a series of online training modules that we automatically assign to students based on the specific assignment (for example, if you want your students to add images, they'll get a module on images; if you don't, they won't). In a dozen disciplines, we also have specific guidebooks showing how to edit in that topic area on Wikipedia. In addition, we have staff who are experienced Wikipedia editors who can help answer students' and instructors' questions. Our system is quite extensive now; we supported more than 6,300 students this fall term, and we're used to working with faculty who have no experience editing Wikipedia, so that shouldn't keep anyone from doing the assignment.
|
||||
|
||||
**What are Visiting Scholars?**
|
||||
|
||||
Our program to encourage teaching with Wikipedia isn't the only connection we make between Wikipedia and academia. In the Visiting Scholars program, a university library or department will open up access to their collection to an established Wikipedia editor (called a "Visiting Scholar") who is lacking sources. Using this university login, the Visiting Scholar will have access to sources, so they can improve articles in broad subject areas of interest to the institution. It's a small but mighty program, because it takes a lot of work to get set up, but the Scholars produce a lot of truly fabulous content on Wikipedia.
|
||||
|
||||
**Who are your partners and how important is their involvement to your success now and in the future?**
|
||||
|
||||
We partner with academic associations who see the value in our work as a service to their discipline. Let's face it: when people want information about a topic, they don't go read the peer-reviewed journal articles published by those associations, they go to Wikipedia. By encouraging faculty in these associations to teach with Wikipedia, they're improving information on Wikipedia in those subject matters. Our partners enable us to reach large numbers of potential new faculty members, and enable us to dramatically improve content in a specific subject area through a partnership.
|
||||
|
||||
We welcome donations at [on our Support Us page][8] if your readers want to support our work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Don Watkins - Educator, education technology specialist, entrepreneur, open source advocate. M.A. in Educational Psychology, MSED in Educational Leadership, Linux system administrator, CCNA, virtualization using Virtual Box and VMware. Follow me at @Don_Watkins .
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/1/Wiki-Education-Foundation
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://wikiedu.org/
|
||||
[2]:https://github.com/WikiEducationFoundation/WikiEduDashboard
|
||||
[3]:https://wikimediafoundation.org/wiki/Home
|
||||
[4]:https://sheg.stanford.edu/upload/V3LessonPlans/Executive%20Summary%2011.21.16.pdf
|
||||
[5]:https://en.wikipedia.org/wiki/Wikipedia:Identifying_reliable_sources
|
||||
[6]:https://teach.wikiedu.org/
|
||||
[7]:http://teach.wikiedu.org/
|
||||
[8]:http://wikiedu.org/donate
|
||||
39
sources/talk/20170116 Terrible Ideas in Git.md
Normal file
39
sources/talk/20170116 Terrible Ideas in Git.md
Normal file
@ -0,0 +1,39 @@
|
||||
Terrible Ideas in Git
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
"Git does let you do some extraordinarily powerful things. Powerful, of course, in this talk, is a polite euphemism for stupid," says Corey Quinn of FutureAdvisor at LinuxCon North America.[The Linux Foundation][2]
|
||||
|
||||
"Git does let you do some extraordinarily powerful things. Powerful, of course, in this talk, is a polite euphemism for stupid," says Corey Quinn of FutureAdvisor at [LinuxCon North America][5]. Who hasn't experienced at least one moment of feeling like a complete dunce when using Git? Sure, Git is wonderful, everyone uses it, and you can do most of your work with a few basic commands. But it also has mighty powers to make us feel like we have no idea what we're doing.
|
||||
|
||||
But that's really not being fair to ourselves. Nobody knows everything, and everyone knows something different. Quinn reminds us, "During the Q and A section for some of my talks, people sometimes raise their hand and say, "Well, I have a really dumb question," and you see people in there are, "Yeah! That's a really dumb question". But when they get an answer, those people are taking an awful lot of notes."
|
||||
|
||||

|
||||
|
||||
[Used with permission][1]
|
||||
|
||||
Quinn starts his talk with some fun demonstrations of terrible things you can do with Git such as messing up an entire project by rebasing master and then making a forced push, mis-typing commands and getting scolded by Git, and committing large binaries. Then he demonstrates how to make these terrible things less terrible, such as managing large binaries more sanely. "You can commit large binaries. You can commit atrocities in Git. If you wind up needing to store large binaries, there are two tools out there that tend to really speed up loads. One is git-annex, which was was created by Joey Hess, a Debian developer, and git-lfs, which is supported by GitHub".
|
||||
|
||||
Do you keep making the same typo, like typing "git stitis" when you want "git status"? Quinn has an answer for this: "Git does have built-in support for aliases, so you can use relatively long, complex things and alias it to a short Git command." You can also use shell aliases.
|
||||
|
||||
Quinn says, "We've all heard about rebasing master, and then doing a forced push, a hilarious prank to all of your co-workers. What that does is it changes history, so that suddenly what happened before is not what people are actually working on, and everyone else winds up getting screwed in the process. A group of whales is called a 'pod', a group of crows is called a 'murder', and a group of developers is called a 'merge conflict'...On a more serious note, if someone does do something like this, you do have a few options." These include restoring master from a known good backup, revert commits, or "Hurl the person responsible, screaming, from the roof of your office." Or, take a dose of prevention and use a little-known Git feature called branch protection. When you enable branch protection, branches cannot be deleted or force-pushed, and pull requests must have at least one review before acceptance.
|
||||
|
||||
Quinn demonstrates several more wonderfully useful tools to make Git more efficient and foolproof such as mr, vcsh, and customized shell prompts. You can see these in the complete video (below), and enjoy more silly jokes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/LinuxCon-Europe/2016/terrible-ideas-git-0
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[3]:https://www.linux.com/files/images/heffalump-git-corey-quinnpng-0
|
||||
[4]:https://www.linux.com/files/images/corey-quinn-lcnapng
|
||||
[5]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
@ -0,0 +1,79 @@
|
||||
# translating by rusking
|
||||
|
||||
Why every business should consider an open source point of sale system
|
||||
============================================================
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
Point of sale (POS) systems have come a long way from the days of simple cash registers that rang up purchases. Today, POS systems can be all-in-one solutions that include payment processing, inventory management, marketing tools, and more. Retailers can receive daily reports on their cash flow and labor costs, often from a mobile device.
|
||||
|
||||
The POS is the lifeblood of a business, and that means you need to choose one carefully. There are a ton of options out there, but if you want to save money, adapt to changing business needs, and keep up with technological advances, you would be wise to consider an open source system. An open source POS, where the source code is exposed for your use, offers significant advantages over a proprietary system that keeps its code rigidly under wraps.
|
||||
|
||||
With an open source POS, you get a few key things.
|
||||
|
||||
### Unlimited flexibility
|
||||
|
||||
Open source systems play well with others. Their ability to integrate and connect with third-party products—from accounting and customer relationship management software to order management and inventory systems—makes them an attractive proposition for business owners who need to expand beyond the feature set of a proprietary POS.
|
||||
|
||||
In a [2014 technology survey][7], restaurant owners said integration would be a major factor influencing their next POS upgrade. This is one area where open source really shines. A proprietary system is what it is. But with open source, you have endless possibilities for integration and customization. If you think your business model is ever going to grow and change, it only makes sense to consider an open source POS that allows you to adapt as needed.
|
||||
|
||||
### Faster development
|
||||
|
||||
Another advantage of open source systems is that they are often backed by a large community of developers who are continually building new functionality and improving on old features. By its very nature, the software development cycle for an open source project is much quicker than it is for a commercial product—bugs get fixed faster, updates get released sooner, and new modules are constantly being developed.
|
||||
|
||||
### Lower cost
|
||||
|
||||
In this case, "lower cost" means "almost free." You still need to buy the hardware, but the software itself is free to use. An open source POS doesn't have the high start-up or ongoing maintenance costs of a proprietary POS, which can be anywhere from $3,000 to $50,000 a year, nor does open source force you into the locked-in pricing of a proprietary model.
|
||||
|
||||
In the [2015 version][8] of the food service technology study, more than half of the restaurant owners surveyed said they were paying for multiple technology vendors—in some cases as many as 10\. The cost savings of switching to a single open source system with custom modifications and no ongoing fees could be significant.
|
||||
|
||||
There is a caveat, however. If you don't have a tech-savvy staff, you may need to hire outside help to install, modify, and upgrade your software. Open source does allow for unlimited integrations and customizations, but you'll need someone with technical expertise to take care of that, which can incur additional fees. Still, it can be a very cost-effective option.
|
||||
|
||||
### Better security
|
||||
|
||||
If the source code is out there for anyone to see, doesn't that mean it's open to malicious programmers who want to hack into your data? Isn't that a security nightmare? On the contrary.
|
||||
|
||||
The large community of developers that builds new functionality also searches out and repairs security flaws. There are many more sets of eyes dissecting and fixing open source code than there are reviewing the code for a proprietary product. In that way, an open source POS is actually _more_ secure.
|
||||
|
||||
There are many options for open source POS solutions, to name some:
|
||||
|
||||
* [Chromis][1]
|
||||
* [Drupal POS][2]
|
||||
* [Floreant][3]
|
||||
* [Odoo][4]
|
||||
* [Open Source Point of Sale][5]
|
||||
* [Unicenta][6]
|
||||
|
||||
### Making the jump
|
||||
|
||||
You know your business better than anyone. Only you can decide what point of sale software is right for you. Given the compelling advantages of an open source POS over a proprietary POS—flexibility, rapid development, lower cost, more security—open source is something every business should consider.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Digital marketing project manager at Acro Media. We excel in custom ecommerce solutions by utilizing the Drupal open source platform.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/open-source-point-sale-system
|
||||
|
||||
作者:[Preston Pilgrim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/preston-pilgrim
|
||||
[1]:http://chromis.co.uk/
|
||||
[2]:https://www.acromediainc.com/drupal-pos
|
||||
[3]:http://floreant.org/
|
||||
[4]:https://www.odoo.com/
|
||||
[5]:https://github.com/jekkos/opensourcepos
|
||||
[6]:https://unicenta.com/
|
||||
[7]:http://hospitalitytechnology.edgl.com/news/POS-Integration-Becoming-a--Must-Have-94389
|
||||
[8]:https://pos.toasttab.com/restaurant-technology-industry-report/2015
|
||||
310
sources/talk/20170117 Arch Linux on a Lenovo Yoga 900.md
Normal file
310
sources/talk/20170117 Arch Linux on a Lenovo Yoga 900.md
Normal file
@ -0,0 +1,310 @@
|
||||
# Arch Linux on a Lenovo Yoga 900
|
||||
|
||||
_Warning: this is about 5,500 words with plenty of interesting links, so wait till you’ve got something to drink and some time._
|
||||
|
||||
After 3 years running Arch Linux on a [Lenovo Yoga 2][2], I decided to upgrade to a Yoga 900:
|
||||

|
||||
|
||||
_Lenovo Yoga 900 [Amazon special][1] for $925 – 8GB RAM, 256GB SSD, 3200×1800, Intel Skylake 3.2GHz + Iris Graphics_
|
||||
|
||||
Dell charges $1650 for a [similar XPS 13][3] albeit with the next generation of Intel chip. The current model of Yoga is the 910, and that laptop costs $1300\. However, I didn’t even consider it because they screwed the pooch on the keyboard. Lots of reviews start with the color and feel of the materials on the outside, but I’m going to start on the keyboard layout.
|
||||
|
||||
### Keyboard
|
||||
|
||||
|
||||
The Yoga 2 Pro and the Yoga 900 have the same design. It is inferior in several ways compared to the traditional and well-regarded IBM Thinkpad keyboards, but not the worst keyboard out there and I got used to it over the 3 years. Unfortunately, Lenovo made things worse in the 910.
|
||||
|
||||

|
||||
_Yoga 2 and Yoga 900 keyboard layout _
|
||||
|
||||

|
||||
_Yoga 910 keyboard_
|
||||
|
||||
The problem with the 910 keyboard is that the right-shift key is in the wrong place, and impossible to reach without moving your hand. It is in a different position than every keyboard I’ve ever used going back to 9<sup>th</sup> grade typing class on the IBM Selectric. I’d expect such a mistake from a company like Asus or Dell, not a company with the legacy of building typewriters that generations of Americans learned and worked on.
|
||||
|
||||
Every year the Yoga team has made changes to the layout. Imagine if every year in the 20<sup>th</sup> century, IBM had changed the layout of their typewriters, and then bragged about the “[efficiency][4]” gains. The company wouldn’t even be around today!
|
||||
|
||||
I probably could get used to the Yoga 910 page up / page down overloaded with arrow keys, and some of the other changes, but the shift-key is a deal breaker and I’d rather not bother with the others.
|
||||
|
||||
There are many ways for Lenovo to truly improve their keyboard, such as making the volume-up key not so close to application-close. And re-thinking whether they really need an easy way to (accidentally) turn off the screen given there is already a way to dim it. And figuring out how to put in an overloaded number pad. Does Lenovo think only businesses deal with numbers?
|
||||
|
||||
The 910 keyboard has so many changes, they might not ever go back to their old layouts again. I’m hoping this hardware will last me years. I’d rather have a great keyboard than a computer 10 times faster.
|
||||
|
||||
I see in the Yoga 910 reviews on the Lenovo website that some people are returning the computer because of the keyboard. Lenovo should have a policy: if an employee wanted to make an alteration to the keyboard, they should have to write down a **very ****good** reason, and then sacrifice one of their fingers in solidarity with the pain it will cause customers. A rule like that would decrease this needless churn. Lenovo went through a lot of work make the Yoga 910, but f*cked it up with the input mechanism.
|
||||
|
||||
### Overall
|
||||
|
||||
The Yoga 2 was generally fast enough for everything I needed to do. An SSD is nice for various reasons, but it is almost overkill on Arch. People who only use Windows might not realize how bloated it is:
|
||||
|
||||

|
||||
|
||||
In the late 90’s, you’d get a new computer every few years because the processors were doubling in speed every 18 months, and the software was doubling in size frequently as well. Things are very different now. The new Yoga is 30% faster than my Yoga 2 running integer benchmarks. This is a 3.2 GHz machine whereas the old one maxed out at 2.6 GHz so most of the difference is the faster frequency.
|
||||
|
||||
Haswell was introduced in 2013, and Skylake was introduced in 2015 so two years of advancement is the other part of the improvements. The big benefit of the new processor is that it is built in 14nm instead of 22nm which means less heat and longer battery life. My old Yoga 2 battery was still giving me about 3.5 hours of battery life with moderate brightness, but this should give me 7.
|
||||
|
||||
The Yoga 2 hinge is starting to weaken and fall apart, and there is no way to tighten it, only to try to find one on the Internet or mail it to Lenovo:
|
||||
|
||||

|
||||
|
||||
The hinge on Yogas is designed to let you lay the device flat, and even fold it back as a tablet, but I found it a heavy and awkward and so never bothered. I’m just happy if I’ll be able to open and close it daily for years.
|
||||
|
||||
The Yoga 900 hinge is a more solid watchband design and should last longer:
|
||||
|
||||

|
||||
|
||||
The only very minor downside is that if you shake it, it sounds like you’ve got broken parts rattling around inside, which usually is something to be worried about for electronics! However, it’s just a false alarm of the 800 pieces sliding.
|
||||
|
||||
The Yoga 2 Pro was overall a quite well-built device, but if I hold it in one hand with the screen open, it sags a bit, and sometimes the keyboard backlight goes out. Both Yogas are thin and light, but the 900 feels more solid.
|
||||
|
||||
### Clickpad
|
||||
|
||||
The biggest problem with the Yoga 2 was the Synaptics Clickpad it used. It actually wasn’t the hardware, it was the driver, which is basically unmaintained, and of course had some bugs. It’s a shame because Synaptics could easily afford one engineer to help maintain a few thousand lines of code. They actually wrote another driver, they just never released it freely so it could be included with the kernel.
|
||||
|
||||
However, a new library called [Libinput][5] was created, and they support Clickpads and things work well out of the box now. The best thing about Libinput is that they fixed the bug where if you have your left finger touching in the mouse-click area, it will now register pointer movements by your right finger. It’s hard to believe, but that basic functionality was broken for many years with Synaptics hardware on Linux.
|
||||
|
||||
The Clickpad hardware was still working fine, but it didn’t give any audible click sound anymore. That actually isn’t a problem, but it did make me wonder if it was going to wear out at some point. The old Thinkpads had multiple left and right mouse buttons, so if one broke, you could use the other while you ordered a new part, but since there’s only one button here, there is no backup except to plug a mouse in. (Lenovo expects you to mail in the computer to get a new mouse.)
|
||||
|
||||
### Kernel Support
|
||||
|
||||
When I bought the Haswell laptop, the hardware design was brand new, so I ran into a lot of Linux driver problems initially that took months to resolve. In this generation, Skylake crashing bugs were still being fixed [8 months after the architecture was introduced,][6] but now it appears they’ve all been resolved. And even when those were fixed, there were still problems with [power management support,][7] but today these also appear to be improved. The laptop will settle into the lower power C6-C10 states if nothing is going on. (This is verifiable with **powertop**.)
|
||||
|
||||
The power management features are important not only for battery life, but because these very small circuits eventually wear out because of something known as [electromigration][8]. Intel even warns that: “Long term reliability cannot be assured unless all the Low-Power Idle States are enabled.” By running in lower power mode, and therefore using the circuits less, they will last longer.
|
||||
|
||||
Linux’s Haswell support is very reliable now, but it was definitely flakey for a long time. I wrote about some of the issues at the beginning and after the first year, but I can say finally that things are great for Haswell and Skylake.
|
||||
|
||||
### Lenovo BIOS Linux Incompatibility
|
||||
|
||||
Before I could install Linux on the Yoga 900, I had to flash a new BIOS in Windows. In fact, I had to install 2 BIOSes. The latest Yoga 900 BIOS didn’t [include][9] the necessary fix I needed, so after scratching my head for a while I eventually discovered and [installed][10] a separate “Linux-only” BIOS update, which also says that Windows is no longer supported by Lenovo: “Are we not [merciful][11]?”
|
||||
|
||||
As people who followed the Linux news are aware, the Yoga 900 and certain other recent models of Lenovo laptops were impossible to install Linux on, because it couldn’t even [detect the hard drive][12]. Lenovo’s first reply was that the laptops didn’t work on Linux because it uses a [new RAID controller mode][13]. However, RAID is meant for multiple disks, and this laptop only has one hard drive, and there isn’t even room to install another.
|
||||
|
||||
Here’s some more of Lenovo’s [official explanation][14]:
|
||||
|
||||
> “To support our Yoga products and our industry-leading 360-hinge design in the best way possible we have used a storage controller mode that is unfortunately not supported by Linux and as a result, does not allow Linux to be installed.”
|
||||
|
||||
I found it funny that the reason for their different storage controller is because of their hinge! It would be like a car company saying they had to change their rims because of their new radio.
|
||||
|
||||
This turned into a controversy thanks to the efforts of [Baron][15][H][16][K][17] on Reddit who wrote about it, provided information to the media, and contacted his local Attorney General in Illinois. Searching for “[Lenovo Yoga ][18][L][19][inux compatibility][20]” turns up 300,000 results. Lenovo could be criminally liable for selling a “general purpose” PC that didn’t let you install your own operating system. The default OS is meaningless on a machine that is truly mine.
|
||||
|
||||
Hackers got involved, and they eventually discovered via playing with the UEFI settings, that the machine still supported the AHCI controller mode, it was just disabled. In short, Lenovo took away Linux compatibility for no good purpose. Because of all the information people learned, if this case had ever gone to court, Lenovo would have gotten their ass handed to them.
|
||||
|
||||
Fortunately, all the news got their attention, and they eventually updated the BIOS. I type this on a Yoga 900 running Linux, so we should celebrate this victory. Let’s hope they learn a lesson, but I’m not optimistic. They ought to offer you an option to choose the operating system for your machine. They would have found this bug long before any customers did. I’d wait an extra week to get a custom computer. They could also do a better job setting up the partitions and letting people customize lots of things, and grabbing all the latest software, rather than using a generic old image which needs lots of updates.
|
||||
|
||||
Some people like Lenovo said it was Linux’s fault for not supporting this new RAID driver mode. However, AHCI is a very popular standard, and the Linux kernel team rejected Intel’s code for this hardware as “[too ugly to live][21]”! The team also asked Intel for a specification describing the device’s behavior, but wasn’t given this information.
|
||||
|
||||
### Heat Dissipation
|
||||
|
||||
The Yoga 2 could get hot when pushing the CPUs hard. I charred the bottom of the plastic case while compiling LibreOffice on a blanket, which was an eyesore and made me look like a homeless programmer. I tried a metal brush and some turpentine to get the worst of it off, but it didn’t really improve the situation:
|
||||
|
||||

|
||||
|
||||
This new computer has a metal case which shouldn’t get discolored, and Skylake definitely runs cooler than Haswell. It also seems to do better job of pushing heat out sideways through the hinge, instead of down which could easily be obstructed.
|
||||
|
||||
One of the annoying things about the Yoga 2 over time is that the fan blades had collected dust over the years, but it sounded like sand! It was uneven and distracting and made it much louder. I did take the laptop apart and vacuum everything, but the blades are hidden. I’d have to replace the fans. They don’t run on the Yoga 2 for typical tasks of word processing and web browsing, but when they do spin up it’s annoying if I’m not wearing headphones.
|
||||
|
||||
The Yoga 900 fans are higher pitch, but it is just a smooth whir and not distracting. The Yoga 900 fans seem to run all the time, but at a low speed that is quiet. The sound of my refrigerator and air filter are louder unless the fans crank up under load, and even then it is not a big deal.
|
||||
|
||||
### Graphics
|
||||
|
||||
The Yoga 2 had a great screen, but it also had widely reported issues because the yellow looked like orange. However, everything looked so crisp and all the other colors looked fine. The Yoga 900 screen has fixed the yellow issue. It’s not true 4K, being only 3200×1800, but the pixels are smaller than 4K on a 15.6” monitor, so that it looks very sharp.
|
||||
|
||||
When I first got the Yoga 2, Haswell was still a new chipset, so I saw various Intel graphics display glitches which went away within a couple of months. However, I eventually discovered a memory leak that could crash Linux, and this bug was in there for years.
|
||||
|
||||
My computer ran out of RAM a number of times skipping through video in VLC (shift + arrow). The memory didn’t show up as in use by VLC, but my computer ran out of RAM, so clearly it was kernel memory. Eventually I setup a swap file which gave more time, but even then a couple of times it filled up when I wasn’t keeping track. Eventually the bug disappeared, and Linux is very stable right now, but it was there for years.
|
||||
|
||||
Everyone says Intel has the best Linux drivers, but they seem like a skunkworks project inside Microsoft. The driver developers working on Linux at Intel are good, there just aren’t enough of them. They should be perfecting the drivers before they release the hardware! Intel produced [1][22][13][23] [processors][24] as part of Skylake, with subtle feature differences. That sounds like a lot, but they released 256 chips during the [Haswell generation][25], so maybe things are getting more focused. I was told 10 years ago by an Intel employee that they invested 1% into Linux compared to Windows, and today that still seems to be true.
|
||||
|
||||
The only performance issue I ran into with the Yoga 2 was that it couldn’t play 4K video reliably. It would often show screen glitches, or just do around 5 frames per second:
|
||||
|
||||

|
||||
|
||||
The Yoga 2 would even sometimes struggle playing 1920×1080 video, which it was supposed to be able to handle at 60fps. Part of this is probably because I always have other applications like Firefox and LibreOffice running.
|
||||
|
||||
The Skylake processor is spec’ed to do 4K video at 60 fps for H.264, VP9, and other codecs. In fact, the processor has a lot of hardware accelerated [multimedia][26][capabilities][27]. I tried out hardware encoding of H264 with **ffmpeg** and found it was 4 times faster while using just 1 CPU. It’s cool to see this feature. Unfortunately, it is a little annoying to setup because you have to use a number of additional command line parameters:
|
||||
|
||||
“**-threads 1 -vaapi_device /dev/dri/renderD128 -vcodec h264_vaapi -vf format=’nv12|vaapi,hwupload’**”
|
||||
|
||||
I tried to find a way to have **ffmpeg** remember these for me so I wouldn’t have to type it in every time, but couldn’t. I can’t just pass those in automatically either, as other things need to go before and after. I also discovered that it won’t resize video while using the hardware, and will just ignore the request, so only sometimes can it be used. It would be really great if **ffmpeg** could figure this out automatically. There is a lot of unused hardware because users don’t know or can’t be bothered. Unfortunately [it’s kind of a mess][28] for video encoding and decoding as there are multiple APIs for Linux and Windows.
|
||||
|
||||
Skylake does a much better job playing 4K video, but it will still glitch sometimes and briefly drop down to 10 fps. I think part of it is X. I tried playing 4K videos in Wayland, and it was smoother, so I’m hopeful. It is great to see that the OpenGL support has improved. On this hardware, Intel supports version 4.5 which is the latest version from 2014.
|
||||
|
||||
My Yoga 900 (-13ISK2) is actually a revised version of the original offering with an Iris 540 graphics co-processor which is supposed to be [faster][29] than the stock 520 because of 24 more shader units. However, it can only play SuperTuxKart with moderate settings running 1600×900 at 20 fps, so I wouldn’t say it’s anything to brag about yet. Speaking of which, the game has improved tremendously over the years and is beautiful now:
|
||||
|
||||

|
||||
|
||||
There is an Intel team in China working on [enabling][30] support OpenCL using the graphics card. However, I don’t see any mention of people using it in Blender yet, so I wonder the status and whether it is just demoware. Intel’s OpenCL support has been missing for so long, people doing serious work with Blender already use NVidia or AMD cards, and even when Intel finally writes the code, there’s not much testing or interest.
|
||||
|
||||
One thing that was surprising to me is that I did some experiments on another machine, and found that a quad-core processor is faster than the NVidia 960M for ray-tracing with the Cycles engine. Apparently the 640 CUDA cores aren’t enough to beat 4 Intel CPUs on that task. Newer processors have 2000+ cores and those provide faster performance.
|
||||
|
||||
### HiDPI
|
||||
|
||||
The situation has gotten better for Linux on these high-res screens over the last 3 years, but it still has a ways to go. The good news is that Gnome is almost perfect with HiDPI in current versions. Firefox generally looks great if you set the **layout.css.devPixelsPerPx** to 2\. However because this 13.3” screen’s pixels are so small, I also install a No-Squint Plus plugin and have it render everything at 120% to make it a bit easier to read.
|
||||
|
||||
I was happy to help LibreOffice look better on these screens with [some patches][31] that were shipped in April, 2014, and the work has continued since. The biggest issue remaining is that LibreOffice is still doubling toolbar icons. A number of themes have SVG icons, but they aren’t packaged and shipped with the product. SVGs are much slower to load compared to PNGs and need to be cached. [Tomaž Vajngerl has done some more work][32] in this area, but it hasn’t released yet. Even so, LibreOffice looks better than many other Linux apps which don’t have recognizable icons.
|
||||
|
||||
Applications are generally improving with regards to detecting and being usable on high-res screens, but even some of the most popular such as Gimp and Audacity and Inkscape are still hard to use. I installed a large custom theme for Gimp, but all the icons are different so even though they are bigger, it takes time to recognize them.
|
||||
|
||||
The unfortunate thing about Linux’s 1.5% marketshare is that these sorts of issues don’t get much priority. Many codebases are moving to GTK 3, but in Audacity’s case, it seems to be [stalled][33]. I talked in my first review about a long tail of applications that will need improvements but 3 years later, even some of the most popular apps still need work.
|
||||
|
||||
### SSD
|
||||
|
||||
The old hard drive was doing fine because of the various optimizations I did, especially to Firefox. I also kept in mind that the **/tmp** directory had automatically been setup as a RAM drive, and so I would usually save downloads there first. Sometimes I’d find a 500 MB video I want to grab a short 20 MB clip from, or convert to another format, so by doing it in /tmp I saved a lot of writes. It is more work, and possibly unnecessary, but it’s faster to work in RAM.
|
||||
|
||||
I had written to each cell 25 times over the 3 years, which meant the drive could last for 350 years. The vast majority of the writes were for Arch updates. It gets new LibreOffice builds every month, and a new “stable” kernel release every week. It was great to be up to date all the time, but it did cost 100 times more writes compared to running Debian stable. However, given that each component has their own release cycle, it was necessary.
|
||||
|
||||
The new Samsung drive diagnostics don’t tell the number of times it has written to each cell. In fact, I can’t even find out what cell type it is and how many writes it is specified to handle. I believe the “Percentage Used” value will me the age of the drive, but perhaps it relates only to the number of spare cells. I haven’t found any documentation so I can only guess:
|
||||
|
||||
|||
|
||||
|--|--|
|
||||
| **Model Number:** | **SAMSUNG MZVLV256HCHP-000L2** |
|
||||
| **Firmware Updates (0x06):** | **3 Slots** |
|
||||
| **Available Spare:** | **100%** |
|
||||
| **Available Spare Threshold:** | **10%** |
|
||||
| **Percentage Used:** | **0%** |
|
||||
| ****Data Units Written:**** | **198,997 [101 GB]** |
|
||||
| **Data Units Written:** | **305,302 [156 GB]** |
|
||||
| **Host Read Commands:** | **3,480,816** |
|
||||
| **Host Write Commands:** | **10,176,457** |
|
||||
| **Error Information Log Entries:** | **5** |
|
||||
|
||||
### Broken Left-Ctrl Key
|
||||
|
||||
One thing I noticed after just a few hours of use is that the left-control key pops off if pressed in the upper-left corner:
|
||||
|
||||

|
||||
|
||||
_Broken Yoga 900 key: Note the tiny cylinder missing in the left box vs the right
|
||||
_
|
||||
|
||||
The layout of the Yoga 900 keyboard is the same as the Yoga 2 Pro, but the internals are different. The keys of the Yoga 2 Pro cannot be removed and replaced individually, and there is no way to pop off any of the keys without doing permanent damage. The Yoga 900 has the old style Thinkpad keys: which can be detached, and replaced individually.
|
||||
|
||||
However, there is a defect and one of the 4 tiny cylinder notches in the hinge was missing so that it only connects to the key top at 3 points, and if you don’t press the key in the middle, it will slip off.
|
||||
|
||||
I contacted Lenovo about this. Even though the keys are replaceable and serviceable, they will only replace the entire keyboard, and refuse to mail out any parts. They recommend I mail the computer in, or take it to the Geek Squad service center. I knew that mailing it in would take 2 weeks, so I called my local store to ask if they had Yoga keyboard parts in stock. They told me they don’t take the computers apart, they just mail them to Atlanta. There used to be places that could make many repairs to IBM laptops, and stocked the common parts, but that industry is apparently gone.
|
||||
|
||||
I noticed this mistake within a couple of hours of using the computer, so I’m pretty sure it was a manufacturing defect. It is such a tiny piece of plastic that was deformed or broke off during assembly.
|
||||
|
||||
Even though the computer is under warranty and could be fixed for free, I didn’t want to wait for something so minor, so I just went on the Internet and found a website called laptopkey.com and ordered a replacement key and hinge. It was actually tricky because there are 3 types of hinges! It took me several minutes to figure out which one my computer has because y’all look the same to me:
|
||||
|
||||

|
||||
|
||||
So I ordered the part, but I read it would arrive in about a week. It was very frustrating because I use left-Ctrl all the time when doing copy/paste, skipping through video or by word in text editors, etc. so I thought maybe I could swap the hinge from the right-ctrl, which I never use.
|
||||
|
||||
So I tried to remove this key following instructions I found on the Internet: I got my fingernail under the upper left corner, and lifted till it clicked. And then I put my nail under the upper right corner, and did the same thing. But another one of those tiny pieces of plastic broke off, so now I have two broken hinges. It might not be possible to remove the keys without breaking these very tiny clips. These keyboards are serviceable perhaps only in theory.
|
||||
|
||||
So I decided to go old-school and use superglue. I’d rather have the damn key stay on and have no urgent plans to replace them. It was tricky because I needed a small dab of glue about 1mm in diameter: too much in there it could gum up the works.
|
||||
|
||||
My experience building R/C airplanes came in handy and I fixed it and now the left-Ctrl key is holding on. The right one still slips off but I hardly use it. I was happy again! This is a long sidetrack, but it is important to keep in mind maintenance of a machine.
|
||||
|
||||
### Antergos vs. Arch
|
||||
|
||||
After 3 years with Arch Linux, I had no interest in trying anything else. The Intel drivers had regressions, but otherwise Arch has been painless to run on a daily basis, and it got a little better every week. It’s exciting to be up to date with everything. I often had packages newer than what was in Ubuntu on their release date. Ubuntu users can find newer software in custom PPAs, but there isn’t any testing or coordination across them, so that people who use multiple run into problems.
|
||||
|
||||
People also complain about Ubuntu upgrades hosing the machine and forcing a re-install, so even though their installation process is quicker, the ongoing maintenance isn’t. Every time I’ve read about someone borking an Arch installation, they would always admit it was a user error or something like btrfs corruption.
|
||||
|
||||
I wanted to install [Antergos][34], which provides a GUI installer for Arch. However, the setup looked unreadable on my screen, and it didn’t recognize the Clickpad in their minimal install, which is the only one I had space for on my old 1GB USB key. So I decided to just install Arch old-school again. Thankfully, the Yoga still supports legacy BIOS, so I didn’t have to mess with [UEFI][35].
|
||||
|
||||
I was sorry I didn’t try out Antergos, because I think it could be a great distro for less technical people or those who want to quickly get into Arch Linux. The Arch wiki is filled with tips for best running Linux. I’d love to have something which setup weekly TRIM for my SSD, [Profile-Sync-Daemon][36], Android support, hardware-accelerated video playback, etc. There are quite a few things that nearly all users would want, and are just a few lines to detect and enable.
|
||||
|
||||
Manjaro is a very popular Arch-based distribution with a GUI installer, but having run Arch for 3 years, I trust their packagers to work out issues between components. I’ve read a number of comments on Reddit from people who found their Manjaro installation broken after an update.
|
||||
|
||||
My only complaint about my Arch installation now is the ugly unreadable bootloader screen. I just need to copy over the **grub.cfg** from my old machine.
|
||||
|
||||
### Arch Install
|
||||
|
||||
At first I just wanted to just move the hard drive from one laptop to the next so that I wouldn’t even have to install anything, but after taking the computers apart, I noticed the M.2 SSDs are a different shape. I could have done a low-level block copy, but just decided to start from scratch because it would be a good refresher. It had been 3 years. I had installed a lot of random crap over the years, and even when I remembered to un-install it there were all kinds of digital remnants.
|
||||
|
||||
The Arch install went quite smoothly this time because the hardware had been around for so long. I still needed to do **rfkill unblock wifi**, but other than that everything else just worked. Apparently Linux still doesn’t know how to properly read the rfkill information from this model. Fortunately **systemd** has the ability to restore rfkill values on startup.
|
||||
|
||||
### Kernel Buglist
|
||||
|
||||
One of the things that continues to surprise me is that the Linux buglist is a mess. I know there are all of these people and this great rate of change, but what isn’t changing is the worst case scenario for a bug report. I don’t know why bugs sit around for years, but there clearly is no escalation process.
|
||||
|
||||
I wrote an analogy in my last review I think is useful. Imagine if it took an airline 1-2 years to return your lost luggage. Would you use trust that company? In fact, what’s the point of making a new release if you’ve still got thousands of known bugs and hundreds of regressions? If 1% of every Boeing airplane crashed, would they just keep continuing like that for years?
|
||||
|
||||
Maybe the Linux Foundation should hire some engineers to work on all the bugs that everyone else seems to be ignoring. There are a lot of people paid to work on Linux, and there are a lot of old bugs – which is usually what amateurs do. In my opinion the kernel would be better off not releasing anything for months until the bug count was under 50\. Right now it is 4672\. That would be a good reason to increment the major release number.
|
||||
|
||||
There is something contradictory about making a new stable release every week, but they’ve been doing it that way for years, and they have critical fixes every time, so they are clearly doing something valuable. The kernel gets better at a great rate, so far be it for me to criticize, but I do think they should try something different.
|
||||
|
||||
At least, bugs should get resolved within a specific timeframe. If that is exceeded, than it should escalate up to the maintainer and eventually to Linus. If there is a problem area with a lot of old bugs in a place that no one is working on, then Linus can point this out and crack the whip on the relevant parties. They need to think more like Boeing.
|
||||
|
||||
### Lenovo
|
||||
|
||||
Many Linux users hammer Lenovo for their lack of support on their consumer laptops, but they build quality hardware at a good price. As I wrote years ago, it was obvious not one person at Lenovo had bothered to install Linux on the Yoga 2 before they released it, and it is true for the Yoga 900 because it was impossible.
|
||||
|
||||
I think everyone in their company should be dual-booting. It isn’t that hard to setup, and their customers might want that. Lenovo has 60,000 employees. At least, they need to hire a few people on their Yoga team willing to try out this thing called **Linux**. Windows is painful to use compared to Linux in various ways. Windows runs more applications, but I think perhaps half of their users would be happier with a properly configured Linux installation.
|
||||
|
||||
While it is bad how Lenovo is still ignoring Linux, their problems apply to more than the software. On many models, the RAM chips are soldered on. In some devices, there are whitelists and only pre-approved cards can be installed. The Yogas don’t have a discrete graphics card, but even Lenovos that do provide no mechanism to upgrade the card, like you can with a desktop. I think someone needs to put a horse head in the bed of the Lenovo CEO.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This Yoga 900 is an amazing laptop for the price, and it’s a definite step up from the Yoga 2 with the improvements. A similar Apple Macbook Pro is $1500, but it has 40% less pixels.
|
||||
|
||||
Windows is adopting some of the best features of Linux, but they still don’t have native support for a package manager with all of the interesting free software components pre-compiled. Installing **ffmpeg** on Windows is a huge pain because of all the [dependent libraries][37] it uses.
|
||||
|
||||
Microsoft built a Windows store, which is sort of like a repository, but it doesn’t handle inter-package dependencies, and isn’t setup to manage individual libraries. Microsoft also has a new package manager called [NuGet][38], but it seems to be used mostly for .Net software. It did have a package for ffmpeg, but it didn’t have any dependencies for the codecs so even after installing it, it won’t do anything useful yet.
|
||||
|
||||
Last March, [Microsoft demonstrated][39] the ability to run Ubuntu command-line applications, which is quite a revolution. (They should have [started with Debian][40].) There’s even [a discussion][41] in their buglist to add support for more distros which could be quite tempting.
|
||||
|
||||
For me at least, I have no need for Windows apps, and the extra maintenance time. Fixing issues in Windows involves hunting down things in lots of different places. Linux still has a fair number of places to configure a system, but overall it’s much simpler.
|
||||
|
||||
I have friends who install 3<sup>rd</sup> party software on Windows just to keep their drivers up to date, because it grabs code from many more websites than just Microsoft’s. Windows has gotten better over the years, and it has more games and desktop applications, but it is an aging, closed system.
|
||||
|
||||
I find Gnome classic a streamlined experience. I wish it wasn’t written in the clunky [fad Javascript][42], and they re-enabled a community around custom themes and color schemes. It’s also still missing some nice features from Gnome 2 and Windows 10, and could be a bit more stable. Gnome 3.0 in 2011 was a step backwards, but six years later we’re up to Gnome 3.22, and things are mature again.
|
||||
|
||||
Gnome Classic is one of the best GUIs, but there are a [number of good ones][43] and all are getting better. This machine is working quite well now and I’m just going to sit back and keep waiting for the HiDPI and other improvements! I’m looking forward to deep learning inside the grammar checker of LibreOffice.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://keithcu.com/wordpress/?p=3739
|
||||
|
||||
作者:[keithccurtis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://twitter.com/keithccurtis
|
||||
[1]:https://www.amazon.com/Lenovo-13-3-inch-Multitouch-Convertible-Platinum/dp/B01NA6ANNK/
|
||||
[2]:http://keithcu.com/wordpress/?p=3270
|
||||
[3]:http://configure.us.dell.com/dellstore/config.aspx?oc=cax13w10ph5122&model_id=xps-13-9360-laptop&c=us&l=en&s=bsd&cs=04
|
||||
[4]:http://blog.lenovo.com/en/blog/why-you-should-give-in-to-the-new-thinkpad-keyboard
|
||||
[5]:https://www.freedesktop.org/wiki/Software/libinput/
|
||||
[6]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=762ce4458974534a2407cc924db05840c89105df
|
||||
[7]:https://mjg59.dreamwidth.org/41713.html
|
||||
[8]:https://en.wikipedia.org/wiki/Electromigration
|
||||
[9]:http://support.lenovo.com/us/en/products/Laptops-and-netbooks/Yoga-Series/yoga-900-13isk2/80UE/downloads/DS112754
|
||||
[10]:http://support.lenovo.com/us/en/products/laptops-and-netbooks/yoga-series/yoga-900-13isk2/downloads/ds119354
|
||||
[11]:https://linux.slashdot.org/comments.pl?sid=9861381&cid=53241071
|
||||
[12]:https://www.reddit.com/r/linux/comments/54gtpc/letter_to_the_federal_trade_commission_regarding/
|
||||
[13]:http://venturebeat.com/2016/09/21/lenovo-confirms-that-linux-wont-work-on-yoga-900-and-900s-laptops/
|
||||
[14]:http://venturebeat.com/2016/09/21/lenovo-confirms-that-linux-wont-work-on-yoga-900-and-900s-laptops/
|
||||
[15]:https://www.reddit.com/user/baronhk/
|
||||
[16]:https://www.reddit.com/user/baronhk/
|
||||
[17]:https://www.reddit.com/user/baronhk/
|
||||
[18]:https://duckduckgo.com/?q=lenovo+yoga+linux+compatibility&t=hs&ia=web
|
||||
[19]:https://duckduckgo.com/?q=lenovo+yoga+linux+compatibility&t=hs&ia=web
|
||||
[20]:https://duckduckgo.com/?q=lenovo+yoga+linux+compatibility&t=hs&ia=web
|
||||
[21]:https://www.spinics.net/lists/linux-ide/msg53370.html
|
||||
[22]:http://ark.intel.com/products/codename/37572/Skylake
|
||||
[23]:http://ark.intel.com/products/codename/37572/Skylake
|
||||
[24]:http://ark.intel.com/products/codename/37572/Skylake
|
||||
[25]:http://ark.intel.com/products/codename/42174/Haswell#@All
|
||||
[26]:http://www.anandtech.com/show/9562/intels-skylake-gpu-analyzing-the-media-capabilities
|
||||
[27]:http://www.anandtech.com/show/9562/intels-skylake-gpu-analyzing-the-media-capabilities
|
||||
[28]:https://trac.ffmpeg.org/wiki/HWAccelIntro
|
||||
[29]:http://www.game-debate.com/gpu/index.php?gid=3295&gid2=3285&compare=iris-graphics-540-mobile-vs-intel-hd-graphics-520-mobile
|
||||
[30]:https://www.freedesktop.org/wiki/Software/Beignet/
|
||||
[31]:http://keithcu.com/wordpress/?p=3444
|
||||
[32]:https://cgit.freedesktop.org/libreoffice/core/log/?qt=grep&q=hidpi
|
||||
[33]:http://wiki.audacityteam.org/wiki/Linux_Issues#Hi-DPI
|
||||
[34]:https://antergos.com/
|
||||
[35]:https://wiki.archlinux.org/index.php/Unified_Extensible_Firmware_Interface
|
||||
[36]:https://wiki.archlinux.org/index.php/Profile-sync-daemon
|
||||
[37]:https://ffmpeg.zeranoe.com/builds/
|
||||
[38]:https://www.nuget.org/
|
||||
[39]:https://blogs.windows.com/buildingapps/2016/03/30/run-bash-on-ubuntu-on-windows/
|
||||
[40]:http://keithcu.com/wordpress/?page_id=558
|
||||
[41]:https://github.com/Microsoft/BashOnWindows/issues/992
|
||||
[42]:http://notes.ericjiang.com/posts/751
|
||||
[43]:https://wiki.archlinux.org/index.php/Desktop_environment
|
||||
@ -0,0 +1,79 @@
|
||||
GHLandy Translating
|
||||
|
||||
How to gain confidence to participate in open source
|
||||
============================================================
|
||||

|
||||
Image credits :
|
||||
|
||||
Original photo by [Gabriel Kamener, Sown Together][1], Modified by Jen Wike Huger
|
||||
|
||||
As your brain develops, you learn about what you can and should do in the world, and what you can't and shouldn't. Your actions are influenced by surroundings and norms, and many times what keeps you from participating is a lack of self-confidence.
|
||||
|
||||
Throughout our lives, we've been taught the "rules" in civil discourse and social behavior. We've been taught that that the speaker is notable, that the CEO has vision, that the teacher is the expert, that the police maintain control, that respect means being quiet and letting others have the floor, and if someone is wrong, gently speaking up, but only in certain situations—it's all a bit complicated.
|
||||
|
||||
When participating in open source, self-confidence plays a huge role. Open source communities are inherently participatory. Participation is a currency in the open source world and that currency is contingent on self-confidence. The more you participate, hone your skills, network, and share your ideas and insights, the more you are able to improve the projects you commit to. All of these things require the belief that you have something valuable to share, and guess what, you do.
|
||||
|
||||
Here's a truth: All of us have something valuable to share. Finding out what that thing is and where our sharing it makes the most positive impact is the point.
|
||||
|
||||
Reflecting on this list will help you develop your self-confidence and make forging ahead in the open source community easier.
|
||||
|
||||
### No one thinks about you as much as you think about yourself
|
||||
|
||||
Reminding yourself that you are in control and that the judgement of others is likely nonexistent can help you gain self-confidence.
|
||||
|
||||
We've been conditioned to understand that people around us are judging us for our actions. This conditioning is a byproduct of learning how to function as social creatures. Likely, it started in childhood when our parents implemented reward systems for how we acted. It continued into adolescence when teachers literally judged our performance and awarded grades and marks, comparing us to others. These systems of motivation and reward caused our brains to establish feedback loops that included self-reflection. We needed to determine if we would get the cookie and prepare ourselves for that eventuality.
|
||||
|
||||
Today, we wonder, "What does this person think about me?" because of this, but the secret is that most people don't spend much time judging you. All of us are thinking about our own cookies. We each have our own ambitions to follow and our own problems to solve. Other people are busy worrying about how they affect people around them, and they aren't paying much attention to you. They likely don't notice if you make mistakes or talk too loud or recede into the background. All the doubts you have about yourself are in your head, not in anyone else's.
|
||||
|
||||
Our desire to be accepted is part of what it means to be human, but acceptance comes at the whim of the person across from us. That person lacks the context of who we are, where we came from, the experiences that shaped us. we have no control. However, we can hope to influence this person through communication.
|
||||
|
||||
In the community-intense world of open source, remembering that people are not thinking about you is especially important. Expect that your peers and mentors are concerned with other projects or community members.
|
||||
|
||||
Once you acknowledge this, embrace the world of proactive communication. Ask for help, tell people what you need, and point out your contributions and remind people that you are there and that you are an active participant in an open community. Both your open source credibility and your self-confidence will improve when people start coming to you, instead of the other way around.
|
||||
|
||||
### People love to share what they know
|
||||
|
||||
Any successful open source community is a teaching and learning community. To get started in open source, not only do you need to be forthcoming with your own knowledge, you need to soak up the lessons other people have to offer. Fortunately, we humans love to share what we know.
|
||||
|
||||
Think about how you feel when someone else asks you for your opinion. Knowing that someone values what you have to say is like a shot of sugar to your Id and Ego.
|
||||
|
||||
As children, our physical brains are not developed enough for us to place ourselves into the larger context of the world and reality. We believe that we are the center of the universe. The majority of our cognitive function develops before we are six years old. During that time our parents respond to our cries and adults everywhere fulfill our desires. We are given evidence that we are the most important thing in the universe.
|
||||
|
||||
Our neural pathways are established during this time, and our egos develop. As we learn to participate in social and civic life, little by little we learn that we aren't the center of the world. However, the initial justifications our egos made don't fully vanish. Understanding the importance of the ego in our social atmospheres can help you connect and relate to people.
|
||||
|
||||
Working in collaboration and seeking out learning experiences will help you hone and develop both your social and technical skills. Constant learning is absolutely integral to advancing in the world of open source.
|
||||
|
||||
What does this have to do with confidence? Not only do you work to improve someone else's confidence by showing them that you value this person's knowledge and input, you develop your own. There will be a moment when you become more flexible. You will at some point admit you don't know something.
|
||||
|
||||
Confident people can say "I don't know" without an air of disappointment.
|
||||
|
||||
### You reap what you sow
|
||||
|
||||
You've heard the phrase "Fake it, 'til you make it"? Well, confidence is like many psychological phenomena. Actively telling yourself that you are smart, funny, interesting, talented, a good communicator, a good friend, unique, knowledgeable, a quick study, an introspective thinker, or whatever other aspect you want to be, will eventually result in you persuading yourself that this is true. And if it's true for you, it becomes true for other people.
|
||||
|
||||
Call it the practice of self-affirmation.
|
||||
|
||||
Additionally, in the world of open source how you think about and treat others is how they will think about and treat you. The Golden Rule is once again valid. If you want to be successful in open source, you have to be confident enough to stand up for what you believe in, but do so in a way that is welcoming and inclusive to other perspectives and opinions. The mark of a leader is someone who models the behaviors they want to see in the world, whether anyone else follows suit or not.
|
||||
|
||||
Do you have other ways to develop confidence? Let us know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Laura Hilliger - Laura Hilliger is an artist, educator, writer and technologist. She's a multimedia designer and developer, a technical liaison, a project manager, an Open Web hacktivist who is happiest in collaborative environments. She's an advocate for change and is currently working to help open up Greenpeace. Alum @Mozilla, UC Berkeley, BAVC, Adobe. Find her onTwitter as @epilepticrabbit
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/3-ways-improve-your-confidence
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laurahilliger
|
||||
[1]:https://www.flickr.com/photos/42647587@N06/
|
||||
128
sources/talk/20170119 Be a force for good in your community.md
Normal file
128
sources/talk/20170119 Be a force for good in your community.md
Normal file
@ -0,0 +1,128 @@
|
||||
Be a force for good in your community
|
||||
============================================================
|
||||
|
||||
>Find out how to give the gift of an out, learn about the power of positive intent, and more.
|
||||
|
||||

|
||||
|
||||
>Image by : opensource.com
|
||||
|
||||
Passionate debate is among the hallmark traits of open source communities and open organizations. On our best days, these debates are energetic and constructive. They are heated, yet moderated with humor and goodwill. All parties remain focused on facts, on the shared purpose of collaborative problem-solving, and driving continuous improvement. And for many of us, they're just plain fun.
|
||||
|
||||
On our worst days, these debates devolve into rehashing the same old arguments on the same old topics. Or we turn on one another, delivering insults—passive-aggressive or outright nasty, depending on our style—and eroding the passion, trust, and productivity of our communities.
|
||||
|
||||
We've all been there, watching and feeling helpless, as a community conversation begins to turn toxic. Yet, as [DeLisa Alexander recently shared][1], there are so many ways that each and every one of us can be a force for good in our communities.
|
||||
|
||||
In the first article of this "open culture" series, I will share a few strategies for how you can intervene, in that crucial moment, and steer everyone to a more positive and productive place.
|
||||
|
||||
### Don't call people out. Call them up.
|
||||
|
||||
Recently, I had lunch with my friend and colleague, [Mark Rumbles][2]. Over the years, we've collaborated on a number of projects that support open culture and leadership at Red Hat. On this day, Mark asked me how I was holding up, as he saw I'd recently intervened in a mailing list conversation when I saw the debate was getting ugly.
|
||||
|
||||
Fortunately, the dust had long since settled, and in fact I'd almost forgotten about the conversation. Nevertheless, it led us to talk about the challenges of open and frank debate in a community that has thousands of members.
|
||||
|
||||
>One of the biggest ways we can be a force for good in our communities is to respond to conflict in a way that compels everyone to elevate their behavior, rather than escalate it.
|
||||
|
||||
Mark said something that struck me as rather insightful. He said, "You know, as a community, we are really good at calling each other out. But what I'd like to see us do more of is calling each other _up_."
|
||||
|
||||
Mark is absolutely right. One of the biggest ways we can be a force for good in our communities is to respond to conflict in a way that compels everyone to elevate their behavior, rather than escalate it.
|
||||
|
||||
### Assume positive intent
|
||||
|
||||
We can start by making a simple assumption when we observe poor behavior in a heated conversation: It's entirely possible that there are positive intentions somewhere in the mix.
|
||||
|
||||
This is admittedly not an easy thing to do. When I see signs that a debate is turning nasty, I pause and ask myself what Steven Covey calls The Humanizing Question:
|
||||
|
||||
"Why would a reasonable, rational, and decent person do something like this?"
|
||||
|
||||
Now, if this is one of your "usual suspects"—a community member with a propensity toward negative behavior--perhaps your first thought is, "Um, what if this person _isn't_ reasonable, rational, or decent?"
|
||||
|
||||
Stay with me, now. I'm not suggesting that you engage in some touchy-feely form of self-delusion. It's called The Humanizing Question not only because asking it humanizes the other person, but also because it humanizes _you_.
|
||||
|
||||
And that, in turn, helps you respond or intervene from the most productive possible place.
|
||||
|
||||
### Seek to understand the reasons for community dissent
|
||||
|
||||
When I ask myself why a reasonable, rational, and decent person might do something like this, time and again, it comes down to the same few reasons:
|
||||
|
||||
* They don't feel heard.
|
||||
* They don't feel respected.
|
||||
* They don't feel understood.
|
||||
|
||||
One easy positive intention we can apply to almost any poor behavior, then, is that the person wants to be heard, respected, or understood. That's pretty reasonable, I suppose.
|
||||
|
||||
By standing in this more objective and compassionate place, we can see that their behavior is _almost certainly _**_not_**_ going to help them get what they want, _and that the community will suffer as a result . . . without our help.
|
||||
|
||||
For me, that inspires a desire to help everyone get "unstuck" from this ugly place we're in.
|
||||
|
||||
Before I intervene, though, I ask myself a follow-up question: _What other positive intentions might be driving this behavior?_
|
||||
|
||||
Examples that readily jump to mind include:
|
||||
|
||||
* They are worried that we're missing something important, or we're making a mistake, and no one else seems to see it.
|
||||
* They want to feel valued for their contributions.
|
||||
* They are burned out, because of overworking in the community or things happening in their personal life.
|
||||
* They are tired of something being broken and frustrated that no one else seems to see the damage or inconvenience that creates.
|
||||
* ...and so on and so forth.
|
||||
|
||||
With that, I have a rich supply of positive intent that I can ascribe to their behavior. I'm ready to reach out and offer them some help, in the form of an out.
|
||||
|
||||
### Give the gift of an out
|
||||
|
||||
What is an out? Think of it as an escape hatch. It's a way to exit the conversation, or abandon the poor behavior and resume behaving like a decent person, without losing face. It's calling someone up, rather than calling them out.
|
||||
|
||||
You've probably experienced this, as some point in your life, when _you_ were behaving poorly in a conversation, ranting and hollering and generally raising a fuss about something or another, and someone graciously offered _you_ a way out. Perhaps they chose not to "take the bait" by responding to your unkind choice of words, and instead, said something that demonstrated they believed you were a reasonable, rational, and decent human being with positive intentions, such as:
|
||||
|
||||
> _So, uh, what I'm hearing is that you're really worried about this, and you're frustrated because it seems like no one is listening. Or maybe you're concerned that we're missing the significance of it. Is that about right?_
|
||||
|
||||
And here's the thing: Even if that wasn't entirely true (perhaps you had less-than-noble intentions), in that moment, you probably grabbed ahold of that life preserver they handed you, and gladly accepted the opportunity to reframe your poor behavior. You almost certainly pivoted and moved to a more productive place, likely without even recognizing it.
|
||||
|
||||
Perhaps you said something like, "Well, it's not that exactly, but I just worry that we're headed down the wrong path here, and I get what you're saying that as community, we can't solve every problem at the same time, but if we don't solve this one soon, bad things are going to happen…"
|
||||
|
||||
In the end, the conversation almost certainly began to move to a more productive place, or you all agreed to disagree.
|
||||
|
||||
We all have the opportunity to offer an upset person a safe way out of that destructive place they're operating from. Here's how.
|
||||
|
||||
### Bad behavior or bad actor?
|
||||
|
||||
If the person is particularly agitated, they may not hear or accept the first out you hand them. That's okay. Most likely, their lizard brain--that prehistoric amygdala that was once critical for human survival—has taken over, and they need a few more moments to recognize you're not a threat. Just keep gently but firmly treating them as if they _were_ a rational, reasonable, decent human being, and watch what happens.
|
||||
|
||||
In my experience, these community interventions end in one of three ways:
|
||||
|
||||
Most often, the person actually _is_ a reasonable person, and soon enough, they gratefully and graciously accept the out. In the process, everyone breaks out of the black vs. white, "win or lose" mindset. People begin to think up creative alternatives and "win-win" outcomes that benefit everyone.
|
||||
|
||||
>Why would a reasonable, rational, and decent person do something like this?
|
||||
|
||||
Occasionally, the person is not particularly reasonable, rational, or decent by nature, but when treated with such consistent, tireless, patient generosity and kindness (by you), they are shamed into retreating from the conversation. This sounds like, "Well, I think I've said all I have to say. Thanks for hearing me out." Or, for less enlightened types, "Well, I'm tired of this conversation. Let's drop it." (Yes, please. Thank you.)
|
||||
|
||||
Less often, the person is what's known as a _bad actor_, or in community management circles, a pot-stirrer. These folks do exist, and they thrive on drama. Guess what? By consistently engaging in a kind, generous, community-calming way, and entirely ignoring all attempts to escalate the situation, you effectively shift the conversation into an area that holds little interest for them. They have no choice but to abandon it. Winners all around.
|
||||
|
||||
That's the power of assuming positive intent. By responding to angry and hostile words with grace and dignity, you can diffuse a flamewar, untangle and solve tricky problems, and quite possibly make a new friend or two in the process.
|
||||
|
||||
Am I successful every time I apply this principle? Heck, no. But I never regret the choice to assume positive intent. And I can vividly recall a few unfortunate occasions when I assumed negative intent and responded in a way that further contributed to the problem.
|
||||
|
||||
Now it's your turn. I'd love to hear about some strategies and principles you apply, to be a force for good when conversations get heated in your community. Share your thoughts in the comments below.
|
||||
|
||||
Next time, we'll explore more ways to be a force for good in your community, and I'll share some tips for handling "Mr. Grumpy."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Rebecca Fernandez is a Principal Employment Branding + Communications Specialist at Red Hat, a contributor to The Open Organization book, and the maintainer of the Open Decision Framework. She is interested in open source and the intersection of the open source way with business management models. Twitter: @ruhbehka
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/1/force-for-good-community
|
||||
|
||||
作者:[Rebecca Fernandez][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rebecca
|
||||
[1]:https://opensource.com/business/15/5/5-ways-promote-inclusive-environment
|
||||
[2]:https://twitter.com/leadership_365
|
||||
@ -0,0 +1,54 @@
|
||||
The Many, the Humble, the Ubuntu Users
|
||||
============================================================
|
||||
|
||||
#### The proverbial “better mousetrap” isn’t one that takes a certified biologist to use. Like Ubuntu, it just needs to do its job extremely well and with little fuss.
|
||||
|
||||
### Roblimo’s Hideaway
|
||||
|
||||

|
||||
|
||||
I have never been much of a leading-edge computing person. In fact, I first got mildly famous online writing a weekly column titled “This Old PC” for Time/Life about making do with used gear — often by installing Linux on it — and after that an essentially identical column for Andover.net titled “Cheap Computing,” which was also about saving money in a world where most online computing columns seemed to be about getting you to spend until you had no money left to spend on food.
|
||||
|
||||
Most of the early Linux adopters I knew were infatuated with their computers and the software that made them useful. They loved poring over source code and making minor changes. They were, for the most part, computer science students or worked as IT people. Their computers and computer networks fascinated them, as they should have.
|
||||
|
||||
I was (and still am) a writer, not a computer science guy. For me, computers have always been tools. I want them to sit quietly until I tell them to do something, then follow my orders with the minimum possible fuss and bother. I like a GUI, since I don’t administer my PC or network often enough to memorize long command strings. Sure, I can look them up and type them in, but I’d really rather be at the beach.
|
||||
|
||||
There was a time when, in Linux circles, mere _users_ were rare. “What do you mean, you just want to use your computer to type articles and maybe add a little HTML to them?” the developer and admin types seemed to ask, as if all fields of endeavor other than coding were inferior to what they did.
|
||||
|
||||
But despite the sneers, I kept hammering a theme in speech after speech and conversation after conversation that went sort of like this: “Instead of scratching only your own itches, why not scratch your girlfriend’s itch? How about your coworkers? And people who work at your favorite restaurant? And what about your doctor? Don’t you want him to spend his time doctoring, not worrying about apt get this and grep that?”
|
||||
|
||||
So yes, since I wanted easy-to-use Linux, I was an [early Mandrake user][1]. And today, I am a happy Ubuntu user.
|
||||
|
||||
Why Ubuntu? Hey! Why not?! It’s the Toyota Camry (or maybe Honda Civic) of Linux distros. Plain-jane. So popular that support is easy to find on IRC, Linux Questions, and Ubuntu’s own extensive forums, and many other places.
|
||||
|
||||
Sure, it’s cooler to use Debian or Fedora, and Mint looks jazzier out of the box, but I’m _still_ mostly interested in writing stories and adding a little HTML to them, along with reading this and that in my browser, editing work in Google Docs for a corporate client or two, keeping up with my email, doing this or that with a picture now and then…. all basic computer user stuff.
|
||||
|
||||
And with all this going on, the appearance of my desktop is meaningless. I can’t see it! It’s covered with application windows! And I’m talking two monitors, not just one. I have, let’s see…. 17 Chrome tabs open in two windows. And GIMP running. And [Bluefish][2], which I’m using right now, to type this essay.
|
||||
|
||||
So for me Ubuntu is the path of least resistance. Mint may be a little cuter, but when you come right down to it, and strip away the trim, isn’t it really Ubuntu? So if I use the same few programs over and over, which I do, and can’t see the desktop anyway, who cares if it’s brown?
|
||||
|
||||
Some studies say Mint is more popular. Others say Debian. But they all show Ubuntu in the top few, year after year.
|
||||
|
||||
So call me mass-average. Call me boring. Call me one of the many, the humble, the Ubuntu users — at least for now…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Robin "Roblimo" Miller is a freelance writer and former editor-in-chief at Open Source Technology Group, the company that owned SourceForge, freshmeat, Linux.com, NewsForge, ThinkGeek and Slashdot, and until recently served as a video editor at Slashdot. He also publishes the blog Robin ‘Roblimo’ Miller’s Personal Site. @robinAKAroblimo
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2017/01/many-humble-ubuntu-users/
|
||||
|
||||
作者:[Robin "Roblimo" Miller][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.roblimo.com/
|
||||
[1]:https://linux.slashdot.org/story/00/11/02/2324224/mandrake-72-in-wal-mart-a-good-idea
|
||||
[2]:http://bluefish.openoffice.nl/index.html
|
||||
@ -1,230 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
### Android 6.0 Marshmallow
|
||||
|
||||
In October 2015, Google brought Android 6.0 Marshmallow into the world. For the OS's launch, Google commissioned two new Nexus devices: the [Huawei Nexus 6P and LG Nexus 5X][39]. Rather than just the usual speed increase, the new phones also included a key piece of hardware: a fingerprint reader for Marshmallow's new fingerprint API. Marshmallow was also packing a crazy new search feature called "Google Now on Tap," user controlled app permissions, a new data backup system, and plenty of other refinements.
|
||||
|
||||
#### The new Google App
|
||||
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][3]
|
||||
* [
|
||||

|
||||
][4]
|
||||
* [
|
||||
|
||||
][5]
|
||||
* [
|
||||
|
||||
][6]
|
||||
* [
|
||||
|
||||
][7]
|
||||
* [
|
||||
|
||||
][8]
|
||||
* [
|
||||
|
||||
][9]
|
||||
* [
|
||||
|
||||
][10]
|
||||
* [
|
||||

|
||||
][11]
|
||||
|
||||
Marshmallow was the first version of Android after [Google's big logo redesign][40]. The OS was updated accordingly, mainly with a new Google app that added a colorful logo to the search widget, search page, and the app icon.
|
||||
|
||||
Google reverted the app drawer from a paginated horizontal layout back to the single, vertically scrolling sheet. The earliest versions of Android all had vertically scrolling sheets until Google changed to a horizontal page system in Honeycomb. The scrolling single sheet made finding things in a large selection of apps much faster. A "quick scroll" feature, which let you drag on the scroll bar to bring up letter indexing, helped too. This new app drawer layout also carried over to the widget drawer. Given that the old system could easily grow to 15+ pages, this was a big improvement.
|
||||
|
||||
The "suggested apps" bar at the top of Marshmallow's app drawer made finding apps faster, too.
|
||||
This bar changed from time to time and tried to surface the apps you needed when you needed them. It used an algorithm that took into account app usage, apps that are normally launched together, and time of day.
|
||||
|
||||
#### Google Now on Tap—a feature that didn't quite work out
|
||||
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][12]
|
||||
* [
|
||||
|
||||
][13]
|
||||
* [
|
||||
|
||||
][14]
|
||||
* [
|
||||
|
||||
][15]
|
||||
* [
|
||||
|
||||
][16]
|
||||
* [
|
||||
|
||||
][17]
|
||||
* [
|
||||
|
||||
][18]
|
||||
* [
|
||||
|
||||
][19]
|
||||
* [
|
||||
|
||||
][20]
|
||||
* [
|
||||
|
||||
][21]
|
||||
* [
|
||||
|
||||
][22]
|
||||
|
||||
One of Marshmallow's headline features was "Google Now on Tap." With Now on Tap, you could hold down the home button on any screen and Android would send the entire screen to Google for processing. Google would then try to figure out what the screen was about, and a special list of search results would pop up from the bottom of the screen.
|
||||
|
||||
Results yielded by Now on Tap weren't the usual 10 blue links—though there was always a link to a Google Search. Now on Tap could also deep link into other apps using Google's App Indexing feature. The idea was you could call up Now on Tap for a YouTube music video and get a link to the Google Play or Amazon "buy" page. Now on Tapping (am I allowed to verb that?) a news article about an actor could link to his page inside the IMDb app.
|
||||
|
||||
Rather than make this a proprietary feature, Google built a whole new "Assistant API" into Android. The user could pick an "Assist App" which would be granted scads of information upon long-pressing the home button. The Assist app would get all the text that was currently loaded by the app—not just what was immediately on screen—along with all the images and any special metadata the developer wanted to include. This API powered Google Now on Tap, and it also allowed third parties to make Now on Tap rivals if they wished.
|
||||
|
||||
Google hyped Now on Tap during Marshmallow's initial presentation, but in practice, the feature wasn't very useful. Google Search is worthwhile because you're asking it an exact question—you type in whatever you want, and it scours the entire Internet looking for the answer or web page. Now on Tap made things infinitely harder because it didn't even know what question you were asking. You opened Now on Tap with a very specific intent, but you sent Google the very unspecific query of "everything on your screen." Google had to guess what your query was and then tried to deliver useful search results or actions based on that.
|
||||
|
||||
Behind the scenes, Google was probably processing like crazy to brute-force out the result you wanted from an entire page of text and images. But more often than not, Now on Tap yielded what felt like a list of search results for every proper noun on the page. Sifting through the list of results for multiple queries was like being trapped in one of those Bing "[Search Overload][41]" commercials. The lack of any kind of query targeting made Now on Tap feel like you were asking Google to read your mind, and it never could. Google eventually patched in an "Assist" button to the text selection menu, giving Now on Tap some of the query targeting that it desperately needed.
|
||||
|
||||
Calling Now on Tap anything other than a failure is hard. The shortcut to access Now on Tap—long pressing on the home button—basically made it a hidden, hard-to-discover feature that was easy to forget about. We speculate the feature had extremely low usage numbers. Even when users did discover Now on Tap, it failed to read your mind so often that, after a few attempts, most users probably gave up on it.
|
||||
|
||||
With the launch of the Google Pixels in 2016, the company seemingly admitted defeat. It renamed Now on Tap "Screen Search" and demoted it in favor of the Google Assistant. The Assistant—Google's new voice command system—took over On Tap's home button gesture and related it to a second gesture once the voice system was activated. Google also seems to have learned from Now on Tap's poor discoverability. With the Assistant, Google added a set of animated colored dots to the home button that helped users discover and be reminded about the feature.
|
||||
|
||||
#### Permissions
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][23]
|
||||
* [
|
||||
|
||||
][24]
|
||||
* [
|
||||
|
||||
][25]
|
||||
* [
|
||||
|
||||
][26]
|
||||
* [
|
||||
|
||||
][27]
|
||||
* [
|
||||
|
||||
][28]
|
||||
* [
|
||||
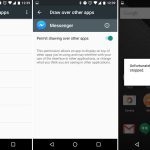
|
||||
][29]
|
||||
* [
|
||||
|
||||
][30]
|
||||
* [
|
||||
|
||||
][31]
|
||||
* [
|
||||

|
||||
][32]
|
||||
|
||||
Android 6.0 finally introduced an app permissions system that gave users granular control over what data apps had access to.
|
||||
|
||||
Apps no longer gave you a huge list of permissions at install. With Marshmallow, apps installed without asking for any permissions at all. When apps needed a permission—like access to your location, camera, microphone, or contact list—they asked at the exact time they needed it. During your usage of an app, an "Allow or Deny" dialog popped up anytime the app wanted a new permission. Some app setup flow tackled this by asking for a few key permissions at startup, and everything else popped up as the app needed it. This better communicated to the user what the permissions are for—this app needs camera access because you just tapped on the camera button.
|
||||
|
||||
Besides the in-the-moment "Allow or Deny" dialogs, Marshmallow also added a permissions setting screen. This big list of checkboxes allowed data-conscious users to browse which apps have access to what permissions. They can browse not only by app, but also by permission. For instance, you could see every app that has access to the microphone.
|
||||
|
||||
Google had been experimenting with app permissions for some time, and these screens were basically the rebirth of the hidden "[App Ops][42]" system that was accidentally introduced in Android 4.3 and quickly removed.
|
||||
|
||||
While Google experimented in previous versions, the big difference with Marshmallow's permissions system was that it represented an orderly transition to a permission OS. Android 4.3's App Ops was never meant to be exposed to users, so developers didn't know about it. The result of denying an app a permission in 4.3 was often a weird error message or an outright crash. Marshmallow's system was opt-in for developers—the new permission system only applied to apps that were targeting the Marshmallow SDK, which Google used as a signal that the developer was ready for permission handling. The system also allowed for communication to users when a feature didn't work because of a denied permission. Apps were told when they were denied a permission, and they could instruct the user to turn the permission back on if you wanted to use a feature.
|
||||
|
||||
#### The Fingerprint API
|
||||
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][33]
|
||||
* [
|
||||
|
||||
][34]
|
||||
* [
|
||||
|
||||
][35]
|
||||
* [
|
||||
|
||||
][36]
|
||||
* [
|
||||
|
||||
][37]
|
||||
* [
|
||||

|
||||
][38]
|
||||
|
||||
Before Marshmallow, few OEMs had come up with their own fingerprint solution in response to [Apple's Touch ID][43]. But with Marshmallow, Google finally came up with an ecosystem-wide API for fingerprint recognition. The new system included UI for registering fingerprints, a fingerprint-guarded lock screen, and APIs that allowed apps to protect content behind a fingerprint scan or lock-screen challenge.
|
||||
|
||||
The Play Store was one of the first apps to support the API. Instead of having to enter your password to purchase an app, you could just use your fingerprint. The Nexus 5X and 6P were the first phones to support the fingerprint API with an actual hardware fingerprint reader on the back.
|
||||
|
||||
Later the fingerprint API became one of the rare examples of the Android ecosystem actually cooperating and working together. Every phone with a fingerprint reader uses Google's API, and most banking and purchasing apps are pretty good about supporting it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[1]:https://www.youtube.com/watch?v=f17qe9vZ8RM
|
||||
[2]:https://www.youtube.com/watch?v=VOn7VrTRlA4&list=PLOU2XLYxmsIJDPXCTt5TLDu67271PruEk&index=11
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[25]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[26]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[27]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[28]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[29]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[30]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[31]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[32]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[33]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[34]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[35]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[36]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[37]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[38]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[39]:http://arstechnica.com/gadgets/2015/10/nexus-5x-and-nexus-6p-review-the-true-flagships-of-the-android-ecosystem/
|
||||
[40]:http://arstechnica.com/gadgets/2015/09/google-gets-a-new-logo/
|
||||
[41]:https://www.youtube.com/watch?v=9yfMVbaehOE
|
||||
[42]:http://www.androidpolice.com/2013/07/25/app-ops-android-4-3s-hidden-app-permission-manager-control-permissions-for-individual-apps/
|
||||
[43]:http://arstechnica.com/apple/2014/09/ios-8-thoroughly-reviewed/10/#h3
|
||||
@ -1,171 +0,0 @@
|
||||
# Behind-the-scenes changes
|
||||
|
||||
Marshmallow expanded on the power-saving JobScheduler APIs that were originally introduced in Lollipop. JobScheduler turned app background processing from a free-for-all that frequently woke up the device to an organized system. JobScheduler was basically a background-processing traffic cop.
|
||||
|
||||
In Marshmallow, Google added a "Doze" mode to save even more power when a device is left alone. If a device was stationary, unplugged, and had its screen off, it would slowly drift into a low-power, disconnected mode that locked down background processing. After a period of time, network access was disabled. Wake locks—an app's request to keep your phone awake so it can do background processing—got ignored. System Alarms (not user-set alarm clock alarms) and the [JobScheduler][25] shut down, too.
|
||||
|
||||
If you've ever put a device in airplane mode and noticed the battery lasts forever, Doze was like an automatic airplane mode that kicked in when you left your device alone—it really did boost battery life. It worked for phones that were left alone on a desk all day or all night, and it was great for tablets, which are often forgotten about on the coffee table.
|
||||
|
||||
The only notification that could punch through Doze mode was a "high priority message" from Google Cloud Messaging. This was meant for texting services so, even if a device is dozing, messages still came through.
|
||||
|
||||
|
||||
* [
|
||||
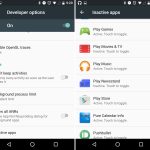
|
||||
][1]
|
||||
* [
|
||||
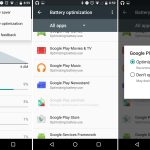
|
||||
][2]
|
||||
|
||||
"App Standby" was another power saving feature that more-or-less worked quietly in the background. The idea behind it was simple: if you stopped interacting with an app for a period of time, Android deemed it unimportant and took away its internet access and background processing privileges.
|
||||
|
||||
For the purposes of App Standby, "interacting" with an app meant opening the app, starting a foreground service, or generating a notification. Any one of these actions would reset the Standby timer on an app. For every other edge case, Google added a cryptically-named "Battery Optimizations" screen in the settings. This let users whitelist apps to make them immune from app standby. As for developers, they had an option in Developer Settings called "Inactive apps" which let them manually put an app on standby for testing.
|
||||
|
||||
App Standby basically auto-disabled apps you weren't using, which was a great way to fight battery drain from crapware or forgotten-about apps. Because it was completely silent and automatically happened in the background, it helped even novice users have a well-tuned device.
|
||||
|
||||
* [
|
||||
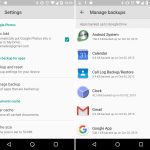
|
||||
][3]
|
||||
* [
|
||||
|
||||
][4]
|
||||
* [
|
||||
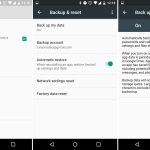
|
||||
][5]
|
||||
|
||||
Google tried many app backup schemes over the years, and in Marshmallow it [took another swing][26]. Marshmallow's brute force app backup system aimed to dump the entire app data folder to the cloud. It was possible and technically worked, but app support for it was bad, even among Google apps. Setting up a new Android phone is still a huge hassle, with countless sign-ins and tutorial popups.
|
||||
|
||||
In terms of interface, Marshmallow's backup system used the Google Drive app. In the settings of Google Drive, there's now a "Manage Backups" screen, which showed app data not only from the new system, but also every other app backup scheme Google has tried over the years.
|
||||
|
||||
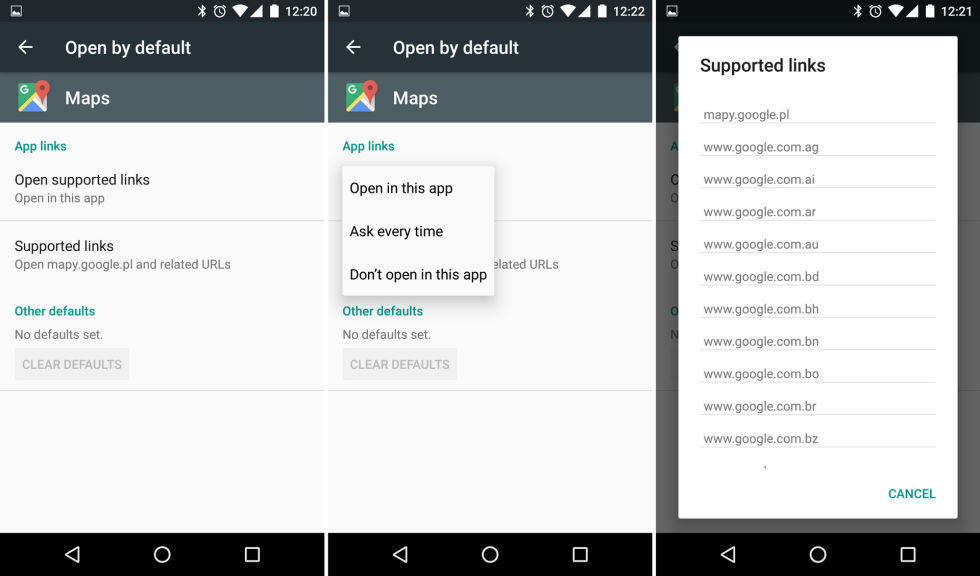
|
||||
|
||||
|
||||
Buried in the settings was a new "App linking" feature, which could "link" an app to a website. Before app linking, opening up a Google Maps URL on a fresh install usually popped up an "Open With" dialog box that wanted to know if it should open the URL in a browser or in the Google Maps app.
|
||||
|
||||
This was a silly question, since of course you wanted to use the app instead of the website—that's why you had the app installed. App linking let website owners associate their app with their webpage. If users had the app installed, Android would suppress the "Open With" dialog and use that app instead. To activate app linking, developers just had to throw some JSON code on their website that Android would pick up.
|
||||
|
||||
App linking was great for sites with an obvious app client, like Google Maps, Instagram, and Facebook. For sites with an API and multiple clients, like Twitter, the App Linking settings screen gave users control over the default app association for any URL. Out-of-the-box app linking covered 90 percent of use cases though, which cut down on the annoying pop ups on a new phone.
|
||||
|
||||
|
||||
* [
|
||||
|
||||
][6]
|
||||
* [
|
||||
|
||||
][7]
|
||||
* [
|
||||
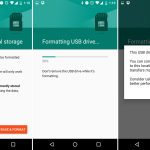
|
||||
][8]
|
||||
* [
|
||||
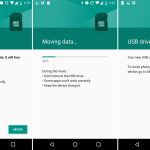
|
||||
][9]
|
||||
* [
|
||||
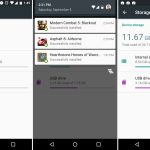
|
||||
][10]
|
||||
* [
|
||||
|
||||
][11]
|
||||
* [
|
||||
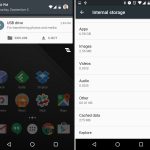
|
||||
][12]
|
||||
* [
|
||||
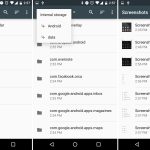
|
||||
][13]
|
||||
* [
|
||||
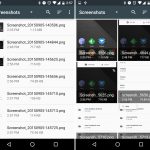
|
||||
][14]
|
||||
* [
|
||||
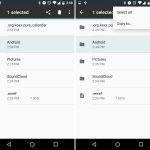
|
||||
][15]
|
||||
|
||||
Adoptable storage was one of Marshmallow's best features. It turned SD cards from a janky secondary storage pool into a perfect merged-storage solution. Slide in an SD card, format it, and you instantly had more storage in your device that you never had to think about again.
|
||||
|
||||
Sliding in a SD card showed a setup notification, and users could choose to format the card as "portable" or "internal" storage. The "Internal" option was the new adoptable storage mode, and it paved over the card with an ext4 file system. The only downside? The card and the data were both "locked" to your phone. You couldn't pull the card out and plug it into anything without formatting it first. Google was going for a set-it-and-forget-it use case with internal storage.
|
||||
|
||||
If you did yank the card out, Android did its best to deal with things. It popped up a message along the lines of "You'd better put that back or else!" along with an option to "forget" the card. Of course "forgetting" the card would result in all sorts of data loss, and it was not recommended.
|
||||
|
||||
The sad part of adoptable storage is that devices that could actually use it didn't come for a long time. Neither Nexus device had an SD card, so for the review we rigged up a USB stick as our adoptable storage. OEMs initially resisted the feature, with [LG and Samsung][27] disabling it on their early 2016 flagships. Samsung stated that "We believe that our users want a microSD card to transfer files between their phone and other devices," which was not possible once the card was formatted to ext4.
|
||||
|
||||
Google's implementation let users choose between portable and internal formatting options. But rather than give users that choice, OEMs completely took the internal storage feature away. Advanced users were unhappy about this, and of course the Android modding scene quickly re-enabled adoptable storage. On the Galaxy S7, modders actually defeated Samsung's SD card lockdown [a day before][28] the device was even officially released!
|
||||
|
||||
#### Volume and Notifications
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][16]
|
||||
* [
|
||||

|
||||
][17]
|
||||
* [
|
||||
|
||||
][18]
|
||||
* [
|
||||
|
||||
][19]
|
||||
* [
|
||||
|
||||
][20]
|
||||
* [
|
||||
|
||||
][21]
|
||||
* [
|
||||
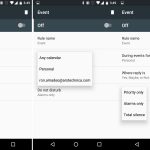
|
||||
][22]
|
||||
* [
|
||||
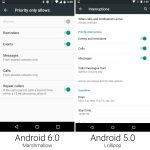
|
||||
][23]
|
||||
* [
|
||||
|
||||
][24]
|
||||
|
||||
Google walked back the priority notification controls that were in the volume popup in favor of a simpler design. Hitting the volume key popped up a single slider for the current audio source, along with a drop down button that expanded the controls to show all three audio sliders: Notifications, media, and alarms. All the priority notification controls still existed—they just lived in a "do not disturb" quick-settings tile now.
|
||||
|
||||
One of the most relieving additions to the notification controls gave users control over Heads-Up notifications—now renamed "Peek" notifications. This feature let notifications pop up over the top portion of the screen, just like on iOS. The idea was that the most important notifications should be elevated over your normal, everyday notifications.
|
||||
|
||||
However, in Lollipop, when this feature was introduced, Google had the terrible idea of letting developers decide if their apps were "important" or not. Of course, every developer thinks its app is the most important thing in the world. So while the feature was originally envisioned for instant messages from your closest contacts, it ended up being hijacked by Facebook "Like" notifications. In Marshmallow, every app got a "treat as priority" checkbox in the notification settings, which gave users an easy ban hammer for unruly apps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[25]:http://arstechnica.com/gadgets/2014/11/android-5-0-lollipop-thoroughly-reviewed/6/#h2
|
||||
[26]:http://arstechnica.com/gadgets/2015/10/android-6-0-marshmallow-thoroughly-reviewed/6/#h2
|
||||
[27]:http://arstechnica.com/gadgets/2016/02/the-lg-g5-and-galaxy-s7-wont-support-android-6-0s-adoptable-storage/
|
||||
[28]:http://www.androidpolice.com/2016/03/10/modaco-manages-to-get-adoptable-sd-card-storage-working-on-the-galaxy-s7-and-galaxy-s7-edge-no-root-required/
|
||||
@ -1,3 +1,5 @@
|
||||
Martin translating...
|
||||
|
||||
Vim Keyboard Shortcuts Cheatsheet
|
||||
============================================================
|
||||

|
||||
|
||||
@ -1,131 +0,0 @@
|
||||
ucasFL translating
|
||||
5 Vim Tips and Tricks for Experienced Users
|
||||
============================================================
|
||||

|
||||
|
||||
This article is part of the [VIM User Guide][12] series:
|
||||
|
||||
* [The Beginner’s Guide to Start Using Vim][3]
|
||||
* [Vim Keyboard Shortcuts Cheatsheet][4]
|
||||
* 5 Vim Tips and Tricks for Experienced Users
|
||||
* [3 Useful VIM Editor Tips and Tricks for Advanced Users][5]
|
||||
|
||||
The Vim editor offers so many features that it’s very difficult to learn all of them. While, of course, spending more and more time on the command line editor always helps, there is no denying the fact that you learn new and productive things faster while interacting with fellow Vim users. Here are some Vim tips and tricks for you.
|
||||
|
||||
|
||||
**Note** – To create the examples here, I used Vim version 7.4.52.
|
||||
|
||||
### 1\. Working with multiple files
|
||||
|
||||
If you are a software developer or someone who uses Vim as their primary editor, chances are that you have to work with multiple files simultaneously. Following are some useful tips that you can use while working with multiple files.
|
||||
|
||||
Instead of opening different files in different shell tabs, you can open multiple files in a single tab by passing their filenames as arguments to the vim command. For example:
|
||||
|
||||
```
|
||||
vim file1 file2 file3
|
||||
```
|
||||
|
||||
The first file (file1 in the example) will be the current file and read into the buffer.
|
||||
|
||||
Once inside the editor, use the `:next` or `:n` command to move to the next file, and the `:prev` or `:N` command to return to the previous one. To directly switch to the first or the last file, use `:bf` and `:bl` commands, respectively. To open and start editing another file, use the `:e` command with the filename as argument (use the complete path in case the file is not present in the current directory).
|
||||
|
||||
At any point if it is required to list down currently opened files, use the `:ls` command. See the screen shot shown below.
|
||||
|
||||

|
||||
|
||||
Note that “%a” represents the file in the current active window, while “#” represents the file in the previous active window.
|
||||
|
||||
### 2\. Save time with auto complete
|
||||
|
||||
Want to save time and improve accuracy? Use abbreviations. They come in handy while writing long, complex words that recur frequently throughout the file. The Vim command for abbreviations is `ab`. For example, after you run the command
|
||||
|
||||
```
|
||||
:ab asap as soon as possible
|
||||
```
|
||||
|
||||
each occurrence of the word “asap” will be automatically replaced by “as soon as possible”, as you type.
|
||||
|
||||
Similarly, you can also use abbreviations to correct common typing mistakes. For example, the command
|
||||
|
||||
```
|
||||
:ab recieve receive
|
||||
```
|
||||
|
||||
will automatically correct the spelling mistake as you type. If you want to prevent the expansion/correction from happening at a particular occurrence, just type “Ctrl + V” after the last character of the word and then press the space bar key.
|
||||
|
||||
If you want to save the abbreviation you’ve created so that it is available to you the next time you use the Vim editor, add the complete `ab` command (without the initial colon) to “/etc/vim/vimrc” file. To remove a particular abbreviation, you can use the `una`command. For example, `:una asap`.
|
||||
|
||||
### 3\. Split windows to easily copy/paste
|
||||
|
||||
There are times when you want to copy a piece of code or a portion of text from one file to another. While the process is easy when working with GUI editors, it gets a bit tedious and time-consuming while working with a command line editor. Fortunately, Vim provides a way to minimize the time and effort required to do this.
|
||||
|
||||
Open one of the two files and then split the Vim window to open the other file. This can be done by using the `split` command with the file name as argument. For example,
|
||||
|
||||
```
|
||||
:split test.c
|
||||
```
|
||||
|
||||
will split the window and open “test.c”.
|
||||
|
||||

|
||||
|
||||
Observe that the command split the Vim window horizontally. In case you want to split the window vertically, you can do so using the `vsplit` command. Once both the files are opened, copy the stuff from one file, press “Ctrl + w” to switch the control to another file, and paste.
|
||||
|
||||
### 4\. Save a file you edited without the required permissions
|
||||
|
||||
There are times when you realize that a file is read-only only after making a bunch of changes to it.
|
||||
|
||||

|
||||
|
||||
Although closing the file and reopening it with the required permissions is a way out, it’s a sheer waste of time if you’ve already made a lot of changes, as all of them will be lost during the process. Vim provides you a way to handle this situation by allowing you to change the file permissions from within the editor before you save it. The command for this is:
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
```
|
||||
|
||||
The command will ask you for the password, just like `sudo` does on the command line, and will then save the changes.
|
||||
|
||||
**A related tip**: To quickly access the command prompt while editing a file in Vim, run the `:sh` command from within the editor. This will place you in an interactive shell. Once you are done, run the `exit` command to quickly return to your Vim session.
|
||||
|
||||
### 5\. Preserve indentation during copy/paste
|
||||
|
||||
Most of the experienced programmers work on Vim with auto indentation enabled. Although it’s a time-saving practice, it creates a problem while pasting an already indented code. For example, this is what happened when I pasted an already indented code into a file opened in Vim editor with auto indent on.
|
||||
|
||||

|
||||
|
||||
The solution to this problem is the `pastetoggle` option. Add the line
|
||||
|
||||
```
|
||||
set pastetoggle=<F2>
|
||||
```
|
||||
|
||||
to your vimrc file, and press F2 in insert mode just before pasting the code. This should preserve the original indentation. Note that you can replace F2 with any other key if it’s already mapped to some other functionality.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The only way you can further improve your Vim editor skills is by using the command line editor for your day-to-day work. Just note down the actions that take time and then try to find out if there is an editor command that will do the actions more quickly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://www.maketecheasier.com/author/himanshu/
|
||||
[2]:https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/#comments
|
||||
[3]:https://www.maketecheasier.com/start-with-vim-linux/
|
||||
[4]:https://www.maketecheasier.com/vim-keyboard-shortcuts-cheatsheet/
|
||||
[5]:https://www.maketecheasier.com/vim-tips-tricks-advanced-users/
|
||||
[6]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[7]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-for-experienced-users%2F
|
||||
[8]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-for-experienced-users%2F&text=5+Vim+Tips+and+Tricks+for+Experienced+Users
|
||||
[9]:mailto:?subject=5%20Vim%20Tips%20and%20Tricks%20for%20Experienced%20Users&body=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-for-experienced-users%2F
|
||||
[10]:https://www.maketecheasier.com/enable-two-step-verification-apple-icloud-account/
|
||||
[11]:https://www.maketecheasier.com/mistakes-wordpress-user-should-avoid/
|
||||
[12]:https://www.maketecheasier.com/series/vim-user-guide/
|
||||
[13]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang翻译中
|
||||
|
||||
Installing, Obtaining, and Making GTK Themes
|
||||
----------------
|
||||
|
||||
|
||||
96
sources/tech/20161222 LFCS Command Line Basics.md
Normal file
96
sources/tech/20161222 LFCS Command Line Basics.md
Normal file
@ -0,0 +1,96 @@
|
||||
LFCS Command Line Basics
|
||||
=======================
|
||||
|
||||
There are quite a few command line basics to cover in this article. We will go over the TeleTYpe (TTY) and a few commands with operators. Be sure to practice all of these and be aware that these are the same for CentOS and Ubuntu unless otherwise noted.
|
||||
|
||||
**TTY**
|
||||
|
||||
The TTY is used in Linux when there is no Graphical User Interface (GUI) running or when the user is outside of the GUI. TTY is also used when a terminal window is opened, but these are different types of TTY.
|
||||
|
||||
There are three types of TTYs:
|
||||
|
||||
1. Physical
|
||||
2. Local Pseudo
|
||||
3. Remote Pseudo
|
||||
|
||||
Basically, each Linux system has around six or seven Physical TTYs. These are accessible by holding down a CTRL+ALT key and pressing F1 through F6 for CentOS and CTRL+ALT and F1 through F7 for Ubuntu.
|
||||
|
||||
**NOTE: **Some distros might have a different number of TTYs and different defaults for the GUI. Some distros may have a different key combination of CTRL+F# or ALT+F# to change between the Physical TTYs. When using VirtualBox use the Right CTRL key unless you have changed the Host key.
|
||||
|
||||
In CentOS the GUI will be on TTY 1 (CTRL+ALT+F1) and the other Physical TTYs are text based. On Ubuntu the GUI is on TTY 7 (CTRL+ALT+F7) and the other Physical TTYs are text based.
|
||||
|
||||
**NOTE:** It is not wise to attempt to load the GUI under another TTY since this can use up a lot of resources, but it is possible.
|
||||
|
||||
When Linux starts up, whether CentOS or Ubuntu, the default TTY is opened. If a GUI is installed then it goes to TTY1 for CentOS and TTY7 for Ubuntu. If you open a Terminal window (Pseudo TTY) and use the command 'who' you will see a listing of TTYs in use. An example is shown in Figure 1.
|
||||
|
||||

|
||||
|
||||
**FIGURE 1**
|
||||
|
||||
In Figure 1 you can see that I am currently logged in to TTY1 (non-GUI). The second line of connections show that I am logged in to the GUI (TTY7) as well as two Pseudo TTYs (PTS/1 and PTS/2). Looking at Figure 2 you can see that the new entry shows a Remote Pseudo TTY (PTS/3). The Remote Pseudo connection is from a system with the IP address of 192.168.0.11.
|
||||
|
||||

|
||||
|
||||
**FIGURE 2**
|
||||
|
||||
Remote TTY connections can be made with applications such as 'PuTTY' or any SSH Client (if SSH is enabled on the remote Linux system).
|
||||
|
||||
If a terminal window has small fonts you can use the keys CTRL+SHIFT and the '+' to enlarge the fonts. Press it multiple times to make it even bigger each time. To shrink it down in size use the CTRL+- to continually make it smaller. To make the terminal font back to the original size press CTRL+0.
|
||||
|
||||
**NOTE:** Be aware that the font will only get so large or so small before the key combination will not work anymore.
|
||||
|
||||
Hopefully you now understand the various type of TTYs. Let's look at some of the commands which can be used in a TTY.
|
||||
|
||||
**Commands**
|
||||
|
||||
One of the commands was already discussed previously. The command 'who' is used to show who is logged onto a system.
|
||||
|
||||
Another command is 'pwd'. The command 'pwd' stands for 'Print Working Directory'. The command returns the current directory in which you are located. For example, if the terminal prompt is '[jbuse@localhost ~]$' the username is 'jbuse' and the current directory is ~. The tilde (~) designates the user's home folder. The home folder should be '/home/_username_'. The username is the name used to log into the system.
|
||||
|
||||
To list the contents of the current folder use the command 'ls'. The 'ls' command stands for List. If no options are specified then the current folder is listed. If you give a folder name then the contents of that folder is listed. For example, to see the contents of the contents of the 'media' folder you would use the command 'ls /media'.
|
||||
|
||||
Along with the 'ls' command are a few options we can add to show more detail or specific details. If you wish to see all folder and files, even the hidden ones, use the option '-a'. To see all files and folders in the current directory use the command 'ls -a'. Hidden files and folders will appear with a period in front of the name.
|
||||
|
||||
To see a forward slash (/) after each folder name use the option '-F'. A listing of the current folder would be 'ls -F'. The '-F' is used to classify the files by file type. Symbolic links are signified by '@' after the folder name.
|
||||
|
||||
You can put the two together to have a command of 'ls -aF'.
|
||||
|
||||
**NOTE:** Some options may be of different cases. The options can be case-sensitive.
|
||||
|
||||
Another option is the '-l' for a long listing. A sample output is shown in Figure 3\. The folder and file names are listed to the right side. The files are colored white, the folders are dark blue and the symbolic links are light blue. As you can see in Figure 3 the symbolic link 'vtrgb' is linked from '/etc/alternatives/vtrgb'.
|
||||
|
||||

|
||||
|
||||
**FIGURE 3**
|
||||
|
||||
The first column to the left is the permissions for the file or folder. The first letter is either a 'd' for directory or a '-' for a file. The next three letters show permissions for the owner ('r' – read, 'w' – write and 'x' – execute) followed by the group permissions and permissions for 'others'. The next column of numbers shows the number of links to the file or folder. The next column is the owner name followed by the group name of ownership. The next column is the number of bytes which the file or folder takes up on the storage device. The next three columns are the month, day and year the file was last modified. Finally, the final column is the path name.
|
||||
|
||||
So far you have seen that the listing is sorted alphabetically. To reverse the order from 'z to a' and not 'a to z' use the '-r' option. The '-r' or reverse option causes the ls command to reverse the output order.
|
||||
|
||||
To list the files by the modified timestamp use the '-t' option. The order is from the most recently modified to the oldest modification date. Of course to reverse the order use both the '-t' and the '-r' together in the command 'ls -tr'.
|
||||
|
||||
If you do not like looking at the long number of bytes which the file takes up use the option '-h'. The output will be more readable such as '4.0K' and not '4096'.
|
||||
|
||||
To get specific information on a single folder use the option '-d', but the folder must be specified. For example to see the specifics for the folder '/media' use the command 'ls -ld /media'.
|
||||
|
||||
Another command to be familiar with is the command 'cat'. The command 'cat' is used to copy a standard input (a file) to the standard output (the screen). Use 'cat' to easily view the contents of a file. For example to see the contents of a file called 'text' use the command 'cat text' if you are in the same folder as the file 'text'. If you are not in the same folder then you must specify the location. For example, if the file 'text' is in the folder '/home/jarret/test/' then the command would be 'cat /home/jarret/test/text'.
|
||||
|
||||
Another very useful command is 'man'. The 'man' command is used to view documentation for specific commands. For example, to see the MANual pages for the command 'ls' use the command 'man ls'.
|
||||
|
||||
**NOTE:** Remember that on the LFCS exam you have access to the 'man' command and can use it.
|
||||
|
||||
Look over these commands and test them out to be familiar with them. Use the 'man' command and look over the commands covered in this article to see what other options are available.
|
||||
|
||||
**NOTE:** I tend to use the word 'options' for the characters passed to a command to change its function or output. Some people may use the words 'parameters', 'arguments' and the like. They tend to be interchangeable.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/lfcs-command-line-basics.3334/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
@ -1,147 +0,0 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
Minecraft Server on Linux
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
Minecraft is a major game being played on many different consoles and computer systems. As of June 2016 there have been over 106 million units sold on all platforms. Because of the popularity, you may want to host a Minecraft party at home. To do this you install a Minecraft Server to allow all users to connect locally and play in the same world together.
|
||||
|
||||
**System Requirements**
|
||||
|
||||
To start, you need a Linux system with a fair amount of Random Access Memory (RAM). The more players you will host on the server the more RAM you will need. Hard Drive space is not a large requirement, just enough to install Java and the Minecraft Server Java file. The Minecraft Server should have a decent network connection whether wired or WiFi.
|
||||
|
||||
Let's look at some minimum requirements for the Minecraft Server:
|
||||
|
||||
**Processor: **Duo Core or better
|
||||
**RAM:** 2 GB (20-40 players), 3 GB (30-60 players), 8 GB (60+ players)
|
||||
**OS:** An OS with no Graphical User Interface (GUI) to allow more resources free
|
||||
|
||||
**NOTE:** The requirements are for the Minecraft Server program and not for the whole OS! If more resources can be allocated to the Minecraft Server it will operate better.
|
||||
|
||||
**Installing JAVA**
|
||||
|
||||
Once you have a system with Linux running on it you will need to install the latest version of Java.
|
||||
|
||||
To verify your Java version enter the following command in a terminal: “java -version”. The result should be:
|
||||
|
||||
```
|
||||
java version "1.8.0_101"
|
||||
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
|
||||
|
||||
Java HotSpot(TM) Client VM (build 25.101-b13, mixed mode)
|
||||
```
|
||||
|
||||
If your current Java version is not 1.8 or higher then install Java version 8 by performing the following from a terminal on a Ubuntu system:
|
||||
|
||||
1. _sudo add-apt-repository ppa:webupd8team/java_
|
||||
2. _sudo apt-get update_
|
||||
3. _sudo apt-get install oracle-java8-installer_
|
||||
|
||||
**NOTE:** If the 'add-apt-repository' command is not found, run 'sudo apt-get install software-properties-common'. You could also change the third command to be 'oracle-java9-installer' for the newest version of JAVA.
|
||||
|
||||
For a Redhat system, such as CentOS, use the following command:
|
||||
|
||||
1. _sudo yum install java-1.8.0-openjdk_
|
||||
|
||||
After the installation verify the version by entering the version command, 'java -version', and verify the output. Once you have the appropriate version of Java you may proceed with the rest of the installation.
|
||||
|
||||
**Minecraft Server Version Download**
|
||||
|
||||
The next thing is to check the version of Minecraft which the users will be running. See Figure 1 taken from a system running Minecraft and notice the version number in the bottom left corner.
|
||||
|
||||

|
||||
|
||||
**FIGURE 1**
|
||||
|
||||
Keep in mind the version number of the Minecraft client software. Each client should be the same version to make this work.
|
||||
|
||||
The next thing to do is download the Minecraft Server for the version you will need for the clients. To download the version you need you will need to know its location. The command to get the needed file is:
|
||||
|
||||
_sudo wget _[_https://s3.amazonaws.com/Minecraft.Download/versions/[version]/minecraft_server.[version].jar_][1]
|
||||
|
||||
As seen in Figure 1, the version number is 1.10.2\. The command would then be:
|
||||
|
||||
_sudo wget _[_https://s3.amazonaws.com/Minecraft.Download/versions/1.10.2/minecraft_server.1.10.2.jar_][2]
|
||||
|
||||
When you download the file it will be saved to the current directory in which you are currently in when you run the command. To determine the current location use the command 'pwd'.
|
||||
|
||||
Once you have the file and know the folder where it has been saved you are ready to continue.
|
||||
|
||||
**Server Information**
|
||||
|
||||
Before starting the Minecraft Server you must know the amount of available RAM on the current system to be able to use what is needed. When starting the Minecraft Server you will specify the starting amount of RAM and the maximum amount of RAM to use as more players join. Again, it is important to have enough RAM. If needed, use a minimal install of an Operating System (OS) such as a Minimal install of Ubuntu to have more RAM available.
|
||||
|
||||
Once you have the Minecraft Server file you need it is time to determine the amount of RAM which can be allocated to Minecraft. To determine the available RAM open a terminal and type the following command – a sample output is shown in Figure 2:
|
||||
|
||||
_free -h_
|
||||
|
||||

|
||||
|
||||
**FIGURE 2**
|
||||
|
||||
On this low end system as shown in Figure 2, you can see there is only 684 MB of free RAM. This is not an adequate system to use for a Minecraft Server. On another system I have 2.8 GB available to use for the Minecraft Server.
|
||||
|
||||
Before we start the server we need to find the IP Address of the server. To do this, run the command 'ifconfig'. As shown in Figure 3, there should be a listing for a network connection that shows an Internet Address, or 'inet addr', which is '192.168.0.2'. On my server system it is listed with the address of '192.168.0.14', which is the address that will be used from the client systems.
|
||||
|
||||

|
||||
|
||||
**FIGURE 3**
|
||||
|
||||
**Start Minecraft Server**
|
||||
|
||||
The next step is to actually start the Minecraft Server. There are a few items to cover before we actually start it. When starting the Minecraft Server you specify how much memory to initialize for Minecraft. You also will designate the maximum amount to use as well.
|
||||
|
||||
If my system has 3.7 GB free and I know I will have less than 40 players, then I only need 2 GB set aside. Of course, I may add a little to allow for any growth of users. I also want to leave some memory for the system to use if needed. I will set my minimum at 2 GB and my maximum at 3 GB. Since my maximum is 3 GB I will leave the system 700 MB of RAM if needed, but this is only if the Minecraft Server uses more than the initial 2 GB.
|
||||
|
||||
The command line to start the server is:
|
||||
|
||||
_sudo java -Xms# -Xmx# -jar [path]/minecraft_server.[version].jar nogui_
|
||||
|
||||
Now for a breakdown of the command structure:
|
||||
|
||||
-Xms# - the amount of the initial startup RAM (-Xms2048m)
|
||||
-Xmx# - the amount of the maximum RAM (-Xmx3096m)
|
||||
[path] – the path to the Minecraft Server File (/home/tux/MCS/)
|
||||
[version] – the version of the Minecraft Server downloaded (1.10.2)
|
||||
nogui – used to show that the system is text based only to help reduce RAM use. If you install the GUI, then remove the _nogui_ parameter
|
||||
|
||||
An example of the full command for a system using an initial 2 GB of RAM with a maximum of 3 GB with a path to '/home/tux/MCS/' and a version of '1.10.2' would be:
|
||||
|
||||
_sudo java -Xms2048m -Xmx3096m -jar /home/tux/MCS/minecraft_server.1.10.2.jar nogui_
|
||||
|
||||
**NOTE:** The RAM sizes are in values of megabytes. Multiply the value by 1024\. For example, for 2 GB of RAM multiply 2x1024 for a value of 2048\. Do not forget the lowercase 'm' to specify megabytes. You can easily specify '2g' and '3g' for 2 GB and 3 GB.
|
||||
|
||||
After you run the server the first time there will be an error. It states that the EULA must be agreed to before starting the server.
|
||||
|
||||
To agree to the EULA you need to edit the 'eula.txt' file in the same folder as the Minecraft Server JAR file.
|
||||
|
||||
Open the 'eula.txt' file in a text editor such as nano. Make sure you do this with root privileges. Change the line 'eula=false' to 'eula=true' and save the file.
|
||||
|
||||
Now, enter the command again to start the server. A screen full of information should pass by and then a section of lines which states it is preparing the spawn area. The lines will count up to 100% as it creates the initial world. Any error messages about the system time changing are normal so ignore them.
|
||||
|
||||
At this point you can open the client program and see a screen similar to Figure 1 above. Click on the button 'Multiplayer'. At the next screen, Figure 4, choose 'Direct Connect'. You will then be prompted for the server address, so type in the IP Address of the Minecraft Server. You should now be able to connect to the game.
|
||||
|
||||

|
||||
|
||||
**FIGURE 4**
|
||||
|
||||
**Troubleshooting certain connections**
|
||||
|
||||
If some clients cannot connect to the server, then you need to exit the JAVA program by pressing CTRL+Z. Open the file 'server.properties' with an editor such as 'nano'. Remember to be root. Edit the line 'online-mode'. It should be set to 'true'. Change this to 'false' and save the file. Reboot the system and start the Minecraft Server. Have the clients reconnect to the server and everything should be working.
|
||||
|
||||
Happy mining!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/minecraft-server-on-linux.3202/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
[1]:https://s3.amazonaws.com/Minecraft.Download/versions/%5Bversion%5D/minecraft_server.%5Bversion%5D.jar
|
||||
[2]:https://s3.amazonaws.com/Minecraft.Download/versions/%5Bversion%5D/minecraft_server.%5Bversion%5D.jar
|
||||
165
sources/tech/20170105 OpenSSL For Apache and Dovecot part 1.md
Normal file
165
sources/tech/20170105 OpenSSL For Apache and Dovecot part 1.md
Normal file
@ -0,0 +1,165 @@
|
||||
translating---geekpi
|
||||
|
||||
OpenSSL For Apache and Dovecot : part 1
|
||||
============================================================
|
||||
|
||||

|
||||
In this two-part series, Carla Schroder shows how to create your own OpenSSL certificates and how to configure Apache and Dovecot to use them.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
|
||||
At long last, my wonderful readers, here is your promised OpenSSL how-to for Apache, and next week you get SSL for Dovecot. In this two-part series, we'll learn how to create our own OpenSSL certificates and how to configure Apache and Dovecot to use them.
|
||||
|
||||
The examples here build on these tutorials:
|
||||
|
||||
* [Apache on Ubuntu Linux For Beginners][3]
|
||||
* [Apache on Ubuntu Linux For Beginners: Part 2][4]
|
||||
* [Apache on CentOS Linux For Beginners][5]
|
||||
|
||||
### Creating Your Own Certificate
|
||||
|
||||
Debian/Ubuntu/Mint store private keys and symlinks to certificates in `/etc/ssl`. The certificates bundled with your system are kept in `/usr/share/ca-certificates`. Certificates that you install or create go in `/usr/local/share/ca-certificates/`.
|
||||
|
||||
This example for Debian/etc. creates a private key and public certificate, converts the certificate to the correct format, and symlinks it to the correct directory:
|
||||
|
||||
```
|
||||
|
||||
$ sudo openssl req -x509 -days 365 -nodes -newkey rsa:2048 \
|
||||
-keyout /etc/ssl/private/test-com.key -out \
|
||||
/usr/local/share/ca-certificates/test-com.crt
|
||||
Generating a 2048 bit RSA private key
|
||||
.......+++
|
||||
......................................+++
|
||||
writing new private key to '/etc/ssl/private/test-com.key'
|
||||
-----
|
||||
You are about to be asked to enter information that will
|
||||
be incorporated into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished
|
||||
Name or a DN. There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [AU]:US
|
||||
State or Province Name (full name) [Some-State]:WA
|
||||
Locality Name (eg, city) []:Seattle
|
||||
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Alrac Writing Sweatshop
|
||||
Organizational Unit Name (eg, section) []:home dungeon
|
||||
Common Name (e.g. server FQDN or YOUR name) []:www.test.com
|
||||
Email Address []:admin@test.com
|
||||
|
||||
$ sudo update-ca-certificates
|
||||
Updating certificates in /etc/ssl/certs...
|
||||
1 added, 0 removed; done.
|
||||
Running hooks in /etc/ca-certificates/update.d...
|
||||
|
||||
Adding debian:test-com.pem
|
||||
done.
|
||||
done.
|
||||
```
|
||||
|
||||
CentOS/Fedora use a different file structure and don't use `update-ca-certificates`, so use this command:
|
||||
|
||||
```
|
||||
|
||||
$ sudo openssl req -x509 -days 365 -nodes -newkey rsa:2048 \
|
||||
-keyout /etc/httpd/ssl/test-com.key -out \
|
||||
/etc/httpd/ssl/test-com.crt
|
||||
```
|
||||
|
||||
The most important item is the Common Name, which must exactly match your fully qualified domain name. Everything else is arbitrary. `-nodes`creates a password-less certificate, which is necessary for Apache. `- days`defines an expiration date. It's a hassle to renew expired certificates, but it supposedly provides some extra security. See [Pros and cons of 90-day certificate lifetimes][10] for a good discussion.
|
||||
|
||||
### Configure Apache
|
||||
|
||||
Now configure Apache to use your new certificate. If you followed [Apache on Ubuntu Linux For Beginners: Part 2][11], all you do is modify the `SSLCertificateFile` and `SSLCertificateKeyFile` lines in your virtual host configuration to point to your new private key and public certificate. The `test.com` example from the tutorial now looks like this:
|
||||
|
||||
```
|
||||
|
||||
SSLCertificateFile /etc/ssl/certs/test-com.pem
|
||||
SSLCertificateKeyFile /etc/ssl/private/test-com.key
|
||||
```
|
||||
|
||||
CentOS users, see [Setting up an SSL secured Webserver with CentOS][12] in the CentOS wiki. The process is similar, and the wiki tells how to deal with SELinux.
|
||||
|
||||
### Testing Apache SSL
|
||||
|
||||
The easy way is to point your web browser to [https://yoursite.com][13] and see if it works. The first time you do this you will get the scary warning from your over-protective web browser how the site is unsafe because it uses a self-signed certificate. Ignore your hysterical browser and click through the nag screens to create a permanent exception. If you followed the example virtual host configuration in [Apache on Ubuntu Linux For Beginners: Part 2][14]all traffic to your site will be forced over HTTPS, even if your site visitors try plain HTTP.
|
||||
|
||||
The cool nerdy way to test is by using OpenSSL. Yes, it has a nifty command for testing these things. Try this:
|
||||
|
||||
```
|
||||
|
||||
$ openssl s_client -connect www.test.com:443
|
||||
CONNECTED(00000003)
|
||||
depth=0 C = US, ST = WA, L = Seattle, O = Alrac Writing Sweatshop,
|
||||
OU = home dungeon, CN = www.test.com, emailAddress = admin@test.com
|
||||
verify return:1
|
||||
---
|
||||
Certificate chain
|
||||
0 s:/C=US/ST=WA/L=Seattle/O=Alrac Writing Sweatshop/OU=home
|
||||
dungeon/CN=www.test.com/emailAddress=admin@test.com
|
||||
i:/C=US/ST=WA/L=Seattle/O=Alrac Writing Sweatshop/OU=home
|
||||
dungeon/CN=www.test.com/emailAddress=admin@test.com
|
||||
---
|
||||
Server certificate
|
||||
-----BEGIN CERTIFICATE-----
|
||||
[...]
|
||||
```
|
||||
|
||||
This spits out a giant torrent of information. There is a lot of nerdy fun to be had with `openssl s_client`; for now it is enough that we know if our web server is using the correct SSL certificate.
|
||||
|
||||
### Creating a Certificate Signing Request
|
||||
|
||||
Should you decide to use a third-party certificate authority (CA), you will have to create a certificate signing request (CSR). You will send this to your new CA, and they will sign it and send it back to you. They may have their own requirements for creating your CSR; this a typical example of how to create a new private key and CSR:
|
||||
|
||||
```
|
||||
|
||||
$ openssl req -newkey rsa:2048 -nodes \
|
||||
-keyout yourdomain.key -out yourdomain.csr
|
||||
```
|
||||
|
||||
You can also create a CSR from an existing key:
|
||||
|
||||
```
|
||||
|
||||
$ openssl req -key yourdomain.key \
|
||||
-new -out domain.csr
|
||||
```
|
||||
|
||||
That is all for today. Come back next week to [learn how to properly set up Dovecot to use OpenSSL][15].
|
||||
|
||||
### Additional Tutorials
|
||||
|
||||
[Quieting Scary Web Browser SSL Alerts][16]
|
||||
[How to Set Up Secure Remote Networking with OpenVPN on Linux, Part 1][17]
|
||||
[How to Set Up Secure Remote Networking with OpenVPN on Linux, Part 2][18]
|
||||
|
||||
_Advance your career in system administration! Check out the[ ][6][Essentials of System Administration][7][ ][8]course from The Linux Foundation._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/sysadmin/openssl-apache-and-dovecot
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/openssljpg
|
||||
[3]:https://www.linux.com/learn/apache-ubuntu-linux-beginners
|
||||
[4]:https://www.linux.com/learn/apache-ubuntu-linux-beginners-part-2
|
||||
[5]:https://www.linux.com/learn/apache-centos-linux-beginners
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration
|
||||
[7]:https://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration
|
||||
[8]:https://training.linuxfoundation.org/linux-courses/system-administration-training/essentials-of-system-administration
|
||||
[9]:https://www.addtoany.com/share#url=https%3A%2F%2Fwww.linux.com%2Flearn%2Fsysadmin%2Fopenssl-apache-and-dovecot&title=OpenSSL%20For%20Apache%20and%20Dovecot%20
|
||||
[10]:https://community.letsencrypt.org/t/pros-and-cons-of-90-day-certificate-lifetimes/4621
|
||||
[11]:https://www.linux.com/learn/apache-ubuntu-linux-beginners-part-2
|
||||
[12]:https://wiki.centos.org/HowTos/Https
|
||||
[13]:https://yoursite.com/
|
||||
[14]:https://www.linux.com/learn/apache-ubuntu-linux-beginners-part-2
|
||||
[15]:https://www.linux.com/learn/intro-to-linux/openssl-apache-and-dovecot-part-2
|
||||
[16]:https://www.linux.com/learn/quieting-scary-web-browser-ssl-alerts
|
||||
[17]:https://www.linux.com/learn/how-set-secure-remote-networking-openvpn-linux-part-1
|
||||
[18]:https://www.linux.com/learn/how-set-secure-remote-networking-openvpn-linux-part-2
|
||||
@ -1,251 +0,0 @@
|
||||
GHLandy Translating
|
||||
|
||||
|
||||
10 Useful Sudoers Configurations for Setting ‘sudo’ in Linux
|
||||
============================================================
|
||||
|
||||
In Linux and other Unix-like operating systems, only the root user can run all commands and perform certain critical operations on the system such as install and update, remove packages, [create users and groups][1], modify important system configuration files and so on.
|
||||
|
||||
However, a system administrator who assumes the role of the root user can permit other normal system users with the help of [sudo command][2] and a few configurations to run some commands as well as carry out a number of vital system operations including the ones mentioned above.
|
||||
|
||||
Alternatively, the system administrator can share the root user password (which is not a recommended method) so that normal system users have access to the root user account via su command.
|
||||
|
||||
sudo allows a permitted user to execute a command as root (or another user), as specified by the security policy:
|
||||
|
||||
1. It reads and parses /etc/sudoers, looks up the invoking user and its permissions,
|
||||
2. then prompts the invoking user for a password (normally the user’s password, but it can as well be the target user’s password. Or it can be skipped with NOPASSWD tag),
|
||||
3. after that, sudo creates a child process in which it calls setuid() to switch to the target user
|
||||
4. next, it executes a shell or the command given as arguments in the child process above.
|
||||
|
||||
Below are ten /etc/sudoers file configurations to modify the behavior of sudo command using Defaults entries.
|
||||
|
||||
```
|
||||
$ sudo cat /etc/sudoers
|
||||
```
|
||||
/etc/sudoers File
|
||||
```
|
||||
#
|
||||
# This file MUST be edited with the 'visudo' command as root.
|
||||
#
|
||||
# Please consider adding local content in /etc/sudoers.d/ instead of
|
||||
# directly modifying this file.
|
||||
#
|
||||
# See the man page for details on how to write a sudoers file.
|
||||
#
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
|
||||
Defaults logfile="/var/log/sudo.log"
|
||||
Defaults lecture="always"
|
||||
Defaults badpass_message="Password is wrong, please try again"
|
||||
Defaults passwd_tries=5
|
||||
Defaults insults
|
||||
Defaults log_input,log_output
|
||||
```
|
||||
|
||||
#### Types of Defaults Entries
|
||||
|
||||
```
|
||||
Defaults parameter, parameter_list #affect all users on any host
|
||||
Defaults@Host_List parameter, parameter_list #affects all users on a specific host
|
||||
Defaults:User_List parameter, parameter_list #affects a specific user
|
||||
Defaults!Cmnd_List parameter, parameter_list #affects a specific command
|
||||
Defaults>Runas_List parameter, parameter_list #affects commands being run as a specific user
|
||||
```
|
||||
|
||||
For the scope of this guide, we will zero down to the first type of Defaults in the forms below. Parameters may be flags, integer values, strings, or lists.
|
||||
|
||||
You should note that flags are implicitly boolean and can be turned off using the `'!'` operator, and lists have two additional assignment operators, `+=` (add to list) and `-=` (remove from list).
|
||||
|
||||
```
|
||||
Defaults parameter
|
||||
OR
|
||||
Defaults parameter=value
|
||||
OR
|
||||
Defaults parameter -=value
|
||||
Defaults parameter +=value
|
||||
OR
|
||||
Defaults !parameter
|
||||
```
|
||||
|
||||
### 1\. Set a Secure PATH
|
||||
|
||||
This is the path used for every command run with sudo, it has two importances:
|
||||
|
||||
1. Used when a system administrator does not trust sudo users to have a secure PATH environment variable
|
||||
2. To separate “root path” and “user path”, only users defined by exempt_group are not affected by this setting.
|
||||
|
||||
To set it, add the line:
|
||||
|
||||
```
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||
```
|
||||
|
||||
### 2\. Enable sudo on TTY User Login Session
|
||||
|
||||
To enable sudo to be invoked from a real tty but not through methods such as cron or cgi-bin scripts, add the line:
|
||||
|
||||
```
|
||||
Defaults requiretty
|
||||
```
|
||||
|
||||
### 3\. Run Sudo Command Using a pty
|
||||
|
||||
A few times, attackers can run a malicious program (such as a virus or malware) using sudo, which would again fork a background process that remains on the user’s terminal device even when the main program has finished executing.
|
||||
|
||||
To avoid such a scenario, you can configure sudo to run other commands only from a psuedo-pty using the `use_pty` parameter, whether I/O logging is turned on or not as follows:
|
||||
|
||||
```
|
||||
Defaults use_pty
|
||||
```
|
||||
|
||||
### 4\. Create a Sudo Log File
|
||||
|
||||
By default, sudo logs through syslog(3). However, to specify a custom log file, use the logfile parameter like so:
|
||||
|
||||
```
|
||||
Defaults logfile="/var/log/sudo.log"
|
||||
```
|
||||
|
||||
To log hostname and the four-digit year in the custom log file, use log_host and log_year parameters respectively as follows:
|
||||
|
||||
```
|
||||
Defaults log_host, log_year, logfile="/var/log/sudo.log"
|
||||
```
|
||||
|
||||
Below is an example of a custom sudo log file:
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Create Custom Sudo Log File
|
||||
|
||||
### 5\. Log Sudo Command Input/Output
|
||||
|
||||
The log_input and log_output parameters enable sudo to run a command in pseudo-tty and log all user input and all output sent to the screen receptively.
|
||||
|
||||
The default I/O log directory is /var/log/sudo-io, and if there is a session sequence number, it is stored in this directory. You can specify a custom directory through the iolog_dir parameter.
|
||||
|
||||
```
|
||||
Defaults log_input, log_output
|
||||
```
|
||||
|
||||
There are some escape sequences are supported such as `%{seq}` which expands to a monotonically increasing base-36 sequence number, such as 000001, where every two digits are used to form a new directory, e.g. 00/00/01 as in the example below:
|
||||
|
||||
```
|
||||
$ cd /var/log/sudo-io/
|
||||
$ ls
|
||||
$ cd 00/00/01
|
||||
$ ls
|
||||
$ cat log
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Log sudo Input Output
|
||||
|
||||
You can view the rest of the files in that directory using the [cat command][5].
|
||||
|
||||
### 6\. Lecture Sudo Users
|
||||
|
||||
To lecture sudo users about password usage on the system, use the lecture parameter as below.
|
||||
|
||||
It has 3 possible values:
|
||||
|
||||
1. always – always lecture a user.
|
||||
2. once – only lecture a user the first time they execute sudo command (this is used when no value is specified)
|
||||
3. never – never lecture the user.
|
||||
|
||||
```
|
||||
|
||||
Defaults lecture="always"
|
||||
```
|
||||
|
||||
Additionally, you can set a custom lecture file with the lecture_file parameter, type the appropriate message in the file:
|
||||
|
||||
```
|
||||
Defaults lecture_file="/path/to/file"
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Lecture Sudo Users
|
||||
|
||||
### 7\. Show Custom Message When You Enter Wrong sudo Password
|
||||
|
||||
When a user enters a wrong password, a certain message is displayed on the command line. The default message is “sorry, try again”, you can modify the message using the badpass_message parameter as follows:
|
||||
|
||||
```
|
||||
Defaults badpass_message="Password is wrong, please try again"
|
||||
```
|
||||
|
||||
### 8\. Increase sudo Password Tries Limit
|
||||
|
||||
The parameter passwd_tries is used to specify the number of times a user can try to enter a password.
|
||||
|
||||
The default value is 3:
|
||||
|
||||
```
|
||||
Defaults passwd_tries=5
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Increase Sudo Password Attempts
|
||||
|
||||
To set a password timeout (default is 5 minutes) using passwd_timeout parameter, add the line below:
|
||||
|
||||
```
|
||||
Defaults passwd_timeout=2
|
||||
```
|
||||
|
||||
### 9\. Let Sudo Insult You When You Enter Wrong Password
|
||||
|
||||
In case a user types a wrong password, sudo will display insults on the terminal with the insults parameter. This will automatically turn off the badpass_message parameter.
|
||||
|
||||
```
|
||||
Defaults insults
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Let’s Sudo Insult You When Enter Wrong Password
|
||||
|
||||
### 10\. Learn More Sudo Configurations
|
||||
|
||||
Additionally, you can learn more sudo command configurations by reading: [Difference Between su and sudo and How to Configure sudo in Linux][9].
|
||||
|
||||
That’s it! You can share other useful sudo command configurations or [tricks and tips with Linux][10] users out there via the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Create-Sudo-Log-File.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/Log-sudo-Input-Output.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/01/Lecture-Sudo-Users.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/01/Increase-Sudo-Password-Attempts.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/01/Sudo-Insult-Message.png
|
||||
[9]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[10]:http://www.tecmint.com/tag/linux-tricks/
|
||||
@ -1,74 +0,0 @@
|
||||
Martin translating…
|
||||
|
||||
Explore climate data with open source tools
|
||||
============================================================[up][1]
|
||||

|
||||
Image credits :
|
||||
|
||||
[Flickr user: theaucitron][2] (CC BY-SA 2.0)
|
||||
|
||||
You can't look anywhere these days without seeing evidence of the changing weather patterns on the earth. Monthly, we are confronted with facts and figures that point to a warming planet.
|
||||
|
||||
Climate scientists warn us that inaction could be fatal to our futures here. Military strategists at the Pentagon have [recently cautioned][3] President-Elect Trump that inaction on climate change could spell disaster for our national security as shrinking water supplies and meager rainfall cause crop failures will force large numbers of people to migrate to other parts of the world that can sustain them.
|
||||
|
||||
With all of the research on our climate by NASA, the US Defense Department, and others, I was curious if there are open source tools that would allow interested citizens to explore climate data and draw our own conclusions. A quick search of the Internet led me to the [Open Climate Workbench][4], a project that is part of the [Apache Software Foundation][5].
|
||||
|
||||
The Open Climate Workbench (OCW) develops software that performs climate model evaluation on data that comes from the [Earth System Grid Federation][6], [Coordinated Regional Climate Downscaling Environment][7], the U.S. Global Change Research Program's [National Climate Assessment][8], the[ North American Regional Climate Assessment Program][9], and from NASA, NOAA, and others.
|
||||
|
||||
You can download the OCW's [tar ball][10] and install it on your Linux computer by following the [prerequisites][11]. You can also install the OCW in a virtual machine using Vagrant and a provider like VirtualBox. [Get the instructions][12] for an OCW virtual machine.
|
||||
|
||||
I found the easiest way to see how the OCW works is to download a [virtual machine image][13] from the Regional Climate Model Evaluation System (RCMES).
|
||||
|
||||
According to its website, the RCMES "is designed to facilitate regional-scale evaluations of climate and Earth system models by providing standardized access to a vast and comprehensive set of observations (e.g., satellite, reanalyzes and in-situ) and modeling resources (e.g., [CMIP][14] & [CORDEX][15] on the [ESGF][16]), as well as tools for performing common analysis and visualization tasks (e.g., OCW)."
|
||||
|
||||
You will need to have VirtualBox and Vagrant installed on your host computer. With it you can see an excellent example of the OCW in operation. The RCMES provides [detailed instructions][17] for downloading, importing, and running the virtual machine. Once your virtual machine is up and running you can log into it with the following credentials.
|
||||
|
||||
**Username:vagrant, password:vagrant. **
|
||||
|
||||

|
||||
|
||||
RCMES data plot sample
|
||||
|
||||
[Tutorials][18] for the RCMES are available on their website to help you quickly become familiar with the software. The community [is active][19] and they are looking for more [developers][20]. You can [subscribe to their mailing lists][21], too.
|
||||
|
||||
[Source code][22] for the project is on GitHub and licensed under the Apache License, Version 2.0.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||

|
||||
|
||||
Don Watkins - Educator, education technology specialist, entrepreneur, open source advocate. M.A. in Educational Psychology, MSED in Educational Leadership, Linux system administrator, CCNA, virtualization using Virtual Box and VMware. Follow me at @Don_Watkins .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/apache-open-climate-workbench
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://opensource.com/article/17/1/apache-open-climate-workbench?rate=Hv4_T-1gbcRNsiP9jnevzP1OTNKHIyQLXwqdjnBy2Bs
|
||||
[2]:https://www.flickr.com/photos/theaucitron/5810163712/in/photolist-5p9nh3-6EkSKG-6EgGEF-9hYBcr-abCSpq-9zbjDz-4PVqwm-9RqBfq-abA2T4-4nXfwv-9RQkdN-dmjSdA-84o2ER-abA2Wp-ehyhPC-7oFYrc-4nvqBz-csMQXb-nRegFf-ntS23C-nXRyaB-6Xw3Mq-cRMaCq-b6wkkP-7u8sVQ-yqcg-6fTmk7-bzm3vU-6Xw3vL-6EkzCQ-d3W8PG-5MoveP-oMWsyY-jtMME6-XEMwS-2SeRXT-d2hjzJ-p2ZZVZ-7oFYoX-84r6Mo-cCizvm-gnnsg5-77YfPx-iDjqK-8gszbW-6MUZEZ-dhtwtk-gmpTob-6TBJ8p-mWQaAC/
|
||||
[3]:https://www.scientificamerican.com/article/military-leaders-urge-trump-to-see-climate-as-a-security-threat/
|
||||
[4]:https://climate.apache.org/
|
||||
[5]:https://www.apache.org/
|
||||
[6]:http://esgf.llnl.gov/
|
||||
[7]:http://www.cordex.org/
|
||||
[8]:http://nca2014.globalchange.gov/
|
||||
[9]:http://www.narccap.ucar.edu/
|
||||
[10]:http://climate.apache.org/downloads.html
|
||||
[11]:http://climate.apache.org/downloads.html#prerequsites
|
||||
[12]:https://cwiki.apache.org/confluence/display/CLIMATE/OCW+VM+-+A+Self+Contained+OCW+Environment
|
||||
[13]:https://rcmes.jpl.nasa.gov/RCMES_Turtorial_data/RCMES_June09-2016.ova
|
||||
[14]:http://cmip-pcmdi.llnl.gov/
|
||||
[15]:http://www.cordex.org/
|
||||
[16]:http://esgf.org/
|
||||
[17]:https://rcmes.jpl.nasa.gov/content/running-rcmes-virtual-machine
|
||||
[18]:https://rcmes.jpl.nasa.gov/content/tutorials-overview
|
||||
[19]:http://climate.apache.org/community/get-involved.html
|
||||
[20]:https://cwiki.apache.org/confluence/display/CLIMATE/Developer+Getting+Started+Guide
|
||||
[21]:http://climate.apache.org/community/mailing-lists.html
|
||||
[22]:https://github.com/apache/climate
|
||||
@ -0,0 +1,150 @@
|
||||
# translating by ruskking
|
||||
Linux command line navigation tips and tricks - part 1
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Linux command line tips/tricks][3]
|
||||
1. [Easily switch between two directories - the quick tip][1]
|
||||
2. [Easily switch between two directories - related details][2]
|
||||
2. [Conclusion][4]
|
||||
|
||||
If you've just started using the command line in Linux, then it's worth knowing that it is one of the most powerful and useful features of the OS. The learning curve may or may not be steep depending on how deep you want to dive into the topic. However, there are some Linux command line tips/tricks that'll always be helpful regardless of your level of expertise.
|
||||
|
||||
In this article series, we'll be discussing several such tips/tricks, hoping that they'll make your command line experience even more pleasant.
|
||||
|
||||
But before we move ahead, it's worth mentioning that all the instructions as well examples presented in this article have been tested on Ubuntu 14.04LTS. The command line shell we've used is bash (version 4.3.11)
|
||||
|
||||
### Linux command line tips/tricks
|
||||
|
||||
Please note that we've assumed that you know the basics of the command line in Linux, like what is root and home directory, what are environment variables, how to navigate directories, and more. Also, keep in mind that tips/tricks will be accompanied by the how and why of the concept involved (wherever applicable).
|
||||
|
||||
### Easily switch between two directories - the quick tip
|
||||
|
||||
Suppose you are doing some work on the command line that requires you to switch between two directories multiple times. And these two directories are located in completely different branches, say, under /home/ and under /usr/, respectively. What would you do?
|
||||
|
||||
One, and the most straightforward, option is to switch by typing the complete paths to these directories. While there's no problem with the approach per se, it's very time consuming. Other option could be to open two separate terminals and carry on with your work. But again, neither this approach is convenient, nor it looks elegant.
|
||||
|
||||
You'll be glad to know that there exists an easy solution to this problem. All you have to do is to first switch between the two directories manually (by passing their respective paths to the **cd** command), and then subsequent switches can be accomplished using the **cd -** command.
|
||||
|
||||
For example:
|
||||
|
||||
I am in the following directory:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
```
|
||||
|
||||
And then I switched to some other directory in the /usr/ branch:
|
||||
|
||||
```
|
||||
cd /usr/lib/
|
||||
```
|
||||
|
||||
Now, I can easily switch back and forth using the following command:
|
||||
|
||||
```
|
||||
cd -
|
||||
```
|
||||
|
||||
Here's a screenshot showing the **cd -** command in action.
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
An important point worth mentioning here is that if you make a switch to a third directory in between all this, then the **cd -** command will work for the new directory and the directory from which the switch was made.
|
||||
|
||||
### Easily switch between two directories - related details
|
||||
|
||||
For the curious bunch, who want to know how the **cd -** command works, here's the explanation: As we all know, the cd command requires a path as its argument. Now, when a hyphen (-) is passed as an argument to the command, it's replaced by the value that OLDPWD environment variable contains at that moment.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
As it would be clear by now, the OLDPWD environment variable stores the path of previous working directory. This explanation is there is the man page of the cd command, but sadly, it's likely that you'll not find the man page pre-installed on your system (it's not there on Ubuntu at least).
|
||||
|
||||
However, installing it is not a big deal, all you have to do is to run the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install manpages-posix
|
||||
```
|
||||
|
||||
And then do:
|
||||
|
||||
```
|
||||
man cd
|
||||
```
|
||||
|
||||
Once the man page opens, you'll see that it clearly says:
|
||||
|
||||
```
|
||||
- When a hyphen is used as the operand, this shall be equivalent
|
||||
to the command:
|
||||
|
||||
cd "$OLDPWD" && pwd
|
||||
```
|
||||
|
||||
Needless to say, it's the cd command that sets the OLDPWD variable. So every time you change the directory, the previous working directory gets stored in this variable. This brings us to another important point here: whenever a new shell instance is launched (both manually or through a script), it does not have a 'previous working directory.'
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
That's logical because it's the cd command which sets this variable. So until you run the cd command at-least once, the OLDPWD environment variable will not contain any value.
|
||||
|
||||
Moving on, while it may seem counterintuitive, the **cd -** and **cd $OLDWPD** commands do not produce same results in all situations. Case in point, when a new shell has just been launched.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
As clear from the screenshot above, while the **cd -** command complained about the OLDPWD variable not being set, the **cd $OLDPWD** command did not produce any error; in fact it changed the present working directory to the user's home directory.
|
||||
|
||||
That's because given that the OLDPWD variable is currently not set, $OLDPWD is nothing but an empty string. So, the **cd $OLDPWD** command is as good as just running **cd**, which - by default - takes you to your home directory.
|
||||
|
||||
Finally, I've also been through situations where-in it's desirable to suppress the output the **cd -** command produces. What I mean is, there can be cases (for example, while writing a shell script), where-in you'll want the **cd -** command to not produce the usual directory path in output. For those situations, you can use the command in the following way:
|
||||
|
||||
```
|
||||
cd - &>/dev/null
|
||||
```
|
||||
|
||||
The above command will redirect both file descriptor 2 (STDERR) and descriptor 1 (STDOUT) to [/dev/null][9]. This means that any error the command produces will also be suppressed. However, you'll still be able to check the success of failure of the command using the generic [$? technique][10] - the command **echo $?** will produce '1' if there was some error, and '0' otherwise.
|
||||
|
||||
Alternatively, if you're ok with the **cd -** command producing an output in error cases, then you can use the following command instead:
|
||||
|
||||
```
|
||||
cd - > /dev/null
|
||||
```
|
||||
|
||||
This command will only redirect the file descriptor 1 (STDOUT) to `/dev/null`.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Sadly, we could only cover one command line-related tip here, but the good thing is that we managed to discuss a lot of in-depth stuff about the **cd -**command. You are advised to go through the tutorial thoroughly and test everything - that we've discussed here - on your Linux box's command line terminal. Also, do go through the command's man page, and try out all the features documented there.
|
||||
|
||||
In case you face any issue or have some doubt, do share with us in comments below. Meanwhile, wait for the second part, where-in we'll discuss some more useful command line-related tips/tricks in the same manner as has been done here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/#easily-switch-between-two-directories-the-quick-tip
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/#easily-switch-between-two-directories-related-details
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/#linux-command-line-tipstricks
|
||||
[4]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/#conclusion
|
||||
[5]:https://www.howtoforge.com/images/linux-command-line-tips-for-beginners/big/cmd-line-tips.png
|
||||
[6]:https://www.howtoforge.com/images/linux-command-line-tips-for-beginners/big/cmd-line-tips-oldpwd.png
|
||||
[7]:https://www.howtoforge.com/images/linux-command-line-tips-for-beginners/big/cmd-line-tips-no-oldpwd.png
|
||||
[8]:https://www.howtoforge.com/images/linux-command-line-tips-for-beginners/big/cmd-line-tips-oldpwd-home.png
|
||||
[9]:https://en.wikipedia.org/wiki/Null_device
|
||||
[10]:http://askubuntu.com/questions/29370/how-to-check-if-a-command-succeeded
|
||||
@ -1,101 +0,0 @@
|
||||
ucasFL translating
|
||||
3 Useful VIM Editor Tips and Tricks for Advanced Users
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
This article is part of the [VIM User Guide][12] series:
|
||||
|
||||
* [The Beginner’s Guide to Start Using Vim][3]
|
||||
* [Vim Keyboard Shortcuts Cheatsheet][4]
|
||||
* [5 Vim Tips and Tricks for Experienced Users][5]
|
||||
* 3 Useful VIM Editor Tips and Tricks for Advanced Users
|
||||
|
||||
Vim is undoubtedly a very powerful text editor. It offers a plethora of features which means that studying and remembering every Vim functionality isn’t practically possible. But what we can do at least is keep learning easier ways of doing things so that our experience with the editor keeps on getting better with time.
|
||||
|
||||
With that in mind, in this article we will discuss some Vim editor tips/tricks that are aimed at advanced users.
|
||||
|
||||
**Note**: If you are completely new to Vim, you can first go through our [getting started guide][14]. For those who’ve just started using the editor, I’m sure our [Vim keyboard shortcuts cheatsheet][15] will be extremely useful to you. And if you’re already an experienced user, you might also want to find out [some tips and tricks for experienced users][16].
|
||||
|
||||
Please note that all the tips mentioned in this article have been mostly explained using easy-to-understand coding situations, as they come in really handy while software development. But that does not mean normal users (who aren’t coders and use Vim for general text editing) can’t use them in their work.
|
||||
|
||||
### 1\. Set file specific variables
|
||||
|
||||
There may be times when – in a particular file – you would want any tab character that you type to get replaced by spaces. Or you may want a source code file to use two spaces for indentation even if the editor’s default indentation is set to four spaces.
|
||||
|
||||
Basically we’re talking about file-specific changes here. There’s a feature that Vim provides which allows you to change certain settings only for a particular file. That feature is called “Modeline.”
|
||||
|
||||
For example, to make sure that each tab you type gets replaced by spaces, all you have to do is to add the following modeline in the first or last few lines of the file in question:
|
||||
|
||||
```
|
||||
# vim: set expandtab:
|
||||
```
|
||||
|
||||
And to change the indentation from default (4) to 2, use the following modeline in the source file:
|
||||
|
||||
```
|
||||
// vim: noai:ts=2:sw=2
|
||||
```
|
||||
|
||||
Here are some important points that you need to keep in mind when dealing with modelines:
|
||||
|
||||
* Modelines should only be added in the first or last five lines of the file.
|
||||
* The “modeline” option must be set (`:set modeline`) in the “.vimrc” file order to take advantage of this feature.
|
||||
* The feature is off by default when editing as root.
|
||||
|
||||
For more information, head to the feature’s [official documentation][17].
|
||||
|
||||
### 2\. Keyword completion
|
||||
|
||||
As you start writing more and more complex code or start working on large source files, you deal with several variable names. Sometimes it’s not easy to remember all the names, so whenever you have to write a variable name you usually copy it from where it’s already used.
|
||||
|
||||
Thankfully, with Vim you can just write some initial letters of the variable. Without leaving the Insert mode, press “Ctrl + n” or “Ctrl + p” to get a list of matching keywords. While “Ctrl + n” is used to insert the next matching word, “Ctrl + p” gives you a list of previous matching words.
|
||||
|
||||
Here’s this feature in action.
|
||||
|
||||

|
||||
|
||||
As is clear from the screenshot above, the list that pops up also contains words from other source files. For more information on this feature, head [here][18].
|
||||
|
||||
### 3\. Searching
|
||||
|
||||
Suppose you are debugging your code, and as part of that you need to quickly see all the occurrences of a variable in a file. A commonly used way to do this is to come out of the Insert mode, write `/[var-name]`, press Enter, and then go back and forth using the “n” and “p” keys.
|
||||
|
||||
There’s no problem with the aforementioned approach, per se, but there’s a slightly more easier and quicker way to do this kind of search. For that, first you have to make sure that you are out of Insert mode and that the cursor is under the word/variable you’re trying to search, which isn’t time consuming at all. And next, all you have to do is press “Shift + *.”
|
||||
|
||||
Do this repeatedly, and the editor will quickly take you to all the places where the word/variable is used in the file.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Although aimed at advanced users, the tips/tricks discussed here aren’t difficult to understand and use. If your basics are clear, you can really benefit from them. Needless to say, as with any new feature or concept, you need to practice these tips to make them a habit.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/vim-tips-tricks-advanced-users/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://www.maketecheasier.com/author/himanshu/
|
||||
[2]:https://www.maketecheasier.com/vim-tips-tricks-advanced-users/#respond
|
||||
[3]:https://www.maketecheasier.com/start-with-vim-linux/
|
||||
[4]:https://www.maketecheasier.com/vim-keyboard-shortcuts-cheatsheet/
|
||||
[5]:https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/
|
||||
[6]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[7]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-advanced-users%2F
|
||||
[8]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-advanced-users%2F&text=3+Useful+VIM+Editor+Tips+and+Tricks+for+Advanced+Users
|
||||
[9]:mailto:?subject=3%20Useful%20VIM%20Editor%20Tips%20and%20Tricks%20for%20Advanced%20Users&body=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-advanced-users%2F
|
||||
[10]:https://www.maketecheasier.com/opt-out-google-personalized-ads/
|
||||
[11]:https://www.maketecheasier.com/wi-fi-vs-ethernet-vs-4g/
|
||||
[12]:https://www.maketecheasier.com/series/vim-user-guide/
|
||||
[13]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[14]:https://www.maketecheasier.com/start-with-vim-linux/
|
||||
[15]:https://www.maketecheasier.com/vim-keyboard-shortcuts-cheatsheet/
|
||||
[16]:https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/
|
||||
[17]:http://vim.wikia.com/wiki/Modeline_magic
|
||||
[18]:http://vim.wikia.com/wiki/Any_word_completion
|
||||
@ -1,115 +0,0 @@
|
||||
ucasFL translating
|
||||
Best Linux Distributions for New Users
|
||||
============================================================
|
||||
|
||||

|
||||
Jack Wallen considers which Linux distributions are best designed for new users coming from different environments.[Creative Commons Zero][5]Pixabay
|
||||
|
||||
Ah, the age-old question...one that holds far more importance than simply pointing out which Linux distribution is a fan-favorite. Why is that?
|
||||
|
||||
Let me set the stage: You have a user—one who has, most likely, spent the majority of their time in front of either a Windows or Mac machine—and they’ve come to you for an alternative. You want to point them in a direction that will bring about the least amount of hiccups along the way and highlight the power and flexibility of Linux.
|
||||
|
||||
But, remember, the single most important aspect is that they must _get it_, out of the box.
|
||||
|
||||
That’s why we often take the time to point out which distributions are best designed for new users -- because bringing new users into the mix is the best way to spread the word and grow the base.
|
||||
|
||||
With that said, what are the best distributions for new users? I’m going to take a bit of a different approach this time and point out which distributions would be best for users coming from different environments. You can also check out my list of [best distros for 2017][11].
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
### From Windows 7 to Linux: ZorinOS
|
||||
|
||||
When Windows 8 rolled out, there was a reason so many wanted to stick with Windows 7—familiarity. Users had been working with the same desktop metaphor for decades and they had no desire to migrate to the more touchscreen-centric platform of Windows 8\. So, what distribution do you turn to for that? You first must consider desktop environment. Why? Because that is where you immediately hook those Windows 7 users. And what better distribution for such a task than [ZorinOS][13]?
|
||||
|
||||
ZorinOS was designed specifically as a replacement for Windows (and Mac) computers, so it goes a very long way to replicate the look and feel of those desktops. In fact, you’d be hard-pressed to find a Linux distribution that does as good a job of making the transition from Windows 7 to Linux—while still retaining that which makes Linux such a powerful, flexible platform.
|
||||
|
||||
Beyond the desktop environment (Figure 1), ZorinOS is based on Ubuntu, so under the hood, everything is going to just work (so there’s little need to worry their hardware won’t be detected). Couple that with the readily available software and you have the perfect distribution for new users coming from Windows 7.
|
||||
|
||||
### [zorinos.jpg][6]
|
||||
|
||||

|
||||
|
||||
Figure 1: The ZorinOS Windows 7-like desktop ready to serve.[Used with permission][1]
|
||||
|
||||
Do note, however, there are two versions of ZorinOS: Zorin Ultimate and Zorin Core. While Core is free, it doesn’t include nearly the amount of software that you’ll find in Ultimate. If you want an out of the box distribution that will please anyone coming from Windows 7, I highly recommend purchasing [Zorin Ultimate][14] (for approximately $20.00 USD). Of course, if you don’t want to splurge for the Ultimate edition, you can always install nearly everything you need from the included Software package management tool.
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
### From Windows 8 to Linux: Ubuntu GNOME
|
||||
|
||||
The shift to Windows 8, brought about a very touchscreen-centric environment that changed the way users interact with their machines. The old metaphor of Star Menu/Panel/System tray was replaced with an interface that shined in a touchscreen environment. If you’re looking for the best environment to give a new-to-Linux user something different, yet still function as a best-in-breed should, look no further than [Ubuntu GNOME][16].
|
||||
|
||||
Ubuntu GNOME is a best of two worlds amalgamation between Ubuntu and GNOME (Figure 2). Replacing the Unity interface with a desktop that is equal parts modern elegance and user-friendly simplicity, Ubuntu GNOME shouldn’t cause much in the way of issues for any user coming from Windows 8\. Not only does this distribution lay its foundation on the latest LTS release of Ubuntu (so support will last), it makes use of the latest stable release of the GNOME desktop—which means the user will enjoy an incredibly solid experience.
|
||||
|
||||
### [ubuntugnome.jpg][7]
|
||||
|
||||

|
||||
|
||||
Figure 2: Simplicity at its elegant best can be found in Ubuntu GNOME.[Used with permission][2]
|
||||
|
||||
### From Mac to Linux: Elementary OS
|
||||
|
||||
Without a doubt, the hands-down winner for this category is [Elementary OS][17]. Although Elementary does an incredible job of looking and feeling like an OS X desktop, it is much more than that. Elementary OS is, at its very heart, Linux—it just happens to have taken a cue from OS X for many of the design elements.
|
||||
|
||||
Any Mac user would feel immediately at home on the desktop environment (Figure 3). With an all-too familiar doc and the inclusion of an applications menu, Elementary OS always stands at the top of my best-of distribution list. And, if we’re talking about Mac users, there is no better drop-in replacement than Elementary OS.
|
||||
|
||||
### [elementaryos.jpg][8]
|
||||
|
||||

|
||||
|
||||
Figure 3: The glory that is the Elementary OS desktop.[Used with permission][3]
|
||||
|
||||
One thing that Mac users will greatly appreciate is how great a job the Elementary OS developers have done keeping design consistency throughout the desktop. From the dock, panel, menus, and included applications, you will not find a single element that doesn’t look and feel like it belongs.
|
||||
|
||||
There is one caveat that I would add to Elementary OS. You’ll need to install a sufficient browser (as it “ships” with Epiphany—a browser not widely supported by many necessary sites) and you’ll want to install LibreOffice from the downloadable package from the official [LibreOffice site][18] (as the package found in the Elementary OS AppCenter is a bit out of date).
|
||||
|
||||
### From Android to Linux: Ubuntu
|
||||
|
||||
This may seem like a bit of a stretch, but considering how dominant Android is within the global market, you will come across users who might need a Linux desktop that would make them feel instantly at home, after coming from a more mobile-centric interface. For me, there is no clearer winner than [Ubuntu][19]. Why? Ubuntu Unity does an outstanding job of making the desktop feel more like an all-encompassing interface than any other. If you want, you can include online search results (now disabled by default), which is something found in nearly every mobile environment. Also, the Unity HUD menu system (Figure 4) is one of the most unique menu systems found in any interface. With this, users can depend less on the mouse (as they would on a mobile device powered by Android).
|
||||
|
||||
### [ubuntu.jpg][9]
|
||||
|
||||

|
||||
|
||||
Figure 4: The Unity Heads Up Display in action.[Used with permission][4]
|
||||
|
||||
Of course, Ubuntu also offers one of the most stable desktop platforms on the market, so the user experience will be nearly flawless.
|
||||
|
||||
### There’s a distribution for everyone
|
||||
|
||||
One of the important things to remember is that there is a distribution of Linux that is sure to please everyone. But for those coming from specific environments, I highly recommend finding a flavor of Linux that will help make the transition seamless. Give one of these a try and see if you find yourself humming along smoothly with the power of Linux and open source at your fingertips.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/best-linux-distributions-new-users
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[6]:https://www.linux.com/files/images/zorinosjpg
|
||||
[7]:https://www.linux.com/files/images/ubuntugnomejpg
|
||||
[8]:https://www.linux.com/files/images/elementaryosjpg-1
|
||||
[9]:https://www.linux.com/files/images/ubuntujpg
|
||||
[10]:https://www.linux.com/files/images/distros-new-usersjpg
|
||||
[11]:https://www.linux.com/news/learn/sysadmin/best-linux-distributions-2017
|
||||
[12]:http://bit.ly/2jJgK0Q
|
||||
[13]:https://zorinos.com/
|
||||
[14]:https://zorinos.com/download/#ultimate
|
||||
[15]:https://training.linuxfoundation.org/certification/lfcs?utm_source=linux-inline-ad&utm_campaign=new-users-2017&utm_medium=online-advertising&utm_content=new-year
|
||||
[16]:https://ubuntugnome.org/
|
||||
[17]:https://elementary.io/
|
||||
[18]:http://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[19]:https://www.ubuntu.com/
|
||||
105
sources/tech/20170113 How to Encrypt Your Hard Disk in Ubuntu.md
Normal file
105
sources/tech/20170113 How to Encrypt Your Hard Disk in Ubuntu.md
Normal file
@ -0,0 +1,105 @@
|
||||
How to Encrypt Your Hard Disk in Ubuntu
|
||||
============================================================
|
||||

|
||||
|
||||
Privacy, security and encryption go hand in hand. With encryption users can take extra steps to increase the security and privacy of their operating system. In this article we’ll go over the benefits and downsides of encrypting the entire hard drive on Ubuntu Linux. Additionally, we’ll cover exactly how to set up encryption at the OS level and encrypt the home directory. The encryption process is rewarding and not as complicated as some might think! With all that in mind, let’s get started!
|
||||
|
||||
|
||||
### Pros and Cons of Encryption
|
||||
|
||||
Though encrypting an entire hard drive sounds like a flawless idea, there are some issues in doing it. Let’s go over the pros and cons.
|
||||
|
||||
### Benefits of Encryption
|
||||
|
||||
* Increased privacy
|
||||
* Only those with the encryption key can access the operating system and all the files on it
|
||||
* No state-governments or hackers can spy on your machine and invade your privacy
|
||||
|
||||
### Downsides of Encryption
|
||||
|
||||
* Accessing and mounting Linux file systems on other Linux operating systems will be difficult if not practically impossible
|
||||
* Recovering data from these partitions is impossible
|
||||
* If a user loses the decryption key, they are out of luck
|
||||
|
||||
### Preparing Installation
|
||||
|
||||
Encrypting with Ubuntu is best done at the OS level right when the installation starts. It isn’t feasible to encrypt an active Ubuntu installation, so back up all your important files to [Dropbox][10], [Google Drive][11] (or even to extra hard drives) and prepare to reinstall Ubuntu.
|
||||
|
||||

|
||||
|
||||
Start out by downloading the latest version of Ubuntu from [here][12], and get a USB flash drive (of at least 2GBs in size) ready.
|
||||
|
||||
A program is needed in order to make a live USB disk. Head to [etcher.io][13] and download the Etcher tool. Extract it from the zip archive, and right click (or highlight with the mouse and press the Enter key) on the extracted file to run it.
|
||||
|
||||

|
||||
|
||||
**Note**: Etcher will ask to create an icon – select “yes.”
|
||||
|
||||
Inside Etcher click the “Select Image” button, and navigate towards the Ubuntu ISO image downloaded earlier. Then, plug in the USB flash drive. Etcher will automatically detect it and select for you. Finally, select the “Flash!” button to start the creation process.
|
||||
|
||||
Once completed, reboot the computer with the flash drive still plugged in, load the computer’s BIOS and select the option to boot from USB.
|
||||
|
||||
**Note**: if your machine does not support booting from USB, download the 32bit version of Ubuntu and burn the ISO to a DVD using the burning software on your computer.
|
||||
|
||||
### Encrypting Your Entire Hard Disk
|
||||
|
||||
With the live Ubuntu disk loaded, the installation can begin. When the Ubuntu installation begins, a window similar to this will appear. Keep in mind that each installation process is different and may say different things.
|
||||
|
||||

|
||||
|
||||
To begin the encrypted installation, select “Erase disk and install Ubuntu,” and check “**Encrypt the new Ubuntu installation for Security**” box. This will automatically select LVM as well. Both boxes must be checked. After selecting the encryption options, click “Install Now” to begin installation.
|
||||
|
||||
**Note**: if this is a dual-boot machine, you may notice install alongside instead of erase. Select it, and select the encryption options mentioned above as well.
|
||||
|
||||
Clicking “Install Now” with the encryption options selected in Ubuntu will bring up a configuration page. This page allows the user to set the encryption key for the installation.
|
||||
|
||||

|
||||
|
||||
Enter the security key. The security key window will grade the effectiveness of the security key, so use this tool as a barometer and try to get a security key that says “strong password.” Once chosen, enter it again to confirm it, and then write this key down on a piece of paper for safekeeping.
|
||||
|
||||
Additionally, check the box that says “Overwrite empty disk space.” This is an optional step. Select install now once everything is entered.
|
||||
|
||||

|
||||
|
||||
What follows selecting the encryption key is the typical Ubuntu installation configuration. Select the time zone, and create a username along with a secure password.
|
||||
|
||||

|
||||
|
||||
Along with creating an encrypted hard drive on Ubuntu, select the “require my password to log in” box and the “encrypt my home folder” box during the username creation process. This will add yet another layer of encryption for data on the system.
|
||||
|
||||
With the username, encryption settings and everything else configured, the Ubuntu installation will begin. Soon after, Ubuntu will inform the user that the installation has been completed and that everything is ready to go!
|
||||
|
||||
### Conclusion
|
||||
|
||||
From this point on Ubuntu will not be able to be accessed without the decryption key at startup. Though tedious, encrypting Ubuntu this way is the easiest and takes advantage of the features already present in the operating system. Users will not need to learn much, nor will they need to rely on third party programs to accomplish this task.
|
||||
|
||||

|
||||
|
||||
With Ubuntu decrypted, it runs like normal. No extra hoops to jump through nor overly complicated decryption methods to learn. This method of security is a must for those who value their privacy but don’t want to fuss.
|
||||
|
||||
Would you encrypt your Ubuntu installation? Tell us below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/encrypt-hard-disk-in-ubuntu/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]:https://www.maketecheasier.com/encrypt-hard-disk-in-ubuntu/#comments
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fencrypt-hard-disk-in-ubuntu%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fencrypt-hard-disk-in-ubuntu%2F&text=How+to+Encrypt+Your+Hard+Disk+in+Ubuntu
|
||||
[6]:mailto:?subject=How%20to%20Encrypt%20Your%20Hard%20Disk%20in%20Ubuntu&body=https%3A%2F%2Fwww.maketecheasier.com%2Fencrypt-hard-disk-in-ubuntu%2F
|
||||
[7]:https://www.maketecheasier.com/why-is-iphone-overheating/
|
||||
[8]:https://www.maketecheasier.com/it-security-ethical-hacking-training/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:http://www.maketecheasier.com/tag/dropbox
|
||||
[11]:http://www.maketecheasier.com/tag/google-drive
|
||||
[12]:https://www.ubuntu.com/download/alternative-downloads
|
||||
[13]:https://etcher.io/
|
||||
131
sources/tech/20170113 How to Speed up Odoo.md
Normal file
131
sources/tech/20170113 How to Speed up Odoo.md
Normal file
@ -0,0 +1,131 @@
|
||||
How to Speed up Odoo
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Odoo is the most popular ERP (Enterprise Resource Planning) software, written in Python and uses PostgreSQL as database back-end. The Odoo community edition is a free and open source software which includes project management, manufacturing, accounting, billing and sales management, warehouse management, human resources and more. There are about 30 core modules and more than 3000 community modules. Odoo is a complex software, and deploying a number of modules, having huge data inside the database etc. could induce a slowdown. The two major Odoo bottlenecks are disk access and database query time.
|
||||
|
||||
In order to increase the performance of an Odoo instance, make sure to use:
|
||||
|
||||
* a fast disk drive for storage (preferably SSD)
|
||||
* a [Linux VPS with lots of RAM][1].
|
||||
* activate multiprocessing mode in Odoo.
|
||||
* configure and optimize the PostgreSQL service properly.
|
||||
|
||||
### Get an SSD VPS with more RAM
|
||||
|
||||
Like we mentioned previously, the random disk access speed is one of the major Odoo bottlenecks, so make sure to host Odoo on an [SSD based VPS][2]. Always install Odoo on a VPS with more RAM because Odoo is known as resource intensive application, and load the entire Odoo instance and its database into RAM if possible. Solid state disk drives excel especially in random access and they can achieve random access IOPS hundreds of times higher than conventional mechanical har disk drives because SSDs do not have any moving parts. No matter how much optimizations and configurations you do on your Odoo, if the server is not fast or powered by SSD, your Odoo will be slow. Getting the right hosting for your Odoo is the most important factor of your Odoo’s performance.
|
||||
|
||||
Did we mention that Odoo is a resource-hungry app? It seems so. But fear not, RoseHosting will provide you the ultimate solution – a performance-tailored [Odoo SSD VPS][3] optimized to match your most demanding needs. Get an SSD VPS from us and find out what record-breaking Odoo speed really means.
|
||||
|
||||
Other Odoo optimizations include:
|
||||
|
||||
### Enable the Multiprocessing option in your Odoo configuration
|
||||
|
||||
To do so, locate the openerp-server binary file:
|
||||
|
||||
```
|
||||
#updatedb
|
||||
#locate openerp-server
|
||||
|
||||
/usr/bin/openerp-server
|
||||
```
|
||||
|
||||
Run the following command:
|
||||
|
||||
```
|
||||
#/usr/bin/openerp-server --help
|
||||
```
|
||||
|
||||
The output of this command should be like this:
|
||||
|
||||
```
|
||||
Usage: openerp-server [options]
|
||||
|
||||
Options:
|
||||
--version show program's version number and exit
|
||||
|
||||
(...)
|
||||
|
||||
Multiprocessing options:
|
||||
--workers=WORKERS Specify the number of workers, 0 disable prefork mode.
|
||||
--limit-memory-soft=LIMIT_MEMORY_SOFT
|
||||
Maximum allowed virtual memory per worker, when
|
||||
reached the worker be reset after the current request
|
||||
(default 671088640 aka 640MB).
|
||||
--limit-memory-hard=LIMIT_MEMORY_HARD
|
||||
Maximum allowed virtual memory per worker, when
|
||||
reached, any memory allocation will fail (default
|
||||
805306368 aka 768MB).
|
||||
--limit-time-cpu=LIMIT_TIME_CPU
|
||||
Maximum allowed CPU time per request (default 60).
|
||||
--limit-time-real=LIMIT_TIME_REAL
|
||||
Maximum allowed Real time per request (default 120).
|
||||
--limit-request=LIMIT_REQUEST
|
||||
Maximum number of request to be processed per worker
|
||||
(default 8192).
|
||||
```
|
||||
|
||||
The number of workers should be equal to number of CPU cores allocated to the VPS, or if you want to leave some CPU cores exclusively for the PostgreSQL database, cron jobs or other applications installed on the same VPS where the Odoo instance is installed and running, set the number of workers to a lower value than CPU cores available on the VPS to avoid resources exhaustion.
|
||||
The limit-memory-soft and limit-memory-hard are self-explanatory, and you should leave them to the default value or modify them depending on the RAM available on the actual VPS.
|
||||
For example, if you have a VPS with 8 CPU cores and 16 GB of RAM, the number of workers should be 17 (CPU cores * 2 + 1), total limit-memory-soft value will be 640 x 17 = 10880 MB , and total limit-memory-hard 768MB x 17 = 13056 MB, so Odoo will use maximum 12.75 GB of RAM.
|
||||
|
||||
For example, on a VPS with 16 GB of RAM and 8 CPU cores, edit the Odoo configuration file (e.g. /etc/odoo-server.conf), and add the following lines to it:
|
||||
|
||||
```
|
||||
vi /etc/odoo-server.conf
|
||||
```
|
||||
|
||||
```
|
||||
workers = 17
|
||||
|
||||
limit_memory_hard = 805306368
|
||||
|
||||
limit_memory_soft = 671088640
|
||||
|
||||
limit_request = 8192
|
||||
|
||||
limit_time_cpu = 60
|
||||
|
||||
limit_time_real = 120
|
||||
|
||||
max_cron_threads = 2
|
||||
```
|
||||
|
||||
Do not forget to restart Odoo for the changes to take effect.
|
||||
|
||||
### Properly configure and optimize PostgreSQL
|
||||
|
||||
As for the PostgreSQL optimization, it is a good idea to update to the latest PostgreSQL version whenever a new version comes out. There are two settings in PostgreSQL configuration file (pg_hba.conf) which should be modified: shared_buffers and effective_cache_size. Set shared_buffers to 20% of the available memory, and effective_cache_size to 50% of the available memory.
|
||||
|
||||
For example, if Odoo is installed on an SSD VPS with 16 GB of RAM, use the following settings to pg_hba.conf file:
|
||||
|
||||
```
|
||||
vi /var/lib/postgresql/data/pg_hba.conf
|
||||
```
|
||||
|
||||
```
|
||||
shared_buffers = 3072MB
|
||||
effective_cache_size = 8192MB
|
||||
```
|
||||
|
||||
Restart the PostgreSQL service for the changes to take effect.
|
||||
|
||||
Also, do not forget to run ‘[VACUUM][4]‘ manually periodically. ‘Vacuuming’ cleans up stale or temporary data, but please keep in mind that it is heavy on both CPU and disk usage.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/how-to-speed-up-odoo/
|
||||
|
||||
作者:[rosehosting.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com/
|
||||
[1]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[2]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[3]:https://www.rosehosting.com/odoo-hosting.html
|
||||
[4]:https://wiki.postgresql.org/wiki/Introduction_to_VACUUM,_ANALYZE,_EXPLAIN,_and_COUNT
|
||||
@ -1,465 +0,0 @@
|
||||
wyangsun translating
|
||||
|
||||
How to install a Ceph Storage Cluster on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Configure All Nodes][1]
|
||||
2. [Step 2 - Configure the SSH Server][2]
|
||||
3. [Step 3 - Configure the Ubuntu Firewall][3]
|
||||
4. [Step 4 - Configure the Ceph OSD Nodes][4]
|
||||
5. [Step 5 - Build the Ceph Cluster][5]
|
||||
6. [Step 6 - Testing Ceph][6]
|
||||
7. [Reference][7]
|
||||
|
||||
Ceph is an open source storage platform, it provides high performance, reliability, and scalability. It's a free distributed storage system that provides an interface for object, block, and file-level storage and can operate without a single point of failure.
|
||||
|
||||
In this tutorial, I will guide you to install and build a Ceph cluster on Ubuntu 16.04 server. A Ceph cluster consists of these components:
|
||||
|
||||
* **Ceph OSDs (ceph-osd)** - Handles the data storage, data replication, and recovery. A Ceph cluster needs at least two Ceph OSD servers. We will use three Ubuntu 16.04 servers in this setup.
|
||||
* **Ceph Monitor (ceph-mon)** - Monitors the cluster state and runs the OSD map and CRUSH map. We will use one server here.
|
||||
* **Ceph Meta Data Server (ceph-mds)** - this is needed if you want to use Ceph as a File System.
|
||||
|
||||
### **Prerequisites**
|
||||
|
||||
* 6 server nodes with Ubuntu 16.04 server installed
|
||||
* Root privileges on all nodes
|
||||
|
||||
I will use the following hostname / IP setup:
|
||||
|
||||
**hostname** **IP address**
|
||||
|
||||
_ceph-admin 10.0.15.10
|
||||
mon1 10.0.15.11
|
||||
osd1 10.0.15.21
|
||||
osd2 10.0.15.22
|
||||
osd3 10.0.15.23
|
||||
client 10.0.15.15_
|
||||
|
||||
### Step 1 - Configure All Nodes
|
||||
|
||||
In this step, we will configure all 6 nodes to prepare them for the installation of the Ceph Cluster software. So you have to follow and run the commands below on all nodes. And make sure that ssh-server is installed on all nodes.
|
||||
|
||||
**Create the Ceph User**
|
||||
|
||||
Create a new user named '**cephuser**' on all nodes.
|
||||
|
||||
useradd -m -s /bin/bash cephuser
|
||||
passwd cephuser
|
||||
|
||||
After creating the new user, we need to configure **cephuser** for passwordless sudo privileges. This means that 'cephuser' can run and get sudo privileges without having to enter a password first.
|
||||
|
||||
Run the commands below to achieve that.
|
||||
|
||||
echo "cephuser ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephuser
|
||||
chmod 0440 /etc/sudoers.d/cephuser
|
||||
sed -i s'/Defaults requiretty/#Defaults requiretty'/g /etc/sudoers
|
||||
|
||||
**Install and Configure NTP**
|
||||
|
||||
Install NTP to synchronize date and time on all nodes. Run the ntpdate command to set the date and time via NTP. We will use the US pool NTP servers. Then start and enable NTP server to run at boot time.
|
||||
|
||||
sudo apt-get install -y ntp ntpdate ntp-doc
|
||||
ntpdate 0.us.pool.ntp.org
|
||||
hwclock --systohc
|
||||
systemctl enable ntp
|
||||
systemctl start ntp
|
||||
|
||||
**Install Open-vm-tools
|
||||
**
|
||||
|
||||
If you are running all nodes inside VMware, you need to install this virtualization utility.
|
||||
|
||||
sudo apt-get install -y open-vm-tools
|
||||
|
||||
**Install Python and parted
|
||||
**
|
||||
|
||||
In this tutorial, we need python packages for building the ceph-cluster. Install python and python-pip.
|
||||
|
||||
sudo apt-get install -y python python-pip parted
|
||||
|
||||
**Configure the Hosts File**
|
||||
|
||||
Edit the hosts file on all nodes with vim editor.
|
||||
|
||||
vim /etc/hosts
|
||||
|
||||
Paste the configuration below:
|
||||
|
||||
```
|
||||
10.0.15.10 ceph-admin
|
||||
10.0.15.11 mon1
|
||||
10.0.15.21 ceph-osd1
|
||||
10.0.15.22 ceph-osd2
|
||||
10.0.15.23 ceph-osd3
|
||||
10.0.15.15 ceph-client
|
||||
```
|
||||
|
||||
Save the hosts file and exit the vim editor.
|
||||
|
||||
Now you can try to ping between the server hostnames to test the network connectivity.
|
||||
|
||||
ping -c 5 mon1
|
||||
|
||||
[
|
||||
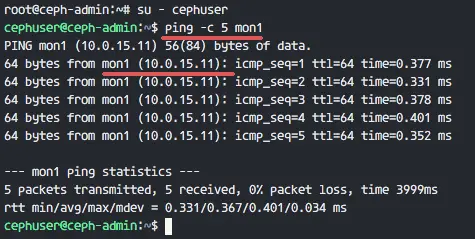
|
||||
][8]
|
||||
|
||||
### Step 2 - Configure the SSH Server
|
||||
|
||||
In this step, we will configure the **ceph-admin node**. The admin node is used for configuring the monitor node and osd nodes. Login to the ceph-admin node and access the '**cephuser**'.
|
||||
|
||||
ssh root@ceph-admin
|
||||
su - cephuser
|
||||
|
||||
The admin node is used for installing and configuring all cluster node, so the user on the ceph-admin node must have privileges to connect to all nodes without a password. We need to configure password-less SSH access for 'cephuser' on the 'ceph-admin' node.
|
||||
|
||||
Generate the ssh keys for '**cephuser**'.
|
||||
|
||||
ssh-keygen
|
||||
|
||||
Leave passphrase is blank/empty.
|
||||
|
||||
Next, create a configuration file for the ssh config.
|
||||
|
||||
vim ~/.ssh/config
|
||||
|
||||
Paste the configuration below:
|
||||
|
||||
```
|
||||
Host ceph-admin
|
||||
Hostname ceph-admin
|
||||
User cephuser
|
||||
|
||||
Host mon1
|
||||
Hostname mon1
|
||||
User cephuser
|
||||
|
||||
Host ceph-osd1
|
||||
Hostname ceph-osd1
|
||||
User cephuser
|
||||
|
||||
Host ceph-osd2
|
||||
Hostname ceph-osd2
|
||||
User cephuser
|
||||
|
||||
Host ceph-osd3
|
||||
Hostname ceph-osd3
|
||||
User cephuser
|
||||
|
||||
Host ceph-client
|
||||
Hostname ceph-client
|
||||
User cephuser
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
[
|
||||
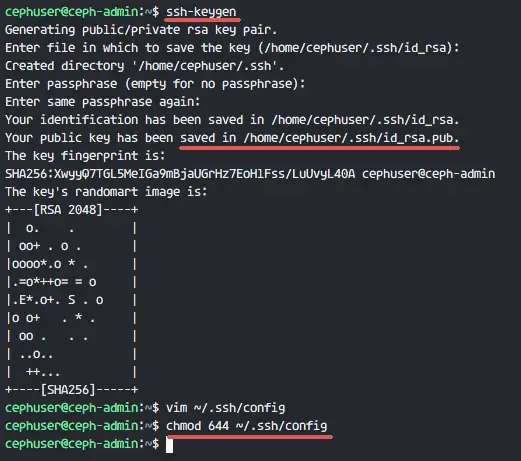
|
||||
][9]
|
||||
|
||||
Change the permission of the config file to 644.
|
||||
|
||||
chmod 644 ~/.ssh/config
|
||||
|
||||
Now add the key to all nodes with the ssh-copy-id command.
|
||||
|
||||
ssh-keyscan ceph-osd1 ceph-osd2 ceph-osd3 ceph-client mon1 >> ~/.ssh/known_hosts
|
||||
ssh-copy-id ceph-osd1
|
||||
ssh-copy-id ceph-osd2
|
||||
ssh-copy-id ceph-osd3
|
||||
ssh-copy-id mon1
|
||||
|
||||
Type in your cephuser password when requested.
|
||||
|
||||
[
|
||||
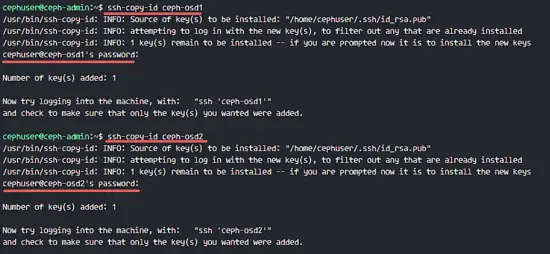
|
||||
][10]
|
||||
|
||||
Now try to access the osd1 server from the ceph-admin node to test if the password-less login works.
|
||||
|
||||
ssh ceph-osd1
|
||||
|
||||
[
|
||||
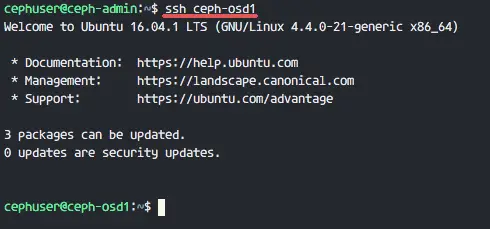
|
||||
][11]
|
||||
|
||||
### Step 3 - Configure the Ubuntu Firewall
|
||||
|
||||
For security reasons, we need to turn on the firewall on the servers. Preferably we use Ufw (Uncomplicated Firewall), the default Ubuntu firewall, to protect the system. In this step, we will enable ufw on all nodes, then open the ports needed by ceph-admin, ceph-mon and ceph-osd.
|
||||
|
||||
Login to the ceph-admin node and install the ufw packages.
|
||||
|
||||
ssh root@ceph-admin
|
||||
sudo apt-get install -y ufw
|
||||
|
||||
Open port 80, 2003 and 4505-4506, then reload firewalld.
|
||||
|
||||
sudo ufw allow 22/tcp
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow 2003/tcp
|
||||
sudo ufw allow 4505:4506/tcp
|
||||
|
||||
Start and enable ufw to start at boot time.
|
||||
|
||||
sudo ufw enable
|
||||
|
||||
[
|
||||
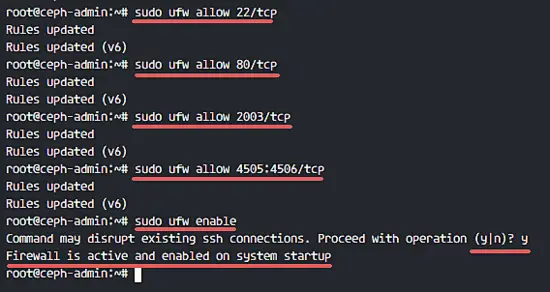
|
||||
][12]
|
||||
|
||||
From the ceph-admin node, login to the monitor node 'mon1' and install ufw.
|
||||
|
||||
ssh mon1
|
||||
sudo apt-get install -y ufw
|
||||
|
||||
Open the ports for the ceph monitor node and start ufw.
|
||||
|
||||
sudo ufw allow 22/tcp
|
||||
sudo ufw allow 6789/tcp
|
||||
sudo ufw enable
|
||||
|
||||
Finally, open these ports on each osd node: ceph-osd1, ceph-osd2 and ceph-osd3 - port 6800-7300.
|
||||
|
||||
Login to each of the ceph-osd nodes from the ceph-admin, and install ufw.
|
||||
|
||||
ssh ceph-osd1
|
||||
sudo apt-get install -y ufw
|
||||
|
||||
Open the ports on the osd nodes and reload firewalld.
|
||||
|
||||
sudo ufw allow 22/tcp
|
||||
sudo ufw allow 6800:7300/tcp
|
||||
sudo ufw enable
|
||||
|
||||
The ufw firewall configuration is finished.
|
||||
|
||||
### Step 4 - Configure the Ceph OSD Nodes
|
||||
|
||||
In this tutorial, we have 3 OSD nodes, each of these nodes has two hard disk partitions.
|
||||
|
||||
1. **/dev/sda** for root partition
|
||||
2. **/dev/sdb** is empty partition - 20GB
|
||||
|
||||
We will use **/dev/sdb** for the ceph disk. From the ceph-admin node, login to all OSD nodes and format the /dev/sdb partition with **XFS** file system.
|
||||
|
||||
ssh ceph-osd1
|
||||
ssh ceph-osd2
|
||||
ssh ceph-osd3
|
||||
|
||||
Check the partition scheme with the fdisk command.
|
||||
|
||||
sudo fdisk -l /dev/sdb
|
||||
|
||||
Format the /dev/sdb partition with an XFS filesystem and with a GPT partition table by using the parted command.
|
||||
|
||||
sudo parted -s /dev/sdb mklabel gpt mkpart primary xfs 0% 100%
|
||||
|
||||
Next, format the partition in XFS format with the mkfs command.
|
||||
|
||||
sudo mkfs.xfs -f /dev/sdb
|
||||
|
||||
Now check the partition, and you will see a XFS /dev/sdb partition.
|
||||
|
||||
sudo fdisk -s /dev/sdb
|
||||
sudo blkid -o value -s TYPE /dev/sdb
|
||||
|
||||
[
|
||||
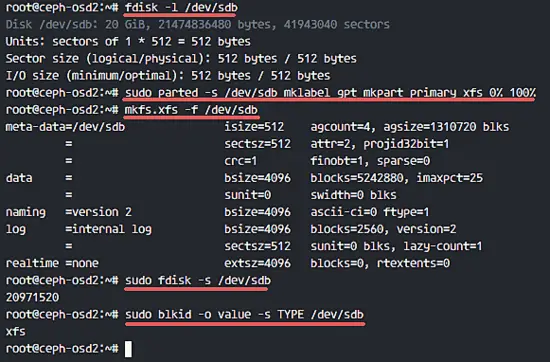
|
||||
][13]
|
||||
|
||||
### Step 5 - Build the Ceph Cluster
|
||||
|
||||
In this step, we will install Ceph on all nodes from the ceph-admin. To get started, login to the ceph-admin node.
|
||||
|
||||
ssh root@ceph-admin
|
||||
su - cephuser
|
||||
|
||||
**Install ceph-deploy on ceph-admin node**
|
||||
|
||||
In the first step we've already installed python and python-pip on to the system. Now we need to install the Ceph deployment tool '**ceph-deploy**' from the pypi python repository.
|
||||
|
||||
Install ceph-deploy on the ceph-admin node with the pip command.
|
||||
|
||||
sudo pip install ceph-deploy
|
||||
|
||||
Note: Make sure all nodes are updated.
|
||||
|
||||
After the ceph-deploy tool has been installed, create a new directory for the Ceph cluster configuration.
|
||||
|
||||
**Create a new Cluster**
|
||||
|
||||
Create a new cluster directory.
|
||||
|
||||
mkdir cluster
|
||||
cd cluster/
|
||||
|
||||
Next, create a new cluster with the '**ceph-deploy**' command by defining the monitor node '**mon1**'.
|
||||
|
||||
ceph-deploy new mon1
|
||||
|
||||
The command will generate the Ceph cluster configuration file 'ceph.conf' in cluster directory.
|
||||
|
||||
[
|
||||
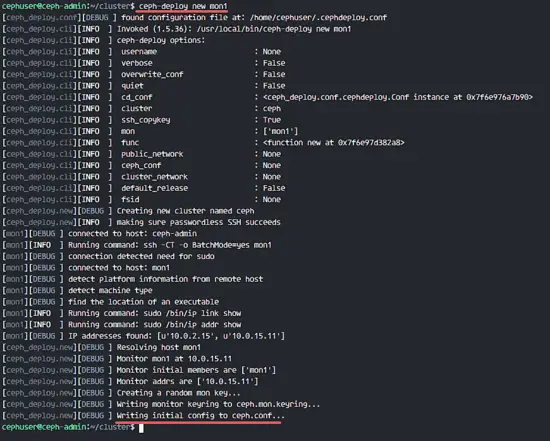
|
||||
][14]
|
||||
|
||||
Edit the ceph.conf file with vim.
|
||||
|
||||
vim ceph.conf
|
||||
|
||||
Under the [global] block, paste the configuration below.
|
||||
|
||||
```
|
||||
# Your network address
|
||||
public network = 10.0.15.0/24
|
||||
osd pool default size = 2
|
||||
```
|
||||
|
||||
Save the file and exit the editor.
|
||||
|
||||
**Install Ceph on All Nodes**
|
||||
|
||||
Now install Ceph on all nodes from the ceph-admin node with a single command.
|
||||
|
||||
ceph-deploy install ceph-admin ceph-osd1 ceph-osd2 ceph-osd3 mon1
|
||||
|
||||
The command will automatically install Ceph on all nodes: mon1, osd1-3 and ceph-admin - The installation will take some time.
|
||||
|
||||
Now deploy the monitor node on the mon1 node.
|
||||
|
||||
ceph-deploy mon create-initial
|
||||
|
||||
The command will create a monitor key, check the key with this ceph command.
|
||||
|
||||
ceph-deploy gatherkeys mon1
|
||||
|
||||
[
|
||||
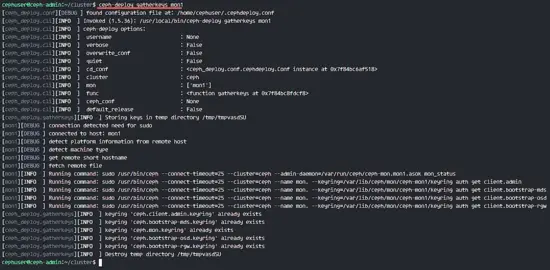
|
||||
][15]
|
||||
|
||||
**Adding OSDS to the Cluster**
|
||||
|
||||
After Ceph has been installed on all nodes, now we can add the OSD daemons to the cluster. OSD Daemons will create the data and journal partition on the disk /dev/sdb.
|
||||
|
||||
Check the available disk /dev/sdb on all osd nodes.
|
||||
|
||||
ceph-deploy disk list ceph-osd1 ceph-osd2 ceph-osd3
|
||||
|
||||
[
|
||||
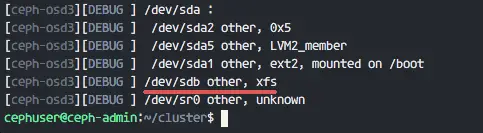
|
||||
][16]
|
||||
|
||||
You will see /dev/sdb with the XFS format that we created before.
|
||||
|
||||
Next, delete the partition tables on all nodes with the zap option.
|
||||
|
||||
ceph-deploy disk zap ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
|
||||
|
||||
The command will delete all data on /dev/sdb on the Ceph OSD nodes.
|
||||
|
||||
Now prepare all OSD nodes and ensure that there are no errors in the results.
|
||||
|
||||
ceph-deploy osd prepare ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
|
||||
|
||||
When you see the ceph-osd1-3 is ready for OSD use in the result, then the command was successful.
|
||||
|
||||
[
|
||||
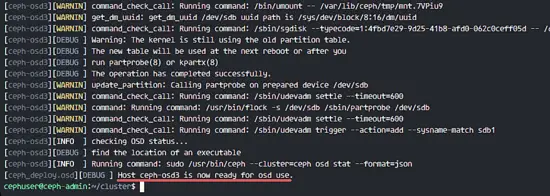
|
||||
][17]
|
||||
|
||||
Activate the OSD'S with the command below:
|
||||
|
||||
ceph-deploy osd activate ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
|
||||
|
||||
Now you can check the sdb disk on OSDS nodes again.
|
||||
|
||||
ceph-deploy disk list ceph-osd1 ceph-osd2 ceph-osd3
|
||||
|
||||
[
|
||||
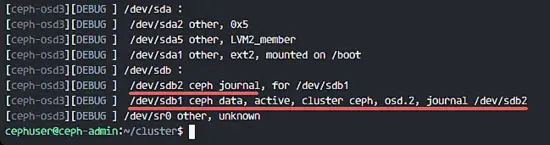
|
||||
][18]
|
||||
|
||||
The result is that /dev/sdb has two partitions now:
|
||||
|
||||
1. **/dev/sdb1** - Ceph Data
|
||||
2. **/dev/sdb2** - Ceph Journal
|
||||
|
||||
Or you check it directly on the OSD node.
|
||||
|
||||
ssh ceph-osd1
|
||||
sudo fdisk -l /dev/sdb
|
||||
|
||||
[
|
||||
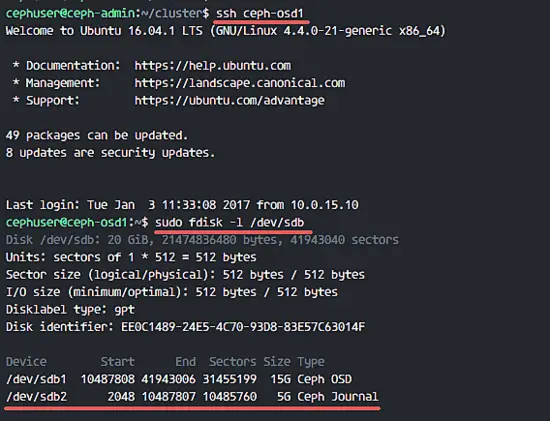
|
||||
][19]
|
||||
|
||||
Next, deploy the management-key to all associated nodes.
|
||||
|
||||
ceph-deploy admin ceph-admin mon1 ceph-osd1 ceph-osd2 ceph-osd3
|
||||
|
||||
Change the permission of the key file by running the command below on all nodes.
|
||||
|
||||
sudo chmod 644 /etc/ceph/ceph.client.admin.keyring
|
||||
|
||||
The Ceph Cluster on Ubuntu 16.04 has been created.
|
||||
|
||||
### Step 6 - Testing Ceph
|
||||
|
||||
In step 4, we've installed and created a new Ceph cluster, and added OSDS nodes to the cluster. Now we should test the cluster to make sure that it works as intended.
|
||||
|
||||
From the ceph-admin node, log in to the Ceph monitor server '**mon1**'.
|
||||
|
||||
ssh mon1
|
||||
|
||||
Run the command below to check the cluster health.
|
||||
|
||||
sudo ceph health
|
||||
|
||||
Now check the cluster status.
|
||||
|
||||
sudo ceph -s
|
||||
|
||||
You can see results below:
|
||||
|
||||
[
|
||||
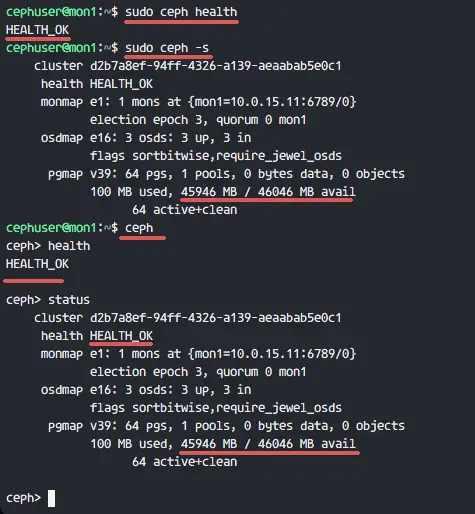
|
||||
][20]
|
||||
|
||||
Make sure the Ceph health is **OK** and there is a monitor node '**mon1**' with IP address '**10.0.15.11**'. There are **3 OSD** servers and all are **up** and running, and there should be an available disk space of **45GB** - 3x15GB Ceph Data OSD partition.
|
||||
|
||||
We build a new Ceph Cluster on Ubuntu 16.04 successfully.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-all-nodes
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-the-ssh-server
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-the-ubuntu-firewall
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-the-ceph-osd-nodes
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-build-the-ceph-cluster
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-testing-ceph
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#reference
|
||||
[8]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/1.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/2.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/3.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/4.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/5.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/6.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/7.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/8.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/9.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/10.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/11.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/12.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/13.png
|
||||
@ -0,0 +1,123 @@
|
||||
Build your own wiki on Ubuntu with DokuWiki
|
||||
============================================================
|
||||
|
||||
|
||||
We use [DokuWiki][2] and it’s awesome. Our team has an internal knowledgebase and we use DokuWiki to store all our reviews, tutorials etc. It’s simple, easy to install and easy to use. Most importantly, it’s not resource-heavy. In this post, we’re going to show you how to install DokuWiki on an Ubuntu 16.04 server.
|
||||
|
||||
### Requirements
|
||||
|
||||
DokuWiki doesn’t need much since it doesn’t need a database. Here are the requirements of DokuWiki:
|
||||
|
||||
* PHP 5.3.4 or newer (PHP 7+ recommended)
|
||||
* A web server (Apache/Nginx/Any other)
|
||||
* A VPS. [Get a cheap managed VPS][1] and you won’t have to do any of this. Just contact the support team and they will install it for you.
|
||||
|
||||
### Instructions
|
||||
|
||||
Before you do anything, you should upgrade your system. Run the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update && sudo apt-get upgrade
|
||||
```
|
||||
|
||||
### Install Apache
|
||||
|
||||
We are going to need a web server for our wiki. We’ll be using Apache for our tutorial, but you can also use Nginx or any other web server. Install apache with:
|
||||
|
||||
```
|
||||
apt-get install apache2
|
||||
```
|
||||
|
||||
### Install PHP7 and modules
|
||||
|
||||
Next, you should install PHP if you don’t already have it installed. In this tutorial, we’ll be using PHP7\. So, install PHP7 and a few other PHP modules with the following command:
|
||||
|
||||
```
|
||||
apt-get install php7.0-fpm php7.0-cli php-apcu php7.0-gd php7.0-xml php7.0-curl php7.0-json php7.0-mcrypt php7.0-cgi php7.0 libapache2-mod-php7.0
|
||||
```
|
||||
|
||||
### Download and install DokuWiki
|
||||
|
||||
Here comes the main part – the actual installation of DokuWiki.
|
||||
|
||||
First, create a directory for your DokuWiki:
|
||||
|
||||
```
|
||||
mkdir -p /var/www/thrwiki
|
||||
```
|
||||
|
||||
Navigate to the directory you just created:
|
||||
|
||||
```
|
||||
cd /var/www/thrwiki
|
||||
```
|
||||
|
||||
Run the following command to download the latest (stable) version of DokuWiki:
|
||||
|
||||
```
|
||||
wget http://download.dokuwiki.org/src/dokuwiki/dokuwiki-stable.tgz
|
||||
```
|
||||
|
||||
Unpack the .tgz file:
|
||||
|
||||
```
|
||||
tar xvf dokuwiki-stable.tgz
|
||||
```
|
||||
|
||||
Change some file/folder permissions:
|
||||
|
||||
```
|
||||
www-data:www-data -R /var/www/thrwiki
|
||||
chmod -R 707 /var/www/thrwiki
|
||||
```
|
||||
|
||||
### Configure Apache for DokuWiki
|
||||
|
||||
Create a .conf file for your DokuWiki (we’ll name it thrwiki.conf, but you can name it however you want) and open it with your favorite text editor. We’ll be using nano:
|
||||
|
||||
```
|
||||
touch /etc/apache2/sites-available/thrwiki.conf
|
||||
ln -s /etc/apache2/sites-available/thrwiki.conf /etc/apache2/sites-enabled/thrwiki.conf
|
||||
nano /etc/apache2/sites-available/thrwiki.conf
|
||||
```
|
||||
Add the following in your thrwiki.conf file:
|
||||
```
|
||||
<VirtualHost yourServerIP:80>
|
||||
ServerAdmin wikiadmin@thishosting.rocks
|
||||
DocumentRoot /var/www/thrwiki/
|
||||
ServerName wiki.thishosting.rocks
|
||||
ServerAlias www.wiki.thishosting.rocks
|
||||
<Directory /var/www/thrwiki/>
|
||||
Options FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
allow from all
|
||||
</Directory>
|
||||
ErrorLog /var/log/apache2/wiki.thishosting.rocks-error_log
|
||||
CustomLog /var/log/apache2/wiki.thishosting.rocks-access_log common
|
||||
</VirtualHost>
|
||||
```
|
||||
Edit the lines to correspond with your server setup. Replace wikiadmin@thishosting.rocks, wiki.thishosting.rocks etc with your own dataNow, restart apache for the changes to take effect:
|
||||
```
|
||||
systemctl restart apache2.service
|
||||
```
|
||||
That’s it. You are done. Now you can continue installing and configuring DokuWiki via the front-end interface at http://wiki.thishosting.rocks/install.phpOnce you are done with the installation, you can remove the install.php file with:
|
||||
```
|
||||
rm -f /var/www/html/thrwiki/install.php
|
||||
```
|
||||
|
||||
Feel free to leave a comment below if you need any help.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thishosting.rocks/build-your-own-wiki-on-ubuntu-with-dokuwiki/
|
||||
|
||||
作者:[thishostrocks.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/thishostrocks
|
||||
[1]:https://thishosting.rocks/best-cheap-managed-vps/
|
||||
[2]:https://github.com/splitbrain/dokuwiki
|
||||
356
sources/tech/20170116 Getting started with shell scripting.md
Normal file
356
sources/tech/20170116 Getting started with shell scripting.md
Normal file
@ -0,0 +1,356 @@
|
||||
Getting started with shell scripting
|
||||
============================================================
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
[ajmexico][1]. Modified by [Jason Baker][2]. [CC BY-SA 2.0][3].
|
||||
|
||||
The world's best conceptual introduction to shell scripting comes from an old [AT&T training video][4]. In the video, Brian W. Kernighan (the "K" in **awk**) and Lorinda L. Cherry (co-author of **bc**) demonstrate how one of the founding principles of UNIX was to empower users to leverage existing utilities to create complex and customized tools.
|
||||
|
||||
In the words of [Kernighan][5]: "Think of the UNIX system programs basically as [...] building blocks with which you can create things. [...] The notion of pipe-lining is the fundamental contribution of the [UNIX] system; you can take a bunch of programs...and stick them together end to end so that the data flows from the one on the left to the one on the right and the system itself looks after all the connections. The programs themselves don't know anything about the connection; as far as they're concerned, they're just talking to the terminal."
|
||||
|
||||
He's talking about giving everyday users the ability to program.
|
||||
|
||||
The POSIX operating system is, figuratively, an API for itself. If you can figure out how to complete a task in a POSIX shell, then you can automate that task. That's programming, and the main vehicle for this everyday POSIX programming method is the shell script.
|
||||
|
||||
True to its name, the shell _script_ is a line-by-line recipe for what you want your computer to do, just as you would have done it manually.
|
||||
|
||||
Because a shell script consists of common, everyday commands, familiarity with a UNIX or Linux (generically known as **POSIX**) shell is helpful. The more you practice using the shell, the easier it becomes to formulate new scripts. It's like learning a foreign language: the more vocabulary you internalize, the easier it is to form complex sentences.
|
||||
|
||||
When you open a terminal window, you are opening a _shell_. There are several shells out there, and this tutorial is valid for **bash**, **tcsh**, **ksh**, **zsh**, and probably others. In a few sections, I do provide some bash-specific examples, but the final script abandons those, so you can either switch to bash for the lesson about setting variables, or do some simple [syntax adjustment][6].
|
||||
|
||||
If you're new to all of this, just use **bash**. It's a good shell with lots of friendly features, and the default on Linux, Cygwin, WSL, Mac, and an option on BSD.
|
||||
|
||||
### Hello world
|
||||
|
||||
You can generate your own **hello world** script from a terminal window. Mind your quotation marks; single and double have different effects.
|
||||
|
||||
```
|
||||
$ echo "#\!/bin/sh" > hello.sh
|
||||
$ echo "echo 'hello world' " >> hello.sh
|
||||
```
|
||||
|
||||
As you can see, writing a shell script consists, with the exception of the first line, of echoing or pasting commands into a text file.
|
||||
|
||||
To run the script as an application:
|
||||
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
hello world
|
||||
```
|
||||
|
||||
And that's, more or less, all there is to it!
|
||||
|
||||
Now let's tackle something a little more useful.
|
||||
|
||||
### Despacer
|
||||
|
||||
If there's one thing that confuses the computer and human interaction, it's spaces in file names. You've seen it on the internet: URLs like **http: //example.com/omg%2ccutest%20cat%20photo%21%211.jpg**. Or maybe spaces have tripped you up when running a simple command:
|
||||
|
||||
```
|
||||
$ cp llama pic.jpg ~/photos
|
||||
cp: cannot stat 'llama': No such file or directory
|
||||
cp: cannot stat 'pic.jpg': No such file or directory
|
||||
```
|
||||
|
||||
The solution is to "escape" the space with a backslash, or quotation marks:
|
||||
|
||||
```
|
||||
$ touch foo\ bar.txt
|
||||
$ ls "foo bar.txt"
|
||||
foo bar.txt
|
||||
```
|
||||
|
||||
Those are important tricks to know, but it gets inconvenient, so why not write a script to remove those annoying spaces from file names?
|
||||
|
||||
Create a file to hold the script, starting with a "shebang" (**#!**) to let your system know that the file should run in a shell:
|
||||
|
||||
```
|
||||
$ echo '#!/bin/sh' > despace
|
||||
```
|
||||
|
||||
Good code starts with documentation. Defining the purpose lets us know what to aim for. Here's a good README:
|
||||
|
||||
```
|
||||
despace is a shell script for removing spaces from file names.
|
||||
|
||||
Usage:
|
||||
$ despace "foo bar.txt"
|
||||
```
|
||||
|
||||
Now let's figure out how to do it manually, and build the script as we go.
|
||||
|
||||
Assuming you have a file called "foo bar.txt" in an otherwise empty directory, try this:
|
||||
|
||||
```
|
||||
$ ls
|
||||
hello.sh
|
||||
foo bar.txt
|
||||
```
|
||||
|
||||
Computers are all about input and output. In this case, the input has been a request to **ls** a specific directory. The output is what you would expect: the name of the file in that directory.
|
||||
|
||||
In UNIX, output can be sent as the input of another command through a "pipe." Whatever is on the opposite side of the pipe acts as a sort of filter. The **tr** utility happens to be designed especially to modify strings passed through it; for this task, use the **--delete** option to delete a character defined in quotes.
|
||||
|
||||
```
|
||||
$ ls "foo bar.txt" | tr --delete ' '
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
Now you have just the output you need.
|
||||
|
||||
In the BASH shell, you can store output as a **variable**. Think of a variable as an empty box into which you place information for storage:
|
||||
|
||||
```
|
||||
$ NAME=foo
|
||||
```
|
||||
|
||||
When you need the information back, you can look in the box by referencing a variable name preceded by a dollar sign (**$**).
|
||||
|
||||
```
|
||||
$ echo $NAME
|
||||
foo
|
||||
```
|
||||
|
||||
To get the output of your despacing command and set it aside for later, use a variable. To place the _results_ of a command into a variable, use backticks:
|
||||
|
||||
```
|
||||
$ NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
$ echo $NAME
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
This gets you halfway to your goal, you have a method to determine the destination filename from the source filename.
|
||||
|
||||
So far, the script looks like this:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
echo $NAME
|
||||
```
|
||||
|
||||
The second part of the script must perform the renaming. You probably already now that command:
|
||||
|
||||
```
|
||||
$ mv "foo bar.txt" foobar.txt
|
||||
```
|
||||
|
||||
However, remember in the script that you're using a variable to hold the destination name. You do know how to reference variables:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
echo $NAME
|
||||
mv "foo bar.txt" $NAME
|
||||
```
|
||||
|
||||
You can try out your first draft by marking it executable and running it in your test directory. Make sure you have a test file called "foo bar.txt" (or whatever you use in your script).
|
||||
|
||||
```
|
||||
$ touch "foo bar.txt"
|
||||
$ chmod +x despace
|
||||
$ ./despace
|
||||
foobar.txt
|
||||
$ ls
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
### Despacer v2.0
|
||||
|
||||
The script works, but not exactly as your documentation describes. It's currently very specific, and only works on a file called **foo\ bar.txt**, and nothing else.
|
||||
|
||||
A POSIX command refers to itself as **$0** and to anything typed after it, sequentially, as **$1**, **$2**, **$3**, and so on. Your shell script counts as a POSIX command, so try swapping out **foo\ bar.txt** with **$1**.
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls $1 | tr -d ' '`
|
||||
echo $NAME
|
||||
mv $1 $NAME
|
||||
```
|
||||
|
||||
Create a few new test files with spaces in the names:
|
||||
|
||||
```
|
||||
$ touch "one two.txt"
|
||||
$ touch "cat dog.txt"
|
||||
```
|
||||
|
||||
Then test your new script:
|
||||
|
||||
```
|
||||
$ ./despace "one two.txt"
|
||||
ls: cannot access 'one': No such file or directory
|
||||
ls: cannot access 'two.txt': No such file or directory
|
||||
```
|
||||
|
||||
Looks like you've found a bug!
|
||||
|
||||
The bug is not actually a bug, as such; everything is working as designed, but not how you want it to work. Your script is "expanding" the **$1** variable to exactly what it is: "one two.txt", and along with that comes that bothersome space you're trying to eliminate.
|
||||
|
||||
The answer is to wrap the variable in quotations the same way you wrap filenames in quotes:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "$1" | tr -d ' '`
|
||||
echo $NAME
|
||||
mv "$1" $NAME
|
||||
```
|
||||
|
||||
Another test or two:
|
||||
|
||||
```
|
||||
$ ./despace "one two.txt"
|
||||
onetwo.txt
|
||||
$ ./despace c*g.txt
|
||||
catdog.txt
|
||||
```
|
||||
|
||||
This script acts the same as any other POSIX command. You can use it in conjunction with other commands just as you would expect to be able to use any POSIX utility. You can use it in conjunction with a command:
|
||||
|
||||
```
|
||||
$ find ~/test0 -type f -exec /path/to/despace {} \;
|
||||
```
|
||||
|
||||
Or you can use it as a part of a loop:
|
||||
|
||||
`$ for FILE in ~/test1/* ; do /path/to/despace $FILE ; done`
|
||||
|
||||
and so on.
|
||||
|
||||
### Despacer v2.5
|
||||
|
||||
The despace script is functional, but technically it could be optimized, and it could use a few usability improvements.
|
||||
|
||||
First of all, the variable is actually not needed. The shell can calculate the required information all in one go.
|
||||
|
||||
POSIX shells have an order of operations. The same way you, in math, solve for statements in brackets first, the shell resolves statements in backticks (**`**), or **$()** in BASH, before executing a command. Therefore, the statement:
|
||||
|
||||
```
|
||||
$ mv foo\ bar.txt `ls foo\ bar.txt | tr -d ' '`
|
||||
```
|
||||
|
||||
gets transformed into:
|
||||
|
||||
```
|
||||
$ mv foo\ bar.txt foobar.txt
|
||||
```
|
||||
|
||||
and then the actual **mv** command is performed, leaving us with just **foobar.txt**.
|
||||
|
||||
Knowing this, you can condense the shell script into:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
mv "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
That looks disappointingly simple. You might think that reducing it to a one-liner makes the script unnecessary, but shell scripts don't have to have lots of lines to be useful. A script that saves typing even a simple command can still save you from deadly typos, which is especially important when moving files is involved.
|
||||
|
||||
Besides, your script can still use improvement. Additional testing reveals a few weak points. For example, running **despace** with no argument renders an unhelpful error:
|
||||
|
||||
```
|
||||
$ ./despace
|
||||
ls: cannot access '': No such file or directory
|
||||
|
||||
mv: missing destination file operand after ''
|
||||
Try 'mv --help' for more information.
|
||||
```
|
||||
|
||||
These errors are confusing because they're for **ls** and **mv**, but as far as users know, it wasn't **ls** or **mv**, but **despace**, that they ran.
|
||||
|
||||
If you think about it, this little script shouldn't even attempt to rename a file if it didn't get a file as part of the command in the first place, so try using what you know about variables along with the **test** function.
|
||||
|
||||
### If and test
|
||||
|
||||
The **if** statement is what turns your little despace utility from a script into a program. This is serious code territory, but don't worry, it's also pretty easy to understand and use.
|
||||
|
||||
An **if** statement is a kind of switch; if something is true, then you'll do one thing, and if it's false, you'll do something different. This if-then instruction is exactly the kind of binary decision making computers are best at; all you have to do is define for the computer what needs to be true or false and what to do as a result.
|
||||
|
||||
The easiest way you test for True or False is the **test** utility. You don't call it directly, you use its syntax. Try this in a terminal:
|
||||
|
||||
```
|
||||
$ if [ 1 == 1 ]; then echo "yes, true, affirmative"; fi
|
||||
yes, true, affirmative
|
||||
$ if [ 1 == 123 ]; then echo "yes, true, affirmative"; fi
|
||||
$
|
||||
```
|
||||
|
||||
That's how **test** works. You have all manner of shorthand to choose from, and the one you'll use is the **-z** option, which detects if the length of a string of characters is zero (0). The idea translates in your despace script as:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
if [ -z "$1" ]; then
|
||||
echo "Provide a \"file name\", using quotes to nullify the space."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mv "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
The **if** statement is broken into separate lines for readability, but the concept remains: if the data inside the **$1** variable is empty (zero characters are present), then print an error statement.
|
||||
|
||||
Try it:
|
||||
|
||||
```
|
||||
$ ./despace
|
||||
Provide a "file name", using quotes to nullify the space.
|
||||
$
|
||||
```
|
||||
|
||||
Success!
|
||||
|
||||
Well, actually it was a failure, but it was a _pretty_ failure, and more importantly, a _helpful_ failure.
|
||||
|
||||
Notice the statement **exit 1**. This is a way for POSIX applications to send an alert to the system that it has encountered an error. This capability is important for yourself and for other people who may want to use despace in scripts that depend on despace succeeding in order for everything else to happen correctly.
|
||||
|
||||
The final improvement is to add something to protect the user from overwriting files accidentally. Ideally, you'd pass this option through to the script so that it's optional, but for the sake of simplicity, you'll hard code it. The **-i** option tells **mv** to ask for permission before overwriting a file that already exists:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
if [ -z "$1" ]; then
|
||||
echo "Provide a \"file name\", using quotes to nullify the space."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mv -i "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
Now your shell script is helpful, useful, and friendly—and you're a programmer, so don't stop now. Learn new commands, use them in your terminal, take note of what you do, and then script it. Eventually, you'll put yourself out of a job, and the rest of your life will be spent relaxing while your robotic minions run shell scripts.
|
||||
|
||||
Happy hacking!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Seth Kenlon is an independent multimedia artist, free culture advocate, and UNIX geek. He is one of the maintainers of the Slackware-based multimedia production project, http://slackermedia.ml
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/getting-started-shell-scripting
|
||||
|
||||
作者:[Seth Kenlon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://www.flickr.com/photos/15587432@N02/3281139507/
|
||||
[2]:https://opensource.com/users/jason-baker
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://youtu.be/XvDZLjaCJuw
|
||||
[5]:https://youtu.be/tc4ROCJYbm0
|
||||
[6]:http://hyperpolyglot.org/unix-shells
|
||||
@ -0,0 +1,178 @@
|
||||
Translating by zhb127
|
||||
How to debug C programs in Linux using gdb
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [GDB debugger basics][1]
|
||||
2. [GDB usage example][2]
|
||||
3. [Conclusion][3]
|
||||
|
||||
Regardless of how experienced a coder you are, any software you develop can't be completely free of bugs. So, identifying bugs and fixing them is one of the most important tasks in the software development cycle. While there are many ways of identifying bugs (testing, self review of code, and more), there are dedicated software - dubbed debuggers - that help you understand exactly where the problem is, so that you can easily fix it.
|
||||
|
||||
If you are a C/C++ programmer or develop software using the Fortran and Modula-2 programming languages, you'll be glad to know there exists an excellent debugger - dubbed [GDB][4] - that lets you easily debug your code for bugs and other problems. In this article, we will discuss the basics of GDB, including some of the useful features/options it provides.
|
||||
|
||||
But before we move ahead, it's worth mentioning that all the instructions as well examples presented in this article have been tested on Ubuntu 14.04LTS. The example code used in the tutorial is written in C language; the command line shell we've used is bash (version 4.3.11); and the GDB version we've used is 7.7.1.
|
||||
|
||||
### GDB debugger basics
|
||||
|
||||
In layman's terms, GDB lets you peek inside a program while the program is executing, something that lets you help identify where exactly the problem is. We'll discuss the usage of the GDB debugger through a working example in the next section, but before that, here, we'll discuss a few basic points that'll help you later on.
|
||||
|
||||
Firstly, in order to successfully use debuggers like GDB, you have to compile your program in such a way that the compiler also produces debugging information that's required by debuggers. For example, in case of the gcc compiler, which we'll be using to compile the example C program later on this tutorial, you need to use the -g command line option while compiling your code.
|
||||
|
||||
To know what the gcc compiler's manual page says about this command line option, head [here][5].
|
||||
|
||||
Next step is to make sure that you have GDB installed on your system. If that's not the case, and you're on a Debian-based system like Ubuntu, you can easily install the tool using the following command:
|
||||
|
||||
sudo apt-get install gdb
|
||||
|
||||
For installation on any other distro, head [here][6].
|
||||
|
||||
Now, once you've compiled your program in a way that it's debugging-ready, and GDB is there on your system, you can execute your program in debugging mode using the following command:
|
||||
|
||||
gdb [prog-executable-name]
|
||||
|
||||
While this will initiate the GDB debugger, your program executable won't be launched at this point. This is the time where you can define your debugging-related settings. For example, you can define a breakpoint that tells GDB to pause the program execution at a particular line number or function.
|
||||
|
||||
Moving on, to actually launch your program, you'll have to execute the following gdb command:
|
||||
|
||||
run
|
||||
|
||||
It's worth mentioning here that if your program requires some command line arguments to be passed to it, you can specify them here. For example:
|
||||
|
||||
run [arguments]
|
||||
|
||||
GDB provides many useful commands that come in handy while debugging. We'll discuss some of them in the example in next section.
|
||||
|
||||
### GDB usage example
|
||||
|
||||
Now we have a basic idea about GDB as well as its usage. So let's take an example and apply the knowledge there. Here's an example code:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
int out = 0, tot = 0, cnt = 0;
|
||||
int val[] = {5, 54, 76, 91, 35, 27, 45, 15, 99, 0};
|
||||
|
||||
while(cnt < 10)
|
||||
{
|
||||
out = val[cnt];
|
||||
tot = tot + 0xffffffff/out;
|
||||
cnt++;
|
||||
}
|
||||
|
||||
printf("\n Total = [%d]\n", tot);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
So basically, what this code does is, it picks each value contained in the 'val' array, assigns it to the 'out' integer, and then calculates 'tot' by summing up the variable's previous value and the result of '0xffffffff/out.'
|
||||
|
||||
The problem here is that when the code is run, it produces the following error:
|
||||
|
||||
$ ./gdb-test
|
||||
Floating point exception (core dumped)
|
||||
|
||||
So, to debug the code, the first step would be to compile the program with -g. Here's the command:
|
||||
|
||||
gcc -g -Wall gdb-test.c -o gdb-test
|
||||
|
||||
Next up, let's run GDB and let it know which executable we want to debug. Here's the command for that:
|
||||
|
||||
gdb ./gdb-test
|
||||
|
||||
Now, the error I am getting is 'floating point exception,' and as most of you might already know, it's caused by n % x, when x is 0\. So, with that in mind, I put a break point at line number 11, where the division is taking place. This was done in the following way:
|
||||
|
||||
(gdb) **break 11**
|
||||
|
||||
Note that '(gdb)' is the debugger's prompt, I just wrote the 'break' command.
|
||||
|
||||
Now, I asked GDB to start the execution of the program:
|
||||
|
||||
run
|
||||
|
||||
So, when the breakpoint was hit for the first time, here's what GDB showed in the output:
|
||||
|
||||
```
|
||||
Breakpoint 1, main () at gdb-test.c:11
|
||||
11 tot = tot + 0xffffffff/out;
|
||||
(gdb)
|
||||
```
|
||||
|
||||
As you can see in the output above, the debugger showed the line where the breakpoint was put. Now, let's print the current value of 'out.' This can be done in the following way:
|
||||
|
||||
(gdb)** print out**
|
||||
**$1 = 5**
|
||||
(gdb)
|
||||
|
||||
As you can see that the value '5' was printed. So, things are fine at the moment. I asked the debugger to continue the execution of the program until the next breakpoint, something which can be done using the 'c' command.
|
||||
|
||||
c
|
||||
|
||||
I kept on doing this work, until I saw that the value of 'out' was zero.
|
||||
|
||||
```
|
||||
...
|
||||
...
|
||||
...
|
||||
Breakpoint 1, main () at gdb-test.c:11
|
||||
11 tot = tot + 0xffffffff/out;
|
||||
(gdb) print out
|
||||
$2 = 99
|
||||
(gdb) c
|
||||
Continuing.
|
||||
|
||||
Breakpoint 1, main () at gdb-test.c:11
|
||||
11 tot = tot + 0xffffffff/out;
|
||||
(gdb) print out
|
||||
$3 = 0
|
||||
(gdb)
|
||||
```
|
||||
|
||||
Now, to confirm that this is the exact problem, I used GDB's 's' (or 'step') command instead of 'c' this time. Reason being, I just wanted line 11, where the program execution currently stands paused, to execute, and see if crash occurs at this point.
|
||||
|
||||
Here's what happened:
|
||||
|
||||
```
|
||||
(gdb) s
|
||||
|
||||
Program received signal SIGFPE, Arithmetic exception.
|
||||
0x080484aa in main () at gdb-test.c:11
|
||||
11 tot = tot + 0xffffffff/out;
|
||||
```
|
||||
|
||||
Yes, as confirmed by the highlighted output above, this is where the exception was thrown. The final confirmation came when I tried running the 's' command once again:
|
||||
|
||||
```
|
||||
(gdb) s
|
||||
|
||||
Program terminated with signal SIGFPE, Arithmetic exception.
|
||||
The program no longer exists.
|
||||
```
|
||||
|
||||
So this way, you can debug your programs using GDB.
|
||||
|
||||
### Conclusion
|
||||
|
||||
We've just scratched the surface here, as GDB offers a lot of features for users to explore and use. Go through the man page of GDB to know more about the tool, and try using it whenever you're debugging something in your code. The debugger has a bit of learning curve associated with it, but it's worth the hard work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-debug-c-programs-in-linux-using-gdb/
|
||||
|
||||
作者:[Ansh
|
||||
][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-debug-c-programs-in-linux-using-gdb/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-debug-c-programs-in-linux-using-gdb/#gdb-debugger-basics
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-debug-c-programs-in-linux-using-gdb/#gdb-usage-example
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-debug-c-programs-in-linux-using-gdb/#conclusion
|
||||
[4]:https://www.sourceware.org/gdb/
|
||||
[5]:https://linux.die.net/man/1/gcc
|
||||
[6]:https://www.sourceware.org/gdb/download/
|
||||
@ -0,0 +1,198 @@
|
||||
# rusking translating
|
||||
Setup SysVol Replication Across Two Samba4 AD DC with Rsync – Part 6
|
||||
============================================================
|
||||
|
||||
This topic will cover SysVol replication across two Samba4 Active Directory Domain Controllers performed with the help of a few powerful Linux tools, such as [Rsync file synchronization utility][2], [Cron scheduling daemon][3] and [SSH protocol][4].
|
||||
|
||||
#### Requirements:
|
||||
|
||||
1. [Join Ubuntu 16.04 as Additional Domain Controller to Samba4 AD DC – Part 5][1]
|
||||
|
||||
### Step 1: Accurate Time Synchronization Across DCs
|
||||
|
||||
1. Before starting to replicate the contents of the sysvol directory across both domain controllers you need to provide an accurate time for these machines.
|
||||
|
||||
If the delay is greater than 5 minutes on both directions and their clocks are not properly in sync, you should start experiencing various problems with AD accounts and domain replication.
|
||||
|
||||
To overcome the problem of time drifting between two or more domain controllers, you need to [install and configure NTP server][5] on your machine by executing the below command.
|
||||
|
||||
```
|
||||
# apt-get install ntp
|
||||
```
|
||||
|
||||
2. After NTP daemon has been installed, open the main configuration file, comment the default pools (add a # in front of each pool line) and add a new pool which will point back to the main Samba4 AD DC FQDN with NTPserver installed, as suggested on the below example.
|
||||
|
||||
```
|
||||
# nano /etc/ntp.conf
|
||||
```
|
||||
|
||||
Add following lines to ntp.conf file.
|
||||
|
||||
```
|
||||
pool 0.ubuntu.pool.ntp.org iburst
|
||||
#pool 1.ubuntu.pool.ntp.org iburst
|
||||
#pool 2.ubuntu.pool.ntp.org iburst
|
||||
#pool 3.ubuntu.pool.ntp.org iburst
|
||||
pool adc1.tecmint.lan
|
||||
# Use Ubuntu's ntp server as a fallback.
|
||||
pool ntp.ubuntu.com
|
||||
```
|
||||
[
|
||||
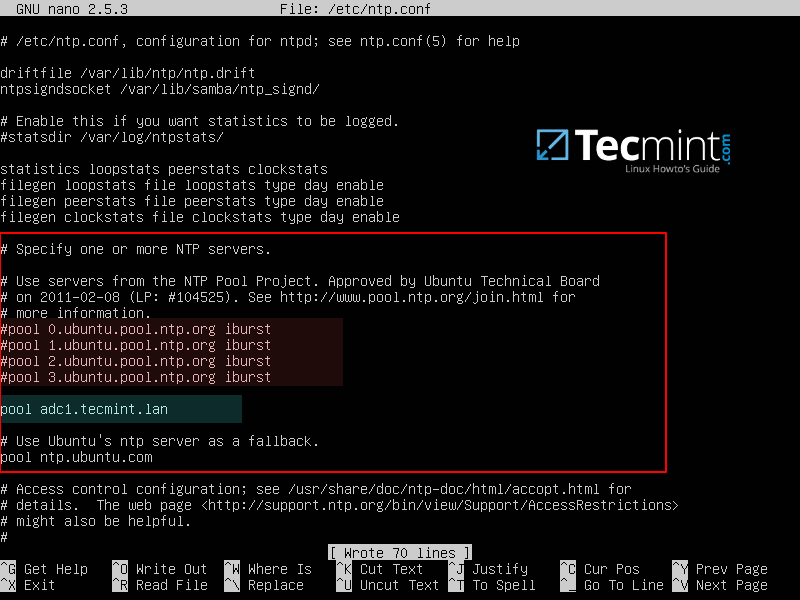
|
||||
][6]
|
||||
|
||||
Configure NTP for Samba4
|
||||
|
||||
3. Don’t close the file yet, move to the bottom of the file and add the following lines in order for other clients to be able to query and [sync the time with this NTP server][7], issuing signed NTP requests, in case the primary DC goes offline:
|
||||
|
||||
```
|
||||
restrict source notrap nomodify noquery mssntp
|
||||
ntpsigndsocket /var/lib/samba/ntp_signd/
|
||||
```
|
||||
|
||||
4. Finally, save and close the configuration file and restart NTP daemon in order to apply the changes. Wait for a few seconds or minutes for the time to synchronize and issue ntpq command in order to print the current summary state of the adc1 peer in sync.
|
||||
|
||||
```
|
||||
# systemctl restart ntp
|
||||
# ntpq -p
|
||||
```
|
||||
[
|
||||
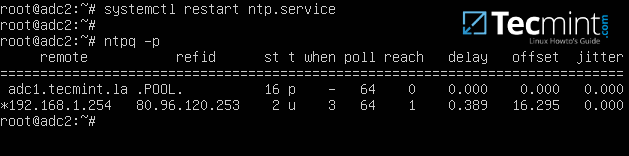
|
||||
][8]
|
||||
|
||||
Synchronize NTP Time with Samba4 AD
|
||||
|
||||
### Step 2: SysVol Replication with First DC via Rsync
|
||||
|
||||
By default, Samba4 AD DC doesn’t perform SysVol replication via DFS-R (Distributed File System Replication) or the FRS (File Replication Service).
|
||||
|
||||
This means that Group Policy objects are available only if the first domain controller is online. If the first DC becomes unavailable, the Group Policy settings and logon scripts will not apply further on Windows machines enrolled into the domain.
|
||||
|
||||
To overcome this obstacle and achieve a rudimentary form of SysVol replication we will schedule a [Linux rsync command][9] combined with a SSH encrypted tunnel with [key-based SSH authentication][10] in order to securely transfer GPO objects from the first domain controller to the second domain controller.
|
||||
|
||||
This method ensures GPO objects consistency across domain controllers, but has one huge drawback. It works only in one direction because rsync will transfer all changes from the source DC to the destination DC when synchronizing GPO directories.
|
||||
|
||||
Objects which no longer exist on the source will be deleted from the destination as well. In order to limit and avoid any conflicts, all GPO edits should be made only on the first DC.
|
||||
|
||||
5. To start the process of SysVol replication, first [generate a SSH key on the first Samba AD DC][11] and transfer the key to the second DC by issuing the below commands.
|
||||
|
||||
Do not use a passphrase for this key in order for the scheduled transfer to run without user interference.
|
||||
|
||||
```
|
||||
# ssh-keygen -t RSA
|
||||
# ssh-copy-id root@adc2
|
||||
# ssh adc2
|
||||
# exit
|
||||
```
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
Generate SSH Key on Samba4 DC
|
||||
|
||||
6. After you’ve assured that the root user from the first DC can automatically login on the second DC, run the following Rsync command with `--dry-run` parameter in order simulate SysVol replication. Replace adc2accordingly.
|
||||
|
||||
```
|
||||
# rsync --dry-run -XAavz --chmod=775 --delete-after --progress --stats /var/lib/samba/sysvol/ root@adc2:/var/lib/samba/sysvol/
|
||||
```
|
||||
|
||||
7. If the simulation process works as expected, run the rsync command again without the `--dry-run` option in order to actually replicate GPO objects across your domain controllers.
|
||||
|
||||
```
|
||||
# rsync -XAavz --chmod=775 --delete-after --progress --stats /var/lib/samba/sysvol/ root@adc2:/var/lib/samba/sysvol/
|
||||
```
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Samba4 AD DC SysVol Replication
|
||||
|
||||
8. After SysVol replication process has finished, login to the destination domain controller and list the contents of one of the GPO objects directory by running the below command.
|
||||
|
||||
The same GPO objects from the first DC should be replicated here too.
|
||||
|
||||
```
|
||||
# ls -alh /var/lib/samba/sysvol/your_domain/Policiers/
|
||||
```
|
||||
[
|
||||
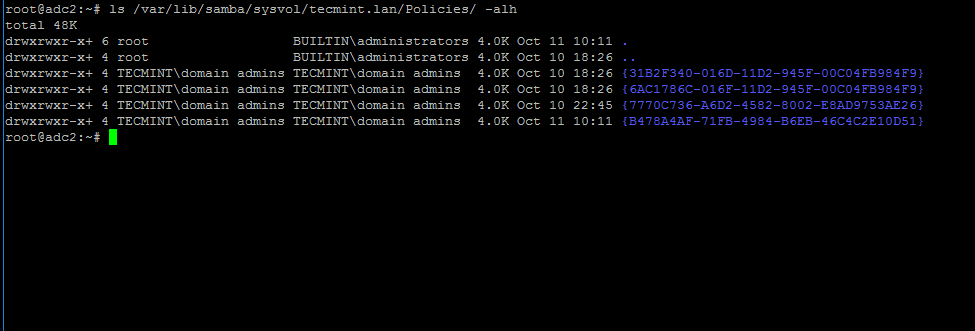
|
||||
][14]
|
||||
|
||||
Verify Samba4 DC SysVol Replication
|
||||
|
||||
9. To automate the process of Group Policy replication (sysvol directory transport over network), schedule a root job to run the rsync command used earlier every 5 minutes by issuing the below command.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
```
|
||||
|
||||
Add rsync command to run every 5 minutes and direct the output of the command, including the errors, to the log file /var/log/sysvol-replication.log .In case something doesn’t work as expected you should consult this file in order to troubleshoot the problem.
|
||||
|
||||
```
|
||||
*/5 * * * * rsync -XAavz --chmod=775 --delete-after --progress --stats /var/lib/samba/sysvol/ root@adc2:/var/lib/samba/sysvol/ > /var/log/sysvol-replication.log 2>&1
|
||||
```
|
||||
|
||||
10. Assuming that in future there will be some related issues with SysVol ACL permissions, you can run the following commands in order to detect and repair these errors.
|
||||
|
||||
```
|
||||
# samba-tool ntacl sysvolcheck
|
||||
# samba-tool ntacl sysvolreset
|
||||
```
|
||||
[
|
||||
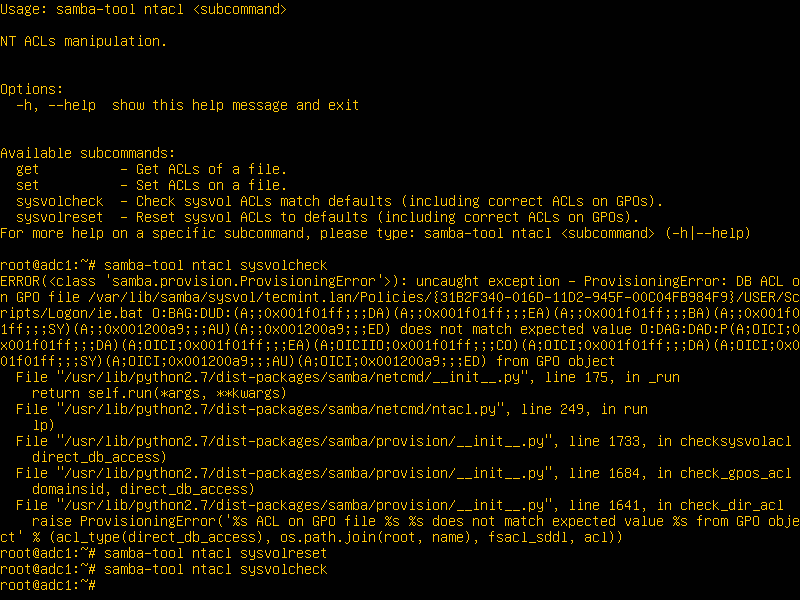
|
||||
][15]
|
||||
|
||||
Fix SysVol ACL Permissions
|
||||
|
||||
11. In case the first Samba4 AD DC with FSMO role as “PDC Emulator” becomes unavailable, you can force the Group Policy Management Console installed on a Microsoft Windows system to connect only to the second domain controller by choosing Change Domain Controller option and manually selecting the target machine as illustrated below.
|
||||
|
||||
[
|
||||
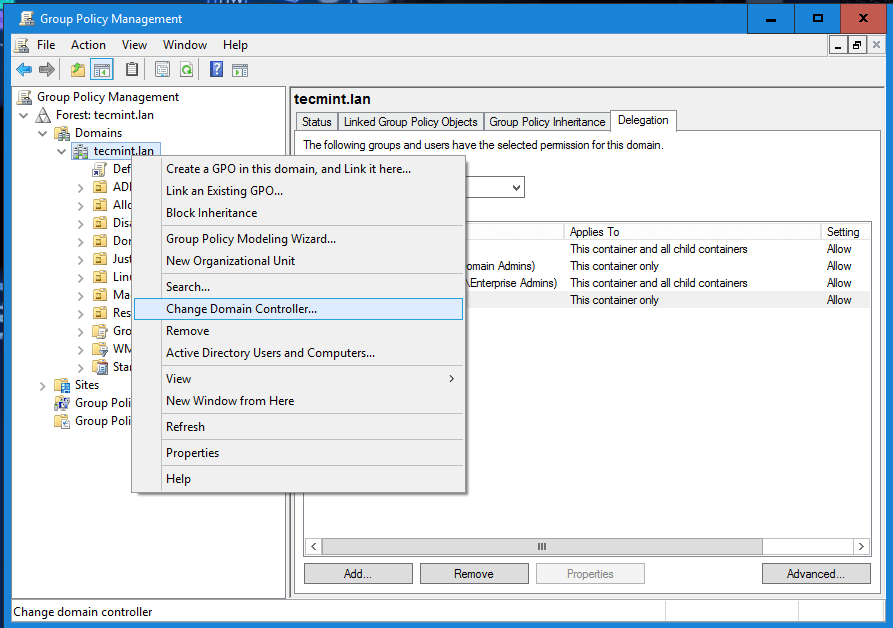
|
||||
][16]
|
||||
|
||||
Change Samba4 Domain Controller
|
||||
|
||||
[
|
||||
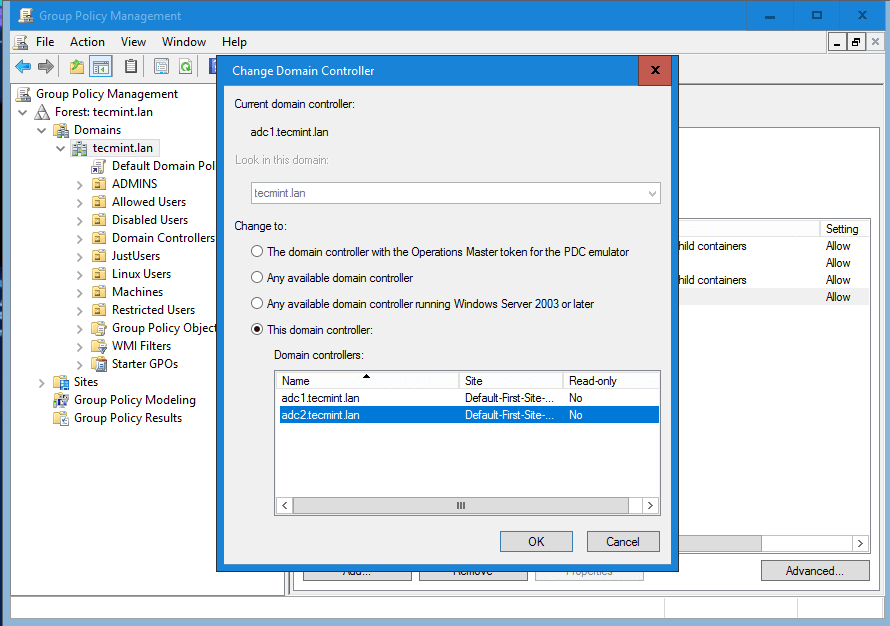
|
||||
][17]
|
||||
|
||||
Select Samba4 Domain Controller
|
||||
|
||||
While connected to the second DC from Group Policy Management Console, you should avoid making any modification to your domain Group Policy. When the first DC will become available again, rsync command will destroy all changes made on this second domain controller.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/samba4-ad-dc-sysvol-replication/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/join-additional-ubuntu-dc-to-samba4-ad-dc-failover-replication/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/5-best-practices-to-secure-and-protect-ssh-server/
|
||||
[5]:http://www.tecmint.com/install-and-configure-ntp-server-client-in-debian/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/01/Configure-NTP-for-Samba4.png
|
||||
[7]:http://www.tecmint.com/how-to-synchronize-time-with-ntp-server-in-ubuntu-linux-mint-xubuntu-debian/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/01/Synchronize-Time.png
|
||||
[9]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[10]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[11]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/01/Generate-SSH-Key.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/01/SysVol-Replication-for-Samba4-DC.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/01/Verify-Samba4-DC-SysVol-Replication.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/01/Fix-SysVol-ACL-Permissions.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/01/Change-Samba4-Domain-Controller.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/01/Select-Samba4-Domain-Controller.png
|
||||
@ -0,0 +1,446 @@
|
||||
How to Install WordPress with HHVM and Nginx on CentOS 7
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Configure SELinux and add the Epel Repository][1]
|
||||
2. [Step 2 - Install Nginx][2]
|
||||
3. [Step 3 - Install and Configure MariaDB][3]
|
||||
4. [Step 4 - Install HHVM][4]
|
||||
5. [Step 5 - Configure HHVM][5]
|
||||
6. [Step 6 - Configure HHVM and Nginx][6]
|
||||
7. [Step 7 - Create a Virtual Host with HHVM and Nginx][7]
|
||||
8. [Step 8 - Install WordPress][8]
|
||||
9. [Reference][9]
|
||||
|
||||
HHVM (HipHop Virtual Machine) is an open source virtual machine for executing programs written in PHP and Hack language. HHVM has been developed by Facebook, it provides most features of the current PHP 7 version. To run HHVM on your server, you can use a FastCGI to connect HHVM with a Nginx or Apache web server, or you can use the web server built into HHVM called "Proxygen".
|
||||
|
||||
In this tutorial, I will show you how to install WordPress with HHVM and Nginx as web server. I will use CentOS 7 as the operating system, so basic knowledge of CentOS is required.
|
||||
|
||||
**Prerequisite**
|
||||
|
||||
* CentOS 7 - 64bit
|
||||
* Root privileges
|
||||
|
||||
### Step 1 - Configure SELinux and add the Epel Repository
|
||||
|
||||
In this tutorial, we will use SELinux in enforcing mode, so we need the SELinux management tools installed on the system. We will use setools and setrobleshoot to manage SELinux policies.
|
||||
|
||||
By default, SELinux is enabled on CentOS 7, We can check that for with command below:
|
||||
|
||||
sestatus
|
||||
getenforce
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
You can see SELinux is enabled with enforcing mode.
|
||||
|
||||
Next, Install setools and setroubleshoot with the yum command.
|
||||
|
||||
yum -y install setroubleshoot setools net-tools
|
||||
|
||||
When the installation has been completed, you can install the EPEL repository.
|
||||
|
||||
yum -y install epel-release
|
||||
|
||||
### Step 2 - Install Nginx
|
||||
|
||||
Nginx or engine-x is a lightweight web server with high performance and low memory consumption. On CentOS, we can use yum to install the Nginx packages. Make sure you are logged in as root user!
|
||||
|
||||
Install nginx with this yum command from the CentOS repository:
|
||||
|
||||
yum -y install nginx
|
||||
|
||||
Now start Nginx and enable it to be started at boot time with the systemctl command:
|
||||
|
||||
systemctl start nginx
|
||||
systemctl enable nginx
|
||||
|
||||
To ensure Nginx is running on our server, visit the server IP address with your browser, or use the curl command as shown below to get the results:
|
||||
|
||||
curl 192.168.1.110
|
||||
|
||||
I'll cehck it with my web browser here:
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
### Step 3 - Install and Configure MariaDB
|
||||
|
||||
MariaDB is an open source database developed by the original MySQL developer Monty Widenius, it has been forked from the MySQL database but stays compatible with it in its major functions. In this step, we will install MariaDB and configure the root password for the MariaDB database. Then we will create a new database and new user that are required for our WordPress installation.
|
||||
|
||||
Install mariadb and mariadb-server:
|
||||
|
||||
yum -y install mariadb mariadb-server
|
||||
|
||||
Start MariaDB and add the service to be automatically started at boot time:
|
||||
|
||||
systemctl start mariadb
|
||||
systemctl enable mariadb
|
||||
|
||||
MariaDB has been started, and now we have to configure the root password for the mariadb/mysql database. Type in the command below to setup the MariaDB root password.
|
||||
|
||||
mysql_secure_installation
|
||||
|
||||
Type in your new password for the MariaDB root user when requested.
|
||||
|
||||
Set root password? [Y/n] Y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
|
||||
Remove anonymous users? [Y/n] Y
|
||||
... Success!
|
||||
Disallow root login remotely? [Y/n] Y
|
||||
... Success!
|
||||
Remove test database and access to it? [Y/n] Y
|
||||
Reload privilege tables now? [Y/n] Y
|
||||
... Success!
|
||||
|
||||
The MariaDB root password has been configured. Now login to the MariaDB/MySQL shell and create a new database **"wordpressdb"** and a new user **"wpuser"** with password **"wpuser@"** for our WordPress installation. Choose a secure password for your installation!
|
||||
|
||||
Login to the MariaDB/MySQL shell:
|
||||
|
||||
mysql -u root -p
|
||||
TYPE YOUR PASSWORD
|
||||
|
||||
Create a new database and new user:
|
||||
|
||||
create database wordpressdb;
|
||||
create user wpuser@localhost identified by 'wpuser@';
|
||||
grant all privileges on wordpressdb.* to wpuser@localhost identified by 'wpuser@';
|
||||
flush privileges;
|
||||
\q
|
||||
|
||||
[
|
||||
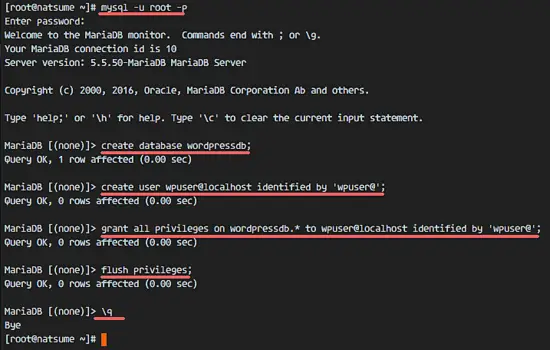
|
||||
][12]
|
||||
|
||||
MariaDB has been installed and the new database for our WordPress installation has been created.
|
||||
|
||||
### Step 4 - Install HHVM
|
||||
|
||||
For the HHVM installation, we need to install many dependencies. We can install HHVM from source by downloading the source from github, or installing prebuilt packages that are available on the internet. In this tutorial, I will install HHVM from prebuilt packages.
|
||||
|
||||
Install the dependencies for the HHVM installation
|
||||
|
||||
yum -y install cpp gcc-c++ cmake git psmisc {binutils,boost,jemalloc,numactl}-devel \
|
||||
{ImageMagick,sqlite,tbb,bzip2,openldap,readline,elfutils-libelf,gmp,lz4,pcre}-devel \
|
||||
lib{xslt,event,yaml,vpx,png,zip,icu,mcrypt,memcached,cap,dwarf}-devel \
|
||||
{unixODBC,expat,mariadb}-devel lib{edit,curl,xml2,xslt}-devel \
|
||||
glog-devel oniguruma-devel ocaml gperf enca libjpeg-turbo-devel openssl-devel \
|
||||
mariadb mariadb-server libc-client make
|
||||
|
||||
Then install the HHVM prebuilt packages from [this site][13] with the rpm command.
|
||||
|
||||
rpm -Uvh http://mirrors.linuxeye.com/hhvm-repo/7/x86_64/hhvm-3.15.2-1.el7.centos.x86_64.rpm
|
||||
ln -s /usr/local/bin/hhvm /bin/hhvm
|
||||
|
||||
HHVM has been installed, check it with the command below:
|
||||
|
||||
hhvm --version
|
||||
|
||||
In order to use the php command, we can set the hhvm command as php. So when you type 'php' on the shell, you will see the same result as from the hhvm command.
|
||||
|
||||
sudo update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
php --version
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
### Step 5 - Configure HHVM
|
||||
|
||||
In this step, we will configure HHVM. We will run hhvm as a systemd service. Instead of running it on a system port, we will run hhvm on a unix socket file which is faster.
|
||||
|
||||
Go to the systemd directory and create the hhvm.service file.
|
||||
|
||||
cd /etc/systemd/system/
|
||||
vim hhvm.service
|
||||
|
||||
Paste the service configuration belowinto that file.
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=HHVM HipHop Virtual Machine (FCGI)
|
||||
After=network.target nginx.service mariadb.service
|
||||
|
||||
[Service]
|
||||
ExecStart=/usr/local/bin/hhvm --config /etc/hhvm/server.ini --user nginx --mode daemon -vServer.Type=fastcgi -vServer.FileSocket=/var/run/hhvm/hhvm.sock
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
Next, go to the hhvm directory and edit the server.ini file.
|
||||
|
||||
cd /etc/hhvm/
|
||||
vim server.ini
|
||||
|
||||
Replace the hhvm.server.port on line 7 with unix socket configuration below:
|
||||
|
||||
hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
Save the file and exit th editor.
|
||||
|
||||
In the hhvm service file, we've defined that hhvm is running under the 'nginx' user, so we must change the owner of the socket file directory to the 'nginx' user. Then we must change the SELinux context of the hhvm directoryto allow access to the socket file.
|
||||
|
||||
chown -R nginx:nginx /var/run/hhvm/
|
||||
semanage fcontext -a -t httpd_var_run_t "/var/run/hhvm(/.*)?"
|
||||
restorecon -Rv /var/run/hhvm
|
||||
|
||||
After rebooting the server, hhvm will not be running because there is no directory for the socket file, so we must create it automatically at the boot time.
|
||||
|
||||
Edit the rc.local file with vim.
|
||||
|
||||
vim /etc/rc.local
|
||||
|
||||
Paste configuration below to the end of line.
|
||||
|
||||
```
|
||||
mkdir -p /var/run/hhvm/
|
||||
chown -R nginx:nginx /var/run/hhvm/
|
||||
semanage fcontext -a -t httpd_var_run_t "/var/run/hhvm(/.*)?"
|
||||
restorecon -Rv /var/run/hhvm
|
||||
```
|
||||
|
||||
Save the file and exit vim. Make the file executable.
|
||||
|
||||
chmod +x /etc/rc.local
|
||||
|
||||
Reload the systemd service, start hhvm and add it to be started at boot time.
|
||||
|
||||
systemctl daemon-reload
|
||||
systemctl start hhvm
|
||||
systemctl enable hhvm
|
||||
|
||||
Make sure that there is no error. Check that hhvm is running under the socket file with the netstat command.
|
||||
|
||||
netstat -pl | grep hhvm
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
### Step 6 - Configure HHVM and Nginx
|
||||
|
||||
In this step, we will configure HHVM to run with the Nginx web server. We need to create a new hhvm configuration file in the Nginx directory.
|
||||
|
||||
Go to the /etc/nginx directory and create a hhvm.conf file.
|
||||
|
||||
cd /etc/nginx/
|
||||
vim hhvm.conf
|
||||
|
||||
Paste the configuration below:
|
||||
|
||||
```
|
||||
location ~ \.(hh|php)$ {
|
||||
root /usr/share/nginx/html;
|
||||
fastcgi_keep_conn on;
|
||||
fastcgi_pass unix:/var/run/hhvm/hhvm.sock;
|
||||
fastcgi_index index.php;
|
||||
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
|
||||
include fastcgi_params;
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, edit the nginx.conf file and add the hhvm configuration include line.
|
||||
|
||||
vim nginx.conf
|
||||
|
||||
Add the configuration to the server directive line 57.
|
||||
|
||||
```
|
||||
include /etc/nginx/hhvm.conf;
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Then change the SELinux context of the hhvm configuration file.
|
||||
|
||||
semanage fcontext -a -t httpd_config_t /etc/nginx/hhvm.conf
|
||||
restorecon -v /etc/nginx/hhvm.conf
|
||||
|
||||
Test the Nginx configuration and restart the service.
|
||||
|
||||
nginx -t
|
||||
systemctl restart nginx
|
||||
|
||||
Make sure there is no error.
|
||||
|
||||
### Step 7 - Create a Virtual Host with HHVM and Nginx
|
||||
|
||||
In this step, we will create a new virtual host configuration with Nginx and hhvm. I will use the domain name **"natsume.co"** for this example. Please use your own domain name and replace it in the configuration files and WordPress installation wherever it appears.
|
||||
|
||||
Go to the nginx conf.d directory where we will store virtual host file:
|
||||
|
||||
cd /etc/nginx/conf.d/
|
||||
|
||||
Create the new configuration "natsume.conf" with vim:
|
||||
|
||||
vim natsume.conf
|
||||
|
||||
Paste the virtual host configuration below:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
server_name natsume.co;
|
||||
|
||||
# note that these lines are originally from the "location /" block
|
||||
root /var/www/hakase;
|
||||
index index.php index.html index.htm;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ =404;
|
||||
}
|
||||
error_page 404 /404.html;
|
||||
location = /50x.html {
|
||||
root /var/www/hakase;
|
||||
}
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri =404;
|
||||
fastcgi_pass unix:/var/run/hhvm/hhvm.sock;
|
||||
fastcgi_index index.php;
|
||||
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
|
||||
include fastcgi_params;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
In our virtual host configuration, we've defined the web root directory for the domain name to be the "/var/www/hakase" directory. That directory does not exist yet, so we have to create it and change the ownership to the nginx user and group.
|
||||
|
||||
mkdir -p /var/www/hakase
|
||||
chown -R nginx:nginx /var/www/hakase
|
||||
|
||||
Next, configure the SELinux context for the file and directory.
|
||||
|
||||
semanage fcontext -a -t httpd_config_t "/etc/nginx/conf.d(/.*)?"
|
||||
restorecon -Rv /etc/nginx/conf.d
|
||||
|
||||
Finally, test the nginx configuration to ensure there is no error, then restart nginx:
|
||||
|
||||
nginx -t
|
||||
systemctl restart nginx
|
||||
|
||||
### Step 8 - Install WordPress
|
||||
|
||||
In step 5 we've created the virtual host configuration for our WordPress installation. Now we just have to download WordPress and edit the database configuration by using the database and user that we've created in step 3.
|
||||
|
||||
Go to the web root directory "/var/www/hakase" and download WordPress with the wget command:
|
||||
|
||||
cd /var/www/hakase
|
||||
wget wordpress.org/latest.tar.gz
|
||||
|
||||
Extract "latest.tar.gz" and move all WordPress files and directories to the current directory:
|
||||
|
||||
tar -xzvf latest.tar.gz
|
||||
mv wordpress/* .
|
||||
|
||||
Next, copy "wp-config-sample.php" file to "wp-config.php" and edit it with vim:
|
||||
|
||||
cp wp-config-sample.php wp-config.php
|
||||
vim wp-config.php
|
||||
|
||||
Set DB_NAME to **"wordpressdb"**, DB_USER to **"wpuser"** and DB_PASSWORD to **"wpuser@"**.
|
||||
|
||||
```
|
||||
define('DB_NAME', 'wordpressdb');
|
||||
define('DB_USER', 'wpuser');
|
||||
define('DB_PASSWORD', 'wpuser@');
|
||||
define('DB_HOST', 'localhost');
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
Change the SELinux context for the WordPress directory.
|
||||
|
||||
semanage fcontext -a -t httpd_sys_content_t "/var/www/hakase(/.*)?"
|
||||
restorecon -Rv /var/www/hakase
|
||||
|
||||
Now open a web browser and type in the domain name of your wordpress domain into the address bar, mine is "natsume.co".
|
||||
|
||||
Choose English language and click on 'Continue'.
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
Fill in the site title and description with your info and click "Install Wordpress".
|
||||
|
||||
[
|
||||
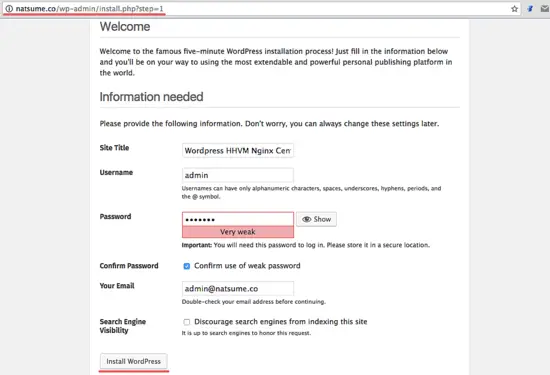
|
||||
][18]
|
||||
|
||||
Wait until the installation is finished. You will see the page below, click on "Log In" to log in to the WordPress admin dashboard:
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
Type in your admin user and password, then click "Log In" again.
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
Now you're on the WordPress admin dashboard.
|
||||
|
||||
[
|
||||
|
||||
][21]
|
||||
|
||||
Wordpress Home Page.
|
||||
|
||||
[
|
||||
|
||||
][22]
|
||||
|
||||
Wordpress with Nginx and HHVM on CentOS 7 has been installed successfully.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/
|
||||
|
||||
作者:[ Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-configure-selinux-and-add-the-epel-repository
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-install-nginx
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-install-and-configure-mariadb
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-install-hhvm
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-configure-hhvm
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-configure-hhvm-and-nginx
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-create-a-virtual-host-with-hhvm-and-nginx
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#step-install-wordpress
|
||||
[9]:https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/#reference
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/1.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/2.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/3.png
|
||||
[13]:http://mirrors.linuxeye.com/hhvm-repo/7/x86_64/
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/4.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/5.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/6.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/7.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/8.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/9.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/10.png
|
||||
[21]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/11.png
|
||||
[22]:https://www.howtoforge.com/images/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/big/12.png
|
||||
@ -0,0 +1,94 @@
|
||||
The Age of the Unikernel: 10 Projects to Know
|
||||
============================================================
|
||||
|
||||

|
||||
A unikernel is essentially a pared-down operating system that can pair with an application into a unikernel application, typically running within a virtual machine. Download the Guide to the Open Cloud to learn more.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
When it comes to operating systems, container technologies, and unikernels, the trend toward tiny continues. What is a unikernel? It is essentially a pared-down operating system (the unikernel) that can pair with an application into a unikernel application, typically running within a virtual machine. They are sometimes called library operating systems because they include libraries that enable applications to use hardware and network protocols in combination with a set of policies for access control and isolation of the network layer.
|
||||
|
||||
Containers often come to mind when discussion turns to cloud computing and Linux, but unikernels are doing transformative things, too. Neither containers nor unikernels are brand new. There were unikernel-like systems in the 1990s such as Exokernel, but today popular unikernels include MirageOS and OSv. Unikernel applications can be used independently and deployed across heterogeneous environments. They can facilitate specialized and isolated services and have become widely used for developing applications within a microservices architecture.
|
||||
|
||||
As an example of how unikernels are attracting attention, consider the fact that Docker purchased[ Cambridge-based Unikernel Systems][3], and has been working with unikernels in numerous scenarios.
|
||||
|
||||
Unikernels, like container technologies, strip away non-essentials and thus they have a very positive impact on application stability and availability, as well as security. They are also attracting many of the top, most creative developers on the open source scene.
|
||||
|
||||
The Linux Foundation recently[ announced][4] the release of its 2016 report[Guide to the Open Cloud: Current Trends and Open Source Projects.][5] This third annual report provides a comprehensive look at the state of open cloud computing and includes a section on unikernels. You can[ download the report][6] now. It aggregates and analyzes research, illustrating how trends in containers, unikernels, and more are reshaping cloud computing. The report provides descriptions and links to categorized projects central to today’s open cloud environment.
|
||||
|
||||
In this series of articles, we are looking at the projects mentioned in the guide, by category, providing extra insights on how the overall category is evolving. Below, you’ll find a list of several important unikernels and the impact that they are having, along with links to their GitHub repositories, all gathered from the Guide to the Open Cloud:
|
||||
|
||||
[CLICKOS][7]
|
||||
|
||||
ClickOS is NEC’s high-performance, virtualized software middlebox platform for network function virtualization (NFV) built on top of MiniOS/ MirageOS. [ClickOS on GitHub][8]
|
||||
|
||||
[CLIVE][9]
|
||||
|
||||
Clive is an operating system written in Go and designed to work in distributed and cloud computing environments.
|
||||
|
||||
[HALVM][10]
|
||||
|
||||
The Haskell Lightweight Virtual Machine (HaLVM) is a port of the Glasgow Haskell Compiler toolsuite that enables developers to write high-level, lightweight virtual machines that can run directly on the Xen hypervisor. [HaLVM on GitHub][11]
|
||||
|
||||
[INCLUDEOS][12]
|
||||
|
||||
IncludeOS is a unikernel operating system for C++ services running in the cloud. It provides a bootloader, standard libraries and the build- and deployment system on which to run services. Test in VirtualBox or QEMU, and deploy services on OpenStack. [IncludeOS on GitHub][13]
|
||||
|
||||
[LING][14]
|
||||
|
||||
Ling is an Erlang platform for building super-scalable clouds that runs directly on top of the Xen hypervisor. It runs on only three external libraries — no OpenSSL — and the filesystem is read-only to remove the majority of attack vectors. [Ling on GitHub][15]
|
||||
|
||||
[MIRAGEOS][16]
|
||||
|
||||
MirageOS is a library operating system incubating under the Xen Project at The Linux Foundation. It uses the OCaml language to construct unikernels for secure, high-performance network applications across a variety of cloud computing and mobile platforms. Code can be developed on a normal OS such as Linux or MacOS X, and then compiled into a fully-standalone, specialised unikernel that runs under the Xen hypervisor.[ MirageOS on GitHub][17]
|
||||
|
||||
[OSV][18]
|
||||
|
||||
OSv is the open source operating system from Cloudius Systems designed for the cloud. It supports applications written in Java, Ruby (via JRuby), JavaScript (via Rhino and Nashorn), Scala, and others. And it runs on the VMware, VirtualBox, KVM, and Xen hypervisors. [OSv on GitHub][19]
|
||||
|
||||
[RUMPRUN][20]
|
||||
|
||||
Rumprun is a production-ready unikernel that uses the drivers offered by rump kernels, adds a libc and an application environment on top, and provides a toolchain with which to build existing POSIX-y applications as Rumprun unikernels. It works on KVM and Xen hypervisors and on bare metal and supports applications written in C, C++, Erlang, Go, Java, Javascript (Node.js), Python, Ruby, Rust, and more. [Rumprun on GitHub][21]
|
||||
|
||||
[RUNTIME.JS][22]
|
||||
|
||||
Runtime.js is an open source library operating system (unikernel) for the cloud that runs JavaScript, can be bundled up with an application and deployed as a lightweight and immutable VM image. It’s built on V8 JavaScript engine and uses event-driven and non- blocking I/O model inspired by Node.js. KVM is the only supported hypervisor. [Runtime.js on GitHub][23]
|
||||
|
||||
[UNIK][24]
|
||||
|
||||
Unik is EMC’s tool for compiling application sources into unikernels (lightweight bootable disk images) rather than binaries. It allows applications to be deployed securely and with minimal footprint across a variety of cloud providers, embedded devices (IoT), as well as a developer laptop or workstation. It supports multiple unikernel types, processor architectures, hypervisors and orchestration tools including Cloud Foundry, Docker, and Kubernetes. [Unik on GitHub][25]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-age-unikernel
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/unikernelsjpg-0
|
||||
[3]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[4]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[5]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[6]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[7]:http://cnp.neclab.eu/clickos/
|
||||
[8]:https://github.com/cnplab/clickos
|
||||
[9]:http://lsub.org/ls/clive.html
|
||||
[10]:https://galois.com/project/halvm/
|
||||
[11]:https://github.com/GaloisInc/HaLVM
|
||||
[12]:http://www.includeos.org/
|
||||
[13]:https://github.com/hioa-cs/IncludeOS
|
||||
[14]:http://erlangonxen.org/
|
||||
[15]:https://github.com/cloudozer/ling
|
||||
[16]:https://mirage.io/
|
||||
[17]:https://github.com/mirage/mirage
|
||||
[18]:http://osv.io/
|
||||
[19]:https://github.com/cloudius-systems/osv
|
||||
[20]:http://rumpkernel.org/
|
||||
[21]:https://github.com/rumpkernel/rumprun
|
||||
[22]:http://runtimejs.org/
|
||||
[23]:https://github.com/runtimejs/runtime
|
||||
[24]:http://dojoblog.emc.com/unikernels/unik-build-run-unikernels-easy/
|
||||
[25]:https://github.com/emc-advanced-dev/unik
|
||||
@ -0,0 +1,88 @@
|
||||
This Script Updates Hosts Files Using a Multi-Source Unified Block List With Whitelisting
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
There are many helpful lists maintained online with constantly-updated hosts files that contain the domains of various Internet crap peddlers. Copying these lists into your hosts file can easily block a large number of domains that your system would be better off unable to connect to. This method works without installing a browser plug-in and will handle blocking for any browser (and any other program) on the system.
|
||||
|
||||
In this tutorial, I'll show you how to get Steven Black's [Unified Hosts script][1] up and running in Linux. The script will keep your computer's hosts file updated (from multiple sources) with the latest known ad servers, phishing sites and other web scum, all while providing a nice, clean way to manage your own black/whitelists separately from the lists the script manages.
|
||||
|
||||
There are two caveats to note before putting 30,000 domains into your hosts file. First off, these huge lists contain servers that you might need unblocked in order to make an online purchase or for some other temporary situation. You'll know you have a problem when something on the web is broken since you messed with your hosts file. To remedy this, I'm going to show you how to make a handy on/off switch so you can quickly disable your blocklist to buy that Himalayan salt lamp (it's the ions). I still consider it a feature of these lists that all manner of things get blocked (it was only annoying until I thought of making that off switch). If you have a repeat problem with a blocked server that you need often, just add it to your whitelist file and you're all set.
|
||||
|
||||
The second problem is a slight performance hit because the system has to check the entire list each time a domain is called up. Maybe there's a small hit, but not big enough for me to ditch the list and let every connection through. However, consider yourself warned.
|
||||
|
||||
Hosts files block a server by directing requests to that server to either 127.0.0.1 or 0.0.0.0 - in other words, nowhere. Some say using zero's is a faster, less problematic way to accomplish the blocking. You can configure the script to use any blocking ip you want by executing it with the --ip option like "--ip nnn.nnn.nnn.nnn", but the default is 0.0.0.0 and that's where I'm leaving it.
|
||||
|
||||
I used to do what Steven's script does by hand every once in a while, going to each site, copy/pasting their lists into my hosts file, doing a find-replace to change the one-twenty-seven's to zeros, etc. I knew the whole thing could be automated and there were tons of dupes, but I never took the time to address the problems. Since finding this script, that's now a forgotten chore.
|
||||
|
||||
Let's start by getting a fresh copy of Mr. Black's code downloaded (~150MB) so we can push some electrons around. You'll need git installed, so if it's not, go to the terminal and enter:
|
||||
|
||||
**sudo apt-get install git**
|
||||
|
||||
After it's done installing, enter:
|
||||
|
||||
**mkdir unifiedhosts**
|
||||
**cd unifiedhosts**
|
||||
**git clone** [**https://github.com/StevenBlack/hosts.git** ][2]
|
||||
**cd hosts**
|
||||
|
||||
While your cursor blinks at Steven's script, let's talk about choices. The script has a few options and extensions that I wont cover here, but I figure if you got this far and you're interested, the [readme.md][3] file can tell you all you need to know.
|
||||
|
||||
You need python installed to run the script, and which version you have matters. To find the version of Python you have, enter:
|
||||
|
||||
**python --version**
|
||||
|
||||
If you don't have python installed:
|
||||
|
||||
**sudo apt-get install python**
|
||||
|
||||
For Python 2.7, execute the script by entering "python" as I do below. For Python 3, replace "python" in the command with "python3". Upon execution, the script makes sure it has the most recent version of each list and if not, grabs a new copy. It then writes a new hosts file, including anything in your black/whitelists. Let's give it a try using the -r option to replace our active hosts file and the -a option so the script wont ask any questions. Back to the terminal, and:
|
||||
|
||||
**python updateHostsFile.py -r -a**
|
||||
|
||||
The command will ask for your password so it can write to /etc/. For the newly updated list to be active, some systems require a good flush of the DNS cache. On the same hardware, I've observed different operating systems express very different behavior regarding the length of time it takes for a server to become reachable/unreachable after updating the hosts file without a flush. I've seen everything from instantaneously (Slackware) to never/reboot (Windows). There are commands to flush the DNS cache, but they're different on each OS and even each distro, so just reboot if the changes don't take.
|
||||
|
||||
Now it's as simple as adding your personal exceptions to the black/whitelist files and running the script whenever you want to update the hosts file. The script will adjust the resultant hosts file according to your specs, appending the file with your additions automatically each time you run it.
|
||||
|
||||
Finally, let's create the on/off switches. We need a script for each function, so go back to the terminal to create the OFF switch by entering (replacing leafpad with your text editor):
|
||||
|
||||
**leafpad hosts-off.sh**
|
||||
|
||||
and enter the following into the new file:
|
||||
|
||||
**#!/bin/sh**
|
||||
**sudo mv /etc/hosts /etc/hostsDISABLED**
|
||||
|
||||
And then make it executable with:
|
||||
|
||||
**chmod +x hosts-off.sh**
|
||||
|
||||
Similarly, for the ON switch:
|
||||
|
||||
**leafpad hosts-on.sh
|
||||
**
|
||||
and enter the following into the new file:
|
||||
|
||||
**#!/bin/sh**
|
||||
**sudo mv /etc/hostsDISABLED /etc/hosts
|
||||
**
|
||||
And finally make it executable with:
|
||||
|
||||
**chmod +x hosts-on.sh
|
||||
|
||||
**All you need to do is create a shortcut somewhere for each script, labeling them HOSTS-ON and HOSTS-OFF and there you have it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.darrentoback.com/this-script-updates-hosts-files-using-a-multi-source-unified-block-list-with-whitelisting
|
||||
|
||||
作者:[dmt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.darrentoback.com/about-me
|
||||
[1]:https://github.com/StevenBlack/hosts
|
||||
[2]:https://github.com/StevenBlack/hosts.git
|
||||
[3]:https://github.com/StevenBlack/hosts/blob/master/readme.md
|
||||
@ -0,0 +1,80 @@
|
||||
10 reasons to use Cinnamon as your Linux desktop environment
|
||||
============================================================
|
||||
|
||||
### Cinnamon is a Linux desktop environment reminiscent of GNOME 2 that offers flexibility, speed, and a slew of features.
|
||||
|
||||

|
||||
Image credits :
|
||||
|
||||
[Sam Mugraby][1], Photos8.com. [CC BY 2.0][2].
|
||||
|
||||
Recently I installed Fedora 25, and found that the current version of [KDE][3] Plasma was unstable for me; it crashed several times a day before I decided to try to try something different. After installing a number of alternative desktops and trying them all for a couple hours each, I finally settled on using Cinnamon until Plasma is patched and stable. Here's what I found.
|
||||
|
||||
### Introducing Cinnamon
|
||||
|
||||
In 2011, GNOME 3, with the new GNOME Shell was released and the new interface immediately generated both positive and negative responses. Many users and developers liked the original GNOME interface enough that multiple groups forked it and one of those forks was Cinnamon.
|
||||
|
||||
One of the reasons behind the development of the GNOME shell for GNOME 3 was that many components of the original GNOME user interface were no longer being actively developed. This was also an issue for Cinnamon and some of the other forked GNOME projects. The Linux Mint project was one of the prime movers for Cinnamon because GNOME is the official desktop environment for Mint. The Mint developers have continued to develop Cinnamon to the point where GNOME itself is no longer required, and Cinnamon is a completely independent desktop environment that retains many of the interface features that users appreciated about the GNOME interface.
|
||||
|
||||
|
||||
|
||||
Figure 1: The default Cinnamon desktop with the System Settings tool open.
|
||||
|
||||
Cinnamon 3.2 is the current release version. Cinnamon is available for many distros besides Mint, including Fedora, Arch, Gentoo, Debian, and OpenSUSE, among others.
|
||||
|
||||
### Reasons for using Cinnamon
|
||||
|
||||
Here are my top 10 reasons for using Cinnamon.
|
||||
|
||||
1. **Integration.** The choice of a desktop has not been contingent upon the availability of applications written for it in a long time. All of the applications I use, regardless of the desktop for which they were written, will run just fine on any other desktop, and Cinnamon is no exception. All of the libraries required to run applications written for KDE, GNOME—or any other desktop that I use—are available and make using any application with the Cinnamon desktop a seamless experience.
|
||||
|
||||
2. **Looks.** Let's face it, looks are important. Cinnamon has a crisp, clean look that uses easy to read fonts and color combinations. The desktop is not hampered by unnecessary clutter, and you can configure which icons are shown on the desktop using the **System Settings => Desktop** menu. This menu also allows you to specify whether the desktop icons are shown only on the primary monitor, only on secondary monitors, or on all monitors.
|
||||
|
||||
3. **Desklets.** Desklets are small, usually single-purpose applications that can be added to your desktop. Only a few of these are available, but you can choose from things like CPU or disk monitors, a weather app, sticky notes, a desktop photo frame app, and time and date, among others. I like the time and date desklet because it is easier to read than the applet in the Cinnamon panel.
|
||||
|
||||
4. **Speed.** Cinnamon is fast and snappy. Programs load and display fast. The desktop itself loads quickly during login, though this is just my subjective experience and is not based on any timed testing.
|
||||
|
||||
5. **Configuration. **Cinnamon is not as configurable as KDE Plasma, but it is much more configurable than I originally thought the first time I tried it. The Cinnamon Control Center provides centralized access to many of the desktop configuration options. It has a main window from which the specific feature configuration windows can be launched. It is easy to select a new look from those available in the Themes section of System Settings. You can choose window borders, icons, controls, pointers, and the desktop basic scheme. Other choices include fonts and backgrounds. I find many of these configuration tools among the best I have encountered. A modest number of desktop themes are available, providing the ability to significantly alter the look of the desktop without the confusion of the massive numbers of choices that KDE provides.
|
||||
|
||||
6. **The Cinnamon Panel. **The Cinnamon Panel, i.e., the toolbar, is initially configured very simply. It contains the menu used to launch programs, a basic system tray, and an application selector. The panel is easy to configure and adding new program launchers is simply a matter of locating the program you want to add in the main Menu; right click on the program icon and select "Add to panel." You can also add the launcher icon to the desktop itself, and to the Cinnamon "Favorites" launcher bar. You can also enter the panel's **Edit** mode and rearrange the icons.
|
||||
|
||||
7. **Flexibility****.** It can sometimes be difficult to locate a minimized or hidden running application and finding it on the toolbar application selector can be challenging if there are a number of running applications. In part, this is because the applications are not always in a sequence on the selector that makes them easy to find. So one of my favorite features is the ability to drag the buttons for the running applications and rearrange them on the selector. This can make it much easier to find and display windows belonging to applications because they can now be where I put them on the selector.
|
||||
|
||||
The Cinnamon desktop also has a very nice pop-up menu that you can access with a right click. This menu has selections for some frequently used tasks such as accessing the Desktop Settings and adding Desklets, as well as other desktop-related tasks.
|
||||
|
||||
One of these other menu items is “Create New Document” which uses the document templates located in the ~/Templates directory and lists each of them. Simply click on the template you want to use and a new document using that template is created using the default office application. In my case, that is LibreOffice.
|
||||
|
||||
8. **Multiple ****workspaces****.** Cinnamon offers multiple desktops like many other desktop environments. Cinnamon calls these "workspaces." The workspace selector is located on the Cinnamon panel and shows the outlines of the windows located on each workspace. Windows can be moved between workspaces or assigned to all. I did find that the workspace selector is sometimes a bit slow to catch up with the display of window locations so I switched the workspace selector to show the workspace numbers and not shadows of the windows in the workspaces.
|
||||
|
||||
9. **Nemo.** Most desktops use their own preferred default applications for various purposes and Cinnamon is no exception. My preferred desktop file manager is Krusader, but Cinnamon uses Nemo as its default, so I just went with that for the duration of my test. I find that I like Nemo—a lot. It has a nice clean interface and most of the features I like and use frequently. It is easy to use while being flexible enough for my needs. Although Nemo is a fork of Nautilus, I find Nemo to be better integrated into the Cinnamon environment. The Nautilus interface seems to be somewhat poorly integrated and discordant with Cinnamon.
|
||||
|
||||
10. **Stability.** Cinnamon is very stable and just works.
|
||||
|
||||
### Conclusions
|
||||
|
||||
Cinnamon is a fork of the GNOME 3 desktop and appears to be intended as the GNOME desktop that never was. Its development seems to be the logical improvements that the Cinnamon developers thought were needed to improve and extend GNOME while retaining its unique and highly appreciated personality. It is no longer GNOME 3—it is different and better. Cinnamon looks good and it works very well for me and is a very nice change from KDE—which I still like very much. It took me a few days to learn how Cinnamon's differences could make my desktop experience better, and I am very glad to have learned a lot more about an excellent desktop.
|
||||
|
||||
Though I like Cinnamon, I would like to experiment with some others as well, and I am now going to switch to the LXDE desktop and try that out for a few weeks. I will share my experience with LXDE after I have spent some time using it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://commons.wikimedia.org/wiki/File:Cinnamon-other.jpg
|
||||
[2]:https://creativecommons.org/licenses/by/2.0/deed.en
|
||||
[3]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
@ -0,0 +1,61 @@
|
||||
Arrive On Time With NTP -- Part 1: Usage Overview
|
||||
============================================================
|
||||
|
||||

|
||||
In this first of a three-part series, Chris Binnie looks at why NTP services are essential to a happy infrastructure.[Used with permission][1]
|
||||
|
||||
Few services on the Internet can claim to be so critical in nature as time. Subtle issues which affect the timekeeping of your systems can sometimes take a day or two to be realized, and they are almost always unwelcome because of the knock-on effects they cause.
|
||||
|
||||
Consider as an example that your backup server loses connectivity to your Network Time Protocol (NTP) server and, over a period of a few days, introduces several hours of clock skew. Your colleagues arrive at work at 9am as usual only to find the bandwidth-intensive backups consuming all the network resources meaning that they can barely even log into their workstations to start their day’s work until the backup has finished.
|
||||
|
||||
In this first of a three-part series, I’ll provide brief overview of NTP to help prevent such disasters. From the timestamps on your emails to remembering when you started your shift at work, NTP services are essential to a happy infrastructure.
|
||||
|
||||
You might consider that the really important NTP servers (from which other servers pick up their clock data) are at the bottom of an inverted pyramid and referred to as Stratum 1 servers (also known as “primary” servers). These servers speak directly to national time services (known as Stratum 0, which might be devices such as atomic clocks or GPS clocks, for example). There are a number of ways of communicating with them securely, via satellite or radio, for example.
|
||||
|
||||
Somewhat surprisingly, it’s reasonably common for even large enterprises to connect to Stratum 2 servers (or “secondary” servers) as opposed to primary servers. Stratum 2 servers, as you’d expect, synchronize directly with Stratum 1 servers. If you consider that a corporation might have their own onsite NTP servers (at least two, usually three, for resilience) then these would be Stratum 3 servers. As a result, such a corporation’s Stratum 3 servers would then connect upstream to predefined secondary servers and dutifully pass the time onto its many client and server machines as an accurate reflection of the current time.
|
||||
|
||||
A simple design component of NTP is that it works on the premise -- thanks to the large geographical distances travelled by Internet traffic -- that round-trip times (of when a packet was sent and how many seconds later it was received) are sensibly taken into account before trusting to a time as being entirely accurate. There’s a lot more to setting a computer’s clock than you might at first think, if you don’t believe me, then [this fascinating web page][3] is well worth looking at.
|
||||
|
||||
At the risk of revisiting the point, NTP is so key to making sure your infrastructure functions as expected that the Stratum servers to which your NTP servers connect to fuel your internal timekeeping must be absolutely trusted and additionally offer redundancy. There’s an informative list of the Stratum 1 servers available at the [main NTP site][4].
|
||||
|
||||
As you can see from that list, some NTP Stratum 1 servers run in a “ClosedAccount” state; these servers can’t be used without prior consent. However, as long as you adhere to their usage guidelines, “OpenAccess” servers are indeed open for polling. Any “RestrictedAccess” servers can sometimes be limited due to a maximum number of clients or a minimum poll interval. Additionally, these are sometimes only available to certain types of organizations, such as academia.
|
||||
|
||||
### Respect My Authority
|
||||
|
||||
On a public NTP server, you are likely to find that the usage guidelines follow several rules. Let’s have a look at some of them now.
|
||||
|
||||
The “iburst” option involves a client sending a number of packets (eight packets rather than the usual single packet) to an NTP server should it not respond during at a standard polling interval. If, after shouting loudly at the NTP server a few times within a short period of time, a recognized response isn’t forthcoming, then the local time is not changed.
|
||||
|
||||
Unlike “iburst” the “burst” option is not commonly allowed (so don’t use it!) as per the general rules for NTP servers. That option instead sends numerous packets (eight again apparently) at each polling interval and also when the server is available. If you are continually throwing packets at higher-up Stratum servers even when they are responding normally, you may get blacklisted for using the “burst” option.
|
||||
|
||||
Clearly, how often you connect to a server makes a difference to its load (and the negligible amount of bandwidth used). These settings can be configured locally using the “minpoll” and “maxpoll” options. However, to follow the connecting rules on to an NTP server, you shouldn’t generally alter the the defaults of 64 seconds and 1024 seconds, respectively.
|
||||
|
||||
Another, far from tacit, rule is that clients should always respect Kiss-Of-Death (KOD) messages generated by those servers from which they request time. If an NTP server doesn’t want to respond to a particular request, similar to certain routing and firewalling techniques, then it’s perfectly possible for it to simply discard or blackhole any associated packets.
|
||||
|
||||
In other words, the recipient server of these unwanted packets takes on no extra load to speak of and simply drops the traffic that it doesn’t think it should serve a response to. As you can imagine, however, this isn’t always entirely helpful, and sometimes it’s better to politely ask the client to cease and desist, rather than ignoring the requests. For this reason, there’s a specific packet type called the KOD packet. Should a client be sent an unwelcome KOD packet then it should then remember that particular server as having responded with an access-denied style marker.
|
||||
|
||||
If it’s not the first KOD packet received from back the server, then the client assumes that there is a rate-limiting condition (or something similar) present on the server. It’s common at this stage for the client to write to its local logs, noting the less-than-satisfactory outcome of the transaction with that particular server, if you ever need to troubleshoot such a scenario.
|
||||
|
||||
Bear in mind that, for obvious reasons, it’s key that your NTP’s infrastructure be dynamic. Thus, it’s important not to hard-code IP addresses into your NTP config. By using DNS names, individual servers can fall off the network and the service can still be maintained, IP address space can be reallocated and simple load balancing (with a degree of resilience) can be introduced.
|
||||
|
||||
Let’s not forget that we also need to consider that the exponential growth of the Internet of Things (IoT), eventually involving billions of new devices, will mean a whole host of equipment will need to keep its wristwatches set to the correct time. Should a hardware vendor inadvertently (or purposely) configure their devices to only communicate with one provider’s NTP servers (or even a single server) then there can be -- and have been in the past -- very unwelcome issues.
|
||||
|
||||
As you might imagine, as more units of hardware are purchased and brought online, the owner of the NTP infrastructure is likely to be less than grateful for the associated fees that they are incurring without any clear gain. This scenario is far from being unique to the realms of fantasy. Ongoing headaches -- thanks to NTP traffic forcing a provider’s infrastructure to creak -- have been seen several times over the last few years.
|
||||
|
||||
In the next two articles, I’ll look at some important NTP configuration options and examine server setup.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/arrive-time-ntp-part-1-usage-overview
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/ntp-timejpg
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm
|
||||
[4]:http://support.ntp.org/bin/view/Servers/StratumOneTimeServers
|
||||
@ -0,0 +1,88 @@
|
||||
[Improve your sleep by using Redshift on Fedora][1]
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
The blue light emitted by most electronic devices, is known for having a negative impact on our sleep. We could simply quit using each of our electronic devices after dark, as an attempt to improve our sleep. However, since that is not really convenient for most of us, a better way is to adjusts the color temperature of your screen according to your surroundings. One of the most popular ways to achieve this is with the Redshift utility. Jon Lund Steffensen , the creator of Redshift, describes his program in the following way:
|
||||
|
||||
> Redshift adjusts the color temperature of your screen according to your surroundings. This may help your eyes hurt less if you are working in front of the screen at night.
|
||||
|
||||
The Redshift utility only works in the X11 session on Fedora Workstation. So if you’re using Fedora 24, Redshift will work with the default login session. However, on Fedora 25, the default session at login is Wayland, so you will have to use the GNOME shell extension instead. Note, too that the GNOME Shell extension also works with X11 sessions.
|
||||
|
||||
### **Redshift utility**
|
||||
|
||||
#### Installation
|
||||
|
||||
Redshift is in the Fedora’s repos, and thus, all we have to do to install is run this command:
|
||||
|
||||
```
|
||||
sudo dnf install redshift
|
||||
```
|
||||
|
||||
The package also provides a GUI. To use this, install `redshift-gtk` instead. Remember, though, that the utility only works on X11 sessions.
|
||||
|
||||
#### Using the Redshift utility
|
||||
|
||||
Run the utility from the command line with a command like the following:
|
||||
|
||||
```
|
||||
redshift -l 23.6980:133.8807 -t 5600:3400
|
||||
```
|
||||
|
||||
In the above command, the_ -l 23.6980:133.8807 _means we are informing Redshift that our current location is 23.6980° S, 133.8807° E. The_ -t 5600:3400_ declares that during the day you want a colour temperature of 5600, and 3400 at night.
|
||||
|
||||
The temperature is proportional to the amount of blue light emitted: a lower temperature, implies a lower amount of blue light. I prefer to use 5600K (6500K is neutral daylight) during the day, and 3400K at night (anything lower makes me feel like I’m staring at a tomato), but feel free to experiment with it.
|
||||
|
||||
If you don’t specify a location, Redshift attempts to use the Geoclue method in order to determine your location coordinates. If this method doesn’t work, you could use multiple [websites][2] and online maps to find the coordinates.
|
||||
|
||||
|
||||
|
||||
Don’t forget to set Redshift as an autostart command, and to check [Jon’s website][3] for more information.
|
||||
|
||||
### Redshift GNOME Shell extension
|
||||
|
||||
The utility does not work when running the Wayland display server (which is standard in Fedora 25). Fortunately, there is a handy GNOME Shell extension that will do the same job. To install, run the the following commands`:`
|
||||
|
||||
```
|
||||
sudo dnf copr enable mystro256/gnome-redshift
|
||||
sudo dnf install gnome-shell-extension-redshift
|
||||
```
|
||||
|
||||
After installing from the COPR repo, log out and log back in of your Fedora Workstation, then enable it in the GNOME Tweak tool. For more information, check the gnome-redshift [copr repo][4], or the [github repo][5].
|
||||
|
||||
After enabling the extension, a little sun (or moon) icon appears in the top right of your GNOME shell. The extension also provides a settings dialog to tweak the times of the redshift and the temperature.
|
||||
|
||||
|
||||
|
||||
### Relative software
|
||||
|
||||
#### F.lux
|
||||
|
||||
Redshift could be seen as the open-source variant of F.lux. There is a [linux version of F.lux][6] now. You could consider using it if you don’t mind using closed-source software, or if Redshift doesn’t work properly.
|
||||
|
||||
#### Twilight for Android
|
||||
|
||||
Twilight is similar to Redshift, but for Android. It makes reading on your smartphone or tablet late at night more comfortable.
|
||||
|
||||
#### Redshift plasmoid
|
||||
|
||||
This is the Redshift GUI version for KDE. You can find more information on [github][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/safe-eyes-redshift/
|
||||
|
||||
作者:[novel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://novel.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/safe-eyes-redshift/
|
||||
[2]:http://www.latlong.net/
|
||||
[3]:http://jonls.dk/redshift/
|
||||
[4]:https://copr.fedorainfracloud.org/coprs/mystro256/gnome-redshift/
|
||||
[5]:https://github.com/benzea/gnome-shell-extension-redshift
|
||||
[6]:https://justgetflux.com/linux.html
|
||||
[7]:https://github.com/simgunz/redshift-plasmoid
|
||||
@ -0,0 +1,71 @@
|
||||
Why Linux Installers Need to Add Security Features
|
||||
============================================================
|
||||
|
||||
>_With the heightened security concerns, Linux distros need to make basic security options prominently available in their installers rather than options that users can add manually later._
|
||||
|
||||
Twelve years ago, Linux distributions were struggling to make installation simple. Led by Ubuntu and Fedora, they long ago achieved that goal. Now, with the growing concerns over security, they need to reverse directions slightly, and make basic security options prominently available in their installers rather than options that users can add manually later.
|
||||
|
||||
At the best of times, of course, convincing users to come anywhere near security features is difficult. Too many users are reluctant even to add features as simple as unprivileged user accounts or passwords, apparently preferring the convenience of the moment to reducing the risk of an intrusion that will require reinstallation, or a consultation with a computer expert at eighty dollars an hour.
|
||||
|
||||
However, if average users are ever going to pay attention to security, it will probably be during installation. They may never think of it again for another eighteen months, but perhaps for one moment during installation when their attention is focused, they might be persuaded to select a check box, especially if visible online help explains the advantages.
|
||||
|
||||
Nor is this shift such a great one. Many installers already offer the choice of automatic logins -- a feature that might be acceptable for a virtue install that contains no personal data, but is all too likely to be selected by those who find logins inconvenient. Similarly, thanks to Ubuntu, choosing to encrypt filesystems -- or at least home directories -- has already become standard in many installers. All I am really suggesting is more of the same.
|
||||
|
||||
Moreover, outside installers, Firefox has merged Private Browsing seamlessly into user choices, and [Signal Private Messenger][8] is a drop-in replacement for standard Android Phone and Contact apps.
|
||||
|
||||
The suggestion, then, is far from radical. It simply requires the will and the imagination to implement it.
|
||||
|
||||
### Linux Security First Steps
|
||||
|
||||
What sort of security features should be added to installers?
|
||||
|
||||
To start with, a firewall. Dozens of graphical interfaces are available for setting up firewalls, but to paraphrase Byron talking about Coleridge's metaphysical speculations, despite seventeen years of experience, I sometimes wish someone would explain their explanations.
|
||||
|
||||
Despite being well-intentioned, most of these firewall tools make dealing directly with iptables seem straightforward. [Bastille Linux][9], the now-defunct system hardener, used to install a basic firewall, and I see no reason why other distributions could not do the same.
|
||||
|
||||
Other tools already exist for post-installation use, and could be added without much difficulty in an installer. For instance, [Grub 2][10], the boot manager used by most distribution includes basic password protection. Admittedly, the password can be bypassed by booting from a Live CD, but it still provides a certain amount of protection in everyday circumstances, including remote log ins.
|
||||
|
||||
Similarly, a post-install password enforcer like [pwgen][11] could be added to the section of the installer for setting up accounts. These tools enforce the length of acceptable passwords, and their combination of upper and lower case letters, numbers, and special characters. Many generate a password for you, some even making it pronouncable for help in remembering.
|
||||
|
||||
Still other tools could be added as part of the installation. For example, an installer could ask for a schedule for regular backups, and add a cronjob and a simple backup tool like [kbackup][12].
|
||||
|
||||
And what about encrypted email? Most popular email readers today include the capacity for encrypted email, but setting up and using encryption require extra steps to be taken by the users, complicating common tasks to the point that the temptation to ignore them is almost irresistible. Yet seeing how simple Signal makes encryption on phones, it is obvious that much more can be done to make encryption easier on laptops and workstations as well. Probably, most distributions would prefer peer to peer encryption rather than Signal's centralized servers, but applications like [Ring][13] could provide that feature.
|
||||
|
||||
Whatever features are added to the installer, perhaps the precautions could also be extended to productivity software such as LibreOffice. Most efforts at security focus on email, web browsing, and chat, yet word processors and spreadsheets, with their macro languages, are an obvious source of malware infection, and a privacy concern as well. Yet aside from a few outliers like [Qubes OS][14] or [Subgraph][15], few make any effort to include productivity software in their security precautions -- a lapse that potentially leaves a gaping security hole.
|
||||
|
||||
### Modern Adaptations
|
||||
|
||||
Of course, users who take such matters seriously will probably settle on a security-conscious approach. However, such users can be trust to take care of themselves.
|
||||
|
||||
What I am concerned about here are users who are less knowledgeable or less inclined to do their own tinkering. Easy to use security is a growing need, and overdue to be addressed.
|
||||
|
||||
The examples here are simply places to start. Most of them already exist, and the need is to implement them in such a way that users cannot ignore them, and can use them with a minimum of knowledge. Probably, implementing all of them would require no more than a month's work by a single coder, including prototyping,UI design, and testing.
|
||||
|
||||
Yet, until such features are added, most major Linux distributions can hardly be said to be concerned about security at all. After all, what good are tools if users never use them?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/security/why-linux-installers-need-to-add-security-features.html
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
[1]:http://www.datamation.com/feedback/http://www.datamation.com/security/why-linux-installers-need-to-add-security-features.html
|
||||
[2]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
[3]:http://www.datamation.com/e-mail/http://www.datamation.com/security/why-linux-installers-need-to-add-security-features.html
|
||||
[4]:http://www.datamation.com/print/http://www.datamation.com/security/why-linux-installers-need-to-add-security-features.html
|
||||
[5]:http://www.datamation.com/security/why-linux-installers-need-to-add-security-features.html#comment_form
|
||||
[6]:http://www.datamation.com/security/why-linux-installers-need-to-add-security-features.html#
|
||||
[7]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
[8]:https://whispersystems.org/
|
||||
[9]:http://bastille-linux.sourceforge.net/
|
||||
[10]:https://help.ubuntu.com/community/Grub2/Passwords
|
||||
[11]:http://pwgen-win.sourceforge.net/downloads.html
|
||||
[12]:http://kbackup.sourceforge.net/
|
||||
[13]:https://savannah.gnu.org/projects/ring/
|
||||
[14]:https://www.qubes-os.org/
|
||||
[15]:https://subgraph.com/sgos/
|
||||
@ -0,0 +1,77 @@
|
||||
Get to know Tuleap for project management
|
||||
============================================================
|
||||
|
||||
### Tuleap is being used by the Eclipse Foundation, replacing Bugzilla.
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
Tuleap is a unique open source project management tool with great momentum right now, every month they have one major release. It's also been listed it in both the [Top 5 open source project management tools in 2015][1] and the [Top 11 project management tools for 2016][2].
|
||||
|
||||
"Tuleap is a complete GPLv2 platform to host software projects. It provides a central place where teams can find all the tools they need to track their software projects lifecycle successfully. They will find support for project management (scrum, kanban, waterfall, hybrid, etc.), source control (git and svn) and code review (pull requests and gerrit), continuous integration, issue tracking, wiki, and documentation," said Manuel Vacelet, co-founder and CTO of Enalean, the company behind the Tuleap project.
|
||||
|
||||
In this interview I talk with Manuel about how it all got started and how they manage Tuleap in an open source way.
|
||||
|
||||
**Nitish Tiwari (NT): Why does the Tuleap project matter? **
|
||||
|
||||
**Manuel Vacelet (MV):** Tuleap matters because we strongly believe that a successful (software) project must involve all the stakeholders: developers, project managers, QA, customers, and users.
|
||||
|
||||
A long time ago I was an intern on a fork of SourceForge (back when SourceForge was a free and open source project), and it would eventually become Tuleap years after. My first contribution was to integrate PhpWiki into the tool (don't tell anybody, the code is scary).
|
||||
|
||||
Now, I'm happy to work as CTO and product owner at Enalean, the main company contributing to the Tuleap project.
|
||||
|
||||
**NT: Tell us about the technical aspects.**
|
||||
|
||||
**MV:** Tuleap core system is LAMP-based and relies on CentOS. Today's development stack is done with AngularJS (v1) with a REST backend (PHP) and a NodeJS-based real-time server for push notification. But if you wish to be a fullstack Tuleap developer, you will also touch bash, Perl, Python, Docker, Make.
|
||||
|
||||
Speaking of technical aspects, it's important to underline that one of the distinctive features of Tuleap is its scalability. A single instance of Tuleap, on a single server, with no complicated IT, can handle over 10,000 people.
|
||||
|
||||
**NT: Tell us about the users and the community around the project. Who's involved? How do they use the tool?**
|
||||
|
||||
**MV:** The users are very varied. From small startups using Tuleap to keep track of their project advancement and manage their source code to very large companies, like the French telecom operator Orange, which deployed it to over 17,000 users and 5,000 projects hosted.
|
||||
|
||||
Many users rely on Tuleap to facilitate agile projects and track their progress. Developers and customers share the same workspace. There is no need for customers to learn how to use GitHub, nor for developers to have an additional layer of work to transcribe their work on a "customer accessible" platform.
|
||||
|
||||
This year, Tuleap is being used by the [Eclipse Foundation][3], replacing Bugzilla.
|
||||
|
||||
The Indian Ministry of Electronics & Information Technology has created the Government of India's platform for open collaborative development of e-governance applications using Tuleap.
|
||||
|
||||
Tuleap is used in a number of different ways and configurations. Some people use it as a backend for their Drupal customer facing websites; they plug via the REST API's into Tuleap to manage bugs and service requests.
|
||||
|
||||
Even some architects are using it to manage their work advancement and AutoCAD files.
|
||||
|
||||
**NT: Does Tuleap do anything special to make the community a safe and diverse place?**
|
||||
|
||||
**MV:** We haven't created a "Code of Conduct" yet; the community is really peaceful and welcoming, but we plan to do that. Tuleap developers and contributors come from different countries (i.e., Canada, Tunisia, France). And 35% of active developers and contributors are women.
|
||||
|
||||
**NT: What percentage of Tuleap features are suggested by the community?**
|
||||
|
||||
**MV:** Almost 100% of the features are community-driven.
|
||||
|
||||
It was one of Enalean's key challenges: to find a business model that allows us to do open source software the right way. To us, the "open core" model (where the core of the application is open, but the interesting and useful parts are closed source) is not the right way because you depend on closed source at the end of the day. So we invented the [OpenRoadmap][4], a way for us to gather needs from community and end users and find companies to pay for it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Nitish is a software developer by profession & an open source enthusiast by heart. As a tech author for Linux based magazines, he covers new Open Source tools. He loves to read and explore anything open source. In his free time, he likes to read motivational books. He is currently building DevUp - a platform to let developers connect all their tools and embrace DevOps in a true manner. You can follow him on twitter
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/interview-Tuleap-project
|
||||
|
||||
作者:[Nitish Tiwari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tiwarinitish86
|
||||
[1]:https://opensource.com/business/15/1/top-project-management-tools-2015
|
||||
[2]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[3]:http://www.eclipse.org/
|
||||
[4]:https://blog.enalean.com/enalean-open-roadmap-how-it-works/
|
||||
@ -0,0 +1,81 @@
|
||||
GHLandy Translating
|
||||
|
||||
How To Assign Output of a Linux Command to a Variable
|
||||
============================================================
|
||||
|
||||
When you run a command, it produces some kind of output: either the result of a program is suppose to produce or status/error messages of the program execution details. Sometimes, you may want to store the output of a command in a variable to be used in a later operation.
|
||||
|
||||
In this post, we will review the different ways of assigning the output of a shell command to a variable, specifically useful for shell scripting purpose.
|
||||
|
||||
To store the output of a command in a variable, you can use the shell command substitution feature in the forms below:
|
||||
|
||||
```
|
||||
variable_name=$(command)
|
||||
variable_name=$(command [option ...] arg1 arg2 ...)
|
||||
OR
|
||||
variable_name='command'
|
||||
variable_name='command [option ...] arg1 arg2 ...'
|
||||
```
|
||||
|
||||
Below are a few examples of using command substitution.
|
||||
|
||||
In this first example, we will store the value of `who` (which shows who is logged on the system) command in the variable `CURRENT_USERS` user:
|
||||
|
||||
```
|
||||
$ CURRENT_USERS=$(who)
|
||||
```
|
||||
|
||||
Then we can use the variable in a sentence displayed using the [echo command][1] like so:
|
||||
|
||||
```
|
||||
$ echo -e "The following users are logged on the system:\n\n $CURRENT_USERS"
|
||||
```
|
||||
|
||||
In the command above: the flag `-e` means interpret any escape sequences ( such as `\n` for newline) used. To avoid wasting time as well as memory, simply perform the command substitution within the [echo command][2] as follows:
|
||||
|
||||
```
|
||||
$ echo -e "The following users are logged on the system:\n\n $(who)"
|
||||
```
|
||||
[
|
||||
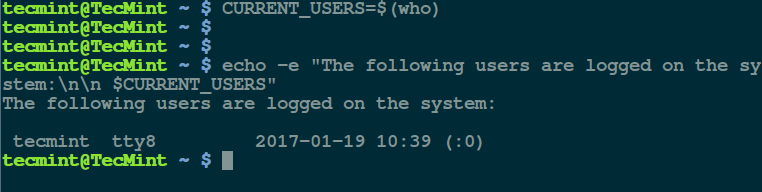
|
||||
][3]
|
||||
|
||||
Shows Current Logged Users in Linux
|
||||
|
||||
Next, to demonstrate the concept using the second form; we can store the total number of files in the current working directory in a variable called `FILES` and echo it later as follows:
|
||||
|
||||
```
|
||||
$ FILES=`sudo find . -type f -print | wc -l`
|
||||
$ echo "There are $FILES in the current working directory."
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Show Number of Files in Directory
|
||||
|
||||
That’s it for now, in this article, we explained the methods of assigning the output of a shell command to a variable. You can add your thoughts to this post via the feedback section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/assign-linux-command-output-to-variable/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[2]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Shows-Current-Logged-Users-in-Linux.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/Show-Number-of-Files-in-Directory.png
|
||||
@ -0,0 +1,126 @@
|
||||
How to get started contributing to Mozilla
|
||||
============================================================
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
_The journey of a thousand miles begins with one step. —Lao Tzu_
|
||||
|
||||
Open source participation offers a sea of benefits that can fine-tune and speed up your career in the tech, including but not limited to real-world technical experience and expanding your professional network. There are a lot of open source projects out there you can contribute to—of small, medium, and large size, as well as unknown and popular. In this article we'll focus on how to contribute to one of the largest and most popular open source projects on the web: Mozilla.
|
||||
|
||||
### Why contribute to Mozilla?
|
||||
|
||||
### Real world experience
|
||||
|
||||
Mozilla is one of the largest open source projects on the web and is itself a host to many other open source projects. So, when you contribute to large-scale open source projects like Mozilla, you gain real-world exposure to how things really work in the tech field, increased knowledge of technical jargon and complex system functionalities, and most importantly, an understanding of how to take code from a local system to a live code repository. You'll learn many of the tools and techniques contributors are using to manage these large-scale projects, like GitHub, Docker, Bugzilla, etc.
|
||||
|
||||
### Community connections
|
||||
|
||||
Community is the heart of any open source project. Contributing to Mozilla connects you with official Mozilla staff and mentors, senior Mozilla contributors (aka Mozillians), and your own local Mozilla community. These are like-minded people who care and strive for improving open source like you do.
|
||||
|
||||
Also, you'll have a chance to build your own identity in the Mozilla community and to inspire other fellow Mozillians. If you want to, you can also eventually mentor others.
|
||||
|
||||
### Events and swag
|
||||
|
||||
No community is complete without a few fun-filled events and bags of swag. Mozilla is no exception.
|
||||
|
||||
Contributing to Mozilla will give you a chance to take part in exclusive Mozilla events. And once you've become a seasoned Mozilla contributor, you'll be able to host your own local Mozilla community events (and Mozilla may assist with funding). Plus, of course, some cool swag—stickers, T-shirts, mugs, and more.
|
||||
|
||||

|
||||
|
||||
CC BY-SA 4.0 Mozilla India Meetup 2016 by Moin Shaikh
|
||||
|
||||
### How to contribute to Mozilla
|
||||
|
||||
Whether you are a programmer, web designer, QA tester, translator, or something in-between, there are many different ways you can contribute to Mozilla. Let's view it in two main parts: technical contribution and nontechnical contribution.
|
||||
|
||||

|
||||
|
||||
CC BY-SA 3.0 by [Mozilla.org][1]
|
||||
|
||||
### Technical contribution
|
||||
|
||||
Technical contribution is for people who love programming and who want to make an impact with their code. There are a number of projects built in specific programming languages where you can hone your talents:
|
||||
|
||||
* If love C++, you can contribute to the core layers of Firefox and other Mozilla products.
|
||||
* If you know JavaScript, HTML, and CSS, you can contribute to the front-end of Firefox.
|
||||
* If you know Java, you can contribute to Firefox Mobile, Firefox on Android, and MozStumbler.
|
||||
* If you know Python, you can contribute to web services, including Firefox Sync or Firefox Accounts.
|
||||
* If you know Shell, Make, Perl, or Python, you can contribute to Mozilla's build systems and release engineering and automation.
|
||||
* If you know C language, you can contribute to NSS, Opus, and Daala projects.
|
||||
* If you know Rust language, you can contribute to RustC, Servo (a web browser engine designed for parallelism and safety), or Quantum (a project to bring large pieces of Servo into Gecko).
|
||||
* If you know Go language, you can contribute to Heka, a tool for data processing.
|
||||
|
||||
To learn more, visit the [Getting Started][3] section on the Mozilla Developer Network (MDN) to take a look at various contributions areas.
|
||||
|
||||
Apart from languages and code, you can also contribute with your QA and testing skills by actively testing various parts of Firefox web browser, Firefox Android browser, and Mozilla's many web properties, such as Firefox add-ons, etc.
|
||||
|
||||
### Nontechnical contribution
|
||||
|
||||
You can also make nontechnical contributions to Mozilla, focusing on areas like QA testing, document translation, UX/UI design, web literacy, open source advocacy, and providing user support to Mozilla Firefox and Thunderbird users.
|
||||
|
||||
**QA testing:** The Mozilla QA team has a large and vibrant community around the world that is deeply involved in the workings of Firefox and other Mozilla projects. The QA contributors take an early look at various products, explore new features, file bugs, triage existing bugs, write and execute test cases, automate tests, and provide valuable feedback from a usability perspective. To get started or to learn more about the Mozilla QA community resources, visit the [Mozilla QA community][4] website.
|
||||
|
||||
**UX design:** If you're a creative designer or a passionate geek who loves to play with colors and graphics, Mozilla has a lot of space for you in its community where you can design usable, accessible, delightful Mozilla projects. Check out this [Open Design repository][5] on Mozilla's GitHub page.
|
||||
|
||||
**User support (forum and social support):** This is where hundreds of thousands of Firefox and Thunderbird users like you and me come and post questions about Firefox and Thunderbird, and this is where they get answers from Mozilla contributors like us. This requires no coding genius, no design skills, and no testing abilities, only handful of Firefox knowledge to get started as a Firefox User Support contributor. Check out this [Get Involved][6] section to join User Support at [SUMO][7]. Support is probably the easiest yet most important areas to commence your Mozilla journey. (Note: Three years ago, I began my Mozilla journey at the Social Support forums.)
|
||||
|
||||
**Writing knowledgebase and help articles:** If you like writing and teaching, then the Knowledge Base is the place for you. Mozilla is always looking for contributors who can write, edit, or proofread articles in English for Firefox and other products. Thousands of users surf these knowledgebase articles every week, and you can make a robust impact by sharing your wisdom and writing help articles for them. Visit the [Mozilla Knowledge Base][8] site to get involved.
|
||||
|
||||
**Localization, aka l10n:** Mozilla's products, like Firefox, are used by millions around the globe and by those speaking many different languages. People need these products in their own language. Language localization is an area that is very much in need of contributors. Projects requiring your translation and localization skills include:
|
||||
|
||||
* Mozilla products, such as Firefox
|
||||
* Mozilla websites and services
|
||||
* Mozilla marketing campaigns
|
||||
* SUMO product support documentation
|
||||
* MDN developer documentation
|
||||
|
||||
You can visit [Mozilla's l10n][9] site to get involved.
|
||||
|
||||
**Teaching and web literacy:** One of the fundamental mission objectives of Mozilla is to keep the web accessible to all. To achieve this mission objective, Mozilla strives hard to educate and enable web users by providing them with the tools and technologies of web literacy. This is where you can help with your teaching skills. If you are a passionate teacher who loves to share knowledge and show the masses all about the Internet, take a look at [Teach the Web][10] initiative by Mozilla. Teach your local community, school kids, your friends, and others about the Internet and web literacy.
|
||||
|
||||
**Advocacy:** If you are passionate about Mozilla's mission, you can spread the word by advocating for the Mozilla mission. While advocating for Mozilla's mission, you can contribute by:
|
||||
|
||||
* Tackling public policy and fight for an open internet and user privacy
|
||||
* Helping the web be more interoperable by working with site owners on compatibility
|
||||
* Helping web authors improve how they write about the open web
|
||||
* Showing your Mozilla and Firefox pride as [Firefox Friends][2]
|
||||
|
||||
To begin promoting Mozilla's mission, take a look at the [Mozilla Advocacy][11] page.
|
||||
|
||||
### If you're lost, I'm here to help you get started!
|
||||
|
||||
I know that as a novice contributor, this article might be an overwhelming amount of information for you. If you need further directions, resources, or references, you can ask me in the comments below or you can [ping me on Twitter][12]. I would be very happy to help you get started with your first contribution (of many more!) to Mozilla.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I am an open source tech geek working as a web analyst and have combined IT experience of over 7 years. I have been contributing to Mozilla for over 2 years. I mainly contribute to: Firefox Web QA, Firefox Technical Support, Localization and community mentoring. Apart from open source contribution, I read, write and speak about UX, Material Design and eCommerce Analysis.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/how-get-started-contributing-mozilla
|
||||
|
||||
作者:[Moin Shaikh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/moinshaikh
|
||||
[1]:http://mozilla.org/
|
||||
[2]:https://www.mozilla.org/en-US/contribute/friends/
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Mozilla/Developer_guide/Introduction#Find_a_bug_we've_identified_as_a_good_fit_for_new_contributors.
|
||||
[4]:https://quality.mozilla.org/get-involved/
|
||||
[5]:https://github.com/mozilla/OpenDesign
|
||||
[6]:https://support.mozilla.org/en-US/get-involved/questions
|
||||
[7]:http://support.mozilla.org/
|
||||
[8]:https://support.mozilla.org/en-US/get-involved/kb
|
||||
[9]:https://l10n.mozilla.org/
|
||||
[10]:https://learning.mozilla.org/en-US/
|
||||
[11]:https://advocacy.mozilla.org/en-US
|
||||
[12]:https://twitter.com/moingshaikh
|
||||
@ -0,0 +1,53 @@
|
||||
Long-term Embedded Linux Maintenance Made Easier
|
||||
============================================================
|
||||
|
||||

|
||||
Pengutronix kernel hacker Jan Lübbe summarized growing security threats in embedded Linux and outlined a plan to keep long-life devices secure and fully functional in this talk from Embedded Linux Conference Europe.[The Linux Foundation][1]
|
||||
|
||||
The good old days when security breaches only happened to Windows folk are fading fast. Malware hackers and denial of service specialists are increasingly targeting out of date embedded Linux devices, and fixing Linux security vulnerabilities was the topic of several presentations at the [Embedded Linux Conference Europe ][3](ELCE) in October.
|
||||
|
||||
One of the best attended was “Long-Term Maintenance, or How to (Mis-)Manage Embedded Systems for 10+ Years” by [Pengutronix][4] kernel hacker Jan Lübbe. After summarizing the growing security threats in embedded Linux, Lübbe laid out a plan to keep long-life devices secure and fully functional. “We need to move to newer, more stable kernels and do continuous maintenance to fix critical vulnerabilities,” said Lübbe. “We need to do the upstreaming and automate processes, and put in place a sustainable workflow. We don’t have any more excuses for leaving systems in the field with outdated software.”
|
||||
|
||||
As Linux devices grow older, traditional lifecycle procedures are no longer up to the job. “Typically, you would take a kernel from a SoC vendor or mainline, take a build system, and add user space,” said Lübbe. “You customize that and add an application, and do some testing and you’re done. But then there’s a maintenance phase for 15 years, and you better hope you have no platform changes, or want to add new features, or need to apply regulatory changes.”
|
||||
|
||||
All these changes increasingly expose your system to new errors, and require massive updates to keep in sync with upstream software. “But it’s not always unintentional errors that occur in the kernel that lead to problems,” said Lübbe. “These vendor kernels never went through the mainline community review process,” he added, noting the [backdoor][5] found last year in an Allwinner kernel.
|
||||
|
||||
“You cannot trust that your vendor will do the correct thing,” continued Lübbe. “Maybe only one or two engineers looked at that backdoor code. That would never happen if the patch was posted on a Linux kernel mailing list. Somebody would notice. Hardware vendors don’t care about security or maintenance. Maybe you get an update after one or two years, but even then it usually takes years between the time they start developing based on one fixed version to the point they declare it stable. If you then start developing on that base, you add maybe another half a year, and it’s even more obsolete.”
|
||||
|
||||
Increasingly, embedded developers working with long-life products build on Long Term Stable (LTS) kernels. But that doesn’t mean your work is done. “After a product is released, people don’t often follow the stable release chain anymore, so they don’t apply the security patches,” said Lübbe. “You’re getting the worst of both worlds: an obsolete kernel and no security. You don’t get the benefit of testing by many people.”
|
||||
|
||||
Lübbe noted that Pengutronix customers that used server-oriented distributions like Red Hat often ran into problems due to the rapid rate of customizations, as well as deployment and update systems that assume a sysadmin is on duty.
|
||||
|
||||
“The updates can work for some things, especially if they are x86, but each project is basically on its own to build infrastructure to update to new releases.”
|
||||
|
||||
Many developers choose backporting as a solution for updating long-life products. “It’s easy in the beginning, but once you are no longer in the project's maintenance window, they don’t tell you if the version you use is affected by a bug, so it becomes much more difficult to find out if a fix is relevant,” said Lübbe. “So you pile up patches and changes and the bugs accumulate, and you have to maintain them yourself because no one else is using those patches. The benefits of using open source software are lost.”
|
||||
|
||||
### Follow Upstream Projects
|
||||
|
||||
The best solution, argues Lübbe, is to follow releases maintained by upstream projects. “We’ve mostly focused on mainline based development, so we have as little difference as possible between the product and the mainstream kernel and other upstream projects. Long-term systems are well supported in mainline. Most systems that don’t use 3D graphics can run very few patches. Newer kernel versions also have lots of [new hardening features][6] that reduce the impact of vulnerabilities.”
|
||||
|
||||
Following mainline seems daunting to many developers, but it’s relatively easy if you implement procedures from the start, and then stick to them, said Lübbe. “You need to develop processes for everything you do on the system,” he said. “You always need to know what software is running, which is easier when you use a good build system. Each software release should define the complete system so you can update everything in the field. If you don’t know what’s there, you can’t fix it. You also want to have automated testing and automated deployment of updates.”
|
||||
|
||||
To “save an update cycle,” Lübbe recommends using the most recent Linux kernel when you start developing, and only moving to a stable kernel when you enter testing. After that, he suggests updating all the software in the system, including kernel, build system, user space, glibc, and components like OpenSSL every year, to versions that are supported by the upstream projects for the rest of the year.
|
||||
|
||||
“Just because you update at that point doesn’t mean you need to deploy,” said Lübbe. “If you see no security vulnerabilities, you can just put the patch on the shelf and have it ready if you need it.”
|
||||
|
||||
Finally, Lübbe recommends looking at release announcements every month, and checking out security announcements on CVE and mainline lists every week. You only need to respond “if the security announcement actually affects you,” he added. “If your kernel is current enough, it’s not too much work. You don’t want to get feedback on your product by seeing your device in the news.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/ELCE/2017/long-term-embedded-linux-maintenance-made-easier
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/ericstephenbrown
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/files/images/jan-lubbe-elcpng
|
||||
[3]:http://events.linuxfoundation.org/events/archive/2016/embedded-linux-conference-europe
|
||||
[4]:http://www.pengutronix.de/index_en.html
|
||||
[5]:http://arstechnica.com/security/2016/05/chinese-arm-vendor-left-developer-backdoor-in-kernel-for-android-pi-devices/
|
||||
[6]:https://www.linux.com/news/event/ELCE/2017hardening-kernel-protect-against-attackers
|
||||
@ -0,0 +1,152 @@
|
||||
2017年:前端开发者都应该回顾并掌握的基础
|
||||
======================
|
||||
|
||||

|
||||
|
||||
在当今的快节奏生态中,我们都倾向于将时间花在尝试那些最新的创意软件中,然后在网络进行激烈的辩论。
|
||||
|
||||
这里,我并不是说我们不能这样做。但我们的确应该把脚步放慢一些,并认真了解那些变化不太大的事情。这样不仅会提高工作质量和我们创造的价值 —— 这还讲循序渐进的帮助我们更快理解这些行的工具。
|
||||
|
||||
本文融合了我的个人经历以及对新一年的希冀。正如我想热切表达自己想法一样,我也期待能在评论区看到你的建议。
|
||||
|
||||
### 学习如何写出易读的代码
|
||||
|
||||
我们多数的工作并不是编写新代码,而是维护已有代码。这意味着你最终阅读代码的时间要比编写它所花费的时间要长,所以你需要为 _之后需要阅读你代码的程序员_ 精简代码,而非让代码区适应解释器。
|
||||
|
||||
这里我推荐你按以下顺序 — 由浅入深 — 阅读下面三本书:
|
||||
|
||||
* Dustin Boswell 的 《[编写可读代码的艺术 (The Art of Readable Code)][1]》
|
||||
* Robert C. Martin 的 《[代码整洁之道 (Clean Code: A Handbook of Agile Software Craftsmanship)][2]》
|
||||
* Steve McConnell 的 《[代码大全 (Code Complete: A Practical Handbook of Software Construction)][3]》
|
||||
|
||||

|
||||
|
||||
### 深入学习 JavaScript
|
||||
|
||||
现如今,每周都会出现一个新的 JavaScript 框架,并标榜自己比其他的任何旧框架都要好用。这样的情况下,我们很多人更倾向于花费时间来学习框架,而且这样也要比学习 JavaScript 本身要容易的多。如果说你正在使用框架,但并不了解该框架的工作方式,_立刻停止,并学习 JavaScript,直到你能够理解这些工具的工作方式为止_ 。
|
||||
|
||||
* 可以从 [Kyle Simpson][4] 的 [你所不知道的 JavaScript][5] 系列开始,这个可以在线免费阅读。
|
||||
* [Eric Elliott][6] 列出的 [2017 年:JavaScript 的学习目标][7].
|
||||
* [Henrique Alves][8] 列出的 [进行响应式开发之前必须了解的事情][9](实际上就是一个知识框架)。
|
||||
* Mike Pennisi 的 [JavaScript 开发者:注意你的语言][10] — 了解 ECMAScript 新特性的中 TC-39 发展过程。
|
||||
|
||||
### 学习函数式编程
|
||||
|
||||
多年以来,我们一直期待着 JavaScript 引入类,但真正有类之后,我们却不想在 JavaScript 中使用类了,我们只想使用函数。即使是编写 HTML,我们也是使用函数 (JSX)。
|
||||
|
||||
* Kyle Simpson 的 [轻量级函数式 JavaScript][11]。
|
||||
* Professor Frisby 的 [函数式编程完全指南][12] 和 [在线免费课程][13]。
|
||||
|
||||

|
||||
|
||||
### 学习设计基础知识
|
||||
|
||||
作为一个前端开发者,我们比这个生态中的任何人 —— 可能甚至是设计人员 —— 都要更加接近用户。如果设计人员要指定你呈现在屏幕上的每一个像素,你可能会遇到各种莫名其妙的错误。
|
||||
|
||||
* [David Kadavy][16] 的《[黑客设计][14]》或对应的 [免费课程][15]。
|
||||
* [Tracy Osborn][18] 的讲座:[为非设计人员的设计知识][17]。
|
||||
* [Nathan Barry][20] 的 [Web 应用设计][19]。
|
||||
* [Jason Santa Maria][22] 的 [Web 页面设计][21]。
|
||||
* Alan Cooper 的 [The Inmates Are Running the Asylum: Why High Tech Products Drive Us Crazy and How to Restore the Sanity][23]。
|
||||
* 两篇关于 UI 动画的文章:[如何使用动画来提高 UX][24]、[过渡界面][25]。
|
||||
|
||||
### 学习如何与人协作
|
||||
|
||||
有些人很喜欢通过编程来与电脑而非与人进行交互。不幸的是,这样的结果并不是很好。
|
||||
|
||||
我们基本上不可能完全脱离群体来工作:我们总是需要和其他开发者、设计师以及项目经理 —— 有时候甚至要和用户 —— 交换意见。这是比较难的任务,但如果你想要真正理解你在做什么以及为什么要这么做的话,这一步是非常重要的,因为这正是我们工作的价值所在。
|
||||
|
||||
* [John Sonmez][27] 的《[软技能:代码之外的生存指南][26]》。
|
||||
* Robert C. Martin 的《[代码整洁之道:程序员的职业素养][28]》。
|
||||
* Jim Camp 的 《[从零开始:专业人士不想让你了解的谈判工具][29]》。
|
||||
|
||||

|
||||
|
||||
### 学习如何为用户编写代码
|
||||
|
||||
与同事或其他人的交流大部分是以文本的形式进行的:目标描述和评论、代码注释、Git commit、即时聊天消息、电子邮件、推文、博客等。
|
||||
|
||||
想象一下,人们要花费多少时间来理解所有以上提到的这些。你过你能够书写的更加明确和简洁,这个时间便会大大减少,然后世界将是一个更好工作的地方。
|
||||
|
||||
* William Zinsserd 的《[On Writing Well: The Classic Guide to Writing Nonfiction][30]》。
|
||||
* William Strunk 和 E. B. White 的《[英文写作指南 (The Elements of Style)][31]》。
|
||||
* [奥威尔写作规则][32]。
|
||||
* 俄国:很好的 [Glavred course][33]。
|
||||
|
||||
### 学习计算机科学智慧
|
||||
|
||||
前端开发已经不仅仅简单的下拉菜单了,它比以前要复杂的多了。随着我们所需解决问题的复杂度越来越高,声名狼藉的“JavaScript 疲乏症”也随之出现了。
|
||||
|
||||
这意味着现在需要学习非前端开发人员近十年所积累形成的知识精华。而这也是我最想听到你向我推荐的内容了。
|
||||
|
||||
以下是我个人给大家的推荐:
|
||||
|
||||
* Coursera 的 [学习想计算机科学家的思考方式][34]。
|
||||
* [DHH][36] 的 [对我意义非凡的五本书][35]。
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
读完本文,你有些什么建议呢?在这新的 2017 年里你又想学习些什么呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Web 开发者,充满激情的摄影者,疯狗的主人 (owner of crazy dogs ?)。
|
||||
|
||||
译者简介:
|
||||
|
||||

|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 欲得之,则为之奋斗 (If you want it, work for it.)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.com/what-to-learn-in-2017-if-youre-a-frontend-developer-b6cfef46effd#.ss9xbwrew
|
||||
|
||||
作者:[Artem Sapegin][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.com/@sapegin
|
||||
[1]:https://www.amazon.com/gp/product/0596802293/
|
||||
[2]:https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882/
|
||||
[3]:https://www.amazon.com/Code-Complete-Practical-Handbook-Construction/dp/0735619670/
|
||||
[4]:https://medium.com/u/5dccb9bb4625
|
||||
[5]:https://github.com/getify/You-Dont-Know-JS
|
||||
[6]:https://medium.com/u/c359511de780
|
||||
[7]:https://medium.com/javascript-scene/top-javascript-frameworks-topics-to-learn-in-2017-700a397b711#.zhnbn4rvg
|
||||
[8]:https://medium.com/u/b6c3841651ac
|
||||
[9]:http://alves.im/blog/before-dive-into-react.html
|
||||
[10]:https://bocoup.com/weblog/javascript-developers-watch-your-language
|
||||
[11]:https://github.com/getify/Functional-Light-JS
|
||||
[12]:https://github.com/MostlyAdequate/mostly-adequate-guide
|
||||
[13]:https://egghead.io/courses/professor-frisby-introduces-composable-functional-javascript
|
||||
[14]:https://www.amazon.com/Design-Hackers-Reverse-Engineering-Beauty-ebook/dp/B005J578EW
|
||||
[15]:http://designforhackers.com/
|
||||
[16]:https://medium.com/u/5377a93ef640
|
||||
[17]:https://youtu.be/ZbrzdMaumNk
|
||||
[18]:https://medium.com/u/e611097a5bd4
|
||||
[19]:http://nathanbarry.com/webapps/
|
||||
[20]:https://medium.com/u/ac3090433602
|
||||
[21]:https://abookapart.com/products/on-web-typography
|
||||
[22]:https://medium.com/u/8eddcb9e4ac4
|
||||
[23]:https://www.amazon.com/Inmates-Are-Running-Asylum-Products-ebook/dp/B000OZ0N62/
|
||||
[24]:http://babich.biz/how-to-use-animation-to-improve-ux/
|
||||
[25]:https://medium.com/@pasql/transitional-interfaces-926eb80d64e3#.igcwawszz
|
||||
[26]:https://www.amazon.com/Soft-Skills-software-developers-manual/dp/1617292397/
|
||||
[27]:https://medium.com/u/56e8cba02b
|
||||
[28]:https://www.amazon.com/Clean-Coder-Conduct-Professional-Programmers/dp/0137081073/
|
||||
[29]:https://www.amazon.com/Start-No-Negotiating-Tools-that-ebook/dp/B003EY7JEE/
|
||||
[30]:https://www.amazon.com/gp/product/0060891548/
|
||||
[31]:https://www.amazon.com/Elements-Style-4th-William-Strunk/dp/0205313426/
|
||||
[32]:http://www.economist.com/blogs/prospero/2013/07/george-orwell-writing
|
||||
[33]:http://maximilyahov.ru/glvrd-pro/
|
||||
[34]:https://www.coursera.org/specializations/algorithms
|
||||
[35]:https://signalvnoise.com/posts/3375-the-five-programming-books-that-meant-most-to-me
|
||||
[36]:https://medium.com/u/54bcbf647830
|
||||
@ -0,0 +1,104 @@
|
||||
|
||||
What engineers and marketers can learn from each other
|
||||
============================================================
|
||||
工程师和市场营销人员之间能够相互学习什么?
|
||||
|
||||
### 营销人员觉得工程师在工作中都太严谨了;而工程师则认为营销人员都很懒散。但是他们都错了。
|
||||
|
||||

|
||||
图片来源 :
|
||||
|
||||
opensource.com
|
||||
|
||||
在 B2B 行业从事多年的销售实践过程中,我经常听到工程师对营销人员的各种误解。下面这些是比较常见的:
|
||||
|
||||
* ”搞市场营销真是浪费钱,还不如把更多的资金投入到实际的产品开发中来。“
|
||||
* ”那些营销人员只是一个劲儿往墙上贴各种广告,还祈祷着它们不要掉下来。这么做有啥科学依据啊?“
|
||||
* ”谁愿意去看哪些广告啊?“
|
||||
* ”对待一个营销人员最好的办法就是不订阅,不关注,也不理睬。“
|
||||
|
||||
这是我最感兴趣的一点:
|
||||
_“营销人员都很懒散。”_
|
||||
|
||||
最后一点说的不对,不够全面,懒散实际上是阻碍一个公司发展的巨大绊脚石。
|
||||
|
||||
我来跟大家解释一下原因吧。
|
||||
|
||||
### 看到自己的身影
|
||||
|
||||
这些工程师的的评论让我十分的苦恼,因为我从中看到了自己当年的身影。
|
||||
|
||||
你们知道吗?我曾经也跟你们一样是一位自豪的技术极客。我在 Rensselaer Polytechnic 学院的电气工程专业本科毕业后便在美国空军开始了我的职业生涯,而且美国空军在那段时间还发动了军事上的沙漠风暴行动。在那里我主要负责开发并部属一套智能的实时战况分析系统,用于根据各种各样的数据源来构建出战场上的画面。
|
||||
|
||||
在我离开空军之后,我本打算去麻省理工学院攻读博士学位。但是上校强烈建议我去报读这个学校的商学院。“你真的想一辈子待实验室里吗?”他问我。“你想就这么去大学里当个教书匠吗? Jackie ,你在组织管理那些复杂的工作中比较有天赋。我觉得你非常有必要去了解下 MIT 的斯隆商学院。”
|
||||
|
||||
我觉得自己也可以同时参加一些 MIT 技术方面的课程,因此我采纳了他的建议。但是,如果要参加市场营销管理方面的课程,我还有很长的路要走,这完全是在浪费时间。因此,在日常工作学习中,我始终是用自己所擅长的分析能力去解决一切问题。
|
||||
|
||||
不久后,我在波士顿咨询集团公司做咨询顾问工作。在那六年的时间里,我经常听到大家对我的评论: Jackie ,你太没远见了。考虑问题也不够周全。你总是通过自己的分析数据去找答案。“
|
||||
|
||||
确实如此啊,我很赞同他们的想法——因为这个世界的工作方式本该如此,任何问题都要基于数据进行分析,不对吗?直到现在我才意识到(我多么希望自己早一些发现自己的问题)自己以前惯用的分析问题的方法遗漏了很多重要的东西:开放的心态,艺术修养,情感——人和创造性思维相关的因素。
|
||||
|
||||
我在 2001 年 9 月 11 日加入达美航空公司不久后,被调去管理消费者市场部门,之前我意识到的所有问题变得更加明显。这本来不是我的强项,但是在公司需要的情况下,我也愿意出手相肋。
|
||||
|
||||
但是突然之间,我一直惯用的方法获取到的常规数据分析结果却与实际情况完全相反。这个问题导致上千人(包括航线内外的人)受到影响。我忽略了一个很重要的人本身的情感因素。我所面临的问题需要各种各样的解决方案才能处理,而不是简单的从那些死板的分析数据中就能得到答案。
|
||||
|
||||
那段时间,我快速地学到了很多东西,因为如果我们想把达美航空公司恢复到正常状态,还需要做很多的工作——市场营销更像是一个以解决问题为导向,以用户为中心的充满挑战性的大工程,只是销售人员和工程师这两大阵营都没有迅速地意识到这个问题。
|
||||
|
||||
### 两大文件差异
|
||||
|
||||
工程管理和市场营销之间的这个“巨大鸿沟”确实是根深蒂固的,这跟 C.P. Snow (英语物理化学家和小说家)提出的[“两大文化差异"问题][1]很相似。具有科学素质的工程师和具有艺术细胞的营销人员操着不同的语言,不同的文化观念导致他们不同的价值取向。
|
||||
|
||||
但是,事实上他们有更多的相似之处。华盛顿大学[最新研究][2](由微软、谷歌和美国国家科学基金会共同赞助)发现”一个伟大软件工程师必须具备哪些优秀的素质,“毫无疑问,一个伟大的销售人员同样也应该具备这些素质。例如,专家们给出的一些优秀品质如下:
|
||||
|
||||
* 充满激情
|
||||
* 性格开朗
|
||||
* 强烈的好奇心
|
||||
* 技艺精湛
|
||||
* 解决复杂难题的能力
|
||||
|
||||
这些只是其中很小的一部分!当然,并不是所有的素质都适用于市场营销人员,但是如果用文氏图来表示这“两大文化“的交集,就很容易看出营销人员和工程师之间的关系要远比我们想象中密切得多。他们都是竭力去解决与用户或客户相关的难题,只是他们所采取的方式和角度不一致罢了。
|
||||
|
||||
看到上面的那几点后,我深深的陷入思考:_要是这两类员工彼此之间再多了解对方一些会怎样呢?这会给公司带来很强大的动力吧?_
|
||||
|
||||
确实如此。我在红帽公司就亲眼看到过样的情形,我身边都是一些“思想极端”的员工,要是之前,肯定早被我炒鱿鱼了。我相信公司里绝对发生过很多次类似这样的事情,一个销售人员看完工程师递交上来的分析报表后,心想,“这些书呆子,思想太局限了。真是一叶障目,不见泰山;两豆塞耳,不闻雷霆。”
|
||||
|
||||
现在我才明白了公司里有这两种人才的重要性。在现实工作当中,工程师和营销人员都是围绕着客户、创新及数据分析来完成工作。如果他们能够懂得相互尊重、彼此理解、相辅相成,那么我们将会看到公司里所产生的那种积极强大的动力,这种超乎寻常的革新力量要远比两个独立的团队强大得多。
|
||||
|
||||
### 听一听他们的想法
|
||||
|
||||
成功案例:_建立开放式组织_
|
||||
|
||||
在红帽任职期间,我的主要工作就是想办法提升公司的品牌影响力——但是我从未想过让公司的 CEO 去写一本书。我把公司多个部门的“想法极端”的同事召集在一起,希望他们帮我设计出一个新颖的解决方案来提升公司的影响力,结果他们提出让公司的 CEO 写书这样一个想法。
|
||||
|
||||
当我听到这个想法的时候,我很快意识到应该把红帽公司一些经典的管理模式写入到这本书里:它将对整个开源社区的创业者带来很重要的参考价值,同时也有助于宣扬开源精神。通过优先考虑这两方面的作用,我们提升了红帽在整个开源软件世界中的品牌价值,红帽是一个可靠的随时准备着为客户在[数字化颠覆][3]年代指明方向的公司。
|
||||
|
||||
这一点才是主要的:确切的说是指导红帽工程师解决代码问题的共同精神力量。 Red Hatters 小组一直在催着我赶紧把开放式组织的模式在全公司推广起来,以显示出内外部程序员共同推动整个开源社区发展的强大动力之一:那就是强烈的共享欲望。
|
||||
|
||||
最后,要把开放式组织的管理模式完全推广起来,还需要大家的共同能力,包括工程师们强大的数据分析能力和营销人员美好的艺术素养。这个项目让我更加坚定自己的想法,工程师和营销人员有更多的相似之处。
|
||||
|
||||
但是,有些东西我还得强调下:开放模式的实现,要求公司上下没有任何偏见,不能偏袒工程师和市场营销人员任何一方文化。一个更加理想的开放式环境能够促使员工之间和平共处,并在这个组织规定的范围内点燃大家的热情。
|
||||
|
||||
所以,这绝对不是我听到大家所说的懒散之意。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Jackie Yeaney —— Ellucian 公司市场总监
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/1/engineers-marketers-can-learn
|
||||
|
||||
作者:[Jackie Yeaney][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jackie-yeaney
|
||||
[1]:https://en.wikipedia.org/wiki/The_Two_Cultures#Implications_and_influence
|
||||
[2]:https://faculty.washington.edu/ajko/papers/Li2015GreatEngineers.pdf
|
||||
[3]:https://opensource.com/open-organization/16/7/future-belongs-open-leaders
|
||||
@ -0,0 +1,128 @@
|
||||
如何挑选你的第一门编程语言
|
||||
============================================================[
|
||||
|
||||
][1]
|
||||

|
||||
|
||||
|
||||
opensource.com 供图
|
||||
|
||||
人们有着各种各样的原因想学编程。你也许想要做一个程序,或者你只是想投入其中。所以,在选择你的第一门编程语言之前,问问你自己:你想要程序运行在哪里?你想要程序做什么?
|
||||
|
||||
你选择编程的原因决定第一门编程语言的选择。
|
||||
|
||||
_在这篇文章里,我会交换着使用“编程”(code , program)、“开发”(develop) 等动词,“代码”(code)、“程序”(program)、“应用”(application/app)等名词。这是考虑到你可能听过的语言用法_
|
||||
|
||||
### 了解你的设备
|
||||
|
||||
在你编程语言的选择上,你的程序将运行在何处是个决定性因素。
|
||||
|
||||
桌面应用是运行在台式机或者笔记本电脑上的传统软件程序。这样你将会编写同一时间内只能在一台电脑上运行的代码。移动应用,也就是熟知的“ APP ”,运行在使用 IOS Android 或者其他操作系统上的移动设备上。网页应用是功能像应用的网页。
|
||||
|
||||
按网络的 客户-服务器 架构分,网页开发者经常被分为两类:
|
||||
|
||||
* 前端开发,就是编写运行在浏览器自身的代码。这是个面对用户的部分,或者说是程序的前端。有时候被称为客户端编程,因为浏览器是网络的客户-服务器架构的半壁江山。浏览器运行在你本地的电脑或者设备上。
|
||||
|
||||
* 后台开发,也就是大家所熟知的服务器端开发,编写的代码运行在你不能实际接触的服务器电脑上。
|
||||
|
||||
### 创造什么
|
||||
|
||||
编程是一门广泛的学科,能应用在不同的领域。常见的应用有:
|
||||
|
||||
* 数据科学
|
||||
* 网页开发
|
||||
* 游戏开发
|
||||
* 不同类型的工作自动化
|
||||
|
||||
现在我们已经讨论了为什么你要编程,你要为运行在哪里而编程,让我们看一下两门对于新手来说不错的编程语言吧。
|
||||
|
||||
### Python
|
||||
|
||||
[Python][2] 是对于第一次编程的人来说是最为流行的编程语言之一,而且这不是巧合。Python 是一门通用的编程语言。这意味着它能应用在广泛的编程任务上。你能用 Python 完成几乎_所有_事情。这一点使得很多新手能实际应用这门编程语言。另外, Python 有两个重要的设计特征,使得其对于新手更友好:清晰、类似于英语的[语法][3]和强调代码的[可读性][4]。
|
||||
|
||||
从本质上讲,一门编程语言的语法就是你所输入的能让这编程语言生效的内容。这包括单词,特殊字符(例如“ ; ”、“ $ ”、“ % ” 或者 “ {} ”),空格或者以上任意的组合。Python 尽可能地使用英语,不像其他编程语言那样经常使用标点符号或者特殊的字符。所以,Python 阅读起来更自然、更像是人类语言。这一点帮助新的编程人员聚焦于解决问题,而且他们能花费更少的时间挣扎在语言自身的特性上。
|
||||
|
||||
清晰语法的同时注重于可读性。在编写代码的时候,你将会创造代码的逻辑“块”,就是一些为了相关联目标而共同工作的代码。在许多编程语言里,这些块用特殊字符所标记(或限定)。他们或许被“ {} ”或者其他字符所包住。块分割字符和你写代码的能力,这两者的任意组合都能增加可读性。让我们来看一个例子。
|
||||
|
||||
这有个被称为 “ fun ”的简短函数。它要求输入一个数字,“ x ”就是它的输入。如果“ x ” 等于 ** 0 **,它将会运行另一个被称为“ no_fun ”的函数(这功能做了些很无趣的事情)。新函数不需要输入。反之,简短函数将会运行一个使用输入 “ x ” 的名为 “ big_fun ”的函数。
|
||||
|
||||
这个函数用[ C 语言 ][5]将会是这样写的:
|
||||
|
||||
```
|
||||
void fun(int x)
|
||||
{
|
||||
if (x == 0) {
|
||||
no_fun();
|
||||
} else {
|
||||
big_fun(x);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
或者,像是这样:
|
||||
|
||||
```
|
||||
void fun(int x) { if (x == 0) {no_fun(); } else {big_fun(x); }}
|
||||
```
|
||||
|
||||
功能上两者等价,而且都能运行。" {} " 和 “ ;” 告诉我们哪里是代码块的不同部分。然而,第一个对于人们来说_明显_更容易阅读。相比之下完成相同功能的 Python 是这样的:
|
||||
|
||||
```
|
||||
def fun(x):
|
||||
if x == 0:
|
||||
no_fun()
|
||||
else:
|
||||
big_fun(x)
|
||||
```
|
||||
|
||||
在这里,只有一个选择。如果代码不是这样排列的,它将不能工作。如果你编写了可以工作的代码,你就有了可阅读的代码。同样也留意一下在语法上的差异。不同的是“ def ” ,在 Python 代码中这个词是英语单词,大家都很熟悉这单词的含义(译者注:def 是 definition 的缩写,定义的意思)。在 C 语言的例子中 “ void ” 和 “ int ” 就没有那么直接。
|
||||
|
||||
Python 也有个优秀的生态系统。这有两层意思,第一,你有一个使用该语言的庞大、活跃的社区,当你需要帮助指导的时候,你能向他们求助。第二,它有大量早已存在的库,库是指完成特定功能的代码集合。从高级数学运算、图形到计算机视觉,甚至是你能想象到的任何事情。
|
||||
|
||||
Python 成为你第一门编程语言有两个缺点。第一是它有时候安装起来很复杂,特别是在运行着 Windows 的电脑上。(如果你有一台 Mac 或者 Linux 的电脑,Python 已经安装好了。)虽然这问题不是不能克服,而且情况总在改善,但是这对于一些人来说还是个阻碍。第二个缺点是,对于那些明确想要建设网站的人来讲,虽然有很多用 Python 写的项目(例如 [Django][6] 和[Flask][7] ),但是编写运行在浏览器上的 Python 代码却没有多少选择。它主要是后台或者服务器端语言。
|
||||
|
||||
### JavaScript
|
||||
|
||||
如果你知道你学习编程的主要原因是建设网站的话,[JavaScript][8]或许是你的最佳选择。 JavaScript 是关于网页的编程语言。除了是网页的默认编程语言之外, JavaScript 作为初学的语言有几点优点。
|
||||
|
||||
第一,无须安装任何东西。你可以打开文本编辑器(例如 Windows 上的记事本,但不是一个文字处理软件例如 Microsoft Word)然后开始输入 JavaScript 。代码将在你的浏览器中运行。最顶尖的浏览器内置了JavaScript 引擎,所以你的代码将会运行在几乎所有的电脑和很多的移动设备上。事实是,能马上在浏览器中运行代码提供了一个非常_快_的反馈,这对于新手来说是很好的。你能尝试一些事情然后很快地看到结果。
|
||||
|
||||
当 JavaScript 开始作为前端语言时,一个名为[Node.js][9] 的环境能让你编写运行在浏览器或者服务器上的代码。现在 JavaScript 能当作前端或者后台语言使用。这增加了它的使用人数。JavaScript 也有很多能提供除核心功能外的额外功能的包,这使得它能当作一门通用语言来使用。JavaScript 不只是网页开发语言,就像 Python 那样,它也有个充满生气的、活跃的生态系统。
|
||||
|
||||
尽管有这些优点,但是 JavaScript 对于新手来说并非十全十美。JavaScript 的语法并不像 Python 那样清晰,也不怎么像英语。更像是之前例子里提到的 C 语言。它并不是把可读性当作主要的设计特性。
|
||||
|
||||
### 做出选择
|
||||
|
||||
选 Python 或者 JavaScript 作为入门语言都很难出错。关键是你打算做什么。为什么你要学习编程?你的回答很大程度上影响你的决定。如果你是想为开源做贡献,你将会找到_大量_用这两门语言编写的项目。另外,许多原本不是用 JavaScript 写的项目仍能被用作前端部件。当你做决定时,别忘了你本地的社区。你有在使用其中一门语言的朋友或者同事吗?对于一个新手来说,有实时的帮助是非常重要的。
|
||||
|
||||
祝好运,开心编程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Kojo Idrissa - 我是一个新晋的软件开发者(1 年),从会计和大学教学转型而来。自从有开源软件以来,我就是它的一个粉丝。但是在我之前的事业中并不需要做很多的编程工作。技术上,我专注于 Python ,自动化测试和学习 Django 。我希望我能尽快地学更多的 JavaScript 。话题上,我专注于帮助刚开始学习编程或想参与为开源项目做贡献的人们。我也关注在技术领域的包容文化。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/choosing-your-first-programming-language
|
||||
|
||||
作者:[Kojo Idrissa][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/transitionkojo
|
||||
[1]: https://opensource.com/article/17/1/choosing-your-first-programming-language?rate=fWoYXudAZ59IkAKZ8n5lQpsa4bErlSzDEo512Al6Onk
|
||||
[2]: https://www.python.org/about/
|
||||
[3]: https://en.wikipedia.org/wiki/Python_syntax_and_semantics
|
||||
[4]: https://en.wikipedia.org/wiki/Python_syntax_and_semantics#Indentation
|
||||
[5]: https://en.wikipedia.org/wiki/C_(programming_language
|
||||
[6]: https://www.djangoproject.com/
|
||||
[7]: http://flask.pocoo.org/
|
||||
[8]: https://en.wikipedia.org/wiki/JavaScript
|
||||
[9]: https://nodejs.org/en/
|
||||
[10]: https://en.wikipedia.org/wiki/JavaScript_syntax#Basics5
|
||||
@ -0,0 +1,38 @@
|
||||
我需要在 AGPLv3 许可证下提供源码么?
|
||||
============================================================
|
||||

|
||||
|
||||
图片提供:
|
||||
|
||||
opensource.com
|
||||
|
||||
[GNU Affero 通用公共许可证版本 3][1](AGPLv3)是与 GPLv3 几乎相同的公共版权许可证。两个许可证具有相同的公共版权范围,但在一个重要方面有重大差异。 AGPLv3 的第 13 节规定了 GPLv2 或 GPLv3 中不存在的附加条件:
|
||||
|
||||
>你必须给你那些使用计算机网络远程(如果你的版本支持此类交互)与它交互的用户提供一个通过网络服务器利用一些标准或者常规复制手段免费获得相关你的版本的源码的机会。
|
||||
|
||||
尽管“通过计算机网络远程交互”的范围应该被理解为涵盖超越常规 SaaS 的情况,但是这个条件主要适用于目前被认为是 SaaS 的部署。目标是在用户使用 web 服务提供功能但是不提供功能代码的分发的环境中关闭普通 GPL 中的感知漏洞。因此,第 13 节提供了超出 GPLv2 第 3 节以及 GPLv3 和 AGPLv3 第 6 节中包含的目标代码分发触发要求的额外源码公开要求。
|
||||
|
||||
常常被误解的是,AGPLv3 第 13 节中的源代码要求仅在 AGPLv3 软件已被“你”(例如,提供网络服务的实体)修改的地方触发。我的解释是,只要“你”不修改 AGPLv3 的代码,许可证不应该被理解为需要按照第 13 节规定的方式访问相应的源码。如我所见,尽管即使公开许可证不必要的源代码也是一个好主意,但在 AGPL 下许多未修改以及标准部署的软件模块根本不会触发第 13 节。
|
||||
|
||||
如何解释 AGPL 的条款和条件,包括 AGPL 软件是否已被修改,可能需要根据具体情况的事实和细节进行法律分析。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Jeffrey R. Kaufman 是全球领先的开源软件解决方案提供商 Red Hat 公司的开源 IP 律师。Jeffrey 也是托马斯·杰斐逊法学院的兼职教授。在入职 Red Hat 之前,Jeffrey 曾经担任高通公司的专利顾问,向首席科学家办公室提供开源顾问。Jeffrey在 RFID、条形码、图像处理和打印技术方面拥有多项专利。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/providing-corresponding-source-agplv3-license
|
||||
|
||||
作者:[Jeffrey Robert Kaufman][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkaufman
|
||||
[1]:https://www.gnu.org/licenses/agpl-3.0-standalone.html
|
||||
@ -0,0 +1,229 @@
|
||||
安卓编年史
|
||||
|
||||
### 安卓 6.0 棉花糖
|
||||
|
||||
2015 年 10 月,谷歌给世界带来了安卓 6.0 棉花糖。配合这个版本的发布,谷歌委托生产了两部新的 Nexus 设备:[华为 Nexus 6P 和 LG Nexus 5X][39]。除了常规的性能升级,新手机还带有一套关键硬件:为棉花糖的新指纹 API 准备的指纹识别器。棉花糖还引入了一个疯狂的全新搜索特性,被称作“Google Now on Tap”,用户控制的应用权限,一个全新的数据备份系统,以及许多其它的改良。
|
||||
|
||||
#### 新谷歌应用
|
||||
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][3]
|
||||
* [
|
||||

|
||||
][4]
|
||||
* [
|
||||

|
||||
][5]
|
||||
* [
|
||||

|
||||
][6]
|
||||
* [
|
||||

|
||||
][7]
|
||||
* [
|
||||

|
||||
][8]
|
||||
* [
|
||||

|
||||
][9]
|
||||
* [
|
||||

|
||||
][10]
|
||||
* [
|
||||

|
||||
][11]
|
||||
|
||||
棉花糖是[谷歌大标志重新设计][40]后的第一个安卓版本。系统也随之升级,主要是一个新的谷歌应用,给搜索小部件,搜索页面以及应用图标添加了一个多彩的标志。
|
||||
|
||||
谷歌将应用抽屉从页面导航的横向布局还原回了单页竖直滚动表的形式。早期版本的安卓用的都是竖直滚动表的形式,直到谷歌在蜂巢中改成了横向页面系统。滚动单页面让人更容易从很多应用中找到目标。一项“快速滚动”的特性同样好用,它可以让你拖动滚动条来激活字母索引。新的应用抽屉布局也用到了小部件抽屉上。考虑到旧系统中小部件轻松就超过了 15 页,这是个大改进。
|
||||
|
||||
棉花糖应用抽屉顶部的“建议应用”栏也让查找应用变得更快。该栏显示的内容一直在变化,试图在你需要的时候为你提供你需要的应用。它使用了算法来统计应用使用,经常一起打开的应用以及每天的打开次数。
|
||||
|
||||
#### Google Now on Tap——一个没有完美实现的特性
|
||||
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][12]
|
||||
* [
|
||||

|
||||
][13]
|
||||
* [
|
||||

|
||||
][14]
|
||||
* [
|
||||

|
||||
][15]
|
||||
* [
|
||||

|
||||
][16]
|
||||
* [
|
||||

|
||||
][17]
|
||||
* [
|
||||

|
||||
][18]
|
||||
* [
|
||||

|
||||
][19]
|
||||
* [
|
||||

|
||||
][20]
|
||||
* [
|
||||

|
||||
][21]
|
||||
* [
|
||||

|
||||
][22]
|
||||
|
||||
棉花糖的头等新特性之一就是“Google Now on Tap”。有了 Now on Tap,你可以在安卓的任意界面长按 home 键,安卓会将整个屏幕发送给谷歌进行处理。谷歌会试着分析页面上的内容,并从屏幕底部弹出显示一个特殊的搜索结果列表。
|
||||
|
||||
Now on Tap 产生的结果不是通常的 10 个蓝色链接——即便那必定有一个通往谷歌搜索的链接。Now on Tap 还可以深度连接到其它使用了谷歌的应用索引功能的应用。他们的想法是你可以在 Youtube 音乐视频那里唤出 Now on tap,然后获得一个到谷歌 Play 或亚马逊“购买”页面的链接。在演员新闻文章处唤出 Now on Tap 可以链接到 IMDb 应用中该演员的页面上。
|
||||
|
||||
谷歌没有让这成为私有特性,而是给安卓创建了一个全新的“Assistant API(助理 API)”。用户可以挑选一个“助理应用”,它可以在长按 home 键的时候获取很多信息。助理应用会获取所有由当前应用加载的数据——不仅是直接从屏幕获取到的——连同所有这些图片还有任何开发者想要包含的元数据。这个 API 驱动了谷歌 Now on Tap,如果愿意的话,它还允许第三方打造 Now on Tap 的竞争对手。
|
||||
|
||||
谷歌在棉花糖的发布会上炒作了 Now on Tap,但实际上,这项特性不是很实用。谷歌搜索的价值在于你可以问它准确的问题——你输入你想要的内容,它搜索整个互联网寻找答案或网页。Now on Tap 让事情变得无限困难,因为它甚至不知道你要问的是什么。你带着特定意图打开了 Now on Tap,但你发送给谷歌的查询是很不准确的“屏幕上的所有内容”。谷歌需要猜测你查询的内容然后试着基于它给出有用的结果或操作。
|
||||
|
||||
在这背后,谷歌可能在疯狂处理整个页面文字和图片来强行获得你想要的结果。但往往 Now on Tap 给出的结果像是页面每个合适的名词的搜索结果列表。从结果列表中筛选多个查询就像是陷入必应的“[搜索结果过载][41]”广告里那样的情形。查询目标的缺失让 Now on Tap 感觉像是让谷歌给你读心,而它永远做不到。谷歌最终给文本选中菜单打了补丁,添加了一个“助理”按钮,给 Now on Tap 提供一些它极度需要的搜索目标。
|
||||
|
||||
不得不说 Now on Tap 是个失败的产物。Now on Tap 的快捷方式——长按 home 键——基本上让它成为了一个隐藏,难以发现的特性,很容易就被遗忘了。我们推测这个特性的使用率非常低。即便用户发现了 Now on Tap,它经常没法读取你的想法,在几次尝试之后,大多数用户可能会选择放弃。
|
||||
|
||||
随着 2016 年 Google Pixels 的发布,谷歌似乎承认了失败。它把 Now on Tap 改名成了“屏幕搜索”并把它降级成了谷歌助手的支援。谷歌助理——谷歌的新语音命令系统——接管了 Now on Tap 的 home 键手势并将它关联到了语音系统激活后的二次手势。谷歌似乎还从 Now on Tap 差劲的可发现性中学到了教训。谷歌给助理给 home 键添加了一组带动画的彩点,帮助用户发现并记住这个特性。
|
||||
|
||||
#### 权限
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][23]
|
||||
* [
|
||||

|
||||
][24]
|
||||
* [
|
||||

|
||||
][25]
|
||||
* [
|
||||

|
||||
][26]
|
||||
* [
|
||||

|
||||
][27]
|
||||
* [
|
||||

|
||||
][28]
|
||||
* [
|
||||

|
||||
][29]
|
||||
* [
|
||||

|
||||
][30]
|
||||
* [
|
||||

|
||||
][31]
|
||||
* [
|
||||

|
||||
][32]
|
||||
|
||||
安卓 6.0 终于引入了应用权限系统,让用户可以细粒度地控制应用可以访问的数据。
|
||||
|
||||
应用在安装的时候不再给你一份长长的权限列表。在棉花糖中,应用安装根本不询问任何权限。当应用需要一个权限的时候——比如访问你的位置、摄像头、麦克风,或联系人列表的时候——它们会在需要用到的时候询问。在你使用应用的时候,如果需要新权限时会弹出一个“允许或拒绝”的对话框。一些应用的设置流程这么处理:在启动的时候询问获取一些关键权限,其它的等到需要用到的时候再弹出提示。这样更好地与用户沟通了需要权限是为了做什么——应用需要摄像头权限,因为你刚刚点击了摄像头按钮。
|
||||
|
||||
除了及时的“允许或拒绝”对话框,棉花糖还添加了一个权限设置界面。这个复选框大列表让数据敏感用户可以浏览应用拥有的权限。他们不仅可以通过应用来查询,也可以通过权限来查询。举个例子,你可以查看所有拥有访问麦克风权限的应用。
|
||||
|
||||
谷歌试验应用权限已经有一段时间了,这些设置界面基本就是隐藏的“[App Ops][42]”系统的重生,它是在安卓 4.3 中不小心引入并很快被移除的权限管理系统。
|
||||
|
||||
尽管谷歌在之前版本就试验过了,棉花糖的权限系统最大的不同是它代表了一个向权限系统的有序过渡。安卓 4.3 的 App Ops 从没有计划暴露给用户,所以开发者不了解它。在 4.3 中拒绝一个应用需要的一个权限经常导致奇怪的错误信息或一个彻底的崩溃。棉花糖的系统对开发者是缺省的——新的权限系统只适用于针对棉花糖 SDK 开发的应用,谷歌将它作为开发者已经为权限处理做好准备的信号。权限系统还允许在一项功能由于权限被拒绝无法正常工作时与用户进行沟通。应用会被告知它们的权限请求被拒绝,它们可以指导用户在需要该功能的时候去打开该权限访问。
|
||||
|
||||
#### 指纹 API
|
||||
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][33]
|
||||
* [
|
||||

|
||||
][34]
|
||||
* [
|
||||

|
||||
][35]
|
||||
* [
|
||||

|
||||
][36]
|
||||
* [
|
||||

|
||||
][37]
|
||||
* [
|
||||

|
||||
][38]
|
||||
|
||||
在棉花糖出现之前,少数厂商推出了他们自己的指纹解决方案以作为对[苹果的 Touch ID][43] 的回应。但在棉花糖中,谷歌终于带来了生态级别的指纹识别 API。新系统包含了指纹注册界面,指纹验证锁屏以及允许应用将内容保护在一个指纹扫描或锁屏验证之后的 API。
|
||||
|
||||
Play 商店是最先支持该 API 的应用之一。你可以使用你的指纹来购买应用,而不用输入你的密码。Nexus 5X 和 6P 是最先支持指纹 API 的手机,手机背面带有指纹读取硬件。
|
||||
|
||||
指纹 API 推出不久后时间,是罕见的安卓生态合作例子之一。所有带有指纹识别的手机都使用谷歌的 API,并且大多数银行和购物应用都很好地支持了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron 是 Ars Technica 的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[1]:https://www.youtube.com/watch?v=f17qe9vZ8RM
|
||||
[2]:https://www.youtube.com/watch?v=VOn7VrTRlA4&list=PLOU2XLYxmsIJDPXCTt5TLDu67271PruEk&index=11
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[25]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[26]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[27]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[28]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[29]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[30]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[31]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[32]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[33]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[34]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[35]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[36]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[37]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[38]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/31/#
|
||||
[39]:http://arstechnica.com/gadgets/2015/10/nexus-5x-and-nexus-6p-review-the-true-flagships-of-the-android-ecosystem/
|
||||
[40]:http://arstechnica.com/gadgets/2015/09/google-gets-a-new-logo/
|
||||
[41]:https://www.youtube.com/watch?v=9yfMVbaehOE
|
||||
[42]:http://www.androidpolice.com/2013/07/25/app-ops-android-4-3s-hidden-app-permission-manager-control-permissions-for-individual-apps/
|
||||
[43]:http://arstechnica.com/apple/2014/09/ios-8-thoroughly-reviewed/10/#h3
|
||||
@ -0,0 +1,171 @@
|
||||
# 幕后变化
|
||||
|
||||
棉花糖对自棒棒糖引入的节电任务调度器 API 进行了扩展。任务调度器将应用后台进程从随意唤醒设备规整成一个有组织的系统。任务调度器基本上就是一个后台进程的交通警察。
|
||||
|
||||
在棉花糖中,谷歌还添加了一个“Doze(休眠)”模式来在设备闲置的时候节约更多电量。如果设备静止不动,未接入电源,并且屏幕处于关闭状态,它会慢慢进入低功耗离线模式,锁定后台进程。在一段时间之后,网络连接会被禁用。唤醒会被锁定——应用会请求唤醒手机来运行后台进程——而它会被忽略。系统警报(不含用户设置的闹钟)以及[任务调度器][25]也会被关闭。
|
||||
|
||||
如果你曾经发现把设备设置为飞行模式,并且注意到电池续航延长了许多,Doze 就像是一个自动飞行模式,在你手机不用的时候介入——它真的延长了电池续航。它对于整天或整夜放在桌子上的手机很有效,对于平板就更好了,因为它常常被遗忘在咖啡桌上。
|
||||
|
||||
唯一能把设备从 Doze 模式唤醒的来自谷歌云消息推送服务的“高优先级消息”。这是为信息服务准备的,所以即使设备处于休眠状态,也能够收取信息。
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][1]
|
||||
* [
|
||||

|
||||
][2]
|
||||
|
||||
“应用待机”是另一项或多或少有用的节电特性,它在后台静默运行。这背后的逻辑很简单:如果你和应用停止交互一段时间,安卓就认为它是不重要的,并取消它访问网络和后台进程的权力。
|
||||
|
||||
对于应用待机而言,和一个应用“交互”意味着打开一个应用,开始一项前台服务,或者生成一条通知。任何其中的一条操作就会重置该应用的待机计时器。对于每种其它边界情况,谷歌在设置里添加了一个名字意味模糊的“电池优化”界面。用户可以在这里设置应用白名单让它免疫应用待机。至于开发者,他们在开发者设置中有个“不活跃应用”选项可以手动设置应用到待机状态来测试。
|
||||
|
||||
应用待机主要是自动禁用你不用的应用,这是个对抗垃圾应用或被遗忘的应用消耗电量的好方法。因为它是完全静默且后台自动执行的,它还能让新手也能拥有一部精心调教过的设备。
|
||||
|
||||
* [
|
||||

|
||||
][3]
|
||||
* [
|
||||

|
||||
][4]
|
||||
* [
|
||||

|
||||
][5]
|
||||
|
||||
谷歌在过去几年尝试了很多应用备份方案,在棉花糖中它又[换了个方案][26]。棉花糖的暴力应用备份系统的目标是保存整个应用数据文件夹到云端。这是可能的并且在技术上是可行的,但即便是谷歌自己的应用对它的支持都不怎么好。设置好一部新安卓手机依然是个大麻烦,要处理无数的登录和弹出教程。
|
||||
|
||||
到界面这里,棉花糖的备份系统使用了谷歌 Drive 应用。在谷歌 Drive 的设置中有一个“管理备份”界面,不仅会显示新备份系统的应用数据,还有谷歌过去几年尝试的其它应用备份方案的数据。
|
||||
|
||||

|
||||
|
||||
|
||||
藏在设置里的还有一个新的“应用关联”功能,它可以将应用“链接”到网站。在应用关联出现之前,在全新安装的机器上打开一个谷歌地图链接通常会弹出一个“使用以下方式打开”的对话框,来获知你是想在浏览器还是在谷歌地图应用中打开这个链接。
|
||||
|
||||
这是个愚蠢的问题,因为你当然是想用应用而不是网站——这不就是你安装这个应用的原因嘛。应用关联让网站拥有者可以将他们的应用和网页相关联。如果用户安装了应用,安卓会跳过“使用以下方式打开”直接使用应用。要激活应用关联,开发者只需要在网站放一些安卓会识别的 json 代码。
|
||||
|
||||
应用关联对拥有指定客户端应用的站点来说很棒,比如谷歌地图、Instagram、Facebook。对于有 API 以及多种客户端的站点,比如 Twitter,应用关联界面让用户可以设置任意地址的默认关联应用。不过默认应用关联覆盖了百分之九十的用例,在新手机上大大减少了烦人的弹窗。
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][6]
|
||||
* [
|
||||

|
||||
][7]
|
||||
* [
|
||||

|
||||
][8]
|
||||
* [
|
||||

|
||||
][9]
|
||||
* [
|
||||

|
||||
][10]
|
||||
* [
|
||||

|
||||
][11]
|
||||
* [
|
||||

|
||||
][12]
|
||||
* [
|
||||

|
||||
][13]
|
||||
* [
|
||||

|
||||
][14]
|
||||
* [
|
||||

|
||||
][15]
|
||||
|
||||
可选存储是棉花糖的最佳特性之一。它将 SD 卡从一个二级存储池转换成一个完美的合并存储方案。插入 SD 卡,将它格式化,然后你就有了更多的存储空间,而这是你从来没有想过的事情。
|
||||
|
||||
插入 SD 卡会弹出一条设置通知,用户可以选择将卡格式化成“外置”或“内置”存储。“内置”存储选项就是新的可选存储模式,它会将存储卡格式化为 ext4 文件系统。唯一的缺点?那就是存储卡和数据都被“锁定”到你的手机上了。如果不格式化的话,你没法取出存储卡茶道其它地方使用。谷歌对于内置存储的使用场景判断就是一旦设置就不再更改。
|
||||
|
||||
如果你强行拔出了 SD 卡,安卓会尽它最大的努力处理好。它会弹出一条消息“建议最好将 SD 卡插回”和一个“忘记”这张卡的选项。当然“忘记”这张卡将会导致各种数据丢失,建议最好不要这么做。
|
||||
|
||||
不幸的是实际上可以使用可选存储的设备很长时间都没有出现。Nexus 设备不支持存储卡,所以为了测试我们插上了一个 U 盘作为我们的可选存储。OEM 厂商最初抵制这项功能,[LG 和三星][27]都在他们 2016 年初的旗舰机上禁用了它。三星说“我们相信我们的用户需要 microSD 卡是用来在手机和其它设备之间转移数据的”,一旦卡被格式化成 ext4 这就不可能了。
|
||||
|
||||
谷歌的实现让用户可以在外置和内置存储选项之间选择。但 OEM 厂商完全拿掉了内置存储功能,不给用户选择的机会。高级用户们对此很不高兴,并且安卓定制组们很快就重启启用了可选存储。在 Galaxy S7 上,第三方定制组甚至在官方发布的[的前一天][28]解除了三星的 SD 卡锁定。
|
||||
|
||||
#### 音量和通知
|
||||
|
||||
|
||||
* [
|
||||

|
||||
][16]
|
||||
* [
|
||||

|
||||
][17]
|
||||
* [
|
||||

|
||||
][18]
|
||||
* [
|
||||

|
||||
][19]
|
||||
* [
|
||||

|
||||
][20]
|
||||
* [
|
||||

|
||||
][21]
|
||||
* [
|
||||

|
||||
][22]
|
||||
* [
|
||||

|
||||
][23]
|
||||
* [
|
||||

|
||||
][24]
|
||||
|
||||
为了更简洁的设计,谷歌将通知优先级控制从音量弹窗中移除了。按下音量键会弹出一个单独的滑动条,对应当前音源控制,还有一个下拉按钮可以展开控制面板,显示所有的三个声音控制条:通知,媒体和闹钟。所有的通知优先级控制还在——它们现在在一个“勿扰模式”的快速设置方块中。
|
||||
|
||||
通知控制最有用的新功能之一是允许用户控制抬头通知——现在叫“预览”通知。这项功能让通知在屏幕顶部弹出,就像 iOS 那样。谷歌认为最重要的通知应该提升到高于你普通日常通知的地位。
|
||||
|
||||
但是,在棒棒糖中,这项特性引入的时候,谷歌糟糕地让开发者来决定他们的应用是否“重要”。毫无疑问,所有开发者都认为他的应用是世界上最重要的东西。所以尽管最初这项特性是为你亲密联系人的即时消息设计的,最后变成了被 Facebook 的点赞通知所操控。在棉花糖中,每个应用在通知设置都有一个“设置为优先”复选框,给了用户一把大锤来收拾不守规矩的应用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron 是 Ars Technica 的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/32/#
|
||||
[25]:http://arstechnica.com/gadgets/2014/11/android-5-0-lollipop-thoroughly-reviewed/6/#h2
|
||||
[26]:http://arstechnica.com/gadgets/2015/10/android-6-0-marshmallow-thoroughly-reviewed/6/#h2
|
||||
[27]:http://arstechnica.com/gadgets/2016/02/the-lg-g5-and-galaxy-s7-wont-support-android-6-0s-adoptable-storage/
|
||||
[28]:http://www.androidpolice.com/2016/03/10/modaco-manages-to-get-adoptable-sd-card-storage-working-on-the-galaxy-s7-and-galaxy-s7-edge-no-root-required/
|
||||
@ -0,0 +1,132 @@
|
||||
5 个针对有经验用户的 Vim 实用技巧
|
||||
============================================================
|
||||

|
||||
|
||||
这篇文章是 [Vim 用户指南][12]系列文章中的一篇:
|
||||
|
||||
* [Vim 初学者入门指南][3]
|
||||
* [Vim 快捷键速查表][4]
|
||||
* [3 个针对高级用户的 Vim 编辑器实用技巧][5]
|
||||
|
||||
Vim 编辑器提供了很多的特性,要想全部掌握它们很困难。然而,花费更多的时间在命令行编辑器上总是有帮助的。毫无疑问,和 Vim 用户们进行交流能够让你更快地学习新颖有创造性的东西。
|
||||
|
||||
|
||||
**注** - 本文中用到的例子,使用的 Vim 版本是 7.4.52 。
|
||||
|
||||
### 1\. 同时编辑多个文件
|
||||
|
||||
如果你是一名软件开发者或者把 Vim 作为主要的编辑器,那么可能很多时候你需要同时编辑多个文件。“紧跟(following)”是在同时编辑多个文件时可用的实用技巧。
|
||||
|
||||
不需要在多个 shell 界面中打开多个文件,你可以通过把多个文件的文件名作为 Vim 命令的参数从而在一个 shell 界面中打开多个文件。比如:
|
||||
|
||||
```
|
||||
vim 文件1 文件2 文件3
|
||||
```
|
||||
|
||||
第一个文件(例子中的文件1)将成为当前文件并被读入缓冲区。
|
||||
|
||||
在编辑器中,使用 ‘:next’ 或 ’:n’ 命令来移动到下一个文件,使用 ‘:prev’ 或 ‘:N’ 命令返回上一个文件。如果想直接切换到第一个文件或最后一个文件,使用 ‘:bf’ 和 ‘:bl’ 命令。特别地,如果想打开另外的文件并编辑,使用 ‘:e’ 命令并把文件名作为参数(如果该文件不在当前目录中则需要完整路径做为参数)。
|
||||
|
||||
任何时候如果需要列出当前打开的所有文件,使用 ‘:ls’ 命令。看下面展示的屏幕截图。
|
||||
|
||||

|
||||
|
||||
注意 ”%a” 表示文件在当前活动窗口,而 “#” 表示文件在上一个活动窗口。
|
||||
|
||||
### 2\. 通过自动补全节约时间
|
||||
|
||||
想节约时间并提高效率吗?使用 ‘abbreviations(缩写)’吧。使用它们能够快速写出文件中多次出现、复杂冗长的词。在 Vim 命令中 ‘abbreviations(缩写)’的缩写就是 ‘ab’ 。
|
||||
比如,当你运行下面的命令以后:
|
||||
|
||||
```
|
||||
:ab asap as soon as possible
|
||||
```
|
||||
|
||||
文件中出现的每一个 "asap" 都会被自动替换为 “as soon as possible” ,就像你自己输入的一样。
|
||||
|
||||
类似地,你可以使用缩写来更正常见的输入错误。比如,下面的命令
|
||||
|
||||
```
|
||||
:ab recieve receive
|
||||
```
|
||||
|
||||
将会自动更正拼写错误,就像你自己输入的一样。如果在一次特殊情况下你想阻止扩展/更正发生,那么你只需要在输入一个单词的最后一个字母以后按 “Ctrl + V” ,然后按空格键。
|
||||
|
||||
如果你想把刚才使用的缩写保存下来,从而当你下次使用 Vim 编辑器的时候可以再次使用,那么只需将完整的 ‘ab’ 命令(没有起始的冒号)添加到 ”/etc/vim/vimrc“ 文件中。如果想删除某个缩写,你可以使用 “una” 命令。比如: ‘una asap’ 。
|
||||
|
||||
|
||||
### 3\. 分离窗口来进行‘复制/粘贴’
|
||||
|
||||
有时,你需要将一段代码或文本的一部分从一个文件复制到另一个。当使用 GUI(图形界面)编辑器的时候,这很容易实现,但是当使用一个命令行编辑器的时候,这就变得比较困难并且很费时间。幸运的是, Vim 提供了一种高效、节约时间的方式来完成这件事。
|
||||
|
||||
打开两个文件中的一个然后分离 Vim 窗口来打开另一个文件。可以通过使用 ‘split’ 命令并以文件名作为参数来完成这件事。比如:
|
||||
|
||||
```
|
||||
:split test.c
|
||||
```
|
||||
|
||||
上面的命令将分离窗口并打开文件 “test.c”
|
||||
|
||||

|
||||
|
||||
注意到 ‘split’ 命令水平分离 Vim 窗口。如果你想垂直分离窗口,那么你可以使用 ‘vsplit’ 命令。当同时打开了两个文件并从一个文件中复制好内容以后,按 “Ctrl + W” 切换到另一个文件,然后’粘贴’。
|
||||
|
||||
### 4\. 保存一个没有权限的已编辑文件
|
||||
|
||||
有时候当你对一个文件做了大量更改以后才会意识到该文件仅有 ‘只读’ 权限。
|
||||
|
||||

|
||||
|
||||
虽然把文件关闭,获取权限以后再重新打开是一种解决方法。但是如果你已经做了大量更改,这样做会很浪费时间,因为在这个过程中所有的更改都会丢失。 Vim 提供了一种方式来处理这种情况:你可以在编辑器中在保存文件前更改文件权限。命令是:
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
```
|
||||
|
||||
这个命令将会向你询问密码,就像在命令行中使用 ‘sudo’ 一样,然后就能保存更改。
|
||||
|
||||
**一个相关的技巧**:在 Vim 中编辑一个文件的时候,如果想快速进入命令行提示符,可以在编辑器中运行 ‘:sh’ 命令,从而你将进入一个交互的 shell 中。完成以后,运行 ‘exit’ 命令可以快速回到 Vim 模式中。
|
||||
|
||||
### 5\. 在复制/粘贴过程中保持缩进
|
||||
|
||||
大多数有经验的程序员在 Vim 上工作时都会启用自动缩进。虽然这是一个节约时间的做法,但是在粘贴一段已经缩进了的代码的时候会产生新的问题。比如,下图是我把一段已缩进代码粘贴到一个在自动缩进的 Vim 编辑器中打开的文件中时遇到的问题:
|
||||
|
||||

|
||||
|
||||
这个问题的解决方法是 ‘pastetoggle’ 选项。
|
||||
在 ‘/etc/vim/vimrc’ 文件中加入下面这行内容:
|
||||
|
||||
```
|
||||
set pastetoggle=<F2>
|
||||
```
|
||||
|
||||
然后当你在 ‘插入’ 模式中准备粘贴代码前先按 ‘F2’ 键,就不会再出现上图中的问题,这样会保留原始的缩进。注意,你可以用其他的任何键来代替 ‘F2’ 如果它已经映射到了别的功能上。
|
||||
|
||||
### 结论
|
||||
|
||||
更进一步的提高你的 Vim 编辑器技巧的唯一方法是,在你日复一日的工作中使用命令行编辑器。留意那些耗时多的操作,然后尝试去寻找是否有编辑器命令可以很快地完成这个操作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://www.maketecheasier.com/author/himanshu/
|
||||
[2]:https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/#comments
|
||||
[3]:https://www.maketecheasier.com/start-with-vim-linux/
|
||||
[4]:https://www.maketecheasier.com/vim-keyboard-shortcuts-cheatsheet/
|
||||
[5]:https://www.maketecheasier.com/vim-tips-tricks-advanced-users/
|
||||
[6]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[7]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-for-experienced-users%2F
|
||||
[8]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-for-experienced-users%2F&text=5+Vim+Tips+and+Tricks+for+Experienced+Users
|
||||
[9]:mailto:?subject=5%20Vim%20Tips%20and%20Tricks%20for%20Experienced%20Users&body=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-for-experienced-users%2F
|
||||
[10]:https://www.maketecheasier.com/enable-two-step-verification-apple-icloud-account/
|
||||
[11]:https://www.maketecheasier.com/mistakes-wordpress-user-should-avoid/
|
||||
[12]:https://www.maketecheasier.com/series/vim-user-guide/
|
||||
[13]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
@ -1,210 +0,0 @@
|
||||
3 个在 Linux 中永久并安全删除`文件和目录`的方法
|
||||
============================================================
|
||||
|
||||
在大多数情况下,我们习惯于[从我们的计算机中删除文件][1],例如使用 `Delete` 键、垃圾箱或 `rm` 命令,这不是永久安全地从硬盘中(或任何存储介质)删除文件的方法。
|
||||
|
||||
该文件只是对用户隐藏,它驻留在硬盘上的某个地方。它可以通过数据窃贼、执法或其他威胁来恢复。
|
||||
|
||||
假设文件包含密级或机密内容,例如安全系统的用户名和密码,具有必要知识和技能的攻击者可以轻松地[恢复删除文件的副本][2]并访问这些用户凭证(你可以猜测到这种情况的后果)。
|
||||
|
||||
在本文中,我们将解释一些命令行工具,用于永久并安全地删除 Linux 中的文件。
|
||||
|
||||
### 1\. shred – 覆盖文件来隐藏内容
|
||||
|
||||
shred 会覆盖文件来隐藏它的内容,并且也可以选择删除它。
|
||||
|
||||
```
|
||||
$ shred -zvu -n 5 passwords.list
|
||||
```
|
||||
|
||||
在下面的命令中,选项有:
|
||||
|
||||
1. `-z` - 用零覆盖以隐藏碎片
|
||||
2. `-v` - 显示操作进度
|
||||
3. `-u` - 在覆盖后截断并删除文件
|
||||
4. `-n` - 指定覆盖文件内容的次数(默认值为3)
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
shred - 覆盖文件来隐藏它的内容
|
||||
|
||||
你可以在 shred 的帮助页中找到更多的用法选项和信息:
|
||||
|
||||
```
|
||||
$ man shred
|
||||
```
|
||||
|
||||
### 2\. wipe – 在 Linux 中安全删除文件
|
||||
|
||||
Linux wipe 命令可以安全地擦除磁盘中的文件,从而不可能[恢复删除的文件或目录内容] 4]。
|
||||
|
||||
首先,你需要安装 wipe 工具,运行以下适当的命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get install wipe [On Debian and its derivatives]
|
||||
$ sudo yum install wipe [On RedHat based systems]
|
||||
```
|
||||
|
||||
下面的命令会摧毁 private 目录下的所有文件。
|
||||
|
||||
```
|
||||
$ wipe -rfi private/*
|
||||
```
|
||||
|
||||
当使用下面的标志时:
|
||||
|
||||
1. `-r` - 告诉 wipe 递归擦除子目录
|
||||
2. `-f` - 启用强制删除并禁用确认查询
|
||||
3. `-i` - 显示擦除进度
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
wipe – 在 Linux 中安全擦除文件
|
||||
|
||||
注意:wipe 仅在磁性存储上可以可靠地工作,因此对固态磁盘(内存)请使用其他方法。
|
||||
|
||||
阅读 wipe 手册以获取其他使用选项和说明:
|
||||
|
||||
```
|
||||
$ man wipe
|
||||
```
|
||||
|
||||
### 3\. Linux 中的安全删除工具集
|
||||
|
||||
secure-delete 是一个安全文件删除工具的集合,它包含srm(secure_deletion)工具,用于安全删除文件。
|
||||
|
||||
首先,你需要使用以下相关命令安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install secure-delete [On Debian and its derivatives]
|
||||
$ sudo yum install secure-delete [On RedHat based systems]
|
||||
```
|
||||
|
||||
安装完成后,你可以使用 srm 工具在 Linux 中安全地删除文件和目录。
|
||||
|
||||
```
|
||||
$ srm -vz private/*
|
||||
```
|
||||
|
||||
下面是使用的选项:
|
||||
|
||||
1. `-v` – 启用 verbose 模式
|
||||
2. `-z` – 用0而不是随机数据来擦除最后的写入
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
srm – 在 Linux 中安全删除文件
|
||||
|
||||
阅读 srm 手册来获取更多的使用选项和信息:
|
||||
|
||||
```
|
||||
$ man srm
|
||||
```
|
||||
|
||||
### 4\. sfill -安全免费的磁盘/inode 空间擦除器
|
||||
|
||||
sfill 是 secure-deletetion 工具包的一部分,是一个安全免费的磁盘和 inode 空间擦除器,它以安全的方法删除可用磁盘空间中的文件。 sfill 会[检查指定分区上的可用空间][7],并使用来自 /dev/urandom 的随机数据填充它。
|
||||
|
||||
以下命令将在我的根分区上执行 sfill,使用 `-v' 选项启用 verbose 模式:
|
||||
|
||||
```
|
||||
$ sudo sfill -v /home/aaronkilik/tmp/
|
||||
```
|
||||
|
||||
假设你创建了一个单独的分区 `/home` 来存储正常的系统用户主目录,你可以在该分区上指定一个目录,以便在其上应用 sfill:
|
||||
|
||||
```
|
||||
$ sudo sfill -v /home/username
|
||||
```
|
||||
|
||||
你可以在 sfill 的手册上看到一些限制,你也可以看到额外的使用标志和命令:
|
||||
|
||||
```
|
||||
$ man sfill
|
||||
```
|
||||
|
||||
注意:secure-deletetion 工具包中的两个工具(sswap 和 sdmem)与本指南的范围不直接相关,但是,我们会在将来为了传播知识的目的来解释它们。
|
||||
|
||||
### 5\. sswap – 安全 swap 擦除器
|
||||
|
||||
它是一个安全的分区擦除器,sswap以安全的方式删除 swap 分区上存在的数据。
|
||||
|
||||
警告:请记住在使用 sswap 之前卸载 swap 分区! 否则你的系统可能会崩溃!
|
||||
|
||||
只需确定交换分区(并检查分页和交换设备/文件是否使用 swapon 命令打开),接下来,使用 swapoff 命令禁用分页和交换设备/文件(使 swap 分区不可用)。
|
||||
|
||||
然后在 swap 分区上运行 sswap 命令:
|
||||
|
||||
```
|
||||
$ cat /proc/swaps
|
||||
$ swapon
|
||||
$ sudo swapoff /dev/sda6
|
||||
$ sudo sswap /dev/sda6 #this command may take some time to complete with 38 default passes
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
sswap – 安全 swap 擦除器
|
||||
|
||||
阅读 sswap 的手册来获取更多的选项和信息:
|
||||
|
||||
```
|
||||
$ man sswap
|
||||
```
|
||||
|
||||
### 6\. sdmem – 安全内存擦除器
|
||||
|
||||
sdmem 是一个安全的内存擦除器,它被设计为以安全的方式删除存储器(RAM)中的数据。
|
||||
|
||||
它最初命名为[smem][9],但是因为在 Debain 系统上存在另一个包[smem - 报告每个进程和每个用户的内存消耗][10],开发人员决定将它重命名为 sdmem。
|
||||
|
||||
```
|
||||
$ sudo sdmem -f -v
|
||||
```
|
||||
|
||||
关于更多的使用信息,阅读 sdmen 的手册:
|
||||
|
||||
```
|
||||
$ man sdmem
|
||||
```
|
||||
|
||||
**推荐阅读:** [PhotoRec – 在 Linux 中恢复删除或遗失的文件][11]
|
||||
|
||||
就是这样了!在本文中,我们审查了一系列可以永久安全地删除 Linux 中的文件的工具。像往常一样,通过下面的评论栏发表你对本篇文章的想法或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
我是 Ravi Saive,TecMint 的创建者。 一个计算机 Geek 和 Linux 大师,喜欢在互联网上分享技巧和贴士。我的服务器大多数运行在称为 Linux 的开源平台上。关注我:Twitter、Facebook 和 Google+
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/delete-all-files-in-directory-except-one-few-file-extensions/
|
||||
[2]:http://www.tecmint.com/photorec-recover-deleted-lost-files-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/shred-command-example.png
|
||||
[4]:http://www.tecmint.com/recover-deleted-file-in-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/01/Wipe-Securely-Erase-Files.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/01/srm-securely-delete-Files-in-Linux.png
|
||||
[7]:http://www.tecmint.com/find-top-large-directories-and-files-sizes-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/01/sswap-Secure-Swap-Wiper.png
|
||||
[9]:http://www.tecmint.com/smem-linux-memory-usage-per-process-per-user/
|
||||
[10]:http://www.tecmint.com/smem-linux-memory-usage-per-process-per-user/
|
||||
[11]:http://www.tecmint.com/photorec-recover-deleted-lost-files-in-linux/
|
||||
@ -1,109 +0,0 @@
|
||||
Linux 下 4 个最好的命令行下载管理器/加速器
|
||||
============================================================
|
||||
|
||||
我们经常由于不同需求使用下载管理器从互联网下载文件,这是对我和其他人的主要贡献之一。我们都想要一个超级快速的下载管理器来完成下载尽可能多的任务,以便我们可以节省时间来进一步地工作。这里有很多可以加速下载的下载管理器和加速器可用(图形化界面和命令行界面)。
|
||||
|
||||
所有的下载工具做着同样的任务,但它们的处理和功能是不同的,单线程和多线程、交互和非交互。 在这里,我们将列出四个最好的我们日常工作使用的命令行下载加速器。
|
||||
|
||||
#### #1 Aria2
|
||||
|
||||
[Aria2][1] 是一个用于 Linux、Windows 和 Mac OSX 的轻量级多协议和多来源的命令行下载管理器/实用程序。它支持HTTP/HTTPS、FTP、SFTP、BitTorrent 和 Metalink。aria2 可以通过内置的 JSON-RPC 和 XML-RPC 接口操作。
|
||||
|
||||
它支持多线程,使用多个源/协议下载文件,确实可以加速并尽可能多的完成下载。
|
||||
|
||||
它非常轻量级,不需要太多的内存和 CPU。我们可以使用它作为 BitTorrent 客户端,因为它有所有你想要的 BitTorrent 客户端的功能。
|
||||
|
||||
#### Aria2 功能
|
||||
|
||||
* HTTP/HTTPS GET支持
|
||||
* HTTP 代理支持
|
||||
* 支持 HTTP BASIC 认证
|
||||
* HTTP 代理认证支持
|
||||
* FTP 支持(主动、被动模式)
|
||||
* FTP 通过 HTTP 代理(GET 命令或隧道)
|
||||
* 分段下载
|
||||
* Cookie 支持
|
||||
* 它可以作为守护进程运行。
|
||||
* BitTorrent 协议支持与快速扩展。
|
||||
* 在含有多个文件的 torrent 中的选择性下载
|
||||
* Metalink 版本 3.0 支持(HTTP/FTP/BitTorrent)。
|
||||
* 限制下载/上传速度
|
||||
|
||||
有关 Aria2 的进一步用法,请参阅以下文章。
|
||||
|
||||
[如何在 Linux 中安装和使用 Aria2][2]。
|
||||
|
||||
#### #2 Axel
|
||||
|
||||
[Axel][3] 是一个轻量级下载程序,它如其他加速器那样做着同样的事情。它为一个文件打开多个连接,每个连接下载单独的文件片段以更快地完成下载。
|
||||
|
||||
Axel 支持 HTTP、HTTPS、FTP和 FTPS 协议。它也可以使用多个镜像下载单个文件。 所以,Axel 可以为下载加速高达40%(大约,我个人认为)。 它非常轻量级,因为没有依赖,而且使用非常少的 CPU 和 RAM。
|
||||
|
||||
Axel 使用一个单线程将所有数据直接下载到目标文件。
|
||||
|
||||
注意:没有选项可以在单条命令中下载两个文件。
|
||||
|
||||
有关 Axel 的更多使用,请参阅以下文章。
|
||||
|
||||
[如何在 Linux 中安装和使用 Axel][4]。
|
||||
|
||||
#### #3 Wget
|
||||
|
||||
[wget][5](以前称为 Geturl)是一个免费的、开源的命令行下载程序,它使用 HTTP、HTTPS 和 FTP 这些最广泛使用的 Internet 协议检索文件。它是一个非交互式命令行工具,其名字表示从万维网中获取文件。
|
||||
|
||||
wget 相比其它工具将下载处理得相当好,即使它不支持多线程和包括后台工作、递归下载、多个文件下载、恢复下载、非交互式下载和大文件下载等功能。
|
||||
|
||||
默认情况下,所有的 Linux 发行版都包含 wget,所以我们可以从官方仓库轻松安装,也可以安装到 windows 和 Mac 操作系统。
|
||||
|
||||
wget 可在慢速或不稳定的网络连接下保持鲁棒性,如果由于网络问题下载失败,它将继续重试,直到整个文件下载完成。如果服务器支持重新获取,它将指示服务器从中断的地方继续下载。
|
||||
|
||||
#### wget 功能
|
||||
|
||||
* 可以使用 REST 和 RANGE 恢复中止的下载
|
||||
* 可以使用文件名通配符和递归镜像目录
|
||||
* 为许多不同语言的基于 NLS 的消息文件
|
||||
* 可选将下载的文档中的绝对链接转换为相对链接,以便下载的文档可以在本地链接到彼此
|
||||
* 可在大多数类 UNIX 操作系统以及 Microsoft Windows 上运行
|
||||
* 支持 HTTP 代理
|
||||
* 支持 HTTP cookie
|
||||
* 支持持久 HTTP 连接
|
||||
* 无人值守/后台操作
|
||||
* 使用本地文件时间戳来确定是否需要在镜像时重新下载文档
|
||||
|
||||
有关 wget 的进一步用法,请参阅以下文章。
|
||||
|
||||
[如何在 Linux 中安装和使用 wget][6]。
|
||||
|
||||
#### #4 Curl
|
||||
|
||||
[curl][7] 类似于 wget,但是不支持多线程,但令人惊讶的是,与 wget 相比,它的下载速度更快。
|
||||
|
||||
curl 是一个向服务器上传或下载的数据传输工具,支持的协议有 DICT、FILE、FTP、FTPS、GOPHER、HTTP、HTTPS、IMAP、IMAPS、LDAP、LDAPS、POP3、POP3S、RTMP、RTSP、SCP、SFTP、SMTP、SMTPS、TELNET 和 TFT 等。
|
||||
|
||||
该命令无需用户交互即可工作。此外,curl 支持代理、用户身份验证、FTP 上传、HTTP POST、SSL 连接、Cookie、恢复文件传输、Metalink 等。curl 由 libcurl 为所有相关传输功能提供支持。
|
||||
|
||||
如果指定的 URL 没有 `protocol://` 前缀,curl 将尝试猜测你可能需要什么协议。例如,以 “ftp.” 开头的主机名 curl 将假定你要使用 FTP。如果没有找到特定的协议,那么默认为 HTTP。
|
||||
|
||||
参考下面的文章来进一步使用 curl。
|
||||
|
||||
[如何在 Linux 中安装和使用 curl] [8]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/best-4-command-line-download-managers-accelerators-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:https://aria2.github.io/
|
||||
[2]:http://www.2daygeek.com/aria2-command-line-download-utility-tool/
|
||||
[3]:https://axel.alioth.debian.org/
|
||||
[4]:http://www.2daygeek.com/axel-command-line-downloader-accelerator-for-linux/
|
||||
[5]:https://www.gnu.org/software/wget/
|
||||
[6]:http://www.2daygeek.com/wget-command-line-download-utility-tool/
|
||||
[7]:https://curl.haxx.se/
|
||||
[8]:http://www.2daygeek.com/curl-command-line-download-manager/
|
||||
149
translated/tech/20161225 Minecraft Server on Linux.md
Normal file
149
translated/tech/20161225 Minecraft Server on Linux.md
Normal file
@ -0,0 +1,149 @@
|
||||
# Linux 上搭建 Minecraft 服务器
|
||||
|
||||
|
||||

|
||||
|
||||
“我的世界”是一个在不同的控制器和计算机系统存在较多玩家的游戏。 截至2016年6月,在所有平台上已经超过 10亿6千万在所有平台上售卖。因为它受欢迎,你可能想在家里举办一个 Minecraft 派对。为此,你(需要)安装一个 “我的世界” 服务器去允许所有用户连接在同一个世界中一起玩
|
||||
|
||||
**系统要求**
|
||||
|
||||
为了玩耍,你需要一个 Linux 操作系统有相当数量 RAM (译者:就是 “RW内存条”,这游戏内存要求高)更多的玩家你将需要更多的 RAM 在服务器上。硬件设备空间不是需求很大,只要足够去安装 Java 以及 ”我的世界“ 服务器 Java 文件。无论有线或无线网络,Minecraft服务器应该有一个体面的网络连接。
|
||||
|
||||
让我们看看 ”我的世界“ 服务器最低要求:
|
||||
|
||||
**CPU: **双核或更好
|
||||
|
||||
**RAM:** 2 GB ( 20-40 用户量 ), 3 GB ( 30-60 用户量 ), 8 GB ( 60+ 用户量 )
|
||||
**OS:** 没有图形化用户接口(GUI)去允许更多资源空闲。
|
||||
|
||||
**NOTE:** ”我的世界“ 针对服务端程序而不是一个完整的操作系统!如果资源较多可以分配到 Minecraft 服务器,它将变得更易操作。
|
||||
|
||||
**安装 Java **
|
||||
|
||||
Linux 操作系统首次运行,需要你去安装最新版本的 Java 程序。
|
||||
|
||||
为了验证你的 Java 版本,位于终端输入以下命令:”java -version“。结果应该是:
|
||||
|
||||
```
|
||||
java version "1.8.0_101"
|
||||
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
|
||||
|
||||
Java HotSpot(TM) Client VM (build 25.101-b13, mixed mode)
|
||||
```
|
||||
|
||||
如果你的 Java 版本正确不是 1.8 或者更高,则通过在Ubuntu系统上的终端执行以下操作来安装Java版本8:
|
||||
|
||||
1. _sudo add-apt-repository ppa:webupd8team/java_
|
||||
2. _sudo apt-get update_
|
||||
3. sudo apt-get install oracle-java8-*installer*
|
||||
|
||||
**NOTE:**如果 'add-apt-repository' 命令无法找到,运行'sudo apt-get install software-properties-common'。 您还可以将第三个命令更改为最新版本的 'oracle-java9-installer' java 版本。
|
||||
|
||||
对于 Redhat 系统(如 CentOS),请使用以下命令:
|
||||
|
||||
1. _sudo yum install java-1.8.0-openjdk_
|
||||
|
||||
安装后,核实键入版本命令, 'java-version' , 并且核实输出。这样你就有了一个适当的 Java 版本,你可以继续前进接下去的安装。
|
||||
|
||||
**Minecraft 服务器版本下载**
|
||||
|
||||
接下来做的事就是去检查用户将运行的 Minecraft 的版本。图1 显示一个系统运行 ”我的世界“ 并注意左下角的版本号。
|
||||
|
||||

|
||||
|
||||
**图 1**
|
||||
|
||||
请记住”我的世界“客户端版本号。每个客户端应该是相同的版本去完成这项工作。
|
||||
|
||||
您接下来要做的是下载,客户端需要的 Minecraft 服务器的版本。为了下载版本你需要知道它的位置。命令得到需要的文件是:
|
||||
|
||||
_sudo wget _[_https://s3.amazonaws.com/Minecraft.Download/versions/[version]/minecraft_server.[version].jar_][1]
|
||||
|
||||
在图1看到,版本号是 1.10.2。那么这个命令就该变成:
|
||||
|
||||
_sudo wget _[_https://s3.amazonaws.com/Minecraft.Download/versions/1.10.2/minecraft_server.1.10.2.jar_][2]
|
||||
|
||||
当你下载文件,使用命令它可以保存到正确的目录。为了确定正确位置用命令 'pwd'
|
||||
|
||||
一旦你有了文件,知道它已被保存的文件夹就可以继续了。
|
||||
|
||||
**服务器信息**
|
||||
|
||||
在启动 Minecraft 服务器之前,您必须知道当前系统上可用 RAM 的大小以及能被使用的内存。 当启动 Minecraft 服务器时,您将指定 RAM 的初始值和最大值的 RAM,以供更多玩家加入。 再次重要的是有足够的 RAM 。 如果可以,使用最小安装操作系统(OS),例如最小安装 Ubuntu 以获得更多 RAM 。
|
||||
|
||||
一旦你有你需要的 Minecraft 服务器文件,就可以确定分配给 Minecraft 的 RAM 的数量。 要确定可用RAM打开一个终端并键入以下命令 ,一个示例输出如 图 2 所示:
|
||||
|
||||
_free -h_
|
||||
|
||||

|
||||
|
||||
**图 2**
|
||||
|
||||
如图2所示,在这个低端系统上,立你可以看到那只有 684 MB 空余 RAM。这不是一个满足要求的系统去搭建一个 “我的世界” 服务器。在另一个服务器我有 2.8G(内存)可供给 “我的世界” 用。
|
||||
|
||||
在我们启动服务器之前,我们需要找到服务器的IP地址。 为此,请运行命令'ifconfig'。 如图3所示,应该有一个网络连接的列表,显示一个Internet地址或'inet addr',它是'192.168.0.2'。 在我的服务器系统上,它列出了地址“192.168.0.14”,这是将从客户端系统使用的地址。
|
||||
|
||||

|
||||
|
||||
**图 3**
|
||||
|
||||
**搭建 Minecraft 服务器**
|
||||
|
||||
下一步才是真正的开始 ”我的世界“ 服务器。事实上在开始前,有几个项目要修改(覆盖?)。 当启动“我的世界”服务器,指定为 Minecraft 初始化多少内存。 您还将指定使用的最大内存。
|
||||
|
||||
如果我的系统有 3.7GB 闲置内存,我便知道将有小于 40 位玩家(可以游戏),于是我只需要划出 2GB。当然,我可以增加些(内存)以允许用户增长。如果(系统)需要,我还想留一点内存给系统(运行)。(说干就干,)我将最小值设置为 2 GB,最大值设置为 3 GB。 由于最大值设置为 3 GB,可以保留(除去?)系统需要的 700 MB RAM,但这只有当 Minecraft 服务器使用超过最初的2 GB。(译者注:作者的意思是说,3.7GB内存,划分2GB给40位游戏玩家。玩家最多是把 3GB 全用掉。但即便 3GB 全部用掉,系统还有 700MB 可以运行,事实上系统远远不止 700MB 可用)
|
||||
|
||||
启动服务器的命令行是:
|
||||
|
||||
_sudo java -Xms# -Xmx# -jar [path]/minecraft_server.[version].jar nogui_
|
||||
|
||||
现在命令结构的细分:
|
||||
|
||||
-Xms# - 初始启动 RAM (-Xms2048m)
|
||||
-Xmx# - 最大 RAM 数 (-Xmx3096m)
|
||||
[path] – “我的世界” 服务器文件路径 (/home/tux/MCS/)
|
||||
[version] – “我的世界” 服务器下载版本 (1.10.2)
|
||||
nogui – 用于显示基于文本界面去帮助缩小 RAM 使用。如果你使用GUI(用户图形化接口),那么移除 *nogui* 选项。
|
||||
|
||||
一个系统使用 2GB 内存 以及 最大 3GB 位置为 '/home/tux/MCS' 版本号为 ‘1.10.2' 的命令完整实例将变成:
|
||||
|
||||
_sudo java -Xms2048m -Xmx3096m -jar /home/tux/MCS/minecraft_server.1.10.2.jar nogui_
|
||||
|
||||
**NOTE:** 这 RAM 容量大小是兆字节单位。使容量以 1024 增加。举个例子,2GB 的 RAM 使 2 与 1024 相乘为容量 2048 . 但别忘小写字母 “m” 是特殊兆字节。你可以使用特殊简易的 '2g‘ 和 ’3g‘ 代替 2GB 和 3GB
|
||||
|
||||
在你首次运行服务器(时)会发成一些错误。开始之前,它申明 “最终用户许可协议” 必须被同意。
|
||||
|
||||
为了同意 “最终用户许可协议” 你需要进行编辑位于同样文件夹的 “Minecraft” 服务器 JAR 文件的 “eula.txt” 文件。
|
||||
|
||||
使用一个比如 “nano” 的文件编辑器打开文件 'eula.txt' 文件。确定你进行这步使用的是 root 权限。将行“eula = false”更改为“eula = true”并保存文件。
|
||||
|
||||
现在,再次输入命令以启动服务器。 屏幕完整信息应该通过,然后走一段进度,说明它正在准备加载世界。 进度将计数高达100%,因为它创建的初始世界。 有关系统时间更改的任何错误消息是正常的,因此忽略它们。
|
||||
|
||||
在这个方面你可以打开客户端程序并且看到如上 图1。点击 “多人” 按钮。再下面的屏幕,图4,选择 “直接连接”。将提示您输入服务器地址,因此键入Minecraft服务器的IP地址。你现在应该可以连接游戏了。
|
||||
|
||||
|
||||

|
||||
|
||||
**图 4**
|
||||
|
||||
**连接的某些麻烦**
|
||||
|
||||
如果一些客户端无法连接到服务器,那么你需要按下 “CTRL+Z” 退出 Java 程序。打开文件 “server.propertices” 使用一个像nano的编辑器。记住要root(权限)编辑“在线模式”行...它应该被改变为了 “true” ,改变这个文件为 “false” 并保存。重启服务器并打开 Minecraft 服务器。客户端重新连接服务器并且一切都开始工作。
|
||||
|
||||
快乐挖掘!
|
||||
|
||||
------
|
||||
|
||||
via: https://www.linuxforum.com/threads/minecraft-server-on-linux.3202/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[erlinux](http://www.itxdm.me)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxforum.com/members/jarret.268/
|
||||
[1]: https://s3.amazonaws.com/Minecraft.Download/versions/%5Bversion%5D/minecraft_server.%5Bversion%5D.jar
|
||||
[2]: https://s3.amazonaws.com/Minecraft.Download/versions/%5Bversion%5D/minecraft_server.%5Bversion%5D.jar
|
||||
@ -0,0 +1,246 @@
|
||||
Linux 中设置 ‘sudo’ 的十条使用的 Sudoers 配置
|
||||
===================
|
||||
|
||||
在 Linux 和其他的类 Unix 操作系统中,只有 root 用户可以运行所有的命令,以及在系统中执行那些需要鉴权的操作,比如安装、升级和移除软件包、[创建用户和用户组][1]、修改系统重要的配置文件等等。
|
||||
|
||||
然而,作为使用 root 用户角色的系统管理员可以通过 [sudo 命令][2] 和一些配置选项来给普通用户进行授权,从而让该普通用户可以运行某些命令已经上述的那些相当重要的系统级操作。
|
||||
|
||||
另外,系统管理员还可以共用 root 用户密码 (这个做法是不值得提倡的),这样普通用户就可以通过 su 命令来转化为 root 用户角色。
|
||||
|
||||
sudo 允许已授权用户按照指定的安全策略、以 root 用户 (或者是其他的用户角色) 权限来执行某个命令。
|
||||
|
||||
1. sudo 会读取和解析 /etc/sudoer 文件、查找调用命令的用户及其权限。
|
||||
2. 然后提示调用命令的用户输入密码 (通常是用户密码,但也可能是目标用户的密码。也可以通过 NOPASSWD 标志来跳过密码验证)。
|
||||
3. after that, sudo creates a child process in which it calls setuid() to switch to the target user
|
||||
4. next, it executes a shell or the command given as arguments in the child process above.
|
||||
|
||||
一下列出十个 /etc/sudoers 文件配置,使用默认入口来执行 sudo 命令是会有不同的动作。
|
||||
|
||||
```
|
||||
$ sudo cat /etc/sudoers
|
||||
```
|
||||
|
||||
/etc/sudoers 文件
|
||||
```
|
||||
#
|
||||
# This file MUST be edited with the 'visudo' command as root.
|
||||
#
|
||||
# Please consider adding local content in /etc/sudoers.d/ instead of
|
||||
# directly modifying this file.
|
||||
#
|
||||
# See the man page for details on how to write a sudoers file.
|
||||
#
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
|
||||
Defaults logfile="/var/log/sudo.log"
|
||||
Defaults lecture="always"
|
||||
Defaults badpass_message="Password is wrong, please try again"
|
||||
Defaults passwd_tries=5
|
||||
Defaults insults
|
||||
Defaults log_input,log_output
|
||||
```
|
||||
|
||||
#### 默认入口的类型
|
||||
|
||||
```
|
||||
Defaults parameter, parameter_list #对任意主机登录的所有用户起作用
|
||||
Defaults@Host_List parameter, parameter_list #对指定主机登录的所有用户起作用
|
||||
Defaults:User_List parameter, parameter_list #对指定用户起作用
|
||||
Defaults!Cmnd_List parameter, parameter_list #对指定命令起作用
|
||||
Defaults>Runas_List parameter, parameter_list #对指定目标用户运行命令起作用
|
||||
```
|
||||
|
||||
在本文讨论范围内,我们下面的将以第一个 Defaults 作为基准来参考。Parameter 可以是标记 (flags)、整数值或者是列表 (lists)。
|
||||
|
||||
值得注意的是,标记 (flag) 是指布尔类型值,可以使用 `'!'` 操作符来进行取反,列表 (lists) 有两个赋值运算符:`+=` (添加到列表) and `-=` (从列表中移除)。
|
||||
|
||||
```
|
||||
Defaults parameter
|
||||
或
|
||||
Defaults parameter=值
|
||||
或
|
||||
Defaults parameter -=值
|
||||
Defaults parameter +=值
|
||||
或
|
||||
Defaults !parameter
|
||||
```
|
||||
|
||||
### 1\. 安置一个安全的 PATH
|
||||
|
||||
该 PATH 应用于每个通过 sudo 执行的命令,需要注意两点:
|
||||
|
||||
1. 当系统管理员不信任 sudo 用户,便可以设置一个安全的 PATH 环境变量。
|
||||
2. 该设置将 “root PATH” 和 “user PATH” 分离,只有在 exempt_group 组的用户不受该设置的影响。
|
||||
|
||||
可以添加一下内容来设置:
|
||||
|
||||
```
|
||||
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
|
||||
```
|
||||
|
||||
### 2\. 启用允许 tty 用户回话使用 sudo
|
||||
|
||||
该设置允许在一个真实的 tty 中进行调用,但不允许通过 cron 或者 cgi-bin 脚本等方法来调用。添加一下内容来设置:
|
||||
|
||||
```
|
||||
Defaults requiretty
|
||||
```
|
||||
|
||||
### 3\. 使用 pty 运行 sudo 命令
|
||||
|
||||
少数情况下,攻击者可以通过 sudo 来运行一个而已程序 (比如病毒或者恶意代码),这种恶意程序可能会复制一个后台运行的进程,即时主程序完成执行,它仍能够运行在用户的终端设备上。
|
||||
|
||||
为了防止出现这样的情况,你可以通过 `use_pty` 参数来设置 sudo 使用伪终端来运行其他命令,而不必管 I/O 登录的开启状态。如下:
|
||||
|
||||
```
|
||||
Defaults use_pty
|
||||
```
|
||||
|
||||
### 4\. 创建 sudo log 文件
|
||||
|
||||
默认下,sudo 通过 syslog(3) 来记录到 logs。但是我们可以通过 logfile 参数来指定一个自定义的 log 文件。如下:
|
||||
|
||||
```
|
||||
Defaults logfile="/var/log/sudo.log"
|
||||
```
|
||||
|
||||
使用 use log_host 和 log_year 参数可以对应记录登录主机名和 4 位数年份到自定义 log 文件。如下:
|
||||
|
||||
```
|
||||
Defaults log_host, log_year, logfile="/var/log/sudo.log"
|
||||
```
|
||||
|
||||
下面是自定义 sudo log 文件的例示:
|
||||
|
||||
[][3]
|
||||
|
||||
创建 sudo log 文件
|
||||
|
||||
### 5\. 记录 sudo 命令的输入/输出
|
||||
|
||||
log_input 和 log_output 参数可以让 sudo 命令运行在伪终端,并可以对应的记录所有用户在屏幕上的输入和输出。
|
||||
|
||||
默认的 I/O log 目录为 /var/log/sudo-io,如果存在一个会话的话,它将被存储到该目录。你可以通过 iolog_dir 参数来指定一个目录.
|
||||
|
||||
```
|
||||
Defaults log_input, log_output
|
||||
```
|
||||
|
||||
这其中支持转义字符,像 `%{seq}` —— 以 36 为基数的单调递增序列,比如 000001,这里每两个数字都分别用来形成一个新目录。请看下边例示 00/00/01:
|
||||
|
||||
```
|
||||
$ cd /var/log/sudo-io/
|
||||
$ ls
|
||||
$ cd 00/00/01
|
||||
$ ls
|
||||
$ cat log
|
||||
```
|
||||
|
||||
[][4]
|
||||
|
||||
记录 sudo 命令的输入/输出
|
||||
|
||||
[cat 命令][5] 来查看 该目录的其余部分。
|
||||
|
||||
### 6\. 为 sudo 用户提示命令用法
|
||||
|
||||
如下,使用 lecture 参数可以在系统中为 sudo 用户提示命令的用法:
|
||||
|
||||
参数属性值有三个选择:
|
||||
|
||||
1. always – 一直提示
|
||||
2. once – 用户首次运行 sudo 时提示 (未指定参数属性值时的默认值)
|
||||
3. never – 从不提示
|
||||
|
||||
```
|
||||
Defaults lecture="always"
|
||||
```
|
||||
|
||||
此外,你还可以使用 lecture_file 参数类自定义提示内容,在指定的文件中输入适当的提示内容即可:
|
||||
|
||||
```
|
||||
Defaults lecture_file="/path/to/file"
|
||||
```
|
||||
|
||||
[][6]
|
||||
|
||||
为 sudo 用户提示命令用法
|
||||
|
||||
### 7\. 输入错误的 sudo 密码是显示自定义信息
|
||||
|
||||
当某个用户输错密码时,会有一个对应的信息显示在屏幕上。默认是“抱歉,请重新尝试。(sorry, try again)”,你可以通过 badpass_message 参数来修改该信息:
|
||||
|
||||
```
|
||||
Defaults badpass_message="Password is wrong, please try again"
|
||||
```
|
||||
|
||||
### 8\. 增加 sudo 密码尝试限制次数
|
||||
|
||||
passwd_tries 参数用于指定用户尝试输入密码的次数。
|
||||
|
||||
默认为 3。
|
||||
|
||||
```
|
||||
Defaults passwd_tries=5
|
||||
```
|
||||
|
||||
[][7]
|
||||
|
||||
增加 sudo 密码尝试限制次数
|
||||
|
||||
使用 passwd_timeout 参数设置密码超时 (默认为 5 分钟),如下:
|
||||
|
||||
```
|
||||
Defaults passwd_timeout=2
|
||||
```
|
||||
|
||||
### 9\. 在输错密码时让 sudo 羞辱用户
|
||||
|
||||
使用了 insults 参数之后,一旦你输出了密码,sudo 便会在命令窗口中显示羞辱你的信息。这个参数会自动关闭 badpass_message 参数。
|
||||
|
||||
```
|
||||
Defaults insults
|
||||
```
|
||||
|
||||
[][8]
|
||||
|
||||
在输错密码时让 sudo 羞辱用户
|
||||
|
||||
### 10\. 更多关于 sudo 的配置
|
||||
|
||||
此外,欲了解更多 sudo 命令的配置,请自行阅读:[su 与 sudo 的差异以及如何配置 sudo][9]。
|
||||
|
||||
文毕。你也可以在评论区分享其他有用的 sudo 配置或者 [Linux 技巧][10]。
|
||||
|
||||
---------------------------------------------------------------------
|
||||
|
||||
作者简介:Aaron Kili 是一名 Linux 和 F.O.S.S 忠实拥护者、高级 Linux 系统管理员、Web 开发者,目前在 TecMint 是一名活跃的博主,热衷于计算机并有着强烈的只是分享意愿。
|
||||
|
||||

|
||||
|
||||
译者简介:[GHLandy](http://GHLandy.com) —— 欲得之,则为之奋斗 (If you want it, work for it.)。
|
||||
|
||||

|
||||
|
||||
---------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Create-Sudo-Log-File.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/Log-sudo-Input-Output.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/01/Lecture-Sudo-Users.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/01/Increase-Sudo-Password-Attempts.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/01/Sudo-Insult-Message.png
|
||||
[9]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[10]:http://www.tecmint.com/tag/linux-tricks/
|
||||
@ -0,0 +1,76 @@
|
||||
CentOS vs Ubuntu:哪个对服务器更好?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
已经决定买一个VPS,但还不能决定使用哪个 Linux 发行版?我们都经历过。在考虑到了所有的发行版后,即使对 Linux 发行版而言,这个[_决定_][3]甚至可能是压倒性的。虽然两个最广泛使用和最流行的服务器发行版是 CentOS 和 Ubuntu。这是管理员、初学者和专业人士之间的主要困境。有了(和更多)发行版的经验,我们决定在用于服务器时比较 CentOS 和 Ubuntu。
|
||||
|
||||
### 快速浏览
|
||||
|
||||
|  CentOS |  Ubuntu |
|
||||
| --- | --- |
|
||||
| 基于 Red Hat Linux Enterprise | 基于 Debian |
|
||||
| 更少频率更新 | 经常更新 |
|
||||
| 可以更稳定和更安全,因为不经常更新。 | 更新的软件包可能不稳定,不安全,这是不可能的,因为他们在推出正式发布前进行了大量测试。 |
|
||||
| 没有足够的教程和更小的用户群 | 丰富的文档,活跃的社区和大量的在线教程|
|
||||
| 对初学者困难,因为没有流行和广泛使用的基于 Red Hat 桌面发行版| 更容易为已经熟悉桌面版 Ubuntu 的初学者使用|
|
||||
| 支持 cPanel | 不支持 cPanel |
|
||||
| .rpm 软件包和 “yum” 软件包管理器 | .deb 软件包和 “apt-get” 软件包管理器 |
|
||||
| 在 [DigitalOcean][1] 免费试用 CentOS 服务器 | 在[DigitalOcean][2] 免费试用 Ubuntu 服务器 |
|
||||
|
||||
### 哪个对新手更好?
|
||||
|
||||
Ubuntu。一如往常那样,它高度取决于你的需求和以前的经验,但一般来说,Ubuntu 是初学者的更好的选择。主要是因为这两个原因:
|
||||
|
||||
* Ubuntu有一个庞大的社区,随时可以免费提供帮助。我指的是真正的大。数以千计的用户在数百个不同的在线论坛和组内。甚至有现实生活中的大会。你仍然可以为 CentOS 找到很多教程和帮助,特别是对于简单的 LAMP 栈和流行的应用程序而言。
|
||||
* Ubuntu 服务器对于以前使用过 Ubuntu 桌面的人来说会容易得多。 CentOS 和 Fedora 也是如此,但是 Ubuntu 桌面版比任何其他基于 Linux 的家庭版本更受欢迎。
|
||||
|
||||
所以,如果你是一个初学者,而且没有任何特殊要求,那就去使用 Ubuntu 服务器。 更好的是,如果你从一个[便宜的托管服务提供商][4]那购买服务,你可以在你的服务器上进行实验,还有一个[专业的 24/7 支持团队][7]准备好帮助你。
|
||||
|
||||
### 哪个在商业上更好?
|
||||
|
||||
CentOS。再说一次,你仍然可以使用 Ubuntu 作为商业网站或公司内部服务器,但 CentOS 有它的优势:
|
||||
|
||||
* CentOS(可以说)更稳定以及更安全。由于 CentOS 的更新频率较低,这意味着软件测试的时间更长,并且只有真正稳定的版本才会得到发布。如果你使用 CentOS,你不会在一个新的有 bug 版本的应用程序得到任何稳定性问题,因为你不会得到那个新的有 bug 的版本。
|
||||
* 大多数控制面板(包括最受欢迎的控制面板 - cPanel)仅支持CentOS。所以这意味着如果你是一个网络托管公司,或者如果你是一个有很多客户的网络代理,并且需要一个控制面板 - CentOS 是一个更好的选择。
|
||||
|
||||
### 尝试一下它们并选择一个
|
||||
|
||||
如果你还是不能决定,你可以免费试试它们。你可以在本地安装或使用 live 镜像。你还可以从 [Vultr][6] 和 [DigitalOcean][7] 买到便宜的 VPS($5/月)。你可以在几秒钟内启动 CentOS/Ubuntu 服务器。当你通过推广链接(如我们的)注册,你可能会得到免费金额 - 这意味着你会真的可以免费试用。
|
||||
|
||||
### 哪个更快?
|
||||
|
||||
它们在速度方面是相同的。它们和在你的硬件上运行一样快。它们将与你配置它们一样快。不管怎样,你都应该正确配置并且保护所有的服务器、配置和应用程序。
|
||||
|
||||
你会使用哪个发行版?想告诉我们我们是怎样一群[这里插入发行版]的拥趸么?请随时留下评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
我的大多数 Linux 服务器部署都是针对企业客户端的,所以我对文章作者在引用 GUI 客户端版本中对任何服务器管理功能感到困惑。通常,即使在虚拟专用服务器(VPN)环境中,许多服务提供商也会在 CentOS、Ubuntu上或经常部署的 OpenSuse Leap 和 FreeBSD 10+ 服务器操作系统上使用 WebMin、VirtualAdmin 或类似工具作为控制面板。
|
||||
|
||||
CentOS 在许多业务程序以及高级网络/虚拟化和云计算环境方面具有优于 Ubuntu 的优势,并且 CentOS 充分利用 SELinux 框架用于加强的安全层,目前在 Ubuntu 中不可用(或不容易)。
|
||||
|
||||
这种类型的比较通常是多余的,因为几乎总是有特定的和细微的要求和服务器实现的需求,将决定哪个发行版具有更多的优势或目的 - 基于技术专家/托管公司的专业知识和广泛的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thishosting.rocks/centos-vs-ubuntu-server/
|
||||
|
||||
作者:[W. Anderson][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://thishosting.rocks/centos-vs-ubuntu-server/
|
||||
[1]:https://thishosting.rocks/go/digitalocean/
|
||||
[2]:https://thishosting.rocks/go/digitalocean/
|
||||
[3]:https://thishosting.rocks/how-to-choose-web-hosting/
|
||||
[4]:https://thishosting.rocks/best-cheap-managed-vps/
|
||||
[5]:https://thishosting.rocks/support/
|
||||
[6]:https://thishosting.rocks/go/vultr/
|
||||
[7]:https://thishosting.rocks/go/digitalocean/
|
||||
@ -0,0 +1,72 @@
|
||||
使用开源工具探索气候数据的奥秘
|
||||
============================================================[up][1]
|
||||

|
||||
图片源自:
|
||||
|
||||
[Flickr user: theaucitron][2] (CC BY-SA 2.0)
|
||||
|
||||
如果这些天地球天气变化的不明显,你几乎无法察觉其中变化的格局。每个月,事实和数据都在向我们诠释一点——全球变暖。
|
||||
|
||||
气候学家如是告诫我们——如今的不作为,对于我们的将来可能是致命的。五角大楼高层[最近警告][3]当选总统的川普。申明如果不对气候变化有所动作,可能会造成威胁国家安全的灾难。愈趋减少的的水供应和微薄的降雨量会导致作物歉收,这将迫使大量的移民逃往世界各地,到那些可以维持他们生计的地方去。
|
||||
|
||||
遍览 NASA,美国国防部,以及其他机构针对气候的研究成果,我的心中有个疑惑。那就是是否有开源的工具,使对此感兴趣的人们能够自行去探索气候数据的奥秘,并总结出我们自己的结论。我在网上快速的检索了一下,然后找到了[Open Climate Workbench (开源气候工作台)][4],[Apache 软件基金会][5]旗下的一个工程。
|
||||
|
||||
Open Climate Workbench (缩写 OCW) 开发用于对来自[Earth System Grid Federation (地球系统网格联盟,缩写 ESGF)][6],[Coordinated Regional Climate Downscaling Experiment (协调区域气候降尺度实验,缩写 CORDEX)][7],美国全球变化研究计划的 [National Climate Assessment (国家气候研究)][8],[North American Regional Climate Assessment Program (北美区域气候评估计划)][9],和 NASA,NOAA,以及其他组织或机构的数据进行气候模型评价。
|
||||
|
||||
你可下载 OCW 的 [tar ball (压缩包)][10] 并将它安装到满足以下[条件][11]的 Linux 电脑上。也可以将它安装到 Vagrant 或者 VirtualBox 虚拟机中,详见 OCW 的[虚拟机指南][12]。
|
||||
|
||||
个人觉得想要了解 OCW 是如何工作的,最便捷的方式就是到 Regional Climate Model Evaluation System (区域气候模式评价系统,缩写 RCMES)下载一个[虚拟机镜像][13]。
|
||||
|
||||
从 RCMES 的网站上看,他们旨在通过为一系列广泛而全面的观测(例如,卫星观测,重新分析,现场观测)和建模资源(例如,[ESGF][16] 上的 [CMIP][14] 和 [CORDEX][15])提供标准化的访问,以及常规分析和可视化任务的工具(例如,OCW),来促进气候和地球系统模型的区域规模评估。
|
||||
|
||||
你需要在宿主机上安装 VirtualBox 和 Vagrant。通过它们,你就能看到一个超赞的 OCW 作业示例。RCMES 为下载,导入,运行虚拟机提供了[详细的说明][17]。当你的虚拟机开始工作时,你可以用以下身份登陆。
|
||||
|
||||
** 用户名:vagrant,密码:vagrant。 **
|
||||
|
||||

|
||||
|
||||
RCMES 数据样图
|
||||
|
||||
RCMES 网页上的[教程][18]能帮助你迅速上手该软件。他们的[社区][19]十分活跃,而且看上去需要更多的[开发者][20]。 你也可以订阅他们[邮件列表][21]。
|
||||
|
||||
工程的[源代码][22]部署在 GitHub 上,遵寻 Apache License, Version 2.0。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||

|
||||
|
||||
Don Watkins(唐 沃特金斯) - 教育家,教育技术专家,企业家,开源支持者。心理学硕士,教育学硕士,Linux 系统管理员,CCNA,通过使用 Virtual Box 和 VMware 完成虚拟化。twitter 关注 @Don_Watkins。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/apache-open-climate-workbench
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://opensource.com/article/17/1/apache-open-climate-workbench?rate=Hv4_T-1gbcRNsiP9jnevzP1OTNKHIyQLXwqdjnBy2Bs
|
||||
[2]:https://www.flickr.com/photos/theaucitron/5810163712/in/photolist-5p9nh3-6EkSKG-6EgGEF-9hYBcr-abCSpq-9zbjDz-4PVqwm-9RqBfq-abA2T4-4nXfwv-9RQkdN-dmjSdA-84o2ER-abA2Wp-ehyhPC-7oFYrc-4nvqBz-csMQXb-nRegFf-ntS23C-nXRyaB-6Xw3Mq-cRMaCq-b6wkkP-7u8sVQ-yqcg-6fTmk7-bzm3vU-6Xw3vL-6EkzCQ-d3W8PG-5MoveP-oMWsyY-jtMME6-XEMwS-2SeRXT-d2hjzJ-p2ZZVZ-7oFYoX-84r6Mo-cCizvm-gnnsg5-77YfPx-iDjqK-8gszbW-6MUZEZ-dhtwtk-gmpTob-6TBJ8p-mWQaAC/
|
||||
[3]:https://www.scientificamerican.com/article/military-leaders-urge-trump-to-see-climate-as-a-security-threat/
|
||||
[4]:https://climate.apache.org/
|
||||
[5]:https://www.apache.org/
|
||||
[6]:http://esgf.llnl.gov/
|
||||
[7]:http://www.cordex.org/
|
||||
[8]:http://nca2014.globalchange.gov/
|
||||
[9]:http://www.narccap.ucar.edu/
|
||||
[10]:http://climate.apache.org/downloads.html
|
||||
[11]:http://climate.apache.org/downloads.html#prerequsites
|
||||
[12]:https://cwiki.apache.org/confluence/display/CLIMATE/OCW+VM+-+A+Self+Contained+OCW+Environment
|
||||
[13]:https://rcmes.jpl.nasa.gov/RCMES_Turtorial_data/RCMES_June09-2016.ova
|
||||
[14]:http://cmip-pcmdi.llnl.gov/
|
||||
[15]:http://www.cordex.org/
|
||||
[16]:http://esgf.org/
|
||||
[17]:https://rcmes.jpl.nasa.gov/content/running-rcmes-virtual-machine
|
||||
[18]:https://rcmes.jpl.nasa.gov/content/tutorials-overview
|
||||
[19]:http://climate.apache.org/community/get-involved.html
|
||||
[20]:https://cwiki.apache.org/confluence/display/CLIMATE/Developer+Getting+Started+Guide
|
||||
[21]:http://climate.apache.org/community/mailing-lists.html
|
||||
[22]:https://github.com/apache/climate
|
||||
@ -412,13 +412,14 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||

|
||||
|
||||
我叫 Ravi Saive,TecMint 网站博主。一个喜欢在网上分享技术知识及经验的电脑极客和 Linux 系统专家。我的大多数的服务器都运行在 Linux 开源平台上。关注我:Twitter ,Facebook 和 Google+ 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/join-additional-ubuntu-dc-to-samba4-ad-dc-failover-replication/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
3 个针对高级用户的 Vim 编辑器实用技巧
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
这篇文章是[ Vim 用户指南][12]系列文章中的一篇:
|
||||
|
||||
* [Vim 初学者入门指南][3]
|
||||
* [Vim 快捷键速查表][4]
|
||||
* [5 个针对有经验用户的 Vim 技巧][4]
|
||||
* 3 个针对高级用户的 Vim 编辑器实用技巧
|
||||
|
||||
毫无疑问, Vim 是一个很强大的文本编辑器。它提供了大量的特性,这意味着学习并记住 Vim 的所有功能实际上是不可能的。但是我们至少可以
|
||||
不断学习简单的方法来完成事情,从而随着时间的增长,我们使用编辑器的经验将会变得更好。
|
||||
|
||||
请记住,在这篇文章中我们将讨论的一些 Vim 编辑器技巧是针对高级用户的。
|
||||
|
||||
**注**:如果你是第一次接触 Vim,你可以首先阅读我们的[入门指南][14]。对于已经使用过 Vim 编辑器的用户,我确信[ Vim 快捷键速查表][15]将会对你很有帮助。如果你已经是一名有经验的用户,你可能对[一些针对有经验用户的技巧][16]比较感兴趣。
|
||||
|
||||
请注意文中提到的所有技巧绝大多数都是在简单、易于理解的代码环境中进行阐述的,因为它们在软件开发中确实很实用。但这并不意味着普通用户(非程序员、没有把 Vim 作为一般的文本编辑器)在他们的工作中用不到。
|
||||
|
||||
### 1\.为文件设置特殊变量
|
||||
|
||||
有时候,在一个特殊文件中,你可能想把输入的某个字母用空格代替,或者想把一个源代码文件使用两个空格缩进,而编辑器的默认缩进是四个空格。
|
||||
|
||||
我们在这儿基本讨论对特殊文件进行的更改。 Vim 提供了一个特性允许你对一个特殊的文件更改特定的设置。这个特性叫做 “Modeline” 。
|
||||
|
||||
比如,如果你想把输入的每一个制表符 (Tab) 用空格代替,那么你需要做的就是考虑在文件的前几行或最后几行加入下面的 ‘modeline’ :
|
||||
|
||||
```
|
||||
# vim: set expandtab:
|
||||
```
|
||||
|
||||
如果想把默认缩进从 4 个空格变成 2 个空格,可以在源文件中添加下面的 ‘modeline’ :
|
||||
|
||||
```
|
||||
// vim: noai:ts=2:sw=2
|
||||
```
|
||||
|
||||
在使用 ‘modeline’ 时,请记住下面这几个重要的点:
|
||||
|
||||
* ‘Modeline’ 只能添加在文件中的前五行或者最后五行。
|
||||
* 为了使用 “modeline” 选项这个特性,必须在 “.vimrc” 文件中添加 ‘:set modeline’ 。
|
||||
* 在以 root 用户身份对文件进行编辑的时候该特性失效。
|
||||
|
||||
了解更多的信息,请阅读该特性的[官方文档][17]
|
||||
|
||||
### 2\. 关键字补全
|
||||
|
||||
当你开始写更多的复杂代码或者开始开发大量的源文件时,你需要设置一些变量名字。有时,要记住所有的变量名字不太容易,所以当需要输入变量名字的时候,你通常从已经使用过的地方复制过来。
|
||||
|
||||
幸运的是,使用 Vim 你只需要输入变量的几个起始字母即可。在’插入模式’中,按 “Ctrl + n” 或者 “Ctrl + p” 可以得到匹配关键词。 “Ctrl + n” 用来插入下一个匹配词; “Ctrl + p” 给出一系列过去的匹配词。
|
||||
|
||||
下图是该特性的一个展示:
|
||||
|
||||

|
||||
|
||||
正如上面的屏幕截图清晰展示的那样,列表中也会出现其他源文件中包含的词。关于该特性的更多信息,请访问[这儿][18]。
|
||||
|
||||
### 3\. 搜索
|
||||
|
||||
假设你正在调试代码,其中一部分需要做的工作是快速查看一个变量在一个文件中所有出现的地方。一个常用的方法是退出‘插入模式’,输入 ‘/[变量名字]’ 命令,按 ‘Press’ ,然后返回‘插入模式’,使用 “n” 和 “p” 关键字。
|
||||
|
||||
上面讲到的方法是挺好的,但是还有一种更简单、更快捷的方法可以来完成这样的搜索。使用这种方法,首先你需要退出‘插入模式’,然后把光标移动到你想要搜索的词/变量下面,这并不费时。接下来,你只需要按 “Shift + .” 即可。
|
||||
|
||||
重复这样做,然后编辑器将会带你找到在文件中所有使用了这个词/变量的地方。
|
||||
|
||||
### 结论
|
||||
|
||||
尽管是针对高级用户,但文章中讨论的这些技巧并不难理解,也比较容易使用。如果你具有一定的基础,那么你能够从中获益很多。不必多说,无论是任何新特性或观念,你需要勤于练习这些技巧才能够把它们变成一种习惯。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/vim-tips-tricks-advanced-users/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://www.maketecheasier.com/author/himanshu/
|
||||
[2]:https://www.maketecheasier.com/vim-tips-tricks-advanced-users/#respond
|
||||
[3]:https://www.maketecheasier.com/start-with-vim-linux/
|
||||
[4]:https://www.maketecheasier.com/vim-keyboard-shortcuts-cheatsheet/
|
||||
[5]:https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/
|
||||
[6]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[7]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-advanced-users%2F
|
||||
[8]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-advanced-users%2F&text=3+Useful+VIM+Editor+Tips+and+Tricks+for+Advanced+Users
|
||||
[9]:mailto:?subject=3%20Useful%20VIM%20Editor%20Tips%20and%20Tricks%20for%20Advanced%20Users&body=https%3A%2F%2Fwww.maketecheasier.com%2Fvim-tips-tricks-advanced-users%2F
|
||||
[10]:https://www.maketecheasier.com/opt-out-google-personalized-ads/
|
||||
[11]:https://www.maketecheasier.com/wi-fi-vs-ethernet-vs-4g/
|
||||
[12]:https://www.maketecheasier.com/series/vim-user-guide/
|
||||
[13]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[14]:https://www.maketecheasier.com/start-with-vim-linux/
|
||||
[15]:https://www.maketecheasier.com/vim-keyboard-shortcuts-cheatsheet/
|
||||
[16]:https://www.maketecheasier.com/vim-tips-tricks-for-experienced-users/
|
||||
[17]:http://vim.wikia.com/wiki/Modeline_magic
|
||||
[18]:http://vim.wikia.com/wiki/Any_word_completion
|
||||
@ -0,0 +1,243 @@
|
||||
OpenSSL 在 Apache 和 Dovecot 下的使用:第二部分
|
||||
============================================================
|
||||
|
||||

|
||||
本篇中,Carla Schroder 会解释如何使用 OpenSSL 保护你的 Postfix/Dovecot 邮件服务器
|
||||
|
||||
[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在[上周][11],作为我们 OpenSSL 系列的一部分,我们学习了如何配置 Apache 以使用 OpenSSL 并强制所有会话使用 HTTPS。 今天,我们将使用 OpenSSL 保护我们的 Postfix/Dovecot 邮件服务器。这些示例基于前面的教程; 请参阅最后的参考资料部分,了解本系列中以前的所有教程的链接。
|
||||
|
||||
你需要配置 Postfix 以及 Dovecot 来使用 OpenSSL,我们将使用我们在[在 Apache 和 Dovecot 中使用 OpenSSL][12]中创建的密钥和证书。
|
||||
|
||||
### Postfix 配置
|
||||
|
||||
你必须编辑 `/etc/postfix/main.cf` 以及 `/etc/postfix/master.cf`。`main.cf` 这个例子是完整的配置,它在我们先前的教程中构建过了。替换成你自己的 OpenSSL 密钥和证书名以及本地网络。
|
||||
|
||||
```
|
||||
compatibility_level=2
|
||||
smtpd_banner = $myhostname ESMTP $mail_name (Ubuntu/GNU)
|
||||
biff = no
|
||||
append_dot_mydomain = no
|
||||
|
||||
myhostname = localhost
|
||||
alias_maps = hash:/etc/aliases
|
||||
alias_database = hash:/etc/aliases
|
||||
myorigin = $myhostname
|
||||
mynetworks = 127.0.0.0/8 [::ffff:127.0.0.0]/104 [::1]/128 192.168.0.0/24
|
||||
mailbox_size_limit = 0
|
||||
recipient_delimiter = +
|
||||
inet_interfaces = all
|
||||
|
||||
virtual_mailbox_domains = /etc/postfix/vhosts.txt
|
||||
virtual_mailbox_base = /home/vmail
|
||||
virtual_mailbox_maps = hash:/etc/postfix/vmaps.txt
|
||||
virtual_minimum_uid = 1000
|
||||
virtual_uid_maps = static:5000
|
||||
virtual_gid_maps = static:5000
|
||||
virtual_transport = lmtp:unix:private/dovecot-lmtp
|
||||
|
||||
smtpd_tls_cert_file=/etc/ssl/certs/test-com.pem
|
||||
smtpd_tls_key_file=/etc/ssl/private/test-com.key
|
||||
smtpd_use_tls=yes
|
||||
|
||||
smtpd_sasl_auth_enable = yes
|
||||
smtpd_sasl_type = dovecot
|
||||
smtpd_sasl_path = private/auth
|
||||
smtpd_sasl_authenticated_header = yes
|
||||
```
|
||||
|
||||
在 `master.cf` 解除 `submission inet` 部分的注释,并编辑 `smtpd_recipient_restrictions`:
|
||||
|
||||
```
|
||||
#submission inet n - y - - smtpd
|
||||
-o syslog_name=postfix/submission
|
||||
-o smtpd_tls_security_level=encrypt
|
||||
-o smtpd_sasl_auth_enable=yes
|
||||
-o milter_macro_daemon_name=ORIGINATING
|
||||
-o smtpd_recipient_restrictions=permit_mynetworks,permit_sasl_authenticated,reject
|
||||
-o smtpd_tls_wrappermode=no
|
||||
```
|
||||
|
||||
完成后重新加载 Postfix:
|
||||
|
||||
```
|
||||
$ sudo service postfix reload
|
||||
```
|
||||
|
||||
### Dovecot 配置
|
||||
|
||||
在我们以前的教程中,我们为 Dovecot 在 `/etc/dovecot/dovecot.conf` 创建了一个配置文件,而不是使用多个默认配置文件。这是一个建立在我们以前的教程的完整配置。再说一次,使用你自己的 OpenSSL 密钥和证书,以及你自己的 `userdb` 家文件:
|
||||
|
||||
```
|
||||
protocols = imap pop3 lmtp
|
||||
log_path = /var/log/dovecot.log
|
||||
info_log_path = /var/log/dovecot-info.log
|
||||
disable_plaintext_auth = no
|
||||
mail_location = maildir:~/.Mail
|
||||
pop3_uidl_format = %g
|
||||
auth_mechanisms = plain
|
||||
|
||||
passdb {
|
||||
driver = passwd-file
|
||||
args = /etc/dovecot/passwd
|
||||
}
|
||||
|
||||
userdb {
|
||||
driver = static
|
||||
args = uid=vmail gid=vmail home=/home/vmail/studio/%u
|
||||
}
|
||||
|
||||
service lmtp {
|
||||
unix_listener /var/spool/postfix/private/dovecot-lmtp {
|
||||
group = postfix
|
||||
mode = 0600
|
||||
user = postfix
|
||||
}
|
||||
}
|
||||
|
||||
protocol lmtp {
|
||||
postmaster_address = postmaster@studio
|
||||
}
|
||||
|
||||
service lmtp {
|
||||
user = vmail
|
||||
}
|
||||
|
||||
service auth {
|
||||
unix_listener /var/spool/postfix/private/auth {
|
||||
mode = 0660
|
||||
user=postfix
|
||||
group=postfix
|
||||
}
|
||||
}
|
||||
|
||||
ssl=required
|
||||
ssl_cert = </etc/ssl/certs/test-com.pem
|
||||
ssl_key = </etc/ssl/private/test-com.key
|
||||
```
|
||||
|
||||
重启 Dovecot:
|
||||
|
||||
```
|
||||
$ sudo service postfix reload
|
||||
```
|
||||
|
||||
### 用 telnet 测试
|
||||
|
||||
就像我们以前一样,现在我们可以通过使用 telnet 发送消息来测试我们的设置。 但是等等,你说 telnet 不支持 TLS/SSL,那么怎么能这样呢?首先通过使用 `openssl s_client` 打开一个加密会话。`openssl s_client` 的输出将显示你的证书、指纹和大量其他信息,以便你知道你的服务器正在使用正确的证书。会话建立后输入的命令以粗体显示:
|
||||
|
||||
```
|
||||
$ openssl s_client -starttls smtp -connect studio:25
|
||||
CONNECTED(00000003)
|
||||
[masses of output snipped]
|
||||
Verify return code: 0 (ok)
|
||||
---
|
||||
250 SMTPUTF8
|
||||
EHLO studio
|
||||
250-localhost
|
||||
250-PIPELINING
|
||||
250-SIZE 10240000
|
||||
250-VRFY
|
||||
250-ETRN
|
||||
250-AUTH PLAIN
|
||||
250-ENHANCEDSTATUSCODES
|
||||
250-8BITMIME
|
||||
250-DSN
|
||||
250 SMTPUTF8
|
||||
mail from: <carla@domain.com>
|
||||
250 2.1.0 Ok
|
||||
rcpt to: <alrac@studio>
|
||||
250 2.1.5 Ok
|
||||
data
|
||||
354 End data with .subject: TLS/SSL test
|
||||
Hello, we are testing TLS/SSL. Looking good so far.
|
||||
.
|
||||
250 2.0.0 Ok: queued as B9B529FE59
|
||||
quit
|
||||
221 2.0.0 Bye
|
||||
```
|
||||
|
||||
你应该可以在邮件客户端中看到一条新邮件,并在打开 SSL 证书时要求你验证 SSL 证书。你也可以使用 `openssl s_client` 来测试 Dovecot POP3 和 IMAP 服务。此示例测试加密的 POP3,#5 消息是我们在 telnet(上面)中创建的:
|
||||
|
||||
```
|
||||
$ openssl s_client -connect studio:995
|
||||
CONNECTED(00000003)
|
||||
[masses of output snipped]
|
||||
Verify return code: 0 (ok)
|
||||
---
|
||||
+OK Dovecot ready
|
||||
user alrac@studio
|
||||
+OK
|
||||
pass password
|
||||
+OK Logged in.
|
||||
list
|
||||
+OK 5 messages:
|
||||
1 499
|
||||
2 504
|
||||
3 514
|
||||
4 513
|
||||
5 565
|
||||
.
|
||||
retr 5
|
||||
+OK 565 octets
|
||||
Return-Path: <carla@domain.com>
|
||||
Delivered-To: alrac@studio
|
||||
Received: from localhost
|
||||
by studio.alrac.net (Dovecot) with LMTP id y8G5C8aablgKIQAAYelYQA
|
||||
for <alrac@studio>; Thu, 05 Jan 2017 11:13:10 -0800
|
||||
Received: from studio (localhost [127.0.0.1])
|
||||
by localhost (Postfix) with ESMTPS id B9B529FE59
|
||||
for <alrac@studio>; Thu, 5 Jan 2017 11:12:13 -0800 (PST)
|
||||
subject: TLS/SSL test
|
||||
Message-Id: <20170105191240.B9B529FE59@localhost>
|
||||
Date: Thu, 5 Jan 2017 11:12:13 -0800 (PST)
|
||||
From: carla@domain.com
|
||||
|
||||
Hello, we are testing TLS/SSL. Looking good so far.
|
||||
.
|
||||
quit
|
||||
+OK Logging out.
|
||||
closed
|
||||
```
|
||||
|
||||
### 现在做什么?
|
||||
|
||||
现在你有一个很好的有适当的 TLS/SSL 保护的邮件服务器了。我鼓励你深入学习 Postfix 以及 Dovecot; 这些教程中的示例尽可能地简单,不包括对安全性、防病毒扫描程序、垃圾邮件过滤器或任何其他高级功能的微调。我认为当你有一个基本工作系统时更容易学习高级功能。
|
||||
|
||||
下周回到 openSUSE 包管理备忘录上。
|
||||
|
||||
### 资源
|
||||
|
||||
* [为 Apache 和 Dovecot 使用 OpenSSL][3]
|
||||
* [如何在 Ubuntu Linux 上构建电子邮件服务器][4]
|
||||
* [在 Ubuntu Linux 上构建电子邮件服务器:第2部分][5]
|
||||
* [在 Ubuntu Linux 上构建电子邮件服务器:第3部分][6]
|
||||
* [给初学者看的在 Ubuntu Linux 上使用 Apache][7]
|
||||
* [初学者看的在 Ubuntu Linux 上使用 Apache:第二部分][8]
|
||||
* [给初学者看的在 CentOS Linux 上使用 Apache][9]
|
||||
* [消灭让人害怕的 web 浏览器 SSL 警告][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/openssl-apache-and-dovecot-part-2
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/key-openssljpg-0
|
||||
[3]:https://www.linux.com/learn/sysadmin/openssl-apache-and-dovecot
|
||||
[4]:https://www.linux.com/learn/how-build-email-server-ubuntu-linux
|
||||
[5]:https://www.linux.com/learn/sysadmin/building-email-server-ubuntu-linux-part-2
|
||||
[6]:https://www.linux.com/learn/sysadmin/building-email-server-ubuntu-linux-part-3
|
||||
[7]:https://www.linux.com/learn/apache-ubuntu-linux-beginners
|
||||
[8]:https://www.linux.com/learn/apache-ubuntu-linux-beginners-part-2
|
||||
[9]:https://www.linux.com/learn/apache-centos-linux-beginners
|
||||
[10]:https://www.linux.com/learn/quieting-scary-web-browser-ssl-alerts
|
||||
[11]:https://www.linux.com/learn/sysadmin/openssl-apache-and-dovecot
|
||||
[12]:https://www.linux.com/learn/sysadmin/openssl-apache-and-dovecot
|
||||
@ -0,0 +1,32 @@
|
||||
你现在可以下载包含所有版本的 Ubuntu 16.10 的单独 ISO 镜像了
|
||||
======================================
|
||||
|
||||
Softpedia 被 Linux AIO 开发商 Željko Popivoda 通知可以下载 Linux AIO(All-in-One)Ubuntu 16.10 Live DVD 了,该 DVD 包含所有必需的 Ubuntu 16.10 版本。
|
||||
|
||||
如果你梦想有一个可以写在 USB 或 DVD 光盘上的单独 ISO 镜像,然后在需要时启动某个 Ubuntu Linux 操作系统(如 Ubuntu、Kubuntu、Xubuntu、Lubuntu 或者 Ubuntu MATE)时使用它,现在你可以用 Linux AIO Ubuntu 16.10。
|
||||
|
||||
[Linux AIO][1] 团队以开发这种完全免费的多发行版 ISO 镜像而闻名,而Linux AIO Ubuntu 16.10 有两个版本,分别用于64位和32位平台,里面有 Ubuntu 16.10、Kubuntu 16.10、Xubuntu 16.10、Lubuntu 16.10、Ubuntu MATE 16.10 和 Ubuntu GNOME 16.10。
|
||||
|
||||
这些都是未修改的官方发行版。Linux AIO 团队把它们都放在一个容易使用的容器中,例如,当你在客户那,你需要向他/她展示各种基于 Linux 的操作系统来选择,你就不必带来六个不同的 U 盘或 DVD 光盘。
|
||||
|
||||
<q class="subhead" style="font-size: 18px; line-height: 26px; margin-top: 30px; margin-bottom: 10px; position: relative; display: block; font-weight: 700; letter-spacing: -0.6px; color: rgb(0, 40, 115); font-family: museo_slab, serif;">包含了硬件和内存测试工具</q>
|
||||
|
||||
两种 Linux AIO Ubuntu 16.10 都附带两个重要的实用程序,即HDT(硬件检测工具),查看目标计算机上是否与不同的 Ubuntu 16.10 完全兼容,还有 Memtest86+,一个非常流行的命令行工具,用于测试系统内存错误并验证其完整性。
|
||||
|
||||
[Linux AIO Ubuntu 16.10 现在可以通过我们的网站下载][2],但请记住,由于文件托管的 SourceForge 服务器的存储限制,镜像被分为两个 .7z 存档,你需要下载并解压缩以获取可用的 ISO。
|
||||
|
||||
我们曾经被许多读者问过 UEFI 是否支持 Linux AIO Live DVD,答案仍然是没有,但是团队正在努力在未来实现对 UEFI 的支持。还请查看最近发布的 Linux AIO Ubuntu Mixture 2017.01。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/you-can-now-have-a-single-iso-image-with-all-essential-ubuntu-16-10-flavors-exclusive-511788.shtml
|
||||
|
||||
作者:[ Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://linuxaio.net/
|
||||
[2]:http://linux.softpedia.com/get/Linux-Distributions/Ubuntu-AIO-DVD-103429.shtml
|
||||
@ -0,0 +1,119 @@
|
||||
针对不同新手最好的 Linux 版本
|
||||
============================================================
|
||||
|
||||

|
||||
Jack Wallen 在考虑对于来自不同环境的新手们来说哪种 Linux 版本是专门为他们设计的。[CC0][5]社区。
|
||||
|
||||
一个很古老的问题,哪种 Linux 版本更适合比简单的指出哪种 Linux 版本受欢迎更重要。为什么是这样?
|
||||
|
||||
|
||||
|
||||
让我们设置一个情景:你有一位用户,最有可能地,他过去大多数时候都是在 Windows 或者 Mac 系统上工作,它们二者都是可供选择的。现在,你想要在很短的时间里直截了当的说明 Linux 系统的工作方式并突出它的强大性和灵活性。
|
||||
|
||||
但是,请记住,最重要的一个方面是他们必须能够 _get it_(得到它),即开箱即用。
|
||||
|
||||
这就是为什么我们经常需要花费时间来找出哪种版本是最适合新手的 -- 因为把新手们带入 Linux 系统是传播 Linux 并增加 Linux 用户的最好方式。
|
||||
|
||||
对于新手来说最好的版本是什么?这次,我将要花费一定时间来说明对于来自不同环境的用户哪种版本才是最适合的。你也可以查看我的列表:[2017 最好的 OS 版本][11]
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
### 从 Windows 7 到 Linux:ZorinOS
|
||||
|
||||
当 Windows 8 发布以后,有一个理由让如此多的用户依然坚持使用 Windows 7, 那就是相似度。用户们已经在相同的桌面环境上工作了数十年,他们不想转移到 Windows 8 类似触摸屏的平台上。所以,你会去选择哪种版本呢?你首先必须要考虑的是桌面环境。为什么?因为这是你能够立刻吸引上这些 Windows 7 用户的地方。对于这个任务,还有什么版本会比 [ZorinOS][13] 更好呢?
|
||||
|
||||
ZorinOS 就是专门设计为 Windows 和 Mac 系统的替代品的,所以需要走很长一段路来模仿 Windows 和 Mac 桌面的外观和感觉。事实上,除了 ZorinOS 以外,你很难找到一个别的 Linux 版本,能够完美的从 Windows 7 转移到 Linux 系统上,同时保留 Linux 系统如此强大、灵活的平台。
|
||||
|
||||
|
||||
除了桌面环境(图片 1)以外, ZorinOS 完全基于 Ubuntu 系统,所以在“外表”下面, ZorinOS 和 Ubuntu 一样的工作(所以基本不用去担心硬件不能够被检测到)。同时伴有已准备好的可用软件,你便有了针对来自 Windows 7 用户的最完美的 Linux 版本。
|
||||
|
||||
### [zorinos.jpg][6]
|
||||
|
||||

|
||||
|
||||
图片 1:类 Windows 7 的 ZorinOS 桌面,准备开始服务。[使用许可][1]
|
||||
|
||||
请注意:然而, ZorinOS 有两个版本: Zorin Ultimate 和 Zorin Core 。 Zorin Core 是免费的,但它不包含几乎所有你能够在 Zorin Ultimate 中找到的软件。如果你想要一个适合所有来自 Windows 7 用户的开箱即用的版本,那么我强烈推荐购买 [Zorin Ultimate][14](大约需要花费 20 美元)。当然,如果你不想花钱购买 Ultimate 版本,你也可以从 Core 版本包含的软件包管理工具中安装几乎所有你需要的东西。
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
### 从 Windows 8 到 Linux : Ubuntu GNOME
|
||||
|
||||
转向 Windows 8, 它带来了一个以触摸屏为中心的环境,从而改变了用户与电脑互动的方式。老式的星菜单/面板/系统托盘桌面已经被触摸屏环境界面所取代。如果你正在找一个能给 Linux 新手们带来不同体验的最好环境,同时功能也要是最好的,那么没有比 [Ubuntu GNOME][16] 更合适的了。
|
||||
|
||||
Ubuntu GNOME 是 Ubuntu 和 GNOME(图 2)这两个世界之间最好的融合。
|
||||
用一个现代、优雅、简洁并且用户友好性的桌面代替了 Unity 界面, 因此 Ubuntu GNOME 不会给任何来自 Windows 8 的用户造成太多的麻烦。这个版本不仅基于 LFS 最新的 Ubuntu 发行版(支持将持续),同时使用了最新的 GNOME 桌面的稳定发行版 - 这意味着用户将能够享受到难以置信的稳定体验。
|
||||
|
||||
### [ubuntugnome.jpg][7]
|
||||
|
||||

|
||||
|
||||
图片 2 :在 Ubuntu GNOME 中可以发现,在最大化保证优雅性的情况下提高简洁性。 [使用许可][2]
|
||||
|
||||
### 从 Mac 到 Linux : Elementary OS
|
||||
|
||||
毫无疑问,这一环节的绝对赢家是 [Elementary OS][17] 。尽管 Elementary OS 在外观和感觉上所达到的效果和 OS X 桌面非常相似,但实际还有更多优秀的地方。 Elementary OS 同样是基于 Linux 系统的,只不过是它采取了很多 Mac X 桌面的设计元素。
|
||||
|
||||
任何的 Mac 用户使用 Elementary OS 的桌面环境(图片 3)都会感觉就像是“在家一样”(使用 Mac 一样)。伴有如此熟悉的文档,同时包含一个熟悉的应用菜单, Elementary OS 总是位于我的‘最好的版本列表’的顶部。如果我们正在和 Mac 用户交谈,那么没有比 Elementary OS 更好的 Mac 替代品了。
|
||||
|
||||
### [elementaryos.jpg][8]
|
||||
|
||||

|
||||
|
||||
图片 3 :值得骄傲的 Elementary OS 桌面。[使用许可][3]
|
||||
|
||||
有一件事情 Mac 用户们将会非常感激,那就是 Elementary OS 的开发者们很好的保持了桌面的一致性。从 dock, 到面板、菜单,包括应用,你找不到任何一个单一的应用看起来或感觉没有归属。
|
||||
|
||||
我将在这儿说一个关于 Elementary OS 的警告。你需要安装一个好的浏览器(因为它自带安装的 Epiphany-a 浏览器没有得到许多必要站点的支持),同时,你需要从官方的 [LibreOffice 网站][18]下载安装包安装 LibreOffice (因为在 Elementary OS 的软件中心找到的安装包已经有些过时了)。
|
||||
|
||||
### 从 Android 到 Linux:Ubuntu
|
||||
|
||||
这似乎有点像是一个延伸,但考虑到 Android 在全球市场中占主导地位,所以你可能遇到一个来自以移动为中心的用户,他可能需要一个 Linux 桌面,从而让他一直感觉像是‘在家’一样。对于我来说, [Ubuntu][19] 是最清晰的赢家。为什么?和其他系统相比, Ubuntu Unity 在桌面上做出了很杰出的工作,它使得桌面感觉像是一个包罗万象的界面。如果你愿意,那么可以包含在线搜索结果(默认情况下禁用),这是在几乎每一移动环境中均可找到的东西。同样, Unity HUD 菜单系统(图片 4)是在任何界面中所能找到的最独一无二的菜单系统之一。伴随有 Unity HUD 菜单系统,用户可以更少的依赖鼠标(因为他们将在 Android 支持的移动设备上工作)。
|
||||
|
||||
|
||||
### [ubuntu.jpg][9]
|
||||
|
||||

|
||||
|
||||
图片 4: Unity 桌面显示运转中。[使用许可][4]
|
||||
|
||||
当然, Ubuntu 也提供了市场上最稳定的桌面平台,所以用户体验近乎完美。
|
||||
|
||||
### 有一个适合每一个人的版本
|
||||
|
||||
有一件很重要的事情需要记住,那就是存在一个 Linux 版本适合每一个人。但是对于那些来自特殊环境的人,我强烈推荐找到一个最喜爱的 Linux 版本,从而能够帮助他们无缝过渡。给自己一个机会尝试一下,看一看在‘位于指尖’的开源和 Linux 的强大力量之下,你是否感到更加游刃有余。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/best-linux-distributions-new-users
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[6]:https://www.linux.com/files/images/zorinosjpg
|
||||
[7]:https://www.linux.com/files/images/ubuntugnomejpg
|
||||
[8]:https://www.linux.com/files/images/elementaryosjpg-1
|
||||
[9]:https://www.linux.com/files/images/ubuntujpg
|
||||
[10]:https://www.linux.com/files/images/distros-new-usersjpg
|
||||
[11]:https://www.linux.com/news/learn/sysadmin/best-linux-distributions-2017
|
||||
[12]:http://bit.ly/2jJgK0Q
|
||||
[13]:https://zorinos.com/
|
||||
[14]:https://zorinos.com/download/#ultimate
|
||||
[15]:https://training.linuxfoundation.org/certification/lfcs?utm_source=linux-inline-ad&utm_campaign=new-users-2017&utm_medium=online-advertising&utm_content=new-year
|
||||
[16]:https://ubuntugnome.org/
|
||||
[17]:https://elementary.io/
|
||||
[18]:http://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[19]:https://www.ubuntu.com/
|
||||
@ -0,0 +1,555 @@
|
||||
如何在Ubuntu 16.04中安装 Ceph 存储集群
|
||||
============================================================
|
||||
|
||||
### 在此页
|
||||
|
||||
1. [第1步 - 配置所有节点][1]
|
||||
2. [第2步 - 配置 SSH 服务器][2]
|
||||
3. [第3步 - 配置 Ubuntu 防火墙][3]
|
||||
4. [第4步 - 配置 Ceph OSD 节点][4]
|
||||
5. [第5步 - 建立 Ceph 集群][5]
|
||||
6. [第6步 - 测试 Ceph][6]
|
||||
7. [参考][7]
|
||||
|
||||
Ceph 是一个高性能,可靠行和可扩展性的开源存储平台。他是一个自由的分部署存储系统,提供了一个对象,块,文件级存储接口和缺少一个节点依然可以运行的特性。
|
||||
|
||||
在这个教程中,我将指导你在 Ubuntu 16.04 服务器上安装建立一个 Ceph 集群。Ceph 集群包括这些组件:
|
||||
|
||||
* **Ceph OSDs (ceph-osd)** - 控制数据存储,数据复制和恢复。Ceph 集群需要至少两个 Ceph OSD 服务器。这次安装我们将使用三个 Ubuntu 16.04 服务器。
|
||||
* **Ceph Monitor (ceph-mon)** - 监控集群状态和运行的 OSD 映射 和 CRUSH 映射。这里我们使用一个服务器。
|
||||
* **Ceph Meta Data Server (ceph-mds)** - 如果你想把 Ceph 作为文件系统使用,就需要这个。
|
||||
|
||||
### **前提条件**
|
||||
|
||||
* 6个安装了 Ubuntu 16.04 的服务器节点
|
||||
* 所有节点上的 root 权限
|
||||
|
||||
我将使用下面这些 hostname /IP 安装:
|
||||
|
||||
```
|
||||
hostname IP address
|
||||
ceph-admin 10.0.15.10
|
||||
mon1 10.0.15.11
|
||||
osd1 10.0.15.21
|
||||
osd2 10.0.15.22
|
||||
osd3 10.0.15.23
|
||||
client 10.0.15.15
|
||||
```
|
||||
|
||||
### 第1步 - 配置所有节点
|
||||
|
||||
这次安装,我将配置所有的6个节点来准备安装 Ceph 集群软件。所以你必须在所有节点运行下面的命令。然后确保所有节点都安装了 ssh-server。
|
||||
|
||||
**创建 Ceph 用户**
|
||||
|
||||
在所有节点创建一个名为'**cephuser**'的新用户
|
||||
|
||||
```
|
||||
useradd -m -s /bin/bash cephuser
|
||||
passwd cephuser
|
||||
```
|
||||
|
||||
创建完新用户后,我们需要配置 **cephuser** 无密码 sudo 权限。这意味着 ‘cephuser’ 首次可以不输入密码执行和获取 sudo 权限。
|
||||
|
||||
运行下面的命令来完成配置。
|
||||
|
||||
```
|
||||
echo "cephuser ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephuser
|
||||
chmod 0440 /etc/sudoers.d/cephuser
|
||||
sed -i s'/Defaults requiretty/#Defaults requiretty'/g /etc/sudoers
|
||||
```
|
||||
|
||||
**安装和配置 NTP**
|
||||
|
||||
安装 NTP 来同步所有节点的日期和时间。运行 ntpdate 命令通过 NTP 设置日期。我们将使用 US 池 NTP 服务器。然后开启并使 NTP 服务在开机时启动。
|
||||
|
||||
```
|
||||
sudo apt-get install -y ntp ntpdate ntp-doc
|
||||
ntpdate 0.us.pool.ntp.org
|
||||
hwclock --systohc
|
||||
systemctl enable ntp
|
||||
systemctl start ntp
|
||||
```
|
||||
|
||||
**安装 Open-vm-tools**
|
||||
|
||||
如果你正在VMware里运行所有节点,你需要安装这个虚拟化工具。
|
||||
|
||||
```
|
||||
sudo apt-get install -y open-vm-tools
|
||||
```
|
||||
|
||||
**安装 Python 和 parted**
|
||||
|
||||
在这个教程,我们需要 python 包来建立 ceph 集群。安装 python 和 python-pip。
|
||||
|
||||
```
|
||||
sudo apt-get install -y python python-pip parted
|
||||
```
|
||||
|
||||
**配置 Hosts 文件**
|
||||
|
||||
用 vim 编辑器编辑所有节点的 hosts 文件。
|
||||
|
||||
```
|
||||
vim /etc/hosts
|
||||
```
|
||||
|
||||
Paste the configuration below:
|
||||
|
||||
```
|
||||
10.0.15.10 ceph-admin
|
||||
10.0.15.11 mon1
|
||||
10.0.15.21 ceph-osd1
|
||||
10.0.15.22 ceph-osd2
|
||||
10.0.15.23 ceph-osd3
|
||||
10.0.15.15 ceph-client
|
||||
```
|
||||
|
||||
保存 hosts 文件,然后退出 vim 编辑器。
|
||||
|
||||
现在你可以试着在两个服务器间 ping 主机名来测试网络连通性。
|
||||
|
||||
```
|
||||
ping -c 5 mon1
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
### 第2步 - 配置 SSH 服务器
|
||||
|
||||
这一步,我们将配置 **ceph-admin 节点**。管理节点是用来配置监控节点和 osd 节点的。登录到 ceph-admin 节点然后使用 '**cephuser**'。
|
||||
|
||||
```
|
||||
ssh root@ceph-admin
|
||||
su - cephuser
|
||||
```
|
||||
|
||||
管理节点用来安装配置所有集群节点,所以 ceph-admin 用户必须有不使用密码连接到所有节点的权限。我们需要为 'ceph-admin' 节点的 'cephuser' 用户配置无密码登录权限。
|
||||
|
||||
生成 '**cephuser**' 的 ssh 密钥。
|
||||
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
|
||||
让密码为空
|
||||
|
||||
下面,为 ssh 创建一个配置文件
|
||||
|
||||
```
|
||||
vim ~/.ssh/config
|
||||
```
|
||||
|
||||
Paste the configuration below:
|
||||
|
||||
```
|
||||
Host ceph-admin
|
||||
Hostname ceph-admin
|
||||
User cephuser
|
||||
|
||||
Host mon1
|
||||
Hostname mon1
|
||||
User cephuser
|
||||
|
||||
Host ceph-osd1
|
||||
Hostname ceph-osd1
|
||||
User cephuser
|
||||
|
||||
Host ceph-osd2
|
||||
Hostname ceph-osd2
|
||||
User cephuser
|
||||
|
||||
Host ceph-osd3
|
||||
Hostname ceph-osd3
|
||||
User cephuser
|
||||
|
||||
Host ceph-client
|
||||
Hostname ceph-client
|
||||
User cephuser
|
||||
```
|
||||
|
||||
保存文件并退出 vim。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
改变配置文件权限为644。
|
||||
|
||||
```
|
||||
chmod 644 ~/.ssh/config
|
||||
```
|
||||
|
||||
现在使用 ssh-copy-id 命令增加密钥到所有节点。
|
||||
|
||||
```
|
||||
ssh-keyscan ceph-osd1 ceph-osd2 ceph-osd3 ceph-client mon1 >> ~/.ssh/known_hosts
|
||||
ssh-copy-id ceph-osd1
|
||||
ssh-copy-id ceph-osd2
|
||||
ssh-copy-id ceph-osd3
|
||||
ssh-copy-id mon1
|
||||
```
|
||||
|
||||
当请求输入密码时输入你的 cephuser 密码。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
现在尝试从 ceph-admin 节点登录 osd1 服务器,测试无密登录是否正常。
|
||||
|
||||
```
|
||||
ssh ceph-osd1
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### 第3步 - 配置 Ubuntu 防火墙
|
||||
|
||||
出于安全原因,我们需要在服务器打开防火墙。我们更愿使用 Ufw(不复杂的防火墙),Ubuntu 默认的防火墙,来保护系统。在这一步,我们在所有节点开启 ufw,然后打开 ceph-admin,ceph-mon 和 ceph-osd 需要使用的端口。
|
||||
|
||||
登录到 ceph-admin 节点,然后安装 ufw 包。
|
||||
|
||||
```
|
||||
ssh root@ceph-admin
|
||||
sudo apt-get install -y ufw
|
||||
```
|
||||
|
||||
打开 80,2003 和 4505-4506 端口,然后重载防火墙。
|
||||
|
||||
```
|
||||
sudo ufw allow 22/tcp
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow 2003/tcp
|
||||
sudo ufw allow 4505:4506/tcp
|
||||
```
|
||||
|
||||
开启 ufw 并设置开机启动。
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
从 ceph-admin 节点,登录到监控节点 'mon1' 然后安装 ufw。
|
||||
|
||||
```
|
||||
ssh mon1
|
||||
sudo apt-get install -y ufw
|
||||
```
|
||||
|
||||
打开 ceph 监控节点的端口然后开启 ufw。
|
||||
|
||||
```
|
||||
sudo ufw allow 22/tcp
|
||||
sudo ufw allow 6789/tcp
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
最后,在每个 osd 节点:ceph-osd1,ceph-osd2 和 ceph-osd3 打开这些端口 6800-7300。
|
||||
|
||||
从 ceph-admin 登录到每个 ceph-osd 节点安装 ufw。
|
||||
|
||||
```
|
||||
ssh ceph-osd1
|
||||
sudo apt-get install -y ufw
|
||||
```
|
||||
|
||||
在 osd 节点打开端口并重载防火墙。
|
||||
|
||||
```
|
||||
sudo ufw allow 22/tcp
|
||||
sudo ufw allow 6800:7300/tcp
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
ufw 防火墙配置完成。
|
||||
|
||||
### 第4步 - 配置 Ceph OSD 节点
|
||||
|
||||
这个教程里,我们有 3 个 OSD 节点,每个节点有两块硬盘分区。
|
||||
|
||||
1. **/dev/sda** for root partition
|
||||
2. **/dev/sdb** is empty partition - 20GB
|
||||
|
||||
我们要使用 **/dev/sdb** 作为 ceph 磁盘。从 ceph-admin 节点,登录到所有 OSD 节点,然后格式化 /dev/sdb 分区为 **XFS** 文件系统。
|
||||
|
||||
```
|
||||
ssh ceph-osd1
|
||||
ssh ceph-osd2
|
||||
ssh ceph-osd3
|
||||
```
|
||||
|
||||
使用 fdisk 命令检查分区表。
|
||||
|
||||
```
|
||||
sudo fdisk -l /dev/sdb
|
||||
```
|
||||
|
||||
格式化 /dev/sdb 分区为 XFS 文件系统,使用 parted 命令创建一个 GPT 分区表。
|
||||
|
||||
```
|
||||
sudo parted -s /dev/sdb mklabel gpt mkpart primary xfs 0% 100%
|
||||
```
|
||||
|
||||
下面,使用 mkfs 命令格式化分区为 XFS 格式。
|
||||
|
||||
```
|
||||
sudo mkfs.xfs -f /dev/sdb
|
||||
```
|
||||
|
||||
现在检查分区,然后你会看见 XFS /dev/sdb 分区。
|
||||
|
||||
```
|
||||
sudo fdisk -s /dev/sdb
|
||||
sudo blkid -o value -s TYPE /dev/sdb
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
### 第5步 - 创建 Ceph 集群
|
||||
|
||||
在这步,我们将从 ceph-admin 安装 Ceph 到所有节点。马上开始,登录到 ceph-admin 节点。
|
||||
|
||||
```
|
||||
ssh root@ceph-admin
|
||||
su - cephuser
|
||||
```
|
||||
|
||||
**在 ceph-admin 节点上安装 ceph-deploy**
|
||||
|
||||
首先我们已经在系统上安装了 python 和 python-pip。现在我们需要从 pypi python 仓库安装 Ceph 部署工具 '**ceph-deploy**'。
|
||||
|
||||
Install ceph-deploy on the ceph-admin node with the pip command.
|
||||
用 pip 命令在 ceph-admin 节点安装 ceph-deploy 。
|
||||
|
||||
```
|
||||
sudo pip install ceph-deploy
|
||||
```
|
||||
|
||||
注意: 确保所有节点都已经更新.
|
||||
|
||||
ceph-deploy 工具已经安装完毕后,为 Ceph 集群配置创建一个新目录。
|
||||
|
||||
**创建一个新集群**
|
||||
|
||||
创建一个新集群目录。
|
||||
|
||||
```
|
||||
mkdir cluster
|
||||
cd cluster/
|
||||
```
|
||||
|
||||
下一步,用 '**ceph-deploy**' 命令通过定义监控节点 '**mon1**' 创建一个新集群。
|
||||
|
||||
```
|
||||
ceph-deploy new mon1
|
||||
```
|
||||
|
||||
命令将在集群目录生成 Ceph 集群配置文件 'ceph.conf'。
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
用 vim 编辑 ceph.conf。
|
||||
|
||||
```
|
||||
vim ceph.conf
|
||||
```
|
||||
|
||||
在 [global] 块下,粘贴下面的配置。
|
||||
|
||||
```
|
||||
# Your network address
|
||||
public network = 10.0.15.0/24
|
||||
osd pool default size = 2
|
||||
```
|
||||
|
||||
保存文件并推出编辑器。
|
||||
|
||||
**安装 Ceph 到所有节点**
|
||||
|
||||
现在用一个命令从 ceph-admin 节点安装 Ceph 到所有节点。
|
||||
|
||||
```
|
||||
ceph-deploy install ceph-admin ceph-osd1 ceph-osd2 ceph-osd3 mon1
|
||||
```
|
||||
|
||||
命令将自动安装 Ceph 到所有节点:mon1,osd1-3 和 ceph-admin - 安装将花一些时间。
|
||||
|
||||
现在到 mon1 节点部署监控节点。
|
||||
|
||||
```
|
||||
ceph-deploy mon create-initial
|
||||
```
|
||||
|
||||
命令将创建一个监控密钥,用 ceph 命令检查密钥。
|
||||
|
||||
```
|
||||
ceph-deploy gatherkeys mon1
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
**增加 OSDS 到集群**
|
||||
|
||||
在所有节点上安装了 Ceph 之后,现在我们可以增加 OSD 守护进程到集群。OSD 守护进程将在磁盘 /dev/sdb 分区上创建数据和日志 。
|
||||
|
||||
检查所有 osd 节点的 /dev/sdb 磁盘可用性。
|
||||
|
||||
```
|
||||
ceph-deploy disk list ceph-osd1 ceph-osd2 ceph-osd3
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
你将看见我们之前创建 XFS 格式的 /dev/sdb。
|
||||
|
||||
下面,在所有节点用 zap 选项删除分区表。
|
||||
|
||||
```
|
||||
ceph-deploy disk zap ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
|
||||
```
|
||||
|
||||
这个命令将删除所有 Ceph OSD 节点的 /dev/sdb 上的数据。
|
||||
|
||||
现在准备所有 OSD 节点并确保结果没有报错。
|
||||
|
||||
```
|
||||
ceph-deploy osd prepare ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
|
||||
```
|
||||
|
||||
当你看到 ceph-osd1-3 结果已经准备好 OSD 使用,然后命令已经成功。
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
用下面的命令激活 OSD:
|
||||
|
||||
```
|
||||
ceph-deploy osd activate ceph-osd1:/dev/sdb ceph-osd2:/dev/sdb ceph-osd3:/dev/sdb
|
||||
```
|
||||
|
||||
现在你可以再一次检查 OSDS 节点的 sdb 磁盘。
|
||||
|
||||
```
|
||||
ceph-deploy disk list ceph-osd1 ceph-osd2 ceph-osd3
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
结果是 /dev/sdb 现在已经分为两个区:
|
||||
|
||||
1. **/dev/sdb1** - Ceph Data
|
||||
2. **/dev/sdb2** - Ceph Journal
|
||||
|
||||
或者你直接在 OSD 节点山检查。
|
||||
|
||||
```
|
||||
ssh ceph-osd1
|
||||
sudo fdisk -l /dev/sdb
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
接下来,部署管理密钥到所有关联节点。
|
||||
|
||||
```
|
||||
ceph-deploy admin ceph-admin mon1 ceph-osd1 ceph-osd2 ceph-osd3
|
||||
```
|
||||
|
||||
在所有节点运行下面的命令,改变密钥文件权限。
|
||||
|
||||
```
|
||||
sudo chmod 644 /etc/ceph/ceph.client.admin.keyring
|
||||
```
|
||||
|
||||
Ceph 集群在 Ubuntu 16.04 已经创建完成。
|
||||
|
||||
### 第6步 - 测试 Ceph
|
||||
|
||||
在第4步,我们已经安装并创建了一个新 Ceph 集群,然后添加了 OSDS 节点到集群。现在我们应该测试集群确保它如期工作。
|
||||
|
||||
从 ceph-admin 节点,登录到 Ceph 监控服务器 '**mon1**'。
|
||||
|
||||
```
|
||||
ssh mon1
|
||||
```
|
||||
|
||||
运行下面命令来检查集群健康。
|
||||
|
||||
```
|
||||
sudo ceph health
|
||||
```
|
||||
|
||||
现在检查集群状态。
|
||||
|
||||
```
|
||||
sudo ceph -s
|
||||
```
|
||||
|
||||
你可以看到下面返回结果:
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
确保 Ceph 健康是 **OK** 并且有一个监控节点 '**mon1**' IP 地址为 '**10.0.15.11**'。有 **3 OSD** 服务器都是 **up** 状态并且正在运行,可用磁盘空间为 **45GB** - 3x15GB Ceph 数据 OSD 分区。
|
||||
|
||||
我们在 Ubuntu 16.04 建立一个新 Ceph 集群成功。
|
||||
|
||||
### 参考
|
||||
|
||||
* http://docs.ceph.com/docs/jewel/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-all-nodes
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-the-ssh-server
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-the-ubuntu-firewall
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-configure-the-ceph-osd-nodes
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-build-the-ceph-cluster
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#step-testing-ceph
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/#reference
|
||||
[8]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/1.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/2.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/3.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/4.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/5.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/6.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/7.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/8.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/9.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/10.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/11.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/12.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-a-ceph-cluster-on-ubuntu-16-04/big/13.png
|
||||
@ -0,0 +1,60 @@
|
||||
5 个让你的 WordPress 站点安全的贴士
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
WordPress 是迄今为止最流行的博客平台。
|
||||
|
||||
由于它的流行,它有它自己的优势和弱点。事实上,几乎每个人都使用它,使它更容易出现漏洞。因为新的缺陷被发现,WordPress 的开发人员正在不停地发布修复和补丁,但这并不意味着你可以简单地安装和忘记安装。
|
||||
|
||||
在这篇文章中,我们将提供一些最常见的保护和强化 WordPress 网站的方法。
|
||||
|
||||
### 在登录后台时总是使用 SSL
|
||||
|
||||
不用说的是如果你并不只打算做一个随意的博客,你应该总是使用SSL。不使用加密连接登录到你的网站会暴露你的用户名和密码。目前任何人嗅探流量都可能会发现你的密码。如果你使用 WiFi 冲浪或者连接到一个公共热点,那么你会被黑客的机会更高,这是特别真实的。你可以从[这里][1]获取受信任的 SSL 证书。
|
||||
|
||||
### 对任何额外的插件挑剔
|
||||
|
||||
由第三方开发人员开发,每个插件的质量和安全性总是值得怀疑,并且它仅取决于其开发人员的经验。当安装任何额外的插件时,你应该仔细选择,并考虑其受欢迎程度以及插件的维护频率。应该避免维护不良的插件,因为它们更容易出现易于被利用的错误和漏洞。
|
||||
|
||||
此主题也是上一个关于 SSL 主题的补充,因为许多插件包含请求不安全(HTTP)连接的脚本。只要你的网站通过 HTTP 访问,一切似乎很好。但是,一旦你决定使用加密并强制使用 SSL 访问,则会立即导致网站损坏,因为当你使用 HTTPS 访问其他网站时,这些插件上的脚本将继续通过 HTTP 提供请求。
|
||||
|
||||
### 安装 Wordfence
|
||||
|
||||
Wordfence 是由 Feedjit Inc. 开发的,Wordfence 是目前最流行的 WordPress 安全插件,并且是每个严肃的 WordPress 网站必备的,特别是那些使用[WooCommerce][2]或另一个 WordPress 电子商务平台的网站。 Wordfence 不只是一个插件,因为它提供了一系列的安全功能,它将加强您的网站。它具有 web 程序防火墙、恶意软件扫描程序、实时流量分析器和各种其他工具,它们可以提高你网站的安全性。防火墙将默认阻止恶意登录尝试,甚至可以配置为按照 IP 地址范围阻止整个国家/地区的访问。我们真正喜欢 Wordfence 的原因是,即使你的网站因为某些原因被危害,例如恶意脚本,Wordfence 可以在安装以后扫描和清理你的网站从被感染的文件。
|
||||
|
||||
公司提供插件的免费和付费订阅计划,但即使是免费计划,你的网站仍将获得令人满意的水平。
|
||||
|
||||
### 用额外的密码锁住 /wp-admin 和 /wp-login.php
|
||||
|
||||
保护你的 WordPress 后端的另一个步骤是使用额外的密码保护任何除了你以外不打算让任何人使用的目录(读取URL)。 /wp-admin 目录已经在此关键目录列表中。 如果你不允许普通用户登录 WordPress,你应该使用其他密码限制 wp.login.php 文件。无论是使用 [Apache][3] 还是 [Nginx][4],你都可以访问这两篇文章,了解如何额外保护 WordPress 安装。
|
||||
|
||||
### 禁用/停止用户枚举
|
||||
|
||||
这是攻击者发现你网站上的有效用户名的一种相当简单的方法(阅读找出管理员用户名)。那么它是如何工作的?这很简单。在任何 WordPress 站点上的主要 URL 后面跟上 /?author=1 。 例如:wordpressexample.com/?author=1
|
||||
|
||||
要保护您的网站免受此影响,只需安装[停止用户枚举][5]插件。
|
||||
|
||||
### 禁用 XML-RPC
|
||||
|
||||
RPC 代表远程过程调用,它可以用来从位于网络上另一台计算机上的程序请求服务的协议。在 WordPress 方面,XML-RPC 允许你使用流行的网络日志客户端(如Windows Live Writer)在你的 WordPress 博客上发布文章,但如果你使用 WordPress 移动应用程序那么也需要它。 XML-RPC 在早期版本中被禁用,但是从 WordPress 3.5 时它被默认启用,这让你的网站有更大的攻击面。虽然各种安全研究人员建议这不是一个大问题,如果你不打算使用网络博客客户端或 WP 移动应用程序,你应该禁用XML-RPC服务。
|
||||
|
||||
有多种方法可以做到这一点,最简单的是安装[禁用 XML-RPC][6]插件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/5-tips-for-securing-your-wordpress-sites/
|
||||
|
||||
作者:[rosehosting.com][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:rosehosting.com
|
||||
[1]:https://www.rosehosting.com/ssl-certificates.html
|
||||
[2]:https://www.rosehosting.com/woocommerce-hosting.html
|
||||
[3]:https://www.rosehosting.com/blog/password-protect-a-directory-using-htaccess/
|
||||
[4]:https://www.rosehosting.com/blog/password-protecting-directories-with-nginx/
|
||||
[5]:https://wordpress.org/plugins/stop-user-enumeration/
|
||||
[6]:https://wordpress.org/plugins/disable-xml-rpc/
|
||||
@ -0,0 +1,49 @@
|
||||
RISC-V - Linux 的微处理器 - 会开启一个开源硬件的文艺复兴么?
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
<figcaption data-blog-inner="caption" class="inner-caption" style="border: 0px solid rgb(5, 28, 42); -webkit-font-smoothing: antialiased; margin-top: 10px; -webkit-tap-highlight-color: transparent;"></figcaption>
|
||||
|
||||
我与许多人分享过一个希望,我们很快就能使用由开源硬件([OSH][1])_和_软件驱动的现代,强大的设备。
|
||||
|
||||
开放硬件有完整的文档,并且可以根据你的需求自由使用、研究、修改和复制。从原理图到 PCB 布局的所有内容都已发布,包括驱动硬件的软件。近年来有所进步,有更多的硬件被开放了,但是我们的 pc 和其他桌面或者智能手机/平板设备中的微处理器被限制在了以 x86 为主导的,封闭的指令集架构([ISA][2])或者 ARM 的 变体。这两个 ISA 都是闭源的并且不是开放设备的候选。此外,许多广泛使用的 ARM 实现像 A9 或 Snapdragon 添加了进一步的专有层到这些已经专有的 ISA 上。
|
||||
|
||||
[RISC-V][3]是不同的。在 UC Berkeley 的研究人员于 2010 年推出的 RISC-V(发音 risk-five)是根据同样的原始[RISC][4](精简指令集计算) CPU 设计构建的,其基础是其他熟悉的 ISA,如ARM、MIPS、PowerPC 和 SPARC,但目的是开放且不受专利保护(注意:目前,RISC-V 规范仅供私人或教育用途使用,并且计划在将来开放)。RISC 设计策略与 x86 系列的复杂指令集计算(CISC)设计相反。
|
||||
|
||||
虽然 RISC-V 不是现有唯一开放的 ISA,但它是唯一一个极速推进的。RISC-V 基金会指导 ISA 的开发和采用,它有一些相当大的捐赠者,如 Oracle、Western Digital、HP、Google、IBM 和 Nvidia。我可以想到几个名单上缺少的著名的芯片制造商。似乎大的玩家已经意识到,与软件一样,硬件会在开放下发展得更快更好。而且,任何人使用它你都不必支付。因为发展的困难和成本,一个像这样的项目并没有被更快地征服。现在,一个公开的结果是大公司正在跟进,开发资金正在源源而来。
|
||||
|
||||
RISC-V 在学术界也有很多支持。从在伯克利的孵化到在世界范围内超过 35 个大学项目协助其发展,在那里不缺乏聪明的头脑为这个项目工作。
|
||||
|
||||
背后也有进展。在软件方面,人们正在将程序移植到 RISC-V 上,并且可以让它启动起来。Fedora 已经移植了成千上万的程序 - 下面是 [Fedora/RISC-V][5] 在 QEMU 中启动:
|
||||
|
||||

|
||||
|
||||
<figcaption data-blog-inner="caption" class="inner-caption" style="border: 0px solid rgb(5, 28, 42); -webkit-font-smoothing: antialiased; margin-top: 10px; -webkit-tap-highlight-color: transparent;">_Hat tip to Richard WM Jones for this awesome gif._</figcaption>
|
||||
|
||||
在硬件方面,人们正在制造开发板。HiFive1 是一个成功众筹项目,是来自 SiFive 的一块 Arduino 板,由自己的 FE310 SoC 供电,这是一块 32 位的 RISC-V 芯片,运行频率为 320+ MHz。 它会在 2 月发货,你可以[在这里][6]预订一个,价格为 $59。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
这一切听起来很棒 - 我希望他们能够交付,因为我们都将从中受益非浅。如果可以,请支持这个项目。告诉人们这个东西。购买一块 HiFive1,看看它上面运行了什么。我在你的未来看到了这些芯片。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.darrentoback.com/can-risc-v-linux-of-microprocessors-start-an-open-hardware-renaissance
|
||||
|
||||
作者:[ dmt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.darrentoback.com/about-me
|
||||
[1]:https://en.wikipedia.org/wiki/Open-source_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/Comparison_of_instruction_set_architectures
|
||||
[3]:https://en.wikipedia.org/wiki/RISC-V
|
||||
[4]:https://en.wikipedia.org/wiki/Reduced_instruction_set_computing
|
||||
[5]:https://fedoraproject.org/wiki/Architectures/RISC-V
|
||||
[6]:https://www.crowdsupply.com/sifive/hifive1/
|
||||
170
translated/tech/20170116 Use Docker remotely on Atomic Host.md
Normal file
170
translated/tech/20170116 Use Docker remotely on Atomic Host.md
Normal file
@ -0,0 +1,170 @@
|
||||
[远程在 Atomic 主机上使用 Docker][1]
|
||||
---------------------
|
||||
|
||||

|
||||
|
||||
来自 [Atomic 项目][2] 的 Atomic 主机是一个基于轻量级容器的操作系统,它可以运行 Linux 容器。它已被优化为用作云环境的容器运行时系统。例如,它可以托管 Docker 守护进程和容器。有时,你可能需要在该主机上运行 docker 命令,并从其他地方管理服务器。本文介绍如何远程访问 Fedora Atomic 主机上的[Docker][3]守护进程,[你可以在这里下载到它][4]。整个过程由[Ansible][5]自动完成 - 在涉及到自动化的一切上,这是一个伟大的工具。
|
||||
|
||||
### 一份安全笔记
|
||||
|
||||
由于我们通过网络连接,所以我们使用[TLS][6]保护 Docker 守护进程。此过程需要客户端证书和服务器证书。OpenSSL 包用于创建用于建立 TLS 连接的证书密钥。这里,Atomic 主机运行守护程序,我们的本地的 [Fedora Workstation][7] 充当客户端。
|
||||
|
||||
在你按照这些步骤进行之前,请注意,_任何_在客户端上可以访问 TLS 证书的进程在服务器上具有**完全根访问权限。** 因此,客户端可以在服务器上做任何它想做的事情。因此,我们需要仅向可信任的特定客户端主机授予证书访问权限。你应该将客户端证书仅复制到完全由你控制的客户端主机。即使在这种情况下,客户端机器的安全也至关重要。
|
||||
|
||||
但是,此方法只是远程访问守护程序的一种方法。编排工具通常提供更安全的控制。下面的简单方法适用于个人实验,但可能不适合开放式网络。
|
||||
|
||||
### 获取 Ansible role
|
||||
|
||||
[Chris Houseknecht][8] 写了一个 Ansible role,它会创造所需的所有证书。这样,你不需要手动运行 _openssl_ 命令了。 这些在[ Ansible role 仓库][9]中提供。将它克隆到你当前的工作主机。
|
||||
|
||||
```
|
||||
$ mkdir docker-remote-access
|
||||
$ cd docker-remote-access
|
||||
$ git clone https://github.com/ansible/role-secure-docker-daemon.git
|
||||
```
|
||||
|
||||
### 创建配置文件
|
||||
|
||||
接下来,你必须创建 Ansible 配置文件、inventory 和 playbook 文件以设置客户端和守护进程。以下说明在 Atomic 主机上创建客户端和服务器证书。然后,获取客户端证书到本地。最后,它们会配置守护进程以及客户端,使它们能彼此交互。
|
||||
|
||||
这里是你需要的目录结构。如下所示,创建下面的每个文件。
|
||||
|
||||
```
|
||||
$ tree docker-remote-access/
|
||||
docker-remote-access/
|
||||
├── ansible.cfg
|
||||
├── inventory
|
||||
├── remote-access.yml
|
||||
└── role-secure-docker-daemon
|
||||
```
|
||||
|
||||
### _ansible.cfg_
|
||||
|
||||
```
|
||||
$ vim ansible.cfg
|
||||
[defaults]
|
||||
inventory=inventory
|
||||
```
|
||||
|
||||
### _inventory_
|
||||
|
||||
```
|
||||
$ vim inventory
|
||||
[daemonhost]
|
||||
'IP_OF_ATOMIC_HOST' ansible_ssh_private_key_file='PRIVATE_KEY_FILE'
|
||||
```
|
||||
|
||||
将 inventory 中的 _IP_OF_ATOMIC_HOST_ 替换为 Atomic 主机的 IP。将 _PRIVATE_KEY_FILE_ 替换为本地系统上的 SSH 私钥文件的位置。
|
||||
|
||||
### _remote-access.yml_
|
||||
|
||||
```
|
||||
$ vim remote-access.yml
|
||||
---
|
||||
- name: Docker Client Set up
|
||||
hosts: daemonhost
|
||||
gather_facts: no
|
||||
tasks:
|
||||
- name: Make ~/.docker directory for docker certs
|
||||
local_action: file path='~/.docker' state='directory'
|
||||
|
||||
- name: Add Environment variables to ~/.bashrc
|
||||
local_action: lineinfile dest='~/.bashrc' line='export DOCKER_TLS_VERIFY=1\nexport DOCKER_CERT_PATH=~/.docker/\nexport DOCKER_HOST=tcp://{{ inventory_hostname }}:2376\n' state='present'
|
||||
|
||||
- name: Source ~/.bashrc file
|
||||
local_action: shell source ~/.bashrc
|
||||
|
||||
- name: Docker Daemon Set up
|
||||
hosts: daemonhost
|
||||
gather_facts: no
|
||||
remote_user: fedora
|
||||
become: yes
|
||||
become_method: sudo
|
||||
become_user: root
|
||||
roles:
|
||||
- role: role-secure-docker-daemon
|
||||
dds_host: "{{ inventory_hostname }}"
|
||||
dds_server_cert_path: /etc/docker
|
||||
dds_restart_docker: no
|
||||
tasks:
|
||||
- name: fetch ca.pem from daemon host
|
||||
fetch:
|
||||
src: /root/.docker/ca.pem
|
||||
dest: ~/.docker/
|
||||
fail_on_missing: yes
|
||||
flat: yes
|
||||
- name: fetch cert.pem from daemon host
|
||||
fetch:
|
||||
src: /root/.docker/cert.pem
|
||||
dest: ~/.docker/
|
||||
fail_on_missing: yes
|
||||
flat: yes
|
||||
- name: fetch key.pem from daemon host
|
||||
fetch:
|
||||
src: /root/.docker/key.pem
|
||||
dest: ~/.docker/
|
||||
fail_on_missing: yes
|
||||
flat: yes
|
||||
- name: Remove Environment variable OPTIONS from /etc/sysconfig/docker
|
||||
lineinfile:
|
||||
dest: /etc/sysconfig/docker
|
||||
regexp: '^OPTIONS'
|
||||
state: absent
|
||||
|
||||
- name: Modify Environment variable OPTIONS in /etc/sysconfig/docker
|
||||
lineinfile:
|
||||
dest: /etc/sysconfig/docker
|
||||
line: "OPTIONS='--selinux-enabled --log-driver=journald --tlsverify --tlscacert=/etc/docker/ca.pem --tlscert=/etc/docker/server-cert.pem --tlskey=/etc/docker/server-key.pem -H=0.0.0.0:2376 -H=unix:///var/run/docker.sock'"
|
||||
state: present
|
||||
|
||||
- name: Remove client certs from daemon host
|
||||
file:
|
||||
path: /root/.docker
|
||||
state: absent
|
||||
|
||||
- name: Reload Docker daemon
|
||||
command: systemctl daemon-reload
|
||||
- name: Restart Docker daemon
|
||||
command: systemctl restart docker.service
|
||||
```
|
||||
|
||||
### 访问 Atomic 主机
|
||||
|
||||
现在运行 Ansible playbook:
|
||||
|
||||
```
|
||||
$ ansible-playbook remote-access.yml
|
||||
```
|
||||
|
||||
确保 tcp 端口 2376 在你的 Atomic 主机上打开了。如果你在使用 Openstack,请在安全规则中添加 TCP 端口 2376。 如果你使用 AWS,请将其添加到你的安全组。
|
||||
|
||||
现在,在你的工作站上作为普通用户运行的 _docker_ 命令与 Atomic 主机的守护进程通信了,并在那里执行命令。你不需要手动 _ssh_ 或在 Atomic 主机上发出命令。这允许你远程、轻松、安全地启动容器化应用程序。
|
||||
|
||||
如果你想克隆 playbook 和配置文件,这里有[一个可用的 git 仓库][10]。
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-docker-remotely-atomic-host/
|
||||
|
||||
作者:[Trishna Guha][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://trishnag.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/use-docker-remotely-atomic-host/
|
||||
[2]:http://www.projectatomic.io/
|
||||
[3]:https://www.docker.com/
|
||||
[4]:https://getfedora.org/atomic/
|
||||
[5]:https://www.ansible.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[7]:https://getfedora.org/en/workstation/
|
||||
[8]:https://twitter.com/CHouseknecht
|
||||
[9]:https://github.com/ansible/role-secure-docker-daemon
|
||||
[10]:https://github.com/trishnaguha/fedora-cloud-ansible/tree/master/docker-remote-access
|
||||
[11]:https://cdn.fedoramagazine.org/wp-content/uploads/2017/01/docker-daemon.jpg
|
||||
@ -0,0 +1,75 @@
|
||||
5 个在基于 Debian 的 Linux 发行版上找到 deb 软件包的方法
|
||||
============================================================
|
||||

|
||||
|
||||
|
||||
基于 Debian 的 Linux 发行版上有一个问题:为用户提供高级软件选择。当涉及到为 Linux 制作软件时,所有的大公司都首先瞄准这种类型的 Linux 发行版。通常一些开发人员甚至不打算为其他类型的 Linux 发行版做并且_只_做 DEB 包。
|
||||
|
||||
然而,只是因为许多开发人员针对这些类型的 Linux 发行版并不意味着用户从来没有遇到寻找软件的问题。大多数 Debian 和 Ubuntu 用户会自己在互联网上搜索 DEB 包。
|
||||
|
||||
因此,我们决定写一篇文章,它涵盖了五个最好的网站以找到基于 Debian 的 Linux 发行版的 DEB 软件包。 这样用户就能够更容易地找到他们需要的软件,而不是浪费时间在互联网上搜索。
|
||||
|
||||
### 1\. Launchpad
|
||||
|
||||
[Launchpad][11]是互联网上最大的基于 Debian 的软件包仓库。 为什么? 这是 PPA 所在的地方!Canonical 创建了这个服务,所以任何开发商(大的或小的)都可以使用它,并且轻松地将其软件包分发给 Ubuntu 用户。
|
||||
|
||||
不幸的是,并不是所有基于 Debian 的 Linux 发行版都是 Ubuntu。但是,只是因为你的 Linux 发行版不使用 PPA 并不意味着此服务是无用的。Launchpad 使得很有可能直接下载任何 Debian 软件包进行安装。
|
||||
|
||||

|
||||
|
||||
### 2\. Pkgs.org
|
||||
|
||||
除了 Launchpad,[Pkgs.org][12]可能是互联网上查找 Debian 软件包的最大的地方。如果一个 Linux 用户需要一个 deb,并且不能在它的发布包的软件包仓库中找到它,它很可能在这个网站上找到。
|
||||
|
||||

|
||||
|
||||
### 3\. Getdeb
|
||||
|
||||
Getdeb][13] 是一个特定于 Ubuntu 的项目,它托管最新的 Ubuntu 版本的软件。这使它成为一个找 Debian 包很好的地方。特别是如果用户是在 Ubuntu、Linux Mint、Elementary OS和其他许多基于 Ubuntu 的 Linux 发行版上。此外,这些软件包甚至可以在 Debian 上工作!
|
||||
|
||||

|
||||
|
||||
### 4\. RPM Seek
|
||||
|
||||
即使[这个网站][14]声称是 “Linux RPM 包搜索引擎”,奇怪的是,它也可以搜索 DEB 包。如果你试图找到一个特定的 DEB 包,并且在其他地方都找过了,再检查下 RPM Seek 或许是一个好主意,因为它可能有你所需要的。
|
||||
|
||||

|
||||
|
||||
### 5\. Open Suse Software
|
||||
|
||||
[Open SUSE 构建服务][15]是 Linux 上最知名的软件构建工具之一。有了它,开发人员可以轻松地获取他们的代码,并为许多不同的 Linux 发行版打包。因此,OSB 的包搜索允许用户下载 DEB 文件。
|
||||
|
||||
更有趣的是,许多开发人员选择使用 OSB 分发他们的软件,因为它可以轻松地生成 RPM、DEB等。如果用户急切需要 DEB,Open SUSE Build 的服务很值得去看下。
|
||||
|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
寻找 Linux 发行版的包可能是乏味的,有时令人沮丧。这就是为什么很高兴了解到有基于 Debian 的 Linux 发行版的用户可以访问获得他们需要的软件的网站。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-places-find-debs-packages/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]:https://www.maketecheasier.com/best-places-find-debs-packages/#comments
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fbest-places-find-debs-packages%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fbest-places-find-debs-packages%2F&text=5+of+the+Best+Places+to+Find+DEBs+Packages+for+Debian-Based+Linux+Distros
|
||||
[6]:mailto:?subject=5%20of%20the%20Best%20Places%20to%20Find%20DEBs%20Packages%20for%20Debian-Based%20Linux%20Distros&body=https%3A%2F%2Fwww.maketecheasier.com%2Fbest-places-find-debs-packages%2F
|
||||
[7]:https://www.maketecheasier.com/add-paypal-wordpress/
|
||||
[8]:https://www.maketecheasier.com/keep-kids-videos-out-youtube-history/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:https://www.maketecheasier.com/find-rpms-for-redhat-based-distros/
|
||||
[11]:https://launchpad.net/
|
||||
[12]:https://pkgs.org/
|
||||
[13]:http://www.getdeb.net/welcome/
|
||||
[14]:http://www.rpmseek.com/index.html
|
||||
[15]:https://build.opensuse.org/
|
||||
@ -0,0 +1,75 @@
|
||||
如何知道目录和子目录下文件的数量
|
||||
============================================================
|
||||
|
||||
在本指南中,我们将介绍如何在 Linux 系统上显示当前工作目录或任何其他目录及其子目录中的文件数量。
|
||||
|
||||
我们将使用[ find 命令][6],它用于搜索目录层次结构中的文件以及[ wc 命令][7],它会打印每个文件或标准输入的换行符、单词和字节计数。
|
||||
|
||||
以下是我们可以使用[ find 命令][8]的选项,如下所示:
|
||||
|
||||
1. `-type` - 指定要搜索的文件类型,在上面的情况下,`f`表示查找所有常规文件。
|
||||
2. `-print` - 打印文件绝对路径。
|
||||
3. `-l` - 此选项打印换行符的总数,等于由[ find 命令][1]输出的绝对文件路径总数。
|
||||
|
||||
find 命令的一般语法。
|
||||
|
||||
```
|
||||
# find . -type f -print | wc -l
|
||||
$ sudo find . -type f -print | wc -l
|
||||
```
|
||||
|
||||
重要:使用[ sudo 命令][9]读取指定目录中的所有文件,包括具有超级用户权限的子目录中的文件,以避免 “Permission denied” 错误,如下截图所示:
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
Linux 中的文件数量
|
||||
|
||||
你可以看到,在上面的第一个命令中,find 命令没有读取当前工作目录中的所有文件。
|
||||
|
||||
下面是额外的示例,分别显示 `/var/log` 和 `/etc` 目录中的常规文件总数:
|
||||
|
||||
```
|
||||
$ sudo find /var/log/ -type f -print | wc -l
|
||||
$ sudo find /etc/ -type f -print | wc -l
|
||||
```
|
||||
|
||||
有关Linux find 和 wc 命令的更多示例,请查看以下系列文章以了解其他使用选项,提示和相关命令:
|
||||
|
||||
1. [35 个 Linux 中的 “find” 命令示例][2]
|
||||
2. [如何在 Linux 中查找最近或今天的修改的文件][3]
|
||||
3. [在 Linux 中查找十个占用最大的目录和文件][4]
|
||||
4. [6 个有用的 “wc” 命令示例来计算行数、单词和字符][5]
|
||||
|
||||
就是这样了!如果你知道其他任何方法来显示目录及其子目录中的文件总数,请在评论中与我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin、web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/find-number-of-files-in-directory-subdirectories-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/find-top-large-directories-and-files-sizes-in-linux/
|
||||
[2]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
[3]:http://www.tecmint.com/find-recent-modified-files-in-linux/
|
||||
[4]:http://www.tecmint.com/find-top-large-directories-and-files-sizes-in-linux/
|
||||
[5]:http://www.tecmint.com/wc-command-examples/
|
||||
[6]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
[7]:http://www.tecmint.com/wc-command-examples/
|
||||
[8]:http://www.tecmint.com/find-recent-modified-files-in-linux/
|
||||
[9]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/01/Find-Number-of-Files-in-Linux.png
|
||||
@ -0,0 +1,61 @@
|
||||
如何在 Linux 让 ‘sudo’ 密码会话超时更长些
|
||||
============================================================
|
||||
|
||||
在最近的文章中,我们向你展示了[ Linux 中的 10 个有用的 sudoers 配置][1]以及[让 sudo 在输入不正确的密码时冒犯你][2],在本文中,我们发现了另一个 sudo 贴士,在 Ubuntu Linux 中使 sudo 密码会话(超时)更长或更短。
|
||||
|
||||
在 Ubuntu 及其衍生版如 Linux Mint 或任何其他基于 Ubuntu 的发行版中,当你执行 [sudo command][3] 时,它将提示你输入管理密码。
|
||||
|
||||
在第一次执行 sudo 命令后,默认情况下密码将保持 15 分钟,因此你不需要为每个 sudo 命令键入密码。
|
||||
|
||||
如果,你因为某种原因觉得 15 分钟太长或太短,你可以在 sudoers 文件中做一个简单的调整。
|
||||
|
||||
要设置 sudo 密码超时值,请使用 `passwd_timeout` 参数。首先使用 sudo 和 visudo 命令以超级用户权限打开 /etc/sudoers 文件,如下所示:
|
||||
|
||||
```
|
||||
$ sudo visudo
|
||||
```
|
||||
|
||||
接着添加下面的默认值,这意味着 sudo 密码提示将会在用户使用 sudo 20 分钟后过期。
|
||||
|
||||
```
|
||||
Defaults env_reset,timestamp_timeout=20
|
||||
```
|
||||
|
||||
注意:你可以马上设置任何所需的时间,并确保在超时之前等待。 如果要为每个执行的 sudo 命令弹出密码提示,你也可以将时间设置为0,或者通过设置值 `-1` 永久禁用密码提示。
|
||||
|
||||
下面的截图显示了我在 /etc/sudoers 文件中设置的默认参数。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
改变 sudo 密码超时
|
||||
|
||||
按 `[Ctrl + O]` 保存文件,然后使用 `[Ctrl + X]` 退出。 然后,使用 sudo 运行命令并等待 2 分钟以检查密码提示是否超时以测试设置是否正常。
|
||||
|
||||
在本篇中,我们解释了如何设置 sudo 密码提示超时之前的分钟数,记得在评论栏分享你对这篇文章的想法或者其他[对系统管理员配置有用的 sudo 配置][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin 以及 web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
|
||||
|
||||
via: http://www.tecmint.com/set-sudo-password-timeout-session-longer-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[2]:http://www.tecmint.com/sudo-insult-when-enter-wrong-password/
|
||||
[3]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/set-sudo-password-timeout-session.png
|
||||
[5]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
@ -0,0 +1,144 @@
|
||||
Linux 命令行导航贴士:pushd 和 popd 命令基础
|
||||
============================================================
|
||||
|
||||
### 在本篇中
|
||||
|
||||
1. [pushd 和 popd 命令基础][1]
|
||||
2. [一些高级用法][2]
|
||||
3. [总结][3]
|
||||
|
||||
在本系列的[第一部分][4]中,我们通过讨论 **cd -** 命令的用法,重点介绍了 Linux 中的命令行导航。还讨论了一些其他相关要点/概念。现在进一步讨论,在本文中,我们将讨论如何使用 pushd 和 popd 命令在 Linux 命令行上获得更快的导航体验。
|
||||
|
||||
在我们开始之前,值得分享的一点是,此后提到的所有指导和命令已经在 Ubuntu 14.04 和 Bash shell(4.3.11)上测试过。
|
||||
|
||||
### pushd 和 popd 命令基础
|
||||
|
||||
为了更好地理解 pushd 和 popd 命令的作用,让我们先讨论堆栈的概念。想象一下你厨房案板上的一个空白区域,现在想象一下你想在上面放一套盘子。你会怎么做?很简单,一个接一个地放在上面。
|
||||
|
||||
所以在整个过程的最后,案板上的第一个盘子是盘子中的最后一个,你手中最后一个盘子是盘子堆中的第一个。现在当你需要一个盘子时,你选择在堆的顶部使用它,然后在下次需要时选择下一个。
|
||||
|
||||
pushd 和 popd 命令是类似的概念。在Linux系统上有一个目录堆栈,你可以堆叠目录路径以供将来使用。你可以使用 **dirs** 命令来在任何时间点快速查看堆栈的内容。
|
||||
|
||||
下面的例子显示了在命令行终端启动后立即在我的系统上使用 dirs 命令的输出:
|
||||
|
||||
$ dirs
|
||||
~
|
||||
|
||||
输出中的波浪号(〜)表示目录堆栈当前仅包含用户的主目录。
|
||||
|
||||
继续下去,使用 pushd 和 popd 命令来执行存储目录路径并删除它的操作。使用 pushd 非常容易 - 只需将要存储在目录堆栈中的路径作为此命令的参数传递。这里有一个例子:
|
||||
|
||||
pushd /home/himanshu/Downloads/
|
||||
|
||||
上述命令的作用是,将当前工作目录更改为你作为参数传递的目录,并且还将路径添加到目录堆栈中。为了方便用户,pushd 命令在其输出中产生目录堆栈的内容。因此,当运行上面的命令时,产生了以下输出:
|
||||
|
||||
```
|
||||
~/Downloads ~
|
||||
```
|
||||
|
||||
输出显示现在堆栈中有两个目录路径:一个是用户的主目录,还有用户的下载目录。它们的保存顺序是:主目录位于底部,新添加的 Downloads 目录位于其上。
|
||||
|
||||
要验证 pushd 的输出是正确的,你还可以使用dirs命令:
|
||||
|
||||
$ dirs
|
||||
~/Downloads ~
|
||||
|
||||
因此你可以看到 dirs 命令同样产生相同的输出。
|
||||
|
||||
让我们再使用下 pushd 命令:
|
||||
|
||||
$ pushd /usr/lib/; pushd /home/himanshu/Desktop/
|
||||
/usr/lib ~/Downloads ~
|
||||
~/Desktop /usr/lib ~/Downloads ~
|
||||
|
||||
所以目录堆栈现在包含总共四个目录路径,其中主目录(〜)在底部,并且用户的桌面目录在顶部。
|
||||
|
||||
一定要记住的是堆栈的头是你当前的目录。这意味着现在我们当前的工作目录是 ~/Desktop。
|
||||
|
||||
现在,假设你想回到 /usr/lib 目录,所以你所要做的就是执行 popd 命令:
|
||||
|
||||
$ popd
|
||||
/usr/lib ~/Downloads ~
|
||||
|
||||
popd 命令不仅会将当前目录切换到 /usr/lib,它还会从目录堆栈中删除 ~/Desktop,这一点可以从命令输出中看出。这样,popd 命令将允许你以相反的顺序浏览这些目录。
|
||||
|
||||
### 一些高级用法
|
||||
|
||||
现在我们已经讨论了 pushd 和 popd 命令的基础知识,让我们继续讨论与这些命令相关的一些其他细节。首先,这些命令还允许你操作目录堆栈。例如,假设你的目录堆栈看起来像这样:
|
||||
|
||||
$ dirs
|
||||
~/Desktop /usr/lib ~ ~/Downloads
|
||||
|
||||
现在,我们的要求是改变堆栈中目录路径的顺序,最上面的元素(~/Desktop)放到底部,剩下的每个都向上移动一个位置。这可以使用以下命令实现:
|
||||
|
||||
pushd +1
|
||||
|
||||
这里是上面的命令对目录堆栈做的:
|
||||
|
||||
$ dirs
|
||||
/usr/lib ~ ~/Downloads ~/Desktop
|
||||
|
||||
因此,我们看到目录堆栈中的元素顺序已经改变,并且现在和我们想要的一样。当然,你可以让目录堆栈元素移动任何次数。例如,以下命令会将它们向上移动两次:
|
||||
|
||||
$ pushd +2
|
||||
~/Downloads ~/Desktop /usr/lib ~
|
||||
|
||||
你也可以使用负的索引值:
|
||||
|
||||
$ pushd -1
|
||||
/usr/lib ~ ~/Downloads ~/Desktop
|
||||
|
||||
相似地,你可以在 popd 命令中使用此技术来从目录堆栈删除任何条目,而不用离开当前工作目录。例如,如果要使用 popd 从顶部(目前是 ~/Downloads)删除第三个条目,你可以运行以下命令:
|
||||
|
||||
popd +2
|
||||
|
||||
记住堆栈索引的初始值是 0,因此我们使用 2 来访问第三个条目。
|
||||
|
||||
因此目录堆栈现在包含:
|
||||
|
||||
$ dirs
|
||||
/usr/lib ~ ~/Desktop
|
||||
|
||||
确认条目已经被移除了。
|
||||
|
||||
如果由于某些原因,你发现你很难记住元素在目录堆栈中的位置以及它们的索引,你则可以对在 dirs 命令中使用 -v 选项。这里有一个例子:
|
||||
|
||||
$ dirs -v
|
||||
0 /usr/lib
|
||||
1 ~
|
||||
2 ~/Desktop
|
||||
|
||||
你可能已经猜到了,左边的数字是索引,接下来跟的是这个索引对应的目录路径。
|
||||
|
||||
**注意**: 在 dir 中使用 -c 选项清除目录堆栈。
|
||||
|
||||
现在让我们简要地讨论一下 popd 和 pushd 命令的实际用法。虽然它们第一眼看起来可能有点复杂,但是这些命令在编写 shell 脚本时会派上用场 - 你不需要记住你从哪里来; 只要执行一下 popd,你就能回到你来的目录。
|
||||
|
||||
经验丰富的脚本编写者通常以以下方式使用这些命令:
|
||||
|
||||
`popd >/dev/null 2>&1`
|
||||
|
||||
上述命令确保 popd 保持静默(不产生任何输出)。同样,你也可以静默 pushd。
|
||||
|
||||
pushd 和 popd 命令也被 Linux 服务器管理员使用,他们通常在几个相同的目录之间移动。 [这里][5]一些其他真正有信息量的案例解释。
|
||||
|
||||
### 总结
|
||||
|
||||
我同意 pushd 和 popd 的概念不是很直接。但是,它需要的只是一点练习 - 是的,你需要让你实践。花一些时间在这些命令上,你就会开始喜欢他们,特别是如果有一些能方便你生活的用例存在时。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/
|
||||
|
||||
作者:[Ansh ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/#the-basics-of-pushd-and-popd-commands
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/#some-advanced-points
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/#conclusion
|
||||
[4]:https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-tricks-part-1/
|
||||
[5]:http://unix.stackexchange.com/questions/77077/how-do-i-use-pushd-and-popd-commands
|
||||
@ -1,3 +1,5 @@
|
||||
校对中
|
||||
|
||||
- [名称](#名称)
|
||||
- [用法](#用法)
|
||||
- [描述](#描述)
|
||||
|
||||
Loading…
Reference in New Issue
Block a user